
php多线程抓取多个网页
php多线程抓取多个网页(2017年7月10日16:17用PHP来加密解密Cloudflare邮箱保护Cloudflare)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-15 10:22
WHMCS 限制每个订单的数量
默认情况下,在 whmcs 中,可以在购物车中选择无限数量的产品。虽然说可以设置产品的上限,但也可以暂时用完所有剩余的可用数量。那么后台会产生很多无用的数据,大量的订单会导致数据库出现异常,所以我们需要防止这种情况发生。
2017年7月10日16:17
使用 PHP 加解密 Cloudflare 邮箱保护
Cloudflare 有一个非常好的功能,就是对页面上所有的邮箱地址进行加密,防止机器人抓取和做坏事。对于该功能,在后台启用邮箱地址混淆后,您可以在页面中添加邮箱地址。例如,如果您查看源代码,您可以找到类似于以下的代码
2016 年 9 月 28 日 12:28
WHMCS密码加密方式
我今天无事可做,看了WHMCS在网上流传的代码。网上只找到了5.2.17个版本,但是对于我们这些曾经研究过代码的人来说,已经足够了。他使用的加密不是传统的 MD5 + salt 实现。加密后的数据只会出现一次,但是每个密码得到的密码都是一样的,类似于openssl的加密方式。然后是硬通货时间:
2015 年 8 月 10 日 17:13
PHP多线程的实现
在某些情况下,我们想用PHP来执行重复性的任务,但是只有一次,叠加的时候执行时间会很长,所以应该将任务分配给多个线程分别执行。但是PHP默认没有多线程,必须使用pthreadsPHP扩展,它才能真正支持和实现多线程。在处理重复的循环任务时,多线程可以大大减少程序执行时间。要使用此扩展,您必须使用线程安全版本。编译 PHP […]
2014 年 7 月 6 日 10:47
更换 Discuz 的内存缓存
最近论坛一直卡,负载经常跑到130%。正常情况下,负载达到10%,非常高。通过跟踪日志,我找不到任何重大问题。我只能暂时屏蔽爬取大量网页的ip和ua,但最终不是解决办法。最后实在看不下去了,就装了一个newrelic来跟踪问题。安装后发现问题,如图:
2014 年 5 月 6 日 18:15 查看全部
php多线程抓取多个网页(2017年7月10日16:17用PHP来加密解密Cloudflare邮箱保护Cloudflare)
WHMCS 限制每个订单的数量
默认情况下,在 whmcs 中,可以在购物车中选择无限数量的产品。虽然说可以设置产品的上限,但也可以暂时用完所有剩余的可用数量。那么后台会产生很多无用的数据,大量的订单会导致数据库出现异常,所以我们需要防止这种情况发生。
2017年7月10日16:17
使用 PHP 加解密 Cloudflare 邮箱保护
Cloudflare 有一个非常好的功能,就是对页面上所有的邮箱地址进行加密,防止机器人抓取和做坏事。对于该功能,在后台启用邮箱地址混淆后,您可以在页面中添加邮箱地址。例如,如果您查看源代码,您可以找到类似于以下的代码
2016 年 9 月 28 日 12:28
WHMCS密码加密方式
我今天无事可做,看了WHMCS在网上流传的代码。网上只找到了5.2.17个版本,但是对于我们这些曾经研究过代码的人来说,已经足够了。他使用的加密不是传统的 MD5 + salt 实现。加密后的数据只会出现一次,但是每个密码得到的密码都是一样的,类似于openssl的加密方式。然后是硬通货时间:
2015 年 8 月 10 日 17:13
PHP多线程的实现
在某些情况下,我们想用PHP来执行重复性的任务,但是只有一次,叠加的时候执行时间会很长,所以应该将任务分配给多个线程分别执行。但是PHP默认没有多线程,必须使用pthreadsPHP扩展,它才能真正支持和实现多线程。在处理重复的循环任务时,多线程可以大大减少程序执行时间。要使用此扩展,您必须使用线程安全版本。编译 PHP […]
2014 年 7 月 6 日 10:47
更换 Discuz 的内存缓存
最近论坛一直卡,负载经常跑到130%。正常情况下,负载达到10%,非常高。通过跟踪日志,我找不到任何重大问题。我只能暂时屏蔽爬取大量网页的ip和ua,但最终不是解决办法。最后实在看不下去了,就装了一个newrelic来跟踪问题。安装后发现问题,如图:
2014 年 5 月 6 日 18:15
php多线程抓取多个网页(使用线程和Selenium的简单代码示例:使用参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-14 07:02
大多数时候,我必须抓取的页面数量低于 100,因此使用 for 循环,我可以在合理的时间内解析它们。但现在我有 1000 多个网页要分析。在
在寻找实现此目标的方法时,我发现了可能有用的线程。我看过一些教程,我相信我理解一般逻辑。在
我知道如果我有 100 个网页,我可以创建 100 个线程。不建议这样做,尤其是对于大量网页。例如,我还没有真正弄清楚如何创建 5 个线程,每个线程上有 200 个网页。在
这是一个使用线程和 Selenium 的简单代码示例:
import threading
from selenium import webdriver
def parse_page(page_url):
driver = webdriver.PhantomJS()
driver.get(url)
text = driver.page_source
..........
return parsed_items
def threader():
worker = q.get()
parse_page(page_url)
q.task_one()
urls = [.......]
q = Queue()
for x in range(len(urls)):
t = threading.Thread(target=threader)
t.daemon = True
t.start()
for worker in range(20):
q.put(worker)
q.join()
我不清楚的另一件事是参数如何在线程中使用。在 查看全部
php多线程抓取多个网页(使用线程和Selenium的简单代码示例:使用参数)
大多数时候,我必须抓取的页面数量低于 100,因此使用 for 循环,我可以在合理的时间内解析它们。但现在我有 1000 多个网页要分析。在
在寻找实现此目标的方法时,我发现了可能有用的线程。我看过一些教程,我相信我理解一般逻辑。在
我知道如果我有 100 个网页,我可以创建 100 个线程。不建议这样做,尤其是对于大量网页。例如,我还没有真正弄清楚如何创建 5 个线程,每个线程上有 200 个网页。在
这是一个使用线程和 Selenium 的简单代码示例:
import threading
from selenium import webdriver
def parse_page(page_url):
driver = webdriver.PhantomJS()
driver.get(url)
text = driver.page_source
..........
return parsed_items
def threader():
worker = q.get()
parse_page(page_url)
q.task_one()
urls = [.......]
q = Queue()
for x in range(len(urls)):
t = threading.Thread(target=threader)
t.daemon = True
t.start()
for worker in range(20):
q.put(worker)
q.join()
我不清楚的另一件事是参数如何在线程中使用。在
php多线程抓取多个网页(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-05 23:03
新鲜出炉的PHP面向对象编程来了,程序狗的速度来了!
PHP开源脚本语言PHP(外文名:Hypertext Preprocessor,中文名:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。 PHP的文件扩展名为php。
本文章主要介绍PHP中foreach结合curl实现多线程的方法,分析foreach语句结合curl循环调用的原理和实现技巧,以如下形式模拟多线程例子。有需要的朋友可以参考以下
本文的例子介绍了php中foreach结合curl实现多线程的方法。分享给大家,供大家参考,如下:
php不支持多线程,但是我们可以通过foreach实现伪多线程,但是这种伪多线程的速度不一定比单线程快,我们来看一个例子。
在使用foreach语句循环图片URL并通过CURL将所有图片保存在本地时,存在一个问题,只能是采集。现将foreach与CURL结合进行多个URL请求的方法做如下总结。
方法一:循环请求
$sr=array(url_1,url_2,url_3);
foreach ($sr as $k=>$v) {
$curlPost=$v.'?f=传入参数';
$ch = curl_init($curlPost) ;
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true) ; // 获取数据返回
curl_setopt($ch, CURLOPT_BINARYTRANSFER, true) ; // 在启用 CURLOPT_RETURNTRANSFER 时候将获取数据返回
$data = curl_exec($ch) ;
echo $k.'##:'.$data.'
';
}
curl_close($ch);
上面的代码需要特别注意,curl_close必须放在foreach循环结束的外面,如果放在里面会出现我上面提到的多个IMGURL,而且只有一个URL可以是采集的问题。
方法二:多线程循环
<p> 查看全部
php多线程抓取多个网页(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
新鲜出炉的PHP面向对象编程来了,程序狗的速度来了!
PHP开源脚本语言PHP(外文名:Hypertext Preprocessor,中文名:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。 PHP的文件扩展名为php。
本文章主要介绍PHP中foreach结合curl实现多线程的方法,分析foreach语句结合curl循环调用的原理和实现技巧,以如下形式模拟多线程例子。有需要的朋友可以参考以下
本文的例子介绍了php中foreach结合curl实现多线程的方法。分享给大家,供大家参考,如下:
php不支持多线程,但是我们可以通过foreach实现伪多线程,但是这种伪多线程的速度不一定比单线程快,我们来看一个例子。
在使用foreach语句循环图片URL并通过CURL将所有图片保存在本地时,存在一个问题,只能是采集。现将foreach与CURL结合进行多个URL请求的方法做如下总结。
方法一:循环请求
$sr=array(url_1,url_2,url_3);
foreach ($sr as $k=>$v) {
$curlPost=$v.'?f=传入参数';
$ch = curl_init($curlPost) ;
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true) ; // 获取数据返回
curl_setopt($ch, CURLOPT_BINARYTRANSFER, true) ; // 在启用 CURLOPT_RETURNTRANSFER 时候将获取数据返回
$data = curl_exec($ch) ;
echo $k.'##:'.$data.'
';
}
curl_close($ch);
上面的代码需要特别注意,curl_close必须放在foreach循环结束的外面,如果放在里面会出现我上面提到的多个IMGURL,而且只有一个URL可以是采集的问题。
方法二:多线程循环
<p>
php多线程抓取多个网页(PHP支持多线程线程,有时称为轻量级进程的一个实体!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-05 23:02
我们可以通过安装 Pthread 扩展使 PHP 支持多线程。线程,有时称为轻量级进程,是程序执行的最小单位。线程是进程中的一个实体,是系统独立调度和调度的基本单元。线程本身不拥有系统资源,属于同一个
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说php Pthread多线程的基本介绍(一),希望能帮助大家提高!!!
我们可以通过安装 Pthread 扩展使 PHP 支持多线程。
线程,有时称为轻量级进程,是程序执行的最小单位。
线程是进程中的一个实体,是系统独立调度和调度的基本单元。线程本身并不拥有系统资源。它与属于同一进程的其他线程共享该进程拥有的所有资源。一个线程可以创建和取消另一个线程,同一进程中的多个线程可以并发执行。
每个程序至少有一个线程,也就是程序本身,通常称为主线程
. 线程是程序中的单个顺序控制流。在一个程序中同时运行多个线程来完成不同的工作称为多线程。
只听山间传来建筑师的声音:
与此同时,多代人在路上,通往天堂的道路是危险的,难以走的。谁将向上或向下匹配?
我们把上面的代码修改一下看看效果
此代码由Java架构师必看网-架构君整理
我们直接调用start方法而不调用join。主线程不等待,而是输出主线程。子线程在输出 Hello World 之前等待 3 秒。
示例 1 如下:
我们通过创建两个线程 a 和 b 来读取文件 test.log 的内容。(*注意,并发读写文件时,一定要加锁文件。这里给文件加排他锁。如果加了共享锁,会读取相同的数据。
)
test.log 的内容如下:
此代码由Java架构师必看网-架构君整理
111111
222222
333333
444444
555555
666666
执行结果如下:
示例 2 如下:
<p> 查看全部
php多线程抓取多个网页(PHP支持多线程线程,有时称为轻量级进程的一个实体!)
我们可以通过安装 Pthread 扩展使 PHP 支持多线程。线程,有时称为轻量级进程,是程序执行的最小单位。线程是进程中的一个实体,是系统独立调度和调度的基本单元。线程本身不拥有系统资源,属于同一个
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说php Pthread多线程的基本介绍(一),希望能帮助大家提高!!!
我们可以通过安装 Pthread 扩展使 PHP 支持多线程。
线程,有时称为轻量级进程,是程序执行的最小单位。
线程是进程中的一个实体,是系统独立调度和调度的基本单元。线程本身并不拥有系统资源。它与属于同一进程的其他线程共享该进程拥有的所有资源。一个线程可以创建和取消另一个线程,同一进程中的多个线程可以并发执行。
每个程序至少有一个线程,也就是程序本身,通常称为主线程
. 线程是程序中的单个顺序控制流。在一个程序中同时运行多个线程来完成不同的工作称为多线程。
只听山间传来建筑师的声音:
与此同时,多代人在路上,通往天堂的道路是危险的,难以走的。谁将向上或向下匹配?
我们把上面的代码修改一下看看效果
此代码由Java架构师必看网-架构君整理
我们直接调用start方法而不调用join。主线程不等待,而是输出主线程。子线程在输出 Hello World 之前等待 3 秒。
示例 1 如下:
我们通过创建两个线程 a 和 b 来读取文件 test.log 的内容。(*注意,并发读写文件时,一定要加锁文件。这里给文件加排他锁。如果加了共享锁,会读取相同的数据。
)
test.log 的内容如下:
此代码由Java架构师必看网-架构君整理
111111
222222
333333
444444
555555
666666
执行结果如下:

示例 2 如下:
<p>
php多线程抓取多个网页(php多线程抓取多个网页!(第一步))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-01 22:02
php多线程抓取多个网页!第一步,先进入php解释器mime_trace,查看有没有显示出此操作。其实不必这么细心,因为你以为你放置了同一个文件,其实可能只是改了文件扩展名,比如mime_trace"./",但是实际上放置了文件;再比如,你,通过php注入方式传递参数,php解释器是不处理的,所以该文件抓取出来的结果也是空的。
以下举例是不同的url地址,请求该url,抓取一个地址,解析数据,php解释器会返回结果:api.php->api:location/{api_log:0;}使用php_request_set返回:php_request_set("method","method","location/{api_log:0;}")//线程一:php_request_set("method","get",true)//线程二:php_request_set("method","post",false)//线程三:php_request_set("method","put",false)//线程四:php_request_set("method","delete",false)//线程五:php_request_set("method","fetch",false)//线程六:php_request_set("method","redirect",false)然后把抓取的结果redirect起来,redirect到任何结果api.php:location/{api_log:0;}//参数更新了:参数api_log,redirect_file是同一个内容以后的更新方式api.php->api:api{api_log:api_sync("api_log");}api.php->location/{api_log:api_sync("api_log");}最后统计返回结果,统计api.php:location/{api_log:[];}//参数更新了:可以看到已经正常返回了,因为api.php->api:api,api.php->location/已经成功返回了抓取的结果,还差一个参数,参数api_log,api.php->location/的更新方式。
以下是百度首页,抓取后存储:百度首页抓取三点提示:1../页面名称抓取到请求上传地址,使用location//是地址上传,否则会报错api.php->api:api{api_log:0;}//timeout返回错误,导致读取失败api.php->location//api_log返回一个错误,意味着api无法获取成功api.php->location//如果api返回错误,下一次请求将会跳过这个api.php->location//因为这个没用了下一次请求如果返回错误,那么抓取的结果为空,所以我们使用set_location修改参数,值,让它不是当前api.php:api{api_log:api_sync("api_log");}//timeout返回错误。 查看全部
php多线程抓取多个网页(php多线程抓取多个网页!(第一步))
php多线程抓取多个网页!第一步,先进入php解释器mime_trace,查看有没有显示出此操作。其实不必这么细心,因为你以为你放置了同一个文件,其实可能只是改了文件扩展名,比如mime_trace"./",但是实际上放置了文件;再比如,你,通过php注入方式传递参数,php解释器是不处理的,所以该文件抓取出来的结果也是空的。
以下举例是不同的url地址,请求该url,抓取一个地址,解析数据,php解释器会返回结果:api.php->api:location/{api_log:0;}使用php_request_set返回:php_request_set("method","method","location/{api_log:0;}")//线程一:php_request_set("method","get",true)//线程二:php_request_set("method","post",false)//线程三:php_request_set("method","put",false)//线程四:php_request_set("method","delete",false)//线程五:php_request_set("method","fetch",false)//线程六:php_request_set("method","redirect",false)然后把抓取的结果redirect起来,redirect到任何结果api.php:location/{api_log:0;}//参数更新了:参数api_log,redirect_file是同一个内容以后的更新方式api.php->api:api{api_log:api_sync("api_log");}api.php->location/{api_log:api_sync("api_log");}最后统计返回结果,统计api.php:location/{api_log:[];}//参数更新了:可以看到已经正常返回了,因为api.php->api:api,api.php->location/已经成功返回了抓取的结果,还差一个参数,参数api_log,api.php->location/的更新方式。
以下是百度首页,抓取后存储:百度首页抓取三点提示:1../页面名称抓取到请求上传地址,使用location//是地址上传,否则会报错api.php->api:api{api_log:0;}//timeout返回错误,导致读取失败api.php->location//api_log返回一个错误,意味着api无法获取成功api.php->location//如果api返回错误,下一次请求将会跳过这个api.php->location//因为这个没用了下一次请求如果返回错误,那么抓取的结果为空,所以我们使用set_location修改参数,值,让它不是当前api.php:api{api_log:api_sync("api_log");}//timeout返回错误。
php多线程抓取多个网页( PHPCurlFunctions例子(一)-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-26 18:06
PHPCurlFunctions例子(一)-上海怡健医学)
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。 查看全部
php多线程抓取多个网页(
PHPCurlFunctions例子(一)-上海怡健医学)
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
php多线程抓取多个网页(php7的优势和特点php各个版本的区别.2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-22 19:24
php7的优点和特点php各个版本的区别
PHP5.2 before:自动加载,PDO 和 MySQLi,类型约束 PHP5.2:JSON 支持 PHP5.3:不推荐使用的函数,匿名函数,新的魔法方法,命名空间,后期静态绑定, Heredoc 和 Nowdoc, const, 三元运算符, Phar PHP5.4: Short Open Tag, 数组速记, Traits, 内置web server, 细节修改 PHP5.5: yield, list() is用于foreach,细节修改 PHP5.6:常量增强,可变函数参数,命名空间增强 php7:改动太多,总之,性能提升不少。
php接口,抽象类但不是如何在php中实现多线程
pthread扩展可以支持真正的多线程,但是很多问题不推荐。还有一些多线程变向的使用方法:比如通过fsockopen开启一个新的请求等,这种方法只能解决一些简单的问题,不推荐。业务复杂后,很难控制。考虑像 swoole 和 workerman 这样的多进程模型。
如何提高php的执行效率
从客观的角度来看,这是一个大大小小的话题
使用哪些数据库
常用mysql、sqlite、MongoDB、redis。
mysql引擎有什么特点和区别
主要使用:
数据量过大怎么办
这也是一个可大可小的话题。从数据库的角度来看:结合业务进行拆分、分区、分库、分布式数据库、分布式事务的问题从web的角度来看:负载均衡(7层和4层)缓存。
如何优化sql索引的类型及使用场景联合索引的优缺点
mongodb是真正的数据库,适合mysql比赛;而redis缓存数据库,不同的东西根据不同的特点选择应用。
lnmp 的工作原理
首先浏览器向服务器(Nginx)发送http请求,服务器响应并处理web请求,在服务器上保存一些静态资源(CSS、图片、视频等),然后通过接口传输协议(网关协议) PHP-FCGI(fast-cgi)传输到PHP-FPM(进程管理程序),PHP-FPM不处理,然后PHP-FPM调用PHP解析器进程,PHP解析器解析php 脚本信息。可以启动多个 PHP 解析器进程以进行并发执行。然后将解析后的脚本返回给PHP-FPM,PHP-FPM将脚本信息以fast-cgi的形式传给Nginx。服务器以 Http 响应的形式传输给浏览器。浏览器然后解析和呈现然后呈现。
熟悉的框架有什么区别和优势
应用了哪些设计模式以及如何实现它们。
详细描述排序算法的时间复杂度和空间复杂度 *插入气泡选择。
Time O(n2) Space O(1)nginx如何实现负载均衡?
上游的配置和原理比较多,简单来说就是轮换训练、权重等等。
描述一下以前项目中使用的架构,有什么优势?
小项目 ci 简单快速 大项目 yii2 phalcon laravel 结构清晰,解耦度更高。
给app提供一个接口,如何保证稳定性和响应速度。
谈谈你做过的一个你认为技术含量最高的项目,以及应用了哪些技术。
这个问题真的很难说,写一个php扩展算不算?其实,能解决实际问题的都是好事,都代表着你的成功。做应用开发,技术含量很难衡量,因为很低。上学的时候,编译原理里面的所有算法都是用C语言写的。我认为这比我现在所做的更具技术性。现在被多次使用。技术含量的考验应该是如何发现问题,然后如何解决问题。毕竟,我们不是从事科学研究的。
了解其他开发语言并做过项目吗?
java、python、wpf。
redis中存储了哪些类型的数据,分别用在了哪些场景中? 查看全部
php多线程抓取多个网页(php7的优势和特点php各个版本的区别.2)
php7的优点和特点php各个版本的区别
PHP5.2 before:自动加载,PDO 和 MySQLi,类型约束 PHP5.2:JSON 支持 PHP5.3:不推荐使用的函数,匿名函数,新的魔法方法,命名空间,后期静态绑定, Heredoc 和 Nowdoc, const, 三元运算符, Phar PHP5.4: Short Open Tag, 数组速记, Traits, 内置web server, 细节修改 PHP5.5: yield, list() is用于foreach,细节修改 PHP5.6:常量增强,可变函数参数,命名空间增强 php7:改动太多,总之,性能提升不少。
php接口,抽象类但不是如何在php中实现多线程
pthread扩展可以支持真正的多线程,但是很多问题不推荐。还有一些多线程变向的使用方法:比如通过fsockopen开启一个新的请求等,这种方法只能解决一些简单的问题,不推荐。业务复杂后,很难控制。考虑像 swoole 和 workerman 这样的多进程模型。
如何提高php的执行效率
从客观的角度来看,这是一个大大小小的话题
使用哪些数据库
常用mysql、sqlite、MongoDB、redis。
mysql引擎有什么特点和区别
主要使用:
数据量过大怎么办
这也是一个可大可小的话题。从数据库的角度来看:结合业务进行拆分、分区、分库、分布式数据库、分布式事务的问题从web的角度来看:负载均衡(7层和4层)缓存。
如何优化sql索引的类型及使用场景联合索引的优缺点
mongodb是真正的数据库,适合mysql比赛;而redis缓存数据库,不同的东西根据不同的特点选择应用。
lnmp 的工作原理
首先浏览器向服务器(Nginx)发送http请求,服务器响应并处理web请求,在服务器上保存一些静态资源(CSS、图片、视频等),然后通过接口传输协议(网关协议) PHP-FCGI(fast-cgi)传输到PHP-FPM(进程管理程序),PHP-FPM不处理,然后PHP-FPM调用PHP解析器进程,PHP解析器解析php 脚本信息。可以启动多个 PHP 解析器进程以进行并发执行。然后将解析后的脚本返回给PHP-FPM,PHP-FPM将脚本信息以fast-cgi的形式传给Nginx。服务器以 Http 响应的形式传输给浏览器。浏览器然后解析和呈现然后呈现。
熟悉的框架有什么区别和优势
应用了哪些设计模式以及如何实现它们。
详细描述排序算法的时间复杂度和空间复杂度 *插入气泡选择。
Time O(n2) Space O(1)nginx如何实现负载均衡?
