
php用正则表达抓取网页中文章
php用正则表达抓取网页中文章(Python教程正则表达式学习参考使用慕课Python网络爬虫专栏教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-15 18:01
)
重新库和正则表达式
版权所有:韦敬敏,华中科技大学人工智能学院模式识别与智能系统
网络爬虫专栏链接
文章目录
本教程主要参考中国大学MOOCs的Python网络爬虫和信息提取,是个人学习笔记。
在学习过程中遇到了一些问题,手动记录修改,保证所有代码都是有效的。并结合其他博客总结了一些常见问题的解决方案。
本教程非商用,仅供学习参考。如需转载,请联系我。
参考
爬虫MOOC
数据分析 MOOC
廖雪峰的Python教程
正则表达式的概念
正则表达式是用来简洁地表达一组字符串的表达式。
介绍:
简洁,一行胜千言,一行就是一个特征(模式)。
正则表达式是用来简洁地表达一组字符串的表达式;正则表达式是一个通用的字符串表达式框架;进一步说,正则表达式是字符串的一种“简洁”和“特征”,用来表达“思维的工具;正则表达式可以用来判断字符串的属性。
正则表达式在文本处理中很常见:
编译:将符合正则表达式语法的字符串转换为正则表达式特征。
正则表达式语法
正则表达式的常用运算符
操作员规范示例
.
代表任意单个字符
[ ]
字符集,给单个字符的取值范围
[abc] 表示 a 或 b 或 c,[a-z] 表示 a 到 z 单个字符
[^]
非字符集,给出单个字符的排除范围
[^abc] 表示除 a 或 b 或 c 以外的单个字符
*
前一个字符被扩展0次或无限次
abc* 表示 ab、abc、abcc、abccc 等。
+
前一个字符扩展一次或无限次
abc+ 表示 abc、abcc、abccc 等。
前一个字符被扩展0或1倍
ABC?表示ab,abc
|
任何左或右表达式
abc|def 表示 abc,def
{m}
将前一个字符展开 m 次
ab{2}c 表示 abbc
{m,n}
将前一个字符 m 扩展为 n 次(含)
ab{1,2}c 表示 abc、abbc
^
匹配字符串的开头
^abc 表示 abc,位于字符串的开头
$
匹配字符串结尾
abc$ 表示 abc,位于字符串的末尾
( )
分组标签,只有 |运算符可以在里面使用
(abc) 表示 abc,(abc|def) 表示 abc,def
\d
数字,相当于[0-9]
\w
单词字符,相当于[A-Za-z0-9_]
相关?对于组合语法和最小匹配,直接跳到贪婪和最小匹配。
正则表达式语法示例
经典正则表达式示例
正则表达式匹配IP地址
Re库的基本使用
Re库是Python的标准库,主要用于字符串匹配
import re
原创字符串类型(原创字符串类型)。 re库使用原创字符串类型来表示正则表达式,表示为:
原创字符串是一个不收录重新转义转义字符的字符串
re库也可以使用字符串类型来表示正则表达式,但是比较麻烦,例如:
建议:当正则表达式收录转义字符时使用原创字符串
1.Re库的主要功能
功能说明
re.search()
搜索字符串中第一个匹配正则表达式的位置,返回一个匹配对象
re.match()
从字符串开头匹配正则表达式,返回匹配对象
re.findall()
搜索字符串,返回列表类型的所有匹配子字符串
re.split()
根据正则表达式匹配结果拆分字符串并返回列表类型
re.finditer()
搜索字符串,返回一个迭代类型的匹配结果,每个迭代元素都是一个匹配对象
re.sub()
替换字符串中所有匹配正则表达式的子字符串,返回替换后的字符串
常用参数类型
∙模式:正则表达式的字符串或原生字符串表示
∙string : 要匹配的字符串
∙ flags : 使用正则表达式时控制标志
常用标签说明
re.Ire.IGNORECASE
忽略正则表达式的大小写,[A-Z]匹配小写字符
re.M re.MULTILINE
正则表达式中的 ^ 运算符可以将给定字符串的每一行作为匹配项开始
re.S re.DOTALL
.正则表达式中的操作符可以匹配所有字符,默认匹配除换行符以外的所有字符
∙maxsplit:最大分割数,余数作为最后一个元素输出
∙repl : 替换匹配字符串的字符串
∙ count : 要匹配的最大替换数
1.
re.search(pattern, string, flags=0)
搜索字符串中第一个匹配正则表达式的位置,返回一个匹配对象
>>> import re
>>> match = re.search(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
print(match.group(0))
100081
2.
re.match(pattern, string, flags=0)
从字符串开头匹配正则表达式,返回匹配对象
>>> import re
>>> match = re.match(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
match.group(0)
>>> match.group(0)
Traceback (most recent call last):
File "", line 1, in
match.group(0)
AttributeError: 'NoneType' object has no attribute 'group'
>>> match = re.match(r'[1-9]\d{5}', '100081 BIT')
>>> if match:
print(match.group(0))
100081
3.
re.findall(pattern, string, flags=0)
搜索字符串,返回列表类型的所有匹配子字符串
>>> import re
>>> ls = re.findall(r'[1-9]\d{5}', 'BIT100081 TSU100084')
>>> ls
['100081', '100084']
4.
re.split(pattern, string, maxsplit=0, flags=0)
根据正则表达式匹配结果拆分字符串并返回列表类型
>>> import re
>>> re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084')
['BIT', ' TSU', '']
>>> re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084', maxsplit=1)
['BIT', ' TSU100084']
5.
re.finditer(pattern, string, flags=0)
搜索字符串,返回一个迭代类型的匹配结果,每个迭代元素都是一个匹配对象
>>> import re
>>> for m in re.finditer(r'[1-9]\d{5}', 'BIT100081 TSU100084'):
if m:
print(m.group(0))
100081
100084
6.
re.sub(pattern, repl, string, count=0, flags=0)
替换字符串中所有匹配正则表达式的子字符串,返回替换后的字符串
>>> import re
>>> re.sub(r'[1-9]\d{5}', ':zipcode', 'BIT100081 TSU100084')
'BIT:zipcode TSU:zipcode'
2.Re 库的另一种等效用法
功能用法:一次性操作
>>> rst = re.search(r'[1-9]\d{5}', 'BIT 100081')
相当于
面向对象的用法:编译后的多次操作
>>> pat = re.compile(r'[1-9]\d{5}')
>>> rst = pat.search('BIT 100081')
>>> if rst:
print(rst.group(0))
100081
编译:
regex = re.compile(pattern, flags=0)
将正则表达式的字符串形式编译成正则表达式对象
>>> regex = re.compile(r'[1‐9]\d{5}')
然后调用对应的方法,注意不要再写pattern了
Re 库的 Match 对象
Match 对象是匹配的结果,收录很多关于匹配的信息
>>> match = re.search(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
print(match.group(0))
100081
>>> type(match)
Match 对象的属性:
属性说明
.字符串
要匹配的文本
.re
匹配时使用的模式对象(正则表达式)
.pos
正则表达式搜索文本开始
.endpos
正则表达式搜索文本结束
Match 对象的方法
方法说明
.group(0)
获取匹配的字符串
.start()
匹配的字符串在原字符串的开头
.end()
匹配的字符串在原字符串的末尾
.span()
返回(.start(), .end())
例子:
>>> import re
>>> m = re.search(r'[1-9]\d{5}', 'BIT100081 TSU100084')
>>> m.string
'BIT100081 TSU100084'
>>> m.re
re.compile('[1-9]\\d{5}')
>>> m.pos
0
>>> m.endpos
19
>>> m.group(0)
'100081'
>>> m.start
>>> m.start()
3
>>> m.end()
9
>>> m.span()
(3, 9)
Re库的贪婪匹配和最小匹配
>>> match = re.search(r'PY.*N', 'PYANBNCNDN')
>>> match.group(0)
同时匹配多个不同长度的项目,返回哪一个?
贪婪匹配:
>>> match = re.search(r'PY.*N', 'PYANBNCNDN')
>>> match.group(0)
'PYANBNCNDN'
Re库默认使用贪心匹配,即输出匹配最长的子串
最小匹配:
如何输出最短的子串?
>>> match = re.search(r'PY.*?N', 'PYANBNCNDN')
>>> match.group(0)
'PYAN'
最小匹配运算符
运营商说明
前一个字符扩展0或无限次,最小匹配
前一个字符扩展 1 或无限,最小匹配
前一个字符 0 或 1 扩展,最小匹配
{m,n}?
将前一个字符m扩展到n次(含),最小匹配
只要输出的长度可能不同,可以通过加?变成最小匹配在运算符之后
总结
查看全部
php用正则表达抓取网页中文章(Python教程正则表达式学习参考使用慕课Python网络爬虫专栏教程
)
重新库和正则表达式
版权所有:韦敬敏,华中科技大学人工智能学院模式识别与智能系统
网络爬虫专栏链接
文章目录
本教程主要参考中国大学MOOCs的Python网络爬虫和信息提取,是个人学习笔记。
在学习过程中遇到了一些问题,手动记录修改,保证所有代码都是有效的。并结合其他博客总结了一些常见问题的解决方案。
本教程非商用,仅供学习参考。如需转载,请联系我。
参考
爬虫MOOC
数据分析 MOOC
廖雪峰的Python教程
正则表达式的概念
正则表达式是用来简洁地表达一组字符串的表达式。
介绍:

简洁,一行胜千言,一行就是一个特征(模式)。


正则表达式是用来简洁地表达一组字符串的表达式;正则表达式是一个通用的字符串表达式框架;进一步说,正则表达式是字符串的一种“简洁”和“特征”,用来表达“思维的工具;正则表达式可以用来判断字符串的属性。
正则表达式在文本处理中很常见:
编译:将符合正则表达式语法的字符串转换为正则表达式特征。

正则表达式语法
正则表达式的常用运算符
操作员规范示例
.
代表任意单个字符
[ ]
字符集,给单个字符的取值范围
[abc] 表示 a 或 b 或 c,[a-z] 表示 a 到 z 单个字符
[^]
非字符集,给出单个字符的排除范围
[^abc] 表示除 a 或 b 或 c 以外的单个字符
*
前一个字符被扩展0次或无限次
abc* 表示 ab、abc、abcc、abccc 等。
+
前一个字符扩展一次或无限次
abc+ 表示 abc、abcc、abccc 等。
前一个字符被扩展0或1倍
ABC?表示ab,abc
|
任何左或右表达式
abc|def 表示 abc,def
{m}
将前一个字符展开 m 次
ab{2}c 表示 abbc
{m,n}
将前一个字符 m 扩展为 n 次(含)
ab{1,2}c 表示 abc、abbc
^
匹配字符串的开头
^abc 表示 abc,位于字符串的开头
$
匹配字符串结尾
abc$ 表示 abc,位于字符串的末尾
( )
分组标签,只有 |运算符可以在里面使用
(abc) 表示 abc,(abc|def) 表示 abc,def
\d
数字,相当于[0-9]
\w
单词字符,相当于[A-Za-z0-9_]
相关?对于组合语法和最小匹配,直接跳到贪婪和最小匹配。
正则表达式语法示例

经典正则表达式示例

正则表达式匹配IP地址

Re库的基本使用
Re库是Python的标准库,主要用于字符串匹配
import re
原创字符串类型(原创字符串类型)。 re库使用原创字符串类型来表示正则表达式,表示为:

原创字符串是一个不收录重新转义转义字符的字符串
re库也可以使用字符串类型来表示正则表达式,但是比较麻烦,例如:

建议:当正则表达式收录转义字符时使用原创字符串
1.Re库的主要功能
功能说明
re.search()
搜索字符串中第一个匹配正则表达式的位置,返回一个匹配对象
re.match()
从字符串开头匹配正则表达式,返回匹配对象
re.findall()
搜索字符串,返回列表类型的所有匹配子字符串
re.split()
根据正则表达式匹配结果拆分字符串并返回列表类型
re.finditer()
搜索字符串,返回一个迭代类型的匹配结果,每个迭代元素都是一个匹配对象
re.sub()
替换字符串中所有匹配正则表达式的子字符串,返回替换后的字符串
常用参数类型
∙模式:正则表达式的字符串或原生字符串表示
∙string : 要匹配的字符串
∙ flags : 使用正则表达式时控制标志
常用标签说明
re.Ire.IGNORECASE
忽略正则表达式的大小写,[A-Z]匹配小写字符
re.M re.MULTILINE
正则表达式中的 ^ 运算符可以将给定字符串的每一行作为匹配项开始
re.S re.DOTALL
.正则表达式中的操作符可以匹配所有字符,默认匹配除换行符以外的所有字符
∙maxsplit:最大分割数,余数作为最后一个元素输出
∙repl : 替换匹配字符串的字符串
∙ count : 要匹配的最大替换数
1.
re.search(pattern, string, flags=0)
搜索字符串中第一个匹配正则表达式的位置,返回一个匹配对象
>>> import re
>>> match = re.search(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
print(match.group(0))
100081
2.
re.match(pattern, string, flags=0)
从字符串开头匹配正则表达式,返回匹配对象
>>> import re
>>> match = re.match(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
match.group(0)
>>> match.group(0)
Traceback (most recent call last):
File "", line 1, in
match.group(0)
AttributeError: 'NoneType' object has no attribute 'group'
>>> match = re.match(r'[1-9]\d{5}', '100081 BIT')
>>> if match:
print(match.group(0))
100081
3.
re.findall(pattern, string, flags=0)
搜索字符串,返回列表类型的所有匹配子字符串
>>> import re
>>> ls = re.findall(r'[1-9]\d{5}', 'BIT100081 TSU100084')
>>> ls
['100081', '100084']
4.
re.split(pattern, string, maxsplit=0, flags=0)
根据正则表达式匹配结果拆分字符串并返回列表类型
>>> import re
>>> re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084')
['BIT', ' TSU', '']
>>> re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084', maxsplit=1)
['BIT', ' TSU100084']
5.
re.finditer(pattern, string, flags=0)
搜索字符串,返回一个迭代类型的匹配结果,每个迭代元素都是一个匹配对象
>>> import re
>>> for m in re.finditer(r'[1-9]\d{5}', 'BIT100081 TSU100084'):
if m:
print(m.group(0))
100081
100084
6.
re.sub(pattern, repl, string, count=0, flags=0)
替换字符串中所有匹配正则表达式的子字符串,返回替换后的字符串
>>> import re
>>> re.sub(r'[1-9]\d{5}', ':zipcode', 'BIT100081 TSU100084')
'BIT:zipcode TSU:zipcode'
2.Re 库的另一种等效用法
功能用法:一次性操作
>>> rst = re.search(r'[1-9]\d{5}', 'BIT 100081')
相当于
面向对象的用法:编译后的多次操作
>>> pat = re.compile(r'[1-9]\d{5}')
>>> rst = pat.search('BIT 100081')
>>> if rst:
print(rst.group(0))
100081
编译:
regex = re.compile(pattern, flags=0)
将正则表达式的字符串形式编译成正则表达式对象
>>> regex = re.compile(r'[1‐9]\d{5}')
然后调用对应的方法,注意不要再写pattern了

Re 库的 Match 对象
Match 对象是匹配的结果,收录很多关于匹配的信息
>>> match = re.search(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
print(match.group(0))
100081
>>> type(match)
Match 对象的属性:
属性说明
.字符串
要匹配的文本
.re
匹配时使用的模式对象(正则表达式)
.pos
正则表达式搜索文本开始
.endpos
正则表达式搜索文本结束
Match 对象的方法
方法说明
.group(0)
获取匹配的字符串
.start()
匹配的字符串在原字符串的开头
.end()
匹配的字符串在原字符串的末尾
.span()
返回(.start(), .end())
例子:
>>> import re
>>> m = re.search(r'[1-9]\d{5}', 'BIT100081 TSU100084')
>>> m.string
'BIT100081 TSU100084'
>>> m.re
re.compile('[1-9]\\d{5}')
>>> m.pos
0
>>> m.endpos
19
>>> m.group(0)
'100081'
>>> m.start
>>> m.start()
3
>>> m.end()
9
>>> m.span()
(3, 9)
Re库的贪婪匹配和最小匹配
>>> match = re.search(r'PY.*N', 'PYANBNCNDN')
>>> match.group(0)
同时匹配多个不同长度的项目,返回哪一个?
贪婪匹配:
>>> match = re.search(r'PY.*N', 'PYANBNCNDN')
>>> match.group(0)
'PYANBNCNDN'
Re库默认使用贪心匹配,即输出匹配最长的子串
最小匹配:
如何输出最短的子串?
>>> match = re.search(r'PY.*?N', 'PYANBNCNDN')
>>> match.group(0)
'PYAN'
最小匹配运算符
运营商说明
前一个字符扩展0或无限次,最小匹配
前一个字符扩展 1 或无限,最小匹配
前一个字符 0 或 1 扩展,最小匹配
{m,n}?
将前一个字符m扩展到n次(含),最小匹配
只要输出的长度可能不同,可以通过加?变成最小匹配在运算符之后
总结

php用正则表达抓取网页中文章(zblogzblog采集插件实现自动化的科学有效的内链建设(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-10 20:08
)
ZBlog是ZBlog开发团队开发的一款基于Asp和PHP平台的小而强大的开源程序,致力于为用户提供优秀的博客写作体验。但是zblog不提供文章采集功能,市面上大部分zblog采集插件都需要编写复杂的文章采集规则。没有专门的 SEO 优化,就没有完整的 采集伪原创 发布流程。 zblog采集插件按关键词采集文章,基于百度、搜狗、好搜等搜索引擎,全网采集精美好文章,zblog 采集@ >插件用户不必费力寻找采集源代码。
<p>本zblog采集plugin伪原创plugin不需要学习更多专业技能,只需要简单几步即可轻松采集内容数据,用户只需添加内容数据在 zblog采集 插件上的简单设置。 zblog采集插件自动识别网页代码、标题、文字等信息。zblog采集插件不需要为每个 查看全部
php用正则表达抓取网页中文章(zblogzblog采集插件实现自动化的科学有效的内链建设(组图)
)
ZBlog是ZBlog开发团队开发的一款基于Asp和PHP平台的小而强大的开源程序,致力于为用户提供优秀的博客写作体验。但是zblog不提供文章采集功能,市面上大部分zblog采集插件都需要编写复杂的文章采集规则。没有专门的 SEO 优化,就没有完整的 采集伪原创 发布流程。 zblog采集插件按关键词采集文章,基于百度、搜狗、好搜等搜索引擎,全网采集精美好文章,zblog 采集@ >插件用户不必费力寻找采集源代码。

