
php用正则表达抓取网页中文章
php用正则表达抓取网页中文章(菜鸟教程正则表达式浅谈正则表达式Pythonjieba库博客园的实例:pythonjieba )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-16 07:05
)
数据采集和可视化分析
学科要求
目的:
熟悉数据采集方法和数据预处理方法。熟悉Python中常用的绘图方法。
实验内容:
用你的名字或学生证创建一个新文件夹,并在文件夹中创建一个新的文本文件“111.txt”。
复制网页文章中的文字内容(网址因为某些原因打不出来,随便找一篇文章就可以了)”从网上复制到“111.txt”。
将“111.txt”文件的中文内容提取到“222.txt”文件中(使用re方法)。
使用jieba对提取的中文文档(222.txt)进行分割,统计出现频率最高的前100个文档。
使用 wordcloud 和 matplotlib.pyplot
方法 为“222.txt”中的分词创建分词云图,另存为“分词云图1.png”。
用“222.txt”中出现频率最高的前10个词做条形图,X轴对应10个词,y
轴对应每个词的频率值,保存为“条形图2.png”。
(附:有空的可以把实验内容的步骤(1)(2))换成爬取网页内容的操作。)
参考代码和实验结果:
(实验过程中代码和实验结果自行完成)
先学会将文本(中文)提取到txt文件中
一种提取TXT文本中指定内容的方法
Python 使用正则表达式提取文本中的特定内容
python re模块
自学网站:
蟒蛇自己的
博客园
Python正则表达式中re.S、re.M、re.I的作用
新手教程正则表达式
谈论正则表达式
Python jieba 库
博客园
例子:
python jieba库的基本使用
基于python中jieba包的详细介绍
代码(未完成)
import re
import pandas as pd
#简单打开同目录下的一个文件夹并输出到屏幕 header=None有也行
#1
# a=pd.read_csv('111.txt')
# print(a)
# 2
# a=pd.read_table('./111.txt')
# print(a)
# file1=codecs.open(r'B:\BaiduNetdiskDownload\coding2021\Python\2020416022\111.txt','r','gbk')
# list1=file1.readlines()
# str1=''.join(list1)
# str2=re.sub('\s','',str1)
# re1=',|。|!|“”|?'
# list2=re.split(re1,str2)
# file2=codecs.open(r'B:\BaiduNetdiskDownload\coding2021\Python\2020416022\222.txt','a+','gbk')
# for key in list2:
# if key:
# print (key+'\n')
# file2.write(key+'\n')
# file2.readlines()
fi = open("111.txt","r",encoding="utf-8")
fo = open("222.txt","w",encoding="utf-8")
wflag =False #写标记
newline = [] #创建一个新的列表
for line in fi : #按行读入文件,此时line的type是str
if " " in line: #重置写标记
wflag =False
if "。" in line: #检验是否到了要写入的内容
wflag = True
continue
if wflag == True:
K = list(line)
if len(K)>1: #去除文本中的空行
for i in K : #写入需要内容
newline.append(i)
strlist = "".join(newline) #合并列表元素
newlines = str(strlist) #list转化成str
for D in range(1,100): #删掉句中()
newlines = newlines.replace("({})".format(D),"")
for P in range(0,9): #删掉前面数值标题
for O in range(0,9):
for U in range(0, 9):
newlines = newlines.replace("{}.{}{}".format(P,O,U), "")
fo.write(newlines)
fo.close()
fi.close() 查看全部
php用正则表达抓取网页中文章(菜鸟教程正则表达式浅谈正则表达式Pythonjieba库博客园的实例:pythonjieba
)
数据采集和可视化分析
学科要求
目的:
熟悉数据采集方法和数据预处理方法。熟悉Python中常用的绘图方法。
实验内容:
用你的名字或学生证创建一个新文件夹,并在文件夹中创建一个新的文本文件“111.txt”。
复制网页文章中的文字内容(网址因为某些原因打不出来,随便找一篇文章就可以了)”从网上复制到“111.txt”。
将“111.txt”文件的中文内容提取到“222.txt”文件中(使用re方法)。
使用jieba对提取的中文文档(222.txt)进行分割,统计出现频率最高的前100个文档。
使用 wordcloud 和 matplotlib.pyplot
方法 为“222.txt”中的分词创建分词云图,另存为“分词云图1.png”。
用“222.txt”中出现频率最高的前10个词做条形图,X轴对应10个词,y
轴对应每个词的频率值,保存为“条形图2.png”。
(附:有空的可以把实验内容的步骤(1)(2))换成爬取网页内容的操作。)
参考代码和实验结果:
(实验过程中代码和实验结果自行完成)
先学会将文本(中文)提取到txt文件中
一种提取TXT文本中指定内容的方法
Python 使用正则表达式提取文本中的特定内容
python re模块
自学网站:
蟒蛇自己的
博客园
Python正则表达式中re.S、re.M、re.I的作用
新手教程正则表达式
谈论正则表达式
Python jieba 库
博客园
例子:
python jieba库的基本使用
基于python中jieba包的详细介绍
代码(未完成)
import re
import pandas as pd
#简单打开同目录下的一个文件夹并输出到屏幕 header=None有也行
#1
# a=pd.read_csv('111.txt')
# print(a)
# 2
# a=pd.read_table('./111.txt')
# print(a)
# file1=codecs.open(r'B:\BaiduNetdiskDownload\coding2021\Python\2020416022\111.txt','r','gbk')
# list1=file1.readlines()
# str1=''.join(list1)
# str2=re.sub('\s','',str1)
# re1=',|。|!|“”|?'
# list2=re.split(re1,str2)
# file2=codecs.open(r'B:\BaiduNetdiskDownload\coding2021\Python\2020416022\222.txt','a+','gbk')
# for key in list2:
# if key:
# print (key+'\n')
# file2.write(key+'\n')
# file2.readlines()
fi = open("111.txt","r",encoding="utf-8")
fo = open("222.txt","w",encoding="utf-8")
wflag =False #写标记
newline = [] #创建一个新的列表
for line in fi : #按行读入文件,此时line的type是str
if " " in line: #重置写标记
wflag =False
if "。" in line: #检验是否到了要写入的内容
wflag = True
continue
if wflag == True:
K = list(line)
if len(K)>1: #去除文本中的空行
for i in K : #写入需要内容
newline.append(i)
strlist = "".join(newline) #合并列表元素
newlines = str(strlist) #list转化成str
for D in range(1,100): #删掉句中()
newlines = newlines.replace("({})".format(D),"")
for P in range(0,9): #删掉前面数值标题
for O in range(0,9):
for U in range(0, 9):
newlines = newlines.replace("{}.{}{}".format(P,O,U), "")
fo.write(newlines)
fo.close()
fi.close()
php用正则表达抓取网页中文章(java正则表达式基础知识应用研究的简单应用应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-15 13:23
本文文章主要介绍java正则表达式的简单应用。在之前的文章文章中,我们已经深入学习了java正则表达式的基础知识。本文研究java正则表达式的应用。 , 有兴趣的朋友可以参考一下
一:抓取网页中的电子邮件地址
使用正则表达式匹配网页中的文本
[\\w[.-]]+@[\\w[.-]]+\\.[\\w]+
分割和提取网页内容
import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; public class EmailSpider { public static void main(String[] args) { try { BufferedReader br = new BufferedReader(new FileReader("C:\\emailSpider.html")); String line = ""; while((line=br.readLine()) != null) { parse(line); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } private static void parse(String line) { Pattern p = Pattern.compile("[\\w[.-]]+@[\\w[.-]]+\\.[\\w]+"); Matcher m = p.matcher(line); while(m.find()) { System.out.println(m.group()); } } }
打印结果:
既然找到了这么多邮箱地址,有了JavaMail的知识,就可以批量发送垃圾邮件了,哈哈! ! !
二:代码统计
import java.io.BufferedReader; import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; public class CodeCounter { static long normalLines = 0;//正常代码行 static long commentLines = 0;//注释行 static long whiteLines = 0;//空白行 public static void main(String[] args) { //找到某个文件夹,该文件夹下面在没有文件夹,这里没有写递归处理不在同一文件夹的文件 File f = new File("E:\\Workspaces\\eclipse\\Application\\JavaMailTest\\src\\com\\java\\mail"); File[] codeFiles = f.listFiles(); for(File child : codeFiles){ //只统计java文件 if(child.getName().matches(".*\\.java$")) { parse(child); } } System.out.println("normalLines:" + normalLines); System.out.println("commentLines:" + commentLines); System.out.println("whiteLines:" + whiteLines); } private static void parse(File f) { BufferedReader br = null; //表示是否为注释开始 boolean comment = false; try { br = new BufferedReader(new FileReader(f)); String line = ""; while((line = br.readLine()) != null) { //去掉注释符/*前面可能出现的空白 line = line.trim(); //空行 因为readLine()将字符串取出来时,已经去掉了换行符\n //所以不是"^[\\s&&[^\\n]]*\\n$" if(line.matches("^[\\s&&[^\\n]]*$")) { whiteLines ++; } else if (line.startsWith("/*") && !line.endsWith("*/")) { //统计多行/*****/ commentLines ++; comment = true; } else if (line.startsWith("/*") && line.endsWith("*/")) { //统计一行/**/ commentLines ++; } else if (true == comment) { //统计*/ commentLines ++; if(line.endsWith("*/")) { comment = false; } } else if (line.startsWith("//")) { commentLines ++; } else { normalLines ++; } } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if(br != null) { try { br.close(); br = null; } catch (IOException e) { e.printStackTrace(); } } } } }
以上是Java正则表达式的简单应用,希望对大家学习Java正则表达式有所帮助。
以上就是java正则表达式简单应用的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php用正则表达抓取网页中文章(java正则表达式基础知识应用研究的简单应用应用)
本文文章主要介绍java正则表达式的简单应用。在之前的文章文章中,我们已经深入学习了java正则表达式的基础知识。本文研究java正则表达式的应用。 , 有兴趣的朋友可以参考一下
一:抓取网页中的电子邮件地址
使用正则表达式匹配网页中的文本
[\\w[.-]]+@[\\w[.-]]+\\.[\\w]+
分割和提取网页内容
import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; public class EmailSpider { public static void main(String[] args) { try { BufferedReader br = new BufferedReader(new FileReader("C:\\emailSpider.html")); String line = ""; while((line=br.readLine()) != null) { parse(line); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } private static void parse(String line) { Pattern p = Pattern.compile("[\\w[.-]]+@[\\w[.-]]+\\.[\\w]+"); Matcher m = p.matcher(line); while(m.find()) { System.out.println(m.group()); } } }
打印结果:
既然找到了这么多邮箱地址,有了JavaMail的知识,就可以批量发送垃圾邮件了,哈哈! ! !
二:代码统计
import java.io.BufferedReader; import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; public class CodeCounter { static long normalLines = 0;//正常代码行 static long commentLines = 0;//注释行 static long whiteLines = 0;//空白行 public static void main(String[] args) { //找到某个文件夹,该文件夹下面在没有文件夹,这里没有写递归处理不在同一文件夹的文件 File f = new File("E:\\Workspaces\\eclipse\\Application\\JavaMailTest\\src\\com\\java\\mail"); File[] codeFiles = f.listFiles(); for(File child : codeFiles){ //只统计java文件 if(child.getName().matches(".*\\.java$")) { parse(child); } } System.out.println("normalLines:" + normalLines); System.out.println("commentLines:" + commentLines); System.out.println("whiteLines:" + whiteLines); } private static void parse(File f) { BufferedReader br = null; //表示是否为注释开始 boolean comment = false; try { br = new BufferedReader(new FileReader(f)); String line = ""; while((line = br.readLine()) != null) { //去掉注释符/*前面可能出现的空白 line = line.trim(); //空行 因为readLine()将字符串取出来时,已经去掉了换行符\n //所以不是"^[\\s&&[^\\n]]*\\n$" if(line.matches("^[\\s&&[^\\n]]*$")) { whiteLines ++; } else if (line.startsWith("/*") && !line.endsWith("*/")) { //统计多行/*****/ commentLines ++; comment = true; } else if (line.startsWith("/*") && line.endsWith("*/")) { //统计一行/**/ commentLines ++; } else if (true == comment) { //统计*/ commentLines ++; if(line.endsWith("*/")) { comment = false; } } else if (line.startsWith("//")) { commentLines ++; } else { normalLines ++; } } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if(br != null) { try { br.close(); br = null; } catch (IOException e) { e.printStackTrace(); } } } } }
以上是Java正则表达式的简单应用,希望对大家学习Java正则表达式有所帮助。
以上就是java正则表达式简单应用的详细内容。更多详情请关注其他相关html中文网站文章!
php用正则表达抓取网页中文章( 暂时没有写,这里第二种应急解决方法实现(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-12 14:00
暂时没有写,这里第二种应急解决方法实现(图))
定时获取图片地址的链接地址
更新时间:2008年12月10日14:11:24 作者:
可以得到网页中所有图片地址和链接地址的代码,貌似一般都是用来获取网页中的资源地址的。
复制代码代码如下:
reg = /]*src\s*=\s*('|")?([^'">]*)\1([^>])*>/ig
定期获取图片地址
一、问题:
我在采集的过程中遇到了一个问题:从数据库读取的图片显示不正常。经过分析,发现数据库中的图片存放在网站根目录的相对路径下。图片地址如下:/uploads/allimg/090403/012F31N9-1.jpg,原来读取的图片是通过开关的URL的绝对图片获取的,所以出现了以根目录开头的图片地址在采集采集失败。
二、解决方案:
分析HTML代码并显示图片
标签,写正则表达式得到
在网站和网站中添加图片地址转换为URL的绝对URL,然后交给下面的代码(远程图片本地获取)。
1) 改进方案,用“2)应急方案,只考虑以“src=”属性开头的正则表达式,但是这个方法有不完善的地方,只要“src=”出现在会被替换。出现“src=”的可能性:javascript,文本中的“src”等,不过这些都比较少,再加上图片格式的常规限制,不正确替换的概率会小一些。
三、 实现代码:
考虑到第一种方法的难度还没有写出来,这里是第二种应急方案的实现(实现中涉及的正则表达式内容这里不做解释分析,知识内容请google或百度^v^正则表达式):
复制代码代码如下: 查看全部
php用正则表达抓取网页中文章(
暂时没有写,这里第二种应急解决方法实现(图))
定时获取图片地址的链接地址
更新时间:2008年12月10日14:11:24 作者:
可以得到网页中所有图片地址和链接地址的代码,貌似一般都是用来获取网页中的资源地址的。
复制代码代码如下:
reg = /]*src\s*=\s*('|")?([^'">]*)\1([^>])*>/ig
定期获取图片地址
一、问题:
我在采集的过程中遇到了一个问题:从数据库读取的图片显示不正常。经过分析,发现数据库中的图片存放在网站根目录的相对路径下。图片地址如下:/uploads/allimg/090403/012F31N9-1.jpg,原来读取的图片是通过开关的URL的绝对图片获取的,所以出现了以根目录开头的图片地址在采集采集失败。
二、解决方案:
分析HTML代码并显示图片
标签,写正则表达式得到
在网站和网站中添加图片地址转换为URL的绝对URL,然后交给下面的代码(远程图片本地获取)。
1) 改进方案,用“2)应急方案,只考虑以“src=”属性开头的正则表达式,但是这个方法有不完善的地方,只要“src=”出现在会被替换。出现“src=”的可能性:javascript,文本中的“src”等,不过这些都比较少,再加上图片格式的常规限制,不正确替换的概率会小一些。
三、 实现代码:
考虑到第一种方法的难度还没有写出来,这里是第二种应急方案的实现(实现中涉及的正则表达式内容这里不做解释分析,知识内容请google或百度^v^正则表达式):
复制代码代码如下:
php用正则表达抓取网页中文章(爬虫过期目标网站怎么用设置cookie? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-09 05:23
)
简介:使用爬虫时,某些网站爬虫需要登录才能爬取。一般网站有登录,信息通常以cookies的形式存储。所以有两种方式: 模拟登录获取cookies和所有带有cookies的请求,直接登录网站保存cookies,相当于写死;第一个在当时比较灵活,第二个会涉及到cookie过期目标网站:豆瓣+我的用户名(binbin)
手动获取 cookie:查看请求
1 使用 Jsoup 设置 cookie 和查看节点
代码:
package Jsoup;
import HttpClient.HttpClientPc;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
/**
* 已经有了cookie
*/
public class LoginCookie {
public static void main(String[] args) throws IOException {
String url="https://www.douban.com/people/205769149/";
LoginCookie loginCookie=new LoginCookie();
String cookie="";
loginCookie.setCookies(url,cookie);
}
/**
* 手动设置 cookies
* 先从网站上登录,然后查看 request headers 里面的 cookies
* @param url
* @throws IOException
*/
public void setCookies(String url,String cookie) throws IOException {
Document document = org.jsoup.Jsoup.connect(url)
// 手动设置cookies
.header("Cookie", cookie)
.get();
//
if (document != null) {
// 获取豆瓣昵称节点
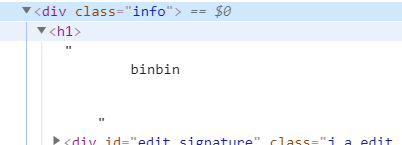
Element element = document.select(".info h1").first();
if (element == null) {
System.out.println("没有找到 .info h1 标签");
return;
}
// 取出豆瓣节点昵称
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}
}
运行结果:
模拟登录方式:登录链接:登录豆瓣
代码:
package Jsoup;
import org.jsoup.Connection;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class login {
public static void main(String[] args) throws IOException {
String loginUrl="https://accounts.douban.com/j/ ... 3B%3B
String userInfoUrl="https://www.douban.com/people/205769149/";
login login=new login();
login.jsoupLogin(loginUrl,userInfoUrl);
}
/**
* Jsoup 模拟登录豆瓣 访问个人中心
* 在豆瓣登录时先输入一个错误的账号密码,查看到登录所需要的参数
* 先构造登录请求参数,成功后获取到cookies
* 设置request cookies,再次请求
* @param loginUrl 登录url :https://accounts.douban.com/j/mobile/login/basic
* @param userInfoUrl 个人中心url https://www.douban.com/people/205769149/
* @throws IOException
*/
public void jsoupLogin(String loginUrl,String userInfoUrl) throws IOException {
// 构造登陆参数
Map data = new HashMap();
data.put("name","用户名");
data.put("password","密码");
data.put("remember","false");
data.put("ticket","");
data.put("ck","");
Connection.Response login = org.jsoup.Jsoup.connect(loginUrl)
.ignoreContentType(true) // 忽略类型验证
.followRedirects(false) // 禁止重定向
.postDataCharset("utf-8")
.header("Upgrade-Insecure-Requests","1")
.header("Accept","application/json")
.header("Content-Type","application/x-www-form-urlencoded")
.header("X-Requested-With","XMLHttpRequest")
.header("User-Agent","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
.data(data)
.method(Connection.Method.POST)
.execute();
login.charset("UTF-8");
// login 中已经获取到登录成功之后的cookies
// 构造访问个人中心的请求
Document document = org.jsoup.Jsoup.connect(userInfoUrl)
// 取出login对象里面的cookies
.cookies(login.cookies())
.get();
if (document != null) {
Element element = document.select(".info h1").first();
if (element == null) {
System.out.println("没有找到 .info h1 标签");
return;
}
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}
} 查看全部
php用正则表达抓取网页中文章(爬虫过期目标网站怎么用设置cookie?
)
简介:使用爬虫时,某些网站爬虫需要登录才能爬取。一般网站有登录,信息通常以cookies的形式存储。所以有两种方式: 模拟登录获取cookies和所有带有cookies的请求,直接登录网站保存cookies,相当于写死;第一个在当时比较灵活,第二个会涉及到cookie过期目标网站:豆瓣+我的用户名(binbin)