上游的配置和原理比较多,简单来说就是轮换训练、权重等等。
描述一下以前项目中使用的架构,有什么优势?
小项目 ci 简单快速 大项目 yii2 phalcon laravel 结构清晰,解耦度更高。
给app提供一个接口,如何保证稳定性和响应速度。
谈谈你做过的一个你认为技术含量最高的项目,以及应用了哪些技术。
这个问题真的很难说,写一个php扩展算不算?其实,能解决实际问题的都是好事,都代表着你的成功。做应用开发,技术含量很难衡量,因为很低。上学的时候,编译原理里面的所有算法都是用C语言写的。我认为这比我现在所做的更具技术性。现在被多次使用。技术含量的考验应该是如何发现问题,然后如何解决问题。毕竟,我们不是从事科学研究的。
了解其他开发语言并做过项目吗?
java、python、wpf。
redis中存储了哪些类型的数据,分别用在了哪些场景中?
php多线程抓取多个网页(php多线程抓取多个网页的方法是直接使用php代码去抓取的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-21 02:06
<p>php多线程抓取多个网页的方法是直接使用php代码去抓取的,这样很容易造成代码冲突,代码不统一,但其实很简单,只需要注意以下几点就可以了。在正式开始之前,我们需要添加下面的代码varfile="/private/phpwind/phpwind";varphp=newphpwind();varparam=['php','path','/'];file.open(param,'r');varself=file.get();file.send(self);varresult=self.get('php\n?file=/');print(result);测试页面接下来,我们在网页中随意地输入一些代码,测试下输出的结果:打印出来的结果如下: 查看全部
php多线程抓取多个网页(php多线程抓取多个网页的方法是直接使用php代码去抓取的)
<p>php多线程抓取多个网页的方法是直接使用php代码去抓取的,这样很容易造成代码冲突,代码不统一,但其实很简单,只需要注意以下几点就可以了。在正式开始之前,我们需要添加下面的代码varfile="/private/phpwind/phpwind";varphp=newphpwind();varparam=['php','path','/'];file.open(param,'r');varself=file.get();file.send(self);varresult=self.get('php\n?file=/');print(result);测试页面接下来,我们在网页中随意地输入一些代码,测试下输出的结果:打印出来的结果如下:
php多线程抓取多个网页(php多线程抓取多个网页,后台放好待抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-14 10:02
php多线程抓取多个网页,后台放好待抓取所有网页的txt文件,加入要抓取的网页的idphp进程放在内存中,系统启动后在命令行启动进程ngx_util。php如果一个页面加入了多个待抓取的txt文件,加入多个php进程这里加入多个php进程就是加入多个php文件抓取后页面用txt文件渲染每个页面文件php程序之间不存在竞争php通过多进程部署到多个主机,通过网关访问不同主机php的多线程抓取、tpl_util。
php和ngx_util。php的一对多关系如何从互联网抓取多个网页的txt文件php多线程抓取多个网页的txt文件,和php的多进程关系多线程抓取多个页面文件,和ngx_util。php__php___a_b_c_d多个页面文件php文件txt文件,每个页面文件用txt文件打包压缩(压缩方式是分块压缩)网关在命令行启动启动一个php进程ngx_util。
php访问ngx_util。php文件,进程定位到具体页面进程启动后通过抓包,抓取到页面数据,下载下来放到待抓取网页的txt文件txt文件php所有线程同时执行抓取多个页面文件时,每个进程因为有多个页面数据线程上数据线程一个进程抓取一个页面时,抓取的页面到一个php进程,再到其他进程php进程使用cgi格式的程序、服务器端java访问php进程httpbinlib程序java程序从txt文件抓取数据会走httpbinlib程序模拟用户访问phpurl,txt文件对应的url就是下载下来的数据,转存存储成为php访问的urlhttpbinlib的代码示例cgi程序从页面数据load()中读取一个url地址(url中含有数据),并转存到txt文件中,该url对应的url格式为:(url,value)---数据_数据,类似socket套接字php访问php。
io/1,页面中就包含一个txt文件将所有页面转存到txt文件中,获取url地址()函数:调用tcp_value()获取flag()传输txt文件传输后的txt文件放到txt_raw_txt文件中txt_raw_txt文件就是一个文件,由两个文件组成第一个url(t+)是txt_raw_txt文件路径echo'{{t+}}'|echo'flag'用java写出同样格式的cgi程序后缀名:cgi。
javanginx读取nginx配置、expires,epoll等数据,将url地址发送给tp进程nginx进程去下载页面数据,将txt文件放到expires表中,并传给tp,tp去抓取数据expires表中:1月份;nginx进程将页面数据从expires字段中取出来nginx需要去gzip或者压缩开源:wget,pandownloadcgi程序启动后nginx会从e。 查看全部
php多线程抓取多个网页(php多线程抓取多个网页,后台放好待抓取)
php多线程抓取多个网页,后台放好待抓取所有网页的txt文件,加入要抓取的网页的idphp进程放在内存中,系统启动后在命令行启动进程ngx_util。php如果一个页面加入了多个待抓取的txt文件,加入多个php进程这里加入多个php进程就是加入多个php文件抓取后页面用txt文件渲染每个页面文件php程序之间不存在竞争php通过多进程部署到多个主机,通过网关访问不同主机php的多线程抓取、tpl_util。
php和ngx_util。php的一对多关系如何从互联网抓取多个网页的txt文件php多线程抓取多个网页的txt文件,和php的多进程关系多线程抓取多个页面文件,和ngx_util。php__php___a_b_c_d多个页面文件php文件txt文件,每个页面文件用txt文件打包压缩(压缩方式是分块压缩)网关在命令行启动启动一个php进程ngx_util。
php访问ngx_util。php文件,进程定位到具体页面进程启动后通过抓包,抓取到页面数据,下载下来放到待抓取网页的txt文件txt文件php所有线程同时执行抓取多个页面文件时,每个进程因为有多个页面数据线程上数据线程一个进程抓取一个页面时,抓取的页面到一个php进程,再到其他进程php进程使用cgi格式的程序、服务器端java访问php进程httpbinlib程序java程序从txt文件抓取数据会走httpbinlib程序模拟用户访问phpurl,txt文件对应的url就是下载下来的数据,转存存储成为php访问的urlhttpbinlib的代码示例cgi程序从页面数据load()中读取一个url地址(url中含有数据),并转存到txt文件中,该url对应的url格式为:(url,value)---数据_数据,类似socket套接字php访问php。
io/1,页面中就包含一个txt文件将所有页面转存到txt文件中,获取url地址()函数:调用tcp_value()获取flag()传输txt文件传输后的txt文件放到txt_raw_txt文件中txt_raw_txt文件就是一个文件,由两个文件组成第一个url(t+)是txt_raw_txt文件路径echo'{{t+}}'|echo'flag'用java写出同样格式的cgi程序后缀名:cgi。
javanginx读取nginx配置、expires,epoll等数据,将url地址发送给tp进程nginx进程去下载页面数据,将txt文件放到expires表中,并传给tp,tp去抓取数据expires表中:1月份;nginx进程将页面数据从expires字段中取出来nginx需要去gzip或者压缩开源:wget,pandownloadcgi程序启动后nginx会从e。
php多线程抓取多个网页(2021-07-29介绍大家好!(上)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-14 07:19
2021-07-29介绍
大家好!回顾上一期,在介绍了爬虫的基本概念之后,我们用各种工具横冲直撞完成了一个小爬虫。目的是猛、粗、快,方便初学者上手,建立信心。有一定基础的读者请不要着急,未来我们会学习主流开源框架,打造强大专业的爬虫系统!但在此之前,我们必须继续打好基础。本期我们将首先介绍爬虫的类型,然后选择最典型的通用网络爬虫为其设计一个迷你框架。对框架有了自己的思考之后,在学习复杂的开源框架时,就会有一个线索。
今天,我们将花更多时间思考,而不是编码。80%的时间思考,20%的时间打字,更有利于进步。
语言环境
语言:带上足够的弹药,继续用Python开路!
线程:线程库可以在单独的线程中执行 Python 中可调用的任何对象。Python 2.x 中的线程模块已被弃用,用户可以改用线程模块。在 Python 3 中不能再使用 thread 模块。为了兼容性,Python 3 将 thread 重命名为 _thread。
队列:队列模块提供同步的、线程安全的队列类,包括FIFO(先进先出)队列Queue、LIFO(后进先出)队列LifoQueue和优先级队列PriorityQueue。这些队列都实现了锁定原语,可以直接在多个线程中使用。队列可用于实现线程之间的同步。
re:Python 从 1.5 开始添加了 re 模块,它提供了 Perl 风格的正则表达式模式。re 模块为 Python 语言带来了完整的正则表达式功能。
argparse:Python 用于解析命令行参数和选项的标准模块,替换了过时的 optparse 模块。argparse 模块的作用是解析命令行参数。
configparser:读取配置文件的模块。
爬行动物的种类
网络爬虫根据系统结构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
通用网络爬虫
通用网络爬虫,也称为Scalable Web Crawler,将爬取对象从一些种子URL扩展到整个Web。主要针对门户网站搜索引擎和大型网络服务商采集数据。
一般网络爬虫的结构大致可以分为几个部分:页面爬取模块、页面分析模块、链接过滤模块、页面存储模块、URL队列、初始URL采集。为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有:深度优先策略、广度优先策略。
1) 深度优先策略(DFS):基本方法是按照深度从低到高的顺序访问下一级的网页链接,直到不能再深入为止。
2) 广度优先策略(BFS):该策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫深入到下一个级别继续爬取。
聚焦网络爬虫
Focused Crawler,也称为Topical Crawler,是指选择性爬取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。域信息需求。我们之前爬过的播放列表属于这一类。
增量网络爬虫
增量网络爬虫(Incremental Web Crawler)是指增量更新下载的网页,只爬取新生成或更改的网页的爬虫。可能是新页面。与周期性爬取和刷新页面的网络爬虫相比,增量爬虫只在需要的时候爬取新生成或更新的页面,不会重新下载没有变化的页面,可以有效减少数据下载量,对爬取的网页进行更新页,减少时间和空间消耗,但增加了爬取算法的复杂度和实现难度。现在流行的舆情爬虫一般都是增量网络爬虫。
深度网络爬虫
网页按存在方式可分为表层网页(Surface Web)和深层网页(Deep Web,又称隐形网页或隐藏网页)。表面网页是指可以被传统搜索引擎检索到的页面,以及主要由可以通过超链接到达的静态网页组成的网页。深网是那些通过静态链接大多不可用的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。例如,那些内容只有在用户注册后才可见的网页属于深网。
一个迷你框架
下面以一个典型的通用爬虫为例,分析其工程要点,设计并实现一个mini框架。架构图如下:
代码结构:
config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url 队列,url 表
urls.txt 种子 url 集合
pages_parse.py 网页分析
pages_save.py 网页保存
查看配置文件中的内容:
蜘蛛.conf
步骤 1.BFS 还是 DFS?
理论上,这两种算法都可以在大致相同的时间内爬取整个互联网。但显然每个网站最重要的页面应该是它的主页。在极端情况下,如果只能下载非常有限的页面,那么应该下载网站的所有主页。如果爬虫展开,应该爬到首页直接链接的页面,因为这些页面是网站设计者认为相当重要的网页。在这个前提下,显然 BFS 明显优于 DFS。事实上,在搜索引擎的爬虫中,主要使用的是BFS。我们的框架采用了这种策略。
爬取深度可以通过配置文件中的max_depth来设置。只要未达到指定的深度,程序就会不断将解析后的 url 放入队列中:
迷你蜘蛛.py
步骤 2. 初始 URL 采集,URL 队列
让我们看看通用爬虫如何下载整个互联网。假设从一个门户网站的首页开始,首先下载这个网页(depth=0),然后通过分析这个网页,可以找到页面中的所有超链接,也就是说你知道这个入口网站所有直接连接到首页的网页,如京东金融、京东白条、京东众筹等(深度=1)。接下来访问、下载和分析京东金融等网页,并且可以找到其他连接的页面网页(深度=2)。让电脑继续做,整个网站都可以下载了。
在这个过程中,我们需要一个“初始 URL 集合”来保存门户的主页,以及一个“URL 队列”来保存通过分析网页获得的超链接。
迷你蜘蛛.py
url_table.py
步骤3.在小本子——URL表中记录下载了哪些网页。
在互联网上,一个网页可能被多个网页中的超链接指向。这样,在遍历互联网的这张图片时,这个网页可能会被访问很多次。为了防止一个网页被多次下载和解析,需要一个URL表来记录哪些网页被下载了。当我们再次遇到这个页面时,我们可以跳过它。
crawl_thread.py
步骤 4. 多个抓取线程
为了提高爬虫的性能,需要多个爬取线程从URL队列中获取链接进行处理。多线程并没有错,但是Python的多线程可能会引起很多人的质疑,这源于Python设计的最初考虑:GIL。GIL的全称是Global Interpreter Lock(全局解释器锁)。如果一个线程要执行,首先要获得 GIL,而在一个 Python 进程中,只有一个 GIL。结果是Python中的一个进程每次只能执行一个线程,这就是Python的多线程效率在多核CPU上不高的原因。那么为什么我们仍然使用 Python 多线程呢?
CPU密集型代码(各种循环处理、编解码器等),在这种情况下,由于计算工作量很大,tick count很快就会达到阈值,然后触发GIL的释放和重新竞争(多个线程来回切换当然需要消耗资源),Python下的多线程对CPU密集型代码不友好。
IO密集型代码(文件处理、网络爬虫等),多线程可以有效提高效率(单线程下的IO操作会进行IO等待,造成不必要的时间浪费,启用多线程可以自动等待线程A当线程A等待时,切换到线程B不会浪费CPU资源,从而提高程序执行效率)。Python的多线程对IO密集型代码更加友好。
所以,对于IO密集型爬虫程序来说,使用Python多线程是没有问题的。
crawl_thread.py
步骤5.页面分析模块
从网页解析 URL 或其他有用数据。这是上一期的重点,可以参考之前的代码。
步骤6.页面存储模块
保存页面的模块,目前将文件保存为文件,未来可以扩展成多种存储方式,如mysql、mongodb、hbase等。
网页保存.py
至此,整个框架已经清晰的呈现在大家面前。不要低估它。无论框架多么复杂,它都在这些基本元素上进行了扩展。
下一步
基础知识的学习暂时告一段落,希望能帮助大家打下一定的基础。下一期我会介绍强大成熟的爬虫框架Scrapy,它提供了很多强大的功能让爬取更简单、更高效、更精彩,敬请期待!
最后觉得有帮助的朋友可以加入学习交流群
沉迷Python,无法自拔:862672474 查看全部
php多线程抓取多个网页(2021-07-29介绍大家好!(上)(图))
2021-07-29介绍
大家好!回顾上一期,在介绍了爬虫的基本概念之后,我们用各种工具横冲直撞完成了一个小爬虫。目的是猛、粗、快,方便初学者上手,建立信心。有一定基础的读者请不要着急,未来我们会学习主流开源框架,打造强大专业的爬虫系统!但在此之前,我们必须继续打好基础。本期我们将首先介绍爬虫的类型,然后选择最典型的通用网络爬虫为其设计一个迷你框架。对框架有了自己的思考之后,在学习复杂的开源框架时,就会有一个线索。
今天,我们将花更多时间思考,而不是编码。80%的时间思考,20%的时间打字,更有利于进步。
语言环境
语言:带上足够的弹药,继续用Python开路!
线程:线程库可以在单独的线程中执行 Python 中可调用的任何对象。Python 2.x 中的线程模块已被弃用,用户可以改用线程模块。在 Python 3 中不能再使用 thread 模块。为了兼容性,Python 3 将 thread 重命名为 _thread。
队列:队列模块提供同步的、线程安全的队列类,包括FIFO(先进先出)队列Queue、LIFO(后进先出)队列LifoQueue和优先级队列PriorityQueue。这些队列都实现了锁定原语,可以直接在多个线程中使用。队列可用于实现线程之间的同步。
re:Python 从 1.5 开始添加了 re 模块,它提供了 Perl 风格的正则表达式模式。re 模块为 Python 语言带来了完整的正则表达式功能。
argparse:Python 用于解析命令行参数和选项的标准模块,替换了过时的 optparse 模块。argparse 模块的作用是解析命令行参数。
configparser:读取配置文件的模块。
爬行动物的种类
网络爬虫根据系统结构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
通用网络爬虫
通用网络爬虫,也称为Scalable Web Crawler,将爬取对象从一些种子URL扩展到整个Web。主要针对门户网站搜索引擎和大型网络服务商采集数据。
一般网络爬虫的结构大致可以分为几个部分:页面爬取模块、页面分析模块、链接过滤模块、页面存储模块、URL队列、初始URL采集。为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有:深度优先策略、广度优先策略。
1) 深度优先策略(DFS):基本方法是按照深度从低到高的顺序访问下一级的网页链接,直到不能再深入为止。
2) 广度优先策略(BFS):该策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫深入到下一个级别继续爬取。
聚焦网络爬虫
Focused Crawler,也称为Topical Crawler,是指选择性爬取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。域信息需求。我们之前爬过的播放列表属于这一类。
增量网络爬虫
增量网络爬虫(Incremental Web Crawler)是指增量更新下载的网页,只爬取新生成或更改的网页的爬虫。可能是新页面。与周期性爬取和刷新页面的网络爬虫相比,增量爬虫只在需要的时候爬取新生成或更新的页面,不会重新下载没有变化的页面,可以有效减少数据下载量,对爬取的网页进行更新页,减少时间和空间消耗,但增加了爬取算法的复杂度和实现难度。现在流行的舆情爬虫一般都是增量网络爬虫。
深度网络爬虫
网页按存在方式可分为表层网页(Surface Web)和深层网页(Deep Web,又称隐形网页或隐藏网页)。表面网页是指可以被传统搜索引擎检索到的页面,以及主要由可以通过超链接到达的静态网页组成的网页。深网是那些通过静态链接大多不可用的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。例如,那些内容只有在用户注册后才可见的网页属于深网。
一个迷你框架
下面以一个典型的通用爬虫为例,分析其工程要点,设计并实现一个mini框架。架构图如下:
代码结构:
config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url 队列,url 表
urls.txt 种子 url 集合
pages_parse.py 网页分析
pages_save.py 网页保存
查看配置文件中的内容:
蜘蛛.conf
步骤 1.BFS 还是 DFS?
理论上,这两种算法都可以在大致相同的时间内爬取整个互联网。但显然每个网站最重要的页面应该是它的主页。在极端情况下,如果只能下载非常有限的页面,那么应该下载网站的所有主页。如果爬虫展开,应该爬到首页直接链接的页面,因为这些页面是网站设计者认为相当重要的网页。在这个前提下,显然 BFS 明显优于 DFS。事实上,在搜索引擎的爬虫中,主要使用的是BFS。我们的框架采用了这种策略。
爬取深度可以通过配置文件中的max_depth来设置。只要未达到指定的深度,程序就会不断将解析后的 url 放入队列中:
迷你蜘蛛.py
步骤 2. 初始 URL 采集,URL 队列
让我们看看通用爬虫如何下载整个互联网。假设从一个门户网站的首页开始,首先下载这个网页(depth=0),然后通过分析这个网页,可以找到页面中的所有超链接,也就是说你知道这个入口网站所有直接连接到首页的网页,如京东金融、京东白条、京东众筹等(深度=1)。接下来访问、下载和分析京东金融等网页,并且可以找到其他连接的页面网页(深度=2)。让电脑继续做,整个网站都可以下载了。
在这个过程中,我们需要一个“初始 URL 集合”来保存门户的主页,以及一个“URL 队列”来保存通过分析网页获得的超链接。
迷你蜘蛛.py
url_table.py
步骤3.在小本子——URL表中记录下载了哪些网页。
在互联网上,一个网页可能被多个网页中的超链接指向。这样,在遍历互联网的这张图片时,这个网页可能会被访问很多次。为了防止一个网页被多次下载和解析,需要一个URL表来记录哪些网页被下载了。当我们再次遇到这个页面时,我们可以跳过它。
crawl_thread.py
步骤 4. 多个抓取线程
为了提高爬虫的性能,需要多个爬取线程从URL队列中获取链接进行处理。多线程并没有错,但是Python的多线程可能会引起很多人的质疑,这源于Python设计的最初考虑:GIL。GIL的全称是Global Interpreter Lock(全局解释器锁)。如果一个线程要执行,首先要获得 GIL,而在一个 Python 进程中,只有一个 GIL。结果是Python中的一个进程每次只能执行一个线程,这就是Python的多线程效率在多核CPU上不高的原因。那么为什么我们仍然使用 Python 多线程呢?
CPU密集型代码(各种循环处理、编解码器等),在这种情况下,由于计算工作量很大,tick count很快就会达到阈值,然后触发GIL的释放和重新竞争(多个线程来回切换当然需要消耗资源),Python下的多线程对CPU密集型代码不友好。
IO密集型代码(文件处理、网络爬虫等),多线程可以有效提高效率(单线程下的IO操作会进行IO等待,造成不必要的时间浪费,启用多线程可以自动等待线程A当线程A等待时,切换到线程B不会浪费CPU资源,从而提高程序执行效率)。Python的多线程对IO密集型代码更加友好。
所以,对于IO密集型爬虫程序来说,使用Python多线程是没有问题的。
crawl_thread.py
步骤5.页面分析模块
从网页解析 URL 或其他有用数据。这是上一期的重点,可以参考之前的代码。
步骤6.页面存储模块
保存页面的模块,目前将文件保存为文件,未来可以扩展成多种存储方式,如mysql、mongodb、hbase等。
网页保存.py
至此,整个框架已经清晰的呈现在大家面前。不要低估它。无论框架多么复杂,它都在这些基本元素上进行了扩展。
下一步
基础知识的学习暂时告一段落,希望能帮助大家打下一定的基础。下一期我会介绍强大成熟的爬虫框架Scrapy,它提供了很多强大的功能让爬取更简单、更高效、更精彩,敬请期待!
最后觉得有帮助的朋友可以加入学习交流群
沉迷Python,无法自拔:862672474
php多线程抓取多个网页(Python处理网页相关的工具+BeautifulSoup抓取Goolge搜索链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-11 03:24
)
1)urllib2+BeautifulSoup 抓取 Goolge 搜索链接
最近参与的项目需要处理谷歌搜索结果,之前学过Python处理web相关的工具。在实际应用中,使用urllib2和beautifulsoup来爬取网页,但是在爬取google搜索结果的时候,发现如果直接处理google搜索结果页面的源码,会得到很多“脏”链接。
请看下图“泰坦尼克号詹姆斯”的搜索结果:
图中红色标注的是不需要的,蓝色标注的是需要抓取的。
当然,这个“脏链接”可以通过规则过滤来过滤掉,但是程序的复杂度很高。就在我皱着眉头写过滤规则的时候。同学们提醒谷歌应该提供相关的API,这才恍然大悟。
(2)Google 网页搜索 API + 多线程
该文档提供了一个在 Python 中搜索的示例:
在实际应用中,可能需要爬取google的很多网页,所以需要使用多个线程来分担爬取任务。有关使用 google web search api 的详细参考,请参见此处(此处介绍了标准 URL 参数)。另外要特别注意url中的参数rsz必须为8(包括8)下面的值,如果大于8会报错!