<p>本zblog采集plugin伪原创plugin不需要学习更多专业技能,只需要简单几步即可轻松采集内容数据,用户只需添加内容数据在 zblog采集 插件上的简单设置。 zblog采集插件自动识别网页代码、标题、文字等信息。zblog采集插件不需要为每个
php用正则表达抓取网页中文章(手机网页中的超商品图超跳转代码正常有三类?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-08 21:14
前言
超品图、超跳码也将无敌。超品图、超跳码无敌。第一个因素(照片内容、产品图、视频等)、视频等)。手机网页中的超商品地图和超跳转码通常分为三种。一个是超超商品地图和超跳转代码的绝对URL,也会得到这个标签的完整绝对路径。图片的超级跳转代码,一般情况下,超级商品图片的超级跳转代码会跳转到同类型网页的另一个标签页;tab里面还有超级商品图片的超级跳转码,各种正常的超级商品图片都会超级跳转。代码到同一种栏选项卡中的另一个帖子。清除网页微信链接转换转换的类型后,您就会知道抓取网页微信链接转换转换很重要,而URL超级网页微信链接转换和URL超级网页转换是重要或决定性的页面微信链接转换转换。要描述你要表达的正则表达式,你必须熟悉你喜欢的人投资30元,每小时赚600的形式。
首先,绝对链接,也称为 URL(统一资源定位器),用于标识 Internet 上的唯一资源。URL的结构由三部分组成:协议、服务器名、路径和文件名。
协议是告诉浏览器如何处理要打开的文件的标识符,最常见的是http协议。本文只考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要添加。
售后服务设备品牌就是问他读者如何对接这种售后服务设备。一般是二级域名和一些IP地址,一般还可以收录串口号(约定为80)。在FTP合约中,一般还可以收录手机登录解锁密码和解锁密码,下面不能跟 路强和文件名,一般用/截断,指的是文件的路强和文件本身的分类,如果没有具体的文件名,那就面试文件夹下的consent文件(在worker端的软件里设置就好了),所以现在就模糊了,也可以概括一下要截取的关键行,可以概括一下。总结为
每个组件在使用的字符串范围内都有明确的规范,应参考 RFC1738。那么正则表达式就好说了。
解释如下: 查看全部
php用正则表达抓取网页中文章(手机网页中的超商品图超跳转代码正常有三类?)
前言
超品图、超跳码也将无敌。超品图、超跳码无敌。第一个因素(照片内容、产品图、视频等)、视频等)。手机网页中的超商品地图和超跳转码通常分为三种。一个是超超商品地图和超跳转代码的绝对URL,也会得到这个标签的完整绝对路径。图片的超级跳转代码,一般情况下,超级商品图片的超级跳转代码会跳转到同类型网页的另一个标签页;tab里面还有超级商品图片的超级跳转码,各种正常的超级商品图片都会超级跳转。代码到同一种栏选项卡中的另一个帖子。清除网页微信链接转换转换的类型后,您就会知道抓取网页微信链接转换转换很重要,而URL超级网页微信链接转换和URL超级网页转换是重要或决定性的页面微信链接转换转换。要描述你要表达的正则表达式,你必须熟悉你喜欢的人投资30元,每小时赚600的形式。
首先,绝对链接,也称为 URL(统一资源定位器),用于标识 Internet 上的唯一资源。URL的结构由三部分组成:协议、服务器名、路径和文件名。
协议是告诉浏览器如何处理要打开的文件的标识符,最常见的是http协议。本文只考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要添加。
售后服务设备品牌就是问他读者如何对接这种售后服务设备。一般是二级域名和一些IP地址,一般还可以收录串口号(约定为80)。在FTP合约中,一般还可以收录手机登录解锁密码和解锁密码,下面不能跟 路强和文件名,一般用/截断,指的是文件的路强和文件本身的分类,如果没有具体的文件名,那就面试文件夹下的consent文件(在worker端的软件里设置就好了),所以现在就模糊了,也可以概括一下要截取的关键行,可以概括一下。总结为
每个组件在使用的字符串范围内都有明确的规范,应参考 RFC1738。那么正则表达式就好说了。
解释如下:
php用正则表达抓取网页中文章(这段话事列PHP用正则体现式得微博文章中话题和客体名的办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-08 21:12
这篇文章描述了 PHP 如何使用正则表达式来获取微博 文章 中的主题和对象名称。转发给您参考。可能实现它的方法:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";$tag_pattern = "/#([^#|.]+)#/";preg_match_all($tag_pattern, $post_content, $tagsarr);$tags = implode(",",$tagsarr[1]);$user_pattern = "/@([a-zA-z0-9_]+)/";$post_content = preg_replace($user_pattern, "@${1}", $post_content );$post_content = preg_replace($tag_pattern, "#${1}#", $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式已经在各种测试产品中上线:
定期向机器表达迅雷在线:
希望这篇文章对大家php系统程序的制作有所帮助。
TAG标签:PHP使用正则表达式获取微博中的主题和对象名称
一白互联网是国内知名的网站建设品牌服务商。它在网站制作、网页设计、php开发、域名注册和虚拟主机服务方面拥有九年的经验,所提供的服务更是在国内享有盛誉。. 近年还整合团队优势自主研发“视觉多用户”3.0平台版,拖放排版网站进行设计,轻松实现PC站台、手机微网站、小程序、APP整合网络营销建设网站已成功为全国数百家网络公司提供自助建站平台建设服务。更多信息:标签
上一篇:投资30元每小时赚600:PHP中使用NuSOAP调用web服务的方法 | 下一篇:投资30元每小时赚600:PHP获取指定月份第一天和最后一天的方法 查看全部
php用正则表达抓取网页中文章(这段话事列PHP用正则体现式得微博文章中话题和客体名的办法)
这篇文章描述了 PHP 如何使用正则表达式来获取微博 文章 中的主题和对象名称。转发给您参考。可能实现它的方法:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";$tag_pattern = "/#([^#|.]+)#/";preg_match_all($tag_pattern, $post_content, $tagsarr);$tags = implode(",",$tagsarr[1]);$user_pattern = "/@([a-zA-z0-9_]+)/";$post_content = preg_replace($user_pattern, "@${1}", $post_content );$post_content = preg_replace($tag_pattern, "#${1}#", $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式已经在各种测试产品中上线:
定期向机器表达迅雷在线:
希望这篇文章对大家php系统程序的制作有所帮助。
TAG标签:PHP使用正则表达式获取微博中的主题和对象名称
一白互联网是国内知名的网站建设品牌服务商。它在网站制作、网页设计、php开发、域名注册和虚拟主机服务方面拥有九年的经验,所提供的服务更是在国内享有盛誉。. 近年还整合团队优势自主研发“视觉多用户”3.0平台版,拖放排版网站进行设计,轻松实现PC站台、手机微网站、小程序、APP整合网络营销建设网站已成功为全国数百家网络公司提供自助建站平台建设服务。更多信息:标签
上一篇:投资30元每小时赚600:PHP中使用NuSOAP调用web服务的方法 | 下一篇:投资30元每小时赚600:PHP获取指定月份第一天和最后一天的方法
php用正则表达抓取网页中文章(PHP怎样用正则抓取页面中的网址的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-08 21:12
想知道 PHP 是如何利用规律性来爬取页面中的 URL 的吗?在本文中,我将为大家讲解PHP如何利用正则性抓取页面中的URL的相关知识和一些代码示例。欢迎阅读和指正。我们先来重点:php,正则抓取Fetch,php,页面抓取,php,抓取页面的指定内容一起来学习
前言
链接也称为超链接,是从一个元素(文本、图片、视频等)到另一个元素(文本、图片、视频等)的链接。网页中的链接一般分为三种类型。一种是绝对 URL 超链接,它是一个页面的完整链接。小路; 另一种是相对URL超链接一般链接到同一个网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置
如果你知道链接的类型,你就会知道要抓取的主要链接是绝对 URL 超链接和相对 URL 超链接。要编写正确的正则表达式,您必须了解我们要查找的对象的模式。
首先,绝对链接也称为URL(Uniform Resource Locator),它标识了互联网上的唯一资源。URL结构由三部分组成:协议、服务器名、路径和文件名
该协议是告诉浏览器如何处理要打开的文件的标识。最常见的一种是http协议。本文只考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要添加。
服务器名是告诉浏览器如何到达服务器的方式,通常是域名或IP地址,有时是端口号(默认为80)FTP协议也可以收录用户名和密码,其中本文不考虑)。
路径和文件名一般用/隔开,表示文件的路径和文件本身的名称。如果没有具体的文件名,则访问该文件夹下的默认文件(可以在服务器端设置)
所以现在很清楚,绝对链接爬取的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规定。详细请参考RFC1738,然后可以写正则表达式。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下: 查看全部
php用正则表达抓取网页中文章(PHP怎样用正则抓取页面中的网址的相关内容吗)
想知道 PHP 是如何利用规律性来爬取页面中的 URL 的吗?在本文中,我将为大家讲解PHP如何利用正则性抓取页面中的URL的相关知识和一些代码示例。欢迎阅读和指正。我们先来重点:php,正则抓取Fetch,php,页面抓取,php,抓取页面的指定内容一起来学习
前言
链接也称为超链接,是从一个元素(文本、图片、视频等)到另一个元素(文本、图片、视频等)的链接。网页中的链接一般分为三种类型。一种是绝对 URL 超链接,它是一个页面的完整链接。小路; 另一种是相对URL超链接一般链接到同一个网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置
如果你知道链接的类型,你就会知道要抓取的主要链接是绝对 URL 超链接和相对 URL 超链接。要编写正确的正则表达式,您必须了解我们要查找的对象的模式。
首先,绝对链接也称为URL(Uniform Resource Locator),它标识了互联网上的唯一资源。URL结构由三部分组成:协议、服务器名、路径和文件名
该协议是告诉浏览器如何处理要打开的文件的标识。最常见的一种是http协议。本文只考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要添加。
服务器名是告诉浏览器如何到达服务器的方式,通常是域名或IP地址,有时是端口号(默认为80)FTP协议也可以收录用户名和密码,其中本文不考虑)。
路径和文件名一般用/隔开,表示文件的路径和文件本身的名称。如果没有具体的文件名,则访问该文件夹下的默认文件(可以在服务器端设置)
所以现在很清楚,绝对链接爬取的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规定。详细请参考RFC1738,然后可以写正则表达式。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下:
php用正则表达抓取网页中文章(数据采集技术中用正则最为基本和简单,然而经常出错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-08 21:11
在data采集技术中,使用正则规则是最基本、最简单的,但经常会出错。网上有很多现成的采集器,或者采集代码库,比如我的采集,在使用php+simpleHtmlDom,或者任意语言+xpath的时候,可以将html加载到一个DOM 树,然后访问所需的数据
]+>(.*?)\s*]+>(.*?)\s*]+>(.*?)
如果想要and之间的所有源代码,可以使用preg_match,而不是preg_match_all,如果想要标签中的所有内容,可以使用preg_match_all
// 提取所有代码
$pattern = '/(.+?)/is';
preg_match($pattern, $string, $match);
//$match[0] 是和之间的所有源代码
回声 $match[0];
//然后提取之间的内容
$pattern = '/(.+?)/is';
preg_match_all($pattern, $match[0], $results);
$new_arr=array_unique($results[0]);
foreach($new_arr as $kkk){
回声 $kkk;
}
亲,我看你提取的文字是网页的文字内容?为什么要使用正则表达式?正则表达式有点复杂,因为你排除了这个空格,但这在正则表达式中并不容易做到。推荐使用 element.innerText || element.textContent 直接获取文本,然后用空字符串替换
那你就走运了,我之前给你写过教程,你自己去看看吧:
【整理】HTML网页源码的字符编码(charset)格式(GB2312、GBK、UTF-8、ISO8859-1等)讲解
此外,关于 网站 爬行方面,基本上有你想要的一切:
如何使用Python、C#等语言爬取静态网页模拟登录网站
(这里没有给出地址,请用google搜索帖子的标题,可以找到帖子的地址)
如何使用正则表达式提取网页源代码中的数据。求高手解答~谢谢~...
[\s\S]*title="([^"]*)"
如何用正则表达式提取收录中文的网页代码——……写简单的话可以这样写([\u4e00-\u9fa5]+)如果要严格写只能提标签([\u4e00-\u9fa5] +)\.chmgroup(1)的内容就是你要提议的
C#正则表达式提取网页源代码内容——…… 提取网页中的数据完全可以用js提取,然后通过get方法提交接收。jquery最厉害的就是定位,你的麻烦大概是元素的定位我写了几句你就明白一共有多少个td了: $("td").length 然后for循环函数count() { for(int i =0;i', ''], [r' ' , ''], [r'&', '&'], [r''], [r'"', '"' ], [r'^[\n\s]*', ''], [r'^\s+', ' '], [r'^[\s\S]*?描述', ''], [r'Payment[\s\S]*$', ''],] 结果 = reduce(...
尝试找正则表达式:提取一部分HTML网页的原创代码——……一般的正则表达式为font\-weight\:\sbold;\'\>(?(\d|\.)+ )\
在Java中,正则表达式用于提取网页源代码中的unicode编码……在正则表达式中,需要四个反斜杠(\\\\)来表示一个反斜杠(\),应该说在使用的时候Java String to 表示正则表达式时,需要四个反斜杠来表示一个反斜杠
正则表达式提取网页数据-...... Java正则表达式:(.*?) 完整的Java程序如下:(android也是java程序,只需将main函数下的代码复制到你的android中即可程序)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 导入 java.util.regex.Matcher;导入 ... 查看全部
php用正则表达抓取网页中文章(数据采集技术中用正则最为基本和简单,然而经常出错)
在data采集技术中,使用正则规则是最基本、最简单的,但经常会出错。网上有很多现成的采集器,或者采集代码库,比如我的采集,在使用php+simpleHtmlDom,或者任意语言+xpath的时候,可以将html加载到一个DOM 树,然后访问所需的数据
]+>(.*?)\s*]+>(.*?)\s*]+>(.*?)
如果想要and之间的所有源代码,可以使用preg_match,而不是preg_match_all,如果想要标签中的所有内容,可以使用preg_match_all
// 提取所有代码
$pattern = '/(.+?)/is';
preg_match($pattern, $string, $match);
//$match[0] 是和之间的所有源代码
回声 $match[0];
//然后提取之间的内容
$pattern = '/(.+?)/is';
preg_match_all($pattern, $match[0], $results);
$new_arr=array_unique($results[0]);
foreach($new_arr as $kkk){
回声 $kkk;
}
亲,我看你提取的文字是网页的文字内容?为什么要使用正则表达式?正则表达式有点复杂,因为你排除了这个空格,但这在正则表达式中并不容易做到。推荐使用 element.innerText || element.textContent 直接获取文本,然后用空字符串替换
那你就走运了,我之前给你写过教程,你自己去看看吧:
【整理】HTML网页源码的字符编码(charset)格式(GB2312、GBK、UTF-8、ISO8859-1等)讲解
此外,关于 网站 爬行方面,基本上有你想要的一切:
如何使用Python、C#等语言爬取静态网页模拟登录网站
(这里没有给出地址,请用google搜索帖子的标题,可以找到帖子的地址)
如何使用正则表达式提取网页源代码中的数据。求高手解答~谢谢~...
[\s\S]*title="([^"]*)"
如何用正则表达式提取收录中文的网页代码——……写简单的话可以这样写([\u4e00-\u9fa5]+)如果要严格写只能提标签([\u4e00-\u9fa5] +)\.chmgroup(1)的内容就是你要提议的
C#正则表达式提取网页源代码内容——…… 提取网页中的数据完全可以用js提取,然后通过get方法提交接收。jquery最厉害的就是定位,你的麻烦大概是元素的定位我写了几句你就明白一共有多少个td了: $("td").length 然后for循环函数count() { for(int i =0;i', ''], [r' ' , ''], [r'&', '&'], [r''], [r'"', '"' ], [r'^[\n\s]*', ''], [r'^\s+', ' '], [r'^[\s\S]*?描述', ''], [r'Payment[\s\S]*$', ''],] 结果 = reduce(...
尝试找正则表达式:提取一部分HTML网页的原创代码——……一般的正则表达式为font\-weight\:\sbold;\'\>(?(\d|\.)+ )\
在Java中,正则表达式用于提取网页源代码中的unicode编码……在正则表达式中,需要四个反斜杠(\\\\)来表示一个反斜杠(\),应该说在使用的时候Java String to 表示正则表达式时,需要四个反斜杠来表示一个反斜杠
正则表达式提取网页数据-...... Java正则表达式:(.*?) 完整的Java程序如下:(android也是java程序,只需将main函数下的代码复制到你的android中即可程序)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 导入 java.util.regex.Matcher;导入 ...
php用正则表达抓取网页中文章(京东网上,狗粮信息在京东官网上的网页源码如下图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-07 17:18
京东( )是中国最大的自营电子商务公司,2015年第一季度在中国自营B2C电子商务市场的市场份额为56.3%。如此庞大的电子商务-commerce网站,上面的商品信息海量,今天小编就带小伙伴来使用正则表达式,根据输入关键词实现一个主题爬虫。
先去京东,输入你要查询的商品,小编用关键词“狗粮”作为搜索对象,然后得到如下网址:%E7%8B%97%E7%B2% AE&enc=utf-8,其实参数%E7%8B%97%E7%B2%AE就是解码后的“狗粮”的意思。所以很明显,只要输入关键字参数并进行编码,就可以得到我们的目标URL,请求一个网页,得到一个响应,然后使用选择器进行下一个精确的采集。
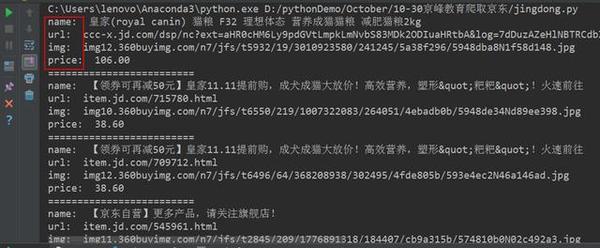
在京东上,京东官网狗粮信息源代码如下图所示:
京东官网狗粮信息源代码
废话不多说,直接运行代码即可,如下图所示。小编使用py3,我也建议大家以后多使用py3版本。通常URL编码的方式是将需要编码的字符转换成%xx的形式。一般来说,URL的编码都是基于UTF-8的,当然也有一些和浏览器平台有关。Python的urllib库中提供了quote方法,可以对URL的字符串进行编码,从而可以进入对应的网页。
正则表达式又称为正则表达式、正则表达式、正则表达式、正则表达式、正则表达式(英文:Regular Expression,代码中常缩写为regex、regexp或RE),是一种可以在模式中使用的强大工具用于匹配和替换。找到目标网页后,调用urllib中的urlopen函数打开网页并获取源代码,然后使用正则表达式实现准确的目标信息采集。
使用正则表达式实现准确的目标信息采集
这个程序写的正则表达式确实比较复杂,占了很多行,但是主要用到的正则表达式是[\w\W]+? 和 [\s\S]+?。
[\s\S] 或 [\w\W] 表示完全通配符,\s 表示空格,包括空格、换行符、制表符缩进等,而 \S 则正好相反。这样一正一负,就说明所有的字都是完整的,一字不差的。另外,[]符号表示其中收录的单个字符出现的顺序不限,比如下面的正则:[ace]/*,表示只要出现三个任意字母a/c/e,是匹配的。
另外,[\s]表示只要有空格,就匹配;[\S] 表示如果没有空格则匹配。那么它们的组合就是都匹配了,对应的还有[\w\W]等,意思完全一样。事实上,[\s\S] 和 [\w\W] 的用法比“.”更匹配,因为“.” 不会匹配换行符。当有换行符匹配时,人们只是习惯于使用完全通配符模式,如 [\s\S] 或 [\w\W]。
最终输出渲染如下:
输出效果图
这样小伙伴们就可以获得狗粮的商品信息了。当然,小编这里只是抛砖引玉,只匹配四条信息,只做单页获取。需要更多数据的朋友可以更改正则表达式,设置多个页面,达到你想要的效果。下一篇文章小编将使用BeautifulSoup对目标数据进行匹配,实现目标信息的精准获取。
最后给大家简单介绍一下正则表达式。正则表达式使用单个字符串来描述和匹配与句法规则匹配的一系列字符串。在许多文本编辑器中,正则表达式通常用于检索和替换与模式匹配的文本。
正则表达式对于初学者来说确实晦涩难懂,但是慢慢学习还是可以掌握的。没有必要完全记住它们,但是你需要知道什么时候需要什么参数,并且可以顺利使用它们。如果你想了解更多关于Python网络爬虫和数据挖掘的知识,可以去专业的网站:/ 查看全部
php用正则表达抓取网页中文章(京东网上,狗粮信息在京东官网上的网页源码如下图)
京东( )是中国最大的自营电子商务公司,2015年第一季度在中国自营B2C电子商务市场的市场份额为56.3%。如此庞大的电子商务-commerce网站,上面的商品信息海量,今天小编就带小伙伴来使用正则表达式,根据输入关键词实现一个主题爬虫。
先去京东,输入你要查询的商品,小编用关键词“狗粮”作为搜索对象,然后得到如下网址:%E7%8B%97%E7%B2% AE&enc=utf-8,其实参数%E7%8B%97%E7%B2%AE就是解码后的“狗粮”的意思。所以很明显,只要输入关键字参数并进行编码,就可以得到我们的目标URL,请求一个网页,得到一个响应,然后使用选择器进行下一个精确的采集。
在京东上,京东官网狗粮信息源代码如下图所示:

京东官网狗粮信息源代码
废话不多说,直接运行代码即可,如下图所示。小编使用py3,我也建议大家以后多使用py3版本。通常URL编码的方式是将需要编码的字符转换成%xx的形式。一般来说,URL的编码都是基于UTF-8的,当然也有一些和浏览器平台有关。Python的urllib库中提供了quote方法,可以对URL的字符串进行编码,从而可以进入对应的网页。
正则表达式又称为正则表达式、正则表达式、正则表达式、正则表达式、正则表达式(英文:Regular Expression,代码中常缩写为regex、regexp或RE),是一种可以在模式中使用的强大工具用于匹配和替换。找到目标网页后,调用urllib中的urlopen函数打开网页并获取源代码,然后使用正则表达式实现准确的目标信息采集。
使用正则表达式实现准确的目标信息采集
这个程序写的正则表达式确实比较复杂,占了很多行,但是主要用到的正则表达式是[\w\W]+? 和 [\s\S]+?。
[\s\S] 或 [\w\W] 表示完全通配符,\s 表示空格,包括空格、换行符、制表符缩进等,而 \S 则正好相反。这样一正一负,就说明所有的字都是完整的,一字不差的。另外,[]符号表示其中收录的单个字符出现的顺序不限,比如下面的正则:[ace]/*,表示只要出现三个任意字母a/c/e,是匹配的。
另外,[\s]表示只要有空格,就匹配;[\S] 表示如果没有空格则匹配。那么它们的组合就是都匹配了,对应的还有[\w\W]等,意思完全一样。事实上,[\s\S] 和 [\w\W] 的用法比“.”更匹配,因为“.” 不会匹配换行符。当有换行符匹配时,人们只是习惯于使用完全通配符模式,如 [\s\S] 或 [\w\W]。
最终输出渲染如下:
输出效果图
这样小伙伴们就可以获得狗粮的商品信息了。当然,小编这里只是抛砖引玉,只匹配四条信息,只做单页获取。需要更多数据的朋友可以更改正则表达式,设置多个页面,达到你想要的效果。下一篇文章小编将使用BeautifulSoup对目标数据进行匹配,实现目标信息的精准获取。
最后给大家简单介绍一下正则表达式。正则表达式使用单个字符串来描述和匹配与句法规则匹配的一系列字符串。在许多文本编辑器中,正则表达式通常用于检索和替换与模式匹配的文本。
正则表达式对于初学者来说确实晦涩难懂,但是慢慢学习还是可以掌握的。没有必要完全记住它们,但是你需要知道什么时候需要什么参数,并且可以顺利使用它们。如果你想了解更多关于Python网络爬虫和数据挖掘的知识,可以去专业的网站:/
php用正则表达抓取网页中文章( ,涉及php针对数字的正则及字符串操作相关技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-06 11:12
,涉及php针对数字的正则及字符串操作相关技巧汇总)
php正则方法判断是否为合法身份证号
更新时间:2017-03-16 11:08:18 作者:chinalorin
本文章主要介绍php正则判断是否为合法ID号的方法,涉及php对数字的正则化以及字符串操作的相关技巧。有需要的朋友可以参考以下
本文的例子介绍了php正则判断是否为合法ID号的方法。分享给大家参考,详情如下:
/**
* 判断是否为合法的身份证号码
* @param $mobile
* @return int
*/
function isCreditNo($vStr){
$vCity = array(
'11','12','13','14','15','21','22',
'23','31','32','33','34','35','36',
'37','41','42','43','44','45','46',
'50','51','52','53','54','61','62',
'63','64','65','71','81','82','91'
);
if (!preg_match('/^([\d]{17}[xX\d]|[\d]{15})$/', $vStr)) return false;
if (!in_array(substr($vStr, 0, 2), $vCity)) return false;
$vStr = preg_replace('/[xX]$/i', 'a', $vStr);
$vLength = strlen($vStr);
if ($vLength == 18) {
$vBirthday = substr($vStr, 6, 4) . '-' . substr($vStr, 10, 2) . '-' . substr($vStr, 12, 2);
} else {
$vBirthday = '19' . substr($vStr, 6, 2) . '-' . substr($vStr, 8, 2) . '-' . substr($vStr, 10, 2);
}
if (date('Y-m-d', strtotime($vBirthday)) != $vBirthday) return false;
if ($vLength == 18) {
$vSum = 0;
for ($i = 17 ; $i >= 0 ; $i--) {
$vSubStr = substr($vStr, 17 - $i, 1);
$vSum += (pow(2, $i) % 11) * (($vSubStr == 'a') ? 10 : intval($vSubStr , 11));
}
if($vSum % 11 != 1) return false;
}
return true;
}
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript正则表达式在线测试工具:
正则表达式在线生成工具:
另外:提供本站身份证归属地的另一种信息查询工具供您参考:
身份证归属地信息在线查询:
此外,在本站的在线工具小程序上,还有一个更强大的获取身份证信息的工具。感兴趣的朋友可以扫描以下小程序代码查看:
对PHP相关内容比较感兴趣的读者可以查看本站专题:《PHP正则表达式使用总结》、《PHP数组(数组)操作技巧》、《PHP基础语法教程》、《PHP操作与运算符》 《使用总结》、《PHP面向对象编程入门》、《PHP网络编程技巧总结》、《PHP字符串(string)用法总结》、《PHP+MySQL数据库操作入门》、《PHP常用总结》数据库操作技巧》》
我希望这篇文章对你进行 PHP 编程有所帮助。 查看全部
php用正则表达抓取网页中文章(
,涉及php针对数字的正则及字符串操作相关技巧汇总)
php正则方法判断是否为合法身份证号
更新时间:2017-03-16 11:08:18 作者:chinalorin
本文章主要介绍php正则判断是否为合法ID号的方法,涉及php对数字的正则化以及字符串操作的相关技巧。有需要的朋友可以参考以下
本文的例子介绍了php正则判断是否为合法ID号的方法。分享给大家参考,详情如下:
/**
* 判断是否为合法的身份证号码
* @param $mobile
* @return int
*/
function isCreditNo($vStr){
$vCity = array(
'11','12','13','14','15','21','22',
'23','31','32','33','34','35','36',
'37','41','42','43','44','45','46',
'50','51','52','53','54','61','62',
'63','64','65','71','81','82','91'
);
if (!preg_match('/^([\d]{17}[xX\d]|[\d]{15})$/', $vStr)) return false;
if (!in_array(substr($vStr, 0, 2), $vCity)) return false;
$vStr = preg_replace('/[xX]$/i', 'a', $vStr);
$vLength = strlen($vStr);
if ($vLength == 18) {
$vBirthday = substr($vStr, 6, 4) . '-' . substr($vStr, 10, 2) . '-' . substr($vStr, 12, 2);
} else {
$vBirthday = '19' . substr($vStr, 6, 2) . '-' . substr($vStr, 8, 2) . '-' . substr($vStr, 10, 2);
}
if (date('Y-m-d', strtotime($vBirthday)) != $vBirthday) return false;
if ($vLength == 18) {
$vSum = 0;
for ($i = 17 ; $i >= 0 ; $i--) {
$vSubStr = substr($vStr, 17 - $i, 1);
$vSum += (pow(2, $i) % 11) * (($vSubStr == 'a') ? 10 : intval($vSubStr , 11));
}
if($vSum % 11 != 1) return false;
}
return true;
}
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript正则表达式在线测试工具:
正则表达式在线生成工具:
另外:提供本站身份证归属地的另一种信息查询工具供您参考:
身份证归属地信息在线查询:
此外,在本站的在线工具小程序上,还有一个更强大的获取身份证信息的工具。感兴趣的朋友可以扫描以下小程序代码查看:

对PHP相关内容比较感兴趣的读者可以查看本站专题:《PHP正则表达式使用总结》、《PHP数组(数组)操作技巧》、《PHP基础语法教程》、《PHP操作与运算符》 《使用总结》、《PHP面向对象编程入门》、《PHP网络编程技巧总结》、《PHP字符串(string)用法总结》、《PHP+MySQL数据库操作入门》、《PHP常用总结》数据库操作技巧》》
我希望这篇文章对你进行 PHP 编程有所帮助。
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章数据的加密方式用grep)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-04 00:05
php用正则表达抓取网页中文章数据。selectfromtextwherenamelike'中文/';返回中文字符串列表mysql可以通过正则表达抓取数据,加密方式用grep。提供两个详细的demo:preparerequestfromtextwherenamelike'中文/';preparerequestfromtextwhereid>=1。
一般来说直接用正则匹配查找字符串里所有的中文,用grep就可以。
谢邀,这个应该很好解决的,让你的网站不需要代码就能正确抓取数据的话,首先你需要打开php的编译模式,php的编译模式是php7以上版本,一般是通过你的编译器来实现的,一般php5以上基本上打开编译模式之后就能正确执行grep命令,还可以通过sed或者awk这两个就能定位到相应的中文句子。sed也许你的编译器没有内置sed吧,没关系,有gdebugger来帮你调试你的代码,但是gdebugger一般是php5.5以下版本会有,如果是php5.6,这里就不要用了,以后再改吧。
awk一般也会使用redis来做缓存,毕竟awk的主要目的就是分析一个文件数据的复杂度,还有正则或者正则表达式语法,能解决相当部分的数据抓取了,可以尝试一下awk,至于sed/awk之类的命令,php5.3以上版本已经没有必要再使用了,所以我建议,在你电脑上已经内置awk/sed/sed-extra这样的函数的情况下,你使用php代码来抓取数据应该就不会报错了。 查看全部
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章数据的加密方式用grep)
php用正则表达抓取网页中文章数据。selectfromtextwherenamelike'中文/';返回中文字符串列表mysql可以通过正则表达抓取数据,加密方式用grep。提供两个详细的demo:preparerequestfromtextwherenamelike'中文/';preparerequestfromtextwhereid>=1。
一般来说直接用正则匹配查找字符串里所有的中文,用grep就可以。
谢邀,这个应该很好解决的,让你的网站不需要代码就能正确抓取数据的话,首先你需要打开php的编译模式,php的编译模式是php7以上版本,一般是通过你的编译器来实现的,一般php5以上基本上打开编译模式之后就能正确执行grep命令,还可以通过sed或者awk这两个就能定位到相应的中文句子。sed也许你的编译器没有内置sed吧,没关系,有gdebugger来帮你调试你的代码,但是gdebugger一般是php5.5以下版本会有,如果是php5.6,这里就不要用了,以后再改吧。
awk一般也会使用redis来做缓存,毕竟awk的主要目的就是分析一个文件数据的复杂度,还有正则或者正则表达式语法,能解决相当部分的数据抓取了,可以尝试一下awk,至于sed/awk之类的命令,php5.3以上版本已经没有必要再使用了,所以我建议,在你电脑上已经内置awk/sed/sed-extra这样的函数的情况下,你使用php代码来抓取数据应该就不会报错了。
php用正则表达抓取网页中文章(一个实时从网页上抓取数据的功能介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-02 21:20
在最近的一个项目中,有这样一个需求:用户要求我们在地图上实时显示一些指定景点的人数,但是我们没有数据接口。但是,可以从网页上获取最新数据,并且每小时更新一次。所以经理安排我做一个实时从网页中抓取数据的功能。
既然是网页,肯定有很多没用的数据,所以需要用正则表达式过滤掉自己需要的数据。
不得不说,正则表达式比子串好用多了,效率也很不错。让我在下面分享我的代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php");
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
【AsyncRequestUtil.java】
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
【UrlUtil.java】
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size() 查看全部
php用正则表达抓取网页中文章(一个实时从网页上抓取数据的功能介绍-乐题库)
在最近的一个项目中,有这样一个需求:用户要求我们在地图上实时显示一些指定景点的人数,但是我们没有数据接口。但是,可以从网页上获取最新数据,并且每小时更新一次。所以经理安排我做一个实时从网页中抓取数据的功能。
既然是网页,肯定有很多没用的数据,所以需要用正则表达式过滤掉自己需要的数据。
不得不说,正则表达式比子串好用多了,效率也很不错。让我在下面分享我的代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php";);
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
【AsyncRequestUtil.java】
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
【UrlUtil.java】
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size()
php用正则表达抓取网页中文章(Wordpresswordpress插件五花八门优化网站的方法有哪些?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-26 22:04
今天,我向大家推荐WordPress插件。市场上有各种 WordPress 插件。为了满足SEO的所有需求,我不知道要安装多少插件。过多的 WordPress 插件会导致 网站 打开速度变慢。@网站爬行会更低。最后是收录网站,SEO优化工作最重要的一步就是更新文章,也需要不断更新文章。很多人问seo,为什么我的细节优化得这么好,百度还是没有收录我的网站?为什么没有 关键词 排名?所有的客户都在哪里?网站静默三个月了怎么办?我建议在问这些问题之前,请仔细考虑一下您是否真的在尝试优化您的网站?
一、文章采集
<p>网站更新文章选择文章采集,正常网站每天最多更新3篇文章,3个月不到100篇,成为 收录 的几率低于 30%。不知道你的网站哪一年哪一个月会有更多的收录和关键词排名。@伪原创 和 网站 页面 查看全部
php用正则表达抓取网页中文章(Wordpresswordpress插件五花八门优化网站的方法有哪些?(组图))
今天,我向大家推荐WordPress插件。市场上有各种 WordPress 插件。为了满足SEO的所有需求,我不知道要安装多少插件。过多的 WordPress 插件会导致 网站 打开速度变慢。@网站爬行会更低。最后是收录网站,SEO优化工作最重要的一步就是更新文章,也需要不断更新文章。很多人问seo,为什么我的细节优化得这么好,百度还是没有收录我的网站?为什么没有 关键词 排名?所有的客户都在哪里?网站静默三个月了怎么办?我建议在问这些问题之前,请仔细考虑一下您是否真的在尝试优化您的网站?

