
php用正则表达抓取网页中文章
php用正则表达抓取网页中文章( 老是/php/Snoopy.gz本地下载类类特征)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-18 14:18
老是/php/Snoopy.gz本地下载类类特征)
史努比PHP版网络客户端提供本地下载
更新时间:2008-04-15 21:29:47 作者:
snoopy是一个很好的模仿网络客户端的php类,但是本地下载的很少,国外下载又麻烦又慢,所以弄了这个网站给大家下载
史努比在magpierss中使用,这让我有点兴趣研究这个dong dong。在 SF 上,我找到了这个源代码。它其实是一个类,但不要笑,功能很强大。
官方介绍,我翻译了(汗……最近一直在做翻译)
snoopy 是一个模仿网络浏览器功能的 php 类,它可以完成获取网页内容和发送表单的任务。
以下是它的一些特点:
1、轻松抓取网页内容
2、轻松抓取网页文本(去掉HTML代码)
3、方便抓取网页的链接
4、支持代理主机
5、支持基本用户/密码认证方式
6、支持自定义用户代理、referer、cookies和header内容
7、支持浏览器转向和控制转向深度
8、 可以将网页中的链接扩展成高质量的url(默认)
9、方便提交数据并获取返回值
10、支持跟踪HTML框架(v0.92增加)
11、支持重定向时传递cookies
下面是一个简单的例子,比如我们抓取我博客的文字
^_^,还不错,比如抢链接
哎,效果不错,还有我们需要的url,没有/blog/read.php/85.htm这样的东西。
还要为以后测试的人提交数据。. .
元马/php/Snoopy-1.2.3.tar.gz本地下载 查看全部
php用正则表达抓取网页中文章(
老是/php/Snoopy.gz本地下载类类特征)
史努比PHP版网络客户端提供本地下载
更新时间:2008-04-15 21:29:47 作者:
snoopy是一个很好的模仿网络客户端的php类,但是本地下载的很少,国外下载又麻烦又慢,所以弄了这个网站给大家下载
史努比在magpierss中使用,这让我有点兴趣研究这个dong dong。在 SF 上,我找到了这个源代码。它其实是一个类,但不要笑,功能很强大。
官方介绍,我翻译了(汗……最近一直在做翻译)
snoopy 是一个模仿网络浏览器功能的 php 类,它可以完成获取网页内容和发送表单的任务。
以下是它的一些特点:
1、轻松抓取网页内容
2、轻松抓取网页文本(去掉HTML代码)
3、方便抓取网页的链接
4、支持代理主机
5、支持基本用户/密码认证方式
6、支持自定义用户代理、referer、cookies和header内容
7、支持浏览器转向和控制转向深度
8、 可以将网页中的链接扩展成高质量的url(默认)
9、方便提交数据并获取返回值
10、支持跟踪HTML框架(v0.92增加)
11、支持重定向时传递cookies
下面是一个简单的例子,比如我们抓取我博客的文字
^_^,还不错,比如抢链接
哎,效果不错,还有我们需要的url,没有/blog/read.php/85.htm这样的东西。
还要为以后测试的人提交数据。. .
元马/php/Snoopy-1.2.3.tar.gz本地下载
php用正则表达抓取网页中文章(常用的nginx正则表达式^:匹配输入字符串的路径地址地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-15 03:16
常用的nginx正则表达式
^ : 匹配输入字符串的开头
$:匹配输入字符串的结尾
*:匹配前面的字符零次或多次
+:匹配前面的字符一次或多次
?:匹配前面的字符零次或一次
. : 匹配除 "\n" 之外的任何单词。如果要匹配 "\n" 字符串,请使用 [.\n] 之类的模式
\:将后面的字符标记为特殊字符或文字或反向引用
\d : 匹配纯数字 [0-9], \s: 空格 \w: 任何单个,包括下划线 [A-Za-z0-9]
{n}:重复 n 次
{n,} :重复 n 次或更多
{n,m}:重复 n 到 m 这个
[ ] : 定义匹配的字符转置
[ c ] : 匹配单个字符 c
[az]:匹配 az 的任何小写字符
[A-Za-z0-9]:匹配所有大小写字符或数字
() : 表达式的开始和结束位置
| : OR 运算符
从功能上看,rewrite和location似乎有点类似,都可以实现跳转。主要区别在于rewrite改变了获取同域名下资源的路径,而location是一对用于控制访问或反向代理的类路径。可以proxy_pass到其他机器吗
rewrite 重写访问域名中的 URL 路径地址
location 对访问路径进行访问控制或代理转发
地点
位置大致可以分为三类:
完全匹配:位置 = / {...}
一般匹配:location/{...}#最长匹配原则(如果有屁匹配最长的会选择最长的)
正则匹配:location ~ / {...}
位置常用匹配选项:
= :对普通字符进行精确匹配,即精确匹配
^~ :对普通字符进行精确匹配,即精确匹配。
~ :区分大小写的匹配。
~* :不区分大小写的匹配。
!~* :!~: 区分大小写的匹配否定。
!~* :不区分大小写的匹配否定。
位置匹配优先级
首先是完全匹配=
二是前缀匹配(匹配后停止搜索,直接用这个!)
后跟按照文件中的顺序进行正则匹配,~或~*
然后匹配前缀匹配,不做任何修改(正常匹配)
最后传给“/”(万能匹配)
位置示例说明:
1、位置 = / {}
=。要完全匹配/,主机名后面不能跟任何字符串,比如访问/和/data,那么/匹配,/data不匹配。例如 location = /abc,它只匹配 /abc、/abc/ 或 /abcd 不匹配。如果位置 /abc,它匹配 /abc、/abcd/ 并且还匹配 /abc/。
(2) 位置 / {}
因为所有地址都以1开头,所以这条规则会匹配访问/和/data等所有请求,那么1会匹配,/data也会匹配,但是如果后面是正则表达式,会匹配最长的字符串第一个(最长的字符串)。长比赛)
(3) location /documents/ {} 匹配任何以/documents/开头的地址,匹配后会继续搜索其他位置,只有当其他位置后面的正则表达式不匹配时才会使用。这个
(4) location /documents/abc {} 匹配任何以 /documents/abc 开头的地址。匹配后会继续搜索其他位置。只有当其他位置后面的正则表达式不匹配时,将使用这个
(5) 位置 ^~ /images/ {}
匹配任何以/images/开头的地址,匹配后停止搜索正则,使用这个
(6) 位置 ~* . (gifljpg ljpeg)$ {}
匹配所有以 gif、jpg 或 jpeg 结尾的请求,但是 /images/ 下的所有请求都会被位置 ^~ /images/ 处理,因为 ^~ 具有更高的优先级,因此无法达到此规则
(7) 位置 /images/abc {}
最长的字符匹配 /images/abc,优先级最低。如果继续搜索其他位置,会发现^~和~存在
(8) 位置 ~ /images/abc {}
以 /images/abc 开头的匹配,优先级次之,仅当 location ^~ /images/ 被删除时,才会使用此条目
(9) 位置 /images/abc/1.html {}
匹配 /images/abc/1.html 文件,如果与常规位置 ~/images/abc/1.html 相比,常规优先级更高
优先级总结:
(location = 全路径) > (location ^~path) > (location ~,~*正则) > (location 部分起始路径) > (location /)
位置匹配
先看优先级:Precise > Prefix > Regular > General > General
优先级是一样的:正则看上下顺序,上面的优先级:一般匹配看长度,最长匹配优先级是精确,前缀,正则,一般不匹配,最后看一般匹配。
在实际网站的使用中,至少定义了三个匹配规则:
#第一条强制规则
直接匹配网站的根,通过域名访问网站的主页更频繁。使用这个会加快处理速度,比如官网。可以是静态首页,也可以直接转发到后台应用服务器
location = / {
root html;
index index.html index.html;
}
#第二条强制规则是处理静态文件请求,这是nginx作为http服务器的强项。有两种配置方式,目录匹配或后缀匹配,任选其一或一起使用
location ^~ /static/ {
root /webroot/static/;
}
location ~* \.(html|gif|jpg|jpeg|png|css|js|ico)$ {
root /webroot/res/;
}
#第三条规则是一般规则。例如,用于将带有 .php 和 .jsp 后缀的动态请求转发到后端应用服务器。默认情况下,非静态文件请求是动态请求。
location / {
proxy_pass http://tomcat_server;
}
改写
重写功能是利用nginx提供的全局变量或者自己设置的变量,结合正则表达式和标签位来实现URL的重写和重定向。
例如:更改域名后需要保留旧域名跳转到新域名,网页更改时跳转到新页面,网站防盗链等等。
改写。只能放在server{}、location{}、if{}中,默认只能作用于域名后面的字符串,除了传入的参数,
例如 http:L //abc/bbs/index.php?a=1&b=2 只重写 /abc/bbs/index.php。
重写跳转实现:
nginx:ngx http rewrite_模块模块支持url重写和if条件判断,但不支持else跳转:从一个位置跳转到另一个位置,循环最多可以执行10次,之后nginx会返回500错误
PCRE 支持:Perl 兼容的正则表达式语法规则匹配
覆盖模块设置指令:创建新变量并设置其值
重写执行顺序如下:
(1) 在服务器块内执行重写指令。
(2) 执行位置匹配。
(3) 在选定位置执行重写命令。
语法格式: rewrite [flag];
regex:表示正则匹配规则。
replacement:表示跳转后的内容。
flag:表示rewrite支持的flag标记。
重写跳跃场景:
调整用户浏览的网址,使其看起来更规范,符合开发和生产
人员的需求。
为了让搜索引擎更好地搜索网站内容和用户体验,公司将
将动态 URL 地址伪装成静态地址提供服务。
网站改成新域名后,让旧访问跳转到新域名。比如访问京东的都会跳转。
服务器端的一些业务调整,比如基于特殊变量、目录、客户端信息的URL调整。
###flag 标志说明 ###
last :本规则匹配完成后,继续向下匹配新的location URL规则,一般用在server和if中。
break :该规则匹配后终止,不再匹配任何后续规则。一般用于定位。
redirect:返回一个302临时重定向,浏览器地址会显示重定向后的URL地址。
永久:返回301永久重定向,浏览器地址栏会显示重定向后的URL。
重写示例:
(1)根据域名重定向
现在公司老域名业务需求发生变化,需要更换新域名,但是老域名不能取消,需要跳转到新域名,vim /usr/local/nginx/conf /nginx.conf
server {
listen 80;
server_nameWWw.kgc.com; #域名修改
charset utf-8; #编码格式
access_ 1og /var/log/nginx/www.kgc.com-access.log; #日志修改
location / { #添加域名重定向
if ($host = 'WWW.kgc.com') { #$host为rewrite全局变量,代表请求主机头字段或主机名
rewrite ^/(.*)$ http://www.benet.com/$1 permanent; #$1为 正则匹配的内容,即“域名/"之后的字符串
}
root html;
index index.html index.htm;
}
}
echo "192.168.80.10 www.kgc.com www.benet.com" >> /etc/hosts
systemctl restart nginx
浏览器输入模拟访问http://www.kgc.com/test/1.html (虽然这个请求内容是不存在的)
会跳转到www.benet.com/test/1.html,查看元素可以看到返回301,实现了永久重定向跳转,而且域名后的参数也正常跳转。
(2)基于客户端IP的访问跳转
今天公司新版业务上线,要求所有IP访问任何内容显示,固定维护页面,只有公司IP:192.168.80. 10访问是正常的。
vim /usr/local/nginx/conf /nginx.conf
server {
server_nameWWw.kgc.com; #域名修改
charset utf-8; #编码格式
access_ 1og /var/log/nginx/www.kgc.com-access.log; #日志修改
#设置是否合法的IP标记
set $rewrite true; #设置变量$rewrite,变量值为boole值true
#判断是否为合法IP
if ($remote_addr = "192.168.80.10"){ #当客户端IP为192.168.80.10时,将变量值设为false,不进行重写
set $rewrite false;
}
#除了合法IP,其它都是非法IP,进行重写跳转维护页面
if ($rewrite = true) { #当变量值为true时,进行重写
rewrite (.+) /weihu.html; #将域名后边的路径重写成/weihu. html,例如www. kgc.com/weihu.html
}
location = /weihu.html {
root /var/ www/html; #网页返回/var/www/ html/weihu. html的内容
}
location / {
root html;
index index.html index.htm;
}
}
(3)基于旧域名,跳转到新域名后跟目录
现在访问了,现在这个域名下的访问需要跳转到http:L //bbs/post
vim /usr/1ocal/nginx/conf/nginx.conf
server {
listen 80;
server_namebbs.kgc.com; #域名修改
charset utf-8;
access_1og /var/1og/nginx/WWW.kgc.com-access.log;
#添加
location /post {
rewrite (.+) http://www.kgc.com/bbs$1 permanent; #这里的$1为位置变量,代表/post
}
location / {
root html;
index index.html index.htm;
}
}
mkdir -p /usr/local/nginx/html/bbs/post
echo "this is 1.html" >> /usr/1ocal/nginx/html/bbs/post/1 . html
echo "192.168.80.10 bbs.kgc.com"
systemctl restart nginx
使用浏览器访问http://bbs.kgc.com/post/1.html跳转到http://www. kgc.com/bbs/post/1.html
(4)根据参数匹配跳转 查看全部
php用正则表达抓取网页中文章(常用的nginx正则表达式^:匹配输入字符串的路径地址地址)
常用的nginx正则表达式
^ : 匹配输入字符串的开头
$:匹配输入字符串的结尾
*:匹配前面的字符零次或多次
+:匹配前面的字符一次或多次
?:匹配前面的字符零次或一次
. : 匹配除 "\n" 之外的任何单词。如果要匹配 "\n" 字符串,请使用 [.\n] 之类的模式
\:将后面的字符标记为特殊字符或文字或反向引用
\d : 匹配纯数字 [0-9], \s: 空格 \w: 任何单个,包括下划线 [A-Za-z0-9]
{n}:重复 n 次
{n,} :重复 n 次或更多
{n,m}:重复 n 到 m 这个
[ ] : 定义匹配的字符转置
[ c ] : 匹配单个字符 c
[az]:匹配 az 的任何小写字符
[A-Za-z0-9]:匹配所有大小写字符或数字
() : 表达式的开始和结束位置
| : OR 运算符
从功能上看,rewrite和location似乎有点类似,都可以实现跳转。主要区别在于rewrite改变了获取同域名下资源的路径,而location是一对用于控制访问或反向代理的类路径。可以proxy_pass到其他机器吗
rewrite 重写访问域名中的 URL 路径地址
location 对访问路径进行访问控制或代理转发
地点
位置大致可以分为三类:
完全匹配:位置 = / {...}
一般匹配:location/{...}#最长匹配原则(如果有屁匹配最长的会选择最长的)
正则匹配:location ~ / {...}
位置常用匹配选项:
= :对普通字符进行精确匹配,即精确匹配
^~ :对普通字符进行精确匹配,即精确匹配。
~ :区分大小写的匹配。
~* :不区分大小写的匹配。
!~* :!~: 区分大小写的匹配否定。
!~* :不区分大小写的匹配否定。
位置匹配优先级
首先是完全匹配=
二是前缀匹配(匹配后停止搜索,直接用这个!)
后跟按照文件中的顺序进行正则匹配,~或~*
然后匹配前缀匹配,不做任何修改(正常匹配)
最后传给“/”(万能匹配)
位置示例说明:
1、位置 = / {}
=。要完全匹配/,主机名后面不能跟任何字符串,比如访问/和/data,那么/匹配,/data不匹配。例如 location = /abc,它只匹配 /abc、/abc/ 或 /abcd 不匹配。如果位置 /abc,它匹配 /abc、/abcd/ 并且还匹配 /abc/。
(2) 位置 / {}
因为所有地址都以1开头,所以这条规则会匹配访问/和/data等所有请求,那么1会匹配,/data也会匹配,但是如果后面是正则表达式,会匹配最长的字符串第一个(最长的字符串)。长比赛)
(3) location /documents/ {} 匹配任何以/documents/开头的地址,匹配后会继续搜索其他位置,只有当其他位置后面的正则表达式不匹配时才会使用。这个
(4) location /documents/abc {} 匹配任何以 /documents/abc 开头的地址。匹配后会继续搜索其他位置。只有当其他位置后面的正则表达式不匹配时,将使用这个
(5) 位置 ^~ /images/ {}
匹配任何以/images/开头的地址,匹配后停止搜索正则,使用这个
(6) 位置 ~* . (gifljpg ljpeg)$ {}
匹配所有以 gif、jpg 或 jpeg 结尾的请求,但是 /images/ 下的所有请求都会被位置 ^~ /images/ 处理,因为 ^~ 具有更高的优先级,因此无法达到此规则
(7) 位置 /images/abc {}
最长的字符匹配 /images/abc,优先级最低。如果继续搜索其他位置,会发现^~和~存在
(8) 位置 ~ /images/abc {}
以 /images/abc 开头的匹配,优先级次之,仅当 location ^~ /images/ 被删除时,才会使用此条目
(9) 位置 /images/abc/1.html {}
匹配 /images/abc/1.html 文件,如果与常规位置 ~/images/abc/1.html 相比,常规优先级更高
优先级总结:
(location = 全路径) > (location ^~path) > (location ~,~*正则) > (location 部分起始路径) > (location /)
位置匹配
先看优先级:Precise > Prefix > Regular > General > General
优先级是一样的:正则看上下顺序,上面的优先级:一般匹配看长度,最长匹配优先级是精确,前缀,正则,一般不匹配,最后看一般匹配。
在实际网站的使用中,至少定义了三个匹配规则:
#第一条强制规则
直接匹配网站的根,通过域名访问网站的主页更频繁。使用这个会加快处理速度,比如官网。可以是静态首页,也可以直接转发到后台应用服务器
location = / {
root html;
index index.html index.html;
}
#第二条强制规则是处理静态文件请求,这是nginx作为http服务器的强项。有两种配置方式,目录匹配或后缀匹配,任选其一或一起使用
location ^~ /static/ {
root /webroot/static/;
}
location ~* \.(html|gif|jpg|jpeg|png|css|js|ico)$ {
root /webroot/res/;
}
#第三条规则是一般规则。例如,用于将带有 .php 和 .jsp 后缀的动态请求转发到后端应用服务器。默认情况下,非静态文件请求是动态请求。
location / {
proxy_pass http://tomcat_server;
}
改写
重写功能是利用nginx提供的全局变量或者自己设置的变量,结合正则表达式和标签位来实现URL的重写和重定向。
例如:更改域名后需要保留旧域名跳转到新域名,网页更改时跳转到新页面,网站防盗链等等。
改写。只能放在server{}、location{}、if{}中,默认只能作用于域名后面的字符串,除了传入的参数,
例如 http:L //abc/bbs/index.php?a=1&b=2 只重写 /abc/bbs/index.php。
重写跳转实现:
nginx:ngx http rewrite_模块模块支持url重写和if条件判断,但不支持else跳转:从一个位置跳转到另一个位置,循环最多可以执行10次,之后nginx会返回500错误
PCRE 支持:Perl 兼容的正则表达式语法规则匹配
覆盖模块设置指令:创建新变量并设置其值
重写执行顺序如下:
(1) 在服务器块内执行重写指令。
(2) 执行位置匹配。
(3) 在选定位置执行重写命令。
语法格式: rewrite [flag];
regex:表示正则匹配规则。
replacement:表示跳转后的内容。
flag:表示rewrite支持的flag标记。

重写跳跃场景:
调整用户浏览的网址,使其看起来更规范,符合开发和生产
人员的需求。
为了让搜索引擎更好地搜索网站内容和用户体验,公司将
将动态 URL 地址伪装成静态地址提供服务。
网站改成新域名后,让旧访问跳转到新域名。比如访问京东的都会跳转。
服务器端的一些业务调整,比如基于特殊变量、目录、客户端信息的URL调整。
###flag 标志说明 ###
last :本规则匹配完成后,继续向下匹配新的location URL规则,一般用在server和if中。
break :该规则匹配后终止,不再匹配任何后续规则。一般用于定位。
redirect:返回一个302临时重定向,浏览器地址会显示重定向后的URL地址。
永久:返回301永久重定向,浏览器地址栏会显示重定向后的URL。
重写示例:
(1)根据域名重定向
现在公司老域名业务需求发生变化,需要更换新域名,但是老域名不能取消,需要跳转到新域名,vim /usr/local/nginx/conf /nginx.conf
server {
listen 80;
server_nameWWw.kgc.com; #域名修改
charset utf-8; #编码格式
access_ 1og /var/log/nginx/www.kgc.com-access.log; #日志修改
location / { #添加域名重定向
if ($host = 'WWW.kgc.com') { #$host为rewrite全局变量,代表请求主机头字段或主机名
rewrite ^/(.*)$ http://www.benet.com/$1 permanent; #$1为 正则匹配的内容,即“域名/"之后的字符串
}
root html;
index index.html index.htm;
}
}
echo "192.168.80.10 www.kgc.com www.benet.com" >> /etc/hosts
systemctl restart nginx
浏览器输入模拟访问http://www.kgc.com/test/1.html (虽然这个请求内容是不存在的)
会跳转到www.benet.com/test/1.html,查看元素可以看到返回301,实现了永久重定向跳转,而且域名后的参数也正常跳转。
(2)基于客户端IP的访问跳转
今天公司新版业务上线,要求所有IP访问任何内容显示,固定维护页面,只有公司IP:192.168.80. 10访问是正常的。
vim /usr/local/nginx/conf /nginx.conf
server {
server_nameWWw.kgc.com; #域名修改
charset utf-8; #编码格式
access_ 1og /var/log/nginx/www.kgc.com-access.log; #日志修改
#设置是否合法的IP标记
set $rewrite true; #设置变量$rewrite,变量值为boole值true
#判断是否为合法IP
if ($remote_addr = "192.168.80.10"){ #当客户端IP为192.168.80.10时,将变量值设为false,不进行重写
set $rewrite false;
}
#除了合法IP,其它都是非法IP,进行重写跳转维护页面
if ($rewrite = true) { #当变量值为true时,进行重写
rewrite (.+) /weihu.html; #将域名后边的路径重写成/weihu. html,例如www. kgc.com/weihu.html
}
location = /weihu.html {
root /var/ www/html; #网页返回/var/www/ html/weihu. html的内容
}
location / {
root html;
index index.html index.htm;
}
}
(3)基于旧域名,跳转到新域名后跟目录
现在访问了,现在这个域名下的访问需要跳转到http:L //bbs/post
vim /usr/1ocal/nginx/conf/nginx.conf
server {
listen 80;
server_namebbs.kgc.com; #域名修改
charset utf-8;
access_1og /var/1og/nginx/WWW.kgc.com-access.log;
#添加
location /post {
rewrite (.+) http://www.kgc.com/bbs$1 permanent; #这里的$1为位置变量,代表/post
}
location / {
root html;
index index.html index.htm;
}
}
mkdir -p /usr/local/nginx/html/bbs/post
echo "this is 1.html" >> /usr/1ocal/nginx/html/bbs/post/1 . html
echo "192.168.80.10 bbs.kgc.com"
systemctl restart nginx
使用浏览器访问http://bbs.kgc.com/post/1.html跳转到http://www. kgc.com/bbs/post/1.html
(4)根据参数匹配跳转
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章(针对各大门户网站))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-14 13:01
php用正则表达抓取网页中文章(针对各大门户网站如新浪、网易、腾讯、网易等);python用xpath处理含有相关关键字的网页;用requests异步加载网页中的json字符串;mysql处理数据库字符串;这里不再一一介绍
<p>看到这个题目,想到学校老师布置的每周小组作业,就是要批量下载网页中的中文标题。鉴于可以用较简单的语言来达到这个目的,我简单说一下思路。首先,打开chrome浏览器,打开开发者工具,并且按住ctrl+shift+s调出浏览器的代理栏。这里提一下,代理栏位于浏览器顶部。代理栏图标里包含”.”和”*”两个字符串,代理栏里存储的是你当前浏览器的代理ip地址,这个代理ip地址就相当于我们的机器电脑路由器端口,我们在浏览器中访问网页时,浏览器默认使用的地址栏里输入的其实就是浏览器中输入的该代理ip地址,要获取某网页的中文标题就是获取该代理ip对应的端口,思路大致如此。当然,我们有更好的办法。发布会 查看全部
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章(针对各大门户网站))
php用正则表达抓取网页中文章(针对各大门户网站如新浪、网易、腾讯、网易等);python用xpath处理含有相关关键字的网页;用requests异步加载网页中的json字符串;mysql处理数据库字符串;这里不再一一介绍
<p>看到这个题目,想到学校老师布置的每周小组作业,就是要批量下载网页中的中文标题。鉴于可以用较简单的语言来达到这个目的,我简单说一下思路。首先,打开chrome浏览器,打开开发者工具,并且按住ctrl+shift+s调出浏览器的代理栏。这里提一下,代理栏位于浏览器顶部。代理栏图标里包含”.”和”*”两个字符串,代理栏里存储的是你当前浏览器的代理ip地址,这个代理ip地址就相当于我们的机器电脑路由器端口,我们在浏览器中访问网页时,浏览器默认使用的地址栏里输入的其实就是浏览器中输入的该代理ip地址,要获取某网页的中文标题就是获取该代理ip对应的端口,思路大致如此。当然,我们有更好的办法。发布会
php用正则表达抓取网页中文章(Linux操作系统中只有三个命令使用正则技术(命令) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-12 18:17
)
一、基本概述
用户可以使用正则表达式技术来匹配和提取数据集中的一些特殊或关键数据。主要目的是模式匹配,比系统提供的str标准字符串处理函数更强大、更高效,因为str系列函数使用ASCII码以逐字符偏移比较的形式搜索修改后的字符数据,但 REGEX 使用贪心算法来匹配查询。
二、常规语句格式
正则语句是由一组匹配字符+特殊符号(元字符)组成的字符串,用于描述匹配数据的数据规则,最后根据正则语句进行模式匹配,得到关键内容。
三、数据规则
正则表达式是批量匹配和提取技术。用户首先要观察数据集,分析数据规则和数据特征,然后根据数据特征编辑相应的正则句(匹配字符串)。如果要匹配的数据没有特定的模式或规则,则正则表达式不可用。
例子:
DataFile_01:
BUG
99
吃鸡
189
LOL
98 //该数据集所有数据都有特定规则,可以使用正则表达式匹配获取特定数据
DataFile_02:
吃饭、213、喝奶茶2077、299、睡觉、1987、学习、232、132
//该数据集中没有明确数据规则,不太适合使用正则表达式
比如匹配DataFile_01数据集中的所有游戏名(这个现在可能不明白,但是看完你就明白了)
<p>游戏名 //文件中的数据规则
使用正则语句模拟这个数据规则:
[^ 查看全部
php用正则表达抓取网页中文章(Linux操作系统中只有三个命令使用正则技术(命令)
)
一、基本概述
用户可以使用正则表达式技术来匹配和提取数据集中的一些特殊或关键数据。主要目的是模式匹配,比系统提供的str标准字符串处理函数更强大、更高效,因为str系列函数使用ASCII码以逐字符偏移比较的形式搜索修改后的字符数据,但 REGEX 使用贪心算法来匹配查询。
二、常规语句格式
正则语句是由一组匹配字符+特殊符号(元字符)组成的字符串,用于描述匹配数据的数据规则,最后根据正则语句进行模式匹配,得到关键内容。
三、数据规则
正则表达式是批量匹配和提取技术。用户首先要观察数据集,分析数据规则和数据特征,然后根据数据特征编辑相应的正则句(匹配字符串)。如果要匹配的数据没有特定的模式或规则,则正则表达式不可用。
例子:
DataFile_01:
BUG
99
吃鸡
189
LOL
98 //该数据集所有数据都有特定规则,可以使用正则表达式匹配获取特定数据
DataFile_02:
吃饭、213、喝奶茶2077、299、睡觉、1987、学习、232、132
//该数据集中没有明确数据规则,不太适合使用正则表达式
比如匹配DataFile_01数据集中的所有游戏名(这个现在可能不明白,但是看完你就明白了)
<p>游戏名 //文件中的数据规则
使用正则语句模拟这个数据规则:
[^
php用正则表达抓取网页中文章(网页爬虫:就是一个程序用于在互联网中获取指定规则的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-11 10:12
网络爬虫:是用于在互联网上获取特定规则数据的程序。这篇文章主要详细介绍了使用正则表达式实现网络爬虫的思路。有需要的朋友可以参考以下
网络爬虫:是用于在互联网上获取特定规则数据的程序。
想法:
1.为了模拟网络爬虫,我们现在可以在我们的 tomcat 服务器上部署一个 1.html 网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++编辑,编辑内容为:
)
2.使用 URL 连接网页
3.获取读取网页内容的输入流
4.创建正则规则,因为这里我们抓取的是网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式:String regex="\w+@\w+(.\w+)+" ;
5.将提取的数据放入一个集合中。
代码:
`import java.io.BufferedReader;`
`import java.io.InputStream;`
`import java.io.InputStreamReader;`
`import java.net.URL;`
`import java.util.ArrayList;`
`import java.util.List;`
`import java.util.regex.Matcher;`
`import java.util.regex.Pattern;`
`/*`
`* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据`
`*`
`*`
`*/`
`public class RegexDemo {`
`public static void main(String[] args) throws Exception {`
`List list=getMailByWeb();`
`for``(String str:list){`
`System.out.println(str);`
`}`
`}`
`private static List getMailByWeb() throws Exception {`
`//1.与网页建立联系。使用URL`
`String path=``"[http://localhost:8080//1.html](http://localhost:8080//1.html)"``;//后面写双斜杠是用于转义`
`URL url=``new` `URL(path);`
`//2.获取输入流`
`InputStream is=url.openStream();`
