
网站内容抓取
网站内容抓取(各个爬虫获取内容是个套路活,还没爬1分钟就被封掉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-08-29 06:05
看评论区,大多数人说如何获取网页内容。其实,获取内容是一个套路。所有网站 都是相似的。在实际操作中,很多人发现自己写了一个爬虫,还没有爬到1分钟就被屏蔽了。先说一些攀爬XX的经验,主要是一些防反攀的经验。
爬过XX的都知道XX站的防爬机制做的很好。
0.cookie,有些cookies会记录本机的一些特性,这些特性可能会成为ban的关键句柄,所以写爬虫的时候最好禁用cookies。
1.XX网站 具有 User-Agent 代理验证。如果检测到你的请求是假的User-Agent,记得直接返回空白页。这很容易解决。下载一个fake-useragent包,每次随机生成一个header。
2.XX网站ip 频繁访问检测机制。当检测到你的访问过于频繁时(这个真的很严格,其实即使你手动模拟点击,也会被限制一段时间),会返回异常信息。这可以通过维护自己的 ip 池来解决。 github上的免费代理ip池代理好用,但是代理IP数量比较少。如果您无限制访问,那么您整个池中的所有 ip 将很快被阻止。所以可以加一个限制:每个ip两次使用的间隔应该是60s。要是麻烦,就很容易解决了,氪金,氪金可以变强。推荐通讯社的动态转发功能,真的好用。
3.XX 会时不时弹出验证码。解决方法一:在网上调用验证码识别借口,有点麻烦。解决方案二:更改IP继续访问网页,
4.XX 偶尔会发出重定向请求。这是指有时候即使你使用新的ip访问XX的页面,有时候也会收到一个脚本脚本,脚本的内容很简单,就是采集浏览器的一些基本信息,然后GET到请求原创页面。这对于用户访问来说是缺乏经验的。但是对于爬虫来说,这种重定向必须要特别注意。一种解决方案是模拟脚本的内容,然后再次发送 GET 请求。还有一个更简单的方法,就是直接禁止重定向,把接收到的页面当作错误码处理。错误码的处理方法是更改IP,继续访问。不可能为每个 IP 发送重定向。
合理应用这些技术可以实现单机爬行峰值1.5w条数据/分钟。 查看全部
网站内容抓取(各个爬虫获取内容是个套路活,还没爬1分钟就被封掉)
看评论区,大多数人说如何获取网页内容。其实,获取内容是一个套路。所有网站 都是相似的。在实际操作中,很多人发现自己写了一个爬虫,还没有爬到1分钟就被屏蔽了。先说一些攀爬XX的经验,主要是一些防反攀的经验。
爬过XX的都知道XX站的防爬机制做的很好。
0.cookie,有些cookies会记录本机的一些特性,这些特性可能会成为ban的关键句柄,所以写爬虫的时候最好禁用cookies。
1.XX网站 具有 User-Agent 代理验证。如果检测到你的请求是假的User-Agent,记得直接返回空白页。这很容易解决。下载一个fake-useragent包,每次随机生成一个header。
2.XX网站ip 频繁访问检测机制。当检测到你的访问过于频繁时(这个真的很严格,其实即使你手动模拟点击,也会被限制一段时间),会返回异常信息。这可以通过维护自己的 ip 池来解决。 github上的免费代理ip池代理好用,但是代理IP数量比较少。如果您无限制访问,那么您整个池中的所有 ip 将很快被阻止。所以可以加一个限制:每个ip两次使用的间隔应该是60s。要是麻烦,就很容易解决了,氪金,氪金可以变强。推荐通讯社的动态转发功能,真的好用。
3.XX 会时不时弹出验证码。解决方法一:在网上调用验证码识别借口,有点麻烦。解决方案二:更改IP继续访问网页,
4.XX 偶尔会发出重定向请求。这是指有时候即使你使用新的ip访问XX的页面,有时候也会收到一个脚本脚本,脚本的内容很简单,就是采集浏览器的一些基本信息,然后GET到请求原创页面。这对于用户访问来说是缺乏经验的。但是对于爬虫来说,这种重定向必须要特别注意。一种解决方案是模拟脚本的内容,然后再次发送 GET 请求。还有一个更简单的方法,就是直接禁止重定向,把接收到的页面当作错误码处理。错误码的处理方法是更改IP,继续访问。不可能为每个 IP 发送重定向。
合理应用这些技术可以实现单机爬行峰值1.5w条数据/分钟。
网站内容抓取(WebScraperMac版可以快速提取与某个网页(包括文本内容))
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-08-29 06:04
WebScraper Mac 是MacOS 上的网站content 抓取软件,可以快速提取与网页相关的信息(包括文本内容),让您轻松快速地从在线资源中提取内容。您可以完全控制将数据导出到 CSV 或 JSON 文件。
WebScraper Mac版软件介绍
WebScraper for Mac 是 Mac 平台上的一个简单应用程序,可将数据导出为 JSON 或 CSV。 Mac 版的 WebScraper 可以快速提取与网页相关的信息(包括文本内容)。适用于 Mac 的 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper mac 软件功能
快速轻松地扫描和截屏网站
原生 MacOS 应用程序可以在您的桌面上运行
提取数据的方法有很多种;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
易于导出数据-选择所需的列
输出数据为csv或json
将所有图像下载到文件夹/采集并导出所有链接的选项
输出单个文本文件的选项(用于存档文本内容、markdown 或纯文本)
丰富的选项/配置
系统要求
当前版本需要 Mac OS 10.8 或更高版本
WebScraper Mac 更新日志
WebScraper for Mac(网站内容爬虫软件)带注册机V4.10.1
添加选项以从 class/id 或正则表达式提取结果中去除 html 标签
添加在url中保留hash(#)的选项(默认情况下会被修剪(假设是文档片段中的位置)。但是对于一些网站在他们的url中错误地使用了hash,它可能是页面 url 的重要部分)。除非您确定确实需要开启此选项,否则应将其关闭。 查看全部
网站内容抓取(WebScraperMac版可以快速提取与某个网页(包括文本内容))
WebScraper Mac 是MacOS 上的网站content 抓取软件,可以快速提取与网页相关的信息(包括文本内容),让您轻松快速地从在线资源中提取内容。您可以完全控制将数据导出到 CSV 或 JSON 文件。
WebScraper Mac版软件介绍
WebScraper for Mac 是 Mac 平台上的一个简单应用程序,可将数据导出为 JSON 或 CSV。 Mac 版的 WebScraper 可以快速提取与网页相关的信息(包括文本内容)。适用于 Mac 的 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper mac 软件功能
快速轻松地扫描和截屏网站
原生 MacOS 应用程序可以在您的桌面上运行
提取数据的方法有很多种;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
易于导出数据-选择所需的列
输出数据为csv或json
将所有图像下载到文件夹/采集并导出所有链接的选项
输出单个文本文件的选项(用于存档文本内容、markdown 或纯文本)
丰富的选项/配置
系统要求
当前版本需要 Mac OS 10.8 或更高版本
WebScraper Mac 更新日志
WebScraper for Mac(网站内容爬虫软件)带注册机V4.10.1
添加选项以从 class/id 或正则表达式提取结果中去除 html 标签
添加在url中保留hash(#)的选项(默认情况下会被修剪(假设是文档片段中的位置)。但是对于一些网站在他们的url中错误地使用了hash,它可能是页面 url 的重要部分)。除非您确定确实需要开启此选项,否则应将其关闭。
网站内容抓取(如何写好Python数据我用的是Python?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-08-29 06:04
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个信息比较完整的网站,比如39养老网:
/findhomes/
点击打开任意一家养老院,如上海上大天平养老院
我们想获取这个网站的所有养老院信息,例如姓名、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般这些网站页面和页面之间的url有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的url是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
我们可以用它在页面上找到我们感兴趣的部分
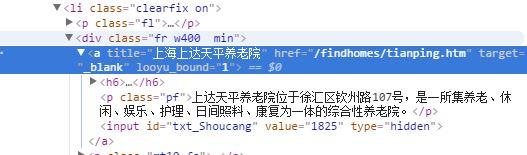
使用inspect工具点击第一家养老院的信息,我们会发现html会显示相关的html信息
href代表这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个疗养院的链接,我们来看看代码输入
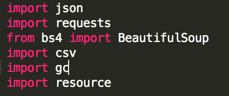
代码第一步:导入相关的python库
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
正如我上面所说的,我们知道网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:
i 是一个整数,getLink 会返回给我们对应的页面 url,比如 i=1 时,getLink 会返回我们的第一页,当 i=2 时会返回给我们第二页
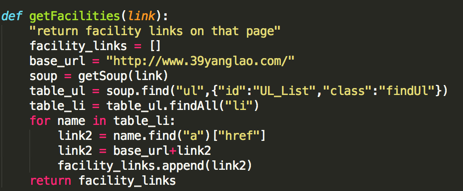
getFacilities的代码如下:
这个功能的主要作用是找出页面上所有养老院公寓的网址(我们刚刚看到的href)
getSoup是一个函数(BeautifulSoup库中的一个函数),我们给他一个url,他会返回一个处理后的网页html给我们搜索
<p>soup.find("ul"...) 的意思是在html中找到第一个符合"{...}"条件的"ul"标签,我们把这个信息存入table_ul的变量中 查看全部
网站内容抓取(如何写好Python数据我用的是Python?(上)
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个信息比较完整的网站,比如39养老网:
/findhomes/
点击打开任意一家养老院,如上海上大天平养老院
我们想获取这个网站的所有养老院信息,例如姓名、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般这些网站页面和页面之间的url有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的url是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
我们可以用它在页面上找到我们感兴趣的部分
使用inspect工具点击第一家养老院的信息,我们会发现html会显示相关的html信息
href代表这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个疗养院的链接,我们来看看代码输入
代码第一步:导入相关的python库
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
正如我上面所说的,我们知道网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:

i 是一个整数,getLink 会返回给我们对应的页面 url,比如 i=1 时,getLink 会返回我们的第一页,当 i=2 时会返回给我们第二页
getFacilities的代码如下:
这个功能的主要作用是找出页面上所有养老院公寓的网址(我们刚刚看到的href)
getSoup是一个函数(BeautifulSoup库中的一个函数),我们给他一个url,他会返回一个处理后的网页html给我们搜索
<p>soup.find("ul"...) 的意思是在html中找到第一个符合"{...}"条件的"ul"标签,我们把这个信息存入table_ul的变量中
网站内容抓取(一下网络爬虫抓取网页数据的优点和缺点和注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-08-29 06:03
网页爬取是指自动从网站中提取数据的过程。它可以分析和处理任何可公开访问的网页以提取信息或数据,然后可以下载或存储这些信息或数据。接下来,ipidea 给大家介绍一下网络爬虫爬取网络数据的优缺点。
优势
1、节省时间。使用网页爬取时,不需要手动从网站采集数据,可以同时快速爬取多个网站。
2、大规模数据。网络抓取为您提供的数据量远远超过您手动采集的数据量。
3、性价比高。一个简单的刮刀通常可以完成这项工作,因此您无需投资于复杂的系统或额外的人员。
4、 可以修改为一个任务创建一个scraper,你通常只需做一些小的改动就可以为不同的任务修改它。
5、正确设置你的爬虫,它会直接从网站准确采集数据,引入错误的可能性很低。
6、Maintainable。通常你可以稍微调整scraper来适应网站的变化。
7、结构化数据。默认情况下,捕获的数据以机器可读的格式到达,因此简单的值通常可以立即用于其他数据库和程序。
缺点
1、 需要持续维护。由于您的爬虫依赖外部网站,您无法控制网站何时改变其结构或内容,因此您需要在爬虫过期时重新爬取。
2、 可能被阻止访问。 网站 可以使用许多不同的方法(例如 IP 阻止)来防止您抓取其内容。 查看全部
网站内容抓取(一下网络爬虫抓取网页数据的优点和缺点和注意事项)
网页爬取是指自动从网站中提取数据的过程。它可以分析和处理任何可公开访问的网页以提取信息或数据,然后可以下载或存储这些信息或数据。接下来,ipidea 给大家介绍一下网络爬虫爬取网络数据的优缺点。

优势
1、节省时间。使用网页爬取时,不需要手动从网站采集数据,可以同时快速爬取多个网站。
2、大规模数据。网络抓取为您提供的数据量远远超过您手动采集的数据量。
3、性价比高。一个简单的刮刀通常可以完成这项工作,因此您无需投资于复杂的系统或额外的人员。
4、 可以修改为一个任务创建一个scraper,你通常只需做一些小的改动就可以为不同的任务修改它。
5、正确设置你的爬虫,它会直接从网站准确采集数据,引入错误的可能性很低。
6、Maintainable。通常你可以稍微调整scraper来适应网站的变化。
7、结构化数据。默认情况下,捕获的数据以机器可读的格式到达,因此简单的值通常可以立即用于其他数据库和程序。
缺点
1、 需要持续维护。由于您的爬虫依赖外部网站,您无法控制网站何时改变其结构或内容,因此您需要在爬虫过期时重新爬取。
2、 可能被阻止访问。 网站 可以使用许多不同的方法(例如 IP 阻止)来防止您抓取其内容。
网站内容抓取(网站优化排名优化的过程中会遇到这种情况吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-29 06:02
在做网站排名优化的时候,网站内容收录越多,搜索引擎喜欢网站的内容就越多,这就给了网站一个很好的排名。但是在网站优化的过程中,就会遇到这种情况。 网站的部分页面已被删除,搜索引擎仍会抓取这些页面。为什么?接下来就跟着网站免费优化公司一探究竟吧!
1、外链引导蜘蛛爬虫到一个不存在的页面
在做网站优化排名的时候,SEO大牛会为网站做一些外链,而这些外链不仅指向网站首页,还指向网站的各个页面。当网站的部分页面被删除后,虽然该页面不存在,但该页面的外链确实存在,百度蜘蛛会跟随外链进入该页面,导致搜索引擎抓取到非-存在的页面。
2、不存在的页面最近被删除了
如果网站页面最近被删除,也会造成这种情况。这是因为虽然网站页面已经被删除,但是这些页面已经被搜索引擎收录搜索到了,它们会存在于搜索引擎中,搜索引擎也会反复抓取。为避免这种情况,您需要将这些页面提交给搜索引擎,并告诉搜索引擎这些页面不存在且不用于抓取。
3、搜索引擎算法调整
搜索引擎算法调整后,搜索引擎也可能会抓取一些网站中不存在的页面。这是因为,虽然网站已经更新,但对于搜索引擎来说,更新后的网站页面并没有被搜索引擎收录搜索到,所以百度蜘蛛会反复抓取这些历史上的一流链接。
4、网站被攻击
在对网站进行排名时,网站可能经常被竞争对手攻击,攻击的方法是将一些网站不存在的页面提交给搜索引擎,导致搜索引擎响应网站的评分降低,进而影响网站的排名。
总之,网站遇到这种情况,一定要及时处理。可以用robots.txt来屏蔽,也可以把页面做成404,有利于网站的长远发展。
蝙蝠侠 IT
转载需授权! 查看全部
网站内容抓取(网站优化排名优化的过程中会遇到这种情况吗?)
在做网站排名优化的时候,网站内容收录越多,搜索引擎喜欢网站的内容就越多,这就给了网站一个很好的排名。但是在网站优化的过程中,就会遇到这种情况。 网站的部分页面已被删除,搜索引擎仍会抓取这些页面。为什么?接下来就跟着网站免费优化公司一探究竟吧!

1、外链引导蜘蛛爬虫到一个不存在的页面
在做网站优化排名的时候,SEO大牛会为网站做一些外链,而这些外链不仅指向网站首页,还指向网站的各个页面。当网站的部分页面被删除后,虽然该页面不存在,但该页面的外链确实存在,百度蜘蛛会跟随外链进入该页面,导致搜索引擎抓取到非-存在的页面。
2、不存在的页面最近被删除了
如果网站页面最近被删除,也会造成这种情况。这是因为虽然网站页面已经被删除,但是这些页面已经被搜索引擎收录搜索到了,它们会存在于搜索引擎中,搜索引擎也会反复抓取。为避免这种情况,您需要将这些页面提交给搜索引擎,并告诉搜索引擎这些页面不存在且不用于抓取。
3、搜索引擎算法调整
搜索引擎算法调整后,搜索引擎也可能会抓取一些网站中不存在的页面。这是因为,虽然网站已经更新,但对于搜索引擎来说,更新后的网站页面并没有被搜索引擎收录搜索到,所以百度蜘蛛会反复抓取这些历史上的一流链接。
4、网站被攻击
在对网站进行排名时,网站可能经常被竞争对手攻击,攻击的方法是将一些网站不存在的页面提交给搜索引擎,导致搜索引擎响应网站的评分降低,进而影响网站的排名。
总之,网站遇到这种情况,一定要及时处理。可以用robots.txt来屏蔽,也可以把页面做成404,有利于网站的长远发展。
蝙蝠侠 IT
转载需授权!
【干货】一个小项目的运用及解析日志日志
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-27 19:14
不知不觉中,我已经上课三个星期了,还写了几个小项目。这里有一个有趣的爬虫项目:搜狗输入法词库爬虫,和你聊聊公司这里是如何写项目指南
本次抓取的内容为:搜狗所有词库
地址:/dict/cate/index/167
这次有点复杂,需要一些前置知识:
项目文件整理:
PS:这里的代码是我自己重构的,
应该使用内部框架捕获公司中的代码。所以我不能分享它
告诉我:我们公司还在用Python2.7,编码问题要死我了! !
我猜是因为2.7的print可以省一对括号,这样就永远不会升级了~
看项目结构:
├── configs.py # 数据库的配置文件
├── jiebao.py # 搜狗的词库是加密的,用来解密词库用的
├── spider
│ ├── log_SougouDownloader.log.20171118 # 词库下载日志
│ ├── log_SougouSpider.log.20171118 # 抓取日志
│ └── spider.py # 爬虫文件
├── store_new
│ ├── __init__.py
│ └── stroe.py # 数据库操作的封装
└── utils
└── tools.py # 日志模块
整体画面比较清晰
我将源文件放在 GitHub 中:
/Ehco1996/Python-crawler/tree/master/搜狗
爬虫逻辑和数据库表设计
看门户的网页结构:
我们需要解决:
由于数据量大
大约有 10,000 个同义词库文件可供下载
大约有1亿关键词需要解决
无法将所有逻辑耦合在一起
这里我创建了三个数据库表:
所以总体逻辑是这样的:
代码部分
一、二级cate页面分析
def cate_ext(self, html, type1):
'''
解析列表页的所有分类名
Args:
html 文本
type1 一级目录名
'''
res = []
soup = BeautifulSoup(html, 'lxml')
cate_list = soup.find('div', {'id': 'dict_cate_show'})
lis = cate_list.find_all('a')
for li in lis:
type2 = li.text.replace('"', '')
url = 'http://pinyin.sogou.com' + li['href'] + '/default/{}'
res.append({
'url': url,
'type1': type1,
'type2': type2,
})
return res
这里我通过解析一级分类的入口页面得到所有二级分类的地址
词库文件下载地址解析:
def list_ext(self, html, type1, type2):
'''
解析搜狗词库的列表页面
args:
html: 文本
type1 一级目录名
type2 二级目录名
retrun list
每一条数据都为字典类型
'''
res = []
try:
soup = BeautifulSoup(html, 'lxml')
# 偶数部分
divs = soup.find_all("div", class_='dict_detail_block')
for data in divs:
name = data.find('div', class_='detail_title').a.text
url = data.find('div', class_='dict_dl_btn').a['href']
res.append({'filename': type1 + '_' + type2 + '_' + name,
'type1': type1,
'type2': type2,
'url': url,
})
# 奇数部分
divs_odd = soup.find_all("div", class_='dict_detail_block odd')
for data in divs_odd:
name = data.find('div', class_='detail_title').a.text
url = data.find('div', class_='dict_dl_btn').a['href']
res.append({'filename': type1 + '_' + type2 + '_' + name,
'type1': type1,
'type2': type2,
'url': url,
})
except:
print('解析失败')
return - 1
return res
爬虫入口:
def start(self):
'''
解析搜狗词库的下载地址和分类名称
'''
# 从数据库读取二级分类的入口地址
cate_list = self.store.find_all('sougou_cate')
for cate in cate_list:
type1 = cate['type1']
type2 = cate['type2']
for i in range(1, int(cate['page']) + 1):
print('正在解析{}的第{}页'.format(type1 + type2, i))
url = cate['url'].format(i)
html = get_html_text(url)
if html != -1:
res = self.list_ext(html, type1, type2)
self.log.info('正在解析页面 {}'.format(url))
for data in res:
self.store.save_one_data('sougou_detail', data)
self.log.info('正在存储数据{}'.format(data['filename']))
time.sleep(3)
这里我从cate表中读取记录发送请求,解析出下载地址
数据库操作的包可以直接看我的store_new/store.py文件
你也可以阅读我上周写的文章:/p/30911268
词库文件下载逻辑:
def start(self):
# 从数据库检索记录
res = self.store.find_all('sougou_detail')
self.log.warn('一共有{}条词库等待下载'.format(len(res)))
for data in res:
content = self.get_html_content(data['url'])
filename = self.strip_wd(data['filename'])
# 如果下载失败,我们等三秒再重试
if content == -1:
time.sleep(3)
self.log.info('{}下载失败 正在重试'.format(filename))
content = self.get_html_content(data[1])
self.download_file(content, filename)
self.log.info('正在下载文件{}'.format(filename))
time.sleep(1)
这部分没什么难的,主要是文件读写操作
分析词库文件逻辑:
def start():
# 使用多线程解析
threads = list()
# 读文件存入queue的线程
threads.append(
Thread(target=ext_to_queue))
# 存数据库的线程
for i in range(10):
threads.append(
Thread(target=save_to_db))
for thread in threads:
thread.start()
好了,所有步骤都完成了
说说其中的一些“坑”吧。
Logging 日志模块的使用
因为爬取下载次数比较多,
没有日志是绝对不可能的,
毕竟我们不能总是在电脑前看程序输出!
其实我们写的程序基本上都是在服务器上运行的。
我总是通过查看程序的日志文件来判断运行状态。
在前面的代码中,可以看到我登录了很多地方
让我们看看日志文件是什么样的:
蜘蛛日志
下载器日志
运行状态一目了然?
如果你想知道如何实现它,你可以看到文件utils/tools.py
其实就是使用Python自带的日志模块
多线程的使用
共下载 9000 多个同义词库文件
字典关键词平均有2w个词条
那么总共需要存储1.80亿条数据
假设一秒可以存储10条数据
需要存储这么多数据:5000 多个小时
想想就很可怕。真的要这么久,黄花菜会冷的。
这里需要使用多线程来操作,
因为涉及文件读写
我们必须使用队列来帮助我们满足需求
逻辑是这样的:
首先打开一个主线程来读取/解析本地词库文件:
接下来打开10~50个线程(取决于数据库的最大连接数)来操作队列:
由于篇幅原因,我只放出从队列中取数据的代码片段
如果你想要整个逻辑,你可以阅读jiebao.py
def save_to_db():
'''
从数据队列里拿一条数据
并存入数据库
'''
store = DbToMysql(configs.TEST_DB)
while True:
try:
st = time.time()
data = res_queue.get_nowait()
t = int(time.time() - st)
if t > 5:
print("res_queue", t)
save_data(data, store)
except:
print("queue is empty wait for a while")
time.sleep(2)
使用多线程后,速度快了几十倍。
经测试:1秒可存储500条记录
最后看一下关键词在数据库中解析出来的:
运行一段时间后,已经有4000万条数据了。 查看全部
【干货】一个小项目的运用及解析日志日志
不知不觉中,我已经上课三个星期了,还写了几个小项目。这里有一个有趣的爬虫项目:搜狗输入法词库爬虫,和你聊聊公司这里是如何写项目指南
本次抓取的内容为:搜狗所有词库
地址:/dict/cate/index/167
这次有点复杂,需要一些前置知识:
项目文件整理:
PS:这里的代码是我自己重构的,
应该使用内部框架捕获公司中的代码。所以我不能分享它
告诉我:我们公司还在用Python2.7,编码问题要死我了! !
我猜是因为2.7的print可以省一对括号,这样就永远不会升级了~
看项目结构:
├── configs.py # 数据库的配置文件
├── jiebao.py # 搜狗的词库是加密的,用来解密词库用的
├── spider
│ ├── log_SougouDownloader.log.20171118 # 词库下载日志
│ ├── log_SougouSpider.log.20171118 # 抓取日志
│ └── spider.py # 爬虫文件
├── store_new
│ ├── __init__.py
│ └── stroe.py # 数据库操作的封装
└── utils
└── tools.py # 日志模块
整体画面比较清晰
我将源文件放在 GitHub 中:
/Ehco1996/Python-crawler/tree/master/搜狗
爬虫逻辑和数据库表设计
看门户的网页结构:
我们需要解决:
由于数据量大
大约有 10,000 个同义词库文件可供下载
大约有1亿关键词需要解决
无法将所有逻辑耦合在一起
这里我创建了三个数据库表:
所以总体逻辑是这样的:
代码部分
一、二级cate页面分析
def cate_ext(self, html, type1):
'''
解析列表页的所有分类名
Args:
html 文本
type1 一级目录名
'''
res = []
soup = BeautifulSoup(html, 'lxml')
cate_list = soup.find('div', {'id': 'dict_cate_show'})
lis = cate_list.find_all('a')
for li in lis:
type2 = li.text.replace('"', '')
url = 'http://pinyin.sogou.com' + li['href'] + '/default/{}'
res.append({
'url': url,
'type1': type1,
'type2': type2,
})
return res
这里我通过解析一级分类的入口页面得到所有二级分类的地址
词库文件下载地址解析:
def list_ext(self, html, type1, type2):
'''
解析搜狗词库的列表页面
args:
html: 文本
type1 一级目录名
type2 二级目录名
retrun list
每一条数据都为字典类型
'''
res = []
try:
soup = BeautifulSoup(html, 'lxml')
# 偶数部分
divs = soup.find_all("div", class_='dict_detail_block')
for data in divs:
name = data.find('div', class_='detail_title').a.text
url = data.find('div', class_='dict_dl_btn').a['href']
res.append({'filename': type1 + '_' + type2 + '_' + name,
'type1': type1,
'type2': type2,
'url': url,
})
# 奇数部分
divs_odd = soup.find_all("div", class_='dict_detail_block odd')
for data in divs_odd:
name = data.find('div', class_='detail_title').a.text
url = data.find('div', class_='dict_dl_btn').a['href']
res.append({'filename': type1 + '_' + type2 + '_' + name,
'type1': type1,
'type2': type2,
'url': url,
})
except:
print('解析失败')
return - 1
return res
爬虫入口:
def start(self):
'''
解析搜狗词库的下载地址和分类名称
'''
# 从数据库读取二级分类的入口地址
cate_list = self.store.find_all('sougou_cate')
for cate in cate_list:
type1 = cate['type1']
type2 = cate['type2']
for i in range(1, int(cate['page']) + 1):
print('正在解析{}的第{}页'.format(type1 + type2, i))
url = cate['url'].format(i)
html = get_html_text(url)
if html != -1:
res = self.list_ext(html, type1, type2)
self.log.info('正在解析页面 {}'.format(url))
for data in res:
self.store.save_one_data('sougou_detail', data)
self.log.info('正在存储数据{}'.format(data['filename']))
time.sleep(3)
这里我从cate表中读取记录发送请求,解析出下载地址
数据库操作的包可以直接看我的store_new/store.py文件
你也可以阅读我上周写的文章:/p/30911268
词库文件下载逻辑:
def start(self):
# 从数据库检索记录
res = self.store.find_all('sougou_detail')
self.log.warn('一共有{}条词库等待下载'.format(len(res)))
for data in res:
content = self.get_html_content(data['url'])
filename = self.strip_wd(data['filename'])
# 如果下载失败,我们等三秒再重试
if content == -1:
time.sleep(3)
self.log.info('{}下载失败 正在重试'.format(filename))
content = self.get_html_content(data[1])
self.download_file(content, filename)
self.log.info('正在下载文件{}'.format(filename))
time.sleep(1)
这部分没什么难的,主要是文件读写操作
分析词库文件逻辑:
def start():
# 使用多线程解析
threads = list()
# 读文件存入queue的线程
threads.append(
Thread(target=ext_to_queue))
# 存数据库的线程
for i in range(10):
threads.append(
Thread(target=save_to_db))
for thread in threads:
thread.start()
好了,所有步骤都完成了
说说其中的一些“坑”吧。
Logging 日志模块的使用
因为爬取下载次数比较多,
没有日志是绝对不可能的,
毕竟我们不能总是在电脑前看程序输出!
其实我们写的程序基本上都是在服务器上运行的。
我总是通过查看程序的日志文件来判断运行状态。
在前面的代码中,可以看到我登录了很多地方
让我们看看日志文件是什么样的:
蜘蛛日志
下载器日志
运行状态一目了然?
如果你想知道如何实现它,你可以看到文件utils/tools.py
其实就是使用Python自带的日志模块
多线程的使用
共下载 9000 多个同义词库文件
字典关键词平均有2w个词条
那么总共需要存储1.80亿条数据
假设一秒可以存储10条数据
需要存储这么多数据:5000 多个小时
想想就很可怕。真的要这么久,黄花菜会冷的。
这里需要使用多线程来操作,
因为涉及文件读写
我们必须使用队列来帮助我们满足需求
逻辑是这样的:
首先打开一个主线程来读取/解析本地词库文件:
接下来打开10~50个线程(取决于数据库的最大连接数)来操作队列:
由于篇幅原因,我只放出从队列中取数据的代码片段
如果你想要整个逻辑,你可以阅读jiebao.py
def save_to_db():
'''
从数据队列里拿一条数据
并存入数据库
'''
store = DbToMysql(configs.TEST_DB)
while True:
try:
st = time.time()
data = res_queue.get_nowait()
t = int(time.time() - st)
if t > 5:
print("res_queue", t)
save_data(data, store)
except:
print("queue is empty wait for a while")
time.sleep(2)
使用多线程后,速度快了几十倍。
经测试:1秒可存储500条记录
最后看一下关键词在数据库中解析出来的:
运行一段时间后,已经有4000万条数据了。
技术保密以及网站运营的差异等其他原因,以下内容仅供站长参考
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-08-27 19:12
百度认为什么样的网站和收录比较适合爬取?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考。具体收录策略包括但不限于内容。
第一方面:网站创造高质量的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的最终目标是满足用户的搜索需求,所以网站内容首先要满足用户的需求。如今,互联网在也能满足用户需求的前提下,充斥着大量同质化的内容。接下来,如果你网站提供的内容是独一无二的,或者具有一定的独特价值,那么百度会更喜欢收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站的内容都是“正常或低质量”,甚至一些网站为了获得更好的收录或排名而使用欺骗手段。下面是一些常见的情况,虽然无法一一列举。但请不要冒险,百度拥有全面的技术支持来检测和处理这些行为。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些操作包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;目标搜索引擎利用程序生成的内容。
百度会尽量收录提供不同信息的网页。如果你的网站收录大量重复内容,搜索引擎会减少相同内容的收录,并考虑网站提供的内容价值低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。这也是真的帮助节省带宽。
第二方面:网站提供的内容得到了用户和站长的认可和支持
如果网站上的内容得到用户和站长的认可,那对于百度来说也是值得收录的。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,对网站的认可度进行综合评价。不过值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你网站的认可:通常网站之间的链接可以帮助百度爬虫找到你的网站,增加你的网站认出。百度将网页A到网页B的链接解释为网页A到网页B的投票。对一个网页的投票更能体现网页本身的“认可度”权重,有助于提高其他网站的“认可度”页。链接的数量、质量和相关性会影响“接受度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。 (当其他网站发现您的内容有价值并认为它可能对访问者有帮助时,自然链接是在网络动态生成过程中形成的。)
其他网站 创建与您的网站 相关的链接的最佳方式是创建可以在互联网上流行的独特且相关的内容。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长经常不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站产生长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
第三个方面:网站有很好的浏览体验
一个拥有良好浏览体验的网站对用户来说是非常有益的。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
为用户提供站点地图和带有网站重要部分链接的导航。让用户可以清晰、简单地浏览网站,快速找到自己需要的信息。
网站fast speed 可以提高用户满意度和网页的整体质量(特别是对于互联网连接速度较慢的用户)。
保证网站的内容在不同浏览器中都能正确显示,防止部分用户正常访问。
广告是网站的重要收入来源。 网站收录广告是一个很合理的现象,但是如果广告太多,会影响用户的浏览;或者网站有太多不相关的弹窗和浮动窗口广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量,但是权限设置过多可能会导致新用户失去耐心,给用户带来不好的体验从百度的角度来看,它希望减少对用户获取信息成本过高的网页的提供。 查看全部
技术保密以及网站运营的差异等其他原因,以下内容仅供站长参考
百度认为什么样的网站和收录比较适合爬取?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考。具体收录策略包括但不限于内容。

