
php 循环抓取网页内容
php循环抓取网页内容,先抓取再保存首先,
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-05-29 06:00
php循环抓取网页内容,先抓取再保存首先,看下开发工具自带的循环抓取效果—程序开发环境,phpstorm程序使用函数保存(reporter函数),
如果你追求完美,可以用cvf这样直接可以存到本地的,还有reporterforphp这样专门做这种事情的编译好的程序,加个签名就可以用,
cvf(newphpstormopt),
reporter(){storage('');//默认是false,不能单独存储md5值,不适合存储摘要md5('');//默认是false,存储摘要也不对,因为不能存储摘要与摘要的关联型关系时的摘要(例如ff文件或video),因为这些数据会上传到服务器存储,然后再存储最后一层md5(‘4454444555444');//不要执行此语句,reporter只能存储常量和整数,对于string类型变量如extensionname变量不能存储(例如caller语句),因为extensionname值必须是数字型或字符串型}。
你可以查一下jdx就是用java做的,开源的, 查看全部
php循环抓取网页内容,先抓取再保存首先,
php循环抓取网页内容,先抓取再保存首先,看下开发工具自带的循环抓取效果—程序开发环境,phpstorm程序使用函数保存(reporter函数),
如果你追求完美,可以用cvf这样直接可以存到本地的,还有reporterforphp这样专门做这种事情的编译好的程序,加个签名就可以用,
cvf(newphpstormopt),
reporter(){storage('');//默认是false,不能单独存储md5值,不适合存储摘要md5('');//默认是false,存储摘要也不对,因为不能存储摘要与摘要的关联型关系时的摘要(例如ff文件或video),因为这些数据会上传到服务器存储,然后再存储最后一层md5(‘4454444555444');//不要执行此语句,reporter只能存储常量和整数,对于string类型变量如extensionname变量不能存储(例如caller语句),因为extensionname值必须是数字型或字符串型}。
你可以查一下jdx就是用java做的,开源的,
php 循环抓取网页内容 _variables介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-05-26 03:21
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
查看全部
php 循环抓取网页内容 _variables介绍
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
php 循环抓取网页内容 _variables介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-05-26 02:09
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
查看全部
php 循环抓取网页内容 _variables介绍
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
php 循环抓取网页内容 _variables介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-25 01:13
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
查看全部
php 循环抓取网页内容 _variables介绍
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
php 循环抓取网页内容 _variables介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-05-16 06:41
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
查看全部
php 循环抓取网页内容 _variables介绍
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
php 循环抓取网页内容 _variables介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-13 15:17
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
查看全部
php 循环抓取网页内容 _variables介绍
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
php循环抓取网页内容,php代码可以遍历整个网页,所以所有网页都能抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-05-04 05:00
php循环抓取网页内容,php代码可以遍历整个网页,所以所有网页都能抓取,存在主动限制次数,activex控件控制,请求头信息很容易理解,内容请求会给匹配的数据html5formdata;[[ajax]];注意:input的ajax控件给的数据,可能有重复,但是经过php解析的数据,可以不用重复比如第一条,"data{"""url"}"""中间的数据不要重复,第二条"data{url"""}"""中间的内容,没有重复次数。
如何判断是否重复phppreg_match_for_content,preg_match_for_json_list=str;[[ajax]];preg_match_for_content:基于原始的xml文件,可以是网页或者php页面.preg_match_json_list:基于json解析json.2.phpduplistfromjson_data.preg_match_all_that();forjson_dataofphp_json_data:preg_match_all_that()返回xml数据,先从数据获取,rawdata是php的rawencodeddata.[[ajax]]:基于xml解析json,读取php的json_data数据.rawdata数据数据放在php代码中.[[ajax]];preg_match_content:基于json获取数据,返回json数据,json数据放在json数据库中.3.activex控件控制,例如$a=$_get['activex'];。 查看全部
php循环抓取网页内容,php代码可以遍历整个网页,所以所有网页都能抓取
php循环抓取网页内容,php代码可以遍历整个网页,所以所有网页都能抓取,存在主动限制次数,activex控件控制,请求头信息很容易理解,内容请求会给匹配的数据html5formdata;[[ajax]];注意:input的ajax控件给的数据,可能有重复,但是经过php解析的数据,可以不用重复比如第一条,"data{"""url"}"""中间的数据不要重复,第二条"data{url"""}"""中间的内容,没有重复次数。
如何判断是否重复phppreg_match_for_content,preg_match_for_json_list=str;[[ajax]];preg_match_for_content:基于原始的xml文件,可以是网页或者php页面.preg_match_json_list:基于json解析json.2.phpduplistfromjson_data.preg_match_all_that();forjson_dataofphp_json_data:preg_match_all_that()返回xml数据,先从数据获取,rawdata是php的rawencodeddata.[[ajax]]:基于xml解析json,读取php的json_data数据.rawdata数据数据放在php代码中.[[ajax]];preg_match_content:基于json获取数据,返回json数据,json数据放在json数据库中.3.activex控件控制,例如$a=$_get['activex'];。
php 循环抓取网页内容(这节课开始学习如何使用PHP结合HTML网页来实现?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-18 18:11
前两节课都是以前用 PHP 编程语言编写和重新实现的程序。
本课开始学习如何使用PHP结合HTML页面来实现特定的动态数据页面。
学歌打算做一个有学生成绩管理功能的网页,首先要做一个列表查询页面。
在查询页面,可以输入一些查询条件,如学生姓名或学科信息。点击查询按钮后,下方显示对应的查询结果,查询结果以表格的形式展示。
PHP 如何嵌入 HTML
前几课是纯PHP代码,然后通过PHP命令执行PHP文件代码来运行PHP代码。
在本章的第一课中,您实际上已经学会了如何将 PHP 代码嵌入到 HTML 页面中,所以让我们回顾一下:
可以看出,虽然文件名最终保存为helloworld.php,但其本质还是一个html规范格式的文件,因为这个文件的内容最终显示在浏览器中,所以本质上还是一个html规范文件.
PHP代码的作用只是通过动态编程语言生成需要的数据或显示格式。
可以理解为PHP代码运行在服务器端,运行后的文件内容为HTML内容。这样做的好处不言而喻,因为每个客户端浏览器都可以根据需要生成完全不同的 网站 内容。
上面的代码,其实也可以完全用PHP代码实现:
运行此代码的结果与运行上述代码的结果完全相同。
也就是说,在PHP代码中,不在这组开始和结束标记中的内容实际上是默认返回给浏览器的,相当于使用echo输出。这也是 PHP 的默认代码规范。
除了 echo 函数外,还使用了其他标准输出函数,类似于 echo 将输出内容返回给浏览器。比如print函数、print_r函数、var_dump函数等等。但是,如果输出内容不符合 html 规范,则可能无法在浏览器中按预期显示。
编写列表查询页面
创建 2 个文件 studentlist.php 文件和 student.css 文件。
参考前面的 index.html 和 index.css 样式编写html文件和显示样式。
首先将div分为上下3个区域,顶部显示一个标题“学生信息查询”,然后下面的两个div分别显示查询条件和查询按钮。
查询条件如下:姓名(文本输入)/性别(单选)/主题(多选)/分数段(下拉框选择)。
以下区域显示查询列表的结果,使用表格显示。第一行是标题,显示以下数据:
ID/姓名/性别/主题/分数。
修改 studentlist.php 文件:
修改 student.css 文件:
将这2个文件部署到本地服务器对应目录下,然后启动本地web服务程序,然后通过浏览器访问这个php网页:
然后写一个表,在下一行的 td 中显示查询列表的结果。
显示以下数据:ID/姓名/性别/主题/分数。
第一行是标题,第二行是数据。表头和数据的显示样式可以不同以显示差异。
修改 studentlist.php 文件:
修改student.css文件,添加如下代码:
刷新页面:
可以看到网页上显示了一个表格,内容是学生成绩的查询结果。
将数据行复制到多行,使奇数行和偶数行显示不同的背景色,看起来更美观。
修改 studentlist.php 文件:
修改student.css文件,添加样式tdb:
刷新页面:
可以看到表格中显示了多行数据,并且各行明显分开。
使用 PHP 代码循环遍历表的数据
通过编写静态html内容,即可完成显示样式的编码。
然后在这里修改多行显示内容,用PHP代码动态生成。
首先,删除刚刚添加的4行数据,只留下一行数据。
然后,在数据行前后添加PHP代码,并将这行数据放入一个for循环,即让这行数据重复显示5次。
修改 studentlist.php 文件:
刷新页面:
如您所见,页面显示了 5 行完全相同的数据。这就是 PHP 代码的力量。
如果要将5行变成100行,只需要修改一个数字即可。而如果是纯HTML代码,如果要重复100行的话,复制粘贴会耗费大量时间。
如果希望奇数行和偶数行的显示不同,可以这样修改:
首先设置一个变量,用于显示样式是tda还是tdb,命名为tds;
然后根据当前行是偶数行,将tds的值赋给一个tdb字符串;
然后在需要显示样式的地方输出这个变量。在这个循环中,当变量$i发生变化时,模2的结果会是0或者1,也就是奇数或者偶数,所以变量tds的值会变成tda或者tdb,最终输出的结果会不一样。.
修改 studentlist.php 文件:
刷新页面:
如果我想以不同的方式显示这5行的ID和名称怎么办?
一个简单的方法是修改显示的内容以跟随当前循环变量生成:
修改studentlist.php文件,调整代码的分支位置:
刷新页面:
可以看到,每一行的 ID 和名称都是不同的。
当然,在实际项目中,一般不采用这种方式。一般来说,必须将整个数据结果集返回到一起显示的页面,然后通过访问数据结果集嵌入到HTML表格中。显示。
一般的方式是使用二维数组变量来保存数据结果集。
添加一个变量$alldatas,那么内容就是二维数据,外层是每一行的含义,内层用key和value来表示不同的字段数据。
然后显示循环内部,通过访问这个二维数组的一个key得到对应的数据,通过echo输出到网页内容中。
修改 studentlist.php 文件:
刷新页面:
可以看到数据显示了5行,每行的名称都是根据数组变量中的值来显示的。这样,可以很容易地显示背景数据。
但是有个不正确的地方,就是数据行数的长度是5,代码还是用了for循环5次,加上数据的行数长度不是5,那么for 循环在这里不正确。应该改成foreach遍历二维数组变量,这样就可以完全根据变量中存储的数据显示行数和内容。
修改循环方式和变量显示,修改其他字段以这种方式显示。
修改 studentlist.php 文件:
刷新页面:
如您所见,所有显示的内容都取决于存储在数组变量中的值。只要修改了这个变量中存储的数据,网页就会显示不同的内容。
这就是动态网站的本质。
编写单个查询项和查询按钮
接下来,编写上面的查询条件和查询按钮。
3-4节大致介绍了各种输入项的写法,我们来回顾一下:
可以在网页上显示文本输入框。
单选按钮可以显示在网页上。
可以在网页上显示多选按钮。
一个按钮可以显示在网页上。
使用选择元素显示一个下拉框。
上面的代码可以在网页中显示一个下拉框选项,里面有2个选择项。
通过上述方式,在上方区域添加如下查询条件和查询按钮。
姓名(文字输入)/性别(单选)/主题(多选)/小数段(下拉框选择)/查询按钮。
首先,让我们规划一下这 5 个项目是如何放置在页面上的。
我打算把查询按钮放在最右边,然后把左边分成上下2行,上面分成3列,分别显示姓名、性别和分数段;
因为下面一行是选择题,要求的长度比较长,所以下面一行占了3列的宽度,正好利用表格的合并单元格属性来实现。
首先,写出表格每个tr和td的分布,显示边框,验证排版是否正确:
修改 studentlist.php 文件:
刷新页面查看效果:
然后,编写所有查询条件和查询按钮:
修改 studentlist.php 文件:
修改 student.css 文件:
刷新页面查看效果:
可以看出,查询网页已经基本形成,接下来就是实现点击查询按钮后的功能,即根据输入的不同条件,返回不同的查询数据结果。
特别说明
这堂课的内容很关键,是写动态网站的核心入门教程。由于本课的内容使用了很多之前课程的相关内容,如果你是第一次碰巧看到这个文章,可能有很多不明白的地方,所以你可能需要看雪歌之前写的。文章,建议从0001类开始,这样前后有连贯性,然后会有更好的理解。返回搜狐,查看更多 查看全部
php 循环抓取网页内容(这节课开始学习如何使用PHP结合HTML网页来实现?)
前两节课都是以前用 PHP 编程语言编写和重新实现的程序。
本课开始学习如何使用PHP结合HTML页面来实现特定的动态数据页面。
学歌打算做一个有学生成绩管理功能的网页,首先要做一个列表查询页面。
在查询页面,可以输入一些查询条件,如学生姓名或学科信息。点击查询按钮后,下方显示对应的查询结果,查询结果以表格的形式展示。
PHP 如何嵌入 HTML
前几课是纯PHP代码,然后通过PHP命令执行PHP文件代码来运行PHP代码。
在本章的第一课中,您实际上已经学会了如何将 PHP 代码嵌入到 HTML 页面中,所以让我们回顾一下:
可以看出,虽然文件名最终保存为helloworld.php,但其本质还是一个html规范格式的文件,因为这个文件的内容最终显示在浏览器中,所以本质上还是一个html规范文件.
PHP代码的作用只是通过动态编程语言生成需要的数据或显示格式。
可以理解为PHP代码运行在服务器端,运行后的文件内容为HTML内容。这样做的好处不言而喻,因为每个客户端浏览器都可以根据需要生成完全不同的 网站 内容。
上面的代码,其实也可以完全用PHP代码实现:
运行此代码的结果与运行上述代码的结果完全相同。
也就是说,在PHP代码中,不在这组开始和结束标记中的内容实际上是默认返回给浏览器的,相当于使用echo输出。这也是 PHP 的默认代码规范。
除了 echo 函数外,还使用了其他标准输出函数,类似于 echo 将输出内容返回给浏览器。比如print函数、print_r函数、var_dump函数等等。但是,如果输出内容不符合 html 规范,则可能无法在浏览器中按预期显示。
编写列表查询页面
创建 2 个文件 studentlist.php 文件和 student.css 文件。
参考前面的 index.html 和 index.css 样式编写html文件和显示样式。
首先将div分为上下3个区域,顶部显示一个标题“学生信息查询”,然后下面的两个div分别显示查询条件和查询按钮。
查询条件如下:姓名(文本输入)/性别(单选)/主题(多选)/分数段(下拉框选择)。
以下区域显示查询列表的结果,使用表格显示。第一行是标题,显示以下数据:
ID/姓名/性别/主题/分数。
修改 studentlist.php 文件:
修改 student.css 文件:
将这2个文件部署到本地服务器对应目录下,然后启动本地web服务程序,然后通过浏览器访问这个php网页:
然后写一个表,在下一行的 td 中显示查询列表的结果。
显示以下数据:ID/姓名/性别/主题/分数。
第一行是标题,第二行是数据。表头和数据的显示样式可以不同以显示差异。
修改 studentlist.php 文件:
修改student.css文件,添加如下代码:
刷新页面:
可以看到网页上显示了一个表格,内容是学生成绩的查询结果。
将数据行复制到多行,使奇数行和偶数行显示不同的背景色,看起来更美观。
修改 studentlist.php 文件:
修改student.css文件,添加样式tdb:
刷新页面:
可以看到表格中显示了多行数据,并且各行明显分开。
使用 PHP 代码循环遍历表的数据
通过编写静态html内容,即可完成显示样式的编码。
然后在这里修改多行显示内容,用PHP代码动态生成。
首先,删除刚刚添加的4行数据,只留下一行数据。
然后,在数据行前后添加PHP代码,并将这行数据放入一个for循环,即让这行数据重复显示5次。
修改 studentlist.php 文件:
刷新页面:
如您所见,页面显示了 5 行完全相同的数据。这就是 PHP 代码的力量。
如果要将5行变成100行,只需要修改一个数字即可。而如果是纯HTML代码,如果要重复100行的话,复制粘贴会耗费大量时间。
如果希望奇数行和偶数行的显示不同,可以这样修改:
首先设置一个变量,用于显示样式是tda还是tdb,命名为tds;
然后根据当前行是偶数行,将tds的值赋给一个tdb字符串;
然后在需要显示样式的地方输出这个变量。在这个循环中,当变量$i发生变化时,模2的结果会是0或者1,也就是奇数或者偶数,所以变量tds的值会变成tda或者tdb,最终输出的结果会不一样。.
修改 studentlist.php 文件:
刷新页面:
如果我想以不同的方式显示这5行的ID和名称怎么办?
