
php 循环抓取网页内容
php 循环抓取网页内容(PHP抓取页面上的数组并循环输出急在线等我用file_get_contents)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-13 04:18
PHP抓取页面上的数组,紧急循环输出在线等
我使用 file_get_contents() 来爬取这个 URL 的内容
它似乎正在返回一个数组。 但是无论我如何使用 foreach 循环,我都会遇到错误。 .
我只想获取数组中单词中的值。 谁能帮帮我,急
------解决方案----------
$s = file_get_contents('#39;);
preg_match_all('/\[word\] => (.+)/', $s, $m);
print_r($m[1]);数组
(
[0] => 1314
[1] => abc
)
------解决方案----------
$s=file_get_contents('#39;);
$rule='#(?)\s\w+#';
preg_match_all($rule,$s,$arr);
print_r($arr);
数组
(
[0] => 数组
(
[0] => 1314
[1] => abc
)
)
------解决方案----------
返回的是:
string(247) "数组 ( [0] => 数组 ( [字] => 1314 [字标签] => 90 [索引] => 0 ) [1] => 数组 ( [字] => abc [word_tag] => 95 [index] => 1 ) ) "
//数组结构的字符串,不是数组
//编码
$arr = 数组(
0=>数组(
'单词'=> 1314,
'word_tag'=> 90,
'索引' => 0
),
1 => 数组(
'单词' => 'abc',
'word_tag' => 95,
'索引' => 1
)
);
echo(json_encode($arr));
//解码
$arr = 数组();
$url = '#39;;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$output = curl_exec($ch);
$arr = json_decode($output,true);
curl_close($ch);
您也可以使用 serialize() 和 unserialize() 序列化函数来代替 json。
------解决方案----------
补充:
//json返回的字符串
[{"word":1314,"word_tag":90,"index":0},{"word":"abc","word_tag":95,"index":1}]
//序列化返回的字符串
a:2:{i:0;a:3:{s:5:"word";i:1314;s:8:"word_tag";i:90;s:5:"index";i :0;}i:1;a:3:{s:4:"word";s:3:"abc";s:8:"word_tag";i:95;s:5:"index";i :1;}}
明显短于直接 var_export($val,true);输出,并且可以很容易地恢复。
相关文章
相关视频 查看全部
php 循环抓取网页内容(PHP抓取页面上的数组并循环输出急在线等我用file_get_contents)
PHP抓取页面上的数组,紧急循环输出在线等
我使用 file_get_contents() 来爬取这个 URL 的内容
它似乎正在返回一个数组。 但是无论我如何使用 foreach 循环,我都会遇到错误。 .
我只想获取数组中单词中的值。 谁能帮帮我,急
------解决方案----------
$s = file_get_contents('#39;);
preg_match_all('/\[word\] => (.+)/', $s, $m);
print_r($m[1]);数组
(
[0] => 1314
[1] => abc
)
------解决方案----------
$s=file_get_contents('#39;);
$rule='#(?)\s\w+#';
preg_match_all($rule,$s,$arr);
print_r($arr);
数组
(
[0] => 数组
(
[0] => 1314
[1] => abc
)
)
------解决方案----------
返回的是:
string(247) "数组 ( [0] => 数组 ( [字] => 1314 [字标签] => 90 [索引] => 0 ) [1] => 数组 ( [字] => abc [word_tag] => 95 [index] => 1 ) ) "
//数组结构的字符串,不是数组
//编码
$arr = 数组(
0=>数组(
'单词'=> 1314,
'word_tag'=> 90,
'索引' => 0
),
1 => 数组(
'单词' => 'abc',
'word_tag' => 95,
'索引' => 1
)
);
echo(json_encode($arr));
//解码
$arr = 数组();
$url = '#39;;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$output = curl_exec($ch);
$arr = json_decode($output,true);
curl_close($ch);
您也可以使用 serialize() 和 unserialize() 序列化函数来代替 json。
------解决方案----------
补充:
//json返回的字符串
[{"word":1314,"word_tag":90,"index":0},{"word":"abc","word_tag":95,"index":1}]
//序列化返回的字符串
a:2:{i:0;a:3:{s:5:"word";i:1314;s:8:"word_tag";i:90;s:5:"index";i :0;}i:1;a:3:{s:4:"word";s:3:"abc";s:8:"word_tag";i:95;s:5:"index";i :1;}}
明显短于直接 var_export($val,true);输出,并且可以很容易地恢复。
相关文章
相关视频
php 循环抓取网页内容(PHP实现网页内容html标签补全和过滤的方法结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-10 22:11
本文文章主要介绍PHP补全和过滤网页内容HTML标签的方法,结合PHP标签检查、补全、关闭、过滤等相关操作技巧分析常用操作技巧举例。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,有些表格标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。
以上是PHP完成和过滤网页内容中html标签的两种方法的详细介绍。更多详情请关注第一PHP社区其他相关话题文章! 查看全部
php 循环抓取网页内容(PHP实现网页内容html标签补全和过滤的方法结合实例)
本文文章主要介绍PHP补全和过滤网页内容HTML标签的方法,结合PHP标签检查、补全、关闭、过滤等相关操作技巧分析常用操作技巧举例。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,有些表格标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。
以上是PHP完成和过滤网页内容中html标签的两种方法的详细介绍。更多详情请关注第一PHP社区其他相关话题文章!
php 循环抓取网页内容(php循环抓取网页内容,你别指望轻易被搬走了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-06 14:03
php循环抓取网页内容,例如把站点的所有不同web地址发送到gulp中,最后选择生成静态或者渲染页面,最终的页面还是渲染器生成,继续使用lamp或者其他建站系统。
你别费劲了,php在这块环境配置,基本只能是那个什么玩意了,别指望轻易被搬走。
php这个东西只能是套牢的,能结束掉也就只能是php5了
说真的,单单靠一套简单的解释执行引擎,php依然可以做网站,而且开发效率很高,速度很快,laravel这类框架适合对于简单页面,从外部解析到js,然后执行。但是如果你的网站不是一些静态资源很多的静态网站,还是建议以模板加载为主吧。因为这样可以减少很多的网站代码配置和缓存,特别是如果你的服务器容量很大的话,这个对速度是有影响的。
说个实际点的,我们做爬虫,我也曾考虑到这个问题,有个项目就是找个存储网页数据的框架,然后做后端。php另一个解决方案是当数据量大时,用分布式存储,还有使用分布式缓存,varnish也是能支持的。速度应该不错,而且架构也灵活。关键就是得分析数据,就好像运用模板一样,甚至可以在应用程序里弄成接口用php接受数据,然后读取数据到后端存储。
额,你没有提供一个可以细化到三级以上简单网站结构,而且还得有很多出发点很丰富的小模块,是大而全好,还是小而精好呢。 查看全部
php 循环抓取网页内容(php循环抓取网页内容,你别指望轻易被搬走了)
php循环抓取网页内容,例如把站点的所有不同web地址发送到gulp中,最后选择生成静态或者渲染页面,最终的页面还是渲染器生成,继续使用lamp或者其他建站系统。
你别费劲了,php在这块环境配置,基本只能是那个什么玩意了,别指望轻易被搬走。
php这个东西只能是套牢的,能结束掉也就只能是php5了
说真的,单单靠一套简单的解释执行引擎,php依然可以做网站,而且开发效率很高,速度很快,laravel这类框架适合对于简单页面,从外部解析到js,然后执行。但是如果你的网站不是一些静态资源很多的静态网站,还是建议以模板加载为主吧。因为这样可以减少很多的网站代码配置和缓存,特别是如果你的服务器容量很大的话,这个对速度是有影响的。
说个实际点的,我们做爬虫,我也曾考虑到这个问题,有个项目就是找个存储网页数据的框架,然后做后端。php另一个解决方案是当数据量大时,用分布式存储,还有使用分布式缓存,varnish也是能支持的。速度应该不错,而且架构也灵活。关键就是得分析数据,就好像运用模板一样,甚至可以在应用程序里弄成接口用php接受数据,然后读取数据到后端存储。
额,你没有提供一个可以细化到三级以上简单网站结构,而且还得有很多出发点很丰富的小模块,是大而全好,还是小而精好呢。
php 循环抓取网页内容(利用Excel快速获取网页内容的方法你是否已经掌握了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-06 04:20
下载Win7 64位旗舰版后浏览网页时,总会需要保存一些需要的数据信息。
该信息包括表格或文本。一般我们使用鼠标和组合键Ctrl+C来保存,但这种方法在一定程度上可以看作是一种相对低效的方法。是否可以更快地访问 Web 内容?路呢?当我们浏览一些较大的门户并需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。
具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行导出到Microsoft Office Excel的命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示新建Web查询信息。当我们等待网页完全显示时,在左下角找到完成提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容放到导入操作中。
STEP5 接下来,我们在弹出的窗口中找到确认信息,将文本和表格信息导入Excel。其他无用的格式将被自动过滤。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧!陈述:
本文内容由电脑大师网整理,感谢作者分享!发表/转载本文的目的是为了更广泛的传播和分享,但并不意味着同意其观点或证明其描述。
如有版权或其他纠纷,请准备相关证明材料与站长联系,谢谢! 查看全部
php 循环抓取网页内容(利用Excel快速获取网页内容的方法你是否已经掌握了?)
下载Win7 64位旗舰版后浏览网页时,总会需要保存一些需要的数据信息。
该信息包括表格或文本。一般我们使用鼠标和组合键Ctrl+C来保存,但这种方法在一定程度上可以看作是一种相对低效的方法。是否可以更快地访问 Web 内容?路呢?当我们浏览一些较大的门户并需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。
具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行导出到Microsoft Office Excel的命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示新建Web查询信息。当我们等待网页完全显示时,在左下角找到完成提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容放到导入操作中。
STEP5 接下来,我们在弹出的窗口中找到确认信息,将文本和表格信息导入Excel。其他无用的格式将被自动过滤。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧!陈述:
本文内容由电脑大师网整理,感谢作者分享!发表/转载本文的目的是为了更广泛的传播和分享,但并不意味着同意其观点或证明其描述。
如有版权或其他纠纷,请准备相关证明材料与站长联系,谢谢!
php 循环抓取网页内容(php循环抓取网页内容,数据量不是很大,为什么需要多线程?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-30 15:08
php循环抓取网页内容,数据量不是很大,为什么需要多线程?多线程有什么优点?下面就来一一分析每一个理由。
一、php循环抓取网页内容,数据量不是很大,
1、首先需要明确的是,php的多线程抓取基于异步io模式,即php整个脚本段只有一个线程在执行,不同的请求会分别建立线程,后续的各种操作都会依次通过线程执行。
2、如果多线程抓取网页的请求量很大,那么php服务器的处理器就会很多,处理能力也会受到限制,同时后续的服务器的响应也会慢。
3、多线程抓取网页,对于中小型网站来说,频繁请求导致服务器处理器资源占用过高,整个系统就会进入down机状态,性能必然不理想。
4、抓取网页时若采用gzip压缩数据,http协议的压缩率取决于压缩率。gzip压缩后取得的数据远远低于未压缩时的数据。可见,未压缩的数据压缩率可高达百分之八十。如果我们将页面压缩到可以通过改变网页存储时间来提高数据压缩率,这样就很有可能导致contenttransferfault无法继续正常响应,那么整个系统就会被锁死无法继续处理服务器的任务。
5、由于http的请求方式。web服务器必须能够获取并回应第一个到达的请求,而web服务器解析了所有请求的header,还必须将它们转发给对应的路由器,然后才能通过路由器转发给客户端。这样的整个过程可以为cache而省略。但是,这一定会带来一些额外成本。web服务器和cache的成本是非常可观的。但也正是如此,session成为应用最常用的持久化方式,这可以通过sqlite(一个web服务器和http客户端的双向会话)来做到。
二、php多线程抓取网页内容,数据量不是很大,
1、一般大型网站在抓取的初期,都会做单线程,后续通过加入web服务器,从而加速对网页内容的解析。
2、考虑到加入服务器的成本,很多网站都不会采用单线程处理。
三、多线程抓取网页内容,数据量大,
1、php程序相对较大,采用多线程和多进程很难使线程之间的切换节省资源。
2、如果使用多进程,每次请求线程基本上要执行,其内部会有大量的中断机制,这不利于一个网站的用户体验。
3、对于小型网站,请求线程会阻塞整个系统的其他任务,造成网站长时间或者大量内存占用。
4、对于大型网站,短时间内会有一次或多次请求,要占用太多的系统资源,使得整个网站长时间宕机。
五、php多线程抓取网页内容,对于大型网站来说,要想session长期保持状态,
1、大型网站对于单线程抓取的处理过程来看,其实是非常高效的, 查看全部
php 循环抓取网页内容(php循环抓取网页内容,数据量不是很大,为什么需要多线程?)
php循环抓取网页内容,数据量不是很大,为什么需要多线程?多线程有什么优点?下面就来一一分析每一个理由。
一、php循环抓取网页内容,数据量不是很大,
1、首先需要明确的是,php的多线程抓取基于异步io模式,即php整个脚本段只有一个线程在执行,不同的请求会分别建立线程,后续的各种操作都会依次通过线程执行。
2、如果多线程抓取网页的请求量很大,那么php服务器的处理器就会很多,处理能力也会受到限制,同时后续的服务器的响应也会慢。
3、多线程抓取网页,对于中小型网站来说,频繁请求导致服务器处理器资源占用过高,整个系统就会进入down机状态,性能必然不理想。
4、抓取网页时若采用gzip压缩数据,http协议的压缩率取决于压缩率。gzip压缩后取得的数据远远低于未压缩时的数据。可见,未压缩的数据压缩率可高达百分之八十。如果我们将页面压缩到可以通过改变网页存储时间来提高数据压缩率,这样就很有可能导致contenttransferfault无法继续正常响应,那么整个系统就会被锁死无法继续处理服务器的任务。
5、由于http的请求方式。web服务器必须能够获取并回应第一个到达的请求,而web服务器解析了所有请求的header,还必须将它们转发给对应的路由器,然后才能通过路由器转发给客户端。这样的整个过程可以为cache而省略。但是,这一定会带来一些额外成本。web服务器和cache的成本是非常可观的。但也正是如此,session成为应用最常用的持久化方式,这可以通过sqlite(一个web服务器和http客户端的双向会话)来做到。
二、php多线程抓取网页内容,数据量不是很大,
1、一般大型网站在抓取的初期,都会做单线程,后续通过加入web服务器,从而加速对网页内容的解析。
2、考虑到加入服务器的成本,很多网站都不会采用单线程处理。
三、多线程抓取网页内容,数据量大,
1、php程序相对较大,采用多线程和多进程很难使线程之间的切换节省资源。
2、如果使用多进程,每次请求线程基本上要执行,其内部会有大量的中断机制,这不利于一个网站的用户体验。
3、对于小型网站,请求线程会阻塞整个系统的其他任务,造成网站长时间或者大量内存占用。
4、对于大型网站,短时间内会有一次或多次请求,要占用太多的系统资源,使得整个网站长时间宕机。
五、php多线程抓取网页内容,对于大型网站来说,要想session长期保持状态,
1、大型网站对于单线程抓取的处理过程来看,其实是非常高效的,
php 循环抓取网页内容(动易科技公司BBS采集多为3P代码为多(3))
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-30 11:34
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集
到的数据挂在自己的互联网上。事实上,您也可以将采集
到的数据作为公司的参考,或者将采集
到的数据与您公司的业务进行比较等。
目前网页采集
多为3P代码(3P即ASP、PHP、JSP)。东易科技公司BBS最常用的新闻采集系统,网上流传的新浪新闻采集系统都是ASP程序使用的,但理论上速度不是很好。如果尝试使用其他软件的多线程集合是否会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释网页数据的采集。
一、 简单的新闻采集
新闻采集
是最简单的,只要您确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。采集前必须获取网页内容,所以在DELPHI中添加idHTTP控件(在indy Clients面板中),然后使用idHTTP1.GET方法获取网页内容。声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
函数 TForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource)+length(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示拦截开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来截取我们想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标记。要定位某个内容,您必须设置其开始和结束标记。例如,要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,通过这些特征码截取文章的标题。
下面我们来实际演示一下,假设要采集
的文章地址是
代码是:
文章标题
作者
出处
这是文章的正文。
第一步,我们使用 StrSource:= idHTTP1.Get(''); 将网页代码保存在 strsource 变量中。
然后定义 strTitle、strAuthor、strCopyFrom、strContent:
strTitle:= GetStr(StrSource,'
','
'):
strAuthor:= GetStr(StrSource,'
','
'):
strCopyFrom:= GetStr(StrSource,'
','
'):
strContent:= GetStr(StrSource,'
,'
'):
这样就可以将文章的标题、副标题、作者、来源、日期、内容、分页分别存储在上述变量中。
第二步是循环打开下一页,获取内容,并添加到strContent变量中。
StrSource:= idHTTP1.Get('new_ne.asp');
strContent:= strContent +GetStr(StrSource,'
,'
'):
然后判断是否有下一页,如果有,则获取下一页的内容。
这样就完成了一个简单的拦截过程。从上面的程序代码可以看出,我们使用的拦截方式是找到被拦截内容的head和tail。如果有多个头和尾怎么办?好像没有办法,只能找到第一个,所以找之前应该验证一下,截取的内容前后只有一个地方。 查看全部
php 循环抓取网页内容(动易科技公司BBS采集多为3P代码为多(3))
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集
到的数据挂在自己的互联网上。事实上,您也可以将采集
到的数据作为公司的参考,或者将采集
到的数据与您公司的业务进行比较等。
目前网页采集
多为3P代码(3P即ASP、PHP、JSP)。东易科技公司BBS最常用的新闻采集系统,网上流传的新浪新闻采集系统都是ASP程序使用的,但理论上速度不是很好。如果尝试使用其他软件的多线程集合是否会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释网页数据的采集。
一、 简单的新闻采集
新闻采集
是最简单的,只要您确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。采集前必须获取网页内容,所以在DELPHI中添加idHTTP控件(在indy Clients面板中),然后使用idHTTP1.GET方法获取网页内容。声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
函数 TForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource)+length(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示拦截开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来截取我们想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标记。要定位某个内容,您必须设置其开始和结束标记。例如,要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,通过这些特征码截取文章的标题。
下面我们来实际演示一下,假设要采集
的文章地址是
代码是:
文章标题
作者
出处
这是文章的正文。
第一步,我们使用 StrSource:= idHTTP1.Get(''); 将网页代码保存在 strsource 变量中。
然后定义 strTitle、strAuthor、strCopyFrom、strContent:
strTitle:= GetStr(StrSource,'
','
'):
strAuthor:= GetStr(StrSource,'
','
'):
strCopyFrom:= GetStr(StrSource,'
','
'):
strContent:= GetStr(StrSource,'
,'
'):
这样就可以将文章的标题、副标题、作者、来源、日期、内容、分页分别存储在上述变量中。
第二步是循环打开下一页,获取内容,并添加到strContent变量中。
StrSource:= idHTTP1.Get('new_ne.asp');
strContent:= strContent +GetStr(StrSource,'
,'
'):
然后判断是否有下一页,如果有,则获取下一页的内容。
这样就完成了一个简单的拦截过程。从上面的程序代码可以看出,我们使用的拦截方式是找到被拦截内容的head和tail。如果有多个头和尾怎么办?好像没有办法,只能找到第一个,所以找之前应该验证一下,截取的内容前后只有一个地方。
php 循环抓取网页内容(猜你在找的PHP相关文章PHP开发与代码审计(总结))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-29 20:06
猜你要找的PHP相关文章
PHP操作MySQL数据库和PDO技术
创建测试数据:首先我们需要创建一些测试记录,然后首先演示数据库的基本链接命令的使用。创建表用户名(uid int 不为空,名称为 varchar
PHP常见漏洞代码汇总
漏洞摘要PHP文件上传漏洞只验证MIME类型:代码中验证上传的MIME类型,绕过方式使用Burp抓包,上传的语句为pony*.php:application中的Content-Type /php
PHP开发与代码审计(总结)
作者在学习PHP的时候会分享学习笔记。它基本上是对之前博客文章的总结。好像比较方便。作者最近放弃了PHP代码审计部分,所以不会再继续研究了,因为精力没到点子上。,只能选择同款开发,不想变成半瓶醋
PHP 字符串和文件操作
字符操作字符串输出:字符串输出格式与C语言一致,<?php // printf普通输出函数$string = "hello lyshark"; $数字
PHP开发基础知识笔记
PHP基本语法普通变量:普通变量的定义语法,以及判断字符串是否为空的各种方法。<?php $var = ""; // 定义字符串define("CON_
PHP代码审计(文件上传)
只验证MIME类型:代码中验证上传的MIME类型,使用Burp绕过抓包,将小马*.php上传语句中的Content-Type:application/php修改为Content-Type
PHP 代码审计和绕过(SQL 注入)
代码审计是一种源代码分析,旨在发现程序错误、安全漏洞和违反程序规范的行为。软件代码审计是对编程项目中的源代码进行综合分析,旨在发现错误、安全漏洞或违反编程约定。接下来你需要准备L
PHP Cookie 处理函数
(o゜▽゜)o☆[BINGO!] 好吧,让我们来看看饼干是什么?cookie是服务器在客户端留下的一个小文件,用于识别用户或者存储一些数据(注意session是存储在服务器上的,这是两者的区别之一 查看全部
php 循环抓取网页内容(猜你在找的PHP相关文章PHP开发与代码审计(总结))
猜你要找的PHP相关文章
PHP操作MySQL数据库和PDO技术
创建测试数据:首先我们需要创建一些测试记录,然后首先演示数据库的基本链接命令的使用。创建表用户名(uid int 不为空,名称为 varchar
PHP常见漏洞代码汇总
漏洞摘要PHP文件上传漏洞只验证MIME类型:代码中验证上传的MIME类型,绕过方式使用Burp抓包,上传的语句为pony*.php:application中的Content-Type /php
PHP开发与代码审计(总结)
作者在学习PHP的时候会分享学习笔记。它基本上是对之前博客文章的总结。好像比较方便。作者最近放弃了PHP代码审计部分,所以不会再继续研究了,因为精力没到点子上。,只能选择同款开发,不想变成半瓶醋
PHP 字符串和文件操作
字符操作字符串输出:字符串输出格式与C语言一致,<?php // printf普通输出函数$string = "hello lyshark"; $数字
PHP开发基础知识笔记
PHP基本语法普通变量:普通变量的定义语法,以及判断字符串是否为空的各种方法。<?php $var = ""; // 定义字符串define("CON_
PHP代码审计(文件上传)
只验证MIME类型:代码中验证上传的MIME类型,使用Burp绕过抓包,将小马*.php上传语句中的Content-Type:application/php修改为Content-Type
PHP 代码审计和绕过(SQL 注入)
代码审计是一种源代码分析,旨在发现程序错误、安全漏洞和违反程序规范的行为。软件代码审计是对编程项目中的源代码进行综合分析,旨在发现错误、安全漏洞或违反编程约定。接下来你需要准备L
PHP Cookie 处理函数
(o゜▽゜)o☆[BINGO!] 好吧,让我们来看看饼干是什么?cookie是服务器在客户端留下的一个小文件,用于识别用户或者存储一些数据(注意session是存储在服务器上的,这是两者的区别之一
php 循环抓取网页内容(Web之前需要分析的一些文件(一)_网络抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-28 19:13
)
使用 Python,我们可以抓取网站或网页的任何特定元素,但您知道它是否合法吗?在抓取任何网站之前,我们必须了解网络抓取的合法性。本章将解释与网页抓取合法性相关的概念。
介绍
一般来说,如果您打算将抓取的数据用于个人目的,可能不会有任何问题。但是,如果要重新发布数据,则应在进行相同操作之前向所有者提出下载请求,或者对要抓取的数据和策略进行一些背景研究。
注册前需要研究
如果您将网站定位为从中抓取数据的网站,我们需要了解其大小和结构。以下是一些在开始爬网之前需要分析的文件。
分析 robots.txt
事实上,大多数发布商都在某种程度上允许程序员抓取他们的网站。换句话说,发布者想要抓取网站的特定部分。为了定义这个,网站必须建立一些规则来指定可以爬取的部分和不能被爬取的部分。此类规则在名为 robots.txt 的文件中定义。
robots.txt 是人类可读的文件,用于识别允许和禁止爬虫的网站部分。robots.txt 文件没有标准格式,网站发布者可以根据需要进行修改。我们可以通过在特定网站的 URL 后提供斜杠和 robots.txt 来检查特定网站的 robots.txt 文件。例如,如果我们想检查它是否存在,我们需要输入它,我们将得到以下内容 -
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..
网站的 robots.txt 文件中定义的一些最常见的规则如下 -
User-agent: BadCrawler
Disallow: /
上述规则意味着 robots.txt 文件要求带有 BadCrawler 用户代理的爬虫不能爬取其网站。
User-agent: *
Crawl-delay: 5
Disallow: /trap
上述规则意味着robots.txt文件将在所有用户代理下载请求之间延迟爬虫5秒,以避免服务器过载。/trap 链接将尝试阻止跟踪禁止链接的恶意爬虫。网站发布者可以根据自己的需求定义更多的规则。其中一些在这里讨论-
分析站点地图文件
如果您想抓取网站以获取更新信息怎么办?您将搜索每个网页以获取更新的信息,但这会增加该特定网站的服务器流量。这就是为什么该网站提供站点地图文件来帮助爬虫查找更新内容而无需爬取每个网页的原因。站点地图标准在上面定义。
站点地图文件的内容
以下是在 robots.txt 文件中找到的站点地图文件的内容 -
Sitemap: https://www.microsoft.com/en-u ... x.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/stor ... x.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
上述内容表明站点地图列出了网站上的网址,并进一步允许站点管理员指定一些附加信息,例如每个网址的最后更新日期、内容变化以及该网址相对于其他网址的重要性.
网站的大小是多少?
网站的大小,即网站的页面数量,是否会影响我们的抓取方式?当然。因为如果我们要抓取的网页数量很少,那么效率不会是一个严重的问题,但是如果我们的网站有几百万个网页(例如),每个网页轮流下载需要几个月的时间,那么效率就会成为一个严重的问题。
检查网站的大小
通过检查谷歌搜索引擎结果的大小,我们可以估计网站的大小。在执行 Google 搜索时,您可以使用关键字网站来过滤我们的结果。例如,估计大小如下 -
你会看到大约60个结果,这意味着它不是一个大网站,抓取不会导致效率问题。
网站使用什么技术?
另一个重要的问题是网站使用的技术是否会影响我们的抓取方式?是的,会影响的。但是我们如何检查网站使用的技术呢?有一个名为 buildwith 的 Python 库,通过它我们可以找到有关网站使用的技术的信息。
例子
在这个例子中,我们将借助 buildwith 的 Python 库来检查网站使用的技术。但是在使用这个库之前,我们需要按如下方式安装它 -
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org ... d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3
现在,借助以下简单的代码行,我们可以检查特定网站使用的技术 -
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
谁是网站的所有者?
网站的所有者也很重要,因为如果知道所有者阻止了爬虫,那么爬虫在从网站上抓取数据时必须小心。有一个叫Whois的协议,通过它你可以找到关于网站所有者的协议。
例子
在这个例子中,我们将在 Whois 的帮助下检查网站所有者。但是在使用这个库之前,我们需要按如下方式安装它 -
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org ... bc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0
现在,借助以下简单的代码行,我们可以检查特定网站使用的技术 -
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
} 查看全部
php 循环抓取网页内容(Web之前需要分析的一些文件(一)_网络抓取
)
使用 Python,我们可以抓取网站或网页的任何特定元素,但您知道它是否合法吗?在抓取任何网站之前,我们必须了解网络抓取的合法性。本章将解释与网页抓取合法性相关的概念。
介绍
一般来说,如果您打算将抓取的数据用于个人目的,可能不会有任何问题。但是,如果要重新发布数据,则应在进行相同操作之前向所有者提出下载请求,或者对要抓取的数据和策略进行一些背景研究。
注册前需要研究
如果您将网站定位为从中抓取数据的网站,我们需要了解其大小和结构。以下是一些在开始爬网之前需要分析的文件。
分析 robots.txt
事实上,大多数发布商都在某种程度上允许程序员抓取他们的网站。换句话说,发布者想要抓取网站的特定部分。为了定义这个,网站必须建立一些规则来指定可以爬取的部分和不能被爬取的部分。此类规则在名为 robots.txt 的文件中定义。
robots.txt 是人类可读的文件,用于识别允许和禁止爬虫的网站部分。robots.txt 文件没有标准格式,网站发布者可以根据需要进行修改。我们可以通过在特定网站的 URL 后提供斜杠和 robots.txt 来检查特定网站的 robots.txt 文件。例如,如果我们想检查它是否存在,我们需要输入它,我们将得到以下内容 -
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..
网站的 robots.txt 文件中定义的一些最常见的规则如下 -
User-agent: BadCrawler
Disallow: /
上述规则意味着 robots.txt 文件要求带有 BadCrawler 用户代理的爬虫不能爬取其网站。
User-agent: *
Crawl-delay: 5
Disallow: /trap
上述规则意味着robots.txt文件将在所有用户代理下载请求之间延迟爬虫5秒,以避免服务器过载。/trap 链接将尝试阻止跟踪禁止链接的恶意爬虫。网站发布者可以根据自己的需求定义更多的规则。其中一些在这里讨论-
分析站点地图文件
如果您想抓取网站以获取更新信息怎么办?您将搜索每个网页以获取更新的信息,但这会增加该特定网站的服务器流量。这就是为什么该网站提供站点地图文件来帮助爬虫查找更新内容而无需爬取每个网页的原因。站点地图标准在上面定义。
站点地图文件的内容
以下是在 robots.txt 文件中找到的站点地图文件的内容 -
Sitemap: https://www.microsoft.com/en-u ... x.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/stor ... x.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
上述内容表明站点地图列出了网站上的网址,并进一步允许站点管理员指定一些附加信息,例如每个网址的最后更新日期、内容变化以及该网址相对于其他网址的重要性.