第一方面:网站创造高质量的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的最终目标是满足用户的搜索需求,所以网站内容首先要满足用户的需求。如今,互联网在也能满足用户需求的前提下,充斥着大量同质化的内容。接下来,如果你网站提供的内容是独一无二的,或者具有一定的独特价值,那么百度会更喜欢收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站的内容都是“正常或低质量”,甚至一些网站为了获得更好的收录或排名而使用欺骗手段。下面是一些常见的情况,虽然无法一一列举。但请不要冒险,百度拥有全面的技术支持来检测和处理这些行为。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些操作包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;目标搜索引擎利用程序生成的内容。
百度会尽量收录提供不同信息的网页。如果你的网站收录大量重复内容,搜索引擎会减少相同内容的收录,并考虑网站提供的内容价值低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。这也是真的帮助节省带宽。
第二方面:网站提供的内容得到了用户和站长的认可和支持
如果网站上的内容得到用户和站长的认可,那对于百度来说也是值得收录的。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,对网站的认可度进行综合评价。不过值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你网站的认可:通常网站之间的链接可以帮助百度爬虫找到你的网站,增加你的网站认出。百度将网页A到网页B的链接解释为网页A到网页B的投票。对一个网页的投票更能体现网页本身的“认可度”权重,有助于提高其他网站的“认可度”页。链接的数量、质量和相关性会影响“接受度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。 (当其他网站发现您的内容有价值并认为它可能对访问者有帮助时,自然链接是在网络动态生成过程中形成的。)
其他网站 创建与您的网站 相关的链接的最佳方式是创建可以在互联网上流行的独特且相关的内容。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长经常不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站产生长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
第三个方面:网站有很好的浏览体验
一个拥有良好浏览体验的网站对用户来说是非常有益的。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
为用户提供站点地图和带有网站重要部分链接的导航。让用户可以清晰、简单地浏览网站,快速找到自己需要的信息。
网站fast speed 可以提高用户满意度和网页的整体质量(特别是对于互联网连接速度较慢的用户)。
保证网站的内容在不同浏览器中都能正确显示,防止部分用户正常访问。
广告是网站的重要收入来源。 网站收录广告是一个很合理的现象,但是如果广告太多,会影响用户的浏览;或者网站有太多不相关的弹窗和浮动窗口广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量,但是权限设置过多可能会导致新用户失去耐心,给用户带来不好的体验从百度的角度来看,它希望减少对用户获取信息成本过高的网页的提供。
第四章:动态网页抓取((解析真实地址+selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-08-27 19:11
第四章:动态网页爬取(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现更新到这里。请参考文章:
之前抓取的网页都是静态网页,浏览器中显示的此类网页的内容都在HTML源代码中。但是,由于主流网站都使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容不会出现在HTML源代码中,所以抓取静态网页的技术可能无法正常工作因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态捕捉示例
在抓取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果需要更新传统网页的内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的抓取过程比较麻烦。
首先,让我们看一个动态网页的例子。打开作者博客的Hello World文章,文章地址为:/2018/07/04/hello-world/。网址可能会变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的url地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。显示。
如图4-4所示,我们也可以查看该产品网页的源码。里面没有用户评论,这段内容是空白的。
如果使用 AJAX 加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2)Selenium 模拟浏览器爬行。
请查看第四章的其他章节
4.2 解析真实地址爬取
4.3 通过 selenium 模拟浏览器爬行 查看全部
第四章:动态网页抓取((解析真实地址+selenium)
第四章:动态网页爬取(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现更新到这里。请参考文章:
之前抓取的网页都是静态网页,浏览器中显示的此类网页的内容都在HTML源代码中。但是,由于主流网站都使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容不会出现在HTML源代码中,所以抓取静态网页的技术可能无法正常工作因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态捕捉示例
在抓取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果需要更新传统网页的内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的抓取过程比较麻烦。
首先,让我们看一个动态网页的例子。打开作者博客的Hello World文章,文章地址为:/2018/07/04/hello-world/。网址可能会变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的url地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。显示。
如图4-4所示,我们也可以查看该产品网页的源码。里面没有用户评论,这段内容是空白的。

如果使用 AJAX 加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2)Selenium 模拟浏览器爬行。
请查看第四章的其他章节
4.2 解析真实地址爬取
4.3 通过 selenium 模拟浏览器爬行
[RSS入门]不妨再受:你可能感兴趣的内容(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-08-27 07:12
我们每天都在接收信息。无论是社交网络好友分享的新鲜事物,还是今日头条等聚合阅读工具中的文章,依靠推荐算法,总能带来“你可能感兴趣的内容”。这些有用或无用的信息不仅消耗了我们大量的时间,无休止的“时间流”也让我们信息过载,无形中让我们接触到的信息种类越来越窄。 ”。
为了解决信息过载的问题,让我们在接收到的信息中掌握主动权,RSS重新进入了我们的视野:我们可以自由选择订阅的信息源,不受算法“控制” ,还要及时调整信息源,避免信息过载。
但是,由于RSS有一定的使用门槛,很多刚接触RSS的用户都无法回避一些问题,比如:
如果您在使用 RSS 获取信息的过程中也被工具和技术所困扰,不妨阅读这份 RSS 入门指南,与我们一起“摆脱”信息过载。
为什么选择 RSS
RSS的全称是ReallySimpleSyndication,是一种消息来源的格式规范。 网站可以向订阅者提供文章标题、摘要、全文等信息,用户按照这个格式规范可以通过订阅不同的网站RSS链接聚合不同的信息源,并在一个工具中阅读这些内容。
简单来说,RSS就是订阅某个网站内容更新的协议。这个略显“旧”的协议在社交媒体和聚合阅读的影响下逐渐走下坡路。就连谷歌也在 2013 年关闭了自己的 RSS 服务 GoogleReader。那么,我们为什么要选择 RSS?
当我还是学生的时候,我相信每个班级里都有两种人:调皮的学生和听话的学生。社交媒体、今日头条等聚合阅读工具与前者无异。他们不会乖乖按照你的要求做事。他们总能给你意想不到的惊喜(或惊吓)。相比之下,RSS学生比较听话,每天准时上课,交作业,从不出错。虽然顽皮的学生可以活跃课堂气氛,给生活增添乐趣,但老师往往会把重要的任务交给乖巧的学生。
信息的获取也是如此。社交媒体的混乱时间线和聚合阅读工具烦人的算法推荐,让我们无法高效获取所需信息。 RSS只抓取订阅的信息源,按时间顺序展示内容的特点,显然更符合我们作为一个想要掌控信息主动权的“老师”的期待。
相关阅读:你的新闻APP被推荐算法“毁了”,RSS真的能救你吗?
什么是RSS服务
虽然RSS只能呈现你订阅的内容,但并不是所有的网站都像少数人一样,每天只推送几个文章。以科技媒体Engadget为例,它每周推送数百条新闻。我相信你不想也没有时间一一阅读这些项目。这时候,如何使用RSS只查看自己想阅读的内容,防止信息过载就成了我们需要解决的问题。
RSS 服务是基于 RSS 协议开发的聚合服务。目前比较知名的RSS服务有Feedly、NewsBlur、Inoreader等,这些服务大部分都提供了过滤文章的功能。他们在可以自动抓取RSS提要中更新的内容的同时,也可以根据你设置的过滤条件,将符合条件的文章以文件夹或标签的形式聚合呈现给你,让你只能看到你想要的看到并告别信息过载。
此外,每个RSS服务也有自己独特的功能:例如Feedly支持文章内容的高亮和笔记,Inoreader支持丰富的过滤规则,可以链接自动化服务。您可以根据自己的需要选择合适的RSS服务,通过RSS获取信息越来越方便。
相关阅读:2018年选择哪些主流RSS服务? Feedly、Inoreader 和 NewsBlur 综合评论
如何查找 RSS 提要
就像给朋友打电话一样,你需要知道对方的号码才能建立连接。 RSS 也是如此。 RSS订阅链接相当于我们要拨打的电话号码。
了解网站是否支持RSS订阅最直接的方法就是查看网站底部或侧边栏是否有RSS图标。一般来说,图标指向的地址就是网站的订阅链接。您可以直接点击RSS订阅链接跳转到RSS客户端订阅,也可以将按钮中的地址复制粘贴到您正在使用的RSS服务订阅网站中的内容。
在大多数情况下,支持RSS订阅的网站会显示RSS图标。然而,总有例外。这时候你也可以尝试在网站域名后面加上/feed或者/rss。您可能会偶然猜到,例如少数 RSS 订阅链接。当然也可以直接通过搜索引擎使用网站名+RSS关键字搜索,经常可以找到支持网站的RSS链接。
除了手动搜索订阅链接,RSSHub Radar 是一款 Chrome 浏览器扩展,可以帮助您一键发现和订阅当前的网站 RSS 链接。如果您当前浏览的网页支持RSS,您可以通过本插件直接复制RSS订阅链接,或者订阅RSS链接到Feedly、Inoreader等RSS服务。
相关阅读:在网络上搜索RSS链接?为什么不使用这个Chrome插件一键订阅
如果您是 RSS 新手,您不知道哪个网站 值得订阅。除了小众,还可以订阅The Verge、9to5Mac获取苹果、三星等大公司的科技资讯,订阅核心获取主机游戏信息,订阅好奇日报获取行业新闻和生活信息。
如何自己制作 RSS 提要
当你想给没有号码的朋友打电话时,最简单的方法就是给他一个号码。 RSS 也是如此。我们常用的公众号、B站等网站不支持RSS,也许您想准确订阅特定页面。在这些情况下,学习如何制作 Feed 尤为重要。
借助 RSSHub 等工具,您可以轻松创建提要。比如我在哔哩哔哩发现了一位多产的UP主,名叫“Minority sspai”,想订阅他的视频更新。我们可以在他的个人空间找到这位UP主的UID:176321970。然后根据官方文档的介绍,填写UID完成制作。
RSSHub目前支持的网站已经很丰富了,足以满足生活中的大部分需求。少数族裔还分享了许多方便快捷的方式来创建提要。你可以参考这些文章:
对于追求更多可能性的高级用户,可以选择构建自己的RSS服务,满足更多个性化的需求。以下文章或许能帮到你:
构建RSS阅读流程
选择RSS服务后,我们当然希望提高阅读效率。粗读往往只是肤浅的信息。对于一些有价值的文章,花一些时间反复阅读和消化可能会更好。因此,构建适合您的阅读流程可以大大提高我们的效率。
虽然构建阅读过程听起来很复杂,但实际上很容易。简化后,其实只需要三步:
过滤内容来源:选择优质的Feed,使用RSS服务过滤内容,只留下你感兴趣的内容。分类处理文章:阅读标题、摘要,或者通读文章,善用“采集”和阅读后期工具,把有价值的文章留住。精读优质内容:在采集夹或阅读后期应用中,精读有价值的文章,并使用摘录、笔记等形式帮助消化内容。
相关阅读:在线阅读过程:从需求、到方法、再到工具
值得一试的RSS阅读工具
工人要想做好本职工作,就必须先磨砺他的工具。一旦我们掌握了获取提要的方法并构建了自己的阅读流程,我们还需要一个得心应手的工具。那么,我们如何选择工具呢?一个优秀的 RSS 工具应该做到以下几点:
支持您使用的服务:RSS 工具一般访问众所周知的服务,例如 Feedly 和 Innoreader。但是对于一些自建服务或者小众服务,每个应用的支持是有很大区别的。因此,RSS 工具是否支持您使用的服务是首先要考虑的。支持全文爬取:很多网站RSS采用“标题+摘要”的方式,需要用户手动打开网页阅读。支持全文爬取的客户端可以为我们省去不少精力。支持扩展服务等:支持“稍后阅读”服务、网页重定向等功能,可以大大提升我们的阅读体验。在构建RSS阅读流程时,此类工具可以帮助我们架起RSS与“稍后阅读”之间的界限。
如果您仍然不确定自己的需求,也没关系。我们为您精选了四大主流平台上最好的一批RSS工具,相信一定能让您满意。
macOS:Reeder4
Reeder 是 macOS 和 iOS 上的老牌 RSS 工具。它以操作流畅、设计精美而著称。在“百花盛开”的iOS平台上,虽然Reeder在功能上没有那么全面,但仍然是macOS最全的RSS客户端选择。
相关阅读
iOS:里拉
lire兼顾人性化设计和操作体验。该应用程序在支持全文抓取和手势操作等功能的同时,还支持自动化和旁白。您还可以在里拉中单独设置不同的提要,非常人性化。
相关阅读
Windows:RSS 跟踪
“RSS 跟踪”提供清晰的界面级别、便捷的获取提要的方式以及独特的特定于平台的时间轴和 OneDrive 同步方法。该应用程序支持手动输入提要、通过 Feedly 服务关键词 搜索或导入 OPML 文件。
相关阅读:无缝且无压力的 RSS 体验。此阅读器最适合 Windows 10:RSS Stalker
安卓:FeedMe
FeedMe 是一个简单的设计和全功能的 RSS 工具。由于网络环境的限制,我们在国内使用RSS服务时总会遇到障碍。 FeedMe贴心提供了“中国模式”,即使你没有开启网络代理,也能顺利获得文章更新。
相关阅读:Android上如何选择RSS阅读器?这7款好看好用的APP不容错过
如果您想与我们分享有关 RSS 的其他有用工具和技术,请在评论部分告诉我们。如果您想进一步了解RSS实用工具和技巧,可以阅读我们为您准备的RSS专题:
高效获取信息,从这些 RSS 工具和技术开始
>下载小众客户端,关注小众公众号,让您的工作更有效率⏱
>特殊好用的硬件产品,尽在小众sspai官方商城 查看全部
[RSS入门]不妨再受:你可能感兴趣的内容(组图)
我们每天都在接收信息。无论是社交网络好友分享的新鲜事物,还是今日头条等聚合阅读工具中的文章,依靠推荐算法,总能带来“你可能感兴趣的内容”。这些有用或无用的信息不仅消耗了我们大量的时间,无休止的“时间流”也让我们信息过载,无形中让我们接触到的信息种类越来越窄。 ”。
为了解决信息过载的问题,让我们在接收到的信息中掌握主动权,RSS重新进入了我们的视野:我们可以自由选择订阅的信息源,不受算法“控制” ,还要及时调整信息源,避免信息过载。
但是,由于RSS有一定的使用门槛,很多刚接触RSS的用户都无法回避一些问题,比如:
如果您在使用 RSS 获取信息的过程中也被工具和技术所困扰,不妨阅读这份 RSS 入门指南,与我们一起“摆脱”信息过载。
为什么选择 RSS
RSS的全称是ReallySimpleSyndication,是一种消息来源的格式规范。 网站可以向订阅者提供文章标题、摘要、全文等信息,用户按照这个格式规范可以通过订阅不同的网站RSS链接聚合不同的信息源,并在一个工具中阅读这些内容。
简单来说,RSS就是订阅某个网站内容更新的协议。这个略显“旧”的协议在社交媒体和聚合阅读的影响下逐渐走下坡路。就连谷歌也在 2013 年关闭了自己的 RSS 服务 GoogleReader。那么,我们为什么要选择 RSS?
当我还是学生的时候,我相信每个班级里都有两种人:调皮的学生和听话的学生。社交媒体、今日头条等聚合阅读工具与前者无异。他们不会乖乖按照你的要求做事。他们总能给你意想不到的惊喜(或惊吓)。相比之下,RSS学生比较听话,每天准时上课,交作业,从不出错。虽然顽皮的学生可以活跃课堂气氛,给生活增添乐趣,但老师往往会把重要的任务交给乖巧的学生。
信息的获取也是如此。社交媒体的混乱时间线和聚合阅读工具烦人的算法推荐,让我们无法高效获取所需信息。 RSS只抓取订阅的信息源,按时间顺序展示内容的特点,显然更符合我们作为一个想要掌控信息主动权的“老师”的期待。
相关阅读:你的新闻APP被推荐算法“毁了”,RSS真的能救你吗?
什么是RSS服务
虽然RSS只能呈现你订阅的内容,但并不是所有的网站都像少数人一样,每天只推送几个文章。以科技媒体Engadget为例,它每周推送数百条新闻。我相信你不想也没有时间一一阅读这些项目。这时候,如何使用RSS只查看自己想阅读的内容,防止信息过载就成了我们需要解决的问题。
RSS 服务是基于 RSS 协议开发的聚合服务。目前比较知名的RSS服务有Feedly、NewsBlur、Inoreader等,这些服务大部分都提供了过滤文章的功能。他们在可以自动抓取RSS提要中更新的内容的同时,也可以根据你设置的过滤条件,将符合条件的文章以文件夹或标签的形式聚合呈现给你,让你只能看到你想要的看到并告别信息过载。
此外,每个RSS服务也有自己独特的功能:例如Feedly支持文章内容的高亮和笔记,Inoreader支持丰富的过滤规则,可以链接自动化服务。您可以根据自己的需要选择合适的RSS服务,通过RSS获取信息越来越方便。
相关阅读:2018年选择哪些主流RSS服务? Feedly、Inoreader 和 NewsBlur 综合评论
如何查找 RSS 提要
就像给朋友打电话一样,你需要知道对方的号码才能建立连接。 RSS 也是如此。 RSS订阅链接相当于我们要拨打的电话号码。
了解网站是否支持RSS订阅最直接的方法就是查看网站底部或侧边栏是否有RSS图标。一般来说,图标指向的地址就是网站的订阅链接。您可以直接点击RSS订阅链接跳转到RSS客户端订阅,也可以将按钮中的地址复制粘贴到您正在使用的RSS服务订阅网站中的内容。

在大多数情况下,支持RSS订阅的网站会显示RSS图标。然而,总有例外。这时候你也可以尝试在网站域名后面加上/feed或者/rss。您可能会偶然猜到,例如少数 RSS 订阅链接。当然也可以直接通过搜索引擎使用网站名+RSS关键字搜索,经常可以找到支持网站的RSS链接。

除了手动搜索订阅链接,RSSHub Radar 是一款 Chrome 浏览器扩展,可以帮助您一键发现和订阅当前的网站 RSS 链接。如果您当前浏览的网页支持RSS,您可以通过本插件直接复制RSS订阅链接,或者订阅RSS链接到Feedly、Inoreader等RSS服务。
相关阅读:在网络上搜索RSS链接?为什么不使用这个Chrome插件一键订阅
如果您是 RSS 新手,您不知道哪个网站 值得订阅。除了小众,还可以订阅The Verge、9to5Mac获取苹果、三星等大公司的科技资讯,订阅核心获取主机游戏信息,订阅好奇日报获取行业新闻和生活信息。
如何自己制作 RSS 提要
当你想给没有号码的朋友打电话时,最简单的方法就是给他一个号码。 RSS 也是如此。我们常用的公众号、B站等网站不支持RSS,也许您想准确订阅特定页面。在这些情况下,学习如何制作 Feed 尤为重要。
借助 RSSHub 等工具,您可以轻松创建提要。比如我在哔哩哔哩发现了一位多产的UP主,名叫“Minority sspai”,想订阅他的视频更新。我们可以在他的个人空间找到这位UP主的UID:176321970。然后根据官方文档的介绍,填写UID完成制作。

