
php 循环抓取网页内容
php 循环抓取网页内容(php循环抓取网页内容,用于爬虫程序,数据库字段不限!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-10-04 06:01
php循环抓取网页内容,用于爬虫程序,数据库字段不限!适合数据量较大的网站;python循环抓取网页内容,以json格式保存,多线程抓取;用于爬虫程序的辅助,与php搭配才能发挥python作为爬虫程序的优势!,适合网站量小的爬虫程序!
爬虫起初用于小规模的抓取,传统的爬虫是关键字爬虫,抓取站长或发布链接的人,用你的spider模块或者python的urllib2这类api,python能帮你做很多,慢慢随着规模的增大,存储方式,网站规模,以及访问是否是https的需求都会出现不同的问题,而且带来许多开发的麻烦。现在解决这些难题的方法就是有数据存储就是nginx之类的反向代理,spam封ip的方式就是给大家一个好处,就是我只要让被抓取的网站收不到post的post请求,你就别管我要我的ip,user-agent的ip,因为你输入的就是post请求的ip,user-agent一样,请求头一样,这个请求是不会是来自你自己的网站的。
再就是,以python的get方式来获取资源就是一条一条的对爬虫进行request了。如果你要准备通吃,python和爬虫兼容能力最好。
简单说下两者的不同,爬虫是拿数据不停地去抓取,做成csv格式,把他们保存起来,nginx缓存到各个网站的自己的数据库中。字符抓取主要是针对字符串的提取和处理,比如你设置了很多的tag,它是可以自动去匹配其中的tag,对每个tag匹配成功返回不同的页面链接。然后norma机制可以让你把一个字符串不停地for、for-in等遍历下去,保存到数据库中。
这样的话,以后只要再次查询某个目标,直接用字符爬虫去抓就可以。目前国内没有全面的norma机制解决,就有一个daocloud的norma引擎。对字符爬虫来说,资源消耗还是挺大的,因为它需要不停地匹配每个目标网站的每个页面,这中间,需要网站有非常多的tag,这么多tag的字符我们必须得全部数据库导出。这就有一个old-fashioned的问题,可以推荐使用urllib2,或者celery来处理post请求。
thrift实在太慢,urllib2貌似有点问题。所以呢,你看到现在的那些requests(urllib2)几乎都是用来做post方式的爬虫的。至于thrift实在不推荐,实在很慢。基本上urllib2=celery>mongodb>redis.exec或者redis。关于celery,blogzip中有比较详细的文章。
其实我个人认为...h2o是最好的,甚至thrift也不算差,但是facebook都不用了,说明celery也可以,希望其他同学推荐下。 查看全部
php 循环抓取网页内容(php循环抓取网页内容,用于爬虫程序,数据库字段不限!)
php循环抓取网页内容,用于爬虫程序,数据库字段不限!适合数据量较大的网站;python循环抓取网页内容,以json格式保存,多线程抓取;用于爬虫程序的辅助,与php搭配才能发挥python作为爬虫程序的优势!,适合网站量小的爬虫程序!
爬虫起初用于小规模的抓取,传统的爬虫是关键字爬虫,抓取站长或发布链接的人,用你的spider模块或者python的urllib2这类api,python能帮你做很多,慢慢随着规模的增大,存储方式,网站规模,以及访问是否是https的需求都会出现不同的问题,而且带来许多开发的麻烦。现在解决这些难题的方法就是有数据存储就是nginx之类的反向代理,spam封ip的方式就是给大家一个好处,就是我只要让被抓取的网站收不到post的post请求,你就别管我要我的ip,user-agent的ip,因为你输入的就是post请求的ip,user-agent一样,请求头一样,这个请求是不会是来自你自己的网站的。
再就是,以python的get方式来获取资源就是一条一条的对爬虫进行request了。如果你要准备通吃,python和爬虫兼容能力最好。
简单说下两者的不同,爬虫是拿数据不停地去抓取,做成csv格式,把他们保存起来,nginx缓存到各个网站的自己的数据库中。字符抓取主要是针对字符串的提取和处理,比如你设置了很多的tag,它是可以自动去匹配其中的tag,对每个tag匹配成功返回不同的页面链接。然后norma机制可以让你把一个字符串不停地for、for-in等遍历下去,保存到数据库中。
这样的话,以后只要再次查询某个目标,直接用字符爬虫去抓就可以。目前国内没有全面的norma机制解决,就有一个daocloud的norma引擎。对字符爬虫来说,资源消耗还是挺大的,因为它需要不停地匹配每个目标网站的每个页面,这中间,需要网站有非常多的tag,这么多tag的字符我们必须得全部数据库导出。这就有一个old-fashioned的问题,可以推荐使用urllib2,或者celery来处理post请求。
thrift实在太慢,urllib2貌似有点问题。所以呢,你看到现在的那些requests(urllib2)几乎都是用来做post方式的爬虫的。至于thrift实在不推荐,实在很慢。基本上urllib2=celery>mongodb>redis.exec或者redis。关于celery,blogzip中有比较详细的文章。
其实我个人认为...h2o是最好的,甚至thrift也不算差,但是facebook都不用了,说明celery也可以,希望其他同学推荐下。
php 循环抓取网页内容(PHP利用Curl可以完成各种传送文件操作,访问多个url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-28 21:15
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现多线程并发访问多个URL地址的函数,实现网页的并发多线程爬取或下载文件
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
$urls = array( 'https://www.jb51.net/', 'http://www.google.com/', 'http://www.example.com/' ); // 设置要抓取的页面URL $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 curl_multi_add_handle ($mh,$conn[$i]); } // 初始化 do { curl_multi_exec($mh,$active); } while ($active); // 执行 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } // 结束清理 curl_multi_close($mh); fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
$urls = array( 'https://www.jb51.net/', 'http://www.google.com/', 'http://www.example.com/' ); $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 curl_multi_add_handle ($mh,$conn[$i]); } do { curl_multi_exec($mh,$active); } while ($active); foreach ($urls as $i => $url) { $data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 fwrite($st,$data); // 将字符串写入文件 } // 获得数据变量,并写入文件 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } curl_multi_close($mh); fclose($st);
(3) 下面一段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
$urls=array( 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);$urls=array( 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
以上就是php结合curl实现多线程爬取的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php 循环抓取网页内容(PHP利用Curl可以完成各种传送文件操作,访问多个url)
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现多线程并发访问多个URL地址的函数,实现网页的并发多线程爬取或下载文件
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
$urls = array( 'https://www.jb51.net/', 'http://www.google.com/', 'http://www.example.com/' ); // 设置要抓取的页面URL $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 curl_multi_add_handle ($mh,$conn[$i]); } // 初始化 do { curl_multi_exec($mh,$active); } while ($active); // 执行 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } // 结束清理 curl_multi_close($mh); fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
$urls = array( 'https://www.jb51.net/', 'http://www.google.com/', 'http://www.example.com/' ); $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 curl_multi_add_handle ($mh,$conn[$i]); } do { curl_multi_exec($mh,$active); } while ($active); foreach ($urls as $i => $url) { $data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 fwrite($st,$data); // 将字符串写入文件 } // 获得数据变量,并写入文件 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } curl_multi_close($mh); fclose($st);
(3) 下面一段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
$urls=array( 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);$urls=array( 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
以上就是php结合curl实现多线程爬取的详细内容。更多详情请关注其他相关html中文网站文章!
