
js 爬虫抓取网页数据
js 爬虫抓取网页数据(网站快速收录,网站怎么做才会快速收录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-16 18:04
网站快收录,网站怎么做才能快收录?首先,要想网站快收录,必须保证网站的质量。然后主动提交给搜索引擎。无论是百度、360还是搜狗等搜索引擎,所有搜索引擎都需要主动向搜索引擎提交链接。只有提交链接后,搜索引擎才能更快地发现网站链接。网站 时效性内容建议尽快提交,推送数据实时搜索。可以加快爬取速度,促进更快收录。
只有两种方法可以使搜索引擎 收录 快速。一个是做好站内优化和文章原创优化等搜索引擎主动爬取你的网站,另一个第一是你主动提交给搜索引擎并告诉它抓取。第一个周期太长,所以这篇文章讲第二个
1.准备就绪网站:
首先,想做SEO的同学需要考虑自己选择的前端框架。现在主流的angularJs、Vue.js、react.js,这些动态渲染数据的框架,对爬虫非常不友好,但是这些框架都有对应的后端渲染方案,或者曲线的方案就是专门写一套静态页面搜索引擎优化。当然,只想收录的同学可以忽略这些,可以通过bind的形式绑定数据,这样百度搜索结果至少不会出现{{}}这样的乱码。
标题标签是关键标签,它不仅是你的页面名称,也是百度搜索结果中的重要参考。如:
元标签的关键词和描述:谷歌和百度不再使用这两个标签作为排名因素,但描述对网站的流量还是有帮助的,因为描述是直接在谷歌搜索结果中使用的。页面的描述,当用户搜索看到描述好的时候,更容易找到你的网站,而关键词基本是无效的,有时会适得其反,百度会认为你过分了搜索引擎优化。怀疑。
2、加速网站收录:
虽然搜索引擎的爬虫不能实时爬取你的网站,但是爬到它并不代表它就是收录。一般百度会在一定期限内收录你的网站。您可以通过其他方式加速百度收录。提交sitemap,或者代码自动推送,提交网站的sitemap文件,让爬虫一一抓取页面。或者在页面插入自动推送代码,每个搜索引擎资源管理平台都会有自动推送代码。
这样,您的页面将在您每次访问时被抓取。
通过其他的网站名字,最常见的引导百度爬的就是网站下面的很多链接,在一些高权重的网站下面加一个你的链接,百度也会爬你的网站 沿着页面;或者把你的网站网址放在高权重的网站上发布文章,也会吸引百度进来。这大大增加了 收录 的机会。
3、改进网站收录方法
做好网站内部链接。在这方面,很多网站都没有做好。一开始他们以为内页需要正常收录才可以做内链,但是文章没有做内链。现在想想,如果文章里面没有内链,那么搜索引擎蜘蛛只会爬一页就走了,太浪费了。所以,文章页面的相关推荐和头条推荐是非常重要的,我们不得不用它们来进行SEO优化。
总结:很多朋友对网站的投稿知之甚少。这里给大家分享一个SEO人员正在使用的网站收录工具,包括:百度/搜狗/360/今日头条/神马/谷歌/等。只需导入自动提交的链接,还附带一个站点地图网站地图生成器。如果您想网站快速收录,请务必进行这些主动提交收录。返回搜狐,查看更多 查看全部
js 爬虫抓取网页数据(网站快速收录,网站怎么做才会快速收录?)
网站快收录,网站怎么做才能快收录?首先,要想网站快收录,必须保证网站的质量。然后主动提交给搜索引擎。无论是百度、360还是搜狗等搜索引擎,所有搜索引擎都需要主动向搜索引擎提交链接。只有提交链接后,搜索引擎才能更快地发现网站链接。网站 时效性内容建议尽快提交,推送数据实时搜索。可以加快爬取速度,促进更快收录。
只有两种方法可以使搜索引擎 收录 快速。一个是做好站内优化和文章原创优化等搜索引擎主动爬取你的网站,另一个第一是你主动提交给搜索引擎并告诉它抓取。第一个周期太长,所以这篇文章讲第二个
1.准备就绪网站:
首先,想做SEO的同学需要考虑自己选择的前端框架。现在主流的angularJs、Vue.js、react.js,这些动态渲染数据的框架,对爬虫非常不友好,但是这些框架都有对应的后端渲染方案,或者曲线的方案就是专门写一套静态页面搜索引擎优化。当然,只想收录的同学可以忽略这些,可以通过bind的形式绑定数据,这样百度搜索结果至少不会出现{{}}这样的乱码。
标题标签是关键标签,它不仅是你的页面名称,也是百度搜索结果中的重要参考。如:
元标签的关键词和描述:谷歌和百度不再使用这两个标签作为排名因素,但描述对网站的流量还是有帮助的,因为描述是直接在谷歌搜索结果中使用的。页面的描述,当用户搜索看到描述好的时候,更容易找到你的网站,而关键词基本是无效的,有时会适得其反,百度会认为你过分了搜索引擎优化。怀疑。
2、加速网站收录:
虽然搜索引擎的爬虫不能实时爬取你的网站,但是爬到它并不代表它就是收录。一般百度会在一定期限内收录你的网站。您可以通过其他方式加速百度收录。提交sitemap,或者代码自动推送,提交网站的sitemap文件,让爬虫一一抓取页面。或者在页面插入自动推送代码,每个搜索引擎资源管理平台都会有自动推送代码。
这样,您的页面将在您每次访问时被抓取。
通过其他的网站名字,最常见的引导百度爬的就是网站下面的很多链接,在一些高权重的网站下面加一个你的链接,百度也会爬你的网站 沿着页面;或者把你的网站网址放在高权重的网站上发布文章,也会吸引百度进来。这大大增加了 收录 的机会。
3、改进网站收录方法
做好网站内部链接。在这方面,很多网站都没有做好。一开始他们以为内页需要正常收录才可以做内链,但是文章没有做内链。现在想想,如果文章里面没有内链,那么搜索引擎蜘蛛只会爬一页就走了,太浪费了。所以,文章页面的相关推荐和头条推荐是非常重要的,我们不得不用它们来进行SEO优化。
总结:很多朋友对网站的投稿知之甚少。这里给大家分享一个SEO人员正在使用的网站收录工具,包括:百度/搜狗/360/今日头条/神马/谷歌/等。只需导入自动提交的链接,还附带一个站点地图网站地图生成器。如果您想网站快速收录,请务必进行这些主动提交收录。返回搜狐,查看更多
js 爬虫抓取网页数据(快速采集高质量文章的织梦采集文章方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-16 17:46
)
经常听到站长抱怨织梦网站跑了一段时间网站not收录关键词优化不排名或者只有收录首页,这个真的很烦人。事实上,网站 内容的收录 情况很大程度上取决于搜索引擎蜘蛛所花费的时间。抓取时间越长,深圳SEO针对这个问题总结了以下方法:
一、优化网站导航结构
1.添加内链:如及时出现的描述性文字,如网页右侧或底部出现的相关链接和相关文章,这些内链可以吸引用户的注意力,点击量,以及用户最喜欢的 网站 ,自然搜索引擎也会关注。
2. 降低目录层次或减少首页间隔:目录有条理,蜘蛛喜欢的越少,距离首页越远,页面的权重越低。
二、代码和图片优化
对于太多的js或者动态页面,应该优化网页的代码,即使网页是静态页面,提高网页对于搜索引擎的可读性。对于图片过多的网站,应结合图文并添加alt图片标签。毕竟像笔墨这样的搜索引擎的识别度要比图片高很多。
三、制作网站地图
网站地图在文章收录中起到了很大的作用,它可以为搜索引擎爬虫提供网站各个地方的链接,有效减少爬虫的工作量,可以有效的减少爬虫的工作量。增加搜索引擎的数量收录文章。
四、静态化 网站 URL
网站如果不是静态的,会导致动态URL过长,动态页面访问速度太慢,出现重复页面。实际上,您可以使整个站点保持静态。如果不能生成静态,可以使用伪静态。
五、上传原创或高质量伪原创文章定期更新
不得不说,新网站往往内容太少,不断更新会引起搜索引擎关注网站。像 原创 的 文章 这样的搜索引擎,尤其是定期定量发布 原创文章 的 网站。每天坚持战斗,用不了多久,你的网站快照和收录s就会快速增加。今天给大家分享一个快速采集高品质文章织梦采集插件(所有网站通用插件)。
这个织梦采集插件不需要学习更多的专业技能,只需要简单几步就可以轻松搞定采集内容数据,用户只需要添加织梦采集 在插件上进行了简单的设置。完成后,织梦采集插件会根据用户设置的关键词,对内容和图片进行高精度匹配。您可以选择保存在本地,也可以选择伪原创发布后,提供方便快捷的内容采集伪原创发布服务!!
