
php 抓取网页生成图片
php 抓取网页生成图片(php实现网站图片尺寸重写时,默认情况下浏览器不会将重写的图片数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-02 08:22
)
当我们使用php实现网站图片大小重写时,浏览器默认不会在本地缓存重写后的图片。现在我将告诉你如何让浏览器缓存这样的图像数据。
// 将以下代码添加到 php 脚本文件中
session_start();
header("Cache-Control: private, max-age=10800, pre-check=10800");
header("Pragma: private");
header("Expires: " . date(DATE_RFC822,strtotime(" 2 day")));
1:如果浏览器已经有缓存版本,它会向后端传递一个$_SERVER['HTTP_IF_MODIFIED_SINCE']。简单来说,我们只需要告诉浏览器使用缓存即可。
if(isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])){
// if the browser has a cached version of this image, send 304
header('Last-Modified: '.$_SERVER['HTTP_IF_MODIFIED_SINCE'],true,304);
exit;
}
2:如果浏览器有缓存版本,更明智的做法是后端判断图片是否已经更新,并据此通知浏览器是否使用缓存版本
$img = "some_image.png";
if (isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])
&&
(strtotime($_SERVER['HTTP_IF_MODIFIED_SINCE']) == filemtime($img))) {
// send the last mod time of the file back
header('Last-Modified: '.gmdate('D, d M Y H:i:s', filemtime($img)).' GMT',
true, 304);
exit;
}
完整代码
session_start();
header("Cache-Control: private, max-age=10800, pre-check=10800");
header("Pragma: private");
header("Expires: " . date(DATE_RFC822,strtotime(" 2 day")));
$img = "some_image.png";
if (isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])
&&
(strtotime($_SERVER['HTTP_IF_MODIFIED_SINCE']) == filemtime($img))) {
// send the last mod time of the file back
header('Last-Modified: '.gmdate('D, d M Y H:i:s', filemtime($img)).' GMT',
true, 304);
exit;
}
// 裁剪图片并告诉浏览器缓存图片
$is = new ImageSizer($img);
$is->resizeImage(75); // resize image to 75px wide
// and here we send the image to the browser with all the stuff required for tell it to cache
header("Content-type: image/jpeg");
header('Last-Modified: ' . gmdate('D, d M Y H:i:s', filemtime($thumbnail)) . ' GMT');
$is->showImage();
图像裁剪类
class ImageSizer {
var $_baseDir;
var $_baseImg;
var $_imgData;
var $_newImg;
var $_newData;
var $_newFormat;
var $_loadPath;
var $_defaultColor = array(255,255,255);
var $keepAspectRatio;
var $makeBigger;
function ImageSizer($baseDir) {
$this->changeBaseDir($baseDir);
$this->keepAspectRatio = true;
$this->makeBigger = false;
}
function changeBaseDir($baseDir) {
$this->_baseDir = $baseDir;
}
function setDefaultColor($r, $g, $b) {
$this->_defaultColor = array($r, $g, $b);
}
function changeFormat($str) {
$str = strtolower($str);
if ($str == 'jpg') $str = "jpeg";
$acceptable_formats = array('jpeg', 'gif', 'png');
if (!in_array($str, $acceptable_formats)) return false;
$this->_newFormat = $str;
}
function loadImage($imgPath) {
// $this->_imgData = getimagesize($this->_baseDir. $imgPath);
$this->_imgData = getimagesize( $imgPath);
$this->_imgData['funcType'] = preg_replace('#image/#i', '', $this->_imgData['mime']);
$acceptable_formats = array('jpeg', 'gif', 'png');
if (!in_array($this->_imgData['funcType'], $acceptable_formats)) return false;
$this->_newData = $this->_imgData;
$funcName = 'imagecreatefrom' . $this->_imgData['funcType'];
//$this->_newImg = $this->_baseImg = $funcName($this->_baseDir. $imgPath);
$this->_newImg = $this->_baseImg = @$funcName( $imgPath);
if(!$this->_baseImg){
echo "
Failed on this image $imgPath
";
return false;
}
$this->_loadPath = $imgPath;
return true;
}
/*function genImageData(){
$funcName = 'image'.$this->getNewType();
$data = $funcName($this->_newImg ? $this->_newImg : $this->_baseImg);
return $data;
}*/
function resizeImage($w, $h, $crop=false) {
$current_w = $this->getWidth();
$current_h = $this->getHeight();
$src_x = $src_y = 0;
$dst_x = $dst_y = 0;
if($w && $h && $crop=="f"){
// fill in the image centre it in white.
// all the src stuff stays the same, just changing the destination suff
$src_x = 0;
$src_y = 0;
$current_h = $current_h;
$current_w = $current_w;
// the destination stuff changes
if($h && $w){
$h_percent = $percent = $h / $current_h;
$w_percent = $percent = $w / $current_w;
$percent = min($h_percent, $w_percent);
}else if($h){
$h_percent = $percent = $h / $current_h;
$percent = $h_percent;
}else if($w){
$w_percent = $percent = $w / $current_w;
$percent = $w_percent;
}
$dst_w = $current_w * $percent;
$dst_h = $current_h * $percent;
$new_w = $w;
$new_h = $h;
// work out destination x and y points
$dst_x = ($new_w - $dst_w)/2;
$dst_y = ($new_h - $dst_h)/2;
}else if($w && $h && $crop=="c"){
$dst_w = $w;
$dst_h = $h;
$new_w = $w;
$new_h = $h;
// if the image we are tyring to crop is smaller than the crop request we dont do aynthing
if($w > $current_w || $h > $current_h){
// the image is smaller than we are trying to crop!
}else{
//the image is bigger on x and y axis.
// check if we can fit horizontally
$w_percent = $current_w/$w;
$h_percent = $current_h/$h;
if($w_percent < $h_percent){
$src_x = 0;
$src_y = ($current_h/2) - (($h * $w_percent)/2);
$current_w = $current_w;
$current_h = ($h * $w_percent);
}else{
$src_x = ($current_w/2) - (($w * $h_percent)/2);
$src_y = 0;
$current_w = ($w * $h_percent);
$current_h = $current_h;
}
}
}else if ($this->keepAspectRatio) {
$percent = 1;
// if ($current_w > $w || $current_h > $h || $this->makeBigger) {
$do_resize=false;
if($w && $current_w > $w){
$do_resize=true;
}else if($h && $current_h > $h){
$do_resize=true;
}else if($w && $current_w < $w && $this->makeBigger){
$do_resize=true;
}else{
// imaeg is alreaedy smaller than requested size
}
if ( $do_resize ) {
if($h && $w){
$h_percent = $percent = $h / $current_h;
$w_percent = $percent = $w / $current_w;
$percent = min($h_percent, $w_percent);
}else if($h){
$h_percent = $percent = $h / $current_h;
$percent = $h_percent;
}else if($w){
$w_percent = $percent = $w / $current_w;
$percent = $w_percent;
}
}
$dst_w = $new_w = $current_w * $percent;
$dst_h = $new_h = $current_h * $percent;
} else{
$dst_w = $new_w = $w;
$dst_h = $new_h = $h;
}
$this->_newImg = ImageCreateTrueColor($new_w, $new_h);
$this->_newData = array($new_w, $new_h);
if ($this->getNewType() == 'png' || $this->getNewType() == 'gif') { // This preserves the transparency
imageAlphaBlending($this->_newImg, false);
imageSaveAlpha($this->_newImg, true);
} else { // This is if converting from PNG to another image format
list($r, $g, $b) = $this->_defaultColor;
$color = imagecolorallocate($this->_newImg, $r, $g, $b);
imagefilledrectangle($this->_newImg, 0,0, $new_w, $new_h, $color);
}
// dst_w dst_h src_w src_h
imagecopyresampled($this->_newImg, $this->_baseImg, $dst_x, $dst_y,$src_x,$src_y, $dst_w, $dst_h, $current_w, $current_h);
return true;
}
function showImage() {
header('Content-type: ' . $this->getNewMime());
$funcName = 'image'.$this->getNewType();
$funcName($this->_newImg ? $this->_newImg : $this->_baseImg);
}
function saveToFile($fileloc) {
$funcName = 'image'.$this->getNewType();
$funcName($this->_newImg ? $this->_newImg : $this->_baseImg, $fileloc,100);
}
function addWatermark($pngloc,$offset_x=0) {
$overlay = imagecreatefrompng($pngloc);
imageAlphaBlending($overlay, false);
imageSaveAlpha($overlay, true);
imagecopy($this->_newImg, $overlay, (imagesx($this->_newImg))-(imagesx($overlay)+$offset_x), (imagesy($this->_newImg))-(imagesy($overlay)), 0, 0, imagesx($overlay), imagesy($overlay));
}
function getBaseDir() { return $this->_baseDir; }
function getWidth() { return $this->_imgData[0]; }
function getHeight() { return $this->_imgData[1]; }
function getMime() { return $this->_imgData['mime']; }
function getType() { return $this->_imgData['funcType'];}
function getNewWidth() { return $this->_newData[0]; }
function getNewHeight() { return $this->_newData[1]; }
function getNewMime() {return $this->_newFormat ? 'image/' . $this->_newFormat : $this->_imgData['mime'];}
function getNewType() {return $this->_newFormat ? $this->_newFormat : $this->_imgData['funcType'];}
} 查看全部
php 抓取网页生成图片(php实现网站图片尺寸重写时,默认情况下浏览器不会将重写的图片数据
)
当我们使用php实现网站图片大小重写时,浏览器默认不会在本地缓存重写后的图片。现在我将告诉你如何让浏览器缓存这样的图像数据。
// 将以下代码添加到 php 脚本文件中
session_start();
header("Cache-Control: private, max-age=10800, pre-check=10800");
header("Pragma: private");
header("Expires: " . date(DATE_RFC822,strtotime(" 2 day")));
1:如果浏览器已经有缓存版本,它会向后端传递一个$_SERVER['HTTP_IF_MODIFIED_SINCE']。简单来说,我们只需要告诉浏览器使用缓存即可。
if(isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])){
// if the browser has a cached version of this image, send 304
header('Last-Modified: '.$_SERVER['HTTP_IF_MODIFIED_SINCE'],true,304);
exit;
}
2:如果浏览器有缓存版本,更明智的做法是后端判断图片是否已经更新,并据此通知浏览器是否使用缓存版本
$img = "some_image.png";
if (isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])
&&
(strtotime($_SERVER['HTTP_IF_MODIFIED_SINCE']) == filemtime($img))) {
// send the last mod time of the file back
header('Last-Modified: '.gmdate('D, d M Y H:i:s', filemtime($img)).' GMT',
true, 304);
exit;
}
完整代码
session_start();
header("Cache-Control: private, max-age=10800, pre-check=10800");
header("Pragma: private");
header("Expires: " . date(DATE_RFC822,strtotime(" 2 day")));
$img = "some_image.png";
if (isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])
&&
(strtotime($_SERVER['HTTP_IF_MODIFIED_SINCE']) == filemtime($img))) {
// send the last mod time of the file back
header('Last-Modified: '.gmdate('D, d M Y H:i:s', filemtime($img)).' GMT',
true, 304);
exit;
}
// 裁剪图片并告诉浏览器缓存图片
$is = new ImageSizer($img);
$is->resizeImage(75); // resize image to 75px wide
// and here we send the image to the browser with all the stuff required for tell it to cache
header("Content-type: image/jpeg");
header('Last-Modified: ' . gmdate('D, d M Y H:i:s', filemtime($thumbnail)) . ' GMT');
$is->showImage();
图像裁剪类
class ImageSizer {
var $_baseDir;
var $_baseImg;
var $_imgData;
var $_newImg;
var $_newData;
var $_newFormat;
var $_loadPath;
var $_defaultColor = array(255,255,255);
var $keepAspectRatio;
var $makeBigger;
function ImageSizer($baseDir) {
$this->changeBaseDir($baseDir);
$this->keepAspectRatio = true;
$this->makeBigger = false;
}
function changeBaseDir($baseDir) {
$this->_baseDir = $baseDir;
}
function setDefaultColor($r, $g, $b) {
$this->_defaultColor = array($r, $g, $b);
}
function changeFormat($str) {
$str = strtolower($str);
if ($str == 'jpg') $str = "jpeg";
$acceptable_formats = array('jpeg', 'gif', 'png');
if (!in_array($str, $acceptable_formats)) return false;
$this->_newFormat = $str;
}
function loadImage($imgPath) {
// $this->_imgData = getimagesize($this->_baseDir. $imgPath);
$this->_imgData = getimagesize( $imgPath);
$this->_imgData['funcType'] = preg_replace('#image/#i', '', $this->_imgData['mime']);
$acceptable_formats = array('jpeg', 'gif', 'png');
if (!in_array($this->_imgData['funcType'], $acceptable_formats)) return false;
$this->_newData = $this->_imgData;
$funcName = 'imagecreatefrom' . $this->_imgData['funcType'];
//$this->_newImg = $this->_baseImg = $funcName($this->_baseDir. $imgPath);
$this->_newImg = $this->_baseImg = @$funcName( $imgPath);
if(!$this->_baseImg){
echo "
Failed on this image $imgPath
";
return false;
}
$this->_loadPath = $imgPath;
return true;
}
/*function genImageData(){
$funcName = 'image'.$this->getNewType();
$data = $funcName($this->_newImg ? $this->_newImg : $this->_baseImg);
return $data;
}*/
function resizeImage($w, $h, $crop=false) {
$current_w = $this->getWidth();
$current_h = $this->getHeight();
$src_x = $src_y = 0;
$dst_x = $dst_y = 0;
if($w && $h && $crop=="f"){
// fill in the image centre it in white.
// all the src stuff stays the same, just changing the destination suff
$src_x = 0;
$src_y = 0;
$current_h = $current_h;
$current_w = $current_w;
// the destination stuff changes
if($h && $w){
$h_percent = $percent = $h / $current_h;
$w_percent = $percent = $w / $current_w;
$percent = min($h_percent, $w_percent);
}else if($h){
$h_percent = $percent = $h / $current_h;
$percent = $h_percent;
}else if($w){
$w_percent = $percent = $w / $current_w;
$percent = $w_percent;
}
$dst_w = $current_w * $percent;
$dst_h = $current_h * $percent;
$new_w = $w;
$new_h = $h;
// work out destination x and y points
$dst_x = ($new_w - $dst_w)/2;
$dst_y = ($new_h - $dst_h)/2;
}else if($w && $h && $crop=="c"){
$dst_w = $w;
$dst_h = $h;
$new_w = $w;
$new_h = $h;
// if the image we are tyring to crop is smaller than the crop request we dont do aynthing
if($w > $current_w || $h > $current_h){
// the image is smaller than we are trying to crop!
}else{
//the image is bigger on x and y axis.
// check if we can fit horizontally
$w_percent = $current_w/$w;
$h_percent = $current_h/$h;
if($w_percent < $h_percent){
$src_x = 0;
$src_y = ($current_h/2) - (($h * $w_percent)/2);
$current_w = $current_w;
$current_h = ($h * $w_percent);
}else{
$src_x = ($current_w/2) - (($w * $h_percent)/2);
$src_y = 0;
$current_w = ($w * $h_percent);
$current_h = $current_h;
}
}
}else if ($this->keepAspectRatio) {
$percent = 1;
// if ($current_w > $w || $current_h > $h || $this->makeBigger) {
$do_resize=false;
if($w && $current_w > $w){
$do_resize=true;
}else if($h && $current_h > $h){
$do_resize=true;
}else if($w && $current_w < $w && $this->makeBigger){
$do_resize=true;
}else{
// imaeg is alreaedy smaller than requested size
}
if ( $do_resize ) {
if($h && $w){
$h_percent = $percent = $h / $current_h;
$w_percent = $percent = $w / $current_w;
$percent = min($h_percent, $w_percent);
}else if($h){
$h_percent = $percent = $h / $current_h;
$percent = $h_percent;
}else if($w){
$w_percent = $percent = $w / $current_w;
$percent = $w_percent;
}
}
$dst_w = $new_w = $current_w * $percent;
$dst_h = $new_h = $current_h * $percent;
} else{
$dst_w = $new_w = $w;
$dst_h = $new_h = $h;
}
$this->_newImg = ImageCreateTrueColor($new_w, $new_h);
$this->_newData = array($new_w, $new_h);
if ($this->getNewType() == 'png' || $this->getNewType() == 'gif') { // This preserves the transparency
imageAlphaBlending($this->_newImg, false);
imageSaveAlpha($this->_newImg, true);
} else { // This is if converting from PNG to another image format
list($r, $g, $b) = $this->_defaultColor;
$color = imagecolorallocate($this->_newImg, $r, $g, $b);
imagefilledrectangle($this->_newImg, 0,0, $new_w, $new_h, $color);
}
// dst_w dst_h src_w src_h
imagecopyresampled($this->_newImg, $this->_baseImg, $dst_x, $dst_y,$src_x,$src_y, $dst_w, $dst_h, $current_w, $current_h);
return true;
}
function showImage() {
header('Content-type: ' . $this->getNewMime());
$funcName = 'image'.$this->getNewType();
$funcName($this->_newImg ? $this->_newImg : $this->_baseImg);
}
function saveToFile($fileloc) {
$funcName = 'image'.$this->getNewType();
$funcName($this->_newImg ? $this->_newImg : $this->_baseImg, $fileloc,100);
}
function addWatermark($pngloc,$offset_x=0) {
$overlay = imagecreatefrompng($pngloc);
imageAlphaBlending($overlay, false);
imageSaveAlpha($overlay, true);
imagecopy($this->_newImg, $overlay, (imagesx($this->_newImg))-(imagesx($overlay)+$offset_x), (imagesy($this->_newImg))-(imagesy($overlay)), 0, 0, imagesx($overlay), imagesy($overlay));
}
function getBaseDir() { return $this->_baseDir; }
function getWidth() { return $this->_imgData[0]; }
function getHeight() { return $this->_imgData[1]; }
function getMime() { return $this->_imgData['mime']; }
function getType() { return $this->_imgData['funcType'];}
function getNewWidth() { return $this->_newData[0]; }
function getNewHeight() { return $this->_newData[1]; }
function getNewMime() {return $this->_newFormat ? 'image/' . $this->_newFormat : $this->_imgData['mime'];}
function getNewType() {return $this->_newFormat ? $this->_newFormat : $this->_imgData['funcType'];}
}
php 抓取网页生成图片(php抓取网页生成图片这个挺适合做字幕外挂+模糊特效之类的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-01 02:01
php抓取网页生成图片这个挺适合做字幕外挂+模糊特效之类的如果要抓取知乎文章,php文章封面之类的,php封装好抓取脚本,就能每天网页全是爬虫脚本,但这个版本的php语言有点老了,有点不适合抓取php网页,但可以爬其他php的网页。php实现redis的定向消息通信google和百度的通信是异步的,不太容易,im应用流行使用同步php处理然后js接受请求然后通过ajax进行处理,php负责保证通信质量如果仅仅是增加小功能需要构建新的框架,不过真做好了还是只能自己一点点实现一个框架吧,不会c语言用个php现成的应该就能满足。
而且做应用框架用的肯定是php语言的标准库和封装好的一些经典库,这些库能直接使用。实现功能用另一个语言可能会产生性能的问题,自己了解这个可能要花些功夫了。
可以尝试学习多进程+http的方式来进行开发。
php处理接口要接受多个字段来判断这个是否为true。(这句话换成java/c#是不是也通用?)发送字段a(年龄)给接收字段b(用户名)来判断这个是否为true,或者e.g.m_id===b.a.age.判断最终结果为true的则返回true,
谢邀,不过我不是计算机专业的,更别说是不是it专业的了。所以更新了一下答案。 查看全部
php 抓取网页生成图片(php抓取网页生成图片这个挺适合做字幕外挂+模糊特效之类的)
php抓取网页生成图片这个挺适合做字幕外挂+模糊特效之类的如果要抓取知乎文章,php文章封面之类的,php封装好抓取脚本,就能每天网页全是爬虫脚本,但这个版本的php语言有点老了,有点不适合抓取php网页,但可以爬其他php的网页。php实现redis的定向消息通信google和百度的通信是异步的,不太容易,im应用流行使用同步php处理然后js接受请求然后通过ajax进行处理,php负责保证通信质量如果仅仅是增加小功能需要构建新的框架,不过真做好了还是只能自己一点点实现一个框架吧,不会c语言用个php现成的应该就能满足。
而且做应用框架用的肯定是php语言的标准库和封装好的一些经典库,这些库能直接使用。实现功能用另一个语言可能会产生性能的问题,自己了解这个可能要花些功夫了。
可以尝试学习多进程+http的方式来进行开发。
php处理接口要接受多个字段来判断这个是否为true。(这句话换成java/c#是不是也通用?)发送字段a(年龄)给接收字段b(用户名)来判断这个是否为true,或者e.g.m_id===b.a.age.判断最终结果为true的则返回true,
谢邀,不过我不是计算机专业的,更别说是不是it专业的了。所以更新了一下答案。
php 抓取网页生成图片( tag页面是什么?如何提高页面加载速度之图片优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-31 03:14
tag页面是什么?如何提高页面加载速度之图片优化)
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
图片优化提高页面加载速度
由于大家追求个性,很多博主喜欢用图片来美化自己的页面,但是你知道如果不好好优化图片,页面打开速度会慢很多吗?今天我们来谈谈如何优化图像。
搜索引擎蜘蛛抓取页面的流程示意图
学seo的人经常在网上看到一句话:搜索引擎蜘蛛类似于浏览器,都是爬网页。那么哪些是相同的,哪些是不同的呢?我将帮助您了解搜索引擎蜘蛛如何通过浏览器抓取页面。
当 PHP 删除 文章 时,它也会删除生成的 HTML 页面
添加文章时会生成一个静态html页面,但是如果要删除文章,添加文章时生成的html静态页面也要同时删除,否则会变成多余的文件,所以我们在删除无用的文章的时候,要同时删除生成的HTML静态页面。让我们看看如何同时删除PHP文章系统中生成的HTML静态页面。这里只是一个简单的原理系统,可以作为参考。比较成熟的系统可以参考比较成熟的cms系统。以下是源代码文件。
IE无法加载页面Java怎么办
页面Java无法在IE中加载的解决方法:先打开Java的编写;然后单击安全选项卡中的[编辑站点列表...],然后单击添加;最后,在新的输入框中添加需要使用Java的新输入框。网址就可以了。IE中的页面Java
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
如何在页面上显示java错误消息
页面显示java错误信息的方法:先自定义异常类;然后在服务层抛出异常类,控制器类继承主异常类;然后定义主异常类,可以编写多个自定义异常类;终于完成了信息类
百度的索引量是百度SEO蜘蛛抓取的页面数网站
百度的索引量是百度SEO蜘蛛抓取的页面数网站;而site命令查询到的页面只是被释放的页面,也就是所谓的百度展示页面已经收录。总体而言,百度索引量和站点查询收入
五个细节要做好网站图片页面SEO优化
目前大家都在讨论如何优化文章页面,带有文字内容的页面很容易被搜索引擎识别。但是现在很多专注于图片内容的网站,比如摄影网站、照片分享网站等,都无法原封不动地照搬这些理论。毕竟,能写的字不多。不错的 网站 是从基本页面优化而来的。今天,我将分享一些我在图片页面的SEO优化方面的一些经验。
谷歌通过提交表单来抓取新页面
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细的,但是看到写了幻灭,直接引用了主要内容
使用java的html解析器jsoup和jQuery实现对任意网站页面指定元素的自动重复抓取...
日期:2012-7-20 来源:在线Demo 本地下载 如果你曾经开发过内容聚合类网站,那么使用程序动态整合不同页面或网站的内容的功能一定非常棒对你熟悉的有用。通常使用java,我们会用到一些HTML解析,比如httpparser,最早的集成搜索就是用httpparser抓取谷歌和百度的搜索结果,集成呈现给搜索用户。
使用 Google WebP 图像格式来帮助控制 网站 页面大小
导致网页膨胀的罪魁祸首不是大量使用的 JavaScript 库、CSS 和无休止的分享按钮,而是漂亮的图片。根据 HTTPArchive 的研究,图像约占页面内容的 60%。这意味着大多数 网站 可以压缩图像以减小页面本身的大小。如果你有兴趣了解HTTPArchive的研究以及如何优化网页加载速度,推荐阅读文章-分享过去gbin1发布的一些优化网页加载速度的技巧?
SEO 页面 收录分析和爬虫
蜘蛛爬取分析是分析蜘蛛网站所抓取的页面的行为,目的是分析蜘蛛所抓取的页面占实际页面数的百分比,并检测网站内部的连通性链接并深入了解蜘蛛爬行规则。蜘蛛爬取一般根据URL级别进行分析
大型网站SEO页面生成机制及数据分析
页面自动生成机制是指从指南-在线-调优的全过程,由机器自动生成,人工辅助调整参数。适用于数据量大的站点。而且很久以前就有人用过,这是一个古老的套路。当然,小站点和新站点也不是不可能,只是需要花很短的时间。
大型网站SEO页面生成机制及数据分析
页面自动生成机制是指从指南-在线-调优的全过程,由机器自动生成,人工辅助调整参数。适用于数据量大的站点。而且很久以前就有人用过,这是一个古老的套路。当然,小站点和新站点也不是不可能,只是需要花很短的时间。 查看全部
php 抓取网页生成图片(
tag页面是什么?如何提高页面加载速度之图片优化)

什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
图片优化提高页面加载速度
由于大家追求个性,很多博主喜欢用图片来美化自己的页面,但是你知道如果不好好优化图片,页面打开速度会慢很多吗?今天我们来谈谈如何优化图像。
搜索引擎蜘蛛抓取页面的流程示意图
学seo的人经常在网上看到一句话:搜索引擎蜘蛛类似于浏览器,都是爬网页。那么哪些是相同的,哪些是不同的呢?我将帮助您了解搜索引擎蜘蛛如何通过浏览器抓取页面。
当 PHP 删除 文章 时,它也会删除生成的 HTML 页面
添加文章时会生成一个静态html页面,但是如果要删除文章,添加文章时生成的html静态页面也要同时删除,否则会变成多余的文件,所以我们在删除无用的文章的时候,要同时删除生成的HTML静态页面。让我们看看如何同时删除PHP文章系统中生成的HTML静态页面。这里只是一个简单的原理系统,可以作为参考。比较成熟的系统可以参考比较成熟的cms系统。以下是源代码文件。
IE无法加载页面Java怎么办
页面Java无法在IE中加载的解决方法:先打开Java的编写;然后单击安全选项卡中的[编辑站点列表...],然后单击添加;最后,在新的输入框中添加需要使用Java的新输入框。网址就可以了。IE中的页面Java
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
如何在页面上显示java错误消息
页面显示java错误信息的方法:先自定义异常类;然后在服务层抛出异常类,控制器类继承主异常类;然后定义主异常类,可以编写多个自定义异常类;终于完成了信息类
百度的索引量是百度SEO蜘蛛抓取的页面数网站
百度的索引量是百度SEO蜘蛛抓取的页面数网站;而site命令查询到的页面只是被释放的页面,也就是所谓的百度展示页面已经收录。总体而言,百度索引量和站点查询收入
五个细节要做好网站图片页面SEO优化
目前大家都在讨论如何优化文章页面,带有文字内容的页面很容易被搜索引擎识别。但是现在很多专注于图片内容的网站,比如摄影网站、照片分享网站等,都无法原封不动地照搬这些理论。毕竟,能写的字不多。不错的 网站 是从基本页面优化而来的。今天,我将分享一些我在图片页面的SEO优化方面的一些经验。
谷歌通过提交表单来抓取新页面
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细的,但是看到写了幻灭,直接引用了主要内容
使用java的html解析器jsoup和jQuery实现对任意网站页面指定元素的自动重复抓取...
日期:2012-7-20 来源:在线Demo 本地下载 如果你曾经开发过内容聚合类网站,那么使用程序动态整合不同页面或网站的内容的功能一定非常棒对你熟悉的有用。通常使用java,我们会用到一些HTML解析,比如httpparser,最早的集成搜索就是用httpparser抓取谷歌和百度的搜索结果,集成呈现给搜索用户。
使用 Google WebP 图像格式来帮助控制 网站 页面大小
导致网页膨胀的罪魁祸首不是大量使用的 JavaScript 库、CSS 和无休止的分享按钮,而是漂亮的图片。根据 HTTPArchive 的研究,图像约占页面内容的 60%。这意味着大多数 网站 可以压缩图像以减小页面本身的大小。如果你有兴趣了解HTTPArchive的研究以及如何优化网页加载速度,推荐阅读文章-分享过去gbin1发布的一些优化网页加载速度的技巧?
SEO 页面 收录分析和爬虫
蜘蛛爬取分析是分析蜘蛛网站所抓取的页面的行为,目的是分析蜘蛛所抓取的页面占实际页面数的百分比,并检测网站内部的连通性链接并深入了解蜘蛛爬行规则。蜘蛛爬取一般根据URL级别进行分析
大型网站SEO页面生成机制及数据分析
页面自动生成机制是指从指南-在线-调优的全过程,由机器自动生成,人工辅助调整参数。适用于数据量大的站点。而且很久以前就有人用过,这是一个古老的套路。当然,小站点和新站点也不是不可能,只是需要花很短的时间。
大型网站SEO页面生成机制及数据分析
页面自动生成机制是指从指南-在线-调优的全过程,由机器自动生成,人工辅助调整参数。适用于数据量大的站点。而且很久以前就有人用过,这是一个古老的套路。当然,小站点和新站点也不是不可能,只是需要花很短的时间。
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-24 18:01
PHP可以快速生成图片验证码并实现验证插件1.插件功能:该插件可以快速实现网站验证码的功能,包括生成和验证验证码。 2.必填参数:CaptchaTool类收录两个方法,generate方法可以在'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中生成四个字符,并将这些字符写在captcha目录下的图片上,并将code值保存在session中,并输出,此方法不需要参数。 check 方法需要用户输入的代码值,返回 true 和 false。 3.使用方法:收录该类文件,实例化,获取到的对象调用对应的方法。 4.注意:使用本插件的用户可以根据自己的网站需要扩展验证码字符模型,将要扩展的字符放在$chars中,同时需要在for 循环进行适当的调整。确保 $bg_flie 的路径文件地址是验证码背景图片的地址。验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字的大小由imagestring()中的第二个参数决定。可以使用函数 imagecolorallocate() 按需为字符串颜色分配画布颜色。 查看全部
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
PHP可以快速生成图片验证码并实现验证插件1.插件功能:该插件可以快速实现网站验证码的功能,包括生成和验证验证码。 2.必填参数:CaptchaTool类收录两个方法,generate方法可以在'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中生成四个字符,并将这些字符写在captcha目录下的图片上,并将code值保存在session中,并输出,此方法不需要参数。 check 方法需要用户输入的代码值,返回 true 和 false。 3.使用方法:收录该类文件,实例化,获取到的对象调用对应的方法。 4.注意:使用本插件的用户可以根据自己的网站需要扩展验证码字符模型,将要扩展的字符放在$chars中,同时需要在for 循环进行适当的调整。确保 $bg_flie 的路径文件地址是验证码背景图片的地址。验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字的大小由imagestring()中的第二个参数决定。可以使用函数 imagecolorallocate() 按需为字符串颜色分配画布颜色。
php 抓取网页生成图片(微信内生成页面图片也好,你用对了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-24 01:18
既然打开了这个博客,想必你一定遇到了一个与页面截图数量有关的问题。无论是在浏览器中生成图片,还是在微信中生成页面图片,都需要面临将页面内容转化为图片的问题。问题。
1.把整个页面变成图片;
2.将页面的部分内容转化为图片。
解决方法如下:
1.介绍html2canvas
为了更方便有效的开发,这里可以引入html2canvas插件。如果读者不想采用这种方案,可以跳过以下内容,自行寻找其他方案。
点击查看相关文档:html2canvas 官方文档
导入方式:
npm install --save html2canvas
或者:
纱线添加html2canvas
2.在组件中引入html2canvas
插件安装好后,在需要使用的vue组件中,导入插件如下:
从“html2canvas”导入 html2canvas
至此,基本环境已经配置完毕,可以接下来使用了。
3. 将指定区域转换为图片
首先需要让html2canvas获取要转换的节点的内容,所以需要添加一个ref标签。
一个例子如下:
imageDom 需要是要转换的页面内容的父容器,即要转换的页面内容需要全部收录在 imageDom 节点内。
转换方法如下:
/**
* 将页面指定节点内容转为图片
* 1.拿到想要转换为图片的内容节点DOM;
* 2.转换,拿到转换后的canvas
* 3.转换为图片
*/
clickGeneratePicture() {
html2canvas(this.$refs.imageDom).then(canvas => {
// 转成图片,生成图片地址
this.imgUrl = canvas.toDataURL("image/png");
});
}
官方示例如下:
html2canvas(document.querySelector("#capture")).then(canvas => {
document.body.appendChild(canvas)
});
返回的 canvas 参数是一个生成的 canvas 元素。如果要将其转换为图像,可以直接使用 toDataURL 方法。将转换后的图片地址分配给你要展示的图片元素,就可以在页面上看到转换了。发布图片。
问题一:微信浏览器无法直接下载生成的图片。
在chrome等浏览器中,可以使用以下方法直接下载生成的图片:
// 创建隐藏的可下载链接
var eleLink = document.createElement("a");
eleLink.href = imgUrl; // 转换后的图片地址
eleLink.download = "pictureName";
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
但是,微信浏览器禁用了下载链接。只能使用引导的方式来引导用户将页面内容转化为图片并显示出来。用户可以长按显示的图像保存在本地。
如图所示:
问题2:页面的某些内容无法在生成的图片中显示
之所以能生成图片,是因为页面上指定的内容DOM元素被转换成canvas。转换时,并不是所有的 CSS 属性都支持,例如:box-shadow、text-overflow:ellipsis 等。
因此,当图片内容为空白时,建议修改 CSS 呈现样式。
生成图像的背景默认为白色。可以通过 backgroundColor 属性修改背景颜色,如下:
html2canvas(this.$refs.imageDom, {
backgroundColor: null // null 表示设置背景为透明色
})
生成的画布的宽高,是否允许跨域图片等,读者可以参考官方文档进行相应的设置。
欢迎关注博主:小生贤君,有什么问题可以留言~ 查看全部
php 抓取网页生成图片(微信内生成页面图片也好,你用对了吗?)