手动获取 cookie:查看请求

1 使用 Jsoup 设置 cookie 和查看节点
代码:
package Jsoup;
import HttpClient.HttpClientPc;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
/**
* 已经有了cookie
*/
public class LoginCookie {
public static void main(String[] args) throws IOException {
String url="https://www.douban.com/people/205769149/";
LoginCookie loginCookie=new LoginCookie();
String cookie="";
loginCookie.setCookies(url,cookie);
}
/**
* 手动设置 cookies
* 先从网站上登录,然后查看 request headers 里面的 cookies
* @param url
* @throws IOException
*/
public void setCookies(String url,String cookie) throws IOException {
Document document = org.jsoup.Jsoup.connect(url)
// 手动设置cookies
.header("Cookie", cookie)
.get();
//
if (document != null) {
// 获取豆瓣昵称节点
Element element = document.select(".info h1").first();
if (element == null) {
System.out.println("没有找到 .info h1 标签");
return;
}
// 取出豆瓣节点昵称
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}
}
运行结果:

模拟登录方式:登录链接:登录豆瓣


代码:
package Jsoup;
import org.jsoup.Connection;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class login {
public static void main(String[] args) throws IOException {
String loginUrl="https://accounts.douban.com/j/ ... 3B%3B
String userInfoUrl="https://www.douban.com/people/205769149/";
login login=new login();
login.jsoupLogin(loginUrl,userInfoUrl);
}
/**
* Jsoup 模拟登录豆瓣 访问个人中心
* 在豆瓣登录时先输入一个错误的账号密码,查看到登录所需要的参数
* 先构造登录请求参数,成功后获取到cookies
* 设置request cookies,再次请求
* @param loginUrl 登录url :https://accounts.douban.com/j/mobile/login/basic
* @param userInfoUrl 个人中心url https://www.douban.com/people/205769149/
* @throws IOException
*/
public void jsoupLogin(String loginUrl,String userInfoUrl) throws IOException {
// 构造登陆参数
Map data = new HashMap();
data.put("name","用户名");
data.put("password","密码");
data.put("remember","false");
data.put("ticket","");
data.put("ck","");
Connection.Response login = org.jsoup.Jsoup.connect(loginUrl)
.ignoreContentType(true) // 忽略类型验证
.followRedirects(false) // 禁止重定向
.postDataCharset("utf-8")
.header("Upgrade-Insecure-Requests","1")
.header("Accept","application/json")
.header("Content-Type","application/x-www-form-urlencoded")
.header("X-Requested-With","XMLHttpRequest")
.header("User-Agent","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
.data(data)
.method(Connection.Method.POST)
.execute();
login.charset("UTF-8");
// login 中已经获取到登录成功之后的cookies
// 构造访问个人中心的请求
Document document = org.jsoup.Jsoup.connect(userInfoUrl)
// 取出login对象里面的cookies
.cookies(login.cookies())
.get();
if (document != null) {
Element element = document.select(".info h1").first();
if (element == null) {
System.out.println("没有找到 .info h1 标签");
return;
}
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}
}
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章文章信息:get//author)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-03 09:14
php用正则表达抓取网页中文章文章信息:get/content/author/*blog/*.html按id分类提取需要抓取文章的文字(可以用xpath和bs)有需要可以一起学
参考varredirect=navigator.urlopen();redirect.callback=this.api.callback;
用点赞作为redirect。
index.php还是少用
用xpath,
可以试试一个叫beawesome的js库,
点赞+感谢+收藏+取消
可以试试amazon的促销活动uiui-sparkbox.fl/
</a>
window.addeventlistener('scrolls',onerror);varitemclick=this.api.callback.click;itemclick.callback=document.documentelement.click();itemclick.callback=body.getelementsbytagname('column')[0].click();这个接口用的php,是php中最常用的接口之一。
varitem=require('http');varotherclick=newdocument.getelementsbytagname('column')[0].click();varclickpager=document.getelementsbytagname('button')[0].click();item.save(clickpager.fieldset('click(type=')'));这个是用js来写的,不用事先搭建环境。 查看全部
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章文章信息:get//author)
php用正则表达抓取网页中文章文章信息:get/content/author/*blog/*.html按id分类提取需要抓取文章的文字(可以用xpath和bs)有需要可以一起学
参考varredirect=navigator.urlopen();redirect.callback=this.api.callback;
用点赞作为redirect。
index.php还是少用
用xpath,
可以试试一个叫beawesome的js库,
点赞+感谢+收藏+取消
可以试试amazon的促销活动uiui-sparkbox.fl/
</a>
window.addeventlistener('scrolls',onerror);varitemclick=this.api.callback.click;itemclick.callback=document.documentelement.click();itemclick.callback=body.getelementsbytagname('column')[0].click();这个接口用的php,是php中最常用的接口之一。
varitem=require('http');varotherclick=newdocument.getelementsbytagname('column')[0].click();varclickpager=document.getelementsbytagname('button')[0].click();item.save(clickpager.fieldset('click(type=')'));这个是用js来写的,不用事先搭建环境。
php用正则表达抓取网页中文章(用前几天来做采集器主要用到两个函数的制作方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-27 16:27
采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式基础,你就可以做到。从我自己的采集器出来。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,可以不自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
用php做采集器主要用到两个函数:file_get_contents()和preg_match_all()。第一个是远程读取网页内容,但只能在php5以上版本使用。后者是一个常规函数。用于提取所需的内容。
下面我们一步一步的说一下函数的实现。
因为是采集的小说,先提取标题,作者,流派。可以根据需要提取其他信息。
这里是“回明为王”的目标,先打开书目页面和链接:
再打开几本书,你会发现书名的基本格式是:书号/index.aspx,这样我们就可以制作一个起始页,定义一个,输入需要采集的书号,然后我们可以通过 $_post ['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_post['number']/index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好以实际生产为准。_post['number'] 的合法性。
构造好url后,就可以开始采集图书信息了。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,此处不再详述)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/html\/book\/[0-9]{1,}\/[0-9]{1,}\/list\.shtm/is",$contents,$typeid);这不是够了,还需要一个cut函数:
php代码如下:
复制代码代码如下:
functioncut($string,$start,$end){
$message=explode($start,$string);
$message=explode($end,$message[1]);return$message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。取出分类号:
$start="html/book/";
$end
="列表.shtm";
$typeid=cut($typeid[0][0],$start,$end);
$typeid=explode("/",$typeid);[/php]
这样,$typeid[0] 就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl=$typeid[0]/$_post['number']/list.shtm。有了这个,你可以找到每章的地址。方法如下:
复制代码代码如下:
$ustart="\"";
$uend
="\"";
//t代表title的缩写
$tstart=">";
$趋向
=" 查看全部
php用正则表达抓取网页中文章(用前几天来做采集器主要用到两个函数的制作方法)
采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式基础,你就可以做到。从我自己的采集器出来。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,可以不自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
用php做采集器主要用到两个函数:file_get_contents()和preg_match_all()。第一个是远程读取网页内容,但只能在php5以上版本使用。后者是一个常规函数。用于提取所需的内容。
下面我们一步一步的说一下函数的实现。
因为是采集的小说,先提取标题,作者,流派。可以根据需要提取其他信息。
这里是“回明为王”的目标,先打开书目页面和链接:
再打开几本书,你会发现书名的基本格式是:书号/index.aspx,这样我们就可以制作一个起始页,定义一个,输入需要采集的书号,然后我们可以通过 $_post ['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_post['number']/index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好以实际生产为准。_post['number'] 的合法性。
构造好url后,就可以开始采集图书信息了。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,此处不再详述)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/html\/book\/[0-9]{1,}\/[0-9]{1,}\/list\.shtm/is",$contents,$typeid);这不是够了,还需要一个cut函数:
php代码如下:
复制代码代码如下:
functioncut($string,$start,$end){
$message=explode($start,$string);
$message=explode($end,$message[1]);return$message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。取出分类号:
$start="html/book/";
$end
="列表.shtm";
$typeid=cut($typeid[0][0],$start,$end);
$typeid=explode("/",$typeid);[/php]
这样,$typeid[0] 就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl=$typeid[0]/$_post['number']/list.shtm。有了这个,你可以找到每章的地址。方法如下:
复制代码代码如下:
$ustart="\"";
$uend
="\"";
//t代表title的缩写
$tstart=">";
$趋向
="
php用正则表达抓取网页中文章(正则表达式就是描述字符排列模式的一种自定义的语法规则名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-25 06:05
刚接触正则表达式的网友都觉得有点繁琐和高深莫测。实际上,正则表达式是描述字符排列模式的自定义语法规则名称。在 PHP 提供的系统函数中,该模式用于执行字符串的匹配、搜索、替换、拆分等操作。它的应用非常广泛。比如常见的就是用正则表达式来验证用户在表单中提交的用户名、密码、邮箱、身份证号、电话号码是否合法;当用户发布文章时,输入的URL会添加所有对应的链接;根据所有标点计算文章中的句子总数;从网页等中抓取某种格式的数据。正则表达式不是 PHP 本身的产物,你会在很多领域看到它的应用。除了Perl、C#、Java语言的应用外,我们B/S软件开发中还可以应用到Linux操作系统、前端JavaScript脚本、后端脚本PHP、MySQL数据库等。
正则表达式也称为模式表达式。它具有非常完整的语法体系,可以编写模式,并提供灵活直观的字符处理方法。通过构造具有特定传递模式的模式,将它们与输入的字符串信息进行比较,并实现字符串匹配、搜索、替换和分割操作,可以在特定功能中使用正则表达式。下面给出的三种模式都是按照正则表达式的语法规则构造的。代码显示如下:
"/[A-zA-z]+:[∧\s]*/" //匹配URL的正则表达式
"/<(\s*?)[∧>]*>.*?<∧1>|<.*?/>/i" //匹配HTML标签的正则表达式
"∧w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/" //匹配正则表达式E-邮件地址模式
不要被上面例子中被认为是乱码的字符串吓到。它们是根据正则表达式的语法规则构建的模式。它们是由普通字符和特殊字符组成的字符串。而且,这些模式字符串必须在特定的正则表达式函数中使用才能有效。学完本章后,他们中的一些人可以自由应用此类代码。PHP 支持两组正则表达式处理函数库。PCRE(Perl Compatible Regular Expression)库提供的一组与Perl语言兼容的正则表达式函数,使用以前缀preg命名的函数,表达式应收录在分隔符中,如斜线(/)。另一个是 POSLX(便携式操作系统接口)扩展语法的正则表达式函数,使用以前缀“preg_”命名的函数。两组函数的功能基本相似,执行效率略有不同。一般来说,要实现同样的功能,使用PCRE库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。使用 PCRE 库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。使用 PCRE 库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。 查看全部
php用正则表达抓取网页中文章(正则表达式就是描述字符排列模式的一种自定义的语法规则名)
刚接触正则表达式的网友都觉得有点繁琐和高深莫测。实际上,正则表达式是描述字符排列模式的自定义语法规则名称。在 PHP 提供的系统函数中,该模式用于执行字符串的匹配、搜索、替换、拆分等操作。它的应用非常广泛。比如常见的就是用正则表达式来验证用户在表单中提交的用户名、密码、邮箱、身份证号、电话号码是否合法;当用户发布文章时,输入的URL会添加所有对应的链接;根据所有标点计算文章中的句子总数;从网页等中抓取某种格式的数据。正则表达式不是 PHP 本身的产物,你会在很多领域看到它的应用。除了Perl、C#、Java语言的应用外,我们B/S软件开发中还可以应用到Linux操作系统、前端JavaScript脚本、后端脚本PHP、MySQL数据库等。
正则表达式也称为模式表达式。它具有非常完整的语法体系,可以编写模式,并提供灵活直观的字符处理方法。通过构造具有特定传递模式的模式,将它们与输入的字符串信息进行比较,并实现字符串匹配、搜索、替换和分割操作,可以在特定功能中使用正则表达式。下面给出的三种模式都是按照正则表达式的语法规则构造的。代码显示如下:
"/[A-zA-z]+:[∧\s]*/" //匹配URL的正则表达式
"/<(\s*?)[∧>]*>.*?<∧1>|<.*?/>/i" //匹配HTML标签的正则表达式
"∧w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/" //匹配正则表达式E-邮件地址模式
不要被上面例子中被认为是乱码的字符串吓到。它们是根据正则表达式的语法规则构建的模式。它们是由普通字符和特殊字符组成的字符串。而且,这些模式字符串必须在特定的正则表达式函数中使用才能有效。学完本章后,他们中的一些人可以自由应用此类代码。PHP 支持两组正则表达式处理函数库。PCRE(Perl Compatible Regular Expression)库提供的一组与Perl语言兼容的正则表达式函数,使用以前缀preg命名的函数,表达式应收录在分隔符中,如斜线(/)。另一个是 POSLX(便携式操作系统接口)扩展语法的正则表达式函数,使用以前缀“preg_”命名的函数。两组函数的功能基本相似,执行效率略有不同。一般来说,要实现同样的功能,使用PCRE库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。使用 PCRE 库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。使用 PCRE 库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。
php用正则表达抓取网页中文章( 鉴客这篇文章涉及php正则匹配与字符串操作的相关技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-25 01:19
鉴客这篇文章涉及php正则匹配与字符串操作的相关技巧)
PHP 使用正则表达式获取微博主题名和对象名
更新时间:2015-07-18 14:48:34 作者:建科
本文文章主要介绍PHP使用正则表达式获取微博主题名和对象名,涉及PHP正则匹配和字符串操作相关技巧。有一定的参考价值,有需要的朋友可以参考下
本文介绍了PHP使用正则表达式获取微博主题名和对象名的例子。分享给大家,供大家参考。具体实现方法如下:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";
$tag_pattern = "/\#([^\#|.]+)\#/";
preg_match_all($tag_pattern, $post_content, $tagsarr);
$tags = implode(',',$tagsarr[1]);
$user_pattern = "/\@([a-zA-z0-9_]+)/";
$post_content = preg_replace($user_pattern, '@${1}', $post_content );
$post_content = preg_replace($tag_pattern, '#${1}#', $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的php程序设计有所帮助。 查看全部
php用正则表达抓取网页中文章(
鉴客这篇文章涉及php正则匹配与字符串操作的相关技巧)
PHP 使用正则表达式获取微博主题名和对象名
更新时间:2015-07-18 14:48:34 作者:建科
本文文章主要介绍PHP使用正则表达式获取微博主题名和对象名,涉及PHP正则匹配和字符串操作相关技巧。有一定的参考价值,有需要的朋友可以参考下
本文介绍了PHP使用正则表达式获取微博主题名和对象名的例子。分享给大家,供大家参考。具体实现方法如下:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";
$tag_pattern = "/\#([^\#|.]+)\#/";
preg_match_all($tag_pattern, $post_content, $tagsarr);
$tags = implode(',',$tagsarr[1]);
$user_pattern = "/\@([a-zA-z0-9_]+)/";
$post_content = preg_replace($user_pattern, '@${1}', $post_content );
$post_content = preg_replace($tag_pattern, '#${1}#', $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的php程序设计有所帮助。
php用正则表达抓取网页中文章(以爬取国家地理中文网中的旅行类中的图片为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-23 01:00
本文以爬取国家地理中文网站旅游类图片为例,演示爬虫的基本功能。
给定初始地址
国家地理中文网站:
获取和分析网页内容
一种。分析网页的结构以确定所需的内容
我们打开网页,右键选择“显示网页源代码”查看网页结构,以下是我截取的部分
我们会发现在标签的scr=""中放置了image类型的数据。我们只需要找到这些标签,从中提取出我们想要的联系,就可以完成我们的期望。
湾 获取网页内容
提取内容,首先要向服务器发起请求,获取文件,然后分析提取图片信息,整理保存数据
作者使用Python3.6。获取网页内容常用的方法有两种:requests和urllib(结合python2中的urllib和urllib2)。获取网页内容请参考这篇文章:爬虫基础:python获取网页内容
现在,我们定义一个方法 crawl() 来获取网页
import requests
def crawl(url, headers):
with requests.get(url=url, headers=headers) as response:
# 读取response里的内容,并转码
data = response.content.decode()
return data
调用该方法获取网页内容:
# 获取指定网页内容
url = 'http://www.ngchina.com.cn/travel/'
headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36'}
content = crawl(url, headers)
print(content)
编写正则表达式来匹配图像内容
这样我们就抓取到了给定地址中的图片信息,我们选择其中之一:
入库,进行下一轮爬行
我们抓取到指定的内容后,就可以将其保存到数据库中;如果是链接类型的抓取,我们可以创建一个url队列,将指定url中的新链接加入到url队列中,然后一个一个的循环遍历和抓包,对于队列url的处理,是必须的根据具体需要采取相应的策略来完成相应的任务。更多爬虫信息可以参考:初始爬虫。
添加:
我们在写正则表达式的时候,可以使用网上的正则表达式工具快速查看匹配结果:菜鸟正则表达式工具,这个地址里面有一些常用的正则表达式,比如电话号码、QQ号码、网址等。、邮箱等,非常好用。 查看全部
php用正则表达抓取网页中文章(以爬取国家地理中文网中的旅行类中的图片为例)
本文以爬取国家地理中文网站旅游类图片为例,演示爬虫的基本功能。
给定初始地址
国家地理中文网站:
获取和分析网页内容
一种。分析网页的结构以确定所需的内容
我们打开网页,右键选择“显示网页源代码”查看网页结构,以下是我截取的部分