和其他织梦采集插件相比,这个织梦采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟上手,只需要输入关键词即可实现采集(织梦采集插件也自带关键词 采集 函数)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO方面采集伪原创。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面的原创度,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
六、主动向搜索引擎提交链接
做SEO优化的人都知道,很多时候,我们基于百度搜索引擎对网站的SEO进行优化,研究如何让网站在百度获得排名。现在百度站长平台上有一个链接提交工具,可以让新的网站更快的被收录和网站被搜索引擎更快的抓取。网站只有在收录的时候才能被索引,只有被索引了才能显示出来,而且还有一个网站被点击的概率。因此,网站收录是seo优化的基础。只有打好基础,网站优化才能成功。因此,我们希望做出符合用户需求的内容,并尽可能地改进收录。
如何利用搜索引擎站长平台提升网站收录,这里以百度站长平台为例,加速新的网站收录链接工具?在站长平台上验证新的网站有三种方式:
注册百度站长平台账号,在站点管理中点击添加网站,输入你的网站,添加站点属性,然后验证网站。验证方式有文件验证、HTML标签验证、CNAME验证三种。每种网站验证方式都有对应的说明,可以根据自己的情况选择合适的方式进行验证。
加速新的网站收录有两个关键步骤,这里是加速新的网站收录的关键步骤。提交链接有两种方式,一种是自动提交,包括主动推送(实时)、自动推送和站点地图,另一种是手动提交。在经过验证的百度站长后台,每种提交方式都有详细的说明,大家可以按需操作。使用更高效的推送方式来实现收录的效果。建议使用带实时功能的主动推送功能,优点是速度最快;同时使用自动推送,通过用户行为将网站页面推送到搜索引擎,节省站长操作时间。
需要强调的是,我们将新的网站提交给百度,让搜索引擎抓取我们的网站,无论是收录,还是收录@的时间>,还受网站上线时间长短、网站内容质量等多重因素影响。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
查看全部
js 爬虫抓取网页数据(快速采集高质量文章的织梦采集文章方法
)
经常听到站长抱怨织梦网站跑了一段时间网站not收录关键词优化不排名或者只有收录首页,这个真的很烦人。事实上,网站 内容的收录 情况很大程度上取决于搜索引擎蜘蛛所花费的时间。抓取时间越长,深圳SEO针对这个问题总结了以下方法:
一、优化网站导航结构
1.添加内链:如及时出现的描述性文字,如网页右侧或底部出现的相关链接和相关文章,这些内链可以吸引用户的注意力,点击量,以及用户最喜欢的 网站 ,自然搜索引擎也会关注。
2. 降低目录层次或减少首页间隔:目录有条理,蜘蛛喜欢的越少,距离首页越远,页面的权重越低。
二、代码和图片优化
对于太多的js或者动态页面,应该优化网页的代码,即使网页是静态页面,提高网页对于搜索引擎的可读性。对于图片过多的网站,应结合图文并添加alt图片标签。毕竟像笔墨这样的搜索引擎的识别度要比图片高很多。
三、制作网站地图
网站地图在文章收录中起到了很大的作用,它可以为搜索引擎爬虫提供网站各个地方的链接,有效减少爬虫的工作量,可以有效的减少爬虫的工作量。增加搜索引擎的数量收录文章。
四、静态化 网站 URL
网站如果不是静态的,会导致动态URL过长,动态页面访问速度太慢,出现重复页面。实际上,您可以使整个站点保持静态。如果不能生成静态,可以使用伪静态。
五、上传原创或高质量伪原创文章定期更新
不得不说,新网站往往内容太少,不断更新会引起搜索引擎关注网站。像 原创 的 文章 这样的搜索引擎,尤其是定期定量发布 原创文章 的 网站。每天坚持战斗,用不了多久,你的网站快照和收录s就会快速增加。今天给大家分享一个快速采集高品质文章织梦采集插件(所有网站通用插件)。
这个织梦采集插件不需要学习更多的专业技能,只需要简单几步就可以轻松搞定采集内容数据,用户只需要添加织梦采集 在插件上进行了简单的设置。完成后,织梦采集插件会根据用户设置的关键词,对内容和图片进行高精度匹配。您可以选择保存在本地,也可以选择伪原创发布后,提供方便快捷的内容采集伪原创发布服务!!
