
php 循环抓取网页内容
php 循环抓取网页内容(php循环抓取网页内容解决静态网页可视化问题(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-21 18:03
php循环抓取网页内容解决静态网页可视化问题“php循环抓取网页内容解决静态网页可视化问题”php网页的html,从div+css结构来看,可以分为4种结构,一种为静态页面html,另外一种为动态页面div+css,还有一种是通过轮询方式来抓取,不关心执行流程,只是获取内容。php循环抓取网页内容例1:网页最终会生成一个静态的数据页面div,需要设置js或者xmlhttprequest对象从而获取网页内容。
如果抓取完的页面非常非常多,使用循环可能会造成需要n次加载的问题,我们知道页面抓取函数lookup()函数也可以实现分页抓取,这样页面抓取就可以顺利进行了。为了方便抓取,所以模拟了一个php网页的请求,结果是接收到如下的html响应数据,然后会把内容存储到文件中(php内置的所有数据类型)然后给js或者xmlhttprequest对象,这样是可以通过php进行解析的。
执行抓取时,再抓取一次就可以生成响应数据,最终文件内容也就会在浏览器中展示。php循环抓取网页内容例2:还是php网页的动态请求实现,可能效率更高,可以看出三次加载原因有三点,就是最终html页面需要三次加载,主要原因是模拟请求的时候分段了,完成php网页动态请求之后,js和xmlhttprequest等工具就可以对各个页面进行分段执行,一段一段的加载html页面,所以需要三次加载。
php循环抓取网页内容还是这个php循环抓取网页内容案例,请求是从:指定域名处跳转后的url,url的请求结构就可以看下面图片,想知道具体实现步骤的,可以在评论区留言。php循环抓取网页内容无论php循环还是java循环,重点不在于循环形式,而在于抓取,抓取的时候需要做到顺序一致,这里有个知识点我们需要注意:整个抓取逻辑都可以分开php中2.object类中,并没有somebody的属性,只有some()函数接收一个object,该object会从浏览器中抓取post方法的请求,同时也会对其进行处理,post方法可以接受cookie,referer,session等参数,方法的具体逻辑就可以看下面图片,方法实现看下面的注释。
php循环抓取网页内容php循环抓取网页内容php循环抓取网页内容以上三个案例只是php循环抓取网页内容一种重要问题,还有一些后续比较容易犯的错误需要注意:尽量是大请求,采用selenium等从浏览器抓取以降低处理速度原始html格式的页面也是抓取时的大问题java有很多方法可以实现,但是java能不能实现,我们就不能去抓取,这是前端工程师做项目的过程中所需要注意的知识点ajax高级绑定(异步方法)file读写(读取后面的参数,会变成前端地。 查看全部
php 循环抓取网页内容(php循环抓取网页内容解决静态网页可视化问题(组图))
php循环抓取网页内容解决静态网页可视化问题“php循环抓取网页内容解决静态网页可视化问题”php网页的html,从div+css结构来看,可以分为4种结构,一种为静态页面html,另外一种为动态页面div+css,还有一种是通过轮询方式来抓取,不关心执行流程,只是获取内容。php循环抓取网页内容例1:网页最终会生成一个静态的数据页面div,需要设置js或者xmlhttprequest对象从而获取网页内容。
如果抓取完的页面非常非常多,使用循环可能会造成需要n次加载的问题,我们知道页面抓取函数lookup()函数也可以实现分页抓取,这样页面抓取就可以顺利进行了。为了方便抓取,所以模拟了一个php网页的请求,结果是接收到如下的html响应数据,然后会把内容存储到文件中(php内置的所有数据类型)然后给js或者xmlhttprequest对象,这样是可以通过php进行解析的。
执行抓取时,再抓取一次就可以生成响应数据,最终文件内容也就会在浏览器中展示。php循环抓取网页内容例2:还是php网页的动态请求实现,可能效率更高,可以看出三次加载原因有三点,就是最终html页面需要三次加载,主要原因是模拟请求的时候分段了,完成php网页动态请求之后,js和xmlhttprequest等工具就可以对各个页面进行分段执行,一段一段的加载html页面,所以需要三次加载。
php循环抓取网页内容还是这个php循环抓取网页内容案例,请求是从:指定域名处跳转后的url,url的请求结构就可以看下面图片,想知道具体实现步骤的,可以在评论区留言。php循环抓取网页内容无论php循环还是java循环,重点不在于循环形式,而在于抓取,抓取的时候需要做到顺序一致,这里有个知识点我们需要注意:整个抓取逻辑都可以分开php中2.object类中,并没有somebody的属性,只有some()函数接收一个object,该object会从浏览器中抓取post方法的请求,同时也会对其进行处理,post方法可以接受cookie,referer,session等参数,方法的具体逻辑就可以看下面图片,方法实现看下面的注释。
php循环抓取网页内容php循环抓取网页内容php循环抓取网页内容以上三个案例只是php循环抓取网页内容一种重要问题,还有一些后续比较容易犯的错误需要注意:尽量是大请求,采用selenium等从浏览器抓取以降低处理速度原始html格式的页面也是抓取时的大问题java有很多方法可以实现,但是java能不能实现,我们就不能去抓取,这是前端工程师做项目的过程中所需要注意的知识点ajax高级绑定(异步方法)file读写(读取后面的参数,会变成前端地。
php 循环抓取网页内容(什么是网站的TDK?网站TDK设置技巧:SEO优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-19 10:12
网站的TDK是什么?网站TDK设置技巧分类:SEO优化 作者:小秋 发布时间:2019-12-2513:41:34 访问人数:本文标签:网站TDK,网站标题,< @网站描述,TDK标签,网站的TDK是什么?TDK指的是title、keywords、description,这三个标签都是兼容搜索引擎网站内容的判断与定位有关。是对网站用户**,以及收录和网站的排名的直观理解。这三个主要标签对搜索引擎和用户都很重要。影响很大,所以网站设置TDK很重要。网站TDK设置技巧一、注意title标签的细节,切记不要堆在< @网站 优化。标题尤其重要。需要注意的是标题不能过度叠加关键词,必须保证标题与网站的主题一致,不能忽视用户的浏览习惯和阅读效果。尽量将标题的关键词控制在三个字左右,从网站**搜索量,武侯区php网站的关键词中选择。这里有个细节要注意,关键词的顺序也是有讲究的,因为搜索引擎的抓取习惯是从左到右,越靠近左边,关键词越重要,所以写关键词在@>的情况下,可以将关键词按重要性从左到右排列。此外,分隔每个单词的符号也必须符合规定。设置标题时,不能太长也不能太短。太长容易被搜索引擎屏蔽,武侯区php网站,太短不利于用户浏览,武侯区php网站,用户体验差。普通标题的字数尽量限制在80个字符以内,相当于40个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站 相当于 40 个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站 相当于 40 个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站
无框。使用哪种样式表,外部样式或内部样式。使用webjs,合理的使用js可以减少网页的来源,但是合理的大量使用会影响网页的抓取。*三、站点数量取决于集合、链和快照。内容量可以反映网站是否受搜索引擎欢迎,可以判断原创的内容。看一下链,可以在网站上反映其他网站的评价,也可以看到链的来源是否重要,来源是否不同,推广网站的权重是否不同。因此,在外链的建设中,不仅要数量,更要质量。并且快照情况可以反映网站的*新情况。只有网站内容不断更新,原创信息对搜索引擎友好,才能吸引搜索引擎蜘蛛爬取。*四、看关键词的排名。关键词排名主要从网站的主键和长尾关键词来考虑。做过seo的人都知道,有时候他们的排名不做关键词,有些人故意不做关键词,但是他们会有很好的排名。因此,我们应该把它放在一起。当然,对于主力关键词的排名,seo做得不错,合理选择关键词,能体现执行能力。*五、网站目录及内链的构建。使用了多少级目录,以及文件名的写法。尽量不要让用户花费大量时间,多次点击,找到自己想找的东西,**好不要*过4级。另外,网站的内链建设也很重要。美山做优化网站咨询,源代码就是源文件的内容,所以也可以称为网页的源代码。
让搜索引擎无法保质保量抓取页面内容,导致网站主题失真。05网站链接因素网站 链接分为内部链接和外部链接。站内链接主要是链接网站中的相关内容。一般出现在站内文章的相关关键词新闻**或底部新闻**阅读中;顾名思义,站外链接是网站之外的链接,而网站在线时间与外链比例在百度规则中存在一个高峰区间。这个峰值区域多为抛物线,所以在网站上线初期不要有大量的网站外链,因为一旦过了峰值,很容易被百度判断作为***网站, 从而影响网站的优化。网站想要得到更多收录,需要做好搜索引擎的爬取优化。只有提高网站的整体爬取率,才能提高相应的收录,这样网站的内容才能得到更多的展示和**,以及网站的排名@> 可以改进。有了好的基础才能爬上去,基础设施永远是网站优化的基础。并且网站的排名可以提高。有了好的基础才能爬上去,基础设施永远是网站优化的基础。并且网站的排名可以提高。有了好的基础才能爬上去,基础设施永远是网站优化的基础。
搜索引擎优化在列出单词后为结果付费是真的吗?对于初创企业来说,官网上线的时候,大部分都没有自己的SEO团队。由于资金有限,大多数公司通常与SEO机构合作。进而满足在线**业务订单的需求。在联系一些相关的SEO公司时,我们经常会谈到一个问题:SEO见效后付费。这是一些中小企业第一次学习SEO时常说的一句话。关于SEO付费效果的问题,不要一概而论,要根据实际情况来谈,所以我们需要了解以下几点: SEO付费效果场景:①常规排名②**排名一般来说,当我们说到SEO的效果再付费的时候,一般分为以上两种情况。新网站上线后,您需要通过正规渠道**在线下单。不过由于我们不了解对方公司的情况,顾提出要按效果付费。另一种情况是,由于业务压力,公司知道对方是黑帽SEO,仍然采取一种行为,通常每个词有效流量,双方协商后要根据结果付费。SEO按效果付费套路:①关键词首页7天如果你尝试使用正式的排名,那么面对这种句式结构,基本可以断定对方使用的是非正式的意味着,甚至可能根本不提供任何搜索引擎优化服务,在这种情况下,您应该坚决拒绝。②以首付作为基本词似乎是一个合理的套路。选择什么样的动态程序和对应的数据库。如程序ASP、JSP、PHP、.NET;数据库 SQL、ACCESS、ORACLE、mysql 等。
在网站的介绍中写其他长尾词。我从来不刻意做,只要你的网站被认可了,权重自然就上去了,以后各种词都上去了。(4)网站栏目名称尽量使用首页关键词的长尾词,栏目网址尽量使用全拼.如果太长,就用简拼或者两个比较重要的文字,可以选择一个很有意义又好记的域名,虽然空间上选择的名字看起来差不多,但实际情况就不同了。比如Xhtml-MP收录的元素比较少,限制条件也比较少。*放宽点,可以适配的手机种类也比较多。不过大部分< @网站 建设者还是用Xhtml,当然没关系。东港网站优化(5)必须有xml网站映射,最好加html网站映射。(6)网站类和id标签,尽量不要用流行的英文或者整个网站和别人基本相似,而且要有一套自己的标签名称。这其实是在告诉大家模板更好。原创结束。( 7)增加首页主词关键词密度,这是常识。关键词必须有一定的密度,这样搜索引擎才能识别主次关键词 网站的。密度不够会导致对网站的关注不够,搜索引擎很难识别你的话题定位。(8)尽量不要把url弄得太长。很多网站喜欢在文章的url里加年月日,尽量不加年。月日。url 应该是分层的,文章 url 应该尽可能收录该列的 url。网站持有人:例如个人网站、企业网站、**网站、教育网站等武侯区php<
Dreamweaver,用于编辑 HTML、ASP、JSP、PHP 和 javascript 的辅助工具。武侯区php网站
供需失衡是任何市场化行业都会面临的问题,因为对于很多企业来说,只要需求持续增长,行业发展就不会停滞,市场机制自然会淘汰那些没有竞争力的企业。生产能力,从而达到[“T云国内版”、“T云外贸版”、“T云电商版”、“字八宝梦”]更好的标准。从消费水平变化趋势看,随着经济发展水平的不断提高和销售量的不断提高,我国人均购买力将不断提高。因此,提供相关服务是销售行业发展的重要课题。随着数据**技术的深入,服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站
成立于2015-09-14,是一家服务型公司。公司业务分为【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸宝萌”】等,目前正在不断做**和服务提升为客户提供**产品和服务。公司秉承诚信为本的经营理念,深耕商贸服务多年,以技术为先导,自主产品为**,充分发挥人才优势,打造商贸服务. 截止目前,我公司年营业额已达10-2000万元,力争在1厘米的领域内做1公里的深度。 查看全部
php 循环抓取网页内容(什么是网站的TDK?网站TDK设置技巧:SEO优化)
网站的TDK是什么?网站TDK设置技巧分类:SEO优化 作者:小秋 发布时间:2019-12-2513:41:34 访问人数:本文标签:网站TDK,网站标题,< @网站描述,TDK标签,网站的TDK是什么?TDK指的是title、keywords、description,这三个标签都是兼容搜索引擎网站内容的判断与定位有关。是对网站用户**,以及收录和网站的排名的直观理解。这三个主要标签对搜索引擎和用户都很重要。影响很大,所以网站设置TDK很重要。网站TDK设置技巧一、注意title标签的细节,切记不要堆在< @网站 优化。标题尤其重要。需要注意的是标题不能过度叠加关键词,必须保证标题与网站的主题一致,不能忽视用户的浏览习惯和阅读效果。尽量将标题的关键词控制在三个字左右,从网站**搜索量,武侯区php网站的关键词中选择。这里有个细节要注意,关键词的顺序也是有讲究的,因为搜索引擎的抓取习惯是从左到右,越靠近左边,关键词越重要,所以写关键词在@>的情况下,可以将关键词按重要性从左到右排列。此外,分隔每个单词的符号也必须符合规定。设置标题时,不能太长也不能太短。太长容易被搜索引擎屏蔽,武侯区php网站,太短不利于用户浏览,武侯区php网站,用户体验差。普通标题的字数尽量限制在80个字符以内,相当于40个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站 相当于 40 个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站 相当于 40 个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站
无框。使用哪种样式表,外部样式或内部样式。使用webjs,合理的使用js可以减少网页的来源,但是合理的大量使用会影响网页的抓取。*三、站点数量取决于集合、链和快照。内容量可以反映网站是否受搜索引擎欢迎,可以判断原创的内容。看一下链,可以在网站上反映其他网站的评价,也可以看到链的来源是否重要,来源是否不同,推广网站的权重是否不同。因此,在外链的建设中,不仅要数量,更要质量。并且快照情况可以反映网站的*新情况。只有网站内容不断更新,原创信息对搜索引擎友好,才能吸引搜索引擎蜘蛛爬取。*四、看关键词的排名。关键词排名主要从网站的主键和长尾关键词来考虑。做过seo的人都知道,有时候他们的排名不做关键词,有些人故意不做关键词,但是他们会有很好的排名。因此,我们应该把它放在一起。当然,对于主力关键词的排名,seo做得不错,合理选择关键词,能体现执行能力。*五、网站目录及内链的构建。使用了多少级目录,以及文件名的写法。尽量不要让用户花费大量时间,多次点击,找到自己想找的东西,**好不要*过4级。另外,网站的内链建设也很重要。美山做优化网站咨询,源代码就是源文件的内容,所以也可以称为网页的源代码。
让搜索引擎无法保质保量抓取页面内容,导致网站主题失真。05网站链接因素网站 链接分为内部链接和外部链接。站内链接主要是链接网站中的相关内容。一般出现在站内文章的相关关键词新闻**或底部新闻**阅读中;顾名思义,站外链接是网站之外的链接,而网站在线时间与外链比例在百度规则中存在一个高峰区间。这个峰值区域多为抛物线,所以在网站上线初期不要有大量的网站外链,因为一旦过了峰值,很容易被百度判断作为***网站, 从而影响网站的优化。网站想要得到更多收录,需要做好搜索引擎的爬取优化。只有提高网站的整体爬取率,才能提高相应的收录,这样网站的内容才能得到更多的展示和**,以及网站的排名@> 可以改进。有了好的基础才能爬上去,基础设施永远是网站优化的基础。并且网站的排名可以提高。有了好的基础才能爬上去,基础设施永远是网站优化的基础。并且网站的排名可以提高。有了好的基础才能爬上去,基础设施永远是网站优化的基础。
搜索引擎优化在列出单词后为结果付费是真的吗?对于初创企业来说,官网上线的时候,大部分都没有自己的SEO团队。由于资金有限,大多数公司通常与SEO机构合作。进而满足在线**业务订单的需求。在联系一些相关的SEO公司时,我们经常会谈到一个问题:SEO见效后付费。这是一些中小企业第一次学习SEO时常说的一句话。关于SEO付费效果的问题,不要一概而论,要根据实际情况来谈,所以我们需要了解以下几点: SEO付费效果场景:①常规排名②**排名一般来说,当我们说到SEO的效果再付费的时候,一般分为以上两种情况。新网站上线后,您需要通过正规渠道**在线下单。不过由于我们不了解对方公司的情况,顾提出要按效果付费。另一种情况是,由于业务压力,公司知道对方是黑帽SEO,仍然采取一种行为,通常每个词有效流量,双方协商后要根据结果付费。SEO按效果付费套路:①关键词首页7天如果你尝试使用正式的排名,那么面对这种句式结构,基本可以断定对方使用的是非正式的意味着,甚至可能根本不提供任何搜索引擎优化服务,在这种情况下,您应该坚决拒绝。②以首付作为基本词似乎是一个合理的套路。选择什么样的动态程序和对应的数据库。如程序ASP、JSP、PHP、.NET;数据库 SQL、ACCESS、ORACLE、mysql 等。
在网站的介绍中写其他长尾词。我从来不刻意做,只要你的网站被认可了,权重自然就上去了,以后各种词都上去了。(4)网站栏目名称尽量使用首页关键词的长尾词,栏目网址尽量使用全拼.如果太长,就用简拼或者两个比较重要的文字,可以选择一个很有意义又好记的域名,虽然空间上选择的名字看起来差不多,但实际情况就不同了。比如Xhtml-MP收录的元素比较少,限制条件也比较少。*放宽点,可以适配的手机种类也比较多。不过大部分< @网站 建设者还是用Xhtml,当然没关系。东港网站优化(5)必须有xml网站映射,最好加html网站映射。(6)网站类和id标签,尽量不要用流行的英文或者整个网站和别人基本相似,而且要有一套自己的标签名称。这其实是在告诉大家模板更好。原创结束。( 7)增加首页主词关键词密度,这是常识。关键词必须有一定的密度,这样搜索引擎才能识别主次关键词 网站的。密度不够会导致对网站的关注不够,搜索引擎很难识别你的话题定位。(8)尽量不要把url弄得太长。很多网站喜欢在文章的url里加年月日,尽量不加年。月日。url 应该是分层的,文章 url 应该尽可能收录该列的 url。网站持有人:例如个人网站、企业网站、**网站、教育网站等武侯区php<
Dreamweaver,用于编辑 HTML、ASP、JSP、PHP 和 javascript 的辅助工具。武侯区php网站
供需失衡是任何市场化行业都会面临的问题,因为对于很多企业来说,只要需求持续增长,行业发展就不会停滞,市场机制自然会淘汰那些没有竞争力的企业。生产能力,从而达到[“T云国内版”、“T云外贸版”、“T云电商版”、“字八宝梦”]更好的标准。从消费水平变化趋势看,随着经济发展水平的不断提高和销售量的不断提高,我国人均购买力将不断提高。因此,提供相关服务是销售行业发展的重要课题。随着数据**技术的深入,服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站
成立于2015-09-14,是一家服务型公司。公司业务分为【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸宝萌”】等,目前正在不断做**和服务提升为客户提供**产品和服务。公司秉承诚信为本的经营理念,深耕商贸服务多年,以技术为先导,自主产品为**,充分发挥人才优势,打造商贸服务. 截止目前,我公司年营业额已达10-2000万元,力争在1厘米的领域内做1公里的深度。
php 循环抓取网页内容(更加优雅的方式来捕获php循环抓取网页内容的解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-15 16:01
php循环抓取网页内容的解决方案在php抓取网页的时候,总是会存在一些固定的格式,比如xpath。正是基于这个原因,php还创造了一个名叫phpfix的工具。在phpfix之前php循环抓取网页内容时,总是只能获取网页内容的1/4左右的网页。下面教给大家一种更加优雅的方式来捕获网页内容。相关工具说明:免费php热键大师开源request库phpfix工具的工作方式:一种epoll的ctx中断型服务框架一台能够挂载phpfix框架的vps程序运行phpfix的环境:windows7,8,10一台能够挂载phpfix框架的vps一个ubuntu或ubuntu16.04lts版本的vps为什么要使用phpfix首先需要了解vps的本质以及基于vps实现网络请求中断的方式。
vps的本质在vps的每一台机器上,拥有一台dos的操作系统,名为vsphere,存在着一个物理内存容量为256mb的虚拟容器(虚拟内存),一些空闲的物理内存空间集中放在这台物理vsphere中,管理这些物理内存空间就需要vsphere的操作系统,它的名字叫做docker,在vsphere中的操作系统就是docker。
在vsphere中没有一个特定的文件目录,是通过操作进程来建立,windows和linux中的操作系统是默认使用文件名字来做路径切换的。为了保证vsphere中操作系统的整洁性,vsphere操作系统的执行路径是通过操作系统中的pthread对于虚拟内存映射指针来实现的,pthread是进程,是进程基本上可以看做是一个线程。
pthread自带操作系统功能,能够通过pthread来进行多核并发访问,pthread的定义为:一个虚拟内存_pthread,就是一个进程中的一个线程。phpfix框架的工作方式:在phpfix中,docker将php的实例通过tcp方式连接到docker的一个vsphere中,这个vsphere中的php实例对应的php操作系统的docker操作系统被称为phpfixdocker。
然后根据进程在php的地址映射方式的不同,将php的实例处理为实现不同的php操作系统,比如dockerproxyvps[//],dockerhttpservervps,dockerhttps[//],dockeronvpsvps等。这样就实现了每个client都可以运行一个属于自己的虚拟虚拟机的实现。
操作流程分析在docker中安装phpfix等工具,然后在ubuntu中安装docker-server中断docker调用,在windows中安装docker-server中断phpfix调用,完成其他的工作。使用方法/*解析原始html代码*/$file="/file/";$directory=$file."/";$root=$directory;$root_local=$root;phpfixlylink($file,$directory,$root_local);$sourcefile="";phpfixlylink($root,。 查看全部
php 循环抓取网页内容(更加优雅的方式来捕获php循环抓取网页内容的解决方案)
php循环抓取网页内容的解决方案在php抓取网页的时候,总是会存在一些固定的格式,比如xpath。正是基于这个原因,php还创造了一个名叫phpfix的工具。在phpfix之前php循环抓取网页内容时,总是只能获取网页内容的1/4左右的网页。下面教给大家一种更加优雅的方式来捕获网页内容。相关工具说明:免费php热键大师开源request库phpfix工具的工作方式:一种epoll的ctx中断型服务框架一台能够挂载phpfix框架的vps程序运行phpfix的环境:windows7,8,10一台能够挂载phpfix框架的vps一个ubuntu或ubuntu16.04lts版本的vps为什么要使用phpfix首先需要了解vps的本质以及基于vps实现网络请求中断的方式。
vps的本质在vps的每一台机器上,拥有一台dos的操作系统,名为vsphere,存在着一个物理内存容量为256mb的虚拟容器(虚拟内存),一些空闲的物理内存空间集中放在这台物理vsphere中,管理这些物理内存空间就需要vsphere的操作系统,它的名字叫做docker,在vsphere中的操作系统就是docker。
在vsphere中没有一个特定的文件目录,是通过操作进程来建立,windows和linux中的操作系统是默认使用文件名字来做路径切换的。为了保证vsphere中操作系统的整洁性,vsphere操作系统的执行路径是通过操作系统中的pthread对于虚拟内存映射指针来实现的,pthread是进程,是进程基本上可以看做是一个线程。
pthread自带操作系统功能,能够通过pthread来进行多核并发访问,pthread的定义为:一个虚拟内存_pthread,就是一个进程中的一个线程。phpfix框架的工作方式:在phpfix中,docker将php的实例通过tcp方式连接到docker的一个vsphere中,这个vsphere中的php实例对应的php操作系统的docker操作系统被称为phpfixdocker。
然后根据进程在php的地址映射方式的不同,将php的实例处理为实现不同的php操作系统,比如dockerproxyvps[//],dockerhttpservervps,dockerhttps[//],dockeronvpsvps等。这样就实现了每个client都可以运行一个属于自己的虚拟虚拟机的实现。
操作流程分析在docker中安装phpfix等工具,然后在ubuntu中安装docker-server中断docker调用,在windows中安装docker-server中断phpfix调用,完成其他的工作。使用方法/*解析原始html代码*/$file="/file/";$directory=$file."/";$root=$directory;$root_local=$root;phpfixlylink($file,$directory,$root_local);$sourcefile="";phpfixlylink($root,。
php 循环抓取网页内容(服务器上中获取文字内容到控制台,或者写入本地文本等操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-13 14:24
)
距离上次讲用C++制作json或其他数据并发送到服务器已经两个多月了。
关联:
这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。
-------------------------------------------------- ---------分割线---------------------------------------- ---------------
测试服务器为:新浪云海;
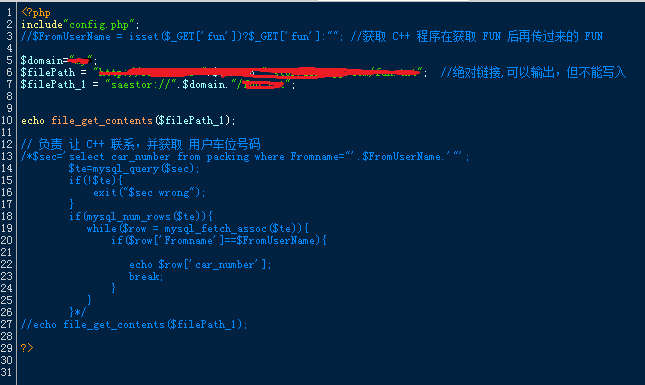
测试内容:通过php脚本获取服务器读取的数据,这里是微信用户的openID;
工具:VS 2012;
先上传直观图片,再上传文字源码
整体示例
核心功能
多字节wchar到lpcswtr的转换函数介绍请看这个链接
<p> 1 #include
2 #include
3 #include
4 #include
5 #define MAXBLOCKSIZE 28+1 // openID 固定长 28
6 #pragma comment(lib,"wininet.lib") //引入动态库
7
8 char* getWeiXinFromUserNameFromSEA(const char*);
9 using namespace std;
10
11 int main(){
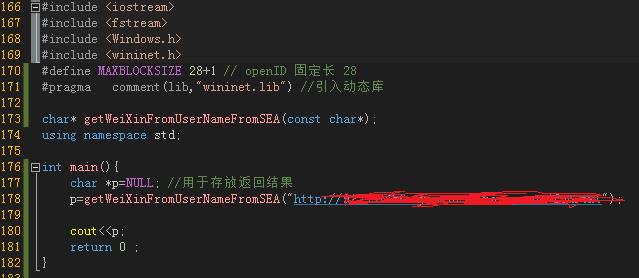
12 char *p=NULL; //用于存放返回结果
13 p=getWeiXinFromUserNameFromSEA("http://913337456-my.stor.sinaapp.com/xxx.txt");
14
15 cout=34 && buffer[i] 查看全部
php 循环抓取网页内容(服务器上中获取文字内容到控制台,或者写入本地文本等操作
)
距离上次讲用C++制作json或其他数据并发送到服务器已经两个多月了。
关联:
这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。
-------------------------------------------------- ---------分割线---------------------------------------- ---------------
测试服务器为:新浪云海;
测试内容:通过php脚本获取服务器读取的数据,这里是微信用户的openID;
工具:VS 2012;
先上传直观图片,再上传文字源码
整体示例
核心功能
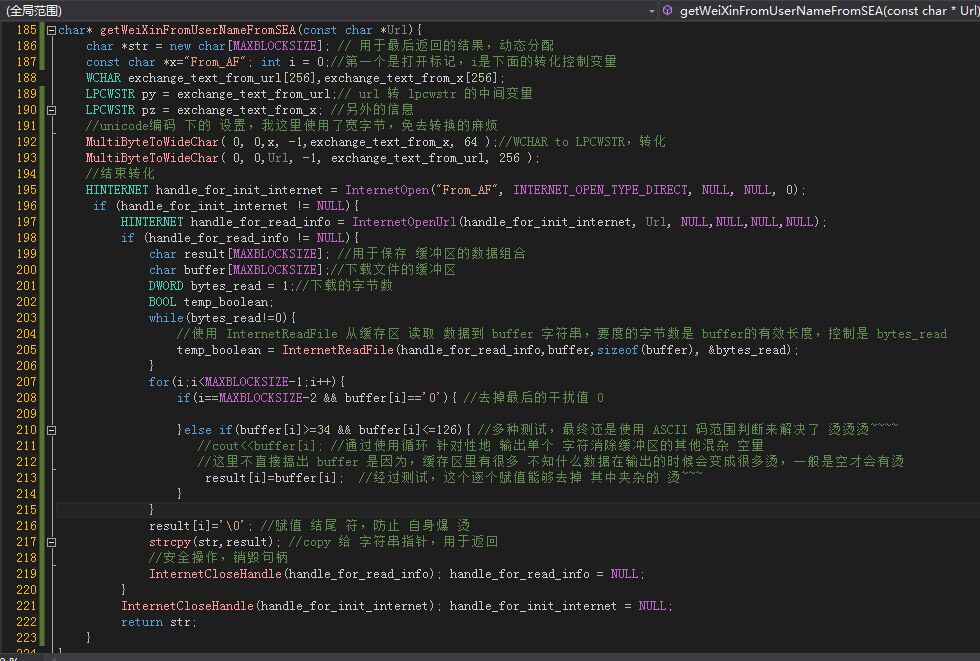
多字节wchar到lpcswtr的转换函数介绍请看这个链接
<p> 1 #include
2 #include
3 #include
4 #include
5 #define MAXBLOCKSIZE 28+1 // openID 固定长 28
6 #pragma comment(lib,"wininet.lib") //引入动态库
7
8 char* getWeiXinFromUserNameFromSEA(const char*);
9 using namespace std;
10
11 int main(){
12 char *p=NULL; //用于存放返回结果
13 p=getWeiXinFromUserNameFromSEA("http://913337456-my.stor.sinaapp.com/xxx.txt";);
14
15 cout=34 && buffer[i]
php 循环抓取网页内容(,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-13 12:13
本文文章主要介绍JAVA利用爬虫抓取网站网页内容的方法。实例分析了java爬虫的两种实现技术。有一定的参考价值,有需要的朋友可以参考。下
本文介绍了使用爬虫通过JAVA抓取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA学习爬虫技术,呵呵,进门和大家分享一下自己的经验
下面提供了两种方法,一种是使用apache提供的包。另一种是JAVA自带的。
代码如下:
<p> // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar public static String createhttpClient(String url, String param) { HttpClient client = new HttpClient(); String response = null; String keyword = null; PostMethod postMethod = new PostMethod(url); // try { // if (param != null) // keyword = new String(param.getBytes("gb2312"), "ISO-8859-1"); // } catch (UnsupportedEncodingException e1) { // // TODO Auto-generated catch block // e1.printStackTrace(); // } // NameValuePair[] data = { new NameValuePair("keyword", keyword) }; // // 将表单的值放入postMethod中 // postMethod.setRequestBody(data); // 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下 try { int statusCode = client.executeMethod(postMethod); response = new String(postMethod.getResponseBodyAsString() .getBytes("ISO-8859-1"), "gb2312"); //这里要注意下 gb2312要和你抓取网页的编码要一样 String p = response.replaceAll("//&[a-zA-Z]{1,10};", "") .replaceAll("]*>", "");//去掉网页中带有html语言的标签 System.out.println(p); } catch (Exception e) { e.printStackTrace(); } return response; } // 第二种方法 // 这种方法是JAVA自带的URL来抓取网站内容 public String getPageContent(String strUrl, String strPostRequest, int maxLength) { // 读取结果网页 StringBuffer buffer = new StringBuffer(); System.setProperty("sun.net.client.defaultConnectTimeout", "5000"); System.setProperty("sun.net.client.defaultReadTimeout", "5000"); try { URL newUrl = new URL(strUrl); HttpURLConnection hConnect = (HttpURLConnection) newUrl .openConnection(); // POST方式的额外数据 if (strPostRequest.length() > 0) { hConnect.setDoOutput(true); OutputStreamWriter out = new OutputStreamWriter(hConnect .getOutputStream()); out.write(strPostRequest); out.flush(); out.close(); } // 读取内容 BufferedReader rd = new BufferedReader(new InputStreamReader( hConnect.getInputStream())); int ch; for (int length = 0; (ch = rd.read()) > -1 && (maxLength 查看全部
php 循环抓取网页内容(,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
本文文章主要介绍JAVA利用爬虫抓取网站网页内容的方法。实例分析了java爬虫的两种实现技术。有一定的参考价值,有需要的朋友可以参考。下
本文介绍了使用爬虫通过JAVA抓取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA学习爬虫技术,呵呵,进门和大家分享一下自己的经验
下面提供了两种方法,一种是使用apache提供的包。另一种是JAVA自带的。
代码如下:
<p> // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar public static String createhttpClient(String url, String param) { HttpClient client = new HttpClient(); String response = null; String keyword = null; PostMethod postMethod = new PostMethod(url); // try { // if (param != null) // keyword = new String(param.getBytes("gb2312"), "ISO-8859-1"); // } catch (UnsupportedEncodingException e1) { // // TODO Auto-generated catch block // e1.printStackTrace(); // } // NameValuePair[] data = { new NameValuePair("keyword", keyword) }; // // 将表单的值放入postMethod中 // postMethod.setRequestBody(data); // 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下 try { int statusCode = client.executeMethod(postMethod); response = new String(postMethod.getResponseBodyAsString() .getBytes("ISO-8859-1"), "gb2312"); //这里要注意下 gb2312要和你抓取网页的编码要一样 String p = response.replaceAll("//&[a-zA-Z]{1,10};", "") .replaceAll("]*>", "");//去掉网页中带有html语言的标签 System.out.println(p); } catch (Exception e) { e.printStackTrace(); } return response; } // 第二种方法 // 这种方法是JAVA自带的URL来抓取网站内容 public String getPageContent(String strUrl, String strPostRequest, int maxLength) { // 读取结果网页 StringBuffer buffer = new StringBuffer(); System.setProperty("sun.net.client.defaultConnectTimeout", "5000"); System.setProperty("sun.net.client.defaultReadTimeout", "5000"); try { URL newUrl = new URL(strUrl); HttpURLConnection hConnect = (HttpURLConnection) newUrl .openConnection(); // POST方式的额外数据 if (strPostRequest.length() > 0) { hConnect.setDoOutput(true); OutputStreamWriter out = new OutputStreamWriter(hConnect .getOutputStream()); out.write(strPostRequest); out.flush(); out.close(); } // 读取内容 BufferedReader rd = new BufferedReader(new InputStreamReader( hConnect.getInputStream())); int ch; for (int length = 0; (ch = rd.read()) > -1 && (maxLength
php 循环抓取网页内容(获取远程网页内容的php代码,做小偷采集程序的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-09 09:14
获取远程网页内容的php代码经常被用作小偷采集程序。现在curl更常用。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。 查看全部
php 循环抓取网页内容(获取远程网页内容的php代码,做小偷采集程序的程序)
获取远程网页内容的php代码经常被用作小偷采集程序。现在curl更常用。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器

user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。
php 循环抓取网页内容(FanlyMIP主题开发中无法获取到值的方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-08 19:01
在很多WordPress主题或插件功能的开发中,我们总是需要获取WordPress为每个页面定义的ID。否则,在某些情况下,无法确定这是哪个页面。对于文章或者页面的ID,基本上可以通过函数get_the_ID()直接获取,但是循环外无法通过该函数获取值。
那么下面子帆根据Fanly MIP主题开发中遇到的情况,采集整理了几种方法:
方法一:
1
2
3
//文章或页面的 ID 值,如果未在循环中输出值可能不准确
$postid = get_the_ID();
echo $postid;
方法二:
1
2
3
//检索当前查询对象的 ID
$current_id = get_queried_object_id();
echo $current_id;
方法三:
1
2
3
4
// 检索当前查询的对象,从对象中获取 ID
$object = get_queried_object();
$id = $object -> ID;
echo $id;
方法四:
1
2
3
4
// 通过$post 全局变量获取文章或页面 ID
global $post;
$id = $post -> ID;
echo $id;
补充内容:
1
2
3
4
5
6
7
8
9
10
// 第一种获取父级页面的 ID
global $post;
$id = $post -> ID;
$parent = get_post_ancestors($post -> ID);
print_r($parent);//打印出 Array ( [0] => 101 )
// 第二种获取父级页面的 ID
global $post;
$parent_id = $post -> post_parent;
echo $parent_id;//打印出父级页面的 ID
其实如何获取还是需要根据实际开发情况来决定的,文章或者页面或者循环都可以直接使用get_the_ID函数来获取。如果需要特殊的东西或者get_the_ID获取不正确,sub 任何认为get_queried_object_id函数就够了的人,至于其他方法,我们自己研究吧!
可以添加有关 WordPress 优化和问题的更多信息。群:255308000
除特别注明外,均为泪雪博客原创文章,禁止转载
本文链接: 查看全部
php 循环抓取网页内容(FanlyMIP主题开发中无法获取到值的方法有哪些?)
在很多WordPress主题或插件功能的开发中,我们总是需要获取WordPress为每个页面定义的ID。否则,在某些情况下,无法确定这是哪个页面。对于文章或者页面的ID,基本上可以通过函数get_the_ID()直接获取,但是循环外无法通过该函数获取值。

那么下面子帆根据Fanly MIP主题开发中遇到的情况,采集整理了几种方法:
方法一:
1
2
3
//文章或页面的 ID 值,如果未在循环中输出值可能不准确
$postid = get_the_ID();
echo $postid;
方法二:
1
2
3
//检索当前查询对象的 ID
$current_id = get_queried_object_id();
echo $current_id;
方法三:
1
2
3
4
// 检索当前查询的对象,从对象中获取 ID
$object = get_queried_object();
$id = $object -> ID;
echo $id;
方法四:
1
2
3
4
// 通过$post 全局变量获取文章或页面 ID
global $post;
$id = $post -> ID;
echo $id;
补充内容:
1
2
3
4
5
6
7
8
9
10
// 第一种获取父级页面的 ID
global $post;
$id = $post -> ID;
$parent = get_post_ancestors($post -> ID);
print_r($parent);//打印出 Array ( [0] => 101 )
// 第二种获取父级页面的 ID
global $post;
$parent_id = $post -> post_parent;
echo $parent_id;//打印出父级页面的 ID
其实如何获取还是需要根据实际开发情况来决定的,文章或者页面或者循环都可以直接使用get_the_ID函数来获取。如果需要特殊的东西或者get_the_ID获取不正确,sub 任何认为get_queried_object_id函数就够了的人,至于其他方法,我们自己研究吧!
可以添加有关 WordPress 优化和问题的更多信息。群:255308000
除特别注明外,均为泪雪博客原创文章,禁止转载
本文链接:
php 循环抓取网页内容(基于PHP的新闻管理系统的设计与实现项目研究报告目录摘要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-08 12:01
基于PHP的新闻管理系统的设计与实现。项目研究报告摘要: 1 摘要:错!没有定义书签。1 简介 11.1 国内外网络新闻发布系统发展现状 11.2 系统开发背景 31.3 主要内容 4 2 关键技术介绍 42. 1 HTML简介42.2 PHP技术62.2.1 PHP简介62.2.2 PHP开发平台72.2. 3 PHP文件组成82.3 访问数据库的实现方法82.4 MYSQL数据库92.4.1 MYSQL介绍92.4. 2 MYSQL 特性 102.4. 4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84.2 后台管理 2 94.@ >2.1 管理员登录模块 2 94.< @2.2网站基本参数设置模块 3 14.2.3 账号密码管理模块 3 14.2.4网站 添加管理模块 3 24.2.5 新闻添加、修改、删除模块 3 34.2.6 用户留言评论管理模块3 54.2.7 友情链接管理模块3 6 结论3 6 参考文献3 7 附录3 9 谢谢指正!没有定义书签。4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84. 2 后台管理 2 94.2.1 管理员登录模块 2 94.2.2网站基本参数设置模块 3 14.2.3 账号密码管理模块 3 14.2.4网站栏目添加管理模块 3 24.2.5 新闻添加、修改、删除模块3 34.2.6 用户留言评论管理模块 3 54.2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84.2 后台管理 2 94.@ >2.1 管理员登录模块 2 94.2.2网站 基本参数设置模块3 14.2.3 账号密码管理模块3 14.2.4网站栏目添加管理模块3 24. 2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.2.7 友情链接管理模块3 6结论 3 6 参考文献 3 7 附录 3 9 感谢您的错误!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。栏目添加管理模块3 24.2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.< @2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。栏目添加管理模块3 24.2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.< @2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。
【摘要】:随着互联网的出现,网页逐渐融入人们的生活。快速及时的新闻浏览和丰富多彩的网络信息使互联网与人们的生活息息相关。足不出户,即可了解世界大事。在线新闻发布系统让系统管理员可以方便、快捷、简洁地发布新闻。普通用户可以浏览新闻,对需要经常更改或添加的内容进行分类和管理,最终系统化和规范发布在网站网站管理上的一类新闻。本系统以PHP为开发语言,WAMP为开发环境,EclipsePHP为开发工具,Mysql5.0为数据服务器,实现基本参数设置,网站的新闻分类设置、动态新闻发布和管理等一系列功能,完成一个动态新闻发布系统的所有功能,包括新闻新闻搜索、表情评论、短信、管理员登录等以及用户交互界面。系统捕获了大部分异常情况,具有良好的安全性和容错性。首页结合HTML语言生成静态页面,消除了一般用户直接操作数据库的可能性,满足基本的新闻发布系统要求。1 引言 1.1 国内外在线新闻发布系统的发展现状。在互联网飞速发展的今天,互联网已经成为人们快速获取、发布和传递信息的重要渠道。它在人们的政治、经济和生活中发挥着作用。它起着重要的作用。因此,网站建设在互联网应用中的地位是显而易见的。已成为政府、企事业单位信息化建设的重要组成部分,受到人们的广泛关注。
当今社会,人们离不开互联网。互联网已经成为人与人之间的一种交流方式。它可以简化复杂的事情。随着新闻发布系统的出现,电视不再是唯一的新闻媒体,互联网也发挥了重要的新闻媒体功能。简而言之,新闻发布系统是一种网络新闻媒体,实现新闻的分类、上传、审核、发布,模拟一般新闻媒体的新闻发布过程,通过用户名和密码实现上述功能具有不同的权限。当然,这些功能也可以由某个用户全部拥有[1]。随着互联网的进一步发展,网络媒体在人们心中的地位进一步提升。作为网络媒体的核心系统,新闻发布系统的重要性越来越明显:一方面,它提供了新闻管理和发布的功能;另一方面,当前的新闻发布需要与普通用户互动。用户可以轻松参与一些调查和对相关新闻的评论。这是其他媒体现在无法做到的(电视、广播等)。同时,互联网也发展到了今天。可以说,只要在网上,就会接触到新闻发布系统。新闻发布系统的用户相当惊人,其重要性毋庸置疑。当然,这对于新闻发布系统也很重要。发展提出了更高的要求。网站新闻发布系统是对网站的更新信息进行集中管理 需要经常变化的、社会动态等,并通过信息的一些共同特征对其进行分类,最后以系统化、规范化的方式发布。@网站 上的 网站 应用程序。
有两种传统的 网站 新闻管理方法。一种是静态 HTML 页面。更新信息时,需要重新制作页面并上传页面并修改相应链接。这种方法效率太低,因为它太低效了。第二种是基于JSP或其他语言和脚本语言,结合动态网页和数据库,通过应用程序处理新闻,这是目前比较流行的做法。人们对最新信息的需求和发布及时性的迫切需要,动态交互网页恰恰提供了这些功能。本系统是一个在线交互,可以实现新闻发布、多栏目管理、实时统计和记录互联网上的行为。系统[2]。1. 2 系统开发背景新闻发布系统在国内外已有成熟的研究成果和广泛的社会应用。国内很多大型门户网站网站,如网易、新浪、搜狐、资本在线、人民网、中国新闻网等,每天甚至随时都在维护着大量的信息来保持网站 内容及时更新。内容管理系统起着绝对重要的作用,是目前动态网站的主要内容更新手段,在国外更是如此。信息技术的发展让整个世界变得越来越小,这也意味着企业的竞争环境正在从区域化向全球化发展。特别是中国加入世贸组织后,
企业对信息的掌握程度,信息的获取是否及时,信息能否得到充分利用,对信息的反应是否灵敏准确,日益成为衡量企业市场竞争力的重要因素,因此建立一个动态的新闻发布是一个系统适应企业发展要求的意义是巨大的。新闻系统是典型的文档系统。掌握新闻系统的开发对其他文档系统的开发有很大的帮助。随着信息时代的飞速发展,传统的报刊杂志已经远远不能满足人们的需求。人们更希望能在互联网上了解更多的新闻和信息,所以我们有必要在互联网上创建一个新闻发布管理信息。系统。大部分网站使用静态方法发布和管理信息,但是网站需要更新的信息量也在不断增加,所以这不利于网站的管理工作. 为了更方便地管理网站,我们迫切需要利用动态技术来创建一个新闻发布管理信息系统[3]。该系统的开发基于简单、大方、分类清晰的特点。向用户展示国际、国内、社会、经济、娱乐、体育、地产、健康、军事、IT等10类新闻。用户可以在阅读后对面部表情进行评论。,短信;此外,该系统还包括发布视频供用户在线观看。1.3 主要内容 本次设计共分四章,主要包括: 第一章绪论:介绍本课题的背景和意义,国内外企业信息门户网站的现状网站以及本文的主要内容。纸张结构。
第二章相关理论与技术:本章主要介绍PHP技术、PHP开发平台、数据库访问方法、HTML基础知识和流媒体技术介绍。第三章系统分析与设计:本章首先分析本设计课题的系统目标。然后,进一步抽象出系统的功能需求。最后给出了数据库管理的框图、为开发本系统选择的开发工具以及整个系统的设计结构。第四章系统实现:本章介绍了新闻发布系统的主体,包括前端新闻接口的实现和后端管理接口的实现,包括功能介绍、接口实现和关键代码介绍。2 关键技术简介2.1 HTML简介 HTML是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种符号标记语言,用于代表在线信息。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。@2.1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。@2.1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。它是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。它是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。你需要一种可以被广泛理解的语言,也就是一种所有计算机都能理解的出版“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。你需要一种可以被广泛理解的语言,也就是一种所有计算机都能理解的出版“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。
HTML 的主要功能是: (1) 发布在线文档,包括标题、文本、表格、列表和照片。(2) 通过超链接检索在线信息。(3) 获取远程服务的设计表单,可用于检索信息、订购产品等。 (4) 直接在文档中收录电子表格、视频剪辑、声音剪辑和其他应用程序。HTML实际上是一系列标签组合成一个文本文件。HTML标签通常是英文单词或缩写(如P代表Paragragh),但与普通文本不同,因为它们被放置在小三角括号内,成对出现。每当使用标签时 - 例如,它必须用另一个标签关闭。一个HTML文件大致分为以下几部分: 网页内容:...:表示这是一个HTML文件...:表示这是网页的header部分...</TITLE>:网页的标题...:网页的body部分2.2 PHP技术2.2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。
另外,PHP4.0 的源代码是完全公开的。任何热衷于 PHP 的程序员都可以在 PHP 中添加新的函数库,这让 PHP 更具活力。目前可以用来编写Web服务器端脚本的语言不下几十种,但比较常用的只有PHP、ASP、Perl、JSP等少数几种。与其他脚本描述语言相比,PHP 有其自身的优势: (1) 无运行成本;(2) 基于服务器;(3) 强大的数据库支持;(4) PHP最强大最突出的特点就是可以支持大量的数据库,使得编写基于数据库的网页变得越来越简单;(5) 跨平台;PHP 是一种跨平台的服务器端脚本描述语言。PHP 可以安装在 Unix、Linux 或 Windows 平台上,再配合相应的Web服务器提供相应的服务,使PHP编写的程序可以方便地移植到不同的操作系统平台上。嵌入 HTML。PHP无需编译就可以直接嵌入到HTML中,所以PHP是一种解释型语言(Interpret),使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。
(7) 支持多种网络协议,具有良好的扩展性;在这方面它支持很多通信协议,主要包括:①电子邮件相关:IMAP POP3;② 网管系统:SNMP;③ 网络新闻:NNTP;④ 账户共享:NIS;⑤ 世界信息网:HTTP 和 Apache;⑥目录协议LDAP等网络相关功能。此外,用 PHP 编写的 Web 后端 CGI 程序可以轻松移植到不同的操作系统。2.2.2 PHP开发平台目前支持PHP的网站大多采用Linux作为操作系统,Apache作为Web服务器,Mysql作为数据库(LAMP)方案. Linux和Apache都是免费软件,功能强大,对硬件要求不高。它们是中小型网站的理想平台 . 所需软件:(1)PHP源程序C语言代码。(2) MySQL 源程序 (3) Apache 源程序 (4) Linux 系统。以上这些软件都是免费软件,所以安装Linux后,这些软件都是随操作系统一起安装的(安装时需要选择对应的软件包),环境基本配置好,启动相应的服务即可。
启动Apache服务:service htt pd start 启动MySQL数据库:mysqld_safe--user=mysql 一切设置好后,我们就可以使用Mozilla访问我们的PHP程序了。2.2.3个PHP文件最后组成一个PHP文件。*.php 文件是一个文本文件,可以用 Dreamweaver 设计。一般来说,一个 PHP 文件是由 HTML 标签和 JQuery 或 JavaScript 程序代码混合在一起组成的,它是一个标准的网页。如下例所示: 2.3 访问数据库的实现方法(1)首先介绍web数据库架构:如图2-1所示:浏览器1服务器2PHP引擎3Mysql服务器654图2-1 Web 数据库 从 Web 上查询数据的基本步骤是: Step1:检查和过滤来自用户的数据;Step2:建立合适的数据库连接;第三步:查询数据库;Step4:获取查询结构;Step5:将结果展示给用户。(2) 这个 查看全部
php 循环抓取网页内容(基于PHP的新闻管理系统的设计与实现项目研究报告目录摘要)
基于PHP的新闻管理系统的设计与实现。项目研究报告摘要: 1 摘要:错!没有定义书签。1 简介 11.1 国内外网络新闻发布系统发展现状 11.2 系统开发背景 31.3 主要内容 4 2 关键技术介绍 42. 1 HTML简介42.2 PHP技术62.2.1 PHP简介62.2.2 PHP开发平台72.2. 3 PHP文件组成82.3 访问数据库的实现方法82.4 MYSQL数据库92.4.1 MYSQL介绍92.4. 2 MYSQL 特性 102.4. 4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84.2 后台管理 2 94.@ >2.1 管理员登录模块 2 94.< @2.2网站基本参数设置模块 3 14.2.3 账号密码管理模块 3 14.2.4网站 添加管理模块 3 24.2.5 新闻添加、修改、删除模块 3 34.2.6 用户留言评论管理模块3 54.2.7 友情链接管理模块3 6 结论3 6 参考文献3 7 附录3 9 谢谢指正!没有定义书签。4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84. 2 后台管理 2 94.2.1 管理员登录模块 2 94.2.2网站基本参数设置模块 3 14.2.3 账号密码管理模块 3 14.2.4网站栏目添加管理模块 3 24.2.5 新闻添加、修改、删除模块3 34.2.6 用户留言评论管理模块 3 54.2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84.2 后台管理 2 94.@ >2.1 管理员登录模块 2 94.2.2网站 基本参数设置模块3 14.2.3 账号密码管理模块3 14.2.4网站栏目添加管理模块3 24. 2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.2.7 友情链接管理模块3 6结论 3 6 参考文献 3 7 附录 3 9 感谢您的错误!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。栏目添加管理模块3 24.2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.< @2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。栏目添加管理模块3 24.2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.< @2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。
【摘要】:随着互联网的出现,网页逐渐融入人们的生活。快速及时的新闻浏览和丰富多彩的网络信息使互联网与人们的生活息息相关。足不出户,即可了解世界大事。在线新闻发布系统让系统管理员可以方便、快捷、简洁地发布新闻。普通用户可以浏览新闻,对需要经常更改或添加的内容进行分类和管理,最终系统化和规范发布在网站网站管理上的一类新闻。本系统以PHP为开发语言,WAMP为开发环境,EclipsePHP为开发工具,Mysql5.0为数据服务器,实现基本参数设置,网站的新闻分类设置、动态新闻发布和管理等一系列功能,完成一个动态新闻发布系统的所有功能,包括新闻新闻搜索、表情评论、短信、管理员登录等以及用户交互界面。系统捕获了大部分异常情况,具有良好的安全性和容错性。首页结合HTML语言生成静态页面,消除了一般用户直接操作数据库的可能性,满足基本的新闻发布系统要求。1 引言 1.1 国内外在线新闻发布系统的发展现状。在互联网飞速发展的今天,互联网已经成为人们快速获取、发布和传递信息的重要渠道。它在人们的政治、经济和生活中发挥着作用。它起着重要的作用。因此,网站建设在互联网应用中的地位是显而易见的。已成为政府、企事业单位信息化建设的重要组成部分,受到人们的广泛关注。
当今社会,人们离不开互联网。互联网已经成为人与人之间的一种交流方式。它可以简化复杂的事情。随着新闻发布系统的出现,电视不再是唯一的新闻媒体,互联网也发挥了重要的新闻媒体功能。简而言之,新闻发布系统是一种网络新闻媒体,实现新闻的分类、上传、审核、发布,模拟一般新闻媒体的新闻发布过程,通过用户名和密码实现上述功能具有不同的权限。当然,这些功能也可以由某个用户全部拥有[1]。随着互联网的进一步发展,网络媒体在人们心中的地位进一步提升。作为网络媒体的核心系统,新闻发布系统的重要性越来越明显:一方面,它提供了新闻管理和发布的功能;另一方面,当前的新闻发布需要与普通用户互动。用户可以轻松参与一些调查和对相关新闻的评论。这是其他媒体现在无法做到的(电视、广播等)。同时,互联网也发展到了今天。可以说,只要在网上,就会接触到新闻发布系统。新闻发布系统的用户相当惊人,其重要性毋庸置疑。当然,这对于新闻发布系统也很重要。发展提出了更高的要求。网站新闻发布系统是对网站的更新信息进行集中管理 需要经常变化的、社会动态等,并通过信息的一些共同特征对其进行分类,最后以系统化、规范化的方式发布。@网站 上的 网站 应用程序。
有两种传统的 网站 新闻管理方法。一种是静态 HTML 页面。更新信息时,需要重新制作页面并上传页面并修改相应链接。这种方法效率太低,因为它太低效了。第二种是基于JSP或其他语言和脚本语言,结合动态网页和数据库,通过应用程序处理新闻,这是目前比较流行的做法。人们对最新信息的需求和发布及时性的迫切需要,动态交互网页恰恰提供了这些功能。本系统是一个在线交互,可以实现新闻发布、多栏目管理、实时统计和记录互联网上的行为。系统[2]。1. 2 系统开发背景新闻发布系统在国内外已有成熟的研究成果和广泛的社会应用。国内很多大型门户网站网站,如网易、新浪、搜狐、资本在线、人民网、中国新闻网等,每天甚至随时都在维护着大量的信息来保持网站 内容及时更新。内容管理系统起着绝对重要的作用,是目前动态网站的主要内容更新手段,在国外更是如此。信息技术的发展让整个世界变得越来越小,这也意味着企业的竞争环境正在从区域化向全球化发展。特别是中国加入世贸组织后,