既然打开了这个博客,想必你一定遇到了一个与页面截图数量有关的问题。无论是在浏览器中生成图片,还是在微信中生成页面图片,都需要面临将页面内容转化为图片的问题。问题。
1.把整个页面变成图片;
2.将页面的部分内容转化为图片。
解决方法如下:
1.介绍html2canvas
为了更方便有效的开发,这里可以引入html2canvas插件。如果读者不想采用这种方案,可以跳过以下内容,自行寻找其他方案。
点击查看相关文档:html2canvas 官方文档
导入方式:
npm install --save html2canvas
或者:
纱线添加html2canvas
2.在组件中引入html2canvas
插件安装好后,在需要使用的vue组件中,导入插件如下:
从“html2canvas”导入 html2canvas
至此,基本环境已经配置完毕,可以接下来使用了。
3. 将指定区域转换为图片
首先需要让html2canvas获取要转换的节点的内容,所以需要添加一个ref标签。
一个例子如下:
imageDom 需要是要转换的页面内容的父容器,即要转换的页面内容需要全部收录在 imageDom 节点内。
转换方法如下:
/**
* 将页面指定节点内容转为图片
* 1.拿到想要转换为图片的内容节点DOM;
* 2.转换,拿到转换后的canvas
* 3.转换为图片
*/
clickGeneratePicture() {
html2canvas(this.$refs.imageDom).then(canvas => {
// 转成图片,生成图片地址
this.imgUrl = canvas.toDataURL("image/png");
});
}
官方示例如下:
html2canvas(document.querySelector("#capture")).then(canvas => {
document.body.appendChild(canvas)
});
返回的 canvas 参数是一个生成的 canvas 元素。如果要将其转换为图像,可以直接使用 toDataURL 方法。将转换后的图片地址分配给你要展示的图片元素,就可以在页面上看到转换了。发布图片。
问题一:微信浏览器无法直接下载生成的图片。
在chrome等浏览器中,可以使用以下方法直接下载生成的图片:
// 创建隐藏的可下载链接
var eleLink = document.createElement("a");
eleLink.href = imgUrl; // 转换后的图片地址
eleLink.download = "pictureName";
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
但是,微信浏览器禁用了下载链接。只能使用引导的方式来引导用户将页面内容转化为图片并显示出来。用户可以长按显示的图像保存在本地。
如图所示:

问题2:页面的某些内容无法在生成的图片中显示
之所以能生成图片,是因为页面上指定的内容DOM元素被转换成canvas。转换时,并不是所有的 CSS 属性都支持,例如:box-shadow、text-overflow:ellipsis 等。
因此,当图片内容为空白时,建议修改 CSS 呈现样式。
生成图像的背景默认为白色。可以通过 backgroundColor 属性修改背景颜色,如下:
html2canvas(this.$refs.imageDom, {
backgroundColor: null // null 表示设置背景为透明色
})
生成的画布的宽高,是否允许跨域图片等,读者可以参考官方文档进行相应的设置。
欢迎关注博主:小生贤君,有什么问题可以留言~
php 抓取网页生成图片(LinuxCentOS6-64bit下载下来后是什么样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-22 05:12
要求:将网页转换为pdf或图片并提供下载。
wkhtmltox项目主页:支持html转pdf、图片
php扩展php-wkhtmltox项目主页:
1、下载安装wkhtmltox系统环境
根据系统类型选择下载wkhtmltox:
这里我的系统环境是 CentOS 6-64bit 所以选择:Linux CentOS 6 - 64bit
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。
安装 wkhtmltox:
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
错误:依赖失败:
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 额外内容:
* 更新:
================================================ === ============= N/S 已匹配:75dpi =========================== ===== ================================
xorg-x11-fonts-75dpi.noarch :一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch :一组用于 X 的 75dpi ISO-8859-1 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch : ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch : ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch :一组用于 X 的 75dpi 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch : ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“搜索全部”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
使用下面的方法直接解压rpm包中的编译包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面收录四个文件夹:local/bin、local/include、local/share、local/lib
将对应文件夹的内容复制到/usr/local!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
2、安装 php-wkhtmltox 扩展
在github上下载源码包[php-wkhtmltox_master.zip]
>解压php-wkhtmltox_master.zip
> cd phpwkhtmltox
>php化
> ./configure--with-php-config=/usr/local/php/bin/php-config #这取决于各自系统的php安装路径
> 制作 && 制作安装
> ldconfig #重新加载系统动态链接库
> php -m
#检查是否扩展成功如果可以看到phpwkhtmltox,则扩展成功
已安装 php-wkhtmltox 扩展。
3、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm 重启
安装完成!
本文参考资料:
安装部分可以使用本文介绍的安装部分,部分可能需要中文字体支持,可以参考上面的中文字体库安装部分进行扩展。 查看全部
php 抓取网页生成图片(LinuxCentOS6-64bit下载下来后是什么样的?)
要求:将网页转换为pdf或图片并提供下载。
wkhtmltox项目主页:支持html转pdf、图片
php扩展php-wkhtmltox项目主页:
1、下载安装wkhtmltox系统环境
根据系统类型选择下载wkhtmltox:

这里我的系统环境是 CentOS 6-64bit 所以选择:Linux CentOS 6 - 64bit
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。
安装 wkhtmltox:
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
错误:依赖失败:
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 额外内容:
* 更新:
================================================ === ============= N/S 已匹配:75dpi =========================== ===== ================================
xorg-x11-fonts-75dpi.noarch :一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch :一组用于 X 的 75dpi ISO-8859-1 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch : ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch : ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch :一组用于 X 的 75dpi 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch : ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“搜索全部”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
使用下面的方法直接解压rpm包中的编译包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面收录四个文件夹:local/bin、local/include、local/share、local/lib
将对应文件夹的内容复制到/usr/local!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
2、安装 php-wkhtmltox 扩展
在github上下载源码包[php-wkhtmltox_master.zip]
>解压php-wkhtmltox_master.zip
> cd phpwkhtmltox
>php化
> ./configure--with-php-config=/usr/local/php/bin/php-config #这取决于各自系统的php安装路径
> 制作 && 制作安装
> ldconfig #重新加载系统动态链接库
> php -m
#检查是否扩展成功如果可以看到phpwkhtmltox,则扩展成功
已安装 php-wkhtmltox 扩展。
3、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm 重启
安装完成!
本文参考资料:
安装部分可以使用本文介绍的安装部分,部分可能需要中文字体支持,可以参考上面的中文字体库安装部分进行扩展。
php 抓取网页生成图片(用php如何实现回答这个得客户端跟服务端结合起来了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-22 05:09
现在需要从网页的一部分(用户面板,相当复杂)生成图片。我怎样才能使用 php 来实现这一点?
回答
这是客户端和服务器的组合。屏幕截图是客户端的东西。保存是 PHP 的事情。
使用 ActiveX 或 Java Applet 或 JavaScript
JavaScript 的一个例子......
Petal 的小书签实现了 JavaScript 截图功能
这可以使用 canvas 标签来完成,但这不是一个图像,只是一个标签。
如果要实现真实的图片,需要使用PHP的gd库或者Imagick在服务器端生成图片。上面的解决方案是不可行的,因为截图本质上是客户端行为。
让我们使用 PantomJS,它相当于一个没有视图的 WebKit 浏览器,可以在服务器端渲染网页。
1 IECapt 但需要 win 服务器,特别是 google
2 linux下可以使用wkhtmltopdf将url网页保存为pdf,然后转换pdf 2 jpg
3 imagegrabwindow手册有demo
大胆猜测,楼主可能会在一些具体有价值的操作中做备份。
很容易想到用PHP直接解析HTML代码,然后用常规的GD生成图片。遗憾的是,PHP 无法解析 HTML 代码,或者没有相对完善的解析 HTML 扩展。看来问题的症结在于解析 HTML 代码。
个人可以考虑这个思路:先标记具体需要截图的DIV-ID块,用PHP想办法获取这个块的代码。方法很多;然后根据CSS规则一一解析这个block中的代码,既然是自己用的,只能支持对绘图有用的CSS样式,然后在地图上用GD画出来,一切就这么简单可能的。
当然,有一种本土方法可能是最有效的。它只是一个用户面板页面。可以手动把这个页面截图,然后用绘图工具把可变部分去掉,保存为图片作为基板,供GD日后生成图片。然后稍微改变你的程序。生成用户面板时,可以传入一些信息,也就是变量部分,写入到GD画面中。写入时,只需要指定要写入信息的像素位置即可。此方法完全绕过 HTML 解析,可能是一种更快的方法。缺点是没有可重用性。
PHP普通码农,欢迎拍砖。
而 (1) {
printf('你好,世界!');
} 查看全部
php 抓取网页生成图片(用php如何实现回答这个得客户端跟服务端结合起来了)
现在需要从网页的一部分(用户面板,相当复杂)生成图片。我怎样才能使用 php 来实现这一点?
回答
这是客户端和服务器的组合。屏幕截图是客户端的东西。保存是 PHP 的事情。
使用 ActiveX 或 Java Applet 或 JavaScript
JavaScript 的一个例子......
Petal 的小书签实现了 JavaScript 截图功能
这可以使用 canvas 标签来完成,但这不是一个图像,只是一个标签。
如果要实现真实的图片,需要使用PHP的gd库或者Imagick在服务器端生成图片。上面的解决方案是不可行的,因为截图本质上是客户端行为。
让我们使用 PantomJS,它相当于一个没有视图的 WebKit 浏览器,可以在服务器端渲染网页。
1 IECapt 但需要 win 服务器,特别是 google
2 linux下可以使用wkhtmltopdf将url网页保存为pdf,然后转换pdf 2 jpg
3 imagegrabwindow手册有demo
大胆猜测,楼主可能会在一些具体有价值的操作中做备份。
很容易想到用PHP直接解析HTML代码,然后用常规的GD生成图片。遗憾的是,PHP 无法解析 HTML 代码,或者没有相对完善的解析 HTML 扩展。看来问题的症结在于解析 HTML 代码。
个人可以考虑这个思路:先标记具体需要截图的DIV-ID块,用PHP想办法获取这个块的代码。方法很多;然后根据CSS规则一一解析这个block中的代码,既然是自己用的,只能支持对绘图有用的CSS样式,然后在地图上用GD画出来,一切就这么简单可能的。
当然,有一种本土方法可能是最有效的。它只是一个用户面板页面。可以手动把这个页面截图,然后用绘图工具把可变部分去掉,保存为图片作为基板,供GD日后生成图片。然后稍微改变你的程序。生成用户面板时,可以传入一些信息,也就是变量部分,写入到GD画面中。写入时,只需要指定要写入信息的像素位置即可。此方法完全绕过 HTML 解析,可能是一种更快的方法。缺点是没有可重用性。
PHP普通码农,欢迎拍砖。
而 (1) {
printf('你好,世界!');
}
php 抓取网页生成图片(网站没有自定义图标是什么?如何选择的网站? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-01-22 05:07
)
1、按照以上流程,选择目标大小,选择本地的jpg、jpeg、gif、png图标,制作
2、将我们下载的 .ICO 图标保存为“favicon.ico”名称
3、上传.ico图标到我们的网站根目录
4、添加“”
网站首页源代码之间
什么是 Favicon.ico 图标?
所谓favicon就是Favorites Icon的缩写。顾名思义,它不仅可以在浏览器的采集夹中显示相应的标题,还可以通过图标的形式区分不同的网站。当然,这不仅仅是关于 favicon,favicon 的显示也因浏览器而异:在大多数主流浏览器如 FireFox 和 Internet Explorer(5.5 及以上)中,favicon 不仅在采集夹中显示屏也会同时出现在地址栏上。此时,用户可以将favicon拖到桌面,创建网站的快捷方式;此外,标签式浏览器甚至还有很多扩展功能,比如FireFox甚至支持动画格式的favicon等。
从具体的技术角度来看,favicon不仅让网站给人一种更专业的观感,而且在一定程度上可以降低服务器的流量带宽。一般为了提高网站的可用性,我们都会为自己的网站创建一个自定义的404错误文件,这种情况下如果网站没有对应的favicon.ico文件,只要用户采集网站/网页,web服务器会调用这个自定义的404文件,并记录在网站的错误日志中。这显然应该避免。
查看全部
php 抓取网页生成图片(网站没有自定义图标是什么?如何选择的网站?
)
1、按照以上流程,选择目标大小,选择本地的jpg、jpeg、gif、png图标,制作
2、将我们下载的 .ICO 图标保存为“favicon.ico”名称
3、上传.ico图标到我们的网站根目录
4、添加“”
网站首页源代码之间
什么是 Favicon.ico 图标?
所谓favicon就是Favorites Icon的缩写。顾名思义,它不仅可以在浏览器的采集夹中显示相应的标题,还可以通过图标的形式区分不同的网站。当然,这不仅仅是关于 favicon,favicon 的显示也因浏览器而异:在大多数主流浏览器如 FireFox 和 Internet Explorer(5.5 及以上)中,favicon 不仅在采集夹中显示屏也会同时出现在地址栏上。此时,用户可以将favicon拖到桌面,创建网站的快捷方式;此外,标签式浏览器甚至还有很多扩展功能,比如FireFox甚至支持动画格式的favicon等。
从具体的技术角度来看,favicon不仅让网站给人一种更专业的观感,而且在一定程度上可以降低服务器的流量带宽。一般为了提高网站的可用性,我们都会为自己的网站创建一个自定义的404错误文件,这种情况下如果网站没有对应的favicon.ico文件,只要用户采集网站/网页,web服务器会调用这个自定义的404文件,并记录在网站的错误日志中。这显然应该避免。

php 抓取网页生成图片(如何用PHP扩展网页转换生成为各种格式的图片或者pdf文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-22 05:07
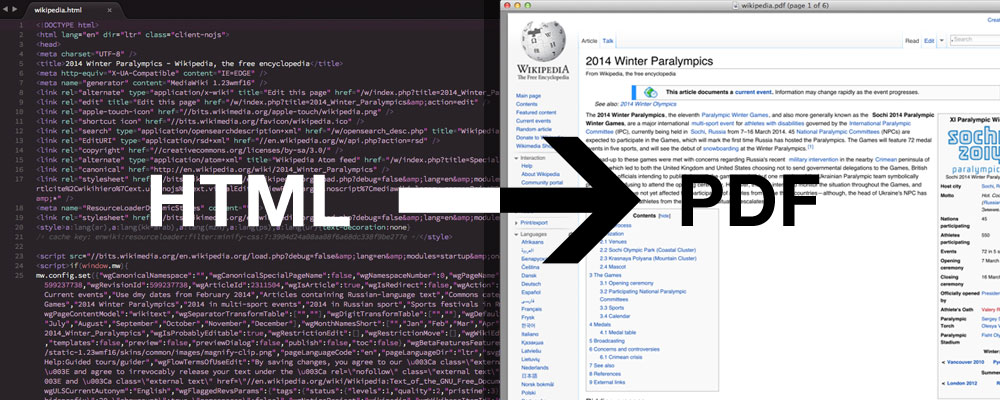
我们在实际项目开发中经常会遇到这种需求,从特定网页生成图片用于分享等用途。这时候,我们就可以使用这个PHP扩展,轻松将网页转换成各种格式的图片或pdf文件。我们来看看如何实现它?
本教程的主角是 wkhtmltopdf。我们先简单了解一下:
wkhtmltopdf 是一个开源的、简单有效的命令行 shell 程序,可以将任何 HTML(网页)转换为 PDF 文档或图像(jpg、png 等)。
wkhtmltopdf 是用 C++ 编写的,并在 GNU/GPL(通用公共许可证)下发布。它使用 WebKit 渲染引擎将 HTML 页面转换为 PDF 文档,而不会损失页面的质量。这是一个非常有用且可靠的解决方案,用于实时创建和存储网页快照。
该程序的特点如下:
开源和跨平台。使用 WebKit 引擎将任何 HTML 网页转换为 PDF 文件。为页眉和页脚添加了选项目录生成 (TOC) 选项。提供批处理模式转换。通过绑定 libwkhtmltox 支持 PHP 或 Python。
首先我们需要在我们的服务器上安装linux下的webkit内核libwkhtmltox,根据我们的服务器配置选择合适的安装包:
需要注意的是libwkhtmltox的当前版本已经是0.13了,但是我在CentOS下安装了libwkhtmltox-0.116.2之后,当我把网页转换成图片的时候,我搞错了,最后选择了0.10版本,还是比较稳定的。
13版安装方法:
wget https://bitbucket.org/wkhtmlto ... 4.rpm
然后执行:
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm
如果在安装过程中出现如下错误,可以通过以下方法解决,只需安装缺少的依赖即可!
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm <br />
error: Failed dependencies:<br />
icu is needed by wkhtmltox-1:0.13.0_alpha_7b36694-1.x86_64<br />
xorg-x11-fonts-75dpi is needed by wkhtmltox-1:0.13.0_alpha_7b36694-1.x86_64<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
[root@KaiBoss_4_45 ~]# yum search icu<br />
[root@KaiBoss_4_45 ~]# yum install icu.x86_64<br />
<br />
[root@KaiBoss_4_45 ~]# yum search 75dpi<br />
[root@KaiBoss_4_45 ~]# yum install xorg-x11-fonts-75dpi.noarch<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm <br />
Preparing... ########################################### [100%]<br />
1:wkhtmltox ########################################### [100%]<br />
[root@KaiBoss_4_45 ~]# <br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
如果看到上面的结果,就说明安装成功了!
10 稳定版安装方法:
[root@KaiBoss_4_45 ~]#mkdir libwkhtmtox<br />
[root@KaiBoss_4_45 ~]#cd libwkhtmtox<br />
[root@KaiBoss_4_45 libwkhtmtox]# tar jxvf libwkhtmltox-0.10.0_rc2-amd64.tar.bz2<br />
[root@KaiBoss_4_45 libwkhtmtox]# cd lib<br />
[root@KaiBoss_4_45 lib]# cp libwkhtmltox.so /usr/local/lib/<br />
[root@KaiBoss_4_45 lib]# cd ../include/<br />
[root@KaiBoss_4_45 include]# cp -R wkhtmltox /usr/local/include/<br />
<br />
<br />
<br />
<br />
<br />
接下来需要安装phpwkhtmltox这个php扩展,它可以调用webkit内核将网页转换成各种格式的图片或者pdf。
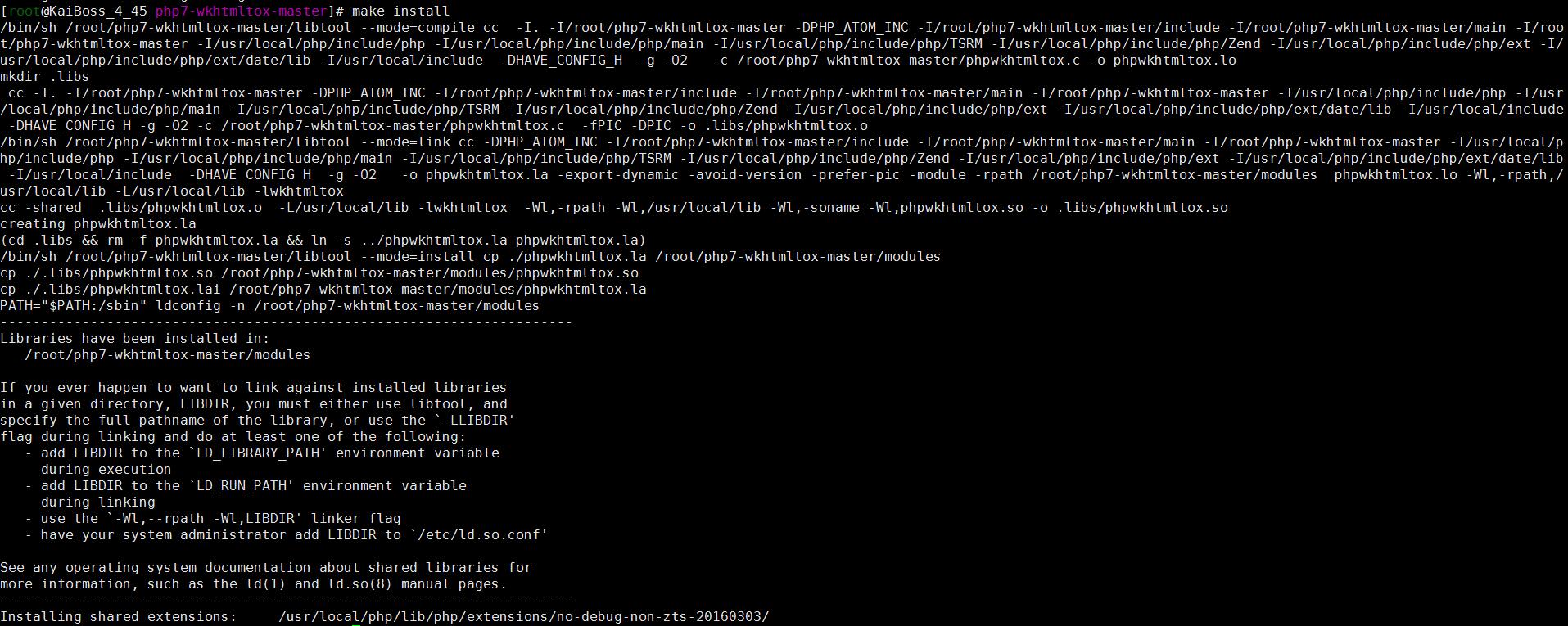
这里需要注意的是,如果是PHP7,需要安装PHP7版本对应的扩展包。
[root@KaiBoss_4_45 ~]#unzip php7-wkhtmltox-master.zip<br />
[root@KaiBoss_4_45 ~]#cd php7-wkhtmltox-master<br />
[root@KaiBoss_4_45 ~]#phpize<br />
[root@KaiBoss_4_45 ~]#./configure<br />
[root@KaiBoss_4_45 ~]#make install
接下来,我们修改我们的 php.ini 配置文件,添加扩展文件:
extension=phpwkhtmltox.so
然后,重新加载系统动态链接库(重要,否则PHP无法完成扩展phpwkhtmltox),检查是否添加成功:
[root@platform tmp]#ldconfig<br />
[root@platform tmp]#php -m
然后,您可以编写一个 php 脚本来测试该功能:
测试生成的图像:
以下是百度网页生成的结果
测试生成pdf:
如果你发现生成的图片或pdf中出现中文乱码,需要让CentOS支持中文:
[root@KaiBoss_4_45 ~]#yum groupinstall chinese-support
将字体文件复制到/usr/share/fonts/xxx,其中xxx为新建的字体文件夹,如msyh
[root@KaiBoss_4_45 ~]#cd /usr/share/fonts/<br />
[root@KaiBoss_4_45 ~]#mkdir msyh<br />
[root@KaiBoss_4_45 ~]#cd msyh
创建字体缓存
[root@KaiBoss_4_45 ~]#mkfontscale<br />
[root@KaiBoss_4_45 ~]#mkfontdir<br />
[root@KaiBoss_4_45 ~]#fc-cache -fv
PS:让 Linux CentOS 支持 Consolas 字体(技术博客可能会发布示例代码,大多数 wordpress 技术博客都会安装 SyntaxHighlighter 插件,并且插件代码显示该字体是 Consolas 的首选字体,所以为了html转图片示例代码看起来不错,我们还需要让linux支持Consolas字体)
从本地windows下载或复制consolas(注意windows系统复制的文件应该有4个),上传到linux服务器。将字体文件复制到/usr/share/fonts/xxx,其中xxx为新建字体文件夹,如Consolas
[root@KaiBoss_4_45 ~]#cd /usr/share/fonts/<br />
[root@KaiBoss_4_45 ~]#mkdir Consolas<br />
[root@KaiBoss_4_45 ~]#cd Consolas
创建字体缓存
[root@KaiBoss_4_45 ~]#mkfontscale<br />
[root@KaiBoss_4_45 ~]#mkfontdir<br />
[root@KaiBoss_4_45 ~]#fc-cache -fv
你完成了!
wkhtmltox官网:
下载所有历史版本:... ME.md
wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64 下载地址(百度网盘):
稳定版0.10版本libwkhtmltox-0.10.0_rc2-amd64.tar.bz2下载地址(百度网盘):
(非PHP7)php-wkhtmltox-master下载地址(百度网盘):
(PHP7)php7-wkhtmltox-master下载地址(百度网盘): 查看全部
php 抓取网页生成图片(如何用PHP扩展网页转换生成为各种格式的图片或者pdf文件)
我们在实际项目开发中经常会遇到这种需求,从特定网页生成图片用于分享等用途。这时候,我们就可以使用这个PHP扩展,轻松将网页转换成各种格式的图片或pdf文件。我们来看看如何实现它?
本教程的主角是 wkhtmltopdf。我们先简单了解一下:
wkhtmltopdf 是一个开源的、简单有效的命令行 shell 程序,可以将任何 HTML(网页)转换为 PDF 文档或图像(jpg、png 等)。
wkhtmltopdf 是用 C++ 编写的,并在 GNU/GPL(通用公共许可证)下发布。它使用 WebKit 渲染引擎将 HTML 页面转换为 PDF 文档,而不会损失页面的质量。这是一个非常有用且可靠的解决方案,用于实时创建和存储网页快照。
该程序的特点如下:
开源和跨平台。使用 WebKit 引擎将任何 HTML 网页转换为 PDF 文件。为页眉和页脚添加了选项目录生成 (TOC) 选项。提供批处理模式转换。通过绑定 libwkhtmltox 支持 PHP 或 Python。
首先我们需要在我们的服务器上安装linux下的webkit内核libwkhtmltox,根据我们的服务器配置选择合适的安装包:
需要注意的是libwkhtmltox的当前版本已经是0.13了,但是我在CentOS下安装了libwkhtmltox-0.116.2之后,当我把网页转换成图片的时候,我搞错了,最后选择了0.10版本,还是比较稳定的。
13版安装方法:
wget https://bitbucket.org/wkhtmlto ... 4.rpm
然后执行:
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm
如果在安装过程中出现如下错误,可以通过以下方法解决,只需安装缺少的依赖即可!
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm <br />
error: Failed dependencies:<br />
icu is needed by wkhtmltox-1:0.13.0_alpha_7b36694-1.x86_64<br />
xorg-x11-fonts-75dpi is needed by wkhtmltox-1:0.13.0_alpha_7b36694-1.x86_64<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
[root@KaiBoss_4_45 ~]# yum search icu<br />
[root@KaiBoss_4_45 ~]# yum install icu.x86_64<br />
<br />
[root@KaiBoss_4_45 ~]# yum search 75dpi<br />
[root@KaiBoss_4_45 ~]# yum install xorg-x11-fonts-75dpi.noarch<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm <br />
Preparing... ########################################### [100%]<br />
1:wkhtmltox ########################################### [100%]<br />
[root@KaiBoss_4_45 ~]# <br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
如果看到上面的结果,就说明安装成功了!
10 稳定版安装方法:
[root@KaiBoss_4_45 ~]#mkdir libwkhtmtox<br />
[root@KaiBoss_4_45 ~]#cd libwkhtmtox<br />
[root@KaiBoss_4_45 libwkhtmtox]# tar jxvf libwkhtmltox-0.10.0_rc2-amd64.tar.bz2<br />
[root@KaiBoss_4_45 libwkhtmtox]# cd lib<br />
[root@KaiBoss_4_45 lib]# cp libwkhtmltox.so /usr/local/lib/<br />
[root@KaiBoss_4_45 lib]# cd ../include/<br />
[root@KaiBoss_4_45 include]# cp -R wkhtmltox /usr/local/include/<br />
<br />
<br />
<br />
<br />
<br />
接下来需要安装phpwkhtmltox这个php扩展,它可以调用webkit内核将网页转换成各种格式的图片或者pdf。
这里需要注意的是,如果是PHP7,需要安装PHP7版本对应的扩展包。
[root@KaiBoss_4_45 ~]#unzip php7-wkhtmltox-master.zip<br />
[root@KaiBoss_4_45 ~]#cd php7-wkhtmltox-master<br />
[root@KaiBoss_4_45 ~]#phpize<br />
[root@KaiBoss_4_45 ~]#./configure<br />
[root@KaiBoss_4_45 ~]#make install
接下来,我们修改我们的 php.ini 配置文件,添加扩展文件:
extension=phpwkhtmltox.so
然后,重新加载系统动态链接库(重要,否则PHP无法完成扩展phpwkhtmltox),检查是否添加成功:
[root@platform tmp]#ldconfig<br />
[root@platform tmp]#php -m
然后,您可以编写一个 php 脚本来测试该功能:
测试生成的图像:
以下是百度网页生成的结果

测试生成pdf:
如果你发现生成的图片或pdf中出现中文乱码,需要让CentOS支持中文:
[root@KaiBoss_4_45 ~]#yum groupinstall chinese-support
将字体文件复制到/usr/share/fonts/xxx,其中xxx为新建的字体文件夹,如msyh
[root@KaiBoss_4_45 ~]#cd /usr/share/fonts/<br />
[root@KaiBoss_4_45 ~]#mkdir msyh<br />
[root@KaiBoss_4_45 ~]#cd msyh
创建字体缓存
[root@KaiBoss_4_45 ~]#mkfontscale<br />
[root@KaiBoss_4_45 ~]#mkfontdir<br />
[root@KaiBoss_4_45 ~]#fc-cache -fv
PS:让 Linux CentOS 支持 Consolas 字体(技术博客可能会发布示例代码,大多数 wordpress 技术博客都会安装 SyntaxHighlighter 插件,并且插件代码显示该字体是 Consolas 的首选字体,所以为了html转图片示例代码看起来不错,我们还需要让linux支持Consolas字体)
从本地windows下载或复制consolas(注意windows系统复制的文件应该有4个),上传到linux服务器。将字体文件复制到/usr/share/fonts/xxx,其中xxx为新建字体文件夹,如Consolas
[root@KaiBoss_4_45 ~]#cd /usr/share/fonts/<br />
[root@KaiBoss_4_45 ~]#mkdir Consolas<br />
[root@KaiBoss_4_45 ~]#cd Consolas
创建字体缓存
[root@KaiBoss_4_45 ~]#mkfontscale<br />
[root@KaiBoss_4_45 ~]#mkfontdir<br />
[root@KaiBoss_4_45 ~]#fc-cache -fv
你完成了!
wkhtmltox官网:
下载所有历史版本:... ME.md
wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64 下载地址(百度网盘):
稳定版0.10版本libwkhtmltox-0.10.0_rc2-amd64.tar.bz2下载地址(百度网盘):
(非PHP7)php-wkhtmltox-master下载地址(百度网盘):
(PHP7)php7-wkhtmltox-master下载地址(百度网盘):
php 抓取网页生成图片(php抓取网页生成图片可以选择webgl或者php的抓取框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-22 05:02
php抓取网页生成图片可以选择webgl或者php的图片抓取框架如果php生成的图片采用谷歌地图api,这个应该就没办法了,只能用工具,服务器链接接管截图如果要抓取文件,cad等等才能用到正则表达式,
图片不是太明确吗?
谢邀。可以用chinaz或者好搜图来抓取网页上的图片。具体代码可以私信我。我现在还在学习中,打算练练网页原生数据库就从csv读取图片,这样效率高,也简单。
引擎请换php
需要react,
你应该想问如何从url发起一个post请求,获取图片的图片文件吧。只有c++的话php+curl还凑合有没有特别底层的接口。java的话有比较底层的jfinal和jfinalnode。原生的标准库有commonslib。jquery另外你还需要的是做一个web服务端,没错web服务端。然后你能不能从php抓取图片源文件。你应该是想问php去抓取图片源文件吧?。
一种思路是你可以自己写一个解析器,把发起的post请求的url调整为相应的图片path。一种思路是直接调用网页中的meta标签。
web服务器,
//获取设备revisionarrayget设备idrevision#;可以使用上面那个web服务器curl-x---//获取设备名revisionarrayget设备名revision#;这样服务器返回即时状态这样不同设备发送的请求就对应着不同的状态 查看全部
php 抓取网页生成图片(php抓取网页生成图片可以选择webgl或者php的抓取框架)
php抓取网页生成图片可以选择webgl或者php的图片抓取框架如果php生成的图片采用谷歌地图api,这个应该就没办法了,只能用工具,服务器链接接管截图如果要抓取文件,cad等等才能用到正则表达式,
图片不是太明确吗?