和其他织梦采集插件相比,这个织梦采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟上手,只需要输入关键词即可实现采集(织梦采集插件也自带关键词 采集 函数)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO方面采集伪原创。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面的原创度,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
六、主动向搜索引擎提交链接
做SEO优化的人都知道,很多时候,我们基于百度搜索引擎对网站的SEO进行优化,研究如何让网站在百度获得排名。现在百度站长平台上有一个链接提交工具,可以让新的网站更快的被收录和网站被搜索引擎更快的抓取。网站只有在收录的时候才能被索引,只有被索引了才能显示出来,而且还有一个网站被点击的概率。因此,网站收录是seo优化的基础。只有打好基础,网站优化才能成功。因此,我们希望做出符合用户需求的内容,并尽可能地改进收录。
如何利用搜索引擎站长平台提升网站收录,这里以百度站长平台为例,加速新的网站收录链接工具?在站长平台上验证新的网站有三种方式:
注册百度站长平台账号,在站点管理中点击添加网站,输入你的网站,添加站点属性,然后验证网站。验证方式有文件验证、HTML标签验证、CNAME验证三种。每种网站验证方式都有对应的说明,可以根据自己的情况选择合适的方式进行验证。
加速新的网站收录有两个关键步骤,这里是加速新的网站收录的关键步骤。提交链接有两种方式,一种是自动提交,包括主动推送(实时)、自动推送和站点地图,另一种是手动提交。在经过验证的百度站长后台,每种提交方式都有详细的说明,大家可以按需操作。使用更高效的推送方式来实现收录的效果。建议使用带实时功能的主动推送功能,优点是速度最快;同时使用自动推送,通过用户行为将网站页面推送到搜索引擎,节省站长操作时间。
需要强调的是,我们将新的网站提交给百度,让搜索引擎抓取我们的网站,无论是收录,还是收录@的时间>,还受网站上线时间长短、网站内容质量等多重因素影响。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
js 爬虫抓取网页数据(联想虚拟货币爬取这是酷安老哥找我做的一个项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-16 05:20
在此期间总共制作了三种爬行动物:
我使用了两种不同的技术。前两个是我自己的想法。我使用 nodejs+express+superagent。说实话,nodejs对后台的数据真的很友好。然后我使用 Sequelize 进行 ORM 对象映射,确实非常好。方便。
这也是要熟悉express的架构,以后再补坑,虽然坑的不多。
我还为 Sequelize 文档做了一个镜像仓库,方便访问。
但是,在 JavaScript 中编写程序时,有一点是无法避免的,那就是异步操作。
JavaScript作为浏览器的主要逻辑实现语言,对于支持网络操作是必不可少的。如果浏览器不使用异步获取数据,就会出现页面加载慢等问题,用JavaScript编写的后端也无法避免处理异步操作。,比较头疼的是循环异步操作。我在网上查了很多文件。主要的解决方案是递归地循环嵌套promise,然后确保获取到最后一个promise对象,然后等待他的resolve或者reject。
让我们详细谈谈这些项目。
丁香园数据爬取
这个项目我是自发开始的,大概用了三四天的时间。
分析页面数据
打开丁香园的网站,右键查看网页源代码,可以看到丁香园的数据是后端渲染出来的,所有需要的数据都嵌入到了JavaScript中json 格式的 HTML。
事实上,最初的丁香园页面并不是这样的。一开始不是很直观,都是用html标签写的。
估计是为了方便网友抓取它的数据吧?毕竟写html+JavaScript对爬虫很有好处
而且里面几乎所有的数据都是完美而严格的json格式,用JSON.parse()就行了。后台没什么好说的,写个定时器,定时爬取。公开一些接口可以在 GitHub ⭐ 上收获。
联想虚拟货币爬行
这是关弟兄让我做的一个项目。毕竟,这是我人生中的第一次外包。我犹豫了两分钟,立刻开始了。第一天,我花了半天时间研究页面并分析困难。
第一点是我在这部分遇到的第一个坑。因为我之前做的是一个不需要登录的页面,只能直接分析得到的html数据,所以上网查了一些资料。
其实解决方法很简单。就是模拟登录操作,获取联想服务器返回的cookie数据,然后带着这个cookie访问币种查询页面。
以下是我对网络安全的一些看法:
网页安全吗?
不,没有网页是安全的,纯网页几乎不可能完全安全,所以很多网上银行都需要外挂一些硬件工具来保证安全。
那么一个网页可以相对安全吗?
是的,而且应该是。
使用 session 或 cookie 或 token 区分用户属性,防止未登录的未知用户查看敏感页面,并添加过期功能,确保数据安全。
使用不可逆加密来保护用户输入的密码。只有这样,后台才能在不知道用户真实密码的情况下确认用户的登录状态。个人认为MD5加密对于我这个级别来说是比较好的用户信息加密方式。
在分析联想的登录界面时,我发现了一个让我哭笑不得的地方。
百度百科
Base64 是 Internet 上传输 8Bit 字节码最常见的编码方法之一。Base64 是一种基于 64 个可打印字符表示二进制数据的方法。可以查看RFC2045~RFC2049,里面有MIME的详细规范。
Base64 编码是一种二进制到字符的过程,可用于在 HTTP 环境中传送更长的标识信息。使用 Base64 编码是不可读的,需要先解码才能读取。
连联想的一些登录页面,密码都是明文传输的……联想的技术水平我真的无语,具体是哪些页面就不说了。
解决了登录问题后,基本搞定了大半。
然后是运维和调优。这段时间,当IP被封时,我设置了爬取时间间隔,基本没有问题。
如何获取信息
有两种主要类型的网页
后端渲染SSR页面,或者prerender预渲染单页应用,前端请求数据前端渲染
第二种对爬虫不友好。只能手动找前端接口,然后看运气能不能请求对应的数据,比较随机。
在第一种情况下,我现在主要使用正则表达式。JavaScript对正则表达式比较友好,操作DOM也很方便。基本流程是
在使用正则表达式之前,您可以使用 DOM 操作工具来缩小搜索范围以方便匹配。 查看全部
js 爬虫抓取网页数据(联想虚拟货币爬取这是酷安老哥找我做的一个项目)
在此期间总共制作了三种爬行动物:
我使用了两种不同的技术。前两个是我自己的想法。我使用 nodejs+express+superagent。说实话,nodejs对后台的数据真的很友好。然后我使用 Sequelize 进行 ORM 对象映射,确实非常好。方便。
这也是要熟悉express的架构,以后再补坑,虽然坑的不多。
我还为 Sequelize 文档做了一个镜像仓库,方便访问。
但是,在 JavaScript 中编写程序时,有一点是无法避免的,那就是异步操作。
JavaScript作为浏览器的主要逻辑实现语言,对于支持网络操作是必不可少的。如果浏览器不使用异步获取数据,就会出现页面加载慢等问题,用JavaScript编写的后端也无法避免处理异步操作。,比较头疼的是循环异步操作。我在网上查了很多文件。主要的解决方案是递归地循环嵌套promise,然后确保获取到最后一个promise对象,然后等待他的resolve或者reject。
让我们详细谈谈这些项目。
丁香园数据爬取
这个项目我是自发开始的,大概用了三四天的时间。
分析页面数据
打开丁香园的网站,右键查看网页源代码,可以看到丁香园的数据是后端渲染出来的,所有需要的数据都嵌入到了JavaScript中json 格式的 HTML。
事实上,最初的丁香园页面并不是这样的。一开始不是很直观,都是用html标签写的。
估计是为了方便网友抓取它的数据吧?毕竟写html+JavaScript对爬虫很有好处
而且里面几乎所有的数据都是完美而严格的json格式,用JSON.parse()就行了。后台没什么好说的,写个定时器,定时爬取。公开一些接口可以在 GitHub ⭐ 上收获。
联想虚拟货币爬行
这是关弟兄让我做的一个项目。毕竟,这是我人生中的第一次外包。我犹豫了两分钟,立刻开始了。第一天,我花了半天时间研究页面并分析困难。
第一点是我在这部分遇到的第一个坑。因为我之前做的是一个不需要登录的页面,只能直接分析得到的html数据,所以上网查了一些资料。
其实解决方法很简单。就是模拟登录操作,获取联想服务器返回的cookie数据,然后带着这个cookie访问币种查询页面。
以下是我对网络安全的一些看法:
网页安全吗?
不,没有网页是安全的,纯网页几乎不可能完全安全,所以很多网上银行都需要外挂一些硬件工具来保证安全。
那么一个网页可以相对安全吗?
