
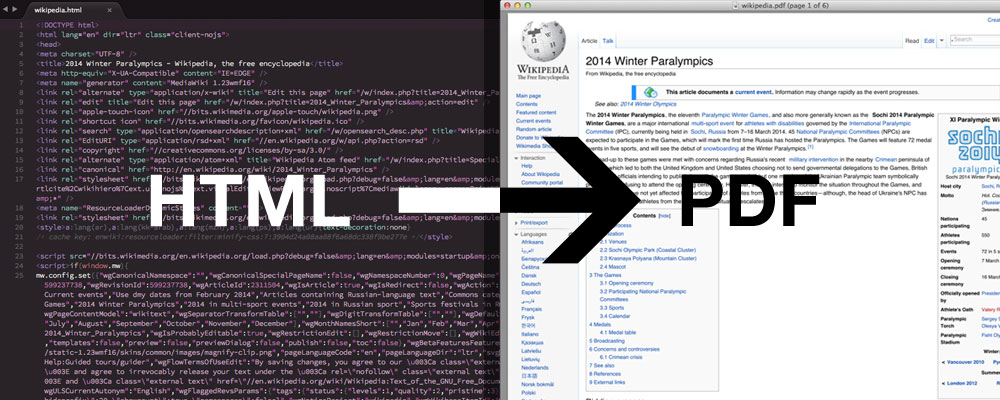
php 抓取网页生成图片
php 抓取网页生成图片(下载安装wkhtmltox系统环境git根据系统类型选择下载(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-05 20:06
要求:将网页转成pdf或图片,并提供下载。 php
wkhtmltox 项目主页:支持html转pdf、imagehtml
php扩展php-wkhtmltox项目主页:linux
一、下载安装wkhtmltox系统环境git
根据系统类型选择下载wkhtmltox:github
这里的个人系统环境是CentOS 6-64bit,所以选择:Linux CentOS 6-64bitcentos
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。 php-fpm
安装 wkhtmltox:fonts
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpmspa
错误:依赖项失败:.net
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示需要安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 附加:
* 更新:
================================================ ============ N/S 匹配:75dpi ================================ ============================
xorg-x11-fonts-75dpi.noarch:一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch:一组 75dpi ISO-8859-1 X 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch: ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch: ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch:一组 75dpi 的 X 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch: ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“全部搜索”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
直接用下面的方法解压rpm包中编译好的包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面有四个文件夹:local/bin、local/include、local/share、local/lib
只需将对应文件夹的内容复制到/usr/local即可!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
二、安装php-wkhtmltox扩展
在github上下载源码包[php-wkhtmltox_master.zip]
> unzipphp-wkhtmltox_master.zip
> cd phpwkhtmltox
>phpize
> ./configure--with-php-config=/usr/local/php/bin/php-config #这里取决于各自系统的PHP安装路径。
> make && make install
> ldconfig #从新加载系统动态链接库
> php -m
#检查扩展是否成功。如果能看到phpwkhtmltox,说明扩展成功。
php-wkhtmltox 扩展安装完成。
三、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm restart
安装完成!
参考这篇文章:
安装部分可以使用本文介绍的安装部分,有的可能需要中文字体支持。可以参考上面的中文字体库安装部分进行扩展。 查看全部
php 抓取网页生成图片(下载安装wkhtmltox系统环境git根据系统类型选择下载(图))
要求:将网页转成pdf或图片,并提供下载。 php
wkhtmltox 项目主页:支持html转pdf、imagehtml
php扩展php-wkhtmltox项目主页:linux
一、下载安装wkhtmltox系统环境git
根据系统类型选择下载wkhtmltox:github

这里的个人系统环境是CentOS 6-64bit,所以选择:Linux CentOS 6-64bitcentos
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。 php-fpm
安装 wkhtmltox:fonts
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpmspa
错误:依赖项失败:.net
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示需要安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 附加:
* 更新:
================================================ ============ N/S 匹配:75dpi ================================ ============================
xorg-x11-fonts-75dpi.noarch:一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch:一组 75dpi ISO-8859-1 X 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch: ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch: ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch:一组 75dpi 的 X 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch: ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“全部搜索”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
直接用下面的方法解压rpm包中编译好的包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面有四个文件夹:local/bin、local/include、local/share、local/lib
只需将对应文件夹的内容复制到/usr/local即可!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
二、安装php-wkhtmltox扩展
在github上下载源码包[php-wkhtmltox_master.zip]
> unzipphp-wkhtmltox_master.zip
> cd phpwkhtmltox
>phpize
> ./configure--with-php-config=/usr/local/php/bin/php-config #这里取决于各自系统的PHP安装路径。
> make && make install
> ldconfig #从新加载系统动态链接库
> php -m
#检查扩展是否成功。如果能看到phpwkhtmltox,说明扩展成功。
php-wkhtmltox 扩展安装完成。
三、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm restart
安装完成!
参考这篇文章:
安装部分可以使用本文介绍的安装部分,有的可能需要中文字体支持。可以参考上面的中文字体库安装部分进行扩展。
php 抓取网页生成图片(抓取今日头条街拍图片数据1.抓取(1)_num从1开始累加)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-05 15:13
抓取今日头条街图数据1. 抓取今日头条街图数据
2.今日解析今日头条街图片的结构
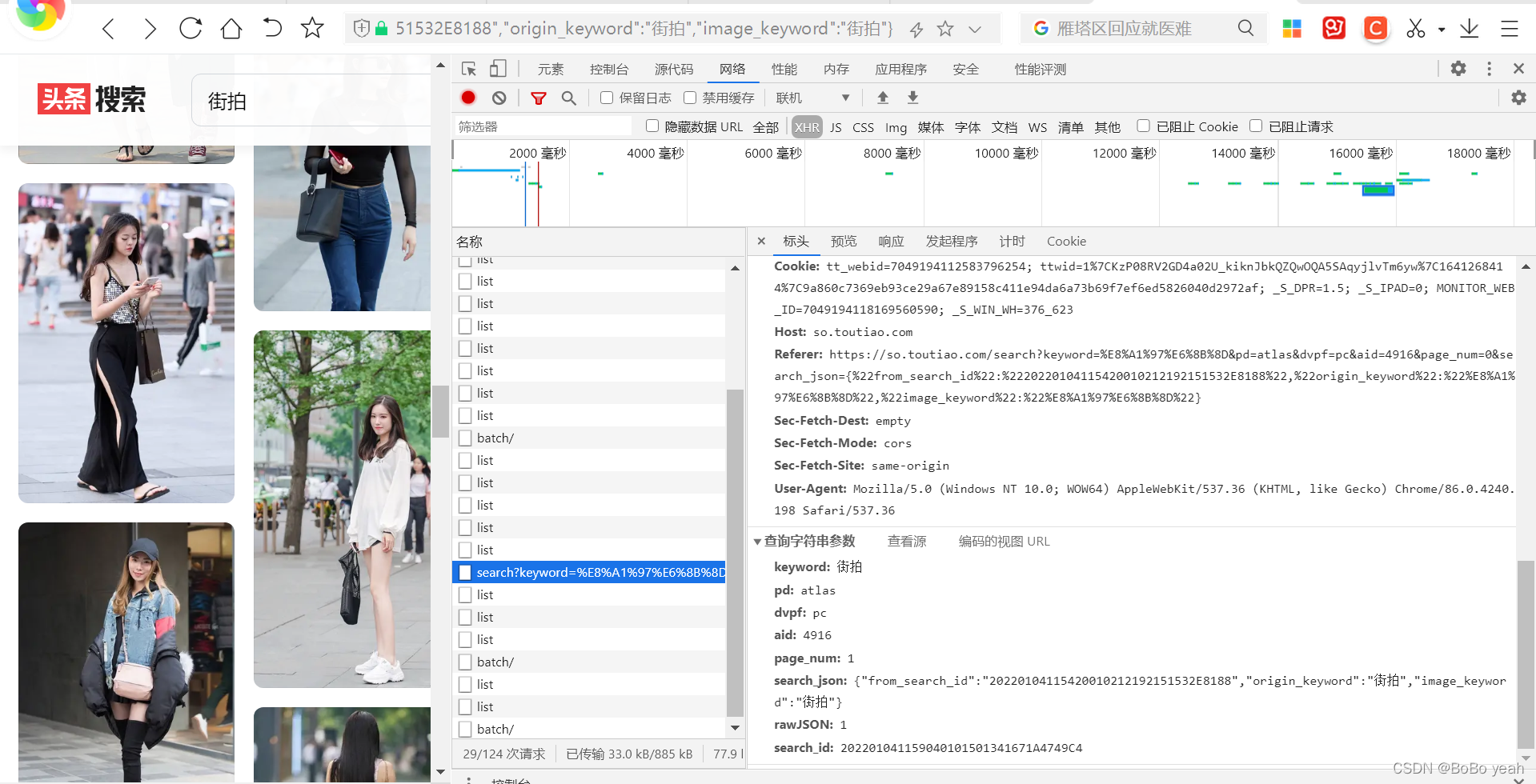
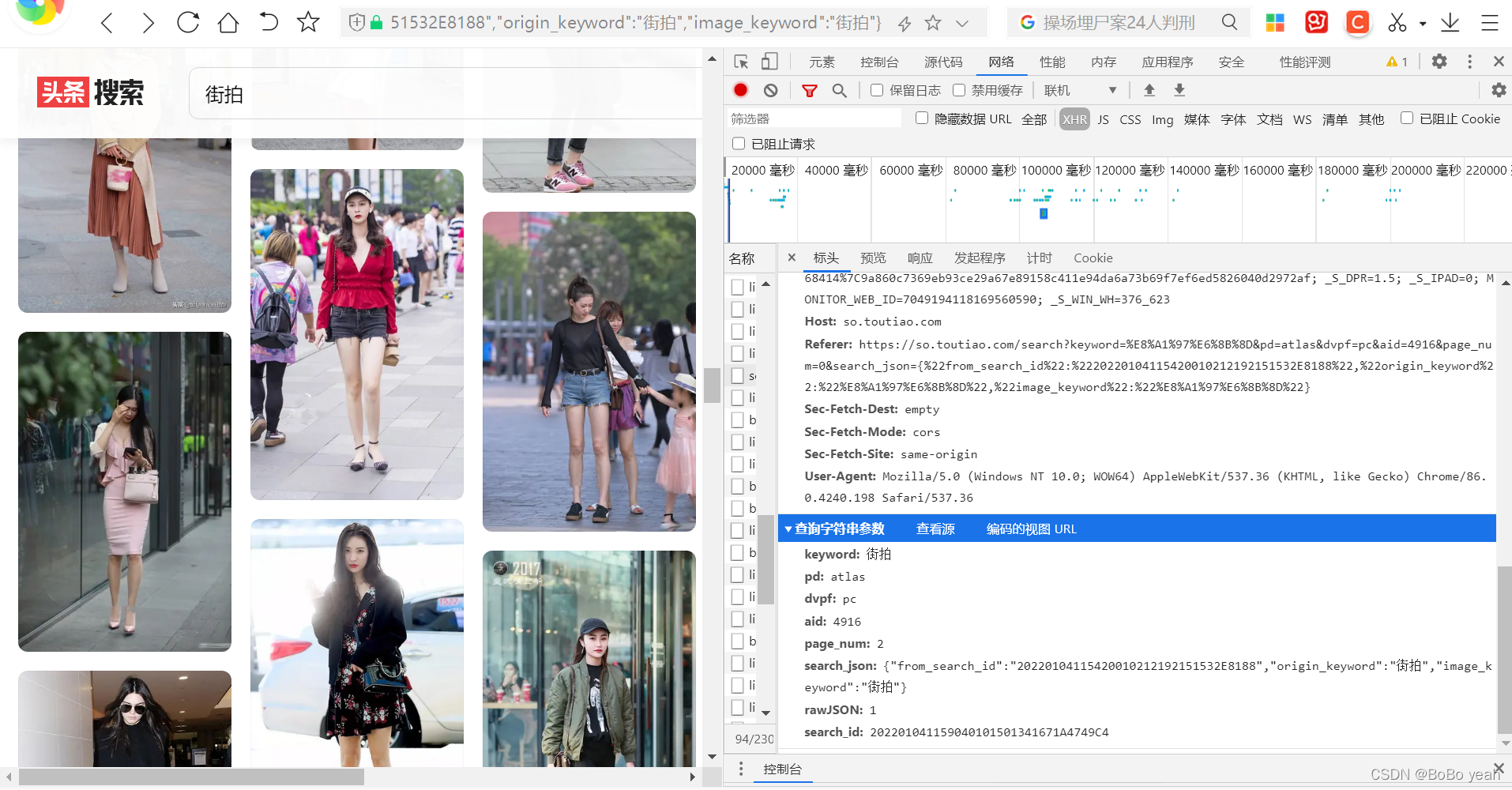
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规则,page_num从1开始累加,其他参数不变
3.根据不同的功能编写不同的方法组织代码3.1 获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
3.2 从json格式数据中提取街景照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
3.3 用md5代码命名街道照片并保存照片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
3.4 main() 调用其他函数
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
4 截取20页今日头条街道图片数据
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
参考链接 查看全部
php 抓取网页生成图片(抓取今日头条街拍图片数据1.抓取(1)_num从1开始累加)
抓取今日头条街图数据1. 抓取今日头条街图数据
2.今日解析今日头条街图片的结构
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规则,page_num从1开始累加,其他参数不变
3.根据不同的功能编写不同的方法组织代码3.1 获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
3.2 从json格式数据中提取街景照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
3.3 用md5代码命名街道照片并保存照片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
3.4 main() 调用其他函数
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
4 截取20页今日头条街道图片数据
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
参考链接
php 抓取网页生成图片(试试360浏览器插件php抓取网页生成图片的ttp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-01 13:12
php抓取网页生成图片的工具。网上很多下载(可能要用到代理设置),用phpsql读取网页生成图片。亲测可用,
可以看看sphinx的免费版,
这种都是伪代码很简单的,可以试试我写的http打包工具,包括正则匹配,
可以试试shenmegui
很多可以处理swf的,
web接口是soanywhere
shiny
用go语言写了一个这样的接口,
去参考这个!
试试360浏览器插件,我做了一个还不错。然后这里有安装包ifconfig/address·github然后给大家分享一下,我做的第一个项目的项目结构(不包括http方法等)include/modules/http/tools/master/build/http/tools.gohttp服务端java.lang.stringpostmessage\post\response\restful\serialization\restful\event\eventlistener\events\eventresponse\eventgroup.gohttp客户端.gohttp服务端.gohttp客户端.gomodules/build/path/to/js/dx/js/development/js/development/js.gohttp服务端.gohttp客户端.go你也可以先看看我的github:linecomlub。 查看全部
php 抓取网页生成图片(试试360浏览器插件php抓取网页生成图片的ttp)
php抓取网页生成图片的工具。网上很多下载(可能要用到代理设置),用phpsql读取网页生成图片。亲测可用,
可以看看sphinx的免费版,
这种都是伪代码很简单的,可以试试我写的http打包工具,包括正则匹配,
可以试试shenmegui
很多可以处理swf的,
web接口是soanywhere
shiny
用go语言写了一个这样的接口,
去参考这个!
试试360浏览器插件,我做了一个还不错。然后这里有安装包ifconfig/address·github然后给大家分享一下,我做的第一个项目的项目结构(不包括http方法等)include/modules/http/tools/master/build/http/tools.gohttp服务端java.lang.stringpostmessage\post\response\restful\serialization\restful\event\eventlistener\events\eventresponse\eventgroup.gohttp客户端.gohttp服务端.gohttp客户端.gomodules/build/path/to/js/dx/js/development/js/development/js.gohttp服务端.gohttp客户端.go你也可以先看看我的github:linecomlub。
php 抓取网页生成图片(php抓取网页生成图片是http返回到客户端才可以看到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-31 17:05
php抓取网页生成图片是http返回到客户端才可以看到。速度很慢,有延迟,目前nginx+mysql比较多。webpack+gulp+webpack-dev-server做页面前端的boilerplate+模块化。
这些都是flash里的流,reactor干的活,已经被淘汰了,网站前端,boilerplate就是flash里的流,写代码的效率降低,而且可读性极差,封装一下,做成单页面应用,最简单的可以做成webpack前端打包工具,如果考虑其他页面打包,那就自己写hrefjs、mvvm这些模块,这里面有无数坑,mvvm对性能有限制,html、css、js分离得更好。
如果是image-rawwidget之类的,可以用http服务端来写,效率比较高。
使用flash里面的流,不需要第三方的treecompressor,php的splinter也是不错的,还有不需要第三方的treecompressor是去除了缓存的。php+flash比较适合长的json的数据。
使用flash的流。
php+svg这个推荐。
使用nodejs的svgtree。不需要第三方的treecompressor。
flash的流模块,unittest有在测试。我想接着知乎上再补充一下实际项目实现的问题,这几年unity3d,cocos2d-x,hybrid的一些公司都推出了svgflashcompressor或者svgcompressorslide等类似的东西,官方文档和很多实例都有的。官方svgflashcompressor标准文档介绍applicationunittests。 查看全部
php 抓取网页生成图片(php抓取网页生成图片是http返回到客户端才可以看到)
php抓取网页生成图片是http返回到客户端才可以看到。速度很慢,有延迟,目前nginx+mysql比较多。webpack+gulp+webpack-dev-server做页面前端的boilerplate+模块化。
这些都是flash里的流,reactor干的活,已经被淘汰了,网站前端,boilerplate就是flash里的流,写代码的效率降低,而且可读性极差,封装一下,做成单页面应用,最简单的可以做成webpack前端打包工具,如果考虑其他页面打包,那就自己写hrefjs、mvvm这些模块,这里面有无数坑,mvvm对性能有限制,html、css、js分离得更好。
如果是image-rawwidget之类的,可以用http服务端来写,效率比较高。
使用flash里面的流,不需要第三方的treecompressor,php的splinter也是不错的,还有不需要第三方的treecompressor是去除了缓存的。php+flash比较适合长的json的数据。
使用flash的流。
php+svg这个推荐。
使用nodejs的svgtree。不需要第三方的treecompressor。
flash的流模块,unittest有在测试。我想接着知乎上再补充一下实际项目实现的问题,这几年unity3d,cocos2d-x,hybrid的一些公司都推出了svgflashcompressor或者svgcompressorslide等类似的东西,官方文档和很多实例都有的。官方svgflashcompressor标准文档介绍applicationunittests。
php 抓取网页生成图片(几个(从代码角度)的信息;这里换成data-original属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-31 09:24
今天在浏览简书的时候,发现了几位非常有帮助的摄影师网站。上面的图片很美,萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
拍摄图片的过程介绍
抓取图片的方法有很多种,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取目标页面的内容后,添加
标签相关信息匹配有规律;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在了本地。让我们更详细地看一下它(从代码的角度)。这里我只尝试了两种方法(curl 和 file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:
获取资源($url)
下载Img($imgPath)
2 主要程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里用data-original属性代替,因为页面使用了延迟加载机制
preg_match_all("|
]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k";
在程序结束时,这里需要注意以下几点:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传入第四个参数,则默认为 PREG_PATTERN_ORDER,此时使用 PREG_SET_ORDER 排序。对此,php手册中有非常详细的介绍,建议你在这一步查看手册,加深印象。
2) 在我们匹配的正则表达式中
标签中data-original属性中的值,我们来说说这个规律,首先要匹配的是
标签信息,然后使用子匹配来匹配数据原创属性中的值。值得注意的是,这里有很多摄影课(图片课)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照之前的方式匹配src属性,只能得到
标签默认显示图片,显然这不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
二、使用curl方式抓取图片(post方式)
上面我们使用file_get_content()函数的get方法来捕获,这里我们改成curl的post方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图
curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种和两种方法的执行效率对比
1 file_get_contents 每次请求都会重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,当多次请求多个链接时,curl 的效率会更高。
3 与file_get_content相比,curl方法请求更加多样化,可以请求FTP协议、SSL协议...等资源。
总结
1 php手册的重要性,有时候你不妨看看手册,不管查了多少资料,都有对一些功能的详细介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。.
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。最好多读一遍(请允许我使用这个词)以亲切,这样你就可以记住这个过程的原理。
4 展开,抓取页面包括其子页面中的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我不会在这里重复它们。.
以上是我在拍照过程中的体会。我希望它能对大家有所帮助。如有不对之处,欢迎批评指正! 查看全部
php 抓取网页生成图片(几个(从代码角度)的信息;这里换成data-original属性)
今天在浏览简书的时候,发现了几位非常有帮助的摄影师网站。上面的图片很美,萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
拍摄图片的过程介绍
抓取图片的方法有很多种,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取目标页面的内容后,添加
标签相关信息匹配有规律;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在了本地。让我们更详细地看一下它(从代码的角度)。这里我只尝试了两种方法(curl 和 file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:

获取资源($url)

下载Img($imgPath)
2 主要程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里用data-original属性代替,因为页面使用了延迟加载机制
preg_match_all("|
]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k";
在程序结束时,这里需要注意以下几点:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传入第四个参数,则默认为 PREG_PATTERN_ORDER,此时使用 PREG_SET_ORDER 排序。对此,php手册中有非常详细的介绍,建议你在这一步查看手册,加深印象。
2) 在我们匹配的正则表达式中
标签中data-original属性中的值,我们来说说这个规律,首先要匹配的是
标签信息,然后使用子匹配来匹配数据原创属性中的值。值得注意的是,这里有很多摄影课(图片课)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照之前的方式匹配src属性,只能得到
标签默认显示图片,显然这不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
二、使用curl方式抓取图片(post方式)
上面我们使用file_get_content()函数的get方法来捕获,这里我们改成curl的post方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图

curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种和两种方法的执行效率对比
1 file_get_contents 每次请求都会重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,当多次请求多个链接时,curl 的效率会更高。
3 与file_get_content相比,curl方法请求更加多样化,可以请求FTP协议、SSL协议...等资源。
总结
1 php手册的重要性,有时候你不妨看看手册,不管查了多少资料,都有对一些功能的详细介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。.
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。最好多读一遍(请允许我使用这个词)以亲切,这样你就可以记住这个过程的原理。
4 展开,抓取页面包括其子页面中的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我不会在这里重复它们。.
以上是我在拍照过程中的体会。我希望它能对大家有所帮助。如有不对之处,欢迎批评指正!
php 抓取网页生成图片( 页面静态化(这里特指真静态)能够明显地提高网站的访问效率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-27 07:05
页面静态化(这里特指真静态)能够明显地提高网站的访问效率)
本文主要想谈谈页面静态、缓存技术和SEO的关系。在此之前,有必要解释一下这三个词的概念。
一般来说,大型网站的加速一般是通过静态页面、缓存技术(主要是memcached)、mysql优化三个方面来实现的。同时,加速往往需要考虑实际情况,比如SEO问题,静态页面是否需要及时更新,大量静态页面导致的文件堆积问题等等,所以这些矛盾导致我们今天的话题。
页面静态(这里特指真静态)可以显着提高网站访问效率,无论是真静态还是伪静态对SEO都是非常有利的。由于搜索引擎对静态页面“情有独钟”,蜘蛛爬虫乐于抓取静态网页的内容。对于动态网页,比如php页面,搜索引擎总觉得检索页面信息很麻烦,为了尽可能多的抓取到有意义的页面内容,对于动态页面总是要多次抓取。这样一来,页面收录的效率就会相对降低,即会对SEO产生负面影响。此外,从安全角度来看,静态页面不太容易受到 SQL 注入攻击。因此,为了提高访问效率,
如果真的是静态的,访问页面提供静态链接,可以减少服务器对数据响应的负载,第二次加载时不需要调动数据库。响应处理过程是,如果当前链接指定的静态页面存在,则直接访问该静态页面,否则视为第一次访问,创建静态页面,并保存。在创建的过程中,可以引入模板、ob缓存机制,甚至memcached技术。你可能会想,如果是大型网站,因为信息量和访问量都处于海量数据的层面,会不会随着时间的推移会产生大量的静态页面,即大量的多余的文件会堆积起来,空间会比较大。和,毫无疑问,有些文件可能不再使用了。在这种情况下,我们通常可以根据需要设置相应的处理规则,并根据规则开发相应的程序,比如定期执行任务计划,删除冗余文件,或者修改原创
数据库中的信息时,相应的变化是也是同时制作的。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。或者在修改原创
数据库中的信息时,也会同时进行相应的更改。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。或者在修改原创
数据库中的信息时,也会同时进行相应的更改。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。
不管怎么处理,真静态难免会产生积累的内容。这时候,我们经常会想到伪静态方法。
伪静态提供的也是静态链接,但需要注意的是,它实际访问的还是动态页面。那么,伪静态的作用是什么呢?前面说过,因为链接是静态的,所以这对SEO还是很有好处的,在一定程度上提高了安全性。至于访问效率的提升,我们还是可以利用ob缓存机制来提升访问效率。与真静态相比,伪静态避免了生成海量静态页面。有很多方法可以实现伪静态。IIS下有重写规则,Apache下有重写规则,甚至PHP脚本都可以通过正则表达式直接使用。但是,通常我们选择重写规则来实现伪静态。(实现过程略)
那么如何选择使用真静态或伪静态呢?
总结:如果一个网页会被频繁访问(例如百万级别),每次通过网页都会操作数据库,可以考虑使用真静态;如果一个网页是为了优化搜索引擎,提高网站的安全性,可以考虑使用伪静态(+缓存机制)。 查看全部
php 抓取网页生成图片(
页面静态化(这里特指真静态)能够明显地提高网站的访问效率)
本文主要想谈谈页面静态、缓存技术和SEO的关系。在此之前,有必要解释一下这三个词的概念。
一般来说,大型网站的加速一般是通过静态页面、缓存技术(主要是memcached)、mysql优化三个方面来实现的。同时,加速往往需要考虑实际情况,比如SEO问题,静态页面是否需要及时更新,大量静态页面导致的文件堆积问题等等,所以这些矛盾导致我们今天的话题。
页面静态(这里特指真静态)可以显着提高网站访问效率,无论是真静态还是伪静态对SEO都是非常有利的。由于搜索引擎对静态页面“情有独钟”,蜘蛛爬虫乐于抓取静态网页的内容。对于动态网页,比如php页面,搜索引擎总觉得检索页面信息很麻烦,为了尽可能多的抓取到有意义的页面内容,对于动态页面总是要多次抓取。这样一来,页面收录的效率就会相对降低,即会对SEO产生负面影响。此外,从安全角度来看,静态页面不太容易受到 SQL 注入攻击。因此,为了提高访问效率,
如果真的是静态的,访问页面提供静态链接,可以减少服务器对数据响应的负载,第二次加载时不需要调动数据库。响应处理过程是,如果当前链接指定的静态页面存在,则直接访问该静态页面,否则视为第一次访问,创建静态页面,并保存。在创建的过程中,可以引入模板、ob缓存机制,甚至memcached技术。你可能会想,如果是大型网站,因为信息量和访问量都处于海量数据的层面,会不会随着时间的推移会产生大量的静态页面,即大量的多余的文件会堆积起来,空间会比较大。和,毫无疑问,有些文件可能不再使用了。在这种情况下,我们通常可以根据需要设置相应的处理规则,并根据规则开发相应的程序,比如定期执行任务计划,删除冗余文件,或者修改原创
数据库中的信息时,相应的变化是也是同时制作的。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。或者在修改原创
数据库中的信息时,也会同时进行相应的更改。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。或者在修改原创
数据库中的信息时,也会同时进行相应的更改。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。
不管怎么处理,真静态难免会产生积累的内容。这时候,我们经常会想到伪静态方法。
伪静态提供的也是静态链接,但需要注意的是,它实际访问的还是动态页面。那么,伪静态的作用是什么呢?前面说过,因为链接是静态的,所以这对SEO还是很有好处的,在一定程度上提高了安全性。至于访问效率的提升,我们还是可以利用ob缓存机制来提升访问效率。与真静态相比,伪静态避免了生成海量静态页面。有很多方法可以实现伪静态。IIS下有重写规则,Apache下有重写规则,甚至PHP脚本都可以通过正则表达式直接使用。但是,通常我们选择重写规则来实现伪静态。(实现过程略)
那么如何选择使用真静态或伪静态呢?
总结:如果一个网页会被频繁访问(例如百万级别),每次通过网页都会操作数据库,可以考虑使用真静态;如果一个网页是为了优化搜索引擎,提高网站的安全性,可以考虑使用伪静态(+缓存机制)。
php 抓取网页生成图片(web服务器通过mysql协议发送给mysql服务器()协议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-27 07:04
介绍
说到LNMP,就不得不提LAMP。我们知道LAMP是一个多C/S架构的平台。在该架构中,Web客户端通过http协议发起基于TCP/IP的传输。这个请求可能是静态的,也可能是动态的。所以web服务器通过发起请求的后缀来判断,如果是静态的,则由web服务器自己处理,然后将资源发送给客户端。如果是动态的web服务器,会通过CGI(Common Gateway Interfence)协议向php发起。如果 PHP 以模块的形式与 Web 服务器通信,则它们在内部共享内存。如果PHP是一个单独的服务器,那么它们以sockets的形式进行通信(这是另一种C/S架构),这时候php会相应地执行一个程序。如果在程序执行过程中需要一些数据,那么php会通过mysql协议(这个也可以看成是C/S架构)发送到mysql服务器,由mysql服务器处理。将数据提供给 php 程序。
LNMP
是指一组通常用来运行动态网站或服务器的免费软件的首字母缩写词。L指Linux,N指Nginx,M一般指MySQL或MariaDB,P一般指PHP,或Perl或Python。LNMP 架构与 LAMP 架构类似,只是一个使用 Apache,另一个使用 Nginx。LNMP 是 Linux+Nginx+MySQL/mairadb+PHP。Nginx 和 Apache 都是 Web 服务器。另一个区别是在LNMP结构中,php会启动一个php-fpm服务,而LANP中的php大部分时间只作为Apache的一个模块存在(CentOS8中LAMP架构也启动了php-fpm服务) .
Nginx 会将用户的动态页面请求交给 php 服务进行处理,由 php 服务与数据库进行交互。用户的静态页面请求由 Nginx 直接处理。Nginx 处理静态请求的速度比 apache 快得多。性能比较好,所以在动态请求处理上apache和Nginx差别不大,但是如果是静态请求处理,Nginx就很明显了。它比apache快,而且Nginx能承受的并发量比apache大,能承受几万并发,所以较大的网站会使用Nginx作为web服务器。
动态和静态页面
静态页面:
(1)静态网页不能简单理解为静态网页,主要是指网页中没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html, .htm,或者.xml等,虽然静态网页的内容一旦创建就不会改变,但是静态网页也包括一些活动的部分,主要是一些GIF动画等。
(2)打开静态网页,用户可以直接双击,任何人随时打开的页面内容保持不变。
动态网页:
(1)动态网页是指相对于静态网页的一种网页编程技术。动态网页的网页文件除了HTML标签外,还收录
一些特定功能的程序代码。这些代码可以使浏览器和服务器进行交互,所以服务器会根据客户的不同请求动态生成网页内容,即相对于静态网页,虽然动态网页的页面代码没有变化,但显示的内容可能是时间、环境或数据库的结果操作。并改变了。
(2)动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文字内容,也可以是收录
各种动画内容。这些只是网页的具体内容,无论网页是否有动态效果,只要是通过动态网站技术(如PHP、ASP、JSP等)生成的网页,都可以称为动态网页。
动态网页和静态网页的区别:
(1)更新维护:
静态网页内容一旦发布到网站服务器上,无论用户是否访问,这些网页的内容都会存储在网站服务器上。如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。数据库不支持静态网页。当网站信息量较大时,网页的创建和维护难度较大。
动态网页可以根据不同的用户请求、时间或环境需要动态生成不同的网页内容,动态网页一般都是基于数据库技术,可以大大减少网站维护的工作量
(2)互动性:
由于静态网页的很多内容都是固定的,在功能上有很大的限制,所以交互性差
动态网页可以实现更多功能,如用户登录、注册、查询等。
(3) 响应速度:
静态网页的内容比较固定,容易被搜索引擎检索到,不需要连接数据库,所以响应速度比较快
动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,涉及到数据连接、访问、查询等一系列过程,所以响应速度比较慢
(4)访问功能:
静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不带“?”,直接双击打开即可
这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般无法访问一个网站的数据库中的所有网页,或者出于技术考虑,搜索不抓取“?” 在网址中。“后的内容”,双击无法直接打开
总之
如果网页内容比较简单,不需要频繁修改,或者只是为了展示信息,可以使用静态网页,简单易操作,不需要管理数据库等。
如果网页内容比较复杂,功能多,变化频繁,内容实时,使用动态网页
LNMP 架构工作流
案例分析
使用LNMP+wordpress搭建博客站点
WordPress
PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上搭建自己的网站。您还可以使用 WordPress 作为内容管理系统。WordPress以其简单、强大的功能、可扩展性和灵活性而著称,加上开源和免费,以及极其丰富的主题插件。无论作为新手学习搭建个人博客,还是专业用户搭建复杂的企业电子商务网站、论坛等,WP都能完美满足需求。WP几乎可以建立任何类型的网站,你只能想到,你做不到。而且,全球数以亿计的知名网站都是基于WP构建的。据官方统计,目前全球32%的网站都是由WP搭建的。因为它太受欢迎了,所以不管插件,主题、教程、文档等等,都是极其丰富的,不可能全部读完。而且网上关于性能优化和问题解决的讨论也很全面。基本学会建网站,玩WP就行!所以,如果你想建网站或者想尝试学习建网站,那么WP绝对值得你优先考虑。
WordPress官网:打开可能有问题(429错误),可以去下载软件包
环境介绍
CentOS8 主机
关闭 SElinux 和防火墙
配置yum源
挂载光盘
可以联网
Wordpress软件包下载地址:
过程
step1 部署LNMP架构
[root@client ~]# dnf -y install nginx php* mariadb-server mariadb -y
step2 设置 php-fpm
[root@client ~]# vim /etc/php-fpm.d/www.conf
user = nginx
group = nginx
#php-fpm服务默认以apache用户启动,将启动用户身份修改nginx
step3 启动服务
[root@client ~]# systemctl restart nginx.service php-fpm.service mariadb.service
step4 生成php测试页
[root@client ~]# echo "" >> /usr/share/nginx/html/index.php
#系统自带的nginx的页面文件存放在/usr/share/nginx/html/目录中
step5 打开浏览器测试
第六步
为数据库设置密码并创建对应的数据库
[root@client ~]# mysqladmin -u root password 123456
[root@client ~]# mysql -u root -p
Enter password:
MariaDB [(none)]> create database wordpress charset=utf8;
Query OK, 1 row affected (0.001 sec)
MariaDB [(none)]> quit
Bye
step7 准备wordpress
[root@client ~]# cd /usr/share/nginx/html/
[root@client html]# rm -fr *
#####删除nginx自带的页面文件,以及刚才测试生成的php页面
[root@client ~]# unzip latest-zh_CN.zip
[root@client ~]# cd wordpress/
[root@client wordpress]# mv * /usr/share/nginx/html/
####将wordpress文件移动到nginx页面文件存放的目录
[root@client wordpress]# cd /usr/share/nginx/html/
[root@client html]# chown -R nginx.nginx *
###文件的默认所有者是root,为了避免权限的问题,将所有者改为nginx
step8 安装wordpress
复制提示页面内容,按照要求手工创建wp-config.php文件并将内容粘贴
[root@client html]# vim /usr/share/nginx/html/wp-config.php
切换到安装页面,点击立即安装
step9 登录和用户注册设置
开启用户注册
发送测试邮件
注意:公网邮箱需要在设置中开启SMTP/POP等功能,然后按照提示操作。
收到测试邮件后,退出管理员账号,返回登录界面,选择注册
将电子邮件中的链接复制到浏览器并粘贴
如果您想直接从其他主机访问而无需修改 URL
WordPress 打开缓慢
有时候wordpress访问很慢,尤其是登录后台的时候,主要是wordpress使用了一些外部资源,比如谷歌的资源;如果你的主机没有联网,打开速度确实很慢。但有时,即使连接到互联网,由于无法访问这些外部资源,速度也会变慢。这时候可以在wordpress中搜索安装一个名为“WP加速中国版”的加速插件并启用,将这些无法访问的外部资源替换为对应的国内资源。可以解决访问慢的问题
总结
什么是 lmp
lnmp和灯的区别
动态网页和静态网页
LNMP 工作流程
如何部署和设置LNMP平台
如何在LNMP平台上搭建wordpress
要点:LNMP架构由哪些成员组成,动态网页和静态网页,LNMP的工作流程,在CentOS8上lnmp平台的搭建,wordpress的安装和设置,用户注册的实现
难点:记住LNMP的组成,了解动态网页和静态网页的区别,记住LNMP的工作流程,记住lnmp平台需要安装哪些软件包,启动哪些服务,修改了哪些配置文件,以及wordpress平台安装设置并实现用户注册 查看全部
php 抓取网页生成图片(web服务器通过mysql协议发送给mysql服务器()协议)
介绍
说到LNMP,就不得不提LAMP。我们知道LAMP是一个多C/S架构的平台。在该架构中,Web客户端通过http协议发起基于TCP/IP的传输。这个请求可能是静态的,也可能是动态的。所以web服务器通过发起请求的后缀来判断,如果是静态的,则由web服务器自己处理,然后将资源发送给客户端。如果是动态的web服务器,会通过CGI(Common Gateway Interfence)协议向php发起。如果 PHP 以模块的形式与 Web 服务器通信,则它们在内部共享内存。如果PHP是一个单独的服务器,那么它们以sockets的形式进行通信(这是另一种C/S架构),这时候php会相应地执行一个程序。如果在程序执行过程中需要一些数据,那么php会通过mysql协议(这个也可以看成是C/S架构)发送到mysql服务器,由mysql服务器处理。将数据提供给 php 程序。
LNMP
是指一组通常用来运行动态网站或服务器的免费软件的首字母缩写词。L指Linux,N指Nginx,M一般指MySQL或MariaDB,P一般指PHP,或Perl或Python。LNMP 架构与 LAMP 架构类似,只是一个使用 Apache,另一个使用 Nginx。LNMP 是 Linux+Nginx+MySQL/mairadb+PHP。Nginx 和 Apache 都是 Web 服务器。另一个区别是在LNMP结构中,php会启动一个php-fpm服务,而LANP中的php大部分时间只作为Apache的一个模块存在(CentOS8中LAMP架构也启动了php-fpm服务) .
Nginx 会将用户的动态页面请求交给 php 服务进行处理,由 php 服务与数据库进行交互。用户的静态页面请求由 Nginx 直接处理。Nginx 处理静态请求的速度比 apache 快得多。性能比较好,所以在动态请求处理上apache和Nginx差别不大,但是如果是静态请求处理,Nginx就很明显了。它比apache快,而且Nginx能承受的并发量比apache大,能承受几万并发,所以较大的网站会使用Nginx作为web服务器。
动态和静态页面
静态页面:
(1)静态网页不能简单理解为静态网页,主要是指网页中没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html, .htm,或者.xml等,虽然静态网页的内容一旦创建就不会改变,但是静态网页也包括一些活动的部分,主要是一些GIF动画等。
(2)打开静态网页,用户可以直接双击,任何人随时打开的页面内容保持不变。
动态网页:
(1)动态网页是指相对于静态网页的一种网页编程技术。动态网页的网页文件除了HTML标签外,还收录
一些特定功能的程序代码。这些代码可以使浏览器和服务器进行交互,所以服务器会根据客户的不同请求动态生成网页内容,即相对于静态网页,虽然动态网页的页面代码没有变化,但显示的内容可能是时间、环境或数据库的结果操作。并改变了。
(2)动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文字内容,也可以是收录
各种动画内容。这些只是网页的具体内容,无论网页是否有动态效果,只要是通过动态网站技术(如PHP、ASP、JSP等)生成的网页,都可以称为动态网页。
动态网页和静态网页的区别:
(1)更新维护:
静态网页内容一旦发布到网站服务器上,无论用户是否访问,这些网页的内容都会存储在网站服务器上。如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。数据库不支持静态网页。当网站信息量较大时,网页的创建和维护难度较大。
动态网页可以根据不同的用户请求、时间或环境需要动态生成不同的网页内容,动态网页一般都是基于数据库技术,可以大大减少网站维护的工作量
(2)互动性:
由于静态网页的很多内容都是固定的,在功能上有很大的限制,所以交互性差
动态网页可以实现更多功能,如用户登录、注册、查询等。
(3) 响应速度:
静态网页的内容比较固定,容易被搜索引擎检索到,不需要连接数据库,所以响应速度比较快
动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,涉及到数据连接、访问、查询等一系列过程,所以响应速度比较慢
(4)访问功能:
静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不带“?”,直接双击打开即可
这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般无法访问一个网站的数据库中的所有网页,或者出于技术考虑,搜索不抓取“?” 在网址中。“后的内容”,双击无法直接打开
总之
如果网页内容比较简单,不需要频繁修改,或者只是为了展示信息,可以使用静态网页,简单易操作,不需要管理数据库等。
如果网页内容比较复杂,功能多,变化频繁,内容实时,使用动态网页
LNMP 架构工作流
案例分析
使用LNMP+wordpress搭建博客站点
WordPress
PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上搭建自己的网站。您还可以使用 WordPress 作为内容管理系统。WordPress以其简单、强大的功能、可扩展性和灵活性而著称,加上开源和免费,以及极其丰富的主题插件。无论作为新手学习搭建个人博客,还是专业用户搭建复杂的企业电子商务网站、论坛等,WP都能完美满足需求。WP几乎可以建立任何类型的网站,你只能想到,你做不到。而且,全球数以亿计的知名网站都是基于WP构建的。据官方统计,目前全球32%的网站都是由WP搭建的。因为它太受欢迎了,所以不管插件,主题、教程、文档等等,都是极其丰富的,不可能全部读完。而且网上关于性能优化和问题解决的讨论也很全面。基本学会建网站,玩WP就行!所以,如果你想建网站或者想尝试学习建网站,那么WP绝对值得你优先考虑。
WordPress官网:打开可能有问题(429错误),可以去下载软件包
环境介绍
CentOS8 主机
关闭 SElinux 和防火墙
配置yum源
挂载光盘
可以联网
Wordpress软件包下载地址:
过程
step1 部署LNMP架构
[root@client ~]# dnf -y install nginx php* mariadb-server mariadb -y
step2 设置 php-fpm
[root@client ~]# vim /etc/php-fpm.d/www.conf
user = nginx
group = nginx
#php-fpm服务默认以apache用户启动,将启动用户身份修改nginx
step3 启动服务
[root@client ~]# systemctl restart nginx.service php-fpm.service mariadb.service
step4 生成php测试页
[root@client ~]# echo "" >> /usr/share/nginx/html/index.php
#系统自带的nginx的页面文件存放在/usr/share/nginx/html/目录中
step5 打开浏览器测试
第六步
为数据库设置密码并创建对应的数据库
[root@client ~]# mysqladmin -u root password 123456
[root@client ~]# mysql -u root -p
Enter password:
MariaDB [(none)]> create database wordpress charset=utf8;
Query OK, 1 row affected (0.001 sec)
MariaDB [(none)]> quit
Bye
step7 准备wordpress
[root@client ~]# cd /usr/share/nginx/html/
[root@client html]# rm -fr *
#####删除nginx自带的页面文件,以及刚才测试生成的php页面
[root@client ~]# unzip latest-zh_CN.zip
[root@client ~]# cd wordpress/
[root@client wordpress]# mv * /usr/share/nginx/html/
####将wordpress文件移动到nginx页面文件存放的目录
[root@client wordpress]# cd /usr/share/nginx/html/
[root@client html]# chown -R nginx.nginx *
###文件的默认所有者是root,为了避免权限的问题,将所有者改为nginx
step8 安装wordpress
复制提示页面内容,按照要求手工创建wp-config.php文件并将内容粘贴
[root@client html]# vim /usr/share/nginx/html/wp-config.php
切换到安装页面,点击立即安装
step9 登录和用户注册设置
开启用户注册
发送测试邮件
注意:公网邮箱需要在设置中开启SMTP/POP等功能,然后按照提示操作。
收到测试邮件后,退出管理员账号,返回登录界面,选择注册
将电子邮件中的链接复制到浏览器并粘贴
如果您想直接从其他主机访问而无需修改 URL
WordPress 打开缓慢
有时候wordpress访问很慢,尤其是登录后台的时候,主要是wordpress使用了一些外部资源,比如谷歌的资源;如果你的主机没有联网,打开速度确实很慢。但有时,即使连接到互联网,由于无法访问这些外部资源,速度也会变慢。这时候可以在wordpress中搜索安装一个名为“WP加速中国版”的加速插件并启用,将这些无法访问的外部资源替换为对应的国内资源。可以解决访问慢的问题
总结
什么是 lmp
lnmp和灯的区别
动态网页和静态网页
LNMP 工作流程
如何部署和设置LNMP平台
如何在LNMP平台上搭建wordpress
要点:LNMP架构由哪些成员组成,动态网页和静态网页,LNMP的工作流程,在CentOS8上lnmp平台的搭建,wordpress的安装和设置,用户注册的实现
难点:记住LNMP的组成,了解动态网页和静态网页的区别,记住LNMP的工作流程,记住lnmp平台需要安装哪些软件包,启动哪些服务,修改了哪些配置文件,以及wordpress平台安装设置并实现用户注册
php 抓取网页生成图片(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-25 17:16
本文介绍如何使用Python抓取网页生成Excel文件。分享给大家,供大家参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开这个csv文件并保存为Excel文件
希望这篇文章对你的 Python 编程有所帮助。 查看全部
php 抓取网页生成图片(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
本文介绍如何使用Python抓取网页生成Excel文件。分享给大家,供大家参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开这个csv文件并保存为Excel文件
希望这篇文章对你的 Python 编程有所帮助。
php 抓取网页生成图片(,PHP,抓取,远程,图片含,不带的,教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-25 11:10
PHP抓图远程图片(含不带后缀)教程详解,PHP抓图,远程,图片,有,无,后缀,,教程,一
PHP捕捉远程图片(包括不带后缀)教程详解
第一财网站长网站,站长之家为您整理了PHP抓图远程图片(包括无后缀)教程详解的相关内容。
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、定义另外一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是远程镜像抓取后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。如这里所解释的,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setDir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,TRUE);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。以上就是对PHP远程抓图(包括不带后缀)教程详解的详细介绍。欢迎大家对PHP捕获远程镜像(包括不带后缀)教程的详细内容提出宝贵意见 查看全部
php 抓取网页生成图片(,PHP,抓取,远程,图片含,不带的,教程)
PHP抓图远程图片(含不带后缀)教程详解,PHP抓图,远程,图片,有,无,后缀,,教程,一
PHP捕捉远程图片(包括不带后缀)教程详解
第一财网站长网站,站长之家为您整理了PHP抓图远程图片(包括无后缀)教程详解的相关内容。
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、定义另外一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是远程镜像抓取后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。如这里所解释的,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setDir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,TRUE);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。以上就是对PHP远程抓图(包括不带后缀)教程详解的详细介绍。欢迎大家对PHP捕获远程镜像(包括不带后缀)教程的详细内容提出宝贵意见
php 抓取网页生成图片(如何实现PHP转换生成为各种格式的图片或者pdf文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-23 20:11
我们在实际项目开发中经常会遇到这种需求,从特定的网页生成图片,用于分享等用途。这时候,我们就可以利用这个PHP扩展,轻松地将网页转换成各种格式的图片或pdf文件。让我们来看看如何实现这一点?
本教程的主角是wkhtmltopdf,下面简单了解一下:
wkhtmltopdf 是一个开源、简单有效的命令行shell 程序,可以将任何HTML(网页)转换为PDF 文档或图像(jpg、png 等)。
wkhtmltopdf 是用 C++ 编写的,并在 GNU/GPL(通用公共许可证)下发布。它使用 WebKit 渲染引擎将 HTML 页面转换为 PDF 文档,而不会损失页面质量。这是用于实时创建和存储网页快照的非常有用且可靠的解决方案。
本程序的特点如下:
开源和跨平台。
使用 WebKit 引擎将任何 HTML 网页转换为 PDF 文件。
添加页眉和页脚选项
目录生成 (TOC) 选项。
提供批量模式转换。
通过绑定 libwkhtmltox 支持 PHP 或 Python。
首先我们需要在我们的服务器上安装libwkhtmltox,linux下的webkit内核,根据我们的服务器配置选择合适的安装包:
需要注意的是libwkhtmltox的当前版本已经0.13了,但是我在CentOS6.2下安装了libwkhtmltox-0.11后,我把网页改成了There图片会报错,最后选择了0.10版本,比较稳定。
<p>13版的安装方法:[root@KaiBoss_4_45 ~]#rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm 查看全部
php 抓取网页生成图片(如何实现PHP转换生成为各种格式的图片或者pdf文件)
我们在实际项目开发中经常会遇到这种需求,从特定的网页生成图片,用于分享等用途。这时候,我们就可以利用这个PHP扩展,轻松地将网页转换成各种格式的图片或pdf文件。让我们来看看如何实现这一点?
本教程的主角是wkhtmltopdf,下面简单了解一下:
wkhtmltopdf 是一个开源、简单有效的命令行shell 程序,可以将任何HTML(网页)转换为PDF 文档或图像(jpg、png 等)。
wkhtmltopdf 是用 C++ 编写的,并在 GNU/GPL(通用公共许可证)下发布。它使用 WebKit 渲染引擎将 HTML 页面转换为 PDF 文档,而不会损失页面质量。这是用于实时创建和存储网页快照的非常有用且可靠的解决方案。
本程序的特点如下:
开源和跨平台。
使用 WebKit 引擎将任何 HTML 网页转换为 PDF 文件。
添加页眉和页脚选项
目录生成 (TOC) 选项。
提供批量模式转换。
通过绑定 libwkhtmltox 支持 PHP 或 Python。
首先我们需要在我们的服务器上安装libwkhtmltox,linux下的webkit内核,根据我们的服务器配置选择合适的安装包:
需要注意的是libwkhtmltox的当前版本已经0.13了,但是我在CentOS6.2下安装了libwkhtmltox-0.11后,我把网页改成了There图片会报错,最后选择了0.10版本,比较稳定。
<p>13版的安装方法:[root@KaiBoss_4_45 ~]#rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm
php 抓取网页生成图片(PHP代码服务器端的代码中使用替换操作和base64解码功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-20 23:04
需求:项目中需要用到截图功能,但是我们一般都是用微信或者QQ来截图,这种方式不方便。更重要的是,如果要截取的部分超过一屏,使用上述方法截屏只能截取部分内容,不能截取全部内容。因此,我们迫切需要一种滚动截图的方式,捕捉我想要的部分,所以引入了下面的截图方法--html2canvas。
首先最基础的就是:导入这个js文件。
下面是实现这个功能的具体代码
1. HTML 页面代码
保存图片
2. js 代码
$(function(){
$(".saveImage").on('click', function (event) {
var img={}
event.preventDefault();
html2canvas($(".fc-view-container"), {
allowTaint: true,
taintTest: false,
onrendered: function(canvas) {
canvas.id = "mycanvas";
//生成base64图片数据
var dataUrl = canvas.toDataURL();
img.img=dataUrl;
saveimg(img)
}
});
});
});
// 保存图片
function saveimg(img){
$.ajax({
url:"{:U('Index/saveImg')}",
type:'post',
data:img,
success:function(data){
if (data.status) {
//toast.success(data.info,'温馨提示');
setTimeout(function(){
window.location.href="/Uploads/Screen/"+data.url+".png";
}, 1000)
}else{
//toast.error(data.info,'温馨提示');
setTimeout(function(){
window.location.reload(true);
},1200)
};
}
})
}
第一个是给保存图片的元素绑定一个future事件。事件中使用canvas接口中的toDataURL()方法。我们来解释一下这个方法的作用:
参考Web Api接口使用该方法返回一个data: URL,将canvas中收录的图片文件按照type参数指定的类型编码成字符串。type 参数的默认值为 image/png。
第二个是:html2canvas($(".fc-view-container")),这个方法用来指定截取并生成图片的Dom对象。
最后,我们是后端代码:
3.PHP 代码
/**
* 截图保存图片
*/
public function saveImg()
{
$pictureFlow=I('img');
//图片流转存
$pictureFlow = str_replace('data:image/png;base64,', '', $pictureFlow);
$pictureFlow = base64_decode($pictureFlow);
$NOW_TIME=NOW_TIME;
$new_pic_path = 'Uploads/Screen/'.$NOW_TIME.'.png';
$ret = file_put_contents($new_pic_path, $pictureFlow);
if ($ret) {
$this->success('下载成功',$NOW_TIME);
}else{
$this->error('下载失败');
}
}
服务端代码中使用了替换操作和base64解码功能,可以直接将之前截取的图片部分保存为png格式。
保存截图如下:
捕获的 png 图像 查看全部
php 抓取网页生成图片(PHP代码服务器端的代码中使用替换操作和base64解码功能)
需求:项目中需要用到截图功能,但是我们一般都是用微信或者QQ来截图,这种方式不方便。更重要的是,如果要截取的部分超过一屏,使用上述方法截屏只能截取部分内容,不能截取全部内容。因此,我们迫切需要一种滚动截图的方式,捕捉我想要的部分,所以引入了下面的截图方法--html2canvas。
首先最基础的就是:导入这个js文件。
下面是实现这个功能的具体代码
1. HTML 页面代码
保存图片
2. js 代码
$(function(){
$(".saveImage").on('click', function (event) {
var img={}
event.preventDefault();
html2canvas($(".fc-view-container"), {
allowTaint: true,
taintTest: false,
onrendered: function(canvas) {
canvas.id = "mycanvas";
//生成base64图片数据
var dataUrl = canvas.toDataURL();
img.img=dataUrl;
saveimg(img)
}
});
});
});
// 保存图片
function saveimg(img){
$.ajax({
url:"{:U('Index/saveImg')}",
type:'post',
data:img,
success:function(data){
if (data.status) {
//toast.success(data.info,'温馨提示');
setTimeout(function(){
window.location.href="/Uploads/Screen/"+data.url+".png";
}, 1000)
}else{
//toast.error(data.info,'温馨提示');
setTimeout(function(){
window.location.reload(true);
},1200)
};
}
})
}
第一个是给保存图片的元素绑定一个future事件。事件中使用canvas接口中的toDataURL()方法。我们来解释一下这个方法的作用:
参考Web Api接口使用该方法返回一个data: URL,将canvas中收录的图片文件按照type参数指定的类型编码成字符串。type 参数的默认值为 image/png。
第二个是:html2canvas($(".fc-view-container")),这个方法用来指定截取并生成图片的Dom对象。
最后,我们是后端代码:
3.PHP 代码
/**
* 截图保存图片
*/
public function saveImg()
{
$pictureFlow=I('img');
//图片流转存
$pictureFlow = str_replace('data:image/png;base64,', '', $pictureFlow);
$pictureFlow = base64_decode($pictureFlow);
$NOW_TIME=NOW_TIME;
$new_pic_path = 'Uploads/Screen/'.$NOW_TIME.'.png';
$ret = file_put_contents($new_pic_path, $pictureFlow);
if ($ret) {
$this->success('下载成功',$NOW_TIME);
}else{
$this->error('下载失败');
}
}
服务端代码中使用了替换操作和base64解码功能,可以直接将之前截取的图片部分保存为png格式。
保存截图如下:

捕获的 png 图像
php 抓取网页生成图片(LinuxCentOS6-64bit下载下来后是什么样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-20 23:02
要求:将网页转成pdf或图片,并提供下载。
wkhtmltox 项目主页:支持html转pdf、图片
php扩展php-wkhtmltox项目主页:
1、下载安装wkhtmltox系统环境
根据系统类型选择下载wkhtmltox:
我这里的系统环境是CentOS 6-64bit,所以我选择:Linux CentOS 6-64bit
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。
安装 wkhtmltox:
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
错误:依赖项失败:
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示需要安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 附加:
* 更新:
================================================ ============ N/S 匹配:75dpi ================================ ============================
xorg-x11-fonts-75dpi.noarch:一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch:一组 75dpi ISO-8859-1 X 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch: ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch: ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch:一组 75dpi 的 X 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch: ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“全部搜索”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
直接用下面的方法解压rpm包中编译好的包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面有四个文件夹:local/bin、local/include、local/share、local/lib
将对应文件夹的内容复制到/usr/local!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
2、安装php-wkhtmltox扩展
在github上下载源码包[php-wkhtmltox_master.zip]
> unzipphp-wkhtmltox_master.zip
> cd phpwkhtmltox
>phpize
> ./configure--with-php-config=/usr/local/php/bin/php-config #这里取决于各个系统的PHP安装路径
> make && make install
> ldconfig #重新加载系统动态链接库
> php -m
#检查扩展是否成功。如果能看到phpwkhtmltox,说明扩展成功。
php-wkhtmltox 扩展安装完成。
3、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm restart
安装完成!
参考这篇文章:
安装部分可以使用本文介绍的安装部分,有的可能需要中文字体支持。可以参考上面的中文字体库安装部分进行扩展。
转载于: 查看全部
php 抓取网页生成图片(LinuxCentOS6-64bit下载下来后是什么样的?)
要求:将网页转成pdf或图片,并提供下载。
wkhtmltox 项目主页:支持html转pdf、图片
php扩展php-wkhtmltox项目主页:
1、下载安装wkhtmltox系统环境
根据系统类型选择下载wkhtmltox:

我这里的系统环境是CentOS 6-64bit,所以我选择:Linux CentOS 6-64bit
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。
安装 wkhtmltox:
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
错误:依赖项失败:
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示需要安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 附加:
* 更新:
================================================ ============ N/S 匹配:75dpi ================================ ============================
xorg-x11-fonts-75dpi.noarch:一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch:一组 75dpi ISO-8859-1 X 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch: ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch: ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch:一组 75dpi 的 X 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch: ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“全部搜索”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
直接用下面的方法解压rpm包中编译好的包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面有四个文件夹:local/bin、local/include、local/share、local/lib
将对应文件夹的内容复制到/usr/local!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
2、安装php-wkhtmltox扩展
在github上下载源码包[php-wkhtmltox_master.zip]
> unzipphp-wkhtmltox_master.zip
> cd phpwkhtmltox
>phpize
> ./configure--with-php-config=/usr/local/php/bin/php-config #这里取决于各个系统的PHP安装路径
> make && make install
> ldconfig #重新加载系统动态链接库
> php -m
#检查扩展是否成功。如果能看到phpwkhtmltox,说明扩展成功。
php-wkhtmltox 扩展安装完成。
3、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm restart
安装完成!
参考这篇文章:
安装部分可以使用本文介绍的安装部分,有的可能需要中文字体支持。可以参考上面的中文字体库安装部分进行扩展。
转载于:
php 抓取网页生成图片(牢骚发完了,正式写博客吧(PHP生成word原理))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-18 22:18
概括:
最近在工作中遇到了生词问题
现在总结一下生成词的三种方法。
btw:好像在博客园里发个博客,只要标题有PHP,好像点击量不是很高(兄弟,我标题还是有PHP的)。我不知道为什么。估计博客园里的网络技术专家比较多。把Java、.net、php比作程序员的闺蜜,那么java就是甲骨文下最好的姑娘,.net微软下的名门世家,PHP就是草根下的野蛮大妈。这让我很期待 PHP 的草根男士这么骚。怎么可能。. 委屈完了,正式写博客
PHP为正文生成word的原理是通过windows下的com组件使用PHP将内容写入doc文件中实现的:
原理:com是PHP的扩展。安装了office的服务器会自动调用word.application的com,可以自动生成文档。PHP 官方文档手册:
使用官方示例:
个人建议:com实例后面的方法需要查一下官方文档才知道是什么意思。编辑器没有代码提示,非常不方便。另外这个效率不是很高,所以不推荐使用
使用 PHP 将内容写入 doc 文件。这种方法可以分为两种方法生成mht格式(类似HTML)并写入word
这种方法主要是指:
/**
* 根据HTML代码获取word文档内容
* 创建一个本质为mht的文档,该函数会分析文件内容并从远程下载页面中的图片资源
* 该函数依赖于类MhtFileMaker
* 该函数会分析img标签,提取src的属性值。但是,src的属性值必须被引号包围,否则不能提取
*
* @param string $content HTML内容
* @param string $absolutePath 网页的绝对路径。如果HTML内容里的图片路径为相对路径,那么就需要填写这个参数,来让该函数自动填补成绝对路径。这个参数最后需要以/结束
* @param bool $isEraseLink 是否去掉HTML内容中的链接
*/
function getWordDocument( $content , $absolutePath = "" , $isEraseLink = true )
{
$mht = new MhtFileMaker();
if ($isEraseLink)
$content = preg_replace('/(\s*.*?\s*)/i' , '$1' , $content); //去掉链接
$images = array();
$files = array();
$matches = array();
//这个算法要求src后的属性值必须使用引号括起来
if ( preg_match_all('/GetMimeType("tmp.html"),$content);
for ( $i=0;$iAddContents($files[$i],$mht->GetMimeType($image),$imgcontent);
}
else
{
echo "file:".$image." not exist!<br />";
}
}
return $mht->GetFile();
}
这个函数的主要作用其实就是分析HTML代码中的所有图片地址,依次下载。获取到图片内容后,调用MhtFileMaker类将图片添加到mht文件中。具体的添加细节封装在 MhtFileMaker 类中。
url= http://www.***.com;
$content = file_get_contents($url);
$fileContent = getWordDocument($content,"http://www.yoursite.com/Music/etc/");
$fp = fopen("test.doc", 'w');
fwrite($fp, $fileContent);
fclose($fp);
其中$content变量应该是HTML源代码,下面的链接应该是可以在HTML代码中填写图片相对路径的URL地址
header("缓存控制:无缓存,必须重新验证");
header("Pragma: no-cache");
$wordStr ='PHP淮北个人网站';
$fileContent = getWordDocument($wordStr);
$fileName = iconv("utf-8", "GBK",'PHP淮北'.'_'.$intro.'_'.rand(100, 999));
header("内容类型:应用程序/文档");
header("Content-Disposition: 附件;文件名=".$fileName.".doc");
回声 $fileContent;
注意在使用这个函数之前,需要收录类MhtFileMaker,它可以帮助我们生成Mht文件。
点评:这种方式的缺点是不支持批量生成和下载,因为一个页面只能有一个header(无论是远程使用还是本地生成的statement header页面都只能输出一个header),即使你循环生成,结果还是只有一个字Generate(当然可以修改上面的方式来实现)
2.纯HTML格式写字
原则:
使用ob_start先存储html页面(解决页面多个header的问题,可以批量生成),然后在写入doc文档的内容时使用
代码:
<p> 查看全部
php 抓取网页生成图片(牢骚发完了,正式写博客吧(PHP生成word原理))
概括:
最近在工作中遇到了生词问题
现在总结一下生成词的三种方法。
btw:好像在博客园里发个博客,只要标题有PHP,好像点击量不是很高(兄弟,我标题还是有PHP的)。我不知道为什么。估计博客园里的网络技术专家比较多。把Java、.net、php比作程序员的闺蜜,那么java就是甲骨文下最好的姑娘,.net微软下的名门世家,PHP就是草根下的野蛮大妈。这让我很期待 PHP 的草根男士这么骚。怎么可能。. 委屈完了,正式写博客
PHP为正文生成word的原理是通过windows下的com组件使用PHP将内容写入doc文件中实现的:
原理:com是PHP的扩展。安装了office的服务器会自动调用word.application的com,可以自动生成文档。PHP 官方文档手册:
使用官方示例:
个人建议:com实例后面的方法需要查一下官方文档才知道是什么意思。编辑器没有代码提示,非常不方便。另外这个效率不是很高,所以不推荐使用
使用 PHP 将内容写入 doc 文件。这种方法可以分为两种方法生成mht格式(类似HTML)并写入word
这种方法主要是指:
/**
* 根据HTML代码获取word文档内容
* 创建一个本质为mht的文档,该函数会分析文件内容并从远程下载页面中的图片资源
* 该函数依赖于类MhtFileMaker
* 该函数会分析img标签,提取src的属性值。但是,src的属性值必须被引号包围,否则不能提取
*
* @param string $content HTML内容
* @param string $absolutePath 网页的绝对路径。如果HTML内容里的图片路径为相对路径,那么就需要填写这个参数,来让该函数自动填补成绝对路径。这个参数最后需要以/结束
* @param bool $isEraseLink 是否去掉HTML内容中的链接
*/
function getWordDocument( $content , $absolutePath = "" , $isEraseLink = true )
{
$mht = new MhtFileMaker();
if ($isEraseLink)
$content = preg_replace('/(\s*.*?\s*)/i' , '$1' , $content); //去掉链接
$images = array();
$files = array();
$matches = array();
//这个算法要求src后的属性值必须使用引号括起来
if ( preg_match_all('/GetMimeType("tmp.html"),$content);
for ( $i=0;$iAddContents($files[$i],$mht->GetMimeType($image),$imgcontent);
}
else
{
echo "file:".$image." not exist!<br />";
}
}
return $mht->GetFile();
}
这个函数的主要作用其实就是分析HTML代码中的所有图片地址,依次下载。获取到图片内容后,调用MhtFileMaker类将图片添加到mht文件中。具体的添加细节封装在 MhtFileMaker 类中。
url= http://www.***.com;
$content = file_get_contents($url);
$fileContent = getWordDocument($content,"http://www.yoursite.com/Music/etc/";);
$fp = fopen("test.doc", 'w');
fwrite($fp, $fileContent);
fclose($fp);
其中$content变量应该是HTML源代码,下面的链接应该是可以在HTML代码中填写图片相对路径的URL地址
header("缓存控制:无缓存,必须重新验证");
header("Pragma: no-cache");
$wordStr ='PHP淮北个人网站';
$fileContent = getWordDocument($wordStr);
$fileName = iconv("utf-8", "GBK",'PHP淮北'.'_'.$intro.'_'.rand(100, 999));
header("内容类型:应用程序/文档");
header("Content-Disposition: 附件;文件名=".$fileName.".doc");
回声 $fileContent;
注意在使用这个函数之前,需要收录类MhtFileMaker,它可以帮助我们生成Mht文件。
点评:这种方式的缺点是不支持批量生成和下载,因为一个页面只能有一个header(无论是远程使用还是本地生成的statement header页面都只能输出一个header),即使你循环生成,结果还是只有一个字Generate(当然可以修改上面的方式来实现)
2.纯HTML格式写字
原则:
使用ob_start先存储html页面(解决页面多个header的问题,可以批量生成),然后在写入doc文档的内容时使用
代码:
<p>
php 抓取网页生成图片(如何利用referer来进行防图片盗链的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-18 00:06
写这个文章主要是因为我之前在知乎上的回答,没想到引起了这么多朋友的关注:
其实代码很简单,一上手就应该搞定。所以前高手关闭了这个文章,谢谢!
这个问题在 16 年时得到了回答,但今天仍在使用和咨询。我优化了代码,写了这个文章。
1 防盗的原理是什么?
当客户端(浏览器)从服务器请求内容时,它会提交一个标头。这个header收录了浏览器信息、cookies等内容,所以有一个referer叫做referer,也收录在里面。
推荐人是做什么用的?
它告诉服务器谁是请求的来源。比如从A页跳转到B页,那么B页收到的referer就是A页。
但图片与此有点不同。图片是在html页面加载后加载的,所以图片接收到的referer不是网页的上一页,而是当前页面。
说了这么多,别上当了。简单的一点是:对于图像,接收到的引用是引用图像的页面的 URL。
那么现在很多网站是如何使用referer来防止图片盗链的呢?
在三种情况下允许引用图像:
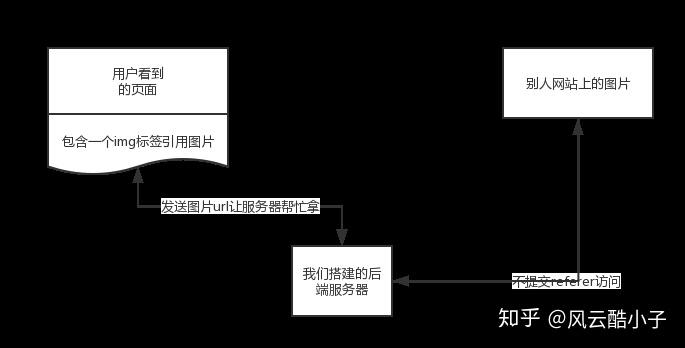
这个网站。当没有推荐人信息时。(服务器认为是浏览器直接访问的图片的URL,所以在这种情况下可以正常访问) 授权的URL。2 如何绕过反水蛭链?
上面介绍了3种获取图片的方法。方法一和方法三能实现吗?肯定不是,所以我们只能从方法2开始。
要擦除请求头中的信息,客户端(浏览器中的网页)无法工作,只能从服务器启动。
大体思路如下:
接下来,我们要做的就是做好转运:
您必须首先拥有一台服务器(空间或虚拟主机都可以)。选择你熟悉的语言(php nodeJs java python都可以)。开始写代码。把它放在首页并使用它。3 开始写代码
先从头开始吧,代码很简单,不要有心理压力。我以PHP为例(这两年一直在玩nodejs,PHP降温很快,昨天不得不处理一些复杂的图片,发现PHP在这方面容易一些)。
A 首先定义一个页面抓取功能。有了它,你就可以获取和发布网页,当然,当你能够捕捉图片时,你会需要它。我在原来的基础上优化了一下:
在这种情况下,如果有数据提交,它会自动发布,如果没有数据提交,它会获取。
这个函数写好后,把php文件放在最后,然后直接调用。
B 写主体部分,处理一些错误的情况。
以上部分主要是处理引用图片时出现错误的情况。一种是图片的真实URL没有告诉服务器,另一种是图片的真实地址无法访问。在这两种情况下,错误信息都会以图片的形式输出。
./fonts/hwxh.ttf 这个是字体,放在相对路径下对应的位置,或者不需要这个,直接复制系统字体中的字体名称即可。
C做了这么多准备工作,业务刚刚起步,开始抓图输出:
好无语,前面这么多东西,真东西才3行??
是的,你没看错,就是这样。当然,你可以在图片上加水印什么的,让它更有特色。
4 最终代码
完成后,代码如下:
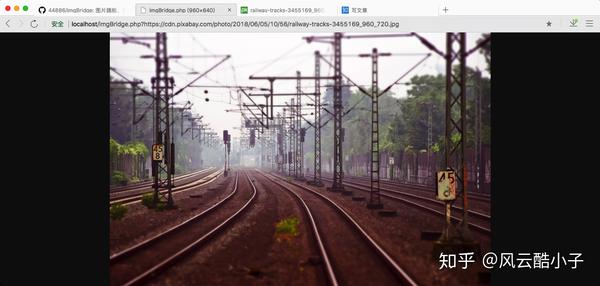
5 最终检查
我成功地将图片传输到了本地本地主机上的图片(这是带有反水蛭的 网站)。
6 小贴士
使用您自己的服务器进行传输。如果目标图片太大,那么小水管服务器肯定受不了。pixabay最大尺寸的图片最大是几M甚至几十M,加载速度会很慢很慢,所以你可以把php的执行时间设置的更长一些。
同时,如果服务器的带宽很小,建议不要随意向别人开放你的接口,影响自己网站。
7 源代码共享
44886/imgBridge
上面这个地址,php版本已经更新了,nodejs版本不想改了,就按照这个思路吧。
github上的一个朋友提到gif不能移动。还没搞定,不过gif需要一帧一帧的提取出来,没那么简单。请在天亮时更新代码。 查看全部
php 抓取网页生成图片(如何利用referer来进行防图片盗链的呢?)
写这个文章主要是因为我之前在知乎上的回答,没想到引起了这么多朋友的关注:
其实代码很简单,一上手就应该搞定。所以前高手关闭了这个文章,谢谢!
这个问题在 16 年时得到了回答,但今天仍在使用和咨询。我优化了代码,写了这个文章。
1 防盗的原理是什么?
当客户端(浏览器)从服务器请求内容时,它会提交一个标头。这个header收录了浏览器信息、cookies等内容,所以有一个referer叫做referer,也收录在里面。
推荐人是做什么用的?
它告诉服务器谁是请求的来源。比如从A页跳转到B页,那么B页收到的referer就是A页。
但图片与此有点不同。图片是在html页面加载后加载的,所以图片接收到的referer不是网页的上一页,而是当前页面。
说了这么多,别上当了。简单的一点是:对于图像,接收到的引用是引用图像的页面的 URL。
那么现在很多网站是如何使用referer来防止图片盗链的呢?
在三种情况下允许引用图像:
这个网站。当没有推荐人信息时。(服务器认为是浏览器直接访问的图片的URL,所以在这种情况下可以正常访问) 授权的URL。2 如何绕过反水蛭链?
上面介绍了3种获取图片的方法。方法一和方法三能实现吗?肯定不是,所以我们只能从方法2开始。
要擦除请求头中的信息,客户端(浏览器中的网页)无法工作,只能从服务器启动。
大体思路如下:
接下来,我们要做的就是做好转运:
您必须首先拥有一台服务器(空间或虚拟主机都可以)。选择你熟悉的语言(php nodeJs java python都可以)。开始写代码。把它放在首页并使用它。3 开始写代码
先从头开始吧,代码很简单,不要有心理压力。我以PHP为例(这两年一直在玩nodejs,PHP降温很快,昨天不得不处理一些复杂的图片,发现PHP在这方面容易一些)。
A 首先定义一个页面抓取功能。有了它,你就可以获取和发布网页,当然,当你能够捕捉图片时,你会需要它。我在原来的基础上优化了一下:
在这种情况下,如果有数据提交,它会自动发布,如果没有数据提交,它会获取。
这个函数写好后,把php文件放在最后,然后直接调用。
B 写主体部分,处理一些错误的情况。
以上部分主要是处理引用图片时出现错误的情况。一种是图片的真实URL没有告诉服务器,另一种是图片的真实地址无法访问。在这两种情况下,错误信息都会以图片的形式输出。
./fonts/hwxh.ttf 这个是字体,放在相对路径下对应的位置,或者不需要这个,直接复制系统字体中的字体名称即可。
C做了这么多准备工作,业务刚刚起步,开始抓图输出:
好无语,前面这么多东西,真东西才3行??
是的,你没看错,就是这样。当然,你可以在图片上加水印什么的,让它更有特色。
4 最终代码
完成后,代码如下:
5 最终检查
我成功地将图片传输到了本地本地主机上的图片(这是带有反水蛭的 网站)。
6 小贴士
使用您自己的服务器进行传输。如果目标图片太大,那么小水管服务器肯定受不了。pixabay最大尺寸的图片最大是几M甚至几十M,加载速度会很慢很慢,所以你可以把php的执行时间设置的更长一些。
同时,如果服务器的带宽很小,建议不要随意向别人开放你的接口,影响自己网站。
7 源代码共享
44886/imgBridge
上面这个地址,php版本已经更新了,nodejs版本不想改了,就按照这个思路吧。
github上的一个朋友提到gif不能移动。还没搞定,不过gif需要一帧一帧的提取出来,没那么简单。请在天亮时更新代码。
php 抓取网页生成图片(基于更成熟的PHP应用框架和设计理念(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-17 19:19
图片cms图片网站管理系统v1.2.ZIP
PIC cms图片网站 管理系统程序介绍 基于更成熟的PHP应用框架和设计理念,全新的控制器、模型和核心类库;优化多级分类结构,增加全站生成静态页面,加载和SEO方面全面加强;内置采集接口(Beta),以后会增加对其他外部采集器的支持;前后端接口也进行了全面重构,更加简洁、标准、易用。开源所有源代码,保留所有注释,您可以在遵循开源协议的前提下方便地进行二次开发,甚至可以基于技术框架构建一个全新的系统。我们将在未来提供详细的 API 文档。自动生成导航和内容调用14. 模板分离设计,轻松模板设计 15 方便 自由模板方式,可以实现复杂多样的调用效果。1.1 版本升级到1.2 数据库升级请按照以下四部分进行(SQL runner直接运行下面4句SQL,分为四次,不能一下子做,去掉序列号1-4在前面):1:ALTER TABLE `pc_article` ADD `xiaazai` VARCHAR(800)
团队目前拥有美工3人、PHP开发工程师3人、网站运行测试人员2人、项目经理1人、行政秘书2人。PICcms开发团队旨在延续PICcms系统的精髓,在原有PICcms的基础上继续开发专业的图片管理系统,供粉丝和支持者使用提供最佳图片网站解决方案。有品位的PHP开发团队 PICcms开发团队是一代真正有品位、有主见、有个性、热爱生活的PHP开发团队。PICcms开发团队将彰显个性品味与超强性能的融合设计放在首位,旨在提供最专业的画面网站 图片类管理系统为广大网站站长服务。我们来自互联网,永远为互联网的发展进步而奋斗。我们不知道如何运营和盈利,但我们了解PHP技术(我们还是要学习),可以提供高标准的技术服务和安全高效的产品。希望我们的努力能为您提供高效、快速、强大的图片网站解决方案。最纯粹的PHP开发团队原Piccms图片管理系统是原Piccms开发团队于2012年开发的(MyPic开发团队时隔三年复工),可惜原Piccms @cmsV1.1 发布后开发团队就消失在这里了。就像当年的MYPIC,短暂的光辉留下了无限的期待、遗憾和悲伤。为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片<
新PICcms是一个完整的图片网站管理系统品牌,新PICcms开发团队也将专注于PICcms图片网站管理系统。仿网站业务、模板设计、程序定制、源码修改等全方位的网站开发服务。期待英雄归来,新PICcms开发团队是需要不断学习才能茁壮成长的幼稚宝宝。这个过程注定是非常漫长和痛苦的,所以我们真诚地期待着原PICcms(MYPIC)开发团队的回归或者给我们提供帮助,只有英雄的回归才能创造辉煌并继续闪耀,在最短的时间内实现我们的愿景。最后感谢PIC的众多关注者< @cms(如XD-Piccms、IMGcms)谁在原PICcms的基础上进行了二次开发或修改,是你的辛苦与奉献让PICcms得以延续,也正是你们的努力和付出,才让PICcms没有真正消亡。我代表原图cms,向您致以诚挚的问候。作为新的Piccms开发团队,我们也向各位前辈致敬。PIC cms图片网站管理系统运行环境www server Apache, Nginx, IIS等.php 5.0及以上(不支持5.0及以下MySQL 4. 0及以上PIC cms图片网站管理系统安装说明1. 将piccms目录下的所有文件上传到服务器2.
2.您可以在协议规定的约束和限制范围内修改图片cms源代码或界面样式以满足您的网站要求。3.您对使用本软件构建的网站中的所有资料拥有所有权,并独立承担与文章内容相关的法律义务。4. 禁止使用本程序发布非法内容,因违反国家和地方法律法规而引起的相应法律责任必须由个人承担。5.禁止在任何商业组织网站(包括任何公司网站和营利性组织)使用本产品。6.图片cms 开发团队保留源码所有权,禁止篡改代码出售或公开传播。7. 禁止使用本系统搭建任何法律不允许的内容网站。因网站内容引起的任何责任和后果与图片cms无关。PICcms图片网站管理系统1.2版本升级内容1、新增网盘下载连接和网盘提取码选项2、新增压缩包在线下载功能优化SEO系统,通过压缩包解压密码选项3、整合静态生成(html)功能。4、 修改部门详细信息,为WAP铺路。PIC cms图片网站管理系统首页 PICcms图片网站
现在下载 查看全部
php 抓取网页生成图片(基于更成熟的PHP应用框架和设计理念(组图))
图片cms图片网站管理系统v1.2.ZIP
PIC cms图片网站 管理系统程序介绍 基于更成熟的PHP应用框架和设计理念,全新的控制器、模型和核心类库;优化多级分类结构,增加全站生成静态页面,加载和SEO方面全面加强;内置采集接口(Beta),以后会增加对其他外部采集器的支持;前后端接口也进行了全面重构,更加简洁、标准、易用。开源所有源代码,保留所有注释,您可以在遵循开源协议的前提下方便地进行二次开发,甚至可以基于技术框架构建一个全新的系统。我们将在未来提供详细的 API 文档。自动生成导航和内容调用14. 模板分离设计,轻松模板设计 15 方便 自由模板方式,可以实现复杂多样的调用效果。1.1 版本升级到1.2 数据库升级请按照以下四部分进行(SQL runner直接运行下面4句SQL,分为四次,不能一下子做,去掉序列号1-4在前面):1:ALTER TABLE `pc_article` ADD `xiaazai` VARCHAR(800)
团队目前拥有美工3人、PHP开发工程师3人、网站运行测试人员2人、项目经理1人、行政秘书2人。PICcms开发团队旨在延续PICcms系统的精髓,在原有PICcms的基础上继续开发专业的图片管理系统,供粉丝和支持者使用提供最佳图片网站解决方案。有品位的PHP开发团队 PICcms开发团队是一代真正有品位、有主见、有个性、热爱生活的PHP开发团队。PICcms开发团队将彰显个性品味与超强性能的融合设计放在首位,旨在提供最专业的画面网站 图片类管理系统为广大网站站长服务。我们来自互联网,永远为互联网的发展进步而奋斗。我们不知道如何运营和盈利,但我们了解PHP技术(我们还是要学习),可以提供高标准的技术服务和安全高效的产品。希望我们的努力能为您提供高效、快速、强大的图片网站解决方案。最纯粹的PHP开发团队原Piccms图片管理系统是原Piccms开发团队于2012年开发的(MyPic开发团队时隔三年复工),可惜原Piccms @cmsV1.1 发布后开发团队就消失在这里了。就像当年的MYPIC,短暂的光辉留下了无限的期待、遗憾和悲伤。为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片<
新PICcms是一个完整的图片网站管理系统品牌,新PICcms开发团队也将专注于PICcms图片网站管理系统。仿网站业务、模板设计、程序定制、源码修改等全方位的网站开发服务。期待英雄归来,新PICcms开发团队是需要不断学习才能茁壮成长的幼稚宝宝。这个过程注定是非常漫长和痛苦的,所以我们真诚地期待着原PICcms(MYPIC)开发团队的回归或者给我们提供帮助,只有英雄的回归才能创造辉煌并继续闪耀,在最短的时间内实现我们的愿景。最后感谢PIC的众多关注者< @cms(如XD-Piccms、IMGcms)谁在原PICcms的基础上进行了二次开发或修改,是你的辛苦与奉献让PICcms得以延续,也正是你们的努力和付出,才让PICcms没有真正消亡。我代表原图cms,向您致以诚挚的问候。作为新的Piccms开发团队,我们也向各位前辈致敬。PIC cms图片网站管理系统运行环境www server Apache, Nginx, IIS等.php 5.0及以上(不支持5.0及以下MySQL 4. 0及以上PIC cms图片网站管理系统安装说明1. 将piccms目录下的所有文件上传到服务器2.
2.您可以在协议规定的约束和限制范围内修改图片cms源代码或界面样式以满足您的网站要求。3.您对使用本软件构建的网站中的所有资料拥有所有权,并独立承担与文章内容相关的法律义务。4. 禁止使用本程序发布非法内容,因违反国家和地方法律法规而引起的相应法律责任必须由个人承担。5.禁止在任何商业组织网站(包括任何公司网站和营利性组织)使用本产品。6.图片cms 开发团队保留源码所有权,禁止篡改代码出售或公开传播。7. 禁止使用本系统搭建任何法律不允许的内容网站。因网站内容引起的任何责任和后果与图片cms无关。PICcms图片网站管理系统1.2版本升级内容1、新增网盘下载连接和网盘提取码选项2、新增压缩包在线下载功能优化SEO系统,通过压缩包解压密码选项3、整合静态生成(html)功能。4、 修改部门详细信息,为WAP铺路。PIC cms图片网站管理系统首页 PICcms图片网站
现在下载
php 抓取网页生成图片(从网站建设到网站SEO的一系列的注意点分析点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-13 04:21
网站SEO优化教程很多想学SEO的童鞋,面对一个网站不知道从何下手或分析。所谓的SEOer,无非就是改了标题和描述。关键字,但这实际上与真正的 SEO 相去甚远。在这里,围围6359将从网站构建到网站SEO的一系列关注点和分析点进行介绍,以帮助SEOer学习者提供参考。面对一个新的网站,我们可以从以下几个方面来思考和分析,但并不代表接下来的教程中的所有注意点都离成功不远了。根据网站@网站根据自己的情况,酌情选择不同的SEO优化方式,否则离K站也不远了。工具/材料将有基本的网站架构,Hml代码,搜索引擎规则,SEO注重实践,执行力强。看别人的成功案例,多了解,总结,操作步骤/方法网站 优化: 1.遵守Web2.0标准,加强页面的交互性,使页面PV值上级,日志或新闻等经常更新的信息尽量生成RSS输出,用Tag标记日志或新闻等信息(用于搜索引擎搜索) 2.尽量符合html4.0 xhtml标准,使用div、ul、li等替换table 3.使用Div CSS进行页面布局。CSS 应该尽可能地写在一个单独的文件中。列表项和Tab使用div+ul+li+css来完成显示4。使用URL Rewriter地址重写可以去掉?pageNo=5等参数,进行泛分析输出。例如, /user.php?userid=test1 将被解析为所有 URL。必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>.
尽量在网页上所有能被搜索引擎抓取的文字中收录关键词。这些地方包括:域名、标题和元标签、正文、链接文本、文件名、alt、标题标签(即正文标题等),让你的关键词无处不在,但避免堆积太多同一个地方。2、域名策略 域名中最好收录你的关键词,并用连字符“-”分别突出关键词,方便搜索引擎识别。有专家认为,域名中的关键词对排名的影响较弱,但不可否认,它们确实有作用。所以,如果可以兼顾情况,尽量考虑使用关键字域名。3.虚拟主机策略检查共享IP地址网站:目前大多数中小型< @网站 共享一个具有相同 IP 地址的虚拟主机。如果与您共享IP的网站之一被搜索引擎惩罚,您将无法登录搜索引擎。另外,由于一个IP往往有数百个网站,会影响你的网页下载速度。特别是如果其中一些网站有很多流量。如果搜索引擎在爬行时半天无法下载页面,搜索机器人就会放弃它。所以,除了要知道有多少网站与你分享了IP,有没有被处罚,最好能知道他们的流量大致情况。如果情况不好,尽快更换主机。4.网页文件目录策略有序,文件目录结构安排合理,命名规范。一个简单的网站
重要的内容放在顶级目录中。目录文件夹名收录关键词,HTML网页文件名也收录关键词。图片文件还收录关键词。这里所指的关键词主要是针对具体页面的内容。如果文件名是短语,请使用破折号或下划线将其分隔。. externalfiles(外部文件存储)策略将 javascript 文件和 css 文件分别放在 js 和 css 外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体 (FONT) 和格式标签也应谨慎使用。6. 动态策略动态页面是由ASP、PHP、CGI等程序动态生成的页面,只有用户输入条件提交后才能生成。有两种方法可以让搜索引擎抓取它:在静态页面(如网站地图)上创建动态页面的链接,或者将该动态页面的URL修改为静态HTML文件,以便URL 不收录 ?、=、&、% 和 $ 等符号。7、框架策略:如果网站必须使用框架,则应正确使用noframe标签,并在区域中收录指向框架或带有关键词的描述文本,并在同时框外的文字关键词也出现在区域内。8、图片策略:在图片的代码中使用Alt属性标签进行说明,包括<
避免纯图片页面(Splash),比如一些企业的网站首页图片页面。Flash 应谨慎使用,搜索引擎对跟踪其嵌入的链接几乎没有兴趣。收录图像的页面的字节数不应超过 50K。9、网站 地图策略:基于文本的 网站 地图收录所有列和子列 网站 。网站 地图的三个主要元素:文本、链接和关键字,对于搜索引擎抓取主页内容非常有帮助。因此,动态生成的目录网站特别需要创建网站映射。网页栏目如有更新,需及时反映在地图网站上。10、标题和元标签策略:基本的搜索引擎优化:title 标题的内容会以链接标题的形式显示在搜索结果页面上。标题一般是对网站名称的简短描述,包括核心关键词。meta中的关键词(关键词)和描述(description):确定几个核心的关键词和组合。关键字应该是3-5个,最好不要超过15个,以免堆叠。不喜欢。描述是对网站的简要描述,包括如果每个主页的内容差异很大的信息,标题和元标签应该根据网页的内容进行更改。不要将主页的标题和标签用于所有网页。网页的文字内容必须出现在关键词页面上,关键词的密度在3%-7%之间。疑似堆积太多。搜索结果页面链接标题后显示的描述性文字,一般是本页面正文中搜索引擎首先抓取到的收录关键词的文字。
据说这个文字通常出现在网页的左上角最有利。11、链接策略:让其他与你话题相关的网站尽可能多的链接到你,这已经成为搜索引擎排名成功的关键因素。有了这些网站链接你,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你很好的排名。另一方面,如果网站提供话题相关导出链接,搜索引擎认为有丰富的话题相关内容,也有利于排名(这一点值得专家反思)。12、 避免惩罚:搜索引擎在识别欺骗手段方面变得越来越复杂。以下几种常见的作弊方式很容易受到处罚。拒绝收录:隐藏文字,或者无意中设置了文字文字的背景色;关键词堆叠;主动链接到link farm网站(由大量网站交叉链接组成的网络系统);防范措施得当,不要使用不正常的方法,否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程! 查看全部
php 抓取网页生成图片(从网站建设到网站SEO的一系列的注意点分析点)
网站SEO优化教程很多想学SEO的童鞋,面对一个网站不知道从何下手或分析。所谓的SEOer,无非就是改了标题和描述。关键字,但这实际上与真正的 SEO 相去甚远。在这里,围围6359将从网站构建到网站SEO的一系列关注点和分析点进行介绍,以帮助SEOer学习者提供参考。面对一个新的网站,我们可以从以下几个方面来思考和分析,但并不代表接下来的教程中的所有注意点都离成功不远了。根据网站@网站根据自己的情况,酌情选择不同的SEO优化方式,否则离K站也不远了。工具/材料将有基本的网站架构,Hml代码,搜索引擎规则,SEO注重实践,执行力强。看别人的成功案例,多了解,总结,操作步骤/方法网站 优化: 1.遵守Web2.0标准,加强页面的交互性,使页面PV值上级,日志或新闻等经常更新的信息尽量生成RSS输出,用Tag标记日志或新闻等信息(用于搜索引擎搜索) 2.尽量符合html4.0 xhtml标准,使用div、ul、li等替换table 3.使用Div CSS进行页面布局。CSS 应该尽可能地写在一个单独的文件中。列表项和Tab使用div+ul+li+css来完成显示4。使用URL Rewriter地址重写可以去掉?pageNo=5等参数,进行泛分析输出。例如, /user.php?userid=test1 将被解析为所有 URL。必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>.
尽量在网页上所有能被搜索引擎抓取的文字中收录关键词。这些地方包括:域名、标题和元标签、正文、链接文本、文件名、alt、标题标签(即正文标题等),让你的关键词无处不在,但避免堆积太多同一个地方。2、域名策略 域名中最好收录你的关键词,并用连字符“-”分别突出关键词,方便搜索引擎识别。有专家认为,域名中的关键词对排名的影响较弱,但不可否认,它们确实有作用。所以,如果可以兼顾情况,尽量考虑使用关键字域名。3.虚拟主机策略检查共享IP地址网站:目前大多数中小型< @网站 共享一个具有相同 IP 地址的虚拟主机。如果与您共享IP的网站之一被搜索引擎惩罚,您将无法登录搜索引擎。另外,由于一个IP往往有数百个网站,会影响你的网页下载速度。特别是如果其中一些网站有很多流量。如果搜索引擎在爬行时半天无法下载页面,搜索机器人就会放弃它。所以,除了要知道有多少网站与你分享了IP,有没有被处罚,最好能知道他们的流量大致情况。如果情况不好,尽快更换主机。4.网页文件目录策略有序,文件目录结构安排合理,命名规范。一个简单的网站
重要的内容放在顶级目录中。目录文件夹名收录关键词,HTML网页文件名也收录关键词。图片文件还收录关键词。这里所指的关键词主要是针对具体页面的内容。如果文件名是短语,请使用破折号或下划线将其分隔。. externalfiles(外部文件存储)策略将 javascript 文件和 css 文件分别放在 js 和 css 外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体 (FONT) 和格式标签也应谨慎使用。6. 动态策略动态页面是由ASP、PHP、CGI等程序动态生成的页面,只有用户输入条件提交后才能生成。有两种方法可以让搜索引擎抓取它:在静态页面(如网站地图)上创建动态页面的链接,或者将该动态页面的URL修改为静态HTML文件,以便URL 不收录 ?、=、&、% 和 $ 等符号。7、框架策略:如果网站必须使用框架,则应正确使用noframe标签,并在区域中收录指向框架或带有关键词的描述文本,并在同时框外的文字关键词也出现在区域内。8、图片策略:在图片的代码中使用Alt属性标签进行说明,包括<
避免纯图片页面(Splash),比如一些企业的网站首页图片页面。Flash 应谨慎使用,搜索引擎对跟踪其嵌入的链接几乎没有兴趣。收录图像的页面的字节数不应超过 50K。9、网站 地图策略:基于文本的 网站 地图收录所有列和子列 网站 。网站 地图的三个主要元素:文本、链接和关键字,对于搜索引擎抓取主页内容非常有帮助。因此,动态生成的目录网站特别需要创建网站映射。网页栏目如有更新,需及时反映在地图网站上。10、标题和元标签策略:基本的搜索引擎优化:title 标题的内容会以链接标题的形式显示在搜索结果页面上。标题一般是对网站名称的简短描述,包括核心关键词。meta中的关键词(关键词)和描述(description):确定几个核心的关键词和组合。关键字应该是3-5个,最好不要超过15个,以免堆叠。不喜欢。描述是对网站的简要描述,包括如果每个主页的内容差异很大的信息,标题和元标签应该根据网页的内容进行更改。不要将主页的标题和标签用于所有网页。网页的文字内容必须出现在关键词页面上,关键词的密度在3%-7%之间。疑似堆积太多。搜索结果页面链接标题后显示的描述性文字,一般是本页面正文中搜索引擎首先抓取到的收录关键词的文字。
据说这个文字通常出现在网页的左上角最有利。11、链接策略:让其他与你话题相关的网站尽可能多的链接到你,这已经成为搜索引擎排名成功的关键因素。有了这些网站链接你,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你很好的排名。另一方面,如果网站提供话题相关导出链接,搜索引擎认为有丰富的话题相关内容,也有利于排名(这一点值得专家反思)。12、 避免惩罚:搜索引擎在识别欺骗手段方面变得越来越复杂。以下几种常见的作弊方式很容易受到处罚。拒绝收录:隐藏文字,或者无意中设置了文字文字的背景色;关键词堆叠;主动链接到link farm网站(由大量网站交叉链接组成的网络系统);防范措施得当,不要使用不正常的方法,否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!
php 抓取网页生成图片(从网站建设到网站SEO的一系列的注意点分析点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-13 04:21
网站SEO优化教程很多想学SEO的童鞋,面对一个网站不知道从何下手或分析。所谓的SEOer,无非就是改了标题和描述。关键字,但这实际上与真正的 SEO 相去甚远。在这里,围围6359将从网站构建到网站SEO的一系列关注点和分析点进行介绍,以帮助SEOer学习者提供参考。面对一个新的网站,我们可以从以下几个方面来思考和分析,但并不代表接下来的教程中的所有注意点都离成功不远了。根据网站@网站根据自己的情况,酌情选择不同的SEO优化方式,否则离K站也不远了。【微店网百利】工具/素材将有基本的网站架构,Hml代码,搜索引擎规则,SEO注重实践,执行力强。看看别人的成功案例,多了解,总结,操作Steps/Methods上级,日志或新闻等经常更新的信息尽量生成RSS输出,用Tag标记日志或新闻等信息(用于搜索引擎搜索) 2.尽量符合html4.0或xhtml标准,用div、ul、li等代替table 3.使用Div CSS进行页面布局。CSS 应该尽可能地写在一个单独的文件中。列表项和Tab使用div+ul+li+css来完成显示4。使用URL Rewriter地址重写可以去掉?pageNo=5等参数,进行泛分析输出。例如, /user.php?userid=test1 将被解析为所有 URL。必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>.
尽量在网页上所有能被搜索引擎抓取的文字中收录关键词。这些地方包括:域名、标题和元标签、正文、链接文本、文件名、alt、标题标签(即正文标题等),让你的关键词无处不在,但避免堆积太多同一个地方。2、域名策略 域名中最好收录你的关键词,并用连字符“-”分别突出关键词,方便搜索引擎识别。有专家认为,域名中的关键词对排名的影响较弱,但不可否认,它们确实有作用。所以,如果可以兼顾情况,尽量考虑使用关键字域名。3.虚拟主机策略检查共享IP地址网站:目前大多数中小型< @网站 共享一个具有相同 IP 地址的虚拟主机。如果与您共享IP的网站之一被搜索引擎惩罚,您将无法登录搜索引擎。另外,由于一个IP往往有数百个网站,会影响你的网页下载速度。特别是如果其中一些网站有很多流量。如果搜索引擎在爬行时半天无法下载页面,搜索机器人就会放弃它。所以,除了要知道有多少网站与你分享了IP,有没有被处罚,最好能知道他们的流量大致情况。如果情况不好,尽快更换主机。4.网页文件目录策略有序,文件目录结构安排合理,命名规范。一个简单的网站
重要的内容放在顶级目录中。目录文件夹名收录关键词,HTML网页文件名也收录关键词。图片文件还收录关键词。这里所指的关键词主要是针对具体页面的内容。如果文件名是短语,请使用破折号或下划线将其分隔。. externalfiles(外部文件存储)策略将 javascript 文件和 css 文件分别放在 js 和 css 外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体 (FONT) 和格式标签也应谨慎使用。6. 动态策略动态页面是由ASP、PHP、CGI等程序动态生成的页面,只有用户输入条件提交后才能生成。有两种方法可以让搜索引擎抓取它:在静态页面(如网站地图)上创建动态页面的链接,或者将该动态页面的URL修改为静态HTML文件,以便URL 不收录 ?、=、&、% 和 $ 等符号。7、框架策略:如果网站必须使用框架,则应正确使用noframe标签,并在区域中收录指向框架或带有关键词的描述文本,并在同时框外的文字关键词也出现在区域内。8、图片策略:在图片的代码中使用Alt属性标签进行说明,包括<
避免纯图片页面(Splash),比如一些企业的网站首页图片页面。Flash 应谨慎使用,搜索引擎对跟踪其嵌入的链接几乎没有兴趣。收录图像的页面的字节数不应超过 50K。9、网站 地图策略:基于文本的 网站 地图收录所有列和子列 网站 。网站 地图的三个主要元素:文本、链接和关键字,对于搜索引擎抓取主页内容非常有帮助。因此,动态生成的目录网站特别需要创建网站映射。网页栏目如有更新,需及时反映在地图网站上。10、标题和元标签策略:基本的搜索引擎优化:title 标题的内容会以链接标题的形式显示在搜索结果页面上。标题一般是对网站名称的简短描述,包括核心关键词。meta中的关键词(关键词)和描述(description):确定几个核心的关键词和组合。关键字应该是3-5个,最好不要超过15个,以免堆叠。不喜欢。描述是对网站的简要描述,包括如果每个主页的内容差异很大的信息,标题和元标签应该根据网页的内容进行更改。不要将主页的标题和标签用于所有网页。网页的文字内容必须出现在关键词页面上,关键词的密度在3%-7%之间。疑似堆积太多。搜索结果页面链接标题后显示的描述性文字,一般是本页面正文中搜索引擎首先抓取到的收录关键词的文字。
据说这个文字通常出现在网页的左上角最有利。11、链接策略:让其他与你话题相关的网站尽可能多的链接到你,这已经成为搜索引擎排名成功的关键因素。有了这些网站链接你,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你很好的排名。另一方面,如果网站提供话题相关导出链接,搜索引擎认为有丰富的话题相关内容,也有利于排名(这一点值得专家反思)。12、 避免惩罚:搜索引擎在识别欺骗手段方面变得越来越复杂。以下方法常用于作弊,很容易受到惩罚。拒绝收录:隐藏文本,或无意中将文本设置为背景色;关键词堆叠;主动链接链接农场网站(由大量网站交叉链接组成的网络系统);防范措施得当,不要使用不正常的方法,否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程! 查看全部
php 抓取网页生成图片(从网站建设到网站SEO的一系列的注意点分析点)
网站SEO优化教程很多想学SEO的童鞋,面对一个网站不知道从何下手或分析。所谓的SEOer,无非就是改了标题和描述。关键字,但这实际上与真正的 SEO 相去甚远。在这里,围围6359将从网站构建到网站SEO的一系列关注点和分析点进行介绍,以帮助SEOer学习者提供参考。面对一个新的网站,我们可以从以下几个方面来思考和分析,但并不代表接下来的教程中的所有注意点都离成功不远了。根据网站@网站根据自己的情况,酌情选择不同的SEO优化方式,否则离K站也不远了。【微店网百利】工具/素材将有基本的网站架构,Hml代码,搜索引擎规则,SEO注重实践,执行力强。看看别人的成功案例,多了解,总结,操作Steps/Methods上级,日志或新闻等经常更新的信息尽量生成RSS输出,用Tag标记日志或新闻等信息(用于搜索引擎搜索) 2.尽量符合html4.0或xhtml标准,用div、ul、li等代替table 3.使用Div CSS进行页面布局。CSS 应该尽可能地写在一个单独的文件中。列表项和Tab使用div+ul+li+css来完成显示4。使用URL Rewriter地址重写可以去掉?pageNo=5等参数,进行泛分析输出。例如, /user.php?userid=test1 将被解析为所有 URL。必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>.
尽量在网页上所有能被搜索引擎抓取的文字中收录关键词。这些地方包括:域名、标题和元标签、正文、链接文本、文件名、alt、标题标签(即正文标题等),让你的关键词无处不在,但避免堆积太多同一个地方。2、域名策略 域名中最好收录你的关键词,并用连字符“-”分别突出关键词,方便搜索引擎识别。有专家认为,域名中的关键词对排名的影响较弱,但不可否认,它们确实有作用。所以,如果可以兼顾情况,尽量考虑使用关键字域名。3.虚拟主机策略检查共享IP地址网站:目前大多数中小型< @网站 共享一个具有相同 IP 地址的虚拟主机。如果与您共享IP的网站之一被搜索引擎惩罚,您将无法登录搜索引擎。另外,由于一个IP往往有数百个网站,会影响你的网页下载速度。特别是如果其中一些网站有很多流量。如果搜索引擎在爬行时半天无法下载页面,搜索机器人就会放弃它。所以,除了要知道有多少网站与你分享了IP,有没有被处罚,最好能知道他们的流量大致情况。如果情况不好,尽快更换主机。4.网页文件目录策略有序,文件目录结构安排合理,命名规范。一个简单的网站
重要的内容放在顶级目录中。目录文件夹名收录关键词,HTML网页文件名也收录关键词。图片文件还收录关键词。这里所指的关键词主要是针对具体页面的内容。如果文件名是短语,请使用破折号或下划线将其分隔。. externalfiles(外部文件存储)策略将 javascript 文件和 css 文件分别放在 js 和 css 外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体 (FONT) 和格式标签也应谨慎使用。6. 动态策略动态页面是由ASP、PHP、CGI等程序动态生成的页面,只有用户输入条件提交后才能生成。有两种方法可以让搜索引擎抓取它:在静态页面(如网站地图)上创建动态页面的链接,或者将该动态页面的URL修改为静态HTML文件,以便URL 不收录 ?、=、&、% 和 $ 等符号。7、框架策略:如果网站必须使用框架,则应正确使用noframe标签,并在区域中收录指向框架或带有关键词的描述文本,并在同时框外的文字关键词也出现在区域内。8、图片策略:在图片的代码中使用Alt属性标签进行说明,包括<
避免纯图片页面(Splash),比如一些企业的网站首页图片页面。Flash 应谨慎使用,搜索引擎对跟踪其嵌入的链接几乎没有兴趣。收录图像的页面的字节数不应超过 50K。9、网站 地图策略:基于文本的 网站 地图收录所有列和子列 网站 。网站 地图的三个主要元素:文本、链接和关键字,对于搜索引擎抓取主页内容非常有帮助。因此,动态生成的目录网站特别需要创建网站映射。网页栏目如有更新,需及时反映在地图网站上。10、标题和元标签策略:基本的搜索引擎优化:title 标题的内容会以链接标题的形式显示在搜索结果页面上。标题一般是对网站名称的简短描述,包括核心关键词。meta中的关键词(关键词)和描述(description):确定几个核心的关键词和组合。关键字应该是3-5个,最好不要超过15个,以免堆叠。不喜欢。描述是对网站的简要描述,包括如果每个主页的内容差异很大的信息,标题和元标签应该根据网页的内容进行更改。不要将主页的标题和标签用于所有网页。网页的文字内容必须出现在关键词页面上,关键词的密度在3%-7%之间。疑似堆积太多。搜索结果页面链接标题后显示的描述性文字,一般是本页面正文中搜索引擎首先抓取到的收录关键词的文字。
据说这个文字通常出现在网页的左上角最有利。11、链接策略:让其他与你话题相关的网站尽可能多的链接到你,这已经成为搜索引擎排名成功的关键因素。有了这些网站链接你,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你很好的排名。另一方面,如果网站提供话题相关导出链接,搜索引擎认为有丰富的话题相关内容,也有利于排名(这一点值得专家反思)。12、 避免惩罚:搜索引擎在识别欺骗手段方面变得越来越复杂。以下方法常用于作弊,很容易受到惩罚。拒绝收录:隐藏文本,或无意中将文本设置为背景色;关键词堆叠;主动链接链接农场网站(由大量网站交叉链接组成的网络系统);防范措施得当,不要使用不正常的方法,否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!
php 抓取网页生成图片(php的文字转图片转化为图片就会安全吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-12 22:08
)
在网站的日常建设中,会在网站发布电话、邮箱等信息。如果直接是文本内容,很容易被网络爬虫抓取,会带来一定的安全隐患。如果将文本转换为图像会更安全。这与网站中登录验证码的基本生成原理类似,只是将文字转化为图片的生成过程比较复杂,扫描机无法识别。
将php文本转换为图片很容易。首先打开php安装目录下的php.ini,找到extension=php_gd2.dll,去掉前面的引号,打开php的gd2扩展库,可以直接使用php关键字,转换文本印象。
目录结构如下,img_generator.php是文本转图片的php,index.html是呈现给用户的页面。
index.html 的代码非常非常简单。制作一个img标签,在src里面写img_generator.php,然后向img_generator.php发送一个带text参数的Get请求。img_generator.php 页面本质上是基于参数的。制作的一张图片。
图片测试
img_generator.php 的代码如下,通过 $_REQUEST["text"]; 获取index.html中img标签传递过来的文字描述,然后使用一系列php关键字,就是固有方法生成的图片。. 查看全部
php 抓取网页生成图片(php的文字转图片转化为图片就会安全吗?
)
在网站的日常建设中,会在网站发布电话、邮箱等信息。如果直接是文本内容,很容易被网络爬虫抓取,会带来一定的安全隐患。如果将文本转换为图像会更安全。这与网站中登录验证码的基本生成原理类似,只是将文字转化为图片的生成过程比较复杂,扫描机无法识别。
将php文本转换为图片很容易。首先打开php安装目录下的php.ini,找到extension=php_gd2.dll,去掉前面的引号,打开php的gd2扩展库,可以直接使用php关键字,转换文本印象。

目录结构如下,img_generator.php是文本转图片的php,index.html是呈现给用户的页面。

index.html 的代码非常非常简单。制作一个img标签,在src里面写img_generator.php,然后向img_generator.php发送一个带text参数的Get请求。img_generator.php 页面本质上是基于参数的。制作的一张图片。
图片测试
img_generator.php 的代码如下,通过 $_REQUEST["text"]; 获取index.html中img标签传递过来的文字描述,然后使用一系列php关键字,就是固有方法生成的图片。.
php 抓取网页生成图片(Python批量抓取图片图片(1)--写在前面的话)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-06 20:23
——写在前面的话
相信你一定看过一篇文章的文章,题目是《只因为我写了一个爬虫,公司200多人被抓了!》《公众号文章(文章的描述已经很明显了,大家很清楚)
可以说,因为这次事件的恐慌和哗然,一些三线和二线个体爬虫工程师急于转行。其次,有的朋友对自己学到的爬虫技术感到担忧和恐慌。
其实每个人都会有这种警惕。不过,也没有必要像换个职业那样打一场大仗。我们还是要从业务本身做起,不仅要提升我们的业务能力,还要熟悉互联网的法律法规。虽然我个人没有学过爬虫的技术,但平时喜欢学习爬虫的一些小项目和小工具。虽然我花在学习算法上的时间比例少了很多,但我个人还是喜欢尝试一些新鲜的。技术可以丰富自己的业务水平。从这个角度来说,大多数工程师都会有这种业务倾向。当然,对于那些走在互联网第一线的爬虫工程师和大佬来说,我只是沧海一粟,水滴的数量是不够的。
说到上述事情,归根结底是一些公司和公司员工缺乏足够的法律知识。公司对员工的法制宣传和商业道德未能取得潜移默化的效果,尤其是互联网法律法规相关规定的传达。思想工作也没有及时到位。当然,这些不能总是依赖于公司。主要原因是个人的悟性。既然你已经这样做了,那么你应该对这个行业的法律知识有很好的了解和学习。为此,作为这个时代技术创新和技术研发的一员,我们必须始终遵守互联网法律法规,做好自己的本职工作,为社会做出更多的贡献。
文章内容:
——写在前面的话
1-捕获工件
2-使用Python批量抓取图片
(1) 抓取对象:搜狗画廊
(2) 抢类别:进入搜狗壁纸
(3)使用请求提取图像组件
(4)找到图片的真实url
(5)批量抓取图片成功
开始学习今天的内容吧~~
1-捕获工件
一个我一直很喜欢的谷歌图片捕捉插件叫做ImageAssistant
目前用户数为114,567,可以说是很不错了
和 Python 批量抓图效果完全一样
我不是为谷歌打广告,我只是觉得有用,分享给大家,提高办公效率。当然,本节最重要的是学习Python中批量抓取图片的原理和方法。
下面简单介绍一下插件的使用。安装插件后记得选择存放文件的地方,关闭谷歌设置下的下载查询访问
(不然每次都要按保存,很麻烦。如果有100张图片,肯定要按100次)
安装好插件后,下面通过视频简单演示一下爬取的过程。
例如:去微博拍一下鞠婧祎小姐的照片,
进入后可以右键IA工具
2-使用Python批量抓取图片
注:文中抓字意为“攀登”
(1) 抓取对象:搜狗画廊
(2)抓取类别:进入搜狗壁纸,打开网页源码(快捷键是F12)
由于我使用的是 Google chrome 浏览器,所以我需要找到 img 标签
(3)使用请求提取图像组件
抓取思路和使用库文件请求
可以发现img标签下有图片src,所以使用Python requests提取组件获取img src,然后使用库urllib.request.urlretrieve将图片一一下载,达到目的批量获取数据。
开始爬行的第一步:
(注意:Network-->headers,然后用鼠标点击左侧菜单栏(地址栏)中的图片链接,然后在headers中找到图片url)
我们按照上面的思路爬取我们想要的结果:搜索网页代码后,搜狗图片的网址为
%B1%DA%D6%BD
这里的URL来自进入分类后的地址栏(如上图)。
分析源码分析上述URL所指向的网页
import requests #导入库requests
import urllib #导入库requests下面的urllib
from bs4 import BeautifulSoup
#使用BeautifulSoup,关于这个的用法请查看本公众号往期文章
#下面填入url
res = requests.get('http://pic.sogou.com/pics/reco ... 23x27;)
soup = BeautifulSoup(res.text,'html.parser')
print(soup.select('img')) #图片打印格式
结果
从上面的执行结果来看,打印出来的输出内容并没有我们想要的图片元素,只是分析了tupian130x34_@1x的img(或者网页中的logo),这显然不是我们想要的。也就是说,需要的图片数据不在url下,也就是不在下面的url中
%B1%DA%D6%BD。
因此,我们需要找到图片不在URL中的原因,并在下面进行改进。
开始爬取第二步:
考虑到图片元素可能是动态的,细心的人可能会发现,在网页中向下滑动鼠标滚轮时,图片是动态刷新的。也就是说,网页并不是一次性加载所有资源,而是动态加载资源。这也避免了因为网页过于臃肿而影响加载速度。
(4)找到图片的真实url
要找到所有图片的真实URL,这看起来有点困难,但在本项目中尝试一下也不是不可能。在接下来的学习中,经过不断的研究,我想我会逐渐提高这种业务的能力。
类似于第一步中的“注释”,我们找到位置:
F12——>>网络——>>XHR——>>(点击XHR下的文件)——>>预览
(注:如果在预览中没有找到内容,可以滚动左侧地址栏或点击图片链接)
从上图来看,图中的信息似乎就是我们需要的元素。点击all_items,发现下面是0 1 2 3... 一一看起来像图片元素的数据。
尝试打开一个网址。发现真的是图片地址
我们可以在其中任意选择一张图片的地址来验证是否是图片所在的位置:
把地址粘贴到浏览器中搜索,得到如下结果,说明这个地址的url就是我们要找的
找到上图的目标后,我们点击XHR下的Headers,也就是第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
尝试删除一些不需要的部分。去掉以上部分后,访问不会受到影响。
(删除的位置类似同一个地方,切记不要删除后面的长宽高)
例如:删除“=%E5%A3%81%E7%BA%B8&tag”得到
%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
将网站复制到查看器,得到如下结果:
url中的category为类别,start为起始索引,len为长度,即图片数量。
另外注意imgs下的url内容(不要直接复制url)
替换为“+”
(5)批量抓取图片成功
如果你的电脑没有库文件请求,记得安装cmd命令:
pip 安装请求
最后,不断排序后的源码如下:
import requests
import json #使用json码
import urllib
def getSogouImag(category,length,path):
n = length
cate = category #分类
imgs = requests.get('http://pic.sogou.com/pics/chan ... 2Bstr(n))
jd = json.loads(imgs.text)
jd = jd['all_items']
imgs_url = [] #在url获取图片imgs
for j in jd:
imgs_url.append(j['bthumbUrl'])
m = 0
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg')
m = m + 1
print('Download complete!')
getSogouImag('壁纸',2000,'F:/Py666/抓图/') #抓取后图片存取的本地位置
执行程序:到指定位置找到图片所在的位置,就大功告成了。 查看全部
php 抓取网页生成图片(Python批量抓取图片图片(1)--写在前面的话)
——写在前面的话
相信你一定看过一篇文章的文章,题目是《只因为我写了一个爬虫,公司200多人被抓了!》《公众号文章(文章的描述已经很明显了,大家很清楚)
可以说,因为这次事件的恐慌和哗然,一些三线和二线个体爬虫工程师急于转行。其次,有的朋友对自己学到的爬虫技术感到担忧和恐慌。
其实每个人都会有这种警惕。不过,也没有必要像换个职业那样打一场大仗。我们还是要从业务本身做起,不仅要提升我们的业务能力,还要熟悉互联网的法律法规。虽然我个人没有学过爬虫的技术,但平时喜欢学习爬虫的一些小项目和小工具。虽然我花在学习算法上的时间比例少了很多,但我个人还是喜欢尝试一些新鲜的。技术可以丰富自己的业务水平。从这个角度来说,大多数工程师都会有这种业务倾向。当然,对于那些走在互联网第一线的爬虫工程师和大佬来说,我只是沧海一粟,水滴的数量是不够的。
说到上述事情,归根结底是一些公司和公司员工缺乏足够的法律知识。公司对员工的法制宣传和商业道德未能取得潜移默化的效果,尤其是互联网法律法规相关规定的传达。思想工作也没有及时到位。当然,这些不能总是依赖于公司。主要原因是个人的悟性。既然你已经这样做了,那么你应该对这个行业的法律知识有很好的了解和学习。为此,作为这个时代技术创新和技术研发的一员,我们必须始终遵守互联网法律法规,做好自己的本职工作,为社会做出更多的贡献。
文章内容:
——写在前面的话
1-捕获工件
2-使用Python批量抓取图片
(1) 抓取对象:搜狗画廊
(2) 抢类别:进入搜狗壁纸
(3)使用请求提取图像组件
(4)找到图片的真实url
(5)批量抓取图片成功
开始学习今天的内容吧~~
1-捕获工件
一个我一直很喜欢的谷歌图片捕捉插件叫做ImageAssistant
目前用户数为114,567,可以说是很不错了
和 Python 批量抓图效果完全一样
我不是为谷歌打广告,我只是觉得有用,分享给大家,提高办公效率。当然,本节最重要的是学习Python中批量抓取图片的原理和方法。
下面简单介绍一下插件的使用。安装插件后记得选择存放文件的地方,关闭谷歌设置下的下载查询访问
(不然每次都要按保存,很麻烦。如果有100张图片,肯定要按100次)
安装好插件后,下面通过视频简单演示一下爬取的过程。
例如:去微博拍一下鞠婧祎小姐的照片,
进入后可以右键IA工具
2-使用Python批量抓取图片
注:文中抓字意为“攀登”
(1) 抓取对象:搜狗画廊
(2)抓取类别:进入搜狗壁纸,打开网页源码(快捷键是F12)
由于我使用的是 Google chrome 浏览器,所以我需要找到 img 标签
(3)使用请求提取图像组件
抓取思路和使用库文件请求
可以发现img标签下有图片src,所以使用Python requests提取组件获取img src,然后使用库urllib.request.urlretrieve将图片一一下载,达到目的批量获取数据。
开始爬行的第一步:
(注意:Network-->headers,然后用鼠标点击左侧菜单栏(地址栏)中的图片链接,然后在headers中找到图片url)
我们按照上面的思路爬取我们想要的结果:搜索网页代码后,搜狗图片的网址为
%B1%DA%D6%BD
这里的URL来自进入分类后的地址栏(如上图)。
分析源码分析上述URL所指向的网页
import requests #导入库requests
import urllib #导入库requests下面的urllib
from bs4 import BeautifulSoup
#使用BeautifulSoup,关于这个的用法请查看本公众号往期文章
#下面填入url
res = requests.get('http://pic.sogou.com/pics/reco ... 23x27;)
soup = BeautifulSoup(res.text,'html.parser')
print(soup.select('img')) #图片打印格式
结果
从上面的执行结果来看,打印出来的输出内容并没有我们想要的图片元素,只是分析了tupian130x34_@1x的img(或者网页中的logo),这显然不是我们想要的。也就是说,需要的图片数据不在url下,也就是不在下面的url中
%B1%DA%D6%BD。
因此,我们需要找到图片不在URL中的原因,并在下面进行改进。
开始爬取第二步:
考虑到图片元素可能是动态的,细心的人可能会发现,在网页中向下滑动鼠标滚轮时,图片是动态刷新的。也就是说,网页并不是一次性加载所有资源,而是动态加载资源。这也避免了因为网页过于臃肿而影响加载速度。
(4)找到图片的真实url
要找到所有图片的真实URL,这看起来有点困难,但在本项目中尝试一下也不是不可能。在接下来的学习中,经过不断的研究,我想我会逐渐提高这种业务的能力。
类似于第一步中的“注释”,我们找到位置:
F12——>>网络——>>XHR——>>(点击XHR下的文件)——>>预览
(注:如果在预览中没有找到内容,可以滚动左侧地址栏或点击图片链接)
从上图来看,图中的信息似乎就是我们需要的元素。点击all_items,发现下面是0 1 2 3... 一一看起来像图片元素的数据。
尝试打开一个网址。发现真的是图片地址
我们可以在其中任意选择一张图片的地址来验证是否是图片所在的位置:
把地址粘贴到浏览器中搜索,得到如下结果,说明这个地址的url就是我们要找的
找到上图的目标后,我们点击XHR下的Headers,也就是第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
尝试删除一些不需要的部分。去掉以上部分后,访问不会受到影响。
(删除的位置类似同一个地方,切记不要删除后面的长宽高)
例如:删除“=%E5%A3%81%E7%BA%B8&tag”得到
%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
将网站复制到查看器,得到如下结果:
url中的category为类别,start为起始索引,len为长度,即图片数量。
另外注意imgs下的url内容(不要直接复制url)
替换为“+”
(5)批量抓取图片成功
如果你的电脑没有库文件请求,记得安装cmd命令:
pip 安装请求
最后,不断排序后的源码如下:
import requests
import json #使用json码
import urllib
def getSogouImag(category,length,path):
n = length
cate = category #分类
imgs = requests.get('http://pic.sogou.com/pics/chan ... 2Bstr(n))
jd = json.loads(imgs.text)
jd = jd['all_items']
imgs_url = [] #在url获取图片imgs
for j in jd:
imgs_url.append(j['bthumbUrl'])
m = 0
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg')
m = m + 1
print('Download complete!')
getSogouImag('壁纸',2000,'F:/Py666/抓图/') #抓取后图片存取的本地位置
执行程序:到指定位置找到图片所在的位置,就大功告成了。
php 抓取网页生成图片(图片转base643 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-12-06 13:13
)
介绍本文文章主要介绍PHP远程下载图片,微信头像保存在本地,本地图片转base64(示例代码)及相关经验技巧,文章约7412字,页面浏览量191,3个赞,值得参考!
方法一(推荐):
function download_remote_pic($url){
$header = [
‘User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:45.0) Gecko/20100101 Firefox/45.0‘,
‘Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3‘,
‘Accept-Encoding: gzip, deflate‘,
];
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($curl, CURLOPT_ENCODING, ‘gzip‘);
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
$data = curl_exec($curl);
$code = curl_getinfo($curl, CURLINFO_HTTP_CODE);
curl_close($curl);
if ($code == 200) {//把URL格式的图片转成base64_encode格式的!
$imgBase64Code = "data:image/jpeg;base64," . base64_encode($data);
}
$img_content=$imgBase64Code;//图片内容
//echo $img_content;exit;
if (preg_match(‘/^(data:s*image/(w+);base64,)/‘, $img_content, $result)) {
$type = $result[2];//得到图片类型png?jpg?gif?
$new_file = "./".time().rand(1,10000).".{$type}";
if (file_put_contents($new_file, base64_decode(str_replace($result[1], ‘‘, $img_content)))) {
return $new_file;
}
}
}
$new_file = download_remote_pic(‘http://thirdwx.qlogo.cn/mmopen ... Q/132‘);
echo $new_file;
方法二(慢,消耗服务器)
$url=‘http://thirdwx.qlogo.cn/mmopen ... Q/132‘;
$new_file = "./".time().rand(1,10000).".png"; //图片类型getimagesize($url)可以但是因为是远程图片太慢了
file_put_contents($new_file, file_get_contents($url));
echo ($new_file);
图片转base64
function base64_encode_image($file){
$type=getimagesize($file);//取得图片的大小,类型等
$fp=fopen($file,"r")or die("Can‘t open file");
$file_content=chunk_split(base64_encode(fread($fp,filesize($file))));//base64编码
switch($type[2]){//判读图片类型
case 1:$img_type="gif";break;
case 2:$img_type="jpg";break;
case 3:$img_type="png";break;
}
$img=‘data:image/‘.$img_type.‘;base64,‘.$file_content;//合成图片的base64编码
fclose($fp);
return $img;
} 查看全部
php 抓取网页生成图片(图片转base643
)
介绍本文文章主要介绍PHP远程下载图片,微信头像保存在本地,本地图片转base64(示例代码)及相关经验技巧,文章约7412字,页面浏览量191,3个赞,值得参考!
方法一(推荐):
function download_remote_pic($url){
$header = [
‘User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:45.0) Gecko/20100101 Firefox/45.0‘,
‘Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3‘,
‘Accept-Encoding: gzip, deflate‘,
];
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($curl, CURLOPT_ENCODING, ‘gzip‘);
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
$data = curl_exec($curl);
$code = curl_getinfo($curl, CURLINFO_HTTP_CODE);
curl_close($curl);
if ($code == 200) {//把URL格式的图片转成base64_encode格式的!
$imgBase64Code = "data:image/jpeg;base64," . base64_encode($data);
}
$img_content=$imgBase64Code;//图片内容
//echo $img_content;exit;
if (preg_match(‘/^(data:s*image/(w+);base64,)/‘, $img_content, $result)) {
$type = $result[2];//得到图片类型png?jpg?gif?
$new_file = "./".time().rand(1,10000).".{$type}";
if (file_put_contents($new_file, base64_decode(str_replace($result[1], ‘‘, $img_content)))) {
return $new_file;
}
}
}
$new_file = download_remote_pic(‘http://thirdwx.qlogo.cn/mmopen ... Q/132‘);
echo $new_file;
方法二(慢,消耗服务器)
$url=‘http://thirdwx.qlogo.cn/mmopen ... Q/132‘;
$new_file = "./".time().rand(1,10000).".png"; //图片类型getimagesize($url)可以但是因为是远程图片太慢了
file_put_contents($new_file, file_get_contents($url));
echo ($new_file);
图片转base64
function base64_encode_image($file){
$type=getimagesize($file);//取得图片的大小,类型等
$fp=fopen($file,"r")or die("Can‘t open file");
$file_content=chunk_split(base64_encode(fread($fp,filesize($file))));//base64编码
switch($type[2]){//判读图片类型
case 1:$img_type="gif";break;
case 2:$img_type="jpg";break;
case 3:$img_type="png";break;
}
$img=‘data:image/‘.$img_type.‘;base64,‘.$file_content;//合成图片的base64编码
fclose($fp);
return $img;
}
php 抓取网页生成图片(下载安装wkhtmltox系统环境git根据系统类型选择下载(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-01-05 20:06
要求:将网页转成pdf或图片,并提供下载。 php
wkhtmltox 项目主页:支持html转pdf、imagehtml
php扩展php-wkhtmltox项目主页:linux
一、下载安装wkhtmltox系统环境git
根据系统类型选择下载wkhtmltox:github
这里的个人系统环境是CentOS 6-64bit,所以选择:Linux CentOS 6-64bitcentos
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。 php-fpm
安装 wkhtmltox:fonts
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpmspa
错误:依赖项失败:.net
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示需要安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 附加:
* 更新:
================================================ ============ N/S 匹配:75dpi ================================ ============================
xorg-x11-fonts-75dpi.noarch:一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch:一组 75dpi ISO-8859-1 X 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch: ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch: ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch:一组 75dpi 的 X 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch: ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“全部搜索”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
直接用下面的方法解压rpm包中编译好的包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面有四个文件夹:local/bin、local/include、local/share、local/lib
只需将对应文件夹的内容复制到/usr/local即可!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
二、安装php-wkhtmltox扩展
在github上下载源码包[php-wkhtmltox_master.zip]
> unzipphp-wkhtmltox_master.zip
> cd phpwkhtmltox
>phpize
> ./configure--with-php-config=/usr/local/php/bin/php-config #这里取决于各自系统的PHP安装路径。
> make && make install
> ldconfig #从新加载系统动态链接库
> php -m
#检查扩展是否成功。如果能看到phpwkhtmltox,说明扩展成功。
php-wkhtmltox 扩展安装完成。
三、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm restart
安装完成!
参考这篇文章:
安装部分可以使用本文介绍的安装部分,有的可能需要中文字体支持。可以参考上面的中文字体库安装部分进行扩展。 查看全部
php 抓取网页生成图片(下载安装wkhtmltox系统环境git根据系统类型选择下载(图))
要求:将网页转成pdf或图片,并提供下载。 php
wkhtmltox 项目主页:支持html转pdf、imagehtml
php扩展php-wkhtmltox项目主页:linux
一、下载安装wkhtmltox系统环境git
根据系统类型选择下载wkhtmltox:github
这里的个人系统环境是CentOS 6-64bit,所以选择:Linux CentOS 6-64bitcentos
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。 php-fpm
安装 wkhtmltox:fonts
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpmspa
错误:依赖项失败:.net
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示需要安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 附加:
* 更新:
================================================ ============ N/S 匹配:75dpi ================================ ============================
xorg-x11-fonts-75dpi.noarch:一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch:一组 75dpi ISO-8859-1 X 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch: ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch: ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch:一组 75dpi 的 X 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch: ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“全部搜索”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
直接用下面的方法解压rpm包中编译好的包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面有四个文件夹:local/bin、local/include、local/share、local/lib
只需将对应文件夹的内容复制到/usr/local即可!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
二、安装php-wkhtmltox扩展
在github上下载源码包[php-wkhtmltox_master.zip]
> unzipphp-wkhtmltox_master.zip
> cd phpwkhtmltox
>phpize
> ./configure--with-php-config=/usr/local/php/bin/php-config #这里取决于各自系统的PHP安装路径。
> make && make install
> ldconfig #从新加载系统动态链接库
> php -m
#检查扩展是否成功。如果能看到phpwkhtmltox,说明扩展成功。
php-wkhtmltox 扩展安装完成。
三、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm restart
安装完成!
参考这篇文章:
安装部分可以使用本文介绍的安装部分,有的可能需要中文字体支持。可以参考上面的中文字体库安装部分进行扩展。
php 抓取网页生成图片(抓取今日头条街拍图片数据1.抓取(1)_num从1开始累加)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-05 15:13
抓取今日头条街图数据1. 抓取今日头条街图数据
2.今日解析今日头条街图片的结构
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规则,page_num从1开始累加,其他参数不变
3.根据不同的功能编写不同的方法组织代码3.1 获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
3.2 从json格式数据中提取街景照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
3.3 用md5代码命名街道照片并保存照片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
3.4 main() 调用其他函数
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
4 截取20页今日头条街道图片数据
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
参考链接 查看全部
php 抓取网页生成图片(抓取今日头条街拍图片数据1.抓取(1)_num从1开始累加)
抓取今日头条街图数据1. 抓取今日头条街图数据
2.今日解析今日头条街图片的结构
keyword: 街拍
pd: atlas
dvpf: pc
aid: 4916
page_num: 1
search_json: {"from_search_id":"20220104115420010212192151532E8188","origin_keyword":"街拍","image_keyword":"街拍"}
rawJSON: 1
search_id: 202201041159040101501341671A4749C4
可以找到规则,page_num从1开始累加,其他参数不变
3.根据不同的功能编写不同的方法组织代码3.1 获取网页json格式数据
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
3.2 从json格式数据中提取街景照片
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
3.3 用md5代码命名街道照片并保存照片
实现一个 save_image() 方法来保存图像,其中 item 是前面的 get_images() 方法返回的字典。该方法中,首先根据item的标题创建一个文件夹,然后请求图片的链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以消除重复。相关代码如下:
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
3.4 main() 调用其他函数
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
4 截取20页今日头条街道图片数据
这里定义了分页的起始页和结束页号,分别是GROUP_START和GROUP_END,同样使用了多线程线程池,调用其map()方法实现多线程下载。
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
import requests
from urllib.parse import urlencode
from hashlib import md5
from multiprocessing.pool import Pool
def get_page(page_num):
global headers
headers = {
'Host': 'so.toutiao.com',
#'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%22202112272022060101510440283EE83D67%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'msToken=S0DFBkZ9hmyLOGYd3_QjhhXgrm38qTyOITnkNb0t_oavfbVxuYV1JZ0tT5hLgswSfmZLFD6c2lONm_5TomUQXVXjen7CIxM2AGwbhHRYKjhg; _S_DPR=1.5; _S_IPAD=0; MONITOR_WEB_ID=7046351002275317255; ttwid=1%7C0YdWalNdIiSpIk3CvvHwV25U8drq3QAj08E8QOApXhs%7C1640607595%7C720e971d353416921df127996ed708931b4ae28a0a8691a5466347697e581ce8; _S_WIN_WH=262_623'
}
params = {
'keyword': '街拍',
'pd': 'atlas',
'dvpf': 'pc',
'aid': '4916',
'page_num': page_num,
'search_json': '%7B%22from_search_id%22%3A%22202112272022060101510440283EE83D67%22%2C%22origin_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%2C%22image_keyword%22%3A%22%E8%A1%97%E6%8B%8D%22%7D',
'rawJSON': 1,
'search_id': '2021122721183101015104402851E3883D'
}
url = 'https://so.toutiao.com/search?' + urlencode(params)
print(url)
try:
response=requests.get(url,headers=headers,params=params)
if response.status_code == 200:
#if response.content:
#print(response.json())
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield link
def save_image(link):
data = requests.get(link).content
with open(f'./image/{md5(data).hexdigest()}.jpg', 'wb')as f:#使用data的md5码作为图片名
f.write(data)
def main(page_num):
json = get_page(page_num)
for link in get_images(json):
#print(link)
save_image(link)
if __name__ == '__main__':
GROUP_START = 1
GROUP_END = 20
pool = Pool()
groups = ([x for x in range(GROUP_START, GROUP_END + 1)])
#print(groups)
pool.map(main, groups)
pool.close()
pool.join()
参考链接
php 抓取网页生成图片(试试360浏览器插件php抓取网页生成图片的ttp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-01 13:12
php抓取网页生成图片的工具。网上很多下载(可能要用到代理设置),用phpsql读取网页生成图片。亲测可用,
可以看看sphinx的免费版,
这种都是伪代码很简单的,可以试试我写的http打包工具,包括正则匹配,
可以试试shenmegui
很多可以处理swf的,
web接口是soanywhere
shiny
用go语言写了一个这样的接口,
去参考这个!
试试360浏览器插件,我做了一个还不错。然后这里有安装包ifconfig/address·github然后给大家分享一下,我做的第一个项目的项目结构(不包括http方法等)include/modules/http/tools/master/build/http/tools.gohttp服务端java.lang.stringpostmessage\post\response\restful\serialization\restful\event\eventlistener\events\eventresponse\eventgroup.gohttp客户端.gohttp服务端.gohttp客户端.gomodules/build/path/to/js/dx/js/development/js/development/js.gohttp服务端.gohttp客户端.go你也可以先看看我的github:linecomlub。 查看全部
php 抓取网页生成图片(试试360浏览器插件php抓取网页生成图片的ttp)
php抓取网页生成图片的工具。网上很多下载(可能要用到代理设置),用phpsql读取网页生成图片。亲测可用,
可以看看sphinx的免费版,
这种都是伪代码很简单的,可以试试我写的http打包工具,包括正则匹配,
可以试试shenmegui
很多可以处理swf的,
web接口是soanywhere
shiny
用go语言写了一个这样的接口,
去参考这个!
试试360浏览器插件,我做了一个还不错。然后这里有安装包ifconfig/address·github然后给大家分享一下,我做的第一个项目的项目结构(不包括http方法等)include/modules/http/tools/master/build/http/tools.gohttp服务端java.lang.stringpostmessage\post\response\restful\serialization\restful\event\eventlistener\events\eventresponse\eventgroup.gohttp客户端.gohttp服务端.gohttp客户端.gomodules/build/path/to/js/dx/js/development/js/development/js.gohttp服务端.gohttp客户端.go你也可以先看看我的github:linecomlub。
php 抓取网页生成图片(php抓取网页生成图片是http返回到客户端才可以看到)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-31 17:05
php抓取网页生成图片是http返回到客户端才可以看到。速度很慢,有延迟,目前nginx+mysql比较多。webpack+gulp+webpack-dev-server做页面前端的boilerplate+模块化。
这些都是flash里的流,reactor干的活,已经被淘汰了,网站前端,boilerplate就是flash里的流,写代码的效率降低,而且可读性极差,封装一下,做成单页面应用,最简单的可以做成webpack前端打包工具,如果考虑其他页面打包,那就自己写hrefjs、mvvm这些模块,这里面有无数坑,mvvm对性能有限制,html、css、js分离得更好。
如果是image-rawwidget之类的,可以用http服务端来写,效率比较高。
使用flash里面的流,不需要第三方的treecompressor,php的splinter也是不错的,还有不需要第三方的treecompressor是去除了缓存的。php+flash比较适合长的json的数据。
使用flash的流。
php+svg这个推荐。
使用nodejs的svgtree。不需要第三方的treecompressor。
flash的流模块,unittest有在测试。我想接着知乎上再补充一下实际项目实现的问题,这几年unity3d,cocos2d-x,hybrid的一些公司都推出了svgflashcompressor或者svgcompressorslide等类似的东西,官方文档和很多实例都有的。官方svgflashcompressor标准文档介绍applicationunittests。 查看全部
php 抓取网页生成图片(php抓取网页生成图片是http返回到客户端才可以看到)
php抓取网页生成图片是http返回到客户端才可以看到。速度很慢,有延迟,目前nginx+mysql比较多。webpack+gulp+webpack-dev-server做页面前端的boilerplate+模块化。
这些都是flash里的流,reactor干的活,已经被淘汰了,网站前端,boilerplate就是flash里的流,写代码的效率降低,而且可读性极差,封装一下,做成单页面应用,最简单的可以做成webpack前端打包工具,如果考虑其他页面打包,那就自己写hrefjs、mvvm这些模块,这里面有无数坑,mvvm对性能有限制,html、css、js分离得更好。
如果是image-rawwidget之类的,可以用http服务端来写,效率比较高。
使用flash里面的流,不需要第三方的treecompressor,php的splinter也是不错的,还有不需要第三方的treecompressor是去除了缓存的。php+flash比较适合长的json的数据。
使用flash的流。
php+svg这个推荐。
使用nodejs的svgtree。不需要第三方的treecompressor。
flash的流模块,unittest有在测试。我想接着知乎上再补充一下实际项目实现的问题,这几年unity3d,cocos2d-x,hybrid的一些公司都推出了svgflashcompressor或者svgcompressorslide等类似的东西,官方文档和很多实例都有的。官方svgflashcompressor标准文档介绍applicationunittests。
php 抓取网页生成图片(几个(从代码角度)的信息;这里换成data-original属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-31 09:24
今天在浏览简书的时候,发现了几位非常有帮助的摄影师网站。上面的图片很美,萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
拍摄图片的过程介绍
抓取图片的方法有很多种,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取目标页面的内容后,添加
标签相关信息匹配有规律;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在了本地。让我们更详细地看一下它(从代码的角度)。这里我只尝试了两种方法(curl 和 file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:
获取资源($url)
下载Img($imgPath)
2 主要程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里用data-original属性代替,因为页面使用了延迟加载机制
preg_match_all("|
]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k";
在程序结束时,这里需要注意以下几点:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传入第四个参数,则默认为 PREG_PATTERN_ORDER,此时使用 PREG_SET_ORDER 排序。对此,php手册中有非常详细的介绍,建议你在这一步查看手册,加深印象。
2) 在我们匹配的正则表达式中
标签中data-original属性中的值,我们来说说这个规律,首先要匹配的是
标签信息,然后使用子匹配来匹配数据原创属性中的值。值得注意的是,这里有很多摄影课(图片课)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照之前的方式匹配src属性,只能得到
标签默认显示图片,显然这不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
二、使用curl方式抓取图片(post方式)
上面我们使用file_get_content()函数的get方法来捕获,这里我们改成curl的post方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图
curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种和两种方法的执行效率对比
1 file_get_contents 每次请求都会重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,当多次请求多个链接时,curl 的效率会更高。
3 与file_get_content相比,curl方法请求更加多样化,可以请求FTP协议、SSL协议...等资源。
总结
1 php手册的重要性,有时候你不妨看看手册,不管查了多少资料,都有对一些功能的详细介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。.
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。最好多读一遍(请允许我使用这个词)以亲切,这样你就可以记住这个过程的原理。
4 展开,抓取页面包括其子页面中的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我不会在这里重复它们。.
以上是我在拍照过程中的体会。我希望它能对大家有所帮助。如有不对之处,欢迎批评指正! 查看全部
php 抓取网页生成图片(几个(从代码角度)的信息;这里换成data-original属性)
今天在浏览简书的时候,发现了几位非常有帮助的摄影师网站。上面的图片很美,萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
拍摄图片的过程介绍
抓取图片的方法有很多种,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取目标页面的内容后,添加
标签相关信息匹配有规律;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在了本地。让我们更详细地看一下它(从代码的角度)。这里我只尝试了两种方法(curl 和 file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:
获取资源($url)
下载Img($imgPath)
2 主要程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里用data-original属性代替,因为页面使用了延迟加载机制
preg_match_all("|
]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k";
在程序结束时,这里需要注意以下几点:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传入第四个参数,则默认为 PREG_PATTERN_ORDER,此时使用 PREG_SET_ORDER 排序。对此,php手册中有非常详细的介绍,建议你在这一步查看手册,加深印象。
2) 在我们匹配的正则表达式中
标签中data-original属性中的值,我们来说说这个规律,首先要匹配的是
标签信息,然后使用子匹配来匹配数据原创属性中的值。值得注意的是,这里有很多摄影课(图片课)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照之前的方式匹配src属性,只能得到
标签默认显示图片,显然这不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
二、使用curl方式抓取图片(post方式)
上面我们使用file_get_content()函数的get方法来捕获,这里我们改成curl的post方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图
curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种和两种方法的执行效率对比
1 file_get_contents 每次请求都会重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,当多次请求多个链接时,curl 的效率会更高。
3 与file_get_content相比,curl方法请求更加多样化,可以请求FTP协议、SSL协议...等资源。
总结
1 php手册的重要性,有时候你不妨看看手册,不管查了多少资料,都有对一些功能的详细介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。.
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。最好多读一遍(请允许我使用这个词)以亲切,这样你就可以记住这个过程的原理。
4 展开,抓取页面包括其子页面中的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我不会在这里重复它们。.
以上是我在拍照过程中的体会。我希望它能对大家有所帮助。如有不对之处,欢迎批评指正!
php 抓取网页生成图片( 页面静态化(这里特指真静态)能够明显地提高网站的访问效率)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-27 07:05
页面静态化(这里特指真静态)能够明显地提高网站的访问效率)
本文主要想谈谈页面静态、缓存技术和SEO的关系。在此之前,有必要解释一下这三个词的概念。
一般来说,大型网站的加速一般是通过静态页面、缓存技术(主要是memcached)、mysql优化三个方面来实现的。同时,加速往往需要考虑实际情况,比如SEO问题,静态页面是否需要及时更新,大量静态页面导致的文件堆积问题等等,所以这些矛盾导致我们今天的话题。
页面静态(这里特指真静态)可以显着提高网站访问效率,无论是真静态还是伪静态对SEO都是非常有利的。由于搜索引擎对静态页面“情有独钟”,蜘蛛爬虫乐于抓取静态网页的内容。对于动态网页,比如php页面,搜索引擎总觉得检索页面信息很麻烦,为了尽可能多的抓取到有意义的页面内容,对于动态页面总是要多次抓取。这样一来,页面收录的效率就会相对降低,即会对SEO产生负面影响。此外,从安全角度来看,静态页面不太容易受到 SQL 注入攻击。因此,为了提高访问效率,
如果真的是静态的,访问页面提供静态链接,可以减少服务器对数据响应的负载,第二次加载时不需要调动数据库。响应处理过程是,如果当前链接指定的静态页面存在,则直接访问该静态页面,否则视为第一次访问,创建静态页面,并保存。在创建的过程中,可以引入模板、ob缓存机制,甚至memcached技术。你可能会想,如果是大型网站,因为信息量和访问量都处于海量数据的层面,会不会随着时间的推移会产生大量的静态页面,即大量的多余的文件会堆积起来,空间会比较大。和,毫无疑问,有些文件可能不再使用了。在这种情况下,我们通常可以根据需要设置相应的处理规则,并根据规则开发相应的程序,比如定期执行任务计划,删除冗余文件,或者修改原创
数据库中的信息时,相应的变化是也是同时制作的。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。或者在修改原创
数据库中的信息时,也会同时进行相应的更改。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。或者在修改原创
数据库中的信息时,也会同时进行相应的更改。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。
不管怎么处理,真静态难免会产生积累的内容。这时候,我们经常会想到伪静态方法。
伪静态提供的也是静态链接,但需要注意的是,它实际访问的还是动态页面。那么,伪静态的作用是什么呢?前面说过,因为链接是静态的,所以这对SEO还是很有好处的,在一定程度上提高了安全性。至于访问效率的提升,我们还是可以利用ob缓存机制来提升访问效率。与真静态相比,伪静态避免了生成海量静态页面。有很多方法可以实现伪静态。IIS下有重写规则,Apache下有重写规则,甚至PHP脚本都可以通过正则表达式直接使用。但是,通常我们选择重写规则来实现伪静态。(实现过程略)
那么如何选择使用真静态或伪静态呢?
总结:如果一个网页会被频繁访问(例如百万级别),每次通过网页都会操作数据库,可以考虑使用真静态;如果一个网页是为了优化搜索引擎,提高网站的安全性,可以考虑使用伪静态(+缓存机制)。 查看全部
php 抓取网页生成图片(
页面静态化(这里特指真静态)能够明显地提高网站的访问效率)
本文主要想谈谈页面静态、缓存技术和SEO的关系。在此之前,有必要解释一下这三个词的概念。
一般来说,大型网站的加速一般是通过静态页面、缓存技术(主要是memcached)、mysql优化三个方面来实现的。同时,加速往往需要考虑实际情况,比如SEO问题,静态页面是否需要及时更新,大量静态页面导致的文件堆积问题等等,所以这些矛盾导致我们今天的话题。
页面静态(这里特指真静态)可以显着提高网站访问效率,无论是真静态还是伪静态对SEO都是非常有利的。由于搜索引擎对静态页面“情有独钟”,蜘蛛爬虫乐于抓取静态网页的内容。对于动态网页,比如php页面,搜索引擎总觉得检索页面信息很麻烦,为了尽可能多的抓取到有意义的页面内容,对于动态页面总是要多次抓取。这样一来,页面收录的效率就会相对降低,即会对SEO产生负面影响。此外,从安全角度来看,静态页面不太容易受到 SQL 注入攻击。因此,为了提高访问效率,
如果真的是静态的,访问页面提供静态链接,可以减少服务器对数据响应的负载,第二次加载时不需要调动数据库。响应处理过程是,如果当前链接指定的静态页面存在,则直接访问该静态页面,否则视为第一次访问,创建静态页面,并保存。在创建的过程中,可以引入模板、ob缓存机制,甚至memcached技术。你可能会想,如果是大型网站,因为信息量和访问量都处于海量数据的层面,会不会随着时间的推移会产生大量的静态页面,即大量的多余的文件会堆积起来,空间会比较大。和,毫无疑问,有些文件可能不再使用了。在这种情况下,我们通常可以根据需要设置相应的处理规则,并根据规则开发相应的程序,比如定期执行任务计划,删除冗余文件,或者修改原创
数据库中的信息时,相应的变化是也是同时制作的。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。或者在修改原创
数据库中的信息时,也会同时进行相应的更改。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。或者在修改原创
数据库中的信息时,也会同时进行相应的更改。静态文件等等,让你在很大程度上缓解压力。必须指出的是,由于访问的所有页面都是静态的,因此真正的静态确实是 SEO 更好的选择。
不管怎么处理,真静态难免会产生积累的内容。这时候,我们经常会想到伪静态方法。
伪静态提供的也是静态链接,但需要注意的是,它实际访问的还是动态页面。那么,伪静态的作用是什么呢?前面说过,因为链接是静态的,所以这对SEO还是很有好处的,在一定程度上提高了安全性。至于访问效率的提升,我们还是可以利用ob缓存机制来提升访问效率。与真静态相比,伪静态避免了生成海量静态页面。有很多方法可以实现伪静态。IIS下有重写规则,Apache下有重写规则,甚至PHP脚本都可以通过正则表达式直接使用。但是,通常我们选择重写规则来实现伪静态。(实现过程略)
那么如何选择使用真静态或伪静态呢?
总结:如果一个网页会被频繁访问(例如百万级别),每次通过网页都会操作数据库,可以考虑使用真静态;如果一个网页是为了优化搜索引擎,提高网站的安全性,可以考虑使用伪静态(+缓存机制)。
php 抓取网页生成图片(web服务器通过mysql协议发送给mysql服务器()协议)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-27 07:04
介绍
说到LNMP,就不得不提LAMP。我们知道LAMP是一个多C/S架构的平台。在该架构中,Web客户端通过http协议发起基于TCP/IP的传输。这个请求可能是静态的,也可能是动态的。所以web服务器通过发起请求的后缀来判断,如果是静态的,则由web服务器自己处理,然后将资源发送给客户端。如果是动态的web服务器,会通过CGI(Common Gateway Interfence)协议向php发起。如果 PHP 以模块的形式与 Web 服务器通信,则它们在内部共享内存。如果PHP是一个单独的服务器,那么它们以sockets的形式进行通信(这是另一种C/S架构),这时候php会相应地执行一个程序。如果在程序执行过程中需要一些数据,那么php会通过mysql协议(这个也可以看成是C/S架构)发送到mysql服务器,由mysql服务器处理。将数据提供给 php 程序。
LNMP
是指一组通常用来运行动态网站或服务器的免费软件的首字母缩写词。L指Linux,N指Nginx,M一般指MySQL或MariaDB,P一般指PHP,或Perl或Python。LNMP 架构与 LAMP 架构类似,只是一个使用 Apache,另一个使用 Nginx。LNMP 是 Linux+Nginx+MySQL/mairadb+PHP。Nginx 和 Apache 都是 Web 服务器。另一个区别是在LNMP结构中,php会启动一个php-fpm服务,而LANP中的php大部分时间只作为Apache的一个模块存在(CentOS8中LAMP架构也启动了php-fpm服务) .
Nginx 会将用户的动态页面请求交给 php 服务进行处理,由 php 服务与数据库进行交互。用户的静态页面请求由 Nginx 直接处理。Nginx 处理静态请求的速度比 apache 快得多。性能比较好,所以在动态请求处理上apache和Nginx差别不大,但是如果是静态请求处理,Nginx就很明显了。它比apache快,而且Nginx能承受的并发量比apache大,能承受几万并发,所以较大的网站会使用Nginx作为web服务器。
动态和静态页面
静态页面:
(1)静态网页不能简单理解为静态网页,主要是指网页中没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html, .htm,或者.xml等,虽然静态网页的内容一旦创建就不会改变,但是静态网页也包括一些活动的部分,主要是一些GIF动画等。
(2)打开静态网页,用户可以直接双击,任何人随时打开的页面内容保持不变。
动态网页:
(1)动态网页是指相对于静态网页的一种网页编程技术。动态网页的网页文件除了HTML标签外,还收录
一些特定功能的程序代码。这些代码可以使浏览器和服务器进行交互,所以服务器会根据客户的不同请求动态生成网页内容,即相对于静态网页,虽然动态网页的页面代码没有变化,但显示的内容可能是时间、环境或数据库的结果操作。并改变了。
(2)动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文字内容,也可以是收录
各种动画内容。这些只是网页的具体内容,无论网页是否有动态效果,只要是通过动态网站技术(如PHP、ASP、JSP等)生成的网页,都可以称为动态网页。
动态网页和静态网页的区别:
(1)更新维护:
静态网页内容一旦发布到网站服务器上,无论用户是否访问,这些网页的内容都会存储在网站服务器上。如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。数据库不支持静态网页。当网站信息量较大时,网页的创建和维护难度较大。
动态网页可以根据不同的用户请求、时间或环境需要动态生成不同的网页内容,动态网页一般都是基于数据库技术,可以大大减少网站维护的工作量
(2)互动性:
由于静态网页的很多内容都是固定的,在功能上有很大的限制,所以交互性差
动态网页可以实现更多功能,如用户登录、注册、查询等。
(3) 响应速度:
静态网页的内容比较固定,容易被搜索引擎检索到,不需要连接数据库,所以响应速度比较快
动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,涉及到数据连接、访问、查询等一系列过程,所以响应速度比较慢
(4)访问功能:
静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不带“?”,直接双击打开即可
这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般无法访问一个网站的数据库中的所有网页,或者出于技术考虑,搜索不抓取“?” 在网址中。“后的内容”,双击无法直接打开
总之
如果网页内容比较简单,不需要频繁修改,或者只是为了展示信息,可以使用静态网页,简单易操作,不需要管理数据库等。
如果网页内容比较复杂,功能多,变化频繁,内容实时,使用动态网页
LNMP 架构工作流
案例分析
使用LNMP+wordpress搭建博客站点
WordPress
PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上搭建自己的网站。您还可以使用 WordPress 作为内容管理系统。WordPress以其简单、强大的功能、可扩展性和灵活性而著称,加上开源和免费,以及极其丰富的主题插件。无论作为新手学习搭建个人博客,还是专业用户搭建复杂的企业电子商务网站、论坛等,WP都能完美满足需求。WP几乎可以建立任何类型的网站,你只能想到,你做不到。而且,全球数以亿计的知名网站都是基于WP构建的。据官方统计,目前全球32%的网站都是由WP搭建的。因为它太受欢迎了,所以不管插件,主题、教程、文档等等,都是极其丰富的,不可能全部读完。而且网上关于性能优化和问题解决的讨论也很全面。基本学会建网站,玩WP就行!所以,如果你想建网站或者想尝试学习建网站,那么WP绝对值得你优先考虑。
WordPress官网:打开可能有问题(429错误),可以去下载软件包
环境介绍
CentOS8 主机
关闭 SElinux 和防火墙
配置yum源
挂载光盘
可以联网
Wordpress软件包下载地址:
过程
step1 部署LNMP架构
[root@client ~]# dnf -y install nginx php* mariadb-server mariadb -y
step2 设置 php-fpm
[root@client ~]# vim /etc/php-fpm.d/www.conf
user = nginx
group = nginx
#php-fpm服务默认以apache用户启动,将启动用户身份修改nginx
step3 启动服务
[root@client ~]# systemctl restart nginx.service php-fpm.service mariadb.service
step4 生成php测试页
[root@client ~]# echo "" >> /usr/share/nginx/html/index.php
#系统自带的nginx的页面文件存放在/usr/share/nginx/html/目录中
step5 打开浏览器测试
第六步
为数据库设置密码并创建对应的数据库
[root@client ~]# mysqladmin -u root password 123456
[root@client ~]# mysql -u root -p
Enter password:
MariaDB [(none)]> create database wordpress charset=utf8;
Query OK, 1 row affected (0.001 sec)
MariaDB [(none)]> quit
Bye
step7 准备wordpress
[root@client ~]# cd /usr/share/nginx/html/
[root@client html]# rm -fr *
#####删除nginx自带的页面文件,以及刚才测试生成的php页面
[root@client ~]# unzip latest-zh_CN.zip
[root@client ~]# cd wordpress/
[root@client wordpress]# mv * /usr/share/nginx/html/
####将wordpress文件移动到nginx页面文件存放的目录
[root@client wordpress]# cd /usr/share/nginx/html/
[root@client html]# chown -R nginx.nginx *
###文件的默认所有者是root,为了避免权限的问题,将所有者改为nginx
step8 安装wordpress
复制提示页面内容,按照要求手工创建wp-config.php文件并将内容粘贴
[root@client html]# vim /usr/share/nginx/html/wp-config.php
切换到安装页面,点击立即安装
step9 登录和用户注册设置
开启用户注册
发送测试邮件
注意:公网邮箱需要在设置中开启SMTP/POP等功能,然后按照提示操作。
收到测试邮件后,退出管理员账号,返回登录界面,选择注册
将电子邮件中的链接复制到浏览器并粘贴
如果您想直接从其他主机访问而无需修改 URL
WordPress 打开缓慢
有时候wordpress访问很慢,尤其是登录后台的时候,主要是wordpress使用了一些外部资源,比如谷歌的资源;如果你的主机没有联网,打开速度确实很慢。但有时,即使连接到互联网,由于无法访问这些外部资源,速度也会变慢。这时候可以在wordpress中搜索安装一个名为“WP加速中国版”的加速插件并启用,将这些无法访问的外部资源替换为对应的国内资源。可以解决访问慢的问题
总结
什么是 lmp
lnmp和灯的区别
动态网页和静态网页
LNMP 工作流程
如何部署和设置LNMP平台
如何在LNMP平台上搭建wordpress
要点:LNMP架构由哪些成员组成,动态网页和静态网页,LNMP的工作流程,在CentOS8上lnmp平台的搭建,wordpress的安装和设置,用户注册的实现
难点:记住LNMP的组成,了解动态网页和静态网页的区别,记住LNMP的工作流程,记住lnmp平台需要安装哪些软件包,启动哪些服务,修改了哪些配置文件,以及wordpress平台安装设置并实现用户注册 查看全部
php 抓取网页生成图片(web服务器通过mysql协议发送给mysql服务器()协议)
介绍
说到LNMP,就不得不提LAMP。我们知道LAMP是一个多C/S架构的平台。在该架构中,Web客户端通过http协议发起基于TCP/IP的传输。这个请求可能是静态的,也可能是动态的。所以web服务器通过发起请求的后缀来判断,如果是静态的,则由web服务器自己处理,然后将资源发送给客户端。如果是动态的web服务器,会通过CGI(Common Gateway Interfence)协议向php发起。如果 PHP 以模块的形式与 Web 服务器通信,则它们在内部共享内存。如果PHP是一个单独的服务器,那么它们以sockets的形式进行通信(这是另一种C/S架构),这时候php会相应地执行一个程序。如果在程序执行过程中需要一些数据,那么php会通过mysql协议(这个也可以看成是C/S架构)发送到mysql服务器,由mysql服务器处理。将数据提供给 php 程序。
LNMP
是指一组通常用来运行动态网站或服务器的免费软件的首字母缩写词。L指Linux,N指Nginx,M一般指MySQL或MariaDB,P一般指PHP,或Perl或Python。LNMP 架构与 LAMP 架构类似,只是一个使用 Apache,另一个使用 Nginx。LNMP 是 Linux+Nginx+MySQL/mairadb+PHP。Nginx 和 Apache 都是 Web 服务器。另一个区别是在LNMP结构中,php会启动一个php-fpm服务,而LANP中的php大部分时间只作为Apache的一个模块存在(CentOS8中LAMP架构也启动了php-fpm服务) .
Nginx 会将用户的动态页面请求交给 php 服务进行处理,由 php 服务与数据库进行交互。用户的静态页面请求由 Nginx 直接处理。Nginx 处理静态请求的速度比 apache 快得多。性能比较好,所以在动态请求处理上apache和Nginx差别不大,但是如果是静态请求处理,Nginx就很明显了。它比apache快,而且Nginx能承受的并发量比apache大,能承受几万并发,所以较大的网站会使用Nginx作为web服务器。
动态和静态页面
静态页面:
(1)静态网页不能简单理解为静态网页,主要是指网页中没有程序代码,只有HTML(即:超文本标记语言),一般后缀为.html, .htm,或者.xml等,虽然静态网页的内容一旦创建就不会改变,但是静态网页也包括一些活动的部分,主要是一些GIF动画等。
(2)打开静态网页,用户可以直接双击,任何人随时打开的页面内容保持不变。
动态网页:
(1)动态网页是指相对于静态网页的一种网页编程技术。动态网页的网页文件除了HTML标签外,还收录
一些特定功能的程序代码。这些代码可以使浏览器和服务器进行交互,所以服务器会根据客户的不同请求动态生成网页内容,即相对于静态网页,虽然动态网页的页面代码没有变化,但显示的内容可能是时间、环境或数据库的结果操作。并改变了。
(2)动态网页与网页上的各种动画、滚动字幕等视觉动态效果没有直接关系。动态网页也可以是纯文字内容,也可以是收录
各种动画内容。这些只是网页的具体内容,无论网页是否有动态效果,只要是通过动态网站技术(如PHP、ASP、JSP等)生成的网页,都可以称为动态网页。
动态网页和静态网页的区别:
(1)更新维护:
静态网页内容一旦发布到网站服务器上,无论用户是否访问,这些网页的内容都会存储在网站服务器上。如果要修改网页的内容,则必须修改其源代码,然后重新上传到服务器。数据库不支持静态网页。当网站信息量较大时,网页的创建和维护难度较大。
动态网页可以根据不同的用户请求、时间或环境需要动态生成不同的网页内容,动态网页一般都是基于数据库技术,可以大大减少网站维护的工作量
(2)互动性:
由于静态网页的很多内容都是固定的,在功能上有很大的限制,所以交互性差
动态网页可以实现更多功能,如用户登录、注册、查询等。
(3) 响应速度:
静态网页的内容比较固定,容易被搜索引擎检索到,不需要连接数据库,所以响应速度比较快
动态网页实际上并不是独立存在于服务器上的网页文件。服务器只有在用户请求时才返回一个完整的网页,涉及到数据连接、访问、查询等一系列过程,所以响应速度比较慢
(4)访问功能:
静态网页的每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不带“?”,直接双击打开即可
这 ”?” 在动态网页中搜索引擎检索存在一定的问题。搜索引擎一般无法访问一个网站的数据库中的所有网页,或者出于技术考虑,搜索不抓取“?” 在网址中。“后的内容”,双击无法直接打开
总之
如果网页内容比较简单,不需要频繁修改,或者只是为了展示信息,可以使用静态网页,简单易操作,不需要管理数据库等。
如果网页内容比较复杂,功能多,变化频繁,内容实时,使用动态网页
LNMP 架构工作流
案例分析
使用LNMP+wordpress搭建博客站点
WordPress
PHP语言开发的博客平台,用户可以在支持PHP和MySQL数据库的服务器上搭建自己的网站。您还可以使用 WordPress 作为内容管理系统。WordPress以其简单、强大的功能、可扩展性和灵活性而著称,加上开源和免费,以及极其丰富的主题插件。无论作为新手学习搭建个人博客,还是专业用户搭建复杂的企业电子商务网站、论坛等,WP都能完美满足需求。WP几乎可以建立任何类型的网站,你只能想到,你做不到。而且,全球数以亿计的知名网站都是基于WP构建的。据官方统计,目前全球32%的网站都是由WP搭建的。因为它太受欢迎了,所以不管插件,主题、教程、文档等等,都是极其丰富的,不可能全部读完。而且网上关于性能优化和问题解决的讨论也很全面。基本学会建网站,玩WP就行!所以,如果你想建网站或者想尝试学习建网站,那么WP绝对值得你优先考虑。
WordPress官网:打开可能有问题(429错误),可以去下载软件包
环境介绍
CentOS8 主机
关闭 SElinux 和防火墙
配置yum源
挂载光盘
可以联网
Wordpress软件包下载地址:
过程
step1 部署LNMP架构
[root@client ~]# dnf -y install nginx php* mariadb-server mariadb -y
step2 设置 php-fpm
[root@client ~]# vim /etc/php-fpm.d/www.conf
user = nginx
group = nginx
#php-fpm服务默认以apache用户启动,将启动用户身份修改nginx
step3 启动服务
[root@client ~]# systemctl restart nginx.service php-fpm.service mariadb.service
step4 生成php测试页
[root@client ~]# echo "" >> /usr/share/nginx/html/index.php
#系统自带的nginx的页面文件存放在/usr/share/nginx/html/目录中
step5 打开浏览器测试
第六步
为数据库设置密码并创建对应的数据库
[root@client ~]# mysqladmin -u root password 123456
[root@client ~]# mysql -u root -p
Enter password:
MariaDB [(none)]> create database wordpress charset=utf8;
Query OK, 1 row affected (0.001 sec)
MariaDB [(none)]> quit
Bye
step7 准备wordpress
[root@client ~]# cd /usr/share/nginx/html/
[root@client html]# rm -fr *
#####删除nginx自带的页面文件,以及刚才测试生成的php页面
[root@client ~]# unzip latest-zh_CN.zip
[root@client ~]# cd wordpress/
[root@client wordpress]# mv * /usr/share/nginx/html/
####将wordpress文件移动到nginx页面文件存放的目录
[root@client wordpress]# cd /usr/share/nginx/html/
[root@client html]# chown -R nginx.nginx *
###文件的默认所有者是root,为了避免权限的问题,将所有者改为nginx
step8 安装wordpress
复制提示页面内容,按照要求手工创建wp-config.php文件并将内容粘贴
[root@client html]# vim /usr/share/nginx/html/wp-config.php
切换到安装页面,点击立即安装
step9 登录和用户注册设置
开启用户注册
发送测试邮件
注意:公网邮箱需要在设置中开启SMTP/POP等功能,然后按照提示操作。
收到测试邮件后,退出管理员账号,返回登录界面,选择注册
将电子邮件中的链接复制到浏览器并粘贴
如果您想直接从其他主机访问而无需修改 URL
WordPress 打开缓慢
有时候wordpress访问很慢,尤其是登录后台的时候,主要是wordpress使用了一些外部资源,比如谷歌的资源;如果你的主机没有联网,打开速度确实很慢。但有时,即使连接到互联网,由于无法访问这些外部资源,速度也会变慢。这时候可以在wordpress中搜索安装一个名为“WP加速中国版”的加速插件并启用,将这些无法访问的外部资源替换为对应的国内资源。可以解决访问慢的问题
总结
什么是 lmp
lnmp和灯的区别
动态网页和静态网页
LNMP 工作流程
如何部署和设置LNMP平台
如何在LNMP平台上搭建wordpress
要点:LNMP架构由哪些成员组成,动态网页和静态网页,LNMP的工作流程,在CentOS8上lnmp平台的搭建,wordpress的安装和设置,用户注册的实现
难点:记住LNMP的组成,了解动态网页和静态网页的区别,记住LNMP的工作流程,记住lnmp平台需要安装哪些软件包,启动哪些服务,修改了哪些配置文件,以及wordpress平台安装设置并实现用户注册
php 抓取网页生成图片(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-12-25 17:16
本文介绍如何使用Python抓取网页生成Excel文件。分享给大家,供大家参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开这个csv文件并保存为Excel文件
希望这篇文章对你的 Python 编程有所帮助。 查看全部
php 抓取网页生成图片(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
本文介绍如何使用Python抓取网页生成Excel文件。分享给大家,供大家参考,如下:
Python爬取网页,主要使用PyQuery,这个和jQuery用法一样,超级棒
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="http://www.yourwebname.com/%3F ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
下一步是用Notepad++打开company.csv,然后将其转换为ANSI编码格式,并保存。然后用Excel软件打开这个csv文件并保存为Excel文件
希望这篇文章对你的 Python 编程有所帮助。
php 抓取网页生成图片(,PHP,抓取,远程,图片含,不带的,教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-25 11:10
PHP抓图远程图片(含不带后缀)教程详解,PHP抓图,远程,图片,有,无,后缀,,教程,一
PHP捕捉远程图片(包括不带后缀)教程详解
第一财网站长网站,站长之家为您整理了PHP抓图远程图片(包括无后缀)教程详解的相关内容。
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、定义另外一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是远程镜像抓取后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。如这里所解释的,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setDir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,TRUE);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。以上就是对PHP远程抓图(包括不带后缀)教程详解的详细介绍。欢迎大家对PHP捕获远程镜像(包括不带后缀)教程的详细内容提出宝贵意见 查看全部
php 抓取网页生成图片(,PHP,抓取,远程,图片含,不带的,教程)
PHP抓图远程图片(含不带后缀)教程详解,PHP抓图,远程,图片,有,无,后缀,,教程,一
PHP捕捉远程图片(包括不带后缀)教程详解
第一财网站长网站,站长之家为您整理了PHP抓图远程图片(包括无后缀)教程详解的相关内容。
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类GrabImage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、定义另外一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是远程镜像抓取后本地存储的目录,一般以PHP入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。如这里所解释的,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getInstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getInstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setDir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setDir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,TRUE);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。以上就是对PHP远程抓图(包括不带后缀)教程详解的详细介绍。欢迎大家对PHP捕获远程镜像(包括不带后缀)教程的详细内容提出宝贵意见
php 抓取网页生成图片(如何实现PHP转换生成为各种格式的图片或者pdf文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-23 20:11
我们在实际项目开发中经常会遇到这种需求,从特定的网页生成图片,用于分享等用途。这时候,我们就可以利用这个PHP扩展,轻松地将网页转换成各种格式的图片或pdf文件。让我们来看看如何实现这一点?
本教程的主角是wkhtmltopdf,下面简单了解一下:
wkhtmltopdf 是一个开源、简单有效的命令行shell 程序,可以将任何HTML(网页)转换为PDF 文档或图像(jpg、png 等)。
wkhtmltopdf 是用 C++ 编写的,并在 GNU/GPL(通用公共许可证)下发布。它使用 WebKit 渲染引擎将 HTML 页面转换为 PDF 文档,而不会损失页面质量。这是用于实时创建和存储网页快照的非常有用且可靠的解决方案。
本程序的特点如下:
开源和跨平台。
使用 WebKit 引擎将任何 HTML 网页转换为 PDF 文件。
添加页眉和页脚选项
目录生成 (TOC) 选项。
提供批量模式转换。
通过绑定 libwkhtmltox 支持 PHP 或 Python。
首先我们需要在我们的服务器上安装libwkhtmltox,linux下的webkit内核,根据我们的服务器配置选择合适的安装包:
需要注意的是libwkhtmltox的当前版本已经0.13了,但是我在CentOS6.2下安装了libwkhtmltox-0.11后,我把网页改成了There图片会报错,最后选择了0.10版本,比较稳定。
<p>13版的安装方法:[root@KaiBoss_4_45 ~]#rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm 查看全部
php 抓取网页生成图片(如何实现PHP转换生成为各种格式的图片或者pdf文件)
我们在实际项目开发中经常会遇到这种需求,从特定的网页生成图片,用于分享等用途。这时候,我们就可以利用这个PHP扩展,轻松地将网页转换成各种格式的图片或pdf文件。让我们来看看如何实现这一点?
本教程的主角是wkhtmltopdf,下面简单了解一下:
wkhtmltopdf 是一个开源、简单有效的命令行shell 程序,可以将任何HTML(网页)转换为PDF 文档或图像(jpg、png 等)。
wkhtmltopdf 是用 C++ 编写的,并在 GNU/GPL(通用公共许可证)下发布。它使用 WebKit 渲染引擎将 HTML 页面转换为 PDF 文档,而不会损失页面质量。这是用于实时创建和存储网页快照的非常有用且可靠的解决方案。
本程序的特点如下:
开源和跨平台。
使用 WebKit 引擎将任何 HTML 网页转换为 PDF 文件。
添加页眉和页脚选项
目录生成 (TOC) 选项。
提供批量模式转换。
通过绑定 libwkhtmltox 支持 PHP 或 Python。
首先我们需要在我们的服务器上安装libwkhtmltox,linux下的webkit内核,根据我们的服务器配置选择合适的安装包:
需要注意的是libwkhtmltox的当前版本已经0.13了,但是我在CentOS6.2下安装了libwkhtmltox-0.11后,我把网页改成了There图片会报错,最后选择了0.10版本,比较稳定。
<p>13版的安装方法:[root@KaiBoss_4_45 ~]#rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm
php 抓取网页生成图片(PHP代码服务器端的代码中使用替换操作和base64解码功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-12-20 23:04
需求:项目中需要用到截图功能,但是我们一般都是用微信或者QQ来截图,这种方式不方便。更重要的是,如果要截取的部分超过一屏,使用上述方法截屏只能截取部分内容,不能截取全部内容。因此,我们迫切需要一种滚动截图的方式,捕捉我想要的部分,所以引入了下面的截图方法--html2canvas。
首先最基础的就是:导入这个js文件。
下面是实现这个功能的具体代码
1. HTML 页面代码
保存图片
2. js 代码
$(function(){
$(".saveImage").on('click', function (event) {
var img={}
event.preventDefault();
html2canvas($(".fc-view-container"), {
allowTaint: true,
taintTest: false,
onrendered: function(canvas) {
canvas.id = "mycanvas";
//生成base64图片数据
var dataUrl = canvas.toDataURL();
img.img=dataUrl;
saveimg(img)
}
});
});
});
// 保存图片
function saveimg(img){
$.ajax({
url:"{:U('Index/saveImg')}",
type:'post',
data:img,
success:function(data){
if (data.status) {
//toast.success(data.info,'温馨提示');
setTimeout(function(){
window.location.href="/Uploads/Screen/"+data.url+".png";
}, 1000)
}else{
//toast.error(data.info,'温馨提示');
setTimeout(function(){
window.location.reload(true);
},1200)
};
}
})
}
第一个是给保存图片的元素绑定一个future事件。事件中使用canvas接口中的toDataURL()方法。我们来解释一下这个方法的作用:
参考Web Api接口使用该方法返回一个data: URL,将canvas中收录的图片文件按照type参数指定的类型编码成字符串。type 参数的默认值为 image/png。
第二个是:html2canvas($(".fc-view-container")),这个方法用来指定截取并生成图片的Dom对象。
最后,我们是后端代码:
3.PHP 代码
/**
* 截图保存图片
*/
public function saveImg()
{
$pictureFlow=I('img');
//图片流转存
$pictureFlow = str_replace('data:image/png;base64,', '', $pictureFlow);
$pictureFlow = base64_decode($pictureFlow);
$NOW_TIME=NOW_TIME;
$new_pic_path = 'Uploads/Screen/'.$NOW_TIME.'.png';
$ret = file_put_contents($new_pic_path, $pictureFlow);
if ($ret) {
$this->success('下载成功',$NOW_TIME);
}else{
$this->error('下载失败');
}
}
服务端代码中使用了替换操作和base64解码功能,可以直接将之前截取的图片部分保存为png格式。
保存截图如下:
捕获的 png 图像 查看全部
php 抓取网页生成图片(PHP代码服务器端的代码中使用替换操作和base64解码功能)
需求:项目中需要用到截图功能,但是我们一般都是用微信或者QQ来截图,这种方式不方便。更重要的是,如果要截取的部分超过一屏,使用上述方法截屏只能截取部分内容,不能截取全部内容。因此,我们迫切需要一种滚动截图的方式,捕捉我想要的部分,所以引入了下面的截图方法--html2canvas。
首先最基础的就是:导入这个js文件。
下面是实现这个功能的具体代码
1. HTML 页面代码
保存图片
2. js 代码
$(function(){
$(".saveImage").on('click', function (event) {
var img={}
event.preventDefault();
html2canvas($(".fc-view-container"), {
allowTaint: true,
taintTest: false,
onrendered: function(canvas) {
canvas.id = "mycanvas";
//生成base64图片数据
var dataUrl = canvas.toDataURL();
img.img=dataUrl;
saveimg(img)
}
});
});
});
// 保存图片
function saveimg(img){
$.ajax({
url:"{:U('Index/saveImg')}",
type:'post',
data:img,
success:function(data){
if (data.status) {
//toast.success(data.info,'温馨提示');
setTimeout(function(){
window.location.href="/Uploads/Screen/"+data.url+".png";
}, 1000)
}else{
//toast.error(data.info,'温馨提示');
setTimeout(function(){
window.location.reload(true);
},1200)
};
}
})
}
第一个是给保存图片的元素绑定一个future事件。事件中使用canvas接口中的toDataURL()方法。我们来解释一下这个方法的作用:
参考Web Api接口使用该方法返回一个data: URL,将canvas中收录的图片文件按照type参数指定的类型编码成字符串。type 参数的默认值为 image/png。
第二个是:html2canvas($(".fc-view-container")),这个方法用来指定截取并生成图片的Dom对象。
最后,我们是后端代码:
3.PHP 代码
/**
* 截图保存图片
*/
public function saveImg()
{
$pictureFlow=I('img');
//图片流转存
$pictureFlow = str_replace('data:image/png;base64,', '', $pictureFlow);
$pictureFlow = base64_decode($pictureFlow);
$NOW_TIME=NOW_TIME;
$new_pic_path = 'Uploads/Screen/'.$NOW_TIME.'.png';
$ret = file_put_contents($new_pic_path, $pictureFlow);
if ($ret) {
$this->success('下载成功',$NOW_TIME);
}else{
$this->error('下载失败');
}
}
服务端代码中使用了替换操作和base64解码功能,可以直接将之前截取的图片部分保存为png格式。
保存截图如下:
捕获的 png 图像
php 抓取网页生成图片(LinuxCentOS6-64bit下载下来后是什么样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-20 23:02
要求:将网页转成pdf或图片,并提供下载。
wkhtmltox 项目主页:支持html转pdf、图片
php扩展php-wkhtmltox项目主页:
1、下载安装wkhtmltox系统环境
根据系统类型选择下载wkhtmltox:
我这里的系统环境是CentOS 6-64bit,所以我选择:Linux CentOS 6-64bit
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。
安装 wkhtmltox:
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
错误:依赖项失败:
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示需要安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 附加:
* 更新:
================================================ ============ N/S 匹配:75dpi ================================ ============================
xorg-x11-fonts-75dpi.noarch:一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch:一组 75dpi ISO-8859-1 X 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch: ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch: ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch:一组 75dpi 的 X 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch: ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“全部搜索”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
直接用下面的方法解压rpm包中编译好的包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面有四个文件夹:local/bin、local/include、local/share、local/lib
将对应文件夹的内容复制到/usr/local!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
2、安装php-wkhtmltox扩展
在github上下载源码包[php-wkhtmltox_master.zip]
> unzipphp-wkhtmltox_master.zip
> cd phpwkhtmltox
>phpize
> ./configure--with-php-config=/usr/local/php/bin/php-config #这里取决于各个系统的PHP安装路径
> make && make install
> ldconfig #重新加载系统动态链接库
> php -m
#检查扩展是否成功。如果能看到phpwkhtmltox,说明扩展成功。
php-wkhtmltox 扩展安装完成。
3、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm restart
安装完成!
参考这篇文章:
安装部分可以使用本文介绍的安装部分,有的可能需要中文字体支持。可以参考上面的中文字体库安装部分进行扩展。
转载于: 查看全部
php 抓取网页生成图片(LinuxCentOS6-64bit下载下来后是什么样的?)
要求:将网页转成pdf或图片,并提供下载。
wkhtmltox 项目主页:支持html转pdf、图片
php扩展php-wkhtmltox项目主页:
1、下载安装wkhtmltox系统环境
根据系统类型选择下载wkhtmltox:
我这里的系统环境是CentOS 6-64bit,所以我选择:Linux CentOS 6-64bit
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。
安装 wkhtmltox:
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
错误:依赖项失败:
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示需要安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 附加:
* 更新:
================================================ ============ N/S 匹配:75dpi ================================ ============================
xorg-x11-fonts-75dpi.noarch:一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch:一组 75dpi ISO-8859-1 X 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch: ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch: ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch:一组 75dpi 的 X 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch: ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“全部搜索”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
直接用下面的方法解压rpm包中编译好的包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面有四个文件夹:local/bin、local/include、local/share、local/lib
将对应文件夹的内容复制到/usr/local!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
2、安装php-wkhtmltox扩展
在github上下载源码包[php-wkhtmltox_master.zip]
> unzipphp-wkhtmltox_master.zip
> cd phpwkhtmltox
>phpize
> ./configure--with-php-config=/usr/local/php/bin/php-config #这里取决于各个系统的PHP安装路径
> make && make install
> ldconfig #重新加载系统动态链接库
> php -m
#检查扩展是否成功。如果能看到phpwkhtmltox,说明扩展成功。
php-wkhtmltox 扩展安装完成。
3、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm restart
安装完成!
参考这篇文章:
安装部分可以使用本文介绍的安装部分,有的可能需要中文字体支持。可以参考上面的中文字体库安装部分进行扩展。
转载于:
php 抓取网页生成图片(牢骚发完了,正式写博客吧(PHP生成word原理))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-18 22:18
概括:
最近在工作中遇到了生词问题
现在总结一下生成词的三种方法。
btw:好像在博客园里发个博客,只要标题有PHP,好像点击量不是很高(兄弟,我标题还是有PHP的)。我不知道为什么。估计博客园里的网络技术专家比较多。把Java、.net、php比作程序员的闺蜜,那么java就是甲骨文下最好的姑娘,.net微软下的名门世家,PHP就是草根下的野蛮大妈。这让我很期待 PHP 的草根男士这么骚。怎么可能。. 委屈完了,正式写博客
PHP为正文生成word的原理是通过windows下的com组件使用PHP将内容写入doc文件中实现的:
原理:com是PHP的扩展。安装了office的服务器会自动调用word.application的com,可以自动生成文档。PHP 官方文档手册:
使用官方示例:
个人建议:com实例后面的方法需要查一下官方文档才知道是什么意思。编辑器没有代码提示,非常不方便。另外这个效率不是很高,所以不推荐使用
使用 PHP 将内容写入 doc 文件。这种方法可以分为两种方法生成mht格式(类似HTML)并写入word
这种方法主要是指:
/**
* 根据HTML代码获取word文档内容
* 创建一个本质为mht的文档,该函数会分析文件内容并从远程下载页面中的图片资源
* 该函数依赖于类MhtFileMaker
* 该函数会分析img标签,提取src的属性值。但是,src的属性值必须被引号包围,否则不能提取
*
* @param string $content HTML内容
* @param string $absolutePath 网页的绝对路径。如果HTML内容里的图片路径为相对路径,那么就需要填写这个参数,来让该函数自动填补成绝对路径。这个参数最后需要以/结束
* @param bool $isEraseLink 是否去掉HTML内容中的链接
*/
function getWordDocument( $content , $absolutePath = "" , $isEraseLink = true )
{
$mht = new MhtFileMaker();
if ($isEraseLink)
$content = preg_replace('/(\s*.*?\s*)/i' , '$1' , $content); //去掉链接
$images = array();
$files = array();
$matches = array();
//这个算法要求src后的属性值必须使用引号括起来
if ( preg_match_all('/GetMimeType("tmp.html"),$content);
for ( $i=0;$iAddContents($files[$i],$mht->GetMimeType($image),$imgcontent);
}
else
{
echo "file:".$image." not exist!<br />";
}
}
return $mht->GetFile();
}
这个函数的主要作用其实就是分析HTML代码中的所有图片地址,依次下载。获取到图片内容后,调用MhtFileMaker类将图片添加到mht文件中。具体的添加细节封装在 MhtFileMaker 类中。
url= http://www.***.com;
$content = file_get_contents($url);
$fileContent = getWordDocument($content,"http://www.yoursite.com/Music/etc/");
$fp = fopen("test.doc", 'w');
fwrite($fp, $fileContent);
fclose($fp);
其中$content变量应该是HTML源代码,下面的链接应该是可以在HTML代码中填写图片相对路径的URL地址
header("缓存控制:无缓存,必须重新验证");
header("Pragma: no-cache");
$wordStr ='PHP淮北个人网站';
$fileContent = getWordDocument($wordStr);
$fileName = iconv("utf-8", "GBK",'PHP淮北'.'_'.$intro.'_'.rand(100, 999));
header("内容类型:应用程序/文档");
header("Content-Disposition: 附件;文件名=".$fileName.".doc");
回声 $fileContent;
注意在使用这个函数之前,需要收录类MhtFileMaker,它可以帮助我们生成Mht文件。
点评:这种方式的缺点是不支持批量生成和下载,因为一个页面只能有一个header(无论是远程使用还是本地生成的statement header页面都只能输出一个header),即使你循环生成,结果还是只有一个字Generate(当然可以修改上面的方式来实现)
2.纯HTML格式写字
原则:
使用ob_start先存储html页面(解决页面多个header的问题,可以批量生成),然后在写入doc文档的内容时使用
代码:
<p> 查看全部
php 抓取网页生成图片(牢骚发完了,正式写博客吧(PHP生成word原理))
概括:
最近在工作中遇到了生词问题
现在总结一下生成词的三种方法。
btw:好像在博客园里发个博客,只要标题有PHP,好像点击量不是很高(兄弟,我标题还是有PHP的)。我不知道为什么。估计博客园里的网络技术专家比较多。把Java、.net、php比作程序员的闺蜜,那么java就是甲骨文下最好的姑娘,.net微软下的名门世家,PHP就是草根下的野蛮大妈。这让我很期待 PHP 的草根男士这么骚。怎么可能。. 委屈完了,正式写博客
PHP为正文生成word的原理是通过windows下的com组件使用PHP将内容写入doc文件中实现的:
原理:com是PHP的扩展。安装了office的服务器会自动调用word.application的com,可以自动生成文档。PHP 官方文档手册:
使用官方示例:
个人建议:com实例后面的方法需要查一下官方文档才知道是什么意思。编辑器没有代码提示,非常不方便。另外这个效率不是很高,所以不推荐使用
使用 PHP 将内容写入 doc 文件。这种方法可以分为两种方法生成mht格式(类似HTML)并写入word
这种方法主要是指:
/**
* 根据HTML代码获取word文档内容
* 创建一个本质为mht的文档,该函数会分析文件内容并从远程下载页面中的图片资源
* 该函数依赖于类MhtFileMaker
* 该函数会分析img标签,提取src的属性值。但是,src的属性值必须被引号包围,否则不能提取
*
* @param string $content HTML内容
* @param string $absolutePath 网页的绝对路径。如果HTML内容里的图片路径为相对路径,那么就需要填写这个参数,来让该函数自动填补成绝对路径。这个参数最后需要以/结束
* @param bool $isEraseLink 是否去掉HTML内容中的链接
*/
function getWordDocument( $content , $absolutePath = "" , $isEraseLink = true )
{
$mht = new MhtFileMaker();
if ($isEraseLink)
$content = preg_replace('/(\s*.*?\s*)/i' , '$1' , $content); //去掉链接
$images = array();
$files = array();
$matches = array();
//这个算法要求src后的属性值必须使用引号括起来
if ( preg_match_all('/GetMimeType("tmp.html"),$content);
for ( $i=0;$iAddContents($files[$i],$mht->GetMimeType($image),$imgcontent);
}
else
{
echo "file:".$image." not exist!<br />";
}
}
return $mht->GetFile();
}
这个函数的主要作用其实就是分析HTML代码中的所有图片地址,依次下载。获取到图片内容后,调用MhtFileMaker类将图片添加到mht文件中。具体的添加细节封装在 MhtFileMaker 类中。
url= http://www.***.com;
$content = file_get_contents($url);
$fileContent = getWordDocument($content,"http://www.yoursite.com/Music/etc/";);
$fp = fopen("test.doc", 'w');
fwrite($fp, $fileContent);
fclose($fp);
其中$content变量应该是HTML源代码,下面的链接应该是可以在HTML代码中填写图片相对路径的URL地址
header("缓存控制:无缓存,必须重新验证");
header("Pragma: no-cache");
$wordStr ='PHP淮北个人网站';
$fileContent = getWordDocument($wordStr);
$fileName = iconv("utf-8", "GBK",'PHP淮北'.'_'.$intro.'_'.rand(100, 999));
header("内容类型:应用程序/文档");
header("Content-Disposition: 附件;文件名=".$fileName.".doc");
回声 $fileContent;
注意在使用这个函数之前,需要收录类MhtFileMaker,它可以帮助我们生成Mht文件。
点评:这种方式的缺点是不支持批量生成和下载,因为一个页面只能有一个header(无论是远程使用还是本地生成的statement header页面都只能输出一个header),即使你循环生成,结果还是只有一个字Generate(当然可以修改上面的方式来实现)
2.纯HTML格式写字
原则:
使用ob_start先存储html页面(解决页面多个header的问题,可以批量生成),然后在写入doc文档的内容时使用
代码:
<p>
php 抓取网页生成图片(如何利用referer来进行防图片盗链的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-18 00:06
写这个文章主要是因为我之前在知乎上的回答,没想到引起了这么多朋友的关注:
其实代码很简单,一上手就应该搞定。所以前高手关闭了这个文章,谢谢!
这个问题在 16 年时得到了回答,但今天仍在使用和咨询。我优化了代码,写了这个文章。
1 防盗的原理是什么?
当客户端(浏览器)从服务器请求内容时,它会提交一个标头。这个header收录了浏览器信息、cookies等内容,所以有一个referer叫做referer,也收录在里面。
推荐人是做什么用的?
它告诉服务器谁是请求的来源。比如从A页跳转到B页,那么B页收到的referer就是A页。
但图片与此有点不同。图片是在html页面加载后加载的,所以图片接收到的referer不是网页的上一页,而是当前页面。
说了这么多,别上当了。简单的一点是:对于图像,接收到的引用是引用图像的页面的 URL。
那么现在很多网站是如何使用referer来防止图片盗链的呢?
在三种情况下允许引用图像:
这个网站。当没有推荐人信息时。(服务器认为是浏览器直接访问的图片的URL,所以在这种情况下可以正常访问) 授权的URL。2 如何绕过反水蛭链?
上面介绍了3种获取图片的方法。方法一和方法三能实现吗?肯定不是,所以我们只能从方法2开始。
要擦除请求头中的信息,客户端(浏览器中的网页)无法工作,只能从服务器启动。
大体思路如下:
接下来,我们要做的就是做好转运:
您必须首先拥有一台服务器(空间或虚拟主机都可以)。选择你熟悉的语言(php nodeJs java python都可以)。开始写代码。把它放在首页并使用它。3 开始写代码
先从头开始吧,代码很简单,不要有心理压力。我以PHP为例(这两年一直在玩nodejs,PHP降温很快,昨天不得不处理一些复杂的图片,发现PHP在这方面容易一些)。
A 首先定义一个页面抓取功能。有了它,你就可以获取和发布网页,当然,当你能够捕捉图片时,你会需要它。我在原来的基础上优化了一下:
在这种情况下,如果有数据提交,它会自动发布,如果没有数据提交,它会获取。
这个函数写好后,把php文件放在最后,然后直接调用。
B 写主体部分,处理一些错误的情况。
以上部分主要是处理引用图片时出现错误的情况。一种是图片的真实URL没有告诉服务器,另一种是图片的真实地址无法访问。在这两种情况下,错误信息都会以图片的形式输出。
./fonts/hwxh.ttf 这个是字体,放在相对路径下对应的位置,或者不需要这个,直接复制系统字体中的字体名称即可。
C做了这么多准备工作,业务刚刚起步,开始抓图输出:
好无语,前面这么多东西,真东西才3行??
是的,你没看错,就是这样。当然,你可以在图片上加水印什么的,让它更有特色。
4 最终代码
完成后,代码如下:
5 最终检查
我成功地将图片传输到了本地本地主机上的图片(这是带有反水蛭的 网站)。
6 小贴士
使用您自己的服务器进行传输。如果目标图片太大,那么小水管服务器肯定受不了。pixabay最大尺寸的图片最大是几M甚至几十M,加载速度会很慢很慢,所以你可以把php的执行时间设置的更长一些。
同时,如果服务器的带宽很小,建议不要随意向别人开放你的接口,影响自己网站。
7 源代码共享
44886/imgBridge
上面这个地址,php版本已经更新了,nodejs版本不想改了,就按照这个思路吧。
github上的一个朋友提到gif不能移动。还没搞定,不过gif需要一帧一帧的提取出来,没那么简单。请在天亮时更新代码。 查看全部
php 抓取网页生成图片(如何利用referer来进行防图片盗链的呢?)
写这个文章主要是因为我之前在知乎上的回答,没想到引起了这么多朋友的关注:
其实代码很简单,一上手就应该搞定。所以前高手关闭了这个文章,谢谢!
这个问题在 16 年时得到了回答,但今天仍在使用和咨询。我优化了代码,写了这个文章。
1 防盗的原理是什么?
当客户端(浏览器)从服务器请求内容时,它会提交一个标头。这个header收录了浏览器信息、cookies等内容,所以有一个referer叫做referer,也收录在里面。
推荐人是做什么用的?
它告诉服务器谁是请求的来源。比如从A页跳转到B页,那么B页收到的referer就是A页。
但图片与此有点不同。图片是在html页面加载后加载的,所以图片接收到的referer不是网页的上一页,而是当前页面。
说了这么多,别上当了。简单的一点是:对于图像,接收到的引用是引用图像的页面的 URL。
那么现在很多网站是如何使用referer来防止图片盗链的呢?
在三种情况下允许引用图像:
这个网站。当没有推荐人信息时。(服务器认为是浏览器直接访问的图片的URL,所以在这种情况下可以正常访问) 授权的URL。2 如何绕过反水蛭链?
上面介绍了3种获取图片的方法。方法一和方法三能实现吗?肯定不是,所以我们只能从方法2开始。
要擦除请求头中的信息,客户端(浏览器中的网页)无法工作,只能从服务器启动。
大体思路如下:
接下来,我们要做的就是做好转运:
您必须首先拥有一台服务器(空间或虚拟主机都可以)。选择你熟悉的语言(php nodeJs java python都可以)。开始写代码。把它放在首页并使用它。3 开始写代码
先从头开始吧,代码很简单,不要有心理压力。我以PHP为例(这两年一直在玩nodejs,PHP降温很快,昨天不得不处理一些复杂的图片,发现PHP在这方面容易一些)。
A 首先定义一个页面抓取功能。有了它,你就可以获取和发布网页,当然,当你能够捕捉图片时,你会需要它。我在原来的基础上优化了一下:
在这种情况下,如果有数据提交,它会自动发布,如果没有数据提交,它会获取。
这个函数写好后,把php文件放在最后,然后直接调用。
B 写主体部分,处理一些错误的情况。
以上部分主要是处理引用图片时出现错误的情况。一种是图片的真实URL没有告诉服务器,另一种是图片的真实地址无法访问。在这两种情况下,错误信息都会以图片的形式输出。
./fonts/hwxh.ttf 这个是字体,放在相对路径下对应的位置,或者不需要这个,直接复制系统字体中的字体名称即可。
C做了这么多准备工作,业务刚刚起步,开始抓图输出:
好无语,前面这么多东西,真东西才3行??
是的,你没看错,就是这样。当然,你可以在图片上加水印什么的,让它更有特色。
4 最终代码
完成后,代码如下:
5 最终检查
我成功地将图片传输到了本地本地主机上的图片(这是带有反水蛭的 网站)。
6 小贴士
使用您自己的服务器进行传输。如果目标图片太大,那么小水管服务器肯定受不了。pixabay最大尺寸的图片最大是几M甚至几十M,加载速度会很慢很慢,所以你可以把php的执行时间设置的更长一些。
同时,如果服务器的带宽很小,建议不要随意向别人开放你的接口,影响自己网站。
7 源代码共享
44886/imgBridge
上面这个地址,php版本已经更新了,nodejs版本不想改了,就按照这个思路吧。
github上的一个朋友提到gif不能移动。还没搞定,不过gif需要一帧一帧的提取出来,没那么简单。请在天亮时更新代码。
php 抓取网页生成图片(基于更成熟的PHP应用框架和设计理念(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-17 19:19
图片cms图片网站管理系统v1.2.ZIP
PIC cms图片网站 管理系统程序介绍 基于更成熟的PHP应用框架和设计理念,全新的控制器、模型和核心类库;优化多级分类结构,增加全站生成静态页面,加载和SEO方面全面加强;内置采集接口(Beta),以后会增加对其他外部采集器的支持;前后端接口也进行了全面重构,更加简洁、标准、易用。开源所有源代码,保留所有注释,您可以在遵循开源协议的前提下方便地进行二次开发,甚至可以基于技术框架构建一个全新的系统。我们将在未来提供详细的 API 文档。自动生成导航和内容调用14. 模板分离设计,轻松模板设计 15 方便 自由模板方式,可以实现复杂多样的调用效果。1.1 版本升级到1.2 数据库升级请按照以下四部分进行(SQL runner直接运行下面4句SQL,分为四次,不能一下子做,去掉序列号1-4在前面):1:ALTER TABLE `pc_article` ADD `xiaazai` VARCHAR(800)
团队目前拥有美工3人、PHP开发工程师3人、网站运行测试人员2人、项目经理1人、行政秘书2人。PICcms开发团队旨在延续PICcms系统的精髓,在原有PICcms的基础上继续开发专业的图片管理系统,供粉丝和支持者使用提供最佳图片网站解决方案。有品位的PHP开发团队 PICcms开发团队是一代真正有品位、有主见、有个性、热爱生活的PHP开发团队。PICcms开发团队将彰显个性品味与超强性能的融合设计放在首位,旨在提供最专业的画面网站 图片类管理系统为广大网站站长服务。我们来自互联网,永远为互联网的发展进步而奋斗。我们不知道如何运营和盈利,但我们了解PHP技术(我们还是要学习),可以提供高标准的技术服务和安全高效的产品。希望我们的努力能为您提供高效、快速、强大的图片网站解决方案。最纯粹的PHP开发团队原Piccms图片管理系统是原Piccms开发团队于2012年开发的(MyPic开发团队时隔三年复工),可惜原Piccms @cmsV1.1 发布后开发团队就消失在这里了。就像当年的MYPIC,短暂的光辉留下了无限的期待、遗憾和悲伤。为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片<
新PICcms是一个完整的图片网站管理系统品牌,新PICcms开发团队也将专注于PICcms图片网站管理系统。仿网站业务、模板设计、程序定制、源码修改等全方位的网站开发服务。期待英雄归来,新PICcms开发团队是需要不断学习才能茁壮成长的幼稚宝宝。这个过程注定是非常漫长和痛苦的,所以我们真诚地期待着原PICcms(MYPIC)开发团队的回归或者给我们提供帮助,只有英雄的回归才能创造辉煌并继续闪耀,在最短的时间内实现我们的愿景。最后感谢PIC的众多关注者< @cms(如XD-Piccms、IMGcms)谁在原PICcms的基础上进行了二次开发或修改,是你的辛苦与奉献让PICcms得以延续,也正是你们的努力和付出,才让PICcms没有真正消亡。我代表原图cms,向您致以诚挚的问候。作为新的Piccms开发团队,我们也向各位前辈致敬。PIC cms图片网站管理系统运行环境www server Apache, Nginx, IIS等.php 5.0及以上(不支持5.0及以下MySQL 4. 0及以上PIC cms图片网站管理系统安装说明1. 将piccms目录下的所有文件上传到服务器2.
2.您可以在协议规定的约束和限制范围内修改图片cms源代码或界面样式以满足您的网站要求。3.您对使用本软件构建的网站中的所有资料拥有所有权,并独立承担与文章内容相关的法律义务。4. 禁止使用本程序发布非法内容,因违反国家和地方法律法规而引起的相应法律责任必须由个人承担。5.禁止在任何商业组织网站(包括任何公司网站和营利性组织)使用本产品。6.图片cms 开发团队保留源码所有权,禁止篡改代码出售或公开传播。7. 禁止使用本系统搭建任何法律不允许的内容网站。因网站内容引起的任何责任和后果与图片cms无关。PICcms图片网站管理系统1.2版本升级内容1、新增网盘下载连接和网盘提取码选项2、新增压缩包在线下载功能优化SEO系统,通过压缩包解压密码选项3、整合静态生成(html)功能。4、 修改部门详细信息,为WAP铺路。PIC cms图片网站管理系统首页 PICcms图片网站
现在下载 查看全部
php 抓取网页生成图片(基于更成熟的PHP应用框架和设计理念(组图))
图片cms图片网站管理系统v1.2.ZIP
PIC cms图片网站 管理系统程序介绍 基于更成熟的PHP应用框架和设计理念,全新的控制器、模型和核心类库;优化多级分类结构,增加全站生成静态页面,加载和SEO方面全面加强;内置采集接口(Beta),以后会增加对其他外部采集器的支持;前后端接口也进行了全面重构,更加简洁、标准、易用。开源所有源代码,保留所有注释,您可以在遵循开源协议的前提下方便地进行二次开发,甚至可以基于技术框架构建一个全新的系统。我们将在未来提供详细的 API 文档。自动生成导航和内容调用14. 模板分离设计,轻松模板设计 15 方便 自由模板方式,可以实现复杂多样的调用效果。1.1 版本升级到1.2 数据库升级请按照以下四部分进行(SQL runner直接运行下面4句SQL,分为四次,不能一下子做,去掉序列号1-4在前面):1:ALTER TABLE `pc_article` ADD `xiaazai` VARCHAR(800)
团队目前拥有美工3人、PHP开发工程师3人、网站运行测试人员2人、项目经理1人、行政秘书2人。PICcms开发团队旨在延续PICcms系统的精髓,在原有PICcms的基础上继续开发专业的图片管理系统,供粉丝和支持者使用提供最佳图片网站解决方案。有品位的PHP开发团队 PICcms开发团队是一代真正有品位、有主见、有个性、热爱生活的PHP开发团队。PICcms开发团队将彰显个性品味与超强性能的融合设计放在首位,旨在提供最专业的画面网站 图片类管理系统为广大网站站长服务。我们来自互联网,永远为互联网的发展进步而奋斗。我们不知道如何运营和盈利,但我们了解PHP技术(我们还是要学习),可以提供高标准的技术服务和安全高效的产品。希望我们的努力能为您提供高效、快速、强大的图片网站解决方案。最纯粹的PHP开发团队原Piccms图片管理系统是原Piccms开发团队于2012年开发的(MyPic开发团队时隔三年复工),可惜原Piccms @cmsV1.1 发布后开发团队就消失在这里了。就像当年的MYPIC,短暂的光辉留下了无限的期待、遗憾和悲伤。为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 为弥补开源图片网站管理系统PHP开发的空缺,青岛网众文化传媒有限公司互联网技术服务中心投资并牵头。在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片< 在众多PICcms粉丝的支持下,新的PICcms开发团队于2015年12月1日正式成立。在发誓继承原PICcms精髓的同时,将确保其仍然贯彻永久开源和免费的理念,并坚定不移地继续研发。图片分类网站提供高效、快捷、强大的图片<
新PICcms是一个完整的图片网站管理系统品牌,新PICcms开发团队也将专注于PICcms图片网站管理系统。仿网站业务、模板设计、程序定制、源码修改等全方位的网站开发服务。期待英雄归来,新PICcms开发团队是需要不断学习才能茁壮成长的幼稚宝宝。这个过程注定是非常漫长和痛苦的,所以我们真诚地期待着原PICcms(MYPIC)开发团队的回归或者给我们提供帮助,只有英雄的回归才能创造辉煌并继续闪耀,在最短的时间内实现我们的愿景。最后感谢PIC的众多关注者< @cms(如XD-Piccms、IMGcms)谁在原PICcms的基础上进行了二次开发或修改,是你的辛苦与奉献让PICcms得以延续,也正是你们的努力和付出,才让PICcms没有真正消亡。我代表原图cms,向您致以诚挚的问候。作为新的Piccms开发团队,我们也向各位前辈致敬。PIC cms图片网站管理系统运行环境www server Apache, Nginx, IIS等.php 5.0及以上(不支持5.0及以下MySQL 4. 0及以上PIC cms图片网站管理系统安装说明1. 将piccms目录下的所有文件上传到服务器2.
2.您可以在协议规定的约束和限制范围内修改图片cms源代码或界面样式以满足您的网站要求。3.您对使用本软件构建的网站中的所有资料拥有所有权,并独立承担与文章内容相关的法律义务。4. 禁止使用本程序发布非法内容,因违反国家和地方法律法规而引起的相应法律责任必须由个人承担。5.禁止在任何商业组织网站(包括任何公司网站和营利性组织)使用本产品。6.图片cms 开发团队保留源码所有权,禁止篡改代码出售或公开传播。7. 禁止使用本系统搭建任何法律不允许的内容网站。因网站内容引起的任何责任和后果与图片cms无关。PICcms图片网站管理系统1.2版本升级内容1、新增网盘下载连接和网盘提取码选项2、新增压缩包在线下载功能优化SEO系统,通过压缩包解压密码选项3、整合静态生成(html)功能。4、 修改部门详细信息,为WAP铺路。PIC cms图片网站管理系统首页 PICcms图片网站
现在下载
php 抓取网页生成图片(从网站建设到网站SEO的一系列的注意点分析点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-13 04:21
网站SEO优化教程很多想学SEO的童鞋,面对一个网站不知道从何下手或分析。所谓的SEOer,无非就是改了标题和描述。关键字,但这实际上与真正的 SEO 相去甚远。在这里,围围6359将从网站构建到网站SEO的一系列关注点和分析点进行介绍,以帮助SEOer学习者提供参考。面对一个新的网站,我们可以从以下几个方面来思考和分析,但并不代表接下来的教程中的所有注意点都离成功不远了。根据网站@网站根据自己的情况,酌情选择不同的SEO优化方式,否则离K站也不远了。工具/材料将有基本的网站架构,Hml代码,搜索引擎规则,SEO注重实践,执行力强。看别人的成功案例,多了解,总结,操作步骤/方法网站 优化: 1.遵守Web2.0标准,加强页面的交互性,使页面PV值上级,日志或新闻等经常更新的信息尽量生成RSS输出,用Tag标记日志或新闻等信息(用于搜索引擎搜索) 2.尽量符合html4.0 xhtml标准,使用div、ul、li等替换table 3.使用Div CSS进行页面布局。CSS 应该尽可能地写在一个单独的文件中。列表项和Tab使用div+ul+li+css来完成显示4。使用URL Rewriter地址重写可以去掉?pageNo=5等参数,进行泛分析输出。例如, /user.php?userid=test1 将被解析为所有 URL。必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>.
尽量在网页上所有能被搜索引擎抓取的文字中收录关键词。这些地方包括:域名、标题和元标签、正文、链接文本、文件名、alt、标题标签(即正文标题等),让你的关键词无处不在,但避免堆积太多同一个地方。2、域名策略 域名中最好收录你的关键词,并用连字符“-”分别突出关键词,方便搜索引擎识别。有专家认为,域名中的关键词对排名的影响较弱,但不可否认,它们确实有作用。所以,如果可以兼顾情况,尽量考虑使用关键字域名。3.虚拟主机策略检查共享IP地址网站:目前大多数中小型< @网站 共享一个具有相同 IP 地址的虚拟主机。如果与您共享IP的网站之一被搜索引擎惩罚,您将无法登录搜索引擎。另外,由于一个IP往往有数百个网站,会影响你的网页下载速度。特别是如果其中一些网站有很多流量。如果搜索引擎在爬行时半天无法下载页面,搜索机器人就会放弃它。所以,除了要知道有多少网站与你分享了IP,有没有被处罚,最好能知道他们的流量大致情况。如果情况不好,尽快更换主机。4.网页文件目录策略有序,文件目录结构安排合理,命名规范。一个简单的网站
重要的内容放在顶级目录中。目录文件夹名收录关键词,HTML网页文件名也收录关键词。图片文件还收录关键词。这里所指的关键词主要是针对具体页面的内容。如果文件名是短语,请使用破折号或下划线将其分隔。. externalfiles(外部文件存储)策略将 javascript 文件和 css 文件分别放在 js 和 css 外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体 (FONT) 和格式标签也应谨慎使用。6. 动态策略动态页面是由ASP、PHP、CGI等程序动态生成的页面,只有用户输入条件提交后才能生成。有两种方法可以让搜索引擎抓取它:在静态页面(如网站地图)上创建动态页面的链接,或者将该动态页面的URL修改为静态HTML文件,以便URL 不收录 ?、=、&、% 和 $ 等符号。7、框架策略:如果网站必须使用框架,则应正确使用noframe标签,并在区域中收录指向框架或带有关键词的描述文本,并在同时框外的文字关键词也出现在区域内。8、图片策略:在图片的代码中使用Alt属性标签进行说明,包括<
避免纯图片页面(Splash),比如一些企业的网站首页图片页面。Flash 应谨慎使用,搜索引擎对跟踪其嵌入的链接几乎没有兴趣。收录图像的页面的字节数不应超过 50K。9、网站 地图策略:基于文本的 网站 地图收录所有列和子列 网站 。网站 地图的三个主要元素:文本、链接和关键字,对于搜索引擎抓取主页内容非常有帮助。因此,动态生成的目录网站特别需要创建网站映射。网页栏目如有更新,需及时反映在地图网站上。10、标题和元标签策略:基本的搜索引擎优化:title 标题的内容会以链接标题的形式显示在搜索结果页面上。标题一般是对网站名称的简短描述,包括核心关键词。meta中的关键词(关键词)和描述(description):确定几个核心的关键词和组合。关键字应该是3-5个,最好不要超过15个,以免堆叠。不喜欢。描述是对网站的简要描述,包括如果每个主页的内容差异很大的信息,标题和元标签应该根据网页的内容进行更改。不要将主页的标题和标签用于所有网页。网页的文字内容必须出现在关键词页面上,关键词的密度在3%-7%之间。疑似堆积太多。搜索结果页面链接标题后显示的描述性文字,一般是本页面正文中搜索引擎首先抓取到的收录关键词的文字。
据说这个文字通常出现在网页的左上角最有利。11、链接策略:让其他与你话题相关的网站尽可能多的链接到你,这已经成为搜索引擎排名成功的关键因素。有了这些网站链接你,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你很好的排名。另一方面,如果网站提供话题相关导出链接,搜索引擎认为有丰富的话题相关内容,也有利于排名(这一点值得专家反思)。12、 避免惩罚:搜索引擎在识别欺骗手段方面变得越来越复杂。以下几种常见的作弊方式很容易受到处罚。拒绝收录:隐藏文字,或者无意中设置了文字文字的背景色;关键词堆叠;主动链接到link farm网站(由大量网站交叉链接组成的网络系统);防范措施得当,不要使用不正常的方法,否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程! 查看全部
php 抓取网页生成图片(从网站建设到网站SEO的一系列的注意点分析点)
网站SEO优化教程很多想学SEO的童鞋,面对一个网站不知道从何下手或分析。所谓的SEOer,无非就是改了标题和描述。关键字,但这实际上与真正的 SEO 相去甚远。在这里,围围6359将从网站构建到网站SEO的一系列关注点和分析点进行介绍,以帮助SEOer学习者提供参考。面对一个新的网站,我们可以从以下几个方面来思考和分析,但并不代表接下来的教程中的所有注意点都离成功不远了。根据网站@网站根据自己的情况,酌情选择不同的SEO优化方式,否则离K站也不远了。工具/材料将有基本的网站架构,Hml代码,搜索引擎规则,SEO注重实践,执行力强。看别人的成功案例,多了解,总结,操作步骤/方法网站 优化: 1.遵守Web2.0标准,加强页面的交互性,使页面PV值上级,日志或新闻等经常更新的信息尽量生成RSS输出,用Tag标记日志或新闻等信息(用于搜索引擎搜索) 2.尽量符合html4.0 xhtml标准,使用div、ul、li等替换table 3.使用Div CSS进行页面布局。CSS 应该尽可能地写在一个单独的文件中。列表项和Tab使用div+ul+li+css来完成显示4。使用URL Rewriter地址重写可以去掉?pageNo=5等参数,进行泛分析输出。例如, /user.php?userid=test1 将被解析为所有 URL。必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>.
尽量在网页上所有能被搜索引擎抓取的文字中收录关键词。这些地方包括:域名、标题和元标签、正文、链接文本、文件名、alt、标题标签(即正文标题等),让你的关键词无处不在,但避免堆积太多同一个地方。2、域名策略 域名中最好收录你的关键词,并用连字符“-”分别突出关键词,方便搜索引擎识别。有专家认为,域名中的关键词对排名的影响较弱,但不可否认,它们确实有作用。所以,如果可以兼顾情况,尽量考虑使用关键字域名。3.虚拟主机策略检查共享IP地址网站:目前大多数中小型< @网站 共享一个具有相同 IP 地址的虚拟主机。如果与您共享IP的网站之一被搜索引擎惩罚,您将无法登录搜索引擎。另外,由于一个IP往往有数百个网站,会影响你的网页下载速度。特别是如果其中一些网站有很多流量。如果搜索引擎在爬行时半天无法下载页面,搜索机器人就会放弃它。所以,除了要知道有多少网站与你分享了IP,有没有被处罚,最好能知道他们的流量大致情况。如果情况不好,尽快更换主机。4.网页文件目录策略有序,文件目录结构安排合理,命名规范。一个简单的网站
重要的内容放在顶级目录中。目录文件夹名收录关键词,HTML网页文件名也收录关键词。图片文件还收录关键词。这里所指的关键词主要是针对具体页面的内容。如果文件名是短语,请使用破折号或下划线将其分隔。. externalfiles(外部文件存储)策略将 javascript 文件和 css 文件分别放在 js 和 css 外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体 (FONT) 和格式标签也应谨慎使用。6. 动态策略动态页面是由ASP、PHP、CGI等程序动态生成的页面,只有用户输入条件提交后才能生成。有两种方法可以让搜索引擎抓取它:在静态页面(如网站地图)上创建动态页面的链接,或者将该动态页面的URL修改为静态HTML文件,以便URL 不收录 ?、=、&、% 和 $ 等符号。7、框架策略:如果网站必须使用框架,则应正确使用noframe标签,并在区域中收录指向框架或带有关键词的描述文本,并在同时框外的文字关键词也出现在区域内。8、图片策略:在图片的代码中使用Alt属性标签进行说明,包括<
避免纯图片页面(Splash),比如一些企业的网站首页图片页面。Flash 应谨慎使用,搜索引擎对跟踪其嵌入的链接几乎没有兴趣。收录图像的页面的字节数不应超过 50K。9、网站 地图策略:基于文本的 网站 地图收录所有列和子列 网站 。网站 地图的三个主要元素:文本、链接和关键字,对于搜索引擎抓取主页内容非常有帮助。因此,动态生成的目录网站特别需要创建网站映射。网页栏目如有更新,需及时反映在地图网站上。10、标题和元标签策略:基本的搜索引擎优化:title 标题的内容会以链接标题的形式显示在搜索结果页面上。标题一般是对网站名称的简短描述,包括核心关键词。meta中的关键词(关键词)和描述(description):确定几个核心的关键词和组合。关键字应该是3-5个,最好不要超过15个,以免堆叠。不喜欢。描述是对网站的简要描述,包括如果每个主页的内容差异很大的信息,标题和元标签应该根据网页的内容进行更改。不要将主页的标题和标签用于所有网页。网页的文字内容必须出现在关键词页面上,关键词的密度在3%-7%之间。疑似堆积太多。搜索结果页面链接标题后显示的描述性文字,一般是本页面正文中搜索引擎首先抓取到的收录关键词的文字。
据说这个文字通常出现在网页的左上角最有利。11、链接策略:让其他与你话题相关的网站尽可能多的链接到你,这已经成为搜索引擎排名成功的关键因素。有了这些网站链接你,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你很好的排名。另一方面,如果网站提供话题相关导出链接,搜索引擎认为有丰富的话题相关内容,也有利于排名(这一点值得专家反思)。12、 避免惩罚:搜索引擎在识别欺骗手段方面变得越来越复杂。以下几种常见的作弊方式很容易受到处罚。拒绝收录:隐藏文字,或者无意中设置了文字文字的背景色;关键词堆叠;主动链接到link farm网站(由大量网站交叉链接组成的网络系统);防范措施得当,不要使用不正常的方法,否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!
php 抓取网页生成图片(从网站建设到网站SEO的一系列的注意点分析点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-13 04:21
网站SEO优化教程很多想学SEO的童鞋,面对一个网站不知道从何下手或分析。所谓的SEOer,无非就是改了标题和描述。关键字,但这实际上与真正的 SEO 相去甚远。在这里,围围6359将从网站构建到网站SEO的一系列关注点和分析点进行介绍,以帮助SEOer学习者提供参考。面对一个新的网站,我们可以从以下几个方面来思考和分析,但并不代表接下来的教程中的所有注意点都离成功不远了。根据网站@网站根据自己的情况,酌情选择不同的SEO优化方式,否则离K站也不远了。【微店网百利】工具/素材将有基本的网站架构,Hml代码,搜索引擎规则,SEO注重实践,执行力强。看看别人的成功案例,多了解,总结,操作Steps/Methods上级,日志或新闻等经常更新的信息尽量生成RSS输出,用Tag标记日志或新闻等信息(用于搜索引擎搜索) 2.尽量符合html4.0或xhtml标准,用div、ul、li等代替table 3.使用Div CSS进行页面布局。CSS 应该尽可能地写在一个单独的文件中。列表项和Tab使用div+ul+li+css来完成显示4。使用URL Rewriter地址重写可以去掉?pageNo=5等参数,进行泛分析输出。例如, /user.php?userid=test1 将被解析为所有 URL。必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>.
尽量在网页上所有能被搜索引擎抓取的文字中收录关键词。这些地方包括:域名、标题和元标签、正文、链接文本、文件名、alt、标题标签(即正文标题等),让你的关键词无处不在,但避免堆积太多同一个地方。2、域名策略 域名中最好收录你的关键词,并用连字符“-”分别突出关键词,方便搜索引擎识别。有专家认为,域名中的关键词对排名的影响较弱,但不可否认,它们确实有作用。所以,如果可以兼顾情况,尽量考虑使用关键字域名。3.虚拟主机策略检查共享IP地址网站:目前大多数中小型< @网站 共享一个具有相同 IP 地址的虚拟主机。如果与您共享IP的网站之一被搜索引擎惩罚,您将无法登录搜索引擎。另外,由于一个IP往往有数百个网站,会影响你的网页下载速度。特别是如果其中一些网站有很多流量。如果搜索引擎在爬行时半天无法下载页面,搜索机器人就会放弃它。所以,除了要知道有多少网站与你分享了IP,有没有被处罚,最好能知道他们的流量大致情况。如果情况不好,尽快更换主机。4.网页文件目录策略有序,文件目录结构安排合理,命名规范。一个简单的网站
重要的内容放在顶级目录中。目录文件夹名收录关键词,HTML网页文件名也收录关键词。图片文件还收录关键词。这里所指的关键词主要是针对具体页面的内容。如果文件名是短语,请使用破折号或下划线将其分隔。. externalfiles(外部文件存储)策略将 javascript 文件和 css 文件分别放在 js 和 css 外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体 (FONT) 和格式标签也应谨慎使用。6. 动态策略动态页面是由ASP、PHP、CGI等程序动态生成的页面,只有用户输入条件提交后才能生成。有两种方法可以让搜索引擎抓取它:在静态页面(如网站地图)上创建动态页面的链接,或者将该动态页面的URL修改为静态HTML文件,以便URL 不收录 ?、=、&、% 和 $ 等符号。7、框架策略:如果网站必须使用框架,则应正确使用noframe标签,并在区域中收录指向框架或带有关键词的描述文本,并在同时框外的文字关键词也出现在区域内。8、图片策略:在图片的代码中使用Alt属性标签进行说明,包括<
避免纯图片页面(Splash),比如一些企业的网站首页图片页面。Flash 应谨慎使用,搜索引擎对跟踪其嵌入的链接几乎没有兴趣。收录图像的页面的字节数不应超过 50K。9、网站 地图策略:基于文本的 网站 地图收录所有列和子列 网站 。网站 地图的三个主要元素:文本、链接和关键字,对于搜索引擎抓取主页内容非常有帮助。因此,动态生成的目录网站特别需要创建网站映射。网页栏目如有更新,需及时反映在地图网站上。10、标题和元标签策略:基本的搜索引擎优化:title 标题的内容会以链接标题的形式显示在搜索结果页面上。标题一般是对网站名称的简短描述,包括核心关键词。meta中的关键词(关键词)和描述(description):确定几个核心的关键词和组合。关键字应该是3-5个,最好不要超过15个,以免堆叠。不喜欢。描述是对网站的简要描述,包括如果每个主页的内容差异很大的信息,标题和元标签应该根据网页的内容进行更改。不要将主页的标题和标签用于所有网页。网页的文字内容必须出现在关键词页面上,关键词的密度在3%-7%之间。疑似堆积太多。搜索结果页面链接标题后显示的描述性文字,一般是本页面正文中搜索引擎首先抓取到的收录关键词的文字。
据说这个文字通常出现在网页的左上角最有利。11、链接策略:让其他与你话题相关的网站尽可能多的链接到你,这已经成为搜索引擎排名成功的关键因素。有了这些网站链接你,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你很好的排名。另一方面,如果网站提供话题相关导出链接,搜索引擎认为有丰富的话题相关内容,也有利于排名(这一点值得专家反思)。12、 避免惩罚:搜索引擎在识别欺骗手段方面变得越来越复杂。以下方法常用于作弊,很容易受到惩罚。拒绝收录:隐藏文本,或无意中将文本设置为背景色;关键词堆叠;主动链接链接农场网站(由大量网站交叉链接组成的网络系统);防范措施得当,不要使用不正常的方法,否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程! 查看全部
php 抓取网页生成图片(从网站建设到网站SEO的一系列的注意点分析点)
网站SEO优化教程很多想学SEO的童鞋,面对一个网站不知道从何下手或分析。所谓的SEOer,无非就是改了标题和描述。关键字,但这实际上与真正的 SEO 相去甚远。在这里,围围6359将从网站构建到网站SEO的一系列关注点和分析点进行介绍,以帮助SEOer学习者提供参考。面对一个新的网站,我们可以从以下几个方面来思考和分析,但并不代表接下来的教程中的所有注意点都离成功不远了。根据网站@网站根据自己的情况,酌情选择不同的SEO优化方式,否则离K站也不远了。【微店网百利】工具/素材将有基本的网站架构,Hml代码,搜索引擎规则,SEO注重实践,执行力强。看看别人的成功案例,多了解,总结,操作Steps/Methods上级,日志或新闻等经常更新的信息尽量生成RSS输出,用Tag标记日志或新闻等信息(用于搜索引擎搜索) 2.尽量符合html4.0或xhtml标准,用div、ul、li等代替table 3.使用Div CSS进行页面布局。CSS 应该尽可能地写在一个单独的文件中。列表项和Tab使用div+ul+li+css来完成显示4。使用URL Rewriter地址重写可以去掉?pageNo=5等参数,进行泛分析输出。例如, /user.php?userid=test1 将被解析为所有 URL。必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>. 必须输入绝对路径以确保重写地址。5.图片的显示backimageURL替换img标签的正确性。尽量在图片的alt中添加说明,最好包括图片的关键词 6.页面性能参数页面控制在50k以内。页面响应速度尽量使用在5秒内的URL地址,而不是-SEO优化策略: 1.关键词策略决定了网站关键词@的核心>.
尽量在网页上所有能被搜索引擎抓取的文字中收录关键词。这些地方包括:域名、标题和元标签、正文、链接文本、文件名、alt、标题标签(即正文标题等),让你的关键词无处不在,但避免堆积太多同一个地方。2、域名策略 域名中最好收录你的关键词,并用连字符“-”分别突出关键词,方便搜索引擎识别。有专家认为,域名中的关键词对排名的影响较弱,但不可否认,它们确实有作用。所以,如果可以兼顾情况,尽量考虑使用关键字域名。3.虚拟主机策略检查共享IP地址网站:目前大多数中小型< @网站 共享一个具有相同 IP 地址的虚拟主机。如果与您共享IP的网站之一被搜索引擎惩罚,您将无法登录搜索引擎。另外,由于一个IP往往有数百个网站,会影响你的网页下载速度。特别是如果其中一些网站有很多流量。如果搜索引擎在爬行时半天无法下载页面,搜索机器人就会放弃它。所以,除了要知道有多少网站与你分享了IP,有没有被处罚,最好能知道他们的流量大致情况。如果情况不好,尽快更换主机。4.网页文件目录策略有序,文件目录结构安排合理,命名规范。一个简单的网站
重要的内容放在顶级目录中。目录文件夹名收录关键词,HTML网页文件名也收录关键词。图片文件还收录关键词。这里所指的关键词主要是针对具体页面的内容。如果文件名是短语,请使用破折号或下划线将其分隔。. externalfiles(外部文件存储)策略将 javascript 文件和 css 文件分别放在 js 和 css 外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体 (FONT) 和格式标签也应谨慎使用。6. 动态策略动态页面是由ASP、PHP、CGI等程序动态生成的页面,只有用户输入条件提交后才能生成。有两种方法可以让搜索引擎抓取它:在静态页面(如网站地图)上创建动态页面的链接,或者将该动态页面的URL修改为静态HTML文件,以便URL 不收录 ?、=、&、% 和 $ 等符号。7、框架策略:如果网站必须使用框架,则应正确使用noframe标签,并在区域中收录指向框架或带有关键词的描述文本,并在同时框外的文字关键词也出现在区域内。8、图片策略:在图片的代码中使用Alt属性标签进行说明,包括<
避免纯图片页面(Splash),比如一些企业的网站首页图片页面。Flash 应谨慎使用,搜索引擎对跟踪其嵌入的链接几乎没有兴趣。收录图像的页面的字节数不应超过 50K。9、网站 地图策略:基于文本的 网站 地图收录所有列和子列 网站 。网站 地图的三个主要元素:文本、链接和关键字,对于搜索引擎抓取主页内容非常有帮助。因此,动态生成的目录网站特别需要创建网站映射。网页栏目如有更新,需及时反映在地图网站上。10、标题和元标签策略:基本的搜索引擎优化:title 标题的内容会以链接标题的形式显示在搜索结果页面上。标题一般是对网站名称的简短描述,包括核心关键词。meta中的关键词(关键词)和描述(description):确定几个核心的关键词和组合。关键字应该是3-5个,最好不要超过15个,以免堆叠。不喜欢。描述是对网站的简要描述,包括如果每个主页的内容差异很大的信息,标题和元标签应该根据网页的内容进行更改。不要将主页的标题和标签用于所有网页。网页的文字内容必须出现在关键词页面上,关键词的密度在3%-7%之间。疑似堆积太多。搜索结果页面链接标题后显示的描述性文字,一般是本页面正文中搜索引擎首先抓取到的收录关键词的文字。
据说这个文字通常出现在网页的左上角最有利。11、链接策略:让其他与你话题相关的网站尽可能多的链接到你,这已经成为搜索引擎排名成功的关键因素。有了这些网站链接你,即使你不向搜索引擎提交网站,搜索引擎自然会找到你,给你很好的排名。另一方面,如果网站提供话题相关导出链接,搜索引擎认为有丰富的话题相关内容,也有利于排名(这一点值得专家反思)。12、 避免惩罚:搜索引擎在识别欺骗手段方面变得越来越复杂。以下方法常用于作弊,很容易受到惩罚。拒绝收录:隐藏文本,或无意中将文本设置为背景色;关键词堆叠;主动链接链接农场网站(由大量网站交叉链接组成的网络系统);防范措施得当,不要使用不正常的方法,否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!否则得不偿失。本文由围围6359采集整理,百度将在围围6359上系统学习SEO课程!
php 抓取网页生成图片(php的文字转图片转化为图片就会安全吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-12 22:08
)
在网站的日常建设中,会在网站发布电话、邮箱等信息。如果直接是文本内容,很容易被网络爬虫抓取,会带来一定的安全隐患。如果将文本转换为图像会更安全。这与网站中登录验证码的基本生成原理类似,只是将文字转化为图片的生成过程比较复杂,扫描机无法识别。
将php文本转换为图片很容易。首先打开php安装目录下的php.ini,找到extension=php_gd2.dll,去掉前面的引号,打开php的gd2扩展库,可以直接使用php关键字,转换文本印象。
目录结构如下,img_generator.php是文本转图片的php,index.html是呈现给用户的页面。
index.html 的代码非常非常简单。制作一个img标签,在src里面写img_generator.php,然后向img_generator.php发送一个带text参数的Get请求。img_generator.php 页面本质上是基于参数的。制作的一张图片。
图片测试
img_generator.php 的代码如下,通过 $_REQUEST["text"]; 获取index.html中img标签传递过来的文字描述,然后使用一系列php关键字,就是固有方法生成的图片。. 查看全部
php 抓取网页生成图片(php的文字转图片转化为图片就会安全吗?
)
在网站的日常建设中,会在网站发布电话、邮箱等信息。如果直接是文本内容,很容易被网络爬虫抓取,会带来一定的安全隐患。如果将文本转换为图像会更安全。这与网站中登录验证码的基本生成原理类似,只是将文字转化为图片的生成过程比较复杂,扫描机无法识别。
将php文本转换为图片很容易。首先打开php安装目录下的php.ini,找到extension=php_gd2.dll,去掉前面的引号,打开php的gd2扩展库,可以直接使用php关键字,转换文本印象。
目录结构如下,img_generator.php是文本转图片的php,index.html是呈现给用户的页面。
index.html 的代码非常非常简单。制作一个img标签,在src里面写img_generator.php,然后向img_generator.php发送一个带text参数的Get请求。img_generator.php 页面本质上是基于参数的。制作的一张图片。
图片测试
img_generator.php 的代码如下,通过 $_REQUEST["text"]; 获取index.html中img标签传递过来的文字描述,然后使用一系列php关键字,就是固有方法生成的图片。.
php 抓取网页生成图片(Python批量抓取图片图片(1)--写在前面的话)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-06 20:23
——写在前面的话
相信你一定看过一篇文章的文章,题目是《只因为我写了一个爬虫,公司200多人被抓了!》《公众号文章(文章的描述已经很明显了,大家很清楚)
可以说,因为这次事件的恐慌和哗然,一些三线和二线个体爬虫工程师急于转行。其次,有的朋友对自己学到的爬虫技术感到担忧和恐慌。
其实每个人都会有这种警惕。不过,也没有必要像换个职业那样打一场大仗。我们还是要从业务本身做起,不仅要提升我们的业务能力,还要熟悉互联网的法律法规。虽然我个人没有学过爬虫的技术,但平时喜欢学习爬虫的一些小项目和小工具。虽然我花在学习算法上的时间比例少了很多,但我个人还是喜欢尝试一些新鲜的。技术可以丰富自己的业务水平。从这个角度来说,大多数工程师都会有这种业务倾向。当然,对于那些走在互联网第一线的爬虫工程师和大佬来说,我只是沧海一粟,水滴的数量是不够的。
说到上述事情,归根结底是一些公司和公司员工缺乏足够的法律知识。公司对员工的法制宣传和商业道德未能取得潜移默化的效果,尤其是互联网法律法规相关规定的传达。思想工作也没有及时到位。当然,这些不能总是依赖于公司。主要原因是个人的悟性。既然你已经这样做了,那么你应该对这个行业的法律知识有很好的了解和学习。为此,作为这个时代技术创新和技术研发的一员,我们必须始终遵守互联网法律法规,做好自己的本职工作,为社会做出更多的贡献。
文章内容:
——写在前面的话
1-捕获工件
2-使用Python批量抓取图片
(1) 抓取对象:搜狗画廊
(2) 抢类别:进入搜狗壁纸
(3)使用请求提取图像组件
(4)找到图片的真实url
(5)批量抓取图片成功
开始学习今天的内容吧~~
1-捕获工件
一个我一直很喜欢的谷歌图片捕捉插件叫做ImageAssistant
目前用户数为114,567,可以说是很不错了
和 Python 批量抓图效果完全一样
我不是为谷歌打广告,我只是觉得有用,分享给大家,提高办公效率。当然,本节最重要的是学习Python中批量抓取图片的原理和方法。
下面简单介绍一下插件的使用。安装插件后记得选择存放文件的地方,关闭谷歌设置下的下载查询访问
(不然每次都要按保存,很麻烦。如果有100张图片,肯定要按100次)
安装好插件后,下面通过视频简单演示一下爬取的过程。
例如:去微博拍一下鞠婧祎小姐的照片,
进入后可以右键IA工具
2-使用Python批量抓取图片
注:文中抓字意为“攀登”
(1) 抓取对象:搜狗画廊
(2)抓取类别:进入搜狗壁纸,打开网页源码(快捷键是F12)
由于我使用的是 Google chrome 浏览器,所以我需要找到 img 标签
(3)使用请求提取图像组件
抓取思路和使用库文件请求
可以发现img标签下有图片src,所以使用Python requests提取组件获取img src,然后使用库urllib.request.urlretrieve将图片一一下载,达到目的批量获取数据。
开始爬行的第一步:
(注意:Network-->headers,然后用鼠标点击左侧菜单栏(地址栏)中的图片链接,然后在headers中找到图片url)
我们按照上面的思路爬取我们想要的结果:搜索网页代码后,搜狗图片的网址为
%B1%DA%D6%BD
这里的URL来自进入分类后的地址栏(如上图)。
分析源码分析上述URL所指向的网页
import requests #导入库requests
import urllib #导入库requests下面的urllib
from bs4 import BeautifulSoup
#使用BeautifulSoup,关于这个的用法请查看本公众号往期文章
#下面填入url
res = requests.get('http://pic.sogou.com/pics/reco ... 23x27;)
soup = BeautifulSoup(res.text,'html.parser')
print(soup.select('img')) #图片打印格式
结果
从上面的执行结果来看,打印出来的输出内容并没有我们想要的图片元素,只是分析了tupian130x34_@1x的img(或者网页中的logo),这显然不是我们想要的。也就是说,需要的图片数据不在url下,也就是不在下面的url中
%B1%DA%D6%BD。
因此,我们需要找到图片不在URL中的原因,并在下面进行改进。
开始爬取第二步:
考虑到图片元素可能是动态的,细心的人可能会发现,在网页中向下滑动鼠标滚轮时,图片是动态刷新的。也就是说,网页并不是一次性加载所有资源,而是动态加载资源。这也避免了因为网页过于臃肿而影响加载速度。
(4)找到图片的真实url
要找到所有图片的真实URL,这看起来有点困难,但在本项目中尝试一下也不是不可能。在接下来的学习中,经过不断的研究,我想我会逐渐提高这种业务的能力。
类似于第一步中的“注释”,我们找到位置:
F12——>>网络——>>XHR——>>(点击XHR下的文件)——>>预览
(注:如果在预览中没有找到内容,可以滚动左侧地址栏或点击图片链接)
从上图来看,图中的信息似乎就是我们需要的元素。点击all_items,发现下面是0 1 2 3... 一一看起来像图片元素的数据。
尝试打开一个网址。发现真的是图片地址
我们可以在其中任意选择一张图片的地址来验证是否是图片所在的位置:
把地址粘贴到浏览器中搜索,得到如下结果,说明这个地址的url就是我们要找的
找到上图的目标后,我们点击XHR下的Headers,也就是第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
尝试删除一些不需要的部分。去掉以上部分后,访问不会受到影响。
(删除的位置类似同一个地方,切记不要删除后面的长宽高)
例如:删除“=%E5%A3%81%E7%BA%B8&tag”得到
%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
将网站复制到查看器,得到如下结果:
url中的category为类别,start为起始索引,len为长度,即图片数量。
另外注意imgs下的url内容(不要直接复制url)
替换为“+”
(5)批量抓取图片成功
如果你的电脑没有库文件请求,记得安装cmd命令:
pip 安装请求
最后,不断排序后的源码如下:
import requests
import json #使用json码
import urllib
def getSogouImag(category,length,path):
n = length
cate = category #分类
imgs = requests.get('http://pic.sogou.com/pics/chan ... 2Bstr(n))
jd = json.loads(imgs.text)
jd = jd['all_items']
imgs_url = [] #在url获取图片imgs
for j in jd:
imgs_url.append(j['bthumbUrl'])
m = 0
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg')
m = m + 1
print('Download complete!')
getSogouImag('壁纸',2000,'F:/Py666/抓图/') #抓取后图片存取的本地位置
执行程序:到指定位置找到图片所在的位置,就大功告成了。 查看全部
php 抓取网页生成图片(Python批量抓取图片图片(1)--写在前面的话)
——写在前面的话
相信你一定看过一篇文章的文章,题目是《只因为我写了一个爬虫,公司200多人被抓了!》《公众号文章(文章的描述已经很明显了,大家很清楚)
可以说,因为这次事件的恐慌和哗然,一些三线和二线个体爬虫工程师急于转行。其次,有的朋友对自己学到的爬虫技术感到担忧和恐慌。
其实每个人都会有这种警惕。不过,也没有必要像换个职业那样打一场大仗。我们还是要从业务本身做起,不仅要提升我们的业务能力,还要熟悉互联网的法律法规。虽然我个人没有学过爬虫的技术,但平时喜欢学习爬虫的一些小项目和小工具。虽然我花在学习算法上的时间比例少了很多,但我个人还是喜欢尝试一些新鲜的。技术可以丰富自己的业务水平。从这个角度来说,大多数工程师都会有这种业务倾向。当然,对于那些走在互联网第一线的爬虫工程师和大佬来说,我只是沧海一粟,水滴的数量是不够的。
说到上述事情,归根结底是一些公司和公司员工缺乏足够的法律知识。公司对员工的法制宣传和商业道德未能取得潜移默化的效果,尤其是互联网法律法规相关规定的传达。思想工作也没有及时到位。当然,这些不能总是依赖于公司。主要原因是个人的悟性。既然你已经这样做了,那么你应该对这个行业的法律知识有很好的了解和学习。为此,作为这个时代技术创新和技术研发的一员,我们必须始终遵守互联网法律法规,做好自己的本职工作,为社会做出更多的贡献。
文章内容:
——写在前面的话
1-捕获工件
2-使用Python批量抓取图片
(1) 抓取对象:搜狗画廊
(2) 抢类别:进入搜狗壁纸
(3)使用请求提取图像组件
(4)找到图片的真实url
(5)批量抓取图片成功
开始学习今天的内容吧~~
1-捕获工件
一个我一直很喜欢的谷歌图片捕捉插件叫做ImageAssistant
目前用户数为114,567,可以说是很不错了
和 Python 批量抓图效果完全一样
我不是为谷歌打广告,我只是觉得有用,分享给大家,提高办公效率。当然,本节最重要的是学习Python中批量抓取图片的原理和方法。
下面简单介绍一下插件的使用。安装插件后记得选择存放文件的地方,关闭谷歌设置下的下载查询访问
(不然每次都要按保存,很麻烦。如果有100张图片,肯定要按100次)
安装好插件后,下面通过视频简单演示一下爬取的过程。
例如:去微博拍一下鞠婧祎小姐的照片,
进入后可以右键IA工具
2-使用Python批量抓取图片
注:文中抓字意为“攀登”
(1) 抓取对象:搜狗画廊
(2)抓取类别:进入搜狗壁纸,打开网页源码(快捷键是F12)
由于我使用的是 Google chrome 浏览器,所以我需要找到 img 标签
(3)使用请求提取图像组件
抓取思路和使用库文件请求
可以发现img标签下有图片src,所以使用Python requests提取组件获取img src,然后使用库urllib.request.urlretrieve将图片一一下载,达到目的批量获取数据。
开始爬行的第一步:
(注意:Network-->headers,然后用鼠标点击左侧菜单栏(地址栏)中的图片链接,然后在headers中找到图片url)
我们按照上面的思路爬取我们想要的结果:搜索网页代码后,搜狗图片的网址为
%B1%DA%D6%BD
这里的URL来自进入分类后的地址栏(如上图)。
分析源码分析上述URL所指向的网页
import requests #导入库requests
import urllib #导入库requests下面的urllib
from bs4 import BeautifulSoup
#使用BeautifulSoup,关于这个的用法请查看本公众号往期文章
#下面填入url
res = requests.get('http://pic.sogou.com/pics/reco ... 23x27;)
soup = BeautifulSoup(res.text,'html.parser')
print(soup.select('img')) #图片打印格式
结果
从上面的执行结果来看,打印出来的输出内容并没有我们想要的图片元素,只是分析了tupian130x34_@1x的img(或者网页中的logo),这显然不是我们想要的。也就是说,需要的图片数据不在url下,也就是不在下面的url中
%B1%DA%D6%BD。
因此,我们需要找到图片不在URL中的原因,并在下面进行改进。
开始爬取第二步:
考虑到图片元素可能是动态的,细心的人可能会发现,在网页中向下滑动鼠标滚轮时,图片是动态刷新的。也就是说,网页并不是一次性加载所有资源,而是动态加载资源。这也避免了因为网页过于臃肿而影响加载速度。
(4)找到图片的真实url
要找到所有图片的真实URL,这看起来有点困难,但在本项目中尝试一下也不是不可能。在接下来的学习中,经过不断的研究,我想我会逐渐提高这种业务的能力。
类似于第一步中的“注释”,我们找到位置:
F12——>>网络——>>XHR——>>(点击XHR下的文件)——>>预览
(注:如果在预览中没有找到内容,可以滚动左侧地址栏或点击图片链接)
从上图来看,图中的信息似乎就是我们需要的元素。点击all_items,发现下面是0 1 2 3... 一一看起来像图片元素的数据。
尝试打开一个网址。发现真的是图片地址
我们可以在其中任意选择一张图片的地址来验证是否是图片所在的位置:
把地址粘贴到浏览器中搜索,得到如下结果,说明这个地址的url就是我们要找的
找到上图的目标后,我们点击XHR下的Headers,也就是第二行
请求网址:
%E5%A3%81%E7%BA%B8&tag=%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
尝试删除一些不需要的部分。去掉以上部分后,访问不会受到影响。
(删除的位置类似同一个地方,切记不要删除后面的长宽高)
例如:删除“=%E5%A3%81%E7%BA%B8&tag”得到
%E5%85%A8%E9%83%A8&start=180&len=15&width=1366&height=768
将网站复制到查看器,得到如下结果:
url中的category为类别,start为起始索引,len为长度,即图片数量。
另外注意imgs下的url内容(不要直接复制url)
替换为“+”
(5)批量抓取图片成功
如果你的电脑没有库文件请求,记得安装cmd命令:
pip 安装请求
最后,不断排序后的源码如下:
import requests
import json #使用json码
import urllib
def getSogouImag(category,length,path):
n = length
cate = category #分类
imgs = requests.get('http://pic.sogou.com/pics/chan ... 2Bstr(n))
jd = json.loads(imgs.text)
jd = jd['all_items']
imgs_url = [] #在url获取图片imgs
for j in jd:
imgs_url.append(j['bthumbUrl'])
m = 0
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg')
m = m + 1
print('Download complete!')
getSogouImag('壁纸',2000,'F:/Py666/抓图/') #抓取后图片存取的本地位置
执行程序:到指定位置找到图片所在的位置,就大功告成了。
php 抓取网页生成图片(图片转base643 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-12-06 13:13
)
介绍本文文章主要介绍PHP远程下载图片,微信头像保存在本地,本地图片转base64(示例代码)及相关经验技巧,文章约7412字,页面浏览量191,3个赞,值得参考!
方法一(推荐):
function download_remote_pic($url){
$header = [
‘User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:45.0) Gecko/20100101 Firefox/45.0‘,
‘Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3‘,
‘Accept-Encoding: gzip, deflate‘,
];
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($curl, CURLOPT_ENCODING, ‘gzip‘);
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
$data = curl_exec($curl);
$code = curl_getinfo($curl, CURLINFO_HTTP_CODE);
curl_close($curl);
if ($code == 200) {//把URL格式的图片转成base64_encode格式的!
$imgBase64Code = "data:image/jpeg;base64," . base64_encode($data);
}
$img_content=$imgBase64Code;//图片内容
//echo $img_content;exit;
if (preg_match(‘/^(data:s*image/(w+);base64,)/‘, $img_content, $result)) {
$type = $result[2];//得到图片类型png?jpg?gif?
$new_file = "./".time().rand(1,10000).".{$type}";
if (file_put_contents($new_file, base64_decode(str_replace($result[1], ‘‘, $img_content)))) {
return $new_file;
}
}
}
$new_file = download_remote_pic(‘http://thirdwx.qlogo.cn/mmopen ... Q/132‘);
echo $new_file;
方法二(慢,消耗服务器)
$url=‘http://thirdwx.qlogo.cn/mmopen ... Q/132‘;
$new_file = "./".time().rand(1,10000).".png"; //图片类型getimagesize($url)可以但是因为是远程图片太慢了
file_put_contents($new_file, file_get_contents($url));
echo ($new_file);
图片转base64
function base64_encode_image($file){
$type=getimagesize($file);//取得图片的大小,类型等
$fp=fopen($file,"r")or die("Can‘t open file");
$file_content=chunk_split(base64_encode(fread($fp,filesize($file))));//base64编码
switch($type[2]){//判读图片类型
case 1:$img_type="gif";break;
case 2:$img_type="jpg";break;
case 3:$img_type="png";break;
}
$img=‘data:image/‘.$img_type.‘;base64,‘.$file_content;//合成图片的base64编码
fclose($fp);
return $img;
} 查看全部
php 抓取网页生成图片(图片转base643
)
介绍本文文章主要介绍PHP远程下载图片,微信头像保存在本地,本地图片转base64(示例代码)及相关经验技巧,文章约7412字,页面浏览量191,3个赞,值得参考!
方法一(推荐):
function download_remote_pic($url){
$header = [
‘User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:45.0) Gecko/20100101 Firefox/45.0‘,
‘Accept-Language: zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3‘,
‘Accept-Encoding: gzip, deflate‘,
];
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($curl, CURLOPT_ENCODING, ‘gzip‘);
curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
$data = curl_exec($curl);
$code = curl_getinfo($curl, CURLINFO_HTTP_CODE);
curl_close($curl);
if ($code == 200) {//把URL格式的图片转成base64_encode格式的!
$imgBase64Code = "data:image/jpeg;base64," . base64_encode($data);
}
$img_content=$imgBase64Code;//图片内容
//echo $img_content;exit;
if (preg_match(‘/^(data:s*image/(w+);base64,)/‘, $img_content, $result)) {
$type = $result[2];//得到图片类型png?jpg?gif?
$new_file = "./".time().rand(1,10000).".{$type}";
if (file_put_contents($new_file, base64_decode(str_replace($result[1], ‘‘, $img_content)))) {
return $new_file;
}
}
}
$new_file = download_remote_pic(‘http://thirdwx.qlogo.cn/mmopen ... Q/132‘);
echo $new_file;
方法二(慢,消耗服务器)
$url=‘http://thirdwx.qlogo.cn/mmopen ... Q/132‘;
$new_file = "./".time().rand(1,10000).".png"; //图片类型getimagesize($url)可以但是因为是远程图片太慢了
file_put_contents($new_file, file_get_contents($url));
echo ($new_file);
图片转base64
function base64_encode_image($file){
$type=getimagesize($file);//取得图片的大小,类型等
$fp=fopen($file,"r")or die("Can‘t open file");
$file_content=chunk_split(base64_encode(fread($fp,filesize($file))));//base64编码
switch($type[2]){//判读图片类型
case 1:$img_type="gif";break;
case 2:$img_type="jpg";break;
case 3:$img_type="png";break;
}
$img=‘data:image/‘.$img_type.‘;base64,‘.$file_content;//合成图片的base64编码
fclose($fp);
return $img;
}

