
php正则函数抓取网页连接
php正则函数抓取网页连接(php正则函数抓取网页连接获取方法打开百度ftp网站点击)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-27 15:03
php正则函数抓取网页连接获取方法打开百度ftp网站点击connectphp正则表达式找到你要抓取的连接,
可以用百度爬虫或者google爬虫,没有工具箱什么的,
注册百度并通过生成链接就可以了
用abccoder
没有工具,是通过手写正则表达式来获取,比如foo.getschema("classic")可以去百度搜“手写正则表达式”,
没有工具。就像百度一样,找到正则表达式,
几年前有一套“正则表达式抓取书籍”,讲述了它的工作原理。原理不复杂,就是从连接中寻找,你可以试试。我曾用过。
阿里云搜索:其实现在的,京东和天猫都有开源的爬虫软件可以抓取百度和谷歌的产品。这里面主要有几个地方:以下几个方面开源的爬虫:阿里云搜索:百度集团spider库:googlecrawler(做baidu的爬虫很多,当然你的业务也要比较复杂,实践是王道!)还有一些schema设计和js设计的参考:这些只是其中的几个,spider里面的其他模块和支持会不断丰富。最后更新也会很快,但这些参考书籍资料是应该值得持续学习的。
可以看看这个:正则表达式抓取详细教程 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接获取方法打开百度ftp网站点击)
php正则函数抓取网页连接获取方法打开百度ftp网站点击connectphp正则表达式找到你要抓取的连接,
可以用百度爬虫或者google爬虫,没有工具箱什么的,
注册百度并通过生成链接就可以了
用abccoder
没有工具,是通过手写正则表达式来获取,比如foo.getschema("classic")可以去百度搜“手写正则表达式”,
没有工具。就像百度一样,找到正则表达式,
几年前有一套“正则表达式抓取书籍”,讲述了它的工作原理。原理不复杂,就是从连接中寻找,你可以试试。我曾用过。
阿里云搜索:其实现在的,京东和天猫都有开源的爬虫软件可以抓取百度和谷歌的产品。这里面主要有几个地方:以下几个方面开源的爬虫:阿里云搜索:百度集团spider库:googlecrawler(做baidu的爬虫很多,当然你的业务也要比较复杂,实践是王道!)还有一些schema设计和js设计的参考:这些只是其中的几个,spider里面的其他模块和支持会不断丰富。最后更新也会很快,但这些参考书籍资料是应该值得持续学习的。
可以看看这个:正则表达式抓取详细教程
php正则函数抓取网页连接( 2021-03-21想了解php正则表达式获取内容所有链接的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-25 09:14
2021-03-21想了解php正则表达式获取内容所有链接的相关内容吗)
php正则表达式获取所有内容链接 php正则表达式获取所有内容链接
2021-03-21
想知道php正则表达式获取的所有链接的相关内容吗?在本文中,我将仔细讲解php正则表达式获取内容的所有链接的相关知识和一些代码示例。欢迎阅读和指正。先重点介绍:php正则表达式,获取链接,一起学习。
方法一:
function get_all_url($code){
preg_match_all('/]*>([^>]+)</a>/i',$code,$arr);
return array('name'=>$arr[2],'url'=>$arr[1]);
}
方法二:
<p>
/**
* date 2015-07-24
**/
$site=substr($url,0,strpos($url,"/",8));//站点
$base=substr($url,0,strrpos($url,"/")+1);//文件所在目录
$fp = fopen($url, "r" );//打开url
while(!feof($fp))$contents.=fread($fp,1024);//
$pattern="|href=['"]?([^ '"]+)['" ]|u";
preg_match_all($pattern,$contents, $regarr, preg_set_order);//匹配所有href=
for($i=0;$i 查看全部
php正则函数抓取网页连接(
2021-03-21想了解php正则表达式获取内容所有链接的相关内容吗)
php正则表达式获取所有内容链接 php正则表达式获取所有内容链接
2021-03-21
想知道php正则表达式获取的所有链接的相关内容吗?在本文中,我将仔细讲解php正则表达式获取内容的所有链接的相关知识和一些代码示例。欢迎阅读和指正。先重点介绍:php正则表达式,获取链接,一起学习。
方法一:
function get_all_url($code){
preg_match_all('/]*>([^>]+)</a>/i',$code,$arr);
return array('name'=>$arr[2],'url'=>$arr[1]);
}
方法二:
<p>
/**
* date 2015-07-24
**/
$site=substr($url,0,strpos($url,"/",8));//站点
$base=substr($url,0,strrpos($url,"/")+1);//文件所在目录
$fp = fopen($url, "r" );//打开url
while(!feof($fp))$contents.=fread($fp,1024);//
$pattern="|href=['"]?([^ '"]+)['" ]|u";
preg_match_all($pattern,$contents, $regarr, preg_set_order);//匹配所有href=
for($i=0;$i
php正则函数抓取网页连接(Windows1064位Python2.7.10V使用的编程集成开发环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-23 17:18
通过正则表达式获取一个网页中的所有URL链接,并下载这些URL链接的源码
使用的系统:Windows 10 64位
Python语言版本:Python 2.7.10V
编程Python集成开发环境使用:PyCharm 2016 04
我使用的 urllib 版本:urllib2
注意:我这里没有使用 Python2,也没有使用 Python3
一、简介
通过前面两节(网络爬虫爬取网页和解决爬取的网页显示乱码问题),我们终于完成了最终的download()函数。
而在上一节中,我们通过解析网站映射中的URL,抓取了目标站点的所有网页。在上一节中,我们介绍了一种抓取网页中所有链接页面的方法。在本节中,我们使用正则表达式获取网页中的所有 URL 链接并下载这些 URL 链接的源代码。
2. 介绍
至此,我们已经利用目标网站的结构特征实现了两个简单的爬虫。只要有这两种技术,就应该用于爬取,因为这两种方法最大限度地减少了需要下载的网页数量。但是,对于一些网站,我们需要让爬虫更像普通用户:关注链接,访问感兴趣的内容。
通过点击所有链接,我们可以轻松下载网站 的整个页面。但是这种方法会下载很多我们不需要的网页。例如,如果我们想从某个在线论坛抓取用户账户详情页面,那么此时我们只需要下载账户页面,而不是下载讨论轮帖子页面。本博客中的链接爬虫会使用正则表达式来判断需要下载哪些页面。
3. 主码
import re
def link_crawler(seed_url, link_regex):<br />
"""Crawl from the given seed URL following links matched by link_regex<br />
"""<br />
crawl_queue = [seed_url]<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
# filter for links matching our regular expression<br />
for link in get_links(html):<br />
if re.match(link_regex, link):<br />
crawl_queue.append(link)
def get_links(html):<br />
"""Return a list of links from html<br />
"""<br />
# a regular expression to extract all links from the webpage<br />
webpage_regex = re.compile(']+href=["\'](.*?)["\']', re.IGNORECASE)<br />
# list of all links from the webpage<br />
return webpage_regex.findall(html)
4.解释初级代码
1 .
def link_crawler(seed_url, link_regex):
这个函数就是我们要对外使用的函数。作用:首先下载seed_url网页的源码,然后提取里面的所有链接URL,然后将所有匹配到的链接URL与link_regex进行匹配,如果链接URL中有link_regex内容,则将链接URL放入队列中,下次执行 crawl_queue: 时,将对该链接 URL 执行相同的操作。重复,直到crawl_queue队列为空,然后退出函数。
2 .
get_links(html)函数的作用: 用于获取html页面中的所有链接URL。
3.
webpage_regex = re.compile(']+href=["\']'(.*?)["\']', re.IGNORECASE)
匹配模板被制作并存储在网页正则表达式对象中。匹配这样一个字符串,提取xxx的内容,这个xxx就是网址URL。
4.
return webpage_regex.findall(html)
使用webpage_regex模板匹配html网页源代码上所有符合格式的字符串,提取里面的xxx内容。
正则表达式的详细知识请到这个网站了解:
五。手术
先启动Python终端交互命令,在PyCharm软件的终端窗口或Windows系统的DOS窗口执行如下命令:
C:\Python27\python.exe -i 1-4-4-regular_expression.py
执行 link_crawler() 函数:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: /index/1<br />
Traceback (most recent call last):<br />
File "1-4-4-regular_expression.py", line 50, in <br />
link_crawler('http://example.webscraping.com', '/(index|view)')<br />
File "1-4-4-regular_expression.py", line 36, in link_crawler<br />
html = download(url)<br />
File "1-4-4-regular_expression.py", line 13, in download<br />
html = urllib2.urlopen(request).read()<br />
File "C:\Python27\lib\urllib2.py", line 154, in urlopen<br />
return opener.open(url, data, timeout)<br />
File "C:\Python27\lib\urllib2.py", line 423, in open<br />
protocol = req.get_type()<br />
File "C:\Python27\lib\urllib2.py", line 285, in get_type<br />
raise ValueError, "unknown url type: %s" % self.__original<br />
ValueError: unknown url type: /index/1<br />
运行时,出现错误。下载 /index/1 URL 时发生此错误。这个/index/1是目标站点中的相对链接,是完整网页URL的路径部分,不收录协议和服务器部分。我们无法使用 download() 函数下载它。在浏览器中浏览网页时,相对链接可以正常工作,但是使用urllib2下载网页时,由于上下文不可知,无法下载成功。
七。改进代码
所以为了让urllib2成为网页,我们需要将相对链接转换为绝对链接,这样问题就可以解决了。
Python中有一个模块可以实现这个功能:urlparse。
对 link_crawler() 函数进行了以下改进:
import urlparse<br />
def link_crawler(seed_url, link_regex):<br />
"""Crawl from the given seed URL following links matched by link_regex<br />
"""<br />
crawl_queue = [seed_url]<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
for link in get_links(html):<br />
if re.match(link_regex, link):<br />
link = urlparse.urljoin(seed_url, link)<br />
crawl_queue.append(link)
8. 运行:
运行程序:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: http://example.webscraping.com/index/1<br />
Downloading: http://example.webscraping.com/index/2<br />
Downloading: http://example.webscraping.com/index/3<br />
Downloading: http://example.webscraping.com/index/4<br />
Downloading: http://example.webscraping.com/index/5<br />
Downloading: http://example.webscraping.com/index/6<br />
Downloading: http://example.webscraping.com/index/7<br />
Downloading: http://example.webscraping.com/index/8<br />
Downloading: http://example.webscraping.com/index/9<br />
Downloading: http://example.webscraping.com/index/10<br />
Downloading: http://example.webscraping.com/index/11<br />
Downloading: http://example.webscraping.com/index/12<br />
Downloading: http://example.webscraping.com/index/13<br />
Downloading: http://example.webscraping.com/index/14<br />
Downloading: http://example.webscraping.com/index/15<br />
Downloading: http://example.webscraping.com/index/16<br />
Downloading: http://example.webscraping.com/index/17<br />
Downloading: http://example.webscraping.com/index/18<br />
Downloading: http://example.webscraping.com/index/19<br />
Downloading: http://example.webscraping.com/index/20<br />
Downloading: http://example.webscraping.com/index/21<br />
Downloading: http://example.webscraping.com/index/22<br />
Downloading: http://example.webscraping.com/index/23<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
通过运行结果可以看到:虽然可以无误地下载网页,但是会不断下载同一个网页。为什么会这样?这是因为这些链接 URL 之间存在链接。如果两个网页相互有链接,那么面对这个程序,它会继续无限循环。
因此,我们还需要继续改进程序:避免抓取相同的链接,因此我们需要记录抓取了哪些链接,如果已抓取,则不抓取它。
9、继续完善link_crawler()函数:
def link_crawler(seed_url, link_regex):<br />
crawl_queue = [seed_url]<br />
# keep track which URL's have seen before<br />
seen = set(crawl_queue)<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
for link in get_links(html):<br />
# check if link matches expected regex<br />
if re.match(link_regex, link):<br />
# form absolute link<br />
link = urlparse.urljoin(seed_url, link)<br />
# check if have already seen this link<br />
if link not in seen:<br />
seen.add(link)<br />
crawl_queue.append(link)
10. 运行:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: http://example.webscraping.com/index/1<br />
Downloading: http://example.webscraping.com/index/2<br />
Downloading: http://example.webscraping.com/index/3<br />
Downloading: http://example.webscraping.com/index/4<br />
Downloading: http://example.webscraping.com/index/5<br />
Downloading: http://example.webscraping.com/index/6<br />
Downloading: http://example.webscraping.com/index/7<br />
Downloading: http://example.webscraping.com/index/8<br />
Downloading: http://example.webscraping.com/index/9<br />
Downloading: http://example.webscraping.com/index/10<br />
Downloading: http://example.webscraping.com/index/11<br />
Downloading: http://example.webscraping.com/index/12<br />
Downloading: http://example.webscraping.com/index/13<br />
Downloading: http://example.webscraping.com/index/14<br />
Downloading: http://example.webscraping.com/index/15<br />
Downloading: http://example.webscraping.com/index/16<br />
Downloading: http://example.webscraping.com/index/17<br />
Downloading: http://example.webscraping.com/index/18<br />
Downloading: http://example.webscraping.com/index/19<br />
Downloading: http://example.webscraping.com/index/20<br />
Downloading: http://example.webscraping.com/index/21<br />
Downloading: http://example.webscraping.com/index/22<br />
Downloading: http://example.webscraping.com/index/23<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
现在这个程序是一个非常完美的程序,它会爬取所有位置,并且可以按预期停止。最后,一个可用的爬虫是完美的。
总结:
这样,我们就引入了三个源代码,用于抓取站点或网页中的所有链接 URL。这些只是初步的程序。接下来,我们可能还会遇到这样的问题:
1、如果某些网站设置了禁止爬取的URL,为了实现本站的规则,我们必须根据其robots.txt文件来设计爬取程序。
2.谷歌在中国是不可用的,所以如果我们要使用代理去谷歌,我们需要为我们的爬虫程序设置一个代理。
3、如果我们的爬虫爬取网站太快,可能是被目标站点的服务器屏蔽了,所以需要限制下载速度。
4. 一些网页有日历之类的东西。这个东西中的每个日期都是一个 URL 链接。我们会爬这个毫无意义的东西吗?日期是无止境的,所以对于我们的爬虫程序来说,这是一个爬虫陷阱,我们需要避免掉入爬虫陷阱。
我们需要解决这4个问题。为了得到爬虫程序的最终版本。 查看全部
php正则函数抓取网页连接(Windows1064位Python2.7.10V使用的编程集成开发环境)
通过正则表达式获取一个网页中的所有URL链接,并下载这些URL链接的源码
使用的系统:Windows 10 64位
Python语言版本:Python 2.7.10V
编程Python集成开发环境使用:PyCharm 2016 04
我使用的 urllib 版本:urllib2
注意:我这里没有使用 Python2,也没有使用 Python3
一、简介
通过前面两节(网络爬虫爬取网页和解决爬取的网页显示乱码问题),我们终于完成了最终的download()函数。
而在上一节中,我们通过解析网站映射中的URL,抓取了目标站点的所有网页。在上一节中,我们介绍了一种抓取网页中所有链接页面的方法。在本节中,我们使用正则表达式获取网页中的所有 URL 链接并下载这些 URL 链接的源代码。
2. 介绍
至此,我们已经利用目标网站的结构特征实现了两个简单的爬虫。只要有这两种技术,就应该用于爬取,因为这两种方法最大限度地减少了需要下载的网页数量。但是,对于一些网站,我们需要让爬虫更像普通用户:关注链接,访问感兴趣的内容。
通过点击所有链接,我们可以轻松下载网站 的整个页面。但是这种方法会下载很多我们不需要的网页。例如,如果我们想从某个在线论坛抓取用户账户详情页面,那么此时我们只需要下载账户页面,而不是下载讨论轮帖子页面。本博客中的链接爬虫会使用正则表达式来判断需要下载哪些页面。
3. 主码
import re
def link_crawler(seed_url, link_regex):<br />
"""Crawl from the given seed URL following links matched by link_regex<br />
"""<br />
crawl_queue = [seed_url]<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
# filter for links matching our regular expression<br />
for link in get_links(html):<br />
if re.match(link_regex, link):<br />
crawl_queue.append(link)
def get_links(html):<br />
"""Return a list of links from html<br />
"""<br />
# a regular expression to extract all links from the webpage<br />
webpage_regex = re.compile(']+href=["\'](.*?)["\']', re.IGNORECASE)<br />
# list of all links from the webpage<br />
return webpage_regex.findall(html)
4.解释初级代码
1 .
def link_crawler(seed_url, link_regex):
这个函数就是我们要对外使用的函数。作用:首先下载seed_url网页的源码,然后提取里面的所有链接URL,然后将所有匹配到的链接URL与link_regex进行匹配,如果链接URL中有link_regex内容,则将链接URL放入队列中,下次执行 crawl_queue: 时,将对该链接 URL 执行相同的操作。重复,直到crawl_queue队列为空,然后退出函数。
2 .
get_links(html)函数的作用: 用于获取html页面中的所有链接URL。
3.
webpage_regex = re.compile(']+href=["\']'(.*?)["\']', re.IGNORECASE)
匹配模板被制作并存储在网页正则表达式对象中。匹配这样一个字符串,提取xxx的内容,这个xxx就是网址URL。
4.
return webpage_regex.findall(html)
使用webpage_regex模板匹配html网页源代码上所有符合格式的字符串,提取里面的xxx内容。
正则表达式的详细知识请到这个网站了解:
五。手术
先启动Python终端交互命令,在PyCharm软件的终端窗口或Windows系统的DOS窗口执行如下命令:
C:\Python27\python.exe -i 1-4-4-regular_expression.py
执行 link_crawler() 函数:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: /index/1<br />
Traceback (most recent call last):<br />
File "1-4-4-regular_expression.py", line 50, in <br />
link_crawler('http://example.webscraping.com', '/(index|view)')<br />
File "1-4-4-regular_expression.py", line 36, in link_crawler<br />
html = download(url)<br />
File "1-4-4-regular_expression.py", line 13, in download<br />
html = urllib2.urlopen(request).read()<br />
File "C:\Python27\lib\urllib2.py", line 154, in urlopen<br />
return opener.open(url, data, timeout)<br />
File "C:\Python27\lib\urllib2.py", line 423, in open<br />
protocol = req.get_type()<br />
File "C:\Python27\lib\urllib2.py", line 285, in get_type<br />
raise ValueError, "unknown url type: %s" % self.__original<br />
ValueError: unknown url type: /index/1<br />
运行时,出现错误。下载 /index/1 URL 时发生此错误。这个/index/1是目标站点中的相对链接,是完整网页URL的路径部分,不收录协议和服务器部分。我们无法使用 download() 函数下载它。在浏览器中浏览网页时,相对链接可以正常工作,但是使用urllib2下载网页时,由于上下文不可知,无法下载成功。
七。改进代码
所以为了让urllib2成为网页,我们需要将相对链接转换为绝对链接,这样问题就可以解决了。
Python中有一个模块可以实现这个功能:urlparse。
对 link_crawler() 函数进行了以下改进:
import urlparse<br />
def link_crawler(seed_url, link_regex):<br />
"""Crawl from the given seed URL following links matched by link_regex<br />
"""<br />
crawl_queue = [seed_url]<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
for link in get_links(html):<br />
if re.match(link_regex, link):<br />
link = urlparse.urljoin(seed_url, link)<br />
crawl_queue.append(link)
8. 运行:
运行程序:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: http://example.webscraping.com/index/1<br />
Downloading: http://example.webscraping.com/index/2<br />
Downloading: http://example.webscraping.com/index/3<br />
Downloading: http://example.webscraping.com/index/4<br />
Downloading: http://example.webscraping.com/index/5<br />
Downloading: http://example.webscraping.com/index/6<br />
Downloading: http://example.webscraping.com/index/7<br />
Downloading: http://example.webscraping.com/index/8<br />
Downloading: http://example.webscraping.com/index/9<br />
Downloading: http://example.webscraping.com/index/10<br />
Downloading: http://example.webscraping.com/index/11<br />
Downloading: http://example.webscraping.com/index/12<br />
Downloading: http://example.webscraping.com/index/13<br />
Downloading: http://example.webscraping.com/index/14<br />
Downloading: http://example.webscraping.com/index/15<br />
Downloading: http://example.webscraping.com/index/16<br />
Downloading: http://example.webscraping.com/index/17<br />
Downloading: http://example.webscraping.com/index/18<br />
Downloading: http://example.webscraping.com/index/19<br />
Downloading: http://example.webscraping.com/index/20<br />
Downloading: http://example.webscraping.com/index/21<br />
Downloading: http://example.webscraping.com/index/22<br />
Downloading: http://example.webscraping.com/index/23<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
通过运行结果可以看到:虽然可以无误地下载网页,但是会不断下载同一个网页。为什么会这样?这是因为这些链接 URL 之间存在链接。如果两个网页相互有链接,那么面对这个程序,它会继续无限循环。
因此,我们还需要继续改进程序:避免抓取相同的链接,因此我们需要记录抓取了哪些链接,如果已抓取,则不抓取它。
9、继续完善link_crawler()函数:
def link_crawler(seed_url, link_regex):<br />
crawl_queue = [seed_url]<br />
# keep track which URL's have seen before<br />
seen = set(crawl_queue)<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
for link in get_links(html):<br />
# check if link matches expected regex<br />
if re.match(link_regex, link):<br />
# form absolute link<br />
link = urlparse.urljoin(seed_url, link)<br />
# check if have already seen this link<br />
if link not in seen:<br />
seen.add(link)<br />
crawl_queue.append(link)
10. 运行:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: http://example.webscraping.com/index/1<br />
Downloading: http://example.webscraping.com/index/2<br />
Downloading: http://example.webscraping.com/index/3<br />
Downloading: http://example.webscraping.com/index/4<br />
Downloading: http://example.webscraping.com/index/5<br />
Downloading: http://example.webscraping.com/index/6<br />
Downloading: http://example.webscraping.com/index/7<br />
Downloading: http://example.webscraping.com/index/8<br />
Downloading: http://example.webscraping.com/index/9<br />
Downloading: http://example.webscraping.com/index/10<br />
Downloading: http://example.webscraping.com/index/11<br />
Downloading: http://example.webscraping.com/index/12<br />
Downloading: http://example.webscraping.com/index/13<br />
Downloading: http://example.webscraping.com/index/14<br />
Downloading: http://example.webscraping.com/index/15<br />
Downloading: http://example.webscraping.com/index/16<br />
Downloading: http://example.webscraping.com/index/17<br />
Downloading: http://example.webscraping.com/index/18<br />
Downloading: http://example.webscraping.com/index/19<br />
Downloading: http://example.webscraping.com/index/20<br />
Downloading: http://example.webscraping.com/index/21<br />
Downloading: http://example.webscraping.com/index/22<br />
Downloading: http://example.webscraping.com/index/23<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
现在这个程序是一个非常完美的程序,它会爬取所有位置,并且可以按预期停止。最后,一个可用的爬虫是完美的。
总结:
这样,我们就引入了三个源代码,用于抓取站点或网页中的所有链接 URL。这些只是初步的程序。接下来,我们可能还会遇到这样的问题:
1、如果某些网站设置了禁止爬取的URL,为了实现本站的规则,我们必须根据其robots.txt文件来设计爬取程序。
2.谷歌在中国是不可用的,所以如果我们要使用代理去谷歌,我们需要为我们的爬虫程序设置一个代理。
3、如果我们的爬虫爬取网站太快,可能是被目标站点的服务器屏蔽了,所以需要限制下载速度。
4. 一些网页有日历之类的东西。这个东西中的每个日期都是一个 URL 链接。我们会爬这个毫无意义的东西吗?日期是无止境的,所以对于我们的爬虫程序来说,这是一个爬虫陷阱,我们需要避免掉入爬虫陷阱。
我们需要解决这4个问题。为了得到爬虫程序的最终版本。
php正则函数抓取网页连接(如何利用cookie去访问网页,去get页面代码的函数 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-22 05:12
)
最近帮朋友开发了一个可以查询正方教务系统的微信公众平台号。得到一些东西。以上是个人经验总结。
开讲之前先说一下新浪云服务器。同一个程序中的功能在PC测试中可以正常运行,但是会挂在那里。
像往常一样,我会在代码中清楚地注释。使用下面的函数,你会得到两种形式的cookies,一种存储在文件中,另一种直接作为变量返回。
经验提示:有时候,在不同的代码运行环境下,用cookies访问文件会成功,但变量会失败,但有时是想法。但,
目前,这两种方法中的一种总会成功。
1 function get_cookie($url_,$params_,$referer_){
2
3 if($url_==null){echo "get_cookie_url_null";exit;}
4 if($params_==null){echo "get_params_null";exit;}
5 if($referer_==null){echo "get_referer-null";exit;}
6 $this_header = array("content-type: application/x-www-form-urlencoded; charset=UTF-8");//访问链接时要发送的头信息
7
8 $ch = curl_init($url_);//这里是初始化一个访问对话,并且传入url,这要个必须有
9
10 //curl_setopt就是设置一些选项为以后发起请求服务的
11
12
13 curl_setopt($ch,CURLOPT_HTTPHEADER,$this_header);//一个用来设置HTTP头字段的数组。使用如下的形式的数组进行设置: array('Content-type: text/plain', 'Content-length: 100')
14 curl_setopt($ch, CURLOPT_HEADER,1);//如果你想把一个头包含在输出中,设置这个选项为一个非零值,我这里是要输出,所以为 1
15
16 curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);//将 curl_exec()获取的信息以文件流的形式返回,而不是直接输出。设置为0是直接输出
17
18 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);//设置跟踪页面的跳转,有时候你打开一个链接,在它内部又会跳到另外一个,就是这样理解
19
20 curl_setopt($ch,CURLOPT_POST,1);//开启post数据的功能,这个是为了在访问链接的同时向网页发送数据,一般数urlencode码
21
22 curl_setopt($ch,CURLOPT_POSTFIELDS,$params_); //把你要提交的数据放这
23
24 curl_setopt($ch, CURLOPT_COOKIEJAR, 'cookie.txt');//获取的cookie 保存到指定的 文件路径,我这里是相对路径,可以是$变量
25
26 //curl_setopt($ch, CURLOPT_COOKIEFILE, 'cookie.txt');//要发送的cookie文件,注意这里是文件,还一个是变量形式发送
27
28 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);//例如这句就是设置以变量的形式发送cookie,注意,这里的cookie变量是要先获取的,见下面获取方式
29
30 curl_setopt ($ch, CURLOPT_REFERER,$referer_); //在HTTP请求中包含一个'referer'头的字符串。告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。
31
32 $content=curl_exec($ch); //重点来了,上面的众多设置都是为了这个,进行url访问,带着上面的所有设置
33
34 if(curl_errno($ch)){
35 echo 'Curl error: '.curl_error($ch);exit(); //这里是设置个错误信息的反馈
36 }
37
38 if($content==false){
39 echo "get_content_null";exit();
40 }
41 preg_match('/Set-Cookie:(.*);/iU',$content,$str); //这里采用正则匹配来获取cookie并且保存它到变量$str里,这就是为什么上面可以发送cookie变量的原因
42
43 $cookie = $str[1]; //获得COOKIE(SESSIONID)
44
45 curl_close($ch);//关闭会话
46
47 return $cookie;//返回cookie
48 }
下面是如何使用上面的cookie来访问网页,发布数据,获取页面代码的功能。
1 function post($url,$post_data,$location = 0,$reffer = null,$origin = null,$host = null){
2
3 $post_data = is_array($post_data)?http_build_query($post_data):$post_data;
4 //产生一个urlencode之后的请求字符串,因为我们post,传送给网页的数据都是经过处理,一般是urlencode编码后才发送的
5
6 $header = array( //头部信息,上面的函数已说明
7 'Accept:*/*',
8 'Accept-Charset:text/html,application/xhtml+xml,application/xml;q=0.7,*;q=0.3',
9 'Accept-Encoding:gzip,deflate,sdch',
10 'Accept-Language:zh-CN,zh;q=0.8',
11 'Connection:keep-alive',
12 'Content-Type:application/x-www-form-urlencoded',
13 //'CLIENT-IP:'.$ip,
14 //'X-FORWARDED-FOR:'.$ip,
15 );
16
17 //下面的都是头部信息的设置,请根据他们的变量名字,对应上面函数所说明
18 if($host){
19 $header = array_merge_recursive($header,array("Host:".$host));
20 }
21 else if($this->option["host"]){
22 $header = array_merge_recursive($header,array("Host:".$this->option["host"]));
23 }
24 if($origin){
25 $header = array_merge_recursive($header,array("Origin:".$origin));
26 }
27 else{
28 $header = array_merge_recursive($header,array("Origin:".$url));
29 }
30 if($reffer){
31 $header = array_merge_recursive($header,array("Referer:".$reffer));
32 }
33 else{
34 $header = array_merge_recursive($header,array("Referer:".$url));
35 }
36
37 $curl = curl_init(); //这里并没有带参数初始化
38
39 curl_setopt($curl, CURLOPT_URL, $url);//这里传入url
40
41 curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
42
43 curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0);//对认证证书来源的检查,不开启次功能
44
45 curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1);//从证书中检测 SSL 加密算法
46
47 curl_setopt($curl, CURLOPT_USERAGENT, $this->useragent);
48 //模拟用户使用的浏览器,自己设置,我的是"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0"
49 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, $location);
50
51 curl_setopt($curl, CURLOPT_AUTOREFERER, 1);//自动设置referer
52
53 curl_setopt($curl, CURLOPT_POST, 1);//开启post
54
55 curl_setopt($curl, CURLOPT_ENCODING, "gzip" );
56 //HTTP请求头中"Accept-Encoding: "的值。支持的编码有"identity","deflate"和"gzip"。如果为空字符串"",请求头会发送所有支持的编码类型。
57 //我上面设置的是*/*
58
59 curl_setopt($curl, CURLOPT_POSTFIELDS, $post_data);//要传送的数据
60
61 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);//以变量形式发送cookie,我这里没用它,文件保险点
62
63 curl_setopt($curl, CURLOPT_COOKIEJAR, 'cookie.txt'); //存cookie的文件名,
64
65 curl_setopt($curl, CURLOPT_COOKIEFILE, 'cookie.txt'); //发送
66
67 curl_setopt($curl, CURLOPT_TIMEOUT, 30);//设置超时限制,防止死循环
68
69 curl_setopt($curl, CURLOPT_HEADER, 1);
70
71 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
72
73 $tmpInfo = curl_exec($curl);
74 if (curl_errno($curl)) {
75 echo 'Curl error: ' . curl_error ( $curl );exit();
76 }
77
78 curl_close($curl);
79 list($header, $body) = explode("\r\n\r\n", $tmpInfo, 2);//分割出网页源代码的头和bode
80 $tmpInfo = $this->auto_charest($tmpInfo);//转码,防止乱码,自定义函数
81 return array("header"=>$header,"body"=>$body,"content"=>$tmpInfo);
82 }
上面是post,下面是get。两者很相似。不同的是get没有发帖,将数据传输到发布前访问过的网页,只获取源码。
1 function get($url,$location = 1,$origin = null,$reffer = null,$host = null){
2 //$ip = $this->randip();
3 if($url==null){
4 echo "get-url-null";exit();
5 }
6 $header = array(
7 'Accept:*/*',
8 'Accept-Charset:GBK,utf-8;q=0.7,*;q=0.3',
9 'Accept-Encoding:gzip,deflate,sdch',
10 'Accept-Language:zh-CN,zh;q=0.8',
11 'Connection:keep-alive',
12
13 //'CLIENT-IP:'.$ip,