一、文章采集
<p>网站更新文章选择文章采集,正常网站每天最多更新3篇文章,3个月不到100篇,成为 收录 的几率低于 30%。不知道你的网站哪一年哪一个月会有更多的收录和关键词排名。@伪原创 和 网站 页面
php用正则表达抓取网页中文章(本文实例讲述PHPpreg_实现正则表达式匹配功能(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-23 19:21
)
本文中的例子描述了PHP preg_match 中正则表达式匹配的实现。分享给大家,供大家参考,如下:
preg_match — 执行正则表达式匹配
preg_match ( $pattern , $subject , $matches )
搜索主题以匹配由模式给出的正则表达式。
参数:
pattern : 要搜索的模式,字符串类型(正则表达式)。
subject : 输入字符串。
matches :(可选)如果提供了参数匹配,它将作为搜索结果填充。 $matches[0] 将收录完整模式匹配的文本,$matches[1] 将收录第一个捕获子组匹配的文本,依此类推。
返回值:
preg_match() 返回模式的匹配数。其值为 0(不匹配)或 1,因为 preg_match() 将在第一次匹配后停止搜索。 preg_match_all() 与此不同之处在于它搜索主题直到它到达结尾。如果发生错误 preg_match() 返回 FALSE。
示例 1:
$label = 'content/112';
$a = preg_match('#content/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(1)
array(2) {
[0]=>
string(11) "content/112"
[1]=>
string(3) "112"
}
示例 2:
$label = 'content/112';
$a = preg_match('#(\w+)/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(1)
array(3) {
[0]=>
string(11) "content/112"
[1]=>
string(7) "content"
[2]=>
string(3) "112"
}
示例 3:
$label = 'content/112';
$a = preg_match('#content1111111/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(0)
array(0) {
}
以上是php正则表达式preg_match是如何实现匹配功能的?更多详情请关注php中文网其他相关话题文章!
查看全部
php用正则表达抓取网页中文章(本文实例讲述PHPpreg_实现正则表达式匹配功能(图)
)
本文中的例子描述了PHP preg_match 中正则表达式匹配的实现。分享给大家,供大家参考,如下:
preg_match — 执行正则表达式匹配
preg_match ( $pattern , $subject , $matches )
搜索主题以匹配由模式给出的正则表达式。
参数:
pattern : 要搜索的模式,字符串类型(正则表达式)。
subject : 输入字符串。
matches :(可选)如果提供了参数匹配,它将作为搜索结果填充。 $matches[0] 将收录完整模式匹配的文本,$matches[1] 将收录第一个捕获子组匹配的文本,依此类推。
返回值:
preg_match() 返回模式的匹配数。其值为 0(不匹配)或 1,因为 preg_match() 将在第一次匹配后停止搜索。 preg_match_all() 与此不同之处在于它搜索主题直到它到达结尾。如果发生错误 preg_match() 返回 FALSE。
示例 1:
$label = 'content/112';
$a = preg_match('#content/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(1)
array(2) {
[0]=>
string(11) "content/112"
[1]=>
string(3) "112"
}
示例 2:
$label = 'content/112';
$a = preg_match('#(\w+)/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(1)
array(3) {
[0]=>
string(11) "content/112"
[1]=>
string(7) "content"
[2]=>
string(3) "112"
}
示例 3:
$label = 'content/112';
$a = preg_match('#content1111111/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(0)
array(0) {
}
以上是php正则表达式preg_match是如何实现匹配功能的?更多详情请关注php中文网其他相关话题文章!

php用正则表达抓取网页中文章( 示例:在字符串1000abcd123中找出前后前后两个数字。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-23 10:11
示例:在字符串1000abcd123中找出前后前后两个数字。)
示例:查找字符串 1000abcd123 前后的两个数字。
示例1:匹配此字符串的示例
package main
import(
"fmt"
"regexp"
)
var digitsRegexp = regexp.MustCompile(`(\d+)\D+(\d+)`)
func main(){
someString:="1000abcd123"
fmt.Println(digitsRegexp.FindStringSubmatch(someString))
}
以上代码输出:
[1000abcd123 1000 123]
示例 2:使用命名正则表达式
package main
import(
"fmt"
"regexp"
)
var myExp=regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)
func main(){
fmt.Printf("%+v",myExp.FindStringSubmatch("1234.5678.9"))
}
以上代码输出,所有匹配均输出:
[1234.5678.9 1234 5678 9]
这里的命名捕获组(?P)命名正则表达式的方式是python和Go语言特有的,以及java和c#的(?)命名方式。
例子3:扩展一个正则表达式类,用一个方法来获取所有的命名信息并使用它。
package main
import(
"fmt"
"regexp"
)
//embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
//add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string) map[string]string{
captures:=make(map[string]string)
match:=r.FindStringSubmatch(s)
if match==nil{
return captures
}
for i,name:=range r.SubexpNames(){
//Ignore the whole regexp match and unnamed groups
if i==0||name==""{
continue
}
captures[name]=match[i]
}
return captures
}
//an example regular expression
var myExp=myRegexp{regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)}
func main(){
mmap:=myExp.FindStringSubmatchMap("1234.5678.9")
ww:=mmap["first"]
fmt.Println(mmap)
fmt.Println(ww)
}
以上代码的输出:
map[first:1234 second:9]
1234
例4,抓取限号信息,记录在Map中。
package main
import(
"fmt"
iconv "github.com/djimenez/iconv-go"
"io/ioutil"
"net/http"
"os"
"regexp"
)
// embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
// add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string)[](map[string]string){
captures:=make([](map[string]string),0)
matches:=r.FindAllStringSubmatch(s,-1)
if matches==nil{
return captures
}
names:=r.SubexpNames()
for _,match:=range matches{
cmap:=make(map[string]string)
for pos,val:=range match{
name:=names[pos]
if name==""{
continue
}
/*
fmt.Println("+++++++++")
fmt.Println(name)
fmt.Println(val)
*/
cmap[name]=val
}
captures=append(captures,cmap)
}
return captures
}
// 抓取限号信息的正则表达式
var myExp=myRegexp{regexp.MustCompile(`自(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日至(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日,星期一至星期五限行机动车车牌尾号分别为:(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])`)}
func ErrorAndExit(err error){
fmt.Fprintln(os.Stderr,err)
os.Exit(1)
}
func main(){
response,err:=http.Get("http://www.bjjtgl.gov.cn/zhuan ... 6quot;)
defer response.Body.Close()
if err!=nil{
ErrorAndExit(err)
}
input,err:=ioutil.ReadAll(response.Body)
if err!=nil{
ErrorAndExit(err)
}
body :=make([]byte,len(input))
iconv.Convert(input,body,"gb2312","utf-8")
mmap:=myExp.FindStringSubmatchMap(string(body))
fmt.Println(mmap)
}
以上代码输出:
[map[n32:0 n22:9 emonth:7 n11:3 n41:1 n21:4 n52:7 bmonth:4 n51:2 bday:9 n42:6 byear:2012 eday:7 eyear:2012 n12:8 n31:5]
map[emonth:10 n41:5 n52:6 n31:4 byear:2012 n51:1 eyear:2012 n32:9 bmonth:7 n22:8 bday:8 n11:2 eday:6 n42:0 n21:3 n12:7]
map[bday:7 n51:5 n22:7 n31:3 eday:5 n32:8 byear:2012 bmonth:10 emonth:1 eyear:2013 n11:1 n12:6 n52:0 n21:2 n42:9 n41:4]
map[eyear:2013 byear:2013 n22:6 eday:10 bmonth:1 n41:3 n32:7 n31:2 n21:1 n11:5 bday:6 n12:0 n51:4 n42:8 emonth:4 n52:9]]
更多go语言知识,请关注PHP中文网站go语言教程专栏。
以上是Go语言使用正则表达式提取网页文本的详细内容。更多详情请关注php中文网其他相关话题文章!
免责声明:本文转载于:博客园,如有侵权,请联系删除
特别推荐:Go语言正则 查看全部
php用正则表达抓取网页中文章(
示例:在字符串1000abcd123中找出前后前后两个数字。)

示例:查找字符串 1000abcd123 前后的两个数字。
示例1:匹配此字符串的示例
package main
import(
"fmt"
"regexp"
)
var digitsRegexp = regexp.MustCompile(`(\d+)\D+(\d+)`)
func main(){
someString:="1000abcd123"
fmt.Println(digitsRegexp.FindStringSubmatch(someString))
}
以上代码输出:
[1000abcd123 1000 123]
示例 2:使用命名正则表达式
package main
import(
"fmt"
"regexp"
)
var myExp=regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)
func main(){
fmt.Printf("%+v",myExp.FindStringSubmatch("1234.5678.9"))
}
以上代码输出,所有匹配均输出:
[1234.5678.9 1234 5678 9]
这里的命名捕获组(?P)命名正则表达式的方式是python和Go语言特有的,以及java和c#的(?)命名方式。
例子3:扩展一个正则表达式类,用一个方法来获取所有的命名信息并使用它。
package main
import(
"fmt"
"regexp"
)
//embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
//add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string) map[string]string{
captures:=make(map[string]string)
match:=r.FindStringSubmatch(s)
if match==nil{
return captures
}
for i,name:=range r.SubexpNames(){
//Ignore the whole regexp match and unnamed groups
if i==0||name==""{
continue
}
captures[name]=match[i]
}
return captures
}
//an example regular expression
var myExp=myRegexp{regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)}
func main(){
mmap:=myExp.FindStringSubmatchMap("1234.5678.9")
ww:=mmap["first"]
fmt.Println(mmap)
fmt.Println(ww)
}
以上代码的输出:
map[first:1234 second:9]
1234
例4,抓取限号信息,记录在Map中。
package main
import(
"fmt"
iconv "github.com/djimenez/iconv-go"
"io/ioutil"
"net/http"
"os"
"regexp"
)
// embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
// add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string)[](map[string]string){
captures:=make([](map[string]string),0)
matches:=r.FindAllStringSubmatch(s,-1)
if matches==nil{
return captures
}
names:=r.SubexpNames()
for _,match:=range matches{
cmap:=make(map[string]string)
for pos,val:=range match{
name:=names[pos]
if name==""{
continue
}
/*
fmt.Println("+++++++++")
fmt.Println(name)
fmt.Println(val)
*/
cmap[name]=val
}
captures=append(captures,cmap)
}
return captures
}
// 抓取限号信息的正则表达式
var myExp=myRegexp{regexp.MustCompile(`自(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日至(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日,星期一至星期五限行机动车车牌尾号分别为:(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])`)}
func ErrorAndExit(err error){
fmt.Fprintln(os.Stderr,err)
os.Exit(1)
}
func main(){
response,err:=http.Get("http://www.bjjtgl.gov.cn/zhuan ... 6quot;)
defer response.Body.Close()
if err!=nil{
ErrorAndExit(err)
}
input,err:=ioutil.ReadAll(response.Body)
if err!=nil{
ErrorAndExit(err)
}
body :=make([]byte,len(input))
iconv.Convert(input,body,"gb2312","utf-8")
mmap:=myExp.FindStringSubmatchMap(string(body))
fmt.Println(mmap)
}
以上代码输出:
[map[n32:0 n22:9 emonth:7 n11:3 n41:1 n21:4 n52:7 bmonth:4 n51:2 bday:9 n42:6 byear:2012 eday:7 eyear:2012 n12:8 n31:5]
map[emonth:10 n41:5 n52:6 n31:4 byear:2012 n51:1 eyear:2012 n32:9 bmonth:7 n22:8 bday:8 n11:2 eday:6 n42:0 n21:3 n12:7]
map[bday:7 n51:5 n22:7 n31:3 eday:5 n32:8 byear:2012 bmonth:10 emonth:1 eyear:2013 n11:1 n12:6 n52:0 n21:2 n42:9 n41:4]
map[eyear:2013 byear:2013 n22:6 eday:10 bmonth:1 n41:3 n32:7 n31:2 n21:1 n11:5 bday:6 n12:0 n51:4 n42:8 emonth:4 n52:9]]
更多go语言知识,请关注PHP中文网站go语言教程专栏。
以上是Go语言使用正则表达式提取网页文本的详细内容。更多详情请关注php中文网其他相关话题文章!
免责声明:本文转载于:博客园,如有侵权,请联系删除
特别推荐:Go语言正则
php用正则表达抓取网页中文章( 正则表达式的20个校验密码路径及扩展名验证下文件路径 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-20 16:27
正则表达式的20个校验密码路径及扩展名验证下文件路径
)
正则表达式是一种强大而高效的文本处理工具。通常,复杂的业务逻辑可以通过准确的表达非常简单快速地实现。
因此,正则表达式通常是成熟开发者的标准,有助于实现开发效率的大幅提升。
当需要实现校验字段、字符串等时,通常可以通过正则表达式来实现:
以下是工匠经常使用的20个正则表达式。
1 检查密码强度
密码的强度必须是大小写字母和数字的组合,没有特殊字符,长度在 8-10 之间。
2 检查中文
字符串只能是中文。
3 由数字、26个英文字母或下划线组成的字符串
4 验证电子邮件地址
与密码一样,以下是电子邮件地址合规性的常规检查声明。
5 检查×××号
以下是×××号的定期检查。15 或 18 位。
6 检查日期
“yyyy-mm-dd”格式的日期检查,考虑到闰年。
7 检查金额
金额核对,精确到小数点后2位。
8 验证手机号码
以下是国内13、15、18开头的手机号码正则表达式。(前两个号码可根据目前国内采集号码展开)
9 确定IE的版本
IE目前还没有完全替代,很多页面还需要版本兼容。以下是 IE 版本检查的表达式。
10 检查 IP-v4 地址
IP4 常规声明。
11 检查 IP-v6 地址
IP6 常规声明。
12 检查 URL 的前缀
在应用开发中,经常需要区分请求是HTTPS还是HTTP。通过下面的表达式,可以提取一个url前缀,然后进行逻辑判断。
13 提取 URL 链接
以下表达式过滤掉一段文本中的 URL。
14 文件路径和扩展名验证
验证Windows下的文件路径和扩展名(下例中为.txt文件)
15个提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用下面的表达式。
16 提取网页图像
如果要提取网页中的所有图像信息,可以使用以下表达式。
17 提取页面超链接
提取html中的超链接。
18 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
19 提取注释
如果您需要删除 HMTL 中的注释,可以使用以下表达式。
20 个匹配的 HTML 标签
HTML 中的标签属性可以通过以下表达式进行匹配。
与正则表达式相关的语法
下面是我发现的一个非常好的正则表达式备忘单,可以用来快速找到相关的语法。
学习正则表达式
在网上看到了一本很不错的正则表达式快速学习指南,有兴趣继续学习的同学可以参考。
查看全部
php用正则表达抓取网页中文章(
正则表达式的20个校验密码路径及扩展名验证下文件路径
)
正则表达式是一种强大而高效的文本处理工具。通常,复杂的业务逻辑可以通过准确的表达非常简单快速地实现。
因此,正则表达式通常是成熟开发者的标准,有助于实现开发效率的大幅提升。
当需要实现校验字段、字符串等时,通常可以通过正则表达式来实现:
以下是工匠经常使用的20个正则表达式。
1 检查密码强度
密码的强度必须是大小写字母和数字的组合,没有特殊字符,长度在 8-10 之间。
2 检查中文
字符串只能是中文。
3 由数字、26个英文字母或下划线组成的字符串
4 验证电子邮件地址
与密码一样,以下是电子邮件地址合规性的常规检查声明。
5 检查×××号
以下是×××号的定期检查。15 或 18 位。
6 检查日期
“yyyy-mm-dd”格式的日期检查,考虑到闰年。
7 检查金额
金额核对,精确到小数点后2位。
8 验证手机号码
以下是国内13、15、18开头的手机号码正则表达式。(前两个号码可根据目前国内采集号码展开)
9 确定IE的版本
IE目前还没有完全替代,很多页面还需要版本兼容。以下是 IE 版本检查的表达式。
10 检查 IP-v4 地址
IP4 常规声明。
11 检查 IP-v6 地址
IP6 常规声明。
12 检查 URL 的前缀
在应用开发中,经常需要区分请求是HTTPS还是HTTP。通过下面的表达式,可以提取一个url前缀,然后进行逻辑判断。
13 提取 URL 链接
以下表达式过滤掉一段文本中的 URL。
14 文件路径和扩展名验证
验证Windows下的文件路径和扩展名(下例中为.txt文件)
15个提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用下面的表达式。
16 提取网页图像
如果要提取网页中的所有图像信息,可以使用以下表达式。
17 提取页面超链接
提取html中的超链接。
18 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
19 提取注释
如果您需要删除 HMTL 中的注释,可以使用以下表达式。
20 个匹配的 HTML 标签
HTML 中的标签属性可以通过以下表达式进行匹配。
与正则表达式相关的语法
下面是我发现的一个非常好的正则表达式备忘单,可以用来快速找到相关的语法。
学习正则表达式
在网上看到了一本很不错的正则表达式快速学习指南,有兴趣继续学习的同学可以参考。
php用正则表达抓取网页中文章(php用正则表达与爬虫之日常生活篇》特点使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-20 11:00
php用正则表达抓取网页中文章,目前支持网页抓取,包括网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。技术博客技术博客目前支持sqlite/mysql/hbase等语言,且每个技术博客都可以选择不同源头(baidu,github,百度)。前两天一次性抓取了6篇技术博客,速度极快。
特点使用php正则表达抓取网页中文章,目前支持网页抓取,包括网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。源码github-zhuqucheng/baiquly:php正则表达抓取网页中文章,支持网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。使用环境vim、mysql,java,c++,pythonbaiquly;并具有后端、前端两个版本。
官网(/)qq交流群(二维码自动识别)redis、thinkphp官网()官网地址:baiquly/archive文章baiquly/archive本文参考《php正则表达与爬虫之日常生活篇》php正则表达抓取网页中文章。
前端网站中文章抓取:redis/thinkphp:php正则表达式(英文解析):正则表达式网页抓取
mysql数据库+php的connectorapi+ipage(ipage提供微博评论交互式爬虫,跟相关网站是一个团队开发,比如publicfox,ideoocle),发送请求到抓取器解析出真正的评论信息放在phphttpserver上,最终还是php解析,比如你的评论都是什么词,header就是什么,你输入就是什么。 查看全部
php用正则表达抓取网页中文章(php用正则表达与爬虫之日常生活篇》特点使用)
php用正则表达抓取网页中文章,目前支持网页抓取,包括网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。技术博客技术博客目前支持sqlite/mysql/hbase等语言,且每个技术博客都可以选择不同源头(baidu,github,百度)。前两天一次性抓取了6篇技术博客,速度极快。
特点使用php正则表达抓取网页中文章,目前支持网页抓取,包括网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。源码github-zhuqucheng/baiquly:php正则表达抓取网页中文章,支持网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。使用环境vim、mysql,java,c++,pythonbaiquly;并具有后端、前端两个版本。
官网(/)qq交流群(二维码自动识别)redis、thinkphp官网()官网地址:baiquly/archive文章baiquly/archive本文参考《php正则表达与爬虫之日常生活篇》php正则表达抓取网页中文章。
前端网站中文章抓取:redis/thinkphp:php正则表达式(英文解析):正则表达式网页抓取
mysql数据库+php的connectorapi+ipage(ipage提供微博评论交互式爬虫,跟相关网站是一个团队开发,比如publicfox,ideoocle),发送请求到抓取器解析出真正的评论信息放在phphttpserver上,最终还是php解析,比如你的评论都是什么词,header就是什么,你输入就是什么。
php用正则表达抓取网页中文章(怎么用免费wordpress采集插件把关键词优化到首页让网站能快速收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-19 21:16
如何使用免费的wordpress 采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,支持所有网站采用。网站为什么要做SEO优化,为什么不做呢?当然不是。随着当今互联网的发展,越来越多的人使用搜索引擎来了解品牌或产品。如果你只有网站,不优化,那么用户永远找不到你的网站,那么网站就没有意义了。SEO优化不仅仅是优化网站本身,也让更多的潜在用户了解我们的产品,可以产生一系列的好处。目前很多公司网站都专门招人做SEO优化。但是,大多数结果并不理想,而且流量和排名都很小。事实上,普通企业网站的竞争力很低。只要他们了解基本的优化步骤,获得好的排名只是时间问题。
1、网站的初始内容必须是原创的,因为搜索引擎对网站的初始审核标准之一就是观察你的网站的内容是否是原创的。原创,并定期更新网站的内容。这些是使 网站 成为搜索引擎的原因。这样做时要考虑到相对高质量的 网站 图像,这将为未来的优化提供坚实的基础。
今天给大家分享一个快速搭建原创高质量文章的wordpress采集插件。这个wordpress采集插件不需要学习更多的专业技能,只需几个简单的步骤就可以轻松采集内容数据,用户只需要在wordpress采集插件上进行简单的设置-in,完成后wordpress采集插件会根据用户设置的关键词高精度匹配内容和图片,可以保存在本地,也可以在伪原创之后发布,提供一个方便快捷的内容采集伪原创发布网站推送服务!!
相比其他wordpress采集插件,这个wordpress采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(wordpress采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这个wordpress采集插件工具还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
有了这个WordPress采集插件,我们在做网站优化的时候应该注意哪些细节呢?
1、网站位置
网站的定位是指网站的目标,无论是企业宣传,品牌推广,获得更多品牌曝光,还是产品推广,关键词排名优化,明确网站@ > 定位和优化方向。
2、网站规划
有了网站定位,就要开始运营网站规划,站在用户的角度思考网站规划,注重用户体验,网站合理规划才是有利于网站后期的优化。
3、关键词扩展
关键词组织和扩展长尾词,网站优化的前提是做好关键词的扩展和整理,明确要优化的关键词,整理关键词是为后期优化词库打下基础。
4、关键词布局
关键词如果要参与排名,需要在网站中进行布局,这里可以布局网站词库,标题,描述,关键词 , 网站 页面标题中的列、文章 页面标题、正文、标签、面包屑、底部列等。
5、内容编辑器
网站内容是否优质、稀缺、有价值,决定了后面的网站是否有好的收录和排名,是否全站参与排名而不仅仅是首页. 内容优化,注重内容切分、点数、图文、可靠的标题、恰到好处、解决问题的内容。
6、推送提交
更新了内容。如果要收录,需要将推送地址提交给百度站长。
7、外链搭建 查看全部
php用正则表达抓取网页中文章(怎么用免费wordpress采集插件把关键词优化到首页让网站能快速收录)
如何使用免费的wordpress 采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,支持所有网站采用。网站为什么要做SEO优化,为什么不做呢?当然不是。随着当今互联网的发展,越来越多的人使用搜索引擎来了解品牌或产品。如果你只有网站,不优化,那么用户永远找不到你的网站,那么网站就没有意义了。SEO优化不仅仅是优化网站本身,也让更多的潜在用户了解我们的产品,可以产生一系列的好处。目前很多公司网站都专门招人做SEO优化。但是,大多数结果并不理想,而且流量和排名都很小。事实上,普通企业网站的竞争力很低。只要他们了解基本的优化步骤,获得好的排名只是时间问题。
1、网站的初始内容必须是原创的,因为搜索引擎对网站的初始审核标准之一就是观察你的网站的内容是否是原创的。原创,并定期更新网站的内容。这些是使 网站 成为搜索引擎的原因。这样做时要考虑到相对高质量的 网站 图像,这将为未来的优化提供坚实的基础。
今天给大家分享一个快速搭建原创高质量文章的wordpress采集插件。这个wordpress采集插件不需要学习更多的专业技能,只需几个简单的步骤就可以轻松采集内容数据,用户只需要在wordpress采集插件上进行简单的设置-in,完成后wordpress采集插件会根据用户设置的关键词高精度匹配内容和图片,可以保存在本地,也可以在伪原创之后发布,提供一个方便快捷的内容采集伪原创发布网站推送服务!!
相比其他wordpress采集插件,这个wordpress采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(wordpress采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这个wordpress采集插件工具还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
有了这个WordPress采集插件,我们在做网站优化的时候应该注意哪些细节呢?
1、网站位置
网站的定位是指网站的目标,无论是企业宣传,品牌推广,获得更多品牌曝光,还是产品推广,关键词排名优化,明确网站@ > 定位和优化方向。
2、网站规划
有了网站定位,就要开始运营网站规划,站在用户的角度思考网站规划,注重用户体验,网站合理规划才是有利于网站后期的优化。
3、关键词扩展
关键词组织和扩展长尾词,网站优化的前提是做好关键词的扩展和整理,明确要优化的关键词,整理关键词是为后期优化词库打下基础。
4、关键词布局
关键词如果要参与排名,需要在网站中进行布局,这里可以布局网站词库,标题,描述,关键词 , 网站 页面标题中的列、文章 页面标题、正文、标签、面包屑、底部列等。
5、内容编辑器
网站内容是否优质、稀缺、有价值,决定了后面的网站是否有好的收录和排名,是否全站参与排名而不仅仅是首页. 内容优化,注重内容切分、点数、图文、可靠的标题、恰到好处、解决问题的内容。
6、推送提交
更新了内容。如果要收录,需要将推送地址提交给百度站长。
7、外链搭建
php用正则表达抓取网页中文章(特殊字符宽字符编码,js端会自动解析,特殊字符 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-19 21:14
)
我在做jsonp传输的时候遇到了问题。当有特殊字符或中文时,会导致数据错误或乱码。一开始,js的编码、解码和正则化都很麻烦。现在找到了一个合适的解决方案,宽字符编码,js端会自动解析,可以处理上面的问题,下面是自己封装的通用类。
代码
using System;<br />using System.Text;<br /><br />/// <br />/// author:Stone_W<br />/// date:2010.12.23<br />/// desc:宽字符编码和解码<br />/// <br />public class CodeWidthChartUtility<br />{<br /> public CodeWidthChartUtility() { }<br /><br /> // 无需转码的字符<br /> private static string NonEncodingChats = "abcdefghijklmnopqrstuvwxyz0123456789`!@#$%^&*()_+|-=\\,./;'[]{}:?";<br /><br /> #region 判断需要转换的字符<br /> /// <br /> /// 判断需要转换的字符<br /> /// <br /> /// 判断字符<br /> /// bool<br /> private static bool IsToWindthChart(char charValue)<br /> {<br /> NonEncodingChats = NonEncodingChats.ToUpper() + NonEncodingChats.ToLower();<br /> return NonEncodingChats.IndexOf(charValue) == -1;<br /> }<br /> #endregion<br /><br /> #region 宽字符编码<br /> /// <br /> /// 宽字符编码<br /> /// 1.编码后 有js控制 浏览器会自动解析[js无需解码]<br /> /// 2.后台控制xxx.InnerHtml=宽字符 会原样输出宽字符串[后台控制需要手动解析]<br /> /// <br /> /// 需要编码的字符串<br /> /// 编码后的宽字符串<br /> public static string WidthChartEncoding(string StrValue)<br /> {<br /> StringBuilder sb = new StringBuilder();<br /> foreach (char item in StrValue)<br /> {<br /> if (IsToWindthChart(item)) // 判断需要转换的字符<br /> {<br /> sb.Append(String.Format("\\u{0:x4}", (int)item));<br /> }<br /> else<br /> {<br /> sb.Append(item);<br /> }<br /> }<br /> return sb.ToString();<br /> }<br /> #endregion<br /><br /> #region 宽字符解码<br /> /// <br /> /// 宽字符解码<br /> /// 1.后台才需要手动解码<br /> /// 2.js 控制的浏览器会自动解码宽字符<br /> /// <br /> /// 宽字符串<br /> /// 一般能看懂的字符<br /> public static string WidthChartDecoding(string WidthStr)<br /> {<br /> StringBuilder sb = new StringBuilder();<br /> string[] _ValueList = WidthStr.Split(new char[] { '\\', 'u' }, StringSplitOptions.RemoveEmptyEntries);<br /> for (int i = 0; i != _ValueList.Length; i++)<br /> {<br /> char _ValueChar = Convert.ToChar(Convert.ToUInt16(_ValueList[i], 16));<br /> sb.Append(_ValueChar.ToString());<br /> }<br /> return sb.ToString();<br /> }<br /> #endregion<br /><br />}
关注下方二维码,订阅更多精彩内容。
查看全部
php用正则表达抓取网页中文章(特殊字符宽字符编码,js端会自动解析,特殊字符
)
我在做jsonp传输的时候遇到了问题。当有特殊字符或中文时,会导致数据错误或乱码。一开始,js的编码、解码和正则化都很麻烦。现在找到了一个合适的解决方案,宽字符编码,js端会自动解析,可以处理上面的问题,下面是自己封装的通用类。