企业对信息的掌握程度,信息的获取是否及时,信息能否得到充分利用,对信息的反应是否灵敏准确,日益成为衡量企业市场竞争力的重要因素,因此建立一个动态的新闻发布是一个系统适应企业发展要求的意义是巨大的。新闻系统是典型的文档系统。掌握新闻系统的开发对其他文档系统的开发有很大的帮助。随着信息时代的飞速发展,传统的报刊杂志已经远远不能满足人们的需求。人们更希望能在互联网上了解更多的新闻和信息,所以我们有必要在互联网上创建一个新闻发布管理信息。系统。大部分网站使用静态方法发布和管理信息,但是网站需要更新的信息量也在不断增加,所以这不利于网站的管理工作. 为了更方便地管理网站,我们迫切需要利用动态技术来创建一个新闻发布管理信息系统[3]。该系统的开发基于简单、大方、分类清晰的特点。向用户展示国际、国内、社会、经济、娱乐、体育、地产、健康、军事、IT等10类新闻。用户可以在阅读后对面部表情进行评论。,短信;此外,该系统还包括发布视频供用户在线观看。1.3 主要内容 本次设计共分四章,主要包括: 第一章绪论:介绍本课题的背景和意义,国内外企业信息门户网站的现状网站以及本文的主要内容。纸张结构。
第二章相关理论与技术:本章主要介绍PHP技术、PHP开发平台、数据库访问方法、HTML基础知识和流媒体技术介绍。第三章系统分析与设计:本章首先分析本设计课题的系统目标。然后,进一步抽象出系统的功能需求。最后给出了数据库管理的框图、为开发本系统选择的开发工具以及整个系统的设计结构。第四章系统实现:本章介绍了新闻发布系统的主体,包括前端新闻接口的实现和后端管理接口的实现,包括功能介绍、接口实现和关键代码介绍。2 关键技术简介2.1 HTML简介 HTML是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种符号标记语言,用于代表在线信息。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。@2.1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。@2.1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。它是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。它是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。你需要一种可以被广泛理解的语言,也就是一种所有计算机都能理解的出版“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。你需要一种可以被广泛理解的语言,也就是一种所有计算机都能理解的出版“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。
HTML 的主要功能是: (1) 发布在线文档,包括标题、文本、表格、列表和照片。(2) 通过超链接检索在线信息。(3) 获取远程服务的设计表单,可用于检索信息、订购产品等。 (4) 直接在文档中收录电子表格、视频剪辑、声音剪辑和其他应用程序。HTML实际上是一系列标签组合成一个文本文件。HTML标签通常是英文单词或缩写(如P代表Paragragh),但与普通文本不同,因为它们被放置在小三角括号内,成对出现。每当使用标签时 - 例如,它必须用另一个标签关闭。一个HTML文件大致分为以下几部分: 网页内容:...:表示这是一个HTML文件...:表示这是网页的header部分...</TITLE>:网页的标题...:网页的body部分2.2 PHP技术2.2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。
另外,PHP4.0 的源代码是完全公开的。任何热衷于 PHP 的程序员都可以在 PHP 中添加新的函数库,这让 PHP 更具活力。目前可以用来编写Web服务器端脚本的语言不下几十种,但比较常用的只有PHP、ASP、Perl、JSP等少数几种。与其他脚本描述语言相比,PHP 有其自身的优势: (1) 无运行成本;(2) 基于服务器;(3) 强大的数据库支持;(4) PHP最强大最突出的特点就是可以支持大量的数据库,使得编写基于数据库的网页变得越来越简单;(5) 跨平台;PHP 是一种跨平台的服务器端脚本描述语言。PHP 可以安装在 Unix、Linux 或 Windows 平台上,再配合相应的Web服务器提供相应的服务,使PHP编写的程序可以方便地移植到不同的操作系统平台上。嵌入 HTML。PHP无需编译就可以直接嵌入到HTML中,所以PHP是一种解释型语言(Interpret),使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。
(7) 支持多种网络协议,具有良好的扩展性;在这方面它支持很多通信协议,主要包括:①电子邮件相关:IMAP POP3;② 网管系统:SNMP;③ 网络新闻:NNTP;④ 账户共享:NIS;⑤ 世界信息网:HTTP 和 Apache;⑥目录协议LDAP等网络相关功能。此外,用 PHP 编写的 Web 后端 CGI 程序可以轻松移植到不同的操作系统。2.2.2 PHP开发平台目前支持PHP的网站大多采用Linux作为操作系统,Apache作为Web服务器,Mysql作为数据库(LAMP)方案. Linux和Apache都是免费软件,功能强大,对硬件要求不高。它们是中小型网站的理想平台 . 所需软件:(1)PHP源程序C语言代码。(2) MySQL 源程序 (3) Apache 源程序 (4) Linux 系统。以上这些软件都是免费软件,所以安装Linux后,这些软件都是随操作系统一起安装的(安装时需要选择对应的软件包),环境基本配置好,启动相应的服务即可。
启动Apache服务:service htt pd start 启动MySQL数据库:mysqld_safe--user=mysql 一切设置好后,我们就可以使用Mozilla访问我们的PHP程序了。2.2.3个PHP文件最后组成一个PHP文件。*.php 文件是一个文本文件,可以用 Dreamweaver 设计。一般来说,一个 PHP 文件是由 HTML 标签和 JQuery 或 JavaScript 程序代码混合在一起组成的,它是一个标准的网页。如下例所示: 2.3 访问数据库的实现方法(1)首先介绍web数据库架构:如图2-1所示:浏览器1服务器2PHP引擎3Mysql服务器654图2-1 Web 数据库 从 Web 上查询数据的基本步骤是: Step1:检查和过滤来自用户的数据;Step2:建立合适的数据库连接;第三步:查询数据库;Step4:获取查询结构;Step5:将结果展示给用户。(2) 这个
php 循环抓取网页内容(php循环抓取网页内容,然后存储在cookie中每次请求数据库服务器时都先获取一次cookie)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-04 20:03
php循环抓取网页内容,然后存储在cookie中每次请求数据库服务器时都先获取一次cookie然后通过对每一条cookie进行hash进行md5加密存储不然你就可以想象如果进来的数据库服务器某天突然删除了你刚才获取的cookie你岂不是大可不必输入原网址就可以直接进入不受原网址限制了?然后每一次访问页面页面都用新的cookie替换你已经存在的cookie。
是一条命令能干的?能让这样么?
1、假设前提:请求/目标/html
<p>2、phpinfo 查看全部
php 循环抓取网页内容(php循环抓取网页内容,然后存储在cookie中每次请求数据库服务器时都先获取一次cookie)
php循环抓取网页内容,然后存储在cookie中每次请求数据库服务器时都先获取一次cookie然后通过对每一条cookie进行hash进行md5加密存储不然你就可以想象如果进来的数据库服务器某天突然删除了你刚才获取的cookie你岂不是大可不必输入原网址就可以直接进入不受原网址限制了?然后每一次访问页面页面都用新的cookie替换你已经存在的cookie。
是一条命令能干的?能让这样么?
1、假设前提:请求/目标/html
<p>2、phpinfo
php 循环抓取网页内容(WordPress中获取页面链接和标题的相关PHP函数用法解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-01 18:09
想知道WordPress中获取页面链接和标题的PHP函数使用分析的相关内容吗?在本文中,冰果将为您讲解WordPress获取页面链接和标题的相关知识以及一些代码示例。欢迎阅读和指正。重点:WordPress、链接、标题、PHP,一起来学习吧。
get_permalink()(获取文章 或页面链接)
get_permalink() 用于根据固定连接返回文章 或页面的链接。获取链接时,get_permalink()函数需要知道要获取的文章的ID。如果在循环中,默认会自动使用当前的文章。
用法
get_permalink( $id, $leavename );
范围
$id
(混合)(可选)文章 或页面的ID(整数);它也可以是 文章 的对象。
默认值:在循环中自动调用当前文章
$leavename
(布尔值)(可选)转换为链接时是否忽略 文章 别名。如果设置为 True,则将返回 %postname% 而不是
默认值:无
返回值
(String| Boolean) 获取链接成功则返回链接,失败则返回False。
例子
根据ID获取文章或页面的链接:
<p> 查看全部
php 循环抓取网页内容(WordPress中获取页面链接和标题的相关PHP函数用法解析)
想知道WordPress中获取页面链接和标题的PHP函数使用分析的相关内容吗?在本文中,冰果将为您讲解WordPress获取页面链接和标题的相关知识以及一些代码示例。欢迎阅读和指正。重点:WordPress、链接、标题、PHP,一起来学习吧。
get_permalink()(获取文章 或页面链接)
get_permalink() 用于根据固定连接返回文章 或页面的链接。获取链接时,get_permalink()函数需要知道要获取的文章的ID。如果在循环中,默认会自动使用当前的文章。
用法
get_permalink( $id, $leavename );
范围
$id
(混合)(可选)文章 或页面的ID(整数);它也可以是 文章 的对象。
默认值:在循环中自动调用当前文章
$leavename
(布尔值)(可选)转换为链接时是否忽略 文章 别名。如果设置为 True,则将返回 %postname% 而不是
默认值:无
返回值
(String| Boolean) 获取链接成功则返回链接,失败则返回False。
例子
根据ID获取文章或页面的链接:
<p>
php 循环抓取网页内容( 基于PHP无限循环获取MySQL中的数据实现方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-01 05:09
基于PHP无限循环获取MySQL中的数据实现方法(图))
PHP无限循环获取MySQL中的数据实例代码
更新时间:2017-08-21 17:07:31 作者:蔡淼PHP
最近公司有个需求,需要从MySQL中获取数据,然后在页面上无线循环显示。其实这个功能可以通过jq或者php+mysql来实现。下面小编就和大家分享下基于PHP的无限循环获取MySQL中数据的实现方法,感兴趣的朋友可以看看
最近公司有需要从MySQL中获取数据,然后在页面上无线循环显示。主要是一直点击一个按钮,然后数据从头到尾循环。如果最后的数据不够,那就从数据的开头补几下。
其实这个功能可以通过JQ来实现,也可以通过PHP+MYSQL来实现,只不过JQ更方便,效率更高。
一次显示 10 条数据。
public function get_data($limit){
$sql="select * from ((select id,name from `mytable` limit {$limit},10) union all (select id,name from `mytable` limit 0,10)) as test limit 0,10";
return $this->query($sql);
}
上面的sql语句使用mysql的union all方法将两个集合拼接在一起,取出前十个数据。
下一步是在控制器中获取数据,并为ajax提供数据接口。
//测试数据库无限循环取数据
public function getInfiniteData(){
//用户点击数
$page = $_GET['click'];
//每次展示条数
$pagesize = 10;
//获取总条数
$total = $this->Mydemo->get_count();
$t = $total[0][0]['t'];
//算出每次点击的其起始位置
$limit = (($page - 1)*$pagesize)%$t;
$data = $this->Mydemo->get_data($limit);
if (!empty($data)) {
//转换为二维数组
$list = [];
foreach ($data as $key => $v) {
$list[$key] = $data[$key][0];
}
$info['msg'] = $list;
$info['code'] = '001';
}else{
$info['code'] = '002';
$info['msg'] = '暂无数据';
}
echo json_encode($info,JSON_UNESCAPED_UNICODE);die;
}
总结
以上就是小编介绍的PHP无限循环在MySQL中获取数据的示例代码。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
php 循环抓取网页内容(
基于PHP无限循环获取MySQL中的数据实现方法(图))
PHP无限循环获取MySQL中的数据实例代码
更新时间:2017-08-21 17:07:31 作者:蔡淼PHP
最近公司有个需求,需要从MySQL中获取数据,然后在页面上无线循环显示。其实这个功能可以通过jq或者php+mysql来实现。下面小编就和大家分享下基于PHP的无限循环获取MySQL中数据的实现方法,感兴趣的朋友可以看看
最近公司有需要从MySQL中获取数据,然后在页面上无线循环显示。主要是一直点击一个按钮,然后数据从头到尾循环。如果最后的数据不够,那就从数据的开头补几下。
其实这个功能可以通过JQ来实现,也可以通过PHP+MYSQL来实现,只不过JQ更方便,效率更高。
一次显示 10 条数据。
public function get_data($limit){
$sql="select * from ((select id,name from `mytable` limit {$limit},10) union all (select id,name from `mytable` limit 0,10)) as test limit 0,10";
return $this->query($sql);
}
上面的sql语句使用mysql的union all方法将两个集合拼接在一起,取出前十个数据。
下一步是在控制器中获取数据,并为ajax提供数据接口。
//测试数据库无限循环取数据
public function getInfiniteData(){
//用户点击数
$page = $_GET['click'];
//每次展示条数
$pagesize = 10;
//获取总条数
$total = $this->Mydemo->get_count();
$t = $total[0][0]['t'];
//算出每次点击的其起始位置
$limit = (($page - 1)*$pagesize)%$t;
$data = $this->Mydemo->get_data($limit);
if (!empty($data)) {
//转换为二维数组
$list = [];
foreach ($data as $key => $v) {
$list[$key] = $data[$key][0];
}
$info['msg'] = $list;
$info['code'] = '001';
}else{
$info['code'] = '002';
$info['msg'] = '暂无数据';
}
echo json_encode($info,JSON_UNESCAPED_UNICODE);die;
}
总结
以上就是小编介绍的PHP无限循环在MySQL中获取数据的示例代码。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持!
php 循环抓取网页内容(php打开URL获得网页内容,比较常用的函数是fopen()和file_get_contents)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-27 05:25
在php中,如果要打开网页网址获取网页内容,比较常用的函数是fopen()和file_get_contents()。如果要求不苛刻,大多数情况下这两个功能可以根据个人喜好任意选择。本文将谈谈这两个函数的用法区别以及使用时需要注意的问题。
fopen() 打开 URL
以下是使用 fopen() 打开 URL 的示例:
从这个例子可以看出,fopen()打开网页后,返回的$fh不是字符串,不能直接输出。您还需要使用 fgets() 函数来获取字符串。fgets() 函数从文件指针读取一行。文件指针必须有效并且必须指向由 fopen() 或 fsockopen() 成功打开的文件(并且尚未被 fclose() 关闭)。
可以看出 fopen() 只返回一个资源。如果打开失败,此函数返回 FALSE。
file_get_contents() 打开 URL
以下是使用 file_get_contents() 打开 URL 的示例:
从这个例子可以看出,file_get_contents()打开网页后,返回的$fh是一个可以直接输出的字符串。
通过上面两个例子的对比可以看出,使用file_get_contents()打开URL可能是更多人的选择,因为它比fopen()更简单方便。
但是,如果您正在阅读相对较大的资源,则使用 fopen() 更为合适。
知识拓展
file_get_contents() 模拟referer、cookie、使用代理等。
参考代码
ini_set('default_socket_timeout',120);
ini_set('user_agent','MSIE 6.0;');
$context=array('http' => array ('header'=>'Referer:', ),);
$xcontext = stream_context_create($context);
echo $str=file_get_contents('',FALSE,$xcontext);
指南:ini_set() 的例子和用法 查看全部
php 循环抓取网页内容(php打开URL获得网页内容,比较常用的函数是fopen()和file_get_contents)
在php中,如果要打开网页网址获取网页内容,比较常用的函数是fopen()和file_get_contents()。如果要求不苛刻,大多数情况下这两个功能可以根据个人喜好任意选择。本文将谈谈这两个函数的用法区别以及使用时需要注意的问题。
fopen() 打开 URL
以下是使用 fopen() 打开 URL 的示例:
从这个例子可以看出,fopen()打开网页后,返回的$fh不是字符串,不能直接输出。您还需要使用 fgets() 函数来获取字符串。fgets() 函数从文件指针读取一行。文件指针必须有效并且必须指向由 fopen() 或 fsockopen() 成功打开的文件(并且尚未被 fclose() 关闭)。
可以看出 fopen() 只返回一个资源。如果打开失败,此函数返回 FALSE。
file_get_contents() 打开 URL
以下是使用 file_get_contents() 打开 URL 的示例:
从这个例子可以看出,file_get_contents()打开网页后,返回的$fh是一个可以直接输出的字符串。
通过上面两个例子的对比可以看出,使用file_get_contents()打开URL可能是更多人的选择,因为它比fopen()更简单方便。
但是,如果您正在阅读相对较大的资源,则使用 fopen() 更为合适。
知识拓展
file_get_contents() 模拟referer、cookie、使用代理等。
参考代码
ini_set('default_socket_timeout',120);
ini_set('user_agent','MSIE 6.0;');
$context=array('http' => array ('header'=>'Referer:', ),);
$xcontext = stream_context_create($context);
echo $str=file_get_contents('',FALSE,$xcontext);
指南:ini_set() 的例子和用法
php 循环抓取网页内容(第一步就是获取有哪些城市使用插件XPath进行一个测试? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-24 20:11
)
因此将其分配给名为 base_url 的变量以供后续使用
自动创建的爬出带有爬虫的名字。启动爬虫时需要这个名字,现在不用
name = 'area_spider'
allowed_domains = ['aqistudy.cn'] # 爬取的域名,不会超出这个顶级域名
base_url = "https://www.aqistudy.cn/historydata/"
start_urls = [base_url]
城市信息
进入首页后可以看到大量的城市信息,所以我们第一步就是获取有哪些城市
def parse(self, response):
print('爬取城市信息....')
url_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/@href").extract() # 全部链接
city_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/text()").extract() # 城市名称
for url, city in zip(url_list, city_list):
yield scrapy.Request(url=url, callback=self.parse_month, meta={'city': city})
使用插件XPath Helper可以对xpath进行测试,看定位内容是否正确
xpath.png
随便点击一个地区,可以发现url已经变成了北京
那么url_list得到的就是需要拼接的内容monthdata.php?city=city name
city_list的最后一部分是text(),所以得到的是具体的文本信息
将获取到的url_list和city_list一一传递给scrapy.Request,其中url是需要爬取的页面地址,city是item中需要的内容,所以暂时将item存入meta中并通过它到下一个回调函数 self .parse_month
月份信息
def parse_month(self, response):
print('爬取{}月份...'.format(response.meta['city']))
url_list = response.xpath('//tbody/tr/td/a/@href').extract()
for url in url_list:
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_day, meta={'city': response.meta['city']})
本步骤获取每个城市的所有月份信息,获取每个月份的URL地址。继续向下传递从上面传递的城市
最终数据
获得最终URL后,实例化item,然后完成item字典,返回item
def parse_day(self, response):
print('爬取最终数据...')
item = AirHistoryItem()
node_list = response.xpath('//tr')
node_list.pop(0) # 去除第一行标题栏
for node in node_list:
item['data'] = node.xpath('./td[1]/text()').extract_first()
item['city'] = response.meta['city']
item['aqi'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['pm2_5'] = node.xpath('./td[4]/text()').extract_first()
item['pm10'] = node.xpath('./td[5]/text()').extract_first()
item['so2'] = node.xpath('./td[6]/text()').extract_first()
item['co'] = node.xpath('./td[7]/text()').extract_first()
item['no2'] = node.xpath('./td[8]/text()').extract_first()
item['o3'] = node.xpath('./td[9]/text()').extract_first()
yield item
使用中间件实现selenium操作
打开中间件文件 middlewares.py
因为在服务器上爬取,所以选择使用谷歌的无界面浏览器chrome-headless
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless') # 使用无头谷歌浏览器模式
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
# 指定谷歌浏览器路径
webdriver.Chrome(chrome_options=chrome_options,executable_path='/root/zx/spider/driver/chromedriver')
然后获取页面渲染后的源码
request.url 是传递给中间件的 url。由于首页是静态页面,首页不进行selenium操作
if request.url != 'https://www.aqistudy.cn/historydata/':
self.driver.get(request.url)
time.sleep(1)
html = self.driver.page_source
self.driver.quit()
return scrapy.http.HtmlResponse(url=request.url, body=html.encode('utf-8'), encoding='utf-8',request=request)
后续的操作也很简单,最后对获取到的内容进行正确编码返回到爬虫的下一步
所有中间件代码
使用下载器保存项目内容
修改 pipelines.py 用于文件存储
import json
class AirHistoryPipeline(object):
def open_spider(self, spider):
self.file = open('area.json', 'w')
def process_item(self, item, spider):
context = json.dumps(dict(item),ensure_ascii=False) + '\n'
self.file.write(context)
return item
def close_spider(self,spider):
self.file.close()
修改设置文件使中间件和下载器生效
打开settings.py文件
修改如下内容:DOWNLOADER_MIDDLEWARES使刚才写的中间件中的类,ITEM_PIPELINES是管道中的类
BOT_NAME = 'air_history'
SPIDER_MODULES = ['air_history.spiders']
NEWSPIDER_MODULE = 'air_history.spiders'
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
DOWNLOADER_MIDDLEWARES = {
'air_history.middlewares.AreaSpiderMiddleware': 543,
}
ITEM_PIPELINES = {
'air_history.pipelines.AirHistoryPipeline': 300,
}
运行
使用scrapy crawl area_spider运行爬虫
结果.png
所有蜘蛛代码
# -*- coding: utf-8 -*-
import scrapy
from air_history.items import AirHistoryItem
class AreaSpiderSpider(scrapy.Spider):
name = 'area_spider'
allowed_domains = ['aqistudy.cn'] # 爬取的域名,不会超出这个顶级域名
base_url = "https://www.aqistudy.cn/historydata/"
start_urls = [base_url]
def parse(self, response):
print('爬取城市信息....')
url_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/@href").extract() # 全部链接
city_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/text()").extract() # 城市名称
for url, city in zip(url_list, city_list):
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_month, meta={'city': city})
def parse_month(self, response):
print('爬取{}月份...'.format(response.meta['city']))
url_list = response.xpath('//tbody/tr/td/a/@href').extract()
for url in url_list:
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_day, meta={'city': response.meta['city']})
def parse_day(self, response):
print('爬取最终数据...')
item = AirHistoryItem()
node_list = response.xpath('//tr')
node_list.pop(0) # 去除第一行标题栏
for node in node_list:
item['data'] = node.xpath('./td[1]/text()').extract_first()
item['city'] = response.meta['city']
item['aqi'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['pm2_5'] = node.xpath('./td[4]/text()').extract_first()
item['pm10'] = node.xpath('./td[5]/text()').extract_first()
item['so2'] = node.xpath('./td[6]/text()').extract_first()
item['co'] = node.xpath('./td[7]/text()').extract_first()
item['no2'] = node.xpath('./td[8]/text()').extract_first()
item['o3'] = node.xpath('./td[9]/text()').extract_first()
yield item 查看全部
php 循环抓取网页内容(第一步就是获取有哪些城市使用插件XPath进行一个测试?