14 //'X-FORWARDED-FOR:'.$ip,
15 );
16 if($host){
17 $header = array_merge_recursive($header,array("Host:".$host));
18 }
19 else if($this->option["host"]){
20 $header = array_merge_recursive($header,array("Host:".$this->option["host"]));
21 }
22 if($origin){
23 $header = array_merge_recursive($header,array("Origin:".$origin));
24 }
25 else{
26 $header = array_merge_recursive($header,array("Origin:".$url));
27 }
28 if($reffer){
29 $header = array_merge_recursive($header,array("Referer:".$reffer));
30 }
31 else{
32 $header = array_merge_recursive($header,array("Referer:".$url));
33 }
34
35 $curl = curl_init();
36 curl_setopt($curl, CURLOPT_URL, $url);
37 curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
38 curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0);
39 curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1);
40 curl_setopt($curl, CURLOPT_USERAGENT, $this->useragent);
41 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, $location);
42 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
43 curl_setopt($curl, CURLOPT_AUTOREFERER, 1);
44 curl_setopt($curl, CURLOPT_ENCODING, "gzip" );
45 curl_setopt($curl, CURLOPT_HTTPGET, 1);
46 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);
47 curl_setopt($curl, CURLOPT_COOKIEJAR, 'cookie.txt');
48 curl_setopt($curl, CURLOPT_COOKIEFILE, 'cookie.txt');
49 curl_setopt($curl, CURLOPT_TIMEOUT, 30);
50 curl_setopt($curl, CURLOPT_HEADER, 1);
51 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
52 $tmpInfo = curl_exec($curl);
53
54 if (curl_errno($curl)) {
55 echo 'Curl error: '.curl_error ($curl);exit();
56 }
57 curl_close($curl);
58 list($header, $body) = explode("\r\n\r\n", $tmpInfo, 2);
59 $tmpInfo = $this->auto_charest($tmpInfo);
60 return array("header"=>$header,"body"=>$body,"content"=>$tmpInfo);
61 }
好的,如果觉得对你有用,请默默点开顶。(右下角)
如果你觉得这篇文章文章还不错或者有所收获,可以扫描下方支付宝二维码【素材支持】,或者点击右下角【推荐】按钮奖励我一杯咖啡角[精神]支持],因为这两种支持是我继续写作和分享的最大动力,
查看全部
php正则函数抓取网页连接(如何利用cookie去访问网页,去get页面代码的函数
)
最近帮朋友开发了一个可以查询正方教务系统的微信公众平台号。得到一些东西。以上是个人经验总结。
开讲之前先说一下新浪云服务器。同一个程序中的功能在PC测试中可以正常运行,但是会挂在那里。
像往常一样,我会在代码中清楚地注释。使用下面的函数,你会得到两种形式的cookies,一种存储在文件中,另一种直接作为变量返回。
经验提示:有时候,在不同的代码运行环境下,用cookies访问文件会成功,但变量会失败,但有时是想法。但,
目前,这两种方法中的一种总会成功。
1 function get_cookie($url_,$params_,$referer_){
2
3 if($url_==null){echo "get_cookie_url_null";exit;}
4 if($params_==null){echo "get_params_null";exit;}
5 if($referer_==null){echo "get_referer-null";exit;}
6 $this_header = array("content-type: application/x-www-form-urlencoded; charset=UTF-8");//访问链接时要发送的头信息
7
8 $ch = curl_init($url_);//这里是初始化一个访问对话,并且传入url,这要个必须有
9
10 //curl_setopt就是设置一些选项为以后发起请求服务的
11
12
13 curl_setopt($ch,CURLOPT_HTTPHEADER,$this_header);//一个用来设置HTTP头字段的数组。使用如下的形式的数组进行设置: array('Content-type: text/plain', 'Content-length: 100')
14 curl_setopt($ch, CURLOPT_HEADER,1);//如果你想把一个头包含在输出中,设置这个选项为一个非零值,我这里是要输出,所以为 1
15
16 curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);//将 curl_exec()获取的信息以文件流的形式返回,而不是直接输出。设置为0是直接输出
17
18 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);//设置跟踪页面的跳转,有时候你打开一个链接,在它内部又会跳到另外一个,就是这样理解
19
20 curl_setopt($ch,CURLOPT_POST,1);//开启post数据的功能,这个是为了在访问链接的同时向网页发送数据,一般数urlencode码
21
22 curl_setopt($ch,CURLOPT_POSTFIELDS,$params_); //把你要提交的数据放这
23
24 curl_setopt($ch, CURLOPT_COOKIEJAR, 'cookie.txt');//获取的cookie 保存到指定的 文件路径,我这里是相对路径,可以是$变量
25
26 //curl_setopt($ch, CURLOPT_COOKIEFILE, 'cookie.txt');//要发送的cookie文件,注意这里是文件,还一个是变量形式发送
27
28 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);//例如这句就是设置以变量的形式发送cookie,注意,这里的cookie变量是要先获取的,见下面获取方式
29
30 curl_setopt ($ch, CURLOPT_REFERER,$referer_); //在HTTP请求中包含一个'referer'头的字符串。告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。
31
32 $content=curl_exec($ch); //重点来了,上面的众多设置都是为了这个,进行url访问,带着上面的所有设置
33
34 if(curl_errno($ch)){
35 echo 'Curl error: '.curl_error($ch);exit(); //这里是设置个错误信息的反馈
36 }
37
38 if($content==false){
39 echo "get_content_null";exit();
40 }
41 preg_match('/Set-Cookie:(.*);/iU',$content,$str); //这里采用正则匹配来获取cookie并且保存它到变量$str里,这就是为什么上面可以发送cookie变量的原因
42
43 $cookie = $str[1]; //获得COOKIE(SESSIONID)
44
45 curl_close($ch);//关闭会话
46
47 return $cookie;//返回cookie
48 }
下面是如何使用上面的cookie来访问网页,发布数据,获取页面代码的功能。
1 function post($url,$post_data,$location = 0,$reffer = null,$origin = null,$host = null){
2
3 $post_data = is_array($post_data)?http_build_query($post_data):$post_data;
4 //产生一个urlencode之后的请求字符串,因为我们post,传送给网页的数据都是经过处理,一般是urlencode编码后才发送的
5
6 $header = array( //头部信息,上面的函数已说明
7 'Accept:*/*',
8 'Accept-Charset:text/html,application/xhtml+xml,application/xml;q=0.7,*;q=0.3',
9 'Accept-Encoding:gzip,deflate,sdch',
10 'Accept-Language:zh-CN,zh;q=0.8',
11 'Connection:keep-alive',
12 'Content-Type:application/x-www-form-urlencoded',
13 //'CLIENT-IP:'.$ip,
14 //'X-FORWARDED-FOR:'.$ip,
15 );
16
17 //下面的都是头部信息的设置,请根据他们的变量名字,对应上面函数所说明
18 if($host){
19 $header = array_merge_recursive($header,array("Host:".$host));
20 }
21 else if($this->option["host"]){
22 $header = array_merge_recursive($header,array("Host:".$this->option["host"]));
23 }
24 if($origin){
25 $header = array_merge_recursive($header,array("Origin:".$origin));
26 }
27 else{
28 $header = array_merge_recursive($header,array("Origin:".$url));
29 }
30 if($reffer){
31 $header = array_merge_recursive($header,array("Referer:".$reffer));
32 }
33 else{
34 $header = array_merge_recursive($header,array("Referer:".$url));
35 }
36
37 $curl = curl_init(); //这里并没有带参数初始化
38
39 curl_setopt($curl, CURLOPT_URL, $url);//这里传入url
40
41 curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
42
43 curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0);//对认证证书来源的检查,不开启次功能
44
45 curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1);//从证书中检测 SSL 加密算法
46
47 curl_setopt($curl, CURLOPT_USERAGENT, $this->useragent);
48 //模拟用户使用的浏览器,自己设置,我的是"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0"
49 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, $location);
50
51 curl_setopt($curl, CURLOPT_AUTOREFERER, 1);//自动设置referer
52
53 curl_setopt($curl, CURLOPT_POST, 1);//开启post
54
55 curl_setopt($curl, CURLOPT_ENCODING, "gzip" );
56 //HTTP请求头中"Accept-Encoding: "的值。支持的编码有"identity","deflate"和"gzip"。如果为空字符串"",请求头会发送所有支持的编码类型。
57 //我上面设置的是*/*
58
59 curl_setopt($curl, CURLOPT_POSTFIELDS, $post_data);//要传送的数据
60
61 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);//以变量形式发送cookie,我这里没用它,文件保险点
62
63 curl_setopt($curl, CURLOPT_COOKIEJAR, 'cookie.txt'); //存cookie的文件名,
64
65 curl_setopt($curl, CURLOPT_COOKIEFILE, 'cookie.txt'); //发送
66
67 curl_setopt($curl, CURLOPT_TIMEOUT, 30);//设置超时限制,防止死循环
68
69 curl_setopt($curl, CURLOPT_HEADER, 1);
70
71 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
72
73 $tmpInfo = curl_exec($curl);
74 if (curl_errno($curl)) {
75 echo 'Curl error: ' . curl_error ( $curl );exit();
76 }
77
78 curl_close($curl);
79 list($header, $body) = explode("\r\n\r\n", $tmpInfo, 2);//分割出网页源代码的头和bode
80 $tmpInfo = $this->auto_charest($tmpInfo);//转码,防止乱码,自定义函数
81 return array("header"=>$header,"body"=>$body,"content"=>$tmpInfo);
82 }
上面是post,下面是get。两者很相似。不同的是get没有发帖,将数据传输到发布前访问过的网页,只获取源码。
1 function get($url,$location = 1,$origin = null,$reffer = null,$host = null){
2 //$ip = $this->randip();
3 if($url==null){
4 echo "get-url-null";exit();
5 }
6 $header = array(
7 'Accept:*/*',
8 'Accept-Charset:GBK,utf-8;q=0.7,*;q=0.3',
9 'Accept-Encoding:gzip,deflate,sdch',
10 'Accept-Language:zh-CN,zh;q=0.8',
11 'Connection:keep-alive',
12
13 //'CLIENT-IP:'.$ip,
14 //'X-FORWARDED-FOR:'.$ip,
15 );
16 if($host){
17 $header = array_merge_recursive($header,array("Host:".$host));
18 }
19 else if($this->option["host"]){
20 $header = array_merge_recursive($header,array("Host:".$this->option["host"]));
21 }
22 if($origin){
23 $header = array_merge_recursive($header,array("Origin:".$origin));
24 }
25 else{
26 $header = array_merge_recursive($header,array("Origin:".$url));
27 }
28 if($reffer){
29 $header = array_merge_recursive($header,array("Referer:".$reffer));
30 }
31 else{
32 $header = array_merge_recursive($header,array("Referer:".$url));
33 }
34
35 $curl = curl_init();
36 curl_setopt($curl, CURLOPT_URL, $url);
37 curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
38 curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0);
39 curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1);
40 curl_setopt($curl, CURLOPT_USERAGENT, $this->useragent);
41 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, $location);
42 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
43 curl_setopt($curl, CURLOPT_AUTOREFERER, 1);
44 curl_setopt($curl, CURLOPT_ENCODING, "gzip" );
45 curl_setopt($curl, CURLOPT_HTTPGET, 1);
46 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);
47 curl_setopt($curl, CURLOPT_COOKIEJAR, 'cookie.txt');
48 curl_setopt($curl, CURLOPT_COOKIEFILE, 'cookie.txt');
49 curl_setopt($curl, CURLOPT_TIMEOUT, 30);
50 curl_setopt($curl, CURLOPT_HEADER, 1);
51 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
52 $tmpInfo = curl_exec($curl);
53
54 if (curl_errno($curl)) {
55 echo 'Curl error: '.curl_error ($curl);exit();
56 }
57 curl_close($curl);
58 list($header, $body) = explode("\r\n\r\n", $tmpInfo, 2);
59 $tmpInfo = $this->auto_charest($tmpInfo);
60 return array("header"=>$header,"body"=>$body,"content"=>$tmpInfo);
61 }
好的,如果觉得对你有用,请默默点开顶。(右下角)
如果你觉得这篇文章文章还不错或者有所收获,可以扫描下方支付宝二维码【素材支持】,或者点击右下角【推荐】按钮奖励我一杯咖啡角[精神]支持],因为这两种支持是我继续写作和分享的最大动力,

php正则函数抓取网页连接(本文实现Excel表数据导入SqlServer中的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-16 21:17
本文介绍了基于正则表达式的C#网页爬取类获取网页中所有信息的示例。分享给大家,供大家参考,如下:
类的代码:
<p>
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
using System.Web.UI.MobileControls;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //url
private List m_links; //此网页上的链接
private string m_title; //标题
private string m_html; //HTML代码
private string m_outstr; //网页可输出的纯文本
private bool m_good; //网页是否可用
private int m_pagesize; //网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
#endregion
#region 属性
///
/// 通过此属性可获得本网页的网址,只读
///
public string URL
{
get
{
return m_uri.AbsoluteUri;
}
}
///
/// 通过此属性可获得本网页的标题,只读
///
public string Title
{
get
{
if (m_title == "")
{
Regex reg = new Regex(@"(?m)]*>(?(?:\w|\W)*?)]*>",RegexOptions.Multiline | RegexOptions.IgnoreCase);
Match mc = reg.Match(m_html);
if (mc.Success)
m_title = mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
public string M_html
{
get
{
if (m_html == null)
{
m_html = "";
}
return m_html;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://" + m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
#endregion
///
/// 从HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex(@"(?[^]*>",RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = HttpUtility.UrlDecode(new Uri(m_uri,match.Groups["URL"].Value).AbsoluteUri);
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"",RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value,"");
Link link = new Link();
link.Text = text;
link.NavigateUrl = url;
m_links.Add(link);
}
catch (Exception ex) { Console.WriteLine(ex.Message); };
match = match.Nextmatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr,int firstN,bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>",RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr,"");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ",RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr,"");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+",RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr," ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0,firstN) : m_outstr;
}
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html,firstN,true);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if (m_links.Count == 0) getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt < count)
{
if (new Regex(pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase).Match(i.Current.NavigateUrl).Success)
{
SpecialLinks.Add(i.Current);
cnt++;
}
}
return SpecialLinks;
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的文字满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByText(string pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase).Match(i.Current.Text).Success)
{
SpecialLinks.Add(i.Current);
cnt++;
}
}
return SpecialLinks;
}
///
/// 这公有方法提取本网页的纯文本中满足某正则式的文字 by 何问起
///
/// 正则式
/// 返回文字
public string getSpecialWords(string pattern)
{
if (m_outstr == "") getContext(Int16.MaxValue);
Regex regex = new Regex(pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase);
Match mc = regex.Match(m_outstr);
if (mc.Success)
return mc.Groups[1].Value;
return string.Empty;
}
#endregion
#region 构造函数
private void Init(string _url)
{
try
{
m_uri = new Uri(_url);
m_links = new List();
m_html = "";
m_outstr = "";
m_title = "";
m_good = true;
if (_url.EndsWith(".rar") || _url.EndsWith(".dat") || _url.EndsWith(".msi"))
{
m_good = false;
return;
}
HttpWebRequest rqst = (HttpWebRequest)WebRequest.Create(m_uri);
rqst.AllowAutoRedirect = true;
rqst.MaximumAutomaticRedirections = 3;
rqst.UserAgent = "Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)";
rqst.KeepAlive = true;
rqst.Timeout = 10000;
lock (WebPage.webcookies)
{
if (WebPage.webcookies.ContainsKey(m_uri.Host))
rqst.CookieContainer = WebPage.webcookies[m_uri.Host];
else
{
CookieContainer cc = new CookieContainer();
WebPage.webcookies[m_uri.Host] = cc;
rqst.CookieContainer = cc;
}
}
HttpWebResponse rsps = (HttpWebResponse)rqst.GetResponse();
Stream sm = rsps.GetResponseStream();
if (!rsps.ContentType.ToLower().StartsWith("text/") || rsps.ContentLength > 1 查看全部
php正则函数抓取网页连接(本文实现Excel表数据导入SqlServer中的方法)
本文介绍了基于正则表达式的C#网页爬取类获取网页中所有信息的示例。分享给大家,供大家参考,如下:
类的代码:
<p>
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
using System.Web.UI.MobileControls;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //url
private List m_links; //此网页上的链接
private string m_title; //标题
private string m_html; //HTML代码
private string m_outstr; //网页可输出的纯文本
private bool m_good; //网页是否可用
private int m_pagesize; //网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
#endregion
#region 属性
///
/// 通过此属性可获得本网页的网址,只读
///
public string URL
{
get
{
return m_uri.AbsoluteUri;
}
}
///
/// 通过此属性可获得本网页的标题,只读
///
public string Title
{
get
{
if (m_title == "")
{
Regex reg = new Regex(@"(?m)]*>(?(?:\w|\W)*?)]*>",RegexOptions.Multiline | RegexOptions.IgnoreCase);
Match mc = reg.Match(m_html);
if (mc.Success)
m_title = mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
public string M_html
{
get
{
if (m_html == null)
{
m_html = "";
}
return m_html;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://" + m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
#endregion
///
/// 从HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex(@"(?[^]*>",RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = HttpUtility.UrlDecode(new Uri(m_uri,match.Groups["URL"].Value).AbsoluteUri);
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"",RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value,"");
Link link = new Link();
link.Text = text;
link.NavigateUrl = url;
m_links.Add(link);
}
catch (Exception ex) { Console.WriteLine(ex.Message); };
match = match.Nextmatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr,int firstN,bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>",RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr,"");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ",RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr,"");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+",RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr," ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0,firstN) : m_outstr;
}
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html,firstN,true);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if (m_links.Count == 0) getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt < count)
{
if (new Regex(pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase).Match(i.Current.NavigateUrl).Success)
{
SpecialLinks.Add(i.Current);
cnt++;
}
}
return SpecialLinks;
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的文字满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByText(string pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase).Match(i.Current.Text).Success)
{
SpecialLinks.Add(i.Current);
cnt++;
}
}
return SpecialLinks;
}
///
/// 这公有方法提取本网页的纯文本中满足某正则式的文字 by 何问起
///
/// 正则式
/// 返回文字
public string getSpecialWords(string pattern)
{
if (m_outstr == "") getContext(Int16.MaxValue);
Regex regex = new Regex(pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase);
Match mc = regex.Match(m_outstr);
if (mc.Success)
return mc.Groups[1].Value;
return string.Empty;
}
#endregion
#region 构造函数
private void Init(string _url)
{
try
{
m_uri = new Uri(_url);
m_links = new List();
m_html = "";
m_outstr = "";
m_title = "";
m_good = true;
if (_url.EndsWith(".rar") || _url.EndsWith(".dat") || _url.EndsWith(".msi"))
{
m_good = false;
return;
}
HttpWebRequest rqst = (HttpWebRequest)WebRequest.Create(m_uri);
rqst.AllowAutoRedirect = true;
rqst.MaximumAutomaticRedirections = 3;
rqst.UserAgent = "Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)";
rqst.KeepAlive = true;
rqst.Timeout = 10000;
lock (WebPage.webcookies)
{
if (WebPage.webcookies.ContainsKey(m_uri.Host))
rqst.CookieContainer = WebPage.webcookies[m_uri.Host];
else
{
CookieContainer cc = new CookieContainer();
WebPage.webcookies[m_uri.Host] = cc;
rqst.CookieContainer = cc;
}
}
HttpWebResponse rsps = (HttpWebResponse)rqst.GetResponse();
Stream sm = rsps.GetResponseStream();
if (!rsps.ContentType.ToLower().StartsWith("text/") || rsps.ContentLength > 1
php正则函数抓取网页连接( 2019-03-30Python正则表达式实例讲述Python正则操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-14 15:01
2019-03-30Python正则表达式实例讲述Python正则操作技巧)
Python常规抓取新闻标题和链接方法示例
时间:2019-03-30
本文章为大家介绍了Python定时抓取新闻标题和链接的方法示例,主要包括Python定时抓取新闻标题和链接的示例、使用示例、应用技巧、基础知识点总结和注意事项,具有一定的参考价值,有需要的朋友可以参考。
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/").read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用汇总》、《Python数据结构与算法教程》、《Python Socket编程技巧汇总》、《Python函数使用技巧汇总》、《Python字符串》操作技巧总结《Python入门及进阶经典教程》《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。 查看全部
php正则函数抓取网页连接(
2019-03-30Python正则表达式实例讲述Python正则操作技巧)
Python常规抓取新闻标题和链接方法示例
时间:2019-03-30
本文章为大家介绍了Python定时抓取新闻标题和链接的方法示例,主要包括Python定时抓取新闻标题和链接的示例、使用示例、应用技巧、基础知识点总结和注意事项,具有一定的参考价值,有需要的朋友可以参考。
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/";).read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用汇总》、《Python数据结构与算法教程》、《Python Socket编程技巧汇总》、《Python函数使用技巧汇总》、《Python字符串》操作技巧总结《Python入门及进阶经典教程》《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。
php正则函数抓取网页连接(PHP是什么东西?PHP的爬虫有什么用?Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-14 07:09
一、什么是PHP?
PHP(外文名:PHP:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远高于完全生成HTML标记的CGI;PHP 也可以执行编译后的代码。编译可以实现加密和优化代码执行,使代码运行速度更快。
二、爬虫有什么用?
爬虫有什么用?先说一下什么是爬虫。我认为爬虫是一个网络信息采集程序。可能我自己的理解有误。请纠正我。由于爬虫是网络信息采集程序,所以用来采集信息,采集的信息在网络上。如果你还不知道爬虫的用处,我给你举几个爬虫应用的例子:搜索引擎需要爬虫来采集网络信息供人们搜索;大数据数据,数据从何而来?可以通过爬虫在网络中进行爬取(采集)。
三、听到爬虫一般都会想到Python,但是为什么我用PHP而不是Python呢?
Python 老实说,我不懂 Python。(我真的不懂Python,我想知道也许你得去百度,因为我真的不懂Python。)我一直认为用PHP写东西时,你只需要想到一个算法程序并且您不必考虑太多的数据类型。问题。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。这个想法是错误的。) 其实我也是一个PHP初学者,想通过写点东西来提高自己的水平。(以下代码可能让你觉得不够规范,请指正,谢谢。)
四、PHP爬虫第一步
PHP爬虫的第一步,第一步……当然,第一步是搭建PHP的运行环境。PHP如何在没有环境的情况下运行?就像鱼离不开水一样。(我的知识不够,可能我给的鱼例子不够好,请见谅。)我在Windows系统下使用WAMP,在Linux系统下使用LNMP或LAMP。
WAMP:Windows Apache Mysql PHP
灯:Linux Apache Mysql PHP
LNMP:Linux Nginx Mysql PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache 或 Nginx、Mysql 和 PHP 是 PHP Web 的基本配置环境。网上有PHP Web环境的安装包。这些安装包使用起来非常方便,不需要安装和配置一切。但是如果你担心这些集成安装包的安全性,你可以去这些程序的官网下载,然后在网上找配置教程。(说真的,我真的不想一个人做,我觉得很麻烦。)
五、 PHP爬虫第二步
(感觉废话很多,应该马上来一段代码!!!)
爬虫网络的核心功能已经写好了。为什么说爬虫的核心功能是几行代码写出来的?估计有人已经明白了。爬虫其实就是一个数据采集程序,上面几行代码其实是可以获取数据的,所以爬虫的核心功能已经写好了。可能有人会说:“你太乱了!有什么用?” 虽然我很乱,但请不要告诉我,让我装个X。(再废话两行,抱歉。)
实际上,爬虫的用途取决于您希望它做什么。就像我前几天为了好玩写了一个搜索引擎网站,当然网站是很好的,结果排序不规则,很多都没有。我的搜索引擎爬虫就是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来说明。当然,我的搜索引擎的爬虫还不够完善。不完美的地方将由你来创造和完善。
六、 搜索引擎爬虫的局限性
有时搜索引擎的爬虫不是无法从网站的页面中获取页面源代码,而是有robot.txt文件。这个文件的网站表示站主不希望爬虫爬取页面源代码。. (但如果你只是想得到它,即使你拥有它也会爬行!)
我的搜索引擎的爬虫其实有很多不足导致的局限性。例如,可能因为无法运行JS脚本而无法获取页面的源代码。或者网站有反爬虫机制,防止获取页面源代码。网站带有反爬虫机制就像:知乎,知乎就是带有反爬虫机制的网站。
七、以搜索引擎爬虫为例,准备写爬虫需要什么
PHP写基本正则表达式(也可以用Xpath,抱歉,我不会用) 数据库的使用(本文使用的是MySql数据库) 运行环境(只要有可以运行PHP的环境和数据库< @网站,好的)
八、搜索引擎获取页面源码,获取页面标题信息
错误示例:
警告:file_get_contents("") [function.file-get-contents]:无法打开流:E:\website\blog\test.php 第 25 行中的参数无效
https 是一种 SSL 加密协议。如果您在获取页面时出现上述错误,则表示您的 PHP 可能缺少 OpenSSL 模块。您可以在网上找到解决方案。
九、搜索引擎爬虫的特点
虽然没见过像“百度”、“谷歌”这样的爬虫,但是通过自己的猜测和实际爬取过程中遇到的一些问题,总结了一些特点。(可能有错误或遗漏,请指正,谢谢。)
多功能性
通用性是因为我觉得搜索引擎的爬虫一开始不是针对哪个网站设计的,所以要求尽可能多的爬取网站。这是第一点。第二点是获取网页的信息就是这样。一开始不会因为一些特殊的小网站而放弃一些信息不提取,例如:一个小网站的网页如果没有描述信息(description)或者meta标签中的关键词信息(关键字),直接放弃提取描述信息或关键词信息。当然,如果某个页面没有这样的信息,我会提取页面里面的文字内容作为填充,反正,每个网页的信息项要尽量相同,以实现抓取到的网页信息。这就是我认为的搜索引擎爬虫的多功能性。当然,我的想法可能是错误的。(我可能不会说得很好,我一直在学习。)
不确定
不确定性是我的爬虫获取的网页。我对我能想到的东西没有足够的控制权。这也是我写的算法就是这样的原因。我的算法是抓取我得到的页面。所有的链接,然后去爬取这些链接,其实是因为搜索引擎不是搜索某些东西,而是尽可能多的搜索,因为只有更多的信息才能为用户找到最合适的答案。所以我觉得搜索引擎爬虫会有不确定性。(我自己又看了一遍,感觉有点看不懂我说的,还请见谅,请指正,提问,谢谢!)
以下视频是我搜索网站的视频,找到的信息是通过我写的PHP爬虫获取的。(此网站已不再维护,如有不足请见谅。)
十、目前可能出现的问题
得到的源码出现乱码
2. 无法获取标题信息
3.无法获取页面源码
十个一、获取网页时的处理思路
我们不要考虑很多网页,因为很多网页只是一个循环。
获取页面的源代码,通过源代码从页面中提取信息。
十二、按照十一的思路编码
十个三、PHP保存页面图片的想法
获取页面源码 获取页面图片链接 使用图片保存功能
十四、保存图片示例代码
十五、gzip解压
本来以为自己写的爬虫差不多就完成了,除了反爬虫网站难爬,应该能爬。但是有一天当我试图爬到bilibili时,出现了问题。发现我数据库里的代码全是乱码,而且根本没有标题,好奇怪!后来我发现是因为GZIP压缩。原来我直接用file_get_content函数获取的页面都是未压缩的页面,都是乱码!好的,那我就知道问题在那里了,然后我想解决它。(其实我当时不知道怎么解决gzip解压的问题,靠的就是搜索引擎,哈哈哈哈)。
我得到了两个解决方案:
在请求头中告诉对方我的爬虫(不...应该是我的浏览器)不支持gzip解压,所以请不要压缩,直接把数据发给我!
// 这是request header(请求头)
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n".
"accept-encoding:"
)
);
// 我把accept-encodeing(能接收编码)设为空,代表不接受gzip
2. 如果你告诉对方的服务器浏览器(爬虫)不支持gzip解压,他却继续给你发gzip数据,没办法,所以只能在里面找php解压gzip搜索引擎默默地。函数-gzdecode()。
// 废话:好久没更新了,因为最近又在重做轮子了,不过我好开心——2019.01.14
10.获取六、子链接
网络爬虫就像是一个自动的网页源代码另存为操作,但如果真的是手动输入的网址供爬虫爬取,那么保存为手动会更好!所以在这里你必须解决这些子链接。一个网页实际上有很多a标签,这些a标签的href属性值就是一个子链接。(这句话怎么感觉有点废话?大家应该都知道吧!)通过很多工具的分析,得到了原来的子链接(我没有用html工具,只是用了正则表达式和工具)。为什么叫原创数据?,因为这些子链接很多不是网址链接,或者是一些不完整的链接,或者你要去爬一个网站。当爬虫用完时,你必须删除一些不是网站的链接,以防止爬虫用完。下面我列出了一些原创的子链接。(其实是我喷的坑……)
http://wxample.com/
./index.html
index.html
//example.com/index.html
javascript:;
../index.html
http://example2.com/index.html
可以看到这里有很多种链接。有完整绝对路径的链接,有不完整相对路径的链接,还有一些还运行javascript。如果是相对路径或者javascript链接,就让爬虫直接抓取。让爬虫看起来傻眼,因为它不完整或根本不是链接。因此,需要完成或丢弃子链接。
10. 七、 子链接的处理
说了这么多废话,接下来就是继续废话了。嗯,处理其实就是去重复,丢弃,完成。
丢弃同一个子链接,不保存,补全相对路径链接。丢弃不是链接的链接(什么是非链接的链接?我觉得很奇怪......)
第一种我就不多说了,相信大家都知道怎么做。
对于第二种方法,我会写一个可以运行相对路径的方法,就OK了。相对路径通过父链接转换为绝对路径。(有时间给大家补码……不好意思)
对于第三种,正则匹配结束。
#有什么问题可以评论留言,大家一起解决,谢谢。
未完待续。. . 查看全部
php正则函数抓取网页连接(PHP是什么东西?PHP的爬虫有什么用?Python)
一、什么是PHP?
PHP(外文名:PHP:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远高于完全生成HTML标记的CGI;PHP 也可以执行编译后的代码。编译可以实现加密和优化代码执行,使代码运行速度更快。
二、爬虫有什么用?
爬虫有什么用?先说一下什么是爬虫。我认为爬虫是一个网络信息采集程序。可能我自己的理解有误。请纠正我。由于爬虫是网络信息采集程序,所以用来采集信息,采集的信息在网络上。如果你还不知道爬虫的用处,我给你举几个爬虫应用的例子:搜索引擎需要爬虫来采集网络信息供人们搜索;大数据数据,数据从何而来?可以通过爬虫在网络中进行爬取(采集)。
三、听到爬虫一般都会想到Python,但是为什么我用PHP而不是Python呢?