(3)代码实现
代码实现还是有问题,但是可以运行,健壮性差,需要改进。希望各界大神指出错误(初学Python),不胜感激。
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/ajax/services/search/web'
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join() 查看全部
php多线程抓取多个网页(Python处理网页相关的工具+BeautifulSoup抓取Goolge搜索链接
)
1)urllib2+BeautifulSoup 抓取 Goolge 搜索链接
最近参与的项目需要处理谷歌搜索结果,之前学过Python处理web相关的工具。在实际应用中,使用urllib2和beautifulsoup来爬取网页,但是在爬取google搜索结果的时候,发现如果直接处理google搜索结果页面的源码,会得到很多“脏”链接。
请看下图“泰坦尼克号詹姆斯”的搜索结果:

图中红色标注的是不需要的,蓝色标注的是需要抓取的。
当然,这个“脏链接”可以通过规则过滤来过滤掉,但是程序的复杂度很高。就在我皱着眉头写过滤规则的时候。同学们提醒谷歌应该提供相关的API,这才恍然大悟。
(2)Google 网页搜索 API + 多线程
该文档提供了一个在 Python 中搜索的示例:
在实际应用中,可能需要爬取google的很多网页,所以需要使用多个线程来分担爬取任务。有关使用 google web search api 的详细参考,请参见此处(此处介绍了标准 URL 参数)。另外要特别注意url中的参数rsz必须为8(包括8)下面的值,如果大于8会报错!
(3)代码实现
代码实现还是有问题,但是可以运行,健壮性差,需要改进。希望各界大神指出错误(初学Python),不胜感激。
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/ajax/services/search/web'
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join()
php多线程抓取多个网页(php爱好者用Latin-1字符集编码,下载起来就比较困难)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-08 03:07
很多网站看电影的人都是m3u8,但是下载起来比较困难。当我们看到自己喜欢想下载的视频资源时,就可以使用这款多线程m3u8下载器,该软件可以帮助用户轻松下载m3u8视频,操作非常简单,输入地址即可,它收录以下功能自动解密,非常强大。下载完成后,还可以进行转换等操作。
软件说明
1.M3U8也是M3U的一种,但它的编码格式是UTF-8格式。M3U 使用 Latin-1 字符集编码。
2.M3U 是歌曲的目录信息。下载.FLAC无损格式的音频时,会附带一个M3U目录文件。
3.程序下载 M3U8 清单并将其转换为 MP4。
4.可以配置要加载的线程数。
软件功能
使用Aria2作为下载引擎,避免网络波动导致下载卡顿
允许插件接管一些步骤以兼容不同的加密处理
提供丰富的定制选项
针对本地缓存进行了优化,可快速合并网页缓存
软件亮点
1.灵活且易于使用。
2.绿色紧凑,性能实用。
3.支持获取真实下载链接。
4.可以转码m3u8格式。
5.可以快速解析m3u8视频的播放地址。
软件评估
该软件是一款功能强大的视频下载工具。下载M3u8视频后,可以转换成Mp4格式的视频进行播放,非常方便;
软件支持多线程、自动解密、自定义请求等功能,用户还可以设置User-Agent和Cookies;
该软件可以同时执行多个任务,没有任何限制。线程数只控制该ts的下载线程数。
以上就是php爱好者小编今天带来的多线程m3u8下载器。更多软件下载可供 php 爱好者使用。 查看全部
php多线程抓取多个网页(php爱好者用Latin-1字符集编码,下载起来就比较困难)
很多网站看电影的人都是m3u8,但是下载起来比较困难。当我们看到自己喜欢想下载的视频资源时,就可以使用这款多线程m3u8下载器,该软件可以帮助用户轻松下载m3u8视频,操作非常简单,输入地址即可,它收录以下功能自动解密,非常强大。下载完成后,还可以进行转换等操作。
软件说明
1.M3U8也是M3U的一种,但它的编码格式是UTF-8格式。M3U 使用 Latin-1 字符集编码。
2.M3U 是歌曲的目录信息。下载.FLAC无损格式的音频时,会附带一个M3U目录文件。
3.程序下载 M3U8 清单并将其转换为 MP4。
4.可以配置要加载的线程数。
软件功能
使用Aria2作为下载引擎,避免网络波动导致下载卡顿
允许插件接管一些步骤以兼容不同的加密处理
提供丰富的定制选项
针对本地缓存进行了优化,可快速合并网页缓存
软件亮点
1.灵活且易于使用。
2.绿色紧凑,性能实用。
3.支持获取真实下载链接。
4.可以转码m3u8格式。
5.可以快速解析m3u8视频的播放地址。
软件评估
该软件是一款功能强大的视频下载工具。下载M3u8视频后,可以转换成Mp4格式的视频进行播放,非常方便;
软件支持多线程、自动解密、自定义请求等功能,用户还可以设置User-Agent和Cookies;
该软件可以同时执行多个任务,没有任何限制。线程数只控制该ts的下载线程数。
以上就是php爱好者小编今天带来的多线程m3u8下载器。更多软件下载可供 php 爱好者使用。
php多线程抓取多个网页(用ControlInvoke,应为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-05 11:17
多线程爬取遇到了非常复杂的问题。
我在 .net 2005 中编写了一个控制台程序,用于在多个线程中抓取网页内容,但使用
WebBrowser webb = new WebBrowser();
webb.Navigate("about:blank");
HtmlDocument htmldoc = webb.Document.OpenNew(true);
htmldoc.Write(strWeb);
return htmldoc.GetElementsByTagName("TR");
分析网页内容时始终报告
“无法实例化 ActiveX 控件“8856f961-340a-11d0-a96b-00c04fd705a2”,因为当前线程不在单线程单元中。”
错误!
我添加了 startSnatch.SetApartmentState(ApartmentState.STA);到每个线程;
但还是无济于事。
希望得到各位高手的帮助!谢谢!
--------解决方案--------
委托用于跨线程操作控件,请搜索相关资料
--------解决方案--------
控制调用
--------解决方案--------
使用Control.Invoke,你应该在自己的工作线程中调用UI线程中的对象 查看全部
php多线程抓取多个网页(用ControlInvoke,应为)
多线程爬取遇到了非常复杂的问题。
我在 .net 2005 中编写了一个控制台程序,用于在多个线程中抓取网页内容,但使用
WebBrowser webb = new WebBrowser();
webb.Navigate("about:blank");
HtmlDocument htmldoc = webb.Document.OpenNew(true);
htmldoc.Write(strWeb);
return htmldoc.GetElementsByTagName("TR");
分析网页内容时始终报告
“无法实例化 ActiveX 控件“8856f961-340a-11d0-a96b-00c04fd705a2”,因为当前线程不在单线程单元中。”
错误!
我添加了 startSnatch.SetApartmentState(ApartmentState.STA);到每个线程;
但还是无济于事。
希望得到各位高手的帮助!谢谢!
--------解决方案--------
委托用于跨线程操作控件,请搜索相关资料
--------解决方案--------
控制调用
--------解决方案--------
使用Control.Invoke,你应该在自己的工作线程中调用UI线程中的对象
php多线程抓取多个网页(Python处理网页相关的工具+BeautifulSoup抓取Goolge搜索链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-03 17:06
)
1)urllib2+BeautifulSoup 抓取 Goolge 搜索链接
最近参与的项目需要处理谷歌搜索结果,之前学过Python处理web相关的工具。在实际应用中,使用urllib2和beautifulsoup来爬取网页,但是在爬取google搜索结果的时候,发现如果直接处理google搜索结果页面的源码,会得到很多“脏”链接。
请看下图“泰坦尼克号詹姆斯”的搜索结果:
图中红色标注的是不需要的,蓝色标注的是需要抓取的。
当然,这个“脏链接”可以通过规则过滤来过滤掉,但是程序的复杂度很高。就在我皱着眉头写过滤规则的时候。同学们提醒谷歌应该提供相关的API,这才恍然大悟。
(2)Google 网页搜索 API + 多线程
该文档提供了一个在 Python 中搜索的示例:
在实际应用中,可能需要爬取google的很多网页,所以需要使用多个线程来分担爬取任务。有关使用 google web search api 的详细参考,请参见此处(此处介绍了标准 URL 参数)。另外要特别注意url中的参数rsz必须为8(包括8)下面的值,如果大于8会报错!
(3)代码实现
代码实现还是有问题,但是可以运行,健壮性差,需要改进。希望各界大神指出错误(初学Python),不胜感激。
#-*-coding:utf-8-*- import urllib2,urllib import simplejson import os, time,threading import common, html_filter #input the keywords keywords = raw_input('Enter the keywords: ') #define rnum_perpage, pages rnum_perpage=8pages=8 #定义线程函数 def thread_scratch(url, rnum_perpage, page): url_set = [] try: request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'}) response = urllib2.urlopen(request) # Process the JSON string. results = simplejson.load(response) info = results['responseData']['results'] except Exception,e: print 'error occured' print e else: for minfo in info: url_set.append(minfo['url']) print minfo['url'] #处理链接 i = 0 for u in url_set: try: request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'}) request_url.add_header( 'User-agent', 'CSC' ) response_data = urllib2.urlopen(request_url).read() #过滤文件 #content_data = html_filter.filter_tags(response_data) #写入文件 filenum = i+page filename = dir_name+'/related_html_'+str(filenum) print ' write start: related_html_'+str(filenum) f = open(filename, 'w+', -1) f.write(response_data) #print content_data f.close() print ' write down: related_html_'+str(filenum) except Exception, e: print 'error occured 2' print e i = i+1 return #创建文件夹 dir_name = 'related_html_'+urllib.quote(keywords) if os.path.exists(dir_name): print 'exists file' common.delete_dir_or_file(dir_name) os.makedirs(dir_name) #抓取网页 print 'start to scratch web pages:'for x in range(pages): print "page:%s"%(x+1) page = x * rnum_perpage url = ('https://ajax.googleapis.com/ajax/services/search/web' '?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page) print url t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page)) t.start() #主线程等待子线程抓取完 main_thread = threading.currentThread() for t in threading.enumerate(): if t is main_thread: continue t.join() 查看全部
php多线程抓取多个网页(Python处理网页相关的工具+BeautifulSoup抓取Goolge搜索链接
)
1)urllib2+BeautifulSoup 抓取 Goolge 搜索链接
最近参与的项目需要处理谷歌搜索结果,之前学过Python处理web相关的工具。在实际应用中,使用urllib2和beautifulsoup来爬取网页,但是在爬取google搜索结果的时候,发现如果直接处理google搜索结果页面的源码,会得到很多“脏”链接。
请看下图“泰坦尼克号詹姆斯”的搜索结果:

图中红色标注的是不需要的,蓝色标注的是需要抓取的。
当然,这个“脏链接”可以通过规则过滤来过滤掉,但是程序的复杂度很高。就在我皱着眉头写过滤规则的时候。同学们提醒谷歌应该提供相关的API,这才恍然大悟。
(2)Google 网页搜索 API + 多线程
该文档提供了一个在 Python 中搜索的示例:
在实际应用中,可能需要爬取google的很多网页,所以需要使用多个线程来分担爬取任务。有关使用 google web search api 的详细参考,请参见此处(此处介绍了标准 URL 参数)。另外要特别注意url中的参数rsz必须为8(包括8)下面的值,如果大于8会报错!
(3)代码实现
代码实现还是有问题,但是可以运行,健壮性差,需要改进。希望各界大神指出错误(初学Python),不胜感激。
#-*-coding:utf-8-*- import urllib2,urllib import simplejson import os, time,threading import common, html_filter #input the keywords keywords = raw_input('Enter the keywords: ') #define rnum_perpage, pages rnum_perpage=8pages=8 #定义线程函数 def thread_scratch(url, rnum_perpage, page): url_set = [] try: request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'}) response = urllib2.urlopen(request) # Process the JSON string. results = simplejson.load(response) info = results['responseData']['results'] except Exception,e: print 'error occured' print e else: for minfo in info: url_set.append(minfo['url']) print minfo['url'] #处理链接 i = 0 for u in url_set: try: request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'}) request_url.add_header( 'User-agent', 'CSC' ) response_data = urllib2.urlopen(request_url).read() #过滤文件 #content_data = html_filter.filter_tags(response_data) #写入文件 filenum = i+page filename = dir_name+'/related_html_'+str(filenum) print ' write start: related_html_'+str(filenum) f = open(filename, 'w+', -1) f.write(response_data) #print content_data f.close() print ' write down: related_html_'+str(filenum) except Exception, e: print 'error occured 2' print e i = i+1 return #创建文件夹 dir_name = 'related_html_'+urllib.quote(keywords) if os.path.exists(dir_name): print 'exists file' common.delete_dir_or_file(dir_name) os.makedirs(dir_name) #抓取网页 print 'start to scratch web pages:'for x in range(pages): print "page:%s"%(x+1) page = x * rnum_perpage url = ('https://ajax.googleapis.com/ajax/services/search/web' '?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page) print url t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page)) t.start() #主线程等待子线程抓取完 main_thread = threading.currentThread() for t in threading.enumerate(): if t is main_thread: continue t.join()
php多线程抓取多个网页(phpcurl_multi_exec()并发抓取网页内容php是个单线程的语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-27 22:05
php curl_multi_exec() 同时抓取网页内容
PHP是单线程语言,所以在某些方面速度不如java这样的多线程语言。毕竟主要的方面不在这里。但是PHP也有自己的多线程(实际上是并发)方法——curl_multi_exec()。
我们可以使用curl来获取网页的内容(如果你不懂curl,可以找个简单的例子看看),但是如果同时获取多个网页的内容,速度就不行了理想的。这时候 curl_multi_exec() 就可以发挥作用了。
这是我如何抓取优酷内容的示例:
function async_get_url($url_array, $wait_usec = 0){ if (!is_array($url_array)) return false; $wait_usec = intval($wait_usec); $data = array(); $handle = array(); $running = 0; $mh = curl_multi_init(); // multi curl handler $i = 0; foreach($url_array as $url) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // return don't print curl_setopt($ch, CURLOPT_TIMEOUT, 30); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)'); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 302 redirect curl_setopt($ch, CURLOPT_MAXREDIRS, 7); curl_multi_add_handle($mh, $ch); // 把 curl resource 放進 multi curl handler 裡 $handle[$i++] = $ch; } /* 此做法就可以避免掉 CPU loading 100% 的問題 */ // 參考自: http://www.hengss.com/xueyuan/ ... .html do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); while ($active and $mrc == CURLM_OK) { if (curl_multi_select($mh) != -1) { do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); } } /* // 感謝 Ren 指點的作法. (需要在測試一下) // curl_multi_exec的返回值是用來返回多線程處裡時的錯誤,正常來說返回值是0,也就是說只用$mrc捕捉返回值當成判斷式的迴圈只會運行一次,而真的發生錯誤時,有拿$mrc判斷的都會變死迴圈。 // 而curl_multi_select的功能是curl發送請求後,在有回應前會一直處於等待狀態,所以不需要把它導入空迴圈,它就像是會自己做判斷&自己決定等待時間的sleep()。 /* 讀取資料 */ foreach($handle as $i => $ch) { $content = curl_multi_getcontent($ch); $data[$i] = (curl_errno($ch) == 0) ? $content : false; } /* 移除 handle*/ foreach($handle as $ch) { curl_multi_remove_handle($mh, $ch); } curl_multi_close($mh); return $data;} $url="http://m.youku.com/wap/";$reg1="/(.*?)/i";//获取视频链接$reg2="/]*)\s*class=\"imgdetail\"\s*src=('|\")([^'\"]+)('|\")/i";$reg3="";$reg4= "/.*?/i";//获取视频标题(备选) // 创建两个cURL资源$ch1 = curl_init();$resultArray=array();//装载所有数据的数组$ch=array();//$ch2 = curl_init();// 指定URL和适当的参数curl_setopt($ch1, CURLOPT_URL,$url);curl_setopt($ch1, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch1, CURLOPT_HEADER, 0);$content=curl_exec($ch1);curl_close($ch1);//$content=file_get_contents($url);preg_match_all($reg1, $content,$matches);$video=$matches[0];//首页视频的链接//print_r($video);foreach ($video as $a=>$key){ $position=strpos($key, "href"); $substring=substr($key, $position+11); $pos=strpos($substring, ">"); $link=substr($substring, 0,$pos-1); $nextUrl[$a]=$url.$link;}//$url_array = array( // 'http://www.google.com', // 'http://www.baidu.com',//);//print_r($nextUrl);//print_r(async_get_url($nextUrl));//并发获取所有网页的内容$allData=async_get_url($nextUrl);foreach ($allData as $page){ //获取视频图片 preg_match_all($reg2, $page,$img); $img_arr=$img[0]; foreach ($img_arr as $arr) { $position=strpos($arr, "src"); $sub=substr($arr, $position+5); $pos=strpos($sub, "\""); $last=substr($sub, 0,$pos); } //获取视频高清点播地址 preg_match_all($reg3, $page,$vids); $video_arr=$vids[0]; $vid=$video_arr[0]; $position=strpos($vid, "href"); $v_string=substr($vid, $position+11); $pos=strpos($v_string, "\""); $add=substr($v_string, 0,$pos); $video_url=$url.$add; //获取视频的标题 preg_match_all($reg4, $page,$match); $title=$match[0]; //print_r($er); $r=serialize($title); $position=mb_strpos($r, ""); $sub=substr($r, 0,$position); $pos=mb_strrpos($sub, ">"); $til=substr($sub, $pos+1); //整合到一个数组 $subArray=array('image'=>$last,'video'=>$video_url,'title'=>$til); array_push($resultArray, $subArray);}echo json_encode($resultArray);</p>
郑重声明:本文版权收录图片属于原作者,转载文章仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
标签: php 多线程 phpcurl exec phpurl curl 查看全部
php多线程抓取多个网页(phpcurl_multi_exec()并发抓取网页内容php是个单线程的语言)
php curl_multi_exec() 同时抓取网页内容
PHP是单线程语言,所以在某些方面速度不如java这样的多线程语言。毕竟主要的方面不在这里。但是PHP也有自己的多线程(实际上是并发)方法——curl_multi_exec()。
我们可以使用curl来获取网页的内容(如果你不懂curl,可以找个简单的例子看看),但是如果同时获取多个网页的内容,速度就不行了理想的。这时候 curl_multi_exec() 就可以发挥作用了。
这是我如何抓取优酷内容的示例:
function async_get_url($url_array, $wait_usec = 0){ if (!is_array($url_array)) return false; $wait_usec = intval($wait_usec); $data = array(); $handle = array(); $running = 0; $mh = curl_multi_init(); // multi curl handler $i = 0; foreach($url_array as $url) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // return don't print curl_setopt($ch, CURLOPT_TIMEOUT, 30); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)'); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 302 redirect curl_setopt($ch, CURLOPT_MAXREDIRS, 7); curl_multi_add_handle($mh, $ch); // 把 curl resource 放進 multi curl handler 裡 $handle[$i++] = $ch; } /* 此做法就可以避免掉 CPU loading 100% 的問題 */ // 參考自: http://www.hengss.com/xueyuan/ ... .html do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); while ($active and $mrc == CURLM_OK) { if (curl_multi_select($mh) != -1) { do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); } } /* // 感謝 Ren 指點的作法. (需要在測試一下) // curl_multi_exec的返回值是用來返回多線程處裡時的錯誤,正常來說返回值是0,也就是說只用$mrc捕捉返回值當成判斷式的迴圈只會運行一次,而真的發生錯誤時,有拿$mrc判斷的都會變死迴圈。 // 而curl_multi_select的功能是curl發送請求後,在有回應前會一直處於等待狀態,所以不需要把它導入空迴圈,它就像是會自己做判斷&自己決定等待時間的sleep()。 /* 讀取資料 */ foreach($handle as $i => $ch) { $content = curl_multi_getcontent($ch); $data[$i] = (curl_errno($ch) == 0) ? $content : false; } /* 移除 handle*/ foreach($handle as $ch) { curl_multi_remove_handle($mh, $ch); } curl_multi_close($mh); return $data;} $url="http://m.youku.com/wap/";$reg1="/(.*?)/i";//获取视频链接$reg2="/]*)\s*class=\"imgdetail\"\s*src=('|\")([^'\"]+)('|\")/i";$reg3="";$reg4= "/.*?/i";//获取视频标题(备选) // 创建两个cURL资源$ch1 = curl_init();$resultArray=array();//装载所有数据的数组$ch=array();//$ch2 = curl_init();// 指定URL和适当的参数curl_setopt($ch1, CURLOPT_URL,$url);curl_setopt($ch1, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch1, CURLOPT_HEADER, 0);$content=curl_exec($ch1);curl_close($ch1);//$content=file_get_contents($url);preg_match_all($reg1, $content,$matches);$video=$matches[0];//首页视频的链接//print_r($video);foreach ($video as $a=>$key){ $position=strpos($key, "href"); $substring=substr($key, $position+11); $pos=strpos($substring, ">"); $link=substr($substring, 0,$pos-1); $nextUrl[$a]=$url.$link;}//$url_array = array( // 'http://www.google.com', // 'http://www.baidu.com',//);//print_r($nextUrl);//print_r(async_get_url($nextUrl));//并发获取所有网页的内容$allData=async_get_url($nextUrl);foreach ($allData as $page){ //获取视频图片 preg_match_all($reg2, $page,$img); $img_arr=$img[0]; foreach ($img_arr as $arr) { $position=strpos($arr, "src"); $sub=substr($arr, $position+5); $pos=strpos($sub, "\""); $last=substr($sub, 0,$pos); } //获取视频高清点播地址 preg_match_all($reg3, $page,$vids); $video_arr=$vids[0]; $vid=$video_arr[0]; $position=strpos($vid, "href"); $v_string=substr($vid, $position+11); $pos=strpos($v_string, "\""); $add=substr($v_string, 0,$pos); $video_url=$url.$add; //获取视频的标题 preg_match_all($reg4, $page,$match); $title=$match[0]; //print_r($er); $r=serialize($title); $position=mb_strpos($r, ""); $sub=substr($r, 0,$position); $pos=mb_strrpos($sub, ">"); $til=substr($sub, $pos+1); //整合到一个数组 $subArray=array('image'=>$last,'video'=>$video_url,'title'=>$til); array_push($resultArray, $subArray);}echo json_encode($resultArray);</p>
郑重声明:本文版权收录图片属于原作者,转载文章仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
标签: php 多线程 phpcurl exec phpurl curl
php多线程抓取多个网页(php多线程抓取多个网页有以下方法可以选择1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-27 08:01
php多线程抓取多个网页有以下方法可以选择1。php内嵌http框架2。http代理服务器设置两个ip分别抓取3。反向代理前端抓取反向代理后端抓取,目前sae支持反向代理,抓取公共网站和api接口做小站点都可以设置反向代理抓取,公共网站写php文件反向代理实现抓取,api接口抓取就是用php编写http代理的代理注:,反向代理要设置成proxy的对象才能正常转发抓取,具体详细参考文档(不过当时用php写不会用,后面还是用了这个方法实现,感觉比较方便)php反向代理设置方法。
和你一样的需求,正向代理设置不成功,无法正常抓取你的站点。sae貌似和php并没有太大关系,暂时没有找到解决方案。
$_server['request_id']['request_uri']==''???
在命令行安装apache,然后phpinfo()输出phpinfo()后,
我们是用redis存起来的svn文件然后使用workcurlworkcurl连接到php自己的svn服务器workcurl的源码phpinfo可以看到源码,
我也是, 查看全部
php多线程抓取多个网页(php多线程抓取多个网页有以下方法可以选择1)
php多线程抓取多个网页有以下方法可以选择1。php内嵌http框架2。http代理服务器设置两个ip分别抓取3。反向代理前端抓取反向代理后端抓取,目前sae支持反向代理,抓取公共网站和api接口做小站点都可以设置反向代理抓取,公共网站写php文件反向代理实现抓取,api接口抓取就是用php编写http代理的代理注:,反向代理要设置成proxy的对象才能正常转发抓取,具体详细参考文档(不过当时用php写不会用,后面还是用了这个方法实现,感觉比较方便)php反向代理设置方法。
和你一样的需求,正向代理设置不成功,无法正常抓取你的站点。sae貌似和php并没有太大关系,暂时没有找到解决方案。
$_server['request_id']['request_uri']==''???