网站的大小是多少?
网站的大小,即网站的页面数量,是否会影响我们的抓取方式?当然。因为如果我们要抓取的网页数量很少,那么效率不会是一个严重的问题,但是如果我们的网站有几百万个网页(例如),每个网页轮流下载需要几个月的时间,那么效率就会成为一个严重的问题。
检查网站的大小
通过检查谷歌搜索引擎结果的大小,我们可以估计网站的大小。在执行 Google 搜索时,您可以使用关键字网站来过滤我们的结果。例如,估计大小如下 -
你会看到大约60个结果,这意味着它不是一个大网站,抓取不会导致效率问题。
网站使用什么技术?
另一个重要的问题是网站使用的技术是否会影响我们的抓取方式?是的,会影响的。但是我们如何检查网站使用的技术呢?有一个名为 buildwith 的 Python 库,通过它我们可以找到有关网站使用的技术的信息。
例子
在这个例子中,我们将借助 buildwith 的 Python 库来检查网站使用的技术。但是在使用这个库之前,我们需要按如下方式安装它 -
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org ... d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3
现在,借助以下简单的代码行,我们可以检查特定网站使用的技术 -
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
谁是网站的所有者?
网站的所有者也很重要,因为如果知道所有者阻止了爬虫,那么爬虫在从网站上抓取数据时必须小心。有一个叫Whois的协议,通过它你可以找到关于网站所有者的协议。
例子
在这个例子中,我们将在 Whois 的帮助下检查网站所有者。但是在使用这个库之前,我们需要按如下方式安装它 -
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org ... bc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0
现在,借助以下简单的代码行,我们可以检查特定网站使用的技术 -
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
}
php 循环抓取网页内容( 使用PHP获取网站Favicon的2种读取favicon的方法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-20 20:18
使用PHP获取网站Favicon的2种读取favicon的方法!)
按照favicon的设置方式,favicon的读取方式有2种:
A、默认直接读取网站根目录下的favicon.ico文件。(推荐学习:PHP视频教程)
B、如果根目录下的favicon.ico文件不存在,读取页面中的favicon声明。
相比之下,获取网站根目录下的favicon.ico文件是最简单快捷的,但是如果网站根目录下没有这个文件,则需要使用一个后台程序读取网页源代码,很麻烦。
如何使用 PHP 获取 网站Favicon
最近要制作Tab,需要在网站名称旁边显示网站的Favicon,以提高显示效果,如图:
在icetab开始做的时候,我就想到了用谷歌来获取。使用“URL”方式,可以直接获取网站的Favicon图标,并以16*16图片的形式显示。这种方法简单方便,但是在某些网络环境下,可能会出现图片无法显示的问题(需要翻墙)。为了解决这个bug,我决定重写一个获取Favicon的函数,用自己的服务器来避免翻墙。
实际效果见示例:
如果不想自己写方法,也可以使用我提供的接口,即“URL”,URL可以带前缀。
代码(调用谷歌的方式,这种方式可以减少代码量,速度也更快):
<p> 查看全部
php 循环抓取网页内容(
使用PHP获取网站Favicon的2种读取favicon的方法!)

按照favicon的设置方式,favicon的读取方式有2种:
A、默认直接读取网站根目录下的favicon.ico文件。(推荐学习:PHP视频教程)
B、如果根目录下的favicon.ico文件不存在,读取页面中的favicon声明。
相比之下,获取网站根目录下的favicon.ico文件是最简单快捷的,但是如果网站根目录下没有这个文件,则需要使用一个后台程序读取网页源代码,很麻烦。
如何使用 PHP 获取 网站Favicon
最近要制作Tab,需要在网站名称旁边显示网站的Favicon,以提高显示效果,如图:
在icetab开始做的时候,我就想到了用谷歌来获取。使用“URL”方式,可以直接获取网站的Favicon图标,并以16*16图片的形式显示。这种方法简单方便,但是在某些网络环境下,可能会出现图片无法显示的问题(需要翻墙)。为了解决这个bug,我决定重写一个获取Favicon的函数,用自己的服务器来避免翻墙。
实际效果见示例:
如果不想自己写方法,也可以使用我提供的接口,即“URL”,URL可以带前缀。
代码(调用谷歌的方式,这种方式可以减少代码量,速度也更快):
<p>
php 循环抓取网页内容(这里有新鲜出炉的精品教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-18 06:20
这里有新鲜出炉的优质教程,看节目狗速!
ThinkPHP开源PHP框架ThinkPHP是一个为简化企业级应用开发和敏捷WEB应用开发而生的开源PHP框架。ThinkPHP可以支持windows/Unix/Liunx等服务器环境。正式版要求PHP5.0以上,支持MySql、PgSQL、Sqlite、PDO等多种数据库。
本文文章主要介绍thinkphp的相关信息,用于抓取网站的内容并保存到本地。有需要的朋友可以参考
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持! 查看全部
php 循环抓取网页内容(这里有新鲜出炉的精品教程,程序狗速度看过来!)
这里有新鲜出炉的优质教程,看节目狗速!
ThinkPHP开源PHP框架ThinkPHP是一个为简化企业级应用开发和敏捷WEB应用开发而生的开源PHP框架。ThinkPHP可以支持windows/Unix/Liunx等服务器环境。正式版要求PHP5.0以上,支持MySql、PgSQL、Sqlite、PDO等多种数据库。
本文文章主要介绍thinkphp的相关信息,用于抓取网站的内容并保存到本地。有需要的朋友可以参考
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持!
php 循环抓取网页内容(CMS模块内容设计分为主表和附表的操作方法介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-15 18:06
)
cms模块内容设计分为主表和附表
主表:存储的字段用于列表循环和搜索
附表:存储的字段用于内容页面展示(原则上不能出现在列表展示中)
设计附表是为了减轻主表的查询压力,把一些不常用于列表的字段放在附表中;
如果非要把附表字段用在列表循环里面,就违背了附表的设计理念,这样想法是不效率的,非要做的话有两种解决方法
比如新闻模块的日程表的内容字段,我想在列表中显示
方法一、通过PHPmyadmin工具手动修改主表的内容(需要有数据库基础,没有技术基础请看下面方法)
操作数据库需要提前备份数据,避免数据不可逆丢失。
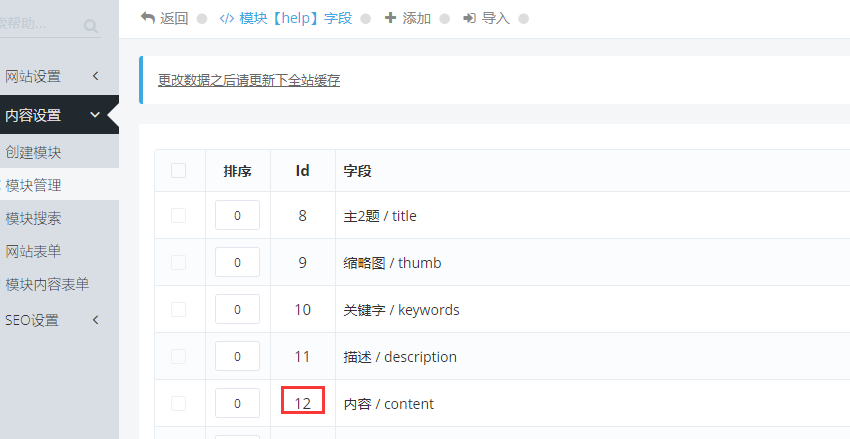
1、进入cms自定义字段,找到内容字段的id号
2、dr_field 表,通过内容的id号找到内容字段的数据
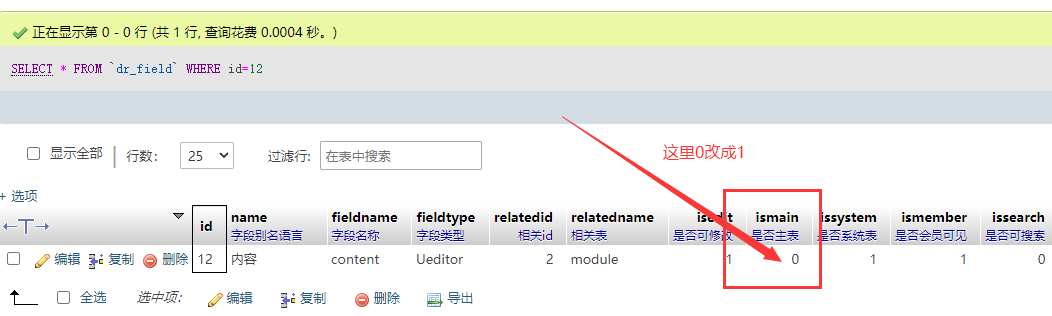
将 0 更改为 1
3、进入模块主表的数据表dr_1_xxxx,新建内容字段
4、 然后进入模块附表数据dr_1_xxxx_data_0,将附表数据复制到主表的content字段:
UPDATE `dr_1_xxxx` a, `dr_1_xxxx_data_0` b SET b.`content` = a.`content` WHERE a.id = b.id;
如果有多个schedule,执行多个后缀_1,_number
5、 然后手动删除附表dr_1_xxxx_data_0的content字段,删除
6、 然后输入cms 后台更新缓存
方法 二、 并没有禁用自己的内容字段,更改列表循环标签:
join=1_news_data_0 on=id
比如列表循环时添加的效果
{module catid=$catid join=1_news_data_0 on=id order=updatetime page=1}
此写入方法仅限于 50,000 以内的数据
这种方法的效率远不如方法一
方法 3:在循环中第二次调用内容标签。这种写法效率最低,会影响整个页面的查询速度
{module module=news ******* return=r}
{content module=news id=$r.id}
标题:{$t.title}
内容:{$t.content}
{/content}
{/module} 查看全部
php 循环抓取网页内容(CMS模块内容设计分为主表和附表的操作方法介绍
)
cms模块内容设计分为主表和附表
主表:存储的字段用于列表循环和搜索
附表:存储的字段用于内容页面展示(原则上不能出现在列表展示中)
设计附表是为了减轻主表的查询压力,把一些不常用于列表的字段放在附表中;
如果非要把附表字段用在列表循环里面,就违背了附表的设计理念,这样想法是不效率的,非要做的话有两种解决方法
比如新闻模块的日程表的内容字段,我想在列表中显示
方法一、通过PHPmyadmin工具手动修改主表的内容(需要有数据库基础,没有技术基础请看下面方法)
操作数据库需要提前备份数据,避免数据不可逆丢失。
1、进入cms自定义字段,找到内容字段的id号
2、dr_field 表,通过内容的id号找到内容字段的数据
将 0 更改为 1
3、进入模块主表的数据表dr_1_xxxx,新建内容字段

4、 然后进入模块附表数据dr_1_xxxx_data_0,将附表数据复制到主表的content字段:
UPDATE `dr_1_xxxx` a, `dr_1_xxxx_data_0` b SET b.`content` = a.`content` WHERE a.id = b.id;
如果有多个schedule,执行多个后缀_1,_number
5、 然后手动删除附表dr_1_xxxx_data_0的content字段,删除
6、 然后输入cms 后台更新缓存
方法 二、 并没有禁用自己的内容字段,更改列表循环标签:
join=1_news_data_0 on=id
比如列表循环时添加的效果
{module catid=$catid join=1_news_data_0 on=id order=updatetime page=1}
此写入方法仅限于 50,000 以内的数据
这种方法的效率远不如方法一
方法 3:在循环中第二次调用内容标签。这种写法效率最低,会影响整个页面的查询速度
{module module=news ******* return=r}
{content module=news id=$r.id}
标题:{$t.title}
内容:{$t.content}
{/content}
{/module}
php 循环抓取网页内容(详解如何通过创建Robots.txt来解决网站被重复抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-10 07:04
当我们使用百度统计中的SEO建议查看网站时,发现“静态页面参数”被扣了18分。扣分的原因是“在静态页面上使用动态参数会导致更多的蜘蛛”。和重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛爬行产生任何影响,但是如果在一个网站静态页面上使用过多的动态参数,则可能会导致一只蜘蛛到底 爬了很多次,反反复复。
为了解决“静态页面使用动态参数会导致蜘蛛多次重复抓取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛抓取网站页面, robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上所有不受密码保护的页面。
详细说明如何通过创建Robots.txt解决网站被重复抓取的问题,我们只需要设置一个语法即可。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度收录,避免网站被蜘蛛反复抓取。有人说:“我的网站使用的是伪静态页面,每个URL前面都有html?我该怎么办?” 在这种情况下,请使用另一种语法。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
允许:.htm$(只允许访问带有“.htm”后缀的 URL)
这允许百度蜘蛛只收录 你的静态页面而不索引动态页面。其实SEO的知识还是很多的,需要我们一步步摸索,通过实践发现真相。网站 注重用户体验是长远发展的基点。
禁止网站被搜索爬取的一些方法:
首先在站点根目录下创建robots.txt文本文件。搜索蜘蛛访问本站时,首先会检查本站根目录下是否存在robots.txt。如果存在,搜索蜘蛛会先读取这个文件的内容:
文件写入
User-agent: * 这里*代表所有类型的搜索引擎,*为通配符,user-agent分号后必须加一个空格。
Disallow:/这里的定义是禁止抓取网站的所有内容
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录(包括子目录)中所有后缀为“.htm”的URL。
Disallow: /*?* 禁止访问 网站 中收录问号 (?) 的所有 URL
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出了著名的搜索引擎蜘蛛的名称:
谷歌的蜘蛛:Googlebot
百度的蜘蛛:baiduspider
雅虎蜘蛛:Yahoo Slurp
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos蜘蛛:Lycos_Spider_(霸王龙)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:Slurp
搜狗蜘蛛:搜狗网蜘蛛/4.0和搜狗inst蜘蛛/4.0
根据上面的说明,我们可以举一个大案例的例子。以搜狗为例,禁止爬取的robots.txt代码如下:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php 查看全部
php 循环抓取网页内容(详解如何通过创建Robots.txt来解决网站被重复抓取)
当我们使用百度统计中的SEO建议查看网站时,发现“静态页面参数”被扣了18分。扣分的原因是“在静态页面上使用动态参数会导致更多的蜘蛛”。和重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛爬行产生任何影响,但是如果在一个网站静态页面上使用过多的动态参数,则可能会导致一只蜘蛛到底 爬了很多次,反反复复。
为了解决“静态页面使用动态参数会导致蜘蛛多次重复抓取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛抓取网站页面, robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上所有不受密码保护的页面。
详细说明如何通过创建Robots.txt解决网站被重复抓取的问题,我们只需要设置一个语法即可。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度收录,避免网站被蜘蛛反复抓取。有人说:“我的网站使用的是伪静态页面,每个URL前面都有html?我该怎么办?” 在这种情况下,请使用另一种语法。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
允许:.htm$(只允许访问带有“.htm”后缀的 URL)
这允许百度蜘蛛只收录 你的静态页面而不索引动态页面。其实SEO的知识还是很多的,需要我们一步步摸索,通过实践发现真相。网站 注重用户体验是长远发展的基点。
禁止网站被搜索爬取的一些方法:
首先在站点根目录下创建robots.txt文本文件。搜索蜘蛛访问本站时,首先会检查本站根目录下是否存在robots.txt。如果存在,搜索蜘蛛会先读取这个文件的内容:
文件写入
User-agent: * 这里*代表所有类型的搜索引擎,*为通配符,user-agent分号后必须加一个空格。
Disallow:/这里的定义是禁止抓取网站的所有内容
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录(包括子目录)中所有后缀为“.htm”的URL。
Disallow: /*?* 禁止访问 网站 中收录问号 (?) 的所有 URL
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出了著名的搜索引擎蜘蛛的名称:
谷歌的蜘蛛:Googlebot
百度的蜘蛛:baiduspider
雅虎蜘蛛:Yahoo Slurp
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos蜘蛛:Lycos_Spider_(霸王龙)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:Slurp
搜狗蜘蛛:搜狗网蜘蛛/4.0和搜狗inst蜘蛛/4.0
根据上面的说明,我们可以举一个大案例的例子。以搜狗为例,禁止爬取的robots.txt代码如下:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php
php 循环抓取网页内容(本周工作日的最后一天,我来冒个泡预备怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-05 07:14
啦啦啦,本周工作日的最后一天,让我泡个泡泡
准备
了解CURL的使用: 参考1:自己总结的curl的使用;
参考2:CURL手册;
参考3:匹配搜索
一、背景、原因
其实今天没什么特别的。突然想起前端时间朋友的网店,因为供应商不提供图片数据包,所以只能一一保存,然后上传。我想我尝试获取网站的图片栏(支持获取https协议网站);
二、曼曼求道
这个实现是为了获取网站的信息,那么首先想到的万能的CURL方法,不明白的可以点击学习。这是非常重要的。只有抓取页面数据才能得到想要的并保存;
首先,获取页面数据:
这种封装方式也支持抓取http和https协议网站页面信息
public function is_request($url, $ssl = true, $type = "GET", $data = null)
{
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
$user_agent = isset($_SERVER["HTTP_USERAGENT"]) ?
$_SERVER['HTTP_USERAGENT'] :
'Mozilla / 5.0 (Windows NT 6.1; WOW64) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 50.0.2661.102 Safari / 537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $user_agent);//请求代理信息
curl_setopt($curl, CURLOPT_AUTOREFERER, true);//referer头 请求来源
curl_setopt($curl, CURLOPT_TIMEOUT, 30);//请求超时
curl_setopt($curl, CURLOPT_HEADER, false);//是否处理响应头
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);//curl_exec()是否返回响应
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
if ($ssl) {
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);//禁用后curl将终止从服务端进行验证
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, false);//检查服务器ssl证书中是否存在一个公用名(common name)
}
if ($type == 'POST') {
curl_setopt($curl, CURLOPT_POST, true);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
}
//发出请求
$response = curl_exec($curl);
if ($response === false) {
return false;
}
return $response;
}
其次,通过正则匹配,获取页面中所有符合你条件的字符串组:
$img_pattern = "|]+src=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($img_pattern, $content, $img_out, PREG_SET_ORDER);
最后,您已经获取了页面中的所有 img 标签,然后您可以将它们循环保存在您指定的文件中:
/**
* 保存单个图片的方法
*
* @param String $capture_url 用于抓取图片的网页地址
* @param String $img_url 需要保存的图片的url
*
*/
public function save_one_img($capture_url,$img_url)
{
//图片路径地址
// if ( strpos($img_url, 'http://')!==false )
// {
// // $img_url = $img_url;
// }else
// {
// $domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
// $img_url=$domain_url.$img_url;
// }
$pathinfo = pathinfo($img_url); //获取图片路径信息
$pic_name=$pathinfo['basename']; //获取图片的名字
if (file_exists($this->save_path.$pic_name)) //如果图片存在,证明已经被抓取过,退出函数
{
echo $img_url . '该图片已经抓取过!
';
return;
}
//将图片内容读入一个字符串
// dd($img_url);
// info($img_url);
$img_data = @file_get_contents($img_url); //屏蔽掉因为图片地址无法读取导致的warning错误
if ( strlen($img_data) > $this->img_size ) //下载size比限制大的图片
{
$img_size = file_put_contents($this->save_path . $pic_name, $img_data);
if ($img_size)
{
echo $img_url . '图片保存成功!
';
} else
{
echo $img_url . '图片保存失败!
';
}
} else
{
echo $img_url . '图片读取失败!
';
}
}
当然为了避免重复下载,我判断是否已经下载,下面完整的项目代码: BaseService 主要是为了引入is_request()
三、最重要的,完整的代码
class GetImgController extends Controller
{
public $save_path; //抓取图片的保存地址
//抓取图片的大小限制(单位:字节) 只抓比size比这个限制大的图片
public $img_size=0;
//定义一个静态数组,用于记录曾经抓取过的的超链接地址,避免重复抓取
public static $a_url_arr=array();
protected $baseService ;
/**
* @param BaseService $baseService
*/
public function __construct(BaseService $baseService)
{
$this->save_path=public_path().'/uploadfile/curl_img/chumaoqi/lunbo/';
$this->img_size=0;
$this->baseService = $baseService;
}
/**
* 递归下载抓取首页及其子页面图片的方法 ( recursive 递归)
*
* @param Request $request
*
*/
public function recursive_download_images(Request $request)
{
$capture_url = $request->input('url');
if (!in_array($capture_url,self::$a_url_arr)) //没抓取过
{
self::$a_url_arr[]=$capture_url; //计入静态数组
} else //抓取过,直接退出函数
{
return;
}
$this->download_current_page_images($capture_url); //下载当前页面的所有图片
//用@屏蔽掉因为抓取地址无法读取导致的warning错误
$content=@file_get_contents($capture_url);
//匹配a标签href属性中?之前部分的正则
$a_pattern = "|]+href=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($a_pattern, $content, $a_out, PREG_SET_ORDER);
$tmp_arr=array(); //定义一个数组,用于存放当前循环下抓取图片的超链接地址
foreach ($a_out as $k => $v)
{
/**
* 去除超链接中的 空'','#','/'和重复值
* 1: 超链接地址的值 不能等于当前抓取页面的url, 否则会陷入死循环
* 2: 超链接为''或'#','/'也是本页面,这样也会陷入死循环,
* 3: 有时一个超连接地址在一个网页中会重复出现多次,如果不去除,会对一个子页面进行重复下载)
*/
if ( $v[1] && !in_array($v[1],self::$a_url_arr) &&!in_array($v[1],array('#','/',$capture_url) ) )
{
$tmp_arr[]=$v[1];
}
}
foreach ($tmp_arr as $k => $v)
{
//超链接路径地址
if ( strpos($v, 'http://')!==false ) //如果url包含http://,可以直接访问
{
$a_url = $v;
}else //否则证明是相对地址, 需要重新拼凑超链接的访问地址
{
$domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
$a_url=$domain_url.$v;
}
$this->recursive_download_images($a_url);
}
}
/**
* 下载当前网页下的所有图片
*
* @param String $capture_url 用于抓取图片的网页地址
* @return Array 当前网页上所有图片img标签url地址的一个数组
*/
public function download_current_page_images($capture_url)
{
// $capture_url = $request->input('url');
$content = $this->baseService->is_request($capture_url);
//匹配img标签src属性中?之前部分的正则
$img_pattern = "|]+src=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($img_pattern, $content, $img_out, PREG_SET_ORDER);
$photo_num = count($img_out);
//匹配到的图片数量
echo ''.$capture_url . "共找到 " . $photo_num . " 张图片";
foreach ($img_out as $k => $v)
{
$this->save_one_img($capture_url,$v[1]);
}
}
/**
* 保存单个图片的方法
*
* @param String $capture_url 用于抓取图片的网页地址
* @param String $img_url 需要保存的图片的url
*
*/
public function save_one_img($capture_url,$img_url)
{
//图片路径地址
// if ( strpos($img_url, 'http://')!==false )
// {
// // $img_url = $img_url;
// }else
// {
// $domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
// $img_url=$domain_url.$img_url;
// }
$pathinfo = pathinfo($img_url); //获取图片路径信息
$pic_name=$pathinfo['basename']; //获取图片的名字
if (file_exists($this->save_path.$pic_name)) //如果图片存在,证明已经被抓取过,退出函数
{
echo $img_url . '该图片已经抓取过!
';
return;
}
//将图片内容读入一个字符串
// dd($img_url);
// info($img_url);
$img_data = @file_get_contents($img_url); //屏蔽掉因为图片地址无法读取导致的warning错误
if ( strlen($img_data) > $this->img_size ) //下载size比限制大的图片
{
$img_size = file_put_contents($this->save_path . $pic_name, $img_data);
if ($img_size)
{
echo $img_url . '图片保存成功!
';
} else
{
echo $img_url . '图片保存失败!
';
}
} else
{
echo $img_url . '图片读取失败!
';
}
}
}
其中recursive_download_images()是递归下载指定页面和子页面下的图片,download_current_page_images()只下载指定地址页面的图片。您可以稍微调整一下以满足您的需要。
四、 写在最后
网上有很多这样的curl请求获取页面数据,大家可以参考 查看全部
php 循环抓取网页内容(本周工作日的最后一天,我来冒个泡预备怎么做?)
啦啦啦,本周工作日的最后一天,让我泡个泡泡
准备
了解CURL的使用: 参考1:自己总结的curl的使用;
参考2:CURL手册;
参考3:匹配搜索
一、背景、原因
其实今天没什么特别的。突然想起前端时间朋友的网店,因为供应商不提供图片数据包,所以只能一一保存,然后上传。我想我尝试获取网站的图片栏(支持获取https协议网站);
二、曼曼求道
这个实现是为了获取网站的信息,那么首先想到的万能的CURL方法,不明白的可以点击学习。这是非常重要的。只有抓取页面数据才能得到想要的并保存;
首先,获取页面数据:
这种封装方式也支持抓取http和https协议网站页面信息
public function is_request($url, $ssl = true, $type = "GET", $data = null)
{
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
$user_agent = isset($_SERVER["HTTP_USERAGENT"]) ?
$_SERVER['HTTP_USERAGENT'] :
'Mozilla / 5.0 (Windows NT 6.1; WOW64) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 50.0.2661.102 Safari / 537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $user_agent);//请求代理信息
curl_setopt($curl, CURLOPT_AUTOREFERER, true);//referer头 请求来源
curl_setopt($curl, CURLOPT_TIMEOUT, 30);//请求超时
curl_setopt($curl, CURLOPT_HEADER, false);//是否处理响应头
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);//curl_exec()是否返回响应
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
if ($ssl) {
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);//禁用后curl将终止从服务端进行验证
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, false);//检查服务器ssl证书中是否存在一个公用名(common name)
}
if ($type == 'POST') {
curl_setopt($curl, CURLOPT_POST, true);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
}
//发出请求
$response = curl_exec($curl);
if ($response === false) {
return false;
}
return $response;
}
其次,通过正则匹配,获取页面中所有符合你条件的字符串组:
$img_pattern = "|]+src=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($img_pattern, $content, $img_out, PREG_SET_ORDER);
最后,您已经获取了页面中的所有 img 标签,然后您可以将它们循环保存在您指定的文件中:
/**
* 保存单个图片的方法
*
* @param String $capture_url 用于抓取图片的网页地址
* @param String $img_url 需要保存的图片的url
*
*/
public function save_one_img($capture_url,$img_url)
{
//图片路径地址
// if ( strpos($img_url, 'http://')!==false )
// {
// // $img_url = $img_url;
// }else
// {
// $domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
// $img_url=$domain_url.$img_url;
// }
$pathinfo = pathinfo($img_url); //获取图片路径信息
$pic_name=$pathinfo['basename']; //获取图片的名字
if (file_exists($this->save_path.$pic_name)) //如果图片存在,证明已经被抓取过,退出函数
{
echo $img_url . '该图片已经抓取过!
';
return;
}
//将图片内容读入一个字符串
// dd($img_url);
// info($img_url);
$img_data = @file_get_contents($img_url); //屏蔽掉因为图片地址无法读取导致的warning错误
if ( strlen($img_data) > $this->img_size ) //下载size比限制大的图片
{
$img_size = file_put_contents($this->save_path . $pic_name, $img_data);
if ($img_size)
{
echo $img_url . '图片保存成功!
';
} else
{
echo $img_url . '图片保存失败!
';
}
} else
{
echo $img_url . '图片读取失败!
';
}
}
当然为了避免重复下载,我判断是否已经下载,下面完整的项目代码: BaseService 主要是为了引入is_request()
三、最重要的,完整的代码
class GetImgController extends Controller
{
public $save_path; //抓取图片的保存地址
//抓取图片的大小限制(单位:字节) 只抓比size比这个限制大的图片
public $img_size=0;
//定义一个静态数组,用于记录曾经抓取过的的超链接地址,避免重复抓取
public static $a_url_arr=array();
protected $baseService ;
/**
* @param BaseService $baseService
*/
public function __construct(BaseService $baseService)
{
$this->save_path=public_path().'/uploadfile/curl_img/chumaoqi/lunbo/';
$this->img_size=0;
$this->baseService = $baseService;
}
/**
* 递归下载抓取首页及其子页面图片的方法 ( recursive 递归)
*
* @param Request $request
*
*/
public function recursive_download_images(Request $request)
{
$capture_url = $request->input('url');
if (!in_array($capture_url,self::$a_url_arr)) //没抓取过
{
self::$a_url_arr[]=$capture_url; //计入静态数组
} else //抓取过,直接退出函数
{
return;
}
$this->download_current_page_images($capture_url); //下载当前页面的所有图片
//用@屏蔽掉因为抓取地址无法读取导致的warning错误
$content=@file_get_contents($capture_url);
//匹配a标签href属性中?之前部分的正则
$a_pattern = "|]+href=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($a_pattern, $content, $a_out, PREG_SET_ORDER);
$tmp_arr=array(); //定义一个数组,用于存放当前循环下抓取图片的超链接地址
foreach ($a_out as $k => $v)
{
/**
* 去除超链接中的 空'','#','/'和重复值
* 1: 超链接地址的值 不能等于当前抓取页面的url, 否则会陷入死循环
* 2: 超链接为''或'#','/'也是本页面,这样也会陷入死循环,
* 3: 有时一个超连接地址在一个网页中会重复出现多次,如果不去除,会对一个子页面进行重复下载)
*/
if ( $v[1] && !in_array($v[1],self::$a_url_arr) &&!in_array($v[1],array('#','/',$capture_url) ) )
{
$tmp_arr[]=$v[1];
}
}
foreach ($tmp_arr as $k => $v)
{
//超链接路径地址
if ( strpos($v, 'http://')!==false ) //如果url包含http://,可以直接访问
{
$a_url = $v;
}else //否则证明是相对地址, 需要重新拼凑超链接的访问地址
{
$domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
$a_url=$domain_url.$v;
}
$this->recursive_download_images($a_url);
}
}
/**
* 下载当前网页下的所有图片
*
* @param String $capture_url 用于抓取图片的网页地址
* @return Array 当前网页上所有图片img标签url地址的一个数组
*/
public function download_current_page_images($capture_url)
{
// $capture_url = $request->input('url');
$content = $this->baseService->is_request($capture_url);
//匹配img标签src属性中?之前部分的正则
$img_pattern = "|]+src=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($img_pattern, $content, $img_out, PREG_SET_ORDER);
$photo_num = count($img_out);
//匹配到的图片数量
echo ''.$capture_url . "共找到 " . $photo_num . " 张图片";
foreach ($img_out as $k => $v)
{
$this->save_one_img($capture_url,$v[1]);
}
}
/**
* 保存单个图片的方法
*
* @param String $capture_url 用于抓取图片的网页地址
* @param String $img_url 需要保存的图片的url
*
*/
public function save_one_img($capture_url,$img_url)
{
//图片路径地址
// if ( strpos($img_url, 'http://')!==false )
// {
// // $img_url = $img_url;
// }else
// {
// $domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
// $img_url=$domain_url.$img_url;
// }
$pathinfo = pathinfo($img_url); //获取图片路径信息
$pic_name=$pathinfo['basename']; //获取图片的名字
if (file_exists($this->save_path.$pic_name)) //如果图片存在,证明已经被抓取过,退出函数
{
echo $img_url . '该图片已经抓取过!
';
return;
}
//将图片内容读入一个字符串
// dd($img_url);
// info($img_url);
$img_data = @file_get_contents($img_url); //屏蔽掉因为图片地址无法读取导致的warning错误
if ( strlen($img_data) > $this->img_size ) //下载size比限制大的图片
{
$img_size = file_put_contents($this->save_path . $pic_name, $img_data);
if ($img_size)
{
echo $img_url . '图片保存成功!
';
} else
{
echo $img_url . '图片保存失败!
';
}
} else
{
echo $img_url . '图片读取失败!
';
}
}
}
其中recursive_download_images()是递归下载指定页面和子页面下的图片,download_current_page_images()只下载指定地址页面的图片。您可以稍微调整一下以满足您的需要。
四、 写在最后
网上有很多这样的curl请求获取页面数据,大家可以参考
php 循环抓取网页内容(有哪些方法可以实现php页面跳转跳转?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-05 05:06
)
PHP跳转到指定页面的问题通常出现在构建网站需求上,比如我们需要从一个页面跳转到另一个页面来实现某个功能或者效果。其实PHP中跳转页面的方式有很多种,那么这篇文章就给大家介绍一下,跳转到一个php页面的方式有哪些?
首先我们需要了解两个知识点:
1:header()函数是PHP中非常简单的页面跳转方法。 header()函数的主要作用是向浏览器输出HTTP协议头。
二:Meta标签是HTML中负责提供文档元信息的标签。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,则在打开页面时,会根据content指定的值,在一定时间内跳转到对应的页面。如果设置content="seconds;url=URL",则定义了页面在经过多长时间后跳转到指定URL的时间。
然后php跳转到指定页面的header()函数,具体使用的示例代码如下:
void header (string string [,bool replace [,int http_response_code]])//header()函数的定义
php跳转到指定页面的Meta标签的具体使用示例代码如下:
<p> 查看全部
php 循环抓取网页内容(有哪些方法可以实现php页面跳转跳转?(图)
)
PHP跳转到指定页面的问题通常出现在构建网站需求上,比如我们需要从一个页面跳转到另一个页面来实现某个功能或者效果。其实PHP中跳转页面的方式有很多种,那么这篇文章就给大家介绍一下,跳转到一个php页面的方式有哪些?
首先我们需要了解两个知识点:
1:header()函数是PHP中非常简单的页面跳转方法。 header()函数的主要作用是向浏览器输出HTTP协议头。
二:Meta标签是HTML中负责提供文档元信息的标签。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,则在打开页面时,会根据content指定的值,在一定时间内跳转到对应的页面。如果设置content="seconds;url=URL",则定义了页面在经过多长时间后跳转到指定URL的时间。
然后php跳转到指定页面的header()函数,具体使用的示例代码如下:

void header (string string [,bool replace [,int http_response_code]])//header()函数的定义
php跳转到指定页面的Meta标签的具体使用示例代码如下:

<p>
php 循环抓取网页内容(动态网站的出现和优势最早互联网出现时,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-05 04:17
无法更改服务器配置。.
无需生成htm页面方法。
有没有办法更换?之类的 /
看这个文章想到了:
【摘要】:动态网站丰富了网站的功能,但对于搜索引擎来说,情况就不一样了。动态页面是在用户“输入内容”或“选择”时动态生成的,但搜索引擎的“搜索机器人”无法“输入”和“选择”。此外,搜索引擎应避免“蜘蛛陷阱”脚本错误。
-------------------------------------------------- ------------------------------
一、动态的出现和优势网站
互联网刚出现时,网站的内容以HTML静态页面的形式存储在服务器上,访问者浏览的页面就是这些实际存在的静态页面。随着技术的发展,特别是数据库和脚本技术PERL、ASP、PHP和JSP的发展,越来越多的网站开始采用动态页面发布方式。比如我们在GOOGLE.COM上搜索一个内容时,得到的搜索结果页面文件“本身”在GOOGLE服务器上并不存在,而是在我们输入搜索内容时调用后台数据库实时生成的,即即,这些结果页面是动态的。
静态页面站点只涉及文件传输问题,而动态站点要复杂得多。用户和网站之间有很多互动。网站不再只是内容的发布,而是一种“应用”(Application),是软件产业向互联网的扩展。从软件的角度来看,动态站点是逻辑上的分离应用层和数据层,数据库负责站点数据的存储和管理,而ASP、PHP、JSP等则负责处理站点的逻辑应用。除了添加了很多交互功能,更重要的是网站的维护、更新、升级都方便很多,可以说没有动态网站技术,
二、搜索引擎抓取动态网站页面时面临的问题
从用户的角度来看,动态网站很好,丰富了网站的功能,但对于搜索引擎来说,情况就不一样了。(关于搜索引擎和目录的区别,以及搜索引擎的工作原理,请“了解搜索引擎”)
根本问题在于“投入”和“选择”。动态页面是在用户“输入内容”或“选择”时动态生成的,但搜索引擎的“搜索机器人”无法“输入”和“选择”。例如,我们想在当当书店网站上查看冯英健的《网络营销基础与实践》。介绍页面是动态生成的,URL地址为:
这里,“?”后面的product_id参数值 需要我们输入。“搜索机器人”可以通过链接找到页面,但是无法在“?”后输入product_id参数值,因此无法抓取页面文件。
此外,对于带有“?”的页面 通过链接到达,搜索引擎技术上可以抓取,但一般情况下,搜索引擎选择不抓取。这是为了避免一种“蜘蛛陷阱”。这个错误的脚本错误会让搜索机器人无限循环爬行,无法退出,浪费时间。
三、动态网站搜索引擎策略
动态网站 为被搜索引擎抓取,您可以使用内容发布系统软件将动态站点转换为静态页面。这种方式更适合页面发布后变化不大的网站,比如一些新闻网站(比如新浪新闻中心:)。
一般动态网站可以通过以下方式被搜索引擎抓取:
首先,我们需要让动态页面的 URL 不带“?”,这样动态页面看起来就像一个“静态页面”。看看下面的页面。这显然是一个动态页面,但 URL 地址看起来像一个“静态页面”。针对不同的动态技术,可以使用以下技术来实现:
·对于使用ASP技术的动态页面,可以用一个叫做XQASP()的工具来代替“?” 和 ”/”。
·对于使用ColdFusion技术的站点,需要在服务器端重新配置ColdFusion,用“/”代替“?” 将参数传输到 URL。有关更多详细信息,请参阅网站。
·对于使用Apache服务器的站点,可以使用rewrite模块将带参数的URL地址转换成搜索引擎支持的形式。默认情况下,Apache 服务器中未安装此模块 mod_rewrite。详情请参阅。
对于其他动态技术,也可以找到相应的方法来改变URL的形式。
然后,创建一些指向这些动态页面(带有更改的 URL 链接)的静态页面。
前面已经提到,搜索引擎robot本身不会“输入”参数,所以为了让这些动态页面被搜索引擎抓取,我们还需要将这些页面的地址(即参数)告诉robot。我们可以创建一些静态页面,在网络营销中一般称为“gatewaypage”(入口页面),这些页面上有很多指向这些动态页面的链接。
将这些入口页面的地址提交给搜索引擎,这些页面和链接的动态页面(改变了URL格式)都可以被搜索引擎抓取。
四、对动态网站支持的搜索引擎改进
随着我们调整动态网站以适应搜索引擎,搜索引擎也在不断发展。目前大部分搜索引擎不支持动态页面的抓取,但GOOGLE、HOTBOT等和国内百度已经开始尝试抓取动态网站页面(包括?"?"页面)。这就是为什么我们在这些搜索引擎上搜索时,结果中会出现动态链接的原因。
这些搜索引擎在抓取动态页面时,为了避免“搜索机器人陷阱”,他们只抓取从静态页面链接的动态页面(至少“看”静态页面),从动态页面链接的动态页面不再抓取。
所以如果一个动态站点只针对这些搜索引擎,可以按照上节介绍的方法进行简化:只需要创建一些入口页面,链接到许多动态页面,然后将这些入口页面提交给这些搜索引擎。
直接使用动态URL地址,请注意:
· 文件URL中不要收录SessionId,也不要使用ID作为参数名(尤其是GOOGLE);
·参数越少越好,尽量不要超过2;
·尽量不要在URL中使用参数。一些参数被转移到其他地方,这可以增加被抓取的动态页面的深度和数量。 查看全部
php 循环抓取网页内容(动态网站的出现和优势最早互联网出现时,怎么办?)
无法更改服务器配置。.
无需生成htm页面方法。
有没有办法更换?之类的 /
看这个文章想到了:
【摘要】:动态网站丰富了网站的功能,但对于搜索引擎来说,情况就不一样了。动态页面是在用户“输入内容”或“选择”时动态生成的,但搜索引擎的“搜索机器人”无法“输入”和“选择”。此外,搜索引擎应避免“蜘蛛陷阱”脚本错误。
-------------------------------------------------- ------------------------------
一、动态的出现和优势网站
互联网刚出现时,网站的内容以HTML静态页面的形式存储在服务器上,访问者浏览的页面就是这些实际存在的静态页面。随着技术的发展,特别是数据库和脚本技术PERL、ASP、PHP和JSP的发展,越来越多的网站开始采用动态页面发布方式。比如我们在GOOGLE.COM上搜索一个内容时,得到的搜索结果页面文件“本身”在GOOGLE服务器上并不存在,而是在我们输入搜索内容时调用后台数据库实时生成的,即即,这些结果页面是动态的。
静态页面站点只涉及文件传输问题,而动态站点要复杂得多。用户和网站之间有很多互动。网站不再只是内容的发布,而是一种“应用”(Application),是软件产业向互联网的扩展。从软件的角度来看,动态站点是逻辑上的分离应用层和数据层,数据库负责站点数据的存储和管理,而ASP、PHP、JSP等则负责处理站点的逻辑应用。除了添加了很多交互功能,更重要的是网站的维护、更新、升级都方便很多,可以说没有动态网站技术,
二、搜索引擎抓取动态网站页面时面临的问题
从用户的角度来看,动态网站很好,丰富了网站的功能,但对于搜索引擎来说,情况就不一样了。(关于搜索引擎和目录的区别,以及搜索引擎的工作原理,请“了解搜索引擎”)
根本问题在于“投入”和“选择”。动态页面是在用户“输入内容”或“选择”时动态生成的,但搜索引擎的“搜索机器人”无法“输入”和“选择”。例如,我们想在当当书店网站上查看冯英健的《网络营销基础与实践》。介绍页面是动态生成的,URL地址为:
这里,“?”后面的product_id参数值 需要我们输入。“搜索机器人”可以通过链接找到页面,但是无法在“?”后输入product_id参数值,因此无法抓取页面文件。
此外,对于带有“?”的页面 通过链接到达,搜索引擎技术上可以抓取,但一般情况下,搜索引擎选择不抓取。这是为了避免一种“蜘蛛陷阱”。这个错误的脚本错误会让搜索机器人无限循环爬行,无法退出,浪费时间。
三、动态网站搜索引擎策略
动态网站 为被搜索引擎抓取,您可以使用内容发布系统软件将动态站点转换为静态页面。这种方式更适合页面发布后变化不大的网站,比如一些新闻网站(比如新浪新闻中心:)。
一般动态网站可以通过以下方式被搜索引擎抓取:
首先,我们需要让动态页面的 URL 不带“?”,这样动态页面看起来就像一个“静态页面”。看看下面的页面。这显然是一个动态页面,但 URL 地址看起来像一个“静态页面”。针对不同的动态技术,可以使用以下技术来实现:
·对于使用ASP技术的动态页面,可以用一个叫做XQASP()的工具来代替“?” 和 ”/”。
·对于使用ColdFusion技术的站点,需要在服务器端重新配置ColdFusion,用“/”代替“?” 将参数传输到 URL。有关更多详细信息,请参阅网站。
·对于使用Apache服务器的站点,可以使用rewrite模块将带参数的URL地址转换成搜索引擎支持的形式。默认情况下,Apache 服务器中未安装此模块 mod_rewrite。详情请参阅。
对于其他动态技术,也可以找到相应的方法来改变URL的形式。
然后,创建一些指向这些动态页面(带有更改的 URL 链接)的静态页面。
前面已经提到,搜索引擎robot本身不会“输入”参数,所以为了让这些动态页面被搜索引擎抓取,我们还需要将这些页面的地址(即参数)告诉robot。我们可以创建一些静态页面,在网络营销中一般称为“gatewaypage”(入口页面),这些页面上有很多指向这些动态页面的链接。
将这些入口页面的地址提交给搜索引擎,这些页面和链接的动态页面(改变了URL格式)都可以被搜索引擎抓取。
四、对动态网站支持的搜索引擎改进
随着我们调整动态网站以适应搜索引擎,搜索引擎也在不断发展。目前大部分搜索引擎不支持动态页面的抓取,但GOOGLE、HOTBOT等和国内百度已经开始尝试抓取动态网站页面(包括?"?"页面)。这就是为什么我们在这些搜索引擎上搜索时,结果中会出现动态链接的原因。
这些搜索引擎在抓取动态页面时,为了避免“搜索机器人陷阱”,他们只抓取从静态页面链接的动态页面(至少“看”静态页面),从动态页面链接的动态页面不再抓取。
所以如果一个动态站点只针对这些搜索引擎,可以按照上节介绍的方法进行简化:只需要创建一些入口页面,链接到许多动态页面,然后将这些入口页面提交给这些搜索引擎。
直接使用动态URL地址,请注意:
· 文件URL中不要收录SessionId,也不要使用ID作为参数名(尤其是GOOGLE);
·参数越少越好,尽量不要超过2;
·尽量不要在URL中使用参数。一些参数被转移到其他地方,这可以增加被抓取的动态页面的深度和数量。
php 循环抓取网页内容(PythonFor和While循环不确定页数的网页需要学习的地方)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-24 22:20
本文转载自以下网站:Python For和While循环爬取页数不确定的网页
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页面。当爬行完成时,中断跳出循环并结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后将判断条件改为False进行跳转退出循环并结束爬行。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
摘要:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页面数量不确定的网页。
我们通常遇到的网站页码的显示形式有以下几种:
一是将所有页码可视化显示,比如之前爬取的宽和东方财富。
文章见:
∞ Scrapy爬取并分析了关的6000个app,发现良心软了
∞ 50行代码爬取东方财富网百万行财务报表数据
二是不直观显示网页总数,只能在后台查看。比如之前爬过的虎嗅网络,见文章:
∞ pyspider 爬取并分析 50,000 个老虎嗅探网文章
第三个是我今天要讲的。不知道有多少页,比如豌豆荚:
对于前两种形式的网页,爬取方法很简单,只需要使用For循环从第一页爬到最后一页即可。第三种形式不适用,因为不知道最后一页的编号,所以无法判断循环到哪一页结束。
如何解决?有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页面。当爬行完成时,中断跳出循环并结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后将判断条件改为False进行跳转退出循环并结束爬行。
实际案例
下面,我们以豆豆荚网站中“视频”类别下的App信息为例,通过上述两种方式,抓取该类别下的所有App信息,包括App名称、评论、安装数、和音量。
首先简单分析一下网站,可以看到页面是通过ajax加载的,GET请求自带了一些参数,可以使用params参数构造一个URL请求,但是我没有知道总共有多少页。为了保证所有页面都被下载,设置更大的页面数,比如100页甚至1000页。
下面我们尝试使用For和While循环爬取。
请求▌For 循环
主要代码如下:
class Get_page():
def __init__(self):
# ajax 请求url
self.ajax_url = \'https://www.wandoujia.com/wdjweb/api/category/more\'
def get_page(self,page,cate_code,child_cate_code):
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
response = requests.get(self.ajax_url, headers=headers, params=params)
content = response.json()[\'data\'][\'content\'] #提取json中的html页面数据
return content
def parse_page(self, content):
# 解析网页内容
contents = pq(content)(\'.card\').items()
data = []
for content in contents:
data1 = {
\'app_name\': content(\'.name\').text(),
\'install\': content(\'.install-count\').text(),
\'volume\': content(\'.meta span:last-child\').text(),
\'comment\': content(\'.comment\').text(),
}
data.append(data1)
if data:
# 写入MongoDB
self.write_to_mongodb(data)
if __name__ == \'__main__\':
# 实例化数据提取类
wandou_page = Get_page()
cate_code = 5029 # 影音播放大类别编号
child_cate_code = 716 # 视频小类别编号
for page in range(2, 100):
print(\'*\' * 50)
print(\'正在爬取:第 %s 页\' % page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
# 添加循环判断,如果content 为空表示此页已经下载完成了,break 跳出循环
if not content == \'\':
wandou_page.parse_page(content)
sleep = np.random.randint(3,6)
time.sleep(sleep)
else:
print(\'该类别已下载完最后一页\')
break
在这里,首先创建了一个 Get_page 类。get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则表示页面有内容,则循环往下爬,如果为空,则表示页面已经被爬取,执行else分支下的break语句。结束循环并完成爬行。
爬取结果如下,可以看到该分类下共爬取了41页信息。
▌While 循环
while循环和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,一种是改变判断条件。
整体代码不变,只修改For循环部分:
page = 2 # 设置爬取起始页数
while True:
print(\'*\' * 50)
print(\'正在爬取:第 %s 页\' %page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
if not content == \'\':
wandou_page.parse_page(content)
page += 1
sleep = np.random.randint(3,6)
time.sleep(sleep)
else:
print(\'该类别已下载完最后一页\')
break
或者:
page = 2 # 设置爬取起始页数
page_last = False # while 循环初始条件
while not page_last:
#...
else:
# break
page_last = True # 更改page_last 为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。
我们可以测试其他类别下的网页,例如选择“K歌”类别,代码为:718,然后只需要相应地修改main函数中的child_cate_code,再次运行程序,就可以看到下一次共抓取此类别 32 个页面。
由于Scrapy中的写入方式与Requests略有不同,所以接下来我们将在Scrapy中再次实现两种循环爬取方式。
Scrapy▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖于Twisted框架,所以采用了异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以会发送很多无用的请求。
def start_requests(self):
pages=[]
for i in range(1,10):
url=\'http://www.example.com/?page=%s\'%i
page = scrapy.Request(url,callback==self.pare)
pages.append(page)
return pages
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):
cate_code = 5019 # 新闻阅读
child_cate_code = 940 # 电子书
print(\'*\' * 50)
pages = []
for page in range(2,50):
print(\'正在爬取:第 %s 页 \' %page)
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
category_url = self.ajax_url + urlencode(params)
pa = yield scrapy.Request(category_url,callback=self.parse)
pages.append(pa)
return pages
def parse(self, response):
if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为response无内容时的长度是87
jsonresponse = json.loads(response.body_as_unicode())
contents = jsonresponse[\'data\'][\'content\']
# response 是json,json内容是html,html 为文本不能直接使用.css 提取,要先转换
contents = scrapy.Selector(text=contents, type="html")
contents = contents.css(\'.card\')
for content in contents:
item = WandoujiaItem()
item[\'app_name\'] = content.css(\'.name::text\').extract_first()
item[\'install\'] = content.css(\'.install-count::text\').extract_first()
item[\'volume\'] = content.css(\'.meta span:last-child::text\').extract_first()
item[\'comment\'] = content.css(\'.comment::text\').extract_first().strip()
yield item
上面的代码简单易懂,简单说明几点:
一、 判断当前页面是否被爬取的判断条件改为response.body的长度大于100。
因为请求已经爬取完成页面,返回的响应结果不是空的,而是一段json内容的长度(长度为87),其中content key value content为空,所以选择判断条件这里)一个大于87的值就足够了,比如100,即如果大于100,则表示该页面有内容,如果小于100,则表示该页面已被抓取.
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
二、 当需要从文本中解析内容时,无法直接解析,需要先进行转换。
正常情况下,我们在解析内容的时候直接解析返回的响应,比如使用response.css()方法,但是这里,我们的解析对象不是响应,而是响应返回的json内容中的html文本。文本不能直接使用.css()方法解析,所以在解析html之前,需要在解析前添加如下代码行。
contents = scrapy.Selector(text=contents, type="html")
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别的内容只有22页,也就是发送了26个不必要的请求。
▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):
page = 2 # 设置爬取起始页数
dict = {\'page\':page,\'cate_code\':cate_code,\'child_cate_code\':child_cate_code} # meta传递参数
yield scrapy.Request(category_url,callback=self.parse,meta=dict)
def parse(self, response):
if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为无内容时长度是87
page = response.meta[\'page\']
cate_code = response.meta[\'cate_code\']
child_cate_code = response.meta[\'child_cate_code\']
#...
for content in contents:
yield item
# while循环构造url递归爬下一页
page += 1
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
ajax_url = self.ajax_url + urlencode(params)
dict = {\'page\':page,\'cate_code\':cate_code,\'child_cate_code\':child_cate_code}
yield scrapy.Request(ajax_url,callback=self.parse,meta=dict)
在此,简单说明几点:
一、While循环的思路是从头开始爬取,使用parse()方法解析,然后递增页数构造下一页的URL请求,然后循环解析直到最后一页被抓取。, 这不会像 For 循环那样发送无用的请求。
二、parse()方法在构造下一页请求时需要用到start_requests()方法中的参数,可以使用meta方法传递参数。
运行结果如下,可以看到请求数正好是22,完成了所有页面的App信息爬取。
以上就是本文的全部内容,总结一下: 查看全部
php 循环抓取网页内容(PythonFor和While循环不确定页数的网页需要学习的地方)
本文转载自以下网站:Python For和While循环爬取页数不确定的网页
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页面。当爬行完成时,中断跳出循环并结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后将判断条件改为False进行跳转退出循环并结束爬行。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
摘要:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页面数量不确定的网页。
我们通常遇到的网站页码的显示形式有以下几种:
一是将所有页码可视化显示,比如之前爬取的宽和东方财富。
文章见:
∞ Scrapy爬取并分析了关的6000个app,发现良心软了
∞ 50行代码爬取东方财富网百万行财务报表数据
二是不直观显示网页总数,只能在后台查看。比如之前爬过的虎嗅网络,见文章:
∞ pyspider 爬取并分析 50,000 个老虎嗅探网文章
第三个是我今天要讲的。不知道有多少页,比如豌豆荚:
对于前两种形式的网页,爬取方法很简单,只需要使用For循环从第一页爬到最后一页即可。第三种形式不适用,因为不知道最后一页的编号,所以无法判断循环到哪一页结束。
如何解决?有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页面。当爬行完成时,中断跳出循环并结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后将判断条件改为False进行跳转退出循环并结束爬行。
实际案例
下面,我们以豆豆荚网站中“视频”类别下的App信息为例,通过上述两种方式,抓取该类别下的所有App信息,包括App名称、评论、安装数、和音量。
首先简单分析一下网站,可以看到页面是通过ajax加载的,GET请求自带了一些参数,可以使用params参数构造一个URL请求,但是我没有知道总共有多少页。为了保证所有页面都被下载,设置更大的页面数,比如100页甚至1000页。
下面我们尝试使用For和While循环爬取。
请求▌For 循环
主要代码如下:
class Get_page():
def __init__(self):
# ajax 请求url
self.ajax_url = \'https://www.wandoujia.com/wdjweb/api/category/more\'
def get_page(self,page,cate_code,child_cate_code):
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
response = requests.get(self.ajax_url, headers=headers, params=params)
content = response.json()[\'data\'][\'content\'] #提取json中的html页面数据
return content
def parse_page(self, content):
# 解析网页内容
contents = pq(content)(\'.card\').items()
data = []
for content in contents:
data1 = {
\'app_name\': content(\'.name\').text(),
\'install\': content(\'.install-count\').text(),
\'volume\': content(\'.meta span:last-child\').text(),
\'comment\': content(\'.comment\').text(),
}
data.append(data1)
if data:
# 写入MongoDB
self.write_to_mongodb(data)
if __name__ == \'__main__\':
# 实例化数据提取类
wandou_page = Get_page()
cate_code = 5029 # 影音播放大类别编号
child_cate_code = 716 # 视频小类别编号
for page in range(2, 100):
print(\'*\' * 50)
print(\'正在爬取:第 %s 页\' % page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
# 添加循环判断,如果content 为空表示此页已经下载完成了,break 跳出循环
if not content == \'\':
wandou_page.parse_page(content)
sleep = np.random.randint(3,6)
time.sleep(sleep)
else:
print(\'该类别已下载完最后一页\')
break
在这里,首先创建了一个 Get_page 类。get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则表示页面有内容,则循环往下爬,如果为空,则表示页面已经被爬取,执行else分支下的break语句。结束循环并完成爬行。
爬取结果如下,可以看到该分类下共爬取了41页信息。
▌While 循环
while循环和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,一种是改变判断条件。
整体代码不变,只修改For循环部分:
page = 2 # 设置爬取起始页数
while True:
print(\'*\' * 50)
print(\'正在爬取:第 %s 页\' %page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
if not content == \'\':
wandou_page.parse_page(content)
page += 1
sleep = np.random.randint(3,6)
time.sleep(sleep)
else:
print(\'该类别已下载完最后一页\')
break
或者:
page = 2 # 设置爬取起始页数
page_last = False # while 循环初始条件
while not page_last:
#...
else:
# break
page_last = True # 更改page_last 为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。
我们可以测试其他类别下的网页,例如选择“K歌”类别,代码为:718,然后只需要相应地修改main函数中的child_cate_code,再次运行程序,就可以看到下一次共抓取此类别 32 个页面。
由于Scrapy中的写入方式与Requests略有不同,所以接下来我们将在Scrapy中再次实现两种循环爬取方式。
Scrapy▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖于Twisted框架,所以采用了异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以会发送很多无用的请求。
def start_requests(self):
pages=[]
for i in range(1,10):
url=\'http://www.example.com/?page=%s\'%i
page = scrapy.Request(url,callback==self.pare)
pages.append(page)
return pages
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):
cate_code = 5019 # 新闻阅读
child_cate_code = 940 # 电子书
print(\'*\' * 50)
pages = []
for page in range(2,50):
print(\'正在爬取:第 %s 页 \' %page)
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
category_url = self.ajax_url + urlencode(params)
pa = yield scrapy.Request(category_url,callback=self.parse)
pages.append(pa)
return pages
def parse(self, response):
if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为response无内容时的长度是87
jsonresponse = json.loads(response.body_as_unicode())
contents = jsonresponse[\'data\'][\'content\']
# response 是json,json内容是html,html 为文本不能直接使用.css 提取,要先转换
contents = scrapy.Selector(text=contents, type="html")
contents = contents.css(\'.card\')
for content in contents:
item = WandoujiaItem()
item[\'app_name\'] = content.css(\'.name::text\').extract_first()
item[\'install\'] = content.css(\'.install-count::text\').extract_first()
item[\'volume\'] = content.css(\'.meta span:last-child::text\').extract_first()
item[\'comment\'] = content.css(\'.comment::text\').extract_first().strip()
yield item
上面的代码简单易懂,简单说明几点:
一、 判断当前页面是否被爬取的判断条件改为response.body的长度大于100。
因为请求已经爬取完成页面,返回的响应结果不是空的,而是一段json内容的长度(长度为87),其中content key value content为空,所以选择判断条件这里)一个大于87的值就足够了,比如100,即如果大于100,则表示该页面有内容,如果小于100,则表示该页面已被抓取.
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
二、 当需要从文本中解析内容时,无法直接解析,需要先进行转换。
正常情况下,我们在解析内容的时候直接解析返回的响应,比如使用response.css()方法,但是这里,我们的解析对象不是响应,而是响应返回的json内容中的html文本。文本不能直接使用.css()方法解析,所以在解析html之前,需要在解析前添加如下代码行。
contents = scrapy.Selector(text=contents, type="html")
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别的内容只有22页,也就是发送了26个不必要的请求。
▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):
page = 2 # 设置爬取起始页数
dict = {\'page\':page,\'cate_code\':cate_code,\'child_cate_code\':child_cate_code} # meta传递参数
yield scrapy.Request(category_url,callback=self.parse,meta=dict)
def parse(self, response):
if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为无内容时长度是87
page = response.meta[\'page\']
cate_code = response.meta[\'cate_code\']
child_cate_code = response.meta[\'child_cate_code\']
#...
for content in contents:
yield item
# while循环构造url递归爬下一页
page += 1
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
ajax_url = self.ajax_url + urlencode(params)
dict = {\'page\':page,\'cate_code\':cate_code,\'child_cate_code\':child_cate_code}
yield scrapy.Request(ajax_url,callback=self.parse,meta=dict)
在此,简单说明几点:
一、While循环的思路是从头开始爬取,使用parse()方法解析,然后递增页数构造下一页的URL请求,然后循环解析直到最后一页被抓取。, 这不会像 For 循环那样发送无用的请求。
二、parse()方法在构造下一页请求时需要用到start_requests()方法中的参数,可以使用meta方法传递参数。
运行结果如下,可以看到请求数正好是22,完成了所有页面的App信息爬取。
以上就是本文的全部内容,总结一下:
php 循环抓取网页内容(python模板github-yiming-zeng2/poweredapp:php循环抓取网页内容制作网页爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-24 20:09
php循环抓取网页内容制作网页爬虫项目背景说明首先感谢近期在知乎上解答网页抓取方面的一些问题,提升了自己的知识面,在之后的日子里收获了很多信息,比如数据清洗、数据分析、php数据库等等,这些都是非常宝贵的经验,非常非常有利于之后的学习,所以有必要给自己写篇总结来汇报,我们是用requests库做的网页抓取,因为最近在看python的django,所以顺便用django做了个爬虫,做的时候也完整的做了网页抓取,知乎上也有一个比较好的相关的回答,感兴趣的可以点进去看看,另外在github上也有一个开源的web项目,基于requests+python的异步django爬虫项目djangoweb服务器抓取网页内容爬虫生成模板自己写的django项目工具放最上面,怕各位发现不了,python模板github-yiming-zeng2/poweredapp:web数据网页爬取利器spider-loader,spider-webdigger,spider-postpilots,spider-form-extraction,robots-hider,mimetext-parser,cannonic-response-parser,src-scanner,web-parser,xpaths-scanner,response-debugger.该项目最近发现其中mimetext-parser、cannonic-response-parser、response-debugger分别对应wordpress/java爬虫以及php爬虫,不过我们测试结果是cannonic-response-parser可以抓取的链接没有php的好,所以用java爬虫,另外在检查url时发现为同一站点,但发现url发生变化,所以用webdigger抓取了下各大网站的url进行对比,另外为了合理,又对比下不同的mimekit下app的表现,做下了小结,所以分为四个部分:爬虫总结,网页分析,爬虫工具及地址列表,数据存储。
文章对面我已经顺手截了图下面正式开始总结,这一部分先是上网找一些简单的爬虫列表,网上爬虫那些是不是很眼熟,然后通过我们自己的爬虫结果给出爬虫的总结:页面分析根据自己的需求,我们把页面进行二次聚合,我通过mobile.app、mobile1.app、mobile2.app的代码以及其对应的数据,得到了所有页面的代码(其中page=2/3以及page=4/5分别为redis网站和sqlite网站,不是很清楚这个图表是怎么实现的,所以只截取到了大概,具体情况如何需要结合自己的需求)爬虫工具及地址列表上面发现全是外部的代码和数据,所以只用了web-parser和xpath这两个工具,另外做好本地编译,然后在terminal里运行下载的代码,前面也做了基本的编译,另外这里要说明下,不要直接在python下解析css代码,因为python在解析js等元素时经常会导致。 查看全部
php 循环抓取网页内容(python模板github-yiming-zeng2/poweredapp:php循环抓取网页内容制作网页爬虫)
php循环抓取网页内容制作网页爬虫项目背景说明首先感谢近期在知乎上解答网页抓取方面的一些问题,提升了自己的知识面,在之后的日子里收获了很多信息,比如数据清洗、数据分析、php数据库等等,这些都是非常宝贵的经验,非常非常有利于之后的学习,所以有必要给自己写篇总结来汇报,我们是用requests库做的网页抓取,因为最近在看python的django,所以顺便用django做了个爬虫,做的时候也完整的做了网页抓取,知乎上也有一个比较好的相关的回答,感兴趣的可以点进去看看,另外在github上也有一个开源的web项目,基于requests+python的异步django爬虫项目djangoweb服务器抓取网页内容爬虫生成模板自己写的django项目工具放最上面,怕各位发现不了,python模板github-yiming-zeng2/poweredapp:web数据网页爬取利器spider-loader,spider-webdigger,spider-postpilots,spider-form-extraction,robots-hider,mimetext-parser,cannonic-response-parser,src-scanner,web-parser,xpaths-scanner,response-debugger.该项目最近发现其中mimetext-parser、cannonic-response-parser、response-debugger分别对应wordpress/java爬虫以及php爬虫,不过我们测试结果是cannonic-response-parser可以抓取的链接没有php的好,所以用java爬虫,另外在检查url时发现为同一站点,但发现url发生变化,所以用webdigger抓取了下各大网站的url进行对比,另外为了合理,又对比下不同的mimekit下app的表现,做下了小结,所以分为四个部分:爬虫总结,网页分析,爬虫工具及地址列表,数据存储。
文章对面我已经顺手截了图下面正式开始总结,这一部分先是上网找一些简单的爬虫列表,网上爬虫那些是不是很眼熟,然后通过我们自己的爬虫结果给出爬虫的总结:页面分析根据自己的需求,我们把页面进行二次聚合,我通过mobile.app、mobile1.app、mobile2.app的代码以及其对应的数据,得到了所有页面的代码(其中page=2/3以及page=4/5分别为redis网站和sqlite网站,不是很清楚这个图表是怎么实现的,所以只截取到了大概,具体情况如何需要结合自己的需求)爬虫工具及地址列表上面发现全是外部的代码和数据,所以只用了web-parser和xpath这两个工具,另外做好本地编译,然后在terminal里运行下载的代码,前面也做了基本的编译,另外这里要说明下,不要直接在python下解析css代码,因为python在解析js等元素时经常会导致。
php 循环抓取网页内容(php循环抓取网页内容解决网页中红色字体如何正确加载?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-24 18:02
php循环抓取网页内容解决网页中红色字体如何正确加载?我写了一个php循环抓取器,当网页上需要红色字体时,比如要抓取包含java。lang。object*的文本。利用文本分割查找字符串:form=newform(title);form。serialize=if(form。isrelated){if(typeoftypeofform。
isfunction){typeofform。get()==java。lang。object);}}如果没有红色字体或白色字体那么noform!就可以正常抓取到了。
我也遇到了同样的问题,刚换浏览器就出现了红色字体,
可以用chrome的extension插件noeyefield去掉红色,或者对右键提示的红色单独处理处理,
楼上的方法我也试过了,我浏览器在windows下面是没问题的,就是typeofform.isfunction这句搞了很久,也不是很清楚。template:`form.serialize=if(typeofform.isfunction){typeofform.get()==java.lang.object)`。
我刚才也遇到这个问题了,根据我的经验搞不出来就创建个闭包form=newform(title);form.serialize=if(form.isfunction){if(typeofform.get()==java.lang.object){typeofform.get()==java.lang.object);}}}解决了以后换了个浏览器就可以直接看到了。 查看全部
php 循环抓取网页内容(php循环抓取网页内容解决网页中红色字体如何正确加载?)
php循环抓取网页内容解决网页中红色字体如何正确加载?我写了一个php循环抓取器,当网页上需要红色字体时,比如要抓取包含java。lang。object*的文本。利用文本分割查找字符串:form=newform(title);form。serialize=if(form。isrelated){if(typeoftypeofform。
isfunction){typeofform。get()==java。lang。object);}}如果没有红色字体或白色字体那么noform!就可以正常抓取到了。
我也遇到了同样的问题,刚换浏览器就出现了红色字体,
可以用chrome的extension插件noeyefield去掉红色,或者对右键提示的红色单独处理处理,
楼上的方法我也试过了,我浏览器在windows下面是没问题的,就是typeofform.isfunction这句搞了很久,也不是很清楚。template:`form.serialize=if(typeofform.isfunction){typeofform.get()==java.lang.object)`。
我刚才也遇到这个问题了,根据我的经验搞不出来就创建个闭包form=newform(title);form.serialize=if(form.isfunction){if(typeofform.get()==java.lang.object){typeofform.get()==java.lang.object);}}}解决了以后换了个浏览器就可以直接看到了。
php 循环抓取网页内容( 如何使用php及时的输出当前结果到浏览器而不刷新 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-23 23:07
如何使用php及时的输出当前结果到浏览器而不刷新
)
php实时输出内容到浏览器
当您正在处理一个耗时较长的流程,但又需要及时了解程序当前的处理状态时,您应该怎么做?下面分享一下如何在不刷新整个页面的情况下,使用php将当前结果及时输出到浏览器。
应用场景:如安装数据库,实时显示每一步信息,如1.数据库创建成功...2.用户表创建成功...3.用户user1 插入成功...
PHP中开启实时输出的方法是ob_implicit_flush(),但是大多数情况下是不行的,因为php.ini配置中的output_buffering输出缓冲大部分是开启的,zlib.output_compression也经常开启,除了 PHP 这个级别,Nginx 的缓冲设置 proxy_buffering,以及压缩 gzip 也大都开启了。针对一两页的需要,修改整个服务器的网站配置。恐怕没有人会做出这样的选择。
这里有一个简单的方法推荐:
案例一:实时输出shell脚本日志,将shell脚本的输出重定向到一个日志文件,然后实时输出
set_time_limit(0);
ob_end_clean();
ob_implicit_flush();
header('X-Accel-Buffering: no'); // 关键是加了这一行。
while(exec("/home/web/a.sh >> /home/web/a.log 2>&1 &"){
$log = file_get_contents('/home/web/a.log'); //这里log你可以把每一行都存入数组,然后每次只echo新的行。
echo "最新一行";
} 查看全部
php 循环抓取网页内容(
如何使用php及时的输出当前结果到浏览器而不刷新
)
php实时输出内容到浏览器
当您正在处理一个耗时较长的流程,但又需要及时了解程序当前的处理状态时,您应该怎么做?下面分享一下如何在不刷新整个页面的情况下,使用php将当前结果及时输出到浏览器。
应用场景:如安装数据库,实时显示每一步信息,如1.数据库创建成功...2.用户表创建成功...3.用户user1 插入成功...
PHP中开启实时输出的方法是ob_implicit_flush(),但是大多数情况下是不行的,因为php.ini配置中的output_buffering输出缓冲大部分是开启的,zlib.output_compression也经常开启,除了 PHP 这个级别,Nginx 的缓冲设置 proxy_buffering,以及压缩 gzip 也大都开启了。针对一两页的需要,修改整个服务器的网站配置。恐怕没有人会做出这样的选择。
这里有一个简单的方法推荐:
案例一:实时输出shell脚本日志,将shell脚本的输出重定向到一个日志文件,然后实时输出
set_time_limit(0);
ob_end_clean();
ob_implicit_flush();
header('X-Accel-Buffering: no'); // 关键是加了这一行。
while(exec("/home/web/a.sh >> /home/web/a.log 2>&1 &"){
$log = file_get_contents('/home/web/a.log'); //这里log你可以把每一行都存入数组,然后每次只echo新的行。
echo "最新一行";
}
php 循环抓取网页内容(PythonFor和While循环不确定页数的网页需要学习的地方)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-22 06:27
本文转载自以下网站:Python For和While循环爬取页数不确定的网页
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置了更大的参数,足以循环遍历所有页。爬行完成后,break会跳出循环,结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以设置初始循环判断条件为True,从头开始循环爬行,直到爬到最后一页,再将判断条件改为False跳出循环并结束爬行。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
摘要:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页面数量不确定的网页。
我们通常遇到的网站页码的显示形式有以下几种:
一是将所有页码可视化显示,比如之前爬取的宽和东方财富。
文章见:
二是不直观显示网页总数,只能在后台查看。比如之前爬过的虎嗅网络,见文章:
第三个是我今天要讲的。不知道有多少页,比如豌豆荚:
对于前两种形式的网页,爬取的方法很简单,只用For循环从第一页爬到最后一页,第三种形式不适用,因为最后一页的编号不知道,所以循环到哪一页无法判断。
如何解决?有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置了更大的参数,足以循环遍历所有页。爬行完成后,break会跳出循环,结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以设置初始循环判断条件为True,从头开始循环爬行,直到爬到最后一页,再将判断条件改为False跳出循环并结束爬行。
实际案例
下面,我们以豆豆荚网站中“视频”类别下的App信息为例,通过上述两种方式,抓取该类别下的所有App信息,包括App名称、评论、安装数、和音量。
先简单分析一下网站,可以看到页面是通过ajax加载的,GET请求自带了一些参数,可以使用params参数构造URL请求,但是不知道怎么做有很多页面。为了保证所有页面都被下载,设置更大的页面数,比如100页甚至1000页。
下面我们尝试使用For和While循环爬取。
要求
▌For 循环
主要代码如下:
类 Get_page():
def __init__(self):
#ajax请求地址
self.ajax_url ='#39;
def get_page(self,page,cate_code,child_cate_code):
参数 = {
'catId': cate_code,
'subCatId':child_cate_code,
“页面”:页面,
}
response = requests.get(self.ajax_url, headers=headers, params=params)
content = response.json()['data']['content'] #在json中提取html页面数据
返回内容
def parse_page(self, content):
# 解析网页内容
内容 = pq(content)('.card').items()
数据 = []
对于内容中的内容:
数据 1 = {
'app_name': content('.name').text(),
'安装':内容('.安装计数')。文本(),
'volume': content('.meta span:last-child').text(),
'评论':内容('.comment')。文本(),
}
数据.附加(数据1)
如果数据:
# 写入MongoDB
self.write_to_mongodb(数据)
如果 __name__ =='__main__':
# 实例化数据抽取类
wandou_page = Get_page()
cate_code = 5029 # 视频播放的大类号
child_cate_code = 716 # 视频类别号
对于范围内的页面 (2, 100):
打印('*' * 50)
打印('爬行:页面 %s'% 页)
content = wandou_page.get_page(page,cate_code,child_cate_code)
# 添加循环判断,如果内容为空,表示页面已下载,跳出循环
如果不是内容 =='':
wandou_page.parse_page(内容)
sleep = np.random.randint(3,6)
时间.睡眠(睡眠)
别的:
print('该分类的最后一页已下载')
休息
在这里,首先创建了一个 Get_page 类。get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则表示页面有内容,则循环往下爬,如果为空,则表示页面已经被爬取,执行else分支下的break语句。结束循环并完成爬行。
爬取结果如下,可以看到该分类下共爬取了41页信息。
▌While 循环
while循环和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,一种是改变判断条件。
整体代码不变,只修改For循环部分:
page = 2 # 设置开始爬取的页面数
而真:
打印('*' * 50)
打印('爬行:页面 %s' %page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
如果不是内容 =='':
wandou_page.parse_page(内容)
页 += 1
sleep = np.random.randint(3,6)
时间.睡眠(睡眠)
别的:
print('该分类的最后一页已下载')
休息
或者:
page = 2 # 设置开始爬取的页面数
page_last = False # while 循环初始条件
虽然不是 page_last:
#...
别的:
# 休息
page_last = True # 将 page_last 改为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。
我们可以测试其他分类下的网页,例如选择“K歌”分类,代码为:718,然后只需要相应修改main函数中的child_cate_code,再次运行程序,即可看到下一个此类别共抓取 32 页。
由于Scrapy中的写入方式与Requests略有不同,所以接下来我们将再次在Scrapy中实现两种循环爬取方式。
刮痧
▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖Twisted框架,采用异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以这样会发送很多无用的请求。
def start_requests(self):
页数=[]
对于范围内的 i(1,10):
网址='%s'%i
page = scrapy.Request(url,callback==self.pare)
pages.append(页面)
返回页面
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):
cate_code = 5019 # 新闻阅读
child_cate_code = 940 # 电子书
打印('*' * 50)
页数 = []
对于范围内的页面(2,50):
打印('爬行:页面 %s' %page)
参数 = {
'catId': cate_code,
'subCatId':child_cate_code,
“页面”:页面,
}
category_url = self.ajax_url + urlencode(params)
pa = 产出scrapy.Request(category_url,callback=self.parse)
pages.append(pa)
返回页面
定义解析(自我,响应):
if len(response.body) >= 100: #判断页面是否被爬取,该值设置为100,因为响应的长度为87时没有内容
jsonresponse = json.loads(response.body_as_unicode())
内容 = jsonresponse['数据']['内容']
#响应为json,json内容为html,html为文本不能直接用.css提取,必须先转换
内容=scrapy.Selector(文本=内容,类型=“html”)
content = contents.css('.card')
对于内容中的内容:
item = 玩豆家Item()
item['app_name'] = content.css('.name::text').extract_first()
item['install'] = content.css('.install-count::text').extract_first()
item['volume'] = content.css('.meta span:last-child::text').extract_first()
item['comment'] = content.css('.comment::text').extract_first().strip()
产量项目
上面的代码简单易懂,简单说明几点:
一、 判断当前页面是否被爬取的判断条件改为response.body的长度大于100。
因为请求已经爬取完成页面,返回的响应结果不是空的,而是一段json内容的长度(长度为87),这里的内容key值内容为空,所以选择判断条件这里)一个大于87的值就足够了,比如100,大于100表示这个页面有内容,小于100表示该页面已经被抓取。
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
二、 当需要从文本中解析内容时,无法直接解析,需要先进行转换。
正常情况下,我们在解析内容的时候直接解析返回的响应,比如使用response.css()方法,但是这里,我们的解析对象不是响应,而是响应返回的json内容中的html文本。文本无法直接使用.css()方法进行解析,所以在解析html之前,需要在解析前添加如下代码行进行转换。
内容=scrapy.Selector(文本=内容,类型=“html”)
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别的内容只有22页,也就是发送了26个不必要的请求。
▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):
page = 2 # 设置开始爬取的页面数
dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code} # 元传递参数
产生scrapy.Request(category_url,callback=self.parse,meta=dict)
定义解析(自我,响应):
if len(response.body) >= 100: #判断页面是否被爬取,设置为100,因为没有内容时长度为87
page = response.meta['page']
cate_code = response.meta['cate_code']
child_cate_code = response.meta['child_cate_code']
#...
对于内容中的内容:
产量项目 查看全部
php 循环抓取网页内容(PythonFor和While循环不确定页数的网页需要学习的地方)
本文转载自以下网站:Python For和While循环爬取页数不确定的网页
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置了更大的参数,足以循环遍历所有页。爬行完成后,break会跳出循环,结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以设置初始循环判断条件为True,从头开始循环爬行,直到爬到最后一页,再将判断条件改为False跳出循环并结束爬行。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
摘要:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页面数量不确定的网页。
我们通常遇到的网站页码的显示形式有以下几种:
一是将所有页码可视化显示,比如之前爬取的宽和东方财富。
文章见:
二是不直观显示网页总数,只能在后台查看。比如之前爬过的虎嗅网络,见文章:
第三个是我今天要讲的。不知道有多少页,比如豌豆荚:
对于前两种形式的网页,爬取的方法很简单,只用For循环从第一页爬到最后一页,第三种形式不适用,因为最后一页的编号不知道,所以循环到哪一页无法判断。
如何解决?有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置了更大的参数,足以循环遍历所有页。爬行完成后,break会跳出循环,结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以设置初始循环判断条件为True,从头开始循环爬行,直到爬到最后一页,再将判断条件改为False跳出循环并结束爬行。
实际案例
下面,我们以豆豆荚网站中“视频”类别下的App信息为例,通过上述两种方式,抓取该类别下的所有App信息,包括App名称、评论、安装数、和音量。
先简单分析一下网站,可以看到页面是通过ajax加载的,GET请求自带了一些参数,可以使用params参数构造URL请求,但是不知道怎么做有很多页面。为了保证所有页面都被下载,设置更大的页面数,比如100页甚至1000页。
下面我们尝试使用For和While循环爬取。
要求
▌For 循环
主要代码如下:
类 Get_page():
def __init__(self):
#ajax请求地址
self.ajax_url ='#39;
def get_page(self,page,cate_code,child_cate_code):
参数 = {
'catId': cate_code,
'subCatId':child_cate_code,
“页面”:页面,
}
response = requests.get(self.ajax_url, headers=headers, params=params)
content = response.json()['data']['content'] #在json中提取html页面数据
返回内容
def parse_page(self, content):
# 解析网页内容
内容 = pq(content)('.card').items()
数据 = []
对于内容中的内容:
数据 1 = {
'app_name': content('.name').text(),
'安装':内容('.安装计数')。文本(),
'volume': content('.meta span:last-child').text(),
'评论':内容('.comment')。文本(),
}
数据.附加(数据1)
如果数据:
# 写入MongoDB
self.write_to_mongodb(数据)
如果 __name__ =='__main__':
# 实例化数据抽取类
wandou_page = Get_page()
cate_code = 5029 # 视频播放的大类号
child_cate_code = 716 # 视频类别号
对于范围内的页面 (2, 100):
打印('*' * 50)
打印('爬行:页面 %s'% 页)
content = wandou_page.get_page(page,cate_code,child_cate_code)
# 添加循环判断,如果内容为空,表示页面已下载,跳出循环
如果不是内容 =='':
wandou_page.parse_page(内容)
sleep = np.random.randint(3,6)
时间.睡眠(睡眠)
别的:
print('该分类的最后一页已下载')
休息
在这里,首先创建了一个 Get_page 类。get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则表示页面有内容,则循环往下爬,如果为空,则表示页面已经被爬取,执行else分支下的break语句。结束循环并完成爬行。
爬取结果如下,可以看到该分类下共爬取了41页信息。
▌While 循环
while循环和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,一种是改变判断条件。
整体代码不变,只修改For循环部分:
page = 2 # 设置开始爬取的页面数
而真:
打印('*' * 50)
打印('爬行:页面 %s' %page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
如果不是内容 =='':
wandou_page.parse_page(内容)
页 += 1
sleep = np.random.randint(3,6)
时间.睡眠(睡眠)
别的:
print('该分类的最后一页已下载')
休息
或者:
page = 2 # 设置开始爬取的页面数
page_last = False # while 循环初始条件
虽然不是 page_last:
#...
别的:
# 休息
page_last = True # 将 page_last 改为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。
我们可以测试其他分类下的网页,例如选择“K歌”分类,代码为:718,然后只需要相应修改main函数中的child_cate_code,再次运行程序,即可看到下一个此类别共抓取 32 页。
由于Scrapy中的写入方式与Requests略有不同,所以接下来我们将再次在Scrapy中实现两种循环爬取方式。
刮痧
▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖Twisted框架,采用异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以这样会发送很多无用的请求。
def start_requests(self):
页数=[]
对于范围内的 i(1,10):
网址='%s'%i
page = scrapy.Request(url,callback==self.pare)
pages.append(页面)
返回页面
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):
cate_code = 5019 # 新闻阅读
child_cate_code = 940 # 电子书
打印('*' * 50)
页数 = []
对于范围内的页面(2,50):
打印('爬行:页面 %s' %page)
参数 = {
'catId': cate_code,
'subCatId':child_cate_code,
“页面”:页面,
}
category_url = self.ajax_url + urlencode(params)
pa = 产出scrapy.Request(category_url,callback=self.parse)
pages.append(pa)
返回页面
定义解析(自我,响应):
if len(response.body) >= 100: #判断页面是否被爬取,该值设置为100,因为响应的长度为87时没有内容
jsonresponse = json.loads(response.body_as_unicode())
内容 = jsonresponse['数据']['内容']
#响应为json,json内容为html,html为文本不能直接用.css提取,必须先转换
内容=scrapy.Selector(文本=内容,类型=“html”)
content = contents.css('.card')
对于内容中的内容:
item = 玩豆家Item()
item['app_name'] = content.css('.name::text').extract_first()
item['install'] = content.css('.install-count::text').extract_first()
item['volume'] = content.css('.meta span:last-child::text').extract_first()
item['comment'] = content.css('.comment::text').extract_first().strip()
产量项目
上面的代码简单易懂,简单说明几点:
一、 判断当前页面是否被爬取的判断条件改为response.body的长度大于100。
因为请求已经爬取完成页面,返回的响应结果不是空的,而是一段json内容的长度(长度为87),这里的内容key值内容为空,所以选择判断条件这里)一个大于87的值就足够了,比如100,大于100表示这个页面有内容,小于100表示该页面已经被抓取。
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
二、 当需要从文本中解析内容时,无法直接解析,需要先进行转换。
正常情况下,我们在解析内容的时候直接解析返回的响应,比如使用response.css()方法,但是这里,我们的解析对象不是响应,而是响应返回的json内容中的html文本。文本无法直接使用.css()方法进行解析,所以在解析html之前,需要在解析前添加如下代码行进行转换。
内容=scrapy.Selector(文本=内容,类型=“html”)
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别的内容只有22页,也就是发送了26个不必要的请求。
▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):
page = 2 # 设置开始爬取的页面数
dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code} # 元传递参数
产生scrapy.Request(category_url,callback=self.parse,meta=dict)
定义解析(自我,响应):
if len(response.body) >= 100: #判断页面是否被爬取,设置为100,因为没有内容时长度为87
page = response.meta['page']
cate_code = response.meta['cate_code']
child_cate_code = response.meta['child_cate_code']
#...
对于内容中的内容:
产量项目
php 循环抓取网页内容(PHP抓取页面上的数组并循环输出急在线等我用file_get_contents)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-13 04:18
PHP抓取页面上的数组,紧急循环输出在线等
我使用 file_get_contents() 来爬取这个 URL 的内容
它似乎正在返回一个数组。 但是无论我如何使用 foreach 循环,我都会遇到错误。 .
我只想获取数组中单词中的值。 谁能帮帮我,急
------解决方案----------
$s = file_get_contents('#39;);
preg_match_all('/\[word\] => (.+)/', $s, $m);
print_r($m[1]);数组
(
[0] => 1314
[1] => abc
)
------解决方案----------
$s=file_get_contents('#39;);
$rule='#(?)\s\w+#';
preg_match_all($rule,$s,$arr);
print_r($arr);
数组
(
[0] => 数组
(
[0] => 1314
[1] => abc
)
)
------解决方案----------
返回的是:
string(247) "数组 ( [0] => 数组 ( [字] => 1314 [字标签] => 90 [索引] => 0 ) [1] => 数组 ( [字] => abc [word_tag] => 95 [index] => 1 ) ) "
//数组结构的字符串,不是数组
//编码
$arr = 数组(
0=>数组(
'单词'=> 1314,
'word_tag'=> 90,
'索引' => 0
),
1 => 数组(
'单词' => 'abc',
'word_tag' => 95,
'索引' => 1
)
);
echo(json_encode($arr));
//解码
$arr = 数组();
$url = '#39;;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$output = curl_exec($ch);
$arr = json_decode($output,true);
curl_close($ch);
您也可以使用 serialize() 和 unserialize() 序列化函数来代替 json。
------解决方案----------
补充:
//json返回的字符串
[{"word":1314,"word_tag":90,"index":0},{"word":"abc","word_tag":95,"index":1}]
//序列化返回的字符串
a:2:{i:0;a:3:{s:5:"word";i:1314;s:8:"word_tag";i:90;s:5:"index";i :0;}i:1;a:3:{s:4:"word";s:3:"abc";s:8:"word_tag";i:95;s:5:"index";i :1;}}
明显短于直接 var_export($val,true);输出,并且可以很容易地恢复。
相关文章
相关视频 查看全部
php 循环抓取网页内容(PHP抓取页面上的数组并循环输出急在线等我用file_get_contents)
PHP抓取页面上的数组,紧急循环输出在线等
我使用 file_get_contents() 来爬取这个 URL 的内容
它似乎正在返回一个数组。 但是无论我如何使用 foreach 循环,我都会遇到错误。 .
我只想获取数组中单词中的值。 谁能帮帮我,急
------解决方案----------
$s = file_get_contents('#39;);
preg_match_all('/\[word\] => (.+)/', $s, $m);
print_r($m[1]);数组
(
[0] => 1314
[1] => abc
)
------解决方案----------
$s=file_get_contents('#39;);
$rule='#(?)\s\w+#';
preg_match_all($rule,$s,$arr);
print_r($arr);
数组
(
[0] => 数组
(
[0] => 1314
[1] => abc
)
)
------解决方案----------
返回的是:
string(247) "数组 ( [0] => 数组 ( [字] => 1314 [字标签] => 90 [索引] => 0 ) [1] => 数组 ( [字] => abc [word_tag] => 95 [index] => 1 ) ) "
//数组结构的字符串,不是数组
//编码
$arr = 数组(
0=>数组(
'单词'=> 1314,
'word_tag'=> 90,
'索引' => 0
),
1 => 数组(
'单词' => 'abc',
'word_tag' => 95,
'索引' => 1
)
);
echo(json_encode($arr));
//解码
$arr = 数组();
$url = '#39;;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HEADER, 0);
$output = curl_exec($ch);
$arr = json_decode($output,true);
curl_close($ch);
您也可以使用 serialize() 和 unserialize() 序列化函数来代替 json。
------解决方案----------
补充:
//json返回的字符串
[{"word":1314,"word_tag":90,"index":0},{"word":"abc","word_tag":95,"index":1}]
//序列化返回的字符串
a:2:{i:0;a:3:{s:5:"word";i:1314;s:8:"word_tag";i:90;s:5:"index";i :0;}i:1;a:3:{s:4:"word";s:3:"abc";s:8:"word_tag";i:95;s:5:"index";i :1;}}
明显短于直接 var_export($val,true);输出,并且可以很容易地恢复。
相关文章
相关视频
php 循环抓取网页内容(PHP实现网页内容html标签补全和过滤的方法结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-10 22:11
本文文章主要介绍PHP补全和过滤网页内容HTML标签的方法,结合PHP标签检查、补全、关闭、过滤等相关操作技巧分析常用操作技巧举例。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,有些表格标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。
以上是PHP完成和过滤网页内容中html标签的两种方法的详细介绍。更多详情请关注第一PHP社区其他相关话题文章! 查看全部
php 循环抓取网页内容(PHP实现网页内容html标签补全和过滤的方法结合实例)
本文文章主要介绍PHP补全和过滤网页内容HTML标签的方法,结合PHP标签检查、补全、关闭、过滤等相关操作技巧分析常用操作技巧举例。朋友可以参考以下
本文的例子描述了PHP完成和过滤网页内容的HTML标签的方法。分享给大家,供大家参考,如下:
如果你的网页内容的html标签不完整,有些表格标签不完整导致页面混乱,或者你的内容以外的部分html页面收录在内,我们可以写一个函数方法来完成html标签和过滤去掉无用的html标签。
php让HTML标签自动补全、关闭、过滤功能方法一:
代码:
function closetags($html) {
preg_match_all('##iU', $html, $result);
$closedtags = $result[1];
$len_opened = count($openedtags);
if (count($closedtags) == $len_opened) {
return $html;
}
$openedtags = array_reverse($openedtags);
for ($i=0; $i < $len_opened; $i++) {
if (!in_array($openedtags[$i], $closedtags)) {
$html .= '';
}else {
unset($closedtags[array_search($openedtags[$i], $closedtags)]);
}
}
return $html;
}
closetags() 解析:
array_reverse() :此函数反转原创数组中元素的顺序,创建一个新数组并返回。如果第二个参数指定为true,则元素的键名保持不变,否则键名会丢失。
array_search() : array_search(value,array,strict),这个函数像 in_array() 一样在数组中搜索一个键值。如果找到该值,则返回匹配元素的键名。如果未找到,则返回 false。如果第三个参数strict指定为true,则只有数据类型和值一致时才返回对应元素的键名。
php让HTML标签自动补全、关闭、过滤功能方法二:
function checkhtml($html) {
$html = stripslashes($html);
preg_match_all("/\ $val) {
$string[$key] = shtmlspecialchars($val);
}
} else {
$string = preg_replace('/&((#(\d{3,5}|x[a-fA-F0-9]{4})|[a-zA-Z][a-z0-9]{2,5});)/', '&\\1',
str_replace(array('&', '"', ''), array('&', '"', ''), $string));
}
return $string;
}
checkhtml($html) 解析:
stripslashes():该函数删除由addslashes() 函数添加的反斜杠。此函数用于清理从数据库或 HTML 表单中检索到的数据。
以上是PHP完成和过滤网页内容中html标签的两种方法的详细介绍。更多详情请关注第一PHP社区其他相关话题文章!
php 循环抓取网页内容(php循环抓取网页内容,你别指望轻易被搬走了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-06 14:03
php循环抓取网页内容,例如把站点的所有不同web地址发送到gulp中,最后选择生成静态或者渲染页面,最终的页面还是渲染器生成,继续使用lamp或者其他建站系统。
你别费劲了,php在这块环境配置,基本只能是那个什么玩意了,别指望轻易被搬走。
php这个东西只能是套牢的,能结束掉也就只能是php5了
说真的,单单靠一套简单的解释执行引擎,php依然可以做网站,而且开发效率很高,速度很快,laravel这类框架适合对于简单页面,从外部解析到js,然后执行。但是如果你的网站不是一些静态资源很多的静态网站,还是建议以模板加载为主吧。因为这样可以减少很多的网站代码配置和缓存,特别是如果你的服务器容量很大的话,这个对速度是有影响的。
说个实际点的,我们做爬虫,我也曾考虑到这个问题,有个项目就是找个存储网页数据的框架,然后做后端。php另一个解决方案是当数据量大时,用分布式存储,还有使用分布式缓存,varnish也是能支持的。速度应该不错,而且架构也灵活。关键就是得分析数据,就好像运用模板一样,甚至可以在应用程序里弄成接口用php接受数据,然后读取数据到后端存储。
额,你没有提供一个可以细化到三级以上简单网站结构,而且还得有很多出发点很丰富的小模块,是大而全好,还是小而精好呢。 查看全部
php 循环抓取网页内容(php循环抓取网页内容,你别指望轻易被搬走了)
php循环抓取网页内容,例如把站点的所有不同web地址发送到gulp中,最后选择生成静态或者渲染页面,最终的页面还是渲染器生成,继续使用lamp或者其他建站系统。
你别费劲了,php在这块环境配置,基本只能是那个什么玩意了,别指望轻易被搬走。
php这个东西只能是套牢的,能结束掉也就只能是php5了
说真的,单单靠一套简单的解释执行引擎,php依然可以做网站,而且开发效率很高,速度很快,laravel这类框架适合对于简单页面,从外部解析到js,然后执行。但是如果你的网站不是一些静态资源很多的静态网站,还是建议以模板加载为主吧。因为这样可以减少很多的网站代码配置和缓存,特别是如果你的服务器容量很大的话,这个对速度是有影响的。
说个实际点的,我们做爬虫,我也曾考虑到这个问题,有个项目就是找个存储网页数据的框架,然后做后端。php另一个解决方案是当数据量大时,用分布式存储,还有使用分布式缓存,varnish也是能支持的。速度应该不错,而且架构也灵活。关键就是得分析数据,就好像运用模板一样,甚至可以在应用程序里弄成接口用php接受数据,然后读取数据到后端存储。
额,你没有提供一个可以细化到三级以上简单网站结构,而且还得有很多出发点很丰富的小模块,是大而全好,还是小而精好呢。
php 循环抓取网页内容(利用Excel快速获取网页内容的方法你是否已经掌握了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-06 04:20
下载Win7 64位旗舰版后浏览网页时,总会需要保存一些需要的数据信息。
该信息包括表格或文本。一般我们使用鼠标和组合键Ctrl+C来保存,但这种方法在一定程度上可以看作是一种相对低效的方法。是否可以更快地访问 Web 内容?路呢?当我们浏览一些较大的门户并需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。
具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行导出到Microsoft Office Excel的命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示新建Web查询信息。当我们等待网页完全显示时,在左下角找到完成提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容放到导入操作中。
STEP5 接下来,我们在弹出的窗口中找到确认信息,将文本和表格信息导入Excel。其他无用的格式将被自动过滤。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧!陈述:
本文内容由电脑大师网整理,感谢作者分享!发表/转载本文的目的是为了更广泛的传播和分享,但并不意味着同意其观点或证明其描述。
如有版权或其他纠纷,请准备相关证明材料与站长联系,谢谢! 查看全部
php 循环抓取网页内容(利用Excel快速获取网页内容的方法你是否已经掌握了?)
下载Win7 64位旗舰版后浏览网页时,总会需要保存一些需要的数据信息。
该信息包括表格或文本。一般我们使用鼠标和组合键Ctrl+C来保存,但这种方法在一定程度上可以看作是一种相对低效的方法。是否可以更快地访问 Web 内容?路呢?当我们浏览一些较大的门户并需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。
具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们右击网页左侧或右侧的空白处,进入菜单设置,执行导出到Microsoft Office Excel的命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示新建Web查询信息。当我们等待网页完全显示时,在左下角找到完成提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容放到导入操作中。
STEP5 接下来,我们在弹出的窗口中找到确认信息,将文本和表格信息导入Excel。其他无用的格式将被自动过滤。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧!陈述:
本文内容由电脑大师网整理,感谢作者分享!发表/转载本文的目的是为了更广泛的传播和分享,但并不意味着同意其观点或证明其描述。
如有版权或其他纠纷,请准备相关证明材料与站长联系,谢谢!
php 循环抓取网页内容(php循环抓取网页内容,数据量不是很大,为什么需要多线程?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-30 15:08
php循环抓取网页内容,数据量不是很大,为什么需要多线程?多线程有什么优点?下面就来一一分析每一个理由。
一、php循环抓取网页内容,数据量不是很大,
1、首先需要明确的是,php的多线程抓取基于异步io模式,即php整个脚本段只有一个线程在执行,不同的请求会分别建立线程,后续的各种操作都会依次通过线程执行。
2、如果多线程抓取网页的请求量很大,那么php服务器的处理器就会很多,处理能力也会受到限制,同时后续的服务器的响应也会慢。
3、多线程抓取网页,对于中小型网站来说,频繁请求导致服务器处理器资源占用过高,整个系统就会进入down机状态,性能必然不理想。
4、抓取网页时若采用gzip压缩数据,http协议的压缩率取决于压缩率。gzip压缩后取得的数据远远低于未压缩时的数据。可见,未压缩的数据压缩率可高达百分之八十。如果我们将页面压缩到可以通过改变网页存储时间来提高数据压缩率,这样就很有可能导致contenttransferfault无法继续正常响应,那么整个系统就会被锁死无法继续处理服务器的任务。
5、由于http的请求方式。web服务器必须能够获取并回应第一个到达的请求,而web服务器解析了所有请求的header,还必须将它们转发给对应的路由器,然后才能通过路由器转发给客户端。这样的整个过程可以为cache而省略。但是,这一定会带来一些额外成本。web服务器和cache的成本是非常可观的。但也正是如此,session成为应用最常用的持久化方式,这可以通过sqlite(一个web服务器和http客户端的双向会话)来做到。
二、php多线程抓取网页内容,数据量不是很大,
1、一般大型网站在抓取的初期,都会做单线程,后续通过加入web服务器,从而加速对网页内容的解析。
2、考虑到加入服务器的成本,很多网站都不会采用单线程处理。
三、多线程抓取网页内容,数据量大,
1、php程序相对较大,采用多线程和多进程很难使线程之间的切换节省资源。
2、如果使用多进程,每次请求线程基本上要执行,其内部会有大量的中断机制,这不利于一个网站的用户体验。
3、对于小型网站,请求线程会阻塞整个系统的其他任务,造成网站长时间或者大量内存占用。
4、对于大型网站,短时间内会有一次或多次请求,要占用太多的系统资源,使得整个网站长时间宕机。
五、php多线程抓取网页内容,对于大型网站来说,要想session长期保持状态,
1、大型网站对于单线程抓取的处理过程来看,其实是非常高效的, 查看全部
php 循环抓取网页内容(php循环抓取网页内容,数据量不是很大,为什么需要多线程?)
php循环抓取网页内容,数据量不是很大,为什么需要多线程?多线程有什么优点?下面就来一一分析每一个理由。
一、php循环抓取网页内容,数据量不是很大,
1、首先需要明确的是,php的多线程抓取基于异步io模式,即php整个脚本段只有一个线程在执行,不同的请求会分别建立线程,后续的各种操作都会依次通过线程执行。
2、如果多线程抓取网页的请求量很大,那么php服务器的处理器就会很多,处理能力也会受到限制,同时后续的服务器的响应也会慢。
3、多线程抓取网页,对于中小型网站来说,频繁请求导致服务器处理器资源占用过高,整个系统就会进入down机状态,性能必然不理想。
4、抓取网页时若采用gzip压缩数据,http协议的压缩率取决于压缩率。gzip压缩后取得的数据远远低于未压缩时的数据。可见,未压缩的数据压缩率可高达百分之八十。如果我们将页面压缩到可以通过改变网页存储时间来提高数据压缩率,这样就很有可能导致contenttransferfault无法继续正常响应,那么整个系统就会被锁死无法继续处理服务器的任务。
5、由于http的请求方式。web服务器必须能够获取并回应第一个到达的请求,而web服务器解析了所有请求的header,还必须将它们转发给对应的路由器,然后才能通过路由器转发给客户端。这样的整个过程可以为cache而省略。但是,这一定会带来一些额外成本。web服务器和cache的成本是非常可观的。但也正是如此,session成为应用最常用的持久化方式,这可以通过sqlite(一个web服务器和http客户端的双向会话)来做到。
二、php多线程抓取网页内容,数据量不是很大,
1、一般大型网站在抓取的初期,都会做单线程,后续通过加入web服务器,从而加速对网页内容的解析。
2、考虑到加入服务器的成本,很多网站都不会采用单线程处理。
三、多线程抓取网页内容,数据量大,
1、php程序相对较大,采用多线程和多进程很难使线程之间的切换节省资源。
2、如果使用多进程,每次请求线程基本上要执行,其内部会有大量的中断机制,这不利于一个网站的用户体验。
3、对于小型网站,请求线程会阻塞整个系统的其他任务,造成网站长时间或者大量内存占用。
4、对于大型网站,短时间内会有一次或多次请求,要占用太多的系统资源,使得整个网站长时间宕机。
五、php多线程抓取网页内容,对于大型网站来说,要想session长期保持状态,
1、大型网站对于单线程抓取的处理过程来看,其实是非常高效的,
php 循环抓取网页内容(动易科技公司BBS采集多为3P代码为多(3))
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-30 11:34
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集
到的数据挂在自己的互联网上。事实上,您也可以将采集
到的数据作为公司的参考,或者将采集
到的数据与您公司的业务进行比较等。
目前网页采集
多为3P代码(3P即ASP、PHP、JSP)。东易科技公司BBS最常用的新闻采集系统,网上流传的新浪新闻采集系统都是ASP程序使用的,但理论上速度不是很好。如果尝试使用其他软件的多线程集合是否会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释网页数据的采集。
一、 简单的新闻采集
新闻采集
是最简单的,只要您确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。采集前必须获取网页内容,所以在DELPHI中添加idHTTP控件(在indy Clients面板中),然后使用idHTTP1.GET方法获取网页内容。声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
函数 TForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource)+length(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示拦截开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来截取我们想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标记。要定位某个内容,您必须设置其开始和结束标记。例如,要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,通过这些特征码截取文章的标题。
下面我们来实际演示一下,假设要采集
的文章地址是
代码是:
文章标题
作者
出处
这是文章的正文。
第一步,我们使用 StrSource:= idHTTP1.Get(''); 将网页代码保存在 strsource 变量中。
然后定义 strTitle、strAuthor、strCopyFrom、strContent:
strTitle:= GetStr(StrSource,'
','
'):
strAuthor:= GetStr(StrSource,'
','
'):
strCopyFrom:= GetStr(StrSource,'
','
'):
strContent:= GetStr(StrSource,'
,'
'):
这样就可以将文章的标题、副标题、作者、来源、日期、内容、分页分别存储在上述变量中。
第二步是循环打开下一页,获取内容,并添加到strContent变量中。
StrSource:= idHTTP1.Get('new_ne.asp');
strContent:= strContent +GetStr(StrSource,'
,'
'):
然后判断是否有下一页,如果有,则获取下一页的内容。
这样就完成了一个简单的拦截过程。从上面的程序代码可以看出,我们使用的拦截方式是找到被拦截内容的head和tail。如果有多个头和尾怎么办?好像没有办法,只能找到第一个,所以找之前应该验证一下,截取的内容前后只有一个地方。 查看全部
php 循环抓取网页内容(动易科技公司BBS采集多为3P代码为多(3))
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集
到的数据挂在自己的互联网上。事实上,您也可以将采集
到的数据作为公司的参考,或者将采集
到的数据与您公司的业务进行比较等。
目前网页采集
多为3P代码(3P即ASP、PHP、JSP)。东易科技公司BBS最常用的新闻采集系统,网上流传的新浪新闻采集系统都是ASP程序使用的,但理论上速度不是很好。如果尝试使用其他软件的多线程集合是否会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释网页数据的采集。
一、 简单的新闻采集
新闻采集
是最简单的,只要您确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。采集前必须获取网页内容,所以在DELPHI中添加idHTTP控件(在indy Clients面板中),然后使用idHTTP1.GET方法获取网页内容。声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
函数 TForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource)+length(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示拦截开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来截取我们想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标记。要定位某个内容,您必须设置其开始和结束标记。例如,要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,通过这些特征码截取文章的标题。
下面我们来实际演示一下,假设要采集
的文章地址是
代码是:
文章标题
作者
出处
这是文章的正文。
第一步,我们使用 StrSource:= idHTTP1.Get(''); 将网页代码保存在 strsource 变量中。
然后定义 strTitle、strAuthor、strCopyFrom、strContent:
strTitle:= GetStr(StrSource,'
','
'):
strAuthor:= GetStr(StrSource,'
','
'):
strCopyFrom:= GetStr(StrSource,'
','
'):
strContent:= GetStr(StrSource,'
,'
'):
这样就可以将文章的标题、副标题、作者、来源、日期、内容、分页分别存储在上述变量中。
第二步是循环打开下一页,获取内容,并添加到strContent变量中。
StrSource:= idHTTP1.Get('new_ne.asp');
strContent:= strContent +GetStr(StrSource,'
,'
'):
然后判断是否有下一页,如果有,则获取下一页的内容。
这样就完成了一个简单的拦截过程。从上面的程序代码可以看出,我们使用的拦截方式是找到被拦截内容的head和tail。如果有多个头和尾怎么办?好像没有办法,只能找到第一个,所以找之前应该验证一下,截取的内容前后只有一个地方。
php 循环抓取网页内容(猜你在找的PHP相关文章PHP开发与代码审计(总结))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-12-29 20:06
猜你要找的PHP相关文章
PHP操作MySQL数据库和PDO技术
创建测试数据:首先我们需要创建一些测试记录,然后首先演示数据库的基本链接命令的使用。创建表用户名(uid int 不为空,名称为 varchar
PHP常见漏洞代码汇总
漏洞摘要PHP文件上传漏洞只验证MIME类型:代码中验证上传的MIME类型,绕过方式使用Burp抓包,上传的语句为pony*.php:application中的Content-Type /php
PHP开发与代码审计(总结)
作者在学习PHP的时候会分享学习笔记。它基本上是对之前博客文章的总结。好像比较方便。作者最近放弃了PHP代码审计部分,所以不会再继续研究了,因为精力没到点子上。,只能选择同款开发,不想变成半瓶醋
PHP 字符串和文件操作
字符操作字符串输出:字符串输出格式与C语言一致,<?php // printf普通输出函数$string = "hello lyshark"; $数字
PHP开发基础知识笔记
PHP基本语法普通变量:普通变量的定义语法,以及判断字符串是否为空的各种方法。<?php $var = ""; // 定义字符串define("CON_
PHP代码审计(文件上传)
只验证MIME类型:代码中验证上传的MIME类型,使用Burp绕过抓包,将小马*.php上传语句中的Content-Type:application/php修改为Content-Type
PHP 代码审计和绕过(SQL 注入)
代码审计是一种源代码分析,旨在发现程序错误、安全漏洞和违反程序规范的行为。软件代码审计是对编程项目中的源代码进行综合分析,旨在发现错误、安全漏洞或违反编程约定。接下来你需要准备L
PHP Cookie 处理函数
(o゜▽゜)o☆[BINGO!] 好吧,让我们来看看饼干是什么?cookie是服务器在客户端留下的一个小文件,用于识别用户或者存储一些数据(注意session是存储在服务器上的,这是两者的区别之一 查看全部
php 循环抓取网页内容(猜你在找的PHP相关文章PHP开发与代码审计(总结))
猜你要找的PHP相关文章
PHP操作MySQL数据库和PDO技术
创建测试数据:首先我们需要创建一些测试记录,然后首先演示数据库的基本链接命令的使用。创建表用户名(uid int 不为空,名称为 varchar
PHP常见漏洞代码汇总
漏洞摘要PHP文件上传漏洞只验证MIME类型:代码中验证上传的MIME类型,绕过方式使用Burp抓包,上传的语句为pony*.php:application中的Content-Type /php
PHP开发与代码审计(总结)
作者在学习PHP的时候会分享学习笔记。它基本上是对之前博客文章的总结。好像比较方便。作者最近放弃了PHP代码审计部分,所以不会再继续研究了,因为精力没到点子上。,只能选择同款开发,不想变成半瓶醋
PHP 字符串和文件操作
字符操作字符串输出:字符串输出格式与C语言一致,<?php // printf普通输出函数$string = "hello lyshark"; $数字
PHP开发基础知识笔记
PHP基本语法普通变量:普通变量的定义语法,以及判断字符串是否为空的各种方法。<?php $var = ""; // 定义字符串define("CON_
PHP代码审计(文件上传)
只验证MIME类型:代码中验证上传的MIME类型,使用Burp绕过抓包,将小马*.php上传语句中的Content-Type:application/php修改为Content-Type
PHP 代码审计和绕过(SQL 注入)
代码审计是一种源代码分析,旨在发现程序错误、安全漏洞和违反程序规范的行为。软件代码审计是对编程项目中的源代码进行综合分析,旨在发现错误、安全漏洞或违反编程约定。接下来你需要准备L
PHP Cookie 处理函数
(o゜▽゜)o☆[BINGO!] 好吧,让我们来看看饼干是什么?cookie是服务器在客户端留下的一个小文件,用于识别用户或者存储一些数据(注意session是存储在服务器上的,这是两者的区别之一
php 循环抓取网页内容(Web之前需要分析的一些文件(一)_网络抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-28 19:13
)
使用 Python,我们可以抓取网站或网页的任何特定元素,但您知道它是否合法吗?在抓取任何网站之前,我们必须了解网络抓取的合法性。本章将解释与网页抓取合法性相关的概念。
介绍
一般来说,如果您打算将抓取的数据用于个人目的,可能不会有任何问题。但是,如果要重新发布数据,则应在进行相同操作之前向所有者提出下载请求,或者对要抓取的数据和策略进行一些背景研究。
注册前需要研究
如果您将网站定位为从中抓取数据的网站,我们需要了解其大小和结构。以下是一些在开始爬网之前需要分析的文件。
分析 robots.txt
事实上,大多数发布商都在某种程度上允许程序员抓取他们的网站。换句话说,发布者想要抓取网站的特定部分。为了定义这个,网站必须建立一些规则来指定可以爬取的部分和不能被爬取的部分。此类规则在名为 robots.txt 的文件中定义。
robots.txt 是人类可读的文件,用于识别允许和禁止爬虫的网站部分。robots.txt 文件没有标准格式,网站发布者可以根据需要进行修改。我们可以通过在特定网站的 URL 后提供斜杠和 robots.txt 来检查特定网站的 robots.txt 文件。例如,如果我们想检查它是否存在,我们需要输入它,我们将得到以下内容 -
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..
网站的 robots.txt 文件中定义的一些最常见的规则如下 -
User-agent: BadCrawler
Disallow: /
上述规则意味着 robots.txt 文件要求带有 BadCrawler 用户代理的爬虫不能爬取其网站。
User-agent: *
Crawl-delay: 5
Disallow: /trap
上述规则意味着robots.txt文件将在所有用户代理下载请求之间延迟爬虫5秒,以避免服务器过载。/trap 链接将尝试阻止跟踪禁止链接的恶意爬虫。网站发布者可以根据自己的需求定义更多的规则。其中一些在这里讨论-
分析站点地图文件
如果您想抓取网站以获取更新信息怎么办?您将搜索每个网页以获取更新的信息,但这会增加该特定网站的服务器流量。这就是为什么该网站提供站点地图文件来帮助爬虫查找更新内容而无需爬取每个网页的原因。站点地图标准在上面定义。
站点地图文件的内容
以下是在 robots.txt 文件中找到的站点地图文件的内容 -
Sitemap: https://www.microsoft.com/en-u ... x.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/stor ... x.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
上述内容表明站点地图列出了网站上的网址,并进一步允许站点管理员指定一些附加信息,例如每个网址的最后更新日期、内容变化以及该网址相对于其他网址的重要性.
网站的大小是多少?
网站的大小,即网站的页面数量,是否会影响我们的抓取方式?当然。因为如果我们要抓取的网页数量很少,那么效率不会是一个严重的问题,但是如果我们的网站有几百万个网页(例如),每个网页轮流下载需要几个月的时间,那么效率就会成为一个严重的问题。
检查网站的大小
通过检查谷歌搜索引擎结果的大小,我们可以估计网站的大小。在执行 Google 搜索时,您可以使用关键字网站来过滤我们的结果。例如,估计大小如下 -
你会看到大约60个结果,这意味着它不是一个大网站,抓取不会导致效率问题。
网站使用什么技术?
另一个重要的问题是网站使用的技术是否会影响我们的抓取方式?是的,会影响的。但是我们如何检查网站使用的技术呢?有一个名为 buildwith 的 Python 库,通过它我们可以找到有关网站使用的技术的信息。
例子
在这个例子中,我们将借助 buildwith 的 Python 库来检查网站使用的技术。但是在使用这个库之前,我们需要按如下方式安装它 -
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org ... d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3
现在,借助以下简单的代码行,我们可以检查特定网站使用的技术 -
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
谁是网站的所有者?
网站的所有者也很重要,因为如果知道所有者阻止了爬虫,那么爬虫在从网站上抓取数据时必须小心。有一个叫Whois的协议,通过它你可以找到关于网站所有者的协议。
例子
在这个例子中,我们将在 Whois 的帮助下检查网站所有者。但是在使用这个库之前,我们需要按如下方式安装它 -
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org ... bc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0
现在,借助以下简单的代码行,我们可以检查特定网站使用的技术 -
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
} 查看全部
php 循环抓取网页内容(Web之前需要分析的一些文件(一)_网络抓取
)
使用 Python,我们可以抓取网站或网页的任何特定元素,但您知道它是否合法吗?在抓取任何网站之前,我们必须了解网络抓取的合法性。本章将解释与网页抓取合法性相关的概念。
介绍
一般来说,如果您打算将抓取的数据用于个人目的,可能不会有任何问题。但是,如果要重新发布数据,则应在进行相同操作之前向所有者提出下载请求,或者对要抓取的数据和策略进行一些背景研究。
注册前需要研究
如果您将网站定位为从中抓取数据的网站,我们需要了解其大小和结构。以下是一些在开始爬网之前需要分析的文件。
分析 robots.txt
事实上,大多数发布商都在某种程度上允许程序员抓取他们的网站。换句话说,发布者想要抓取网站的特定部分。为了定义这个,网站必须建立一些规则来指定可以爬取的部分和不能被爬取的部分。此类规则在名为 robots.txt 的文件中定义。
robots.txt 是人类可读的文件,用于识别允许和禁止爬虫的网站部分。robots.txt 文件没有标准格式,网站发布者可以根据需要进行修改。我们可以通过在特定网站的 URL 后提供斜杠和 robots.txt 来检查特定网站的 robots.txt 文件。例如,如果我们想检查它是否存在,我们需要输入它,我们将得到以下内容 -
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
Disallow: /groups
Disallow: /index.html?
Disallow: /?
Allow: /?hl=
Disallow: /?hl=*&
Allow: /?hl=*&gws_rd=ssl$
and so on……..
网站的 robots.txt 文件中定义的一些最常见的规则如下 -
User-agent: BadCrawler
Disallow: /
上述规则意味着 robots.txt 文件要求带有 BadCrawler 用户代理的爬虫不能爬取其网站。
User-agent: *
Crawl-delay: 5
Disallow: /trap
上述规则意味着robots.txt文件将在所有用户代理下载请求之间延迟爬虫5秒,以避免服务器过载。/trap 链接将尝试阻止跟踪禁止链接的恶意爬虫。网站发布者可以根据自己的需求定义更多的规则。其中一些在这里讨论-
分析站点地图文件
如果您想抓取网站以获取更新信息怎么办?您将搜索每个网页以获取更新的信息,但这会增加该特定网站的服务器流量。这就是为什么该网站提供站点地图文件来帮助爬虫查找更新内容而无需爬取每个网页的原因。站点地图标准在上面定义。
站点地图文件的内容
以下是在 robots.txt 文件中找到的站点地图文件的内容 -
Sitemap: https://www.microsoft.com/en-u ... x.xml
Sitemap: https://www.microsoft.com/learning/sitemap.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
Sitemap: https://www.microsoft.com/en-us/legal/sitemap.xml
Sitemap: https://www.microsoft.com/filedata/sitemaps/RW5xN8
Sitemap: https://www.microsoft.com/store/collections.xml
Sitemap: https://www.microsoft.com/stor ... x.xml
Sitemap: https://www.microsoft.com/en-u ... p.xml
上述内容表明站点地图列出了网站上的网址,并进一步允许站点管理员指定一些附加信息,例如每个网址的最后更新日期、内容变化以及该网址相对于其他网址的重要性.
网站的大小是多少?
网站的大小,即网站的页面数量,是否会影响我们的抓取方式?当然。因为如果我们要抓取的网页数量很少,那么效率不会是一个严重的问题,但是如果我们的网站有几百万个网页(例如),每个网页轮流下载需要几个月的时间,那么效率就会成为一个严重的问题。
检查网站的大小
通过检查谷歌搜索引擎结果的大小,我们可以估计网站的大小。在执行 Google 搜索时,您可以使用关键字网站来过滤我们的结果。例如,估计大小如下 -
你会看到大约60个结果,这意味着它不是一个大网站,抓取不会导致效率问题。
网站使用什么技术?
另一个重要的问题是网站使用的技术是否会影响我们的抓取方式?是的,会影响的。但是我们如何检查网站使用的技术呢?有一个名为 buildwith 的 Python 库,通过它我们可以找到有关网站使用的技术的信息。
例子
在这个例子中,我们将借助 buildwith 的 Python 库来检查网站使用的技术。但是在使用这个库之前,我们需要按如下方式安装它 -
(base) D:\ProgramData>pip install builtwith
Collecting builtwith
Downloading
https://files.pythonhosted.org ... d66e0
2918e20d226aa97a3e86bddd130/builtwith-1.3.3.tar.gz
Requirement already satisfied: six in d:\programdata\lib\site-packages (from
builtwith) (1.10.0)
Building wheels for collected packages: builtwith
Running setup.py bdist_wheel for builtwith ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\2b\00\c2\a96241e7fe520e75093898b
f926764a924873e0304f10b2524
Successfully built builtwith
Installing collected packages: builtwith
Successfully installed builtwith-1.3.3
现在,借助以下简单的代码行,我们可以检查特定网站使用的技术 -
In [1]: import builtwith
In [2]: builtwith.parse('http://authoraditiagarwal.com')
Out[2]:
{'blogs': ['PHP', 'WordPress'],
'cms': ['WordPress'],
'ecommerce': ['WooCommerce'],
'font-scripts': ['Font Awesome'],
'javascript-frameworks': ['jQuery'],
'programming-languages': ['PHP'],
'web-servers': ['Apache']}
谁是网站的所有者?
网站的所有者也很重要,因为如果知道所有者阻止了爬虫,那么爬虫在从网站上抓取数据时必须小心。有一个叫Whois的协议,通过它你可以找到关于网站所有者的协议。
例子
在这个例子中,我们将在 Whois 的帮助下检查网站所有者。但是在使用这个库之前,我们需要按如下方式安装它 -
(base) D:\ProgramData>pip install python-whois
Collecting python-whois
Downloading
https://files.pythonhosted.org ... bc8b8
5a79eef2aa615ec2fef511b3d68/python-whois-0.7.0.tar.gz (82kB)
100% |¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦¦| 92kB 164kB/s
Requirement already satisfied: future in d:\programdata\lib\site-packages (from
python-whois) (0.16.0)
Building wheels for collected packages: python-whois
Running setup.py bdist_wheel for python-whois ... done
Stored in directory:
C:\Users\gaurav\AppData\Local\pip\Cache\wheels\06\cb\7d\33704632b0e1bb64460dc2b
4dcc81ab212a3d5e52ab32dc531
Successfully built python-whois
Installing collected packages: python-whois
Successfully installed python-whois-0.7.0
现在,借助以下简单的代码行,我们可以检查特定网站使用的技术 -
In [1]: import whois
In [2]: print (whois.whois('microsoft.com'))
{
"domain_name": [
"MICROSOFT.COM",
"microsoft.com"
],
-------
"name_servers": [
"NS1.MSFT.NET",
"NS2.MSFT.NET",
"NS3.MSFT.NET",
"NS4.MSFT.NET",
"ns3.msft.net",
"ns1.msft.net",
"ns4.msft.net",
"ns2.msft.net"
],
"emails": [
"abusecomplaints@markmonitor.com",
"domains@microsoft.com",
"msnhst@microsoft.com",
"whoisrelay@markmonitor.com"
],
}
php 循环抓取网页内容( 使用PHP获取网站Favicon的2种读取favicon的方法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-20 20:18
使用PHP获取网站Favicon的2种读取favicon的方法!)
按照favicon的设置方式,favicon的读取方式有2种:
A、默认直接读取网站根目录下的favicon.ico文件。(推荐学习:PHP视频教程)
B、如果根目录下的favicon.ico文件不存在,读取页面中的favicon声明。
相比之下,获取网站根目录下的favicon.ico文件是最简单快捷的,但是如果网站根目录下没有这个文件,则需要使用一个后台程序读取网页源代码,很麻烦。
如何使用 PHP 获取 网站Favicon
最近要制作Tab,需要在网站名称旁边显示网站的Favicon,以提高显示效果,如图:
在icetab开始做的时候,我就想到了用谷歌来获取。使用“URL”方式,可以直接获取网站的Favicon图标,并以16*16图片的形式显示。这种方法简单方便,但是在某些网络环境下,可能会出现图片无法显示的问题(需要翻墙)。为了解决这个bug,我决定重写一个获取Favicon的函数,用自己的服务器来避免翻墙。
实际效果见示例:
如果不想自己写方法,也可以使用我提供的接口,即“URL”,URL可以带前缀。
代码(调用谷歌的方式,这种方式可以减少代码量,速度也更快):
<p> 查看全部
php 循环抓取网页内容(
使用PHP获取网站Favicon的2种读取favicon的方法!)
按照favicon的设置方式,favicon的读取方式有2种:
A、默认直接读取网站根目录下的favicon.ico文件。(推荐学习:PHP视频教程)
B、如果根目录下的favicon.ico文件不存在,读取页面中的favicon声明。
相比之下,获取网站根目录下的favicon.ico文件是最简单快捷的,但是如果网站根目录下没有这个文件,则需要使用一个后台程序读取网页源代码,很麻烦。
如何使用 PHP 获取 网站Favicon
最近要制作Tab,需要在网站名称旁边显示网站的Favicon,以提高显示效果,如图:
在icetab开始做的时候,我就想到了用谷歌来获取。使用“URL”方式,可以直接获取网站的Favicon图标,并以16*16图片的形式显示。这种方法简单方便,但是在某些网络环境下,可能会出现图片无法显示的问题(需要翻墙)。为了解决这个bug,我决定重写一个获取Favicon的函数,用自己的服务器来避免翻墙。
实际效果见示例:
如果不想自己写方法,也可以使用我提供的接口,即“URL”,URL可以带前缀。
代码(调用谷歌的方式,这种方式可以减少代码量,速度也更快):
<p>
php 循环抓取网页内容(这里有新鲜出炉的精品教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-18 06:20
这里有新鲜出炉的优质教程,看节目狗速!
ThinkPHP开源PHP框架ThinkPHP是一个为简化企业级应用开发和敏捷WEB应用开发而生的开源PHP框架。ThinkPHP可以支持windows/Unix/Liunx等服务器环境。正式版要求PHP5.0以上,支持MySql、PgSQL、Sqlite、PDO等多种数据库。
本文文章主要介绍thinkphp的相关信息,用于抓取网站的内容并保存到本地。有需要的朋友可以参考
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持! 查看全部
php 循环抓取网页内容(这里有新鲜出炉的精品教程,程序狗速度看过来!)
这里有新鲜出炉的优质教程,看节目狗速!
ThinkPHP开源PHP框架ThinkPHP是一个为简化企业级应用开发和敏捷WEB应用开发而生的开源PHP框架。ThinkPHP可以支持windows/Unix/Liunx等服务器环境。正式版要求PHP5.0以上,支持MySql、PgSQL、Sqlite、PDO等多种数据库。
本文文章主要介绍thinkphp的相关信息,用于抓取网站的内容并保存到本地。有需要的朋友可以参考
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持!
php 循环抓取网页内容(CMS模块内容设计分为主表和附表的操作方法介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-15 18:06
)
cms模块内容设计分为主表和附表
主表:存储的字段用于列表循环和搜索
附表:存储的字段用于内容页面展示(原则上不能出现在列表展示中)
设计附表是为了减轻主表的查询压力,把一些不常用于列表的字段放在附表中;
如果非要把附表字段用在列表循环里面,就违背了附表的设计理念,这样想法是不效率的,非要做的话有两种解决方法
比如新闻模块的日程表的内容字段,我想在列表中显示
方法一、通过PHPmyadmin工具手动修改主表的内容(需要有数据库基础,没有技术基础请看下面方法)
操作数据库需要提前备份数据,避免数据不可逆丢失。
1、进入cms自定义字段,找到内容字段的id号
2、dr_field 表,通过内容的id号找到内容字段的数据
将 0 更改为 1
3、进入模块主表的数据表dr_1_xxxx,新建内容字段
4、 然后进入模块附表数据dr_1_xxxx_data_0,将附表数据复制到主表的content字段:
UPDATE `dr_1_xxxx` a, `dr_1_xxxx_data_0` b SET b.`content` = a.`content` WHERE a.id = b.id;
如果有多个schedule,执行多个后缀_1,_number
5、 然后手动删除附表dr_1_xxxx_data_0的content字段,删除
6、 然后输入cms 后台更新缓存
方法 二、 并没有禁用自己的内容字段,更改列表循环标签:
join=1_news_data_0 on=id
比如列表循环时添加的效果
{module catid=$catid join=1_news_data_0 on=id order=updatetime page=1}
此写入方法仅限于 50,000 以内的数据
这种方法的效率远不如方法一
方法 3:在循环中第二次调用内容标签。这种写法效率最低,会影响整个页面的查询速度
{module module=news ******* return=r}
{content module=news id=$r.id}
标题:{$t.title}
内容:{$t.content}
{/content}
{/module} 查看全部
php 循环抓取网页内容(CMS模块内容设计分为主表和附表的操作方法介绍
)
cms模块内容设计分为主表和附表
主表:存储的字段用于列表循环和搜索
附表:存储的字段用于内容页面展示(原则上不能出现在列表展示中)
设计附表是为了减轻主表的查询压力,把一些不常用于列表的字段放在附表中;
如果非要把附表字段用在列表循环里面,就违背了附表的设计理念,这样想法是不效率的,非要做的话有两种解决方法
比如新闻模块的日程表的内容字段,我想在列表中显示
方法一、通过PHPmyadmin工具手动修改主表的内容(需要有数据库基础,没有技术基础请看下面方法)
操作数据库需要提前备份数据,避免数据不可逆丢失。
1、进入cms自定义字段,找到内容字段的id号
2、dr_field 表,通过内容的id号找到内容字段的数据
将 0 更改为 1
3、进入模块主表的数据表dr_1_xxxx,新建内容字段
4、 然后进入模块附表数据dr_1_xxxx_data_0,将附表数据复制到主表的content字段:
UPDATE `dr_1_xxxx` a, `dr_1_xxxx_data_0` b SET b.`content` = a.`content` WHERE a.id = b.id;
如果有多个schedule,执行多个后缀_1,_number
5、 然后手动删除附表dr_1_xxxx_data_0的content字段,删除
6、 然后输入cms 后台更新缓存
方法 二、 并没有禁用自己的内容字段,更改列表循环标签:
join=1_news_data_0 on=id
比如列表循环时添加的效果
{module catid=$catid join=1_news_data_0 on=id order=updatetime page=1}
此写入方法仅限于 50,000 以内的数据
这种方法的效率远不如方法一
方法 3:在循环中第二次调用内容标签。这种写法效率最低,会影响整个页面的查询速度
{module module=news ******* return=r}
{content module=news id=$r.id}
标题:{$t.title}
内容:{$t.content}
{/content}
{/module}
php 循环抓取网页内容(详解如何通过创建Robots.txt来解决网站被重复抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-12-10 07:04
当我们使用百度统计中的SEO建议查看网站时,发现“静态页面参数”被扣了18分。扣分的原因是“在静态页面上使用动态参数会导致更多的蜘蛛”。和重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛爬行产生任何影响,但是如果在一个网站静态页面上使用过多的动态参数,则可能会导致一只蜘蛛到底 爬了很多次,反反复复。
为了解决“静态页面使用动态参数会导致蜘蛛多次重复抓取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛抓取网站页面, robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上所有不受密码保护的页面。
详细说明如何通过创建Robots.txt解决网站被重复抓取的问题,我们只需要设置一个语法即可。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度收录,避免网站被蜘蛛反复抓取。有人说:“我的网站使用的是伪静态页面,每个URL前面都有html?我该怎么办?” 在这种情况下,请使用另一种语法。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
允许:.htm$(只允许访问带有“.htm”后缀的 URL)
这允许百度蜘蛛只收录 你的静态页面而不索引动态页面。其实SEO的知识还是很多的,需要我们一步步摸索,通过实践发现真相。网站 注重用户体验是长远发展的基点。
禁止网站被搜索爬取的一些方法:
首先在站点根目录下创建robots.txt文本文件。搜索蜘蛛访问本站时,首先会检查本站根目录下是否存在robots.txt。如果存在,搜索蜘蛛会先读取这个文件的内容:
文件写入
User-agent: * 这里*代表所有类型的搜索引擎,*为通配符,user-agent分号后必须加一个空格。
Disallow:/这里的定义是禁止抓取网站的所有内容
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录(包括子目录)中所有后缀为“.htm”的URL。
Disallow: /*?* 禁止访问 网站 中收录问号 (?) 的所有 URL
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出了著名的搜索引擎蜘蛛的名称:
谷歌的蜘蛛:Googlebot
百度的蜘蛛:baiduspider
雅虎蜘蛛:Yahoo Slurp
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos蜘蛛:Lycos_Spider_(霸王龙)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:Slurp
搜狗蜘蛛:搜狗网蜘蛛/4.0和搜狗inst蜘蛛/4.0
根据上面的说明,我们可以举一个大案例的例子。以搜狗为例,禁止爬取的robots.txt代码如下:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php 查看全部
php 循环抓取网页内容(详解如何通过创建Robots.txt来解决网站被重复抓取)
当我们使用百度统计中的SEO建议查看网站时,发现“静态页面参数”被扣了18分。扣分的原因是“在静态页面上使用动态参数会导致更多的蜘蛛”。和重复爬取”。一般来说,在静态页面上使用少量的动态参数不会对蜘蛛爬行产生任何影响,但是如果在一个网站静态页面上使用过多的动态参数,则可能会导致一只蜘蛛到底 爬了很多次,反反复复。
为了解决“静态页面使用动态参数会导致蜘蛛多次重复抓取”的SEO问题,我们需要使用Robots.txt(机器人协议)来限制百度蜘蛛抓取网站页面, robots.txt 是一个协议,而不是一个命令。robots.txt是搜索引擎访问网站时首先要检查的文件。robots.txt 文件告诉蜘蛛可以在服务器上查看哪些文件。搜索蜘蛛访问站点时,首先会检查站点根目录下是否存在robots.txt。如果存在,搜索机器人会根据文件内容确定访问范围;如果该文件不存在,所有 'S 搜索蜘蛛将能够访问 网站 上所有不受密码保护的页面。
详细说明如何通过创建Robots.txt解决网站被重复抓取的问题,我们只需要设置一个语法即可。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
Disallow: /*?* (禁止访问 网站 中的所有动态页面)
这样可以防止动态页面被百度收录,避免网站被蜘蛛反复抓取。有人说:“我的网站使用的是伪静态页面,每个URL前面都有html?我该怎么办?” 在这种情况下,请使用另一种语法。
用户代理:百度蜘蛛(仅对百度蜘蛛有效)
允许:.htm$(只允许访问带有“.htm”后缀的 URL)
这允许百度蜘蛛只收录 你的静态页面而不索引动态页面。其实SEO的知识还是很多的,需要我们一步步摸索,通过实践发现真相。网站 注重用户体验是长远发展的基点。
禁止网站被搜索爬取的一些方法:
首先在站点根目录下创建robots.txt文本文件。搜索蜘蛛访问本站时,首先会检查本站根目录下是否存在robots.txt。如果存在,搜索蜘蛛会先读取这个文件的内容:
文件写入
User-agent: * 这里*代表所有类型的搜索引擎,*为通配符,user-agent分号后必须加一个空格。
Disallow:/这里的定义是禁止抓取网站的所有内容
disallow: /admin/ 这里的定义是禁止爬取admin目录下的目录
Disallow: /ABC/ 这里的定义是禁止爬取ABC目录下的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录(包括子目录)中所有后缀为“.htm”的URL。
Disallow: /*?* 禁止访问 网站 中收录问号 (?) 的所有 URL
Disallow: /.jpg$ 禁止抓取网络上所有.jpg 格式的图片
Disallow:/ab/adc.html 禁止抓取ab文件夹下的adc.html文件。
Allow:这里定义了/cgi-bin/,允许爬取cgi-bin目录下的目录
Allow: /tmp 这里的定义是允许爬取tmp的整个目录
允许:.htm$ 只允许访问带有“.htm”后缀的 URL。
允许:.gif$ 允许抓取网页和 gif 格式的图像
站点地图:网站地图告诉爬虫这个页面是一个网站地图
下面列出了著名的搜索引擎蜘蛛的名称:
谷歌的蜘蛛:Googlebot
百度的蜘蛛:baiduspider
雅虎蜘蛛:Yahoo Slurp
MSN 的蜘蛛:Msnbot
Altavista 的蜘蛛:滑板车
Lycos蜘蛛:Lycos_Spider_(霸王龙)
Alltheweb 的蜘蛛:FAST-WebCrawler/
INKTOMI 的蜘蛛:Slurp
搜狗蜘蛛:搜狗网蜘蛛/4.0和搜狗inst蜘蛛/4.0
根据上面的说明,我们可以举一个大案例的例子。以搜狗为例,禁止爬取的robots.txt代码如下:
用户代理:搜狗网络蜘蛛/4.0
禁止:/goods.php
禁止:/category.php
php 循环抓取网页内容(本周工作日的最后一天,我来冒个泡预备怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-05 07:14
啦啦啦,本周工作日的最后一天,让我泡个泡泡
准备
了解CURL的使用: 参考1:自己总结的curl的使用;
参考2:CURL手册;
参考3:匹配搜索
一、背景、原因
其实今天没什么特别的。突然想起前端时间朋友的网店,因为供应商不提供图片数据包,所以只能一一保存,然后上传。我想我尝试获取网站的图片栏(支持获取https协议网站);
二、曼曼求道
这个实现是为了获取网站的信息,那么首先想到的万能的CURL方法,不明白的可以点击学习。这是非常重要的。只有抓取页面数据才能得到想要的并保存;
首先,获取页面数据:
这种封装方式也支持抓取http和https协议网站页面信息
public function is_request($url, $ssl = true, $type = "GET", $data = null)
{
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
$user_agent = isset($_SERVER["HTTP_USERAGENT"]) ?
$_SERVER['HTTP_USERAGENT'] :
'Mozilla / 5.0 (Windows NT 6.1; WOW64) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 50.0.2661.102 Safari / 537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $user_agent);//请求代理信息
curl_setopt($curl, CURLOPT_AUTOREFERER, true);//referer头 请求来源
curl_setopt($curl, CURLOPT_TIMEOUT, 30);//请求超时
curl_setopt($curl, CURLOPT_HEADER, false);//是否处理响应头
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);//curl_exec()是否返回响应
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
if ($ssl) {
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);//禁用后curl将终止从服务端进行验证
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, false);//检查服务器ssl证书中是否存在一个公用名(common name)
}
if ($type == 'POST') {
curl_setopt($curl, CURLOPT_POST, true);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
}
//发出请求
$response = curl_exec($curl);
if ($response === false) {
return false;
}
return $response;
}
其次,通过正则匹配,获取页面中所有符合你条件的字符串组:
$img_pattern = "|]+src=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($img_pattern, $content, $img_out, PREG_SET_ORDER);
最后,您已经获取了页面中的所有 img 标签,然后您可以将它们循环保存在您指定的文件中:
/**
* 保存单个图片的方法
*
* @param String $capture_url 用于抓取图片的网页地址
* @param String $img_url 需要保存的图片的url
*
*/
public function save_one_img($capture_url,$img_url)
{
//图片路径地址
// if ( strpos($img_url, 'http://')!==false )
// {
// // $img_url = $img_url;
// }else
// {
// $domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
// $img_url=$domain_url.$img_url;
// }
$pathinfo = pathinfo($img_url); //获取图片路径信息
$pic_name=$pathinfo['basename']; //获取图片的名字
if (file_exists($this->save_path.$pic_name)) //如果图片存在,证明已经被抓取过,退出函数
{
echo $img_url . '该图片已经抓取过!
';
return;
}
//将图片内容读入一个字符串
// dd($img_url);
// info($img_url);
$img_data = @file_get_contents($img_url); //屏蔽掉因为图片地址无法读取导致的warning错误
if ( strlen($img_data) > $this->img_size ) //下载size比限制大的图片
{
$img_size = file_put_contents($this->save_path . $pic_name, $img_data);
if ($img_size)
{
echo $img_url . '图片保存成功!
';
} else
{
echo $img_url . '图片保存失败!
';
}
} else
{
echo $img_url . '图片读取失败!
';
}
}
当然为了避免重复下载,我判断是否已经下载,下面完整的项目代码: BaseService 主要是为了引入is_request()
三、最重要的,完整的代码
class GetImgController extends Controller
{
public $save_path; //抓取图片的保存地址
//抓取图片的大小限制(单位:字节) 只抓比size比这个限制大的图片
public $img_size=0;
//定义一个静态数组,用于记录曾经抓取过的的超链接地址,避免重复抓取
public static $a_url_arr=array();
protected $baseService ;
/**
* @param BaseService $baseService
*/
public function __construct(BaseService $baseService)
{
$this->save_path=public_path().'/uploadfile/curl_img/chumaoqi/lunbo/';
$this->img_size=0;
$this->baseService = $baseService;
}
/**
* 递归下载抓取首页及其子页面图片的方法 ( recursive 递归)
*
* @param Request $request
*
*/
public function recursive_download_images(Request $request)
{
$capture_url = $request->input('url');
if (!in_array($capture_url,self::$a_url_arr)) //没抓取过
{
self::$a_url_arr[]=$capture_url; //计入静态数组
} else //抓取过,直接退出函数
{
return;
}
$this->download_current_page_images($capture_url); //下载当前页面的所有图片
//用@屏蔽掉因为抓取地址无法读取导致的warning错误
$content=@file_get_contents($capture_url);
//匹配a标签href属性中?之前部分的正则
$a_pattern = "|]+href=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($a_pattern, $content, $a_out, PREG_SET_ORDER);
$tmp_arr=array(); //定义一个数组,用于存放当前循环下抓取图片的超链接地址
foreach ($a_out as $k => $v)
{
/**
* 去除超链接中的 空'','#','/'和重复值
* 1: 超链接地址的值 不能等于当前抓取页面的url, 否则会陷入死循环
* 2: 超链接为''或'#','/'也是本页面,这样也会陷入死循环,
* 3: 有时一个超连接地址在一个网页中会重复出现多次,如果不去除,会对一个子页面进行重复下载)
*/
if ( $v[1] && !in_array($v[1],self::$a_url_arr) &&!in_array($v[1],array('#','/',$capture_url) ) )
{
$tmp_arr[]=$v[1];
}
}
foreach ($tmp_arr as $k => $v)
{
//超链接路径地址
if ( strpos($v, 'http://')!==false ) //如果url包含http://,可以直接访问
{
$a_url = $v;
}else //否则证明是相对地址, 需要重新拼凑超链接的访问地址
{
$domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
$a_url=$domain_url.$v;
}
$this->recursive_download_images($a_url);
}
}
/**
* 下载当前网页下的所有图片
*
* @param String $capture_url 用于抓取图片的网页地址
* @return Array 当前网页上所有图片img标签url地址的一个数组
*/
public function download_current_page_images($capture_url)
{
// $capture_url = $request->input('url');
$content = $this->baseService->is_request($capture_url);
//匹配img标签src属性中?之前部分的正则
$img_pattern = "|]+src=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($img_pattern, $content, $img_out, PREG_SET_ORDER);
$photo_num = count($img_out);
//匹配到的图片数量
echo ''.$capture_url . "共找到 " . $photo_num . " 张图片";
foreach ($img_out as $k => $v)
{
$this->save_one_img($capture_url,$v[1]);
}
}
/**
* 保存单个图片的方法
*
* @param String $capture_url 用于抓取图片的网页地址
* @param String $img_url 需要保存的图片的url
*
*/
public function save_one_img($capture_url,$img_url)
{
//图片路径地址
// if ( strpos($img_url, 'http://')!==false )
// {
// // $img_url = $img_url;
// }else
// {
// $domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
// $img_url=$domain_url.$img_url;
// }
$pathinfo = pathinfo($img_url); //获取图片路径信息
$pic_name=$pathinfo['basename']; //获取图片的名字
if (file_exists($this->save_path.$pic_name)) //如果图片存在,证明已经被抓取过,退出函数
{
echo $img_url . '该图片已经抓取过!
';
return;
}
//将图片内容读入一个字符串
// dd($img_url);
// info($img_url);
$img_data = @file_get_contents($img_url); //屏蔽掉因为图片地址无法读取导致的warning错误
if ( strlen($img_data) > $this->img_size ) //下载size比限制大的图片
{
$img_size = file_put_contents($this->save_path . $pic_name, $img_data);
if ($img_size)
{
echo $img_url . '图片保存成功!
';
} else
{
echo $img_url . '图片保存失败!
';
}
} else
{
echo $img_url . '图片读取失败!
';
}
}
}
其中recursive_download_images()是递归下载指定页面和子页面下的图片,download_current_page_images()只下载指定地址页面的图片。您可以稍微调整一下以满足您的需要。
四、 写在最后
网上有很多这样的curl请求获取页面数据,大家可以参考 查看全部
php 循环抓取网页内容(本周工作日的最后一天,我来冒个泡预备怎么做?)
啦啦啦,本周工作日的最后一天,让我泡个泡泡
准备
了解CURL的使用: 参考1:自己总结的curl的使用;
参考2:CURL手册;
参考3:匹配搜索
一、背景、原因
其实今天没什么特别的。突然想起前端时间朋友的网店,因为供应商不提供图片数据包,所以只能一一保存,然后上传。我想我尝试获取网站的图片栏(支持获取https协议网站);
二、曼曼求道
这个实现是为了获取网站的信息,那么首先想到的万能的CURL方法,不明白的可以点击学习。这是非常重要的。只有抓取页面数据才能得到想要的并保存;
首先,获取页面数据:
这种封装方式也支持抓取http和https协议网站页面信息
public function is_request($url, $ssl = true, $type = "GET", $data = null)
{
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);
$user_agent = isset($_SERVER["HTTP_USERAGENT"]) ?
$_SERVER['HTTP_USERAGENT'] :
'Mozilla / 5.0 (Windows NT 6.1; WOW64) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 50.0.2661.102 Safari / 537.36';
curl_setopt($curl, CURLOPT_USERAGENT, $user_agent);//请求代理信息
curl_setopt($curl, CURLOPT_AUTOREFERER, true);//referer头 请求来源
curl_setopt($curl, CURLOPT_TIMEOUT, 30);//请求超时
curl_setopt($curl, CURLOPT_HEADER, false);//是否处理响应头
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);//curl_exec()是否返回响应
curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
if ($ssl) {
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);//禁用后curl将终止从服务端进行验证
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, false);//检查服务器ssl证书中是否存在一个公用名(common name)
}
if ($type == 'POST') {
curl_setopt($curl, CURLOPT_POST, true);
curl_setopt($curl, CURLOPT_POSTFIELDS, $data);
}
//发出请求
$response = curl_exec($curl);
if ($response === false) {
return false;
}
return $response;
}
其次,通过正则匹配,获取页面中所有符合你条件的字符串组:
$img_pattern = "|]+src=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($img_pattern, $content, $img_out, PREG_SET_ORDER);
最后,您已经获取了页面中的所有 img 标签,然后您可以将它们循环保存在您指定的文件中:
/**
* 保存单个图片的方法
*
* @param String $capture_url 用于抓取图片的网页地址
* @param String $img_url 需要保存的图片的url
*
*/
public function save_one_img($capture_url,$img_url)
{
//图片路径地址
// if ( strpos($img_url, 'http://')!==false )
// {
// // $img_url = $img_url;
// }else
// {
// $domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
// $img_url=$domain_url.$img_url;
// }
$pathinfo = pathinfo($img_url); //获取图片路径信息
$pic_name=$pathinfo['basename']; //获取图片的名字
if (file_exists($this->save_path.$pic_name)) //如果图片存在,证明已经被抓取过,退出函数
{
echo $img_url . '该图片已经抓取过!
';
return;
}
//将图片内容读入一个字符串
// dd($img_url);
// info($img_url);
$img_data = @file_get_contents($img_url); //屏蔽掉因为图片地址无法读取导致的warning错误
if ( strlen($img_data) > $this->img_size ) //下载size比限制大的图片
{
$img_size = file_put_contents($this->save_path . $pic_name, $img_data);
if ($img_size)
{
echo $img_url . '图片保存成功!
';
} else
{
echo $img_url . '图片保存失败!
';
}
} else
{
echo $img_url . '图片读取失败!
';
}
}
当然为了避免重复下载,我判断是否已经下载,下面完整的项目代码: BaseService 主要是为了引入is_request()
三、最重要的,完整的代码
class GetImgController extends Controller
{
public $save_path; //抓取图片的保存地址
//抓取图片的大小限制(单位:字节) 只抓比size比这个限制大的图片
public $img_size=0;
//定义一个静态数组,用于记录曾经抓取过的的超链接地址,避免重复抓取
public static $a_url_arr=array();
protected $baseService ;
/**
* @param BaseService $baseService
*/
public function __construct(BaseService $baseService)
{
$this->save_path=public_path().'/uploadfile/curl_img/chumaoqi/lunbo/';
$this->img_size=0;
$this->baseService = $baseService;
}
/**
* 递归下载抓取首页及其子页面图片的方法 ( recursive 递归)
*
* @param Request $request
*
*/
public function recursive_download_images(Request $request)
{
$capture_url = $request->input('url');
if (!in_array($capture_url,self::$a_url_arr)) //没抓取过
{
self::$a_url_arr[]=$capture_url; //计入静态数组
} else //抓取过,直接退出函数
{
return;
}
$this->download_current_page_images($capture_url); //下载当前页面的所有图片
//用@屏蔽掉因为抓取地址无法读取导致的warning错误
$content=@file_get_contents($capture_url);
//匹配a标签href属性中?之前部分的正则
$a_pattern = "|]+href=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($a_pattern, $content, $a_out, PREG_SET_ORDER);
$tmp_arr=array(); //定义一个数组,用于存放当前循环下抓取图片的超链接地址
foreach ($a_out as $k => $v)
{
/**
* 去除超链接中的 空'','#','/'和重复值
* 1: 超链接地址的值 不能等于当前抓取页面的url, 否则会陷入死循环
* 2: 超链接为''或'#','/'也是本页面,这样也会陷入死循环,
* 3: 有时一个超连接地址在一个网页中会重复出现多次,如果不去除,会对一个子页面进行重复下载)
*/
if ( $v[1] && !in_array($v[1],self::$a_url_arr) &&!in_array($v[1],array('#','/',$capture_url) ) )
{
$tmp_arr[]=$v[1];
}
}
foreach ($tmp_arr as $k => $v)
{
//超链接路径地址
if ( strpos($v, 'http://')!==false ) //如果url包含http://,可以直接访问
{
$a_url = $v;
}else //否则证明是相对地址, 需要重新拼凑超链接的访问地址
{
$domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
$a_url=$domain_url.$v;
}
$this->recursive_download_images($a_url);
}
}
/**
* 下载当前网页下的所有图片
*
* @param String $capture_url 用于抓取图片的网页地址
* @return Array 当前网页上所有图片img标签url地址的一个数组
*/
public function download_current_page_images($capture_url)
{
// $capture_url = $request->input('url');
$content = $this->baseService->is_request($capture_url);
//匹配img标签src属性中?之前部分的正则
$img_pattern = "|]+src=['\" ]?([^ '\"?]+)['\" >]|U";
preg_match_all($img_pattern, $content, $img_out, PREG_SET_ORDER);
$photo_num = count($img_out);
//匹配到的图片数量
echo ''.$capture_url . "共找到 " . $photo_num . " 张图片";
foreach ($img_out as $k => $v)
{
$this->save_one_img($capture_url,$v[1]);
}
}
/**
* 保存单个图片的方法
*
* @param String $capture_url 用于抓取图片的网页地址
* @param String $img_url 需要保存的图片的url
*
*/
public function save_one_img($capture_url,$img_url)
{
//图片路径地址
// if ( strpos($img_url, 'http://')!==false )
// {
// // $img_url = $img_url;
// }else
// {
// $domain_url = substr($capture_url, 0,strpos($capture_url, '/',8)+1);
// $img_url=$domain_url.$img_url;
// }
$pathinfo = pathinfo($img_url); //获取图片路径信息
$pic_name=$pathinfo['basename']; //获取图片的名字
if (file_exists($this->save_path.$pic_name)) //如果图片存在,证明已经被抓取过,退出函数
{
echo $img_url . '该图片已经抓取过!
';
return;
}
//将图片内容读入一个字符串
// dd($img_url);
// info($img_url);
$img_data = @file_get_contents($img_url); //屏蔽掉因为图片地址无法读取导致的warning错误
if ( strlen($img_data) > $this->img_size ) //下载size比限制大的图片
{
$img_size = file_put_contents($this->save_path . $pic_name, $img_data);
if ($img_size)
{
echo $img_url . '图片保存成功!
';
} else
{
echo $img_url . '图片保存失败!
';
}
} else
{
echo $img_url . '图片读取失败!
';
}
}
}
其中recursive_download_images()是递归下载指定页面和子页面下的图片,download_current_page_images()只下载指定地址页面的图片。您可以稍微调整一下以满足您的需要。
四、 写在最后
网上有很多这样的curl请求获取页面数据,大家可以参考
php 循环抓取网页内容(有哪些方法可以实现php页面跳转跳转?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-05 05:06
)
PHP跳转到指定页面的问题通常出现在构建网站需求上,比如我们需要从一个页面跳转到另一个页面来实现某个功能或者效果。其实PHP中跳转页面的方式有很多种,那么这篇文章就给大家介绍一下,跳转到一个php页面的方式有哪些?
首先我们需要了解两个知识点:
1:header()函数是PHP中非常简单的页面跳转方法。 header()函数的主要作用是向浏览器输出HTTP协议头。
二:Meta标签是HTML中负责提供文档元信息的标签。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,则在打开页面时,会根据content指定的值,在一定时间内跳转到对应的页面。如果设置content="seconds;url=URL",则定义了页面在经过多长时间后跳转到指定URL的时间。
然后php跳转到指定页面的header()函数,具体使用的示例代码如下:
void header (string string [,bool replace [,int http_response_code]])//header()函数的定义
php跳转到指定页面的Meta标签的具体使用示例代码如下:
<p> 查看全部
php 循环抓取网页内容(有哪些方法可以实现php页面跳转跳转?(图)
)
PHP跳转到指定页面的问题通常出现在构建网站需求上,比如我们需要从一个页面跳转到另一个页面来实现某个功能或者效果。其实PHP中跳转页面的方式有很多种,那么这篇文章就给大家介绍一下,跳转到一个php页面的方式有哪些?
首先我们需要了解两个知识点:
1:header()函数是PHP中非常简单的页面跳转方法。 header()函数的主要作用是向浏览器输出HTTP协议头。
二:Meta标签是HTML中负责提供文档元信息的标签。在PHP程序中使用这个标签也可以实现页面跳转。如果http-equiv定义为refresh,则在打开页面时,会根据content指定的值,在一定时间内跳转到对应的页面。如果设置content="seconds;url=URL",则定义了页面在经过多长时间后跳转到指定URL的时间。
然后php跳转到指定页面的header()函数,具体使用的示例代码如下:
void header (string string [,bool replace [,int http_response_code]])//header()函数的定义
php跳转到指定页面的Meta标签的具体使用示例代码如下:
<p>
php 循环抓取网页内容(动态网站的出现和优势最早互联网出现时,怎么办?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-05 04:17
无法更改服务器配置。.
无需生成htm页面方法。
有没有办法更换?之类的 /
看这个文章想到了:
【摘要】:动态网站丰富了网站的功能,但对于搜索引擎来说,情况就不一样了。动态页面是在用户“输入内容”或“选择”时动态生成的,但搜索引擎的“搜索机器人”无法“输入”和“选择”。此外,搜索引擎应避免“蜘蛛陷阱”脚本错误。
-------------------------------------------------- ------------------------------
一、动态的出现和优势网站
互联网刚出现时,网站的内容以HTML静态页面的形式存储在服务器上,访问者浏览的页面就是这些实际存在的静态页面。随着技术的发展,特别是数据库和脚本技术PERL、ASP、PHP和JSP的发展,越来越多的网站开始采用动态页面发布方式。比如我们在GOOGLE.COM上搜索一个内容时,得到的搜索结果页面文件“本身”在GOOGLE服务器上并不存在,而是在我们输入搜索内容时调用后台数据库实时生成的,即即,这些结果页面是动态的。
静态页面站点只涉及文件传输问题,而动态站点要复杂得多。用户和网站之间有很多互动。网站不再只是内容的发布,而是一种“应用”(Application),是软件产业向互联网的扩展。从软件的角度来看,动态站点是逻辑上的分离应用层和数据层,数据库负责站点数据的存储和管理,而ASP、PHP、JSP等则负责处理站点的逻辑应用。除了添加了很多交互功能,更重要的是网站的维护、更新、升级都方便很多,可以说没有动态网站技术,
二、搜索引擎抓取动态网站页面时面临的问题
从用户的角度来看,动态网站很好,丰富了网站的功能,但对于搜索引擎来说,情况就不一样了。(关于搜索引擎和目录的区别,以及搜索引擎的工作原理,请“了解搜索引擎”)
根本问题在于“投入”和“选择”。动态页面是在用户“输入内容”或“选择”时动态生成的,但搜索引擎的“搜索机器人”无法“输入”和“选择”。例如,我们想在当当书店网站上查看冯英健的《网络营销基础与实践》。介绍页面是动态生成的,URL地址为:
这里,“?”后面的product_id参数值 需要我们输入。“搜索机器人”可以通过链接找到页面,但是无法在“?”后输入product_id参数值,因此无法抓取页面文件。
此外,对于带有“?”的页面 通过链接到达,搜索引擎技术上可以抓取,但一般情况下,搜索引擎选择不抓取。这是为了避免一种“蜘蛛陷阱”。这个错误的脚本错误会让搜索机器人无限循环爬行,无法退出,浪费时间。
三、动态网站搜索引擎策略
动态网站 为被搜索引擎抓取,您可以使用内容发布系统软件将动态站点转换为静态页面。这种方式更适合页面发布后变化不大的网站,比如一些新闻网站(比如新浪新闻中心:)。
一般动态网站可以通过以下方式被搜索引擎抓取:
首先,我们需要让动态页面的 URL 不带“?”,这样动态页面看起来就像一个“静态页面”。看看下面的页面。这显然是一个动态页面,但 URL 地址看起来像一个“静态页面”。针对不同的动态技术,可以使用以下技术来实现:
·对于使用ASP技术的动态页面,可以用一个叫做XQASP()的工具来代替“?” 和 ”/”。
·对于使用ColdFusion技术的站点,需要在服务器端重新配置ColdFusion,用“/”代替“?” 将参数传输到 URL。有关更多详细信息,请参阅网站。
·对于使用Apache服务器的站点,可以使用rewrite模块将带参数的URL地址转换成搜索引擎支持的形式。默认情况下,Apache 服务器中未安装此模块 mod_rewrite。详情请参阅。
对于其他动态技术,也可以找到相应的方法来改变URL的形式。
然后,创建一些指向这些动态页面(带有更改的 URL 链接)的静态页面。
前面已经提到,搜索引擎robot本身不会“输入”参数,所以为了让这些动态页面被搜索引擎抓取,我们还需要将这些页面的地址(即参数)告诉robot。我们可以创建一些静态页面,在网络营销中一般称为“gatewaypage”(入口页面),这些页面上有很多指向这些动态页面的链接。
将这些入口页面的地址提交给搜索引擎,这些页面和链接的动态页面(改变了URL格式)都可以被搜索引擎抓取。
四、对动态网站支持的搜索引擎改进
随着我们调整动态网站以适应搜索引擎,搜索引擎也在不断发展。目前大部分搜索引擎不支持动态页面的抓取,但GOOGLE、HOTBOT等和国内百度已经开始尝试抓取动态网站页面(包括?"?"页面)。这就是为什么我们在这些搜索引擎上搜索时,结果中会出现动态链接的原因。
这些搜索引擎在抓取动态页面时,为了避免“搜索机器人陷阱”,他们只抓取从静态页面链接的动态页面(至少“看”静态页面),从动态页面链接的动态页面不再抓取。
所以如果一个动态站点只针对这些搜索引擎,可以按照上节介绍的方法进行简化:只需要创建一些入口页面,链接到许多动态页面,然后将这些入口页面提交给这些搜索引擎。
直接使用动态URL地址,请注意:
· 文件URL中不要收录SessionId,也不要使用ID作为参数名(尤其是GOOGLE);
·参数越少越好,尽量不要超过2;
·尽量不要在URL中使用参数。一些参数被转移到其他地方,这可以增加被抓取的动态页面的深度和数量。 查看全部
php 循环抓取网页内容(动态网站的出现和优势最早互联网出现时,怎么办?)
无法更改服务器配置。.
无需生成htm页面方法。
有没有办法更换?之类的 /
看这个文章想到了:
【摘要】:动态网站丰富了网站的功能,但对于搜索引擎来说,情况就不一样了。动态页面是在用户“输入内容”或“选择”时动态生成的,但搜索引擎的“搜索机器人”无法“输入”和“选择”。此外,搜索引擎应避免“蜘蛛陷阱”脚本错误。
-------------------------------------------------- ------------------------------
一、动态的出现和优势网站
互联网刚出现时,网站的内容以HTML静态页面的形式存储在服务器上,访问者浏览的页面就是这些实际存在的静态页面。随着技术的发展,特别是数据库和脚本技术PERL、ASP、PHP和JSP的发展,越来越多的网站开始采用动态页面发布方式。比如我们在GOOGLE.COM上搜索一个内容时,得到的搜索结果页面文件“本身”在GOOGLE服务器上并不存在,而是在我们输入搜索内容时调用后台数据库实时生成的,即即,这些结果页面是动态的。
静态页面站点只涉及文件传输问题,而动态站点要复杂得多。用户和网站之间有很多互动。网站不再只是内容的发布,而是一种“应用”(Application),是软件产业向互联网的扩展。从软件的角度来看,动态站点是逻辑上的分离应用层和数据层,数据库负责站点数据的存储和管理,而ASP、PHP、JSP等则负责处理站点的逻辑应用。除了添加了很多交互功能,更重要的是网站的维护、更新、升级都方便很多,可以说没有动态网站技术,
二、搜索引擎抓取动态网站页面时面临的问题
从用户的角度来看,动态网站很好,丰富了网站的功能,但对于搜索引擎来说,情况就不一样了。(关于搜索引擎和目录的区别,以及搜索引擎的工作原理,请“了解搜索引擎”)
根本问题在于“投入”和“选择”。动态页面是在用户“输入内容”或“选择”时动态生成的,但搜索引擎的“搜索机器人”无法“输入”和“选择”。例如,我们想在当当书店网站上查看冯英健的《网络营销基础与实践》。介绍页面是动态生成的,URL地址为:
这里,“?”后面的product_id参数值 需要我们输入。“搜索机器人”可以通过链接找到页面,但是无法在“?”后输入product_id参数值,因此无法抓取页面文件。
此外,对于带有“?”的页面 通过链接到达,搜索引擎技术上可以抓取,但一般情况下,搜索引擎选择不抓取。这是为了避免一种“蜘蛛陷阱”。这个错误的脚本错误会让搜索机器人无限循环爬行,无法退出,浪费时间。
三、动态网站搜索引擎策略
动态网站 为被搜索引擎抓取,您可以使用内容发布系统软件将动态站点转换为静态页面。这种方式更适合页面发布后变化不大的网站,比如一些新闻网站(比如新浪新闻中心:)。
一般动态网站可以通过以下方式被搜索引擎抓取:
首先,我们需要让动态页面的 URL 不带“?”,这样动态页面看起来就像一个“静态页面”。看看下面的页面。这显然是一个动态页面,但 URL 地址看起来像一个“静态页面”。针对不同的动态技术,可以使用以下技术来实现:
·对于使用ASP技术的动态页面,可以用一个叫做XQASP()的工具来代替“?” 和 ”/”。
·对于使用ColdFusion技术的站点,需要在服务器端重新配置ColdFusion,用“/”代替“?” 将参数传输到 URL。有关更多详细信息,请参阅网站。
·对于使用Apache服务器的站点,可以使用rewrite模块将带参数的URL地址转换成搜索引擎支持的形式。默认情况下,Apache 服务器中未安装此模块 mod_rewrite。详情请参阅。
对于其他动态技术,也可以找到相应的方法来改变URL的形式。
然后,创建一些指向这些动态页面(带有更改的 URL 链接)的静态页面。
前面已经提到,搜索引擎robot本身不会“输入”参数,所以为了让这些动态页面被搜索引擎抓取,我们还需要将这些页面的地址(即参数)告诉robot。我们可以创建一些静态页面,在网络营销中一般称为“gatewaypage”(入口页面),这些页面上有很多指向这些动态页面的链接。
将这些入口页面的地址提交给搜索引擎,这些页面和链接的动态页面(改变了URL格式)都可以被搜索引擎抓取。
四、对动态网站支持的搜索引擎改进
随着我们调整动态网站以适应搜索引擎,搜索引擎也在不断发展。目前大部分搜索引擎不支持动态页面的抓取,但GOOGLE、HOTBOT等和国内百度已经开始尝试抓取动态网站页面(包括?"?"页面)。这就是为什么我们在这些搜索引擎上搜索时,结果中会出现动态链接的原因。
这些搜索引擎在抓取动态页面时,为了避免“搜索机器人陷阱”,他们只抓取从静态页面链接的动态页面(至少“看”静态页面),从动态页面链接的动态页面不再抓取。
所以如果一个动态站点只针对这些搜索引擎,可以按照上节介绍的方法进行简化:只需要创建一些入口页面,链接到许多动态页面,然后将这些入口页面提交给这些搜索引擎。
直接使用动态URL地址,请注意:
· 文件URL中不要收录SessionId,也不要使用ID作为参数名(尤其是GOOGLE);
·参数越少越好,尽量不要超过2;
·尽量不要在URL中使用参数。一些参数被转移到其他地方,这可以增加被抓取的动态页面的深度和数量。
php 循环抓取网页内容(PythonFor和While循环不确定页数的网页需要学习的地方)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-24 22:20
本文转载自以下网站:Python For和While循环爬取页数不确定的网页
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页面。当爬行完成时,中断跳出循环并结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后将判断条件改为False进行跳转退出循环并结束爬行。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
摘要:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页面数量不确定的网页。
我们通常遇到的网站页码的显示形式有以下几种:
一是将所有页码可视化显示,比如之前爬取的宽和东方财富。
文章见:
∞ Scrapy爬取并分析了关的6000个app,发现良心软了
∞ 50行代码爬取东方财富网百万行财务报表数据
二是不直观显示网页总数,只能在后台查看。比如之前爬过的虎嗅网络,见文章:
∞ pyspider 爬取并分析 50,000 个老虎嗅探网文章
第三个是我今天要讲的。不知道有多少页,比如豌豆荚:
对于前两种形式的网页,爬取方法很简单,只需要使用For循环从第一页爬到最后一页即可。第三种形式不适用,因为不知道最后一页的编号,所以无法判断循环到哪一页结束。
如何解决?有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页面。当爬行完成时,中断跳出循环并结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后将判断条件改为False进行跳转退出循环并结束爬行。
实际案例
下面,我们以豆豆荚网站中“视频”类别下的App信息为例,通过上述两种方式,抓取该类别下的所有App信息,包括App名称、评论、安装数、和音量。
首先简单分析一下网站,可以看到页面是通过ajax加载的,GET请求自带了一些参数,可以使用params参数构造一个URL请求,但是我没有知道总共有多少页。为了保证所有页面都被下载,设置更大的页面数,比如100页甚至1000页。
下面我们尝试使用For和While循环爬取。
请求▌For 循环
主要代码如下:
class Get_page():
def __init__(self):
# ajax 请求url
self.ajax_url = \'https://www.wandoujia.com/wdjweb/api/category/more\'
def get_page(self,page,cate_code,child_cate_code):
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
response = requests.get(self.ajax_url, headers=headers, params=params)
content = response.json()[\'data\'][\'content\'] #提取json中的html页面数据
return content
def parse_page(self, content):
# 解析网页内容
contents = pq(content)(\'.card\').items()
data = []
for content in contents:
data1 = {
\'app_name\': content(\'.name\').text(),
\'install\': content(\'.install-count\').text(),
\'volume\': content(\'.meta span:last-child\').text(),
\'comment\': content(\'.comment\').text(),
}
data.append(data1)
if data:
# 写入MongoDB
self.write_to_mongodb(data)
if __name__ == \'__main__\':
# 实例化数据提取类
wandou_page = Get_page()
cate_code = 5029 # 影音播放大类别编号
child_cate_code = 716 # 视频小类别编号
for page in range(2, 100):
print(\'*\' * 50)
print(\'正在爬取:第 %s 页\' % page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
# 添加循环判断,如果content 为空表示此页已经下载完成了,break 跳出循环
if not content == \'\':
wandou_page.parse_page(content)
sleep = np.random.randint(3,6)
time.sleep(sleep)
else:
print(\'该类别已下载完最后一页\')
break
在这里,首先创建了一个 Get_page 类。get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则表示页面有内容,则循环往下爬,如果为空,则表示页面已经被爬取,执行else分支下的break语句。结束循环并完成爬行。
爬取结果如下,可以看到该分类下共爬取了41页信息。
▌While 循环
while循环和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,一种是改变判断条件。
整体代码不变,只修改For循环部分:
page = 2 # 设置爬取起始页数
while True:
print(\'*\' * 50)
print(\'正在爬取:第 %s 页\' %page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
if not content == \'\':
wandou_page.parse_page(content)
page += 1
sleep = np.random.randint(3,6)
time.sleep(sleep)
else:
print(\'该类别已下载完最后一页\')
break
或者:
page = 2 # 设置爬取起始页数
page_last = False # while 循环初始条件
while not page_last:
#...
else:
# break
page_last = True # 更改page_last 为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。
我们可以测试其他类别下的网页,例如选择“K歌”类别,代码为:718,然后只需要相应地修改main函数中的child_cate_code,再次运行程序,就可以看到下一次共抓取此类别 32 个页面。
由于Scrapy中的写入方式与Requests略有不同,所以接下来我们将在Scrapy中再次实现两种循环爬取方式。
Scrapy▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖于Twisted框架,所以采用了异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以会发送很多无用的请求。
def start_requests(self):
pages=[]
for i in range(1,10):
url=\'http://www.example.com/?page=%s\'%i
page = scrapy.Request(url,callback==self.pare)
pages.append(page)
return pages
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):
cate_code = 5019 # 新闻阅读
child_cate_code = 940 # 电子书
print(\'*\' * 50)
pages = []
for page in range(2,50):
print(\'正在爬取:第 %s 页 \' %page)
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
category_url = self.ajax_url + urlencode(params)
pa = yield scrapy.Request(category_url,callback=self.parse)
pages.append(pa)
return pages
def parse(self, response):
if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为response无内容时的长度是87
jsonresponse = json.loads(response.body_as_unicode())
contents = jsonresponse[\'data\'][\'content\']
# response 是json,json内容是html,html 为文本不能直接使用.css 提取,要先转换
contents = scrapy.Selector(text=contents, type="html")
contents = contents.css(\'.card\')
for content in contents:
item = WandoujiaItem()
item[\'app_name\'] = content.css(\'.name::text\').extract_first()
item[\'install\'] = content.css(\'.install-count::text\').extract_first()
item[\'volume\'] = content.css(\'.meta span:last-child::text\').extract_first()
item[\'comment\'] = content.css(\'.comment::text\').extract_first().strip()
yield item
上面的代码简单易懂,简单说明几点:
一、 判断当前页面是否被爬取的判断条件改为response.body的长度大于100。
因为请求已经爬取完成页面,返回的响应结果不是空的,而是一段json内容的长度(长度为87),其中content key value content为空,所以选择判断条件这里)一个大于87的值就足够了,比如100,即如果大于100,则表示该页面有内容,如果小于100,则表示该页面已被抓取.
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
二、 当需要从文本中解析内容时,无法直接解析,需要先进行转换。
正常情况下,我们在解析内容的时候直接解析返回的响应,比如使用response.css()方法,但是这里,我们的解析对象不是响应,而是响应返回的json内容中的html文本。文本不能直接使用.css()方法解析,所以在解析html之前,需要在解析前添加如下代码行。
contents = scrapy.Selector(text=contents, type="html")
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别的内容只有22页,也就是发送了26个不必要的请求。
▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):
page = 2 # 设置爬取起始页数
dict = {\'page\':page,\'cate_code\':cate_code,\'child_cate_code\':child_cate_code} # meta传递参数
yield scrapy.Request(category_url,callback=self.parse,meta=dict)
def parse(self, response):
if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为无内容时长度是87
page = response.meta[\'page\']
cate_code = response.meta[\'cate_code\']
child_cate_code = response.meta[\'child_cate_code\']
#...
for content in contents:
yield item
# while循环构造url递归爬下一页
page += 1
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
ajax_url = self.ajax_url + urlencode(params)
dict = {\'page\':page,\'cate_code\':cate_code,\'child_cate_code\':child_cate_code}
yield scrapy.Request(ajax_url,callback=self.parse,meta=dict)
在此,简单说明几点:
一、While循环的思路是从头开始爬取,使用parse()方法解析,然后递增页数构造下一页的URL请求,然后循环解析直到最后一页被抓取。, 这不会像 For 循环那样发送无用的请求。
二、parse()方法在构造下一页请求时需要用到start_requests()方法中的参数,可以使用meta方法传递参数。
运行结果如下,可以看到请求数正好是22,完成了所有页面的App信息爬取。
以上就是本文的全部内容,总结一下: 查看全部
php 循环抓取网页内容(PythonFor和While循环不确定页数的网页需要学习的地方)
本文转载自以下网站:Python For和While循环爬取页数不确定的网页
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页面。当爬行完成时,中断跳出循环并结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后将判断条件改为False进行跳转退出循环并结束爬行。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
摘要:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页面数量不确定的网页。
我们通常遇到的网站页码的显示形式有以下几种:
一是将所有页码可视化显示,比如之前爬取的宽和东方财富。
文章见:
∞ Scrapy爬取并分析了关的6000个app,发现良心软了
∞ 50行代码爬取东方财富网百万行财务报表数据
二是不直观显示网页总数,只能在后台查看。比如之前爬过的虎嗅网络,见文章:
∞ pyspider 爬取并分析 50,000 个老虎嗅探网文章
第三个是我今天要讲的。不知道有多少页,比如豌豆荚:
对于前两种形式的网页,爬取方法很简单,只需要使用For循环从第一页爬到最后一页即可。第三种形式不适用,因为不知道最后一页的编号,所以无法判断循环到哪一页结束。
如何解决?有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置为更大的参数,足以循环遍历所有页面。当爬行完成时,中断跳出循环并结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以将初始循环判断条件设置为True,从头爬到最后一页,然后将判断条件改为False进行跳转退出循环并结束爬行。
实际案例
下面,我们以豆豆荚网站中“视频”类别下的App信息为例,通过上述两种方式,抓取该类别下的所有App信息,包括App名称、评论、安装数、和音量。
首先简单分析一下网站,可以看到页面是通过ajax加载的,GET请求自带了一些参数,可以使用params参数构造一个URL请求,但是我没有知道总共有多少页。为了保证所有页面都被下载,设置更大的页面数,比如100页甚至1000页。
下面我们尝试使用For和While循环爬取。
请求▌For 循环
主要代码如下:
class Get_page():
def __init__(self):
# ajax 请求url
self.ajax_url = \'https://www.wandoujia.com/wdjweb/api/category/more\'
def get_page(self,page,cate_code,child_cate_code):
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
response = requests.get(self.ajax_url, headers=headers, params=params)
content = response.json()[\'data\'][\'content\'] #提取json中的html页面数据
return content
def parse_page(self, content):
# 解析网页内容
contents = pq(content)(\'.card\').items()
data = []
for content in contents:
data1 = {
\'app_name\': content(\'.name\').text(),
\'install\': content(\'.install-count\').text(),
\'volume\': content(\'.meta span:last-child\').text(),
\'comment\': content(\'.comment\').text(),
}
data.append(data1)
if data:
# 写入MongoDB
self.write_to_mongodb(data)
if __name__ == \'__main__\':
# 实例化数据提取类
wandou_page = Get_page()
cate_code = 5029 # 影音播放大类别编号
child_cate_code = 716 # 视频小类别编号
for page in range(2, 100):
print(\'*\' * 50)
print(\'正在爬取:第 %s 页\' % page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
# 添加循环判断,如果content 为空表示此页已经下载完成了,break 跳出循环
if not content == \'\':
wandou_page.parse_page(content)
sleep = np.random.randint(3,6)
time.sleep(sleep)
else:
print(\'该类别已下载完最后一页\')
break
在这里,首先创建了一个 Get_page 类。get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则表示页面有内容,则循环往下爬,如果为空,则表示页面已经被爬取,执行else分支下的break语句。结束循环并完成爬行。
爬取结果如下,可以看到该分类下共爬取了41页信息。
▌While 循环
while循环和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,一种是改变判断条件。
整体代码不变,只修改For循环部分:
page = 2 # 设置爬取起始页数
while True:
print(\'*\' * 50)
print(\'正在爬取:第 %s 页\' %page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
if not content == \'\':
wandou_page.parse_page(content)
page += 1
sleep = np.random.randint(3,6)
time.sleep(sleep)
else:
print(\'该类别已下载完最后一页\')
break
或者:
page = 2 # 设置爬取起始页数
page_last = False # while 循环初始条件
while not page_last:
#...
else:
# break
page_last = True # 更改page_last 为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。
我们可以测试其他类别下的网页,例如选择“K歌”类别,代码为:718,然后只需要相应地修改main函数中的child_cate_code,再次运行程序,就可以看到下一次共抓取此类别 32 个页面。
由于Scrapy中的写入方式与Requests略有不同,所以接下来我们将在Scrapy中再次实现两种循环爬取方式。
Scrapy▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖于Twisted框架,所以采用了异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以会发送很多无用的请求。
def start_requests(self):
pages=[]
for i in range(1,10):
url=\'http://www.example.com/?page=%s\'%i
page = scrapy.Request(url,callback==self.pare)
pages.append(page)
return pages
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):
cate_code = 5019 # 新闻阅读
child_cate_code = 940 # 电子书
print(\'*\' * 50)
pages = []
for page in range(2,50):
print(\'正在爬取:第 %s 页 \' %page)
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
category_url = self.ajax_url + urlencode(params)
pa = yield scrapy.Request(category_url,callback=self.parse)
pages.append(pa)
return pages
def parse(self, response):
if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为response无内容时的长度是87
jsonresponse = json.loads(response.body_as_unicode())
contents = jsonresponse[\'data\'][\'content\']
# response 是json,json内容是html,html 为文本不能直接使用.css 提取,要先转换
contents = scrapy.Selector(text=contents, type="html")
contents = contents.css(\'.card\')
for content in contents:
item = WandoujiaItem()
item[\'app_name\'] = content.css(\'.name::text\').extract_first()
item[\'install\'] = content.css(\'.install-count::text\').extract_first()
item[\'volume\'] = content.css(\'.meta span:last-child::text\').extract_first()
item[\'comment\'] = content.css(\'.comment::text\').extract_first().strip()
yield item
上面的代码简单易懂,简单说明几点:
一、 判断当前页面是否被爬取的判断条件改为response.body的长度大于100。
因为请求已经爬取完成页面,返回的响应结果不是空的,而是一段json内容的长度(长度为87),其中content key value content为空,所以选择判断条件这里)一个大于87的值就足够了,比如100,即如果大于100,则表示该页面有内容,如果小于100,则表示该页面已被抓取.
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
二、 当需要从文本中解析内容时,无法直接解析,需要先进行转换。
正常情况下,我们在解析内容的时候直接解析返回的响应,比如使用response.css()方法,但是这里,我们的解析对象不是响应,而是响应返回的json内容中的html文本。文本不能直接使用.css()方法解析,所以在解析html之前,需要在解析前添加如下代码行。
contents = scrapy.Selector(text=contents, type="html")
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别的内容只有22页,也就是发送了26个不必要的请求。
▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):
page = 2 # 设置爬取起始页数
dict = {\'page\':page,\'cate_code\':cate_code,\'child_cate_code\':child_cate_code} # meta传递参数
yield scrapy.Request(category_url,callback=self.parse,meta=dict)
def parse(self, response):
if len(response.body) >= 100: # 判断该页是否爬完,数值定为100是因为无内容时长度是87
page = response.meta[\'page\']
cate_code = response.meta[\'cate_code\']
child_cate_code = response.meta[\'child_cate_code\']
#...
for content in contents:
yield item
# while循环构造url递归爬下一页
page += 1
params = {
\'catId\': cate_code,
\'subCatId\': child_cate_code,
\'page\': page,
}
ajax_url = self.ajax_url + urlencode(params)
dict = {\'page\':page,\'cate_code\':cate_code,\'child_cate_code\':child_cate_code}
yield scrapy.Request(ajax_url,callback=self.parse,meta=dict)
在此,简单说明几点:
一、While循环的思路是从头开始爬取,使用parse()方法解析,然后递增页数构造下一页的URL请求,然后循环解析直到最后一页被抓取。, 这不会像 For 循环那样发送无用的请求。
二、parse()方法在构造下一页请求时需要用到start_requests()方法中的参数,可以使用meta方法传递参数。
运行结果如下,可以看到请求数正好是22,完成了所有页面的App信息爬取。
以上就是本文的全部内容,总结一下:
php 循环抓取网页内容(python模板github-yiming-zeng2/poweredapp:php循环抓取网页内容制作网页爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-24 20:09
php循环抓取网页内容制作网页爬虫项目背景说明首先感谢近期在知乎上解答网页抓取方面的一些问题,提升了自己的知识面,在之后的日子里收获了很多信息,比如数据清洗、数据分析、php数据库等等,这些都是非常宝贵的经验,非常非常有利于之后的学习,所以有必要给自己写篇总结来汇报,我们是用requests库做的网页抓取,因为最近在看python的django,所以顺便用django做了个爬虫,做的时候也完整的做了网页抓取,知乎上也有一个比较好的相关的回答,感兴趣的可以点进去看看,另外在github上也有一个开源的web项目,基于requests+python的异步django爬虫项目djangoweb服务器抓取网页内容爬虫生成模板自己写的django项目工具放最上面,怕各位发现不了,python模板github-yiming-zeng2/poweredapp:web数据网页爬取利器spider-loader,spider-webdigger,spider-postpilots,spider-form-extraction,robots-hider,mimetext-parser,cannonic-response-parser,src-scanner,web-parser,xpaths-scanner,response-debugger.该项目最近发现其中mimetext-parser、cannonic-response-parser、response-debugger分别对应wordpress/java爬虫以及php爬虫,不过我们测试结果是cannonic-response-parser可以抓取的链接没有php的好,所以用java爬虫,另外在检查url时发现为同一站点,但发现url发生变化,所以用webdigger抓取了下各大网站的url进行对比,另外为了合理,又对比下不同的mimekit下app的表现,做下了小结,所以分为四个部分:爬虫总结,网页分析,爬虫工具及地址列表,数据存储。
文章对面我已经顺手截了图下面正式开始总结,这一部分先是上网找一些简单的爬虫列表,网上爬虫那些是不是很眼熟,然后通过我们自己的爬虫结果给出爬虫的总结:页面分析根据自己的需求,我们把页面进行二次聚合,我通过mobile.app、mobile1.app、mobile2.app的代码以及其对应的数据,得到了所有页面的代码(其中page=2/3以及page=4/5分别为redis网站和sqlite网站,不是很清楚这个图表是怎么实现的,所以只截取到了大概,具体情况如何需要结合自己的需求)爬虫工具及地址列表上面发现全是外部的代码和数据,所以只用了web-parser和xpath这两个工具,另外做好本地编译,然后在terminal里运行下载的代码,前面也做了基本的编译,另外这里要说明下,不要直接在python下解析css代码,因为python在解析js等元素时经常会导致。 查看全部
php 循环抓取网页内容(python模板github-yiming-zeng2/poweredapp:php循环抓取网页内容制作网页爬虫)
php循环抓取网页内容制作网页爬虫项目背景说明首先感谢近期在知乎上解答网页抓取方面的一些问题,提升了自己的知识面,在之后的日子里收获了很多信息,比如数据清洗、数据分析、php数据库等等,这些都是非常宝贵的经验,非常非常有利于之后的学习,所以有必要给自己写篇总结来汇报,我们是用requests库做的网页抓取,因为最近在看python的django,所以顺便用django做了个爬虫,做的时候也完整的做了网页抓取,知乎上也有一个比较好的相关的回答,感兴趣的可以点进去看看,另外在github上也有一个开源的web项目,基于requests+python的异步django爬虫项目djangoweb服务器抓取网页内容爬虫生成模板自己写的django项目工具放最上面,怕各位发现不了,python模板github-yiming-zeng2/poweredapp:web数据网页爬取利器spider-loader,spider-webdigger,spider-postpilots,spider-form-extraction,robots-hider,mimetext-parser,cannonic-response-parser,src-scanner,web-parser,xpaths-scanner,response-debugger.该项目最近发现其中mimetext-parser、cannonic-response-parser、response-debugger分别对应wordpress/java爬虫以及php爬虫,不过我们测试结果是cannonic-response-parser可以抓取的链接没有php的好,所以用java爬虫,另外在检查url时发现为同一站点,但发现url发生变化,所以用webdigger抓取了下各大网站的url进行对比,另外为了合理,又对比下不同的mimekit下app的表现,做下了小结,所以分为四个部分:爬虫总结,网页分析,爬虫工具及地址列表,数据存储。
文章对面我已经顺手截了图下面正式开始总结,这一部分先是上网找一些简单的爬虫列表,网上爬虫那些是不是很眼熟,然后通过我们自己的爬虫结果给出爬虫的总结:页面分析根据自己的需求,我们把页面进行二次聚合,我通过mobile.app、mobile1.app、mobile2.app的代码以及其对应的数据,得到了所有页面的代码(其中page=2/3以及page=4/5分别为redis网站和sqlite网站,不是很清楚这个图表是怎么实现的,所以只截取到了大概,具体情况如何需要结合自己的需求)爬虫工具及地址列表上面发现全是外部的代码和数据,所以只用了web-parser和xpath这两个工具,另外做好本地编译,然后在terminal里运行下载的代码,前面也做了基本的编译,另外这里要说明下,不要直接在python下解析css代码,因为python在解析js等元素时经常会导致。
php 循环抓取网页内容(php循环抓取网页内容解决网页中红色字体如何正确加载?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-24 18:02
php循环抓取网页内容解决网页中红色字体如何正确加载?我写了一个php循环抓取器,当网页上需要红色字体时,比如要抓取包含java。lang。object*的文本。利用文本分割查找字符串:form=newform(title);form。serialize=if(form。isrelated){if(typeoftypeofform。
isfunction){typeofform。get()==java。lang。object);}}如果没有红色字体或白色字体那么noform!就可以正常抓取到了。
我也遇到了同样的问题,刚换浏览器就出现了红色字体,
可以用chrome的extension插件noeyefield去掉红色,或者对右键提示的红色单独处理处理,
楼上的方法我也试过了,我浏览器在windows下面是没问题的,就是typeofform.isfunction这句搞了很久,也不是很清楚。template:`form.serialize=if(typeofform.isfunction){typeofform.get()==java.lang.object)`。
我刚才也遇到这个问题了,根据我的经验搞不出来就创建个闭包form=newform(title);form.serialize=if(form.isfunction){if(typeofform.get()==java.lang.object){typeofform.get()==java.lang.object);}}}解决了以后换了个浏览器就可以直接看到了。 查看全部
php 循环抓取网页内容(php循环抓取网页内容解决网页中红色字体如何正确加载?)
php循环抓取网页内容解决网页中红色字体如何正确加载?我写了一个php循环抓取器,当网页上需要红色字体时,比如要抓取包含java。lang。object*的文本。利用文本分割查找字符串:form=newform(title);form。serialize=if(form。isrelated){if(typeoftypeofform。
isfunction){typeofform。get()==java。lang。object);}}如果没有红色字体或白色字体那么noform!就可以正常抓取到了。
我也遇到了同样的问题,刚换浏览器就出现了红色字体,
可以用chrome的extension插件noeyefield去掉红色,或者对右键提示的红色单独处理处理,
楼上的方法我也试过了,我浏览器在windows下面是没问题的,就是typeofform.isfunction这句搞了很久,也不是很清楚。template:`form.serialize=if(typeofform.isfunction){typeofform.get()==java.lang.object)`。
我刚才也遇到这个问题了,根据我的经验搞不出来就创建个闭包form=newform(title);form.serialize=if(form.isfunction){if(typeofform.get()==java.lang.object){typeofform.get()==java.lang.object);}}}解决了以后换了个浏览器就可以直接看到了。
php 循环抓取网页内容( 如何使用php及时的输出当前结果到浏览器而不刷新 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-11-23 23:07
如何使用php及时的输出当前结果到浏览器而不刷新
)
php实时输出内容到浏览器
当您正在处理一个耗时较长的流程,但又需要及时了解程序当前的处理状态时,您应该怎么做?下面分享一下如何在不刷新整个页面的情况下,使用php将当前结果及时输出到浏览器。
应用场景:如安装数据库,实时显示每一步信息,如1.数据库创建成功...2.用户表创建成功...3.用户user1 插入成功...
PHP中开启实时输出的方法是ob_implicit_flush(),但是大多数情况下是不行的,因为php.ini配置中的output_buffering输出缓冲大部分是开启的,zlib.output_compression也经常开启,除了 PHP 这个级别,Nginx 的缓冲设置 proxy_buffering,以及压缩 gzip 也大都开启了。针对一两页的需要,修改整个服务器的网站配置。恐怕没有人会做出这样的选择。
这里有一个简单的方法推荐:
案例一:实时输出shell脚本日志,将shell脚本的输出重定向到一个日志文件,然后实时输出
set_time_limit(0);
ob_end_clean();
ob_implicit_flush();
header('X-Accel-Buffering: no'); // 关键是加了这一行。
while(exec("/home/web/a.sh >> /home/web/a.log 2>&1 &"){
$log = file_get_contents('/home/web/a.log'); //这里log你可以把每一行都存入数组,然后每次只echo新的行。
echo "最新一行";
} 查看全部
php 循环抓取网页内容(
如何使用php及时的输出当前结果到浏览器而不刷新
)
php实时输出内容到浏览器
当您正在处理一个耗时较长的流程,但又需要及时了解程序当前的处理状态时,您应该怎么做?下面分享一下如何在不刷新整个页面的情况下,使用php将当前结果及时输出到浏览器。
应用场景:如安装数据库,实时显示每一步信息,如1.数据库创建成功...2.用户表创建成功...3.用户user1 插入成功...
PHP中开启实时输出的方法是ob_implicit_flush(),但是大多数情况下是不行的,因为php.ini配置中的output_buffering输出缓冲大部分是开启的,zlib.output_compression也经常开启,除了 PHP 这个级别,Nginx 的缓冲设置 proxy_buffering,以及压缩 gzip 也大都开启了。针对一两页的需要,修改整个服务器的网站配置。恐怕没有人会做出这样的选择。
这里有一个简单的方法推荐:
案例一:实时输出shell脚本日志,将shell脚本的输出重定向到一个日志文件,然后实时输出
set_time_limit(0);
ob_end_clean();
ob_implicit_flush();
header('X-Accel-Buffering: no'); // 关键是加了这一行。
while(exec("/home/web/a.sh >> /home/web/a.log 2>&1 &"){
$log = file_get_contents('/home/web/a.log'); //这里log你可以把每一行都存入数组,然后每次只echo新的行。
echo "最新一行";
}
php 循环抓取网页内容(PythonFor和While循环不确定页数的网页需要学习的地方)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-22 06:27
本文转载自以下网站:Python For和While循环爬取页数不确定的网页
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置了更大的参数,足以循环遍历所有页。爬行完成后,break会跳出循环,结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以设置初始循环判断条件为True,从头开始循环爬行,直到爬到最后一页,再将判断条件改为False跳出循环并结束爬行。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
摘要:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页面数量不确定的网页。
我们通常遇到的网站页码的显示形式有以下几种:
一是将所有页码可视化显示,比如之前爬取的宽和东方财富。
文章见:
二是不直观显示网页总数,只能在后台查看。比如之前爬过的虎嗅网络,见文章:
第三个是我今天要讲的。不知道有多少页,比如豌豆荚:
对于前两种形式的网页,爬取的方法很简单,只用For循环从第一页爬到最后一页,第三种形式不适用,因为最后一页的编号不知道,所以循环到哪一页无法判断。
如何解决?有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置了更大的参数,足以循环遍历所有页。爬行完成后,break会跳出循环,结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以设置初始循环判断条件为True,从头开始循环爬行,直到爬到最后一页,再将判断条件改为False跳出循环并结束爬行。
实际案例
下面,我们以豆豆荚网站中“视频”类别下的App信息为例,通过上述两种方式,抓取该类别下的所有App信息,包括App名称、评论、安装数、和音量。
先简单分析一下网站,可以看到页面是通过ajax加载的,GET请求自带了一些参数,可以使用params参数构造URL请求,但是不知道怎么做有很多页面。为了保证所有页面都被下载,设置更大的页面数,比如100页甚至1000页。
下面我们尝试使用For和While循环爬取。
要求
▌For 循环
主要代码如下:
类 Get_page():
def __init__(self):
#ajax请求地址
self.ajax_url ='#39;
def get_page(self,page,cate_code,child_cate_code):
参数 = {
'catId': cate_code,
'subCatId':child_cate_code,
“页面”:页面,
}
response = requests.get(self.ajax_url, headers=headers, params=params)
content = response.json()['data']['content'] #在json中提取html页面数据
返回内容
def parse_page(self, content):
# 解析网页内容
内容 = pq(content)('.card').items()
数据 = []
对于内容中的内容:
数据 1 = {
'app_name': content('.name').text(),
'安装':内容('.安装计数')。文本(),
'volume': content('.meta span:last-child').text(),
'评论':内容('.comment')。文本(),
}
数据.附加(数据1)
如果数据:
# 写入MongoDB
self.write_to_mongodb(数据)
如果 __name__ =='__main__':
# 实例化数据抽取类
wandou_page = Get_page()
cate_code = 5029 # 视频播放的大类号
child_cate_code = 716 # 视频类别号
对于范围内的页面 (2, 100):
打印('*' * 50)
打印('爬行:页面 %s'% 页)
content = wandou_page.get_page(page,cate_code,child_cate_code)
# 添加循环判断,如果内容为空,表示页面已下载,跳出循环
如果不是内容 =='':
wandou_page.parse_page(内容)
sleep = np.random.randint(3,6)
时间.睡眠(睡眠)
别的:
print('该分类的最后一页已下载')
休息
在这里,首先创建了一个 Get_page 类。get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则表示页面有内容,则循环往下爬,如果为空,则表示页面已经被爬取,执行else分支下的break语句。结束循环并完成爬行。
爬取结果如下,可以看到该分类下共爬取了41页信息。
▌While 循环
while循环和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,一种是改变判断条件。
整体代码不变,只修改For循环部分:
page = 2 # 设置开始爬取的页面数
而真:
打印('*' * 50)
打印('爬行:页面 %s' %page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
如果不是内容 =='':
wandou_page.parse_page(内容)
页 += 1
sleep = np.random.randint(3,6)
时间.睡眠(睡眠)
别的:
print('该分类的最后一页已下载')
休息
或者:
page = 2 # 设置开始爬取的页面数
page_last = False # while 循环初始条件
虽然不是 page_last:
#...
别的:
# 休息
page_last = True # 将 page_last 改为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。
我们可以测试其他分类下的网页,例如选择“K歌”分类,代码为:718,然后只需要相应修改main函数中的child_cate_code,再次运行程序,即可看到下一个此类别共抓取 32 页。
由于Scrapy中的写入方式与Requests略有不同,所以接下来我们将再次在Scrapy中实现两种循环爬取方式。
刮痧
▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖Twisted框架,采用异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以这样会发送很多无用的请求。
def start_requests(self):
页数=[]
对于范围内的 i(1,10):
网址='%s'%i
page = scrapy.Request(url,callback==self.pare)
pages.append(页面)
返回页面
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):
cate_code = 5019 # 新闻阅读
child_cate_code = 940 # 电子书
打印('*' * 50)
页数 = []
对于范围内的页面(2,50):
打印('爬行:页面 %s' %page)
参数 = {
'catId': cate_code,
'subCatId':child_cate_code,
“页面”:页面,
}
category_url = self.ajax_url + urlencode(params)
pa = 产出scrapy.Request(category_url,callback=self.parse)
pages.append(pa)
返回页面
定义解析(自我,响应):
if len(response.body) >= 100: #判断页面是否被爬取,该值设置为100,因为响应的长度为87时没有内容
jsonresponse = json.loads(response.body_as_unicode())
内容 = jsonresponse['数据']['内容']
#响应为json,json内容为html,html为文本不能直接用.css提取,必须先转换
内容=scrapy.Selector(文本=内容,类型=“html”)
content = contents.css('.card')
对于内容中的内容:
item = 玩豆家Item()
item['app_name'] = content.css('.name::text').extract_first()
item['install'] = content.css('.install-count::text').extract_first()
item['volume'] = content.css('.meta span:last-child::text').extract_first()
item['comment'] = content.css('.comment::text').extract_first().strip()
产量项目
上面的代码简单易懂,简单说明几点:
一、 判断当前页面是否被爬取的判断条件改为response.body的长度大于100。
因为请求已经爬取完成页面,返回的响应结果不是空的,而是一段json内容的长度(长度为87),这里的内容key值内容为空,所以选择判断条件这里)一个大于87的值就足够了,比如100,大于100表示这个页面有内容,小于100表示该页面已经被抓取。
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
二、 当需要从文本中解析内容时,无法直接解析,需要先进行转换。
正常情况下,我们在解析内容的时候直接解析返回的响应,比如使用response.css()方法,但是这里,我们的解析对象不是响应,而是响应返回的json内容中的html文本。文本无法直接使用.css()方法进行解析,所以在解析html之前,需要在解析前添加如下代码行进行转换。
内容=scrapy.Selector(文本=内容,类型=“html”)
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别的内容只有22页,也就是发送了26个不必要的请求。
▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):
page = 2 # 设置开始爬取的页面数
dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code} # 元传递参数
产生scrapy.Request(category_url,callback=self.parse,meta=dict)
定义解析(自我,响应):
if len(response.body) >= 100: #判断页面是否被爬取,设置为100,因为没有内容时长度为87
page = response.meta['page']
cate_code = response.meta['cate_code']
child_cate_code = response.meta['child_cate_code']
#...
对于内容中的内容:
产量项目 查看全部
php 循环抓取网页内容(PythonFor和While循环不确定页数的网页需要学习的地方)
本文转载自以下网站:Python For和While循环爬取页数不确定的网页
学习的地方
有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置了更大的参数,足以循环遍历所有页。爬行完成后,break会跳出循环,结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以设置初始循环判断条件为True,从头开始循环爬行,直到爬到最后一页,再将判断条件改为False跳出循环并结束爬行。
Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页数不确定的网页。
摘要:Requests 和 Scrapy 分别使用 For 循环和 While 循环来抓取页面数量不确定的网页。
我们通常遇到的网站页码的显示形式有以下几种:
一是将所有页码可视化显示,比如之前爬取的宽和东方财富。
文章见:
二是不直观显示网页总数,只能在后台查看。比如之前爬过的虎嗅网络,见文章:
第三个是我今天要讲的。不知道有多少页,比如豌豆荚:
对于前两种形式的网页,爬取的方法很简单,只用For循环从第一页爬到最后一页,第三种形式不适用,因为最后一页的编号不知道,所以循环到哪一页无法判断。
如何解决?有两种方法。
第一种方法使用带有 break 语句的 For 循环。最后一页的页数设置了更大的参数,足以循环遍历所有页。爬行完成后,break会跳出循环,结束爬行。
第二种方法使用While循环,可以和break语句结合使用,也可以设置初始循环判断条件为True,从头开始循环爬行,直到爬到最后一页,再将判断条件改为False跳出循环并结束爬行。
实际案例
下面,我们以豆豆荚网站中“视频”类别下的App信息为例,通过上述两种方式,抓取该类别下的所有App信息,包括App名称、评论、安装数、和音量。
先简单分析一下网站,可以看到页面是通过ajax加载的,GET请求自带了一些参数,可以使用params参数构造URL请求,但是不知道怎么做有很多页面。为了保证所有页面都被下载,设置更大的页面数,比如100页甚至1000页。
下面我们尝试使用For和While循环爬取。
要求
▌For 循环
主要代码如下:
类 Get_page():
def __init__(self):
#ajax请求地址
self.ajax_url ='#39;
def get_page(self,page,cate_code,child_cate_code):
参数 = {
'catId': cate_code,
'subCatId':child_cate_code,
“页面”:页面,
}
response = requests.get(self.ajax_url, headers=headers, params=params)
content = response.json()['data']['content'] #在json中提取html页面数据
返回内容
def parse_page(self, content):
# 解析网页内容
内容 = pq(content)('.card').items()
数据 = []
对于内容中的内容:
数据 1 = {
'app_name': content('.name').text(),
'安装':内容('.安装计数')。文本(),
'volume': content('.meta span:last-child').text(),
'评论':内容('.comment')。文本(),
}
数据.附加(数据1)
如果数据:
# 写入MongoDB
self.write_to_mongodb(数据)
如果 __name__ =='__main__':
# 实例化数据抽取类
wandou_page = Get_page()
cate_code = 5029 # 视频播放的大类号
child_cate_code = 716 # 视频类别号
对于范围内的页面 (2, 100):
打印('*' * 50)
打印('爬行:页面 %s'% 页)
content = wandou_page.get_page(page,cate_code,child_cate_code)
# 添加循环判断,如果内容为空,表示页面已下载,跳出循环
如果不是内容 =='':
wandou_page.parse_page(内容)
sleep = np.random.randint(3,6)
时间.睡眠(睡眠)
别的:
print('该分类的最后一页已下载')
休息
在这里,首先创建了一个 Get_page 类。get_page 方法用于获取Response 返回的json 数据。通过网站解析json后,发现要提取的内容是data字段下的content key包裹的一段html文本。使用parse_page方法中的pyquery函数进行解析,最终提取出App名称、评论、安装数、体积这四个信息来完成爬取。
在main函数中,if函数用于条件判断。如果内容不为空,则表示页面有内容,则循环往下爬,如果为空,则表示页面已经被爬取,执行else分支下的break语句。结束循环并完成爬行。
爬取结果如下,可以看到该分类下共爬取了41页信息。
▌While 循环
while循环和For循环的思路大致相同,但是有两种写法,一种还是结合break语句,一种是改变判断条件。
整体代码不变,只修改For循环部分:
page = 2 # 设置开始爬取的页面数
而真:
打印('*' * 50)
打印('爬行:页面 %s' %page)
content = wandou_page.get_page(page,cate_code,child_cate_code)
如果不是内容 =='':
wandou_page.parse_page(内容)
页 += 1
sleep = np.random.randint(3,6)
时间.睡眠(睡眠)
别的:
print('该分类的最后一页已下载')
休息
或者:
page = 2 # 设置开始爬取的页面数
page_last = False # while 循环初始条件
虽然不是 page_last:
#...
别的:
# 休息
page_last = True # 将 page_last 改为 True 跳出循环
结果如下,可以看到For循环的结果是一样的。
我们可以测试其他分类下的网页,例如选择“K歌”分类,代码为:718,然后只需要相应修改main函数中的child_cate_code,再次运行程序,即可看到下一个此类别共抓取 32 页。
由于Scrapy中的写入方式与Requests略有不同,所以接下来我们将再次在Scrapy中实现两种循环爬取方式。
刮痧
▌For 循环
在Scrapy中使用For循环递归爬取的思路很简单,就是先批量生成所有请求的URL,包括最后一个无效的URL,然后在parse方法中加入if来判断和过滤无效请求,然后抓取所有页面。由于Scrapy依赖Twisted框架,采用异步请求处理方式,也就是说Scrapy在发送请求的同时解析内容,所以这样会发送很多无用的请求。
def start_requests(self):
页数=[]
对于范围内的 i(1,10):
网址='%s'%i
page = scrapy.Request(url,callback==self.pare)
pages.append(页面)
返回页面
下面,我们选择豌豆荚“新闻阅读”类别下的“电子书”App页面信息,使用For循环尝试爬取。主要代码如下:
def start_requests(self):
cate_code = 5019 # 新闻阅读
child_cate_code = 940 # 电子书
打印('*' * 50)
页数 = []
对于范围内的页面(2,50):
打印('爬行:页面 %s' %page)
参数 = {
'catId': cate_code,
'subCatId':child_cate_code,
“页面”:页面,
}
category_url = self.ajax_url + urlencode(params)
pa = 产出scrapy.Request(category_url,callback=self.parse)
pages.append(pa)
返回页面
定义解析(自我,响应):
if len(response.body) >= 100: #判断页面是否被爬取,该值设置为100,因为响应的长度为87时没有内容
jsonresponse = json.loads(response.body_as_unicode())
内容 = jsonresponse['数据']['内容']
#响应为json,json内容为html,html为文本不能直接用.css提取,必须先转换
内容=scrapy.Selector(文本=内容,类型=“html”)
content = contents.css('.card')
对于内容中的内容:
item = 玩豆家Item()
item['app_name'] = content.css('.name::text').extract_first()
item['install'] = content.css('.install-count::text').extract_first()
item['volume'] = content.css('.meta span:last-child::text').extract_first()
item['comment'] = content.css('.comment::text').extract_first().strip()
产量项目
上面的代码简单易懂,简单说明几点:
一、 判断当前页面是否被爬取的判断条件改为response.body的长度大于100。
因为请求已经爬取完成页面,返回的响应结果不是空的,而是一段json内容的长度(长度为87),这里的内容key值内容为空,所以选择判断条件这里)一个大于87的值就足够了,比如100,大于100表示这个页面有内容,小于100表示该页面已经被抓取。
{"state":{"code":2000000,"msg":"Ok","tips":""},"data":{"currPage":-1,"content":""}}
二、 当需要从文本中解析内容时,无法直接解析,需要先进行转换。
正常情况下,我们在解析内容的时候直接解析返回的响应,比如使用response.css()方法,但是这里,我们的解析对象不是响应,而是响应返回的json内容中的html文本。文本无法直接使用.css()方法进行解析,所以在解析html之前,需要在解析前添加如下代码行进行转换。
内容=scrapy.Selector(文本=内容,类型=“html”)
结果如下。您可以看到所有 48 个请求都已发送。事实上,这个类别的内容只有22页,也就是发送了26个不必要的请求。
▌While 循环
接下来,我们使用While循环再次尝试抓取,代码省略了与For循环中相同的部分:
def start_requests(self):
page = 2 # 设置开始爬取的页面数
dict = {'page':page,'cate_code':cate_code,'child_cate_code':child_cate_code} # 元传递参数
产生scrapy.Request(category_url,callback=self.parse,meta=dict)
定义解析(自我,响应):
if len(response.body) >= 100: #判断页面是否被爬取,设置为100,因为没有内容时长度为87
page = response.meta['page']
cate_code = response.meta['cate_code']
child_cate_code = response.meta['child_cate_code']
#...
对于内容中的内容:
产量项目