Python 老实说,我不懂 Python。(我真的不懂Python,我想知道也许你得去百度,因为我真的不懂Python。)我一直认为用PHP写东西时,你只需要想到一个算法程序并且您不必考虑太多的数据类型。问题。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。这个想法是错误的。) 其实我也是一个PHP初学者,想通过写点东西来提高自己的水平。(以下代码可能让你觉得不够规范,请指正,谢谢。)
四、PHP爬虫第一步
PHP爬虫的第一步,第一步……当然,第一步是搭建PHP的运行环境。PHP如何在没有环境的情况下运行?就像鱼离不开水一样。(我的知识不够,可能我给的鱼例子不够好,请见谅。)我在Windows系统下使用WAMP,在Linux系统下使用LNMP或LAMP。
WAMP:Windows Apache Mysql PHP
灯:Linux Apache Mysql PHP
LNMP:Linux Nginx Mysql PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache 或 Nginx、Mysql 和 PHP 是 PHP Web 的基本配置环境。网上有PHP Web环境的安装包。这些安装包使用起来非常方便,不需要安装和配置一切。但是如果你担心这些集成安装包的安全性,你可以去这些程序的官网下载,然后在网上找配置教程。(说真的,我真的不想一个人做,我觉得很麻烦。)
五、 PHP爬虫第二步
(感觉废话很多,应该马上来一段代码!!!)
爬虫网络的核心功能已经写好了。为什么说爬虫的核心功能是几行代码写出来的?估计有人已经明白了。爬虫其实就是一个数据采集程序,上面几行代码其实是可以获取数据的,所以爬虫的核心功能已经写好了。可能有人会说:“你太乱了!有什么用?” 虽然我很乱,但请不要告诉我,让我装个X。(再废话两行,抱歉。)
实际上,爬虫的用途取决于您希望它做什么。就像我前几天为了好玩写了一个搜索引擎网站,当然网站是很好的,结果排序不规则,很多都没有。我的搜索引擎爬虫就是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来说明。当然,我的搜索引擎的爬虫还不够完善。不完美的地方将由你来创造和完善。
六、 搜索引擎爬虫的局限性
有时搜索引擎的爬虫不是无法从网站的页面中获取页面源代码,而是有robot.txt文件。这个文件的网站表示站主不希望爬虫爬取页面源代码。. (但如果你只是想得到它,即使你拥有它也会爬行!)
我的搜索引擎的爬虫其实有很多不足导致的局限性。例如,可能因为无法运行JS脚本而无法获取页面的源代码。或者网站有反爬虫机制,防止获取页面源代码。网站带有反爬虫机制就像:知乎,知乎就是带有反爬虫机制的网站。
七、以搜索引擎爬虫为例,准备写爬虫需要什么
PHP写基本正则表达式(也可以用Xpath,抱歉,我不会用) 数据库的使用(本文使用的是MySql数据库) 运行环境(只要有可以运行PHP的环境和数据库< @网站,好的)
八、搜索引擎获取页面源码,获取页面标题信息
错误示例:
警告:file_get_contents("") [function.file-get-contents]:无法打开流:E:\website\blog\test.php 第 25 行中的参数无效
https 是一种 SSL 加密协议。如果您在获取页面时出现上述错误,则表示您的 PHP 可能缺少 OpenSSL 模块。您可以在网上找到解决方案。
九、搜索引擎爬虫的特点
虽然没见过像“百度”、“谷歌”这样的爬虫,但是通过自己的猜测和实际爬取过程中遇到的一些问题,总结了一些特点。(可能有错误或遗漏,请指正,谢谢。)
多功能性
通用性是因为我觉得搜索引擎的爬虫一开始不是针对哪个网站设计的,所以要求尽可能多的爬取网站。这是第一点。第二点是获取网页的信息就是这样。一开始不会因为一些特殊的小网站而放弃一些信息不提取,例如:一个小网站的网页如果没有描述信息(description)或者meta标签中的关键词信息(关键字),直接放弃提取描述信息或关键词信息。当然,如果某个页面没有这样的信息,我会提取页面里面的文字内容作为填充,反正,每个网页的信息项要尽量相同,以实现抓取到的网页信息。这就是我认为的搜索引擎爬虫的多功能性。当然,我的想法可能是错误的。(我可能不会说得很好,我一直在学习。)
不确定
不确定性是我的爬虫获取的网页。我对我能想到的东西没有足够的控制权。这也是我写的算法就是这样的原因。我的算法是抓取我得到的页面。所有的链接,然后去爬取这些链接,其实是因为搜索引擎不是搜索某些东西,而是尽可能多的搜索,因为只有更多的信息才能为用户找到最合适的答案。所以我觉得搜索引擎爬虫会有不确定性。(我自己又看了一遍,感觉有点看不懂我说的,还请见谅,请指正,提问,谢谢!)
以下视频是我搜索网站的视频,找到的信息是通过我写的PHP爬虫获取的。(此网站已不再维护,如有不足请见谅。)
十、目前可能出现的问题
得到的源码出现乱码
2. 无法获取标题信息
3.无法获取页面源码
十个一、获取网页时的处理思路
我们不要考虑很多网页,因为很多网页只是一个循环。
获取页面的源代码,通过源代码从页面中提取信息。
十二、按照十一的思路编码
十个三、PHP保存页面图片的想法
获取页面源码 获取页面图片链接 使用图片保存功能
十四、保存图片示例代码
十五、gzip解压
本来以为自己写的爬虫差不多就完成了,除了反爬虫网站难爬,应该能爬。但是有一天当我试图爬到bilibili时,出现了问题。发现我数据库里的代码全是乱码,而且根本没有标题,好奇怪!后来我发现是因为GZIP压缩。原来我直接用file_get_content函数获取的页面都是未压缩的页面,都是乱码!好的,那我就知道问题在那里了,然后我想解决它。(其实我当时不知道怎么解决gzip解压的问题,靠的就是搜索引擎,哈哈哈哈)。
我得到了两个解决方案:
在请求头中告诉对方我的爬虫(不...应该是我的浏览器)不支持gzip解压,所以请不要压缩,直接把数据发给我!
// 这是request header(请求头)
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n".
"accept-encoding:"
)
);
// 我把accept-encodeing(能接收编码)设为空,代表不接受gzip
2. 如果你告诉对方的服务器浏览器(爬虫)不支持gzip解压,他却继续给你发gzip数据,没办法,所以只能在里面找php解压gzip搜索引擎默默地。函数-gzdecode()。
// 废话:好久没更新了,因为最近又在重做轮子了,不过我好开心——2019.01.14
10.获取六、子链接
网络爬虫就像是一个自动的网页源代码另存为操作,但如果真的是手动输入的网址供爬虫爬取,那么保存为手动会更好!所以在这里你必须解决这些子链接。一个网页实际上有很多a标签,这些a标签的href属性值就是一个子链接。(这句话怎么感觉有点废话?大家应该都知道吧!)通过很多工具的分析,得到了原来的子链接(我没有用html工具,只是用了正则表达式和工具)。为什么叫原创数据?,因为这些子链接很多不是网址链接,或者是一些不完整的链接,或者你要去爬一个网站。当爬虫用完时,你必须删除一些不是网站的链接,以防止爬虫用完。下面我列出了一些原创的子链接。(其实是我喷的坑……)
http://wxample.com/
./index.html
index.html
//example.com/index.html
javascript:;
../index.html
http://example2.com/index.html
可以看到这里有很多种链接。有完整绝对路径的链接,有不完整相对路径的链接,还有一些还运行javascript。如果是相对路径或者javascript链接,就让爬虫直接抓取。让爬虫看起来傻眼,因为它不完整或根本不是链接。因此,需要完成或丢弃子链接。
10. 七、 子链接的处理
说了这么多废话,接下来就是继续废话了。嗯,处理其实就是去重复,丢弃,完成。
丢弃同一个子链接,不保存,补全相对路径链接。丢弃不是链接的链接(什么是非链接的链接?我觉得很奇怪......)
第一种我就不多说了,相信大家都知道怎么做。
对于第二种方法,我会写一个可以运行相对路径的方法,就OK了。相对路径通过父链接转换为绝对路径。(有时间给大家补码……不好意思)
对于第三种,正则匹配结束。
#有什么问题可以评论留言,大家一起解决,谢谢。
未完待续。. .
php正则函数抓取网页连接(PHP怎样用正则抓取页面中的网址的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-09 19:05
想知道PHP如何使用正则抓取页面中URL的相关内容吗?在这篇文章中,我将为大家讲解PHP使用正则抓取页面中的URL的相关知识以及一些代码示例。欢迎阅读和纠正我们。fetch, php, 页面抓取, php, 抓取页面指定内容一起来学习
前言
链接是从一个元素(文本、图片、视频等)链接到另一个元素(文本、图片、视频等)的超链接。通常,一个网页中有三种链接。一种是绝对URL超链接,即一个页面的完整性。小路; 另一种是相对URL超链接,一般链接到同一网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置
如果你知道链接的类型,你就知道要抓取的主要链接是绝对 URL 超链接和相对 URL 超链接。要编写正确的正则表达式,您必须了解我们正在寻找的对象的模式。
先说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源URL。URL 的结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的标识。最常见的是http协议。本文仅考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时也收录端口号(默认为80) FTP协议也可以收录用户名和密码。本文不考虑。
路径和文件名一般用/分隔来表示文件的路径和文件本身的名称。如果没有具体的文件名,访问这个文件夹下的默认文件(可以在服务器端设置)
所以现在很明显,要爬取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的说明,具体可以参考RFC1738,然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下: 查看全部
php正则函数抓取网页连接(PHP怎样用正则抓取页面中的网址的相关内容吗)
想知道PHP如何使用正则抓取页面中URL的相关内容吗?在这篇文章中,我将为大家讲解PHP使用正则抓取页面中的URL的相关知识以及一些代码示例。欢迎阅读和纠正我们。fetch, php, 页面抓取, php, 抓取页面指定内容一起来学习
前言
链接是从一个元素(文本、图片、视频等)链接到另一个元素(文本、图片、视频等)的超链接。通常,一个网页中有三种链接。一种是绝对URL超链接,即一个页面的完整性。小路; 另一种是相对URL超链接,一般链接到同一网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置
如果你知道链接的类型,你就知道要抓取的主要链接是绝对 URL 超链接和相对 URL 超链接。要编写正确的正则表达式,您必须了解我们正在寻找的对象的模式。
先说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源URL。URL 的结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的标识。最常见的是http协议。本文仅考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时也收录端口号(默认为80) FTP协议也可以收录用户名和密码。本文不考虑。
路径和文件名一般用/分隔来表示文件的路径和文件本身的名称。如果没有具体的文件名,访问这个文件夹下的默认文件(可以在服务器端设置)
所以现在很明显,要爬取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的说明,具体可以参考RFC1738,然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下:
php正则函数抓取网页连接(爬虫也可以称为Python爬虫不知 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-09 15:01
)
爬虫也可以称为Python爬虫
不知何时,语言Python和爬行动物就像一对恋人。
当您谈到爬虫时,您会想到 Python。当您谈到 Python 时,您会想到人工智能……和爬虫。
因此,在谈到爬虫时,大多数程序员都会下意识地将其联想为 Python 爬虫。为什么会这样?我认为有两个原因:
任何学习 Python 的程序员都应该或多或少看过甚至研究过爬虫。我当时写 Python 的目的很纯粹就是为了写爬虫。
所以这篇文章的目的很简单,就是谈谈我个人对Python爬虫的理解和实践。作为一个程序员,我觉得只有了解爬虫的相关知识才对你有好处,所以看完这篇文章 ,如果对你有帮助就太好了
什么是爬虫
爬虫是一个程序。这个程序的目的是爬取万维网的信息资源。比如你日常使用的谷歌等搜索引擎,搜索结果都是依赖爬虫定期获取的。
看上面的搜索结果,除了wiki相关的介绍外,所有爬虫相关的搜索结果都收录了Python。前辈说的是Python爬虫,现在看来真的不骗我了~
爬虫的目标对象也很丰富,无论是文字、图片、视频,任何结构化和非结构化数据爬虫都可以爬取。经过爬虫的发展,衍生出各种爬虫类型:
不想讲这些笼统的概念,让我们以一个网页内容获取为例,从爬虫技术本身开始,来谈谈网络爬虫,步骤如下:
什么是爬虫,这是爬虫:
<p>"""让我们根据上面说的步骤来完成一个简单的爬虫程序"""
import requests
<br />
from bs4 import BeautifulSoup
<br />
target_url = 'http://www.baidu.com/s?wd=爬虫'
<br />
# 第一步 发起一个GET请求
res = requests.get(target_url)
<br />
# 第二步 提取HTML并解析想获取的数据 比如获取 title
soup = BeautifulSoup(res.text, "lxml")
# 输出 soup.title.text
title = soup.title.text
<br />
# 第三步 持久化 比如保存到本地
with open('title.txt', 'w') as fp:
fp.write(title)</p>
不到20行代码加注释,就完成了一个爬虫,简单
如何编写爬虫
网络世界丰富多彩,有数以亿计的网络资源供您选择。如何让你的爬虫程序在面对不同的页面时健壮耐用是一个值得讨论的问题
俗话说,磨刀不误砍柴。在开始写爬虫之前,有必要掌握一些基础知识:
这两个描述反映了爬虫开发者需要掌握的基础知识,但是一个基本的后端或者前端工程师可以做到。这也说明爬虫的入门难度是极低的。从这两句话,你能想到爬虫必备的知识点吗?
有了这些知识储备,你就可以选择一种语言,开始编写自己的爬虫程序了。或者按照上一节提到的三个步骤,然后以Python为例,谈谈在编程语言中要做哪些准备:
一旦掌握了以上内容,就可以放开手脚,做很多功课了。万维网是你的名利场,去吧!
我认为对于一个目标网站的网页,可以分为以下四种:
这是什么意思?这可能看起来有点令人费解,但你明白这一点。写好爬虫后,只需要在脑海中浏览网页的类型,然后应用对应类型的程序(写的太多,应该有自己的常用代码库),写的速度爬虫自然不慢
单页单目标
通俗地说,在这个网页中,我们的目标只有一个。假设我们需要抓取这部电影的名字——肖申克的救赎,首先打开网页右键查看元素,找到电影名字对应的元素位置,如下图:
单页看是否只有一个target,标题的CSS Selector规则一目了然:#content> h1> span:nth-child(1),然后使用common自己写的库,不到十行代码就可以写一个爬取这个页面的电影名的爬虫:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
title = TextField(css_select='#content > h1 > span:nth-child(1)')
<br />
async_func = DoubanItem.get_item(url="https://movie.douban.com/subject/1292052/")
item = asyncio.get_event_loop().run_until_complete(async_func)
print(item.title)</p>
Multi-page multi-target 在这种情况下是多个 URL 的衍生
单页多目标
假设当前的需求是抓取豆瓣电影250第一页的所有电影名,需要提取25个电影名,因为这个目标页面的目标数据是多项,所以需要循环获取目标,这就是所谓的具有多个目标的单页:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
async_func = DoubanItem.get_items(url="https://movie.douban.com/top250")
items = asyncio.get_event_loop().run_until_complete(async_func)
for item in items:
print(item)</p>
多页多目标
多页多目标是上述单页多目标情况的派生。从这个角度来说,就是获取此时所有页面的电影名称。
<p>from ruia import TextField, Item, Request, Spider
<br />
<br />
class DoubanItem(Item):
"""
定义爬虫的目标字段
"""
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
class DoubanSpider(Spider):
start_urls = ['https://movie.douban.com/top250']
concurrency = 10
<br />
async def parse(self, res):
etree = res.html_etree
pages = ['?start=0&filter='] + [i.get('href') for i in etree.cssselect('.paginator>a')]
<br />
for index, page in enumerate(pages):
url = self.start_urls[0] + page
yield Request(
url,
callback=self.parse_item,
metadata={'index': index},
request_config=self.request_config
)
<br />
async def parse_item(self, res):
items_data = await DoubanItem.get_items(html=res.html)
res_list = []
for item in items_data:
res_list.append(item.title)
return res_list
<br />
<br />
if __name__ == '__main__':
DoubanSpider.start()</p>
如果网络正常,您将获得以下输出:
注意爬虫运行时间,小于1s,这就是异步的魅力
用Python写爬虫就是这么简单优雅,大家看看网页,想一想:
一个爬虫程序就形成了。顺便说一句,爬虫可以说是反君子,而不是小人。大部分robots.txt网站(它的目的是告诉爬虫什么可以爬,什么不能爬,比如:),你想怎么爬,自己衡量
如何推进
不要以为只要写一个爬虫程序就可以了。这个时候,还有更多的问题等着你。你要深情地看你的爬虫程序,问自己三个问题:
关于人性的前两个问题这里就不多说了,直接跳过,但是如果你是爬虫工程师,千万不要跳过
会被反爬行动物杀死吗?
最后,关于反爬虫的问题是你的爬虫程序是否强大的关键因素。什么是反爬虫?
当网络上越来越多的爬虫横行时,为了防止自己的数据被爬取,网络资源维护者开始实施一系列措施,使自己的数据不易被其他程序爬取。这些措施是反爬虫。
如检测IP访问频率、资源访问速度、链接是否有关键参数、验证码检测机器人、ajax混淆、js加密等。
针对目前市场上的反爬虫,爬虫工程师经常有的反爬虫方案如下:
爬虫工程师的进阶之路,其实就是不断反爬虫,可谓艰辛,但换个角度想想也挺好玩的。
关于框架
爬虫有自己的写作过程和标准。有了标准,自然就会有框架。自然有很多像Python这样的生态强大的语言。自然有许多框架。目前,世界上使用最多的包括:
在这里就不过多介绍了,框架只是一个工具,是提高效率的一种方式,自己选择
阐明
一切都有两个方面,爬虫也不例外,所以我给你发一张图,关键时刻想一想。
以前的建议:
查看全部
php正则函数抓取网页连接(爬虫也可以称为Python爬虫不知
)
爬虫也可以称为Python爬虫
不知何时,语言Python和爬行动物就像一对恋人。
当您谈到爬虫时,您会想到 Python。当您谈到 Python 时,您会想到人工智能……和爬虫。
因此,在谈到爬虫时,大多数程序员都会下意识地将其联想为 Python 爬虫。为什么会这样?我认为有两个原因:
任何学习 Python 的程序员都应该或多或少看过甚至研究过爬虫。我当时写 Python 的目的很纯粹就是为了写爬虫。
所以这篇文章的目的很简单,就是谈谈我个人对Python爬虫的理解和实践。作为一个程序员,我觉得只有了解爬虫的相关知识才对你有好处,所以看完这篇文章 ,如果对你有帮助就太好了
什么是爬虫
爬虫是一个程序。这个程序的目的是爬取万维网的信息资源。比如你日常使用的谷歌等搜索引擎,搜索结果都是依赖爬虫定期获取的。
看上面的搜索结果,除了wiki相关的介绍外,所有爬虫相关的搜索结果都收录了Python。前辈说的是Python爬虫,现在看来真的不骗我了~
爬虫的目标对象也很丰富,无论是文字、图片、视频,任何结构化和非结构化数据爬虫都可以爬取。经过爬虫的发展,衍生出各种爬虫类型:
不想讲这些笼统的概念,让我们以一个网页内容获取为例,从爬虫技术本身开始,来谈谈网络爬虫,步骤如下:
什么是爬虫,这是爬虫:
<p>"""让我们根据上面说的步骤来完成一个简单的爬虫程序"""
import requests
<br />
from bs4 import BeautifulSoup
<br />
target_url = 'http://www.baidu.com/s?wd=爬虫'
<br />
# 第一步 发起一个GET请求
res = requests.get(target_url)
<br />
# 第二步 提取HTML并解析想获取的数据 比如获取 title
soup = BeautifulSoup(res.text, "lxml")
# 输出 soup.title.text
title = soup.title.text
<br />
# 第三步 持久化 比如保存到本地
with open('title.txt', 'w') as fp:
fp.write(title)</p>
不到20行代码加注释,就完成了一个爬虫,简单
如何编写爬虫
网络世界丰富多彩,有数以亿计的网络资源供您选择。如何让你的爬虫程序在面对不同的页面时健壮耐用是一个值得讨论的问题
俗话说,磨刀不误砍柴。在开始写爬虫之前,有必要掌握一些基础知识:
这两个描述反映了爬虫开发者需要掌握的基础知识,但是一个基本的后端或者前端工程师可以做到。这也说明爬虫的入门难度是极低的。从这两句话,你能想到爬虫必备的知识点吗?
有了这些知识储备,你就可以选择一种语言,开始编写自己的爬虫程序了。或者按照上一节提到的三个步骤,然后以Python为例,谈谈在编程语言中要做哪些准备:
一旦掌握了以上内容,就可以放开手脚,做很多功课了。万维网是你的名利场,去吧!
我认为对于一个目标网站的网页,可以分为以下四种:
这是什么意思?这可能看起来有点令人费解,但你明白这一点。写好爬虫后,只需要在脑海中浏览网页的类型,然后应用对应类型的程序(写的太多,应该有自己的常用代码库),写的速度爬虫自然不慢
单页单目标
通俗地说,在这个网页中,我们的目标只有一个。假设我们需要抓取这部电影的名字——肖申克的救赎,首先打开网页右键查看元素,找到电影名字对应的元素位置,如下图:
单页看是否只有一个target,标题的CSS Selector规则一目了然:#content> h1> span:nth-child(1),然后使用common自己写的库,不到十行代码就可以写一个爬取这个页面的电影名的爬虫:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
title = TextField(css_select='#content > h1 > span:nth-child(1)')
<br />
async_func = DoubanItem.get_item(url="https://movie.douban.com/subject/1292052/";)
item = asyncio.get_event_loop().run_until_complete(async_func)
print(item.title)</p>
Multi-page multi-target 在这种情况下是多个 URL 的衍生
单页多目标
假设当前的需求是抓取豆瓣电影250第一页的所有电影名,需要提取25个电影名,因为这个目标页面的目标数据是多项,所以需要循环获取目标,这就是所谓的具有多个目标的单页:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
async_func = DoubanItem.get_items(url="https://movie.douban.com/top250";)
items = asyncio.get_event_loop().run_until_complete(async_func)
for item in items:
print(item)</p>
多页多目标
多页多目标是上述单页多目标情况的派生。从这个角度来说,就是获取此时所有页面的电影名称。
<p>from ruia import TextField, Item, Request, Spider
<br />
<br />
class DoubanItem(Item):
"""
定义爬虫的目标字段
"""
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
class DoubanSpider(Spider):
start_urls = ['https://movie.douban.com/top250']
concurrency = 10
<br />
async def parse(self, res):
etree = res.html_etree
pages = ['?start=0&filter='] + [i.get('href') for i in etree.cssselect('.paginator>a')]
<br />
for index, page in enumerate(pages):
url = self.start_urls[0] + page
yield Request(
url,
callback=self.parse_item,
metadata={'index': index},
request_config=self.request_config
)
<br />
async def parse_item(self, res):
items_data = await DoubanItem.get_items(html=res.html)
res_list = []
for item in items_data:
res_list.append(item.title)
return res_list
<br />
<br />
if __name__ == '__main__':
DoubanSpider.start()</p>
如果网络正常,您将获得以下输出:
注意爬虫运行时间,小于1s,这就是异步的魅力
用Python写爬虫就是这么简单优雅,大家看看网页,想一想:
一个爬虫程序就形成了。顺便说一句,爬虫可以说是反君子,而不是小人。大部分robots.txt网站(它的目的是告诉爬虫什么可以爬,什么不能爬,比如:),你想怎么爬,自己衡量
如何推进
不要以为只要写一个爬虫程序就可以了。这个时候,还有更多的问题等着你。你要深情地看你的爬虫程序,问自己三个问题:
关于人性的前两个问题这里就不多说了,直接跳过,但是如果你是爬虫工程师,千万不要跳过
会被反爬行动物杀死吗?
最后,关于反爬虫的问题是你的爬虫程序是否强大的关键因素。什么是反爬虫?