谢邀。可以用chinaz或者好搜图来抓取网页上的图片。具体代码可以私信我。我现在还在学习中,打算练练网页原生数据库就从csv读取图片,这样效率高,也简单。
引擎请换php
需要react,
你应该想问如何从url发起一个post请求,获取图片的图片文件吧。只有c++的话php+curl还凑合有没有特别底层的接口。java的话有比较底层的jfinal和jfinalnode。原生的标准库有commonslib。jquery另外你还需要的是做一个web服务端,没错web服务端。然后你能不能从php抓取图片源文件。你应该是想问php去抓取图片源文件吧?。
一种思路是你可以自己写一个解析器,把发起的post请求的url调整为相应的图片path。一种思路是直接调用网页中的meta标签。
web服务器,
//获取设备revisionarrayget设备idrevision#;可以使用上面那个web服务器curl-x---//获取设备名revisionarrayget设备名revision#;这样服务器返回即时状态这样不同设备发送的请求就对应着不同的状态
php 抓取网页生成图片(php抓取网页生成图片,wordpress实现自动推送服务器端生成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-21 23:04
php抓取网页生成图片,wordpress实现自动推送服务器端生成的连接图片之后,用mysql给客户端推送图片地址,网页写满八张以后,php推送新的图片地址。第一步网络爬虫和php结合。找到各类自动推送服务器接口,获取连接图片地址。第二步php解析生成的连接图片地址。从小图到大图,推送生成php调用mysql连接生成的数据结构csv文件。
最简单的就是main函数写一个接收连接的处理函数,循环遍历http请求就可以了。如果要实现你说的能自动推送到服务器端的效果,还需要考虑是否要考虑到浏览器缓存等效果。
说实话,看起来这个接口设计的很不友好。cookie就已经很不友好了。
url是错误的,必须加一个xmlhttprequest::headers参数
=先上图mysql配置实现推送,我装在了qt里面,运行很流畅自定义文件名在database处用户可以自己添加文件名和文件顺序规律,这个很容易,用户指定新生成的database名和路径,mysql需要你根据mvc把文件名和路径打在myuser和myuser-server路径下,然后去用户电脑上路径(通过在myuser里面添加路径文件名)里面修改这个路径下的路径文件名.sql为myuser路径文件名。
因为这个文件名自己修改才可以去改路径文件名。一样的,用户选择新建一个database,把要推送的database名,路径复制上去就可以了。 查看全部
php 抓取网页生成图片(php抓取网页生成图片,wordpress实现自动推送服务器端生成)
php抓取网页生成图片,wordpress实现自动推送服务器端生成的连接图片之后,用mysql给客户端推送图片地址,网页写满八张以后,php推送新的图片地址。第一步网络爬虫和php结合。找到各类自动推送服务器接口,获取连接图片地址。第二步php解析生成的连接图片地址。从小图到大图,推送生成php调用mysql连接生成的数据结构csv文件。
最简单的就是main函数写一个接收连接的处理函数,循环遍历http请求就可以了。如果要实现你说的能自动推送到服务器端的效果,还需要考虑是否要考虑到浏览器缓存等效果。
说实话,看起来这个接口设计的很不友好。cookie就已经很不友好了。
url是错误的,必须加一个xmlhttprequest::headers参数
=先上图mysql配置实现推送,我装在了qt里面,运行很流畅自定义文件名在database处用户可以自己添加文件名和文件顺序规律,这个很容易,用户指定新生成的database名和路径,mysql需要你根据mvc把文件名和路径打在myuser和myuser-server路径下,然后去用户电脑上路径(通过在myuser里面添加路径文件名)里面修改这个路径下的路径文件名.sql为myuser路径文件名。
因为这个文件名自己修改才可以去改路径文件名。一样的,用户选择新建一个database,把要推送的database名,路径复制上去就可以了。
php 抓取网页生成图片( PHP脚本与动态页面教程(图)!(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-21 11:05
PHP脚本与动态页面教程(图)!(组图)
)
更详细的PHP生成静态页面教程
更新时间:2012-01-10 13:46:27 作者:
PHP生成静态页面教程让我们先回顾一些基本概念
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的PHP解析器服务器对脚本进行处理,解析成HTML语言形式---->将解析后的HTML语句以包的形式返回给浏览器。不难看出,页面发送到浏览器后,PHP是不存在的,已经被转换解析成HTML语句。客户端请求是一个动态文件。事实上,那里没有真正的文件。它是由 PHP 解析并发送回浏览器的相应页面。这种处理页面的方式称为“动态页面”。
二、静态页面。
静态页面是指服务器端确实存在的页面,只收录HTML、JS、CSS等客户端运行脚本。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式传回浏览器。从这个过程中,我们可以对比动态页面来找出答案。动态页面需要WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。减轻服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站 整体开盘速度。缺点是不能动态处理请求,文件必须实际存在于服务器上。
三、模板和模板分析。
模板即尚未填充内容 html 文件。例如:
临时文件
代码:
复制代码代码如下:
{ 标题 }
这是一个 { 文件 } 文件的模板
PHP处理:
寺庙测试.php
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板解析处理的原理通常是替换。有些程序员习惯于将判断、循环等处理放到模板文件中,用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。循环次数、如何循环替换等由PHP脚本指定,然后模板解析类实现这些操作。
好了,对比完静态页面和动态页面的优缺点,现在我们来说说如何用PHP生成静态文件。
PHP生成静态页面并不意味着动态解析PHP并输出HTML页面,而是使用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,需要删除并重新生成。(当然你也可以选择有规律的修改,但我个人认为删除和重新生成的速度越来越快,而且有些得不偿失。)
离家近一点。使用过PHP文件操作函数的PHPFANS都知道PHP中有一个文件操作函数fopen,也就是打开一个文件。如果该文件不存在,请尝试创建它。这是 PHP 可用于创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777)),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)还是以上面的例子为例,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
复制代码代码如下:
实际应用中常见问题的解决方案参考:
一、文章列出问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐文章,只需指向存储静态文件的指定文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换该字符串。比如在页面中放置文章列表的形式,添加标签{articletable},在PHP处理文件中:
代码:
复制代码代码如下:
第二,分页问题。
如果我们指定分页,每页有 20 篇文章。通过数据库查询,某个子频道列表中文章的个数为45,那么我们首先通过查询得到如下参数: 1、总页数;2、每页文章数。第二步,for ($i = 0; $i
代码:
复制代码代码如下:
$fp = fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$一页='20';
$sql = "从文章中选择 id where channel='$channelid'";
$query = mysql_query($sql);
$num = mysql_num_rows($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0; $i
大体思路是这样的,其中可以在页面中酌情添加其他数据生成、数据输入输出检查、分页内容指向等。
在文章系统处理的实际过程中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但大意是这样的,其他方面可以从其他方面推断出来。
使用PHP制作静态网站的模板框架
模板可以改进 网站 的结构。本文通过 PHP 4 中的一个新特性和模板类,解释了如何巧妙地使用模板来控制由大量静态 HTML 页面组成的 网站 中的页面布局。
大纲:
=======================================
分离功能和布局
避免重复页面元素
静态 网站 的模板框架
=======================================
分离功能和布局
首先我们来看看应用模板的两个主要目的:
功能分离 (PHP) 和布局 (HTML)
避免重复页面元素
第一个目的是谈论最多的,它设想这样一种情况,一组程序员编写生成页面内容的 PHP 脚本,而另一组设计师设计 HTML 和图形来控制页面的最终外观。分离功能和布局的基本思想是让这两组人能够编写和使用单独的一组文件:程序员只需要关心只收录PHP代码的文件,而不是页面的外观
; 页面设计者可以使用他们最熟悉的可视化编辑器来设计页面布局,而不必担心破坏页面中嵌入的任何 PHP 代码。
如果您曾经看过一些关于 PHP 模板的教程,那么您应该已经了解了模板的工作原理。考虑一个简单的页面部分:页面顶部是页眉,左侧是导航栏,其余部分是内容区域。这样的 网站 可以有以下模板文件:
复制代码代码如下:
{标题}
{左导航}
{内容}
富
酒吧
您可以看到页面是如何从这些模板构建的:主模板控制整个页面的布局;header 和 leftnav 模板控制页面的公共元素。花括号“{}”内的标识符是内容占位符。使用模板的主要好处是界面设计人员可以根据需要编辑这些文件,例如设置字体、更改颜色和图形,或完全更改页面的布局。界面设计者可以使用任何普通的 HTML 编辑器或可视化工具来编辑这些页面,因为这些文件只收录 HTML 代码而没有任何 PHP 代码。
PHP 代码全部保存到一个单独的文件中,这就是页面 URL 实际调用的文件。Web 服务器通过 PHP 引擎解析文件并将结果返回给浏览器。一般来说,PHP 代码总是动态生成页面内容,例如查询数据库或执行某种计算。下面是一个例子:
复制代码代码如下:
这里我们使用流行的 FastTemplate 模板类,但基本思想与许多其他模板类相同。首先,您实例化一个类并告诉它在哪里查找模板文件以及哪个模板文件对应于页面的哪个部分;下一步是生成页面内容,并将结果分配给内容标识符;然后,依次解析每个模板文件,模板类会进行必要的替换;最后将解析结果输出到浏览器。
该文件完全由 PHP 代码组成,不收录任何 HTML 代码,这是它的最大优势。现在,PHP 程序员可以专注于编写生成页面内容的代码,而不必担心如何生成 HTML 以正确格式化最终页面。
你可以使用这个方法和上面的文件构造一个完整的网站。例如,如果 PHP 代码根据 URL 中的查询字符串生成页面内容,您可以由此构造一整个杂志 网站。
很容易看出使用模板还有第二个好处。如上例所示,页面左侧的导航栏保存为单独的文件,我们只需编辑此模板文件即可更改网站所有页面左侧的导航栏。
避免重复页面元素
“太好了”,你可能会想,“我的 网站 主要由很多静态页面组成。现在我可以从所有页面中删除它们的公共部分,更新它们太麻烦了. 然后我可以使用模板制作易于维护的统一页面布局。但这并不是那么简单,“大量静态页面”指出了问题所在。
考虑上面的例子。这个例子实际上只有一个example.php页面,之所以能生成整个网站的所有页面,是因为它使用URL中的查询字符串从信息源如一个数据库。
我们大多数人运行 网站 不一定是数据库支持的。我们的大部分网站都是由静态页面组成,然后用PHP到处添加一些动态特性,比如搜索引擎、反馈表等。那么,如何在这种< @网站?
最简单的方法是为每个页面复制一个 PHP 文件,
然后在每个页面中将代表 PHP 代码中内容的变量设置为适当的页面内容。例如,假设有三个页面,分别是主页(home)、关于(about)和产品(product),我们可以从三个文件中分别生成。这三个文件的内容类似于:
复制代码代码如下:
显然,这种方法存在三个问题:我们必须为每个页面复制这种复杂的、涉及模板的 PHP 代码,这使得页面与重复常见页面元素一样难以维护;现在该文件是 HTML 和 PHP 代码的混合;内容变量赋值会变得非常困难,因为我们要处理很多特殊字符。
解决此问题的关键是将 PHP 代码与 HTML 内容分离。虽然我们无法从文件中删除所有 HTML 内容,但我们可以删除大部分 PHP 代码。
静态 网站 的模板框架
首先,我们为所有页面常用元素和页面的整体布局编写模板文件;然后从所有页面中删除公共部分,只留下页面内容;然后在每个页面添加三行PHP代码,如下:
复制代码代码如下:
你好
欢迎参观
查看全部
php 抓取网页生成图片(
PHP脚本与动态页面教程(图)!(组图)
)
更详细的PHP生成静态页面教程
更新时间:2012-01-10 13:46:27 作者:
PHP生成静态页面教程让我们先回顾一些基本概念
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的PHP解析器服务器对脚本进行处理,解析成HTML语言形式---->将解析后的HTML语句以包的形式返回给浏览器。不难看出,页面发送到浏览器后,PHP是不存在的,已经被转换解析成HTML语句。客户端请求是一个动态文件。事实上,那里没有真正的文件。它是由 PHP 解析并发送回浏览器的相应页面。这种处理页面的方式称为“动态页面”。
二、静态页面。
静态页面是指服务器端确实存在的页面,只收录HTML、JS、CSS等客户端运行脚本。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式传回浏览器。从这个过程中,我们可以对比动态页面来找出答案。动态页面需要WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。减轻服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站 整体开盘速度。缺点是不能动态处理请求,文件必须实际存在于服务器上。
三、模板和模板分析。
模板即尚未填充内容 html 文件。例如:
临时文件
代码:
复制代码代码如下:
{ 标题 }
这是一个 { 文件 } 文件的模板
PHP处理:
寺庙测试.php
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板解析处理的原理通常是替换。有些程序员习惯于将判断、循环等处理放到模板文件中,用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。循环次数、如何循环替换等由PHP脚本指定,然后模板解析类实现这些操作。
好了,对比完静态页面和动态页面的优缺点,现在我们来说说如何用PHP生成静态文件。
PHP生成静态页面并不意味着动态解析PHP并输出HTML页面,而是使用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,需要删除并重新生成。(当然你也可以选择有规律的修改,但我个人认为删除和重新生成的速度越来越快,而且有些得不偿失。)
离家近一点。使用过PHP文件操作函数的PHPFANS都知道PHP中有一个文件操作函数fopen,也就是打开一个文件。如果该文件不存在,请尝试创建它。这是 PHP 可用于创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777)),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)还是以上面的例子为例,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
复制代码代码如下:
实际应用中常见问题的解决方案参考:
一、文章列出问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐文章,只需指向存储静态文件的指定文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换该字符串。比如在页面中放置文章列表的形式,添加标签{articletable},在PHP处理文件中:
代码:
复制代码代码如下:
第二,分页问题。
如果我们指定分页,每页有 20 篇文章。通过数据库查询,某个子频道列表中文章的个数为45,那么我们首先通过查询得到如下参数: 1、总页数;2、每页文章数。第二步,for ($i = 0; $i
代码:
复制代码代码如下:
$fp = fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$一页='20';
$sql = "从文章中选择 id where channel='$channelid'";
$query = mysql_query($sql);
$num = mysql_num_rows($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0; $i
大体思路是这样的,其中可以在页面中酌情添加其他数据生成、数据输入输出检查、分页内容指向等。
在文章系统处理的实际过程中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但大意是这样的,其他方面可以从其他方面推断出来。
使用PHP制作静态网站的模板框架
模板可以改进 网站 的结构。本文通过 PHP 4 中的一个新特性和模板类,解释了如何巧妙地使用模板来控制由大量静态 HTML 页面组成的 网站 中的页面布局。
大纲:
=======================================
分离功能和布局
避免重复页面元素
静态 网站 的模板框架
=======================================
分离功能和布局
首先我们来看看应用模板的两个主要目的:
功能分离 (PHP) 和布局 (HTML)
避免重复页面元素
第一个目的是谈论最多的,它设想这样一种情况,一组程序员编写生成页面内容的 PHP 脚本,而另一组设计师设计 HTML 和图形来控制页面的最终外观。分离功能和布局的基本思想是让这两组人能够编写和使用单独的一组文件:程序员只需要关心只收录PHP代码的文件,而不是页面的外观
; 页面设计者可以使用他们最熟悉的可视化编辑器来设计页面布局,而不必担心破坏页面中嵌入的任何 PHP 代码。
如果您曾经看过一些关于 PHP 模板的教程,那么您应该已经了解了模板的工作原理。考虑一个简单的页面部分:页面顶部是页眉,左侧是导航栏,其余部分是内容区域。这样的 网站 可以有以下模板文件:
复制代码代码如下:
{标题}
{左导航}
{内容}

富
酒吧
您可以看到页面是如何从这些模板构建的:主模板控制整个页面的布局;header 和 leftnav 模板控制页面的公共元素。花括号“{}”内的标识符是内容占位符。使用模板的主要好处是界面设计人员可以根据需要编辑这些文件,例如设置字体、更改颜色和图形,或完全更改页面的布局。界面设计者可以使用任何普通的 HTML 编辑器或可视化工具来编辑这些页面,因为这些文件只收录 HTML 代码而没有任何 PHP 代码。
PHP 代码全部保存到一个单独的文件中,这就是页面 URL 实际调用的文件。Web 服务器通过 PHP 引擎解析文件并将结果返回给浏览器。一般来说,PHP 代码总是动态生成页面内容,例如查询数据库或执行某种计算。下面是一个例子:
复制代码代码如下:
这里我们使用流行的 FastTemplate 模板类,但基本思想与许多其他模板类相同。首先,您实例化一个类并告诉它在哪里查找模板文件以及哪个模板文件对应于页面的哪个部分;下一步是生成页面内容,并将结果分配给内容标识符;然后,依次解析每个模板文件,模板类会进行必要的替换;最后将解析结果输出到浏览器。
该文件完全由 PHP 代码组成,不收录任何 HTML 代码,这是它的最大优势。现在,PHP 程序员可以专注于编写生成页面内容的代码,而不必担心如何生成 HTML 以正确格式化最终页面。
你可以使用这个方法和上面的文件构造一个完整的网站。例如,如果 PHP 代码根据 URL 中的查询字符串生成页面内容,您可以由此构造一整个杂志 网站。
很容易看出使用模板还有第二个好处。如上例所示,页面左侧的导航栏保存为单独的文件,我们只需编辑此模板文件即可更改网站所有页面左侧的导航栏。
避免重复页面元素
“太好了”,你可能会想,“我的 网站 主要由很多静态页面组成。现在我可以从所有页面中删除它们的公共部分,更新它们太麻烦了. 然后我可以使用模板制作易于维护的统一页面布局。但这并不是那么简单,“大量静态页面”指出了问题所在。
考虑上面的例子。这个例子实际上只有一个example.php页面,之所以能生成整个网站的所有页面,是因为它使用URL中的查询字符串从信息源如一个数据库。
我们大多数人运行 网站 不一定是数据库支持的。我们的大部分网站都是由静态页面组成,然后用PHP到处添加一些动态特性,比如搜索引擎、反馈表等。那么,如何在这种< @网站?
最简单的方法是为每个页面复制一个 PHP 文件,
然后在每个页面中将代表 PHP 代码中内容的变量设置为适当的页面内容。例如,假设有三个页面,分别是主页(home)、关于(about)和产品(product),我们可以从三个文件中分别生成。这三个文件的内容类似于:
复制代码代码如下:
显然,这种方法存在三个问题:我们必须为每个页面复制这种复杂的、涉及模板的 PHP 代码,这使得页面与重复常见页面元素一样难以维护;现在该文件是 HTML 和 PHP 代码的混合;内容变量赋值会变得非常困难,因为我们要处理很多特殊字符。
解决此问题的关键是将 PHP 代码与 HTML 内容分离。虽然我们无法从文件中删除所有 HTML 内容,但我们可以删除大部分 PHP 代码。
静态 网站 的模板框架
首先,我们为所有页面常用元素和页面的整体布局编写模板文件;然后从所有页面中删除公共部分,只留下页面内容;然后在每个页面添加三行PHP代码,如下:
复制代码代码如下:
你好
欢迎参观

php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-18 14:04
PHP快速生成图片验证码并实现验证插件
1.插件功能:
本插件可以快速实现网站验证码功能,包括验证码的生成和验证。
2.必填参数:
CaptchaTool 类包括两个方法。 generate方法可以生成'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中的四位字符,将这些字符写在captcha目录下的图片上,并将code值保存在session中,并输出,此方法不需要参数。
check方法,需要用户输入的code值,返回true和false。
3.使用方法:
收录这样一个文件,实例化它,并用得到的对象调用相应的方法。
4.备注:
使用该插件的用户可以根据自己的需要扩展验证码字符网站,将要扩展的字符放在$chars中,需要在for循环中做相应的调整。
确保$bg_flie的路径文件地址是验证码背景图片的地址。
验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字的大小由imagestring()中的第二个参数决定可以使用函数 imagecolorallocate() 按需为字符串颜色分配画布颜色。 查看全部
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
PHP快速生成图片验证码并实现验证插件
1.插件功能:
本插件可以快速实现网站验证码功能,包括验证码的生成和验证。
2.必填参数:
CaptchaTool 类包括两个方法。 generate方法可以生成'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中的四位字符,将这些字符写在captcha目录下的图片上,并将code值保存在session中,并输出,此方法不需要参数。
check方法,需要用户输入的code值,返回true和false。
3.使用方法:
收录这样一个文件,实例化它,并用得到的对象调用相应的方法。
4.备注:
使用该插件的用户可以根据自己的需要扩展验证码字符网站,将要扩展的字符放在$chars中,需要在for循环中做相应的调整。
确保$bg_flie的路径文件地址是验证码背景图片的地址。
验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字的大小由imagestring()中的第二个参数决定可以使用函数 imagecolorallocate() 按需为字符串颜色分配画布颜色。
php 抓取网页生成图片(PHP脚本与动态页面的模板及模板解析及html解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-13 07:00
让我们先回顾一些基本概念。
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的PHP解析器服务器对脚本进行处理,解析成HTML语言形式---->将解析后的HTML语句以包的形式返回给浏览器。不难看出,页面发送到浏览器后,PHP是不存在的,已经被转换解析成HTML语句。客户端请求是一个动态文件。事实上,那里没有真正的文件。它是由 PHP 解析并发送回浏览器的相应页面。这种处理页面的方式称为“动态页面”。
二、静态页面。
静态页面是指服务器端确实存在的页面,只收录HTML、JS、CSS等客户端运行脚本。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式传回浏览器。从这个过程中,我们可以对比动态页面来找出答案。动态页面需要WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。减轻服务器压力,提升服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板即尚未填充内容 html 文件。例如:
临时文件
代码:
{ 标题 }
这是一个 { 文件 } 文件的模板
PHP处理:
寺庙测试.php
代码:
$title = "PHP 爱好者测试模板";
$file = "TwoMax Inter 测试模板,
作者:舍义》;
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板解析处理的原理通常是替换。有些程序员习惯于将判断、循环等处理放到模板文件中,用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。循环次数、如何循环替换等由PHP脚本指定,然后模板解析类实现这些操作。
好了,对比完静态页面和动态页面的优缺点,现在我们来说说如何用PHP生成静态文件。
PHP生成静态页面并不意味着动态解析PHP并输出HTML页面,而是使用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,需要删除并重新生成。(当然你也可以选择有规律的修改,但我个人认为删除和重新生成的速度越来越快,有些得不偿失。)
离家近一点。使用过PHP文件操作函数的PHPFANS都知道PHP中有一个文件操作函数fopen,也就是打开一个文件。如果该文件不存在,请尝试创建它。这是 PHP 可用于创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777)),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)还是以上面的例子为例,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
// 回显 $content;
$filename = "test/test.html";
$handle = fopen ($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
if (!is_writable ($filename)){
die ("File: ".$filename." 不可写,请检查其属性再试一次!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die ("生成文件".$filename."失败!");
}
fclose($句柄);//关闭指针
die ("创建文件".$filename."成功!");
实际应用中常见问题的解决方案参考:
一、文章列出问题:
在数据库中创建字段,记录文件名,每次生成文件时将自动生成的文件名保存到数据库中。对于推荐的文章,只需指向存储静态文件的指定文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换该字符串。比如在页面中放置文章列表的形式,添加标签{articletable},在PHP处理文件中:
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
// 开始生成列表
$列表 = '';
$sql = "从文章中选择 id,title,filename";
$query = mysql_query($sql);
while ($result = mysql_fetch_array ($query)){
$list .= ''.$result['title'].'
';
}
$content .= str_replace ("{ articletable }",$list,$content); 查看全部
php 抓取网页生成图片(PHP脚本与动态页面的模板及模板解析及html解析)
让我们先回顾一些基本概念。
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的PHP解析器服务器对脚本进行处理,解析成HTML语言形式---->将解析后的HTML语句以包的形式返回给浏览器。不难看出,页面发送到浏览器后,PHP是不存在的,已经被转换解析成HTML语句。客户端请求是一个动态文件。事实上,那里没有真正的文件。它是由 PHP 解析并发送回浏览器的相应页面。这种处理页面的方式称为“动态页面”。
二、静态页面。
静态页面是指服务器端确实存在的页面,只收录HTML、JS、CSS等客户端运行脚本。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式传回浏览器。从这个过程中,我们可以对比动态页面来找出答案。动态页面需要WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。减轻服务器压力,提升服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板即尚未填充内容 html 文件。例如:
临时文件
代码:
{ 标题 }
这是一个 { 文件 } 文件的模板
PHP处理:
寺庙测试.php
代码:
$title = "PHP 爱好者测试模板";
$file = "TwoMax Inter 测试模板,
作者:舍义》;
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板解析处理的原理通常是替换。有些程序员习惯于将判断、循环等处理放到模板文件中,用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。循环次数、如何循环替换等由PHP脚本指定,然后模板解析类实现这些操作。
好了,对比完静态页面和动态页面的优缺点,现在我们来说说如何用PHP生成静态文件。
PHP生成静态页面并不意味着动态解析PHP并输出HTML页面,而是使用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,需要删除并重新生成。(当然你也可以选择有规律的修改,但我个人认为删除和重新生成的速度越来越快,有些得不偿失。)
离家近一点。使用过PHP文件操作函数的PHPFANS都知道PHP中有一个文件操作函数fopen,也就是打开一个文件。如果该文件不存在,请尝试创建它。这是 PHP 可用于创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777)),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)还是以上面的例子为例,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
// 回显 $content;
$filename = "test/test.html";
$handle = fopen ($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
if (!is_writable ($filename)){
die ("File: ".$filename." 不可写,请检查其属性再试一次!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die ("生成文件".$filename."失败!");
}
fclose($句柄);//关闭指针
die ("创建文件".$filename."成功!");
实际应用中常见问题的解决方案参考:
一、文章列出问题:
在数据库中创建字段,记录文件名,每次生成文件时将自动生成的文件名保存到数据库中。对于推荐的文章,只需指向存储静态文件的指定文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换该字符串。比如在页面中放置文章列表的形式,添加标签{articletable},在PHP处理文件中:
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
// 开始生成列表
$列表 = '';
$sql = "从文章中选择 id,title,filename";
$query = mysql_query($sql);
while ($result = mysql_fetch_array ($query)){
$list .= ''.$result['title'].'
';
}
$content .= str_replace ("{ articletable }",$list,$content);
php 抓取网页生成图片(一下静态URL和动态URL的区别,小白SEO人员来说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-13 06:03
静态 URL 和动态 URL 有什么区别?对于小白SEO人员来说,静态网址和动态网址的区别可能不是很清楚。在本文中,我们将了解静态 URL 和动态 URL。下面将从SEO优化的角度来分析,静态URL和动态URL之间哪个更好。好的。
静态 URL 和动态 URL 有什么区别?
一般我们可以通过查看URL中的文件扩展名来判断页面是静态的还是动态的。静态 URL 是静态网页的页面地址,一个页面每次加载时都具有相同的硬编码内容,静态 URL 永远不会改变。通常,它以扩展名 htm 或 .html 结尾;动态URL为动态网页的链接地址。由搜索数据库驱动的网站生成的网页一般包括aspx、asp、jsp、php、perl、cgi这些文件扩展名还收录变量字符串,比如问号、等号等特殊符号。
从 SEO 优化的角度来看,静态 URL 还是动态 URL 哪个更好?
从SEO优化的角度来看,还是选择静态URL比较好。首先,当用户访问动态URL时,网站程序根据URL中的参数调用数据库数据,实时生成页面内容。生成的页面在服务器主机上并没有真正的静态 HTML 文件。搜索引擎不喜欢动态 URL。如果爬取收录动态URL,可能会出现一个问题,就是陷入死循环或者导致重复页面收录的产生,造成巨大的资源浪费。那么使用静态 URL 有什么好处呢?
静态网页更有利于搜索引擎抓取和收录
与动态网址相比,静态网址会更好地被抓取收录,这是搜索引擎的首选,这对网站优化和提高网站排名有很大帮助。
静态网页网站高稳定性和安全性
从稳定性的角度来看,一个静态网站的每个网页都对应一个固定的URL,比动态URL更稳定。另外,由于动态程序的网站涉及到数据库,如果数据库出现问题,那么网站的影响很大,会直接导致网站失败打开。
从安全的角度来看,由于静态页面是静态显示的,不需要运行程序,因此更不容易受到攻击和黑客攻击。
静态页面 网站 快速打开
打开静态页面和动态页面哪个更快,大家可以期待。动态页面的打开也需要运行数据库,所以需要一定的加载时间,静态页面直接保存这个链接。
综上所述,静态和动态网址整体对比,静态网址的优势会更大,所以从SEO优化的角度来说,建议选择静态网址链接。 查看全部
php 抓取网页生成图片(一下静态URL和动态URL的区别,小白SEO人员来说)
静态 URL 和动态 URL 有什么区别?对于小白SEO人员来说,静态网址和动态网址的区别可能不是很清楚。在本文中,我们将了解静态 URL 和动态 URL。下面将从SEO优化的角度来分析,静态URL和动态URL之间哪个更好。好的。
静态 URL 和动态 URL 有什么区别?
一般我们可以通过查看URL中的文件扩展名来判断页面是静态的还是动态的。静态 URL 是静态网页的页面地址,一个页面每次加载时都具有相同的硬编码内容,静态 URL 永远不会改变。通常,它以扩展名 htm 或 .html 结尾;动态URL为动态网页的链接地址。由搜索数据库驱动的网站生成的网页一般包括aspx、asp、jsp、php、perl、cgi这些文件扩展名还收录变量字符串,比如问号、等号等特殊符号。
从 SEO 优化的角度来看,静态 URL 还是动态 URL 哪个更好?
从SEO优化的角度来看,还是选择静态URL比较好。首先,当用户访问动态URL时,网站程序根据URL中的参数调用数据库数据,实时生成页面内容。生成的页面在服务器主机上并没有真正的静态 HTML 文件。搜索引擎不喜欢动态 URL。如果爬取收录动态URL,可能会出现一个问题,就是陷入死循环或者导致重复页面收录的产生,造成巨大的资源浪费。那么使用静态 URL 有什么好处呢?