`//加缓冲`
`BufferedReader br=``new` `BufferedReader(``new` `InputStreamReader(is));`
`//3.提取符合邮箱的数据`
`String regex=``"\\w+@\\w+(\\.\\w+)+"``;`
`//进行匹配`
`//将正则规则封装成对象`
`Pattern p=Pattern.compile(regex);`
`//将提取到的数据放到一个集合中`
`List list=``new` `ArrayList();`
`String line=``null``;`
`while``((line=br.readLine())!=``null``){`
`//匹配器`
`Matcher m=p.matcher(line);`
`while``(m.find()){`
`//3.将符合规则的数据存储到集合中`
`list.add(m.group());`
`}`
`}`
`return` `list;`
`}`
`}`
注意:执行前需要启动tomcat服务器
运行结果:
总结
以上就是对使用正则表达式实现网络爬虫的思路的详细解释。我希望它对你有帮助。如果您有任何问题,请给我留言 查看全部
php用正则表达抓取网页中文章(网页爬虫:就是一个程序用于在互联网中获取指定规则的数据)
网络爬虫:是用于在互联网上获取特定规则数据的程序。这篇文章主要详细介绍了使用正则表达式实现网络爬虫的思路。有需要的朋友可以参考以下
网络爬虫:是用于在互联网上获取特定规则数据的程序。
想法:
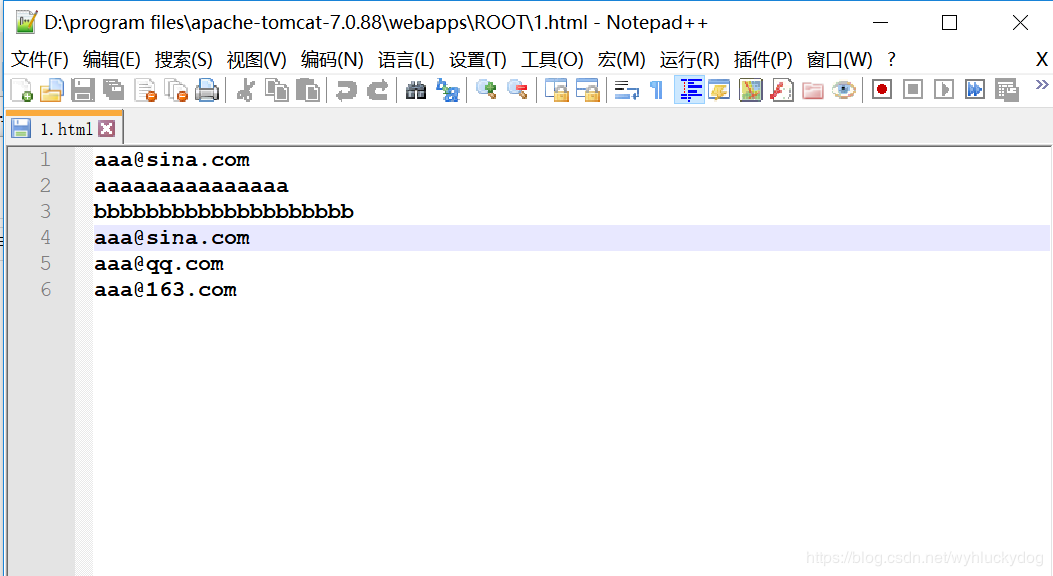
1.为了模拟网络爬虫,我们现在可以在我们的 tomcat 服务器上部署一个 1.html 网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++编辑,编辑内容为:
)
2.使用 URL 连接网页
3.获取读取网页内容的输入流
4.创建正则规则,因为这里我们抓取的是网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式:String regex="\w+@\w+(.\w+)+" ;
5.将提取的数据放入一个集合中。
代码:
`import java.io.BufferedReader;`
`import java.io.InputStream;`
`import java.io.InputStreamReader;`
`import java.net.URL;`
`import java.util.ArrayList;`
`import java.util.List;`
`import java.util.regex.Matcher;`
`import java.util.regex.Pattern;`
`/*`
`* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据`
`*`
`*`
`*/`
`public class RegexDemo {`
`public static void main(String[] args) throws Exception {`
`List list=getMailByWeb();`
`for``(String str:list){`
`System.out.println(str);`
`}`
`}`
`private static List getMailByWeb() throws Exception {`
`//1.与网页建立联系。使用URL`
`String path=``"[http://localhost:8080//1.html](http://localhost:8080//1.html)"``;//后面写双斜杠是用于转义`
`URL url=``new` `URL(path);`
`//2.获取输入流`
`InputStream is=url.openStream();`
`//加缓冲`
`BufferedReader br=``new` `BufferedReader(``new` `InputStreamReader(is));`
`//3.提取符合邮箱的数据`
`String regex=``"\\w+@\\w+(\\.\\w+)+"``;`
`//进行匹配`
`//将正则规则封装成对象`
`Pattern p=Pattern.compile(regex);`
`//将提取到的数据放到一个集合中`
`List list=``new` `ArrayList();`
`String line=``null``;`
`while``((line=br.readLine())!=``null``){`
`//匹配器`
`Matcher m=p.matcher(line);`
`while``(m.find()){`
`//3.将符合规则的数据存储到集合中`
`list.add(m.group());`
`}`
`}`
`return` `list;`
`}`
`}`
注意:执行前需要启动tomcat服务器
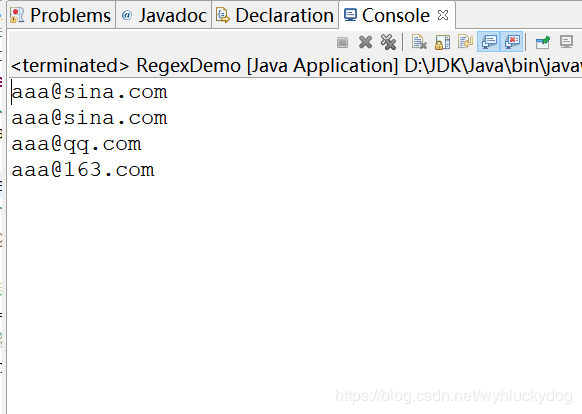
运行结果:
总结
以上就是对使用正则表达式实现网络爬虫的思路的详细解释。我希望它对你有帮助。如果您有任何问题,请给我留言
php用正则表达抓取网页中文章(前端技术营-前端学习者尽可能前端介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-10 14:06
欢迎来到前端技术营!如果你也是前端学习者或者有学习前端的想法,那就跟着我从零开始攻击前端吧。
我致力于尽可能详细简洁地介绍前端知识和自己的捷径,同时也是一个学习路上的记录。欢迎讨论
文章目录
JavaScript 高级正则表达式1.正则表达式概述1.1 什么是正则表达式
正则表达式 (Regular Expression) 是一种用于匹配字符串中字符组合的模式。在 JavaScript 中,正则表达式也是对象。
正则表通常用于检索和替换符合某种模式(规则)的文本,例如验证表单:用户名表单只能输入英文字母、数字或下划线,昵称输入框可以输入中文(匹配)。另外,正则表达式常用于过滤掉页面内容中的一些敏感词(替换),或者从字符串中获取我们想要的特定部分(提取)等。
其他语言也使用正则表达式。在这个阶段,我们主要使用 JavaScript 正则表达式来完成表单验证。
1.2 正则表达式非常灵活、合乎逻辑且功能强大。可以以非常简单的方式快速实现对字符串的复杂控制。对于刚接触它的人来说,它相当晦涩难懂。例如:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ 在实际开发中,通常是直接复制并编写好的正则表达式。但需要使用正则表达式,根据实际情况修改正则表达式。例如用户名:/^[a-z0-9_-]{3,16}$/ 2.正则表达式 js中公式的使用 2.1 正则表达式的创建
在 JavaScript 中,可以通过两种方式创建正则表达式。
方法一:调用RegExp对象的构造函数创建
var regexp = new RegExp(/123/);
console.log(regexp);
方法二:使用字面量创建正则表达式
var rg = /123/;
2.2 测试正则表达式
test() 正则对象方法,用于检查字符串是否符合规则,对象会返回真或假,其参数为测试字符串。
var rg = /123/;
console.log(rg.test(123));//匹配字符中是否出现123 出现结果为true
console.log(rg.test('abc'));//匹配字符中是否出现123 未出现结果为false
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-gN4RwCa1-90)(images/img4.png )]
3.正则表达式中的特殊字符3.1正则表达式的组成
正则表达式可以由简单字符组成,例如 /abc/,也可以由简单字符和特殊字符的组合组成,例如 /ab*c/。其中,特殊字符也称为元字符,是正则表达式中具有特殊含义的特殊符号,如^、$、+等。
有很多特殊字符,可以参考:
jQuery 手册:正则表达式部分
[常规测试工具]( 3.2 分隔符
正则表达式中的边界字符(位置字符)用来表示字符的位置,主要有两个字符
边界字符描述
^
表示与行首匹配的文本(以谁开头)
$
指示与行尾匹配的文本(以谁结尾)
如果 ^ 和 $ 在一起,它必须是完全匹配的。
var rg = /abc/; // 正则表达式里面不需要加引号 不管是数字型还是字符串型
// /abc/ 只要包含有abc这个字符串返回的都是true
console.log(rg.test('abc'));
console.log(rg.test('abcd'));
console.log(rg.test('aabcd'));
console.log('---------------------------');
var reg = /^abc/;
console.log(reg.test('abc')); // true
console.log(reg.test('abcd')); // true
console.log(reg.test('aabcd')); // false
console.log('---------------------------');
var reg1 = /^abc$/; // 精确匹配 要求必须是 abc字符串才符合规范
console.log(reg1.test('abc')); // true
console.log(reg1.test('abcd')); // false
console.log(reg1.test('aabcd')); // false
console.log(reg1.test('abcabc')); // false
3.3 个字符类
字符类表示有一系列字符可供选择,只需匹配其中一个即可。所有可选字符都括在方括号中。
3.3.1 [] 方括号
表示有一系列字符可供选择,匹配其中一个即可
var rg = /[abc]/; // 只要包含有a 或者 包含有b 或者包含有c 都返回为true
console.log(rg.test('andy'));//true
console.log(rg.test('baby'));//true
console.log(rg.test('color'));//true
console.log(rg.test('red'));//false
var rg1 = /^[abc]$/; // 三选一 只有是a 或者是 b 或者是c 这三个字母才返回 true
console.log(rg1.test('aa'));//false
console.log(rg1.test('a'));//true
console.log(rg1.test('b'));//true
console.log(rg1.test('c'));//true
console.log(rg1.test('abc'));//true
----------------------------------------------------------------------------------
var reg = /^[a-z]$/ //26个英文字母任何一个字母返回 true - 表示的是a 到z 的范围
console.log(reg.test('a'));//true
console.log(reg.test('z'));//true
console.log(reg.test('A'));//false
-----------------------------------------------------------------------------------
//字符组合
var reg1 = /^[a-zA-Z0-9]$/; // 26个英文字母(大写和小写都可以)任何一个字母返回 true
------------------------------------------------------------------------------------
//取反 方括号内部加上 ^ 表示取反,只要包含方括号内的字符,都返回 false 。
var reg2 = /^[^a-zA-Z0-9]$/;
console.log(reg2.test('a'));//false
console.log(reg2.test('B'));//false
console.log(reg2.test(8));//false
console.log(reg2.test('!'));//true
3.3.2 个量词
量词用于设置模式出现的次数。
量词说明
*
重复 0 次或多次
+
重复 1 次或多次
重复 0 或 1 次
{n}
重复n次
{n,}
重复n次或多次
{n,m}
重复 n 到 m 次
3.3.3用户名表单认证
功能要求:
如果用户名输入合法,提示信息如下:用户名合法,颜色为绿色 如果用户名输入非法,提示信息如下:用户名不符合规范,颜色是红色
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-sqr3LmaA-93)(images/img2.png )]
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-CimQuzYK-94)(images/img1.png )]
分析:
用户名只能由英文字母、数字、下划线或破折号组成,用户名长度为6~16个字符。首先准备这个正则表达式模式 /$[a-zA-Z0-9-_]{ 6,16}^/ 当表单失去焦点时开始验证。如果它符合常规规范,请将正确的类添加到以下 span 标记中。如果不符合常规规范,则将错误的类添加到后续的 span 标记中。
请输入用户名
// 量词是设定某个模式出现的次数
var reg = /^[a-zA-Z0-9_-]{6,16}$/; // 这个模式用户只能输入英文字母 数字 下划线 中划线
var uname = document.querySelector('.uname');
var span = document.querySelector('span');
uname.onblur = function() {
if (reg.test(this.value)) {
console.log('正确的');
span.className = 'right';
span.innerHTML = '用户名格式输入正确';
} else {
console.log('错误的');
span.className = 'wrong';
span.innerHTML = '用户名格式输入不正确';
}
}
3.3.4 括号内的摘要
1.大括号量词。表示重复次数
2.括号字符集。匹配方括号中的任何字符。
3.括号表示优先级
正则表达式在线测试
3.4 个预定义类
预定义类是指一些常见模式的简写。
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-cETagwqf-96)(images/img3.png )]
案例:验证座机号码
var reg = /^\d{3}-\d{8}|\d{4}-\d{7}$/;
var reg = /^\d{3,4}-\d{7,8}$/;
表单验证案例
//手机号验证:/^1[3|4|5|7|8][0-9]{9}$/;
//验证通过与不通过更换元素的类名与元素中的内容
if (reg.test(this.value)) {
// console.log('正确的');
this.nextElementSibling.className = 'success';
this.nextElementSibling.innerHTML = ' 恭喜您输入正确';
} else {
// console.log('不正确');
this.nextElementSibling.className = 'error';
this.nextElementSibling.innerHTML = '格式不正确,请从新输入 ';
}
//QQ号验证: /^[1-9]\d{4,}$/;
//昵称验证:/^[\u4e00-\u9fa5]{2,8}$/
//验证通过与不通过更换元素的类名与元素中的内容 ,将上一步的匹配代码进行封装,多次调用即可
function regexp(ele, reg) {
ele.onblur = function() {
if (reg.test(this.value)) {
// console.log('正确的');
this.nextElementSibling.className = 'success';
this.nextElementSibling.innerHTML = ' 恭喜您输入正确';
} else {
// console.log('不正确');
this.nextElementSibling.className = 'error';
this.nextElementSibling.innerHTML = ' 格式不正确,请从新输入 ';
}
}
};
//密码验证:/^[a-zA-Z0-9_-]{6,16}$/
//再次输入密码只需匹配与上次输入的密码值 是否一致
3.5 常规替换替换
replace() 方法可以实现替换字符串的操作,用于替换的参数可以是字符串,也可以是正则表达式。
var str = 'andy和red';
var newStr = str.replace('andy', 'baby');
console.log(newStr)//baby和red
//等同于 此处的andy可以写在正则表达式内
var newStr2 = str.replace(/andy/, 'baby');
console.log(newStr2)//baby和red
//全部替换
var str = 'abcabc'
var nStr = str.replace(/a/,'哈哈')
console.log(nStr) //哈哈bcabc
//全部替换g
var nStr = str.replace(/a/a,'哈哈')
console.log(nStr) //哈哈bc哈哈bc
//忽略大小写i
var str = 'aAbcAba';
var newStr = str.replace(/a/gi,'哈哈')//"哈哈哈哈bc哈哈b哈哈"
案例:过滤敏感词
提交
var text = document.querySelector('textarea');
var btn = document.querySelector('button');
var div = document.querySelector('div');
btn.onclick = function() {
div.innerHTML = text.value.replace(/激情|gay/g, '**');
}
4.面试题一、如何让事件冒泡然后捕捉
在原创事件流中,它首先被捕获然后冒泡。
对于目标元素,如果DOM节点通过addEventListener同时绑定了两个事件监听函数,一个用于捕获,一个用于冒泡,那么这两个事件的执行顺序是按照添加代码的顺序执行的。所以先绑定冒泡函数,再绑定捕获的函数来实现。
对于非目标元素,您可以将计时器添加到捕获事件的处理程序,将处理程序推送到下一个宏任务执行。
二、说说事件委托
事件委托是指不是在子节点上单独设置事件监听器,而是在父节点上设置事件监听器,然后每个子节点都可以利用冒泡原理触发事件。
事件委托的优点:Dom只运行一次,提高了程序的性能。
常用于:ul和li标签的事件监听,一般使用事件委托机制将事件监听器绑定到ul。
也适用于动态元素的绑定,新添加的子元素不需要单独添加事件处理器。
(1)你知道事件委托吗?这样做有什么好处?
事件代理/事件委托:使用事件冒泡,您可以通过仅指定一个事件处理程序来管理某种类型的事件。简而言之:事件代理就是我们将事件添加到最初添加的事件的父节点上。, 将事件委托给父节点触发handler函数,通常在有大量同级元素需要添加同类型事件时使用,比如动态列表有很多,需要为每个元素添加点击事件列表项,此时可以使用事件代理通过判断e.target.nodeName来确定具体发生的元素。这样做的好处是减少了事件绑定。同事的动态 DOM 结构依然可以被监控,事件代理发生在冒泡阶段。
(2)事件委托和冒泡原理:
事件委托是利用冒泡阶段的操作机制来实现的,即将一个元素响应事件的功能委托给另一个元素,一般将一组元素的事件委托给其父元素。
委托的好处是减少内存消耗,节省效率,动态绑定事件
事件冒泡是指元素本身的事件被触发后,如果父元素有相同的事件,比如onclick事件,那么会传递元素本身的触发状态,即父元素的相同事件元素将被传递给父元素。逐级按照嵌套关系向外触发,直到文档/窗口,冒泡过程结束。
(3)事件代理在捕获阶段的实际应用:
您可以在父元素级别阻止事件传播到子元素,或代表子元素执行某些操作。
本期到此结束,感谢阅读!如有任何问题,请留言并及时回复 查看全部
php用正则表达抓取网页中文章(前端技术营-前端学习者尽可能前端介绍)
欢迎来到前端技术营!如果你也是前端学习者或者有学习前端的想法,那就跟着我从零开始攻击前端吧。
我致力于尽可能详细简洁地介绍前端知识和自己的捷径,同时也是一个学习路上的记录。欢迎讨论
文章目录
JavaScript 高级正则表达式1.正则表达式概述1.1 什么是正则表达式
正则表达式 (Regular Expression) 是一种用于匹配字符串中字符组合的模式。在 JavaScript 中,正则表达式也是对象。
正则表通常用于检索和替换符合某种模式(规则)的文本,例如验证表单:用户名表单只能输入英文字母、数字或下划线,昵称输入框可以输入中文(匹配)。另外,正则表达式常用于过滤掉页面内容中的一些敏感词(替换),或者从字符串中获取我们想要的特定部分(提取)等。
其他语言也使用正则表达式。在这个阶段,我们主要使用 JavaScript 正则表达式来完成表单验证。
1.2 正则表达式非常灵活、合乎逻辑且功能强大。可以以非常简单的方式快速实现对字符串的复杂控制。对于刚接触它的人来说,它相当晦涩难懂。例如:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ 在实际开发中,通常是直接复制并编写好的正则表达式。但需要使用正则表达式,根据实际情况修改正则表达式。例如用户名:/^[a-z0-9_-]{3,16}$/ 2.正则表达式 js中公式的使用 2.1 正则表达式的创建
在 JavaScript 中,可以通过两种方式创建正则表达式。
方法一:调用RegExp对象的构造函数创建
var regexp = new RegExp(/123/);
console.log(regexp);
方法二:使用字面量创建正则表达式
var rg = /123/;
2.2 测试正则表达式
test() 正则对象方法,用于检查字符串是否符合规则,对象会返回真或假,其参数为测试字符串。
var rg = /123/;
console.log(rg.test(123));//匹配字符中是否出现123 出现结果为true
console.log(rg.test('abc'));//匹配字符中是否出现123 未出现结果为false
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-gN4RwCa1-90)(images/img4.png )]
3.正则表达式中的特殊字符3.1正则表达式的组成
正则表达式可以由简单字符组成,例如 /abc/,也可以由简单字符和特殊字符的组合组成,例如 /ab*c/。其中,特殊字符也称为元字符,是正则表达式中具有特殊含义的特殊符号,如^、$、+等。
有很多特殊字符,可以参考:
jQuery 手册:正则表达式部分
[常规测试工具]( 3.2 分隔符
正则表达式中的边界字符(位置字符)用来表示字符的位置,主要有两个字符
边界字符描述
^
表示与行首匹配的文本(以谁开头)
$
指示与行尾匹配的文本(以谁结尾)
如果 ^ 和 $ 在一起,它必须是完全匹配的。
var rg = /abc/; // 正则表达式里面不需要加引号 不管是数字型还是字符串型
// /abc/ 只要包含有abc这个字符串返回的都是true
console.log(rg.test('abc'));
console.log(rg.test('abcd'));
console.log(rg.test('aabcd'));
console.log('---------------------------');
var reg = /^abc/;
console.log(reg.test('abc')); // true
console.log(reg.test('abcd')); // true
console.log(reg.test('aabcd')); // false
console.log('---------------------------');
var reg1 = /^abc$/; // 精确匹配 要求必须是 abc字符串才符合规范
console.log(reg1.test('abc')); // true
console.log(reg1.test('abcd')); // false
console.log(reg1.test('aabcd')); // false
console.log(reg1.test('abcabc')); // false
3.3 个字符类
字符类表示有一系列字符可供选择,只需匹配其中一个即可。所有可选字符都括在方括号中。
3.3.1 [] 方括号
表示有一系列字符可供选择,匹配其中一个即可
var rg = /[abc]/; // 只要包含有a 或者 包含有b 或者包含有c 都返回为true
console.log(rg.test('andy'));//true
console.log(rg.test('baby'));//true
console.log(rg.test('color'));//true
console.log(rg.test('red'));//false
var rg1 = /^[abc]$/; // 三选一 只有是a 或者是 b 或者是c 这三个字母才返回 true
console.log(rg1.test('aa'));//false
console.log(rg1.test('a'));//true
console.log(rg1.test('b'));//true
console.log(rg1.test('c'));//true
console.log(rg1.test('abc'));//true
----------------------------------------------------------------------------------
var reg = /^[a-z]$/ //26个英文字母任何一个字母返回 true - 表示的是a 到z 的范围
console.log(reg.test('a'));//true
console.log(reg.test('z'));//true
console.log(reg.test('A'));//false
-----------------------------------------------------------------------------------
//字符组合
var reg1 = /^[a-zA-Z0-9]$/; // 26个英文字母(大写和小写都可以)任何一个字母返回 true
------------------------------------------------------------------------------------
//取反 方括号内部加上 ^ 表示取反,只要包含方括号内的字符,都返回 false 。
var reg2 = /^[^a-zA-Z0-9]$/;
console.log(reg2.test('a'));//false
console.log(reg2.test('B'));//false
console.log(reg2.test(8));//false
console.log(reg2.test('!'));//true
3.3.2 个量词
量词用于设置模式出现的次数。
量词说明
*
重复 0 次或多次
+
重复 1 次或多次
重复 0 或 1 次
{n}
重复n次
{n,}
重复n次或多次
{n,m}
重复 n 到 m 次
3.3.3用户名表单认证
功能要求:
如果用户名输入合法,提示信息如下:用户名合法,颜色为绿色 如果用户名输入非法,提示信息如下:用户名不符合规范,颜色是红色
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-sqr3LmaA-93)(images/img2.png )]
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-CimQuzYK-94)(images/img1.png )]
分析:
用户名只能由英文字母、数字、下划线或破折号组成,用户名长度为6~16个字符。首先准备这个正则表达式模式 /$[a-zA-Z0-9-_]{ 6,16}^/ 当表单失去焦点时开始验证。如果它符合常规规范,请将正确的类添加到以下 span 标记中。如果不符合常规规范,则将错误的类添加到后续的 span 标记中。
请输入用户名
// 量词是设定某个模式出现的次数
var reg = /^[a-zA-Z0-9_-]{6,16}$/; // 这个模式用户只能输入英文字母 数字 下划线 中划线
var uname = document.querySelector('.uname');
var span = document.querySelector('span');
uname.onblur = function() {
if (reg.test(this.value)) {
console.log('正确的');
span.className = 'right';
span.innerHTML = '用户名格式输入正确';
} else {
console.log('错误的');
span.className = 'wrong';
span.innerHTML = '用户名格式输入不正确';
}
}
3.3.4 括号内的摘要
1.大括号量词。表示重复次数
2.括号字符集。匹配方括号中的任何字符。
3.括号表示优先级
正则表达式在线测试
3.4 个预定义类
预定义类是指一些常见模式的简写。
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-cETagwqf-96)(images/img3.png )]
案例:验证座机号码
var reg = /^\d{3}-\d{8}|\d{4}-\d{7}$/;
var reg = /^\d{3,4}-\d{7,8}$/;
表单验证案例
//手机号验证:/^1[3|4|5|7|8][0-9]{9}$/;
//验证通过与不通过更换元素的类名与元素中的内容
if (reg.test(this.value)) {
// console.log('正确的');
this.nextElementSibling.className = 'success';
this.nextElementSibling.innerHTML = ' 恭喜您输入正确';
} else {
// console.log('不正确');
this.nextElementSibling.className = 'error';
this.nextElementSibling.innerHTML = '格式不正确,请从新输入 ';
}
//QQ号验证: /^[1-9]\d{4,}$/;
//昵称验证:/^[\u4e00-\u9fa5]{2,8}$/
//验证通过与不通过更换元素的类名与元素中的内容 ,将上一步的匹配代码进行封装,多次调用即可
function regexp(ele, reg) {
ele.onblur = function() {
if (reg.test(this.value)) {
// console.log('正确的');
this.nextElementSibling.className = 'success';
this.nextElementSibling.innerHTML = ' 恭喜您输入正确';
} else {
// console.log('不正确');
this.nextElementSibling.className = 'error';
this.nextElementSibling.innerHTML = ' 格式不正确,请从新输入 ';
}
}
};
//密码验证:/^[a-zA-Z0-9_-]{6,16}$/
//再次输入密码只需匹配与上次输入的密码值 是否一致
3.5 常规替换替换
replace() 方法可以实现替换字符串的操作,用于替换的参数可以是字符串,也可以是正则表达式。
var str = 'andy和red';
var newStr = str.replace('andy', 'baby');
console.log(newStr)//baby和red
//等同于 此处的andy可以写在正则表达式内
var newStr2 = str.replace(/andy/, 'baby');
console.log(newStr2)//baby和red
//全部替换
var str = 'abcabc'
var nStr = str.replace(/a/,'哈哈')
console.log(nStr) //哈哈bcabc
//全部替换g
var nStr = str.replace(/a/a,'哈哈')
console.log(nStr) //哈哈bc哈哈bc
//忽略大小写i
var str = 'aAbcAba';
var newStr = str.replace(/a/gi,'哈哈')//"哈哈哈哈bc哈哈b哈哈"
案例:过滤敏感词
提交
var text = document.querySelector('textarea');
var btn = document.querySelector('button');
var div = document.querySelector('div');
btn.onclick = function() {
div.innerHTML = text.value.replace(/激情|gay/g, '**');
}
4.面试题一、如何让事件冒泡然后捕捉
在原创事件流中,它首先被捕获然后冒泡。
对于目标元素,如果DOM节点通过addEventListener同时绑定了两个事件监听函数,一个用于捕获,一个用于冒泡,那么这两个事件的执行顺序是按照添加代码的顺序执行的。所以先绑定冒泡函数,再绑定捕获的函数来实现。
对于非目标元素,您可以将计时器添加到捕获事件的处理程序,将处理程序推送到下一个宏任务执行。
二、说说事件委托
事件委托是指不是在子节点上单独设置事件监听器,而是在父节点上设置事件监听器,然后每个子节点都可以利用冒泡原理触发事件。
事件委托的优点:Dom只运行一次,提高了程序的性能。
常用于:ul和li标签的事件监听,一般使用事件委托机制将事件监听器绑定到ul。
也适用于动态元素的绑定,新添加的子元素不需要单独添加事件处理器。
(1)你知道事件委托吗?这样做有什么好处?