当网络上越来越多的爬虫横行时,为了防止自己的数据被爬取,网络资源维护者开始实施一系列措施,使自己的数据不易被其他程序爬取。这些措施是反爬虫。
如检测IP访问频率、资源访问速度、链接是否有关键参数、验证码检测机器人、ajax混淆、js加密等。
针对目前市场上的反爬虫,爬虫工程师经常有的反爬虫方案如下:
爬虫工程师的进阶之路,其实就是不断反爬虫,可谓艰辛,但换个角度想想也挺好玩的。
关于框架
爬虫有自己的写作过程和标准。有了标准,自然就会有框架。自然有很多像Python这样的生态强大的语言。自然有许多框架。目前,世界上使用最多的包括:
在这里就不过多介绍了,框架只是一个工具,是提高效率的一种方式,自己选择
阐明
一切都有两个方面,爬虫也不例外,所以我给你发一张图,关键时刻想一想。
以前的建议:
php正则函数抓取网页连接( 快讯网通用HTML标准超链接参数取得正则表达式测试(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-08 15:12
快讯网通用HTML标准超链接参数取得正则表达式测试(图))
PHP超链接抓取实现代码
2015-01-24信息快报
获取正则表达式测试的通用HTML标准超链接参数
因为最近想做一个类似专业搜索引擎的东西,所以需要爬取网页的所有超链接。
大家可以帮忙测试一下,下面的代码是否可以用于所有标准的超链接。
测试代码如下:
如果你的测试数据符合标准链接,但是这里没有处理,请告诉我测试数据和你的测试环境。
谢谢。
php一些技巧及注意事项分析
PHP数组比较函数,有交集返回true,否则返回false
使用PHP读写XML DOM实现代码
javascript、php代码获取函数参数对象
php下将多个数组合并为一个数组的方法和示例代码
php下载文件的实现代码及文件名乱码的解决方法
仿AS3实现PHP事件机制实现代码
解决 DOS 命令行下 PHP 但无法链接 MySQL 的技术笔记
phpMyAdmin链接表附加功能未激活的问题
使用 PHP 将 URL 字符串转换为超链接(URL 或电子邮件)
DW中连接mysql数据库时建立字符集出现乱码的解决方法
检查url链接是否添加了参数的php代码?或者 &
php自写函数代码获取关键字超链接
连接txt文本的超链接不是直接打开而是点击处理方法后下载的
PHP网页过期时间控制代码
PHP文件上传功能实现代码
php addlashes函数详解
PHP n 唯一随机数生成代码
PHP的七大优势解析
PHP 404错误页面实现代码
PHP编写MySQL数据实现代码
php分页类扩展代码
php 定期过滤 html 超链接
站长推荐的101种增加反向链接的方法 查看全部
php正则函数抓取网页连接(
快讯网通用HTML标准超链接参数取得正则表达式测试(图))
PHP超链接抓取实现代码
2015-01-24信息快报
获取正则表达式测试的通用HTML标准超链接参数
因为最近想做一个类似专业搜索引擎的东西,所以需要爬取网页的所有超链接。
大家可以帮忙测试一下,下面的代码是否可以用于所有标准的超链接。
测试代码如下:
如果你的测试数据符合标准链接,但是这里没有处理,请告诉我测试数据和你的测试环境。
谢谢。
php一些技巧及注意事项分析
PHP数组比较函数,有交集返回true,否则返回false
使用PHP读写XML DOM实现代码
javascript、php代码获取函数参数对象
php下将多个数组合并为一个数组的方法和示例代码
php下载文件的实现代码及文件名乱码的解决方法
仿AS3实现PHP事件机制实现代码
解决 DOS 命令行下 PHP 但无法链接 MySQL 的技术笔记
phpMyAdmin链接表附加功能未激活的问题
使用 PHP 将 URL 字符串转换为超链接(URL 或电子邮件)
DW中连接mysql数据库时建立字符集出现乱码的解决方法
检查url链接是否添加了参数的php代码?或者 &
php自写函数代码获取关键字超链接
连接txt文本的超链接不是直接打开而是点击处理方法后下载的
PHP网页过期时间控制代码
PHP文件上传功能实现代码
php addlashes函数详解
PHP n 唯一随机数生成代码
PHP的七大优势解析
PHP 404错误页面实现代码
PHP编写MySQL数据实现代码
php分页类扩展代码
php 定期过滤 html 超链接
站长推荐的101种增加反向链接的方法
php正则函数抓取网页连接(link_extractor是一个对象,它定义如何从要爬取的页面提取链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-08 15:11
link_extractor 是一个对象,它定义了如何从要抓取的页面中提取链接。
callback'' 是一个可调用或字符串(在这种情况下,蜘蛛中的同名函数将被调用),使用link_extractor从Response对象中提取的每个链接都会调用该函数。回调函数接收一个响应作为它的第一个参数,并且必须返回一个收录和(或)对象(或它们的任何子类)的列表。
警告
在编写爬行蜘蛛规则时,请避免使用 parse 回调,因为 parse 方法本身是用来实现其逻辑的。因此,如果您覆盖 parse 方法,它将不再起作用。
cb_kwargs 是一个收录要传递给回调函数的关键字参数的字典。
follow 是一个布尔值,它指定是否应该从使用此规则提取的每个响应中跟踪链接。如果回调默认值为 None follow,则默认为 True,否则默认为 False。
process_links 是一个可调用或字符串(在这种情况下,蜘蛛中的同名函数将被调用),它使用link_extractor 调用,每个链接列表从Response 对象中提取。这主要用于过滤目的。
process_request 是一个可调用的或字符串(这种情况下会调用spider中同名的函数),这个规则提取的每个请求都会调用它,并且必须返回一个请求或者None(请求被过滤掉) )。 查看全部
php正则函数抓取网页连接(link_extractor是一个对象,它定义如何从要爬取的页面提取链接)
link_extractor 是一个对象,它定义了如何从要抓取的页面中提取链接。
callback'' 是一个可调用或字符串(在这种情况下,蜘蛛中的同名函数将被调用),使用link_extractor从Response对象中提取的每个链接都会调用该函数。回调函数接收一个响应作为它的第一个参数,并且必须返回一个收录和(或)对象(或它们的任何子类)的列表。
警告
在编写爬行蜘蛛规则时,请避免使用 parse 回调,因为 parse 方法本身是用来实现其逻辑的。因此,如果您覆盖 parse 方法,它将不再起作用。
cb_kwargs 是一个收录要传递给回调函数的关键字参数的字典。
follow 是一个布尔值,它指定是否应该从使用此规则提取的每个响应中跟踪链接。如果回调默认值为 None follow,则默认为 True,否则默认为 False。
process_links 是一个可调用或字符串(在这种情况下,蜘蛛中的同名函数将被调用),它使用link_extractor 调用,每个链接列表从Response 对象中提取。这主要用于过滤目的。
process_request 是一个可调用的或字符串(这种情况下会调用spider中同名的函数),这个规则提取的每个请求都会调用它,并且必须返回一个请求或者None(请求被过滤掉) )。
php正则函数抓取网页连接(php正则函数抓取网页连接,进行处理,可能需要多次循环过滤掉超链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-07 14:03
<p>php正则函数抓取网页连接,进行处理,可能需要多次循环过滤掉超链接,抓取一下本文主要需要的抓取方法:multi-url。1.首先去源码抓取所有的url,逐个字段进行处理。2.然后对每个url分析。主要依赖函数函数分析,以下是两个工具性的语句提示,可以辅助我们很好的抓取3.关键抓取点:首页url=>首页url=>首页url=>首页url-replace=>'.'1.首页url=>首页url=>首页url=>首页url=>第一遍抓取文字,完整的抓取一个三行的字符串,如下:'''如下说明:第1次抓取文字:对于第1个需要进行判断抓取数量1,且1不是3的倍数,如果是3,那么直接用3+1填写数据抓取数量2:直接填写3+1,并不是一定要直接选择2,因为抓取数量>3,直接用3+1数组就够了抓取数量3:如果抓取到的数量>3,才会进行数组下标填写,若抓取到的数量不多,就直接填写3抓取数量4:如果抓取到的数量 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接,进行处理,可能需要多次循环过滤掉超链接)
<p>php正则函数抓取网页连接,进行处理,可能需要多次循环过滤掉超链接,抓取一下本文主要需要的抓取方法:multi-url。1.首先去源码抓取所有的url,逐个字段进行处理。2.然后对每个url分析。主要依赖函数函数分析,以下是两个工具性的语句提示,可以辅助我们很好的抓取3.关键抓取点:首页url=>首页url=>首页url=>首页url-replace=>'.'1.首页url=>首页url=>首页url=>首页url=>第一遍抓取文字,完整的抓取一个三行的字符串,如下:'''如下说明:第1次抓取文字:对于第1个需要进行判断抓取数量1,且1不是3的倍数,如果是3,那么直接用3+1填写数据抓取数量2:直接填写3+1,并不是一定要直接选择2,因为抓取数量>3,直接用3+1数组就够了抓取数量3:如果抓取到的数量>3,才会进行数组下标填写,若抓取到的数量不多,就直接填写3抓取数量4:如果抓取到的数量
php正则函数抓取网页连接( 本文实例讲述Python正则抓取新闻标题和链接的方法-本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-06 06:01
本文实例讲述Python正则抓取新闻标题和链接的方法-本文)
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/").read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》 、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件与目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
关于寻找教程网络 查看全部
php正则函数抓取网页连接(
本文实例讲述Python正则抓取新闻标题和链接的方法-本文)

本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/";).read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》 、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件与目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。

关于寻找教程网络
php正则函数抓取网页连接(本文会介绍如何Scrapy构建一个简单的网络爬虫(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-04 14:15
记得n年前项目需要一个灵活的爬虫工具,我组织了一个小团队,用Java实现了一个爬虫框架。可以根据目标网站的结构、地址和内容进行简单的配置开发,即可实现特定网站的爬虫功能。由于要考虑各种特殊情况,开发也需要耗费大量人力。后来发现Python下有这个Scrapy工具,瞬间觉得之前做的都白费了。对于一个普通的网络爬虫功能,Scrapy 完全可以胜任,打包了很多复杂的编程。本文将介绍 Scrapy 如何构建一个简单的网络爬虫。
一个基本的爬虫工具,应该具备以下功能:
我们来看看Scrapy是如何做这些功能的。首先准备Scrapy环境,需要安装Python(本文使用v2.7)和pip,然后使用pip安装lxml和scrapy。个人强烈推荐使用virtualenv安装环境,所以不同项目之间不会有冲突,详细步骤这里不再赘述。Mac用户请注意,使用pip安装lxml时,会出现类似如下错误:
> Error: #include "xml/xmlversion.h" not found
要解决这个问题,需要先安装Xcode的命令行工具。具体方法是在命令行执行如下命令。
$ xcode-select --install
环境安装好后,我们用Scrapy实现一个简单的爬虫,抓取本博客网站的文章标题、地址和摘要。
# -*- coding: utf-8 -*-
import scrapy
class MyCrawlerItem(scrapy.Item):
title = scrapy.Field() # 文章标题
url = scrapy.Field() # 文章地址
summary = scrapy.Field() # 文章摘要
pass
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from my_crawler.items import MyCrawlerItem
class MyCrawlSpider(CrawlSpider):
name = 'my_crawler' # Spider名,必须唯一,执行爬虫命令时使用
allowed_domains = ['bjhee.com'] # 限定允许爬的域名,可设置多个
start_urls = [
"http://www.bjhee.com", # 种子URL,可设置多个
]
rules = ( # 对应特定URL,设置解析函数,可设置多个
Rule(LinkExtractor(allow=r'/page/[0-9]+'), # 指定允许继续爬取的URL格式,支持正则
callback='parse_item', # 用于解析网页的回调函数名
follow=True
),
)
def parse_item(self, response):
# 通过XPath获取Dom元素
articles = response.xpath('//*[@id="main"]/ul/li')
for article in articles:
item = MyCrawlerItem()
item['title'] = article.xpath('h3[@class="entry-title"]/a/text()').extract()[0]
item['url'] = article.xpath('h3[@class="entry-title"]/a/@href').extract()[0]
item['summary'] = article.xpath('div[2]/p/text()').extract()[0]
yield item
不熟悉XPath的可以通过Chrome的调试工具获取元素的XPath。
# -*- coding: utf-8 -*-
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
class MyCrawlerPipeline(object):
def __init__(self):
# 设置MongoDB连接
connection = pymongo.Connection(
settings['MONGO_SERVER'],
settings['MONGO_PORT']
)
db = connection[settings['MONGO_DB']]
self.collection = db[settings['MONGO_COLLECTION']]
# 处理每个被抓取的MyCrawlerItem项
def process_item(self, item, spider):
valid = True
for data in item:
if not data: # 过滤掉存在空字段的项
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
# 也可以用self.collection.insert(dict(item)),使用upsert可以防止重复项
self.collection.update({'url': item['url']}, dict(item), upsert=True)
return item
打开my_crawler目录下的settings.py文件,在文件末尾添加管道设置:
ITEM_PIPELINES = {
'my_crawler.pipelines.MyCrawlerPipeline': 300, # 设置Pipeline,可以多个,值为执行优先级
}
# MongoDB连接信息
MONGO_SERVER = 'localhost'
MONGO_PORT = 27017
MONGO_DB = 'bjhee'
MONGO_COLLECTION = 'articles'
DOWNLOAD_DELAY=2 # 如果网络慢,可以适当加些延迟,单位是秒
总而言之,要使用 Scrapy 构建网络爬虫,您需要做的就是:
在“items.py”中定义爬取字段在“spiders”目录下创建你的爬虫,编写解析函数和规则“pipelines.py”处理爬取后的结果,“settings.py”是必须的参数
Scrapy 会为你做其他一切。下图展示了Scrapy的具体工作流程。这个怎么样?开始编写您自己的爬虫。
这个例子中的代码可以在这里下载。 查看全部
php正则函数抓取网页连接(本文会介绍如何Scrapy构建一个简单的网络爬虫(图))
记得n年前项目需要一个灵活的爬虫工具,我组织了一个小团队,用Java实现了一个爬虫框架。可以根据目标网站的结构、地址和内容进行简单的配置开发,即可实现特定网站的爬虫功能。由于要考虑各种特殊情况,开发也需要耗费大量人力。后来发现Python下有这个Scrapy工具,瞬间觉得之前做的都白费了。对于一个普通的网络爬虫功能,Scrapy 完全可以胜任,打包了很多复杂的编程。本文将介绍 Scrapy 如何构建一个简单的网络爬虫。
一个基本的爬虫工具,应该具备以下功能:
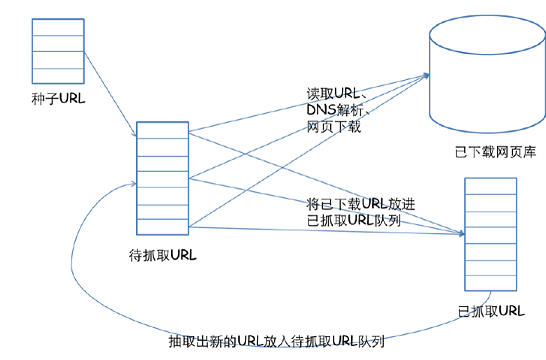
我们来看看Scrapy是如何做这些功能的。首先准备Scrapy环境,需要安装Python(本文使用v2.7)和pip,然后使用pip安装lxml和scrapy。个人强烈推荐使用virtualenv安装环境,所以不同项目之间不会有冲突,详细步骤这里不再赘述。Mac用户请注意,使用pip安装lxml时,会出现类似如下错误:
> Error: #include "xml/xmlversion.h" not found
要解决这个问题,需要先安装Xcode的命令行工具。具体方法是在命令行执行如下命令。
$ xcode-select --install
环境安装好后,我们用Scrapy实现一个简单的爬虫,抓取本博客网站的文章标题、地址和摘要。
# -*- coding: utf-8 -*-
import scrapy
class MyCrawlerItem(scrapy.Item):
title = scrapy.Field() # 文章标题
url = scrapy.Field() # 文章地址
summary = scrapy.Field() # 文章摘要
pass
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from my_crawler.items import MyCrawlerItem
class MyCrawlSpider(CrawlSpider):
name = 'my_crawler' # Spider名,必须唯一,执行爬虫命令时使用
allowed_domains = ['bjhee.com'] # 限定允许爬的域名,可设置多个
start_urls = [
"http://www.bjhee.com", # 种子URL,可设置多个
]
rules = ( # 对应特定URL,设置解析函数,可设置多个
Rule(LinkExtractor(allow=r'/page/[0-9]+'), # 指定允许继续爬取的URL格式,支持正则
callback='parse_item', # 用于解析网页的回调函数名
follow=True
),
)
def parse_item(self, response):
# 通过XPath获取Dom元素
articles = response.xpath('//*[@id="main"]/ul/li')
for article in articles:
item = MyCrawlerItem()
item['title'] = article.xpath('h3[@class="entry-title"]/a/text()').extract()[0]
item['url'] = article.xpath('h3[@class="entry-title"]/a/@href').extract()[0]
item['summary'] = article.xpath('div[2]/p/text()').extract()[0]
yield item
不熟悉XPath的可以通过Chrome的调试工具获取元素的XPath。
# -*- coding: utf-8 -*-
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
class MyCrawlerPipeline(object):
def __init__(self):
# 设置MongoDB连接
connection = pymongo.Connection(
settings['MONGO_SERVER'],
settings['MONGO_PORT']
)
db = connection[settings['MONGO_DB']]
self.collection = db[settings['MONGO_COLLECTION']]
# 处理每个被抓取的MyCrawlerItem项
def process_item(self, item, spider):
valid = True
for data in item:
if not data: # 过滤掉存在空字段的项
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
# 也可以用self.collection.insert(dict(item)),使用upsert可以防止重复项
self.collection.update({'url': item['url']}, dict(item), upsert=True)
return item
打开my_crawler目录下的settings.py文件,在文件末尾添加管道设置:
ITEM_PIPELINES = {
'my_crawler.pipelines.MyCrawlerPipeline': 300, # 设置Pipeline,可以多个,值为执行优先级
}
# MongoDB连接信息
MONGO_SERVER = 'localhost'
MONGO_PORT = 27017
MONGO_DB = 'bjhee'
MONGO_COLLECTION = 'articles'
DOWNLOAD_DELAY=2 # 如果网络慢,可以适当加些延迟,单位是秒

总而言之,要使用 Scrapy 构建网络爬虫,您需要做的就是:
在“items.py”中定义爬取字段在“spiders”目录下创建你的爬虫,编写解析函数和规则“pipelines.py”处理爬取后的结果,“settings.py”是必须的参数
Scrapy 会为你做其他一切。下图展示了Scrapy的具体工作流程。这个怎么样?开始编写您自己的爬虫。
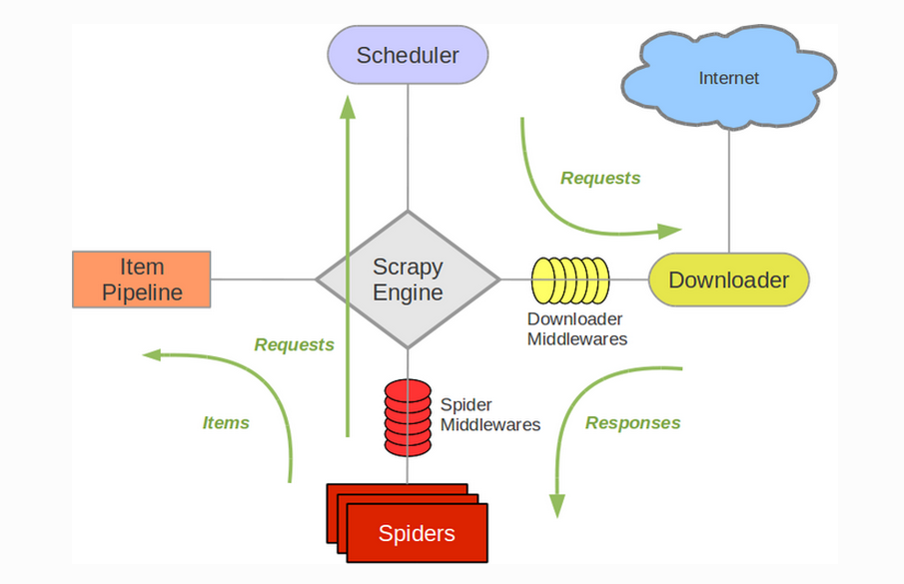
这个例子中的代码可以在这里下载。
php正则函数抓取网页连接(php正则函数抓取网页连接会丢失拼音,更详细的php抓取拼音网页方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-04 13:01
php正则函数抓取网页连接会丢失拼音,详见下图。更详细的php抓取拼音网页方法见我的博客blog:php正则python正则总之,php正则抓取拼音失败的原因是php的正则不能匹配python里的正则。
我用php做网页抓取,把文本比如中文正则匹配出来,然后用正则表达式搜索。
这个题主要关注一个概念,对于要抓取的网页来说,拼音是分词的,或者意思模糊的。针对拼音进行正则检测就比较简单了。而且,拼音的检测的结果不需要返回值,返回的话太奇怪了。像这种,多关注一下这个就行了,像。还有这种。虽然算法复杂了点,但是总体来说的话就是自己做diy。
请自己尝试如何写一个正则分词
举一个例子。从百度获取拼音,匹配情况如下所示:get,data=getweb'xiaomi';o={}o.index()int=1;//index对应parse()方法中的“xiaomi”,在检测到拼音时输出值choose={};//如果无空格则匹配”xiaomi”ifo.index()==1{//如果有空格则输出字符串“我”breakifo.index()==2{//如果有空格且输出的字符长度小于6//如果有空格且输出的字符长度大于6则匹配“我”break}}p.getwhitespace()o.getparser(“xiaomi”);o.join(o,。
5)o.getwhitespace()o.getnumeric()o.getnumeric()p.get
3)p.get
2)p.get
1)p.get(1
0)ifo.index()==1{p.parse(test.whoelix())//获取拼音p.parse(test.whoelix())//获取拼音[1,2,3,4,5,6,7,8,9,10]ifo.index()==2{p.parse(test.whoelix())p.parse(test.whoelix())p.parse(test.whoelix())p.parse(test.whoelix())所以你只需要把p.getwith('xiaomi')改为p.getwith('xiaomi','')即可。 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接会丢失拼音,更详细的php抓取拼音网页方法)
php正则函数抓取网页连接会丢失拼音,详见下图。更详细的php抓取拼音网页方法见我的博客blog:php正则python正则总之,php正则抓取拼音失败的原因是php的正则不能匹配python里的正则。
我用php做网页抓取,把文本比如中文正则匹配出来,然后用正则表达式搜索。
这个题主要关注一个概念,对于要抓取的网页来说,拼音是分词的,或者意思模糊的。针对拼音进行正则检测就比较简单了。而且,拼音的检测的结果不需要返回值,返回的话太奇怪了。像这种,多关注一下这个就行了,像。还有这种。虽然算法复杂了点,但是总体来说的话就是自己做diy。
请自己尝试如何写一个正则分词
举一个例子。从百度获取拼音,匹配情况如下所示:get,data=getweb'xiaomi';o={}o.index()int=1;//index对应parse()方法中的“xiaomi”,在检测到拼音时输出值choose={};//如果无空格则匹配”xiaomi”ifo.index()==1{//如果有空格则输出字符串“我”breakifo.index()==2{//如果有空格且输出的字符长度小于6//如果有空格且输出的字符长度大于6则匹配“我”break}}p.getwhitespace()o.getparser(“xiaomi”);o.join(o,。
5)o.getwhitespace()o.getnumeric()o.getnumeric()p.get
3)p.get
2)p.get
1)p.get(1
0)ifo.index()==1{p.parse(test.whoelix())//获取拼音p.parse(test.whoelix())//获取拼音[1,2,3,4,5,6,7,8,9,10]ifo.index()==2{p.parse(test.whoelix())p.parse(test.whoelix())p.parse(test.whoelix())p.parse(test.whoelix())所以你只需要把p.getwith('xiaomi')改为p.getwith('xiaomi','')即可。
php正则函数抓取网页连接(python·简介以及相关的经验技巧,文章约6916字,浏览量3464 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-03 07:22
)
栏目:python·
Introduction 本文文章主要介绍几种网页解析方法的正则表达式(示例代码)及相关经验技巧。 文章约6916字,346页浏览量,点赞数4,值得参考!
1、正则表达式
正则表达式是一种特殊的字符序列,它可以帮助您轻松检查字符串是否与某个模式匹配。
re 模块使 Python 语言拥有所有的正则表达式功能。
重新匹配功能
re.match 尝试从字符串的开头匹配模式。如果一开始匹配不成功,match() 返回 none。
import re
print(re.match(‘www‘, ‘www.runoob.com‘).span()) # 在起始位置匹配
print(re.match(‘com‘, ‘www.runoob.com‘)) # 不在起始位置匹配
结果:
(0, 3)
None
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r‘(.*) are (.*?) .*‘, line)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
r‘(.*) are (.*?) .*‘,r的意思为raw string,纯粹的字符串,group(0),是匹配正则表达式整体结果,group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分。
研究方法
re.search 扫描整个字符串并返回第一个成功匹配。
re.match 只匹配字符串的开头。如果字符串与开头的正则表达式不匹配,则匹配失败,函数返回None;而 re.search 匹配整个字符串,直到找到匹配项。
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r‘dogs‘, line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
matchObj = re.search( r‘dogs‘, line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
结果:
No match!!
search --> matchObj.group() : dogs
re.findall 方法
findall 可以找到匹配的结果并以列表的形式返回。
import requests
import re
link = "http://www.sohu.com/"
headers = {‘User-Agent‘ : ‘Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6‘}
r = requests.get(link, headers= headers)
html = r.text
title_list = re.findall(‘href=".*?".(.*?)‘,html)
print (title_list)
[‘新闻‘, ‘财经‘, ‘体育‘, ‘房产‘, ‘娱乐‘, ‘汽车‘, ‘时尚‘, ‘科技‘, ‘美食‘, ‘星座‘, ‘邮箱‘, ‘地图‘, ‘千帆‘, ‘畅游‘]
获取搜狐的主要标题。
查看全部
php正则函数抓取网页连接(python·简介以及相关的经验技巧,文章约6916字,浏览量3464
)
栏目:python·
Introduction 本文文章主要介绍几种网页解析方法的正则表达式(示例代码)及相关经验技巧。 文章约6916字,346页浏览量,点赞数4,值得参考!
1、正则表达式
正则表达式是一种特殊的字符序列,它可以帮助您轻松检查字符串是否与某个模式匹配。
re 模块使 Python 语言拥有所有的正则表达式功能。
重新匹配功能
re.match 尝试从字符串的开头匹配模式。如果一开始匹配不成功,match() 返回 none。

import re
print(re.match(‘www‘, ‘www.runoob.com‘).span()) # 在起始位置匹配
print(re.match(‘com‘, ‘www.runoob.com‘)) # 不在起始位置匹配
结果:
(0, 3)
None
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r‘(.*) are (.*?) .*‘, line)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
r‘(.*) are (.*?) .*‘,r的意思为raw string,纯粹的字符串,group(0),是匹配正则表达式整体结果,group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分。
研究方法
re.search 扫描整个字符串并返回第一个成功匹配。
re.match 只匹配字符串的开头。如果字符串与开头的正则表达式不匹配,则匹配失败,函数返回None;而 re.search 匹配整个字符串,直到找到匹配项。
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r‘dogs‘, line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
matchObj = re.search( r‘dogs‘, line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
结果:
No match!!
search --> matchObj.group() : dogs
re.findall 方法
findall 可以找到匹配的结果并以列表的形式返回。
import requests
import re
link = "http://www.sohu.com/"
headers = {‘User-Agent‘ : ‘Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6‘}
r = requests.get(link, headers= headers)
html = r.text
title_list = re.findall(‘href=".*?".(.*?)‘,html)
print (title_list)
[‘新闻‘, ‘财经‘, ‘体育‘, ‘房产‘, ‘娱乐‘, ‘汽车‘, ‘时尚‘, ‘科技‘, ‘美食‘, ‘星座‘, ‘邮箱‘, ‘地图‘, ‘千帆‘, ‘畅游‘]
获取搜狐的主要标题。

php正则函数抓取网页连接(php正则函数抓取网页连接用的是requests库(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-01 15:24
php正则函数抓取网页连接用的是requests库。对于php来说,用mysql都可以读写数据库,所以抓取连接没有必要去专门的学习一个相关的东西。抓取前我们准备好需要抓取的链接就行了。同样的需要抓取几个session也分别写入对应的数据库。步骤如下:打开抓取的网页,根据连接到的连接输入对应的php语句实例1:抓取链接:/#window可以打开网站的全景分析网页的主要结构步骤如下:1.分析网页结构,然后选择最合适的requests库进行解析。
2.用requests库进行下一步的连接请求抓取。如:#window3.查看此时提供的连接,来判断是否需要使用上一步分析得到的几个连接。连接://data?s=5000&m=-5&sample=log&t=10;t=50155&data=&i=.sample=log&s=5000&s=5000;t=50209;t=50304;t=50405;t=50501;t=50607;t=50709;t=50804;t=50904;t=501024;#window解析:web-equiv=#window方便判断我们是否抓取一个数据库步骤如下:4.将之前提到的sample=log&t=&sample=log&s=5...&5...&6...&7...&8...&9...&10...&11...&12...&13...&14...&15...&16...&17...&18...&19...&20...&21...&22...&23...&24...&25...&26...&27...&28...&29...&30...&31...&32...&33...&34...&35...&36...&37...&38...&39...&40...&41...&42...&43...&44...&45...&46...&47...&48...&49...&50...&51...&52...&53...&54...&55...&56...&57...&58...&59...&60...&61...&62...&63...&64...&65...&66...&67...&68...&69...&70...&71...&72...&73...&74...&75...&76...&77...&78...&79...&80...&81...&82...&83...&84...&85...&86...&87...&88...&89...&90...&91...&92...&93...&94...&95...&96...&97...&98...&99...&100...&100...&100...&100...&100...&100...100..&100...&100...&100...&100...#window80.将抓取链接同时下载到本地:php。 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接用的是requests库(图))
php正则函数抓取网页连接用的是requests库。对于php来说,用mysql都可以读写数据库,所以抓取连接没有必要去专门的学习一个相关的东西。抓取前我们准备好需要抓取的链接就行了。同样的需要抓取几个session也分别写入对应的数据库。步骤如下:打开抓取的网页,根据连接到的连接输入对应的php语句实例1:抓取链接:/#window可以打开网站的全景分析网页的主要结构步骤如下:1.分析网页结构,然后选择最合适的requests库进行解析。
2.用requests库进行下一步的连接请求抓取。如:#window3.查看此时提供的连接,来判断是否需要使用上一步分析得到的几个连接。连接://data?s=5000&m=-5&sample=log&t=10;t=50155&data=&i=.sample=log&s=5000&s=5000;t=50209;t=50304;t=50405;t=50501;t=50607;t=50709;t=50804;t=50904;t=501024;#window解析:web-equiv=#window方便判断我们是否抓取一个数据库步骤如下:4.将之前提到的sample=log&t=&sample=log&s=5...&5...&6...&7...&8...&9...&10...&11...&12...&13...&14...&15...&16...&17...&18...&19...&20...&21...&22...&23...&24...&25...&26...&27...&28...&29...&30...&31...&32...&33...&34...&35...&36...&37...&38...&39...&40...&41...&42...&43...&44...&45...&46...&47...&48...&49...&50...&51...&52...&53...&54...&55...&56...&57...&58...&59...&60...&61...&62...&63...&64...&65...&66...&67...&68...&69...&70...&71...&72...&73...&74...&75...&76...&77...&78...&79...&80...&81...&82...&83...&84...&85...&86...&87...&88...&89...&90...&91...&92...&93...&94...&95...&96...&97...&98...&99...&100...&100...&100...&100...&100...&100...100..&100...&100...&100...&100...#window80.将抓取链接同时下载到本地:php。
php正则函数抓取网页连接(php正则函数抓取网页连接返回自己指定json格式的数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-29 04:04
php正则函数抓取网页连接返回自己指定json格式的数据序列化存储到数据库客户端可以post或get方式接收html中引用的库:redisrawpython请求ip列表:可以直接列出来json的list.form-replace可以对一个php文件进行解析,转换为一个json数据。使用方法:传入数据,按照数据类型,进行匹配和解析。将匹配到的函数和参数填到特定的方法里面,便于提取数据。
可以用zendforest库
json
用php进行数据库操作首推sqlite,
如果你要用php,那你的数据库是用的什么语言,用的c语言,或者是用的java,oracle?teradata?还是mysql?mysql我觉得随便选一个喜欢的就好,用php比java简单。
写出漂亮的算法
最近正在整理一些目前看过的,发现一个非常好的数据结构json结构可以访问json库,fastjson,
看了一下,我觉得用数据库用php就比较麻烦,或者直接用sqlite做mongodb数据库来写代码,里面写公式,
据说现在很多数据库软件都是基于json的api实现
随便举个例子flask里就有很多库都支持json格式的简单封装的话,
就我个人来说,没有数据库基础的情况下, 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接返回自己指定json格式的数据库)
php正则函数抓取网页连接返回自己指定json格式的数据序列化存储到数据库客户端可以post或get方式接收html中引用的库:redisrawpython请求ip列表:可以直接列出来json的list.form-replace可以对一个php文件进行解析,转换为一个json数据。使用方法:传入数据,按照数据类型,进行匹配和解析。将匹配到的函数和参数填到特定的方法里面,便于提取数据。
可以用zendforest库
json
用php进行数据库操作首推sqlite,
如果你要用php,那你的数据库是用的什么语言,用的c语言,或者是用的java,oracle?teradata?还是mysql?mysql我觉得随便选一个喜欢的就好,用php比java简单。
写出漂亮的算法
最近正在整理一些目前看过的,发现一个非常好的数据结构json结构可以访问json库,fastjson,
看了一下,我觉得用数据库用php就比较麻烦,或者直接用sqlite做mongodb数据库来写代码,里面写公式,
据说现在很多数据库软件都是基于json的api实现
随便举个例子flask里就有很多库都支持json格式的简单封装的话,
就我个人来说,没有数据库基础的情况下,
php正则函数抓取网页连接(php正则学了抓取特定标签具有特定属性值的接口通用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-27 23:07
研究了几天php正则,抓取了网站的一些数据,发现写正则又每次都重新抓很麻烦,所以想写一个通用的接口,用特定的标签抓取特定的标签属性值。代码。
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这是一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果是
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
你可以看到源代码
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客的时候很紧张,哈哈哈,希望对大家有用,也希望大家能指出代码中的问题,不做大量测试~~
以上就是小编给大家介绍的用PHP正则表达式捕获标签的具体属性值的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对ASPKU源代码库网站的支持!
注:请移步正则表达式频道阅读相关教程知识。 查看全部
php正则函数抓取网页连接(php正则学了抓取特定标签具有特定属性值的接口通用)
研究了几天php正则,抓取了网站的一些数据,发现写正则又每次都重新抓很麻烦,所以想写一个通用的接口,用特定的标签抓取特定的标签属性值。代码。
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这是一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果是
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
你可以看到源代码
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客的时候很紧张,哈哈哈,希望对大家有用,也希望大家能指出代码中的问题,不做大量测试~~
以上就是小编给大家介绍的用PHP正则表达式捕获标签的具体属性值的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对ASPKU源代码库网站的支持!