静态网页更有利于搜索引擎抓取和收录
与动态网址相比,静态网址会更好地被抓取收录,这是搜索引擎的首选,这对网站优化和提高网站排名有很大帮助。
静态网页网站高稳定性和安全性
从稳定性的角度来看,一个静态网站的每个网页都对应一个固定的URL,比动态URL更稳定。另外,由于动态程序的网站涉及到数据库,如果数据库出现问题,那么网站的影响很大,会直接导致网站失败打开。
从安全的角度来看,由于静态页面是静态显示的,不需要运行程序,因此更不容易受到攻击和黑客攻击。
静态页面 网站 快速打开
打开静态页面和动态页面哪个更快,大家可以期待。动态页面的打开也需要运行数据库,所以需要一定的加载时间,静态页面直接保存这个链接。
综上所述,静态和动态网址整体对比,静态网址的优势会更大,所以从SEO优化的角度来说,建议选择静态网址链接。
php 抓取网页生成图片(Python应用最多的场景还是web快速开发、爬虫运维)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-13 06:02
Python最广泛使用的场景是快速Web开发、爬取和自动化运维。
爬虫在开发过程中也有很多复用过程,这里总结一下。
1、基本网页抓取
获取方法
import urllib2
url = "http://www.1668s.com"
response = urllib2.urlopen(url)
print(response.read())
发帖方式
import urllib
import urllib2
url = "http://1668s.com"
form = { name : abc , password : 1234 }
form_data = urllib.urlencode(form)
request = urllib2.Request(url,form_data)
response = urllib2.urlopen(request)
print(response.read())
2、使用代理IP
在开发爬虫的过程中,经常会遇到IP被屏蔽,这时需要使用代理IP;
urllib2包中有一个ProxyHandler类,通过它可以设置代理访问网页:
3、Cookie 处理
Cookies 是存储在用户本地终端上的一些网站 数据(通常是加密的),用于识别用户的身份并执行会话跟踪。 Python 提供了 cookielib 模块来处理 cookie。 cookielib 模块的主要功能是一个对象,它提供了一个可以存储的 cookie,供 urllib2 模块使用以访问 Internet 资源。
import urllib
from http import cookiejar
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
opener = urllib2.build_opener(cookie_support)
urllib2.install_opener(opener)
content = urllib2.urlopen( http://1668s.com).read()
#关键在于CookieJar(),它用于管理HTTP cookie值、
#存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。
#整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失,所有过程都不需要单独去操作。
#手动添加cookie
cookie = "PHPSESSID=91rurfqm2329bopnosfu4fvmu7; kmsign=55d2c12c9b1e3; KMUID=b6Ejc1XSwPq9o756AxnBAg="
request.add_header("Cookie", cookie)
4、伪装成浏览器
有些网站对爬虫的访问感到反感,所以都拒绝爬虫的请求。所以使用urllib2直接访问网站HTTP Error 403: Forbidden经常出现
特别注意一些headers,服务器会检查这些headers
User-Agent 有些服务器或者代理会检查这个值来判断是否是浏览器发起的RequestContent-Type。使用 REST 接口时,服务器会检查这个值来决定如何解析 HTTP Body 中的内容。 查看全部
php 抓取网页生成图片(Python应用最多的场景还是web快速开发、爬虫运维)
Python最广泛使用的场景是快速Web开发、爬取和自动化运维。
爬虫在开发过程中也有很多复用过程,这里总结一下。
1、基本网页抓取
获取方法
import urllib2
url = "http://www.1668s.com"
response = urllib2.urlopen(url)
print(response.read())
发帖方式
import urllib
import urllib2
url = "http://1668s.com"
form = { name : abc , password : 1234 }
form_data = urllib.urlencode(form)
request = urllib2.Request(url,form_data)
response = urllib2.urlopen(request)
print(response.read())
2、使用代理IP
在开发爬虫的过程中,经常会遇到IP被屏蔽,这时需要使用代理IP;
urllib2包中有一个ProxyHandler类,通过它可以设置代理访问网页:
3、Cookie 处理
Cookies 是存储在用户本地终端上的一些网站 数据(通常是加密的),用于识别用户的身份并执行会话跟踪。 Python 提供了 cookielib 模块来处理 cookie。 cookielib 模块的主要功能是一个对象,它提供了一个可以存储的 cookie,供 urllib2 模块使用以访问 Internet 资源。
import urllib
from http import cookiejar
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
opener = urllib2.build_opener(cookie_support)
urllib2.install_opener(opener)
content = urllib2.urlopen( http://1668s.com).read()
#关键在于CookieJar(),它用于管理HTTP cookie值、
#存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。
#整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失,所有过程都不需要单独去操作。
#手动添加cookie
cookie = "PHPSESSID=91rurfqm2329bopnosfu4fvmu7; kmsign=55d2c12c9b1e3; KMUID=b6Ejc1XSwPq9o756AxnBAg="
request.add_header("Cookie", cookie)
4、伪装成浏览器
有些网站对爬虫的访问感到反感,所以都拒绝爬虫的请求。所以使用urllib2直接访问网站HTTP Error 403: Forbidden经常出现
特别注意一些headers,服务器会检查这些headers
User-Agent 有些服务器或者代理会检查这个值来判断是否是浏览器发起的RequestContent-Type。使用 REST 接口时,服务器会检查这个值来决定如何解析 HTTP Body 中的内容。
php 抓取网页生成图片(阿里云osmgitkids第三方demo架构图为什么这个比较有价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-12 13:04
php抓取网页生成图片,如php最新一次生成图片在2014年5月左右,效果不佳,从2015年1月php开始pptv采用php来生成图片了,就算pptv还没更新,也会有很大概率使用php抓取网页,现在微博普遍有图片,那么抓取微博,在网页上生成图片,肯定是未来php可以支持的一个业务线。那么php还有个重要的短板是html5的引入,那么未来flash是基础,也可以支持html5,作为一个同样的问题,不断的上新技术,拼高并发效率一直是php身上存在的问题,不然我们不用去拼html5,这样会更加节省成本,核心技术都不复杂,回归实际业务。
具体实现怎么实现的实时抓取,其实不在本文讨论范围内,只讨论更加有价值的第三方demo,甚至我觉得更有价值的,第三方demo并不会太依赖于webpack,因为如果使用webpack的话,会有各种不兼容,每一代都有优化。更加有价值的会是第三方的demo,我暂时想到的有:真七鱼架构图阿里云osmgitkids第三方demo架构图为什么这个比较有价值,上面第一个实现的webpack是在开源项目中根据自己的项目改造而来,模块化、设计好,可以很好的扩展,但是对于开源项目的兼容性有些差,flash也会有些不一致的地方,当然具体到每个产品,都会有差异,其他的架构图有空再写吧。
接下来给大家展示的是第三方demo并且是全开源的架构图,可以看到很多非常重要的功能已经是对html5支持,但是缺少canvas这些功能,因为html5的引入,这些第三方demo会有更多的应用场景,比如如果推荐一款php生成网页的工具,当然基于soap通信,提供数据交互接口是很好的,但是html5进来太早了,因为html5是基于html的,不支持数据的传输,不支持语义化标签。
具体的demo有:真七鱼架构图阿里云osmfulthon.js对于第三方demo我想要做的是如何基于javascript引入php第三方的demo,这其实是很头疼的事情,接下来做了如下改动,简单说明一下改动逻辑:1.php开发环境的引入:这里需要做的很简单,添加编译依赖,引入js库、浏览器安装依赖等2.利用js与服务器通信,实现php第三方demo与nodejs的通信,具体方法还要查看其他用户的经验。
说完js和nodejs通信,下面我们再说一下config,只有config支持async的上传服务器,那么接下来我们做下载,这里的图片上传通过php推送服务器,上传完成后我们可以解析一下数据进行展示,都可以控制为图片,我们这里的数据抽象一下数据库上传成功,php命令获取数据库redis的数据源推送解析redis数据源上传之后php获。 查看全部
php 抓取网页生成图片(阿里云osmgitkids第三方demo架构图为什么这个比较有价值)
php抓取网页生成图片,如php最新一次生成图片在2014年5月左右,效果不佳,从2015年1月php开始pptv采用php来生成图片了,就算pptv还没更新,也会有很大概率使用php抓取网页,现在微博普遍有图片,那么抓取微博,在网页上生成图片,肯定是未来php可以支持的一个业务线。那么php还有个重要的短板是html5的引入,那么未来flash是基础,也可以支持html5,作为一个同样的问题,不断的上新技术,拼高并发效率一直是php身上存在的问题,不然我们不用去拼html5,这样会更加节省成本,核心技术都不复杂,回归实际业务。
具体实现怎么实现的实时抓取,其实不在本文讨论范围内,只讨论更加有价值的第三方demo,甚至我觉得更有价值的,第三方demo并不会太依赖于webpack,因为如果使用webpack的话,会有各种不兼容,每一代都有优化。更加有价值的会是第三方的demo,我暂时想到的有:真七鱼架构图阿里云osmgitkids第三方demo架构图为什么这个比较有价值,上面第一个实现的webpack是在开源项目中根据自己的项目改造而来,模块化、设计好,可以很好的扩展,但是对于开源项目的兼容性有些差,flash也会有些不一致的地方,当然具体到每个产品,都会有差异,其他的架构图有空再写吧。
接下来给大家展示的是第三方demo并且是全开源的架构图,可以看到很多非常重要的功能已经是对html5支持,但是缺少canvas这些功能,因为html5的引入,这些第三方demo会有更多的应用场景,比如如果推荐一款php生成网页的工具,当然基于soap通信,提供数据交互接口是很好的,但是html5进来太早了,因为html5是基于html的,不支持数据的传输,不支持语义化标签。
具体的demo有:真七鱼架构图阿里云osmfulthon.js对于第三方demo我想要做的是如何基于javascript引入php第三方的demo,这其实是很头疼的事情,接下来做了如下改动,简单说明一下改动逻辑:1.php开发环境的引入:这里需要做的很简单,添加编译依赖,引入js库、浏览器安装依赖等2.利用js与服务器通信,实现php第三方demo与nodejs的通信,具体方法还要查看其他用户的经验。
说完js和nodejs通信,下面我们再说一下config,只有config支持async的上传服务器,那么接下来我们做下载,这里的图片上传通过php推送服务器,上传完成后我们可以解析一下数据进行展示,都可以控制为图片,我们这里的数据抽象一下数据库上传成功,php命令获取数据库redis的数据源推送解析redis数据源上传之后php获。
php 抓取网页生成图片(微信登录开发,封装成一个类的图片抓取方式不奏效)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-12 04:06
最近在开发微信登录的过程中,发现微信头像图片没有后缀名。传统的图像捕获方法不起作用,需要特殊的捕获处理。所以,后来我们把各种情况结合起来,打包成一个类,分享给大家。感兴趣的朋友,一起来看看下面吧。
一、创建项目
作为演示,我们在 www 根目录下创建项目 grabimg,创建一个类 GrabImage.php 和一个 index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{ }
三、属性
接下来,定义一些需要使用的属性。
1、先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能涉及扩展名替换,所以这里定义
3、这后面是扩展名$extension
4、然后我们定义一个$file_dir。该属性的作用是本地抓取远程图片后存放的目录一般以相对于PHP入口文件的位置为起点。但路径一般不会保存到数据库中。
5、最后我们定义一个$save_dir,顾名思义,这个路径就是直接用来保存的数据库的目录。这里解释一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时路径的替换做准备。我们这里的$save_dir一般是日期+文件名。如果需要使用时需要取出,在前面拼出需要的路径即可。
四、方法
属性写完了,接下来我们正式开始爬取工作。
首先,我们定义一个open方法getInstances来获取一些数据,比如抓取图片地址和本地保存路径。也把它放在属性中。
public function getInstances($img_url , $base_dir) { $this->img_url = $img_url; $this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/ $this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/ }
图片保存路径拼接在一起。接下来,我们需要注意一个问题,目录是否存在。日期一天一天过去,但目录不会自动创建。所以,在保存图片之前,我们首先需要检查,如果当前目录不存在,我们需要动态创建它。
我们创建设置目录方法setDir。我们设置的属性private、safe
/** * 检查图片需要保持的目录是否存在 * 如果不存在,则立即创建一个目录 * @return bool */ private function setDir() { if(!file_exists($this->file_dir)) { mkdir($this->file_dir,0777,TRUE); } $this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法 return true; }
下一步是抓取核心代码
第一步是解决一个问题,我们需要抓取的图片可能没有后缀。按照传统的抓取方式,先抓取图片再截取后缀名的方案是行不通的。
我们必须通过其他方式获取图片类型。方法是从文件流信息中获取文件头信息,从而判断文件mime信息,进而可以知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array( 'image/bmp'=>'bmp', 'image/gif'=>'gif', 'image/jpeg'=>'jpg', 'image/png'=>'png', 'image/x-icon'=>'ico' );
这样,当我得到类型 image/gif 时,我就可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为假时,我们将它分配给变量 $headers
取出的Content-Type的值就是mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){ // 获取响应的类型 $type=$headers['Content-Type']; }
使用我们上面定义的映射表,我们可以很容易的得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type在我们的映射表中可能不存在,说明这种类型的文件不是我们想要的,所以直接丢弃就行了。
以下步骤与传统爬取文件相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension; // 获取数据并保存 $contents=file_get_contents($this->img_url); if(file_put_contents($file_path , $contents)) { // 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg-600 return $this->save_dir.$this->file_name.".".$this->extension; }
先获取完整路径$file_path将图片保存到本地,然后使用file_get_contents抓取数据,再使用file_put_contents保存到刚才的文件路径。
最后我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的抓取方法是:
private function getRemoteImg() { // mime 和 扩展名 的映射 $mimes=array( 'image/bmp'=>'bmp', 'image/gif'=>'gif', 'image/jpeg'=>'jpg', 'image/png'=>'png', 'image/x-icon'=>'ico' ); // 获取响应头 if(($headers=get_headers($this->img_url, 1))!==false) { // 获取响应的类型 $type=$headers['Content-Type']; // 如果符合我们要的类型 if(isset($mimes[$type])) { $this->extension=$mimes[$type]; $file_path = $this->file_dir.$this->file_name.".".$this->extension; // 获取数据并保存 $contents=file_get_contents($this->img_url); if(file_put_contents($file_path , $contents)) { // 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg-600 return $this->save_dir.$this->file_name.".".$this->extension; } } } return false; }
最后,为了简单起见,我们想在别处调用这些方法之一来完成获取。所以我们把抓取动作直接放到getInstances中,配置好路径后直接抓取。因此,在初始化配置方法getInstances中添加代码。
if($this->setDir()) { return $this->getRemoteImg(); } else { return false; }
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
真的抓住了
完整代码
<p> 查看全部
php 抓取网页生成图片(微信登录开发,封装成一个类的图片抓取方式不奏效)
最近在开发微信登录的过程中,发现微信头像图片没有后缀名。传统的图像捕获方法不起作用,需要特殊的捕获处理。所以,后来我们把各种情况结合起来,打包成一个类,分享给大家。感兴趣的朋友,一起来看看下面吧。
一、创建项目
作为演示,我们在 www 根目录下创建项目 grabimg,创建一个类 GrabImage.php 和一个 index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{ }
三、属性
接下来,定义一些需要使用的属性。
1、先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能涉及扩展名替换,所以这里定义
3、这后面是扩展名$extension
4、然后我们定义一个$file_dir。该属性的作用是本地抓取远程图片后存放的目录一般以相对于PHP入口文件的位置为起点。但路径一般不会保存到数据库中。
5、最后我们定义一个$save_dir,顾名思义,这个路径就是直接用来保存的数据库的目录。这里解释一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时路径的替换做准备。我们这里的$save_dir一般是日期+文件名。如果需要使用时需要取出,在前面拼出需要的路径即可。
四、方法
属性写完了,接下来我们正式开始爬取工作。
首先,我们定义一个open方法getInstances来获取一些数据,比如抓取图片地址和本地保存路径。也把它放在属性中。
public function getInstances($img_url , $base_dir) { $this->img_url = $img_url; $this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/ $this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/ }
图片保存路径拼接在一起。接下来,我们需要注意一个问题,目录是否存在。日期一天一天过去,但目录不会自动创建。所以,在保存图片之前,我们首先需要检查,如果当前目录不存在,我们需要动态创建它。
我们创建设置目录方法setDir。我们设置的属性private、safe
/** * 检查图片需要保持的目录是否存在 * 如果不存在,则立即创建一个目录 * @return bool */ private function setDir() { if(!file_exists($this->file_dir)) { mkdir($this->file_dir,0777,TRUE); } $this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法 return true; }
下一步是抓取核心代码
第一步是解决一个问题,我们需要抓取的图片可能没有后缀。按照传统的抓取方式,先抓取图片再截取后缀名的方案是行不通的。
我们必须通过其他方式获取图片类型。方法是从文件流信息中获取文件头信息,从而判断文件mime信息,进而可以知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array( 'image/bmp'=>'bmp', 'image/gif'=>'gif', 'image/jpeg'=>'jpg', 'image/png'=>'png', 'image/x-icon'=>'ico' );
这样,当我得到类型 image/gif 时,我就可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为假时,我们将它分配给变量 $headers
取出的Content-Type的值就是mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){ // 获取响应的类型 $type=$headers['Content-Type']; }
使用我们上面定义的映射表,我们可以很容易的得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type在我们的映射表中可能不存在,说明这种类型的文件不是我们想要的,所以直接丢弃就行了。
以下步骤与传统爬取文件相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension; // 获取数据并保存 $contents=file_get_contents($this->img_url); if(file_put_contents($file_path , $contents)) { // 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg-600 return $this->save_dir.$this->file_name.".".$this->extension; }
先获取完整路径$file_path将图片保存到本地,然后使用file_get_contents抓取数据,再使用file_put_contents保存到刚才的文件路径。
最后我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的抓取方法是:
private function getRemoteImg() { // mime 和 扩展名 的映射 $mimes=array( 'image/bmp'=>'bmp', 'image/gif'=>'gif', 'image/jpeg'=>'jpg', 'image/png'=>'png', 'image/x-icon'=>'ico' ); // 获取响应头 if(($headers=get_headers($this->img_url, 1))!==false) { // 获取响应的类型 $type=$headers['Content-Type']; // 如果符合我们要的类型 if(isset($mimes[$type])) { $this->extension=$mimes[$type]; $file_path = $this->file_dir.$this->file_name.".".$this->extension; // 获取数据并保存 $contents=file_get_contents($this->img_url); if(file_put_contents($file_path , $contents)) { // 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg-600 return $this->save_dir.$this->file_name.".".$this->extension; } } } return false; }
最后,为了简单起见,我们想在别处调用这些方法之一来完成获取。所以我们把抓取动作直接放到getInstances中,配置好路径后直接抓取。因此,在初始化配置方法getInstances中添加代码。
if($this->setDir()) { return $this->getRemoteImg(); } else { return false; }
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
真的抓住了

完整代码
<p>
php 抓取网页生成图片(基于的二维码不上传到服务器页面的实现过程及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-06 20:11
一、背景
要求是后台点击生成二维码,然后不上传二维码到服务器。我们需要将二维码返回首页并显示出来。
二、实现过程
1、生成二维码
这里使用的第三方是二维码。网上百度有很多教程,这里就不赘述了。可以参考链接生成二维码
函数索引($ctx){
require_once APP_PATH.'/classes/phpqrcode/phpqrcode.php';
$link_url="";
$level="L";
$size=6;
ob_start();
$QRcode = new QRcode();
$QRcode->png($link_url,false,$level,$size,2);
记录器::信息(base64_encode(ob_get_contents()));
$imageString =base64_encode(ob_get_contents());
记录器::信息($imageString);
ob_end_clean();
如果(ob_end_clean()){
logger::info('end clen');
}
$数据=数组(
'代码'=> 2,
'二维码'=>$imageString
);
header("content-type:application/json; charset=utf-8");
!!!(上面这行代码肯定有,因为Qrcode::png(),在生成二维码的时候,内部把响应的响应类型改为image/jpeg,所以需要自己手动设置响应头类型,否则接口不能返回json数据)
返回 $data;
}
现在要实现的效果是通过接口将二维码路径返回给前端。
这里需要明确的是,png() 方法返回的是一个二进制图像流。所以直接返回是没用的。如果我们打印返回值,我们会发现返回值为空。所以这里使用ob_start()来执行一系列使用缓冲区的操作。
将二维码路径返回给前端。
这里需要明确的是,png() 方法返回的是一个二进制图像流。所以直接返回是没用的。如果我们打印返回值,我们会发现返回值为空。所以这里使用ob_start()来执行一系列使用缓冲区的操作
1. 第一个参数$text就是上面代码中的URL参数。
2. 第二个参数$outfile默认为No,不生成文件,只返回二维码图片,否则需要生成生成的二维码图片的存放路径
3. 第三个参数$level默认为L,这个参数可以传递的值为L(QR_ECLEVEL_L, 7%), M(QR_ECLEVEL_M, 15%), Q(QR_ECLEVEL_Q, 25%), H(QR_ECLEVEL_H, 30%)。该参数控制二维码的容错率,不同的参数表示二维码可以覆盖的面积百分比。利用二维码的容错率,我们可以将头像放置在生成的二维码图片的任意区域。
4. 第四个参数$size,控制生成图片的大小,默认为4
5. 第五个参数 $margin 控制生成二维码的空白区域的大小
6. 第六个参数$saveandprint,保存二维码图片并显示,$outfile必须传递图片路径。
第二个参数默认为false,该方法返回一个二进制图像流。当页面输出时,缓冲区中生成的内容将从缓冲区发送到浏览器。所以在代码中,日志输出没有记录在日志中,内容输出也不需要使用echo。所以直接用base64_encode(QRcode::png)是没用的。
这里使用 ob_start() 方法打开输出缓冲区。所有输出信息都不会直接发送到浏览器,而是存储在输出缓冲区中。这里是将生成的图片流从buffer中保存到内存对象中,使用base64_encode将其转为编码后的字符串,通过json返回给页面。
php缓存区相关的操作函数如下。
一、 相关功能介绍:
1、Flush:刷新缓冲区的内容并输出。
函数格式:flush()
说明:这个功能经常用到,效率很高。
2、ob_start:打开输出缓冲区
函数格式:void ob_start(void)
注意:当缓冲区被激活时,所有来自 PHP 程序的非文件头信息都不会被发送,而是存储在内部缓冲区中。为了输出缓冲区的内容,可以使用ob_end_flush() 或flush() 来输出缓冲区的内容。
3. ob_get_contents:返回内部缓冲区的内容。
如何使用:字符串 ob_get_contents(void)
说明:该函数将返回当前缓冲区的内容,如果输出缓冲区未激活,则返回FALSE。
4、ob_get_length:返回内部缓冲区的长度。
使用方法:int ob_get_length(void)
说明:该函数将返回当前缓冲区的长度;像 ob_get_contents,如果输出缓冲区没有被激活。它返回 FALSE。
5、ob_end_flush:将内部缓冲区的内容发送到浏览器,并关闭输出缓冲区。
使用方法:void ob_end_flush(void)
说明:该函数发送输出缓冲区的内容(如果有)。
6、ob_end_clean:删除内部缓冲区的内容并关闭内部缓冲区
使用方法:void ob_end_clean(void)
说明:该函数不会输出内部缓冲区的内容,而是将其删除!
7、ob_implicit_flush:开启或关闭绝对刷新
使用方法:void ob_implicit_flush([int flag])
注意:任何使用过 Perl 的人都知道 $|=x 的含义。该字符串可以打开/关闭缓冲区,ob_implicit_flush 函数与此相同。默认是关闭缓冲区。开启绝对输出后,每次脚本输出都是直接发送到浏览器,不需要调用flush()
原链接。 查看全部
php 抓取网页生成图片(基于的二维码不上传到服务器页面的实现过程及应用)
一、背景
要求是后台点击生成二维码,然后不上传二维码到服务器。我们需要将二维码返回首页并显示出来。
二、实现过程
1、生成二维码
这里使用的第三方是二维码。网上百度有很多教程,这里就不赘述了。可以参考链接生成二维码
函数索引($ctx){
require_once APP_PATH.'/classes/phpqrcode/phpqrcode.php';
$link_url="";
$level="L";
$size=6;
ob_start();
$QRcode = new QRcode();
$QRcode->png($link_url,false,$level,$size,2);
记录器::信息(base64_encode(ob_get_contents()));
$imageString =base64_encode(ob_get_contents());
记录器::信息($imageString);
ob_end_clean();
如果(ob_end_clean()){
logger::info('end clen');
}
$数据=数组(
'代码'=> 2,
'二维码'=>$imageString
);
header("content-type:application/json; charset=utf-8");
!!!(上面这行代码肯定有,因为Qrcode::png(),在生成二维码的时候,内部把响应的响应类型改为image/jpeg,所以需要自己手动设置响应头类型,否则接口不能返回json数据)
返回 $data;
}
现在要实现的效果是通过接口将二维码路径返回给前端。
这里需要明确的是,png() 方法返回的是一个二进制图像流。所以直接返回是没用的。如果我们打印返回值,我们会发现返回值为空。所以这里使用ob_start()来执行一系列使用缓冲区的操作。
将二维码路径返回给前端。
这里需要明确的是,png() 方法返回的是一个二进制图像流。所以直接返回是没用的。如果我们打印返回值,我们会发现返回值为空。所以这里使用ob_start()来执行一系列使用缓冲区的操作
1. 第一个参数$text就是上面代码中的URL参数。
2. 第二个参数$outfile默认为No,不生成文件,只返回二维码图片,否则需要生成生成的二维码图片的存放路径
3. 第三个参数$level默认为L,这个参数可以传递的值为L(QR_ECLEVEL_L, 7%), M(QR_ECLEVEL_M, 15%), Q(QR_ECLEVEL_Q, 25%), H(QR_ECLEVEL_H, 30%)。该参数控制二维码的容错率,不同的参数表示二维码可以覆盖的面积百分比。利用二维码的容错率,我们可以将头像放置在生成的二维码图片的任意区域。
4. 第四个参数$size,控制生成图片的大小,默认为4
5. 第五个参数 $margin 控制生成二维码的空白区域的大小
6. 第六个参数$saveandprint,保存二维码图片并显示,$outfile必须传递图片路径。
第二个参数默认为false,该方法返回一个二进制图像流。当页面输出时,缓冲区中生成的内容将从缓冲区发送到浏览器。所以在代码中,日志输出没有记录在日志中,内容输出也不需要使用echo。所以直接用base64_encode(QRcode::png)是没用的。
这里使用 ob_start() 方法打开输出缓冲区。所有输出信息都不会直接发送到浏览器,而是存储在输出缓冲区中。这里是将生成的图片流从buffer中保存到内存对象中,使用base64_encode将其转为编码后的字符串,通过json返回给页面。
php缓存区相关的操作函数如下。
一、 相关功能介绍:
1、Flush:刷新缓冲区的内容并输出。
函数格式:flush()
说明:这个功能经常用到,效率很高。
2、ob_start:打开输出缓冲区
函数格式:void ob_start(void)
注意:当缓冲区被激活时,所有来自 PHP 程序的非文件头信息都不会被发送,而是存储在内部缓冲区中。为了输出缓冲区的内容,可以使用ob_end_flush() 或flush() 来输出缓冲区的内容。
3. ob_get_contents:返回内部缓冲区的内容。
如何使用:字符串 ob_get_contents(void)
说明:该函数将返回当前缓冲区的内容,如果输出缓冲区未激活,则返回FALSE。
4、ob_get_length:返回内部缓冲区的长度。
使用方法:int ob_get_length(void)
说明:该函数将返回当前缓冲区的长度;像 ob_get_contents,如果输出缓冲区没有被激活。它返回 FALSE。
5、ob_end_flush:将内部缓冲区的内容发送到浏览器,并关闭输出缓冲区。
使用方法:void ob_end_flush(void)
说明:该函数发送输出缓冲区的内容(如果有)。
6、ob_end_clean:删除内部缓冲区的内容并关闭内部缓冲区
使用方法:void ob_end_clean(void)
说明:该函数不会输出内部缓冲区的内容,而是将其删除!
7、ob_implicit_flush:开启或关闭绝对刷新
使用方法:void ob_implicit_flush([int flag])
注意:任何使用过 Perl 的人都知道 $|=x 的含义。该字符串可以打开/关闭缓冲区,ob_implicit_flush 函数与此相同。默认是关闭缓冲区。开启绝对输出后,每次脚本输出都是直接发送到浏览器,不需要调用flush()
原链接。
php 抓取网页生成图片( 如何使用PHP生成二维码,以及如何生成中间带LOGO图像的二维码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-06 20:09
如何使用PHP生成二维码,以及如何生成中间带LOGO图像的二维码)
使用PHP生成二维码的两种方法(附logo图片)
更新时间:2021年11月16日09:51:59 投稿:俊杰
随着科学技术的进步,二维码的应用领域越来越广泛。今天给大家分享一下如何使用PHP生成二维码,以及如何生成中间有LOGO图片的二维码。
一、使用Google API生成二维码
谷歌提供了比较完善的二维码生成接口,调用API接口很简单,下面是调用代码:
$urlToEncode="//www.jb51.net";
generateQRfromGoogle($urlToEncode);
/**
* google api 二维码生成【QRcode可以存储最多4296个字母数字类型的任意文本,具体可以查看二维码数据格式】
* @param string $chl 二维码包含的信息,可以是数字、字符、二进制信息、汉字。
不能混合数据类型,数据必须经过UTF-8 URL-encoded
* @param int $widhtHeight 生成二维码的尺寸设置
* @param string $EC_level 可选纠错级别,QR码支持四个等级纠错,用来恢复丢失的、读错的、模糊的、数据。
* L-默认:可以识别已损失的7%的数据
* M-可以识别已损失15%的数据
* Q-可以识别已损失25%的数据
* H-可以识别已损失30%的数据
* @param int $margin 生成的二维码离图片边框的距离
*/
function generateQRfromGoogle($chl,$widhtHeight ='150',$EC_level='L',$margin='0')
{
$chl = urlencode($chl);
echo '';
}
二、使用PHP二维码生成类库PHP二维码生成二维码
PHP QR Code 是一个 PHP 二维码生成库,可用于轻松生成二维码。官网提供下载和多个demo demo。检查地址:。
下载官网提供的类库后,只需要使用phpqrcode.php生成二维码即可。当然,你的PHP环境必须开启支持GD2。phpqrcode.php提供了一个关键的png()方法,其中参数$text表示生成两位数的信息文本;参数$outfile表示是否输出二维码图片文件,默认为no;参数$level代表容错率,即Covered area仍可识别,分别是L(QR_ECLEVEL_L, 7%), M (QR_ECLEVEL_M, 15%), Q (QR_ECLEVEL_Q, 25%), H (QR_ECLEVEL_H, 30 %); 参数$size表示生成图像的大小,默认为3;参数$margin表示二维码周围空白区域的边距值;
public static function png($text, $outfile=false, $level=QR_ECLEVEL_L, $size=3, $margin=4,
$saveandprint=false)
{
$enc = QRencode::factory($level, $size, $margin);
return $enc->encodePNG($text, $outfile, $saveandprint=false);
}
调用PHP二维码非常简单,下面的代码可以生成一个内容为“//”的二维码。
php代码
包括'phpqrcode.php';
二维码::png('//');
在实际应用中,我们会在二维码中间添加自己的LOGO,以增强宣传效果。如何生成带有徽标的二维码?其实原理很简单。首先使用PHP QR Code生成二维码图片,然后使用PHP的图片相关函数将准备好的logo图片添加到新生成的原创二维码图片中,再重新生成一张新的。二维码的图像。
include 'phpqrcode.php';
$value = '//www.jb51.net'; //二维码内容
$errorCorrectionLevel = 'L';//容错级别
$matrixPointSize = 6;//生成图片大小
//生成二维码图片
QRcode::png($value, 'qrcode.png', $errorCorrectionLevel, $matrixPointSize, 2);
$logo = 'logo.png';//准备好的logo图片
$QR = 'qrcode.png';//已经生成的原始二维码图
if ($logo !== FALSE) {
$QR = imagecreatefromstring(file_get_contents($QR));
$logo = imagecreatefromstring(file_get_contents($logo));
$QR_width = imagesx($QR);//二维码图片宽度
$QR_height = imagesy($QR);//二维码图片高度
$logo_width = imagesx($logo);//logo图片宽度
$logo_height = imagesy($logo);//logo图片高度
$logo_qr_width = $QR_width / 5;
$scale = $logo_width/$logo_qr_width;
$logo_qr_height = $logo_height/$scale;
$from_width = ($QR_width - $logo_qr_width) / 2;
//重新组合图片并调整大小
imagecopyresampled($QR, $logo, $from_width, $from_width, 0, 0, $logo_qr_width,
$logo_qr_height, $logo_width, $logo_height);
}
//输出图片
imagepng($QR, 'helloweba.png');
echo 'helloweba.png';
以下是对上面代码的引用,不产生图片文件,方便调用,将以下代码保存为img.php
<p> 查看全部
php 抓取网页生成图片(
如何使用PHP生成二维码,以及如何生成中间带LOGO图像的二维码)
使用PHP生成二维码的两种方法(附logo图片)
更新时间:2021年11月16日09:51:59 投稿:俊杰
随着科学技术的进步,二维码的应用领域越来越广泛。今天给大家分享一下如何使用PHP生成二维码,以及如何生成中间有LOGO图片的二维码。
一、使用Google API生成二维码
谷歌提供了比较完善的二维码生成接口,调用API接口很简单,下面是调用代码:
$urlToEncode="//www.jb51.net";
generateQRfromGoogle($urlToEncode);
/**
* google api 二维码生成【QRcode可以存储最多4296个字母数字类型的任意文本,具体可以查看二维码数据格式】
* @param string $chl 二维码包含的信息,可以是数字、字符、二进制信息、汉字。
不能混合数据类型,数据必须经过UTF-8 URL-encoded
* @param int $widhtHeight 生成二维码的尺寸设置
* @param string $EC_level 可选纠错级别,QR码支持四个等级纠错,用来恢复丢失的、读错的、模糊的、数据。
* L-默认:可以识别已损失的7%的数据
* M-可以识别已损失15%的数据
* Q-可以识别已损失25%的数据
* H-可以识别已损失30%的数据
* @param int $margin 生成的二维码离图片边框的距离
*/
function generateQRfromGoogle($chl,$widhtHeight ='150',$EC_level='L',$margin='0')
{
$chl = urlencode($chl);
echo '
}
二、使用PHP二维码生成类库PHP二维码生成二维码
PHP QR Code 是一个 PHP 二维码生成库,可用于轻松生成二维码。官网提供下载和多个demo demo。检查地址:。
下载官网提供的类库后,只需要使用phpqrcode.php生成二维码即可。当然,你的PHP环境必须开启支持GD2。phpqrcode.php提供了一个关键的png()方法,其中参数$text表示生成两位数的信息文本;参数$outfile表示是否输出二维码图片文件,默认为no;参数$level代表容错率,即Covered area仍可识别,分别是L(QR_ECLEVEL_L, 7%), M (QR_ECLEVEL_M, 15%), Q (QR_ECLEVEL_Q, 25%), H (QR_ECLEVEL_H, 30 %); 参数$size表示生成图像的大小,默认为3;参数$margin表示二维码周围空白区域的边距值;
public static function png($text, $outfile=false, $level=QR_ECLEVEL_L, $size=3, $margin=4,
$saveandprint=false)
{
$enc = QRencode::factory($level, $size, $margin);
return $enc->encodePNG($text, $outfile, $saveandprint=false);
}
调用PHP二维码非常简单,下面的代码可以生成一个内容为“//”的二维码。
php代码
包括'phpqrcode.php';
二维码::png('//');
在实际应用中,我们会在二维码中间添加自己的LOGO,以增强宣传效果。如何生成带有徽标的二维码?其实原理很简单。首先使用PHP QR Code生成二维码图片,然后使用PHP的图片相关函数将准备好的logo图片添加到新生成的原创二维码图片中,再重新生成一张新的。二维码的图像。
include 'phpqrcode.php';
$value = '//www.jb51.net'; //二维码内容
$errorCorrectionLevel = 'L';//容错级别
$matrixPointSize = 6;//生成图片大小
//生成二维码图片
QRcode::png($value, 'qrcode.png', $errorCorrectionLevel, $matrixPointSize, 2);
$logo = 'logo.png';//准备好的logo图片
$QR = 'qrcode.png';//已经生成的原始二维码图
if ($logo !== FALSE) {
$QR = imagecreatefromstring(file_get_contents($QR));
$logo = imagecreatefromstring(file_get_contents($logo));
$QR_width = imagesx($QR);//二维码图片宽度
$QR_height = imagesy($QR);//二维码图片高度
$logo_width = imagesx($logo);//logo图片宽度
$logo_height = imagesy($logo);//logo图片高度
$logo_qr_width = $QR_width / 5;
$scale = $logo_width/$logo_qr_width;
$logo_qr_height = $logo_height/$scale;
$from_width = ($QR_width - $logo_qr_width) / 2;
//重新组合图片并调整大小
imagecopyresampled($QR, $logo, $from_width, $from_width, 0, 0, $logo_qr_width,
$logo_qr_height, $logo_width, $logo_height);
}
//输出图片
imagepng($QR, 'helloweba.png');
echo 'helloweba.png';
以下是对上面代码的引用,不产生图片文件,方便调用,将以下代码保存为img.php
<p>
php 抓取网页生成图片(php实现网站图片尺寸重写时,默认情况下浏览器不会将重写的图片数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-02 08:22
)
当我们使用php实现网站图片大小重写时,浏览器默认不会在本地缓存重写后的图片。现在我将告诉你如何让浏览器缓存这样的图像数据。
// 将以下代码添加到 php 脚本文件中
session_start();
header("Cache-Control: private, max-age=10800, pre-check=10800");
header("Pragma: private");
header("Expires: " . date(DATE_RFC822,strtotime(" 2 day")));
1:如果浏览器已经有缓存版本,它会向后端传递一个$_SERVER['HTTP_IF_MODIFIED_SINCE']。简单来说,我们只需要告诉浏览器使用缓存即可。
if(isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])){
// if the browser has a cached version of this image, send 304
header('Last-Modified: '.$_SERVER['HTTP_IF_MODIFIED_SINCE'],true,304);
exit;
}
2:如果浏览器有缓存版本,更明智的做法是后端判断图片是否已经更新,并据此通知浏览器是否使用缓存版本
$img = "some_image.png";
if (isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])
&&
(strtotime($_SERVER['HTTP_IF_MODIFIED_SINCE']) == filemtime($img))) {
// send the last mod time of the file back
header('Last-Modified: '.gmdate('D, d M Y H:i:s', filemtime($img)).' GMT',
true, 304);
exit;
}
完整代码
session_start();
header("Cache-Control: private, max-age=10800, pre-check=10800");
header("Pragma: private");
header("Expires: " . date(DATE_RFC822,strtotime(" 2 day")));
$img = "some_image.png";
if (isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])
&&
(strtotime($_SERVER['HTTP_IF_MODIFIED_SINCE']) == filemtime($img))) {
// send the last mod time of the file back
header('Last-Modified: '.gmdate('D, d M Y H:i:s', filemtime($img)).' GMT',
true, 304);
exit;
}
// 裁剪图片并告诉浏览器缓存图片
$is = new ImageSizer($img);
$is->resizeImage(75); // resize image to 75px wide
// and here we send the image to the browser with all the stuff required for tell it to cache
header("Content-type: image/jpeg");
header('Last-Modified: ' . gmdate('D, d M Y H:i:s', filemtime($thumbnail)) . ' GMT');
$is->showImage();
图像裁剪类
class ImageSizer {
var $_baseDir;
var $_baseImg;
var $_imgData;
var $_newImg;
var $_newData;
var $_newFormat;
var $_loadPath;
var $_defaultColor = array(255,255,255);
var $keepAspectRatio;
var $makeBigger;
function ImageSizer($baseDir) {
$this->changeBaseDir($baseDir);
$this->keepAspectRatio = true;
$this->makeBigger = false;
}
function changeBaseDir($baseDir) {
$this->_baseDir = $baseDir;
}
function setDefaultColor($r, $g, $b) {
$this->_defaultColor = array($r, $g, $b);
}
function changeFormat($str) {
$str = strtolower($str);
if ($str == 'jpg') $str = "jpeg";
$acceptable_formats = array('jpeg', 'gif', 'png');
if (!in_array($str, $acceptable_formats)) return false;
$this->_newFormat = $str;
}
function loadImage($imgPath) {
// $this->_imgData = getimagesize($this->_baseDir. $imgPath);
$this->_imgData = getimagesize( $imgPath);
$this->_imgData['funcType'] = preg_replace('#image/#i', '', $this->_imgData['mime']);
$acceptable_formats = array('jpeg', 'gif', 'png');
if (!in_array($this->_imgData['funcType'], $acceptable_formats)) return false;
$this->_newData = $this->_imgData;
$funcName = 'imagecreatefrom' . $this->_imgData['funcType'];
//$this->_newImg = $this->_baseImg = $funcName($this->_baseDir. $imgPath);
$this->_newImg = $this->_baseImg = @$funcName( $imgPath);
if(!$this->_baseImg){
echo "
Failed on this image $imgPath
";
return false;
}
$this->_loadPath = $imgPath;
return true;
}
/*function genImageData(){
$funcName = 'image'.$this->getNewType();
$data = $funcName($this->_newImg ? $this->_newImg : $this->_baseImg);
return $data;
}*/
function resizeImage($w, $h, $crop=false) {
$current_w = $this->getWidth();
$current_h = $this->getHeight();
$src_x = $src_y = 0;
$dst_x = $dst_y = 0;
if($w && $h && $crop=="f"){
// fill in the image centre it in white.