RSSHub目前支持的网站已经很丰富了,足以满足生活中的大部分需求。少数族裔还分享了许多方便快捷的方式来创建提要。你可以参考这些文章:
对于追求更多可能性的高级用户,可以选择构建自己的RSS服务,满足更多个性化的需求。以下文章或许能帮到你:
构建RSS阅读流程
选择RSS服务后,我们当然希望提高阅读效率。粗读往往只是肤浅的信息。对于一些有价值的文章,花一些时间反复阅读和消化可能会更好。因此,构建适合您的阅读流程可以大大提高我们的效率。
虽然构建阅读过程听起来很复杂,但实际上很容易。简化后,其实只需要三步:
过滤内容来源:选择优质的Feed,使用RSS服务过滤内容,只留下你感兴趣的内容。分类处理文章:阅读标题、摘要,或者通读文章,善用“采集”和阅读后期工具,把有价值的文章留住。精读优质内容:在采集夹或阅读后期应用中,精读有价值的文章,并使用摘录、笔记等形式帮助消化内容。
相关阅读:在线阅读过程:从需求、到方法、再到工具
值得一试的RSS阅读工具
工人要想做好本职工作,就必须先磨砺他的工具。一旦我们掌握了获取提要的方法并构建了自己的阅读流程,我们还需要一个得心应手的工具。那么,我们如何选择工具呢?一个优秀的 RSS 工具应该做到以下几点:
支持您使用的服务:RSS 工具一般访问众所周知的服务,例如 Feedly 和 Innoreader。但是对于一些自建服务或者小众服务,每个应用的支持是有很大区别的。因此,RSS 工具是否支持您使用的服务是首先要考虑的。支持全文爬取:很多网站RSS采用“标题+摘要”的方式,需要用户手动打开网页阅读。支持全文爬取的客户端可以为我们省去不少精力。支持扩展服务等:支持“稍后阅读”服务、网页重定向等功能,可以大大提升我们的阅读体验。在构建RSS阅读流程时,此类工具可以帮助我们架起RSS与“稍后阅读”之间的界限。
如果您仍然不确定自己的需求,也没关系。我们为您精选了四大主流平台上最好的一批RSS工具,相信一定能让您满意。
macOS:Reeder4
Reeder 是 macOS 和 iOS 上的老牌 RSS 工具。它以操作流畅、设计精美而著称。在“百花盛开”的iOS平台上,虽然Reeder在功能上没有那么全面,但仍然是macOS最全的RSS客户端选择。

相关阅读
iOS:里拉
lire兼顾人性化设计和操作体验。该应用程序在支持全文抓取和手势操作等功能的同时,还支持自动化和旁白。您还可以在里拉中单独设置不同的提要,非常人性化。

相关阅读
Windows:RSS 跟踪
“RSS 跟踪”提供清晰的界面级别、便捷的获取提要的方式以及独特的特定于平台的时间轴和 OneDrive 同步方法。该应用程序支持手动输入提要、通过 Feedly 服务关键词 搜索或导入 OPML 文件。

相关阅读:无缝且无压力的 RSS 体验。此阅读器最适合 Windows 10:RSS Stalker
安卓:FeedMe
FeedMe 是一个简单的设计和全功能的 RSS 工具。由于网络环境的限制,我们在国内使用RSS服务时总会遇到障碍。 FeedMe贴心提供了“中国模式”,即使你没有开启网络代理,也能顺利获得文章更新。

相关阅读:Android上如何选择RSS阅读器?这7款好看好用的APP不容错过
如果您想与我们分享有关 RSS 的其他有用工具和技术,请在评论部分告诉我们。如果您想进一步了解RSS实用工具和技巧,可以阅读我们为您准备的RSS专题:
高效获取信息,从这些 RSS 工具和技术开始
>下载小众客户端,关注小众公众号,让您的工作更有效率⏱
>特殊好用的硬件产品,尽在小众sspai官方商城
百度站长平台权威解答会的SEO的问题分析与对策
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-27 07:10
问题:百度搜索会不会调整网站的抓取频率?
百度站长平台权威解答
会的。百度搜索会根据网站内容质量、内容更新频率、网站规模变化等维度进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会减少对网站频率的抓取。
不过,爬取频率不一定与收录量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
沐风SEO讲解
从实际案例来看,百度搜索在调整网站的爬取频率上是比较有效的,尤其是对于原来爬取频率很低的,比如新站。百度搜索提到了影响蜘蛛爬行的几个重要方面,即内容质量、内容更新频率、网站尺度的变化。
这实际上为我指明了方向。我想提高网站的抓取频率,可以提高内容质量,增加内容更新的频率和数量。
其实经过正规优化的网站通常不用担心爬取频率低的问题,因为正规的白帽SEO可以做到以上三个方面。对于那些想要省力又想有好结果的人来说,恐怕不会那么令人满意。
即便如此,百度在调整抓取频率方面仍有很大的提升空间,因为它无法及时分析网站内容。一些采集站的爬取频率也很高,这就是原因。
总之,百度搜索会不定期调整网站的抓取频率。想要这个爬虫频率稳步上升,就必须控制网站内容的质量,以及更新频率和数量。只有网站的内容质量高,网站的体积更大,爬取频率才会越来越好。 查看全部
百度站长平台权威解答会的SEO的问题分析与对策
问题:百度搜索会不会调整网站的抓取频率?
百度站长平台权威解答
会的。百度搜索会根据网站内容质量、内容更新频率、网站规模变化等维度进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会减少对网站频率的抓取。
不过,爬取频率不一定与收录量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
沐风SEO讲解
从实际案例来看,百度搜索在调整网站的爬取频率上是比较有效的,尤其是对于原来爬取频率很低的,比如新站。百度搜索提到了影响蜘蛛爬行的几个重要方面,即内容质量、内容更新频率、网站尺度的变化。
这实际上为我指明了方向。我想提高网站的抓取频率,可以提高内容质量,增加内容更新的频率和数量。
其实经过正规优化的网站通常不用担心爬取频率低的问题,因为正规的白帽SEO可以做到以上三个方面。对于那些想要省力又想有好结果的人来说,恐怕不会那么令人满意。
即便如此,百度在调整抓取频率方面仍有很大的提升空间,因为它无法及时分析网站内容。一些采集站的爬取频率也很高,这就是原因。
总之,百度搜索会不定期调整网站的抓取频率。想要这个爬虫频率稳步上升,就必须控制网站内容的质量,以及更新频率和数量。只有网站的内容质量高,网站的体积更大,爬取频率才会越来越好。
robots协议文件屏蔽百度蜘蛛抓取协议的设置比较简单
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-08-27 07:08
百度蜘蛛抓取我们的网站,希望我们的网页收录能被发送到它的搜索引擎。以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候我们只想抓取我们想在搜索引擎上搜索到的内容。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。有两种最好的方法可以解决这个问题,如下所示:
robots 协议文件阻止百度蜘蛛抓取
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:您的域名/robots.txt。百度蜘蛛抓取我们网站时,会先访问这个文件。因为它告诉蜘蛛哪些可以爬,哪些不能爬。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow三个参数进行设置。
让我们看下面的例子。场景是我不想百度抢到我所有的网站css文件、数据目录、seo-tag.html页面
User-Agent: Baidusppider
Disallow: /*.css
Disallow: /data/
Disallow: /seo/seo-tag.html
如上,user-agent声明的蜘蛛名称表示针对百度蜘蛛。以下无法抓取“/*.css”。首先,前面的/指的是根目录,也就是你的域名。 * 是通配符,代表任何内容。这意味着无法抓取所有以 .css 结尾的文件。亲自体验以下两个。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
403 状态码用于限制内容输出并阻止蜘蛛抓取。
403状态码是http协议中网页返回的状态码。当搜索引擎遇到403状态码时,就知道该类页面是权限受限的。我不能访问。比如你需要登录查看内容,搜索引擎本身是不会登录的,那么当你返回403时,他也知道这是权限设置页面,无法读取内容。自然,收录 不会。
在返回 403 状态代码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛执行他们想要访问的内容。两者缺一不可。你只有一个提示页面,状态码返回200,对于百度蜘蛛来说是很多重复的页面。有一个 403 状态代码,但返回不同的内容。也不是很友好。
最后,关于robot协议,我想补充一点:“现在搜索引擎会通过你网页的布局和布局来识别你网页的体验友好性。如果你屏蔽了css文件的抓取和布局相关的js文件,那么搜索引擎不知道你的网页布局是好是坏,所以不建议蜘蛛屏蔽这个内容。”
好了,今天的分享就到这里,希望对大家有帮助,当然以上两个设置对百度蜘蛛以外的所有蜘蛛都有效。设置时请谨慎。
延伸阅读
原创文章:《如何阻止百度蜘蛛(Baiduspider)爬取网站》,作者:赵延刚。未经许可请勿转载。如转载请注明出处: 查看全部
robots协议文件屏蔽百度蜘蛛抓取协议的设置比较简单
百度蜘蛛抓取我们的网站,希望我们的网页收录能被发送到它的搜索引擎。以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候我们只想抓取我们想在搜索引擎上搜索到的内容。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。有两种最好的方法可以解决这个问题,如下所示:
robots 协议文件阻止百度蜘蛛抓取
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:您的域名/robots.txt。百度蜘蛛抓取我们网站时,会先访问这个文件。因为它告诉蜘蛛哪些可以爬,哪些不能爬。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow三个参数进行设置。
让我们看下面的例子。场景是我不想百度抢到我所有的网站css文件、数据目录、seo-tag.html页面
User-Agent: Baidusppider
Disallow: /*.css
Disallow: /data/
Disallow: /seo/seo-tag.html
如上,user-agent声明的蜘蛛名称表示针对百度蜘蛛。以下无法抓取“/*.css”。首先,前面的/指的是根目录,也就是你的域名。 * 是通配符,代表任何内容。这意味着无法抓取所有以 .css 结尾的文件。亲自体验以下两个。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
403 状态码用于限制内容输出并阻止蜘蛛抓取。
403状态码是http协议中网页返回的状态码。当搜索引擎遇到403状态码时,就知道该类页面是权限受限的。我不能访问。比如你需要登录查看内容,搜索引擎本身是不会登录的,那么当你返回403时,他也知道这是权限设置页面,无法读取内容。自然,收录 不会。
在返回 403 状态代码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛执行他们想要访问的内容。两者缺一不可。你只有一个提示页面,状态码返回200,对于百度蜘蛛来说是很多重复的页面。有一个 403 状态代码,但返回不同的内容。也不是很友好。
最后,关于robot协议,我想补充一点:“现在搜索引擎会通过你网页的布局和布局来识别你网页的体验友好性。如果你屏蔽了css文件的抓取和布局相关的js文件,那么搜索引擎不知道你的网页布局是好是坏,所以不建议蜘蛛屏蔽这个内容。”
好了,今天的分享就到这里,希望对大家有帮助,当然以上两个设置对百度蜘蛛以外的所有蜘蛛都有效。设置时请谨慎。
延伸阅读
原创文章:《如何阻止百度蜘蛛(Baiduspider)爬取网站》,作者:赵延刚。未经许可请勿转载。如转载请注明出处:
在搜索引擎眼里什么才叫高质量的文章吗?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-24 07:19
你知道什么是搜索引擎眼中的优质文章吗?
在SEO圈子里,“内容”必须是一个经久不衰的话题。虽然各个阶段的搜索引擎算法对SEO有不同的规范,但智能算法也让深圳的SEO工作越来越多。不简短,但“好内容”永远是包围的工具。那么问题来了,什么样的内容才是搜索引擎眼中的“优质内容”?
简而言之,“优质内容”是好的内容、优质的代码和出色的用户体验的结合。
一、基本规范
内容最基本的部分是“文本”。写文章时,不得出现错别字、连线、无标点、无分词的长篇幅讨论;不要使用hard、deep,对于难懂的词句,尽量使用简单直观的句子,便于各级用户理解。
二、排版布局
要想制作出让用户满意的“优质内容”,除了内容本身,布局也是一项非常重要的工作。毕竟,人是视觉动物。
将文本内容划分为标题、副标题、正文等不同类型,然后让文本以突出的水平履行职责。清晰的层次结构可以让内容更具可读性,搭配适当的图形会让文章显得更加生动。此外,针对不同的文本类型使用不同格式、大小和颜色的字体也可以让用户获得更好的阅读体验。引用其他平台内容时,尽量保证链接指向高质量、有声望的网站(如政府平台、官方网站等)。
三、加载速度
“网站Loading Speed”到底有多重要?根据调研查询,网站loading时间过长是造成用户流失的主要原因之一,尤其是电商网站So。
“网站Load Speed”与“用户购买行为”的联系如下图所示:
快节奏的日子导致用户缺乏耐心,尤其是在阅读网页时。可以说,速度是网站victory 决议最重要的因素之一。 网站加载时间增加1秒可能导致:转化率下降7%,用户满意度下降16%...
那么,怎样才能提高“加载速度”呢?这里有几点:
1)将JS代码和CSS样式分别合并到一个共享文件中;
2) 适当缩小图片,优化格式;
3)优先显示可见区域的内容,即先加载首屏的内容和样式,当用户滚动鼠标时加载下面的内容;
4) 减去代码,去掉不必要的冗余代码,如空格、注释等
5)Cache 静态资源,通过设置reader缓存来缓存CSS、JS等不经常更新的文件;
四、立异性
现在,互联网、社交媒体、自媒体等平台上总是充斥着“文章怎么写”的套路和教程,比如“10W+的文章头衔怎么写”和“自媒体人必知“10W+文章技能”……等等,导致“内容生产者”文章总是按套路开始写作,失去创新,不断趋于同质化,甚至用户看到在一开始觉得沉闷。
所以,想要被用户喜爱,要么写出有深度、有见地、有沉淀、非商业性的内容。这对很多站长来说比较困难;另一种是写“小说”,这种想法iDea,对写作的要求稍微低一些,但是有一定的需求,比如我们都在写《鹿晗和晓彤秀恩爱》的时候,谁会写《为什么鹿晗》第一刻我没有选择迪丽热巴,这样文章的作者肯定会得到更多的关注(也许文章这样的一些人会被网友喷,但肯定会得到关注)。
那么,应该如何学习 SEO 技术?
这里说的有点多,毕竟涉及的知识还是很多的。一时还不清楚。
如果你也想学习SEO技术,可以加千墨老师微信m247143276接收SEO技术教程,也可以加入学习群和我们seo研究中心老师一起学习。返回搜狐查看更多 查看全部
在搜索引擎眼里什么才叫高质量的文章吗?(图)
你知道什么是搜索引擎眼中的优质文章吗?
在SEO圈子里,“内容”必须是一个经久不衰的话题。虽然各个阶段的搜索引擎算法对SEO有不同的规范,但智能算法也让深圳的SEO工作越来越多。不简短,但“好内容”永远是包围的工具。那么问题来了,什么样的内容才是搜索引擎眼中的“优质内容”?
简而言之,“优质内容”是好的内容、优质的代码和出色的用户体验的结合。
一、基本规范

内容最基本的部分是“文本”。写文章时,不得出现错别字、连线、无标点、无分词的长篇幅讨论;不要使用hard、deep,对于难懂的词句,尽量使用简单直观的句子,便于各级用户理解。
二、排版布局
要想制作出让用户满意的“优质内容”,除了内容本身,布局也是一项非常重要的工作。毕竟,人是视觉动物。

将文本内容划分为标题、副标题、正文等不同类型,然后让文本以突出的水平履行职责。清晰的层次结构可以让内容更具可读性,搭配适当的图形会让文章显得更加生动。此外,针对不同的文本类型使用不同格式、大小和颜色的字体也可以让用户获得更好的阅读体验。引用其他平台内容时,尽量保证链接指向高质量、有声望的网站(如政府平台、官方网站等)。
三、加载速度
“网站Loading Speed”到底有多重要?根据调研查询,网站loading时间过长是造成用户流失的主要原因之一,尤其是电商网站So。
“网站Load Speed”与“用户购买行为”的联系如下图所示:

快节奏的日子导致用户缺乏耐心,尤其是在阅读网页时。可以说,速度是网站victory 决议最重要的因素之一。 网站加载时间增加1秒可能导致:转化率下降7%,用户满意度下降16%...

那么,怎样才能提高“加载速度”呢?这里有几点:
1)将JS代码和CSS样式分别合并到一个共享文件中;
2) 适当缩小图片,优化格式;
3)优先显示可见区域的内容,即先加载首屏的内容和样式,当用户滚动鼠标时加载下面的内容;
4) 减去代码,去掉不必要的冗余代码,如空格、注释等
5)Cache 静态资源,通过设置reader缓存来缓存CSS、JS等不经常更新的文件;
四、立异性
现在,互联网、社交媒体、自媒体等平台上总是充斥着“文章怎么写”的套路和教程,比如“10W+的文章头衔怎么写”和“自媒体人必知“10W+文章技能”……等等,导致“内容生产者”文章总是按套路开始写作,失去创新,不断趋于同质化,甚至用户看到在一开始觉得沉闷。

所以,想要被用户喜爱,要么写出有深度、有见地、有沉淀、非商业性的内容。这对很多站长来说比较困难;另一种是写“小说”,这种想法iDea,对写作的要求稍微低一些,但是有一定的需求,比如我们都在写《鹿晗和晓彤秀恩爱》的时候,谁会写《为什么鹿晗》第一刻我没有选择迪丽热巴,这样文章的作者肯定会得到更多的关注(也许文章这样的一些人会被网友喷,但肯定会得到关注)。
那么,应该如何学习 SEO 技术?
这里说的有点多,毕竟涉及的知识还是很多的。一时还不清楚。
如果你也想学习SEO技术,可以加千墨老师微信m247143276接收SEO技术教程,也可以加入学习群和我们seo研究中心老师一起学习。返回搜狐查看更多
网页书籍抓取器(网页内容抓取工具)是一款很优秀好用
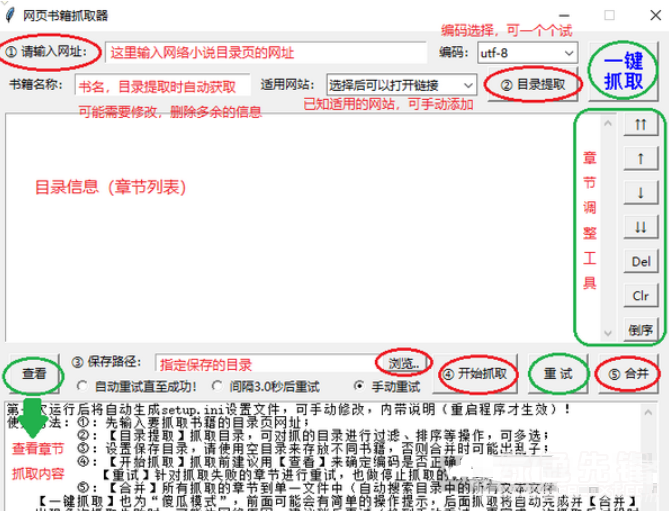
网站优化 • 优采云 发表了文章 • 0 个评论 • 477 次浏览 • 2021-08-24 07:16
Web Book Crawler(Web Content Crawling Tool)是一款优秀且易于使用的网络内容爬行助手。如何更轻松地抓取网页内容?编辑器带来的这个网络图书抓取器可以帮助您。它功能强大且易于操作。使用后,用户可以快速轻松地抓取网页内容。可以很好的帮助大家抓取指定网页的内容,比如抓取一些小说内容,然后通过合并功能合并成一个完整的小说文本。欢迎有需要的朋友下载使用。
软件功能:
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、Automatic retry:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),待网络良好后再试。
3、Stop and resume:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,程序执行后可以恢复抓取下次运行。注意:需要先用停止按钮中断然后退出程序,如果直接退出,将不会恢复)
4、 一键抓图:又称“傻瓜模式”,基本可以实现全自动抓图合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
5、Applicable网站:已经输入了10个适用的网站(选择后可以快速打开网站找到需要的书),自动应用相应的代码,其他小说也可以应用网站进行测试,如果一起使用,可以手动添加到配置文件中以备后用。
6、电子书制作方便:可以在设置文件中添加各章节名称的前缀和后缀,为后期制作电子书目录带来极大的方便。
使用说明:
网络图书抓取器可以提取和调整指定小说目录页的章节信息,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
使用方法:
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击开始爬取开始下载。
软件介绍:
网络图书抓取器是一种可以帮助用户下载某本书和指定网页的某个章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,有需要的可以下载使用。
查看全部
网页书籍抓取器(网页内容抓取工具)是一款很优秀好用
Web Book Crawler(Web Content Crawling Tool)是一款优秀且易于使用的网络内容爬行助手。如何更轻松地抓取网页内容?编辑器带来的这个网络图书抓取器可以帮助您。它功能强大且易于操作。使用后,用户可以快速轻松地抓取网页内容。可以很好的帮助大家抓取指定网页的内容,比如抓取一些小说内容,然后通过合并功能合并成一个完整的小说文本。欢迎有需要的朋友下载使用。
软件功能:
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、Automatic retry:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),待网络良好后再试。
3、Stop and resume:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,程序执行后可以恢复抓取下次运行。注意:需要先用停止按钮中断然后退出程序,如果直接退出,将不会恢复)
4、 一键抓图:又称“傻瓜模式”,基本可以实现全自动抓图合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
5、Applicable网站:已经输入了10个适用的网站(选择后可以快速打开网站找到需要的书),自动应用相应的代码,其他小说也可以应用网站进行测试,如果一起使用,可以手动添加到配置文件中以备后用。
6、电子书制作方便:可以在设置文件中添加各章节名称的前缀和后缀,为后期制作电子书目录带来极大的方便。
使用说明:
网络图书抓取器可以提取和调整指定小说目录页的章节信息,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
使用方法:
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击开始爬取开始下载。
软件介绍:
网络图书抓取器是一种可以帮助用户下载某本书和指定网页的某个章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,有需要的可以下载使用。
网站页面不是让搜索引擎抓的越多越好吗,怎么让冗余
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-08-24 07:09
项目招商找A5快速获取精准代理商名单
有些朋友可能会奇怪网站的页面没有被搜索引擎尽可能多的抓取,怎么可能有想法不让网站页面的内容被抓取。
首先,可以分配给网站的权重是有限的。即使是Pr10站,也不可能无限分配权重。这个权重包括链接到他人网站的链和自己网站内部的链。
对于外部链接,除非是想被链接的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
链内,因为一些网站有很多重复或冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说极其方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外网站管理登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,需要防止网页的某些内容,或某些页面被搜索引擎收录搜索到。
下面笔者先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为收录的内容
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为 Google 和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个多用于网站管理页面、测试页面等
3.使用nofollow标签包裹你不想成为收录的内容
这个方法不能完全保证你不会被收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4.使用Meta Noindex标签添加关注标签
这个方法既可以防止收录,也可以传递权重。想通过就看网站建筑站长的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件,在页面上使用iframe标签显示需要搜索引擎收录的内容
robots 文件可以防止 iframe 标签之外的内容被收录。因此,您可以将不需要的内容收录 放在普通页面标签下。而想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表格
谷歌和百度已经可以抓取表单内容,收录无法屏蔽。
2.使用Javascript和Ajax技术
就目前的技术而言,Ajax 和 javascript 的最终计算结果还是以 HTML 的形式传递给浏览器进行显示,所以这也无法阻止收录。
初学者大多关注如何收录,但细节决定成败。如何防止网站页面内容被抓取也是高级SEO人需要注意的问题。
本文来自(),尊重作者的劳动成果,转载请注明出处。
申请创业报告,分享创业好点子。点击这里一起讨论创业的新机会! 查看全部
网站页面不是让搜索引擎抓的越多越好吗,怎么让冗余
项目招商找A5快速获取精准代理商名单
有些朋友可能会奇怪网站的页面没有被搜索引擎尽可能多的抓取,怎么可能有想法不让网站页面的内容被抓取。
首先,可以分配给网站的权重是有限的。即使是Pr10站,也不可能无限分配权重。这个权重包括链接到他人网站的链和自己网站内部的链。
对于外部链接,除非是想被链接的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
链内,因为一些网站有很多重复或冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说极其方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外网站管理登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,需要防止网页的某些内容,或某些页面被搜索引擎收录搜索到。
下面笔者先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为收录的内容
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为 Google 和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个多用于网站管理页面、测试页面等
3.使用nofollow标签包裹你不想成为收录的内容
这个方法不能完全保证你不会被收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4.使用Meta Noindex标签添加关注标签
这个方法既可以防止收录,也可以传递权重。想通过就看网站建筑站长的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件,在页面上使用iframe标签显示需要搜索引擎收录的内容
robots 文件可以防止 iframe 标签之外的内容被收录。因此,您可以将不需要的内容收录 放在普通页面标签下。而想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表格
谷歌和百度已经可以抓取表单内容,收录无法屏蔽。
2.使用Javascript和Ajax技术
就目前的技术而言,Ajax 和 javascript 的最终计算结果还是以 HTML 的形式传递给浏览器进行显示,所以这也无法阻止收录。
初学者大多关注如何收录,但细节决定成败。如何防止网站页面内容被抓取也是高级SEO人需要注意的问题。
本文来自(),尊重作者的劳动成果,转载请注明出处。
申请创业报告,分享创业好点子。点击这里一起讨论创业的新机会!
搜索引擎是如何抓取内容的?决的条件是什么
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-22 22:38
我们在做关键词排名的时候,第一步就是让搜索引擎抓住我们的网站。作为第一个前提,今天我要告诉你搜索引擎是如何抓取内容的。
如何抓取:
第一步:发现网站Webpage
搜索引擎通常会通过一些其他链接找到新的网站 和网页。所以,当搜索引擎找到网站时,需要添加合适的外链,内链也要丰富、干练。让搜索引擎发送的蜘蛛从内链顺利抓取,以便抓取新页面
第 2 步:搜索网站page
一旦某个网页被百度等搜索引擎理解,就会使用某个“站点”来搜索这些网页。您可能希望搜索整个网站。但是,这很可能受到搜索效率低或基础设施(阻止网站登录网站)等因素的阻碍。
第 3 步:提取内容
搜索引擎发送的蜘蛛一旦登陆页面,就会被选择性存储,搜索引擎会考虑是否存储内容。如果他们认为这些内容大部分比较空洞或者价值不大,那么他们通常不会存储网页(例如,这些网页可能是网站上其他网页内容的总和)。重复内容的常见原因之一是合并,也就是索引。
注意事项:
1、目录问题
我们可以在访问日记中看到蜘蛛的爬行轨迹。在后台,我们将未使用的页面放在不同的目录中。最好直接禁止一些不需要蜘蛛爬行的目录。
.
2、page 状态码
301跳转和404页面的规划很重要。如果外链连接的对应页面在后台被删除了,404页面没有很好的引导客户,那就麻烦了。而且302和301的效果不同,302无助于集中权力。 查看全部
搜索引擎是如何抓取内容的?决的条件是什么
我们在做关键词排名的时候,第一步就是让搜索引擎抓住我们的网站。作为第一个前提,今天我要告诉你搜索引擎是如何抓取内容的。