是的,而且应该是。
使用 session 或 cookie 或 token 区分用户属性,防止未登录的未知用户查看敏感页面,并添加过期功能,确保数据安全。
使用不可逆加密来保护用户输入的密码。只有这样,后台才能在不知道用户真实密码的情况下确认用户的登录状态。个人认为MD5加密对于我这个级别来说是比较好的用户信息加密方式。
在分析联想的登录界面时,我发现了一个让我哭笑不得的地方。
百度百科
Base64 是 Internet 上传输 8Bit 字节码最常见的编码方法之一。Base64 是一种基于 64 个可打印字符表示二进制数据的方法。可以查看RFC2045~RFC2049,里面有MIME的详细规范。
Base64 编码是一种二进制到字符的过程,可用于在 HTTP 环境中传送更长的标识信息。使用 Base64 编码是不可读的,需要先解码才能读取。
连联想的一些登录页面,密码都是明文传输的……联想的技术水平我真的无语,具体是哪些页面就不说了。
解决了登录问题后,基本搞定了大半。
然后是运维和调优。这段时间,当IP被封时,我设置了爬取时间间隔,基本没有问题。
如何获取信息
有两种主要类型的网页
后端渲染SSR页面,或者prerender预渲染单页应用,前端请求数据前端渲染
第二种对爬虫不友好。只能手动找前端接口,然后看运气能不能请求对应的数据,比较随机。
在第一种情况下,我现在主要使用正则表达式。JavaScript对正则表达式比较友好,操作DOM也很方便。基本流程是
在使用正则表达式之前,您可以使用 DOM 操作工具来缩小搜索范围以方便匹配。
js 爬虫抓取网页数据(本文接上文分享:pyspider界面pyspider模拟登录渲染爬取AJAX异步加载网页pyspider)
网站优化 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2022-04-15 13:40
这篇文章继续上面的内容,继续聊聊python爬虫的相关知识。上一篇是关于各种爬虫库的。本文主要介绍一个好用的框架pyspider,标题如下:
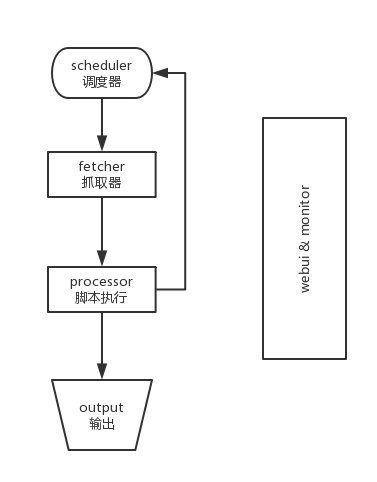
pyspider简介Pyspider接口pyspider脚本模拟登录JS渲染爬取AJAX异步加载网页pyspider简介
Pyspider 是 Binux 制作的爬虫架构的开源实现。主要功能有:
Pyspider使用去重调度、队列抓取、异常处理、监控等功能作为框架,只需要提供抓取脚本,保证灵活性即可。最后,web的编辑调试环境和web任务的监控成为框架。pyspider的设计基础是:一个python脚本驱动的抓环模型爬虫
pyspider 接口
在终端输入pyspider all运行pyspider服务,然后在浏览器中输入localhost:5000就可以看到pyspider的界面,rate用来控制每秒爬取的页面数,burst可以看做是并发控制。
点击create创建项目
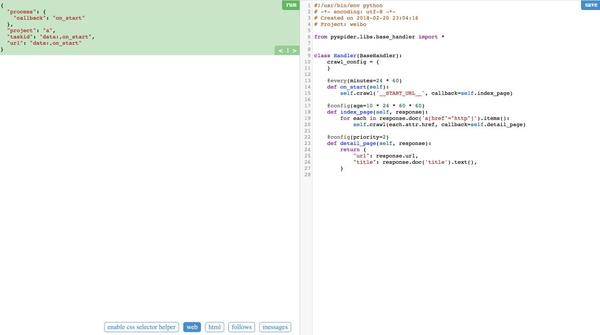
点击新建项目,打开脚本编辑界面
我们可以在这里编写和调试脚本。网络可以在测试期间显示网页。网页左侧的按钮是css选择器,html是网页的源代码,followers显示可以爬取的url。具体调试,亲身体验就知道了。
pyspider 脚本
但是当你创建一个新项目时,你会看到这些默认的脚本模板。接下来简单介绍一下pyspider脚本的编写。
from pyspider.libs.base_handler import *class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60) def on_start(self):
self.crawl('__START_URL__', callback=self.index_page)
@config(age=10 * 24 * 60 * 60) def index_page(self, response): for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2) def detail_page(self, response): return { "url": response.url, "title": response.doc('title').text(),
}
更多参数用法可以查看官方文档。
index_page 和 detail_page 只是初始脚本中的回调函数。除了on_start,其他函数名可以自定义@every(minutes=24 * 60)来设置执行频率(24*60是一天一次,所以可以每天执行一次) 爬取一次获取数据) @config 模拟登录
有很多网站用户需要登录才能浏览更多内容,所以我们的爬虫需要实现模拟登录的功能,我们可以使用selenium来实现模拟登录。
Selenium 是一个 Web 应用测试的工具,我们也可以通过 selenium 来实现登录功能。以微博为例
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://weibo.com/")
username = driver.find_element_by_css_selector("input#loginname")
username.clear()
username.send_keys('your_username')
password = driver.find_element_by_css_selector('span.enter_psw')
password.clear()
password.send_keys('your_password')
输入帐号和密码后,最大的问题来了。验证码都是图片。一般我们需要使用图像识别来识别验证码,但是由于验证码的种类很多(英文、数字、中文或者它们的混合),而且验证码也可能会被旋转、扭曲甚至附着在每个其他,以至于人眼不能很好的识别,所以大部分模型的通用性和准确率都不是很高。因此,最有效的方法是在selenium打开浏览器后手动登录(过程中调用time.sleep()暂停程序)。由于爬虫最重要的不是解决登录问题,这样就节省了很多时间和代码,虽然笨但很有用。
登录后,使用代码获取cookie,并在pyspider全局参数中将cookie_dict传递给cookies。
cookies_dict = {}
cookies = driver.get_cookies()for cookie in cookies:
cookies_dict[cookie['name']] = cookie['value']
JS渲染
普通请求只能爬取静态的HTML页面,但是大部分网站都是混着JS数据加载的,数据是懒加载的。如果要爬取这些内容,可以使用 selenium + PhantomJS 将网页完整渲染,然后再进行网页分析。PhantomJS 是一个非接口、可编写脚本的 WebKit 浏览器引擎。使用方法类似于使用 selenium + Chrome 模拟登录,但由于 PhantomJS 没有接口,内存消耗会少很多。
爬取 AJAX 以异步加载网页
AJAX 是一种用于创建快速和动态网页的技术。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。要爬取AJAX异步加载的网页,我们需要分析网页的请求和返回信息。具体来说,我们需要使用谷歌浏览器的开发者工具(火狐等浏览器也有这个)查看网络的XHR,但是当网页部分更新时,浏览器发出了什么请求,返回了什么通过浏览器。
在我们微博登录的首页,只要将滚动条移到最下方,就会发现刷新了一条新的微博。这是我们打开开发者工具一直往下滚动,然后你会发现,但是你刷出来的时候有新的信息,总是发出新的请求,返回的json中的数据就是刷新微博的html .
