
php用正则表达抓取网页中文章
Pandas爬虫,竟能如此简单!
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-05-08 21:26
文章:菜J学Pythyon
众所周知,一般的爬虫套路无非是构造请求、解析网页、提取要素、存储数据等步骤。构造请求主要用到requests库,提取要素用的比较多的有xpath、bs4、css和re。一个完整的爬虫,代码量少则几十行,多则几百行,对于新手来说学习成本还是比较高的。
那么,有没有什么方法只用几行代码就能爬下所需数据呢?答案是pandas。J哥自从知道了这个神器,尝试了多个网页数据爬取,屡战屡胜,简直不能再舒服!这家伙也太适合初学爬虫的小伙伴玩耍了吧!
本文目录
01定 义
pandas中的pd.read_html()这个函数,功能非常强大,可以轻松实现抓取Table表格型数据。无需掌握正则表达式或者xpath等工具,短短的几行代码就可以将网页数据抓取下来。
02原 理
一.Table表格型数据网页结构
pandas适合抓取Table表格型数据,那么咱们首先得知道什么样的网页具有Table表格型数据结构(有html基础的大佬可自行跳过这一part)。
我们先来看个简单的例子。(快捷键F12可快速查看网页的HTML结构)
指南者留学网
从这个世界大学排行的网站可以看出,数据存储在一个table表格中,thread为表头,tbody为表格数据,tbody中的一个tr对应表中的一行,一个td对应一个表中元素。
我们再来看一个例子:
新浪财经网
也许你已经发现了规律,以Table结构展示的表格数据,大致的网页结构如下:
... ... ... ... ... ... ...
Table表格一般网页结构
只要网页具有以上结构,你就可以尝试用pandas抓取数据。
二.pandas请求表格数据原理
基本流程
针对网页结构类似的表格类型数据,pd.read_html可以将网页上的表格数据都抓取下来,并以DataFrame的形式装在一个list中返回。
三.pd.read_html语法及参数
pandas.read_html(io, match='.+', flavor=None, header=None,index_col=None,skiprows=None, attrs=None, parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
基本语法
io :接收网址、文件、字符串;parse_dates:解析日期;flavor:解析器;header:标题行;skiprows:跳过的行;attrs:属性,比如 attrs = {'id': 'table'}
主要参数
03实 战
一.案例1:抓取世界大学排名(1页数据)
1import pandas as pd 2import csv3url1 = 'http://www.compassedu.hk/qs'4df1 = pd.read_html(url1)[0] #0表示网页中的第一个Table5df1.to_csv('世界大学综合排名.csv',index=0)
没错,5行代码,几秒钟就搞定,我们来预览下爬取到的数据:
世界大学排行榜
二.案例2:抓取新浪财经基金重仓股数据(6页数据)
1import pandas as pd2import csv3df2 = pd.DataFrame()4for i in range(6):5 url2 = 'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={page}'.format(page=i+1)6 df2 = pd.concat([df2,pd.read_html(url2)[0]])7 print('第{page}页抓取完成'.format(page = i + 1))8df2.to_csv('./新浪财经数据.csv',encoding='utf-8',index=0)
没错,8行代码搞定,还是那么简单。如果对翻页爬虫不理解,可查看本公众号历史原创文章「实战|手把手教你用Python爬虫(附详细源码)」,如果对DataFrame合并不理解,可查看本公众号历史原创文章「基础|Pandas常用知识点汇总(四)」。
我们来预览下爬取到的数据:
基金重仓股数据
三.案例3:抓取证监会披露的IPO数据(217页数据)
1import pandas as pd 2from pandas import DataFrame 3import csv 4import time 5start = time.time() #计时 6df3 = DataFrame(data=None,columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料']) #添加列名 7for i in range(1,218): 8 url3 ='http://eid.csrc.gov.cn/ipo/infoDisplay.action?pageNo=%s&temp=&temp1=&blockType=byTime'%str(i) 9 df3_1 = pd.read_html(url3,encoding='utf-8')[2] #必须加utf-8,否则乱码10 df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1] #过滤掉最后一行和最后一列(NaN列)11 df3_2.columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料'] #新的df添加列名12 df3 = pd.concat([df3,df3_2]) #数据合并13 print('第{page}页抓取完成'.format(page=i))14df3.to_csv('./上市公司IPO信息.csv', encoding='utf-8',index=0) #保存数据到csv文件15end = time.time()16print ('共抓取',len(df3),'家公司,' + '用时',round((end-start)/60,2),'分钟')
这里注意要对抓下来的Table数据进行过滤,主要用到iloc方法,详情可查看本公众号往期原创文章「基础|Pandas常用知识点汇总(三)」。另外,我还加了个程序计时,方便查看爬取速度。
2分钟爬下217页4334条数据,相当nice了。我们来预览下爬取到的数据:
上市公司IPO数据
需要注意的是,并不是所有表格都可以用pd.read_html爬取,有的网站表面上看起来是表格,但在网页源代码中不是table格式,而是list列表格式。这种表格则不适用read_html爬取,得用其他的方法,比如selenium。
- 合作、交流、转载请添加微信 moonhmily1 -<p style="white-space: normal;font-size: 16px;"><br />
</p> 查看全部
Pandas爬虫,竟能如此简单!
文章:菜J学Pythyon
众所周知,一般的爬虫套路无非是构造请求、解析网页、提取要素、存储数据等步骤。构造请求主要用到requests库,提取要素用的比较多的有xpath、bs4、css和re。一个完整的爬虫,代码量少则几十行,多则几百行,对于新手来说学习成本还是比较高的。
那么,有没有什么方法只用几行代码就能爬下所需数据呢?答案是pandas。J哥自从知道了这个神器,尝试了多个网页数据爬取,屡战屡胜,简直不能再舒服!这家伙也太适合初学爬虫的小伙伴玩耍了吧!
本文目录
01定 义
pandas中的pd.read_html()这个函数,功能非常强大,可以轻松实现抓取Table表格型数据。无需掌握正则表达式或者xpath等工具,短短的几行代码就可以将网页数据抓取下来。
02原 理
一.Table表格型数据网页结构
pandas适合抓取Table表格型数据,那么咱们首先得知道什么样的网页具有Table表格型数据结构(有html基础的大佬可自行跳过这一part)。
我们先来看个简单的例子。(快捷键F12可快速查看网页的HTML结构)
指南者留学网
从这个世界大学排行的网站可以看出,数据存储在一个table表格中,thread为表头,tbody为表格数据,tbody中的一个tr对应表中的一行,一个td对应一个表中元素。
我们再来看一个例子:
新浪财经网
也许你已经发现了规律,以Table结构展示的表格数据,大致的网页结构如下:
... ... ... ... ... ... ...
Table表格一般网页结构
只要网页具有以上结构,你就可以尝试用pandas抓取数据。
二.pandas请求表格数据原理
基本流程
针对网页结构类似的表格类型数据,pd.read_html可以将网页上的表格数据都抓取下来,并以DataFrame的形式装在一个list中返回。
三.pd.read_html语法及参数
pandas.read_html(io, match='.+', flavor=None, header=None,index_col=None,skiprows=None, attrs=None, parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
基本语法
io :接收网址、文件、字符串;parse_dates:解析日期;flavor:解析器;header:标题行;skiprows:跳过的行;attrs:属性,比如 attrs = {'id': 'table'}
主要参数
03实 战
一.案例1:抓取世界大学排名(1页数据)
1import pandas as pd 2import csv3url1 = 'http://www.compassedu.hk/qs'4df1 = pd.read_html(url1)[0] #0表示网页中的第一个Table5df1.to_csv('世界大学综合排名.csv',index=0)
没错,5行代码,几秒钟就搞定,我们来预览下爬取到的数据:
世界大学排行榜
二.案例2:抓取新浪财经基金重仓股数据(6页数据)
1import pandas as pd2import csv3df2 = pd.DataFrame()4for i in range(6):5 url2 = 'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={page}'.format(page=i+1)6 df2 = pd.concat([df2,pd.read_html(url2)[0]])7 print('第{page}页抓取完成'.format(page = i + 1))8df2.to_csv('./新浪财经数据.csv',encoding='utf-8',index=0)
没错,8行代码搞定,还是那么简单。如果对翻页爬虫不理解,可查看本公众号历史原创文章「实战|手把手教你用Python爬虫(附详细源码)」,如果对DataFrame合并不理解,可查看本公众号历史原创文章「基础|Pandas常用知识点汇总(四)」。
我们来预览下爬取到的数据:
基金重仓股数据
三.案例3:抓取证监会披露的IPO数据(217页数据)
1import pandas as pd 2from pandas import DataFrame 3import csv 4import time 5start = time.time() #计时 6df3 = DataFrame(data=None,columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料']) #添加列名 7for i in range(1,218): 8 url3 ='http://eid.csrc.gov.cn/ipo/infoDisplay.action?pageNo=%s&temp=&temp1=&blockType=byTime'%str(i) 9 df3_1 = pd.read_html(url3,encoding='utf-8')[2] #必须加utf-8,否则乱码10 df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1] #过滤掉最后一行和最后一列(NaN列)11 df3_2.columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料'] #新的df添加列名12 df3 = pd.concat([df3,df3_2]) #数据合并13 print('第{page}页抓取完成'.format(page=i))14df3.to_csv('./上市公司IPO信息.csv', encoding='utf-8',index=0) #保存数据到csv文件15end = time.time()16print ('共抓取',len(df3),'家公司,' + '用时',round((end-start)/60,2),'分钟')
这里注意要对抓下来的Table数据进行过滤,主要用到iloc方法,详情可查看本公众号往期原创文章「基础|Pandas常用知识点汇总(三)」。另外,我还加了个程序计时,方便查看爬取速度。
2分钟爬下217页4334条数据,相当nice了。我们来预览下爬取到的数据:
上市公司IPO数据
需要注意的是,并不是所有表格都可以用pd.read_html爬取,有的网站表面上看起来是表格,但在网页源代码中不是table格式,而是list列表格式。这种表格则不适用read_html爬取,得用其他的方法,比如selenium。
- 合作、交流、转载请添加微信 moonhmily1 -<p style="white-space: normal;font-size: 16px;"><br />
我用Python做了一个编程语言20年的动态排行榜!
网站优化 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2022-05-08 21:24
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
王师北定中原日,家祭无忘告乃翁。
在编程语言的舞台上,一直有着谁是最好的语言的竞争,小编虽然一直用着几种编程语言,但是感觉个人的想法不能代表着大家的想法。虽然关于最好语言的争论从未停止过,但是关于编程语言的热度排名,我们可以从TIOBE 编程语言排行榜上进行探索。
今天,小编就带领大家爬取一下,自2001年5月至今,TIOBE 编程语言排行榜上编程语言的变化情况,看一下在接近20年的时间里,编程语言的热度是如何变化的。
01.编程语言资料获取
首先我们是进行的是资料的获取,我们打开链接,就可以看到TIOBE编程语言的排行榜,通过查看其网页源代码,可以发现,我们想要爬取的资料,都显示在网页源代码里,如下图所示:
接下来就可以直接利用爬虫来获取网页源代码,并利用正则表达式来匹配我们需要的关键字内容,部分程序如下图所示:
上述程序中,我们对于抓取到的数据,进行正则表达式匹配,然后提取各个编程语言在不同时间段的热度数值,并保存到本地的文件中。
02.清洗数据
接下来,我们要完成的就是利用动态可视化的柱状图来观察各种编程语言随着时间的热度变化。我们先对数据进行清洗,获取编程语言的名字一起设置一个嵌套的字典,程序如下图所示:
上述程序中的嵌套字典含义为每一个月份下的每种编程语言的热度值,其结构格式如下所示:
{“2020-1-12”:{“Java”:16, “C++”:14, “python”:10,…}, “2020-2-13”:{“Java”:16.3, “C++”:15.6, …},…}。
03.设置柱状图的颜色
为了在可视化过程中区分每一种编程语言,需要为柱状图中的每一柱都设置不同的颜色,同时,将嵌套字典按照月份的顺序进行排序,程序如下所示:
04.大功告成,动态显示
最后,我们便可以对数据进行可视化的展示,程序如下图所示:
上述程序中,首先需要清除figure 中的活动轴,我们对于嵌套字典的每一个月份,将每一个月份中的编程语言,按照其热度值进行从小到大的排序,然后将排序号的编程语言,关联其对应的柱状图颜色。
05.动态现实图
接下来就可以画出我们的柱状图,然后暂停显示结果,并不断循环,从而达到动态柱状图的功能,其效果如下图所示:
06.更炫酷的动态图
如果大家觉得图做的不够优美,大家可以利用js进行数据渲染制作,这里小编也为大家利用Flourish制作了一个更加好看的界面,如下图所示:
从上面的可视化动图可以看出,Java和C语言一直是牢牢地掌控着编程语言热度前两名的宝座,而python语言,凭借着人工智能的热潮,逐渐的从排名末尾,一路追赶,排名在第三位,并逐渐拉开了与第四名的差距,可谓是编程语言界的逆袭王者。
而像是C++和PHP,其热度却逐渐的走低。虽然编程语言热度有高有低,但是不可否认的是,每一门编程语言,都有其应用的价值,能够在编程语言的历史长河中历经洗礼,而没有被淘汰,只要好好掌握一门语言,都会有用武之地。
-------------------End------------------- 查看全部
我用Python做了一个编程语言20年的动态排行榜!
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
王师北定中原日,家祭无忘告乃翁。
在编程语言的舞台上,一直有着谁是最好的语言的竞争,小编虽然一直用着几种编程语言,但是感觉个人的想法不能代表着大家的想法。虽然关于最好语言的争论从未停止过,但是关于编程语言的热度排名,我们可以从TIOBE 编程语言排行榜上进行探索。
今天,小编就带领大家爬取一下,自2001年5月至今,TIOBE 编程语言排行榜上编程语言的变化情况,看一下在接近20年的时间里,编程语言的热度是如何变化的。
01.编程语言资料获取
首先我们是进行的是资料的获取,我们打开链接,就可以看到TIOBE编程语言的排行榜,通过查看其网页源代码,可以发现,我们想要爬取的资料,都显示在网页源代码里,如下图所示:
接下来就可以直接利用爬虫来获取网页源代码,并利用正则表达式来匹配我们需要的关键字内容,部分程序如下图所示:
上述程序中,我们对于抓取到的数据,进行正则表达式匹配,然后提取各个编程语言在不同时间段的热度数值,并保存到本地的文件中。
02.清洗数据
接下来,我们要完成的就是利用动态可视化的柱状图来观察各种编程语言随着时间的热度变化。我们先对数据进行清洗,获取编程语言的名字一起设置一个嵌套的字典,程序如下图所示:
上述程序中的嵌套字典含义为每一个月份下的每种编程语言的热度值,其结构格式如下所示:
{“2020-1-12”:{“Java”:16, “C++”:14, “python”:10,…}, “2020-2-13”:{“Java”:16.3, “C++”:15.6, …},…}。
03.设置柱状图的颜色
为了在可视化过程中区分每一种编程语言,需要为柱状图中的每一柱都设置不同的颜色,同时,将嵌套字典按照月份的顺序进行排序,程序如下所示:
04.大功告成,动态显示
最后,我们便可以对数据进行可视化的展示,程序如下图所示:
上述程序中,首先需要清除figure 中的活动轴,我们对于嵌套字典的每一个月份,将每一个月份中的编程语言,按照其热度值进行从小到大的排序,然后将排序号的编程语言,关联其对应的柱状图颜色。
05.动态现实图
接下来就可以画出我们的柱状图,然后暂停显示结果,并不断循环,从而达到动态柱状图的功能,其效果如下图所示:
06.更炫酷的动态图
如果大家觉得图做的不够优美,大家可以利用js进行数据渲染制作,这里小编也为大家利用Flourish制作了一个更加好看的界面,如下图所示:
从上面的可视化动图可以看出,Java和C语言一直是牢牢地掌控着编程语言热度前两名的宝座,而python语言,凭借着人工智能的热潮,逐渐的从排名末尾,一路追赶,排名在第三位,并逐渐拉开了与第四名的差距,可谓是编程语言界的逆袭王者。
而像是C++和PHP,其热度却逐渐的走低。虽然编程语言热度有高有低,但是不可否认的是,每一门编程语言,都有其应用的价值,能够在编程语言的历史长河中历经洗礼,而没有被淘汰,只要好好掌握一门语言,都会有用武之地。
-------------------End-------------------
php用正则表达抓取网页中文章(Python爬虫怎么学?看看你的技术能拿多少薪资)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-19 14:32
如何学习 Python 爬虫?了解工作职责,看看你的技术能赚多少钱
大家好,我是麻辣烫。大家都知道拉条发的文章帖子都是和爬虫有关的,我自己也想往这个方向发展,所以提前了解一下爬虫工程师的就业市场,希望大家不要踩坑。跟大家聊聊爬虫工程师需要掌握哪些技术,以及市场各个区域的薪资水平和发展前景。目录 工作职责 就业前景 发展前景 招聘需求 区域排名(全国) 按教育年数划分的工资收入统计 工资趋势 招聘示例 工作职责 爬虫工程师做什么?工作内容是什么?需要具备哪些能力?
Python“爬虫”出发前装备的正则表达式之一
1.正则表达式正则表达式是一种模板表达式语言,通过定义规则来匹配、查找、替换和拆分长字符串中的特定子字符信息。如果您在 文章 中找到所有合法的电子邮件地址,您可以先用正则表达式定义一个电子邮件规则,然后使用该规则搜索整个字符串。爬虫程序一般使用正则表达式定义的规则对爬取的内容进行精细筛选。正则表达式有自己独立于其他计算机语言的语法结构,大多数计算机编程语言都提供了对正则表达式的支持。
正则表达式匹配
正则表达式在线生成工具:常用正则表达式正则表达式在线测试工具
211004
正则表达式定义字符串的模式。正则表达式可用于搜索、编辑或处理文本。字符串实际上是一个简单的正则表达式
爬行动物的基本原理
ttp比作一条高速公路,他有规则哪些语言可以实现爬虫#1.php:爬虫可以实现。PHP号称是世界上最美的语言(当然是它自己的名字,就是王婆卖瓜的意思),但是PHP在爬虫中并不擅长支持多线程和多进程。#2.java:可以实现爬虫。Java可以很好的处理和实现爬虫,是唯一能与python并驾齐驱的,也是python的头号敌人。但是爬虫代码的Java实现比较臃肿,重构成本高。#3.c,c++:是的
计算 VsCode 中的代码行数
直接使用正则查询显示查询的行数。正则表达式:^b*[^:b#/]+.*$
jmeter 断言
1.有的可以使用正则表达式,有的不能使用正则表达式2.前后区分大小写
正则表达式 [待完成]
Python 正则表达式指南 - AstralWind
Python爬虫之Scrapy进阶(全站爬取、分布式、增量爬虫)
scrapy全站爬取1.1全站爬取介绍1.2CrawlSpider1.2.1基本解释1.2.2使用CrawlSpider1.@ >2.2.1爬虫文件1.2.2.2items.py文件2分布式爬虫2.1分布式爬虫概念2.2环境安装< @2.3使用方法2.3.1爬虫配置2.3.2redis相关配置2.3.3启动项目3增量爬虫3.1概念解释3.2使用3.2.1爬虫文件3.2.2管道文件1scra
Python中正则表达式的使用
在进行正则表达式匹配时,直接使用正则表达式引擎,在python中通过字符串输入正则表达式引擎,需要输入不同的字符串。主要区别在于转义字符的使用,共有三种。情况:转义字符需要被python解析,所以输入部分python中的特殊字符需要被正则表达式引擎解析,从而输入正则表达式语句部分的特殊字符。转义字符需要通过正则表达式匹配。下面总结了python处理这个问题的三种方式:1、鉴于python的第一个解决方案 查看全部
php用正则表达抓取网页中文章(Python爬虫怎么学?看看你的技术能拿多少薪资)
如何学习 Python 爬虫?了解工作职责,看看你的技术能赚多少钱
大家好,我是麻辣烫。大家都知道拉条发的文章帖子都是和爬虫有关的,我自己也想往这个方向发展,所以提前了解一下爬虫工程师的就业市场,希望大家不要踩坑。跟大家聊聊爬虫工程师需要掌握哪些技术,以及市场各个区域的薪资水平和发展前景。目录 工作职责 就业前景 发展前景 招聘需求 区域排名(全国) 按教育年数划分的工资收入统计 工资趋势 招聘示例 工作职责 爬虫工程师做什么?工作内容是什么?需要具备哪些能力?
Python“爬虫”出发前装备的正则表达式之一
1.正则表达式正则表达式是一种模板表达式语言,通过定义规则来匹配、查找、替换和拆分长字符串中的特定子字符信息。如果您在 文章 中找到所有合法的电子邮件地址,您可以先用正则表达式定义一个电子邮件规则,然后使用该规则搜索整个字符串。爬虫程序一般使用正则表达式定义的规则对爬取的内容进行精细筛选。正则表达式有自己独立于其他计算机语言的语法结构,大多数计算机编程语言都提供了对正则表达式的支持。
正则表达式匹配
正则表达式在线生成工具:常用正则表达式正则表达式在线测试工具
211004
正则表达式定义字符串的模式。正则表达式可用于搜索、编辑或处理文本。字符串实际上是一个简单的正则表达式
爬行动物的基本原理
ttp比作一条高速公路,他有规则哪些语言可以实现爬虫#1.php:爬虫可以实现。PHP号称是世界上最美的语言(当然是它自己的名字,就是王婆卖瓜的意思),但是PHP在爬虫中并不擅长支持多线程和多进程。#2.java:可以实现爬虫。Java可以很好的处理和实现爬虫,是唯一能与python并驾齐驱的,也是python的头号敌人。但是爬虫代码的Java实现比较臃肿,重构成本高。#3.c,c++:是的
计算 VsCode 中的代码行数
直接使用正则查询显示查询的行数。正则表达式:^b*[^:b#/]+.*$
jmeter 断言
1.有的可以使用正则表达式,有的不能使用正则表达式2.前后区分大小写
正则表达式 [待完成]
Python 正则表达式指南 - AstralWind
Python爬虫之Scrapy进阶(全站爬取、分布式、增量爬虫)
scrapy全站爬取1.1全站爬取介绍1.2CrawlSpider1.2.1基本解释1.2.2使用CrawlSpider1.@ >2.2.1爬虫文件1.2.2.2items.py文件2分布式爬虫2.1分布式爬虫概念2.2环境安装< @2.3使用方法2.3.1爬虫配置2.3.2redis相关配置2.3.3启动项目3增量爬虫3.1概念解释3.2使用3.2.1爬虫文件3.2.2管道文件1scra
Python中正则表达式的使用
在进行正则表达式匹配时,直接使用正则表达式引擎,在python中通过字符串输入正则表达式引擎,需要输入不同的字符串。主要区别在于转义字符的使用,共有三种。情况:转义字符需要被python解析,所以输入部分python中的特殊字符需要被正则表达式引擎解析,从而输入正则表达式语句部分的特殊字符。转义字符需要通过正则表达式匹配。下面总结了python处理这个问题的三种方式:1、鉴于python的第一个解决方案
php用正则表达抓取网页中文章(用默认的nopic.jpg替换再看一个函数相对比较复杂了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-19 01:31
概括
php 获取文章 内容的第一个图像实例。要使用php获取文章中所有图片的第一张图片,我们只需要一个简单的正则表达式即可实现。下面给大家分享两个例子。先看一个
要使用php获取文章中所有图片的第一张图片,我们只需要一个简单的正则表达式即可实现。下面给大家分享两个例子。
先看一个函数:
代码显示如下
复制代码
函数getpic($str_img){
preg_match_all("/ /isU",$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
返回 $img_path;
}
//如果数据库是打开的,使用$nr获取数据库中的新闻内容
$nr=$row_news["nr"];
$aa=getpic($nr_a);
if(!$aa){$aa="images/nopic.jpg";} //如果新闻中没有图片,则替换为默认的nopic.jpg
我们来看一个比较复杂的函数。
在做项目的时候,有时候页面的设计会留下文章特色图片的位置,但是有时候,这个文章没有上传图片,显示的时候没有图片在页面上。画风很丑。如果默认图片根本不上传,有时会引起一些误解;那么先考虑是否细化这个文章图片的问题:首先判断是否有上传图片,如果有,显示上传图片,如果没有,判断内容中是否有图片,选择这里第一张图片作为特色图片,如果内容中没有图片,则在此处显示默认图片;
下面是在 文章 中选择第一张图片的代码:
代码显示如下
复制代码
$obj=M("新闻");
$info=$obj->where('id=1')->find();
//方法1*********
$soContent = $info['content'];
$soImages = '~
]* />~';
preg_match_all($soImages, $soContent, $thePics);
$allPics = count($thePics[0]);
preg_match('/ /i',$thePics[0][0],$match);
转储($thePics);
如果( $allPics > 0 ){
回声“
";//获取图片名称
}
别的 {
echo "没有图片";
}
//****************
$soContent = $info['content'];
$soImages = '~
]* />~';
preg_match_all($soImages, $soContent, $thePics);
$allPics = count($thePics[0]);
转储($thePics);
如果( $allPics > 0 ){
回声 $thePics[0][0]; //获取整个Img属性
} 别的 {
echo "没有图片";
}
//****************
$soImages = '~]* />~';
$str=$info['内容'];
preg_match_all($soImages,$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
如果(!$img_path){
$img_path="images/nopic.jpg";
} //如果新闻中不存在图片,则替换为默认的nopic.jpg*/
回声 $img_path;
//****************88
$str=$info['内容'];
preg_match_all("/ /isU",$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
如果(!$img_path){
$img_path="images/nopic.jpg";
} //如果新闻中不存在图片,则替换为默认的nopic.jpg*/
回声 $img_path; 查看全部
php用正则表达抓取网页中文章(用默认的nopic.jpg替换再看一个函数相对比较复杂了)
概括
php 获取文章 内容的第一个图像实例。要使用php获取文章中所有图片的第一张图片,我们只需要一个简单的正则表达式即可实现。下面给大家分享两个例子。先看一个
要使用php获取文章中所有图片的第一张图片,我们只需要一个简单的正则表达式即可实现。下面给大家分享两个例子。
先看一个函数:
代码显示如下
复制代码
函数getpic($str_img){
preg_match_all("/ /isU",$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
返回 $img_path;
}
//如果数据库是打开的,使用$nr获取数据库中的新闻内容
$nr=$row_news["nr"];
$aa=getpic($nr_a);
if(!$aa){$aa="images/nopic.jpg";} //如果新闻中没有图片,则替换为默认的nopic.jpg
我们来看一个比较复杂的函数。
在做项目的时候,有时候页面的设计会留下文章特色图片的位置,但是有时候,这个文章没有上传图片,显示的时候没有图片在页面上。画风很丑。如果默认图片根本不上传,有时会引起一些误解;那么先考虑是否细化这个文章图片的问题:首先判断是否有上传图片,如果有,显示上传图片,如果没有,判断内容中是否有图片,选择这里第一张图片作为特色图片,如果内容中没有图片,则在此处显示默认图片;
下面是在 文章 中选择第一张图片的代码:
代码显示如下
复制代码
$obj=M("新闻");
$info=$obj->where('id=1')->find();
//方法1*********
$soContent = $info['content'];
$soImages = '~
]* />~';
preg_match_all($soImages, $soContent, $thePics);
$allPics = count($thePics[0]);
preg_match('/ /i',$thePics[0][0],$match);
转储($thePics);
如果( $allPics > 0 ){
回声“
";//获取图片名称
}
别的 {
echo "没有图片";
}
//****************
$soContent = $info['content'];
$soImages = '~
]* />~';
preg_match_all($soImages, $soContent, $thePics);
$allPics = count($thePics[0]);
转储($thePics);
如果( $allPics > 0 ){
回声 $thePics[0][0]; //获取整个Img属性
} 别的 {
echo "没有图片";
}
//****************
$soImages = '~]* />~';
$str=$info['内容'];
preg_match_all($soImages,$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
如果(!$img_path){
$img_path="images/nopic.jpg";
} //如果新闻中不存在图片,则替换为默认的nopic.jpg*/
回声 $img_path;
//****************88
$str=$info['内容'];
preg_match_all("/ /isU",$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
如果(!$img_path){
$img_path="images/nopic.jpg";
} //如果新闻中不存在图片,则替换为默认的nopic.jpg*/
回声 $img_path;
php用正则表达抓取网页中文章(dreamweaver中的正则表达式使用方法使用步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-16 19:16
Dreamweaver 是第一套专为专业网页设计师开发的可视化网页开发工具。它也是最新版本。它可以轻松创建跨平台限制和浏览器限制的动态网页。在dreamweaver 页面中存在需求。如何替换要替换的内容?我们可以使用正则表达式来替换。在 Dreamweaver 中使用正则表达式替换字符串的朋友很少。如何使用正则表达式?一起来看看详细教程吧。.
使用正则表达式的步骤:
1、我们在dreamweaver中编码的时候,一般的查找替换不能满足我们大范围的替换来替换一些内容相同的不同链接:比如“#”,你有没有想过用dreamweaver regex
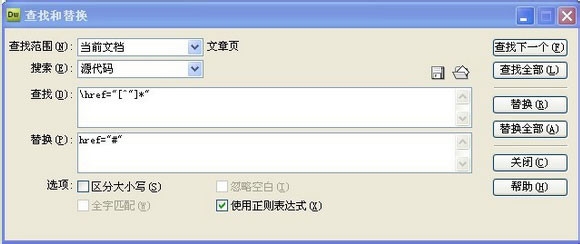
2、先在桌面打开dreamweaver,在dreamweaver中打开你担心的页面
3、如果后面href里面的内容复杂多样,href="/html/u.html", href="/tuho/huko.html",我想全部替换成href="# ",同时按住ctrl+f键调用查找替换框
4、在搜索中输入:href="[^"]*"在替换中输入:href="#"并选择“使用正则表达式”,回车
5、(#是替换后的内容,可以根据需要更改!一定要勾选:使用正则表达式(X),以上只是对href内容的一般替换,因为很多标签都有href属性,例如 a、link 等。
以上就是小编和大家分享的关于dreamweaver中正则表达式的使用。有兴趣的用户可以按照以上步骤进行试用。我希望上面的教程可以帮助你。 查看全部
php用正则表达抓取网页中文章(dreamweaver中的正则表达式使用方法使用步骤)
Dreamweaver 是第一套专为专业网页设计师开发的可视化网页开发工具。它也是最新版本。它可以轻松创建跨平台限制和浏览器限制的动态网页。在dreamweaver 页面中存在需求。如何替换要替换的内容?我们可以使用正则表达式来替换。在 Dreamweaver 中使用正则表达式替换字符串的朋友很少。如何使用正则表达式?一起来看看详细教程吧。.
使用正则表达式的步骤:
1、我们在dreamweaver中编码的时候,一般的查找替换不能满足我们大范围的替换来替换一些内容相同的不同链接:比如“#”,你有没有想过用dreamweaver regex
2、先在桌面打开dreamweaver,在dreamweaver中打开你担心的页面
3、如果后面href里面的内容复杂多样,href="/html/u.html", href="/tuho/huko.html",我想全部替换成href="# ",同时按住ctrl+f键调用查找替换框
4、在搜索中输入:href="[^"]*"在替换中输入:href="#"并选择“使用正则表达式”,回车
5、(#是替换后的内容,可以根据需要更改!一定要勾选:使用正则表达式(X),以上只是对href内容的一般替换,因为很多标签都有href属性,例如 a、link 等。
以上就是小编和大家分享的关于dreamweaver中正则表达式的使用。有兴趣的用户可以按照以上步骤进行试用。我希望上面的教程可以帮助你。
php用正则表达抓取网页中文章(大佬教程收集整理的这篇文章主要介绍了,欢迎将大佬推荐给程序员好友)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-16 19:13
大哥教程采集的这篇文章主要介绍php-正则表达式获取数字和数字后面的字符串。大哥教程大哥觉得还不错。现在我将与您分享并为您制作。参考。
我需要从两个不同的字符串中提取数字后的数字和单位。有些字符串在数字和单位之间有空格,例如 150g,而其他字符串不是 150g
$text = 'Rexona Ap Deo Aerosol 150ml Active CPD-05923';
$text='Cutex Nail Polish Remover Moisture 100ml ';
preg_match_all('!\d+!', $text, $matches);
if(sizeof($matches[0]) > 1){
// how can I extract 'ml'
}
else {
// how can I extract 150 ml ?
}
你能帮我吗?
解决方案:
你可以使用它:
preg_match_all('~\b(\d+(?:\.\d{1,2})?)\s*(ml|gm?|kg|cm)\b~i', $text, $matches);
并使用匹配组 #1 和 #2.
正则表达式演示
大佬总结
以上就是php-正则表达式获取数字后的数字和字符串的全部内容,希望文章可以帮助大家解决php-正则表达式获取数字后的数字和字符串。程序开发遇到的问题。
如果你觉得大哥教程网站的内容还不错,欢迎你把大哥教程推荐给你的程序员朋友。 查看全部
php用正则表达抓取网页中文章(大佬教程收集整理的这篇文章主要介绍了,欢迎将大佬推荐给程序员好友)
大哥教程采集的这篇文章主要介绍php-正则表达式获取数字和数字后面的字符串。大哥教程大哥觉得还不错。现在我将与您分享并为您制作。参考。
我需要从两个不同的字符串中提取数字后的数字和单位。有些字符串在数字和单位之间有空格,例如 150g,而其他字符串不是 150g
$text = 'Rexona Ap Deo Aerosol 150ml Active CPD-05923';
$text='Cutex Nail Polish Remover Moisture 100ml ';
preg_match_all('!\d+!', $text, $matches);
if(sizeof($matches[0]) > 1){
// how can I extract 'ml'
}
else {
// how can I extract 150 ml ?
}
你能帮我吗?
解决方案:
你可以使用它:
preg_match_all('~\b(\d+(?:\.\d{1,2})?)\s*(ml|gm?|kg|cm)\b~i', $text, $matches);
并使用匹配组 #1 和 #2.
正则表达式演示
大佬总结
以上就是php-正则表达式获取数字后的数字和字符串的全部内容,希望文章可以帮助大家解决php-正则表达式获取数字后的数字和字符串。程序开发遇到的问题。
如果你觉得大哥教程网站的内容还不错,欢迎你把大哥教程推荐给你的程序员朋友。
php用正则表达抓取网页中文章(学习正则表达式之前中的几个容易混洗的术语(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-16 19:11
正则表达式是描述字符串结构的语法规则。它是一种特定的格式化模式,可以匹配、替换和截取匹配的字符串。对于之前可能接触过DOS的用户,如果要匹配当前文件夹中的所有文本文件,可以输入“dir *.txt”命令,按回车键后,所有“.txt”文件将被列出。这里的“*.txt”可以理解为一个简单的正则表达式。
在学习正则表达式之前,我们先来了解几个正则表达式中容易打乱的术语,这对学习正则表达式很有帮助。
grep:最初是ED编辑器中的一个命令,用来显示文件中的特定内容,后来变成了一个独立的工具grep。
egrep:虽然grep在不断更新升级,但还是跟不上技术的步伐。为此,塔灯网推出了egrep。意思是“扩展的grep”,大大增强了正则表达式的威力。
POSIX(Portable Operating System Interface of Vnix,Portable Operating System Interface):在grep开发的同时,其他一些开发者也根据自己的喜好开发了风格独特的版本。但随之而来的问题是,一些程序支持某个元字符,而另一些则不支持。因此,POSIX 是一组确保操作系统之间可移植性的标准。但是 POSIX 和 SQL 一样,并没有成为最终的标准,只能作为参考。
Perl(实用提取和报告语言):1987 年,Larry Wall 发布了 Perl。在接下来的 7 年里,Perl 经历了从 Perl 1 到现在的 Perl 5 的发展,最终 Perl 成为继 POSIX 之后的又一标准。
PCER:Perl的成功让其他开发者在一定程度上兼容了Perl,包括C/C++、Java、Python等,都有自己的正则表达式。1997 年,Philip Hazel 开发了 PCRE 库,这是一组与 Perl 正则表达式兼容的正则表达式。其他开发者可以将PCRE集成到自己的语言中,为用户提供丰富的常规功能。很多语言都使用PCRE,PHP官方就是其中之一。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接: 查看全部
php用正则表达抓取网页中文章(学习正则表达式之前中的几个容易混洗的术语(一))
正则表达式是描述字符串结构的语法规则。它是一种特定的格式化模式,可以匹配、替换和截取匹配的字符串。对于之前可能接触过DOS的用户,如果要匹配当前文件夹中的所有文本文件,可以输入“dir *.txt”命令,按回车键后,所有“.txt”文件将被列出。这里的“*.txt”可以理解为一个简单的正则表达式。