如何抓取:
第一步:发现网站Webpage
搜索引擎通常会通过一些其他链接找到新的网站 和网页。所以,当搜索引擎找到网站时,需要添加合适的外链,内链也要丰富、干练。让搜索引擎发送的蜘蛛从内链顺利抓取,以便抓取新页面
第 2 步:搜索网站page
一旦某个网页被百度等搜索引擎理解,就会使用某个“站点”来搜索这些网页。您可能希望搜索整个网站。但是,这很可能受到搜索效率低或基础设施(阻止网站登录网站)等因素的阻碍。
第 3 步:提取内容
搜索引擎发送的蜘蛛一旦登陆页面,就会被选择性存储,搜索引擎会考虑是否存储内容。如果他们认为这些内容大部分比较空洞或者价值不大,那么他们通常不会存储网页(例如,这些网页可能是网站上其他网页内容的总和)。重复内容的常见原因之一是合并,也就是索引。
注意事项:
1、目录问题
我们可以在访问日记中看到蜘蛛的爬行轨迹。在后台,我们将未使用的页面放在不同的目录中。最好直接禁止一些不需要蜘蛛爬行的目录。
.
2、page 状态码
301跳转和404页面的规划很重要。如果外链连接的对应页面在后台被删除了,404页面没有很好的引导客户,那就麻烦了。而且302和301的效果不同,302无助于集中权力。
抓取网页中的特定内容-抓取网并提取网页源码
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-08-22 19:05
背景
很多时候,很多人需要抓取网页上的某些特定内容。
不过,除了前面介绍的,我还想从一些静态网页中提取具体的内容,比如:
【教程】python版爬取网页并提取网页中需要的信息
和
【教程】C#版抓取网页并提取网页中需要的信息
除了
,有些人会发现自己要爬取的网页的内容不在网页的源代码中。
所以,这个时候,我不知道如何实现它。
在这里,让我们解释一下如何抓取所谓的动态网页中的特定内容。
必备知识
阅读本文前,您需要具备相关的基础知识:
1.Fetch 网页,模拟登录等相关逻辑
不熟悉的请参考:
【整理中】关于爬取网页、分析网页内容、模拟登录网站的逻辑/流程及注意事项
2.学习使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的请参考:
【教程】教你使用工具(IE9中F12)分析模拟登录网站(百度首页)内部逻辑流程)
3.对于普通静态网页,如何提取需要的内容
如果你对此不熟悉,可以参考:
(1)Python 版本:
【教程】python版爬取网页并提取网页中需要的信息
(2)C#Version:
【教程】C#版抓取网页并提取网页中需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指在浏览器中查看网页源代码时所看到的网页源代码中的内容以及网页上显示的内容。
也就是说,当我想在网页上显示某个内容时,可以通过搜索网页的源代码来找到相应的部分。
对于动态网页,则相反,如果想获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
简而言之,它是通过其他方式生成或获得的。
目前,我学到了几件事:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个URL的过程,你会发现很可能会涉及到,
在网页正常显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些想要抓取的内容,有时这些js脚本是动态执行最后计算出来的。
通过访问另一个 url 地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要爬取的动态内容
其实,关于如何抓取需要的动态内容,简单来说,有一个解决方案:
根据自己通过工具分析的结果,自己找到对应的数据,提取出来;
只是这样,有时可以在分析结果的过程中直接提取这些数据,有时可能会通过js进行计算。
如果要抓取数据,由js脚本生成
虽然最终的一些动态内容是通过js脚本的执行产生的,但是对于你想要抓取的数据:
你要抓取的数据是通过访问另一个url获取的
如果对应你要抓取的内容,需要访问另外一个url地址和返回的数据,那么就很简单了,你也需要单独访问这个url,然后获取对应的返回内容,并提取你从它得到你想要的数据。
总结
同一句话,不管你访问的内容是怎么生成的,最后还是可以用工具分析一下对应的内容是怎么从头生成的。
然后用代码模拟这个过程,最后提取出你需要的; 查看全部
抓取网页中的特定内容-抓取网并提取网页源码
背景
很多时候,很多人需要抓取网页上的某些特定内容。
不过,除了前面介绍的,我还想从一些静态网页中提取具体的内容,比如:
【教程】python版爬取网页并提取网页中需要的信息
和
【教程】C#版抓取网页并提取网页中需要的信息
除了
,有些人会发现自己要爬取的网页的内容不在网页的源代码中。
所以,这个时候,我不知道如何实现它。
在这里,让我们解释一下如何抓取所谓的动态网页中的特定内容。
必备知识
阅读本文前,您需要具备相关的基础知识:
1.Fetch 网页,模拟登录等相关逻辑
不熟悉的请参考:
【整理中】关于爬取网页、分析网页内容、模拟登录网站的逻辑/流程及注意事项
2.学习使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的请参考:
【教程】教你使用工具(IE9中F12)分析模拟登录网站(百度首页)内部逻辑流程)
3.对于普通静态网页,如何提取需要的内容
如果你对此不熟悉,可以参考:
(1)Python 版本:
【教程】python版爬取网页并提取网页中需要的信息
(2)C#Version:
【教程】C#版抓取网页并提取网页中需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指在浏览器中查看网页源代码时所看到的网页源代码中的内容以及网页上显示的内容。
也就是说,当我想在网页上显示某个内容时,可以通过搜索网页的源代码来找到相应的部分。
对于动态网页,则相反,如果想获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
简而言之,它是通过其他方式生成或获得的。
目前,我学到了几件事:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个URL的过程,你会发现很可能会涉及到,
在网页正常显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些想要抓取的内容,有时这些js脚本是动态执行最后计算出来的。
通过访问另一个 url 地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要爬取的动态内容
其实,关于如何抓取需要的动态内容,简单来说,有一个解决方案:
根据自己通过工具分析的结果,自己找到对应的数据,提取出来;
只是这样,有时可以在分析结果的过程中直接提取这些数据,有时可能会通过js进行计算。
如果要抓取数据,由js脚本生成
虽然最终的一些动态内容是通过js脚本的执行产生的,但是对于你想要抓取的数据:
你要抓取的数据是通过访问另一个url获取的
如果对应你要抓取的内容,需要访问另外一个url地址和返回的数据,那么就很简单了,你也需要单独访问这个url,然后获取对应的返回内容,并提取你从它得到你想要的数据。
总结
同一句话,不管你访问的内容是怎么生成的,最后还是可以用工具分析一下对应的内容是怎么从头生成的。
然后用代码模拟这个过程,最后提取出你需要的;
如何爬取不同不同分页类型网站的数据教你使用Python并存储网页数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-08-20 23:00
如何爬取不同分页类型的数据网站,因为内容比较多,我会放到本文下一节详细介绍。 3.过滤表单网页在网站 上更为常见。这种网页最大的特点就是过滤项很多,不同的选项不会加载。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。
内容抓取-内容可以从网站 抓取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到你的网站,让你的网站内容打开。
网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员...
Python 爬虫入门!它将教您如何抓取网络数据。
它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。 查看全部
如何爬取不同不同分页类型网站的数据教你使用Python并存储网页数据
如何爬取不同分页类型的数据网站,因为内容比较多,我会放到本文下一节详细介绍。 3.过滤表单网页在网站 上更为常见。这种网页最大的特点就是过滤项很多,不同的选项不会加载。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。
内容抓取-内容可以从网站 抓取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到你的网站,让你的网站内容打开。

网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员...
Python 爬虫入门!它将教您如何抓取网络数据。

它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。
阿里云为您提供网站内容抓取工具相关的8933条产品文档内容及常见问题解答内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-20 22:39
阿里巴巴云为您提供8933产品文档内容和网站内容爬虫工具相关FAQ,以及路由网站打不开网页怎么办,计算机网络技术大学毕业论文,关键value Store kvstore,以下哪个是数据库,以及其他云计算产品。
网页内容的智能抓取和详细的实战实例,完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用程序的开源组件包括:DOM4J: Parsing XMLjericho-。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .
它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。
内容抓取-内容可以从网站 抓取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到你的网站,让你的网站内容打开。
爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行庞大的爬虫系统,从网站全世界爬取。
优采云采集器免费网络爬虫软件_网络大数据爬虫工具。
1.打开站长工具,在网页信息查询中,找到模拟机器人抓取。2.输入自己的网站网址,输入,点击查询。这时候会在下面显示你的网站被抓到后是什么样子的? 3.在网页信息查询中,点击网页检测,可以查看自己网页的关键词密度、网站安全情况、关键词挖掘... 查看全部
阿里云为您提供网站内容抓取工具相关的8933条产品文档内容及常见问题解答内容
阿里巴巴云为您提供8933产品文档内容和网站内容爬虫工具相关FAQ,以及路由网站打不开网页怎么办,计算机网络技术大学毕业论文,关键value Store kvstore,以下哪个是数据库,以及其他云计算产品。
网页内容的智能抓取和详细的实战实例,完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用程序的开源组件包括:DOM4J: Parsing XMLjericho-。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .
它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。
内容抓取-内容可以从网站 抓取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到你的网站,让你的网站内容打开。

爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行庞大的爬虫系统,从网站全世界爬取。
优采云采集器免费网络爬虫软件_网络大数据爬虫工具。

1.打开站长工具,在网页信息查询中,找到模拟机器人抓取。2.输入自己的网站网址,输入,点击查询。这时候会在下面显示你的网站被抓到后是什么样子的? 3.在网页信息查询中,点击网页检测,可以查看自己网页的关键词密度、网站安全情况、关键词挖掘...
如何做好百度收录的五类网站图-1:
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-08-20 05:20
第一类网站:网站结构复杂;第二类网站:不可读网站;第三类网站:不稳定网站;第四类网站:网站,重复内容较多;第五类网站:经常修改的网站
图片 14456-1:
现在建网站已经不是什么神秘的事情了。很多新手站长只需学习一两个月就可以使用WordPress和cms系统搭建自己的第一个网站。但是网站要成功运营并获取利润就更难了。
自从SEO走红,个别站长参加了XX培训学习SEO,希望能用SEO的方法把网站core关键词排在百度首页,获得更多的搜索引擎流量,赚得更多广告费。但是很多个人站长都会遇到百度不收录网站或者网站收录不好的情况。 网站收录 做的不好,怎么可能从搜索引擎上获取流量。从搜索引擎获取流量,前提是网站的所有页面都是百度收录。当然,这个难度更大。 网站收录 80%以上才算好的。
如果网站不是百度收录,首先要检查网站的内容是否不好。如果网站的内容是原创,可能是网站架构的问题。下面笔者总结了五类不利于百度收录的网站。
第一类网站:网站复杂结构
网站结构对网站很重要,相当于房子的柱子。如果网站的结构比较复杂,搜索引擎蜘蛛抓取网站时很容易被困,导致搜索引擎蜘蛛抓取的页面较少。 SEO优化的第一点要求网站有一个简单明了的网站结构。我们在设计网站navigation的时候,如果网站小,一级导航就够了,不是二级导航,大网站导航可以分为两级,但不要用三级。同时需要在网站添加面包屑导航,页面添加子导航。另外,还要注意 URL 的长度,尽量保持 URL 的短。 (参考:如何做网址优化)
第二类网站:不可读网站
不可读?这是指搜索引擎蜘蛛无法理解。什么是不可读的网站? FLASH网站是不可读的网站,因为搜索引擎技术有限,我暂时无法读取FLASH网站。如果你的公司网站是FLASH网站,对于搜索引擎来说,不知道你的网站是做什么的,因为我看不懂。所以从SEO的角度,不推荐搭建FLASH网站。如果你已经在使用FLASH网站,建议获取一个普通的网站供搜索引擎抓取。
第三类网站:不稳定网站
不稳定是指网站的访问情况。如果你的网站能被访问一段时间,对用户和搜索引擎来说都是非常不利的。导致用户流失,给搜索引擎蜘蛛留下不好的印象。如果网站经常出现这样的网站,搜索引擎蜘蛛就出现了网站爬取的问题,结果就是网站收录移除问题。所以建议个人站长想建网站赚钱,不能省网站空间的钱,有稳定的网站空间,更有利于SEO优化。
第四类网站:重复很多内容的网站
有些网站,经常是采集,或者使用自动化生成网站内容,这样的网站网站文章还有很多,但是有一个严重的问题就是内容重复很多如果你的网站有很多重复的内容,百度会认为你的网站是垃圾网站,最后你的网站会被百度惩罚。
第五类网站:经常修改的网站
一些新手站长,刚开始建网站的时候,没有全面研究关键词,后期经常修改网站title,早期网站随意使用在线模板几个月后如果模板不好看,那就更换模板。这些新手站长经常修改网站,今天就因为这个原因修改,明天就因为这个原因修改。最后,这些新手站长的网站会被百度惩罚,因为频繁修改网站是SEO大忌,尤其是频繁修改网站标题。作者,我百度第二页有网站关键词。如果你想让这个关键词上百度首页,去修改网站title,故意增加关键词密度,最后网站被百度掉了,这个关键词排名落后100了,它已经几个月没有恢复了。所以网站上线前,一定要做好调研。 网站不建议在上线后半年内修改网站,尤其是网站title。
如果你的网站收录不好,你的网站是否有以上五种网站的问题?今天总结了五类不利于百度的网站收录。希望对大家有所帮助,解决网站不收录的问题。 查看全部
如何做好百度收录的五类网站图-1:
第一类网站:网站结构复杂;第二类网站:不可读网站;第三类网站:不稳定网站;第四类网站:网站,重复内容较多;第五类网站:经常修改的网站

图片 14456-1:
现在建网站已经不是什么神秘的事情了。很多新手站长只需学习一两个月就可以使用WordPress和cms系统搭建自己的第一个网站。但是网站要成功运营并获取利润就更难了。
自从SEO走红,个别站长参加了XX培训学习SEO,希望能用SEO的方法把网站core关键词排在百度首页,获得更多的搜索引擎流量,赚得更多广告费。但是很多个人站长都会遇到百度不收录网站或者网站收录不好的情况。 网站收录 做的不好,怎么可能从搜索引擎上获取流量。从搜索引擎获取流量,前提是网站的所有页面都是百度收录。当然,这个难度更大。 网站收录 80%以上才算好的。
如果网站不是百度收录,首先要检查网站的内容是否不好。如果网站的内容是原创,可能是网站架构的问题。下面笔者总结了五类不利于百度收录的网站。
第一类网站:网站复杂结构
网站结构对网站很重要,相当于房子的柱子。如果网站的结构比较复杂,搜索引擎蜘蛛抓取网站时很容易被困,导致搜索引擎蜘蛛抓取的页面较少。 SEO优化的第一点要求网站有一个简单明了的网站结构。我们在设计网站navigation的时候,如果网站小,一级导航就够了,不是二级导航,大网站导航可以分为两级,但不要用三级。同时需要在网站添加面包屑导航,页面添加子导航。另外,还要注意 URL 的长度,尽量保持 URL 的短。 (参考:如何做网址优化)
第二类网站:不可读网站
不可读?这是指搜索引擎蜘蛛无法理解。什么是不可读的网站? FLASH网站是不可读的网站,因为搜索引擎技术有限,我暂时无法读取FLASH网站。如果你的公司网站是FLASH网站,对于搜索引擎来说,不知道你的网站是做什么的,因为我看不懂。所以从SEO的角度,不推荐搭建FLASH网站。如果你已经在使用FLASH网站,建议获取一个普通的网站供搜索引擎抓取。
第三类网站:不稳定网站
不稳定是指网站的访问情况。如果你的网站能被访问一段时间,对用户和搜索引擎来说都是非常不利的。导致用户流失,给搜索引擎蜘蛛留下不好的印象。如果网站经常出现这样的网站,搜索引擎蜘蛛就出现了网站爬取的问题,结果就是网站收录移除问题。所以建议个人站长想建网站赚钱,不能省网站空间的钱,有稳定的网站空间,更有利于SEO优化。
第四类网站:重复很多内容的网站
有些网站,经常是采集,或者使用自动化生成网站内容,这样的网站网站文章还有很多,但是有一个严重的问题就是内容重复很多如果你的网站有很多重复的内容,百度会认为你的网站是垃圾网站,最后你的网站会被百度惩罚。
第五类网站:经常修改的网站
一些新手站长,刚开始建网站的时候,没有全面研究关键词,后期经常修改网站title,早期网站随意使用在线模板几个月后如果模板不好看,那就更换模板。这些新手站长经常修改网站,今天就因为这个原因修改,明天就因为这个原因修改。最后,这些新手站长的网站会被百度惩罚,因为频繁修改网站是SEO大忌,尤其是频繁修改网站标题。作者,我百度第二页有网站关键词。如果你想让这个关键词上百度首页,去修改网站title,故意增加关键词密度,最后网站被百度掉了,这个关键词排名落后100了,它已经几个月没有恢复了。所以网站上线前,一定要做好调研。 网站不建议在上线后半年内修改网站,尤其是网站title。
如果你的网站收录不好,你的网站是否有以上五种网站的问题?今天总结了五类不利于百度的网站收录。希望对大家有所帮助,解决网站不收录的问题。
1.网站为什么抓取一些不存在的页面?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-08-20 05:19
网站Grabbing 这个指标对于做seo很重要,不爬就没有收录,但是我们在做网站爬检测的时候经常会看到一些404的返回码,这些页面根本不存在在我们网站,那么,网站爬取,目录和页面不存在的原因,怎么办?
基于对百度搜索引擎的研究,我们认为:
1.网站 为什么有些页面不存在?
网站被爬取,页面不存在的原因有很多,比如:
①页面删除
在很多情况下,网站在优化过程中需要进行调整,您调整的页面可能不会被搜索引擎抓取。有时,你看到的页面没有被索引,但实际这些页面可能正在评估中,所以一段时间后,蜘蛛仍然会抓取这些页面。
②旧域名
有时候我们做seo,为了更快的效果,会用老域名,但是老域名一定要有建站历史,不然我们不会选择,有历史就有历史大概率会有蜘蛛,而且蜘蛛有记忆,所以总是爬一些旧的网址,所以买旧域名有利有弊,但利大于弊。
③恶意扫描
当然,有时候,我们的域名没有问题,没有页面被删除,仍然会有不存在的页面。这时候就需要观察这些爬取到的ip是否有一定的规律,有很多时候,我们网站就会面临各种扫描的需求,比如漏洞扫描,文章采集等爬取,如果这些 IP 是正规的,那么扫描漏洞的可能性就很大。
2.如何处理抓取不存在的页面
了解抓取不存在页面的一些原因,那么我们如何解决这些问题?
①机器人
首先,我们知道这些不存在的页面被反复抓取。我们需要采取措施告诉蜘蛛,这些页面是不允许被抓取的。我们可以使用Robots协议来禁止这些页面的抓取,通常对于大多数蜘蛛来说,这种方法是有效的,因为这是所有常规搜索引擎都需要遵守的协议。
②提交死链接
如果还存在被重复抓取的问题,可以查看这些页面是否有幸存的百度快照。如果有快照,蜘蛛会反复爬取,因为你在屏蔽没有被索引的页面,而这些页面已经被索引后,我们可以汇总这些页面的网址,并通过资源平台提交死链接。
③屏蔽ip
当然,以上方法都是各大搜索引擎蜘蛛的策略。如果被非搜索引擎蜘蛛恶意扫描或抓取怎么办?
我们认为最直接的方式就是屏蔽这些IP。可以通过修改服务器中的文件来实现这个功能:
1)云主机
下载.htaccess文件,直接修改,上传覆盖原文件。
2)宝塔
到宝塔后台找到安全选项,选择防火墙,在防火墙中选择屏蔽ip。
3)plugin
现在各大cms系统都推出了各种功能插件。我们可以直接搜索blocking ip来查找插件进行ipblocking。
总结:网站grabbing,目录和页面不存在的原因,以及如何处理,我们在这里讨论,以上内容仅供参考。
转载蝙蝠侠IT需要授权! 查看全部
1.网站为什么抓取一些不存在的页面?(图)
网站Grabbing 这个指标对于做seo很重要,不爬就没有收录,但是我们在做网站爬检测的时候经常会看到一些404的返回码,这些页面根本不存在在我们网站,那么,网站爬取,目录和页面不存在的原因,怎么办?