仔细观察发现pagebar的变化是有规律的,id减15,对应新刷新的15微博。因此,可以推测pagebar应该是刷新微博的关键。在此之前,我们需要给爬虫添加请求头,否则很可能被服务器识别为机器人,无法成功访问。请求标头也可以在开发者工具中找到。
def on_start(self): for i in range(10):
url = 'https://weibo.com/aj/mblog/fse ... B%25i
self.crawl(url, callback=self.index_page)
发现微博内容被成功抓取并返回。然后只需处理您需要的信息。 查看全部
js 爬虫抓取网页数据(本文接上文分享:pyspider界面pyspider模拟登录渲染爬取AJAX异步加载网页pyspider)
这篇文章继续上面的内容,继续聊聊python爬虫的相关知识。上一篇是关于各种爬虫库的。本文主要介绍一个好用的框架pyspider,标题如下:
pyspider简介Pyspider接口pyspider脚本模拟登录JS渲染爬取AJAX异步加载网页pyspider简介
Pyspider 是 Binux 制作的爬虫架构的开源实现。主要功能有:
Pyspider使用去重调度、队列抓取、异常处理、监控等功能作为框架,只需要提供抓取脚本,保证灵活性即可。最后,web的编辑调试环境和web任务的监控成为框架。pyspider的设计基础是:一个python脚本驱动的抓环模型爬虫
pyspider 接口
在终端输入pyspider all运行pyspider服务,然后在浏览器中输入localhost:5000就可以看到pyspider的界面,rate用来控制每秒爬取的页面数,burst可以看做是并发控制。

点击create创建项目
点击新建项目,打开脚本编辑界面
我们可以在这里编写和调试脚本。网络可以在测试期间显示网页。网页左侧的按钮是css选择器,html是网页的源代码,followers显示可以爬取的url。具体调试,亲身体验就知道了。
pyspider 脚本
但是当你创建一个新项目时,你会看到这些默认的脚本模板。接下来简单介绍一下pyspider脚本的编写。
from pyspider.libs.base_handler import *class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60) def on_start(self):
self.crawl('__START_URL__', callback=self.index_page)
@config(age=10 * 24 * 60 * 60) def index_page(self, response): for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2) def detail_page(self, response): return { "url": response.url, "title": response.doc('title').text(),
}
更多参数用法可以查看官方文档。
index_page 和 detail_page 只是初始脚本中的回调函数。除了on_start,其他函数名可以自定义@every(minutes=24 * 60)来设置执行频率(24*60是一天一次,所以可以每天执行一次) 爬取一次获取数据) @config 模拟登录
有很多网站用户需要登录才能浏览更多内容,所以我们的爬虫需要实现模拟登录的功能,我们可以使用selenium来实现模拟登录。
Selenium 是一个 Web 应用测试的工具,我们也可以通过 selenium 来实现登录功能。以微博为例
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://weibo.com/";)
username = driver.find_element_by_css_selector("input#loginname")
username.clear()
username.send_keys('your_username')
password = driver.find_element_by_css_selector('span.enter_psw')
password.clear()
password.send_keys('your_password')
输入帐号和密码后,最大的问题来了。验证码都是图片。一般我们需要使用图像识别来识别验证码,但是由于验证码的种类很多(英文、数字、中文或者它们的混合),而且验证码也可能会被旋转、扭曲甚至附着在每个其他,以至于人眼不能很好的识别,所以大部分模型的通用性和准确率都不是很高。因此,最有效的方法是在selenium打开浏览器后手动登录(过程中调用time.sleep()暂停程序)。由于爬虫最重要的不是解决登录问题,这样就节省了很多时间和代码,虽然笨但很有用。
登录后,使用代码获取cookie,并在pyspider全局参数中将cookie_dict传递给cookies。
cookies_dict = {}
cookies = driver.get_cookies()for cookie in cookies:
cookies_dict[cookie['name']] = cookie['value']
JS渲染
普通请求只能爬取静态的HTML页面,但是大部分网站都是混着JS数据加载的,数据是懒加载的。如果要爬取这些内容,可以使用 selenium + PhantomJS 将网页完整渲染,然后再进行网页分析。PhantomJS 是一个非接口、可编写脚本的 WebKit 浏览器引擎。使用方法类似于使用 selenium + Chrome 模拟登录,但由于 PhantomJS 没有接口,内存消耗会少很多。
爬取 AJAX 以异步加载网页
AJAX 是一种用于创建快速和动态网页的技术。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。要爬取AJAX异步加载的网页,我们需要分析网页的请求和返回信息。具体来说,我们需要使用谷歌浏览器的开发者工具(火狐等浏览器也有这个)查看网络的XHR,但是当网页部分更新时,浏览器发出了什么请求,返回了什么通过浏览器。
在我们微博登录的首页,只要将滚动条移到最下方,就会发现刷新了一条新的微博。这是我们打开开发者工具一直往下滚动,然后你会发现,但是你刷出来的时候有新的信息,总是发出新的请求,返回的json中的数据就是刷新微博的html .




仔细观察发现pagebar的变化是有规律的,id减15,对应新刷新的15微博。因此,可以推测pagebar应该是刷新微博的关键。在此之前,我们需要给爬虫添加请求头,否则很可能被服务器识别为机器人,无法成功访问。请求标头也可以在开发者工具中找到。
def on_start(self): for i in range(10):
url = 'https://weibo.com/aj/mblog/fse ... B%25i
self.crawl(url, callback=self.index_page)
发现微博内容被成功抓取并返回。然后只需处理您需要的信息。
js 爬虫抓取网页数据(js爬虫抓取网页数据,其实也是需要构建数据库的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-15 02:00
js爬虫抓取网页数据,其实也是需要构建网页数据库的,然后将抓取的数据放入数据库进行数据的存储。最常见的数据库是mysql。而javaredis这些应用,只是会使用java语言来实现一个容器,然后将数据进行读写操作,并不会直接提供数据库功能。因此可以通过使用spring+mybatis等框架对于数据库进行操作。
这里面使用spring作为核心,可以轻松实现一个spring中的数据库操作对象,并且提供mybatis标准类库,来封装其他同类型的开发接口。不要觉得这里列举的东西很简单,其实背后需要用到的资料很多,比如利用druid轻松实现批量加载数据。按f5键提取数据并按enter回车查询,不要给sql语句加上#,#或等符号,会报错。
如果字符串允许标点符号,还要使用一个formitem去解析。index.sql从新建数据库或webserver中导入数据源,保存至spring的配置文件当中importjava.io.file;importjava.io.filereader;importjava.io.filewriter;importjava.io.filewriterlistener;importorg.springframework.beans.factory.annotation.annotationmethod;importorg.springframework.beans.factory.annotation.annotation;importjava.lang.string;importjava.lang.stringbuffer;importjava.util.list;importjava.util.listener;importorg.springframework.stereotype.scope.scoped;importorg.springframework.stereotype.scope.wrapper;importjava.util.list;importjava.util.listener;importjava.util.filesystem;importorg.springframework.annotation.windowshooks.bindinputwithobjectwithunimmediatewithfileinputwithobject(windowsize_inches);importjava.util.filesystem;importjava.util.filesystem;importjava.util.filesystem;importjava.util.filesystem;importorg.springframework.web.filesystem;importorg.springframework.web.filesystem;importorg.springframework.web.filesystem;/***@author小琪**/@webmvcconfigurationpublicclasswebmvcconfig{privatestaticspringapplicationcontextcontext=newspringapplicationcontext();@beanpublicindivisiblewebmodeviewmockviewmodeview(webmvcconfigcontext){indivisiblewebmodeviewmyviewmodeview=newindivisiblewebmodeview(context);myviewmodeview.init();returnmyviewmodeview;}@beanpublicthepredefineds。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,其实也是需要构建数据库的)