)
因此将其分配给名为 base_url 的变量以供后续使用
自动创建的爬出带有爬虫的名字。启动爬虫时需要这个名字,现在不用
name = 'area_spider'
allowed_domains = ['aqistudy.cn'] # 爬取的域名,不会超出这个顶级域名
base_url = "https://www.aqistudy.cn/historydata/"
start_urls = [base_url]
城市信息
进入首页后可以看到大量的城市信息,所以我们第一步就是获取有哪些城市
def parse(self, response):
print('爬取城市信息....')
url_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/@href").extract() # 全部链接
city_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/text()").extract() # 城市名称
for url, city in zip(url_list, city_list):
yield scrapy.Request(url=url, callback=self.parse_month, meta={'city': city})
使用插件XPath Helper可以对xpath进行测试,看定位内容是否正确

xpath.png
随便点击一个地区,可以发现url已经变成了北京
那么url_list得到的就是需要拼接的内容monthdata.php?city=city name
city_list的最后一部分是text(),所以得到的是具体的文本信息
将获取到的url_list和city_list一一传递给scrapy.Request,其中url是需要爬取的页面地址,city是item中需要的内容,所以暂时将item存入meta中并通过它到下一个回调函数 self .parse_month
月份信息
def parse_month(self, response):
print('爬取{}月份...'.format(response.meta['city']))
url_list = response.xpath('//tbody/tr/td/a/@href').extract()
for url in url_list:
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_day, meta={'city': response.meta['city']})
本步骤获取每个城市的所有月份信息,获取每个月份的URL地址。继续向下传递从上面传递的城市
最终数据
获得最终URL后,实例化item,然后完成item字典,返回item
def parse_day(self, response):
print('爬取最终数据...')
item = AirHistoryItem()
node_list = response.xpath('//tr')
node_list.pop(0) # 去除第一行标题栏
for node in node_list:
item['data'] = node.xpath('./td[1]/text()').extract_first()
item['city'] = response.meta['city']
item['aqi'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['pm2_5'] = node.xpath('./td[4]/text()').extract_first()
item['pm10'] = node.xpath('./td[5]/text()').extract_first()
item['so2'] = node.xpath('./td[6]/text()').extract_first()
item['co'] = node.xpath('./td[7]/text()').extract_first()
item['no2'] = node.xpath('./td[8]/text()').extract_first()
item['o3'] = node.xpath('./td[9]/text()').extract_first()
yield item
使用中间件实现selenium操作
打开中间件文件 middlewares.py
因为在服务器上爬取,所以选择使用谷歌的无界面浏览器chrome-headless
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless') # 使用无头谷歌浏览器模式
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
# 指定谷歌浏览器路径
webdriver.Chrome(chrome_options=chrome_options,executable_path='/root/zx/spider/driver/chromedriver')
然后获取页面渲染后的源码
request.url 是传递给中间件的 url。由于首页是静态页面,首页不进行selenium操作
if request.url != 'https://www.aqistudy.cn/historydata/':
self.driver.get(request.url)
time.sleep(1)
html = self.driver.page_source
self.driver.quit()
return scrapy.http.HtmlResponse(url=request.url, body=html.encode('utf-8'), encoding='utf-8',request=request)
后续的操作也很简单,最后对获取到的内容进行正确编码返回到爬虫的下一步
所有中间件代码
使用下载器保存项目内容
修改 pipelines.py 用于文件存储
import json
class AirHistoryPipeline(object):
def open_spider(self, spider):
self.file = open('area.json', 'w')
def process_item(self, item, spider):
context = json.dumps(dict(item),ensure_ascii=False) + '\n'
self.file.write(context)
return item
def close_spider(self,spider):
self.file.close()
修改设置文件使中间件和下载器生效
打开settings.py文件
修改如下内容:DOWNLOADER_MIDDLEWARES使刚才写的中间件中的类,ITEM_PIPELINES是管道中的类
BOT_NAME = 'air_history'
SPIDER_MODULES = ['air_history.spiders']
NEWSPIDER_MODULE = 'air_history.spiders'
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
DOWNLOADER_MIDDLEWARES = {
'air_history.middlewares.AreaSpiderMiddleware': 543,
}
ITEM_PIPELINES = {
'air_history.pipelines.AirHistoryPipeline': 300,
}
运行
使用scrapy crawl area_spider运行爬虫
结果.png
所有蜘蛛代码
# -*- coding: utf-8 -*-
import scrapy
from air_history.items import AirHistoryItem
class AreaSpiderSpider(scrapy.Spider):
name = 'area_spider'
allowed_domains = ['aqistudy.cn'] # 爬取的域名,不会超出这个顶级域名
base_url = "https://www.aqistudy.cn/historydata/"
start_urls = [base_url]
def parse(self, response):
print('爬取城市信息....')
url_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/@href").extract() # 全部链接
city_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/text()").extract() # 城市名称
for url, city in zip(url_list, city_list):
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_month, meta={'city': city})
def parse_month(self, response):
print('爬取{}月份...'.format(response.meta['city']))
url_list = response.xpath('//tbody/tr/td/a/@href').extract()
for url in url_list:
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_day, meta={'city': response.meta['city']})
def parse_day(self, response):
print('爬取最终数据...')
item = AirHistoryItem()
node_list = response.xpath('//tr')
node_list.pop(0) # 去除第一行标题栏
for node in node_list:
item['data'] = node.xpath('./td[1]/text()').extract_first()
item['city'] = response.meta['city']
item['aqi'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['pm2_5'] = node.xpath('./td[4]/text()').extract_first()
item['pm10'] = node.xpath('./td[5]/text()').extract_first()
item['so2'] = node.xpath('./td[6]/text()').extract_first()
item['co'] = node.xpath('./td[7]/text()').extract_first()
item['no2'] = node.xpath('./td[8]/text()').extract_first()
item['o3'] = node.xpath('./td[9]/text()').extract_first()
yield item
php 循环抓取网页内容(免费资源网,使用phpcurl获取页面内容或提交数据有时候)
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-24 13:18
免费资源网,
使用 php curl 获取页面内容或提交数据。有时您希望将返回的内容存储为变量而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
以上php curl获取https页面内容的设置方法,不直接输出返回结果,都是编辑器共享的内容。希望能给大家参考,也希望大家多多支持免费资源网。
免费资源网, 查看全部
php 循环抓取网页内容(免费资源网,使用phpcurl获取页面内容或提交数据有时候)
免费资源网,
使用 php curl 获取页面内容或提交数据。有时您希望将返回的内容存储为变量而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
以上php curl获取https页面内容的设置方法,不直接输出返回结果,都是编辑器共享的内容。希望能给大家参考,也希望大家多多支持免费资源网。
免费资源网,
php 循环抓取网页内容(php循环抓取网页内容,主要有两种方式,1。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-21 15:05
php循环抓取网页内容,主要有两种方式,1。循环网页内容中使用循环依赖指定的字符串就行,include/memcpy/xendesize/xendesize。c等方法。2。循环字符串使用模糊匹配,比如:字符串"admin",使用自定义函数find("/admin")获取返回值就是字符串"admin"这个字符串。
1循环操作时因为涉及到缓存使用的操作时就很方便,先获取元素后缓存,而2中因为避免被缓存就使用了缓存规则。但是include/memcpy等方法都带来了问题,就是获取字符串后字符串并不是预期的,会存在扩展编译时误识别的问题。这时就需要对浏览器字符串进行解析提取提前使用content-type的语义,使用xendesize/xendesize。
<p>c等提取字符串并且获取响应的字符串。第一种方法是相对简单的解决方案,需要做两个同步的缓存队列。php直接使用shell。io解析解析数据使用{xendesize}{xendesize}等方法。php不支持多个线程,无法一次获取多个页面的数据,但是有时会使用前端的js来实现多个页面同步获取,将变量与解析数据同步, 查看全部
php 循环抓取网页内容(php循环抓取网页内容,主要有两种方式,1。)
php循环抓取网页内容,主要有两种方式,1。循环网页内容中使用循环依赖指定的字符串就行,include/memcpy/xendesize/xendesize。c等方法。2。循环字符串使用模糊匹配,比如:字符串"admin",使用自定义函数find("/admin")获取返回值就是字符串"admin"这个字符串。
1循环操作时因为涉及到缓存使用的操作时就很方便,先获取元素后缓存,而2中因为避免被缓存就使用了缓存规则。但是include/memcpy等方法都带来了问题,就是获取字符串后字符串并不是预期的,会存在扩展编译时误识别的问题。这时就需要对浏览器字符串进行解析提取提前使用content-type的语义,使用xendesize/xendesize。
<p>c等提取字符串并且获取响应的字符串。第一种方法是相对简单的解决方案,需要做两个同步的缓存队列。php直接使用shell。io解析解析数据使用{xendesize}{xendesize}等方法。php不支持多个线程,无法一次获取多个页面的数据,但是有时会使用前端的js来实现多个页面同步获取,将变量与解析数据同步,
php 循环抓取网页内容(WordPress主循环和全局变量的部分模板函数假设我们写了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-17 07:09
我们在开发WordPress的时候,首先要了解主循环和全局变量,这样才能知道哪些全局变量是可以访问的。下面我们来解释一下 WordPress 主循环,以更好地了解主循环中的模板函数可以调用哪些全局变量。
WordPress 主循环
WordPress 主循环(The Loop)用于在单个日志页面上显示日志列表和消息列表。
在默认主题的index.php中,主循环代码如下:
调用 the_post() 函数后,我们可以使用很多模板函数和全局变量。
以下是目前可用的一些模板函数:
以下是主循环中可用的全局变量:
制作自己的模板函数
假设我们写了一个自定义的模板函数,叫做get_my_trackback,它可以在文章的消息循环中每次检测到消息是否为trackback时,做一些动作。我们可以把这个函数放到comment.php模板文件的foreach消息循环中。
然后在当前主题的函数文件中添加get_my_trackback函数代码:
全局变量comments 允许我们访问当前评论的所有数据,因此它允许我们对评论做任何事情。
©我喜欢水煮鱼。本站推荐主机:阿里云。国外主机推荐使用 BlueHost。 查看全部
php 循环抓取网页内容(WordPress主循环和全局变量的部分模板函数假设我们写了)
我们在开发WordPress的时候,首先要了解主循环和全局变量,这样才能知道哪些全局变量是可以访问的。下面我们来解释一下 WordPress 主循环,以更好地了解主循环中的模板函数可以调用哪些全局变量。
WordPress 主循环
WordPress 主循环(The Loop)用于在单个日志页面上显示日志列表和消息列表。

在默认主题的index.php中,主循环代码如下:
调用 the_post() 函数后,我们可以使用很多模板函数和全局变量。
以下是目前可用的一些模板函数:
以下是主循环中可用的全局变量:
制作自己的模板函数
假设我们写了一个自定义的模板函数,叫做get_my_trackback,它可以在文章的消息循环中每次检测到消息是否为trackback时,做一些动作。我们可以把这个函数放到comment.php模板文件的foreach消息循环中。
然后在当前主题的函数文件中添加get_my_trackback函数代码:

全局变量comments 允许我们访问当前评论的所有数据,因此它允许我们对评论做任何事情。
©我喜欢水煮鱼。本站推荐主机:阿里云。国外主机推荐使用 BlueHost。
php 循环抓取网页内容(调用博客日志的主循环(TheLoop)中如何调用日志标题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-10-17 07:05
调用博文的主循环(The Loop)是WordPress中最重要的一组PHP代码,几乎在所有页面中都会用到。这也是从头开始创建 WordPress 主题的系列教程中的第五篇。
在我们继续学习之前,让我们回顾一下到目前为止我们学到的东西。
到目前为止,我们已经学会了:
现在让我们开始第 5 部分:循环
打开Xampp,“教程”主题文件夹,浏览器,在浏览器中去,最后打开index.php文件。
下面应该是此时index.php文件的内容:
再说一遍:为了学习这些代码,请尝试手动输入它们,而不是复制和粘贴它们。
第 1 步:创建容器 Div
在头部DIV标签下添加一个DIV标签,并将其ID赋给“container”,如下:
“容器”DIV 标签用于将博客的主要内容与其他内容(例如侧边栏和页脚)区分开来。
第二步:输入主循环代码
将以下代码添加到容器的 DIV 标签中:
这段代码是 WordPress 中的主循环(The Loop)。在详细解释这些代码的功能之前,我们先来看看目前index.php中收录的代码:
您可能已经注意到,Container DIV 中的每一行都是缩进的。这是为了更好地组织代码并方便阅读(使用tab键代替空格键进行代码缩进)。
刚才发生了什么?
第三步:调用日志标题
在上一课中,我们学习了如何使用 bloginfo('name') 来调用博客的标题。现在我们将学习如何在主循环(The Loop)中调用博客的标题。
在 the_post() 之后输入;?> 及之前
保存 index.php 文件并刷新浏览器。您应该会在博客描述下方看到 Hello World。WordPress默认安装后,博客只有一个帖子,而我的测试站点有多个帖子,所以有多个日志标题,而且由于我使用的日志标题是相同的,它们看起来像一长串Hello World。
第 4 步:添加指向帖子标题的链接
将帖子标题转换为帖子标题链接。还记得如何将博客的标题变成链接吗?
两边增加。
保存并刷新浏览器。现在日志的标题变成了链接,但它们没有指向哪里。为了让每个头指向正确的日志,我们需要用 the_permalink() 替换 #。
<p> 查看全部
php 循环抓取网页内容(调用博客日志的主循环(TheLoop)中如何调用日志标题)
调用博文的主循环(The Loop)是WordPress中最重要的一组PHP代码,几乎在所有页面中都会用到。这也是从头开始创建 WordPress 主题的系列教程中的第五篇。
在我们继续学习之前,让我们回顾一下到目前为止我们学到的东西。
到目前为止,我们已经学会了:
现在让我们开始第 5 部分:循环
打开Xampp,“教程”主题文件夹,浏览器,在浏览器中去,最后打开index.php文件。
下面应该是此时index.php文件的内容:

再说一遍:为了学习这些代码,请尝试手动输入它们,而不是复制和粘贴它们。
第 1 步:创建容器 Div
在头部DIV标签下添加一个DIV标签,并将其ID赋给“container”,如下:
“容器”DIV 标签用于将博客的主要内容与其他内容(例如侧边栏和页脚)区分开来。
第二步:输入主循环代码
将以下代码添加到容器的 DIV 标签中:
这段代码是 WordPress 中的主循环(The Loop)。在详细解释这些代码的功能之前,我们先来看看目前index.php中收录的代码:

您可能已经注意到,Container DIV 中的每一行都是缩进的。这是为了更好地组织代码并方便阅读(使用tab键代替空格键进行代码缩进)。
刚才发生了什么?
第三步:调用日志标题
在上一课中,我们学习了如何使用 bloginfo('name') 来调用博客的标题。现在我们将学习如何在主循环(The Loop)中调用博客的标题。
在 the_post() 之后输入;?> 及之前

保存 index.php 文件并刷新浏览器。您应该会在博客描述下方看到 Hello World。WordPress默认安装后,博客只有一个帖子,而我的测试站点有多个帖子,所以有多个日志标题,而且由于我使用的日志标题是相同的,它们看起来像一长串Hello World。

第 4 步:添加指向帖子标题的链接
将帖子标题转换为帖子标题链接。还记得如何将博客的标题变成链接吗?
两边增加。
保存并刷新浏览器。现在日志的标题变成了链接,但它们没有指向哪里。为了让每个头指向正确的日志,我们需要用 the_permalink() 替换 #。
<p>
php 循环抓取网页内容(js(javascript)写的函数前面都要加个functionshowSite)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-17 07:04
js(javascript)写的函数前面必须有函数。函数 showSite(str) 括号中的 str 显然是一个参数,这是一个约定。if(str=="")的判断是指当参数为空时,return出来时,中间的大段与参数str无关。忽略它。最后一个 xmlhttp.open("GET","getsite_mysql.php?q="+str,true) 收录 str。你需要注意它。很明显,getsite_mysql.php.php是接受数据的。移植功能时要注意变化。true 好像是说设置为异步的。我不明白。简单了解一下功能,复制粘贴就可以了。mysql
先展示效果图
如果文本框为空,点击【搜索】
在文本框中输入【报纸】,点击【搜索】(数据库有报纸信息)
在文本框中输入【拉拉拉】,点击【搜索】(数据库中没有信息)
网络
在文本框中输入【报纸】,然后点击搜索按钮查看下表。表中显示的【ID】【Recyclable Garbage】的内容是通过查询数据库得到的。如果是在文本框中输入的东西,在数据库中没有,它会显示[不知道] sql
下面直接看代码
HTML全码数据库
简单交互 //这里就是上网时候的标签页的名字
function showSite(str)
{
if (str=="")
{
document.getElementById("txtHint").innerHTML="无输入";//这里小改,参数为空显示【无输入】
return;
}
if (window.XMLHttpRequest)
{
// IE7+, Firefox, Chrome, Opera, Safari 浏览器执行代码
xmlhttp=new XMLHttpRequest();
}
else
{
// IE6, IE5 浏览器执行代码
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.getElementById("txtHint").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("GET","mysql.php?q="+str,true);
xmlhttp.send();
}
我要查询//laber其实有没有都不差,据说是方便人点击用的
//换行操做,屡试不爽
//id 这个很关键,后面函数调用的参数要用到, placeholder 就是文本框为空时显示的东西
//onclick 点击触发函数运行,经过【.litter】指定 id="litter" 的文本框,【.value】指定文本框的输入内容
网站信息显示在这里……
//这里也很关键,这里是 HTML 显示数据表格的地方,函数里面用到
PHP全码浏览器
数据库方面
代码中有分析,很详细。HTML 文件和 PHP 文件应放在同一目录中。我不需要说这些。不然函数的php路径也要改,./…/Superior Directory,上级目录,这些东西就不说了
我不需要安装MySQL、在数据库中创建表、插入数据和其他MySQL语句。东西太多了,就接受吧。如果你有任何问题,你可以问我。, 可以的话回答一下
---------------====------------------------ -------------------------------------------------- ---------------------
以上如果有什么不对的地方,或者有错误,请指正,emmmmm
最后,如果推荐学习制作网页的话,我觉得三个网站都挺好的,菜鸟教程,w3school,PHP中文网站,干货很多,希望对大家学习有帮助,嘻嘻嘻嘻 查看全部
php 循环抓取网页内容(js(javascript)写的函数前面都要加个functionshowSite)
js(javascript)写的函数前面必须有函数。函数 showSite(str) 括号中的 str 显然是一个参数,这是一个约定。if(str=="")的判断是指当参数为空时,return出来时,中间的大段与参数str无关。忽略它。最后一个 xmlhttp.open("GET","getsite_mysql.php?q="+str,true) 收录 str。你需要注意它。很明显,getsite_mysql.php.php是接受数据的。移植功能时要注意变化。true 好像是说设置为异步的。我不明白。简单了解一下功能,复制粘贴就可以了。mysql
先展示效果图
如果文本框为空,点击【搜索】

在文本框中输入【报纸】,点击【搜索】(数据库有报纸信息)
在文本框中输入【拉拉拉】,点击【搜索】(数据库中没有信息)
网络
在文本框中输入【报纸】,然后点击搜索按钮查看下表。表中显示的【ID】【Recyclable Garbage】的内容是通过查询数据库得到的。如果是在文本框中输入的东西,在数据库中没有,它会显示[不知道] sql
下面直接看代码
HTML全码数据库
简单交互 //这里就是上网时候的标签页的名字
function showSite(str)
{
if (str=="")
{
document.getElementById("txtHint").innerHTML="无输入";//这里小改,参数为空显示【无输入】
return;
}
if (window.XMLHttpRequest)
{
// IE7+, Firefox, Chrome, Opera, Safari 浏览器执行代码
xmlhttp=new XMLHttpRequest();
}
else
{
// IE6, IE5 浏览器执行代码
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.getElementById("txtHint").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("GET","mysql.php?q="+str,true);
xmlhttp.send();
}
我要查询//laber其实有没有都不差,据说是方便人点击用的
//换行操做,屡试不爽
//id 这个很关键,后面函数调用的参数要用到, placeholder 就是文本框为空时显示的东西
//onclick 点击触发函数运行,经过【.litter】指定 id="litter" 的文本框,【.value】指定文本框的输入内容
网站信息显示在这里……
//这里也很关键,这里是 HTML 显示数据表格的地方,函数里面用到
PHP全码浏览器
数据库方面
代码中有分析,很详细。HTML 文件和 PHP 文件应放在同一目录中。我不需要说这些。不然函数的php路径也要改,./…/Superior Directory,上级目录,这些东西就不说了
我不需要安装MySQL、在数据库中创建表、插入数据和其他MySQL语句。东西太多了,就接受吧。如果你有任何问题,你可以问我。, 可以的话回答一下
---------------====------------------------ -------------------------------------------------- ---------------------
以上如果有什么不对的地方,或者有错误,请指正,emmmmm
最后,如果推荐学习制作网页的话,我觉得三个网站都挺好的,菜鸟教程,w3school,PHP中文网站,干货很多,希望对大家学习有帮助,嘻嘻嘻嘻
php 循环抓取网页内容(WordPress附带不依赖循环的single_title()函数的用法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-13 12:16
本文文章主要介绍WordPress中文章循环复位函数rewind_posts(),并介绍不依赖循环的single_cat_title()函数的用法。有需要的朋友可以参考
有时,在索引页(首页、分类文章、标签文章、作者文章索引...)提前进入WordPress文章循环(Loop)获取一些我们想要获取的信息,但是在WP中,单个页面一般只会跳入循环一次,也就是下次我们从循环中抽取信息时,我们会在循环中获取第二个日志的信息,以便解决这个尴尬的情况,WordPress 有一个内置函数,rewind_posts() 函数专门用于重置循环指针。
描述 描述
倒回循环帖子。
重置 文章 循环。
用
该函数不接受变量。
实例
在此引用 WordPress 默认主题二十一点,author.php 文件的第 15-55 行进行了简化和简化。
实例
这是 WordPress 2011 默认主题的摘录,category.php 文件第 18 行的代码
以上就是对WordPress中重置文章循环的rewind_posts()函数的详细说明。更多详情请关注其他相关html中文网站文章! 查看全部
php 循环抓取网页内容(WordPress附带不依赖循环的single_title()函数的用法介绍)
本文文章主要介绍WordPress中文章循环复位函数rewind_posts(),并介绍不依赖循环的single_cat_title()函数的用法。有需要的朋友可以参考
有时,在索引页(首页、分类文章、标签文章、作者文章索引...)提前进入WordPress文章循环(Loop)获取一些我们想要获取的信息,但是在WP中,单个页面一般只会跳入循环一次,也就是下次我们从循环中抽取信息时,我们会在循环中获取第二个日志的信息,以便解决这个尴尬的情况,WordPress 有一个内置函数,rewind_posts() 函数专门用于重置循环指针。
描述 描述
倒回循环帖子。
重置 文章 循环。
用
该函数不接受变量。
实例
在此引用 WordPress 默认主题二十一点,author.php 文件的第 15-55 行进行了简化和简化。
实例
这是 WordPress 2011 默认主题的摘录,category.php 文件第 18 行的代码
以上就是对WordPress中重置文章循环的rewind_posts()函数的详细说明。更多详情请关注其他相关html中文网站文章!