在命令行安装apache,然后phpinfo()输出phpinfo()后,
我们是用redis存起来的svn文件然后使用workcurlworkcurl连接到php自己的svn服务器workcurl的源码phpinfo可以看到源码,
我也是,
php多线程抓取多个网页(3.怎样支持分布式?暂时最简单的想法-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-26 02:16
一、要求
1.定期抓取网站新闻标题、内容、发布时间和来源。
2.程序需要支持分布式、多线程
二、设计
1.网站是固定的,但是以后可能会添加新的网站来抢,每个网站内容节点设计都不一样,所以需要支持动态配置才能添加网站 以方便未来的扩展,每次都需要开发干预。
2.网站html 节点的结构可能会发生变化,因此也可以支持可配置的提取节点。
3.如何支持分布式?暂时最简单的思路就是在多台机器上部署一个程序,新建一个或者一个部署程序来创建一个定时任务,在某个时间开始每台机器应该抓取哪一个网站 ,暂时不能支持同一个网站@网站同时可以支持被多台机器同时抓取,会比较麻烦,使用分布式队列。所以暂时一个 网站 只会被单台机器同时抓取。
4.多线程,如何多线程?多线程爬取我这里有两种实现:
(1)一个线程抓取一个网站,维护自己的url队列进行广度抓取,同时抓取多个网站。如图:
(2)多个线程同时抓取不同的网站。如图:
以上两种方法其实各有优缺点。这取决于我们如何选择。
方法一:每个线程创建自己的队列。图中的队列可以不用concurrentQueue。优点:不涉及控制并发。每个网站线程抓取一个网站,抓取完成后销毁线程自动回收。易于控制。缺点:无法扩展线程数。比如只有3个网站时,最多只能开3个线程去抢,不能开更多,有一定的局限性。
方法二:N个线程同时抢N个网站s,线程数与网站s个数无关。优点:线程数可以调整,与抓取网站的个数无关。3 网站我们可以开 4 5 或者 10 这个可以根据你的硬件资源来调整。缺点:需要控制并发,并且控制什么时候销毁线程(thread1空闲,队列为空不代表任务可以结束,可能thread2的结果还没有返回),当捕获到网站响应慢,会拖慢整个爬虫的进度。
三、实现
爬取方式最终选择了方式二,因为线程数是可以配置的!
使用的技术:
用了jfinal后,发现这个东西不太合适,但是由于项目进度问题,还是用了。
maven项目管理
码头服务器
mysql
日食发展
项目需要关注的难点:
(1)合理控制N个线程正常抓取网站,当所有线程工作完成且待抓取队列为空时,N个线程同时退出并销毁。
(2)不同网站设计节点不同,需要为每个网站配置需要抓取的URL以及抓取的节点内容在html节点中的位置。
(3)个性化内容处理,由于html结构设计问题,爬取的内容可能会有一些多余的html标签,或者如何处理多余的内容。
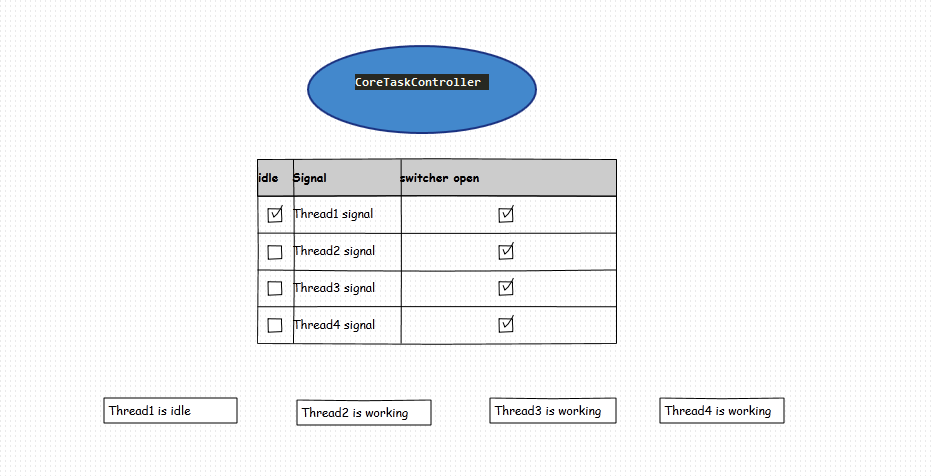
实现一:线程管理建立一个以线程为中心的管理控制器,负责线程销毁。如图所示:
(1)创建一个中央管理器,管理器存储N个线程的信号数组标记来标记线程是否空闲,并创建N个标记的线程切换。用于同时结束N个线程。
(2)线程开始抓取请求链接时设置idle为false,抓取链接后继续循环取队列(循环过程中判断开关是否为真)。当轮询结果从队列为空,把线程设为idle=true,并休眠1S(看个人喜好)。
(3)线程中心中央管理器调度定时检测任务,每1s检测一次线程的信号数组tag和queue.size(),此时queue.size()==0且数组tag全部标记为 idle ,将线程切换器设置为 false (关闭,所以线程将结束 while 退出)
如图,线程在4个线程状态后可以自行退出:
核心控制函数和线程函数代码如下:
CoreTaskController.java
<p>import java.util.Arrays;
import java.util.Timer;
import java.util.TimerTask;
import org.apache.log4j.Logger;
import com.crawler.core.conf.CrawlerConf;
/**
* 任务核心控制器
* @author Jacky
* 2015-9-30
*/
public class CoreTaskController {
public static Logger log = Logger.getLogger(CoreTaskController.class);
/**
* 信号量,用来标记当前线程是否空闲
* 0表示空闲
* 1表示繁忙
* CrawlerConf.getMaxT()表示获取最大线程数
*/
public static volatile int[] signal = new int[CrawlerConf.getMaxT()];;
public static volatile boolean totalSwitcher = true;
/**
* 线程开关
* 1表示打开
* 0表示关闭
*/
public static volatile int[] switcher = new int[CrawlerConf.getMaxT()];
public static Timer timer;
public static void init() {
// 开启所有线程开关
for(int i=0;i 查看全部
php多线程抓取多个网页(3.怎样支持分布式?暂时最简单的想法-苏州安嘉)
一、要求
1.定期抓取网站新闻标题、内容、发布时间和来源。
2.程序需要支持分布式、多线程
二、设计
1.网站是固定的,但是以后可能会添加新的网站来抢,每个网站内容节点设计都不一样,所以需要支持动态配置才能添加网站 以方便未来的扩展,每次都需要开发干预。
2.网站html 节点的结构可能会发生变化,因此也可以支持可配置的提取节点。
3.如何支持分布式?暂时最简单的思路就是在多台机器上部署一个程序,新建一个或者一个部署程序来创建一个定时任务,在某个时间开始每台机器应该抓取哪一个网站 ,暂时不能支持同一个网站@网站同时可以支持被多台机器同时抓取,会比较麻烦,使用分布式队列。所以暂时一个 网站 只会被单台机器同时抓取。
4.多线程,如何多线程?多线程爬取我这里有两种实现:
(1)一个线程抓取一个网站,维护自己的url队列进行广度抓取,同时抓取多个网站。如图:
(2)多个线程同时抓取不同的网站。如图:
以上两种方法其实各有优缺点。这取决于我们如何选择。
方法一:每个线程创建自己的队列。图中的队列可以不用concurrentQueue。优点:不涉及控制并发。每个网站线程抓取一个网站,抓取完成后销毁线程自动回收。易于控制。缺点:无法扩展线程数。比如只有3个网站时,最多只能开3个线程去抢,不能开更多,有一定的局限性。
方法二:N个线程同时抢N个网站s,线程数与网站s个数无关。优点:线程数可以调整,与抓取网站的个数无关。3 网站我们可以开 4 5 或者 10 这个可以根据你的硬件资源来调整。缺点:需要控制并发,并且控制什么时候销毁线程(thread1空闲,队列为空不代表任务可以结束,可能thread2的结果还没有返回),当捕获到网站响应慢,会拖慢整个爬虫的进度。
三、实现
爬取方式最终选择了方式二,因为线程数是可以配置的!
使用的技术:
用了jfinal后,发现这个东西不太合适,但是由于项目进度问题,还是用了。
maven项目管理
码头服务器
mysql
日食发展
项目需要关注的难点:
(1)合理控制N个线程正常抓取网站,当所有线程工作完成且待抓取队列为空时,N个线程同时退出并销毁。
(2)不同网站设计节点不同,需要为每个网站配置需要抓取的URL以及抓取的节点内容在html节点中的位置。
(3)个性化内容处理,由于html结构设计问题,爬取的内容可能会有一些多余的html标签,或者如何处理多余的内容。
实现一:线程管理建立一个以线程为中心的管理控制器,负责线程销毁。如图所示:
(1)创建一个中央管理器,管理器存储N个线程的信号数组标记来标记线程是否空闲,并创建N个标记的线程切换。用于同时结束N个线程。
(2)线程开始抓取请求链接时设置idle为false,抓取链接后继续循环取队列(循环过程中判断开关是否为真)。当轮询结果从队列为空,把线程设为idle=true,并休眠1S(看个人喜好)。
(3)线程中心中央管理器调度定时检测任务,每1s检测一次线程的信号数组tag和queue.size(),此时queue.size()==0且数组tag全部标记为 idle ,将线程切换器设置为 false (关闭,所以线程将结束 while 退出)
如图,线程在4个线程状态后可以自行退出:
核心控制函数和线程函数代码如下:
CoreTaskController.java
<p>import java.util.Arrays;
import java.util.Timer;
import java.util.TimerTask;
import org.apache.log4j.Logger;
import com.crawler.core.conf.CrawlerConf;
/**
* 任务核心控制器
* @author Jacky
* 2015-9-30
*/
public class CoreTaskController {
public static Logger log = Logger.getLogger(CoreTaskController.class);
/**
* 信号量,用来标记当前线程是否空闲
* 0表示空闲
* 1表示繁忙
* CrawlerConf.getMaxT()表示获取最大线程数
*/
public static volatile int[] signal = new int[CrawlerConf.getMaxT()];;
public static volatile boolean totalSwitcher = true;
/**
* 线程开关
* 1表示打开
* 0表示关闭
*/
public static volatile int[] switcher = new int[CrawlerConf.getMaxT()];
public static Timer timer;
public static void init() {
// 开启所有线程开关
for(int i=0;i
php多线程抓取多个网页(php才算是真正的支持多线程,使用的是pthreads的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-25 13:03
到php5.3以上的版本,php确实支持多线程,使用pthreads的扩展,php在处理多个循环任务时可以大大缩短程序的执行时间。
网站的大部分性能瓶颈不在php服务器上,而是在mysql服务器上。因为可以通过横向增加server或者cpu core的数量来处理。如果使用Mysql数据库,联合查询可能会处理非常复杂的业务逻辑,但是遇到大量并发查询时,服务器可能会瘫痪。因此,我们可以使用 NoSQL 数据库代替 mysql 服务器。一个很复杂的SQL语句可能需要几条NOSQL语句才能完成,但是在大量并发的情况下,速度确实非常明显。然后再加上使用php多线程,通过十个php线程查询NOSQL,然后聚合返回结果输出,速度非常快。
1 PHP扩展下载:https://github.com/krakjoe/pthreads
2 PHP手册文档:http://php.net/manual/zh/book.pthreads.php
1、扩展编译安装(Linux),编辑参数--enable-maintainer-zts为必选项:
1 cd /Data/tgz/php-5.5.1
2 ./configure --prefix=/Data/apps/php --with-config-file-path=/Data/apps/php/etc --with-mysql=/Data/apps/mysql --with-mysqli=/Data/apps/mysql/bin/mysql_config --with-iconv-dir --with-freetype-dir=/Data/apps/libs --with-jpeg-dir=/Data/apps/libs --with-png-dir=/Data/apps/libs --with-zlib --with-libxml-dir=/usr --enable-xml --disable-rpath --enable-bcmath --enable-shmop --enable-sysvsem --enable-inline-optimization --with-curl --enable-mbregex --enable-fpm --enable-mbstring --with-mcrypt=/Data/apps/libs --with-gd --enable-gd-native-ttf --with-openssl --with-mhash --enable-pcntl --enable-sockets --with-xmlrpc --enable-zip --enable-soap --enable-opcache --with-pdo-mysql --enable-maintainer-zts
3 make clean
4 make
5 make install
6
7 unzip pthreads-master.zip
8 cd pthreads-master
9 /Data/apps/php/bin/phpize
10 ./configure --with-php-config=/Data/apps/php/bin/php-config
11 make
12 make install
vi /Data/apps/php/etc/php.ini
extension = "pthreads.so"
2、给出一个PHP多线程和For循环爬取百度搜索页面的PHP代码示例:
1
以上是一个官方php多线程的扩展。由于需要重新编译,所以我自己没有测试过,但其实本质是在linux中开启多个线程进行处理。
2、讲一个我自己伪造的PHP多线程的例子:
下面是一段测试代码:
for.php
1
test.php(只显示phpinfo信息):
1
采用多线程的执行的时间:32.89448595047
采用普通的执行的时间:85.191102027893
循环执行的次数越多,这个时间差就越明显。
ps:我们可以写一个python或者shell脚本来实时检测php进程数的变化:
1 #!/usr/bin/env/ python
2 import os
3 from time import sleep
4
5 while 1:
6 os.system("ps -aux|grep php|wc -l");
7 sleep(1);
8
9 上面是一个简单的统计php进程数的一个脚本,在shell界面执行的时候,可以将输出定位到一个文件中。
记录:
最大并发记录数:
在公司机器上运行多线程程序之前,
机器的配置是48G内存6个CPU,
一次并发线程数在3000左右,超过4000会导致内存溢出,机器会死机。这是并发线程的最大数量。
但是当我们在线运行时,为了安全,我们必须记住我们最多会有几十到一百个并发进程。如果超出范围,就会出现数据丢失和一些奇怪的现象。 查看全部
php多线程抓取多个网页(php才算是真正的支持多线程,使用的是pthreads的扩展)
到php5.3以上的版本,php确实支持多线程,使用pthreads的扩展,php在处理多个循环任务时可以大大缩短程序的执行时间。
网站的大部分性能瓶颈不在php服务器上,而是在mysql服务器上。因为可以通过横向增加server或者cpu core的数量来处理。如果使用Mysql数据库,联合查询可能会处理非常复杂的业务逻辑,但是遇到大量并发查询时,服务器可能会瘫痪。因此,我们可以使用 NoSQL 数据库代替 mysql 服务器。一个很复杂的SQL语句可能需要几条NOSQL语句才能完成,但是在大量并发的情况下,速度确实非常明显。然后再加上使用php多线程,通过十个php线程查询NOSQL,然后聚合返回结果输出,速度非常快。
1 PHP扩展下载:https://github.com/krakjoe/pthreads
2 PHP手册文档:http://php.net/manual/zh/book.pthreads.php
1、扩展编译安装(Linux),编辑参数--enable-maintainer-zts为必选项:
1 cd /Data/tgz/php-5.5.1
2 ./configure --prefix=/Data/apps/php --with-config-file-path=/Data/apps/php/etc --with-mysql=/Data/apps/mysql --with-mysqli=/Data/apps/mysql/bin/mysql_config --with-iconv-dir --with-freetype-dir=/Data/apps/libs --with-jpeg-dir=/Data/apps/libs --with-png-dir=/Data/apps/libs --with-zlib --with-libxml-dir=/usr --enable-xml --disable-rpath --enable-bcmath --enable-shmop --enable-sysvsem --enable-inline-optimization --with-curl --enable-mbregex --enable-fpm --enable-mbstring --with-mcrypt=/Data/apps/libs --with-gd --enable-gd-native-ttf --with-openssl --with-mhash --enable-pcntl --enable-sockets --with-xmlrpc --enable-zip --enable-soap --enable-opcache --with-pdo-mysql --enable-maintainer-zts
3 make clean
4 make
5 make install
6
7 unzip pthreads-master.zip
8 cd pthreads-master
9 /Data/apps/php/bin/phpize
10 ./configure --with-php-config=/Data/apps/php/bin/php-config
11 make
12 make install
vi /Data/apps/php/etc/php.ini
extension = "pthreads.so"
2、给出一个PHP多线程和For循环爬取百度搜索页面的PHP代码示例:
1
以上是一个官方php多线程的扩展。由于需要重新编译,所以我自己没有测试过,但其实本质是在linux中开启多个线程进行处理。
2、讲一个我自己伪造的PHP多线程的例子:
下面是一段测试代码:
for.php
1
test.php(只显示phpinfo信息):
1
采用多线程的执行的时间:32.89448595047
采用普通的执行的时间:85.191102027893
循环执行的次数越多,这个时间差就越明显。
ps:我们可以写一个python或者shell脚本来实时检测php进程数的变化:
1 #!/usr/bin/env/ python
2 import os
3 from time import sleep
4
5 while 1:
6 os.system("ps -aux|grep php|wc -l");
7 sleep(1);
8
9 上面是一个简单的统计php进程数的一个脚本,在shell界面执行的时候,可以将输出定位到一个文件中。
记录:
最大并发记录数:
在公司机器上运行多线程程序之前,
机器的配置是48G内存6个CPU,
一次并发线程数在3000左右,超过4000会导致内存溢出,机器会死机。这是并发线程的最大数量。
但是当我们在线运行时,为了安全,我们必须记住我们最多会有几十到一百个并发进程。如果超出范围,就会出现数据丢失和一些奇怪的现象。
php多线程抓取多个网页( php使用pthreadsv3多线程实现抓取新浪新闻信息操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-22 21:20
php使用pthreadsv3多线程实现抓取新浪新闻信息操作技巧汇总)
php使用pthreads v3多线程实现抓取新浪新闻信息的操作示例
更新时间:2020-02-21 08:47:31 作者:怀素贞
本文文章主要介绍使用pthreads v3多线程实现抓取新浪新闻信息的操作,分析php使用pthreads多线程抓取新浪新闻的具体实现步骤和操作技巧信息结合示例。朋友可以参考以下
本文中的示例描述了php如何使用pthreads v3多线程来捕获新浪新闻信息。分享给大家,供大家参考,如下:
我们使用 pthreads 编写一个多线程小程序来抓取页面并将结果存储在数据库中。
数据表结构如下:
CREATE TABLE `tb_sina` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`url` varchar(256) DEFAULT '' COMMENT 'url地址',
`title` varchar(128) DEFAULT '' COMMENT '标题',
`time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='sina新闻';
代码如下:
<p> 查看全部
php多线程抓取多个网页(
php使用pthreadsv3多线程实现抓取新浪新闻信息操作技巧汇总)
php使用pthreads v3多线程实现抓取新浪新闻信息的操作示例
更新时间:2020-02-21 08:47:31 作者:怀素贞
本文文章主要介绍使用pthreads v3多线程实现抓取新浪新闻信息的操作,分析php使用pthreads多线程抓取新浪新闻的具体实现步骤和操作技巧信息结合示例。朋友可以参考以下
本文中的示例描述了php如何使用pthreads v3多线程来捕获新浪新闻信息。分享给大家,供大家参考,如下:
我们使用 pthreads 编写一个多线程小程序来抓取页面并将结果存储在数据库中。
数据表结构如下:
CREATE TABLE `tb_sina` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`url` varchar(256) DEFAULT '' COMMENT 'url地址',
`title` varchar(128) DEFAULT '' COMMENT '标题',
`time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='sina新闻';
代码如下:
<p>
php多线程抓取多个网页(php中curl_init()的具体使用方法及相关效率比较)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-22 16:09
php使用curl_init()和curl_multi_init()多线程的速度详解
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文章主要介绍了php使用curl_init()和curl_multi_init()多线程的速度对比,并结合示例表格详细分析了curl_init()和curl_multi_init()的具体用法和相关效率对比。需要的朋友可以参考以下
本文的例子描述了php使用curl_init()和curl_multi_init()多线程的速度对比。分享给大家参考,详情如下:
curl_init()在php中的作用非常大,尤其是在抓取网页内容或者文件信息的时候。比如之前的文章《php使用curl获取header检测并启用GZip压缩》介绍了curl_init()的威力。
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_init()和curl_multi_init()的速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p> 查看全部
php多线程抓取多个网页(php中curl_init()的具体使用方法及相关效率比较)
php使用curl_init()和curl_multi_init()多线程的速度详解
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文章主要介绍了php使用curl_init()和curl_multi_init()多线程的速度对比,并结合示例表格详细分析了curl_init()和curl_multi_init()的具体用法和相关效率对比。需要的朋友可以参考以下
本文的例子描述了php使用curl_init()和curl_multi_init()多线程的速度对比。分享给大家参考,详情如下:
curl_init()在php中的作用非常大,尤其是在抓取网页内容或者文件信息的时候。比如之前的文章《php使用curl获取header检测并启用GZip压缩》介绍了curl_init()的威力。
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_init()和curl_multi_init()的速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p>
php多线程抓取多个网页(2017年7月10日16:17用PHP来加密解密Cloudflare邮箱保护Cloudflare)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-15 10:22
WHMCS 限制每个订单的数量
默认情况下,在 whmcs 中,可以在购物车中选择无限数量的产品。虽然说可以设置产品的上限,但也可以暂时用完所有剩余的可用数量。那么后台会产生很多无用的数据,大量的订单会导致数据库出现异常,所以我们需要防止这种情况发生。
2017年7月10日16:17
使用 PHP 加解密 Cloudflare 邮箱保护
Cloudflare 有一个非常好的功能,就是对页面上所有的邮箱地址进行加密,防止机器人抓取和做坏事。对于该功能,在后台启用邮箱地址混淆后,您可以在页面中添加邮箱地址。例如,如果您查看源代码,您可以找到类似于以下的代码
2016 年 9 月 28 日 12:28
WHMCS密码加密方式
我今天无事可做,看了WHMCS在网上流传的代码。网上只找到了5.2.17个版本,但是对于我们这些曾经研究过代码的人来说,已经足够了。他使用的加密不是传统的 MD5 + salt 实现。加密后的数据只会出现一次,但是每个密码得到的密码都是一样的,类似于openssl的加密方式。然后是硬通货时间:
2015 年 8 月 10 日 17:13
PHP多线程的实现
在某些情况下,我们想用PHP来执行重复性的任务,但是只有一次,叠加的时候执行时间会很长,所以应该将任务分配给多个线程分别执行。但是PHP默认没有多线程,必须使用pthreadsPHP扩展,它才能真正支持和实现多线程。在处理重复的循环任务时,多线程可以大大减少程序执行时间。要使用此扩展,您必须使用线程安全版本。编译 PHP […]
2014 年 7 月 6 日 10:47
更换 Discuz 的内存缓存
最近论坛一直卡,负载经常跑到130%。正常情况下,负载达到10%,非常高。通过跟踪日志,我找不到任何重大问题。我只能暂时屏蔽爬取大量网页的ip和ua,但最终不是解决办法。最后实在看不下去了,就装了一个newrelic来跟踪问题。安装后发现问题,如图:
2014 年 5 月 6 日 18:15 查看全部
php多线程抓取多个网页(2017年7月10日16:17用PHP来加密解密Cloudflare邮箱保护Cloudflare)
WHMCS 限制每个订单的数量
默认情况下,在 whmcs 中,可以在购物车中选择无限数量的产品。虽然说可以设置产品的上限,但也可以暂时用完所有剩余的可用数量。那么后台会产生很多无用的数据,大量的订单会导致数据库出现异常,所以我们需要防止这种情况发生。
2017年7月10日16:17
使用 PHP 加解密 Cloudflare 邮箱保护
Cloudflare 有一个非常好的功能,就是对页面上所有的邮箱地址进行加密,防止机器人抓取和做坏事。对于该功能,在后台启用邮箱地址混淆后,您可以在页面中添加邮箱地址。例如,如果您查看源代码,您可以找到类似于以下的代码
2016 年 9 月 28 日 12:28
WHMCS密码加密方式
我今天无事可做,看了WHMCS在网上流传的代码。网上只找到了5.2.17个版本,但是对于我们这些曾经研究过代码的人来说,已经足够了。他使用的加密不是传统的 MD5 + salt 实现。加密后的数据只会出现一次,但是每个密码得到的密码都是一样的,类似于openssl的加密方式。然后是硬通货时间:
2015 年 8 月 10 日 17:13
PHP多线程的实现
在某些情况下,我们想用PHP来执行重复性的任务,但是只有一次,叠加的时候执行时间会很长,所以应该将任务分配给多个线程分别执行。但是PHP默认没有多线程,必须使用pthreadsPHP扩展,它才能真正支持和实现多线程。在处理重复的循环任务时,多线程可以大大减少程序执行时间。要使用此扩展,您必须使用线程安全版本。编译 PHP […]
2014 年 7 月 6 日 10:47
更换 Discuz 的内存缓存
最近论坛一直卡,负载经常跑到130%。正常情况下,负载达到10%,非常高。通过跟踪日志,我找不到任何重大问题。我只能暂时屏蔽爬取大量网页的ip和ua,但最终不是解决办法。最后实在看不下去了,就装了一个newrelic来跟踪问题。安装后发现问题,如图:
2014 年 5 月 6 日 18:15
php多线程抓取多个网页(使用线程和Selenium的简单代码示例:使用参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-14 07:02
大多数时候,我必须抓取的页面数量低于 100,因此使用 for 循环,我可以在合理的时间内解析它们。但现在我有 1000 多个网页要分析。在
在寻找实现此目标的方法时,我发现了可能有用的线程。我看过一些教程,我相信我理解一般逻辑。在
我知道如果我有 100 个网页,我可以创建 100 个线程。不建议这样做,尤其是对于大量网页。例如,我还没有真正弄清楚如何创建 5 个线程,每个线程上有 200 个网页。在
这是一个使用线程和 Selenium 的简单代码示例:
import threading
from selenium import webdriver
def parse_page(page_url):
driver = webdriver.PhantomJS()
driver.get(url)
text = driver.page_source
..........