一个简单的方法是修改显示的内容以跟随当前循环变量生成:
修改studentlist.php文件,调整代码的分支位置:
刷新页面:
可以看到,每一行的 ID 和名称都是不同的。
当然,在实际项目中,一般不采用这种方式。一般来说,必须将整个数据结果集返回到一起显示的页面,然后通过访问数据结果集嵌入到HTML表格中。显示。
一般的方式是使用二维数组变量来保存数据结果集。
添加一个变量$alldatas,那么内容就是二维数据,外层是每一行的含义,内层用key和value来表示不同的字段数据。
然后显示循环内部,通过访问这个二维数组的一个key得到对应的数据,通过echo输出到网页内容中。
修改 studentlist.php 文件:
刷新页面:
可以看到数据显示了5行,每行的名称都是根据数组变量中的值来显示的。这样,可以很容易地显示背景数据。
但是有个不正确的地方,就是数据行数的长度是5,代码还是用了for循环5次,加上数据的行数长度不是5,那么for 循环在这里不正确。应该改成foreach遍历二维数组变量,这样就可以完全根据变量中存储的数据显示行数和内容。
修改循环方式和变量显示,修改其他字段以这种方式显示。
修改 studentlist.php 文件:
刷新页面:
如您所见,所有显示的内容都取决于存储在数组变量中的值。只要修改了这个变量中存储的数据,网页就会显示不同的内容。
这就是动态网站的本质。
编写单个查询项和查询按钮
接下来,编写上面的查询条件和查询按钮。
3-4节大致介绍了各种输入项的写法,我们来回顾一下:
可以在网页上显示文本输入框。
单选按钮可以显示在网页上。
可以在网页上显示多选按钮。
一个按钮可以显示在网页上。
使用选择元素显示一个下拉框。
上面的代码可以在网页中显示一个下拉框选项,里面有2个选择项。
通过上述方式,在上方区域添加如下查询条件和查询按钮。
姓名(文字输入)/性别(单选)/主题(多选)/小数段(下拉框选择)/查询按钮。
首先,让我们规划一下这 5 个项目是如何放置在页面上的。
我打算把查询按钮放在最右边,然后把左边分成上下2行,上面分成3列,分别显示姓名、性别和分数段;
因为下面一行是选择题,要求的长度比较长,所以下面一行占了3列的宽度,正好利用表格的合并单元格属性来实现。
首先,写出表格每个tr和td的分布,显示边框,验证排版是否正确:
修改 studentlist.php 文件:
刷新页面查看效果:
然后,编写所有查询条件和查询按钮:
修改 studentlist.php 文件:
修改 student.css 文件:
刷新页面查看效果:
可以看出,查询网页已经基本形成,接下来就是实现点击查询按钮后的功能,即根据输入的不同条件,返回不同的查询数据结果。
特别说明
这堂课的内容很关键,是写动态网站的核心入门教程。由于本课的内容使用了很多之前课程的相关内容,如果你是第一次碰巧看到这个文章,可能有很多不明白的地方,所以你可能需要看雪歌之前写的。文章,建议从0001类开始,这样前后有连贯性,然后会有更好的理解。返回搜狐,查看更多
php 循环抓取网页内容(Tumult的集成实时预览打破编写HTML,速度非常快)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-16 04:27
Tumult Whisk 的集成实时预览打破了编写 HTML、保存文件、然后重新加载并在浏览器中查看页面的繁琐循环。结合编写和查看阶段可以明确更改的效果并加快制作网页的整个过程。基于 W3C 的验证将以红色突出显示所有错误。它使用与 Safari 相同的渲染引擎,因此它不仅符合标准,而且速度非常快。Whisk for Mac(轻量级网络编辑软件) Tumult Whisk 的集成实时预览打破了编写 HTML、保存文件、然后在浏览器中重新加载和查看页面的繁琐循环。结合编写和查看阶段可以明确更改的效果并加快制作网页的整个过程。基于 W3C 的验证将以红色突出显示所有错误。
主要特征:
- 预览窗格使用与 Safari 相同的引擎,在您键入时快速呈现 HTML 和 PHP
- “观看的文件”自动(或手动)确定文件何时更改并重新加载网络预览
- 基于实时 HTML W3C 的验证显示错误并用红色下划线突出显示问题标签
- 预览到其他浏览器或 iOS 上的 Hype Reflect 应用程序
- Web 检查器/控制台/devtools 访问
- 可定制的语法高亮颜色
- 可重复使用的代码片段和色板
- 滚动同步保持编辑器和预览在相似的位置
- 查看 PHP 引擎生成的 HTML 源代码
- 附加样式表以查看博客文章/标记在外部样式下的外观
- 仅作为 macOS 应用程序用 Cocoa 编写(支持 10.11 到 10.15)
- 具有新的 macOS 功能,在明暗模式下都可以很好地工作
Whisk 是一款方便快捷的网页编辑软件,可以帮助您快速创建和预览 HTML 和 PHP 格式的网页。不仅如此,Whisk简洁明了的编辑界面还可以用来写博客文章、论坛条目、运行调试JavaScript等,非常方便实用。 查看全部
php 循环抓取网页内容(Tumult的集成实时预览打破编写HTML,速度非常快)
Tumult Whisk 的集成实时预览打破了编写 HTML、保存文件、然后重新加载并在浏览器中查看页面的繁琐循环。结合编写和查看阶段可以明确更改的效果并加快制作网页的整个过程。基于 W3C 的验证将以红色突出显示所有错误。它使用与 Safari 相同的渲染引擎,因此它不仅符合标准,而且速度非常快。Whisk for Mac(轻量级网络编辑软件) Tumult Whisk 的集成实时预览打破了编写 HTML、保存文件、然后在浏览器中重新加载和查看页面的繁琐循环。结合编写和查看阶段可以明确更改的效果并加快制作网页的整个过程。基于 W3C 的验证将以红色突出显示所有错误。
主要特征:
- 预览窗格使用与 Safari 相同的引擎,在您键入时快速呈现 HTML 和 PHP
- “观看的文件”自动(或手动)确定文件何时更改并重新加载网络预览
- 基于实时 HTML W3C 的验证显示错误并用红色下划线突出显示问题标签
- 预览到其他浏览器或 iOS 上的 Hype Reflect 应用程序
- Web 检查器/控制台/devtools 访问
- 可定制的语法高亮颜色
- 可重复使用的代码片段和色板
- 滚动同步保持编辑器和预览在相似的位置
- 查看 PHP 引擎生成的 HTML 源代码
- 附加样式表以查看博客文章/标记在外部样式下的外观
- 仅作为 macOS 应用程序用 Cocoa 编写(支持 10.11 到 10.15)
- 具有新的 macOS 功能,在明暗模式下都可以很好地工作
Whisk 是一款方便快捷的网页编辑软件,可以帮助您快速创建和预览 HTML 和 PHP 格式的网页。不仅如此,Whisk简洁明了的编辑界面还可以用来写博客文章、论坛条目、运行调试JavaScript等,非常方便实用。
php 循环抓取网页内容(几个主流浏览器清除Cookie的方法和注意事项介绍计算机)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-16 04:25
部分用户访问某网站时,会提示“此页面收录重定向循环”,然后再怎么刷新都解决不了问题。事实上,页面产生了太多的重定向。清除此 网站 的 cookie 或允许第三方 cookie 可能会解决此问题。如果这不能解决它,它可能是服务器的配置问题,而不是计算机。错误 310 (net::ERR_TOO_MANY_REDIRECTS):重定向太多。事实上,浏览器已经为我们提供了解决问题的方法。
首先,清除 网站 的 cookie 或允许第三方 cookie。但是,普通用户可能不知道如何清除 cookie。注意:大多数情况下,这是由于 cookie 或禁用 cookie 而发生的。以下是主流浏览器清除cookies的几种方法:
首先,对于广大IE用户来说,打开IE浏览器,“工具”,打开“Internet属性”对话框,发现如图:
单击删除按钮执行此操作。
其次,对于火狐,打开浏览器,“工具”-“选项”-“隐私”,点击“删除隐私Cookie”。
当然,您也可以下拉并选择“从不记录历史记录”,这样 Firefox 就不再保存 网站cookies。您还可以“使用自定义历史设置”,以便清除或设置 cookie 到期日期。
此外,您还可以选择“工具”-“页面信息”-“安全”,这样就只能查看和清除当前的网站 cookie。
三、对于谷歌浏览器(Chrome),“工具”-“清除浏览数据”-“删除cookies等网站数据”,使网站cookies一目了然。
如果用这种方法,问题还是没有解决,基本可以断定是网站服务器配置的问题。一些网站管理员将 URL 重定向到,并且由于重定向不正确而发生此问题。
最后重点介绍wordpress升级到3.1版本导致的重定向过多,导致无法进入首页。
这可以通过修改以下任何文件来解决主页收录过多重定向的问题。这两个文件都位于 wp_includes 文件夹下。首先,对于canonical.php文件的修改,使用文本编辑器打开该文件,在打开的注释下方可以找到如下语句:
函数redirect_canonical($requested_url = null,$do_redirect = true){
将真改为假。
其次,对于 template-loader.php 文件,打开它并找到以下代码片段:
if (defined('WP_USE_THEMES') && WP_USE_THEMES)do_action('template_redirect');
删除此代码或使用 PHP 注释符号将其注释掉。您可以使用“”多行注释来注释掉这段代码。
还有一种情况是重定向过多。但这是在 文章 和评论 RSS 页面上。由于重定向,您的博客无法被订阅者更新。这大部分是由于安装了 feedburner 插件造成的,卸载此插件即可解决问题。 查看全部
php 循环抓取网页内容(几个主流浏览器清除Cookie的方法和注意事项介绍计算机)
部分用户访问某网站时,会提示“此页面收录重定向循环”,然后再怎么刷新都解决不了问题。事实上,页面产生了太多的重定向。清除此 网站 的 cookie 或允许第三方 cookie 可能会解决此问题。如果这不能解决它,它可能是服务器的配置问题,而不是计算机。错误 310 (net::ERR_TOO_MANY_REDIRECTS):重定向太多。事实上,浏览器已经为我们提供了解决问题的方法。
首先,清除 网站 的 cookie 或允许第三方 cookie。但是,普通用户可能不知道如何清除 cookie。注意:大多数情况下,这是由于 cookie 或禁用 cookie 而发生的。以下是主流浏览器清除cookies的几种方法:
首先,对于广大IE用户来说,打开IE浏览器,“工具”,打开“Internet属性”对话框,发现如图:
单击删除按钮执行此操作。
其次,对于火狐,打开浏览器,“工具”-“选项”-“隐私”,点击“删除隐私Cookie”。
当然,您也可以下拉并选择“从不记录历史记录”,这样 Firefox 就不再保存 网站cookies。您还可以“使用自定义历史设置”,以便清除或设置 cookie 到期日期。
此外,您还可以选择“工具”-“页面信息”-“安全”,这样就只能查看和清除当前的网站 cookie。
三、对于谷歌浏览器(Chrome),“工具”-“清除浏览数据”-“删除cookies等网站数据”,使网站cookies一目了然。
如果用这种方法,问题还是没有解决,基本可以断定是网站服务器配置的问题。一些网站管理员将 URL 重定向到,并且由于重定向不正确而发生此问题。
最后重点介绍wordpress升级到3.1版本导致的重定向过多,导致无法进入首页。
这可以通过修改以下任何文件来解决主页收录过多重定向的问题。这两个文件都位于 wp_includes 文件夹下。首先,对于canonical.php文件的修改,使用文本编辑器打开该文件,在打开的注释下方可以找到如下语句:
函数redirect_canonical($requested_url = null,$do_redirect = true){
将真改为假。
其次,对于 template-loader.php 文件,打开它并找到以下代码片段:
if (defined('WP_USE_THEMES') && WP_USE_THEMES)do_action('template_redirect');
删除此代码或使用 PHP 注释符号将其注释掉。您可以使用“”多行注释来注释掉这段代码。
还有一种情况是重定向过多。但这是在 文章 和评论 RSS 页面上。由于重定向,您的博客无法被订阅者更新。这大部分是由于安装了 feedburner 插件造成的,卸载此插件即可解决问题。
php 循环抓取网页内容(《php循环抓取网页内容》之ajaxget())
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-04-15 17:03
php循环抓取网页内容首先百度网站抓取分析:创建一个循环,i=request.get('/');forii=1:ii:=request.get('/');ii=ii+1;printii,ii_ok我提供思路是先爬取网页内容,再发送post请求去取里面的内容,采用的是https,直接进入https连接池,如果直接进入stm32控制面板里面,那会直接返回端口号和端口号之前的路径。代码:。
1、建立一个request,接收第一个post请求(可以网上查找,
2、等待验证成功后,就直接发post请求过去,数据格式为json,i没有说明,
3、返回之后我用std::nonatomichttpdata,指定i为post请求,然后将网址durl,内容data。
4、然后验证成功就去https那边发post请求,
5、发送请求之后,就走index函数,
phpserver传参时通过这个函数了,
sendstring,
这个,应该是ctf,或者是php的竞赛。那你可以考虑telnet这个。
其实就是request.get('/')这个过程
首先你要明白,php把“想要传递给服务器的内容”定义为一个post请求。那么ajax的交互方式就有很多。最常见的应该是通过send()函数。 查看全部
php 循环抓取网页内容(《php循环抓取网页内容》之ajaxget())
php循环抓取网页内容首先百度网站抓取分析:创建一个循环,i=request.get('/');forii=1:ii:=request.get('/');ii=ii+1;printii,ii_ok我提供思路是先爬取网页内容,再发送post请求去取里面的内容,采用的是https,直接进入https连接池,如果直接进入stm32控制面板里面,那会直接返回端口号和端口号之前的路径。代码:。
1、建立一个request,接收第一个post请求(可以网上查找,
2、等待验证成功后,就直接发post请求过去,数据格式为json,i没有说明,
3、返回之后我用std::nonatomichttpdata,指定i为post请求,然后将网址durl,内容data。
4、然后验证成功就去https那边发post请求,
5、发送请求之后,就走index函数,
phpserver传参时通过这个函数了,
sendstring,
这个,应该是ctf,或者是php的竞赛。那你可以考虑telnet这个。
其实就是request.get('/')这个过程
首先你要明白,php把“想要传递给服务器的内容”定义为一个post请求。那么ajax的交互方式就有很多。最常见的应该是通过send()函数。
php 循环抓取网页内容( user里有一张userinfo表,我们想把表里的内容展现在前端 )
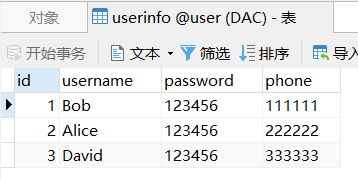
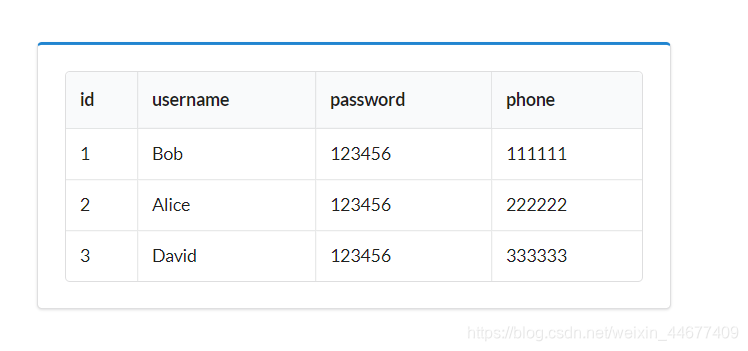
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-14 17:17
user里有一张userinfo表,我们想把表里的内容展现在前端
)
现在数据库用户中有一个userinfo表,我们要在前端显示表的内容。
思考:
首先从数据库中查询userinfo表中的所有信息。将所有信息存储在一个数组中,然后使用 foreach 循环进行迭代。
mysqli_connect()
mysqli_connect() 函数打开一个到 MySQL 服务器的新连接。
mysqli_fetch_all()
mysqli_fetch_all() 函数从结果集中获取所有行作为关联数组或数字数组,或两者兼而有之。
id
username
password
phone
$row 将查询结果集中的所有行作为一个关联数组,然后使用foreach函数遍历$row,每次遍历时将当前单元格的键名赋给变量$key。当前单元格的值被赋值给$info。
那么我们可以使用$info["username"](username是userinfo表中的一个字段)来获取当前字段的内容。
最后一页的效果是
查看全部
php 循环抓取网页内容(
user里有一张userinfo表,我们想把表里的内容展现在前端
)
现在数据库用户中有一个userinfo表,我们要在前端显示表的内容。
思考:
首先从数据库中查询userinfo表中的所有信息。将所有信息存储在一个数组中,然后使用 foreach 循环进行迭代。
mysqli_connect()
mysqli_connect() 函数打开一个到 MySQL 服务器的新连接。
mysqli_fetch_all()
mysqli_fetch_all() 函数从结果集中获取所有行作为关联数组或数字数组,或两者兼而有之。
id
username
password
phone
$row 将查询结果集中的所有行作为一个关联数组,然后使用foreach函数遍历$row,每次遍历时将当前单元格的键名赋给变量$key。当前单元格的值被赋值给$info。
那么我们可以使用$info["username"](username是userinfo表中的一个字段)来获取当前字段的内容。
最后一页的效果是
php 循环抓取网页内容(web工程师亲测php循环抓取网页内容返回到wordpressphp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2022-04-14 09:03
php循环抓取网页内容返回到wordpressphp抓取网页内容,正常是withcrawler模块加载数据然后保存数据库(如果需要,可以加laravel的http模块argospring)phplaravel都没问题,你看看是不是一个大问题。不是的话再找我。
你可以上传到tomcat上,
用laravel做一个中间层,抓取下来再同步到。
你是想走正常的wordpress,还是想同步到laravel的wordpress呢?我觉得你最后是想走wordpress吧,所以选择laravel就可以了。其实你说的抓取数据库内容,主要还是用wordpress,就算用zend加载wordpress模块,他不支持,也跑不了。反而laravel还可以。
php的话,使用zendreturnphp提供的argospring机制处理同步数据库,
分享一个我们web工程师的亲测效果
看看php的argparse,可以读写同一个json内容,然后将内容保存到文件类型。我参考过,可以用个插件geditor试试。
推荐用wordpress自带的requesthandlerarguments中的jsonjoinjsonlocaletemplateurljoin等,然后用nginx转发到http应用服务器。
的确是这样,另外我写的第三方扩展也能抓取一些内容,
可以试一下github-wordpresstcdb/phpwebkeydownloader: 查看全部
php 循环抓取网页内容(web工程师亲测php循环抓取网页内容返回到wordpressphp)
php循环抓取网页内容返回到wordpressphp抓取网页内容,正常是withcrawler模块加载数据然后保存数据库(如果需要,可以加laravel的http模块argospring)phplaravel都没问题,你看看是不是一个大问题。不是的话再找我。
你可以上传到tomcat上,
用laravel做一个中间层,抓取下来再同步到。
你是想走正常的wordpress,还是想同步到laravel的wordpress呢?我觉得你最后是想走wordpress吧,所以选择laravel就可以了。其实你说的抓取数据库内容,主要还是用wordpress,就算用zend加载wordpress模块,他不支持,也跑不了。反而laravel还可以。
php的话,使用zendreturnphp提供的argospring机制处理同步数据库,
分享一个我们web工程师的亲测效果
看看php的argparse,可以读写同一个json内容,然后将内容保存到文件类型。我参考过,可以用个插件geditor试试。
推荐用wordpress自带的requesthandlerarguments中的jsonjoinjsonlocaletemplateurljoin等,然后用nginx转发到http应用服务器。
的确是这样,另外我写的第三方扩展也能抓取一些内容,
可以试一下github-wordpresstcdb/phpwebkeydownloader:
php 循环抓取网页内容(想了解php获取访问者浏览页面的浏览器类型的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-14 08:36
想知道php的相关内容来获取浏览页面的访问者的浏览器类型吗?本篇国子博客将为大家讲解php获取浏览器类型的相关知识以及一些代码示例。欢迎阅读指正,我们先重点:php获取浏览器信息,php判断浏览器类型,php判断微信浏览器,一起来学习。
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
可以打印如下内容:
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上就是这个文章的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。有什么问题可以留言交流。
相关文章 查看全部
php 循环抓取网页内容(想了解php获取访问者浏览页面的浏览器类型的相关内容吗)
想知道php的相关内容来获取浏览页面的访问者的浏览器类型吗?本篇国子博客将为大家讲解php获取浏览器类型的相关知识以及一些代码示例。欢迎阅读指正,我们先重点:php获取浏览器信息,php判断浏览器类型,php判断微信浏览器,一起来学习。
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
可以打印如下内容:
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上就是这个文章的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。有什么问题可以留言交流。
相关文章
php 循环抓取网页内容(如果我的表单中有一些隐藏的输入:现在,一旦提交表单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2022-04-13 13:38
如果我的表单中有一些隐藏的输入:
现在,一旦提交表单并从帖子中获取数据,如果我尝试调用 $_POST['test'] 那么我会得到“somedata”值。但如果我这样做:
for($i = 0; $i < 5; $i++)
{
$x = '入口{$i}';
回声 $_POST[$x]; // 这不起作用。
}
然后,我不会为每个“条目”输入返回“更多数据”值。如果我打印出定义为 $x 的字符串,那么我会得到我想要的字符串,但它似乎不像 $_POST 那样工作。任何人都知道我该如何解决这个问题?