js爬虫抓取网页数据,其实也是需要构建网页数据库的,然后将抓取的数据放入数据库进行数据的存储。最常见的数据库是mysql。而javaredis这些应用,只是会使用java语言来实现一个容器,然后将数据进行读写操作,并不会直接提供数据库功能。因此可以通过使用spring+mybatis等框架对于数据库进行操作。
这里面使用spring作为核心,可以轻松实现一个spring中的数据库操作对象,并且提供mybatis标准类库,来封装其他同类型的开发接口。不要觉得这里列举的东西很简单,其实背后需要用到的资料很多,比如利用druid轻松实现批量加载数据。按f5键提取数据并按enter回车查询,不要给sql语句加上#,#或等符号,会报错。
如果字符串允许标点符号,还要使用一个formitem去解析。index.sql从新建数据库或webserver中导入数据源,保存至spring的配置文件当中importjava.io.file;importjava.io.filereader;importjava.io.filewriter;importjava.io.filewriterlistener;importorg.springframework.beans.factory.annotation.annotationmethod;importorg.springframework.beans.factory.annotation.annotation;importjava.lang.string;importjava.lang.stringbuffer;importjava.util.list;importjava.util.listener;importorg.springframework.stereotype.scope.scoped;importorg.springframework.stereotype.scope.wrapper;importjava.util.list;importjava.util.listener;importjava.util.filesystem;importorg.springframework.annotation.windowshooks.bindinputwithobjectwithunimmediatewithfileinputwithobject(windowsize_inches);importjava.util.filesystem;importjava.util.filesystem;importjava.util.filesystem;importjava.util.filesystem;importorg.springframework.web.filesystem;importorg.springframework.web.filesystem;importorg.springframework.web.filesystem;/***@author小琪**/@webmvcconfigurationpublicclasswebmvcconfig{privatestaticspringapplicationcontextcontext=newspringapplicationcontext();@beanpublicindivisiblewebmodeviewmockviewmodeview(webmvcconfigcontext){indivisiblewebmodeviewmyviewmodeview=newindivisiblewebmodeview(context);myviewmodeview.init();returnmyviewmodeview;}@beanpublicthepredefineds。
js 爬虫抓取网页数据(网络爬虫的三个优点代码简单明了适合python的语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-14 14:24
一、爬虫介绍
根据百度百科的定义:网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常被称为网络追逐者),是根据一定的规则或脚本自动爬取万维网上信息的程序. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
二、适合爬虫的几种语言1.phantomjs
2017 年 4 月,该语言的核心开发者之一 Vitaly 辞去维护工作,表示不再维护。其原话如下:
我看不到 PhantomJS 的未来,作为一个单独的开发者在 PhantomJS 2 和 2.5 上工作简直就是地狱。即使最近发布了带有新的、闪亮的 QtWebKit 的 2.5 Beta 版本,我仍然不能真正支持 3 个平台。我们没有其他势力支持!
并且 Vitaly 发帖称 Chrome 59 将支持无头模式,用户最终会转向它。Chrome 比 PhantomJS 更快更稳定,不会像 PhantomJS 那样吃内存,但不代表语言结束,语言还是可以用的
2.casperJS
CasperJs 是基于 PhantomJs 的工具,可以比 PhantomJs 更方便的导航。就个人而言,我对这门语言了解不多,也没有过多阐述。
3.nodejs
nodejs适合垂直爬取,分布式爬取难度较大,对部分功能支持较弱,不推荐使用
4.Python
我喜欢python的语言,强烈推荐使用python,尤其是它的语言爬虫框架scrapy特别值得学习。支持xpath,可以定义多个爬虫,支持多线程爬取等,以后我会一步步入手。流程发给大家,附上源码
ps:另外可以使用c++、PHP、java等语言爬取网页。爬虫因人而异。我推荐的不一定是最好的。
三、python爬虫的优点
代码简洁明了,适合根据实际情况快速修改代码。网络的内容和布局会随时变化。python的快速发展是有优势的。如果不加修改或者少加修改写得好,其他高性能语言更有优势。(来自 知乎)
1)相比其他静态编程语言,如java、c#、C++、python,爬取网页的界面更加简洁;与其他动态脚本语言相比,如perl、shell、python urllib2 包提供了比较完整的访问web 文档的API。(当然,ruby 也是一个不错的选择。)另外,爬取网页有时需要模拟浏览器的行为,很多网站都被屏蔽了用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理 抓取的网页通常需要进行处理,例如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。(摘自博客园)
以上就是前人为我们总结的诸多优势。我整理了其中两个供大家参考。
四、后续安排 查看全部
js 爬虫抓取网页数据(网络爬虫的三个优点代码简单明了适合python的语言)
一、爬虫介绍
根据百度百科的定义:网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常被称为网络追逐者),是根据一定的规则或脚本自动爬取万维网上信息的程序. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
二、适合爬虫的几种语言1.phantomjs
2017 年 4 月,该语言的核心开发者之一 Vitaly 辞去维护工作,表示不再维护。其原话如下:
我看不到 PhantomJS 的未来,作为一个单独的开发者在 PhantomJS 2 和 2.5 上工作简直就是地狱。即使最近发布了带有新的、闪亮的 QtWebKit 的 2.5 Beta 版本,我仍然不能真正支持 3 个平台。我们没有其他势力支持!
并且 Vitaly 发帖称 Chrome 59 将支持无头模式,用户最终会转向它。Chrome 比 PhantomJS 更快更稳定,不会像 PhantomJS 那样吃内存,但不代表语言结束,语言还是可以用的
2.casperJS
CasperJs 是基于 PhantomJs 的工具,可以比 PhantomJs 更方便的导航。就个人而言,我对这门语言了解不多,也没有过多阐述。
3.nodejs
nodejs适合垂直爬取,分布式爬取难度较大,对部分功能支持较弱,不推荐使用
4.Python
我喜欢python的语言,强烈推荐使用python,尤其是它的语言爬虫框架scrapy特别值得学习。支持xpath,可以定义多个爬虫,支持多线程爬取等,以后我会一步步入手。流程发给大家,附上源码
ps:另外可以使用c++、PHP、java等语言爬取网页。爬虫因人而异。我推荐的不一定是最好的。
三、python爬虫的优点
代码简洁明了,适合根据实际情况快速修改代码。网络的内容和布局会随时变化。python的快速发展是有优势的。如果不加修改或者少加修改写得好,其他高性能语言更有优势。(来自 知乎)
1)相比其他静态编程语言,如java、c#、C++、python,爬取网页的界面更加简洁;与其他动态脚本语言相比,如perl、shell、python urllib2 包提供了比较完整的访问web 文档的API。(当然,ruby 也是一个不错的选择。)另外,爬取网页有时需要模拟浏览器的行为,很多网站都被屏蔽了用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理 抓取的网页通常需要进行处理,例如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。(摘自博客园)
以上就是前人为我们总结的诸多优势。我整理了其中两个供大家参考。
四、后续安排
js 爬虫抓取网页数据(从爬虫抓取到索引期间到底经过了哪些步骤,为什么网页但不收录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-13 23:16
从爬取到索引的步骤是什么,为什么是网页爬取而不是收录?今天我就结合SEO数据,说说为什么你的页面爬虫爬了1000次,却不是收录!