return parsed_items
def threader():
worker = q.get()
parse_page(page_url)
q.task_one()
urls = [.......]
q = Queue()
for x in range(len(urls)):
t = threading.Thread(target=threader)
t.daemon = True
t.start()
for worker in range(20):
q.put(worker)
q.join()
我不清楚的另一件事是参数如何在线程中使用。在 查看全部
php多线程抓取多个网页(使用线程和Selenium的简单代码示例:使用参数)
大多数时候,我必须抓取的页面数量低于 100,因此使用 for 循环,我可以在合理的时间内解析它们。但现在我有 1000 多个网页要分析。在
在寻找实现此目标的方法时,我发现了可能有用的线程。我看过一些教程,我相信我理解一般逻辑。在
我知道如果我有 100 个网页,我可以创建 100 个线程。不建议这样做,尤其是对于大量网页。例如,我还没有真正弄清楚如何创建 5 个线程,每个线程上有 200 个网页。在
这是一个使用线程和 Selenium 的简单代码示例:
import threading
from selenium import webdriver
def parse_page(page_url):
driver = webdriver.PhantomJS()
driver.get(url)
text = driver.page_source
..........
return parsed_items
def threader():
worker = q.get()
parse_page(page_url)
q.task_one()
urls = [.......]
q = Queue()
for x in range(len(urls)):
t = threading.Thread(target=threader)
t.daemon = True
t.start()
for worker in range(20):
q.put(worker)
q.join()
我不清楚的另一件事是参数如何在线程中使用。在
php多线程抓取多个网页(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-05 23:03
新鲜出炉的PHP面向对象编程来了,程序狗的速度来了!
PHP开源脚本语言PHP(外文名:Hypertext Preprocessor,中文名:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。 PHP的文件扩展名为php。
本文章主要介绍PHP中foreach结合curl实现多线程的方法,分析foreach语句结合curl循环调用的原理和实现技巧,以如下形式模拟多线程例子。有需要的朋友可以参考以下
本文的例子介绍了php中foreach结合curl实现多线程的方法。分享给大家,供大家参考,如下:
php不支持多线程,但是我们可以通过foreach实现伪多线程,但是这种伪多线程的速度不一定比单线程快,我们来看一个例子。
在使用foreach语句循环图片URL并通过CURL将所有图片保存在本地时,存在一个问题,只能是采集。现将foreach与CURL结合进行多个URL请求的方法做如下总结。
方法一:循环请求
$sr=array(url_1,url_2,url_3);
foreach ($sr as $k=>$v) {
$curlPost=$v.'?f=传入参数';
$ch = curl_init($curlPost) ;
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true) ; // 获取数据返回
curl_setopt($ch, CURLOPT_BINARYTRANSFER, true) ; // 在启用 CURLOPT_RETURNTRANSFER 时候将获取数据返回
$data = curl_exec($ch) ;
echo $k.'##:'.$data.'
';
}
curl_close($ch);
上面的代码需要特别注意,curl_close必须放在foreach循环结束的外面,如果放在里面会出现我上面提到的多个IMGURL,而且只有一个URL可以是采集的问题。
方法二:多线程循环
<p> 查看全部
php多线程抓取多个网页(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
新鲜出炉的PHP面向对象编程来了,程序狗的速度来了!
PHP开源脚本语言PHP(外文名:Hypertext Preprocessor,中文名:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。 PHP的文件扩展名为php。
本文章主要介绍PHP中foreach结合curl实现多线程的方法,分析foreach语句结合curl循环调用的原理和实现技巧,以如下形式模拟多线程例子。有需要的朋友可以参考以下
本文的例子介绍了php中foreach结合curl实现多线程的方法。分享给大家,供大家参考,如下:
php不支持多线程,但是我们可以通过foreach实现伪多线程,但是这种伪多线程的速度不一定比单线程快,我们来看一个例子。
在使用foreach语句循环图片URL并通过CURL将所有图片保存在本地时,存在一个问题,只能是采集。现将foreach与CURL结合进行多个URL请求的方法做如下总结。
方法一:循环请求
$sr=array(url_1,url_2,url_3);
foreach ($sr as $k=>$v) {
$curlPost=$v.'?f=传入参数';
$ch = curl_init($curlPost) ;
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true) ; // 获取数据返回
curl_setopt($ch, CURLOPT_BINARYTRANSFER, true) ; // 在启用 CURLOPT_RETURNTRANSFER 时候将获取数据返回
$data = curl_exec($ch) ;
echo $k.'##:'.$data.'
';
}
curl_close($ch);
上面的代码需要特别注意,curl_close必须放在foreach循环结束的外面,如果放在里面会出现我上面提到的多个IMGURL,而且只有一个URL可以是采集的问题。
方法二:多线程循环
<p>
php多线程抓取多个网页(PHP支持多线程线程,有时称为轻量级进程的一个实体!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-05 23:02
我们可以通过安装 Pthread 扩展使 PHP 支持多线程。线程,有时称为轻量级进程,是程序执行的最小单位。线程是进程中的一个实体,是系统独立调度和调度的基本单元。线程本身不拥有系统资源,属于同一个
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说php Pthread多线程的基本介绍(一),希望能帮助大家提高!!!
我们可以通过安装 Pthread 扩展使 PHP 支持多线程。
线程,有时称为轻量级进程,是程序执行的最小单位。
线程是进程中的一个实体,是系统独立调度和调度的基本单元。线程本身并不拥有系统资源。它与属于同一进程的其他线程共享该进程拥有的所有资源。一个线程可以创建和取消另一个线程,同一进程中的多个线程可以并发执行。
每个程序至少有一个线程,也就是程序本身,通常称为主线程
. 线程是程序中的单个顺序控制流。在一个程序中同时运行多个线程来完成不同的工作称为多线程。
只听山间传来建筑师的声音:
与此同时,多代人在路上,通往天堂的道路是危险的,难以走的。谁将向上或向下匹配?
我们把上面的代码修改一下看看效果
此代码由Java架构师必看网-架构君整理
我们直接调用start方法而不调用join。主线程不等待,而是输出主线程。子线程在输出 Hello World 之前等待 3 秒。
示例 1 如下:
我们通过创建两个线程 a 和 b 来读取文件 test.log 的内容。(*注意,并发读写文件时,一定要加锁文件。这里给文件加排他锁。如果加了共享锁,会读取相同的数据。
)
test.log 的内容如下:
此代码由Java架构师必看网-架构君整理
111111
222222
333333
444444
555555
666666
执行结果如下:
示例 2 如下:
<p> 查看全部
php多线程抓取多个网页(PHP支持多线程线程,有时称为轻量级进程的一个实体!)
我们可以通过安装 Pthread 扩展使 PHP 支持多线程。线程,有时称为轻量级进程,是程序执行的最小单位。线程是进程中的一个实体,是系统独立调度和调度的基本单元。线程本身不拥有系统资源,属于同一个
强烈推荐IDEA2021.1.3破解激活,IntelliJ IDEA注册码,2021.1.3IDEA激活码
大家好,我是建筑师,一个会写代码,会背诗的建筑师。今天就来说说php Pthread多线程的基本介绍(一),希望能帮助大家提高!!!
我们可以通过安装 Pthread 扩展使 PHP 支持多线程。
线程,有时称为轻量级进程,是程序执行的最小单位。
线程是进程中的一个实体,是系统独立调度和调度的基本单元。线程本身并不拥有系统资源。它与属于同一进程的其他线程共享该进程拥有的所有资源。一个线程可以创建和取消另一个线程,同一进程中的多个线程可以并发执行。
每个程序至少有一个线程,也就是程序本身,通常称为主线程
. 线程是程序中的单个顺序控制流。在一个程序中同时运行多个线程来完成不同的工作称为多线程。
只听山间传来建筑师的声音:
与此同时,多代人在路上,通往天堂的道路是危险的,难以走的。谁将向上或向下匹配?
我们把上面的代码修改一下看看效果
此代码由Java架构师必看网-架构君整理
我们直接调用start方法而不调用join。主线程不等待,而是输出主线程。子线程在输出 Hello World 之前等待 3 秒。
示例 1 如下:
我们通过创建两个线程 a 和 b 来读取文件 test.log 的内容。(*注意,并发读写文件时,一定要加锁文件。这里给文件加排他锁。如果加了共享锁,会读取相同的数据。
)
test.log 的内容如下:
此代码由Java架构师必看网-架构君整理
111111
222222
333333
444444
555555
666666
执行结果如下:
示例 2 如下:
<p>
php多线程抓取多个网页(php多线程抓取多个网页!(第一步))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-01 22:02
php多线程抓取多个网页!第一步,先进入php解释器mime_trace,查看有没有显示出此操作。其实不必这么细心,因为你以为你放置了同一个文件,其实可能只是改了文件扩展名,比如mime_trace"./",但是实际上放置了文件;再比如,你,通过php注入方式传递参数,php解释器是不处理的,所以该文件抓取出来的结果也是空的。
以下举例是不同的url地址,请求该url,抓取一个地址,解析数据,php解释器会返回结果:api.php->api:location/{api_log:0;}使用php_request_set返回:php_request_set("method","method","location/{api_log:0;}")//线程一:php_request_set("method","get",true)//线程二:php_request_set("method","post",false)//线程三:php_request_set("method","put",false)//线程四:php_request_set("method","delete",false)//线程五:php_request_set("method","fetch",false)//线程六:php_request_set("method","redirect",false)然后把抓取的结果redirect起来,redirect到任何结果api.php:location/{api_log:0;}//参数更新了:参数api_log,redirect_file是同一个内容以后的更新方式api.php->api:api{api_log:api_sync("api_log");}api.php->location/{api_log:api_sync("api_log");}最后统计返回结果,统计api.php:location/{api_log:[];}//参数更新了:可以看到已经正常返回了,因为api.php->api:api,api.php->location/已经成功返回了抓取的结果,还差一个参数,参数api_log,api.php->location/的更新方式。
以下是百度首页,抓取后存储:百度首页抓取三点提示:1../页面名称抓取到请求上传地址,使用location//是地址上传,否则会报错api.php->api:api{api_log:0;}//timeout返回错误,导致读取失败api.php->location//api_log返回一个错误,意味着api无法获取成功api.php->location//如果api返回错误,下一次请求将会跳过这个api.php->location//因为这个没用了下一次请求如果返回错误,那么抓取的结果为空,所以我们使用set_location修改参数,值,让它不是当前api.php:api{api_log:api_sync("api_log");}//timeout返回错误。 查看全部
php多线程抓取多个网页(php多线程抓取多个网页!(第一步))
php多线程抓取多个网页!第一步,先进入php解释器mime_trace,查看有没有显示出此操作。其实不必这么细心,因为你以为你放置了同一个文件,其实可能只是改了文件扩展名,比如mime_trace"./",但是实际上放置了文件;再比如,你,通过php注入方式传递参数,php解释器是不处理的,所以该文件抓取出来的结果也是空的。
以下举例是不同的url地址,请求该url,抓取一个地址,解析数据,php解释器会返回结果:api.php->api:location/{api_log:0;}使用php_request_set返回:php_request_set("method","method","location/{api_log:0;}")//线程一:php_request_set("method","get",true)//线程二:php_request_set("method","post",false)//线程三:php_request_set("method","put",false)//线程四:php_request_set("method","delete",false)//线程五:php_request_set("method","fetch",false)//线程六:php_request_set("method","redirect",false)然后把抓取的结果redirect起来,redirect到任何结果api.php:location/{api_log:0;}//参数更新了:参数api_log,redirect_file是同一个内容以后的更新方式api.php->api:api{api_log:api_sync("api_log");}api.php->location/{api_log:api_sync("api_log");}最后统计返回结果,统计api.php:location/{api_log:[];}//参数更新了:可以看到已经正常返回了,因为api.php->api:api,api.php->location/已经成功返回了抓取的结果,还差一个参数,参数api_log,api.php->location/的更新方式。
以下是百度首页,抓取后存储:百度首页抓取三点提示:1../页面名称抓取到请求上传地址,使用location//是地址上传,否则会报错api.php->api:api{api_log:0;}//timeout返回错误,导致读取失败api.php->location//api_log返回一个错误,意味着api无法获取成功api.php->location//如果api返回错误,下一次请求将会跳过这个api.php->location//因为这个没用了下一次请求如果返回错误,那么抓取的结果为空,所以我们使用set_location修改参数,值,让它不是当前api.php:api{api_log:api_sync("api_log");}//timeout返回错误。
php多线程抓取多个网页( PHPCurlFunctions例子(一)-上海怡健医学)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-26 18:06
PHPCurlFunctions例子(一)-上海怡健医学)
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。 查看全部
php多线程抓取多个网页(
PHPCurlFunctions例子(一)-上海怡健医学)
PHP结合curl实现多线程爬取
让我们再看几个例子
(1)下面的代码是爬取多个URL,然后将爬取到的URL的页面代码写入到指定文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
); // 设置要抓取的页面URL
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i], CURLOPT_FILE,$st); // 将爬取的代码写入文件
curl_multi_add_handle ($mh,$conn[$i]);
} // 初始化
do {
curl_multi_exec($mh,$active);
} while ($active); // 执行
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
} // 结束清理
curl_multi_close($mh);
fclose($st);
(2)下面的代码和上面类似,只不过这个地方是先把获取到的代码放到一个变量中,然后再将获取到的内容写入到指定的文件中
$urls = array(
'http://www.uoften.com/',
'http://www.google.com/',
'http://www.example.com/'
);
$save_to='/test.txt'; // 把抓取的代码写入该文件
$st = fopen($save_to,"a");
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_USERAGENT, "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i], CURLOPT_HEADER ,0);
curl_setopt($conn[$i], CURLOPT_CONNECTTIMEOUT,60);
curl_setopt($conn[$i],CURLOPT_RETURNTRANSFER,true); // 不将爬取代码写到浏览器,而是转化为字符串
curl_multi_add_handle ($mh,$conn[$i]);
}
do {
curl_multi_exec($mh,$active);
} while ($active);
foreach ($urls as $i => $url) {
$data = curl_multi_getcontent($conn[$i]); // 获得爬取的代码字符串
fwrite($st,$data); // 将字符串写入文件
} // 获得数据变量,并写入文件
foreach ($urls as $i => $url) {
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
}
curl_multi_close($mh);
fclose($st);
(3)以下代码实现使用PHP的Curl Functions实现并发多线程下载文件
$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);$urls=array(
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip',
'http://www.uoften.com/5w.zip'
);
$save_to='./home/';
$mh=curl_multi_init();
foreach($urls as $i=>$url){
$g=$save_to.basename($url);
if(!is_file($g)){
$conn[$i]=curl_init($url);
$fp[$i]=fopen($g,"w");
curl_setopt($conn[$i],CURLOPT_USERAGENT,"Mozilla/4.0(compatible; MSIE 7.0; Windows NT 6.0)");
curl_setopt($conn[$i],CURLOPT_FILE,$fp[$i]);
curl_setopt($conn[$i],CURLOPT_HEADER ,0);
curl_setopt($conn[$i],CURLOPT_CONNECTTIMEOUT,60);
curl_multi_add_handle($mh,$conn[$i]);
}
}
do{
$n=curl_multi_exec($mh,$active);
}while($active);
foreach($urls as $i=>$url){
curl_multi_remove_handle($mh,$conn[$i]);
curl_close($conn[$i]);
fclose($fp[$i]);
}
curl_multi_close($mh);
以上就是本文的全部内容,希望大家喜欢。
php多线程抓取多个网页(php7的优势和特点php各个版本的区别.2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-22 19:24
php7的优点和特点php各个版本的区别
PHP5.2 before:自动加载,PDO 和 MySQLi,类型约束 PHP5.2:JSON 支持 PHP5.3:不推荐使用的函数,匿名函数,新的魔法方法,命名空间,后期静态绑定, Heredoc 和 Nowdoc, const, 三元运算符, Phar PHP5.4: Short Open Tag, 数组速记, Traits, 内置web server, 细节修改 PHP5.5: yield, list() is用于foreach,细节修改 PHP5.6:常量增强,可变函数参数,命名空间增强 php7:改动太多,总之,性能提升不少。
php接口,抽象类但不是如何在php中实现多线程
pthread扩展可以支持真正的多线程,但是很多问题不推荐。还有一些多线程变向的使用方法:比如通过fsockopen开启一个新的请求等,这种方法只能解决一些简单的问题,不推荐。业务复杂后,很难控制。考虑像 swoole 和 workerman 这样的多进程模型。
如何提高php的执行效率
从客观的角度来看,这是一个大大小小的话题
使用哪些数据库
常用mysql、sqlite、MongoDB、redis。
mysql引擎有什么特点和区别
主要使用:
数据量过大怎么办
这也是一个可大可小的话题。从数据库的角度来看:结合业务进行拆分、分区、分库、分布式数据库、分布式事务的问题从web的角度来看:负载均衡(7层和4层)缓存。
如何优化sql索引的类型及使用场景联合索引的优缺点
mongodb是真正的数据库,适合mysql比赛;而redis缓存数据库,不同的东西根据不同的特点选择应用。
lnmp 的工作原理
首先浏览器向服务器(Nginx)发送http请求,服务器响应并处理web请求,在服务器上保存一些静态资源(CSS、图片、视频等),然后通过接口传输协议(网关协议) PHP-FCGI(fast-cgi)传输到PHP-FPM(进程管理程序),PHP-FPM不处理,然后PHP-FPM调用PHP解析器进程,PHP解析器解析php 脚本信息。可以启动多个 PHP 解析器进程以进行并发执行。然后将解析后的脚本返回给PHP-FPM,PHP-FPM将脚本信息以fast-cgi的形式传给Nginx。服务器以 Http 响应的形式传输给浏览器。浏览器然后解析和呈现然后呈现。
熟悉的框架有什么区别和优势
应用了哪些设计模式以及如何实现它们。
详细描述排序算法的时间复杂度和空间复杂度 *插入气泡选择。
Time O(n2) Space O(1)nginx如何实现负载均衡?
上游的配置和原理比较多,简单来说就是轮换训练、权重等等。
描述一下以前项目中使用的架构,有什么优势?
小项目 ci 简单快速 大项目 yii2 phalcon laravel 结构清晰,解耦度更高。
给app提供一个接口,如何保证稳定性和响应速度。
谈谈你做过的一个你认为技术含量最高的项目,以及应用了哪些技术。
这个问题真的很难说,写一个php扩展算不算?其实,能解决实际问题的都是好事,都代表着你的成功。做应用开发,技术含量很难衡量,因为很低。上学的时候,编译原理里面的所有算法都是用C语言写的。我认为这比我现在所做的更具技术性。现在被多次使用。技术含量的考验应该是如何发现问题,然后如何解决问题。毕竟,我们不是从事科学研究的。
了解其他开发语言并做过项目吗?
java、python、wpf。
redis中存储了哪些类型的数据,分别用在了哪些场景中? 查看全部
php多线程抓取多个网页(php7的优势和特点php各个版本的区别.2)
php7的优点和特点php各个版本的区别
PHP5.2 before:自动加载,PDO 和 MySQLi,类型约束 PHP5.2:JSON 支持 PHP5.3:不推荐使用的函数,匿名函数,新的魔法方法,命名空间,后期静态绑定, Heredoc 和 Nowdoc, const, 三元运算符, Phar PHP5.4: Short Open Tag, 数组速记, Traits, 内置web server, 细节修改 PHP5.5: yield, list() is用于foreach,细节修改 PHP5.6:常量增强,可变函数参数,命名空间增强 php7:改动太多,总之,性能提升不少。
php接口,抽象类但不是如何在php中实现多线程
pthread扩展可以支持真正的多线程,但是很多问题不推荐。还有一些多线程变向的使用方法:比如通过fsockopen开启一个新的请求等,这种方法只能解决一些简单的问题,不推荐。业务复杂后,很难控制。考虑像 swoole 和 workerman 这样的多进程模型。
如何提高php的执行效率
从客观的角度来看,这是一个大大小小的话题
使用哪些数据库
常用mysql、sqlite、MongoDB、redis。
mysql引擎有什么特点和区别
主要使用:
数据量过大怎么办
这也是一个可大可小的话题。从数据库的角度来看:结合业务进行拆分、分区、分库、分布式数据库、分布式事务的问题从web的角度来看:负载均衡(7层和4层)缓存。
如何优化sql索引的类型及使用场景联合索引的优缺点
mongodb是真正的数据库,适合mysql比赛;而redis缓存数据库,不同的东西根据不同的特点选择应用。
lnmp 的工作原理
首先浏览器向服务器(Nginx)发送http请求,服务器响应并处理web请求,在服务器上保存一些静态资源(CSS、图片、视频等),然后通过接口传输协议(网关协议) PHP-FCGI(fast-cgi)传输到PHP-FPM(进程管理程序),PHP-FPM不处理,然后PHP-FPM调用PHP解析器进程,PHP解析器解析php 脚本信息。可以启动多个 PHP 解析器进程以进行并发执行。然后将解析后的脚本返回给PHP-FPM,PHP-FPM将脚本信息以fast-cgi的形式传给Nginx。服务器以 Http 响应的形式传输给浏览器。浏览器然后解析和呈现然后呈现。
熟悉的框架有什么区别和优势
应用了哪些设计模式以及如何实现它们。
详细描述排序算法的时间复杂度和空间复杂度 *插入气泡选择。
Time O(n2) Space O(1)nginx如何实现负载均衡?