在学习正则表达式之前,我们先来了解几个正则表达式中容易打乱的术语,这对学习正则表达式很有帮助。
grep:最初是ED编辑器中的一个命令,用来显示文件中的特定内容,后来变成了一个独立的工具grep。
egrep:虽然grep在不断更新升级,但还是跟不上技术的步伐。为此,塔灯网推出了egrep。意思是“扩展的grep”,大大增强了正则表达式的威力。
POSIX(Portable Operating System Interface of Vnix,Portable Operating System Interface):在grep开发的同时,其他一些开发者也根据自己的喜好开发了风格独特的版本。但随之而来的问题是,一些程序支持某个元字符,而另一些则不支持。因此,POSIX 是一组确保操作系统之间可移植性的标准。但是 POSIX 和 SQL 一样,并没有成为最终的标准,只能作为参考。
Perl(实用提取和报告语言):1987 年,Larry Wall 发布了 Perl。在接下来的 7 年里,Perl 经历了从 Perl 1 到现在的 Perl 5 的发展,最终 Perl 成为继 POSIX 之后的又一标准。
PCER:Perl的成功让其他开发者在一定程度上兼容了Perl,包括C/C++、Java、Python等,都有自己的正则表达式。1997 年,Philip Hazel 开发了 PCRE 库,这是一组与 Perl 正则表达式兼容的正则表达式。其他开发者可以将PCRE集成到自己的语言中,为用户提供丰富的常规功能。很多语言都使用PCRE,PHP官方就是其中之一。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接:
php用正则表达抓取网页中文章(正则表达式就是用于描述这些规则的工具(,),,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-15 17:08
我们经常遇到要获取字符串指定部分的内容。让我们使用正则匹配来获取下一页的 url。代码如下:
$str='ht///>第一页上一页下一页';preg_match_all('/]*href=([^>]*)>下一页/是',$str,$matches); print_r($matches[1]);//方法二,代码如下: preg_match('/next page/u', $s, $arr);
究竟什么是正则表达式?
在编写处理字符串的程序或网页时,经常需要找到符合一些复杂规则的字符串。正则表达式就是用来描述这些规则的工具,换句话说,正则表达式就是记录文本规则的代码。
很有可能你用过windows/dos下用于文件搜索的通配符,即*和?,如果要查找一个目录下的所有word文档,就会搜索*.doc,这里,*会被解释作为任意字符串。与通配符类似,正则表达式也是文本匹配的工具,只是它们可以比通配符更准确地描述你的需求——当然,代价是更复杂——例如你可以编写一个正则表达式来查找所有以0,后跟 2-3 个数字,然后是连字符“-”,最后是 7 位或 8 位数字的字符串(如 or 0376-7654321).
来源: 查看全部
php用正则表达抓取网页中文章(正则表达式就是用于描述这些规则的工具(,),,)
我们经常遇到要获取字符串指定部分的内容。让我们使用正则匹配来获取下一页的 url。代码如下:
$str='ht///>第一页上一页下一页';preg_match_all('/]*href=([^>]*)>下一页/是',$str,$matches); print_r($matches[1]);//方法二,代码如下: preg_match('/next page/u', $s, $arr);
究竟什么是正则表达式?
在编写处理字符串的程序或网页时,经常需要找到符合一些复杂规则的字符串。正则表达式就是用来描述这些规则的工具,换句话说,正则表达式就是记录文本规则的代码。
很有可能你用过windows/dos下用于文件搜索的通配符,即*和?,如果要查找一个目录下的所有word文档,就会搜索*.doc,这里,*会被解释作为任意字符串。与通配符类似,正则表达式也是文本匹配的工具,只是它们可以比通配符更准确地描述你的需求——当然,代价是更复杂——例如你可以编写一个正则表达式来查找所有以0,后跟 2-3 个数字,然后是连字符“-”,最后是 7 位或 8 位数字的字符串(如 or 0376-7654321).
来源:
php用正则表达抓取网页中文章(PHP中从中有效的JSON )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-15 06:31
)
我得到了一个字符串转储,其中收录最初在网上抓取的 Js 对象文字,我需要在 PHP 中从中获取一些数据。这些不是有效的 JSON,所以我不能使用 json_decode。它们具有以下格式,其中 DETAILS 是我需要捕获的内容。
...data: [DETAILS]...
在某些来源中,数据元素出现不止一次,我需要捕获每个匹配项。DETAILS 可以收录任何字符,包括 [ { } ]、引号和逗号,但我需要将它们全部捕获。
我正在尝试使用正则表达式。这是我在一些教程之后尝试过的,但这绝对是错误的。
preg_match_all('~(?:\G(?!^),|(data: )\{)\s+([^:]+): (\d+|"[^"]*")~', $html, $out, PREG_SET_ORDER) ? $out : []
请我真的需要一些帮助。
编辑:这只是显示详细信息的数据字段的示例。它并不总是采用这种形式。
series:[{name:'Records',data:[[Date.parse('2013-11-01'),1],[Date.parse('2013-12-01'),2],[Date.parse('2014-01-01'),1],[Date.parse('2014-02-01'),4],[Date.parse('2014-03-01'),23],[Date.parse('2014-04-01'),22],[Date.parse('2014-05-01'),19],[Date.parse('2014-06-01'),26],[Date.parse('2014-07-01'),43],[Date.parse('2014-08-01'),29],[Date.parse('2014-09-01'),47],[Date.parse('2014-10-01'),31],[Date.parse('2014-11-01'),32],[Date.parse('2014-12-01'),17],[Date.parse('2015-01-01'),28],[Date.parse('2015-02-01'),2],[Date.parse('2015-03-01'),18],[Date.parse('2015-04-01'),16],[Date.parse('2015-05-01'),10],[Date.parse('2015-06-01'),25],[Date.parse('2015-07-01'),20],[Date.parse('2015-08-01'),21],[Date.parse('2015-09-01'),6],[Date.parse('2015-10-01'),10],[Date.parse('2015-11-01'),-11],[Date.parse('2015-12-01'),12],[Date.parse('2016-01-01'),46],[Date.parse('2016-02-01'),32],[Date.parse('2016-03-01'),16],[Date.parse('2016-04-01'),28],[Date.parse('2016-05-01'),34],[Date.parse('2016-06-01'),24],[Date.parse('2016-07-01'),40],[Date.parse('2016-08-01'),24],[Date.parse('2016-09-01'),57],[Date.parse('2016-10-01'),42],[Date.parse('2016-11-01'),51],[Date.parse('2016-12-01'),53],[Date.parse('2017-01-01'),63],[Date.parse('2017-02-01'),23],[Date.parse('2017-03-01'),80],[Date.parse('2017-04-01'),56],[Date.parse('2017-05-01'),61],[Date.parse('2017-06-01'),74],[Date.parse('2017-07-01'),107],[Date.parse('2017-08-01'),74],[Date.parse('2017-09-01'),120],[Date.parse('2017-10-01'),79],[Date.parse('2017-11-01'),163],[Date.parse('2017-12-01'),130],[Date.parse('2018-01-01'),126] 查看全部
php用正则表达抓取网页中文章(PHP中从中有效的JSON
)
我得到了一个字符串转储,其中收录最初在网上抓取的 Js 对象文字,我需要在 PHP 中从中获取一些数据。这些不是有效的 JSON,所以我不能使用 json_decode。它们具有以下格式,其中 DETAILS 是我需要捕获的内容。
...data: [DETAILS]...
在某些来源中,数据元素出现不止一次,我需要捕获每个匹配项。DETAILS 可以收录任何字符,包括 [ { } ]、引号和逗号,但我需要将它们全部捕获。
我正在尝试使用正则表达式。这是我在一些教程之后尝试过的,但这绝对是错误的。
preg_match_all('~(?:\G(?!^),|(data: )\{)\s+([^:]+): (\d+|"[^"]*")~', $html, $out, PREG_SET_ORDER) ? $out : []
请我真的需要一些帮助。
编辑:这只是显示详细信息的数据字段的示例。它并不总是采用这种形式。
series:[{name:'Records',data:[[Date.parse('2013-11-01'),1],[Date.parse('2013-12-01'),2],[Date.parse('2014-01-01'),1],[Date.parse('2014-02-01'),4],[Date.parse('2014-03-01'),23],[Date.parse('2014-04-01'),22],[Date.parse('2014-05-01'),19],[Date.parse('2014-06-01'),26],[Date.parse('2014-07-01'),43],[Date.parse('2014-08-01'),29],[Date.parse('2014-09-01'),47],[Date.parse('2014-10-01'),31],[Date.parse('2014-11-01'),32],[Date.parse('2014-12-01'),17],[Date.parse('2015-01-01'),28],[Date.parse('2015-02-01'),2],[Date.parse('2015-03-01'),18],[Date.parse('2015-04-01'),16],[Date.parse('2015-05-01'),10],[Date.parse('2015-06-01'),25],[Date.parse('2015-07-01'),20],[Date.parse('2015-08-01'),21],[Date.parse('2015-09-01'),6],[Date.parse('2015-10-01'),10],[Date.parse('2015-11-01'),-11],[Date.parse('2015-12-01'),12],[Date.parse('2016-01-01'),46],[Date.parse('2016-02-01'),32],[Date.parse('2016-03-01'),16],[Date.parse('2016-04-01'),28],[Date.parse('2016-05-01'),34],[Date.parse('2016-06-01'),24],[Date.parse('2016-07-01'),40],[Date.parse('2016-08-01'),24],[Date.parse('2016-09-01'),57],[Date.parse('2016-10-01'),42],[Date.parse('2016-11-01'),51],[Date.parse('2016-12-01'),53],[Date.parse('2017-01-01'),63],[Date.parse('2017-02-01'),23],[Date.parse('2017-03-01'),80],[Date.parse('2017-04-01'),56],[Date.parse('2017-05-01'),61],[Date.parse('2017-06-01'),74],[Date.parse('2017-07-01'),107],[Date.parse('2017-08-01'),74],[Date.parse('2017-09-01'),120],[Date.parse('2017-10-01'),79],[Date.parse('2017-11-01'),163],[Date.parse('2017-12-01'),130],[Date.parse('2018-01-01'),126]
php用正则表达抓取网页中文章( 管理ModSecurity日志的开源项目-FLEWAF-WAF)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-04-13 22:34
管理ModSecurity日志的开源项目-FLEWAF-WAF)
之前介绍过ModSecurity,一个优秀的开源WAF。它是一个入侵检测和防御引擎。它最初是 Apache 的一个模块。现在它可以被编译并作为一个单独的模块添加到 Nginx 服务中。
这个WAF虽然很不错,但是用起来没那么好用。之前我也组织过文章介绍它的原理和规则。但是,还有一个问题,就是它的日志分析。之前介绍过原理和规则的时候,也介绍过它的日志规则,但是在使用过程中,纯文本记录的方式对于入侵分析来说太不友好了
所以今天给大家介绍一个管理ModSecurity日志的开源项目WAF-FLE
WAF-FLE 是专门用于处理 ModSecurity 日志和事件的控制台。管理员可以通过WAF-FLE查看和搜索ModSecurity记录的日志。
WAF-FLE是一个用PHP编写的开源项目,需要LNMP/LAMP环境搭建
环境要求:
php-geoipMySQL5.1+
安装环境就不赘述了,只说一个GeoIP库的安装。这里GeoIP库是用来展示入侵IP信息的,所以需要这个库。安装非常简单。其实就是下载一个dat数据库,从
下载后解压dat文件。
环境准备好后,从github下载WAF-FLE:
在 waf-fle 的 extra 目录中,存放了数据库 sql 文件和 Apache 配置文件。如果你使用的是 Apache,可以直接把这个配置复制到 apache 配置目录下。如果使用Nginx,参考如下配置
修改config.php的时候,因为我没有安装apc的缓存扩展,这个扩展很老了,所以直接设置APC_ON=false关闭缓存
完成以上操作后,即可通过域名访问进入安装界面。
这里检查php扩展的时候,如果你不是Apache,就会有问题,就是在setup.php的499行,它使用apache_getenv来检查Apache是否在运行。,所以打开 setup.php 文件的第 499 行并注释掉这部分代码。
然后点击运行创建数据库
这里创建数据库的时候还有一个问题。在setup.php代码第28行,执行创建函数的时候,引用了一个$databaseSchema,在这里修改定义了一个位置,但是我放的是我的位置,所以这里需要。根据自己的情况修改
修改完成后,通过页面继续进行数据库创建操作。创建完成如下:
安装完成后,默认用户名和密码为admin/admin。之后,在 config.php 中配置 $SETUP=false。关闭安装后,重新访问
使用默认用户密码登录后,需要修改用户名和密码。
设置新密码后,您将被重定向到主界面。
目前没有数据,现在开始访问日志数据,点击菜单栏中的管理,添加传感器
保存后,创建一个传感器来接收日志
创建后,在这个传感器上,开始配置事件接收器
这里我们选择使用mlog2waffle接收日志,然后选择service deamon查询日志。这是一个实时查询。WAF-FLE控制器URL是配置waf-fle的控制器地址,mlog2waffle通过put请求向这个接口发送数据。地址,下面是配置ModSecurity日志的配置路径,配置完成后点击下一步
系统会给出提示配置,需要根据给定的配置配置这些配置文件,这里可以按照提示配置操作,需要的mlog2waffle配置文件和启动脚本在extra目录下
配置完成后,启动mlog2waffle
mlog2waffle 通过 put 方法向 waf-fle 发送日志,但是默认情况下 Nginx 不允许 put 请求,所以启动会报错。需要通过 nginx 中的 dav 方法允许 put 请求
在启动mlog2waffle的过程中,遇到了很多问题,记录如下:
这里,通过PUT方法发送检测请求。这里的trick是PUT请求发送时没有URI,但是当Nginx检测到PUT请求没有URI时,会报409,认为有资源冲突
所以,无论你做什么,这里的测试都不会通过。有两种方法可以处理它。一种是直接关闭测试,mlog2waffle可以正常启动。另一种方法是修改测试方法,带上uri。mlog2waffle 是 perl 脚本,非常简单
这里需要手动替换,通过$_SERVER获取客户端IP,需要手动编写getallheaders()方法,如下:
另外,在index.php中,第65行的位置原来是通过apache_setenv()得到的sensor的名字,复制到Apache的“REMOTE_USER”中。此处未使用 Apache,因此只需将其注释掉即可。
修改完这些,就可以通过脚本启动mlog2waffle了
启动后,通过waf的访问日志,可以看到mlog2waffle已经开始通过put方法将日志解析成event并传递给waf-fle
在mlog2waffle的readIndex方法中,由于需要读取和解析日志索引文件,所以有一个正则匹配,如图:
这里需要修改和匹配自己记录的日志格式。完全匹配后可以正确读取日志,解析后将解析后的内容通过send_event方法通过PUT方法传递给waf-fle进行显示。
waf-fle接收到的文件是一个index.php,它通过正则解析所有步骤。有兴趣的可以看源码。至此,waf-fle就部署好了,可以看到效果了。
waf-fle虽然是老牌开源项目,但是对于modsecurity日志分析来说已经足够了 查看全部
php用正则表达抓取网页中文章(
管理ModSecurity日志的开源项目-FLEWAF-WAF)
之前介绍过ModSecurity,一个优秀的开源WAF。它是一个入侵检测和防御引擎。它最初是 Apache 的一个模块。现在它可以被编译并作为一个单独的模块添加到 Nginx 服务中。
这个WAF虽然很不错,但是用起来没那么好用。之前我也组织过文章介绍它的原理和规则。但是,还有一个问题,就是它的日志分析。之前介绍过原理和规则的时候,也介绍过它的日志规则,但是在使用过程中,纯文本记录的方式对于入侵分析来说太不友好了
所以今天给大家介绍一个管理ModSecurity日志的开源项目WAF-FLE
WAF-FLE 是专门用于处理 ModSecurity 日志和事件的控制台。管理员可以通过WAF-FLE查看和搜索ModSecurity记录的日志。
WAF-FLE是一个用PHP编写的开源项目,需要LNMP/LAMP环境搭建
环境要求:
php-geoipMySQL5.1+
安装环境就不赘述了,只说一个GeoIP库的安装。这里GeoIP库是用来展示入侵IP信息的,所以需要这个库。安装非常简单。其实就是下载一个dat数据库,从
下载后解压dat文件。
环境准备好后,从github下载WAF-FLE:
在 waf-fle 的 extra 目录中,存放了数据库 sql 文件和 Apache 配置文件。如果你使用的是 Apache,可以直接把这个配置复制到 apache 配置目录下。如果使用Nginx,参考如下配置
修改config.php的时候,因为我没有安装apc的缓存扩展,这个扩展很老了,所以直接设置APC_ON=false关闭缓存
完成以上操作后,即可通过域名访问进入安装界面。
这里检查php扩展的时候,如果你不是Apache,就会有问题,就是在setup.php的499行,它使用apache_getenv来检查Apache是否在运行。,所以打开 setup.php 文件的第 499 行并注释掉这部分代码。
然后点击运行创建数据库
这里创建数据库的时候还有一个问题。在setup.php代码第28行,执行创建函数的时候,引用了一个$databaseSchema,在这里修改定义了一个位置,但是我放的是我的位置,所以这里需要。根据自己的情况修改
修改完成后,通过页面继续进行数据库创建操作。创建完成如下:
安装完成后,默认用户名和密码为admin/admin。之后,在 config.php 中配置 $SETUP=false。关闭安装后,重新访问
使用默认用户密码登录后,需要修改用户名和密码。
设置新密码后,您将被重定向到主界面。
目前没有数据,现在开始访问日志数据,点击菜单栏中的管理,添加传感器
保存后,创建一个传感器来接收日志
创建后,在这个传感器上,开始配置事件接收器
这里我们选择使用mlog2waffle接收日志,然后选择service deamon查询日志。这是一个实时查询。WAF-FLE控制器URL是配置waf-fle的控制器地址,mlog2waffle通过put请求向这个接口发送数据。地址,下面是配置ModSecurity日志的配置路径,配置完成后点击下一步
系统会给出提示配置,需要根据给定的配置配置这些配置文件,这里可以按照提示配置操作,需要的mlog2waffle配置文件和启动脚本在extra目录下
配置完成后,启动mlog2waffle
mlog2waffle 通过 put 方法向 waf-fle 发送日志,但是默认情况下 Nginx 不允许 put 请求,所以启动会报错。需要通过 nginx 中的 dav 方法允许 put 请求
在启动mlog2waffle的过程中,遇到了很多问题,记录如下:
这里,通过PUT方法发送检测请求。这里的trick是PUT请求发送时没有URI,但是当Nginx检测到PUT请求没有URI时,会报409,认为有资源冲突
所以,无论你做什么,这里的测试都不会通过。有两种方法可以处理它。一种是直接关闭测试,mlog2waffle可以正常启动。另一种方法是修改测试方法,带上uri。mlog2waffle 是 perl 脚本,非常简单
这里需要手动替换,通过$_SERVER获取客户端IP,需要手动编写getallheaders()方法,如下:
另外,在index.php中,第65行的位置原来是通过apache_setenv()得到的sensor的名字,复制到Apache的“REMOTE_USER”中。此处未使用 Apache,因此只需将其注释掉即可。
修改完这些,就可以通过脚本启动mlog2waffle了
启动后,通过waf的访问日志,可以看到mlog2waffle已经开始通过put方法将日志解析成event并传递给waf-fle
在mlog2waffle的readIndex方法中,由于需要读取和解析日志索引文件,所以有一个正则匹配,如图:
这里需要修改和匹配自己记录的日志格式。完全匹配后可以正确读取日志,解析后将解析后的内容通过send_event方法通过PUT方法传递给waf-fle进行显示。
waf-fle接收到的文件是一个index.php,它通过正则解析所有步骤。有兴趣的可以看源码。至此,waf-fle就部署好了,可以看到效果了。
waf-fle虽然是老牌开源项目,但是对于modsecurity日志分析来说已经足够了
php用正则表达抓取网页中文章(266.26No.6第卷(期北))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-13 09:28
26 6卷。26 第 6 卷。No. 2011 12Journal of Beijing Information Science and Technology University Dec. 2011 Month 文章No.: 1674-6864 (20 11)06-0086-04 正则表达式在Web信息抽取中的应用, 胡俊伟秦一清 张伟(, 100 192)@ >北京信息工程大学北京计算机学院: HTML,. 摘要 针对基于结构的信息抽取方法,提出了正则表达式的处理方法,使用正则表达式的功能,匹配、替换和提取正则表达式。在信息提取过程中的应用正,Web正则表达式已成功应用于数据采集页面优化规则学习、信息抽取等信息抽取全过程。:网络;;; ;关键词信息抽取正则表达式匹配替换抽取CLC编号:TP 311 文献编号:A正则表达式及其在Web信息抽取中的应用胡俊伟,秦一清,张伟(北京信息科技大学计算机学院) , 北京 100 192) 摘要: 结合基于 HTML 结构的信息抽取方法, 提出了一种正则表达式的处理方法。讨论了正则表达式在Web信息抽取过程中的应用,利用正则表达式的匹配、替换、提取等。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息提取;正则表达式;匹配;替换;提取,提取字符串数据的有力工具是由特定0介绍意义组成的字符串。具有匹配、替换、提取等功能。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息抽取;正则表达式;匹配;替换;抽取,提取字符串数据的有力工具是由特定的0介绍意义组成的字符串。具有匹配、替换、提取等功能。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息提取;正则表达式;匹配;替换;提取,提取字符串数据的有力工具是由特定0介绍意义组成的字符串。
它代表一定的匹配规则。随着Internet的快速发展,Web信息得到了发展。本文讨论了正则表达式在Web信息抽取过程中的作用。用于全球分布和共享的信息,但目前已应用。WebHTML上的大部分数据主要是以Web信息提取的形式,这是为了展示的方便,允许人们通过浏览器浏览而无需数据本身的描述。HTML 收录不明确的语义信息 [1] 信息提取是指从文本文档中提取特定目的,信息架构不是很清晰,这使得应用程序无法直接解析()、标签信息或事件等数据事实形成一个结构化的网络。并使用上海' 大量的信息造成了资源(XML)的极大浪费,而供用户查询的数据库等表示形式,Web,在此背景下,信息抽取技术应运而生。网络信息抽取是指以网络为信息源的一种信息抽取方式,可以帮助用户摆脱噪声干扰,直接获取所需信息。兴趣。Web信息抽取技术的核心是能够从网页中收录的非结构化或半结构化信息中识别出用户感兴趣的内容。自由结构化的半结构化和结构化文本
, 在语法的基础上,需要结合机器学习等人工智能。正则表达式提供给计算机操作和检查。起草日期:20 11-10-27:(KM2014)基金项目北京教育科技计划面上项目:(1983—),,,,。作者简介 胡军伟,湖北枣阳市研究生,主要从事信息检索技术及应用研究。和学习结构化文本 正则表达式是由普通字符组成的文字模式,例如字符 , , z)(),通常来自具有严格格式的数据库的信息以及称为元字符的特殊字符;。为了使用定义的格式进行提取,半结构化文本描述了要搜索的字符串的匹配模式。意义的特殊字符用于指定,。() 消息通常是不合语法的,并且不遵循任何严格的格式,其前导字符是目标 Web 上元字符之前的字符。. /page 是半结构化文本的典型实例。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。
基于层次结构的信息提取和归纳方法以及基于概念模型图像的模式匹配。用户只需要寻找匹配对 2 ;"/"。该类的多记录信息提取方法可以根据不同图像的图案内容,以不同的自动化程度表示为正则表达式[8],1。还可以分为手动模式、半自动模式和全自动模式。元字符和限定符见表 3 [3];根据各种信息抽取工具所采用的抽取原理和抽取方法的不同,Web表元字符和限定符可以将信息抽取分为基于描述自然语言理解的名称字符的信息抽取,基于机器学习的信息抽取方法、本体、^匹配输入字符串的起始位置、基于信息抽取的方法、基于HTML结构的信息抽取方法、基于Web查询的信息抽取方法。匹配除换行符以外的所有字符一次 [4]5。HTMLMYM匹配输入字符串的结束位置、信息提取等。目前最常用的方法是基于[][]、Web、匹配内字符结构的信息提取技术,由于页面,只需要一点处理就可以转换成一棵格式良好的树[0 - 9]匹配所有数字字符,
元字符 [^0 - 9] 匹配所有非数字字符 [^a - z] 匹配所有非小写字母字符 2 正则表达式 \d, [0 - 9] 匹配一个数字字符 相当于美国数学家组成的正则表达式Stephen Kleene,1956,用于匹配任何单词字符,包括下划线等。\w。主要用于描述正则集代数。它是一种abc匹配字符或字符或一个| 乙 | c,它提供abcabc将字符串中收录的字符串匹配到计算机上来操作和检查要提取的字符串数据。是由具有特定含义的字符组成的字符词串 [5]。该字符串表示某个匹配规则。可以应用正则表达式 * 来匹配前面的子表达式零次或多次。Linux、Unix、Windows、在各种操作系统中,几乎所有 + 匹配前面的子表达式一次或多次。部分语言PHP、C#、C++、Java等都支持。?匹配前面的子表达式零次或一次3、正则表达式最基本的功能是匹配替换和{n}n限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。正则表达式最基本的功能是匹配替换和 {n}n 限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。正则表达式最基本的功能是匹配替换和 {n}n 限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。
卡ID数据格式合法性检测等替换功能,可用于利用文档中的匹配模式识别特定字符,然后在Web信息抽取过程中应用,然后删除或替换,如删除Web脚本注释等。, SQL 注入。HTML、句子注入攻击代码等的提取,参考本文中基于结构的提取方法。HTML根据模式匹配从字符串中提取子字符串,例如提出了基于结构提取的正则表达式的应用。1. 如何快速提取页面中的图片超链接、文本等正则表达式的大致流程如图所示。Web5 可以准确处理一系列复杂的搜索、替换和提取字符串。整个信息提取过程大致可以分为[9]。, . 因此,我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。
第一阶段的规则学习将优化页面作为训练[11] XMLDOM;然后通过遍历树的方式提取出DOM树,用训练样本标注用户感兴趣的信息。 DOM,通过树作为转换工具的信息生成和提取规则 XPATH、XSLT等技术编写提取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。信息生成和抽取规则通过树作为转换工具 XPATH、XSLT 等技术编写抽取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。信息生成和抽取规则通过树作为转换工具 XPATH、XSLT 等技术编写抽取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。
提取用户感兴趣的信息,格式可视化,方便用户完成样本页面信息的标注。[12] 在数据存储阶段,将提取的信息用正则表达式的三种匹配模式表示作为存储。<(?<htmltag>[az]+[\d]?)^[>]* 3.1 个数据采集>> . * ? < / \ k < htmltag > > (3),网页一般通过网络爬虫工具从网上下载 < [az]+[\d]?[^>]*>(4)1URL 工作原理爬虫的过程就是从(?>[^<]*)5()中获取对初始网页的网页进行抓取的过程,一个或多个初始网页的URL(3)1HTML表达式表示它是匹配一对标签、URL、并不断从当前页面中提取新的并放入队列中,直到,,,."而零>""</\k<htmltag>>"又代表开始和结束或多个"/"、"."、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。and 表示开头和结尾或多个“/”、“.”、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。and 表示开头和结尾或多个“/”、“.”、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。
“[^>]*”。例如,使用有效字体来匹配其属性 URL。提取的正则表达式的匹配模式表示为“.* ?”。表示标记 http 中收录的内容表达式: (\\ w + (- \\ w + )* )(\\ . (\\ w + (- \\ w∥(4 ), HTML,表示一个单标签没有结束标签 + )* ))* (\\ ?\\ S * )?http : 表示任何标签收录 ∥: "< img src = aaa.jpg > " 例如,该标签是未配对的 "/ “”。和零个或多个或相等的符号是必需的 HTML。(5) HTML,标记表达式是匹配非标记URL。网络爬虫将通过这个常规匹配匹配所有需求。3 比如一些纯文本等通过上面的正则表达式URL,。它被视为放入队列。借助正则表达式HTML,网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,还可以准确的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,而且精准的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,而且精准的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。
标准文档通过正则表达式、DOM过滤;点添加到当前树节点函数,HTML,可以实现对代码的过滤,以达到优化的目的 4)匹配得到的HTML标签中的代码被认为是新的。例如:“<img src=a.jpg>”、“<b>J5<HTML,3),文本会将/b>中的节点转为“<b></b>”中的当前节点<h1> 1); 在战斗机中还有一些</h1>,HTML5)。等标签被移除以简化提取并将文本添加到当前节点。6:网络问题胡俊伟等。正则表达式在信息抽取中的应用89DOM,Web[J].正则表达式生成的树提供了计算机工程DOM、DOM、[J]. 现代智能,2007 (10):215- 219 3. 4 提取 [3] Line Eikvil。从 worldHTML 中提取信息,广网调查 [R]。挪威:挪威人应该充分考虑 HTML, . [J]. 现代智能,2007 (10):215- 219 3. 4 提取 [3] Line Eikvil。从 worldHTML 中提取信息,广网调查 [R]。挪威:挪威人应该充分考虑 HTML, .
HTMLComputing Center, 1999 Pages of Complex Instability Complex Pages [10], :[4] Alberto H ELaender, Berthier A Ribeiro-Neto, 还包括一些固定结构信息,例如在介绍中,Altigran S da Silva 等。网络简述 图书介绍的页面有图书的价格和图书销售商的电话号码。,数据提取工具[J].ACM SIGMOD Record、box等信息被视为固定结构的信息。通过正则表达式的匹配功能,可以从第2002、31行提取固定结构的信息(2)@>:84-93.,,[5].[M].:对于商品价格,电话号码,手机号和邮箱 沙金精通正则表达式,北京人民邮电,2008等信息,正则表达式的匹配模式表示为 Publishing House ():^ [0-9] *[1 - 9][6] Liger F, Queen CM, Wilton P. C# 商品价格有两位小数,正数 [0 - 9] *\.(\d{2})[M]., .: $ 正则表达式参考手册 刘乐亭 京庆 电话号码:^ ((\ (\ d {2 ,3 }\ ))| ( \ d {3 }\ - ))?华大学出版社, 2003 (\(0\d{2, 3}\)|0\d{2, 3}-)?1[-9]\d{6, 7}[7], . 张静和张艳正则表达式及其在信息抽取中的应用(\ - \ d {1, 4 }) ? [J]., 2009, 5 (15):3867$ 应用计算机知识与技术 手机号:^((\(\d{2, 3}\))|(\d{3}\ - ))? - 3868 1 (3 |5 |8) \d{9}[8], . Boost. Regex$ 吴鹏飞马凤娟的邮箱:^ [\ w - ] + (\ . [ \w-]+)*@[\w信息提取[J].武汉理工大学匹配这些正则表达式,可以直接输出需要的[10] Man I Lam, Zhiguo Gong, Maybin Muyeba。一个信息。武汉理工大学匹配这些正则表达式,可以直接输出需要的[10] Man I Lam, Zhiguo Gong, Maybin Muyeba。一个信息。
网络信息抽取方法[C]∥计算机科学讲义。德国:4 结论 Springer-Verlag Berlin Heidelberg, 2008, 4976: Web, 383-394 本文使用正则表达式快速提取信息,[11]。DOM Web[J].精确匹配、替换和抽取功能集中在基于正则表崔继新的信息抽取。河北URL, 2005 (3):90-93) 表达式对的提取功能和页面优化的替换功能是基于农大学报的DOM。, . [12],,,。固定格式信息的提取匹配功能与构建 杨震 赵延平 朱东华 基于正则表达式的信息仅仅依靠正则表达式来完成信息提取是不现实的。提取系统在国防科技监测中的应用[J].北京,,, 2006, 26( ): 74-78 还需借助其他工具完成, 实现大学学报的增刊科学和技术。有效提取可用于提取过程中的其他方面。,. 正则表达式仍需进一步研究参考文献:[1],,,。XPath 杨文竹 许林 吴陈少飞等基于 . XPath 杨文竹 许林 吴陈少飞等基于 . XPath 杨文竹 许林 吴陈少飞等基于 查看全部
php用正则表达抓取网页中文章(266.26No.6第卷(期北))
26 6卷。26 第 6 卷。No. 2011 12Journal of Beijing Information Science and Technology University Dec. 2011 Month 文章No.: 1674-6864 (20 11)06-0086-04 正则表达式在Web信息抽取中的应用, 胡俊伟秦一清 张伟(, 100 192)@ >北京信息工程大学北京计算机学院: HTML,. 摘要 针对基于结构的信息抽取方法,提出了正则表达式的处理方法,使用正则表达式的功能,匹配、替换和提取正则表达式。在信息提取过程中的应用正,Web正则表达式已成功应用于数据采集页面优化规则学习、信息抽取等信息抽取全过程。:网络;;; ;关键词信息抽取正则表达式匹配替换抽取CLC编号:TP 311 文献编号:A正则表达式及其在Web信息抽取中的应用胡俊伟,秦一清,张伟(北京信息科技大学计算机学院) , 北京 100 192) 摘要: 结合基于 HTML 结构的信息抽取方法, 提出了一种正则表达式的处理方法。讨论了正则表达式在Web信息抽取过程中的应用,利用正则表达式的匹配、替换、提取等。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息提取;正则表达式;匹配;替换;提取,提取字符串数据的有力工具是由特定0介绍意义组成的字符串。具有匹配、替换、提取等功能。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息抽取;正则表达式;匹配;替换;抽取,提取字符串数据的有力工具是由特定的0介绍意义组成的字符串。具有匹配、替换、提取等功能。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息提取;正则表达式;匹配;替换;提取,提取字符串数据的有力工具是由特定0介绍意义组成的字符串。
它代表一定的匹配规则。随着Internet的快速发展,Web信息得到了发展。本文讨论了正则表达式在Web信息抽取过程中的作用。用于全球分布和共享的信息,但目前已应用。WebHTML上的大部分数据主要是以Web信息提取的形式,这是为了展示的方便,允许人们通过浏览器浏览而无需数据本身的描述。HTML 收录不明确的语义信息 [1] 信息提取是指从文本文档中提取特定目的,信息架构不是很清晰,这使得应用程序无法直接解析()、标签信息或事件等数据事实形成一个结构化的网络。并使用上海' 大量的信息造成了资源(XML)的极大浪费,而供用户查询的数据库等表示形式,Web,在此背景下,信息抽取技术应运而生。网络信息抽取是指以网络为信息源的一种信息抽取方式,可以帮助用户摆脱噪声干扰,直接获取所需信息。兴趣。Web信息抽取技术的核心是能够从网页中收录的非结构化或半结构化信息中识别出用户感兴趣的内容。自由结构化的半结构化和结构化文本
, 在语法的基础上,需要结合机器学习等人工智能。正则表达式提供给计算机操作和检查。起草日期:20 11-10-27:(KM2014)基金项目北京教育科技计划面上项目:(1983—),,,,。作者简介 胡军伟,湖北枣阳市研究生,主要从事信息检索技术及应用研究。和学习结构化文本 正则表达式是由普通字符组成的文字模式,例如字符 , , z)(),通常来自具有严格格式的数据库的信息以及称为元字符的特殊字符;。为了使用定义的格式进行提取,半结构化文本描述了要搜索的字符串的匹配模式。意义的特殊字符用于指定,。() 消息通常是不合语法的,并且不遵循任何严格的格式,其前导字符是目标 Web 上元字符之前的字符。. /page 是半结构化文本的典型实例。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。
基于层次结构的信息提取和归纳方法以及基于概念模型图像的模式匹配。用户只需要寻找匹配对 2 ;"/"。该类的多记录信息提取方法可以根据不同图像的图案内容,以不同的自动化程度表示为正则表达式[8],1。还可以分为手动模式、半自动模式和全自动模式。元字符和限定符见表 3 [3];根据各种信息抽取工具所采用的抽取原理和抽取方法的不同,Web表元字符和限定符可以将信息抽取分为基于描述自然语言理解的名称字符的信息抽取,基于机器学习的信息抽取方法、本体、^匹配输入字符串的起始位置、基于信息抽取的方法、基于HTML结构的信息抽取方法、基于Web查询的信息抽取方法。匹配除换行符以外的所有字符一次 [4]5。HTMLMYM匹配输入字符串的结束位置、信息提取等。目前最常用的方法是基于[][]、Web、匹配内字符结构的信息提取技术,由于页面,只需要一点处理就可以转换成一棵格式良好的树[0 - 9]匹配所有数字字符,
元字符 [^0 - 9] 匹配所有非数字字符 [^a - z] 匹配所有非小写字母字符 2 正则表达式 \d, [0 - 9] 匹配一个数字字符 相当于美国数学家组成的正则表达式Stephen Kleene,1956,用于匹配任何单词字符,包括下划线等。\w。主要用于描述正则集代数。它是一种abc匹配字符或字符或一个| 乙 | c,它提供abcabc将字符串中收录的字符串匹配到计算机上来操作和检查要提取的字符串数据。是由具有特定含义的字符组成的字符词串 [5]。该字符串表示某个匹配规则。可以应用正则表达式 * 来匹配前面的子表达式零次或多次。Linux、Unix、Windows、在各种操作系统中,几乎所有 + 匹配前面的子表达式一次或多次。部分语言PHP、C#、C++、Java等都支持。?匹配前面的子表达式零次或一次3、正则表达式最基本的功能是匹配替换和{n}n限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。正则表达式最基本的功能是匹配替换和 {n}n 限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。正则表达式最基本的功能是匹配替换和 {n}n 限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。
卡ID数据格式合法性检测等替换功能,可用于利用文档中的匹配模式识别特定字符,然后在Web信息抽取过程中应用,然后删除或替换,如删除Web脚本注释等。, SQL 注入。HTML、句子注入攻击代码等的提取,参考本文中基于结构的提取方法。HTML根据模式匹配从字符串中提取子字符串,例如提出了基于结构提取的正则表达式的应用。1. 如何快速提取页面中的图片超链接、文本等正则表达式的大致流程如图所示。Web5 可以准确处理一系列复杂的搜索、替换和提取字符串。整个信息提取过程大致可以分为[9]。, . 因此,我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。
第一阶段的规则学习将优化页面作为训练[11] XMLDOM;然后通过遍历树的方式提取出DOM树,用训练样本标注用户感兴趣的信息。 DOM,通过树作为转换工具的信息生成和提取规则 XPATH、XSLT等技术编写提取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。信息生成和抽取规则通过树作为转换工具 XPATH、XSLT 等技术编写抽取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。信息生成和抽取规则通过树作为转换工具 XPATH、XSLT 等技术编写抽取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。
提取用户感兴趣的信息,格式可视化,方便用户完成样本页面信息的标注。[12] 在数据存储阶段,将提取的信息用正则表达式的三种匹配模式表示作为存储。<(?<htmltag>[az]+[\d]?)^[>]* 3.1 个数据采集>> . * ? < / \ k < htmltag > > (3),网页一般通过网络爬虫工具从网上下载 < [az]+[\d]?[^>]*>(4)1URL 工作原理爬虫的过程就是从(?>[^<]*)5()中获取对初始网页的网页进行抓取的过程,一个或多个初始网页的URL(3)1HTML表达式表示它是匹配一对标签、URL、并不断从当前页面中提取新的并放入队列中,直到,,,."而零>""</\k<htmltag>>"又代表开始和结束或多个"/"、"."、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。and 表示开头和结尾或多个“/”、“.”、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。and 表示开头和结尾或多个“/”、“.”、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。
“[^>]*”。例如,使用有效字体来匹配其属性 URL。提取的正则表达式的匹配模式表示为“.* ?”。表示标记 http 中收录的内容表达式: (\\ w + (- \\ w + )* )(\\ . (\\ w + (- \\ w∥(4 ), HTML,表示一个单标签没有结束标签 + )* ))* (\\ ?\\ S * )?http : 表示任何标签收录 ∥: "< img src = aaa.jpg > " 例如,该标签是未配对的 "/ “”。和零个或多个或相等的符号是必需的 HTML。(5) HTML,标记表达式是匹配非标记URL。网络爬虫将通过这个常规匹配匹配所有需求。3 比如一些纯文本等通过上面的正则表达式URL,。它被视为放入队列。借助正则表达式HTML,网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,还可以准确的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,而且精准的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,而且精准的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。
标准文档通过正则表达式、DOM过滤;点添加到当前树节点函数,HTML,可以实现对代码的过滤,以达到优化的目的 4)匹配得到的HTML标签中的代码被认为是新的。例如:“<img src=a.jpg>”、“<b>J5<HTML,3),文本会将/b>中的节点转为“<b></b>”中的当前节点<h1> 1); 在战斗机中还有一些</h1>,HTML5)。等标签被移除以简化提取并将文本添加到当前节点。6:网络问题胡俊伟等。正则表达式在信息抽取中的应用89DOM,Web[J].正则表达式生成的树提供了计算机工程DOM、DOM、[J]. 现代智能,2007 (10):215- 219 3. 4 提取 [3] Line Eikvil。从 worldHTML 中提取信息,广网调查 [R]。挪威:挪威人应该充分考虑 HTML, . [J]. 现代智能,2007 (10):215- 219 3. 4 提取 [3] Line Eikvil。从 worldHTML 中提取信息,广网调查 [R]。挪威:挪威人应该充分考虑 HTML, .
HTMLComputing Center, 1999 Pages of Complex Instability Complex Pages [10], :[4] Alberto H ELaender, Berthier A Ribeiro-Neto, 还包括一些固定结构信息,例如在介绍中,Altigran S da Silva 等。网络简述 图书介绍的页面有图书的价格和图书销售商的电话号码。,数据提取工具[J].ACM SIGMOD Record、box等信息被视为固定结构的信息。通过正则表达式的匹配功能,可以从第2002、31行提取固定结构的信息(2)@>:84-93.,,[5].[M].:对于商品价格,电话号码,手机号和邮箱 沙金精通正则表达式,北京人民邮电,2008等信息,正则表达式的匹配模式表示为 Publishing House ():^ [0-9] *[1 - 9][6] Liger F, Queen CM, Wilton P. C# 商品价格有两位小数,正数 [0 - 9] *\.(\d{2})[M]., .: $ 正则表达式参考手册 刘乐亭 京庆 电话号码:^ ((\ (\ d {2 ,3 }\ ))| ( \ d {3 }\ - ))?华大学出版社, 2003 (\(0\d{2, 3}\)|0\d{2, 3}-)?1[-9]\d{6, 7}[7], . 张静和张艳正则表达式及其在信息抽取中的应用(\ - \ d {1, 4 }) ? [J]., 2009, 5 (15):3867$ 应用计算机知识与技术 手机号:^((\(\d{2, 3}\))|(\d{3}\ - ))? - 3868 1 (3 |5 |8) \d{9}[8], . Boost. Regex$ 吴鹏飞马凤娟的邮箱:^ [\ w - ] + (\ . [ \w-]+)*@[\w信息提取[J].武汉理工大学匹配这些正则表达式,可以直接输出需要的[10] Man I Lam, Zhiguo Gong, Maybin Muyeba。一个信息。武汉理工大学匹配这些正则表达式,可以直接输出需要的[10] Man I Lam, Zhiguo Gong, Maybin Muyeba。一个信息。
网络信息抽取方法[C]∥计算机科学讲义。德国:4 结论 Springer-Verlag Berlin Heidelberg, 2008, 4976: Web, 383-394 本文使用正则表达式快速提取信息,[11]。DOM Web[J].精确匹配、替换和抽取功能集中在基于正则表崔继新的信息抽取。河北URL, 2005 (3):90-93) 表达式对的提取功能和页面优化的替换功能是基于农大学报的DOM。, . [12],,,。固定格式信息的提取匹配功能与构建 杨震 赵延平 朱东华 基于正则表达式的信息仅仅依靠正则表达式来完成信息提取是不现实的。提取系统在国防科技监测中的应用[J].北京,,, 2006, 26( ): 74-78 还需借助其他工具完成, 实现大学学报的增刊科学和技术。有效提取可用于提取过程中的其他方面。,. 正则表达式仍需进一步研究参考文献:[1],,,。XPath 杨文竹 许林 吴陈少飞等基于 . XPath 杨文竹 许林 吴陈少飞等基于 . XPath 杨文竹 许林 吴陈少飞等基于
php用正则表达抓取网页中文章(PHP联系我们脚本无需修改即可运行的zip文件文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-13 03:11
PHPcontact-us 脚本无需修改即可运行。它检测域并通过电子邮件发送与我们联系的所有表单数据
一个现成的 PHP 联系我们脚本,无需修改,它将检测域并将收录联系消息的电子邮件发送到表单中的任何字段;它将检测到它们并通过电子邮件发送表单数据。
PHP 中的新功能联系我们脚本
用户必须在提交前在名称字段、电子邮件、主题和消息中输入数据
新版本包括更多的用户输入过滤。因此,通过使用函数 htmlspecialchars() 和过滤器 FILTER_SANITIZE_STRING 清理每个输入键和值,脚本是安全的。我会删除任何 HTML 代码或无效字符。
介绍
即用型 PHPcontact-us 脚本,无需修改,它将检测域并将收录联系信息的电子邮件发送到表单中的任何字段;它将检测到它们并通过电子邮件发送表单数据。
系统要求
任何带有支持 PHP 的主机的 网站;几乎所有主机都支持它。
换句话说,您可以将它与任何 网站 一起使用,无论其用途如何:纯 HTML/PHP、WordPress、Joomla、Drupal 或任何其他系统
PHP版本:
PHP5.6/PHP7.0/PHP7.1/PHP7.2/PHP7.3/PHP7.4/PHP< @8.0
背景
互联网上有很多脚本与我们联系。另一方面,其他脚本在使用前需要修改 PHP 文件,而此脚本将直接运行。
因此,这个脚本对于不懂 PHP 的人和 PHP 的初学者来说非常有用。
使用代码
解压下载的 zip 文件
然后在您的 网站 www 目录中创建一个contact-us 文件夹
之后,将文件上传到contact-us文件夹
就这样。
最后,contact-us URL 类似于 /contact-us,将您的域替换为
修改联系我们表单设计
您可以根据需要修改联系我们页面的设计,
根据需要添加或省略字段
使用 from_email、from_name、主题、消息和验证码字段名称
放置您自己的广告或使您的表单无广告
随意添加链接到我们。
关于我们的联系代码
从行动
1复制代码类型:[html]
字段名称
使用 from_email、from_name、主题、消息和验证码作为表单名称中的主要字段。
验证码
如果您不想使用验证码,请将 1 行“send.php”代码替换为:
$captcha = false;1复制代码类型:[html]
如果你想使用验证码,你不需要做任何更改和 1 行“send.php”代码:
$captcha = true;1复制代码类型:[html]
如果需要修改表格;请注意,我们正在使用验证码,请将以下内容添加到您的表单中:
<p> 查看全部
php用正则表达抓取网页中文章(PHP联系我们脚本无需修改即可运行的zip文件文件)
PHPcontact-us 脚本无需修改即可运行。它检测域并通过电子邮件发送与我们联系的所有表单数据
一个现成的 PHP 联系我们脚本,无需修改,它将检测域并将收录联系消息的电子邮件发送到表单中的任何字段;它将检测到它们并通过电子邮件发送表单数据。
PHP 中的新功能联系我们脚本
用户必须在提交前在名称字段、电子邮件、主题和消息中输入数据
新版本包括更多的用户输入过滤。因此,通过使用函数 htmlspecialchars() 和过滤器 FILTER_SANITIZE_STRING 清理每个输入键和值,脚本是安全的。我会删除任何 HTML 代码或无效字符。
介绍
即用型 PHPcontact-us 脚本,无需修改,它将检测域并将收录联系信息的电子邮件发送到表单中的任何字段;它将检测到它们并通过电子邮件发送表单数据。
系统要求
任何带有支持 PHP 的主机的 网站;几乎所有主机都支持它。
换句话说,您可以将它与任何 网站 一起使用,无论其用途如何:纯 HTML/PHP、WordPress、Joomla、Drupal 或任何其他系统
PHP版本:
PHP5.6/PHP7.0/PHP7.1/PHP7.2/PHP7.3/PHP7.4/PHP< @8.0
背景
互联网上有很多脚本与我们联系。另一方面,其他脚本在使用前需要修改 PHP 文件,而此脚本将直接运行。
因此,这个脚本对于不懂 PHP 的人和 PHP 的初学者来说非常有用。
使用代码
解压下载的 zip 文件
然后在您的 网站 www 目录中创建一个contact-us 文件夹
之后,将文件上传到contact-us文件夹
就这样。
最后,contact-us URL 类似于 /contact-us,将您的域替换为
修改联系我们表单设计
您可以根据需要修改联系我们页面的设计,
根据需要添加或省略字段
使用 from_email、from_name、主题、消息和验证码字段名称
放置您自己的广告或使您的表单无广告
随意添加链接到我们。
关于我们的联系代码
从行动
1复制代码类型:[html]
字段名称
使用 from_email、from_name、主题、消息和验证码作为表单名称中的主要字段。
验证码
如果您不想使用验证码,请将 1 行“send.php”代码替换为:
$captcha = false;1复制代码类型:[html]
如果你想使用验证码,你不需要做任何更改和 1 行“send.php”代码:
$captcha = true;1复制代码类型:[html]
如果需要修改表格;请注意,我们正在使用验证码,请将以下内容添加到您的表单中:
<p>
php用正则表达抓取网页中文章(正则表达式就是描述字符排列模式的一种自定义的语法规则名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-10 11:31
第一次接触正则表达式的网友会觉得有点繁琐,会有一种深不可测的感觉。实际上,正则表达式是描述字符排列模式的自定义语法规则名称。在 PHP 提供的系统函数中,该模式用于执行字符串的匹配、查找、替换和分割等操作。它的应用非常广泛。例如,常用正则表达式来验证用户在表单中提交的用户名、密码、邮箱地址、身份证号甚至电话号码是否合法;当用户发布文章时,会在有URL的地方添加所有对应的链接;根据所有标点符号计算文章中的句子总数;抓取网页中某种格式的数据等。正则表达式不是PHP自己的产物,在很多领域都会看到它的应用。除了 Perl、C#、Java 语言的应用外,在我们的 B/S 架构软件开发中,正则表达式可以应用于 Linux 操作系统、前端 JavaScript 脚本、后台脚本 PHP 和 MySQL 数据库。
正则表达式也称为模式表达式,具有非常完整的可以编写模式的语法系统,并提供了一种灵活直观的字符处理方法。正则表达式用于通过构造具有特定模式的模式,将其与输入字符串信息进行比较,并在特定函数中使用来匹配、查找、替换和划分字符串。下面给出的三种模式是根据正则表达式的语法规则构造的。代码显示如下:
"/[a-zA-z]+:[∧\s]*/" //正则表达式匹配网址
"/<(\s*?)[∧>]*>.*?<∧1>|<.*?/>/i" //正则表达式匹配HTML标签
"∧w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/" //正则表达式匹配邮箱模式
不要被上面例子中的乱码吓到,它们是按照正则表达式的语法规则构造的模式,是由普通字符和特殊字符组成的字符串。并且仅在特定的正则表达式函数中使用这些模式字符串才有效。学完本章,你就可以自由地应用这样的代码了。PHP 支持两组正则表达式处理函数库。PCRE(Perl Compatible Regular Expression)库提供的一组正则表达式函数,与Perl语言兼容,使用以preg前缀命名的函数,表达式应收录在分隔符中,如斜杠(/)。另一个是正则表达式函数,其语法由 POSLX(便携式操作系统接口)扩展,使用前缀为“preg_”的函数。两组函数的功能基本相似,但执行效率略有不同。一般来说,要实现同样的功能,PCRE库提供的正则表达式效率会稍微高一些。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。 查看全部
php用正则表达抓取网页中文章(正则表达式就是描述字符排列模式的一种自定义的语法规则名)
第一次接触正则表达式的网友会觉得有点繁琐,会有一种深不可测的感觉。实际上,正则表达式是描述字符排列模式的自定义语法规则名称。在 PHP 提供的系统函数中,该模式用于执行字符串的匹配、查找、替换和分割等操作。它的应用非常广泛。例如,常用正则表达式来验证用户在表单中提交的用户名、密码、邮箱地址、身份证号甚至电话号码是否合法;当用户发布文章时,会在有URL的地方添加所有对应的链接;根据所有标点符号计算文章中的句子总数;抓取网页中某种格式的数据等。正则表达式不是PHP自己的产物,在很多领域都会看到它的应用。除了 Perl、C#、Java 语言的应用外,在我们的 B/S 架构软件开发中,正则表达式可以应用于 Linux 操作系统、前端 JavaScript 脚本、后台脚本 PHP 和 MySQL 数据库。
正则表达式也称为模式表达式,具有非常完整的可以编写模式的语法系统,并提供了一种灵活直观的字符处理方法。正则表达式用于通过构造具有特定模式的模式,将其与输入字符串信息进行比较,并在特定函数中使用来匹配、查找、替换和划分字符串。下面给出的三种模式是根据正则表达式的语法规则构造的。代码显示如下:
"/[a-zA-z]+:[∧\s]*/" //正则表达式匹配网址
"/<(\s*?)[∧>]*>.*?<∧1>|<.*?/>/i" //正则表达式匹配HTML标签
"∧w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/" //正则表达式匹配邮箱模式
不要被上面例子中的乱码吓到,它们是按照正则表达式的语法规则构造的模式,是由普通字符和特殊字符组成的字符串。并且仅在特定的正则表达式函数中使用这些模式字符串才有效。学完本章,你就可以自由地应用这样的代码了。PHP 支持两组正则表达式处理函数库。PCRE(Perl Compatible Regular Expression)库提供的一组正则表达式函数,与Perl语言兼容,使用以preg前缀命名的函数,表达式应收录在分隔符中,如斜杠(/)。另一个是正则表达式函数,其语法由 POSLX(便携式操作系统接口)扩展,使用前缀为“preg_”的函数。两组函数的功能基本相似,但执行效率略有不同。一般来说,要实现同样的功能,PCRE库提供的正则表达式效率会稍微高一些。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。
php用正则表达抓取网页中文章(初出茅庐的你带着仍残留的10项无需指导)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-04-07 22:04
作为一个初出茅庐的你,拿着一张还保留着墨香的毕业证踏上工作岗位,马上就被书本上没有的规矩和各种繁杂的日常事务给拆散了。像这样的故事很常见,编程工作也不例外。
很少有学生 100% 准备好迎接第一份真正的工作。如果您不想成为其中之一,请学习以下 10 项无需动手指导即可学习的基本技能:
1、版本控制系统(VCS)
VCS 可能是计算机课程中最大的遗漏。这些课程只记得教如何编码,却常常忘记教学生如何管理代码。每个程序员都应该知道如何使用 Git 或 Subversion 来有效地创建存储库、编辑和提交代码、分支和合并,以及了解项目工作流程。
2、学习写作
成为一名程序员不仅仅是写代码。您还为项目编写发行说明,提交版本控制消息,并在系统中编写错误报告。这些以及许多地方都需要清晰有效的书面交流——这是计算机科学中很少强调的一项技能。
3、正则表达式
正则表达式本身就是一种语言,每个现代程序员都应该擅长它。每种现代语言都支持正则表达式或具有相关的标准库。如果您的代码需要检查一个字符串是否收录 5 个字符、1 个破折号和 1 个数字,您应该能够立即编写 /^[AZ]{5}-\d$/。
4、图书馆的使用
现在是 2014 年,所以没有人需要使用正则表达式从 URL 中提取主机名。因为每一种现代编程语言都有执行通用功能的标准库。
程序员需要了解,经过开发、测试和调试的代码通常比重写的代码更好。更重要的是,不需要编写的代码实现起来要快得多。
5、SQL
许多人在工作中学习 SQL。数据库如何成为选修课?有没有没有数据库的?
将数据存储在平面文件中的时代已经结束。一切都进出数据库,而 SQL 是访问数据的语言。这是一种声明性语言,而不是程序性语言,因此使用它来解决问题需要新的思维方式。每个程序员都应该了解数据库规范化的基础知识,并且能够执行 SELECT(以及 INNER、OUTER JOIN)、INSERT、UPDATE 和 DELETE。
6、能够使用 IDE、编辑器和 CLI 工具
一个只知道如何使用锯子的木匠永远不会做出它,所以一个计算机专业的毕业生只知道记事本或 pico 是令人惊讶的。编程工具通过帮助操作代码和其他数据使程序员的生活更轻松。所以每个程序员都应该知道命令行、shell脚本、find、grep和sed的使用。
7、调试
每个程序员都应该知道如何使用交互式调试器或通过在代码中添加一些输出语句来调试程序。通过逐步完善来追踪问题的能力实在是太重要了。
8、防错编程
错误总是不可避免的,即使对于明星程序员也是如此。失去控制是世界上的常态,出现问题也就不足为奇了。防错编程理解这个事实。如果事情没有出错,我们不会检查文件是否已成功打开,我们不会检查客户端 ID 是否是有效数字,并且我们不会测试代码是否正确。
程序员需要知道编译器警告是使我们的生活更舒适的有用工具,而不是要避免的麻烦。每个程序员都应该知道为什么每个 PHP 程序都是这样开始的:
设置错误报告(E_ALL)
每个 Perl 程序都应该编写这些语句:
使用严格;使用警告;
9、团队合作
编程很少靠你自己工作,如果你经常这样做,你的智力会受到影响,你的表现也会变弱。您的代码必须与其他人的代码交互或混合。即使是最有才华的程序员,如果不能与他人合作,也会对项目产生负面影响,并很快成为组织的负担。
10、利用现有代码
在学校里,每一项作业都是一个新项目。但现实世界并非如此。对于刚开始工作的人来说,他们收到的第一个任务通常是修复代码错误。然后,在现有代码库之上向现有系统添加一个小功能。如果幸运的话,设计新代码需要几个月的时间。
【本文编译自:】
AD:云屋,一种新的工作方式。 查看全部
php用正则表达抓取网页中文章(初出茅庐的你带着仍残留的10项无需指导)
作为一个初出茅庐的你,拿着一张还保留着墨香的毕业证踏上工作岗位,马上就被书本上没有的规矩和各种繁杂的日常事务给拆散了。像这样的故事很常见,编程工作也不例外。
很少有学生 100% 准备好迎接第一份真正的工作。如果您不想成为其中之一,请学习以下 10 项无需动手指导即可学习的基本技能:
1、版本控制系统(VCS)
VCS 可能是计算机课程中最大的遗漏。这些课程只记得教如何编码,却常常忘记教学生如何管理代码。每个程序员都应该知道如何使用 Git 或 Subversion 来有效地创建存储库、编辑和提交代码、分支和合并,以及了解项目工作流程。
2、学习写作
成为一名程序员不仅仅是写代码。您还为项目编写发行说明,提交版本控制消息,并在系统中编写错误报告。这些以及许多地方都需要清晰有效的书面交流——这是计算机科学中很少强调的一项技能。
3、正则表达式
正则表达式本身就是一种语言,每个现代程序员都应该擅长它。每种现代语言都支持正则表达式或具有相关的标准库。如果您的代码需要检查一个字符串是否收录 5 个字符、1 个破折号和 1 个数字,您应该能够立即编写 /^[AZ]{5}-\d$/。
4、图书馆的使用
现在是 2014 年,所以没有人需要使用正则表达式从 URL 中提取主机名。因为每一种现代编程语言都有执行通用功能的标准库。
程序员需要了解,经过开发、测试和调试的代码通常比重写的代码更好。更重要的是,不需要编写的代码实现起来要快得多。
5、SQL
许多人在工作中学习 SQL。数据库如何成为选修课?有没有没有数据库的?
将数据存储在平面文件中的时代已经结束。一切都进出数据库,而 SQL 是访问数据的语言。这是一种声明性语言,而不是程序性语言,因此使用它来解决问题需要新的思维方式。每个程序员都应该了解数据库规范化的基础知识,并且能够执行 SELECT(以及 INNER、OUTER JOIN)、INSERT、UPDATE 和 DELETE。
6、能够使用 IDE、编辑器和 CLI 工具
一个只知道如何使用锯子的木匠永远不会做出它,所以一个计算机专业的毕业生只知道记事本或 pico 是令人惊讶的。编程工具通过帮助操作代码和其他数据使程序员的生活更轻松。所以每个程序员都应该知道命令行、shell脚本、find、grep和sed的使用。
7、调试
每个程序员都应该知道如何使用交互式调试器或通过在代码中添加一些输出语句来调试程序。通过逐步完善来追踪问题的能力实在是太重要了。
8、防错编程
错误总是不可避免的,即使对于明星程序员也是如此。失去控制是世界上的常态,出现问题也就不足为奇了。防错编程理解这个事实。如果事情没有出错,我们不会检查文件是否已成功打开,我们不会检查客户端 ID 是否是有效数字,并且我们不会测试代码是否正确。
程序员需要知道编译器警告是使我们的生活更舒适的有用工具,而不是要避免的麻烦。每个程序员都应该知道为什么每个 PHP 程序都是这样开始的:
设置错误报告(E_ALL)
每个 Perl 程序都应该编写这些语句:
使用严格;使用警告;
9、团队合作
编程很少靠你自己工作,如果你经常这样做,你的智力会受到影响,你的表现也会变弱。您的代码必须与其他人的代码交互或混合。即使是最有才华的程序员,如果不能与他人合作,也会对项目产生负面影响,并很快成为组织的负担。
10、利用现有代码
在学校里,每一项作业都是一个新项目。但现实世界并非如此。对于刚开始工作的人来说,他们收到的第一个任务通常是修复代码错误。然后,在现有代码库之上向现有系统添加一个小功能。如果幸运的话,设计新代码需要几个月的时间。
【本文编译自:】
AD:云屋,一种新的工作方式。
php用正则表达抓取网页中文章(魔王想提升代码搜索效果?首先你得知道怎么才算提升)
网站优化 • 优采云 发表了文章 • 0 个评论 • 472 次浏览 • 2022-04-07 22:01
机器之心编译
参与:魔王
想要提高代码搜索性能?首先,您必须知道什么是改进。GitHub 团队创建 CodeSearchNet 语料库,为代码搜索领域提供基准数据集,提高代码搜索结果的质量。
搜索代码以重用、调用或使用以查看其他人如何处理问题是软件开发人员每天最常见的任务之一。但是,代码搜索引擎通常不能很好地工作,并且与常规的网络搜索引擎不同,它们不能完全理解您的需求。GitHub 团队尝试使用现代机器学习技术来改进代码搜索结果,但很快意识到一个问题:他们无法衡量改进。自然语言处理领域有 GLUE 基准,但代码搜索评估领域没有合适的标准数据集。
因此,GitHub 昨天与 Weights & Biases 合作,推出了 CodeSearchNet Challenge 评估环境和排行榜。同时,GitHub 还发布了一个大型数据集,帮助数据科学家构建适合该任务的模型,多个基线模型代表了当前的最先进水平。排行榜使用查询注释数据集来评估代码搜索工具的质量。
代码搜索网络语料库
创建一个足够大的数据集来训练具有专家注释的大容量模型既昂贵又不切实际,因此 GitHub 创建了一个质量较低的代理数据集。GitHub 遵循 [5, 6, 9, 11] 中的做法,将开源软件中的功能与其相应文档中的自然语言相匹配。但是,这样做需要许多预处理步骤和启发式方法。
通过对常见错误案例的深入分析,GitHub 团队总结出了一些通用的规则和决策。
CodeSearchNet 语料库采集过程
GitHub 团队从开源非分叉 GitHub 存储库中采集语料库,使用 library.io 确认所有项目都被至少一个其他项目使用,并按“受欢迎程度”对它们进行排序(受欢迎程度通过星号和分叉数来衡量)当然)。然后,删除没有许可证或未明确允许重新分发的项目。然后,GitHub 团队使用其通用解析器 TreeSitter 对所有 Go、Java、JavaScript、Python、PHP 和 Ruby 函数(或方法)进行标记,并使用启发式正则表达式对与函数对应的文档文本进行标记。
筛选
为了生成 CodeSearchNet 挑战赛的训练数据,GitHub 团队首先考虑了语料库中收录相关文档的函数。这会产生一组 (c_i , d_i) 对,其中 c_i 是函数,d_i 是相应的文档。为了使数据更适合代码搜索任务,GitHub 团队执行了一系列预处理步骤:
详情见过滤后的语料库和数据提取代码:
数据集详细信息
该数据集收录 200 万个函数-文档对和大约 400 万个没有相应文档的函数(见下表 1)。GitHub 团队将数据集以 80-10-10 的比例划分为训练/验证)。set/test set,建议用户按这个比例使用这个数据集。
表 1:数据集详细信息。
局限性
这个数据集非常嘈杂。首先,文档和查询之间存在根本区别,因为它们使用不同的语言形式。文档通常与代码作者在编写代码的同时编写,并且倾向于使用相同的词汇表,这与搜索查询不同。其次,尽管 GitHub 团队在创建数据集的过程中进行了数据清理,但他们无法知道每个文档 d_i 描述相应代码段 c_i 的准确程度。最后,一些文档是用非英语文本编写的,而 CodeSearchNet Challenge 评估数据集主要关注英语查询。
CodeSearchNet 基线模型
在 GitHub 之前在语义代码搜索方面的努力的基础上,该团队发布了一组基线模型,这些模型利用现代技术来学习序列(包括类似 BERT 的自注意力模型),以帮助数据科学家开始代码搜索。
与之前的工作一样,GitHub 团队使用代码和查询的联合嵌入来实现神经搜索系统。该架构为每种输入(自然或编程)语言使用编码器,并训练它们以使输入映射到联合向量空间。训练目标是将代码及其对应的语言映射到附近的向量,这样我们就可以嵌入查询来执行搜索,然后返回嵌入空间中“附近”的一组代码段。
考虑到查询和代码之间更多交互的更复杂的模型当然性能更好,但为每个查询或代码段生成单个向量可以实现更有效的索引和搜索。
为了学习这些嵌入功能,GitHub 团队在架构中加入了标准的序列编码器模型,如图 3 所示。首先,根据输入序列的语义进行预处理:将代码令牌中的标识符拆分为子令牌(例如变量camelCase变成了两个子标记:camel和case),使用字节对编码(byte-pair encoding),BPE)来分割自然语言标记。
图 3:模型架构概述。
然后使用以下架构之一处理令牌序列以获得(上下文化的)令牌嵌入。
之后,这些令牌嵌入使用池化函数组合成序列嵌入,GitHub 团队实现了均值/最大池化和类注意力的加权求和机制。
下图显示了基线模型的一般架构:
CodeSearchNet 挑战
为了评估代码搜索模型,GitHub 团队采集了一组代码搜索查询,并要求程序员注释查询与可能结果的相关程度。他们首先从 Bing 中采集了一些常见的搜索查询,并结合 StaQC 中的查询,总共得到了 99 个与代码概念相关的查询(GitHub 团队删除了 API 文档查询问题)。
图 1:注释器说明。
之后,GitHub 团队使用标准 Elasticsearch 和基线模型从 CodeSearchNet 语料库中为每个查询获取 10 个可能的结果。最后,GitHub 团队要求程序员、数据科学家和机器学习研究人员按照 [0, 3] 标准标记每个结果与查询的相关程度(0 表示“完全不相关”,3 表示“完全匹配” )。
将来,GitHub 团队希望在此评估数据集中收录更多语言、查询和注释。在接下来的几个月里,他们将继续添加新数据,为下一版 CodeSearchNet 挑战赛生成扩展数据集。
原文链接: 查看全部
php用正则表达抓取网页中文章(魔王想提升代码搜索效果?首先你得知道怎么才算提升)
机器之心编译
参与:魔王
想要提高代码搜索性能?首先,您必须知道什么是改进。GitHub 团队创建 CodeSearchNet 语料库,为代码搜索领域提供基准数据集,提高代码搜索结果的质量。