从之前优化的页面中取出一个案例详情页面(/35950345.html),我将描述普通页面收录的路径:
99高级爬虫抓取IP段:111.206.221.27————111.206.198.125Finally完成收录,抓取IP段:220.181.108.99 Advanced UA的IP:111.206.221.27————111.206. 198.125(截图时间) 注:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密; 还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)@1.108.99 高级UA的IP:111.206.221.27————111.206. 198.125(快照时间) 注意:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密;还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)@1.108.99 高级UA的IP:111.206.221.27————111.206. 198.125(快照时间) 注意:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密;还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)
如果不了解爬虫蜘蛛的UA和IP段,可以看看国内主流搜索引擎的UA和对应的蜘蛛IP段。
说完了正例,再来说说为什么页面还是爬不上1000次收录,我们先来看下面的优化案例: URLpathname:/news/t-35950346.html
二级目录文章详情页,内链非常丰富,百度蜘蛛总共爬取816次(平均每天100次),IP段和爬取路径没有问题,但是结果不是 收录@ >。
爬虫爬到收录的日志分析
问题分析一:把标题放在百度上搜索,搜索结果都是网站内详情页链接的锚文本,但是在内容页找不到锚文本,所以打开百度快照,问题部分解决
分析结果1:由于爬虫第一次爬取的内容与第二次爬取的内容页面不一致(多见于网站detail页面,内部链接数不足),可以查看PC页面与M站页面收录综合对比(PC收录,M站不接受)。
解决方案一:优化内部链接以匹配站点内的更新频率(有时可能需要更改子目录,常用于大型站点)
--------------华丽的分割线-------------
问题分析2:同样的问题,如果没有页面不一致,分析高级爬虫UA看页面是否收录动态参数或者JS渲染隐藏数据,导致页面不一致,可以通过请求数据的大小来判断
分析结果2:看页面JS对页面主要内容的具体影响。动态 URL 参数优化同样重要。PC端和M端数据分开比较也比较好。
方案二:优化页面JS或者爬虫显示优化。
大展页面不收录详细分析——也有可能出现问题:页面主要内容的布局,内容的可读性。
如果觉得有点难,可以看一个简单的逻辑分析:蜘蛛爬还是不爬收录原因 查看全部
js 爬虫抓取网页数据(从爬虫抓取到索引期间到底经过了哪些步骤,为什么网页但不收录?)
从爬取到索引的步骤是什么,为什么是网页爬取而不是收录?今天我就结合SEO数据,说说为什么你的页面爬虫爬了1000次,却不是收录!
从之前优化的页面中取出一个案例详情页面(/35950345.html),我将描述普通页面收录的路径:
99高级爬虫抓取IP段:111.206.221.27————111.206.198.125Finally完成收录,抓取IP段:220.181.108.99 Advanced UA的IP:111.206.221.27————111.206. 198.125(截图时间) 注:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密; 还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)@1.108.99 高级UA的IP:111.206.221.27————111.206. 198.125(快照时间) 注意:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密;还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)@1.108.99 高级UA的IP:111.206.221.27————111.206. 198.125(快照时间) 注意:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密;还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)
如果不了解爬虫蜘蛛的UA和IP段,可以看看国内主流搜索引擎的UA和对应的蜘蛛IP段。
说完了正例,再来说说为什么页面还是爬不上1000次收录,我们先来看下面的优化案例: URLpathname:/news/t-35950346.html
二级目录文章详情页,内链非常丰富,百度蜘蛛总共爬取816次(平均每天100次),IP段和爬取路径没有问题,但是结果不是 收录@ >。
爬虫爬到收录的日志分析
问题分析一:把标题放在百度上搜索,搜索结果都是网站内详情页链接的锚文本,但是在内容页找不到锚文本,所以打开百度快照,问题部分解决

分析结果1:由于爬虫第一次爬取的内容与第二次爬取的内容页面不一致(多见于网站detail页面,内部链接数不足),可以查看PC页面与M站页面收录综合对比(PC收录,M站不接受)。
解决方案一:优化内部链接以匹配站点内的更新频率(有时可能需要更改子目录,常用于大型站点)
--------------华丽的分割线-------------
问题分析2:同样的问题,如果没有页面不一致,分析高级爬虫UA看页面是否收录动态参数或者JS渲染隐藏数据,导致页面不一致,可以通过请求数据的大小来判断

分析结果2:看页面JS对页面主要内容的具体影响。动态 URL 参数优化同样重要。PC端和M端数据分开比较也比较好。
方案二:优化页面JS或者爬虫显示优化。
大展页面不收录详细分析——也有可能出现问题:页面主要内容的布局,内容的可读性。
如果觉得有点难,可以看一个简单的逻辑分析:蜘蛛爬还是不爬收录原因
js 爬虫抓取网页数据(Python调用Phantomjs搭一个代理的部分拆了出来的模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-11 10:29
最近需要爬取某个网站,可惜页面都是JS渲染后生成的,普通爬虫框架处理不了,于是想到了用Phantomjs搭建代理。
貌似没有现成的Python调用Phantomjs的第三方库(如果有,请告知小编)。逛了一圈,发现只有pyspider提供了现成的解决方案。
简单试用了一下,感觉pyspider更像是新手的爬虫工具,像个老妈妈,时而细致,时而喋喋不休。轻量级的小工具应该更受欢迎。我也有一点自私。可以一起使用我最喜欢的BeautifulSoup,而不用学习PyQuery(pyspider是用来解析HTML的),也不必忍受浏览器写Python。糟糕的经历(窃笑)。
于是花了一个下午把pyspider实现Phantomjs代理的部分拆解,做成一个小的爬虫模块。我希望每个人都会喜欢它(感谢 binux!)。
准备好工作了
当然你有 Phantomjs,废话!(Linux下最好使用supervisord来守护,爬取时必须保持打开Phantomjs)
以项目路径中的 phantomjs_fetcher.js 开头:phantomjs phantomjs_fetcher.js [port]
安装 tornado 依赖项(使用 tornado 的 httpclient 模块)
调用超级简单
from tornado_fetcher import Fetcher
# 创建一个爬虫
>>> fetcher=Fetcher(
user_agent='phantomjs', # 模拟浏览器的User-Agent
phantomjs_proxy='http://localhost:12306', # phantomjs的地址
poolsize=10, # 最大的httpclient数量
async=False # 同步还是异步
)
# 开始连接Phantomjs的代码,可以渲染JS!
>>> fetcher.fetch(url)
# 渲染成功后执行额外的JS脚本(注意用function包起来!)
>>> fetcher.fetch(url, js_script='function(){setTimeout("window.scrollTo(0,100000)}", 1000)')
代码 查看全部
js 爬虫抓取网页数据(Python调用Phantomjs搭一个代理的部分拆了出来的模块)
最近需要爬取某个网站,可惜页面都是JS渲染后生成的,普通爬虫框架处理不了,于是想到了用Phantomjs搭建代理。
貌似没有现成的Python调用Phantomjs的第三方库(如果有,请告知小编)。逛了一圈,发现只有pyspider提供了现成的解决方案。
简单试用了一下,感觉pyspider更像是新手的爬虫工具,像个老妈妈,时而细致,时而喋喋不休。轻量级的小工具应该更受欢迎。我也有一点自私。可以一起使用我最喜欢的BeautifulSoup,而不用学习PyQuery(pyspider是用来解析HTML的),也不必忍受浏览器写Python。糟糕的经历(窃笑)。
于是花了一个下午把pyspider实现Phantomjs代理的部分拆解,做成一个小的爬虫模块。我希望每个人都会喜欢它(感谢 binux!)。
准备好工作了
当然你有 Phantomjs,废话!(Linux下最好使用supervisord来守护,爬取时必须保持打开Phantomjs)
以项目路径中的 phantomjs_fetcher.js 开头:phantomjs phantomjs_fetcher.js [port]
安装 tornado 依赖项(使用 tornado 的 httpclient 模块)
调用超级简单
from tornado_fetcher import Fetcher
# 创建一个爬虫
>>> fetcher=Fetcher(
user_agent='phantomjs', # 模拟浏览器的User-Agent
phantomjs_proxy='http://localhost:12306', # phantomjs的地址
poolsize=10, # 最大的httpclient数量
async=False # 同步还是异步
)
# 开始连接Phantomjs的代码,可以渲染JS!
>>> fetcher.fetch(url)
# 渲染成功后执行额外的JS脚本(注意用function包起来!)
>>> fetcher.fetch(url, js_script='function(){setTimeout("window.scrollTo(0,100000)}", 1000)')
代码
js 爬虫抓取网页数据( 学爬虫的流程简单来说获取网页并提取和保存信息程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-10 04:15
学爬虫的流程简单来说获取网页并提取和保存信息程序)
总之,爬虫可以帮助我们快速提取并保存网站上的信息。
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬虫爬到这个页面就相当于访问了这个页面,它可以提取网页上的信息。我们可以将节点之间的连接比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着该节点连接爬行到达下一个节点,即继续获取后续web页面通过一个网页,这样整个web的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫是干什么用的?