上游的配置和原理比较多,简单来说就是轮换训练、权重等等。
描述一下以前项目中使用的架构,有什么优势?
小项目 ci 简单快速 大项目 yii2 phalcon laravel 结构清晰,解耦度更高。
给app提供一个接口,如何保证稳定性和响应速度。
谈谈你做过的一个你认为技术含量最高的项目,以及应用了哪些技术。
这个问题真的很难说,写一个php扩展算不算?其实,能解决实际问题的都是好事,都代表着你的成功。做应用开发,技术含量很难衡量,因为很低。上学的时候,编译原理里面的所有算法都是用C语言写的。我认为这比我现在所做的更具技术性。现在被多次使用。技术含量的考验应该是如何发现问题,然后如何解决问题。毕竟,我们不是从事科学研究的。
了解其他开发语言并做过项目吗?
java、python、wpf。
redis中存储了哪些类型的数据,分别用在了哪些场景中?
php多线程抓取多个网页(php多线程抓取多个网页的方法是直接使用php代码去抓取的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-21 02:06
<p>php多线程抓取多个网页的方法是直接使用php代码去抓取的,这样很容易造成代码冲突,代码不统一,但其实很简单,只需要注意以下几点就可以了。在正式开始之前,我们需要添加下面的代码varfile="/private/phpwind/phpwind";varphp=newphpwind();varparam=['php','path','/'];file.open(param,'r');varself=file.get();file.send(self);varresult=self.get('php\n?file=/');print(result);测试页面接下来,我们在网页中随意地输入一些代码,测试下输出的结果:打印出来的结果如下: 查看全部
php多线程抓取多个网页(php多线程抓取多个网页的方法是直接使用php代码去抓取的)
<p>php多线程抓取多个网页的方法是直接使用php代码去抓取的,这样很容易造成代码冲突,代码不统一,但其实很简单,只需要注意以下几点就可以了。在正式开始之前,我们需要添加下面的代码varfile="/private/phpwind/phpwind";varphp=newphpwind();varparam=['php','path','/'];file.open(param,'r');varself=file.get();file.send(self);varresult=self.get('php\n?file=/');print(result);测试页面接下来,我们在网页中随意地输入一些代码,测试下输出的结果:打印出来的结果如下:
php多线程抓取多个网页(php多线程抓取多个网页,后台放好待抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-14 10:02
php多线程抓取多个网页,后台放好待抓取所有网页的txt文件,加入要抓取的网页的idphp进程放在内存中,系统启动后在命令行启动进程ngx_util。php如果一个页面加入了多个待抓取的txt文件,加入多个php进程这里加入多个php进程就是加入多个php文件抓取后页面用txt文件渲染每个页面文件php程序之间不存在竞争php通过多进程部署到多个主机,通过网关访问不同主机php的多线程抓取、tpl_util。
php和ngx_util。php的一对多关系如何从互联网抓取多个网页的txt文件php多线程抓取多个网页的txt文件,和php的多进程关系多线程抓取多个页面文件,和ngx_util。php__php___a_b_c_d多个页面文件php文件txt文件,每个页面文件用txt文件打包压缩(压缩方式是分块压缩)网关在命令行启动启动一个php进程ngx_util。
php访问ngx_util。php文件,进程定位到具体页面进程启动后通过抓包,抓取到页面数据,下载下来放到待抓取网页的txt文件txt文件php所有线程同时执行抓取多个页面文件时,每个进程因为有多个页面数据线程上数据线程一个进程抓取一个页面时,抓取的页面到一个php进程,再到其他进程php进程使用cgi格式的程序、服务器端java访问php进程httpbinlib程序java程序从txt文件抓取数据会走httpbinlib程序模拟用户访问phpurl,txt文件对应的url就是下载下来的数据,转存存储成为php访问的urlhttpbinlib的代码示例cgi程序从页面数据load()中读取一个url地址(url中含有数据),并转存到txt文件中,该url对应的url格式为:(url,value)---数据_数据,类似socket套接字php访问php。
io/1,页面中就包含一个txt文件将所有页面转存到txt文件中,获取url地址()函数:调用tcp_value()获取flag()传输txt文件传输后的txt文件放到txt_raw_txt文件中txt_raw_txt文件就是一个文件,由两个文件组成第一个url(t+)是txt_raw_txt文件路径echo'{{t+}}'|echo'flag'用java写出同样格式的cgi程序后缀名:cgi。
javanginx读取nginx配置、expires,epoll等数据,将url地址发送给tp进程nginx进程去下载页面数据,将txt文件放到expires表中,并传给tp,tp去抓取数据expires表中:1月份;nginx进程将页面数据从expires字段中取出来nginx需要去gzip或者压缩开源:wget,pandownloadcgi程序启动后nginx会从e。 查看全部
php多线程抓取多个网页(php多线程抓取多个网页,后台放好待抓取)
php多线程抓取多个网页,后台放好待抓取所有网页的txt文件,加入要抓取的网页的idphp进程放在内存中,系统启动后在命令行启动进程ngx_util。php如果一个页面加入了多个待抓取的txt文件,加入多个php进程这里加入多个php进程就是加入多个php文件抓取后页面用txt文件渲染每个页面文件php程序之间不存在竞争php通过多进程部署到多个主机,通过网关访问不同主机php的多线程抓取、tpl_util。
php和ngx_util。php的一对多关系如何从互联网抓取多个网页的txt文件php多线程抓取多个网页的txt文件,和php的多进程关系多线程抓取多个页面文件,和ngx_util。php__php___a_b_c_d多个页面文件php文件txt文件,每个页面文件用txt文件打包压缩(压缩方式是分块压缩)网关在命令行启动启动一个php进程ngx_util。
php访问ngx_util。php文件,进程定位到具体页面进程启动后通过抓包,抓取到页面数据,下载下来放到待抓取网页的txt文件txt文件php所有线程同时执行抓取多个页面文件时,每个进程因为有多个页面数据线程上数据线程一个进程抓取一个页面时,抓取的页面到一个php进程,再到其他进程php进程使用cgi格式的程序、服务器端java访问php进程httpbinlib程序java程序从txt文件抓取数据会走httpbinlib程序模拟用户访问phpurl,txt文件对应的url就是下载下来的数据,转存存储成为php访问的urlhttpbinlib的代码示例cgi程序从页面数据load()中读取一个url地址(url中含有数据),并转存到txt文件中,该url对应的url格式为:(url,value)---数据_数据,类似socket套接字php访问php。
io/1,页面中就包含一个txt文件将所有页面转存到txt文件中,获取url地址()函数:调用tcp_value()获取flag()传输txt文件传输后的txt文件放到txt_raw_txt文件中txt_raw_txt文件就是一个文件,由两个文件组成第一个url(t+)是txt_raw_txt文件路径echo'{{t+}}'|echo'flag'用java写出同样格式的cgi程序后缀名:cgi。
javanginx读取nginx配置、expires,epoll等数据,将url地址发送给tp进程nginx进程去下载页面数据,将txt文件放到expires表中,并传给tp,tp去抓取数据expires表中:1月份;nginx进程将页面数据从expires字段中取出来nginx需要去gzip或者压缩开源:wget,pandownloadcgi程序启动后nginx会从e。
php多线程抓取多个网页(2021-07-29介绍大家好!(上)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-14 07:19
2021-07-29介绍
大家好!回顾上一期,在介绍了爬虫的基本概念之后,我们用各种工具横冲直撞完成了一个小爬虫。目的是猛、粗、快,方便初学者上手,建立信心。有一定基础的读者请不要着急,未来我们会学习主流开源框架,打造强大专业的爬虫系统!但在此之前,我们必须继续打好基础。本期我们将首先介绍爬虫的类型,然后选择最典型的通用网络爬虫为其设计一个迷你框架。对框架有了自己的思考之后,在学习复杂的开源框架时,就会有一个线索。
今天,我们将花更多时间思考,而不是编码。80%的时间思考,20%的时间打字,更有利于进步。
语言环境
语言:带上足够的弹药,继续用Python开路!
线程:线程库可以在单独的线程中执行 Python 中可调用的任何对象。Python 2.x 中的线程模块已被弃用,用户可以改用线程模块。在 Python 3 中不能再使用 thread 模块。为了兼容性,Python 3 将 thread 重命名为 _thread。
队列:队列模块提供同步的、线程安全的队列类,包括FIFO(先进先出)队列Queue、LIFO(后进先出)队列LifoQueue和优先级队列PriorityQueue。这些队列都实现了锁定原语,可以直接在多个线程中使用。队列可用于实现线程之间的同步。
re:Python 从 1.5 开始添加了 re 模块,它提供了 Perl 风格的正则表达式模式。re 模块为 Python 语言带来了完整的正则表达式功能。
argparse:Python 用于解析命令行参数和选项的标准模块,替换了过时的 optparse 模块。argparse 模块的作用是解析命令行参数。
configparser:读取配置文件的模块。
爬行动物的种类
网络爬虫根据系统结构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
通用网络爬虫
通用网络爬虫,也称为Scalable Web Crawler,将爬取对象从一些种子URL扩展到整个Web。主要针对门户网站搜索引擎和大型网络服务商采集数据。
一般网络爬虫的结构大致可以分为几个部分:页面爬取模块、页面分析模块、链接过滤模块、页面存储模块、URL队列、初始URL采集。为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有:深度优先策略、广度优先策略。
1) 深度优先策略(DFS):基本方法是按照深度从低到高的顺序访问下一级的网页链接,直到不能再深入为止。
2) 广度优先策略(BFS):该策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫深入到下一个级别继续爬取。
聚焦网络爬虫
Focused Crawler,也称为Topical Crawler,是指选择性爬取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。域信息需求。我们之前爬过的播放列表属于这一类。
增量网络爬虫
增量网络爬虫(Incremental Web Crawler)是指增量更新下载的网页,只爬取新生成或更改的网页的爬虫。可能是新页面。与周期性爬取和刷新页面的网络爬虫相比,增量爬虫只在需要的时候爬取新生成或更新的页面,不会重新下载没有变化的页面,可以有效减少数据下载量,对爬取的网页进行更新页,减少时间和空间消耗,但增加了爬取算法的复杂度和实现难度。现在流行的舆情爬虫一般都是增量网络爬虫。
深度网络爬虫
网页按存在方式可分为表层网页(Surface Web)和深层网页(Deep Web,又称隐形网页或隐藏网页)。表面网页是指可以被传统搜索引擎检索到的页面,以及主要由可以通过超链接到达的静态网页组成的网页。深网是那些通过静态链接大多不可用的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。例如,那些内容只有在用户注册后才可见的网页属于深网。
一个迷你框架
下面以一个典型的通用爬虫为例,分析其工程要点,设计并实现一个mini框架。架构图如下:
代码结构:
config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url 队列,url 表
urls.txt 种子 url 集合
pages_parse.py 网页分析
pages_save.py 网页保存
查看配置文件中的内容:
蜘蛛.conf
步骤 1.BFS 还是 DFS?
理论上,这两种算法都可以在大致相同的时间内爬取整个互联网。但显然每个网站最重要的页面应该是它的主页。在极端情况下,如果只能下载非常有限的页面,那么应该下载网站的所有主页。如果爬虫展开,应该爬到首页直接链接的页面,因为这些页面是网站设计者认为相当重要的网页。在这个前提下,显然 BFS 明显优于 DFS。事实上,在搜索引擎的爬虫中,主要使用的是BFS。我们的框架采用了这种策略。
爬取深度可以通过配置文件中的max_depth来设置。只要未达到指定的深度,程序就会不断将解析后的 url 放入队列中:
迷你蜘蛛.py
步骤 2. 初始 URL 采集,URL 队列
让我们看看通用爬虫如何下载整个互联网。假设从一个门户网站的首页开始,首先下载这个网页(depth=0),然后通过分析这个网页,可以找到页面中的所有超链接,也就是说你知道这个入口网站所有直接连接到首页的网页,如京东金融、京东白条、京东众筹等(深度=1)。接下来访问、下载和分析京东金融等网页,并且可以找到其他连接的页面网页(深度=2)。让电脑继续做,整个网站都可以下载了。
在这个过程中,我们需要一个“初始 URL 集合”来保存门户的主页,以及一个“URL 队列”来保存通过分析网页获得的超链接。
迷你蜘蛛.py
url_table.py
步骤3.在小本子——URL表中记录下载了哪些网页。
在互联网上,一个网页可能被多个网页中的超链接指向。这样,在遍历互联网的这张图片时,这个网页可能会被访问很多次。为了防止一个网页被多次下载和解析,需要一个URL表来记录哪些网页被下载了。当我们再次遇到这个页面时,我们可以跳过它。
crawl_thread.py
步骤 4. 多个抓取线程
为了提高爬虫的性能,需要多个爬取线程从URL队列中获取链接进行处理。多线程并没有错,但是Python的多线程可能会引起很多人的质疑,这源于Python设计的最初考虑:GIL。GIL的全称是Global Interpreter Lock(全局解释器锁)。如果一个线程要执行,首先要获得 GIL,而在一个 Python 进程中,只有一个 GIL。结果是Python中的一个进程每次只能执行一个线程,这就是Python的多线程效率在多核CPU上不高的原因。那么为什么我们仍然使用 Python 多线程呢?
CPU密集型代码(各种循环处理、编解码器等),在这种情况下,由于计算工作量很大,tick count很快就会达到阈值,然后触发GIL的释放和重新竞争(多个线程来回切换当然需要消耗资源),Python下的多线程对CPU密集型代码不友好。
IO密集型代码(文件处理、网络爬虫等),多线程可以有效提高效率(单线程下的IO操作会进行IO等待,造成不必要的时间浪费,启用多线程可以自动等待线程A当线程A等待时,切换到线程B不会浪费CPU资源,从而提高程序执行效率)。Python的多线程对IO密集型代码更加友好。
所以,对于IO密集型爬虫程序来说,使用Python多线程是没有问题的。
crawl_thread.py
步骤5.页面分析模块
从网页解析 URL 或其他有用数据。这是上一期的重点,可以参考之前的代码。
步骤6.页面存储模块
保存页面的模块,目前将文件保存为文件,未来可以扩展成多种存储方式,如mysql、mongodb、hbase等。
网页保存.py
至此,整个框架已经清晰的呈现在大家面前。不要低估它。无论框架多么复杂,它都在这些基本元素上进行了扩展。
下一步
基础知识的学习暂时告一段落,希望能帮助大家打下一定的基础。下一期我会介绍强大成熟的爬虫框架Scrapy,它提供了很多强大的功能让爬取更简单、更高效、更精彩,敬请期待!
最后觉得有帮助的朋友可以加入学习交流群
沉迷Python,无法自拔:862672474 查看全部
php多线程抓取多个网页(2021-07-29介绍大家好!(上)(图))
2021-07-29介绍
大家好!回顾上一期,在介绍了爬虫的基本概念之后,我们用各种工具横冲直撞完成了一个小爬虫。目的是猛、粗、快,方便初学者上手,建立信心。有一定基础的读者请不要着急,未来我们会学习主流开源框架,打造强大专业的爬虫系统!但在此之前,我们必须继续打好基础。本期我们将首先介绍爬虫的类型,然后选择最典型的通用网络爬虫为其设计一个迷你框架。对框架有了自己的思考之后,在学习复杂的开源框架时,就会有一个线索。
今天,我们将花更多时间思考,而不是编码。80%的时间思考,20%的时间打字,更有利于进步。
语言环境
语言:带上足够的弹药,继续用Python开路!
线程:线程库可以在单独的线程中执行 Python 中可调用的任何对象。Python 2.x 中的线程模块已被弃用,用户可以改用线程模块。在 Python 3 中不能再使用 thread 模块。为了兼容性,Python 3 将 thread 重命名为 _thread。
队列:队列模块提供同步的、线程安全的队列类,包括FIFO(先进先出)队列Queue、LIFO(后进先出)队列LifoQueue和优先级队列PriorityQueue。这些队列都实现了锁定原语,可以直接在多个线程中使用。队列可用于实现线程之间的同步。
re:Python 从 1.5 开始添加了 re 模块,它提供了 Perl 风格的正则表达式模式。re 模块为 Python 语言带来了完整的正则表达式功能。
argparse:Python 用于解析命令行参数和选项的标准模块,替换了过时的 optparse 模块。argparse 模块的作用是解析命令行参数。
configparser:读取配置文件的模块。
爬行动物的种类
网络爬虫根据系统结构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
通用网络爬虫
通用网络爬虫,也称为Scalable Web Crawler,将爬取对象从一些种子URL扩展到整个Web。主要针对门户网站搜索引擎和大型网络服务商采集数据。
一般网络爬虫的结构大致可以分为几个部分:页面爬取模块、页面分析模块、链接过滤模块、页面存储模块、URL队列、初始URL采集。为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略有:深度优先策略、广度优先策略。
1) 深度优先策略(DFS):基本方法是按照深度从低到高的顺序访问下一级的网页链接,直到不能再深入为止。
2) 广度优先策略(BFS):该策略根据网页内容目录层次的深度对页面进行爬取,较浅的目录层次的页面先爬取。当同一级别的页面被爬取时,爬虫深入到下一个级别继续爬取。
聚焦网络爬虫
Focused Crawler,也称为Topical Crawler,是指选择性爬取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要抓取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。域信息需求。我们之前爬过的播放列表属于这一类。
增量网络爬虫
增量网络爬虫(Incremental Web Crawler)是指增量更新下载的网页,只爬取新生成或更改的网页的爬虫。可能是新页面。与周期性爬取和刷新页面的网络爬虫相比,增量爬虫只在需要的时候爬取新生成或更新的页面,不会重新下载没有变化的页面,可以有效减少数据下载量,对爬取的网页进行更新页,减少时间和空间消耗,但增加了爬取算法的复杂度和实现难度。现在流行的舆情爬虫一般都是增量网络爬虫。
深度网络爬虫
网页按存在方式可分为表层网页(Surface Web)和深层网页(Deep Web,又称隐形网页或隐藏网页)。表面网页是指可以被传统搜索引擎检索到的页面,以及主要由可以通过超链接到达的静态网页组成的网页。深网是那些通过静态链接大多不可用的网页,隐藏在搜索表单后面,只有提交一些 关键词 的用户才能访问。例如,那些内容只有在用户注册后才可见的网页属于深网。
一个迷你框架
下面以一个典型的通用爬虫为例,分析其工程要点,设计并实现一个mini框架。架构图如下:
代码结构:
config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url 队列,url 表
urls.txt 种子 url 集合
pages_parse.py 网页分析
pages_save.py 网页保存
查看配置文件中的内容:
蜘蛛.conf
步骤 1.BFS 还是 DFS?
理论上,这两种算法都可以在大致相同的时间内爬取整个互联网。但显然每个网站最重要的页面应该是它的主页。在极端情况下,如果只能下载非常有限的页面,那么应该下载网站的所有主页。如果爬虫展开,应该爬到首页直接链接的页面,因为这些页面是网站设计者认为相当重要的网页。在这个前提下,显然 BFS 明显优于 DFS。事实上,在搜索引擎的爬虫中,主要使用的是BFS。我们的框架采用了这种策略。
爬取深度可以通过配置文件中的max_depth来设置。只要未达到指定的深度,程序就会不断将解析后的 url 放入队列中:
迷你蜘蛛.py
步骤 2. 初始 URL 采集,URL 队列
让我们看看通用爬虫如何下载整个互联网。假设从一个门户网站的首页开始,首先下载这个网页(depth=0),然后通过分析这个网页,可以找到页面中的所有超链接,也就是说你知道这个入口网站所有直接连接到首页的网页,如京东金融、京东白条、京东众筹等(深度=1)。接下来访问、下载和分析京东金融等网页,并且可以找到其他连接的页面网页(深度=2)。让电脑继续做,整个网站都可以下载了。
在这个过程中,我们需要一个“初始 URL 集合”来保存门户的主页,以及一个“URL 队列”来保存通过分析网页获得的超链接。
迷你蜘蛛.py
url_table.py
步骤3.在小本子——URL表中记录下载了哪些网页。
在互联网上,一个网页可能被多个网页中的超链接指向。这样,在遍历互联网的这张图片时,这个网页可能会被访问很多次。为了防止一个网页被多次下载和解析,需要一个URL表来记录哪些网页被下载了。当我们再次遇到这个页面时,我们可以跳过它。
crawl_thread.py
步骤 4. 多个抓取线程
为了提高爬虫的性能,需要多个爬取线程从URL队列中获取链接进行处理。多线程并没有错,但是Python的多线程可能会引起很多人的质疑,这源于Python设计的最初考虑:GIL。GIL的全称是Global Interpreter Lock(全局解释器锁)。如果一个线程要执行,首先要获得 GIL,而在一个 Python 进程中,只有一个 GIL。结果是Python中的一个进程每次只能执行一个线程,这就是Python的多线程效率在多核CPU上不高的原因。那么为什么我们仍然使用 Python 多线程呢?
CPU密集型代码(各种循环处理、编解码器等),在这种情况下,由于计算工作量很大,tick count很快就会达到阈值,然后触发GIL的释放和重新竞争(多个线程来回切换当然需要消耗资源),Python下的多线程对CPU密集型代码不友好。
IO密集型代码(文件处理、网络爬虫等),多线程可以有效提高效率(单线程下的IO操作会进行IO等待,造成不必要的时间浪费,启用多线程可以自动等待线程A当线程A等待时,切换到线程B不会浪费CPU资源,从而提高程序执行效率)。Python的多线程对IO密集型代码更加友好。
所以,对于IO密集型爬虫程序来说,使用Python多线程是没有问题的。
crawl_thread.py
步骤5.页面分析模块
从网页解析 URL 或其他有用数据。这是上一期的重点,可以参考之前的代码。
步骤6.页面存储模块
保存页面的模块,目前将文件保存为文件,未来可以扩展成多种存储方式,如mysql、mongodb、hbase等。
网页保存.py
至此,整个框架已经清晰的呈现在大家面前。不要低估它。无论框架多么复杂,它都在这些基本元素上进行了扩展。
下一步
基础知识的学习暂时告一段落,希望能帮助大家打下一定的基础。下一期我会介绍强大成熟的爬虫框架Scrapy,它提供了很多强大的功能让爬取更简单、更高效、更精彩,敬请期待!
最后觉得有帮助的朋友可以加入学习交流群
沉迷Python,无法自拔:862672474
php多线程抓取多个网页(Python处理网页相关的工具+BeautifulSoup抓取Goolge搜索链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-11 03:24
)
1)urllib2+BeautifulSoup 抓取 Goolge 搜索链接
最近参与的项目需要处理谷歌搜索结果,之前学过Python处理web相关的工具。在实际应用中,使用urllib2和beautifulsoup来爬取网页,但是在爬取google搜索结果的时候,发现如果直接处理google搜索结果页面的源码,会得到很多“脏”链接。
请看下图“泰坦尼克号詹姆斯”的搜索结果:
图中红色标注的是不需要的,蓝色标注的是需要抓取的。
当然,这个“脏链接”可以通过规则过滤来过滤掉,但是程序的复杂度很高。就在我皱着眉头写过滤规则的时候。同学们提醒谷歌应该提供相关的API,这才恍然大悟。
(2)Google 网页搜索 API + 多线程
该文档提供了一个在 Python 中搜索的示例:
在实际应用中,可能需要爬取google的很多网页,所以需要使用多个线程来分担爬取任务。有关使用 google web search api 的详细参考,请参见此处(此处介绍了标准 URL 参数)。另外要特别注意url中的参数rsz必须为8(包括8)下面的值,如果大于8会报错!