搜索代码以重用、调用或使用以查看其他人如何处理问题是软件开发人员每天最常见的任务之一。但是,代码搜索引擎通常不能很好地工作,并且与常规的网络搜索引擎不同,它们不能完全理解您的需求。GitHub 团队尝试使用现代机器学习技术来改进代码搜索结果,但很快意识到一个问题:他们无法衡量改进。自然语言处理领域有 GLUE 基准,但代码搜索评估领域没有合适的标准数据集。
因此,GitHub 昨天与 Weights & Biases 合作,推出了 CodeSearchNet Challenge 评估环境和排行榜。同时,GitHub 还发布了一个大型数据集,帮助数据科学家构建适合该任务的模型,多个基线模型代表了当前的最先进水平。排行榜使用查询注释数据集来评估代码搜索工具的质量。
代码搜索网络语料库
创建一个足够大的数据集来训练具有专家注释的大容量模型既昂贵又不切实际,因此 GitHub 创建了一个质量较低的代理数据集。GitHub 遵循 [5, 6, 9, 11] 中的做法,将开源软件中的功能与其相应文档中的自然语言相匹配。但是,这样做需要许多预处理步骤和启发式方法。
通过对常见错误案例的深入分析,GitHub 团队总结出了一些通用的规则和决策。
CodeSearchNet 语料库采集过程
GitHub 团队从开源非分叉 GitHub 存储库中采集语料库,使用 library.io 确认所有项目都被至少一个其他项目使用,并按“受欢迎程度”对它们进行排序(受欢迎程度通过星号和分叉数来衡量)当然)。然后,删除没有许可证或未明确允许重新分发的项目。然后,GitHub 团队使用其通用解析器 TreeSitter 对所有 Go、Java、JavaScript、Python、PHP 和 Ruby 函数(或方法)进行标记,并使用启发式正则表达式对与函数对应的文档文本进行标记。
筛选
为了生成 CodeSearchNet 挑战赛的训练数据,GitHub 团队首先考虑了语料库中收录相关文档的函数。这会产生一组 (c_i , d_i) 对,其中 c_i 是函数,d_i 是相应的文档。为了使数据更适合代码搜索任务,GitHub 团队执行了一系列预处理步骤:
详情见过滤后的语料库和数据提取代码:
数据集详细信息
该数据集收录 200 万个函数-文档对和大约 400 万个没有相应文档的函数(见下表 1)。GitHub 团队将数据集以 80-10-10 的比例划分为训练/验证)。set/test set,建议用户按这个比例使用这个数据集。
表 1:数据集详细信息。
局限性
这个数据集非常嘈杂。首先,文档和查询之间存在根本区别,因为它们使用不同的语言形式。文档通常与代码作者在编写代码的同时编写,并且倾向于使用相同的词汇表,这与搜索查询不同。其次,尽管 GitHub 团队在创建数据集的过程中进行了数据清理,但他们无法知道每个文档 d_i 描述相应代码段 c_i 的准确程度。最后,一些文档是用非英语文本编写的,而 CodeSearchNet Challenge 评估数据集主要关注英语查询。
CodeSearchNet 基线模型
在 GitHub 之前在语义代码搜索方面的努力的基础上,该团队发布了一组基线模型,这些模型利用现代技术来学习序列(包括类似 BERT 的自注意力模型),以帮助数据科学家开始代码搜索。
与之前的工作一样,GitHub 团队使用代码和查询的联合嵌入来实现神经搜索系统。该架构为每种输入(自然或编程)语言使用编码器,并训练它们以使输入映射到联合向量空间。训练目标是将代码及其对应的语言映射到附近的向量,这样我们就可以嵌入查询来执行搜索,然后返回嵌入空间中“附近”的一组代码段。
考虑到查询和代码之间更多交互的更复杂的模型当然性能更好,但为每个查询或代码段生成单个向量可以实现更有效的索引和搜索。
为了学习这些嵌入功能,GitHub 团队在架构中加入了标准的序列编码器模型,如图 3 所示。首先,根据输入序列的语义进行预处理:将代码令牌中的标识符拆分为子令牌(例如变量camelCase变成了两个子标记:camel和case),使用字节对编码(byte-pair encoding),BPE)来分割自然语言标记。
图 3:模型架构概述。
然后使用以下架构之一处理令牌序列以获得(上下文化的)令牌嵌入。
之后,这些令牌嵌入使用池化函数组合成序列嵌入,GitHub 团队实现了均值/最大池化和类注意力的加权求和机制。
下图显示了基线模型的一般架构:
CodeSearchNet 挑战
为了评估代码搜索模型,GitHub 团队采集了一组代码搜索查询,并要求程序员注释查询与可能结果的相关程度。他们首先从 Bing 中采集了一些常见的搜索查询,并结合 StaQC 中的查询,总共得到了 99 个与代码概念相关的查询(GitHub 团队删除了 API 文档查询问题)。