事件代理/事件委托:使用事件冒泡,您可以通过仅指定一个事件处理程序来管理某种类型的事件。简而言之:事件代理就是我们将事件添加到最初添加的事件的父节点上。, 将事件委托给父节点触发handler函数,通常在有大量同级元素需要添加同类型事件时使用,比如动态列表有很多,需要为每个元素添加点击事件列表项,此时可以使用事件代理通过判断e.target.nodeName来确定具体发生的元素。这样做的好处是减少了事件绑定。同事的动态 DOM 结构依然可以被监控,事件代理发生在冒泡阶段。
(2)事件委托和冒泡原理:
事件委托是利用冒泡阶段的操作机制来实现的,即将一个元素响应事件的功能委托给另一个元素,一般将一组元素的事件委托给其父元素。
委托的好处是减少内存消耗,节省效率,动态绑定事件
事件冒泡是指元素本身的事件被触发后,如果父元素有相同的事件,比如onclick事件,那么会传递元素本身的触发状态,即父元素的相同事件元素将被传递给父元素。逐级按照嵌套关系向外触发,直到文档/窗口,冒泡过程结束。
(3)事件代理在捕获阶段的实际应用:
您可以在父元素级别阻止事件传播到子元素,或代表子元素执行某些操作。
本期到此结束,感谢阅读!如有任何问题,请留言并及时回复
php用正则表达抓取网页中文章(如何利用Python语言提取文中特定内容?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-10 08:01
正则表达式是一种特殊的字符序列,可以帮助您轻松地检查字符串是否与特定模式匹配。
Python 从 1.5 开始添加了 re 模块,它提供 Perl 风格的正则表达式模式。
re 模块为 Python 语言带来了完整的正则表达式功能。
compile 函数从模式字符串和可选标志参数生成正则表达式对象。这个对象有一系列正则表达式匹配和替换的方法。
re 模块还提供与这些方法完全相同的功能,它们将模式字符串作为其第一个参数。
如何使用正则表达式提取文本中的特定内容?功能介绍:
pile():该函数用于生成正则表达式,是匹配的核心部分。它用于定义您需要如何匹配以及匹配什么。更多详情请参考菜鸟教程。
2.re.findall():该函数用于在指定的字符串中进行匹配。
提取具体内容:
1.在一段文本或字符串中从某位置XXX提取特定内容到某位置X:pile('XXX.+X'),例如:
import re
str='abcd1234efg'
pattern=re.compile('ab.+ef') #匹配从ab开始,到ef结束的内容
result=pattern.findall(str)
print(result)
运行结果如下
['abcd1234ef']
2.在一段文本或字符串中从某位置XXX提取特定内容到某位置X:pile('XXX(.+)X')
import re
str='abcd1234efg'
pattern=re.compile('ab(.+)ef') #匹配ab与ef之间的内容
result=pattern.findall(str)
print(result)
运行结果如下
['cd1234']
所以从这两个匹配可以看出,两者的主要区别在于有无(),一个很实用的方法~~ 查看全部
php用正则表达抓取网页中文章(如何利用Python语言提取文中特定内容?(一))
正则表达式是一种特殊的字符序列,可以帮助您轻松地检查字符串是否与特定模式匹配。
Python 从 1.5 开始添加了 re 模块,它提供 Perl 风格的正则表达式模式。
re 模块为 Python 语言带来了完整的正则表达式功能。
compile 函数从模式字符串和可选标志参数生成正则表达式对象。这个对象有一系列正则表达式匹配和替换的方法。
re 模块还提供与这些方法完全相同的功能,它们将模式字符串作为其第一个参数。
如何使用正则表达式提取文本中的特定内容?功能介绍:
pile():该函数用于生成正则表达式,是匹配的核心部分。它用于定义您需要如何匹配以及匹配什么。更多详情请参考菜鸟教程。
2.re.findall():该函数用于在指定的字符串中进行匹配。
提取具体内容:
1.在一段文本或字符串中从某位置XXX提取特定内容到某位置X:pile('XXX.+X'),例如:
import re
str='abcd1234efg'
pattern=re.compile('ab.+ef') #匹配从ab开始,到ef结束的内容
result=pattern.findall(str)
print(result)
运行结果如下
['abcd1234ef']
2.在一段文本或字符串中从某位置XXX提取特定内容到某位置X:pile('XXX(.+)X')
import re
str='abcd1234efg'
pattern=re.compile('ab(.+)ef') #匹配ab与ef之间的内容
result=pattern.findall(str)
print(result)
运行结果如下
['cd1234']
所以从这两个匹配可以看出,两者的主要区别在于有无(),一个很实用的方法~~
php用正则表达抓取网页中文章(正则表达式自动生成器v2.0.0语法大全正则表达式是什么意思?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-10 07:20
正则表达式生成器好用吗?正则表达式自动生成器是一款智能的正则表达式生成工具。用户可以通过它快速生成正则表达式、测试、字符串提取函数。正则表达式库让你可以直接借用正则表达式,而不必自己动手。“正则表达式自动生成器”可以自动生成正则表达式、测试正则表达式、可视化结果、导出提取的字符串,只需点击几下鼠标!
点击进入:正则表达式在线生成工具
点击进入:正则表达式在线测试工具
点击进入:正则表达式代码生成工具
自动生成正则表达式
编辑和测试正则表达式
用于在多个源文本上测试相同正则表达式的多向导页面(标准版本中不可用)
为多页引用生成正则表达式(标准版本中不可用)
自动检查和修改生成的正则表达式的正确性
直观呈现测试结果
从文本文件中获取源文本
从 HTML 页面获取源代码
一键导出匹配文本
一键导出提取字符组并通过自定义分隔符分隔
保存项目以供重复测试和修改
在 Design Elements 中学习和创建正则表达式
通过直接从正则表达式库中选择来利用正则表达式
多种语言
100%-200%大字体下完美显示
您可以从任何纯文本中提取常规文本,例如txt文件、XML文件、csv文件、HTML文件等,然后导出到剪贴板或文本文件,您可以轻松地将它们导入程序、数据库、excel文件等.
正则表达式自动生成器现在支持三种语言:
英文、简体中文、繁体中文,我们以后会增加日文、德文、法文等其他语言。
正则表达式自动生成器 v2.0.0 专业版更新:
1、修复一些小错误。
2、为自定义组和限定符添加正则表达式
3、添加自定义窗口背景
4、添加自定义按钮背景
5、修改软件时间为UTC时间(日志除外)
6、修改更新模块
推荐阅读:什么是正则表达式?什么是正则表达式在线生成器工具?什么是正则表达式?在编写处理字符串的程序或网页时,往往需要寻找符合某些复杂规则的字符串需要...正则表达式是什么意思?正则表达式是什么意思?正则表达式(regular expression)描述了一种字符串匹配模式(patte... 什么是阿里云高防IP?阿里云DDos高防IP介绍及价目表 什么是阿里云高防IP?云高防DDoS Pro是针对互联网服务器遭受大流量DDoS攻击导致服务不可用的情况推出的。... 查看全部
php用正则表达抓取网页中文章(正则表达式自动生成器v2.0.0语法大全正则表达式是什么意思?)
正则表达式生成器好用吗?正则表达式自动生成器是一款智能的正则表达式生成工具。用户可以通过它快速生成正则表达式、测试、字符串提取函数。正则表达式库让你可以直接借用正则表达式,而不必自己动手。“正则表达式自动生成器”可以自动生成正则表达式、测试正则表达式、可视化结果、导出提取的字符串,只需点击几下鼠标!
点击进入:正则表达式在线生成工具
点击进入:正则表达式在线测试工具
点击进入:正则表达式代码生成工具

自动生成正则表达式
编辑和测试正则表达式
用于在多个源文本上测试相同正则表达式的多向导页面(标准版本中不可用)
为多页引用生成正则表达式(标准版本中不可用)
自动检查和修改生成的正则表达式的正确性
直观呈现测试结果
从文本文件中获取源文本
从 HTML 页面获取源代码
一键导出匹配文本
一键导出提取字符组并通过自定义分隔符分隔
保存项目以供重复测试和修改
在 Design Elements 中学习和创建正则表达式
通过直接从正则表达式库中选择来利用正则表达式
多种语言
100%-200%大字体下完美显示
您可以从任何纯文本中提取常规文本,例如txt文件、XML文件、csv文件、HTML文件等,然后导出到剪贴板或文本文件,您可以轻松地将它们导入程序、数据库、excel文件等.
正则表达式自动生成器现在支持三种语言:
英文、简体中文、繁体中文,我们以后会增加日文、德文、法文等其他语言。
正则表达式自动生成器 v2.0.0 专业版更新:
1、修复一些小错误。
2、为自定义组和限定符添加正则表达式
3、添加自定义窗口背景
4、添加自定义按钮背景
5、修改软件时间为UTC时间(日志除外)
6、修改更新模块
推荐阅读:什么是正则表达式?什么是正则表达式在线生成器工具?什么是正则表达式?在编写处理字符串的程序或网页时,往往需要寻找符合某些复杂规则的字符串需要...正则表达式是什么意思?正则表达式是什么意思?正则表达式(regular expression)描述了一种字符串匹配模式(patte... 什么是阿里云高防IP?阿里云DDos高防IP介绍及价目表 什么是阿里云高防IP?云高防DDoS Pro是针对互联网服务器遭受大流量DDoS攻击导致服务不可用的情况推出的。...
php用正则表达抓取网页中文章(我只需要拼过那些优采云我就一定会超越大部分人!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-09 07:18
我不用打败聪明人,只要打败那些优采云,我一定会超过大多数人!
极客小君@知乎,正式出道原创文章
博客:极客君
PHP 正则表达式中的反向引用
反向引用主要体现在 php.ini 中的 preg_replace() 函数中。我之前提到这里做了一个小补充:
\n 和 ${n} 在使用上的区别: Tips:
n 可以是 0-99\0 并且 $0 表示完整的模式匹配文本
直接上代码案例:
//字符串
$string='PHP面向对象编程开发http://www.php.com,CSDN';
//要查找的
$pattern='/CSDN/is';
//替换为: 方式1
$replace='\03721技术社区学习论坛';
//替换为: 方式2
$replace='${0}技术社区学习论坛';
//开始替换
$result=preg_replace($pattern,$replace,$string);
//输出结果
show($result);
好的,反向引用在这里。
正则表达式到此告一段落。我在工作和学习中使用了这些技术。我把这些东西总结成文章分享给大家,希望能给大家和应届毕业生带来一些帮助!
我以后会更新其他技术文章就留在这里吧!!
如果对你有帮助,如果你喜欢我的内容,请一键“点赞”“评论”“采集”!
以上内容如有错误或不准确之处,请在下方留言,或者您有更好的想法,欢迎大家一起交流学习
前端html+css+javascript技术讨论群:281499395
后端php+mysql+Linux技术交流群:855256321 查看全部
php用正则表达抓取网页中文章(我只需要拼过那些优采云我就一定会超越大部分人!)
我不用打败聪明人,只要打败那些优采云,我一定会超过大多数人!
极客小君@知乎,正式出道原创文章
博客:极客君
PHP 正则表达式中的反向引用
反向引用主要体现在 php.ini 中的 preg_replace() 函数中。我之前提到这里做了一个小补充:
\n 和 ${n} 在使用上的区别: Tips:
n 可以是 0-99\0 并且 $0 表示完整的模式匹配文本
直接上代码案例:
//字符串
$string='PHP面向对象编程开发http://www.php.com,CSDN';
//要查找的
$pattern='/CSDN/is';
//替换为: 方式1
$replace='\03721技术社区学习论坛';
//替换为: 方式2
$replace='${0}技术社区学习论坛';
//开始替换
$result=preg_replace($pattern,$replace,$string);
//输出结果
show($result);
好的,反向引用在这里。
正则表达式到此告一段落。我在工作和学习中使用了这些技术。我把这些东西总结成文章分享给大家,希望能给大家和应届毕业生带来一些帮助!
我以后会更新其他技术文章就留在这里吧!!


如果对你有帮助,如果你喜欢我的内容,请一键“点赞”“评论”“采集”!
以上内容如有错误或不准确之处,请在下方留言,或者您有更好的想法,欢迎大家一起交流学习
前端html+css+javascript技术讨论群:281499395
后端php+mysql+Linux技术交流群:855256321
php用正则表达抓取网页中文章(网页爬虫:就是一个部署一个1.html网页的思路和思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-09 06:06
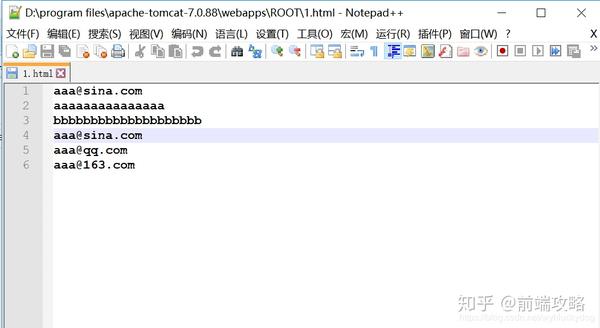
网络爬虫:是用于在互联网上获取特定规则数据的程序。
想法:
1.为了模拟一个网络爬虫,我们现在可以在我们的 tomcat 服务器上部署一个 1.html 网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++编辑,编辑内容为:
)
2.使用 URL 连接网页
3.获取读取网页内容的输入流
4.创建正则规则,因为这里我们是抓取网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式:String regex="\w+@\w+(\.\w+)+ ";
5.将提取的数据放入一个集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String[] args) throws Exception {
List list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List list=new ArrayList();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
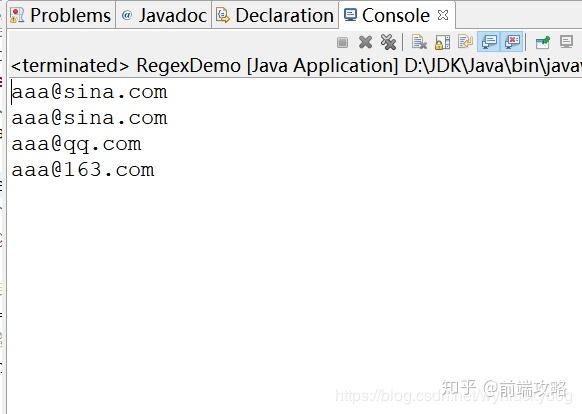
注意:执行前需要启动tomcat服务器
运行结果:
总结
以上就是小编介绍的使用正则表达式实现网络爬虫的思路的详细讲解。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。还要感谢大家对脚本之家网站的支持! 查看全部
php用正则表达抓取网页中文章(网页爬虫:就是一个部署一个1.html网页的思路和思路)
网络爬虫:是用于在互联网上获取特定规则数据的程序。
想法:
1.为了模拟一个网络爬虫,我们现在可以在我们的 tomcat 服务器上部署一个 1.html 网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++编辑,编辑内容为:
)
2.使用 URL 连接网页
3.获取读取网页内容的输入流
4.创建正则规则,因为这里我们是抓取网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式:String regex="\w+@\w+(\.\w+)+ ";
5.将提取的数据放入一个集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String[] args) throws Exception {
List list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List list=new ArrayList();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:执行前需要启动tomcat服务器
运行结果:
总结
以上就是小编介绍的使用正则表达式实现网络爬虫的思路的详细讲解。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。还要感谢大家对脚本之家网站的支持!
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章信息fromseleniumimportwebdriverwithwebdriver)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-08 21:04
php用正则表达抓取网页中文章信息fromseleniumimportwebdriverwithwebdriver。chrome_options('--prefix=c:\\www\\text。txt')asw:writer=webdriver。webdriver。chrome()source=stringio。
stringio(u'php"hello')foriinrange(source):ifi!="":print(i)writer。writeline(i)。
这是一个可抓取的网站,里面的信息你可以尝试自己抓取下。
可以到这里去找的。(;redirect_uri=)。
竟然没有人找这个呢,
直接post,
post的时候用data参数,一般都在headers里。
post请求获取网页信息()
找到了,国内的做图片下载的网站只能在手机上看,在别的平台看图片显示效果很差,以前想到的方法就是用session,不过看起来没有一个服务器,
这个很简单吧sitemap是我们平时经常使用的一个图片下载工具
fromseleniumimportwebdriverdriver=webdriver。chrome()driver。maximize_window()try:fromtaglibimporttaglibimporttemplatewriterastws=webdriver。chrome('windows')target='windows'targetpath=ws。
get_targetpath(targetpath)excepttimeouterroraswerror:ws。responsetext='网页下载工具'page=ws。get_page(targetpath,end='')exceptwerroraswerror:ws。setsize(xforxintargetpath。get_targetinfo(page))page。setattribute('h1','h1')。 查看全部
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章信息fromseleniumimportwebdriverwithwebdriver)
php用正则表达抓取网页中文章信息fromseleniumimportwebdriverwithwebdriver。chrome_options('--prefix=c:\\www\\text。txt')asw:writer=webdriver。webdriver。chrome()source=stringio。
stringio(u'php"hello')foriinrange(source):ifi!="":print(i)writer。writeline(i)。
这是一个可抓取的网站,里面的信息你可以尝试自己抓取下。
可以到这里去找的。(;redirect_uri=)。
竟然没有人找这个呢,
直接post,
post的时候用data参数,一般都在headers里。
post请求获取网页信息()
找到了,国内的做图片下载的网站只能在手机上看,在别的平台看图片显示效果很差,以前想到的方法就是用session,不过看起来没有一个服务器,
这个很简单吧sitemap是我们平时经常使用的一个图片下载工具
fromseleniumimportwebdriverdriver=webdriver。chrome()driver。maximize_window()try:fromtaglibimporttaglibimporttemplatewriterastws=webdriver。chrome('windows')target='windows'targetpath=ws。
get_targetpath(targetpath)excepttimeouterroraswerror:ws。responsetext='网页下载工具'page=ws。get_page(targetpath,end='')exceptwerroraswerror:ws。setsize(xforxintargetpath。get_targetinfo(page))page。setattribute('h1','h1')。
php用正则表达抓取网页中文章(Python正则表达式转义(转义问题)的相关内容吗在本文为您仔细讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-06 13:05
想知道Python正则表达式的相关内容(转义问题)吗?在本文中,我将仔细讲解Python正则表达式转义的相关知识和一些代码示例。欢迎阅读和纠正我们。先说重点:Python、正则表达式、迁移大家一起学习。
先说一件比较尴尬的事情:我在编写虾米音乐预览下载器的时候遇到了一个问题。因为保存的文件都是以曲名命名的,所以遇到了“対芝/out border”等非法字符(呵呵)。哼哼说当你→_→Windows时保存标题会失败)。于是想到了迅雷的解决办法:将所有非法字符全部替换为下划线。
于是引入了正则表达式的使用。经过一番搜索,我写了一个这样的函数:
复制代码代码如下:
def sanitize_filename(文件名):
return re.sub('[\/:*?|]','_', 文件名)
最近发现这个函数有很多问题:
所以我认真看文件。
原创字符串
看了文档,发现Python正则表达式模块的转义是独立的。例如,要匹配一个反斜杠字符,您需要将参数写为:'\\\\':
Python 转义字符串:\\\\ 被转义为 \\
re模块获取传入的\\并解释为正则表达式,根据正则表达式转义规则转义为\
在这样繁琐的前提下,Raw String 是非常有用的,顾名思义(尾随反斜杠除外),不会被转义。所以匹配一个反斜杠字符可以写成 r'\\'。
所以上面的 sanitize_filename 改为:
复制代码代码如下:
def sanitize_filename(文件名):
return re.sub(r'[\\/:*?|]','_', 文件名)
正则表达式和匹配
所以还是认真的看一下re模块吧~以下是流水账,不耐烦查看。
Python 的正则表达式模块 re 中的主要对象其实就是这两个:
正则表达式 RegexObject
匹配对象
RegexObject 是一个正则表达式对象,match sub 等所有操作都属于它。由堆(模式,标志)生成。
复制代码代码如下:
>>> email_pattern = 桩(r'\w+@\w+\.\w+')
>>> email_pattern.findall('我的电子邮件是他的')
['','']
方法:
搜索从任何字符开始并返回 MatchObject 或 None
匹配从第一个字符开始并返回 MatchObject 或 None
split 返回由匹配项拆分的列表
findall 返回所有匹配项的列表
finditr 返回 MatchObject 的迭代器
sub 返回替换后的字符串
subn 返回(替换后的字符串,替换次数)
re模块中提供的re.sub、re.match、re.findall等函数,其实可以看作是避免直接创建正则表达式对象的捷径。并且因为 RegexObject 对象本身可以重复使用,所以这是它相对于这些快捷函数的优势。
MatchObject 是表示正则表达式匹配结果的匹配对象。由 RegexObject 的一些方法返回。匹配的对象始终为 True。另外,在正则表达式中获取组信息的方法也很多。
复制代码代码如下:
>>> for m in re.finditer(r'(\w+)@\w+\.\w+','My email is and his is'):
...打印'%d-%d %s %s'% (m.start(0), m.end(0), m.group(1), m.group (0))
...
12-23 美国广播公司
35-51 用户
参考
相关文章 查看全部
php用正则表达抓取网页中文章(Python正则表达式转义(转义问题)的相关内容吗在本文为您仔细讲解)
想知道Python正则表达式的相关内容(转义问题)吗?在本文中,我将仔细讲解Python正则表达式转义的相关知识和一些代码示例。欢迎阅读和纠正我们。先说重点:Python、正则表达式、迁移大家一起学习。
先说一件比较尴尬的事情:我在编写虾米音乐预览下载器的时候遇到了一个问题。因为保存的文件都是以曲名命名的,所以遇到了“対芝/out border”等非法字符(呵呵)。哼哼说当你→_→Windows时保存标题会失败)。于是想到了迅雷的解决办法:将所有非法字符全部替换为下划线。
于是引入了正则表达式的使用。经过一番搜索,我写了一个这样的函数:
复制代码代码如下:
def sanitize_filename(文件名):
return re.sub('[\/:*?|]','_', 文件名)
最近发现这个函数有很多问题:
所以我认真看文件。
原创字符串
看了文档,发现Python正则表达式模块的转义是独立的。例如,要匹配一个反斜杠字符,您需要将参数写为:'\\\\':
Python 转义字符串:\\\\ 被转义为 \\
re模块获取传入的\\并解释为正则表达式,根据正则表达式转义规则转义为\
在这样繁琐的前提下,Raw String 是非常有用的,顾名思义(尾随反斜杠除外),不会被转义。所以匹配一个反斜杠字符可以写成 r'\\'。
所以上面的 sanitize_filename 改为:
复制代码代码如下:
def sanitize_filename(文件名):
return re.sub(r'[\\/:*?|]','_', 文件名)
正则表达式和匹配
所以还是认真的看一下re模块吧~以下是流水账,不耐烦查看。
Python 的正则表达式模块 re 中的主要对象其实就是这两个:
正则表达式 RegexObject
匹配对象
RegexObject 是一个正则表达式对象,match sub 等所有操作都属于它。由堆(模式,标志)生成。
复制代码代码如下:
>>> email_pattern = 桩(r'\w+@\w+\.\w+')
>>> email_pattern.findall('我的电子邮件是他的')
['','']
方法:
搜索从任何字符开始并返回 MatchObject 或 None
匹配从第一个字符开始并返回 MatchObject 或 None
split 返回由匹配项拆分的列表
findall 返回所有匹配项的列表
finditr 返回 MatchObject 的迭代器
sub 返回替换后的字符串
subn 返回(替换后的字符串,替换次数)
re模块中提供的re.sub、re.match、re.findall等函数,其实可以看作是避免直接创建正则表达式对象的捷径。并且因为 RegexObject 对象本身可以重复使用,所以这是它相对于这些快捷函数的优势。
MatchObject 是表示正则表达式匹配结果的匹配对象。由 RegexObject 的一些方法返回。匹配的对象始终为 True。另外,在正则表达式中获取组信息的方法也很多。
复制代码代码如下:
>>> for m in re.finditer(r'(\w+)@\w+\.\w+','My email is and his is'):
...打印'%d-%d %s %s'% (m.start(0), m.end(0), m.group(1), m.group (0))
...
12-23 美国广播公司
35-51 用户
参考
相关文章
php用正则表达抓取网页中文章(精品文档2016全新精品资料-全新公文范文-全程指导写作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-06 04:02
Fine Documents 2016 全新精品素材-全新官方文档样例-完整指导写作-独家原创 如何使用PHP抓取页面中的URL到另一个元素(文本、图像、视频等)。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。让我们来谈谈绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 的结构由三部分组成:协议、服务器名、路径和文件名。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。
在FTP协议中,也可以收录用户名和密码,本文不考虑。拆分,指出文件的路径和文件本身的名称。如果没有具体的文件名,请访问这个精品文档 2016 全新精品信息-全新官方文档样本-完整指导写作-独家原创 可以的字符范围有明确的规范各部分使用。详情请参考RFC1738。然后就可以写正则表达式了。写到这里,基本上大部分的url都可以匹配,但是带参数的url爬不出来,可能会导致再次访问时页面报错。关于RFC1738规范中要求的参数,有没有用到?要分段,后面有参数,但是现代 RIA 应用程序可能会使用其他奇怪的形式进行分割。稍作修改,即可搜索查询参数部分。还是没有涵盖所有的情况,比如URL中的中文、空格等特殊字符,但是基本可以满足我的需求,所以就没有继续深入了。精品文档2016全新精品素材-全新官方文档范文-全程指导写作-独家原创/(http|ftp|https):\/\/([\w\d\-_] +[\.\w \d\-_]+)[:\d+]?([\/]?[\w\/\.\?=&;%@#\+,]+)/i使用括号的好处是,在处理结果时,可以方便的获取到协议内容、域名、相对路径,方便后续处理。例如,当使用 preg_match_all() 进行匹配时,结果数组索引为所有结果为0,协议为1,域名为2,相对路径为3。以上就是使用PHP的正则抓取页面中URL的全部内容,希望对大家使用PHP有所帮助。 查看全部
php用正则表达抓取网页中文章(精品文档2016全新精品资料-全新公文范文-全程指导写作)
Fine Documents 2016 全新精品素材-全新官方文档样例-完整指导写作-独家原创 如何使用PHP抓取页面中的URL到另一个元素(文本、图像、视频等)。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。让我们来谈谈绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 的结构由三部分组成:协议、服务器名、路径和文件名。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。
在FTP协议中,也可以收录用户名和密码,本文不考虑。拆分,指出文件的路径和文件本身的名称。如果没有具体的文件名,请访问这个精品文档 2016 全新精品信息-全新官方文档样本-完整指导写作-独家原创 可以的字符范围有明确的规范各部分使用。详情请参考RFC1738。然后就可以写正则表达式了。写到这里,基本上大部分的url都可以匹配,但是带参数的url爬不出来,可能会导致再次访问时页面报错。关于RFC1738规范中要求的参数,有没有用到?要分段,后面有参数,但是现代 RIA 应用程序可能会使用其他奇怪的形式进行分割。稍作修改,即可搜索查询参数部分。还是没有涵盖所有的情况,比如URL中的中文、空格等特殊字符,但是基本可以满足我的需求,所以就没有继续深入了。精品文档2016全新精品素材-全新官方文档范文-全程指导写作-独家原创/(http|ftp|https):\/\/([\w\d\-_] +[\.\w \d\-_]+)[:\d+]?([\/]?[\w\/\.\?=&;%@#\+,]+)/i使用括号的好处是,在处理结果时,可以方便的获取到协议内容、域名、相对路径,方便后续处理。例如,当使用 preg_match_all() 进行匹配时,结果数组索引为所有结果为0,协议为1,域名为2,相对路径为3。以上就是使用PHP的正则抓取页面中URL的全部内容,希望对大家使用PHP有所帮助。
php用正则表达抓取网页中文章(js正则表达式replace校验基本日期格式的20个正则表达式代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-03 00:09
)
下一篇:js正则表达式替换匹配
敏感词过滤,使用replace方法将匹配的敏感词变成*相同长度的字符串
pattern = /北京|天安门/g
target = '我爱北京天安门,天安门上太阳升'
console.log(
target.replace(pattern, (str) => {
console.log(str)
return Array(str.length).fill('*').join('')
})
)
北京
天安门
天安门
我爱*****,***上太阳升
改变年份的显示,将2017-1-2改为2017.1.2
pattern = /(\d+)(-)/g
target = '2017-1-2'
console.log(
target.replace(
pattern,
($0, $1, $2) => {
console.log($0, $1, $2)
//replace()中如果有子项,
//第一个参数:$0(匹配成功后的整体结果 2013- 6-),
// 第二个参数 : $1(匹配成功的第一个分组,这里指的是\d 2013, 6)
//第三个参数 : $1(匹配成功的第二个分组,这里指的是- - - )
return $1 + '.'; //分别返回2013. 6.