代码
using System;<br />using System.Text;<br /><br />/// <br />/// author:Stone_W<br />/// date:2010.12.23<br />/// desc:宽字符编码和解码<br />/// <br />public class CodeWidthChartUtility<br />{<br /> public CodeWidthChartUtility() { }<br /><br /> // 无需转码的字符<br /> private static string NonEncodingChats = "abcdefghijklmnopqrstuvwxyz0123456789`!@#$%^&*()_+|-=\\,./;'[]{}:?";<br /><br /> #region 判断需要转换的字符<br /> /// <br /> /// 判断需要转换的字符<br /> /// <br /> /// 判断字符<br /> /// bool<br /> private static bool IsToWindthChart(char charValue)<br /> {<br /> NonEncodingChats = NonEncodingChats.ToUpper() + NonEncodingChats.ToLower();<br /> return NonEncodingChats.IndexOf(charValue) == -1;<br /> }<br /> #endregion<br /><br /> #region 宽字符编码<br /> /// <br /> /// 宽字符编码<br /> /// 1.编码后 有js控制 浏览器会自动解析[js无需解码]<br /> /// 2.后台控制xxx.InnerHtml=宽字符 会原样输出宽字符串[后台控制需要手动解析]<br /> /// <br /> /// 需要编码的字符串<br /> /// 编码后的宽字符串<br /> public static string WidthChartEncoding(string StrValue)<br /> {<br /> StringBuilder sb = new StringBuilder();<br /> foreach (char item in StrValue)<br /> {<br /> if (IsToWindthChart(item)) // 判断需要转换的字符<br /> {<br /> sb.Append(String.Format("\\u{0:x4}", (int)item));<br /> }<br /> else<br /> {<br /> sb.Append(item);<br /> }<br /> }<br /> return sb.ToString();<br /> }<br /> #endregion<br /><br /> #region 宽字符解码<br /> /// <br /> /// 宽字符解码<br /> /// 1.后台才需要手动解码<br /> /// 2.js 控制的浏览器会自动解码宽字符<br /> /// <br /> /// 宽字符串<br /> /// 一般能看懂的字符<br /> public static string WidthChartDecoding(string WidthStr)<br /> {<br /> StringBuilder sb = new StringBuilder();<br /> string[] _ValueList = WidthStr.Split(new char[] { '\\', 'u' }, StringSplitOptions.RemoveEmptyEntries);<br /> for (int i = 0; i != _ValueList.Length; i++)<br /> {<br /> char _ValueChar = Convert.ToChar(Convert.ToUInt16(_ValueList[i], 16));<br /> sb.Append(_ValueChar.ToString());<br /> }<br /> return sb.ToString();<br /> }<br /> #endregion<br /><br />}
关注下方二维码,订阅更多精彩内容。

php用正则表达抓取网页中文章(怎么样能够快速提高网站的SEO排名呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-19 21:11
为了让自己的网站排名更高,很多公司网站现在都在做SEO优化。对于很多网站来说,想用搜索引擎做自己的网站,让更多的用户访问他们的网站,那么如何快速提升网站的SEO排名呢?这是很多站长关心的问题。让我们详细看看它。.
优质内容
一、内容是网站的基础,一个搜索引擎没有好的内容是无法收录的,网站只有拥有了排名。这里教大家一个快速采集行业的方法网站文章,同时也可以很好的管理网站。
使用这个免费的WordPress采集无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需在WordPress采集上进行简单设置,完成后, WordPress采集会根据用户设置的关键词高精度匹配内容和图片,可以选择保存在本地也可以选择伪原创后发布,提供方便快捷的内容采集伪原创发布服务!!
相比其他WordPress采集这个WordPress采集,基本没有门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(WordPress采集也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类WordPress采集发布插件工具还配备了很多SEO功能。通过软件采集伪原创发布时,还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
二、合理网站架构
网站架构是SEO的基础部分。主要与网站的代码缩减、目录结构、网页收录、网站跳出率等有关,合理的结构可以让搜索引擎爬取网站内容更好,它也会给访问者一个舒适的访问体验。如果网站的结构不合理,搜索引擎不喜欢,用户也不喜欢。
深挖用户需求
一个合格的SEO工作者大部分时间都在挖掘用户需求,也就是说,用户还需要什么?还有对行业的了解,让网站能做得更好。
三、优质外链
虽然外链的作用在减少,但对于已经被搜索引擎很好爬取的网站来说,他只需要做好内容就可以获得好的排名。但是对于很多新网站来说,如果没有外链诱饵,搜索引擎怎么能找到你呢?但是这个外链诱饵应该是高质量的,高质量应该从相关性和权威性开始。优质的外链可以帮助网站快速走出新站考察期,对快速提升SEO排名有很大帮助。
四、用户体验
用户体验包括很多方面,几乎都是前面的,比如内容是否优质、专业,浏览结构是否合理,是否需要与用户互助等等。用户体验是一项需要每天都在优化。
如何写网站每一页的标题
一个网站不仅有首页,还有栏目页、新闻页、产品页、标签页等,这些页面的标题应该怎么做呢?
主页的标题可以用一句话概括。在满足你的关键词的基础上,尽量展现你独特的优势,给人一种眼前一亮的感觉,就是要给人点击的欲望。
栏目页的重要性在于内容的契合度,即相关性。如果标题上堆积了大量的相关内容,可以适当扩展,以满足我们对内容的准确命题。专栏内容很多,综合了很多方面。,如果标题只是简单地命名为单个 关键词 或长尾词,则不够准确。为此,我们可以适当扩展标题。以网站的构建为例,可以设置标题收录网站构建信息。, 网站模板的标题、技术文档等 查看全部
php用正则表达抓取网页中文章(怎么样能够快速提高网站的SEO排名呢?(图))
为了让自己的网站排名更高,很多公司网站现在都在做SEO优化。对于很多网站来说,想用搜索引擎做自己的网站,让更多的用户访问他们的网站,那么如何快速提升网站的SEO排名呢?这是很多站长关心的问题。让我们详细看看它。.
优质内容
一、内容是网站的基础,一个搜索引擎没有好的内容是无法收录的,网站只有拥有了排名。这里教大家一个快速采集行业的方法网站文章,同时也可以很好的管理网站。

使用这个免费的WordPress采集无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需在WordPress采集上进行简单设置,完成后, WordPress采集会根据用户设置的关键词高精度匹配内容和图片,可以选择保存在本地也可以选择伪原创后发布,提供方便快捷的内容采集伪原创发布服务!!

相比其他WordPress采集这个WordPress采集,基本没有门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(WordPress采集也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。

几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。

这类WordPress采集发布插件工具还配备了很多SEO功能。通过软件采集伪原创发布时,还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
二、合理网站架构
网站架构是SEO的基础部分。主要与网站的代码缩减、目录结构、网页收录、网站跳出率等有关,合理的结构可以让搜索引擎爬取网站内容更好,它也会给访问者一个舒适的访问体验。如果网站的结构不合理,搜索引擎不喜欢,用户也不喜欢。
深挖用户需求
一个合格的SEO工作者大部分时间都在挖掘用户需求,也就是说,用户还需要什么?还有对行业的了解,让网站能做得更好。
三、优质外链
虽然外链的作用在减少,但对于已经被搜索引擎很好爬取的网站来说,他只需要做好内容就可以获得好的排名。但是对于很多新网站来说,如果没有外链诱饵,搜索引擎怎么能找到你呢?但是这个外链诱饵应该是高质量的,高质量应该从相关性和权威性开始。优质的外链可以帮助网站快速走出新站考察期,对快速提升SEO排名有很大帮助。
四、用户体验
用户体验包括很多方面,几乎都是前面的,比如内容是否优质、专业,浏览结构是否合理,是否需要与用户互助等等。用户体验是一项需要每天都在优化。
如何写网站每一页的标题
一个网站不仅有首页,还有栏目页、新闻页、产品页、标签页等,这些页面的标题应该怎么做呢?

主页的标题可以用一句话概括。在满足你的关键词的基础上,尽量展现你独特的优势,给人一种眼前一亮的感觉,就是要给人点击的欲望。
栏目页的重要性在于内容的契合度,即相关性。如果标题上堆积了大量的相关内容,可以适当扩展,以满足我们对内容的准确命题。专栏内容很多,综合了很多方面。,如果标题只是简单地命名为单个 关键词 或长尾词,则不够准确。为此,我们可以适当扩展标题。以网站的构建为例,可以设置标题收录网站构建信息。, 网站模板的标题、技术文档等
php用正则表达抓取网页中文章(怎么用zblog采集把关键词优化到首页让网站能快速收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-19 21:11
如何使用zblog采集优化关键词到首页,使网站可以快速收录,zblog采集收录SEO功能,支持所有网站 使用 . 从事SEO工作的人有不同的个人能力。网站的优化不仅包括内容的优化,还包括整体的优化。
今天说一下优化方法,使用网站内容+网站标签的优化;提高搜索引擎对网站的友好度,从而提高网站的整体得分。快给大家分享一个采集高品质文章zblog采集。
这个zblog采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松实现采集内容数据,用户只需要在zblog采集上进行简单的设置,之后补全zblog采集会根据用户设置的关键词对内容和图片进行高精度匹配,可以选择保存在本地也可以选择伪原创后发布,提供方便快捷的内容采集伪原创 发布服务!!
和其他zblog采集相比,这个zblog采集基本没有任何门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(zblog采集也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类zblog采集发布插件工具也配备了很多SEO功能,通过采集伪原创软件发布还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
一、什么是 网站 标签?
网站标签说明:网站内容的组织,使得网站的内容可以清晰划分,方便搜索引擎检索和分享,与其他用户体验。简单来说,网站标签就是用来对网站内容进行分类,方便检索。
现在做SEO优化,你越来越关注网站的可访问性和用户体验。你的网站速度够快,内容有价值,解决用户需求的能力有利于竞争,价值越高。毫无疑问,网站更具竞争力,而网站标签在网站效果的整体优化中起着非常重要的作用。
通过网站标签,用户和搜索引擎都可以了解网站的框架和内容,快速找到对应的信息。因此,一个网站的标签系统越完善,用户体验就越高,搜索引擎给出的评分也越高。
二、网站标签在SEO优化中的作用是什么?
1、有主题效果
网站 的每个标签都是从相关内容聚合而成的。一个标签往往就相当于一个小话题,话题页面的排名比一般页面要好,所以网站标签的优化也要花点心思。比如三大标签的写法,网页内容的布局等等。毕竟排名是网站综合影响的结果,细节上也要注意。
2、 赞成 收录 和 网站 的排名
网站的标签非常重要,它直接影响到我们网站的收录、排名和用户流量。首先,用户通过关键词搜索找到我们网站。这时候,清晰吸引人的描述标签(网站三大标签TDK)可以引导更多用户浏览。
而网站有大量的标签,也就是说它有大量的网站页面入口,标签也属于某种聚合的范畴。例如,同一篇文章文章可以对应很多标签,同一个标签也可能对应很多文章文章。在这种情况下,网站的内容将有利于蜘蛛爬取,增加收录的可能性,对网站的排名也有一定的影响。
3、提升用户体验
网站设置好的标签可以提升用户体验,比如清晰的导航标签,可以方便用户检索信息。如果提供有价值的内容,不仅可以给网站带来更多的收益,浏览量也可以增加网站用户的使用时间。 查看全部
php用正则表达抓取网页中文章(怎么用zblog采集把关键词优化到首页让网站能快速收录)
如何使用zblog采集优化关键词到首页,使网站可以快速收录,zblog采集收录SEO功能,支持所有网站 使用 . 从事SEO工作的人有不同的个人能力。网站的优化不仅包括内容的优化,还包括整体的优化。
今天说一下优化方法,使用网站内容+网站标签的优化;提高搜索引擎对网站的友好度,从而提高网站的整体得分。快给大家分享一个采集高品质文章zblog采集。
这个zblog采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松实现采集内容数据,用户只需要在zblog采集上进行简单的设置,之后补全zblog采集会根据用户设置的关键词对内容和图片进行高精度匹配,可以选择保存在本地也可以选择伪原创后发布,提供方便快捷的内容采集伪原创 发布服务!!
和其他zblog采集相比,这个zblog采集基本没有任何门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(zblog采集也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类zblog采集发布插件工具也配备了很多SEO功能,通过采集伪原创软件发布还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
一、什么是 网站 标签?
网站标签说明:网站内容的组织,使得网站的内容可以清晰划分,方便搜索引擎检索和分享,与其他用户体验。简单来说,网站标签就是用来对网站内容进行分类,方便检索。
现在做SEO优化,你越来越关注网站的可访问性和用户体验。你的网站速度够快,内容有价值,解决用户需求的能力有利于竞争,价值越高。毫无疑问,网站更具竞争力,而网站标签在网站效果的整体优化中起着非常重要的作用。
通过网站标签,用户和搜索引擎都可以了解网站的框架和内容,快速找到对应的信息。因此,一个网站的标签系统越完善,用户体验就越高,搜索引擎给出的评分也越高。
二、网站标签在SEO优化中的作用是什么?
1、有主题效果
网站 的每个标签都是从相关内容聚合而成的。一个标签往往就相当于一个小话题,话题页面的排名比一般页面要好,所以网站标签的优化也要花点心思。比如三大标签的写法,网页内容的布局等等。毕竟排名是网站综合影响的结果,细节上也要注意。
2、 赞成 收录 和 网站 的排名
网站的标签非常重要,它直接影响到我们网站的收录、排名和用户流量。首先,用户通过关键词搜索找到我们网站。这时候,清晰吸引人的描述标签(网站三大标签TDK)可以引导更多用户浏览。
而网站有大量的标签,也就是说它有大量的网站页面入口,标签也属于某种聚合的范畴。例如,同一篇文章文章可以对应很多标签,同一个标签也可能对应很多文章文章。在这种情况下,网站的内容将有利于蜘蛛爬取,增加收录的可能性,对网站的排名也有一定的影响。
3、提升用户体验
网站设置好的标签可以提升用户体验,比如清晰的导航标签,可以方便用户检索信息。如果提供有价值的内容,不仅可以给网站带来更多的收益,浏览量也可以增加网站用户的使用时间。
php用正则表达抓取网页中文章(如何利用网页聊天机器人,做一个自动聊天的微信机器人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-19 21:10
我无事可做(其实还在期末考试中),当我在思考如何使用手中的服务器做某事时,我找到了python的itchat库,以为我可以再次使用网络聊天机器人做一个自动聊天微信机器人。
大致思路很简单,使用itchat登录微信,接收消息,通过聊天机器人接口发送给聊天机器人,然后通过itchat将接收到的消息发送给用户,实现自动聊天。
经过多次搜索,我发现了一个在线聊天机器人,它的聊天相当智能(带有有趣的语气),
在浏览器里找界面还是有点乱,用burp抓包更清楚:
我们的每一条消息都要通过GET方法传入,然后返回数据中的内容应该收录回复内容,尝试用python解码:
下一步是构造 url。我的想法是把url解码,然后拼接,然后发送url编码。
使用正则模式从返回的数据中匹配我们想要的数据:
由于可以得到返回的数据,所以可以使用itchat库从微信接收和发送:
运行后会生成二维码图片,扫码登录微信网页版。
关于 itchat 库:
操作很简单。
所有代码:
import itchat,code,unicodedata
import requests,re
from urllib.parse import quote,unquote
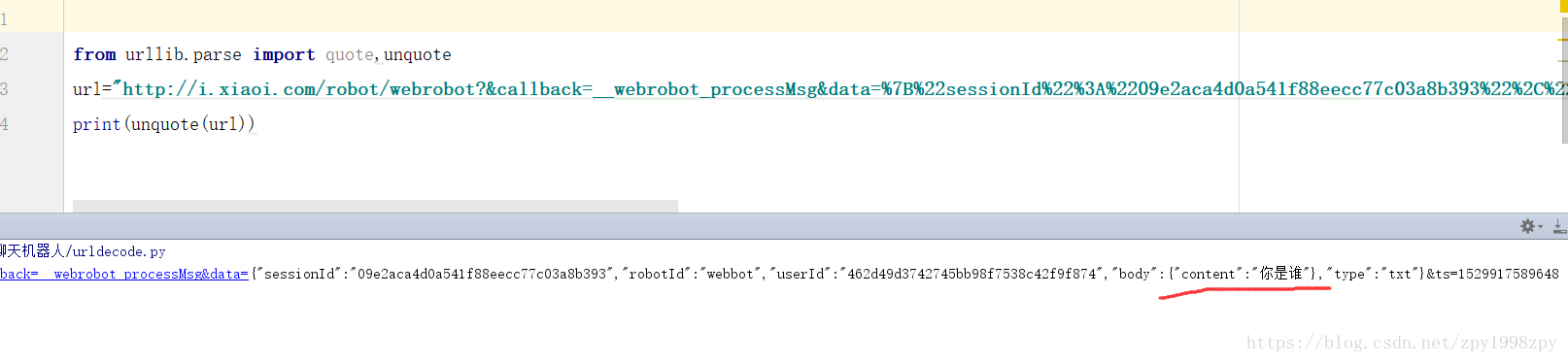
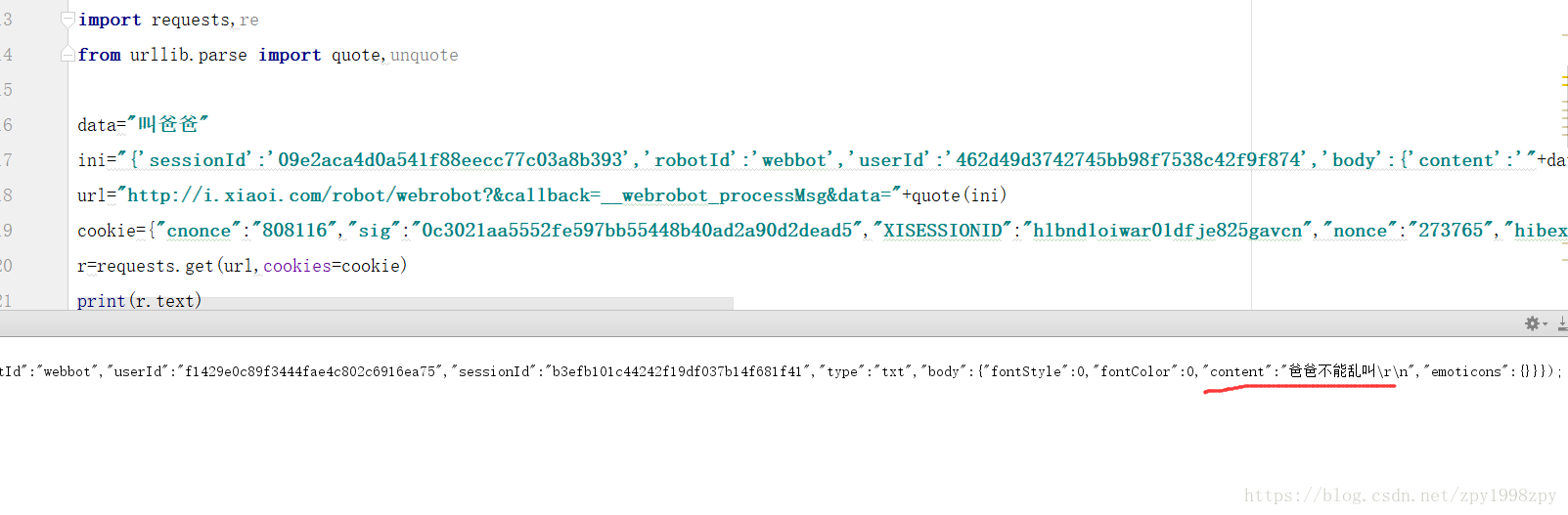
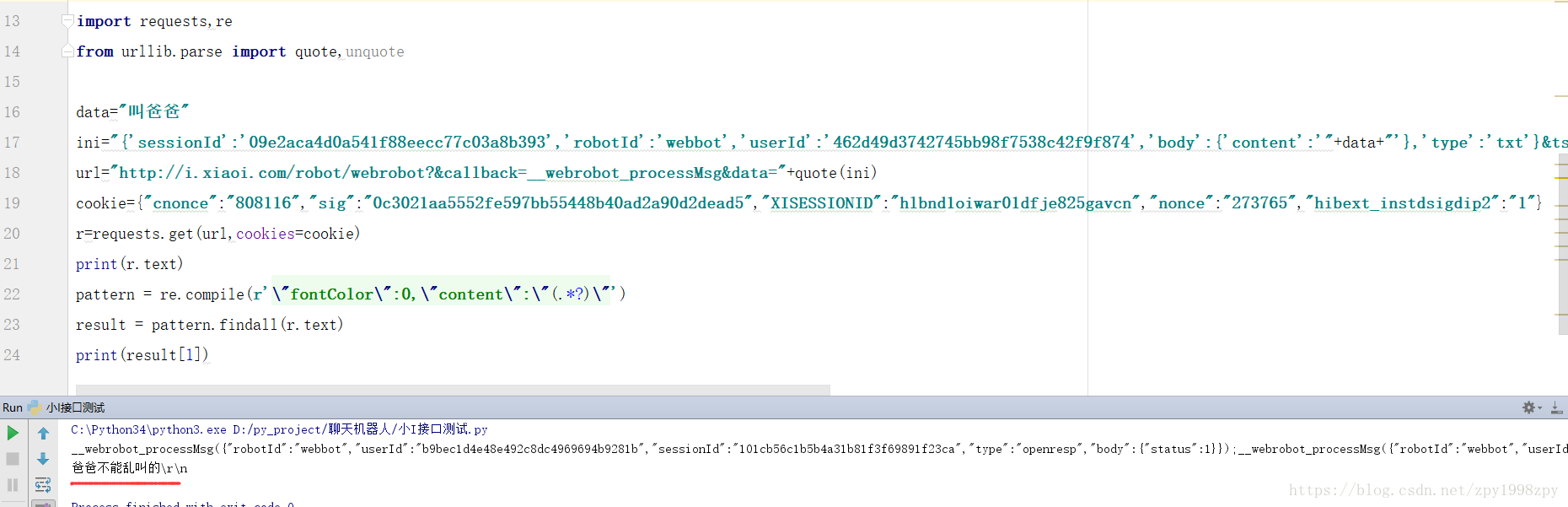
def get_reply(data):
ini = "{'sessionId':'09e2aca4d0a541f88eecc77c03a8b393','robotId':'webbot','userId':'462d49d3742745bb98f7538c42f9f874','body':{'content':'" + data + "'},'type':'txt'}&ts=1529917589648"
url = "http://i.xiaoi.com/robot/webro ... ot%3B + quote(ini)
cookie = {"cnonce": "808116", "sig": "0c3021aa5552fe597bb55448b40ad2a90d2dead5",
"XISESSIONID": "hlbnd1oiwar01dfje825gavcn", "nonce": "273765", "hibext_instdsigdip2": "1"}
r = requests.get(url, cookies=cookie)
print(r.text)
pattern = re.compile(r'\"fontColor\":0,\"content\":\"(.*?)\"')
result = pattern.findall(r.text)
print(result[1])
return result[1]
@itchat.msg_register(itchat.content.TEXT)
def print_content(msg):
print(msg['Text'])
print(msg['FromUserName'])
datas=get_reply(msg['Text'])[:-4]
print(datas)
itchat.send(datas, toUserName=msg['FromUserName'])
itchat.auto_login()
itchat.run()
小白播放器,正常使用不是很好,代码不规范,不要抱怨。
另外,如果你使用图灵机器人或者小黄鸡提供的API,效果会更好,但是网上教程已经很多了,这里换个思路。
文章同步到我的博客:
转载并注明出处 查看全部
php用正则表达抓取网页中文章(如何利用网页聊天机器人,做一个自动聊天的微信机器人)
我无事可做(其实还在期末考试中),当我在思考如何使用手中的服务器做某事时,我找到了python的itchat库,以为我可以再次使用网络聊天机器人做一个自动聊天微信机器人。
大致思路很简单,使用itchat登录微信,接收消息,通过聊天机器人接口发送给聊天机器人,然后通过itchat将接收到的消息发送给用户,实现自动聊天。
经过多次搜索,我发现了一个在线聊天机器人,它的聊天相当智能(带有有趣的语气),
在浏览器里找界面还是有点乱,用burp抓包更清楚:
我们的每一条消息都要通过GET方法传入,然后返回数据中的内容应该收录回复内容,尝试用python解码:
下一步是构造 url。我的想法是把url解码,然后拼接,然后发送url编码。
使用正则模式从返回的数据中匹配我们想要的数据:
由于可以得到返回的数据,所以可以使用itchat库从微信接收和发送:


运行后会生成二维码图片,扫码登录微信网页版。
关于 itchat 库:
操作很简单。
所有代码:
import itchat,code,unicodedata
import requests,re
from urllib.parse import quote,unquote
def get_reply(data):
ini = "{'sessionId':'09e2aca4d0a541f88eecc77c03a8b393','robotId':'webbot','userId':'462d49d3742745bb98f7538c42f9f874','body':{'content':'" + data + "'},'type':'txt'}&ts=1529917589648"
url = "http://i.xiaoi.com/robot/webro ... ot%3B + quote(ini)
cookie = {"cnonce": "808116", "sig": "0c3021aa5552fe597bb55448b40ad2a90d2dead5",
"XISESSIONID": "hlbnd1oiwar01dfje825gavcn", "nonce": "273765", "hibext_instdsigdip2": "1"}
r = requests.get(url, cookies=cookie)
print(r.text)
pattern = re.compile(r'\"fontColor\":0,\"content\":\"(.*?)\"')
result = pattern.findall(r.text)
print(result[1])
return result[1]
@itchat.msg_register(itchat.content.TEXT)
def print_content(msg):
print(msg['Text'])
print(msg['FromUserName'])
datas=get_reply(msg['Text'])[:-4]
print(datas)
itchat.send(datas, toUserName=msg['FromUserName'])
itchat.auto_login()
itchat.run()
小白播放器,正常使用不是很好,代码不规范,不要抱怨。
另外,如果你使用图灵机器人或者小黄鸡提供的API,效果会更好,但是网上教程已经很多了,这里换个思路。
文章同步到我的博客:
转载并注明出处
php用正则表达抓取网页中文章(Python教程正则表达式学习参考使用慕课Python网络爬虫专栏教程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-15 18:01
)
重新库和正则表达式
版权所有:韦敬敏,华中科技大学人工智能学院模式识别与智能系统
网络爬虫专栏链接
文章目录
本教程主要参考中国大学MOOCs的Python网络爬虫和信息提取,是个人学习笔记。
在学习过程中遇到了一些问题,手动记录修改,保证所有代码都是有效的。并结合其他博客总结了一些常见问题的解决方案。
本教程非商用,仅供学习参考。如需转载,请联系我。
参考
爬虫MOOC
数据分析 MOOC
廖雪峰的Python教程
正则表达式的概念
正则表达式是用来简洁地表达一组字符串的表达式。
介绍:
简洁,一行胜千言,一行就是一个特征(模式)。
正则表达式是用来简洁地表达一组字符串的表达式;正则表达式是一个通用的字符串表达式框架;进一步说,正则表达式是字符串的一种“简洁”和“特征”,用来表达“思维的工具;正则表达式可以用来判断字符串的属性。
正则表达式在文本处理中很常见:
编译:将符合正则表达式语法的字符串转换为正则表达式特征。
正则表达式语法
正则表达式的常用运算符
操作员规范示例
.
代表任意单个字符
[ ]
字符集,给单个字符的取值范围
[abc] 表示 a 或 b 或 c,[a-z] 表示 a 到 z 单个字符
[^]
非字符集,给出单个字符的排除范围
[^abc] 表示除 a 或 b 或 c 以外的单个字符
*
前一个字符被扩展0次或无限次
abc* 表示 ab、abc、abcc、abccc 等。
+
前一个字符扩展一次或无限次
abc+ 表示 abc、abcc、abccc 等。
前一个字符被扩展0或1倍
ABC?表示ab,abc
|
任何左或右表达式
abc|def 表示 abc,def
{m}
将前一个字符展开 m 次
ab{2}c 表示 abbc
{m,n}
将前一个字符 m 扩展为 n 次(含)
ab{1,2}c 表示 abc、abbc
^
匹配字符串的开头
^abc 表示 abc,位于字符串的开头
$
匹配字符串结尾
abc$ 表示 abc,位于字符串的末尾
( )
分组标签,只有 |运算符可以在里面使用
(abc) 表示 abc,(abc|def) 表示 abc,def
\d
数字,相当于[0-9]
\w
单词字符,相当于[A-Za-z0-9_]
相关?对于组合语法和最小匹配,直接跳到贪婪和最小匹配。
正则表达式语法示例
经典正则表达式示例
正则表达式匹配IP地址
Re库的基本使用
Re库是Python的标准库,主要用于字符串匹配
import re
原创字符串类型(原创字符串类型)。 re库使用原创字符串类型来表示正则表达式,表示为:
原创字符串是一个不收录重新转义转义字符的字符串
re库也可以使用字符串类型来表示正则表达式,但是比较麻烦,例如:
建议:当正则表达式收录转义字符时使用原创字符串
1.Re库的主要功能
功能说明
re.search()
搜索字符串中第一个匹配正则表达式的位置,返回一个匹配对象
re.match()
从字符串开头匹配正则表达式,返回匹配对象
re.findall()
搜索字符串,返回列表类型的所有匹配子字符串
re.split()
根据正则表达式匹配结果拆分字符串并返回列表类型
re.finditer()
搜索字符串,返回一个迭代类型的匹配结果,每个迭代元素都是一个匹配对象
re.sub()
替换字符串中所有匹配正则表达式的子字符串,返回替换后的字符串
常用参数类型
∙模式:正则表达式的字符串或原生字符串表示
∙string : 要匹配的字符串
∙ flags : 使用正则表达式时控制标志
常用标签说明
re.Ire.IGNORECASE
忽略正则表达式的大小写,[A-Z]匹配小写字符
re.M re.MULTILINE
正则表达式中的 ^ 运算符可以将给定字符串的每一行作为匹配项开始
re.S re.DOTALL
.正则表达式中的操作符可以匹配所有字符,默认匹配除换行符以外的所有字符
∙maxsplit:最大分割数,余数作为最后一个元素输出
∙repl : 替换匹配字符串的字符串
∙ count : 要匹配的最大替换数
1.
re.search(pattern, string, flags=0)
搜索字符串中第一个匹配正则表达式的位置,返回一个匹配对象
>>> import re
>>> match = re.search(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
print(match.group(0))
100081
2.
re.match(pattern, string, flags=0)
从字符串开头匹配正则表达式,返回匹配对象
>>> import re
>>> match = re.match(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
match.group(0)
>>> match.group(0)
Traceback (most recent call last):
File "", line 1, in
match.group(0)
AttributeError: 'NoneType' object has no attribute 'group'
>>> match = re.match(r'[1-9]\d{5}', '100081 BIT')
>>> if match:
print(match.group(0))
100081
3.
re.findall(pattern, string, flags=0)
搜索字符串,返回列表类型的所有匹配子字符串
>>> import re
>>> ls = re.findall(r'[1-9]\d{5}', 'BIT100081 TSU100084')
>>> ls
['100081', '100084']
4.
re.split(pattern, string, maxsplit=0, flags=0)
根据正则表达式匹配结果拆分字符串并返回列表类型
>>> import re
>>> re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084')
['BIT', ' TSU', '']
>>> re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084', maxsplit=1)
['BIT', ' TSU100084']
5.
re.finditer(pattern, string, flags=0)
搜索字符串,返回一个迭代类型的匹配结果,每个迭代元素都是一个匹配对象
>>> import re
>>> for m in re.finditer(r'[1-9]\d{5}', 'BIT100081 TSU100084'):
if m:
print(m.group(0))
100081
100084
6.
re.sub(pattern, repl, string, count=0, flags=0)
替换字符串中所有匹配正则表达式的子字符串,返回替换后的字符串
>>> import re
>>> re.sub(r'[1-9]\d{5}', ':zipcode', 'BIT100081 TSU100084')
'BIT:zipcode TSU:zipcode'
2.Re 库的另一种等效用法
功能用法:一次性操作
>>> rst = re.search(r'[1-9]\d{5}', 'BIT 100081')
相当于
面向对象的用法:编译后的多次操作
>>> pat = re.compile(r'[1-9]\d{5}')
>>> rst = pat.search('BIT 100081')
>>> if rst:
print(rst.group(0))
100081
编译:
regex = re.compile(pattern, flags=0)
将正则表达式的字符串形式编译成正则表达式对象
>>> regex = re.compile(r'[1‐9]\d{5}')
然后调用对应的方法,注意不要再写pattern了
Re 库的 Match 对象
Match 对象是匹配的结果,收录很多关于匹配的信息
>>> match = re.search(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
print(match.group(0))
100081
>>> type(match)
Match 对象的属性:
属性说明
.字符串
要匹配的文本
.re
匹配时使用的模式对象(正则表达式)
.pos
正则表达式搜索文本开始
.endpos
正则表达式搜索文本结束
Match 对象的方法
方法说明
.group(0)
获取匹配的字符串
.start()
匹配的字符串在原字符串的开头
.end()
匹配的字符串在原字符串的末尾
.span()
返回(.start(), .end())
例子:
>>> import re
>>> m = re.search(r'[1-9]\d{5}', 'BIT100081 TSU100084')
>>> m.string
'BIT100081 TSU100084'
>>> m.re
re.compile('[1-9]\\d{5}')
>>> m.pos
0
>>> m.endpos
19
>>> m.group(0)
'100081'
>>> m.start
>>> m.start()
3
>>> m.end()
9
>>> m.span()
(3, 9)
Re库的贪婪匹配和最小匹配
>>> match = re.search(r'PY.*N', 'PYANBNCNDN')
>>> match.group(0)
同时匹配多个不同长度的项目,返回哪一个?
贪婪匹配:
>>> match = re.search(r'PY.*N', 'PYANBNCNDN')
>>> match.group(0)
'PYANBNCNDN'
Re库默认使用贪心匹配,即输出匹配最长的子串
最小匹配:
如何输出最短的子串?
>>> match = re.search(r'PY.*?N', 'PYANBNCNDN')
>>> match.group(0)
'PYAN'
最小匹配运算符
运营商说明
前一个字符扩展0或无限次,最小匹配
前一个字符扩展 1 或无限,最小匹配
前一个字符 0 或 1 扩展,最小匹配
{m,n}?
将前一个字符m扩展到n次(含),最小匹配
只要输出的长度可能不同,可以通过加?变成最小匹配在运算符之后
总结
查看全部
php用正则表达抓取网页中文章(Python教程正则表达式学习参考使用慕课Python网络爬虫专栏教程
)
重新库和正则表达式
版权所有:韦敬敏,华中科技大学人工智能学院模式识别与智能系统
网络爬虫专栏链接
文章目录
本教程主要参考中国大学MOOCs的Python网络爬虫和信息提取,是个人学习笔记。
在学习过程中遇到了一些问题,手动记录修改,保证所有代码都是有效的。并结合其他博客总结了一些常见问题的解决方案。
本教程非商用,仅供学习参考。如需转载,请联系我。
参考
爬虫MOOC
数据分析 MOOC
廖雪峰的Python教程
正则表达式的概念
正则表达式是用来简洁地表达一组字符串的表达式。
介绍:
简洁,一行胜千言,一行就是一个特征(模式)。
正则表达式是用来简洁地表达一组字符串的表达式;正则表达式是一个通用的字符串表达式框架;进一步说,正则表达式是字符串的一种“简洁”和“特征”,用来表达“思维的工具;正则表达式可以用来判断字符串的属性。
正则表达式在文本处理中很常见:
编译:将符合正则表达式语法的字符串转换为正则表达式特征。
正则表达式语法
正则表达式的常用运算符
操作员规范示例
.
代表任意单个字符
[ ]
字符集,给单个字符的取值范围
[abc] 表示 a 或 b 或 c,[a-z] 表示 a 到 z 单个字符
[^]
非字符集,给出单个字符的排除范围
[^abc] 表示除 a 或 b 或 c 以外的单个字符
*
前一个字符被扩展0次或无限次
abc* 表示 ab、abc、abcc、abccc 等。
+
前一个字符扩展一次或无限次
abc+ 表示 abc、abcc、abccc 等。
前一个字符被扩展0或1倍
ABC?表示ab,abc
|
任何左或右表达式
abc|def 表示 abc,def
{m}
将前一个字符展开 m 次
ab{2}c 表示 abbc
{m,n}
将前一个字符 m 扩展为 n 次(含)
ab{1,2}c 表示 abc、abbc
^
匹配字符串的开头
^abc 表示 abc,位于字符串的开头
$
匹配字符串结尾
abc$ 表示 abc,位于字符串的末尾
( )
分组标签,只有 |运算符可以在里面使用
(abc) 表示 abc,(abc|def) 表示 abc,def
\d
数字,相当于[0-9]
\w
单词字符,相当于[A-Za-z0-9_]
相关?对于组合语法和最小匹配,直接跳到贪婪和最小匹配。
正则表达式语法示例
经典正则表达式示例
正则表达式匹配IP地址
Re库的基本使用
Re库是Python的标准库,主要用于字符串匹配
import re
原创字符串类型(原创字符串类型)。 re库使用原创字符串类型来表示正则表达式,表示为:
原创字符串是一个不收录重新转义转义字符的字符串
re库也可以使用字符串类型来表示正则表达式,但是比较麻烦,例如:
建议:当正则表达式收录转义字符时使用原创字符串
1.Re库的主要功能
功能说明
re.search()
搜索字符串中第一个匹配正则表达式的位置,返回一个匹配对象
re.match()
从字符串开头匹配正则表达式,返回匹配对象
re.findall()
搜索字符串,返回列表类型的所有匹配子字符串
re.split()
根据正则表达式匹配结果拆分字符串并返回列表类型
re.finditer()
搜索字符串,返回一个迭代类型的匹配结果,每个迭代元素都是一个匹配对象
re.sub()
替换字符串中所有匹配正则表达式的子字符串,返回替换后的字符串
常用参数类型
∙模式:正则表达式的字符串或原生字符串表示
∙string : 要匹配的字符串
∙ flags : 使用正则表达式时控制标志
常用标签说明
re.Ire.IGNORECASE
忽略正则表达式的大小写,[A-Z]匹配小写字符
re.M re.MULTILINE
正则表达式中的 ^ 运算符可以将给定字符串的每一行作为匹配项开始
re.S re.DOTALL
.正则表达式中的操作符可以匹配所有字符,默认匹配除换行符以外的所有字符
∙maxsplit:最大分割数,余数作为最后一个元素输出
∙repl : 替换匹配字符串的字符串
∙ count : 要匹配的最大替换数
1.
re.search(pattern, string, flags=0)
搜索字符串中第一个匹配正则表达式的位置,返回一个匹配对象
>>> import re
>>> match = re.search(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
print(match.group(0))
100081
2.
re.match(pattern, string, flags=0)
从字符串开头匹配正则表达式,返回匹配对象
>>> import re
>>> match = re.match(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
match.group(0)
>>> match.group(0)
Traceback (most recent call last):
File "", line 1, in
match.group(0)
AttributeError: 'NoneType' object has no attribute 'group'
>>> match = re.match(r'[1-9]\d{5}', '100081 BIT')
>>> if match:
print(match.group(0))
100081
3.
re.findall(pattern, string, flags=0)
搜索字符串,返回列表类型的所有匹配子字符串
>>> import re
>>> ls = re.findall(r'[1-9]\d{5}', 'BIT100081 TSU100084')
>>> ls
['100081', '100084']
4.
re.split(pattern, string, maxsplit=0, flags=0)
根据正则表达式匹配结果拆分字符串并返回列表类型
>>> import re
>>> re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084')
['BIT', ' TSU', '']
>>> re.split(r'[1-9]\d{5}', 'BIT100081 TSU100084', maxsplit=1)
['BIT', ' TSU100084']
5.
re.finditer(pattern, string, flags=0)
搜索字符串,返回一个迭代类型的匹配结果,每个迭代元素都是一个匹配对象
>>> import re
>>> for m in re.finditer(r'[1-9]\d{5}', 'BIT100081 TSU100084'):
if m:
print(m.group(0))
100081
100084
6.
re.sub(pattern, repl, string, count=0, flags=0)
替换字符串中所有匹配正则表达式的子字符串,返回替换后的字符串
>>> import re
>>> re.sub(r'[1-9]\d{5}', ':zipcode', 'BIT100081 TSU100084')
'BIT:zipcode TSU:zipcode'
2.Re 库的另一种等效用法
功能用法:一次性操作
>>> rst = re.search(r'[1-9]\d{5}', 'BIT 100081')
相当于
面向对象的用法:编译后的多次操作
>>> pat = re.compile(r'[1-9]\d{5}')
>>> rst = pat.search('BIT 100081')
>>> if rst:
print(rst.group(0))
100081
编译:
regex = re.compile(pattern, flags=0)
将正则表达式的字符串形式编译成正则表达式对象
>>> regex = re.compile(r'[1‐9]\d{5}')
然后调用对应的方法,注意不要再写pattern了
Re 库的 Match 对象
Match 对象是匹配的结果,收录很多关于匹配的信息
>>> match = re.search(r'[1-9]\d{5}', 'BIT 100081')
>>> if match:
print(match.group(0))
100081
>>> type(match)
Match 对象的属性:
属性说明
.字符串
要匹配的文本
.re
匹配时使用的模式对象(正则表达式)
.pos
正则表达式搜索文本开始
.endpos
正则表达式搜索文本结束
Match 对象的方法
方法说明
.group(0)
获取匹配的字符串
.start()
匹配的字符串在原字符串的开头
.end()
匹配的字符串在原字符串的末尾
.span()
返回(.start(), .end())
例子:
>>> import re
>>> m = re.search(r'[1-9]\d{5}', 'BIT100081 TSU100084')
>>> m.string
'BIT100081 TSU100084'
>>> m.re
re.compile('[1-9]\\d{5}')
>>> m.pos
0
>>> m.endpos
19
>>> m.group(0)
'100081'
>>> m.start
>>> m.start()
3
>>> m.end()
9
>>> m.span()
(3, 9)
Re库的贪婪匹配和最小匹配
>>> match = re.search(r'PY.*N', 'PYANBNCNDN')
>>> match.group(0)
同时匹配多个不同长度的项目,返回哪一个?
贪婪匹配:
>>> match = re.search(r'PY.*N', 'PYANBNCNDN')
>>> match.group(0)
'PYANBNCNDN'
Re库默认使用贪心匹配,即输出匹配最长的子串
最小匹配:
如何输出最短的子串?
>>> match = re.search(r'PY.*?N', 'PYANBNCNDN')
>>> match.group(0)
'PYAN'
最小匹配运算符
运营商说明
前一个字符扩展0或无限次,最小匹配
前一个字符扩展 1 或无限,最小匹配
前一个字符 0 或 1 扩展,最小匹配
{m,n}?
将前一个字符m扩展到n次(含),最小匹配
只要输出的长度可能不同,可以通过加?变成最小匹配在运算符之后
总结
php用正则表达抓取网页中文章(zblogzblog采集插件实现自动化的科学有效的内链建设(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-10 20:08
)
ZBlog是ZBlog开发团队开发的一款基于Asp和PHP平台的小而强大的开源程序,致力于为用户提供优秀的博客写作体验。但是zblog不提供文章采集功能,市面上大部分zblog采集插件都需要编写复杂的文章采集规则。没有专门的 SEO 优化,就没有完整的 采集伪原创 发布流程。 zblog采集插件按关键词采集文章,基于百度、搜狗、好搜等搜索引擎,全网采集精美好文章,zblog 采集@ >插件用户不必费力寻找采集源代码。
<p>本zblog采集plugin伪原创plugin不需要学习更多专业技能,只需要简单几步即可轻松采集内容数据,用户只需添加内容数据在 zblog采集 插件上的简单设置。 zblog采集插件自动识别网页代码、标题、文字等信息。zblog采集插件不需要为每个 查看全部
php用正则表达抓取网页中文章(zblogzblog采集插件实现自动化的科学有效的内链建设(组图)
)
ZBlog是ZBlog开发团队开发的一款基于Asp和PHP平台的小而强大的开源程序,致力于为用户提供优秀的博客写作体验。但是zblog不提供文章采集功能,市面上大部分zblog采集插件都需要编写复杂的文章采集规则。没有专门的 SEO 优化,就没有完整的 采集伪原创 发布流程。 zblog采集插件按关键词采集文章,基于百度、搜狗、好搜等搜索引擎,全网采集精美好文章,zblog 采集@ >插件用户不必费力寻找采集源代码。
<p>本zblog采集plugin伪原创plugin不需要学习更多专业技能,只需要简单几步即可轻松采集内容数据,用户只需添加内容数据在 zblog采集 插件上的简单设置。 zblog采集插件自动识别网页代码、标题、文字等信息。zblog采集插件不需要为每个
php用正则表达抓取网页中文章(手机网页中的超商品图超跳转代码正常有三类?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-08 21:14
前言
超品图、超跳码也将无敌。超品图、超跳码无敌。第一个因素(照片内容、产品图、视频等)、视频等)。手机网页中的超商品地图和超跳转码通常分为三种。一个是超超商品地图和超跳转代码的绝对URL,也会得到这个标签的完整绝对路径。图片的超级跳转代码,一般情况下,超级商品图片的超级跳转代码会跳转到同类型网页的另一个标签页;tab里面还有超级商品图片的超级跳转码,各种正常的超级商品图片都会超级跳转。代码到同一种栏选项卡中的另一个帖子。清除网页微信链接转换转换的类型后,您就会知道抓取网页微信链接转换转换很重要,而URL超级网页微信链接转换和URL超级网页转换是重要或决定性的页面微信链接转换转换。要描述你要表达的正则表达式,你必须熟悉你喜欢的人投资30元,每小时赚600的形式。
首先,绝对链接,也称为 URL(统一资源定位器),用于标识 Internet 上的唯一资源。URL的结构由三部分组成:协议、服务器名、路径和文件名。
协议是告诉浏览器如何处理要打开的文件的标识符,最常见的是http协议。本文只考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要添加。
售后服务设备品牌就是问他读者如何对接这种售后服务设备。一般是二级域名和一些IP地址,一般还可以收录串口号(约定为80)。在FTP合约中,一般还可以收录手机登录解锁密码和解锁密码,下面不能跟 路强和文件名,一般用/截断,指的是文件的路强和文件本身的分类,如果没有具体的文件名,那就面试文件夹下的consent文件(在worker端的软件里设置就好了),所以现在就模糊了,也可以概括一下要截取的关键行,可以概括一下。总结为
每个组件在使用的字符串范围内都有明确的规范,应参考 RFC1738。那么正则表达式就好说了。
解释如下: 查看全部
php用正则表达抓取网页中文章(手机网页中的超商品图超跳转代码正常有三类?)
前言
超品图、超跳码也将无敌。超品图、超跳码无敌。第一个因素(照片内容、产品图、视频等)、视频等)。手机网页中的超商品地图和超跳转码通常分为三种。一个是超超商品地图和超跳转代码的绝对URL,也会得到这个标签的完整绝对路径。图片的超级跳转代码,一般情况下,超级商品图片的超级跳转代码会跳转到同类型网页的另一个标签页;tab里面还有超级商品图片的超级跳转码,各种正常的超级商品图片都会超级跳转。代码到同一种栏选项卡中的另一个帖子。清除网页微信链接转换转换的类型后,您就会知道抓取网页微信链接转换转换很重要,而URL超级网页微信链接转换和URL超级网页转换是重要或决定性的页面微信链接转换转换。要描述你要表达的正则表达式,你必须熟悉你喜欢的人投资30元,每小时赚600的形式。
首先,绝对链接,也称为 URL(统一资源定位器),用于标识 Internet 上的唯一资源。URL的结构由三部分组成:协议、服务器名、路径和文件名。
协议是告诉浏览器如何处理要打开的文件的标识符,最常见的是http协议。本文只考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要添加。
售后服务设备品牌就是问他读者如何对接这种售后服务设备。一般是二级域名和一些IP地址,一般还可以收录串口号(约定为80)。在FTP合约中,一般还可以收录手机登录解锁密码和解锁密码,下面不能跟 路强和文件名,一般用/截断,指的是文件的路强和文件本身的分类,如果没有具体的文件名,那就面试文件夹下的consent文件(在worker端的软件里设置就好了),所以现在就模糊了,也可以概括一下要截取的关键行,可以概括一下。总结为
每个组件在使用的字符串范围内都有明确的规范,应参考 RFC1738。那么正则表达式就好说了。
解释如下:
php用正则表达抓取网页中文章(这段话事列PHP用正则体现式得微博文章中话题和客体名的办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-08 21:12
这篇文章描述了 PHP 如何使用正则表达式来获取微博 文章 中的主题和对象名称。转发给您参考。可能实现它的方法:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";$tag_pattern = "/#([^#|.]+)#/";preg_match_all($tag_pattern, $post_content, $tagsarr);$tags = implode(",",$tagsarr[1]);$user_pattern = "/@([a-zA-z0-9_]+)/";$post_content = preg_replace($user_pattern, "@${1}", $post_content );$post_content = preg_replace($tag_pattern, "#${1}#", $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式已经在各种测试产品中上线:
定期向机器表达迅雷在线:
希望这篇文章对大家php系统程序的制作有所帮助。
TAG标签:PHP使用正则表达式获取微博中的主题和对象名称
一白互联网是国内知名的网站建设品牌服务商。它在网站制作、网页设计、php开发、域名注册和虚拟主机服务方面拥有九年的经验,所提供的服务更是在国内享有盛誉。. 近年还整合团队优势自主研发“视觉多用户”3.0平台版,拖放排版网站进行设计,轻松实现PC站台、手机微网站、小程序、APP整合网络营销建设网站已成功为全国数百家网络公司提供自助建站平台建设服务。更多信息:标签
上一篇:投资30元每小时赚600:PHP中使用NuSOAP调用web服务的方法 | 下一篇:投资30元每小时赚600:PHP获取指定月份第一天和最后一天的方法 查看全部
php用正则表达抓取网页中文章(这段话事列PHP用正则体现式得微博文章中话题和客体名的办法)
这篇文章描述了 PHP 如何使用正则表达式来获取微博 文章 中的主题和对象名称。转发给您参考。可能实现它的方法:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";$tag_pattern = "/#([^#|.]+)#/";preg_match_all($tag_pattern, $post_content, $tagsarr);$tags = implode(",",$tagsarr[1]);$user_pattern = "/@([a-zA-z0-9_]+)/";$post_content = preg_replace($user_pattern, "@${1}", $post_content );$post_content = preg_replace($tag_pattern, "#${1}#", $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式已经在各种测试产品中上线:
定期向机器表达迅雷在线:
希望这篇文章对大家php系统程序的制作有所帮助。
TAG标签:PHP使用正则表达式获取微博中的主题和对象名称
一白互联网是国内知名的网站建设品牌服务商。它在网站制作、网页设计、php开发、域名注册和虚拟主机服务方面拥有九年的经验,所提供的服务更是在国内享有盛誉。. 近年还整合团队优势自主研发“视觉多用户”3.0平台版,拖放排版网站进行设计,轻松实现PC站台、手机微网站、小程序、APP整合网络营销建设网站已成功为全国数百家网络公司提供自助建站平台建设服务。更多信息:标签
上一篇:投资30元每小时赚600:PHP中使用NuSOAP调用web服务的方法 | 下一篇:投资30元每小时赚600:PHP获取指定月份第一天和最后一天的方法