图 1:注释器说明。
之后,GitHub 团队使用标准 Elasticsearch 和基线模型从 CodeSearchNet 语料库中为每个查询获取 10 个可能的结果。最后,GitHub 团队要求程序员、数据科学家和机器学习研究人员按照 [0, 3] 标准标记每个结果与查询的相关程度(0 表示“完全不相关”,3 表示“完全匹配” )。
将来,GitHub 团队希望在此评估数据集中收录更多语言、查询和注释。在接下来的几个月里,他们将继续添加新数据,为下一版 CodeSearchNet 挑战赛生成扩展数据集。
原文链接:
php用正则表达抓取网页中文章(PHP正则表达式完全手册(gt)php正则表达式捕获(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-06 11:22
阿里云 > 云栖社区 > 主题地图 > P > PHP正则表达式捕获
推荐活动:
更多优惠>
当前主题: php regex capture 添加到采集夹
相关话题:
php regex 捕获相关博客 查看更多博客
php正则表达式组捕获
作者:meteric639 浏览评论:011年前
经过测试发现获取组捕获的php正则表达式是从$0开始的,而在工程代码中提取汉字时,JavaScript中的正则在工作中是$1..$9,因为运行速度非常快当时很快(赶上时间),我担心.properties文件中{\d}的数字顺序错误:1、可能来自{1}
阅读全文
C#正则表达式编程(四):正则表达式
作者:科技甜1234 浏览评论:04年前
正则表达式提供了一种强大、灵活、高效的文本处理方式。正则表达式的全面模式匹配表示法让您可以快速分析大量文本以找到特定的字符模式;提取、编辑、替换或删除文本的子字符串;或将提取的字符串添加到集合以生成报告。用于处理字符串,例如 HTML 处理、日志文件分析和
阅读全文
谈论正则表达式
作者:Jack Chen805 浏览评论:07年前
原文:浅谈正则表达式一、什么是正则表达式?简单地说:正则表达式是一种处理字符串匹配的语言;正则表达式描述了字符串匹配的一种模式,可以用来检查一个字符串是否收录某个子字符串,以及匹配的“删除”或“替换”操作的子字符串。二
阅读全文
PHP 正则表达式
作者:thinkyoung825 浏览人数:06年前
PHP正则表达式思维导图点击下图查看具体内容!引入正则表达式,在开发中应该经常使用。现在很多开发语言都有正则表达式的应用,比如javascript、java、.net、php等,今天我就讲讲正则表达式的道理。
阅读全文
PHP正则表达式完整手册
作者:Jack Chen 636 次浏览评论:06 年前
原文:PHP正则表达式完整手册 PHP正则表达式完整手册前言 正则表达式繁琐,但功能强大,学习后的应用不仅会提高你的效率,还会给你带来绝对的成就感。只要仔细阅读这些资料,并在申请时做好一定的参考,掌握正则表达式不是问题。索引1.
阅读全文
大数据的Regex真的是正则表达式吗?
作者:青山无名2031 浏览评论:04年前
文章 讲的是大数据 正则表达式真的是一个正则表达式,正则表达式已经存在了几十年,它甚至早于今天的大数据、UI、机器学习以及几乎所有其他工具和技术。正则表达式通常被许多开发人员认为是晦涩难懂且难以学习的,他们嘲笑使用正则表达式验证电子邮件地址的人。但是,正则表达式
阅读全文
PHP中与正则表达式相关的函数集合
作者:办公桌前的清宇 1450浏览评论:05年前
之前学习正则表达式的目的是从网上抓取一些小说、文档,得到相应的视频链接并批量下载。那时的PHP初学者并不知道PHP有一个专门的抓包工具,比如Simple_html_dom.php(在我的其他博文中提到过)。
阅读全文
PHP 系列(六)PHP 正则表达式
作者:小技术专家1068查看评论:04年前
PHP 正则表达式 正则表达式是描述字符串结果的语法规则。它是一种特定的格式化模式,可以匹配、替换和截取匹配的字符串。常用语言基本都有正则表达式,比如JavaScript、java等。其实只要了解一种语言的正则使用,其他语言的正则使用就比较简单了。艺术
阅读全文
php正则表达式捕获相关问答题
【Java学习全家桶】1460道Java热点问题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522 浏览评论:153年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
php用正则表达抓取网页中文章(PHP正则表达式完全手册(gt)php正则表达式捕获(组图))
阿里云 > 云栖社区 > 主题地图 > P > PHP正则表达式捕获

推荐活动:
更多优惠>
当前主题: php regex capture 添加到采集夹
相关话题:
php regex 捕获相关博客 查看更多博客
php正则表达式组捕获

作者:meteric639 浏览评论:011年前
经过测试发现获取组捕获的php正则表达式是从$0开始的,而在工程代码中提取汉字时,JavaScript中的正则在工作中是$1..$9,因为运行速度非常快当时很快(赶上时间),我担心.properties文件中{\d}的数字顺序错误:1、可能来自{1}
阅读全文
C#正则表达式编程(四):正则表达式

作者:科技甜1234 浏览评论:04年前
正则表达式提供了一种强大、灵活、高效的文本处理方式。正则表达式的全面模式匹配表示法让您可以快速分析大量文本以找到特定的字符模式;提取、编辑、替换或删除文本的子字符串;或将提取的字符串添加到集合以生成报告。用于处理字符串,例如 HTML 处理、日志文件分析和
阅读全文
谈论正则表达式


作者:Jack Chen805 浏览评论:07年前
原文:浅谈正则表达式一、什么是正则表达式?简单地说:正则表达式是一种处理字符串匹配的语言;正则表达式描述了字符串匹配的一种模式,可以用来检查一个字符串是否收录某个子字符串,以及匹配的“删除”或“替换”操作的子字符串。二
阅读全文
PHP 正则表达式


作者:thinkyoung825 浏览人数:06年前
PHP正则表达式思维导图点击下图查看具体内容!引入正则表达式,在开发中应该经常使用。现在很多开发语言都有正则表达式的应用,比如javascript、java、.net、php等,今天我就讲讲正则表达式的道理。
阅读全文
PHP正则表达式完整手册

作者:Jack Chen 636 次浏览评论:06 年前
原文:PHP正则表达式完整手册 PHP正则表达式完整手册前言 正则表达式繁琐,但功能强大,学习后的应用不仅会提高你的效率,还会给你带来绝对的成就感。只要仔细阅读这些资料,并在申请时做好一定的参考,掌握正则表达式不是问题。索引1.
阅读全文
大数据的Regex真的是正则表达式吗?


作者:青山无名2031 浏览评论:04年前
文章 讲的是大数据 正则表达式真的是一个正则表达式,正则表达式已经存在了几十年,它甚至早于今天的大数据、UI、机器学习以及几乎所有其他工具和技术。正则表达式通常被许多开发人员认为是晦涩难懂且难以学习的,他们嘲笑使用正则表达式验证电子邮件地址的人。但是,正则表达式
阅读全文
PHP中与正则表达式相关的函数集合


作者:办公桌前的清宇 1450浏览评论:05年前
之前学习正则表达式的目的是从网上抓取一些小说、文档,得到相应的视频链接并批量下载。那时的PHP初学者并不知道PHP有一个专门的抓包工具,比如Simple_html_dom.php(在我的其他博文中提到过)。
阅读全文
PHP 系列(六)PHP 正则表达式

作者:小技术专家1068查看评论:04年前
PHP 正则表达式 正则表达式是描述字符串结果的语法规则。它是一种特定的格式化模式,可以匹配、替换和截取匹配的字符串。常用语言基本都有正则表达式,比如JavaScript、java等。其实只要了解一种语言的正则使用,其他语言的正则使用就比较简单了。艺术
阅读全文
php正则表达式捕获相关问答题
【Java学习全家桶】1460道Java热点问题,百位阿里巴巴技术专家答疑解惑


作者:管理贝贝19522 浏览评论:153年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
php用正则表达抓取网页中文章(Chapter07||抽取数据之正则表达式在说,先说 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-01 19:16
)
第七章 | 用于提取数据的正则表达式
在说正则表达式之前,先说一下下面的网页结构
根据网站的组成结构,网站可以分为以下两种
一、网站介绍1、网站
对于爬虫:
无论是静态的还是动态的网站,HTML页面“隐藏”有价值的数据信息
使用网络爬虫提取信息需要了解页面的 HTML 标签使用和分布
2、HTML 语言
一个完整的 HTML 文件包括:
一般HTML文件的编写遵循以下格式:
3、从网页中提取数据
借助Python网络库,构建的爬虫可以爬取HTML页面的数据
通过以下方式从抓取的页面数据中提取有价值的数据:
二、正则表达式
面对复杂的HTML页面,往往需要提取出需要的信息,比如ID号等。
使用简短的字符串表达式来匹配此信息:
正则表达式具有独立的语法和处理引擎。在支持正则表达式的语言中,正则表达式的语法是一致的
不同的编程语言实现支持不同数量的语法:
1、正则表达式工作流程
2、正则表达式语言
正则表达式语言由两种基本字符类型组成
3、正则表达式的分组
如果要匹配重复的字符串,用括号()包裹目标字符串
分组可以分为两种形式:
4、正则表达式捕获5、非捕获组和捕获组
eg: 匹配 0 到 100 范围内的整数
三、重新库
re 是一个专门用于处理正则表达式的 Python 模块,通常具有以下功能:
下面依次解释
查看全部
php用正则表达抓取网页中文章(Chapter07||抽取数据之正则表达式在说,先说
)
第七章 | 用于提取数据的正则表达式
在说正则表达式之前,先说一下下面的网页结构
根据网站的组成结构,网站可以分为以下两种
一、网站介绍1、网站
对于爬虫:
无论是静态的还是动态的网站,HTML页面“隐藏”有价值的数据信息
使用网络爬虫提取信息需要了解页面的 HTML 标签使用和分布
2、HTML 语言
一个完整的 HTML 文件包括:
一般HTML文件的编写遵循以下格式:
3、从网页中提取数据
借助Python网络库,构建的爬虫可以爬取HTML页面的数据
通过以下方式从抓取的页面数据中提取有价值的数据:
二、正则表达式
面对复杂的HTML页面,往往需要提取出需要的信息,比如ID号等。
使用简短的字符串表达式来匹配此信息:
正则表达式具有独立的语法和处理引擎。在支持正则表达式的语言中,正则表达式的语法是一致的
不同的编程语言实现支持不同数量的语法:

1、正则表达式工作流程

2、正则表达式语言
正则表达式语言由两种基本字符类型组成
3、正则表达式的分组
如果要匹配重复的字符串,用括号()包裹目标字符串
分组可以分为两种形式:
4、正则表达式捕获5、非捕获组和捕获组
eg: 匹配 0 到 100 范围内的整数

三、重新库
re 是一个专门用于处理正则表达式的 Python 模块,通常具有以下功能:

下面依次解释








php用正则表达抓取网页中文章(Python/JavaScript中是否存在支持可变长度-assertion的正则表达式实现?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-01 04:10
Python/PHP/JavaScript 中是否有支持变长lookbehind-assertion 的正则表达式实现?
/(?
如何写一个意义相同但不使用lookbehind-assertion的正则表达式?
这样的断言一天能实现吗?
我觉得情况好多了。
更新:
(1)已经有一些正则表达式实现支持变长lookbehind断言。
Python 模块正则表达式(不是标准的 re,而是其他正则表达式模块)支持此类断言(并具有许多其他不错的功能)。
>>> import regex
>>> m = regex.search('(?>> print m.group()
bar
>>> m = regex.search('(?>> print m
None
对我来说,Perl 和 Python 不使用正则表达式非常令人惊讶。也许,Perl 也有一个“增强的正则表达式”实现?
(感谢 MRAB + 1)。
(2)现代正则表达式有一个很酷的特性正则表达式。
表示法意味着当您进行替换时(在我看来,断言最有趣的用例是替换),在正则表达式之前找到的所有字符都不得更改。
s/unchanged-part\Kchanged-part/new-part/x
这几乎就像一个后断言,但肯定没有那么灵活。
更多关于正则表达式:
据我了解,您不能在同一个正则表达式中使用 \K 两次。而且,在“杀死”你找到的角色之前,你无法分辨。这总是一直到行首。
(感谢 ikegami +1)。
我的其他问题: 查看全部
php用正则表达抓取网页中文章(Python/JavaScript中是否存在支持可变长度-assertion的正则表达式实现?)
Python/PHP/JavaScript 中是否有支持变长lookbehind-assertion 的正则表达式实现?
/(?
如何写一个意义相同但不使用lookbehind-assertion的正则表达式?
这样的断言一天能实现吗?
我觉得情况好多了。
更新:
(1)已经有一些正则表达式实现支持变长lookbehind断言。
Python 模块正则表达式(不是标准的 re,而是其他正则表达式模块)支持此类断言(并具有许多其他不错的功能)。
>>> import regex
>>> m = regex.search('(?>> print m.group()
bar
>>> m = regex.search('(?>> print m
None
对我来说,Perl 和 Python 不使用正则表达式非常令人惊讶。也许,Perl 也有一个“增强的正则表达式”实现?
(感谢 MRAB + 1)。
(2)现代正则表达式有一个很酷的特性正则表达式。
表示法意味着当您进行替换时(在我看来,断言最有趣的用例是替换),在正则表达式之前找到的所有字符都不得更改。
s/unchanged-part\Kchanged-part/new-part/x
这几乎就像一个后断言,但肯定没有那么灵活。
更多关于正则表达式:
据我了解,您不能在同一个正则表达式中使用 \K 两次。而且,在“杀死”你找到的角色之前,你无法分辨。这总是一直到行首。
(感谢 ikegami +1)。
我的其他问题:
php用正则表达抓取网页中文章(聚焦爬虫过程中数据解析的第一类,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-29 18:05
)
我一直觉得正则表达式非常少见。今天的学习真的很特别。这真的很难理解,但重要的是要学习一些简单的元字符来提取数据。我们不需要自己写,其实可以复制;
有很多在线正则表达式测试,如菜鸟教程、OSCHINA的在线工具等;
它们都可以帮助我们很好地编写一些测试。多了解多点就OK啦~
最重要的就是爬虫中对网页标签内容和标签属性的爬取,这需要我们的懒惰匹配,一定要了解和实践。
以下是我学习的专注爬虫过程中的第一类数据分析:规律性;
最好把代码放在编辑器中浏览,效果会更好,推荐VS Code。
#? 通用爬虫 聚焦爬虫 增量式爬虫
#? 聚焦爬虫:爬取页面中指定的页面内容 满足75%以上的需求
'''
编码流程:
(1)指定URL
(2)发起请求
(3)获取响应数据
(4)数据解析
(5)持久化存储
'''
#? 数据解析分类: 正则 bs4 xpath(重点学习,通用性比较强)
#* 数据解析原理
'''
解析的局部的文本内容都会存储在标签之间或者标签中的属性值
(1) 进行执行标签的定位
(2) 标签或者标签对应的属性中存储的数据值进行提取(解析)
'''
#? 正则表达式
'''
元字符
(1) . 匹配除换行符意外的任意字符
(2) \w 匹配字母或数字或下划线
(3) \s 匹配任意的空白符
(4) \d 匹配数字
(5) \n 匹配一个换行符
(6) \t 匹配一个制表符
(7) ^ 匹配字符串的开始
(8) $ 匹配字符串的结尾
(9) \W 匹配非字母或数字或下划线
(10) \S 匹配非空白符
(11) \D 匹配非数字 (9)
(12) a|b 匹配字符a或者字符b
(13) () 匹配括号内的表达式,也表示一个组
(14) [...] 匹配字符组中的字符
(15) [^...] 匹配除了字符组中字符的所有字符
量词
#? 比如 \d{11}
* 重复零次或者更多次 {0,正无穷}
+ 重复一次或者更多次 {1,正无穷}
? 重复0次或者一次 {0,1}
{n} 重复n次
{n,} 重复n次或者更多次
{n,m} 重复n到m次
#! 贪婪匹配和惰性匹配
(1) .* 贪婪匹配 匹配所有
(2) .*? 惰性匹配 匹配少的,较短的
#! 爬虫用的最多的就是惰性匹配
#! 玩儿吃鸡游戏,晚上一起玩游戏,玩游戏吗?
#? 玩儿.*游戏 -- 匹配结果是 :玩儿吃鸡游戏,晚上一起玩游戏,玩游戏
#? 玩儿.*?游戏 -- 匹配结果是:玩儿吃鸡游戏
#? 玩.*?游戏 -- 匹配结果是 玩儿吃鸡游戏 玩游戏 玩游戏
#! 匹配标签的内容 周杰伦林俊杰
#? .* -- 匹配结果是
#! 周杰伦林俊杰
#? .*? -- 匹配结果是
#! 周杰伦
#? .*? -- 匹配结果是
#! 周杰伦林俊杰
#? .*?
#! 周杰伦
#! 林俊杰
''' 查看全部
php用正则表达抓取网页中文章(聚焦爬虫过程中数据解析的第一类,你知道吗?
)
我一直觉得正则表达式非常少见。今天的学习真的很特别。这真的很难理解,但重要的是要学习一些简单的元字符来提取数据。我们不需要自己写,其实可以复制;
有很多在线正则表达式测试,如菜鸟教程、OSCHINA的在线工具等;
它们都可以帮助我们很好地编写一些测试。多了解多点就OK啦~
最重要的就是爬虫中对网页标签内容和标签属性的爬取,这需要我们的懒惰匹配,一定要了解和实践。
以下是我学习的专注爬虫过程中的第一类数据分析:规律性;
最好把代码放在编辑器中浏览,效果会更好,推荐VS Code。
#? 通用爬虫 聚焦爬虫 增量式爬虫
#? 聚焦爬虫:爬取页面中指定的页面内容 满足75%以上的需求
'''
编码流程:
(1)指定URL
(2)发起请求
(3)获取响应数据
(4)数据解析
(5)持久化存储
'''
#? 数据解析分类: 正则 bs4 xpath(重点学习,通用性比较强)
#* 数据解析原理
'''
解析的局部的文本内容都会存储在标签之间或者标签中的属性值
(1) 进行执行标签的定位
(2) 标签或者标签对应的属性中存储的数据值进行提取(解析)
'''
#? 正则表达式
'''
元字符
(1) . 匹配除换行符意外的任意字符
(2) \w 匹配字母或数字或下划线
(3) \s 匹配任意的空白符
(4) \d 匹配数字
(5) \n 匹配一个换行符
(6) \t 匹配一个制表符
(7) ^ 匹配字符串的开始
(8) $ 匹配字符串的结尾
(9) \W 匹配非字母或数字或下划线
(10) \S 匹配非空白符
(11) \D 匹配非数字 (9)
(12) a|b 匹配字符a或者字符b
(13) () 匹配括号内的表达式,也表示一个组
(14) [...] 匹配字符组中的字符
(15) [^...] 匹配除了字符组中字符的所有字符
量词
#? 比如 \d{11}
* 重复零次或者更多次 {0,正无穷}
+ 重复一次或者更多次 {1,正无穷}
? 重复0次或者一次 {0,1}
{n} 重复n次
{n,} 重复n次或者更多次
{n,m} 重复n到m次
#! 贪婪匹配和惰性匹配
(1) .* 贪婪匹配 匹配所有
(2) .*? 惰性匹配 匹配少的,较短的
#! 爬虫用的最多的就是惰性匹配
#! 玩儿吃鸡游戏,晚上一起玩游戏,玩游戏吗?
#? 玩儿.*游戏 -- 匹配结果是 :玩儿吃鸡游戏,晚上一起玩游戏,玩游戏
#? 玩儿.*?游戏 -- 匹配结果是:玩儿吃鸡游戏
#? 玩.*?游戏 -- 匹配结果是 玩儿吃鸡游戏 玩游戏 玩游戏
#! 匹配标签的内容 周杰伦林俊杰
#? .* -- 匹配结果是
#! 周杰伦林俊杰
#? .*? -- 匹配结果是
#! 周杰伦
#? .*? -- 匹配结果是
#! 周杰伦林俊杰
#? .*?
#! 周杰伦
#! 林俊杰
'''
php用正则表达抓取网页中文章(我正在寻找一个体面的正则表达式来验证作为用户输入的URL )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-19 11:30
)
为了澄清,我正在寻找一个体面的正则表达式来验证作为用户输入输入的 URL。我对从给定的文本字符串解析 URL 列表不感兴趣(即使此页面上的某些正则表达式会这样做)。我也不想允许所有可能的技术上有效的 URL - 恰恰相反。如果您希望以与浏览器相同的方式解析 URL,请参阅
假设这个正则表达式将用于用 PHP 编写的公共 URL 缩短器,所以 URL 像 //foo.bar/,://foo.bar/,data:text/plain;charset=utf-8,OHAIandtel: + 1234567890 不应通过(即使它们在技术上是有效的)。此外,在这种情况下,我只想允许 HTTP、HTTPS 和 FTP 协议。
此外,不测试单个奇数前导和/或尾随字符。想象一下,在使用正则表达式进行测试之前,您正在这样做 $url:
$url = trim($url, '!"#$%&\'()*+,-./@:;[\\]^_`{|}~');
请注意,我已将修饰符添加到 S 所有正则表达式以加快测试速度。在实际使用中,这个修饰符可以省略。
这是测试中使用的所有 URL 的纯文本列表。
Diego Perini 发布了他的版本作为要点。
勺子库(979 个字符)
/(((http|ftp|https):\/{2})+(([0-9a-z_-]+\.)+(aero|asia|biz|cat|com|coop|edu|gov|info|int|jobs|mil|mobi|museum|name|net|org|pro|tel|travel|ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cu|cv|cx|cy|cz|cz|de|dj|dk|dm|do|dz|ec|ee|eg|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|in|io|iq|ir|is|it|je|jm|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mk|ml|mn|mn|mo|mp|mr|ms|mt|mu|mv|mw|mx|my|mz|na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|nom|pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|qa|re|ra|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|sj|sk|sl|sm|sn|so|sr|st|su|sv|sy|sz|tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|ua|ug|uk|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|yu|za|zm|zw|arpa)(:[0-9]+)?((\/([~0-9a-zA-Z\#\+\%@\.\/_-]+))?(\?[0-9a-zA-Z\+\%@\/&\[\];=_-]+)?)?))\b/imuS
@krijnhoetmer(115 个字符)
_(^|[\s.:;?\-\]\)])_i
@gruber(71 个字符)
#\b(([\w-]+://?|www[.])[^\s()]+(?:\([\w\d]+\)|([^[:punct:]\s]|/)))#iS
@gruber v2(218 个字符)
#(?i)\b((?:[a-z][\w-]+:(?:/{1,3}|[a-z0-9%])|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()]+|\(([^\s()]+|(\([^\s()]+\)))*\))+(?:\(([^\s()]+|(\([^\s()]+\)))*\)|[^\s`!()\[\]{};:'".,?«»“”‘’]))#iS
@cowboy(1241 个字符)
~(?:\b[a-z\d.-]+://[^\s]+|\b(?:(?:(?:[^\s!@#$%^&*()_=+[\]{}\|;:'",./?]+)\.)+(?:ac|ad|aero|ae|af|ag|ai|al|am|an|ao|aq|arpa|ar|asia|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|biz|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|cat|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|coop|com|co|cr|cu|cv|cx|cy|cz|de|dj|dk|dm|do|dz|ec|edu|ee|eg|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gov|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|info|int|in|io|iq|ir|is|it|je|jm|jobs|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mil|mk|ml|mm|mn|mobi|mo|mp|mq|mr|ms|mt|museum|mu|mv|mw|mx|my|mz|name|na|nc|net|ne|nf|ng|ni|nl|no|np|nr|nu|nz|om|org|pa|pe|pf|pg|ph|pk|pl|pm|pn|pro|pr|ps|pt|pw|py|qa|re|ro|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|sk|sl|sm|sn|so|sr|st|su|sv|sy|sz|tc|td|tel|tf|tg|th|tj|tk|tl|tm|tn|to|tp|travel|tr|tt|tv|tw|tz|ua|ug|uk|um|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|xn--0zwm56d|xn--11b5bs3a9aj6g|xn--80akhbyknj4f|xn--9t4b11yi5a|xn--deba0ad|xn--g6w251d|xn--hgbk6aj7f53bba|xn--hlcj6aya9esc7a|xn--jxalpdlp|xn--kgbechtv|xn--zckzah|ye|yt|yu|za|zm|zw)|(?:(?:[0-9]|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5])\.){3}(?:[0-9]|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5]))(?:[;/][^#?\s]*)?(?:\?[^#\s]*)?(?:#[^\s]*)?(?!\w))~iS
杰弗里弗里德尔(241 个字符)
@\b((ftp|https?)://[-\w]+(\.\w[-\w]*)+|(?:[a-z0-9](?:[-a-z0-9]*[a-z0-9])?\.)+(?: com\b|edu\b|biz\b|gov\b|in(?:t|fo)\b|mil\b|net\b|org\b|[a-z][a-z]\b))(\:\d+)?(/[^.!,?;"'()\[\]{}\s\x7F-\xFF]*(?:[.!,?]+[^.!,?;"'()\[\]{}\s\x7F-\xFF]+)*)?@iS
@mattfarina(287 个字符)
@stephenhay(38 个字符)
@^(https?|ftp)://[^\s/$.?#].[^\s]*$@iS
@scottgonzales(1347 个字符)
#([a-z]([a-z]|\d|\+|-|\.)*):(\/\/(((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:)*@)?((\[(|(v[\da-f]{1,}\.(([a-z]|\d|-|\.|_|~)|[!\$&'\(\)\*\+,;=]|:)+))\])|((\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5]))|(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=])*)(:\d*)?)(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*|(\/((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)+(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*)?)|((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)+(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*)|((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)){0})(\?((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)|[\xE000-\xF8FF]|\/|\?)*)?(\#((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)|\/|\?)*)?#iS
@rodneyrehm(109 个字符)
#((https?://|ftp://|www\.|[^\s:=]+@www\.).*?[a-z_\/0-9\-\#=&])(?=(\.|,|;|\?|\!)?("|'|«|»|\[|\s|\r|\n|$))#iS
@imme_emosol(54 个字符)
@(https?|ftp)://(-\.)?([^\s/?\.#-]+\.?)+(/[^\s]*)?$@iS
@diegoperini(502 个字符)
_^(?:(?:https?|ftp)://)(?:\S+(?::\S*)?@)?(?:(?!10(?:\.\d{1,3}){3})(?!127(?:\.\d{1,3}){3})(?!169\.254(?:\.\d{1,3}){2})(?!192\.168(?:\.\d{1,3}){2})(?!172\.(?:1[6-9]|2\d|3[0-1])(?:\.\d{1,3}){2})(?:[1-9]\d?|1\d\d|2[01]\d|22[0-3])(?:\.(?:1?\d{1,2}|2[0-4]\d|25[0-5])){2}(?:\.(?:[1-9]\d?|1\d\d|2[0-4]\d|25[0-4]))|(?:(?:[a-z\x{00a1}-\x{ffff}0-9]+-?)*[a-z\x{00a1}-\x{ffff}0-9]+)(?:\.(?:[a-z\x{00a1}-\x{ffff}0-9]+-?)*[a-z\x{00a1}-\x{ffff}0-9]+)*(?:\.(?:[a-z\x{00a1}-\x{ffff}]{2,})))(?::\d{2,5})?(?:/[^\s]*)?$_iuS 查看全部
php用正则表达抓取网页中文章(我正在寻找一个体面的正则表达式来验证作为用户输入的URL
)
为了澄清,我正在寻找一个体面的正则表达式来验证作为用户输入输入的 URL。我对从给定的文本字符串解析 URL 列表不感兴趣(即使此页面上的某些正则表达式会这样做)。我也不想允许所有可能的技术上有效的 URL - 恰恰相反。如果您希望以与浏览器相同的方式解析 URL,请参阅
假设这个正则表达式将用于用 PHP 编写的公共 URL 缩短器,所以 URL 像 //foo.bar/,://foo.bar/,data:text/plain;charset=utf-8,OHAIandtel: + 1234567890 不应通过(即使它们在技术上是有效的)。此外,在这种情况下,我只想允许 HTTP、HTTPS 和 FTP 协议。
此外,不测试单个奇数前导和/或尾随字符。想象一下,在使用正则表达式进行测试之前,您正在这样做 $url:
$url = trim($url, '!"#$%&\'()*+,-./@:;[\\]^_`{|}~');
请注意,我已将修饰符添加到 S 所有正则表达式以加快测试速度。在实际使用中,这个修饰符可以省略。
这是测试中使用的所有 URL 的纯文本列表。
Diego Perini 发布了他的版本作为要点。