}
)
)
2017- 2017 -
1- 1 -
2017.1.2
去掉首尾空字符,匹配首尾空字符,然后用‘’替换
// 替换空字符,用*代替空格
pattern = /^\s+|\s+$/g
target = ' abc \n'
res = target.replace(pattern, '')
console.log(res, res.length);
abc 3
正则表达式通常用于验证字段或任意字符串,例如以下用于验证基本日期格式的 JavaScript 代码:
var reg = /^(\\d{1,4})(-|\\/)(\\d{1,2})\\2(\\d{1,2})$/;
var r = fieldValue.match(reg);
if(r==null)alert('Date format error!');
以下20个正则表达式,由工匠编译,前端开发中经常用到。
1.验证密码强度
密码的强度必须收录大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
2.验证中文
字符串只能是中文。
^[\\u4e00-\\u9fa5]{0,}$
3. 由数字、26 个英文字母或下划线组成的字符串
^\\w+$
4. 验证电子邮件地址
与密码相同,以下是E-mail地址合规性的定期检查声明。
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?
5.验证身份证号码
以下是身份证号码的定期验证。 15 或 18 位数字。
15 人:
^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18 人:
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
6. 验证日期
“yyyy-mm-dd”格式的日期验证已被考虑用于平闰年。
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
7.查看金额
金额验证,精确到小数点后两位。
^[0-9]+(.[0-9]{2})?$
8.验证手机号码
以下是中国13、15、18开头的手机号码的正则表达式。 (前两位可根据目前国内采集号进行扩充)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$
9.判断IE版本
IE 还没有完全替代,很多页面还需要版本兼容。以下是IE版本检查的表达式。
^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$
10. 验证 IP-v4 地址
IP4 正则声明。
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
11. 验证 IP-v6 地址
IP6 正则声明。
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
12.检查网址前缀
在应用开发中,经常需要区分请求是HTTPS还是HTTP。一个url的前缀可以通过下面的表达式提取出来,然后进行逻辑判断。
if (!s.match(/^[a-zA-Z]+:\\/\\//))
{
s = 'http://' + s;
}
13. 提取网址链接
下面的表达式可以过滤掉一段文本中的 URL。
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
14. 文件路径和扩展名验证
验证windows下的文件路径和扩展名(下例中的.txt文件)
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"|]+\\.txt(l)?$
15. 提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用如下表达式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
16.提取网页图片
如果要提取网页中的所有图片信息,可以使用以下表达式。
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
17. 提取页面超链接
在 html 中提取超链接。
(]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
18. 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
19. 提取评论
如果需要去掉HMTL中的注释,可以使用下面的表达式。
20. 匹配 HTML 标签
HTML 中的标签属性可以通过以下表达式进行匹配。
<p> 查看全部
php用正则表达抓取网页中文章(js正则表达式replace校验基本日期格式的20个正则表达式代码
)
下一篇:js正则表达式替换匹配
敏感词过滤,使用replace方法将匹配的敏感词变成*相同长度的字符串
pattern = /北京|天安门/g
target = '我爱北京天安门,天安门上太阳升'
console.log(
target.replace(pattern, (str) => {
console.log(str)
return Array(str.length).fill('*').join('')
})
)
北京
天安门
天安门
我爱*****,***上太阳升
改变年份的显示,将2017-1-2改为2017.1.2
pattern = /(\d+)(-)/g
target = '2017-1-2'
console.log(
target.replace(
pattern,
($0, $1, $2) => {
console.log($0, $1, $2)
//replace()中如果有子项,
//第一个参数:$0(匹配成功后的整体结果 2013- 6-),
// 第二个参数 : $1(匹配成功的第一个分组,这里指的是\d 2013, 6)
//第三个参数 : $1(匹配成功的第二个分组,这里指的是- - - )
return $1 + '.'; //分别返回2013. 6.
}
)
)
2017- 2017 -
1- 1 -
2017.1.2
去掉首尾空字符,匹配首尾空字符,然后用‘’替换
// 替换空字符,用*代替空格
pattern = /^\s+|\s+$/g
target = ' abc \n'
res = target.replace(pattern, '')
console.log(res, res.length);
abc 3
正则表达式通常用于验证字段或任意字符串,例如以下用于验证基本日期格式的 JavaScript 代码:
var reg = /^(\\d{1,4})(-|\\/)(\\d{1,2})\\2(\\d{1,2})$/;
var r = fieldValue.match(reg);
if(r==null)alert('Date format error!');
以下20个正则表达式,由工匠编译,前端开发中经常用到。
1.验证密码强度
密码的强度必须收录大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
2.验证中文
字符串只能是中文。
^[\\u4e00-\\u9fa5]{0,}$
3. 由数字、26 个英文字母或下划线组成的字符串
^\\w+$
4. 验证电子邮件地址
与密码相同,以下是E-mail地址合规性的定期检查声明。
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?
5.验证身份证号码
以下是身份证号码的定期验证。 15 或 18 位数字。
15 人:
^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18 人:
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
6. 验证日期
“yyyy-mm-dd”格式的日期验证已被考虑用于平闰年。
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
7.查看金额
金额验证,精确到小数点后两位。
^[0-9]+(.[0-9]{2})?$
8.验证手机号码
以下是中国13、15、18开头的手机号码的正则表达式。 (前两位可根据目前国内采集号进行扩充)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$
9.判断IE版本
IE 还没有完全替代,很多页面还需要版本兼容。以下是IE版本检查的表达式。
^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$
10. 验证 IP-v4 地址
IP4 正则声明。
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
11. 验证 IP-v6 地址
IP6 正则声明。
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
12.检查网址前缀
在应用开发中,经常需要区分请求是HTTPS还是HTTP。一个url的前缀可以通过下面的表达式提取出来,然后进行逻辑判断。
if (!s.match(/^[a-zA-Z]+:\\/\\//))
{
s = 'http://' + s;
}
13. 提取网址链接
下面的表达式可以过滤掉一段文本中的 URL。
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
14. 文件路径和扩展名验证
验证windows下的文件路径和扩展名(下例中的.txt文件)
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"|]+\\.txt(l)?$
15. 提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用如下表达式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
16.提取网页图片
如果要提取网页中的所有图片信息,可以使用以下表达式。
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
17. 提取页面超链接
在 html 中提取超链接。
(]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
18. 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
19. 提取评论
如果需要去掉HMTL中的注释,可以使用下面的表达式。
20. 匹配 HTML 标签
HTML 中的标签属性可以通过以下表达式进行匹配。
<p>
php用正则表达抓取网页中文章(滁州学院官网获取信息如何使用Simple-Html-Dom来解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-03 00:06
)
获取网页源码中的指定内容需要使用正则表达式!正则表达式让我措手不及,因为我之前没有接触过它们,而且很难使用!
在Java中,有Daniel打包的库,我用的是Jsoup。在项目中引入Jsuop的Jar包,指定唯一标签,然后使用选择器解析数据。最近接触PHP,感觉就像用PHP解析新闻一样好玩! Jsoup分析滁州学院官网获取信息列表
我之前说过,正常的方式是使用正则表达式来获取数据!工作久了,真的控制不住!再怎么学习,鸡蛋也没有用!
最后,我通过谷歌搜索引擎搜索了一篇文章。 文章、文章介绍了几种调用PHP文件解析HTML的方法。上帝帮助我!
文章 以后会转贴发布,因为我发现的也是Biren通过“reposter”发布的。既然很好用,我就带过来!
昨天在尴尬百科首页用Simple-Html-Dom.php文件分析了尴尬,每15分钟定时搞定!因为刚接触PHP,就在昨天11:30断网前把代码贴在了SAE上。有点担心代码不能正常运行。毕竟,我对 PHP 一无所知!
今天早上起来看看数据库
太酸了,数据太多,太多没用,我关闭了收购!
说说如何使用Simple-Html-Dom解析HTML(小弟接触PHP不到两天)。看到了嘿嘿一笑,最好给点建议,不要喷,怕被喷!
1、下载 Simple-Html-Dom 压缩文件
到官网()下载压缩文件;
2、解压文件
解压文件,你会发现以下文件
需要用到的方法基本都在demo里面了,看你怎么用了。
看下面的代码,你会发现如何导入php文件和方法
// 如何使用基本选择器检索 HTML 内容的示例
include('../simple_html_dom.php');//引入php核心文件,注意路径,不要搞错
// 从 URL 或文件中获取 DOM
$html = file_get_html('#39;);
// 查找所有链接
foreach($html->find('a') as $e)
echo $e->href.'
';
// 查找所有图片
foreach($html->find('img') as $e)
echo $e->src.'
';
// 查找带有完整标签的所有图像
foreach($html->find('img') as $e)
echo $e->outertext.'
';
// 查找所有 id=gbar 的 div 标签
foreach($html->find('div#gbar') as $e)
echo $e->innertext.'
';
// 查找 class=gb1 的所有 span 标签
foreach($html->find('span.gb1') as $e)
echo $e->outertext.'
';
// 查找所有具有属性 align=center 的 td 标签
foreach($html->find('td[align=center]') as $e)
echo $e->innertext.'
';
//从表格中提取文本
echo $html->find('td[align="center"]', 1)->plaintext.'
';
// 从 HTML 中提取文本
echo $html->纯文本;
还有这个 php 文件 // 如何使用高级选择器功能的示例
include('../simple_html_dom.php');
// ----------------------------------------- --------------------------------
//后代选择器
$str = find('div div div', 0)->innertext.'
'; // 结果:“ok”
// ----------------------------------------- --------------------------------
// 嵌套选择器
$str = find('ul') as $ul) {
foreach($ul->find('li') as $li)
echo $li->innertext.'
';
}
// ----------------------------------------- --------------------------------
//解析复选框
$str = find('input[type=checkbox]') as $checkbox) {
if ($checkbox->checked)
echo $checkbox->name。 '被检查
';
其他
echo $checkbox->name。 '未检查
';
}
这个demo讲解的比较详细,虽然简洁但不简单!有兴趣的可以下载运行试试
获取网页源码中的指定内容需要使用正则表达式!正则表达式让我措手不及,因为我之前没有接触过它们,而且很难使用!
在Java中,有Daniel打包的库,我用的是Jsoup。在项目中引入Jsuop的Jar包,指定唯一标签,然后使用选择器解析数据。最近接触PHP,感觉就像用PHP解析新闻一样好玩! Jsoup分析滁州学院官网获取信息列表
我之前说过,正常的方式是使用正则表达式来获取数据!工作久了,真的控制不住!再怎么学习,鸡蛋也没有用!
最后,我通过谷歌搜索引擎搜索了一篇文章。 文章、文章介绍了几种调用PHP文件解析HTML的方法。上帝帮助我!
文章 以后会转贴发布,因为我发现的也是Biren通过“reposter”发布的。既然很好用,我就带过来!
昨天在尴尬百科首页用Simple-Html-Dom.php文件分析了尴尬,每15分钟定时搞定!因为刚接触PHP,就在昨天11:30断网前把代码贴在了SAE上。有点担心代码不能正常运行。毕竟,我对 PHP 一无所知!
今天早上起来看看数据库
太酸了,数据太多,太多没用,我关闭了收购!
说说如何使用Simple-Html-Dom解析HTML(小弟接触PHP不到两天)。看到了嘿嘿一笑,最好给点建议,不要喷,怕被喷!
1、下载 Simple-Html-Dom 压缩文件
到官网()下载压缩文件;
2、解压文件
解压文件,你会发现以下文件
需要用到的方法基本都在demo里面了,看你怎么用了。
看下面的代码,你会发现如何导入php文件和方法//示例如何使用基本选择器检索HTML内容
include('../simple_html_dom.php');//引入php核心文件,注意路径,不要搞错
// 从 URL 或文件中获取 DOM
$html = file_get_html('#39;);
// 查找所有链接
foreach($html->find('a') as $e)
echo $e->href.'
';
// 查找所有图片
foreach($html->find('img') as $e)
echo $e->src.'
';
// 查找带有完整标签的所有图像
foreach($html->find('img') as $e)
echo $e->outertext.'
';
// 查找所有 id=gbar 的 div 标签
foreach($html->find('div#gbar') as $e)
echo $e->innertext.'
';
// 查找 class=gb1 的所有 span 标签
foreach($html->find('span.gb1') as $e)
echo $e->outertext.'
';
// 查找所有具有属性 align=center 的 td 标签
foreach($html->find('td[align=center]') as $e)
echo $e->innertext.'
';
//从表格中提取文本
echo $html->find('td[align="center"]', 1)->plaintext.'
';
// 从 HTML 中提取文本
echo $html->纯文本;
还有这个 php 文件 // 如何使用高级选择器功能的示例
include('../simple_html_dom.php');
// ----------------------------------------- --------------------------------
//后代选择器
$str = find('div div div', 0)->innertext.'
'; // 结果:“ok”
// ----------------------------------------- --------------------------------
// 嵌套选择器
$str = find('ul') as $ul) {
foreach($ul->find('li') as $li)
echo $li->innertext.'
';
}
// ----------------------------------------- --------------------------------
//解析复选框
$str = find('input[type=checkbox]') as $checkbox) {
if ($checkbox->checked)
echo $checkbox->name。 '被检查
';
其他
echo $checkbox->name。 '未检查
';
}
这个demo讲解的比较详细,虽然简洁但不简单!有兴趣的可以下载运行试试
文件下载
请我喝杯咖啡 :)
查看全部
php用正则表达抓取网页中文章(滁州学院官网获取信息如何使用Simple-Html-Dom来解析
)
获取网页源码中的指定内容需要使用正则表达式!正则表达式让我措手不及,因为我之前没有接触过它们,而且很难使用!
在Java中,有Daniel打包的库,我用的是Jsoup。在项目中引入Jsuop的Jar包,指定唯一标签,然后使用选择器解析数据。最近接触PHP,感觉就像用PHP解析新闻一样好玩! Jsoup分析滁州学院官网获取信息列表
我之前说过,正常的方式是使用正则表达式来获取数据!工作久了,真的控制不住!再怎么学习,鸡蛋也没有用!
最后,我通过谷歌搜索引擎搜索了一篇文章。 文章、文章介绍了几种调用PHP文件解析HTML的方法。上帝帮助我!
文章 以后会转贴发布,因为我发现的也是Biren通过“reposter”发布的。既然很好用,我就带过来!
昨天在尴尬百科首页用Simple-Html-Dom.php文件分析了尴尬,每15分钟定时搞定!因为刚接触PHP,就在昨天11:30断网前把代码贴在了SAE上。有点担心代码不能正常运行。毕竟,我对 PHP 一无所知!
今天早上起来看看数据库
太酸了,数据太多,太多没用,我关闭了收购!
说说如何使用Simple-Html-Dom解析HTML(小弟接触PHP不到两天)。看到了嘿嘿一笑,最好给点建议,不要喷,怕被喷!
1、下载 Simple-Html-Dom 压缩文件
到官网()下载压缩文件;
2、解压文件
解压文件,你会发现以下文件
需要用到的方法基本都在demo里面了,看你怎么用了。
看下面的代码,你会发现如何导入php文件和方法
// 如何使用基本选择器检索 HTML 内容的示例
include('../simple_html_dom.php');//引入php核心文件,注意路径,不要搞错
// 从 URL 或文件中获取 DOM
$html = file_get_html('#39;);
// 查找所有链接
foreach($html->find('a') as $e)
echo $e->href.'
';
// 查找所有图片
foreach($html->find('img') as $e)
echo $e->src.'
';
// 查找带有完整标签的所有图像
foreach($html->find('img') as $e)
echo $e->outertext.'
';
// 查找所有 id=gbar 的 div 标签
foreach($html->find('div#gbar') as $e)
echo $e->innertext.'
';
// 查找 class=gb1 的所有 span 标签
foreach($html->find('span.gb1') as $e)
echo $e->outertext.'
';
// 查找所有具有属性 align=center 的 td 标签
foreach($html->find('td[align=center]') as $e)
echo $e->innertext.'
';
//从表格中提取文本
echo $html->find('td[align="center"]', 1)->plaintext.'
';
// 从 HTML 中提取文本
echo $html->纯文本;
还有这个 php 文件 // 如何使用高级选择器功能的示例
include('../simple_html_dom.php');
// ----------------------------------------- --------------------------------
//后代选择器
$str = find('div div div', 0)->innertext.'
'; // 结果:“ok”
// ----------------------------------------- --------------------------------
// 嵌套选择器
$str = find('ul') as $ul) {
foreach($ul->find('li') as $li)
echo $li->innertext.'
';
}
// ----------------------------------------- --------------------------------
//解析复选框
$str = find('input[type=checkbox]') as $checkbox) {
if ($checkbox->checked)
echo $checkbox->name。 '被检查
';
其他
echo $checkbox->name。 '未检查
';
}
这个demo讲解的比较详细,虽然简洁但不简单!有兴趣的可以下载运行试试
获取网页源码中的指定内容需要使用正则表达式!正则表达式让我措手不及,因为我之前没有接触过它们,而且很难使用!
在Java中,有Daniel打包的库,我用的是Jsoup。在项目中引入Jsuop的Jar包,指定唯一标签,然后使用选择器解析数据。最近接触PHP,感觉就像用PHP解析新闻一样好玩! Jsoup分析滁州学院官网获取信息列表
我之前说过,正常的方式是使用正则表达式来获取数据!工作久了,真的控制不住!再怎么学习,鸡蛋也没有用!
最后,我通过谷歌搜索引擎搜索了一篇文章。 文章、文章介绍了几种调用PHP文件解析HTML的方法。上帝帮助我!
文章 以后会转贴发布,因为我发现的也是Biren通过“reposter”发布的。既然很好用,我就带过来!
昨天在尴尬百科首页用Simple-Html-Dom.php文件分析了尴尬,每15分钟定时搞定!因为刚接触PHP,就在昨天11:30断网前把代码贴在了SAE上。有点担心代码不能正常运行。毕竟,我对 PHP 一无所知!
今天早上起来看看数据库
太酸了,数据太多,太多没用,我关闭了收购!
说说如何使用Simple-Html-Dom解析HTML(小弟接触PHP不到两天)。看到了嘿嘿一笑,最好给点建议,不要喷,怕被喷!
1、下载 Simple-Html-Dom 压缩文件
到官网()下载压缩文件;
2、解压文件
解压文件,你会发现以下文件
需要用到的方法基本都在demo里面了,看你怎么用了。
看下面的代码,你会发现如何导入php文件和方法//示例如何使用基本选择器检索HTML内容
include('../simple_html_dom.php');//引入php核心文件,注意路径,不要搞错
// 从 URL 或文件中获取 DOM
$html = file_get_html('#39;);
// 查找所有链接
foreach($html->find('a') as $e)
echo $e->href.'
';
// 查找所有图片
foreach($html->find('img') as $e)
echo $e->src.'
';
// 查找带有完整标签的所有图像
foreach($html->find('img') as $e)
echo $e->outertext.'
';
// 查找所有 id=gbar 的 div 标签
foreach($html->find('div#gbar') as $e)
echo $e->innertext.'
';
// 查找 class=gb1 的所有 span 标签
foreach($html->find('span.gb1') as $e)
echo $e->outertext.'
';
// 查找所有具有属性 align=center 的 td 标签
foreach($html->find('td[align=center]') as $e)
echo $e->innertext.'
';
//从表格中提取文本
echo $html->find('td[align="center"]', 1)->plaintext.'
';
// 从 HTML 中提取文本
echo $html->纯文本;
还有这个 php 文件 // 如何使用高级选择器功能的示例
include('../simple_html_dom.php');
// ----------------------------------------- --------------------------------
//后代选择器
$str = find('div div div', 0)->innertext.'
'; // 结果:“ok”
// ----------------------------------------- --------------------------------
// 嵌套选择器
$str = find('ul') as $ul) {
foreach($ul->find('li') as $li)
echo $li->innertext.'
';
}
// ----------------------------------------- --------------------------------
//解析复选框
$str = find('input[type=checkbox]') as $checkbox) {
if ($checkbox->checked)
echo $checkbox->name。 '被检查
';
其他
echo $checkbox->name。 '未检查
';
}
这个demo讲解的比较详细,虽然简洁但不简单!有兴趣的可以下载运行试试
文件下载
请我喝杯咖啡 :)

php用正则表达抓取网页中文章(正则表达式的Python语言通过标准的替换操作;正则表达式简介 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-03 00:06
)
正则表达式介绍
概念
正则表达式是字符串操作的逻辑公式。它使用一些预定义的特定字符和这些特定字符的组合来形成“规则字符串”。这个“规则字符串”用于表达一种对字符串的过滤逻辑(可用于检索、拦截或替换操作)。
正则表达式用于搜索、替换和解析字符串。正则表达式遵循一定的语法规则,非常灵活和强大。使用正则表达式写一些逻辑验证非常方便,比如邮箱地址格式的验证。
<p>正则表达式是对字符串(包括普通字符(例如a和z之间的字母)和特殊字符)进行运算的逻辑公式,就是使用一些预先定义好的特定字符和这些特定字符的组合形成一个“规则串”,这个“规则串”用来表达一种对字符串的过滤逻辑,正则表达式是一个文本模式,在搜索文本字符串时,模式描述必须匹配一个或多个。 查看全部
php用正则表达抓取网页中文章(正则表达式的Python语言通过标准的替换操作;正则表达式简介
)
正则表达式介绍
概念
正则表达式是字符串操作的逻辑公式。它使用一些预定义的特定字符和这些特定字符的组合来形成“规则字符串”。这个“规则字符串”用于表达一种对字符串的过滤逻辑(可用于检索、拦截或替换操作)。
正则表达式用于搜索、替换和解析字符串。正则表达式遵循一定的语法规则,非常灵活和强大。使用正则表达式写一些逻辑验证非常方便,比如邮箱地址格式的验证。
<p>正则表达式是对字符串(包括普通字符(例如a和z之间的字母)和特殊字符)进行运算的逻辑公式,就是使用一些预先定义好的特定字符和这些特定字符的组合形成一个“规则串”,这个“规则串”用来表达一种对字符串的过滤逻辑,正则表达式是一个文本模式,在搜索文本字符串时,模式描述必须匹配一个或多个。
php用正则表达抓取网页中文章(突袭网网站的支持!-->)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-28 08:00
s">PHP正则表达式抓取标签特定属性值的方法
作者:宇轩网字体:【增减】类型:转载时间:2016-07-14我要评论
本文主要介绍用PHP正则表达式抓取标签特定属性值的方法的相关信息。非常好,有参考价值。有需要的朋友可以参考>
学了几天php正则,抓了一些网站数据,发现写正则又每次都重新抓很麻烦,所以想写一个通用的接口,抓具体属性值的具体标签,直接上传代码。
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这是一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果是
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
你可以看到源代码
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客的时候很紧张。我希望它对大家有用。也希望大家能指出代码中的问题。我不做很多测试~~
以上就是小编给大家介绍的用PHP正则表达式抓取标签的具体属性值的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对raid网站的支持! 查看全部
php用正则表达抓取网页中文章(突袭网网站的支持!-->)
s">PHP正则表达式抓取标签特定属性值的方法
作者:宇轩网字体:【增减】类型:转载时间:2016-07-14我要评论
本文主要介绍用PHP正则表达式抓取标签特定属性值的方法的相关信息。非常好,有参考价值。有需要的朋友可以参考>
学了几天php正则,抓了一些网站数据,发现写正则又每次都重新抓很麻烦,所以想写一个通用的接口,抓具体属性值的具体标签,直接上传代码。
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这是一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果是
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
你可以看到源代码
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客的时候很紧张。我希望它对大家有用。也希望大家能指出代码中的问题。我不做很多测试~~
以上就是小编给大家介绍的用PHP正则表达式抓取标签的具体属性值的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对raid网站的支持!
php用正则表达抓取网页中文章(web.py用什么方法可以抓取文章的正文【python】 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-28 07:20
)
python可以用什么方法抓取文章的body部分是我最近在思考的一个问题。我想知道如何通过xpath准确抓取文章正文。它类似于 parselets,但会更简单。
在python代码的设计中,使用正则表达式匹配URL,然后选择回调处理程序。主要参考web.py的分发器。有朋友觉得这个方法不高尚,因为都是python函数形式的回调,没有用到python类。有需要的朋友可以参考web.py进行适当修改后再使用。
Python 通过正则表达式选择并抓取文章正文:
#!/bin/env python
import re, sys
# Define parser first.
def baidu(username):
# Business logic
return "Using parser Baidu. and the user's name is: %s." % username
def qzone(uin):
# Business logic
return "Using parser Qzone, and the user's QQ is: %s." % uin
# From web.py
def group(seq, size):#{{{
"""
Returns an iterator over a series of lists of length size from iterable.
>>> list(group([1,2,3,4], 2))
[[1, 2], [3, 4]]
>>> list(group([1,2,3,4,5], 2))
[[1, 2], [3, 4], [5]]
"""
def take(seq, n):
for i in xrange(n):
yield seq.next()
if not hasattr(seq, 'next'):
seq = iter(seq)
while True:
x = list(take(seq, size))
if x:
yield x
else:
break
#}}}
#www.iplaypy.com
def parser_init(url,mapping):
for pat, what in group(mapping,2):
result = re.compile('^' + pat + '$').match(url)
if result:
return what, [x for x in result.groups()]
return None, None
if __name__ == '__main__':
mapping = (
'http://(?:hi|space).baidu.com/([^/]+)(?:/.*)?','baidu',
'http://(\d+).qzone.qq.com(?:/.*)?','qzone',
)
(func, args) = parser_init(sys.argv[1],mapping)
if func:
callback = func
if func in globals():
callback = globals()[func]
if callable(callback):
print callback(*args)
else:
print 'No parser found.'; 查看全部
php用正则表达抓取网页中文章(web.py用什么方法可以抓取文章的正文【python】
)
python可以用什么方法抓取文章的body部分是我最近在思考的一个问题。我想知道如何通过xpath准确抓取文章正文。它类似于 parselets,但会更简单。
在python代码的设计中,使用正则表达式匹配URL,然后选择回调处理程序。主要参考web.py的分发器。有朋友觉得这个方法不高尚,因为都是python函数形式的回调,没有用到python类。有需要的朋友可以参考web.py进行适当修改后再使用。
Python 通过正则表达式选择并抓取文章正文:
#!/bin/env python
import re, sys
# Define parser first.
def baidu(username):
# Business logic
return "Using parser Baidu. and the user's name is: %s." % username
def qzone(uin):
# Business logic
return "Using parser Qzone, and the user's QQ is: %s." % uin
# From web.py
def group(seq, size):#{{{
"""
Returns an iterator over a series of lists of length size from iterable.
>>> list(group([1,2,3,4], 2))
[[1, 2], [3, 4]]
>>> list(group([1,2,3,4,5], 2))
[[1, 2], [3, 4], [5]]
"""
def take(seq, n):
for i in xrange(n):
yield seq.next()
if not hasattr(seq, 'next'):
seq = iter(seq)
while True:
x = list(take(seq, size))
if x:
yield x
else:
break
#}}}
#www.iplaypy.com
def parser_init(url,mapping):
for pat, what in group(mapping,2):
result = re.compile('^' + pat + '$').match(url)
if result:
return what, [x for x in result.groups()]
return None, None
if __name__ == '__main__':
mapping = (
'http://(?:hi|space).baidu.com/([^/]+)(?:/.*)?','baidu',
'http://(\d+).qzone.qq.com(?:/.*)?','qzone',
)
(func, args) = parser_init(sys.argv[1],mapping)
if func:
callback = func
if func in globals():
callback = globals()[func]
if callable(callback):
print callback(*args)
else:
print 'No parser found.';
php用正则表达抓取网页中文章(php下正则匹配中文的表达式是什么样的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-26 18:20
首先unicode中文区的0x4e00-0x9fa5可以判断一个字符串是否都是java或js等编程语言有unicode编码的字符串/^[\u4e00-\u9fa5]+ $/中文
那么php中的字符编码就看页面了,gbk的字符编码是gbk的utf-8,之前有一个表达式“/^[\x80-\xff]+$/”也是一样can only match 是否收录
非ascll字符,汉字只是较小的区域之一,不是很准确
因为我的页面编码是utf-8,所以把js表达式移到了php中,提醒PCRE不支持“\u”等很多乱七八糟的东西
查资料得知PHP的正则中有个东西叫字符组,用\x{...}表示,所以我把表达式改成"/^[\x{4e00}- \x{9fa5}]+$/ "也提示"\x"表达式后面的数字太大
查资料得知可以使用修正模式“u”让程序将以下内容视为unicode字符,所以我将其改为“/^[\x{4e00}-\x{9fa5} ]+$/u" 测试成功
所以php下匹配中文的正则表达式为"/^[\x{4e00}-\x{9fa5}]+$/u" 这只适用于utf-8编码 查看全部
php用正则表达抓取网页中文章(php下正则匹配中文的表达式是什么样的?(图))
首先unicode中文区的0x4e00-0x9fa5可以判断一个字符串是否都是java或js等编程语言有unicode编码的字符串/^[\u4e00-\u9fa5]+ $/中文
那么php中的字符编码就看页面了,gbk的字符编码是gbk的utf-8,之前有一个表达式“/^[\x80-\xff]+$/”也是一样can only match 是否收录
非ascll字符,汉字只是较小的区域之一,不是很准确
因为我的页面编码是utf-8,所以把js表达式移到了php中,提醒PCRE不支持“\u”等很多乱七八糟的东西
查资料得知PHP的正则中有个东西叫字符组,用\x{...}表示,所以我把表达式改成"/^[\x{4e00}- \x{9fa5}]+$/ "也提示"\x"表达式后面的数字太大
查资料得知可以使用修正模式“u”让程序将以下内容视为unicode字符,所以我将其改为“/^[\x{4e00}-\x{9fa5} ]+$/u" 测试成功
所以php下匹配中文的正则表达式为"/^[\x{4e00}-\x{9fa5}]+$/u" 这只适用于utf-8编码
php用正则表达抓取网页中文章(PHP正则表达式如何处理将要打开文件的标识和几种形式?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-24 12:17
最近有一个任务,从页面中抓取页面上的所有链接。当然,使用 PHP 正则表达式是最方便的方式。要编写正则表达式,您必须首先总结模式。页面上的链接有多少种形式?