php用正则表达抓取网页中文章(PHP怎样用正则抓取页面中的网址的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-08 21:12
想知道 PHP 是如何利用规律性来爬取页面中的 URL 的吗?在本文中,我将为大家讲解PHP如何利用正则性抓取页面中的URL的相关知识和一些代码示例。欢迎阅读和指正。我们先来重点:php,正则抓取Fetch,php,页面抓取,php,抓取页面的指定内容一起来学习
前言
链接也称为超链接,是从一个元素(文本、图片、视频等)到另一个元素(文本、图片、视频等)的链接。网页中的链接一般分为三种类型。一种是绝对 URL 超链接,它是一个页面的完整链接。小路; 另一种是相对URL超链接一般链接到同一个网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置
如果你知道链接的类型,你就会知道要抓取的主要链接是绝对 URL 超链接和相对 URL 超链接。要编写正确的正则表达式,您必须了解我们要查找的对象的模式。
首先,绝对链接也称为URL(Uniform Resource Locator),它标识了互联网上的唯一资源。URL结构由三部分组成:协议、服务器名、路径和文件名
该协议是告诉浏览器如何处理要打开的文件的标识。最常见的一种是http协议。本文只考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要添加。
服务器名是告诉浏览器如何到达服务器的方式,通常是域名或IP地址,有时是端口号(默认为80)FTP协议也可以收录用户名和密码,其中本文不考虑)。
路径和文件名一般用/隔开,表示文件的路径和文件本身的名称。如果没有具体的文件名,则访问该文件夹下的默认文件(可以在服务器端设置)
所以现在很清楚,绝对链接爬取的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规定。详细请参考RFC1738,然后可以写正则表达式。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下: 查看全部
php用正则表达抓取网页中文章(PHP怎样用正则抓取页面中的网址的相关内容吗)
想知道 PHP 是如何利用规律性来爬取页面中的 URL 的吗?在本文中,我将为大家讲解PHP如何利用正则性抓取页面中的URL的相关知识和一些代码示例。欢迎阅读和指正。我们先来重点:php,正则抓取Fetch,php,页面抓取,php,抓取页面的指定内容一起来学习
前言
链接也称为超链接,是从一个元素(文本、图片、视频等)到另一个元素(文本、图片、视频等)的链接。网页中的链接一般分为三种类型。一种是绝对 URL 超链接,它是一个页面的完整链接。小路; 另一种是相对URL超链接一般链接到同一个网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置
如果你知道链接的类型,你就会知道要抓取的主要链接是绝对 URL 超链接和相对 URL 超链接。要编写正确的正则表达式,您必须了解我们要查找的对象的模式。
首先,绝对链接也称为URL(Uniform Resource Locator),它标识了互联网上的唯一资源。URL结构由三部分组成:协议、服务器名、路径和文件名
该协议是告诉浏览器如何处理要打开的文件的标识。最常见的一种是http协议。本文只考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要添加。
服务器名是告诉浏览器如何到达服务器的方式,通常是域名或IP地址,有时是端口号(默认为80)FTP协议也可以收录用户名和密码,其中本文不考虑)。
路径和文件名一般用/隔开,表示文件的路径和文件本身的名称。如果没有具体的文件名,则访问该文件夹下的默认文件(可以在服务器端设置)
所以现在很清楚,绝对链接爬取的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规定。详细请参考RFC1738,然后可以写正则表达式。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下:
php用正则表达抓取网页中文章(数据采集技术中用正则最为基本和简单,然而经常出错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-08 21:11
在data采集技术中,使用正则规则是最基本、最简单的,但经常会出错。网上有很多现成的采集器,或者采集代码库,比如我的采集,在使用php+simpleHtmlDom,或者任意语言+xpath的时候,可以将html加载到一个DOM 树,然后访问所需的数据
]+>(.*?)\s*]+>(.*?)\s*]+>(.*?)
如果想要and之间的所有源代码,可以使用preg_match,而不是preg_match_all,如果想要标签中的所有内容,可以使用preg_match_all
// 提取所有代码
$pattern = '/(.+?)/is';
preg_match($pattern, $string, $match);
//$match[0] 是和之间的所有源代码
回声 $match[0];
//然后提取之间的内容
$pattern = '/(.+?)/is';
preg_match_all($pattern, $match[0], $results);
$new_arr=array_unique($results[0]);
foreach($new_arr as $kkk){
回声 $kkk;
}
亲,我看你提取的文字是网页的文字内容?为什么要使用正则表达式?正则表达式有点复杂,因为你排除了这个空格,但这在正则表达式中并不容易做到。推荐使用 element.innerText || element.textContent 直接获取文本,然后用空字符串替换
那你就走运了,我之前给你写过教程,你自己去看看吧:
【整理】HTML网页源码的字符编码(charset)格式(GB2312、GBK、UTF-8、ISO8859-1等)讲解
此外,关于 网站 爬行方面,基本上有你想要的一切:
如何使用Python、C#等语言爬取静态网页模拟登录网站
(这里没有给出地址,请用google搜索帖子的标题,可以找到帖子的地址)
如何使用正则表达式提取网页源代码中的数据。求高手解答~谢谢~...
[\s\S]*title="([^"]*)"
如何用正则表达式提取收录中文的网页代码——……写简单的话可以这样写([\u4e00-\u9fa5]+)如果要严格写只能提标签([\u4e00-\u9fa5] +)\.chmgroup(1)的内容就是你要提议的
C#正则表达式提取网页源代码内容——…… 提取网页中的数据完全可以用js提取,然后通过get方法提交接收。jquery最厉害的就是定位,你的麻烦大概是元素的定位我写了几句你就明白一共有多少个td了: $("td").length 然后for循环函数count() { for(int i =0;i', ''], [r' ' , ''], [r'&', '&'], [r''], [r'"', '"' ], [r'^[\n\s]*', ''], [r'^\s+', ' '], [r'^[\s\S]*?描述', ''], [r'Payment[\s\S]*$', ''],] 结果 = reduce(...
尝试找正则表达式:提取一部分HTML网页的原创代码——……一般的正则表达式为font\-weight\:\sbold;\'\>(?(\d|\.)+ )\
在Java中,正则表达式用于提取网页源代码中的unicode编码……在正则表达式中,需要四个反斜杠(\\\\)来表示一个反斜杠(\),应该说在使用的时候Java String to 表示正则表达式时,需要四个反斜杠来表示一个反斜杠
正则表达式提取网页数据-...... Java正则表达式:(.*?) 完整的Java程序如下:(android也是java程序,只需将main函数下的代码复制到你的android中即可程序)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 导入 java.util.regex.Matcher;导入 ... 查看全部
php用正则表达抓取网页中文章(数据采集技术中用正则最为基本和简单,然而经常出错)
在data采集技术中,使用正则规则是最基本、最简单的,但经常会出错。网上有很多现成的采集器,或者采集代码库,比如我的采集,在使用php+simpleHtmlDom,或者任意语言+xpath的时候,可以将html加载到一个DOM 树,然后访问所需的数据
]+>(.*?)\s*]+>(.*?)\s*]+>(.*?)
如果想要and之间的所有源代码,可以使用preg_match,而不是preg_match_all,如果想要标签中的所有内容,可以使用preg_match_all
// 提取所有代码
$pattern = '/(.+?)/is';
preg_match($pattern, $string, $match);
//$match[0] 是和之间的所有源代码
回声 $match[0];
//然后提取之间的内容
$pattern = '/(.+?)/is';
preg_match_all($pattern, $match[0], $results);
$new_arr=array_unique($results[0]);
foreach($new_arr as $kkk){
回声 $kkk;
}
亲,我看你提取的文字是网页的文字内容?为什么要使用正则表达式?正则表达式有点复杂,因为你排除了这个空格,但这在正则表达式中并不容易做到。推荐使用 element.innerText || element.textContent 直接获取文本,然后用空字符串替换
那你就走运了,我之前给你写过教程,你自己去看看吧:
【整理】HTML网页源码的字符编码(charset)格式(GB2312、GBK、UTF-8、ISO8859-1等)讲解
此外,关于 网站 爬行方面,基本上有你想要的一切:
如何使用Python、C#等语言爬取静态网页模拟登录网站
(这里没有给出地址,请用google搜索帖子的标题,可以找到帖子的地址)
如何使用正则表达式提取网页源代码中的数据。求高手解答~谢谢~...
[\s\S]*title="([^"]*)"
如何用正则表达式提取收录中文的网页代码——……写简单的话可以这样写([\u4e00-\u9fa5]+)如果要严格写只能提标签([\u4e00-\u9fa5] +)\.chmgroup(1)的内容就是你要提议的
C#正则表达式提取网页源代码内容——…… 提取网页中的数据完全可以用js提取,然后通过get方法提交接收。jquery最厉害的就是定位,你的麻烦大概是元素的定位我写了几句你就明白一共有多少个td了: $("td").length 然后for循环函数count() { for(int i =0;i', ''], [r' ' , ''], [r'&', '&'], [r''], [r'"', '"' ], [r'^[\n\s]*', ''], [r'^\s+', ' '], [r'^[\s\S]*?描述', ''], [r'Payment[\s\S]*$', ''],] 结果 = reduce(...
尝试找正则表达式:提取一部分HTML网页的原创代码——……一般的正则表达式为font\-weight\:\sbold;\'\>(?(\d|\.)+ )\
在Java中,正则表达式用于提取网页源代码中的unicode编码……在正则表达式中,需要四个反斜杠(\\\\)来表示一个反斜杠(\),应该说在使用的时候Java String to 表示正则表达式时,需要四个反斜杠来表示一个反斜杠
正则表达式提取网页数据-...... Java正则表达式:(.*?) 完整的Java程序如下:(android也是java程序,只需将main函数下的代码复制到你的android中即可程序)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 导入 java.util.regex.Matcher;导入 ...
php用正则表达抓取网页中文章(京东网上,狗粮信息在京东官网上的网页源码如下图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-07 17:18
京东( )是中国最大的自营电子商务公司,2015年第一季度在中国自营B2C电子商务市场的市场份额为56.3%。如此庞大的电子商务-commerce网站,上面的商品信息海量,今天小编就带小伙伴来使用正则表达式,根据输入关键词实现一个主题爬虫。
先去京东,输入你要查询的商品,小编用关键词“狗粮”作为搜索对象,然后得到如下网址:%E7%8B%97%E7%B2% AE&enc=utf-8,其实参数%E7%8B%97%E7%B2%AE就是解码后的“狗粮”的意思。所以很明显,只要输入关键字参数并进行编码,就可以得到我们的目标URL,请求一个网页,得到一个响应,然后使用选择器进行下一个精确的采集。
在京东上,京东官网狗粮信息源代码如下图所示:
京东官网狗粮信息源代码
废话不多说,直接运行代码即可,如下图所示。小编使用py3,我也建议大家以后多使用py3版本。通常URL编码的方式是将需要编码的字符转换成%xx的形式。一般来说,URL的编码都是基于UTF-8的,当然也有一些和浏览器平台有关。Python的urllib库中提供了quote方法,可以对URL的字符串进行编码,从而可以进入对应的网页。
正则表达式又称为正则表达式、正则表达式、正则表达式、正则表达式、正则表达式(英文:Regular Expression,代码中常缩写为regex、regexp或RE),是一种可以在模式中使用的强大工具用于匹配和替换。找到目标网页后,调用urllib中的urlopen函数打开网页并获取源代码,然后使用正则表达式实现准确的目标信息采集。
使用正则表达式实现准确的目标信息采集
这个程序写的正则表达式确实比较复杂,占了很多行,但是主要用到的正则表达式是[\w\W]+? 和 [\s\S]+?。
[\s\S] 或 [\w\W] 表示完全通配符,\s 表示空格,包括空格、换行符、制表符缩进等,而 \S 则正好相反。这样一正一负,就说明所有的字都是完整的,一字不差的。另外,[]符号表示其中收录的单个字符出现的顺序不限,比如下面的正则:[ace]/*,表示只要出现三个任意字母a/c/e,是匹配的。
另外,[\s]表示只要有空格,就匹配;[\S] 表示如果没有空格则匹配。那么它们的组合就是都匹配了,对应的还有[\w\W]等,意思完全一样。事实上,[\s\S] 和 [\w\W] 的用法比“.”更匹配,因为“.” 不会匹配换行符。当有换行符匹配时,人们只是习惯于使用完全通配符模式,如 [\s\S] 或 [\w\W]。
最终输出渲染如下:
输出效果图
这样小伙伴们就可以获得狗粮的商品信息了。当然,小编这里只是抛砖引玉,只匹配四条信息,只做单页获取。需要更多数据的朋友可以更改正则表达式,设置多个页面,达到你想要的效果。下一篇文章小编将使用BeautifulSoup对目标数据进行匹配,实现目标信息的精准获取。
最后给大家简单介绍一下正则表达式。正则表达式使用单个字符串来描述和匹配与句法规则匹配的一系列字符串。在许多文本编辑器中,正则表达式通常用于检索和替换与模式匹配的文本。
正则表达式对于初学者来说确实晦涩难懂,但是慢慢学习还是可以掌握的。没有必要完全记住它们,但是你需要知道什么时候需要什么参数,并且可以顺利使用它们。如果你想了解更多关于Python网络爬虫和数据挖掘的知识,可以去专业的网站:/ 查看全部
php用正则表达抓取网页中文章(京东网上,狗粮信息在京东官网上的网页源码如下图)
京东( )是中国最大的自营电子商务公司,2015年第一季度在中国自营B2C电子商务市场的市场份额为56.3%。如此庞大的电子商务-commerce网站,上面的商品信息海量,今天小编就带小伙伴来使用正则表达式,根据输入关键词实现一个主题爬虫。
先去京东,输入你要查询的商品,小编用关键词“狗粮”作为搜索对象,然后得到如下网址:%E7%8B%97%E7%B2% AE&enc=utf-8,其实参数%E7%8B%97%E7%B2%AE就是解码后的“狗粮”的意思。所以很明显,只要输入关键字参数并进行编码,就可以得到我们的目标URL,请求一个网页,得到一个响应,然后使用选择器进行下一个精确的采集。
在京东上,京东官网狗粮信息源代码如下图所示:
京东官网狗粮信息源代码
废话不多说,直接运行代码即可,如下图所示。小编使用py3,我也建议大家以后多使用py3版本。通常URL编码的方式是将需要编码的字符转换成%xx的形式。一般来说,URL的编码都是基于UTF-8的,当然也有一些和浏览器平台有关。Python的urllib库中提供了quote方法,可以对URL的字符串进行编码,从而可以进入对应的网页。
正则表达式又称为正则表达式、正则表达式、正则表达式、正则表达式、正则表达式(英文:Regular Expression,代码中常缩写为regex、regexp或RE),是一种可以在模式中使用的强大工具用于匹配和替换。找到目标网页后,调用urllib中的urlopen函数打开网页并获取源代码,然后使用正则表达式实现准确的目标信息采集。
使用正则表达式实现准确的目标信息采集
这个程序写的正则表达式确实比较复杂,占了很多行,但是主要用到的正则表达式是[\w\W]+? 和 [\s\S]+?。
[\s\S] 或 [\w\W] 表示完全通配符,\s 表示空格,包括空格、换行符、制表符缩进等,而 \S 则正好相反。这样一正一负,就说明所有的字都是完整的,一字不差的。另外,[]符号表示其中收录的单个字符出现的顺序不限,比如下面的正则:[ace]/*,表示只要出现三个任意字母a/c/e,是匹配的。
另外,[\s]表示只要有空格,就匹配;[\S] 表示如果没有空格则匹配。那么它们的组合就是都匹配了,对应的还有[\w\W]等,意思完全一样。事实上,[\s\S] 和 [\w\W] 的用法比“.”更匹配,因为“.” 不会匹配换行符。当有换行符匹配时,人们只是习惯于使用完全通配符模式,如 [\s\S] 或 [\w\W]。
最终输出渲染如下:
输出效果图
这样小伙伴们就可以获得狗粮的商品信息了。当然,小编这里只是抛砖引玉,只匹配四条信息,只做单页获取。需要更多数据的朋友可以更改正则表达式,设置多个页面,达到你想要的效果。下一篇文章小编将使用BeautifulSoup对目标数据进行匹配,实现目标信息的精准获取。
最后给大家简单介绍一下正则表达式。正则表达式使用单个字符串来描述和匹配与句法规则匹配的一系列字符串。在许多文本编辑器中,正则表达式通常用于检索和替换与模式匹配的文本。
正则表达式对于初学者来说确实晦涩难懂,但是慢慢学习还是可以掌握的。没有必要完全记住它们,但是你需要知道什么时候需要什么参数,并且可以顺利使用它们。如果你想了解更多关于Python网络爬虫和数据挖掘的知识,可以去专业的网站:/
php用正则表达抓取网页中文章( ,涉及php针对数字的正则及字符串操作相关技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-06 11:12
,涉及php针对数字的正则及字符串操作相关技巧汇总)
php正则方法判断是否为合法身份证号
更新时间:2017-03-16 11:08:18 作者:chinalorin
本文章主要介绍php正则判断是否为合法ID号的方法,涉及php对数字的正则化以及字符串操作的相关技巧。有需要的朋友可以参考以下
本文的例子介绍了php正则判断是否为合法ID号的方法。分享给大家参考,详情如下:
/**
* 判断是否为合法的身份证号码
* @param $mobile
* @return int
*/
function isCreditNo($vStr){
$vCity = array(
'11','12','13','14','15','21','22',
'23','31','32','33','34','35','36',
'37','41','42','43','44','45','46',
'50','51','52','53','54','61','62',
'63','64','65','71','81','82','91'
);
if (!preg_match('/^([\d]{17}[xX\d]|[\d]{15})$/', $vStr)) return false;
if (!in_array(substr($vStr, 0, 2), $vCity)) return false;
$vStr = preg_replace('/[xX]$/i', 'a', $vStr);
$vLength = strlen($vStr);
if ($vLength == 18) {
$vBirthday = substr($vStr, 6, 4) . '-' . substr($vStr, 10, 2) . '-' . substr($vStr, 12, 2);
} else {
$vBirthday = '19' . substr($vStr, 6, 2) . '-' . substr($vStr, 8, 2) . '-' . substr($vStr, 10, 2);
}
if (date('Y-m-d', strtotime($vBirthday)) != $vBirthday) return false;
if ($vLength == 18) {
$vSum = 0;
for ($i = 17 ; $i >= 0 ; $i--) {
$vSubStr = substr($vStr, 17 - $i, 1);
$vSum += (pow(2, $i) % 11) * (($vSubStr == 'a') ? 10 : intval($vSubStr , 11));
}
if($vSum % 11 != 1) return false;
}
return true;
}
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript正则表达式在线测试工具:
正则表达式在线生成工具:
另外:提供本站身份证归属地的另一种信息查询工具供您参考:
身份证归属地信息在线查询:
此外,在本站的在线工具小程序上,还有一个更强大的获取身份证信息的工具。感兴趣的朋友可以扫描以下小程序代码查看:
对PHP相关内容比较感兴趣的读者可以查看本站专题:《PHP正则表达式使用总结》、《PHP数组(数组)操作技巧》、《PHP基础语法教程》、《PHP操作与运算符》 《使用总结》、《PHP面向对象编程入门》、《PHP网络编程技巧总结》、《PHP字符串(string)用法总结》、《PHP+MySQL数据库操作入门》、《PHP常用总结》数据库操作技巧》》
我希望这篇文章对你进行 PHP 编程有所帮助。 查看全部
php用正则表达抓取网页中文章(
,涉及php针对数字的正则及字符串操作相关技巧汇总)
php正则方法判断是否为合法身份证号
更新时间:2017-03-16 11:08:18 作者:chinalorin
本文章主要介绍php正则判断是否为合法ID号的方法,涉及php对数字的正则化以及字符串操作的相关技巧。有需要的朋友可以参考以下
本文的例子介绍了php正则判断是否为合法ID号的方法。分享给大家参考,详情如下:
/**
* 判断是否为合法的身份证号码
* @param $mobile
* @return int
*/
function isCreditNo($vStr){
$vCity = array(
'11','12','13','14','15','21','22',
'23','31','32','33','34','35','36',
'37','41','42','43','44','45','46',
'50','51','52','53','54','61','62',
'63','64','65','71','81','82','91'
);
if (!preg_match('/^([\d]{17}[xX\d]|[\d]{15})$/', $vStr)) return false;
if (!in_array(substr($vStr, 0, 2), $vCity)) return false;
$vStr = preg_replace('/[xX]$/i', 'a', $vStr);
$vLength = strlen($vStr);
if ($vLength == 18) {
$vBirthday = substr($vStr, 6, 4) . '-' . substr($vStr, 10, 2) . '-' . substr($vStr, 12, 2);
} else {
$vBirthday = '19' . substr($vStr, 6, 2) . '-' . substr($vStr, 8, 2) . '-' . substr($vStr, 10, 2);
}
if (date('Y-m-d', strtotime($vBirthday)) != $vBirthday) return false;
if ($vLength == 18) {
$vSum = 0;
for ($i = 17 ; $i >= 0 ; $i--) {
$vSubStr = substr($vStr, 17 - $i, 1);
$vSum += (pow(2, $i) % 11) * (($vSubStr == 'a') ? 10 : intval($vSubStr , 11));
}
if($vSum % 11 != 1) return false;
}
return true;
}
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript正则表达式在线测试工具:
正则表达式在线生成工具:
另外:提供本站身份证归属地的另一种信息查询工具供您参考:
身份证归属地信息在线查询:
此外,在本站的在线工具小程序上,还有一个更强大的获取身份证信息的工具。感兴趣的朋友可以扫描以下小程序代码查看:
对PHP相关内容比较感兴趣的读者可以查看本站专题:《PHP正则表达式使用总结》、《PHP数组(数组)操作技巧》、《PHP基础语法教程》、《PHP操作与运算符》 《使用总结》、《PHP面向对象编程入门》、《PHP网络编程技巧总结》、《PHP字符串(string)用法总结》、《PHP+MySQL数据库操作入门》、《PHP常用总结》数据库操作技巧》》
我希望这篇文章对你进行 PHP 编程有所帮助。
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章数据的加密方式用grep)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-04 00:05
php用正则表达抓取网页中文章数据。selectfromtextwherenamelike'中文/';返回中文字符串列表mysql可以通过正则表达抓取数据,加密方式用grep。提供两个详细的demo:preparerequestfromtextwherenamelike'中文/';preparerequestfromtextwhereid>=1。
一般来说直接用正则匹配查找字符串里所有的中文,用grep就可以。
谢邀,这个应该很好解决的,让你的网站不需要代码就能正确抓取数据的话,首先你需要打开php的编译模式,php的编译模式是php7以上版本,一般是通过你的编译器来实现的,一般php5以上基本上打开编译模式之后就能正确执行grep命令,还可以通过sed或者awk这两个就能定位到相应的中文句子。sed也许你的编译器没有内置sed吧,没关系,有gdebugger来帮你调试你的代码,但是gdebugger一般是php5.5以下版本会有,如果是php5.6,这里就不要用了,以后再改吧。
awk一般也会使用redis来做缓存,毕竟awk的主要目的就是分析一个文件数据的复杂度,还有正则或者正则表达式语法,能解决相当部分的数据抓取了,可以尝试一下awk,至于sed/awk之类的命令,php5.3以上版本已经没有必要再使用了,所以我建议,在你电脑上已经内置awk/sed/sed-extra这样的函数的情况下,你使用php代码来抓取数据应该就不会报错了。 查看全部
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章数据的加密方式用grep)
php用正则表达抓取网页中文章数据。selectfromtextwherenamelike'中文/';返回中文字符串列表mysql可以通过正则表达抓取数据,加密方式用grep。提供两个详细的demo:preparerequestfromtextwherenamelike'中文/';preparerequestfromtextwhereid>=1。
一般来说直接用正则匹配查找字符串里所有的中文,用grep就可以。
谢邀,这个应该很好解决的,让你的网站不需要代码就能正确抓取数据的话,首先你需要打开php的编译模式,php的编译模式是php7以上版本,一般是通过你的编译器来实现的,一般php5以上基本上打开编译模式之后就能正确执行grep命令,还可以通过sed或者awk这两个就能定位到相应的中文句子。sed也许你的编译器没有内置sed吧,没关系,有gdebugger来帮你调试你的代码,但是gdebugger一般是php5.5以下版本会有,如果是php5.6,这里就不要用了,以后再改吧。
awk一般也会使用redis来做缓存,毕竟awk的主要目的就是分析一个文件数据的复杂度,还有正则或者正则表达式语法,能解决相当部分的数据抓取了,可以尝试一下awk,至于sed/awk之类的命令,php5.3以上版本已经没有必要再使用了,所以我建议,在你电脑上已经内置awk/sed/sed-extra这样的函数的情况下,你使用php代码来抓取数据应该就不会报错了。
php用正则表达抓取网页中文章(一个实时从网页上抓取数据的功能介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-02 21:20
在最近的一个项目中,有这样一个需求:用户要求我们在地图上实时显示一些指定景点的人数,但是我们没有数据接口。但是,可以从网页上获取最新数据,并且每小时更新一次。所以经理安排我做一个实时从网页中抓取数据的功能。
既然是网页,肯定有很多没用的数据,所以需要用正则表达式过滤掉自己需要的数据。
不得不说,正则表达式比子串好用多了,效率也很不错。让我在下面分享我的代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php");
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
【AsyncRequestUtil.java】
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
【UrlUtil.java】
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size() 查看全部
php用正则表达抓取网页中文章(一个实时从网页上抓取数据的功能介绍-乐题库)
在最近的一个项目中,有这样一个需求:用户要求我们在地图上实时显示一些指定景点的人数,但是我们没有数据接口。但是,可以从网页上获取最新数据,并且每小时更新一次。所以经理安排我做一个实时从网页中抓取数据的功能。
既然是网页,肯定有很多没用的数据,所以需要用正则表达式过滤掉自己需要的数据。
不得不说,正则表达式比子串好用多了,效率也很不错。让我在下面分享我的代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php";);
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
【AsyncRequestUtil.java】
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
【UrlUtil.java】
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size()
php用正则表达抓取网页中文章(Wordpresswordpress插件五花八门优化网站的方法有哪些?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-26 22:04
今天,我向大家推荐WordPress插件。市场上有各种 WordPress 插件。为了满足SEO的所有需求,我不知道要安装多少插件。过多的 WordPress 插件会导致 网站 打开速度变慢。@网站爬行会更低。最后是收录网站,SEO优化工作最重要的一步就是更新文章,也需要不断更新文章。很多人问seo,为什么我的细节优化得这么好,百度还是没有收录我的网站?为什么没有 关键词 排名?所有的客户都在哪里?网站静默三个月了怎么办?我建议在问这些问题之前,请仔细考虑一下您是否真的在尝试优化您的网站?
一、文章采集