勺子库(979 个字符)
/(((http|ftp|https):\/{2})+(([0-9a-z_-]+\.)+(aero|asia|biz|cat|com|coop|edu|gov|info|int|jobs|mil|mobi|museum|name|net|org|pro|tel|travel|ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cu|cv|cx|cy|cz|cz|de|dj|dk|dm|do|dz|ec|ee|eg|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|in|io|iq|ir|is|it|je|jm|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mk|ml|mn|mn|mo|mp|mr|ms|mt|mu|mv|mw|mx|my|mz|na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|nom|pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|qa|re|ra|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|sj|sk|sl|sm|sn|so|sr|st|su|sv|sy|sz|tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|ua|ug|uk|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|yu|za|zm|zw|arpa)(:[0-9]+)?((\/([~0-9a-zA-Z\#\+\%@\.\/_-]+))?(\?[0-9a-zA-Z\+\%@\/&\[\];=_-]+)?)?))\b/imuS
@krijnhoetmer(115 个字符)
_(^|[\s.:;?\-\]\)])_i
@gruber(71 个字符)
#\b(([\w-]+://?|www[.])[^\s()]+(?:\([\w\d]+\)|([^[:punct:]\s]|/)))#iS
@gruber v2(218 个字符)
#(?i)\b((?:[a-z][\w-]+:(?:/{1,3}|[a-z0-9%])|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()]+|\(([^\s()]+|(\([^\s()]+\)))*\))+(?:\(([^\s()]+|(\([^\s()]+\)))*\)|[^\s`!()\[\]{};:'".,?«»“”‘’]))#iS
@cowboy(1241 个字符)
~(?:\b[a-z\d.-]+://[^\s]+|\b(?:(?:(?:[^\s!@#$%^&*()_=+[\]{}\|;:'",./?]+)\.)+(?:ac|ad|aero|ae|af|ag|ai|al|am|an|ao|aq|arpa|ar|asia|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|biz|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|cat|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|coop|com|co|cr|cu|cv|cx|cy|cz|de|dj|dk|dm|do|dz|ec|edu|ee|eg|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gov|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|info|int|in|io|iq|ir|is|it|je|jm|jobs|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mil|mk|ml|mm|mn|mobi|mo|mp|mq|mr|ms|mt|museum|mu|mv|mw|mx|my|mz|name|na|nc|net|ne|nf|ng|ni|nl|no|np|nr|nu|nz|om|org|pa|pe|pf|pg|ph|pk|pl|pm|pn|pro|pr|ps|pt|pw|py|qa|re|ro|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|sk|sl|sm|sn|so|sr|st|su|sv|sy|sz|tc|td|tel|tf|tg|th|tj|tk|tl|tm|tn|to|tp|travel|tr|tt|tv|tw|tz|ua|ug|uk|um|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|xn--0zwm56d|xn--11b5bs3a9aj6g|xn--80akhbyknj4f|xn--9t4b11yi5a|xn--deba0ad|xn--g6w251d|xn--hgbk6aj7f53bba|xn--hlcj6aya9esc7a|xn--jxalpdlp|xn--kgbechtv|xn--zckzah|ye|yt|yu|za|zm|zw)|(?:(?:[0-9]|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5])\.){3}(?:[0-9]|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5]))(?:[;/][^#?\s]*)?(?:\?[^#\s]*)?(?:#[^\s]*)?(?!\w))~iS
杰弗里弗里德尔(241 个字符)
@\b((ftp|https?)://[-\w]+(\.\w[-\w]*)+|(?:[a-z0-9](?:[-a-z0-9]*[a-z0-9])?\.)+(?: com\b|edu\b|biz\b|gov\b|in(?:t|fo)\b|mil\b|net\b|org\b|[a-z][a-z]\b))(\:\d+)?(/[^.!,?;"'()\[\]{}\s\x7F-\xFF]*(?:[.!,?]+[^.!,?;"'()\[\]{}\s\x7F-\xFF]+)*)?@iS
@mattfarina(287 个字符)
@stephenhay(38 个字符)
@^(https?|ftp)://[^\s/$.?#].[^\s]*$@iS
@scottgonzales(1347 个字符)
#([a-z]([a-z]|\d|\+|-|\.)*):(\/\/(((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:)*@)?((\[(|(v[\da-f]{1,}\.(([a-z]|\d|-|\.|_|~)|[!\$&'\(\)\*\+,;=]|:)+))\])|((\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5]))|(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=])*)(:\d*)?)(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*|(\/((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)+(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*)?)|((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)+(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*)|((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)){0})(\?((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)|[\xE000-\xF8FF]|\/|\?)*)?(\#((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)|\/|\?)*)?#iS
@rodneyrehm(109 个字符)
#((https?://|ftp://|www\.|[^\s:=]+@www\.).*?[a-z_\/0-9\-\#=&])(?=(\.|,|;|\?|\!)?("|'|«|»|\[|\s|\r|\n|$))#iS
@imme_emosol(54 个字符)
@(https?|ftp)://(-\.)?([^\s/?\.#-]+\.?)+(/[^\s]*)?$@iS
@diegoperini(502 个字符)
_^(?:(?:https?|ftp)://)(?:\S+(?::\S*)?@)?(?:(?!10(?:\.\d{1,3}){3})(?!127(?:\.\d{1,3}){3})(?!169\.254(?:\.\d{1,3}){2})(?!192\.168(?:\.\d{1,3}){2})(?!172\.(?:1[6-9]|2\d|3[0-1])(?:\.\d{1,3}){2})(?:[1-9]\d?|1\d\d|2[01]\d|22[0-3])(?:\.(?:1?\d{1,2}|2[0-4]\d|25[0-5])){2}(?:\.(?:[1-9]\d?|1\d\d|2[0-4]\d|25[0-4]))|(?:(?:[a-z\x{00a1}-\x{ffff}0-9]+-?)*[a-z\x{00a1}-\x{ffff}0-9]+)(?:\.(?:[a-z\x{00a1}-\x{ffff}0-9]+-?)*[a-z\x{00a1}-\x{ffff}0-9]+)*(?:\.(?:[a-z\x{00a1}-\x{ffff}]{2,})))(?::\d{2,5})?(?:/[^\s]*)?$_iuS
Pandas爬虫,竟能如此简单!
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-05-08 21:26
文章:菜J学Pythyon
众所周知,一般的爬虫套路无非是构造请求、解析网页、提取要素、存储数据等步骤。构造请求主要用到requests库,提取要素用的比较多的有xpath、bs4、css和re。一个完整的爬虫,代码量少则几十行,多则几百行,对于新手来说学习成本还是比较高的。
那么,有没有什么方法只用几行代码就能爬下所需数据呢?答案是pandas。J哥自从知道了这个神器,尝试了多个网页数据爬取,屡战屡胜,简直不能再舒服!这家伙也太适合初学爬虫的小伙伴玩耍了吧!
本文目录
01定 义
pandas中的pd.read_html()这个函数,功能非常强大,可以轻松实现抓取Table表格型数据。无需掌握正则表达式或者xpath等工具,短短的几行代码就可以将网页数据抓取下来。
02原 理
一.Table表格型数据网页结构
pandas适合抓取Table表格型数据,那么咱们首先得知道什么样的网页具有Table表格型数据结构(有html基础的大佬可自行跳过这一part)。
我们先来看个简单的例子。(快捷键F12可快速查看网页的HTML结构)
指南者留学网
从这个世界大学排行的网站可以看出,数据存储在一个table表格中,thread为表头,tbody为表格数据,tbody中的一个tr对应表中的一行,一个td对应一个表中元素。
我们再来看一个例子:
新浪财经网
也许你已经发现了规律,以Table结构展示的表格数据,大致的网页结构如下:
... ... ... ... ... ... ...
Table表格一般网页结构
只要网页具有以上结构,你就可以尝试用pandas抓取数据。
二.pandas请求表格数据原理
基本流程
针对网页结构类似的表格类型数据,pd.read_html可以将网页上的表格数据都抓取下来,并以DataFrame的形式装在一个list中返回。
三.pd.read_html语法及参数
pandas.read_html(io, match='.+', flavor=None, header=None,index_col=None,skiprows=None, attrs=None, parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
基本语法
io :接收网址、文件、字符串;parse_dates:解析日期;flavor:解析器;header:标题行;skiprows:跳过的行;attrs:属性,比如 attrs = {'id': 'table'}
主要参数
03实 战
一.案例1:抓取世界大学排名(1页数据)
1import pandas as pd 2import csv3url1 = 'http://www.compassedu.hk/qs'4df1 = pd.read_html(url1)[0] #0表示网页中的第一个Table5df1.to_csv('世界大学综合排名.csv',index=0)
没错,5行代码,几秒钟就搞定,我们来预览下爬取到的数据:
世界大学排行榜
二.案例2:抓取新浪财经基金重仓股数据(6页数据)
1import pandas as pd2import csv3df2 = pd.DataFrame()4for i in range(6):5 url2 = 'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={page}'.format(page=i+1)6 df2 = pd.concat([df2,pd.read_html(url2)[0]])7 print('第{page}页抓取完成'.format(page = i + 1))8df2.to_csv('./新浪财经数据.csv',encoding='utf-8',index=0)
没错,8行代码搞定,还是那么简单。如果对翻页爬虫不理解,可查看本公众号历史原创文章「实战|手把手教你用Python爬虫(附详细源码)」,如果对DataFrame合并不理解,可查看本公众号历史原创文章「基础|Pandas常用知识点汇总(四)」。
我们来预览下爬取到的数据:
基金重仓股数据
三.案例3:抓取证监会披露的IPO数据(217页数据)
1import pandas as pd 2from pandas import DataFrame 3import csv 4import time 5start = time.time() #计时 6df3 = DataFrame(data=None,columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料']) #添加列名 7for i in range(1,218): 8 url3 ='http://eid.csrc.gov.cn/ipo/infoDisplay.action?pageNo=%s&temp=&temp1=&blockType=byTime'%str(i) 9 df3_1 = pd.read_html(url3,encoding='utf-8')[2] #必须加utf-8,否则乱码10 df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1] #过滤掉最后一行和最后一列(NaN列)11 df3_2.columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料'] #新的df添加列名12 df3 = pd.concat([df3,df3_2]) #数据合并13 print('第{page}页抓取完成'.format(page=i))14df3.to_csv('./上市公司IPO信息.csv', encoding='utf-8',index=0) #保存数据到csv文件15end = time.time()16print ('共抓取',len(df3),'家公司,' + '用时',round((end-start)/60,2),'分钟')
这里注意要对抓下来的Table数据进行过滤,主要用到iloc方法,详情可查看本公众号往期原创文章「基础|Pandas常用知识点汇总(三)」。另外,我还加了个程序计时,方便查看爬取速度。
2分钟爬下217页4334条数据,相当nice了。我们来预览下爬取到的数据:
上市公司IPO数据
需要注意的是,并不是所有表格都可以用pd.read_html爬取,有的网站表面上看起来是表格,但在网页源代码中不是table格式,而是list列表格式。这种表格则不适用read_html爬取,得用其他的方法,比如selenium。
- 合作、交流、转载请添加微信 moonhmily1 -<p style="white-space: normal;font-size: 16px;"><br />
</p> 查看全部
Pandas爬虫,竟能如此简单!
文章:菜J学Pythyon
众所周知,一般的爬虫套路无非是构造请求、解析网页、提取要素、存储数据等步骤。构造请求主要用到requests库,提取要素用的比较多的有xpath、bs4、css和re。一个完整的爬虫,代码量少则几十行,多则几百行,对于新手来说学习成本还是比较高的。
那么,有没有什么方法只用几行代码就能爬下所需数据呢?答案是pandas。J哥自从知道了这个神器,尝试了多个网页数据爬取,屡战屡胜,简直不能再舒服!这家伙也太适合初学爬虫的小伙伴玩耍了吧!
本文目录
01定 义
pandas中的pd.read_html()这个函数,功能非常强大,可以轻松实现抓取Table表格型数据。无需掌握正则表达式或者xpath等工具,短短的几行代码就可以将网页数据抓取下来。
02原 理
一.Table表格型数据网页结构
pandas适合抓取Table表格型数据,那么咱们首先得知道什么样的网页具有Table表格型数据结构(有html基础的大佬可自行跳过这一part)。
我们先来看个简单的例子。(快捷键F12可快速查看网页的HTML结构)
指南者留学网
从这个世界大学排行的网站可以看出,数据存储在一个table表格中,thread为表头,tbody为表格数据,tbody中的一个tr对应表中的一行,一个td对应一个表中元素。
我们再来看一个例子:
新浪财经网
也许你已经发现了规律,以Table结构展示的表格数据,大致的网页结构如下:
... ... ... ... ... ... ...
Table表格一般网页结构
只要网页具有以上结构,你就可以尝试用pandas抓取数据。
二.pandas请求表格数据原理
基本流程
针对网页结构类似的表格类型数据,pd.read_html可以将网页上的表格数据都抓取下来,并以DataFrame的形式装在一个list中返回。
三.pd.read_html语法及参数
pandas.read_html(io, match='.+', flavor=None, header=None,index_col=None,skiprows=None, attrs=None, parse_dates=False, thousands=', ', encoding=None, decimal='.', converters=None, na_values=None, keep_default_na=True, displayed_only=True)
基本语法
io :接收网址、文件、字符串;parse_dates:解析日期;flavor:解析器;header:标题行;skiprows:跳过的行;attrs:属性,比如 attrs = {'id': 'table'}
主要参数
03实 战
一.案例1:抓取世界大学排名(1页数据)
1import pandas as pd 2import csv3url1 = 'http://www.compassedu.hk/qs'4df1 = pd.read_html(url1)[0] #0表示网页中的第一个Table5df1.to_csv('世界大学综合排名.csv',index=0)
没错,5行代码,几秒钟就搞定,我们来预览下爬取到的数据:
世界大学排行榜
二.案例2:抓取新浪财经基金重仓股数据(6页数据)
1import pandas as pd2import csv3df2 = pd.DataFrame()4for i in range(6):5 url2 = 'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={page}'.format(page=i+1)6 df2 = pd.concat([df2,pd.read_html(url2)[0]])7 print('第{page}页抓取完成'.format(page = i + 1))8df2.to_csv('./新浪财经数据.csv',encoding='utf-8',index=0)
没错,8行代码搞定,还是那么简单。如果对翻页爬虫不理解,可查看本公众号历史原创文章「实战|手把手教你用Python爬虫(附详细源码)」,如果对DataFrame合并不理解,可查看本公众号历史原创文章「基础|Pandas常用知识点汇总(四)」。
我们来预览下爬取到的数据:
基金重仓股数据
三.案例3:抓取证监会披露的IPO数据(217页数据)
1import pandas as pd 2from pandas import DataFrame 3import csv 4import time 5start = time.time() #计时 6df3 = DataFrame(data=None,columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料']) #添加列名 7for i in range(1,218): 8 url3 ='http://eid.csrc.gov.cn/ipo/infoDisplay.action?pageNo=%s&temp=&temp1=&blockType=byTime'%str(i) 9 df3_1 = pd.read_html(url3,encoding='utf-8')[2] #必须加utf-8,否则乱码10 df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1] #过滤掉最后一行和最后一列(NaN列)11 df3_2.columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料'] #新的df添加列名12 df3 = pd.concat([df3,df3_2]) #数据合并13 print('第{page}页抓取完成'.format(page=i))14df3.to_csv('./上市公司IPO信息.csv', encoding='utf-8',index=0) #保存数据到csv文件15end = time.time()16print ('共抓取',len(df3),'家公司,' + '用时',round((end-start)/60,2),'分钟')
这里注意要对抓下来的Table数据进行过滤,主要用到iloc方法,详情可查看本公众号往期原创文章「基础|Pandas常用知识点汇总(三)」。另外,我还加了个程序计时,方便查看爬取速度。
2分钟爬下217页4334条数据,相当nice了。我们来预览下爬取到的数据:
上市公司IPO数据
需要注意的是,并不是所有表格都可以用pd.read_html爬取,有的网站表面上看起来是表格,但在网页源代码中不是table格式,而是list列表格式。这种表格则不适用read_html爬取,得用其他的方法,比如selenium。
- 合作、交流、转载请添加微信 moonhmily1 -<p style="white-space: normal;font-size: 16px;"><br />
我用Python做了一个编程语言20年的动态排行榜!
网站优化 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2022-05-08 21:24
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
王师北定中原日,家祭无忘告乃翁。
在编程语言的舞台上,一直有着谁是最好的语言的竞争,小编虽然一直用着几种编程语言,但是感觉个人的想法不能代表着大家的想法。虽然关于最好语言的争论从未停止过,但是关于编程语言的热度排名,我们可以从TIOBE 编程语言排行榜上进行探索。
今天,小编就带领大家爬取一下,自2001年5月至今,TIOBE 编程语言排行榜上编程语言的变化情况,看一下在接近20年的时间里,编程语言的热度是如何变化的。
01.编程语言资料获取
首先我们是进行的是资料的获取,我们打开链接,就可以看到TIOBE编程语言的排行榜,通过查看其网页源代码,可以发现,我们想要爬取的资料,都显示在网页源代码里,如下图所示:
接下来就可以直接利用爬虫来获取网页源代码,并利用正则表达式来匹配我们需要的关键字内容,部分程序如下图所示:
上述程序中,我们对于抓取到的数据,进行正则表达式匹配,然后提取各个编程语言在不同时间段的热度数值,并保存到本地的文件中。
02.清洗数据
接下来,我们要完成的就是利用动态可视化的柱状图来观察各种编程语言随着时间的热度变化。我们先对数据进行清洗,获取编程语言的名字一起设置一个嵌套的字典,程序如下图所示:
上述程序中的嵌套字典含义为每一个月份下的每种编程语言的热度值,其结构格式如下所示:
{“2020-1-12”:{“Java”:16, “C++”:14, “python”:10,…}, “2020-2-13”:{“Java”:16.3, “C++”:15.6, …},…}。
03.设置柱状图的颜色
为了在可视化过程中区分每一种编程语言,需要为柱状图中的每一柱都设置不同的颜色,同时,将嵌套字典按照月份的顺序进行排序,程序如下所示:
04.大功告成,动态显示
最后,我们便可以对数据进行可视化的展示,程序如下图所示:
上述程序中,首先需要清除figure 中的活动轴,我们对于嵌套字典的每一个月份,将每一个月份中的编程语言,按照其热度值进行从小到大的排序,然后将排序号的编程语言,关联其对应的柱状图颜色。
05.动态现实图
接下来就可以画出我们的柱状图,然后暂停显示结果,并不断循环,从而达到动态柱状图的功能,其效果如下图所示:
06.更炫酷的动态图
如果大家觉得图做的不够优美,大家可以利用js进行数据渲染制作,这里小编也为大家利用Flourish制作了一个更加好看的界面,如下图所示:
从上面的可视化动图可以看出,Java和C语言一直是牢牢地掌控着编程语言热度前两名的宝座,而python语言,凭借着人工智能的热潮,逐渐的从排名末尾,一路追赶,排名在第三位,并逐渐拉开了与第四名的差距,可谓是编程语言界的逆袭王者。
而像是C++和PHP,其热度却逐渐的走低。虽然编程语言热度有高有低,但是不可否认的是,每一门编程语言,都有其应用的价值,能够在编程语言的历史长河中历经洗礼,而没有被淘汰,只要好好掌握一门语言,都会有用武之地。
-------------------End------------------- 查看全部
我用Python做了一个编程语言20年的动态排行榜!
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
今
日
鸡
汤
王师北定中原日,家祭无忘告乃翁。
在编程语言的舞台上,一直有着谁是最好的语言的竞争,小编虽然一直用着几种编程语言,但是感觉个人的想法不能代表着大家的想法。虽然关于最好语言的争论从未停止过,但是关于编程语言的热度排名,我们可以从TIOBE 编程语言排行榜上进行探索。
今天,小编就带领大家爬取一下,自2001年5月至今,TIOBE 编程语言排行榜上编程语言的变化情况,看一下在接近20年的时间里,编程语言的热度是如何变化的。
01.编程语言资料获取
首先我们是进行的是资料的获取,我们打开链接,就可以看到TIOBE编程语言的排行榜,通过查看其网页源代码,可以发现,我们想要爬取的资料,都显示在网页源代码里,如下图所示:
接下来就可以直接利用爬虫来获取网页源代码,并利用正则表达式来匹配我们需要的关键字内容,部分程序如下图所示:
上述程序中,我们对于抓取到的数据,进行正则表达式匹配,然后提取各个编程语言在不同时间段的热度数值,并保存到本地的文件中。
02.清洗数据
接下来,我们要完成的就是利用动态可视化的柱状图来观察各种编程语言随着时间的热度变化。我们先对数据进行清洗,获取编程语言的名字一起设置一个嵌套的字典,程序如下图所示:
上述程序中的嵌套字典含义为每一个月份下的每种编程语言的热度值,其结构格式如下所示:
{“2020-1-12”:{“Java”:16, “C++”:14, “python”:10,…}, “2020-2-13”:{“Java”:16.3, “C++”:15.6, …},…}。
03.设置柱状图的颜色
为了在可视化过程中区分每一种编程语言,需要为柱状图中的每一柱都设置不同的颜色,同时,将嵌套字典按照月份的顺序进行排序,程序如下所示:
04.大功告成,动态显示
最后,我们便可以对数据进行可视化的展示,程序如下图所示:
上述程序中,首先需要清除figure 中的活动轴,我们对于嵌套字典的每一个月份,将每一个月份中的编程语言,按照其热度值进行从小到大的排序,然后将排序号的编程语言,关联其对应的柱状图颜色。
05.动态现实图
接下来就可以画出我们的柱状图,然后暂停显示结果,并不断循环,从而达到动态柱状图的功能,其效果如下图所示:
06.更炫酷的动态图
如果大家觉得图做的不够优美,大家可以利用js进行数据渲染制作,这里小编也为大家利用Flourish制作了一个更加好看的界面,如下图所示:
从上面的可视化动图可以看出,Java和C语言一直是牢牢地掌控着编程语言热度前两名的宝座,而python语言,凭借着人工智能的热潮,逐渐的从排名末尾,一路追赶,排名在第三位,并逐渐拉开了与第四名的差距,可谓是编程语言界的逆袭王者。
而像是C++和PHP,其热度却逐渐的走低。虽然编程语言热度有高有低,但是不可否认的是,每一门编程语言,都有其应用的价值,能够在编程语言的历史长河中历经洗礼,而没有被淘汰,只要好好掌握一门语言,都会有用武之地。
-------------------End-------------------
php用正则表达抓取网页中文章(Python爬虫怎么学?看看你的技术能拿多少薪资)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-19 14:32
如何学习 Python 爬虫?了解工作职责,看看你的技术能赚多少钱
大家好,我是麻辣烫。大家都知道拉条发的文章帖子都是和爬虫有关的,我自己也想往这个方向发展,所以提前了解一下爬虫工程师的就业市场,希望大家不要踩坑。跟大家聊聊爬虫工程师需要掌握哪些技术,以及市场各个区域的薪资水平和发展前景。目录 工作职责 就业前景 发展前景 招聘需求 区域排名(全国) 按教育年数划分的工资收入统计 工资趋势 招聘示例 工作职责 爬虫工程师做什么?工作内容是什么?需要具备哪些能力?
Python“爬虫”出发前装备的正则表达式之一
1.正则表达式正则表达式是一种模板表达式语言,通过定义规则来匹配、查找、替换和拆分长字符串中的特定子字符信息。如果您在 文章 中找到所有合法的电子邮件地址,您可以先用正则表达式定义一个电子邮件规则,然后使用该规则搜索整个字符串。爬虫程序一般使用正则表达式定义的规则对爬取的内容进行精细筛选。正则表达式有自己独立于其他计算机语言的语法结构,大多数计算机编程语言都提供了对正则表达式的支持。
正则表达式匹配
正则表达式在线生成工具:常用正则表达式正则表达式在线测试工具
211004
正则表达式定义字符串的模式。正则表达式可用于搜索、编辑或处理文本。字符串实际上是一个简单的正则表达式
爬行动物的基本原理
ttp比作一条高速公路,他有规则哪些语言可以实现爬虫#1.php:爬虫可以实现。PHP号称是世界上最美的语言(当然是它自己的名字,就是王婆卖瓜的意思),但是PHP在爬虫中并不擅长支持多线程和多进程。#2.java:可以实现爬虫。Java可以很好的处理和实现爬虫,是唯一能与python并驾齐驱的,也是python的头号敌人。但是爬虫代码的Java实现比较臃肿,重构成本高。#3.c,c++:是的
计算 VsCode 中的代码行数
直接使用正则查询显示查询的行数。正则表达式:^b*[^:b#/]+.*$
jmeter 断言
1.有的可以使用正则表达式,有的不能使用正则表达式2.前后区分大小写
正则表达式 [待完成]
Python 正则表达式指南 - AstralWind
Python爬虫之Scrapy进阶(全站爬取、分布式、增量爬虫)
scrapy全站爬取1.1全站爬取介绍1.2CrawlSpider1.2.1基本解释1.2.2使用CrawlSpider1.@ >2.2.1爬虫文件1.2.2.2items.py文件2分布式爬虫2.1分布式爬虫概念2.2环境安装< @2.3使用方法2.3.1爬虫配置2.3.2redis相关配置2.3.3启动项目3增量爬虫3.1概念解释3.2使用3.2.1爬虫文件3.2.2管道文件1scra
Python中正则表达式的使用
在进行正则表达式匹配时,直接使用正则表达式引擎,在python中通过字符串输入正则表达式引擎,需要输入不同的字符串。主要区别在于转义字符的使用,共有三种。情况:转义字符需要被python解析,所以输入部分python中的特殊字符需要被正则表达式引擎解析,从而输入正则表达式语句部分的特殊字符。转义字符需要通过正则表达式匹配。下面总结了python处理这个问题的三种方式:1、鉴于python的第一个解决方案 查看全部
php用正则表达抓取网页中文章(Python爬虫怎么学?看看你的技术能拿多少薪资)
如何学习 Python 爬虫?了解工作职责,看看你的技术能赚多少钱
大家好,我是麻辣烫。大家都知道拉条发的文章帖子都是和爬虫有关的,我自己也想往这个方向发展,所以提前了解一下爬虫工程师的就业市场,希望大家不要踩坑。跟大家聊聊爬虫工程师需要掌握哪些技术,以及市场各个区域的薪资水平和发展前景。目录 工作职责 就业前景 发展前景 招聘需求 区域排名(全国) 按教育年数划分的工资收入统计 工资趋势 招聘示例 工作职责 爬虫工程师做什么?工作内容是什么?需要具备哪些能力?
Python“爬虫”出发前装备的正则表达式之一
1.正则表达式正则表达式是一种模板表达式语言,通过定义规则来匹配、查找、替换和拆分长字符串中的特定子字符信息。如果您在 文章 中找到所有合法的电子邮件地址,您可以先用正则表达式定义一个电子邮件规则,然后使用该规则搜索整个字符串。爬虫程序一般使用正则表达式定义的规则对爬取的内容进行精细筛选。正则表达式有自己独立于其他计算机语言的语法结构,大多数计算机编程语言都提供了对正则表达式的支持。
正则表达式匹配
正则表达式在线生成工具:常用正则表达式正则表达式在线测试工具
211004
正则表达式定义字符串的模式。正则表达式可用于搜索、编辑或处理文本。字符串实际上是一个简单的正则表达式
爬行动物的基本原理
ttp比作一条高速公路,他有规则哪些语言可以实现爬虫#1.php:爬虫可以实现。PHP号称是世界上最美的语言(当然是它自己的名字,就是王婆卖瓜的意思),但是PHP在爬虫中并不擅长支持多线程和多进程。#2.java:可以实现爬虫。Java可以很好的处理和实现爬虫,是唯一能与python并驾齐驱的,也是python的头号敌人。但是爬虫代码的Java实现比较臃肿,重构成本高。#3.c,c++:是的
计算 VsCode 中的代码行数
直接使用正则查询显示查询的行数。正则表达式:^b*[^:b#/]+.*$
jmeter 断言
1.有的可以使用正则表达式,有的不能使用正则表达式2.前后区分大小写
正则表达式 [待完成]
Python 正则表达式指南 - AstralWind
Python爬虫之Scrapy进阶(全站爬取、分布式、增量爬虫)
scrapy全站爬取1.1全站爬取介绍1.2CrawlSpider1.2.1基本解释1.2.2使用CrawlSpider1.@ >2.2.1爬虫文件1.2.2.2items.py文件2分布式爬虫2.1分布式爬虫概念2.2环境安装< @2.3使用方法2.3.1爬虫配置2.3.2redis相关配置2.3.3启动项目3增量爬虫3.1概念解释3.2使用3.2.1爬虫文件3.2.2管道文件1scra
Python中正则表达式的使用
在进行正则表达式匹配时,直接使用正则表达式引擎,在python中通过字符串输入正则表达式引擎,需要输入不同的字符串。主要区别在于转义字符的使用,共有三种。情况:转义字符需要被python解析,所以输入部分python中的特殊字符需要被正则表达式引擎解析,从而输入正则表达式语句部分的特殊字符。转义字符需要通过正则表达式匹配。下面总结了python处理这个问题的三种方式:1、鉴于python的第一个解决方案
php用正则表达抓取网页中文章(用默认的nopic.jpg替换再看一个函数相对比较复杂了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-19 01:31
概括
php 获取文章 内容的第一个图像实例。要使用php获取文章中所有图片的第一张图片,我们只需要一个简单的正则表达式即可实现。下面给大家分享两个例子。先看一个
要使用php获取文章中所有图片的第一张图片,我们只需要一个简单的正则表达式即可实现。下面给大家分享两个例子。
先看一个函数:
代码显示如下
复制代码
函数getpic($str_img){
preg_match_all("/ /isU",$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
返回 $img_path;
}
//如果数据库是打开的,使用$nr获取数据库中的新闻内容
$nr=$row_news["nr"];
$aa=getpic($nr_a);
if(!$aa){$aa="images/nopic.jpg";} //如果新闻中没有图片,则替换为默认的nopic.jpg
我们来看一个比较复杂的函数。
在做项目的时候,有时候页面的设计会留下文章特色图片的位置,但是有时候,这个文章没有上传图片,显示的时候没有图片在页面上。画风很丑。如果默认图片根本不上传,有时会引起一些误解;那么先考虑是否细化这个文章图片的问题:首先判断是否有上传图片,如果有,显示上传图片,如果没有,判断内容中是否有图片,选择这里第一张图片作为特色图片,如果内容中没有图片,则在此处显示默认图片;
下面是在 文章 中选择第一张图片的代码:
代码显示如下
复制代码
$obj=M("新闻");
$info=$obj->where('id=1')->find();
//方法1*********
$soContent = $info['content'];
$soImages = '~
]* />~';
preg_match_all($soImages, $soContent, $thePics);
$allPics = count($thePics[0]);
preg_match('/ /i',$thePics[0][0],$match);
转储($thePics);
如果( $allPics > 0 ){
回声“
";//获取图片名称
}
别的 {
echo "没有图片";
}
//****************
$soContent = $info['content'];
$soImages = '~
]* />~';
preg_match_all($soImages, $soContent, $thePics);
$allPics = count($thePics[0]);
转储($thePics);
如果( $allPics > 0 ){
回声 $thePics[0][0]; //获取整个Img属性
} 别的 {
echo "没有图片";
}
//****************
$soImages = '~]* />~';
$str=$info['内容'];
preg_match_all($soImages,$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
如果(!$img_path){
$img_path="images/nopic.jpg";
} //如果新闻中不存在图片,则替换为默认的nopic.jpg*/
回声 $img_path;
//****************88
$str=$info['内容'];
preg_match_all("/ /isU",$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
如果(!$img_path){
$img_path="images/nopic.jpg";
} //如果新闻中不存在图片,则替换为默认的nopic.jpg*/
回声 $img_path; 查看全部
php用正则表达抓取网页中文章(用默认的nopic.jpg替换再看一个函数相对比较复杂了)
概括
php 获取文章 内容的第一个图像实例。要使用php获取文章中所有图片的第一张图片,我们只需要一个简单的正则表达式即可实现。下面给大家分享两个例子。先看一个
要使用php获取文章中所有图片的第一张图片,我们只需要一个简单的正则表达式即可实现。下面给大家分享两个例子。
先看一个函数:
代码显示如下
复制代码
函数getpic($str_img){
preg_match_all("/ /isU",$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
返回 $img_path;
}
//如果数据库是打开的,使用$nr获取数据库中的新闻内容
$nr=$row_news["nr"];
$aa=getpic($nr_a);
if(!$aa){$aa="images/nopic.jpg";} //如果新闻中没有图片,则替换为默认的nopic.jpg
我们来看一个比较复杂的函数。
在做项目的时候,有时候页面的设计会留下文章特色图片的位置,但是有时候,这个文章没有上传图片,显示的时候没有图片在页面上。画风很丑。如果默认图片根本不上传,有时会引起一些误解;那么先考虑是否细化这个文章图片的问题:首先判断是否有上传图片,如果有,显示上传图片,如果没有,判断内容中是否有图片,选择这里第一张图片作为特色图片,如果内容中没有图片,则在此处显示默认图片;
下面是在 文章 中选择第一张图片的代码:
代码显示如下
复制代码
$obj=M("新闻");
$info=$obj->where('id=1')->find();
//方法1*********
$soContent = $info['content'];
$soImages = '~
]* />~';
preg_match_all($soImages, $soContent, $thePics);
$allPics = count($thePics[0]);
preg_match('/ /i',$thePics[0][0],$match);
转储($thePics);
如果( $allPics > 0 ){
回声“
";//获取图片名称
}
别的 {
echo "没有图片";
}
//****************
$soContent = $info['content'];
$soImages = '~
]* />~';
preg_match_all($soImages, $soContent, $thePics);
$allPics = count($thePics[0]);
转储($thePics);
如果( $allPics > 0 ){
回声 $thePics[0][0]; //获取整个Img属性
} 别的 {
echo "没有图片";
}
//****************
$soImages = '~]* />~';
$str=$info['内容'];
preg_match_all($soImages,$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
如果(!$img_path){
$img_path="images/nopic.jpg";
} //如果新闻中不存在图片,则替换为默认的nopic.jpg*/
回声 $img_path;
//****************88
$str=$info['内容'];
preg_match_all("/ /isU",$str,$ereg);//正则表达式获取全图
$img=$ereg[0][0];//图片
$p="#src=('|")(.*)('|")#isU";//正则表达式
preg_match_all ($p, $img, $img1);
$img_path =$img1[2][0];//获取第一张图片路径
如果(!$img_path){
$img_path="images/nopic.jpg";
} //如果新闻中不存在图片,则替换为默认的nopic.jpg*/
回声 $img_path;
php用正则表达抓取网页中文章(dreamweaver中的正则表达式使用方法使用步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-16 19:16