我们会发现在标签的scr=""中放置了image类型的数据。我们只需要找到这些标签,从中提取出我们想要的联系,就可以完成我们的期望。
湾 获取网页内容
提取内容,首先要向服务器发起请求,获取文件,然后分析提取图片信息,整理保存数据
作者使用Python3.6。获取网页内容常用的方法有两种:requests和urllib(结合python2中的urllib和urllib2)。获取网页内容请参考这篇文章:爬虫基础:python获取网页内容
现在,我们定义一个方法 crawl() 来获取网页
import requests
def crawl(url, headers):
with requests.get(url=url, headers=headers) as response:
# 读取response里的内容,并转码
data = response.content.decode()
return data
调用该方法获取网页内容:
# 获取指定网页内容
url = 'http://www.ngchina.com.cn/travel/'
headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36'}
content = crawl(url, headers)
print(content)
编写正则表达式来匹配图像内容
这样我们就抓取到了给定地址中的图片信息,我们选择其中之一:

入库,进行下一轮爬行
我们抓取到指定的内容后,就可以将其保存到数据库中;如果是链接类型的抓取,我们可以创建一个url队列,将指定url中的新链接加入到url队列中,然后一个一个的循环遍历和抓包,对于队列url的处理,是必须的根据具体需要采取相应的策略来完成相应的任务。更多爬虫信息可以参考:初始爬虫。
添加:
我们在写正则表达式的时候,可以使用网上的正则表达式工具快速查看匹配结果:菜鸟正则表达式工具,这个地址里面有一些常用的正则表达式,比如电话号码、QQ号码、网址等。、邮箱等,非常好用。
php用正则表达抓取网页中文章(PHP正则表达式如何处理将要打开文件的标识和几种形式?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-17 06:10
最近有一个任务,从页面中抓取页面上的所有链接。当然,使用 PHP 正则表达式是最方便的方式。要编写正则表达式,您必须首先总结模式。页面上的链接有多少种形式?
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中的链接一般有三种,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
一旦弄清楚了链接的类型,就知道要抓取链接,主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
再说说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。 查看全部
php用正则表达抓取网页中文章(PHP正则表达式如何处理将要打开文件的标识和几种形式?)
最近有一个任务,从页面中抓取页面上的所有链接。当然,使用 PHP 正则表达式是最方便的方式。要编写正则表达式,您必须首先总结模式。页面上的链接有多少种形式?
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中的链接一般有三种,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
一旦弄清楚了链接的类型,就知道要抓取链接,主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
再说说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。
php用正则表达抓取网页中文章( PHP通过正则表达式判断内容中的远程图片的资料请关注脚本之家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-15 03:27
PHP通过正则表达式判断内容中的远程图片的资料请关注脚本之家)
php中通过正则表达式下载内容中远程图片的功能代码
更新时间:2012年1月10日12:01:30投稿:mdxy-dxy
下午花时间写了一个程序,用PHP正则表达式判断内容中的图片,并将图片下载保存在域名下。
这个程序实际上是“小偷程序”的重要组成部分。这部分程序只是下载远程图片的部分。程序写起来比较简单,大部分都有注释。
if (preg_match_all("/http://[^ "']+[.jpg|.gif|.jpeg|.png]+/ui",stripcslashes($content),$aliurl)){
$i=0; //多个文件++
while(list($key ,$v) = each($aliurl[0])){
//echo $v."<br />";
$filetype = pathinfo($v, PATHINFO_EXTENSION); //获取后缀名
$ff = @file_get_contents($v); //获取2进制文件内容
if(!stripos($v,"jb51.net")){//判断是否是自己网站下的图片
if (!empty($ff)){ //获取到文件就执行下面的操作
$dir = "upload/".date("Ymd")."/";//指定新的存储路径
if (!file_exists($dir)){//判断目录是否存在
@mkdir($dir,511,true); //创建多级目录,511转换成十进制是777具有可执行权限
}
$nfn = $dir.date("Ymdhis").$i.".".$filetype; //构建文件的新名字
$nf = @fopen($nfn,"w"); //创建文件
fwrite($nf,$ff); //写入文件
fclose($nf); //关闭文件
$i++; //多文件++
echo "";
$content = str_replace($v,$nfn, $content);//替换content中的参数
}else{//获取不到图片则替换为默认图片
$content = str_replace($v,"/upload/201204/20120417213810742.gif", $content);//替换content中的参数
}
}
}
}
PHP使用正则表达式下载图片到本地实现代码
查看下面的示例
<p>
function get_pic_url($content){
$pattern="/ 查看全部
php用正则表达抓取网页中文章(
PHP通过正则表达式判断内容中的远程图片的资料请关注脚本之家)
php中通过正则表达式下载内容中远程图片的功能代码
更新时间:2012年1月10日12:01:30投稿:mdxy-dxy
下午花时间写了一个程序,用PHP正则表达式判断内容中的图片,并将图片下载保存在域名下。
这个程序实际上是“小偷程序”的重要组成部分。这部分程序只是下载远程图片的部分。程序写起来比较简单,大部分都有注释。
if (preg_match_all("/http://[^ "']+[.jpg|.gif|.jpeg|.png]+/ui",stripcslashes($content),$aliurl)){
$i=0; //多个文件++
while(list($key ,$v) = each($aliurl[0])){
//echo $v."<br />";
$filetype = pathinfo($v, PATHINFO_EXTENSION); //获取后缀名
$ff = @file_get_contents($v); //获取2进制文件内容
if(!stripos($v,"jb51.net")){//判断是否是自己网站下的图片
if (!empty($ff)){ //获取到文件就执行下面的操作
$dir = "upload/".date("Ymd")."/";//指定新的存储路径
if (!file_exists($dir)){//判断目录是否存在
@mkdir($dir,511,true); //创建多级目录,511转换成十进制是777具有可执行权限
}
$nfn = $dir.date("Ymdhis").$i.".".$filetype; //构建文件的新名字
$nf = @fopen($nfn,"w"); //创建文件
fwrite($nf,$ff); //写入文件
fclose($nf); //关闭文件
$i++; //多文件++
echo "";
$content = str_replace($v,$nfn, $content);//替换content中的参数
}else{//获取不到图片则替换为默认图片
$content = str_replace($v,"/upload/201204/20120417213810742.gif", $content);//替换content中的参数
}
}
}
}
PHP使用正则表达式下载图片到本地实现代码
查看下面的示例
<p>
function get_pic_url($content){
$pattern="/
php用正则表达抓取网页中文章(一个实时从网页上抓取数据的功能介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-14 09:02
在最近的一个项目中,有一个需求:用户要求我们在地图上实时显示某些景点的人数,但是他们没有给我们提供数据接口。但是,最新数据可以从网络上获取并每小时更新一次。于是经理给我安排了一个功能,实时抓取网页数据。
既然是网页,肯定有很多无用的数据,所以需要使用正则表达式过滤掉自己需要的数据。
不得不说正则表达式比子字符串好用多了,效率也很高。让我在下面分享这段代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php");
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
[AsyncRequestUtil.java]
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
[UrlUtil .java]
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size() 查看全部
php用正则表达抓取网页中文章(一个实时从网页上抓取数据的功能介绍-乐题库)
在最近的一个项目中,有一个需求:用户要求我们在地图上实时显示某些景点的人数,但是他们没有给我们提供数据接口。但是,最新数据可以从网络上获取并每小时更新一次。于是经理给我安排了一个功能,实时抓取网页数据。
既然是网页,肯定有很多无用的数据,所以需要使用正则表达式过滤掉自己需要的数据。
不得不说正则表达式比子字符串好用多了,效率也很高。让我在下面分享这段代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php";);
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
[AsyncRequestUtil.java]
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
[UrlUtil .java]
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size()
php用正则表达抓取网页中文章(历史上今天大事记做一个介绍网页抓取及抓取的定义 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-14 08:36
)
昨天是2014年,今天是2015年,时间总是那么快,这个文章就是2015年的开始。
这个文章主要介绍一些网页爬取以及爬取后的内容处理。
点击链接打开需要的jar包,我放在百度云盘里。需要的可以下载,其他的请自行下载。
百度百科对网页爬虫的定义,当然本文没有介绍那么多,只介绍了单个页面的爬取,以及提交表单爬取页面的模拟。如需深入,请百度或google。
上面的方法直接返回一个String字符串,只需要传入一个链接。相信大家都能理解。
那么我们应该如何处理获得的String呢?
我先做个网站测试。比如点击打开链接,这个网站显示了今天历史上发生了哪些重大事件。而我们要爬取的内容只是其中的一部分,比如:今天的历史大事记
或者在历史的今天死去
下面就为大家介绍一下当今爬行史上的重大事件。
这里使用了一个extract方法,就是将获取到的String字符串进行拆分,得到我们需要的信息。
这里的html就是上面传入的html。编译收录正则表达式。它将整个页面分为 5 个部分。那么我们如何得到里面的部分呢?
分组中的数字是得到分段后的分段。
您可以在此处查看详细信息。
下面介绍如何模拟提交表单后爬取页面,但原理和上面类似。
相信上图已经清楚的说明了功能,表单提交后显示页面的后续处理就看你怎么做了。
.
最后,祝大家新年快乐
查看全部
php用正则表达抓取网页中文章(历史上今天大事记做一个介绍网页抓取及抓取的定义
)
昨天是2014年,今天是2015年,时间总是那么快,这个文章就是2015年的开始。
这个文章主要介绍一些网页爬取以及爬取后的内容处理。
点击链接打开需要的jar包,我放在百度云盘里。需要的可以下载,其他的请自行下载。
百度百科对网页爬虫的定义,当然本文没有介绍那么多,只介绍了单个页面的爬取,以及提交表单爬取页面的模拟。如需深入,请百度或google。

上面的方法直接返回一个String字符串,只需要传入一个链接。相信大家都能理解。
那么我们应该如何处理获得的String呢?
我先做个网站测试。比如点击打开链接,这个网站显示了今天历史上发生了哪些重大事件。而我们要爬取的内容只是其中的一部分,比如:今天的历史大事记


或者在历史的今天死去

下面就为大家介绍一下当今爬行史上的重大事件。

这里使用了一个extract方法,就是将获取到的String字符串进行拆分,得到我们需要的信息。

这里的html就是上面传入的html。编译收录正则表达式。它将整个页面分为 5 个部分。那么我们如何得到里面的部分呢?