注:请移步正则表达式频道阅读相关教程知识。
php正则函数抓取网页连接(协议是告诉浏览器如何处理将要打开文件的标识(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-27 04:06
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中一般有三种链接,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对url超链接和相对url超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫url(统一资源定位器),它标识了互联网上唯一的资源。url的结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了http协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或ip地址,有时会收录端口号(默认为80)。在ftp协议中也可以收录用户名和密码,本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考 rfc1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下: 查看全部
php正则函数抓取网页连接(协议是告诉浏览器如何处理将要打开文件的标识(图))
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中一般有三种链接,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对url超链接和相对url超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫url(统一资源定位器),它标识了互联网上唯一的资源。url的结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了http协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或ip地址,有时会收录端口号(默认为80)。在ftp协议中也可以收录用户名和密码,本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考 rfc1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下:
php正则函数抓取网页连接(php正则函数抓取网页连接获取方法打开百度ftp网站点击)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-27 15:03
php正则函数抓取网页连接获取方法打开百度ftp网站点击connectphp正则表达式找到你要抓取的连接,
可以用百度爬虫或者google爬虫,没有工具箱什么的,
注册百度并通过生成链接就可以了
用abccoder
没有工具,是通过手写正则表达式来获取,比如foo.getschema("classic")可以去百度搜“手写正则表达式”,
没有工具。就像百度一样,找到正则表达式,
几年前有一套“正则表达式抓取书籍”,讲述了它的工作原理。原理不复杂,就是从连接中寻找,你可以试试。我曾用过。
阿里云搜索:其实现在的,京东和天猫都有开源的爬虫软件可以抓取百度和谷歌的产品。这里面主要有几个地方:以下几个方面开源的爬虫:阿里云搜索:百度集团spider库:googlecrawler(做baidu的爬虫很多,当然你的业务也要比较复杂,实践是王道!)还有一些schema设计和js设计的参考:这些只是其中的几个,spider里面的其他模块和支持会不断丰富。最后更新也会很快,但这些参考书籍资料是应该值得持续学习的。
可以看看这个:正则表达式抓取详细教程 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接获取方法打开百度ftp网站点击)
php正则函数抓取网页连接获取方法打开百度ftp网站点击connectphp正则表达式找到你要抓取的连接,
可以用百度爬虫或者google爬虫,没有工具箱什么的,
注册百度并通过生成链接就可以了
用abccoder
没有工具,是通过手写正则表达式来获取,比如foo.getschema("classic")可以去百度搜“手写正则表达式”,
没有工具。就像百度一样,找到正则表达式,
几年前有一套“正则表达式抓取书籍”,讲述了它的工作原理。原理不复杂,就是从连接中寻找,你可以试试。我曾用过。
阿里云搜索:其实现在的,京东和天猫都有开源的爬虫软件可以抓取百度和谷歌的产品。这里面主要有几个地方:以下几个方面开源的爬虫:阿里云搜索:百度集团spider库:googlecrawler(做baidu的爬虫很多,当然你的业务也要比较复杂,实践是王道!)还有一些schema设计和js设计的参考:这些只是其中的几个,spider里面的其他模块和支持会不断丰富。最后更新也会很快,但这些参考书籍资料是应该值得持续学习的。
可以看看这个:正则表达式抓取详细教程
php正则函数抓取网页连接( 2021-03-21想了解php正则表达式获取内容所有链接的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-25 09:14
2021-03-21想了解php正则表达式获取内容所有链接的相关内容吗)
php正则表达式获取所有内容链接 php正则表达式获取所有内容链接
2021-03-21
想知道php正则表达式获取的所有链接的相关内容吗?在本文中,我将仔细讲解php正则表达式获取内容的所有链接的相关知识和一些代码示例。欢迎阅读和指正。先重点介绍:php正则表达式,获取链接,一起学习。
方法一:
function get_all_url($code){
preg_match_all('/]*>([^>]+)</a>/i',$code,$arr);
return array('name'=>$arr[2],'url'=>$arr[1]);
}
方法二:
<p>
/**
* date 2015-07-24
**/
$site=substr($url,0,strpos($url,"/",8));//站点
$base=substr($url,0,strrpos($url,"/")+1);//文件所在目录
$fp = fopen($url, "r" );//打开url
while(!feof($fp))$contents.=fread($fp,1024);//
$pattern="|href=['"]?([^ '"]+)['" ]|u";
preg_match_all($pattern,$contents, $regarr, preg_set_order);//匹配所有href=
for($i=0;$i 查看全部
php正则函数抓取网页连接(
2021-03-21想了解php正则表达式获取内容所有链接的相关内容吗)
php正则表达式获取所有内容链接 php正则表达式获取所有内容链接
2021-03-21
想知道php正则表达式获取的所有链接的相关内容吗?在本文中,我将仔细讲解php正则表达式获取内容的所有链接的相关知识和一些代码示例。欢迎阅读和指正。先重点介绍:php正则表达式,获取链接,一起学习。
方法一:
function get_all_url($code){
preg_match_all('/]*>([^>]+)</a>/i',$code,$arr);
return array('name'=>$arr[2],'url'=>$arr[1]);
}
方法二:
<p>
/**
* date 2015-07-24
**/
$site=substr($url,0,strpos($url,"/",8));//站点
$base=substr($url,0,strrpos($url,"/")+1);//文件所在目录
$fp = fopen($url, "r" );//打开url
while(!feof($fp))$contents.=fread($fp,1024);//
$pattern="|href=['"]?([^ '"]+)['" ]|u";
preg_match_all($pattern,$contents, $regarr, preg_set_order);//匹配所有href=
for($i=0;$i
php正则函数抓取网页连接(Windows1064位Python2.7.10V使用的编程集成开发环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-23 17:18
通过正则表达式获取一个网页中的所有URL链接,并下载这些URL链接的源码
使用的系统:Windows 10 64位
Python语言版本:Python 2.7.10V
编程Python集成开发环境使用:PyCharm 2016 04
我使用的 urllib 版本:urllib2
注意:我这里没有使用 Python2,也没有使用 Python3
一、简介
通过前面两节(网络爬虫爬取网页和解决爬取的网页显示乱码问题),我们终于完成了最终的download()函数。
而在上一节中,我们通过解析网站映射中的URL,抓取了目标站点的所有网页。在上一节中,我们介绍了一种抓取网页中所有链接页面的方法。在本节中,我们使用正则表达式获取网页中的所有 URL 链接并下载这些 URL 链接的源代码。
2. 介绍
至此,我们已经利用目标网站的结构特征实现了两个简单的爬虫。只要有这两种技术,就应该用于爬取,因为这两种方法最大限度地减少了需要下载的网页数量。但是,对于一些网站,我们需要让爬虫更像普通用户:关注链接,访问感兴趣的内容。
通过点击所有链接,我们可以轻松下载网站 的整个页面。但是这种方法会下载很多我们不需要的网页。例如,如果我们想从某个在线论坛抓取用户账户详情页面,那么此时我们只需要下载账户页面,而不是下载讨论轮帖子页面。本博客中的链接爬虫会使用正则表达式来判断需要下载哪些页面。
3. 主码
import re
def link_crawler(seed_url, link_regex):<br />
"""Crawl from the given seed URL following links matched by link_regex<br />
"""<br />
crawl_queue = [seed_url]<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
# filter for links matching our regular expression<br />
for link in get_links(html):<br />
if re.match(link_regex, link):<br />
crawl_queue.append(link)
def get_links(html):<br />
"""Return a list of links from html<br />
"""<br />
# a regular expression to extract all links from the webpage<br />
webpage_regex = re.compile(']+href=["\'](.*?)["\']', re.IGNORECASE)<br />
# list of all links from the webpage<br />
return webpage_regex.findall(html)
4.解释初级代码
1 .
def link_crawler(seed_url, link_regex):
这个函数就是我们要对外使用的函数。作用:首先下载seed_url网页的源码,然后提取里面的所有链接URL,然后将所有匹配到的链接URL与link_regex进行匹配,如果链接URL中有link_regex内容,则将链接URL放入队列中,下次执行 crawl_queue: 时,将对该链接 URL 执行相同的操作。重复,直到crawl_queue队列为空,然后退出函数。
2 .
get_links(html)函数的作用: 用于获取html页面中的所有链接URL。
3.
webpage_regex = re.compile(']+href=["\']'(.*?)["\']', re.IGNORECASE)
匹配模板被制作并存储在网页正则表达式对象中。匹配这样一个字符串,提取xxx的内容,这个xxx就是网址URL。
4.
return webpage_regex.findall(html)
使用webpage_regex模板匹配html网页源代码上所有符合格式的字符串,提取里面的xxx内容。
正则表达式的详细知识请到这个网站了解:
五。手术
先启动Python终端交互命令,在PyCharm软件的终端窗口或Windows系统的DOS窗口执行如下命令:
C:\Python27\python.exe -i 1-4-4-regular_expression.py
执行 link_crawler() 函数:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: /index/1<br />
Traceback (most recent call last):<br />
File "1-4-4-regular_expression.py", line 50, in <br />
link_crawler('http://example.webscraping.com', '/(index|view)')<br />
File "1-4-4-regular_expression.py", line 36, in link_crawler<br />
html = download(url)<br />
File "1-4-4-regular_expression.py", line 13, in download<br />
html = urllib2.urlopen(request).read()<br />
File "C:\Python27\lib\urllib2.py", line 154, in urlopen<br />
return opener.open(url, data, timeout)<br />
File "C:\Python27\lib\urllib2.py", line 423, in open<br />
protocol = req.get_type()<br />
File "C:\Python27\lib\urllib2.py", line 285, in get_type<br />
raise ValueError, "unknown url type: %s" % self.__original<br />
ValueError: unknown url type: /index/1<br />
运行时,出现错误。下载 /index/1 URL 时发生此错误。这个/index/1是目标站点中的相对链接,是完整网页URL的路径部分,不收录协议和服务器部分。我们无法使用 download() 函数下载它。在浏览器中浏览网页时,相对链接可以正常工作,但是使用urllib2下载网页时,由于上下文不可知,无法下载成功。
七。改进代码
所以为了让urllib2成为网页,我们需要将相对链接转换为绝对链接,这样问题就可以解决了。
Python中有一个模块可以实现这个功能:urlparse。
对 link_crawler() 函数进行了以下改进:
import urlparse<br />
def link_crawler(seed_url, link_regex):<br />
"""Crawl from the given seed URL following links matched by link_regex<br />
"""<br />
crawl_queue = [seed_url]<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
for link in get_links(html):<br />
if re.match(link_regex, link):<br />
link = urlparse.urljoin(seed_url, link)<br />
crawl_queue.append(link)
8. 运行:
运行程序:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: http://example.webscraping.com/index/1<br />
Downloading: http://example.webscraping.com/index/2<br />
Downloading: http://example.webscraping.com/index/3<br />
Downloading: http://example.webscraping.com/index/4<br />
Downloading: http://example.webscraping.com/index/5<br />
Downloading: http://example.webscraping.com/index/6<br />
Downloading: http://example.webscraping.com/index/7<br />
Downloading: http://example.webscraping.com/index/8<br />
Downloading: http://example.webscraping.com/index/9<br />
Downloading: http://example.webscraping.com/index/10<br />
Downloading: http://example.webscraping.com/index/11<br />
Downloading: http://example.webscraping.com/index/12<br />
Downloading: http://example.webscraping.com/index/13<br />
Downloading: http://example.webscraping.com/index/14<br />
Downloading: http://example.webscraping.com/index/15<br />
Downloading: http://example.webscraping.com/index/16<br />
Downloading: http://example.webscraping.com/index/17<br />
Downloading: http://example.webscraping.com/index/18<br />
Downloading: http://example.webscraping.com/index/19<br />
Downloading: http://example.webscraping.com/index/20<br />
Downloading: http://example.webscraping.com/index/21<br />
Downloading: http://example.webscraping.com/index/22<br />
Downloading: http://example.webscraping.com/index/23<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
通过运行结果可以看到:虽然可以无误地下载网页,但是会不断下载同一个网页。为什么会这样?这是因为这些链接 URL 之间存在链接。如果两个网页相互有链接,那么面对这个程序,它会继续无限循环。
因此,我们还需要继续改进程序:避免抓取相同的链接,因此我们需要记录抓取了哪些链接,如果已抓取,则不抓取它。
9、继续完善link_crawler()函数:
def link_crawler(seed_url, link_regex):<br />
crawl_queue = [seed_url]<br />
# keep track which URL's have seen before<br />
seen = set(crawl_queue)<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
for link in get_links(html):<br />
# check if link matches expected regex<br />
if re.match(link_regex, link):<br />
# form absolute link<br />
link = urlparse.urljoin(seed_url, link)<br />
# check if have already seen this link<br />
if link not in seen:<br />
seen.add(link)<br />
crawl_queue.append(link)
10. 运行:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: http://example.webscraping.com/index/1<br />
Downloading: http://example.webscraping.com/index/2<br />
Downloading: http://example.webscraping.com/index/3<br />
Downloading: http://example.webscraping.com/index/4<br />
Downloading: http://example.webscraping.com/index/5<br />
Downloading: http://example.webscraping.com/index/6<br />
Downloading: http://example.webscraping.com/index/7<br />
Downloading: http://example.webscraping.com/index/8<br />
Downloading: http://example.webscraping.com/index/9<br />
Downloading: http://example.webscraping.com/index/10<br />
Downloading: http://example.webscraping.com/index/11<br />
Downloading: http://example.webscraping.com/index/12<br />
Downloading: http://example.webscraping.com/index/13<br />
Downloading: http://example.webscraping.com/index/14<br />
Downloading: http://example.webscraping.com/index/15<br />
Downloading: http://example.webscraping.com/index/16<br />
Downloading: http://example.webscraping.com/index/17<br />
Downloading: http://example.webscraping.com/index/18<br />
Downloading: http://example.webscraping.com/index/19<br />
Downloading: http://example.webscraping.com/index/20<br />
Downloading: http://example.webscraping.com/index/21<br />
Downloading: http://example.webscraping.com/index/22<br />
Downloading: http://example.webscraping.com/index/23<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
现在这个程序是一个非常完美的程序,它会爬取所有位置,并且可以按预期停止。最后,一个可用的爬虫是完美的。
总结:
这样,我们就引入了三个源代码,用于抓取站点或网页中的所有链接 URL。这些只是初步的程序。接下来,我们可能还会遇到这样的问题:
1、如果某些网站设置了禁止爬取的URL,为了实现本站的规则,我们必须根据其robots.txt文件来设计爬取程序。
2.谷歌在中国是不可用的,所以如果我们要使用代理去谷歌,我们需要为我们的爬虫程序设置一个代理。
3、如果我们的爬虫爬取网站太快,可能是被目标站点的服务器屏蔽了,所以需要限制下载速度。
4. 一些网页有日历之类的东西。这个东西中的每个日期都是一个 URL 链接。我们会爬这个毫无意义的东西吗?日期是无止境的,所以对于我们的爬虫程序来说,这是一个爬虫陷阱,我们需要避免掉入爬虫陷阱。
我们需要解决这4个问题。为了得到爬虫程序的最终版本。 查看全部
php正则函数抓取网页连接(Windows1064位Python2.7.10V使用的编程集成开发环境)
通过正则表达式获取一个网页中的所有URL链接,并下载这些URL链接的源码
使用的系统:Windows 10 64位
Python语言版本:Python 2.7.10V
编程Python集成开发环境使用:PyCharm 2016 04
我使用的 urllib 版本:urllib2
注意:我这里没有使用 Python2,也没有使用 Python3
一、简介
通过前面两节(网络爬虫爬取网页和解决爬取的网页显示乱码问题),我们终于完成了最终的download()函数。
而在上一节中,我们通过解析网站映射中的URL,抓取了目标站点的所有网页。在上一节中,我们介绍了一种抓取网页中所有链接页面的方法。在本节中,我们使用正则表达式获取网页中的所有 URL 链接并下载这些 URL 链接的源代码。
2. 介绍
至此,我们已经利用目标网站的结构特征实现了两个简单的爬虫。只要有这两种技术,就应该用于爬取,因为这两种方法最大限度地减少了需要下载的网页数量。但是,对于一些网站,我们需要让爬虫更像普通用户:关注链接,访问感兴趣的内容。
通过点击所有链接,我们可以轻松下载网站 的整个页面。但是这种方法会下载很多我们不需要的网页。例如,如果我们想从某个在线论坛抓取用户账户详情页面,那么此时我们只需要下载账户页面,而不是下载讨论轮帖子页面。本博客中的链接爬虫会使用正则表达式来判断需要下载哪些页面。
3. 主码
import re
def link_crawler(seed_url, link_regex):<br />
"""Crawl from the given seed URL following links matched by link_regex<br />
"""<br />
crawl_queue = [seed_url]<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
# filter for links matching our regular expression<br />
for link in get_links(html):<br />
if re.match(link_regex, link):<br />
crawl_queue.append(link)
def get_links(html):<br />
"""Return a list of links from html<br />
"""<br />
# a regular expression to extract all links from the webpage<br />
webpage_regex = re.compile(']+href=["\'](.*?)["\']', re.IGNORECASE)<br />
# list of all links from the webpage<br />
return webpage_regex.findall(html)
4.解释初级代码
1 .
def link_crawler(seed_url, link_regex):
这个函数就是我们要对外使用的函数。作用:首先下载seed_url网页的源码,然后提取里面的所有链接URL,然后将所有匹配到的链接URL与link_regex进行匹配,如果链接URL中有link_regex内容,则将链接URL放入队列中,下次执行 crawl_queue: 时,将对该链接 URL 执行相同的操作。重复,直到crawl_queue队列为空,然后退出函数。
2 .
get_links(html)函数的作用: 用于获取html页面中的所有链接URL。
3.
webpage_regex = re.compile(']+href=["\']'(.*?)["\']', re.IGNORECASE)
匹配模板被制作并存储在网页正则表达式对象中。匹配这样一个字符串,提取xxx的内容,这个xxx就是网址URL。
4.
return webpage_regex.findall(html)
使用webpage_regex模板匹配html网页源代码上所有符合格式的字符串,提取里面的xxx内容。
正则表达式的详细知识请到这个网站了解:
五。手术
先启动Python终端交互命令,在PyCharm软件的终端窗口或Windows系统的DOS窗口执行如下命令:
C:\Python27\python.exe -i 1-4-4-regular_expression.py
执行 link_crawler() 函数:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: /index/1<br />
Traceback (most recent call last):<br />
File "1-4-4-regular_expression.py", line 50, in <br />
link_crawler('http://example.webscraping.com', '/(index|view)')<br />
File "1-4-4-regular_expression.py", line 36, in link_crawler<br />
html = download(url)<br />
File "1-4-4-regular_expression.py", line 13, in download<br />
html = urllib2.urlopen(request).read()<br />
File "C:\Python27\lib\urllib2.py", line 154, in urlopen<br />
return opener.open(url, data, timeout)<br />
File "C:\Python27\lib\urllib2.py", line 423, in open<br />
protocol = req.get_type()<br />
File "C:\Python27\lib\urllib2.py", line 285, in get_type<br />
raise ValueError, "unknown url type: %s" % self.__original<br />
ValueError: unknown url type: /index/1<br />
运行时,出现错误。下载 /index/1 URL 时发生此错误。这个/index/1是目标站点中的相对链接,是完整网页URL的路径部分,不收录协议和服务器部分。我们无法使用 download() 函数下载它。在浏览器中浏览网页时,相对链接可以正常工作,但是使用urllib2下载网页时,由于上下文不可知,无法下载成功。
七。改进代码
所以为了让urllib2成为网页,我们需要将相对链接转换为绝对链接,这样问题就可以解决了。
Python中有一个模块可以实现这个功能:urlparse。
对 link_crawler() 函数进行了以下改进:
import urlparse<br />
def link_crawler(seed_url, link_regex):<br />
"""Crawl from the given seed URL following links matched by link_regex<br />
"""<br />
crawl_queue = [seed_url]<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
for link in get_links(html):<br />
if re.match(link_regex, link):<br />
link = urlparse.urljoin(seed_url, link)<br />
crawl_queue.append(link)
8. 运行:
运行程序:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: http://example.webscraping.com/index/1<br />
Downloading: http://example.webscraping.com/index/2<br />
Downloading: http://example.webscraping.com/index/3<br />
Downloading: http://example.webscraping.com/index/4<br />
Downloading: http://example.webscraping.com/index/5<br />
Downloading: http://example.webscraping.com/index/6<br />
Downloading: http://example.webscraping.com/index/7<br />
Downloading: http://example.webscraping.com/index/8<br />
Downloading: http://example.webscraping.com/index/9<br />
Downloading: http://example.webscraping.com/index/10<br />
Downloading: http://example.webscraping.com/index/11<br />
Downloading: http://example.webscraping.com/index/12<br />
Downloading: http://example.webscraping.com/index/13<br />
Downloading: http://example.webscraping.com/index/14<br />
Downloading: http://example.webscraping.com/index/15<br />
Downloading: http://example.webscraping.com/index/16<br />
Downloading: http://example.webscraping.com/index/17<br />
Downloading: http://example.webscraping.com/index/18<br />
Downloading: http://example.webscraping.com/index/19<br />
Downloading: http://example.webscraping.com/index/20<br />
Downloading: http://example.webscraping.com/index/21<br />
Downloading: http://example.webscraping.com/index/22<br />
Downloading: http://example.webscraping.com/index/23<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com/index/24<br />
通过运行结果可以看到:虽然可以无误地下载网页,但是会不断下载同一个网页。为什么会这样?这是因为这些链接 URL 之间存在链接。如果两个网页相互有链接,那么面对这个程序,它会继续无限循环。
因此,我们还需要继续改进程序:避免抓取相同的链接,因此我们需要记录抓取了哪些链接,如果已抓取,则不抓取它。
9、继续完善link_crawler()函数:
def link_crawler(seed_url, link_regex):<br />
crawl_queue = [seed_url]<br />
# keep track which URL's have seen before<br />
seen = set(crawl_queue)<br />
while crawl_queue:<br />
url = crawl_queue.pop()<br />
html = download(url)<br />
for link in get_links(html):<br />
# check if link matches expected regex<br />
if re.match(link_regex, link):<br />
# form absolute link<br />
link = urlparse.urljoin(seed_url, link)<br />
# check if have already seen this link<br />
if link not in seen:<br />
seen.add(link)<br />
crawl_queue.append(link)
10. 运行:
>>> link_crawler('http://example.webscraping.com', '/(index|view)')
输出:
Downloading: http://example.webscraping.com<br />
Downloading: http://example.webscraping.com/index/1<br />
Downloading: http://example.webscraping.com/index/2<br />
Downloading: http://example.webscraping.com/index/3<br />
Downloading: http://example.webscraping.com/index/4<br />
Downloading: http://example.webscraping.com/index/5<br />
Downloading: http://example.webscraping.com/index/6<br />
Downloading: http://example.webscraping.com/index/7<br />
Downloading: http://example.webscraping.com/index/8<br />
Downloading: http://example.webscraping.com/index/9<br />
Downloading: http://example.webscraping.com/index/10<br />
Downloading: http://example.webscraping.com/index/11<br />
Downloading: http://example.webscraping.com/index/12<br />
Downloading: http://example.webscraping.com/index/13<br />
Downloading: http://example.webscraping.com/index/14<br />
Downloading: http://example.webscraping.com/index/15<br />
Downloading: http://example.webscraping.com/index/16<br />
Downloading: http://example.webscraping.com/index/17<br />
Downloading: http://example.webscraping.com/index/18<br />
Downloading: http://example.webscraping.com/index/19<br />
Downloading: http://example.webscraping.com/index/20<br />
Downloading: http://example.webscraping.com/index/21<br />
Downloading: http://example.webscraping.com/index/22<br />
Downloading: http://example.webscraping.com/index/23<br />
Downloading: http://example.webscraping.com/index/24<br />
Downloading: http://example.webscraping.com/index/25<br />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
Downloading: http://example.webscraping.com ... %3Bbr />
现在这个程序是一个非常完美的程序,它会爬取所有位置,并且可以按预期停止。最后,一个可用的爬虫是完美的。
总结:
这样,我们就引入了三个源代码,用于抓取站点或网页中的所有链接 URL。这些只是初步的程序。接下来,我们可能还会遇到这样的问题:
1、如果某些网站设置了禁止爬取的URL,为了实现本站的规则,我们必须根据其robots.txt文件来设计爬取程序。
2.谷歌在中国是不可用的,所以如果我们要使用代理去谷歌,我们需要为我们的爬虫程序设置一个代理。
3、如果我们的爬虫爬取网站太快,可能是被目标站点的服务器屏蔽了,所以需要限制下载速度。
4. 一些网页有日历之类的东西。这个东西中的每个日期都是一个 URL 链接。我们会爬这个毫无意义的东西吗?日期是无止境的,所以对于我们的爬虫程序来说,这是一个爬虫陷阱,我们需要避免掉入爬虫陷阱。
我们需要解决这4个问题。为了得到爬虫程序的最终版本。
php正则函数抓取网页连接(如何利用cookie去访问网页,去get页面代码的函数 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-22 05:12
)
最近帮朋友开发了一个可以查询正方教务系统的微信公众平台号。得到一些东西。以上是个人经验总结。
开讲之前先说一下新浪云服务器。同一个程序中的功能在PC测试中可以正常运行,但是会挂在那里。
像往常一样,我会在代码中清楚地注释。使用下面的函数,你会得到两种形式的cookies,一种存储在文件中,另一种直接作为变量返回。
经验提示:有时候,在不同的代码运行环境下,用cookies访问文件会成功,但变量会失败,但有时是想法。但,
目前,这两种方法中的一种总会成功。
1 function get_cookie($url_,$params_,$referer_){
2
3 if($url_==null){echo "get_cookie_url_null";exit;}
4 if($params_==null){echo "get_params_null";exit;}
5 if($referer_==null){echo "get_referer-null";exit;}
6 $this_header = array("content-type: application/x-www-form-urlencoded; charset=UTF-8");//访问链接时要发送的头信息
7
8 $ch = curl_init($url_);//这里是初始化一个访问对话,并且传入url,这要个必须有
9
10 //curl_setopt就是设置一些选项为以后发起请求服务的
11
12
13 curl_setopt($ch,CURLOPT_HTTPHEADER,$this_header);//一个用来设置HTTP头字段的数组。使用如下的形式的数组进行设置: array('Content-type: text/plain', 'Content-length: 100')
14 curl_setopt($ch, CURLOPT_HEADER,1);//如果你想把一个头包含在输出中,设置这个选项为一个非零值,我这里是要输出,所以为 1
15
16 curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);//将 curl_exec()获取的信息以文件流的形式返回,而不是直接输出。设置为0是直接输出
17
18 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);//设置跟踪页面的跳转,有时候你打开一个链接,在它内部又会跳到另外一个,就是这样理解
19
20 curl_setopt($ch,CURLOPT_POST,1);//开启post数据的功能,这个是为了在访问链接的同时向网页发送数据,一般数urlencode码
21
22 curl_setopt($ch,CURLOPT_POSTFIELDS,$params_); //把你要提交的数据放这
23
24 curl_setopt($ch, CURLOPT_COOKIEJAR, 'cookie.txt');//获取的cookie 保存到指定的 文件路径,我这里是相对路径,可以是$变量
25
26 //curl_setopt($ch, CURLOPT_COOKIEFILE, 'cookie.txt');//要发送的cookie文件,注意这里是文件,还一个是变量形式发送
27
28 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);//例如这句就是设置以变量的形式发送cookie,注意,这里的cookie变量是要先获取的,见下面获取方式
29
30 curl_setopt ($ch, CURLOPT_REFERER,$referer_); //在HTTP请求中包含一个'referer'头的字符串。告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。
31
32 $content=curl_exec($ch); //重点来了,上面的众多设置都是为了这个,进行url访问,带着上面的所有设置
33
34 if(curl_errno($ch)){
35 echo 'Curl error: '.curl_error($ch);exit(); //这里是设置个错误信息的反馈
36 }
37
38 if($content==false){
39 echo "get_content_null";exit();
40 }
41 preg_match('/Set-Cookie:(.*);/iU',$content,$str); //这里采用正则匹配来获取cookie并且保存它到变量$str里,这就是为什么上面可以发送cookie变量的原因
42
43 $cookie = $str[1]; //获得COOKIE(SESSIONID)
44
45 curl_close($ch);//关闭会话
46
47 return $cookie;//返回cookie
48 }
下面是如何使用上面的cookie来访问网页,发布数据,获取页面代码的功能。
1 function post($url,$post_data,$location = 0,$reffer = null,$origin = null,$host = null){
2
3 $post_data = is_array($post_data)?http_build_query($post_data):$post_data;
4 //产生一个urlencode之后的请求字符串,因为我们post,传送给网页的数据都是经过处理,一般是urlencode编码后才发送的
5
6 $header = array( //头部信息,上面的函数已说明
7 'Accept:*/*',
8 'Accept-Charset:text/html,application/xhtml+xml,application/xml;q=0.7,*;q=0.3',
9 'Accept-Encoding:gzip,deflate,sdch',
10 'Accept-Language:zh-CN,zh;q=0.8',
11 'Connection:keep-alive',
12 'Content-Type:application/x-www-form-urlencoded',
13 //'CLIENT-IP:'.$ip,
14 //'X-FORWARDED-FOR:'.$ip,
15 );
16
17 //下面的都是头部信息的设置,请根据他们的变量名字,对应上面函数所说明
18 if($host){
19 $header = array_merge_recursive($header,array("Host:".$host));
20 }
21 else if($this->option["host"]){
22 $header = array_merge_recursive($header,array("Host:".$this->option["host"]));
23 }
24 if($origin){
25 $header = array_merge_recursive($header,array("Origin:".$origin));
26 }
27 else{
28 $header = array_merge_recursive($header,array("Origin:".$url));
29 }
30 if($reffer){
31 $header = array_merge_recursive($header,array("Referer:".$reffer));
32 }
33 else{
34 $header = array_merge_recursive($header,array("Referer:".$url));
35 }
36
37 $curl = curl_init(); //这里并没有带参数初始化
38
39 curl_setopt($curl, CURLOPT_URL, $url);//这里传入url
40
41 curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
42
43 curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0);//对认证证书来源的检查,不开启次功能
44
45 curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1);//从证书中检测 SSL 加密算法
46
47 curl_setopt($curl, CURLOPT_USERAGENT, $this->useragent);
48 //模拟用户使用的浏览器,自己设置,我的是"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0"
49 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, $location);
50
51 curl_setopt($curl, CURLOPT_AUTOREFERER, 1);//自动设置referer
52
53 curl_setopt($curl, CURLOPT_POST, 1);//开启post
54
55 curl_setopt($curl, CURLOPT_ENCODING, "gzip" );
56 //HTTP请求头中"Accept-Encoding: "的值。支持的编码有"identity","deflate"和"gzip"。如果为空字符串"",请求头会发送所有支持的编码类型。
57 //我上面设置的是*/*
58
59 curl_setopt($curl, CURLOPT_POSTFIELDS, $post_data);//要传送的数据
60
61 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);//以变量形式发送cookie,我这里没用它,文件保险点
62
63 curl_setopt($curl, CURLOPT_COOKIEJAR, 'cookie.txt'); //存cookie的文件名,
64
65 curl_setopt($curl, CURLOPT_COOKIEFILE, 'cookie.txt'); //发送
66
67 curl_setopt($curl, CURLOPT_TIMEOUT, 30);//设置超时限制,防止死循环
68
69 curl_setopt($curl, CURLOPT_HEADER, 1);
70
71 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
72
73 $tmpInfo = curl_exec($curl);
74 if (curl_errno($curl)) {
75 echo 'Curl error: ' . curl_error ( $curl );exit();
76 }