Dreamweaver 是第一套专为专业网页设计师开发的可视化网页开发工具。它也是最新版本。它可以轻松创建跨平台限制和浏览器限制的动态网页。在dreamweaver 页面中存在需求。如何替换要替换的内容?我们可以使用正则表达式来替换。在 Dreamweaver 中使用正则表达式替换字符串的朋友很少。如何使用正则表达式?一起来看看详细教程吧。.
使用正则表达式的步骤:
1、我们在dreamweaver中编码的时候,一般的查找替换不能满足我们大范围的替换来替换一些内容相同的不同链接:比如“#”,你有没有想过用dreamweaver regex
2、先在桌面打开dreamweaver,在dreamweaver中打开你担心的页面
3、如果后面href里面的内容复杂多样,href="/html/u.html", href="/tuho/huko.html",我想全部替换成href="# ",同时按住ctrl+f键调用查找替换框
4、在搜索中输入:href="[^"]*"在替换中输入:href="#"并选择“使用正则表达式”,回车
5、(#是替换后的内容,可以根据需要更改!一定要勾选:使用正则表达式(X),以上只是对href内容的一般替换,因为很多标签都有href属性,例如 a、link 等。
以上就是小编和大家分享的关于dreamweaver中正则表达式的使用。有兴趣的用户可以按照以上步骤进行试用。我希望上面的教程可以帮助你。 查看全部
php用正则表达抓取网页中文章(dreamweaver中的正则表达式使用方法使用步骤)
Dreamweaver 是第一套专为专业网页设计师开发的可视化网页开发工具。它也是最新版本。它可以轻松创建跨平台限制和浏览器限制的动态网页。在dreamweaver 页面中存在需求。如何替换要替换的内容?我们可以使用正则表达式来替换。在 Dreamweaver 中使用正则表达式替换字符串的朋友很少。如何使用正则表达式?一起来看看详细教程吧。.
使用正则表达式的步骤:
1、我们在dreamweaver中编码的时候,一般的查找替换不能满足我们大范围的替换来替换一些内容相同的不同链接:比如“#”,你有没有想过用dreamweaver regex
2、先在桌面打开dreamweaver,在dreamweaver中打开你担心的页面
3、如果后面href里面的内容复杂多样,href="/html/u.html", href="/tuho/huko.html",我想全部替换成href="# ",同时按住ctrl+f键调用查找替换框
4、在搜索中输入:href="[^"]*"在替换中输入:href="#"并选择“使用正则表达式”,回车
5、(#是替换后的内容,可以根据需要更改!一定要勾选:使用正则表达式(X),以上只是对href内容的一般替换,因为很多标签都有href属性,例如 a、link 等。
以上就是小编和大家分享的关于dreamweaver中正则表达式的使用。有兴趣的用户可以按照以上步骤进行试用。我希望上面的教程可以帮助你。
php用正则表达抓取网页中文章(大佬教程收集整理的这篇文章主要介绍了,欢迎将大佬推荐给程序员好友)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-16 19:13
大哥教程采集的这篇文章主要介绍php-正则表达式获取数字和数字后面的字符串。大哥教程大哥觉得还不错。现在我将与您分享并为您制作。参考。
我需要从两个不同的字符串中提取数字后的数字和单位。有些字符串在数字和单位之间有空格,例如 150g,而其他字符串不是 150g
$text = 'Rexona Ap Deo Aerosol 150ml Active CPD-05923';
$text='Cutex Nail Polish Remover Moisture 100ml ';
preg_match_all('!\d+!', $text, $matches);
if(sizeof($matches[0]) > 1){
// how can I extract 'ml'
}
else {
// how can I extract 150 ml ?
}
你能帮我吗?
解决方案:
你可以使用它:
preg_match_all('~\b(\d+(?:\.\d{1,2})?)\s*(ml|gm?|kg|cm)\b~i', $text, $matches);
并使用匹配组 #1 和 #2.
正则表达式演示
大佬总结
以上就是php-正则表达式获取数字后的数字和字符串的全部内容,希望文章可以帮助大家解决php-正则表达式获取数字后的数字和字符串。程序开发遇到的问题。
如果你觉得大哥教程网站的内容还不错,欢迎你把大哥教程推荐给你的程序员朋友。 查看全部
php用正则表达抓取网页中文章(大佬教程收集整理的这篇文章主要介绍了,欢迎将大佬推荐给程序员好友)
大哥教程采集的这篇文章主要介绍php-正则表达式获取数字和数字后面的字符串。大哥教程大哥觉得还不错。现在我将与您分享并为您制作。参考。
我需要从两个不同的字符串中提取数字后的数字和单位。有些字符串在数字和单位之间有空格,例如 150g,而其他字符串不是 150g
$text = 'Rexona Ap Deo Aerosol 150ml Active CPD-05923';
$text='Cutex Nail Polish Remover Moisture 100ml ';
preg_match_all('!\d+!', $text, $matches);
if(sizeof($matches[0]) > 1){
// how can I extract 'ml'
}
else {
// how can I extract 150 ml ?
}
你能帮我吗?
解决方案:
你可以使用它:
preg_match_all('~\b(\d+(?:\.\d{1,2})?)\s*(ml|gm?|kg|cm)\b~i', $text, $matches);
并使用匹配组 #1 和 #2.
正则表达式演示
大佬总结
以上就是php-正则表达式获取数字后的数字和字符串的全部内容,希望文章可以帮助大家解决php-正则表达式获取数字后的数字和字符串。程序开发遇到的问题。
如果你觉得大哥教程网站的内容还不错,欢迎你把大哥教程推荐给你的程序员朋友。
php用正则表达抓取网页中文章(学习正则表达式之前中的几个容易混洗的术语(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-16 19:11
正则表达式是描述字符串结构的语法规则。它是一种特定的格式化模式,可以匹配、替换和截取匹配的字符串。对于之前可能接触过DOS的用户,如果要匹配当前文件夹中的所有文本文件,可以输入“dir *.txt”命令,按回车键后,所有“.txt”文件将被列出。这里的“*.txt”可以理解为一个简单的正则表达式。
在学习正则表达式之前,我们先来了解几个正则表达式中容易打乱的术语,这对学习正则表达式很有帮助。
grep:最初是ED编辑器中的一个命令,用来显示文件中的特定内容,后来变成了一个独立的工具grep。
egrep:虽然grep在不断更新升级,但还是跟不上技术的步伐。为此,塔灯网推出了egrep。意思是“扩展的grep”,大大增强了正则表达式的威力。
POSIX(Portable Operating System Interface of Vnix,Portable Operating System Interface):在grep开发的同时,其他一些开发者也根据自己的喜好开发了风格独特的版本。但随之而来的问题是,一些程序支持某个元字符,而另一些则不支持。因此,POSIX 是一组确保操作系统之间可移植性的标准。但是 POSIX 和 SQL 一样,并没有成为最终的标准,只能作为参考。
Perl(实用提取和报告语言):1987 年,Larry Wall 发布了 Perl。在接下来的 7 年里,Perl 经历了从 Perl 1 到现在的 Perl 5 的发展,最终 Perl 成为继 POSIX 之后的又一标准。
PCER:Perl的成功让其他开发者在一定程度上兼容了Perl,包括C/C++、Java、Python等,都有自己的正则表达式。1997 年,Philip Hazel 开发了 PCRE 库,这是一组与 Perl 正则表达式兼容的正则表达式。其他开发者可以将PCRE集成到自己的语言中,为用户提供丰富的常规功能。很多语言都使用PCRE,PHP官方就是其中之一。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接: 查看全部
php用正则表达抓取网页中文章(学习正则表达式之前中的几个容易混洗的术语(一))
正则表达式是描述字符串结构的语法规则。它是一种特定的格式化模式,可以匹配、替换和截取匹配的字符串。对于之前可能接触过DOS的用户,如果要匹配当前文件夹中的所有文本文件,可以输入“dir *.txt”命令,按回车键后,所有“.txt”文件将被列出。这里的“*.txt”可以理解为一个简单的正则表达式。
在学习正则表达式之前,我们先来了解几个正则表达式中容易打乱的术语,这对学习正则表达式很有帮助。
grep:最初是ED编辑器中的一个命令,用来显示文件中的特定内容,后来变成了一个独立的工具grep。
egrep:虽然grep在不断更新升级,但还是跟不上技术的步伐。为此,塔灯网推出了egrep。意思是“扩展的grep”,大大增强了正则表达式的威力。
POSIX(Portable Operating System Interface of Vnix,Portable Operating System Interface):在grep开发的同时,其他一些开发者也根据自己的喜好开发了风格独特的版本。但随之而来的问题是,一些程序支持某个元字符,而另一些则不支持。因此,POSIX 是一组确保操作系统之间可移植性的标准。但是 POSIX 和 SQL 一样,并没有成为最终的标准,只能作为参考。
Perl(实用提取和报告语言):1987 年,Larry Wall 发布了 Perl。在接下来的 7 年里,Perl 经历了从 Perl 1 到现在的 Perl 5 的发展,最终 Perl 成为继 POSIX 之后的又一标准。
PCER:Perl的成功让其他开发者在一定程度上兼容了Perl,包括C/C++、Java、Python等,都有自己的正则表达式。1997 年,Philip Hazel 开发了 PCRE 库,这是一组与 Perl 正则表达式兼容的正则表达式。其他开发者可以将PCRE集成到自己的语言中,为用户提供丰富的常规功能。很多语言都使用PCRE,PHP官方就是其中之一。
本页面的内容是通过互联网采集和编辑的。所有信息仅供用户参考。本网站没有任何所有权。如果您认为本页内容涉嫌抄袭,请及时联系我们并提供相关证据。5个工作日内联系您。一经核实,本站将立即删除侵权内容。这篇文章的链接:
php用正则表达抓取网页中文章(正则表达式就是用于描述这些规则的工具(,),,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-15 17:08
我们经常遇到要获取字符串指定部分的内容。让我们使用正则匹配来获取下一页的 url。代码如下:
$str='ht///>第一页上一页下一页';preg_match_all('/]*href=([^>]*)>下一页/是',$str,$matches); print_r($matches[1]);//方法二,代码如下: preg_match('/next page/u', $s, $arr);
究竟什么是正则表达式?
在编写处理字符串的程序或网页时,经常需要找到符合一些复杂规则的字符串。正则表达式就是用来描述这些规则的工具,换句话说,正则表达式就是记录文本规则的代码。
很有可能你用过windows/dos下用于文件搜索的通配符,即*和?,如果要查找一个目录下的所有word文档,就会搜索*.doc,这里,*会被解释作为任意字符串。与通配符类似,正则表达式也是文本匹配的工具,只是它们可以比通配符更准确地描述你的需求——当然,代价是更复杂——例如你可以编写一个正则表达式来查找所有以0,后跟 2-3 个数字,然后是连字符“-”,最后是 7 位或 8 位数字的字符串(如 or 0376-7654321).
来源: 查看全部
php用正则表达抓取网页中文章(正则表达式就是用于描述这些规则的工具(,),,)
我们经常遇到要获取字符串指定部分的内容。让我们使用正则匹配来获取下一页的 url。代码如下:
$str='ht///>第一页上一页下一页';preg_match_all('/]*href=([^>]*)>下一页/是',$str,$matches); print_r($matches[1]);//方法二,代码如下: preg_match('/next page/u', $s, $arr);
究竟什么是正则表达式?
在编写处理字符串的程序或网页时,经常需要找到符合一些复杂规则的字符串。正则表达式就是用来描述这些规则的工具,换句话说,正则表达式就是记录文本规则的代码。
很有可能你用过windows/dos下用于文件搜索的通配符,即*和?,如果要查找一个目录下的所有word文档,就会搜索*.doc,这里,*会被解释作为任意字符串。与通配符类似,正则表达式也是文本匹配的工具,只是它们可以比通配符更准确地描述你的需求——当然,代价是更复杂——例如你可以编写一个正则表达式来查找所有以0,后跟 2-3 个数字,然后是连字符“-”,最后是 7 位或 8 位数字的字符串(如 or 0376-7654321).
来源:
php用正则表达抓取网页中文章(PHP中从中有效的JSON )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-15 06:31
)
我得到了一个字符串转储,其中收录最初在网上抓取的 Js 对象文字,我需要在 PHP 中从中获取一些数据。这些不是有效的 JSON,所以我不能使用 json_decode。它们具有以下格式,其中 DETAILS 是我需要捕获的内容。
...data: [DETAILS]...
在某些来源中,数据元素出现不止一次,我需要捕获每个匹配项。DETAILS 可以收录任何字符,包括 [ { } ]、引号和逗号,但我需要将它们全部捕获。
我正在尝试使用正则表达式。这是我在一些教程之后尝试过的,但这绝对是错误的。
preg_match_all('~(?:\G(?!^),|(data: )\{)\s+([^:]+): (\d+|"[^"]*")~', $html, $out, PREG_SET_ORDER) ? $out : []
请我真的需要一些帮助。
编辑:这只是显示详细信息的数据字段的示例。它并不总是采用这种形式。
series:[{name:'Records',data:[[Date.parse('2013-11-01'),1],[Date.parse('2013-12-01'),2],[Date.parse('2014-01-01'),1],[Date.parse('2014-02-01'),4],[Date.parse('2014-03-01'),23],[Date.parse('2014-04-01'),22],[Date.parse('2014-05-01'),19],[Date.parse('2014-06-01'),26],[Date.parse('2014-07-01'),43],[Date.parse('2014-08-01'),29],[Date.parse('2014-09-01'),47],[Date.parse('2014-10-01'),31],[Date.parse('2014-11-01'),32],[Date.parse('2014-12-01'),17],[Date.parse('2015-01-01'),28],[Date.parse('2015-02-01'),2],[Date.parse('2015-03-01'),18],[Date.parse('2015-04-01'),16],[Date.parse('2015-05-01'),10],[Date.parse('2015-06-01'),25],[Date.parse('2015-07-01'),20],[Date.parse('2015-08-01'),21],[Date.parse('2015-09-01'),6],[Date.parse('2015-10-01'),10],[Date.parse('2015-11-01'),-11],[Date.parse('2015-12-01'),12],[Date.parse('2016-01-01'),46],[Date.parse('2016-02-01'),32],[Date.parse('2016-03-01'),16],[Date.parse('2016-04-01'),28],[Date.parse('2016-05-01'),34],[Date.parse('2016-06-01'),24],[Date.parse('2016-07-01'),40],[Date.parse('2016-08-01'),24],[Date.parse('2016-09-01'),57],[Date.parse('2016-10-01'),42],[Date.parse('2016-11-01'),51],[Date.parse('2016-12-01'),53],[Date.parse('2017-01-01'),63],[Date.parse('2017-02-01'),23],[Date.parse('2017-03-01'),80],[Date.parse('2017-04-01'),56],[Date.parse('2017-05-01'),61],[Date.parse('2017-06-01'),74],[Date.parse('2017-07-01'),107],[Date.parse('2017-08-01'),74],[Date.parse('2017-09-01'),120],[Date.parse('2017-10-01'),79],[Date.parse('2017-11-01'),163],[Date.parse('2017-12-01'),130],[Date.parse('2018-01-01'),126] 查看全部
php用正则表达抓取网页中文章(PHP中从中有效的JSON
)
我得到了一个字符串转储,其中收录最初在网上抓取的 Js 对象文字,我需要在 PHP 中从中获取一些数据。这些不是有效的 JSON,所以我不能使用 json_decode。它们具有以下格式,其中 DETAILS 是我需要捕获的内容。
...data: [DETAILS]...
在某些来源中,数据元素出现不止一次,我需要捕获每个匹配项。DETAILS 可以收录任何字符,包括 [ { } ]、引号和逗号,但我需要将它们全部捕获。
我正在尝试使用正则表达式。这是我在一些教程之后尝试过的,但这绝对是错误的。
preg_match_all('~(?:\G(?!^),|(data: )\{)\s+([^:]+): (\d+|"[^"]*")~', $html, $out, PREG_SET_ORDER) ? $out : []
请我真的需要一些帮助。
编辑:这只是显示详细信息的数据字段的示例。它并不总是采用这种形式。
series:[{name:'Records',data:[[Date.parse('2013-11-01'),1],[Date.parse('2013-12-01'),2],[Date.parse('2014-01-01'),1],[Date.parse('2014-02-01'),4],[Date.parse('2014-03-01'),23],[Date.parse('2014-04-01'),22],[Date.parse('2014-05-01'),19],[Date.parse('2014-06-01'),26],[Date.parse('2014-07-01'),43],[Date.parse('2014-08-01'),29],[Date.parse('2014-09-01'),47],[Date.parse('2014-10-01'),31],[Date.parse('2014-11-01'),32],[Date.parse('2014-12-01'),17],[Date.parse('2015-01-01'),28],[Date.parse('2015-02-01'),2],[Date.parse('2015-03-01'),18],[Date.parse('2015-04-01'),16],[Date.parse('2015-05-01'),10],[Date.parse('2015-06-01'),25],[Date.parse('2015-07-01'),20],[Date.parse('2015-08-01'),21],[Date.parse('2015-09-01'),6],[Date.parse('2015-10-01'),10],[Date.parse('2015-11-01'),-11],[Date.parse('2015-12-01'),12],[Date.parse('2016-01-01'),46],[Date.parse('2016-02-01'),32],[Date.parse('2016-03-01'),16],[Date.parse('2016-04-01'),28],[Date.parse('2016-05-01'),34],[Date.parse('2016-06-01'),24],[Date.parse('2016-07-01'),40],[Date.parse('2016-08-01'),24],[Date.parse('2016-09-01'),57],[Date.parse('2016-10-01'),42],[Date.parse('2016-11-01'),51],[Date.parse('2016-12-01'),53],[Date.parse('2017-01-01'),63],[Date.parse('2017-02-01'),23],[Date.parse('2017-03-01'),80],[Date.parse('2017-04-01'),56],[Date.parse('2017-05-01'),61],[Date.parse('2017-06-01'),74],[Date.parse('2017-07-01'),107],[Date.parse('2017-08-01'),74],[Date.parse('2017-09-01'),120],[Date.parse('2017-10-01'),79],[Date.parse('2017-11-01'),163],[Date.parse('2017-12-01'),130],[Date.parse('2018-01-01'),126]
php用正则表达抓取网页中文章( 管理ModSecurity日志的开源项目-FLEWAF-WAF)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-04-13 22:34
管理ModSecurity日志的开源项目-FLEWAF-WAF)
之前介绍过ModSecurity,一个优秀的开源WAF。它是一个入侵检测和防御引擎。它最初是 Apache 的一个模块。现在它可以被编译并作为一个单独的模块添加到 Nginx 服务中。
这个WAF虽然很不错,但是用起来没那么好用。之前我也组织过文章介绍它的原理和规则。但是,还有一个问题,就是它的日志分析。之前介绍过原理和规则的时候,也介绍过它的日志规则,但是在使用过程中,纯文本记录的方式对于入侵分析来说太不友好了
所以今天给大家介绍一个管理ModSecurity日志的开源项目WAF-FLE
WAF-FLE 是专门用于处理 ModSecurity 日志和事件的控制台。管理员可以通过WAF-FLE查看和搜索ModSecurity记录的日志。
WAF-FLE是一个用PHP编写的开源项目,需要LNMP/LAMP环境搭建
环境要求:
php-geoipMySQL5.1+
安装环境就不赘述了,只说一个GeoIP库的安装。这里GeoIP库是用来展示入侵IP信息的,所以需要这个库。安装非常简单。其实就是下载一个dat数据库,从
下载后解压dat文件。
环境准备好后,从github下载WAF-FLE:
在 waf-fle 的 extra 目录中,存放了数据库 sql 文件和 Apache 配置文件。如果你使用的是 Apache,可以直接把这个配置复制到 apache 配置目录下。如果使用Nginx,参考如下配置
修改config.php的时候,因为我没有安装apc的缓存扩展,这个扩展很老了,所以直接设置APC_ON=false关闭缓存
完成以上操作后,即可通过域名访问进入安装界面。
这里检查php扩展的时候,如果你不是Apache,就会有问题,就是在setup.php的499行,它使用apache_getenv来检查Apache是否在运行。,所以打开 setup.php 文件的第 499 行并注释掉这部分代码。
然后点击运行创建数据库
这里创建数据库的时候还有一个问题。在setup.php代码第28行,执行创建函数的时候,引用了一个$databaseSchema,在这里修改定义了一个位置,但是我放的是我的位置,所以这里需要。根据自己的情况修改
修改完成后,通过页面继续进行数据库创建操作。创建完成如下:
安装完成后,默认用户名和密码为admin/admin。之后,在 config.php 中配置 $SETUP=false。关闭安装后,重新访问
使用默认用户密码登录后,需要修改用户名和密码。
设置新密码后,您将被重定向到主界面。
目前没有数据,现在开始访问日志数据,点击菜单栏中的管理,添加传感器
保存后,创建一个传感器来接收日志
创建后,在这个传感器上,开始配置事件接收器
这里我们选择使用mlog2waffle接收日志,然后选择service deamon查询日志。这是一个实时查询。WAF-FLE控制器URL是配置waf-fle的控制器地址,mlog2waffle通过put请求向这个接口发送数据。地址,下面是配置ModSecurity日志的配置路径,配置完成后点击下一步
系统会给出提示配置,需要根据给定的配置配置这些配置文件,这里可以按照提示配置操作,需要的mlog2waffle配置文件和启动脚本在extra目录下
配置完成后,启动mlog2waffle
mlog2waffle 通过 put 方法向 waf-fle 发送日志,但是默认情况下 Nginx 不允许 put 请求,所以启动会报错。需要通过 nginx 中的 dav 方法允许 put 请求
在启动mlog2waffle的过程中,遇到了很多问题,记录如下:
这里,通过PUT方法发送检测请求。这里的trick是PUT请求发送时没有URI,但是当Nginx检测到PUT请求没有URI时,会报409,认为有资源冲突
所以,无论你做什么,这里的测试都不会通过。有两种方法可以处理它。一种是直接关闭测试,mlog2waffle可以正常启动。另一种方法是修改测试方法,带上uri。mlog2waffle 是 perl 脚本,非常简单
这里需要手动替换,通过$_SERVER获取客户端IP,需要手动编写getallheaders()方法,如下:
另外,在index.php中,第65行的位置原来是通过apache_setenv()得到的sensor的名字,复制到Apache的“REMOTE_USER”中。此处未使用 Apache,因此只需将其注释掉即可。
修改完这些,就可以通过脚本启动mlog2waffle了
启动后,通过waf的访问日志,可以看到mlog2waffle已经开始通过put方法将日志解析成event并传递给waf-fle
在mlog2waffle的readIndex方法中,由于需要读取和解析日志索引文件,所以有一个正则匹配,如图:
这里需要修改和匹配自己记录的日志格式。完全匹配后可以正确读取日志,解析后将解析后的内容通过send_event方法通过PUT方法传递给waf-fle进行显示。
waf-fle接收到的文件是一个index.php,它通过正则解析所有步骤。有兴趣的可以看源码。至此,waf-fle就部署好了,可以看到效果了。
waf-fle虽然是老牌开源项目,但是对于modsecurity日志分析来说已经足够了 查看全部
php用正则表达抓取网页中文章(
管理ModSecurity日志的开源项目-FLEWAF-WAF)
之前介绍过ModSecurity,一个优秀的开源WAF。它是一个入侵检测和防御引擎。它最初是 Apache 的一个模块。现在它可以被编译并作为一个单独的模块添加到 Nginx 服务中。
这个WAF虽然很不错,但是用起来没那么好用。之前我也组织过文章介绍它的原理和规则。但是,还有一个问题,就是它的日志分析。之前介绍过原理和规则的时候,也介绍过它的日志规则,但是在使用过程中,纯文本记录的方式对于入侵分析来说太不友好了
所以今天给大家介绍一个管理ModSecurity日志的开源项目WAF-FLE
WAF-FLE 是专门用于处理 ModSecurity 日志和事件的控制台。管理员可以通过WAF-FLE查看和搜索ModSecurity记录的日志。
WAF-FLE是一个用PHP编写的开源项目,需要LNMP/LAMP环境搭建
环境要求:
php-geoipMySQL5.1+
安装环境就不赘述了,只说一个GeoIP库的安装。这里GeoIP库是用来展示入侵IP信息的,所以需要这个库。安装非常简单。其实就是下载一个dat数据库,从
下载后解压dat文件。
环境准备好后,从github下载WAF-FLE:
在 waf-fle 的 extra 目录中,存放了数据库 sql 文件和 Apache 配置文件。如果你使用的是 Apache,可以直接把这个配置复制到 apache 配置目录下。如果使用Nginx,参考如下配置
修改config.php的时候,因为我没有安装apc的缓存扩展,这个扩展很老了,所以直接设置APC_ON=false关闭缓存
完成以上操作后,即可通过域名访问进入安装界面。
这里检查php扩展的时候,如果你不是Apache,就会有问题,就是在setup.php的499行,它使用apache_getenv来检查Apache是否在运行。,所以打开 setup.php 文件的第 499 行并注释掉这部分代码。
然后点击运行创建数据库
这里创建数据库的时候还有一个问题。在setup.php代码第28行,执行创建函数的时候,引用了一个$databaseSchema,在这里修改定义了一个位置,但是我放的是我的位置,所以这里需要。根据自己的情况修改
修改完成后,通过页面继续进行数据库创建操作。创建完成如下:
安装完成后,默认用户名和密码为admin/admin。之后,在 config.php 中配置 $SETUP=false。关闭安装后,重新访问
使用默认用户密码登录后,需要修改用户名和密码。
设置新密码后,您将被重定向到主界面。
目前没有数据,现在开始访问日志数据,点击菜单栏中的管理,添加传感器
保存后,创建一个传感器来接收日志
创建后,在这个传感器上,开始配置事件接收器
这里我们选择使用mlog2waffle接收日志,然后选择service deamon查询日志。这是一个实时查询。WAF-FLE控制器URL是配置waf-fle的控制器地址,mlog2waffle通过put请求向这个接口发送数据。地址,下面是配置ModSecurity日志的配置路径,配置完成后点击下一步
系统会给出提示配置,需要根据给定的配置配置这些配置文件,这里可以按照提示配置操作,需要的mlog2waffle配置文件和启动脚本在extra目录下
配置完成后,启动mlog2waffle
mlog2waffle 通过 put 方法向 waf-fle 发送日志,但是默认情况下 Nginx 不允许 put 请求,所以启动会报错。需要通过 nginx 中的 dav 方法允许 put 请求
在启动mlog2waffle的过程中,遇到了很多问题,记录如下:
这里,通过PUT方法发送检测请求。这里的trick是PUT请求发送时没有URI,但是当Nginx检测到PUT请求没有URI时,会报409,认为有资源冲突
所以,无论你做什么,这里的测试都不会通过。有两种方法可以处理它。一种是直接关闭测试,mlog2waffle可以正常启动。另一种方法是修改测试方法,带上uri。mlog2waffle 是 perl 脚本,非常简单
这里需要手动替换,通过$_SERVER获取客户端IP,需要手动编写getallheaders()方法,如下:
另外,在index.php中,第65行的位置原来是通过apache_setenv()得到的sensor的名字,复制到Apache的“REMOTE_USER”中。此处未使用 Apache,因此只需将其注释掉即可。
修改完这些,就可以通过脚本启动mlog2waffle了
启动后,通过waf的访问日志,可以看到mlog2waffle已经开始通过put方法将日志解析成event并传递给waf-fle
在mlog2waffle的readIndex方法中,由于需要读取和解析日志索引文件,所以有一个正则匹配,如图:
这里需要修改和匹配自己记录的日志格式。完全匹配后可以正确读取日志,解析后将解析后的内容通过send_event方法通过PUT方法传递给waf-fle进行显示。
waf-fle接收到的文件是一个index.php,它通过正则解析所有步骤。有兴趣的可以看源码。至此,waf-fle就部署好了,可以看到效果了。
waf-fle虽然是老牌开源项目,但是对于modsecurity日志分析来说已经足够了
php用正则表达抓取网页中文章(266.26No.6第卷(期北))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-13 09:28
26 6卷。26 第 6 卷。No. 2011 12Journal of Beijing Information Science and Technology University Dec. 2011 Month 文章No.: 1674-6864 (20 11)06-0086-04 正则表达式在Web信息抽取中的应用, 胡俊伟秦一清 张伟(, 100 192)@ >北京信息工程大学北京计算机学院: HTML,. 摘要 针对基于结构的信息抽取方法,提出了正则表达式的处理方法,使用正则表达式的功能,匹配、替换和提取正则表达式。在信息提取过程中的应用正,Web正则表达式已成功应用于数据采集页面优化规则学习、信息抽取等信息抽取全过程。:网络;;; ;关键词信息抽取正则表达式匹配替换抽取CLC编号:TP 311 文献编号:A正则表达式及其在Web信息抽取中的应用胡俊伟,秦一清,张伟(北京信息科技大学计算机学院) , 北京 100 192) 摘要: 结合基于 HTML 结构的信息抽取方法, 提出了一种正则表达式的处理方法。讨论了正则表达式在Web信息抽取过程中的应用,利用正则表达式的匹配、替换、提取等。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息提取;正则表达式;匹配;替换;提取,提取字符串数据的有力工具是由特定0介绍意义组成的字符串。具有匹配、替换、提取等功能。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息抽取;正则表达式;匹配;替换;抽取,提取字符串数据的有力工具是由特定的0介绍意义组成的字符串。具有匹配、替换、提取等功能。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息提取;正则表达式;匹配;替换;提取,提取字符串数据的有力工具是由特定0介绍意义组成的字符串。
它代表一定的匹配规则。随着Internet的快速发展,Web信息得到了发展。本文讨论了正则表达式在Web信息抽取过程中的作用。用于全球分布和共享的信息,但目前已应用。WebHTML上的大部分数据主要是以Web信息提取的形式,这是为了展示的方便,允许人们通过浏览器浏览而无需数据本身的描述。HTML 收录不明确的语义信息 [1] 信息提取是指从文本文档中提取特定目的,信息架构不是很清晰,这使得应用程序无法直接解析()、标签信息或事件等数据事实形成一个结构化的网络。并使用上海' 大量的信息造成了资源(XML)的极大浪费,而供用户查询的数据库等表示形式,Web,在此背景下,信息抽取技术应运而生。网络信息抽取是指以网络为信息源的一种信息抽取方式,可以帮助用户摆脱噪声干扰,直接获取所需信息。兴趣。Web信息抽取技术的核心是能够从网页中收录的非结构化或半结构化信息中识别出用户感兴趣的内容。自由结构化的半结构化和结构化文本
, 在语法的基础上,需要结合机器学习等人工智能。正则表达式提供给计算机操作和检查。起草日期:20 11-10-27:(KM2014)基金项目北京教育科技计划面上项目:(1983—),,,,。作者简介 胡军伟,湖北枣阳市研究生,主要从事信息检索技术及应用研究。和学习结构化文本 正则表达式是由普通字符组成的文字模式,例如字符 , , z)(),通常来自具有严格格式的数据库的信息以及称为元字符的特殊字符;。为了使用定义的格式进行提取,半结构化文本描述了要搜索的字符串的匹配模式。意义的特殊字符用于指定,。() 消息通常是不合语法的,并且不遵循任何严格的格式,其前导字符是目标 Web 上元字符之前的字符。. /page 是半结构化文本的典型实例。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。
基于层次结构的信息提取和归纳方法以及基于概念模型图像的模式匹配。用户只需要寻找匹配对 2 ;"/"。该类的多记录信息提取方法可以根据不同图像的图案内容,以不同的自动化程度表示为正则表达式[8],1。还可以分为手动模式、半自动模式和全自动模式。元字符和限定符见表 3 [3];根据各种信息抽取工具所采用的抽取原理和抽取方法的不同,Web表元字符和限定符可以将信息抽取分为基于描述自然语言理解的名称字符的信息抽取,基于机器学习的信息抽取方法、本体、^匹配输入字符串的起始位置、基于信息抽取的方法、基于HTML结构的信息抽取方法、基于Web查询的信息抽取方法。匹配除换行符以外的所有字符一次 [4]5。HTMLMYM匹配输入字符串的结束位置、信息提取等。目前最常用的方法是基于[][]、Web、匹配内字符结构的信息提取技术,由于页面,只需要一点处理就可以转换成一棵格式良好的树[0 - 9]匹配所有数字字符,
元字符 [^0 - 9] 匹配所有非数字字符 [^a - z] 匹配所有非小写字母字符 2 正则表达式 \d, [0 - 9] 匹配一个数字字符 相当于美国数学家组成的正则表达式Stephen Kleene,1956,用于匹配任何单词字符,包括下划线等。\w。主要用于描述正则集代数。它是一种abc匹配字符或字符或一个| 乙 | c,它提供abcabc将字符串中收录的字符串匹配到计算机上来操作和检查要提取的字符串数据。是由具有特定含义的字符组成的字符词串 [5]。该字符串表示某个匹配规则。可以应用正则表达式 * 来匹配前面的子表达式零次或多次。Linux、Unix、Windows、在各种操作系统中,几乎所有 + 匹配前面的子表达式一次或多次。部分语言PHP、C#、C++、Java等都支持。?匹配前面的子表达式零次或一次3、正则表达式最基本的功能是匹配替换和{n}n限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。正则表达式最基本的功能是匹配替换和 {n}n 限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。正则表达式最基本的功能是匹配替换和 {n}n 限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。
卡ID数据格式合法性检测等替换功能,可用于利用文档中的匹配模式识别特定字符,然后在Web信息抽取过程中应用,然后删除或替换,如删除Web脚本注释等。, SQL 注入。HTML、句子注入攻击代码等的提取,参考本文中基于结构的提取方法。HTML根据模式匹配从字符串中提取子字符串,例如提出了基于结构提取的正则表达式的应用。1. 如何快速提取页面中的图片超链接、文本等正则表达式的大致流程如图所示。Web5 可以准确处理一系列复杂的搜索、替换和提取字符串。整个信息提取过程大致可以分为[9]。, . 因此,我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。
第一阶段的规则学习将优化页面作为训练[11] XMLDOM;然后通过遍历树的方式提取出DOM树,用训练样本标注用户感兴趣的信息。 DOM,通过树作为转换工具的信息生成和提取规则 XPATH、XSLT等技术编写提取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。信息生成和抽取规则通过树作为转换工具 XPATH、XSLT 等技术编写抽取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。信息生成和抽取规则通过树作为转换工具 XPATH、XSLT 等技术编写抽取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。
提取用户感兴趣的信息,格式可视化,方便用户完成样本页面信息的标注。[12] 在数据存储阶段,将提取的信息用正则表达式的三种匹配模式表示作为存储。<(?<htmltag>[az]+[\d]?)^[>]* 3.1 个数据采集>> . * ? < / \ k < htmltag > > (3),网页一般通过网络爬虫工具从网上下载 < [az]+[\d]?[^>]*>(4)1URL 工作原理爬虫的过程就是从(?>[^<]*)5()中获取对初始网页的网页进行抓取的过程,一个或多个初始网页的URL(3)1HTML表达式表示它是匹配一对标签、URL、并不断从当前页面中提取新的并放入队列中,直到,,,."而零>""</\k<htmltag>>"又代表开始和结束或多个"/"、"."、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。and 表示开头和结尾或多个“/”、“.”、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。and 表示开头和结尾或多个“/”、“.”、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。
“[^>]*”。例如,使用有效字体来匹配其属性 URL。提取的正则表达式的匹配模式表示为“.* ?”。表示标记 http 中收录的内容表达式: (\\ w + (- \\ w + )* )(\\ . (\\ w + (- \\ w∥(4 ), HTML,表示一个单标签没有结束标签 + )* ))* (\\ ?\\ S * )?http : 表示任何标签收录 ∥: "< img src = aaa.jpg > " 例如,该标签是未配对的 "/ “”。和零个或多个或相等的符号是必需的 HTML。(5) HTML,标记表达式是匹配非标记URL。网络爬虫将通过这个常规匹配匹配所有需求。3 比如一些纯文本等通过上面的正则表达式URL,。它被视为放入队列。借助正则表达式HTML,网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,还可以准确的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,而且精准的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,而且精准的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。
标准文档通过正则表达式、DOM过滤;点添加到当前树节点函数,HTML,可以实现对代码的过滤,以达到优化的目的 4)匹配得到的HTML标签中的代码被认为是新的。例如:“<img src=a.jpg>”、“<b>J5<HTML,3),文本会将/b>中的节点转为“<b></b>”中的当前节点<h1> 1); 在战斗机中还有一些</h1>,HTML5)。等标签被移除以简化提取并将文本添加到当前节点。6:网络问题胡俊伟等。正则表达式在信息抽取中的应用89DOM,Web[J].正则表达式生成的树提供了计算机工程DOM、DOM、[J]. 现代智能,2007 (10):215- 219 3. 4 提取 [3] Line Eikvil。从 worldHTML 中提取信息,广网调查 [R]。挪威:挪威人应该充分考虑 HTML, . [J]. 现代智能,2007 (10):215- 219 3. 4 提取 [3] Line Eikvil。从 worldHTML 中提取信息,广网调查 [R]。挪威:挪威人应该充分考虑 HTML, .