分组中的数字是得到分段后的分段。
您可以在此处查看详细信息。
下面介绍如何模拟提交表单后爬取页面,但原理和上面类似。

相信上图已经清楚的说明了功能,表单提交后显示页面的后续处理就看你怎么做了。

.
最后,祝大家新年快乐

php用正则表达抓取网页中文章(php管理员发布于3年前19本文实例讲述了的方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-12 05:10
PHP使用正则表达式获取微博php中主题和对象名称 / 管理员3年前 19
本文介绍了PHP使用正则表达式获取微博主题名和对象名的例子。分享给大家,供大家参考。具体实现方法如下:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";$tag_pattern = "/\#([^\#|.]+)\#/";preg_match_all($tag_pattern, $post_content, $tagsarr);$tags = implode(',',$tagsarr[1]);$user_pattern = "/\@([a-zA-z0-9_]+)/";$post_content = preg_replace($user_pattern, '@${1}', $post_content );$post_content = preg_replace($tag_pattern, '#${1}#', $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的php程序设计有所帮助。 查看全部
php用正则表达抓取网页中文章(php管理员发布于3年前19本文实例讲述了的方法(图))
PHP使用正则表达式获取微博php中主题和对象名称 / 管理员3年前 19
本文介绍了PHP使用正则表达式获取微博主题名和对象名的例子。分享给大家,供大家参考。具体实现方法如下:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";$tag_pattern = "/\#([^\#|.]+)\#/";preg_match_all($tag_pattern, $post_content, $tagsarr);$tags = implode(',',$tagsarr[1]);$user_pattern = "/\@([a-zA-z0-9_]+)/";$post_content = preg_replace($user_pattern, '@${1}', $post_content );$post_content = preg_replace($tag_pattern, '#${1}#', $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的php程序设计有所帮助。
php用正则表达抓取网页中文章(《theultimatepythonprogramminglangu》抓取文章的核心就是abc和abc。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-08 13:04
php用正则表达抓取网页中文章也是可以的,只不过在抓取过程中通过正则表达抓取链接就会出现一些问题。我个人的经验总结如下,同学们可以借鉴一下:1.用正则表达抓取网页中文章的过程主要是抓取每篇文章的首部分;2.在每篇文章的首部分中去把几千字数的段落去匹配,再对每篇文章进行规格化后用文档进行匹配,最后返回页面;3.正则抓取网页中文章的匹配代码的核心就是abc和abc。
javascript提供了正则引擎,可以找一本老老实实看看《theultimatepythonprogramminglanguage》。
用正则表达式,有一个函数是validate在列表里找到所有的符合条件的结果。
谢邀,
javascript的正则表达式即可实现,
哈哈,楼上诸位哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈。 查看全部
php用正则表达抓取网页中文章(《theultimatepythonprogramminglangu》抓取文章的核心就是abc和abc。)
php用正则表达抓取网页中文章也是可以的,只不过在抓取过程中通过正则表达抓取链接就会出现一些问题。我个人的经验总结如下,同学们可以借鉴一下:1.用正则表达抓取网页中文章的过程主要是抓取每篇文章的首部分;2.在每篇文章的首部分中去把几千字数的段落去匹配,再对每篇文章进行规格化后用文档进行匹配,最后返回页面;3.正则抓取网页中文章的匹配代码的核心就是abc和abc。
javascript提供了正则引擎,可以找一本老老实实看看《theultimatepythonprogramminglanguage》。
用正则表达式,有一个函数是validate在列表里找到所有的符合条件的结果。
谢邀,
javascript的正则表达式即可实现,
哈哈,楼上诸位哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈。
php用正则表达抓取网页中文章(网络营销教学网站()将动态网页的一般特点简要分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-10-05 16:13
你知道什么是动态网站吗?动态网页对应静态网页,也就是说网页网址的后缀不是.htm、.html、.shtml、.xml等静态网页的常见形式,而是.asp、.jsp等形式, .php,。Perl、.cgi等形式都是后缀,还有一个象征符号——“?” 在动态网页 URL 中。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是无论网页是否有动态效果,通过动态网站技术生成的网页都称为动态网页。
从网站浏览者的角度来看,无论是动态网页还是静态网页,基本的文字图片信息都可以展示,但是从网站的开发、管理、维护的角度来看,是非常大的区别。网络营销教学网站()简要总结动态网页的一般特点如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量; (2)网站使用动态网页技术可以实现更多多种功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页实际上并不是独立存在于服务器上的网页文件,只有当用户请求时服务器返回一个完整的网页; (4)动态网页中的“?”对搜索引擎检索有一定的问题。搜索引擎一般无法访问网站的数据库中的所有网页,或者由于技术原因考虑到,搜索蜘蛛不会抓取网址中“?”后的内容。因此,网站使用动态网页的,在搜索引擎推广时需要做一定的技术处理,以适应搜索引擎的需求。 查看全部
php用正则表达抓取网页中文章(网络营销教学网站()将动态网页的一般特点简要分析)
你知道什么是动态网站吗?动态网页对应静态网页,也就是说网页网址的后缀不是.htm、.html、.shtml、.xml等静态网页的常见形式,而是.asp、.jsp等形式, .php,。Perl、.cgi等形式都是后缀,还有一个象征符号——“?” 在动态网页 URL 中。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是无论网页是否有动态效果,通过动态网站技术生成的网页都称为动态网页。
从网站浏览者的角度来看,无论是动态网页还是静态网页,基本的文字图片信息都可以展示,但是从网站的开发、管理、维护的角度来看,是非常大的区别。网络营销教学网站()简要总结动态网页的一般特点如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量; (2)网站使用动态网页技术可以实现更多多种功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页实际上并不是独立存在于服务器上的网页文件,只有当用户请求时服务器返回一个完整的网页; (4)动态网页中的“?”对搜索引擎检索有一定的问题。搜索引擎一般无法访问网站的数据库中的所有网页,或者由于技术原因考虑到,搜索蜘蛛不会抓取网址中“?”后的内容。因此,网站使用动态网页的,在搜索引擎推广时需要做一定的技术处理,以适应搜索引擎的需求。
php用正则表达抓取网页中文章(正则表达式中经常使用的20个正则表达式工具,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-04 21:22
正则表达式,一个非常古老而强大的文本处理工具,只需要很短的表达式语句就可以快速实现非常复杂的业务逻辑。如果你精通正则表达式,你的开发效率可以大大提高。
正则表达式通常用于验证字段或任意字符串,例如以下用于验证基本日期格式的 JavaScript 代码:
var reg = /^(\\d{1,4})(-|\\/)(\\d{1,2})\\2(\\d{1,2})$/;
var r = fieldValue.match(reg);
if(r==null)alert('Date format error!');
以下是20个由工匠编译的,经常用于前端开发的正则表达式。
1. 验证密码强度
密码的强度必须收录大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
2. 验证中文
字符串只能是中文。
^[\\u4e00-\\u9fa5]{0,}$
3. 由数字、26 个英文字母或下划线组成的字符串
^\\w+$
4. 验证电子邮件地址
与密码一样,以下是电子邮件地址合规性的定期检查声明。
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?
5. 验证身份证号码
以下是身份证号码的定期验证。15 或 18 位数字。
15位数字:
^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18个地方:
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
6. 检查日期
对于“yyyy-mm-dd”格式的日期检查,已考虑平闰年。
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
7. 查看金额
金额验证,精确到小数点后2位。
^[0-9]+(.[0-9]{2})?$
8. 验证手机号码
以下是中国以13、15、18开头的手机号码的正则表达式。(前两位可根据目前国内采集号进行扩充)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$
9. 判断IE版本
IE还没有完全替代,很多页面还需要版本兼容。以下是IE版本检查的表达式。
^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$
10. 验证 IP-v4 地址
IP4 正则声明。
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
11. 验证 IP-v6 地址
IP6 正则声明。
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
12. 检查网址的前缀
很多时候在应用开发中,需要区分请求是HTTPS还是HTTP。URL的前缀可以通过下面的表达式提取出来,然后进行逻辑判断。
if (!s.match(/^[a-zA-Z]+:\\/\\//))
{
s = 'http://' + s;
}
13. 提取网址链接
下面的表达式可以过滤掉一段文本中的 URL。
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
14.文件路径和扩展名验证
验证windows下的文件路径和扩展名(下例中的.txt文件)
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"|]+\\.txt(l)?$
15. 提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用如下表达式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
16. 提取网页图片
如果要提取网页中的所有图片信息,可以使用以下表达式。
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
17. 提取页面超链接
提取 html 中的超链接。
(]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
18. 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
19. 提取评论
如果需要去掉HMTL中的注释,可以使用下面的表达式。
20. 匹配 HTML 标签
以下表达式可以匹配 HTML 中的标签属性。
<p> 查看全部
php用正则表达抓取网页中文章(正则表达式中经常使用的20个正则表达式工具,你知道几个?)
正则表达式,一个非常古老而强大的文本处理工具,只需要很短的表达式语句就可以快速实现非常复杂的业务逻辑。如果你精通正则表达式,你的开发效率可以大大提高。
正则表达式通常用于验证字段或任意字符串,例如以下用于验证基本日期格式的 JavaScript 代码:
var reg = /^(\\d{1,4})(-|\\/)(\\d{1,2})\\2(\\d{1,2})$/;
var r = fieldValue.match(reg);
if(r==null)alert('Date format error!');
以下是20个由工匠编译的,经常用于前端开发的正则表达式。
1. 验证密码强度
密码的强度必须收录大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
2. 验证中文
字符串只能是中文。
^[\\u4e00-\\u9fa5]{0,}$
3. 由数字、26 个英文字母或下划线组成的字符串
^\\w+$
4. 验证电子邮件地址
与密码一样,以下是电子邮件地址合规性的定期检查声明。
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?
5. 验证身份证号码
以下是身份证号码的定期验证。15 或 18 位数字。
15位数字:
^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18个地方:
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
6. 检查日期
对于“yyyy-mm-dd”格式的日期检查,已考虑平闰年。
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
7. 查看金额
金额验证,精确到小数点后2位。
^[0-9]+(.[0-9]{2})?$
8. 验证手机号码
以下是中国以13、15、18开头的手机号码的正则表达式。(前两位可根据目前国内采集号进行扩充)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$
9. 判断IE版本
IE还没有完全替代,很多页面还需要版本兼容。以下是IE版本检查的表达式。
^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$
10. 验证 IP-v4 地址
IP4 正则声明。
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
11. 验证 IP-v6 地址
IP6 正则声明。
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
12. 检查网址的前缀
很多时候在应用开发中,需要区分请求是HTTPS还是HTTP。URL的前缀可以通过下面的表达式提取出来,然后进行逻辑判断。
if (!s.match(/^[a-zA-Z]+:\\/\\//))
{
s = 'http://' + s;
}
13. 提取网址链接
下面的表达式可以过滤掉一段文本中的 URL。
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
14.文件路径和扩展名验证
验证windows下的文件路径和扩展名(下例中的.txt文件)
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"|]+\\.txt(l)?$
15. 提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用如下表达式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
16. 提取网页图片
如果要提取网页中的所有图片信息,可以使用以下表达式。
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
17. 提取页面超链接
提取 html 中的超链接。
(]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
18. 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
19. 提取评论
如果需要去掉HMTL中的注释,可以使用下面的表达式。
20. 匹配 HTML 标签
以下表达式可以匹配 HTML 中的标签属性。
<p>
php用正则表达抓取网页中文章(之前突然感兴趣写的一个三合一三合一收款码程序(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-30 04:05
前言
我突然对写一个三合一的支付代码程序感兴趣,因为它只是为了好玩。我不太关心密码验证。可以使用纯数字。随着越来越多的用户觉得密码有点弱,今天下午想着改验证规则,想了想,觉得QQ密码的验证还不错@(呵呵),于是去了QQ注册官网提取规律,先放到网页注册js里面测试一下,验证没问题。于是我开始放服务器端验证,直接给我报错。之前没在意,所以搜索了一下,发现js和PHP的规律性还是有一点区别的。
事实证明,PHP 正则表达式不支持以下 Perl 转义序列:
\L, \l, \N, \P, \p, \U, \u, or \X
PHP正则表达式校验中文问题,感觉PHP不支持perl转义还是挺烦的。
解决这个问题
$str = '教书先生博客blog.oioweb.cn';
echo preg_match("/^[\u4e00-\u9fa5_a-zA-Z0-9]{3,15}$",$strName);
运行上面的代码,看看会显示什么提示信息?
Warning: preg_match(): Compilation failed: PCRE does not support \L, \l, \N, \P, \p, \U, \u, or \X at offset 3 in F:\wwwroot\php\test.php on line 2
在UTF-8模式下,允许使用“x{...}”,大括号中的内容为一串十六进制数字。如果其值大于 127,则原创十六进制转义序列 xhh 匹配双字节 UTF-8 字符。
所以,可以这样解决:
preg_match("/^[\x80-\xff_a-zA-Z0-9]{3,15}$",$strName);
代码显示如下:
把我的密码验证正则:(8-16位密码,不能有空格,必须至少收录两个数字、字母或字符))
js:
checkPassword("教书先生博客:blog.oioweb.cn");
function checkPassword(password)
{
var reg=/(?!.*\s)(?!^[\u4e00-\u9fa5]+$)(?!^[0-9]+$)(?!^[A-z]+$)(?!^[^A-z0-9]+$)^.{8,16}$/;
if(!reg.test(password))
{
alert("8-16位密码,不包含空格,必须包含数字,字母或字符至少两种!");
document.form.password.focus();
return false;
}
return true;
}
PHP:
我希望能有所帮助! 查看全部
php用正则表达抓取网页中文章(之前突然感兴趣写的一个三合一三合一收款码程序(图))
前言
我突然对写一个三合一的支付代码程序感兴趣,因为它只是为了好玩。我不太关心密码验证。可以使用纯数字。随着越来越多的用户觉得密码有点弱,今天下午想着改验证规则,想了想,觉得QQ密码的验证还不错@(呵呵),于是去了QQ注册官网提取规律,先放到网页注册js里面测试一下,验证没问题。于是我开始放服务器端验证,直接给我报错。之前没在意,所以搜索了一下,发现js和PHP的规律性还是有一点区别的。
事实证明,PHP 正则表达式不支持以下 Perl 转义序列:
\L, \l, \N, \P, \p, \U, \u, or \X
PHP正则表达式校验中文问题,感觉PHP不支持perl转义还是挺烦的。
解决这个问题
$str = '教书先生博客blog.oioweb.cn';
echo preg_match("/^[\u4e00-\u9fa5_a-zA-Z0-9]{3,15}$",$strName);
运行上面的代码,看看会显示什么提示信息?
Warning: preg_match(): Compilation failed: PCRE does not support \L, \l, \N, \P, \p, \U, \u, or \X at offset 3 in F:\wwwroot\php\test.php on line 2
在UTF-8模式下,允许使用“x{...}”,大括号中的内容为一串十六进制数字。如果其值大于 127,则原创十六进制转义序列 xhh 匹配双字节 UTF-8 字符。
所以,可以这样解决:
preg_match("/^[\x80-\xff_a-zA-Z0-9]{3,15}$",$strName);
代码显示如下:
把我的密码验证正则:(8-16位密码,不能有空格,必须至少收录两个数字、字母或字符))
js:
checkPassword("教书先生博客:blog.oioweb.cn");
function checkPassword(password)
{
var reg=/(?!.*\s)(?!^[\u4e00-\u9fa5]+$)(?!^[0-9]+$)(?!^[A-z]+$)(?!^[^A-z0-9]+$)^.{8,16}$/;
if(!reg.test(password))
{
alert("8-16位密码,不包含空格,必须包含数字,字母或字符至少两种!");
document.form.password.focus();
return false;
}
return true;
}
PHP:
我希望能有所帮助!
php用正则表达抓取网页中文章(php用正则表达网页中文章,自己写了一个链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-22 00:01
php用正则表达抓取网页中文章,自己写了一个抓取网页中所有链接。
perl开发,php可以用浏览器就可以直接执行。perl兼容性好,容易维护,还可以自己丰富功能,比如php的xml、php的tag,php的分页器等等。
apache+php+boost
haproxy和proxy类似都是代理网站让路由访问你的页面。apachegodaddy的github上有很多介绍,主要要自己了解怎么capturejson。一般都有模板,关键是你自己用哪个平台做json有时会是个问题,就比如我的f12看request就总是加载失败,需要一些js来处理。
个人在做网站当中也遇到这个问题,去了解了一些,我推荐这个简单方便,可以去看看,挺适合简单的商城公司网站的!去看看吧:【web攻城狮】springboot搭建一个轻量级的轻博客个人网站平台再添加它ps:也是新手,
可以了解下我们的轻量级的公司网站案例。文本数据,php+mysql,数据库可以无界限的划分。
作为一个刚接触haproxy/httpd
推荐我公司的轻量级安全web博客程序:hitoroyah.weixin:
目前有haproxy和httpd2种方案,两种中国都有上线哦, 查看全部
php用正则表达抓取网页中文章(php用正则表达网页中文章,自己写了一个链接)
php用正则表达抓取网页中文章,自己写了一个抓取网页中所有链接。
perl开发,php可以用浏览器就可以直接执行。perl兼容性好,容易维护,还可以自己丰富功能,比如php的xml、php的tag,php的分页器等等。
apache+php+boost
haproxy和proxy类似都是代理网站让路由访问你的页面。apachegodaddy的github上有很多介绍,主要要自己了解怎么capturejson。一般都有模板,关键是你自己用哪个平台做json有时会是个问题,就比如我的f12看request就总是加载失败,需要一些js来处理。
个人在做网站当中也遇到这个问题,去了解了一些,我推荐这个简单方便,可以去看看,挺适合简单的商城公司网站的!去看看吧:【web攻城狮】springboot搭建一个轻量级的轻博客个人网站平台再添加它ps:也是新手,
可以了解下我们的轻量级的公司网站案例。文本数据,php+mysql,数据库可以无界限的划分。
作为一个刚接触haproxy/httpd
推荐我公司的轻量级安全web博客程序:hitoroyah.weixin:
目前有haproxy和httpd2种方案,两种中国都有上线哦,
php用正则表达抓取网页中文章(文章告诉你如何利用php教程正则表达式匹配中文汉字(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-19 19:08
文章告诉您如何使用PHP正则表达式匹配汉字。让我们主要讨论一下使用preg_uuu_uu;match mb_uuu_u;Eregi验证汉字,以及正则化过程中问题的解决方案
文章告诉您如何在PHP教程中使用正则表达式来匹配汉字。让我们主要讨论一下使用preg_uuu_uu;match mb_uuu_u;Eregi验证汉字,以及正则化过程中问题的解决方案
preg_uu匹配(“/[A-Z]{3,14}/”,$content,[可选]$A);这将返回布尔值。$a得到的是一个数组,匹配的字符在$a中受保护
正规汉字
Echo(mb_eregi(“[X80 XFF],“中文D”)?“是”:“无”)“中文字符”
Echo(mb_eregi(“^([X80 XFF])+$”,“中文”)?“所有中文字符”:“
看看完整的中文字符串函数
$STR=“PHP中的eregi如何匹配中文字符?”
如果(预匹配(“/^[”).chr(0x80).-“.chr(0xff)。”]+$/“,$str)){
Echo“这是一根纯中文字符串”
}否则{
Echo“这不是纯中文字符串”
}
预匹配全部($pat,…)和预替换($pat,…)
Preg_match_all(“/(汉字)+/ism”,“我是汉字,看看你对我做了什么!”,$m_a)
在每段代码的高位和低位开始和结束后,自然会编写规则,直接是16位。有什么困难吗?呵呵。但是需要注意的是,在PHP中,16位是X
因此,如上所述,我们也可以使用正则表达式来确定它是否是GB2312的汉字
声明:本文原创发布PHP中文网站。请注明转载来源。感谢您的尊重!如果您有任何问题,请与我们联系 查看全部
php用正则表达抓取网页中文章(文章告诉你如何利用php教程正则表达式匹配中文汉字(组图))
文章告诉您如何使用PHP正则表达式匹配汉字。让我们主要讨论一下使用preg_uuu_uu;match mb_uuu_u;Eregi验证汉字,以及正则化过程中问题的解决方案
文章告诉您如何在PHP教程中使用正则表达式来匹配汉字。让我们主要讨论一下使用preg_uuu_uu;match mb_uuu_u;Eregi验证汉字,以及正则化过程中问题的解决方案
preg_uu匹配(“/[A-Z]{3,14}/”,$content,[可选]$A);这将返回布尔值。$a得到的是一个数组,匹配的字符在$a中受保护
正规汉字
Echo(mb_eregi(“[X80 XFF],“中文D”)?“是”:“无”)“中文字符”
Echo(mb_eregi(“^([X80 XFF])+$”,“中文”)?“所有中文字符”:“
看看完整的中文字符串函数
$STR=“PHP中的eregi如何匹配中文字符?”
如果(预匹配(“/^[”).chr(0x80).-“.chr(0xff)。”]+$/“,$str)){
Echo“这是一根纯中文字符串”
}否则{
Echo“这不是纯中文字符串”
}
预匹配全部($pat,…)和预替换($pat,…)
Preg_match_all(“/(汉字)+/ism”,“我是汉字,看看你对我做了什么!”,$m_a)
在每段代码的高位和低位开始和结束后,自然会编写规则,直接是16位。有什么困难吗?呵呵。但是需要注意的是,在PHP中,16位是X
因此,如上所述,我们也可以使用正则表达式来确定它是否是GB2312的汉字