77
78 curl_close($curl);
79 list($header, $body) = explode("\r\n\r\n", $tmpInfo, 2);//分割出网页源代码的头和bode
80 $tmpInfo = $this->auto_charest($tmpInfo);//转码,防止乱码,自定义函数
81 return array("header"=>$header,"body"=>$body,"content"=>$tmpInfo);
82 }
上面是post,下面是get。两者很相似。不同的是get没有发帖,将数据传输到发布前访问过的网页,只获取源码。
1 function get($url,$location = 1,$origin = null,$reffer = null,$host = null){
2 //$ip = $this->randip();
3 if($url==null){
4 echo "get-url-null";exit();
5 }
6 $header = array(
7 'Accept:*/*',
8 'Accept-Charset:GBK,utf-8;q=0.7,*;q=0.3',
9 'Accept-Encoding:gzip,deflate,sdch',
10 'Accept-Language:zh-CN,zh;q=0.8',
11 'Connection:keep-alive',
12
13 //'CLIENT-IP:'.$ip,
14 //'X-FORWARDED-FOR:'.$ip,
15 );
16 if($host){
17 $header = array_merge_recursive($header,array("Host:".$host));
18 }
19 else if($this->option["host"]){
20 $header = array_merge_recursive($header,array("Host:".$this->option["host"]));
21 }
22 if($origin){
23 $header = array_merge_recursive($header,array("Origin:".$origin));
24 }
25 else{
26 $header = array_merge_recursive($header,array("Origin:".$url));
27 }
28 if($reffer){
29 $header = array_merge_recursive($header,array("Referer:".$reffer));
30 }
31 else{
32 $header = array_merge_recursive($header,array("Referer:".$url));
33 }
34
35 $curl = curl_init();
36 curl_setopt($curl, CURLOPT_URL, $url);
37 curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
38 curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0);
39 curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1);
40 curl_setopt($curl, CURLOPT_USERAGENT, $this->useragent);
41 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, $location);
42 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
43 curl_setopt($curl, CURLOPT_AUTOREFERER, 1);
44 curl_setopt($curl, CURLOPT_ENCODING, "gzip" );
45 curl_setopt($curl, CURLOPT_HTTPGET, 1);
46 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);
47 curl_setopt($curl, CURLOPT_COOKIEJAR, 'cookie.txt');
48 curl_setopt($curl, CURLOPT_COOKIEFILE, 'cookie.txt');
49 curl_setopt($curl, CURLOPT_TIMEOUT, 30);
50 curl_setopt($curl, CURLOPT_HEADER, 1);
51 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
52 $tmpInfo = curl_exec($curl);
53
54 if (curl_errno($curl)) {
55 echo 'Curl error: '.curl_error ($curl);exit();
56 }
57 curl_close($curl);
58 list($header, $body) = explode("\r\n\r\n", $tmpInfo, 2);
59 $tmpInfo = $this->auto_charest($tmpInfo);
60 return array("header"=>$header,"body"=>$body,"content"=>$tmpInfo);
61 }
好的,如果觉得对你有用,请默默点开顶。(右下角)
如果你觉得这篇文章文章还不错或者有所收获,可以扫描下方支付宝二维码【素材支持】,或者点击右下角【推荐】按钮奖励我一杯咖啡角[精神]支持],因为这两种支持是我继续写作和分享的最大动力,
查看全部
php正则函数抓取网页连接(如何利用cookie去访问网页,去get页面代码的函数
)
最近帮朋友开发了一个可以查询正方教务系统的微信公众平台号。得到一些东西。以上是个人经验总结。
开讲之前先说一下新浪云服务器。同一个程序中的功能在PC测试中可以正常运行,但是会挂在那里。
像往常一样,我会在代码中清楚地注释。使用下面的函数,你会得到两种形式的cookies,一种存储在文件中,另一种直接作为变量返回。
经验提示:有时候,在不同的代码运行环境下,用cookies访问文件会成功,但变量会失败,但有时是想法。但,
目前,这两种方法中的一种总会成功。
1 function get_cookie($url_,$params_,$referer_){
2
3 if($url_==null){echo "get_cookie_url_null";exit;}
4 if($params_==null){echo "get_params_null";exit;}
5 if($referer_==null){echo "get_referer-null";exit;}
6 $this_header = array("content-type: application/x-www-form-urlencoded; charset=UTF-8");//访问链接时要发送的头信息
7
8 $ch = curl_init($url_);//这里是初始化一个访问对话,并且传入url,这要个必须有
9
10 //curl_setopt就是设置一些选项为以后发起请求服务的
11
12
13 curl_setopt($ch,CURLOPT_HTTPHEADER,$this_header);//一个用来设置HTTP头字段的数组。使用如下的形式的数组进行设置: array('Content-type: text/plain', 'Content-length: 100')
14 curl_setopt($ch, CURLOPT_HEADER,1);//如果你想把一个头包含在输出中,设置这个选项为一个非零值,我这里是要输出,所以为 1
15
16 curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);//将 curl_exec()获取的信息以文件流的形式返回,而不是直接输出。设置为0是直接输出
17
18 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);//设置跟踪页面的跳转,有时候你打开一个链接,在它内部又会跳到另外一个,就是这样理解
19
20 curl_setopt($ch,CURLOPT_POST,1);//开启post数据的功能,这个是为了在访问链接的同时向网页发送数据,一般数urlencode码
21
22 curl_setopt($ch,CURLOPT_POSTFIELDS,$params_); //把你要提交的数据放这
23
24 curl_setopt($ch, CURLOPT_COOKIEJAR, 'cookie.txt');//获取的cookie 保存到指定的 文件路径,我这里是相对路径,可以是$变量
25
26 //curl_setopt($ch, CURLOPT_COOKIEFILE, 'cookie.txt');//要发送的cookie文件,注意这里是文件,还一个是变量形式发送
27
28 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);//例如这句就是设置以变量的形式发送cookie,注意,这里的cookie变量是要先获取的,见下面获取方式
29
30 curl_setopt ($ch, CURLOPT_REFERER,$referer_); //在HTTP请求中包含一个'referer'头的字符串。告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。
31
32 $content=curl_exec($ch); //重点来了,上面的众多设置都是为了这个,进行url访问,带着上面的所有设置
33
34 if(curl_errno($ch)){
35 echo 'Curl error: '.curl_error($ch);exit(); //这里是设置个错误信息的反馈
36 }
37
38 if($content==false){
39 echo "get_content_null";exit();
40 }
41 preg_match('/Set-Cookie:(.*);/iU',$content,$str); //这里采用正则匹配来获取cookie并且保存它到变量$str里,这就是为什么上面可以发送cookie变量的原因
42
43 $cookie = $str[1]; //获得COOKIE(SESSIONID)
44
45 curl_close($ch);//关闭会话
46
47 return $cookie;//返回cookie
48 }
下面是如何使用上面的cookie来访问网页,发布数据,获取页面代码的功能。
1 function post($url,$post_data,$location = 0,$reffer = null,$origin = null,$host = null){
2
3 $post_data = is_array($post_data)?http_build_query($post_data):$post_data;
4 //产生一个urlencode之后的请求字符串,因为我们post,传送给网页的数据都是经过处理,一般是urlencode编码后才发送的
5
6 $header = array( //头部信息,上面的函数已说明
7 'Accept:*/*',
8 'Accept-Charset:text/html,application/xhtml+xml,application/xml;q=0.7,*;q=0.3',
9 'Accept-Encoding:gzip,deflate,sdch',
10 'Accept-Language:zh-CN,zh;q=0.8',
11 'Connection:keep-alive',
12 'Content-Type:application/x-www-form-urlencoded',
13 //'CLIENT-IP:'.$ip,
14 //'X-FORWARDED-FOR:'.$ip,
15 );
16
17 //下面的都是头部信息的设置,请根据他们的变量名字,对应上面函数所说明
18 if($host){
19 $header = array_merge_recursive($header,array("Host:".$host));
20 }
21 else if($this->option["host"]){
22 $header = array_merge_recursive($header,array("Host:".$this->option["host"]));
23 }
24 if($origin){
25 $header = array_merge_recursive($header,array("Origin:".$origin));
26 }
27 else{
28 $header = array_merge_recursive($header,array("Origin:".$url));
29 }
30 if($reffer){
31 $header = array_merge_recursive($header,array("Referer:".$reffer));
32 }
33 else{
34 $header = array_merge_recursive($header,array("Referer:".$url));
35 }
36
37 $curl = curl_init(); //这里并没有带参数初始化
38
39 curl_setopt($curl, CURLOPT_URL, $url);//这里传入url
40
41 curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
42
43 curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0);//对认证证书来源的检查,不开启次功能
44
45 curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1);//从证书中检测 SSL 加密算法
46
47 curl_setopt($curl, CURLOPT_USERAGENT, $this->useragent);
48 //模拟用户使用的浏览器,自己设置,我的是"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0"
49 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, $location);
50
51 curl_setopt($curl, CURLOPT_AUTOREFERER, 1);//自动设置referer
52
53 curl_setopt($curl, CURLOPT_POST, 1);//开启post
54
55 curl_setopt($curl, CURLOPT_ENCODING, "gzip" );
56 //HTTP请求头中"Accept-Encoding: "的值。支持的编码有"identity","deflate"和"gzip"。如果为空字符串"",请求头会发送所有支持的编码类型。
57 //我上面设置的是*/*
58
59 curl_setopt($curl, CURLOPT_POSTFIELDS, $post_data);//要传送的数据
60
61 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);//以变量形式发送cookie,我这里没用它,文件保险点
62
63 curl_setopt($curl, CURLOPT_COOKIEJAR, 'cookie.txt'); //存cookie的文件名,
64
65 curl_setopt($curl, CURLOPT_COOKIEFILE, 'cookie.txt'); //发送
66
67 curl_setopt($curl, CURLOPT_TIMEOUT, 30);//设置超时限制,防止死循环
68
69 curl_setopt($curl, CURLOPT_HEADER, 1);
70
71 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
72
73 $tmpInfo = curl_exec($curl);
74 if (curl_errno($curl)) {
75 echo 'Curl error: ' . curl_error ( $curl );exit();
76 }
77
78 curl_close($curl);
79 list($header, $body) = explode("\r\n\r\n", $tmpInfo, 2);//分割出网页源代码的头和bode
80 $tmpInfo = $this->auto_charest($tmpInfo);//转码,防止乱码,自定义函数
81 return array("header"=>$header,"body"=>$body,"content"=>$tmpInfo);
82 }
上面是post,下面是get。两者很相似。不同的是get没有发帖,将数据传输到发布前访问过的网页,只获取源码。
1 function get($url,$location = 1,$origin = null,$reffer = null,$host = null){
2 //$ip = $this->randip();
3 if($url==null){
4 echo "get-url-null";exit();
5 }
6 $header = array(
7 'Accept:*/*',
8 'Accept-Charset:GBK,utf-8;q=0.7,*;q=0.3',
9 'Accept-Encoding:gzip,deflate,sdch',
10 'Accept-Language:zh-CN,zh;q=0.8',
11 'Connection:keep-alive',
12
13 //'CLIENT-IP:'.$ip,
14 //'X-FORWARDED-FOR:'.$ip,
15 );
16 if($host){
17 $header = array_merge_recursive($header,array("Host:".$host));
18 }
19 else if($this->option["host"]){
20 $header = array_merge_recursive($header,array("Host:".$this->option["host"]));
21 }
22 if($origin){
23 $header = array_merge_recursive($header,array("Origin:".$origin));
24 }
25 else{
26 $header = array_merge_recursive($header,array("Origin:".$url));
27 }
28 if($reffer){
29 $header = array_merge_recursive($header,array("Referer:".$reffer));
30 }
31 else{
32 $header = array_merge_recursive($header,array("Referer:".$url));
33 }
34
35 $curl = curl_init();
36 curl_setopt($curl, CURLOPT_URL, $url);
37 curl_setopt($curl, CURLOPT_HTTPHEADER, $header);
38 curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, 0);
39 curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, 1);
40 curl_setopt($curl, CURLOPT_USERAGENT, $this->useragent);
41 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, $location);
42 curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1);
43 curl_setopt($curl, CURLOPT_AUTOREFERER, 1);
44 curl_setopt($curl, CURLOPT_ENCODING, "gzip" );
45 curl_setopt($curl, CURLOPT_HTTPGET, 1);
46 //curl_setopt($curl, CURLOPT_COOKIE, $this->cookies);
47 curl_setopt($curl, CURLOPT_COOKIEJAR, 'cookie.txt');
48 curl_setopt($curl, CURLOPT_COOKIEFILE, 'cookie.txt');
49 curl_setopt($curl, CURLOPT_TIMEOUT, 30);
50 curl_setopt($curl, CURLOPT_HEADER, 1);
51 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
52 $tmpInfo = curl_exec($curl);
53
54 if (curl_errno($curl)) {
55 echo 'Curl error: '.curl_error ($curl);exit();
56 }
57 curl_close($curl);
58 list($header, $body) = explode("\r\n\r\n", $tmpInfo, 2);
59 $tmpInfo = $this->auto_charest($tmpInfo);
60 return array("header"=>$header,"body"=>$body,"content"=>$tmpInfo);
61 }
好的,如果觉得对你有用,请默默点开顶。(右下角)
如果你觉得这篇文章文章还不错或者有所收获,可以扫描下方支付宝二维码【素材支持】,或者点击右下角【推荐】按钮奖励我一杯咖啡角[精神]支持],因为这两种支持是我继续写作和分享的最大动力,
php正则函数抓取网页连接(本文实现Excel表数据导入SqlServer中的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-16 21:17
本文介绍了基于正则表达式的C#网页爬取类获取网页中所有信息的示例。分享给大家,供大家参考,如下:
类的代码:
<p>
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
using System.Web.UI.MobileControls;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //url
private List m_links; //此网页上的链接
private string m_title; //标题
private string m_html; //HTML代码
private string m_outstr; //网页可输出的纯文本
private bool m_good; //网页是否可用
private int m_pagesize; //网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
#endregion
#region 属性
///
/// 通过此属性可获得本网页的网址,只读
///
public string URL
{
get
{
return m_uri.AbsoluteUri;
}
}
///
/// 通过此属性可获得本网页的标题,只读
///
public string Title
{
get
{
if (m_title == "")
{
Regex reg = new Regex(@"(?m)]*>(?(?:\w|\W)*?)]*>",RegexOptions.Multiline | RegexOptions.IgnoreCase);
Match mc = reg.Match(m_html);
if (mc.Success)
m_title = mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
public string M_html
{
get
{
if (m_html == null)
{
m_html = "";
}
return m_html;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://" + m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
#endregion
///
/// 从HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex(@"(?[^]*>",RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = HttpUtility.UrlDecode(new Uri(m_uri,match.Groups["URL"].Value).AbsoluteUri);
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"",RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value,"");
Link link = new Link();
link.Text = text;
link.NavigateUrl = url;
m_links.Add(link);
}
catch (Exception ex) { Console.WriteLine(ex.Message); };
match = match.Nextmatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr,int firstN,bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>",RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr,"");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ",RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr,"");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+",RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr," ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0,firstN) : m_outstr;
}
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html,firstN,true);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if (m_links.Count == 0) getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt < count)
{
if (new Regex(pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase).Match(i.Current.NavigateUrl).Success)
{
SpecialLinks.Add(i.Current);
cnt++;
}
}
return SpecialLinks;
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的文字满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByText(string pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase).Match(i.Current.Text).Success)
{
SpecialLinks.Add(i.Current);
cnt++;
}
}
return SpecialLinks;
}
///
/// 这公有方法提取本网页的纯文本中满足某正则式的文字 by 何问起
///
/// 正则式
/// 返回文字
public string getSpecialWords(string pattern)
{
if (m_outstr == "") getContext(Int16.MaxValue);
Regex regex = new Regex(pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase);
Match mc = regex.Match(m_outstr);
if (mc.Success)
return mc.Groups[1].Value;
return string.Empty;
}
#endregion
#region 构造函数
private void Init(string _url)
{
try
{
m_uri = new Uri(_url);
m_links = new List();
m_html = "";
m_outstr = "";
m_title = "";
m_good = true;
if (_url.EndsWith(".rar") || _url.EndsWith(".dat") || _url.EndsWith(".msi"))
{
m_good = false;
return;
}
HttpWebRequest rqst = (HttpWebRequest)WebRequest.Create(m_uri);
rqst.AllowAutoRedirect = true;
rqst.MaximumAutomaticRedirections = 3;
rqst.UserAgent = "Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)";
rqst.KeepAlive = true;
rqst.Timeout = 10000;
lock (WebPage.webcookies)
{
if (WebPage.webcookies.ContainsKey(m_uri.Host))
rqst.CookieContainer = WebPage.webcookies[m_uri.Host];
else
{
CookieContainer cc = new CookieContainer();
WebPage.webcookies[m_uri.Host] = cc;
rqst.CookieContainer = cc;
}
}
HttpWebResponse rsps = (HttpWebResponse)rqst.GetResponse();
Stream sm = rsps.GetResponseStream();
if (!rsps.ContentType.ToLower().StartsWith("text/") || rsps.ContentLength > 1 查看全部
php正则函数抓取网页连接(本文实现Excel表数据导入SqlServer中的方法)
本文介绍了基于正则表达式的C#网页爬取类获取网页中所有信息的示例。分享给大家,供大家参考,如下:
类的代码:
<p>
using System;
using System.Data;
using System.Configuration;
using System.Net;
using System.IO;
using System.Text;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using System.Threading;
using System.Web;
using System.Web.UI.MobileControls;
///
/// 网页类
///
public class WebPage
{
#region 私有成员
private Uri m_uri; //url
private List m_links; //此网页上的链接
private string m_title; //标题
private string m_html; //HTML代码
private string m_outstr; //网页可输出的纯文本
private bool m_good; //网页是否可用
private int m_pagesize; //网页的大小
private static Dictionary webcookies = new Dictionary();//存放所有网页的Cookie
#endregion
#region 属性
///
/// 通过此属性可获得本网页的网址,只读
///
public string URL
{
get
{
return m_uri.AbsoluteUri;
}
}
///
/// 通过此属性可获得本网页的标题,只读
///
public string Title
{
get
{
if (m_title == "")
{
Regex reg = new Regex(@"(?m)]*>(?(?:\w|\W)*?)]*>",RegexOptions.Multiline | RegexOptions.IgnoreCase);
Match mc = reg.Match(m_html);
if (mc.Success)
m_title = mc.Groups["title"].Value.Trim();
}
return m_title;
}
}
public string M_html
{
get
{
if (m_html == null)
{
m_html = "";
}
return m_html;
}
}
///
/// 此属性获得本网页的所有链接信息,只读
///
public List Links
{
get
{
if (m_links.Count == 0) getLinks();
return m_links;
}
}
///
/// 此属性返回本网页的全部纯文本信息,只读
///
public string Context
{
get
{
if (m_outstr == "") getContext(Int16.MaxValue);
return m_outstr;
}
}
///
/// 此属性获得本网页的大小
///
public int PageSize
{
get
{
return m_pagesize;
}
}
///
/// 此属性获得本网页的所有站内链接
///
public List InsiteLinks
{
get
{
return getSpecialLinksByUrl("^http://" + m_uri.Host,Int16.MaxValue);
}
}
///
/// 此属性表示本网页是否可用
///
public bool IsGood
{
get
{
return m_good;
}
}
///
/// 此属性表示网页的所在的网站
///
public string Host
{
get
{
return m_uri.Host;
}
}
#endregion
///
/// 从HTML代码中分析出链接信息
///
/// List
private List getLinks()
{
if (m_links.Count == 0)
{
Regex[] regex = new Regex[2];
regex[0] = new Regex(@"(?[^]*>",RegexOptions.IgnoreCase);
for (int i = 0; i < 2; i++)
{
Match match = regex[i].Match(m_html);
while (match.Success)
{
try
{
string url = HttpUtility.UrlDecode(new Uri(m_uri,match.Groups["URL"].Value).AbsoluteUri);
string text = "";
if (i == 0) text = new Regex("(]+>)|(\\s)|( )|&|\"",RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(match.Groups["text"].Value,"");
Link link = new Link();
link.Text = text;
link.NavigateUrl = url;
m_links.Add(link);
}
catch (Exception ex) { Console.WriteLine(ex.Message); };
match = match.Nextmatch();
}
}
}
return m_links;
}
///
/// 此私有方法从一段HTML文本中提取出一定字数的纯文本
///
/// HTML代码
/// 提取从头数多少个字
/// 是否要链接里面的字
/// 纯文本
private string getFirstNchar(string instr,int firstN,bool withLink)
{
if (m_outstr == "")
{
m_outstr = instr.Clone() as string;
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>",RegexOptions.Multiline | RegexOptions.IgnoreCase).Replace(m_outstr,"");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
if (!withLink) m_outstr = new Regex(@"(?m)]*>(\w|\W)*?]*>","");
Regex objReg = new System.Text.RegularExpressions.Regex("(]+?>)| ",RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg.Replace(m_outstr,"");
Regex objReg2 = new System.Text.RegularExpressions.Regex("(\\s)+",RegexOptions.Multiline | RegexOptions.IgnoreCase);
m_outstr = objReg2.Replace(m_outstr," ");
}
return m_outstr.Length > firstN ? m_outstr.Substring(0,firstN) : m_outstr;
}
#region 公有文法
///
/// 此公有方法提取网页中一定字数的纯文本,包括链接文字
///
/// 字数
///
public string getContext(int firstN)
{
return getFirstNchar(m_html,firstN,true);
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的URL满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByUrl(string pattern,int count)
{
if (m_links.Count == 0) getLinks();
List SpecialLinks = new List();
List.Enumerator i;
i = m_links.GetEnumerator();
int cnt = 0;
while (i.MoveNext() && cnt < count)
{
if (new Regex(pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase).Match(i.Current.NavigateUrl).Success)
{
SpecialLinks.Add(i.Current);
cnt++;
}
}
return SpecialLinks;
}
///
/// 此公有方法从本网页的链接中提取一定数量的链接,该链接的文字满足某正则式
///
/// 正则式
/// 返回的链接的个数
/// List
public List getSpecialLinksByText(string pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase).Match(i.Current.Text).Success)
{
SpecialLinks.Add(i.Current);
cnt++;
}
}
return SpecialLinks;
}
///
/// 这公有方法提取本网页的纯文本中满足某正则式的文字 by 何问起
///
/// 正则式
/// 返回文字
public string getSpecialWords(string pattern)
{
if (m_outstr == "") getContext(Int16.MaxValue);
Regex regex = new Regex(pattern,RegexOptions.Multiline | RegexOptions.IgnoreCase);
Match mc = regex.Match(m_outstr);
if (mc.Success)
return mc.Groups[1].Value;
return string.Empty;
}
#endregion
#region 构造函数
private void Init(string _url)
{
try
{
m_uri = new Uri(_url);
m_links = new List();
m_html = "";
m_outstr = "";
m_title = "";
m_good = true;
if (_url.EndsWith(".rar") || _url.EndsWith(".dat") || _url.EndsWith(".msi"))
{
m_good = false;
return;
}
HttpWebRequest rqst = (HttpWebRequest)WebRequest.Create(m_uri);
rqst.AllowAutoRedirect = true;
rqst.MaximumAutomaticRedirections = 3;
rqst.UserAgent = "Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)";
rqst.KeepAlive = true;
rqst.Timeout = 10000;
lock (WebPage.webcookies)
{
if (WebPage.webcookies.ContainsKey(m_uri.Host))
rqst.CookieContainer = WebPage.webcookies[m_uri.Host];
else
{
CookieContainer cc = new CookieContainer();
WebPage.webcookies[m_uri.Host] = cc;
rqst.CookieContainer = cc;
}
}
HttpWebResponse rsps = (HttpWebResponse)rqst.GetResponse();
Stream sm = rsps.GetResponseStream();
if (!rsps.ContentType.ToLower().StartsWith("text/") || rsps.ContentLength > 1
php正则函数抓取网页连接( 2019-03-30Python正则表达式实例讲述Python正则操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-14 15:01
2019-03-30Python正则表达式实例讲述Python正则操作技巧)
Python常规抓取新闻标题和链接方法示例
时间:2019-03-30
本文章为大家介绍了Python定时抓取新闻标题和链接的方法示例,主要包括Python定时抓取新闻标题和链接的示例、使用示例、应用技巧、基础知识点总结和注意事项,具有一定的参考价值,有需要的朋友可以参考。
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/").read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用汇总》、《Python数据结构与算法教程》、《Python Socket编程技巧汇总》、《Python函数使用技巧汇总》、《Python字符串》操作技巧总结《Python入门及进阶经典教程》《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。 查看全部
php正则函数抓取网页连接(
2019-03-30Python正则表达式实例讲述Python正则操作技巧)
Python常规抓取新闻标题和链接方法示例
时间:2019-03-30
本文章为大家介绍了Python定时抓取新闻标题和链接的方法示例,主要包括Python定时抓取新闻标题和链接的示例、使用示例、应用技巧、基础知识点总结和注意事项,具有一定的参考价值,有需要的朋友可以参考。
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/";).read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用汇总》、《Python数据结构与算法教程》、《Python Socket编程技巧汇总》、《Python函数使用技巧汇总》、《Python字符串》操作技巧总结《Python入门及进阶经典教程》《Python文件与目录操作技巧总结》
我希望这篇文章对你的 Python 编程有所帮助。
php正则函数抓取网页连接(PHP是什么东西?PHP的爬虫有什么用?Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-14 07:09
一、什么是PHP?
PHP(外文名:PHP:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远高于完全生成HTML标记的CGI;PHP 也可以执行编译后的代码。编译可以实现加密和优化代码执行,使代码运行速度更快。
二、爬虫有什么用?
爬虫有什么用?先说一下什么是爬虫。我认为爬虫是一个网络信息采集程序。可能我自己的理解有误。请纠正我。由于爬虫是网络信息采集程序,所以用来采集信息,采集的信息在网络上。如果你还不知道爬虫的用处,我给你举几个爬虫应用的例子:搜索引擎需要爬虫来采集网络信息供人们搜索;大数据数据,数据从何而来?可以通过爬虫在网络中进行爬取(采集)。
三、听到爬虫一般都会想到Python,但是为什么我用PHP而不是Python呢?
Python 老实说,我不懂 Python。(我真的不懂Python,我想知道也许你得去百度,因为我真的不懂Python。)我一直认为用PHP写东西时,你只需要想到一个算法程序并且您不必考虑太多的数据类型。问题。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。这个想法是错误的。) 其实我也是一个PHP初学者,想通过写点东西来提高自己的水平。(以下代码可能让你觉得不够规范,请指正,谢谢。)
四、PHP爬虫第一步
PHP爬虫的第一步,第一步……当然,第一步是搭建PHP的运行环境。PHP如何在没有环境的情况下运行?就像鱼离不开水一样。(我的知识不够,可能我给的鱼例子不够好,请见谅。)我在Windows系统下使用WAMP,在Linux系统下使用LNMP或LAMP。
WAMP:Windows Apache Mysql PHP
灯:Linux Apache Mysql PHP
LNMP:Linux Nginx Mysql PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache 或 Nginx、Mysql 和 PHP 是 PHP Web 的基本配置环境。网上有PHP Web环境的安装包。这些安装包使用起来非常方便,不需要安装和配置一切。但是如果你担心这些集成安装包的安全性,你可以去这些程序的官网下载,然后在网上找配置教程。(说真的,我真的不想一个人做,我觉得很麻烦。)
五、 PHP爬虫第二步
(感觉废话很多,应该马上来一段代码!!!)
爬虫网络的核心功能已经写好了。为什么说爬虫的核心功能是几行代码写出来的?估计有人已经明白了。爬虫其实就是一个数据采集程序,上面几行代码其实是可以获取数据的,所以爬虫的核心功能已经写好了。可能有人会说:“你太乱了!有什么用?” 虽然我很乱,但请不要告诉我,让我装个X。(再废话两行,抱歉。)
实际上,爬虫的用途取决于您希望它做什么。就像我前几天为了好玩写了一个搜索引擎网站,当然网站是很好的,结果排序不规则,很多都没有。我的搜索引擎爬虫就是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来说明。当然,我的搜索引擎的爬虫还不够完善。不完美的地方将由你来创造和完善。
六、 搜索引擎爬虫的局限性
有时搜索引擎的爬虫不是无法从网站的页面中获取页面源代码,而是有robot.txt文件。这个文件的网站表示站主不希望爬虫爬取页面源代码。. (但如果你只是想得到它,即使你拥有它也会爬行!)
我的搜索引擎的爬虫其实有很多不足导致的局限性。例如,可能因为无法运行JS脚本而无法获取页面的源代码。或者网站有反爬虫机制,防止获取页面源代码。网站带有反爬虫机制就像:知乎,知乎就是带有反爬虫机制的网站。
七、以搜索引擎爬虫为例,准备写爬虫需要什么
PHP写基本正则表达式(也可以用Xpath,抱歉,我不会用) 数据库的使用(本文使用的是MySql数据库) 运行环境(只要有可以运行PHP的环境和数据库< @网站,好的)
八、搜索引擎获取页面源码,获取页面标题信息
错误示例:
警告:file_get_contents("") [function.file-get-contents]:无法打开流:E:\website\blog\test.php 第 25 行中的参数无效
https 是一种 SSL 加密协议。如果您在获取页面时出现上述错误,则表示您的 PHP 可能缺少 OpenSSL 模块。您可以在网上找到解决方案。
九、搜索引擎爬虫的特点
虽然没见过像“百度”、“谷歌”这样的爬虫,但是通过自己的猜测和实际爬取过程中遇到的一些问题,总结了一些特点。(可能有错误或遗漏,请指正,谢谢。)
多功能性
通用性是因为我觉得搜索引擎的爬虫一开始不是针对哪个网站设计的,所以要求尽可能多的爬取网站。这是第一点。第二点是获取网页的信息就是这样。一开始不会因为一些特殊的小网站而放弃一些信息不提取,例如:一个小网站的网页如果没有描述信息(description)或者meta标签中的关键词信息(关键字),直接放弃提取描述信息或关键词信息。当然,如果某个页面没有这样的信息,我会提取页面里面的文字内容作为填充,反正,每个网页的信息项要尽量相同,以实现抓取到的网页信息。这就是我认为的搜索引擎爬虫的多功能性。当然,我的想法可能是错误的。(我可能不会说得很好,我一直在学习。)
不确定
不确定性是我的爬虫获取的网页。我对我能想到的东西没有足够的控制权。这也是我写的算法就是这样的原因。我的算法是抓取我得到的页面。所有的链接,然后去爬取这些链接,其实是因为搜索引擎不是搜索某些东西,而是尽可能多的搜索,因为只有更多的信息才能为用户找到最合适的答案。所以我觉得搜索引擎爬虫会有不确定性。(我自己又看了一遍,感觉有点看不懂我说的,还请见谅,请指正,提问,谢谢!)
以下视频是我搜索网站的视频,找到的信息是通过我写的PHP爬虫获取的。(此网站已不再维护,如有不足请见谅。)
十、目前可能出现的问题
得到的源码出现乱码
2. 无法获取标题信息
3.无法获取页面源码
十个一、获取网页时的处理思路
我们不要考虑很多网页,因为很多网页只是一个循环。
获取页面的源代码,通过源代码从页面中提取信息。
十二、按照十一的思路编码
十个三、PHP保存页面图片的想法
获取页面源码 获取页面图片链接 使用图片保存功能
十四、保存图片示例代码
十五、gzip解压
本来以为自己写的爬虫差不多就完成了,除了反爬虫网站难爬,应该能爬。但是有一天当我试图爬到bilibili时,出现了问题。发现我数据库里的代码全是乱码,而且根本没有标题,好奇怪!后来我发现是因为GZIP压缩。原来我直接用file_get_content函数获取的页面都是未压缩的页面,都是乱码!好的,那我就知道问题在那里了,然后我想解决它。(其实我当时不知道怎么解决gzip解压的问题,靠的就是搜索引擎,哈哈哈哈)。
我得到了两个解决方案:
在请求头中告诉对方我的爬虫(不...应该是我的浏览器)不支持gzip解压,所以请不要压缩,直接把数据发给我!
// 这是request header(请求头)
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n".