HTMLComputing Center, 1999 Pages of Complex Instability Complex Pages [10], :[4] Alberto H ELaender, Berthier A Ribeiro-Neto, 还包括一些固定结构信息,例如在介绍中,Altigran S da Silva 等。网络简述 图书介绍的页面有图书的价格和图书销售商的电话号码。,数据提取工具[J].ACM SIGMOD Record、box等信息被视为固定结构的信息。通过正则表达式的匹配功能,可以从第2002、31行提取固定结构的信息(2)@>:84-93.,,[5].[M].:对于商品价格,电话号码,手机号和邮箱 沙金精通正则表达式,北京人民邮电,2008等信息,正则表达式的匹配模式表示为 Publishing House ():^ [0-9] *[1 - 9][6] Liger F, Queen CM, Wilton P. C# 商品价格有两位小数,正数 [0 - 9] *\.(\d{2})[M]., .: $ 正则表达式参考手册 刘乐亭 京庆 电话号码:^ ((\ (\ d {2 ,3 }\ ))| ( \ d {3 }\ - ))?华大学出版社, 2003 (\(0\d{2, 3}\)|0\d{2, 3}-)?1[-9]\d{6, 7}[7], . 张静和张艳正则表达式及其在信息抽取中的应用(\ - \ d {1, 4 }) ? [J]., 2009, 5 (15):3867$ 应用计算机知识与技术 手机号:^((\(\d{2, 3}\))|(\d{3}\ - ))? - 3868 1 (3 |5 |8) \d{9}[8], . Boost. Regex$ 吴鹏飞马凤娟的邮箱:^ [\ w - ] + (\ . [ \w-]+)*@[\w信息提取[J].武汉理工大学匹配这些正则表达式,可以直接输出需要的[10] Man I Lam, Zhiguo Gong, Maybin Muyeba。一个信息。武汉理工大学匹配这些正则表达式,可以直接输出需要的[10] Man I Lam, Zhiguo Gong, Maybin Muyeba。一个信息。
网络信息抽取方法[C]∥计算机科学讲义。德国:4 结论 Springer-Verlag Berlin Heidelberg, 2008, 4976: Web, 383-394 本文使用正则表达式快速提取信息,[11]。DOM Web[J].精确匹配、替换和抽取功能集中在基于正则表崔继新的信息抽取。河北URL, 2005 (3):90-93) 表达式对的提取功能和页面优化的替换功能是基于农大学报的DOM。, . [12],,,。固定格式信息的提取匹配功能与构建 杨震 赵延平 朱东华 基于正则表达式的信息仅仅依靠正则表达式来完成信息提取是不现实的。提取系统在国防科技监测中的应用[J].北京,,, 2006, 26( ): 74-78 还需借助其他工具完成, 实现大学学报的增刊科学和技术。有效提取可用于提取过程中的其他方面。,. 正则表达式仍需进一步研究参考文献:[1],,,。XPath 杨文竹 许林 吴陈少飞等基于 . XPath 杨文竹 许林 吴陈少飞等基于 . XPath 杨文竹 许林 吴陈少飞等基于 查看全部
php用正则表达抓取网页中文章(266.26No.6第卷(期北))
26 6卷。26 第 6 卷。No. 2011 12Journal of Beijing Information Science and Technology University Dec. 2011 Month 文章No.: 1674-6864 (20 11)06-0086-04 正则表达式在Web信息抽取中的应用, 胡俊伟秦一清 张伟(, 100 192)@ >北京信息工程大学北京计算机学院: HTML,. 摘要 针对基于结构的信息抽取方法,提出了正则表达式的处理方法,使用正则表达式的功能,匹配、替换和提取正则表达式。在信息提取过程中的应用正,Web正则表达式已成功应用于数据采集页面优化规则学习、信息抽取等信息抽取全过程。:网络;;; ;关键词信息抽取正则表达式匹配替换抽取CLC编号:TP 311 文献编号:A正则表达式及其在Web信息抽取中的应用胡俊伟,秦一清,张伟(北京信息科技大学计算机学院) , 北京 100 192) 摘要: 结合基于 HTML 结构的信息抽取方法, 提出了一种正则表达式的处理方法。讨论了正则表达式在Web信息抽取过程中的应用,利用正则表达式的匹配、替换、提取等。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息提取;正则表达式;匹配;替换;提取,提取字符串数据的有力工具是由特定0介绍意义组成的字符串。具有匹配、替换、提取等功能。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息抽取;正则表达式;匹配;替换;抽取,提取字符串数据的有力工具是由特定的0介绍意义组成的字符串。具有匹配、替换、提取等功能。正则表达式成功地应用于网页信息抽取的全过程,如网页采集、网页优化、规则学习和信息抽取。关键词:Web信息提取;正则表达式;匹配;替换;提取,提取字符串数据的有力工具是由特定0介绍意义组成的字符串。
它代表一定的匹配规则。随着Internet的快速发展,Web信息得到了发展。本文讨论了正则表达式在Web信息抽取过程中的作用。用于全球分布和共享的信息,但目前已应用。WebHTML上的大部分数据主要是以Web信息提取的形式,这是为了展示的方便,允许人们通过浏览器浏览而无需数据本身的描述。HTML 收录不明确的语义信息 [1] 信息提取是指从文本文档中提取特定目的,信息架构不是很清晰,这使得应用程序无法直接解析()、标签信息或事件等数据事实形成一个结构化的网络。并使用上海' 大量的信息造成了资源(XML)的极大浪费,而供用户查询的数据库等表示形式,Web,在此背景下,信息抽取技术应运而生。网络信息抽取是指以网络为信息源的一种信息抽取方式,可以帮助用户摆脱噪声干扰,直接获取所需信息。兴趣。Web信息抽取技术的核心是能够从网页中收录的非结构化或半结构化信息中识别出用户感兴趣的内容。自由结构化的半结构化和结构化文本
, 在语法的基础上,需要结合机器学习等人工智能。正则表达式提供给计算机操作和检查。起草日期:20 11-10-27:(KM2014)基金项目北京教育科技计划面上项目:(1983—),,,,。作者简介 胡军伟,湖北枣阳市研究生,主要从事信息检索技术及应用研究。和学习结构化文本 正则表达式是由普通字符组成的文字模式,例如字符 , , z)(),通常来自具有严格格式的数据库的信息以及称为元字符的特殊字符;。为了使用定义的格式进行提取,半结构化文本描述了要搜索的字符串的匹配模式。意义的特殊字符用于指定,。() 消息通常是不合语法的,并且不遵循任何严格的格式,其前导字符是目标 Web 上元字符之前的字符。. /page 是半结构化文本的典型实例。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。图像中模式的正则表达式是匹配模Web[2]/的形式。信息提取方法可以根据不同的原则分为分隔符之间的部分。是在目标对上。
基于层次结构的信息提取和归纳方法以及基于概念模型图像的模式匹配。用户只需要寻找匹配对 2 ;"/"。该类的多记录信息提取方法可以根据不同图像的图案内容,以不同的自动化程度表示为正则表达式[8],1。还可以分为手动模式、半自动模式和全自动模式。元字符和限定符见表 3 [3];根据各种信息抽取工具所采用的抽取原理和抽取方法的不同,Web表元字符和限定符可以将信息抽取分为基于描述自然语言理解的名称字符的信息抽取,基于机器学习的信息抽取方法、本体、^匹配输入字符串的起始位置、基于信息抽取的方法、基于HTML结构的信息抽取方法、基于Web查询的信息抽取方法。匹配除换行符以外的所有字符一次 [4]5。HTMLMYM匹配输入字符串的结束位置、信息提取等。目前最常用的方法是基于[][]、Web、匹配内字符结构的信息提取技术,由于页面,只需要一点处理就可以转换成一棵格式良好的树[0 - 9]匹配所有数字字符,
元字符 [^0 - 9] 匹配所有非数字字符 [^a - z] 匹配所有非小写字母字符 2 正则表达式 \d, [0 - 9] 匹配一个数字字符 相当于美国数学家组成的正则表达式Stephen Kleene,1956,用于匹配任何单词字符,包括下划线等。\w。主要用于描述正则集代数。它是一种abc匹配字符或字符或一个| 乙 | c,它提供abcabc将字符串中收录的字符串匹配到计算机上来操作和检查要提取的字符串数据。是由具有特定含义的字符组成的字符词串 [5]。该字符串表示某个匹配规则。可以应用正则表达式 * 来匹配前面的子表达式零次或多次。Linux、Unix、Windows、在各种操作系统中,几乎所有 + 匹配前面的子表达式一次或多次。部分语言PHP、C#、C++、Java等都支持。?匹配前面的子表达式零次或一次3、正则表达式最基本的功能是匹配替换和{n}n限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。正则表达式最基本的功能是匹配替换和 {n}n 限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。正则表达式最基本的功能是匹配替换和 {n}n 限定符一定次数。提取匹配函数用于将设置的匹配表达式与目标对象如数据文件{n,}n的表达式输入进行至少多次Web、文件和页面的比较。[6],,,根据比较结果执行信用卡银行,,Email等相应程序。
卡ID数据格式合法性检测等替换功能,可用于利用文档中的匹配模式识别特定字符,然后在Web信息抽取过程中应用,然后删除或替换,如删除Web脚本注释等。, SQL 注入。HTML、句子注入攻击代码等的提取,参考本文中基于结构的提取方法。HTML根据模式匹配从字符串中提取子字符串,例如提出了基于结构提取的正则表达式的应用。1. 如何快速提取页面中的图片超链接、文本等正则表达式的大致流程如图所示。Web5 可以准确处理一系列复杂的搜索、替换和提取字符串。整个信息提取过程大致可以分为[9]。, . 因此,我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。我们可以使用正则表达式快速匹配文本阶段的特征进行信息提取。HTML 文档本身就是一系列 1。Web ,舞台数据 采集 获取页面保存到,。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。由字符串组成的数据在信息抽取过程中完全适合本地磁盘正则表达式的特点。2.第一阶段,对得到的页面进行页面优化处理。对HTML文档进行了优化,目的是提高提取速度,该文档是不收录图片广告脚本和特效字体的文档。
第一阶段的规则学习将优化页面作为训练[11] XMLDOM;然后通过遍历树的方式提取出DOM树,用训练样本标注用户感兴趣的信息。 DOM,通过树作为转换工具的信息生成和提取规则 XPATH、XSLT等技术编写提取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。信息生成和抽取规则通过树作为转换工具 XPATH、XSLT 等技术编写抽取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。信息生成和抽取规则通过树作为转换工具 XPATH、XSLT 等技术编写抽取规则。HTMLXML()。最终实现将转换为或结构化数据。4、信息抽取的第一阶段是使用写好的抽取规则,HTML会使用正则表达式匹配功能来使用树形的HTML。
提取用户感兴趣的信息,格式可视化,方便用户完成样本页面信息的标注。[12] 在数据存储阶段,将提取的信息用正则表达式的三种匹配模式表示作为存储。<(?<htmltag>[az]+[\d]?)^[>]* 3.1 个数据采集>> . * ? < / \ k < htmltag > > (3),网页一般通过网络爬虫工具从网上下载 < [az]+[\d]?[^>]*>(4)1URL 工作原理爬虫的过程就是从(?>[^<]*)5()中获取对初始网页的网页进行抓取的过程,一个或多个初始网页的URL(3)1HTML表达式表示它是匹配一对标签、URL、并不断从当前页面中提取新的并放入队列中,直到,,,."而零>""</\k<htmltag>>"又代表开始和结束或多个"/"、"."、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。and 表示开头和结尾或多个“/”、“.”、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。and 表示开头和结尾或多个“/”、“.”、. 或由 HTML 的固定表示形式组成,“[az]+[\d]?” tag 表示通过正则表达式 H1、H2 的匹配功能可以很容易地实现特殊的出现。
“[^>]*”。例如,使用有效字体来匹配其属性 URL。提取的正则表达式的匹配模式表示为“.* ?”。表示标记 http 中收录的内容表达式: (\\ w + (- \\ w + )* )(\\ . (\\ w + (- \\ w∥(4 ), HTML,表示一个单标签没有结束标签 + )* ))* (\\ ?\\ S * )?http : 表示任何标签收录 ∥: "< img src = aaa.jpg > " 例如,该标签是未配对的 "/ “”。和零个或多个或相等的符号是必需的 HTML。(5) HTML,标记表达式是匹配非标记URL。网络爬虫将通过这个常规匹配匹配所有需求。3 比如一些纯文本等通过上面的正则表达式URL,。它被视为放入队列。借助正则表达式HTML,网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,还可以准确的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,而且精准的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。网络爬虫可以通过递归算法实现对整个文本的匹配,不仅大大减少了工作量,节省了时间,而且精准的DOM。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如下构建树形的步骤也很不错。1) HTML3,对文本进行上述正则匹配,3. 2页面优化过程定义当前DOM树节点;HTML,页面优化就是将页面优化到节点2)@>,5);如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。如果结构不规则的 HTML 文档无法成功匹配,则将其转换为符合 3) 的结构良好的 HTML 文档。如果可以匹配,则将得到的结果视为一个新的结构XMLXHTML。
标准文档通过正则表达式、DOM过滤;点添加到当前树节点函数,HTML,可以实现对代码的过滤,以达到优化的目的 4)匹配得到的HTML标签中的代码被认为是新的。例如:“<img src=a.jpg>”、“<b>J5<HTML,3),文本会将/b>中的节点转为“<b></b>”中的当前节点<h1> 1); 在战斗机中还有一些</h1>,HTML5)。等标签被移除以简化提取并将文本添加到当前节点。6:网络问题胡俊伟等。正则表达式在信息抽取中的应用89DOM,Web[J].正则表达式生成的树提供了计算机工程DOM、DOM、[J]. 现代智能,2007 (10):215- 219 3. 4 提取 [3] Line Eikvil。从 worldHTML 中提取信息,广网调查 [R]。挪威:挪威人应该充分考虑 HTML, . [J]. 现代智能,2007 (10):215- 219 3. 4 提取 [3] Line Eikvil。从 worldHTML 中提取信息,广网调查 [R]。挪威:挪威人应该充分考虑 HTML, .
HTMLComputing Center, 1999 Pages of Complex Instability Complex Pages [10], :[4] Alberto H ELaender, Berthier A Ribeiro-Neto, 还包括一些固定结构信息,例如在介绍中,Altigran S da Silva 等。网络简述 图书介绍的页面有图书的价格和图书销售商的电话号码。,数据提取工具[J].ACM SIGMOD Record、box等信息被视为固定结构的信息。通过正则表达式的匹配功能,可以从第2002、31行提取固定结构的信息(2)@>:84-93.,,[5].[M].:对于商品价格,电话号码,手机号和邮箱 沙金精通正则表达式,北京人民邮电,2008等信息,正则表达式的匹配模式表示为 Publishing House ():^ [0-9] *[1 - 9][6] Liger F, Queen CM, Wilton P. C# 商品价格有两位小数,正数 [0 - 9] *\.(\d{2})[M]., .: $ 正则表达式参考手册 刘乐亭 京庆 电话号码:^ ((\ (\ d {2 ,3 }\ ))| ( \ d {3 }\ - ))?华大学出版社, 2003 (\(0\d{2, 3}\)|0\d{2, 3}-)?1[-9]\d{6, 7}[7], . 张静和张艳正则表达式及其在信息抽取中的应用(\ - \ d {1, 4 }) ? [J]., 2009, 5 (15):3867$ 应用计算机知识与技术 手机号:^((\(\d{2, 3}\))|(\d{3}\ - ))? - 3868 1 (3 |5 |8) \d{9}[8], . Boost. Regex$ 吴鹏飞马凤娟的邮箱:^ [\ w - ] + (\ . [ \w-]+)*@[\w信息提取[J].武汉理工大学匹配这些正则表达式,可以直接输出需要的[10] Man I Lam, Zhiguo Gong, Maybin Muyeba。一个信息。武汉理工大学匹配这些正则表达式,可以直接输出需要的[10] Man I Lam, Zhiguo Gong, Maybin Muyeba。一个信息。
网络信息抽取方法[C]∥计算机科学讲义。德国:4 结论 Springer-Verlag Berlin Heidelberg, 2008, 4976: Web, 383-394 本文使用正则表达式快速提取信息,[11]。DOM Web[J].精确匹配、替换和抽取功能集中在基于正则表崔继新的信息抽取。河北URL, 2005 (3):90-93) 表达式对的提取功能和页面优化的替换功能是基于农大学报的DOM。, . [12],,,。固定格式信息的提取匹配功能与构建 杨震 赵延平 朱东华 基于正则表达式的信息仅仅依靠正则表达式来完成信息提取是不现实的。提取系统在国防科技监测中的应用[J].北京,,, 2006, 26( ): 74-78 还需借助其他工具完成, 实现大学学报的增刊科学和技术。有效提取可用于提取过程中的其他方面。,. 正则表达式仍需进一步研究参考文献:[1],,,。XPath 杨文竹 许林 吴陈少飞等基于 . XPath 杨文竹 许林 吴陈少飞等基于 . XPath 杨文竹 许林 吴陈少飞等基于
php用正则表达抓取网页中文章(PHP联系我们脚本无需修改即可运行的zip文件文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-13 03:11
PHPcontact-us 脚本无需修改即可运行。它检测域并通过电子邮件发送与我们联系的所有表单数据
一个现成的 PHP 联系我们脚本,无需修改,它将检测域并将收录联系消息的电子邮件发送到表单中的任何字段;它将检测到它们并通过电子邮件发送表单数据。
PHP 中的新功能联系我们脚本
用户必须在提交前在名称字段、电子邮件、主题和消息中输入数据
新版本包括更多的用户输入过滤。因此,通过使用函数 htmlspecialchars() 和过滤器 FILTER_SANITIZE_STRING 清理每个输入键和值,脚本是安全的。我会删除任何 HTML 代码或无效字符。
介绍
即用型 PHPcontact-us 脚本,无需修改,它将检测域并将收录联系信息的电子邮件发送到表单中的任何字段;它将检测到它们并通过电子邮件发送表单数据。
系统要求
任何带有支持 PHP 的主机的 网站;几乎所有主机都支持它。
换句话说,您可以将它与任何 网站 一起使用,无论其用途如何:纯 HTML/PHP、WordPress、Joomla、Drupal 或任何其他系统
PHP版本:
PHP5.6/PHP7.0/PHP7.1/PHP7.2/PHP7.3/PHP7.4/PHP< @8.0
背景
互联网上有很多脚本与我们联系。另一方面,其他脚本在使用前需要修改 PHP 文件,而此脚本将直接运行。
因此,这个脚本对于不懂 PHP 的人和 PHP 的初学者来说非常有用。
使用代码
解压下载的 zip 文件
然后在您的 网站 www 目录中创建一个contact-us 文件夹
之后,将文件上传到contact-us文件夹
就这样。
最后,contact-us URL 类似于 /contact-us,将您的域替换为
修改联系我们表单设计
您可以根据需要修改联系我们页面的设计,
根据需要添加或省略字段
使用 from_email、from_name、主题、消息和验证码字段名称
放置您自己的广告或使您的表单无广告
随意添加链接到我们。
关于我们的联系代码
从行动
1复制代码类型:[html]
字段名称
使用 from_email、from_name、主题、消息和验证码作为表单名称中的主要字段。
验证码
如果您不想使用验证码,请将 1 行“send.php”代码替换为:
$captcha = false;1复制代码类型:[html]
如果你想使用验证码,你不需要做任何更改和 1 行“send.php”代码:
$captcha = true;1复制代码类型:[html]
如果需要修改表格;请注意,我们正在使用验证码,请将以下内容添加到您的表单中:
<p> 查看全部
php用正则表达抓取网页中文章(PHP联系我们脚本无需修改即可运行的zip文件文件)
PHPcontact-us 脚本无需修改即可运行。它检测域并通过电子邮件发送与我们联系的所有表单数据
一个现成的 PHP 联系我们脚本,无需修改,它将检测域并将收录联系消息的电子邮件发送到表单中的任何字段;它将检测到它们并通过电子邮件发送表单数据。
PHP 中的新功能联系我们脚本
用户必须在提交前在名称字段、电子邮件、主题和消息中输入数据
新版本包括更多的用户输入过滤。因此,通过使用函数 htmlspecialchars() 和过滤器 FILTER_SANITIZE_STRING 清理每个输入键和值,脚本是安全的。我会删除任何 HTML 代码或无效字符。
介绍
即用型 PHPcontact-us 脚本,无需修改,它将检测域并将收录联系信息的电子邮件发送到表单中的任何字段;它将检测到它们并通过电子邮件发送表单数据。
系统要求
任何带有支持 PHP 的主机的 网站;几乎所有主机都支持它。
换句话说,您可以将它与任何 网站 一起使用,无论其用途如何:纯 HTML/PHP、WordPress、Joomla、Drupal 或任何其他系统
PHP版本:
PHP5.6/PHP7.0/PHP7.1/PHP7.2/PHP7.3/PHP7.4/PHP< @8.0
背景
互联网上有很多脚本与我们联系。另一方面,其他脚本在使用前需要修改 PHP 文件,而此脚本将直接运行。
因此,这个脚本对于不懂 PHP 的人和 PHP 的初学者来说非常有用。
使用代码
解压下载的 zip 文件
然后在您的 网站 www 目录中创建一个contact-us 文件夹
之后,将文件上传到contact-us文件夹
就这样。
最后,contact-us URL 类似于 /contact-us,将您的域替换为
修改联系我们表单设计
您可以根据需要修改联系我们页面的设计,
根据需要添加或省略字段
使用 from_email、from_name、主题、消息和验证码字段名称
放置您自己的广告或使您的表单无广告
随意添加链接到我们。
关于我们的联系代码
从行动
1复制代码类型:[html]
字段名称
使用 from_email、from_name、主题、消息和验证码作为表单名称中的主要字段。
验证码
如果您不想使用验证码,请将 1 行“send.php”代码替换为:
$captcha = false;1复制代码类型:[html]
如果你想使用验证码,你不需要做任何更改和 1 行“send.php”代码:
$captcha = true;1复制代码类型:[html]
如果需要修改表格;请注意,我们正在使用验证码,请将以下内容添加到您的表单中:
<p>
php用正则表达抓取网页中文章(正则表达式就是描述字符排列模式的一种自定义的语法规则名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-10 11:31
第一次接触正则表达式的网友会觉得有点繁琐,会有一种深不可测的感觉。实际上,正则表达式是描述字符排列模式的自定义语法规则名称。在 PHP 提供的系统函数中,该模式用于执行字符串的匹配、查找、替换和分割等操作。它的应用非常广泛。例如,常用正则表达式来验证用户在表单中提交的用户名、密码、邮箱地址、身份证号甚至电话号码是否合法;当用户发布文章时,会在有URL的地方添加所有对应的链接;根据所有标点符号计算文章中的句子总数;抓取网页中某种格式的数据等。正则表达式不是PHP自己的产物,在很多领域都会看到它的应用。除了 Perl、C#、Java 语言的应用外,在我们的 B/S 架构软件开发中,正则表达式可以应用于 Linux 操作系统、前端 JavaScript 脚本、后台脚本 PHP 和 MySQL 数据库。
正则表达式也称为模式表达式,具有非常完整的可以编写模式的语法系统,并提供了一种灵活直观的字符处理方法。正则表达式用于通过构造具有特定模式的模式,将其与输入字符串信息进行比较,并在特定函数中使用来匹配、查找、替换和划分字符串。下面给出的三种模式是根据正则表达式的语法规则构造的。代码显示如下:
"/[a-zA-z]+:[∧\s]*/" //正则表达式匹配网址
"/<(\s*?)[∧>]*>.*?<∧1>|<.*?/>/i" //正则表达式匹配HTML标签
"∧w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/" //正则表达式匹配邮箱模式
不要被上面例子中的乱码吓到,它们是按照正则表达式的语法规则构造的模式,是由普通字符和特殊字符组成的字符串。并且仅在特定的正则表达式函数中使用这些模式字符串才有效。学完本章,你就可以自由地应用这样的代码了。PHP 支持两组正则表达式处理函数库。PCRE(Perl Compatible Regular Expression)库提供的一组正则表达式函数,与Perl语言兼容,使用以preg前缀命名的函数,表达式应收录在分隔符中,如斜杠(/)。另一个是正则表达式函数,其语法由 POSLX(便携式操作系统接口)扩展,使用前缀为“preg_”的函数。两组函数的功能基本相似,但执行效率略有不同。一般来说,要实现同样的功能,PCRE库提供的正则表达式效率会稍微高一些。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。 查看全部
php用正则表达抓取网页中文章(正则表达式就是描述字符排列模式的一种自定义的语法规则名)
第一次接触正则表达式的网友会觉得有点繁琐,会有一种深不可测的感觉。实际上,正则表达式是描述字符排列模式的自定义语法规则名称。在 PHP 提供的系统函数中,该模式用于执行字符串的匹配、查找、替换和分割等操作。它的应用非常广泛。例如,常用正则表达式来验证用户在表单中提交的用户名、密码、邮箱地址、身份证号甚至电话号码是否合法;当用户发布文章时,会在有URL的地方添加所有对应的链接;根据所有标点符号计算文章中的句子总数;抓取网页中某种格式的数据等。正则表达式不是PHP自己的产物,在很多领域都会看到它的应用。除了 Perl、C#、Java 语言的应用外,在我们的 B/S 架构软件开发中,正则表达式可以应用于 Linux 操作系统、前端 JavaScript 脚本、后台脚本 PHP 和 MySQL 数据库。
正则表达式也称为模式表达式,具有非常完整的可以编写模式的语法系统,并提供了一种灵活直观的字符处理方法。正则表达式用于通过构造具有特定模式的模式,将其与输入字符串信息进行比较,并在特定函数中使用来匹配、查找、替换和划分字符串。下面给出的三种模式是根据正则表达式的语法规则构造的。代码显示如下:
"/[a-zA-z]+:[∧\s]*/" //正则表达式匹配网址
"/<(\s*?)[∧>]*>.*?<∧1>|<.*?/>/i" //正则表达式匹配HTML标签
"∧w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/" //正则表达式匹配邮箱模式
不要被上面例子中的乱码吓到,它们是按照正则表达式的语法规则构造的模式,是由普通字符和特殊字符组成的字符串。并且仅在特定的正则表达式函数中使用这些模式字符串才有效。学完本章,你就可以自由地应用这样的代码了。PHP 支持两组正则表达式处理函数库。PCRE(Perl Compatible Regular Expression)库提供的一组正则表达式函数,与Perl语言兼容,使用以preg前缀命名的函数,表达式应收录在分隔符中,如斜杠(/)。另一个是正则表达式函数,其语法由 POSLX(便携式操作系统接口)扩展,使用前缀为“preg_”的函数。两组函数的功能基本相似,但执行效率略有不同。一般来说,要实现同样的功能,PCRE库提供的正则表达式效率会稍微高一些。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。
php用正则表达抓取网页中文章(初出茅庐的你带着仍残留的10项无需指导)
网站优化 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-04-07 22:04
作为一个初出茅庐的你,拿着一张还保留着墨香的毕业证踏上工作岗位,马上就被书本上没有的规矩和各种繁杂的日常事务给拆散了。像这样的故事很常见,编程工作也不例外。
很少有学生 100% 准备好迎接第一份真正的工作。如果您不想成为其中之一,请学习以下 10 项无需动手指导即可学习的基本技能:
1、版本控制系统(VCS)
VCS 可能是计算机课程中最大的遗漏。这些课程只记得教如何编码,却常常忘记教学生如何管理代码。每个程序员都应该知道如何使用 Git 或 Subversion 来有效地创建存储库、编辑和提交代码、分支和合并,以及了解项目工作流程。
2、学习写作
成为一名程序员不仅仅是写代码。您还为项目编写发行说明,提交版本控制消息,并在系统中编写错误报告。这些以及许多地方都需要清晰有效的书面交流——这是计算机科学中很少强调的一项技能。
3、正则表达式
正则表达式本身就是一种语言,每个现代程序员都应该擅长它。每种现代语言都支持正则表达式或具有相关的标准库。如果您的代码需要检查一个字符串是否收录 5 个字符、1 个破折号和 1 个数字,您应该能够立即编写 /^[AZ]{5}-\d$/。
4、图书馆的使用
现在是 2014 年,所以没有人需要使用正则表达式从 URL 中提取主机名。因为每一种现代编程语言都有执行通用功能的标准库。
程序员需要了解,经过开发、测试和调试的代码通常比重写的代码更好。更重要的是,不需要编写的代码实现起来要快得多。
5、SQL
许多人在工作中学习 SQL。数据库如何成为选修课?有没有没有数据库的?
将数据存储在平面文件中的时代已经结束。一切都进出数据库,而 SQL 是访问数据的语言。这是一种声明性语言,而不是程序性语言,因此使用它来解决问题需要新的思维方式。每个程序员都应该了解数据库规范化的基础知识,并且能够执行 SELECT(以及 INNER、OUTER JOIN)、INSERT、UPDATE 和 DELETE。
6、能够使用 IDE、编辑器和 CLI 工具
一个只知道如何使用锯子的木匠永远不会做出它,所以一个计算机专业的毕业生只知道记事本或 pico 是令人惊讶的。编程工具通过帮助操作代码和其他数据使程序员的生活更轻松。所以每个程序员都应该知道命令行、shell脚本、find、grep和sed的使用。
7、调试
每个程序员都应该知道如何使用交互式调试器或通过在代码中添加一些输出语句来调试程序。通过逐步完善来追踪问题的能力实在是太重要了。
8、防错编程
错误总是不可避免的,即使对于明星程序员也是如此。失去控制是世界上的常态,出现问题也就不足为奇了。防错编程理解这个事实。如果事情没有出错,我们不会检查文件是否已成功打开,我们不会检查客户端 ID 是否是有效数字,并且我们不会测试代码是否正确。
程序员需要知道编译器警告是使我们的生活更舒适的有用工具,而不是要避免的麻烦。每个程序员都应该知道为什么每个 PHP 程序都是这样开始的:
设置错误报告(E_ALL)
每个 Perl 程序都应该编写这些语句:
使用严格;使用警告;
9、团队合作
编程很少靠你自己工作,如果你经常这样做,你的智力会受到影响,你的表现也会变弱。您的代码必须与其他人的代码交互或混合。即使是最有才华的程序员,如果不能与他人合作,也会对项目产生负面影响,并很快成为组织的负担。
10、利用现有代码
在学校里,每一项作业都是一个新项目。但现实世界并非如此。对于刚开始工作的人来说,他们收到的第一个任务通常是修复代码错误。然后,在现有代码库之上向现有系统添加一个小功能。如果幸运的话,设计新代码需要几个月的时间。
【本文编译自:】
AD:云屋,一种新的工作方式。 查看全部
php用正则表达抓取网页中文章(初出茅庐的你带着仍残留的10项无需指导)
作为一个初出茅庐的你,拿着一张还保留着墨香的毕业证踏上工作岗位,马上就被书本上没有的规矩和各种繁杂的日常事务给拆散了。像这样的故事很常见,编程工作也不例外。
很少有学生 100% 准备好迎接第一份真正的工作。如果您不想成为其中之一,请学习以下 10 项无需动手指导即可学习的基本技能:
1、版本控制系统(VCS)
VCS 可能是计算机课程中最大的遗漏。这些课程只记得教如何编码,却常常忘记教学生如何管理代码。每个程序员都应该知道如何使用 Git 或 Subversion 来有效地创建存储库、编辑和提交代码、分支和合并,以及了解项目工作流程。
2、学习写作
成为一名程序员不仅仅是写代码。您还为项目编写发行说明,提交版本控制消息,并在系统中编写错误报告。这些以及许多地方都需要清晰有效的书面交流——这是计算机科学中很少强调的一项技能。
3、正则表达式
正则表达式本身就是一种语言,每个现代程序员都应该擅长它。每种现代语言都支持正则表达式或具有相关的标准库。如果您的代码需要检查一个字符串是否收录 5 个字符、1 个破折号和 1 个数字,您应该能够立即编写 /^[AZ]{5}-\d$/。
4、图书馆的使用
现在是 2014 年,所以没有人需要使用正则表达式从 URL 中提取主机名。因为每一种现代编程语言都有执行通用功能的标准库。
程序员需要了解,经过开发、测试和调试的代码通常比重写的代码更好。更重要的是,不需要编写的代码实现起来要快得多。
5、SQL
许多人在工作中学习 SQL。数据库如何成为选修课?有没有没有数据库的?
将数据存储在平面文件中的时代已经结束。一切都进出数据库,而 SQL 是访问数据的语言。这是一种声明性语言,而不是程序性语言,因此使用它来解决问题需要新的思维方式。每个程序员都应该了解数据库规范化的基础知识,并且能够执行 SELECT(以及 INNER、OUTER JOIN)、INSERT、UPDATE 和 DELETE。
6、能够使用 IDE、编辑器和 CLI 工具
一个只知道如何使用锯子的木匠永远不会做出它,所以一个计算机专业的毕业生只知道记事本或 pico 是令人惊讶的。编程工具通过帮助操作代码和其他数据使程序员的生活更轻松。所以每个程序员都应该知道命令行、shell脚本、find、grep和sed的使用。
7、调试
每个程序员都应该知道如何使用交互式调试器或通过在代码中添加一些输出语句来调试程序。通过逐步完善来追踪问题的能力实在是太重要了。
8、防错编程
错误总是不可避免的,即使对于明星程序员也是如此。失去控制是世界上的常态,出现问题也就不足为奇了。防错编程理解这个事实。如果事情没有出错,我们不会检查文件是否已成功打开,我们不会检查客户端 ID 是否是有效数字,并且我们不会测试代码是否正确。
程序员需要知道编译器警告是使我们的生活更舒适的有用工具,而不是要避免的麻烦。每个程序员都应该知道为什么每个 PHP 程序都是这样开始的:
设置错误报告(E_ALL)
每个 Perl 程序都应该编写这些语句:
使用严格;使用警告;
9、团队合作
编程很少靠你自己工作,如果你经常这样做,你的智力会受到影响,你的表现也会变弱。您的代码必须与其他人的代码交互或混合。即使是最有才华的程序员,如果不能与他人合作,也会对项目产生负面影响,并很快成为组织的负担。
10、利用现有代码
在学校里,每一项作业都是一个新项目。但现实世界并非如此。对于刚开始工作的人来说,他们收到的第一个任务通常是修复代码错误。然后,在现有代码库之上向现有系统添加一个小功能。如果幸运的话,设计新代码需要几个月的时间。
【本文编译自:】
AD:云屋,一种新的工作方式。
php用正则表达抓取网页中文章(魔王想提升代码搜索效果?首先你得知道怎么才算提升)
网站优化 • 优采云 发表了文章 • 0 个评论 • 472 次浏览 • 2022-04-07 22:01
机器之心编译
参与:魔王
想要提高代码搜索性能?首先,您必须知道什么是改进。GitHub 团队创建 CodeSearchNet 语料库,为代码搜索领域提供基准数据集,提高代码搜索结果的质量。
搜索代码以重用、调用或使用以查看其他人如何处理问题是软件开发人员每天最常见的任务之一。但是,代码搜索引擎通常不能很好地工作,并且与常规的网络搜索引擎不同,它们不能完全理解您的需求。GitHub 团队尝试使用现代机器学习技术来改进代码搜索结果,但很快意识到一个问题:他们无法衡量改进。自然语言处理领域有 GLUE 基准,但代码搜索评估领域没有合适的标准数据集。
因此,GitHub 昨天与 Weights & Biases 合作,推出了 CodeSearchNet Challenge 评估环境和排行榜。同时,GitHub 还发布了一个大型数据集,帮助数据科学家构建适合该任务的模型,多个基线模型代表了当前的最先进水平。排行榜使用查询注释数据集来评估代码搜索工具的质量。
代码搜索网络语料库
创建一个足够大的数据集来训练具有专家注释的大容量模型既昂贵又不切实际,因此 GitHub 创建了一个质量较低的代理数据集。GitHub 遵循 [5, 6, 9, 11] 中的做法,将开源软件中的功能与其相应文档中的自然语言相匹配。但是,这样做需要许多预处理步骤和启发式方法。
通过对常见错误案例的深入分析,GitHub 团队总结出了一些通用的规则和决策。
CodeSearchNet 语料库采集过程
GitHub 团队从开源非分叉 GitHub 存储库中采集语料库,使用 library.io 确认所有项目都被至少一个其他项目使用,并按“受欢迎程度”对它们进行排序(受欢迎程度通过星号和分叉数来衡量)当然)。然后,删除没有许可证或未明确允许重新分发的项目。然后,GitHub 团队使用其通用解析器 TreeSitter 对所有 Go、Java、JavaScript、Python、PHP 和 Ruby 函数(或方法)进行标记,并使用启发式正则表达式对与函数对应的文档文本进行标记。
筛选
为了生成 CodeSearchNet 挑战赛的训练数据,GitHub 团队首先考虑了语料库中收录相关文档的函数。这会产生一组 (c_i , d_i) 对,其中 c_i 是函数,d_i 是相应的文档。为了使数据更适合代码搜索任务,GitHub 团队执行了一系列预处理步骤:
详情见过滤后的语料库和数据提取代码:
数据集详细信息
该数据集收录 200 万个函数-文档对和大约 400 万个没有相应文档的函数(见下表 1)。GitHub 团队将数据集以 80-10-10 的比例划分为训练/验证)。set/test set,建议用户按这个比例使用这个数据集。
表 1:数据集详细信息。
局限性
这个数据集非常嘈杂。首先,文档和查询之间存在根本区别,因为它们使用不同的语言形式。文档通常与代码作者在编写代码的同时编写,并且倾向于使用相同的词汇表,这与搜索查询不同。其次,尽管 GitHub 团队在创建数据集的过程中进行了数据清理,但他们无法知道每个文档 d_i 描述相应代码段 c_i 的准确程度。最后,一些文档是用非英语文本编写的,而 CodeSearchNet Challenge 评估数据集主要关注英语查询。
CodeSearchNet 基线模型
在 GitHub 之前在语义代码搜索方面的努力的基础上,该团队发布了一组基线模型,这些模型利用现代技术来学习序列(包括类似 BERT 的自注意力模型),以帮助数据科学家开始代码搜索。
与之前的工作一样,GitHub 团队使用代码和查询的联合嵌入来实现神经搜索系统。该架构为每种输入(自然或编程)语言使用编码器,并训练它们以使输入映射到联合向量空间。训练目标是将代码及其对应的语言映射到附近的向量,这样我们就可以嵌入查询来执行搜索,然后返回嵌入空间中“附近”的一组代码段。
考虑到查询和代码之间更多交互的更复杂的模型当然性能更好,但为每个查询或代码段生成单个向量可以实现更有效的索引和搜索。
为了学习这些嵌入功能,GitHub 团队在架构中加入了标准的序列编码器模型,如图 3 所示。首先,根据输入序列的语义进行预处理:将代码令牌中的标识符拆分为子令牌(例如变量camelCase变成了两个子标记:camel和case),使用字节对编码(byte-pair encoding),BPE)来分割自然语言标记。
图 3:模型架构概述。
然后使用以下架构之一处理令牌序列以获得(上下文化的)令牌嵌入。
之后,这些令牌嵌入使用池化函数组合成序列嵌入,GitHub 团队实现了均值/最大池化和类注意力的加权求和机制。
下图显示了基线模型的一般架构:
CodeSearchNet 挑战
为了评估代码搜索模型,GitHub 团队采集了一组代码搜索查询,并要求程序员注释查询与可能结果的相关程度。他们首先从 Bing 中采集了一些常见的搜索查询,并结合 StaQC 中的查询,总共得到了 99 个与代码概念相关的查询(GitHub 团队删除了 API 文档查询问题)。
图 1:注释器说明。
之后,GitHub 团队使用标准 Elasticsearch 和基线模型从 CodeSearchNet 语料库中为每个查询获取 10 个可能的结果。最后,GitHub 团队要求程序员、数据科学家和机器学习研究人员按照 [0, 3] 标准标记每个结果与查询的相关程度(0 表示“完全不相关”,3 表示“完全匹配” )。
将来,GitHub 团队希望在此评估数据集中收录更多语言、查询和注释。在接下来的几个月里,他们将继续添加新数据,为下一版 CodeSearchNet 挑战赛生成扩展数据集。
原文链接: 查看全部
php用正则表达抓取网页中文章(魔王想提升代码搜索效果?首先你得知道怎么才算提升)
机器之心编译
参与:魔王
想要提高代码搜索性能?首先,您必须知道什么是改进。GitHub 团队创建 CodeSearchNet 语料库,为代码搜索领域提供基准数据集,提高代码搜索结果的质量。
搜索代码以重用、调用或使用以查看其他人如何处理问题是软件开发人员每天最常见的任务之一。但是,代码搜索引擎通常不能很好地工作,并且与常规的网络搜索引擎不同,它们不能完全理解您的需求。GitHub 团队尝试使用现代机器学习技术来改进代码搜索结果,但很快意识到一个问题:他们无法衡量改进。自然语言处理领域有 GLUE 基准,但代码搜索评估领域没有合适的标准数据集。
因此,GitHub 昨天与 Weights & Biases 合作,推出了 CodeSearchNet Challenge 评估环境和排行榜。同时,GitHub 还发布了一个大型数据集,帮助数据科学家构建适合该任务的模型,多个基线模型代表了当前的最先进水平。排行榜使用查询注释数据集来评估代码搜索工具的质量。
代码搜索网络语料库
创建一个足够大的数据集来训练具有专家注释的大容量模型既昂贵又不切实际,因此 GitHub 创建了一个质量较低的代理数据集。GitHub 遵循 [5, 6, 9, 11] 中的做法,将开源软件中的功能与其相应文档中的自然语言相匹配。但是,这样做需要许多预处理步骤和启发式方法。
通过对常见错误案例的深入分析,GitHub 团队总结出了一些通用的规则和决策。
CodeSearchNet 语料库采集过程
GitHub 团队从开源非分叉 GitHub 存储库中采集语料库,使用 library.io 确认所有项目都被至少一个其他项目使用,并按“受欢迎程度”对它们进行排序(受欢迎程度通过星号和分叉数来衡量)当然)。然后,删除没有许可证或未明确允许重新分发的项目。然后,GitHub 团队使用其通用解析器 TreeSitter 对所有 Go、Java、JavaScript、Python、PHP 和 Ruby 函数(或方法)进行标记,并使用启发式正则表达式对与函数对应的文档文本进行标记。
筛选
为了生成 CodeSearchNet 挑战赛的训练数据,GitHub 团队首先考虑了语料库中收录相关文档的函数。这会产生一组 (c_i , d_i) 对,其中 c_i 是函数,d_i 是相应的文档。为了使数据更适合代码搜索任务,GitHub 团队执行了一系列预处理步骤:
详情见过滤后的语料库和数据提取代码:
数据集详细信息
该数据集收录 200 万个函数-文档对和大约 400 万个没有相应文档的函数(见下表 1)。GitHub 团队将数据集以 80-10-10 的比例划分为训练/验证)。set/test set,建议用户按这个比例使用这个数据集。
表 1:数据集详细信息。
局限性
这个数据集非常嘈杂。首先,文档和查询之间存在根本区别,因为它们使用不同的语言形式。文档通常与代码作者在编写代码的同时编写,并且倾向于使用相同的词汇表,这与搜索查询不同。其次,尽管 GitHub 团队在创建数据集的过程中进行了数据清理,但他们无法知道每个文档 d_i 描述相应代码段 c_i 的准确程度。最后,一些文档是用非英语文本编写的,而 CodeSearchNet Challenge 评估数据集主要关注英语查询。