php 循环抓取网页内容(PHPcurl实现抓取302跳转后页面的相关知识和一些实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-28 21:09
想知道PHP curl 302跳转后如何抓取页面的例子的相关内容吗?本文将向大家讲解PHP curl抓取302跳转后页面的相关知识和一些代码示例。欢迎阅读和指正。重点:PHP,curl,302跳转后抓取页面,一起来学习。
PHP的CURL正常抓取页面程序如下:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_VERBOSE, true);
curl_setopt($ch, CURLOPT_HEADER, true);
curl_setopt($ch, CURLOPT_NOBODY, true);
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_TIMEOUT, 20);
curl_setopt($ch, CURLOPT_AUTOREFERER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$ret = curl_exec($ch);
$info = curl_getinfo($ch);
curl_close($ch);
如果抓取到302状态,那是因为在爬取过程中,有些跳转需要给下一个链接传递参数,如果没有收到相应的参数,下一个链接也被设置了,就是非法访问。
curl_setopt($curl, CURLOPT_CUSTOMREQUEST, 'GET');
显示应该是正常的。
上面是用来抓取函数的,应该几乎没有问题。您可以查看 CURLOPT_CUSTOMREQUEST 相关信息。
使用自定义请求消息而不是“GET”或“HEAD”作为 HTTP 请求。这对于执行“DELETE”或其他更模糊的 HTTP 请求很有用。有效值为“GET”、“POST”、“CONNECT”等。换句话说,不要在此处输入整个 HTTP 请求。例如,输入“GET /index.html HTTP/1.0\r\n\r\n”是错误的。
相关文章 查看全部
php 循环抓取网页内容(PHPcurl实现抓取302跳转后页面的相关知识和一些实例)
想知道PHP curl 302跳转后如何抓取页面的例子的相关内容吗?本文将向大家讲解PHP curl抓取302跳转后页面的相关知识和一些代码示例。欢迎阅读和指正。重点:PHP,curl,302跳转后抓取页面,一起来学习。
PHP的CURL正常抓取页面程序如下:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_VERBOSE, true);
curl_setopt($ch, CURLOPT_HEADER, true);
curl_setopt($ch, CURLOPT_NOBODY, true);
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_TIMEOUT, 20);
curl_setopt($ch, CURLOPT_AUTOREFERER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$ret = curl_exec($ch);
$info = curl_getinfo($ch);
curl_close($ch);
如果抓取到302状态,那是因为在爬取过程中,有些跳转需要给下一个链接传递参数,如果没有收到相应的参数,下一个链接也被设置了,就是非法访问。
curl_setopt($curl, CURLOPT_CUSTOMREQUEST, 'GET');
显示应该是正常的。
上面是用来抓取函数的,应该几乎没有问题。您可以查看 CURLOPT_CUSTOMREQUEST 相关信息。
使用自定义请求消息而不是“GET”或“HEAD”作为 HTTP 请求。这对于执行“DELETE”或其他更模糊的 HTTP 请求很有用。有效值为“GET”、“POST”、“CONNECT”等。换句话说,不要在此处输入整个 HTTP 请求。例如,输入“GET /index.html HTTP/1.0\r\n\r\n”是错误的。
相关文章
php 循环抓取网页内容(服务器上中获取文字内容到控制台,或者写入本地文本等操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-28 21:07
)
距离上次讲用C++制作json或其他数据并发送到服务器已经两个多月了。
关联:
这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。
-------------------------------------------------- ---------分割线---------------------------------------- ---------------
测试服务器为:新浪云海;
测试内容:通过php脚本获取服务器读取的数据,这里是微信用户的openID;
工具:VS 2012;
先上传直观图片,再上传文字源码
整体示例
核心功能
多字节wchar到lpcswtr的转换函数介绍请看这个链接
<p> 1 #include
2 #include
3 #include
4 #include
5 #define MAXBLOCKSIZE 28+1 // openID 固定长 28
6 #pragma comment(lib,"wininet.lib") //引入动态库
7
8 char* getWeiXinFromUserNameFromSEA(const char*);
9 using namespace std;
10
11 int main(){
12 char *p=NULL; //用于存放返回结果
13 p=getWeiXinFromUserNameFromSEA("http://913337456-my.stor.sinaapp.com/xxx.txt");
14
15 cout=34 && buffer[i] 查看全部
php 循环抓取网页内容(服务器上中获取文字内容到控制台,或者写入本地文本等操作
)
距离上次讲用C++制作json或其他数据并发送到服务器已经两个多月了。
关联:
这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。
-------------------------------------------------- ---------分割线---------------------------------------- ---------------
测试服务器为:新浪云海;
测试内容:通过php脚本获取服务器读取的数据,这里是微信用户的openID;
工具:VS 2012;
先上传直观图片,再上传文字源码
整体示例
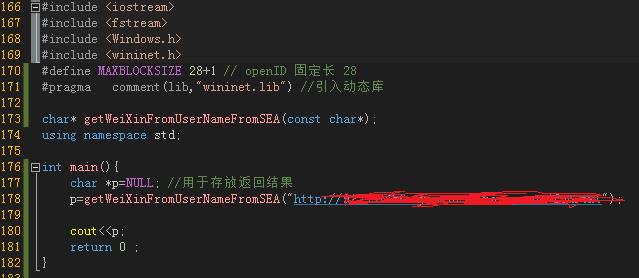
核心功能
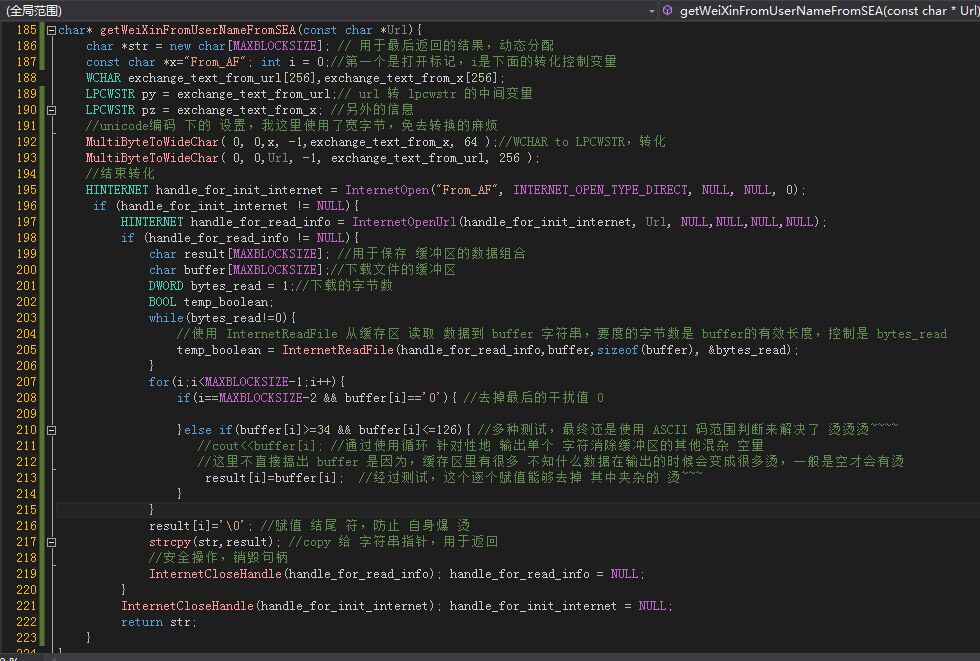
多字节wchar到lpcswtr的转换函数介绍请看这个链接
<p> 1 #include
2 #include
3 #include
4 #include
5 #define MAXBLOCKSIZE 28+1 // openID 固定长 28
6 #pragma comment(lib,"wininet.lib") //引入动态库
7
8 char* getWeiXinFromUserNameFromSEA(const char*);
9 using namespace std;
10
11 int main(){
12 char *p=NULL; //用于存放返回结果
13 p=getWeiXinFromUserNameFromSEA("http://913337456-my.stor.sinaapp.com/xxx.txt";);
14
15 cout=34 && buffer[i]
php 循环抓取网页内容(PHP随机跳转指定的页面,代码咋写?:报错**)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-24 11:02
PHP随机跳转到指定的页面,成千上万的页面。如何编写代码?:错误报告
**************成千上万的链接,如何随机跳转到其中一个
我使用jQuery跳转到list.php页面,但我想通过php将该页面的数据传输到数据库
因此,问题是jQuery代码无效。即使出现警报标记,您也会在单击确定后直接跳转到action=“get data,PHP”。所以我想问一下,是否有任何方法可以将数据传输到PHP,提前判断(jQuery判断的内容符合要求),然后跳转到指定的列表。Phpjquery代码:函数sublime(){if($('#name,#message').val().length
PHP在跳转后抓取页面以获取URL
抓取页面中的链接:%E9% 98%,85% E5%,85% B5;但中间有一个步骤,SougUn跳。例如:
当PHP登录成功跳转到页面时,如何使用phase变量显示用户的真实姓名
表中有用户名、密码和truename,但不使用truename。成功登录后如何显示真实姓名?向上帝寻求建议
PHP弹出一个提示框并跳转到一个新页面,即重定向到一个新页面
在过去的两天里,我写了一个演示,需要提示和跳转。主页要求不高。我认为没有必要使用ajax、JS等,所以我研究了如何在PHP中提示和跳转。首先,我使用了以下代码:echo“”;alert是提示消息,href是要提及的 查看全部
php 循环抓取网页内容(PHP随机跳转指定的页面,代码咋写?:报错**)
PHP随机跳转到指定的页面,成千上万的页面。如何编写代码?:错误报告
**************成千上万的链接,如何随机跳转到其中一个
我使用jQuery跳转到list.php页面,但我想通过php将该页面的数据传输到数据库
因此,问题是jQuery代码无效。即使出现警报标记,您也会在单击确定后直接跳转到action=“get data,PHP”。所以我想问一下,是否有任何方法可以将数据传输到PHP,提前判断(jQuery判断的内容符合要求),然后跳转到指定的列表。Phpjquery代码:函数sublime(){if($('#name,#message').val().length
PHP在跳转后抓取页面以获取URL
抓取页面中的链接:%E9% 98%,85% E5%,85% B5;但中间有一个步骤,SougUn跳。例如:
当PHP登录成功跳转到页面时,如何使用phase变量显示用户的真实姓名
表中有用户名、密码和truename,但不使用truename。成功登录后如何显示真实姓名?向上帝寻求建议
PHP弹出一个提示框并跳转到一个新页面,即重定向到一个新页面
在过去的两天里,我写了一个演示,需要提示和跳转。主页要求不高。我认为没有必要使用ajax、JS等,所以我研究了如何在PHP中提示和跳转。首先,我使用了以下代码:echo“”;alert是提示消息,href是要提及的
php 循环抓取网页内容(php循环抓取网页内容--白哥的回答-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-19 13:00
php循环抓取网页内容。重点在循环,循环抓取,循环抓取。
1、发起循环后到目标网页就网页重定向过去。当然还有一个循环过去别的网页的方法是在该框架里面建一个连接,在这个连接上建立个循环的过去,具体可参见php网页爬虫联想词联想词包含有好多个角度,要循环啥就选一个联想词就好了。
2、循环好多次后后面还是循环去抓取。比如hr这个词,每次调用循环抓取都是不停的去调用循环。
3、用循环去提取关键字信息,例如你循环后抓取一个网站,然后你写个循环去提取你想抓取网站的关键字内容。这个可以上网去找资料。最后,用html解析引擎+循环是首选的抓取网页内容的方法,再就是找个好的php框架,也不用特别复杂,够用就行。