// all the src stuff stays the same, just changing the destination suff
$src_x = 0;
$src_y = 0;
$current_h = $current_h;
$current_w = $current_w;
// the destination stuff changes
if($h && $w){
$h_percent = $percent = $h / $current_h;
$w_percent = $percent = $w / $current_w;
$percent = min($h_percent, $w_percent);
}else if($h){
$h_percent = $percent = $h / $current_h;
$percent = $h_percent;
}else if($w){
$w_percent = $percent = $w / $current_w;
$percent = $w_percent;
}
$dst_w = $current_w * $percent;
$dst_h = $current_h * $percent;
$new_w = $w;
$new_h = $h;
// work out destination x and y points
$dst_x = ($new_w - $dst_w)/2;
$dst_y = ($new_h - $dst_h)/2;
}else if($w && $h && $crop=="c"){
$dst_w = $w;
$dst_h = $h;
$new_w = $w;
$new_h = $h;
// if the image we are tyring to crop is smaller than the crop request we dont do aynthing
if($w > $current_w || $h > $current_h){
// the image is smaller than we are trying to crop!
}else{
//the image is bigger on x and y axis.
// check if we can fit horizontally
$w_percent = $current_w/$w;
$h_percent = $current_h/$h;
if($w_percent < $h_percent){
$src_x = 0;
$src_y = ($current_h/2) - (($h * $w_percent)/2);
$current_w = $current_w;
$current_h = ($h * $w_percent);
}else{
$src_x = ($current_w/2) - (($w * $h_percent)/2);
$src_y = 0;
$current_w = ($w * $h_percent);
$current_h = $current_h;
}
}
}else if ($this->keepAspectRatio) {
$percent = 1;
// if ($current_w > $w || $current_h > $h || $this->makeBigger) {
$do_resize=false;
if($w && $current_w > $w){
$do_resize=true;
}else if($h && $current_h > $h){
$do_resize=true;
}else if($w && $current_w < $w && $this->makeBigger){
$do_resize=true;
}else{
// imaeg is alreaedy smaller than requested size
}
if ( $do_resize ) {
if($h && $w){
$h_percent = $percent = $h / $current_h;
$w_percent = $percent = $w / $current_w;
$percent = min($h_percent, $w_percent);
}else if($h){
$h_percent = $percent = $h / $current_h;
$percent = $h_percent;
}else if($w){
$w_percent = $percent = $w / $current_w;
$percent = $w_percent;
}
}
$dst_w = $new_w = $current_w * $percent;
$dst_h = $new_h = $current_h * $percent;
} else{
$dst_w = $new_w = $w;
$dst_h = $new_h = $h;
}
$this->_newImg = ImageCreateTrueColor($new_w, $new_h);
$this->_newData = array($new_w, $new_h);
if ($this->getNewType() == 'png' || $this->getNewType() == 'gif') { // This preserves the transparency
imageAlphaBlending($this->_newImg, false);
imageSaveAlpha($this->_newImg, true);
} else { // This is if converting from PNG to another image format
list($r, $g, $b) = $this->_defaultColor;
$color = imagecolorallocate($this->_newImg, $r, $g, $b);
imagefilledrectangle($this->_newImg, 0,0, $new_w, $new_h, $color);
}
// dst_w dst_h src_w src_h
imagecopyresampled($this->_newImg, $this->_baseImg, $dst_x, $dst_y,$src_x,$src_y, $dst_w, $dst_h, $current_w, $current_h);
return true;
}
function showImage() {
header('Content-type: ' . $this->getNewMime());
$funcName = 'image'.$this->getNewType();
$funcName($this->_newImg ? $this->_newImg : $this->_baseImg);
}
function saveToFile($fileloc) {
$funcName = 'image'.$this->getNewType();
$funcName($this->_newImg ? $this->_newImg : $this->_baseImg, $fileloc,100);
}
function addWatermark($pngloc,$offset_x=0) {
$overlay = imagecreatefrompng($pngloc);
imageAlphaBlending($overlay, false);
imageSaveAlpha($overlay, true);
imagecopy($this->_newImg, $overlay, (imagesx($this->_newImg))-(imagesx($overlay)+$offset_x), (imagesy($this->_newImg))-(imagesy($overlay)), 0, 0, imagesx($overlay), imagesy($overlay));
}
function getBaseDir() { return $this->_baseDir; }
function getWidth() { return $this->_imgData[0]; }
function getHeight() { return $this->_imgData[1]; }
function getMime() { return $this->_imgData['mime']; }
function getType() { return $this->_imgData['funcType'];}
function getNewWidth() { return $this->_newData[0]; }
function getNewHeight() { return $this->_newData[1]; }
function getNewMime() {return $this->_newFormat ? 'image/' . $this->_newFormat : $this->_imgData['mime'];}
function getNewType() {return $this->_newFormat ? $this->_newFormat : $this->_imgData['funcType'];}
} 查看全部
php 抓取网页生成图片(php实现网站图片尺寸重写时,默认情况下浏览器不会将重写的图片数据
)
当我们使用php实现网站图片大小重写时,浏览器默认不会在本地缓存重写后的图片。现在我将告诉你如何让浏览器缓存这样的图像数据。
// 将以下代码添加到 php 脚本文件中
session_start();
header("Cache-Control: private, max-age=10800, pre-check=10800");
header("Pragma: private");
header("Expires: " . date(DATE_RFC822,strtotime(" 2 day")));
1:如果浏览器已经有缓存版本,它会向后端传递一个$_SERVER['HTTP_IF_MODIFIED_SINCE']。简单来说,我们只需要告诉浏览器使用缓存即可。
if(isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])){
// if the browser has a cached version of this image, send 304
header('Last-Modified: '.$_SERVER['HTTP_IF_MODIFIED_SINCE'],true,304);
exit;
}
2:如果浏览器有缓存版本,更明智的做法是后端判断图片是否已经更新,并据此通知浏览器是否使用缓存版本
$img = "some_image.png";
if (isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])
&&
(strtotime($_SERVER['HTTP_IF_MODIFIED_SINCE']) == filemtime($img))) {
// send the last mod time of the file back
header('Last-Modified: '.gmdate('D, d M Y H:i:s', filemtime($img)).' GMT',
true, 304);
exit;
}
完整代码
session_start();
header("Cache-Control: private, max-age=10800, pre-check=10800");
header("Pragma: private");
header("Expires: " . date(DATE_RFC822,strtotime(" 2 day")));
$img = "some_image.png";
if (isset($_SERVER['HTTP_IF_MODIFIED_SINCE'])
&&
(strtotime($_SERVER['HTTP_IF_MODIFIED_SINCE']) == filemtime($img))) {
// send the last mod time of the file back
header('Last-Modified: '.gmdate('D, d M Y H:i:s', filemtime($img)).' GMT',
true, 304);
exit;
}
// 裁剪图片并告诉浏览器缓存图片
$is = new ImageSizer($img);
$is->resizeImage(75); // resize image to 75px wide
// and here we send the image to the browser with all the stuff required for tell it to cache
header("Content-type: image/jpeg");
header('Last-Modified: ' . gmdate('D, d M Y H:i:s', filemtime($thumbnail)) . ' GMT');
$is->showImage();
图像裁剪类
class ImageSizer {
var $_baseDir;
var $_baseImg;
var $_imgData;
var $_newImg;
var $_newData;
var $_newFormat;
var $_loadPath;
var $_defaultColor = array(255,255,255);
var $keepAspectRatio;
var $makeBigger;
function ImageSizer($baseDir) {
$this->changeBaseDir($baseDir);
$this->keepAspectRatio = true;
$this->makeBigger = false;
}
function changeBaseDir($baseDir) {
$this->_baseDir = $baseDir;
}
function setDefaultColor($r, $g, $b) {
$this->_defaultColor = array($r, $g, $b);
}
function changeFormat($str) {
$str = strtolower($str);
if ($str == 'jpg') $str = "jpeg";
$acceptable_formats = array('jpeg', 'gif', 'png');
if (!in_array($str, $acceptable_formats)) return false;
$this->_newFormat = $str;
}
function loadImage($imgPath) {
// $this->_imgData = getimagesize($this->_baseDir. $imgPath);
$this->_imgData = getimagesize( $imgPath);
$this->_imgData['funcType'] = preg_replace('#image/#i', '', $this->_imgData['mime']);
$acceptable_formats = array('jpeg', 'gif', 'png');
if (!in_array($this->_imgData['funcType'], $acceptable_formats)) return false;
$this->_newData = $this->_imgData;
$funcName = 'imagecreatefrom' . $this->_imgData['funcType'];
//$this->_newImg = $this->_baseImg = $funcName($this->_baseDir. $imgPath);
$this->_newImg = $this->_baseImg = @$funcName( $imgPath);
if(!$this->_baseImg){
echo "
Failed on this image $imgPath
";
return false;
}
$this->_loadPath = $imgPath;
return true;
}
/*function genImageData(){
$funcName = 'image'.$this->getNewType();
$data = $funcName($this->_newImg ? $this->_newImg : $this->_baseImg);
return $data;
}*/
function resizeImage($w, $h, $crop=false) {
$current_w = $this->getWidth();
$current_h = $this->getHeight();
$src_x = $src_y = 0;
$dst_x = $dst_y = 0;
if($w && $h && $crop=="f"){
// fill in the image centre it in white.
// all the src stuff stays the same, just changing the destination suff
$src_x = 0;
$src_y = 0;
$current_h = $current_h;
$current_w = $current_w;
// the destination stuff changes
if($h && $w){
$h_percent = $percent = $h / $current_h;
$w_percent = $percent = $w / $current_w;
$percent = min($h_percent, $w_percent);
}else if($h){
$h_percent = $percent = $h / $current_h;
$percent = $h_percent;
}else if($w){
$w_percent = $percent = $w / $current_w;
$percent = $w_percent;
}
$dst_w = $current_w * $percent;
$dst_h = $current_h * $percent;
$new_w = $w;
$new_h = $h;
// work out destination x and y points
$dst_x = ($new_w - $dst_w)/2;
$dst_y = ($new_h - $dst_h)/2;
}else if($w && $h && $crop=="c"){
$dst_w = $w;
$dst_h = $h;
$new_w = $w;
$new_h = $h;
// if the image we are tyring to crop is smaller than the crop request we dont do aynthing
if($w > $current_w || $h > $current_h){
// the image is smaller than we are trying to crop!
}else{
//the image is bigger on x and y axis.
// check if we can fit horizontally
$w_percent = $current_w/$w;
$h_percent = $current_h/$h;
if($w_percent < $h_percent){
$src_x = 0;
$src_y = ($current_h/2) - (($h * $w_percent)/2);
$current_w = $current_w;
$current_h = ($h * $w_percent);
}else{
$src_x = ($current_w/2) - (($w * $h_percent)/2);
$src_y = 0;
$current_w = ($w * $h_percent);
$current_h = $current_h;
}
}
}else if ($this->keepAspectRatio) {
$percent = 1;
// if ($current_w > $w || $current_h > $h || $this->makeBigger) {
$do_resize=false;
if($w && $current_w > $w){
$do_resize=true;
}else if($h && $current_h > $h){
$do_resize=true;
}else if($w && $current_w < $w && $this->makeBigger){
$do_resize=true;
}else{
// imaeg is alreaedy smaller than requested size
}
if ( $do_resize ) {
if($h && $w){
$h_percent = $percent = $h / $current_h;
$w_percent = $percent = $w / $current_w;
$percent = min($h_percent, $w_percent);
}else if($h){
$h_percent = $percent = $h / $current_h;
$percent = $h_percent;
}else if($w){
$w_percent = $percent = $w / $current_w;
$percent = $w_percent;
}
}
$dst_w = $new_w = $current_w * $percent;
$dst_h = $new_h = $current_h * $percent;
} else{
$dst_w = $new_w = $w;
$dst_h = $new_h = $h;
}
$this->_newImg = ImageCreateTrueColor($new_w, $new_h);
$this->_newData = array($new_w, $new_h);
if ($this->getNewType() == 'png' || $this->getNewType() == 'gif') { // This preserves the transparency
imageAlphaBlending($this->_newImg, false);
imageSaveAlpha($this->_newImg, true);
} else { // This is if converting from PNG to another image format
list($r, $g, $b) = $this->_defaultColor;
$color = imagecolorallocate($this->_newImg, $r, $g, $b);
imagefilledrectangle($this->_newImg, 0,0, $new_w, $new_h, $color);
}
// dst_w dst_h src_w src_h
imagecopyresampled($this->_newImg, $this->_baseImg, $dst_x, $dst_y,$src_x,$src_y, $dst_w, $dst_h, $current_w, $current_h);
return true;
}
function showImage() {
header('Content-type: ' . $this->getNewMime());
$funcName = 'image'.$this->getNewType();
$funcName($this->_newImg ? $this->_newImg : $this->_baseImg);
}
function saveToFile($fileloc) {
$funcName = 'image'.$this->getNewType();
$funcName($this->_newImg ? $this->_newImg : $this->_baseImg, $fileloc,100);
}
function addWatermark($pngloc,$offset_x=0) {
$overlay = imagecreatefrompng($pngloc);
imageAlphaBlending($overlay, false);
imageSaveAlpha($overlay, true);
imagecopy($this->_newImg, $overlay, (imagesx($this->_newImg))-(imagesx($overlay)+$offset_x), (imagesy($this->_newImg))-(imagesy($overlay)), 0, 0, imagesx($overlay), imagesy($overlay));
}
function getBaseDir() { return $this->_baseDir; }
function getWidth() { return $this->_imgData[0]; }
function getHeight() { return $this->_imgData[1]; }
function getMime() { return $this->_imgData['mime']; }
function getType() { return $this->_imgData['funcType'];}
function getNewWidth() { return $this->_newData[0]; }
function getNewHeight() { return $this->_newData[1]; }
function getNewMime() {return $this->_newFormat ? 'image/' . $this->_newFormat : $this->_imgData['mime'];}
function getNewType() {return $this->_newFormat ? $this->_newFormat : $this->_imgData['funcType'];}
}
php 抓取网页生成图片(php抓取网页生成图片这个挺适合做字幕外挂+模糊特效之类的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-02-01 02:01
php抓取网页生成图片这个挺适合做字幕外挂+模糊特效之类的如果要抓取知乎文章,php文章封面之类的,php封装好抓取脚本,就能每天网页全是爬虫脚本,但这个版本的php语言有点老了,有点不适合抓取php网页,但可以爬其他php的网页。php实现redis的定向消息通信google和百度的通信是异步的,不太容易,im应用流行使用同步php处理然后js接受请求然后通过ajax进行处理,php负责保证通信质量如果仅仅是增加小功能需要构建新的框架,不过真做好了还是只能自己一点点实现一个框架吧,不会c语言用个php现成的应该就能满足。
而且做应用框架用的肯定是php语言的标准库和封装好的一些经典库,这些库能直接使用。实现功能用另一个语言可能会产生性能的问题,自己了解这个可能要花些功夫了。
可以尝试学习多进程+http的方式来进行开发。
php处理接口要接受多个字段来判断这个是否为true。(这句话换成java/c#是不是也通用?)发送字段a(年龄)给接收字段b(用户名)来判断这个是否为true,或者e.g.m_id===b.a.age.判断最终结果为true的则返回true,
谢邀,不过我不是计算机专业的,更别说是不是it专业的了。所以更新了一下答案。 查看全部
php 抓取网页生成图片(php抓取网页生成图片这个挺适合做字幕外挂+模糊特效之类的)
php抓取网页生成图片这个挺适合做字幕外挂+模糊特效之类的如果要抓取知乎文章,php文章封面之类的,php封装好抓取脚本,就能每天网页全是爬虫脚本,但这个版本的php语言有点老了,有点不适合抓取php网页,但可以爬其他php的网页。php实现redis的定向消息通信google和百度的通信是异步的,不太容易,im应用流行使用同步php处理然后js接受请求然后通过ajax进行处理,php负责保证通信质量如果仅仅是增加小功能需要构建新的框架,不过真做好了还是只能自己一点点实现一个框架吧,不会c语言用个php现成的应该就能满足。
而且做应用框架用的肯定是php语言的标准库和封装好的一些经典库,这些库能直接使用。实现功能用另一个语言可能会产生性能的问题,自己了解这个可能要花些功夫了。
可以尝试学习多进程+http的方式来进行开发。
php处理接口要接受多个字段来判断这个是否为true。(这句话换成java/c#是不是也通用?)发送字段a(年龄)给接收字段b(用户名)来判断这个是否为true,或者e.g.m_id===b.a.age.判断最终结果为true的则返回true,
谢邀,不过我不是计算机专业的,更别说是不是it专业的了。所以更新了一下答案。
php 抓取网页生成图片( tag页面是什么?如何提高页面加载速度之图片优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-01-31 03:14
tag页面是什么?如何提高页面加载速度之图片优化)
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
图片优化提高页面加载速度
由于大家追求个性,很多博主喜欢用图片来美化自己的页面,但是你知道如果不好好优化图片,页面打开速度会慢很多吗?今天我们来谈谈如何优化图像。
搜索引擎蜘蛛抓取页面的流程示意图
学seo的人经常在网上看到一句话:搜索引擎蜘蛛类似于浏览器,都是爬网页。那么哪些是相同的,哪些是不同的呢?我将帮助您了解搜索引擎蜘蛛如何通过浏览器抓取页面。
当 PHP 删除 文章 时,它也会删除生成的 HTML 页面
添加文章时会生成一个静态html页面,但是如果要删除文章,添加文章时生成的html静态页面也要同时删除,否则会变成多余的文件,所以我们在删除无用的文章的时候,要同时删除生成的HTML静态页面。让我们看看如何同时删除PHP文章系统中生成的HTML静态页面。这里只是一个简单的原理系统,可以作为参考。比较成熟的系统可以参考比较成熟的cms系统。以下是源代码文件。
IE无法加载页面Java怎么办
页面Java无法在IE中加载的解决方法:先打开Java的编写;然后单击安全选项卡中的[编辑站点列表...],然后单击添加;最后,在新的输入框中添加需要使用Java的新输入框。网址就可以了。IE中的页面Java
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
如何在页面上显示java错误消息
页面显示java错误信息的方法:先自定义异常类;然后在服务层抛出异常类,控制器类继承主异常类;然后定义主异常类,可以编写多个自定义异常类;终于完成了信息类
百度的索引量是百度SEO蜘蛛抓取的页面数网站
百度的索引量是百度SEO蜘蛛抓取的页面数网站;而site命令查询到的页面只是被释放的页面,也就是所谓的百度展示页面已经收录。总体而言,百度索引量和站点查询收入
五个细节要做好网站图片页面SEO优化
目前大家都在讨论如何优化文章页面,带有文字内容的页面很容易被搜索引擎识别。但是现在很多专注于图片内容的网站,比如摄影网站、照片分享网站等,都无法原封不动地照搬这些理论。毕竟,能写的字不多。不错的 网站 是从基本页面优化而来的。今天,我将分享一些我在图片页面的SEO优化方面的一些经验。
谷歌通过提交表单来抓取新页面
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细的,但是看到写了幻灭,直接引用了主要内容
使用java的html解析器jsoup和jQuery实现对任意网站页面指定元素的自动重复抓取...
日期:2012-7-20 来源:在线Demo 本地下载 如果你曾经开发过内容聚合类网站,那么使用程序动态整合不同页面或网站的内容的功能一定非常棒对你熟悉的有用。通常使用java,我们会用到一些HTML解析,比如httpparser,最早的集成搜索就是用httpparser抓取谷歌和百度的搜索结果,集成呈现给搜索用户。
使用 Google WebP 图像格式来帮助控制 网站 页面大小
导致网页膨胀的罪魁祸首不是大量使用的 JavaScript 库、CSS 和无休止的分享按钮,而是漂亮的图片。根据 HTTPArchive 的研究,图像约占页面内容的 60%。这意味着大多数 网站 可以压缩图像以减小页面本身的大小。如果你有兴趣了解HTTPArchive的研究以及如何优化网页加载速度,推荐阅读文章-分享过去gbin1发布的一些优化网页加载速度的技巧?
SEO 页面 收录分析和爬虫
蜘蛛爬取分析是分析蜘蛛网站所抓取的页面的行为,目的是分析蜘蛛所抓取的页面占实际页面数的百分比,并检测网站内部的连通性链接并深入了解蜘蛛爬行规则。蜘蛛爬取一般根据URL级别进行分析
大型网站SEO页面生成机制及数据分析
页面自动生成机制是指从指南-在线-调优的全过程,由机器自动生成,人工辅助调整参数。适用于数据量大的站点。而且很久以前就有人用过,这是一个古老的套路。当然,小站点和新站点也不是不可能,只是需要花很短的时间。
大型网站SEO页面生成机制及数据分析
页面自动生成机制是指从指南-在线-调优的全过程,由机器自动生成,人工辅助调整参数。适用于数据量大的站点。而且很久以前就有人用过,这是一个古老的套路。当然,小站点和新站点也不是不可能,只是需要花很短的时间。 查看全部
php 抓取网页生成图片(
tag页面是什么?如何提高页面加载速度之图片优化)
什么是标签页?如何优化标签页?
什么是标签页?如何优化标签页?标签页是很常用的,如果用得好,SEO效果会很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
图片优化提高页面加载速度
由于大家追求个性,很多博主喜欢用图片来美化自己的页面,但是你知道如果不好好优化图片,页面打开速度会慢很多吗?今天我们来谈谈如何优化图像。
搜索引擎蜘蛛抓取页面的流程示意图
学seo的人经常在网上看到一句话:搜索引擎蜘蛛类似于浏览器,都是爬网页。那么哪些是相同的,哪些是不同的呢?我将帮助您了解搜索引擎蜘蛛如何通过浏览器抓取页面。
当 PHP 删除 文章 时,它也会删除生成的 HTML 页面
添加文章时会生成一个静态html页面,但是如果要删除文章,添加文章时生成的html静态页面也要同时删除,否则会变成多余的文件,所以我们在删除无用的文章的时候,要同时删除生成的HTML静态页面。让我们看看如何同时删除PHP文章系统中生成的HTML静态页面。这里只是一个简单的原理系统,可以作为参考。比较成熟的系统可以参考比较成熟的cms系统。以下是源代码文件。
IE无法加载页面Java怎么办
页面Java无法在IE中加载的解决方法:先打开Java的编写;然后单击安全选项卡中的[编辑站点列表...],然后单击添加;最后,在新的输入框中添加需要使用Java的新输入框。网址就可以了。IE中的页面Java
dedecms自动生成标签的方法是什么
文章后台:由于织梦dedecms无法自动生成标签,所以系统后台TAG标签管理生成的标签实际上是复制关键字,然后插入到标签中。所以如果我们想自动生成一个标签,我们需要将关键字的值赋给这个标签
如何在页面上显示java错误消息
页面显示java错误信息的方法:先自定义异常类;然后在服务层抛出异常类,控制器类继承主异常类;然后定义主异常类,可以编写多个自定义异常类;终于完成了信息类
百度的索引量是百度SEO蜘蛛抓取的页面数网站
百度的索引量是百度SEO蜘蛛抓取的页面数网站;而site命令查询到的页面只是被释放的页面,也就是所谓的百度展示页面已经收录。总体而言,百度索引量和站点查询收入
五个细节要做好网站图片页面SEO优化
目前大家都在讨论如何优化文章页面,带有文字内容的页面很容易被搜索引擎识别。但是现在很多专注于图片内容的网站,比如摄影网站、照片分享网站等,都无法原封不动地照搬这些理论。毕竟,能写的字不多。不错的 网站 是从基本页面优化而来的。今天,我将分享一些我在图片页面的SEO优化方面的一些经验。
谷歌通过提交表单来抓取新页面
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细的,但是看到写了幻灭,直接引用了主要内容
使用java的html解析器jsoup和jQuery实现对任意网站页面指定元素的自动重复抓取...
日期:2012-7-20 来源:在线Demo 本地下载 如果你曾经开发过内容聚合类网站,那么使用程序动态整合不同页面或网站的内容的功能一定非常棒对你熟悉的有用。通常使用java,我们会用到一些HTML解析,比如httpparser,最早的集成搜索就是用httpparser抓取谷歌和百度的搜索结果,集成呈现给搜索用户。
使用 Google WebP 图像格式来帮助控制 网站 页面大小
导致网页膨胀的罪魁祸首不是大量使用的 JavaScript 库、CSS 和无休止的分享按钮,而是漂亮的图片。根据 HTTPArchive 的研究,图像约占页面内容的 60%。这意味着大多数 网站 可以压缩图像以减小页面本身的大小。如果你有兴趣了解HTTPArchive的研究以及如何优化网页加载速度,推荐阅读文章-分享过去gbin1发布的一些优化网页加载速度的技巧?
SEO 页面 收录分析和爬虫
蜘蛛爬取分析是分析蜘蛛网站所抓取的页面的行为,目的是分析蜘蛛所抓取的页面占实际页面数的百分比,并检测网站内部的连通性链接并深入了解蜘蛛爬行规则。蜘蛛爬取一般根据URL级别进行分析
大型网站SEO页面生成机制及数据分析
页面自动生成机制是指从指南-在线-调优的全过程,由机器自动生成,人工辅助调整参数。适用于数据量大的站点。而且很久以前就有人用过,这是一个古老的套路。当然,小站点和新站点也不是不可能,只是需要花很短的时间。
大型网站SEO页面生成机制及数据分析
页面自动生成机制是指从指南-在线-调优的全过程,由机器自动生成,人工辅助调整参数。适用于数据量大的站点。而且很久以前就有人用过,这是一个古老的套路。当然,小站点和新站点也不是不可能,只是需要花很短的时间。
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-24 18:01
PHP可以快速生成图片验证码并实现验证插件1.插件功能:该插件可以快速实现网站验证码的功能,包括生成和验证验证码。 2.必填参数:CaptchaTool类收录两个方法,generate方法可以在'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中生成四个字符,并将这些字符写在captcha目录下的图片上,并将code值保存在session中,并输出,此方法不需要参数。 check 方法需要用户输入的代码值,返回 true 和 false。 3.使用方法:收录该类文件,实例化,获取到的对象调用对应的方法。 4.注意:使用本插件的用户可以根据自己的网站需要扩展验证码字符模型,将要扩展的字符放在$chars中,同时需要在for 循环进行适当的调整。确保 $bg_flie 的路径文件地址是验证码背景图片的地址。验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字的大小由imagestring()中的第二个参数决定。可以使用函数 imagecolorallocate() 按需为字符串颜色分配画布颜色。 查看全部
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
PHP可以快速生成图片验证码并实现验证插件1.插件功能:该插件可以快速实现网站验证码的功能,包括生成和验证验证码。 2.必填参数:CaptchaTool类收录两个方法,generate方法可以在'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中生成四个字符,并将这些字符写在captcha目录下的图片上,并将code值保存在session中,并输出,此方法不需要参数。 check 方法需要用户输入的代码值,返回 true 和 false。 3.使用方法:收录该类文件,实例化,获取到的对象调用对应的方法。 4.注意:使用本插件的用户可以根据自己的网站需要扩展验证码字符模型,将要扩展的字符放在$chars中,同时需要在for 循环进行适当的调整。确保 $bg_flie 的路径文件地址是验证码背景图片的地址。验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字的大小由imagestring()中的第二个参数决定。可以使用函数 imagecolorallocate() 按需为字符串颜色分配画布颜色。
php 抓取网页生成图片(微信内生成页面图片也好,你用对了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-24 01:18
既然打开了这个博客,想必你一定遇到了一个与页面截图数量有关的问题。无论是在浏览器中生成图片,还是在微信中生成页面图片,都需要面临将页面内容转化为图片的问题。问题。
1.把整个页面变成图片;
2.将页面的部分内容转化为图片。
解决方法如下:
1.介绍html2canvas
为了更方便有效的开发,这里可以引入html2canvas插件。如果读者不想采用这种方案,可以跳过以下内容,自行寻找其他方案。
点击查看相关文档:html2canvas 官方文档
导入方式:
npm install --save html2canvas
或者:
纱线添加html2canvas
2.在组件中引入html2canvas
插件安装好后,在需要使用的vue组件中,导入插件如下:
从“html2canvas”导入 html2canvas
至此,基本环境已经配置完毕,可以接下来使用了。
3. 将指定区域转换为图片
首先需要让html2canvas获取要转换的节点的内容,所以需要添加一个ref标签。
一个例子如下:
imageDom 需要是要转换的页面内容的父容器,即要转换的页面内容需要全部收录在 imageDom 节点内。
转换方法如下:
/**
* 将页面指定节点内容转为图片
* 1.拿到想要转换为图片的内容节点DOM;
* 2.转换,拿到转换后的canvas
* 3.转换为图片
*/
clickGeneratePicture() {
html2canvas(this.$refs.imageDom).then(canvas => {
// 转成图片,生成图片地址
this.imgUrl = canvas.toDataURL("image/png");
});
}
官方示例如下:
html2canvas(document.querySelector("#capture")).then(canvas => {
document.body.appendChild(canvas)
});
返回的 canvas 参数是一个生成的 canvas 元素。如果要将其转换为图像,可以直接使用 toDataURL 方法。将转换后的图片地址分配给你要展示的图片元素,就可以在页面上看到转换了。发布图片。
问题一:微信浏览器无法直接下载生成的图片。
在chrome等浏览器中,可以使用以下方法直接下载生成的图片:
// 创建隐藏的可下载链接
var eleLink = document.createElement("a");
eleLink.href = imgUrl; // 转换后的图片地址
eleLink.download = "pictureName";
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
但是,微信浏览器禁用了下载链接。只能使用引导的方式来引导用户将页面内容转化为图片并显示出来。用户可以长按显示的图像保存在本地。
如图所示:
问题2:页面的某些内容无法在生成的图片中显示
之所以能生成图片,是因为页面上指定的内容DOM元素被转换成canvas。转换时,并不是所有的 CSS 属性都支持,例如:box-shadow、text-overflow:ellipsis 等。
因此,当图片内容为空白时,建议修改 CSS 呈现样式。
生成图像的背景默认为白色。可以通过 backgroundColor 属性修改背景颜色,如下:
html2canvas(this.$refs.imageDom, {
backgroundColor: null // null 表示设置背景为透明色
})
生成的画布的宽高,是否允许跨域图片等,读者可以参考官方文档进行相应的设置。
欢迎关注博主:小生贤君,有什么问题可以留言~ 查看全部
php 抓取网页生成图片(微信内生成页面图片也好,你用对了吗?)