(3)代码实现
代码实现还是有问题,但是可以运行,健壮性差,需要改进。希望各界大神指出错误(初学Python),不胜感激。
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/ajax/services/search/web'
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join() 查看全部
php多线程抓取多个网页(Python处理网页相关的工具+BeautifulSoup抓取Goolge搜索链接
)
1)urllib2+BeautifulSoup 抓取 Goolge 搜索链接
最近参与的项目需要处理谷歌搜索结果,之前学过Python处理web相关的工具。在实际应用中,使用urllib2和beautifulsoup来爬取网页,但是在爬取google搜索结果的时候,发现如果直接处理google搜索结果页面的源码,会得到很多“脏”链接。
请看下图“泰坦尼克号詹姆斯”的搜索结果:
图中红色标注的是不需要的,蓝色标注的是需要抓取的。
当然,这个“脏链接”可以通过规则过滤来过滤掉,但是程序的复杂度很高。就在我皱着眉头写过滤规则的时候。同学们提醒谷歌应该提供相关的API,这才恍然大悟。
(2)Google 网页搜索 API + 多线程
该文档提供了一个在 Python 中搜索的示例:
在实际应用中,可能需要爬取google的很多网页,所以需要使用多个线程来分担爬取任务。有关使用 google web search api 的详细参考,请参见此处(此处介绍了标准 URL 参数)。另外要特别注意url中的参数rsz必须为8(包括8)下面的值,如果大于8会报错!
(3)代码实现
代码实现还是有问题,但是可以运行,健壮性差,需要改进。希望各界大神指出错误(初学Python),不胜感激。
#-*-coding:utf-8-*-
import urllib2,urllib
import simplejson
import os, time,threading
import common, html_filter
#input the keywords
keywords = raw_input('Enter the keywords: ')
#define rnum_perpage, pages
rnum_perpage=8
pages=8
#定义线程函数
def thread_scratch(url, rnum_perpage, page):
url_set = []
try:
request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'})
response = urllib2.urlopen(request)
# Process the JSON string.
results = simplejson.load(response)
info = results['responseData']['results']
except Exception,e:
print 'error occured'
print e
else:
for minfo in info:
url_set.append(minfo['url'])
print minfo['url']
#处理链接
i = 0
for u in url_set:
try:
request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'})
request_url.add_header(
'User-agent',
'CSC'
)
response_data = urllib2.urlopen(request_url).read()
#过滤文件
#content_data = html_filter.filter_tags(response_data)
#写入文件
filenum = i+page
filename = dir_name+'/related_html_'+str(filenum)
print ' write start: related_html_'+str(filenum)
f = open(filename, 'w+', -1)
f.write(response_data)
#print content_data
f.close()
print ' write down: related_html_'+str(filenum)
except Exception, e:
print 'error occured 2'
print e
i = i+1
return
#创建文件夹
dir_name = 'related_html_'+urllib.quote(keywords)
if os.path.exists(dir_name):
print 'exists file'
common.delete_dir_or_file(dir_name)
os.makedirs(dir_name)
#抓取网页
print 'start to scratch web pages:'
for x in range(pages):
print "page:%s"%(x+1)
page = x * rnum_perpage
url = ('https://ajax.googleapis.com/ajax/services/search/web'
'?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page)
print url
t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page))
t.start()
#主线程等待子线程抓取完
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join()
php多线程抓取多个网页(php爱好者用Latin-1字符集编码,下载起来就比较困难)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-08 03:07
很多网站看电影的人都是m3u8,但是下载起来比较困难。当我们看到自己喜欢想下载的视频资源时,就可以使用这款多线程m3u8下载器,该软件可以帮助用户轻松下载m3u8视频,操作非常简单,输入地址即可,它收录以下功能自动解密,非常强大。下载完成后,还可以进行转换等操作。
软件说明
1.M3U8也是M3U的一种,但它的编码格式是UTF-8格式。M3U 使用 Latin-1 字符集编码。
2.M3U 是歌曲的目录信息。下载.FLAC无损格式的音频时,会附带一个M3U目录文件。
3.程序下载 M3U8 清单并将其转换为 MP4。
4.可以配置要加载的线程数。
软件功能
使用Aria2作为下载引擎,避免网络波动导致下载卡顿
允许插件接管一些步骤以兼容不同的加密处理
提供丰富的定制选项
针对本地缓存进行了优化,可快速合并网页缓存
软件亮点
1.灵活且易于使用。
2.绿色紧凑,性能实用。
3.支持获取真实下载链接。
4.可以转码m3u8格式。
5.可以快速解析m3u8视频的播放地址。
软件评估
该软件是一款功能强大的视频下载工具。下载M3u8视频后,可以转换成Mp4格式的视频进行播放,非常方便;
软件支持多线程、自动解密、自定义请求等功能,用户还可以设置User-Agent和Cookies;
该软件可以同时执行多个任务,没有任何限制。线程数只控制该ts的下载线程数。
以上就是php爱好者小编今天带来的多线程m3u8下载器。更多软件下载可供 php 爱好者使用。 查看全部
php多线程抓取多个网页(php爱好者用Latin-1字符集编码,下载起来就比较困难)
很多网站看电影的人都是m3u8,但是下载起来比较困难。当我们看到自己喜欢想下载的视频资源时,就可以使用这款多线程m3u8下载器,该软件可以帮助用户轻松下载m3u8视频,操作非常简单,输入地址即可,它收录以下功能自动解密,非常强大。下载完成后,还可以进行转换等操作。
软件说明
1.M3U8也是M3U的一种,但它的编码格式是UTF-8格式。M3U 使用 Latin-1 字符集编码。
2.M3U 是歌曲的目录信息。下载.FLAC无损格式的音频时,会附带一个M3U目录文件。
3.程序下载 M3U8 清单并将其转换为 MP4。
4.可以配置要加载的线程数。
软件功能
使用Aria2作为下载引擎,避免网络波动导致下载卡顿
允许插件接管一些步骤以兼容不同的加密处理
提供丰富的定制选项
针对本地缓存进行了优化,可快速合并网页缓存
软件亮点
1.灵活且易于使用。
2.绿色紧凑,性能实用。
3.支持获取真实下载链接。
4.可以转码m3u8格式。
5.可以快速解析m3u8视频的播放地址。
软件评估
该软件是一款功能强大的视频下载工具。下载M3u8视频后,可以转换成Mp4格式的视频进行播放,非常方便;
软件支持多线程、自动解密、自定义请求等功能,用户还可以设置User-Agent和Cookies;
该软件可以同时执行多个任务,没有任何限制。线程数只控制该ts的下载线程数。
以上就是php爱好者小编今天带来的多线程m3u8下载器。更多软件下载可供 php 爱好者使用。
php多线程抓取多个网页(用ControlInvoke,应为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-05 11:17
多线程爬取遇到了非常复杂的问题。
我在 .net 2005 中编写了一个控制台程序,用于在多个线程中抓取网页内容,但使用
WebBrowser webb = new WebBrowser();
webb.Navigate("about:blank");
HtmlDocument htmldoc = webb.Document.OpenNew(true);
htmldoc.Write(strWeb);
return htmldoc.GetElementsByTagName("TR");
分析网页内容时始终报告
“无法实例化 ActiveX 控件“8856f961-340a-11d0-a96b-00c04fd705a2”,因为当前线程不在单线程单元中。”
错误!
我添加了 startSnatch.SetApartmentState(ApartmentState.STA);到每个线程;
但还是无济于事。
希望得到各位高手的帮助!谢谢!
--------解决方案--------
委托用于跨线程操作控件,请搜索相关资料
--------解决方案--------
控制调用
--------解决方案--------
使用Control.Invoke,你应该在自己的工作线程中调用UI线程中的对象 查看全部
php多线程抓取多个网页(用ControlInvoke,应为)
多线程爬取遇到了非常复杂的问题。
我在 .net 2005 中编写了一个控制台程序,用于在多个线程中抓取网页内容,但使用
WebBrowser webb = new WebBrowser();
webb.Navigate("about:blank");
HtmlDocument htmldoc = webb.Document.OpenNew(true);
htmldoc.Write(strWeb);
return htmldoc.GetElementsByTagName("TR");
分析网页内容时始终报告
“无法实例化 ActiveX 控件“8856f961-340a-11d0-a96b-00c04fd705a2”,因为当前线程不在单线程单元中。”
错误!
我添加了 startSnatch.SetApartmentState(ApartmentState.STA);到每个线程;
但还是无济于事。
希望得到各位高手的帮助!谢谢!
--------解决方案--------
委托用于跨线程操作控件,请搜索相关资料
--------解决方案--------
控制调用
--------解决方案--------
使用Control.Invoke,你应该在自己的工作线程中调用UI线程中的对象
php多线程抓取多个网页(Python处理网页相关的工具+BeautifulSoup抓取Goolge搜索链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-03 17:06
)
1)urllib2+BeautifulSoup 抓取 Goolge 搜索链接
最近参与的项目需要处理谷歌搜索结果,之前学过Python处理web相关的工具。在实际应用中,使用urllib2和beautifulsoup来爬取网页,但是在爬取google搜索结果的时候,发现如果直接处理google搜索结果页面的源码,会得到很多“脏”链接。
请看下图“泰坦尼克号詹姆斯”的搜索结果:
图中红色标注的是不需要的,蓝色标注的是需要抓取的。
当然,这个“脏链接”可以通过规则过滤来过滤掉,但是程序的复杂度很高。就在我皱着眉头写过滤规则的时候。同学们提醒谷歌应该提供相关的API,这才恍然大悟。
(2)Google 网页搜索 API + 多线程
该文档提供了一个在 Python 中搜索的示例:
在实际应用中,可能需要爬取google的很多网页,所以需要使用多个线程来分担爬取任务。有关使用 google web search api 的详细参考,请参见此处(此处介绍了标准 URL 参数)。另外要特别注意url中的参数rsz必须为8(包括8)下面的值,如果大于8会报错!
(3)代码实现
代码实现还是有问题,但是可以运行,健壮性差,需要改进。希望各界大神指出错误(初学Python),不胜感激。
#-*-coding:utf-8-*- import urllib2,urllib import simplejson import os, time,threading import common, html_filter #input the keywords keywords = raw_input('Enter the keywords: ') #define rnum_perpage, pages rnum_perpage=8pages=8 #定义线程函数 def thread_scratch(url, rnum_perpage, page): url_set = [] try: request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'}) response = urllib2.urlopen(request) # Process the JSON string. results = simplejson.load(response) info = results['responseData']['results'] except Exception,e: print 'error occured' print e else: for minfo in info: url_set.append(minfo['url']) print minfo['url'] #处理链接 i = 0 for u in url_set: try: request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'}) request_url.add_header( 'User-agent', 'CSC' ) response_data = urllib2.urlopen(request_url).read() #过滤文件 #content_data = html_filter.filter_tags(response_data) #写入文件 filenum = i+page filename = dir_name+'/related_html_'+str(filenum) print ' write start: related_html_'+str(filenum) f = open(filename, 'w+', -1) f.write(response_data) #print content_data f.close() print ' write down: related_html_'+str(filenum) except Exception, e: print 'error occured 2' print e i = i+1 return #创建文件夹 dir_name = 'related_html_'+urllib.quote(keywords) if os.path.exists(dir_name): print 'exists file' common.delete_dir_or_file(dir_name) os.makedirs(dir_name) #抓取网页 print 'start to scratch web pages:'for x in range(pages): print "page:%s"%(x+1) page = x * rnum_perpage url = ('https://ajax.googleapis.com/ajax/services/search/web' '?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page) print url t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page)) t.start() #主线程等待子线程抓取完 main_thread = threading.currentThread() for t in threading.enumerate(): if t is main_thread: continue t.join() 查看全部
php多线程抓取多个网页(Python处理网页相关的工具+BeautifulSoup抓取Goolge搜索链接
)
1)urllib2+BeautifulSoup 抓取 Goolge 搜索链接
最近参与的项目需要处理谷歌搜索结果,之前学过Python处理web相关的工具。在实际应用中,使用urllib2和beautifulsoup来爬取网页,但是在爬取google搜索结果的时候,发现如果直接处理google搜索结果页面的源码,会得到很多“脏”链接。
请看下图“泰坦尼克号詹姆斯”的搜索结果:
图中红色标注的是不需要的,蓝色标注的是需要抓取的。
当然,这个“脏链接”可以通过规则过滤来过滤掉,但是程序的复杂度很高。就在我皱着眉头写过滤规则的时候。同学们提醒谷歌应该提供相关的API,这才恍然大悟。
(2)Google 网页搜索 API + 多线程
该文档提供了一个在 Python 中搜索的示例:
在实际应用中,可能需要爬取google的很多网页,所以需要使用多个线程来分担爬取任务。有关使用 google web search api 的详细参考,请参见此处(此处介绍了标准 URL 参数)。另外要特别注意url中的参数rsz必须为8(包括8)下面的值,如果大于8会报错!
(3)代码实现
代码实现还是有问题,但是可以运行,健壮性差,需要改进。希望各界大神指出错误(初学Python),不胜感激。
#-*-coding:utf-8-*- import urllib2,urllib import simplejson import os, time,threading import common, html_filter #input the keywords keywords = raw_input('Enter the keywords: ') #define rnum_perpage, pages rnum_perpage=8pages=8 #定义线程函数 def thread_scratch(url, rnum_perpage, page): url_set = [] try: request = urllib2.Request(url, None, {'Referer': 'http://www.sina.com'}) response = urllib2.urlopen(request) # Process the JSON string. results = simplejson.load(response) info = results['responseData']['results'] except Exception,e: print 'error occured' print e else: for minfo in info: url_set.append(minfo['url']) print minfo['url'] #处理链接 i = 0 for u in url_set: try: request_url = urllib2.Request(u, None, {'Referer': 'http://www.sina.com'}) request_url.add_header( 'User-agent', 'CSC' ) response_data = urllib2.urlopen(request_url).read() #过滤文件 #content_data = html_filter.filter_tags(response_data) #写入文件 filenum = i+page filename = dir_name+'/related_html_'+str(filenum) print ' write start: related_html_'+str(filenum) f = open(filename, 'w+', -1) f.write(response_data) #print content_data f.close() print ' write down: related_html_'+str(filenum) except Exception, e: print 'error occured 2' print e i = i+1 return #创建文件夹 dir_name = 'related_html_'+urllib.quote(keywords) if os.path.exists(dir_name): print 'exists file' common.delete_dir_or_file(dir_name) os.makedirs(dir_name) #抓取网页 print 'start to scratch web pages:'for x in range(pages): print "page:%s"%(x+1) page = x * rnum_perpage url = ('https://ajax.googleapis.com/ajax/services/search/web' '?v=1.0&q=%s&rsz=%s&start=%s') % (urllib.quote(keywords), rnum_perpage,page) print url t = threading.Thread(target=thread_scratch, args=(url,rnum_perpage, page)) t.start() #主线程等待子线程抓取完 main_thread = threading.currentThread() for t in threading.enumerate(): if t is main_thread: continue t.join()
php多线程抓取多个网页(phpcurl_multi_exec()并发抓取网页内容php是个单线程的语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-01-27 22:05
php curl_multi_exec() 同时抓取网页内容
PHP是单线程语言,所以在某些方面速度不如java这样的多线程语言。毕竟主要的方面不在这里。但是PHP也有自己的多线程(实际上是并发)方法——curl_multi_exec()。
我们可以使用curl来获取网页的内容(如果你不懂curl,可以找个简单的例子看看),但是如果同时获取多个网页的内容,速度就不行了理想的。这时候 curl_multi_exec() 就可以发挥作用了。
这是我如何抓取优酷内容的示例:
function async_get_url($url_array, $wait_usec = 0){ if (!is_array($url_array)) return false; $wait_usec = intval($wait_usec); $data = array(); $handle = array(); $running = 0; $mh = curl_multi_init(); // multi curl handler $i = 0; foreach($url_array as $url) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // return don't print curl_setopt($ch, CURLOPT_TIMEOUT, 30); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)'); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 302 redirect curl_setopt($ch, CURLOPT_MAXREDIRS, 7); curl_multi_add_handle($mh, $ch); // 把 curl resource 放進 multi curl handler 裡 $handle[$i++] = $ch; } /* 此做法就可以避免掉 CPU loading 100% 的問題 */ // 參考自: http://www.hengss.com/xueyuan/ ... .html do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); while ($active and $mrc == CURLM_OK) { if (curl_multi_select($mh) != -1) { do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); } } /* // 感謝 Ren 指點的作法. (需要在測試一下) // curl_multi_exec的返回值是用來返回多線程處裡時的錯誤,正常來說返回值是0,也就是說只用$mrc捕捉返回值當成判斷式的迴圈只會運行一次,而真的發生錯誤時,有拿$mrc判斷的都會變死迴圈。 // 而curl_multi_select的功能是curl發送請求後,在有回應前會一直處於等待狀態,所以不需要把它導入空迴圈,它就像是會自己做判斷&自己決定等待時間的sleep()。 /* 讀取資料 */ foreach($handle as $i => $ch) { $content = curl_multi_getcontent($ch); $data[$i] = (curl_errno($ch) == 0) ? $content : false; } /* 移除 handle*/ foreach($handle as $ch) { curl_multi_remove_handle($mh, $ch); } curl_multi_close($mh); return $data;} $url="http://m.youku.com/wap/";$reg1="/(.*?)/i";//获取视频链接$reg2="/]*)\s*class=\"imgdetail\"\s*src=('|\")([^'\"]+)('|\")/i";$reg3="";$reg4= "/.*?/i";//获取视频标题(备选) // 创建两个cURL资源$ch1 = curl_init();$resultArray=array();//装载所有数据的数组$ch=array();//$ch2 = curl_init();// 指定URL和适当的参数curl_setopt($ch1, CURLOPT_URL,$url);curl_setopt($ch1, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch1, CURLOPT_HEADER, 0);$content=curl_exec($ch1);curl_close($ch1);//$content=file_get_contents($url);preg_match_all($reg1, $content,$matches);$video=$matches[0];//首页视频的链接//print_r($video);foreach ($video as $a=>$key){ $position=strpos($key, "href"); $substring=substr($key, $position+11); $pos=strpos($substring, ">"); $link=substr($substring, 0,$pos-1); $nextUrl[$a]=$url.$link;}//$url_array = array( // 'http://www.google.com', // 'http://www.baidu.com',//);//print_r($nextUrl);//print_r(async_get_url($nextUrl));//并发获取所有网页的内容$allData=async_get_url($nextUrl);foreach ($allData as $page){ //获取视频图片 preg_match_all($reg2, $page,$img); $img_arr=$img[0]; foreach ($img_arr as $arr) { $position=strpos($arr, "src"); $sub=substr($arr, $position+5); $pos=strpos($sub, "\""); $last=substr($sub, 0,$pos); } //获取视频高清点播地址 preg_match_all($reg3, $page,$vids); $video_arr=$vids[0]; $vid=$video_arr[0]; $position=strpos($vid, "href"); $v_string=substr($vid, $position+11); $pos=strpos($v_string, "\""); $add=substr($v_string, 0,$pos); $video_url=$url.$add; //获取视频的标题 preg_match_all($reg4, $page,$match); $title=$match[0]; //print_r($er); $r=serialize($title); $position=mb_strpos($r, ""); $sub=substr($r, 0,$position); $pos=mb_strrpos($sub, ">"); $til=substr($sub, $pos+1); //整合到一个数组 $subArray=array('image'=>$last,'video'=>$video_url,'title'=>$til); array_push($resultArray, $subArray);}echo json_encode($resultArray);</p>
郑重声明:本文版权收录图片属于原作者,转载文章仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
标签: php 多线程 phpcurl exec phpurl curl 查看全部
php多线程抓取多个网页(phpcurl_multi_exec()并发抓取网页内容php是个单线程的语言)
php curl_multi_exec() 同时抓取网页内容
PHP是单线程语言,所以在某些方面速度不如java这样的多线程语言。毕竟主要的方面不在这里。但是PHP也有自己的多线程(实际上是并发)方法——curl_multi_exec()。
我们可以使用curl来获取网页的内容(如果你不懂curl,可以找个简单的例子看看),但是如果同时获取多个网页的内容,速度就不行了理想的。这时候 curl_multi_exec() 就可以发挥作用了。
这是我如何抓取优酷内容的示例:
function async_get_url($url_array, $wait_usec = 0){ if (!is_array($url_array)) return false; $wait_usec = intval($wait_usec); $data = array(); $handle = array(); $running = 0; $mh = curl_multi_init(); // multi curl handler $i = 0; foreach($url_array as $url) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // return don't print curl_setopt($ch, CURLOPT_TIMEOUT, 30); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)'); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 302 redirect curl_setopt($ch, CURLOPT_MAXREDIRS, 7); curl_multi_add_handle($mh, $ch); // 把 curl resource 放進 multi curl handler 裡 $handle[$i++] = $ch; } /* 此做法就可以避免掉 CPU loading 100% 的問題 */ // 參考自: http://www.hengss.com/xueyuan/ ... .html do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); while ($active and $mrc == CURLM_OK) { if (curl_multi_select($mh) != -1) { do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); } } /* // 感謝 Ren 指點的作法. (需要在測試一下) // curl_multi_exec的返回值是用來返回多線程處裡時的錯誤,正常來說返回值是0,也就是說只用$mrc捕捉返回值當成判斷式的迴圈只會運行一次,而真的發生錯誤時,有拿$mrc判斷的都會變死迴圈。 // 而curl_multi_select的功能是curl發送請求後,在有回應前會一直處於等待狀態,所以不需要把它導入空迴圈,它就像是會自己做判斷&自己決定等待時間的sleep()。 /* 讀取資料 */ foreach($handle as $i => $ch) { $content = curl_multi_getcontent($ch); $data[$i] = (curl_errno($ch) == 0) ? $content : false; } /* 移除 handle*/ foreach($handle as $ch) { curl_multi_remove_handle($mh, $ch); } curl_multi_close($mh); return $data;} $url="http://m.youku.com/wap/";$reg1="/(.*?)/i";//获取视频链接$reg2="/]*)\s*class=\"imgdetail\"\s*src=('|\")([^'\"]+)('|\")/i";$reg3="";$reg4= "/.*?/i";//获取视频标题(备选) // 创建两个cURL资源$ch1 = curl_init();$resultArray=array();//装载所有数据的数组$ch=array();//$ch2 = curl_init();// 指定URL和适当的参数curl_setopt($ch1, CURLOPT_URL,$url);curl_setopt($ch1, CURLOPT_RETURNTRANSFER, 1);curl_setopt($ch1, CURLOPT_HEADER, 0);$content=curl_exec($ch1);curl_close($ch1);//$content=file_get_contents($url);preg_match_all($reg1, $content,$matches);$video=$matches[0];//首页视频的链接//print_r($video);foreach ($video as $a=>$key){ $position=strpos($key, "href"); $substring=substr($key, $position+11); $pos=strpos($substring, ">"); $link=substr($substring, 0,$pos-1); $nextUrl[$a]=$url.$link;}//$url_array = array( // 'http://www.google.com', // 'http://www.baidu.com',//);//print_r($nextUrl);//print_r(async_get_url($nextUrl));//并发获取所有网页的内容$allData=async_get_url($nextUrl);foreach ($allData as $page){ //获取视频图片 preg_match_all($reg2, $page,$img); $img_arr=$img[0]; foreach ($img_arr as $arr) { $position=strpos($arr, "src"); $sub=substr($arr, $position+5); $pos=strpos($sub, "\""); $last=substr($sub, 0,$pos); } //获取视频高清点播地址 preg_match_all($reg3, $page,$vids); $video_arr=$vids[0]; $vid=$video_arr[0]; $position=strpos($vid, "href"); $v_string=substr($vid, $position+11); $pos=strpos($v_string, "\""); $add=substr($v_string, 0,$pos); $video_url=$url.$add; //获取视频的标题 preg_match_all($reg4, $page,$match); $title=$match[0]; //print_r($er); $r=serialize($title); $position=mb_strpos($r, ""); $sub=substr($r, 0,$position); $pos=mb_strrpos($sub, ">"); $til=substr($sub, $pos+1); //整合到一个数组 $subArray=array('image'=>$last,'video'=>$video_url,'title'=>$til); array_push($resultArray, $subArray);}echo json_encode($resultArray);</p>
郑重声明:本文版权收录图片属于原作者,转载文章仅用于传播更多信息。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
郑重声明:本文版权归原作者所有,转载文章仅出于传播更多信息之目的。如果作者信息标注有误,请尽快联系我们修改或删除,谢谢。
标签: php 多线程 phpcurl exec phpurl curl
php多线程抓取多个网页(php多线程抓取多个网页有以下方法可以选择1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-27 08:01
php多线程抓取多个网页有以下方法可以选择1。php内嵌http框架2。http代理服务器设置两个ip分别抓取3。反向代理前端抓取反向代理后端抓取,目前sae支持反向代理,抓取公共网站和api接口做小站点都可以设置反向代理抓取,公共网站写php文件反向代理实现抓取,api接口抓取就是用php编写http代理的代理注:,反向代理要设置成proxy的对象才能正常转发抓取,具体详细参考文档(不过当时用php写不会用,后面还是用了这个方法实现,感觉比较方便)php反向代理设置方法。
和你一样的需求,正向代理设置不成功,无法正常抓取你的站点。sae貌似和php并没有太大关系,暂时没有找到解决方案。
$_server['request_id']['request_uri']==''???