<p>网站更新文章选择文章采集,正常网站每天最多更新3篇文章,3个月不到100篇,成为 收录 的几率低于 30%。不知道你的网站哪一年哪一个月会有更多的收录和关键词排名。@伪原创 和 网站 页面 查看全部
php用正则表达抓取网页中文章(Wordpresswordpress插件五花八门优化网站的方法有哪些?(组图))
今天,我向大家推荐WordPress插件。市场上有各种 WordPress 插件。为了满足SEO的所有需求,我不知道要安装多少插件。过多的 WordPress 插件会导致 网站 打开速度变慢。@网站爬行会更低。最后是收录网站,SEO优化工作最重要的一步就是更新文章,也需要不断更新文章。很多人问seo,为什么我的细节优化得这么好,百度还是没有收录我的网站?为什么没有 关键词 排名?所有的客户都在哪里?网站静默三个月了怎么办?我建议在问这些问题之前,请仔细考虑一下您是否真的在尝试优化您的网站?
一、文章采集
<p>网站更新文章选择文章采集,正常网站每天最多更新3篇文章,3个月不到100篇,成为 收录 的几率低于 30%。不知道你的网站哪一年哪一个月会有更多的收录和关键词排名。@伪原创 和 网站 页面
php用正则表达抓取网页中文章(本文实例讲述PHPpreg_实现正则表达式匹配功能(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-23 19:21
)
本文中的例子描述了PHP preg_match 中正则表达式匹配的实现。分享给大家,供大家参考,如下:
preg_match — 执行正则表达式匹配
preg_match ( $pattern , $subject , $matches )
搜索主题以匹配由模式给出的正则表达式。
参数:
pattern : 要搜索的模式,字符串类型(正则表达式)。
subject : 输入字符串。
matches :(可选)如果提供了参数匹配,它将作为搜索结果填充。 $matches[0] 将收录完整模式匹配的文本,$matches[1] 将收录第一个捕获子组匹配的文本,依此类推。
返回值:
preg_match() 返回模式的匹配数。其值为 0(不匹配)或 1,因为 preg_match() 将在第一次匹配后停止搜索。 preg_match_all() 与此不同之处在于它搜索主题直到它到达结尾。如果发生错误 preg_match() 返回 FALSE。
示例 1:
$label = 'content/112';
$a = preg_match('#content/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(1)
array(2) {
[0]=>
string(11) "content/112"
[1]=>
string(3) "112"
}
示例 2:
$label = 'content/112';
$a = preg_match('#(\w+)/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(1)
array(3) {
[0]=>
string(11) "content/112"
[1]=>
string(7) "content"
[2]=>
string(3) "112"
}
示例 3:
$label = 'content/112';
$a = preg_match('#content1111111/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(0)
array(0) {
}
以上是php正则表达式preg_match是如何实现匹配功能的?更多详情请关注php中文网其他相关话题文章!
查看全部
php用正则表达抓取网页中文章(本文实例讲述PHPpreg_实现正则表达式匹配功能(图)
)
本文中的例子描述了PHP preg_match 中正则表达式匹配的实现。分享给大家,供大家参考,如下:
preg_match — 执行正则表达式匹配
preg_match ( $pattern , $subject , $matches )
搜索主题以匹配由模式给出的正则表达式。
参数:
pattern : 要搜索的模式,字符串类型(正则表达式)。
subject : 输入字符串。
matches :(可选)如果提供了参数匹配,它将作为搜索结果填充。 $matches[0] 将收录完整模式匹配的文本,$matches[1] 将收录第一个捕获子组匹配的文本,依此类推。
返回值:
preg_match() 返回模式的匹配数。其值为 0(不匹配)或 1,因为 preg_match() 将在第一次匹配后停止搜索。 preg_match_all() 与此不同之处在于它搜索主题直到它到达结尾。如果发生错误 preg_match() 返回 FALSE。
示例 1:
$label = 'content/112';
$a = preg_match('#content/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(1)
array(2) {
[0]=>
string(11) "content/112"
[1]=>
string(3) "112"
}
示例 2:
$label = 'content/112';
$a = preg_match('#(\w+)/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(1)
array(3) {
[0]=>
string(11) "content/112"
[1]=>
string(7) "content"
[2]=>
string(3) "112"
}
示例 3:
$label = 'content/112';
$a = preg_match('#content1111111/(\d+)#i', $label, $mc);
var_dump($a);
var_dump($mc);
输出:
int(0)
array(0) {
}
以上是php正则表达式preg_match是如何实现匹配功能的?更多详情请关注php中文网其他相关话题文章!
php用正则表达抓取网页中文章( 示例:在字符串1000abcd123中找出前后前后两个数字。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-23 10:11
示例:在字符串1000abcd123中找出前后前后两个数字。)
示例:查找字符串 1000abcd123 前后的两个数字。
示例1:匹配此字符串的示例
package main
import(
"fmt"
"regexp"
)
var digitsRegexp = regexp.MustCompile(`(\d+)\D+(\d+)`)
func main(){
someString:="1000abcd123"
fmt.Println(digitsRegexp.FindStringSubmatch(someString))
}
以上代码输出:
[1000abcd123 1000 123]
示例 2:使用命名正则表达式
package main
import(
"fmt"
"regexp"
)
var myExp=regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)
func main(){
fmt.Printf("%+v",myExp.FindStringSubmatch("1234.5678.9"))
}
以上代码输出,所有匹配均输出:
[1234.5678.9 1234 5678 9]
这里的命名捕获组(?P)命名正则表达式的方式是python和Go语言特有的,以及java和c#的(?)命名方式。
例子3:扩展一个正则表达式类,用一个方法来获取所有的命名信息并使用它。
package main
import(
"fmt"
"regexp"
)
//embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
//add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string) map[string]string{
captures:=make(map[string]string)
match:=r.FindStringSubmatch(s)
if match==nil{
return captures
}
for i,name:=range r.SubexpNames(){
//Ignore the whole regexp match and unnamed groups
if i==0||name==""{
continue
}
captures[name]=match[i]
}
return captures
}
//an example regular expression
var myExp=myRegexp{regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)}
func main(){
mmap:=myExp.FindStringSubmatchMap("1234.5678.9")
ww:=mmap["first"]
fmt.Println(mmap)
fmt.Println(ww)
}
以上代码的输出:
map[first:1234 second:9]
1234
例4,抓取限号信息,记录在Map中。
package main
import(
"fmt"
iconv "github.com/djimenez/iconv-go"
"io/ioutil"
"net/http"
"os"
"regexp"
)
// embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
// add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string)[](map[string]string){
captures:=make([](map[string]string),0)
matches:=r.FindAllStringSubmatch(s,-1)
if matches==nil{
return captures
}
names:=r.SubexpNames()
for _,match:=range matches{
cmap:=make(map[string]string)
for pos,val:=range match{
name:=names[pos]
if name==""{
continue
}
/*
fmt.Println("+++++++++")
fmt.Println(name)
fmt.Println(val)
*/
cmap[name]=val
}
captures=append(captures,cmap)
}
return captures
}
// 抓取限号信息的正则表达式
var myExp=myRegexp{regexp.MustCompile(`自(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日至(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日,星期一至星期五限行机动车车牌尾号分别为:(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])`)}
func ErrorAndExit(err error){
fmt.Fprintln(os.Stderr,err)
os.Exit(1)
}
func main(){
response,err:=http.Get("http://www.bjjtgl.gov.cn/zhuan ... 6quot;)
defer response.Body.Close()
if err!=nil{
ErrorAndExit(err)
}
input,err:=ioutil.ReadAll(response.Body)
if err!=nil{
ErrorAndExit(err)
}
body :=make([]byte,len(input))
iconv.Convert(input,body,"gb2312","utf-8")
mmap:=myExp.FindStringSubmatchMap(string(body))
fmt.Println(mmap)
}
以上代码输出:
[map[n32:0 n22:9 emonth:7 n11:3 n41:1 n21:4 n52:7 bmonth:4 n51:2 bday:9 n42:6 byear:2012 eday:7 eyear:2012 n12:8 n31:5]
map[emonth:10 n41:5 n52:6 n31:4 byear:2012 n51:1 eyear:2012 n32:9 bmonth:7 n22:8 bday:8 n11:2 eday:6 n42:0 n21:3 n12:7]
map[bday:7 n51:5 n22:7 n31:3 eday:5 n32:8 byear:2012 bmonth:10 emonth:1 eyear:2013 n11:1 n12:6 n52:0 n21:2 n42:9 n41:4]
map[eyear:2013 byear:2013 n22:6 eday:10 bmonth:1 n41:3 n32:7 n31:2 n21:1 n11:5 bday:6 n12:0 n51:4 n42:8 emonth:4 n52:9]]
更多go语言知识,请关注PHP中文网站go语言教程专栏。
以上是Go语言使用正则表达式提取网页文本的详细内容。更多详情请关注php中文网其他相关话题文章!
免责声明:本文转载于:博客园,如有侵权,请联系删除
特别推荐:Go语言正则 查看全部
php用正则表达抓取网页中文章(
示例:在字符串1000abcd123中找出前后前后两个数字。)
示例:查找字符串 1000abcd123 前后的两个数字。
示例1:匹配此字符串的示例
package main
import(
"fmt"
"regexp"
)
var digitsRegexp = regexp.MustCompile(`(\d+)\D+(\d+)`)
func main(){
someString:="1000abcd123"
fmt.Println(digitsRegexp.FindStringSubmatch(someString))
}
以上代码输出:
[1000abcd123 1000 123]
示例 2:使用命名正则表达式
package main
import(
"fmt"
"regexp"
)
var myExp=regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)
func main(){
fmt.Printf("%+v",myExp.FindStringSubmatch("1234.5678.9"))
}
以上代码输出,所有匹配均输出:
[1234.5678.9 1234 5678 9]
这里的命名捕获组(?P)命名正则表达式的方式是python和Go语言特有的,以及java和c#的(?)命名方式。
例子3:扩展一个正则表达式类,用一个方法来获取所有的命名信息并使用它。
package main
import(
"fmt"
"regexp"
)
//embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
//add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string) map[string]string{
captures:=make(map[string]string)
match:=r.FindStringSubmatch(s)
if match==nil{
return captures
}
for i,name:=range r.SubexpNames(){
//Ignore the whole regexp match and unnamed groups
if i==0||name==""{
continue
}
captures[name]=match[i]
}
return captures
}
//an example regular expression
var myExp=myRegexp{regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)}
func main(){
mmap:=myExp.FindStringSubmatchMap("1234.5678.9")
ww:=mmap["first"]
fmt.Println(mmap)
fmt.Println(ww)
}
以上代码的输出:
map[first:1234 second:9]
1234
例4,抓取限号信息,记录在Map中。
package main
import(
"fmt"
iconv "github.com/djimenez/iconv-go"
"io/ioutil"
"net/http"
"os"
"regexp"
)
// embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
// add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string)[](map[string]string){
captures:=make([](map[string]string),0)
matches:=r.FindAllStringSubmatch(s,-1)
if matches==nil{
return captures
}
names:=r.SubexpNames()
for _,match:=range matches{
cmap:=make(map[string]string)
for pos,val:=range match{
name:=names[pos]
if name==""{
continue
}
/*
fmt.Println("+++++++++")
fmt.Println(name)
fmt.Println(val)
*/
cmap[name]=val
}
captures=append(captures,cmap)
}
return captures
}
// 抓取限号信息的正则表达式
var myExp=myRegexp{regexp.MustCompile(`自(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日至(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日,星期一至星期五限行机动车车牌尾号分别为:(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])`)}
func ErrorAndExit(err error){
fmt.Fprintln(os.Stderr,err)
os.Exit(1)
}
func main(){
response,err:=http.Get("http://www.bjjtgl.gov.cn/zhuan ... 6quot;)
defer response.Body.Close()
if err!=nil{
ErrorAndExit(err)
}
input,err:=ioutil.ReadAll(response.Body)
if err!=nil{
ErrorAndExit(err)
}
body :=make([]byte,len(input))
iconv.Convert(input,body,"gb2312","utf-8")
mmap:=myExp.FindStringSubmatchMap(string(body))
fmt.Println(mmap)
}
以上代码输出:
[map[n32:0 n22:9 emonth:7 n11:3 n41:1 n21:4 n52:7 bmonth:4 n51:2 bday:9 n42:6 byear:2012 eday:7 eyear:2012 n12:8 n31:5]
map[emonth:10 n41:5 n52:6 n31:4 byear:2012 n51:1 eyear:2012 n32:9 bmonth:7 n22:8 bday:8 n11:2 eday:6 n42:0 n21:3 n12:7]
map[bday:7 n51:5 n22:7 n31:3 eday:5 n32:8 byear:2012 bmonth:10 emonth:1 eyear:2013 n11:1 n12:6 n52:0 n21:2 n42:9 n41:4]
map[eyear:2013 byear:2013 n22:6 eday:10 bmonth:1 n41:3 n32:7 n31:2 n21:1 n11:5 bday:6 n12:0 n51:4 n42:8 emonth:4 n52:9]]
更多go语言知识,请关注PHP中文网站go语言教程专栏。
以上是Go语言使用正则表达式提取网页文本的详细内容。更多详情请关注php中文网其他相关话题文章!
免责声明:本文转载于:博客园,如有侵权,请联系删除
特别推荐:Go语言正则
php用正则表达抓取网页中文章( 正则表达式的20个校验密码路径及扩展名验证下文件路径 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-20 16:27
正则表达式的20个校验密码路径及扩展名验证下文件路径
)
正则表达式是一种强大而高效的文本处理工具。通常,复杂的业务逻辑可以通过准确的表达非常简单快速地实现。
因此,正则表达式通常是成熟开发者的标准,有助于实现开发效率的大幅提升。
当需要实现校验字段、字符串等时,通常可以通过正则表达式来实现:
以下是工匠经常使用的20个正则表达式。
1 检查密码强度
密码的强度必须是大小写字母和数字的组合,没有特殊字符,长度在 8-10 之间。
2 检查中文
字符串只能是中文。
3 由数字、26个英文字母或下划线组成的字符串
4 验证电子邮件地址
与密码一样,以下是电子邮件地址合规性的常规检查声明。
5 检查×××号
以下是×××号的定期检查。15 或 18 位。
6 检查日期
“yyyy-mm-dd”格式的日期检查,考虑到闰年。
7 检查金额
金额核对,精确到小数点后2位。
8 验证手机号码
以下是国内13、15、18开头的手机号码正则表达式。(前两个号码可根据目前国内采集号码展开)
9 确定IE的版本
IE目前还没有完全替代,很多页面还需要版本兼容。以下是 IE 版本检查的表达式。
10 检查 IP-v4 地址
IP4 常规声明。
11 检查 IP-v6 地址
IP6 常规声明。
12 检查 URL 的前缀
在应用开发中,经常需要区分请求是HTTPS还是HTTP。通过下面的表达式,可以提取一个url前缀,然后进行逻辑判断。
13 提取 URL 链接
以下表达式过滤掉一段文本中的 URL。
14 文件路径和扩展名验证
验证Windows下的文件路径和扩展名(下例中为.txt文件)
15个提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用下面的表达式。
16 提取网页图像
如果要提取网页中的所有图像信息,可以使用以下表达式。
17 提取页面超链接
提取html中的超链接。
18 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
19 提取注释
如果您需要删除 HMTL 中的注释,可以使用以下表达式。
20 个匹配的 HTML 标签
HTML 中的标签属性可以通过以下表达式进行匹配。
与正则表达式相关的语法
下面是我发现的一个非常好的正则表达式备忘单,可以用来快速找到相关的语法。
学习正则表达式
在网上看到了一本很不错的正则表达式快速学习指南,有兴趣继续学习的同学可以参考。
查看全部
php用正则表达抓取网页中文章(
正则表达式的20个校验密码路径及扩展名验证下文件路径
)
正则表达式是一种强大而高效的文本处理工具。通常,复杂的业务逻辑可以通过准确的表达非常简单快速地实现。
因此,正则表达式通常是成熟开发者的标准,有助于实现开发效率的大幅提升。
当需要实现校验字段、字符串等时,通常可以通过正则表达式来实现:
以下是工匠经常使用的20个正则表达式。
1 检查密码强度
密码的强度必须是大小写字母和数字的组合,没有特殊字符,长度在 8-10 之间。
2 检查中文
字符串只能是中文。
3 由数字、26个英文字母或下划线组成的字符串
4 验证电子邮件地址
与密码一样,以下是电子邮件地址合规性的常规检查声明。
5 检查×××号
以下是×××号的定期检查。15 或 18 位。
6 检查日期
“yyyy-mm-dd”格式的日期检查,考虑到闰年。
7 检查金额
金额核对,精确到小数点后2位。
8 验证手机号码
以下是国内13、15、18开头的手机号码正则表达式。(前两个号码可根据目前国内采集号码展开)
9 确定IE的版本
IE目前还没有完全替代,很多页面还需要版本兼容。以下是 IE 版本检查的表达式。
10 检查 IP-v4 地址
IP4 常规声明。
11 检查 IP-v6 地址
IP6 常规声明。
12 检查 URL 的前缀
在应用开发中,经常需要区分请求是HTTPS还是HTTP。通过下面的表达式,可以提取一个url前缀,然后进行逻辑判断。
13 提取 URL 链接
以下表达式过滤掉一段文本中的 URL。
14 文件路径和扩展名验证
验证Windows下的文件路径和扩展名(下例中为.txt文件)
15个提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用下面的表达式。
16 提取网页图像
如果要提取网页中的所有图像信息,可以使用以下表达式。
17 提取页面超链接
提取html中的超链接。
18 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
19 提取注释
如果您需要删除 HMTL 中的注释,可以使用以下表达式。
20 个匹配的 HTML 标签
HTML 中的标签属性可以通过以下表达式进行匹配。
与正则表达式相关的语法
下面是我发现的一个非常好的正则表达式备忘单,可以用来快速找到相关的语法。
学习正则表达式
在网上看到了一本很不错的正则表达式快速学习指南,有兴趣继续学习的同学可以参考。
php用正则表达抓取网页中文章(php用正则表达与爬虫之日常生活篇》特点使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-02-20 11:00
php用正则表达抓取网页中文章,目前支持网页抓取,包括网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。技术博客技术博客目前支持sqlite/mysql/hbase等语言,且每个技术博客都可以选择不同源头(baidu,github,百度)。前两天一次性抓取了6篇技术博客,速度极快。
特点使用php正则表达抓取网页中文章,目前支持网页抓取,包括网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。源码github-zhuqucheng/baiquly:php正则表达抓取网页中文章,支持网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。使用环境vim、mysql,java,c++,pythonbaiquly;并具有后端、前端两个版本。
官网(/)qq交流群(二维码自动识别)redis、thinkphp官网()官网地址:baiquly/archive文章baiquly/archive本文参考《php正则表达与爬虫之日常生活篇》php正则表达抓取网页中文章。
前端网站中文章抓取:redis/thinkphp:php正则表达式(英文解析):正则表达式网页抓取
mysql数据库+php的connectorapi+ipage(ipage提供微博评论交互式爬虫,跟相关网站是一个团队开发,比如publicfox,ideoocle),发送请求到抓取器解析出真正的评论信息放在phphttpserver上,最终还是php解析,比如你的评论都是什么词,header就是什么,你输入就是什么。 查看全部
php用正则表达抓取网页中文章(php用正则表达与爬虫之日常生活篇》特点使用)
php用正则表达抓取网页中文章,目前支持网页抓取,包括网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。技术博客技术博客目前支持sqlite/mysql/hbase等语言,且每个技术博客都可以选择不同源头(baidu,github,百度)。前两天一次性抓取了6篇技术博客,速度极快。
特点使用php正则表达抓取网页中文章,目前支持网页抓取,包括网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。源码github-zhuqucheng/baiquly:php正则表达抓取网页中文章,支持网站信息抓取,文章列表抓取,url聚合抓取,url截取,采集速度极快。使用环境vim、mysql,java,c++,pythonbaiquly;并具有后端、前端两个版本。
官网(/)qq交流群(二维码自动识别)redis、thinkphp官网()官网地址:baiquly/archive文章baiquly/archive本文参考《php正则表达与爬虫之日常生活篇》php正则表达抓取网页中文章。
前端网站中文章抓取:redis/thinkphp:php正则表达式(英文解析):正则表达式网页抓取
mysql数据库+php的connectorapi+ipage(ipage提供微博评论交互式爬虫,跟相关网站是一个团队开发,比如publicfox,ideoocle),发送请求到抓取器解析出真正的评论信息放在phphttpserver上,最终还是php解析,比如你的评论都是什么词,header就是什么,你输入就是什么。
php用正则表达抓取网页中文章(怎么用免费wordpress采集插件把关键词优化到首页让网站能快速收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-19 21:16
如何使用免费的wordpress 采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,支持所有网站采用。网站为什么要做SEO优化,为什么不做呢?当然不是。随着当今互联网的发展,越来越多的人使用搜索引擎来了解品牌或产品。如果你只有网站,不优化,那么用户永远找不到你的网站,那么网站就没有意义了。SEO优化不仅仅是优化网站本身,也让更多的潜在用户了解我们的产品,可以产生一系列的好处。目前很多公司网站都专门招人做SEO优化。但是,大多数结果并不理想,而且流量和排名都很小。事实上,普通企业网站的竞争力很低。只要他们了解基本的优化步骤,获得好的排名只是时间问题。
1、网站的初始内容必须是原创的,因为搜索引擎对网站的初始审核标准之一就是观察你的网站的内容是否是原创的。原创,并定期更新网站的内容。这些是使 网站 成为搜索引擎的原因。这样做时要考虑到相对高质量的 网站 图像,这将为未来的优化提供坚实的基础。
今天给大家分享一个快速搭建原创高质量文章的wordpress采集插件。这个wordpress采集插件不需要学习更多的专业技能,只需几个简单的步骤就可以轻松采集内容数据,用户只需要在wordpress采集插件上进行简单的设置-in,完成后wordpress采集插件会根据用户设置的关键词高精度匹配内容和图片,可以保存在本地,也可以在伪原创之后发布,提供一个方便快捷的内容采集伪原创发布网站推送服务!!
相比其他wordpress采集插件,这个wordpress采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(wordpress采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这个wordpress采集插件工具还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
有了这个WordPress采集插件,我们在做网站优化的时候应该注意哪些细节呢?
1、网站位置
网站的定位是指网站的目标,无论是企业宣传,品牌推广,获得更多品牌曝光,还是产品推广,关键词排名优化,明确网站@ > 定位和优化方向。
2、网站规划
有了网站定位,就要开始运营网站规划,站在用户的角度思考网站规划,注重用户体验,网站合理规划才是有利于网站后期的优化。
3、关键词扩展
关键词组织和扩展长尾词,网站优化的前提是做好关键词的扩展和整理,明确要优化的关键词,整理关键词是为后期优化词库打下基础。
4、关键词布局
关键词如果要参与排名,需要在网站中进行布局,这里可以布局网站词库,标题,描述,关键词 , 网站 页面标题中的列、文章 页面标题、正文、标签、面包屑、底部列等。
5、内容编辑器
