爬虫抓取网页数据( 阿里码栈爬虫系列文章会连载几篇(一))
优采云 发布时间: 2021-09-21 23:10爬虫抓取网页数据(
阿里码栈爬虫系列文章会连载几篇(一))
代码栈爬虫系列文章的几篇文章将被序列化,主要关注使用阿里巴巴的代码栈软件快速构建爬虫应用。代码栈是阿里官方发布的自动机器人软件。操作简单,启动速度快。在它的众*敏*感*词*中,爬虫只是一个很小的功能。与市场上其他爬虫软件相比,它启动速度很快。通过拖动函数滑块,可以在几分钟内完成一个爬虫应用程序,例如本文中编写的抓取商品评估应用程序
在文章的最后,将介绍一个词频分析工具“商品评估词频分析工具”来分析捕获的评估
产品评估爬虫的一般流程如下:
步骤1:在参数面板中设置两个参数
1.[产品链接]:用于填写所需采集产品的链接
2.[评估保存路径]:由于采集的评估数据存储在本地TXT文件中,因此您需要在计算机中创建一个新的TXT文件,然后在[评估保存路径]中选择TXT文件的路径
在设置参数后,在过程设计参数面板中,将读取参数面板拖动到中间的空白画布区域。您需要拖动两个来读取刚刚设置的商品链接和评估保存路径
双击拖动的滑块并检查相应的参数
同样,拖动“浏览器-打开网页”,然后设置
将浏览器-单击网页元素拖到画布上,单击捕获网页元素,然后单击开始录制
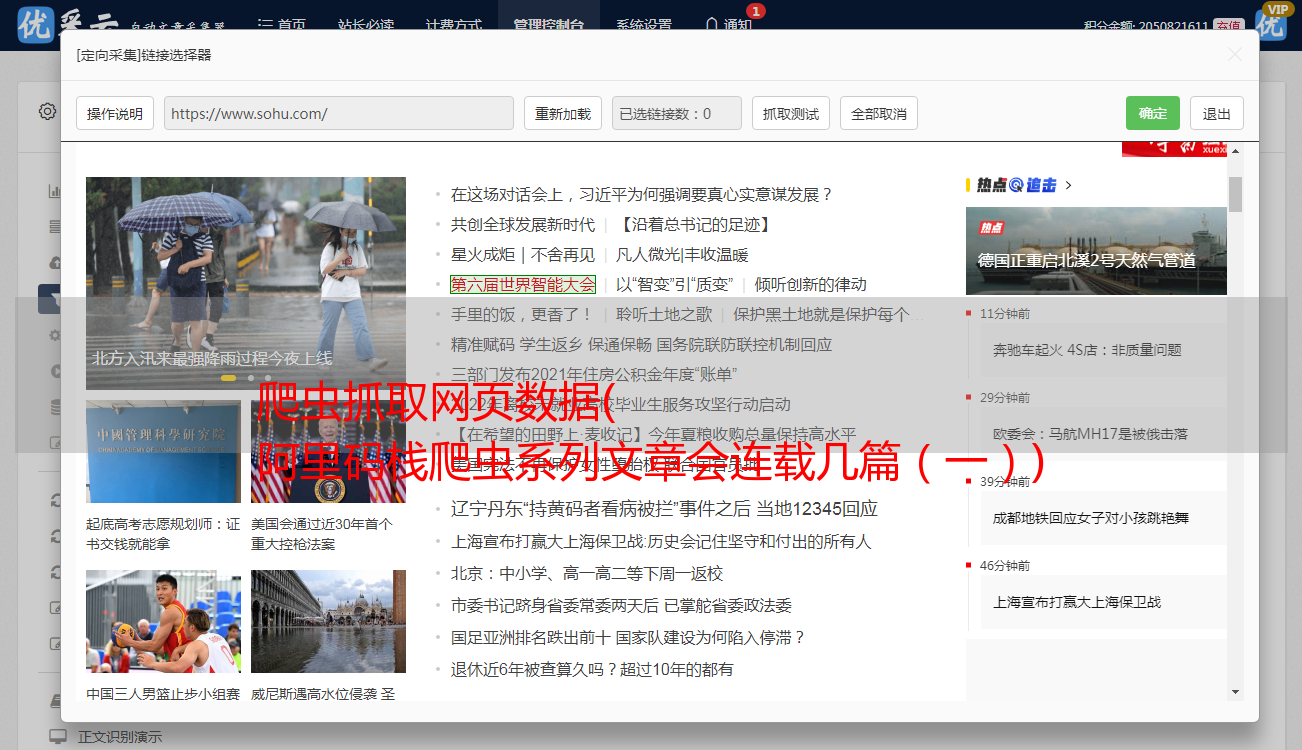
在右侧浏览器窗口中打开的商品页面中,单击累积评估,然后单击保存
单击左上角的开始录制流程,然后单击任意评估,在弹出窗口中单击批次采集数据,然后单击保存
双击新生成的周期元素列表,分别获取第一列文本,将打开的网页更改为打开商品详情页面,最后删除上面打开的网页