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。 查看全部
php用正则表达抓取网页中文章(PHP正则表达式如何处理将要打开文件的标识和几种形式?)
最近有一个任务,从页面中抓取页面上的所有链接。当然,使用 PHP 正则表达式是最方便的方式。要编写正则表达式,您必须首先总结模式。页面上的链接有多少种形式?
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。
php用正则表达抓取网页中文章( 老是/php/Snoopy.gz本地下载类类特征)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-18 14:18
老是/php/Snoopy.gz本地下载类类特征)
史努比PHP版网络客户端提供本地下载
更新时间:2008-04-15 21:29:47 作者:
snoopy是一个很好的模仿网络客户端的php类,但是本地下载的很少,国外下载又麻烦又慢,所以弄了这个网站给大家下载
史努比在magpierss中使用,这让我有点兴趣研究这个dong dong。在 SF 上,我找到了这个源代码。它其实是一个类,但不要笑,功能很强大。
官方介绍,我翻译了(汗……最近一直在做翻译)
snoopy 是一个模仿网络浏览器功能的 php 类,它可以完成获取网页内容和发送表单的任务。
以下是它的一些特点:
1、轻松抓取网页内容
2、轻松抓取网页文本(去掉HTML代码)
3、方便抓取网页的链接
4、支持代理主机
5、支持基本用户/密码认证方式
6、支持自定义用户代理、referer、cookies和header内容
7、支持浏览器转向和控制转向深度
8、 可以将网页中的链接扩展成高质量的url(默认)
9、方便提交数据并获取返回值
10、支持跟踪HTML框架(v0.92增加)
11、支持重定向时传递cookies
下面是一个简单的例子,比如我们抓取我博客的文字
^_^,还不错,比如抢链接
哎,效果不错,还有我们需要的url,没有/blog/read.php/85.htm这样的东西。
还要为以后测试的人提交数据。. .
元马/php/Snoopy-1.2.3.tar.gz本地下载 查看全部
php用正则表达抓取网页中文章(
老是/php/Snoopy.gz本地下载类类特征)
史努比PHP版网络客户端提供本地下载
更新时间:2008-04-15 21:29:47 作者:
snoopy是一个很好的模仿网络客户端的php类,但是本地下载的很少,国外下载又麻烦又慢,所以弄了这个网站给大家下载
史努比在magpierss中使用,这让我有点兴趣研究这个dong dong。在 SF 上,我找到了这个源代码。它其实是一个类,但不要笑,功能很强大。
官方介绍,我翻译了(汗……最近一直在做翻译)
snoopy 是一个模仿网络浏览器功能的 php 类,它可以完成获取网页内容和发送表单的任务。
以下是它的一些特点:
1、轻松抓取网页内容
2、轻松抓取网页文本(去掉HTML代码)
3、方便抓取网页的链接
4、支持代理主机
5、支持基本用户/密码认证方式
6、支持自定义用户代理、referer、cookies和header内容
7、支持浏览器转向和控制转向深度
8、 可以将网页中的链接扩展成高质量的url(默认)
9、方便提交数据并获取返回值
10、支持跟踪HTML框架(v0.92增加)
11、支持重定向时传递cookies
下面是一个简单的例子,比如我们抓取我博客的文字
^_^,还不错,比如抢链接
哎,效果不错,还有我们需要的url,没有/blog/read.php/85.htm这样的东西。
还要为以后测试的人提交数据。. .
元马/php/Snoopy-1.2.3.tar.gz本地下载
php用正则表达抓取网页中文章(常用的nginx正则表达式^:匹配输入字符串的路径地址地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-15 03:16
常用的nginx正则表达式
^ : 匹配输入字符串的开头
$:匹配输入字符串的结尾
*:匹配前面的字符零次或多次
+:匹配前面的字符一次或多次
?:匹配前面的字符零次或一次
. : 匹配除 "\n" 之外的任何单词。如果要匹配 "\n" 字符串,请使用 [.\n] 之类的模式
\:将后面的字符标记为特殊字符或文字或反向引用
\d : 匹配纯数字 [0-9], \s: 空格 \w: 任何单个,包括下划线 [A-Za-z0-9]
{n}:重复 n 次
{n,} :重复 n 次或更多
{n,m}:重复 n 到 m 这个
[ ] : 定义匹配的字符转置
[ c ] : 匹配单个字符 c
[az]:匹配 az 的任何小写字符
[A-Za-z0-9]:匹配所有大小写字符或数字
() : 表达式的开始和结束位置
| : OR 运算符
从功能上看,rewrite和location似乎有点类似,都可以实现跳转。主要区别在于rewrite改变了获取同域名下资源的路径,而location是一对用于控制访问或反向代理的类路径。可以proxy_pass到其他机器吗
rewrite 重写访问域名中的 URL 路径地址
location 对访问路径进行访问控制或代理转发
地点
位置大致可以分为三类:
完全匹配:位置 = / {...}
一般匹配:location/{...}#最长匹配原则(如果有屁匹配最长的会选择最长的)
正则匹配:location ~ / {...}
位置常用匹配选项:
= :对普通字符进行精确匹配,即精确匹配
^~ :对普通字符进行精确匹配,即精确匹配。
~ :区分大小写的匹配。
~* :不区分大小写的匹配。
!~* :!~: 区分大小写的匹配否定。
!~* :不区分大小写的匹配否定。
位置匹配优先级
首先是完全匹配=
二是前缀匹配(匹配后停止搜索,直接用这个!)
后跟按照文件中的顺序进行正则匹配,~或~*
然后匹配前缀匹配,不做任何修改(正常匹配)
最后传给“/”(万能匹配)
位置示例说明:
1、位置 = / {}
=。要完全匹配/,主机名后面不能跟任何字符串,比如访问/和/data,那么/匹配,/data不匹配。例如 location = /abc,它只匹配 /abc、/abc/ 或 /abcd 不匹配。如果位置 /abc,它匹配 /abc、/abcd/ 并且还匹配 /abc/。
(2) 位置 / {}
因为所有地址都以1开头,所以这条规则会匹配访问/和/data等所有请求,那么1会匹配,/data也会匹配,但是如果后面是正则表达式,会匹配最长的字符串第一个(最长的字符串)。长比赛)
(3) location /documents/ {} 匹配任何以/documents/开头的地址,匹配后会继续搜索其他位置,只有当其他位置后面的正则表达式不匹配时才会使用。这个
(4) location /documents/abc {} 匹配任何以 /documents/abc 开头的地址。匹配后会继续搜索其他位置。只有当其他位置后面的正则表达式不匹配时,将使用这个
(5) 位置 ^~ /images/ {}
匹配任何以/images/开头的地址,匹配后停止搜索正则,使用这个
(6) 位置 ~* . (gifljpg ljpeg)$ {}
匹配所有以 gif、jpg 或 jpeg 结尾的请求,但是 /images/ 下的所有请求都会被位置 ^~ /images/ 处理,因为 ^~ 具有更高的优先级,因此无法达到此规则
(7) 位置 /images/abc {}
最长的字符匹配 /images/abc,优先级最低。如果继续搜索其他位置,会发现^~和~存在
(8) 位置 ~ /images/abc {}
以 /images/abc 开头的匹配,优先级次之,仅当 location ^~ /images/ 被删除时,才会使用此条目
(9) 位置 /images/abc/1.html {}
匹配 /images/abc/1.html 文件,如果与常规位置 ~/images/abc/1.html 相比,常规优先级更高
优先级总结:
(location = 全路径) > (location ^~path) > (location ~,~*正则) > (location 部分起始路径) > (location /)
位置匹配
先看优先级:Precise > Prefix > Regular > General > General
优先级是一样的:正则看上下顺序,上面的优先级:一般匹配看长度,最长匹配优先级是精确,前缀,正则,一般不匹配,最后看一般匹配。
在实际网站的使用中,至少定义了三个匹配规则:
#第一条强制规则
直接匹配网站的根,通过域名访问网站的主页更频繁。使用这个会加快处理速度,比如官网。可以是静态首页,也可以直接转发到后台应用服务器
location = / {
root html;
index index.html index.html;
}
#第二条强制规则是处理静态文件请求,这是nginx作为http服务器的强项。有两种配置方式,目录匹配或后缀匹配,任选其一或一起使用
location ^~ /static/ {
root /webroot/static/;
}
location ~* \.(html|gif|jpg|jpeg|png|css|js|ico)$ {
root /webroot/res/;
}
#第三条规则是一般规则。例如,用于将带有 .php 和 .jsp 后缀的动态请求转发到后端应用服务器。默认情况下,非静态文件请求是动态请求。
location / {
proxy_pass http://tomcat_server;
}
改写
重写功能是利用nginx提供的全局变量或者自己设置的变量,结合正则表达式和标签位来实现URL的重写和重定向。
例如:更改域名后需要保留旧域名跳转到新域名,网页更改时跳转到新页面,网站防盗链等等。
改写。只能放在server{}、location{}、if{}中,默认只能作用于域名后面的字符串,除了传入的参数,
例如 http:L //abc/bbs/index.php?a=1&b=2 只重写 /abc/bbs/index.php。
重写跳转实现:
nginx:ngx http rewrite_模块模块支持url重写和if条件判断,但不支持else跳转:从一个位置跳转到另一个位置,循环最多可以执行10次,之后nginx会返回500错误
PCRE 支持:Perl 兼容的正则表达式语法规则匹配
覆盖模块设置指令:创建新变量并设置其值
重写执行顺序如下:
(1) 在服务器块内执行重写指令。
(2) 执行位置匹配。
(3) 在选定位置执行重写命令。
语法格式: rewrite [flag];
regex:表示正则匹配规则。
replacement:表示跳转后的内容。
flag:表示rewrite支持的flag标记。
重写跳跃场景:
调整用户浏览的网址,使其看起来更规范,符合开发和生产
人员的需求。
为了让搜索引擎更好地搜索网站内容和用户体验,公司将
将动态 URL 地址伪装成静态地址提供服务。
网站改成新域名后,让旧访问跳转到新域名。比如访问京东的都会跳转。
服务器端的一些业务调整,比如基于特殊变量、目录、客户端信息的URL调整。
###flag 标志说明 ###
last :本规则匹配完成后,继续向下匹配新的location URL规则,一般用在server和if中。
break :该规则匹配后终止,不再匹配任何后续规则。一般用于定位。
redirect:返回一个302临时重定向,浏览器地址会显示重定向后的URL地址。
永久:返回301永久重定向,浏览器地址栏会显示重定向后的URL。
重写示例:
(1)根据域名重定向
现在公司老域名业务需求发生变化,需要更换新域名,但是老域名不能取消,需要跳转到新域名,vim /usr/local/nginx/conf /nginx.conf
server {
listen 80;
server_nameWWw.kgc.com; #域名修改
charset utf-8; #编码格式
access_ 1og /var/log/nginx/www.kgc.com-access.log; #日志修改
location / { #添加域名重定向
if ($host = 'WWW.kgc.com') { #$host为rewrite全局变量,代表请求主机头字段或主机名
rewrite ^/(.*)$ http://www.benet.com/$1 permanent; #$1为 正则匹配的内容,即“域名/"之后的字符串
}
root html;
index index.html index.htm;
}
}
echo "192.168.80.10 www.kgc.com www.benet.com" >> /etc/hosts
systemctl restart nginx
浏览器输入模拟访问http://www.kgc.com/test/1.html (虽然这个请求内容是不存在的)
会跳转到www.benet.com/test/1.html,查看元素可以看到返回301,实现了永久重定向跳转,而且域名后的参数也正常跳转。
(2)基于客户端IP的访问跳转
今天公司新版业务上线,要求所有IP访问任何内容显示,固定维护页面,只有公司IP:192.168.80. 10访问是正常的。
vim /usr/local/nginx/conf /nginx.conf
server {
server_nameWWw.kgc.com; #域名修改
charset utf-8; #编码格式
access_ 1og /var/log/nginx/www.kgc.com-access.log; #日志修改
#设置是否合法的IP标记
set $rewrite true; #设置变量$rewrite,变量值为boole值true
#判断是否为合法IP
if ($remote_addr = "192.168.80.10"){ #当客户端IP为192.168.80.10时,将变量值设为false,不进行重写
set $rewrite false;
}
#除了合法IP,其它都是非法IP,进行重写跳转维护页面
if ($rewrite = true) { #当变量值为true时,进行重写
rewrite (.+) /weihu.html; #将域名后边的路径重写成/weihu. html,例如www. kgc.com/weihu.html
}
location = /weihu.html {
root /var/ www/html; #网页返回/var/www/ html/weihu. html的内容
}
location / {
root html;
index index.html index.htm;
}
}
(3)基于旧域名,跳转到新域名后跟目录
现在访问了,现在这个域名下的访问需要跳转到http:L //bbs/post
vim /usr/1ocal/nginx/conf/nginx.conf
server {
listen 80;
server_namebbs.kgc.com; #域名修改
charset utf-8;
access_1og /var/1og/nginx/WWW.kgc.com-access.log;
#添加
location /post {
rewrite (.+) http://www.kgc.com/bbs$1 permanent; #这里的$1为位置变量,代表/post
}
location / {
root html;
index index.html index.htm;
}
}
mkdir -p /usr/local/nginx/html/bbs/post
echo "this is 1.html" >> /usr/1ocal/nginx/html/bbs/post/1 . html
echo "192.168.80.10 bbs.kgc.com"
systemctl restart nginx
使用浏览器访问http://bbs.kgc.com/post/1.html跳转到http://www. kgc.com/bbs/post/1.html
(4)根据参数匹配跳转 查看全部
php用正则表达抓取网页中文章(常用的nginx正则表达式^:匹配输入字符串的路径地址地址)
常用的nginx正则表达式
^ : 匹配输入字符串的开头
$:匹配输入字符串的结尾
*:匹配前面的字符零次或多次
+:匹配前面的字符一次或多次
?:匹配前面的字符零次或一次
. : 匹配除 "\n" 之外的任何单词。如果要匹配 "\n" 字符串,请使用 [.\n] 之类的模式
\:将后面的字符标记为特殊字符或文字或反向引用
\d : 匹配纯数字 [0-9], \s: 空格 \w: 任何单个,包括下划线 [A-Za-z0-9]
{n}:重复 n 次
{n,} :重复 n 次或更多
{n,m}:重复 n 到 m 这个
[ ] : 定义匹配的字符转置
[ c ] : 匹配单个字符 c
[az]:匹配 az 的任何小写字符
[A-Za-z0-9]:匹配所有大小写字符或数字
() : 表达式的开始和结束位置
| : OR 运算符
从功能上看,rewrite和location似乎有点类似,都可以实现跳转。主要区别在于rewrite改变了获取同域名下资源的路径,而location是一对用于控制访问或反向代理的类路径。可以proxy_pass到其他机器吗
rewrite 重写访问域名中的 URL 路径地址
location 对访问路径进行访问控制或代理转发
地点
位置大致可以分为三类:
完全匹配:位置 = / {...}
一般匹配:location/{...}#最长匹配原则(如果有屁匹配最长的会选择最长的)
正则匹配:location ~ / {...}
位置常用匹配选项:
= :对普通字符进行精确匹配,即精确匹配
^~ :对普通字符进行精确匹配,即精确匹配。
~ :区分大小写的匹配。
~* :不区分大小写的匹配。
!~* :!~: 区分大小写的匹配否定。
!~* :不区分大小写的匹配否定。
位置匹配优先级
首先是完全匹配=
二是前缀匹配(匹配后停止搜索,直接用这个!)
后跟按照文件中的顺序进行正则匹配,~或~*
然后匹配前缀匹配,不做任何修改(正常匹配)
最后传给“/”(万能匹配)
位置示例说明:
1、位置 = / {}
=。要完全匹配/,主机名后面不能跟任何字符串,比如访问/和/data,那么/匹配,/data不匹配。例如 location = /abc,它只匹配 /abc、/abc/ 或 /abcd 不匹配。如果位置 /abc,它匹配 /abc、/abcd/ 并且还匹配 /abc/。
(2) 位置 / {}
因为所有地址都以1开头,所以这条规则会匹配访问/和/data等所有请求,那么1会匹配,/data也会匹配,但是如果后面是正则表达式,会匹配最长的字符串第一个(最长的字符串)。长比赛)
(3) location /documents/ {} 匹配任何以/documents/开头的地址,匹配后会继续搜索其他位置,只有当其他位置后面的正则表达式不匹配时才会使用。这个
(4) location /documents/abc {} 匹配任何以 /documents/abc 开头的地址。匹配后会继续搜索其他位置。只有当其他位置后面的正则表达式不匹配时,将使用这个
(5) 位置 ^~ /images/ {}
匹配任何以/images/开头的地址,匹配后停止搜索正则,使用这个
(6) 位置 ~* . (gifljpg ljpeg)$ {}
匹配所有以 gif、jpg 或 jpeg 结尾的请求,但是 /images/ 下的所有请求都会被位置 ^~ /images/ 处理,因为 ^~ 具有更高的优先级,因此无法达到此规则
(7) 位置 /images/abc {}
最长的字符匹配 /images/abc,优先级最低。如果继续搜索其他位置,会发现^~和~存在
(8) 位置 ~ /images/abc {}
以 /images/abc 开头的匹配,优先级次之,仅当 location ^~ /images/ 被删除时,才会使用此条目
(9) 位置 /images/abc/1.html {}
匹配 /images/abc/1.html 文件,如果与常规位置 ~/images/abc/1.html 相比,常规优先级更高
优先级总结:
(location = 全路径) > (location ^~path) > (location ~,~*正则) > (location 部分起始路径) > (location /)
位置匹配
先看优先级:Precise > Prefix > Regular > General > General
优先级是一样的:正则看上下顺序,上面的优先级:一般匹配看长度,最长匹配优先级是精确,前缀,正则,一般不匹配,最后看一般匹配。
在实际网站的使用中,至少定义了三个匹配规则:
#第一条强制规则
直接匹配网站的根,通过域名访问网站的主页更频繁。使用这个会加快处理速度,比如官网。可以是静态首页,也可以直接转发到后台应用服务器
location = / {
root html;
index index.html index.html;
}
#第二条强制规则是处理静态文件请求,这是nginx作为http服务器的强项。有两种配置方式,目录匹配或后缀匹配,任选其一或一起使用
location ^~ /static/ {
root /webroot/static/;
}
location ~* \.(html|gif|jpg|jpeg|png|css|js|ico)$ {
root /webroot/res/;
}
#第三条规则是一般规则。例如,用于将带有 .php 和 .jsp 后缀的动态请求转发到后端应用服务器。默认情况下,非静态文件请求是动态请求。
location / {
proxy_pass http://tomcat_server;
}
改写
重写功能是利用nginx提供的全局变量或者自己设置的变量,结合正则表达式和标签位来实现URL的重写和重定向。
例如:更改域名后需要保留旧域名跳转到新域名,网页更改时跳转到新页面,网站防盗链等等。
改写。只能放在server{}、location{}、if{}中,默认只能作用于域名后面的字符串,除了传入的参数,
例如 http:L //abc/bbs/index.php?a=1&b=2 只重写 /abc/bbs/index.php。
重写跳转实现:
nginx:ngx http rewrite_模块模块支持url重写和if条件判断,但不支持else跳转:从一个位置跳转到另一个位置,循环最多可以执行10次,之后nginx会返回500错误
PCRE 支持:Perl 兼容的正则表达式语法规则匹配
覆盖模块设置指令:创建新变量并设置其值
重写执行顺序如下:
(1) 在服务器块内执行重写指令。
(2) 执行位置匹配。
(3) 在选定位置执行重写命令。
语法格式: rewrite [flag];
regex:表示正则匹配规则。
replacement:表示跳转后的内容。
flag:表示rewrite支持的flag标记。
重写跳跃场景:
调整用户浏览的网址,使其看起来更规范,符合开发和生产
人员的需求。
为了让搜索引擎更好地搜索网站内容和用户体验,公司将
将动态 URL 地址伪装成静态地址提供服务。
网站改成新域名后,让旧访问跳转到新域名。比如访问京东的都会跳转。
服务器端的一些业务调整,比如基于特殊变量、目录、客户端信息的URL调整。
###flag 标志说明 ###
last :本规则匹配完成后,继续向下匹配新的location URL规则,一般用在server和if中。
break :该规则匹配后终止,不再匹配任何后续规则。一般用于定位。
redirect:返回一个302临时重定向,浏览器地址会显示重定向后的URL地址。
永久:返回301永久重定向,浏览器地址栏会显示重定向后的URL。
重写示例:
(1)根据域名重定向
现在公司老域名业务需求发生变化,需要更换新域名,但是老域名不能取消,需要跳转到新域名,vim /usr/local/nginx/conf /nginx.conf
server {
listen 80;
server_nameWWw.kgc.com; #域名修改
charset utf-8; #编码格式
access_ 1og /var/log/nginx/www.kgc.com-access.log; #日志修改
location / { #添加域名重定向
if ($host = 'WWW.kgc.com') { #$host为rewrite全局变量,代表请求主机头字段或主机名
rewrite ^/(.*)$ http://www.benet.com/$1 permanent; #$1为 正则匹配的内容,即“域名/"之后的字符串
}
root html;
index index.html index.htm;
}
}
echo "192.168.80.10 www.kgc.com www.benet.com" >> /etc/hosts
systemctl restart nginx
浏览器输入模拟访问http://www.kgc.com/test/1.html (虽然这个请求内容是不存在的)
会跳转到www.benet.com/test/1.html,查看元素可以看到返回301,实现了永久重定向跳转,而且域名后的参数也正常跳转。
(2)基于客户端IP的访问跳转
今天公司新版业务上线,要求所有IP访问任何内容显示,固定维护页面,只有公司IP:192.168.80. 10访问是正常的。
vim /usr/local/nginx/conf /nginx.conf
server {
server_nameWWw.kgc.com; #域名修改
charset utf-8; #编码格式
access_ 1og /var/log/nginx/www.kgc.com-access.log; #日志修改
#设置是否合法的IP标记
set $rewrite true; #设置变量$rewrite,变量值为boole值true
#判断是否为合法IP
if ($remote_addr = "192.168.80.10"){ #当客户端IP为192.168.80.10时,将变量值设为false,不进行重写
set $rewrite false;
}
#除了合法IP,其它都是非法IP,进行重写跳转维护页面
if ($rewrite = true) { #当变量值为true时,进行重写
rewrite (.+) /weihu.html; #将域名后边的路径重写成/weihu. html,例如www. kgc.com/weihu.html
}
location = /weihu.html {
root /var/ www/html; #网页返回/var/www/ html/weihu. html的内容
}
location / {
root html;
index index.html index.htm;
}
}
(3)基于旧域名,跳转到新域名后跟目录
现在访问了,现在这个域名下的访问需要跳转到http:L //bbs/post
vim /usr/1ocal/nginx/conf/nginx.conf
server {
listen 80;
server_namebbs.kgc.com; #域名修改
charset utf-8;
access_1og /var/1og/nginx/WWW.kgc.com-access.log;
#添加
location /post {
rewrite (.+) http://www.kgc.com/bbs$1 permanent; #这里的$1为位置变量,代表/post
}
location / {
root html;
index index.html index.htm;
}
}
mkdir -p /usr/local/nginx/html/bbs/post
echo "this is 1.html" >> /usr/1ocal/nginx/html/bbs/post/1 . html
echo "192.168.80.10 bbs.kgc.com"
systemctl restart nginx
使用浏览器访问http://bbs.kgc.com/post/1.html跳转到http://www. kgc.com/bbs/post/1.html
(4)根据参数匹配跳转
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章(针对各大门户网站))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-14 13:01
php用正则表达抓取网页中文章(针对各大门户网站如新浪、网易、腾讯、网易等);python用xpath处理含有相关关键字的网页;用requests异步加载网页中的json字符串;mysql处理数据库字符串;这里不再一一介绍
<p>看到这个题目,想到学校老师布置的每周小组作业,就是要批量下载网页中的中文标题。鉴于可以用较简单的语言来达到这个目的,我简单说一下思路。首先,打开chrome浏览器,打开开发者工具,并且按住ctrl+shift+s调出浏览器的代理栏。这里提一下,代理栏位于浏览器顶部。代理栏图标里包含”.”和”*”两个字符串,代理栏里存储的是你当前浏览器的代理ip地址,这个代理ip地址就相当于我们的机器电脑路由器端口,我们在浏览器中访问网页时,浏览器默认使用的地址栏里输入的其实就是浏览器中输入的该代理ip地址,要获取某网页的中文标题就是获取该代理ip对应的端口,思路大致如此。当然,我们有更好的办法。发布会 查看全部
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章(针对各大门户网站))
php用正则表达抓取网页中文章(针对各大门户网站如新浪、网易、腾讯、网易等);python用xpath处理含有相关关键字的网页;用requests异步加载网页中的json字符串;mysql处理数据库字符串;这里不再一一介绍
<p>看到这个题目,想到学校老师布置的每周小组作业,就是要批量下载网页中的中文标题。鉴于可以用较简单的语言来达到这个目的,我简单说一下思路。首先,打开chrome浏览器,打开开发者工具,并且按住ctrl+shift+s调出浏览器的代理栏。这里提一下,代理栏位于浏览器顶部。代理栏图标里包含”.”和”*”两个字符串,代理栏里存储的是你当前浏览器的代理ip地址,这个代理ip地址就相当于我们的机器电脑路由器端口,我们在浏览器中访问网页时,浏览器默认使用的地址栏里输入的其实就是浏览器中输入的该代理ip地址,要获取某网页的中文标题就是获取该代理ip对应的端口,思路大致如此。当然,我们有更好的办法。发布会
php用正则表达抓取网页中文章(Linux操作系统中只有三个命令使用正则技术(命令) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-12 18:17
)
一、基本概述
用户可以使用正则表达式技术来匹配和提取数据集中的一些特殊或关键数据。主要目的是模式匹配,比系统提供的str标准字符串处理函数更强大、更高效,因为str系列函数使用ASCII码以逐字符偏移比较的形式搜索修改后的字符数据,但 REGEX 使用贪心算法来匹配查询。
二、常规语句格式
正则语句是由一组匹配字符+特殊符号(元字符)组成的字符串,用于描述匹配数据的数据规则,最后根据正则语句进行模式匹配,得到关键内容。
三、数据规则
正则表达式是批量匹配和提取技术。用户首先要观察数据集,分析数据规则和数据特征,然后根据数据特征编辑相应的正则句(匹配字符串)。如果要匹配的数据没有特定的模式或规则,则正则表达式不可用。
例子:
DataFile_01:
BUG
99
吃鸡
189
LOL
98 //该数据集所有数据都有特定规则,可以使用正则表达式匹配获取特定数据
DataFile_02:
吃饭、213、喝奶茶2077、299、睡觉、1987、学习、232、132
//该数据集中没有明确数据规则,不太适合使用正则表达式
比如匹配DataFile_01数据集中的所有游戏名(这个现在可能不明白,但是看完你就明白了)
<p>游戏名 //文件中的数据规则
使用正则语句模拟这个数据规则:
[^ 查看全部
php用正则表达抓取网页中文章(Linux操作系统中只有三个命令使用正则技术(命令)
)
一、基本概述
用户可以使用正则表达式技术来匹配和提取数据集中的一些特殊或关键数据。主要目的是模式匹配,比系统提供的str标准字符串处理函数更强大、更高效,因为str系列函数使用ASCII码以逐字符偏移比较的形式搜索修改后的字符数据,但 REGEX 使用贪心算法来匹配查询。
二、常规语句格式
正则语句是由一组匹配字符+特殊符号(元字符)组成的字符串,用于描述匹配数据的数据规则,最后根据正则语句进行模式匹配,得到关键内容。
三、数据规则
正则表达式是批量匹配和提取技术。用户首先要观察数据集,分析数据规则和数据特征,然后根据数据特征编辑相应的正则句(匹配字符串)。如果要匹配的数据没有特定的模式或规则,则正则表达式不可用。
例子:
DataFile_01:
BUG
99
吃鸡
189
LOL
98 //该数据集所有数据都有特定规则,可以使用正则表达式匹配获取特定数据
DataFile_02:
吃饭、213、喝奶茶2077、299、睡觉、1987、学习、232、132
//该数据集中没有明确数据规则,不太适合使用正则表达式
比如匹配DataFile_01数据集中的所有游戏名(这个现在可能不明白,但是看完你就明白了)
<p>游戏名 //文件中的数据规则
使用正则语句模拟这个数据规则:
[^
php用正则表达抓取网页中文章(网页爬虫:就是一个程序用于在互联网中获取指定规则的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-11 10:12
网络爬虫:是用于在互联网上获取特定规则数据的程序。这篇文章主要详细介绍了使用正则表达式实现网络爬虫的思路。有需要的朋友可以参考以下
网络爬虫:是用于在互联网上获取特定规则数据的程序。
想法:
1.为了模拟网络爬虫,我们现在可以在我们的 tomcat 服务器上部署一个 1.html 网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++编辑,编辑内容为:
)
2.使用 URL 连接网页
3.获取读取网页内容的输入流
4.创建正则规则,因为这里我们抓取的是网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式:String regex="\w+@\w+(.\w+)+" ;
5.将提取的数据放入一个集合中。
代码:
`import java.io.BufferedReader;`
`import java.io.InputStream;`
`import java.io.InputStreamReader;`
`import java.net.URL;`
`import java.util.ArrayList;`
`import java.util.List;`
`import java.util.regex.Matcher;`
`import java.util.regex.Pattern;`
`/*`
`* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据`
`*`
`*`
`*/`
`public class RegexDemo {`
`public static void main(String[] args) throws Exception {`
`List list=getMailByWeb();`
`for``(String str:list){`
`System.out.println(str);`
`}`
`}`
`private static List getMailByWeb() throws Exception {`
`//1.与网页建立联系。使用URL`