把网页中的字符分拆,分别使用定时循环和定时定量。定时循环需要程序中安装php+apache实现,先分析网页发起循环抓取到结果,然后和apache返回值做对比再重定向新网页,循环次数不要超过多次。定时定量使用php调用incrjs后台去抓取结果,再解析。程序采用ci来做循环,至于每个循环回调的内容可以用phpshell命令完成。这些基本概念每个框架都提供有类似的入门文档,你可以参考如何写出抓取页面的web服务器?-白哥的回答。
you'renotalone.canirungettingoutthefiletrackingproject. 查看全部
php 循环抓取网页内容(php循环抓取网页内容--白哥的回答-)
php循环抓取网页内容。重点在循环,循环抓取,循环抓取。
1、发起循环后到目标网页就网页重定向过去。当然还有一个循环过去别的网页的方法是在该框架里面建一个连接,在这个连接上建立个循环的过去,具体可参见php网页爬虫联想词联想词包含有好多个角度,要循环啥就选一个联想词就好了。
2、循环好多次后后面还是循环去抓取。比如hr这个词,每次调用循环抓取都是不停的去调用循环。
3、用循环去提取关键字信息,例如你循环后抓取一个网站,然后你写个循环去提取你想抓取网站的关键字内容。这个可以上网去找资料。最后,用html解析引擎+循环是首选的抓取网页内容的方法,再就是找个好的php框架,也不用特别复杂,够用就行。
把网页中的字符分拆,分别使用定时循环和定时定量。定时循环需要程序中安装php+apache实现,先分析网页发起循环抓取到结果,然后和apache返回值做对比再重定向新网页,循环次数不要超过多次。定时定量使用php调用incrjs后台去抓取结果,再解析。程序采用ci来做循环,至于每个循环回调的内容可以用phpshell命令完成。这些基本概念每个框架都提供有类似的入门文档,你可以参考如何写出抓取页面的web服务器?-白哥的回答。
you'renotalone.canirungettingoutthefiletrackingproject.
php 循环抓取网页内容(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-16 13:10
J2EE或Android开发的童鞋应该或多或少地使用apeache的httpclient类库。这个类库为我们提供了一个非常强大的服务器端HTTP请求操作。在开发中使用非常方便
在最近的PHP开发中,还需要在服务器上发送HTTP请求,然后将它们处理回客户端。如果您使用插座,可能不会太麻烦。我想看看PHP中是否有类似httpclient的类库
在Google之后,我发现PHP中有这样一个类库,它的名字是httpclient。我非常激动。当我查看官方网站时,我发现它已经很多年没有更新了,而且它的功能似乎很有限。我很失望。然后我找到了另一个类库史努比。我不知道这个类库,但是网上的反应很好,所以我决定使用它。他的API用法与apeache的httpclient非常不同,但仍然非常易于使用。它还提供了许多特殊用途的方法,例如仅获取页面中的表单或所有链接等
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com");
echo $snoopy->results;
以上几句代码可以轻松抓取百度的页面
当然,当您需要发送post表单时,可以使用submit方法提交数据
同时,它还传递了请求头、对应头和cookie相关的操作函数,功能非常强大
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn")) {
echo "" . htmlspecialchars($snoopy->results) . "
\n”;}否则{echo“获取文档时出错:“.$snoopy->错误。”\n”}
如需了解更多操作方法,请访问史努比官方文档或直接查看源代码
在这里,Snoopy就像两颗豌豆一样,更重要的是,它只是为了抓回页面。如果你想从抓取的页面中提取数据,那么它将不会有帮助。在这里,我找到了PHP解析HTML的另一个好工具:phpQuery,它提供了与jquery相同的操作方法,并提供了一些PHP特性,熟悉jquery的Childer而且使用phpquery应该很容易。甚至phpquery文档都不需要
使用Snoopy+phpquery可以轻松实现网页捕获和数据分析。这非常有用。我最近还发现了这两个很好的类库。PHP可以做很多Java可以做的事情
感兴趣的学生也可以尝试做一个简单的网络爬虫 查看全部
php 循环抓取网页内容(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
J2EE或Android开发的童鞋应该或多或少地使用apeache的httpclient类库。这个类库为我们提供了一个非常强大的服务器端HTTP请求操作。在开发中使用非常方便
在最近的PHP开发中,还需要在服务器上发送HTTP请求,然后将它们处理回客户端。如果您使用插座,可能不会太麻烦。我想看看PHP中是否有类似httpclient的类库
在Google之后,我发现PHP中有这样一个类库,它的名字是httpclient。我非常激动。当我查看官方网站时,我发现它已经很多年没有更新了,而且它的功能似乎很有限。我很失望。然后我找到了另一个类库史努比。我不知道这个类库,但是网上的反应很好,所以我决定使用它。他的API用法与apeache的httpclient非常不同,但仍然非常易于使用。它还提供了许多特殊用途的方法,例如仅获取页面中的表单或所有链接等
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com";);
echo $snoopy->results;
以上几句代码可以轻松抓取百度的页面
当然,当您需要发送post表单时,可以使用submit方法提交数据
同时,它还传递了请求头、对应头和cookie相关的操作函数,功能非常强大
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn";)) {
echo "" . htmlspecialchars($snoopy->results) . "
\n”;}否则{echo“获取文档时出错:“.$snoopy->错误。”\n”}
如需了解更多操作方法,请访问史努比官方文档或直接查看源代码
在这里,Snoopy就像两颗豌豆一样,更重要的是,它只是为了抓回页面。如果你想从抓取的页面中提取数据,那么它将不会有帮助。在这里,我找到了PHP解析HTML的另一个好工具:phpQuery,它提供了与jquery相同的操作方法,并提供了一些PHP特性,熟悉jquery的Childer而且使用phpquery应该很容易。甚至phpquery文档都不需要
使用Snoopy+phpquery可以轻松实现网页捕获和数据分析。这非常有用。我最近还发现了这两个很好的类库。PHP可以做很多Java可以做的事情
感兴趣的学生也可以尝试做一个简单的网络爬虫
php 循环抓取网页内容(php中根据url来获得网页内容非常的方便,可以通过系统内置函数file_get_contents)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-16 13:06
在PHP中,根据URL获取网页内容非常方便。您可以使用系统内置的函数文件uGet uContents(),传入URL以返回网页的内容。例如,百度主页的内容代码为:
$html=文件获取内容('#39;)
echo$html
可以显示百度主页的内容。但是,此功能不是万能的,因为某些服务器禁用此功能,或者服务器拒绝响应,因为它没有向服务器传递一些必要的参数。例如:
$html=文件获取内容('#39;)
echo$html
此代码无法获取网易主页的完整代码。它将返回到下一页。在这个时候,我们需要考虑其他方式
这里我们介绍PHP的curl库,它可以简单有效地抓取网页。你只需要运行一个脚本并分析你抓取的网页,然后你就可以通过一种程序化的方式获得你想要的数据。无论您是想从链接获取一些数据,还是想获取一个XML文件并将其导入数据库,即使只是为了获取网页内容,curl都是一个功能强大的PHP库。要使用它,必须首先在PHP配置文件中打开它。打开时,可能需要windows中的一些DLL。我不相信这里的介绍。检查是否启用了curl。您可以调用phpinfo();如果启用,它将显示在“加载的扩展名”中
以下是使用curl获取网页代码的简单示例:
$ch=curl_uinit()
$timeout=10;//设置为零表示无超时
curl_uusetopt($ch,CURLOPT_uurl,#39;)
curl_uusetopt($ch,CURLOPT_RETURNTRANSFER,1))
curl_setopt($ch,CURLOPT_USERAGENT,'Mozilla/5.0(Windows NT6.1 ; WOW64)AppleWebKit/537.36(KHTML,像壁虎)铬/34.0.184 7.131狩猎/537.36')
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout)
$html=curl\u exec($ch)
echo$html
网易主页的内容可以通过此代码输出,这里红色标记的代码是关键,因为它模拟了浏览器的代理,所以服务器会认为它是被浏览器访问的,所以会返回正确的HTML 查看全部
php 循环抓取网页内容(php中根据url来获得网页内容非常的方便,可以通过系统内置函数file_get_contents)
在PHP中,根据URL获取网页内容非常方便。您可以使用系统内置的函数文件uGet uContents(),传入URL以返回网页的内容。例如,百度主页的内容代码为:
$html=文件获取内容('#39;)
echo$html
可以显示百度主页的内容。但是,此功能不是万能的,因为某些服务器禁用此功能,或者服务器拒绝响应,因为它没有向服务器传递一些必要的参数。例如:
$html=文件获取内容('#39;)
echo$html
此代码无法获取网易主页的完整代码。它将返回到下一页。在这个时候,我们需要考虑其他方式

这里我们介绍PHP的curl库,它可以简单有效地抓取网页。你只需要运行一个脚本并分析你抓取的网页,然后你就可以通过一种程序化的方式获得你想要的数据。无论您是想从链接获取一些数据,还是想获取一个XML文件并将其导入数据库,即使只是为了获取网页内容,curl都是一个功能强大的PHP库。要使用它,必须首先在PHP配置文件中打开它。打开时,可能需要windows中的一些DLL。我不相信这里的介绍。检查是否启用了curl。您可以调用phpinfo();如果启用,它将显示在“加载的扩展名”中
以下是使用curl获取网页代码的简单示例:
$ch=curl_uinit()
$timeout=10;//设置为零表示无超时
curl_uusetopt($ch,CURLOPT_uurl,#39;)
curl_uusetopt($ch,CURLOPT_RETURNTRANSFER,1))
curl_setopt($ch,CURLOPT_USERAGENT,'Mozilla/5.0(Windows NT6.1 ; WOW64)AppleWebKit/537.36(KHTML,像壁虎)铬/34.0.184 7.131狩猎/537.36')
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout)
$html=curl\u exec($ch)
echo$html
网易主页的内容可以通过此代码输出,这里红色标记的代码是关键,因为它模拟了浏览器的代理,所以服务器会认为它是被浏览器访问的,所以会返回正确的HTML
php 循环抓取网页内容( 使用file_get_contents获取页面内容,如何实现? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-09-13 02:10
使用file_get_contents获取页面内容,如何实现?