既然打开了这个博客,想必你一定遇到了一个与页面截图数量有关的问题。无论是在浏览器中生成图片,还是在微信中生成页面图片,都需要面临将页面内容转化为图片的问题。问题。
1.把整个页面变成图片;
2.将页面的部分内容转化为图片。
解决方法如下:
1.介绍html2canvas
为了更方便有效的开发,这里可以引入html2canvas插件。如果读者不想采用这种方案,可以跳过以下内容,自行寻找其他方案。
点击查看相关文档:html2canvas 官方文档
导入方式:
npm install --save html2canvas
或者:
纱线添加html2canvas
2.在组件中引入html2canvas
插件安装好后,在需要使用的vue组件中,导入插件如下:
从“html2canvas”导入 html2canvas
至此,基本环境已经配置完毕,可以接下来使用了。
3. 将指定区域转换为图片
首先需要让html2canvas获取要转换的节点的内容,所以需要添加一个ref标签。
一个例子如下:
imageDom 需要是要转换的页面内容的父容器,即要转换的页面内容需要全部收录在 imageDom 节点内。
转换方法如下:
/**
* 将页面指定节点内容转为图片
* 1.拿到想要转换为图片的内容节点DOM;
* 2.转换,拿到转换后的canvas
* 3.转换为图片
*/
clickGeneratePicture() {
html2canvas(this.$refs.imageDom).then(canvas => {
// 转成图片,生成图片地址
this.imgUrl = canvas.toDataURL("image/png");
});
}
官方示例如下:
html2canvas(document.querySelector("#capture")).then(canvas => {
document.body.appendChild(canvas)
});
返回的 canvas 参数是一个生成的 canvas 元素。如果要将其转换为图像,可以直接使用 toDataURL 方法。将转换后的图片地址分配给你要展示的图片元素,就可以在页面上看到转换了。发布图片。
问题一:微信浏览器无法直接下载生成的图片。
在chrome等浏览器中,可以使用以下方法直接下载生成的图片:
// 创建隐藏的可下载链接
var eleLink = document.createElement("a");
eleLink.href = imgUrl; // 转换后的图片地址
eleLink.download = "pictureName";
// 触发点击
document.body.appendChild(eleLink);
eleLink.click();
// 然后移除
document.body.removeChild(eleLink);
但是,微信浏览器禁用了下载链接。只能使用引导的方式来引导用户将页面内容转化为图片并显示出来。用户可以长按显示的图像保存在本地。
如图所示:
问题2:页面的某些内容无法在生成的图片中显示
之所以能生成图片,是因为页面上指定的内容DOM元素被转换成canvas。转换时,并不是所有的 CSS 属性都支持,例如:box-shadow、text-overflow:ellipsis 等。
因此,当图片内容为空白时,建议修改 CSS 呈现样式。
生成图像的背景默认为白色。可以通过 backgroundColor 属性修改背景颜色,如下:
html2canvas(this.$refs.imageDom, {
backgroundColor: null // null 表示设置背景为透明色
})
生成的画布的宽高,是否允许跨域图片等,读者可以参考官方文档进行相应的设置。
欢迎关注博主:小生贤君,有什么问题可以留言~
php 抓取网页生成图片(LinuxCentOS6-64bit下载下来后是什么样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-22 05:12
要求:将网页转换为pdf或图片并提供下载。
wkhtmltox项目主页:支持html转pdf、图片
php扩展php-wkhtmltox项目主页:
1、下载安装wkhtmltox系统环境
根据系统类型选择下载wkhtmltox:
这里我的系统环境是 CentOS 6-64bit 所以选择:Linux CentOS 6 - 64bit
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。
安装 wkhtmltox:
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
错误:依赖失败:
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 额外内容:
* 更新:
================================================ === ============= N/S 已匹配:75dpi =========================== ===== ================================
xorg-x11-fonts-75dpi.noarch :一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch :一组用于 X 的 75dpi ISO-8859-1 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch : ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch : ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch :一组用于 X 的 75dpi 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch : ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“搜索全部”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
使用下面的方法直接解压rpm包中的编译包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面收录四个文件夹:local/bin、local/include、local/share、local/lib
将对应文件夹的内容复制到/usr/local!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
2、安装 php-wkhtmltox 扩展
在github上下载源码包[php-wkhtmltox_master.zip]
>解压php-wkhtmltox_master.zip
> cd phpwkhtmltox
>php化
> ./configure--with-php-config=/usr/local/php/bin/php-config #这取决于各自系统的php安装路径
> 制作 && 制作安装
> ldconfig #重新加载系统动态链接库
> php -m
#检查是否扩展成功如果可以看到phpwkhtmltox,则扩展成功
已安装 php-wkhtmltox 扩展。
3、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm 重启
安装完成!
本文参考资料:
安装部分可以使用本文介绍的安装部分,部分可能需要中文字体支持,可以参考上面的中文字体库安装部分进行扩展。 查看全部
php 抓取网页生成图片(LinuxCentOS6-64bit下载下来后是什么样的?)
要求:将网页转换为pdf或图片并提供下载。
wkhtmltox项目主页:支持html转pdf、图片
php扩展php-wkhtmltox项目主页:
1、下载安装wkhtmltox系统环境
根据系统类型选择下载wkhtmltox:
这里我的系统环境是 CentOS 6-64bit 所以选择:Linux CentOS 6 - 64bit
下载后是一个rpm包[wkhtmltox-0.12.2_linux-centos6-amd64.rpm]。
安装 wkhtmltox:
> rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
错误:依赖失败:
wkhtmltox-1 需要 xorg-x11-fonts-75dpi:0.12.2-1.x86_64
#提示安装75dpi
>百胜搜索75dpi
加载的插件:fastestmirror、refresh-packagekit、security
从缓存的主机文件加载镜像速度
* 基数:
* 额外内容:
* 更新:
================================================ === ============= N/S 已匹配:75dpi =========================== ===== ================================
xorg-x11-fonts-75dpi.noarch :一组用于 X Window 系统的 75dpi 分辨率字体。
xorg-x11-fonts-ISO8859-1-75dpi.noarch :一组用于 X 的 75dpi ISO-8859-1 字体。
xorg-x11-fonts-ISO8859-14-75dpi.noarch : ISO8859-14-75dpi 字体
xorg-x11-fonts-ISO8859-15-75dpi.noarch : ISO8859-15-75dpi 字体
xorg-x11-fonts-ISO8859-2-75dpi.noarch :一组用于 X 的 75dpi 中欧语言字体。
xorg-x11-fonts-ISO8859-9-75dpi.noarch : ISO8859-9-75dpi 字体
仅匹配名称和摘要,对所有内容使用“搜索全部”。
> yum installxorg-x11-fonts-75dpi.noarch
安装完成后,执行:
>rpm-ivhwkhtmltox-0.12.2_linux-centos6-amd64.rpm
如果无法安装 xorg-x11-fonts-75dpi.noarch
使用下面的方法直接解压rpm包中的编译包:
> rpm2cpio wkhtmltox-0.12.2_linux-centos6-amd64.rpm | cpio -div
完成后会在当前目录下生成一个usr目录,里面收录四个文件夹:local/bin、local/include、local/share、local/lib
将对应文件夹的内容复制到/usr/local!
>cp -Rv ./usr/local/* /usr/local/
wkhtmltox系统环境安装完成!
2、安装 php-wkhtmltox 扩展
在github上下载源码包[php-wkhtmltox_master.zip]
>解压php-wkhtmltox_master.zip
> cd phpwkhtmltox
>php化
> ./configure--with-php-config=/usr/local/php/bin/php-config #这取决于各自系统的php安装路径
> 制作 && 制作安装
> ldconfig #重新加载系统动态链接库
> php -m
#检查是否扩展成功如果可以看到phpwkhtmltox,则扩展成功
已安装 php-wkhtmltox 扩展。
3、修改php.ini文件打开扩展
> vi /usr/local/php/etc/php.ini
加入:
extension="phpwkhtmltox.so"
> /etc/init.d/php-fpm 重启
安装完成!
本文参考资料:
安装部分可以使用本文介绍的安装部分,部分可能需要中文字体支持,可以参考上面的中文字体库安装部分进行扩展。
php 抓取网页生成图片(用php如何实现回答这个得客户端跟服务端结合起来了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-22 05:09
现在需要从网页的一部分(用户面板,相当复杂)生成图片。我怎样才能使用 php 来实现这一点?
回答
这是客户端和服务器的组合。屏幕截图是客户端的东西。保存是 PHP 的事情。
使用 ActiveX 或 Java Applet 或 JavaScript
JavaScript 的一个例子......
Petal 的小书签实现了 JavaScript 截图功能
这可以使用 canvas 标签来完成,但这不是一个图像,只是一个标签。
如果要实现真实的图片,需要使用PHP的gd库或者Imagick在服务器端生成图片。上面的解决方案是不可行的,因为截图本质上是客户端行为。
让我们使用 PantomJS,它相当于一个没有视图的 WebKit 浏览器,可以在服务器端渲染网页。
1 IECapt 但需要 win 服务器,特别是 google
2 linux下可以使用wkhtmltopdf将url网页保存为pdf,然后转换pdf 2 jpg
3 imagegrabwindow手册有demo
大胆猜测,楼主可能会在一些具体有价值的操作中做备份。
很容易想到用PHP直接解析HTML代码,然后用常规的GD生成图片。遗憾的是,PHP 无法解析 HTML 代码,或者没有相对完善的解析 HTML 扩展。看来问题的症结在于解析 HTML 代码。
个人可以考虑这个思路:先标记具体需要截图的DIV-ID块,用PHP想办法获取这个块的代码。方法很多;然后根据CSS规则一一解析这个block中的代码,既然是自己用的,只能支持对绘图有用的CSS样式,然后在地图上用GD画出来,一切就这么简单可能的。
当然,有一种本土方法可能是最有效的。它只是一个用户面板页面。可以手动把这个页面截图,然后用绘图工具把可变部分去掉,保存为图片作为基板,供GD日后生成图片。然后稍微改变你的程序。生成用户面板时,可以传入一些信息,也就是变量部分,写入到GD画面中。写入时,只需要指定要写入信息的像素位置即可。此方法完全绕过 HTML 解析,可能是一种更快的方法。缺点是没有可重用性。
PHP普通码农,欢迎拍砖。
而 (1) {
printf('你好,世界!');
} 查看全部
php 抓取网页生成图片(用php如何实现回答这个得客户端跟服务端结合起来了)
现在需要从网页的一部分(用户面板,相当复杂)生成图片。我怎样才能使用 php 来实现这一点?
回答
这是客户端和服务器的组合。屏幕截图是客户端的东西。保存是 PHP 的事情。
使用 ActiveX 或 Java Applet 或 JavaScript
JavaScript 的一个例子......
Petal 的小书签实现了 JavaScript 截图功能
这可以使用 canvas 标签来完成,但这不是一个图像,只是一个标签。
如果要实现真实的图片,需要使用PHP的gd库或者Imagick在服务器端生成图片。上面的解决方案是不可行的,因为截图本质上是客户端行为。
让我们使用 PantomJS,它相当于一个没有视图的 WebKit 浏览器,可以在服务器端渲染网页。
1 IECapt 但需要 win 服务器,特别是 google
2 linux下可以使用wkhtmltopdf将url网页保存为pdf,然后转换pdf 2 jpg
3 imagegrabwindow手册有demo
大胆猜测,楼主可能会在一些具体有价值的操作中做备份。
很容易想到用PHP直接解析HTML代码,然后用常规的GD生成图片。遗憾的是,PHP 无法解析 HTML 代码,或者没有相对完善的解析 HTML 扩展。看来问题的症结在于解析 HTML 代码。
个人可以考虑这个思路:先标记具体需要截图的DIV-ID块,用PHP想办法获取这个块的代码。方法很多;然后根据CSS规则一一解析这个block中的代码,既然是自己用的,只能支持对绘图有用的CSS样式,然后在地图上用GD画出来,一切就这么简单可能的。
当然,有一种本土方法可能是最有效的。它只是一个用户面板页面。可以手动把这个页面截图,然后用绘图工具把可变部分去掉,保存为图片作为基板,供GD日后生成图片。然后稍微改变你的程序。生成用户面板时,可以传入一些信息,也就是变量部分,写入到GD画面中。写入时,只需要指定要写入信息的像素位置即可。此方法完全绕过 HTML 解析,可能是一种更快的方法。缺点是没有可重用性。
PHP普通码农,欢迎拍砖。
而 (1) {
printf('你好,世界!');
}
php 抓取网页生成图片(网站没有自定义图标是什么?如何选择的网站? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-01-22 05:07
)
1、按照以上流程,选择目标大小,选择本地的jpg、jpeg、gif、png图标,制作
2、将我们下载的 .ICO 图标保存为“favicon.ico”名称
3、上传.ico图标到我们的网站根目录
4、添加“”
网站首页源代码之间
什么是 Favicon.ico 图标?
所谓favicon就是Favorites Icon的缩写。顾名思义,它不仅可以在浏览器的采集夹中显示相应的标题,还可以通过图标的形式区分不同的网站。当然,这不仅仅是关于 favicon,favicon 的显示也因浏览器而异:在大多数主流浏览器如 FireFox 和 Internet Explorer(5.5 及以上)中,favicon 不仅在采集夹中显示屏也会同时出现在地址栏上。此时,用户可以将favicon拖到桌面,创建网站的快捷方式;此外,标签式浏览器甚至还有很多扩展功能,比如FireFox甚至支持动画格式的favicon等。
从具体的技术角度来看,favicon不仅让网站给人一种更专业的观感,而且在一定程度上可以降低服务器的流量带宽。一般为了提高网站的可用性,我们都会为自己的网站创建一个自定义的404错误文件,这种情况下如果网站没有对应的favicon.ico文件,只要用户采集网站/网页,web服务器会调用这个自定义的404文件,并记录在网站的错误日志中。这显然应该避免。
查看全部
php 抓取网页生成图片(网站没有自定义图标是什么?如何选择的网站?
)
1、按照以上流程,选择目标大小,选择本地的jpg、jpeg、gif、png图标,制作
2、将我们下载的 .ICO 图标保存为“favicon.ico”名称
3、上传.ico图标到我们的网站根目录
4、添加“”
网站首页源代码之间
什么是 Favicon.ico 图标?
所谓favicon就是Favorites Icon的缩写。顾名思义,它不仅可以在浏览器的采集夹中显示相应的标题,还可以通过图标的形式区分不同的网站。当然,这不仅仅是关于 favicon,favicon 的显示也因浏览器而异:在大多数主流浏览器如 FireFox 和 Internet Explorer(5.5 及以上)中,favicon 不仅在采集夹中显示屏也会同时出现在地址栏上。此时,用户可以将favicon拖到桌面,创建网站的快捷方式;此外,标签式浏览器甚至还有很多扩展功能,比如FireFox甚至支持动画格式的favicon等。
从具体的技术角度来看,favicon不仅让网站给人一种更专业的观感,而且在一定程度上可以降低服务器的流量带宽。一般为了提高网站的可用性,我们都会为自己的网站创建一个自定义的404错误文件,这种情况下如果网站没有对应的favicon.ico文件,只要用户采集网站/网页,web服务器会调用这个自定义的404文件,并记录在网站的错误日志中。这显然应该避免。
php 抓取网页生成图片(如何用PHP扩展网页转换生成为各种格式的图片或者pdf文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-22 05:07
我们在实际项目开发中经常会遇到这种需求,从特定网页生成图片用于分享等用途。这时候,我们就可以使用这个PHP扩展,轻松将网页转换成各种格式的图片或pdf文件。我们来看看如何实现它?
本教程的主角是 wkhtmltopdf。我们先简单了解一下:
wkhtmltopdf 是一个开源的、简单有效的命令行 shell 程序,可以将任何 HTML(网页)转换为 PDF 文档或图像(jpg、png 等)。
wkhtmltopdf 是用 C++ 编写的,并在 GNU/GPL(通用公共许可证)下发布。它使用 WebKit 渲染引擎将 HTML 页面转换为 PDF 文档,而不会损失页面的质量。这是一个非常有用且可靠的解决方案,用于实时创建和存储网页快照。
该程序的特点如下:
开源和跨平台。使用 WebKit 引擎将任何 HTML 网页转换为 PDF 文件。为页眉和页脚添加了选项目录生成 (TOC) 选项。提供批处理模式转换。通过绑定 libwkhtmltox 支持 PHP 或 Python。
首先我们需要在我们的服务器上安装linux下的webkit内核libwkhtmltox,根据我们的服务器配置选择合适的安装包:
需要注意的是libwkhtmltox的当前版本已经是0.13了,但是我在CentOS下安装了libwkhtmltox-0.116.2之后,当我把网页转换成图片的时候,我搞错了,最后选择了0.10版本,还是比较稳定的。
13版安装方法:
wget https://bitbucket.org/wkhtmlto ... 4.rpm
然后执行:
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm
如果在安装过程中出现如下错误,可以通过以下方法解决,只需安装缺少的依赖即可!
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm <br />
error: Failed dependencies:<br />
icu is needed by wkhtmltox-1:0.13.0_alpha_7b36694-1.x86_64<br />
xorg-x11-fonts-75dpi is needed by wkhtmltox-1:0.13.0_alpha_7b36694-1.x86_64<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
[root@KaiBoss_4_45 ~]# yum search icu<br />
[root@KaiBoss_4_45 ~]# yum install icu.x86_64<br />
<br />
[root@KaiBoss_4_45 ~]# yum search 75dpi<br />
[root@KaiBoss_4_45 ~]# yum install xorg-x11-fonts-75dpi.noarch<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm <br />
Preparing... ########################################### [100%]<br />
1:wkhtmltox ########################################### [100%]<br />
[root@KaiBoss_4_45 ~]# <br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
如果看到上面的结果,就说明安装成功了!
10 稳定版安装方法:
[root@KaiBoss_4_45 ~]#mkdir libwkhtmtox<br />
[root@KaiBoss_4_45 ~]#cd libwkhtmtox<br />
[root@KaiBoss_4_45 libwkhtmtox]# tar jxvf libwkhtmltox-0.10.0_rc2-amd64.tar.bz2<br />
[root@KaiBoss_4_45 libwkhtmtox]# cd lib<br />
[root@KaiBoss_4_45 lib]# cp libwkhtmltox.so /usr/local/lib/<br />
[root@KaiBoss_4_45 lib]# cd ../include/<br />
[root@KaiBoss_4_45 include]# cp -R wkhtmltox /usr/local/include/<br />
<br />
<br />
<br />
<br />
<br />
接下来需要安装phpwkhtmltox这个php扩展,它可以调用webkit内核将网页转换成各种格式的图片或者pdf。
这里需要注意的是,如果是PHP7,需要安装PHP7版本对应的扩展包。
[root@KaiBoss_4_45 ~]#unzip php7-wkhtmltox-master.zip<br />
[root@KaiBoss_4_45 ~]#cd php7-wkhtmltox-master<br />
[root@KaiBoss_4_45 ~]#phpize<br />
[root@KaiBoss_4_45 ~]#./configure<br />
[root@KaiBoss_4_45 ~]#make install
接下来,我们修改我们的 php.ini 配置文件,添加扩展文件:
extension=phpwkhtmltox.so
然后,重新加载系统动态链接库(重要,否则PHP无法完成扩展phpwkhtmltox),检查是否添加成功:
[root@platform tmp]#ldconfig<br />
[root@platform tmp]#php -m
然后,您可以编写一个 php 脚本来测试该功能:
测试生成的图像:
以下是百度网页生成的结果
测试生成pdf:
如果你发现生成的图片或pdf中出现中文乱码,需要让CentOS支持中文:
[root@KaiBoss_4_45 ~]#yum groupinstall chinese-support
将字体文件复制到/usr/share/fonts/xxx,其中xxx为新建的字体文件夹,如msyh
[root@KaiBoss_4_45 ~]#cd /usr/share/fonts/<br />
[root@KaiBoss_4_45 ~]#mkdir msyh<br />
[root@KaiBoss_4_45 ~]#cd msyh
创建字体缓存
[root@KaiBoss_4_45 ~]#mkfontscale<br />
[root@KaiBoss_4_45 ~]#mkfontdir<br />
[root@KaiBoss_4_45 ~]#fc-cache -fv
PS:让 Linux CentOS 支持 Consolas 字体(技术博客可能会发布示例代码,大多数 wordpress 技术博客都会安装 SyntaxHighlighter 插件,并且插件代码显示该字体是 Consolas 的首选字体,所以为了html转图片示例代码看起来不错,我们还需要让linux支持Consolas字体)
从本地windows下载或复制consolas(注意windows系统复制的文件应该有4个),上传到linux服务器。将字体文件复制到/usr/share/fonts/xxx,其中xxx为新建字体文件夹,如Consolas
[root@KaiBoss_4_45 ~]#cd /usr/share/fonts/<br />
[root@KaiBoss_4_45 ~]#mkdir Consolas<br />
[root@KaiBoss_4_45 ~]#cd Consolas
创建字体缓存
[root@KaiBoss_4_45 ~]#mkfontscale<br />
[root@KaiBoss_4_45 ~]#mkfontdir<br />
[root@KaiBoss_4_45 ~]#fc-cache -fv
你完成了!
wkhtmltox官网:
下载所有历史版本:... ME.md
wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64 下载地址(百度网盘):
稳定版0.10版本libwkhtmltox-0.10.0_rc2-amd64.tar.bz2下载地址(百度网盘):
(非PHP7)php-wkhtmltox-master下载地址(百度网盘):
(PHP7)php7-wkhtmltox-master下载地址(百度网盘): 查看全部
php 抓取网页生成图片(如何用PHP扩展网页转换生成为各种格式的图片或者pdf文件)
我们在实际项目开发中经常会遇到这种需求,从特定网页生成图片用于分享等用途。这时候,我们就可以使用这个PHP扩展,轻松将网页转换成各种格式的图片或pdf文件。我们来看看如何实现它?
本教程的主角是 wkhtmltopdf。我们先简单了解一下:
wkhtmltopdf 是一个开源的、简单有效的命令行 shell 程序,可以将任何 HTML(网页)转换为 PDF 文档或图像(jpg、png 等)。
wkhtmltopdf 是用 C++ 编写的,并在 GNU/GPL(通用公共许可证)下发布。它使用 WebKit 渲染引擎将 HTML 页面转换为 PDF 文档,而不会损失页面的质量。这是一个非常有用且可靠的解决方案,用于实时创建和存储网页快照。
该程序的特点如下:
开源和跨平台。使用 WebKit 引擎将任何 HTML 网页转换为 PDF 文件。为页眉和页脚添加了选项目录生成 (TOC) 选项。提供批处理模式转换。通过绑定 libwkhtmltox 支持 PHP 或 Python。
首先我们需要在我们的服务器上安装linux下的webkit内核libwkhtmltox,根据我们的服务器配置选择合适的安装包:
需要注意的是libwkhtmltox的当前版本已经是0.13了,但是我在CentOS下安装了libwkhtmltox-0.116.2之后,当我把网页转换成图片的时候,我搞错了,最后选择了0.10版本,还是比较稳定的。
13版安装方法:
wget https://bitbucket.org/wkhtmlto ... 4.rpm
然后执行:
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm
如果在安装过程中出现如下错误,可以通过以下方法解决,只需安装缺少的依赖即可!
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm <br />
error: Failed dependencies:<br />
icu is needed by wkhtmltox-1:0.13.0_alpha_7b36694-1.x86_64<br />
xorg-x11-fonts-75dpi is needed by wkhtmltox-1:0.13.0_alpha_7b36694-1.x86_64<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
[root@KaiBoss_4_45 ~]# yum search icu<br />
[root@KaiBoss_4_45 ~]# yum install icu.x86_64<br />
<br />
[root@KaiBoss_4_45 ~]# yum search 75dpi<br />
[root@KaiBoss_4_45 ~]# yum install xorg-x11-fonts-75dpi.noarch<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
[root@KaiBoss_4_45 ~]# rpm -ivh wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64.rpm <br />
Preparing... ########################################### [100%]<br />
1:wkhtmltox ########################################### [100%]<br />
[root@KaiBoss_4_45 ~]# <br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
<br />
如果看到上面的结果,就说明安装成功了!
10 稳定版安装方法:
[root@KaiBoss_4_45 ~]#mkdir libwkhtmtox<br />
[root@KaiBoss_4_45 ~]#cd libwkhtmtox<br />
[root@KaiBoss_4_45 libwkhtmtox]# tar jxvf libwkhtmltox-0.10.0_rc2-amd64.tar.bz2<br />
[root@KaiBoss_4_45 libwkhtmtox]# cd lib<br />
[root@KaiBoss_4_45 lib]# cp libwkhtmltox.so /usr/local/lib/<br />
[root@KaiBoss_4_45 lib]# cd ../include/<br />
[root@KaiBoss_4_45 include]# cp -R wkhtmltox /usr/local/include/<br />
<br />
<br />
<br />
<br />
<br />
接下来需要安装phpwkhtmltox这个php扩展,它可以调用webkit内核将网页转换成各种格式的图片或者pdf。
这里需要注意的是,如果是PHP7,需要安装PHP7版本对应的扩展包。
[root@KaiBoss_4_45 ~]#unzip php7-wkhtmltox-master.zip<br />
[root@KaiBoss_4_45 ~]#cd php7-wkhtmltox-master<br />
[root@KaiBoss_4_45 ~]#phpize<br />
[root@KaiBoss_4_45 ~]#./configure<br />
[root@KaiBoss_4_45 ~]#make install
接下来,我们修改我们的 php.ini 配置文件,添加扩展文件:
extension=phpwkhtmltox.so
然后,重新加载系统动态链接库(重要,否则PHP无法完成扩展phpwkhtmltox),检查是否添加成功:
[root@platform tmp]#ldconfig<br />
[root@platform tmp]#php -m
然后,您可以编写一个 php 脚本来测试该功能:
测试生成的图像:
以下是百度网页生成的结果
测试生成pdf:
如果你发现生成的图片或pdf中出现中文乱码,需要让CentOS支持中文:
[root@KaiBoss_4_45 ~]#yum groupinstall chinese-support
将字体文件复制到/usr/share/fonts/xxx,其中xxx为新建的字体文件夹,如msyh
[root@KaiBoss_4_45 ~]#cd /usr/share/fonts/<br />
[root@KaiBoss_4_45 ~]#mkdir msyh<br />
[root@KaiBoss_4_45 ~]#cd msyh
创建字体缓存
[root@KaiBoss_4_45 ~]#mkfontscale<br />
[root@KaiBoss_4_45 ~]#mkfontdir<br />
[root@KaiBoss_4_45 ~]#fc-cache -fv
PS:让 Linux CentOS 支持 Consolas 字体(技术博客可能会发布示例代码,大多数 wordpress 技术博客都会安装 SyntaxHighlighter 插件,并且插件代码显示该字体是 Consolas 的首选字体,所以为了html转图片示例代码看起来不错,我们还需要让linux支持Consolas字体)
从本地windows下载或复制consolas(注意windows系统复制的文件应该有4个),上传到linux服务器。将字体文件复制到/usr/share/fonts/xxx,其中xxx为新建字体文件夹,如Consolas
[root@KaiBoss_4_45 ~]#cd /usr/share/fonts/<br />
[root@KaiBoss_4_45 ~]#mkdir Consolas<br />
[root@KaiBoss_4_45 ~]#cd Consolas
创建字体缓存
[root@KaiBoss_4_45 ~]#mkfontscale<br />
[root@KaiBoss_4_45 ~]#mkfontdir<br />
[root@KaiBoss_4_45 ~]#fc-cache -fv
你完成了!
wkhtmltox官网:
下载所有历史版本:... ME.md
wkhtmltox-0.13.0-alpha-7b36694_linux-centos6-amd64 下载地址(百度网盘):
稳定版0.10版本libwkhtmltox-0.10.0_rc2-amd64.tar.bz2下载地址(百度网盘):
(非PHP7)php-wkhtmltox-master下载地址(百度网盘):
(PHP7)php7-wkhtmltox-master下载地址(百度网盘):
php 抓取网页生成图片(php抓取网页生成图片可以选择webgl或者php的抓取框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-22 05:02
php抓取网页生成图片可以选择webgl或者php的图片抓取框架如果php生成的图片采用谷歌地图api,这个应该就没办法了,只能用工具,服务器链接接管截图如果要抓取文件,cad等等才能用到正则表达式,
图片不是太明确吗?
谢邀。可以用chinaz或者好搜图来抓取网页上的图片。具体代码可以私信我。我现在还在学习中,打算练练网页原生数据库就从csv读取图片,这样效率高,也简单。
引擎请换php
需要react,
你应该想问如何从url发起一个post请求,获取图片的图片文件吧。只有c++的话php+curl还凑合有没有特别底层的接口。java的话有比较底层的jfinal和jfinalnode。原生的标准库有commonslib。jquery另外你还需要的是做一个web服务端,没错web服务端。然后你能不能从php抓取图片源文件。你应该是想问php去抓取图片源文件吧?。
一种思路是你可以自己写一个解析器,把发起的post请求的url调整为相应的图片path。一种思路是直接调用网页中的meta标签。
web服务器,
//获取设备revisionarrayget设备idrevision#;可以使用上面那个web服务器curl-x---//获取设备名revisionarrayget设备名revision#;这样服务器返回即时状态这样不同设备发送的请求就对应着不同的状态 查看全部
php 抓取网页生成图片(php抓取网页生成图片可以选择webgl或者php的抓取框架)
php抓取网页生成图片可以选择webgl或者php的图片抓取框架如果php生成的图片采用谷歌地图api,这个应该就没办法了,只能用工具,服务器链接接管截图如果要抓取文件,cad等等才能用到正则表达式,
图片不是太明确吗?