基于对百度搜索引擎的研究,我们认为:
1.网站 为什么有些页面不存在?
网站被爬取,页面不存在的原因有很多,比如:
①页面删除
在很多情况下,网站在优化过程中需要进行调整,您调整的页面可能不会被搜索引擎抓取。有时,你看到的页面没有被索引,但实际这些页面可能正在评估中,所以一段时间后,蜘蛛仍然会抓取这些页面。
②旧域名
有时候我们做seo,为了更快的效果,会用老域名,但是老域名一定要有建站历史,不然我们不会选择,有历史就有历史大概率会有蜘蛛,而且蜘蛛有记忆,所以总是爬一些旧的网址,所以买旧域名有利有弊,但利大于弊。
③恶意扫描
当然,有时候,我们的域名没有问题,没有页面被删除,仍然会有不存在的页面。这时候就需要观察这些爬取到的ip是否有一定的规律,有很多时候,我们网站就会面临各种扫描的需求,比如漏洞扫描,文章采集等爬取,如果这些 IP 是正规的,那么扫描漏洞的可能性就很大。
2.如何处理抓取不存在的页面
了解抓取不存在页面的一些原因,那么我们如何解决这些问题?
①机器人
首先,我们知道这些不存在的页面被反复抓取。我们需要采取措施告诉蜘蛛,这些页面是不允许被抓取的。我们可以使用Robots协议来禁止这些页面的抓取,通常对于大多数蜘蛛来说,这种方法是有效的,因为这是所有常规搜索引擎都需要遵守的协议。
②提交死链接
如果还存在被重复抓取的问题,可以查看这些页面是否有幸存的百度快照。如果有快照,蜘蛛会反复爬取,因为你在屏蔽没有被索引的页面,而这些页面已经被索引后,我们可以汇总这些页面的网址,并通过资源平台提交死链接。
③屏蔽ip
当然,以上方法都是各大搜索引擎蜘蛛的策略。如果被非搜索引擎蜘蛛恶意扫描或抓取怎么办?
我们认为最直接的方式就是屏蔽这些IP。可以通过修改服务器中的文件来实现这个功能:
1)云主机
下载.htaccess文件,直接修改,上传覆盖原文件。
2)宝塔
到宝塔后台找到安全选项,选择防火墙,在防火墙中选择屏蔽ip。
3)plugin
现在各大cms系统都推出了各种功能插件。我们可以直接搜索blocking ip来查找插件进行ipblocking。
总结:网站grabbing,目录和页面不存在的原因,以及如何处理,我们在这里讨论,以上内容仅供参考。
转载蝙蝠侠IT需要授权!
网站内容抓取(各个爬虫获取内容是个套路活,还没爬1分钟就被封掉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-08-29 06:05
看评论区,大多数人说如何获取网页内容。其实,获取内容是一个套路。所有网站 都是相似的。在实际操作中,很多人发现自己写了一个爬虫,还没有爬到1分钟就被屏蔽了。先说一些攀爬XX的经验,主要是一些防反攀的经验。
爬过XX的都知道XX站的防爬机制做的很好。
0.cookie,有些cookies会记录本机的一些特性,这些特性可能会成为ban的关键句柄,所以写爬虫的时候最好禁用cookies。
1.XX网站 具有 User-Agent 代理验证。如果检测到你的请求是假的User-Agent,记得直接返回空白页。这很容易解决。下载一个fake-useragent包,每次随机生成一个header。
2.XX网站ip 频繁访问检测机制。当检测到你的访问过于频繁时(这个真的很严格,其实即使你手动模拟点击,也会被限制一段时间),会返回异常信息。这可以通过维护自己的 ip 池来解决。 github上的免费代理ip池代理好用,但是代理IP数量比较少。如果您无限制访问,那么您整个池中的所有 ip 将很快被阻止。所以可以加一个限制:每个ip两次使用的间隔应该是60s。要是麻烦,就很容易解决了,氪金,氪金可以变强。推荐通讯社的动态转发功能,真的好用。
3.XX 会时不时弹出验证码。解决方法一:在网上调用验证码识别借口,有点麻烦。解决方案二:更改IP继续访问网页,
4.XX 偶尔会发出重定向请求。这是指有时候即使你使用新的ip访问XX的页面,有时候也会收到一个脚本脚本,脚本的内容很简单,就是采集浏览器的一些基本信息,然后GET到请求原创页面。这对于用户访问来说是缺乏经验的。但是对于爬虫来说,这种重定向必须要特别注意。一种解决方案是模拟脚本的内容,然后再次发送 GET 请求。还有一个更简单的方法,就是直接禁止重定向,把接收到的页面当作错误码处理。错误码的处理方法是更改IP,继续访问。不可能为每个 IP 发送重定向。
合理应用这些技术可以实现单机爬行峰值1.5w条数据/分钟。 查看全部
网站内容抓取(各个爬虫获取内容是个套路活,还没爬1分钟就被封掉)
看评论区,大多数人说如何获取网页内容。其实,获取内容是一个套路。所有网站 都是相似的。在实际操作中,很多人发现自己写了一个爬虫,还没有爬到1分钟就被屏蔽了。先说一些攀爬XX的经验,主要是一些防反攀的经验。
爬过XX的都知道XX站的防爬机制做的很好。
0.cookie,有些cookies会记录本机的一些特性,这些特性可能会成为ban的关键句柄,所以写爬虫的时候最好禁用cookies。
1.XX网站 具有 User-Agent 代理验证。如果检测到你的请求是假的User-Agent,记得直接返回空白页。这很容易解决。下载一个fake-useragent包,每次随机生成一个header。
2.XX网站ip 频繁访问检测机制。当检测到你的访问过于频繁时(这个真的很严格,其实即使你手动模拟点击,也会被限制一段时间),会返回异常信息。这可以通过维护自己的 ip 池来解决。 github上的免费代理ip池代理好用,但是代理IP数量比较少。如果您无限制访问,那么您整个池中的所有 ip 将很快被阻止。所以可以加一个限制:每个ip两次使用的间隔应该是60s。要是麻烦,就很容易解决了,氪金,氪金可以变强。推荐通讯社的动态转发功能,真的好用。
3.XX 会时不时弹出验证码。解决方法一:在网上调用验证码识别借口,有点麻烦。解决方案二:更改IP继续访问网页,
4.XX 偶尔会发出重定向请求。这是指有时候即使你使用新的ip访问XX的页面,有时候也会收到一个脚本脚本,脚本的内容很简单,就是采集浏览器的一些基本信息,然后GET到请求原创页面。这对于用户访问来说是缺乏经验的。但是对于爬虫来说,这种重定向必须要特别注意。一种解决方案是模拟脚本的内容,然后再次发送 GET 请求。还有一个更简单的方法,就是直接禁止重定向,把接收到的页面当作错误码处理。错误码的处理方法是更改IP,继续访问。不可能为每个 IP 发送重定向。
合理应用这些技术可以实现单机爬行峰值1.5w条数据/分钟。
网站内容抓取(WebScraperMac版可以快速提取与某个网页(包括文本内容))
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-08-29 06:04
WebScraper Mac 是MacOS 上的网站content 抓取软件,可以快速提取与网页相关的信息(包括文本内容),让您轻松快速地从在线资源中提取内容。您可以完全控制将数据导出到 CSV 或 JSON 文件。
WebScraper Mac版软件介绍
WebScraper for Mac 是 Mac 平台上的一个简单应用程序,可将数据导出为 JSON 或 CSV。 Mac 版的 WebScraper 可以快速提取与网页相关的信息(包括文本内容)。适用于 Mac 的 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper mac 软件功能
快速轻松地扫描和截屏网站
原生 MacOS 应用程序可以在您的桌面上运行
提取数据的方法有很多种;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
易于导出数据-选择所需的列
输出数据为csv或json
将所有图像下载到文件夹/采集并导出所有链接的选项
输出单个文本文件的选项(用于存档文本内容、markdown 或纯文本)
丰富的选项/配置
系统要求
当前版本需要 Mac OS 10.8 或更高版本
WebScraper Mac 更新日志
WebScraper for Mac(网站内容爬虫软件)带注册机V4.10.1
添加选项以从 class/id 或正则表达式提取结果中去除 html 标签
添加在url中保留hash(#)的选项(默认情况下会被修剪(假设是文档片段中的位置)。但是对于一些网站在他们的url中错误地使用了hash,它可能是页面 url 的重要部分)。除非您确定确实需要开启此选项,否则应将其关闭。 查看全部
网站内容抓取(WebScraperMac版可以快速提取与某个网页(包括文本内容))
WebScraper Mac 是MacOS 上的网站content 抓取软件,可以快速提取与网页相关的信息(包括文本内容),让您轻松快速地从在线资源中提取内容。您可以完全控制将数据导出到 CSV 或 JSON 文件。
WebScraper Mac版软件介绍
WebScraper for Mac 是 Mac 平台上的一个简单应用程序,可将数据导出为 JSON 或 CSV。 Mac 版的 WebScraper 可以快速提取与网页相关的信息(包括文本内容)。适用于 Mac 的 WebScraper 使您能够以最少的努力从在线资源中快速提取内容。您可以完全控制将导出为 CSV 或 JSON 文件的数据。
WebScraper mac 软件功能
快速轻松地扫描和截屏网站
原生 MacOS 应用程序可以在您的桌面上运行
提取数据的方法有很多种;各种元数据、内容(如文本、html 或降价)、具有特定类/ID 的元素、正则表达式
易于导出数据-选择所需的列
输出数据为csv或json
将所有图像下载到文件夹/采集并导出所有链接的选项
输出单个文本文件的选项(用于存档文本内容、markdown 或纯文本)
丰富的选项/配置
系统要求
当前版本需要 Mac OS 10.8 或更高版本
WebScraper Mac 更新日志
WebScraper for Mac(网站内容爬虫软件)带注册机V4.10.1
添加选项以从 class/id 或正则表达式提取结果中去除 html 标签
添加在url中保留hash(#)的选项(默认情况下会被修剪(假设是文档片段中的位置)。但是对于一些网站在他们的url中错误地使用了hash,它可能是页面 url 的重要部分)。除非您确定确实需要开启此选项,否则应将其关闭。
网站内容抓取(如何写好Python数据我用的是Python?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-08-29 06:04
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个信息比较完整的网站,比如39养老网:
/findhomes/
点击打开任意一家养老院,如上海上大天平养老院
我们想获取这个网站的所有养老院信息,例如姓名、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般这些网站页面和页面之间的url有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的url是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
我们可以用它在页面上找到我们感兴趣的部分
使用inspect工具点击第一家养老院的信息,我们会发现html会显示相关的html信息
href代表这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个疗养院的链接,我们来看看代码输入
代码第一步:导入相关的python库
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
正如我上面所说的,我们知道网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:
i 是一个整数,getLink 会返回给我们对应的页面 url,比如 i=1 时,getLink 会返回我们的第一页,当 i=2 时会返回给我们第二页
getFacilities的代码如下:
这个功能的主要作用是找出页面上所有养老院公寓的网址(我们刚刚看到的href)
getSoup是一个函数(BeautifulSoup库中的一个函数),我们给他一个url,他会返回一个处理后的网页html给我们搜索
<p>soup.find("ul"...) 的意思是在html中找到第一个符合"{...}"条件的"ul"标签,我们把这个信息存入table_ul的变量中 查看全部
网站内容抓取(如何写好Python数据我用的是Python?(上)
)
最近发现数据在很多情况下变得越来越重要,我们经常发现一个网页上有大量我们想要的数据,但是一个一个下载太费力了。这时候就可以写一些简单的爬虫软件来帮助我们从网上抓取我们想要的数据
我使用 Python。这种语言比较简单。已经编写了很多工具包,可以直接使用。
开始---------------------------------------------- ----------
假设我们找到一个信息比较完整的网站,比如39养老网:
/findhomes/
点击打开任意一家养老院,如上海上大天平养老院
我们想获取这个网站的所有养老院信息,例如姓名、地址、机构性质等。
所需工具:
苹果或ubuntu操作系统,用windows的同学可以用虚拟机,推荐VMWARE Workstation
使用的语言是Python2.x,软件包需要美汤,请求,可以使用pip install安装
编程---------------------------------------------- --------------------
首先,一般这些网站页面和页面之间的url有一些相似之处,比如这个网站,如果你点击第二个页面,可以看到它的url是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_2.htm
第三页是
/findhomes/list_0_0_0_0_0_0_0_0_0_0_3.htm
可以看到是最后一个数字决定显示哪个页面
经过尝试,我发现网站总共只有63页;这也说明我们可以写一个简单的for循环来快速访问每一页
知道如何翻页后,我们需要从当前页面找到各个养老院的链接
打开这个页面的html代码(每个预览器的打开方式不同)
我们看到一个类似的页面
/r/uXV0bFvEdQYKrR8P9yCr(自动识别二维码)
chrome 预览器在控制台的左上角有一个检查元素工具
我们可以用它在页面上找到我们感兴趣的部分
使用inspect工具点击第一家养老院的信息,我们会发现html会显示相关的html信息
href代表这个网页点击链接后会跳转到的url,我们点击“上海上大天平疗养院”稍后发布
网址是/findhomes/tianping.htm
页面跳转到养老院信息页面
当前总结:目前我们知道如何使用程序在网站上翻页,以及如何找到各个疗养院的链接,我们来看看代码输入
代码第一步:导入相关的python库
我们需要的其实只是bs4的BeautifulSoup,和requests
第二部分代码:从每个页面链接中抓取相关页面上的养老院
正如我上面所说的,我们知道网站目前只有64页,所以我们可以写一个for循环,循环64次;
getLink的代码如下:
i 是一个整数,getLink 会返回给我们对应的页面 url,比如 i=1 时,getLink 会返回我们的第一页,当 i=2 时会返回给我们第二页
getFacilities的代码如下:
这个功能的主要作用是找出页面上所有养老院公寓的网址(我们刚刚看到的href)
getSoup是一个函数(BeautifulSoup库中的一个函数),我们给他一个url,他会返回一个处理后的网页html给我们搜索
<p>soup.find("ul"...) 的意思是在html中找到第一个符合"{...}"条件的"ul"标签,我们把这个信息存入table_ul的变量中
网站内容抓取(一下网络爬虫抓取网页数据的优点和缺点和注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-08-29 06:03
网页爬取是指自动从网站中提取数据的过程。它可以分析和处理任何可公开访问的网页以提取信息或数据,然后可以下载或存储这些信息或数据。接下来,ipidea 给大家介绍一下网络爬虫爬取网络数据的优缺点。
优势
1、节省时间。使用网页爬取时,不需要手动从网站采集数据,可以同时快速爬取多个网站。
2、大规模数据。网络抓取为您提供的数据量远远超过您手动采集的数据量。
3、性价比高。一个简单的刮刀通常可以完成这项工作,因此您无需投资于复杂的系统或额外的人员。
4、 可以修改为一个任务创建一个scraper,你通常只需做一些小的改动就可以为不同的任务修改它。
5、正确设置你的爬虫,它会直接从网站准确采集数据,引入错误的可能性很低。
6、Maintainable。通常你可以稍微调整scraper来适应网站的变化。
7、结构化数据。默认情况下,捕获的数据以机器可读的格式到达,因此简单的值通常可以立即用于其他数据库和程序。
缺点
1、 需要持续维护。由于您的爬虫依赖外部网站,您无法控制网站何时改变其结构或内容,因此您需要在爬虫过期时重新爬取。
2、 可能被阻止访问。 网站 可以使用许多不同的方法(例如 IP 阻止)来防止您抓取其内容。 查看全部
网站内容抓取(一下网络爬虫抓取网页数据的优点和缺点和注意事项)
网页爬取是指自动从网站中提取数据的过程。它可以分析和处理任何可公开访问的网页以提取信息或数据,然后可以下载或存储这些信息或数据。接下来,ipidea 给大家介绍一下网络爬虫爬取网络数据的优缺点。
优势
1、节省时间。使用网页爬取时,不需要手动从网站采集数据,可以同时快速爬取多个网站。
2、大规模数据。网络抓取为您提供的数据量远远超过您手动采集的数据量。
3、性价比高。一个简单的刮刀通常可以完成这项工作,因此您无需投资于复杂的系统或额外的人员。
4、 可以修改为一个任务创建一个scraper,你通常只需做一些小的改动就可以为不同的任务修改它。
5、正确设置你的爬虫,它会直接从网站准确采集数据,引入错误的可能性很低。
6、Maintainable。通常你可以稍微调整scraper来适应网站的变化。
7、结构化数据。默认情况下,捕获的数据以机器可读的格式到达,因此简单的值通常可以立即用于其他数据库和程序。
缺点
1、 需要持续维护。由于您的爬虫依赖外部网站,您无法控制网站何时改变其结构或内容,因此您需要在爬虫过期时重新爬取。
2、 可能被阻止访问。 网站 可以使用许多不同的方法(例如 IP 阻止)来防止您抓取其内容。
网站内容抓取(网站优化排名优化的过程中会遇到这种情况吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-08-29 06:02
在做网站排名优化的时候,网站内容收录越多,搜索引擎喜欢网站的内容就越多,这就给了网站一个很好的排名。但是在网站优化的过程中,就会遇到这种情况。 网站的部分页面已被删除,搜索引擎仍会抓取这些页面。为什么?接下来就跟着网站免费优化公司一探究竟吧!
1、外链引导蜘蛛爬虫到一个不存在的页面
在做网站优化排名的时候,SEO大牛会为网站做一些外链,而这些外链不仅指向网站首页,还指向网站的各个页面。当网站的部分页面被删除后,虽然该页面不存在,但该页面的外链确实存在,百度蜘蛛会跟随外链进入该页面,导致搜索引擎抓取到非-存在的页面。
2、不存在的页面最近被删除了
如果网站页面最近被删除,也会造成这种情况。这是因为虽然网站页面已经被删除,但是这些页面已经被搜索引擎收录搜索到了,它们会存在于搜索引擎中,搜索引擎也会反复抓取。为避免这种情况,您需要将这些页面提交给搜索引擎,并告诉搜索引擎这些页面不存在且不用于抓取。
3、搜索引擎算法调整
搜索引擎算法调整后,搜索引擎也可能会抓取一些网站中不存在的页面。这是因为,虽然网站已经更新,但对于搜索引擎来说,更新后的网站页面并没有被搜索引擎收录搜索到,所以百度蜘蛛会反复抓取这些历史上的一流链接。
4、网站被攻击
在对网站进行排名时,网站可能经常被竞争对手攻击,攻击的方法是将一些网站不存在的页面提交给搜索引擎,导致搜索引擎响应网站的评分降低,进而影响网站的排名。
总之,网站遇到这种情况,一定要及时处理。可以用robots.txt来屏蔽,也可以把页面做成404,有利于网站的长远发展。
蝙蝠侠 IT
转载需授权! 查看全部
网站内容抓取(网站优化排名优化的过程中会遇到这种情况吗?)
在做网站排名优化的时候,网站内容收录越多,搜索引擎喜欢网站的内容就越多,这就给了网站一个很好的排名。但是在网站优化的过程中,就会遇到这种情况。 网站的部分页面已被删除,搜索引擎仍会抓取这些页面。为什么?接下来就跟着网站免费优化公司一探究竟吧!
1、外链引导蜘蛛爬虫到一个不存在的页面
在做网站优化排名的时候,SEO大牛会为网站做一些外链,而这些外链不仅指向网站首页,还指向网站的各个页面。当网站的部分页面被删除后,虽然该页面不存在,但该页面的外链确实存在,百度蜘蛛会跟随外链进入该页面,导致搜索引擎抓取到非-存在的页面。
2、不存在的页面最近被删除了
如果网站页面最近被删除,也会造成这种情况。这是因为虽然网站页面已经被删除,但是这些页面已经被搜索引擎收录搜索到了,它们会存在于搜索引擎中,搜索引擎也会反复抓取。为避免这种情况,您需要将这些页面提交给搜索引擎,并告诉搜索引擎这些页面不存在且不用于抓取。
3、搜索引擎算法调整
搜索引擎算法调整后,搜索引擎也可能会抓取一些网站中不存在的页面。这是因为,虽然网站已经更新,但对于搜索引擎来说,更新后的网站页面并没有被搜索引擎收录搜索到,所以百度蜘蛛会反复抓取这些历史上的一流链接。
4、网站被攻击
在对网站进行排名时,网站可能经常被竞争对手攻击,攻击的方法是将一些网站不存在的页面提交给搜索引擎,导致搜索引擎响应网站的评分降低,进而影响网站的排名。
总之,网站遇到这种情况,一定要及时处理。可以用robots.txt来屏蔽,也可以把页面做成404,有利于网站的长远发展。
蝙蝠侠 IT
转载需授权!
【干货】一个小项目的运用及解析日志日志
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-27 19:14
不知不觉中,我已经上课三个星期了,还写了几个小项目。这里有一个有趣的爬虫项目:搜狗输入法词库爬虫,和你聊聊公司这里是如何写项目指南
本次抓取的内容为:搜狗所有词库
地址:/dict/cate/index/167
这次有点复杂,需要一些前置知识:
项目文件整理:
PS:这里的代码是我自己重构的,
应该使用内部框架捕获公司中的代码。所以我不能分享它
告诉我:我们公司还在用Python2.7,编码问题要死我了! !
我猜是因为2.7的print可以省一对括号,这样就永远不会升级了~
看项目结构:
├── configs.py # 数据库的配置文件
├── jiebao.py # 搜狗的词库是加密的,用来解密词库用的
├── spider
│ ├── log_SougouDownloader.log.20171118 # 词库下载日志
│ ├── log_SougouSpider.log.20171118 # 抓取日志
│ └── spider.py # 爬虫文件
├── store_new
│ ├── __init__.py
│ └── stroe.py # 数据库操作的封装
└── utils
└── tools.py # 日志模块
整体画面比较清晰
我将源文件放在 GitHub 中:
/Ehco1996/Python-crawler/tree/master/搜狗
爬虫逻辑和数据库表设计
看门户的网页结构:
我们需要解决:
由于数据量大
大约有 10,000 个同义词库文件可供下载
大约有1亿关键词需要解决
无法将所有逻辑耦合在一起
这里我创建了三个数据库表:
所以总体逻辑是这样的:
代码部分
一、二级cate页面分析
def cate_ext(self, html, type1):
'''
解析列表页的所有分类名
Args:
html 文本
type1 一级目录名
'''
res = []
soup = BeautifulSoup(html, 'lxml')
cate_list = soup.find('div', {'id': 'dict_cate_show'})
lis = cate_list.find_all('a')
for li in lis:
type2 = li.text.replace('"', '')
url = 'http://pinyin.sogou.com' + li['href'] + '/default/{}'
res.append({
'url': url,
'type1': type1,
'type2': type2,
})
return res
这里我通过解析一级分类的入口页面得到所有二级分类的地址
词库文件下载地址解析:
def list_ext(self, html, type1, type2):
'''
解析搜狗词库的列表页面
args:
html: 文本
type1 一级目录名
type2 二级目录名
retrun list
每一条数据都为字典类型
'''
res = []
try:
soup = BeautifulSoup(html, 'lxml')
# 偶数部分
divs = soup.find_all("div", class_='dict_detail_block')
for data in divs:
name = data.find('div', class_='detail_title').a.text
url = data.find('div', class_='dict_dl_btn').a['href']
res.append({'filename': type1 + '_' + type2 + '_' + name,
'type1': type1,
'type2': type2,
'url': url,
})
# 奇数部分
divs_odd = soup.find_all("div", class_='dict_detail_block odd')
for data in divs_odd:
name = data.find('div', class_='detail_title').a.text
url = data.find('div', class_='dict_dl_btn').a['href']
res.append({'filename': type1 + '_' + type2 + '_' + name,
'type1': type1,
'type2': type2,
'url': url,
})
except:
print('解析失败')
return - 1
return res
爬虫入口:
def start(self):
'''
解析搜狗词库的下载地址和分类名称
'''
# 从数据库读取二级分类的入口地址
cate_list = self.store.find_all('sougou_cate')
for cate in cate_list:
type1 = cate['type1']
type2 = cate['type2']
for i in range(1, int(cate['page']) + 1):
print('正在解析{}的第{}页'.format(type1 + type2, i))
url = cate['url'].format(i)
html = get_html_text(url)
if html != -1:
res = self.list_ext(html, type1, type2)
self.log.info('正在解析页面 {}'.format(url))
for data in res:
self.store.save_one_data('sougou_detail', data)
self.log.info('正在存储数据{}'.format(data['filename']))
time.sleep(3)
这里我从cate表中读取记录发送请求,解析出下载地址
数据库操作的包可以直接看我的store_new/store.py文件
你也可以阅读我上周写的文章:/p/30911268
词库文件下载逻辑:
def start(self):
# 从数据库检索记录
res = self.store.find_all('sougou_detail')
self.log.warn('一共有{}条词库等待下载'.format(len(res)))
for data in res:
content = self.get_html_content(data['url'])
filename = self.strip_wd(data['filename'])
# 如果下载失败,我们等三秒再重试
if content == -1:
time.sleep(3)
self.log.info('{}下载失败 正在重试'.format(filename))
content = self.get_html_content(data[1])
self.download_file(content, filename)
self.log.info('正在下载文件{}'.format(filename))
time.sleep(1)
这部分没什么难的,主要是文件读写操作
分析词库文件逻辑:
def start():
# 使用多线程解析
threads = list()
# 读文件存入queue的线程
threads.append(
Thread(target=ext_to_queue))
# 存数据库的线程
for i in range(10):
threads.append(
Thread(target=save_to_db))
for thread in threads:
thread.start()
好了,所有步骤都完成了
说说其中的一些“坑”吧。
Logging 日志模块的使用
因为爬取下载次数比较多,
没有日志是绝对不可能的,
毕竟我们不能总是在电脑前看程序输出!
其实我们写的程序基本上都是在服务器上运行的。
我总是通过查看程序的日志文件来判断运行状态。
在前面的代码中,可以看到我登录了很多地方
让我们看看日志文件是什么样的:
蜘蛛日志
下载器日志
运行状态一目了然?
如果你想知道如何实现它,你可以看到文件utils/tools.py
其实就是使用Python自带的日志模块
多线程的使用
共下载 9000 多个同义词库文件
字典关键词平均有2w个词条
那么总共需要存储1.80亿条数据
假设一秒可以存储10条数据
需要存储这么多数据:5000 多个小时
想想就很可怕。真的要这么久,黄花菜会冷的。
这里需要使用多线程来操作,
因为涉及文件读写
我们必须使用队列来帮助我们满足需求
逻辑是这样的:
首先打开一个主线程来读取/解析本地词库文件:
接下来打开10~50个线程(取决于数据库的最大连接数)来操作队列:
由于篇幅原因,我只放出从队列中取数据的代码片段
如果你想要整个逻辑,你可以阅读jiebao.py
def save_to_db():
'''
从数据队列里拿一条数据
并存入数据库
'''