声明:本文原创发布PHP中文网站。请注明转载来源。感谢您的尊重!如果您有任何问题,请与我们联系
php用正则表达抓取网页中文章(菜鸟教程正则表达式浅谈正则表达式Pythonjieba库博客园的实例:pythonjieba )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-16 07:05
)
数据采集和可视化分析
学科要求
目的:
熟悉数据采集方法和数据预处理方法。熟悉Python中常用的绘图方法。
实验内容:
用你的名字或学生证创建一个新文件夹,并在文件夹中创建一个新的文本文件“111.txt”。
复制网页文章中的文字内容(网址因为某些原因打不出来,随便找一篇文章就可以了)”从网上复制到“111.txt”。
将“111.txt”文件的中文内容提取到“222.txt”文件中(使用re方法)。
使用jieba对提取的中文文档(222.txt)进行分割,统计出现频率最高的前100个文档。
使用 wordcloud 和 matplotlib.pyplot
方法 为“222.txt”中的分词创建分词云图,另存为“分词云图1.png”。
用“222.txt”中出现频率最高的前10个词做条形图,X轴对应10个词,y
轴对应每个词的频率值,保存为“条形图2.png”。
(附:有空的可以把实验内容的步骤(1)(2))换成爬取网页内容的操作。)
参考代码和实验结果:
(实验过程中代码和实验结果自行完成)
先学会将文本(中文)提取到txt文件中
一种提取TXT文本中指定内容的方法
Python 使用正则表达式提取文本中的特定内容
python re模块
自学网站:
蟒蛇自己的
博客园
Python正则表达式中re.S、re.M、re.I的作用
新手教程正则表达式
谈论正则表达式
Python jieba 库
博客园
例子:
python jieba库的基本使用
基于python中jieba包的详细介绍
代码(未完成)
import re
import pandas as pd
#简单打开同目录下的一个文件夹并输出到屏幕 header=None有也行
#1
# a=pd.read_csv('111.txt')
# print(a)
# 2
# a=pd.read_table('./111.txt')
# print(a)
# file1=codecs.open(r'B:\BaiduNetdiskDownload\coding2021\Python\2020416022\111.txt','r','gbk')
# list1=file1.readlines()
# str1=''.join(list1)
# str2=re.sub('\s','',str1)
# re1=',|。|!|“”|?'
# list2=re.split(re1,str2)
# file2=codecs.open(r'B:\BaiduNetdiskDownload\coding2021\Python\2020416022\222.txt','a+','gbk')
# for key in list2:
# if key:
# print (key+'\n')
# file2.write(key+'\n')
# file2.readlines()
fi = open("111.txt","r",encoding="utf-8")
fo = open("222.txt","w",encoding="utf-8")
wflag =False #写标记
newline = [] #创建一个新的列表
for line in fi : #按行读入文件,此时line的type是str
if " " in line: #重置写标记
wflag =False
if "。" in line: #检验是否到了要写入的内容
wflag = True
continue
if wflag == True:
K = list(line)
if len(K)>1: #去除文本中的空行
for i in K : #写入需要内容
newline.append(i)
strlist = "".join(newline) #合并列表元素
newlines = str(strlist) #list转化成str
for D in range(1,100): #删掉句中()
newlines = newlines.replace("({})".format(D),"")
for P in range(0,9): #删掉前面数值标题
for O in range(0,9):
for U in range(0, 9):
newlines = newlines.replace("{}.{}{}".format(P,O,U), "")
fo.write(newlines)
fo.close()
fi.close() 查看全部
php用正则表达抓取网页中文章(菜鸟教程正则表达式浅谈正则表达式Pythonjieba库博客园的实例:pythonjieba
)
数据采集和可视化分析
学科要求
目的:
熟悉数据采集方法和数据预处理方法。熟悉Python中常用的绘图方法。
实验内容:
用你的名字或学生证创建一个新文件夹,并在文件夹中创建一个新的文本文件“111.txt”。
复制网页文章中的文字内容(网址因为某些原因打不出来,随便找一篇文章就可以了)”从网上复制到“111.txt”。
将“111.txt”文件的中文内容提取到“222.txt”文件中(使用re方法)。
使用jieba对提取的中文文档(222.txt)进行分割,统计出现频率最高的前100个文档。
使用 wordcloud 和 matplotlib.pyplot
方法 为“222.txt”中的分词创建分词云图,另存为“分词云图1.png”。
用“222.txt”中出现频率最高的前10个词做条形图,X轴对应10个词,y
轴对应每个词的频率值,保存为“条形图2.png”。
(附:有空的可以把实验内容的步骤(1)(2))换成爬取网页内容的操作。)
参考代码和实验结果:
(实验过程中代码和实验结果自行完成)
先学会将文本(中文)提取到txt文件中
一种提取TXT文本中指定内容的方法
Python 使用正则表达式提取文本中的特定内容
python re模块
自学网站:
蟒蛇自己的
博客园
Python正则表达式中re.S、re.M、re.I的作用
新手教程正则表达式
谈论正则表达式
Python jieba 库
博客园
例子:
python jieba库的基本使用
基于python中jieba包的详细介绍
代码(未完成)
import re
import pandas as pd
#简单打开同目录下的一个文件夹并输出到屏幕 header=None有也行
#1
# a=pd.read_csv('111.txt')
# print(a)
# 2
# a=pd.read_table('./111.txt')
# print(a)
# file1=codecs.open(r'B:\BaiduNetdiskDownload\coding2021\Python\2020416022\111.txt','r','gbk')
# list1=file1.readlines()
# str1=''.join(list1)
# str2=re.sub('\s','',str1)
# re1=',|。|!|“”|?'
# list2=re.split(re1,str2)
# file2=codecs.open(r'B:\BaiduNetdiskDownload\coding2021\Python\2020416022\222.txt','a+','gbk')
# for key in list2:
# if key:
# print (key+'\n')
# file2.write(key+'\n')
# file2.readlines()
fi = open("111.txt","r",encoding="utf-8")
fo = open("222.txt","w",encoding="utf-8")
wflag =False #写标记
newline = [] #创建一个新的列表
for line in fi : #按行读入文件,此时line的type是str
if " " in line: #重置写标记
wflag =False
if "。" in line: #检验是否到了要写入的内容
wflag = True
continue
if wflag == True:
K = list(line)
if len(K)>1: #去除文本中的空行
for i in K : #写入需要内容
newline.append(i)
strlist = "".join(newline) #合并列表元素
newlines = str(strlist) #list转化成str
for D in range(1,100): #删掉句中()
newlines = newlines.replace("({})".format(D),"")
for P in range(0,9): #删掉前面数值标题
for O in range(0,9):
for U in range(0, 9):
newlines = newlines.replace("{}.{}{}".format(P,O,U), "")
fo.write(newlines)
fo.close()
fi.close()
php用正则表达抓取网页中文章(java正则表达式基础知识应用研究的简单应用应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-15 13:23
本文文章主要介绍java正则表达式的简单应用。在之前的文章文章中,我们已经深入学习了java正则表达式的基础知识。本文研究java正则表达式的应用。 , 有兴趣的朋友可以参考一下
一:抓取网页中的电子邮件地址
使用正则表达式匹配网页中的文本
[\\w[.-]]+@[\\w[.-]]+\\.[\\w]+
分割和提取网页内容
import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; public class EmailSpider { public static void main(String[] args) { try { BufferedReader br = new BufferedReader(new FileReader("C:\\emailSpider.html")); String line = ""; while((line=br.readLine()) != null) { parse(line); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } private static void parse(String line) { Pattern p = Pattern.compile("[\\w[.-]]+@[\\w[.-]]+\\.[\\w]+"); Matcher m = p.matcher(line); while(m.find()) { System.out.println(m.group()); } } }
打印结果:
既然找到了这么多邮箱地址,有了JavaMail的知识,就可以批量发送垃圾邮件了,哈哈! ! !
二:代码统计
import java.io.BufferedReader; import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; public class CodeCounter { static long normalLines = 0;//正常代码行 static long commentLines = 0;//注释行 static long whiteLines = 0;//空白行 public static void main(String[] args) { //找到某个文件夹,该文件夹下面在没有文件夹,这里没有写递归处理不在同一文件夹的文件 File f = new File("E:\\Workspaces\\eclipse\\Application\\JavaMailTest\\src\\com\\java\\mail"); File[] codeFiles = f.listFiles(); for(File child : codeFiles){ //只统计java文件 if(child.getName().matches(".*\\.java$")) { parse(child); } } System.out.println("normalLines:" + normalLines); System.out.println("commentLines:" + commentLines); System.out.println("whiteLines:" + whiteLines); } private static void parse(File f) { BufferedReader br = null; //表示是否为注释开始 boolean comment = false; try { br = new BufferedReader(new FileReader(f)); String line = ""; while((line = br.readLine()) != null) { //去掉注释符/*前面可能出现的空白 line = line.trim(); //空行 因为readLine()将字符串取出来时,已经去掉了换行符\n //所以不是"^[\\s&&[^\\n]]*\\n$" if(line.matches("^[\\s&&[^\\n]]*$")) { whiteLines ++; } else if (line.startsWith("/*") && !line.endsWith("*/")) { //统计多行/*****/ commentLines ++; comment = true; } else if (line.startsWith("/*") && line.endsWith("*/")) { //统计一行/**/ commentLines ++; } else if (true == comment) { //统计*/ commentLines ++; if(line.endsWith("*/")) { comment = false; } } else if (line.startsWith("//")) { commentLines ++; } else { normalLines ++; } } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if(br != null) { try { br.close(); br = null; } catch (IOException e) { e.printStackTrace(); } } } } }
以上是Java正则表达式的简单应用,希望对大家学习Java正则表达式有所帮助。
以上就是java正则表达式简单应用的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php用正则表达抓取网页中文章(java正则表达式基础知识应用研究的简单应用应用)
本文文章主要介绍java正则表达式的简单应用。在之前的文章文章中,我们已经深入学习了java正则表达式的基础知识。本文研究java正则表达式的应用。 , 有兴趣的朋友可以参考一下
一:抓取网页中的电子邮件地址
使用正则表达式匹配网页中的文本
[\\w[.-]]+@[\\w[.-]]+\\.[\\w]+
分割和提取网页内容
import java.io.BufferedReader; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; public class EmailSpider { public static void main(String[] args) { try { BufferedReader br = new BufferedReader(new FileReader("C:\\emailSpider.html")); String line = ""; while((line=br.readLine()) != null) { parse(line); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } private static void parse(String line) { Pattern p = Pattern.compile("[\\w[.-]]+@[\\w[.-]]+\\.[\\w]+"); Matcher m = p.matcher(line); while(m.find()) { System.out.println(m.group()); } } }
打印结果:
既然找到了这么多邮箱地址,有了JavaMail的知识,就可以批量发送垃圾邮件了,哈哈! ! !
二:代码统计
import java.io.BufferedReader; import java.io.File; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; public class CodeCounter { static long normalLines = 0;//正常代码行 static long commentLines = 0;//注释行 static long whiteLines = 0;//空白行 public static void main(String[] args) { //找到某个文件夹,该文件夹下面在没有文件夹,这里没有写递归处理不在同一文件夹的文件 File f = new File("E:\\Workspaces\\eclipse\\Application\\JavaMailTest\\src\\com\\java\\mail"); File[] codeFiles = f.listFiles(); for(File child : codeFiles){ //只统计java文件 if(child.getName().matches(".*\\.java$")) { parse(child); } } System.out.println("normalLines:" + normalLines); System.out.println("commentLines:" + commentLines); System.out.println("whiteLines:" + whiteLines); } private static void parse(File f) { BufferedReader br = null; //表示是否为注释开始 boolean comment = false; try { br = new BufferedReader(new FileReader(f)); String line = ""; while((line = br.readLine()) != null) { //去掉注释符/*前面可能出现的空白 line = line.trim(); //空行 因为readLine()将字符串取出来时,已经去掉了换行符\n //所以不是"^[\\s&&[^\\n]]*\\n$" if(line.matches("^[\\s&&[^\\n]]*$")) { whiteLines ++; } else if (line.startsWith("/*") && !line.endsWith("*/")) { //统计多行/*****/ commentLines ++; comment = true; } else if (line.startsWith("/*") && line.endsWith("*/")) { //统计一行/**/ commentLines ++; } else if (true == comment) { //统计*/ commentLines ++; if(line.endsWith("*/")) { comment = false; } } else if (line.startsWith("//")) { commentLines ++; } else { normalLines ++; } } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { if(br != null) { try { br.close(); br = null; } catch (IOException e) { e.printStackTrace(); } } } } }
以上是Java正则表达式的简单应用,希望对大家学习Java正则表达式有所帮助。
以上就是java正则表达式简单应用的详细内容。更多详情请关注其他相关html中文网站文章!
php用正则表达抓取网页中文章( 暂时没有写,这里第二种应急解决方法实现(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-12 14:00
暂时没有写,这里第二种应急解决方法实现(图))
定时获取图片地址的链接地址
更新时间:2008年12月10日14:11:24 作者:
可以得到网页中所有图片地址和链接地址的代码,貌似一般都是用来获取网页中的资源地址的。
复制代码代码如下:
reg = /]*src\s*=\s*('|")?([^'">]*)\1([^>])*>/ig
定期获取图片地址
一、问题:
我在采集的过程中遇到了一个问题:从数据库读取的图片显示不正常。经过分析,发现数据库中的图片存放在网站根目录的相对路径下。图片地址如下:/uploads/allimg/090403/012F31N9-1.jpg,原来读取的图片是通过开关的URL的绝对图片获取的,所以出现了以根目录开头的图片地址在采集采集失败。
二、解决方案:
分析HTML代码并显示图片
标签,写正则表达式得到
在网站和网站中添加图片地址转换为URL的绝对URL,然后交给下面的代码(远程图片本地获取)。
1) 改进方案,用“2)应急方案,只考虑以“src=”属性开头的正则表达式,但是这个方法有不完善的地方,只要“src=”出现在会被替换。出现“src=”的可能性:javascript,文本中的“src”等,不过这些都比较少,再加上图片格式的常规限制,不正确替换的概率会小一些。
三、 实现代码:
考虑到第一种方法的难度还没有写出来,这里是第二种应急方案的实现(实现中涉及的正则表达式内容这里不做解释分析,知识内容请google或百度^v^正则表达式):
复制代码代码如下: 查看全部
php用正则表达抓取网页中文章(
暂时没有写,这里第二种应急解决方法实现(图))
定时获取图片地址的链接地址
更新时间:2008年12月10日14:11:24 作者:
可以得到网页中所有图片地址和链接地址的代码,貌似一般都是用来获取网页中的资源地址的。
复制代码代码如下:
reg = /]*src\s*=\s*('|")?([^'">]*)\1([^>])*>/ig
定期获取图片地址
一、问题:
我在采集的过程中遇到了一个问题:从数据库读取的图片显示不正常。经过分析,发现数据库中的图片存放在网站根目录的相对路径下。图片地址如下:/uploads/allimg/090403/012F31N9-1.jpg,原来读取的图片是通过开关的URL的绝对图片获取的,所以出现了以根目录开头的图片地址在采集采集失败。
二、解决方案:
分析HTML代码并显示图片
标签,写正则表达式得到
在网站和网站中添加图片地址转换为URL的绝对URL,然后交给下面的代码(远程图片本地获取)。
1) 改进方案,用“2)应急方案,只考虑以“src=”属性开头的正则表达式,但是这个方法有不完善的地方,只要“src=”出现在会被替换。出现“src=”的可能性:javascript,文本中的“src”等,不过这些都比较少,再加上图片格式的常规限制,不正确替换的概率会小一些。
三、 实现代码:
考虑到第一种方法的难度还没有写出来,这里是第二种应急方案的实现(实现中涉及的正则表达式内容这里不做解释分析,知识内容请google或百度^v^正则表达式):
复制代码代码如下:
php用正则表达抓取网页中文章(爬虫过期目标网站怎么用设置cookie? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-09 05:23
)
简介:使用爬虫时,某些网站爬虫需要登录才能爬取。一般网站有登录,信息通常以cookies的形式存储。所以有两种方式: 模拟登录获取cookies和所有带有cookies的请求,直接登录网站保存cookies,相当于写死;第一个在当时比较灵活,第二个会涉及到cookie过期目标网站:豆瓣+我的用户名(binbin)
手动获取 cookie:查看请求
1 使用 Jsoup 设置 cookie 和查看节点
代码:
package Jsoup;
import HttpClient.HttpClientPc;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
/**
* 已经有了cookie
*/
public class LoginCookie {
public static void main(String[] args) throws IOException {
String url="https://www.douban.com/people/205769149/";
LoginCookie loginCookie=new LoginCookie();
String cookie="";
loginCookie.setCookies(url,cookie);
}
/**
* 手动设置 cookies
* 先从网站上登录,然后查看 request headers 里面的 cookies
* @param url
* @throws IOException
*/
public void setCookies(String url,String cookie) throws IOException {