`String path=``"[http://localhost:8080//1.html](http://localhost:8080//1.html)"``;//后面写双斜杠是用于转义`
`URL url=``new` `URL(path);`
`//2.获取输入流`
`InputStream is=url.openStream();`
`//加缓冲`
`BufferedReader br=``new` `BufferedReader(``new` `InputStreamReader(is));`
`//3.提取符合邮箱的数据`
`String regex=``"\\w+@\\w+(\\.\\w+)+"``;`
`//进行匹配`
`//将正则规则封装成对象`
`Pattern p=Pattern.compile(regex);`
`//将提取到的数据放到一个集合中`
`List list=``new` `ArrayList();`
`String line=``null``;`
`while``((line=br.readLine())!=``null``){`
`//匹配器`
`Matcher m=p.matcher(line);`
`while``(m.find()){`
`//3.将符合规则的数据存储到集合中`
`list.add(m.group());`
`}`
`}`
`return` `list;`
`}`
`}`
注意:执行前需要启动tomcat服务器
运行结果:
总结
以上就是对使用正则表达式实现网络爬虫的思路的详细解释。我希望它对你有帮助。如果您有任何问题,请给我留言 查看全部
php用正则表达抓取网页中文章(网页爬虫:就是一个程序用于在互联网中获取指定规则的数据)
网络爬虫:是用于在互联网上获取特定规则数据的程序。这篇文章主要详细介绍了使用正则表达式实现网络爬虫的思路。有需要的朋友可以参考以下
网络爬虫:是用于在互联网上获取特定规则数据的程序。
想法:
1.为了模拟网络爬虫,我们现在可以在我们的 tomcat 服务器上部署一个 1.html 网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++编辑,编辑内容为:
)
2.使用 URL 连接网页
3.获取读取网页内容的输入流
4.创建正则规则,因为这里我们抓取的是网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式:String regex="\w+@\w+(.\w+)+" ;
5.将提取的数据放入一个集合中。
代码:
`import java.io.BufferedReader;`
`import java.io.InputStream;`
`import java.io.InputStreamReader;`
`import java.net.URL;`
`import java.util.ArrayList;`
`import java.util.List;`
`import java.util.regex.Matcher;`
`import java.util.regex.Pattern;`
`/*`
`* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据`
`*`
`*`
`*/`
`public class RegexDemo {`
`public static void main(String[] args) throws Exception {`
`List list=getMailByWeb();`
`for``(String str:list){`
`System.out.println(str);`
`}`
`}`
`private static List getMailByWeb() throws Exception {`
`//1.与网页建立联系。使用URL`
`String path=``"[http://localhost:8080//1.html](http://localhost:8080//1.html)"``;//后面写双斜杠是用于转义`
`URL url=``new` `URL(path);`
`//2.获取输入流`
`InputStream is=url.openStream();`
`//加缓冲`
`BufferedReader br=``new` `BufferedReader(``new` `InputStreamReader(is));`
`//3.提取符合邮箱的数据`
`String regex=``"\\w+@\\w+(\\.\\w+)+"``;`
`//进行匹配`
`//将正则规则封装成对象`
`Pattern p=Pattern.compile(regex);`
`//将提取到的数据放到一个集合中`
`List list=``new` `ArrayList();`
`String line=``null``;`
`while``((line=br.readLine())!=``null``){`
`//匹配器`
`Matcher m=p.matcher(line);`
`while``(m.find()){`
`//3.将符合规则的数据存储到集合中`
`list.add(m.group());`
`}`
`}`
`return` `list;`
`}`
`}`
注意:执行前需要启动tomcat服务器
运行结果:
总结
以上就是对使用正则表达式实现网络爬虫的思路的详细解释。我希望它对你有帮助。如果您有任何问题,请给我留言
php用正则表达抓取网页中文章(前端技术营-前端学习者尽可能前端介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-10 14:06
欢迎来到前端技术营!如果你也是前端学习者或者有学习前端的想法,那就跟着我从零开始攻击前端吧。
我致力于尽可能详细简洁地介绍前端知识和自己的捷径,同时也是一个学习路上的记录。欢迎讨论
文章目录
JavaScript 高级正则表达式1.正则表达式概述1.1 什么是正则表达式
正则表达式 (Regular Expression) 是一种用于匹配字符串中字符组合的模式。在 JavaScript 中,正则表达式也是对象。
正则表通常用于检索和替换符合某种模式(规则)的文本,例如验证表单:用户名表单只能输入英文字母、数字或下划线,昵称输入框可以输入中文(匹配)。另外,正则表达式常用于过滤掉页面内容中的一些敏感词(替换),或者从字符串中获取我们想要的特定部分(提取)等。
其他语言也使用正则表达式。在这个阶段,我们主要使用 JavaScript 正则表达式来完成表单验证。
1.2 正则表达式非常灵活、合乎逻辑且功能强大。可以以非常简单的方式快速实现对字符串的复杂控制。对于刚接触它的人来说,它相当晦涩难懂。例如:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ 在实际开发中,通常是直接复制并编写好的正则表达式。但需要使用正则表达式,根据实际情况修改正则表达式。例如用户名:/^[a-z0-9_-]{3,16}$/ 2.正则表达式 js中公式的使用 2.1 正则表达式的创建
在 JavaScript 中,可以通过两种方式创建正则表达式。
方法一:调用RegExp对象的构造函数创建
var regexp = new RegExp(/123/);
console.log(regexp);
方法二:使用字面量创建正则表达式
var rg = /123/;
2.2 测试正则表达式
test() 正则对象方法,用于检查字符串是否符合规则,对象会返回真或假,其参数为测试字符串。
var rg = /123/;
console.log(rg.test(123));//匹配字符中是否出现123 出现结果为true
console.log(rg.test('abc'));//匹配字符中是否出现123 未出现结果为false
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-gN4RwCa1-90)(images/img4.png )]
3.正则表达式中的特殊字符3.1正则表达式的组成
正则表达式可以由简单字符组成,例如 /abc/,也可以由简单字符和特殊字符的组合组成,例如 /ab*c/。其中,特殊字符也称为元字符,是正则表达式中具有特殊含义的特殊符号,如^、$、+等。
有很多特殊字符,可以参考:
jQuery 手册:正则表达式部分
[常规测试工具]( 3.2 分隔符
正则表达式中的边界字符(位置字符)用来表示字符的位置,主要有两个字符
边界字符描述
^
表示与行首匹配的文本(以谁开头)
$
指示与行尾匹配的文本(以谁结尾)
如果 ^ 和 $ 在一起,它必须是完全匹配的。
var rg = /abc/; // 正则表达式里面不需要加引号 不管是数字型还是字符串型
// /abc/ 只要包含有abc这个字符串返回的都是true
console.log(rg.test('abc'));
console.log(rg.test('abcd'));
console.log(rg.test('aabcd'));
console.log('---------------------------');
var reg = /^abc/;
console.log(reg.test('abc')); // true
console.log(reg.test('abcd')); // true
console.log(reg.test('aabcd')); // false
console.log('---------------------------');
var reg1 = /^abc$/; // 精确匹配 要求必须是 abc字符串才符合规范
console.log(reg1.test('abc')); // true
console.log(reg1.test('abcd')); // false
console.log(reg1.test('aabcd')); // false
console.log(reg1.test('abcabc')); // false
3.3 个字符类
字符类表示有一系列字符可供选择,只需匹配其中一个即可。所有可选字符都括在方括号中。
3.3.1 [] 方括号
表示有一系列字符可供选择,匹配其中一个即可
var rg = /[abc]/; // 只要包含有a 或者 包含有b 或者包含有c 都返回为true
console.log(rg.test('andy'));//true
console.log(rg.test('baby'));//true
console.log(rg.test('color'));//true
console.log(rg.test('red'));//false
var rg1 = /^[abc]$/; // 三选一 只有是a 或者是 b 或者是c 这三个字母才返回 true
console.log(rg1.test('aa'));//false
console.log(rg1.test('a'));//true
console.log(rg1.test('b'));//true
console.log(rg1.test('c'));//true
console.log(rg1.test('abc'));//true
----------------------------------------------------------------------------------
var reg = /^[a-z]$/ //26个英文字母任何一个字母返回 true - 表示的是a 到z 的范围
console.log(reg.test('a'));//true
console.log(reg.test('z'));//true
console.log(reg.test('A'));//false
-----------------------------------------------------------------------------------
//字符组合
var reg1 = /^[a-zA-Z0-9]$/; // 26个英文字母(大写和小写都可以)任何一个字母返回 true
------------------------------------------------------------------------------------
//取反 方括号内部加上 ^ 表示取反,只要包含方括号内的字符,都返回 false 。
var reg2 = /^[^a-zA-Z0-9]$/;
console.log(reg2.test('a'));//false
console.log(reg2.test('B'));//false
console.log(reg2.test(8));//false
console.log(reg2.test('!'));//true
3.3.2 个量词
量词用于设置模式出现的次数。
量词说明
*
重复 0 次或多次
+
重复 1 次或多次
重复 0 或 1 次
{n}
重复n次
{n,}
重复n次或多次
{n,m}
重复 n 到 m 次
3.3.3用户名表单认证
功能要求:
如果用户名输入合法,提示信息如下:用户名合法,颜色为绿色 如果用户名输入非法,提示信息如下:用户名不符合规范,颜色是红色
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-sqr3LmaA-93)(images/img2.png )]
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-CimQuzYK-94)(images/img1.png )]
分析:
用户名只能由英文字母、数字、下划线或破折号组成,用户名长度为6~16个字符。首先准备这个正则表达式模式 /$[a-zA-Z0-9-_]{ 6,16}^/ 当表单失去焦点时开始验证。如果它符合常规规范,请将正确的类添加到以下 span 标记中。如果不符合常规规范,则将错误的类添加到后续的 span 标记中。
请输入用户名
// 量词是设定某个模式出现的次数
var reg = /^[a-zA-Z0-9_-]{6,16}$/; // 这个模式用户只能输入英文字母 数字 下划线 中划线
var uname = document.querySelector('.uname');
var span = document.querySelector('span');
uname.onblur = function() {
if (reg.test(this.value)) {
console.log('正确的');
span.className = 'right';
span.innerHTML = '用户名格式输入正确';
} else {
console.log('错误的');
span.className = 'wrong';
span.innerHTML = '用户名格式输入不正确';
}
}
3.3.4 括号内的摘要
1.大括号量词。表示重复次数
2.括号字符集。匹配方括号中的任何字符。
3.括号表示优先级
正则表达式在线测试
3.4 个预定义类
预定义类是指一些常见模式的简写。
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-cETagwqf-96)(images/img3.png )]
案例:验证座机号码
var reg = /^\d{3}-\d{8}|\d{4}-\d{7}$/;
var reg = /^\d{3,4}-\d{7,8}$/;
表单验证案例
//手机号验证:/^1[3|4|5|7|8][0-9]{9}$/;
//验证通过与不通过更换元素的类名与元素中的内容
if (reg.test(this.value)) {
// console.log('正确的');
this.nextElementSibling.className = 'success';
this.nextElementSibling.innerHTML = ' 恭喜您输入正确';
} else {
// console.log('不正确');
this.nextElementSibling.className = 'error';
this.nextElementSibling.innerHTML = '格式不正确,请从新输入 ';
}
//QQ号验证: /^[1-9]\d{4,}$/;
//昵称验证:/^[\u4e00-\u9fa5]{2,8}$/
//验证通过与不通过更换元素的类名与元素中的内容 ,将上一步的匹配代码进行封装,多次调用即可
function regexp(ele, reg) {
ele.onblur = function() {
if (reg.test(this.value)) {
// console.log('正确的');
this.nextElementSibling.className = 'success';
this.nextElementSibling.innerHTML = ' 恭喜您输入正确';
} else {
// console.log('不正确');
this.nextElementSibling.className = 'error';
this.nextElementSibling.innerHTML = ' 格式不正确,请从新输入 ';
}
}
};
//密码验证:/^[a-zA-Z0-9_-]{6,16}$/
//再次输入密码只需匹配与上次输入的密码值 是否一致
3.5 常规替换替换
replace() 方法可以实现替换字符串的操作,用于替换的参数可以是字符串,也可以是正则表达式。
var str = 'andy和red';
var newStr = str.replace('andy', 'baby');
console.log(newStr)//baby和red
//等同于 此处的andy可以写在正则表达式内
var newStr2 = str.replace(/andy/, 'baby');
console.log(newStr2)//baby和red
//全部替换
var str = 'abcabc'
var nStr = str.replace(/a/,'哈哈')
console.log(nStr) //哈哈bcabc
//全部替换g
var nStr = str.replace(/a/a,'哈哈')
console.log(nStr) //哈哈bc哈哈bc
//忽略大小写i
var str = 'aAbcAba';
var newStr = str.replace(/a/gi,'哈哈')//"哈哈哈哈bc哈哈b哈哈"
案例:过滤敏感词
提交
var text = document.querySelector('textarea');
var btn = document.querySelector('button');
var div = document.querySelector('div');
btn.onclick = function() {
div.innerHTML = text.value.replace(/激情|gay/g, '**');
}
4.面试题一、如何让事件冒泡然后捕捉
在原创事件流中,它首先被捕获然后冒泡。
对于目标元素,如果DOM节点通过addEventListener同时绑定了两个事件监听函数,一个用于捕获,一个用于冒泡,那么这两个事件的执行顺序是按照添加代码的顺序执行的。所以先绑定冒泡函数,再绑定捕获的函数来实现。
对于非目标元素,您可以将计时器添加到捕获事件的处理程序,将处理程序推送到下一个宏任务执行。
二、说说事件委托
事件委托是指不是在子节点上单独设置事件监听器,而是在父节点上设置事件监听器,然后每个子节点都可以利用冒泡原理触发事件。
事件委托的优点:Dom只运行一次,提高了程序的性能。
常用于:ul和li标签的事件监听,一般使用事件委托机制将事件监听器绑定到ul。
也适用于动态元素的绑定,新添加的子元素不需要单独添加事件处理器。
(1)你知道事件委托吗?这样做有什么好处?
事件代理/事件委托:使用事件冒泡,您可以通过仅指定一个事件处理程序来管理某种类型的事件。简而言之:事件代理就是我们将事件添加到最初添加的事件的父节点上。, 将事件委托给父节点触发handler函数,通常在有大量同级元素需要添加同类型事件时使用,比如动态列表有很多,需要为每个元素添加点击事件列表项,此时可以使用事件代理通过判断e.target.nodeName来确定具体发生的元素。这样做的好处是减少了事件绑定。同事的动态 DOM 结构依然可以被监控,事件代理发生在冒泡阶段。
(2)事件委托和冒泡原理:
事件委托是利用冒泡阶段的操作机制来实现的,即将一个元素响应事件的功能委托给另一个元素,一般将一组元素的事件委托给其父元素。
委托的好处是减少内存消耗,节省效率,动态绑定事件
事件冒泡是指元素本身的事件被触发后,如果父元素有相同的事件,比如onclick事件,那么会传递元素本身的触发状态,即父元素的相同事件元素将被传递给父元素。逐级按照嵌套关系向外触发,直到文档/窗口,冒泡过程结束。
(3)事件代理在捕获阶段的实际应用:
您可以在父元素级别阻止事件传播到子元素,或代表子元素执行某些操作。
本期到此结束,感谢阅读!如有任何问题,请留言并及时回复 查看全部
php用正则表达抓取网页中文章(前端技术营-前端学习者尽可能前端介绍)
欢迎来到前端技术营!如果你也是前端学习者或者有学习前端的想法,那就跟着我从零开始攻击前端吧。
我致力于尽可能详细简洁地介绍前端知识和自己的捷径,同时也是一个学习路上的记录。欢迎讨论
文章目录
JavaScript 高级正则表达式1.正则表达式概述1.1 什么是正则表达式
正则表达式 (Regular Expression) 是一种用于匹配字符串中字符组合的模式。在 JavaScript 中,正则表达式也是对象。
正则表通常用于检索和替换符合某种模式(规则)的文本,例如验证表单:用户名表单只能输入英文字母、数字或下划线,昵称输入框可以输入中文(匹配)。另外,正则表达式常用于过滤掉页面内容中的一些敏感词(替换),或者从字符串中获取我们想要的特定部分(提取)等。
其他语言也使用正则表达式。在这个阶段,我们主要使用 JavaScript 正则表达式来完成表单验证。
1.2 正则表达式非常灵活、合乎逻辑且功能强大。可以以非常简单的方式快速实现对字符串的复杂控制。对于刚接触它的人来说,它相当晦涩难懂。例如:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ 在实际开发中,通常是直接复制并编写好的正则表达式。但需要使用正则表达式,根据实际情况修改正则表达式。例如用户名:/^[a-z0-9_-]{3,16}$/ 2.正则表达式 js中公式的使用 2.1 正则表达式的创建
在 JavaScript 中,可以通过两种方式创建正则表达式。
方法一:调用RegExp对象的构造函数创建
var regexp = new RegExp(/123/);
console.log(regexp);
方法二:使用字面量创建正则表达式
var rg = /123/;
2.2 测试正则表达式
test() 正则对象方法,用于检查字符串是否符合规则,对象会返回真或假,其参数为测试字符串。
var rg = /123/;
console.log(rg.test(123));//匹配字符中是否出现123 出现结果为true
console.log(rg.test('abc'));//匹配字符中是否出现123 未出现结果为false
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-gN4RwCa1-90)(images/img4.png )]
3.正则表达式中的特殊字符3.1正则表达式的组成
正则表达式可以由简单字符组成,例如 /abc/,也可以由简单字符和特殊字符的组合组成,例如 /ab*c/。其中,特殊字符也称为元字符,是正则表达式中具有特殊含义的特殊符号,如^、$、+等。
有很多特殊字符,可以参考:
jQuery 手册:正则表达式部分
[常规测试工具]( 3.2 分隔符
正则表达式中的边界字符(位置字符)用来表示字符的位置,主要有两个字符
边界字符描述
^
表示与行首匹配的文本(以谁开头)
$
指示与行尾匹配的文本(以谁结尾)
如果 ^ 和 $ 在一起,它必须是完全匹配的。
var rg = /abc/; // 正则表达式里面不需要加引号 不管是数字型还是字符串型
// /abc/ 只要包含有abc这个字符串返回的都是true
console.log(rg.test('abc'));
console.log(rg.test('abcd'));
console.log(rg.test('aabcd'));
console.log('---------------------------');
var reg = /^abc/;
console.log(reg.test('abc')); // true
console.log(reg.test('abcd')); // true
console.log(reg.test('aabcd')); // false
console.log('---------------------------');
var reg1 = /^abc$/; // 精确匹配 要求必须是 abc字符串才符合规范
console.log(reg1.test('abc')); // true
console.log(reg1.test('abcd')); // false
console.log(reg1.test('aabcd')); // false
console.log(reg1.test('abcabc')); // false
3.3 个字符类
字符类表示有一系列字符可供选择,只需匹配其中一个即可。所有可选字符都括在方括号中。
3.3.1 [] 方括号
表示有一系列字符可供选择,匹配其中一个即可
var rg = /[abc]/; // 只要包含有a 或者 包含有b 或者包含有c 都返回为true
console.log(rg.test('andy'));//true
console.log(rg.test('baby'));//true
console.log(rg.test('color'));//true
console.log(rg.test('red'));//false
var rg1 = /^[abc]$/; // 三选一 只有是a 或者是 b 或者是c 这三个字母才返回 true
console.log(rg1.test('aa'));//false
console.log(rg1.test('a'));//true
console.log(rg1.test('b'));//true
console.log(rg1.test('c'));//true
console.log(rg1.test('abc'));//true
----------------------------------------------------------------------------------
var reg = /^[a-z]$/ //26个英文字母任何一个字母返回 true - 表示的是a 到z 的范围
console.log(reg.test('a'));//true
console.log(reg.test('z'));//true
console.log(reg.test('A'));//false
-----------------------------------------------------------------------------------
//字符组合
var reg1 = /^[a-zA-Z0-9]$/; // 26个英文字母(大写和小写都可以)任何一个字母返回 true
------------------------------------------------------------------------------------
//取反 方括号内部加上 ^ 表示取反,只要包含方括号内的字符,都返回 false 。
var reg2 = /^[^a-zA-Z0-9]$/;
console.log(reg2.test('a'));//false
console.log(reg2.test('B'));//false
console.log(reg2.test(8));//false
console.log(reg2.test('!'));//true
3.3.2 个量词
量词用于设置模式出现的次数。
量词说明
*
重复 0 次或多次
+
重复 1 次或多次
重复 0 或 1 次
{n}
重复n次
{n,}
重复n次或多次
{n,m}
重复 n 到 m 次
3.3.3用户名表单认证
功能要求:
如果用户名输入合法,提示信息如下:用户名合法,颜色为绿色 如果用户名输入非法,提示信息如下:用户名不符合规范,颜色是红色
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-sqr3LmaA-93)(images/img2.png )]
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-CimQuzYK-94)(images/img1.png )]
分析:
用户名只能由英文字母、数字、下划线或破折号组成,用户名长度为6~16个字符。首先准备这个正则表达式模式 /$[a-zA-Z0-9-_]{ 6,16}^/ 当表单失去焦点时开始验证。如果它符合常规规范,请将正确的类添加到以下 span 标记中。如果不符合常规规范,则将错误的类添加到后续的 span 标记中。
请输入用户名
// 量词是设定某个模式出现的次数
var reg = /^[a-zA-Z0-9_-]{6,16}$/; // 这个模式用户只能输入英文字母 数字 下划线 中划线
var uname = document.querySelector('.uname');
var span = document.querySelector('span');
uname.onblur = function() {
if (reg.test(this.value)) {
console.log('正确的');
span.className = 'right';
span.innerHTML = '用户名格式输入正确';
} else {
console.log('错误的');
span.className = 'wrong';
span.innerHTML = '用户名格式输入不正确';
}
}
3.3.4 括号内的摘要
1.大括号量词。表示重复次数
2.括号字符集。匹配方括号中的任何字符。
3.括号表示优先级
正则表达式在线测试
3.4 个预定义类
预定义类是指一些常见模式的简写。
【外链图片传输失败,源站可能有防盗链机制,建议保存图片直接上传(img-cETagwqf-96)(images/img3.png )]
案例:验证座机号码
var reg = /^\d{3}-\d{8}|\d{4}-\d{7}$/;
var reg = /^\d{3,4}-\d{7,8}$/;
表单验证案例
//手机号验证:/^1[3|4|5|7|8][0-9]{9}$/;
//验证通过与不通过更换元素的类名与元素中的内容
if (reg.test(this.value)) {
// console.log('正确的');
this.nextElementSibling.className = 'success';
this.nextElementSibling.innerHTML = ' 恭喜您输入正确';
} else {
// console.log('不正确');
this.nextElementSibling.className = 'error';
this.nextElementSibling.innerHTML = '格式不正确,请从新输入 ';
}
//QQ号验证: /^[1-9]\d{4,}$/;
//昵称验证:/^[\u4e00-\u9fa5]{2,8}$/
//验证通过与不通过更换元素的类名与元素中的内容 ,将上一步的匹配代码进行封装,多次调用即可
function regexp(ele, reg) {
ele.onblur = function() {
if (reg.test(this.value)) {
// console.log('正确的');
this.nextElementSibling.className = 'success';
this.nextElementSibling.innerHTML = ' 恭喜您输入正确';
} else {
// console.log('不正确');
this.nextElementSibling.className = 'error';
this.nextElementSibling.innerHTML = ' 格式不正确,请从新输入 ';
}
}
};
//密码验证:/^[a-zA-Z0-9_-]{6,16}$/
//再次输入密码只需匹配与上次输入的密码值 是否一致
3.5 常规替换替换
replace() 方法可以实现替换字符串的操作,用于替换的参数可以是字符串,也可以是正则表达式。
var str = 'andy和red';
var newStr = str.replace('andy', 'baby');
console.log(newStr)//baby和red
//等同于 此处的andy可以写在正则表达式内
var newStr2 = str.replace(/andy/, 'baby');
console.log(newStr2)//baby和red
//全部替换
var str = 'abcabc'
var nStr = str.replace(/a/,'哈哈')
console.log(nStr) //哈哈bcabc
//全部替换g
var nStr = str.replace(/a/a,'哈哈')
console.log(nStr) //哈哈bc哈哈bc
//忽略大小写i
var str = 'aAbcAba';
var newStr = str.replace(/a/gi,'哈哈')//"哈哈哈哈bc哈哈b哈哈"
案例:过滤敏感词
提交
var text = document.querySelector('textarea');
var btn = document.querySelector('button');
var div = document.querySelector('div');
btn.onclick = function() {
div.innerHTML = text.value.replace(/激情|gay/g, '**');
}
4.面试题一、如何让事件冒泡然后捕捉
在原创事件流中,它首先被捕获然后冒泡。
对于目标元素,如果DOM节点通过addEventListener同时绑定了两个事件监听函数,一个用于捕获,一个用于冒泡,那么这两个事件的执行顺序是按照添加代码的顺序执行的。所以先绑定冒泡函数,再绑定捕获的函数来实现。
对于非目标元素,您可以将计时器添加到捕获事件的处理程序,将处理程序推送到下一个宏任务执行。
二、说说事件委托
事件委托是指不是在子节点上单独设置事件监听器,而是在父节点上设置事件监听器,然后每个子节点都可以利用冒泡原理触发事件。
事件委托的优点:Dom只运行一次,提高了程序的性能。
常用于:ul和li标签的事件监听,一般使用事件委托机制将事件监听器绑定到ul。
也适用于动态元素的绑定,新添加的子元素不需要单独添加事件处理器。
(1)你知道事件委托吗?这样做有什么好处?