store = DbToMysql(configs.TEST_DB)
while True:
try:
st = time.time()
data = res_queue.get_nowait()
t = int(time.time() - st)
if t > 5:
print("res_queue", t)
save_data(data, store)
except:
print("queue is empty wait for a while")
time.sleep(2)
使用多线程后,速度快了几十倍。
经测试:1秒可存储500条记录
最后看一下关键词在数据库中解析出来的:
运行一段时间后,已经有4000万条数据了。 查看全部
【干货】一个小项目的运用及解析日志日志
不知不觉中,我已经上课三个星期了,还写了几个小项目。这里有一个有趣的爬虫项目:搜狗输入法词库爬虫,和你聊聊公司这里是如何写项目指南
本次抓取的内容为:搜狗所有词库
地址:/dict/cate/index/167
这次有点复杂,需要一些前置知识:
项目文件整理:
PS:这里的代码是我自己重构的,
应该使用内部框架捕获公司中的代码。所以我不能分享它
告诉我:我们公司还在用Python2.7,编码问题要死我了! !
我猜是因为2.7的print可以省一对括号,这样就永远不会升级了~
看项目结构:
├── configs.py # 数据库的配置文件
├── jiebao.py # 搜狗的词库是加密的,用来解密词库用的
├── spider
│ ├── log_SougouDownloader.log.20171118 # 词库下载日志
│ ├── log_SougouSpider.log.20171118 # 抓取日志
│ └── spider.py # 爬虫文件
├── store_new
│ ├── __init__.py
│ └── stroe.py # 数据库操作的封装
└── utils
└── tools.py # 日志模块
整体画面比较清晰
我将源文件放在 GitHub 中:
/Ehco1996/Python-crawler/tree/master/搜狗
爬虫逻辑和数据库表设计
看门户的网页结构:
我们需要解决:
由于数据量大
大约有 10,000 个同义词库文件可供下载
大约有1亿关键词需要解决
无法将所有逻辑耦合在一起
这里我创建了三个数据库表:
所以总体逻辑是这样的:
代码部分
一、二级cate页面分析
def cate_ext(self, html, type1):
'''
解析列表页的所有分类名
Args:
html 文本
type1 一级目录名
'''
res = []
soup = BeautifulSoup(html, 'lxml')
cate_list = soup.find('div', {'id': 'dict_cate_show'})
lis = cate_list.find_all('a')
for li in lis:
type2 = li.text.replace('"', '')
url = 'http://pinyin.sogou.com' + li['href'] + '/default/{}'
res.append({
'url': url,
'type1': type1,
'type2': type2,
})
return res
这里我通过解析一级分类的入口页面得到所有二级分类的地址
词库文件下载地址解析:
def list_ext(self, html, type1, type2):
'''
解析搜狗词库的列表页面
args:
html: 文本
type1 一级目录名
type2 二级目录名
retrun list
每一条数据都为字典类型
'''
res = []
try:
soup = BeautifulSoup(html, 'lxml')
# 偶数部分
divs = soup.find_all("div", class_='dict_detail_block')
for data in divs:
name = data.find('div', class_='detail_title').a.text
url = data.find('div', class_='dict_dl_btn').a['href']
res.append({'filename': type1 + '_' + type2 + '_' + name,
'type1': type1,
'type2': type2,
'url': url,
})
# 奇数部分
divs_odd = soup.find_all("div", class_='dict_detail_block odd')
for data in divs_odd:
name = data.find('div', class_='detail_title').a.text
url = data.find('div', class_='dict_dl_btn').a['href']
res.append({'filename': type1 + '_' + type2 + '_' + name,
'type1': type1,
'type2': type2,
'url': url,
})
except:
print('解析失败')
return - 1
return res
爬虫入口:
def start(self):
'''
解析搜狗词库的下载地址和分类名称
'''
# 从数据库读取二级分类的入口地址
cate_list = self.store.find_all('sougou_cate')
for cate in cate_list:
type1 = cate['type1']
type2 = cate['type2']
for i in range(1, int(cate['page']) + 1):
print('正在解析{}的第{}页'.format(type1 + type2, i))
url = cate['url'].format(i)
html = get_html_text(url)
if html != -1:
res = self.list_ext(html, type1, type2)
self.log.info('正在解析页面 {}'.format(url))
for data in res:
self.store.save_one_data('sougou_detail', data)
self.log.info('正在存储数据{}'.format(data['filename']))
time.sleep(3)
这里我从cate表中读取记录发送请求,解析出下载地址
数据库操作的包可以直接看我的store_new/store.py文件
你也可以阅读我上周写的文章:/p/30911268
词库文件下载逻辑:
def start(self):
# 从数据库检索记录
res = self.store.find_all('sougou_detail')
self.log.warn('一共有{}条词库等待下载'.format(len(res)))
for data in res:
content = self.get_html_content(data['url'])
filename = self.strip_wd(data['filename'])
# 如果下载失败,我们等三秒再重试
if content == -1:
time.sleep(3)
self.log.info('{}下载失败 正在重试'.format(filename))
content = self.get_html_content(data[1])
self.download_file(content, filename)
self.log.info('正在下载文件{}'.format(filename))
time.sleep(1)
这部分没什么难的,主要是文件读写操作
分析词库文件逻辑:
def start():
# 使用多线程解析
threads = list()
# 读文件存入queue的线程
threads.append(
Thread(target=ext_to_queue))
# 存数据库的线程
for i in range(10):
threads.append(
Thread(target=save_to_db))
for thread in threads:
thread.start()
好了,所有步骤都完成了
说说其中的一些“坑”吧。
Logging 日志模块的使用
因为爬取下载次数比较多,
没有日志是绝对不可能的,
毕竟我们不能总是在电脑前看程序输出!
其实我们写的程序基本上都是在服务器上运行的。
我总是通过查看程序的日志文件来判断运行状态。
在前面的代码中,可以看到我登录了很多地方
让我们看看日志文件是什么样的:
蜘蛛日志
下载器日志
运行状态一目了然?
如果你想知道如何实现它,你可以看到文件utils/tools.py
其实就是使用Python自带的日志模块
多线程的使用
共下载 9000 多个同义词库文件
字典关键词平均有2w个词条
那么总共需要存储1.80亿条数据
假设一秒可以存储10条数据
需要存储这么多数据:5000 多个小时
想想就很可怕。真的要这么久,黄花菜会冷的。
这里需要使用多线程来操作,
因为涉及文件读写
我们必须使用队列来帮助我们满足需求
逻辑是这样的:
首先打开一个主线程来读取/解析本地词库文件:
接下来打开10~50个线程(取决于数据库的最大连接数)来操作队列:
由于篇幅原因,我只放出从队列中取数据的代码片段
如果你想要整个逻辑,你可以阅读jiebao.py
def save_to_db():
'''
从数据队列里拿一条数据
并存入数据库
'''
store = DbToMysql(configs.TEST_DB)
while True:
try:
st = time.time()
data = res_queue.get_nowait()
t = int(time.time() - st)
if t > 5:
print("res_queue", t)
save_data(data, store)
except:
print("queue is empty wait for a while")
time.sleep(2)
使用多线程后,速度快了几十倍。
经测试:1秒可存储500条记录
最后看一下关键词在数据库中解析出来的:
运行一段时间后,已经有4000万条数据了。
技术保密以及网站运营的差异等其他原因,以下内容仅供站长参考
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-08-27 19:12
百度认为什么样的网站和收录比较适合爬取?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考。具体收录策略包括但不限于内容。
第一方面:网站创造高质量的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的最终目标是满足用户的搜索需求,所以网站内容首先要满足用户的需求。如今,互联网在也能满足用户需求的前提下,充斥着大量同质化的内容。接下来,如果你网站提供的内容是独一无二的,或者具有一定的独特价值,那么百度会更喜欢收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站的内容都是“正常或低质量”,甚至一些网站为了获得更好的收录或排名而使用欺骗手段。下面是一些常见的情况,虽然无法一一列举。但请不要冒险,百度拥有全面的技术支持来检测和处理这些行为。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些操作包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;目标搜索引擎利用程序生成的内容。
百度会尽量收录提供不同信息的网页。如果你的网站收录大量重复内容,搜索引擎会减少相同内容的收录,并考虑网站提供的内容价值低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。这也是真的帮助节省带宽。
第二方面:网站提供的内容得到了用户和站长的认可和支持
如果网站上的内容得到用户和站长的认可,那对于百度来说也是值得收录的。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,对网站的认可度进行综合评价。不过值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你网站的认可:通常网站之间的链接可以帮助百度爬虫找到你的网站,增加你的网站认出。百度将网页A到网页B的链接解释为网页A到网页B的投票。对一个网页的投票更能体现网页本身的“认可度”权重,有助于提高其他网站的“认可度”页。链接的数量、质量和相关性会影响“接受度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。 (当其他网站发现您的内容有价值并认为它可能对访问者有帮助时,自然链接是在网络动态生成过程中形成的。)
其他网站 创建与您的网站 相关的链接的最佳方式是创建可以在互联网上流行的独特且相关的内容。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长经常不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站产生长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
第三个方面:网站有很好的浏览体验
一个拥有良好浏览体验的网站对用户来说是非常有益的。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
为用户提供站点地图和带有网站重要部分链接的导航。让用户可以清晰、简单地浏览网站,快速找到自己需要的信息。
网站fast speed 可以提高用户满意度和网页的整体质量(特别是对于互联网连接速度较慢的用户)。
保证网站的内容在不同浏览器中都能正确显示,防止部分用户正常访问。
广告是网站的重要收入来源。 网站收录广告是一个很合理的现象,但是如果广告太多,会影响用户的浏览;或者网站有太多不相关的弹窗和浮动窗口广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量,但是权限设置过多可能会导致新用户失去耐心,给用户带来不好的体验从百度的角度来看,它希望减少对用户获取信息成本过高的网页的提供。 查看全部
技术保密以及网站运营的差异等其他原因,以下内容仅供站长参考
百度认为什么样的网站和收录比较适合爬取?我们简要介绍以下几个方面。鉴于技术保密及网站操作差异等原因,以下内容仅供站长参考。具体收录策略包括但不限于内容。
第一方面:网站创造高质量的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的最终目标是满足用户的搜索需求,所以网站内容首先要满足用户的需求。如今,互联网在也能满足用户需求的前提下,充斥着大量同质化的内容。接下来,如果你网站提供的内容是独一无二的,或者具有一定的独特价值,那么百度会更喜欢收录你的网站。
温馨提示:百度希望收录这样网站:
相反,很多网站的内容都是“正常或低质量”,甚至一些网站为了获得更好的收录或排名而使用欺骗手段。下面是一些常见的情况,虽然无法一一列举。但请不要冒险,百度拥有全面的技术支持来检测和处理这些行为。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些操作包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;目标搜索引擎利用程序生成的内容。
百度会尽量收录提供不同信息的网页。如果你的网站收录大量重复内容,搜索引擎会减少相同内容的收录,并考虑网站提供的内容价值低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。这也是真的帮助节省带宽。
第二方面:网站提供的内容得到了用户和站长的认可和支持
如果网站上的内容得到用户和站长的认可,那对于百度来说也是值得收录的。百度将通过分析真实用户的搜索行为、访问行为以及网站之间的关系,对网站的认可度进行综合评价。不过值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你网站的认可:通常网站之间的链接可以帮助百度爬虫找到你的网站,增加你的网站认出。百度将网页A到网页B的链接解释为网页A到网页B的投票。对一个网页的投票更能体现网页本身的“认可度”权重,有助于提高其他网站的“认可度”页。链接的数量、质量和相关性会影响“接受度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。 (当其他网站发现您的内容有价值并认为它可能对访问者有帮助时,自然链接是在网络动态生成过程中形成的。)
其他网站 创建与您的网站 相关的链接的最佳方式是创建可以在互联网上流行的独特且相关的内容。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长经常不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站产生长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
第三个方面:网站有很好的浏览体验
一个拥有良好浏览体验的网站对用户来说是非常有益的。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
为用户提供站点地图和带有网站重要部分链接的导航。让用户可以清晰、简单地浏览网站,快速找到自己需要的信息。
网站fast speed 可以提高用户满意度和网页的整体质量(特别是对于互联网连接速度较慢的用户)。
保证网站的内容在不同浏览器中都能正确显示,防止部分用户正常访问。
广告是网站的重要收入来源。 网站收录广告是一个很合理的现象,但是如果广告太多,会影响用户的浏览;或者网站有太多不相关的弹窗和浮动窗口广告可能会冒犯用户。
百度的目标是为用户提供最相关的搜索结果和最佳的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量,但是权限设置过多可能会导致新用户失去耐心,给用户带来不好的体验从百度的角度来看,它希望减少对用户获取信息成本过高的网页的提供。
第四章:动态网页抓取((解析真实地址+selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-08-27 19:11
第四章:动态网页爬取(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现更新到这里。请参考文章:
之前抓取的网页都是静态网页,浏览器中显示的此类网页的内容都在HTML源代码中。但是,由于主流网站都使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容不会出现在HTML源代码中,所以抓取静态网页的技术可能无法正常工作因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态捕捉示例
在抓取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果需要更新传统网页的内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的抓取过程比较麻烦。
首先,让我们看一个动态网页的例子。打开作者博客的Hello World文章,文章地址为:/2018/07/04/hello-world/。网址可能会变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的url地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。显示。
如图4-4所示,我们也可以查看该产品网页的源码。里面没有用户评论,这段内容是空白的。
如果使用 AJAX 加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2)Selenium 模拟浏览器爬行。
请查看第四章的其他章节
4.2 解析真实地址爬取
4.3 通过 selenium 模拟浏览器爬行 查看全部
第四章:动态网页抓取((解析真实地址+selenium)
第四章:动态网页爬取(解析真实地址+selenium)
由于网易云线程服务暂停,新写的第4章现更新到这里。请参考文章:
之前抓取的网页都是静态网页,浏览器中显示的此类网页的内容都在HTML源代码中。但是,由于主流网站都使用JavaScript来展示网页内容,不像静态网页,使用JavaScript时,很多内容不会出现在HTML源代码中,所以抓取静态网页的技术可能无法正常工作因此,我们需要使用两种技术进行动态网络爬虫:通过浏览器评论元素解析真实网址和使用 selenium 模拟浏览器。
本章首先介绍动态网页的例子,让读者了解什么是动态抓取,然后利用以上两种动态网页抓取技术获取动态网页数据。
4.1 动态捕捉示例
在抓取动态网页之前,我们还需要了解一种异步更新技术——AJAX(Asynchronous Javascript And XML)。它的价值在于通过后台与服务器的少量数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。一方面减少了网页重复内容的下载,另一方面也节省了流量,所以AJAX被广泛使用。
与使用 AJAX 网页相比,如果需要更新传统网页的内容,则必须重新加载整个网页。因此,AJAX 使 Internet 应用程序更小、更快、更用户友好。但是AJAX网页的抓取过程比较麻烦。
首先,让我们看一个动态网页的例子。打开作者博客的Hello World文章,文章地址为:/2018/07/04/hello-world/。网址可能会变动,请到作者官网查找Hello World文章地址。如图4-1所示,页面下方的评论加载了JavaScript,这些评论数据不会出现在网页的源代码中。
为了验证页面下方的评论是否加载了 JavaScript,我们可以查看该页面的源代码。如图4-2所示,放置注释的代码中没有注释数据。只有一段 JavaScript 代码。最后呈现的数据是通过JavaScript提取出来的,加载到源代码中进行呈现。
除了作者的博客,你还可以在天猫电商网站上找到AJAX技术的例子。比如打开天猫iPhone XS Max的产品页面,点击“累计评价”,可以发现上面的url地址没有变化,整个网页没有重新加载,网页的评论部分有已更新,如图 4-3 所示。显示。
如图4-4所示,我们也可以查看该产品网页的源码。里面没有用户评论,这段内容是空白的。
如果使用 AJAX 加载的动态网页,如何抓取动态加载的内容?有两种方式:
(1)通过浏览器评论元素解析地址。
(2)Selenium 模拟浏览器爬行。
请查看第四章的其他章节
4.2 解析真实地址爬取
4.3 通过 selenium 模拟浏览器爬行
[RSS入门]不妨再受:你可能感兴趣的内容(组图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-08-27 07:12
我们每天都在接收信息。无论是社交网络好友分享的新鲜事物,还是今日头条等聚合阅读工具中的文章,依靠推荐算法,总能带来“你可能感兴趣的内容”。这些有用或无用的信息不仅消耗了我们大量的时间,无休止的“时间流”也让我们信息过载,无形中让我们接触到的信息种类越来越窄。 ”。
为了解决信息过载的问题,让我们在接收到的信息中掌握主动权,RSS重新进入了我们的视野:我们可以自由选择订阅的信息源,不受算法“控制” ,还要及时调整信息源,避免信息过载。
但是,由于RSS有一定的使用门槛,很多刚接触RSS的用户都无法回避一些问题,比如:
如果您在使用 RSS 获取信息的过程中也被工具和技术所困扰,不妨阅读这份 RSS 入门指南,与我们一起“摆脱”信息过载。
为什么选择 RSS
RSS的全称是ReallySimpleSyndication,是一种消息来源的格式规范。 网站可以向订阅者提供文章标题、摘要、全文等信息,用户按照这个格式规范可以通过订阅不同的网站RSS链接聚合不同的信息源,并在一个工具中阅读这些内容。
简单来说,RSS就是订阅某个网站内容更新的协议。这个略显“旧”的协议在社交媒体和聚合阅读的影响下逐渐走下坡路。就连谷歌也在 2013 年关闭了自己的 RSS 服务 GoogleReader。那么,我们为什么要选择 RSS?
当我还是学生的时候,我相信每个班级里都有两种人:调皮的学生和听话的学生。社交媒体、今日头条等聚合阅读工具与前者无异。他们不会乖乖按照你的要求做事。他们总能给你意想不到的惊喜(或惊吓)。相比之下,RSS学生比较听话,每天准时上课,交作业,从不出错。虽然顽皮的学生可以活跃课堂气氛,给生活增添乐趣,但老师往往会把重要的任务交给乖巧的学生。
信息的获取也是如此。社交媒体的混乱时间线和聚合阅读工具烦人的算法推荐,让我们无法高效获取所需信息。 RSS只抓取订阅的信息源,按时间顺序展示内容的特点,显然更符合我们作为一个想要掌控信息主动权的“老师”的期待。
相关阅读:你的新闻APP被推荐算法“毁了”,RSS真的能救你吗?
什么是RSS服务
虽然RSS只能呈现你订阅的内容,但并不是所有的网站都像少数人一样,每天只推送几个文章。以科技媒体Engadget为例,它每周推送数百条新闻。我相信你不想也没有时间一一阅读这些项目。这时候,如何使用RSS只查看自己想阅读的内容,防止信息过载就成了我们需要解决的问题。
RSS 服务是基于 RSS 协议开发的聚合服务。目前比较知名的RSS服务有Feedly、NewsBlur、Inoreader等,这些服务大部分都提供了过滤文章的功能。他们在可以自动抓取RSS提要中更新的内容的同时,也可以根据你设置的过滤条件,将符合条件的文章以文件夹或标签的形式聚合呈现给你,让你只能看到你想要的看到并告别信息过载。
此外,每个RSS服务也有自己独特的功能:例如Feedly支持文章内容的高亮和笔记,Inoreader支持丰富的过滤规则,可以链接自动化服务。您可以根据自己的需要选择合适的RSS服务,通过RSS获取信息越来越方便。
相关阅读:2018年选择哪些主流RSS服务? Feedly、Inoreader 和 NewsBlur 综合评论
如何查找 RSS 提要
就像给朋友打电话一样,你需要知道对方的号码才能建立连接。 RSS 也是如此。 RSS订阅链接相当于我们要拨打的电话号码。
了解网站是否支持RSS订阅最直接的方法就是查看网站底部或侧边栏是否有RSS图标。一般来说,图标指向的地址就是网站的订阅链接。您可以直接点击RSS订阅链接跳转到RSS客户端订阅,也可以将按钮中的地址复制粘贴到您正在使用的RSS服务订阅网站中的内容。
在大多数情况下,支持RSS订阅的网站会显示RSS图标。然而,总有例外。这时候你也可以尝试在网站域名后面加上/feed或者/rss。您可能会偶然猜到,例如少数 RSS 订阅链接。当然也可以直接通过搜索引擎使用网站名+RSS关键字搜索,经常可以找到支持网站的RSS链接。
除了手动搜索订阅链接,RSSHub Radar 是一款 Chrome 浏览器扩展,可以帮助您一键发现和订阅当前的网站 RSS 链接。如果您当前浏览的网页支持RSS,您可以通过本插件直接复制RSS订阅链接,或者订阅RSS链接到Feedly、Inoreader等RSS服务。
相关阅读:在网络上搜索RSS链接?为什么不使用这个Chrome插件一键订阅
如果您是 RSS 新手,您不知道哪个网站 值得订阅。除了小众,还可以订阅The Verge、9to5Mac获取苹果、三星等大公司的科技资讯,订阅核心获取主机游戏信息,订阅好奇日报获取行业新闻和生活信息。
如何自己制作 RSS 提要
当你想给没有号码的朋友打电话时,最简单的方法就是给他一个号码。 RSS 也是如此。我们常用的公众号、B站等网站不支持RSS,也许您想准确订阅特定页面。在这些情况下,学习如何制作 Feed 尤为重要。
借助 RSSHub 等工具,您可以轻松创建提要。比如我在哔哩哔哩发现了一位多产的UP主,名叫“Minority sspai”,想订阅他的视频更新。我们可以在他的个人空间找到这位UP主的UID:176321970。然后根据官方文档的介绍,填写UID完成制作。
RSSHub目前支持的网站已经很丰富了,足以满足生活中的大部分需求。少数族裔还分享了许多方便快捷的方式来创建提要。你可以参考这些文章:
对于追求更多可能性的高级用户,可以选择构建自己的RSS服务,满足更多个性化的需求。以下文章或许能帮到你:
构建RSS阅读流程
选择RSS服务后,我们当然希望提高阅读效率。粗读往往只是肤浅的信息。对于一些有价值的文章,花一些时间反复阅读和消化可能会更好。因此,构建适合您的阅读流程可以大大提高我们的效率。
虽然构建阅读过程听起来很复杂,但实际上很容易。简化后,其实只需要三步:
过滤内容来源:选择优质的Feed,使用RSS服务过滤内容,只留下你感兴趣的内容。分类处理文章:阅读标题、摘要,或者通读文章,善用“采集”和阅读后期工具,把有价值的文章留住。精读优质内容:在采集夹或阅读后期应用中,精读有价值的文章,并使用摘录、笔记等形式帮助消化内容。
相关阅读:在线阅读过程:从需求、到方法、再到工具
值得一试的RSS阅读工具
工人要想做好本职工作,就必须先磨砺他的工具。一旦我们掌握了获取提要的方法并构建了自己的阅读流程,我们还需要一个得心应手的工具。那么,我们如何选择工具呢?一个优秀的 RSS 工具应该做到以下几点:
支持您使用的服务:RSS 工具一般访问众所周知的服务,例如 Feedly 和 Innoreader。但是对于一些自建服务或者小众服务,每个应用的支持是有很大区别的。因此,RSS 工具是否支持您使用的服务是首先要考虑的。支持全文爬取:很多网站RSS采用“标题+摘要”的方式,需要用户手动打开网页阅读。支持全文爬取的客户端可以为我们省去不少精力。支持扩展服务等:支持“稍后阅读”服务、网页重定向等功能,可以大大提升我们的阅读体验。在构建RSS阅读流程时,此类工具可以帮助我们架起RSS与“稍后阅读”之间的界限。
如果您仍然不确定自己的需求,也没关系。我们为您精选了四大主流平台上最好的一批RSS工具,相信一定能让您满意。
macOS:Reeder4
Reeder 是 macOS 和 iOS 上的老牌 RSS 工具。它以操作流畅、设计精美而著称。在“百花盛开”的iOS平台上,虽然Reeder在功能上没有那么全面,但仍然是macOS最全的RSS客户端选择。
相关阅读
iOS:里拉
lire兼顾人性化设计和操作体验。该应用程序在支持全文抓取和手势操作等功能的同时,还支持自动化和旁白。您还可以在里拉中单独设置不同的提要,非常人性化。
相关阅读
Windows:RSS 跟踪
“RSS 跟踪”提供清晰的界面级别、便捷的获取提要的方式以及独特的特定于平台的时间轴和 OneDrive 同步方法。该应用程序支持手动输入提要、通过 Feedly 服务关键词 搜索或导入 OPML 文件。
相关阅读:无缝且无压力的 RSS 体验。此阅读器最适合 Windows 10:RSS Stalker
安卓:FeedMe
FeedMe 是一个简单的设计和全功能的 RSS 工具。由于网络环境的限制,我们在国内使用RSS服务时总会遇到障碍。 FeedMe贴心提供了“中国模式”,即使你没有开启网络代理,也能顺利获得文章更新。
相关阅读:Android上如何选择RSS阅读器?这7款好看好用的APP不容错过
如果您想与我们分享有关 RSS 的其他有用工具和技术,请在评论部分告诉我们。如果您想进一步了解RSS实用工具和技巧,可以阅读我们为您准备的RSS专题:
高效获取信息,从这些 RSS 工具和技术开始
>下载小众客户端,关注小众公众号,让您的工作更有效率⏱
>特殊好用的硬件产品,尽在小众sspai官方商城 查看全部
[RSS入门]不妨再受:你可能感兴趣的内容(组图)
我们每天都在接收信息。无论是社交网络好友分享的新鲜事物,还是今日头条等聚合阅读工具中的文章,依靠推荐算法,总能带来“你可能感兴趣的内容”。这些有用或无用的信息不仅消耗了我们大量的时间,无休止的“时间流”也让我们信息过载,无形中让我们接触到的信息种类越来越窄。 ”。
为了解决信息过载的问题,让我们在接收到的信息中掌握主动权,RSS重新进入了我们的视野:我们可以自由选择订阅的信息源,不受算法“控制” ,还要及时调整信息源,避免信息过载。
但是,由于RSS有一定的使用门槛,很多刚接触RSS的用户都无法回避一些问题,比如:
如果您在使用 RSS 获取信息的过程中也被工具和技术所困扰,不妨阅读这份 RSS 入门指南,与我们一起“摆脱”信息过载。
为什么选择 RSS
RSS的全称是ReallySimpleSyndication,是一种消息来源的格式规范。 网站可以向订阅者提供文章标题、摘要、全文等信息,用户按照这个格式规范可以通过订阅不同的网站RSS链接聚合不同的信息源,并在一个工具中阅读这些内容。
简单来说,RSS就是订阅某个网站内容更新的协议。这个略显“旧”的协议在社交媒体和聚合阅读的影响下逐渐走下坡路。就连谷歌也在 2013 年关闭了自己的 RSS 服务 GoogleReader。那么,我们为什么要选择 RSS?
当我还是学生的时候,我相信每个班级里都有两种人:调皮的学生和听话的学生。社交媒体、今日头条等聚合阅读工具与前者无异。他们不会乖乖按照你的要求做事。他们总能给你意想不到的惊喜(或惊吓)。相比之下,RSS学生比较听话,每天准时上课,交作业,从不出错。虽然顽皮的学生可以活跃课堂气氛,给生活增添乐趣,但老师往往会把重要的任务交给乖巧的学生。
信息的获取也是如此。社交媒体的混乱时间线和聚合阅读工具烦人的算法推荐,让我们无法高效获取所需信息。 RSS只抓取订阅的信息源,按时间顺序展示内容的特点,显然更符合我们作为一个想要掌控信息主动权的“老师”的期待。
相关阅读:你的新闻APP被推荐算法“毁了”,RSS真的能救你吗?
什么是RSS服务
虽然RSS只能呈现你订阅的内容,但并不是所有的网站都像少数人一样,每天只推送几个文章。以科技媒体Engadget为例,它每周推送数百条新闻。我相信你不想也没有时间一一阅读这些项目。这时候,如何使用RSS只查看自己想阅读的内容,防止信息过载就成了我们需要解决的问题。
RSS 服务是基于 RSS 协议开发的聚合服务。目前比较知名的RSS服务有Feedly、NewsBlur、Inoreader等,这些服务大部分都提供了过滤文章的功能。他们在可以自动抓取RSS提要中更新的内容的同时,也可以根据你设置的过滤条件,将符合条件的文章以文件夹或标签的形式聚合呈现给你,让你只能看到你想要的看到并告别信息过载。
此外,每个RSS服务也有自己独特的功能:例如Feedly支持文章内容的高亮和笔记,Inoreader支持丰富的过滤规则,可以链接自动化服务。您可以根据自己的需要选择合适的RSS服务,通过RSS获取信息越来越方便。
相关阅读:2018年选择哪些主流RSS服务? Feedly、Inoreader 和 NewsBlur 综合评论
如何查找 RSS 提要
就像给朋友打电话一样,你需要知道对方的号码才能建立连接。 RSS 也是如此。 RSS订阅链接相当于我们要拨打的电话号码。
了解网站是否支持RSS订阅最直接的方法就是查看网站底部或侧边栏是否有RSS图标。一般来说,图标指向的地址就是网站的订阅链接。您可以直接点击RSS订阅链接跳转到RSS客户端订阅,也可以将按钮中的地址复制粘贴到您正在使用的RSS服务订阅网站中的内容。
在大多数情况下,支持RSS订阅的网站会显示RSS图标。然而,总有例外。这时候你也可以尝试在网站域名后面加上/feed或者/rss。您可能会偶然猜到,例如少数 RSS 订阅链接。当然也可以直接通过搜索引擎使用网站名+RSS关键字搜索,经常可以找到支持网站的RSS链接。
除了手动搜索订阅链接,RSSHub Radar 是一款 Chrome 浏览器扩展,可以帮助您一键发现和订阅当前的网站 RSS 链接。如果您当前浏览的网页支持RSS,您可以通过本插件直接复制RSS订阅链接,或者订阅RSS链接到Feedly、Inoreader等RSS服务。
相关阅读:在网络上搜索RSS链接?为什么不使用这个Chrome插件一键订阅
如果您是 RSS 新手,您不知道哪个网站 值得订阅。除了小众,还可以订阅The Verge、9to5Mac获取苹果、三星等大公司的科技资讯,订阅核心获取主机游戏信息,订阅好奇日报获取行业新闻和生活信息。
如何自己制作 RSS 提要
当你想给没有号码的朋友打电话时,最简单的方法就是给他一个号码。 RSS 也是如此。我们常用的公众号、B站等网站不支持RSS,也许您想准确订阅特定页面。在这些情况下,学习如何制作 Feed 尤为重要。
借助 RSSHub 等工具,您可以轻松创建提要。比如我在哔哩哔哩发现了一位多产的UP主,名叫“Minority sspai”,想订阅他的视频更新。我们可以在他的个人空间找到这位UP主的UID:176321970。然后根据官方文档的介绍,填写UID完成制作。
RSSHub目前支持的网站已经很丰富了,足以满足生活中的大部分需求。少数族裔还分享了许多方便快捷的方式来创建提要。你可以参考这些文章:
对于追求更多可能性的高级用户,可以选择构建自己的RSS服务,满足更多个性化的需求。以下文章或许能帮到你:
构建RSS阅读流程
选择RSS服务后,我们当然希望提高阅读效率。粗读往往只是肤浅的信息。对于一些有价值的文章,花一些时间反复阅读和消化可能会更好。因此,构建适合您的阅读流程可以大大提高我们的效率。
虽然构建阅读过程听起来很复杂,但实际上很容易。简化后,其实只需要三步:
过滤内容来源:选择优质的Feed,使用RSS服务过滤内容,只留下你感兴趣的内容。分类处理文章:阅读标题、摘要,或者通读文章,善用“采集”和阅读后期工具,把有价值的文章留住。精读优质内容:在采集夹或阅读后期应用中,精读有价值的文章,并使用摘录、笔记等形式帮助消化内容。
相关阅读:在线阅读过程:从需求、到方法、再到工具
值得一试的RSS阅读工具
工人要想做好本职工作,就必须先磨砺他的工具。一旦我们掌握了获取提要的方法并构建了自己的阅读流程,我们还需要一个得心应手的工具。那么,我们如何选择工具呢?一个优秀的 RSS 工具应该做到以下几点:
支持您使用的服务:RSS 工具一般访问众所周知的服务,例如 Feedly 和 Innoreader。但是对于一些自建服务或者小众服务,每个应用的支持是有很大区别的。因此,RSS 工具是否支持您使用的服务是首先要考虑的。支持全文爬取:很多网站RSS采用“标题+摘要”的方式,需要用户手动打开网页阅读。支持全文爬取的客户端可以为我们省去不少精力。支持扩展服务等:支持“稍后阅读”服务、网页重定向等功能,可以大大提升我们的阅读体验。在构建RSS阅读流程时,此类工具可以帮助我们架起RSS与“稍后阅读”之间的界限。
如果您仍然不确定自己的需求,也没关系。我们为您精选了四大主流平台上最好的一批RSS工具,相信一定能让您满意。
macOS:Reeder4
Reeder 是 macOS 和 iOS 上的老牌 RSS 工具。它以操作流畅、设计精美而著称。在“百花盛开”的iOS平台上,虽然Reeder在功能上没有那么全面,但仍然是macOS最全的RSS客户端选择。
相关阅读
iOS:里拉
lire兼顾人性化设计和操作体验。该应用程序在支持全文抓取和手势操作等功能的同时,还支持自动化和旁白。您还可以在里拉中单独设置不同的提要,非常人性化。
相关阅读
Windows:RSS 跟踪
“RSS 跟踪”提供清晰的界面级别、便捷的获取提要的方式以及独特的特定于平台的时间轴和 OneDrive 同步方法。该应用程序支持手动输入提要、通过 Feedly 服务关键词 搜索或导入 OPML 文件。
相关阅读:无缝且无压力的 RSS 体验。此阅读器最适合 Windows 10:RSS Stalker
安卓:FeedMe
FeedMe 是一个简单的设计和全功能的 RSS 工具。由于网络环境的限制,我们在国内使用RSS服务时总会遇到障碍。 FeedMe贴心提供了“中国模式”,即使你没有开启网络代理,也能顺利获得文章更新。
相关阅读:Android上如何选择RSS阅读器?这7款好看好用的APP不容错过
如果您想与我们分享有关 RSS 的其他有用工具和技术,请在评论部分告诉我们。如果您想进一步了解RSS实用工具和技巧,可以阅读我们为您准备的RSS专题:
高效获取信息,从这些 RSS 工具和技术开始
>下载小众客户端,关注小众公众号,让您的工作更有效率⏱
>特殊好用的硬件产品,尽在小众sspai官方商城
百度站长平台权威解答会的SEO的问题分析与对策
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-08-27 07:10
问题:百度搜索会不会调整网站的抓取频率?
百度站长平台权威解答
会的。百度搜索会根据网站内容质量、内容更新频率、网站规模变化等维度进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会减少对网站频率的抓取。
不过,爬取频率不一定与收录量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
沐风SEO讲解
从实际案例来看,百度搜索在调整网站的爬取频率上是比较有效的,尤其是对于原来爬取频率很低的,比如新站。百度搜索提到了影响蜘蛛爬行的几个重要方面,即内容质量、内容更新频率、网站尺度的变化。
这实际上为我指明了方向。我想提高网站的抓取频率,可以提高内容质量,增加内容更新的频率和数量。
其实经过正规优化的网站通常不用担心爬取频率低的问题,因为正规的白帽SEO可以做到以上三个方面。对于那些想要省力又想有好结果的人来说,恐怕不会那么令人满意。
即便如此,百度在调整抓取频率方面仍有很大的提升空间,因为它无法及时分析网站内容。一些采集站的爬取频率也很高,这就是原因。
总之,百度搜索会不定期调整网站的抓取频率。想要这个爬虫频率稳步上升,就必须控制网站内容的质量,以及更新频率和数量。只有网站的内容质量高,网站的体积更大,爬取频率才会越来越好。 查看全部
百度站长平台权威解答会的SEO的问题分析与对策
问题:百度搜索会不会调整网站的抓取频率?
百度站长平台权威解答
会的。百度搜索会根据网站内容质量、内容更新频率、网站规模变化等维度进行综合计算。如果内容质量或内容更新频率下降,百度搜索可能会减少对网站频率的抓取。
不过,爬取频率不一定与收录量有关。比如降低历史资源的爬取频率不会影响新资源的收录效果。
沐风SEO讲解
从实际案例来看,百度搜索在调整网站的爬取频率上是比较有效的,尤其是对于原来爬取频率很低的,比如新站。百度搜索提到了影响蜘蛛爬行的几个重要方面,即内容质量、内容更新频率、网站尺度的变化。
这实际上为我指明了方向。我想提高网站的抓取频率,可以提高内容质量,增加内容更新的频率和数量。
其实经过正规优化的网站通常不用担心爬取频率低的问题,因为正规的白帽SEO可以做到以上三个方面。对于那些想要省力又想有好结果的人来说,恐怕不会那么令人满意。
即便如此,百度在调整抓取频率方面仍有很大的提升空间,因为它无法及时分析网站内容。一些采集站的爬取频率也很高,这就是原因。
总之,百度搜索会不定期调整网站的抓取频率。想要这个爬虫频率稳步上升,就必须控制网站内容的质量,以及更新频率和数量。只有网站的内容质量高,网站的体积更大,爬取频率才会越来越好。
robots协议文件屏蔽百度蜘蛛抓取协议的设置比较简单
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-08-27 07:08
百度蜘蛛抓取我们的网站,希望我们的网页收录能被发送到它的搜索引擎。以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候我们只想抓取我们想在搜索引擎上搜索到的内容。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。有两种最好的方法可以解决这个问题,如下所示:
robots 协议文件阻止百度蜘蛛抓取
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:您的域名/robots.txt。百度蜘蛛抓取我们网站时,会先访问这个文件。因为它告诉蜘蛛哪些可以爬,哪些不能爬。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow三个参数进行设置。
让我们看下面的例子。场景是我不想百度抢到我所有的网站css文件、数据目录、seo-tag.html页面
User-Agent: Baidusppider
Disallow: /*.css
Disallow: /data/
Disallow: /seo/seo-tag.html
如上,user-agent声明的蜘蛛名称表示针对百度蜘蛛。以下无法抓取“/*.css”。首先,前面的/指的是根目录,也就是你的域名。 * 是通配符,代表任何内容。这意味着无法抓取所有以 .css 结尾的文件。亲自体验以下两个。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
403 状态码用于限制内容输出并阻止蜘蛛抓取。
403状态码是http协议中网页返回的状态码。当搜索引擎遇到403状态码时,就知道该类页面是权限受限的。我不能访问。比如你需要登录查看内容,搜索引擎本身是不会登录的,那么当你返回403时,他也知道这是权限设置页面,无法读取内容。自然,收录 不会。
在返回 403 状态代码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛执行他们想要访问的内容。两者缺一不可。你只有一个提示页面,状态码返回200,对于百度蜘蛛来说是很多重复的页面。有一个 403 状态代码,但返回不同的内容。也不是很友好。
最后,关于robot协议,我想补充一点:“现在搜索引擎会通过你网页的布局和布局来识别你网页的体验友好性。如果你屏蔽了css文件的抓取和布局相关的js文件,那么搜索引擎不知道你的网页布局是好是坏,所以不建议蜘蛛屏蔽这个内容。”
好了,今天的分享就到这里,希望对大家有帮助,当然以上两个设置对百度蜘蛛以外的所有蜘蛛都有效。设置时请谨慎。
延伸阅读
原创文章:《如何阻止百度蜘蛛(Baiduspider)爬取网站》,作者:赵延刚。未经许可请勿转载。如转载请注明出处: 查看全部
robots协议文件屏蔽百度蜘蛛抓取协议的设置比较简单
百度蜘蛛抓取我们的网站,希望我们的网页收录能被发送到它的搜索引擎。以后用户搜索的时候,可以给我们带来一定的SEO流量。当然,我们不希望搜索引擎抓取所有内容。
所以,这个时候我们只想抓取我们想在搜索引擎上搜索到的内容。像用户隐私、背景信息等,不希望搜索引擎被爬取和收录。有两种最好的方法可以解决这个问题,如下所示:
robots 协议文件阻止百度蜘蛛抓取
robots协议是放置在网站根目录下的协议文件,可以通过URL地址访问:您的域名/robots.txt。百度蜘蛛抓取我们网站时,会先访问这个文件。因为它告诉蜘蛛哪些可以爬,哪些不能爬。
robots协议文件的设置比较简单,可以通过User-Agent、Disallow、Allow三个参数进行设置。
让我们看下面的例子。场景是我不想百度抢到我所有的网站css文件、数据目录、seo-tag.html页面
User-Agent: Baidusppider
Disallow: /*.css
Disallow: /data/
Disallow: /seo/seo-tag.html
如上,user-agent声明的蜘蛛名称表示针对百度蜘蛛。以下无法抓取“/*.css”。首先,前面的/指的是根目录,也就是你的域名。 * 是通配符,代表任何内容。这意味着无法抓取所有以 .css 结尾的文件。亲自体验以下两个。逻辑是一样的。
如果你想检查你上次设置的robots文件是否正确,可以访问这个文章《检查Robots是否正确的工具介绍》,里面有详细的工具可以检查你的设置。
403 状态码用于限制内容输出并阻止蜘蛛抓取。
403状态码是http协议中网页返回的状态码。当搜索引擎遇到403状态码时,就知道该类页面是权限受限的。我不能访问。比如你需要登录查看内容,搜索引擎本身是不会登录的,那么当你返回403时,他也知道这是权限设置页面,无法读取内容。自然,收录 不会。
在返回 403 状态代码时,应该有一个类似于 404 页面的页面。提示用户或蜘蛛执行他们想要访问的内容。两者缺一不可。你只有一个提示页面,状态码返回200,对于百度蜘蛛来说是很多重复的页面。有一个 403 状态代码,但返回不同的内容。也不是很友好。
最后,关于robot协议,我想补充一点:“现在搜索引擎会通过你网页的布局和布局来识别你网页的体验友好性。如果你屏蔽了css文件的抓取和布局相关的js文件,那么搜索引擎不知道你的网页布局是好是坏,所以不建议蜘蛛屏蔽这个内容。”
好了,今天的分享就到这里,希望对大家有帮助,当然以上两个设置对百度蜘蛛以外的所有蜘蛛都有效。设置时请谨慎。
延伸阅读
原创文章:《如何阻止百度蜘蛛(Baiduspider)爬取网站》,作者:赵延刚。未经许可请勿转载。如转载请注明出处:
在搜索引擎眼里什么才叫高质量的文章吗?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-08-24 07:19
你知道什么是搜索引擎眼中的优质文章吗?
在SEO圈子里,“内容”必须是一个经久不衰的话题。虽然各个阶段的搜索引擎算法对SEO有不同的规范,但智能算法也让深圳的SEO工作越来越多。不简短,但“好内容”永远是包围的工具。那么问题来了,什么样的内容才是搜索引擎眼中的“优质内容”?
简而言之,“优质内容”是好的内容、优质的代码和出色的用户体验的结合。
一、基本规范
内容最基本的部分是“文本”。写文章时,不得出现错别字、连线、无标点、无分词的长篇幅讨论;不要使用hard、deep,对于难懂的词句,尽量使用简单直观的句子,便于各级用户理解。
二、排版布局
要想制作出让用户满意的“优质内容”,除了内容本身,布局也是一项非常重要的工作。毕竟,人是视觉动物。
将文本内容划分为标题、副标题、正文等不同类型,然后让文本以突出的水平履行职责。清晰的层次结构可以让内容更具可读性,搭配适当的图形会让文章显得更加生动。此外,针对不同的文本类型使用不同格式、大小和颜色的字体也可以让用户获得更好的阅读体验。引用其他平台内容时,尽量保证链接指向高质量、有声望的网站(如政府平台、官方网站等)。
三、加载速度
“网站Loading Speed”到底有多重要?根据调研查询,网站loading时间过长是造成用户流失的主要原因之一,尤其是电商网站So。
“网站Load Speed”与“用户购买行为”的联系如下图所示:
快节奏的日子导致用户缺乏耐心,尤其是在阅读网页时。可以说,速度是网站victory 决议最重要的因素之一。 网站加载时间增加1秒可能导致:转化率下降7%,用户满意度下降16%...
那么,怎样才能提高“加载速度”呢?这里有几点:
1)将JS代码和CSS样式分别合并到一个共享文件中;
2) 适当缩小图片,优化格式;
3)优先显示可见区域的内容,即先加载首屏的内容和样式,当用户滚动鼠标时加载下面的内容;
4) 减去代码,去掉不必要的冗余代码,如空格、注释等
5)Cache 静态资源,通过设置reader缓存来缓存CSS、JS等不经常更新的文件;
四、立异性
现在,互联网、社交媒体、自媒体等平台上总是充斥着“文章怎么写”的套路和教程,比如“10W+的文章头衔怎么写”和“自媒体人必知“10W+文章技能”……等等,导致“内容生产者”文章总是按套路开始写作,失去创新,不断趋于同质化,甚至用户看到在一开始觉得沉闷。
所以,想要被用户喜爱,要么写出有深度、有见地、有沉淀、非商业性的内容。这对很多站长来说比较困难;另一种是写“小说”,这种想法iDea,对写作的要求稍微低一些,但是有一定的需求,比如我们都在写《鹿晗和晓彤秀恩爱》的时候,谁会写《为什么鹿晗》第一刻我没有选择迪丽热巴,这样文章的作者肯定会得到更多的关注(也许文章这样的一些人会被网友喷,但肯定会得到关注)。
那么,应该如何学习 SEO 技术?
这里说的有点多,毕竟涉及的知识还是很多的。一时还不清楚。
如果你也想学习SEO技术,可以加千墨老师微信m247143276接收SEO技术教程,也可以加入学习群和我们seo研究中心老师一起学习。返回搜狐查看更多 查看全部
在搜索引擎眼里什么才叫高质量的文章吗?(图)
你知道什么是搜索引擎眼中的优质文章吗?
在SEO圈子里,“内容”必须是一个经久不衰的话题。虽然各个阶段的搜索引擎算法对SEO有不同的规范,但智能算法也让深圳的SEO工作越来越多。不简短,但“好内容”永远是包围的工具。那么问题来了,什么样的内容才是搜索引擎眼中的“优质内容”?
简而言之,“优质内容”是好的内容、优质的代码和出色的用户体验的结合。
一、基本规范
内容最基本的部分是“文本”。写文章时,不得出现错别字、连线、无标点、无分词的长篇幅讨论;不要使用hard、deep,对于难懂的词句,尽量使用简单直观的句子,便于各级用户理解。
二、排版布局
要想制作出让用户满意的“优质内容”,除了内容本身,布局也是一项非常重要的工作。毕竟,人是视觉动物。
将文本内容划分为标题、副标题、正文等不同类型,然后让文本以突出的水平履行职责。清晰的层次结构可以让内容更具可读性,搭配适当的图形会让文章显得更加生动。此外,针对不同的文本类型使用不同格式、大小和颜色的字体也可以让用户获得更好的阅读体验。引用其他平台内容时,尽量保证链接指向高质量、有声望的网站(如政府平台、官方网站等)。
三、加载速度
“网站Loading Speed”到底有多重要?根据调研查询,网站loading时间过长是造成用户流失的主要原因之一,尤其是电商网站So。
“网站Load Speed”与“用户购买行为”的联系如下图所示:
快节奏的日子导致用户缺乏耐心,尤其是在阅读网页时。可以说,速度是网站victory 决议最重要的因素之一。 网站加载时间增加1秒可能导致:转化率下降7%,用户满意度下降16%...
那么,怎样才能提高“加载速度”呢?这里有几点:
1)将JS代码和CSS样式分别合并到一个共享文件中;
2) 适当缩小图片,优化格式;
3)优先显示可见区域的内容,即先加载首屏的内容和样式,当用户滚动鼠标时加载下面的内容;
4) 减去代码,去掉不必要的冗余代码,如空格、注释等
5)Cache 静态资源,通过设置reader缓存来缓存CSS、JS等不经常更新的文件;
四、立异性
现在,互联网、社交媒体、自媒体等平台上总是充斥着“文章怎么写”的套路和教程,比如“10W+的文章头衔怎么写”和“自媒体人必知“10W+文章技能”……等等,导致“内容生产者”文章总是按套路开始写作,失去创新,不断趋于同质化,甚至用户看到在一开始觉得沉闷。
所以,想要被用户喜爱,要么写出有深度、有见地、有沉淀、非商业性的内容。这对很多站长来说比较困难;另一种是写“小说”,这种想法iDea,对写作的要求稍微低一些,但是有一定的需求,比如我们都在写《鹿晗和晓彤秀恩爱》的时候,谁会写《为什么鹿晗》第一刻我没有选择迪丽热巴,这样文章的作者肯定会得到更多的关注(也许文章这样的一些人会被网友喷,但肯定会得到关注)。
那么,应该如何学习 SEO 技术?
这里说的有点多,毕竟涉及的知识还是很多的。一时还不清楚。
如果你也想学习SEO技术,可以加千墨老师微信m247143276接收SEO技术教程,也可以加入学习群和我们seo研究中心老师一起学习。返回搜狐查看更多
网页书籍抓取器(网页内容抓取工具)是一款很优秀好用
网站优化 • 优采云 发表了文章 • 0 个评论 • 477 次浏览 • 2021-08-24 07:16
Web Book Crawler(Web Content Crawling Tool)是一款优秀且易于使用的网络内容爬行助手。如何更轻松地抓取网页内容?编辑器带来的这个网络图书抓取器可以帮助您。它功能强大且易于操作。使用后,用户可以快速轻松地抓取网页内容。可以很好的帮助大家抓取指定网页的内容,比如抓取一些小说内容,然后通过合并功能合并成一个完整的小说文本。欢迎有需要的朋友下载使用。
软件功能:
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、Automatic retry:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),待网络良好后再试。
3、Stop and resume:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,程序执行后可以恢复抓取下次运行。注意:需要先用停止按钮中断然后退出程序,如果直接退出,将不会恢复)
4、 一键抓图:又称“傻瓜模式”,基本可以实现全自动抓图合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
5、Applicable网站:已经输入了10个适用的网站(选择后可以快速打开网站找到需要的书),自动应用相应的代码,其他小说也可以应用网站进行测试,如果一起使用,可以手动添加到配置文件中以备后用。
6、电子书制作方便:可以在设置文件中添加各章节名称的前缀和后缀,为后期制作电子书目录带来极大的方便。
使用说明:
网络图书抓取器可以提取和调整指定小说目录页的章节信息,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
使用方法:
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击开始爬取开始下载。
软件介绍:
网络图书抓取器是一种可以帮助用户下载某本书和指定网页的某个章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,有需要的可以下载使用。
查看全部
网页书籍抓取器(网页内容抓取工具)是一款很优秀好用
Web Book Crawler(Web Content Crawling Tool)是一款优秀且易于使用的网络内容爬行助手。如何更轻松地抓取网页内容?编辑器带来的这个网络图书抓取器可以帮助您。它功能强大且易于操作。使用后,用户可以快速轻松地抓取网页内容。可以很好的帮助大家抓取指定网页的内容,比如抓取一些小说内容,然后通过合并功能合并成一个完整的小说文本。欢迎有需要的朋友下载使用。
软件功能:
1、章节调整:提取目录后,可以进行移动、删除、倒序等调整操作。调整会直接影响最终的书籍,也会以调整后的章节顺序输出。
2、Automatic retry:在爬取过程中,由于网络因素,可能会出现爬取失败的情况。程序可能会自动重试直到成功,也可以暂时中断爬取(中断后关闭程序不影响进度),待网络良好后再试。
3、Stop and resume:抓取过程可以随时停止,退出程序后不影响进度(章节信息会保存在记录中,程序执行后可以恢复抓取下次运行。注意:需要先用停止按钮中断然后退出程序,如果直接退出,将不会恢复)
4、 一键抓图:又称“傻瓜模式”,基本可以实现全自动抓图合并功能,直接输出最终的文本文件。前面可能需要输入最基本的网址、保存位置等信息(会有明显的操作提示),调整章节后也可以使用一键抓取,抓取合并操作会自动完成.
5、Applicable网站:已经输入了10个适用的网站(选择后可以快速打开网站找到需要的书),自动应用相应的代码,其他小说也可以应用网站进行测试,如果一起使用,可以手动添加到配置文件中以备后用。
6、电子书制作方便:可以在设置文件中添加各章节名称的前缀和后缀,为后期制作电子书目录带来极大的方便。
使用说明:
网络图书抓取器可以提取和调整指定小说目录页的章节信息,然后按照章节顺序抓取小说内容,然后合并。抓取过程可以随时中断,关闭程序后可以继续上一个任务。
使用方法:
一、首先进入你要下载的小说的网页。
二、输入书名,点击目录提取。
三、设置保存路径,点击开始爬取开始下载。
软件介绍:
网络图书抓取器是一种可以帮助用户下载某本书和指定网页的某个章节的软件。在线图书抓取器可以快速下载小说。同时软件支持断点续传功能,非常方便,有需要的可以下载使用。
网站页面不是让搜索引擎抓的越多越好吗,怎么让冗余
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-08-24 07:09
项目招商找A5快速获取精准代理商名单
有些朋友可能会奇怪网站的页面没有被搜索引擎尽可能多的抓取,怎么可能有想法不让网站页面的内容被抓取。
首先,可以分配给网站的权重是有限的。即使是Pr10站,也不可能无限分配权重。这个权重包括链接到他人网站的链和自己网站内部的链。
对于外部链接,除非是想被链接的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
链内,因为一些网站有很多重复或冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说极其方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外网站管理登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,需要防止网页的某些内容,或某些页面被搜索引擎收录搜索到。
下面笔者先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为收录的内容
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为 Google 和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个多用于网站管理页面、测试页面等
3.使用nofollow标签包裹你不想成为收录的内容
这个方法不能完全保证你不会被收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4.使用Meta Noindex标签添加关注标签