CodeSearchNet 基线模型
在 GitHub 之前在语义代码搜索方面的努力的基础上,该团队发布了一组基线模型,这些模型利用现代技术来学习序列(包括类似 BERT 的自注意力模型),以帮助数据科学家开始代码搜索。
与之前的工作一样,GitHub 团队使用代码和查询的联合嵌入来实现神经搜索系统。该架构为每种输入(自然或编程)语言使用编码器,并训练它们以使输入映射到联合向量空间。训练目标是将代码及其对应的语言映射到附近的向量,这样我们就可以嵌入查询来执行搜索,然后返回嵌入空间中“附近”的一组代码段。
考虑到查询和代码之间更多交互的更复杂的模型当然性能更好,但为每个查询或代码段生成单个向量可以实现更有效的索引和搜索。
为了学习这些嵌入功能,GitHub 团队在架构中加入了标准的序列编码器模型,如图 3 所示。首先,根据输入序列的语义进行预处理:将代码令牌中的标识符拆分为子令牌(例如变量camelCase变成了两个子标记:camel和case),使用字节对编码(byte-pair encoding),BPE)来分割自然语言标记。
图 3:模型架构概述。
然后使用以下架构之一处理令牌序列以获得(上下文化的)令牌嵌入。
之后,这些令牌嵌入使用池化函数组合成序列嵌入,GitHub 团队实现了均值/最大池化和类注意力的加权求和机制。
下图显示了基线模型的一般架构:
CodeSearchNet 挑战
为了评估代码搜索模型,GitHub 团队采集了一组代码搜索查询,并要求程序员注释查询与可能结果的相关程度。他们首先从 Bing 中采集了一些常见的搜索查询,并结合 StaQC 中的查询,总共得到了 99 个与代码概念相关的查询(GitHub 团队删除了 API 文档查询问题)。
图 1:注释器说明。
之后,GitHub 团队使用标准 Elasticsearch 和基线模型从 CodeSearchNet 语料库中为每个查询获取 10 个可能的结果。最后,GitHub 团队要求程序员、数据科学家和机器学习研究人员按照 [0, 3] 标准标记每个结果与查询的相关程度(0 表示“完全不相关”,3 表示“完全匹配” )。
将来,GitHub 团队希望在此评估数据集中收录更多语言、查询和注释。在接下来的几个月里,他们将继续添加新数据,为下一版 CodeSearchNet 挑战赛生成扩展数据集。
原文链接:
php用正则表达抓取网页中文章(PHP正则表达式完全手册(gt)php正则表达式捕获(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-06 11:22
阿里云 > 云栖社区 > 主题地图 > P > PHP正则表达式捕获
推荐活动:
更多优惠>
当前主题: php regex capture 添加到采集夹
相关话题:
php regex 捕获相关博客 查看更多博客
php正则表达式组捕获
作者:meteric639 浏览评论:011年前
经过测试发现获取组捕获的php正则表达式是从$0开始的,而在工程代码中提取汉字时,JavaScript中的正则在工作中是$1..$9,因为运行速度非常快当时很快(赶上时间),我担心.properties文件中{\d}的数字顺序错误:1、可能来自{1}
阅读全文
C#正则表达式编程(四):正则表达式
作者:科技甜1234 浏览评论:04年前
正则表达式提供了一种强大、灵活、高效的文本处理方式。正则表达式的全面模式匹配表示法让您可以快速分析大量文本以找到特定的字符模式;提取、编辑、替换或删除文本的子字符串;或将提取的字符串添加到集合以生成报告。用于处理字符串,例如 HTML 处理、日志文件分析和
阅读全文
谈论正则表达式
作者:Jack Chen805 浏览评论:07年前
原文:浅谈正则表达式一、什么是正则表达式?简单地说:正则表达式是一种处理字符串匹配的语言;正则表达式描述了字符串匹配的一种模式,可以用来检查一个字符串是否收录某个子字符串,以及匹配的“删除”或“替换”操作的子字符串。二
阅读全文
PHP 正则表达式
作者:thinkyoung825 浏览人数:06年前
PHP正则表达式思维导图点击下图查看具体内容!引入正则表达式,在开发中应该经常使用。现在很多开发语言都有正则表达式的应用,比如javascript、java、.net、php等,今天我就讲讲正则表达式的道理。
阅读全文
PHP正则表达式完整手册
作者:Jack Chen 636 次浏览评论:06 年前
原文:PHP正则表达式完整手册 PHP正则表达式完整手册前言 正则表达式繁琐,但功能强大,学习后的应用不仅会提高你的效率,还会给你带来绝对的成就感。只要仔细阅读这些资料,并在申请时做好一定的参考,掌握正则表达式不是问题。索引1.
阅读全文
大数据的Regex真的是正则表达式吗?
作者:青山无名2031 浏览评论:04年前
文章 讲的是大数据 正则表达式真的是一个正则表达式,正则表达式已经存在了几十年,它甚至早于今天的大数据、UI、机器学习以及几乎所有其他工具和技术。正则表达式通常被许多开发人员认为是晦涩难懂且难以学习的,他们嘲笑使用正则表达式验证电子邮件地址的人。但是,正则表达式
阅读全文
PHP中与正则表达式相关的函数集合
作者:办公桌前的清宇 1450浏览评论:05年前
之前学习正则表达式的目的是从网上抓取一些小说、文档,得到相应的视频链接并批量下载。那时的PHP初学者并不知道PHP有一个专门的抓包工具,比如Simple_html_dom.php(在我的其他博文中提到过)。
阅读全文
PHP 系列(六)PHP 正则表达式
作者:小技术专家1068查看评论:04年前
PHP 正则表达式 正则表达式是描述字符串结果的语法规则。它是一种特定的格式化模式,可以匹配、替换和截取匹配的字符串。常用语言基本都有正则表达式,比如JavaScript、java等。其实只要了解一种语言的正则使用,其他语言的正则使用就比较简单了。艺术
阅读全文
php正则表达式捕获相关问答题
【Java学习全家桶】1460道Java热点问题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522 浏览评论:153年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
php用正则表达抓取网页中文章(PHP正则表达式完全手册(gt)php正则表达式捕获(组图))
阿里云 > 云栖社区 > 主题地图 > P > PHP正则表达式捕获
推荐活动:
更多优惠>
当前主题: php regex capture 添加到采集夹
相关话题:
php regex 捕获相关博客 查看更多博客
php正则表达式组捕获
作者:meteric639 浏览评论:011年前
经过测试发现获取组捕获的php正则表达式是从$0开始的,而在工程代码中提取汉字时,JavaScript中的正则在工作中是$1..$9,因为运行速度非常快当时很快(赶上时间),我担心.properties文件中{\d}的数字顺序错误:1、可能来自{1}
阅读全文
C#正则表达式编程(四):正则表达式
作者:科技甜1234 浏览评论:04年前
正则表达式提供了一种强大、灵活、高效的文本处理方式。正则表达式的全面模式匹配表示法让您可以快速分析大量文本以找到特定的字符模式;提取、编辑、替换或删除文本的子字符串;或将提取的字符串添加到集合以生成报告。用于处理字符串,例如 HTML 处理、日志文件分析和
阅读全文
谈论正则表达式
作者:Jack Chen805 浏览评论:07年前
原文:浅谈正则表达式一、什么是正则表达式?简单地说:正则表达式是一种处理字符串匹配的语言;正则表达式描述了字符串匹配的一种模式,可以用来检查一个字符串是否收录某个子字符串,以及匹配的“删除”或“替换”操作的子字符串。二
阅读全文
PHP 正则表达式
作者:thinkyoung825 浏览人数:06年前
PHP正则表达式思维导图点击下图查看具体内容!引入正则表达式,在开发中应该经常使用。现在很多开发语言都有正则表达式的应用,比如javascript、java、.net、php等,今天我就讲讲正则表达式的道理。
阅读全文
PHP正则表达式完整手册
作者:Jack Chen 636 次浏览评论:06 年前
原文:PHP正则表达式完整手册 PHP正则表达式完整手册前言 正则表达式繁琐,但功能强大,学习后的应用不仅会提高你的效率,还会给你带来绝对的成就感。只要仔细阅读这些资料,并在申请时做好一定的参考,掌握正则表达式不是问题。索引1.
阅读全文
大数据的Regex真的是正则表达式吗?
作者:青山无名2031 浏览评论:04年前
文章 讲的是大数据 正则表达式真的是一个正则表达式,正则表达式已经存在了几十年,它甚至早于今天的大数据、UI、机器学习以及几乎所有其他工具和技术。正则表达式通常被许多开发人员认为是晦涩难懂且难以学习的,他们嘲笑使用正则表达式验证电子邮件地址的人。但是,正则表达式
阅读全文
PHP中与正则表达式相关的函数集合
作者:办公桌前的清宇 1450浏览评论:05年前
之前学习正则表达式的目的是从网上抓取一些小说、文档,得到相应的视频链接并批量下载。那时的PHP初学者并不知道PHP有一个专门的抓包工具,比如Simple_html_dom.php(在我的其他博文中提到过)。
阅读全文
PHP 系列(六)PHP 正则表达式
作者:小技术专家1068查看评论:04年前
PHP 正则表达式 正则表达式是描述字符串结果的语法规则。它是一种特定的格式化模式,可以匹配、替换和截取匹配的字符串。常用语言基本都有正则表达式,比如JavaScript、java等。其实只要了解一种语言的正则使用,其他语言的正则使用就比较简单了。艺术
阅读全文
php正则表达式捕获相关问答题
【Java学习全家桶】1460道Java热点问题,百位阿里巴巴技术专家答疑解惑
作者:管理贝贝19522 浏览评论:153年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
php用正则表达抓取网页中文章(Chapter07||抽取数据之正则表达式在说,先说 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-01 19:16
)
第七章 | 用于提取数据的正则表达式
在说正则表达式之前,先说一下下面的网页结构
根据网站的组成结构,网站可以分为以下两种
一、网站介绍1、网站
对于爬虫:
无论是静态的还是动态的网站,HTML页面“隐藏”有价值的数据信息
使用网络爬虫提取信息需要了解页面的 HTML 标签使用和分布
2、HTML 语言
一个完整的 HTML 文件包括:
一般HTML文件的编写遵循以下格式:
3、从网页中提取数据
借助Python网络库,构建的爬虫可以爬取HTML页面的数据
通过以下方式从抓取的页面数据中提取有价值的数据:
二、正则表达式
面对复杂的HTML页面,往往需要提取出需要的信息,比如ID号等。
使用简短的字符串表达式来匹配此信息:
正则表达式具有独立的语法和处理引擎。在支持正则表达式的语言中,正则表达式的语法是一致的
不同的编程语言实现支持不同数量的语法:
1、正则表达式工作流程
2、正则表达式语言
正则表达式语言由两种基本字符类型组成
3、正则表达式的分组
如果要匹配重复的字符串,用括号()包裹目标字符串
分组可以分为两种形式:
4、正则表达式捕获5、非捕获组和捕获组
eg: 匹配 0 到 100 范围内的整数
三、重新库
re 是一个专门用于处理正则表达式的 Python 模块,通常具有以下功能:
下面依次解释
查看全部
php用正则表达抓取网页中文章(Chapter07||抽取数据之正则表达式在说,先说
)
第七章 | 用于提取数据的正则表达式
在说正则表达式之前,先说一下下面的网页结构
根据网站的组成结构,网站可以分为以下两种
一、网站介绍1、网站
对于爬虫:
无论是静态的还是动态的网站,HTML页面“隐藏”有价值的数据信息
使用网络爬虫提取信息需要了解页面的 HTML 标签使用和分布
2、HTML 语言
一个完整的 HTML 文件包括:
一般HTML文件的编写遵循以下格式:
3、从网页中提取数据
借助Python网络库,构建的爬虫可以爬取HTML页面的数据
通过以下方式从抓取的页面数据中提取有价值的数据:
二、正则表达式
面对复杂的HTML页面,往往需要提取出需要的信息,比如ID号等。
使用简短的字符串表达式来匹配此信息:
正则表达式具有独立的语法和处理引擎。在支持正则表达式的语言中,正则表达式的语法是一致的
不同的编程语言实现支持不同数量的语法:
1、正则表达式工作流程
2、正则表达式语言
正则表达式语言由两种基本字符类型组成
3、正则表达式的分组
如果要匹配重复的字符串,用括号()包裹目标字符串
分组可以分为两种形式:
4、正则表达式捕获5、非捕获组和捕获组
eg: 匹配 0 到 100 范围内的整数
三、重新库
re 是一个专门用于处理正则表达式的 Python 模块,通常具有以下功能:
下面依次解释
php用正则表达抓取网页中文章(Python/JavaScript中是否存在支持可变长度-assertion的正则表达式实现?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-04-01 04:10
Python/PHP/JavaScript 中是否有支持变长lookbehind-assertion 的正则表达式实现?
/(?
如何写一个意义相同但不使用lookbehind-assertion的正则表达式?
这样的断言一天能实现吗?
我觉得情况好多了。
更新:
(1)已经有一些正则表达式实现支持变长lookbehind断言。
Python 模块正则表达式(不是标准的 re,而是其他正则表达式模块)支持此类断言(并具有许多其他不错的功能)。
>>> import regex
>>> m = regex.search('(?>> print m.group()
bar
>>> m = regex.search('(?>> print m
None
对我来说,Perl 和 Python 不使用正则表达式非常令人惊讶。也许,Perl 也有一个“增强的正则表达式”实现?
(感谢 MRAB + 1)。
(2)现代正则表达式有一个很酷的特性正则表达式。
表示法意味着当您进行替换时(在我看来,断言最有趣的用例是替换),在正则表达式之前找到的所有字符都不得更改。
s/unchanged-part\Kchanged-part/new-part/x
这几乎就像一个后断言,但肯定没有那么灵活。
更多关于正则表达式:
据我了解,您不能在同一个正则表达式中使用 \K 两次。而且,在“杀死”你找到的角色之前,你无法分辨。这总是一直到行首。
(感谢 ikegami +1)。
我的其他问题: 查看全部
php用正则表达抓取网页中文章(Python/JavaScript中是否存在支持可变长度-assertion的正则表达式实现?)
Python/PHP/JavaScript 中是否有支持变长lookbehind-assertion 的正则表达式实现?
/(?
如何写一个意义相同但不使用lookbehind-assertion的正则表达式?
这样的断言一天能实现吗?
我觉得情况好多了。
更新:
(1)已经有一些正则表达式实现支持变长lookbehind断言。
Python 模块正则表达式(不是标准的 re,而是其他正则表达式模块)支持此类断言(并具有许多其他不错的功能)。
>>> import regex
>>> m = regex.search('(?>> print m.group()
bar
>>> m = regex.search('(?>> print m
None
对我来说,Perl 和 Python 不使用正则表达式非常令人惊讶。也许,Perl 也有一个“增强的正则表达式”实现?
(感谢 MRAB + 1)。
(2)现代正则表达式有一个很酷的特性正则表达式。
表示法意味着当您进行替换时(在我看来,断言最有趣的用例是替换),在正则表达式之前找到的所有字符都不得更改。
s/unchanged-part\Kchanged-part/new-part/x
这几乎就像一个后断言,但肯定没有那么灵活。
更多关于正则表达式:
据我了解,您不能在同一个正则表达式中使用 \K 两次。而且,在“杀死”你找到的角色之前,你无法分辨。这总是一直到行首。
(感谢 ikegami +1)。
我的其他问题:
php用正则表达抓取网页中文章(聚焦爬虫过程中数据解析的第一类,你知道吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-29 18:05
)
我一直觉得正则表达式非常少见。今天的学习真的很特别。这真的很难理解,但重要的是要学习一些简单的元字符来提取数据。我们不需要自己写,其实可以复制;
有很多在线正则表达式测试,如菜鸟教程、OSCHINA的在线工具等;
它们都可以帮助我们很好地编写一些测试。多了解多点就OK啦~
最重要的就是爬虫中对网页标签内容和标签属性的爬取,这需要我们的懒惰匹配,一定要了解和实践。
以下是我学习的专注爬虫过程中的第一类数据分析:规律性;
最好把代码放在编辑器中浏览,效果会更好,推荐VS Code。
#? 通用爬虫 聚焦爬虫 增量式爬虫
#? 聚焦爬虫:爬取页面中指定的页面内容 满足75%以上的需求
'''
编码流程:
(1)指定URL
(2)发起请求
(3)获取响应数据
(4)数据解析
(5)持久化存储
'''
#? 数据解析分类: 正则 bs4 xpath(重点学习,通用性比较强)
#* 数据解析原理
'''
解析的局部的文本内容都会存储在标签之间或者标签中的属性值
(1) 进行执行标签的定位
(2) 标签或者标签对应的属性中存储的数据值进行提取(解析)
'''
#? 正则表达式
'''
元字符
(1) . 匹配除换行符意外的任意字符
(2) \w 匹配字母或数字或下划线
(3) \s 匹配任意的空白符
(4) \d 匹配数字
(5) \n 匹配一个换行符
(6) \t 匹配一个制表符
(7) ^ 匹配字符串的开始
(8) $ 匹配字符串的结尾
(9) \W 匹配非字母或数字或下划线
(10) \S 匹配非空白符
(11) \D 匹配非数字 (9)
(12) a|b 匹配字符a或者字符b
(13) () 匹配括号内的表达式,也表示一个组
(14) [...] 匹配字符组中的字符
(15) [^...] 匹配除了字符组中字符的所有字符
量词
#? 比如 \d{11}
* 重复零次或者更多次 {0,正无穷}
+ 重复一次或者更多次 {1,正无穷}
? 重复0次或者一次 {0,1}
{n} 重复n次
{n,} 重复n次或者更多次
{n,m} 重复n到m次
#! 贪婪匹配和惰性匹配
(1) .* 贪婪匹配 匹配所有
(2) .*? 惰性匹配 匹配少的,较短的
#! 爬虫用的最多的就是惰性匹配
#! 玩儿吃鸡游戏,晚上一起玩游戏,玩游戏吗?
#? 玩儿.*游戏 -- 匹配结果是 :玩儿吃鸡游戏,晚上一起玩游戏,玩游戏
#? 玩儿.*?游戏 -- 匹配结果是:玩儿吃鸡游戏
#? 玩.*?游戏 -- 匹配结果是 玩儿吃鸡游戏 玩游戏 玩游戏
#! 匹配标签的内容 周杰伦林俊杰
#? .* -- 匹配结果是
#! 周杰伦林俊杰
#? .*? -- 匹配结果是
#! 周杰伦
#? .*? -- 匹配结果是
#! 周杰伦林俊杰
#? .*?
#! 周杰伦
#! 林俊杰
''' 查看全部
php用正则表达抓取网页中文章(聚焦爬虫过程中数据解析的第一类,你知道吗?
)
我一直觉得正则表达式非常少见。今天的学习真的很特别。这真的很难理解,但重要的是要学习一些简单的元字符来提取数据。我们不需要自己写,其实可以复制;
有很多在线正则表达式测试,如菜鸟教程、OSCHINA的在线工具等;
它们都可以帮助我们很好地编写一些测试。多了解多点就OK啦~
最重要的就是爬虫中对网页标签内容和标签属性的爬取,这需要我们的懒惰匹配,一定要了解和实践。
以下是我学习的专注爬虫过程中的第一类数据分析:规律性;
最好把代码放在编辑器中浏览,效果会更好,推荐VS Code。
#? 通用爬虫 聚焦爬虫 增量式爬虫
#? 聚焦爬虫:爬取页面中指定的页面内容 满足75%以上的需求
'''
编码流程:
(1)指定URL
(2)发起请求
(3)获取响应数据
(4)数据解析
(5)持久化存储
'''
#? 数据解析分类: 正则 bs4 xpath(重点学习,通用性比较强)
#* 数据解析原理
'''
解析的局部的文本内容都会存储在标签之间或者标签中的属性值
(1) 进行执行标签的定位
(2) 标签或者标签对应的属性中存储的数据值进行提取(解析)
'''
#? 正则表达式
'''
元字符
(1) . 匹配除换行符意外的任意字符
(2) \w 匹配字母或数字或下划线
(3) \s 匹配任意的空白符
(4) \d 匹配数字
(5) \n 匹配一个换行符
(6) \t 匹配一个制表符
(7) ^ 匹配字符串的开始
(8) $ 匹配字符串的结尾
(9) \W 匹配非字母或数字或下划线
(10) \S 匹配非空白符
(11) \D 匹配非数字 (9)
(12) a|b 匹配字符a或者字符b
(13) () 匹配括号内的表达式,也表示一个组
(14) [...] 匹配字符组中的字符
(15) [^...] 匹配除了字符组中字符的所有字符
量词
#? 比如 \d{11}
* 重复零次或者更多次 {0,正无穷}
+ 重复一次或者更多次 {1,正无穷}
? 重复0次或者一次 {0,1}
{n} 重复n次
{n,} 重复n次或者更多次
{n,m} 重复n到m次
#! 贪婪匹配和惰性匹配
(1) .* 贪婪匹配 匹配所有
(2) .*? 惰性匹配 匹配少的,较短的
#! 爬虫用的最多的就是惰性匹配
#! 玩儿吃鸡游戏,晚上一起玩游戏,玩游戏吗?
#? 玩儿.*游戏 -- 匹配结果是 :玩儿吃鸡游戏,晚上一起玩游戏,玩游戏
#? 玩儿.*?游戏 -- 匹配结果是:玩儿吃鸡游戏
#? 玩.*?游戏 -- 匹配结果是 玩儿吃鸡游戏 玩游戏 玩游戏
#! 匹配标签的内容 周杰伦林俊杰
#? .* -- 匹配结果是
#! 周杰伦林俊杰
#? .*? -- 匹配结果是
#! 周杰伦
#? .*? -- 匹配结果是
#! 周杰伦林俊杰
#? .*?
#! 周杰伦
#! 林俊杰
'''
php用正则表达抓取网页中文章(我正在寻找一个体面的正则表达式来验证作为用户输入的URL )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-19 11:30
)
为了澄清,我正在寻找一个体面的正则表达式来验证作为用户输入输入的 URL。我对从给定的文本字符串解析 URL 列表不感兴趣(即使此页面上的某些正则表达式会这样做)。我也不想允许所有可能的技术上有效的 URL - 恰恰相反。如果您希望以与浏览器相同的方式解析 URL,请参阅
假设这个正则表达式将用于用 PHP 编写的公共 URL 缩短器,所以 URL 像 //foo.bar/,://foo.bar/,data:text/plain;charset=utf-8,OHAIandtel: + 1234567890 不应通过(即使它们在技术上是有效的)。此外,在这种情况下,我只想允许 HTTP、HTTPS 和 FTP 协议。
此外,不测试单个奇数前导和/或尾随字符。想象一下,在使用正则表达式进行测试之前,您正在这样做 $url:
$url = trim($url, '!"#$%&\'()*+,-./@:;[\\]^_`{|}~');
请注意,我已将修饰符添加到 S 所有正则表达式以加快测试速度。在实际使用中,这个修饰符可以省略。
这是测试中使用的所有 URL 的纯文本列表。
Diego Perini 发布了他的版本作为要点。
勺子库(979 个字符)
/(((http|ftp|https):\/{2})+(([0-9a-z_-]+\.)+(aero|asia|biz|cat|com|coop|edu|gov|info|int|jobs|mil|mobi|museum|name|net|org|pro|tel|travel|ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cu|cv|cx|cy|cz|cz|de|dj|dk|dm|do|dz|ec|ee|eg|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|in|io|iq|ir|is|it|je|jm|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mk|ml|mn|mn|mo|mp|mr|ms|mt|mu|mv|mw|mx|my|mz|na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|nom|pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|qa|re|ra|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|sj|sk|sl|sm|sn|so|sr|st|su|sv|sy|sz|tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|ua|ug|uk|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|yu|za|zm|zw|arpa)(:[0-9]+)?((\/([~0-9a-zA-Z\#\+\%@\.\/_-]+))?(\?[0-9a-zA-Z\+\%@\/&\[\];=_-]+)?)?))\b/imuS
@krijnhoetmer(115 个字符)
_(^|[\s.:;?\-\]\)])_i
@gruber(71 个字符)
#\b(([\w-]+://?|www[.])[^\s()]+(?:\([\w\d]+\)|([^[:punct:]\s]|/)))#iS
@gruber v2(218 个字符)
#(?i)\b((?:[a-z][\w-]+:(?:/{1,3}|[a-z0-9%])|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()]+|\(([^\s()]+|(\([^\s()]+\)))*\))+(?:\(([^\s()]+|(\([^\s()]+\)))*\)|[^\s`!()\[\]{};:'".,?«»“”‘’]))#iS
@cowboy(1241 个字符)
~(?:\b[a-z\d.-]+://[^\s]+|\b(?:(?:(?:[^\s!@#$%^&*()_=+[\]{}\|;:'",./?]+)\.)+(?:ac|ad|aero|ae|af|ag|ai|al|am|an|ao|aq|arpa|ar|asia|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|biz|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|cat|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|coop|com|co|cr|cu|cv|cx|cy|cz|de|dj|dk|dm|do|dz|ec|edu|ee|eg|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gov|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|info|int|in|io|iq|ir|is|it|je|jm|jobs|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mil|mk|ml|mm|mn|mobi|mo|mp|mq|mr|ms|mt|museum|mu|mv|mw|mx|my|mz|name|na|nc|net|ne|nf|ng|ni|nl|no|np|nr|nu|nz|om|org|pa|pe|pf|pg|ph|pk|pl|pm|pn|pro|pr|ps|pt|pw|py|qa|re|ro|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|sk|sl|sm|sn|so|sr|st|su|sv|sy|sz|tc|td|tel|tf|tg|th|tj|tk|tl|tm|tn|to|tp|travel|tr|tt|tv|tw|tz|ua|ug|uk|um|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|xn--0zwm56d|xn--11b5bs3a9aj6g|xn--80akhbyknj4f|xn--9t4b11yi5a|xn--deba0ad|xn--g6w251d|xn--hgbk6aj7f53bba|xn--hlcj6aya9esc7a|xn--jxalpdlp|xn--kgbechtv|xn--zckzah|ye|yt|yu|za|zm|zw)|(?:(?:[0-9]|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5])\.){3}(?:[0-9]|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5]))(?:[;/][^#?\s]*)?(?:\?[^#\s]*)?(?:#[^\s]*)?(?!\w))~iS
杰弗里弗里德尔(241 个字符)
@\b((ftp|https?)://[-\w]+(\.\w[-\w]*)+|(?:[a-z0-9](?:[-a-z0-9]*[a-z0-9])?\.)+(?: com\b|edu\b|biz\b|gov\b|in(?:t|fo)\b|mil\b|net\b|org\b|[a-z][a-z]\b))(\:\d+)?(/[^.!,?;"'()\[\]{}\s\x7F-\xFF]*(?:[.!,?]+[^.!,?;"'()\[\]{}\s\x7F-\xFF]+)*)?@iS
@mattfarina(287 个字符)
@stephenhay(38 个字符)
@^(https?|ftp)://[^\s/$.?#].[^\s]*$@iS
@scottgonzales(1347 个字符)
#([a-z]([a-z]|\d|\+|-|\.)*):(\/\/(((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:)*@)?((\[(|(v[\da-f]{1,}\.(([a-z]|\d|-|\.|_|~)|[!\$&'\(\)\*\+,;=]|:)+))\])|((\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5]))|(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=])*)(:\d*)?)(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*|(\/((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)+(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*)?)|((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)+(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*)|((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)){0})(\?((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)|[\xE000-\xF8FF]|\/|\?)*)?(\#((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)|\/|\?)*)?#iS
@rodneyrehm(109 个字符)
#((https?://|ftp://|www\.|[^\s:=]+@www\.).*?[a-z_\/0-9\-\#=&])(?=(\.|,|;|\?|\!)?("|'|«|»|\[|\s|\r|\n|$))#iS
@imme_emosol(54 个字符)
@(https?|ftp)://(-\.)?([^\s/?\.#-]+\.?)+(/[^\s]*)?$@iS
@diegoperini(502 个字符)
_^(?:(?:https?|ftp)://)(?:\S+(?::\S*)?@)?(?:(?!10(?:\.\d{1,3}){3})(?!127(?:\.\d{1,3}){3})(?!169\.254(?:\.\d{1,3}){2})(?!192\.168(?:\.\d{1,3}){2})(?!172\.(?:1[6-9]|2\d|3[0-1])(?:\.\d{1,3}){2})(?:[1-9]\d?|1\d\d|2[01]\d|22[0-3])(?:\.(?:1?\d{1,2}|2[0-4]\d|25[0-5])){2}(?:\.(?:[1-9]\d?|1\d\d|2[0-4]\d|25[0-4]))|(?:(?:[a-z\x{00a1}-\x{ffff}0-9]+-?)*[a-z\x{00a1}-\x{ffff}0-9]+)(?:\.(?:[a-z\x{00a1}-\x{ffff}0-9]+-?)*[a-z\x{00a1}-\x{ffff}0-9]+)*(?:\.(?:[a-z\x{00a1}-\x{ffff}]{2,})))(?::\d{2,5})?(?:/[^\s]*)?$_iuS 查看全部
php用正则表达抓取网页中文章(我正在寻找一个体面的正则表达式来验证作为用户输入的URL
)
为了澄清,我正在寻找一个体面的正则表达式来验证作为用户输入输入的 URL。我对从给定的文本字符串解析 URL 列表不感兴趣(即使此页面上的某些正则表达式会这样做)。我也不想允许所有可能的技术上有效的 URL - 恰恰相反。如果您希望以与浏览器相同的方式解析 URL,请参阅
假设这个正则表达式将用于用 PHP 编写的公共 URL 缩短器,所以 URL 像 //foo.bar/,://foo.bar/,data:text/plain;charset=utf-8,OHAIandtel: + 1234567890 不应通过(即使它们在技术上是有效的)。此外,在这种情况下,我只想允许 HTTP、HTTPS 和 FTP 协议。
此外,不测试单个奇数前导和/或尾随字符。想象一下,在使用正则表达式进行测试之前,您正在这样做 $url:
$url = trim($url, '!"#$%&\'()*+,-./@:;[\\]^_`{|}~');
请注意,我已将修饰符添加到 S 所有正则表达式以加快测试速度。在实际使用中,这个修饰符可以省略。
这是测试中使用的所有 URL 的纯文本列表。
Diego Perini 发布了他的版本作为要点。
勺子库(979 个字符)
/(((http|ftp|https):\/{2})+(([0-9a-z_-]+\.)+(aero|asia|biz|cat|com|coop|edu|gov|info|int|jobs|mil|mobi|museum|name|net|org|pro|tel|travel|ac|ad|ae|af|ag|ai|al|am|an|ao|aq|ar|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|co|cr|cu|cv|cx|cy|cz|cz|de|dj|dk|dm|do|dz|ec|ee|eg|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|in|io|iq|ir|is|it|je|jm|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mk|ml|mn|mn|mo|mp|mr|ms|mt|mu|mv|mw|mx|my|mz|na|nc|ne|nf|ng|ni|nl|no|np|nr|nu|nz|nom|pa|pe|pf|pg|ph|pk|pl|pm|pn|pr|ps|pt|pw|py|qa|re|ra|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|sj|sk|sl|sm|sn|so|sr|st|su|sv|sy|sz|tc|td|tf|tg|th|tj|tk|tl|tm|tn|to|tp|tr|tt|tv|tw|tz|ua|ug|uk|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|ye|yt|yu|za|zm|zw|arpa)(:[0-9]+)?((\/([~0-9a-zA-Z\#\+\%@\.\/_-]+))?(\?[0-9a-zA-Z\+\%@\/&\[\];=_-]+)?)?))\b/imuS
@krijnhoetmer(115 个字符)
_(^|[\s.:;?\-\]\)])_i
@gruber(71 个字符)
#\b(([\w-]+://?|www[.])[^\s()]+(?:\([\w\d]+\)|([^[:punct:]\s]|/)))#iS
@gruber v2(218 个字符)
#(?i)\b((?:[a-z][\w-]+:(?:/{1,3}|[a-z0-9%])|www\d{0,3}[.]|[a-z0-9.\-]+[.][a-z]{2,4}/)(?:[^\s()]+|\(([^\s()]+|(\([^\s()]+\)))*\))+(?:\(([^\s()]+|(\([^\s()]+\)))*\)|[^\s`!()\[\]{};:'".,?«»“”‘’]))#iS
@cowboy(1241 个字符)
~(?:\b[a-z\d.-]+://[^\s]+|\b(?:(?:(?:[^\s!@#$%^&*()_=+[\]{}\|;:'",./?]+)\.)+(?:ac|ad|aero|ae|af|ag|ai|al|am|an|ao|aq|arpa|ar|asia|as|at|au|aw|ax|az|ba|bb|bd|be|bf|bg|bh|biz|bi|bj|bm|bn|bo|br|bs|bt|bv|bw|by|bz|cat|ca|cc|cd|cf|cg|ch|ci|ck|cl|cm|cn|coop|com|co|cr|cu|cv|cx|cy|cz|de|dj|dk|dm|do|dz|ec|edu|ee|eg|er|es|et|eu|fi|fj|fk|fm|fo|fr|ga|gb|gd|ge|gf|gg|gh|gi|gl|gm|gn|gov|gp|gq|gr|gs|gt|gu|gw|gy|hk|hm|hn|hr|ht|hu|id|ie|il|im|info|int|in|io|iq|ir|is|it|je|jm|jobs|jo|jp|ke|kg|kh|ki|km|kn|kp|kr|kw|ky|kz|la|lb|lc|li|lk|lr|ls|lt|lu|lv|ly|ma|mc|md|me|mg|mh|mil|mk|ml|mm|mn|mobi|mo|mp|mq|mr|ms|mt|museum|mu|mv|mw|mx|my|mz|name|na|nc|net|ne|nf|ng|ni|nl|no|np|nr|nu|nz|om|org|pa|pe|pf|pg|ph|pk|pl|pm|pn|pro|pr|ps|pt|pw|py|qa|re|ro|rs|ru|rw|sa|sb|sc|sd|se|sg|sh|si|sj|sk|sl|sm|sn|so|sr|st|su|sv|sy|sz|tc|td|tel|tf|tg|th|tj|tk|tl|tm|tn|to|tp|travel|tr|tt|tv|tw|tz|ua|ug|uk|um|us|uy|uz|va|vc|ve|vg|vi|vn|vu|wf|ws|xn--0zwm56d|xn--11b5bs3a9aj6g|xn--80akhbyknj4f|xn--9t4b11yi5a|xn--deba0ad|xn--g6w251d|xn--hgbk6aj7f53bba|xn--hlcj6aya9esc7a|xn--jxalpdlp|xn--kgbechtv|xn--zckzah|ye|yt|yu|za|zm|zw)|(?:(?:[0-9]|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5])\.){3}(?:[0-9]|[1-9]\d|1\d{2}|2[0-4]\d|25[0-5]))(?:[;/][^#?\s]*)?(?:\?[^#\s]*)?(?:#[^\s]*)?(?!\w))~iS
杰弗里弗里德尔(241 个字符)
@\b((ftp|https?)://[-\w]+(\.\w[-\w]*)+|(?:[a-z0-9](?:[-a-z0-9]*[a-z0-9])?\.)+(?: com\b|edu\b|biz\b|gov\b|in(?:t|fo)\b|mil\b|net\b|org\b|[a-z][a-z]\b))(\:\d+)?(/[^.!,?;"'()\[\]{}\s\x7F-\xFF]*(?:[.!,?]+[^.!,?;"'()\[\]{}\s\x7F-\xFF]+)*)?@iS
@mattfarina(287 个字符)
@stephenhay(38 个字符)
@^(https?|ftp)://[^\s/$.?#].[^\s]*$@iS
@scottgonzales(1347 个字符)
#([a-z]([a-z]|\d|\+|-|\.)*):(\/\/(((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:)*@)?((\[(|(v[\da-f]{1,}\.(([a-z]|\d|-|\.|_|~)|[!\$&'\(\)\*\+,;=]|:)+))\])|((\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5]))|(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=])*)(:\d*)?)(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*|(\/((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)+(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*)?)|((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)+(\/(([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)*)*)|((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)){0})(\?((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)|[\xE000-\xF8FF]|\/|\?)*)?(\#((([a-z]|\d|-|\.|_|~|[\x00A0-\xD7FF\xF900-\xFDCF\xFDF0-\xFFEF])|(%[\da-f]{2})|[!\$&'\(\)\*\+,;=]|:|@)|\/|\?)*)?#iS
@rodneyrehm(109 个字符)
#((https?://|ftp://|www\.|[^\s:=]+@www\.).*?[a-z_\/0-9\-\#=&])(?=(\.|,|;|\?|\!)?("|'|«|»|\[|\s|\r|\n|$))#iS
@imme_emosol(54 个字符)
@(https?|ftp)://(-\.)?([^\s/?\.#-]+\.?)+(/[^\s]*)?$@iS
@diegoperini(502 个字符)
_^(?:(?:https?|ftp)://)(?:\S+(?::\S*)?@)?(?:(?!10(?:\.\d{1,3}){3})(?!127(?:\.\d{1,3}){3})(?!169\.254(?:\.\d{1,3}){2})(?!192\.168(?:\.\d{1,3}){2})(?!172\.(?:1[6-9]|2\d|3[0-1])(?:\.\d{1,3}){2})(?:[1-9]\d?|1\d\d|2[01]\d|22[0-3])(?:\.(?:1?\d{1,2}|2[0-4]\d|25[0-5])){2}(?:\.(?:[1-9]\d?|1\d\d|2[0-4]\d|25[0-4]))|(?:(?:[a-z\x{00a1}-\x{ffff}0-9]+-?)*[a-z\x{00a1}-\x{ffff}0-9]+)(?:\.(?:[a-z\x{00a1}-\x{ffff}0-9]+-?)*[a-z\x{00a1}-\x{ffff}0-9]+)*(?:\.(?:[a-z\x{00a1}-\x{ffff}]{2,})))(?::\d{2,5})?(?:/[^\s]*)?$_iuS