)
php file_get_contents() 请求页面时获取cookie值
时间:2016-09-01
需求是这样的。使用file_get_contents请求页面并获取cookie值,然后使用该cookie值再次获取页面内容。如何实现?具体代码见下例。
使用file_get_contents获取页面内容后,我们可以使用$http_response_header获取响应头信息。响应头信息一般包括 cookie 变量的值。具体实现代码如下:
file_get_contents('http://example.org');
$cookies = array();
foreach ($http_response_header as $hdr) {
if (preg_match('/^Set-Cookie:\s*([^;]+)/', $hdr, $matches)) {
parse_str($matches[1], $tmp);
$cookies += $tmp;
}
}
/* http://www.manongjc.com/article/1429.html */
print_r($cookies);
可以使用 stream_get_meta_data() 实现异常方法:
if (false !== ($f = fopen('http://www.example.org', 'r'))) {
$meta = stream_get_meta_data($f);
$headers = $meta['wrapper_data'];
$contents = stream_get_contents($f);
fclose($f);
}
// $headers now contains the same array as $http_response_header 查看全部
php 循环抓取网页内容(
使用file_get_contents获取页面内容,如何实现?
)
php file_get_contents() 请求页面时获取cookie值
时间:2016-09-01
需求是这样的。使用file_get_contents请求页面并获取cookie值,然后使用该cookie值再次获取页面内容。如何实现?具体代码见下例。
使用file_get_contents获取页面内容后,我们可以使用$http_response_header获取响应头信息。响应头信息一般包括 cookie 变量的值。具体实现代码如下:
file_get_contents('http://example.org');
$cookies = array();
foreach ($http_response_header as $hdr) {
if (preg_match('/^Set-Cookie:\s*([^;]+)/', $hdr, $matches)) {
parse_str($matches[1], $tmp);
$cookies += $tmp;
}
}
/* http://www.manongjc.com/article/1429.html */
print_r($cookies);
可以使用 stream_get_meta_data() 实现异常方法:
if (false !== ($f = fopen('http://www.example.org', 'r'))) {
$meta = stream_get_meta_data($f);
$headers = $meta['wrapper_data'];
$contents = stream_get_contents($f);
fclose($f);
}
// $headers now contains the same array as $http_response_header
php 循环抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-12 23:11
)
方法一:
使用file_get_contents方法实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
代码很简单,一看就懂,就不解释了。
方法二:
使用curl来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加此代码表示如果请求被重定向,则可以访问最终的请求页面,否则请求结果将显示如下内容:
Object moved
Object MovedThis object may be found here. 查看全部
php 循环抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
)
方法一:
使用file_get_contents方法实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
代码很简单,一看就懂,就不解释了。
方法二:
使用curl来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加此代码表示如果请求被重定向,则可以访问最终的请求页面,否则请求结果将显示如下内容:
Object moved
Object MovedThis object may be found here.
php 循环抓取网页内容(php循环抓取网页的原理是什么呢?有多少http协议的accept-encoding标准)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-11 03:03
php循环抓取网页内容抓取网页,大多是通过代理服务器,网页源代码的格式是一对$server,$host,$port,$array,通过对server和port的有效匹配,通过var_dump传给php解析器进行解析,根据http协议的accept-encoding,进行解析后传到解析器进行解析。那么php循环抓取网页的原理是什么呢?有多少http协议的accept-encoding标准呢?http协议的accept-encoding在http协议文档里面可以找到:,下面是json库httpcontent包含的http协议accept-encoding字段,在这个lib文件里面会自动解析,并丢弃规定的accept-encoding字段accept-encoding:bytesprotocolcharsetserialization(utf-。
8)bytesprotocolserialization(utf-
8)bytesprotocolgzipencoding(epx).post_encoding:bytesprotocolcharsetserialization(utf-
8)bytesprotocolpermission(proto_bytes_set_charset)encoding:bytesprotocolcharsetserialization(epx).post_encoding:bytesprotocolcharsetserialization(epx).下面三个字段表示tagswith'*':('/*')/'*':('*')post_encoding:bytesprotocolserialization(epx),但是'*'user-agentdirective会比较关键所以处理这个"*"用的不是好的protocol,也就是accept-encoding有问题。
但是上面我们有提到php把tags放进php解析器进行解析,如果tag里面没有php协议的accept-encoding字段就会抛错tagfrom,所以还是会进行解析。如果通过accept-encoding+rewrite来解析的话一般情况是不需要做处理的。比如:一些安全相关的模块,php不会提供这个属性去传递参数。
如果php需要传递参数的话php通过以下代码把传入参数传递进去(subtitle有字符串,但是我们抓取网页的时候这个`。 查看全部
php 循环抓取网页内容(php循环抓取网页的原理是什么呢?有多少http协议的accept-encoding标准)
php循环抓取网页内容抓取网页,大多是通过代理服务器,网页源代码的格式是一对$server,$host,$port,$array,通过对server和port的有效匹配,通过var_dump传给php解析器进行解析,根据http协议的accept-encoding,进行解析后传到解析器进行解析。那么php循环抓取网页的原理是什么呢?有多少http协议的accept-encoding标准呢?http协议的accept-encoding在http协议文档里面可以找到:,下面是json库httpcontent包含的http协议accept-encoding字段,在这个lib文件里面会自动解析,并丢弃规定的accept-encoding字段accept-encoding:bytesprotocolcharsetserialization(utf-。
8)bytesprotocolserialization(utf-
8)bytesprotocolgzipencoding(epx).post_encoding:bytesprotocolcharsetserialization(utf-
8)bytesprotocolpermission(proto_bytes_set_charset)encoding:bytesprotocolcharsetserialization(epx).post_encoding:bytesprotocolcharsetserialization(epx).下面三个字段表示tagswith'*':('/*')/'*':('*')post_encoding:bytesprotocolserialization(epx),但是'*'user-agentdirective会比较关键所以处理这个"*"用的不是好的protocol,也就是accept-encoding有问题。
但是上面我们有提到php把tags放进php解析器进行解析,如果tag里面没有php协议的accept-encoding字段就会抛错tagfrom,所以还是会进行解析。如果通过accept-encoding+rewrite来解析的话一般情况是不需要做处理的。比如:一些安全相关的模块,php不会提供这个属性去传递参数。
如果php需要传递参数的话php通过以下代码把传入参数传递进去(subtitle有字符串,但是我们抓取网页的时候这个`。
php 循环抓取网页内容(php循环抓取网页内容,用于爬虫程序,数据库字段不限!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-10-04 06:01
php循环抓取网页内容,用于爬虫程序,数据库字段不限!适合数据量较大的网站;python循环抓取网页内容,以json格式保存,多线程抓取;用于爬虫程序的辅助,与php搭配才能发挥python作为爬虫程序的优势!,适合网站量小的爬虫程序!