谢邀。可以用chinaz或者好搜图来抓取网页上的图片。具体代码可以私信我。我现在还在学习中,打算练练网页原生数据库就从csv读取图片,这样效率高,也简单。
引擎请换php
需要react,
你应该想问如何从url发起一个post请求,获取图片的图片文件吧。只有c++的话php+curl还凑合有没有特别底层的接口。java的话有比较底层的jfinal和jfinalnode。原生的标准库有commonslib。jquery另外你还需要的是做一个web服务端,没错web服务端。然后你能不能从php抓取图片源文件。你应该是想问php去抓取图片源文件吧?。
一种思路是你可以自己写一个解析器,把发起的post请求的url调整为相应的图片path。一种思路是直接调用网页中的meta标签。
web服务器,
//获取设备revisionarrayget设备idrevision#;可以使用上面那个web服务器curl-x---//获取设备名revisionarrayget设备名revision#;这样服务器返回即时状态这样不同设备发送的请求就对应着不同的状态
php 抓取网页生成图片(php抓取网页生成图片,wordpress实现自动推送服务器端生成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-21 23:04
php抓取网页生成图片,wordpress实现自动推送服务器端生成的连接图片之后,用mysql给客户端推送图片地址,网页写满八张以后,php推送新的图片地址。第一步网络爬虫和php结合。找到各类自动推送服务器接口,获取连接图片地址。第二步php解析生成的连接图片地址。从小图到大图,推送生成php调用mysql连接生成的数据结构csv文件。
最简单的就是main函数写一个接收连接的处理函数,循环遍历http请求就可以了。如果要实现你说的能自动推送到服务器端的效果,还需要考虑是否要考虑到浏览器缓存等效果。
说实话,看起来这个接口设计的很不友好。cookie就已经很不友好了。
url是错误的,必须加一个xmlhttprequest::headers参数
=先上图mysql配置实现推送,我装在了qt里面,运行很流畅自定义文件名在database处用户可以自己添加文件名和文件顺序规律,这个很容易,用户指定新生成的database名和路径,mysql需要你根据mvc把文件名和路径打在myuser和myuser-server路径下,然后去用户电脑上路径(通过在myuser里面添加路径文件名)里面修改这个路径下的路径文件名.sql为myuser路径文件名。
因为这个文件名自己修改才可以去改路径文件名。一样的,用户选择新建一个database,把要推送的database名,路径复制上去就可以了。 查看全部
php 抓取网页生成图片(php抓取网页生成图片,wordpress实现自动推送服务器端生成)
php抓取网页生成图片,wordpress实现自动推送服务器端生成的连接图片之后,用mysql给客户端推送图片地址,网页写满八张以后,php推送新的图片地址。第一步网络爬虫和php结合。找到各类自动推送服务器接口,获取连接图片地址。第二步php解析生成的连接图片地址。从小图到大图,推送生成php调用mysql连接生成的数据结构csv文件。
最简单的就是main函数写一个接收连接的处理函数,循环遍历http请求就可以了。如果要实现你说的能自动推送到服务器端的效果,还需要考虑是否要考虑到浏览器缓存等效果。
说实话,看起来这个接口设计的很不友好。cookie就已经很不友好了。
url是错误的,必须加一个xmlhttprequest::headers参数
=先上图mysql配置实现推送,我装在了qt里面,运行很流畅自定义文件名在database处用户可以自己添加文件名和文件顺序规律,这个很容易,用户指定新生成的database名和路径,mysql需要你根据mvc把文件名和路径打在myuser和myuser-server路径下,然后去用户电脑上路径(通过在myuser里面添加路径文件名)里面修改这个路径下的路径文件名.sql为myuser路径文件名。
因为这个文件名自己修改才可以去改路径文件名。一样的,用户选择新建一个database,把要推送的database名,路径复制上去就可以了。
php 抓取网页生成图片( PHP脚本与动态页面教程(图)!(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-21 11:05
PHP脚本与动态页面教程(图)!(组图)
)
更详细的PHP生成静态页面教程
更新时间:2012-01-10 13:46:27 作者:
PHP生成静态页面教程让我们先回顾一些基本概念
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的PHP解析器服务器对脚本进行处理,解析成HTML语言形式---->将解析后的HTML语句以包的形式返回给浏览器。不难看出,页面发送到浏览器后,PHP是不存在的,已经被转换解析成HTML语句。客户端请求是一个动态文件。事实上,那里没有真正的文件。它是由 PHP 解析并发送回浏览器的相应页面。这种处理页面的方式称为“动态页面”。
二、静态页面。
静态页面是指服务器端确实存在的页面,只收录HTML、JS、CSS等客户端运行脚本。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式传回浏览器。从这个过程中,我们可以对比动态页面来找出答案。动态页面需要WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。减轻服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站 整体开盘速度。缺点是不能动态处理请求,文件必须实际存在于服务器上。
三、模板和模板分析。
模板即尚未填充内容 html 文件。例如:
临时文件
代码:
复制代码代码如下:
{ 标题 }
这是一个 { 文件 } 文件的模板
PHP处理:
寺庙测试.php
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板解析处理的原理通常是替换。有些程序员习惯于将判断、循环等处理放到模板文件中,用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。循环次数、如何循环替换等由PHP脚本指定,然后模板解析类实现这些操作。
好了,对比完静态页面和动态页面的优缺点,现在我们来说说如何用PHP生成静态文件。
PHP生成静态页面并不意味着动态解析PHP并输出HTML页面,而是使用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,需要删除并重新生成。(当然你也可以选择有规律的修改,但我个人认为删除和重新生成的速度越来越快,而且有些得不偿失。)
离家近一点。使用过PHP文件操作函数的PHPFANS都知道PHP中有一个文件操作函数fopen,也就是打开一个文件。如果该文件不存在,请尝试创建它。这是 PHP 可用于创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777)),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)还是以上面的例子为例,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
复制代码代码如下:
实际应用中常见问题的解决方案参考:
一、文章列出问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐文章,只需指向存储静态文件的指定文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换该字符串。比如在页面中放置文章列表的形式,添加标签{articletable},在PHP处理文件中:
代码:
复制代码代码如下:
第二,分页问题。
如果我们指定分页,每页有 20 篇文章。通过数据库查询,某个子频道列表中文章的个数为45,那么我们首先通过查询得到如下参数: 1、总页数;2、每页文章数。第二步,for ($i = 0; $i
代码:
复制代码代码如下:
$fp = fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$一页='20';
$sql = "从文章中选择 id where channel='$channelid'";
$query = mysql_query($sql);
$num = mysql_num_rows($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0; $i
大体思路是这样的,其中可以在页面中酌情添加其他数据生成、数据输入输出检查、分页内容指向等。
在文章系统处理的实际过程中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但大意是这样的,其他方面可以从其他方面推断出来。
使用PHP制作静态网站的模板框架
模板可以改进 网站 的结构。本文通过 PHP 4 中的一个新特性和模板类,解释了如何巧妙地使用模板来控制由大量静态 HTML 页面组成的 网站 中的页面布局。
大纲:
=======================================
分离功能和布局
避免重复页面元素
静态 网站 的模板框架
=======================================
分离功能和布局
首先我们来看看应用模板的两个主要目的:
功能分离 (PHP) 和布局 (HTML)
避免重复页面元素
第一个目的是谈论最多的,它设想这样一种情况,一组程序员编写生成页面内容的 PHP 脚本,而另一组设计师设计 HTML 和图形来控制页面的最终外观。分离功能和布局的基本思想是让这两组人能够编写和使用单独的一组文件:程序员只需要关心只收录PHP代码的文件,而不是页面的外观
; 页面设计者可以使用他们最熟悉的可视化编辑器来设计页面布局,而不必担心破坏页面中嵌入的任何 PHP 代码。
如果您曾经看过一些关于 PHP 模板的教程,那么您应该已经了解了模板的工作原理。考虑一个简单的页面部分:页面顶部是页眉,左侧是导航栏,其余部分是内容区域。这样的 网站 可以有以下模板文件:
复制代码代码如下:
{标题}
{左导航}
{内容}
富
酒吧
您可以看到页面是如何从这些模板构建的:主模板控制整个页面的布局;header 和 leftnav 模板控制页面的公共元素。花括号“{}”内的标识符是内容占位符。使用模板的主要好处是界面设计人员可以根据需要编辑这些文件,例如设置字体、更改颜色和图形,或完全更改页面的布局。界面设计者可以使用任何普通的 HTML 编辑器或可视化工具来编辑这些页面,因为这些文件只收录 HTML 代码而没有任何 PHP 代码。
PHP 代码全部保存到一个单独的文件中,这就是页面 URL 实际调用的文件。Web 服务器通过 PHP 引擎解析文件并将结果返回给浏览器。一般来说,PHP 代码总是动态生成页面内容,例如查询数据库或执行某种计算。下面是一个例子:
复制代码代码如下:
这里我们使用流行的 FastTemplate 模板类,但基本思想与许多其他模板类相同。首先,您实例化一个类并告诉它在哪里查找模板文件以及哪个模板文件对应于页面的哪个部分;下一步是生成页面内容,并将结果分配给内容标识符;然后,依次解析每个模板文件,模板类会进行必要的替换;最后将解析结果输出到浏览器。
该文件完全由 PHP 代码组成,不收录任何 HTML 代码,这是它的最大优势。现在,PHP 程序员可以专注于编写生成页面内容的代码,而不必担心如何生成 HTML 以正确格式化最终页面。
你可以使用这个方法和上面的文件构造一个完整的网站。例如,如果 PHP 代码根据 URL 中的查询字符串生成页面内容,您可以由此构造一整个杂志 网站。
很容易看出使用模板还有第二个好处。如上例所示,页面左侧的导航栏保存为单独的文件,我们只需编辑此模板文件即可更改网站所有页面左侧的导航栏。
避免重复页面元素
“太好了”,你可能会想,“我的 网站 主要由很多静态页面组成。现在我可以从所有页面中删除它们的公共部分,更新它们太麻烦了. 然后我可以使用模板制作易于维护的统一页面布局。但这并不是那么简单,“大量静态页面”指出了问题所在。
考虑上面的例子。这个例子实际上只有一个example.php页面,之所以能生成整个网站的所有页面,是因为它使用URL中的查询字符串从信息源如一个数据库。
我们大多数人运行 网站 不一定是数据库支持的。我们的大部分网站都是由静态页面组成,然后用PHP到处添加一些动态特性,比如搜索引擎、反馈表等。那么,如何在这种< @网站?
最简单的方法是为每个页面复制一个 PHP 文件,
然后在每个页面中将代表 PHP 代码中内容的变量设置为适当的页面内容。例如,假设有三个页面,分别是主页(home)、关于(about)和产品(product),我们可以从三个文件中分别生成。这三个文件的内容类似于:
复制代码代码如下:
显然,这种方法存在三个问题:我们必须为每个页面复制这种复杂的、涉及模板的 PHP 代码,这使得页面与重复常见页面元素一样难以维护;现在该文件是 HTML 和 PHP 代码的混合;内容变量赋值会变得非常困难,因为我们要处理很多特殊字符。
解决此问题的关键是将 PHP 代码与 HTML 内容分离。虽然我们无法从文件中删除所有 HTML 内容,但我们可以删除大部分 PHP 代码。
静态 网站 的模板框架
首先,我们为所有页面常用元素和页面的整体布局编写模板文件;然后从所有页面中删除公共部分,只留下页面内容;然后在每个页面添加三行PHP代码,如下:
复制代码代码如下:
你好
欢迎参观
查看全部
php 抓取网页生成图片(
PHP脚本与动态页面教程(图)!(组图)
)
更详细的PHP生成静态页面教程
更新时间:2012-01-10 13:46:27 作者:
PHP生成静态页面教程让我们先回顾一些基本概念
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的PHP解析器服务器对脚本进行处理,解析成HTML语言形式---->将解析后的HTML语句以包的形式返回给浏览器。不难看出,页面发送到浏览器后,PHP是不存在的,已经被转换解析成HTML语句。客户端请求是一个动态文件。事实上,那里没有真正的文件。它是由 PHP 解析并发送回浏览器的相应页面。这种处理页面的方式称为“动态页面”。
二、静态页面。
静态页面是指服务器端确实存在的页面,只收录HTML、JS、CSS等客户端运行脚本。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式传回浏览器。从这个过程中,我们可以对比动态页面来找出答案。动态页面需要WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。减轻服务器压力,提高服务器负载能力,大幅提升页面打开速度和网站 整体开盘速度。缺点是不能动态处理请求,文件必须实际存在于服务器上。
三、模板和模板分析。
模板即尚未填充内容 html 文件。例如:
临时文件
代码:
复制代码代码如下:
{ 标题 }
这是一个 { 文件 } 文件的模板
PHP处理:
寺庙测试.php
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp = fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板解析处理的原理通常是替换。有些程序员习惯于将判断、循环等处理放到模板文件中,用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。循环次数、如何循环替换等由PHP脚本指定,然后模板解析类实现这些操作。
好了,对比完静态页面和动态页面的优缺点,现在我们来说说如何用PHP生成静态文件。
PHP生成静态页面并不意味着动态解析PHP并输出HTML页面,而是使用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,需要删除并重新生成。(当然你也可以选择有规律的修改,但我个人认为删除和重新生成的速度越来越快,而且有些得不偿失。)
离家近一点。使用过PHP文件操作函数的PHPFANS都知道PHP中有一个文件操作函数fopen,也就是打开一个文件。如果该文件不存在,请尝试创建它。这是 PHP 可用于创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777)),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)还是以上面的例子为例,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
复制代码代码如下:
实际应用中常见问题的解决方案参考:
一、文章列出问题:
在数据库中创建一个字段,记录文件名,每次生成文件时将自动生成的文件名存入数据库。对于推荐文章,只需指向存储静态文件的指定文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换该字符串。比如在页面中放置文章列表的形式,添加标签{articletable},在PHP处理文件中:
代码:
复制代码代码如下:
第二,分页问题。
如果我们指定分页,每页有 20 篇文章。通过数据库查询,某个子频道列表中文章的个数为45,那么我们首先通过查询得到如下参数: 1、总页数;2、每页文章数。第二步,for ($i = 0; $i
代码:
复制代码代码如下:
$fp = fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$一页='20';
$sql = "从文章中选择 id where channel='$channelid'";
$query = mysql_query($sql);
$num = mysql_num_rows($query);
$allpages = ceil ($num / $onepage);
对于 ($i = 0; $i
大体思路是这样的,其中可以在页面中酌情添加其他数据生成、数据输入输出检查、分页内容指向等。
在文章系统处理的实际过程中,还有很多问题需要考虑。与动态页面不同,还有很多需要注意的地方。但大意是这样的,其他方面可以从其他方面推断出来。
使用PHP制作静态网站的模板框架
模板可以改进 网站 的结构。本文通过 PHP 4 中的一个新特性和模板类,解释了如何巧妙地使用模板来控制由大量静态 HTML 页面组成的 网站 中的页面布局。
大纲:
=======================================
分离功能和布局
避免重复页面元素
静态 网站 的模板框架
=======================================
分离功能和布局
首先我们来看看应用模板的两个主要目的:
功能分离 (PHP) 和布局 (HTML)
避免重复页面元素
第一个目的是谈论最多的,它设想这样一种情况,一组程序员编写生成页面内容的 PHP 脚本,而另一组设计师设计 HTML 和图形来控制页面的最终外观。分离功能和布局的基本思想是让这两组人能够编写和使用单独的一组文件:程序员只需要关心只收录PHP代码的文件,而不是页面的外观
; 页面设计者可以使用他们最熟悉的可视化编辑器来设计页面布局,而不必担心破坏页面中嵌入的任何 PHP 代码。
如果您曾经看过一些关于 PHP 模板的教程,那么您应该已经了解了模板的工作原理。考虑一个简单的页面部分:页面顶部是页眉,左侧是导航栏,其余部分是内容区域。这样的 网站 可以有以下模板文件:
复制代码代码如下:
{标题}
{左导航}
{内容}
富
酒吧
您可以看到页面是如何从这些模板构建的:主模板控制整个页面的布局;header 和 leftnav 模板控制页面的公共元素。花括号“{}”内的标识符是内容占位符。使用模板的主要好处是界面设计人员可以根据需要编辑这些文件,例如设置字体、更改颜色和图形,或完全更改页面的布局。界面设计者可以使用任何普通的 HTML 编辑器或可视化工具来编辑这些页面,因为这些文件只收录 HTML 代码而没有任何 PHP 代码。
PHP 代码全部保存到一个单独的文件中,这就是页面 URL 实际调用的文件。Web 服务器通过 PHP 引擎解析文件并将结果返回给浏览器。一般来说,PHP 代码总是动态生成页面内容,例如查询数据库或执行某种计算。下面是一个例子:
复制代码代码如下:
这里我们使用流行的 FastTemplate 模板类,但基本思想与许多其他模板类相同。首先,您实例化一个类并告诉它在哪里查找模板文件以及哪个模板文件对应于页面的哪个部分;下一步是生成页面内容,并将结果分配给内容标识符;然后,依次解析每个模板文件,模板类会进行必要的替换;最后将解析结果输出到浏览器。
该文件完全由 PHP 代码组成,不收录任何 HTML 代码,这是它的最大优势。现在,PHP 程序员可以专注于编写生成页面内容的代码,而不必担心如何生成 HTML 以正确格式化最终页面。
你可以使用这个方法和上面的文件构造一个完整的网站。例如,如果 PHP 代码根据 URL 中的查询字符串生成页面内容,您可以由此构造一整个杂志 网站。
很容易看出使用模板还有第二个好处。如上例所示,页面左侧的导航栏保存为单独的文件,我们只需编辑此模板文件即可更改网站所有页面左侧的导航栏。
避免重复页面元素
“太好了”,你可能会想,“我的 网站 主要由很多静态页面组成。现在我可以从所有页面中删除它们的公共部分,更新它们太麻烦了. 然后我可以使用模板制作易于维护的统一页面布局。但这并不是那么简单,“大量静态页面”指出了问题所在。
考虑上面的例子。这个例子实际上只有一个example.php页面,之所以能生成整个网站的所有页面,是因为它使用URL中的查询字符串从信息源如一个数据库。
我们大多数人运行 网站 不一定是数据库支持的。我们的大部分网站都是由静态页面组成,然后用PHP到处添加一些动态特性,比如搜索引擎、反馈表等。那么,如何在这种< @网站?
最简单的方法是为每个页面复制一个 PHP 文件,
然后在每个页面中将代表 PHP 代码中内容的变量设置为适当的页面内容。例如,假设有三个页面,分别是主页(home)、关于(about)和产品(product),我们可以从三个文件中分别生成。这三个文件的内容类似于:
复制代码代码如下:
显然,这种方法存在三个问题:我们必须为每个页面复制这种复杂的、涉及模板的 PHP 代码,这使得页面与重复常见页面元素一样难以维护;现在该文件是 HTML 和 PHP 代码的混合;内容变量赋值会变得非常困难,因为我们要处理很多特殊字符。
解决此问题的关键是将 PHP 代码与 HTML 内容分离。虽然我们无法从文件中删除所有 HTML 内容,但我们可以删除大部分 PHP 代码。
静态 网站 的模板框架
首先,我们为所有页面常用元素和页面的整体布局编写模板文件;然后从所有页面中删除公共部分,只留下页面内容;然后在每个页面添加三行PHP代码,如下:
复制代码代码如下:
你好
欢迎参观
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-18 14:04
PHP快速生成图片验证码并实现验证插件
1.插件功能:
本插件可以快速实现网站验证码功能,包括验证码的生成和验证。
2.必填参数:
CaptchaTool 类包括两个方法。 generate方法可以生成'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中的四位字符,将这些字符写在captcha目录下的图片上,并将code值保存在session中,并输出,此方法不需要参数。
check方法,需要用户输入的code值,返回true和false。
3.使用方法:
收录这样一个文件,实例化它,并用得到的对象调用相应的方法。
4.备注:
使用该插件的用户可以根据自己的需要扩展验证码字符网站,将要扩展的字符放在$chars中,需要在for循环中做相应的调整。
确保$bg_flie的路径文件地址是验证码背景图片的地址。
验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字的大小由imagestring()中的第二个参数决定可以使用函数 imagecolorallocate() 按需为字符串颜色分配画布颜色。 查看全部
php 抓取网页生成图片(PHP快速生成图片验证码并且实现验证插件1.插件(图))
PHP快速生成图片验证码并实现验证插件
1.插件功能:
本插件可以快速实现网站验证码功能,包括验证码的生成和验证。
2.必填参数:
CaptchaTool 类包括两个方法。 generate方法可以生成'ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'中的四位字符,将这些字符写在captcha目录下的图片上,并将code值保存在session中,并输出,此方法不需要参数。
check方法,需要用户输入的code值,返回true和false。
3.使用方法:
收录这样一个文件,实例化它,并用得到的对象调用相应的方法。
4.备注:
使用该插件的用户可以根据自己的需要扩展验证码字符网站,将要扩展的字符放在$chars中,需要在for循环中做相应的调整。
确保$bg_flie的路径文件地址是验证码背景图片的地址。
验证码图片的边框颜色由imagerectangle($img, 0, 0, 144, 19, $white)中的$white决定,文字的大小由imagestring()中的第二个参数决定可以使用函数 imagecolorallocate() 按需为字符串颜色分配画布颜色。
php 抓取网页生成图片(PHP脚本与动态页面的模板及模板解析及html解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-13 07:00
让我们先回顾一些基本概念。
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的PHP解析器服务器对脚本进行处理,解析成HTML语言形式---->将解析后的HTML语句以包的形式返回给浏览器。不难看出,页面发送到浏览器后,PHP是不存在的,已经被转换解析成HTML语句。客户端请求是一个动态文件。事实上,那里没有真正的文件。它是由 PHP 解析并发送回浏览器的相应页面。这种处理页面的方式称为“动态页面”。
二、静态页面。
静态页面是指服务器端确实存在的页面,只收录HTML、JS、CSS等客户端运行脚本。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式传回浏览器。从这个过程中,我们可以对比动态页面来找出答案。动态页面需要WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。减轻服务器压力,提升服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板即尚未填充内容 html 文件。例如:
临时文件
代码:
{ 标题 }
这是一个 { 文件 } 文件的模板
PHP处理:
寺庙测试.php
代码:
$title = "PHP 爱好者测试模板";
$file = "TwoMax Inter 测试模板,
作者:舍义》;
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板解析处理的原理通常是替换。有些程序员习惯于将判断、循环等处理放到模板文件中,用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。循环次数、如何循环替换等由PHP脚本指定,然后模板解析类实现这些操作。
好了,对比完静态页面和动态页面的优缺点,现在我们来说说如何用PHP生成静态文件。
PHP生成静态页面并不意味着动态解析PHP并输出HTML页面,而是使用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,需要删除并重新生成。(当然你也可以选择有规律的修改,但我个人认为删除和重新生成的速度越来越快,有些得不偿失。)
离家近一点。使用过PHP文件操作函数的PHPFANS都知道PHP中有一个文件操作函数fopen,也就是打开一个文件。如果该文件不存在,请尝试创建它。这是 PHP 可用于创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777)),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)还是以上面的例子为例,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
// 回显 $content;
$filename = "test/test.html";
$handle = fopen ($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
if (!is_writable ($filename)){
die ("File: ".$filename." 不可写,请检查其属性再试一次!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die ("生成文件".$filename."失败!");
}
fclose($句柄);//关闭指针
die ("创建文件".$filename."成功!");
实际应用中常见问题的解决方案参考:
一、文章列出问题:
在数据库中创建字段,记录文件名,每次生成文件时将自动生成的文件名保存到数据库中。对于推荐的文章,只需指向存储静态文件的指定文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换该字符串。比如在页面中放置文章列表的形式,添加标签{articletable},在PHP处理文件中:
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
// 开始生成列表
$列表 = '';
$sql = "从文章中选择 id,title,filename";
$query = mysql_query($sql);
while ($result = mysql_fetch_array ($query)){
$list .= ''.$result['title'].'
';
}
$content .= str_replace ("{ articletable }",$list,$content); 查看全部
php 抓取网页生成图片(PHP脚本与动态页面的模板及模板解析及html解析)
让我们先回顾一些基本概念。
一、PHP脚本和动态页面。
PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的PHP解析器服务器对脚本进行处理,解析成HTML语言形式---->将解析后的HTML语句以包的形式返回给浏览器。不难看出,页面发送到浏览器后,PHP是不存在的,已经被转换解析成HTML语句。客户端请求是一个动态文件。事实上,那里没有真正的文件。它是由 PHP 解析并发送回浏览器的相应页面。这种处理页面的方式称为“动态页面”。
二、静态页面。
静态页面是指服务器端确实存在的页面,只收录HTML、JS、CSS等客户端运行脚本。它的处理方式是。客户端发出请求请求某个页面---->WEB服务器确认并加载某个页面---->WEB服务器将该页面以包的形式传回浏览器。从这个过程中,我们可以对比动态页面来找出答案。动态页面需要WEB服务器的PHP解析器进行解析,通常需要连接数据库进行数据库访问操作,然后形成HTML语言信息包;而静态页面不需要解析,不需要连接数据库,直接发送即可。减轻服务器压力,提升服务器负载能力,大幅提升页面打开速度和网站整体打开速度。
三、模板和模板分析。
模板即尚未填充内容 html 文件。例如:
临时文件
代码:
{ 标题 }
这是一个 { 文件 } 文件的模板
PHP处理:
寺庙测试.php
代码:
$title = "PHP 爱好者测试模板";
$file = "TwoMax Inter 测试模板,
作者:舍义》;
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
回声$内容;
模板解析过程是将PHP脚本解析过程得到的结果填充(内容)到模板中的过程。通常在模板类的帮助下。目前比较流行的模板解析类有phplib、smarty、fastsmarty等。模板解析处理的原理通常是替换。有些程序员习惯于将判断、循环等处理放到模板文件中,用解析类进行处理。典型的应用是块的概念,它只是一个循环处理。循环次数、如何循环替换等由PHP脚本指定,然后模板解析类实现这些操作。
好了,对比完静态页面和动态页面的优缺点,现在我们来说说如何用PHP生成静态文件。
PHP生成静态页面并不意味着动态解析PHP并输出HTML页面,而是使用PHP创建HTML页面。同时,由于 HTML 的不可写性,如果我们创建的 HTML 被修改,需要删除并重新生成。(当然你也可以选择有规律的修改,但我个人认为删除和重新生成的速度越来越快,有些得不偿失。)
离家近一点。使用过PHP文件操作函数的PHPFANS都知道PHP中有一个文件操作函数fopen,也就是打开一个文件。如果该文件不存在,请尝试创建它。这是 PHP 可用于创建 HTML 文件的理论基础。只要存放HTML文件的文件夹有写权限(即权限定义0777)),就可以创建文件。(对于UNIX系统,Win系统不需要考虑。)还是以上面的例子为例,如果我们修改最后一句,并指定在test目录下生成一个名为test.html的静态文件:
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
// 回显 $content;
$filename = "test/test.html";
$handle = fopen ($filename,"w"); //打开文件指针并创建文件
/*
检查文件是否已创建且可写
*/
if (!is_writable ($filename)){
die ("File: ".$filename." 不可写,请检查其属性再试一次!");
}
if (!fwrite ($handle,$content)){ //将信息写入文件
die ("生成文件".$filename."失败!");
}
fclose($句柄);//关闭指针
die ("创建文件".$filename."成功!");
实际应用中常见问题的解决方案参考:
一、文章列出问题:
在数据库中创建字段,记录文件名,每次生成文件时将自动生成的文件名保存到数据库中。对于推荐的文章,只需指向存储静态文件的指定文件夹中的页面即可。使用PHP操作处理文章列表,保存为字符串,生成页面时替换该字符串。比如在页面中放置文章列表的形式,添加标签{articletable},在PHP处理文件中:
代码:
$title = "Tormei 国际测试模板";
$file = "TwoMax Inter 测试模板,
作者:Matrix@Two_Max";
$fp= fopen("temp.html","r");
$content = fread($fp,filesize("temp.html"));
$content .= str_replace ("{ file }",$file,$content);
$content .= str_replace ("{ title }",$title,$content);
// 开始生成列表
$列表 = '';
$sql = "从文章中选择 id,title,filename";
$query = mysql_query($sql);
while ($result = mysql_fetch_array ($query)){
$list .= ''.$result['title'].'
';
}
$content .= str_replace ("{ articletable }",$list,$content);
php 抓取网页生成图片(一下静态URL和动态URL的区别,小白SEO人员来说)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-01-13 06:03
静态 URL 和动态 URL 有什么区别?对于小白SEO人员来说,静态网址和动态网址的区别可能不是很清楚。在本文中,我们将了解静态 URL 和动态 URL。下面将从SEO优化的角度来分析,静态URL和动态URL之间哪个更好。好的。
静态 URL 和动态 URL 有什么区别?
一般我们可以通过查看URL中的文件扩展名来判断页面是静态的还是动态的。静态 URL 是静态网页的页面地址,一个页面每次加载时都具有相同的硬编码内容,静态 URL 永远不会改变。通常,它以扩展名 htm 或 .html 结尾;动态URL为动态网页的链接地址。由搜索数据库驱动的网站生成的网页一般包括aspx、asp、jsp、php、perl、cgi这些文件扩展名还收录变量字符串,比如问号、等号等特殊符号。
从 SEO 优化的角度来看,静态 URL 还是动态 URL 哪个更好?
从SEO优化的角度来看,还是选择静态URL比较好。首先,当用户访问动态URL时,网站程序根据URL中的参数调用数据库数据,实时生成页面内容。生成的页面在服务器主机上并没有真正的静态 HTML 文件。搜索引擎不喜欢动态 URL。如果爬取收录动态URL,可能会出现一个问题,就是陷入死循环或者导致重复页面收录的产生,造成巨大的资源浪费。那么使用静态 URL 有什么好处呢?
静态网页更有利于搜索引擎抓取和收录
与动态网址相比,静态网址会更好地被抓取收录,这是搜索引擎的首选,这对网站优化和提高网站排名有很大帮助。
静态网页网站高稳定性和安全性
从稳定性的角度来看,一个静态网站的每个网页都对应一个固定的URL,比动态URL更稳定。另外,由于动态程序的网站涉及到数据库,如果数据库出现问题,那么网站的影响很大,会直接导致网站失败打开。
从安全的角度来看,由于静态页面是静态显示的,不需要运行程序,因此更不容易受到攻击和黑客攻击。
静态页面 网站 快速打开
打开静态页面和动态页面哪个更快,大家可以期待。动态页面的打开也需要运行数据库,所以需要一定的加载时间,静态页面直接保存这个链接。
综上所述,静态和动态网址整体对比,静态网址的优势会更大,所以从SEO优化的角度来说,建议选择静态网址链接。 查看全部
php 抓取网页生成图片(一下静态URL和动态URL的区别,小白SEO人员来说)
静态 URL 和动态 URL 有什么区别?对于小白SEO人员来说,静态网址和动态网址的区别可能不是很清楚。在本文中,我们将了解静态 URL 和动态 URL。下面将从SEO优化的角度来分析,静态URL和动态URL之间哪个更好。好的。
静态 URL 和动态 URL 有什么区别?
一般我们可以通过查看URL中的文件扩展名来判断页面是静态的还是动态的。静态 URL 是静态网页的页面地址,一个页面每次加载时都具有相同的硬编码内容,静态 URL 永远不会改变。通常,它以扩展名 htm 或 .html 结尾;动态URL为动态网页的链接地址。由搜索数据库驱动的网站生成的网页一般包括aspx、asp、jsp、php、perl、cgi这些文件扩展名还收录变量字符串,比如问号、等号等特殊符号。
从 SEO 优化的角度来看,静态 URL 还是动态 URL 哪个更好?
从SEO优化的角度来看,还是选择静态URL比较好。首先,当用户访问动态URL时,网站程序根据URL中的参数调用数据库数据,实时生成页面内容。生成的页面在服务器主机上并没有真正的静态 HTML 文件。搜索引擎不喜欢动态 URL。如果爬取收录动态URL,可能会出现一个问题,就是陷入死循环或者导致重复页面收录的产生,造成巨大的资源浪费。那么使用静态 URL 有什么好处呢?