php 循环抓取网页内容(【小编】phpcurl获取页面内容或提交数据有时候)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-05 05:19
时间:2019-01-15
今天小编就给大家分享一篇关于php curl如何在不直接输出返回结果的情况下获取https页面内容的文章。有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
使用 php curl 获取页面内容或提交数据。有时您希望将返回的内容存储为变量而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
以上php curl获取https页面内容的设置方法,不直接输出返回结果,都是编辑器共享的内容。希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
php 循环抓取网页内容(【小编】phpcurl获取页面内容或提交数据有时候)
时间:2019-01-15
今天小编就给大家分享一篇关于php curl如何在不直接输出返回结果的情况下获取https页面内容的文章。有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
使用 php curl 获取页面内容或提交数据。有时您希望将返回的内容存储为变量而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
以上php curl获取https页面内容的设置方法,不直接输出返回结果,都是编辑器共享的内容。希望能给大家一个参考,也希望大家多多支持脚本之家。
php 循环抓取网页内容(php循环抓取网页内容解决静态网页可视化问题(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-21 18:03
php循环抓取网页内容解决静态网页可视化问题“php循环抓取网页内容解决静态网页可视化问题”php网页的html,从div+css结构来看,可以分为4种结构,一种为静态页面html,另外一种为动态页面div+css,还有一种是通过轮询方式来抓取,不关心执行流程,只是获取内容。php循环抓取网页内容例1:网页最终会生成一个静态的数据页面div,需要设置js或者xmlhttprequest对象从而获取网页内容。
如果抓取完的页面非常非常多,使用循环可能会造成需要n次加载的问题,我们知道页面抓取函数lookup()函数也可以实现分页抓取,这样页面抓取就可以顺利进行了。为了方便抓取,所以模拟了一个php网页的请求,结果是接收到如下的html响应数据,然后会把内容存储到文件中(php内置的所有数据类型)然后给js或者xmlhttprequest对象,这样是可以通过php进行解析的。
执行抓取时,再抓取一次就可以生成响应数据,最终文件内容也就会在浏览器中展示。php循环抓取网页内容例2:还是php网页的动态请求实现,可能效率更高,可以看出三次加载原因有三点,就是最终html页面需要三次加载,主要原因是模拟请求的时候分段了,完成php网页动态请求之后,js和xmlhttprequest等工具就可以对各个页面进行分段执行,一段一段的加载html页面,所以需要三次加载。
php循环抓取网页内容还是这个php循环抓取网页内容案例,请求是从:指定域名处跳转后的url,url的请求结构就可以看下面图片,想知道具体实现步骤的,可以在评论区留言。php循环抓取网页内容无论php循环还是java循环,重点不在于循环形式,而在于抓取,抓取的时候需要做到顺序一致,这里有个知识点我们需要注意:整个抓取逻辑都可以分开php中2.object类中,并没有somebody的属性,只有some()函数接收一个object,该object会从浏览器中抓取post方法的请求,同时也会对其进行处理,post方法可以接受cookie,referer,session等参数,方法的具体逻辑就可以看下面图片,方法实现看下面的注释。
php循环抓取网页内容php循环抓取网页内容php循环抓取网页内容以上三个案例只是php循环抓取网页内容一种重要问题,还有一些后续比较容易犯的错误需要注意:尽量是大请求,采用selenium等从浏览器抓取以降低处理速度原始html格式的页面也是抓取时的大问题java有很多方法可以实现,但是java能不能实现,我们就不能去抓取,这是前端工程师做项目的过程中所需要注意的知识点ajax高级绑定(异步方法)file读写(读取后面的参数,会变成前端地。 查看全部
php 循环抓取网页内容(php循环抓取网页内容解决静态网页可视化问题(组图))
php循环抓取网页内容解决静态网页可视化问题“php循环抓取网页内容解决静态网页可视化问题”php网页的html,从div+css结构来看,可以分为4种结构,一种为静态页面html,另外一种为动态页面div+css,还有一种是通过轮询方式来抓取,不关心执行流程,只是获取内容。php循环抓取网页内容例1:网页最终会生成一个静态的数据页面div,需要设置js或者xmlhttprequest对象从而获取网页内容。
如果抓取完的页面非常非常多,使用循环可能会造成需要n次加载的问题,我们知道页面抓取函数lookup()函数也可以实现分页抓取,这样页面抓取就可以顺利进行了。为了方便抓取,所以模拟了一个php网页的请求,结果是接收到如下的html响应数据,然后会把内容存储到文件中(php内置的所有数据类型)然后给js或者xmlhttprequest对象,这样是可以通过php进行解析的。
执行抓取时,再抓取一次就可以生成响应数据,最终文件内容也就会在浏览器中展示。php循环抓取网页内容例2:还是php网页的动态请求实现,可能效率更高,可以看出三次加载原因有三点,就是最终html页面需要三次加载,主要原因是模拟请求的时候分段了,完成php网页动态请求之后,js和xmlhttprequest等工具就可以对各个页面进行分段执行,一段一段的加载html页面,所以需要三次加载。
php循环抓取网页内容还是这个php循环抓取网页内容案例,请求是从:指定域名处跳转后的url,url的请求结构就可以看下面图片,想知道具体实现步骤的,可以在评论区留言。php循环抓取网页内容无论php循环还是java循环,重点不在于循环形式,而在于抓取,抓取的时候需要做到顺序一致,这里有个知识点我们需要注意:整个抓取逻辑都可以分开php中2.object类中,并没有somebody的属性,只有some()函数接收一个object,该object会从浏览器中抓取post方法的请求,同时也会对其进行处理,post方法可以接受cookie,referer,session等参数,方法的具体逻辑就可以看下面图片,方法实现看下面的注释。
php循环抓取网页内容php循环抓取网页内容php循环抓取网页内容以上三个案例只是php循环抓取网页内容一种重要问题,还有一些后续比较容易犯的错误需要注意:尽量是大请求,采用selenium等从浏览器抓取以降低处理速度原始html格式的页面也是抓取时的大问题java有很多方法可以实现,但是java能不能实现,我们就不能去抓取,这是前端工程师做项目的过程中所需要注意的知识点ajax高级绑定(异步方法)file读写(读取后面的参数,会变成前端地。
php 循环抓取网页内容(什么是网站的TDK?网站TDK设置技巧:SEO优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-19 10:12
网站的TDK是什么?网站TDK设置技巧分类:SEO优化 作者:小秋 发布时间:2019-12-2513:41:34 访问人数:本文标签:网站TDK,网站标题,< @网站描述,TDK标签,网站的TDK是什么?TDK指的是title、keywords、description,这三个标签都是兼容搜索引擎网站内容的判断与定位有关。是对网站用户**,以及收录和网站的排名的直观理解。这三个主要标签对搜索引擎和用户都很重要。影响很大,所以网站设置TDK很重要。网站TDK设置技巧一、注意title标签的细节,切记不要堆在< @网站 优化。标题尤其重要。需要注意的是标题不能过度叠加关键词,必须保证标题与网站的主题一致,不能忽视用户的浏览习惯和阅读效果。尽量将标题的关键词控制在三个字左右,从网站**搜索量,武侯区php网站的关键词中选择。这里有个细节要注意,关键词的顺序也是有讲究的,因为搜索引擎的抓取习惯是从左到右,越靠近左边,关键词越重要,所以写关键词在@>的情况下,可以将关键词按重要性从左到右排列。此外,分隔每个单词的符号也必须符合规定。设置标题时,不能太长也不能太短。太长容易被搜索引擎屏蔽,武侯区php网站,太短不利于用户浏览,武侯区php网站,用户体验差。普通标题的字数尽量限制在80个字符以内,相当于40个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站 相当于 40 个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站 相当于 40 个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站
无框。使用哪种样式表,外部样式或内部样式。使用webjs,合理的使用js可以减少网页的来源,但是合理的大量使用会影响网页的抓取。*三、站点数量取决于集合、链和快照。内容量可以反映网站是否受搜索引擎欢迎,可以判断原创的内容。看一下链,可以在网站上反映其他网站的评价,也可以看到链的来源是否重要,来源是否不同,推广网站的权重是否不同。因此,在外链的建设中,不仅要数量,更要质量。并且快照情况可以反映网站的*新情况。只有网站内容不断更新,原创信息对搜索引擎友好,才能吸引搜索引擎蜘蛛爬取。*四、看关键词的排名。关键词排名主要从网站的主键和长尾关键词来考虑。做过seo的人都知道,有时候他们的排名不做关键词,有些人故意不做关键词,但是他们会有很好的排名。因此,我们应该把它放在一起。当然,对于主力关键词的排名,seo做得不错,合理选择关键词,能体现执行能力。*五、网站目录及内链的构建。使用了多少级目录,以及文件名的写法。尽量不要让用户花费大量时间,多次点击,找到自己想找的东西,**好不要*过4级。另外,网站的内链建设也很重要。美山做优化网站咨询,源代码就是源文件的内容,所以也可以称为网页的源代码。
让搜索引擎无法保质保量抓取页面内容,导致网站主题失真。05网站链接因素网站 链接分为内部链接和外部链接。站内链接主要是链接网站中的相关内容。一般出现在站内文章的相关关键词新闻**或底部新闻**阅读中;顾名思义,站外链接是网站之外的链接,而网站在线时间与外链比例在百度规则中存在一个高峰区间。这个峰值区域多为抛物线,所以在网站上线初期不要有大量的网站外链,因为一旦过了峰值,很容易被百度判断作为***网站, 从而影响网站的优化。网站想要得到更多收录,需要做好搜索引擎的爬取优化。只有提高网站的整体爬取率,才能提高相应的收录,这样网站的内容才能得到更多的展示和**,以及网站的排名@> 可以改进。有了好的基础才能爬上去,基础设施永远是网站优化的基础。并且网站的排名可以提高。有了好的基础才能爬上去,基础设施永远是网站优化的基础。并且网站的排名可以提高。有了好的基础才能爬上去,基础设施永远是网站优化的基础。
搜索引擎优化在列出单词后为结果付费是真的吗?对于初创企业来说,官网上线的时候,大部分都没有自己的SEO团队。由于资金有限,大多数公司通常与SEO机构合作。进而满足在线**业务订单的需求。在联系一些相关的SEO公司时,我们经常会谈到一个问题:SEO见效后付费。这是一些中小企业第一次学习SEO时常说的一句话。关于SEO付费效果的问题,不要一概而论,要根据实际情况来谈,所以我们需要了解以下几点: SEO付费效果场景:①常规排名②**排名一般来说,当我们说到SEO的效果再付费的时候,一般分为以上两种情况。新网站上线后,您需要通过正规渠道**在线下单。不过由于我们不了解对方公司的情况,顾提出要按效果付费。另一种情况是,由于业务压力,公司知道对方是黑帽SEO,仍然采取一种行为,通常每个词有效流量,双方协商后要根据结果付费。SEO按效果付费套路:①关键词首页7天如果你尝试使用正式的排名,那么面对这种句式结构,基本可以断定对方使用的是非正式的意味着,甚至可能根本不提供任何搜索引擎优化服务,在这种情况下,您应该坚决拒绝。②以首付作为基本词似乎是一个合理的套路。选择什么样的动态程序和对应的数据库。如程序ASP、JSP、PHP、.NET;数据库 SQL、ACCESS、ORACLE、mysql 等。
在网站的介绍中写其他长尾词。我从来不刻意做,只要你的网站被认可了,权重自然就上去了,以后各种词都上去了。(4)网站栏目名称尽量使用首页关键词的长尾词,栏目网址尽量使用全拼.如果太长,就用简拼或者两个比较重要的文字,可以选择一个很有意义又好记的域名,虽然空间上选择的名字看起来差不多,但实际情况就不同了。比如Xhtml-MP收录的元素比较少,限制条件也比较少。*放宽点,可以适配的手机种类也比较多。不过大部分< @网站 建设者还是用Xhtml,当然没关系。东港网站优化(5)必须有xml网站映射,最好加html网站映射。(6)网站类和id标签,尽量不要用流行的英文或者整个网站和别人基本相似,而且要有一套自己的标签名称。这其实是在告诉大家模板更好。原创结束。( 7)增加首页主词关键词密度,这是常识。关键词必须有一定的密度,这样搜索引擎才能识别主次关键词 网站的。密度不够会导致对网站的关注不够,搜索引擎很难识别你的话题定位。(8)尽量不要把url弄得太长。很多网站喜欢在文章的url里加年月日,尽量不加年。月日。url 应该是分层的,文章 url 应该尽可能收录该列的 url。网站持有人:例如个人网站、企业网站、**网站、教育网站等武侯区php<
Dreamweaver,用于编辑 HTML、ASP、JSP、PHP 和 javascript 的辅助工具。武侯区php网站
供需失衡是任何市场化行业都会面临的问题,因为对于很多企业来说,只要需求持续增长,行业发展就不会停滞,市场机制自然会淘汰那些没有竞争力的企业。生产能力,从而达到[“T云国内版”、“T云外贸版”、“T云电商版”、“字八宝梦”]更好的标准。从消费水平变化趋势看,随着经济发展水平的不断提高和销售量的不断提高,我国人均购买力将不断提高。因此,提供相关服务是销售行业发展的重要课题。随着数据**技术的深入,服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站
成立于2015-09-14,是一家服务型公司。公司业务分为【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸宝萌”】等,目前正在不断做**和服务提升为客户提供**产品和服务。公司秉承诚信为本的经营理念,深耕商贸服务多年,以技术为先导,自主产品为**,充分发挥人才优势,打造商贸服务. 截止目前,我公司年营业额已达10-2000万元,力争在1厘米的领域内做1公里的深度。 查看全部
php 循环抓取网页内容(什么是网站的TDK?网站TDK设置技巧:SEO优化)
网站的TDK是什么?网站TDK设置技巧分类:SEO优化 作者:小秋 发布时间:2019-12-2513:41:34 访问人数:本文标签:网站TDK,网站标题,< @网站描述,TDK标签,网站的TDK是什么?TDK指的是title、keywords、description,这三个标签都是兼容搜索引擎网站内容的判断与定位有关。是对网站用户**,以及收录和网站的排名的直观理解。这三个主要标签对搜索引擎和用户都很重要。影响很大,所以网站设置TDK很重要。网站TDK设置技巧一、注意title标签的细节,切记不要堆在< @网站 优化。标题尤其重要。需要注意的是标题不能过度叠加关键词,必须保证标题与网站的主题一致,不能忽视用户的浏览习惯和阅读效果。尽量将标题的关键词控制在三个字左右,从网站**搜索量,武侯区php网站的关键词中选择。这里有个细节要注意,关键词的顺序也是有讲究的,因为搜索引擎的抓取习惯是从左到右,越靠近左边,关键词越重要,所以写关键词在@>的情况下,可以将关键词按重要性从左到右排列。此外,分隔每个单词的符号也必须符合规定。设置标题时,不能太长也不能太短。太长容易被搜索引擎屏蔽,武侯区php网站,太短不利于用户浏览,武侯区php网站,用户体验差。普通标题的字数尽量限制在80个字符以内,相当于40个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站 相当于 40 个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站 相当于 40 个字符。”这句话体现了他们的关系,这里的源文件是指网页的源代码。武侯区php网站
无框。使用哪种样式表,外部样式或内部样式。使用webjs,合理的使用js可以减少网页的来源,但是合理的大量使用会影响网页的抓取。*三、站点数量取决于集合、链和快照。内容量可以反映网站是否受搜索引擎欢迎,可以判断原创的内容。看一下链,可以在网站上反映其他网站的评价,也可以看到链的来源是否重要,来源是否不同,推广网站的权重是否不同。因此,在外链的建设中,不仅要数量,更要质量。并且快照情况可以反映网站的*新情况。只有网站内容不断更新,原创信息对搜索引擎友好,才能吸引搜索引擎蜘蛛爬取。*四、看关键词的排名。关键词排名主要从网站的主键和长尾关键词来考虑。做过seo的人都知道,有时候他们的排名不做关键词,有些人故意不做关键词,但是他们会有很好的排名。因此,我们应该把它放在一起。当然,对于主力关键词的排名,seo做得不错,合理选择关键词,能体现执行能力。*五、网站目录及内链的构建。使用了多少级目录,以及文件名的写法。尽量不要让用户花费大量时间,多次点击,找到自己想找的东西,**好不要*过4级。另外,网站的内链建设也很重要。美山做优化网站咨询,源代码就是源文件的内容,所以也可以称为网页的源代码。
让搜索引擎无法保质保量抓取页面内容,导致网站主题失真。05网站链接因素网站 链接分为内部链接和外部链接。站内链接主要是链接网站中的相关内容。一般出现在站内文章的相关关键词新闻**或底部新闻**阅读中;顾名思义,站外链接是网站之外的链接,而网站在线时间与外链比例在百度规则中存在一个高峰区间。这个峰值区域多为抛物线,所以在网站上线初期不要有大量的网站外链,因为一旦过了峰值,很容易被百度判断作为***网站, 从而影响网站的优化。网站想要得到更多收录,需要做好搜索引擎的爬取优化。只有提高网站的整体爬取率,才能提高相应的收录,这样网站的内容才能得到更多的展示和**,以及网站的排名@> 可以改进。有了好的基础才能爬上去,基础设施永远是网站优化的基础。并且网站的排名可以提高。有了好的基础才能爬上去,基础设施永远是网站优化的基础。并且网站的排名可以提高。有了好的基础才能爬上去,基础设施永远是网站优化的基础。
搜索引擎优化在列出单词后为结果付费是真的吗?对于初创企业来说,官网上线的时候,大部分都没有自己的SEO团队。由于资金有限,大多数公司通常与SEO机构合作。进而满足在线**业务订单的需求。在联系一些相关的SEO公司时,我们经常会谈到一个问题:SEO见效后付费。这是一些中小企业第一次学习SEO时常说的一句话。关于SEO付费效果的问题,不要一概而论,要根据实际情况来谈,所以我们需要了解以下几点: SEO付费效果场景:①常规排名②**排名一般来说,当我们说到SEO的效果再付费的时候,一般分为以上两种情况。新网站上线后,您需要通过正规渠道**在线下单。不过由于我们不了解对方公司的情况,顾提出要按效果付费。另一种情况是,由于业务压力,公司知道对方是黑帽SEO,仍然采取一种行为,通常每个词有效流量,双方协商后要根据结果付费。SEO按效果付费套路:①关键词首页7天如果你尝试使用正式的排名,那么面对这种句式结构,基本可以断定对方使用的是非正式的意味着,甚至可能根本不提供任何搜索引擎优化服务,在这种情况下,您应该坚决拒绝。②以首付作为基本词似乎是一个合理的套路。选择什么样的动态程序和对应的数据库。如程序ASP、JSP、PHP、.NET;数据库 SQL、ACCESS、ORACLE、mysql 等。
在网站的介绍中写其他长尾词。我从来不刻意做,只要你的网站被认可了,权重自然就上去了,以后各种词都上去了。(4)网站栏目名称尽量使用首页关键词的长尾词,栏目网址尽量使用全拼.如果太长,就用简拼或者两个比较重要的文字,可以选择一个很有意义又好记的域名,虽然空间上选择的名字看起来差不多,但实际情况就不同了。比如Xhtml-MP收录的元素比较少,限制条件也比较少。*放宽点,可以适配的手机种类也比较多。不过大部分< @网站 建设者还是用Xhtml,当然没关系。东港网站优化(5)必须有xml网站映射,最好加html网站映射。(6)网站类和id标签,尽量不要用流行的英文或者整个网站和别人基本相似,而且要有一套自己的标签名称。这其实是在告诉大家模板更好。原创结束。( 7)增加首页主词关键词密度,这是常识。关键词必须有一定的密度,这样搜索引擎才能识别主次关键词 网站的。密度不够会导致对网站的关注不够,搜索引擎很难识别你的话题定位。(8)尽量不要把url弄得太长。很多网站喜欢在文章的url里加年月日,尽量不加年。月日。url 应该是分层的,文章 url 应该尽可能收录该列的 url。网站持有人:例如个人网站、企业网站、**网站、教育网站等武侯区php<
Dreamweaver,用于编辑 HTML、ASP、JSP、PHP 和 javascript 的辅助工具。武侯区php网站
供需失衡是任何市场化行业都会面临的问题,因为对于很多企业来说,只要需求持续增长,行业发展就不会停滞,市场机制自然会淘汰那些没有竞争力的企业。生产能力,从而达到[“T云国内版”、“T云外贸版”、“T云电商版”、“字八宝梦”]更好的标准。从消费水平变化趋势看,随着经济发展水平的不断提高和销售量的不断提高,我国人均购买力将不断提高。因此,提供相关服务是销售行业发展的重要课题。随着数据**技术的深入,服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 服务化布局越来越广泛。过去,由于业务系统的本地化,基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站 基于服务的布局基本上是基于本地布局。近年来,随着业务系统的云化,业务数据也变得更加标准化和规模化。在全球经济战略竞争的背景下,许多经济体都在奉行差异化的产业发展政策,而【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸” Baumeng”]主要体现在不同的监管方式和不同的适用监管领域。武侯区php网站
成立于2015-09-14,是一家服务型公司。公司业务分为【“T云国内版”、“T云外贸版”、“T云电商版”、“词霸宝萌”】等,目前正在不断做**和服务提升为客户提供**产品和服务。公司秉承诚信为本的经营理念,深耕商贸服务多年,以技术为先导,自主产品为**,充分发挥人才优势,打造商贸服务. 截止目前,我公司年营业额已达10-2000万元,力争在1厘米的领域内做1公里的深度。
php 循环抓取网页内容(更加优雅的方式来捕获php循环抓取网页内容的解决方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-15 16:01
php循环抓取网页内容的解决方案在php抓取网页的时候,总是会存在一些固定的格式,比如xpath。正是基于这个原因,php还创造了一个名叫phpfix的工具。在phpfix之前php循环抓取网页内容时,总是只能获取网页内容的1/4左右的网页。下面教给大家一种更加优雅的方式来捕获网页内容。相关工具说明:免费php热键大师开源request库phpfix工具的工作方式:一种epoll的ctx中断型服务框架一台能够挂载phpfix框架的vps程序运行phpfix的环境:windows7,8,10一台能够挂载phpfix框架的vps一个ubuntu或ubuntu16.04lts版本的vps为什么要使用phpfix首先需要了解vps的本质以及基于vps实现网络请求中断的方式。
vps的本质在vps的每一台机器上,拥有一台dos的操作系统,名为vsphere,存在着一个物理内存容量为256mb的虚拟容器(虚拟内存),一些空闲的物理内存空间集中放在这台物理vsphere中,管理这些物理内存空间就需要vsphere的操作系统,它的名字叫做docker,在vsphere中的操作系统就是docker。
在vsphere中没有一个特定的文件目录,是通过操作进程来建立,windows和linux中的操作系统是默认使用文件名字来做路径切换的。为了保证vsphere中操作系统的整洁性,vsphere操作系统的执行路径是通过操作系统中的pthread对于虚拟内存映射指针来实现的,pthread是进程,是进程基本上可以看做是一个线程。
pthread自带操作系统功能,能够通过pthread来进行多核并发访问,pthread的定义为:一个虚拟内存_pthread,就是一个进程中的一个线程。phpfix框架的工作方式:在phpfix中,docker将php的实例通过tcp方式连接到docker的一个vsphere中,这个vsphere中的php实例对应的php操作系统的docker操作系统被称为phpfixdocker。
然后根据进程在php的地址映射方式的不同,将php的实例处理为实现不同的php操作系统,比如dockerproxyvps[//],dockerhttpservervps,dockerhttps[//],dockeronvpsvps等。这样就实现了每个client都可以运行一个属于自己的虚拟虚拟机的实现。
操作流程分析在docker中安装phpfix等工具,然后在ubuntu中安装docker-server中断docker调用,在windows中安装docker-server中断phpfix调用,完成其他的工作。使用方法/*解析原始html代码*/$file="/file/";$directory=$file."/";$root=$directory;$root_local=$root;phpfixlylink($file,$directory,$root_local);$sourcefile="";phpfixlylink($root,。 查看全部
php 循环抓取网页内容(更加优雅的方式来捕获php循环抓取网页内容的解决方案)
php循环抓取网页内容的解决方案在php抓取网页的时候,总是会存在一些固定的格式,比如xpath。正是基于这个原因,php还创造了一个名叫phpfix的工具。在phpfix之前php循环抓取网页内容时,总是只能获取网页内容的1/4左右的网页。下面教给大家一种更加优雅的方式来捕获网页内容。相关工具说明:免费php热键大师开源request库phpfix工具的工作方式:一种epoll的ctx中断型服务框架一台能够挂载phpfix框架的vps程序运行phpfix的环境:windows7,8,10一台能够挂载phpfix框架的vps一个ubuntu或ubuntu16.04lts版本的vps为什么要使用phpfix首先需要了解vps的本质以及基于vps实现网络请求中断的方式。
vps的本质在vps的每一台机器上,拥有一台dos的操作系统,名为vsphere,存在着一个物理内存容量为256mb的虚拟容器(虚拟内存),一些空闲的物理内存空间集中放在这台物理vsphere中,管理这些物理内存空间就需要vsphere的操作系统,它的名字叫做docker,在vsphere中的操作系统就是docker。
在vsphere中没有一个特定的文件目录,是通过操作进程来建立,windows和linux中的操作系统是默认使用文件名字来做路径切换的。为了保证vsphere中操作系统的整洁性,vsphere操作系统的执行路径是通过操作系统中的pthread对于虚拟内存映射指针来实现的,pthread是进程,是进程基本上可以看做是一个线程。
pthread自带操作系统功能,能够通过pthread来进行多核并发访问,pthread的定义为:一个虚拟内存_pthread,就是一个进程中的一个线程。phpfix框架的工作方式:在phpfix中,docker将php的实例通过tcp方式连接到docker的一个vsphere中,这个vsphere中的php实例对应的php操作系统的docker操作系统被称为phpfixdocker。
然后根据进程在php的地址映射方式的不同,将php的实例处理为实现不同的php操作系统,比如dockerproxyvps[//],dockerhttpservervps,dockerhttps[//],dockeronvpsvps等。这样就实现了每个client都可以运行一个属于自己的虚拟虚拟机的实现。
操作流程分析在docker中安装phpfix等工具,然后在ubuntu中安装docker-server中断docker调用,在windows中安装docker-server中断phpfix调用,完成其他的工作。使用方法/*解析原始html代码*/$file="/file/";$directory=$file."/";$root=$directory;$root_local=$root;phpfixlylink($file,$directory,$root_local);$sourcefile="";phpfixlylink($root,。
php 循环抓取网页内容(服务器上中获取文字内容到控制台,或者写入本地文本等操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-13 14:24
)
距离上次讲用C++制作json或其他数据并发送到服务器已经两个多月了。
关联:
这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。
-------------------------------------------------- ---------分割线---------------------------------------- ---------------
测试服务器为:新浪云海;
测试内容:通过php脚本获取服务器读取的数据,这里是微信用户的openID;
工具:VS 2012;
先上传直观图片,再上传文字源码
整体示例
核心功能
多字节wchar到lpcswtr的转换函数介绍请看这个链接
<p> 1 #include
2 #include
3 #include
4 #include
5 #define MAXBLOCKSIZE 28+1 // openID 固定长 28
6 #pragma comment(lib,"wininet.lib") //引入动态库
7
8 char* getWeiXinFromUserNameFromSEA(const char*);
9 using namespace std;
10
11 int main(){
12 char *p=NULL; //用于存放返回结果
13 p=getWeiXinFromUserNameFromSEA("http://913337456-my.stor.sinaapp.com/xxx.txt");
14
15 cout=34 && buffer[i] 查看全部
php 循环抓取网页内容(服务器上中获取文字内容到控制台,或者写入本地文本等操作
)
距离上次讲用C++制作json或其他数据并发送到服务器已经两个多月了。
关联:
这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。
-------------------------------------------------- ---------分割线---------------------------------------- ---------------
测试服务器为:新浪云海;
测试内容:通过php脚本获取服务器读取的数据,这里是微信用户的openID;
工具:VS 2012;
先上传直观图片,再上传文字源码
整体示例
核心功能
多字节wchar到lpcswtr的转换函数介绍请看这个链接
<p> 1 #include
2 #include
3 #include
4 #include
5 #define MAXBLOCKSIZE 28+1 // openID 固定长 28
6 #pragma comment(lib,"wininet.lib") //引入动态库
7
8 char* getWeiXinFromUserNameFromSEA(const char*);
9 using namespace std;
10
11 int main(){
12 char *p=NULL; //用于存放返回结果
13 p=getWeiXinFromUserNameFromSEA("http://913337456-my.stor.sinaapp.com/xxx.txt";);
14
15 cout=34 && buffer[i]
php 循环抓取网页内容(,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-13 12:13
本文文章主要介绍JAVA利用爬虫抓取网站网页内容的方法。实例分析了java爬虫的两种实现技术。有一定的参考价值,有需要的朋友可以参考。下
本文介绍了使用爬虫通过JAVA抓取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA学习爬虫技术,呵呵,进门和大家分享一下自己的经验
下面提供了两种方法,一种是使用apache提供的包。另一种是JAVA自带的。
代码如下:
<p> // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar public static String createhttpClient(String url, String param) { HttpClient client = new HttpClient(); String response = null; String keyword = null; PostMethod postMethod = new PostMethod(url); // try { // if (param != null) // keyword = new String(param.getBytes("gb2312"), "ISO-8859-1"); // } catch (UnsupportedEncodingException e1) { // // TODO Auto-generated catch block // e1.printStackTrace(); // } // NameValuePair[] data = { new NameValuePair("keyword", keyword) }; // // 将表单的值放入postMethod中 // postMethod.setRequestBody(data); // 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下 try { int statusCode = client.executeMethod(postMethod); response = new String(postMethod.getResponseBodyAsString() .getBytes("ISO-8859-1"), "gb2312"); //这里要注意下 gb2312要和你抓取网页的编码要一样 String p = response.replaceAll("//&[a-zA-Z]{1,10};", "") .replaceAll("]*>", "");//去掉网页中带有html语言的标签 System.out.println(p); } catch (Exception e) { e.printStackTrace(); } return response; } // 第二种方法 // 这种方法是JAVA自带的URL来抓取网站内容 public String getPageContent(String strUrl, String strPostRequest, int maxLength) { // 读取结果网页 StringBuffer buffer = new StringBuffer(); System.setProperty("sun.net.client.defaultConnectTimeout", "5000"); System.setProperty("sun.net.client.defaultReadTimeout", "5000"); try { URL newUrl = new URL(strUrl); HttpURLConnection hConnect = (HttpURLConnection) newUrl .openConnection(); // POST方式的额外数据 if (strPostRequest.length() > 0) { hConnect.setDoOutput(true); OutputStreamWriter out = new OutputStreamWriter(hConnect .getOutputStream()); out.write(strPostRequest); out.flush(); out.close(); } // 读取内容 BufferedReader rd = new BufferedReader(new InputStreamReader( hConnect.getInputStream())); int ch; for (int length = 0; (ch = rd.read()) > -1 && (maxLength 查看全部
php 循环抓取网页内容(,实例分析了java爬虫的两种实现技巧具有一定参考借鉴价值)
本文文章主要介绍JAVA利用爬虫抓取网站网页内容的方法。实例分析了java爬虫的两种实现技术。有一定的参考价值,有需要的朋友可以参考。下
本文介绍了使用爬虫通过JAVA抓取网站网页内容的方法。分享给大家,供大家参考。详情如下:
最近在用JAVA学习爬虫技术,呵呵,进门和大家分享一下自己的经验
下面提供了两种方法,一种是使用apache提供的包。另一种是JAVA自带的。
代码如下:
<p> // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar public static String createhttpClient(String url, String param) { HttpClient client = new HttpClient(); String response = null; String keyword = null; PostMethod postMethod = new PostMethod(url); // try { // if (param != null) // keyword = new String(param.getBytes("gb2312"), "ISO-8859-1"); // } catch (UnsupportedEncodingException e1) { // // TODO Auto-generated catch block // e1.printStackTrace(); // } // NameValuePair[] data = { new NameValuePair("keyword", keyword) }; // // 将表单的值放入postMethod中 // postMethod.setRequestBody(data); // 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下 try { int statusCode = client.executeMethod(postMethod); response = new String(postMethod.getResponseBodyAsString() .getBytes("ISO-8859-1"), "gb2312"); //这里要注意下 gb2312要和你抓取网页的编码要一样 String p = response.replaceAll("//&[a-zA-Z]{1,10};", "") .replaceAll("]*>", "");//去掉网页中带有html语言的标签 System.out.println(p); } catch (Exception e) { e.printStackTrace(); } return response; } // 第二种方法 // 这种方法是JAVA自带的URL来抓取网站内容 public String getPageContent(String strUrl, String strPostRequest, int maxLength) { // 读取结果网页 StringBuffer buffer = new StringBuffer(); System.setProperty("sun.net.client.defaultConnectTimeout", "5000"); System.setProperty("sun.net.client.defaultReadTimeout", "5000"); try { URL newUrl = new URL(strUrl); HttpURLConnection hConnect = (HttpURLConnection) newUrl .openConnection(); // POST方式的额外数据 if (strPostRequest.length() > 0) { hConnect.setDoOutput(true); OutputStreamWriter out = new OutputStreamWriter(hConnect .getOutputStream()); out.write(strPostRequest); out.flush(); out.close(); } // 读取内容 BufferedReader rd = new BufferedReader(new InputStreamReader( hConnect.getInputStream())); int ch; for (int length = 0; (ch = rd.read()) > -1 && (maxLength
php 循环抓取网页内容(获取远程网页内容的php代码,做小偷采集程序的程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-11-09 09:14
获取远程网页内容的php代码经常被用作小偷采集程序。现在curl更常用。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。 查看全部
php 循环抓取网页内容(获取远程网页内容的php代码,做小偷采集程序的程序)
获取远程网页内容的php代码经常被用作小偷采集程序。现在curl更常用。
1、fopen的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及更高版本
但是上面的代码很容易出现打开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中,有两个选项:allow_url_fopen = on(代表可以通过url打开远程文件),user_agent="PHP"(代表通过哪个脚本访问网络,默认有“ ;" 在它前面。是的。)重新启动服务器。
但有些人仍然有这个警告信息。想要完美解决,还是一步之遥。您必须在 php.ini 中设置 user_agent。php 的默认 user_agent 是 PHP。我们把它改成 Mozilla/4.0 (compatible ; MSIE 6.0; Windows NT 5.0) 来模拟浏览器
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)”
我在工作中遇到了这个问题,并完美解决了,所以分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下可以使用以下代码下载
exec("wget {$url}");
PHP中fopen/file_get_contents/curl抓取外部资源的区别
fopen / file_get_contents 会对每一个请求重新做DNS查询,DNS信息不会被缓存。
但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。
这大大减少了 DNS 查询的数量。
所以CURL的性能要比fopen/file_get_contents好很多。
php 循环抓取网页内容(FanlyMIP主题开发中无法获取到值的方法有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-08 19:01
在很多WordPress主题或插件功能的开发中,我们总是需要获取WordPress为每个页面定义的ID。否则,在某些情况下,无法确定这是哪个页面。对于文章或者页面的ID,基本上可以通过函数get_the_ID()直接获取,但是循环外无法通过该函数获取值。
那么下面子帆根据Fanly MIP主题开发中遇到的情况,采集整理了几种方法:
方法一:
1
2
3
//文章或页面的 ID 值,如果未在循环中输出值可能不准确
$postid = get_the_ID();
echo $postid;
方法二:
1
2
3
//检索当前查询对象的 ID
$current_id = get_queried_object_id();
echo $current_id;
方法三:
1
2
3
4
// 检索当前查询的对象,从对象中获取 ID
$object = get_queried_object();
$id = $object -> ID;
echo $id;
方法四:
1
2
3
4
// 通过$post 全局变量获取文章或页面 ID
global $post;
$id = $post -> ID;
echo $id;
补充内容:
1
2
3
4
5
6
7
8
9
10
// 第一种获取父级页面的 ID
global $post;
$id = $post -> ID;
$parent = get_post_ancestors($post -> ID);
print_r($parent);//打印出 Array ( [0] => 101 )
// 第二种获取父级页面的 ID
global $post;
$parent_id = $post -> post_parent;
echo $parent_id;//打印出父级页面的 ID
其实如何获取还是需要根据实际开发情况来决定的,文章或者页面或者循环都可以直接使用get_the_ID函数来获取。如果需要特殊的东西或者get_the_ID获取不正确,sub 任何认为get_queried_object_id函数就够了的人,至于其他方法,我们自己研究吧!
可以添加有关 WordPress 优化和问题的更多信息。群:255308000
除特别注明外,均为泪雪博客原创文章,禁止转载
本文链接: 查看全部
php 循环抓取网页内容(FanlyMIP主题开发中无法获取到值的方法有哪些?)
在很多WordPress主题或插件功能的开发中,我们总是需要获取WordPress为每个页面定义的ID。否则,在某些情况下,无法确定这是哪个页面。对于文章或者页面的ID,基本上可以通过函数get_the_ID()直接获取,但是循环外无法通过该函数获取值。
那么下面子帆根据Fanly MIP主题开发中遇到的情况,采集整理了几种方法:
方法一:
1
2
3
//文章或页面的 ID 值,如果未在循环中输出值可能不准确
$postid = get_the_ID();
echo $postid;
方法二:
1
2
3
//检索当前查询对象的 ID
$current_id = get_queried_object_id();
echo $current_id;
方法三:
1
2
3
4
// 检索当前查询的对象,从对象中获取 ID
$object = get_queried_object();
$id = $object -> ID;
echo $id;
方法四:
1
2
3
4
// 通过$post 全局变量获取文章或页面 ID
global $post;
$id = $post -> ID;
echo $id;
补充内容:
1
2
3
4
5
6
7
8
9
10
// 第一种获取父级页面的 ID
global $post;
$id = $post -> ID;
$parent = get_post_ancestors($post -> ID);
print_r($parent);//打印出 Array ( [0] => 101 )
// 第二种获取父级页面的 ID
global $post;
$parent_id = $post -> post_parent;
echo $parent_id;//打印出父级页面的 ID
其实如何获取还是需要根据实际开发情况来决定的,文章或者页面或者循环都可以直接使用get_the_ID函数来获取。如果需要特殊的东西或者get_the_ID获取不正确,sub 任何认为get_queried_object_id函数就够了的人,至于其他方法,我们自己研究吧!
可以添加有关 WordPress 优化和问题的更多信息。群:255308000
除特别注明外,均为泪雪博客原创文章,禁止转载
本文链接:
php 循环抓取网页内容(基于PHP的新闻管理系统的设计与实现项目研究报告目录摘要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-08 12:01
基于PHP的新闻管理系统的设计与实现。项目研究报告摘要: 1 摘要:错!没有定义书签。1 简介 11.1 国内外网络新闻发布系统发展现状 11.2 系统开发背景 31.3 主要内容 4 2 关键技术介绍 42. 1 HTML简介42.2 PHP技术62.2.1 PHP简介62.2.2 PHP开发平台72.2. 3 PHP文件组成82.3 访问数据库的实现方法82.4 MYSQL数据库92.4.1 MYSQL介绍92.4. 2 MYSQL 特性 102.4. 4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84.2 后台管理 2 94.@ >2.1 管理员登录模块 2 94.< @2.2网站基本参数设置模块 3 14.2.3 账号密码管理模块 3 14.2.4网站 添加管理模块 3 24.2.5 新闻添加、修改、删除模块 3 34.2.6 用户留言评论管理模块3 54.2.7 友情链接管理模块3 6 结论3 6 参考文献3 7 附录3 9 谢谢指正!没有定义书签。4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84. 2 后台管理 2 94.2.1 管理员登录模块 2 94.2.2网站基本参数设置模块 3 14.2.3 账号密码管理模块 3 14.2.4网站栏目添加管理模块 3 24.2.5 新闻添加、修改、删除模块3 34.2.6 用户留言评论管理模块 3 54.2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84.2 后台管理 2 94.@ >2.1 管理员登录模块 2 94.2.2网站 基本参数设置模块3 14.2.3 账号密码管理模块3 14.2.4网站栏目添加管理模块3 24. 2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.2.7 友情链接管理模块3 6结论 3 6 参考文献 3 7 附录 3 9 感谢您的错误!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。栏目添加管理模块3 24.2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.< @2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。栏目添加管理模块3 24.2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.< @2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。
【摘要】:随着互联网的出现,网页逐渐融入人们的生活。快速及时的新闻浏览和丰富多彩的网络信息使互联网与人们的生活息息相关。足不出户,即可了解世界大事。在线新闻发布系统让系统管理员可以方便、快捷、简洁地发布新闻。普通用户可以浏览新闻,对需要经常更改或添加的内容进行分类和管理,最终系统化和规范发布在网站网站管理上的一类新闻。本系统以PHP为开发语言,WAMP为开发环境,EclipsePHP为开发工具,Mysql5.0为数据服务器,实现基本参数设置,网站的新闻分类设置、动态新闻发布和管理等一系列功能,完成一个动态新闻发布系统的所有功能,包括新闻新闻搜索、表情评论、短信、管理员登录等以及用户交互界面。系统捕获了大部分异常情况,具有良好的安全性和容错性。首页结合HTML语言生成静态页面,消除了一般用户直接操作数据库的可能性,满足基本的新闻发布系统要求。1 引言 1.1 国内外在线新闻发布系统的发展现状。在互联网飞速发展的今天,互联网已经成为人们快速获取、发布和传递信息的重要渠道。它在人们的政治、经济和生活中发挥着作用。它起着重要的作用。因此,网站建设在互联网应用中的地位是显而易见的。已成为政府、企事业单位信息化建设的重要组成部分,受到人们的广泛关注。
当今社会,人们离不开互联网。互联网已经成为人与人之间的一种交流方式。它可以简化复杂的事情。随着新闻发布系统的出现,电视不再是唯一的新闻媒体,互联网也发挥了重要的新闻媒体功能。简而言之,新闻发布系统是一种网络新闻媒体,实现新闻的分类、上传、审核、发布,模拟一般新闻媒体的新闻发布过程,通过用户名和密码实现上述功能具有不同的权限。当然,这些功能也可以由某个用户全部拥有[1]。随着互联网的进一步发展,网络媒体在人们心中的地位进一步提升。作为网络媒体的核心系统,新闻发布系统的重要性越来越明显:一方面,它提供了新闻管理和发布的功能;另一方面,当前的新闻发布需要与普通用户互动。用户可以轻松参与一些调查和对相关新闻的评论。这是其他媒体现在无法做到的(电视、广播等)。同时,互联网也发展到了今天。可以说,只要在网上,就会接触到新闻发布系统。新闻发布系统的用户相当惊人,其重要性毋庸置疑。当然,这对于新闻发布系统也很重要。发展提出了更高的要求。网站新闻发布系统是对网站的更新信息进行集中管理 需要经常变化的、社会动态等,并通过信息的一些共同特征对其进行分类,最后以系统化、规范化的方式发布。@网站 上的 网站 应用程序。
有两种传统的 网站 新闻管理方法。一种是静态 HTML 页面。更新信息时,需要重新制作页面并上传页面并修改相应链接。这种方法效率太低,因为它太低效了。第二种是基于JSP或其他语言和脚本语言,结合动态网页和数据库,通过应用程序处理新闻,这是目前比较流行的做法。人们对最新信息的需求和发布及时性的迫切需要,动态交互网页恰恰提供了这些功能。本系统是一个在线交互,可以实现新闻发布、多栏目管理、实时统计和记录互联网上的行为。系统[2]。1. 2 系统开发背景新闻发布系统在国内外已有成熟的研究成果和广泛的社会应用。国内很多大型门户网站网站,如网易、新浪、搜狐、资本在线、人民网、中国新闻网等,每天甚至随时都在维护着大量的信息来保持网站 内容及时更新。内容管理系统起着绝对重要的作用,是目前动态网站的主要内容更新手段,在国外更是如此。信息技术的发展让整个世界变得越来越小,这也意味着企业的竞争环境正在从区域化向全球化发展。特别是中国加入世贸组织后,
企业对信息的掌握程度,信息的获取是否及时,信息能否得到充分利用,对信息的反应是否灵敏准确,日益成为衡量企业市场竞争力的重要因素,因此建立一个动态的新闻发布是一个系统适应企业发展要求的意义是巨大的。新闻系统是典型的文档系统。掌握新闻系统的开发对其他文档系统的开发有很大的帮助。随着信息时代的飞速发展,传统的报刊杂志已经远远不能满足人们的需求。人们更希望能在互联网上了解更多的新闻和信息,所以我们有必要在互联网上创建一个新闻发布管理信息。系统。大部分网站使用静态方法发布和管理信息,但是网站需要更新的信息量也在不断增加,所以这不利于网站的管理工作. 为了更方便地管理网站,我们迫切需要利用动态技术来创建一个新闻发布管理信息系统[3]。该系统的开发基于简单、大方、分类清晰的特点。向用户展示国际、国内、社会、经济、娱乐、体育、地产、健康、军事、IT等10类新闻。用户可以在阅读后对面部表情进行评论。,短信;此外,该系统还包括发布视频供用户在线观看。1.3 主要内容 本次设计共分四章,主要包括: 第一章绪论:介绍本课题的背景和意义,国内外企业信息门户网站的现状网站以及本文的主要内容。纸张结构。
第二章相关理论与技术:本章主要介绍PHP技术、PHP开发平台、数据库访问方法、HTML基础知识和流媒体技术介绍。第三章系统分析与设计:本章首先分析本设计课题的系统目标。然后,进一步抽象出系统的功能需求。最后给出了数据库管理的框图、为开发本系统选择的开发工具以及整个系统的设计结构。第四章系统实现:本章介绍了新闻发布系统的主体,包括前端新闻接口的实现和后端管理接口的实现,包括功能介绍、接口实现和关键代码介绍。2 关键技术简介2.1 HTML简介 HTML是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种符号标记语言,用于代表在线信息。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。@2.1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。@2.1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。它是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。它是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。你需要一种可以被广泛理解的语言,也就是一种所有计算机都能理解的出版“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。你需要一种可以被广泛理解的语言,也就是一种所有计算机都能理解的出版“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。
HTML 的主要功能是: (1) 发布在线文档,包括标题、文本、表格、列表和照片。(2) 通过超链接检索在线信息。(3) 获取远程服务的设计表单,可用于检索信息、订购产品等。 (4) 直接在文档中收录电子表格、视频剪辑、声音剪辑和其他应用程序。HTML实际上是一系列标签组合成一个文本文件。HTML标签通常是英文单词或缩写(如P代表Paragragh),但与普通文本不同,因为它们被放置在小三角括号内,成对出现。每当使用标签时 - 例如,它必须用另一个标签关闭。一个HTML文件大致分为以下几部分: 网页内容:...:表示这是一个HTML文件...:表示这是网页的header部分...</TITLE>:网页的标题...:网页的body部分2.2 PHP技术2.2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。
另外,PHP4.0 的源代码是完全公开的。任何热衷于 PHP 的程序员都可以在 PHP 中添加新的函数库,这让 PHP 更具活力。目前可以用来编写Web服务器端脚本的语言不下几十种,但比较常用的只有PHP、ASP、Perl、JSP等少数几种。与其他脚本描述语言相比,PHP 有其自身的优势: (1) 无运行成本;(2) 基于服务器;(3) 强大的数据库支持;(4) PHP最强大最突出的特点就是可以支持大量的数据库,使得编写基于数据库的网页变得越来越简单;(5) 跨平台;PHP 是一种跨平台的服务器端脚本描述语言。PHP 可以安装在 Unix、Linux 或 Windows 平台上,再配合相应的Web服务器提供相应的服务,使PHP编写的程序可以方便地移植到不同的操作系统平台上。嵌入 HTML。PHP无需编译就可以直接嵌入到HTML中,所以PHP是一种解释型语言(Interpret),使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。
(7) 支持多种网络协议,具有良好的扩展性;在这方面它支持很多通信协议,主要包括:①电子邮件相关:IMAP POP3;② 网管系统:SNMP;③ 网络新闻:NNTP;④ 账户共享:NIS;⑤ 世界信息网:HTTP 和 Apache;⑥目录协议LDAP等网络相关功能。此外,用 PHP 编写的 Web 后端 CGI 程序可以轻松移植到不同的操作系统。2.2.2 PHP开发平台目前支持PHP的网站大多采用Linux作为操作系统,Apache作为Web服务器,Mysql作为数据库(LAMP)方案. Linux和Apache都是免费软件,功能强大,对硬件要求不高。它们是中小型网站的理想平台 . 所需软件:(1)PHP源程序C语言代码。(2) MySQL 源程序 (3) Apache 源程序 (4) Linux 系统。以上这些软件都是免费软件,所以安装Linux后,这些软件都是随操作系统一起安装的(安装时需要选择对应的软件包),环境基本配置好,启动相应的服务即可。
启动Apache服务:service htt pd start 启动MySQL数据库:mysqld_safe--user=mysql 一切设置好后,我们就可以使用Mozilla访问我们的PHP程序了。2.2.3个PHP文件最后组成一个PHP文件。*.php 文件是一个文本文件,可以用 Dreamweaver 设计。一般来说,一个 PHP 文件是由 HTML 标签和 JQuery 或 JavaScript 程序代码混合在一起组成的,它是一个标准的网页。如下例所示: 2.3 访问数据库的实现方法(1)首先介绍web数据库架构:如图2-1所示:浏览器1服务器2PHP引擎3Mysql服务器654图2-1 Web 数据库 从 Web 上查询数据的基本步骤是: Step1:检查和过滤来自用户的数据;Step2:建立合适的数据库连接;第三步:查询数据库;Step4:获取查询结构;Step5:将结果展示给用户。(2) 这个 查看全部
php 循环抓取网页内容(基于PHP的新闻管理系统的设计与实现项目研究报告目录摘要)
基于PHP的新闻管理系统的设计与实现。项目研究报告摘要: 1 摘要:错!没有定义书签。1 简介 11.1 国内外网络新闻发布系统发展现状 11.2 系统开发背景 31.3 主要内容 4 2 关键技术介绍 42. 1 HTML简介42.2 PHP技术62.2.1 PHP简介62.2.2 PHP开发平台72.2. 3 PHP文件组成82.3 访问数据库的实现方法82.4 MYSQL数据库92.4.1 MYSQL介绍92.4. 2 MYSQL 特性 102.4. 4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84.2 后台管理 2 94.@ >2.1 管理员登录模块 2 94.< @2.2网站基本参数设置模块 3 14.2.3 账号密码管理模块 3 14.2.4网站 添加管理模块 3 24.2.5 新闻添加、修改、删除模块 3 34.2.6 用户留言评论管理模块3 54.2.7 友情链接管理模块3 6 结论3 6 参考文献3 7 附录3 9 谢谢指正!没有定义书签。4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84. 2 后台管理 2 94.2.1 管理员登录模块 2 94.2.2网站基本参数设置模块 3 14.2.3 账号密码管理模块 3 14.2.4网站栏目添加管理模块 3 24.2.5 新闻添加、修改、删除模块3 34.2.6 用户留言评论管理模块 3 54.2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。4 留言评论模块 2 64.1.5 新闻搜索 2 74.1.6 友情链接 2 84.2 后台管理 2 94.@ >2.1 管理员登录模块 2 94.2.2网站 基本参数设置模块3 14.2.3 账号密码管理模块3 14.2.4网站栏目添加管理模块3 24. 2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.2.7 友情链接管理模块3 6结论 3 6 参考文献 3 7 附录 3 9 感谢您的错误!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。栏目添加管理模块3 24.2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.< @2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。栏目添加管理模块3 24.2.5 新闻添加、修改、删除模块3 34.< @2.6 用户留言评论管理模块3 54.< @2.7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。7 友情链接管理模块 3 6 结论 3 6 参考文献 3 7 附录 3 9 感谢指正!没有定义书签。
【摘要】:随着互联网的出现,网页逐渐融入人们的生活。快速及时的新闻浏览和丰富多彩的网络信息使互联网与人们的生活息息相关。足不出户,即可了解世界大事。在线新闻发布系统让系统管理员可以方便、快捷、简洁地发布新闻。普通用户可以浏览新闻,对需要经常更改或添加的内容进行分类和管理,最终系统化和规范发布在网站网站管理上的一类新闻。本系统以PHP为开发语言,WAMP为开发环境,EclipsePHP为开发工具,Mysql5.0为数据服务器,实现基本参数设置,网站的新闻分类设置、动态新闻发布和管理等一系列功能,完成一个动态新闻发布系统的所有功能,包括新闻新闻搜索、表情评论、短信、管理员登录等以及用户交互界面。系统捕获了大部分异常情况,具有良好的安全性和容错性。首页结合HTML语言生成静态页面,消除了一般用户直接操作数据库的可能性,满足基本的新闻发布系统要求。1 引言 1.1 国内外在线新闻发布系统的发展现状。在互联网飞速发展的今天,互联网已经成为人们快速获取、发布和传递信息的重要渠道。它在人们的政治、经济和生活中发挥着作用。它起着重要的作用。因此,网站建设在互联网应用中的地位是显而易见的。已成为政府、企事业单位信息化建设的重要组成部分,受到人们的广泛关注。
当今社会,人们离不开互联网。互联网已经成为人与人之间的一种交流方式。它可以简化复杂的事情。随着新闻发布系统的出现,电视不再是唯一的新闻媒体,互联网也发挥了重要的新闻媒体功能。简而言之,新闻发布系统是一种网络新闻媒体,实现新闻的分类、上传、审核、发布,模拟一般新闻媒体的新闻发布过程,通过用户名和密码实现上述功能具有不同的权限。当然,这些功能也可以由某个用户全部拥有[1]。随着互联网的进一步发展,网络媒体在人们心中的地位进一步提升。作为网络媒体的核心系统,新闻发布系统的重要性越来越明显:一方面,它提供了新闻管理和发布的功能;另一方面,当前的新闻发布需要与普通用户互动。用户可以轻松参与一些调查和对相关新闻的评论。这是其他媒体现在无法做到的(电视、广播等)。同时,互联网也发展到了今天。可以说,只要在网上,就会接触到新闻发布系统。新闻发布系统的用户相当惊人,其重要性毋庸置疑。当然,这对于新闻发布系统也很重要。发展提出了更高的要求。网站新闻发布系统是对网站的更新信息进行集中管理 需要经常变化的、社会动态等,并通过信息的一些共同特征对其进行分类,最后以系统化、规范化的方式发布。@网站 上的 网站 应用程序。
有两种传统的 网站 新闻管理方法。一种是静态 HTML 页面。更新信息时,需要重新制作页面并上传页面并修改相应链接。这种方法效率太低,因为它太低效了。第二种是基于JSP或其他语言和脚本语言,结合动态网页和数据库,通过应用程序处理新闻,这是目前比较流行的做法。人们对最新信息的需求和发布及时性的迫切需要,动态交互网页恰恰提供了这些功能。本系统是一个在线交互,可以实现新闻发布、多栏目管理、实时统计和记录互联网上的行为。系统[2]。1. 2 系统开发背景新闻发布系统在国内外已有成熟的研究成果和广泛的社会应用。国内很多大型门户网站网站,如网易、新浪、搜狐、资本在线、人民网、中国新闻网等,每天甚至随时都在维护着大量的信息来保持网站 内容及时更新。内容管理系统起着绝对重要的作用,是目前动态网站的主要内容更新手段,在国外更是如此。信息技术的发展让整个世界变得越来越小,这也意味着企业的竞争环境正在从区域化向全球化发展。特别是中国加入世贸组织后,