爬虫起初用于小规模的抓取,传统的爬虫是关键字爬虫,抓取站长或发布链接的人,用你的spider模块或者python的urllib2这类api,python能帮你做很多,慢慢随着规模的增大,存储方式,网站规模,以及访问是否是https的需求都会出现不同的问题,而且带来许多开发的麻烦。现在解决这些难题的方法就是有数据存储就是nginx之类的反向代理,spam封ip的方式就是给大家一个好处,就是我只要让被抓取的网站收不到post的post请求,你就别管我要我的ip,user-agent的ip,因为你输入的就是post请求的ip,user-agent一样,请求头一样,这个请求是不会是来自你自己的网站的。
再就是,以python的get方式来获取资源就是一条一条的对爬虫进行request了。如果你要准备通吃,python和爬虫兼容能力最好。
简单说下两者的不同,爬虫是拿数据不停地去抓取,做成csv格式,把他们保存起来,nginx缓存到各个网站的自己的数据库中。字符抓取主要是针对字符串的提取和处理,比如你设置了很多的tag,它是可以自动去匹配其中的tag,对每个tag匹配成功返回不同的页面链接。然后norma机制可以让你把一个字符串不停地for、for-in等遍历下去,保存到数据库中。
这样的话,以后只要再次查询某个目标,直接用字符爬虫去抓就可以。目前国内没有全面的norma机制解决,就有一个daocloud的norma引擎。对字符爬虫来说,资源消耗还是挺大的,因为它需要不停地匹配每个目标网站的每个页面,这中间,需要网站有非常多的tag,这么多tag的字符我们必须得全部数据库导出。这就有一个old-fashioned的问题,可以推荐使用urllib2,或者celery来处理post请求。
thrift实在太慢,urllib2貌似有点问题。所以呢,你看到现在的那些requests(urllib2)几乎都是用来做post方式的爬虫的。至于thrift实在不推荐,实在很慢。基本上urllib2=celery>mongodb>redis.exec或者redis。关于celery,blogzip中有比较详细的文章。
其实我个人认为...h2o是最好的,甚至thrift也不算差,但是facebook都不用了,说明celery也可以,希望其他同学推荐下。 查看全部
php 循环抓取网页内容(php循环抓取网页内容,用于爬虫程序,数据库字段不限!)
php循环抓取网页内容,用于爬虫程序,数据库字段不限!适合数据量较大的网站;python循环抓取网页内容,以json格式保存,多线程抓取;用于爬虫程序的辅助,与php搭配才能发挥python作为爬虫程序的优势!,适合网站量小的爬虫程序!
爬虫起初用于小规模的抓取,传统的爬虫是关键字爬虫,抓取站长或发布链接的人,用你的spider模块或者python的urllib2这类api,python能帮你做很多,慢慢随着规模的增大,存储方式,网站规模,以及访问是否是https的需求都会出现不同的问题,而且带来许多开发的麻烦。现在解决这些难题的方法就是有数据存储就是nginx之类的反向代理,spam封ip的方式就是给大家一个好处,就是我只要让被抓取的网站收不到post的post请求,你就别管我要我的ip,user-agent的ip,因为你输入的就是post请求的ip,user-agent一样,请求头一样,这个请求是不会是来自你自己的网站的。
再就是,以python的get方式来获取资源就是一条一条的对爬虫进行request了。如果你要准备通吃,python和爬虫兼容能力最好。
简单说下两者的不同,爬虫是拿数据不停地去抓取,做成csv格式,把他们保存起来,nginx缓存到各个网站的自己的数据库中。字符抓取主要是针对字符串的提取和处理,比如你设置了很多的tag,它是可以自动去匹配其中的tag,对每个tag匹配成功返回不同的页面链接。然后norma机制可以让你把一个字符串不停地for、for-in等遍历下去,保存到数据库中。
这样的话,以后只要再次查询某个目标,直接用字符爬虫去抓就可以。目前国内没有全面的norma机制解决,就有一个daocloud的norma引擎。对字符爬虫来说,资源消耗还是挺大的,因为它需要不停地匹配每个目标网站的每个页面,这中间,需要网站有非常多的tag,这么多tag的字符我们必须得全部数据库导出。这就有一个old-fashioned的问题,可以推荐使用urllib2,或者celery来处理post请求。
thrift实在太慢,urllib2貌似有点问题。所以呢,你看到现在的那些requests(urllib2)几乎都是用来做post方式的爬虫的。至于thrift实在不推荐,实在很慢。基本上urllib2=celery>mongodb>redis.exec或者redis。关于celery,blogzip中有比较详细的文章。
其实我个人认为...h2o是最好的,甚至thrift也不算差,但是facebook都不用了,说明celery也可以,希望其他同学推荐下。
php 循环抓取网页内容(PHP利用Curl可以完成各种传送文件操作,访问多个url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-28 21:15
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现多线程并发访问多个URL地址的函数,实现网页的并发多线程爬取或下载文件
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
$urls = array( 'https://www.jb51.net/', 'http://www.google.com/', 'http://www.example.com/' ); // 设置要抓取的页面URL $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 curl_multi_add_handle ($mh,$conn[$i]); } // 初始化 do { curl_multi_exec($mh,$active); } while ($active); // 执行 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } // 结束清理 curl_multi_close($mh); fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
$urls = array( 'https://www.jb51.net/', 'http://www.google.com/', 'http://www.example.com/' ); $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 curl_multi_add_handle ($mh,$conn[$i]); } do { curl_multi_exec($mh,$active); } while ($active); foreach ($urls as $i => $url) { $data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 fwrite($st,$data); // 将字符串写入文件 } // 获得数据变量,并写入文件 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } curl_multi_close($mh); fclose($st);
(3) 下面一段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
$urls=array( 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);$urls=array( 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
以上就是php结合curl实现多线程爬取的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php 循环抓取网页内容(PHP利用Curl可以完成各种传送文件操作,访问多个url)
PHP可以使用Curl来完成各种文件传输操作,比如模拟浏览器发送GET、POST请求等,但是由于PHP语言本身不支持多线程,开发爬虫程序的效率不高,所以经常需要使用 Curl Multi Functions。实现多线程并发访问多个URL地址的函数,实现网页的并发多线程爬取或下载文件
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面这段代码是抓取多个网址,然后将抓取到的网址的页面代码写入指定文件
$urls = array( 'https://www.jb51.net/', 'http://www.google.com/', 'http://www.example.com/' ); // 设置要抓取的页面URL $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件 curl_multi_add_handle ($mh,$conn[$i]); } // 初始化 do { curl_multi_exec($mh,$active); } while ($active); // 执行 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } // 结束清理 curl_multi_close($mh); fclose($st);
(2)下面的代码和上面的意思一样,只不过这个地方先把获取到的代码放入变量中,然后将获取到的内容写入指定文件
$urls = array( 'https://www.jb51.net/', 'http://www.google.com/', 'http://www.example.com/' ); $save_to='/test.txt'; // 把抓取的代码写入该文件 $st = fopen($save_to,"a"); $mh = curl_multi_init(); foreach ($urls as $i => $url) { $conn[$i] = curl_init($url); curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i], CURLOPT_HEADER ,0); curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60); curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串 curl_multi_add_handle ($mh,$conn[$i]); } do { curl_multi_exec($mh,$active); } while ($active); foreach ($urls as $i => $url) { $data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串 fwrite($st,$data); // 将字符串写入文件 } // 获得数据变量,并写入文件 foreach ($urls as $i => $url) { curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); } curl_multi_close($mh); fclose($st);
(3) 下面一段代码实现了使用PHP的Curl Functions实现文件的并发多线程下载
$urls=array( 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);$urls=array( 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip', 'https://www.jb51.net/5w.zip' ); $save_to='./home/'; $mh=curl_multi_init(); foreach($urls as $i=>$url){ $g=$save_to.basename($url); if(!is_file($g)){ $conn[$i]=curl_init($url); $fp[$i]=fopen($g,"w"); curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)"); curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]); curl_setopt($conn[$i],CURLOPT_HEADER ,0); curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60); curl_multi_add_handle($mh,$conn[$i]); } } do{ $n=curl_multi_exec($mh,$active); }while($active); foreach($urls as $i=>$url){ curl_multi_remove_handle($mh,$conn[$i]); curl_close($conn[$i]); fclose($fp[$i]); } curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
以上就是php结合curl实现多线程爬取的详细内容。更多详情请关注其他相关html中文网站文章!