在命令行安装apache,然后phpinfo()输出phpinfo()后,
我们是用redis存起来的svn文件然后使用workcurlworkcurl连接到php自己的svn服务器workcurl的源码phpinfo可以看到源码,
我也是, 查看全部
php多线程抓取多个网页(php多线程抓取多个网页有以下方法可以选择1)
php多线程抓取多个网页有以下方法可以选择1。php内嵌http框架2。http代理服务器设置两个ip分别抓取3。反向代理前端抓取反向代理后端抓取,目前sae支持反向代理,抓取公共网站和api接口做小站点都可以设置反向代理抓取,公共网站写php文件反向代理实现抓取,api接口抓取就是用php编写http代理的代理注:,反向代理要设置成proxy的对象才能正常转发抓取,具体详细参考文档(不过当时用php写不会用,后面还是用了这个方法实现,感觉比较方便)php反向代理设置方法。
和你一样的需求,正向代理设置不成功,无法正常抓取你的站点。sae貌似和php并没有太大关系,暂时没有找到解决方案。
$_server['request_id']['request_uri']==''???
在命令行安装apache,然后phpinfo()输出phpinfo()后,
我们是用redis存起来的svn文件然后使用workcurlworkcurl连接到php自己的svn服务器workcurl的源码phpinfo可以看到源码,
我也是,
php多线程抓取多个网页(3.怎样支持分布式?暂时最简单的想法-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-26 02:16
一、要求
1.定期抓取网站新闻标题、内容、发布时间和来源。
2.程序需要支持分布式、多线程
二、设计
1.网站是固定的,但是以后可能会添加新的网站来抢,每个网站内容节点设计都不一样,所以需要支持动态配置才能添加网站 以方便未来的扩展,每次都需要开发干预。
2.网站html 节点的结构可能会发生变化,因此也可以支持可配置的提取节点。
3.如何支持分布式?暂时最简单的思路就是在多台机器上部署一个程序,新建一个或者一个部署程序来创建一个定时任务,在某个时间开始每台机器应该抓取哪一个网站 ,暂时不能支持同一个网站@网站同时可以支持被多台机器同时抓取,会比较麻烦,使用分布式队列。所以暂时一个 网站 只会被单台机器同时抓取。
4.多线程,如何多线程?多线程爬取我这里有两种实现:
(1)一个线程抓取一个网站,维护自己的url队列进行广度抓取,同时抓取多个网站。如图:
(2)多个线程同时抓取不同的网站。如图:
以上两种方法其实各有优缺点。这取决于我们如何选择。
方法一:每个线程创建自己的队列。图中的队列可以不用concurrentQueue。优点:不涉及控制并发。每个网站线程抓取一个网站,抓取完成后销毁线程自动回收。易于控制。缺点:无法扩展线程数。比如只有3个网站时,最多只能开3个线程去抢,不能开更多,有一定的局限性。
方法二:N个线程同时抢N个网站s,线程数与网站s个数无关。优点:线程数可以调整,与抓取网站的个数无关。3 网站我们可以开 4 5 或者 10 这个可以根据你的硬件资源来调整。缺点:需要控制并发,并且控制什么时候销毁线程(thread1空闲,队列为空不代表任务可以结束,可能thread2的结果还没有返回),当捕获到网站响应慢,会拖慢整个爬虫的进度。
三、实现
爬取方式最终选择了方式二,因为线程数是可以配置的!
使用的技术:
用了jfinal后,发现这个东西不太合适,但是由于项目进度问题,还是用了。
maven项目管理
码头服务器
mysql
日食发展
项目需要关注的难点:
(1)合理控制N个线程正常抓取网站,当所有线程工作完成且待抓取队列为空时,N个线程同时退出并销毁。
(2)不同网站设计节点不同,需要为每个网站配置需要抓取的URL以及抓取的节点内容在html节点中的位置。
(3)个性化内容处理,由于html结构设计问题,爬取的内容可能会有一些多余的html标签,或者如何处理多余的内容。
实现一:线程管理建立一个以线程为中心的管理控制器,负责线程销毁。如图所示:
(1)创建一个中央管理器,管理器存储N个线程的信号数组标记来标记线程是否空闲,并创建N个标记的线程切换。用于同时结束N个线程。
(2)线程开始抓取请求链接时设置idle为false,抓取链接后继续循环取队列(循环过程中判断开关是否为真)。当轮询结果从队列为空,把线程设为idle=true,并休眠1S(看个人喜好)。
(3)线程中心中央管理器调度定时检测任务,每1s检测一次线程的信号数组tag和queue.size(),此时queue.size()==0且数组tag全部标记为 idle ,将线程切换器设置为 false (关闭,所以线程将结束 while 退出)
如图,线程在4个线程状态后可以自行退出:
核心控制函数和线程函数代码如下:
CoreTaskController.java
<p>import java.util.Arrays;
import java.util.Timer;
import java.util.TimerTask;
import org.apache.log4j.Logger;
import com.crawler.core.conf.CrawlerConf;
/**
* 任务核心控制器
* @author Jacky
* 2015-9-30
*/
public class CoreTaskController {
public static Logger log = Logger.getLogger(CoreTaskController.class);
/**
* 信号量,用来标记当前线程是否空闲
* 0表示空闲
* 1表示繁忙
* CrawlerConf.getMaxT()表示获取最大线程数
*/
public static volatile int[] signal = new int[CrawlerConf.getMaxT()];;
public static volatile boolean totalSwitcher = true;
/**
* 线程开关
* 1表示打开
* 0表示关闭
*/
public static volatile int[] switcher = new int[CrawlerConf.getMaxT()];
public static Timer timer;
public static void init() {
// 开启所有线程开关
for(int i=0;i 查看全部
php多线程抓取多个网页(3.怎样支持分布式?暂时最简单的想法-苏州安嘉)
一、要求
1.定期抓取网站新闻标题、内容、发布时间和来源。
2.程序需要支持分布式、多线程
二、设计
1.网站是固定的,但是以后可能会添加新的网站来抢,每个网站内容节点设计都不一样,所以需要支持动态配置才能添加网站 以方便未来的扩展,每次都需要开发干预。
2.网站html 节点的结构可能会发生变化,因此也可以支持可配置的提取节点。
3.如何支持分布式?暂时最简单的思路就是在多台机器上部署一个程序,新建一个或者一个部署程序来创建一个定时任务,在某个时间开始每台机器应该抓取哪一个网站 ,暂时不能支持同一个网站@网站同时可以支持被多台机器同时抓取,会比较麻烦,使用分布式队列。所以暂时一个 网站 只会被单台机器同时抓取。
4.多线程,如何多线程?多线程爬取我这里有两种实现:
(1)一个线程抓取一个网站,维护自己的url队列进行广度抓取,同时抓取多个网站。如图:
(2)多个线程同时抓取不同的网站。如图:
以上两种方法其实各有优缺点。这取决于我们如何选择。
方法一:每个线程创建自己的队列。图中的队列可以不用concurrentQueue。优点:不涉及控制并发。每个网站线程抓取一个网站,抓取完成后销毁线程自动回收。易于控制。缺点:无法扩展线程数。比如只有3个网站时,最多只能开3个线程去抢,不能开更多,有一定的局限性。
方法二:N个线程同时抢N个网站s,线程数与网站s个数无关。优点:线程数可以调整,与抓取网站的个数无关。3 网站我们可以开 4 5 或者 10 这个可以根据你的硬件资源来调整。缺点:需要控制并发,并且控制什么时候销毁线程(thread1空闲,队列为空不代表任务可以结束,可能thread2的结果还没有返回),当捕获到网站响应慢,会拖慢整个爬虫的进度。
三、实现
爬取方式最终选择了方式二,因为线程数是可以配置的!
使用的技术:
用了jfinal后,发现这个东西不太合适,但是由于项目进度问题,还是用了。
maven项目管理
码头服务器
mysql
日食发展
项目需要关注的难点:
(1)合理控制N个线程正常抓取网站,当所有线程工作完成且待抓取队列为空时,N个线程同时退出并销毁。
(2)不同网站设计节点不同,需要为每个网站配置需要抓取的URL以及抓取的节点内容在html节点中的位置。
(3)个性化内容处理,由于html结构设计问题,爬取的内容可能会有一些多余的html标签,或者如何处理多余的内容。
实现一:线程管理建立一个以线程为中心的管理控制器,负责线程销毁。如图所示:
(1)创建一个中央管理器,管理器存储N个线程的信号数组标记来标记线程是否空闲,并创建N个标记的线程切换。用于同时结束N个线程。
(2)线程开始抓取请求链接时设置idle为false,抓取链接后继续循环取队列(循环过程中判断开关是否为真)。当轮询结果从队列为空,把线程设为idle=true,并休眠1S(看个人喜好)。
(3)线程中心中央管理器调度定时检测任务,每1s检测一次线程的信号数组tag和queue.size(),此时queue.size()==0且数组tag全部标记为 idle ,将线程切换器设置为 false (关闭,所以线程将结束 while 退出)
如图,线程在4个线程状态后可以自行退出:
核心控制函数和线程函数代码如下:
CoreTaskController.java
<p>import java.util.Arrays;
import java.util.Timer;
import java.util.TimerTask;
import org.apache.log4j.Logger;
import com.crawler.core.conf.CrawlerConf;
/**
* 任务核心控制器
* @author Jacky
* 2015-9-30
*/
public class CoreTaskController {
public static Logger log = Logger.getLogger(CoreTaskController.class);
/**
* 信号量,用来标记当前线程是否空闲
* 0表示空闲
* 1表示繁忙
* CrawlerConf.getMaxT()表示获取最大线程数
*/
public static volatile int[] signal = new int[CrawlerConf.getMaxT()];;
public static volatile boolean totalSwitcher = true;
/**
* 线程开关
* 1表示打开
* 0表示关闭
*/
public static volatile int[] switcher = new int[CrawlerConf.getMaxT()];
public static Timer timer;
public static void init() {
// 开启所有线程开关
for(int i=0;i
php多线程抓取多个网页(php才算是真正的支持多线程,使用的是pthreads的扩展)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-25 13:03
到php5.3以上的版本,php确实支持多线程,使用pthreads的扩展,php在处理多个循环任务时可以大大缩短程序的执行时间。
网站的大部分性能瓶颈不在php服务器上,而是在mysql服务器上。因为可以通过横向增加server或者cpu core的数量来处理。如果使用Mysql数据库,联合查询可能会处理非常复杂的业务逻辑,但是遇到大量并发查询时,服务器可能会瘫痪。因此,我们可以使用 NoSQL 数据库代替 mysql 服务器。一个很复杂的SQL语句可能需要几条NOSQL语句才能完成,但是在大量并发的情况下,速度确实非常明显。然后再加上使用php多线程,通过十个php线程查询NOSQL,然后聚合返回结果输出,速度非常快。
1 PHP扩展下载:https://github.com/krakjoe/pthreads
2 PHP手册文档:http://php.net/manual/zh/book.pthreads.php
1、扩展编译安装(Linux),编辑参数--enable-maintainer-zts为必选项:
1 cd /Data/tgz/php-5.5.1
2 ./configure --prefix=/Data/apps/php --with-config-file-path=/Data/apps/php/etc --with-mysql=/Data/apps/mysql --with-mysqli=/Data/apps/mysql/bin/mysql_config --with-iconv-dir --with-freetype-dir=/Data/apps/libs --with-jpeg-dir=/Data/apps/libs --with-png-dir=/Data/apps/libs --with-zlib --with-libxml-dir=/usr --enable-xml --disable-rpath --enable-bcmath --enable-shmop --enable-sysvsem --enable-inline-optimization --with-curl --enable-mbregex --enable-fpm --enable-mbstring --with-mcrypt=/Data/apps/libs --with-gd --enable-gd-native-ttf --with-openssl --with-mhash --enable-pcntl --enable-sockets --with-xmlrpc --enable-zip --enable-soap --enable-opcache --with-pdo-mysql --enable-maintainer-zts
3 make clean
4 make
5 make install
6
7 unzip pthreads-master.zip
8 cd pthreads-master
9 /Data/apps/php/bin/phpize
10 ./configure --with-php-config=/Data/apps/php/bin/php-config
11 make
12 make install
vi /Data/apps/php/etc/php.ini
extension = "pthreads.so"
2、给出一个PHP多线程和For循环爬取百度搜索页面的PHP代码示例:
1
以上是一个官方php多线程的扩展。由于需要重新编译,所以我自己没有测试过,但其实本质是在linux中开启多个线程进行处理。
2、讲一个我自己伪造的PHP多线程的例子:
下面是一段测试代码:
for.php
1
test.php(只显示phpinfo信息):
1
采用多线程的执行的时间:32.89448595047
采用普通的执行的时间:85.191102027893
循环执行的次数越多,这个时间差就越明显。
ps:我们可以写一个python或者shell脚本来实时检测php进程数的变化:
1 #!/usr/bin/env/ python
2 import os
3 from time import sleep
4
5 while 1:
6 os.system("ps -aux|grep php|wc -l");
7 sleep(1);
8
9 上面是一个简单的统计php进程数的一个脚本,在shell界面执行的时候,可以将输出定位到一个文件中。
记录:
最大并发记录数:
在公司机器上运行多线程程序之前,
机器的配置是48G内存6个CPU,
一次并发线程数在3000左右,超过4000会导致内存溢出,机器会死机。这是并发线程的最大数量。
但是当我们在线运行时,为了安全,我们必须记住我们最多会有几十到一百个并发进程。如果超出范围,就会出现数据丢失和一些奇怪的现象。 查看全部
php多线程抓取多个网页(php才算是真正的支持多线程,使用的是pthreads的扩展)
到php5.3以上的版本,php确实支持多线程,使用pthreads的扩展,php在处理多个循环任务时可以大大缩短程序的执行时间。
网站的大部分性能瓶颈不在php服务器上,而是在mysql服务器上。因为可以通过横向增加server或者cpu core的数量来处理。如果使用Mysql数据库,联合查询可能会处理非常复杂的业务逻辑,但是遇到大量并发查询时,服务器可能会瘫痪。因此,我们可以使用 NoSQL 数据库代替 mysql 服务器。一个很复杂的SQL语句可能需要几条NOSQL语句才能完成,但是在大量并发的情况下,速度确实非常明显。然后再加上使用php多线程,通过十个php线程查询NOSQL,然后聚合返回结果输出,速度非常快。
1 PHP扩展下载:https://github.com/krakjoe/pthreads
2 PHP手册文档:http://php.net/manual/zh/book.pthreads.php
1、扩展编译安装(Linux),编辑参数--enable-maintainer-zts为必选项:
1 cd /Data/tgz/php-5.5.1
2 ./configure --prefix=/Data/apps/php --with-config-file-path=/Data/apps/php/etc --with-mysql=/Data/apps/mysql --with-mysqli=/Data/apps/mysql/bin/mysql_config --with-iconv-dir --with-freetype-dir=/Data/apps/libs --with-jpeg-dir=/Data/apps/libs --with-png-dir=/Data/apps/libs --with-zlib --with-libxml-dir=/usr --enable-xml --disable-rpath --enable-bcmath --enable-shmop --enable-sysvsem --enable-inline-optimization --with-curl --enable-mbregex --enable-fpm --enable-mbstring --with-mcrypt=/Data/apps/libs --with-gd --enable-gd-native-ttf --with-openssl --with-mhash --enable-pcntl --enable-sockets --with-xmlrpc --enable-zip --enable-soap --enable-opcache --with-pdo-mysql --enable-maintainer-zts
3 make clean
4 make
5 make install
6
7 unzip pthreads-master.zip
8 cd pthreads-master
9 /Data/apps/php/bin/phpize
10 ./configure --with-php-config=/Data/apps/php/bin/php-config
11 make
12 make install
vi /Data/apps/php/etc/php.ini
extension = "pthreads.so"
2、给出一个PHP多线程和For循环爬取百度搜索页面的PHP代码示例:
1
以上是一个官方php多线程的扩展。由于需要重新编译,所以我自己没有测试过,但其实本质是在linux中开启多个线程进行处理。
2、讲一个我自己伪造的PHP多线程的例子:
下面是一段测试代码:
for.php
1
test.php(只显示phpinfo信息):
1
采用多线程的执行的时间:32.89448595047
采用普通的执行的时间:85.191102027893
循环执行的次数越多,这个时间差就越明显。
ps:我们可以写一个python或者shell脚本来实时检测php进程数的变化:
1 #!/usr/bin/env/ python
2 import os
3 from time import sleep
4
5 while 1:
6 os.system("ps -aux|grep php|wc -l");
7 sleep(1);
8
9 上面是一个简单的统计php进程数的一个脚本,在shell界面执行的时候,可以将输出定位到一个文件中。
记录:
最大并发记录数:
在公司机器上运行多线程程序之前,
机器的配置是48G内存6个CPU,
一次并发线程数在3000左右,超过4000会导致内存溢出,机器会死机。这是并发线程的最大数量。
但是当我们在线运行时,为了安全,我们必须记住我们最多会有几十到一百个并发进程。如果超出范围,就会出现数据丢失和一些奇怪的现象。
php多线程抓取多个网页( php使用pthreadsv3多线程实现抓取新浪新闻信息操作技巧汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-22 21:20
php使用pthreadsv3多线程实现抓取新浪新闻信息操作技巧汇总)
php使用pthreads v3多线程实现抓取新浪新闻信息的操作示例
更新时间:2020-02-21 08:47:31 作者:怀素贞
本文文章主要介绍使用pthreads v3多线程实现抓取新浪新闻信息的操作,分析php使用pthreads多线程抓取新浪新闻的具体实现步骤和操作技巧信息结合示例。朋友可以参考以下
本文中的示例描述了php如何使用pthreads v3多线程来捕获新浪新闻信息。分享给大家,供大家参考,如下:
我们使用 pthreads 编写一个多线程小程序来抓取页面并将结果存储在数据库中。
数据表结构如下:
CREATE TABLE `tb_sina` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`url` varchar(256) DEFAULT '' COMMENT 'url地址',
`title` varchar(128) DEFAULT '' COMMENT '标题',
`time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='sina新闻';
代码如下:
<p> 查看全部
php多线程抓取多个网页(
php使用pthreadsv3多线程实现抓取新浪新闻信息操作技巧汇总)
php使用pthreads v3多线程实现抓取新浪新闻信息的操作示例
更新时间:2020-02-21 08:47:31 作者:怀素贞
本文文章主要介绍使用pthreads v3多线程实现抓取新浪新闻信息的操作,分析php使用pthreads多线程抓取新浪新闻的具体实现步骤和操作技巧信息结合示例。朋友可以参考以下
本文中的示例描述了php如何使用pthreads v3多线程来捕获新浪新闻信息。分享给大家,供大家参考,如下:
我们使用 pthreads 编写一个多线程小程序来抓取页面并将结果存储在数据库中。
数据表结构如下:
CREATE TABLE `tb_sina` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`url` varchar(256) DEFAULT '' COMMENT 'url地址',
`title` varchar(128) DEFAULT '' COMMENT '标题',
`time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='sina新闻';
代码如下:
<p>
php多线程抓取多个网页(php中curl_init()的具体使用方法及相关效率比较)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-01-22 16:09
php使用curl_init()和curl_multi_init()多线程的速度详解
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文章主要介绍了php使用curl_init()和curl_multi_init()多线程的速度对比,并结合示例表格详细分析了curl_init()和curl_multi_init()的具体用法和相关效率对比。需要的朋友可以参考以下
本文的例子描述了php使用curl_init()和curl_multi_init()多线程的速度对比。分享给大家参考,详情如下:
curl_init()在php中的作用非常大,尤其是在抓取网页内容或者文件信息的时候。比如之前的文章《php使用curl获取header检测并启用GZip压缩》介绍了curl_init()的威力。
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_init()和curl_multi_init()的速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p> 查看全部
php多线程抓取多个网页(php中curl_init()的具体使用方法及相关效率比较)
php使用curl_init()和curl_multi_init()多线程的速度详解
更新时间:2018-08-15 10:06:55 作者:CC_小硕
本文章主要介绍了php使用curl_init()和curl_multi_init()多线程的速度对比,并结合示例表格详细分析了curl_init()和curl_multi_init()的具体用法和相关效率对比。需要的朋友可以参考以下
本文的例子描述了php使用curl_init()和curl_multi_init()多线程的速度对比。分享给大家参考,详情如下:
curl_init()在php中的作用非常大,尤其是在抓取网页内容或者文件信息的时候。比如之前的文章《php使用curl获取header检测并启用GZip压缩》介绍了curl_init()的威力。
curl_init() 以单线程模式处理事物。如果需要使用多线程模式进行事务处理,那么PHP为我们提供了一个函数curl_multi_init(),就是多线程模式处理事务的函数。
curl_init()和curl_multi_init()的速度对比
curl_multi_init() 多线程可以提高网页的处理速度吗?今天我将通过一个实验来验证这个问题。
我今天的测试很简单,就是抓取网页的内容,需要连续抓取5次,使用curl_init()和curl_multi_init()函数完成,记录两次耗时,并比较得出结论。
首先,使用 curl_init() 单线程连续抓取网页内容 5 次。
程序代码如下:
然后,使用 curl_multi_init() 多线程连续抓取网页内容 5 次。
代码显示如下:
<p>