然后找到带有后续注释的注释,并重复上述步骤
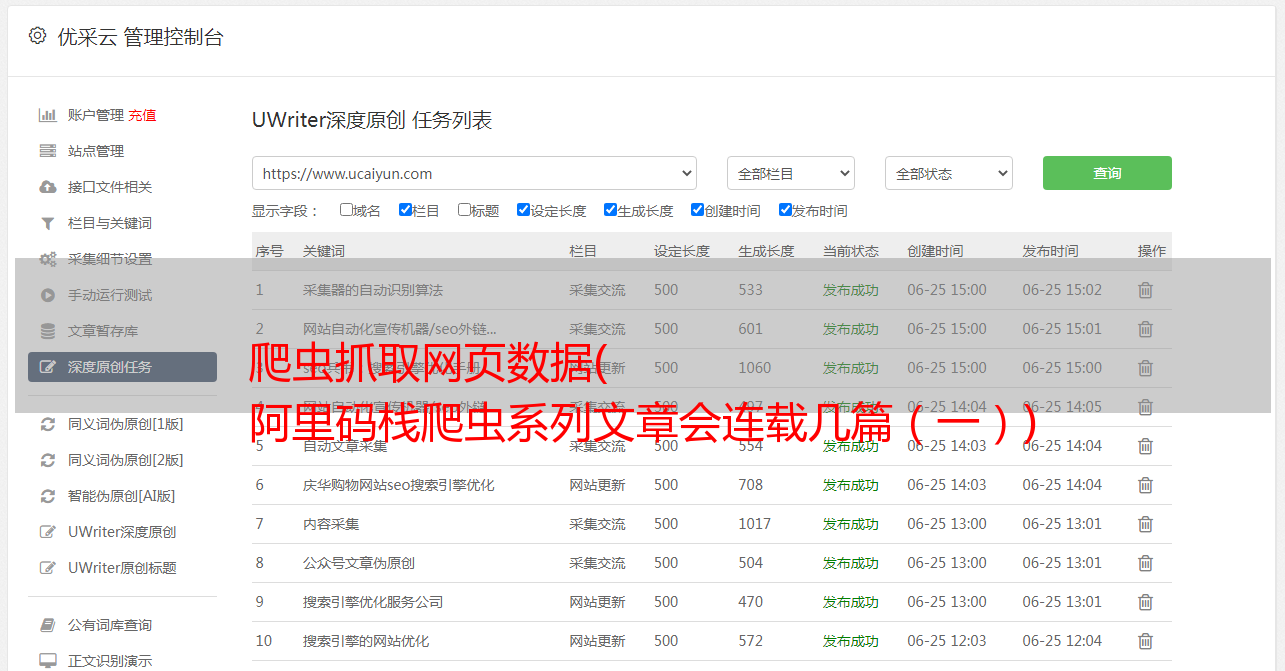
第1页的初始评估和后续评估数据已在此处采集找到,申请流程如下:
目前,有两个尚未解决的问题:一是如何应用采集多页评论;第二个是如何将数据保存到TXT文件
将process-cycle execution滑块拖动到如图所示的位置
循环次数即使页面需要循环,这里我先填写10页,也就是说10页,其他值可以根据实际情况填写
有一种更智能的循环时间方法,可以自动确定需要循环多少页。这篇文章是一篇介绍性文章,暂时不会介绍
将两个循环评估的滑块拖动到“循环”页面中
在循环结束时添加click page元素以单击下一页
单击捕获网页元素-开始录制,然后移动鼠标并单击下一页进行保存
到目前为止,已经建立了捕获数据的过程,但是如何保存数据还不够。以前,代码栈有导出到excel的功能,但是现在基本版本不能直接导出,所以我们需要使用前面提到的新TXT文件
在计算机桌面或其他文件夹中创建新的文本文档,并在代码堆栈的[evaluation save path]中选择文本文档的路径
将系统文件操作滑块拖动到两个评估周期
两种文件操作设置如下所示:
最后,添加一个[关闭网页]滑块,建立产品评估爬虫
在【界面设计与调试预览】中填写【商品链接】和【评估保存路径】,点击启动爬虫开始执行
打开商品评估词频分析工具。Xlsm,点击开始,选择刚到达采集的评估文件,稍等片刻,查看评估的词频统计
代码栈简介&;下载地址:/home/clientdownload.htm
代码栈官方学习手册:/help/index.html