Document document = org.jsoup.Jsoup.connect(url)
// 手动设置cookies
.header("Cookie", cookie)
.get();
//
if (document != null) {
// 获取豆瓣昵称节点
Element element = document.select(".info h1").first();
if (element == null) {
System.out.println("没有找到 .info h1 标签");
return;
}
// 取出豆瓣节点昵称
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}
}
运行结果:
模拟登录方式:登录链接:登录豆瓣
代码:
package Jsoup;
import org.jsoup.Connection;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class login {
public static void main(String[] args) throws IOException {
String loginUrl="https://accounts.douban.com/j/ ... 3B%3B
String userInfoUrl="https://www.douban.com/people/205769149/";
login login=new login();
login.jsoupLogin(loginUrl,userInfoUrl);
}
/**
* Jsoup 模拟登录豆瓣 访问个人中心
* 在豆瓣登录时先输入一个错误的账号密码,查看到登录所需要的参数
* 先构造登录请求参数,成功后获取到cookies
* 设置request cookies,再次请求
* @param loginUrl 登录url :https://accounts.douban.com/j/mobile/login/basic
* @param userInfoUrl 个人中心url https://www.douban.com/people/205769149/
* @throws IOException
*/
public void jsoupLogin(String loginUrl,String userInfoUrl) throws IOException {
// 构造登陆参数
Map data = new HashMap();
data.put("name","用户名");
data.put("password","密码");
data.put("remember","false");
data.put("ticket","");
data.put("ck","");
Connection.Response login = org.jsoup.Jsoup.connect(loginUrl)
.ignoreContentType(true) // 忽略类型验证
.followRedirects(false) // 禁止重定向
.postDataCharset("utf-8")
.header("Upgrade-Insecure-Requests","1")
.header("Accept","application/json")
.header("Content-Type","application/x-www-form-urlencoded")
.header("X-Requested-With","XMLHttpRequest")
.header("User-Agent","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
.data(data)
.method(Connection.Method.POST)
.execute();
login.charset("UTF-8");
// login 中已经获取到登录成功之后的cookies
// 构造访问个人中心的请求
Document document = org.jsoup.Jsoup.connect(userInfoUrl)
// 取出login对象里面的cookies
.cookies(login.cookies())
.get();
if (document != null) {
Element element = document.select(".info h1").first();
if (element == null) {
System.out.println("没有找到 .info h1 标签");
return;
}
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}
} 查看全部
php用正则表达抓取网页中文章(爬虫过期目标网站怎么用设置cookie?
)
简介:使用爬虫时,某些网站爬虫需要登录才能爬取。一般网站有登录,信息通常以cookies的形式存储。所以有两种方式: 模拟登录获取cookies和所有带有cookies的请求,直接登录网站保存cookies,相当于写死;第一个在当时比较灵活,第二个会涉及到cookie过期目标网站:豆瓣+我的用户名(binbin)
手动获取 cookie:查看请求
1 使用 Jsoup 设置 cookie 和查看节点
代码:
package Jsoup;
import HttpClient.HttpClientPc;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
/**
* 已经有了cookie
*/
public class LoginCookie {
public static void main(String[] args) throws IOException {
String url="https://www.douban.com/people/205769149/";
LoginCookie loginCookie=new LoginCookie();
String cookie="";
loginCookie.setCookies(url,cookie);
}
/**
* 手动设置 cookies
* 先从网站上登录,然后查看 request headers 里面的 cookies
* @param url
* @throws IOException
*/
public void setCookies(String url,String cookie) throws IOException {
Document document = org.jsoup.Jsoup.connect(url)
// 手动设置cookies
.header("Cookie", cookie)
.get();
//
if (document != null) {
// 获取豆瓣昵称节点
Element element = document.select(".info h1").first();
if (element == null) {
System.out.println("没有找到 .info h1 标签");
return;
}
// 取出豆瓣节点昵称
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}
}
运行结果:
模拟登录方式:登录链接:登录豆瓣
代码:
package Jsoup;
import org.jsoup.Connection;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class login {
public static void main(String[] args) throws IOException {
String loginUrl="https://accounts.douban.com/j/ ... 3B%3B
String userInfoUrl="https://www.douban.com/people/205769149/";
login login=new login();
login.jsoupLogin(loginUrl,userInfoUrl);
}
/**
* Jsoup 模拟登录豆瓣 访问个人中心
* 在豆瓣登录时先输入一个错误的账号密码,查看到登录所需要的参数
* 先构造登录请求参数,成功后获取到cookies
* 设置request cookies,再次请求
* @param loginUrl 登录url :https://accounts.douban.com/j/mobile/login/basic
* @param userInfoUrl 个人中心url https://www.douban.com/people/205769149/
* @throws IOException
*/
public void jsoupLogin(String loginUrl,String userInfoUrl) throws IOException {
// 构造登陆参数
Map data = new HashMap();
data.put("name","用户名");
data.put("password","密码");
data.put("remember","false");
data.put("ticket","");
data.put("ck","");
Connection.Response login = org.jsoup.Jsoup.connect(loginUrl)
.ignoreContentType(true) // 忽略类型验证
.followRedirects(false) // 禁止重定向
.postDataCharset("utf-8")
.header("Upgrade-Insecure-Requests","1")
.header("Accept","application/json")
.header("Content-Type","application/x-www-form-urlencoded")
.header("X-Requested-With","XMLHttpRequest")
.header("User-Agent","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
.data(data)
.method(Connection.Method.POST)
.execute();
login.charset("UTF-8");
// login 中已经获取到登录成功之后的cookies
// 构造访问个人中心的请求
Document document = org.jsoup.Jsoup.connect(userInfoUrl)
// 取出login对象里面的cookies
.cookies(login.cookies())
.get();
if (document != null) {
Element element = document.select(".info h1").first();
if (element == null) {
System.out.println("没有找到 .info h1 标签");
return;
}
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}
}
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章文章信息:get//author)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-03 09:14
php用正则表达抓取网页中文章文章信息:get/content/author/*blog/*.html按id分类提取需要抓取文章的文字(可以用xpath和bs)有需要可以一起学
参考varredirect=navigator.urlopen();redirect.callback=this.api.callback;
用点赞作为redirect。
index.php还是少用
用xpath,
可以试试一个叫beawesome的js库,
点赞+感谢+收藏+取消
可以试试amazon的促销活动uiui-sparkbox.fl/
</a>
window.addeventlistener('scrolls',onerror);varitemclick=this.api.callback.click;itemclick.callback=document.documentelement.click();itemclick.callback=body.getelementsbytagname('column')[0].click();这个接口用的php,是php中最常用的接口之一。
varitem=require('http');varotherclick=newdocument.getelementsbytagname('column')[0].click();varclickpager=document.getelementsbytagname('button')[0].click();item.save(clickpager.fieldset('click(type=')'));这个是用js来写的,不用事先搭建环境。 查看全部
php用正则表达抓取网页中文章(php用正则表达抓取网页中文章文章信息:get//author)
php用正则表达抓取网页中文章文章信息:get/content/author/*blog/*.html按id分类提取需要抓取文章的文字(可以用xpath和bs)有需要可以一起学
参考varredirect=navigator.urlopen();redirect.callback=this.api.callback;
用点赞作为redirect。
index.php还是少用
用xpath,
可以试试一个叫beawesome的js库,
点赞+感谢+收藏+取消
可以试试amazon的促销活动uiui-sparkbox.fl/
</a>
window.addeventlistener('scrolls',onerror);varitemclick=this.api.callback.click;itemclick.callback=document.documentelement.click();itemclick.callback=body.getelementsbytagname('column')[0].click();这个接口用的php,是php中最常用的接口之一。
varitem=require('http');varotherclick=newdocument.getelementsbytagname('column')[0].click();varclickpager=document.getelementsbytagname('button')[0].click();item.save(clickpager.fieldset('click(type=')'));这个是用js来写的,不用事先搭建环境。
php用正则表达抓取网页中文章(用前几天来做采集器主要用到两个函数的制作方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-27 16:27
采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式基础,你就可以做到。从我自己的采集器出来。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,可以不自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
用php做采集器主要用到两个函数:file_get_contents()和preg_match_all()。第一个是远程读取网页内容,但只能在php5以上版本使用。后者是一个常规函数。用于提取所需的内容。
下面我们一步一步的说一下函数的实现。
因为是采集的小说,先提取标题,作者,流派。可以根据需要提取其他信息。
这里是“回明为王”的目标,先打开书目页面和链接:
再打开几本书,你会发现书名的基本格式是:书号/index.aspx,这样我们就可以制作一个起始页,定义一个,输入需要采集的书号,然后我们可以通过 $_post ['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_post['number']/index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好以实际生产为准。_post['number'] 的合法性。
构造好url后,就可以开始采集图书信息了。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,此处不再详述)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/html\/book\/[0-9]{1,}\/[0-9]{1,}\/list\.shtm/is",$contents,$typeid);这不是够了,还需要一个cut函数:
php代码如下:
复制代码代码如下:
functioncut($string,$start,$end){
$message=explode($start,$string);
$message=explode($end,$message[1]);return$message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。取出分类号:
$start="html/book/";
$end
="列表.shtm";
$typeid=cut($typeid[0][0],$start,$end);
$typeid=explode("/",$typeid);[/php]
这样,$typeid[0] 就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl=$typeid[0]/$_post['number']/list.shtm。有了这个,你可以找到每章的地址。方法如下:
复制代码代码如下:
$ustart="\"";
$uend
="\"";
//t代表title的缩写
$tstart=">";
$趋向
=" 查看全部
php用正则表达抓取网页中文章(用前几天来做采集器主要用到两个函数的制作方法)
采集器,通常称为小偷程序,主要用于抓取他人网页的内容。关于采集器的制作,其实并不难。就是远程打开采集的网页,然后用正则表达式匹配需要的内容。只要你有一点正则表达式基础,你就可以做到。从我自己的采集器出来。
前几天做了一个小说连载程序,因为怕更新麻烦,写了个采集器,采集八路中文网,功能比较简单,可以不自定义规则,不过大概思路都在里面,自定义规则可以自己扩展。
用php做采集器主要用到两个函数:file_get_contents()和preg_match_all()。第一个是远程读取网页内容,但只能在php5以上版本使用。后者是一个常规函数。用于提取所需的内容。
下面我们一步一步的说一下函数的实现。
因为是采集的小说,先提取标题,作者,流派。可以根据需要提取其他信息。
这里是“回明为王”的目标,先打开书目页面和链接:
再打开几本书,你会发现书名的基本格式是:书号/index.aspx,这样我们就可以制作一个起始页,定义一个,输入需要采集的书号,然后我们可以通过 $_post ['number'] 这个格式来接收采集的书号。收到书号后,接下来要做的就是构造书目页面:$url=$_post['number']/index.aspx,当然这里是一个例子,主要是为了方便说明,就是最好以实际生产为准。_post['number'] 的合法性。
构造好url后,就可以开始采集图书信息了。使用file_get_contents()函数打开书目页面:$content=file_get_contents($url),这样就可以读取书目页面的内容了。下一步是匹配书名、作者和类型。这是一个带有书名的例子,其他一切都是一样的。打开书目页面,查看源文件,找到《回明为主》,这是要提取的书名。提取书名的正则表达式:/(.*?)\/is,使用preg_match_all()函数提取书名:preg_match_all("/(.*?)\/is",$contents,$title ); $title[0][0]的内容就是我们想要的title(preg_match_all函数的用法可以百度查,此处不再详述)。取出书籍信息后,下一步就是取出章节内容。取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:取章节内容,首先要找到每个章节的地址,然后远程打开章节,使用正则规则取出内容,存入库或者直接生成html静态文件。这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:这是章节列表的地址: 可以看出这个和参考书目页面是一样的,可以定期找到:分类号/书号/list.shtm。ISBN已经拿到了。这里的关键是找到分类号。分类号可以在之前的参考书目页面上找到。提取分类号:
preg_match_all("/html\/book\/[0-9]{1,}\/[0-9]{1,}\/list\.shtm/is",$contents,$typeid);这不是够了,还需要一个cut函数:
php代码如下:
复制代码代码如下:
functioncut($string,$start,$end){
$message=explode($start,$string);
$message=explode($end,$message[1]);return$message[0];} 其中 $string 是要剪切的内容,$start 是开头,$end 是结尾。取出分类号:
$start="html/book/";
$end
="列表.shtm";
$typeid=cut($typeid[0][0],$start,$end);
$typeid=explode("/",$typeid);[/php]
这样,$typeid[0] 就是我们要找的分类号。下一步是构造章节列表的地址:$chapterurl=$typeid[0]/$_post['number']/list.shtm。有了这个,你可以找到每章的地址。方法如下:
复制代码代码如下:
$ustart="\"";
$uend
="\"";
//t代表title的缩写
$tstart=">";
$趋向
="
php用正则表达抓取网页中文章(正则表达式就是描述字符排列模式的一种自定义的语法规则名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-25 06:05
刚接触正则表达式的网友都觉得有点繁琐和高深莫测。实际上,正则表达式是描述字符排列模式的自定义语法规则名称。在 PHP 提供的系统函数中,该模式用于执行字符串的匹配、搜索、替换、拆分等操作。它的应用非常广泛。比如常见的就是用正则表达式来验证用户在表单中提交的用户名、密码、邮箱、身份证号、电话号码是否合法;当用户发布文章时,输入的URL会添加所有对应的链接;根据所有标点计算文章中的句子总数;从网页等中抓取某种格式的数据。正则表达式不是 PHP 本身的产物,你会在很多领域看到它的应用。除了Perl、C#、Java语言的应用外,我们B/S软件开发中还可以应用到Linux操作系统、前端JavaScript脚本、后端脚本PHP、MySQL数据库等。
正则表达式也称为模式表达式。它具有非常完整的语法体系,可以编写模式,并提供灵活直观的字符处理方法。通过构造具有特定传递模式的模式,将它们与输入的字符串信息进行比较,并实现字符串匹配、搜索、替换和分割操作,可以在特定功能中使用正则表达式。下面给出的三种模式都是按照正则表达式的语法规则构造的。代码显示如下:
"/[A-zA-z]+:[∧\s]*/" //匹配URL的正则表达式
"/<(\s*?)[∧>]*>.*?<∧1>|<.*?/>/i" //匹配HTML标签的正则表达式
"∧w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/" //匹配正则表达式E-邮件地址模式
不要被上面例子中被认为是乱码的字符串吓到。它们是根据正则表达式的语法规则构建的模式。它们是由普通字符和特殊字符组成的字符串。而且,这些模式字符串必须在特定的正则表达式函数中使用才能有效。学完本章后,他们中的一些人可以自由应用此类代码。PHP 支持两组正则表达式处理函数库。PCRE(Perl Compatible Regular Expression)库提供的一组与Perl语言兼容的正则表达式函数,使用以前缀preg命名的函数,表达式应收录在分隔符中,如斜线(/)。另一个是 POSLX(便携式操作系统接口)扩展语法的正则表达式函数,使用以前缀“preg_”命名的函数。两组函数的功能基本相似,执行效率略有不同。一般来说,要实现同样的功能,使用PCRE库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。使用 PCRE 库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。使用 PCRE 库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。 查看全部
php用正则表达抓取网页中文章(正则表达式就是描述字符排列模式的一种自定义的语法规则名)