事件代理/事件委托:使用事件冒泡,您可以通过仅指定一个事件处理程序来管理某种类型的事件。简而言之:事件代理就是我们将事件添加到最初添加的事件的父节点上。, 将事件委托给父节点触发handler函数,通常在有大量同级元素需要添加同类型事件时使用,比如动态列表有很多,需要为每个元素添加点击事件列表项,此时可以使用事件代理通过判断e.target.nodeName来确定具体发生的元素。这样做的好处是减少了事件绑定。同事的动态 DOM 结构依然可以被监控,事件代理发生在冒泡阶段。
(2)事件委托和冒泡原理:
事件委托是利用冒泡阶段的操作机制来实现的,即将一个元素响应事件的功能委托给另一个元素,一般将一组元素的事件委托给其父元素。
委托的好处是减少内存消耗,节省效率,动态绑定事件
事件冒泡是指元素本身的事件被触发后,如果父元素有相同的事件,比如onclick事件,那么会传递元素本身的触发状态,即父元素的相同事件元素将被传递给父元素。逐级按照嵌套关系向外触发,直到文档/窗口,冒泡过程结束。
(3)事件代理在捕获阶段的实际应用:
您可以在父元素级别阻止事件传播到子元素,或代表子元素执行某些操作。
本期到此结束,感谢阅读!如有任何问题,请留言并及时回复
php用正则表达抓取网页中文章(如何利用Python语言提取文中特定内容?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-10 08:01
正则表达式是一种特殊的字符序列,可以帮助您轻松地检查字符串是否与特定模式匹配。
Python 从 1.5 开始添加了 re 模块,它提供 Perl 风格的正则表达式模式。
re 模块为 Python 语言带来了完整的正则表达式功能。
compile 函数从模式字符串和可选标志参数生成正则表达式对象。这个对象有一系列正则表达式匹配和替换的方法。
re 模块还提供与这些方法完全相同的功能,它们将模式字符串作为其第一个参数。
如何使用正则表达式提取文本中的特定内容?功能介绍:
pile():该函数用于生成正则表达式,是匹配的核心部分。它用于定义您需要如何匹配以及匹配什么。更多详情请参考菜鸟教程。
2.re.findall():该函数用于在指定的字符串中进行匹配。
提取具体内容:
1.在一段文本或字符串中从某位置XXX提取特定内容到某位置X:pile('XXX.+X'),例如:
import re
str='abcd1234efg'
pattern=re.compile('ab.+ef') #匹配从ab开始,到ef结束的内容
result=pattern.findall(str)
print(result)
运行结果如下
['abcd1234ef']
2.在一段文本或字符串中从某位置XXX提取特定内容到某位置X:pile('XXX(.+)X')
import re
str='abcd1234efg'
pattern=re.compile('ab(.+)ef') #匹配ab与ef之间的内容
result=pattern.findall(str)
print(result)
运行结果如下
['cd1234']
所以从这两个匹配可以看出,两者的主要区别在于有无(),一个很实用的方法~~ 查看全部
php用正则表达抓取网页中文章(如何利用Python语言提取文中特定内容?(一))
正则表达式是一种特殊的字符序列,可以帮助您轻松地检查字符串是否与特定模式匹配。
Python 从 1.5 开始添加了 re 模块,它提供 Perl 风格的正则表达式模式。
re 模块为 Python 语言带来了完整的正则表达式功能。
compile 函数从模式字符串和可选标志参数生成正则表达式对象。这个对象有一系列正则表达式匹配和替换的方法。
re 模块还提供与这些方法完全相同的功能,它们将模式字符串作为其第一个参数。
如何使用正则表达式提取文本中的特定内容?功能介绍:
pile():该函数用于生成正则表达式,是匹配的核心部分。它用于定义您需要如何匹配以及匹配什么。更多详情请参考菜鸟教程。
2.re.findall():该函数用于在指定的字符串中进行匹配。
提取具体内容:
1.在一段文本或字符串中从某位置XXX提取特定内容到某位置X:pile('XXX.+X'),例如:
import re
str='abcd1234efg'
pattern=re.compile('ab.+ef') #匹配从ab开始,到ef结束的内容
result=pattern.findall(str)
print(result)
运行结果如下
['abcd1234ef']
2.在一段文本或字符串中从某位置XXX提取特定内容到某位置X:pile('XXX(.+)X')
import re
str='abcd1234efg'
pattern=re.compile('ab(.+)ef') #匹配ab与ef之间的内容
result=pattern.findall(str)
print(result)
运行结果如下
['cd1234']
所以从这两个匹配可以看出,两者的主要区别在于有无(),一个很实用的方法~~
php用正则表达抓取网页中文章(正则表达式自动生成器v2.0.0语法大全正则表达式是什么意思?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-10 07:20
正则表达式生成器好用吗?正则表达式自动生成器是一款智能的正则表达式生成工具。用户可以通过它快速生成正则表达式、测试、字符串提取函数。正则表达式库让你可以直接借用正则表达式,而不必自己动手。“正则表达式自动生成器”可以自动生成正则表达式、测试正则表达式、可视化结果、导出提取的字符串,只需点击几下鼠标!
点击进入:正则表达式在线生成工具
点击进入:正则表达式在线测试工具
点击进入:正则表达式代码生成工具
自动生成正则表达式
编辑和测试正则表达式
用于在多个源文本上测试相同正则表达式的多向导页面(标准版本中不可用)
为多页引用生成正则表达式(标准版本中不可用)
自动检查和修改生成的正则表达式的正确性
直观呈现测试结果
从文本文件中获取源文本
从 HTML 页面获取源代码
一键导出匹配文本
一键导出提取字符组并通过自定义分隔符分隔
保存项目以供重复测试和修改
在 Design Elements 中学习和创建正则表达式
通过直接从正则表达式库中选择来利用正则表达式
多种语言
100%-200%大字体下完美显示
您可以从任何纯文本中提取常规文本,例如txt文件、XML文件、csv文件、HTML文件等,然后导出到剪贴板或文本文件,您可以轻松地将它们导入程序、数据库、excel文件等.
正则表达式自动生成器现在支持三种语言:
英文、简体中文、繁体中文,我们以后会增加日文、德文、法文等其他语言。
正则表达式自动生成器 v2.0.0 专业版更新:
1、修复一些小错误。
2、为自定义组和限定符添加正则表达式
3、添加自定义窗口背景
4、添加自定义按钮背景
5、修改软件时间为UTC时间(日志除外)
6、修改更新模块
推荐阅读:什么是正则表达式?什么是正则表达式在线生成器工具?什么是正则表达式?在编写处理字符串的程序或网页时,往往需要寻找符合某些复杂规则的字符串需要...正则表达式是什么意思?正则表达式是什么意思?正则表达式(regular expression)描述了一种字符串匹配模式(patte... 什么是阿里云高防IP?阿里云DDos高防IP介绍及价目表 什么是阿里云高防IP?云高防DDoS Pro是针对互联网服务器遭受大流量DDoS攻击导致服务不可用的情况推出的。... 查看全部
php用正则表达抓取网页中文章(正则表达式自动生成器v2.0.0语法大全正则表达式是什么意思?)
正则表达式生成器好用吗?正则表达式自动生成器是一款智能的正则表达式生成工具。用户可以通过它快速生成正则表达式、测试、字符串提取函数。正则表达式库让你可以直接借用正则表达式,而不必自己动手。“正则表达式自动生成器”可以自动生成正则表达式、测试正则表达式、可视化结果、导出提取的字符串,只需点击几下鼠标!
点击进入:正则表达式在线生成工具
点击进入:正则表达式在线测试工具
点击进入:正则表达式代码生成工具
自动生成正则表达式
编辑和测试正则表达式
用于在多个源文本上测试相同正则表达式的多向导页面(标准版本中不可用)
为多页引用生成正则表达式(标准版本中不可用)
自动检查和修改生成的正则表达式的正确性
直观呈现测试结果
从文本文件中获取源文本
从 HTML 页面获取源代码
一键导出匹配文本
一键导出提取字符组并通过自定义分隔符分隔
保存项目以供重复测试和修改
在 Design Elements 中学习和创建正则表达式
通过直接从正则表达式库中选择来利用正则表达式
多种语言
100%-200%大字体下完美显示
您可以从任何纯文本中提取常规文本,例如txt文件、XML文件、csv文件、HTML文件等,然后导出到剪贴板或文本文件,您可以轻松地将它们导入程序、数据库、excel文件等.
正则表达式自动生成器现在支持三种语言:
英文、简体中文、繁体中文,我们以后会增加日文、德文、法文等其他语言。
正则表达式自动生成器 v2.0.0 专业版更新:
1、修复一些小错误。
2、为自定义组和限定符添加正则表达式
3、添加自定义窗口背景
4、添加自定义按钮背景
5、修改软件时间为UTC时间(日志除外)
6、修改更新模块
推荐阅读:什么是正则表达式?什么是正则表达式在线生成器工具?什么是正则表达式?在编写处理字符串的程序或网页时,往往需要寻找符合某些复杂规则的字符串需要...正则表达式是什么意思?正则表达式是什么意思?正则表达式(regular expression)描述了一种字符串匹配模式(patte... 什么是阿里云高防IP?阿里云DDos高防IP介绍及价目表 什么是阿里云高防IP?云高防DDoS Pro是针对互联网服务器遭受大流量DDoS攻击导致服务不可用的情况推出的。...
php用正则表达抓取网页中文章(我只需要拼过那些优采云我就一定会超越大部分人!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-09 07:18
我不用打败聪明人,只要打败那些优采云,我一定会超过大多数人!
极客小君@知乎,正式出道原创文章
博客:极客君
PHP 正则表达式中的反向引用
反向引用主要体现在 php.ini 中的 preg_replace() 函数中。我之前提到这里做了一个小补充:
\n 和 ${n} 在使用上的区别: Tips:
n 可以是 0-99\0 并且 $0 表示完整的模式匹配文本
直接上代码案例:
//字符串
$string='PHP面向对象编程开发http://www.php.com,CSDN';
//要查找的
$pattern='/CSDN/is';
//替换为: 方式1
$replace='\03721技术社区学习论坛';
//替换为: 方式2
$replace='${0}技术社区学习论坛';
//开始替换
$result=preg_replace($pattern,$replace,$string);
//输出结果
show($result);
好的,反向引用在这里。
正则表达式到此告一段落。我在工作和学习中使用了这些技术。我把这些东西总结成文章分享给大家,希望能给大家和应届毕业生带来一些帮助!
我以后会更新其他技术文章就留在这里吧!!
如果对你有帮助,如果你喜欢我的内容,请一键“点赞”“评论”“采集”!
以上内容如有错误或不准确之处,请在下方留言,或者您有更好的想法,欢迎大家一起交流学习
前端html+css+javascript技术讨论群:281499395
后端php+mysql+Linux技术交流群:855256321 查看全部
php用正则表达抓取网页中文章(我只需要拼过那些优采云我就一定会超越大部分人!)
我不用打败聪明人,只要打败那些优采云,我一定会超过大多数人!
极客小君@知乎,正式出道原创文章
博客:极客君
PHP 正则表达式中的反向引用
反向引用主要体现在 php.ini 中的 preg_replace() 函数中。我之前提到这里做了一个小补充:
\n 和 ${n} 在使用上的区别: Tips:
n 可以是 0-99\0 并且 $0 表示完整的模式匹配文本
直接上代码案例:
//字符串
$string='PHP面向对象编程开发http://www.php.com,CSDN';
//要查找的
$pattern='/CSDN/is';
//替换为: 方式1
$replace='\03721技术社区学习论坛';
//替换为: 方式2
$replace='${0}技术社区学习论坛';
//开始替换
$result=preg_replace($pattern,$replace,$string);
//输出结果
show($result);
好的,反向引用在这里。
正则表达式到此告一段落。我在工作和学习中使用了这些技术。我把这些东西总结成文章分享给大家,希望能给大家和应届毕业生带来一些帮助!
我以后会更新其他技术文章就留在这里吧!!
如果对你有帮助,如果你喜欢我的内容,请一键“点赞”“评论”“采集”!
以上内容如有错误或不准确之处,请在下方留言,或者您有更好的想法,欢迎大家一起交流学习
前端html+css+javascript技术讨论群:281499395
后端php+mysql+Linux技术交流群:855256321
php用正则表达抓取网页中文章(网页爬虫:就是一个部署一个1.html网页的思路和思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-09 06:06
网络爬虫:是用于在互联网上获取特定规则数据的程序。
想法:
1.为了模拟一个网络爬虫,我们现在可以在我们的 tomcat 服务器上部署一个 1.html 网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++编辑,编辑内容为:
)
2.使用 URL 连接网页
3.获取读取网页内容的输入流
4.创建正则规则,因为这里我们是抓取网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式:String regex="\w+@\w+(\.\w+)+ ";
5.将提取的数据放入一个集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String[] args) throws Exception {
List list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List list=new ArrayList();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:执行前需要启动tomcat服务器
运行结果:
总结
以上就是小编介绍的使用正则表达式实现网络爬虫的思路的详细讲解。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。还要感谢大家对脚本之家网站的支持! 查看全部
php用正则表达抓取网页中文章(网页爬虫:就是一个部署一个1.html网页的思路和思路)
网络爬虫:是用于在互联网上获取特定规则数据的程序。
想法:
1.为了模拟一个网络爬虫,我们现在可以在我们的 tomcat 服务器上部署一个 1.html 网页。(部署步骤:在tomcat目录的webapps目录的ROOTS目录下新建1.html。使用notepad++编辑,编辑内容为:
)
2.使用 URL 连接网页
3.获取读取网页内容的输入流
4.创建正则规则,因为这里我们是抓取网页中的邮箱信息,所以创建一个匹配邮箱的正则表达式:String regex="\w+@\w+(\.\w+)+ ";
5.将提取的数据放入一个集合中。
代码:
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/*
* 网页爬虫:就是一个程序用于在互联网中获取指定规则的数据
*
*
*/
public class RegexDemo {
public static void main(String[] args) throws Exception {
List list=getMailByWeb();
for(String str:list){
System.out.println(str);
}
}
private static List getMailByWeb() throws Exception {
//1.与网页建立联系。使用URL
String path="http://localhost:8080//1.html";//后面写双斜杠是用于转义
URL url=new URL(path);
//2.获取输入流
InputStream is=url.openStream();
//加缓冲
BufferedReader br=new BufferedReader(new InputStreamReader(is));
//3.提取符合邮箱的数据
String regex="\\w+@\\w+(\\.\\w+)+";
//进行匹配
//将正则规则封装成对象
Pattern p=Pattern.compile(regex);
//将提取到的数据放到一个集合中
List list=new ArrayList();
String line=null;
while((line=br.readLine())!=null){
//匹配器
Matcher m=p.matcher(line);
while(m.find()){
//3.将符合规则的数据存储到集合中
list.add(m.group());
}
}
return list;
}
}
注意:执行前需要启动tomcat服务器
运行结果:
总结
以上就是小编介绍的使用正则表达式实现网络爬虫的思路的详细讲解。我希望它对你有帮助。有任何问题请给我留言,小编会及时回复你的。还要感谢大家对脚本之家网站的支持!
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章信息fromseleniumimportwebdriverwithwebdriver)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-08 21:04
php用正则表达抓取网页中文章信息fromseleniumimportwebdriverwithwebdriver。chrome_options('--prefix=c:\\www\\text。txt')asw:writer=webdriver。webdriver。chrome()source=stringio。
stringio(u'php"hello')foriinrange(source):ifi!="":print(i)writer。writeline(i)。
这是一个可抓取的网站,里面的信息你可以尝试自己抓取下。
可以到这里去找的。(;redirect_uri=)。
竟然没有人找这个呢,
直接post,
post的时候用data参数,一般都在headers里。
post请求获取网页信息()
找到了,国内的做图片下载的网站只能在手机上看,在别的平台看图片显示效果很差,以前想到的方法就是用session,不过看起来没有一个服务器,
这个很简单吧sitemap是我们平时经常使用的一个图片下载工具
fromseleniumimportwebdriverdriver=webdriver。chrome()driver。maximize_window()try:fromtaglibimporttaglibimporttemplatewriterastws=webdriver。chrome('windows')target='windows'targetpath=ws。
get_targetpath(targetpath)excepttimeouterroraswerror:ws。responsetext='网页下载工具'page=ws。get_page(targetpath,end='')exceptwerroraswerror:ws。setsize(xforxintargetpath。get_targetinfo(page))page。setattribute('h1','h1')。 查看全部
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章信息fromseleniumimportwebdriverwithwebdriver)
php用正则表达抓取网页中文章信息fromseleniumimportwebdriverwithwebdriver。chrome_options('--prefix=c:\\www\\text。txt')asw:writer=webdriver。webdriver。chrome()source=stringio。
stringio(u'php"hello')foriinrange(source):ifi!="":print(i)writer。writeline(i)。
这是一个可抓取的网站,里面的信息你可以尝试自己抓取下。
可以到这里去找的。(;redirect_uri=)。
竟然没有人找这个呢,
直接post,
post的时候用data参数,一般都在headers里。
post请求获取网页信息()
找到了,国内的做图片下载的网站只能在手机上看,在别的平台看图片显示效果很差,以前想到的方法就是用session,不过看起来没有一个服务器,
这个很简单吧sitemap是我们平时经常使用的一个图片下载工具
fromseleniumimportwebdriverdriver=webdriver。chrome()driver。maximize_window()try:fromtaglibimporttaglibimporttemplatewriterastws=webdriver。chrome('windows')target='windows'targetpath=ws。
get_targetpath(targetpath)excepttimeouterroraswerror:ws。responsetext='网页下载工具'page=ws。get_page(targetpath,end='')exceptwerroraswerror:ws。setsize(xforxintargetpath。get_targetinfo(page))page。setattribute('h1','h1')。
php用正则表达抓取网页中文章(Python正则表达式转义(转义问题)的相关内容吗在本文为您仔细讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-06 13:05
想知道Python正则表达式的相关内容(转义问题)吗?在本文中,我将仔细讲解Python正则表达式转义的相关知识和一些代码示例。欢迎阅读和纠正我们。先说重点:Python、正则表达式、迁移大家一起学习。
先说一件比较尴尬的事情:我在编写虾米音乐预览下载器的时候遇到了一个问题。因为保存的文件都是以曲名命名的,所以遇到了“対芝/out border”等非法字符(呵呵)。哼哼说当你→_→Windows时保存标题会失败)。于是想到了迅雷的解决办法:将所有非法字符全部替换为下划线。
于是引入了正则表达式的使用。经过一番搜索,我写了一个这样的函数:
复制代码代码如下:
def sanitize_filename(文件名):
return re.sub('[\/:*?|]','_', 文件名)
最近发现这个函数有很多问题:
所以我认真看文件。
原创字符串
看了文档,发现Python正则表达式模块的转义是独立的。例如,要匹配一个反斜杠字符,您需要将参数写为:'\\\\':
Python 转义字符串:\\\\ 被转义为 \\
re模块获取传入的\\并解释为正则表达式,根据正则表达式转义规则转义为\
在这样繁琐的前提下,Raw String 是非常有用的,顾名思义(尾随反斜杠除外),不会被转义。所以匹配一个反斜杠字符可以写成 r'\\'。
所以上面的 sanitize_filename 改为:
复制代码代码如下:
def sanitize_filename(文件名):
return re.sub(r'[\\/:*?|]','_', 文件名)
正则表达式和匹配
所以还是认真的看一下re模块吧~以下是流水账,不耐烦查看。
Python 的正则表达式模块 re 中的主要对象其实就是这两个:
正则表达式 RegexObject
匹配对象
RegexObject 是一个正则表达式对象,match sub 等所有操作都属于它。由堆(模式,标志)生成。
复制代码代码如下:
>>> email_pattern = 桩(r'\w+@\w+\.\w+')
>>> email_pattern.findall('我的电子邮件是他的')
['','']
方法:
搜索从任何字符开始并返回 MatchObject 或 None
匹配从第一个字符开始并返回 MatchObject 或 None
split 返回由匹配项拆分的列表
findall 返回所有匹配项的列表
finditr 返回 MatchObject 的迭代器
sub 返回替换后的字符串
subn 返回(替换后的字符串,替换次数)
re模块中提供的re.sub、re.match、re.findall等函数,其实可以看作是避免直接创建正则表达式对象的捷径。并且因为 RegexObject 对象本身可以重复使用,所以这是它相对于这些快捷函数的优势。
MatchObject 是表示正则表达式匹配结果的匹配对象。由 RegexObject 的一些方法返回。匹配的对象始终为 True。另外,在正则表达式中获取组信息的方法也很多。
复制代码代码如下:
>>> for m in re.finditer(r'(\w+)@\w+\.\w+','My email is and his is'):
...打印'%d-%d %s %s'% (m.start(0), m.end(0), m.group(1), m.group (0))
...
12-23 美国广播公司
35-51 用户
参考
相关文章 查看全部
php用正则表达抓取网页中文章(Python正则表达式转义(转义问题)的相关内容吗在本文为您仔细讲解)
想知道Python正则表达式的相关内容(转义问题)吗?在本文中,我将仔细讲解Python正则表达式转义的相关知识和一些代码示例。欢迎阅读和纠正我们。先说重点:Python、正则表达式、迁移大家一起学习。
先说一件比较尴尬的事情:我在编写虾米音乐预览下载器的时候遇到了一个问题。因为保存的文件都是以曲名命名的,所以遇到了“対芝/out border”等非法字符(呵呵)。哼哼说当你→_→Windows时保存标题会失败)。于是想到了迅雷的解决办法:将所有非法字符全部替换为下划线。
于是引入了正则表达式的使用。经过一番搜索,我写了一个这样的函数:
复制代码代码如下:
def sanitize_filename(文件名):
return re.sub('[\/:*?|]','_', 文件名)
最近发现这个函数有很多问题:
所以我认真看文件。
原创字符串
看了文档,发现Python正则表达式模块的转义是独立的。例如,要匹配一个反斜杠字符,您需要将参数写为:'\\\\':
Python 转义字符串:\\\\ 被转义为 \\
re模块获取传入的\\并解释为正则表达式,根据正则表达式转义规则转义为\
在这样繁琐的前提下,Raw String 是非常有用的,顾名思义(尾随反斜杠除外),不会被转义。所以匹配一个反斜杠字符可以写成 r'\\'。
所以上面的 sanitize_filename 改为:
复制代码代码如下:
def sanitize_filename(文件名):
return re.sub(r'[\\/:*?|]','_', 文件名)
正则表达式和匹配
所以还是认真的看一下re模块吧~以下是流水账,不耐烦查看。
Python 的正则表达式模块 re 中的主要对象其实就是这两个:
正则表达式 RegexObject
匹配对象
RegexObject 是一个正则表达式对象,match sub 等所有操作都属于它。由堆(模式,标志)生成。
复制代码代码如下:
>>> email_pattern = 桩(r'\w+@\w+\.\w+')
>>> email_pattern.findall('我的电子邮件是他的')
['','']
方法:
搜索从任何字符开始并返回 MatchObject 或 None
匹配从第一个字符开始并返回 MatchObject 或 None
split 返回由匹配项拆分的列表
findall 返回所有匹配项的列表
finditr 返回 MatchObject 的迭代器
sub 返回替换后的字符串
subn 返回(替换后的字符串,替换次数)
re模块中提供的re.sub、re.match、re.findall等函数,其实可以看作是避免直接创建正则表达式对象的捷径。并且因为 RegexObject 对象本身可以重复使用,所以这是它相对于这些快捷函数的优势。
MatchObject 是表示正则表达式匹配结果的匹配对象。由 RegexObject 的一些方法返回。匹配的对象始终为 True。另外,在正则表达式中获取组信息的方法也很多。
复制代码代码如下:
>>> for m in re.finditer(r'(\w+)@\w+\.\w+','My email is and his is'):
...打印'%d-%d %s %s'% (m.start(0), m.end(0), m.group(1), m.group (0))
...
12-23 美国广播公司
35-51 用户
参考
相关文章
php用正则表达抓取网页中文章(精品文档2016全新精品资料-全新公文范文-全程指导写作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-06 04:02
Fine Documents 2016 全新精品素材-全新官方文档样例-完整指导写作-独家原创 如何使用PHP抓取页面中的URL到另一个元素(文本、图像、视频等)。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。让我们来谈谈绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 的结构由三部分组成:协议、服务器名、路径和文件名。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。
在FTP协议中,也可以收录用户名和密码,本文不考虑。拆分,指出文件的路径和文件本身的名称。如果没有具体的文件名,请访问这个精品文档 2016 全新精品信息-全新官方文档样本-完整指导写作-独家原创 可以的字符范围有明确的规范各部分使用。详情请参考RFC1738。然后就可以写正则表达式了。写到这里,基本上大部分的url都可以匹配,但是带参数的url爬不出来,可能会导致再次访问时页面报错。关于RFC1738规范中要求的参数,有没有用到?要分段,后面有参数,但是现代 RIA 应用程序可能会使用其他奇怪的形式进行分割。稍作修改,即可搜索查询参数部分。还是没有涵盖所有的情况,比如URL中的中文、空格等特殊字符,但是基本可以满足我的需求,所以就没有继续深入了。精品文档2016全新精品素材-全新官方文档范文-全程指导写作-独家原创/(http|ftp|https):\/\/([\w\d\-_] +[\.\w \d\-_]+)[:\d+]?([\/]?[\w\/\.\?=&;%@#\+,]+)/i使用括号的好处是,在处理结果时,可以方便的获取到协议内容、域名、相对路径,方便后续处理。例如,当使用 preg_match_all() 进行匹配时,结果数组索引为所有结果为0,协议为1,域名为2,相对路径为3。以上就是使用PHP的正则抓取页面中URL的全部内容,希望对大家使用PHP有所帮助。 查看全部
php用正则表达抓取网页中文章(精品文档2016全新精品资料-全新公文范文-全程指导写作)
Fine Documents 2016 全新精品素材-全新官方文档样例-完整指导写作-独家原创 如何使用PHP抓取页面中的URL到另一个元素(文本、图像、视频等)。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。让我们来谈谈绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 的结构由三部分组成:协议、服务器名、路径和文件名。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。服务器名称是告诉浏览器如何到达该服务器的方式。它通常是域名或IP地址,有时还包括端口号(默认为80)。
在FTP协议中,也可以收录用户名和密码,本文不考虑。拆分,指出文件的路径和文件本身的名称。如果没有具体的文件名,请访问这个精品文档 2016 全新精品信息-全新官方文档样本-完整指导写作-独家原创 可以的字符范围有明确的规范各部分使用。详情请参考RFC1738。然后就可以写正则表达式了。写到这里,基本上大部分的url都可以匹配,但是带参数的url爬不出来,可能会导致再次访问时页面报错。关于RFC1738规范中要求的参数,有没有用到?要分段,后面有参数,但是现代 RIA 应用程序可能会使用其他奇怪的形式进行分割。稍作修改,即可搜索查询参数部分。还是没有涵盖所有的情况,比如URL中的中文、空格等特殊字符,但是基本可以满足我的需求,所以就没有继续深入了。精品文档2016全新精品素材-全新官方文档范文-全程指导写作-独家原创/(http|ftp|https):\/\/([\w\d\-_] +[\.\w \d\-_]+)[:\d+]?([\/]?[\w\/\.\?=&;%@#\+,]+)/i使用括号的好处是,在处理结果时,可以方便的获取到协议内容、域名、相对路径,方便后续处理。例如,当使用 preg_match_all() 进行匹配时,结果数组索引为所有结果为0,协议为1,域名为2,相对路径为3。以上就是使用PHP的正则抓取页面中URL的全部内容,希望对大家使用PHP有所帮助。
php用正则表达抓取网页中文章(js正则表达式replace校验基本日期格式的20个正则表达式代码 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-03 00:09
)
下一篇:js正则表达式替换匹配
敏感词过滤,使用replace方法将匹配的敏感词变成*相同长度的字符串
pattern = /北京|天安门/g
target = '我爱北京天安门,天安门上太阳升'
console.log(
target.replace(pattern, (str) => {
console.log(str)
return Array(str.length).fill('*').join('')
})
)
北京
天安门
天安门
我爱*****,***上太阳升
改变年份的显示,将2017-1-2改为2017.1.2
pattern = /(\d+)(-)/g
target = '2017-1-2'
console.log(
target.replace(
pattern,
($0, $1, $2) => {
console.log($0, $1, $2)
//replace()中如果有子项,
//第一个参数:$0(匹配成功后的整体结果 2013- 6-),
// 第二个参数 : $1(匹配成功的第一个分组,这里指的是\d 2013, 6)
//第三个参数 : $1(匹配成功的第二个分组,这里指的是- - - )
return $1 + '.'; //分别返回2013. 6.
}
)
)
2017- 2017 -
1- 1 -
2017.1.2
去掉首尾空字符,匹配首尾空字符,然后用‘’替换
// 替换空字符,用*代替空格
pattern = /^\s+|\s+$/g
target = ' abc \n'
res = target.replace(pattern, '')
console.log(res, res.length);
abc 3
正则表达式通常用于验证字段或任意字符串,例如以下用于验证基本日期格式的 JavaScript 代码:
var reg = /^(\\d{1,4})(-|\\/)(\\d{1,2})\\2(\\d{1,2})$/;
var r = fieldValue.match(reg);
if(r==null)alert('Date format error!');
以下20个正则表达式,由工匠编译,前端开发中经常用到。
1.验证密码强度
密码的强度必须收录大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
2.验证中文
字符串只能是中文。
^[\\u4e00-\\u9fa5]{0,}$
3. 由数字、26 个英文字母或下划线组成的字符串
^\\w+$
4. 验证电子邮件地址
与密码相同,以下是E-mail地址合规性的定期检查声明。
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?