企业对信息的掌握程度,信息的获取是否及时,信息能否得到充分利用,对信息的反应是否灵敏准确,日益成为衡量企业市场竞争力的重要因素,因此建立一个动态的新闻发布是一个系统适应企业发展要求的意义是巨大的。新闻系统是典型的文档系统。掌握新闻系统的开发对其他文档系统的开发有很大的帮助。随着信息时代的飞速发展,传统的报刊杂志已经远远不能满足人们的需求。人们更希望能在互联网上了解更多的新闻和信息,所以我们有必要在互联网上创建一个新闻发布管理信息。系统。大部分网站使用静态方法发布和管理信息,但是网站需要更新的信息量也在不断增加,所以这不利于网站的管理工作. 为了更方便地管理网站,我们迫切需要利用动态技术来创建一个新闻发布管理信息系统[3]。该系统的开发基于简单、大方、分类清晰的特点。向用户展示国际、国内、社会、经济、娱乐、体育、地产、健康、军事、IT等10类新闻。用户可以在阅读后对面部表情进行评论。,短信;此外,该系统还包括发布视频供用户在线观看。1.3 主要内容 本次设计共分四章,主要包括: 第一章绪论:介绍本课题的背景和意义,国内外企业信息门户网站的现状网站以及本文的主要内容。纸张结构。
第二章相关理论与技术:本章主要介绍PHP技术、PHP开发平台、数据库访问方法、HTML基础知识和流媒体技术介绍。第三章系统分析与设计:本章首先分析本设计课题的系统目标。然后,进一步抽象出系统的功能需求。最后给出了数据库管理的框图、为开发本系统选择的开发工具以及整个系统的设计结构。第四章系统实现:本章介绍了新闻发布系统的主体,包括前端新闻接口的实现和后端管理接口的实现,包括功能介绍、接口实现和关键代码介绍。2 关键技术简介2.1 HTML简介 HTML是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种符号标记语言,用于代表在线信息。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。@2.1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。@2.1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。1 HTML 简介 HTML 是超文本标记语言(Hypertext Markup Language)的缩写,是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。它是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。它是构成网页(Page)的主要工具,是一种用来表示在线信息的符号标记语言。在互联网上,如果要在全球范围内发布和分发信息,就需要一种可以被广泛理解的语言,即所有计算机都能理解的发布“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。你需要一种可以被广泛理解的语言,也就是一种所有计算机都能理解的出版“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。你需要一种可以被广泛理解的语言,也就是一种所有计算机都能理解的出版“母语”。WWW(万维网)使用的发布语言是 HTML 语言。通过HTML,将需要表达的信息按照一定的规则写入HTML文件,由专用浏览器识别,并将这些HTML“翻译”成可识别的信息,也就是我们现在看到的网页。
HTML 的主要功能是: (1) 发布在线文档,包括标题、文本、表格、列表和照片。(2) 通过超链接检索在线信息。(3) 获取远程服务的设计表单,可用于检索信息、订购产品等。 (4) 直接在文档中收录电子表格、视频剪辑、声音剪辑和其他应用程序。HTML实际上是一系列标签组合成一个文本文件。HTML标签通常是英文单词或缩写(如P代表Paragragh),但与普通文本不同,因为它们被放置在小三角括号内,成对出现。每当使用标签时 - 例如,它必须用另一个标签关闭。一个HTML文件大致分为以下几部分: 网页内容:...:表示这是一个HTML文件...:表示这是网页的header部分...</TITLE>:网页的标题...:网页的body部分2.2 PHP技术2.2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。2.1 PHP 简介 PHP(超文本处理器)是目前最常用的动态网页生成工具之一。它也是一种易于学习和使用的 Web 服务器端脚本描述语言。它是一种 HTML(超文本标记语言,Hypertext Markup Language)嵌入式语言(类似于 IIS 上的 ASP),PHP 的语法结合了 UnixShell、C、C++、Java、Perl 和 PHP 自身的特点与传统的 CGI 或 Perl 相比,PHP语法规则更简单,开发效率更高。
另外,PHP4.0 的源代码是完全公开的。任何热衷于 PHP 的程序员都可以在 PHP 中添加新的函数库,这让 PHP 更具活力。目前可以用来编写Web服务器端脚本的语言不下几十种,但比较常用的只有PHP、ASP、Perl、JSP等少数几种。与其他脚本描述语言相比,PHP 有其自身的优势: (1) 无运行成本;(2) 基于服务器;(3) 强大的数据库支持;(4) PHP最强大最突出的特点就是可以支持大量的数据库,使得编写基于数据库的网页变得越来越简单;(5) 跨平台;PHP 是一种跨平台的服务器端脚本描述语言。PHP 可以安装在 Unix、Linux 或 Windows 平台上,再配合相应的Web服务器提供相应的服务,使PHP编写的程序可以方便地移植到不同的操作系统平台上。嵌入 HTML。PHP无需编译就可以直接嵌入到HTML中,所以PHP是一种解释型语言(Interpret),使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。使用起来非常方便。(6)简单高效。与Java、Perl、C++等编程语言不同,PHP遵循基础语言,但同时其功能强大到足以支持任何类型的网站。
(7) 支持多种网络协议,具有良好的扩展性;在这方面它支持很多通信协议,主要包括:①电子邮件相关:IMAP POP3;② 网管系统:SNMP;③ 网络新闻:NNTP;④ 账户共享:NIS;⑤ 世界信息网:HTTP 和 Apache;⑥目录协议LDAP等网络相关功能。此外,用 PHP 编写的 Web 后端 CGI 程序可以轻松移植到不同的操作系统。2.2.2 PHP开发平台目前支持PHP的网站大多采用Linux作为操作系统,Apache作为Web服务器,Mysql作为数据库(LAMP)方案. Linux和Apache都是免费软件,功能强大,对硬件要求不高。它们是中小型网站的理想平台 . 所需软件:(1)PHP源程序C语言代码。(2) MySQL 源程序 (3) Apache 源程序 (4) Linux 系统。以上这些软件都是免费软件,所以安装Linux后,这些软件都是随操作系统一起安装的(安装时需要选择对应的软件包),环境基本配置好,启动相应的服务即可。
启动Apache服务:service htt pd start 启动MySQL数据库:mysqld_safe--user=mysql 一切设置好后,我们就可以使用Mozilla访问我们的PHP程序了。2.2.3个PHP文件最后组成一个PHP文件。*.php 文件是一个文本文件,可以用 Dreamweaver 设计。一般来说,一个 PHP 文件是由 HTML 标签和 JQuery 或 JavaScript 程序代码混合在一起组成的,它是一个标准的网页。如下例所示: 2.3 访问数据库的实现方法(1)首先介绍web数据库架构:如图2-1所示:浏览器1服务器2PHP引擎3Mysql服务器654图2-1 Web 数据库 从 Web 上查询数据的基本步骤是: Step1:检查和过滤来自用户的数据;Step2:建立合适的数据库连接;第三步:查询数据库;Step4:获取查询结构;Step5:将结果展示给用户。(2) 这个
php 循环抓取网页内容(php循环抓取网页内容,然后存储在cookie中每次请求数据库服务器时都先获取一次cookie)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-04 20:03
php循环抓取网页内容,然后存储在cookie中每次请求数据库服务器时都先获取一次cookie然后通过对每一条cookie进行hash进行md5加密存储不然你就可以想象如果进来的数据库服务器某天突然删除了你刚才获取的cookie你岂不是大可不必输入原网址就可以直接进入不受原网址限制了?然后每一次访问页面页面都用新的cookie替换你已经存在的cookie。
是一条命令能干的?能让这样么?
1、假设前提:请求/目标/html
<p>2、phpinfo 查看全部
php 循环抓取网页内容(php循环抓取网页内容,然后存储在cookie中每次请求数据库服务器时都先获取一次cookie)
php循环抓取网页内容,然后存储在cookie中每次请求数据库服务器时都先获取一次cookie然后通过对每一条cookie进行hash进行md5加密存储不然你就可以想象如果进来的数据库服务器某天突然删除了你刚才获取的cookie你岂不是大可不必输入原网址就可以直接进入不受原网址限制了?然后每一次访问页面页面都用新的cookie替换你已经存在的cookie。
是一条命令能干的?能让这样么?
1、假设前提:请求/目标/html
<p>2、phpinfo
php 循环抓取网页内容(WordPress中获取页面链接和标题的相关PHP函数用法解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-01 18:09
想知道WordPress中获取页面链接和标题的PHP函数使用分析的相关内容吗?在本文中,冰果将为您讲解WordPress获取页面链接和标题的相关知识以及一些代码示例。欢迎阅读和指正。重点:WordPress、链接、标题、PHP,一起来学习吧。
get_permalink()(获取文章 或页面链接)
get_permalink() 用于根据固定连接返回文章 或页面的链接。获取链接时,get_permalink()函数需要知道要获取的文章的ID。如果在循环中,默认会自动使用当前的文章。
用法
get_permalink( $id, $leavename );
范围
$id
(混合)(可选)文章 或页面的ID(整数);它也可以是 文章 的对象。
默认值:在循环中自动调用当前文章
$leavename
(布尔值)(可选)转换为链接时是否忽略 文章 别名。如果设置为 True,则将返回 %postname% 而不是
默认值:无
返回值
(String| Boolean) 获取链接成功则返回链接,失败则返回False。
例子
根据ID获取文章或页面的链接:
<p> 查看全部
php 循环抓取网页内容(WordPress中获取页面链接和标题的相关PHP函数用法解析)
想知道WordPress中获取页面链接和标题的PHP函数使用分析的相关内容吗?在本文中,冰果将为您讲解WordPress获取页面链接和标题的相关知识以及一些代码示例。欢迎阅读和指正。重点:WordPress、链接、标题、PHP,一起来学习吧。
get_permalink()(获取文章 或页面链接)
get_permalink() 用于根据固定连接返回文章 或页面的链接。获取链接时,get_permalink()函数需要知道要获取的文章的ID。如果在循环中,默认会自动使用当前的文章。
用法
get_permalink( $id, $leavename );
范围
$id
(混合)(可选)文章 或页面的ID(整数);它也可以是 文章 的对象。
默认值:在循环中自动调用当前文章
$leavename
(布尔值)(可选)转换为链接时是否忽略 文章 别名。如果设置为 True,则将返回 %postname% 而不是
默认值:无
返回值
(String| Boolean) 获取链接成功则返回链接,失败则返回False。
例子
根据ID获取文章或页面的链接:
<p>
php 循环抓取网页内容( 基于PHP无限循环获取MySQL中的数据实现方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-01 05:09
基于PHP无限循环获取MySQL中的数据实现方法(图))
PHP无限循环获取MySQL中的数据实例代码
更新时间:2017-08-21 17:07:31 作者:蔡淼PHP
最近公司有个需求,需要从MySQL中获取数据,然后在页面上无线循环显示。其实这个功能可以通过jq或者php+mysql来实现。下面小编就和大家分享下基于PHP的无限循环获取MySQL中数据的实现方法,感兴趣的朋友可以看看
最近公司有需要从MySQL中获取数据,然后在页面上无线循环显示。主要是一直点击一个按钮,然后数据从头到尾循环。如果最后的数据不够,那就从数据的开头补几下。
其实这个功能可以通过JQ来实现,也可以通过PHP+MYSQL来实现,只不过JQ更方便,效率更高。
一次显示 10 条数据。
public function get_data($limit){
$sql="select * from ((select id,name from `mytable` limit {$limit},10) union all (select id,name from `mytable` limit 0,10)) as test limit 0,10";
return $this->query($sql);
}
上面的sql语句使用mysql的union all方法将两个集合拼接在一起,取出前十个数据。
下一步是在控制器中获取数据,并为ajax提供数据接口。
//测试数据库无限循环取数据
public function getInfiniteData(){
//用户点击数
$page = $_GET['click'];
//每次展示条数
$pagesize = 10;
//获取总条数
$total = $this->Mydemo->get_count();
$t = $total[0][0]['t'];
//算出每次点击的其起始位置
$limit = (($page - 1)*$pagesize)%$t;
$data = $this->Mydemo->get_data($limit);
if (!empty($data)) {
//转换为二维数组
$list = [];
foreach ($data as $key => $v) {
$list[$key] = $data[$key][0];
}
$info['msg'] = $list;
$info['code'] = '001';
}else{
$info['code'] = '002';
$info['msg'] = '暂无数据';
}
echo json_encode($info,JSON_UNESCAPED_UNICODE);die;
}
总结
以上就是小编介绍的PHP无限循环在MySQL中获取数据的示例代码。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持! 查看全部
php 循环抓取网页内容(
基于PHP无限循环获取MySQL中的数据实现方法(图))
PHP无限循环获取MySQL中的数据实例代码
更新时间:2017-08-21 17:07:31 作者:蔡淼PHP
最近公司有个需求,需要从MySQL中获取数据,然后在页面上无线循环显示。其实这个功能可以通过jq或者php+mysql来实现。下面小编就和大家分享下基于PHP的无限循环获取MySQL中数据的实现方法,感兴趣的朋友可以看看
最近公司有需要从MySQL中获取数据,然后在页面上无线循环显示。主要是一直点击一个按钮,然后数据从头到尾循环。如果最后的数据不够,那就从数据的开头补几下。
其实这个功能可以通过JQ来实现,也可以通过PHP+MYSQL来实现,只不过JQ更方便,效率更高。
一次显示 10 条数据。
public function get_data($limit){
$sql="select * from ((select id,name from `mytable` limit {$limit},10) union all (select id,name from `mytable` limit 0,10)) as test limit 0,10";
return $this->query($sql);
}
上面的sql语句使用mysql的union all方法将两个集合拼接在一起,取出前十个数据。
下一步是在控制器中获取数据,并为ajax提供数据接口。
//测试数据库无限循环取数据
public function getInfiniteData(){
//用户点击数
$page = $_GET['click'];
//每次展示条数
$pagesize = 10;
//获取总条数
$total = $this->Mydemo->get_count();
$t = $total[0][0]['t'];
//算出每次点击的其起始位置
$limit = (($page - 1)*$pagesize)%$t;
$data = $this->Mydemo->get_data($limit);
if (!empty($data)) {
//转换为二维数组
$list = [];
foreach ($data as $key => $v) {
$list[$key] = $data[$key][0];
}
$info['msg'] = $list;
$info['code'] = '001';
}else{
$info['code'] = '002';
$info['msg'] = '暂无数据';
}
echo json_encode($info,JSON_UNESCAPED_UNICODE);die;
}
总结
以上就是小编介绍的PHP无限循环在MySQL中获取数据的示例代码。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。非常感谢您对脚本之家网站的支持!
php 循环抓取网页内容(php打开URL获得网页内容,比较常用的函数是fopen()和file_get_contents)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-27 05:25
在php中,如果要打开网页网址获取网页内容,比较常用的函数是fopen()和file_get_contents()。如果要求不苛刻,大多数情况下这两个功能可以根据个人喜好任意选择。本文将谈谈这两个函数的用法区别以及使用时需要注意的问题。
fopen() 打开 URL
以下是使用 fopen() 打开 URL 的示例:
从这个例子可以看出,fopen()打开网页后,返回的$fh不是字符串,不能直接输出。您还需要使用 fgets() 函数来获取字符串。fgets() 函数从文件指针读取一行。文件指针必须有效并且必须指向由 fopen() 或 fsockopen() 成功打开的文件(并且尚未被 fclose() 关闭)。
可以看出 fopen() 只返回一个资源。如果打开失败,此函数返回 FALSE。
file_get_contents() 打开 URL
以下是使用 file_get_contents() 打开 URL 的示例:
从这个例子可以看出,file_get_contents()打开网页后,返回的$fh是一个可以直接输出的字符串。
通过上面两个例子的对比可以看出,使用file_get_contents()打开URL可能是更多人的选择,因为它比fopen()更简单方便。
但是,如果您正在阅读相对较大的资源,则使用 fopen() 更为合适。
知识拓展
file_get_contents() 模拟referer、cookie、使用代理等。
参考代码
ini_set('default_socket_timeout',120);
ini_set('user_agent','MSIE 6.0;');
$context=array('http' => array ('header'=>'Referer:', ),);
$xcontext = stream_context_create($context);
echo $str=file_get_contents('',FALSE,$xcontext);
指南:ini_set() 的例子和用法 查看全部
php 循环抓取网页内容(php打开URL获得网页内容,比较常用的函数是fopen()和file_get_contents)
在php中,如果要打开网页网址获取网页内容,比较常用的函数是fopen()和file_get_contents()。如果要求不苛刻,大多数情况下这两个功能可以根据个人喜好任意选择。本文将谈谈这两个函数的用法区别以及使用时需要注意的问题。
fopen() 打开 URL
以下是使用 fopen() 打开 URL 的示例:
从这个例子可以看出,fopen()打开网页后,返回的$fh不是字符串,不能直接输出。您还需要使用 fgets() 函数来获取字符串。fgets() 函数从文件指针读取一行。文件指针必须有效并且必须指向由 fopen() 或 fsockopen() 成功打开的文件(并且尚未被 fclose() 关闭)。
可以看出 fopen() 只返回一个资源。如果打开失败,此函数返回 FALSE。
file_get_contents() 打开 URL
以下是使用 file_get_contents() 打开 URL 的示例:
从这个例子可以看出,file_get_contents()打开网页后,返回的$fh是一个可以直接输出的字符串。
通过上面两个例子的对比可以看出,使用file_get_contents()打开URL可能是更多人的选择,因为它比fopen()更简单方便。
但是,如果您正在阅读相对较大的资源,则使用 fopen() 更为合适。
知识拓展
file_get_contents() 模拟referer、cookie、使用代理等。
参考代码
ini_set('default_socket_timeout',120);
ini_set('user_agent','MSIE 6.0;');
$context=array('http' => array ('header'=>'Referer:', ),);
$xcontext = stream_context_create($context);
echo $str=file_get_contents('',FALSE,$xcontext);
指南:ini_set() 的例子和用法
php 循环抓取网页内容(第一步就是获取有哪些城市使用插件XPath进行一个测试? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-24 20:11
)
因此将其分配给名为 base_url 的变量以供后续使用
自动创建的爬出带有爬虫的名字。启动爬虫时需要这个名字,现在不用
name = 'area_spider'
allowed_domains = ['aqistudy.cn'] # 爬取的域名,不会超出这个顶级域名
base_url = "https://www.aqistudy.cn/historydata/"
start_urls = [base_url]
城市信息
进入首页后可以看到大量的城市信息,所以我们第一步就是获取有哪些城市
def parse(self, response):
print('爬取城市信息....')
url_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/@href").extract() # 全部链接
city_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/text()").extract() # 城市名称
for url, city in zip(url_list, city_list):
yield scrapy.Request(url=url, callback=self.parse_month, meta={'city': city})
使用插件XPath Helper可以对xpath进行测试,看定位内容是否正确
xpath.png
随便点击一个地区,可以发现url已经变成了北京
那么url_list得到的就是需要拼接的内容monthdata.php?city=city name
city_list的最后一部分是text(),所以得到的是具体的文本信息
将获取到的url_list和city_list一一传递给scrapy.Request,其中url是需要爬取的页面地址,city是item中需要的内容,所以暂时将item存入meta中并通过它到下一个回调函数 self .parse_month
月份信息
def parse_month(self, response):
print('爬取{}月份...'.format(response.meta['city']))
url_list = response.xpath('//tbody/tr/td/a/@href').extract()
for url in url_list:
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_day, meta={'city': response.meta['city']})
本步骤获取每个城市的所有月份信息,获取每个月份的URL地址。继续向下传递从上面传递的城市
最终数据
获得最终URL后,实例化item,然后完成item字典,返回item
def parse_day(self, response):
print('爬取最终数据...')
item = AirHistoryItem()
node_list = response.xpath('//tr')
node_list.pop(0) # 去除第一行标题栏
for node in node_list:
item['data'] = node.xpath('./td[1]/text()').extract_first()
item['city'] = response.meta['city']
item['aqi'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['pm2_5'] = node.xpath('./td[4]/text()').extract_first()
item['pm10'] = node.xpath('./td[5]/text()').extract_first()
item['so2'] = node.xpath('./td[6]/text()').extract_first()
item['co'] = node.xpath('./td[7]/text()').extract_first()
item['no2'] = node.xpath('./td[8]/text()').extract_first()
item['o3'] = node.xpath('./td[9]/text()').extract_first()
yield item
使用中间件实现selenium操作
打开中间件文件 middlewares.py
因为在服务器上爬取,所以选择使用谷歌的无界面浏览器chrome-headless
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless') # 使用无头谷歌浏览器模式
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
# 指定谷歌浏览器路径
webdriver.Chrome(chrome_options=chrome_options,executable_path='/root/zx/spider/driver/chromedriver')
然后获取页面渲染后的源码
request.url 是传递给中间件的 url。由于首页是静态页面,首页不进行selenium操作
if request.url != 'https://www.aqistudy.cn/historydata/':
self.driver.get(request.url)
time.sleep(1)
html = self.driver.page_source
self.driver.quit()
return scrapy.http.HtmlResponse(url=request.url, body=html.encode('utf-8'), encoding='utf-8',request=request)
后续的操作也很简单,最后对获取到的内容进行正确编码返回到爬虫的下一步
所有中间件代码
使用下载器保存项目内容
修改 pipelines.py 用于文件存储
import json
class AirHistoryPipeline(object):
def open_spider(self, spider):
self.file = open('area.json', 'w')
def process_item(self, item, spider):
context = json.dumps(dict(item),ensure_ascii=False) + '\n'
self.file.write(context)
return item
def close_spider(self,spider):
self.file.close()
修改设置文件使中间件和下载器生效
打开settings.py文件
修改如下内容:DOWNLOADER_MIDDLEWARES使刚才写的中间件中的类,ITEM_PIPELINES是管道中的类
BOT_NAME = 'air_history'
SPIDER_MODULES = ['air_history.spiders']
NEWSPIDER_MODULE = 'air_history.spiders'
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
DOWNLOADER_MIDDLEWARES = {
'air_history.middlewares.AreaSpiderMiddleware': 543,
}
ITEM_PIPELINES = {
'air_history.pipelines.AirHistoryPipeline': 300,
}
运行
使用scrapy crawl area_spider运行爬虫
结果.png
所有蜘蛛代码
# -*- coding: utf-8 -*-
import scrapy
from air_history.items import AirHistoryItem
class AreaSpiderSpider(scrapy.Spider):
name = 'area_spider'
allowed_domains = ['aqistudy.cn'] # 爬取的域名,不会超出这个顶级域名
base_url = "https://www.aqistudy.cn/historydata/"
start_urls = [base_url]
def parse(self, response):
print('爬取城市信息....')
url_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/@href").extract() # 全部链接
city_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/text()").extract() # 城市名称
for url, city in zip(url_list, city_list):
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_month, meta={'city': city})
def parse_month(self, response):
print('爬取{}月份...'.format(response.meta['city']))
url_list = response.xpath('//tbody/tr/td/a/@href').extract()
for url in url_list:
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_day, meta={'city': response.meta['city']})
def parse_day(self, response):
print('爬取最终数据...')
item = AirHistoryItem()
node_list = response.xpath('//tr')
node_list.pop(0) # 去除第一行标题栏
for node in node_list:
item['data'] = node.xpath('./td[1]/text()').extract_first()
item['city'] = response.meta['city']
item['aqi'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['pm2_5'] = node.xpath('./td[4]/text()').extract_first()
item['pm10'] = node.xpath('./td[5]/text()').extract_first()
item['so2'] = node.xpath('./td[6]/text()').extract_first()
item['co'] = node.xpath('./td[7]/text()').extract_first()
item['no2'] = node.xpath('./td[8]/text()').extract_first()
item['o3'] = node.xpath('./td[9]/text()').extract_first()
yield item 查看全部
php 循环抓取网页内容(第一步就是获取有哪些城市使用插件XPath进行一个测试?