"accept-encoding:"
)
);
// 我把accept-encodeing(能接收编码)设为空,代表不接受gzip
2. 如果你告诉对方的服务器浏览器(爬虫)不支持gzip解压,他却继续给你发gzip数据,没办法,所以只能在里面找php解压gzip搜索引擎默默地。函数-gzdecode()。
// 废话:好久没更新了,因为最近又在重做轮子了,不过我好开心——2019.01.14
10.获取六、子链接
网络爬虫就像是一个自动的网页源代码另存为操作,但如果真的是手动输入的网址供爬虫爬取,那么保存为手动会更好!所以在这里你必须解决这些子链接。一个网页实际上有很多a标签,这些a标签的href属性值就是一个子链接。(这句话怎么感觉有点废话?大家应该都知道吧!)通过很多工具的分析,得到了原来的子链接(我没有用html工具,只是用了正则表达式和工具)。为什么叫原创数据?,因为这些子链接很多不是网址链接,或者是一些不完整的链接,或者你要去爬一个网站。当爬虫用完时,你必须删除一些不是网站的链接,以防止爬虫用完。下面我列出了一些原创的子链接。(其实是我喷的坑……)
http://wxample.com/
./index.html
index.html
//example.com/index.html
javascript:;
../index.html
http://example2.com/index.html
可以看到这里有很多种链接。有完整绝对路径的链接,有不完整相对路径的链接,还有一些还运行javascript。如果是相对路径或者javascript链接,就让爬虫直接抓取。让爬虫看起来傻眼,因为它不完整或根本不是链接。因此,需要完成或丢弃子链接。
10. 七、 子链接的处理
说了这么多废话,接下来就是继续废话了。嗯,处理其实就是去重复,丢弃,完成。
丢弃同一个子链接,不保存,补全相对路径链接。丢弃不是链接的链接(什么是非链接的链接?我觉得很奇怪......)
第一种我就不多说了,相信大家都知道怎么做。
对于第二种方法,我会写一个可以运行相对路径的方法,就OK了。相对路径通过父链接转换为绝对路径。(有时间给大家补码……不好意思)
对于第三种,正则匹配结束。
#有什么问题可以评论留言,大家一起解决,谢谢。
未完待续。. . 查看全部
php正则函数抓取网页连接(PHP是什么东西?PHP的爬虫有什么用?Python)
一、什么是PHP?
PHP(外文名:PHP:Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远高于完全生成HTML标记的CGI;PHP 也可以执行编译后的代码。编译可以实现加密和优化代码执行,使代码运行速度更快。
二、爬虫有什么用?
爬虫有什么用?先说一下什么是爬虫。我认为爬虫是一个网络信息采集程序。可能我自己的理解有误。请纠正我。由于爬虫是网络信息采集程序,所以用来采集信息,采集的信息在网络上。如果你还不知道爬虫的用处,我给你举几个爬虫应用的例子:搜索引擎需要爬虫来采集网络信息供人们搜索;大数据数据,数据从何而来?可以通过爬虫在网络中进行爬取(采集)。
三、听到爬虫一般都会想到Python,但是为什么我用PHP而不是Python呢?
Python 老实说,我不懂 Python。(我真的不懂Python,我想知道也许你得去百度,因为我真的不懂Python。)我一直认为用PHP写东西时,你只需要想到一个算法程序并且您不必考虑太多的数据类型。问题。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。PHP 的语法与其他编程语言类似,即使您一开始不了解 PHP,也可以立即上手。这个想法是错误的。) 其实我也是一个PHP初学者,想通过写点东西来提高自己的水平。(以下代码可能让你觉得不够规范,请指正,谢谢。)
四、PHP爬虫第一步
PHP爬虫的第一步,第一步……当然,第一步是搭建PHP的运行环境。PHP如何在没有环境的情况下运行?就像鱼离不开水一样。(我的知识不够,可能我给的鱼例子不够好,请见谅。)我在Windows系统下使用WAMP,在Linux系统下使用LNMP或LAMP。
WAMP:Windows Apache Mysql PHP
灯:Linux Apache Mysql PHP
LNMP:Linux Nginx Mysql PHP
Apache 和 Nginx 是 Web 服务器软件。
Apache 或 Nginx、Mysql 和 PHP 是 PHP Web 的基本配置环境。网上有PHP Web环境的安装包。这些安装包使用起来非常方便,不需要安装和配置一切。但是如果你担心这些集成安装包的安全性,你可以去这些程序的官网下载,然后在网上找配置教程。(说真的,我真的不想一个人做,我觉得很麻烦。)
五、 PHP爬虫第二步
(感觉废话很多,应该马上来一段代码!!!)
爬虫网络的核心功能已经写好了。为什么说爬虫的核心功能是几行代码写出来的?估计有人已经明白了。爬虫其实就是一个数据采集程序,上面几行代码其实是可以获取数据的,所以爬虫的核心功能已经写好了。可能有人会说:“你太乱了!有什么用?” 虽然我很乱,但请不要告诉我,让我装个X。(再废话两行,抱歉。)
实际上,爬虫的用途取决于您希望它做什么。就像我前几天为了好玩写了一个搜索引擎网站,当然网站是很好的,结果排序不规则,很多都没有。我的搜索引擎爬虫就是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来说明。当然,我的搜索引擎的爬虫还不够完善。不完美的地方将由你来创造和完善。
六、 搜索引擎爬虫的局限性
有时搜索引擎的爬虫不是无法从网站的页面中获取页面源代码,而是有robot.txt文件。这个文件的网站表示站主不希望爬虫爬取页面源代码。. (但如果你只是想得到它,即使你拥有它也会爬行!)
我的搜索引擎的爬虫其实有很多不足导致的局限性。例如,可能因为无法运行JS脚本而无法获取页面的源代码。或者网站有反爬虫机制,防止获取页面源代码。网站带有反爬虫机制就像:知乎,知乎就是带有反爬虫机制的网站。
七、以搜索引擎爬虫为例,准备写爬虫需要什么
PHP写基本正则表达式(也可以用Xpath,抱歉,我不会用) 数据库的使用(本文使用的是MySql数据库) 运行环境(只要有可以运行PHP的环境和数据库< @网站,好的)
八、搜索引擎获取页面源码,获取页面标题信息
错误示例:
警告:file_get_contents("") [function.file-get-contents]:无法打开流:E:\website\blog\test.php 第 25 行中的参数无效
https 是一种 SSL 加密协议。如果您在获取页面时出现上述错误,则表示您的 PHP 可能缺少 OpenSSL 模块。您可以在网上找到解决方案。
九、搜索引擎爬虫的特点
虽然没见过像“百度”、“谷歌”这样的爬虫,但是通过自己的猜测和实际爬取过程中遇到的一些问题,总结了一些特点。(可能有错误或遗漏,请指正,谢谢。)
多功能性
通用性是因为我觉得搜索引擎的爬虫一开始不是针对哪个网站设计的,所以要求尽可能多的爬取网站。这是第一点。第二点是获取网页的信息就是这样。一开始不会因为一些特殊的小网站而放弃一些信息不提取,例如:一个小网站的网页如果没有描述信息(description)或者meta标签中的关键词信息(关键字),直接放弃提取描述信息或关键词信息。当然,如果某个页面没有这样的信息,我会提取页面里面的文字内容作为填充,反正,每个网页的信息项要尽量相同,以实现抓取到的网页信息。这就是我认为的搜索引擎爬虫的多功能性。当然,我的想法可能是错误的。(我可能不会说得很好,我一直在学习。)
不确定
不确定性是我的爬虫获取的网页。我对我能想到的东西没有足够的控制权。这也是我写的算法就是这样的原因。我的算法是抓取我得到的页面。所有的链接,然后去爬取这些链接,其实是因为搜索引擎不是搜索某些东西,而是尽可能多的搜索,因为只有更多的信息才能为用户找到最合适的答案。所以我觉得搜索引擎爬虫会有不确定性。(我自己又看了一遍,感觉有点看不懂我说的,还请见谅,请指正,提问,谢谢!)
以下视频是我搜索网站的视频,找到的信息是通过我写的PHP爬虫获取的。(此网站已不再维护,如有不足请见谅。)
十、目前可能出现的问题
得到的源码出现乱码
2. 无法获取标题信息
3.无法获取页面源码
十个一、获取网页时的处理思路
我们不要考虑很多网页,因为很多网页只是一个循环。
获取页面的源代码,通过源代码从页面中提取信息。
十二、按照十一的思路编码
十个三、PHP保存页面图片的想法
获取页面源码 获取页面图片链接 使用图片保存功能
十四、保存图片示例代码
十五、gzip解压
本来以为自己写的爬虫差不多就完成了,除了反爬虫网站难爬,应该能爬。但是有一天当我试图爬到bilibili时,出现了问题。发现我数据库里的代码全是乱码,而且根本没有标题,好奇怪!后来我发现是因为GZIP压缩。原来我直接用file_get_content函数获取的页面都是未压缩的页面,都是乱码!好的,那我就知道问题在那里了,然后我想解决它。(其实我当时不知道怎么解决gzip解压的问题,靠的就是搜索引擎,哈哈哈哈)。
我得到了两个解决方案:
在请求头中告诉对方我的爬虫(不...应该是我的浏览器)不支持gzip解压,所以请不要压缩,直接把数据发给我!
// 这是request header(请求头)
$opts = array(
'http'=>array(
'method'=>"GET",
"timeout"=>20,
'header'=>"User-Agent: Spider \r\n".
"accept-encoding:"
)
);
// 我把accept-encodeing(能接收编码)设为空,代表不接受gzip
2. 如果你告诉对方的服务器浏览器(爬虫)不支持gzip解压,他却继续给你发gzip数据,没办法,所以只能在里面找php解压gzip搜索引擎默默地。函数-gzdecode()。
// 废话:好久没更新了,因为最近又在重做轮子了,不过我好开心——2019.01.14
10.获取六、子链接
网络爬虫就像是一个自动的网页源代码另存为操作,但如果真的是手动输入的网址供爬虫爬取,那么保存为手动会更好!所以在这里你必须解决这些子链接。一个网页实际上有很多a标签,这些a标签的href属性值就是一个子链接。(这句话怎么感觉有点废话?大家应该都知道吧!)通过很多工具的分析,得到了原来的子链接(我没有用html工具,只是用了正则表达式和工具)。为什么叫原创数据?,因为这些子链接很多不是网址链接,或者是一些不完整的链接,或者你要去爬一个网站。当爬虫用完时,你必须删除一些不是网站的链接,以防止爬虫用完。下面我列出了一些原创的子链接。(其实是我喷的坑……)
http://wxample.com/
./index.html
index.html
//example.com/index.html
javascript:;
../index.html
http://example2.com/index.html
可以看到这里有很多种链接。有完整绝对路径的链接,有不完整相对路径的链接,还有一些还运行javascript。如果是相对路径或者javascript链接,就让爬虫直接抓取。让爬虫看起来傻眼,因为它不完整或根本不是链接。因此,需要完成或丢弃子链接。
10. 七、 子链接的处理
说了这么多废话,接下来就是继续废话了。嗯,处理其实就是去重复,丢弃,完成。
丢弃同一个子链接,不保存,补全相对路径链接。丢弃不是链接的链接(什么是非链接的链接?我觉得很奇怪......)
第一种我就不多说了,相信大家都知道怎么做。
对于第二种方法,我会写一个可以运行相对路径的方法,就OK了。相对路径通过父链接转换为绝对路径。(有时间给大家补码……不好意思)
对于第三种,正则匹配结束。
#有什么问题可以评论留言,大家一起解决,谢谢。
未完待续。. .
php正则函数抓取网页连接(PHP怎样用正则抓取页面中的网址的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-09 19:05
想知道PHP如何使用正则抓取页面中URL的相关内容吗?在这篇文章中,我将为大家讲解PHP使用正则抓取页面中的URL的相关知识以及一些代码示例。欢迎阅读和纠正我们。fetch, php, 页面抓取, php, 抓取页面指定内容一起来学习
前言
链接是从一个元素(文本、图片、视频等)链接到另一个元素(文本、图片、视频等)的超链接。通常,一个网页中有三种链接。一种是绝对URL超链接,即一个页面的完整性。小路; 另一种是相对URL超链接,一般链接到同一网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置
如果你知道链接的类型,你就知道要抓取的主要链接是绝对 URL 超链接和相对 URL 超链接。要编写正确的正则表达式,您必须了解我们正在寻找的对象的模式。
先说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源URL。URL 的结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的标识。最常见的是http协议。本文仅考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时也收录端口号(默认为80) FTP协议也可以收录用户名和密码。本文不考虑。
路径和文件名一般用/分隔来表示文件的路径和文件本身的名称。如果没有具体的文件名,访问这个文件夹下的默认文件(可以在服务器端设置)
所以现在很明显,要爬取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的说明,具体可以参考RFC1738,然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下: 查看全部
php正则函数抓取网页连接(PHP怎样用正则抓取页面中的网址的相关内容吗)
想知道PHP如何使用正则抓取页面中URL的相关内容吗?在这篇文章中,我将为大家讲解PHP使用正则抓取页面中的URL的相关知识以及一些代码示例。欢迎阅读和纠正我们。fetch, php, 页面抓取, php, 抓取页面指定内容一起来学习
前言
链接是从一个元素(文本、图片、视频等)链接到另一个元素(文本、图片、视频等)的超链接。通常,一个网页中有三种链接。一种是绝对URL超链接,即一个页面的完整性。小路; 另一种是相对URL超链接,一般链接到同一网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置
如果你知道链接的类型,你就知道要抓取的主要链接是绝对 URL 超链接和相对 URL 超链接。要编写正确的正则表达式,您必须了解我们正在寻找的对象的模式。
先说绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源URL。URL 的结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的标识。最常见的是http协议。本文仅考虑 HTTP 协议。至于其他的https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时也收录端口号(默认为80) FTP协议也可以收录用户名和密码。本文不考虑。
路径和文件名一般用/分隔来表示文件的路径和文件本身的名称。如果没有具体的文件名,访问这个文件夹下的默认文件(可以在服务器端设置)
所以现在很明显,要爬取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的说明,具体可以参考RFC1738,然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下:
php正则函数抓取网页连接(爬虫也可以称为Python爬虫不知 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-09 15:01
)
爬虫也可以称为Python爬虫
不知何时,语言Python和爬行动物就像一对恋人。
当您谈到爬虫时,您会想到 Python。当您谈到 Python 时,您会想到人工智能……和爬虫。
因此,在谈到爬虫时,大多数程序员都会下意识地将其联想为 Python 爬虫。为什么会这样?我认为有两个原因:
任何学习 Python 的程序员都应该或多或少看过甚至研究过爬虫。我当时写 Python 的目的很纯粹就是为了写爬虫。
所以这篇文章的目的很简单,就是谈谈我个人对Python爬虫的理解和实践。作为一个程序员,我觉得只有了解爬虫的相关知识才对你有好处,所以看完这篇文章 ,如果对你有帮助就太好了
什么是爬虫
爬虫是一个程序。这个程序的目的是爬取万维网的信息资源。比如你日常使用的谷歌等搜索引擎,搜索结果都是依赖爬虫定期获取的。
看上面的搜索结果,除了wiki相关的介绍外,所有爬虫相关的搜索结果都收录了Python。前辈说的是Python爬虫,现在看来真的不骗我了~
爬虫的目标对象也很丰富,无论是文字、图片、视频,任何结构化和非结构化数据爬虫都可以爬取。经过爬虫的发展,衍生出各种爬虫类型:
不想讲这些笼统的概念,让我们以一个网页内容获取为例,从爬虫技术本身开始,来谈谈网络爬虫,步骤如下:
什么是爬虫,这是爬虫:
<p>"""让我们根据上面说的步骤来完成一个简单的爬虫程序"""
import requests
<br />
from bs4 import BeautifulSoup
<br />
target_url = 'http://www.baidu.com/s?wd=爬虫'
<br />
# 第一步 发起一个GET请求
res = requests.get(target_url)
<br />
# 第二步 提取HTML并解析想获取的数据 比如获取 title
soup = BeautifulSoup(res.text, "lxml")
# 输出 soup.title.text
title = soup.title.text
<br />
# 第三步 持久化 比如保存到本地
with open('title.txt', 'w') as fp:
fp.write(title)</p>
不到20行代码加注释,就完成了一个爬虫,简单
如何编写爬虫
网络世界丰富多彩,有数以亿计的网络资源供您选择。如何让你的爬虫程序在面对不同的页面时健壮耐用是一个值得讨论的问题
俗话说,磨刀不误砍柴。在开始写爬虫之前,有必要掌握一些基础知识:
这两个描述反映了爬虫开发者需要掌握的基础知识,但是一个基本的后端或者前端工程师可以做到。这也说明爬虫的入门难度是极低的。从这两句话,你能想到爬虫必备的知识点吗?
有了这些知识储备,你就可以选择一种语言,开始编写自己的爬虫程序了。或者按照上一节提到的三个步骤,然后以Python为例,谈谈在编程语言中要做哪些准备:
一旦掌握了以上内容,就可以放开手脚,做很多功课了。万维网是你的名利场,去吧!
我认为对于一个目标网站的网页,可以分为以下四种:
这是什么意思?这可能看起来有点令人费解,但你明白这一点。写好爬虫后,只需要在脑海中浏览网页的类型,然后应用对应类型的程序(写的太多,应该有自己的常用代码库),写的速度爬虫自然不慢
单页单目标
通俗地说,在这个网页中,我们的目标只有一个。假设我们需要抓取这部电影的名字——肖申克的救赎,首先打开网页右键查看元素,找到电影名字对应的元素位置,如下图:
单页看是否只有一个target,标题的CSS Selector规则一目了然:#content> h1> span:nth-child(1),然后使用common自己写的库,不到十行代码就可以写一个爬取这个页面的电影名的爬虫:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
title = TextField(css_select='#content > h1 > span:nth-child(1)')
<br />
async_func = DoubanItem.get_item(url="https://movie.douban.com/subject/1292052/")
item = asyncio.get_event_loop().run_until_complete(async_func)
print(item.title)</p>
Multi-page multi-target 在这种情况下是多个 URL 的衍生
单页多目标
假设当前的需求是抓取豆瓣电影250第一页的所有电影名,需要提取25个电影名,因为这个目标页面的目标数据是多项,所以需要循环获取目标,这就是所谓的具有多个目标的单页:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
async_func = DoubanItem.get_items(url="https://movie.douban.com/top250")
items = asyncio.get_event_loop().run_until_complete(async_func)
for item in items:
print(item)</p>
多页多目标
多页多目标是上述单页多目标情况的派生。从这个角度来说,就是获取此时所有页面的电影名称。
<p>from ruia import TextField, Item, Request, Spider
<br />
<br />
class DoubanItem(Item):
"""
定义爬虫的目标字段
"""
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
class DoubanSpider(Spider):
start_urls = ['https://movie.douban.com/top250']
concurrency = 10
<br />
async def parse(self, res):
etree = res.html_etree
pages = ['?start=0&filter='] + [i.get('href') for i in etree.cssselect('.paginator>a')]
<br />
for index, page in enumerate(pages):
url = self.start_urls[0] + page
yield Request(
url,
callback=self.parse_item,
metadata={'index': index},
request_config=self.request_config
)
<br />
async def parse_item(self, res):
items_data = await DoubanItem.get_items(html=res.html)
res_list = []
for item in items_data:
res_list.append(item.title)
return res_list
<br />
<br />
if __name__ == '__main__':
DoubanSpider.start()</p>
如果网络正常,您将获得以下输出:
注意爬虫运行时间,小于1s,这就是异步的魅力
用Python写爬虫就是这么简单优雅,大家看看网页,想一想:
一个爬虫程序就形成了。顺便说一句,爬虫可以说是反君子,而不是小人。大部分robots.txt网站(它的目的是告诉爬虫什么可以爬,什么不能爬,比如:),你想怎么爬,自己衡量
如何推进
不要以为只要写一个爬虫程序就可以了。这个时候,还有更多的问题等着你。你要深情地看你的爬虫程序,问自己三个问题:
关于人性的前两个问题这里就不多说了,直接跳过,但是如果你是爬虫工程师,千万不要跳过
会被反爬行动物杀死吗?
最后,关于反爬虫的问题是你的爬虫程序是否强大的关键因素。什么是反爬虫?
当网络上越来越多的爬虫横行时,为了防止自己的数据被爬取,网络资源维护者开始实施一系列措施,使自己的数据不易被其他程序爬取。这些措施是反爬虫。
如检测IP访问频率、资源访问速度、链接是否有关键参数、验证码检测机器人、ajax混淆、js加密等。
针对目前市场上的反爬虫,爬虫工程师经常有的反爬虫方案如下:
爬虫工程师的进阶之路,其实就是不断反爬虫,可谓艰辛,但换个角度想想也挺好玩的。
关于框架
爬虫有自己的写作过程和标准。有了标准,自然就会有框架。自然有很多像Python这样的生态强大的语言。自然有许多框架。目前,世界上使用最多的包括:
在这里就不过多介绍了,框架只是一个工具,是提高效率的一种方式,自己选择
阐明
一切都有两个方面,爬虫也不例外,所以我给你发一张图,关键时刻想一想。
以前的建议:
查看全部
php正则函数抓取网页连接(爬虫也可以称为Python爬虫不知
)
爬虫也可以称为Python爬虫
不知何时,语言Python和爬行动物就像一对恋人。
当您谈到爬虫时,您会想到 Python。当您谈到 Python 时,您会想到人工智能……和爬虫。
因此,在谈到爬虫时,大多数程序员都会下意识地将其联想为 Python 爬虫。为什么会这样?我认为有两个原因:
任何学习 Python 的程序员都应该或多或少看过甚至研究过爬虫。我当时写 Python 的目的很纯粹就是为了写爬虫。
所以这篇文章的目的很简单,就是谈谈我个人对Python爬虫的理解和实践。作为一个程序员,我觉得只有了解爬虫的相关知识才对你有好处,所以看完这篇文章 ,如果对你有帮助就太好了
什么是爬虫
爬虫是一个程序。这个程序的目的是爬取万维网的信息资源。比如你日常使用的谷歌等搜索引擎,搜索结果都是依赖爬虫定期获取的。
看上面的搜索结果,除了wiki相关的介绍外,所有爬虫相关的搜索结果都收录了Python。前辈说的是Python爬虫,现在看来真的不骗我了~
爬虫的目标对象也很丰富,无论是文字、图片、视频,任何结构化和非结构化数据爬虫都可以爬取。经过爬虫的发展,衍生出各种爬虫类型:
不想讲这些笼统的概念,让我们以一个网页内容获取为例,从爬虫技术本身开始,来谈谈网络爬虫,步骤如下:
什么是爬虫,这是爬虫:
<p>"""让我们根据上面说的步骤来完成一个简单的爬虫程序"""
import requests
<br />
from bs4 import BeautifulSoup
<br />
target_url = 'http://www.baidu.com/s?wd=爬虫'
<br />
# 第一步 发起一个GET请求
res = requests.get(target_url)
<br />
# 第二步 提取HTML并解析想获取的数据 比如获取 title
soup = BeautifulSoup(res.text, "lxml")
# 输出 soup.title.text
title = soup.title.text
<br />
# 第三步 持久化 比如保存到本地
with open('title.txt', 'w') as fp:
fp.write(title)</p>
不到20行代码加注释,就完成了一个爬虫,简单
如何编写爬虫
网络世界丰富多彩,有数以亿计的网络资源供您选择。如何让你的爬虫程序在面对不同的页面时健壮耐用是一个值得讨论的问题
俗话说,磨刀不误砍柴。在开始写爬虫之前,有必要掌握一些基础知识:
这两个描述反映了爬虫开发者需要掌握的基础知识,但是一个基本的后端或者前端工程师可以做到。这也说明爬虫的入门难度是极低的。从这两句话,你能想到爬虫必备的知识点吗?
有了这些知识储备,你就可以选择一种语言,开始编写自己的爬虫程序了。或者按照上一节提到的三个步骤,然后以Python为例,谈谈在编程语言中要做哪些准备:
一旦掌握了以上内容,就可以放开手脚,做很多功课了。万维网是你的名利场,去吧!
我认为对于一个目标网站的网页,可以分为以下四种:
这是什么意思?这可能看起来有点令人费解,但你明白这一点。写好爬虫后,只需要在脑海中浏览网页的类型,然后应用对应类型的程序(写的太多,应该有自己的常用代码库),写的速度爬虫自然不慢
单页单目标
通俗地说,在这个网页中,我们的目标只有一个。假设我们需要抓取这部电影的名字——肖申克的救赎,首先打开网页右键查看元素,找到电影名字对应的元素位置,如下图:
单页看是否只有一个target,标题的CSS Selector规则一目了然:#content> h1> span:nth-child(1),然后使用common自己写的库,不到十行代码就可以写一个爬取这个页面的电影名的爬虫:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
title = TextField(css_select='#content > h1 > span:nth-child(1)')
<br />
async_func = DoubanItem.get_item(url="https://movie.douban.com/subject/1292052/";)
item = asyncio.get_event_loop().run_until_complete(async_func)
print(item.title)</p>
Multi-page multi-target 在这种情况下是多个 URL 的衍生
单页多目标
假设当前的需求是抓取豆瓣电影250第一页的所有电影名,需要提取25个电影名,因为这个目标页面的目标数据是多项,所以需要循环获取目标,这就是所谓的具有多个目标的单页:
<p>import asyncio
<br />
from ruia import Item, TextField
<br />
class DoubanItem(Item):
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
async_func = DoubanItem.get_items(url="https://movie.douban.com/top250";)
items = asyncio.get_event_loop().run_until_complete(async_func)
for item in items:
print(item)</p>
多页多目标
多页多目标是上述单页多目标情况的派生。从这个角度来说,就是获取此时所有页面的电影名称。
<p>from ruia import TextField, Item, Request, Spider
<br />
<br />
class DoubanItem(Item):
"""
定义爬虫的目标字段
"""
target_item = TextField(css_select='div.item')
title = TextField(css_select='span.title')
<br />
async def clean_title(self, title):
if isinstance(title, str):
return title
else:
return ''.join([i.text.strip().replace('\xa0', '') for i in title])
<br />
<br />
class DoubanSpider(Spider):
start_urls = ['https://movie.douban.com/top250']
concurrency = 10
<br />
async def parse(self, res):
etree = res.html_etree
pages = ['?start=0&filter='] + [i.get('href') for i in etree.cssselect('.paginator>a')]
<br />
for index, page in enumerate(pages):
url = self.start_urls[0] + page
yield Request(
url,
callback=self.parse_item,
metadata={'index': index},
request_config=self.request_config
)
<br />
async def parse_item(self, res):
items_data = await DoubanItem.get_items(html=res.html)
res_list = []
for item in items_data:
res_list.append(item.title)
return res_list
<br />
<br />
if __name__ == '__main__':
DoubanSpider.start()</p>
如果网络正常,您将获得以下输出:
注意爬虫运行时间,小于1s,这就是异步的魅力
用Python写爬虫就是这么简单优雅,大家看看网页,想一想:
一个爬虫程序就形成了。顺便说一句,爬虫可以说是反君子,而不是小人。大部分robots.txt网站(它的目的是告诉爬虫什么可以爬,什么不能爬,比如:),你想怎么爬,自己衡量
如何推进
不要以为只要写一个爬虫程序就可以了。这个时候,还有更多的问题等着你。你要深情地看你的爬虫程序,问自己三个问题:
关于人性的前两个问题这里就不多说了,直接跳过,但是如果你是爬虫工程师,千万不要跳过
会被反爬行动物杀死吗?
最后,关于反爬虫的问题是你的爬虫程序是否强大的关键因素。什么是反爬虫?