刚接触正则表达式的网友都觉得有点繁琐和高深莫测。实际上,正则表达式是描述字符排列模式的自定义语法规则名称。在 PHP 提供的系统函数中,该模式用于执行字符串的匹配、搜索、替换、拆分等操作。它的应用非常广泛。比如常见的就是用正则表达式来验证用户在表单中提交的用户名、密码、邮箱、身份证号、电话号码是否合法;当用户发布文章时,输入的URL会添加所有对应的链接;根据所有标点计算文章中的句子总数;从网页等中抓取某种格式的数据。正则表达式不是 PHP 本身的产物,你会在很多领域看到它的应用。除了Perl、C#、Java语言的应用外,我们B/S软件开发中还可以应用到Linux操作系统、前端JavaScript脚本、后端脚本PHP、MySQL数据库等。
正则表达式也称为模式表达式。它具有非常完整的语法体系,可以编写模式,并提供灵活直观的字符处理方法。通过构造具有特定传递模式的模式,将它们与输入的字符串信息进行比较,并实现字符串匹配、搜索、替换和分割操作,可以在特定功能中使用正则表达式。下面给出的三种模式都是按照正则表达式的语法规则构造的。代码显示如下:
"/[A-zA-z]+:[∧\s]*/" //匹配URL的正则表达式
"/<(\s*?)[∧>]*>.*?<∧1>|<.*?/>/i" //匹配HTML标签的正则表达式
"∧w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/" //匹配正则表达式E-邮件地址模式
不要被上面例子中被认为是乱码的字符串吓到。它们是根据正则表达式的语法规则构建的模式。它们是由普通字符和特殊字符组成的字符串。而且,这些模式字符串必须在特定的正则表达式函数中使用才能有效。学完本章后,他们中的一些人可以自由应用此类代码。PHP 支持两组正则表达式处理函数库。PCRE(Perl Compatible Regular Expression)库提供的一组与Perl语言兼容的正则表达式函数,使用以前缀preg命名的函数,表达式应收录在分隔符中,如斜线(/)。另一个是 POSLX(便携式操作系统接口)扩展语法的正则表达式函数,使用以前缀“preg_”命名的函数。两组函数的功能基本相似,执行效率略有不同。一般来说,要实现同样的功能,使用PCRE库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。使用 PCRE 库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。使用 PCRE 库提供的正则表达式效率略有优势。因此,本文主要介绍以“preg_”为前缀的正则表达式函数。
php用正则表达抓取网页中文章( 鉴客这篇文章涉及php正则匹配与字符串操作的相关技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-25 01:19
鉴客这篇文章涉及php正则匹配与字符串操作的相关技巧)
PHP 使用正则表达式获取微博主题名和对象名
更新时间:2015-07-18 14:48:34 作者:建科
本文文章主要介绍PHP使用正则表达式获取微博主题名和对象名,涉及PHP正则匹配和字符串操作相关技巧。有一定的参考价值,有需要的朋友可以参考下
本文介绍了PHP使用正则表达式获取微博主题名和对象名的例子。分享给大家,供大家参考。具体实现方法如下:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";
$tag_pattern = "/\#([^\#|.]+)\#/";
preg_match_all($tag_pattern, $post_content, $tagsarr);
$tags = implode(',',$tagsarr[1]);
$user_pattern = "/\@([a-zA-z0-9_]+)/";
$post_content = preg_replace($user_pattern, '@${1}', $post_content );
$post_content = preg_replace($tag_pattern, '#${1}#', $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的php程序设计有所帮助。 查看全部
php用正则表达抓取网页中文章(
鉴客这篇文章涉及php正则匹配与字符串操作的相关技巧)
PHP 使用正则表达式获取微博主题名和对象名
更新时间:2015-07-18 14:48:34 作者:建科
本文文章主要介绍PHP使用正则表达式获取微博主题名和对象名,涉及PHP正则匹配和字符串操作相关技巧。有一定的参考价值,有需要的朋友可以参考下
本文介绍了PHP使用正则表达式获取微博主题名和对象名的例子。分享给大家,供大家参考。具体实现方法如下:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";
$tag_pattern = "/\#([^\#|.]+)\#/";
preg_match_all($tag_pattern, $post_content, $tagsarr);
$tags = implode(',',$tagsarr[1]);
$user_pattern = "/\@([a-zA-z0-9_]+)/";
$post_content = preg_replace($user_pattern, '@${1}', $post_content );
$post_content = preg_replace($tag_pattern, '#${1}#', $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的php程序设计有所帮助。
php用正则表达抓取网页中文章(以爬取国家地理中文网中的旅行类中的图片为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-23 01:00
本文以爬取国家地理中文网站旅游类图片为例,演示爬虫的基本功能。
给定初始地址
国家地理中文网站:
获取和分析网页内容
一种。分析网页的结构以确定所需的内容
我们打开网页,右键选择“显示网页源代码”查看网页结构,以下是我截取的部分
我们会发现在标签的scr=""中放置了image类型的数据。我们只需要找到这些标签,从中提取出我们想要的联系,就可以完成我们的期望。
湾 获取网页内容
提取内容,首先要向服务器发起请求,获取文件,然后分析提取图片信息,整理保存数据
作者使用Python3.6。获取网页内容常用的方法有两种:requests和urllib(结合python2中的urllib和urllib2)。获取网页内容请参考这篇文章:爬虫基础:python获取网页内容
现在,我们定义一个方法 crawl() 来获取网页
import requests
def crawl(url, headers):
with requests.get(url=url, headers=headers) as response:
# 读取response里的内容,并转码
data = response.content.decode()
return data
调用该方法获取网页内容:
# 获取指定网页内容
url = 'http://www.ngchina.com.cn/travel/'
headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36'}
content = crawl(url, headers)
print(content)
编写正则表达式来匹配图像内容
这样我们就抓取到了给定地址中的图片信息,我们选择其中之一:
入库,进行下一轮爬行
我们抓取到指定的内容后,就可以将其保存到数据库中;如果是链接类型的抓取,我们可以创建一个url队列,将指定url中的新链接加入到url队列中,然后一个一个的循环遍历和抓包,对于队列url的处理,是必须的根据具体需要采取相应的策略来完成相应的任务。更多爬虫信息可以参考:初始爬虫。
添加:
我们在写正则表达式的时候,可以使用网上的正则表达式工具快速查看匹配结果:菜鸟正则表达式工具,这个地址里面有一些常用的正则表达式,比如电话号码、QQ号码、网址等。、邮箱等,非常好用。 查看全部
php用正则表达抓取网页中文章(以爬取国家地理中文网中的旅行类中的图片为例)
本文以爬取国家地理中文网站旅游类图片为例,演示爬虫的基本功能。
给定初始地址
国家地理中文网站:
获取和分析网页内容
一种。分析网页的结构以确定所需的内容
我们打开网页,右键选择“显示网页源代码”查看网页结构,以下是我截取的部分
我们会发现在标签的scr=""中放置了image类型的数据。我们只需要找到这些标签,从中提取出我们想要的联系,就可以完成我们的期望。
湾 获取网页内容
提取内容,首先要向服务器发起请求,获取文件,然后分析提取图片信息,整理保存数据
作者使用Python3.6。获取网页内容常用的方法有两种:requests和urllib(结合python2中的urllib和urllib2)。获取网页内容请参考这篇文章:爬虫基础:python获取网页内容
现在,我们定义一个方法 crawl() 来获取网页
import requests
def crawl(url, headers):
with requests.get(url=url, headers=headers) as response:
# 读取response里的内容,并转码
data = response.content.decode()
return data
调用该方法获取网页内容:
# 获取指定网页内容
url = 'http://www.ngchina.com.cn/travel/'
headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36'}
content = crawl(url, headers)
print(content)
编写正则表达式来匹配图像内容
这样我们就抓取到了给定地址中的图片信息,我们选择其中之一:
入库,进行下一轮爬行
我们抓取到指定的内容后,就可以将其保存到数据库中;如果是链接类型的抓取,我们可以创建一个url队列,将指定url中的新链接加入到url队列中,然后一个一个的循环遍历和抓包,对于队列url的处理,是必须的根据具体需要采取相应的策略来完成相应的任务。更多爬虫信息可以参考:初始爬虫。
添加:
我们在写正则表达式的时候,可以使用网上的正则表达式工具快速查看匹配结果:菜鸟正则表达式工具,这个地址里面有一些常用的正则表达式,比如电话号码、QQ号码、网址等。、邮箱等,非常好用。
php用正则表达抓取网页中文章(PHP正则表达式如何处理将要打开文件的标识和几种形式?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-17 06:10
最近有一个任务,从页面中抓取页面上的所有链接。当然,使用 PHP 正则表达式是最方便的方式。要编写正则表达式,您必须首先总结模式。页面上的链接有多少种形式?
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中的链接一般有三种,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
一旦弄清楚了链接的类型,就知道要抓取链接,主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
再说说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。 查看全部
php用正则表达抓取网页中文章(PHP正则表达式如何处理将要打开文件的标识和几种形式?)
最近有一个任务,从页面中抓取页面上的所有链接。当然,使用 PHP 正则表达式是最方便的方式。要编写正则表达式,您必须首先总结模式。页面上的链接有多少种形式?
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中的链接一般有三种,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
一旦弄清楚了链接的类型,就知道要抓取链接,主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
再说说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。
php用正则表达抓取网页中文章( PHP通过正则表达式判断内容中的远程图片的资料请关注脚本之家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-15 03:27
PHP通过正则表达式判断内容中的远程图片的资料请关注脚本之家)
php中通过正则表达式下载内容中远程图片的功能代码
更新时间:2012年1月10日12:01:30投稿:mdxy-dxy
下午花时间写了一个程序,用PHP正则表达式判断内容中的图片,并将图片下载保存在域名下。
这个程序实际上是“小偷程序”的重要组成部分。这部分程序只是下载远程图片的部分。程序写起来比较简单,大部分都有注释。
if (preg_match_all("/http://[^ "']+[.jpg|.gif|.jpeg|.png]+/ui",stripcslashes($content),$aliurl)){
$i=0; //多个文件++
while(list($key ,$v) = each($aliurl[0])){
//echo $v."<br />";
$filetype = pathinfo($v, PATHINFO_EXTENSION); //获取后缀名
$ff = @file_get_contents($v); //获取2进制文件内容
if(!stripos($v,"jb51.net")){//判断是否是自己网站下的图片
if (!empty($ff)){ //获取到文件就执行下面的操作
$dir = "upload/".date("Ymd")."/";//指定新的存储路径
if (!file_exists($dir)){//判断目录是否存在
@mkdir($dir,511,true); //创建多级目录,511转换成十进制是777具有可执行权限
}
$nfn = $dir.date("Ymdhis").$i.".".$filetype; //构建文件的新名字
$nf = @fopen($nfn,"w"); //创建文件
fwrite($nf,$ff); //写入文件
fclose($nf); //关闭文件
$i++; //多文件++
echo "";
$content = str_replace($v,$nfn, $content);//替换content中的参数
}else{//获取不到图片则替换为默认图片
$content = str_replace($v,"/upload/201204/20120417213810742.gif", $content);//替换content中的参数
}
}
}
}
PHP使用正则表达式下载图片到本地实现代码
查看下面的示例
<p>
function get_pic_url($content){
$pattern="/ 查看全部
php用正则表达抓取网页中文章(
PHP通过正则表达式判断内容中的远程图片的资料请关注脚本之家)
php中通过正则表达式下载内容中远程图片的功能代码
更新时间:2012年1月10日12:01:30投稿:mdxy-dxy
下午花时间写了一个程序,用PHP正则表达式判断内容中的图片,并将图片下载保存在域名下。
这个程序实际上是“小偷程序”的重要组成部分。这部分程序只是下载远程图片的部分。程序写起来比较简单,大部分都有注释。
if (preg_match_all("/http://[^ "']+[.jpg|.gif|.jpeg|.png]+/ui",stripcslashes($content),$aliurl)){
$i=0; //多个文件++
while(list($key ,$v) = each($aliurl[0])){
//echo $v."<br />";
$filetype = pathinfo($v, PATHINFO_EXTENSION); //获取后缀名
$ff = @file_get_contents($v); //获取2进制文件内容
if(!stripos($v,"jb51.net")){//判断是否是自己网站下的图片
if (!empty($ff)){ //获取到文件就执行下面的操作
$dir = "upload/".date("Ymd")."/";//指定新的存储路径
if (!file_exists($dir)){//判断目录是否存在
@mkdir($dir,511,true); //创建多级目录,511转换成十进制是777具有可执行权限
}
$nfn = $dir.date("Ymdhis").$i.".".$filetype; //构建文件的新名字
$nf = @fopen($nfn,"w"); //创建文件
fwrite($nf,$ff); //写入文件
fclose($nf); //关闭文件
$i++; //多文件++
echo "";
$content = str_replace($v,$nfn, $content);//替换content中的参数
}else{//获取不到图片则替换为默认图片
$content = str_replace($v,"/upload/201204/20120417213810742.gif", $content);//替换content中的参数
}
}
}
}
PHP使用正则表达式下载图片到本地实现代码
查看下面的示例
<p>
function get_pic_url($content){
$pattern="/
php用正则表达抓取网页中文章(一个实时从网页上抓取数据的功能介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-14 09:02
在最近的一个项目中,有一个需求:用户要求我们在地图上实时显示某些景点的人数,但是他们没有给我们提供数据接口。但是,最新数据可以从网络上获取并每小时更新一次。于是经理给我安排了一个功能,实时抓取网页数据。
既然是网页,肯定有很多无用的数据,所以需要使用正则表达式过滤掉自己需要的数据。
不得不说正则表达式比子字符串好用多了,效率也很高。让我在下面分享这段代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php");
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
[AsyncRequestUtil.java]
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
[UrlUtil .java]
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size() 查看全部
php用正则表达抓取网页中文章(一个实时从网页上抓取数据的功能介绍-乐题库)
在最近的一个项目中,有一个需求:用户要求我们在地图上实时显示某些景点的人数,但是他们没有给我们提供数据接口。但是,最新数据可以从网络上获取并每小时更新一次。于是经理给我安排了一个功能,实时抓取网页数据。
既然是网页,肯定有很多无用的数据,所以需要使用正则表达式过滤掉自己需要的数据。
不得不说正则表达式比子字符串好用多了,效率也很高。让我在下面分享这段代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php";);
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
[AsyncRequestUtil.java]
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
[UrlUtil .java]
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size()
php用正则表达抓取网页中文章(历史上今天大事记做一个介绍网页抓取及抓取的定义 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-10-14 08:36
)
昨天是2014年,今天是2015年,时间总是那么快,这个文章就是2015年的开始。
这个文章主要介绍一些网页爬取以及爬取后的内容处理。
点击链接打开需要的jar包,我放在百度云盘里。需要的可以下载,其他的请自行下载。
百度百科对网页爬虫的定义,当然本文没有介绍那么多,只介绍了单个页面的爬取,以及提交表单爬取页面的模拟。如需深入,请百度或google。
上面的方法直接返回一个String字符串,只需要传入一个链接。相信大家都能理解。
那么我们应该如何处理获得的String呢?
我先做个网站测试。比如点击打开链接,这个网站显示了今天历史上发生了哪些重大事件。而我们要爬取的内容只是其中的一部分,比如:今天的历史大事记
或者在历史的今天死去
下面就为大家介绍一下当今爬行史上的重大事件。
这里使用了一个extract方法,就是将获取到的String字符串进行拆分,得到我们需要的信息。
这里的html就是上面传入的html。编译收录正则表达式。它将整个页面分为 5 个部分。那么我们如何得到里面的部分呢?
分组中的数字是得到分段后的分段。
您可以在此处查看详细信息。
下面介绍如何模拟提交表单后爬取页面,但原理和上面类似。
相信上图已经清楚的说明了功能,表单提交后显示页面的后续处理就看你怎么做了。
.
最后,祝大家新年快乐
查看全部
php用正则表达抓取网页中文章(历史上今天大事记做一个介绍网页抓取及抓取的定义
)
昨天是2014年,今天是2015年,时间总是那么快,这个文章就是2015年的开始。
这个文章主要介绍一些网页爬取以及爬取后的内容处理。
点击链接打开需要的jar包,我放在百度云盘里。需要的可以下载,其他的请自行下载。
百度百科对网页爬虫的定义,当然本文没有介绍那么多,只介绍了单个页面的爬取,以及提交表单爬取页面的模拟。如需深入,请百度或google。
上面的方法直接返回一个String字符串,只需要传入一个链接。相信大家都能理解。
那么我们应该如何处理获得的String呢?
我先做个网站测试。比如点击打开链接,这个网站显示了今天历史上发生了哪些重大事件。而我们要爬取的内容只是其中的一部分,比如:今天的历史大事记
或者在历史的今天死去
下面就为大家介绍一下当今爬行史上的重大事件。
这里使用了一个extract方法,就是将获取到的String字符串进行拆分,得到我们需要的信息。
这里的html就是上面传入的html。编译收录正则表达式。它将整个页面分为 5 个部分。那么我们如何得到里面的部分呢?
分组中的数字是得到分段后的分段。
您可以在此处查看详细信息。
下面介绍如何模拟提交表单后爬取页面,但原理和上面类似。
相信上图已经清楚的说明了功能,表单提交后显示页面的后续处理就看你怎么做了。
.
最后,祝大家新年快乐
php用正则表达抓取网页中文章(php管理员发布于3年前19本文实例讲述了的方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-12 05:10
PHP使用正则表达式获取微博php中主题和对象名称 / 管理员3年前 19
本文介绍了PHP使用正则表达式获取微博主题名和对象名的例子。分享给大家,供大家参考。具体实现方法如下:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";$tag_pattern = "/\#([^\#|.]+)\#/";preg_match_all($tag_pattern, $post_content, $tagsarr);$tags = implode(',',$tagsarr[1]);$user_pattern = "/\@([a-zA-z0-9_]+)/";$post_content = preg_replace($user_pattern, '@${1}', $post_content );$post_content = preg_replace($tag_pattern, '#${1}#', $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的php程序设计有所帮助。 查看全部
php用正则表达抓取网页中文章(php管理员发布于3年前19本文实例讲述了的方法(图))
PHP使用正则表达式获取微博php中主题和对象名称 / 管理员3年前 19
本文介绍了PHP使用正则表达式获取微博主题名和对象名的例子。分享给大家,供大家参考。具体实现方法如下:
$post_content = "@jb51和@twitter在研究用#PHP#的#正则表达式#过滤话题和对象名";$tag_pattern = "/\#([^\#|.]+)\#/";preg_match_all($tag_pattern, $post_content, $tagsarr);$tags = implode(',',$tagsarr[1]);$user_pattern = "/\@([a-zA-z0-9_]+)/";$post_content = preg_replace($user_pattern, '@${1}', $post_content );$post_content = preg_replace($tag_pattern, '#${1}#', $post_content);
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
希望这篇文章对你的php程序设计有所帮助。
php用正则表达抓取网页中文章(《theultimatepythonprogramminglangu》抓取文章的核心就是abc和abc。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-08 13:04
php用正则表达抓取网页中文章也是可以的,只不过在抓取过程中通过正则表达抓取链接就会出现一些问题。我个人的经验总结如下,同学们可以借鉴一下:1.用正则表达抓取网页中文章的过程主要是抓取每篇文章的首部分;2.在每篇文章的首部分中去把几千字数的段落去匹配,再对每篇文章进行规格化后用文档进行匹配,最后返回页面;3.正则抓取网页中文章的匹配代码的核心就是abc和abc。