5.验证身份证号码
以下是身份证号码的定期验证。 15 或 18 位数字。
15 人:
^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18 人:
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
6. 验证日期
“yyyy-mm-dd”格式的日期验证已被考虑用于平闰年。
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
7.查看金额
金额验证,精确到小数点后两位。
^[0-9]+(.[0-9]{2})?$
8.验证手机号码
以下是中国13、15、18开头的手机号码的正则表达式。 (前两位可根据目前国内采集号进行扩充)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$
9.判断IE版本
IE 还没有完全替代,很多页面还需要版本兼容。以下是IE版本检查的表达式。
^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$
10. 验证 IP-v4 地址
IP4 正则声明。
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
11. 验证 IP-v6 地址
IP6 正则声明。
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
12.检查网址前缀
在应用开发中,经常需要区分请求是HTTPS还是HTTP。一个url的前缀可以通过下面的表达式提取出来,然后进行逻辑判断。
if (!s.match(/^[a-zA-Z]+:\\/\\//))
{
s = 'http://' + s;
}
13. 提取网址链接
下面的表达式可以过滤掉一段文本中的 URL。
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
14. 文件路径和扩展名验证
验证windows下的文件路径和扩展名(下例中的.txt文件)
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"|]+\\.txt(l)?$
15. 提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用如下表达式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
16.提取网页图片
如果要提取网页中的所有图片信息,可以使用以下表达式。
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
17. 提取页面超链接
在 html 中提取超链接。
(]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
18. 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
19. 提取评论
如果需要去掉HMTL中的注释,可以使用下面的表达式。
20. 匹配 HTML 标签
HTML 中的标签属性可以通过以下表达式进行匹配。
<p> 查看全部
php用正则表达抓取网页中文章(js正则表达式replace校验基本日期格式的20个正则表达式代码
)
下一篇:js正则表达式替换匹配
敏感词过滤,使用replace方法将匹配的敏感词变成*相同长度的字符串
pattern = /北京|天安门/g
target = '我爱北京天安门,天安门上太阳升'
console.log(
target.replace(pattern, (str) => {
console.log(str)
return Array(str.length).fill('*').join('')
})
)
北京
天安门
天安门
我爱*****,***上太阳升
改变年份的显示,将2017-1-2改为2017.1.2
pattern = /(\d+)(-)/g
target = '2017-1-2'
console.log(
target.replace(
pattern,
($0, $1, $2) => {
console.log($0, $1, $2)
//replace()中如果有子项,
//第一个参数:$0(匹配成功后的整体结果 2013- 6-),
// 第二个参数 : $1(匹配成功的第一个分组,这里指的是\d 2013, 6)
//第三个参数 : $1(匹配成功的第二个分组,这里指的是- - - )
return $1 + '.'; //分别返回2013. 6.
}
)
)
2017- 2017 -
1- 1 -
2017.1.2
去掉首尾空字符,匹配首尾空字符,然后用‘’替换
// 替换空字符,用*代替空格
pattern = /^\s+|\s+$/g
target = ' abc \n'
res = target.replace(pattern, '')
console.log(res, res.length);
abc 3
正则表达式通常用于验证字段或任意字符串,例如以下用于验证基本日期格式的 JavaScript 代码:
var reg = /^(\\d{1,4})(-|\\/)(\\d{1,2})\\2(\\d{1,2})$/;
var r = fieldValue.match(reg);
if(r==null)alert('Date format error!');
以下20个正则表达式,由工匠编译,前端开发中经常用到。
1.验证密码强度
密码的强度必须收录大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
2.验证中文
字符串只能是中文。
^[\\u4e00-\\u9fa5]{0,}$
3. 由数字、26 个英文字母或下划线组成的字符串
^\\w+$
4. 验证电子邮件地址
与密码相同,以下是E-mail地址合规性的定期检查声明。
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?
5.验证身份证号码
以下是身份证号码的定期验证。 15 或 18 位数字。
15 人:
^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18 人:
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
6. 验证日期
“yyyy-mm-dd”格式的日期验证已被考虑用于平闰年。
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
7.查看金额
金额验证,精确到小数点后两位。
^[0-9]+(.[0-9]{2})?$
8.验证手机号码
以下是中国13、15、18开头的手机号码的正则表达式。 (前两位可根据目前国内采集号进行扩充)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$
9.判断IE版本
IE 还没有完全替代,很多页面还需要版本兼容。以下是IE版本检查的表达式。
^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$
10. 验证 IP-v4 地址
IP4 正则声明。
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
11. 验证 IP-v6 地址
IP6 正则声明。
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
12.检查网址前缀
在应用开发中,经常需要区分请求是HTTPS还是HTTP。一个url的前缀可以通过下面的表达式提取出来,然后进行逻辑判断。
if (!s.match(/^[a-zA-Z]+:\\/\\//))
{
s = 'http://' + s;
}
13. 提取网址链接
下面的表达式可以过滤掉一段文本中的 URL。
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
14. 文件路径和扩展名验证
验证windows下的文件路径和扩展名(下例中的.txt文件)
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"|]+\\.txt(l)?$
15. 提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用如下表达式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
16.提取网页图片
如果要提取网页中的所有图片信息,可以使用以下表达式。
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
17. 提取页面超链接
在 html 中提取超链接。
(]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
18. 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
19. 提取评论
如果需要去掉HMTL中的注释,可以使用下面的表达式。
20. 匹配 HTML 标签
HTML 中的标签属性可以通过以下表达式进行匹配。
<p>
php用正则表达抓取网页中文章(滁州学院官网获取信息如何使用Simple-Html-Dom来解析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-03 00:06
)
获取网页源码中的指定内容需要使用正则表达式!正则表达式让我措手不及,因为我之前没有接触过它们,而且很难使用!
在Java中,有Daniel打包的库,我用的是Jsoup。在项目中引入Jsuop的Jar包,指定唯一标签,然后使用选择器解析数据。最近接触PHP,感觉就像用PHP解析新闻一样好玩! Jsoup分析滁州学院官网获取信息列表
我之前说过,正常的方式是使用正则表达式来获取数据!工作久了,真的控制不住!再怎么学习,鸡蛋也没有用!
最后,我通过谷歌搜索引擎搜索了一篇文章。 文章、文章介绍了几种调用PHP文件解析HTML的方法。上帝帮助我!
文章 以后会转贴发布,因为我发现的也是Biren通过“reposter”发布的。既然很好用,我就带过来!
昨天在尴尬百科首页用Simple-Html-Dom.php文件分析了尴尬,每15分钟定时搞定!因为刚接触PHP,就在昨天11:30断网前把代码贴在了SAE上。有点担心代码不能正常运行。毕竟,我对 PHP 一无所知!
今天早上起来看看数据库
太酸了,数据太多,太多没用,我关闭了收购!
说说如何使用Simple-Html-Dom解析HTML(小弟接触PHP不到两天)。看到了嘿嘿一笑,最好给点建议,不要喷,怕被喷!
1、下载 Simple-Html-Dom 压缩文件
到官网()下载压缩文件;
2、解压文件
解压文件,你会发现以下文件
需要用到的方法基本都在demo里面了,看你怎么用了。
看下面的代码,你会发现如何导入php文件和方法
// 如何使用基本选择器检索 HTML 内容的示例
include('../simple_html_dom.php');//引入php核心文件,注意路径,不要搞错
// 从 URL 或文件中获取 DOM
$html = file_get_html('#39;);
// 查找所有链接
foreach($html->find('a') as $e)
echo $e->href.'
';
// 查找所有图片
foreach($html->find('img') as $e)
echo $e->src.'
';
// 查找带有完整标签的所有图像
foreach($html->find('img') as $e)
echo $e->outertext.'
';
// 查找所有 id=gbar 的 div 标签
foreach($html->find('div#gbar') as $e)
echo $e->innertext.'
';
// 查找 class=gb1 的所有 span 标签
foreach($html->find('span.gb1') as $e)
echo $e->outertext.'
';
// 查找所有具有属性 align=center 的 td 标签
foreach($html->find('td[align=center]') as $e)
echo $e->innertext.'
';
//从表格中提取文本
echo $html->find('td[align="center"]', 1)->plaintext.'
';
// 从 HTML 中提取文本
echo $html->纯文本;
还有这个 php 文件 // 如何使用高级选择器功能的示例
include('../simple_html_dom.php');
// ----------------------------------------- --------------------------------
//后代选择器
$str = find('div div div', 0)->innertext.'
'; // 结果:“ok”
// ----------------------------------------- --------------------------------
// 嵌套选择器
$str = find('ul') as $ul) {
foreach($ul->find('li') as $li)
echo $li->innertext.'
';
}
// ----------------------------------------- --------------------------------
//解析复选框
$str = find('input[type=checkbox]') as $checkbox) {
if ($checkbox->checked)
echo $checkbox->name。 '被检查
';
其他
echo $checkbox->name。 '未检查
';
}
这个demo讲解的比较详细,虽然简洁但不简单!有兴趣的可以下载运行试试
获取网页源码中的指定内容需要使用正则表达式!正则表达式让我措手不及,因为我之前没有接触过它们,而且很难使用!
在Java中,有Daniel打包的库,我用的是Jsoup。在项目中引入Jsuop的Jar包,指定唯一标签,然后使用选择器解析数据。最近接触PHP,感觉就像用PHP解析新闻一样好玩! Jsoup分析滁州学院官网获取信息列表
我之前说过,正常的方式是使用正则表达式来获取数据!工作久了,真的控制不住!再怎么学习,鸡蛋也没有用!
最后,我通过谷歌搜索引擎搜索了一篇文章。 文章、文章介绍了几种调用PHP文件解析HTML的方法。上帝帮助我!
文章 以后会转贴发布,因为我发现的也是Biren通过“reposter”发布的。既然很好用,我就带过来!
昨天在尴尬百科首页用Simple-Html-Dom.php文件分析了尴尬,每15分钟定时搞定!因为刚接触PHP,就在昨天11:30断网前把代码贴在了SAE上。有点担心代码不能正常运行。毕竟,我对 PHP 一无所知!
今天早上起来看看数据库
太酸了,数据太多,太多没用,我关闭了收购!
说说如何使用Simple-Html-Dom解析HTML(小弟接触PHP不到两天)。看到了嘿嘿一笑,最好给点建议,不要喷,怕被喷!
1、下载 Simple-Html-Dom 压缩文件
到官网()下载压缩文件;
2、解压文件
解压文件,你会发现以下文件
需要用到的方法基本都在demo里面了,看你怎么用了。
看下面的代码,你会发现如何导入php文件和方法//示例如何使用基本选择器检索HTML内容
include('../simple_html_dom.php');//引入php核心文件,注意路径,不要搞错
// 从 URL 或文件中获取 DOM
$html = file_get_html('#39;);
// 查找所有链接
foreach($html->find('a') as $e)
echo $e->href.'
';
// 查找所有图片
foreach($html->find('img') as $e)
echo $e->src.'
';
// 查找带有完整标签的所有图像
foreach($html->find('img') as $e)
echo $e->outertext.'
';
// 查找所有 id=gbar 的 div 标签
foreach($html->find('div#gbar') as $e)
echo $e->innertext.'
';
// 查找 class=gb1 的所有 span 标签
foreach($html->find('span.gb1') as $e)
echo $e->outertext.'
';
// 查找所有具有属性 align=center 的 td 标签
foreach($html->find('td[align=center]') as $e)
echo $e->innertext.'
';
//从表格中提取文本
echo $html->find('td[align="center"]', 1)->plaintext.'
';
// 从 HTML 中提取文本
echo $html->纯文本;
还有这个 php 文件 // 如何使用高级选择器功能的示例
include('../simple_html_dom.php');
// ----------------------------------------- --------------------------------
//后代选择器
$str = find('div div div', 0)->innertext.'
'; // 结果:“ok”
// ----------------------------------------- --------------------------------
// 嵌套选择器
$str = find('ul') as $ul) {
foreach($ul->find('li') as $li)
echo $li->innertext.'
';
}
// ----------------------------------------- --------------------------------
//解析复选框
$str = find('input[type=checkbox]') as $checkbox) {
if ($checkbox->checked)
echo $checkbox->name。 '被检查
';
其他
echo $checkbox->name。 '未检查
';
}
这个demo讲解的比较详细,虽然简洁但不简单!有兴趣的可以下载运行试试
文件下载
请我喝杯咖啡 :)
查看全部
php用正则表达抓取网页中文章(滁州学院官网获取信息如何使用Simple-Html-Dom来解析
)
获取网页源码中的指定内容需要使用正则表达式!正则表达式让我措手不及,因为我之前没有接触过它们,而且很难使用!
在Java中,有Daniel打包的库,我用的是Jsoup。在项目中引入Jsuop的Jar包,指定唯一标签,然后使用选择器解析数据。最近接触PHP,感觉就像用PHP解析新闻一样好玩! Jsoup分析滁州学院官网获取信息列表
我之前说过,正常的方式是使用正则表达式来获取数据!工作久了,真的控制不住!再怎么学习,鸡蛋也没有用!
最后,我通过谷歌搜索引擎搜索了一篇文章。 文章、文章介绍了几种调用PHP文件解析HTML的方法。上帝帮助我!
文章 以后会转贴发布,因为我发现的也是Biren通过“reposter”发布的。既然很好用,我就带过来!
昨天在尴尬百科首页用Simple-Html-Dom.php文件分析了尴尬,每15分钟定时搞定!因为刚接触PHP,就在昨天11:30断网前把代码贴在了SAE上。有点担心代码不能正常运行。毕竟,我对 PHP 一无所知!
今天早上起来看看数据库
太酸了,数据太多,太多没用,我关闭了收购!
说说如何使用Simple-Html-Dom解析HTML(小弟接触PHP不到两天)。看到了嘿嘿一笑,最好给点建议,不要喷,怕被喷!
1、下载 Simple-Html-Dom 压缩文件
到官网()下载压缩文件;
2、解压文件
解压文件,你会发现以下文件
需要用到的方法基本都在demo里面了,看你怎么用了。
看下面的代码,你会发现如何导入php文件和方法
// 如何使用基本选择器检索 HTML 内容的示例
include('../simple_html_dom.php');//引入php核心文件,注意路径,不要搞错
// 从 URL 或文件中获取 DOM
$html = file_get_html('#39;);
// 查找所有链接
foreach($html->find('a') as $e)
echo $e->href.'
';
// 查找所有图片
foreach($html->find('img') as $e)
echo $e->src.'
';
// 查找带有完整标签的所有图像
foreach($html->find('img') as $e)
echo $e->outertext.'
';
// 查找所有 id=gbar 的 div 标签
foreach($html->find('div#gbar') as $e)
echo $e->innertext.'
';
// 查找 class=gb1 的所有 span 标签
foreach($html->find('span.gb1') as $e)
echo $e->outertext.'
';
// 查找所有具有属性 align=center 的 td 标签
foreach($html->find('td[align=center]') as $e)
echo $e->innertext.'
';
//从表格中提取文本
echo $html->find('td[align="center"]', 1)->plaintext.'
';
// 从 HTML 中提取文本
echo $html->纯文本;
还有这个 php 文件 // 如何使用高级选择器功能的示例
include('../simple_html_dom.php');
// ----------------------------------------- --------------------------------
//后代选择器
$str = find('div div div', 0)->innertext.'
'; // 结果:“ok”
// ----------------------------------------- --------------------------------
// 嵌套选择器
$str = find('ul') as $ul) {
foreach($ul->find('li') as $li)
echo $li->innertext.'
';
}
// ----------------------------------------- --------------------------------
//解析复选框
$str = find('input[type=checkbox]') as $checkbox) {
if ($checkbox->checked)
echo $checkbox->name。 '被检查
';
其他
echo $checkbox->name。 '未检查
';
}
这个demo讲解的比较详细,虽然简洁但不简单!有兴趣的可以下载运行试试
获取网页源码中的指定内容需要使用正则表达式!正则表达式让我措手不及,因为我之前没有接触过它们,而且很难使用!
在Java中,有Daniel打包的库,我用的是Jsoup。在项目中引入Jsuop的Jar包,指定唯一标签,然后使用选择器解析数据。最近接触PHP,感觉就像用PHP解析新闻一样好玩! Jsoup分析滁州学院官网获取信息列表
我之前说过,正常的方式是使用正则表达式来获取数据!工作久了,真的控制不住!再怎么学习,鸡蛋也没有用!
最后,我通过谷歌搜索引擎搜索了一篇文章。 文章、文章介绍了几种调用PHP文件解析HTML的方法。上帝帮助我!
文章 以后会转贴发布,因为我发现的也是Biren通过“reposter”发布的。既然很好用,我就带过来!
昨天在尴尬百科首页用Simple-Html-Dom.php文件分析了尴尬,每15分钟定时搞定!因为刚接触PHP,就在昨天11:30断网前把代码贴在了SAE上。有点担心代码不能正常运行。毕竟,我对 PHP 一无所知!
今天早上起来看看数据库
太酸了,数据太多,太多没用,我关闭了收购!
说说如何使用Simple-Html-Dom解析HTML(小弟接触PHP不到两天)。看到了嘿嘿一笑,最好给点建议,不要喷,怕被喷!
1、下载 Simple-Html-Dom 压缩文件
到官网()下载压缩文件;
2、解压文件
解压文件,你会发现以下文件
需要用到的方法基本都在demo里面了,看你怎么用了。
看下面的代码,你会发现如何导入php文件和方法//示例如何使用基本选择器检索HTML内容
include('../simple_html_dom.php');//引入php核心文件,注意路径,不要搞错
// 从 URL 或文件中获取 DOM
$html = file_get_html('#39;);
// 查找所有链接
foreach($html->find('a') as $e)
echo $e->href.'
';
// 查找所有图片
foreach($html->find('img') as $e)
echo $e->src.'
';
// 查找带有完整标签的所有图像
foreach($html->find('img') as $e)
echo $e->outertext.'
';
// 查找所有 id=gbar 的 div 标签
foreach($html->find('div#gbar') as $e)
echo $e->innertext.'
';
// 查找 class=gb1 的所有 span 标签
foreach($html->find('span.gb1') as $e)
echo $e->outertext.'
';
// 查找所有具有属性 align=center 的 td 标签
foreach($html->find('td[align=center]') as $e)
echo $e->innertext.'
';
//从表格中提取文本
echo $html->find('td[align="center"]', 1)->plaintext.'
';
// 从 HTML 中提取文本
echo $html->纯文本;
还有这个 php 文件 // 如何使用高级选择器功能的示例
include('../simple_html_dom.php');
// ----------------------------------------- --------------------------------
//后代选择器
$str = find('div div div', 0)->innertext.'
'; // 结果:“ok”
// ----------------------------------------- --------------------------------
// 嵌套选择器
$str = find('ul') as $ul) {
foreach($ul->find('li') as $li)
echo $li->innertext.'
';
}
// ----------------------------------------- --------------------------------
//解析复选框
$str = find('input[type=checkbox]') as $checkbox) {
if ($checkbox->checked)
echo $checkbox->name。 '被检查
';
其他
echo $checkbox->name。 '未检查
';
}
这个demo讲解的比较详细,虽然简洁但不简单!有兴趣的可以下载运行试试
文件下载
请我喝杯咖啡 :)
php用正则表达抓取网页中文章(正则表达式的Python语言通过标准的替换操作;正则表达式简介 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-03 00:06
)
正则表达式介绍
概念
正则表达式是字符串操作的逻辑公式。它使用一些预定义的特定字符和这些特定字符的组合来形成“规则字符串”。这个“规则字符串”用于表达一种对字符串的过滤逻辑(可用于检索、拦截或替换操作)。
正则表达式用于搜索、替换和解析字符串。正则表达式遵循一定的语法规则,非常灵活和强大。使用正则表达式写一些逻辑验证非常方便,比如邮箱地址格式的验证。
<p>正则表达式是对字符串(包括普通字符(例如a和z之间的字母)和特殊字符)进行运算的逻辑公式,就是使用一些预先定义好的特定字符和这些特定字符的组合形成一个“规则串”,这个“规则串”用来表达一种对字符串的过滤逻辑,正则表达式是一个文本模式,在搜索文本字符串时,模式描述必须匹配一个或多个。 查看全部
php用正则表达抓取网页中文章(正则表达式的Python语言通过标准的替换操作;正则表达式简介
)
正则表达式介绍
概念
正则表达式是字符串操作的逻辑公式。它使用一些预定义的特定字符和这些特定字符的组合来形成“规则字符串”。这个“规则字符串”用于表达一种对字符串的过滤逻辑(可用于检索、拦截或替换操作)。
正则表达式用于搜索、替换和解析字符串。正则表达式遵循一定的语法规则,非常灵活和强大。使用正则表达式写一些逻辑验证非常方便,比如邮箱地址格式的验证。
<p>正则表达式是对字符串(包括普通字符(例如a和z之间的字母)和特殊字符)进行运算的逻辑公式,就是使用一些预先定义好的特定字符和这些特定字符的组合形成一个“规则串”,这个“规则串”用来表达一种对字符串的过滤逻辑,正则表达式是一个文本模式,在搜索文本字符串时,模式描述必须匹配一个或多个。
php用正则表达抓取网页中文章(突袭网网站的支持!-->)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-28 08:00
s">PHP正则表达式抓取标签特定属性值的方法
作者:宇轩网字体:【增减】类型:转载时间:2016-07-14我要评论
本文主要介绍用PHP正则表达式抓取标签特定属性值的方法的相关信息。非常好,有参考价值。有需要的朋友可以参考>
学了几天php正则,抓了一些网站数据,发现写正则又每次都重新抓很麻烦,所以想写一个通用的接口,抓具体属性值的具体标签,直接上传代码。
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这是一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果是
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
你可以看到源代码
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客的时候很紧张。我希望它对大家有用。也希望大家能指出代码中的问题。我不做很多测试~~
以上就是小编给大家介绍的用PHP正则表达式抓取标签的具体属性值的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对raid网站的支持! 查看全部
php用正则表达抓取网页中文章(突袭网网站的支持!-->)
s">PHP正则表达式抓取标签特定属性值的方法
作者:宇轩网字体:【增减】类型:转载时间:2016-07-14我要评论
本文主要介绍用PHP正则表达式抓取标签特定属性值的方法的相关信息。非常好,有参考价值。有需要的朋友可以参考>
学了几天php正则,抓了一些网站数据,发现写正则又每次都重新抓很麻烦,所以想写一个通用的接口,抓具体属性值的具体标签,直接上传代码。
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这是一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果是
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
你可以看到源代码
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客的时候很紧张。我希望它对大家有用。也希望大家能指出代码中的问题。我不做很多测试~~
以上就是小编给大家介绍的用PHP正则表达式抓取标签的具体属性值的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对raid网站的支持!
php用正则表达抓取网页中文章(web.py用什么方法可以抓取文章的正文【python】 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-28 07:20
)
python可以用什么方法抓取文章的body部分是我最近在思考的一个问题。我想知道如何通过xpath准确抓取文章正文。它类似于 parselets,但会更简单。
在python代码的设计中,使用正则表达式匹配URL,然后选择回调处理程序。主要参考web.py的分发器。有朋友觉得这个方法不高尚,因为都是python函数形式的回调,没有用到python类。有需要的朋友可以参考web.py进行适当修改后再使用。
Python 通过正则表达式选择并抓取文章正文:
#!/bin/env python
import re, sys
# Define parser first.
def baidu(username):
# Business logic
return "Using parser Baidu. and the user's name is: %s." % username
def qzone(uin):
# Business logic
return "Using parser Qzone, and the user's QQ is: %s." % uin
# From web.py
def group(seq, size):#{{{
"""
Returns an iterator over a series of lists of length size from iterable.
>>> list(group([1,2,3,4], 2))
[[1, 2], [3, 4]]
>>> list(group([1,2,3,4,5], 2))
[[1, 2], [3, 4], [5]]
"""
def take(seq, n):
for i in xrange(n):
yield seq.next()
if not hasattr(seq, 'next'):
seq = iter(seq)
while True:
x = list(take(seq, size))
if x:
yield x
else:
break
#}}}
#www.iplaypy.com
def parser_init(url,mapping):
for pat, what in group(mapping,2):
result = re.compile('^' + pat + '$').match(url)
if result:
return what, [x for x in result.groups()]
return None, None
if __name__ == '__main__':
mapping = (
'http://(?:hi|space).baidu.com/([^/]+)(?:/.*)?','baidu',
'http://(\d+).qzone.qq.com(?:/.*)?','qzone',
)
(func, args) = parser_init(sys.argv[1],mapping)
if func:
callback = func
if func in globals():
callback = globals()[func]
if callable(callback):
print callback(*args)
else:
print 'No parser found.'; 查看全部
php用正则表达抓取网页中文章(web.py用什么方法可以抓取文章的正文【python】
)
python可以用什么方法抓取文章的body部分是我最近在思考的一个问题。我想知道如何通过xpath准确抓取文章正文。它类似于 parselets,但会更简单。
在python代码的设计中,使用正则表达式匹配URL,然后选择回调处理程序。主要参考web.py的分发器。有朋友觉得这个方法不高尚,因为都是python函数形式的回调,没有用到python类。有需要的朋友可以参考web.py进行适当修改后再使用。
Python 通过正则表达式选择并抓取文章正文:
#!/bin/env python
import re, sys
# Define parser first.
def baidu(username):
# Business logic
return "Using parser Baidu. and the user's name is: %s." % username
def qzone(uin):
# Business logic
return "Using parser Qzone, and the user's QQ is: %s." % uin
# From web.py
def group(seq, size):#{{{
"""
Returns an iterator over a series of lists of length size from iterable.
>>> list(group([1,2,3,4], 2))
[[1, 2], [3, 4]]
>>> list(group([1,2,3,4,5], 2))
[[1, 2], [3, 4], [5]]
"""
def take(seq, n):
for i in xrange(n):
yield seq.next()
if not hasattr(seq, 'next'):
seq = iter(seq)
while True:
x = list(take(seq, size))
if x:
yield x
else:
break
#}}}
#www.iplaypy.com
def parser_init(url,mapping):
for pat, what in group(mapping,2):
result = re.compile('^' + pat + '$').match(url)
if result:
return what, [x for x in result.groups()]
return None, None
if __name__ == '__main__':
mapping = (
'http://(?:hi|space).baidu.com/([^/]+)(?:/.*)?','baidu',
'http://(\d+).qzone.qq.com(?:/.*)?','qzone',
)
(func, args) = parser_init(sys.argv[1],mapping)
if func:
callback = func
if func in globals():
callback = globals()[func]
if callable(callback):
print callback(*args)
else:
print 'No parser found.';
php用正则表达抓取网页中文章(php下正则匹配中文的表达式是什么样的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-26 18:20
首先unicode中文区的0x4e00-0x9fa5可以判断一个字符串是否都是java或js等编程语言有unicode编码的字符串/^[\u4e00-\u9fa5]+ $/中文
那么php中的字符编码就看页面了,gbk的字符编码是gbk的utf-8,之前有一个表达式“/^[\x80-\xff]+$/”也是一样can only match 是否收录
非ascll字符,汉字只是较小的区域之一,不是很准确
因为我的页面编码是utf-8,所以把js表达式移到了php中,提醒PCRE不支持“\u”等很多乱七八糟的东西
查资料得知PHP的正则中有个东西叫字符组,用\x{...}表示,所以我把表达式改成"/^[\x{4e00}- \x{9fa5}]+$/ "也提示"\x"表达式后面的数字太大
查资料得知可以使用修正模式“u”让程序将以下内容视为unicode字符,所以我将其改为“/^[\x{4e00}-\x{9fa5} ]+$/u" 测试成功
所以php下匹配中文的正则表达式为"/^[\x{4e00}-\x{9fa5}]+$/u" 这只适用于utf-8编码 查看全部
php用正则表达抓取网页中文章(php下正则匹配中文的表达式是什么样的?(图))
首先unicode中文区的0x4e00-0x9fa5可以判断一个字符串是否都是java或js等编程语言有unicode编码的字符串/^[\u4e00-\u9fa5]+ $/中文
那么php中的字符编码就看页面了,gbk的字符编码是gbk的utf-8,之前有一个表达式“/^[\x80-\xff]+$/”也是一样can only match 是否收录
非ascll字符,汉字只是较小的区域之一,不是很准确
因为我的页面编码是utf-8,所以把js表达式移到了php中,提醒PCRE不支持“\u”等很多乱七八糟的东西
查资料得知PHP的正则中有个东西叫字符组,用\x{...}表示,所以我把表达式改成"/^[\x{4e00}- \x{9fa5}]+$/ "也提示"\x"表达式后面的数字太大
查资料得知可以使用修正模式“u”让程序将以下内容视为unicode字符,所以我将其改为“/^[\x{4e00}-\x{9fa5} ]+$/u" 测试成功
所以php下匹配中文的正则表达式为"/^[\x{4e00}-\x{9fa5}]+$/u" 这只适用于utf-8编码
php用正则表达抓取网页中文章(PHP正则表达式如何处理将要打开文件的标识和几种形式?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-24 12:17
最近有一个任务,从页面中抓取页面上的所有链接。当然,使用 PHP 正则表达式是最方便的方式。要编写正则表达式,您必须首先总结模式。页面上的链接有多少种形式?
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。 查看全部
php用正则表达抓取网页中文章(PHP正则表达式如何处理将要打开文件的标识和几种形式?)
最近有一个任务,从页面中抓取页面上的所有链接。当然,使用 PHP 正则表达式是最方便的方式。要编写正则表达式,您必须首先总结模式。页面上的链接有多少种形式?
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。