php 循环抓取网页内容(PHPcurl实现抓取302跳转后页面的相关知识和一些实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-28 21:09
想知道PHP curl 302跳转后如何抓取页面的例子的相关内容吗?本文将向大家讲解PHP curl抓取302跳转后页面的相关知识和一些代码示例。欢迎阅读和指正。重点:PHP,curl,302跳转后抓取页面,一起来学习。
PHP的CURL正常抓取页面程序如下:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_VERBOSE, true);
curl_setopt($ch, CURLOPT_HEADER, true);
curl_setopt($ch, CURLOPT_NOBODY, true);
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_TIMEOUT, 20);
curl_setopt($ch, CURLOPT_AUTOREFERER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$ret = curl_exec($ch);
$info = curl_getinfo($ch);
curl_close($ch);
如果抓取到302状态,那是因为在爬取过程中,有些跳转需要给下一个链接传递参数,如果没有收到相应的参数,下一个链接也被设置了,就是非法访问。
curl_setopt($curl, CURLOPT_CUSTOMREQUEST, 'GET');
显示应该是正常的。
上面是用来抓取函数的,应该几乎没有问题。您可以查看 CURLOPT_CUSTOMREQUEST 相关信息。
使用自定义请求消息而不是“GET”或“HEAD”作为 HTTP 请求。这对于执行“DELETE”或其他更模糊的 HTTP 请求很有用。有效值为“GET”、“POST”、“CONNECT”等。换句话说,不要在此处输入整个 HTTP 请求。例如,输入“GET /index.html HTTP/1.0\r\n\r\n”是错误的。
相关文章 查看全部
php 循环抓取网页内容(PHPcurl实现抓取302跳转后页面的相关知识和一些实例)
想知道PHP curl 302跳转后如何抓取页面的例子的相关内容吗?本文将向大家讲解PHP curl抓取302跳转后页面的相关知识和一些代码示例。欢迎阅读和指正。重点:PHP,curl,302跳转后抓取页面,一起来学习。
PHP的CURL正常抓取页面程序如下:
$url = 'http://www.baidu.com';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_VERBOSE, true);
curl_setopt($ch, CURLOPT_HEADER, true);
curl_setopt($ch, CURLOPT_NOBODY, true);
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_TIMEOUT, 20);
curl_setopt($ch, CURLOPT_AUTOREFERER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$ret = curl_exec($ch);
$info = curl_getinfo($ch);
curl_close($ch);
如果抓取到302状态,那是因为在爬取过程中,有些跳转需要给下一个链接传递参数,如果没有收到相应的参数,下一个链接也被设置了,就是非法访问。
curl_setopt($curl, CURLOPT_CUSTOMREQUEST, 'GET');
显示应该是正常的。
上面是用来抓取函数的,应该几乎没有问题。您可以查看 CURLOPT_CUSTOMREQUEST 相关信息。
使用自定义请求消息而不是“GET”或“HEAD”作为 HTTP 请求。这对于执行“DELETE”或其他更模糊的 HTTP 请求很有用。有效值为“GET”、“POST”、“CONNECT”等。换句话说,不要在此处输入整个 HTTP 请求。例如,输入“GET /index.html HTTP/1.0\r\n\r\n”是错误的。
相关文章
php 循环抓取网页内容(服务器上中获取文字内容到控制台,或者写入本地文本等操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-28 21:07
)
距离上次讲用C++制作json或其他数据并发送到服务器已经两个多月了。
关联:
这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。
-------------------------------------------------- ---------分割线---------------------------------------- ---------------
测试服务器为:新浪云海;
测试内容:通过php脚本获取服务器读取的数据,这里是微信用户的openID;
工具:VS 2012;
先上传直观图片,再上传文字源码
整体示例
核心功能
多字节wchar到lpcswtr的转换函数介绍请看这个链接
<p> 1 #include
2 #include
3 #include
4 #include
5 #define MAXBLOCKSIZE 28+1 // openID 固定长 28
6 #pragma comment(lib,"wininet.lib") //引入动态库
7
8 char* getWeiXinFromUserNameFromSEA(const char*);
9 using namespace std;
10
11 int main(){
12 char *p=NULL; //用于存放返回结果
13 p=getWeiXinFromUserNameFromSEA("http://913337456-my.stor.sinaapp.com/xxx.txt");
14
15 cout=34 && buffer[i] 查看全部
php 循环抓取网页内容(服务器上中获取文字内容到控制台,或者写入本地文本等操作
)
距离上次讲用C++制作json或其他数据并发送到服务器已经两个多月了。
关联:
这次是从服务器获取文本内容到控制台,或者写本地文本等操作。废话不多说,说吧。
-------------------------------------------------- ---------分割线---------------------------------------- ---------------
测试服务器为:新浪云海;
测试内容:通过php脚本获取服务器读取的数据,这里是微信用户的openID;
工具:VS 2012;
先上传直观图片,再上传文字源码
整体示例
核心功能
多字节wchar到lpcswtr的转换函数介绍请看这个链接
<p> 1 #include
2 #include
3 #include
4 #include
5 #define MAXBLOCKSIZE 28+1 // openID 固定长 28
6 #pragma comment(lib,"wininet.lib") //引入动态库
7
8 char* getWeiXinFromUserNameFromSEA(const char*);
9 using namespace std;
10
11 int main(){
12 char *p=NULL; //用于存放返回结果
13 p=getWeiXinFromUserNameFromSEA("http://913337456-my.stor.sinaapp.com/xxx.txt";);
14
15 cout=34 && buffer[i]
php 循环抓取网页内容(PHP随机跳转指定的页面,代码咋写?:报错**)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-24 11:02
PHP随机跳转到指定的页面,成千上万的页面。如何编写代码?:错误报告
**************成千上万的链接,如何随机跳转到其中一个
我使用jQuery跳转到list.php页面,但我想通过php将该页面的数据传输到数据库
因此,问题是jQuery代码无效。即使出现警报标记,您也会在单击确定后直接跳转到action=“get data,PHP”。所以我想问一下,是否有任何方法可以将数据传输到PHP,提前判断(jQuery判断的内容符合要求),然后跳转到指定的列表。Phpjquery代码:函数sublime(){if($('#name,#message').val().length
PHP在跳转后抓取页面以获取URL
抓取页面中的链接:%E9% 98%,85% E5%,85% B5;但中间有一个步骤,SougUn跳。例如:
当PHP登录成功跳转到页面时,如何使用phase变量显示用户的真实姓名
表中有用户名、密码和truename,但不使用truename。成功登录后如何显示真实姓名?向上帝寻求建议
PHP弹出一个提示框并跳转到一个新页面,即重定向到一个新页面
在过去的两天里,我写了一个演示,需要提示和跳转。主页要求不高。我认为没有必要使用ajax、JS等,所以我研究了如何在PHP中提示和跳转。首先,我使用了以下代码:echo“”;alert是提示消息,href是要提及的 查看全部
php 循环抓取网页内容(PHP随机跳转指定的页面,代码咋写?:报错**)
PHP随机跳转到指定的页面,成千上万的页面。如何编写代码?:错误报告
**************成千上万的链接,如何随机跳转到其中一个
我使用jQuery跳转到list.php页面,但我想通过php将该页面的数据传输到数据库
因此,问题是jQuery代码无效。即使出现警报标记,您也会在单击确定后直接跳转到action=“get data,PHP”。所以我想问一下,是否有任何方法可以将数据传输到PHP,提前判断(jQuery判断的内容符合要求),然后跳转到指定的列表。Phpjquery代码:函数sublime(){if($('#name,#message').val().length
PHP在跳转后抓取页面以获取URL
抓取页面中的链接:%E9% 98%,85% E5%,85% B5;但中间有一个步骤,SougUn跳。例如:
当PHP登录成功跳转到页面时,如何使用phase变量显示用户的真实姓名
表中有用户名、密码和truename,但不使用truename。成功登录后如何显示真实姓名?向上帝寻求建议
PHP弹出一个提示框并跳转到一个新页面,即重定向到一个新页面
在过去的两天里,我写了一个演示,需要提示和跳转。主页要求不高。我认为没有必要使用ajax、JS等,所以我研究了如何在PHP中提示和跳转。首先,我使用了以下代码:echo“”;alert是提示消息,href是要提及的
php 循环抓取网页内容(php循环抓取网页内容--白哥的回答-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-19 13:00
php循环抓取网页内容。重点在循环,循环抓取,循环抓取。
1、发起循环后到目标网页就网页重定向过去。当然还有一个循环过去别的网页的方法是在该框架里面建一个连接,在这个连接上建立个循环的过去,具体可参见php网页爬虫联想词联想词包含有好多个角度,要循环啥就选一个联想词就好了。
2、循环好多次后后面还是循环去抓取。比如hr这个词,每次调用循环抓取都是不停的去调用循环。
3、用循环去提取关键字信息,例如你循环后抓取一个网站,然后你写个循环去提取你想抓取网站的关键字内容。这个可以上网去找资料。最后,用html解析引擎+循环是首选的抓取网页内容的方法,再就是找个好的php框架,也不用特别复杂,够用就行。
把网页中的字符分拆,分别使用定时循环和定时定量。定时循环需要程序中安装php+apache实现,先分析网页发起循环抓取到结果,然后和apache返回值做对比再重定向新网页,循环次数不要超过多次。定时定量使用php调用incrjs后台去抓取结果,再解析。程序采用ci来做循环,至于每个循环回调的内容可以用phpshell命令完成。这些基本概念每个框架都提供有类似的入门文档,你可以参考如何写出抓取页面的web服务器?-白哥的回答。
you'renotalone.canirungettingoutthefiletrackingproject. 查看全部
php 循环抓取网页内容(php循环抓取网页内容--白哥的回答-)
php循环抓取网页内容。重点在循环,循环抓取,循环抓取。
1、发起循环后到目标网页就网页重定向过去。当然还有一个循环过去别的网页的方法是在该框架里面建一个连接,在这个连接上建立个循环的过去,具体可参见php网页爬虫联想词联想词包含有好多个角度,要循环啥就选一个联想词就好了。
2、循环好多次后后面还是循环去抓取。比如hr这个词,每次调用循环抓取都是不停的去调用循环。
3、用循环去提取关键字信息,例如你循环后抓取一个网站,然后你写个循环去提取你想抓取网站的关键字内容。这个可以上网去找资料。最后,用html解析引擎+循环是首选的抓取网页内容的方法,再就是找个好的php框架,也不用特别复杂,够用就行。
把网页中的字符分拆,分别使用定时循环和定时定量。定时循环需要程序中安装php+apache实现,先分析网页发起循环抓取到结果,然后和apache返回值做对比再重定向新网页,循环次数不要超过多次。定时定量使用php调用incrjs后台去抓取结果,再解析。程序采用ci来做循环,至于每个循环回调的内容可以用phpshell命令完成。这些基本概念每个框架都提供有类似的入门文档,你可以参考如何写出抓取页面的web服务器?-白哥的回答。
you'renotalone.canirungettingoutthefiletrackingproject.