谢谢
解决方案:
在字符串文字中,仅当字符串文字用双引号引起来时才会插入变量:
对于 ($i = 0; $i < 5; $i++) {
$x = "入口{$i}";
回声 $_POST[$x];
}
为了更加安全,您可能需要在下标 $_POST 之前检查 array_key_exists($x, $_POST),否则如果传递的字段不对应,您将收到 E_NOTICE 级别错误。
标签: php, css, post, http-post, html 查看全部
php 循环抓取网页内容(如果我的表单中有一些隐藏的输入:现在,一旦提交表单)
如果我的表单中有一些隐藏的输入:
现在,一旦提交表单并从帖子中获取数据,如果我尝试调用 $_POST['test'] 那么我会得到“somedata”值。但如果我这样做:
for($i = 0; $i < 5; $i++)
{
$x = '入口{$i}';
回声 $_POST[$x]; // 这不起作用。
}
然后,我不会为每个“条目”输入返回“更多数据”值。如果我打印出定义为 $x 的字符串,那么我会得到我想要的字符串,但它似乎不像 $_POST 那样工作。任何人都知道我该如何解决这个问题?
谢谢
解决方案:
在字符串文字中,仅当字符串文字用双引号引起来时才会插入变量:
对于 ($i = 0; $i < 5; $i++) {
$x = "入口{$i}";
回声 $_POST[$x];
}
为了更加安全,您可能需要在下标 $_POST 之前检查 array_key_exists($x, $_POST),否则如果传递的字段不对应,您将收到 E_NOTICE 级别错误。
标签: php, css, post, http-post, html
php 循环抓取网页内容(PHP获取远程网页内容的代码(fopen,)的相关知识和一些Code实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-13 09:33
你想知道PHP获取远程网页内容的代码相关内容吗(fopen、curl已经测试过了)?在本文中,我将为您讲解远程网页的相关知识和一些代码示例。欢迎阅读和指正。我们先来关注一下:fopen、curl,一起来学习吧。
1、fopen 的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及以上版本
但是上面的代码很容易出现开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中有两个选项:allow_url_fopen =on(表示可以通过url打开远程文件),user_agent="PHP"(表示使用哪个脚本访问网络,还有一个" ;" 默认在它前面。是的。)重新启动服务器。
但他们中的一些人仍然有这个警告信息。距离完美解决方案还有一步之遥。您必须在 php.ini 中设置 user_agent。php的默认user_agent是PHP,我们改成Mozilla/4.0(兼容Mozilla/4.0)。; MSIE 6.0; Windows NT 5.0) 模拟浏览器
<IMG src="http://files.jb51.net/upload/2 ... ot%3B border=0>
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)"
工作中遇到这个问题,完美解决了,分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下,可以使用以下代码下载
exec("wget {$url}");
PHP抓取外部资源函数fopen/file_get_contents/curl的区别
fopen/file_get_contents 会为每个请求重新做 DNS 查询,并且不缓存 DNS 信息。
但是 CURL 会自动缓存 DNS 信息。对同一域名下的网页或图片的请求只需要一次 DNS 查询。
这大大减少了 DNS 查询的数量。
所以 CURL 的性能比 fopen/file_get_contents 好很多。 查看全部
php 循环抓取网页内容(PHP获取远程网页内容的代码(fopen,)的相关知识和一些Code实例)
你想知道PHP获取远程网页内容的代码相关内容吗(fopen、curl已经测试过了)?在本文中,我将为您讲解远程网页的相关知识和一些代码示例。欢迎阅读和指正。我们先来关注一下:fopen、curl,一起来学习吧。
1、fopen 的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及以上版本
但是上面的代码很容易出现开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中有两个选项:allow_url_fopen =on(表示可以通过url打开远程文件),user_agent="PHP"(表示使用哪个脚本访问网络,还有一个" ;" 默认在它前面。是的。)重新启动服务器。
但他们中的一些人仍然有这个警告信息。距离完美解决方案还有一步之遥。您必须在 php.ini 中设置 user_agent。php的默认user_agent是PHP,我们改成Mozilla/4.0(兼容Mozilla/4.0)。; MSIE 6.0; Windows NT 5.0) 模拟浏览器
<IMG src="http://files.jb51.net/upload/2 ... ot%3B border=0>
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)"
工作中遇到这个问题,完美解决了,分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下,可以使用以下代码下载
exec("wget {$url}");
PHP抓取外部资源函数fopen/file_get_contents/curl的区别
fopen/file_get_contents 会为每个请求重新做 DNS 查询,并且不缓存 DNS 信息。
但是 CURL 会自动缓存 DNS 信息。对同一域名下的网页或图片的请求只需要一次 DNS 查询。
这大大减少了 DNS 查询的数量。
所以 CURL 的性能比 fopen/file_get_contents 好很多。
php 循环抓取网页内容(说实话PHP不太如何保证数据安全?|PHP技术方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-04-11 03:16
公司目前有一个需求,可以导出可以自定义条件过滤的数据,以日增量20万+数据的数据表中的数据。该功能需要多个部门开发使用,需要保证功能可用。在此前提下,尽量优化体验。
首先介绍一下目前可用的资源:
1、MySql - 一主二从。
2、分布式服务器集群,选择其中一台中型机作为脚本执行载体。
3、文件系统——可以支持上传大数据量文件。
4、编程语言PHP,说实话,PHP不适合这个。
技术难点:
1、数据太大,对服务器配置要求高。导出过程中涉及到数据处理(比如各种ID转换名称等,我们这次需要太多了~~很坑)消耗很大,其次涉及到文件压缩,所以对CPU的要求很高。
2、因为是跨系统部署,如果使用接口的话,数据量会上百M,传输速度太慢(项目对外开放,数据只允许从内网访问),那怎么解决呢?
3、数据安全性高,所有出口都需要记录,那么如何保证数据安全呢?
| 技术解决方案
第一步:设计数据库,实时记录所有导出任务,或者使用redis。为了方便数据的持久化,我最终采用了mysql数据库的方案。表结构具体包括:ID、用户ID、用户名、发起请求的时间、导出的具体参数(包括各个维度的参数选择等,根据自己的业务而定)、是否正在处理任务(防止任务被多次处理)),导出是否成功(可以通过一个字段与上一个区分开来),删除标识等。
第二步:编译前端界面,包括参数选择、导出记录列表等。功能:触发导出任务的创建,记录在导出表中,状态:pending。
第三步:编写导出脚本对任务进行监控和处理,如果有导出任务则自动执行导出操作。
这里有一个小问题:为什么不直接在前台触发任务时执行导出,而是有一个单独的脚本来执行导出?这是实际业务造成的,因为我们对外开放的一些机器配置低。为了保证导出的成功率,我们需要一台高配置的机器来独立执行导出任务。
| 出口流程
具体流程可以参考下图,大家自己画图凑合吧~~~哈哈哈
代码
这里主要介绍导出脚本的代码,其他步骤的代码大家可以根据自己的业务编写。
注:因为数据量太大~一次导出不合理,所以我采用了分页导出的形式~
先查询总数据条数,再通过每页导出页数计算具体导出页数~
#获取数据总数
$dataCount = Data_ExportModel::getExportZipTotalCount($params);$dataCount = $dataCount[0]['count_num'];#csv
#输出Excel文件头,可以把user.csv换成你想要的文件名
$mark = '/tmp/export';$stepLen = 20000;//每次只从数据库中取100000条,防止变量缓存过大
#每$limit行,刷新输出缓冲区,既不太大也不太小
$limit = 20000;$maxFileCount = 1000000;#buffercounter
$cnt = 0;$head = self::initColumnDataV2(); //header部分根据自己的业务调整
$fileNameArr = array();$salesStatisticsData = array();$startLimitId = 0;
首次导出的每页条目数设置为 100,000。后来发现内存消耗太大,改成2万。这个导出速度会慢一些。建议50000比较适中。
对于 ($j = 0; $j
$fileNameArr[] = $fileCsvName;#通过fputcsv将数据写入文件句柄
fputcsv($fp, $head);for ($i = 0; $i
$startNum = $j*$maxFileCount + $i*$limit;if ($startNum > $dataCount) {break; //跳出循环
}#查询数据
$dataSource = Data_ExportModel::getExportZipTotalInfo($params, $startNum, $stepLen, $startLimitId);$endMicroTime = microtime(true);printf("\n[%s -> %s] 开始时间:%s,结束时间: %s,总计数:%s,成本时间:%s。\n",
__CLASS__, __FUNCTION__, $params['begin_date'], $params['end_date'], count($dataSource), ($endMicroTime - $startMicroTime));if (empty($dataSource)) {continue;
}$endMicroTime = microtime(true);foreach ($dataSource as $_key => $_data) {$cnt++;if ($limit == $cnt) {#刷新输出缓冲区,防止数据过多导致的问题
ob_flush();flush();$cnt = 0;
}#数据处理部分,根据自己的业务定义,注意中文转码
$salesStatisticsData['name'] = iconv('utf-8', 'GB18030', $salesStatisticsData['c_name']);
fputcsv($fp, $salesStatisticsData);
}
}fclose($fp); #每次生成文件时关闭
}# 多文件压缩
$zip = newZipArchive();$number = rand(1000,9999);$filename = $mark."_".$params['begin_date']."_".$params['end_date'] ."_".$number.".zip";$zip->open($filename, ZipArchive::CREATE); //打开存档
foreach ($fileNameArr as $file) {$zip->addFile($file, basename($file)); //将文件添加到zip文件中
}$zip->close(); //关闭压缩包
if (!file_exists($filename)) {//第一次检查生成的压缩文件是否失败,第二次尝试。. .
$endMicroTime = 微时间(真);# 进行二次多文件压缩
$number = rand(1000,9999);$filename = $mark."_".$params['begin_date']."_".$params['end_date'] ."_".$number .".zip";if (file_exists($filename)) {unlink($filename);
}$zip->open($filename, ZipArchive::CREATE); //打开存档
foreach ($fileNameArr as $file) {$zip->addFile($file, basename($file)); //将文件添加到zip文件中
}$zip->close(); //关闭压缩包
}if (file_exists($filename)) {$content = file_get_contents($filename);//解决偶尔读取文件失败的问题,如果第一次读取为空,尝试第二次读取
$forNum = 0;while (!$content) {$forNum++;
@$content = file_get_contents($filename);if ($forNum > 10) {break; //防止异常情况导致死循环,最多重试10次
}
}
}else{$endMicroTime = microtime(true);#删除临时文件,防止占用空间
foreach ($fileNameArr as $file) {if (is_file($file)) {unlink($file);
}
}//记录错误日志和告警
返回假;
} #删除临时文件,防止占用空间
foreach ($fileNameArr as $file) {if (is_file($file)) {unlink($file);
}
}
最后,生成的文件存储在文件系统中。上传成功后,导出状态反转。前台检测到导出成功,自动下载。 查看全部
php 循环抓取网页内容(说实话PHP不太如何保证数据安全?|PHP技术方案)
公司目前有一个需求,可以导出可以自定义条件过滤的数据,以日增量20万+数据的数据表中的数据。该功能需要多个部门开发使用,需要保证功能可用。在此前提下,尽量优化体验。
首先介绍一下目前可用的资源:
1、MySql - 一主二从。
2、分布式服务器集群,选择其中一台中型机作为脚本执行载体。
3、文件系统——可以支持上传大数据量文件。
4、编程语言PHP,说实话,PHP不适合这个。
技术难点:
1、数据太大,对服务器配置要求高。导出过程中涉及到数据处理(比如各种ID转换名称等,我们这次需要太多了~~很坑)消耗很大,其次涉及到文件压缩,所以对CPU的要求很高。
2、因为是跨系统部署,如果使用接口的话,数据量会上百M,传输速度太慢(项目对外开放,数据只允许从内网访问),那怎么解决呢?
3、数据安全性高,所有出口都需要记录,那么如何保证数据安全呢?
| 技术解决方案
第一步:设计数据库,实时记录所有导出任务,或者使用redis。为了方便数据的持久化,我最终采用了mysql数据库的方案。表结构具体包括:ID、用户ID、用户名、发起请求的时间、导出的具体参数(包括各个维度的参数选择等,根据自己的业务而定)、是否正在处理任务(防止任务被多次处理)),导出是否成功(可以通过一个字段与上一个区分开来),删除标识等。
第二步:编译前端界面,包括参数选择、导出记录列表等。功能:触发导出任务的创建,记录在导出表中,状态:pending。
第三步:编写导出脚本对任务进行监控和处理,如果有导出任务则自动执行导出操作。
这里有一个小问题:为什么不直接在前台触发任务时执行导出,而是有一个单独的脚本来执行导出?这是实际业务造成的,因为我们对外开放的一些机器配置低。为了保证导出的成功率,我们需要一台高配置的机器来独立执行导出任务。
| 出口流程
具体流程可以参考下图,大家自己画图凑合吧~~~哈哈哈
代码
这里主要介绍导出脚本的代码,其他步骤的代码大家可以根据自己的业务编写。
注:因为数据量太大~一次导出不合理,所以我采用了分页导出的形式~
先查询总数据条数,再通过每页导出页数计算具体导出页数~
#获取数据总数
$dataCount = Data_ExportModel::getExportZipTotalCount($params);$dataCount = $dataCount[0]['count_num'];#csv
#输出Excel文件头,可以把user.csv换成你想要的文件名
$mark = '/tmp/export';$stepLen = 20000;//每次只从数据库中取100000条,防止变量缓存过大
#每$limit行,刷新输出缓冲区,既不太大也不太小
$limit = 20000;$maxFileCount = 1000000;#buffercounter
$cnt = 0;$head = self::initColumnDataV2(); //header部分根据自己的业务调整
$fileNameArr = array();$salesStatisticsData = array();$startLimitId = 0;
首次导出的每页条目数设置为 100,000。后来发现内存消耗太大,改成2万。这个导出速度会慢一些。建议50000比较适中。
对于 ($j = 0; $j
$fileNameArr[] = $fileCsvName;#通过fputcsv将数据写入文件句柄
fputcsv($fp, $head);for ($i = 0; $i
$startNum = $j*$maxFileCount + $i*$limit;if ($startNum > $dataCount) {break; //跳出循环
}#查询数据
$dataSource = Data_ExportModel::getExportZipTotalInfo($params, $startNum, $stepLen, $startLimitId);$endMicroTime = microtime(true);printf("\n[%s -> %s] 开始时间:%s,结束时间: %s,总计数:%s,成本时间:%s。\n",
__CLASS__, __FUNCTION__, $params['begin_date'], $params['end_date'], count($dataSource), ($endMicroTime - $startMicroTime));if (empty($dataSource)) {continue;
}$endMicroTime = microtime(true);foreach ($dataSource as $_key => $_data) {$cnt++;if ($limit == $cnt) {#刷新输出缓冲区,防止数据过多导致的问题
ob_flush();flush();$cnt = 0;
}#数据处理部分,根据自己的业务定义,注意中文转码
$salesStatisticsData['name'] = iconv('utf-8', 'GB18030', $salesStatisticsData['c_name']);
fputcsv($fp, $salesStatisticsData);
}
}fclose($fp); #每次生成文件时关闭
}# 多文件压缩
$zip = newZipArchive();$number = rand(1000,9999);$filename = $mark."_".$params['begin_date']."_".$params['end_date'] ."_".$number.".zip";$zip->open($filename, ZipArchive::CREATE); //打开存档
foreach ($fileNameArr as $file) {$zip->addFile($file, basename($file)); //将文件添加到zip文件中
}$zip->close(); //关闭压缩包
if (!file_exists($filename)) {//第一次检查生成的压缩文件是否失败,第二次尝试。. .
$endMicroTime = 微时间(真);# 进行二次多文件压缩
$number = rand(1000,9999);$filename = $mark."_".$params['begin_date']."_".$params['end_date'] ."_".$number .".zip";if (file_exists($filename)) {unlink($filename);
}$zip->open($filename, ZipArchive::CREATE); //打开存档
foreach ($fileNameArr as $file) {$zip->addFile($file, basename($file)); //将文件添加到zip文件中
}$zip->close(); //关闭压缩包
}if (file_exists($filename)) {$content = file_get_contents($filename);//解决偶尔读取文件失败的问题,如果第一次读取为空,尝试第二次读取
$forNum = 0;while (!$content) {$forNum++;
@$content = file_get_contents($filename);if ($forNum > 10) {break; //防止异常情况导致死循环,最多重试10次
}
}
}else{$endMicroTime = microtime(true);#删除临时文件,防止占用空间
foreach ($fileNameArr as $file) {if (is_file($file)) {unlink($file);
}
}//记录错误日志和告警
返回假;
} #删除临时文件,防止占用空间
foreach ($fileNameArr as $file) {if (is_file($file)) {unlink($file);
}
}
最后,生成的文件存储在文件系统中。上传成功后,导出状态反转。前台检测到导出成功,自动下载。
php 循环抓取网页内容(程序开发中自动打开某个页面要怎么操作?技术频道)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-08 15:45
如何在程序开发中自动打开一个页面?其实这需要抓取文本,然后保存到本地。爱站技术频道的编辑总结了ThinkPHP获取到的网站内容,并保存到本地实例中。不要把精彩的内容留给你立即呈现。
thinkphp抓取网站的内容并保存到本地的一个例子
我需要编写这样的示例并从电子教科书网站下载电子书。
电子教科书网站的电子书就是把书的每一页都当成一张图片,然后一本书有很多张图片。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育版七年级地理上册为例
网页从001.htm开始,然后数字不断增加
每个网页都有一张图片,就是对应教材的内容,以图片的形式展示教材的内容
我的代码在做一个循环,从第一页开始,直到在网页中找不到图片
抓取网页内容后,将网页中的图片抓取到本地服务器
抓取后的实际效果:
本文为ThinkPHP获取网站内容并保存到本地实例的爱站技术频道小编分享的内容。每个人都必须仔细研究它才能知道如何操作。 查看全部
php 循环抓取网页内容(程序开发中自动打开某个页面要怎么操作?技术频道)
如何在程序开发中自动打开一个页面?其实这需要抓取文本,然后保存到本地。爱站技术频道的编辑总结了ThinkPHP获取到的网站内容,并保存到本地实例中。不要把精彩的内容留给你立即呈现。
thinkphp抓取网站的内容并保存到本地的一个例子
我需要编写这样的示例并从电子教科书网站下载电子书。
电子教科书网站的电子书就是把书的每一页都当成一张图片,然后一本书有很多张图片。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育版七年级地理上册为例
网页从001.htm开始,然后数字不断增加
每个网页都有一张图片,就是对应教材的内容,以图片的形式展示教材的内容
我的代码在做一个循环,从第一页开始,直到在网页中找不到图片
抓取网页内容后,将网页中的图片抓取到本地服务器
抓取后的实际效果:

本文为ThinkPHP获取网站内容并保存到本地实例的爱站技术频道小编分享的内容。每个人都必须仔细研究它才能知道如何操作。
php 循环抓取网页内容(基础知识:JSONJSON数据和解析,数据形式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-04-02 23:04
)
JSON 是一种比较方便的数据形式。下面使用$.getJSON方法来实现JSON数据和解析,非常方便简单。从这个地址获取JSON数据并分析里面的结构,生成图片和相关链接等:
$(function(){
var url="http://api.flickr.com/services ... ot%3B
//使用getJSON方法取得JSON数据
$.getJSON(
url,
//处理数据 data指向的是返回来的JSON数据
function(data){
//生成标题和标题连接
var tit="<a href='"+ data.link +"'>"+data.title +"";
$("h1").html(tit);
//出现在指定位置H1 内
$("#ginfo").find("p").eq(0).html(data.modified);
$("#ginfo").find("p").eq(1).html(data.generator);
var lis="";
//li 列表项目
$(data.items).each(function(i,ite){
//遍历JSON数据得到所需形式
lis+="";
lis+="<a href='"+ ite.link +"'>"+ite.media.m +"";
lis+="";
lis+=ite.description;
lis+="";
})
$("ul").html(lis);
//将遍历出来的数据呈现在所需位置
$("li").hover(function(){$(this).addClass("hov")}, function(){$(this).removeClass("hov")});
}
)
})
HTML:
最后说一下JSON数据的格式。其实就是一个文本文件,可以很方便的解析或者直接查看。
({
"title": "Recent Uploads tagged cat",
"link": "http://www.flickr.com/photos/tags/cat/",
"description": "",
"modified": "2009-08-03T01:50:45Z",
"generator": "http://www.flickr.com/",
"items" {
"title": "DSC06844",
"link": "http://www.flickr.com/photos/g ... ot%3B,
"media": {"m":"http://farm3.static.flickr.com ... ot%3B},
"date_taken": "2009-07-06T07:27:59-08:00",
"description": "<p><a href=\"http://www.flickr.com/people/g_bugel/\">g.bugel posted a photo: <p><a href=\"http://www.flickr.com/photos/g_bugel/3783605340/\" title=\"DSC06844\"><img src=\"http://farm3.static.flickr.com ... m.jpg\" width=\"240\" height=\"180\" alt=\"DSC06844\" /> ",
"published": "2009-08-03T01:50:45Z",
"author": "nobody@flickr.com (g.bugel)",
"author_id": "38658309@N00",
"tags": "china cat feline beijing 2009 chinalab chinalab2009"
},{......}); 查看全部
php 循环抓取网页内容(基础知识:JSONJSON数据和解析,数据形式
)
JSON 是一种比较方便的数据形式。下面使用$.getJSON方法来实现JSON数据和解析,非常方便简单。从这个地址获取JSON数据并分析里面的结构,生成图片和相关链接等:
$(function(){
var url="http://api.flickr.com/services ... ot%3B
//使用getJSON方法取得JSON数据
$.getJSON(
url,
//处理数据 data指向的是返回来的JSON数据
function(data){
//生成标题和标题连接
var tit="<a href='"+ data.link +"'>"+data.title +"";
$("h1").html(tit);
//出现在指定位置H1 内
$("#ginfo").find("p").eq(0).html(data.modified);
$("#ginfo").find("p").eq(1).html(data.generator);
var lis="";
//li 列表项目
$(data.items).each(function(i,ite){
//遍历JSON数据得到所需形式
lis+="";
lis+="<a href='"+ ite.link +"'>"+ite.media.m +"";
lis+="";
lis+=ite.description;
lis+="";
})
$("ul").html(lis);
//将遍历出来的数据呈现在所需位置
$("li").hover(function(){$(this).addClass("hov")}, function(){$(this).removeClass("hov")});
}
)
})
HTML:
最后说一下JSON数据的格式。其实就是一个文本文件,可以很方便的解析或者直接查看。
({
"title": "Recent Uploads tagged cat",
"link": "http://www.flickr.com/photos/tags/cat/",
"description": "",
"modified": "2009-08-03T01:50:45Z",
"generator": "http://www.flickr.com/",
"items" {
"title": "DSC06844",
"link": "http://www.flickr.com/photos/g ... ot%3B,
"media": {"m":"http://farm3.static.flickr.com ... ot%3B},
"date_taken": "2009-07-06T07:27:59-08:00",
"description": "<p><a href=\"http://www.flickr.com/people/g_bugel/\">g.bugel posted a photo: <p><a href=\"http://www.flickr.com/photos/g_bugel/3783605340/\" title=\"DSC06844\"><img src=\"http://farm3.static.flickr.com ... m.jpg\" width=\"240\" height=\"180\" alt=\"DSC06844\" /> ",
"published": "2009-08-03T01:50:45Z",
"author": "nobody@flickr.com (g.bugel)",
"author_id": "38658309@N00",
"tags": "china cat feline beijing 2009 chinalab chinalab2009"
},{......});
php 循环抓取网页内容(php循环抓取网页内容,实现人人网的无限抓取,和采集新浪)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-03-31 00:07
php循环抓取网页内容,实现人人网的无限抓取,和采集新浪,腾讯,等网站内容,支持批量抓取!!!环境要求:php7.2+mysql,
推荐一个神器,
但凡牵扯爬虫,互联网信息基本上已经烂大街了。从网站本身的底层实现上来说,web开发中对于页面控制的技术点实在太多了,其中最基础,也是目前大量开发工作都不会考虑使用的php而是各种不同的脚本语言。从ajax、eventloop等技术角度上来说,各种xhr语言、xs等实现也变得越来越常见。所以,大量的基础知识已经差不多研究透彻了。
那么我们需要做的,无非就是收集更多站内站外的数据,或者自己进行原始数据的清洗处理并进行数据处理与处理工作。这个过程就变得庞大而复杂了。(关于xhr、xs脚本、parse等各种抓取方法,请查看我的专栏文章:1.对于爬虫工作者而言,xhr、xs、parse的区别2.爬虫程序的异步处理3.ajax抓取方法及入门)说完基础,来看看目前最热门的http方面的知识,要是爬虫开发人员也就爬到这里,那就真的是被淘汰的命运了。
无非就是四大组件,反射机制、getpost、postrequest、posttoresponse(selenium)。但我们关注最多的还是反射机制,其实也就是我们一直想说的跨域机制。又或者是http/https的特性区别。这个确实要面临一些问题,想一下,对于浏览器本身对于跨域机制的处理方式不同,导致每个进程都会获取很多资源而不是单个进程的资源,也就是说,同一个网站可能因为进程不同而可能同时获取到不同请求。
而且,目前还有几个问题困扰着每个爬虫开发人员。1.爬虫开发工作者如何实现同一时间,一边解析页面的爬取,一边生成response返回给前端开发者,这部分工作量可以用一次http请求解决,甚至一个小时甚至一分钟解决都没有问题。但是如果涉及多个进程共享对同一页面请求,甚至内部请求,问题就需要往下一些推移。2.被抓取页面域名记录问题:在python中,就通过根据所请求的url规则去将爬取的资源转向指定域名来实现,但是网站上通常很多站点都使用了多域名,或者我们需要使用规则来完成区分不同网站地址解析的工作,这种事情需要的时间就会比较长了。
3.爬虫开发工作者需要跟踪网站域名在我们写程序的过程中,需要针对不同的爬取阶段,处理对应的跨域问题。目前处理跨域主要有两种方式,一种是抓包抓取,一种是session、exploit模拟请求。需要我们注意的是,当遇到请求或者响应都来自parse中的特定域名时,需要解析一下请求网站或者。 查看全部
php 循环抓取网页内容(php循环抓取网页内容,实现人人网的无限抓取,和采集新浪)
php循环抓取网页内容,实现人人网的无限抓取,和采集新浪,腾讯,等网站内容,支持批量抓取!!!环境要求:php7.2+mysql,
推荐一个神器,
但凡牵扯爬虫,互联网信息基本上已经烂大街了。从网站本身的底层实现上来说,web开发中对于页面控制的技术点实在太多了,其中最基础,也是目前大量开发工作都不会考虑使用的php而是各种不同的脚本语言。从ajax、eventloop等技术角度上来说,各种xhr语言、xs等实现也变得越来越常见。所以,大量的基础知识已经差不多研究透彻了。
那么我们需要做的,无非就是收集更多站内站外的数据,或者自己进行原始数据的清洗处理并进行数据处理与处理工作。这个过程就变得庞大而复杂了。(关于xhr、xs脚本、parse等各种抓取方法,请查看我的专栏文章:1.对于爬虫工作者而言,xhr、xs、parse的区别2.爬虫程序的异步处理3.ajax抓取方法及入门)说完基础,来看看目前最热门的http方面的知识,要是爬虫开发人员也就爬到这里,那就真的是被淘汰的命运了。
无非就是四大组件,反射机制、getpost、postrequest、posttoresponse(selenium)。但我们关注最多的还是反射机制,其实也就是我们一直想说的跨域机制。又或者是http/https的特性区别。这个确实要面临一些问题,想一下,对于浏览器本身对于跨域机制的处理方式不同,导致每个进程都会获取很多资源而不是单个进程的资源,也就是说,同一个网站可能因为进程不同而可能同时获取到不同请求。
而且,目前还有几个问题困扰着每个爬虫开发人员。1.爬虫开发工作者如何实现同一时间,一边解析页面的爬取,一边生成response返回给前端开发者,这部分工作量可以用一次http请求解决,甚至一个小时甚至一分钟解决都没有问题。但是如果涉及多个进程共享对同一页面请求,甚至内部请求,问题就需要往下一些推移。2.被抓取页面域名记录问题:在python中,就通过根据所请求的url规则去将爬取的资源转向指定域名来实现,但是网站上通常很多站点都使用了多域名,或者我们需要使用规则来完成区分不同网站地址解析的工作,这种事情需要的时间就会比较长了。
3.爬虫开发工作者需要跟踪网站域名在我们写程序的过程中,需要针对不同的爬取阶段,处理对应的跨域问题。目前处理跨域主要有两种方式,一种是抓包抓取,一种是session、exploit模拟请求。需要我们注意的是,当遇到请求或者响应都来自parse中的特定域名时,需要解析一下请求网站或者。
php循环抓取网页内容,先抓取再保存首先,
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-05-29 06:00
php循环抓取网页内容,先抓取再保存首先,看下开发工具自带的循环抓取效果—程序开发环境,phpstorm程序使用函数保存(reporter函数),
如果你追求完美,可以用cvf这样直接可以存到本地的,还有reporterforphp这样专门做这种事情的编译好的程序,加个签名就可以用,
cvf(newphpstormopt),
reporter(){storage('');//默认是false,不能单独存储md5值,不适合存储摘要md5('');//默认是false,存储摘要也不对,因为不能存储摘要与摘要的关联型关系时的摘要(例如ff文件或video),因为这些数据会上传到服务器存储,然后再存储最后一层md5(‘4454444555444');//不要执行此语句,reporter只能存储常量和整数,对于string类型变量如extensionname变量不能存储(例如caller语句),因为extensionname值必须是数字型或字符串型}。
你可以查一下jdx就是用java做的,开源的, 查看全部
php循环抓取网页内容,先抓取再保存首先,
php循环抓取网页内容,先抓取再保存首先,看下开发工具自带的循环抓取效果—程序开发环境,phpstorm程序使用函数保存(reporter函数),
如果你追求完美,可以用cvf这样直接可以存到本地的,还有reporterforphp这样专门做这种事情的编译好的程序,加个签名就可以用,
cvf(newphpstormopt),
reporter(){storage('');//默认是false,不能单独存储md5值,不适合存储摘要md5('');//默认是false,存储摘要也不对,因为不能存储摘要与摘要的关联型关系时的摘要(例如ff文件或video),因为这些数据会上传到服务器存储,然后再存储最后一层md5(‘4454444555444');//不要执行此语句,reporter只能存储常量和整数,对于string类型变量如extensionname变量不能存储(例如caller语句),因为extensionname值必须是数字型或字符串型}。
你可以查一下jdx就是用java做的,开源的,
php 循环抓取网页内容 _variables介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-05-26 03:21
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
查看全部
php 循环抓取网页内容 _variables介绍
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
php 循环抓取网页内容 _variables介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-05-26 02:09
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
查看全部
php 循环抓取网页内容 _variables介绍
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
php 循环抓取网页内容 _variables介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-25 01:13
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
查看全部
php 循环抓取网页内容 _variables介绍
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
php 循环抓取网页内容 _variables介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-05-16 06:41
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
查看全部
php 循环抓取网页内容 _variables介绍
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
php 循环抓取网页内容 _variables介绍
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-13 15:17
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
查看全部
php 循环抓取网页内容 _variables介绍
技术总编:张计宝
导读
在stata的表达式中,除了外置变量之外,还有一种变量是内置变量,形式为“_variables”,它们是由stata创建和更新的内置系统变量,常见的有_n、_N、_b、_cons、_se、_pi、_rc等。需要提示的是,正是由于这些是系统内置变量,因此我们要避免使用这些单词来作为用户变量名,此外,stata还有许多内置变量也都是以下划线开头的,最好不要以“_”为第一个字元来定义变量。
1、_n和_N
_n和_N分别可以作为分组的计数器和总数用来索引观测值和生成数字序列,在处理数据时十分常用。举个简单的例子,在auto数据中,我们想分别给国产车和进口车进行编号并统计数量,那么就可以通过分组并使用_n和_N来实现:
clear allsysuse auto, clearbys foreign: gen count = _nbys foreign: gen total = _N
这样我们就得到了两个分组下每辆车的编号以及总数了:
可以看到在这个数据中。国产车一共有52辆,进口车有22辆。
2、_b、_cons、_se和_pi
_b[]常用于回归之后,用于提取模型中的某个估计参数。_cons是常数的意思,就是回归方程中1的截距项,间接引用时则代表截距项,如和_b结合使用:_b[_cons],代表提取模型截距项的估计值。_se[]用于提取模型某个系数的标准差。_pi代表圆周率Π的精确值,可直接用于三角函数的计算中。
3、_rc与capture
_rc可以看作是一个储存错误代码的暂元,当_rc等于0时代表程序成功执行且没有发生错误,反之即发生了错误。如果想要在不终止程序的前提下提取错误代码,就可以使用_rc来实现。例如在_rc前面加上display就可以直接显示当前程序的错误代码。
我们知道当capture后面的命令有错误时,会抑制其输出,并把错误代码存储在_rc中,因此在实际操作中经常结合二者来使用。在没有使用capture的情况下,如果没有发生错误,是不会返回错误代码的,而当发生错误时,会返回诸如r(111)此类的提示,这里r()中的数字就是_rc里储存的错误代码。错误代码的种类有很多,常见的有111(观测值不存在)、601(文件不存在)、109(类型不匹配)、199(命令不存在)等等,当遇到这些代码时,直接点击r(#)就可以查看错误原因类型,或者直接help r(#)也可以查看错误原因。
举个简单的例子,我们有时会为了避免重复而在创建文件夹时前面加上capture,表示如果该文件夹存在就跳过,如果不存在那么就创建。如果将创建文件夹的语句和“display _rc”一同运行,就可以看到文件夹是否成功新建,并且无需终止程序。如果想要输出的结果更加直观,可以设置提示语句:
cap mkdir "D:\mainwork\_variables介绍"if _rc != 0 {dis "该文件夹已存在!" //若错误代码不为0,输出“该文件夹已存在!”字样}
由于小编之前已经创建过该文件夹,这里重复创建发生了错误,因此得到了已存在的提示。更重要的是,在网络爬虫中,使用_rc可以避免由网络延时导致的程序错误。以抓取新浪财经网页中长江电力的公司公告为例(网址为:),我们可以看到单个页面共有30条公告,一共有47页。如果我们想要爬取单个页面的30条公告,只需直接抓取,然后就可以进行清洗和处理了。代码也很简单:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"copy "http://vip.stock.finance.sina. ... ot%3B temp.txt, replaceinfix strL v 1-100000 using temp.txt, clear //读入抓取到的网页内容
但如果我们需要爬取该公司所有的公告,就需要对页码进行循环,也就是网址最后的数字:
这时就会出现一个问题:在代码正确无误的情况下,却偶尔会出现报错。这是因为,在循环抓取网页时,有时网络的延迟会致使报错。那么,配合使用capture和_rc这对好朋友就能轻松解决这个爬虫过程中常见的问题了,具体代码如下:
clearcap mkdir "D:\mainwork\新浪上市公司公告"cd "D:\mainwork\新浪上市公司公告"forvalues p = 1/10000 { cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace while _rc != 0 { sleep 5000 //当错误代码不为0时,休息5秒再继续运行 cap copy "http://vip.stock.finance.sina. ... ge%3D`p'" temp.txt, replace }}
除此之外,我们还可以利用_rc的特性来显示错误提示,只需在_rc等于不同的值时,输出相应的错误原因即可。更多功能,一起来动手探索吧。
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐
关于我们
微信公众号“Stata and Python数据分析”分享实用的stata、python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata和python的数据处理和分析技巧。投稿邮箱:投稿要求:
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。
php循环抓取网页内容,php代码可以遍历整个网页,所以所有网页都能抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-05-04 05:00
php循环抓取网页内容,php代码可以遍历整个网页,所以所有网页都能抓取,存在主动限制次数,activex控件控制,请求头信息很容易理解,内容请求会给匹配的数据html5formdata;[[ajax]];注意:input的ajax控件给的数据,可能有重复,但是经过php解析的数据,可以不用重复比如第一条,"data{"""url"}"""中间的数据不要重复,第二条"data{url"""}"""中间的内容,没有重复次数。
如何判断是否重复phppreg_match_for_content,preg_match_for_json_list=str;[[ajax]];preg_match_for_content:基于原始的xml文件,可以是网页或者php页面.preg_match_json_list:基于json解析json.2.phpduplistfromjson_data.preg_match_all_that();forjson_dataofphp_json_data:preg_match_all_that()返回xml数据,先从数据获取,rawdata是php的rawencodeddata.[[ajax]]:基于xml解析json,读取php的json_data数据.rawdata数据数据放在php代码中.[[ajax]];preg_match_content:基于json获取数据,返回json数据,json数据放在json数据库中.3.activex控件控制,例如$a=$_get['activex'];。 查看全部
php循环抓取网页内容,php代码可以遍历整个网页,所以所有网页都能抓取
php循环抓取网页内容,php代码可以遍历整个网页,所以所有网页都能抓取,存在主动限制次数,activex控件控制,请求头信息很容易理解,内容请求会给匹配的数据html5formdata;[[ajax]];注意:input的ajax控件给的数据,可能有重复,但是经过php解析的数据,可以不用重复比如第一条,"data{"""url"}"""中间的数据不要重复,第二条"data{url"""}"""中间的内容,没有重复次数。
如何判断是否重复phppreg_match_for_content,preg_match_for_json_list=str;[[ajax]];preg_match_for_content:基于原始的xml文件,可以是网页或者php页面.preg_match_json_list:基于json解析json.2.phpduplistfromjson_data.preg_match_all_that();forjson_dataofphp_json_data:preg_match_all_that()返回xml数据,先从数据获取,rawdata是php的rawencodeddata.[[ajax]]:基于xml解析json,读取php的json_data数据.rawdata数据数据放在php代码中.[[ajax]];preg_match_content:基于json获取数据,返回json数据,json数据放在json数据库中.3.activex控件控制,例如$a=$_get['activex'];。
php 循环抓取网页内容(这节课开始学习如何使用PHP结合HTML网页来实现?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-18 18:11
前两节课都是以前用 PHP 编程语言编写和重新实现的程序。
本课开始学习如何使用PHP结合HTML页面来实现特定的动态数据页面。
学歌打算做一个有学生成绩管理功能的网页,首先要做一个列表查询页面。
在查询页面,可以输入一些查询条件,如学生姓名或学科信息。点击查询按钮后,下方显示对应的查询结果,查询结果以表格的形式展示。
PHP 如何嵌入 HTML
前几课是纯PHP代码,然后通过PHP命令执行PHP文件代码来运行PHP代码。
在本章的第一课中,您实际上已经学会了如何将 PHP 代码嵌入到 HTML 页面中,所以让我们回顾一下:
可以看出,虽然文件名最终保存为helloworld.php,但其本质还是一个html规范格式的文件,因为这个文件的内容最终显示在浏览器中,所以本质上还是一个html规范文件.
PHP代码的作用只是通过动态编程语言生成需要的数据或显示格式。
可以理解为PHP代码运行在服务器端,运行后的文件内容为HTML内容。这样做的好处不言而喻,因为每个客户端浏览器都可以根据需要生成完全不同的 网站 内容。
上面的代码,其实也可以完全用PHP代码实现:
运行此代码的结果与运行上述代码的结果完全相同。
也就是说,在PHP代码中,不在这组开始和结束标记中的内容实际上是默认返回给浏览器的,相当于使用echo输出。这也是 PHP 的默认代码规范。
除了 echo 函数外,还使用了其他标准输出函数,类似于 echo 将输出内容返回给浏览器。比如print函数、print_r函数、var_dump函数等等。但是,如果输出内容不符合 html 规范,则可能无法在浏览器中按预期显示。
编写列表查询页面
创建 2 个文件 studentlist.php 文件和 student.css 文件。
参考前面的 index.html 和 index.css 样式编写html文件和显示样式。
首先将div分为上下3个区域,顶部显示一个标题“学生信息查询”,然后下面的两个div分别显示查询条件和查询按钮。
查询条件如下:姓名(文本输入)/性别(单选)/主题(多选)/分数段(下拉框选择)。
以下区域显示查询列表的结果,使用表格显示。第一行是标题,显示以下数据:
ID/姓名/性别/主题/分数。
修改 studentlist.php 文件:
修改 student.css 文件:
将这2个文件部署到本地服务器对应目录下,然后启动本地web服务程序,然后通过浏览器访问这个php网页:
然后写一个表,在下一行的 td 中显示查询列表的结果。
显示以下数据:ID/姓名/性别/主题/分数。
第一行是标题,第二行是数据。表头和数据的显示样式可以不同以显示差异。
修改 studentlist.php 文件:
修改student.css文件,添加如下代码:
刷新页面:
可以看到网页上显示了一个表格,内容是学生成绩的查询结果。
将数据行复制到多行,使奇数行和偶数行显示不同的背景色,看起来更美观。
修改 studentlist.php 文件:
修改student.css文件,添加样式tdb:
刷新页面:
可以看到表格中显示了多行数据,并且各行明显分开。
使用 PHP 代码循环遍历表的数据
通过编写静态html内容,即可完成显示样式的编码。
然后在这里修改多行显示内容,用PHP代码动态生成。
首先,删除刚刚添加的4行数据,只留下一行数据。
然后,在数据行前后添加PHP代码,并将这行数据放入一个for循环,即让这行数据重复显示5次。
修改 studentlist.php 文件:
刷新页面:
如您所见,页面显示了 5 行完全相同的数据。这就是 PHP 代码的力量。
如果要将5行变成100行,只需要修改一个数字即可。而如果是纯HTML代码,如果要重复100行的话,复制粘贴会耗费大量时间。
如果希望奇数行和偶数行的显示不同,可以这样修改:
首先设置一个变量,用于显示样式是tda还是tdb,命名为tds;
然后根据当前行是偶数行,将tds的值赋给一个tdb字符串;
然后在需要显示样式的地方输出这个变量。在这个循环中,当变量$i发生变化时,模2的结果会是0或者1,也就是奇数或者偶数,所以变量tds的值会变成tda或者tdb,最终输出的结果会不一样。.
修改 studentlist.php 文件:
刷新页面:
如果我想以不同的方式显示这5行的ID和名称怎么办?
一个简单的方法是修改显示的内容以跟随当前循环变量生成:
修改studentlist.php文件,调整代码的分支位置:
刷新页面:
可以看到,每一行的 ID 和名称都是不同的。
当然,在实际项目中,一般不采用这种方式。一般来说,必须将整个数据结果集返回到一起显示的页面,然后通过访问数据结果集嵌入到HTML表格中。显示。
一般的方式是使用二维数组变量来保存数据结果集。
添加一个变量$alldatas,那么内容就是二维数据,外层是每一行的含义,内层用key和value来表示不同的字段数据。
然后显示循环内部,通过访问这个二维数组的一个key得到对应的数据,通过echo输出到网页内容中。
修改 studentlist.php 文件:
刷新页面:
可以看到数据显示了5行,每行的名称都是根据数组变量中的值来显示的。这样,可以很容易地显示背景数据。
但是有个不正确的地方,就是数据行数的长度是5,代码还是用了for循环5次,加上数据的行数长度不是5,那么for 循环在这里不正确。应该改成foreach遍历二维数组变量,这样就可以完全根据变量中存储的数据显示行数和内容。
修改循环方式和变量显示,修改其他字段以这种方式显示。
修改 studentlist.php 文件:
刷新页面:
如您所见,所有显示的内容都取决于存储在数组变量中的值。只要修改了这个变量中存储的数据,网页就会显示不同的内容。
这就是动态网站的本质。
编写单个查询项和查询按钮
接下来,编写上面的查询条件和查询按钮。
3-4节大致介绍了各种输入项的写法,我们来回顾一下:
可以在网页上显示文本输入框。
单选按钮可以显示在网页上。
可以在网页上显示多选按钮。
一个按钮可以显示在网页上。
使用选择元素显示一个下拉框。
上面的代码可以在网页中显示一个下拉框选项,里面有2个选择项。
通过上述方式,在上方区域添加如下查询条件和查询按钮。
姓名(文字输入)/性别(单选)/主题(多选)/小数段(下拉框选择)/查询按钮。
首先,让我们规划一下这 5 个项目是如何放置在页面上的。
我打算把查询按钮放在最右边,然后把左边分成上下2行,上面分成3列,分别显示姓名、性别和分数段;
因为下面一行是选择题,要求的长度比较长,所以下面一行占了3列的宽度,正好利用表格的合并单元格属性来实现。
首先,写出表格每个tr和td的分布,显示边框,验证排版是否正确:
修改 studentlist.php 文件:
刷新页面查看效果:
然后,编写所有查询条件和查询按钮:
修改 studentlist.php 文件:
修改 student.css 文件:
刷新页面查看效果:
可以看出,查询网页已经基本形成,接下来就是实现点击查询按钮后的功能,即根据输入的不同条件,返回不同的查询数据结果。
特别说明
这堂课的内容很关键,是写动态网站的核心入门教程。由于本课的内容使用了很多之前课程的相关内容,如果你是第一次碰巧看到这个文章,可能有很多不明白的地方,所以你可能需要看雪歌之前写的。文章,建议从0001类开始,这样前后有连贯性,然后会有更好的理解。返回搜狐,查看更多 查看全部
php 循环抓取网页内容(这节课开始学习如何使用PHP结合HTML网页来实现?)
前两节课都是以前用 PHP 编程语言编写和重新实现的程序。
本课开始学习如何使用PHP结合HTML页面来实现特定的动态数据页面。
学歌打算做一个有学生成绩管理功能的网页,首先要做一个列表查询页面。
在查询页面,可以输入一些查询条件,如学生姓名或学科信息。点击查询按钮后,下方显示对应的查询结果,查询结果以表格的形式展示。
PHP 如何嵌入 HTML
前几课是纯PHP代码,然后通过PHP命令执行PHP文件代码来运行PHP代码。
在本章的第一课中,您实际上已经学会了如何将 PHP 代码嵌入到 HTML 页面中,所以让我们回顾一下:
可以看出,虽然文件名最终保存为helloworld.php,但其本质还是一个html规范格式的文件,因为这个文件的内容最终显示在浏览器中,所以本质上还是一个html规范文件.
PHP代码的作用只是通过动态编程语言生成需要的数据或显示格式。
可以理解为PHP代码运行在服务器端,运行后的文件内容为HTML内容。这样做的好处不言而喻,因为每个客户端浏览器都可以根据需要生成完全不同的 网站 内容。
上面的代码,其实也可以完全用PHP代码实现:
运行此代码的结果与运行上述代码的结果完全相同。
也就是说,在PHP代码中,不在这组开始和结束标记中的内容实际上是默认返回给浏览器的,相当于使用echo输出。这也是 PHP 的默认代码规范。
除了 echo 函数外,还使用了其他标准输出函数,类似于 echo 将输出内容返回给浏览器。比如print函数、print_r函数、var_dump函数等等。但是,如果输出内容不符合 html 规范,则可能无法在浏览器中按预期显示。
编写列表查询页面
创建 2 个文件 studentlist.php 文件和 student.css 文件。
参考前面的 index.html 和 index.css 样式编写html文件和显示样式。
首先将div分为上下3个区域,顶部显示一个标题“学生信息查询”,然后下面的两个div分别显示查询条件和查询按钮。
查询条件如下:姓名(文本输入)/性别(单选)/主题(多选)/分数段(下拉框选择)。
以下区域显示查询列表的结果,使用表格显示。第一行是标题,显示以下数据:
ID/姓名/性别/主题/分数。
修改 studentlist.php 文件:
修改 student.css 文件:
将这2个文件部署到本地服务器对应目录下,然后启动本地web服务程序,然后通过浏览器访问这个php网页:
然后写一个表,在下一行的 td 中显示查询列表的结果。
显示以下数据:ID/姓名/性别/主题/分数。
第一行是标题,第二行是数据。表头和数据的显示样式可以不同以显示差异。
修改 studentlist.php 文件:
修改student.css文件,添加如下代码:
刷新页面:
可以看到网页上显示了一个表格,内容是学生成绩的查询结果。
将数据行复制到多行,使奇数行和偶数行显示不同的背景色,看起来更美观。
修改 studentlist.php 文件:
修改student.css文件,添加样式tdb:
刷新页面:
可以看到表格中显示了多行数据,并且各行明显分开。
使用 PHP 代码循环遍历表的数据
通过编写静态html内容,即可完成显示样式的编码。
然后在这里修改多行显示内容,用PHP代码动态生成。
首先,删除刚刚添加的4行数据,只留下一行数据。
然后,在数据行前后添加PHP代码,并将这行数据放入一个for循环,即让这行数据重复显示5次。
修改 studentlist.php 文件:
刷新页面:
如您所见,页面显示了 5 行完全相同的数据。这就是 PHP 代码的力量。
如果要将5行变成100行,只需要修改一个数字即可。而如果是纯HTML代码,如果要重复100行的话,复制粘贴会耗费大量时间。
如果希望奇数行和偶数行的显示不同,可以这样修改:
首先设置一个变量,用于显示样式是tda还是tdb,命名为tds;
然后根据当前行是偶数行,将tds的值赋给一个tdb字符串;
然后在需要显示样式的地方输出这个变量。在这个循环中,当变量$i发生变化时,模2的结果会是0或者1,也就是奇数或者偶数,所以变量tds的值会变成tda或者tdb,最终输出的结果会不一样。.
修改 studentlist.php 文件:
刷新页面:
如果我想以不同的方式显示这5行的ID和名称怎么办?
一个简单的方法是修改显示的内容以跟随当前循环变量生成:
修改studentlist.php文件,调整代码的分支位置:
刷新页面:
可以看到,每一行的 ID 和名称都是不同的。
当然,在实际项目中,一般不采用这种方式。一般来说,必须将整个数据结果集返回到一起显示的页面,然后通过访问数据结果集嵌入到HTML表格中。显示。
一般的方式是使用二维数组变量来保存数据结果集。
添加一个变量$alldatas,那么内容就是二维数据,外层是每一行的含义,内层用key和value来表示不同的字段数据。
然后显示循环内部,通过访问这个二维数组的一个key得到对应的数据,通过echo输出到网页内容中。
修改 studentlist.php 文件:
刷新页面:
可以看到数据显示了5行,每行的名称都是根据数组变量中的值来显示的。这样,可以很容易地显示背景数据。
但是有个不正确的地方,就是数据行数的长度是5,代码还是用了for循环5次,加上数据的行数长度不是5,那么for 循环在这里不正确。应该改成foreach遍历二维数组变量,这样就可以完全根据变量中存储的数据显示行数和内容。
修改循环方式和变量显示,修改其他字段以这种方式显示。
修改 studentlist.php 文件:
刷新页面:
如您所见,所有显示的内容都取决于存储在数组变量中的值。只要修改了这个变量中存储的数据,网页就会显示不同的内容。
这就是动态网站的本质。
编写单个查询项和查询按钮
接下来,编写上面的查询条件和查询按钮。
3-4节大致介绍了各种输入项的写法,我们来回顾一下:
可以在网页上显示文本输入框。
单选按钮可以显示在网页上。
可以在网页上显示多选按钮。
一个按钮可以显示在网页上。
使用选择元素显示一个下拉框。
上面的代码可以在网页中显示一个下拉框选项,里面有2个选择项。
通过上述方式,在上方区域添加如下查询条件和查询按钮。
姓名(文字输入)/性别(单选)/主题(多选)/小数段(下拉框选择)/查询按钮。
首先,让我们规划一下这 5 个项目是如何放置在页面上的。
我打算把查询按钮放在最右边,然后把左边分成上下2行,上面分成3列,分别显示姓名、性别和分数段;
因为下面一行是选择题,要求的长度比较长,所以下面一行占了3列的宽度,正好利用表格的合并单元格属性来实现。
首先,写出表格每个tr和td的分布,显示边框,验证排版是否正确:
修改 studentlist.php 文件:
刷新页面查看效果:
然后,编写所有查询条件和查询按钮:
修改 studentlist.php 文件:
修改 student.css 文件:
刷新页面查看效果:
可以看出,查询网页已经基本形成,接下来就是实现点击查询按钮后的功能,即根据输入的不同条件,返回不同的查询数据结果。
特别说明
这堂课的内容很关键,是写动态网站的核心入门教程。由于本课的内容使用了很多之前课程的相关内容,如果你是第一次碰巧看到这个文章,可能有很多不明白的地方,所以你可能需要看雪歌之前写的。文章,建议从0001类开始,这样前后有连贯性,然后会有更好的理解。返回搜狐,查看更多
php 循环抓取网页内容(Tumult的集成实时预览打破编写HTML,速度非常快)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-16 04:27
Tumult Whisk 的集成实时预览打破了编写 HTML、保存文件、然后重新加载并在浏览器中查看页面的繁琐循环。结合编写和查看阶段可以明确更改的效果并加快制作网页的整个过程。基于 W3C 的验证将以红色突出显示所有错误。它使用与 Safari 相同的渲染引擎,因此它不仅符合标准,而且速度非常快。Whisk for Mac(轻量级网络编辑软件) Tumult Whisk 的集成实时预览打破了编写 HTML、保存文件、然后在浏览器中重新加载和查看页面的繁琐循环。结合编写和查看阶段可以明确更改的效果并加快制作网页的整个过程。基于 W3C 的验证将以红色突出显示所有错误。
主要特征:
- 预览窗格使用与 Safari 相同的引擎,在您键入时快速呈现 HTML 和 PHP
- “观看的文件”自动(或手动)确定文件何时更改并重新加载网络预览
- 基于实时 HTML W3C 的验证显示错误并用红色下划线突出显示问题标签
- 预览到其他浏览器或 iOS 上的 Hype Reflect 应用程序
- Web 检查器/控制台/devtools 访问
- 可定制的语法高亮颜色
- 可重复使用的代码片段和色板
- 滚动同步保持编辑器和预览在相似的位置
- 查看 PHP 引擎生成的 HTML 源代码
- 附加样式表以查看博客文章/标记在外部样式下的外观
- 仅作为 macOS 应用程序用 Cocoa 编写(支持 10.11 到 10.15)
- 具有新的 macOS 功能,在明暗模式下都可以很好地工作
Whisk 是一款方便快捷的网页编辑软件,可以帮助您快速创建和预览 HTML 和 PHP 格式的网页。不仅如此,Whisk简洁明了的编辑界面还可以用来写博客文章、论坛条目、运行调试JavaScript等,非常方便实用。 查看全部
php 循环抓取网页内容(Tumult的集成实时预览打破编写HTML,速度非常快)
Tumult Whisk 的集成实时预览打破了编写 HTML、保存文件、然后重新加载并在浏览器中查看页面的繁琐循环。结合编写和查看阶段可以明确更改的效果并加快制作网页的整个过程。基于 W3C 的验证将以红色突出显示所有错误。它使用与 Safari 相同的渲染引擎,因此它不仅符合标准,而且速度非常快。Whisk for Mac(轻量级网络编辑软件) Tumult Whisk 的集成实时预览打破了编写 HTML、保存文件、然后在浏览器中重新加载和查看页面的繁琐循环。结合编写和查看阶段可以明确更改的效果并加快制作网页的整个过程。基于 W3C 的验证将以红色突出显示所有错误。
主要特征:
- 预览窗格使用与 Safari 相同的引擎,在您键入时快速呈现 HTML 和 PHP
- “观看的文件”自动(或手动)确定文件何时更改并重新加载网络预览
- 基于实时 HTML W3C 的验证显示错误并用红色下划线突出显示问题标签
- 预览到其他浏览器或 iOS 上的 Hype Reflect 应用程序
- Web 检查器/控制台/devtools 访问
- 可定制的语法高亮颜色
- 可重复使用的代码片段和色板
- 滚动同步保持编辑器和预览在相似的位置
- 查看 PHP 引擎生成的 HTML 源代码
- 附加样式表以查看博客文章/标记在外部样式下的外观
- 仅作为 macOS 应用程序用 Cocoa 编写(支持 10.11 到 10.15)
- 具有新的 macOS 功能,在明暗模式下都可以很好地工作
Whisk 是一款方便快捷的网页编辑软件,可以帮助您快速创建和预览 HTML 和 PHP 格式的网页。不仅如此,Whisk简洁明了的编辑界面还可以用来写博客文章、论坛条目、运行调试JavaScript等,非常方便实用。
php 循环抓取网页内容(几个主流浏览器清除Cookie的方法和注意事项介绍计算机)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-16 04:25
部分用户访问某网站时,会提示“此页面收录重定向循环”,然后再怎么刷新都解决不了问题。事实上,页面产生了太多的重定向。清除此 网站 的 cookie 或允许第三方 cookie 可能会解决此问题。如果这不能解决它,它可能是服务器的配置问题,而不是计算机。错误 310 (net::ERR_TOO_MANY_REDIRECTS):重定向太多。事实上,浏览器已经为我们提供了解决问题的方法。
首先,清除 网站 的 cookie 或允许第三方 cookie。但是,普通用户可能不知道如何清除 cookie。注意:大多数情况下,这是由于 cookie 或禁用 cookie 而发生的。以下是主流浏览器清除cookies的几种方法:
首先,对于广大IE用户来说,打开IE浏览器,“工具”,打开“Internet属性”对话框,发现如图:
单击删除按钮执行此操作。
其次,对于火狐,打开浏览器,“工具”-“选项”-“隐私”,点击“删除隐私Cookie”。
当然,您也可以下拉并选择“从不记录历史记录”,这样 Firefox 就不再保存 网站cookies。您还可以“使用自定义历史设置”,以便清除或设置 cookie 到期日期。
此外,您还可以选择“工具”-“页面信息”-“安全”,这样就只能查看和清除当前的网站 cookie。
三、对于谷歌浏览器(Chrome),“工具”-“清除浏览数据”-“删除cookies等网站数据”,使网站cookies一目了然。
如果用这种方法,问题还是没有解决,基本可以断定是网站服务器配置的问题。一些网站管理员将 URL 重定向到,并且由于重定向不正确而发生此问题。
最后重点介绍wordpress升级到3.1版本导致的重定向过多,导致无法进入首页。
这可以通过修改以下任何文件来解决主页收录过多重定向的问题。这两个文件都位于 wp_includes 文件夹下。首先,对于canonical.php文件的修改,使用文本编辑器打开该文件,在打开的注释下方可以找到如下语句:
函数redirect_canonical($requested_url = null,$do_redirect = true){
将真改为假。
其次,对于 template-loader.php 文件,打开它并找到以下代码片段:
if (defined('WP_USE_THEMES') && WP_USE_THEMES)do_action('template_redirect');
删除此代码或使用 PHP 注释符号将其注释掉。您可以使用“”多行注释来注释掉这段代码。
还有一种情况是重定向过多。但这是在 文章 和评论 RSS 页面上。由于重定向,您的博客无法被订阅者更新。这大部分是由于安装了 feedburner 插件造成的,卸载此插件即可解决问题。 查看全部
php 循环抓取网页内容(几个主流浏览器清除Cookie的方法和注意事项介绍计算机)
部分用户访问某网站时,会提示“此页面收录重定向循环”,然后再怎么刷新都解决不了问题。事实上,页面产生了太多的重定向。清除此 网站 的 cookie 或允许第三方 cookie 可能会解决此问题。如果这不能解决它,它可能是服务器的配置问题,而不是计算机。错误 310 (net::ERR_TOO_MANY_REDIRECTS):重定向太多。事实上,浏览器已经为我们提供了解决问题的方法。
首先,清除 网站 的 cookie 或允许第三方 cookie。但是,普通用户可能不知道如何清除 cookie。注意:大多数情况下,这是由于 cookie 或禁用 cookie 而发生的。以下是主流浏览器清除cookies的几种方法:
首先,对于广大IE用户来说,打开IE浏览器,“工具”,打开“Internet属性”对话框,发现如图:
单击删除按钮执行此操作。
其次,对于火狐,打开浏览器,“工具”-“选项”-“隐私”,点击“删除隐私Cookie”。
当然,您也可以下拉并选择“从不记录历史记录”,这样 Firefox 就不再保存 网站cookies。您还可以“使用自定义历史设置”,以便清除或设置 cookie 到期日期。
此外,您还可以选择“工具”-“页面信息”-“安全”,这样就只能查看和清除当前的网站 cookie。
三、对于谷歌浏览器(Chrome),“工具”-“清除浏览数据”-“删除cookies等网站数据”,使网站cookies一目了然。
如果用这种方法,问题还是没有解决,基本可以断定是网站服务器配置的问题。一些网站管理员将 URL 重定向到,并且由于重定向不正确而发生此问题。
最后重点介绍wordpress升级到3.1版本导致的重定向过多,导致无法进入首页。
这可以通过修改以下任何文件来解决主页收录过多重定向的问题。这两个文件都位于 wp_includes 文件夹下。首先,对于canonical.php文件的修改,使用文本编辑器打开该文件,在打开的注释下方可以找到如下语句:
函数redirect_canonical($requested_url = null,$do_redirect = true){
将真改为假。
其次,对于 template-loader.php 文件,打开它并找到以下代码片段:
if (defined('WP_USE_THEMES') && WP_USE_THEMES)do_action('template_redirect');
删除此代码或使用 PHP 注释符号将其注释掉。您可以使用“”多行注释来注释掉这段代码。
还有一种情况是重定向过多。但这是在 文章 和评论 RSS 页面上。由于重定向,您的博客无法被订阅者更新。这大部分是由于安装了 feedburner 插件造成的,卸载此插件即可解决问题。
php 循环抓取网页内容(《php循环抓取网页内容》之ajaxget())
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-04-15 17:03
php循环抓取网页内容首先百度网站抓取分析:创建一个循环,i=request.get('/');forii=1:ii:=request.get('/');ii=ii+1;printii,ii_ok我提供思路是先爬取网页内容,再发送post请求去取里面的内容,采用的是https,直接进入https连接池,如果直接进入stm32控制面板里面,那会直接返回端口号和端口号之前的路径。代码:。
1、建立一个request,接收第一个post请求(可以网上查找,
2、等待验证成功后,就直接发post请求过去,数据格式为json,i没有说明,
3、返回之后我用std::nonatomichttpdata,指定i为post请求,然后将网址durl,内容data。
4、然后验证成功就去https那边发post请求,
5、发送请求之后,就走index函数,
phpserver传参时通过这个函数了,
sendstring,
这个,应该是ctf,或者是php的竞赛。那你可以考虑telnet这个。
其实就是request.get('/')这个过程
首先你要明白,php把“想要传递给服务器的内容”定义为一个post请求。那么ajax的交互方式就有很多。最常见的应该是通过send()函数。 查看全部
php 循环抓取网页内容(《php循环抓取网页内容》之ajaxget())
php循环抓取网页内容首先百度网站抓取分析:创建一个循环,i=request.get('/');forii=1:ii:=request.get('/');ii=ii+1;printii,ii_ok我提供思路是先爬取网页内容,再发送post请求去取里面的内容,采用的是https,直接进入https连接池,如果直接进入stm32控制面板里面,那会直接返回端口号和端口号之前的路径。代码:。
1、建立一个request,接收第一个post请求(可以网上查找,
2、等待验证成功后,就直接发post请求过去,数据格式为json,i没有说明,
3、返回之后我用std::nonatomichttpdata,指定i为post请求,然后将网址durl,内容data。
4、然后验证成功就去https那边发post请求,
5、发送请求之后,就走index函数,
phpserver传参时通过这个函数了,
sendstring,
这个,应该是ctf,或者是php的竞赛。那你可以考虑telnet这个。
其实就是request.get('/')这个过程
首先你要明白,php把“想要传递给服务器的内容”定义为一个post请求。那么ajax的交互方式就有很多。最常见的应该是通过send()函数。
php 循环抓取网页内容( user里有一张userinfo表,我们想把表里的内容展现在前端 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-14 17:17
user里有一张userinfo表,我们想把表里的内容展现在前端
)
现在数据库用户中有一个userinfo表,我们要在前端显示表的内容。
思考:
首先从数据库中查询userinfo表中的所有信息。将所有信息存储在一个数组中,然后使用 foreach 循环进行迭代。
mysqli_connect()
mysqli_connect() 函数打开一个到 MySQL 服务器的新连接。
mysqli_fetch_all()
mysqli_fetch_all() 函数从结果集中获取所有行作为关联数组或数字数组,或两者兼而有之。
id
username
password
phone
$row 将查询结果集中的所有行作为一个关联数组,然后使用foreach函数遍历$row,每次遍历时将当前单元格的键名赋给变量$key。当前单元格的值被赋值给$info。
那么我们可以使用$info["username"](username是userinfo表中的一个字段)来获取当前字段的内容。
最后一页的效果是
查看全部
php 循环抓取网页内容(
user里有一张userinfo表,我们想把表里的内容展现在前端
)
现在数据库用户中有一个userinfo表,我们要在前端显示表的内容。
思考:
首先从数据库中查询userinfo表中的所有信息。将所有信息存储在一个数组中,然后使用 foreach 循环进行迭代。
mysqli_connect()
mysqli_connect() 函数打开一个到 MySQL 服务器的新连接。
mysqli_fetch_all()
mysqli_fetch_all() 函数从结果集中获取所有行作为关联数组或数字数组,或两者兼而有之。
id
username
password
phone
$row 将查询结果集中的所有行作为一个关联数组,然后使用foreach函数遍历$row,每次遍历时将当前单元格的键名赋给变量$key。当前单元格的值被赋值给$info。
那么我们可以使用$info["username"](username是userinfo表中的一个字段)来获取当前字段的内容。
最后一页的效果是
php 循环抓取网页内容(web工程师亲测php循环抓取网页内容返回到wordpressphp)
网站优化 • 优采云 发表了文章 • 0 个评论 • 209 次浏览 • 2022-04-14 09:03
php循环抓取网页内容返回到wordpressphp抓取网页内容,正常是withcrawler模块加载数据然后保存数据库(如果需要,可以加laravel的http模块argospring)phplaravel都没问题,你看看是不是一个大问题。不是的话再找我。
你可以上传到tomcat上,
用laravel做一个中间层,抓取下来再同步到。
你是想走正常的wordpress,还是想同步到laravel的wordpress呢?我觉得你最后是想走wordpress吧,所以选择laravel就可以了。其实你说的抓取数据库内容,主要还是用wordpress,就算用zend加载wordpress模块,他不支持,也跑不了。反而laravel还可以。
php的话,使用zendreturnphp提供的argospring机制处理同步数据库,
分享一个我们web工程师的亲测效果
看看php的argparse,可以读写同一个json内容,然后将内容保存到文件类型。我参考过,可以用个插件geditor试试。
推荐用wordpress自带的requesthandlerarguments中的jsonjoinjsonlocaletemplateurljoin等,然后用nginx转发到http应用服务器。
的确是这样,另外我写的第三方扩展也能抓取一些内容,
可以试一下github-wordpresstcdb/phpwebkeydownloader: 查看全部
php 循环抓取网页内容(web工程师亲测php循环抓取网页内容返回到wordpressphp)
php循环抓取网页内容返回到wordpressphp抓取网页内容,正常是withcrawler模块加载数据然后保存数据库(如果需要,可以加laravel的http模块argospring)phplaravel都没问题,你看看是不是一个大问题。不是的话再找我。
你可以上传到tomcat上,
用laravel做一个中间层,抓取下来再同步到。
你是想走正常的wordpress,还是想同步到laravel的wordpress呢?我觉得你最后是想走wordpress吧,所以选择laravel就可以了。其实你说的抓取数据库内容,主要还是用wordpress,就算用zend加载wordpress模块,他不支持,也跑不了。反而laravel还可以。
php的话,使用zendreturnphp提供的argospring机制处理同步数据库,
分享一个我们web工程师的亲测效果
看看php的argparse,可以读写同一个json内容,然后将内容保存到文件类型。我参考过,可以用个插件geditor试试。
推荐用wordpress自带的requesthandlerarguments中的jsonjoinjsonlocaletemplateurljoin等,然后用nginx转发到http应用服务器。
的确是这样,另外我写的第三方扩展也能抓取一些内容,
可以试一下github-wordpresstcdb/phpwebkeydownloader:
php 循环抓取网页内容(想了解php获取访问者浏览页面的浏览器类型的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-14 08:36
想知道php的相关内容来获取浏览页面的访问者的浏览器类型吗?本篇国子博客将为大家讲解php获取浏览器类型的相关知识以及一些代码示例。欢迎阅读指正,我们先重点:php获取浏览器信息,php判断浏览器类型,php判断微信浏览器,一起来学习。
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
可以打印如下内容:
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上就是这个文章的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。有什么问题可以留言交流。
相关文章 查看全部
php 循环抓取网页内容(想了解php获取访问者浏览页面的浏览器类型的相关内容吗)
想知道php的相关内容来获取浏览页面的访问者的浏览器类型吗?本篇国子博客将为大家讲解php获取浏览器类型的相关知识以及一些代码示例。欢迎阅读指正,我们先重点:php获取浏览器信息,php判断浏览器类型,php判断微信浏览器,一起来学习。
方法如下
检查用户的代理字符串,它是浏览器发送的 HTTP 请求的一部分。使用 $_SERVER['HTTP_USER_AGENT'] 获取代理字符串信息。
例如:
可以打印如下内容:
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)
封装为函数:
function my_get_browser(){
if(empty($_SERVER['HTTP_USER_AGENT'])){
return 'robot!';
}
if( (false == strpos($_SERVER['HTTP_USER_AGENT'],'MSIE')) && (strpos($_SERVER['HTTP_USER_AGENT'], 'Trident')!==FALSE) ){
return 'Internet Explorer 11.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 10.0')){
return 'Internet Explorer 10.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 9.0')){
return 'Internet Explorer 9.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 8.0')){
return 'Internet Explorer 8.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 7.0')){
return 'Internet Explorer 7.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MSIE 6.0')){
return 'Internet Explorer 6.0';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Edge')){
return 'Edge';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Firefox')){
return 'Firefox';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Chrome')){
return 'Chrome';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Safari')){
return 'Safari';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'Opera')){
return 'Opera';
}
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'360SE')){
return '360SE';
}
//微信浏览器
if(false!==strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessage')){
return 'MicroMessage';
}>
}
总结
以上就是这个文章的全部内容。希望本文的内容能给大家的学习或工作带来一些帮助。有什么问题可以留言交流。
相关文章
php 循环抓取网页内容(如果我的表单中有一些隐藏的输入:现在,一旦提交表单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2022-04-13 13:38
如果我的表单中有一些隐藏的输入:
现在,一旦提交表单并从帖子中获取数据,如果我尝试调用 $_POST['test'] 那么我会得到“somedata”值。但如果我这样做:
for($i = 0; $i < 5; $i++)
{
$x = '入口{$i}';
回声 $_POST[$x]; // 这不起作用。
}
然后,我不会为每个“条目”输入返回“更多数据”值。如果我打印出定义为 $x 的字符串,那么我会得到我想要的字符串,但它似乎不像 $_POST 那样工作。任何人都知道我该如何解决这个问题?
谢谢
解决方案:
在字符串文字中,仅当字符串文字用双引号引起来时才会插入变量:
对于 ($i = 0; $i < 5; $i++) {
$x = "入口{$i}";
回声 $_POST[$x];
}
为了更加安全,您可能需要在下标 $_POST 之前检查 array_key_exists($x, $_POST),否则如果传递的字段不对应,您将收到 E_NOTICE 级别错误。
标签: php, css, post, http-post, html 查看全部
php 循环抓取网页内容(如果我的表单中有一些隐藏的输入:现在,一旦提交表单)
如果我的表单中有一些隐藏的输入:
现在,一旦提交表单并从帖子中获取数据,如果我尝试调用 $_POST['test'] 那么我会得到“somedata”值。但如果我这样做:
for($i = 0; $i < 5; $i++)
{
$x = '入口{$i}';
回声 $_POST[$x]; // 这不起作用。
}
然后,我不会为每个“条目”输入返回“更多数据”值。如果我打印出定义为 $x 的字符串,那么我会得到我想要的字符串,但它似乎不像 $_POST 那样工作。任何人都知道我该如何解决这个问题?
谢谢
解决方案:
在字符串文字中,仅当字符串文字用双引号引起来时才会插入变量:
对于 ($i = 0; $i < 5; $i++) {
$x = "入口{$i}";
回声 $_POST[$x];
}
为了更加安全,您可能需要在下标 $_POST 之前检查 array_key_exists($x, $_POST),否则如果传递的字段不对应,您将收到 E_NOTICE 级别错误。
标签: php, css, post, http-post, html
php 循环抓取网页内容(PHP获取远程网页内容的代码(fopen,)的相关知识和一些Code实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-13 09:33
你想知道PHP获取远程网页内容的代码相关内容吗(fopen、curl已经测试过了)?在本文中,我将为您讲解远程网页的相关知识和一些代码示例。欢迎阅读和指正。我们先来关注一下:fopen、curl,一起来学习吧。
1、fopen 的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及以上版本
但是上面的代码很容易出现开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中有两个选项:allow_url_fopen =on(表示可以通过url打开远程文件),user_agent="PHP"(表示使用哪个脚本访问网络,还有一个" ;" 默认在它前面。是的。)重新启动服务器。
但他们中的一些人仍然有这个警告信息。距离完美解决方案还有一步之遥。您必须在 php.ini 中设置 user_agent。php的默认user_agent是PHP,我们改成Mozilla/4.0(兼容Mozilla/4.0)。; MSIE 6.0; Windows NT 5.0) 模拟浏览器
<IMG src="http://files.jb51.net/upload/2 ... ot%3B border=0>
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)"
工作中遇到这个问题,完美解决了,分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下,可以使用以下代码下载
exec("wget {$url}");
PHP抓取外部资源函数fopen/file_get_contents/curl的区别
fopen/file_get_contents 会为每个请求重新做 DNS 查询,并且不缓存 DNS 信息。
但是 CURL 会自动缓存 DNS 信息。对同一域名下的网页或图片的请求只需要一次 DNS 查询。
这大大减少了 DNS 查询的数量。
所以 CURL 的性能比 fopen/file_get_contents 好很多。 查看全部
php 循环抓取网页内容(PHP获取远程网页内容的代码(fopen,)的相关知识和一些Code实例)
你想知道PHP获取远程网页内容的代码相关内容吗(fopen、curl已经测试过了)?在本文中,我将为您讲解远程网页的相关知识和一些代码示例。欢迎阅读和指正。我们先来关注一下:fopen、curl,一起来学习吧。
1、fopen 的使用
复制代码代码如下:
复制代码代码如下:
// 以下代码可用于 PHP 5 及以上版本
但是上面的代码很容易出现开流失败:HTTP request failed!错误,解决方法
有人说在php.ini中有两个选项:allow_url_fopen =on(表示可以通过url打开远程文件),user_agent="PHP"(表示使用哪个脚本访问网络,还有一个" ;" 默认在它前面。是的。)重新启动服务器。
但他们中的一些人仍然有这个警告信息。距离完美解决方案还有一步之遥。您必须在 php.ini 中设置 user_agent。php的默认user_agent是PHP,我们改成Mozilla/4.0(兼容Mozilla/4.0)。; MSIE 6.0; Windows NT 5.0) 模拟浏览器
<IMG src="http://files.jb51.net/upload/2 ... ot%3B border=0>
user_agent="Mozilla/4.0(兼容;MSIE 6.0;Windows NT 5.0)"
工作中遇到这个问题,完美解决了,分享给大家。
2、由 curl 实现
复制代码代码如下:
linux下,可以使用以下代码下载
exec("wget {$url}");
PHP抓取外部资源函数fopen/file_get_contents/curl的区别
fopen/file_get_contents 会为每个请求重新做 DNS 查询,并且不缓存 DNS 信息。
但是 CURL 会自动缓存 DNS 信息。对同一域名下的网页或图片的请求只需要一次 DNS 查询。
这大大减少了 DNS 查询的数量。
所以 CURL 的性能比 fopen/file_get_contents 好很多。
php 循环抓取网页内容(说实话PHP不太如何保证数据安全?|PHP技术方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-04-11 03:16
公司目前有一个需求,可以导出可以自定义条件过滤的数据,以日增量20万+数据的数据表中的数据。该功能需要多个部门开发使用,需要保证功能可用。在此前提下,尽量优化体验。
首先介绍一下目前可用的资源:
1、MySql - 一主二从。
2、分布式服务器集群,选择其中一台中型机作为脚本执行载体。
3、文件系统——可以支持上传大数据量文件。
4、编程语言PHP,说实话,PHP不适合这个。
技术难点:
1、数据太大,对服务器配置要求高。导出过程中涉及到数据处理(比如各种ID转换名称等,我们这次需要太多了~~很坑)消耗很大,其次涉及到文件压缩,所以对CPU的要求很高。
2、因为是跨系统部署,如果使用接口的话,数据量会上百M,传输速度太慢(项目对外开放,数据只允许从内网访问),那怎么解决呢?
3、数据安全性高,所有出口都需要记录,那么如何保证数据安全呢?
| 技术解决方案
第一步:设计数据库,实时记录所有导出任务,或者使用redis。为了方便数据的持久化,我最终采用了mysql数据库的方案。表结构具体包括:ID、用户ID、用户名、发起请求的时间、导出的具体参数(包括各个维度的参数选择等,根据自己的业务而定)、是否正在处理任务(防止任务被多次处理)),导出是否成功(可以通过一个字段与上一个区分开来),删除标识等。
第二步:编译前端界面,包括参数选择、导出记录列表等。功能:触发导出任务的创建,记录在导出表中,状态:pending。
第三步:编写导出脚本对任务进行监控和处理,如果有导出任务则自动执行导出操作。
这里有一个小问题:为什么不直接在前台触发任务时执行导出,而是有一个单独的脚本来执行导出?这是实际业务造成的,因为我们对外开放的一些机器配置低。为了保证导出的成功率,我们需要一台高配置的机器来独立执行导出任务。
| 出口流程
具体流程可以参考下图,大家自己画图凑合吧~~~哈哈哈
代码
这里主要介绍导出脚本的代码,其他步骤的代码大家可以根据自己的业务编写。
注:因为数据量太大~一次导出不合理,所以我采用了分页导出的形式~
先查询总数据条数,再通过每页导出页数计算具体导出页数~
#获取数据总数
$dataCount = Data_ExportModel::getExportZipTotalCount($params);$dataCount = $dataCount[0]['count_num'];#csv
#输出Excel文件头,可以把user.csv换成你想要的文件名
$mark = '/tmp/export';$stepLen = 20000;//每次只从数据库中取100000条,防止变量缓存过大
#每$limit行,刷新输出缓冲区,既不太大也不太小
$limit = 20000;$maxFileCount = 1000000;#buffercounter
$cnt = 0;$head = self::initColumnDataV2(); //header部分根据自己的业务调整
$fileNameArr = array();$salesStatisticsData = array();$startLimitId = 0;
首次导出的每页条目数设置为 100,000。后来发现内存消耗太大,改成2万。这个导出速度会慢一些。建议50000比较适中。
对于 ($j = 0; $j
$fileNameArr[] = $fileCsvName;#通过fputcsv将数据写入文件句柄
fputcsv($fp, $head);for ($i = 0; $i
$startNum = $j*$maxFileCount + $i*$limit;if ($startNum > $dataCount) {break; //跳出循环
}#查询数据
$dataSource = Data_ExportModel::getExportZipTotalInfo($params, $startNum, $stepLen, $startLimitId);$endMicroTime = microtime(true);printf("\n[%s -> %s] 开始时间:%s,结束时间: %s,总计数:%s,成本时间:%s。\n",
__CLASS__, __FUNCTION__, $params['begin_date'], $params['end_date'], count($dataSource), ($endMicroTime - $startMicroTime));if (empty($dataSource)) {continue;
}$endMicroTime = microtime(true);foreach ($dataSource as $_key => $_data) {$cnt++;if ($limit == $cnt) {#刷新输出缓冲区,防止数据过多导致的问题
ob_flush();flush();$cnt = 0;
}#数据处理部分,根据自己的业务定义,注意中文转码
$salesStatisticsData['name'] = iconv('utf-8', 'GB18030', $salesStatisticsData['c_name']);
fputcsv($fp, $salesStatisticsData);
}
}fclose($fp); #每次生成文件时关闭
}# 多文件压缩
$zip = newZipArchive();$number = rand(1000,9999);$filename = $mark."_".$params['begin_date']."_".$params['end_date'] ."_".$number.".zip";$zip->open($filename, ZipArchive::CREATE); //打开存档
foreach ($fileNameArr as $file) {$zip->addFile($file, basename($file)); //将文件添加到zip文件中
}$zip->close(); //关闭压缩包
if (!file_exists($filename)) {//第一次检查生成的压缩文件是否失败,第二次尝试。. .
$endMicroTime = 微时间(真);# 进行二次多文件压缩
$number = rand(1000,9999);$filename = $mark."_".$params['begin_date']."_".$params['end_date'] ."_".$number .".zip";if (file_exists($filename)) {unlink($filename);
}$zip->open($filename, ZipArchive::CREATE); //打开存档
foreach ($fileNameArr as $file) {$zip->addFile($file, basename($file)); //将文件添加到zip文件中
}$zip->close(); //关闭压缩包
}if (file_exists($filename)) {$content = file_get_contents($filename);//解决偶尔读取文件失败的问题,如果第一次读取为空,尝试第二次读取
$forNum = 0;while (!$content) {$forNum++;
@$content = file_get_contents($filename);if ($forNum > 10) {break; //防止异常情况导致死循环,最多重试10次
}
}
}else{$endMicroTime = microtime(true);#删除临时文件,防止占用空间
foreach ($fileNameArr as $file) {if (is_file($file)) {unlink($file);
}
}//记录错误日志和告警
返回假;
} #删除临时文件,防止占用空间
foreach ($fileNameArr as $file) {if (is_file($file)) {unlink($file);
}
}
最后,生成的文件存储在文件系统中。上传成功后,导出状态反转。前台检测到导出成功,自动下载。 查看全部
php 循环抓取网页内容(说实话PHP不太如何保证数据安全?|PHP技术方案)
公司目前有一个需求,可以导出可以自定义条件过滤的数据,以日增量20万+数据的数据表中的数据。该功能需要多个部门开发使用,需要保证功能可用。在此前提下,尽量优化体验。
首先介绍一下目前可用的资源:
1、MySql - 一主二从。
2、分布式服务器集群,选择其中一台中型机作为脚本执行载体。
3、文件系统——可以支持上传大数据量文件。
4、编程语言PHP,说实话,PHP不适合这个。
技术难点:
1、数据太大,对服务器配置要求高。导出过程中涉及到数据处理(比如各种ID转换名称等,我们这次需要太多了~~很坑)消耗很大,其次涉及到文件压缩,所以对CPU的要求很高。
2、因为是跨系统部署,如果使用接口的话,数据量会上百M,传输速度太慢(项目对外开放,数据只允许从内网访问),那怎么解决呢?
3、数据安全性高,所有出口都需要记录,那么如何保证数据安全呢?
| 技术解决方案
第一步:设计数据库,实时记录所有导出任务,或者使用redis。为了方便数据的持久化,我最终采用了mysql数据库的方案。表结构具体包括:ID、用户ID、用户名、发起请求的时间、导出的具体参数(包括各个维度的参数选择等,根据自己的业务而定)、是否正在处理任务(防止任务被多次处理)),导出是否成功(可以通过一个字段与上一个区分开来),删除标识等。
第二步:编译前端界面,包括参数选择、导出记录列表等。功能:触发导出任务的创建,记录在导出表中,状态:pending。
第三步:编写导出脚本对任务进行监控和处理,如果有导出任务则自动执行导出操作。
这里有一个小问题:为什么不直接在前台触发任务时执行导出,而是有一个单独的脚本来执行导出?这是实际业务造成的,因为我们对外开放的一些机器配置低。为了保证导出的成功率,我们需要一台高配置的机器来独立执行导出任务。
| 出口流程
具体流程可以参考下图,大家自己画图凑合吧~~~哈哈哈
代码
这里主要介绍导出脚本的代码,其他步骤的代码大家可以根据自己的业务编写。
注:因为数据量太大~一次导出不合理,所以我采用了分页导出的形式~
先查询总数据条数,再通过每页导出页数计算具体导出页数~
#获取数据总数
$dataCount = Data_ExportModel::getExportZipTotalCount($params);$dataCount = $dataCount[0]['count_num'];#csv
#输出Excel文件头,可以把user.csv换成你想要的文件名
$mark = '/tmp/export';$stepLen = 20000;//每次只从数据库中取100000条,防止变量缓存过大
#每$limit行,刷新输出缓冲区,既不太大也不太小
$limit = 20000;$maxFileCount = 1000000;#buffercounter
$cnt = 0;$head = self::initColumnDataV2(); //header部分根据自己的业务调整
$fileNameArr = array();$salesStatisticsData = array();$startLimitId = 0;
首次导出的每页条目数设置为 100,000。后来发现内存消耗太大,改成2万。这个导出速度会慢一些。建议50000比较适中。
对于 ($j = 0; $j
$fileNameArr[] = $fileCsvName;#通过fputcsv将数据写入文件句柄
fputcsv($fp, $head);for ($i = 0; $i
$startNum = $j*$maxFileCount + $i*$limit;if ($startNum > $dataCount) {break; //跳出循环
}#查询数据
$dataSource = Data_ExportModel::getExportZipTotalInfo($params, $startNum, $stepLen, $startLimitId);$endMicroTime = microtime(true);printf("\n[%s -> %s] 开始时间:%s,结束时间: %s,总计数:%s,成本时间:%s。\n",
__CLASS__, __FUNCTION__, $params['begin_date'], $params['end_date'], count($dataSource), ($endMicroTime - $startMicroTime));if (empty($dataSource)) {continue;
}$endMicroTime = microtime(true);foreach ($dataSource as $_key => $_data) {$cnt++;if ($limit == $cnt) {#刷新输出缓冲区,防止数据过多导致的问题
ob_flush();flush();$cnt = 0;
}#数据处理部分,根据自己的业务定义,注意中文转码
$salesStatisticsData['name'] = iconv('utf-8', 'GB18030', $salesStatisticsData['c_name']);
fputcsv($fp, $salesStatisticsData);
}
}fclose($fp); #每次生成文件时关闭
}# 多文件压缩
$zip = newZipArchive();$number = rand(1000,9999);$filename = $mark."_".$params['begin_date']."_".$params['end_date'] ."_".$number.".zip";$zip->open($filename, ZipArchive::CREATE); //打开存档
foreach ($fileNameArr as $file) {$zip->addFile($file, basename($file)); //将文件添加到zip文件中
}$zip->close(); //关闭压缩包
if (!file_exists($filename)) {//第一次检查生成的压缩文件是否失败,第二次尝试。. .
$endMicroTime = 微时间(真);# 进行二次多文件压缩
$number = rand(1000,9999);$filename = $mark."_".$params['begin_date']."_".$params['end_date'] ."_".$number .".zip";if (file_exists($filename)) {unlink($filename);
}$zip->open($filename, ZipArchive::CREATE); //打开存档
foreach ($fileNameArr as $file) {$zip->addFile($file, basename($file)); //将文件添加到zip文件中
}$zip->close(); //关闭压缩包
}if (file_exists($filename)) {$content = file_get_contents($filename);//解决偶尔读取文件失败的问题,如果第一次读取为空,尝试第二次读取
$forNum = 0;while (!$content) {$forNum++;
@$content = file_get_contents($filename);if ($forNum > 10) {break; //防止异常情况导致死循环,最多重试10次
}
}
}else{$endMicroTime = microtime(true);#删除临时文件,防止占用空间
foreach ($fileNameArr as $file) {if (is_file($file)) {unlink($file);
}
}//记录错误日志和告警
返回假;
} #删除临时文件,防止占用空间
foreach ($fileNameArr as $file) {if (is_file($file)) {unlink($file);
}
}
最后,生成的文件存储在文件系统中。上传成功后,导出状态反转。前台检测到导出成功,自动下载。
php 循环抓取网页内容(程序开发中自动打开某个页面要怎么操作?技术频道)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-08 15:45
如何在程序开发中自动打开一个页面?其实这需要抓取文本,然后保存到本地。爱站技术频道的编辑总结了ThinkPHP获取到的网站内容,并保存到本地实例中。不要把精彩的内容留给你立即呈现。
thinkphp抓取网站的内容并保存到本地的一个例子
我需要编写这样的示例并从电子教科书网站下载电子书。
电子教科书网站的电子书就是把书的每一页都当成一张图片,然后一本书有很多张图片。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育版七年级地理上册为例
网页从001.htm开始,然后数字不断增加
每个网页都有一张图片,就是对应教材的内容,以图片的形式展示教材的内容
我的代码在做一个循环,从第一页开始,直到在网页中找不到图片
抓取网页内容后,将网页中的图片抓取到本地服务器
抓取后的实际效果:
本文为ThinkPHP获取网站内容并保存到本地实例的爱站技术频道小编分享的内容。每个人都必须仔细研究它才能知道如何操作。 查看全部
php 循环抓取网页内容(程序开发中自动打开某个页面要怎么操作?技术频道)
如何在程序开发中自动打开一个页面?其实这需要抓取文本,然后保存到本地。爱站技术频道的编辑总结了ThinkPHP获取到的网站内容,并保存到本地实例中。不要把精彩的内容留给你立即呈现。
thinkphp抓取网站的内容并保存到本地的一个例子
我需要编写这样的示例并从电子教科书网站下载电子书。
电子教科书网站的电子书就是把书的每一页都当成一张图片,然后一本书有很多张图片。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育版七年级地理上册为例
网页从001.htm开始,然后数字不断增加
每个网页都有一张图片,就是对应教材的内容,以图片的形式展示教材的内容
我的代码在做一个循环,从第一页开始,直到在网页中找不到图片
抓取网页内容后,将网页中的图片抓取到本地服务器
抓取后的实际效果:
本文为ThinkPHP获取网站内容并保存到本地实例的爱站技术频道小编分享的内容。每个人都必须仔细研究它才能知道如何操作。
php 循环抓取网页内容(基础知识:JSONJSON数据和解析,数据形式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-04-02 23:04
)
JSON 是一种比较方便的数据形式。下面使用$.getJSON方法来实现JSON数据和解析,非常方便简单。从这个地址获取JSON数据并分析里面的结构,生成图片和相关链接等:
$(function(){
var url="http://api.flickr.com/services ... ot%3B
//使用getJSON方法取得JSON数据
$.getJSON(
url,
//处理数据 data指向的是返回来的JSON数据
function(data){
//生成标题和标题连接
var tit="<a href='"+ data.link +"'>"+data.title +"";
$("h1").html(tit);
//出现在指定位置H1 内
$("#ginfo").find("p").eq(0).html(data.modified);
$("#ginfo").find("p").eq(1).html(data.generator);
var lis="";
//li 列表项目
$(data.items).each(function(i,ite){
//遍历JSON数据得到所需形式
lis+="";
lis+="<a href='"+ ite.link +"'>"+ite.media.m +"";
lis+="";
lis+=ite.description;
lis+="";
})
$("ul").html(lis);
//将遍历出来的数据呈现在所需位置
$("li").hover(function(){$(this).addClass("hov")}, function(){$(this).removeClass("hov")});
}
)
})
HTML:
最后说一下JSON数据的格式。其实就是一个文本文件,可以很方便的解析或者直接查看。
({
"title": "Recent Uploads tagged cat",
"link": "http://www.flickr.com/photos/tags/cat/",
"description": "",
"modified": "2009-08-03T01:50:45Z",
"generator": "http://www.flickr.com/",
"items" {
"title": "DSC06844",
"link": "http://www.flickr.com/photos/g ... ot%3B,
"media": {"m":"http://farm3.static.flickr.com ... ot%3B},
"date_taken": "2009-07-06T07:27:59-08:00",
"description": "<p><a href=\"http://www.flickr.com/people/g_bugel/\">g.bugel posted a photo: <p><a href=\"http://www.flickr.com/photos/g_bugel/3783605340/\" title=\"DSC06844\"><img src=\"http://farm3.static.flickr.com ... m.jpg\" width=\"240\" height=\"180\" alt=\"DSC06844\" /> ",
"published": "2009-08-03T01:50:45Z",
"author": "nobody@flickr.com (g.bugel)",
"author_id": "38658309@N00",
"tags": "china cat feline beijing 2009 chinalab chinalab2009"
},{......}); 查看全部
php 循环抓取网页内容(基础知识:JSONJSON数据和解析,数据形式
)
JSON 是一种比较方便的数据形式。下面使用$.getJSON方法来实现JSON数据和解析,非常方便简单。从这个地址获取JSON数据并分析里面的结构,生成图片和相关链接等:
$(function(){
var url="http://api.flickr.com/services ... ot%3B
//使用getJSON方法取得JSON数据
$.getJSON(
url,
//处理数据 data指向的是返回来的JSON数据
function(data){
//生成标题和标题连接
var tit="<a href='"+ data.link +"'>"+data.title +"";
$("h1").html(tit);
//出现在指定位置H1 内
$("#ginfo").find("p").eq(0).html(data.modified);
$("#ginfo").find("p").eq(1).html(data.generator);
var lis="";
//li 列表项目
$(data.items).each(function(i,ite){
//遍历JSON数据得到所需形式
lis+="";
lis+="<a href='"+ ite.link +"'>"+ite.media.m +"";
lis+="";
lis+=ite.description;
lis+="";
})
$("ul").html(lis);
//将遍历出来的数据呈现在所需位置
$("li").hover(function(){$(this).addClass("hov")}, function(){$(this).removeClass("hov")});
}
)
})
HTML:
最后说一下JSON数据的格式。其实就是一个文本文件,可以很方便的解析或者直接查看。
({
"title": "Recent Uploads tagged cat",
"link": "http://www.flickr.com/photos/tags/cat/",
"description": "",
"modified": "2009-08-03T01:50:45Z",
"generator": "http://www.flickr.com/",
"items" {
"title": "DSC06844",
"link": "http://www.flickr.com/photos/g ... ot%3B,
"media": {"m":"http://farm3.static.flickr.com ... ot%3B},
"date_taken": "2009-07-06T07:27:59-08:00",
"description": "<p><a href=\"http://www.flickr.com/people/g_bugel/\">g.bugel posted a photo: <p><a href=\"http://www.flickr.com/photos/g_bugel/3783605340/\" title=\"DSC06844\"><img src=\"http://farm3.static.flickr.com ... m.jpg\" width=\"240\" height=\"180\" alt=\"DSC06844\" /> ",
"published": "2009-08-03T01:50:45Z",
"author": "nobody@flickr.com (g.bugel)",
"author_id": "38658309@N00",
"tags": "china cat feline beijing 2009 chinalab chinalab2009"
},{......});
php 循环抓取网页内容(php循环抓取网页内容,实现人人网的无限抓取,和采集新浪)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-03-31 00:07
php循环抓取网页内容,实现人人网的无限抓取,和采集新浪,腾讯,等网站内容,支持批量抓取!!!环境要求:php7.2+mysql,
推荐一个神器,
但凡牵扯爬虫,互联网信息基本上已经烂大街了。从网站本身的底层实现上来说,web开发中对于页面控制的技术点实在太多了,其中最基础,也是目前大量开发工作都不会考虑使用的php而是各种不同的脚本语言。从ajax、eventloop等技术角度上来说,各种xhr语言、xs等实现也变得越来越常见。所以,大量的基础知识已经差不多研究透彻了。
那么我们需要做的,无非就是收集更多站内站外的数据,或者自己进行原始数据的清洗处理并进行数据处理与处理工作。这个过程就变得庞大而复杂了。(关于xhr、xs脚本、parse等各种抓取方法,请查看我的专栏文章:1.对于爬虫工作者而言,xhr、xs、parse的区别2.爬虫程序的异步处理3.ajax抓取方法及入门)说完基础,来看看目前最热门的http方面的知识,要是爬虫开发人员也就爬到这里,那就真的是被淘汰的命运了。
无非就是四大组件,反射机制、getpost、postrequest、posttoresponse(selenium)。但我们关注最多的还是反射机制,其实也就是我们一直想说的跨域机制。又或者是http/https的特性区别。这个确实要面临一些问题,想一下,对于浏览器本身对于跨域机制的处理方式不同,导致每个进程都会获取很多资源而不是单个进程的资源,也就是说,同一个网站可能因为进程不同而可能同时获取到不同请求。
而且,目前还有几个问题困扰着每个爬虫开发人员。1.爬虫开发工作者如何实现同一时间,一边解析页面的爬取,一边生成response返回给前端开发者,这部分工作量可以用一次http请求解决,甚至一个小时甚至一分钟解决都没有问题。但是如果涉及多个进程共享对同一页面请求,甚至内部请求,问题就需要往下一些推移。2.被抓取页面域名记录问题:在python中,就通过根据所请求的url规则去将爬取的资源转向指定域名来实现,但是网站上通常很多站点都使用了多域名,或者我们需要使用规则来完成区分不同网站地址解析的工作,这种事情需要的时间就会比较长了。
3.爬虫开发工作者需要跟踪网站域名在我们写程序的过程中,需要针对不同的爬取阶段,处理对应的跨域问题。目前处理跨域主要有两种方式,一种是抓包抓取,一种是session、exploit模拟请求。需要我们注意的是,当遇到请求或者响应都来自parse中的特定域名时,需要解析一下请求网站或者。 查看全部
php 循环抓取网页内容(php循环抓取网页内容,实现人人网的无限抓取,和采集新浪)
php循环抓取网页内容,实现人人网的无限抓取,和采集新浪,腾讯,等网站内容,支持批量抓取!!!环境要求:php7.2+mysql,
推荐一个神器,
但凡牵扯爬虫,互联网信息基本上已经烂大街了。从网站本身的底层实现上来说,web开发中对于页面控制的技术点实在太多了,其中最基础,也是目前大量开发工作都不会考虑使用的php而是各种不同的脚本语言。从ajax、eventloop等技术角度上来说,各种xhr语言、xs等实现也变得越来越常见。所以,大量的基础知识已经差不多研究透彻了。
那么我们需要做的,无非就是收集更多站内站外的数据,或者自己进行原始数据的清洗处理并进行数据处理与处理工作。这个过程就变得庞大而复杂了。(关于xhr、xs脚本、parse等各种抓取方法,请查看我的专栏文章:1.对于爬虫工作者而言,xhr、xs、parse的区别2.爬虫程序的异步处理3.ajax抓取方法及入门)说完基础,来看看目前最热门的http方面的知识,要是爬虫开发人员也就爬到这里,那就真的是被淘汰的命运了。
无非就是四大组件,反射机制、getpost、postrequest、posttoresponse(selenium)。但我们关注最多的还是反射机制,其实也就是我们一直想说的跨域机制。又或者是http/https的特性区别。这个确实要面临一些问题,想一下,对于浏览器本身对于跨域机制的处理方式不同,导致每个进程都会获取很多资源而不是单个进程的资源,也就是说,同一个网站可能因为进程不同而可能同时获取到不同请求。
而且,目前还有几个问题困扰着每个爬虫开发人员。1.爬虫开发工作者如何实现同一时间,一边解析页面的爬取,一边生成response返回给前端开发者,这部分工作量可以用一次http请求解决,甚至一个小时甚至一分钟解决都没有问题。但是如果涉及多个进程共享对同一页面请求,甚至内部请求,问题就需要往下一些推移。2.被抓取页面域名记录问题:在python中,就通过根据所请求的url规则去将爬取的资源转向指定域名来实现,但是网站上通常很多站点都使用了多域名,或者我们需要使用规则来完成区分不同网站地址解析的工作,这种事情需要的时间就会比较长了。
3.爬虫开发工作者需要跟踪网站域名在我们写程序的过程中,需要针对不同的爬取阶段,处理对应的跨域问题。目前处理跨域主要有两种方式,一种是抓包抓取,一种是session、exploit模拟请求。需要我们注意的是,当遇到请求或者响应都来自parse中的特定域名时,需要解析一下请求网站或者。