网站内容是否优质、稀缺、有价值,决定了后面的网站是否有好的收录和排名,是否全站参与排名而不仅仅是首页. 内容优化,注重内容切分、点数、图文、可靠的标题、恰到好处、解决问题的内容。
6、推送提交
更新了内容。如果要收录,需要将推送地址提交给百度站长。
7、外链搭建 查看全部
php用正则表达抓取网页中文章(怎么用免费wordpress采集插件把关键词优化到首页让网站能快速收录)
如何使用免费的wordpress 采集插件将关键词优化到首页,使网站可以快速收录,包括所有SEO优化功能,支持所有网站采用。网站为什么要做SEO优化,为什么不做呢?当然不是。随着当今互联网的发展,越来越多的人使用搜索引擎来了解品牌或产品。如果你只有网站,不优化,那么用户永远找不到你的网站,那么网站就没有意义了。SEO优化不仅仅是优化网站本身,也让更多的潜在用户了解我们的产品,可以产生一系列的好处。目前很多公司网站都专门招人做SEO优化。但是,大多数结果并不理想,而且流量和排名都很小。事实上,普通企业网站的竞争力很低。只要他们了解基本的优化步骤,获得好的排名只是时间问题。
1、网站的初始内容必须是原创的,因为搜索引擎对网站的初始审核标准之一就是观察你的网站的内容是否是原创的。原创,并定期更新网站的内容。这些是使 网站 成为搜索引擎的原因。这样做时要考虑到相对高质量的 网站 图像,这将为未来的优化提供坚实的基础。
今天给大家分享一个快速搭建原创高质量文章的wordpress采集插件。这个wordpress采集插件不需要学习更多的专业技能,只需几个简单的步骤就可以轻松采集内容数据,用户只需要在wordpress采集插件上进行简单的设置-in,完成后wordpress采集插件会根据用户设置的关键词高精度匹配内容和图片,可以保存在本地,也可以在伪原创之后发布,提供一个方便快捷的内容采集伪原创发布网站推送服务!!
相比其他wordpress采集插件,这个wordpress采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(wordpress采集插件也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这个wordpress采集插件工具还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)
自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
有了这个WordPress采集插件,我们在做网站优化的时候应该注意哪些细节呢?
1、网站位置
网站的定位是指网站的目标,无论是企业宣传,品牌推广,获得更多品牌曝光,还是产品推广,关键词排名优化,明确网站@ > 定位和优化方向。
2、网站规划
有了网站定位,就要开始运营网站规划,站在用户的角度思考网站规划,注重用户体验,网站合理规划才是有利于网站后期的优化。
3、关键词扩展
关键词组织和扩展长尾词,网站优化的前提是做好关键词的扩展和整理,明确要优化的关键词,整理关键词是为后期优化词库打下基础。
4、关键词布局
关键词如果要参与排名,需要在网站中进行布局,这里可以布局网站词库,标题,描述,关键词 , 网站 页面标题中的列、文章 页面标题、正文、标签、面包屑、底部列等。
5、内容编辑器
网站内容是否优质、稀缺、有价值,决定了后面的网站是否有好的收录和排名,是否全站参与排名而不仅仅是首页. 内容优化,注重内容切分、点数、图文、可靠的标题、恰到好处、解决问题的内容。
6、推送提交
更新了内容。如果要收录,需要将推送地址提交给百度站长。
7、外链搭建
php用正则表达抓取网页中文章(特殊字符宽字符编码,js端会自动解析,特殊字符 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-19 21:14
)
我在做jsonp传输的时候遇到了问题。当有特殊字符或中文时,会导致数据错误或乱码。一开始,js的编码、解码和正则化都很麻烦。现在找到了一个合适的解决方案,宽字符编码,js端会自动解析,可以处理上面的问题,下面是自己封装的通用类。
代码
using System;<br />using System.Text;<br /><br />/// <br />/// author:Stone_W<br />/// date:2010.12.23<br />/// desc:宽字符编码和解码<br />/// <br />public class CodeWidthChartUtility<br />{<br /> public CodeWidthChartUtility() { }<br /><br /> // 无需转码的字符<br /> private static string NonEncodingChats = "abcdefghijklmnopqrstuvwxyz0123456789`!@#$%^&*()_+|-=\\,./;'[]{}:?";<br /><br /> #region 判断需要转换的字符<br /> /// <br /> /// 判断需要转换的字符<br /> /// <br /> /// 判断字符<br /> /// bool<br /> private static bool IsToWindthChart(char charValue)<br /> {<br /> NonEncodingChats = NonEncodingChats.ToUpper() + NonEncodingChats.ToLower();<br /> return NonEncodingChats.IndexOf(charValue) == -1;<br /> }<br /> #endregion<br /><br /> #region 宽字符编码<br /> /// <br /> /// 宽字符编码<br /> /// 1.编码后 有js控制 浏览器会自动解析[js无需解码]<br /> /// 2.后台控制xxx.InnerHtml=宽字符 会原样输出宽字符串[后台控制需要手动解析]<br /> /// <br /> /// 需要编码的字符串<br /> /// 编码后的宽字符串<br /> public static string WidthChartEncoding(string StrValue)<br /> {<br /> StringBuilder sb = new StringBuilder();<br /> foreach (char item in StrValue)<br /> {<br /> if (IsToWindthChart(item)) // 判断需要转换的字符<br /> {<br /> sb.Append(String.Format("\\u{0:x4}", (int)item));<br /> }<br /> else<br /> {<br /> sb.Append(item);<br /> }<br /> }<br /> return sb.ToString();<br /> }<br /> #endregion<br /><br /> #region 宽字符解码<br /> /// <br /> /// 宽字符解码<br /> /// 1.后台才需要手动解码<br /> /// 2.js 控制的浏览器会自动解码宽字符<br /> /// <br /> /// 宽字符串<br /> /// 一般能看懂的字符<br /> public static string WidthChartDecoding(string WidthStr)<br /> {<br /> StringBuilder sb = new StringBuilder();<br /> string[] _ValueList = WidthStr.Split(new char[] { '\\', 'u' }, StringSplitOptions.RemoveEmptyEntries);<br /> for (int i = 0; i != _ValueList.Length; i++)<br /> {<br /> char _ValueChar = Convert.ToChar(Convert.ToUInt16(_ValueList[i], 16));<br /> sb.Append(_ValueChar.ToString());<br /> }<br /> return sb.ToString();<br /> }<br /> #endregion<br /><br />}
关注下方二维码,订阅更多精彩内容。
查看全部
php用正则表达抓取网页中文章(特殊字符宽字符编码,js端会自动解析,特殊字符
)
我在做jsonp传输的时候遇到了问题。当有特殊字符或中文时,会导致数据错误或乱码。一开始,js的编码、解码和正则化都很麻烦。现在找到了一个合适的解决方案,宽字符编码,js端会自动解析,可以处理上面的问题,下面是自己封装的通用类。
代码
using System;<br />using System.Text;<br /><br />/// <br />/// author:Stone_W<br />/// date:2010.12.23<br />/// desc:宽字符编码和解码<br />/// <br />public class CodeWidthChartUtility<br />{<br /> public CodeWidthChartUtility() { }<br /><br /> // 无需转码的字符<br /> private static string NonEncodingChats = "abcdefghijklmnopqrstuvwxyz0123456789`!@#$%^&*()_+|-=\\,./;'[]{}:?";<br /><br /> #region 判断需要转换的字符<br /> /// <br /> /// 判断需要转换的字符<br /> /// <br /> /// 判断字符<br /> /// bool<br /> private static bool IsToWindthChart(char charValue)<br /> {<br /> NonEncodingChats = NonEncodingChats.ToUpper() + NonEncodingChats.ToLower();<br /> return NonEncodingChats.IndexOf(charValue) == -1;<br /> }<br /> #endregion<br /><br /> #region 宽字符编码<br /> /// <br /> /// 宽字符编码<br /> /// 1.编码后 有js控制 浏览器会自动解析[js无需解码]<br /> /// 2.后台控制xxx.InnerHtml=宽字符 会原样输出宽字符串[后台控制需要手动解析]<br /> /// <br /> /// 需要编码的字符串<br /> /// 编码后的宽字符串<br /> public static string WidthChartEncoding(string StrValue)<br /> {<br /> StringBuilder sb = new StringBuilder();<br /> foreach (char item in StrValue)<br /> {<br /> if (IsToWindthChart(item)) // 判断需要转换的字符<br /> {<br /> sb.Append(String.Format("\\u{0:x4}", (int)item));<br /> }<br /> else<br /> {<br /> sb.Append(item);<br /> }<br /> }<br /> return sb.ToString();<br /> }<br /> #endregion<br /><br /> #region 宽字符解码<br /> /// <br /> /// 宽字符解码<br /> /// 1.后台才需要手动解码<br /> /// 2.js 控制的浏览器会自动解码宽字符<br /> /// <br /> /// 宽字符串<br /> /// 一般能看懂的字符<br /> public static string WidthChartDecoding(string WidthStr)<br /> {<br /> StringBuilder sb = new StringBuilder();<br /> string[] _ValueList = WidthStr.Split(new char[] { '\\', 'u' }, StringSplitOptions.RemoveEmptyEntries);<br /> for (int i = 0; i != _ValueList.Length; i++)<br /> {<br /> char _ValueChar = Convert.ToChar(Convert.ToUInt16(_ValueList[i], 16));<br /> sb.Append(_ValueChar.ToString());<br /> }<br /> return sb.ToString();<br /> }<br /> #endregion<br /><br />}
关注下方二维码,订阅更多精彩内容。
php用正则表达抓取网页中文章(怎么样能够快速提高网站的SEO排名呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-19 21:11
为了让自己的网站排名更高,很多公司网站现在都在做SEO优化。对于很多网站来说,想用搜索引擎做自己的网站,让更多的用户访问他们的网站,那么如何快速提升网站的SEO排名呢?这是很多站长关心的问题。让我们详细看看它。.
优质内容
一、内容是网站的基础,一个搜索引擎没有好的内容是无法收录的,网站只有拥有了排名。这里教大家一个快速采集行业的方法网站文章,同时也可以很好的管理网站。
使用这个免费的WordPress采集无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需在WordPress采集上进行简单设置,完成后, WordPress采集会根据用户设置的关键词高精度匹配内容和图片,可以选择保存在本地也可以选择伪原创后发布,提供方便快捷的内容采集伪原创发布服务!!
相比其他WordPress采集这个WordPress采集,基本没有门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(WordPress采集也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类WordPress采集发布插件工具还配备了很多SEO功能。通过软件采集伪原创发布时,还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
二、合理网站架构
网站架构是SEO的基础部分。主要与网站的代码缩减、目录结构、网页收录、网站跳出率等有关,合理的结构可以让搜索引擎爬取网站内容更好,它也会给访问者一个舒适的访问体验。如果网站的结构不合理,搜索引擎不喜欢,用户也不喜欢。
深挖用户需求
一个合格的SEO工作者大部分时间都在挖掘用户需求,也就是说,用户还需要什么?还有对行业的了解,让网站能做得更好。
三、优质外链
虽然外链的作用在减少,但对于已经被搜索引擎很好爬取的网站来说,他只需要做好内容就可以获得好的排名。但是对于很多新网站来说,如果没有外链诱饵,搜索引擎怎么能找到你呢?但是这个外链诱饵应该是高质量的,高质量应该从相关性和权威性开始。优质的外链可以帮助网站快速走出新站考察期,对快速提升SEO排名有很大帮助。
四、用户体验
用户体验包括很多方面,几乎都是前面的,比如内容是否优质、专业,浏览结构是否合理,是否需要与用户互助等等。用户体验是一项需要每天都在优化。
如何写网站每一页的标题
一个网站不仅有首页,还有栏目页、新闻页、产品页、标签页等,这些页面的标题应该怎么做呢?
主页的标题可以用一句话概括。在满足你的关键词的基础上,尽量展现你独特的优势,给人一种眼前一亮的感觉,就是要给人点击的欲望。
栏目页的重要性在于内容的契合度,即相关性。如果标题上堆积了大量的相关内容,可以适当扩展,以满足我们对内容的准确命题。专栏内容很多,综合了很多方面。,如果标题只是简单地命名为单个 关键词 或长尾词,则不够准确。为此,我们可以适当扩展标题。以网站的构建为例,可以设置标题收录网站构建信息。, 网站模板的标题、技术文档等 查看全部
php用正则表达抓取网页中文章(怎么样能够快速提高网站的SEO排名呢?(图))
为了让自己的网站排名更高,很多公司网站现在都在做SEO优化。对于很多网站来说,想用搜索引擎做自己的网站,让更多的用户访问他们的网站,那么如何快速提升网站的SEO排名呢?这是很多站长关心的问题。让我们详细看看它。.
优质内容
一、内容是网站的基础,一个搜索引擎没有好的内容是无法收录的,网站只有拥有了排名。这里教大家一个快速采集行业的方法网站文章,同时也可以很好的管理网站。
使用这个免费的WordPress采集无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需在WordPress采集上进行简单设置,完成后, WordPress采集会根据用户设置的关键词高精度匹配内容和图片,可以选择保存在本地也可以选择伪原创后发布,提供方便快捷的内容采集伪原创发布服务!!
相比其他WordPress采集这个WordPress采集,基本没有门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(WordPress采集也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类WordPress采集发布插件工具还配备了很多SEO功能。通过软件采集伪原创发布时,还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
二、合理网站架构
网站架构是SEO的基础部分。主要与网站的代码缩减、目录结构、网页收录、网站跳出率等有关,合理的结构可以让搜索引擎爬取网站内容更好,它也会给访问者一个舒适的访问体验。如果网站的结构不合理,搜索引擎不喜欢,用户也不喜欢。
深挖用户需求
一个合格的SEO工作者大部分时间都在挖掘用户需求,也就是说,用户还需要什么?还有对行业的了解,让网站能做得更好。
三、优质外链
虽然外链的作用在减少,但对于已经被搜索引擎很好爬取的网站来说,他只需要做好内容就可以获得好的排名。但是对于很多新网站来说,如果没有外链诱饵,搜索引擎怎么能找到你呢?但是这个外链诱饵应该是高质量的,高质量应该从相关性和权威性开始。优质的外链可以帮助网站快速走出新站考察期,对快速提升SEO排名有很大帮助。
四、用户体验
用户体验包括很多方面,几乎都是前面的,比如内容是否优质、专业,浏览结构是否合理,是否需要与用户互助等等。用户体验是一项需要每天都在优化。
如何写网站每一页的标题
一个网站不仅有首页,还有栏目页、新闻页、产品页、标签页等,这些页面的标题应该怎么做呢?
主页的标题可以用一句话概括。在满足你的关键词的基础上,尽量展现你独特的优势,给人一种眼前一亮的感觉,就是要给人点击的欲望。
栏目页的重要性在于内容的契合度,即相关性。如果标题上堆积了大量的相关内容,可以适当扩展,以满足我们对内容的准确命题。专栏内容很多,综合了很多方面。,如果标题只是简单地命名为单个 关键词 或长尾词,则不够准确。为此,我们可以适当扩展标题。以网站的构建为例,可以设置标题收录网站构建信息。, 网站模板的标题、技术文档等
php用正则表达抓取网页中文章(怎么用zblog采集把关键词优化到首页让网站能快速收录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-19 21:11
如何使用zblog采集优化关键词到首页,使网站可以快速收录,zblog采集收录SEO功能,支持所有网站 使用 . 从事SEO工作的人有不同的个人能力。网站的优化不仅包括内容的优化,还包括整体的优化。
今天说一下优化方法,使用网站内容+网站标签的优化;提高搜索引擎对网站的友好度,从而提高网站的整体得分。快给大家分享一个采集高品质文章zblog采集。
这个zblog采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松实现采集内容数据,用户只需要在zblog采集上进行简单的设置,之后补全zblog采集会根据用户设置的关键词对内容和图片进行高精度匹配,可以选择保存在本地也可以选择伪原创后发布,提供方便快捷的内容采集伪原创 发布服务!!
和其他zblog采集相比,这个zblog采集基本没有任何门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(zblog采集也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类zblog采集发布插件工具也配备了很多SEO功能,通过采集伪原创软件发布还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
一、什么是 网站 标签?
网站标签说明:网站内容的组织,使得网站的内容可以清晰划分,方便搜索引擎检索和分享,与其他用户体验。简单来说,网站标签就是用来对网站内容进行分类,方便检索。
现在做SEO优化,你越来越关注网站的可访问性和用户体验。你的网站速度够快,内容有价值,解决用户需求的能力有利于竞争,价值越高。毫无疑问,网站更具竞争力,而网站标签在网站效果的整体优化中起着非常重要的作用。
通过网站标签,用户和搜索引擎都可以了解网站的框架和内容,快速找到对应的信息。因此,一个网站的标签系统越完善,用户体验就越高,搜索引擎给出的评分也越高。
二、网站标签在SEO优化中的作用是什么?
1、有主题效果
网站 的每个标签都是从相关内容聚合而成的。一个标签往往就相当于一个小话题,话题页面的排名比一般页面要好,所以网站标签的优化也要花点心思。比如三大标签的写法,网页内容的布局等等。毕竟排名是网站综合影响的结果,细节上也要注意。
2、 赞成 收录 和 网站 的排名
网站的标签非常重要,它直接影响到我们网站的收录、排名和用户流量。首先,用户通过关键词搜索找到我们网站。这时候,清晰吸引人的描述标签(网站三大标签TDK)可以引导更多用户浏览。
而网站有大量的标签,也就是说它有大量的网站页面入口,标签也属于某种聚合的范畴。例如,同一篇文章文章可以对应很多标签,同一个标签也可能对应很多文章文章。在这种情况下,网站的内容将有利于蜘蛛爬取,增加收录的可能性,对网站的排名也有一定的影响。
3、提升用户体验
网站设置好的标签可以提升用户体验,比如清晰的导航标签,可以方便用户检索信息。如果提供有价值的内容,不仅可以给网站带来更多的收益,浏览量也可以增加网站用户的使用时间。 查看全部
php用正则表达抓取网页中文章(怎么用zblog采集把关键词优化到首页让网站能快速收录)
如何使用zblog采集优化关键词到首页,使网站可以快速收录,zblog采集收录SEO功能,支持所有网站 使用 . 从事SEO工作的人有不同的个人能力。网站的优化不仅包括内容的优化,还包括整体的优化。
今天说一下优化方法,使用网站内容+网站标签的优化;提高搜索引擎对网站的友好度,从而提高网站的整体得分。快给大家分享一个采集高品质文章zblog采集。
这个zblog采集插件不需要学习更专业的技术,只需要几个简单的步骤就可以轻松实现采集内容数据,用户只需要在zblog采集上进行简单的设置,之后补全zblog采集会根据用户设置的关键词对内容和图片进行高精度匹配,可以选择保存在本地也可以选择伪原创后发布,提供方便快捷的内容采集伪原创 发布服务!!
和其他zblog采集相比,这个zblog采集基本没有任何门槛,也不需要花很多时间去学习正则表达式或者html标签,一分钟就能上手,只需输入关键词即可实现采集(zblog采集也自带关键词采集功能)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类zblog采集发布插件工具也配备了很多SEO功能,通过采集伪原创软件发布还可以提升很多SEO优化。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面原创的度数,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
一、什么是 网站 标签?
网站标签说明:网站内容的组织,使得网站的内容可以清晰划分,方便搜索引擎检索和分享,与其他用户体验。简单来说,网站标签就是用来对网站内容进行分类,方便检索。
现在做SEO优化,你越来越关注网站的可访问性和用户体验。你的网站速度够快,内容有价值,解决用户需求的能力有利于竞争,价值越高。毫无疑问,网站更具竞争力,而网站标签在网站效果的整体优化中起着非常重要的作用。
通过网站标签,用户和搜索引擎都可以了解网站的框架和内容,快速找到对应的信息。因此,一个网站的标签系统越完善,用户体验就越高,搜索引擎给出的评分也越高。
二、网站标签在SEO优化中的作用是什么?
1、有主题效果
网站 的每个标签都是从相关内容聚合而成的。一个标签往往就相当于一个小话题,话题页面的排名比一般页面要好,所以网站标签的优化也要花点心思。比如三大标签的写法,网页内容的布局等等。毕竟排名是网站综合影响的结果,细节上也要注意。
2、 赞成 收录 和 网站 的排名
网站的标签非常重要,它直接影响到我们网站的收录、排名和用户流量。首先,用户通过关键词搜索找到我们网站。这时候,清晰吸引人的描述标签(网站三大标签TDK)可以引导更多用户浏览。
而网站有大量的标签,也就是说它有大量的网站页面入口,标签也属于某种聚合的范畴。例如,同一篇文章文章可以对应很多标签,同一个标签也可能对应很多文章文章。在这种情况下,网站的内容将有利于蜘蛛爬取,增加收录的可能性,对网站的排名也有一定的影响。
3、提升用户体验
网站设置好的标签可以提升用户体验,比如清晰的导航标签,可以方便用户检索信息。如果提供有价值的内容,不仅可以给网站带来更多的收益,浏览量也可以增加网站用户的使用时间。
php用正则表达抓取网页中文章(如何利用网页聊天机器人,做一个自动聊天的微信机器人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-19 21:10
我无事可做(其实还在期末考试中),当我在思考如何使用手中的服务器做某事时,我找到了python的itchat库,以为我可以再次使用网络聊天机器人做一个自动聊天微信机器人。
大致思路很简单,使用itchat登录微信,接收消息,通过聊天机器人接口发送给聊天机器人,然后通过itchat将接收到的消息发送给用户,实现自动聊天。
经过多次搜索,我发现了一个在线聊天机器人,它的聊天相当智能(带有有趣的语气),
在浏览器里找界面还是有点乱,用burp抓包更清楚:
我们的每一条消息都要通过GET方法传入,然后返回数据中的内容应该收录回复内容,尝试用python解码:
下一步是构造 url。我的想法是把url解码,然后拼接,然后发送url编码。
使用正则模式从返回的数据中匹配我们想要的数据:
由于可以得到返回的数据,所以可以使用itchat库从微信接收和发送:
运行后会生成二维码图片,扫码登录微信网页版。
关于 itchat 库:
操作很简单。
所有代码:
import itchat,code,unicodedata
import requests,re
from urllib.parse import quote,unquote
def get_reply(data):
ini = "{'sessionId':'09e2aca4d0a541f88eecc77c03a8b393','robotId':'webbot','userId':'462d49d3742745bb98f7538c42f9f874','body':{'content':'" + data + "'},'type':'txt'}&ts=1529917589648"
url = "http://i.xiaoi.com/robot/webro ... ot%3B + quote(ini)
cookie = {"cnonce": "808116", "sig": "0c3021aa5552fe597bb55448b40ad2a90d2dead5",
"XISESSIONID": "hlbnd1oiwar01dfje825gavcn", "nonce": "273765", "hibext_instdsigdip2": "1"}
r = requests.get(url, cookies=cookie)
print(r.text)
pattern = re.compile(r'\"fontColor\":0,\"content\":\"(.*?)\"')
result = pattern.findall(r.text)
print(result[1])
return result[1]
@itchat.msg_register(itchat.content.TEXT)
def print_content(msg):
print(msg['Text'])
print(msg['FromUserName'])
datas=get_reply(msg['Text'])[:-4]
print(datas)
itchat.send(datas, toUserName=msg['FromUserName'])
itchat.auto_login()
itchat.run()
小白播放器,正常使用不是很好,代码不规范,不要抱怨。
另外,如果你使用图灵机器人或者小黄鸡提供的API,效果会更好,但是网上教程已经很多了,这里换个思路。
文章同步到我的博客:
转载并注明出处 查看全部
php用正则表达抓取网页中文章(如何利用网页聊天机器人,做一个自动聊天的微信机器人)
我无事可做(其实还在期末考试中),当我在思考如何使用手中的服务器做某事时,我找到了python的itchat库,以为我可以再次使用网络聊天机器人做一个自动聊天微信机器人。
大致思路很简单,使用itchat登录微信,接收消息,通过聊天机器人接口发送给聊天机器人,然后通过itchat将接收到的消息发送给用户,实现自动聊天。
经过多次搜索,我发现了一个在线聊天机器人,它的聊天相当智能(带有有趣的语气),
在浏览器里找界面还是有点乱,用burp抓包更清楚:
我们的每一条消息都要通过GET方法传入,然后返回数据中的内容应该收录回复内容,尝试用python解码:
下一步是构造 url。我的想法是把url解码,然后拼接,然后发送url编码。
使用正则模式从返回的数据中匹配我们想要的数据:
由于可以得到返回的数据,所以可以使用itchat库从微信接收和发送:
运行后会生成二维码图片,扫码登录微信网页版。
关于 itchat 库:
操作很简单。
所有代码:
import itchat,code,unicodedata
import requests,re
from urllib.parse import quote,unquote
def get_reply(data):
ini = "{'sessionId':'09e2aca4d0a541f88eecc77c03a8b393','robotId':'webbot','userId':'462d49d3742745bb98f7538c42f9f874','body':{'content':'" + data + "'},'type':'txt'}&ts=1529917589648"
url = "http://i.xiaoi.com/robot/webro ... ot%3B + quote(ini)
cookie = {"cnonce": "808116", "sig": "0c3021aa5552fe597bb55448b40ad2a90d2dead5",
"XISESSIONID": "hlbnd1oiwar01dfje825gavcn", "nonce": "273765", "hibext_instdsigdip2": "1"}
r = requests.get(url, cookies=cookie)
print(r.text)
pattern = re.compile(r'\"fontColor\":0,\"content\":\"(.*?)\"')
result = pattern.findall(r.text)
print(result[1])
return result[1]
@itchat.msg_register(itchat.content.TEXT)
def print_content(msg):
print(msg['Text'])
print(msg['FromUserName'])
datas=get_reply(msg['Text'])[:-4]
print(datas)
itchat.send(datas, toUserName=msg['FromUserName'])
itchat.auto_login()
itchat.run()
小白播放器,正常使用不是很好,代码不规范,不要抱怨。
另外,如果你使用图灵机器人或者小黄鸡提供的API,效果会更好,但是网上教程已经很多了,这里换个思路。
文章同步到我的博客:
转载并注明出处