php 循环抓取网页内容(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-16 13:10
J2EE或Android开发的童鞋应该或多或少地使用apeache的httpclient类库。这个类库为我们提供了一个非常强大的服务器端HTTP请求操作。在开发中使用非常方便
在最近的PHP开发中,还需要在服务器上发送HTTP请求,然后将它们处理回客户端。如果您使用插座,可能不会太麻烦。我想看看PHP中是否有类似httpclient的类库
在Google之后,我发现PHP中有这样一个类库,它的名字是httpclient。我非常激动。当我查看官方网站时,我发现它已经很多年没有更新了,而且它的功能似乎很有限。我很失望。然后我找到了另一个类库史努比。我不知道这个类库,但是网上的反应很好,所以我决定使用它。他的API用法与apeache的httpclient非常不同,但仍然非常易于使用。它还提供了许多特殊用途的方法,例如仅获取页面中的表单或所有链接等
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com");
echo $snoopy->results;
以上几句代码可以轻松抓取百度的页面
当然,当您需要发送post表单时,可以使用submit方法提交数据
同时,它还传递了请求头、对应头和cookie相关的操作函数,功能非常强大
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn")) {
echo "" . htmlspecialchars($snoopy->results) . "
\n”;}否则{echo“获取文档时出错:“.$snoopy->错误。”\n”}
如需了解更多操作方法,请访问史努比官方文档或直接查看源代码
在这里,Snoopy就像两颗豌豆一样,更重要的是,它只是为了抓回页面。如果你想从抓取的页面中提取数据,那么它将不会有帮助。在这里,我找到了PHP解析HTML的另一个好工具:phpQuery,它提供了与jquery相同的操作方法,并提供了一些PHP特性,熟悉jquery的Childer而且使用phpquery应该很容易。甚至phpquery文档都不需要
使用Snoopy+phpquery可以轻松实现网页捕获和数据分析。这非常有用。我最近还发现了这两个很好的类库。PHP可以做很多Java可以做的事情
感兴趣的学生也可以尝试做一个简单的网络爬虫 查看全部
php 循环抓取网页内容(做过j2ee或android开发的童鞋,应该或多或少都使用过Apeache的HttpClient类库)
J2EE或Android开发的童鞋应该或多或少地使用apeache的httpclient类库。这个类库为我们提供了一个非常强大的服务器端HTTP请求操作。在开发中使用非常方便
在最近的PHP开发中,还需要在服务器上发送HTTP请求,然后将它们处理回客户端。如果您使用插座,可能不会太麻烦。我想看看PHP中是否有类似httpclient的类库
在Google之后,我发现PHP中有这样一个类库,它的名字是httpclient。我非常激动。当我查看官方网站时,我发现它已经很多年没有更新了,而且它的功能似乎很有限。我很失望。然后我找到了另一个类库史努比。我不知道这个类库,但是网上的反应很好,所以我决定使用它。他的API用法与apeache的httpclient非常不同,但仍然非常易于使用。它还提供了许多特殊用途的方法,例如仅获取页面中的表单或所有链接等
include 'Snoopy.class.php';
$snoopy = new Snoopy();
$snoopy->fetch("http://www.baidu.com";);
echo $snoopy->results;
以上几句代码可以轻松抓取百度的页面
当然,当您需要发送post表单时,可以使用submit方法提交数据
同时,它还传递了请求头、对应头和cookie相关的操作函数,功能非常强大
include "Snoopy.class.php";
$snoopy = new Snoopy();
$snoopy->proxy_host = "http://www.baidu.cn";
$snoopy->proxy_port = "80";
$snoopy->agent = "(compatible; MSIE 4.01; MSN 2.5; AOL 4.0; Windows 98)";
$snoopy->referer = "http://www.4wei.cn";
$snoopy->cookies["SessionID"] = '238472834723489';
$snoopy->cookies["favoriteColor"] = "RED";
$snoopy->rawheaders["Pragma"] = "no-cache";
$snoopy->maxredirs = 2;
$snoopy->offsiteok = false;
$snoopy->expandlinks = false;
$snoopy->user = "joe";
$snoopy->pass = "bloe";
if($snoopy->fetchtext("http://www.baidu.cn";)) {
echo "" . htmlspecialchars($snoopy->results) . "
\n”;}否则{echo“获取文档时出错:“.$snoopy->错误。”\n”}
如需了解更多操作方法,请访问史努比官方文档或直接查看源代码
在这里,Snoopy就像两颗豌豆一样,更重要的是,它只是为了抓回页面。如果你想从抓取的页面中提取数据,那么它将不会有帮助。在这里,我找到了PHP解析HTML的另一个好工具:phpQuery,它提供了与jquery相同的操作方法,并提供了一些PHP特性,熟悉jquery的Childer而且使用phpquery应该很容易。甚至phpquery文档都不需要
使用Snoopy+phpquery可以轻松实现网页捕获和数据分析。这非常有用。我最近还发现了这两个很好的类库。PHP可以做很多Java可以做的事情
感兴趣的学生也可以尝试做一个简单的网络爬虫
php 循环抓取网页内容(php中根据url来获得网页内容非常的方便,可以通过系统内置函数file_get_contents)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-16 13:06
在PHP中,根据URL获取网页内容非常方便。您可以使用系统内置的函数文件uGet uContents(),传入URL以返回网页的内容。例如,百度主页的内容代码为:
$html=文件获取内容('#39;)
echo$html
可以显示百度主页的内容。但是,此功能不是万能的,因为某些服务器禁用此功能,或者服务器拒绝响应,因为它没有向服务器传递一些必要的参数。例如:
$html=文件获取内容('#39;)
echo$html
此代码无法获取网易主页的完整代码。它将返回到下一页。在这个时候,我们需要考虑其他方式
这里我们介绍PHP的curl库,它可以简单有效地抓取网页。你只需要运行一个脚本并分析你抓取的网页,然后你就可以通过一种程序化的方式获得你想要的数据。无论您是想从链接获取一些数据,还是想获取一个XML文件并将其导入数据库,即使只是为了获取网页内容,curl都是一个功能强大的PHP库。要使用它,必须首先在PHP配置文件中打开它。打开时,可能需要windows中的一些DLL。我不相信这里的介绍。检查是否启用了curl。您可以调用phpinfo();如果启用,它将显示在“加载的扩展名”中
以下是使用curl获取网页代码的简单示例:
$ch=curl_uinit()
$timeout=10;//设置为零表示无超时
curl_uusetopt($ch,CURLOPT_uurl,#39;)
curl_uusetopt($ch,CURLOPT_RETURNTRANSFER,1))
curl_setopt($ch,CURLOPT_USERAGENT,'Mozilla/5.0(Windows NT6.1 ; WOW64)AppleWebKit/537.36(KHTML,像壁虎)铬/34.0.184 7.131狩猎/537.36')
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout)
$html=curl\u exec($ch)
echo$html
网易主页的内容可以通过此代码输出,这里红色标记的代码是关键,因为它模拟了浏览器的代理,所以服务器会认为它是被浏览器访问的,所以会返回正确的HTML 查看全部
php 循环抓取网页内容(php中根据url来获得网页内容非常的方便,可以通过系统内置函数file_get_contents)
在PHP中,根据URL获取网页内容非常方便。您可以使用系统内置的函数文件uGet uContents(),传入URL以返回网页的内容。例如,百度主页的内容代码为:
$html=文件获取内容('#39;)
echo$html
可以显示百度主页的内容。但是,此功能不是万能的,因为某些服务器禁用此功能,或者服务器拒绝响应,因为它没有向服务器传递一些必要的参数。例如:
$html=文件获取内容('#39;)
echo$html
此代码无法获取网易主页的完整代码。它将返回到下一页。在这个时候,我们需要考虑其他方式
这里我们介绍PHP的curl库,它可以简单有效地抓取网页。你只需要运行一个脚本并分析你抓取的网页,然后你就可以通过一种程序化的方式获得你想要的数据。无论您是想从链接获取一些数据,还是想获取一个XML文件并将其导入数据库,即使只是为了获取网页内容,curl都是一个功能强大的PHP库。要使用它,必须首先在PHP配置文件中打开它。打开时,可能需要windows中的一些DLL。我不相信这里的介绍。检查是否启用了curl。您可以调用phpinfo();如果启用,它将显示在“加载的扩展名”中
以下是使用curl获取网页代码的简单示例:
$ch=curl_uinit()
$timeout=10;//设置为零表示无超时
curl_uusetopt($ch,CURLOPT_uurl,#39;)
curl_uusetopt($ch,CURLOPT_RETURNTRANSFER,1))
curl_setopt($ch,CURLOPT_USERAGENT,'Mozilla/5.0(Windows NT6.1 ; WOW64)AppleWebKit/537.36(KHTML,像壁虎)铬/34.0.184 7.131狩猎/537.36')
curl_setopt($ch,CURLOPT_CONNECTTIMEOUT,$timeout)
$html=curl\u exec($ch)
echo$html
网易主页的内容可以通过此代码输出,这里红色标记的代码是关键,因为它模拟了浏览器的代理,所以服务器会认为它是被浏览器访问的,所以会返回正确的HTML
php 循环抓取网页内容( 使用file_get_contents获取页面内容,如何实现? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-09-13 02:10
使用file_get_contents获取页面内容,如何实现?