这个方法既可以防止收录,也可以传递权重。想通过就看网站建筑站长的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件,在页面上使用iframe标签显示需要搜索引擎收录的内容
robots 文件可以防止 iframe 标签之外的内容被收录。因此,您可以将不需要的内容收录 放在普通页面标签下。而想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表格
谷歌和百度已经可以抓取表单内容,收录无法屏蔽。
2.使用Javascript和Ajax技术
就目前的技术而言,Ajax 和 javascript 的最终计算结果还是以 HTML 的形式传递给浏览器进行显示,所以这也无法阻止收录。
初学者大多关注如何收录,但细节决定成败。如何防止网站页面内容被抓取也是高级SEO人需要注意的问题。
本文来自(),尊重作者的劳动成果,转载请注明出处。
申请创业报告,分享创业好点子。点击这里一起讨论创业的新机会! 查看全部
网站页面不是让搜索引擎抓的越多越好吗,怎么让冗余
项目招商找A5快速获取精准代理商名单
有些朋友可能会奇怪网站的页面没有被搜索引擎尽可能多的抓取,怎么可能有想法不让网站页面的内容被抓取。
首先,可以分配给网站的权重是有限的。即使是Pr10站,也不可能无限分配权重。这个权重包括链接到他人网站的链和自己网站内部的链。
对于外部链接,除非是想被链接的人。否则,所有的外部链接都需要被搜索引擎抓取。这超出了本文的范围。
链内,因为一些网站有很多重复或冗余的内容。例如,一些基于条件的搜索结果。特别是对于一些B2C站,您可以在特殊查询页面或在所有产品页面的某个位置按产品类型、型号、颜色、尺寸等进行搜索。虽然这些页面对于浏览者来说极其方便,但是对于搜索引擎来说,它们会消耗大量的蜘蛛爬行时间,尤其是在网站页面很多的情况下。同时页面权重会分散,不利于SEO。
另外网站管理登录页、备份页、测试页等,站长不想让搜索引擎收录。
因此,需要防止网页的某些内容,或某些页面被搜索引擎收录搜索到。
下面笔者先介绍几种比较有效的方法:
1.在FLASH中展示你不想成为收录的内容
众所周知,搜索引擎对FLASH中内容的抓取能力有限,无法完全抓取FLASH中的所有内容。不幸的是,不能保证 FLASH 的所有内容都不会被抓取。因为 Google 和 Adobe 正在努力实现 FLASH 捕获技术。
2.使用robos文件
这是目前最有效的方法,但它有一个很大的缺点。只是不要发送任何内容或链接。众所周知,在SEO方面,更健康的页面应该进进出出。有外链链接,页面也需要有外链网站,所以robots文件控件让这个页面只能访问,搜索引擎不知道内容是什么。此页面将被归类为低质量页面。重量可能会受到惩罚。这个多用于网站管理页面、测试页面等
3.使用nofollow标签包裹你不想成为收录的内容
这个方法不能完全保证你不会被收录,因为这不是一个严格要求遵守的标签。另外,如果有外部网站链接到带有nofollow标签的页面。这很可能会被搜索引擎抓取。
4.使用Meta Noindex标签添加关注标签
这个方法既可以防止收录,也可以传递权重。想通过就看网站建筑站长的需求了。这种方法的缺点是也会大大浪费蜘蛛爬行的时间。
5.使用robots文件,在页面上使用iframe标签显示需要搜索引擎收录的内容
robots 文件可以防止 iframe 标签之外的内容被收录。因此,您可以将不需要的内容收录 放在普通页面标签下。而想要成为收录的内容放在iframe标签中。
接下来说说失败的方法。以后不要使用这些方法。
1.使用表格
谷歌和百度已经可以抓取表单内容,收录无法屏蔽。
2.使用Javascript和Ajax技术
就目前的技术而言,Ajax 和 javascript 的最终计算结果还是以 HTML 的形式传递给浏览器进行显示,所以这也无法阻止收录。
初学者大多关注如何收录,但细节决定成败。如何防止网站页面内容被抓取也是高级SEO人需要注意的问题。
本文来自(),尊重作者的劳动成果,转载请注明出处。
申请创业报告,分享创业好点子。点击这里一起讨论创业的新机会!
搜索引擎是如何抓取内容的?决的条件是什么
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-08-22 22:38
我们在做关键词排名的时候,第一步就是让搜索引擎抓住我们的网站。作为第一个前提,今天我要告诉你搜索引擎是如何抓取内容的。
如何抓取:
第一步:发现网站Webpage
搜索引擎通常会通过一些其他链接找到新的网站 和网页。所以,当搜索引擎找到网站时,需要添加合适的外链,内链也要丰富、干练。让搜索引擎发送的蜘蛛从内链顺利抓取,以便抓取新页面
第 2 步:搜索网站page
一旦某个网页被百度等搜索引擎理解,就会使用某个“站点”来搜索这些网页。您可能希望搜索整个网站。但是,这很可能受到搜索效率低或基础设施(阻止网站登录网站)等因素的阻碍。
第 3 步:提取内容
搜索引擎发送的蜘蛛一旦登陆页面,就会被选择性存储,搜索引擎会考虑是否存储内容。如果他们认为这些内容大部分比较空洞或者价值不大,那么他们通常不会存储网页(例如,这些网页可能是网站上其他网页内容的总和)。重复内容的常见原因之一是合并,也就是索引。
注意事项:
1、目录问题
我们可以在访问日记中看到蜘蛛的爬行轨迹。在后台,我们将未使用的页面放在不同的目录中。最好直接禁止一些不需要蜘蛛爬行的目录。
.
2、page 状态码
301跳转和404页面的规划很重要。如果外链连接的对应页面在后台被删除了,404页面没有很好的引导客户,那就麻烦了。而且302和301的效果不同,302无助于集中权力。 查看全部
搜索引擎是如何抓取内容的?决的条件是什么
我们在做关键词排名的时候,第一步就是让搜索引擎抓住我们的网站。作为第一个前提,今天我要告诉你搜索引擎是如何抓取内容的。
如何抓取:
第一步:发现网站Webpage
搜索引擎通常会通过一些其他链接找到新的网站 和网页。所以,当搜索引擎找到网站时,需要添加合适的外链,内链也要丰富、干练。让搜索引擎发送的蜘蛛从内链顺利抓取,以便抓取新页面
第 2 步:搜索网站page
一旦某个网页被百度等搜索引擎理解,就会使用某个“站点”来搜索这些网页。您可能希望搜索整个网站。但是,这很可能受到搜索效率低或基础设施(阻止网站登录网站)等因素的阻碍。
第 3 步:提取内容
搜索引擎发送的蜘蛛一旦登陆页面,就会被选择性存储,搜索引擎会考虑是否存储内容。如果他们认为这些内容大部分比较空洞或者价值不大,那么他们通常不会存储网页(例如,这些网页可能是网站上其他网页内容的总和)。重复内容的常见原因之一是合并,也就是索引。
注意事项:
1、目录问题
我们可以在访问日记中看到蜘蛛的爬行轨迹。在后台,我们将未使用的页面放在不同的目录中。最好直接禁止一些不需要蜘蛛爬行的目录。
.
2、page 状态码
301跳转和404页面的规划很重要。如果外链连接的对应页面在后台被删除了,404页面没有很好的引导客户,那就麻烦了。而且302和301的效果不同,302无助于集中权力。
抓取网页中的特定内容-抓取网并提取网页源码
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-08-22 19:05
背景
很多时候,很多人需要抓取网页上的某些特定内容。
不过,除了前面介绍的,我还想从一些静态网页中提取具体的内容,比如:
【教程】python版爬取网页并提取网页中需要的信息
和
【教程】C#版抓取网页并提取网页中需要的信息
除了
,有些人会发现自己要爬取的网页的内容不在网页的源代码中。
所以,这个时候,我不知道如何实现它。
在这里,让我们解释一下如何抓取所谓的动态网页中的特定内容。
必备知识
阅读本文前,您需要具备相关的基础知识:
1.Fetch 网页,模拟登录等相关逻辑
不熟悉的请参考:
【整理中】关于爬取网页、分析网页内容、模拟登录网站的逻辑/流程及注意事项
2.学习使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的请参考:
【教程】教你使用工具(IE9中F12)分析模拟登录网站(百度首页)内部逻辑流程)
3.对于普通静态网页,如何提取需要的内容
如果你对此不熟悉,可以参考:
(1)Python 版本:
【教程】python版爬取网页并提取网页中需要的信息
(2)C#Version:
【教程】C#版抓取网页并提取网页中需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指在浏览器中查看网页源代码时所看到的网页源代码中的内容以及网页上显示的内容。
也就是说,当我想在网页上显示某个内容时,可以通过搜索网页的源代码来找到相应的部分。
对于动态网页,则相反,如果想获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
简而言之,它是通过其他方式生成或获得的。
目前,我学到了几件事:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个URL的过程,你会发现很可能会涉及到,
在网页正常显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些想要抓取的内容,有时这些js脚本是动态执行最后计算出来的。
通过访问另一个 url 地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要爬取的动态内容
其实,关于如何抓取需要的动态内容,简单来说,有一个解决方案:
根据自己通过工具分析的结果,自己找到对应的数据,提取出来;
只是这样,有时可以在分析结果的过程中直接提取这些数据,有时可能会通过js进行计算。
如果要抓取数据,由js脚本生成
虽然最终的一些动态内容是通过js脚本的执行产生的,但是对于你想要抓取的数据:
你要抓取的数据是通过访问另一个url获取的
如果对应你要抓取的内容,需要访问另外一个url地址和返回的数据,那么就很简单了,你也需要单独访问这个url,然后获取对应的返回内容,并提取你从它得到你想要的数据。
总结
同一句话,不管你访问的内容是怎么生成的,最后还是可以用工具分析一下对应的内容是怎么从头生成的。
然后用代码模拟这个过程,最后提取出你需要的; 查看全部
抓取网页中的特定内容-抓取网并提取网页源码
背景
很多时候,很多人需要抓取网页上的某些特定内容。
不过,除了前面介绍的,我还想从一些静态网页中提取具体的内容,比如:
【教程】python版爬取网页并提取网页中需要的信息
和
【教程】C#版抓取网页并提取网页中需要的信息
除了
,有些人会发现自己要爬取的网页的内容不在网页的源代码中。
所以,这个时候,我不知道如何实现它。
在这里,让我们解释一下如何抓取所谓的动态网页中的特定内容。
必备知识
阅读本文前,您需要具备相关的基础知识:
1.Fetch 网页,模拟登录等相关逻辑
不熟悉的请参考:
【整理中】关于爬取网页、分析网页内容、模拟登录网站的逻辑/流程及注意事项
2.学习使用工具,比如IE9的F12,爬取对应的网页执行流程
不熟悉的请参考:
【教程】教你使用工具(IE9中F12)分析模拟登录网站(百度首页)内部逻辑流程)
3.对于普通静态网页,如何提取需要的内容
如果你对此不熟悉,可以参考:
(1)Python 版本:
【教程】python版爬取网页并提取网页中需要的信息
(2)C#Version:
【教程】C#版抓取网页并提取网页中需要的信息
什么是动态网页
这里所谓的动态网页是相对于那些静态网页而言的。
这里所说的静态网页是指在浏览器中查看网页源代码时所看到的网页源代码中的内容以及网页上显示的内容。
也就是说,当我想在网页上显示某个内容时,可以通过搜索网页的源代码来找到相应的部分。
对于动态网页,则相反,如果想获取动态网页中的具体内容,直接查看网页源代码是找不到的。
动态网页中的动态内容从何而来?
所以,这里有一个问题:
所谓动态网页中的动态内容从何而来?
简而言之,它是通过其他方式生成或获得的。
目前,我学到了几件事:
由本地 Javascript 脚本生成
如果你用IE9的F12来分析访问一个URL的过程,你会发现很可能会涉及到,
在网页正常显示之前,这段时间会访问很多javascript脚本,简称js脚本或js。
这些js脚本实现了很多动态的交互内容。
其中,对于一些想要抓取的内容,有时这些js脚本是动态执行最后计算出来的。
通过访问另一个 url 地址获得
很多时候,有些内容是访问另一个url地址后返回的数据;
如何获取我要爬取的动态内容
其实,关于如何抓取需要的动态内容,简单来说,有一个解决方案:
根据自己通过工具分析的结果,自己找到对应的数据,提取出来;
只是这样,有时可以在分析结果的过程中直接提取这些数据,有时可能会通过js进行计算。
如果要抓取数据,由js脚本生成
虽然最终的一些动态内容是通过js脚本的执行产生的,但是对于你想要抓取的数据:
你要抓取的数据是通过访问另一个url获取的
如果对应你要抓取的内容,需要访问另外一个url地址和返回的数据,那么就很简单了,你也需要单独访问这个url,然后获取对应的返回内容,并提取你从它得到你想要的数据。
总结
同一句话,不管你访问的内容是怎么生成的,最后还是可以用工具分析一下对应的内容是怎么从头生成的。
然后用代码模拟这个过程,最后提取出你需要的;
如何爬取不同不同分页类型网站的数据教你使用Python并存储网页数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-08-20 23:00
如何爬取不同分页类型的数据网站,因为内容比较多,我会放到本文下一节详细介绍。 3.过滤表单网页在网站 上更为常见。这种网页最大的特点就是过滤项很多,不同的选项不会加载。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。
内容抓取-内容可以从网站 抓取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到你的网站,让你的网站内容打开。
网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员...
Python 爬虫入门!它将教您如何抓取网络数据。
它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。 查看全部
如何爬取不同不同分页类型网站的数据教你使用Python并存储网页数据
如何爬取不同分页类型的数据网站,因为内容比较多,我会放到本文下一节详细介绍。 3.过滤表单网页在网站 上更为常见。这种网页最大的特点就是过滤项很多,不同的选项不会加载。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
链接提交工具是网站主动推送数据到百度搜索的工具。这个工具可以缩短爬虫发现网站link的时间,网站时效率推荐使用链接提交工具实时推送数据搜索。该工具可以加快爬虫爬行速度,无法解决网站。
内容抓取-内容可以从网站 抓取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到你的网站,让你的网站内容打开。
网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员...
Python 爬虫入门!它将教您如何抓取网络数据。
它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。
阿里云为您提供网站内容抓取工具相关的8933条产品文档内容及常见问题解答内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-08-20 22:39
阿里巴巴云为您提供8933产品文档内容和网站内容爬虫工具相关FAQ,以及路由网站打不开网页怎么办,计算机网络技术大学毕业论文,关键value Store kvstore,以下哪个是数据库,以及其他云计算产品。
网页内容的智能抓取和详细的实战实例,完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用程序的开源组件包括:DOM4J: Parsing XMLjericho-。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .
它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。
内容抓取-内容可以从网站 抓取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到你的网站,让你的网站内容打开。
爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行庞大的爬虫系统,从网站全世界爬取。
优采云采集器免费网络爬虫软件_网络大数据爬虫工具。
1.打开站长工具,在网页信息查询中,找到模拟机器人抓取。2.输入自己的网站网址,输入,点击查询。这时候会在下面显示你的网站被抓到后是什么样子的? 3.在网页信息查询中,点击网页检测,可以查看自己网页的关键词密度、网站安全情况、关键词挖掘... 查看全部
阿里云为您提供网站内容抓取工具相关的8933条产品文档内容及常见问题解答内容
阿里巴巴云为您提供8933产品文档内容和网站内容爬虫工具相关FAQ,以及路由网站打不开网页怎么办,计算机网络技术大学毕业论文,关键value Store kvstore,以下哪个是数据库,以及其他云计算产品。
网页内容的智能抓取和详细的实战实例,完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。应用程序的开源组件包括:DOM4J: Parsing XMLjericho-。
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。 .
它可以帮助我们快速采集互联网上的海量内容,从而进行深入的数据分析和挖掘。比如抢大网站的排行榜,抢大购物网站的价格信息等等。而我们今天常用的搜索引擎是“网络爬虫”。但毕竟。
内容抓取-内容可以从网站 抓取,以复制依赖该内容的独特产品或服务优势。例如,Yelp 等产品依赖于评论。参赛者可以从Yelp抓取所有评论内容,然后复制到你的网站,让你的网站内容打开。
爬虫是自动获取网页内容的程序,如搜索引擎、谷歌、百度等,每天运行庞大的爬虫系统,从网站全世界爬取。
优采云采集器免费网络爬虫软件_网络大数据爬虫工具。
1.打开站长工具,在网页信息查询中,找到模拟机器人抓取。2.输入自己的网站网址,输入,点击查询。这时候会在下面显示你的网站被抓到后是什么样子的? 3.在网页信息查询中,点击网页检测,可以查看自己网页的关键词密度、网站安全情况、关键词挖掘...
如何做好百度收录的五类网站图-1:
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-08-20 05:20
第一类网站:网站结构复杂;第二类网站:不可读网站;第三类网站:不稳定网站;第四类网站:网站,重复内容较多;第五类网站:经常修改的网站
图片 14456-1:
现在建网站已经不是什么神秘的事情了。很多新手站长只需学习一两个月就可以使用WordPress和cms系统搭建自己的第一个网站。但是网站要成功运营并获取利润就更难了。
自从SEO走红,个别站长参加了XX培训学习SEO,希望能用SEO的方法把网站core关键词排在百度首页,获得更多的搜索引擎流量,赚得更多广告费。但是很多个人站长都会遇到百度不收录网站或者网站收录不好的情况。 网站收录 做的不好,怎么可能从搜索引擎上获取流量。从搜索引擎获取流量,前提是网站的所有页面都是百度收录。当然,这个难度更大。 网站收录 80%以上才算好的。
如果网站不是百度收录,首先要检查网站的内容是否不好。如果网站的内容是原创,可能是网站架构的问题。下面笔者总结了五类不利于百度收录的网站。
第一类网站:网站复杂结构
网站结构对网站很重要,相当于房子的柱子。如果网站的结构比较复杂,搜索引擎蜘蛛抓取网站时很容易被困,导致搜索引擎蜘蛛抓取的页面较少。 SEO优化的第一点要求网站有一个简单明了的网站结构。我们在设计网站navigation的时候,如果网站小,一级导航就够了,不是二级导航,大网站导航可以分为两级,但不要用三级。同时需要在网站添加面包屑导航,页面添加子导航。另外,还要注意 URL 的长度,尽量保持 URL 的短。 (参考:如何做网址优化)
第二类网站:不可读网站
不可读?这是指搜索引擎蜘蛛无法理解。什么是不可读的网站? FLASH网站是不可读的网站,因为搜索引擎技术有限,我暂时无法读取FLASH网站。如果你的公司网站是FLASH网站,对于搜索引擎来说,不知道你的网站是做什么的,因为我看不懂。所以从SEO的角度,不推荐搭建FLASH网站。如果你已经在使用FLASH网站,建议获取一个普通的网站供搜索引擎抓取。
第三类网站:不稳定网站
不稳定是指网站的访问情况。如果你的网站能被访问一段时间,对用户和搜索引擎来说都是非常不利的。导致用户流失,给搜索引擎蜘蛛留下不好的印象。如果网站经常出现这样的网站,搜索引擎蜘蛛就出现了网站爬取的问题,结果就是网站收录移除问题。所以建议个人站长想建网站赚钱,不能省网站空间的钱,有稳定的网站空间,更有利于SEO优化。
第四类网站:重复很多内容的网站
有些网站,经常是采集,或者使用自动化生成网站内容,这样的网站网站文章还有很多,但是有一个严重的问题就是内容重复很多如果你的网站有很多重复的内容,百度会认为你的网站是垃圾网站,最后你的网站会被百度惩罚。
第五类网站:经常修改的网站
一些新手站长,刚开始建网站的时候,没有全面研究关键词,后期经常修改网站title,早期网站随意使用在线模板几个月后如果模板不好看,那就更换模板。这些新手站长经常修改网站,今天就因为这个原因修改,明天就因为这个原因修改。最后,这些新手站长的网站会被百度惩罚,因为频繁修改网站是SEO大忌,尤其是频繁修改网站标题。作者,我百度第二页有网站关键词。如果你想让这个关键词上百度首页,去修改网站title,故意增加关键词密度,最后网站被百度掉了,这个关键词排名落后100了,它已经几个月没有恢复了。所以网站上线前,一定要做好调研。 网站不建议在上线后半年内修改网站,尤其是网站title。
如果你的网站收录不好,你的网站是否有以上五种网站的问题?今天总结了五类不利于百度的网站收录。希望对大家有所帮助,解决网站不收录的问题。 查看全部
如何做好百度收录的五类网站图-1:
第一类网站:网站结构复杂;第二类网站:不可读网站;第三类网站:不稳定网站;第四类网站:网站,重复内容较多;第五类网站:经常修改的网站
图片 14456-1:
现在建网站已经不是什么神秘的事情了。很多新手站长只需学习一两个月就可以使用WordPress和cms系统搭建自己的第一个网站。但是网站要成功运营并获取利润就更难了。
自从SEO走红,个别站长参加了XX培训学习SEO,希望能用SEO的方法把网站core关键词排在百度首页,获得更多的搜索引擎流量,赚得更多广告费。但是很多个人站长都会遇到百度不收录网站或者网站收录不好的情况。 网站收录 做的不好,怎么可能从搜索引擎上获取流量。从搜索引擎获取流量,前提是网站的所有页面都是百度收录。当然,这个难度更大。 网站收录 80%以上才算好的。
如果网站不是百度收录,首先要检查网站的内容是否不好。如果网站的内容是原创,可能是网站架构的问题。下面笔者总结了五类不利于百度收录的网站。
第一类网站:网站复杂结构
网站结构对网站很重要,相当于房子的柱子。如果网站的结构比较复杂,搜索引擎蜘蛛抓取网站时很容易被困,导致搜索引擎蜘蛛抓取的页面较少。 SEO优化的第一点要求网站有一个简单明了的网站结构。我们在设计网站navigation的时候,如果网站小,一级导航就够了,不是二级导航,大网站导航可以分为两级,但不要用三级。同时需要在网站添加面包屑导航,页面添加子导航。另外,还要注意 URL 的长度,尽量保持 URL 的短。 (参考:如何做网址优化)
第二类网站:不可读网站
不可读?这是指搜索引擎蜘蛛无法理解。什么是不可读的网站? FLASH网站是不可读的网站,因为搜索引擎技术有限,我暂时无法读取FLASH网站。如果你的公司网站是FLASH网站,对于搜索引擎来说,不知道你的网站是做什么的,因为我看不懂。所以从SEO的角度,不推荐搭建FLASH网站。如果你已经在使用FLASH网站,建议获取一个普通的网站供搜索引擎抓取。
第三类网站:不稳定网站
不稳定是指网站的访问情况。如果你的网站能被访问一段时间,对用户和搜索引擎来说都是非常不利的。导致用户流失,给搜索引擎蜘蛛留下不好的印象。如果网站经常出现这样的网站,搜索引擎蜘蛛就出现了网站爬取的问题,结果就是网站收录移除问题。所以建议个人站长想建网站赚钱,不能省网站空间的钱,有稳定的网站空间,更有利于SEO优化。
第四类网站:重复很多内容的网站
有些网站,经常是采集,或者使用自动化生成网站内容,这样的网站网站文章还有很多,但是有一个严重的问题就是内容重复很多如果你的网站有很多重复的内容,百度会认为你的网站是垃圾网站,最后你的网站会被百度惩罚。
第五类网站:经常修改的网站
一些新手站长,刚开始建网站的时候,没有全面研究关键词,后期经常修改网站title,早期网站随意使用在线模板几个月后如果模板不好看,那就更换模板。这些新手站长经常修改网站,今天就因为这个原因修改,明天就因为这个原因修改。最后,这些新手站长的网站会被百度惩罚,因为频繁修改网站是SEO大忌,尤其是频繁修改网站标题。作者,我百度第二页有网站关键词。如果你想让这个关键词上百度首页,去修改网站title,故意增加关键词密度,最后网站被百度掉了,这个关键词排名落后100了,它已经几个月没有恢复了。所以网站上线前,一定要做好调研。 网站不建议在上线后半年内修改网站,尤其是网站title。
如果你的网站收录不好,你的网站是否有以上五种网站的问题?今天总结了五类不利于百度的网站收录。希望对大家有所帮助,解决网站不收录的问题。
1.网站为什么抓取一些不存在的页面?(图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-08-20 05:19
网站Grabbing 这个指标对于做seo很重要,不爬就没有收录,但是我们在做网站爬检测的时候经常会看到一些404的返回码,这些页面根本不存在在我们网站,那么,网站爬取,目录和页面不存在的原因,怎么办?
基于对百度搜索引擎的研究,我们认为:
1.网站 为什么有些页面不存在?
网站被爬取,页面不存在的原因有很多,比如:
①页面删除
在很多情况下,网站在优化过程中需要进行调整,您调整的页面可能不会被搜索引擎抓取。有时,你看到的页面没有被索引,但实际这些页面可能正在评估中,所以一段时间后,蜘蛛仍然会抓取这些页面。
②旧域名
有时候我们做seo,为了更快的效果,会用老域名,但是老域名一定要有建站历史,不然我们不会选择,有历史就有历史大概率会有蜘蛛,而且蜘蛛有记忆,所以总是爬一些旧的网址,所以买旧域名有利有弊,但利大于弊。
③恶意扫描
当然,有时候,我们的域名没有问题,没有页面被删除,仍然会有不存在的页面。这时候就需要观察这些爬取到的ip是否有一定的规律,有很多时候,我们网站就会面临各种扫描的需求,比如漏洞扫描,文章采集等爬取,如果这些 IP 是正规的,那么扫描漏洞的可能性就很大。
2.如何处理抓取不存在的页面
了解抓取不存在页面的一些原因,那么我们如何解决这些问题?
①机器人
首先,我们知道这些不存在的页面被反复抓取。我们需要采取措施告诉蜘蛛,这些页面是不允许被抓取的。我们可以使用Robots协议来禁止这些页面的抓取,通常对于大多数蜘蛛来说,这种方法是有效的,因为这是所有常规搜索引擎都需要遵守的协议。
②提交死链接
如果还存在被重复抓取的问题,可以查看这些页面是否有幸存的百度快照。如果有快照,蜘蛛会反复爬取,因为你在屏蔽没有被索引的页面,而这些页面已经被索引后,我们可以汇总这些页面的网址,并通过资源平台提交死链接。
③屏蔽ip
当然,以上方法都是各大搜索引擎蜘蛛的策略。如果被非搜索引擎蜘蛛恶意扫描或抓取怎么办?
我们认为最直接的方式就是屏蔽这些IP。可以通过修改服务器中的文件来实现这个功能:
1)云主机
下载.htaccess文件,直接修改,上传覆盖原文件。
2)宝塔
到宝塔后台找到安全选项,选择防火墙,在防火墙中选择屏蔽ip。
3)plugin
现在各大cms系统都推出了各种功能插件。我们可以直接搜索blocking ip来查找插件进行ipblocking。
总结:网站grabbing,目录和页面不存在的原因,以及如何处理,我们在这里讨论,以上内容仅供参考。
转载蝙蝠侠IT需要授权! 查看全部
1.网站为什么抓取一些不存在的页面?(图)
网站Grabbing 这个指标对于做seo很重要,不爬就没有收录,但是我们在做网站爬检测的时候经常会看到一些404的返回码,这些页面根本不存在在我们网站,那么,网站爬取,目录和页面不存在的原因,怎么办?
基于对百度搜索引擎的研究,我们认为:
1.网站 为什么有些页面不存在?
网站被爬取,页面不存在的原因有很多,比如:
①页面删除
在很多情况下,网站在优化过程中需要进行调整,您调整的页面可能不会被搜索引擎抓取。有时,你看到的页面没有被索引,但实际这些页面可能正在评估中,所以一段时间后,蜘蛛仍然会抓取这些页面。
②旧域名
有时候我们做seo,为了更快的效果,会用老域名,但是老域名一定要有建站历史,不然我们不会选择,有历史就有历史大概率会有蜘蛛,而且蜘蛛有记忆,所以总是爬一些旧的网址,所以买旧域名有利有弊,但利大于弊。
③恶意扫描
当然,有时候,我们的域名没有问题,没有页面被删除,仍然会有不存在的页面。这时候就需要观察这些爬取到的ip是否有一定的规律,有很多时候,我们网站就会面临各种扫描的需求,比如漏洞扫描,文章采集等爬取,如果这些 IP 是正规的,那么扫描漏洞的可能性就很大。
2.如何处理抓取不存在的页面
了解抓取不存在页面的一些原因,那么我们如何解决这些问题?
①机器人
首先,我们知道这些不存在的页面被反复抓取。我们需要采取措施告诉蜘蛛,这些页面是不允许被抓取的。我们可以使用Robots协议来禁止这些页面的抓取,通常对于大多数蜘蛛来说,这种方法是有效的,因为这是所有常规搜索引擎都需要遵守的协议。
②提交死链接
如果还存在被重复抓取的问题,可以查看这些页面是否有幸存的百度快照。如果有快照,蜘蛛会反复爬取,因为你在屏蔽没有被索引的页面,而这些页面已经被索引后,我们可以汇总这些页面的网址,并通过资源平台提交死链接。
③屏蔽ip
当然,以上方法都是各大搜索引擎蜘蛛的策略。如果被非搜索引擎蜘蛛恶意扫描或抓取怎么办?
我们认为最直接的方式就是屏蔽这些IP。可以通过修改服务器中的文件来实现这个功能:
1)云主机
下载.htaccess文件,直接修改,上传覆盖原文件。
2)宝塔
到宝塔后台找到安全选项,选择防火墙,在防火墙中选择屏蔽ip。
3)plugin
现在各大cms系统都推出了各种功能插件。我们可以直接搜索blocking ip来查找插件进行ipblocking。
总结:网站grabbing,目录和页面不存在的原因,以及如何处理,我们在这里讨论,以上内容仅供参考。
转载蝙蝠侠IT需要授权!