javascript提供了正则引擎,可以找一本老老实实看看《theultimatepythonprogramminglanguage》。
用正则表达式,有一个函数是validate在列表里找到所有的符合条件的结果。
谢邀,
javascript的正则表达式即可实现,
哈哈,楼上诸位哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈。 查看全部
php用正则表达抓取网页中文章(《theultimatepythonprogramminglangu》抓取文章的核心就是abc和abc。)
php用正则表达抓取网页中文章也是可以的,只不过在抓取过程中通过正则表达抓取链接就会出现一些问题。我个人的经验总结如下,同学们可以借鉴一下:1.用正则表达抓取网页中文章的过程主要是抓取每篇文章的首部分;2.在每篇文章的首部分中去把几千字数的段落去匹配,再对每篇文章进行规格化后用文档进行匹配,最后返回页面;3.正则抓取网页中文章的匹配代码的核心就是abc和abc。
javascript提供了正则引擎,可以找一本老老实实看看《theultimatepythonprogramminglanguage》。
用正则表达式,有一个函数是validate在列表里找到所有的符合条件的结果。
谢邀,
javascript的正则表达式即可实现,
哈哈,楼上诸位哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈哈。
php用正则表达抓取网页中文章(网络营销教学网站()将动态网页的一般特点简要分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-10-05 16:13
你知道什么是动态网站吗?动态网页对应静态网页,也就是说网页网址的后缀不是.htm、.html、.shtml、.xml等静态网页的常见形式,而是.asp、.jsp等形式, .php,。Perl、.cgi等形式都是后缀,还有一个象征符号——“?” 在动态网页 URL 中。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是无论网页是否有动态效果,通过动态网站技术生成的网页都称为动态网页。
从网站浏览者的角度来看,无论是动态网页还是静态网页,基本的文字图片信息都可以展示,但是从网站的开发、管理、维护的角度来看,是非常大的区别。网络营销教学网站()简要总结动态网页的一般特点如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量; (2)网站使用动态网页技术可以实现更多多种功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页实际上并不是独立存在于服务器上的网页文件,只有当用户请求时服务器返回一个完整的网页; (4)动态网页中的“?”对搜索引擎检索有一定的问题。搜索引擎一般无法访问网站的数据库中的所有网页,或者由于技术原因考虑到,搜索蜘蛛不会抓取网址中“?”后的内容。因此,网站使用动态网页的,在搜索引擎推广时需要做一定的技术处理,以适应搜索引擎的需求。 查看全部
php用正则表达抓取网页中文章(网络营销教学网站()将动态网页的一般特点简要分析)
你知道什么是动态网站吗?动态网页对应静态网页,也就是说网页网址的后缀不是.htm、.html、.shtml、.xml等静态网页的常见形式,而是.asp、.jsp等形式, .php,。Perl、.cgi等形式都是后缀,还有一个象征符号——“?” 在动态网页 URL 中。这里所说的动态网页与网页上的各种动画、滚动字幕等视觉“动态效果”没有直接关系。动态网页也可以是纯文本内容或收录各种动画的内容。这些只是无论网页是否有动态效果,通过动态网站技术生成的网页都称为动态网页。
从网站浏览者的角度来看,无论是动态网页还是静态网页,基本的文字图片信息都可以展示,但是从网站的开发、管理、维护的角度来看,是非常大的区别。网络营销教学网站()简要总结动态网页的一般特点如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量; (2)网站使用动态网页技术可以实现更多多种功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;(3)动态网页实际上并不是独立存在于服务器上的网页文件,只有当用户请求时服务器返回一个完整的网页; (4)动态网页中的“?”对搜索引擎检索有一定的问题。搜索引擎一般无法访问网站的数据库中的所有网页,或者由于技术原因考虑到,搜索蜘蛛不会抓取网址中“?”后的内容。因此,网站使用动态网页的,在搜索引擎推广时需要做一定的技术处理,以适应搜索引擎的需求。
php用正则表达抓取网页中文章(正则表达式中经常使用的20个正则表达式工具,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-04 21:22
正则表达式,一个非常古老而强大的文本处理工具,只需要很短的表达式语句就可以快速实现非常复杂的业务逻辑。如果你精通正则表达式,你的开发效率可以大大提高。
正则表达式通常用于验证字段或任意字符串,例如以下用于验证基本日期格式的 JavaScript 代码:
var reg = /^(\\d{1,4})(-|\\/)(\\d{1,2})\\2(\\d{1,2})$/;
var r = fieldValue.match(reg);
if(r==null)alert('Date format error!');
以下是20个由工匠编译的,经常用于前端开发的正则表达式。
1. 验证密码强度
密码的强度必须收录大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
2. 验证中文
字符串只能是中文。
^[\\u4e00-\\u9fa5]{0,}$
3. 由数字、26 个英文字母或下划线组成的字符串
^\\w+$
4. 验证电子邮件地址
与密码一样,以下是电子邮件地址合规性的定期检查声明。
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?
5. 验证身份证号码
以下是身份证号码的定期验证。15 或 18 位数字。
15位数字:
^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18个地方:
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
6. 检查日期
对于“yyyy-mm-dd”格式的日期检查,已考虑平闰年。
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
7. 查看金额
金额验证,精确到小数点后2位。
^[0-9]+(.[0-9]{2})?$
8. 验证手机号码
以下是中国以13、15、18开头的手机号码的正则表达式。(前两位可根据目前国内采集号进行扩充)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$
9. 判断IE版本
IE还没有完全替代,很多页面还需要版本兼容。以下是IE版本检查的表达式。
^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$
10. 验证 IP-v4 地址
IP4 正则声明。
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
11. 验证 IP-v6 地址
IP6 正则声明。
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
12. 检查网址的前缀
很多时候在应用开发中,需要区分请求是HTTPS还是HTTP。URL的前缀可以通过下面的表达式提取出来,然后进行逻辑判断。
if (!s.match(/^[a-zA-Z]+:\\/\\//))
{
s = 'http://' + s;
}
13. 提取网址链接
下面的表达式可以过滤掉一段文本中的 URL。
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
14.文件路径和扩展名验证
验证windows下的文件路径和扩展名(下例中的.txt文件)
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"|]+\\.txt(l)?$
15. 提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用如下表达式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
16. 提取网页图片
如果要提取网页中的所有图片信息,可以使用以下表达式。
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
17. 提取页面超链接
提取 html 中的超链接。
(]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
18. 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
19. 提取评论
如果需要去掉HMTL中的注释,可以使用下面的表达式。
20. 匹配 HTML 标签
以下表达式可以匹配 HTML 中的标签属性。
<p> 查看全部
php用正则表达抓取网页中文章(正则表达式中经常使用的20个正则表达式工具,你知道几个?)
正则表达式,一个非常古老而强大的文本处理工具,只需要很短的表达式语句就可以快速实现非常复杂的业务逻辑。如果你精通正则表达式,你的开发效率可以大大提高。
正则表达式通常用于验证字段或任意字符串,例如以下用于验证基本日期格式的 JavaScript 代码:
var reg = /^(\\d{1,4})(-|\\/)(\\d{1,2})\\2(\\d{1,2})$/;
var r = fieldValue.match(reg);
if(r==null)alert('Date format error!');
以下是20个由工匠编译的,经常用于前端开发的正则表达式。
1. 验证密码强度
密码的强度必须收录大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。
^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
2. 验证中文
字符串只能是中文。
^[\\u4e00-\\u9fa5]{0,}$
3. 由数字、26 个英文字母或下划线组成的字符串
^\\w+$
4. 验证电子邮件地址
与密码一样,以下是电子邮件地址合规性的定期检查声明。
[\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])?
5. 验证身份证号码
以下是身份证号码的定期验证。15 或 18 位数字。
15位数字:
^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$
18个地方:
^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$
6. 检查日期
对于“yyyy-mm-dd”格式的日期检查,已考虑平闰年。
^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$
7. 查看金额
金额验证,精确到小数点后2位。
^[0-9]+(.[0-9]{2})?$
8. 验证手机号码
以下是中国以13、15、18开头的手机号码的正则表达式。(前两位可根据目前国内采集号进行扩充)
^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$
9. 判断IE版本
IE还没有完全替代,很多页面还需要版本兼容。以下是IE版本检查的表达式。
^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$
10. 验证 IP-v4 地址
IP4 正则声明。
\\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b
11. 验证 IP-v6 地址
IP6 正则声明。
(([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]))
12. 检查网址的前缀
很多时候在应用开发中,需要区分请求是HTTPS还是HTTP。URL的前缀可以通过下面的表达式提取出来,然后进行逻辑判断。
if (!s.match(/^[a-zA-Z]+:\\/\\//))
{
s = 'http://' + s;
}
13. 提取网址链接
下面的表达式可以过滤掉一段文本中的 URL。
^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)?
14.文件路径和扩展名验证
验证windows下的文件路径和扩展名(下例中的.txt文件)
^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"|]+\\.txt(l)?$
15. 提取颜色十六进制代码
有时需要提取网页中的颜色代码,可以使用如下表达式。
^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$
16. 提取网页图片
如果要提取网页中的所有图片信息,可以使用以下表达式。
\\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*)
17. 提取页面超链接
提取 html 中的超链接。
(]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)>
18. 查找 CSS 属性
通过以下表达式,您可以搜索匹配的 CSS 属性。
^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1}
19. 提取评论
如果需要去掉HMTL中的注释,可以使用下面的表达式。
20. 匹配 HTML 标签
以下表达式可以匹配 HTML 中的标签属性。
<p>
php用正则表达抓取网页中文章(之前突然感兴趣写的一个三合一三合一收款码程序(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-30 04:05
前言
我突然对写一个三合一的支付代码程序感兴趣,因为它只是为了好玩。我不太关心密码验证。可以使用纯数字。随着越来越多的用户觉得密码有点弱,今天下午想着改验证规则,想了想,觉得QQ密码的验证还不错@(呵呵),于是去了QQ注册官网提取规律,先放到网页注册js里面测试一下,验证没问题。于是我开始放服务器端验证,直接给我报错。之前没在意,所以搜索了一下,发现js和PHP的规律性还是有一点区别的。
事实证明,PHP 正则表达式不支持以下 Perl 转义序列:
\L, \l, \N, \P, \p, \U, \u, or \X
PHP正则表达式校验中文问题,感觉PHP不支持perl转义还是挺烦的。
解决这个问题
$str = '教书先生博客blog.oioweb.cn';
echo preg_match("/^[\u4e00-\u9fa5_a-zA-Z0-9]{3,15}$",$strName);
运行上面的代码,看看会显示什么提示信息?
Warning: preg_match(): Compilation failed: PCRE does not support \L, \l, \N, \P, \p, \U, \u, or \X at offset 3 in F:\wwwroot\php\test.php on line 2
在UTF-8模式下,允许使用“x{...}”,大括号中的内容为一串十六进制数字。如果其值大于 127,则原创十六进制转义序列 xhh 匹配双字节 UTF-8 字符。
所以,可以这样解决:
preg_match("/^[\x80-\xff_a-zA-Z0-9]{3,15}$",$strName);
代码显示如下:
把我的密码验证正则:(8-16位密码,不能有空格,必须至少收录两个数字、字母或字符))
js:
checkPassword("教书先生博客:blog.oioweb.cn");
function checkPassword(password)
{
var reg=/(?!.*\s)(?!^[\u4e00-\u9fa5]+$)(?!^[0-9]+$)(?!^[A-z]+$)(?!^[^A-z0-9]+$)^.{8,16}$/;
if(!reg.test(password))
{
alert("8-16位密码,不包含空格,必须包含数字,字母或字符至少两种!");
document.form.password.focus();
return false;
}
return true;
}
PHP:
我希望能有所帮助! 查看全部
php用正则表达抓取网页中文章(之前突然感兴趣写的一个三合一三合一收款码程序(图))
前言
我突然对写一个三合一的支付代码程序感兴趣,因为它只是为了好玩。我不太关心密码验证。可以使用纯数字。随着越来越多的用户觉得密码有点弱,今天下午想着改验证规则,想了想,觉得QQ密码的验证还不错@(呵呵),于是去了QQ注册官网提取规律,先放到网页注册js里面测试一下,验证没问题。于是我开始放服务器端验证,直接给我报错。之前没在意,所以搜索了一下,发现js和PHP的规律性还是有一点区别的。
事实证明,PHP 正则表达式不支持以下 Perl 转义序列:
\L, \l, \N, \P, \p, \U, \u, or \X
PHP正则表达式校验中文问题,感觉PHP不支持perl转义还是挺烦的。
解决这个问题
$str = '教书先生博客blog.oioweb.cn';
echo preg_match("/^[\u4e00-\u9fa5_a-zA-Z0-9]{3,15}$",$strName);
运行上面的代码,看看会显示什么提示信息?
Warning: preg_match(): Compilation failed: PCRE does not support \L, \l, \N, \P, \p, \U, \u, or \X at offset 3 in F:\wwwroot\php\test.php on line 2
在UTF-8模式下,允许使用“x{...}”,大括号中的内容为一串十六进制数字。如果其值大于 127,则原创十六进制转义序列 xhh 匹配双字节 UTF-8 字符。
所以,可以这样解决:
preg_match("/^[\x80-\xff_a-zA-Z0-9]{3,15}$",$strName);
代码显示如下:
把我的密码验证正则:(8-16位密码,不能有空格,必须至少收录两个数字、字母或字符))
js:
checkPassword("教书先生博客:blog.oioweb.cn");
function checkPassword(password)
{
var reg=/(?!.*\s)(?!^[\u4e00-\u9fa5]+$)(?!^[0-9]+$)(?!^[A-z]+$)(?!^[^A-z0-9]+$)^.{8,16}$/;
if(!reg.test(password))
{
alert("8-16位密码,不包含空格,必须包含数字,字母或字符至少两种!");
document.form.password.focus();
return false;
}
return true;
}
PHP:
我希望能有所帮助!
php用正则表达抓取网页中文章(php用正则表达网页中文章,自己写了一个链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-22 00:01
php用正则表达抓取网页中文章,自己写了一个抓取网页中所有链接。
perl开发,php可以用浏览器就可以直接执行。perl兼容性好,容易维护,还可以自己丰富功能,比如php的xml、php的tag,php的分页器等等。
apache+php+boost
haproxy和proxy类似都是代理网站让路由访问你的页面。apachegodaddy的github上有很多介绍,主要要自己了解怎么capturejson。一般都有模板,关键是你自己用哪个平台做json有时会是个问题,就比如我的f12看request就总是加载失败,需要一些js来处理。
个人在做网站当中也遇到这个问题,去了解了一些,我推荐这个简单方便,可以去看看,挺适合简单的商城公司网站的!去看看吧:【web攻城狮】springboot搭建一个轻量级的轻博客个人网站平台再添加它ps:也是新手,
可以了解下我们的轻量级的公司网站案例。文本数据,php+mysql,数据库可以无界限的划分。
作为一个刚接触haproxy/httpd
推荐我公司的轻量级安全web博客程序:hitoroyah.weixin:
目前有haproxy和httpd2种方案,两种中国都有上线哦, 查看全部
php用正则表达抓取网页中文章(php用正则表达网页中文章,自己写了一个链接)
php用正则表达抓取网页中文章,自己写了一个抓取网页中所有链接。
perl开发,php可以用浏览器就可以直接执行。perl兼容性好,容易维护,还可以自己丰富功能,比如php的xml、php的tag,php的分页器等等。
apache+php+boost
haproxy和proxy类似都是代理网站让路由访问你的页面。apachegodaddy的github上有很多介绍,主要要自己了解怎么capturejson。一般都有模板,关键是你自己用哪个平台做json有时会是个问题,就比如我的f12看request就总是加载失败,需要一些js来处理。
个人在做网站当中也遇到这个问题,去了解了一些,我推荐这个简单方便,可以去看看,挺适合简单的商城公司网站的!去看看吧:【web攻城狮】springboot搭建一个轻量级的轻博客个人网站平台再添加它ps:也是新手,
可以了解下我们的轻量级的公司网站案例。文本数据,php+mysql,数据库可以无界限的划分。
作为一个刚接触haproxy/httpd
推荐我公司的轻量级安全web博客程序:hitoroyah.weixin:
目前有haproxy和httpd2种方案,两种中国都有上线哦,
php用正则表达抓取网页中文章(文章告诉你如何利用php教程正则表达式匹配中文汉字(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-19 19:08
文章告诉您如何使用PHP正则表达式匹配汉字。让我们主要讨论一下使用preg_uuu_uu;match mb_uuu_u;Eregi验证汉字,以及正则化过程中问题的解决方案
文章告诉您如何在PHP教程中使用正则表达式来匹配汉字。让我们主要讨论一下使用preg_uuu_uu;match mb_uuu_u;Eregi验证汉字,以及正则化过程中问题的解决方案
preg_uu匹配(“/[A-Z]{3,14}/”,$content,[可选]$A);这将返回布尔值。$a得到的是一个数组,匹配的字符在$a中受保护
正规汉字
Echo(mb_eregi(“[X80 XFF],“中文D”)?“是”:“无”)“中文字符”
Echo(mb_eregi(“^([X80 XFF])+$”,“中文”)?“所有中文字符”:“
看看完整的中文字符串函数
$STR=“PHP中的eregi如何匹配中文字符?”
如果(预匹配(“/^[”).chr(0x80).-“.chr(0xff)。”]+$/“,$str)){
Echo“这是一根纯中文字符串”
}否则{
Echo“这不是纯中文字符串”
}
预匹配全部($pat,…)和预替换($pat,…)
Preg_match_all(“/(汉字)+/ism”,“我是汉字,看看你对我做了什么!”,$m_a)
在每段代码的高位和低位开始和结束后,自然会编写规则,直接是16位。有什么困难吗?呵呵。但是需要注意的是,在PHP中,16位是X
因此,如上所述,我们也可以使用正则表达式来确定它是否是GB2312的汉字
声明:本文原创发布PHP中文网站。请注明转载来源。感谢您的尊重!如果您有任何问题,请与我们联系 查看全部
php用正则表达抓取网页中文章(文章告诉你如何利用php教程正则表达式匹配中文汉字(组图))
文章告诉您如何使用PHP正则表达式匹配汉字。让我们主要讨论一下使用preg_uuu_uu;match mb_uuu_u;Eregi验证汉字,以及正则化过程中问题的解决方案
文章告诉您如何在PHP教程中使用正则表达式来匹配汉字。让我们主要讨论一下使用preg_uuu_uu;match mb_uuu_u;Eregi验证汉字,以及正则化过程中问题的解决方案
preg_uu匹配(“/[A-Z]{3,14}/”,$content,[可选]$A);这将返回布尔值。$a得到的是一个数组,匹配的字符在$a中受保护
正规汉字
Echo(mb_eregi(“[X80 XFF],“中文D”)?“是”:“无”)“中文字符”
Echo(mb_eregi(“^([X80 XFF])+$”,“中文”)?“所有中文字符”:“
看看完整的中文字符串函数
$STR=“PHP中的eregi如何匹配中文字符?”
如果(预匹配(“/^[”).chr(0x80).-“.chr(0xff)。”]+$/“,$str)){
Echo“这是一根纯中文字符串”
}否则{
Echo“这不是纯中文字符串”
}
预匹配全部($pat,…)和预替换($pat,…)
Preg_match_all(“/(汉字)+/ism”,“我是汉字,看看你对我做了什么!”,$m_a)
在每段代码的高位和低位开始和结束后,自然会编写规则,直接是16位。有什么困难吗?呵呵。但是需要注意的是,在PHP中,16位是X
因此,如上所述,我们也可以使用正则表达式来确定它是否是GB2312的汉字
声明:本文原创发布PHP中文网站。请注明转载来源。感谢您的尊重!如果您有任何问题,请与我们联系