当网络上越来越多的爬虫横行时,为了防止自己的数据被爬取,网络资源维护者开始实施一系列措施,使自己的数据不易被其他程序爬取。这些措施是反爬虫。
如检测IP访问频率、资源访问速度、链接是否有关键参数、验证码检测机器人、ajax混淆、js加密等。
针对目前市场上的反爬虫,爬虫工程师经常有的反爬虫方案如下:
爬虫工程师的进阶之路,其实就是不断反爬虫,可谓艰辛,但换个角度想想也挺好玩的。
关于框架
爬虫有自己的写作过程和标准。有了标准,自然就会有框架。自然有很多像Python这样的生态强大的语言。自然有许多框架。目前,世界上使用最多的包括:
在这里就不过多介绍了,框架只是一个工具,是提高效率的一种方式,自己选择
阐明
一切都有两个方面,爬虫也不例外,所以我给你发一张图,关键时刻想一想。
以前的建议:
php正则函数抓取网页连接( 快讯网通用HTML标准超链接参数取得正则表达式测试(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-08 15:12
快讯网通用HTML标准超链接参数取得正则表达式测试(图))
PHP超链接抓取实现代码
2015-01-24信息快报
获取正则表达式测试的通用HTML标准超链接参数
因为最近想做一个类似专业搜索引擎的东西,所以需要爬取网页的所有超链接。
大家可以帮忙测试一下,下面的代码是否可以用于所有标准的超链接。
测试代码如下:
如果你的测试数据符合标准链接,但是这里没有处理,请告诉我测试数据和你的测试环境。
谢谢。
php一些技巧及注意事项分析
PHP数组比较函数,有交集返回true,否则返回false
使用PHP读写XML DOM实现代码
javascript、php代码获取函数参数对象
php下将多个数组合并为一个数组的方法和示例代码
php下载文件的实现代码及文件名乱码的解决方法
仿AS3实现PHP事件机制实现代码
解决 DOS 命令行下 PHP 但无法链接 MySQL 的技术笔记
phpMyAdmin链接表附加功能未激活的问题
使用 PHP 将 URL 字符串转换为超链接(URL 或电子邮件)
DW中连接mysql数据库时建立字符集出现乱码的解决方法
检查url链接是否添加了参数的php代码?或者 &
php自写函数代码获取关键字超链接
连接txt文本的超链接不是直接打开而是点击处理方法后下载的
PHP网页过期时间控制代码
PHP文件上传功能实现代码
php addlashes函数详解
PHP n 唯一随机数生成代码
PHP的七大优势解析
PHP 404错误页面实现代码
PHP编写MySQL数据实现代码
php分页类扩展代码
php 定期过滤 html 超链接
站长推荐的101种增加反向链接的方法 查看全部
php正则函数抓取网页连接(
快讯网通用HTML标准超链接参数取得正则表达式测试(图))
PHP超链接抓取实现代码
2015-01-24信息快报
获取正则表达式测试的通用HTML标准超链接参数
因为最近想做一个类似专业搜索引擎的东西,所以需要爬取网页的所有超链接。
大家可以帮忙测试一下,下面的代码是否可以用于所有标准的超链接。
测试代码如下:
如果你的测试数据符合标准链接,但是这里没有处理,请告诉我测试数据和你的测试环境。
谢谢。
php一些技巧及注意事项分析
PHP数组比较函数,有交集返回true,否则返回false
使用PHP读写XML DOM实现代码
javascript、php代码获取函数参数对象
php下将多个数组合并为一个数组的方法和示例代码
php下载文件的实现代码及文件名乱码的解决方法
仿AS3实现PHP事件机制实现代码
解决 DOS 命令行下 PHP 但无法链接 MySQL 的技术笔记
phpMyAdmin链接表附加功能未激活的问题
使用 PHP 将 URL 字符串转换为超链接(URL 或电子邮件)
DW中连接mysql数据库时建立字符集出现乱码的解决方法
检查url链接是否添加了参数的php代码?或者 &
php自写函数代码获取关键字超链接
连接txt文本的超链接不是直接打开而是点击处理方法后下载的
PHP网页过期时间控制代码
PHP文件上传功能实现代码
php addlashes函数详解
PHP n 唯一随机数生成代码
PHP的七大优势解析
PHP 404错误页面实现代码
PHP编写MySQL数据实现代码
php分页类扩展代码
php 定期过滤 html 超链接
站长推荐的101种增加反向链接的方法
php正则函数抓取网页连接(link_extractor是一个对象,它定义如何从要爬取的页面提取链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-08 15:11
link_extractor 是一个对象,它定义了如何从要抓取的页面中提取链接。
callback'' 是一个可调用或字符串(在这种情况下,蜘蛛中的同名函数将被调用),使用link_extractor从Response对象中提取的每个链接都会调用该函数。回调函数接收一个响应作为它的第一个参数,并且必须返回一个收录和(或)对象(或它们的任何子类)的列表。
警告
在编写爬行蜘蛛规则时,请避免使用 parse 回调,因为 parse 方法本身是用来实现其逻辑的。因此,如果您覆盖 parse 方法,它将不再起作用。
cb_kwargs 是一个收录要传递给回调函数的关键字参数的字典。
follow 是一个布尔值,它指定是否应该从使用此规则提取的每个响应中跟踪链接。如果回调默认值为 None follow,则默认为 True,否则默认为 False。
process_links 是一个可调用或字符串(在这种情况下,蜘蛛中的同名函数将被调用),它使用link_extractor 调用,每个链接列表从Response 对象中提取。这主要用于过滤目的。
process_request 是一个可调用的或字符串(这种情况下会调用spider中同名的函数),这个规则提取的每个请求都会调用它,并且必须返回一个请求或者None(请求被过滤掉) )。 查看全部
php正则函数抓取网页连接(link_extractor是一个对象,它定义如何从要爬取的页面提取链接)
link_extractor 是一个对象,它定义了如何从要抓取的页面中提取链接。
callback'' 是一个可调用或字符串(在这种情况下,蜘蛛中的同名函数将被调用),使用link_extractor从Response对象中提取的每个链接都会调用该函数。回调函数接收一个响应作为它的第一个参数,并且必须返回一个收录和(或)对象(或它们的任何子类)的列表。
警告
在编写爬行蜘蛛规则时,请避免使用 parse 回调,因为 parse 方法本身是用来实现其逻辑的。因此,如果您覆盖 parse 方法,它将不再起作用。
cb_kwargs 是一个收录要传递给回调函数的关键字参数的字典。
follow 是一个布尔值,它指定是否应该从使用此规则提取的每个响应中跟踪链接。如果回调默认值为 None follow,则默认为 True,否则默认为 False。
process_links 是一个可调用或字符串(在这种情况下,蜘蛛中的同名函数将被调用),它使用link_extractor 调用,每个链接列表从Response 对象中提取。这主要用于过滤目的。
process_request 是一个可调用的或字符串(这种情况下会调用spider中同名的函数),这个规则提取的每个请求都会调用它,并且必须返回一个请求或者None(请求被过滤掉) )。
php正则函数抓取网页连接(php正则函数抓取网页连接,进行处理,可能需要多次循环过滤掉超链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-07 14:03
<p>php正则函数抓取网页连接,进行处理,可能需要多次循环过滤掉超链接,抓取一下本文主要需要的抓取方法:multi-url。1.首先去源码抓取所有的url,逐个字段进行处理。2.然后对每个url分析。主要依赖函数函数分析,以下是两个工具性的语句提示,可以辅助我们很好的抓取3.关键抓取点:首页url=>首页url=>首页url=>首页url-replace=>'.'1.首页url=>首页url=>首页url=>首页url=>第一遍抓取文字,完整的抓取一个三行的字符串,如下:'''如下说明:第1次抓取文字:对于第1个需要进行判断抓取数量1,且1不是3的倍数,如果是3,那么直接用3+1填写数据抓取数量2:直接填写3+1,并不是一定要直接选择2,因为抓取数量>3,直接用3+1数组就够了抓取数量3:如果抓取到的数量>3,才会进行数组下标填写,若抓取到的数量不多,就直接填写3抓取数量4:如果抓取到的数量 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接,进行处理,可能需要多次循环过滤掉超链接)
<p>php正则函数抓取网页连接,进行处理,可能需要多次循环过滤掉超链接,抓取一下本文主要需要的抓取方法:multi-url。1.首先去源码抓取所有的url,逐个字段进行处理。2.然后对每个url分析。主要依赖函数函数分析,以下是两个工具性的语句提示,可以辅助我们很好的抓取3.关键抓取点:首页url=>首页url=>首页url=>首页url-replace=>'.'1.首页url=>首页url=>首页url=>首页url=>第一遍抓取文字,完整的抓取一个三行的字符串,如下:'''如下说明:第1次抓取文字:对于第1个需要进行判断抓取数量1,且1不是3的倍数,如果是3,那么直接用3+1填写数据抓取数量2:直接填写3+1,并不是一定要直接选择2,因为抓取数量>3,直接用3+1数组就够了抓取数量3:如果抓取到的数量>3,才会进行数组下标填写,若抓取到的数量不多,就直接填写3抓取数量4:如果抓取到的数量
php正则函数抓取网页连接( 本文实例讲述Python正则抓取新闻标题和链接的方法-本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-06 06:01
本文实例讲述Python正则抓取新闻标题和链接的方法-本文)
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/").read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》 、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件与目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
关于寻找教程网络 查看全部
php正则函数抓取网页连接(
本文实例讲述Python正则抓取新闻标题和链接的方法-本文)
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/";).read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》 、《Python字符串操作技巧总结》、《Python入门及进阶经典教程》、《Python文件与目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
关于寻找教程网络
php正则函数抓取网页连接(本文会介绍如何Scrapy构建一个简单的网络爬虫(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-04 14:15
记得n年前项目需要一个灵活的爬虫工具,我组织了一个小团队,用Java实现了一个爬虫框架。可以根据目标网站的结构、地址和内容进行简单的配置开发,即可实现特定网站的爬虫功能。由于要考虑各种特殊情况,开发也需要耗费大量人力。后来发现Python下有这个Scrapy工具,瞬间觉得之前做的都白费了。对于一个普通的网络爬虫功能,Scrapy 完全可以胜任,打包了很多复杂的编程。本文将介绍 Scrapy 如何构建一个简单的网络爬虫。
一个基本的爬虫工具,应该具备以下功能:
我们来看看Scrapy是如何做这些功能的。首先准备Scrapy环境,需要安装Python(本文使用v2.7)和pip,然后使用pip安装lxml和scrapy。个人强烈推荐使用virtualenv安装环境,所以不同项目之间不会有冲突,详细步骤这里不再赘述。Mac用户请注意,使用pip安装lxml时,会出现类似如下错误:
> Error: #include "xml/xmlversion.h" not found
要解决这个问题,需要先安装Xcode的命令行工具。具体方法是在命令行执行如下命令。
$ xcode-select --install
环境安装好后,我们用Scrapy实现一个简单的爬虫,抓取本博客网站的文章标题、地址和摘要。
# -*- coding: utf-8 -*-
import scrapy
class MyCrawlerItem(scrapy.Item):
title = scrapy.Field() # 文章标题
url = scrapy.Field() # 文章地址
summary = scrapy.Field() # 文章摘要
pass
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from my_crawler.items import MyCrawlerItem
class MyCrawlSpider(CrawlSpider):
name = 'my_crawler' # Spider名,必须唯一,执行爬虫命令时使用
allowed_domains = ['bjhee.com'] # 限定允许爬的域名,可设置多个
start_urls = [
"http://www.bjhee.com", # 种子URL,可设置多个
]
rules = ( # 对应特定URL,设置解析函数,可设置多个
Rule(LinkExtractor(allow=r'/page/[0-9]+'), # 指定允许继续爬取的URL格式,支持正则
callback='parse_item', # 用于解析网页的回调函数名
follow=True
),
)
def parse_item(self, response):
# 通过XPath获取Dom元素
articles = response.xpath('//*[@id="main"]/ul/li')
for article in articles:
item = MyCrawlerItem()
item['title'] = article.xpath('h3[@class="entry-title"]/a/text()').extract()[0]
item['url'] = article.xpath('h3[@class="entry-title"]/a/@href').extract()[0]
item['summary'] = article.xpath('div[2]/p/text()').extract()[0]
yield item
不熟悉XPath的可以通过Chrome的调试工具获取元素的XPath。
# -*- coding: utf-8 -*-
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
class MyCrawlerPipeline(object):
def __init__(self):
# 设置MongoDB连接
connection = pymongo.Connection(
settings['MONGO_SERVER'],
settings['MONGO_PORT']
)
db = connection[settings['MONGO_DB']]
self.collection = db[settings['MONGO_COLLECTION']]
# 处理每个被抓取的MyCrawlerItem项
def process_item(self, item, spider):
valid = True
for data in item:
if not data: # 过滤掉存在空字段的项
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
# 也可以用self.collection.insert(dict(item)),使用upsert可以防止重复项
self.collection.update({'url': item['url']}, dict(item), upsert=True)
return item
打开my_crawler目录下的settings.py文件,在文件末尾添加管道设置:
ITEM_PIPELINES = {
'my_crawler.pipelines.MyCrawlerPipeline': 300, # 设置Pipeline,可以多个,值为执行优先级
}
# MongoDB连接信息
MONGO_SERVER = 'localhost'
MONGO_PORT = 27017
MONGO_DB = 'bjhee'
MONGO_COLLECTION = 'articles'
DOWNLOAD_DELAY=2 # 如果网络慢,可以适当加些延迟,单位是秒
总而言之,要使用 Scrapy 构建网络爬虫,您需要做的就是:
在“items.py”中定义爬取字段在“spiders”目录下创建你的爬虫,编写解析函数和规则“pipelines.py”处理爬取后的结果,“settings.py”是必须的参数
Scrapy 会为你做其他一切。下图展示了Scrapy的具体工作流程。这个怎么样?开始编写您自己的爬虫。
这个例子中的代码可以在这里下载。 查看全部
php正则函数抓取网页连接(本文会介绍如何Scrapy构建一个简单的网络爬虫(图))
记得n年前项目需要一个灵活的爬虫工具,我组织了一个小团队,用Java实现了一个爬虫框架。可以根据目标网站的结构、地址和内容进行简单的配置开发,即可实现特定网站的爬虫功能。由于要考虑各种特殊情况,开发也需要耗费大量人力。后来发现Python下有这个Scrapy工具,瞬间觉得之前做的都白费了。对于一个普通的网络爬虫功能,Scrapy 完全可以胜任,打包了很多复杂的编程。本文将介绍 Scrapy 如何构建一个简单的网络爬虫。
一个基本的爬虫工具,应该具备以下功能:
我们来看看Scrapy是如何做这些功能的。首先准备Scrapy环境,需要安装Python(本文使用v2.7)和pip,然后使用pip安装lxml和scrapy。个人强烈推荐使用virtualenv安装环境,所以不同项目之间不会有冲突,详细步骤这里不再赘述。Mac用户请注意,使用pip安装lxml时,会出现类似如下错误:
> Error: #include "xml/xmlversion.h" not found
要解决这个问题,需要先安装Xcode的命令行工具。具体方法是在命令行执行如下命令。
$ xcode-select --install
环境安装好后,我们用Scrapy实现一个简单的爬虫,抓取本博客网站的文章标题、地址和摘要。
# -*- coding: utf-8 -*-
import scrapy
class MyCrawlerItem(scrapy.Item):
title = scrapy.Field() # 文章标题
url = scrapy.Field() # 文章地址
summary = scrapy.Field() # 文章摘要
pass
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from my_crawler.items import MyCrawlerItem
class MyCrawlSpider(CrawlSpider):
name = 'my_crawler' # Spider名,必须唯一,执行爬虫命令时使用
allowed_domains = ['bjhee.com'] # 限定允许爬的域名,可设置多个
start_urls = [
"http://www.bjhee.com", # 种子URL,可设置多个
]
rules = ( # 对应特定URL,设置解析函数,可设置多个
Rule(LinkExtractor(allow=r'/page/[0-9]+'), # 指定允许继续爬取的URL格式,支持正则
callback='parse_item', # 用于解析网页的回调函数名
follow=True
),
)
def parse_item(self, response):
# 通过XPath获取Dom元素
articles = response.xpath('//*[@id="main"]/ul/li')
for article in articles:
item = MyCrawlerItem()
item['title'] = article.xpath('h3[@class="entry-title"]/a/text()').extract()[0]
item['url'] = article.xpath('h3[@class="entry-title"]/a/@href').extract()[0]
item['summary'] = article.xpath('div[2]/p/text()').extract()[0]
yield item
不熟悉XPath的可以通过Chrome的调试工具获取元素的XPath。
# -*- coding: utf-8 -*-
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
class MyCrawlerPipeline(object):
def __init__(self):
# 设置MongoDB连接
connection = pymongo.Connection(
settings['MONGO_SERVER'],
settings['MONGO_PORT']
)
db = connection[settings['MONGO_DB']]
self.collection = db[settings['MONGO_COLLECTION']]
# 处理每个被抓取的MyCrawlerItem项
def process_item(self, item, spider):
valid = True
for data in item:
if not data: # 过滤掉存在空字段的项
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
# 也可以用self.collection.insert(dict(item)),使用upsert可以防止重复项
self.collection.update({'url': item['url']}, dict(item), upsert=True)
return item
打开my_crawler目录下的settings.py文件,在文件末尾添加管道设置:
ITEM_PIPELINES = {
'my_crawler.pipelines.MyCrawlerPipeline': 300, # 设置Pipeline,可以多个,值为执行优先级
}
# MongoDB连接信息
MONGO_SERVER = 'localhost'
MONGO_PORT = 27017
MONGO_DB = 'bjhee'
MONGO_COLLECTION = 'articles'
DOWNLOAD_DELAY=2 # 如果网络慢,可以适当加些延迟,单位是秒
总而言之,要使用 Scrapy 构建网络爬虫,您需要做的就是:
在“items.py”中定义爬取字段在“spiders”目录下创建你的爬虫,编写解析函数和规则“pipelines.py”处理爬取后的结果,“settings.py”是必须的参数
Scrapy 会为你做其他一切。下图展示了Scrapy的具体工作流程。这个怎么样?开始编写您自己的爬虫。
这个例子中的代码可以在这里下载。
php正则函数抓取网页连接(php正则函数抓取网页连接会丢失拼音,更详细的php抓取拼音网页方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-04 13:01
php正则函数抓取网页连接会丢失拼音,详见下图。更详细的php抓取拼音网页方法见我的博客blog:php正则python正则总之,php正则抓取拼音失败的原因是php的正则不能匹配python里的正则。
我用php做网页抓取,把文本比如中文正则匹配出来,然后用正则表达式搜索。
这个题主要关注一个概念,对于要抓取的网页来说,拼音是分词的,或者意思模糊的。针对拼音进行正则检测就比较简单了。而且,拼音的检测的结果不需要返回值,返回的话太奇怪了。像这种,多关注一下这个就行了,像。还有这种。虽然算法复杂了点,但是总体来说的话就是自己做diy。
请自己尝试如何写一个正则分词
举一个例子。从百度获取拼音,匹配情况如下所示:get,data=getweb'xiaomi';o={}o.index()int=1;//index对应parse()方法中的“xiaomi”,在检测到拼音时输出值choose={};//如果无空格则匹配”xiaomi”ifo.index()==1{//如果有空格则输出字符串“我”breakifo.index()==2{//如果有空格且输出的字符长度小于6//如果有空格且输出的字符长度大于6则匹配“我”break}}p.getwhitespace()o.getparser(“xiaomi”);o.join(o,。
5)o.getwhitespace()o.getnumeric()o.getnumeric()p.get
3)p.get
2)p.get
1)p.get(1
0)ifo.index()==1{p.parse(test.whoelix())//获取拼音p.parse(test.whoelix())//获取拼音[1,2,3,4,5,6,7,8,9,10]ifo.index()==2{p.parse(test.whoelix())p.parse(test.whoelix())p.parse(test.whoelix())p.parse(test.whoelix())所以你只需要把p.getwith('xiaomi')改为p.getwith('xiaomi','')即可。 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接会丢失拼音,更详细的php抓取拼音网页方法)
php正则函数抓取网页连接会丢失拼音,详见下图。更详细的php抓取拼音网页方法见我的博客blog:php正则python正则总之,php正则抓取拼音失败的原因是php的正则不能匹配python里的正则。
我用php做网页抓取,把文本比如中文正则匹配出来,然后用正则表达式搜索。
这个题主要关注一个概念,对于要抓取的网页来说,拼音是分词的,或者意思模糊的。针对拼音进行正则检测就比较简单了。而且,拼音的检测的结果不需要返回值,返回的话太奇怪了。像这种,多关注一下这个就行了,像。还有这种。虽然算法复杂了点,但是总体来说的话就是自己做diy。
请自己尝试如何写一个正则分词
举一个例子。从百度获取拼音,匹配情况如下所示:get,data=getweb'xiaomi';o={}o.index()int=1;//index对应parse()方法中的“xiaomi”,在检测到拼音时输出值choose={};//如果无空格则匹配”xiaomi”ifo.index()==1{//如果有空格则输出字符串“我”breakifo.index()==2{//如果有空格且输出的字符长度小于6//如果有空格且输出的字符长度大于6则匹配“我”break}}p.getwhitespace()o.getparser(“xiaomi”);o.join(o,。
5)o.getwhitespace()o.getnumeric()o.getnumeric()p.get
3)p.get
2)p.get
1)p.get(1
0)ifo.index()==1{p.parse(test.whoelix())//获取拼音p.parse(test.whoelix())//获取拼音[1,2,3,4,5,6,7,8,9,10]ifo.index()==2{p.parse(test.whoelix())p.parse(test.whoelix())p.parse(test.whoelix())p.parse(test.whoelix())所以你只需要把p.getwith('xiaomi')改为p.getwith('xiaomi','')即可。
php正则函数抓取网页连接(python·简介以及相关的经验技巧,文章约6916字,浏览量3464 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-03 07:22
)
栏目:python·
Introduction 本文文章主要介绍几种网页解析方法的正则表达式(示例代码)及相关经验技巧。 文章约6916字,346页浏览量,点赞数4,值得参考!
1、正则表达式
正则表达式是一种特殊的字符序列,它可以帮助您轻松检查字符串是否与某个模式匹配。
re 模块使 Python 语言拥有所有的正则表达式功能。
重新匹配功能
re.match 尝试从字符串的开头匹配模式。如果一开始匹配不成功,match() 返回 none。
import re
print(re.match(‘www‘, ‘www.runoob.com‘).span()) # 在起始位置匹配
print(re.match(‘com‘, ‘www.runoob.com‘)) # 不在起始位置匹配
结果:
(0, 3)
None
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r‘(.*) are (.*?) .*‘, line)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
r‘(.*) are (.*?) .*‘,r的意思为raw string,纯粹的字符串,group(0),是匹配正则表达式整体结果,group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分。
研究方法
re.search 扫描整个字符串并返回第一个成功匹配。
re.match 只匹配字符串的开头。如果字符串与开头的正则表达式不匹配,则匹配失败,函数返回None;而 re.search 匹配整个字符串,直到找到匹配项。
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r‘dogs‘, line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
matchObj = re.search( r‘dogs‘, line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
结果:
No match!!
search --> matchObj.group() : dogs
re.findall 方法
findall 可以找到匹配的结果并以列表的形式返回。
import requests
import re
link = "http://www.sohu.com/"
headers = {‘User-Agent‘ : ‘Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6‘}
r = requests.get(link, headers= headers)
html = r.text
title_list = re.findall(‘href=".*?".(.*?)‘,html)
print (title_list)
[‘新闻‘, ‘财经‘, ‘体育‘, ‘房产‘, ‘娱乐‘, ‘汽车‘, ‘时尚‘, ‘科技‘, ‘美食‘, ‘星座‘, ‘邮箱‘, ‘地图‘, ‘千帆‘, ‘畅游‘]
获取搜狐的主要标题。
查看全部
php正则函数抓取网页连接(python·简介以及相关的经验技巧,文章约6916字,浏览量3464
)
栏目:python·
Introduction 本文文章主要介绍几种网页解析方法的正则表达式(示例代码)及相关经验技巧。 文章约6916字,346页浏览量,点赞数4,值得参考!
1、正则表达式
正则表达式是一种特殊的字符序列,它可以帮助您轻松检查字符串是否与某个模式匹配。
re 模块使 Python 语言拥有所有的正则表达式功能。
重新匹配功能
re.match 尝试从字符串的开头匹配模式。如果一开始匹配不成功,match() 返回 none。
import re
print(re.match(‘www‘, ‘www.runoob.com‘).span()) # 在起始位置匹配
print(re.match(‘com‘, ‘www.runoob.com‘)) # 不在起始位置匹配
结果:
(0, 3)
None
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r‘(.*) are (.*?) .*‘, line)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
r‘(.*) are (.*?) .*‘,r的意思为raw string,纯粹的字符串,group(0),是匹配正则表达式整体结果,group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分。
研究方法
re.search 扫描整个字符串并返回第一个成功匹配。
re.match 只匹配字符串的开头。如果字符串与开头的正则表达式不匹配,则匹配失败,函数返回None;而 re.search 匹配整个字符串,直到找到匹配项。
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r‘dogs‘, line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
matchObj = re.search( r‘dogs‘, line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
结果:
No match!!
search --> matchObj.group() : dogs
re.findall 方法
findall 可以找到匹配的结果并以列表的形式返回。
import requests
import re
link = "http://www.sohu.com/"
headers = {‘User-Agent‘ : ‘Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6‘}
r = requests.get(link, headers= headers)
html = r.text
title_list = re.findall(‘href=".*?".(.*?)‘,html)
print (title_list)
[‘新闻‘, ‘财经‘, ‘体育‘, ‘房产‘, ‘娱乐‘, ‘汽车‘, ‘时尚‘, ‘科技‘, ‘美食‘, ‘星座‘, ‘邮箱‘, ‘地图‘, ‘千帆‘, ‘畅游‘]
获取搜狐的主要标题。
php正则函数抓取网页连接(php正则函数抓取网页连接用的是requests库(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-01 15:24
php正则函数抓取网页连接用的是requests库。对于php来说,用mysql都可以读写数据库,所以抓取连接没有必要去专门的学习一个相关的东西。抓取前我们准备好需要抓取的链接就行了。同样的需要抓取几个session也分别写入对应的数据库。步骤如下:打开抓取的网页,根据连接到的连接输入对应的php语句实例1:抓取链接:/#window可以打开网站的全景分析网页的主要结构步骤如下:1.分析网页结构,然后选择最合适的requests库进行解析。
2.用requests库进行下一步的连接请求抓取。如:#window3.查看此时提供的连接,来判断是否需要使用上一步分析得到的几个连接。连接://data?s=5000&m=-5&sample=log&t=10;t=50155&data=&i=.sample=log&s=5000&s=5000;t=50209;t=50304;t=50405;t=50501;t=50607;t=50709;t=50804;t=50904;t=501024;#window解析:web-equiv=#window方便判断我们是否抓取一个数据库步骤如下:4.将之前提到的sample=log&t=&sample=log&s=5...&5...&6...&7...&8...&9...&10...&11...&12...&13...&14...&15...&16...&17...&18...&19...&20...&21...&22...&23...&24...&25...&26...&27...&28...&29...&30...&31...&32...&33...&34...&35...&36...&37...&38...&39...&40...&41...&42...&43...&44...&45...&46...&47...&48...&49...&50...&51...&52...&53...&54...&55...&56...&57...&58...&59...&60...&61...&62...&63...&64...&65...&66...&67...&68...&69...&70...&71...&72...&73...&74...&75...&76...&77...&78...&79...&80...&81...&82...&83...&84...&85...&86...&87...&88...&89...&90...&91...&92...&93...&94...&95...&96...&97...&98...&99...&100...&100...&100...&100...&100...&100...100..&100...&100...&100...&100...#window80.将抓取链接同时下载到本地:php。 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接用的是requests库(图))
php正则函数抓取网页连接用的是requests库。对于php来说,用mysql都可以读写数据库,所以抓取连接没有必要去专门的学习一个相关的东西。抓取前我们准备好需要抓取的链接就行了。同样的需要抓取几个session也分别写入对应的数据库。步骤如下:打开抓取的网页,根据连接到的连接输入对应的php语句实例1:抓取链接:/#window可以打开网站的全景分析网页的主要结构步骤如下:1.分析网页结构,然后选择最合适的requests库进行解析。
2.用requests库进行下一步的连接请求抓取。如:#window3.查看此时提供的连接,来判断是否需要使用上一步分析得到的几个连接。连接://data?s=5000&m=-5&sample=log&t=10;t=50155&data=&i=.sample=log&s=5000&s=5000;t=50209;t=50304;t=50405;t=50501;t=50607;t=50709;t=50804;t=50904;t=501024;#window解析:web-equiv=#window方便判断我们是否抓取一个数据库步骤如下:4.将之前提到的sample=log&t=&sample=log&s=5...&5...&6...&7...&8...&9...&10...&11...&12...&13...&14...&15...&16...&17...&18...&19...&20...&21...&22...&23...&24...&25...&26...&27...&28...&29...&30...&31...&32...&33...&34...&35...&36...&37...&38...&39...&40...&41...&42...&43...&44...&45...&46...&47...&48...&49...&50...&51...&52...&53...&54...&55...&56...&57...&58...&59...&60...&61...&62...&63...&64...&65...&66...&67...&68...&69...&70...&71...&72...&73...&74...&75...&76...&77...&78...&79...&80...&81...&82...&83...&84...&85...&86...&87...&88...&89...&90...&91...&92...&93...&94...&95...&96...&97...&98...&99...&100...&100...&100...&100...&100...&100...100..&100...&100...&100...&100...#window80.将抓取链接同时下载到本地:php。
php正则函数抓取网页连接(php正则函数抓取网页连接返回自己指定json格式的数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-29 04:04
php正则函数抓取网页连接返回自己指定json格式的数据序列化存储到数据库客户端可以post或get方式接收html中引用的库:redisrawpython请求ip列表:可以直接列出来json的list.form-replace可以对一个php文件进行解析,转换为一个json数据。使用方法:传入数据,按照数据类型,进行匹配和解析。将匹配到的函数和参数填到特定的方法里面,便于提取数据。
可以用zendforest库
json
用php进行数据库操作首推sqlite,
如果你要用php,那你的数据库是用的什么语言,用的c语言,或者是用的java,oracle?teradata?还是mysql?mysql我觉得随便选一个喜欢的就好,用php比java简单。
写出漂亮的算法
最近正在整理一些目前看过的,发现一个非常好的数据结构json结构可以访问json库,fastjson,
看了一下,我觉得用数据库用php就比较麻烦,或者直接用sqlite做mongodb数据库来写代码,里面写公式,
据说现在很多数据库软件都是基于json的api实现
随便举个例子flask里就有很多库都支持json格式的简单封装的话,
就我个人来说,没有数据库基础的情况下, 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接返回自己指定json格式的数据库)
php正则函数抓取网页连接返回自己指定json格式的数据序列化存储到数据库客户端可以post或get方式接收html中引用的库:redisrawpython请求ip列表:可以直接列出来json的list.form-replace可以对一个php文件进行解析,转换为一个json数据。使用方法:传入数据,按照数据类型,进行匹配和解析。将匹配到的函数和参数填到特定的方法里面,便于提取数据。
可以用zendforest库
json
用php进行数据库操作首推sqlite,
如果你要用php,那你的数据库是用的什么语言,用的c语言,或者是用的java,oracle?teradata?还是mysql?mysql我觉得随便选一个喜欢的就好,用php比java简单。
写出漂亮的算法
最近正在整理一些目前看过的,发现一个非常好的数据结构json结构可以访问json库,fastjson,
看了一下,我觉得用数据库用php就比较麻烦,或者直接用sqlite做mongodb数据库来写代码,里面写公式,
据说现在很多数据库软件都是基于json的api实现
随便举个例子flask里就有很多库都支持json格式的简单封装的话,
就我个人来说,没有数据库基础的情况下,
php正则函数抓取网页连接(php正则学了抓取特定标签具有特定属性值的接口通用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-27 23:07
研究了几天php正则,抓取了网站的一些数据,发现写正则又每次都重新抓很麻烦,所以想写一个通用的接口,用特定的标签抓取特定的标签属性值。代码。
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这是一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果是
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
你可以看到源代码
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客的时候很紧张,哈哈哈,希望对大家有用,也希望大家能指出代码中的问题,不做大量测试~~
以上就是小编给大家介绍的用PHP正则表达式捕获标签的具体属性值的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对ASPKU源代码库网站的支持!
注:请移步正则表达式频道阅读相关教程知识。 查看全部
php正则函数抓取网页连接(php正则学了抓取特定标签具有特定属性值的接口通用)
研究了几天php正则,抓取了网站的一些数据,发现写正则又每次都重新抓很麻烦,所以想写一个通用的接口,用特定的标签抓取特定的标签属性值。代码。
//$html-被查找的字符串 $tag-被查找的标签 $attr-被查找的属性名 $value-被查找的属性值
function get_tag_data($html,$tag,$attr,$value){
$regex = "/(.*?)/is";
echo $regex."
";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];
}
//返回值为数组 查找到的标签内的内容
这是一个例子
header("Content-type: text/html; charset=utf-8");
$temp = '
首页
日志
LOFTER
相册
博友
关于我
';
$result = get_tag_data($temp,"a","class","fc01");
var_dump($result);
输出结果是
array(6) { [0]=> string(6) "首页" [1]=> string(6) "日志" [2]=> string(6) "LOFTER" [3]=> string(6) "相册" [4]=> string(6) "博友" [5]=> string(9) "关于我" }
你可以看到源代码
array(6) {
[0]=>
string(6) "首页"
[1]=>
string(6) "日志"
[2]=>
string(6) "LOFTER"
[3]=>
string(6) "相册"
[4]=>
string(6) "博友"
[5]=>
string(9) "关于我"
}
第一次写博客的时候很紧张,哈哈哈,希望对大家有用,也希望大家能指出代码中的问题,不做大量测试~~
以上就是小编给大家介绍的用PHP正则表达式捕获标签的具体属性值的方法。我希望它会对你有所帮助。如果您有任何问题,请给我留言。小编会及时回复您。. 非常感谢您对ASPKU源代码库网站的支持!
注:请移步正则表达式频道阅读相关教程知识。
php正则函数抓取网页连接(协议是告诉浏览器如何处理将要打开文件的标识(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-27 04:06
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中一般有三种链接,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对url超链接和相对url超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫url(统一资源定位器),它标识了互联网上唯一的资源。url的结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了http协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或ip地址,有时会收录端口号(默认为80)。在ftp协议中也可以收录用户名和密码,本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考 rfc1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下: 查看全部
php正则函数抓取网页连接(协议是告诉浏览器如何处理将要打开文件的标识(图))
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。一个网页中一般有三种链接,一种是绝对URL超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对url超链接和相对url超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫url(统一资源定位器),它标识了互联网上唯一的资源。url的结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了http协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或ip地址,有时会收录端口号(默认为80)。在ftp协议中也可以收录用户名和密码,本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考 rfc1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下:

