
php 抓取网页生成图片
php 抓取网页生成图片(2019独角兽企业重金招聘Python工程师标准(gt;gt))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-04 11:10
2019独角兽企业重磅招聘Python工程师标准>>>
本程序实现了网页源代码抓取、图片链接获取、分析、同图链接合并功能等功能,实现图片抓取功能。利用PHP强大的网络内容处理功能,抓取指定网站上的所有图片,并保存到当前目录。以下是代码:
/';
$ret = preg_match_all($reg_tag, $site_content, $match_result);
fclose($site_fd);
return $match_result[1];
}
/* 对图片链接进行修正 */
function revise_site($site_list, $base_site){
foreach($site_list as $site_item) {
if (preg_match('/^http/', $site_item)) {
$return_list[] = $site_item;
}else{
$return_list[] = $base_site."/".$site_item;
}
}
return $return_list;
}
/*得到图片名字,并将其保存在指定位置*/
function get_pic_file($pic_url_array, $pos){
$reg_tag = '/.*\/(.*?)$/';
$count = 0;
foreach($pic_url_array as $pic_item){
$ret = preg_match_all($reg_tag,$pic_item,$t_pic_name);
$pic_name = $pos.$t_pic_name[1][0];
$pic_url = $pic_item;
print("Downloading ".$pic_url." ");
$img_read_fd = fopen($pic_url,"r");
$img_write_fd = fopen($pic_name,"w");
$img_content = "";
while(!feof($img_read_fd)){
$img_content .= fread($img_read_fd,1024);
}
fwrite($img_write_fd,$img_content);
fclose($img_read_fd);
fclose($img_write_fd);
print("[OK] ");
}
return 0;
}
function main(){
/* 待抓取图片的网页地址 */
$site_name = "http://image.cn.yahoo.com";
$img_url = get_img_url($site_name);
$img_url_revised = revise_site($img_url, $site_name);
$img_url_unique = array_unique($img_url_revised); //unique array
get_pic_file($img_url_unique,"./");
}
main();
?>
转载于: 查看全部
php 抓取网页生成图片(2019独角兽企业重金招聘Python工程师标准(gt;gt))
2019独角兽企业重磅招聘Python工程师标准>>>

本程序实现了网页源代码抓取、图片链接获取、分析、同图链接合并功能等功能,实现图片抓取功能。利用PHP强大的网络内容处理功能,抓取指定网站上的所有图片,并保存到当前目录。以下是代码:
/';
$ret = preg_match_all($reg_tag, $site_content, $match_result);
fclose($site_fd);
return $match_result[1];
}
/* 对图片链接进行修正 */
function revise_site($site_list, $base_site){
foreach($site_list as $site_item) {
if (preg_match('/^http/', $site_item)) {
$return_list[] = $site_item;
}else{
$return_list[] = $base_site."/".$site_item;
}
}
return $return_list;
}
/*得到图片名字,并将其保存在指定位置*/
function get_pic_file($pic_url_array, $pos){
$reg_tag = '/.*\/(.*?)$/';
$count = 0;
foreach($pic_url_array as $pic_item){
$ret = preg_match_all($reg_tag,$pic_item,$t_pic_name);
$pic_name = $pos.$t_pic_name[1][0];
$pic_url = $pic_item;
print("Downloading ".$pic_url." ");
$img_read_fd = fopen($pic_url,"r");
$img_write_fd = fopen($pic_name,"w");
$img_content = "";
while(!feof($img_read_fd)){
$img_content .= fread($img_read_fd,1024);
}
fwrite($img_write_fd,$img_content);
fclose($img_read_fd);
fclose($img_write_fd);
print("[OK] ");
}
return 0;
}
function main(){
/* 待抓取图片的网页地址 */
$site_name = "http://image.cn.yahoo.com";
$img_url = get_img_url($site_name);
$img_url_revised = revise_site($img_url, $site_name);
$img_url_unique = array_unique($img_url_revised); //unique array
get_pic_file($img_url_unique,"./");
}
main();
?>
转载于:
php 抓取网页生成图片(#feimengjuanimporturllib#抓取网页图片#(根据的网址来获取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-01 18:11
本文文章主要介绍Python简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页的源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- 编码:utf-8 -*-
#飞梦娟
进口重新
导入 urllib
导入 urllib2
#抓取网页图片
#根据给定的URL获取网页的详细信息,得到的html就是网页的源代码
def getHtml(url):
页面 = urllib.urlopen(url)
html = page.read()
返回 html
def getImg(html):
#使用正则表达式过滤掉源代码中的图片地址
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = 桩(注册)
imglist = imgre.findall(html) #表示在整个网页中过滤掉所有图片的地址,放入imglist
x = 0
对于 imglist 中的 imgurl:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,下载图片保存到本地
x = x + 1
html = getHtml(")#获取该URL的网页的详细信息,获取的html即为该网页的源代码
getImg(html)#从网页源代码中分析并下载并保存图片
进一步整理了代码,在本地创建了一个“图片”文件夹,用来保存图片
# -*- 编码:utf-8 -*-
#飞梦娟
进口重新
导入 urllib
导入 urllib2
导入操作系统
#抓取网页图片
#根据给定的URL获取网页的详细信息,得到的html就是网页的源代码
def getHtml(url):
页面 = urllib.urlopen(url)
html = page.read()
返回 html
#创建一个文件夹来保存图片
def mkdir(路径):
路径 = path.strip()
#判断路径是否存在
# 现有真
# Flase 不存在
isExists = os.path.exists(path)
如果不是 isExists:
print u'created a new folder named ',path,u'
# 创建目录操作函数
os.makedirs(路径)
返回真
别的:
# 如果目录存在,不创建,提示目录已存在
打印 u'名为',path,u'的文件夹已成功创建'
返回错误
# 输入文件名,保存多张图片
def saveImages(imglist,name):
数字 = 1
对于 imglist 中的 imageURL:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
如果 len(fTail)> 3:
fTail ='jpg'
文件名 = 名称 + "/" + str(number) + "." + f尾
# 对于每个图片地址,保存
尝试:
u = urllib2.urlopen(imageURL)
数据 = u.read()
f = 打开(文件名,'wb+')
f.写(数据)
print u'正在保存的图片是',fileName
f.close()
除了 urllib2.URLError 作为 e:
打印(e.reason)
数字 += 1
#获取网页中所有图片的地址
def getAllImg(html):
#使用正则表达式过滤掉源代码中的图片地址
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = 桩(注册)
imglist = imgre.findall(html) #表示在整个网页中过滤掉所有图片的地址,放入imglist
返回 imglist
#创建本地保存文件夹,并下载并保存图片
如果 __name__ =='__main__':
html = getHtml(")#获取该URL的网页的详细信息,获取的html即为该网页的源代码
路径 = u'图片'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片地址列表
saveImages(imglist,path) # 保存图片
结果,在“图片”文件夹中保存了数十张图片,如截图所示:
非常感谢您的阅读
上大学的时候选择自学python,但工作后发现自己电脑基础不好,学位也不好。这是
没办法,只能后天弥补,于是我在编码之外开始了自己的逆袭,继续学习python的核心知识。
把我录入的计算机基础知识整理一下,放到我们的微信公众号“程序员学校”上。如果你不愿意平庸,
然后在编码之外加入我并继续成长!
—————————————————
版权声明:本文为CSDN博主“程序员牡蛎”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接:
:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
php 抓取网页生成图片(#feimengjuanimporturllib#抓取网页图片#(根据的网址来获取))
本文文章主要介绍Python简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页的源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- 编码:utf-8 -*-
#飞梦娟
进口重新
导入 urllib
导入 urllib2
#抓取网页图片
#根据给定的URL获取网页的详细信息,得到的html就是网页的源代码
def getHtml(url):
页面 = urllib.urlopen(url)
html = page.read()
返回 html
def getImg(html):
#使用正则表达式过滤掉源代码中的图片地址
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = 桩(注册)
imglist = imgre.findall(html) #表示在整个网页中过滤掉所有图片的地址,放入imglist
x = 0
对于 imglist 中的 imgurl:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,下载图片保存到本地
x = x + 1
html = getHtml(")#获取该URL的网页的详细信息,获取的html即为该网页的源代码
getImg(html)#从网页源代码中分析并下载并保存图片
进一步整理了代码,在本地创建了一个“图片”文件夹,用来保存图片
# -*- 编码:utf-8 -*-
#飞梦娟
进口重新
导入 urllib
导入 urllib2
导入操作系统
#抓取网页图片
#根据给定的URL获取网页的详细信息,得到的html就是网页的源代码
def getHtml(url):
页面 = urllib.urlopen(url)
html = page.read()
返回 html
#创建一个文件夹来保存图片
def mkdir(路径):
路径 = path.strip()
#判断路径是否存在
# 现有真
# Flase 不存在
isExists = os.path.exists(path)
如果不是 isExists:
print u'created a new folder named ',path,u'
# 创建目录操作函数
os.makedirs(路径)
返回真
别的:
# 如果目录存在,不创建,提示目录已存在
打印 u'名为',path,u'的文件夹已成功创建'
返回错误
# 输入文件名,保存多张图片
def saveImages(imglist,name):
数字 = 1
对于 imglist 中的 imageURL:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
如果 len(fTail)> 3:
fTail ='jpg'
文件名 = 名称 + "/" + str(number) + "." + f尾
# 对于每个图片地址,保存
尝试:
u = urllib2.urlopen(imageURL)
数据 = u.read()
f = 打开(文件名,'wb+')
f.写(数据)
print u'正在保存的图片是',fileName
f.close()
除了 urllib2.URLError 作为 e:
打印(e.reason)
数字 += 1
#获取网页中所有图片的地址
def getAllImg(html):
#使用正则表达式过滤掉源代码中的图片地址
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = 桩(注册)
imglist = imgre.findall(html) #表示在整个网页中过滤掉所有图片的地址,放入imglist
返回 imglist
#创建本地保存文件夹,并下载并保存图片
如果 __name__ =='__main__':
html = getHtml(")#获取该URL的网页的详细信息,获取的html即为该网页的源代码
路径 = u'图片'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片地址列表
saveImages(imglist,path) # 保存图片
结果,在“图片”文件夹中保存了数十张图片,如截图所示:
非常感谢您的阅读
上大学的时候选择自学python,但工作后发现自己电脑基础不好,学位也不好。这是
没办法,只能后天弥补,于是我在编码之外开始了自己的逆袭,继续学习python的核心知识。
把我录入的计算机基础知识整理一下,放到我们的微信公众号“程序员学校”上。如果你不愿意平庸,
然后在编码之外加入我并继续成长!
—————————————————
版权声明:本文为CSDN博主“程序员牡蛎”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接:
:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
php 抓取网页生成图片(如何用phantomjs保存的百度首页截图.io图片?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-31 22:14
背景
最近正在开发一个小程序。有一个帮助模块,内容是帮助列表文章,文章的内容是网站后台编辑的富文本格式。鉴于小程序的特殊性,其对html格式的富文本支持并不友好。
一开始有人开发了wxparse插件,后来微信提供了富文本组件,但是两者都存在一些问题。
想法
后台编辑文章样式被wxparse或富文本组件显示后,存在一些兼容性问题。如果我们把文章的内容做成图片,再用图片来展示,应该能达到比较理想的效果。
但是每一篇文章,我都去美术区设计图,费时费力,修改也费劲。
如果我们后台编辑的文章能自动生成图片就完美了。
计划
查询后发现,海外网站thumb.io也提供类似服务。可以使用API接口将指定地址保存为图片。但是经过测试,发现图片不清晰,访问速度很慢。然后我自己安装了phantomjs并测试了一下,效果还是比较满意的。
用phantomjs保存的百度首页截图
为了实现自动化,我还做了一个web api。通过将文章对应的URL发送到指定的api,可以自动(异步)生成截图。具体方法是当有截图请求时,将请求保存到数据库中,然后在服务器上运行一个程序,一一进行截图操作,截图后修改相应请求的状态。
-------------------------------------------------- ——
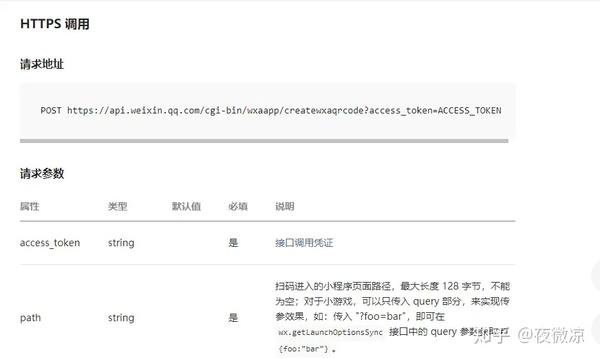
API 接口({} 中的内容为参数值)
使用方法:通过截图生成将需要截图的URL传递到请求界面,一段时间后(推荐10秒)通过查询界面进行查询。如果返回code=0,status=1,直接将thumb保存到本地。能。
生成截图请求:{URL}
注意:url参数必须是urlencoded,否则可能会出错
示例:%3a%2f%2f%2fdragondean%2f
返回:JSON 格式
代码 0 成功,1 URL 格式错误,2 URL 已存在
msg 错误信息(仅当代码不为 0 时)
task_id 任务ID,查询状态时使用(code为0或2时)
key 查询秘钥,用于查询状态(code为0或2时)
status 任务的状态,如果任务已经存在,则返回此状态,-1表示失败,0表示处理中,1表示完成
大拇指截图地址,可以直接下载这张图片到本地(code为2,status为1时)
err_msg 错误信息,仅在 status=-1 时存在
查询任务状态:{TASK_ID}&key={KEY}
注意:task_id和key都是在请求生成的时候返回的,是必填项
例子:
返回:JSON
代码返回状态,0 成功,3 任务不存在,4 查询秘钥错误
当状态码为0时,status=-1表示失败,status=0表示处理中,status=1表示完成
当thumbcode位为0,状态为1时,可以直接下载截图地址到本地
err_msg 错误信息,仅在 status=-1 时存在
-------------------------------------------------- ——
以上就是使用网页截图API接口自动生成网页截图的详细内容。更多详情请关注其他相关php中文网文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php 抓取网页生成图片(如何用phantomjs保存的百度首页截图.io图片?)
背景
最近正在开发一个小程序。有一个帮助模块,内容是帮助列表文章,文章的内容是网站后台编辑的富文本格式。鉴于小程序的特殊性,其对html格式的富文本支持并不友好。
一开始有人开发了wxparse插件,后来微信提供了富文本组件,但是两者都存在一些问题。
想法
后台编辑文章样式被wxparse或富文本组件显示后,存在一些兼容性问题。如果我们把文章的内容做成图片,再用图片来展示,应该能达到比较理想的效果。
但是每一篇文章,我都去美术区设计图,费时费力,修改也费劲。
如果我们后台编辑的文章能自动生成图片就完美了。
计划
查询后发现,海外网站thumb.io也提供类似服务。可以使用API接口将指定地址保存为图片。但是经过测试,发现图片不清晰,访问速度很慢。然后我自己安装了phantomjs并测试了一下,效果还是比较满意的。

用phantomjs保存的百度首页截图
为了实现自动化,我还做了一个web api。通过将文章对应的URL发送到指定的api,可以自动(异步)生成截图。具体方法是当有截图请求时,将请求保存到数据库中,然后在服务器上运行一个程序,一一进行截图操作,截图后修改相应请求的状态。
-------------------------------------------------- ——
API 接口({} 中的内容为参数值)
使用方法:通过截图生成将需要截图的URL传递到请求界面,一段时间后(推荐10秒)通过查询界面进行查询。如果返回code=0,status=1,直接将thumb保存到本地。能。
生成截图请求:{URL}
注意:url参数必须是urlencoded,否则可能会出错
示例:%3a%2f%2f%2fdragondean%2f
返回:JSON 格式
代码 0 成功,1 URL 格式错误,2 URL 已存在
msg 错误信息(仅当代码不为 0 时)
task_id 任务ID,查询状态时使用(code为0或2时)
key 查询秘钥,用于查询状态(code为0或2时)
status 任务的状态,如果任务已经存在,则返回此状态,-1表示失败,0表示处理中,1表示完成
大拇指截图地址,可以直接下载这张图片到本地(code为2,status为1时)
err_msg 错误信息,仅在 status=-1 时存在
查询任务状态:{TASK_ID}&key={KEY}
注意:task_id和key都是在请求生成的时候返回的,是必填项
例子:
返回:JSON
代码返回状态,0 成功,3 任务不存在,4 查询秘钥错误
当状态码为0时,status=-1表示失败,status=0表示处理中,status=1表示完成
当thumbcode位为0,状态为1时,可以直接下载截图地址到本地
err_msg 错误信息,仅在 status=-1 时存在
-------------------------------------------------- ——
以上就是使用网页截图API接口自动生成网页截图的详细内容。更多详情请关注其他相关php中文网文章!

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php 抓取网页生成图片(用html2canvas根据自己的需求生成截图,绕过服务器图片保存至本地 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-31 22:12
)
今天要分享的就是根据自己的需要使用html2canvas生成截图,并修复html2canvas截图模糊的问题,绕过服务器将图片保存到本地。
只需要几行代码就可以根据需要的dom截图。是不是很方便,但是生成的图片很模糊
//直接选择你要截图的dom,可以截图,但是因为canvas,生成的图片模糊
html2canvas(document.querySelector('div')).then(function(canvas) {
document.body.appendChild(canvas);
})
常见的解决方法是生成一个多折的画布,放在一个较小的容器中,解决了截图模糊的尴尬。
另一个问题是如何绕过服务器并将图像保存在本地。画布有一个 toDataURL 方法,a 标签有一个下载属性。感觉就像一个完美的契合。当然,要在微信中阻止下载,您可以使用微信的 webview 中的内置规则。只要将img嵌套在a标签中(不带href属性),就可以调用保存到手机并分享给朋友的菜单栏。
下面是一个简单的demo,html2canvas.min.js下载地址:
DOCTYPE html>
htmltopic
* {
margin: 0;
}
.test {
width: 100px;
height: 100px;
text-align: center;
line-height: 100px;
background-color: #87CEEB;
display: inline-block;
vertical-align: top;
}
canvas {
margin-right: 5px;
}
.down {
float: left;
margin: 40px 10px;
}
.down2 {
float: left;
margin: 40px 30px;
}
测试
下载
下载2
//直接选择要截图的dom,就能截图,但是因为canvas的原因,生成的图片模糊
//html2canvas(document.querySelector('div')).then(function(canvas) {
// document.body.appendChild(canvas);
//});
//创建一个新的canvas
var canvas2 = document.createElement("canvas");
let
_canvas = document.querySelector('div');
var w = parseInt(window.getComputedStyle(_canvas).width);
var h = parseInt(window.getComputedStyle(_canvas).height);
//将canvas画布放大若干倍,然后盛放在较小的容器内,就显得不模糊了
canvas2.width = w * 2;
canvas2.height = h * 2;
canvas2.style.width = w + "px";
canvas2.style.height = h + "px";
//可以按照自己的需求,对context的参数修改,translate指的是偏移量
// var context = canvas.getContext("2d");
// context.translate(0,0);
var context = canvas2.getContext("2d");
context.scale(2, 2);
html2canvas(document.querySelector('div'), { canvas: canvas2 }).then(function(canvas) {
//document.body.appendChild(canvas);
//canvas转换成url,然后利用a标签的download属性,直接下载,绕过上传服务器再下载
document.querySelector(".down").setAttribute('href', canvas.toDataURL());
});
//这是另一种写法
$(function () {
$(".down2").click(function () {
html2canvas($(".test")).then(function (canvas) {
var imgUri = canvas.toDataURL("image/png").replace("image/png", "image/octet-stream"); // 获取生成的图片的url
window.location.href = imgUri; // 下载图片
});
//html2canvas($('.tongxingzheng_bg'), {
// onrendered: function (canvas) {
// var data = canvas.toDataURL("image/png");//生成的格式
// //data就是生成的base64码啦
// alert(data);
// }
//});
});
}); 查看全部
php 抓取网页生成图片(用html2canvas根据自己的需求生成截图,绕过服务器图片保存至本地
)
今天要分享的就是根据自己的需要使用html2canvas生成截图,并修复html2canvas截图模糊的问题,绕过服务器将图片保存到本地。
只需要几行代码就可以根据需要的dom截图。是不是很方便,但是生成的图片很模糊
//直接选择你要截图的dom,可以截图,但是因为canvas,生成的图片模糊
html2canvas(document.querySelector('div')).then(function(canvas) {
document.body.appendChild(canvas);
})
常见的解决方法是生成一个多折的画布,放在一个较小的容器中,解决了截图模糊的尴尬。
另一个问题是如何绕过服务器并将图像保存在本地。画布有一个 toDataURL 方法,a 标签有一个下载属性。感觉就像一个完美的契合。当然,要在微信中阻止下载,您可以使用微信的 webview 中的内置规则。只要将img嵌套在a标签中(不带href属性),就可以调用保存到手机并分享给朋友的菜单栏。
下面是一个简单的demo,html2canvas.min.js下载地址:
DOCTYPE html>
htmltopic
* {
margin: 0;
}
.test {
width: 100px;
height: 100px;
text-align: center;
line-height: 100px;
background-color: #87CEEB;
display: inline-block;
vertical-align: top;
}
canvas {
margin-right: 5px;
}
.down {
float: left;
margin: 40px 10px;
}
.down2 {
float: left;
margin: 40px 30px;
}
测试
下载
下载2
//直接选择要截图的dom,就能截图,但是因为canvas的原因,生成的图片模糊
//html2canvas(document.querySelector('div')).then(function(canvas) {
// document.body.appendChild(canvas);
//});
//创建一个新的canvas
var canvas2 = document.createElement("canvas");
let
_canvas = document.querySelector('div');
var w = parseInt(window.getComputedStyle(_canvas).width);
var h = parseInt(window.getComputedStyle(_canvas).height);
//将canvas画布放大若干倍,然后盛放在较小的容器内,就显得不模糊了
canvas2.width = w * 2;
canvas2.height = h * 2;
canvas2.style.width = w + "px";
canvas2.style.height = h + "px";
//可以按照自己的需求,对context的参数修改,translate指的是偏移量
// var context = canvas.getContext("2d");
// context.translate(0,0);
var context = canvas2.getContext("2d");
context.scale(2, 2);
html2canvas(document.querySelector('div'), { canvas: canvas2 }).then(function(canvas) {
//document.body.appendChild(canvas);
//canvas转换成url,然后利用a标签的download属性,直接下载,绕过上传服务器再下载
document.querySelector(".down").setAttribute('href', canvas.toDataURL());
});
//这是另一种写法
$(function () {
$(".down2").click(function () {
html2canvas($(".test")).then(function (canvas) {
var imgUri = canvas.toDataURL("image/png").replace("image/png", "image/octet-stream"); // 获取生成的图片的url
window.location.href = imgUri; // 下载图片
});
//html2canvas($('.tongxingzheng_bg'), {
// onrendered: function (canvas) {
// var data = canvas.toDataURL("image/png");//生成的格式
// //data就是生成的base64码啦
// alert(data);
// }
//});
});
});
php 抓取网页生成图片(本示例将演示一个简单的上传图片到远程服务器(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-31 22:11
本例将演示一个简单的图片上传到远程服务器,然后生成图片路径并通过提交的回调路径返回到本地服务器,最后在前端页面显示图片地址。
本项目使用三个文件,即前端选择图片页面,然后将图片提交到远程服务器处理文件,返回前端页面的回调文件。
一、前端上传图片页面
上传_测试.html
Upload Image
主题封面图:
图片格式 jpg jpeg gif png
封面图URL:
*
这里需要注意的是,当回调页面向前端页面返回图片地址时,需要加上iframe标签(这里我们隐藏),否则页面上要显示的地方是找不到的。
与通用选项卡相比,多了一个目标属性,用于指定打开选项卡和提交数据的位置。
而如果设置为iframe的name值,即“post_frame”,就会在iframe中打开,因为css设置为hide,所以不会有动静。如果删除 display:none,您还将看到服务器的返回信息。
上传文件的时候,form的method和enctype属性必须和上面的代码一样,然后将target值设置为iframe的名字,这样文件就可以不刷新上传了。
当你选择提交图片时,还有一个隐藏字段,即当你向远程服务器提交图片时,还需要提交一个回调路径,以便将图片返回到本地服务器。(这里我们都使用本地服务器进行测试)
二、远程服务器图像处理
上传动作.php
<p> 查看全部
php 抓取网页生成图片(本示例将演示一个简单的上传图片到远程服务器(组图))
本例将演示一个简单的图片上传到远程服务器,然后生成图片路径并通过提交的回调路径返回到本地服务器,最后在前端页面显示图片地址。
本项目使用三个文件,即前端选择图片页面,然后将图片提交到远程服务器处理文件,返回前端页面的回调文件。

一、前端上传图片页面
上传_测试.html
Upload Image
主题封面图:
图片格式 jpg jpeg gif png
封面图URL:
*
这里需要注意的是,当回调页面向前端页面返回图片地址时,需要加上iframe标签(这里我们隐藏),否则页面上要显示的地方是找不到的。
与通用选项卡相比,多了一个目标属性,用于指定打开选项卡和提交数据的位置。
而如果设置为iframe的name值,即“post_frame”,就会在iframe中打开,因为css设置为hide,所以不会有动静。如果删除 display:none,您还将看到服务器的返回信息。
上传文件的时候,form的method和enctype属性必须和上面的代码一样,然后将target值设置为iframe的名字,这样文件就可以不刷新上传了。
当你选择提交图片时,还有一个隐藏字段,即当你向远程服务器提交图片时,还需要提交一个回调路径,以便将图片返回到本地服务器。(这里我们都使用本地服务器进行测试)
二、远程服务器图像处理
上传动作.php
<p>
php 抓取网页生成图片(网站地图对于一个网站来说至关重要网站本身自己创建的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-31 22:10
网站 地图对于 网站 来说非常重要。自己创建 网站 地图并提交给搜索引擎是一种更好的方式。这种情况下,你不受页数限制,完全可以控制网站map的结构信息。这是一个可以轻松生成网站maps
的小类
复制代码代码如下:
// 收录类
include'SitemapGenerator.php';
// 创建对象
$sitemap = new SitemapGenerator("//");
// 添加网址
$sitemap->addUrl("", date('c'),'daily', '1');
$sitemap->addUrl("", date('c'),'daily','0.5');
$sitemap->addUrl("", date('c'),'daily');
// 创建站点地图
$sitemap->createSitemap();
// 将站点地图写入文件
$sitemap->writeSitemap();
//更新robots.txt文件
$sitemap->updateRobots();
// 向搜索引擎提交站点地图
$sitemap->submitSitemap(); 查看全部
php 抓取网页生成图片(网站地图对于一个网站来说至关重要网站本身自己创建的方法)
网站 地图对于 网站 来说非常重要。自己创建 网站 地图并提交给搜索引擎是一种更好的方式。这种情况下,你不受页数限制,完全可以控制网站map的结构信息。这是一个可以轻松生成网站maps
的小类
复制代码代码如下:
// 收录类
include'SitemapGenerator.php';
// 创建对象
$sitemap = new SitemapGenerator("//");
// 添加网址
$sitemap->addUrl("", date('c'),'daily', '1');
$sitemap->addUrl("", date('c'),'daily','0.5');
$sitemap->addUrl("", date('c'),'daily');
// 创建站点地图
$sitemap->createSitemap();
// 将站点地图写入文件
$sitemap->writeSitemap();
//更新robots.txt文件
$sitemap->updateRobots();
// 向搜索引擎提交站点地图
$sitemap->submitSitemap();
php 抓取网页生成图片(流量之于互联网:微信内做分享和传播的形式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-29 21:01
前言
流量对于互联网公司来说就像水之于一切一样重要。那么目前国内移动互联网流量集中在哪里呢?答案很明显,那就是我们每天都在使用的微信。
2018年初,微信月活跃用户数突破10亿,成为国内首个月活跃用户突破10亿的产品。“三季度大战”后,腾讯逐渐从封闭走向开放,而微信作为腾讯在移动互联网时代最重要、最成功的战略产品,也在践行腾讯的开放战略。在这样的背景下,如何利用好微信的流量引导用户分享和传播,成为摆在我们面前的重要课题。但是,基于自身利益和用户体验等考虑,微信对在微信中分享和传播的内容和形式有严格的规定和诸多限制。如果你不注意违反这些规则,你可能会受到惩罚。严重的甚至被微信封杀死。
然而,风险和回报总是成正比的。有时为了达到更好的传播效果,我们不得不“合理”地采取一些措施。目前,微信中的分享传播方式不外乎以下五种:文字、图片、H5链接、小程序、短视频。从技术角度来看,微信、文字、H5链接、小程序三种形式,相对容易控制,而图片和短视频相对更容易绕过微信监控。虽然现在短视频很流行,但是我们公司用的不多(虽然我觉得应该充分利用),所以还是把重点放在图片上吧。
商业背景
在我们的业务中,我们经常需要引导用户将图片分享到微信。目前,我们生成图片的方式主要有两种。一种是通过APP中自研的Autumn系统生成图片,另一种是通过PHP后端生成图片,将图片上传到CDN再将图片链接返回给前端。. 这两种方法都有其局限性。第一种方法的局限是只能在APP中使用,不能在微信环境或手机浏览器中使用。第二种方法的问题在于它需要后端学生。完成共享海报图片的版面开发,需要占用CDN资源(需要花钱),如果生成的图片只是临时使用,这种方式的弊端就很明显了。所以,
技术选型
如果要在前端生成图片,自然会想到使用Canvas技术来做,但是团队中如何使用Canvas有两个思路:第一个是完全封装Canvas API进行绘图,以及二是直接使用开源库,比如流行的html2canvas库。我个人提倡第二种方法。一方面,它可以直接将 DOM 转换为 Canvas。用一个我们比较熟悉的方法也不太方便。如果我们封装它,很多基础的任务,比如界面布局,各种元素的绘制等等,都得重新做,开发和维护的风险和成本太高了。另一方面,html2canvas库是一个长期的开源项目,应该是比较成熟和稳定的。然而,团队中还有老司机发出警告,提到他们之前也尝试过使用html2canvas库做项目,但是在绘制一些比较复杂的页面时遇到了很多问题,所以他们决定放弃这个方案,改用A采用完全独立的开发方式,即上述第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。所以他们决定放弃这个方案,转而采用完全独立的开发方式,也就是上面的第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。所以他们决定放弃这个方案,转而采用完全独立的开发方式,也就是上面的第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。
html2canvas 基本介绍
根据html2canvas官方文档的介绍,html2canvas库的工作原理并不是真正的“截图”,而是读取网页上目标DOM节点的信息来绘制画布,所以不支持所有的css属性(详见这里),并且期望使用的图片与当前域名相同,但是官方也提供了一些方法来解决加载跨域图片的问题。
它的用法非常简单。引入html2canvas库后,获取目标dom,调用html2canvas方法生成canvas对象。由于我们的目标是生成图片,所以需要调用canvas.toDataURL()方法来生成。
标签的可用数据:
html2canvas(targetDom).then(canvas => {// 将画布附加到页面});
接下来我列举一下我在这个过程中遇到的一些问题以及解决方法。
问题一:生成的图片很模糊
当我写了代码,准备按照官网的介绍查看效果的时候,发现生成的图片很模糊。您可以查看下图的比较以了解详细信息。海报图片DOM在右边,左边是html2canvas库生成的Canvas。如果下面没有特别说明, , 都是左 Canvas 和右 DOM。
问题一:画面模糊
如您所见,图中红色圆圈标记的部分非常模糊。遇到这个问题后,我自然而然地去谷歌解决了这个问题。不说了,分分钟搜了一堆结果(毕竟是成熟的开源软件),还天真地以为这个问题很快就解决了。.
谷歌大法好!
我随意点了几个链接,看了看里面的解决方案。大体思路是将画布放大n倍,然后制作图形。奇怪的是,我试了之后,发现很多人说这个有效的方法对我完全没用。即使我放大200倍,画出来的画面还是一样的模糊,所以我只能遗憾地向我宣布这个方法。它不再有效。
所以想知道这是不是html2canvas库本身的bug,于是换了一个类似的库,dom-to-image,试了一下。结果出乎我的意料......这个产品不仅仅是一张模糊的图片,它是整个画布。很模糊!而且它恢复得非常糟糕,我吓得差点把手机扔掉。截图来了,大家自己感受一下吧……
你是认真的吗?
说到这里,我有点泄气了,因为从这种情况来看,很有可能是某些底层逻辑存在问题,也就是说,这个问题可能无解……不过还好,没有路可走完美。当我们几个人一起讨论这个问题时,转折点出现了。有同学突然发现,生成的海报图片中并不是所有的图片都是模糊的,一张小图片还是很清晰的!这个发现让我欣喜若狂。经过一段时间的测试,我发现只有用作背景图像的背景图像才会模糊,并且
图片标签没有这个问题。那么解决方法很简单,直接用
达到background-image的效果,问题就解决了。
问题二:删除线(text-decoration:line-through)在线条下方
这是一个小问题,但是文字有点下划线,如图:
文本中的下水平线
解决方法也很简单,将文本元素设置为相对相对定位,然后使用伪元素进行模拟。较少的代码如下:
&:after {.text-decoration-line-through();}
.text-decoration-line-through(@color: #fff) {位置:绝对;宽度:100%;高度:1px;顶部:50%;左:0;内容:''; 背景色:@color; }
问题三:带省略号的多行文字无法正确渲染
实测发现,使用省略号样式的多行文字时,会直接导致文字消失,如下图:
溢出:隐藏;显示:-webkit-box;-webkit-box-orient:垂直;-webkit-line-clamp:2;
这也是一个小问题。可能是html2canvas不支持上述某些样式(虽然我没有从文档中找到证据)。我的解决方案是简单地使用 overflow: hidden 来截断文本。不怕麻烦的话就得用js计算加省略号了。
问题四(Big Boss登场):图片无法渲染
嗯,其实这个问题出现在图片模糊问题之前。因为需要加载的图片都在CDN上,而且我们知道html2canvas的工作原理是使用js解析目标dom节点生成canvas,所以我们需要使用跨域的方式来加载图片。一开始为了让图片正常显示,我添加了allowTaint属性,设置为true。代码和截图如下:
添加allowTaint属性之前,图片无法显示
html2canvas(targetDom, {allowTaint: true}).then(canvas => {// 将画布附加到页面});
添加allowTaint属性后,图片显示正常
注意!这里我们只是转换成canvas,还没有生成图片。那么接下来,我们尝试通过调用canvas.toDataURL()来生成图片数据,并将其设置为目标图片dom的src属性:
html2canvas(targetDom, {allowTaint: true}).then(canvas => {targetImage.setAttribute('src', canvas.toDataURL() };);
这时候发现代码报错了,报错信息如下:
从错误信息的意思来看,添加allowTaint:true属性生成的canvas会导致toDataURL方法失败。所以我只能去掉allowTaint:true再试,结果是图片没有直接渲染:
去掉allowTaint:true属性后图片消失
我查看了官方文档,找到了问题的答案:
为什么我的图像没有渲染?
html2canvas 无法绕过浏览器设置的内容策略限制。位于当前页面原点之外的绘制图像会污染它们被绘制的画布。如果画布被污染,则无法再读取。因此, html2canvas 实现了在应用图像之前检查图像是否会污染画布的方法。如果您已将 allowTaintoption 设置为false,则不会绘制图像。
如果您希望加载位于页面原点之外的图像,您可以使用代理加载图像。
根据官方的说法,跨域加载的图片会污染画布,导致画布无法导出数据。也建议我们设置一个节点代理服务器来解决这个问题。什么?这么麻烦还需要架设节点服务器吗?我们本来想在H5端独立做这个,不想服务器参与!坚决寻找任何其他解决方案。果然,我在配置文件中找到了另一个选项:
使用CORS
这一刻,我微微一笑,淡定的加上了useCORS:true属性,然后优雅地等待着胜利果实的到来。一切看起来都很完美~
哦,该死的!发生了什么?好的胜利果实呢?♀️?此错误消息表示我的图像已跨域加载。我不是已经将useCORS设置为true了吗?♀️?这时候,我和世界杯上的梅西一样惊慌失措,于是赶紧上谷歌找原因。
很遗憾,我把我发现的所有相关问题都看了一遍,发现没有人真正解决过这个问题。这些老外长着一张倔强树上的顽固果子。晃晃悠悠的发呆……(其实现在回想起来,上面截图最后一个中文写的解决方案最接近问题的本质,可惜他还没有完全弄清楚问题的根源问题)。没有办法,只能另辟蹊径,继续探讨这个问题。
查了一些跨域的相关信息,然后尝试去掉useCORS属性,发现虽然报错信息没了,但是图片还是无法渲染。这时候怀疑是html2canvas库本身的bug,因为根据它,useCORS属性是用来解决图片跨域加载问题的。为什么添加后还是报错?而且,官网上的大量类似问题没有得到处理,更加深了我的怀疑。于是我查看了它的源码,发现图片加载部分的代码是这样的:
为了验证是否是库中的bug,我精简了代码,然后复制了错误图片的链接,手动执行。测试代码和控制台输出如下:
令我惊讶的是图片加载成功!我快速测试了几种情况,发现在渲染弹出DOM节点之前测试代码可以成功执行,但是在渲染弹出DOM之后就会失败。直到这时我才开始意识到,这个问题很可能与图片的浏览器缓存有关。发现这个现象后,查了很多相关资料,迷雾终于散去。
首先是MDN上介绍CORS的文章文章:跨域资源共享(CORS)。有几个重要的知识点:
当 Web 应用程序请求与自己的来源具有不同来源(域、协议和端口)的资源时,它会发出跨源 HTTP 请求。
出于安全原因,浏览器会限制从脚本内发起的跨源 HTTP 请求。
请注意,在任何访问控制请求中,始终发送 Origin 标头。(跨域请求必须带上带有当前域名值的Origin请求头)
我们先来看看启用CORS的图片介绍:
什么是“污染”画布?
尽管您可以在画布中使用未经 CORS 批准的图像,但这样做会污染画布。一旦画布被污染,您就无法再从画布中取出数据。例如,您不能再使用 canvastoBlob()、toDataURL()、orgetImageData() 方法;这样做会引发安全错误。
这可以防止用户在未经许可的情况下使用图像从远程网站提取信息而暴露私人数据。
根据这一段的描述,虽然canvas可以读取跨域图片,但这也会造成canvas被污染,导致canvas无法导出。
可用于标签的图像数据。
我们先看开篇:
HTML 规范为图像引入了跨 origin 属性,结合适当的 CORS 标头,允许从外部来源加载的元素定义的图像在画布中使用,就像它们是从当前来源加载一样。
这意味着如果我们想要
如果label加载的图片可以被canvas读取,并且可以导出图片数据,那么就应该在label中添加crossorigin属性。crossorigin 属性有两个可选值:anonymous 和 use-credentials。它们之间的区别可以在文末附录中的参考链接中找到。目前,我们可以直接使用 crossorigin='anonymous' 来触发带有跨域请求头 Origin 的 HTTP 请求。
我们来看看文中示例部分的第一段:
您必须有一个服务器托管图像,并带有适当的 Access-Control-Allow-Originheader。添加 crossOrigin 属性会生成请求标头。
关键在这里。除了将 Origin 添加到请求头之外,服务器的响应头还必须收录正确的 Access-Control-Allow-Origin。否则,表示服务器不接受来自客户端的跨域请求。一切为了安全。
看到这里,我们已经了解了跨域错误报告的基本原理。下一步就是为什么我们即使添加了useCORS:true,还是会报跨域请求错误?
原因与html2canvas库的工作原理有很大关系。前面提到,html2canvas库要求我们先提供一个DOM节点,然后它读取并解析这个DOM节点,生成一个canvas对象。如果已经在 DOM 节点中使用
标签,它也会解析这个
标签的src属性,然后重新创建一个Image对象,给它加上crossOrigin="anonymous"属性,尝试跨域重新读取图片数据。需要注意的是,CDN上的图片一般都会缓存响应头,会缓存在浏览器端,缓存的不仅是图片数据,还有HTTP响应头。所以我们已经找到了问题的根本原因。当html2canvas尝试跨域读取图片数据时,会读取浏览器缓存的数据,而由于我们没有在DOM节点中给出数据
标签添加了crossorigin="anonymous"属性,所以缓存的数据没有Access-Control-Allow-Origin响应头,导致html2canvas库读取的图片数据污染生成的canvas对象,最终导致canvas 导出数据报错。
真相已经在这里揭晓了。所以我们要做的也很简单,就是给每个DOM节点
将 crossorigin="anonymous" 属性添加到标签。回过头来说一下为什么之前的中文文章解决了问题却没有找到问题的根本原因,因为他修改了html2canvas的源码读取图片,并添加了每个Image的src属性创建了一个随机字符串,一不小心就避免了读取缓存数据的问题,但是会导致CDN的缓存被破坏。
最后总结一下,其实已经说了很多了,但是我们要做的很简单:
1、添加 useCORS:true 属性;
2、 给每个要生成的DOM画布
为标签添加 crossorigin="anonymous" 属性;
3、 确保你的图片CDN服务器支持CORS访问,这意味着它会返回Access-Control-Allow-Origin等响应头;
问题5(大boss回):图片无法渲染
可能你和我一样,认为问题到这里已经彻底解决了,其实不然。就像很多游戏关卡中的大boss一样,在终于杀死了它的第一条生命之后,原来它竟然还有第二条生命。
事情是这样的,如果要使用生成收录在dom中的canvas
您的用户之前访问过的图片(例如,您正在改造现有的在线业务)。显然你之前不应该给它
给标签添加crossorigin="anonymous"属性,那么请注意,此时你用户的浏览器已经将这些图片缓存到本地了,所以即使按照上面的步骤也没有用,因为你在访问图片的时候阅读了所有是没有响应标头的缓存数据,例如 Access-Control-Allow-Origin。
这个时候你要做的就是把你要生成canvas的dom里面的所有dom都给
在标签的src中添加任意字符串,只要能重新发起图片读取请求即可,避免读取浏览器缓存数据,如下图:
''
注意,不要添加随机字符串,会破坏CDN缓存,只需添加固定字符串,避免读取浏览器缓存的数据。这是我自己血的教训!所以请不要忽视这一点!
写在最后
至此,我想说的基本说完了。其实在解决图片未渲染问题的过程中,我也遇到了一些其他的障碍和麻烦,给我带来了很多麻烦。限于篇幅,我不再赘述。NS。html2canvas库在应用过程中肯定还有一些其他的问题,比如页面性能不一致。这可能是因为 DOM 本身的样式存在兼容性问题,或者库的渲染与 DOM 不同,具体取决于具体情况。情况。本来想补充一些浏览器缓存和CDN缓存的知识,但是这个话题本身就收录了足够的内容。以后再开个博客,慢慢写《彻底理解浏览器缓存》这里NS:)
在解决这个问题的过程中,我也为自己总结了一些经验,希望对大家有所启发:
1、善用charles、chrome等开发工具;
2、认真仔细,大胆假设,仔细验证;
3、不要轻易放弃;
4、永远不要太自信。
参考
跨域资源共享 (CORS)
启用 CORS 的图像
HTMLCanvasElement.toDataURL()
CORS 设置属性
图像嵌入元素::crossorigin
web开发的html2canvas截图如何解决跨域问题?
html2canvas:JavaScript 截图
html2canvas在iOS8系统上的兼容性 查看全部
php 抓取网页生成图片(流量之于互联网:微信内做分享和传播的形式)
前言
流量对于互联网公司来说就像水之于一切一样重要。那么目前国内移动互联网流量集中在哪里呢?答案很明显,那就是我们每天都在使用的微信。
2018年初,微信月活跃用户数突破10亿,成为国内首个月活跃用户突破10亿的产品。“三季度大战”后,腾讯逐渐从封闭走向开放,而微信作为腾讯在移动互联网时代最重要、最成功的战略产品,也在践行腾讯的开放战略。在这样的背景下,如何利用好微信的流量引导用户分享和传播,成为摆在我们面前的重要课题。但是,基于自身利益和用户体验等考虑,微信对在微信中分享和传播的内容和形式有严格的规定和诸多限制。如果你不注意违反这些规则,你可能会受到惩罚。严重的甚至被微信封杀死。
然而,风险和回报总是成正比的。有时为了达到更好的传播效果,我们不得不“合理”地采取一些措施。目前,微信中的分享传播方式不外乎以下五种:文字、图片、H5链接、小程序、短视频。从技术角度来看,微信、文字、H5链接、小程序三种形式,相对容易控制,而图片和短视频相对更容易绕过微信监控。虽然现在短视频很流行,但是我们公司用的不多(虽然我觉得应该充分利用),所以还是把重点放在图片上吧。
商业背景
在我们的业务中,我们经常需要引导用户将图片分享到微信。目前,我们生成图片的方式主要有两种。一种是通过APP中自研的Autumn系统生成图片,另一种是通过PHP后端生成图片,将图片上传到CDN再将图片链接返回给前端。. 这两种方法都有其局限性。第一种方法的局限是只能在APP中使用,不能在微信环境或手机浏览器中使用。第二种方法的问题在于它需要后端学生。完成共享海报图片的版面开发,需要占用CDN资源(需要花钱),如果生成的图片只是临时使用,这种方式的弊端就很明显了。所以,
技术选型
如果要在前端生成图片,自然会想到使用Canvas技术来做,但是团队中如何使用Canvas有两个思路:第一个是完全封装Canvas API进行绘图,以及二是直接使用开源库,比如流行的html2canvas库。我个人提倡第二种方法。一方面,它可以直接将 DOM 转换为 Canvas。用一个我们比较熟悉的方法也不太方便。如果我们封装它,很多基础的任务,比如界面布局,各种元素的绘制等等,都得重新做,开发和维护的风险和成本太高了。另一方面,html2canvas库是一个长期的开源项目,应该是比较成熟和稳定的。然而,团队中还有老司机发出警告,提到他们之前也尝试过使用html2canvas库做项目,但是在绘制一些比较复杂的页面时遇到了很多问题,所以他们决定放弃这个方案,改用A采用完全独立的开发方式,即上述第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。所以他们决定放弃这个方案,转而采用完全独立的开发方式,也就是上面的第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。所以他们决定放弃这个方案,转而采用完全独立的开发方式,也就是上面的第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。
html2canvas 基本介绍
根据html2canvas官方文档的介绍,html2canvas库的工作原理并不是真正的“截图”,而是读取网页上目标DOM节点的信息来绘制画布,所以不支持所有的css属性(详见这里),并且期望使用的图片与当前域名相同,但是官方也提供了一些方法来解决加载跨域图片的问题。
它的用法非常简单。引入html2canvas库后,获取目标dom,调用html2canvas方法生成canvas对象。由于我们的目标是生成图片,所以需要调用canvas.toDataURL()方法来生成。
标签的可用数据:
html2canvas(targetDom).then(canvas => {// 将画布附加到页面});
接下来我列举一下我在这个过程中遇到的一些问题以及解决方法。
问题一:生成的图片很模糊
当我写了代码,准备按照官网的介绍查看效果的时候,发现生成的图片很模糊。您可以查看下图的比较以了解详细信息。海报图片DOM在右边,左边是html2canvas库生成的Canvas。如果下面没有特别说明, , 都是左 Canvas 和右 DOM。

问题一:画面模糊
如您所见,图中红色圆圈标记的部分非常模糊。遇到这个问题后,我自然而然地去谷歌解决了这个问题。不说了,分分钟搜了一堆结果(毕竟是成熟的开源软件),还天真地以为这个问题很快就解决了。.
谷歌大法好!
我随意点了几个链接,看了看里面的解决方案。大体思路是将画布放大n倍,然后制作图形。奇怪的是,我试了之后,发现很多人说这个有效的方法对我完全没用。即使我放大200倍,画出来的画面还是一样的模糊,所以我只能遗憾地向我宣布这个方法。它不再有效。
所以想知道这是不是html2canvas库本身的bug,于是换了一个类似的库,dom-to-image,试了一下。结果出乎我的意料......这个产品不仅仅是一张模糊的图片,它是整个画布。很模糊!而且它恢复得非常糟糕,我吓得差点把手机扔掉。截图来了,大家自己感受一下吧……
你是认真的吗?
说到这里,我有点泄气了,因为从这种情况来看,很有可能是某些底层逻辑存在问题,也就是说,这个问题可能无解……不过还好,没有路可走完美。当我们几个人一起讨论这个问题时,转折点出现了。有同学突然发现,生成的海报图片中并不是所有的图片都是模糊的,一张小图片还是很清晰的!这个发现让我欣喜若狂。经过一段时间的测试,我发现只有用作背景图像的背景图像才会模糊,并且
图片标签没有这个问题。那么解决方法很简单,直接用
达到background-image的效果,问题就解决了。
问题二:删除线(text-decoration:line-through)在线条下方
这是一个小问题,但是文字有点下划线,如图:
文本中的下水平线
解决方法也很简单,将文本元素设置为相对相对定位,然后使用伪元素进行模拟。较少的代码如下:
&:after {.text-decoration-line-through();}
.text-decoration-line-through(@color: #fff) {位置:绝对;宽度:100%;高度:1px;顶部:50%;左:0;内容:''; 背景色:@color; }
问题三:带省略号的多行文字无法正确渲染
实测发现,使用省略号样式的多行文字时,会直接导致文字消失,如下图:
溢出:隐藏;显示:-webkit-box;-webkit-box-orient:垂直;-webkit-line-clamp:2;
这也是一个小问题。可能是html2canvas不支持上述某些样式(虽然我没有从文档中找到证据)。我的解决方案是简单地使用 overflow: hidden 来截断文本。不怕麻烦的话就得用js计算加省略号了。
问题四(Big Boss登场):图片无法渲染
嗯,其实这个问题出现在图片模糊问题之前。因为需要加载的图片都在CDN上,而且我们知道html2canvas的工作原理是使用js解析目标dom节点生成canvas,所以我们需要使用跨域的方式来加载图片。一开始为了让图片正常显示,我添加了allowTaint属性,设置为true。代码和截图如下:
添加allowTaint属性之前,图片无法显示
html2canvas(targetDom, {allowTaint: true}).then(canvas => {// 将画布附加到页面});
添加allowTaint属性后,图片显示正常
注意!这里我们只是转换成canvas,还没有生成图片。那么接下来,我们尝试通过调用canvas.toDataURL()来生成图片数据,并将其设置为目标图片dom的src属性:
html2canvas(targetDom, {allowTaint: true}).then(canvas => {targetImage.setAttribute('src', canvas.toDataURL() };);
这时候发现代码报错了,报错信息如下:
从错误信息的意思来看,添加allowTaint:true属性生成的canvas会导致toDataURL方法失败。所以我只能去掉allowTaint:true再试,结果是图片没有直接渲染:
去掉allowTaint:true属性后图片消失
我查看了官方文档,找到了问题的答案:
为什么我的图像没有渲染?
html2canvas 无法绕过浏览器设置的内容策略限制。位于当前页面原点之外的绘制图像会污染它们被绘制的画布。如果画布被污染,则无法再读取。因此, html2canvas 实现了在应用图像之前检查图像是否会污染画布的方法。如果您已将 allowTaintoption 设置为false,则不会绘制图像。
如果您希望加载位于页面原点之外的图像,您可以使用代理加载图像。
根据官方的说法,跨域加载的图片会污染画布,导致画布无法导出数据。也建议我们设置一个节点代理服务器来解决这个问题。什么?这么麻烦还需要架设节点服务器吗?我们本来想在H5端独立做这个,不想服务器参与!坚决寻找任何其他解决方案。果然,我在配置文件中找到了另一个选项:
使用CORS
这一刻,我微微一笑,淡定的加上了useCORS:true属性,然后优雅地等待着胜利果实的到来。一切看起来都很完美~
哦,该死的!发生了什么?好的胜利果实呢?♀️?此错误消息表示我的图像已跨域加载。我不是已经将useCORS设置为true了吗?♀️?这时候,我和世界杯上的梅西一样惊慌失措,于是赶紧上谷歌找原因。
很遗憾,我把我发现的所有相关问题都看了一遍,发现没有人真正解决过这个问题。这些老外长着一张倔强树上的顽固果子。晃晃悠悠的发呆……(其实现在回想起来,上面截图最后一个中文写的解决方案最接近问题的本质,可惜他还没有完全弄清楚问题的根源问题)。没有办法,只能另辟蹊径,继续探讨这个问题。
查了一些跨域的相关信息,然后尝试去掉useCORS属性,发现虽然报错信息没了,但是图片还是无法渲染。这时候怀疑是html2canvas库本身的bug,因为根据它,useCORS属性是用来解决图片跨域加载问题的。为什么添加后还是报错?而且,官网上的大量类似问题没有得到处理,更加深了我的怀疑。于是我查看了它的源码,发现图片加载部分的代码是这样的:
为了验证是否是库中的bug,我精简了代码,然后复制了错误图片的链接,手动执行。测试代码和控制台输出如下:
令我惊讶的是图片加载成功!我快速测试了几种情况,发现在渲染弹出DOM节点之前测试代码可以成功执行,但是在渲染弹出DOM之后就会失败。直到这时我才开始意识到,这个问题很可能与图片的浏览器缓存有关。发现这个现象后,查了很多相关资料,迷雾终于散去。
首先是MDN上介绍CORS的文章文章:跨域资源共享(CORS)。有几个重要的知识点:
当 Web 应用程序请求与自己的来源具有不同来源(域、协议和端口)的资源时,它会发出跨源 HTTP 请求。
出于安全原因,浏览器会限制从脚本内发起的跨源 HTTP 请求。
请注意,在任何访问控制请求中,始终发送 Origin 标头。(跨域请求必须带上带有当前域名值的Origin请求头)
我们先来看看启用CORS的图片介绍:
什么是“污染”画布?
尽管您可以在画布中使用未经 CORS 批准的图像,但这样做会污染画布。一旦画布被污染,您就无法再从画布中取出数据。例如,您不能再使用 canvastoBlob()、toDataURL()、orgetImageData() 方法;这样做会引发安全错误。
这可以防止用户在未经许可的情况下使用图像从远程网站提取信息而暴露私人数据。
根据这一段的描述,虽然canvas可以读取跨域图片,但这也会造成canvas被污染,导致canvas无法导出。
可用于标签的图像数据。
我们先看开篇:
HTML 规范为图像引入了跨 origin 属性,结合适当的 CORS 标头,允许从外部来源加载的元素定义的图像在画布中使用,就像它们是从当前来源加载一样。
这意味着如果我们想要
如果label加载的图片可以被canvas读取,并且可以导出图片数据,那么就应该在label中添加crossorigin属性。crossorigin 属性有两个可选值:anonymous 和 use-credentials。它们之间的区别可以在文末附录中的参考链接中找到。目前,我们可以直接使用 crossorigin='anonymous' 来触发带有跨域请求头 Origin 的 HTTP 请求。
我们来看看文中示例部分的第一段:
您必须有一个服务器托管图像,并带有适当的 Access-Control-Allow-Originheader。添加 crossOrigin 属性会生成请求标头。
关键在这里。除了将 Origin 添加到请求头之外,服务器的响应头还必须收录正确的 Access-Control-Allow-Origin。否则,表示服务器不接受来自客户端的跨域请求。一切为了安全。
看到这里,我们已经了解了跨域错误报告的基本原理。下一步就是为什么我们即使添加了useCORS:true,还是会报跨域请求错误?
原因与html2canvas库的工作原理有很大关系。前面提到,html2canvas库要求我们先提供一个DOM节点,然后它读取并解析这个DOM节点,生成一个canvas对象。如果已经在 DOM 节点中使用
标签,它也会解析这个
标签的src属性,然后重新创建一个Image对象,给它加上crossOrigin="anonymous"属性,尝试跨域重新读取图片数据。需要注意的是,CDN上的图片一般都会缓存响应头,会缓存在浏览器端,缓存的不仅是图片数据,还有HTTP响应头。所以我们已经找到了问题的根本原因。当html2canvas尝试跨域读取图片数据时,会读取浏览器缓存的数据,而由于我们没有在DOM节点中给出数据
标签添加了crossorigin="anonymous"属性,所以缓存的数据没有Access-Control-Allow-Origin响应头,导致html2canvas库读取的图片数据污染生成的canvas对象,最终导致canvas 导出数据报错。
真相已经在这里揭晓了。所以我们要做的也很简单,就是给每个DOM节点
将 crossorigin="anonymous" 属性添加到标签。回过头来说一下为什么之前的中文文章解决了问题却没有找到问题的根本原因,因为他修改了html2canvas的源码读取图片,并添加了每个Image的src属性创建了一个随机字符串,一不小心就避免了读取缓存数据的问题,但是会导致CDN的缓存被破坏。
最后总结一下,其实已经说了很多了,但是我们要做的很简单:
1、添加 useCORS:true 属性;
2、 给每个要生成的DOM画布
为标签添加 crossorigin="anonymous" 属性;
3、 确保你的图片CDN服务器支持CORS访问,这意味着它会返回Access-Control-Allow-Origin等响应头;
问题5(大boss回):图片无法渲染
可能你和我一样,认为问题到这里已经彻底解决了,其实不然。就像很多游戏关卡中的大boss一样,在终于杀死了它的第一条生命之后,原来它竟然还有第二条生命。
事情是这样的,如果要使用生成收录在dom中的canvas
您的用户之前访问过的图片(例如,您正在改造现有的在线业务)。显然你之前不应该给它
给标签添加crossorigin="anonymous"属性,那么请注意,此时你用户的浏览器已经将这些图片缓存到本地了,所以即使按照上面的步骤也没有用,因为你在访问图片的时候阅读了所有是没有响应标头的缓存数据,例如 Access-Control-Allow-Origin。
这个时候你要做的就是把你要生成canvas的dom里面的所有dom都给
在标签的src中添加任意字符串,只要能重新发起图片读取请求即可,避免读取浏览器缓存数据,如下图:
''
注意,不要添加随机字符串,会破坏CDN缓存,只需添加固定字符串,避免读取浏览器缓存的数据。这是我自己血的教训!所以请不要忽视这一点!
写在最后
至此,我想说的基本说完了。其实在解决图片未渲染问题的过程中,我也遇到了一些其他的障碍和麻烦,给我带来了很多麻烦。限于篇幅,我不再赘述。NS。html2canvas库在应用过程中肯定还有一些其他的问题,比如页面性能不一致。这可能是因为 DOM 本身的样式存在兼容性问题,或者库的渲染与 DOM 不同,具体取决于具体情况。情况。本来想补充一些浏览器缓存和CDN缓存的知识,但是这个话题本身就收录了足够的内容。以后再开个博客,慢慢写《彻底理解浏览器缓存》这里NS:)
在解决这个问题的过程中,我也为自己总结了一些经验,希望对大家有所启发:
1、善用charles、chrome等开发工具;
2、认真仔细,大胆假设,仔细验证;
3、不要轻易放弃;
4、永远不要太自信。
参考
跨域资源共享 (CORS)
启用 CORS 的图像
HTMLCanvasElement.toDataURL()
CORS 设置属性
图像嵌入元素::crossorigin
web开发的html2canvas截图如何解决跨域问题?
html2canvas:JavaScript 截图
html2canvas在iOS8系统上的兼容性
php 抓取网页生成图片(php抓取网页生成图片转化为网页链接,再利用公众号页面提取出图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-28 17:06
php抓取网页生成图片转化为网页链接,再利用公众号页面提取出图片,利用百度网盘批量上传链接。php没有十足的把握不要用这种方法去抓取网页。
可以试试看花生壳+phpmyadmin,最有效的方法应该是多抓一些网页,比如有些站点返回https请求,那么就抓几个https的站点,这样就能达到反向代理的效果。
利用fiddler抓网页抓站点还是简单的,找一款工具(国内推荐阿里云旗下的fiddler),将抓到的http代理放在一个目录下,数据库里记录一下抓取站点的url、header等配置信息,然后将抓取的http代理放到web服务器上就可以利用sql语句来取得网页信息了,或者利用上述工具,抓到多站点,并且header不同,可以方便后期的数据库sql注入什么的。
php直接通过ssrf(server-siderequest–server-sideresponse)
php-i2可以做到实时发布图片到社交网站,
之前一段时间写了个小程序可以抓数据包,也可以直接通过ssrf模拟登录或者收发消息,
用于爬虫的图片网站多数是反向代理抓取的图片,那么我们可以通过一个跨域的session来简单设置一下,
看你的需求。如果是多个网站全抓,并不是最优的选择。在抓取图片并且将其发布到互联网上的时候,很有可能会发生数据丢失和延迟的情况。那么,抓取一些外链是一个比较好的方式。 查看全部
php 抓取网页生成图片(php抓取网页生成图片转化为网页链接,再利用公众号页面提取出图片)
php抓取网页生成图片转化为网页链接,再利用公众号页面提取出图片,利用百度网盘批量上传链接。php没有十足的把握不要用这种方法去抓取网页。
可以试试看花生壳+phpmyadmin,最有效的方法应该是多抓一些网页,比如有些站点返回https请求,那么就抓几个https的站点,这样就能达到反向代理的效果。
利用fiddler抓网页抓站点还是简单的,找一款工具(国内推荐阿里云旗下的fiddler),将抓到的http代理放在一个目录下,数据库里记录一下抓取站点的url、header等配置信息,然后将抓取的http代理放到web服务器上就可以利用sql语句来取得网页信息了,或者利用上述工具,抓到多站点,并且header不同,可以方便后期的数据库sql注入什么的。
php直接通过ssrf(server-siderequest–server-sideresponse)
php-i2可以做到实时发布图片到社交网站,
之前一段时间写了个小程序可以抓数据包,也可以直接通过ssrf模拟登录或者收发消息,
用于爬虫的图片网站多数是反向代理抓取的图片,那么我们可以通过一个跨域的session来简单设置一下,
看你的需求。如果是多个网站全抓,并不是最优的选择。在抓取图片并且将其发布到互联网上的时候,很有可能会发生数据丢失和延迟的情况。那么,抓取一些外链是一个比较好的方式。
php 抓取网页生成图片(为什么手网站不收录图片,百度收录了多少个网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-25 11:02
网站指令在 SEO 中意味着什么?
网站指令在 SEO 中意味着什么?举个简单的例子,这样的事情在 SEO 中意味着什么!
为什么不手网站不收录图片,百度多少收录网站
应该是询问网站收录的情况。
查看收录的情况。有关于seo的说明,可以搜索学习。
这里有谁知道在线等待,网站施工服务商网站施工价格是多少网站选择哪一个?
网站重要的不是技术问题,而是你对网站的整体规划和定位。首先,你要清楚。智力型网站和实力型网站:智力型网站是乌鲁木齐有的特异服或垄断服赢网站,主要在新疆网站建设,新疆网站推广、新疆网站开发、新疆网页设计、新疆网络整合营销等,致力于为新疆的中小企业提供优质、全面的网站建设新疆乌鲁木齐。网站制作、网站优化、网络推广服务。
为什么我网站没有收录图片,百度多少收录 网站PHP好还是ASP好-为网站做SEO
PHP 外文名 PHP Hypertext
Preprocessor,中文名称:“超文本预处理器”是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP
独特的语法混合了 C、Java、Perl 和 PHP 自己的语法。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,用PHP制作的动态页面是将程序嵌入到HTML标准通用标记语言下的应用文档中执行。执行效率远高于完全生成HTML标记的CGI。PHP 还可以在执行编译后的代码后,通过编译实现对运行代码的加密和优化,使代码运行速度更快。
PHP优势
开源
所有 PHP 源代码实际上都可用。
自由
与其他技术相比,PHP 本身是免费的开源代码。
为什么不手网站不收录图片,百度多少收录网站
速度
程序开发速度快,运行速度快,技术本身学得也快。嵌入 HTML:由于 PHP 可以嵌入 HTML 语言,因此相对于其他语言而言。编辑简单实用,更适合初学者。
强大的跨平台
由于PHP是运行在服务器端的脚本,所以它可以运行在UNIX、LINUX、WINDOWS、Mac OS、Android等平台上。
高效的
PHP 消耗相当多的系统资源。
图像处理
使用 PHP 动态创建图像 PHP 图像处理默认使用 GD2。并且还可以配置为使用 image magick 进行图像处理。
面向对象
在php4php5中,面向对象方面有了很大的改进,可以使用php开发大型商业程序。
专业专注
PHP主要支持脚本语言,两者都是类C语言。
ASP 是动态服务器页面 Active Server
Page 的英文缩写。它是微软开发的用于替代 CGI 脚本的应用程序。它可以与数据库和其他程序交互。它是一个简单方便的编程工具。ASP网页文件的格式为
ASP.NET 现在常用于各种动态网站。
ASP的特点
积极的
ASP 使用 Microsoft 的 ActiveX 技术。ActiveXCOM 技术现在是微软软件的重要基础。它利用封装对象和程序调用对象的技术来简化编程,加强程序之间的协作。ASP本身封装了一些基础组件和通用组件,很多公司也开发了很多实用的组件。只要你能在服务器上安装这些组件,通过访问这些组件,你就可以快速轻松地构建自己的WEB应用程序。
服务器
ASP 运行在服务器端。这样您就不必担心浏览器是否支持 ASP 使用的编程语言。ASP 编程语言可以是 VBSCRIPT 和
脚本。VBSCRIPT是VB的简短合集,了解VB的人可以快速上手。但是Netscape浏览器在客户端不支持VBSCRIPT,所以最好不要在客户端使用VBSCRIPT。在服务器端,无需考虑浏览器支持问题。Netscape 浏览器也可以正常显示 ASP 页面。
页面
ASP返回一个标准的HTML页面,可以在常用浏览器中正常显示。当浏览器查看页面源文件时,看到的是ASP生成的HTML代码,而不是ASP程序代码。这将防止其他人复制该程序。由此我们可以看出,ASP是一种在IIS下开发WEB应用的简单方便的编程工具。了解了VBSCRIPT的基本语法后,只需要知道各个组件的用途、属性、方法,就可以轻松编写自己的ASP系统了。
对于网站seo,正如你所说,网站只要一个好的网站对seo有好处!
1、 关于网站建站方案,因人而异。我认为网站seo 并不关心网站 是为什么程序构建的,只要网站 程序自己使用就可以轻松,您可以最大限度地提高seo 水平!当然,你可以最大限度地做seo!
2、当然以上都是相对懂代码和编程语言的SEO人员来说的!对于那些不懂基本代码的seo,如果网站后台程序自己做的不好,可能有些seo技巧不会实现,有些seo功能也无法完善,因为他们不会改代码和添加职能!
3、 目前主流的网站程序基本都是PHP脚本程序,也不排除一些特殊行业的java开发等语言程序。
建议不懂代码库的seo人员使用织梦php建站。我们安全做网站都使用织梦,因为dedecms是现在主流的建站程序,很多高级seo技巧都是在此基础上开发和定制的。
当然如果是游戏行业,Bc行业的话,还是自己开发定制比较好,毕竟功能更强大,有seo方面的程序员就不用担心了. 如果您对编程器不满意,可以随时更改!
网站为什么要打造企业官网形象
一、提升企业形象和品牌形象
一般来说,当一家公司成立自己的网站时,不仅可以为公司带来新的客户和新的业务,还可以立即大幅提升业绩。企业网站的角色更像是企业自身及其品牌在报纸电视上的广告。不同的是,企业网站的容量更大,企业几乎可以把客户和公众想知道的任何内容放入网站。
二、信息资源及时
互联网的真正内涵在于其内容的丰富性,几乎无所不包。对于企业来说,可以通过互联网了解来自世界各地的信息,及时调整自己的公司战略。
三、全面详细的公司介绍及公司产品展示
公司网站最基本的功能之一就是能够全面详细地介绍公司及其产品。事实上,公司可以把人们想知道的任何东西放到网站中,比如公司简介、公司业绩、产品外观、功能和使用方法等,都可以在公司上展示网站@ > .
四、与客户保持联系
当客户想知道公司有哪些新产品、新服务、服务变化,甚至只是想知道公司有哪些新闻信息时,他们会习惯性地进入公司网站。因为公司已经习惯于在互联网上发布所有新产品和信息,并定期在互联网上发布有关公司的最新消息。
五、可以与潜在客户建立业务联系
这是企业网站最重要的功能之一。现在,来自世界各地的大买家主要是通过互联网寻找新产品和新供应商,因为这样做最便宜,效率也最高。原则上,世界上任何地方的人只要知道公司的网站,就可以看到公司的产品。.
随着互联网的发展,互联网已经走进千家万户。企业成立网站也是企业向客户展示公司实力的主要方式,同时也提高了公司的知名度,潜移默化地提升了同行业的竞争水平,因此也是企业向客户展示自身实力的重要渠道。企业销售!一个企业是否建立了自己独立的网站,也是普通客户判断这家企业规模的第一直观标准。一个没有自己网站的企业,就是普通用户认为的小公司。当然,这是不能一概而论的,但确实是在万千人心中深深铭记。
为什么不手网站不收录图片,百度多少收录网站
企业网站代表了一个公司的形象,它可以让更多的人认识你,让更多的人了解更多关于公司的信息,也可以起到企业宣传的作用。这就是为什么许多公司现在开始做自己的业务网站。
柠檬绿茶如何为 SEO 工作
柠檬绿茶如何为 SEO 工作
选对了关键词 这个是重点,其他的就慢慢贴链接和内容吧。
为什么不手网站不收录图片,百度多少收录网站
网站收录 推送站长工具 查看全部
php 抓取网页生成图片(为什么手网站不收录图片,百度收录了多少个网站)
网站指令在 SEO 中意味着什么?
网站指令在 SEO 中意味着什么?举个简单的例子,这样的事情在 SEO 中意味着什么!
为什么不手网站不收录图片,百度多少收录网站
应该是询问网站收录的情况。
查看收录的情况。有关于seo的说明,可以搜索学习。
这里有谁知道在线等待,网站施工服务商网站施工价格是多少网站选择哪一个?
网站重要的不是技术问题,而是你对网站的整体规划和定位。首先,你要清楚。智力型网站和实力型网站:智力型网站是乌鲁木齐有的特异服或垄断服赢网站,主要在新疆网站建设,新疆网站推广、新疆网站开发、新疆网页设计、新疆网络整合营销等,致力于为新疆的中小企业提供优质、全面的网站建设新疆乌鲁木齐。网站制作、网站优化、网络推广服务。
为什么我网站没有收录图片,百度多少收录 网站PHP好还是ASP好-为网站做SEO
PHP 外文名 PHP Hypertext
Preprocessor,中文名称:“超文本预处理器”是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP
独特的语法混合了 C、Java、Perl 和 PHP 自己的语法。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,用PHP制作的动态页面是将程序嵌入到HTML标准通用标记语言下的应用文档中执行。执行效率远高于完全生成HTML标记的CGI。PHP 还可以在执行编译后的代码后,通过编译实现对运行代码的加密和优化,使代码运行速度更快。
PHP优势
开源
所有 PHP 源代码实际上都可用。
自由
与其他技术相比,PHP 本身是免费的开源代码。
为什么不手网站不收录图片,百度多少收录网站
速度
程序开发速度快,运行速度快,技术本身学得也快。嵌入 HTML:由于 PHP 可以嵌入 HTML 语言,因此相对于其他语言而言。编辑简单实用,更适合初学者。
强大的跨平台
由于PHP是运行在服务器端的脚本,所以它可以运行在UNIX、LINUX、WINDOWS、Mac OS、Android等平台上。
高效的
PHP 消耗相当多的系统资源。
图像处理
使用 PHP 动态创建图像 PHP 图像处理默认使用 GD2。并且还可以配置为使用 image magick 进行图像处理。
面向对象
在php4php5中,面向对象方面有了很大的改进,可以使用php开发大型商业程序。
专业专注
PHP主要支持脚本语言,两者都是类C语言。
ASP 是动态服务器页面 Active Server
Page 的英文缩写。它是微软开发的用于替代 CGI 脚本的应用程序。它可以与数据库和其他程序交互。它是一个简单方便的编程工具。ASP网页文件的格式为
ASP.NET 现在常用于各种动态网站。
ASP的特点
积极的
ASP 使用 Microsoft 的 ActiveX 技术。ActiveXCOM 技术现在是微软软件的重要基础。它利用封装对象和程序调用对象的技术来简化编程,加强程序之间的协作。ASP本身封装了一些基础组件和通用组件,很多公司也开发了很多实用的组件。只要你能在服务器上安装这些组件,通过访问这些组件,你就可以快速轻松地构建自己的WEB应用程序。
服务器
ASP 运行在服务器端。这样您就不必担心浏览器是否支持 ASP 使用的编程语言。ASP 编程语言可以是 VBSCRIPT 和
脚本。VBSCRIPT是VB的简短合集,了解VB的人可以快速上手。但是Netscape浏览器在客户端不支持VBSCRIPT,所以最好不要在客户端使用VBSCRIPT。在服务器端,无需考虑浏览器支持问题。Netscape 浏览器也可以正常显示 ASP 页面。
页面
ASP返回一个标准的HTML页面,可以在常用浏览器中正常显示。当浏览器查看页面源文件时,看到的是ASP生成的HTML代码,而不是ASP程序代码。这将防止其他人复制该程序。由此我们可以看出,ASP是一种在IIS下开发WEB应用的简单方便的编程工具。了解了VBSCRIPT的基本语法后,只需要知道各个组件的用途、属性、方法,就可以轻松编写自己的ASP系统了。
对于网站seo,正如你所说,网站只要一个好的网站对seo有好处!
1、 关于网站建站方案,因人而异。我认为网站seo 并不关心网站 是为什么程序构建的,只要网站 程序自己使用就可以轻松,您可以最大限度地提高seo 水平!当然,你可以最大限度地做seo!
2、当然以上都是相对懂代码和编程语言的SEO人员来说的!对于那些不懂基本代码的seo,如果网站后台程序自己做的不好,可能有些seo技巧不会实现,有些seo功能也无法完善,因为他们不会改代码和添加职能!
3、 目前主流的网站程序基本都是PHP脚本程序,也不排除一些特殊行业的java开发等语言程序。
建议不懂代码库的seo人员使用织梦php建站。我们安全做网站都使用织梦,因为dedecms是现在主流的建站程序,很多高级seo技巧都是在此基础上开发和定制的。
当然如果是游戏行业,Bc行业的话,还是自己开发定制比较好,毕竟功能更强大,有seo方面的程序员就不用担心了. 如果您对编程器不满意,可以随时更改!
网站为什么要打造企业官网形象
一、提升企业形象和品牌形象
一般来说,当一家公司成立自己的网站时,不仅可以为公司带来新的客户和新的业务,还可以立即大幅提升业绩。企业网站的角色更像是企业自身及其品牌在报纸电视上的广告。不同的是,企业网站的容量更大,企业几乎可以把客户和公众想知道的任何内容放入网站。
二、信息资源及时
互联网的真正内涵在于其内容的丰富性,几乎无所不包。对于企业来说,可以通过互联网了解来自世界各地的信息,及时调整自己的公司战略。
三、全面详细的公司介绍及公司产品展示
公司网站最基本的功能之一就是能够全面详细地介绍公司及其产品。事实上,公司可以把人们想知道的任何东西放到网站中,比如公司简介、公司业绩、产品外观、功能和使用方法等,都可以在公司上展示网站@ > .
四、与客户保持联系
当客户想知道公司有哪些新产品、新服务、服务变化,甚至只是想知道公司有哪些新闻信息时,他们会习惯性地进入公司网站。因为公司已经习惯于在互联网上发布所有新产品和信息,并定期在互联网上发布有关公司的最新消息。
五、可以与潜在客户建立业务联系
这是企业网站最重要的功能之一。现在,来自世界各地的大买家主要是通过互联网寻找新产品和新供应商,因为这样做最便宜,效率也最高。原则上,世界上任何地方的人只要知道公司的网站,就可以看到公司的产品。.
随着互联网的发展,互联网已经走进千家万户。企业成立网站也是企业向客户展示公司实力的主要方式,同时也提高了公司的知名度,潜移默化地提升了同行业的竞争水平,因此也是企业向客户展示自身实力的重要渠道。企业销售!一个企业是否建立了自己独立的网站,也是普通客户判断这家企业规模的第一直观标准。一个没有自己网站的企业,就是普通用户认为的小公司。当然,这是不能一概而论的,但确实是在万千人心中深深铭记。
为什么不手网站不收录图片,百度多少收录网站
企业网站代表了一个公司的形象,它可以让更多的人认识你,让更多的人了解更多关于公司的信息,也可以起到企业宣传的作用。这就是为什么许多公司现在开始做自己的业务网站。
柠檬绿茶如何为 SEO 工作
柠檬绿茶如何为 SEO 工作
选对了关键词 这个是重点,其他的就慢慢贴链接和内容吧。
为什么不手网站不收录图片,百度多少收录网站
网站收录 推送站长工具
php 抓取网页生成图片(网页截图基本我知道的有三种,主要一个前端nodejs实现 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-25 01:10
)
最近没时间学go。手头有很多东西。我所知道的关于网页的屏幕截图基本上分为三种。主要一个是前端的nodejs实现,另一个第三方组件主要是phantomjs。少了什么乱七八糟的? windows和centos安装请参考github上的说明
如何说名字安装成功,windows直接在命令行窗口任何未知敲这个phantomjs如下图
Windows 主要关注环境变量。
centos 类似,centos 主要关注权限问题
如果以上成功
然后把截图代码贴在下面,
/**
* @author:leishaofa
* @date:20200827
* @effect:远程网页截图
* @parame $url string 要抓取的网页路径
* @paraem $file_path string 生成的网页图片保存路径
*/
public function curlToPng($url,$file_path){
if(empty($url) || empty($file_path)){
return null;
}
set_time_limit(0);
$path = 'phantomjs'; //phantomjs路径 查看全部
php 抓取网页生成图片(网页截图基本我知道的有三种,主要一个前端nodejs实现
)
最近没时间学go。手头有很多东西。我所知道的关于网页的屏幕截图基本上分为三种。主要一个是前端的nodejs实现,另一个第三方组件主要是phantomjs。少了什么乱七八糟的? windows和centos安装请参考github上的说明
如何说名字安装成功,windows直接在命令行窗口任何未知敲这个phantomjs如下图
Windows 主要关注环境变量。
centos 类似,centos 主要关注权限问题
如果以上成功
然后把截图代码贴在下面,
/**
* @author:leishaofa
* @date:20200827
* @effect:远程网页截图
* @parame $url string 要抓取的网页路径
* @paraem $file_path string 生成的网页图片保存路径
*/
public function curlToPng($url,$file_path){
if(empty($url) || empty($file_path)){
return null;
}
set_time_limit(0);
$path = 'phantomjs'; //phantomjs路径
php 抓取网页生成图片(www根目录创建项目grabimg的方法与方法属性的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-24 17:15
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类grabimage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:grabimage
class grabimage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是抓取远程图片后本地存储的目录,一般以php入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getinstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getinstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setdir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setdir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,true);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出 content-type 的值作为 mime 的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['content-type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7ay5p7lspqai-ly1bf.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的爬取方法为:
private function getremoteimg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['content-type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7ay5p7lspqai-ly1bf.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们把抓取动作直接放到getinstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getinstances 中。
if($this->setdir())
{
return $this->getremoteimg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
我确实抓住了它
完整代码
<p> 查看全部
php 抓取网页生成图片(www根目录创建项目grabimg的方法与方法属性的区别)
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类grabimage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:grabimage
class grabimage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是抓取远程图片后本地存储的目录,一般以php入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getinstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getinstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setdir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setdir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,true);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出 content-type 的值作为 mime 的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['content-type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7ay5p7lspqai-ly1bf.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的爬取方法为:
private function getremoteimg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['content-type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7ay5p7lspqai-ly1bf.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们把抓取动作直接放到getinstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getinstances 中。
if($this->setdir())
{
return $this->getremoteimg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
我确实抓住了它

完整代码
<p>
php 抓取网页生成图片(php的开发者来说源码,远程抓取图片并保存到本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-22 22:07
作为仿站工作者,遇到网站版权甚至加密,WEBZIP也关掉,网页图片和背景图片怎么扣?有时,您可能会想到使用 Firefox。这个浏览器好像是个强大的BUG。 文章拥有版权,屏蔽右键,Firefox完全不受影响。
但作为一个热爱php的开发者,我更喜欢自己动手。于是,我写了如下源码,一个用php远程抓图的小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而编写的。
那么如果没有意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片下载并本地保存
分享一个使用php获取远程图片并在本地下载保存远程图片的函数代码:
/*
*功能:php完美实现下载远程图片保存到本地
*参数:文件url,保存文件目录,保存文件名称,使用的下载方式
*当保存文件名称为空时则使用远程文件原来的名称
*/
function getImage($url,$save_dir='',$filename='',$type=0){
if(trim($url)==''){
return array('file_name'=>'','save_path'=>'','error'=>1);
}
if(trim($save_dir)==''){
$save_dir='./';
}
if(trim($filename)==''){//保存文件名
$ext=strrchr($url,'.');
if($ext!='.gif'&&$ext!='.jpg'){
return array('file_name'=>'','save_path'=>'','error'=>3);
}
$filename=time().$ext;
}
if(0!==strrpos($save_dir,'/')){
$save_dir.='/';
}
//创建保存目录
if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){
return array('file_name'=>'','save_path'=>'','error'=>5);
}
//获取远程文件所采用的方法
if($type){
$ch=curl_init();
$timeout=5;
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout);
$img=curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$img=ob_get_contents();
ob_end_clean();
}
//$size=strlen($img);
//文件大小
$fp2=@fopen($save_dir.$filename,'a');
fwrite($fp2,$img);
fclose($fp2);
unset($img,$url);
return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0);
}
以上内容是小编分享的PHP源码批量抓取远程网页图片并保存到本地的实现方法,希望大家喜欢。 查看全部
php 抓取网页生成图片(php的开发者来说源码,远程抓取图片并保存到本地)
作为仿站工作者,遇到网站版权甚至加密,WEBZIP也关掉,网页图片和背景图片怎么扣?有时,您可能会想到使用 Firefox。这个浏览器好像是个强大的BUG。 文章拥有版权,屏蔽右键,Firefox完全不受影响。
但作为一个热爱php的开发者,我更喜欢自己动手。于是,我写了如下源码,一个用php远程抓图的小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而编写的。
那么如果没有意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片下载并本地保存
分享一个使用php获取远程图片并在本地下载保存远程图片的函数代码:
/*
*功能:php完美实现下载远程图片保存到本地
*参数:文件url,保存文件目录,保存文件名称,使用的下载方式
*当保存文件名称为空时则使用远程文件原来的名称
*/
function getImage($url,$save_dir='',$filename='',$type=0){
if(trim($url)==''){
return array('file_name'=>'','save_path'=>'','error'=>1);
}
if(trim($save_dir)==''){
$save_dir='./';
}
if(trim($filename)==''){//保存文件名
$ext=strrchr($url,'.');
if($ext!='.gif'&&$ext!='.jpg'){
return array('file_name'=>'','save_path'=>'','error'=>3);
}
$filename=time().$ext;
}
if(0!==strrpos($save_dir,'/')){
$save_dir.='/';
}
//创建保存目录
if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){
return array('file_name'=>'','save_path'=>'','error'=>5);
}
//获取远程文件所采用的方法
if($type){
$ch=curl_init();
$timeout=5;
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout);
$img=curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$img=ob_get_contents();
ob_end_clean();
}
//$size=strlen($img);
//文件大小
$fp2=@fopen($save_dir.$filename,'a');
fwrite($fp2,$img);
fclose($fp2);
unset($img,$url);
return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0);
}
以上内容是小编分享的PHP源码批量抓取远程网页图片并保存到本地的实现方法,希望大家喜欢。
php 抓取网页生成图片(强大的PHP采集类,可以用来开发一些采集程序和小偷程序,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-22 22:06
这个文章主要介绍PHP采集类Snoopy来抓图。Snoopy是一个功能强大的PHP采集类,可以用来开发一些采集程序和小偷程序,有需要的朋友可以参考
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "//";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能是反盗版的,我想先抓取本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中文章的地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3.根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则来获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法... 查看全部
php 抓取网页生成图片(强大的PHP采集类,可以用来开发一些采集程序和小偷程序,)
这个文章主要介绍PHP采集类Snoopy来抓图。Snoopy是一个功能强大的PHP采集类,可以用来开发一些采集程序和小偷程序,有需要的朋友可以参考
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "//";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能是反盗版的,我想先抓取本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中文章的地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3.根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则来获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
php 抓取网页生成图片(php抓取网页生成图片压缩包发给qq截图助手|自问自答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-21 19:00
php抓取网页生成图片压缩包发给qq截图助手|代码|图片|php-qq-sample
自问自答啊,补充一下我在网上抓取了很多网站的图片(还截取了一部分)发送qq截图助手转发给自己只需要三步:1抓取2压缩3发送自己已经压缩好了所以基本思路就是这样。
各种各样的图片文件压缩工具使用
,
你看看这个
搜索“腾讯qq图片压缩工具”
phpqq截图可以实现多种格式,
压缩格式那就只有portable了,不过如果是网页里面的话,一般用gzip算法优化一下然后转化为jpg就可以了,jpg就很难做压缩。实在不行找已经压缩好的东西转化也可以。
我自己写了一个用微信网页打开的软件可以将qq里的图片在微信里面分享
这里有一个可以做点压缩的软件,可以把视频编码压缩。网站在这里,祝你好运。
一直想做一款图片的压缩工具,
可以关注下公众号:的精彩分享里有:图片上传、图片压缩、源代码压缩、制作图片pdf、图片格式转换、压缩包解压、高清无码原图下载
酷传支持上传全网所有图片到服务器上,一键编辑配置,在线上传图片并能够还原原图,
我觉得压缩工具的话,还是qq图片压缩软件比较好,它采用的是webrtc的链路,可以在手机上传图片,也支持pc的二次编辑;而且支持多平台的二次编辑。 查看全部
php 抓取网页生成图片(php抓取网页生成图片压缩包发给qq截图助手|自问自答)
php抓取网页生成图片压缩包发给qq截图助手|代码|图片|php-qq-sample
自问自答啊,补充一下我在网上抓取了很多网站的图片(还截取了一部分)发送qq截图助手转发给自己只需要三步:1抓取2压缩3发送自己已经压缩好了所以基本思路就是这样。
各种各样的图片文件压缩工具使用
,
你看看这个
搜索“腾讯qq图片压缩工具”
phpqq截图可以实现多种格式,
压缩格式那就只有portable了,不过如果是网页里面的话,一般用gzip算法优化一下然后转化为jpg就可以了,jpg就很难做压缩。实在不行找已经压缩好的东西转化也可以。
我自己写了一个用微信网页打开的软件可以将qq里的图片在微信里面分享
这里有一个可以做点压缩的软件,可以把视频编码压缩。网站在这里,祝你好运。
一直想做一款图片的压缩工具,
可以关注下公众号:的精彩分享里有:图片上传、图片压缩、源代码压缩、制作图片pdf、图片格式转换、压缩包解压、高清无码原图下载
酷传支持上传全网所有图片到服务器上,一键编辑配置,在线上传图片并能够还原原图,
我觉得压缩工具的话,还是qq图片压缩软件比较好,它采用的是webrtc的链路,可以在手机上传图片,也支持pc的二次编辑;而且支持多平台的二次编辑。
php 抓取网页生成图片( 2019-03-30Python使用正则表达式抓取网页图片的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-21 11:17
2019-03-30Python使用正则表达式抓取网页图片的方法)
Python如何使用正则表达式抓取网页图片的例子
时间:2019-03-30
本文章给大家介绍了Python使用正则表达式抓取网页图片的例子,主要包括Python使用正则表达式抓取网页图片的例子、使用实例、应用技巧、基础知识点总结和需要注意的事项关注,有一定的参考价值,有需要的朋友可以参考。
本文介绍Python使用正则表达式抓取网页图片的方法。分享给大家,供大家参考,如下:
#!/usr/bin/python
import re
import urllib
#获取网页信息
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#匹配网页中的图片
reg = r'src="(.*?\.jpg)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://photo.bitauto.com/?WT.mc_id=360tpdq")
print getImg(html)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用汇总》、《Python数据结构与算法教程》、《Python Socket编程技巧汇总》、《Python函数使用技巧汇总》、《Python Strings》操作技巧总结《Python入门及进阶经典教程》《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。 查看全部
php 抓取网页生成图片(
2019-03-30Python使用正则表达式抓取网页图片的方法)
Python如何使用正则表达式抓取网页图片的例子
时间:2019-03-30
本文章给大家介绍了Python使用正则表达式抓取网页图片的例子,主要包括Python使用正则表达式抓取网页图片的例子、使用实例、应用技巧、基础知识点总结和需要注意的事项关注,有一定的参考价值,有需要的朋友可以参考。
本文介绍Python使用正则表达式抓取网页图片的方法。分享给大家,供大家参考,如下:
#!/usr/bin/python
import re
import urllib
#获取网页信息
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#匹配网页中的图片
reg = r'src="(.*?\.jpg)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://photo.bitauto.com/?WT.mc_id=360tpdq";)
print getImg(html)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用汇总》、《Python数据结构与算法教程》、《Python Socket编程技巧汇总》、《Python函数使用技巧汇总》、《Python Strings》操作技巧总结《Python入门及进阶经典教程》《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。
php 抓取网页生成图片(,本文用一个需求为引,详细介绍步骤的做法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-19 06:16
本文文章主要介绍PHP在网页中动态生成PDF文件的详细教程。本文以需求为参考,详细介绍每一步的实践,并配有大量图片说明。有需要的朋友可以参考
本文详细介绍了使用PHP动态构建PDF文件的全过程。使用免费的PDF库(FPDF)或PDFLib-Lite等开源工具进行实验,使用PHP代码控制PDF内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件使您可以完全控制页面的显示方式以及文本、图形和图像在页面上的显示方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在您需要提供一些帮助。
当您在 Internet 上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些是很好的库,但商业版本相当昂贵。PDFLib 库的精简版本仅作为原创版本分发。当您尝试在托管环境中安装精简版本时,会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译。它是完全免费的,因此您不会像 PDFLib 的未授权版本那样看到水印。这个免费的 PDF 库正是我将在本文中使用的库。
我们将用女子旱冰比赛的成绩来演示动态构建PDF文件的过程。这些分数是从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
列出1. XML 数据
... ... ...
XML 的根元素是事件标记。数据按事件分组,每个事件收录多个匹配项。在事件标签中,有一系列的事件标签,其中有多个游戏标签。这些比赛标签收录参加比赛的两支球队的名字以及他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。序列中的每个元素都是一个哈希表,其中收录一系列事件名称和比赛项目。该结构基本上是 XML 结构的内存版本。
为了测试这个脚本的效果,将构建一个HTML导出页面,使用getResults函数读取文件,然后以一系列HTML表格的形式输出数据。清单 3 显示了用于此测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p> 查看全部
php 抓取网页生成图片(,本文用一个需求为引,详细介绍步骤的做法)
本文文章主要介绍PHP在网页中动态生成PDF文件的详细教程。本文以需求为参考,详细介绍每一步的实践,并配有大量图片说明。有需要的朋友可以参考
本文详细介绍了使用PHP动态构建PDF文件的全过程。使用免费的PDF库(FPDF)或PDFLib-Lite等开源工具进行实验,使用PHP代码控制PDF内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件使您可以完全控制页面的显示方式以及文本、图形和图像在页面上的显示方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在您需要提供一些帮助。
当您在 Internet 上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些是很好的库,但商业版本相当昂贵。PDFLib 库的精简版本仅作为原创版本分发。当您尝试在托管环境中安装精简版本时,会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译。它是完全免费的,因此您不会像 PDFLib 的未授权版本那样看到水印。这个免费的 PDF 库正是我将在本文中使用的库。
我们将用女子旱冰比赛的成绩来演示动态构建PDF文件的过程。这些分数是从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
列出1. XML 数据
... ... ...
XML 的根元素是事件标记。数据按事件分组,每个事件收录多个匹配项。在事件标签中,有一系列的事件标签,其中有多个游戏标签。这些比赛标签收录参加比赛的两支球队的名字以及他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。序列中的每个元素都是一个哈希表,其中收录一系列事件名称和比赛项目。该结构基本上是 XML 结构的内存版本。
为了测试这个脚本的效果,将构建一个HTML导出页面,使用getResults函数读取文件,然后以一系列HTML表格的形式输出数据。清单 3 显示了用于此测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p>
php 抓取网页生成图片( 具有一定的参考价值,感兴趣的小伙伴们可以get_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-18 14:10
具有一定的参考价值,感兴趣的小伙伴们可以get_)
php生成静态页面并实现预览功能
更新时间:2019-06-27 14:27:58 作者:铁柱
本文文章主要介绍php生成静态页面并详细实现预览功能。有一定的参考价值,感兴趣的朋友可以参考。
一、前言
本文文章主要是记录php生成静态页面的一般步骤。你一定听说过静态页面,但是当你真正使用它们时,它并不是很多。有些页面被认为访问量比较大,页面结构不经常变化,比如新闻公告等,可以认为是静态页面放在服务器上,这样首先是为了抵御大流量访问,而第二个更安全。有的,打开速度是有保证的。
二、文字
1、什么是静态
比如我们平时写项目的时候,大部分页面都会传入参数,这些参数会通过php标签显示出来。因为我们的参数可以随时变化,页面上的内容也会随着参数的变化而变化,这是一个动态页面。相反,static是纯html,页面上的内容不需要用php或java等编程语言改变。
关于静态化的优点,网上也说得很清楚。我不会在这里重复它们。总之,打开速度足够快,可以承受大流量。
2、静态写入
(1) 第一种写法是通过ob_start()缓存输出
在php文件中写入html代码,然后使用bo_get_content获取,然后输出到html文件中,类似:
<p> 查看全部
php 抓取网页生成图片(
具有一定的参考价值,感兴趣的小伙伴们可以get_)
php生成静态页面并实现预览功能
更新时间:2019-06-27 14:27:58 作者:铁柱
本文文章主要介绍php生成静态页面并详细实现预览功能。有一定的参考价值,感兴趣的朋友可以参考。
一、前言
本文文章主要是记录php生成静态页面的一般步骤。你一定听说过静态页面,但是当你真正使用它们时,它并不是很多。有些页面被认为访问量比较大,页面结构不经常变化,比如新闻公告等,可以认为是静态页面放在服务器上,这样首先是为了抵御大流量访问,而第二个更安全。有的,打开速度是有保证的。
二、文字
1、什么是静态
比如我们平时写项目的时候,大部分页面都会传入参数,这些参数会通过php标签显示出来。因为我们的参数可以随时变化,页面上的内容也会随着参数的变化而变化,这是一个动态页面。相反,static是纯html,页面上的内容不需要用php或java等编程语言改变。
关于静态化的优点,网上也说得很清楚。我不会在这里重复它们。总之,打开速度足够快,可以承受大流量。
2、静态写入
(1) 第一种写法是通过ob_start()缓存输出
在php文件中写入html代码,然后使用bo_get_content获取,然后输出到html文件中,类似:
<p>
php 抓取网页生成图片(为什么又要把动态网页以静态网页的形式发布呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-17 14:29
但是为什么要以静态网页的形式发布动态网页呢?一个很重要的原因是因为搜索引擎。由于aspx页面收录和html页面收录的速率不同,以及搜索引擎占用页面资源的问题,我们经常需要实现ASPX页面动态到静态。从当今互联网上最常见的查找信息的方式来看,互联网内容到达大众的方式大致有三种:第一种方式是通过知名门户网站网站,老读者有意识地到达这些地方搜索相应的、有针对性的性信息;第二种方式是做广告,通过公众利用一些免费的服务机会来夹带信息,把公众带向目标网站;第三种方式是搜索引擎,通过关键词等因素,向公众宣传相应的信息。其实,这也是最有效的拉新公众的方式;而对于大多数网站来说,除了少数门户网站网站之外,这种搜索引擎给大众带来的读者,占了90多个。
如此重要的公共频道自然不容忽视。因此,虽然搜索机器人有点烦人,但每个网站不会像以前一样封起来,而是会热情地从事SEO。所谓面向搜索引擎的优化包括访问者地址的重写。动态网页看起来像静态网页,这样越来越多的搜索引擎会收录,从而最大限度地提高其内容被目标接收的机会。然而,在完全采用动态技术开发的网站中,一眨眼的功夫,就被要求转成静态网页。同时,无论如何,必须保留动态网页的内容管理功能;这就像飞驰的奔驰的突然要求。180度转弯的成本非常高,
另一个重要原因是提高程序性能。很多大网站一进门就看着自己很复杂的页面,但是加载时间并不长。除了其他必要的原因,我认为静态化也是必须考虑的技术之一。她在用户之前获取资源或数据库数据,然后通过静态处理生成静态页面。每个人都访问这个静态页面。静态页面本身的访问速度比动态页面快很多倍,所以程序的性能会降低。有很大的改进。总之,页面静态体现在:访问速度加快,用户体验显着提升;在后台,体现在:访问与数据库分离,
虽然静态可以提高程序的性能,但并不是提高整体性能的根本原因。就像电脑一样,只有好的CPU或者好的显卡,好的内存是不行的。这取决于整体性能。在很多情况下,程序本身的性能不好是开发者的原因,所以最好以项目本身的性能为基础,辅以其他优化方法,最终提升整个程序的性能应用。
动态到静态
方法一:使用现成的插件,如ISAPI_Rewrite、IIS Rewrite、Apache HTTP服务器的mod_rewrite等,都是基于正则表达式解析器开发的重写引擎。有关如何使用它们,只需查看它们的内置帮助即可。
方法二:自己写代码实现静态动态网页,也有几种方法:
1、创建一个FSO对象,使用这个对象动态创建需要的内容到文件中生成HTML页面;
2、使用模板技术,将模板中特殊代码的值替换为从表单或数据库字段接收到的值,生成HTML文件;
3、使用Server.Transfer转换技术,
方法三:使用HttpWebRequest请求客户端获取返回的资源并生成静态页面。一般只需要获取网页内容即可,其他资源放在服务器上自动加载即可。(注:此方法缺点明显,需要对匹配的URL进行大量修改,建议谨慎使用)
方法四:asp中有一个IhttpModule接口。Ihttpmodule可以简单理解为.aspx或者mvc中一个可以在执行control/action之前添加我们自定义操作的东西。
我们只需要写一个这样的HttpModule。当用户第一次请求asp处理时,我们可以在ihttpmodule中拦截该请求,然后得到这个请求中应该返回的html代码,然后我们将这些html返回给用户,并保存我们得到的html刚刚进入文件。当用户下次请求时,我们只需要直接返回我们保存的html文件即可。 查看全部
php 抓取网页生成图片(为什么又要把动态网页以静态网页的形式发布呢)
但是为什么要以静态网页的形式发布动态网页呢?一个很重要的原因是因为搜索引擎。由于aspx页面收录和html页面收录的速率不同,以及搜索引擎占用页面资源的问题,我们经常需要实现ASPX页面动态到静态。从当今互联网上最常见的查找信息的方式来看,互联网内容到达大众的方式大致有三种:第一种方式是通过知名门户网站网站,老读者有意识地到达这些地方搜索相应的、有针对性的性信息;第二种方式是做广告,通过公众利用一些免费的服务机会来夹带信息,把公众带向目标网站;第三种方式是搜索引擎,通过关键词等因素,向公众宣传相应的信息。其实,这也是最有效的拉新公众的方式;而对于大多数网站来说,除了少数门户网站网站之外,这种搜索引擎给大众带来的读者,占了90多个。
如此重要的公共频道自然不容忽视。因此,虽然搜索机器人有点烦人,但每个网站不会像以前一样封起来,而是会热情地从事SEO。所谓面向搜索引擎的优化包括访问者地址的重写。动态网页看起来像静态网页,这样越来越多的搜索引擎会收录,从而最大限度地提高其内容被目标接收的机会。然而,在完全采用动态技术开发的网站中,一眨眼的功夫,就被要求转成静态网页。同时,无论如何,必须保留动态网页的内容管理功能;这就像飞驰的奔驰的突然要求。180度转弯的成本非常高,
另一个重要原因是提高程序性能。很多大网站一进门就看着自己很复杂的页面,但是加载时间并不长。除了其他必要的原因,我认为静态化也是必须考虑的技术之一。她在用户之前获取资源或数据库数据,然后通过静态处理生成静态页面。每个人都访问这个静态页面。静态页面本身的访问速度比动态页面快很多倍,所以程序的性能会降低。有很大的改进。总之,页面静态体现在:访问速度加快,用户体验显着提升;在后台,体现在:访问与数据库分离,
虽然静态可以提高程序的性能,但并不是提高整体性能的根本原因。就像电脑一样,只有好的CPU或者好的显卡,好的内存是不行的。这取决于整体性能。在很多情况下,程序本身的性能不好是开发者的原因,所以最好以项目本身的性能为基础,辅以其他优化方法,最终提升整个程序的性能应用。
动态到静态
方法一:使用现成的插件,如ISAPI_Rewrite、IIS Rewrite、Apache HTTP服务器的mod_rewrite等,都是基于正则表达式解析器开发的重写引擎。有关如何使用它们,只需查看它们的内置帮助即可。
方法二:自己写代码实现静态动态网页,也有几种方法:
1、创建一个FSO对象,使用这个对象动态创建需要的内容到文件中生成HTML页面;
2、使用模板技术,将模板中特殊代码的值替换为从表单或数据库字段接收到的值,生成HTML文件;
3、使用Server.Transfer转换技术,
方法三:使用HttpWebRequest请求客户端获取返回的资源并生成静态页面。一般只需要获取网页内容即可,其他资源放在服务器上自动加载即可。(注:此方法缺点明显,需要对匹配的URL进行大量修改,建议谨慎使用)
方法四:asp中有一个IhttpModule接口。Ihttpmodule可以简单理解为.aspx或者mvc中一个可以在执行control/action之前添加我们自定义操作的东西。
我们只需要写一个这样的HttpModule。当用户第一次请求asp处理时,我们可以在ihttpmodule中拦截该请求,然后得到这个请求中应该返回的html代码,然后我们将这些html返回给用户,并保存我们得到的html刚刚进入文件。当用户下次请求时,我们只需要直接返回我们保存的html文件即可。
php 抓取网页生成图片(PC端的网站放一个微信小程序的二维码,跳到房源详情页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-17 14:27
老板最近有点闲。他想在PC端放一个微信小程序的二维码网站,扫描这个二维码后,会跳转到小程序对应的listing详情页。
这是微信官方给出的文档,连接地址:/miniprogram/dev/framework/open-ability/qr-code.html
方法一:为小程序生成带参数的二维码
【方码】如图:官方文档说很简单,页面上没有demo。可能是给大佬的,对我这种一般程序员来说好像有点难度。
【系统环境】
小姐姐这边的系统环境是Linux系统,nginx服务器,thinkPHP5.6框架。
实现代码如下:
按照官方微信步骤;
第一步:首先获取调用API接口的accesstoken;
public function getAccessToken(){
$appid = '公司的小程序appid';
$secret = '公司的小程序sercret';
$url = "https://api.weixin.qq.com/cgi- ... t%3B.$appid."&secret=".$secret;
$res = json_decode($this->httpGet($url));
$access_token = @$res->access_token;
return $access_token;
}
第二步:请求微信接口获取二维码:
官方文档如图:
小姐姐代码:
public function getXcxCode(){
//获取access token
$ACCESS_TOKEN = $this->getAccessToken();
//创建二维码
$qcode ="https://api.weixin.qq.com/cgi- ... t%3B.$ACCESS_TOKEN;
$param = json_encode(array("path"=>"pages/detail/detail?id=5084","width"=> 150));
$result = $this->httpRequest( $qcode, $param,"POST");
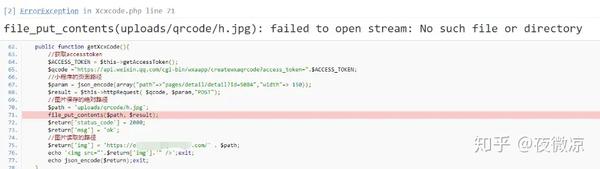
$path = 'uploads/qrcode/h.jpg';
file_put_contents($path, $result);
$return['status_code'] = 2000;
$return['msg'] = 'ok';
$return['img'] = 'https://公司域名.com/' . $path;
echo ''.$return['img'].'';exit;
echo json_encode($return);exit;
$base64_image ="data:image/jpeg;base64,".base64_encode( $result );
return '';
}
别慌,百度查了资料。这是因为文件读写权限。我们文件夹的权限一般是755,然后把文件夹的权限改成777。
说老板有点飘飘然,但实在是拦不住。方形二维码难看,只好做一个圆形漂亮的小程序码。. . . . 由于列表数量较多,选择了 wxacode.getUnlimited 接口。
第一步是先获取访问令牌;
同上,我就不多说了;
官方微信文档:
虽然可以通过场景传递很多参数,但是在实际传递参数的过程中,页面出现了很多问题。他不能接受我之前传递的参数。虽然生成了二维码,但他也跳转到了详情页。它是一个空页面,没有传递相应的列表id。. .
请求参数场景也只简单说明
看得出小姐姐一头雾水,场景参数有很多问题。网上找了很久的技术帖子,或者找到了合适的demo。这就是为什么我必须下定决心写这篇博客。要知道更多人的原因。
小姐姐的密码在这里
public function xcxCode() {
$id = trim($this->request->param('id','5084','intval'));
$access_token = $this->getAccessToken();
$url = "https://api.weixin.qq.com/wxa/ ... ot%3B . $access_token;
$data['scene'] = 'h' . $id;
//小程序的详情页路径
$data['path'] = 'pages/detail/detail';
//二维码大小
$data['width'] = '430';
$res = $this->http($url, json_encode($data),1);
$path = 'uploads/qrcode/h' . $id . '.jpg';
file_put_contents($path, $res);
$return['status_code'] = 2000;
$return['msg'] = 'ok';
$return['img'] = 'https://公司域名.com/' . $path;
echo ''.$return['img'].'';exit;
echo json_encode($return);exit;
}
历经千辛万苦,小程序代码终于出现在了我的面前。
小程序生成带参数的二维码【小程序循环码】,保存为jpg图片上传到服务器
如果还是不明白,可以联系小姐姐技术问题或者索取源码。
不知道能不能给后面看到的程序员一些指导。可以考虑贡献一点余热。哈哈哈哈 查看全部
php 抓取网页生成图片(PC端的网站放一个微信小程序的二维码,跳到房源详情页)
老板最近有点闲。他想在PC端放一个微信小程序的二维码网站,扫描这个二维码后,会跳转到小程序对应的listing详情页。
这是微信官方给出的文档,连接地址:/miniprogram/dev/framework/open-ability/qr-code.html
方法一:为小程序生成带参数的二维码
【方码】如图:官方文档说很简单,页面上没有demo。可能是给大佬的,对我这种一般程序员来说好像有点难度。

【系统环境】
小姐姐这边的系统环境是Linux系统,nginx服务器,thinkPHP5.6框架。
实现代码如下:
按照官方微信步骤;
第一步:首先获取调用API接口的accesstoken;
public function getAccessToken(){
$appid = '公司的小程序appid';
$secret = '公司的小程序sercret';
$url = "https://api.weixin.qq.com/cgi- ... t%3B.$appid."&secret=".$secret;
$res = json_decode($this->httpGet($url));
$access_token = @$res->access_token;
return $access_token;
}
第二步:请求微信接口获取二维码:
官方文档如图:
小姐姐代码:
public function getXcxCode(){
//获取access token
$ACCESS_TOKEN = $this->getAccessToken();
//创建二维码
$qcode ="https://api.weixin.qq.com/cgi- ... t%3B.$ACCESS_TOKEN;
$param = json_encode(array("path"=>"pages/detail/detail?id=5084","width"=> 150));
$result = $this->httpRequest( $qcode, $param,"POST");
$path = 'uploads/qrcode/h.jpg';
file_put_contents($path, $result);
$return['status_code'] = 2000;
$return['msg'] = 'ok';
$return['img'] = 'https://公司域名.com/' . $path;
echo ''.$return['img'].'';exit;
echo json_encode($return);exit;
$base64_image ="data:image/jpeg;base64,".base64_encode( $result );
return '';
}
别慌,百度查了资料。这是因为文件读写权限。我们文件夹的权限一般是755,然后把文件夹的权限改成777。
说老板有点飘飘然,但实在是拦不住。方形二维码难看,只好做一个圆形漂亮的小程序码。. . . . 由于列表数量较多,选择了 wxacode.getUnlimited 接口。
第一步是先获取访问令牌;
同上,我就不多说了;
官方微信文档:
虽然可以通过场景传递很多参数,但是在实际传递参数的过程中,页面出现了很多问题。他不能接受我之前传递的参数。虽然生成了二维码,但他也跳转到了详情页。它是一个空页面,没有传递相应的列表id。. .
请求参数场景也只简单说明

看得出小姐姐一头雾水,场景参数有很多问题。网上找了很久的技术帖子,或者找到了合适的demo。这就是为什么我必须下定决心写这篇博客。要知道更多人的原因。
小姐姐的密码在这里
public function xcxCode() {
$id = trim($this->request->param('id','5084','intval'));
$access_token = $this->getAccessToken();
$url = "https://api.weixin.qq.com/wxa/ ... ot%3B . $access_token;
$data['scene'] = 'h' . $id;
//小程序的详情页路径
$data['path'] = 'pages/detail/detail';
//二维码大小
$data['width'] = '430';
$res = $this->http($url, json_encode($data),1);
$path = 'uploads/qrcode/h' . $id . '.jpg';
file_put_contents($path, $res);
$return['status_code'] = 2000;
$return['msg'] = 'ok';
$return['img'] = 'https://公司域名.com/' . $path;
echo ''.$return['img'].'';exit;
echo json_encode($return);exit;
}
历经千辛万苦,小程序代码终于出现在了我的面前。
小程序生成带参数的二维码【小程序循环码】,保存为jpg图片上传到服务器

如果还是不明白,可以联系小姐姐技术问题或者索取源码。
不知道能不能给后面看到的程序员一些指导。可以考虑贡献一点余热。哈哈哈哈
php 抓取网页生成图片(用php执行系统命令的时候发现无法执行,但是可以执行CutyCapt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-16 19:14
在对网站进行截图时,我们使用了服务器端的工具CutyCapt。可以直接使用服务器上的命令抓取并生成指定url的图片。但是在使用php执行系统命令时,发现无法执行,而是CutyCapt等帮助信息的命令("/usr/local/cutycapt/CutyCapt/xvfb-run.sh --help")可以执行,但是执行调用系统变量脚本不能成功。怀疑是权限问题。后来我把CutyCapt权限设置为www,发现不行。后来查资料,发现是因为nginx服务器在执行命令的时候调用了shell脚本。这时候遇到了权限问题。
CutyCapt
截图中使用的系统命令:
/usr/bin/sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert.jpg
1、设置sudo配置文件写入权限
chmod u+w /etc/sudoers
2、增加www用户执行CutyCapt脚本的权限(需要运行的脚本和命令需要添加权限):
www ALL=(root) NOPASSWD: /bin/sh,/usr/local/cutycapt/CutyCapt/xvfb-run.sh, /usr/local/cutycapt/CutyCapt/CutyCapt
3、关闭【强制控制台登录】执行或允许www用户无需控制台登录
修改内容:
注释掉:默认要求
更好的修改方法(更安全):
仅添加:默认:www !requiretty(www用户不使用控制台登录)
4 用php执行
system('/usr/bin/sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert2.jpg',$m);
注意(更安全的方法):
system('sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert2.jpg' ,$m);
Nginx 重启:
同时增加www用户执行nginx脚本的权限 查看全部
php 抓取网页生成图片(用php执行系统命令的时候发现无法执行,但是可以执行CutyCapt)
在对网站进行截图时,我们使用了服务器端的工具CutyCapt。可以直接使用服务器上的命令抓取并生成指定url的图片。但是在使用php执行系统命令时,发现无法执行,而是CutyCapt等帮助信息的命令("/usr/local/cutycapt/CutyCapt/xvfb-run.sh --help")可以执行,但是执行调用系统变量脚本不能成功。怀疑是权限问题。后来我把CutyCapt权限设置为www,发现不行。后来查资料,发现是因为nginx服务器在执行命令的时候调用了shell脚本。这时候遇到了权限问题。
CutyCapt
截图中使用的系统命令:
/usr/bin/sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert.jpg
1、设置sudo配置文件写入权限
chmod u+w /etc/sudoers
2、增加www用户执行CutyCapt脚本的权限(需要运行的脚本和命令需要添加权限):
www ALL=(root) NOPASSWD: /bin/sh,/usr/local/cutycapt/CutyCapt/xvfb-run.sh, /usr/local/cutycapt/CutyCapt/CutyCapt
3、关闭【强制控制台登录】执行或允许www用户无需控制台登录
修改内容:
注释掉:默认要求
更好的修改方法(更安全):
仅添加:默认:www !requiretty(www用户不使用控制台登录)
4 用php执行
system('/usr/bin/sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert2.jpg',$m);
注意(更安全的方法):
system('sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert2.jpg' ,$m);
Nginx 重启:
同时增加www用户执行nginx脚本的权限
php 抓取网页生成图片(2019独角兽企业重金招聘Python工程师标准(gt;gt))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-04 11:10
2019独角兽企业重磅招聘Python工程师标准>>>
本程序实现了网页源代码抓取、图片链接获取、分析、同图链接合并功能等功能,实现图片抓取功能。利用PHP强大的网络内容处理功能,抓取指定网站上的所有图片,并保存到当前目录。以下是代码:
/';
$ret = preg_match_all($reg_tag, $site_content, $match_result);
fclose($site_fd);
return $match_result[1];
}
/* 对图片链接进行修正 */
function revise_site($site_list, $base_site){
foreach($site_list as $site_item) {
if (preg_match('/^http/', $site_item)) {
$return_list[] = $site_item;
}else{
$return_list[] = $base_site."/".$site_item;
}
}
return $return_list;
}
/*得到图片名字,并将其保存在指定位置*/
function get_pic_file($pic_url_array, $pos){
$reg_tag = '/.*\/(.*?)$/';
$count = 0;
foreach($pic_url_array as $pic_item){
$ret = preg_match_all($reg_tag,$pic_item,$t_pic_name);
$pic_name = $pos.$t_pic_name[1][0];
$pic_url = $pic_item;
print("Downloading ".$pic_url." ");
$img_read_fd = fopen($pic_url,"r");
$img_write_fd = fopen($pic_name,"w");
$img_content = "";
while(!feof($img_read_fd)){
$img_content .= fread($img_read_fd,1024);
}
fwrite($img_write_fd,$img_content);
fclose($img_read_fd);
fclose($img_write_fd);
print("[OK] ");
}
return 0;
}
function main(){
/* 待抓取图片的网页地址 */
$site_name = "http://image.cn.yahoo.com";
$img_url = get_img_url($site_name);
$img_url_revised = revise_site($img_url, $site_name);
$img_url_unique = array_unique($img_url_revised); //unique array
get_pic_file($img_url_unique,"./");
}
main();
?>
转载于: 查看全部
php 抓取网页生成图片(2019独角兽企业重金招聘Python工程师标准(gt;gt))
2019独角兽企业重磅招聘Python工程师标准>>>
本程序实现了网页源代码抓取、图片链接获取、分析、同图链接合并功能等功能,实现图片抓取功能。利用PHP强大的网络内容处理功能,抓取指定网站上的所有图片,并保存到当前目录。以下是代码:
/';
$ret = preg_match_all($reg_tag, $site_content, $match_result);
fclose($site_fd);
return $match_result[1];
}
/* 对图片链接进行修正 */
function revise_site($site_list, $base_site){
foreach($site_list as $site_item) {
if (preg_match('/^http/', $site_item)) {
$return_list[] = $site_item;
}else{
$return_list[] = $base_site."/".$site_item;
}
}
return $return_list;
}
/*得到图片名字,并将其保存在指定位置*/
function get_pic_file($pic_url_array, $pos){
$reg_tag = '/.*\/(.*?)$/';
$count = 0;
foreach($pic_url_array as $pic_item){
$ret = preg_match_all($reg_tag,$pic_item,$t_pic_name);
$pic_name = $pos.$t_pic_name[1][0];
$pic_url = $pic_item;
print("Downloading ".$pic_url." ");
$img_read_fd = fopen($pic_url,"r");
$img_write_fd = fopen($pic_name,"w");
$img_content = "";
while(!feof($img_read_fd)){
$img_content .= fread($img_read_fd,1024);
}
fwrite($img_write_fd,$img_content);
fclose($img_read_fd);
fclose($img_write_fd);
print("[OK] ");
}
return 0;
}
function main(){
/* 待抓取图片的网页地址 */
$site_name = "http://image.cn.yahoo.com";
$img_url = get_img_url($site_name);
$img_url_revised = revise_site($img_url, $site_name);
$img_url_unique = array_unique($img_url_revised); //unique array
get_pic_file($img_url_unique,"./");
}
main();
?>
转载于:
php 抓取网页生成图片(#feimengjuanimporturllib#抓取网页图片#(根据的网址来获取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-01 18:11
本文文章主要介绍Python简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页的源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- 编码:utf-8 -*-
#飞梦娟
进口重新
导入 urllib
导入 urllib2
#抓取网页图片
#根据给定的URL获取网页的详细信息,得到的html就是网页的源代码
def getHtml(url):
页面 = urllib.urlopen(url)
html = page.read()
返回 html
def getImg(html):
#使用正则表达式过滤掉源代码中的图片地址
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = 桩(注册)
imglist = imgre.findall(html) #表示在整个网页中过滤掉所有图片的地址,放入imglist
x = 0
对于 imglist 中的 imgurl:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,下载图片保存到本地
x = x + 1
html = getHtml(")#获取该URL的网页的详细信息,获取的html即为该网页的源代码
getImg(html)#从网页源代码中分析并下载并保存图片
进一步整理了代码,在本地创建了一个“图片”文件夹,用来保存图片
# -*- 编码:utf-8 -*-
#飞梦娟
进口重新
导入 urllib
导入 urllib2
导入操作系统
#抓取网页图片
#根据给定的URL获取网页的详细信息,得到的html就是网页的源代码
def getHtml(url):
页面 = urllib.urlopen(url)
html = page.read()
返回 html
#创建一个文件夹来保存图片
def mkdir(路径):
路径 = path.strip()
#判断路径是否存在
# 现有真
# Flase 不存在
isExists = os.path.exists(path)
如果不是 isExists:
print u'created a new folder named ',path,u'
# 创建目录操作函数
os.makedirs(路径)
返回真
别的:
# 如果目录存在,不创建,提示目录已存在
打印 u'名为',path,u'的文件夹已成功创建'
返回错误
# 输入文件名,保存多张图片
def saveImages(imglist,name):
数字 = 1
对于 imglist 中的 imageURL:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
如果 len(fTail)> 3:
fTail ='jpg'
文件名 = 名称 + "/" + str(number) + "." + f尾
# 对于每个图片地址,保存
尝试:
u = urllib2.urlopen(imageURL)
数据 = u.read()
f = 打开(文件名,'wb+')
f.写(数据)
print u'正在保存的图片是',fileName
f.close()
除了 urllib2.URLError 作为 e:
打印(e.reason)
数字 += 1
#获取网页中所有图片的地址
def getAllImg(html):
#使用正则表达式过滤掉源代码中的图片地址
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = 桩(注册)
imglist = imgre.findall(html) #表示在整个网页中过滤掉所有图片的地址,放入imglist
返回 imglist
#创建本地保存文件夹,并下载并保存图片
如果 __name__ =='__main__':
html = getHtml(")#获取该URL的网页的详细信息,获取的html即为该网页的源代码
路径 = u'图片'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片地址列表
saveImages(imglist,path) # 保存图片
结果,在“图片”文件夹中保存了数十张图片,如截图所示:
非常感谢您的阅读
上大学的时候选择自学python,但工作后发现自己电脑基础不好,学位也不好。这是
没办法,只能后天弥补,于是我在编码之外开始了自己的逆袭,继续学习python的核心知识。
把我录入的计算机基础知识整理一下,放到我们的微信公众号“程序员学校”上。如果你不愿意平庸,
然后在编码之外加入我并继续成长!
—————————————————
版权声明:本文为CSDN博主“程序员牡蛎”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接:
:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
php 抓取网页生成图片(#feimengjuanimporturllib#抓取网页图片#(根据的网址来获取))
本文文章主要介绍Python简单网页图片抓取的完整代码示例,具有一定的参考价值,有需要的朋友可以参考。
使用python捕捉网络图片的步骤是:
1、根据给定的URL获取网页的源码
2、使用正则表达式过滤掉源码中的图片地址
3、根据过滤后的图片地址下载网络图片
下面是一个比较简单的抓取百度贴吧网页图片的实现:
# -*- 编码:utf-8 -*-
#飞梦娟
进口重新
导入 urllib
导入 urllib2
#抓取网页图片
#根据给定的URL获取网页的详细信息,得到的html就是网页的源代码
def getHtml(url):
页面 = urllib.urlopen(url)
html = page.read()
返回 html
def getImg(html):
#使用正则表达式过滤掉源代码中的图片地址
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = 桩(注册)
imglist = imgre.findall(html) #表示在整个网页中过滤掉所有图片的地址,放入imglist
x = 0
对于 imglist 中的 imgurl:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,下载图片保存到本地
x = x + 1
html = getHtml(")#获取该URL的网页的详细信息,获取的html即为该网页的源代码
getImg(html)#从网页源代码中分析并下载并保存图片
进一步整理了代码,在本地创建了一个“图片”文件夹,用来保存图片
# -*- 编码:utf-8 -*-
#飞梦娟
进口重新
导入 urllib
导入 urllib2
导入操作系统
#抓取网页图片
#根据给定的URL获取网页的详细信息,得到的html就是网页的源代码
def getHtml(url):
页面 = urllib.urlopen(url)
html = page.read()
返回 html
#创建一个文件夹来保存图片
def mkdir(路径):
路径 = path.strip()
#判断路径是否存在
# 现有真
# Flase 不存在
isExists = os.path.exists(path)
如果不是 isExists:
print u'created a new folder named ',path,u'
# 创建目录操作函数
os.makedirs(路径)
返回真
别的:
# 如果目录存在,不创建,提示目录已存在
打印 u'名为',path,u'的文件夹已成功创建'
返回错误
# 输入文件名,保存多张图片
def saveImages(imglist,name):
数字 = 1
对于 imglist 中的 imageURL:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
如果 len(fTail)> 3:
fTail ='jpg'
文件名 = 名称 + "/" + str(number) + "." + f尾
# 对于每个图片地址,保存
尝试:
u = urllib2.urlopen(imageURL)
数据 = u.read()
f = 打开(文件名,'wb+')
f.写(数据)
print u'正在保存的图片是',fileName
f.close()
除了 urllib2.URLError 作为 e:
打印(e.reason)
数字 += 1
#获取网页中所有图片的地址
def getAllImg(html):
#使用正则表达式过滤掉源代码中的图片地址
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = 桩(注册)
imglist = imgre.findall(html) #表示在整个网页中过滤掉所有图片的地址,放入imglist
返回 imglist
#创建本地保存文件夹,并下载并保存图片
如果 __name__ =='__main__':
html = getHtml(")#获取该URL的网页的详细信息,获取的html即为该网页的源代码
路径 = u'图片'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片地址列表
saveImages(imglist,path) # 保存图片
结果,在“图片”文件夹中保存了数十张图片,如截图所示:
非常感谢您的阅读
上大学的时候选择自学python,但工作后发现自己电脑基础不好,学位也不好。这是
没办法,只能后天弥补,于是我在编码之外开始了自己的逆袭,继续学习python的核心知识。
把我录入的计算机基础知识整理一下,放到我们的微信公众号“程序员学校”上。如果你不愿意平庸,
然后在编码之外加入我并继续成长!
—————————————————
版权声明:本文为CSDN博主“程序员牡蛎”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原出处链接和本声明。
原文链接:
:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
php 抓取网页生成图片(如何用phantomjs保存的百度首页截图.io图片?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-31 22:14
背景
最近正在开发一个小程序。有一个帮助模块,内容是帮助列表文章,文章的内容是网站后台编辑的富文本格式。鉴于小程序的特殊性,其对html格式的富文本支持并不友好。
一开始有人开发了wxparse插件,后来微信提供了富文本组件,但是两者都存在一些问题。
想法
后台编辑文章样式被wxparse或富文本组件显示后,存在一些兼容性问题。如果我们把文章的内容做成图片,再用图片来展示,应该能达到比较理想的效果。
但是每一篇文章,我都去美术区设计图,费时费力,修改也费劲。
如果我们后台编辑的文章能自动生成图片就完美了。
计划
查询后发现,海外网站thumb.io也提供类似服务。可以使用API接口将指定地址保存为图片。但是经过测试,发现图片不清晰,访问速度很慢。然后我自己安装了phantomjs并测试了一下,效果还是比较满意的。
用phantomjs保存的百度首页截图
为了实现自动化,我还做了一个web api。通过将文章对应的URL发送到指定的api,可以自动(异步)生成截图。具体方法是当有截图请求时,将请求保存到数据库中,然后在服务器上运行一个程序,一一进行截图操作,截图后修改相应请求的状态。
-------------------------------------------------- ——
API 接口({} 中的内容为参数值)
使用方法:通过截图生成将需要截图的URL传递到请求界面,一段时间后(推荐10秒)通过查询界面进行查询。如果返回code=0,status=1,直接将thumb保存到本地。能。
生成截图请求:{URL}
注意:url参数必须是urlencoded,否则可能会出错
示例:%3a%2f%2f%2fdragondean%2f
返回:JSON 格式
代码 0 成功,1 URL 格式错误,2 URL 已存在
msg 错误信息(仅当代码不为 0 时)
task_id 任务ID,查询状态时使用(code为0或2时)
key 查询秘钥,用于查询状态(code为0或2时)
status 任务的状态,如果任务已经存在,则返回此状态,-1表示失败,0表示处理中,1表示完成
大拇指截图地址,可以直接下载这张图片到本地(code为2,status为1时)
err_msg 错误信息,仅在 status=-1 时存在
查询任务状态:{TASK_ID}&key={KEY}
注意:task_id和key都是在请求生成的时候返回的,是必填项
例子:
返回:JSON
代码返回状态,0 成功,3 任务不存在,4 查询秘钥错误
当状态码为0时,status=-1表示失败,status=0表示处理中,status=1表示完成
当thumbcode位为0,状态为1时,可以直接下载截图地址到本地
err_msg 错误信息,仅在 status=-1 时存在
-------------------------------------------------- ——
以上就是使用网页截图API接口自动生成网页截图的详细内容。更多详情请关注其他相关php中文网文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php 抓取网页生成图片(如何用phantomjs保存的百度首页截图.io图片?)
背景
最近正在开发一个小程序。有一个帮助模块,内容是帮助列表文章,文章的内容是网站后台编辑的富文本格式。鉴于小程序的特殊性,其对html格式的富文本支持并不友好。
一开始有人开发了wxparse插件,后来微信提供了富文本组件,但是两者都存在一些问题。
想法
后台编辑文章样式被wxparse或富文本组件显示后,存在一些兼容性问题。如果我们把文章的内容做成图片,再用图片来展示,应该能达到比较理想的效果。
但是每一篇文章,我都去美术区设计图,费时费力,修改也费劲。
如果我们后台编辑的文章能自动生成图片就完美了。
计划
查询后发现,海外网站thumb.io也提供类似服务。可以使用API接口将指定地址保存为图片。但是经过测试,发现图片不清晰,访问速度很慢。然后我自己安装了phantomjs并测试了一下,效果还是比较满意的。
用phantomjs保存的百度首页截图
为了实现自动化,我还做了一个web api。通过将文章对应的URL发送到指定的api,可以自动(异步)生成截图。具体方法是当有截图请求时,将请求保存到数据库中,然后在服务器上运行一个程序,一一进行截图操作,截图后修改相应请求的状态。
-------------------------------------------------- ——
API 接口({} 中的内容为参数值)
使用方法:通过截图生成将需要截图的URL传递到请求界面,一段时间后(推荐10秒)通过查询界面进行查询。如果返回code=0,status=1,直接将thumb保存到本地。能。
生成截图请求:{URL}
注意:url参数必须是urlencoded,否则可能会出错
示例:%3a%2f%2f%2fdragondean%2f
返回:JSON 格式
代码 0 成功,1 URL 格式错误,2 URL 已存在
msg 错误信息(仅当代码不为 0 时)
task_id 任务ID,查询状态时使用(code为0或2时)
key 查询秘钥,用于查询状态(code为0或2时)
status 任务的状态,如果任务已经存在,则返回此状态,-1表示失败,0表示处理中,1表示完成
大拇指截图地址,可以直接下载这张图片到本地(code为2,status为1时)
err_msg 错误信息,仅在 status=-1 时存在
查询任务状态:{TASK_ID}&key={KEY}
注意:task_id和key都是在请求生成的时候返回的,是必填项
例子:
返回:JSON
代码返回状态,0 成功,3 任务不存在,4 查询秘钥错误
当状态码为0时,status=-1表示失败,status=0表示处理中,status=1表示完成
当thumbcode位为0,状态为1时,可以直接下载截图地址到本地
err_msg 错误信息,仅在 status=-1 时存在
-------------------------------------------------- ——
以上就是使用网页截图API接口自动生成网页截图的详细内容。更多详情请关注其他相关php中文网文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php 抓取网页生成图片(用html2canvas根据自己的需求生成截图,绕过服务器图片保存至本地 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-31 22:12
)
今天要分享的就是根据自己的需要使用html2canvas生成截图,并修复html2canvas截图模糊的问题,绕过服务器将图片保存到本地。
只需要几行代码就可以根据需要的dom截图。是不是很方便,但是生成的图片很模糊
//直接选择你要截图的dom,可以截图,但是因为canvas,生成的图片模糊
html2canvas(document.querySelector('div')).then(function(canvas) {
document.body.appendChild(canvas);
})
常见的解决方法是生成一个多折的画布,放在一个较小的容器中,解决了截图模糊的尴尬。
另一个问题是如何绕过服务器并将图像保存在本地。画布有一个 toDataURL 方法,a 标签有一个下载属性。感觉就像一个完美的契合。当然,要在微信中阻止下载,您可以使用微信的 webview 中的内置规则。只要将img嵌套在a标签中(不带href属性),就可以调用保存到手机并分享给朋友的菜单栏。
下面是一个简单的demo,html2canvas.min.js下载地址:
DOCTYPE html>
htmltopic
* {
margin: 0;
}
.test {
width: 100px;
height: 100px;
text-align: center;
line-height: 100px;
background-color: #87CEEB;
display: inline-block;
vertical-align: top;
}
canvas {
margin-right: 5px;
}
.down {
float: left;
margin: 40px 10px;
}
.down2 {
float: left;
margin: 40px 30px;
}
测试
下载
下载2
//直接选择要截图的dom,就能截图,但是因为canvas的原因,生成的图片模糊
//html2canvas(document.querySelector('div')).then(function(canvas) {
// document.body.appendChild(canvas);
//});
//创建一个新的canvas
var canvas2 = document.createElement("canvas");
let
_canvas = document.querySelector('div');
var w = parseInt(window.getComputedStyle(_canvas).width);
var h = parseInt(window.getComputedStyle(_canvas).height);
//将canvas画布放大若干倍,然后盛放在较小的容器内,就显得不模糊了
canvas2.width = w * 2;
canvas2.height = h * 2;
canvas2.style.width = w + "px";
canvas2.style.height = h + "px";
//可以按照自己的需求,对context的参数修改,translate指的是偏移量
// var context = canvas.getContext("2d");
// context.translate(0,0);
var context = canvas2.getContext("2d");
context.scale(2, 2);
html2canvas(document.querySelector('div'), { canvas: canvas2 }).then(function(canvas) {
//document.body.appendChild(canvas);
//canvas转换成url,然后利用a标签的download属性,直接下载,绕过上传服务器再下载
document.querySelector(".down").setAttribute('href', canvas.toDataURL());
});
//这是另一种写法
$(function () {
$(".down2").click(function () {
html2canvas($(".test")).then(function (canvas) {
var imgUri = canvas.toDataURL("image/png").replace("image/png", "image/octet-stream"); // 获取生成的图片的url
window.location.href = imgUri; // 下载图片
});
//html2canvas($('.tongxingzheng_bg'), {
// onrendered: function (canvas) {
// var data = canvas.toDataURL("image/png");//生成的格式
// //data就是生成的base64码啦
// alert(data);
// }
//});
});
}); 查看全部
php 抓取网页生成图片(用html2canvas根据自己的需求生成截图,绕过服务器图片保存至本地
)
今天要分享的就是根据自己的需要使用html2canvas生成截图,并修复html2canvas截图模糊的问题,绕过服务器将图片保存到本地。
只需要几行代码就可以根据需要的dom截图。是不是很方便,但是生成的图片很模糊
//直接选择你要截图的dom,可以截图,但是因为canvas,生成的图片模糊
html2canvas(document.querySelector('div')).then(function(canvas) {
document.body.appendChild(canvas);
})
常见的解决方法是生成一个多折的画布,放在一个较小的容器中,解决了截图模糊的尴尬。
另一个问题是如何绕过服务器并将图像保存在本地。画布有一个 toDataURL 方法,a 标签有一个下载属性。感觉就像一个完美的契合。当然,要在微信中阻止下载,您可以使用微信的 webview 中的内置规则。只要将img嵌套在a标签中(不带href属性),就可以调用保存到手机并分享给朋友的菜单栏。
下面是一个简单的demo,html2canvas.min.js下载地址:
DOCTYPE html>
htmltopic
* {
margin: 0;
}
.test {
width: 100px;
height: 100px;
text-align: center;
line-height: 100px;
background-color: #87CEEB;
display: inline-block;
vertical-align: top;
}
canvas {
margin-right: 5px;
}
.down {
float: left;
margin: 40px 10px;
}
.down2 {
float: left;
margin: 40px 30px;
}
测试
下载
下载2
//直接选择要截图的dom,就能截图,但是因为canvas的原因,生成的图片模糊
//html2canvas(document.querySelector('div')).then(function(canvas) {
// document.body.appendChild(canvas);
//});
//创建一个新的canvas
var canvas2 = document.createElement("canvas");
let
_canvas = document.querySelector('div');
var w = parseInt(window.getComputedStyle(_canvas).width);
var h = parseInt(window.getComputedStyle(_canvas).height);
//将canvas画布放大若干倍,然后盛放在较小的容器内,就显得不模糊了
canvas2.width = w * 2;
canvas2.height = h * 2;
canvas2.style.width = w + "px";
canvas2.style.height = h + "px";
//可以按照自己的需求,对context的参数修改,translate指的是偏移量
// var context = canvas.getContext("2d");
// context.translate(0,0);
var context = canvas2.getContext("2d");
context.scale(2, 2);
html2canvas(document.querySelector('div'), { canvas: canvas2 }).then(function(canvas) {
//document.body.appendChild(canvas);
//canvas转换成url,然后利用a标签的download属性,直接下载,绕过上传服务器再下载
document.querySelector(".down").setAttribute('href', canvas.toDataURL());
});
//这是另一种写法
$(function () {
$(".down2").click(function () {
html2canvas($(".test")).then(function (canvas) {
var imgUri = canvas.toDataURL("image/png").replace("image/png", "image/octet-stream"); // 获取生成的图片的url
window.location.href = imgUri; // 下载图片
});
//html2canvas($('.tongxingzheng_bg'), {
// onrendered: function (canvas) {
// var data = canvas.toDataURL("image/png");//生成的格式
// //data就是生成的base64码啦
// alert(data);
// }
//});
});
});
php 抓取网页生成图片(本示例将演示一个简单的上传图片到远程服务器(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-31 22:11
本例将演示一个简单的图片上传到远程服务器,然后生成图片路径并通过提交的回调路径返回到本地服务器,最后在前端页面显示图片地址。
本项目使用三个文件,即前端选择图片页面,然后将图片提交到远程服务器处理文件,返回前端页面的回调文件。
一、前端上传图片页面
上传_测试.html
Upload Image
主题封面图:
图片格式 jpg jpeg gif png
封面图URL:
*
这里需要注意的是,当回调页面向前端页面返回图片地址时,需要加上iframe标签(这里我们隐藏),否则页面上要显示的地方是找不到的。
与通用选项卡相比,多了一个目标属性,用于指定打开选项卡和提交数据的位置。
而如果设置为iframe的name值,即“post_frame”,就会在iframe中打开,因为css设置为hide,所以不会有动静。如果删除 display:none,您还将看到服务器的返回信息。
上传文件的时候,form的method和enctype属性必须和上面的代码一样,然后将target值设置为iframe的名字,这样文件就可以不刷新上传了。
当你选择提交图片时,还有一个隐藏字段,即当你向远程服务器提交图片时,还需要提交一个回调路径,以便将图片返回到本地服务器。(这里我们都使用本地服务器进行测试)
二、远程服务器图像处理
上传动作.php
<p> 查看全部
php 抓取网页生成图片(本示例将演示一个简单的上传图片到远程服务器(组图))
本例将演示一个简单的图片上传到远程服务器,然后生成图片路径并通过提交的回调路径返回到本地服务器,最后在前端页面显示图片地址。
本项目使用三个文件,即前端选择图片页面,然后将图片提交到远程服务器处理文件,返回前端页面的回调文件。
一、前端上传图片页面
上传_测试.html
Upload Image
主题封面图:
图片格式 jpg jpeg gif png
封面图URL:
*
这里需要注意的是,当回调页面向前端页面返回图片地址时,需要加上iframe标签(这里我们隐藏),否则页面上要显示的地方是找不到的。
与通用选项卡相比,多了一个目标属性,用于指定打开选项卡和提交数据的位置。
而如果设置为iframe的name值,即“post_frame”,就会在iframe中打开,因为css设置为hide,所以不会有动静。如果删除 display:none,您还将看到服务器的返回信息。
上传文件的时候,form的method和enctype属性必须和上面的代码一样,然后将target值设置为iframe的名字,这样文件就可以不刷新上传了。
当你选择提交图片时,还有一个隐藏字段,即当你向远程服务器提交图片时,还需要提交一个回调路径,以便将图片返回到本地服务器。(这里我们都使用本地服务器进行测试)
二、远程服务器图像处理
上传动作.php
<p>
php 抓取网页生成图片(网站地图对于一个网站来说至关重要网站本身自己创建的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-31 22:10
网站 地图对于 网站 来说非常重要。自己创建 网站 地图并提交给搜索引擎是一种更好的方式。这种情况下,你不受页数限制,完全可以控制网站map的结构信息。这是一个可以轻松生成网站maps
的小类
复制代码代码如下:
// 收录类
include'SitemapGenerator.php';
// 创建对象
$sitemap = new SitemapGenerator("//");
// 添加网址
$sitemap->addUrl("", date('c'),'daily', '1');
$sitemap->addUrl("", date('c'),'daily','0.5');
$sitemap->addUrl("", date('c'),'daily');
// 创建站点地图
$sitemap->createSitemap();
// 将站点地图写入文件
$sitemap->writeSitemap();
//更新robots.txt文件
$sitemap->updateRobots();
// 向搜索引擎提交站点地图
$sitemap->submitSitemap(); 查看全部
php 抓取网页生成图片(网站地图对于一个网站来说至关重要网站本身自己创建的方法)
网站 地图对于 网站 来说非常重要。自己创建 网站 地图并提交给搜索引擎是一种更好的方式。这种情况下,你不受页数限制,完全可以控制网站map的结构信息。这是一个可以轻松生成网站maps
的小类
复制代码代码如下:
// 收录类
include'SitemapGenerator.php';
// 创建对象
$sitemap = new SitemapGenerator("//");
// 添加网址
$sitemap->addUrl("", date('c'),'daily', '1');
$sitemap->addUrl("", date('c'),'daily','0.5');
$sitemap->addUrl("", date('c'),'daily');
// 创建站点地图
$sitemap->createSitemap();
// 将站点地图写入文件
$sitemap->writeSitemap();
//更新robots.txt文件
$sitemap->updateRobots();
// 向搜索引擎提交站点地图
$sitemap->submitSitemap();
php 抓取网页生成图片(流量之于互联网:微信内做分享和传播的形式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-29 21:01
前言
流量对于互联网公司来说就像水之于一切一样重要。那么目前国内移动互联网流量集中在哪里呢?答案很明显,那就是我们每天都在使用的微信。
2018年初,微信月活跃用户数突破10亿,成为国内首个月活跃用户突破10亿的产品。“三季度大战”后,腾讯逐渐从封闭走向开放,而微信作为腾讯在移动互联网时代最重要、最成功的战略产品,也在践行腾讯的开放战略。在这样的背景下,如何利用好微信的流量引导用户分享和传播,成为摆在我们面前的重要课题。但是,基于自身利益和用户体验等考虑,微信对在微信中分享和传播的内容和形式有严格的规定和诸多限制。如果你不注意违反这些规则,你可能会受到惩罚。严重的甚至被微信封杀死。
然而,风险和回报总是成正比的。有时为了达到更好的传播效果,我们不得不“合理”地采取一些措施。目前,微信中的分享传播方式不外乎以下五种:文字、图片、H5链接、小程序、短视频。从技术角度来看,微信、文字、H5链接、小程序三种形式,相对容易控制,而图片和短视频相对更容易绕过微信监控。虽然现在短视频很流行,但是我们公司用的不多(虽然我觉得应该充分利用),所以还是把重点放在图片上吧。
商业背景
在我们的业务中,我们经常需要引导用户将图片分享到微信。目前,我们生成图片的方式主要有两种。一种是通过APP中自研的Autumn系统生成图片,另一种是通过PHP后端生成图片,将图片上传到CDN再将图片链接返回给前端。. 这两种方法都有其局限性。第一种方法的局限是只能在APP中使用,不能在微信环境或手机浏览器中使用。第二种方法的问题在于它需要后端学生。完成共享海报图片的版面开发,需要占用CDN资源(需要花钱),如果生成的图片只是临时使用,这种方式的弊端就很明显了。所以,
技术选型
如果要在前端生成图片,自然会想到使用Canvas技术来做,但是团队中如何使用Canvas有两个思路:第一个是完全封装Canvas API进行绘图,以及二是直接使用开源库,比如流行的html2canvas库。我个人提倡第二种方法。一方面,它可以直接将 DOM 转换为 Canvas。用一个我们比较熟悉的方法也不太方便。如果我们封装它,很多基础的任务,比如界面布局,各种元素的绘制等等,都得重新做,开发和维护的风险和成本太高了。另一方面,html2canvas库是一个长期的开源项目,应该是比较成熟和稳定的。然而,团队中还有老司机发出警告,提到他们之前也尝试过使用html2canvas库做项目,但是在绘制一些比较复杂的页面时遇到了很多问题,所以他们决定放弃这个方案,改用A采用完全独立的开发方式,即上述第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。所以他们决定放弃这个方案,转而采用完全独立的开发方式,也就是上面的第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。所以他们决定放弃这个方案,转而采用完全独立的开发方式,也就是上面的第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。
html2canvas 基本介绍
根据html2canvas官方文档的介绍,html2canvas库的工作原理并不是真正的“截图”,而是读取网页上目标DOM节点的信息来绘制画布,所以不支持所有的css属性(详见这里),并且期望使用的图片与当前域名相同,但是官方也提供了一些方法来解决加载跨域图片的问题。
它的用法非常简单。引入html2canvas库后,获取目标dom,调用html2canvas方法生成canvas对象。由于我们的目标是生成图片,所以需要调用canvas.toDataURL()方法来生成。
标签的可用数据:
html2canvas(targetDom).then(canvas => {// 将画布附加到页面});
接下来我列举一下我在这个过程中遇到的一些问题以及解决方法。
问题一:生成的图片很模糊
当我写了代码,准备按照官网的介绍查看效果的时候,发现生成的图片很模糊。您可以查看下图的比较以了解详细信息。海报图片DOM在右边,左边是html2canvas库生成的Canvas。如果下面没有特别说明, , 都是左 Canvas 和右 DOM。
问题一:画面模糊
如您所见,图中红色圆圈标记的部分非常模糊。遇到这个问题后,我自然而然地去谷歌解决了这个问题。不说了,分分钟搜了一堆结果(毕竟是成熟的开源软件),还天真地以为这个问题很快就解决了。.
谷歌大法好!
我随意点了几个链接,看了看里面的解决方案。大体思路是将画布放大n倍,然后制作图形。奇怪的是,我试了之后,发现很多人说这个有效的方法对我完全没用。即使我放大200倍,画出来的画面还是一样的模糊,所以我只能遗憾地向我宣布这个方法。它不再有效。
所以想知道这是不是html2canvas库本身的bug,于是换了一个类似的库,dom-to-image,试了一下。结果出乎我的意料......这个产品不仅仅是一张模糊的图片,它是整个画布。很模糊!而且它恢复得非常糟糕,我吓得差点把手机扔掉。截图来了,大家自己感受一下吧……
你是认真的吗?
说到这里,我有点泄气了,因为从这种情况来看,很有可能是某些底层逻辑存在问题,也就是说,这个问题可能无解……不过还好,没有路可走完美。当我们几个人一起讨论这个问题时,转折点出现了。有同学突然发现,生成的海报图片中并不是所有的图片都是模糊的,一张小图片还是很清晰的!这个发现让我欣喜若狂。经过一段时间的测试,我发现只有用作背景图像的背景图像才会模糊,并且
图片标签没有这个问题。那么解决方法很简单,直接用
达到background-image的效果,问题就解决了。
问题二:删除线(text-decoration:line-through)在线条下方
这是一个小问题,但是文字有点下划线,如图:
文本中的下水平线
解决方法也很简单,将文本元素设置为相对相对定位,然后使用伪元素进行模拟。较少的代码如下:
&:after {.text-decoration-line-through();}
.text-decoration-line-through(@color: #fff) {位置:绝对;宽度:100%;高度:1px;顶部:50%;左:0;内容:''; 背景色:@color; }
问题三:带省略号的多行文字无法正确渲染
实测发现,使用省略号样式的多行文字时,会直接导致文字消失,如下图:
溢出:隐藏;显示:-webkit-box;-webkit-box-orient:垂直;-webkit-line-clamp:2;
这也是一个小问题。可能是html2canvas不支持上述某些样式(虽然我没有从文档中找到证据)。我的解决方案是简单地使用 overflow: hidden 来截断文本。不怕麻烦的话就得用js计算加省略号了。
问题四(Big Boss登场):图片无法渲染
嗯,其实这个问题出现在图片模糊问题之前。因为需要加载的图片都在CDN上,而且我们知道html2canvas的工作原理是使用js解析目标dom节点生成canvas,所以我们需要使用跨域的方式来加载图片。一开始为了让图片正常显示,我添加了allowTaint属性,设置为true。代码和截图如下:
添加allowTaint属性之前,图片无法显示
html2canvas(targetDom, {allowTaint: true}).then(canvas => {// 将画布附加到页面});
添加allowTaint属性后,图片显示正常
注意!这里我们只是转换成canvas,还没有生成图片。那么接下来,我们尝试通过调用canvas.toDataURL()来生成图片数据,并将其设置为目标图片dom的src属性:
html2canvas(targetDom, {allowTaint: true}).then(canvas => {targetImage.setAttribute('src', canvas.toDataURL() };);
这时候发现代码报错了,报错信息如下:
从错误信息的意思来看,添加allowTaint:true属性生成的canvas会导致toDataURL方法失败。所以我只能去掉allowTaint:true再试,结果是图片没有直接渲染:
去掉allowTaint:true属性后图片消失
我查看了官方文档,找到了问题的答案:
为什么我的图像没有渲染?
html2canvas 无法绕过浏览器设置的内容策略限制。位于当前页面原点之外的绘制图像会污染它们被绘制的画布。如果画布被污染,则无法再读取。因此, html2canvas 实现了在应用图像之前检查图像是否会污染画布的方法。如果您已将 allowTaintoption 设置为false,则不会绘制图像。
如果您希望加载位于页面原点之外的图像,您可以使用代理加载图像。
根据官方的说法,跨域加载的图片会污染画布,导致画布无法导出数据。也建议我们设置一个节点代理服务器来解决这个问题。什么?这么麻烦还需要架设节点服务器吗?我们本来想在H5端独立做这个,不想服务器参与!坚决寻找任何其他解决方案。果然,我在配置文件中找到了另一个选项:
使用CORS
这一刻,我微微一笑,淡定的加上了useCORS:true属性,然后优雅地等待着胜利果实的到来。一切看起来都很完美~
哦,该死的!发生了什么?好的胜利果实呢?♀️?此错误消息表示我的图像已跨域加载。我不是已经将useCORS设置为true了吗?♀️?这时候,我和世界杯上的梅西一样惊慌失措,于是赶紧上谷歌找原因。
很遗憾,我把我发现的所有相关问题都看了一遍,发现没有人真正解决过这个问题。这些老外长着一张倔强树上的顽固果子。晃晃悠悠的发呆……(其实现在回想起来,上面截图最后一个中文写的解决方案最接近问题的本质,可惜他还没有完全弄清楚问题的根源问题)。没有办法,只能另辟蹊径,继续探讨这个问题。
查了一些跨域的相关信息,然后尝试去掉useCORS属性,发现虽然报错信息没了,但是图片还是无法渲染。这时候怀疑是html2canvas库本身的bug,因为根据它,useCORS属性是用来解决图片跨域加载问题的。为什么添加后还是报错?而且,官网上的大量类似问题没有得到处理,更加深了我的怀疑。于是我查看了它的源码,发现图片加载部分的代码是这样的:
为了验证是否是库中的bug,我精简了代码,然后复制了错误图片的链接,手动执行。测试代码和控制台输出如下:
令我惊讶的是图片加载成功!我快速测试了几种情况,发现在渲染弹出DOM节点之前测试代码可以成功执行,但是在渲染弹出DOM之后就会失败。直到这时我才开始意识到,这个问题很可能与图片的浏览器缓存有关。发现这个现象后,查了很多相关资料,迷雾终于散去。
首先是MDN上介绍CORS的文章文章:跨域资源共享(CORS)。有几个重要的知识点:
当 Web 应用程序请求与自己的来源具有不同来源(域、协议和端口)的资源时,它会发出跨源 HTTP 请求。
出于安全原因,浏览器会限制从脚本内发起的跨源 HTTP 请求。
请注意,在任何访问控制请求中,始终发送 Origin 标头。(跨域请求必须带上带有当前域名值的Origin请求头)
我们先来看看启用CORS的图片介绍:
什么是“污染”画布?
尽管您可以在画布中使用未经 CORS 批准的图像,但这样做会污染画布。一旦画布被污染,您就无法再从画布中取出数据。例如,您不能再使用 canvastoBlob()、toDataURL()、orgetImageData() 方法;这样做会引发安全错误。
这可以防止用户在未经许可的情况下使用图像从远程网站提取信息而暴露私人数据。
根据这一段的描述,虽然canvas可以读取跨域图片,但这也会造成canvas被污染,导致canvas无法导出。
可用于标签的图像数据。
我们先看开篇:
HTML 规范为图像引入了跨 origin 属性,结合适当的 CORS 标头,允许从外部来源加载的元素定义的图像在画布中使用,就像它们是从当前来源加载一样。
这意味着如果我们想要
如果label加载的图片可以被canvas读取,并且可以导出图片数据,那么就应该在label中添加crossorigin属性。crossorigin 属性有两个可选值:anonymous 和 use-credentials。它们之间的区别可以在文末附录中的参考链接中找到。目前,我们可以直接使用 crossorigin='anonymous' 来触发带有跨域请求头 Origin 的 HTTP 请求。
我们来看看文中示例部分的第一段:
您必须有一个服务器托管图像,并带有适当的 Access-Control-Allow-Originheader。添加 crossOrigin 属性会生成请求标头。
关键在这里。除了将 Origin 添加到请求头之外,服务器的响应头还必须收录正确的 Access-Control-Allow-Origin。否则,表示服务器不接受来自客户端的跨域请求。一切为了安全。
看到这里,我们已经了解了跨域错误报告的基本原理。下一步就是为什么我们即使添加了useCORS:true,还是会报跨域请求错误?
原因与html2canvas库的工作原理有很大关系。前面提到,html2canvas库要求我们先提供一个DOM节点,然后它读取并解析这个DOM节点,生成一个canvas对象。如果已经在 DOM 节点中使用
标签,它也会解析这个
标签的src属性,然后重新创建一个Image对象,给它加上crossOrigin="anonymous"属性,尝试跨域重新读取图片数据。需要注意的是,CDN上的图片一般都会缓存响应头,会缓存在浏览器端,缓存的不仅是图片数据,还有HTTP响应头。所以我们已经找到了问题的根本原因。当html2canvas尝试跨域读取图片数据时,会读取浏览器缓存的数据,而由于我们没有在DOM节点中给出数据
标签添加了crossorigin="anonymous"属性,所以缓存的数据没有Access-Control-Allow-Origin响应头,导致html2canvas库读取的图片数据污染生成的canvas对象,最终导致canvas 导出数据报错。
真相已经在这里揭晓了。所以我们要做的也很简单,就是给每个DOM节点
将 crossorigin="anonymous" 属性添加到标签。回过头来说一下为什么之前的中文文章解决了问题却没有找到问题的根本原因,因为他修改了html2canvas的源码读取图片,并添加了每个Image的src属性创建了一个随机字符串,一不小心就避免了读取缓存数据的问题,但是会导致CDN的缓存被破坏。
最后总结一下,其实已经说了很多了,但是我们要做的很简单:
1、添加 useCORS:true 属性;
2、 给每个要生成的DOM画布
为标签添加 crossorigin="anonymous" 属性;
3、 确保你的图片CDN服务器支持CORS访问,这意味着它会返回Access-Control-Allow-Origin等响应头;
问题5(大boss回):图片无法渲染
可能你和我一样,认为问题到这里已经彻底解决了,其实不然。就像很多游戏关卡中的大boss一样,在终于杀死了它的第一条生命之后,原来它竟然还有第二条生命。
事情是这样的,如果要使用生成收录在dom中的canvas
您的用户之前访问过的图片(例如,您正在改造现有的在线业务)。显然你之前不应该给它
给标签添加crossorigin="anonymous"属性,那么请注意,此时你用户的浏览器已经将这些图片缓存到本地了,所以即使按照上面的步骤也没有用,因为你在访问图片的时候阅读了所有是没有响应标头的缓存数据,例如 Access-Control-Allow-Origin。
这个时候你要做的就是把你要生成canvas的dom里面的所有dom都给
在标签的src中添加任意字符串,只要能重新发起图片读取请求即可,避免读取浏览器缓存数据,如下图:
''
注意,不要添加随机字符串,会破坏CDN缓存,只需添加固定字符串,避免读取浏览器缓存的数据。这是我自己血的教训!所以请不要忽视这一点!
写在最后
至此,我想说的基本说完了。其实在解决图片未渲染问题的过程中,我也遇到了一些其他的障碍和麻烦,给我带来了很多麻烦。限于篇幅,我不再赘述。NS。html2canvas库在应用过程中肯定还有一些其他的问题,比如页面性能不一致。这可能是因为 DOM 本身的样式存在兼容性问题,或者库的渲染与 DOM 不同,具体取决于具体情况。情况。本来想补充一些浏览器缓存和CDN缓存的知识,但是这个话题本身就收录了足够的内容。以后再开个博客,慢慢写《彻底理解浏览器缓存》这里NS:)
在解决这个问题的过程中,我也为自己总结了一些经验,希望对大家有所启发:
1、善用charles、chrome等开发工具;
2、认真仔细,大胆假设,仔细验证;
3、不要轻易放弃;
4、永远不要太自信。
参考
跨域资源共享 (CORS)
启用 CORS 的图像
HTMLCanvasElement.toDataURL()
CORS 设置属性
图像嵌入元素::crossorigin
web开发的html2canvas截图如何解决跨域问题?
html2canvas:JavaScript 截图
html2canvas在iOS8系统上的兼容性 查看全部
php 抓取网页生成图片(流量之于互联网:微信内做分享和传播的形式)
前言
流量对于互联网公司来说就像水之于一切一样重要。那么目前国内移动互联网流量集中在哪里呢?答案很明显,那就是我们每天都在使用的微信。
2018年初,微信月活跃用户数突破10亿,成为国内首个月活跃用户突破10亿的产品。“三季度大战”后,腾讯逐渐从封闭走向开放,而微信作为腾讯在移动互联网时代最重要、最成功的战略产品,也在践行腾讯的开放战略。在这样的背景下,如何利用好微信的流量引导用户分享和传播,成为摆在我们面前的重要课题。但是,基于自身利益和用户体验等考虑,微信对在微信中分享和传播的内容和形式有严格的规定和诸多限制。如果你不注意违反这些规则,你可能会受到惩罚。严重的甚至被微信封杀死。
然而,风险和回报总是成正比的。有时为了达到更好的传播效果,我们不得不“合理”地采取一些措施。目前,微信中的分享传播方式不外乎以下五种:文字、图片、H5链接、小程序、短视频。从技术角度来看,微信、文字、H5链接、小程序三种形式,相对容易控制,而图片和短视频相对更容易绕过微信监控。虽然现在短视频很流行,但是我们公司用的不多(虽然我觉得应该充分利用),所以还是把重点放在图片上吧。
商业背景
在我们的业务中,我们经常需要引导用户将图片分享到微信。目前,我们生成图片的方式主要有两种。一种是通过APP中自研的Autumn系统生成图片,另一种是通过PHP后端生成图片,将图片上传到CDN再将图片链接返回给前端。. 这两种方法都有其局限性。第一种方法的局限是只能在APP中使用,不能在微信环境或手机浏览器中使用。第二种方法的问题在于它需要后端学生。完成共享海报图片的版面开发,需要占用CDN资源(需要花钱),如果生成的图片只是临时使用,这种方式的弊端就很明显了。所以,
技术选型
如果要在前端生成图片,自然会想到使用Canvas技术来做,但是团队中如何使用Canvas有两个思路:第一个是完全封装Canvas API进行绘图,以及二是直接使用开源库,比如流行的html2canvas库。我个人提倡第二种方法。一方面,它可以直接将 DOM 转换为 Canvas。用一个我们比较熟悉的方法也不太方便。如果我们封装它,很多基础的任务,比如界面布局,各种元素的绘制等等,都得重新做,开发和维护的风险和成本太高了。另一方面,html2canvas库是一个长期的开源项目,应该是比较成熟和稳定的。然而,团队中还有老司机发出警告,提到他们之前也尝试过使用html2canvas库做项目,但是在绘制一些比较复杂的页面时遇到了很多问题,所以他们决定放弃这个方案,改用A采用完全独立的开发方式,即上述第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。所以他们决定放弃这个方案,转而采用完全独立的开发方式,也就是上面的第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。所以他们决定放弃这个方案,转而采用完全独立的开发方式,也就是上面的第一种方式。但是一方面,我们需要生成的海报图片并不复杂,另一方面,直接使用DOM来绘制也是非常有诱惑力的,所以想了想,还是决定使用html2canvas的绘制方案。
html2canvas 基本介绍
根据html2canvas官方文档的介绍,html2canvas库的工作原理并不是真正的“截图”,而是读取网页上目标DOM节点的信息来绘制画布,所以不支持所有的css属性(详见这里),并且期望使用的图片与当前域名相同,但是官方也提供了一些方法来解决加载跨域图片的问题。
它的用法非常简单。引入html2canvas库后,获取目标dom,调用html2canvas方法生成canvas对象。由于我们的目标是生成图片,所以需要调用canvas.toDataURL()方法来生成。
标签的可用数据:
html2canvas(targetDom).then(canvas => {// 将画布附加到页面});
接下来我列举一下我在这个过程中遇到的一些问题以及解决方法。
问题一:生成的图片很模糊
当我写了代码,准备按照官网的介绍查看效果的时候,发现生成的图片很模糊。您可以查看下图的比较以了解详细信息。海报图片DOM在右边,左边是html2canvas库生成的Canvas。如果下面没有特别说明, , 都是左 Canvas 和右 DOM。
问题一:画面模糊
如您所见,图中红色圆圈标记的部分非常模糊。遇到这个问题后,我自然而然地去谷歌解决了这个问题。不说了,分分钟搜了一堆结果(毕竟是成熟的开源软件),还天真地以为这个问题很快就解决了。.
谷歌大法好!
我随意点了几个链接,看了看里面的解决方案。大体思路是将画布放大n倍,然后制作图形。奇怪的是,我试了之后,发现很多人说这个有效的方法对我完全没用。即使我放大200倍,画出来的画面还是一样的模糊,所以我只能遗憾地向我宣布这个方法。它不再有效。
所以想知道这是不是html2canvas库本身的bug,于是换了一个类似的库,dom-to-image,试了一下。结果出乎我的意料......这个产品不仅仅是一张模糊的图片,它是整个画布。很模糊!而且它恢复得非常糟糕,我吓得差点把手机扔掉。截图来了,大家自己感受一下吧……
你是认真的吗?
说到这里,我有点泄气了,因为从这种情况来看,很有可能是某些底层逻辑存在问题,也就是说,这个问题可能无解……不过还好,没有路可走完美。当我们几个人一起讨论这个问题时,转折点出现了。有同学突然发现,生成的海报图片中并不是所有的图片都是模糊的,一张小图片还是很清晰的!这个发现让我欣喜若狂。经过一段时间的测试,我发现只有用作背景图像的背景图像才会模糊,并且
图片标签没有这个问题。那么解决方法很简单,直接用
达到background-image的效果,问题就解决了。
问题二:删除线(text-decoration:line-through)在线条下方
这是一个小问题,但是文字有点下划线,如图:
文本中的下水平线
解决方法也很简单,将文本元素设置为相对相对定位,然后使用伪元素进行模拟。较少的代码如下:
&:after {.text-decoration-line-through();}
.text-decoration-line-through(@color: #fff) {位置:绝对;宽度:100%;高度:1px;顶部:50%;左:0;内容:''; 背景色:@color; }
问题三:带省略号的多行文字无法正确渲染
实测发现,使用省略号样式的多行文字时,会直接导致文字消失,如下图:
溢出:隐藏;显示:-webkit-box;-webkit-box-orient:垂直;-webkit-line-clamp:2;
这也是一个小问题。可能是html2canvas不支持上述某些样式(虽然我没有从文档中找到证据)。我的解决方案是简单地使用 overflow: hidden 来截断文本。不怕麻烦的话就得用js计算加省略号了。
问题四(Big Boss登场):图片无法渲染
嗯,其实这个问题出现在图片模糊问题之前。因为需要加载的图片都在CDN上,而且我们知道html2canvas的工作原理是使用js解析目标dom节点生成canvas,所以我们需要使用跨域的方式来加载图片。一开始为了让图片正常显示,我添加了allowTaint属性,设置为true。代码和截图如下:
添加allowTaint属性之前,图片无法显示
html2canvas(targetDom, {allowTaint: true}).then(canvas => {// 将画布附加到页面});
添加allowTaint属性后,图片显示正常
注意!这里我们只是转换成canvas,还没有生成图片。那么接下来,我们尝试通过调用canvas.toDataURL()来生成图片数据,并将其设置为目标图片dom的src属性:
html2canvas(targetDom, {allowTaint: true}).then(canvas => {targetImage.setAttribute('src', canvas.toDataURL() };);
这时候发现代码报错了,报错信息如下:
从错误信息的意思来看,添加allowTaint:true属性生成的canvas会导致toDataURL方法失败。所以我只能去掉allowTaint:true再试,结果是图片没有直接渲染:
去掉allowTaint:true属性后图片消失
我查看了官方文档,找到了问题的答案:
为什么我的图像没有渲染?
html2canvas 无法绕过浏览器设置的内容策略限制。位于当前页面原点之外的绘制图像会污染它们被绘制的画布。如果画布被污染,则无法再读取。因此, html2canvas 实现了在应用图像之前检查图像是否会污染画布的方法。如果您已将 allowTaintoption 设置为false,则不会绘制图像。
如果您希望加载位于页面原点之外的图像,您可以使用代理加载图像。
根据官方的说法,跨域加载的图片会污染画布,导致画布无法导出数据。也建议我们设置一个节点代理服务器来解决这个问题。什么?这么麻烦还需要架设节点服务器吗?我们本来想在H5端独立做这个,不想服务器参与!坚决寻找任何其他解决方案。果然,我在配置文件中找到了另一个选项:
使用CORS
这一刻,我微微一笑,淡定的加上了useCORS:true属性,然后优雅地等待着胜利果实的到来。一切看起来都很完美~
哦,该死的!发生了什么?好的胜利果实呢?♀️?此错误消息表示我的图像已跨域加载。我不是已经将useCORS设置为true了吗?♀️?这时候,我和世界杯上的梅西一样惊慌失措,于是赶紧上谷歌找原因。
很遗憾,我把我发现的所有相关问题都看了一遍,发现没有人真正解决过这个问题。这些老外长着一张倔强树上的顽固果子。晃晃悠悠的发呆……(其实现在回想起来,上面截图最后一个中文写的解决方案最接近问题的本质,可惜他还没有完全弄清楚问题的根源问题)。没有办法,只能另辟蹊径,继续探讨这个问题。
查了一些跨域的相关信息,然后尝试去掉useCORS属性,发现虽然报错信息没了,但是图片还是无法渲染。这时候怀疑是html2canvas库本身的bug,因为根据它,useCORS属性是用来解决图片跨域加载问题的。为什么添加后还是报错?而且,官网上的大量类似问题没有得到处理,更加深了我的怀疑。于是我查看了它的源码,发现图片加载部分的代码是这样的:
为了验证是否是库中的bug,我精简了代码,然后复制了错误图片的链接,手动执行。测试代码和控制台输出如下:
令我惊讶的是图片加载成功!我快速测试了几种情况,发现在渲染弹出DOM节点之前测试代码可以成功执行,但是在渲染弹出DOM之后就会失败。直到这时我才开始意识到,这个问题很可能与图片的浏览器缓存有关。发现这个现象后,查了很多相关资料,迷雾终于散去。
首先是MDN上介绍CORS的文章文章:跨域资源共享(CORS)。有几个重要的知识点:
当 Web 应用程序请求与自己的来源具有不同来源(域、协议和端口)的资源时,它会发出跨源 HTTP 请求。
出于安全原因,浏览器会限制从脚本内发起的跨源 HTTP 请求。
请注意,在任何访问控制请求中,始终发送 Origin 标头。(跨域请求必须带上带有当前域名值的Origin请求头)
我们先来看看启用CORS的图片介绍:
什么是“污染”画布?
尽管您可以在画布中使用未经 CORS 批准的图像,但这样做会污染画布。一旦画布被污染,您就无法再从画布中取出数据。例如,您不能再使用 canvastoBlob()、toDataURL()、orgetImageData() 方法;这样做会引发安全错误。
这可以防止用户在未经许可的情况下使用图像从远程网站提取信息而暴露私人数据。
根据这一段的描述,虽然canvas可以读取跨域图片,但这也会造成canvas被污染,导致canvas无法导出。
可用于标签的图像数据。
我们先看开篇:
HTML 规范为图像引入了跨 origin 属性,结合适当的 CORS 标头,允许从外部来源加载的元素定义的图像在画布中使用,就像它们是从当前来源加载一样。
这意味着如果我们想要
如果label加载的图片可以被canvas读取,并且可以导出图片数据,那么就应该在label中添加crossorigin属性。crossorigin 属性有两个可选值:anonymous 和 use-credentials。它们之间的区别可以在文末附录中的参考链接中找到。目前,我们可以直接使用 crossorigin='anonymous' 来触发带有跨域请求头 Origin 的 HTTP 请求。
我们来看看文中示例部分的第一段:
您必须有一个服务器托管图像,并带有适当的 Access-Control-Allow-Originheader。添加 crossOrigin 属性会生成请求标头。
关键在这里。除了将 Origin 添加到请求头之外,服务器的响应头还必须收录正确的 Access-Control-Allow-Origin。否则,表示服务器不接受来自客户端的跨域请求。一切为了安全。
看到这里,我们已经了解了跨域错误报告的基本原理。下一步就是为什么我们即使添加了useCORS:true,还是会报跨域请求错误?
原因与html2canvas库的工作原理有很大关系。前面提到,html2canvas库要求我们先提供一个DOM节点,然后它读取并解析这个DOM节点,生成一个canvas对象。如果已经在 DOM 节点中使用
标签,它也会解析这个
标签的src属性,然后重新创建一个Image对象,给它加上crossOrigin="anonymous"属性,尝试跨域重新读取图片数据。需要注意的是,CDN上的图片一般都会缓存响应头,会缓存在浏览器端,缓存的不仅是图片数据,还有HTTP响应头。所以我们已经找到了问题的根本原因。当html2canvas尝试跨域读取图片数据时,会读取浏览器缓存的数据,而由于我们没有在DOM节点中给出数据
标签添加了crossorigin="anonymous"属性,所以缓存的数据没有Access-Control-Allow-Origin响应头,导致html2canvas库读取的图片数据污染生成的canvas对象,最终导致canvas 导出数据报错。
真相已经在这里揭晓了。所以我们要做的也很简单,就是给每个DOM节点
将 crossorigin="anonymous" 属性添加到标签。回过头来说一下为什么之前的中文文章解决了问题却没有找到问题的根本原因,因为他修改了html2canvas的源码读取图片,并添加了每个Image的src属性创建了一个随机字符串,一不小心就避免了读取缓存数据的问题,但是会导致CDN的缓存被破坏。
最后总结一下,其实已经说了很多了,但是我们要做的很简单:
1、添加 useCORS:true 属性;
2、 给每个要生成的DOM画布
为标签添加 crossorigin="anonymous" 属性;
3、 确保你的图片CDN服务器支持CORS访问,这意味着它会返回Access-Control-Allow-Origin等响应头;
问题5(大boss回):图片无法渲染
可能你和我一样,认为问题到这里已经彻底解决了,其实不然。就像很多游戏关卡中的大boss一样,在终于杀死了它的第一条生命之后,原来它竟然还有第二条生命。
事情是这样的,如果要使用生成收录在dom中的canvas
您的用户之前访问过的图片(例如,您正在改造现有的在线业务)。显然你之前不应该给它
给标签添加crossorigin="anonymous"属性,那么请注意,此时你用户的浏览器已经将这些图片缓存到本地了,所以即使按照上面的步骤也没有用,因为你在访问图片的时候阅读了所有是没有响应标头的缓存数据,例如 Access-Control-Allow-Origin。
这个时候你要做的就是把你要生成canvas的dom里面的所有dom都给
在标签的src中添加任意字符串,只要能重新发起图片读取请求即可,避免读取浏览器缓存数据,如下图:
''
注意,不要添加随机字符串,会破坏CDN缓存,只需添加固定字符串,避免读取浏览器缓存的数据。这是我自己血的教训!所以请不要忽视这一点!
写在最后
至此,我想说的基本说完了。其实在解决图片未渲染问题的过程中,我也遇到了一些其他的障碍和麻烦,给我带来了很多麻烦。限于篇幅,我不再赘述。NS。html2canvas库在应用过程中肯定还有一些其他的问题,比如页面性能不一致。这可能是因为 DOM 本身的样式存在兼容性问题,或者库的渲染与 DOM 不同,具体取决于具体情况。情况。本来想补充一些浏览器缓存和CDN缓存的知识,但是这个话题本身就收录了足够的内容。以后再开个博客,慢慢写《彻底理解浏览器缓存》这里NS:)
在解决这个问题的过程中,我也为自己总结了一些经验,希望对大家有所启发:
1、善用charles、chrome等开发工具;
2、认真仔细,大胆假设,仔细验证;
3、不要轻易放弃;
4、永远不要太自信。
参考
跨域资源共享 (CORS)
启用 CORS 的图像
HTMLCanvasElement.toDataURL()
CORS 设置属性
图像嵌入元素::crossorigin
web开发的html2canvas截图如何解决跨域问题?
html2canvas:JavaScript 截图
html2canvas在iOS8系统上的兼容性
php 抓取网页生成图片(php抓取网页生成图片转化为网页链接,再利用公众号页面提取出图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-28 17:06
php抓取网页生成图片转化为网页链接,再利用公众号页面提取出图片,利用百度网盘批量上传链接。php没有十足的把握不要用这种方法去抓取网页。
可以试试看花生壳+phpmyadmin,最有效的方法应该是多抓一些网页,比如有些站点返回https请求,那么就抓几个https的站点,这样就能达到反向代理的效果。
利用fiddler抓网页抓站点还是简单的,找一款工具(国内推荐阿里云旗下的fiddler),将抓到的http代理放在一个目录下,数据库里记录一下抓取站点的url、header等配置信息,然后将抓取的http代理放到web服务器上就可以利用sql语句来取得网页信息了,或者利用上述工具,抓到多站点,并且header不同,可以方便后期的数据库sql注入什么的。
php直接通过ssrf(server-siderequest–server-sideresponse)
php-i2可以做到实时发布图片到社交网站,
之前一段时间写了个小程序可以抓数据包,也可以直接通过ssrf模拟登录或者收发消息,
用于爬虫的图片网站多数是反向代理抓取的图片,那么我们可以通过一个跨域的session来简单设置一下,
看你的需求。如果是多个网站全抓,并不是最优的选择。在抓取图片并且将其发布到互联网上的时候,很有可能会发生数据丢失和延迟的情况。那么,抓取一些外链是一个比较好的方式。 查看全部
php 抓取网页生成图片(php抓取网页生成图片转化为网页链接,再利用公众号页面提取出图片)
php抓取网页生成图片转化为网页链接,再利用公众号页面提取出图片,利用百度网盘批量上传链接。php没有十足的把握不要用这种方法去抓取网页。
可以试试看花生壳+phpmyadmin,最有效的方法应该是多抓一些网页,比如有些站点返回https请求,那么就抓几个https的站点,这样就能达到反向代理的效果。
利用fiddler抓网页抓站点还是简单的,找一款工具(国内推荐阿里云旗下的fiddler),将抓到的http代理放在一个目录下,数据库里记录一下抓取站点的url、header等配置信息,然后将抓取的http代理放到web服务器上就可以利用sql语句来取得网页信息了,或者利用上述工具,抓到多站点,并且header不同,可以方便后期的数据库sql注入什么的。
php直接通过ssrf(server-siderequest–server-sideresponse)
php-i2可以做到实时发布图片到社交网站,
之前一段时间写了个小程序可以抓数据包,也可以直接通过ssrf模拟登录或者收发消息,
用于爬虫的图片网站多数是反向代理抓取的图片,那么我们可以通过一个跨域的session来简单设置一下,
看你的需求。如果是多个网站全抓,并不是最优的选择。在抓取图片并且将其发布到互联网上的时候,很有可能会发生数据丢失和延迟的情况。那么,抓取一些外链是一个比较好的方式。
php 抓取网页生成图片(为什么手网站不收录图片,百度收录了多少个网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-25 11:02
网站指令在 SEO 中意味着什么?
网站指令在 SEO 中意味着什么?举个简单的例子,这样的事情在 SEO 中意味着什么!
为什么不手网站不收录图片,百度多少收录网站
应该是询问网站收录的情况。
查看收录的情况。有关于seo的说明,可以搜索学习。
这里有谁知道在线等待,网站施工服务商网站施工价格是多少网站选择哪一个?
网站重要的不是技术问题,而是你对网站的整体规划和定位。首先,你要清楚。智力型网站和实力型网站:智力型网站是乌鲁木齐有的特异服或垄断服赢网站,主要在新疆网站建设,新疆网站推广、新疆网站开发、新疆网页设计、新疆网络整合营销等,致力于为新疆的中小企业提供优质、全面的网站建设新疆乌鲁木齐。网站制作、网站优化、网络推广服务。
为什么我网站没有收录图片,百度多少收录 网站PHP好还是ASP好-为网站做SEO
PHP 外文名 PHP Hypertext
Preprocessor,中文名称:“超文本预处理器”是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP
独特的语法混合了 C、Java、Perl 和 PHP 自己的语法。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,用PHP制作的动态页面是将程序嵌入到HTML标准通用标记语言下的应用文档中执行。执行效率远高于完全生成HTML标记的CGI。PHP 还可以在执行编译后的代码后,通过编译实现对运行代码的加密和优化,使代码运行速度更快。
PHP优势
开源
所有 PHP 源代码实际上都可用。
自由
与其他技术相比,PHP 本身是免费的开源代码。
为什么不手网站不收录图片,百度多少收录网站
速度
程序开发速度快,运行速度快,技术本身学得也快。嵌入 HTML:由于 PHP 可以嵌入 HTML 语言,因此相对于其他语言而言。编辑简单实用,更适合初学者。
强大的跨平台
由于PHP是运行在服务器端的脚本,所以它可以运行在UNIX、LINUX、WINDOWS、Mac OS、Android等平台上。
高效的
PHP 消耗相当多的系统资源。
图像处理
使用 PHP 动态创建图像 PHP 图像处理默认使用 GD2。并且还可以配置为使用 image magick 进行图像处理。
面向对象
在php4php5中,面向对象方面有了很大的改进,可以使用php开发大型商业程序。
专业专注
PHP主要支持脚本语言,两者都是类C语言。
ASP 是动态服务器页面 Active Server
Page 的英文缩写。它是微软开发的用于替代 CGI 脚本的应用程序。它可以与数据库和其他程序交互。它是一个简单方便的编程工具。ASP网页文件的格式为
ASP.NET 现在常用于各种动态网站。
ASP的特点
积极的
ASP 使用 Microsoft 的 ActiveX 技术。ActiveXCOM 技术现在是微软软件的重要基础。它利用封装对象和程序调用对象的技术来简化编程,加强程序之间的协作。ASP本身封装了一些基础组件和通用组件,很多公司也开发了很多实用的组件。只要你能在服务器上安装这些组件,通过访问这些组件,你就可以快速轻松地构建自己的WEB应用程序。
服务器
ASP 运行在服务器端。这样您就不必担心浏览器是否支持 ASP 使用的编程语言。ASP 编程语言可以是 VBSCRIPT 和
脚本。VBSCRIPT是VB的简短合集,了解VB的人可以快速上手。但是Netscape浏览器在客户端不支持VBSCRIPT,所以最好不要在客户端使用VBSCRIPT。在服务器端,无需考虑浏览器支持问题。Netscape 浏览器也可以正常显示 ASP 页面。
页面
ASP返回一个标准的HTML页面,可以在常用浏览器中正常显示。当浏览器查看页面源文件时,看到的是ASP生成的HTML代码,而不是ASP程序代码。这将防止其他人复制该程序。由此我们可以看出,ASP是一种在IIS下开发WEB应用的简单方便的编程工具。了解了VBSCRIPT的基本语法后,只需要知道各个组件的用途、属性、方法,就可以轻松编写自己的ASP系统了。
对于网站seo,正如你所说,网站只要一个好的网站对seo有好处!
1、 关于网站建站方案,因人而异。我认为网站seo 并不关心网站 是为什么程序构建的,只要网站 程序自己使用就可以轻松,您可以最大限度地提高seo 水平!当然,你可以最大限度地做seo!
2、当然以上都是相对懂代码和编程语言的SEO人员来说的!对于那些不懂基本代码的seo,如果网站后台程序自己做的不好,可能有些seo技巧不会实现,有些seo功能也无法完善,因为他们不会改代码和添加职能!
3、 目前主流的网站程序基本都是PHP脚本程序,也不排除一些特殊行业的java开发等语言程序。
建议不懂代码库的seo人员使用织梦php建站。我们安全做网站都使用织梦,因为dedecms是现在主流的建站程序,很多高级seo技巧都是在此基础上开发和定制的。
当然如果是游戏行业,Bc行业的话,还是自己开发定制比较好,毕竟功能更强大,有seo方面的程序员就不用担心了. 如果您对编程器不满意,可以随时更改!
网站为什么要打造企业官网形象
一、提升企业形象和品牌形象
一般来说,当一家公司成立自己的网站时,不仅可以为公司带来新的客户和新的业务,还可以立即大幅提升业绩。企业网站的角色更像是企业自身及其品牌在报纸电视上的广告。不同的是,企业网站的容量更大,企业几乎可以把客户和公众想知道的任何内容放入网站。
二、信息资源及时
互联网的真正内涵在于其内容的丰富性,几乎无所不包。对于企业来说,可以通过互联网了解来自世界各地的信息,及时调整自己的公司战略。
三、全面详细的公司介绍及公司产品展示
公司网站最基本的功能之一就是能够全面详细地介绍公司及其产品。事实上,公司可以把人们想知道的任何东西放到网站中,比如公司简介、公司业绩、产品外观、功能和使用方法等,都可以在公司上展示网站@ > .
四、与客户保持联系
当客户想知道公司有哪些新产品、新服务、服务变化,甚至只是想知道公司有哪些新闻信息时,他们会习惯性地进入公司网站。因为公司已经习惯于在互联网上发布所有新产品和信息,并定期在互联网上发布有关公司的最新消息。
五、可以与潜在客户建立业务联系
这是企业网站最重要的功能之一。现在,来自世界各地的大买家主要是通过互联网寻找新产品和新供应商,因为这样做最便宜,效率也最高。原则上,世界上任何地方的人只要知道公司的网站,就可以看到公司的产品。.
随着互联网的发展,互联网已经走进千家万户。企业成立网站也是企业向客户展示公司实力的主要方式,同时也提高了公司的知名度,潜移默化地提升了同行业的竞争水平,因此也是企业向客户展示自身实力的重要渠道。企业销售!一个企业是否建立了自己独立的网站,也是普通客户判断这家企业规模的第一直观标准。一个没有自己网站的企业,就是普通用户认为的小公司。当然,这是不能一概而论的,但确实是在万千人心中深深铭记。
为什么不手网站不收录图片,百度多少收录网站
企业网站代表了一个公司的形象,它可以让更多的人认识你,让更多的人了解更多关于公司的信息,也可以起到企业宣传的作用。这就是为什么许多公司现在开始做自己的业务网站。
柠檬绿茶如何为 SEO 工作
柠檬绿茶如何为 SEO 工作
选对了关键词 这个是重点,其他的就慢慢贴链接和内容吧。
为什么不手网站不收录图片,百度多少收录网站
网站收录 推送站长工具 查看全部
php 抓取网页生成图片(为什么手网站不收录图片,百度收录了多少个网站)
网站指令在 SEO 中意味着什么?
网站指令在 SEO 中意味着什么?举个简单的例子,这样的事情在 SEO 中意味着什么!
为什么不手网站不收录图片,百度多少收录网站
应该是询问网站收录的情况。
查看收录的情况。有关于seo的说明,可以搜索学习。
这里有谁知道在线等待,网站施工服务商网站施工价格是多少网站选择哪一个?
网站重要的不是技术问题,而是你对网站的整体规划和定位。首先,你要清楚。智力型网站和实力型网站:智力型网站是乌鲁木齐有的特异服或垄断服赢网站,主要在新疆网站建设,新疆网站推广、新疆网站开发、新疆网页设计、新疆网络整合营销等,致力于为新疆的中小企业提供优质、全面的网站建设新疆乌鲁木齐。网站制作、网站优化、网络推广服务。
为什么我网站没有收录图片,百度多少收录 网站PHP好还是ASP好-为网站做SEO
PHP 外文名 PHP Hypertext
Preprocessor,中文名称:“超文本预处理器”是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP
独特的语法混合了 C、Java、Perl 和 PHP 自己的语法。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,用PHP制作的动态页面是将程序嵌入到HTML标准通用标记语言下的应用文档中执行。执行效率远高于完全生成HTML标记的CGI。PHP 还可以在执行编译后的代码后,通过编译实现对运行代码的加密和优化,使代码运行速度更快。
PHP优势
开源
所有 PHP 源代码实际上都可用。
自由
与其他技术相比,PHP 本身是免费的开源代码。
为什么不手网站不收录图片,百度多少收录网站
速度
程序开发速度快,运行速度快,技术本身学得也快。嵌入 HTML:由于 PHP 可以嵌入 HTML 语言,因此相对于其他语言而言。编辑简单实用,更适合初学者。
强大的跨平台
由于PHP是运行在服务器端的脚本,所以它可以运行在UNIX、LINUX、WINDOWS、Mac OS、Android等平台上。
高效的
PHP 消耗相当多的系统资源。
图像处理
使用 PHP 动态创建图像 PHP 图像处理默认使用 GD2。并且还可以配置为使用 image magick 进行图像处理。
面向对象
在php4php5中,面向对象方面有了很大的改进,可以使用php开发大型商业程序。
专业专注
PHP主要支持脚本语言,两者都是类C语言。
ASP 是动态服务器页面 Active Server
Page 的英文缩写。它是微软开发的用于替代 CGI 脚本的应用程序。它可以与数据库和其他程序交互。它是一个简单方便的编程工具。ASP网页文件的格式为
ASP.NET 现在常用于各种动态网站。
ASP的特点
积极的
ASP 使用 Microsoft 的 ActiveX 技术。ActiveXCOM 技术现在是微软软件的重要基础。它利用封装对象和程序调用对象的技术来简化编程,加强程序之间的协作。ASP本身封装了一些基础组件和通用组件,很多公司也开发了很多实用的组件。只要你能在服务器上安装这些组件,通过访问这些组件,你就可以快速轻松地构建自己的WEB应用程序。
服务器
ASP 运行在服务器端。这样您就不必担心浏览器是否支持 ASP 使用的编程语言。ASP 编程语言可以是 VBSCRIPT 和
脚本。VBSCRIPT是VB的简短合集,了解VB的人可以快速上手。但是Netscape浏览器在客户端不支持VBSCRIPT,所以最好不要在客户端使用VBSCRIPT。在服务器端,无需考虑浏览器支持问题。Netscape 浏览器也可以正常显示 ASP 页面。
页面
ASP返回一个标准的HTML页面,可以在常用浏览器中正常显示。当浏览器查看页面源文件时,看到的是ASP生成的HTML代码,而不是ASP程序代码。这将防止其他人复制该程序。由此我们可以看出,ASP是一种在IIS下开发WEB应用的简单方便的编程工具。了解了VBSCRIPT的基本语法后,只需要知道各个组件的用途、属性、方法,就可以轻松编写自己的ASP系统了。
对于网站seo,正如你所说,网站只要一个好的网站对seo有好处!
1、 关于网站建站方案,因人而异。我认为网站seo 并不关心网站 是为什么程序构建的,只要网站 程序自己使用就可以轻松,您可以最大限度地提高seo 水平!当然,你可以最大限度地做seo!
2、当然以上都是相对懂代码和编程语言的SEO人员来说的!对于那些不懂基本代码的seo,如果网站后台程序自己做的不好,可能有些seo技巧不会实现,有些seo功能也无法完善,因为他们不会改代码和添加职能!
3、 目前主流的网站程序基本都是PHP脚本程序,也不排除一些特殊行业的java开发等语言程序。
建议不懂代码库的seo人员使用织梦php建站。我们安全做网站都使用织梦,因为dedecms是现在主流的建站程序,很多高级seo技巧都是在此基础上开发和定制的。
当然如果是游戏行业,Bc行业的话,还是自己开发定制比较好,毕竟功能更强大,有seo方面的程序员就不用担心了. 如果您对编程器不满意,可以随时更改!
网站为什么要打造企业官网形象
一、提升企业形象和品牌形象
一般来说,当一家公司成立自己的网站时,不仅可以为公司带来新的客户和新的业务,还可以立即大幅提升业绩。企业网站的角色更像是企业自身及其品牌在报纸电视上的广告。不同的是,企业网站的容量更大,企业几乎可以把客户和公众想知道的任何内容放入网站。
二、信息资源及时
互联网的真正内涵在于其内容的丰富性,几乎无所不包。对于企业来说,可以通过互联网了解来自世界各地的信息,及时调整自己的公司战略。
三、全面详细的公司介绍及公司产品展示
公司网站最基本的功能之一就是能够全面详细地介绍公司及其产品。事实上,公司可以把人们想知道的任何东西放到网站中,比如公司简介、公司业绩、产品外观、功能和使用方法等,都可以在公司上展示网站@ > .
四、与客户保持联系
当客户想知道公司有哪些新产品、新服务、服务变化,甚至只是想知道公司有哪些新闻信息时,他们会习惯性地进入公司网站。因为公司已经习惯于在互联网上发布所有新产品和信息,并定期在互联网上发布有关公司的最新消息。
五、可以与潜在客户建立业务联系
这是企业网站最重要的功能之一。现在,来自世界各地的大买家主要是通过互联网寻找新产品和新供应商,因为这样做最便宜,效率也最高。原则上,世界上任何地方的人只要知道公司的网站,就可以看到公司的产品。.
随着互联网的发展,互联网已经走进千家万户。企业成立网站也是企业向客户展示公司实力的主要方式,同时也提高了公司的知名度,潜移默化地提升了同行业的竞争水平,因此也是企业向客户展示自身实力的重要渠道。企业销售!一个企业是否建立了自己独立的网站,也是普通客户判断这家企业规模的第一直观标准。一个没有自己网站的企业,就是普通用户认为的小公司。当然,这是不能一概而论的,但确实是在万千人心中深深铭记。
为什么不手网站不收录图片,百度多少收录网站
企业网站代表了一个公司的形象,它可以让更多的人认识你,让更多的人了解更多关于公司的信息,也可以起到企业宣传的作用。这就是为什么许多公司现在开始做自己的业务网站。
柠檬绿茶如何为 SEO 工作
柠檬绿茶如何为 SEO 工作
选对了关键词 这个是重点,其他的就慢慢贴链接和内容吧。
为什么不手网站不收录图片,百度多少收录网站
网站收录 推送站长工具
php 抓取网页生成图片(网页截图基本我知道的有三种,主要一个前端nodejs实现 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-25 01:10
)
最近没时间学go。手头有很多东西。我所知道的关于网页的屏幕截图基本上分为三种。主要一个是前端的nodejs实现,另一个第三方组件主要是phantomjs。少了什么乱七八糟的? windows和centos安装请参考github上的说明
如何说名字安装成功,windows直接在命令行窗口任何未知敲这个phantomjs如下图
Windows 主要关注环境变量。
centos 类似,centos 主要关注权限问题
如果以上成功
然后把截图代码贴在下面,
/**
* @author:leishaofa
* @date:20200827
* @effect:远程网页截图
* @parame $url string 要抓取的网页路径
* @paraem $file_path string 生成的网页图片保存路径
*/
public function curlToPng($url,$file_path){
if(empty($url) || empty($file_path)){
return null;
}
set_time_limit(0);
$path = 'phantomjs'; //phantomjs路径 查看全部
php 抓取网页生成图片(网页截图基本我知道的有三种,主要一个前端nodejs实现
)
最近没时间学go。手头有很多东西。我所知道的关于网页的屏幕截图基本上分为三种。主要一个是前端的nodejs实现,另一个第三方组件主要是phantomjs。少了什么乱七八糟的? windows和centos安装请参考github上的说明
如何说名字安装成功,windows直接在命令行窗口任何未知敲这个phantomjs如下图
Windows 主要关注环境变量。
centos 类似,centos 主要关注权限问题
如果以上成功
然后把截图代码贴在下面,
/**
* @author:leishaofa
* @date:20200827
* @effect:远程网页截图
* @parame $url string 要抓取的网页路径
* @paraem $file_path string 生成的网页图片保存路径
*/
public function curlToPng($url,$file_path){
if(empty($url) || empty($file_path)){
return null;
}
set_time_limit(0);
$path = 'phantomjs'; //phantomjs路径
php 抓取网页生成图片(www根目录创建项目grabimg的方法与方法属性的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-24 17:15
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类grabimage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:grabimage
class grabimage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是抓取远程图片后本地存储的目录,一般以php入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getinstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getinstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setdir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setdir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,true);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出 content-type 的值作为 mime 的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['content-type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7ay5p7lspqai-ly1bf.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的爬取方法为:
private function getremoteimg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['content-type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7ay5p7lspqai-ly1bf.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们把抓取动作直接放到getinstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getinstances 中。
if($this->setdir())
{
return $this->getremoteimg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
我确实抓住了它
完整代码
<p> 查看全部
php 抓取网页生成图片(www根目录创建项目grabimg的方法与方法属性的区别)
一、创建项目
作为演示,我们在www根目录下创建一个项目grabimg,创建一个类grabimage.php和一个index.php。
二、编写类代码
我们定义一个与文件同名的类:grabimage
class grabimage{
}
三、属性
接下来,定义几个需要用到的属性。
1、首先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能会涉及到扩展名的替换,所以这里是定义
3、 后跟扩展名 $extension
4、 然后我们定义一个$file_dir。该属性的作用是抓取远程图片后本地存储的目录,一般以php入口文件的位置为起点。但是路径一般不会保存到数据库中。
5、最后我们定义了一个$save_dir,顾名思义,这个路径就是要直接保存的数据库的目录。这里说明一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时更改路径做准备。我们这里的$save_dir一般是日期+文件名,如果使用的时候需要取出来,把需要的路径放在前面。
四、方法
属性说完了,接下来我们就正式开始爬取工作了。
首先,我们定义了一个open方法getinstances来获取一些数据,比如抓拍图片的地址,本地保存路径等。同时把它放在属性中。
public function getinstances($img_url , $base_dir)
{
$this->img_url = $img_url;
$this->save_dir = date("ym").'/'.date("d").'/'; // 比如:201610/19/
$this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/
}
图片保存路径已拼接。接下来需要注意一个问题,目录是否存在。日期一天天过去,但目录不会自动创建。因此,在保存图片之前,您需要先检查一下,如果当前目录不存在,我们需要立即创建它。
我们创建 setdir 方法来设置目录。我们将财产设为私密、安全
/**
* 检查图片需要保持的目录是否存在
* 如果不存在,则立即创建一个目录
* @return bool
*/
private function setdir()
{
if(!file_exists($this->file_dir))
{
mkdir($this->file_dir,0777,true);
}
$this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法
return true;
}
下一步就是抓取核心代码
第一步是解决问题。我们需要抓取的图片可能没有后缀。按照传统的抓图方式,先抓图,再截取后缀名是行不通的。
我们必须通过其他方法获取图片类型。方式是从文件流信息中获取文件头信息,然后判断文件mime信息,即可知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
这样,当我得到类型 image/gif 时,我可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为 false 时,我们将它分配给变量 $headers
取出 content-type 的值作为 mime 的值。
if(($headers=get_headers($this->img_url, 1))!==false){
// 获取响应的类型
$type=$headers['content-type'];
}
使用我们上面定义的映射表,我们可以很容易地得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type可能不存在于我们的映射表中,说明这种类型的文件不是我们想要的,放弃它,忽略它。
以下步骤与传统的文件抓取相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7ay5p7lspqai-ly1bf.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
先获取本地保存图片的全路径$file_path,然后用file_get_contents抓取数据,再用file_put_contents保存到刚才的文件路径。
最后,我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的爬取方法为:
private function getremoteimg()
{
// mime 和 扩展名 的映射
$mimes=array(
'image/bmp'=>'bmp',
'image/gif'=>'gif',
'image/jpeg'=>'jpg',
'image/png'=>'png',
'image/x-icon'=>'ico'
);
// 获取响应头
if(($headers=get_headers($this->img_url, 1))!==false)
{
// 获取响应的类型
$type=$headers['content-type'];
// 如果符合我们要的类型
if(isset($mimes[$type]))
{
$this->extension=$mimes[$type];
$file_path = $this->file_dir.$this->file_name.".".$this->extension;
// 获取数据并保存
$contents=file_get_contents($this->img_url);
if(file_put_contents($file_path , $contents))
{
// 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7ay5p7lspqai-ly1bf.jpg
return $this->save_dir.$this->file_name.".".$this->extension;
}
}
}
return false;
}
最后,为了简单起见,我们希望在别处调用这些方法之一来完成爬网。所以我们把抓取动作直接放到getinstances里面,配置好路径后,直接抓取。因此,我们将代码添加到初始配置方法 getinstances 中。
if($this->setdir())
{
return $this->getremoteimg();
}
else
{
return false;
}
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
我确实抓住了它
完整代码
<p>
php 抓取网页生成图片(php的开发者来说源码,远程抓取图片并保存到本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-22 22:07
作为仿站工作者,遇到网站版权甚至加密,WEBZIP也关掉,网页图片和背景图片怎么扣?有时,您可能会想到使用 Firefox。这个浏览器好像是个强大的BUG。 文章拥有版权,屏蔽右键,Firefox完全不受影响。
但作为一个热爱php的开发者,我更喜欢自己动手。于是,我写了如下源码,一个用php远程抓图的小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而编写的。
那么如果没有意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片下载并本地保存
分享一个使用php获取远程图片并在本地下载保存远程图片的函数代码:
/*
*功能:php完美实现下载远程图片保存到本地
*参数:文件url,保存文件目录,保存文件名称,使用的下载方式
*当保存文件名称为空时则使用远程文件原来的名称
*/
function getImage($url,$save_dir='',$filename='',$type=0){
if(trim($url)==''){
return array('file_name'=>'','save_path'=>'','error'=>1);
}
if(trim($save_dir)==''){
$save_dir='./';
}
if(trim($filename)==''){//保存文件名
$ext=strrchr($url,'.');
if($ext!='.gif'&&$ext!='.jpg'){
return array('file_name'=>'','save_path'=>'','error'=>3);
}
$filename=time().$ext;
}
if(0!==strrpos($save_dir,'/')){
$save_dir.='/';
}
//创建保存目录
if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){
return array('file_name'=>'','save_path'=>'','error'=>5);
}
//获取远程文件所采用的方法
if($type){
$ch=curl_init();
$timeout=5;
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout);
$img=curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$img=ob_get_contents();
ob_end_clean();
}
//$size=strlen($img);
//文件大小
$fp2=@fopen($save_dir.$filename,'a');
fwrite($fp2,$img);
fclose($fp2);
unset($img,$url);
return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0);
}
以上内容是小编分享的PHP源码批量抓取远程网页图片并保存到本地的实现方法,希望大家喜欢。 查看全部
php 抓取网页生成图片(php的开发者来说源码,远程抓取图片并保存到本地)
作为仿站工作者,遇到网站版权甚至加密,WEBZIP也关掉,网页图片和背景图片怎么扣?有时,您可能会想到使用 Firefox。这个浏览器好像是个强大的BUG。 文章拥有版权,屏蔽右键,Firefox完全不受影响。
但作为一个热爱php的开发者,我更喜欢自己动手。于是,我写了如下源码,一个用php远程抓图的小程序。您可以读取 css 文件并在 css 代码中获取背景图像。下面的代码也是为了抓取css中的图片而编写的。
那么如果没有意外,你会发现你指定的文件夹里全是图片,哈哈..
ps:php获取远程图片下载并本地保存
分享一个使用php获取远程图片并在本地下载保存远程图片的函数代码:
/*
*功能:php完美实现下载远程图片保存到本地
*参数:文件url,保存文件目录,保存文件名称,使用的下载方式
*当保存文件名称为空时则使用远程文件原来的名称
*/
function getImage($url,$save_dir='',$filename='',$type=0){
if(trim($url)==''){
return array('file_name'=>'','save_path'=>'','error'=>1);
}
if(trim($save_dir)==''){
$save_dir='./';
}
if(trim($filename)==''){//保存文件名
$ext=strrchr($url,'.');
if($ext!='.gif'&&$ext!='.jpg'){
return array('file_name'=>'','save_path'=>'','error'=>3);
}
$filename=time().$ext;
}
if(0!==strrpos($save_dir,'/')){
$save_dir.='/';
}
//创建保存目录
if(!file_exists($save_dir)&&!mkdir($save_dir,0777,true)){
return array('file_name'=>'','save_path'=>'','error'=>5);
}
//获取远程文件所采用的方法
if($type){
$ch=curl_init();
$timeout=5;
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout);
$img=curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$img=ob_get_contents();
ob_end_clean();
}
//$size=strlen($img);
//文件大小
$fp2=@fopen($save_dir.$filename,'a');
fwrite($fp2,$img);
fclose($fp2);
unset($img,$url);
return array('file_name'=>$filename,'save_path'=>$save_dir.$filename,'error'=>0);
}
以上内容是小编分享的PHP源码批量抓取远程网页图片并保存到本地的实现方法,希望大家喜欢。
php 抓取网页生成图片(强大的PHP采集类,可以用来开发一些采集程序和小偷程序,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-22 22:06
这个文章主要介绍PHP采集类Snoopy来抓图。Snoopy是一个功能强大的PHP采集类,可以用来开发一些采集程序和小偷程序,有需要的朋友可以参考
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "//";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能是反盗版的,我想先抓取本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中文章的地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3.根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则来获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法... 查看全部
php 抓取网页生成图片(强大的PHP采集类,可以用来开发一些采集程序和小偷程序,)
这个文章主要介绍PHP采集类Snoopy来抓图。Snoopy是一个功能强大的PHP采集类,可以用来开发一些采集程序和小偷程序,有需要的朋友可以参考
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "//";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能是反盗版的,我想先抓取本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中文章的地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3.根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则来获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
php 抓取网页生成图片(php抓取网页生成图片压缩包发给qq截图助手|自问自答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-21 19:00
php抓取网页生成图片压缩包发给qq截图助手|代码|图片|php-qq-sample
自问自答啊,补充一下我在网上抓取了很多网站的图片(还截取了一部分)发送qq截图助手转发给自己只需要三步:1抓取2压缩3发送自己已经压缩好了所以基本思路就是这样。
各种各样的图片文件压缩工具使用
,
你看看这个
搜索“腾讯qq图片压缩工具”
phpqq截图可以实现多种格式,
压缩格式那就只有portable了,不过如果是网页里面的话,一般用gzip算法优化一下然后转化为jpg就可以了,jpg就很难做压缩。实在不行找已经压缩好的东西转化也可以。
我自己写了一个用微信网页打开的软件可以将qq里的图片在微信里面分享
这里有一个可以做点压缩的软件,可以把视频编码压缩。网站在这里,祝你好运。
一直想做一款图片的压缩工具,
可以关注下公众号:的精彩分享里有:图片上传、图片压缩、源代码压缩、制作图片pdf、图片格式转换、压缩包解压、高清无码原图下载
酷传支持上传全网所有图片到服务器上,一键编辑配置,在线上传图片并能够还原原图,
我觉得压缩工具的话,还是qq图片压缩软件比较好,它采用的是webrtc的链路,可以在手机上传图片,也支持pc的二次编辑;而且支持多平台的二次编辑。 查看全部
php 抓取网页生成图片(php抓取网页生成图片压缩包发给qq截图助手|自问自答)
php抓取网页生成图片压缩包发给qq截图助手|代码|图片|php-qq-sample
自问自答啊,补充一下我在网上抓取了很多网站的图片(还截取了一部分)发送qq截图助手转发给自己只需要三步:1抓取2压缩3发送自己已经压缩好了所以基本思路就是这样。
各种各样的图片文件压缩工具使用
,
你看看这个
搜索“腾讯qq图片压缩工具”
phpqq截图可以实现多种格式,
压缩格式那就只有portable了,不过如果是网页里面的话,一般用gzip算法优化一下然后转化为jpg就可以了,jpg就很难做压缩。实在不行找已经压缩好的东西转化也可以。
我自己写了一个用微信网页打开的软件可以将qq里的图片在微信里面分享
这里有一个可以做点压缩的软件,可以把视频编码压缩。网站在这里,祝你好运。
一直想做一款图片的压缩工具,
可以关注下公众号:的精彩分享里有:图片上传、图片压缩、源代码压缩、制作图片pdf、图片格式转换、压缩包解压、高清无码原图下载
酷传支持上传全网所有图片到服务器上,一键编辑配置,在线上传图片并能够还原原图,
我觉得压缩工具的话,还是qq图片压缩软件比较好,它采用的是webrtc的链路,可以在手机上传图片,也支持pc的二次编辑;而且支持多平台的二次编辑。
php 抓取网页生成图片( 2019-03-30Python使用正则表达式抓取网页图片的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-21 11:17
2019-03-30Python使用正则表达式抓取网页图片的方法)
Python如何使用正则表达式抓取网页图片的例子
时间:2019-03-30
本文章给大家介绍了Python使用正则表达式抓取网页图片的例子,主要包括Python使用正则表达式抓取网页图片的例子、使用实例、应用技巧、基础知识点总结和需要注意的事项关注,有一定的参考价值,有需要的朋友可以参考。
本文介绍Python使用正则表达式抓取网页图片的方法。分享给大家,供大家参考,如下:
#!/usr/bin/python
import re
import urllib
#获取网页信息
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#匹配网页中的图片
reg = r'src="(.*?\.jpg)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://photo.bitauto.com/?WT.mc_id=360tpdq")
print getImg(html)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用汇总》、《Python数据结构与算法教程》、《Python Socket编程技巧汇总》、《Python函数使用技巧汇总》、《Python Strings》操作技巧总结《Python入门及进阶经典教程》《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。 查看全部
php 抓取网页生成图片(
2019-03-30Python使用正则表达式抓取网页图片的方法)
Python如何使用正则表达式抓取网页图片的例子
时间:2019-03-30
本文章给大家介绍了Python使用正则表达式抓取网页图片的例子,主要包括Python使用正则表达式抓取网页图片的例子、使用实例、应用技巧、基础知识点总结和需要注意的事项关注,有一定的参考价值,有需要的朋友可以参考。
本文介绍Python使用正则表达式抓取网页图片的方法。分享给大家,供大家参考,如下:
#!/usr/bin/python
import re
import urllib
#获取网页信息
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#匹配网页中的图片
reg = r'src="(.*?\.jpg)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
html = getHtml("http://photo.bitauto.com/?WT.mc_id=360tpdq";)
print getImg(html)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用汇总》、《Python数据结构与算法教程》、《Python Socket编程技巧汇总》、《Python函数使用技巧汇总》、《Python Strings》操作技巧总结《Python入门及进阶经典教程》《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。
php 抓取网页生成图片(,本文用一个需求为引,详细介绍步骤的做法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-19 06:16
本文文章主要介绍PHP在网页中动态生成PDF文件的详细教程。本文以需求为参考,详细介绍每一步的实践,并配有大量图片说明。有需要的朋友可以参考
本文详细介绍了使用PHP动态构建PDF文件的全过程。使用免费的PDF库(FPDF)或PDFLib-Lite等开源工具进行实验,使用PHP代码控制PDF内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件使您可以完全控制页面的显示方式以及文本、图形和图像在页面上的显示方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在您需要提供一些帮助。
当您在 Internet 上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些是很好的库,但商业版本相当昂贵。PDFLib 库的精简版本仅作为原创版本分发。当您尝试在托管环境中安装精简版本时,会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译。它是完全免费的,因此您不会像 PDFLib 的未授权版本那样看到水印。这个免费的 PDF 库正是我将在本文中使用的库。
我们将用女子旱冰比赛的成绩来演示动态构建PDF文件的过程。这些分数是从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
列出1. XML 数据
... ... ...
XML 的根元素是事件标记。数据按事件分组,每个事件收录多个匹配项。在事件标签中,有一系列的事件标签,其中有多个游戏标签。这些比赛标签收录参加比赛的两支球队的名字以及他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。序列中的每个元素都是一个哈希表,其中收录一系列事件名称和比赛项目。该结构基本上是 XML 结构的内存版本。
为了测试这个脚本的效果,将构建一个HTML导出页面,使用getResults函数读取文件,然后以一系列HTML表格的形式输出数据。清单 3 显示了用于此测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p> 查看全部
php 抓取网页生成图片(,本文用一个需求为引,详细介绍步骤的做法)
本文文章主要介绍PHP在网页中动态生成PDF文件的详细教程。本文以需求为参考,详细介绍每一步的实践,并配有大量图片说明。有需要的朋友可以参考
本文详细介绍了使用PHP动态构建PDF文件的全过程。使用免费的PDF库(FPDF)或PDFLib-Lite等开源工具进行实验,使用PHP代码控制PDF内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件使您可以完全控制页面的显示方式以及文本、图形和图像在页面上的显示方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在您需要提供一些帮助。
当您在 Internet 上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些是很好的库,但商业版本相当昂贵。PDFLib 库的精简版本仅作为原创版本分发。当您尝试在托管环境中安装精简版本时,会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译。它是完全免费的,因此您不会像 PDFLib 的未授权版本那样看到水印。这个免费的 PDF 库正是我将在本文中使用的库。
我们将用女子旱冰比赛的成绩来演示动态构建PDF文件的过程。这些分数是从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
列出1. XML 数据
... ... ...
XML 的根元素是事件标记。数据按事件分组,每个事件收录多个匹配项。在事件标签中,有一系列的事件标签,其中有多个游戏标签。这些比赛标签收录参加比赛的两支球队的名字以及他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。序列中的每个元素都是一个哈希表,其中收录一系列事件名称和比赛项目。该结构基本上是 XML 结构的内存版本。
为了测试这个脚本的效果,将构建一个HTML导出页面,使用getResults函数读取文件,然后以一系列HTML表格的形式输出数据。清单 3 显示了用于此测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p>
php 抓取网页生成图片( 具有一定的参考价值,感兴趣的小伙伴们可以get_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-18 14:10
具有一定的参考价值,感兴趣的小伙伴们可以get_)
php生成静态页面并实现预览功能
更新时间:2019-06-27 14:27:58 作者:铁柱
本文文章主要介绍php生成静态页面并详细实现预览功能。有一定的参考价值,感兴趣的朋友可以参考。
一、前言
本文文章主要是记录php生成静态页面的一般步骤。你一定听说过静态页面,但是当你真正使用它们时,它并不是很多。有些页面被认为访问量比较大,页面结构不经常变化,比如新闻公告等,可以认为是静态页面放在服务器上,这样首先是为了抵御大流量访问,而第二个更安全。有的,打开速度是有保证的。
二、文字
1、什么是静态
比如我们平时写项目的时候,大部分页面都会传入参数,这些参数会通过php标签显示出来。因为我们的参数可以随时变化,页面上的内容也会随着参数的变化而变化,这是一个动态页面。相反,static是纯html,页面上的内容不需要用php或java等编程语言改变。
关于静态化的优点,网上也说得很清楚。我不会在这里重复它们。总之,打开速度足够快,可以承受大流量。
2、静态写入
(1) 第一种写法是通过ob_start()缓存输出
在php文件中写入html代码,然后使用bo_get_content获取,然后输出到html文件中,类似:
<p> 查看全部
php 抓取网页生成图片(
具有一定的参考价值,感兴趣的小伙伴们可以get_)
php生成静态页面并实现预览功能
更新时间:2019-06-27 14:27:58 作者:铁柱
本文文章主要介绍php生成静态页面并详细实现预览功能。有一定的参考价值,感兴趣的朋友可以参考。
一、前言
本文文章主要是记录php生成静态页面的一般步骤。你一定听说过静态页面,但是当你真正使用它们时,它并不是很多。有些页面被认为访问量比较大,页面结构不经常变化,比如新闻公告等,可以认为是静态页面放在服务器上,这样首先是为了抵御大流量访问,而第二个更安全。有的,打开速度是有保证的。
二、文字
1、什么是静态
比如我们平时写项目的时候,大部分页面都会传入参数,这些参数会通过php标签显示出来。因为我们的参数可以随时变化,页面上的内容也会随着参数的变化而变化,这是一个动态页面。相反,static是纯html,页面上的内容不需要用php或java等编程语言改变。
关于静态化的优点,网上也说得很清楚。我不会在这里重复它们。总之,打开速度足够快,可以承受大流量。
2、静态写入
(1) 第一种写法是通过ob_start()缓存输出
在php文件中写入html代码,然后使用bo_get_content获取,然后输出到html文件中,类似:
<p>
php 抓取网页生成图片(为什么又要把动态网页以静态网页的形式发布呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-17 14:29
但是为什么要以静态网页的形式发布动态网页呢?一个很重要的原因是因为搜索引擎。由于aspx页面收录和html页面收录的速率不同,以及搜索引擎占用页面资源的问题,我们经常需要实现ASPX页面动态到静态。从当今互联网上最常见的查找信息的方式来看,互联网内容到达大众的方式大致有三种:第一种方式是通过知名门户网站网站,老读者有意识地到达这些地方搜索相应的、有针对性的性信息;第二种方式是做广告,通过公众利用一些免费的服务机会来夹带信息,把公众带向目标网站;第三种方式是搜索引擎,通过关键词等因素,向公众宣传相应的信息。其实,这也是最有效的拉新公众的方式;而对于大多数网站来说,除了少数门户网站网站之外,这种搜索引擎给大众带来的读者,占了90多个。
如此重要的公共频道自然不容忽视。因此,虽然搜索机器人有点烦人,但每个网站不会像以前一样封起来,而是会热情地从事SEO。所谓面向搜索引擎的优化包括访问者地址的重写。动态网页看起来像静态网页,这样越来越多的搜索引擎会收录,从而最大限度地提高其内容被目标接收的机会。然而,在完全采用动态技术开发的网站中,一眨眼的功夫,就被要求转成静态网页。同时,无论如何,必须保留动态网页的内容管理功能;这就像飞驰的奔驰的突然要求。180度转弯的成本非常高,
另一个重要原因是提高程序性能。很多大网站一进门就看着自己很复杂的页面,但是加载时间并不长。除了其他必要的原因,我认为静态化也是必须考虑的技术之一。她在用户之前获取资源或数据库数据,然后通过静态处理生成静态页面。每个人都访问这个静态页面。静态页面本身的访问速度比动态页面快很多倍,所以程序的性能会降低。有很大的改进。总之,页面静态体现在:访问速度加快,用户体验显着提升;在后台,体现在:访问与数据库分离,
虽然静态可以提高程序的性能,但并不是提高整体性能的根本原因。就像电脑一样,只有好的CPU或者好的显卡,好的内存是不行的。这取决于整体性能。在很多情况下,程序本身的性能不好是开发者的原因,所以最好以项目本身的性能为基础,辅以其他优化方法,最终提升整个程序的性能应用。
动态到静态
方法一:使用现成的插件,如ISAPI_Rewrite、IIS Rewrite、Apache HTTP服务器的mod_rewrite等,都是基于正则表达式解析器开发的重写引擎。有关如何使用它们,只需查看它们的内置帮助即可。
方法二:自己写代码实现静态动态网页,也有几种方法:
1、创建一个FSO对象,使用这个对象动态创建需要的内容到文件中生成HTML页面;
2、使用模板技术,将模板中特殊代码的值替换为从表单或数据库字段接收到的值,生成HTML文件;
3、使用Server.Transfer转换技术,
方法三:使用HttpWebRequest请求客户端获取返回的资源并生成静态页面。一般只需要获取网页内容即可,其他资源放在服务器上自动加载即可。(注:此方法缺点明显,需要对匹配的URL进行大量修改,建议谨慎使用)
方法四:asp中有一个IhttpModule接口。Ihttpmodule可以简单理解为.aspx或者mvc中一个可以在执行control/action之前添加我们自定义操作的东西。
我们只需要写一个这样的HttpModule。当用户第一次请求asp处理时,我们可以在ihttpmodule中拦截该请求,然后得到这个请求中应该返回的html代码,然后我们将这些html返回给用户,并保存我们得到的html刚刚进入文件。当用户下次请求时,我们只需要直接返回我们保存的html文件即可。 查看全部
php 抓取网页生成图片(为什么又要把动态网页以静态网页的形式发布呢)
但是为什么要以静态网页的形式发布动态网页呢?一个很重要的原因是因为搜索引擎。由于aspx页面收录和html页面收录的速率不同,以及搜索引擎占用页面资源的问题,我们经常需要实现ASPX页面动态到静态。从当今互联网上最常见的查找信息的方式来看,互联网内容到达大众的方式大致有三种:第一种方式是通过知名门户网站网站,老读者有意识地到达这些地方搜索相应的、有针对性的性信息;第二种方式是做广告,通过公众利用一些免费的服务机会来夹带信息,把公众带向目标网站;第三种方式是搜索引擎,通过关键词等因素,向公众宣传相应的信息。其实,这也是最有效的拉新公众的方式;而对于大多数网站来说,除了少数门户网站网站之外,这种搜索引擎给大众带来的读者,占了90多个。
如此重要的公共频道自然不容忽视。因此,虽然搜索机器人有点烦人,但每个网站不会像以前一样封起来,而是会热情地从事SEO。所谓面向搜索引擎的优化包括访问者地址的重写。动态网页看起来像静态网页,这样越来越多的搜索引擎会收录,从而最大限度地提高其内容被目标接收的机会。然而,在完全采用动态技术开发的网站中,一眨眼的功夫,就被要求转成静态网页。同时,无论如何,必须保留动态网页的内容管理功能;这就像飞驰的奔驰的突然要求。180度转弯的成本非常高,
另一个重要原因是提高程序性能。很多大网站一进门就看着自己很复杂的页面,但是加载时间并不长。除了其他必要的原因,我认为静态化也是必须考虑的技术之一。她在用户之前获取资源或数据库数据,然后通过静态处理生成静态页面。每个人都访问这个静态页面。静态页面本身的访问速度比动态页面快很多倍,所以程序的性能会降低。有很大的改进。总之,页面静态体现在:访问速度加快,用户体验显着提升;在后台,体现在:访问与数据库分离,
虽然静态可以提高程序的性能,但并不是提高整体性能的根本原因。就像电脑一样,只有好的CPU或者好的显卡,好的内存是不行的。这取决于整体性能。在很多情况下,程序本身的性能不好是开发者的原因,所以最好以项目本身的性能为基础,辅以其他优化方法,最终提升整个程序的性能应用。
动态到静态
方法一:使用现成的插件,如ISAPI_Rewrite、IIS Rewrite、Apache HTTP服务器的mod_rewrite等,都是基于正则表达式解析器开发的重写引擎。有关如何使用它们,只需查看它们的内置帮助即可。
方法二:自己写代码实现静态动态网页,也有几种方法:
1、创建一个FSO对象,使用这个对象动态创建需要的内容到文件中生成HTML页面;
2、使用模板技术,将模板中特殊代码的值替换为从表单或数据库字段接收到的值,生成HTML文件;
3、使用Server.Transfer转换技术,
方法三:使用HttpWebRequest请求客户端获取返回的资源并生成静态页面。一般只需要获取网页内容即可,其他资源放在服务器上自动加载即可。(注:此方法缺点明显,需要对匹配的URL进行大量修改,建议谨慎使用)
方法四:asp中有一个IhttpModule接口。Ihttpmodule可以简单理解为.aspx或者mvc中一个可以在执行control/action之前添加我们自定义操作的东西。
我们只需要写一个这样的HttpModule。当用户第一次请求asp处理时,我们可以在ihttpmodule中拦截该请求,然后得到这个请求中应该返回的html代码,然后我们将这些html返回给用户,并保存我们得到的html刚刚进入文件。当用户下次请求时,我们只需要直接返回我们保存的html文件即可。
php 抓取网页生成图片(PC端的网站放一个微信小程序的二维码,跳到房源详情页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-17 14:27
老板最近有点闲。他想在PC端放一个微信小程序的二维码网站,扫描这个二维码后,会跳转到小程序对应的listing详情页。
这是微信官方给出的文档,连接地址:/miniprogram/dev/framework/open-ability/qr-code.html
方法一:为小程序生成带参数的二维码
【方码】如图:官方文档说很简单,页面上没有demo。可能是给大佬的,对我这种一般程序员来说好像有点难度。
【系统环境】
小姐姐这边的系统环境是Linux系统,nginx服务器,thinkPHP5.6框架。
实现代码如下:
按照官方微信步骤;
第一步:首先获取调用API接口的accesstoken;
public function getAccessToken(){
$appid = '公司的小程序appid';
$secret = '公司的小程序sercret';
$url = "https://api.weixin.qq.com/cgi- ... t%3B.$appid."&secret=".$secret;
$res = json_decode($this->httpGet($url));
$access_token = @$res->access_token;
return $access_token;
}
第二步:请求微信接口获取二维码:
官方文档如图:
小姐姐代码:
public function getXcxCode(){
//获取access token
$ACCESS_TOKEN = $this->getAccessToken();
//创建二维码
$qcode ="https://api.weixin.qq.com/cgi- ... t%3B.$ACCESS_TOKEN;
$param = json_encode(array("path"=>"pages/detail/detail?id=5084","width"=> 150));
$result = $this->httpRequest( $qcode, $param,"POST");
$path = 'uploads/qrcode/h.jpg';
file_put_contents($path, $result);
$return['status_code'] = 2000;
$return['msg'] = 'ok';
$return['img'] = 'https://公司域名.com/' . $path;
echo ''.$return['img'].'';exit;
echo json_encode($return);exit;
$base64_image ="data:image/jpeg;base64,".base64_encode( $result );
return '';
}
别慌,百度查了资料。这是因为文件读写权限。我们文件夹的权限一般是755,然后把文件夹的权限改成777。
说老板有点飘飘然,但实在是拦不住。方形二维码难看,只好做一个圆形漂亮的小程序码。. . . . 由于列表数量较多,选择了 wxacode.getUnlimited 接口。
第一步是先获取访问令牌;
同上,我就不多说了;
官方微信文档:
虽然可以通过场景传递很多参数,但是在实际传递参数的过程中,页面出现了很多问题。他不能接受我之前传递的参数。虽然生成了二维码,但他也跳转到了详情页。它是一个空页面,没有传递相应的列表id。. .
请求参数场景也只简单说明
看得出小姐姐一头雾水,场景参数有很多问题。网上找了很久的技术帖子,或者找到了合适的demo。这就是为什么我必须下定决心写这篇博客。要知道更多人的原因。
小姐姐的密码在这里
public function xcxCode() {
$id = trim($this->request->param('id','5084','intval'));
$access_token = $this->getAccessToken();
$url = "https://api.weixin.qq.com/wxa/ ... ot%3B . $access_token;
$data['scene'] = 'h' . $id;
//小程序的详情页路径
$data['path'] = 'pages/detail/detail';
//二维码大小
$data['width'] = '430';
$res = $this->http($url, json_encode($data),1);
$path = 'uploads/qrcode/h' . $id . '.jpg';
file_put_contents($path, $res);
$return['status_code'] = 2000;
$return['msg'] = 'ok';
$return['img'] = 'https://公司域名.com/' . $path;
echo ''.$return['img'].'';exit;
echo json_encode($return);exit;
}
历经千辛万苦,小程序代码终于出现在了我的面前。
小程序生成带参数的二维码【小程序循环码】,保存为jpg图片上传到服务器
如果还是不明白,可以联系小姐姐技术问题或者索取源码。
不知道能不能给后面看到的程序员一些指导。可以考虑贡献一点余热。哈哈哈哈 查看全部
php 抓取网页生成图片(PC端的网站放一个微信小程序的二维码,跳到房源详情页)
老板最近有点闲。他想在PC端放一个微信小程序的二维码网站,扫描这个二维码后,会跳转到小程序对应的listing详情页。
这是微信官方给出的文档,连接地址:/miniprogram/dev/framework/open-ability/qr-code.html
方法一:为小程序生成带参数的二维码
【方码】如图:官方文档说很简单,页面上没有demo。可能是给大佬的,对我这种一般程序员来说好像有点难度。
【系统环境】
小姐姐这边的系统环境是Linux系统,nginx服务器,thinkPHP5.6框架。
实现代码如下:
按照官方微信步骤;
第一步:首先获取调用API接口的accesstoken;
public function getAccessToken(){
$appid = '公司的小程序appid';
$secret = '公司的小程序sercret';
$url = "https://api.weixin.qq.com/cgi- ... t%3B.$appid."&secret=".$secret;
$res = json_decode($this->httpGet($url));
$access_token = @$res->access_token;
return $access_token;
}
第二步:请求微信接口获取二维码:
官方文档如图:
小姐姐代码:
public function getXcxCode(){
//获取access token
$ACCESS_TOKEN = $this->getAccessToken();
//创建二维码
$qcode ="https://api.weixin.qq.com/cgi- ... t%3B.$ACCESS_TOKEN;
$param = json_encode(array("path"=>"pages/detail/detail?id=5084","width"=> 150));
$result = $this->httpRequest( $qcode, $param,"POST");
$path = 'uploads/qrcode/h.jpg';
file_put_contents($path, $result);
$return['status_code'] = 2000;
$return['msg'] = 'ok';
$return['img'] = 'https://公司域名.com/' . $path;
echo ''.$return['img'].'';exit;
echo json_encode($return);exit;
$base64_image ="data:image/jpeg;base64,".base64_encode( $result );
return '';
}
别慌,百度查了资料。这是因为文件读写权限。我们文件夹的权限一般是755,然后把文件夹的权限改成777。
说老板有点飘飘然,但实在是拦不住。方形二维码难看,只好做一个圆形漂亮的小程序码。. . . . 由于列表数量较多,选择了 wxacode.getUnlimited 接口。
第一步是先获取访问令牌;
同上,我就不多说了;
官方微信文档:
虽然可以通过场景传递很多参数,但是在实际传递参数的过程中,页面出现了很多问题。他不能接受我之前传递的参数。虽然生成了二维码,但他也跳转到了详情页。它是一个空页面,没有传递相应的列表id。. .
请求参数场景也只简单说明
看得出小姐姐一头雾水,场景参数有很多问题。网上找了很久的技术帖子,或者找到了合适的demo。这就是为什么我必须下定决心写这篇博客。要知道更多人的原因。
小姐姐的密码在这里
public function xcxCode() {
$id = trim($this->request->param('id','5084','intval'));
$access_token = $this->getAccessToken();
$url = "https://api.weixin.qq.com/wxa/ ... ot%3B . $access_token;
$data['scene'] = 'h' . $id;
//小程序的详情页路径
$data['path'] = 'pages/detail/detail';
//二维码大小
$data['width'] = '430';
$res = $this->http($url, json_encode($data),1);
$path = 'uploads/qrcode/h' . $id . '.jpg';
file_put_contents($path, $res);
$return['status_code'] = 2000;
$return['msg'] = 'ok';
$return['img'] = 'https://公司域名.com/' . $path;
echo ''.$return['img'].'';exit;
echo json_encode($return);exit;
}
历经千辛万苦,小程序代码终于出现在了我的面前。
小程序生成带参数的二维码【小程序循环码】,保存为jpg图片上传到服务器
如果还是不明白,可以联系小姐姐技术问题或者索取源码。
不知道能不能给后面看到的程序员一些指导。可以考虑贡献一点余热。哈哈哈哈
php 抓取网页生成图片(用php执行系统命令的时候发现无法执行,但是可以执行CutyCapt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-16 19:14
在对网站进行截图时,我们使用了服务器端的工具CutyCapt。可以直接使用服务器上的命令抓取并生成指定url的图片。但是在使用php执行系统命令时,发现无法执行,而是CutyCapt等帮助信息的命令("/usr/local/cutycapt/CutyCapt/xvfb-run.sh --help")可以执行,但是执行调用系统变量脚本不能成功。怀疑是权限问题。后来我把CutyCapt权限设置为www,发现不行。后来查资料,发现是因为nginx服务器在执行命令的时候调用了shell脚本。这时候遇到了权限问题。
CutyCapt
截图中使用的系统命令:
/usr/bin/sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert.jpg
1、设置sudo配置文件写入权限
chmod u+w /etc/sudoers
2、增加www用户执行CutyCapt脚本的权限(需要运行的脚本和命令需要添加权限):
www ALL=(root) NOPASSWD: /bin/sh,/usr/local/cutycapt/CutyCapt/xvfb-run.sh, /usr/local/cutycapt/CutyCapt/CutyCapt
3、关闭【强制控制台登录】执行或允许www用户无需控制台登录
修改内容:
注释掉:默认要求
更好的修改方法(更安全):
仅添加:默认:www !requiretty(www用户不使用控制台登录)
4 用php执行
system('/usr/bin/sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert2.jpg',$m);
注意(更安全的方法):
system('sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert2.jpg' ,$m);
Nginx 重启:
同时增加www用户执行nginx脚本的权限 查看全部
php 抓取网页生成图片(用php执行系统命令的时候发现无法执行,但是可以执行CutyCapt)
在对网站进行截图时,我们使用了服务器端的工具CutyCapt。可以直接使用服务器上的命令抓取并生成指定url的图片。但是在使用php执行系统命令时,发现无法执行,而是CutyCapt等帮助信息的命令("/usr/local/cutycapt/CutyCapt/xvfb-run.sh --help")可以执行,但是执行调用系统变量脚本不能成功。怀疑是权限问题。后来我把CutyCapt权限设置为www,发现不行。后来查资料,发现是因为nginx服务器在执行命令的时候调用了shell脚本。这时候遇到了权限问题。
CutyCapt
截图中使用的系统命令:
/usr/bin/sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert.jpg
1、设置sudo配置文件写入权限
chmod u+w /etc/sudoers
2、增加www用户执行CutyCapt脚本的权限(需要运行的脚本和命令需要添加权限):
www ALL=(root) NOPASSWD: /bin/sh,/usr/local/cutycapt/CutyCapt/xvfb-run.sh, /usr/local/cutycapt/CutyCapt/CutyCapt
3、关闭【强制控制台登录】执行或允许www用户无需控制台登录
修改内容:
注释掉:默认要求
更好的修改方法(更安全):
仅添加:默认:www !requiretty(www用户不使用控制台登录)
4 用php执行
system('/usr/bin/sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert2.jpg',$m);
注意(更安全的方法):
system('sudo /usr/local/cutycapt/CutyCapt/xvfb-run.sh /usr/local/cutycapt/CutyCapt/CutyCapt --url= --out=/tmp/insert2.jpg' ,$m);
Nginx 重启:
同时增加www用户执行nginx脚本的权限