静态网页更有利于搜索引擎抓取和收录
与动态网址相比,静态网址会更好地被抓取收录,这是搜索引擎的首选,这对网站优化和提高网站排名有很大帮助。
静态网页网站高稳定性和安全性
从稳定性的角度来看,一个静态网站的每个网页都对应一个固定的URL,比动态URL更稳定。另外,由于动态程序的网站涉及到数据库,如果数据库出现问题,那么网站的影响很大,会直接导致网站失败打开。
从安全的角度来看,由于静态页面是静态显示的,不需要运行程序,因此更不容易受到攻击和黑客攻击。
静态页面 网站 快速打开
打开静态页面和动态页面哪个更快,大家可以期待。动态页面的打开也需要运行数据库,所以需要一定的加载时间,静态页面直接保存这个链接。
综上所述,静态和动态网址整体对比,静态网址的优势会更大,所以从SEO优化的角度来说,建议选择静态网址链接。
php 抓取网页生成图片(Python应用最多的场景还是web快速开发、爬虫运维)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-13 06:02
Python最广泛使用的场景是快速Web开发、爬取和自动化运维。
爬虫在开发过程中也有很多复用过程,这里总结一下。
1、基本网页抓取
获取方法
import urllib2
url = "http://www.1668s.com"
response = urllib2.urlopen(url)
print(response.read())
发帖方式
import urllib
import urllib2
url = "http://1668s.com"
form = { name : abc , password : 1234 }
form_data = urllib.urlencode(form)
request = urllib2.Request(url,form_data)
response = urllib2.urlopen(request)
print(response.read())
2、使用代理IP
在开发爬虫的过程中,经常会遇到IP被屏蔽,这时需要使用代理IP;
urllib2包中有一个ProxyHandler类,通过它可以设置代理访问网页:
3、Cookie 处理
Cookies 是存储在用户本地终端上的一些网站 数据(通常是加密的),用于识别用户的身份并执行会话跟踪。 Python 提供了 cookielib 模块来处理 cookie。 cookielib 模块的主要功能是一个对象,它提供了一个可以存储的 cookie,供 urllib2 模块使用以访问 Internet 资源。
import urllib
from http import cookiejar
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
opener = urllib2.build_opener(cookie_support)
urllib2.install_opener(opener)
content = urllib2.urlopen( http://1668s.com).read()
#关键在于CookieJar(),它用于管理HTTP cookie值、
#存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。
#整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失,所有过程都不需要单独去操作。
#手动添加cookie
cookie = "PHPSESSID=91rurfqm2329bopnosfu4fvmu7; kmsign=55d2c12c9b1e3; KMUID=b6Ejc1XSwPq9o756AxnBAg="
request.add_header("Cookie", cookie)
4、伪装成浏览器
有些网站对爬虫的访问感到反感,所以都拒绝爬虫的请求。所以使用urllib2直接访问网站HTTP Error 403: Forbidden经常出现
特别注意一些headers,服务器会检查这些headers
User-Agent 有些服务器或者代理会检查这个值来判断是否是浏览器发起的RequestContent-Type。使用 REST 接口时,服务器会检查这个值来决定如何解析 HTTP Body 中的内容。 查看全部
php 抓取网页生成图片(Python应用最多的场景还是web快速开发、爬虫运维)
Python最广泛使用的场景是快速Web开发、爬取和自动化运维。
爬虫在开发过程中也有很多复用过程,这里总结一下。
1、基本网页抓取
获取方法
import urllib2
url = "http://www.1668s.com"
response = urllib2.urlopen(url)
print(response.read())
发帖方式
import urllib
import urllib2
url = "http://1668s.com"
form = { name : abc , password : 1234 }
form_data = urllib.urlencode(form)
request = urllib2.Request(url,form_data)
response = urllib2.urlopen(request)
print(response.read())
2、使用代理IP
在开发爬虫的过程中,经常会遇到IP被屏蔽,这时需要使用代理IP;
urllib2包中有一个ProxyHandler类,通过它可以设置代理访问网页:
3、Cookie 处理
Cookies 是存储在用户本地终端上的一些网站 数据(通常是加密的),用于识别用户的身份并执行会话跟踪。 Python 提供了 cookielib 模块来处理 cookie。 cookielib 模块的主要功能是一个对象,它提供了一个可以存储的 cookie,供 urllib2 模块使用以访问 Internet 资源。
import urllib
from http import cookiejar
cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
opener = urllib2.build_opener(cookie_support)
urllib2.install_opener(opener)
content = urllib2.urlopen( http://1668s.com).read()
#关键在于CookieJar(),它用于管理HTTP cookie值、
#存储HTTP请求生成的cookie、向传出的HTTP请求添加cookie的对象。
#整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失,所有过程都不需要单独去操作。
#手动添加cookie
cookie = "PHPSESSID=91rurfqm2329bopnosfu4fvmu7; kmsign=55d2c12c9b1e3; KMUID=b6Ejc1XSwPq9o756AxnBAg="
request.add_header("Cookie", cookie)
4、伪装成浏览器
有些网站对爬虫的访问感到反感,所以都拒绝爬虫的请求。所以使用urllib2直接访问网站HTTP Error 403: Forbidden经常出现
特别注意一些headers,服务器会检查这些headers
User-Agent 有些服务器或者代理会检查这个值来判断是否是浏览器发起的RequestContent-Type。使用 REST 接口时,服务器会检查这个值来决定如何解析 HTTP Body 中的内容。
php 抓取网页生成图片(阿里云osmgitkids第三方demo架构图为什么这个比较有价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-12 13:04
php抓取网页生成图片,如php最新一次生成图片在2014年5月左右,效果不佳,从2015年1月php开始pptv采用php来生成图片了,就算pptv还没更新,也会有很大概率使用php抓取网页,现在微博普遍有图片,那么抓取微博,在网页上生成图片,肯定是未来php可以支持的一个业务线。那么php还有个重要的短板是html5的引入,那么未来flash是基础,也可以支持html5,作为一个同样的问题,不断的上新技术,拼高并发效率一直是php身上存在的问题,不然我们不用去拼html5,这样会更加节省成本,核心技术都不复杂,回归实际业务。
具体实现怎么实现的实时抓取,其实不在本文讨论范围内,只讨论更加有价值的第三方demo,甚至我觉得更有价值的,第三方demo并不会太依赖于webpack,因为如果使用webpack的话,会有各种不兼容,每一代都有优化。更加有价值的会是第三方的demo,我暂时想到的有:真七鱼架构图阿里云osmgitkids第三方demo架构图为什么这个比较有价值,上面第一个实现的webpack是在开源项目中根据自己的项目改造而来,模块化、设计好,可以很好的扩展,但是对于开源项目的兼容性有些差,flash也会有些不一致的地方,当然具体到每个产品,都会有差异,其他的架构图有空再写吧。
接下来给大家展示的是第三方demo并且是全开源的架构图,可以看到很多非常重要的功能已经是对html5支持,但是缺少canvas这些功能,因为html5的引入,这些第三方demo会有更多的应用场景,比如如果推荐一款php生成网页的工具,当然基于soap通信,提供数据交互接口是很好的,但是html5进来太早了,因为html5是基于html的,不支持数据的传输,不支持语义化标签。
具体的demo有:真七鱼架构图阿里云osmfulthon.js对于第三方demo我想要做的是如何基于javascript引入php第三方的demo,这其实是很头疼的事情,接下来做了如下改动,简单说明一下改动逻辑:1.php开发环境的引入:这里需要做的很简单,添加编译依赖,引入js库、浏览器安装依赖等2.利用js与服务器通信,实现php第三方demo与nodejs的通信,具体方法还要查看其他用户的经验。
说完js和nodejs通信,下面我们再说一下config,只有config支持async的上传服务器,那么接下来我们做下载,这里的图片上传通过php推送服务器,上传完成后我们可以解析一下数据进行展示,都可以控制为图片,我们这里的数据抽象一下数据库上传成功,php命令获取数据库redis的数据源推送解析redis数据源上传之后php获。 查看全部
php 抓取网页生成图片(阿里云osmgitkids第三方demo架构图为什么这个比较有价值)
php抓取网页生成图片,如php最新一次生成图片在2014年5月左右,效果不佳,从2015年1月php开始pptv采用php来生成图片了,就算pptv还没更新,也会有很大概率使用php抓取网页,现在微博普遍有图片,那么抓取微博,在网页上生成图片,肯定是未来php可以支持的一个业务线。那么php还有个重要的短板是html5的引入,那么未来flash是基础,也可以支持html5,作为一个同样的问题,不断的上新技术,拼高并发效率一直是php身上存在的问题,不然我们不用去拼html5,这样会更加节省成本,核心技术都不复杂,回归实际业务。
具体实现怎么实现的实时抓取,其实不在本文讨论范围内,只讨论更加有价值的第三方demo,甚至我觉得更有价值的,第三方demo并不会太依赖于webpack,因为如果使用webpack的话,会有各种不兼容,每一代都有优化。更加有价值的会是第三方的demo,我暂时想到的有:真七鱼架构图阿里云osmgitkids第三方demo架构图为什么这个比较有价值,上面第一个实现的webpack是在开源项目中根据自己的项目改造而来,模块化、设计好,可以很好的扩展,但是对于开源项目的兼容性有些差,flash也会有些不一致的地方,当然具体到每个产品,都会有差异,其他的架构图有空再写吧。
接下来给大家展示的是第三方demo并且是全开源的架构图,可以看到很多非常重要的功能已经是对html5支持,但是缺少canvas这些功能,因为html5的引入,这些第三方demo会有更多的应用场景,比如如果推荐一款php生成网页的工具,当然基于soap通信,提供数据交互接口是很好的,但是html5进来太早了,因为html5是基于html的,不支持数据的传输,不支持语义化标签。
具体的demo有:真七鱼架构图阿里云osmfulthon.js对于第三方demo我想要做的是如何基于javascript引入php第三方的demo,这其实是很头疼的事情,接下来做了如下改动,简单说明一下改动逻辑:1.php开发环境的引入:这里需要做的很简单,添加编译依赖,引入js库、浏览器安装依赖等2.利用js与服务器通信,实现php第三方demo与nodejs的通信,具体方法还要查看其他用户的经验。
说完js和nodejs通信,下面我们再说一下config,只有config支持async的上传服务器,那么接下来我们做下载,这里的图片上传通过php推送服务器,上传完成后我们可以解析一下数据进行展示,都可以控制为图片,我们这里的数据抽象一下数据库上传成功,php命令获取数据库redis的数据源推送解析redis数据源上传之后php获。
php 抓取网页生成图片(微信登录开发,封装成一个类的图片抓取方式不奏效)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-12 04:06
最近在开发微信登录的过程中,发现微信头像图片没有后缀名。传统的图像捕获方法不起作用,需要特殊的捕获处理。所以,后来我们把各种情况结合起来,打包成一个类,分享给大家。感兴趣的朋友,一起来看看下面吧。
一、创建项目
作为演示,我们在 www 根目录下创建项目 grabimg,创建一个类 GrabImage.php 和一个 index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{ }
三、属性
接下来,定义一些需要使用的属性。
1、先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能涉及扩展名替换,所以这里定义
3、这后面是扩展名$extension
4、然后我们定义一个$file_dir。该属性的作用是本地抓取远程图片后存放的目录一般以相对于PHP入口文件的位置为起点。但路径一般不会保存到数据库中。
5、最后我们定义一个$save_dir,顾名思义,这个路径就是直接用来保存的数据库的目录。这里解释一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时路径的替换做准备。我们这里的$save_dir一般是日期+文件名。如果需要使用时需要取出,在前面拼出需要的路径即可。
四、方法
属性写完了,接下来我们正式开始爬取工作。
首先,我们定义一个open方法getInstances来获取一些数据,比如抓取图片地址和本地保存路径。也把它放在属性中。
public function getInstances($img_url , $base_dir) { $this->img_url = $img_url; $this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/ $this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/ }
图片保存路径拼接在一起。接下来,我们需要注意一个问题,目录是否存在。日期一天一天过去,但目录不会自动创建。所以,在保存图片之前,我们首先需要检查,如果当前目录不存在,我们需要动态创建它。
我们创建设置目录方法setDir。我们设置的属性private、safe
/** * 检查图片需要保持的目录是否存在 * 如果不存在,则立即创建一个目录 * @return bool */ private function setDir() { if(!file_exists($this->file_dir)) { mkdir($this->file_dir,0777,TRUE); } $this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法 return true; }
下一步是抓取核心代码
第一步是解决一个问题,我们需要抓取的图片可能没有后缀。按照传统的抓取方式,先抓取图片再截取后缀名的方案是行不通的。
我们必须通过其他方式获取图片类型。方法是从文件流信息中获取文件头信息,从而判断文件mime信息,进而可以知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array( 'image/bmp'=>'bmp', 'image/gif'=>'gif', 'image/jpeg'=>'jpg', 'image/png'=>'png', 'image/x-icon'=>'ico' );
这样,当我得到类型 image/gif 时,我就可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为假时,我们将它分配给变量 $headers
取出的Content-Type的值就是mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){ // 获取响应的类型 $type=$headers['Content-Type']; }
使用我们上面定义的映射表,我们可以很容易的得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type在我们的映射表中可能不存在,说明这种类型的文件不是我们想要的,所以直接丢弃就行了。
以下步骤与传统爬取文件相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension; // 获取数据并保存 $contents=file_get_contents($this->img_url); if(file_put_contents($file_path , $contents)) { // 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg-600 return $this->save_dir.$this->file_name.".".$this->extension; }
先获取完整路径$file_path将图片保存到本地,然后使用file_get_contents抓取数据,再使用file_put_contents保存到刚才的文件路径。
最后我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的抓取方法是:
private function getRemoteImg() { // mime 和 扩展名 的映射 $mimes=array( 'image/bmp'=>'bmp', 'image/gif'=>'gif', 'image/jpeg'=>'jpg', 'image/png'=>'png', 'image/x-icon'=>'ico' ); // 获取响应头 if(($headers=get_headers($this->img_url, 1))!==false) { // 获取响应的类型 $type=$headers['Content-Type']; // 如果符合我们要的类型 if(isset($mimes[$type])) { $this->extension=$mimes[$type]; $file_path = $this->file_dir.$this->file_name.".".$this->extension; // 获取数据并保存 $contents=file_get_contents($this->img_url); if(file_put_contents($file_path , $contents)) { // 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg-600 return $this->save_dir.$this->file_name.".".$this->extension; } } } return false; }
最后,为了简单起见,我们想在别处调用这些方法之一来完成获取。所以我们把抓取动作直接放到getInstances中,配置好路径后直接抓取。因此,在初始化配置方法getInstances中添加代码。
if($this->setDir()) { return $this->getRemoteImg(); } else { return false; }
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
真的抓住了
完整代码
<p> 查看全部
php 抓取网页生成图片(微信登录开发,封装成一个类的图片抓取方式不奏效)
最近在开发微信登录的过程中,发现微信头像图片没有后缀名。传统的图像捕获方法不起作用,需要特殊的捕获处理。所以,后来我们把各种情况结合起来,打包成一个类,分享给大家。感兴趣的朋友,一起来看看下面吧。
一、创建项目
作为演示,我们在 www 根目录下创建项目 grabimg,创建一个类 GrabImage.php 和一个 index.php。
二、编写类代码
我们定义一个与文件同名的类:GrabImage
class GrabImage{ }
三、属性
接下来,定义一些需要使用的属性。
1、先定义一个需要抓取的图片地址:$img_url
2、再定义一个$file_name来存放文件名,但是不带扩展名,因为可能涉及扩展名替换,所以这里定义
3、这后面是扩展名$extension
4、然后我们定义一个$file_dir。该属性的作用是本地抓取远程图片后存放的目录一般以相对于PHP入口文件的位置为起点。但路径一般不会保存到数据库中。
5、最后我们定义一个$save_dir,顾名思义,这个路径就是直接用来保存的数据库的目录。这里解释一下,我们不直接将文件保存路径存储到数据库中,一般是为以后系统迁移时路径的替换做准备。我们这里的$save_dir一般是日期+文件名。如果需要使用时需要取出,在前面拼出需要的路径即可。
四、方法
属性写完了,接下来我们正式开始爬取工作。
首先,我们定义一个open方法getInstances来获取一些数据,比如抓取图片地址和本地保存路径。也把它放在属性中。
public function getInstances($img_url , $base_dir) { $this->img_url = $img_url; $this->save_dir = date("Ym").'/'.date("d").'/'; // 比如:201610/19/ $this->file_dir = $base_dir.'/'.$this->save_dir.'/'; // 比如:./uploads/image/2016/10/19/ }
图片保存路径拼接在一起。接下来,我们需要注意一个问题,目录是否存在。日期一天一天过去,但目录不会自动创建。所以,在保存图片之前,我们首先需要检查,如果当前目录不存在,我们需要动态创建它。
我们创建设置目录方法setDir。我们设置的属性private、safe
/** * 检查图片需要保持的目录是否存在 * 如果不存在,则立即创建一个目录 * @return bool */ private function setDir() { if(!file_exists($this->file_dir)) { mkdir($this->file_dir,0777,TRUE); } $this->file_name = uniqid().rand(10000,99999);// 文件名,这里只是演示,实际项目中请使用自己的唯一文件名生成方法 return true; }
下一步是抓取核心代码
第一步是解决一个问题,我们需要抓取的图片可能没有后缀。按照传统的抓取方式,先抓取图片再截取后缀名的方案是行不通的。
我们必须通过其他方式获取图片类型。方法是从文件流信息中获取文件头信息,从而判断文件mime信息,进而可以知道文件后缀名。
为方便起见,首先定义一个 mime 和文件扩展名映射。
$mimes=array( 'image/bmp'=>'bmp', 'image/gif'=>'gif', 'image/jpeg'=>'jpg', 'image/png'=>'png', 'image/x-icon'=>'ico' );
这样,当我得到类型 image/gif 时,我就可以知道它是一个 .gif 图像。
使用php函数get_headers获取文件流头信息。当它的值不为假时,我们将它分配给变量 $headers
取出的Content-Type的值就是mime的值。
if(($headers=get_headers($this->img_url, 1))!==false){ // 获取响应的类型 $type=$headers['Content-Type']; }
使用我们上面定义的映射表,我们可以很容易的得到后缀名。
$this->extension=$mimes[$type];
当然,上面得到的$type在我们的映射表中可能不存在,说明这种类型的文件不是我们想要的,所以直接丢弃就行了。
以下步骤与传统爬取文件相同。
$file_path = $this->file_dir.$this->file_name.".".$this->extension; // 获取数据并保存 $contents=file_get_contents($this->img_url); if(file_put_contents($file_path , $contents)) { // 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg-600 return $this->save_dir.$this->file_name.".".$this->extension; }
先获取完整路径$file_path将图片保存到本地,然后使用file_get_contents抓取数据,再使用file_put_contents保存到刚才的文件路径。
最后我们返回一个可以直接保存到数据库的路径,而不是文件存储路径。
完整版的抓取方法是:
private function getRemoteImg() { // mime 和 扩展名 的映射 $mimes=array( 'image/bmp'=>'bmp', 'image/gif'=>'gif', 'image/jpeg'=>'jpg', 'image/png'=>'png', 'image/x-icon'=>'ico' ); // 获取响应头 if(($headers=get_headers($this->img_url, 1))!==false) { // 获取响应的类型 $type=$headers['Content-Type']; // 如果符合我们要的类型 if(isset($mimes[$type])) { $this->extension=$mimes[$type]; $file_path = $this->file_dir.$this->file_name.".".$this->extension; // 获取数据并保存 $contents=file_get_contents($this->img_url); if(file_put_contents($file_path , $contents)) { // 这里返回出去的值是直接保存到数据库的路径 + 文件名,形如:201610/19/57feefd7e2a7aY5p7LsPqaI-lY1BF.jpg-600 return $this->save_dir.$this->file_name.".".$this->extension; } } } return false; }
最后,为了简单起见,我们想在别处调用这些方法之一来完成获取。所以我们把抓取动作直接放到getInstances中,配置好路径后直接抓取。因此,在初始化配置方法getInstances中添加代码。
if($this->setDir()) { return $this->getRemoteImg(); } else { return false; }
测试
让我们在刚刚创建的 index.php 文件中尝试一下。
真的抓住了
完整代码
<p>
php 抓取网页生成图片(基于的二维码不上传到服务器页面的实现过程及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-06 20:11
一、背景
要求是后台点击生成二维码,然后不上传二维码到服务器。我们需要将二维码返回首页并显示出来。
二、实现过程
1、生成二维码
这里使用的第三方是二维码。网上百度有很多教程,这里就不赘述了。可以参考链接生成二维码
函数索引($ctx){
require_once APP_PATH.'/classes/phpqrcode/phpqrcode.php';
$link_url="";
$level="L";
$size=6;
ob_start();
$QRcode = new QRcode();
$QRcode->png($link_url,false,$level,$size,2);
记录器::信息(base64_encode(ob_get_contents()));
$imageString =base64_encode(ob_get_contents());
记录器::信息($imageString);
ob_end_clean();
如果(ob_end_clean()){
logger::info('end clen');
}
$数据=数组(
'代码'=> 2,
'二维码'=>$imageString
);
header("content-type:application/json; charset=utf-8");
!!!(上面这行代码肯定有,因为Qrcode::png(),在生成二维码的时候,内部把响应的响应类型改为image/jpeg,所以需要自己手动设置响应头类型,否则接口不能返回json数据)
返回 $data;
}
现在要实现的效果是通过接口将二维码路径返回给前端。
这里需要明确的是,png() 方法返回的是一个二进制图像流。所以直接返回是没用的。如果我们打印返回值,我们会发现返回值为空。所以这里使用ob_start()来执行一系列使用缓冲区的操作。
将二维码路径返回给前端。
这里需要明确的是,png() 方法返回的是一个二进制图像流。所以直接返回是没用的。如果我们打印返回值,我们会发现返回值为空。所以这里使用ob_start()来执行一系列使用缓冲区的操作
1. 第一个参数$text就是上面代码中的URL参数。
2. 第二个参数$outfile默认为No,不生成文件,只返回二维码图片,否则需要生成生成的二维码图片的存放路径
3. 第三个参数$level默认为L,这个参数可以传递的值为L(QR_ECLEVEL_L, 7%), M(QR_ECLEVEL_M, 15%), Q(QR_ECLEVEL_Q, 25%), H(QR_ECLEVEL_H, 30%)。该参数控制二维码的容错率,不同的参数表示二维码可以覆盖的面积百分比。利用二维码的容错率,我们可以将头像放置在生成的二维码图片的任意区域。
4. 第四个参数$size,控制生成图片的大小,默认为4
5. 第五个参数 $margin 控制生成二维码的空白区域的大小
6. 第六个参数$saveandprint,保存二维码图片并显示,$outfile必须传递图片路径。
第二个参数默认为false,该方法返回一个二进制图像流。当页面输出时,缓冲区中生成的内容将从缓冲区发送到浏览器。所以在代码中,日志输出没有记录在日志中,内容输出也不需要使用echo。所以直接用base64_encode(QRcode::png)是没用的。
这里使用 ob_start() 方法打开输出缓冲区。所有输出信息都不会直接发送到浏览器,而是存储在输出缓冲区中。这里是将生成的图片流从buffer中保存到内存对象中,使用base64_encode将其转为编码后的字符串,通过json返回给页面。
php缓存区相关的操作函数如下。
一、 相关功能介绍:
1、Flush:刷新缓冲区的内容并输出。
函数格式:flush()
说明:这个功能经常用到,效率很高。
2、ob_start:打开输出缓冲区
函数格式:void ob_start(void)
注意:当缓冲区被激活时,所有来自 PHP 程序的非文件头信息都不会被发送,而是存储在内部缓冲区中。为了输出缓冲区的内容,可以使用ob_end_flush() 或flush() 来输出缓冲区的内容。
3. ob_get_contents:返回内部缓冲区的内容。
如何使用:字符串 ob_get_contents(void)
说明:该函数将返回当前缓冲区的内容,如果输出缓冲区未激活,则返回FALSE。
4、ob_get_length:返回内部缓冲区的长度。
使用方法:int ob_get_length(void)
说明:该函数将返回当前缓冲区的长度;像 ob_get_contents,如果输出缓冲区没有被激活。它返回 FALSE。
5、ob_end_flush:将内部缓冲区的内容发送到浏览器,并关闭输出缓冲区。
使用方法:void ob_end_flush(void)
说明:该函数发送输出缓冲区的内容(如果有)。
6、ob_end_clean:删除内部缓冲区的内容并关闭内部缓冲区
使用方法:void ob_end_clean(void)
说明:该函数不会输出内部缓冲区的内容,而是将其删除!
7、ob_implicit_flush:开启或关闭绝对刷新
使用方法:void ob_implicit_flush([int flag])
注意:任何使用过 Perl 的人都知道 $|=x 的含义。该字符串可以打开/关闭缓冲区,ob_implicit_flush 函数与此相同。默认是关闭缓冲区。开启绝对输出后,每次脚本输出都是直接发送到浏览器,不需要调用flush()
原链接。 查看全部
php 抓取网页生成图片(基于的二维码不上传到服务器页面的实现过程及应用)
一、背景
要求是后台点击生成二维码,然后不上传二维码到服务器。我们需要将二维码返回首页并显示出来。
二、实现过程
1、生成二维码
这里使用的第三方是二维码。网上百度有很多教程,这里就不赘述了。可以参考链接生成二维码
函数索引($ctx){
require_once APP_PATH.'/classes/phpqrcode/phpqrcode.php';
$link_url="";
$level="L";
$size=6;
ob_start();
$QRcode = new QRcode();
$QRcode->png($link_url,false,$level,$size,2);
记录器::信息(base64_encode(ob_get_contents()));
$imageString =base64_encode(ob_get_contents());
记录器::信息($imageString);
ob_end_clean();
如果(ob_end_clean()){
logger::info('end clen');
}
$数据=数组(
'代码'=> 2,
'二维码'=>$imageString
);
header("content-type:application/json; charset=utf-8");
!!!(上面这行代码肯定有,因为Qrcode::png(),在生成二维码的时候,内部把响应的响应类型改为image/jpeg,所以需要自己手动设置响应头类型,否则接口不能返回json数据)
返回 $data;
}
现在要实现的效果是通过接口将二维码路径返回给前端。
这里需要明确的是,png() 方法返回的是一个二进制图像流。所以直接返回是没用的。如果我们打印返回值,我们会发现返回值为空。所以这里使用ob_start()来执行一系列使用缓冲区的操作。
将二维码路径返回给前端。
这里需要明确的是,png() 方法返回的是一个二进制图像流。所以直接返回是没用的。如果我们打印返回值,我们会发现返回值为空。所以这里使用ob_start()来执行一系列使用缓冲区的操作
1. 第一个参数$text就是上面代码中的URL参数。
2. 第二个参数$outfile默认为No,不生成文件,只返回二维码图片,否则需要生成生成的二维码图片的存放路径
3. 第三个参数$level默认为L,这个参数可以传递的值为L(QR_ECLEVEL_L, 7%), M(QR_ECLEVEL_M, 15%), Q(QR_ECLEVEL_Q, 25%), H(QR_ECLEVEL_H, 30%)。该参数控制二维码的容错率,不同的参数表示二维码可以覆盖的面积百分比。利用二维码的容错率,我们可以将头像放置在生成的二维码图片的任意区域。
4. 第四个参数$size,控制生成图片的大小,默认为4
5. 第五个参数 $margin 控制生成二维码的空白区域的大小
6. 第六个参数$saveandprint,保存二维码图片并显示,$outfile必须传递图片路径。
第二个参数默认为false,该方法返回一个二进制图像流。当页面输出时,缓冲区中生成的内容将从缓冲区发送到浏览器。所以在代码中,日志输出没有记录在日志中,内容输出也不需要使用echo。所以直接用base64_encode(QRcode::png)是没用的。
这里使用 ob_start() 方法打开输出缓冲区。所有输出信息都不会直接发送到浏览器,而是存储在输出缓冲区中。这里是将生成的图片流从buffer中保存到内存对象中,使用base64_encode将其转为编码后的字符串,通过json返回给页面。
php缓存区相关的操作函数如下。
一、 相关功能介绍:
1、Flush:刷新缓冲区的内容并输出。
函数格式:flush()
说明:这个功能经常用到,效率很高。
2、ob_start:打开输出缓冲区
函数格式:void ob_start(void)
注意:当缓冲区被激活时,所有来自 PHP 程序的非文件头信息都不会被发送,而是存储在内部缓冲区中。为了输出缓冲区的内容,可以使用ob_end_flush() 或flush() 来输出缓冲区的内容。
3. ob_get_contents:返回内部缓冲区的内容。
如何使用:字符串 ob_get_contents(void)
说明:该函数将返回当前缓冲区的内容,如果输出缓冲区未激活,则返回FALSE。
4、ob_get_length:返回内部缓冲区的长度。
使用方法:int ob_get_length(void)
说明:该函数将返回当前缓冲区的长度;像 ob_get_contents,如果输出缓冲区没有被激活。它返回 FALSE。
5、ob_end_flush:将内部缓冲区的内容发送到浏览器,并关闭输出缓冲区。
使用方法:void ob_end_flush(void)
说明:该函数发送输出缓冲区的内容(如果有)。
6、ob_end_clean:删除内部缓冲区的内容并关闭内部缓冲区
使用方法:void ob_end_clean(void)
说明:该函数不会输出内部缓冲区的内容,而是将其删除!
7、ob_implicit_flush:开启或关闭绝对刷新
使用方法:void ob_implicit_flush([int flag])
注意:任何使用过 Perl 的人都知道 $|=x 的含义。该字符串可以打开/关闭缓冲区,ob_implicit_flush 函数与此相同。默认是关闭缓冲区。开启绝对输出后,每次脚本输出都是直接发送到浏览器,不需要调用flush()
原链接。
php 抓取网页生成图片( 如何使用PHP生成二维码,以及如何生成中间带LOGO图像的二维码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-06 20:09
如何使用PHP生成二维码,以及如何生成中间带LOGO图像的二维码)
使用PHP生成二维码的两种方法(附logo图片)
更新时间:2021年11月16日09:51:59 投稿:俊杰
随着科学技术的进步,二维码的应用领域越来越广泛。今天给大家分享一下如何使用PHP生成二维码,以及如何生成中间有LOGO图片的二维码。
一、使用Google API生成二维码
谷歌提供了比较完善的二维码生成接口,调用API接口很简单,下面是调用代码:
$urlToEncode="//www.jb51.net";
generateQRfromGoogle($urlToEncode);
/**
* google api 二维码生成【QRcode可以存储最多4296个字母数字类型的任意文本,具体可以查看二维码数据格式】
* @param string $chl 二维码包含的信息,可以是数字、字符、二进制信息、汉字。
不能混合数据类型,数据必须经过UTF-8 URL-encoded
* @param int $widhtHeight 生成二维码的尺寸设置
* @param string $EC_level 可选纠错级别,QR码支持四个等级纠错,用来恢复丢失的、读错的、模糊的、数据。
* L-默认:可以识别已损失的7%的数据
* M-可以识别已损失15%的数据
* Q-可以识别已损失25%的数据
* H-可以识别已损失30%的数据
* @param int $margin 生成的二维码离图片边框的距离
*/
function generateQRfromGoogle($chl,$widhtHeight ='150',$EC_level='L',$margin='0')
{
$chl = urlencode($chl);
echo '';
}
二、使用PHP二维码生成类库PHP二维码生成二维码
PHP QR Code 是一个 PHP 二维码生成库,可用于轻松生成二维码。官网提供下载和多个demo demo。检查地址:。
下载官网提供的类库后,只需要使用phpqrcode.php生成二维码即可。当然,你的PHP环境必须开启支持GD2。phpqrcode.php提供了一个关键的png()方法,其中参数$text表示生成两位数的信息文本;参数$outfile表示是否输出二维码图片文件,默认为no;参数$level代表容错率,即Covered area仍可识别,分别是L(QR_ECLEVEL_L, 7%), M (QR_ECLEVEL_M, 15%), Q (QR_ECLEVEL_Q, 25%), H (QR_ECLEVEL_H, 30 %); 参数$size表示生成图像的大小,默认为3;参数$margin表示二维码周围空白区域的边距值;
public static function png($text, $outfile=false, $level=QR_ECLEVEL_L, $size=3, $margin=4,
$saveandprint=false)
{
$enc = QRencode::factory($level, $size, $margin);
return $enc->encodePNG($text, $outfile, $saveandprint=false);
}
调用PHP二维码非常简单,下面的代码可以生成一个内容为“//”的二维码。
php代码
包括'phpqrcode.php';
二维码::png('//');
在实际应用中,我们会在二维码中间添加自己的LOGO,以增强宣传效果。如何生成带有徽标的二维码?其实原理很简单。首先使用PHP QR Code生成二维码图片,然后使用PHP的图片相关函数将准备好的logo图片添加到新生成的原创二维码图片中,再重新生成一张新的。二维码的图像。
include 'phpqrcode.php';
$value = '//www.jb51.net'; //二维码内容
$errorCorrectionLevel = 'L';//容错级别
$matrixPointSize = 6;//生成图片大小
//生成二维码图片
QRcode::png($value, 'qrcode.png', $errorCorrectionLevel, $matrixPointSize, 2);
$logo = 'logo.png';//准备好的logo图片
$QR = 'qrcode.png';//已经生成的原始二维码图
if ($logo !== FALSE) {
$QR = imagecreatefromstring(file_get_contents($QR));
$logo = imagecreatefromstring(file_get_contents($logo));
$QR_width = imagesx($QR);//二维码图片宽度
$QR_height = imagesy($QR);//二维码图片高度
$logo_width = imagesx($logo);//logo图片宽度
$logo_height = imagesy($logo);//logo图片高度
$logo_qr_width = $QR_width / 5;
$scale = $logo_width/$logo_qr_width;
$logo_qr_height = $logo_height/$scale;
$from_width = ($QR_width - $logo_qr_width) / 2;
//重新组合图片并调整大小
imagecopyresampled($QR, $logo, $from_width, $from_width, 0, 0, $logo_qr_width,
$logo_qr_height, $logo_width, $logo_height);
}
//输出图片
imagepng($QR, 'helloweba.png');
echo 'helloweba.png';
以下是对上面代码的引用,不产生图片文件,方便调用,将以下代码保存为img.php
<p> 查看全部
php 抓取网页生成图片(
如何使用PHP生成二维码,以及如何生成中间带LOGO图像的二维码)
使用PHP生成二维码的两种方法(附logo图片)
更新时间:2021年11月16日09:51:59 投稿:俊杰
随着科学技术的进步,二维码的应用领域越来越广泛。今天给大家分享一下如何使用PHP生成二维码,以及如何生成中间有LOGO图片的二维码。
一、使用Google API生成二维码
谷歌提供了比较完善的二维码生成接口,调用API接口很简单,下面是调用代码:
$urlToEncode="//www.jb51.net";
generateQRfromGoogle($urlToEncode);
/**
* google api 二维码生成【QRcode可以存储最多4296个字母数字类型的任意文本,具体可以查看二维码数据格式】
* @param string $chl 二维码包含的信息,可以是数字、字符、二进制信息、汉字。
不能混合数据类型,数据必须经过UTF-8 URL-encoded
* @param int $widhtHeight 生成二维码的尺寸设置
* @param string $EC_level 可选纠错级别,QR码支持四个等级纠错,用来恢复丢失的、读错的、模糊的、数据。
* L-默认:可以识别已损失的7%的数据
* M-可以识别已损失15%的数据
* Q-可以识别已损失25%的数据
* H-可以识别已损失30%的数据
* @param int $margin 生成的二维码离图片边框的距离
*/
function generateQRfromGoogle($chl,$widhtHeight ='150',$EC_level='L',$margin='0')
{
$chl = urlencode($chl);
echo '
}
二、使用PHP二维码生成类库PHP二维码生成二维码
PHP QR Code 是一个 PHP 二维码生成库,可用于轻松生成二维码。官网提供下载和多个demo demo。检查地址:。
下载官网提供的类库后,只需要使用phpqrcode.php生成二维码即可。当然,你的PHP环境必须开启支持GD2。phpqrcode.php提供了一个关键的png()方法,其中参数$text表示生成两位数的信息文本;参数$outfile表示是否输出二维码图片文件,默认为no;参数$level代表容错率,即Covered area仍可识别,分别是L(QR_ECLEVEL_L, 7%), M (QR_ECLEVEL_M, 15%), Q (QR_ECLEVEL_Q, 25%), H (QR_ECLEVEL_H, 30 %); 参数$size表示生成图像的大小,默认为3;参数$margin表示二维码周围空白区域的边距值;
public static function png($text, $outfile=false, $level=QR_ECLEVEL_L, $size=3, $margin=4,
$saveandprint=false)
{
$enc = QRencode::factory($level, $size, $margin);
return $enc->encodePNG($text, $outfile, $saveandprint=false);
}
调用PHP二维码非常简单,下面的代码可以生成一个内容为“//”的二维码。
php代码
包括'phpqrcode.php';
二维码::png('//');
在实际应用中,我们会在二维码中间添加自己的LOGO,以增强宣传效果。如何生成带有徽标的二维码?其实原理很简单。首先使用PHP QR Code生成二维码图片,然后使用PHP的图片相关函数将准备好的logo图片添加到新生成的原创二维码图片中,再重新生成一张新的。二维码的图像。
include 'phpqrcode.php';
$value = '//www.jb51.net'; //二维码内容
$errorCorrectionLevel = 'L';//容错级别
$matrixPointSize = 6;//生成图片大小
//生成二维码图片
QRcode::png($value, 'qrcode.png', $errorCorrectionLevel, $matrixPointSize, 2);
$logo = 'logo.png';//准备好的logo图片
$QR = 'qrcode.png';//已经生成的原始二维码图
if ($logo !== FALSE) {
$QR = imagecreatefromstring(file_get_contents($QR));
$logo = imagecreatefromstring(file_get_contents($logo));
$QR_width = imagesx($QR);//二维码图片宽度
$QR_height = imagesy($QR);//二维码图片高度
$logo_width = imagesx($logo);//logo图片宽度
$logo_height = imagesy($logo);//logo图片高度
$logo_qr_width = $QR_width / 5;
$scale = $logo_width/$logo_qr_width;
$logo_qr_height = $logo_height/$scale;
$from_width = ($QR_width - $logo_qr_width) / 2;
//重新组合图片并调整大小
imagecopyresampled($QR, $logo, $from_width, $from_width, 0, 0, $logo_qr_width,
$logo_qr_height, $logo_width, $logo_height);
}
//输出图片
imagepng($QR, 'helloweba.png');
echo 'helloweba.png';
以下是对上面代码的引用,不产生图片文件,方便调用,将以下代码保存为img.php
<p>