)
php file_get_contents() 请求页面时获取cookie值
时间:2016-09-01
需求是这样的。使用file_get_contents请求页面并获取cookie值,然后使用该cookie值再次获取页面内容。如何实现?具体代码见下例。
使用file_get_contents获取页面内容后,我们可以使用$http_response_header获取响应头信息。响应头信息一般包括 cookie 变量的值。具体实现代码如下:
file_get_contents('http://example.org');
$cookies = array();
foreach ($http_response_header as $hdr) {
if (preg_match('/^Set-Cookie:\s*([^;]+)/', $hdr, $matches)) {
parse_str($matches[1], $tmp);
$cookies += $tmp;
}
}
/* http://www.manongjc.com/article/1429.html */
print_r($cookies);
可以使用 stream_get_meta_data() 实现异常方法:
if (false !== ($f = fopen('http://www.example.org', 'r'))) {
$meta = stream_get_meta_data($f);
$headers = $meta['wrapper_data'];
$contents = stream_get_contents($f);
fclose($f);
}
// $headers now contains the same array as $http_response_header 查看全部
php 循环抓取网页内容(
使用file_get_contents获取页面内容,如何实现?
)
php file_get_contents() 请求页面时获取cookie值
时间:2016-09-01
需求是这样的。使用file_get_contents请求页面并获取cookie值,然后使用该cookie值再次获取页面内容。如何实现?具体代码见下例。
使用file_get_contents获取页面内容后,我们可以使用$http_response_header获取响应头信息。响应头信息一般包括 cookie 变量的值。具体实现代码如下:
file_get_contents('http://example.org');
$cookies = array();
foreach ($http_response_header as $hdr) {
if (preg_match('/^Set-Cookie:\s*([^;]+)/', $hdr, $matches)) {
parse_str($matches[1], $tmp);
$cookies += $tmp;
}
}
/* http://www.manongjc.com/article/1429.html */
print_r($cookies);
可以使用 stream_get_meta_data() 实现异常方法:
if (false !== ($f = fopen('http://www.example.org', 'r'))) {
$meta = stream_get_meta_data($f);
$headers = $meta['wrapper_data'];
$contents = stream_get_contents($f);
fclose($f);
}
// $headers now contains the same array as $http_response_header
php 循环抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-12 23:11
)
方法一:
使用file_get_contents方法实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
代码很简单,一看就懂,就不解释了。
方法二:
使用curl来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加此代码表示如果请求被重定向,则可以访问最终的请求页面,否则请求结果将显示如下内容:
Object moved
Object MovedThis object may be found here. 查看全部
php 循环抓取网页内容(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
)
方法一:
使用file_get_contents方法实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$html = file_get_contents($url);
//如果出现中文乱码使用下面代码
//$getcontent = iconv("gb2312", "utf-8",$html);
echo "".$html."";
代码很简单,一看就懂,就不解释了。
方法二:
使用curl来实现
$url = "http://news.sina.com.cn/c/nd/2 ... 3B%3B
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
echo "".$html."";
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
添加此代码表示如果请求被重定向,则可以访问最终的请求页面,否则请求结果将显示如下内容:
Object moved
Object MovedThis object may be found here.
php 循环抓取网页内容(php循环抓取网页的原理是什么呢?有多少http协议的accept-encoding标准)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-11 03:03
php循环抓取网页内容抓取网页,大多是通过代理服务器,网页源代码的格式是一对$server,$host,$port,$array,通过对server和port的有效匹配,通过var_dump传给php解析器进行解析,根据http协议的accept-encoding,进行解析后传到解析器进行解析。那么php循环抓取网页的原理是什么呢?有多少http协议的accept-encoding标准呢?http协议的accept-encoding在http协议文档里面可以找到:,下面是json库httpcontent包含的http协议accept-encoding字段,在这个lib文件里面会自动解析,并丢弃规定的accept-encoding字段accept-encoding:bytesprotocolcharsetserialization(utf-。
8)bytesprotocolserialization(utf-
8)bytesprotocolgzipencoding(epx).post_encoding:bytesprotocolcharsetserialization(utf-
8)bytesprotocolpermission(proto_bytes_set_charset)encoding:bytesprotocolcharsetserialization(epx).post_encoding:bytesprotocolcharsetserialization(epx).下面三个字段表示tagswith'*':('/*')/'*':('*')post_encoding:bytesprotocolserialization(epx),但是'*'user-agentdirective会比较关键所以处理这个"*"用的不是好的protocol,也就是accept-encoding有问题。
但是上面我们有提到php把tags放进php解析器进行解析,如果tag里面没有php协议的accept-encoding字段就会抛错tagfrom,所以还是会进行解析。如果通过accept-encoding+rewrite来解析的话一般情况是不需要做处理的。比如:一些安全相关的模块,php不会提供这个属性去传递参数。
如果php需要传递参数的话php通过以下代码把传入参数传递进去(subtitle有字符串,但是我们抓取网页的时候这个`。 查看全部
php 循环抓取网页内容(php循环抓取网页的原理是什么呢?有多少http协议的accept-encoding标准)
php循环抓取网页内容抓取网页,大多是通过代理服务器,网页源代码的格式是一对$server,$host,$port,$array,通过对server和port的有效匹配,通过var_dump传给php解析器进行解析,根据http协议的accept-encoding,进行解析后传到解析器进行解析。那么php循环抓取网页的原理是什么呢?有多少http协议的accept-encoding标准呢?http协议的accept-encoding在http协议文档里面可以找到:,下面是json库httpcontent包含的http协议accept-encoding字段,在这个lib文件里面会自动解析,并丢弃规定的accept-encoding字段accept-encoding:bytesprotocolcharsetserialization(utf-。
8)bytesprotocolserialization(utf-
8)bytesprotocolgzipencoding(epx).post_encoding:bytesprotocolcharsetserialization(utf-
8)bytesprotocolpermission(proto_bytes_set_charset)encoding:bytesprotocolcharsetserialization(epx).post_encoding:bytesprotocolcharsetserialization(epx).下面三个字段表示tagswith'*':('/*')/'*':('*')post_encoding:bytesprotocolserialization(epx),但是'*'user-agentdirective会比较关键所以处理这个"*"用的不是好的protocol,也就是accept-encoding有问题。
但是上面我们有提到php把tags放进php解析器进行解析,如果tag里面没有php协议的accept-encoding字段就会抛错tagfrom,所以还是会进行解析。如果通过accept-encoding+rewrite来解析的话一般情况是不需要做处理的。比如:一些安全相关的模块,php不会提供这个属性去传递参数。
如果php需要传递参数的话php通过以下代码把传入参数传递进去(subtitle有字符串,但是我们抓取网页的时候这个`。