)
因此将其分配给名为 base_url 的变量以供后续使用
自动创建的爬出带有爬虫的名字。启动爬虫时需要这个名字,现在不用
name = 'area_spider'
allowed_domains = ['aqistudy.cn'] # 爬取的域名,不会超出这个顶级域名
base_url = "https://www.aqistudy.cn/historydata/"
start_urls = [base_url]
城市信息
进入首页后可以看到大量的城市信息,所以我们第一步就是获取有哪些城市
def parse(self, response):
print('爬取城市信息....')
url_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/@href").extract() # 全部链接
city_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/text()").extract() # 城市名称
for url, city in zip(url_list, city_list):
yield scrapy.Request(url=url, callback=self.parse_month, meta={'city': city})
使用插件XPath Helper可以对xpath进行测试,看定位内容是否正确
xpath.png
随便点击一个地区,可以发现url已经变成了北京
那么url_list得到的就是需要拼接的内容monthdata.php?city=city name
city_list的最后一部分是text(),所以得到的是具体的文本信息
将获取到的url_list和city_list一一传递给scrapy.Request,其中url是需要爬取的页面地址,city是item中需要的内容,所以暂时将item存入meta中并通过它到下一个回调函数 self .parse_month
月份信息
def parse_month(self, response):
print('爬取{}月份...'.format(response.meta['city']))
url_list = response.xpath('//tbody/tr/td/a/@href').extract()
for url in url_list:
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_day, meta={'city': response.meta['city']})
本步骤获取每个城市的所有月份信息,获取每个月份的URL地址。继续向下传递从上面传递的城市
最终数据
获得最终URL后,实例化item,然后完成item字典,返回item
def parse_day(self, response):
print('爬取最终数据...')
item = AirHistoryItem()
node_list = response.xpath('//tr')
node_list.pop(0) # 去除第一行标题栏
for node in node_list:
item['data'] = node.xpath('./td[1]/text()').extract_first()
item['city'] = response.meta['city']
item['aqi'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['pm2_5'] = node.xpath('./td[4]/text()').extract_first()
item['pm10'] = node.xpath('./td[5]/text()').extract_first()
item['so2'] = node.xpath('./td[6]/text()').extract_first()
item['co'] = node.xpath('./td[7]/text()').extract_first()
item['no2'] = node.xpath('./td[8]/text()').extract_first()
item['o3'] = node.xpath('./td[9]/text()').extract_first()
yield item
使用中间件实现selenium操作
打开中间件文件 middlewares.py
因为在服务器上爬取,所以选择使用谷歌的无界面浏览器chrome-headless
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless') # 使用无头谷歌浏览器模式
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
# 指定谷歌浏览器路径
webdriver.Chrome(chrome_options=chrome_options,executable_path='/root/zx/spider/driver/chromedriver')
然后获取页面渲染后的源码
request.url 是传递给中间件的 url。由于首页是静态页面,首页不进行selenium操作
if request.url != 'https://www.aqistudy.cn/historydata/':
self.driver.get(request.url)
time.sleep(1)
html = self.driver.page_source
self.driver.quit()
return scrapy.http.HtmlResponse(url=request.url, body=html.encode('utf-8'), encoding='utf-8',request=request)
后续的操作也很简单,最后对获取到的内容进行正确编码返回到爬虫的下一步
所有中间件代码
使用下载器保存项目内容
修改 pipelines.py 用于文件存储
import json
class AirHistoryPipeline(object):
def open_spider(self, spider):
self.file = open('area.json', 'w')
def process_item(self, item, spider):
context = json.dumps(dict(item),ensure_ascii=False) + '\n'
self.file.write(context)
return item
def close_spider(self,spider):
self.file.close()
修改设置文件使中间件和下载器生效
打开settings.py文件
修改如下内容:DOWNLOADER_MIDDLEWARES使刚才写的中间件中的类,ITEM_PIPELINES是管道中的类
BOT_NAME = 'air_history'
SPIDER_MODULES = ['air_history.spiders']
NEWSPIDER_MODULE = 'air_history.spiders'
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
DOWNLOADER_MIDDLEWARES = {
'air_history.middlewares.AreaSpiderMiddleware': 543,
}
ITEM_PIPELINES = {
'air_history.pipelines.AirHistoryPipeline': 300,
}
运行
使用scrapy crawl area_spider运行爬虫
结果.png
所有蜘蛛代码
# -*- coding: utf-8 -*-
import scrapy
from air_history.items import AirHistoryItem
class AreaSpiderSpider(scrapy.Spider):
name = 'area_spider'
allowed_domains = ['aqistudy.cn'] # 爬取的域名,不会超出这个顶级域名
base_url = "https://www.aqistudy.cn/historydata/"
start_urls = [base_url]
def parse(self, response):
print('爬取城市信息....')
url_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/@href").extract() # 全部链接
city_list = response.xpath("//div[@class='all']/div[@class='bottom']/ul/div[2]/li/a/text()").extract() # 城市名称
for url, city in zip(url_list, city_list):
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_month, meta={'city': city})
def parse_month(self, response):
print('爬取{}月份...'.format(response.meta['city']))
url_list = response.xpath('//tbody/tr/td/a/@href').extract()
for url in url_list:
url = self.base_url + url
yield scrapy.Request(url=url, callback=self.parse_day, meta={'city': response.meta['city']})
def parse_day(self, response):
print('爬取最终数据...')
item = AirHistoryItem()
node_list = response.xpath('//tr')
node_list.pop(0) # 去除第一行标题栏
for node in node_list:
item['data'] = node.xpath('./td[1]/text()').extract_first()
item['city'] = response.meta['city']
item['aqi'] = node.xpath('./td[2]/text()').extract_first()
item['level'] = node.xpath('./td[3]/text()').extract_first()
item['pm2_5'] = node.xpath('./td[4]/text()').extract_first()
item['pm10'] = node.xpath('./td[5]/text()').extract_first()
item['so2'] = node.xpath('./td[6]/text()').extract_first()
item['co'] = node.xpath('./td[7]/text()').extract_first()
item['no2'] = node.xpath('./td[8]/text()').extract_first()
item['o3'] = node.xpath('./td[9]/text()').extract_first()
yield item
php 循环抓取网页内容(免费资源网,使用phpcurl获取页面内容或提交数据有时候)
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-24 13:18
免费资源网,
使用 php curl 获取页面内容或提交数据。有时您希望将返回的内容存储为变量而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
以上php curl获取https页面内容的设置方法,不直接输出返回结果,都是编辑器共享的内容。希望能给大家参考,也希望大家多多支持免费资源网。
免费资源网, 查看全部
php 循环抓取网页内容(免费资源网,使用phpcurl获取页面内容或提交数据有时候)
免费资源网,
使用 php curl 获取页面内容或提交数据。有时您希望将返回的内容存储为变量而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
以上php curl获取https页面内容的设置方法,不直接输出返回结果,都是编辑器共享的内容。希望能给大家参考,也希望大家多多支持免费资源网。
免费资源网,
php 循环抓取网页内容(php循环抓取网页内容,主要有两种方式,1。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-21 15:05
php循环抓取网页内容,主要有两种方式,1。循环网页内容中使用循环依赖指定的字符串就行,include/memcpy/xendesize/xendesize。c等方法。2。循环字符串使用模糊匹配,比如:字符串"admin",使用自定义函数find("/admin")获取返回值就是字符串"admin"这个字符串。
1循环操作时因为涉及到缓存使用的操作时就很方便,先获取元素后缓存,而2中因为避免被缓存就使用了缓存规则。但是include/memcpy等方法都带来了问题,就是获取字符串后字符串并不是预期的,会存在扩展编译时误识别的问题。这时就需要对浏览器字符串进行解析提取提前使用content-type的语义,使用xendesize/xendesize。
<p>c等提取字符串并且获取响应的字符串。第一种方法是相对简单的解决方案,需要做两个同步的缓存队列。php直接使用shell。io解析解析数据使用{xendesize}{xendesize}等方法。php不支持多个线程,无法一次获取多个页面的数据,但是有时会使用前端的js来实现多个页面同步获取,将变量与解析数据同步, 查看全部
php 循环抓取网页内容(php循环抓取网页内容,主要有两种方式,1。)
php循环抓取网页内容,主要有两种方式,1。循环网页内容中使用循环依赖指定的字符串就行,include/memcpy/xendesize/xendesize。c等方法。2。循环字符串使用模糊匹配,比如:字符串"admin",使用自定义函数find("/admin")获取返回值就是字符串"admin"这个字符串。
1循环操作时因为涉及到缓存使用的操作时就很方便,先获取元素后缓存,而2中因为避免被缓存就使用了缓存规则。但是include/memcpy等方法都带来了问题,就是获取字符串后字符串并不是预期的,会存在扩展编译时误识别的问题。这时就需要对浏览器字符串进行解析提取提前使用content-type的语义,使用xendesize/xendesize。
<p>c等提取字符串并且获取响应的字符串。第一种方法是相对简单的解决方案,需要做两个同步的缓存队列。php直接使用shell。io解析解析数据使用{xendesize}{xendesize}等方法。php不支持多个线程,无法一次获取多个页面的数据,但是有时会使用前端的js来实现多个页面同步获取,将变量与解析数据同步,
php 循环抓取网页内容(WordPress主循环和全局变量的部分模板函数假设我们写了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-17 07:09
我们在开发WordPress的时候,首先要了解主循环和全局变量,这样才能知道哪些全局变量是可以访问的。下面我们来解释一下 WordPress 主循环,以更好地了解主循环中的模板函数可以调用哪些全局变量。
WordPress 主循环
WordPress 主循环(The Loop)用于在单个日志页面上显示日志列表和消息列表。
在默认主题的index.php中,主循环代码如下:
调用 the_post() 函数后,我们可以使用很多模板函数和全局变量。
以下是目前可用的一些模板函数:
以下是主循环中可用的全局变量:
制作自己的模板函数
假设我们写了一个自定义的模板函数,叫做get_my_trackback,它可以在文章的消息循环中每次检测到消息是否为trackback时,做一些动作。我们可以把这个函数放到comment.php模板文件的foreach消息循环中。
然后在当前主题的函数文件中添加get_my_trackback函数代码:
全局变量comments 允许我们访问当前评论的所有数据,因此它允许我们对评论做任何事情。
©我喜欢水煮鱼。本站推荐主机:阿里云。国外主机推荐使用 BlueHost。 查看全部
php 循环抓取网页内容(WordPress主循环和全局变量的部分模板函数假设我们写了)
我们在开发WordPress的时候,首先要了解主循环和全局变量,这样才能知道哪些全局变量是可以访问的。下面我们来解释一下 WordPress 主循环,以更好地了解主循环中的模板函数可以调用哪些全局变量。
WordPress 主循环
WordPress 主循环(The Loop)用于在单个日志页面上显示日志列表和消息列表。
在默认主题的index.php中,主循环代码如下:
调用 the_post() 函数后,我们可以使用很多模板函数和全局变量。
以下是目前可用的一些模板函数:
以下是主循环中可用的全局变量:
制作自己的模板函数
假设我们写了一个自定义的模板函数,叫做get_my_trackback,它可以在文章的消息循环中每次检测到消息是否为trackback时,做一些动作。我们可以把这个函数放到comment.php模板文件的foreach消息循环中。
然后在当前主题的函数文件中添加get_my_trackback函数代码:
全局变量comments 允许我们访问当前评论的所有数据,因此它允许我们对评论做任何事情。
©我喜欢水煮鱼。本站推荐主机:阿里云。国外主机推荐使用 BlueHost。
php 循环抓取网页内容(调用博客日志的主循环(TheLoop)中如何调用日志标题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-10-17 07:05
调用博文的主循环(The Loop)是WordPress中最重要的一组PHP代码,几乎在所有页面中都会用到。这也是从头开始创建 WordPress 主题的系列教程中的第五篇。
在我们继续学习之前,让我们回顾一下到目前为止我们学到的东西。
到目前为止,我们已经学会了:
现在让我们开始第 5 部分:循环
打开Xampp,“教程”主题文件夹,浏览器,在浏览器中去,最后打开index.php文件。
下面应该是此时index.php文件的内容:
再说一遍:为了学习这些代码,请尝试手动输入它们,而不是复制和粘贴它们。
第 1 步:创建容器 Div
在头部DIV标签下添加一个DIV标签,并将其ID赋给“container”,如下:
“容器”DIV 标签用于将博客的主要内容与其他内容(例如侧边栏和页脚)区分开来。
第二步:输入主循环代码
将以下代码添加到容器的 DIV 标签中:
这段代码是 WordPress 中的主循环(The Loop)。在详细解释这些代码的功能之前,我们先来看看目前index.php中收录的代码:
您可能已经注意到,Container DIV 中的每一行都是缩进的。这是为了更好地组织代码并方便阅读(使用tab键代替空格键进行代码缩进)。
刚才发生了什么?
第三步:调用日志标题
在上一课中,我们学习了如何使用 bloginfo('name') 来调用博客的标题。现在我们将学习如何在主循环(The Loop)中调用博客的标题。
在 the_post() 之后输入;?> 及之前
保存 index.php 文件并刷新浏览器。您应该会在博客描述下方看到 Hello World。WordPress默认安装后,博客只有一个帖子,而我的测试站点有多个帖子,所以有多个日志标题,而且由于我使用的日志标题是相同的,它们看起来像一长串Hello World。
第 4 步:添加指向帖子标题的链接
将帖子标题转换为帖子标题链接。还记得如何将博客的标题变成链接吗?
两边增加。
保存并刷新浏览器。现在日志的标题变成了链接,但它们没有指向哪里。为了让每个头指向正确的日志,我们需要用 the_permalink() 替换 #。
<p> 查看全部
php 循环抓取网页内容(调用博客日志的主循环(TheLoop)中如何调用日志标题)
调用博文的主循环(The Loop)是WordPress中最重要的一组PHP代码,几乎在所有页面中都会用到。这也是从头开始创建 WordPress 主题的系列教程中的第五篇。
在我们继续学习之前,让我们回顾一下到目前为止我们学到的东西。
到目前为止,我们已经学会了:
现在让我们开始第 5 部分:循环
打开Xampp,“教程”主题文件夹,浏览器,在浏览器中去,最后打开index.php文件。
下面应该是此时index.php文件的内容:
再说一遍:为了学习这些代码,请尝试手动输入它们,而不是复制和粘贴它们。
第 1 步:创建容器 Div
在头部DIV标签下添加一个DIV标签,并将其ID赋给“container”,如下:
“容器”DIV 标签用于将博客的主要内容与其他内容(例如侧边栏和页脚)区分开来。
第二步:输入主循环代码
将以下代码添加到容器的 DIV 标签中:
这段代码是 WordPress 中的主循环(The Loop)。在详细解释这些代码的功能之前,我们先来看看目前index.php中收录的代码:
您可能已经注意到,Container DIV 中的每一行都是缩进的。这是为了更好地组织代码并方便阅读(使用tab键代替空格键进行代码缩进)。
刚才发生了什么?
第三步:调用日志标题
在上一课中,我们学习了如何使用 bloginfo('name') 来调用博客的标题。现在我们将学习如何在主循环(The Loop)中调用博客的标题。
在 the_post() 之后输入;?> 及之前
保存 index.php 文件并刷新浏览器。您应该会在博客描述下方看到 Hello World。WordPress默认安装后,博客只有一个帖子,而我的测试站点有多个帖子,所以有多个日志标题,而且由于我使用的日志标题是相同的,它们看起来像一长串Hello World。
第 4 步:添加指向帖子标题的链接
将帖子标题转换为帖子标题链接。还记得如何将博客的标题变成链接吗?
两边增加。
保存并刷新浏览器。现在日志的标题变成了链接,但它们没有指向哪里。为了让每个头指向正确的日志,我们需要用 the_permalink() 替换 #。
<p>
php 循环抓取网页内容(js(javascript)写的函数前面都要加个functionshowSite)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-17 07:04
js(javascript)写的函数前面必须有函数。函数 showSite(str) 括号中的 str 显然是一个参数,这是一个约定。if(str=="")的判断是指当参数为空时,return出来时,中间的大段与参数str无关。忽略它。最后一个 xmlhttp.open("GET","getsite_mysql.php?q="+str,true) 收录 str。你需要注意它。很明显,getsite_mysql.php.php是接受数据的。移植功能时要注意变化。true 好像是说设置为异步的。我不明白。简单了解一下功能,复制粘贴就可以了。mysql
先展示效果图
如果文本框为空,点击【搜索】
在文本框中输入【报纸】,点击【搜索】(数据库有报纸信息)
在文本框中输入【拉拉拉】,点击【搜索】(数据库中没有信息)
网络
在文本框中输入【报纸】,然后点击搜索按钮查看下表。表中显示的【ID】【Recyclable Garbage】的内容是通过查询数据库得到的。如果是在文本框中输入的东西,在数据库中没有,它会显示[不知道] sql
下面直接看代码
HTML全码数据库
简单交互 //这里就是上网时候的标签页的名字
function showSite(str)
{
if (str=="")
{
document.getElementById("txtHint").innerHTML="无输入";//这里小改,参数为空显示【无输入】
return;
}
if (window.XMLHttpRequest)
{
// IE7+, Firefox, Chrome, Opera, Safari 浏览器执行代码
xmlhttp=new XMLHttpRequest();
}
else
{
// IE6, IE5 浏览器执行代码
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.getElementById("txtHint").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("GET","mysql.php?q="+str,true);
xmlhttp.send();
}
我要查询//laber其实有没有都不差,据说是方便人点击用的
//换行操做,屡试不爽
//id 这个很关键,后面函数调用的参数要用到, placeholder 就是文本框为空时显示的东西
//onclick 点击触发函数运行,经过【.litter】指定 id="litter" 的文本框,【.value】指定文本框的输入内容
网站信息显示在这里……
//这里也很关键,这里是 HTML 显示数据表格的地方,函数里面用到
PHP全码浏览器
数据库方面
代码中有分析,很详细。HTML 文件和 PHP 文件应放在同一目录中。我不需要说这些。不然函数的php路径也要改,./…/Superior Directory,上级目录,这些东西就不说了
我不需要安装MySQL、在数据库中创建表、插入数据和其他MySQL语句。东西太多了,就接受吧。如果你有任何问题,你可以问我。, 可以的话回答一下
---------------====------------------------ -------------------------------------------------- ---------------------
以上如果有什么不对的地方,或者有错误,请指正,emmmmm
最后,如果推荐学习制作网页的话,我觉得三个网站都挺好的,菜鸟教程,w3school,PHP中文网站,干货很多,希望对大家学习有帮助,嘻嘻嘻嘻 查看全部
php 循环抓取网页内容(js(javascript)写的函数前面都要加个functionshowSite)
js(javascript)写的函数前面必须有函数。函数 showSite(str) 括号中的 str 显然是一个参数,这是一个约定。if(str=="")的判断是指当参数为空时,return出来时,中间的大段与参数str无关。忽略它。最后一个 xmlhttp.open("GET","getsite_mysql.php?q="+str,true) 收录 str。你需要注意它。很明显,getsite_mysql.php.php是接受数据的。移植功能时要注意变化。true 好像是说设置为异步的。我不明白。简单了解一下功能,复制粘贴就可以了。mysql
先展示效果图
如果文本框为空,点击【搜索】
在文本框中输入【报纸】,点击【搜索】(数据库有报纸信息)
在文本框中输入【拉拉拉】,点击【搜索】(数据库中没有信息)
网络
在文本框中输入【报纸】,然后点击搜索按钮查看下表。表中显示的【ID】【Recyclable Garbage】的内容是通过查询数据库得到的。如果是在文本框中输入的东西,在数据库中没有,它会显示[不知道] sql
下面直接看代码
HTML全码数据库
简单交互 //这里就是上网时候的标签页的名字
function showSite(str)
{
if (str=="")
{
document.getElementById("txtHint").innerHTML="无输入";//这里小改,参数为空显示【无输入】
return;
}
if (window.XMLHttpRequest)
{
// IE7+, Firefox, Chrome, Opera, Safari 浏览器执行代码
xmlhttp=new XMLHttpRequest();
}
else
{
// IE6, IE5 浏览器执行代码
xmlhttp=new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.onreadystatechange=function()
{
if (xmlhttp.readyState==4 && xmlhttp.status==200)
{
document.getElementById("txtHint").innerHTML=xmlhttp.responseText;
}
}
xmlhttp.open("GET","mysql.php?q="+str,true);
xmlhttp.send();
}
我要查询//laber其实有没有都不差,据说是方便人点击用的
//换行操做,屡试不爽
//id 这个很关键,后面函数调用的参数要用到, placeholder 就是文本框为空时显示的东西
//onclick 点击触发函数运行,经过【.litter】指定 id="litter" 的文本框,【.value】指定文本框的输入内容
网站信息显示在这里……
//这里也很关键,这里是 HTML 显示数据表格的地方,函数里面用到
PHP全码浏览器
数据库方面
代码中有分析,很详细。HTML 文件和 PHP 文件应放在同一目录中。我不需要说这些。不然函数的php路径也要改,./…/Superior Directory,上级目录,这些东西就不说了
我不需要安装MySQL、在数据库中创建表、插入数据和其他MySQL语句。东西太多了,就接受吧。如果你有任何问题,你可以问我。, 可以的话回答一下
---------------====------------------------ -------------------------------------------------- ---------------------
以上如果有什么不对的地方,或者有错误,请指正,emmmmm
最后,如果推荐学习制作网页的话,我觉得三个网站都挺好的,菜鸟教程,w3school,PHP中文网站,干货很多,希望对大家学习有帮助,嘻嘻嘻嘻
php 循环抓取网页内容(WordPress附带不依赖循环的single_title()函数的用法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-13 12:16
本文文章主要介绍WordPress中文章循环复位函数rewind_posts(),并介绍不依赖循环的single_cat_title()函数的用法。有需要的朋友可以参考
有时,在索引页(首页、分类文章、标签文章、作者文章索引...)提前进入WordPress文章循环(Loop)获取一些我们想要获取的信息,但是在WP中,单个页面一般只会跳入循环一次,也就是下次我们从循环中抽取信息时,我们会在循环中获取第二个日志的信息,以便解决这个尴尬的情况,WordPress 有一个内置函数,rewind_posts() 函数专门用于重置循环指针。
描述 描述
倒回循环帖子。
重置 文章 循环。
用
该函数不接受变量。
实例
在此引用 WordPress 默认主题二十一点,author.php 文件的第 15-55 行进行了简化和简化。
实例
这是 WordPress 2011 默认主题的摘录,category.php 文件第 18 行的代码
以上就是对WordPress中重置文章循环的rewind_posts()函数的详细说明。更多详情请关注其他相关html中文网站文章! 查看全部
php 循环抓取网页内容(WordPress附带不依赖循环的single_title()函数的用法介绍)
本文文章主要介绍WordPress中文章循环复位函数rewind_posts(),并介绍不依赖循环的single_cat_title()函数的用法。有需要的朋友可以参考
有时,在索引页(首页、分类文章、标签文章、作者文章索引...)提前进入WordPress文章循环(Loop)获取一些我们想要获取的信息,但是在WP中,单个页面一般只会跳入循环一次,也就是下次我们从循环中抽取信息时,我们会在循环中获取第二个日志的信息,以便解决这个尴尬的情况,WordPress 有一个内置函数,rewind_posts() 函数专门用于重置循环指针。
描述 描述
倒回循环帖子。
重置 文章 循环。
用
该函数不接受变量。
实例
在此引用 WordPress 默认主题二十一点,author.php 文件的第 15-55 行进行了简化和简化。
实例
这是 WordPress 2011 默认主题的摘录,category.php 文件第 18 行的代码
以上就是对WordPress中重置文章循环的rewind_posts()函数的详细说明。更多详情请关注其他相关html中文网站文章!
php 循环抓取网页内容(【小编】phpcurl获取页面内容或提交数据有时候)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-10-05 05:19
时间:2019-01-15
今天小编就给大家分享一篇关于php curl如何在不直接输出返回结果的情况下获取https页面内容的文章。有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
使用 php curl 获取页面内容或提交数据。有时您希望将返回的内容存储为变量而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
以上php curl获取https页面内容的设置方法,不直接输出返回结果,都是编辑器共享的内容。希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
php 循环抓取网页内容(【小编】phpcurl获取页面内容或提交数据有时候)
时间:2019-01-15
今天小编就给大家分享一篇关于php curl如何在不直接输出返回结果的情况下获取https页面内容的文章。有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
使用 php curl 获取页面内容或提交数据。有时您希望将返回的内容存储为变量而不是直接输出。
方法:将 curl 的 CURLOPT_RETURNTRANSFER 选项设置为 1 或 true。
例如:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url);
// 不要http header 加快效率
curl_setopt($curl, CURLOPT_HEADER, 0);
// https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$res = curl_exec($ch); //已经获取到内容,没有输出到页面上.
curl_close($ch);
以上php curl获取https页面内容的设置方法,不直接输出返回结果,都是编辑器共享的内容。希望能给大家一个参考,也希望大家多多支持脚本之家。