通过以上的话,大家可能对爬虫是做什么的有了初步的了解,但是一般我们要学一件事,我们要知道怎么处理它,对吧?
事实上,爬行动物更有用。
此外,还有很多其他的技术,比如黄牛抢票、自助抢课、网站排名等技术也离不开爬虫。爬虫的用处可以说是非常大了。可以说大家应该都知道点击爬虫了。
另外,学习爬虫也可以顺便帮助我们学习Python。要学习爬虫,我的第一个建议是 Python 语言。如果对 Python 不熟悉也没关系,爬虫作为学习 Python 的一种方式非常适合。你可以同时学习爬虫和Python。
不仅如此,爬虫技术和其他领域几乎都有交集,比如前端和后端web开发、数据库、数据分析、人工智能、运维、安全等领域都和爬虫有关,所以学好爬虫相当于它也为其他领域铺平了一步,以后如果想进入其他领域,可以更轻松的连接。Python爬虫是学习计算机的很好的入门方向之一。
2. 爬虫进程
简单来说,爬虫是一个自动程序,它获取网页并提取和保存信息,如下所述。
(1) 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
当我们用浏览器浏览网页时,浏览器实际上为我们模拟了这个过程。浏览器一一向服务器发送请求,返回的响应体就是网页的源代码,然后由浏览器解析和渲染。所以,我们要做的爬虫其实和浏览器差不多。获取网页的源代码并解析内容是好的,但是我们使用的不是浏览器,而是Python。
刚才说了,最关键的部分是构造一个请求并发送给服务器,然后接收并解析响应,那么如何在Python中实现这个过程呢?
Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以使用这些库来实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的body部分,即得到网页的源代码,这样我们就可以使用程序来实现获取网页的过程。
(2) 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫中非常重要的一个环节,它可以让杂乱的数据变得有条不紊、清晰明了,方便我们后期对数据进行处理和分析。
(3) 保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
(4) 自动化
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
3. 我可以爬取什么样的数据?
我们可以在网页中看到各种信息,最常见的是常规网页,它们对应的是HTML代码,最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
4. 总结
本节结束,我们对爬虫有了基本的了解,让我们一起走进爬虫学习的世界吧! 查看全部
js 爬虫抓取网页数据(
学爬虫的流程简单来说获取网页并提取和保存信息程序)
总之,爬虫可以帮助我们快速提取并保存网站上的信息。
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬虫爬到这个页面就相当于访问了这个页面,它可以提取网页上的信息。我们可以将节点之间的连接比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着该节点连接爬行到达下一个节点,即继续获取后续web页面通过一个网页,这样整个web的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫是干什么用的?
通过以上的话,大家可能对爬虫是做什么的有了初步的了解,但是一般我们要学一件事,我们要知道怎么处理它,对吧?
事实上,爬行动物更有用。
此外,还有很多其他的技术,比如黄牛抢票、自助抢课、网站排名等技术也离不开爬虫。爬虫的用处可以说是非常大了。可以说大家应该都知道点击爬虫了。
另外,学习爬虫也可以顺便帮助我们学习Python。要学习爬虫,我的第一个建议是 Python 语言。如果对 Python 不熟悉也没关系,爬虫作为学习 Python 的一种方式非常适合。你可以同时学习爬虫和Python。
不仅如此,爬虫技术和其他领域几乎都有交集,比如前端和后端web开发、数据库、数据分析、人工智能、运维、安全等领域都和爬虫有关,所以学好爬虫相当于它也为其他领域铺平了一步,以后如果想进入其他领域,可以更轻松的连接。Python爬虫是学习计算机的很好的入门方向之一。
2. 爬虫进程
简单来说,爬虫是一个自动程序,它获取网页并提取和保存信息,如下所述。
(1) 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
当我们用浏览器浏览网页时,浏览器实际上为我们模拟了这个过程。浏览器一一向服务器发送请求,返回的响应体就是网页的源代码,然后由浏览器解析和渲染。所以,我们要做的爬虫其实和浏览器差不多。获取网页的源代码并解析内容是好的,但是我们使用的不是浏览器,而是Python。
刚才说了,最关键的部分是构造一个请求并发送给服务器,然后接收并解析响应,那么如何在Python中实现这个过程呢?
Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以使用这些库来实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的body部分,即得到网页的源代码,这样我们就可以使用程序来实现获取网页的过程。
(2) 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫中非常重要的一个环节,它可以让杂乱的数据变得有条不紊、清晰明了,方便我们后期对数据进行处理和分析。
(3) 保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
(4) 自动化
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
3. 我可以爬取什么样的数据?
我们可以在网页中看到各种信息,最常见的是常规网页,它们对应的是HTML代码,最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
4. 总结
本节结束,我们对爬虫有了基本的了解,让我们一起走进爬虫学习的世界吧!
js 爬虫抓取网页数据(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-04-09 20:36
概述:
这是pycharm在phthon环境下做的一个简单的爬虫分享。主要通过爬取豆瓣音乐top250的歌名和作者(专辑)来分析爬虫原理
什么是爬行动物?
要想学爬虫,首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
中文名网络爬虫,外文名网络爬虫,网络蜘蛛的别称,目的是根据需要从万维网获取信息
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
准备好工作了:
我们使用的是pycharm,可以参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看它的官方文档:
个人觉得用lxml解析网页是最快的。对于lxml的使用,可以看这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
废话不多说,开始我们的爬虫之旅吧
首先找到我们的目标网址:
可以看到我们要获取的歌名和作者(专辑)页面有十页,每页有十行
所以我们可以使用for循环来获取目标:
然后使用 requests 请求网页:
1import requests
2
1headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
2
1data = requests.get(url, headers=headers).text
2
然后使用lxml解析网页:
1from lxml import etree
2
1s = etree.HTML(data)
2
然后我们就可以提取我们想要的数据了
最后,将获取的数据保存到我们想要放置的位置。
至此,我们基本大功告成,完整代码如下:
然后看看我们爬取的结果
总结:
爬虫流程:
1、提出请求 查看全部
js 爬虫抓取网页数据(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
概述:
这是pycharm在phthon环境下做的一个简单的爬虫分享。主要通过爬取豆瓣音乐top250的歌名和作者(专辑)来分析爬虫原理
什么是爬行动物?
要想学爬虫,首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
中文名网络爬虫,外文名网络爬虫,网络蜘蛛的别称,目的是根据需要从万维网获取信息
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
准备好工作了:
我们使用的是pycharm,可以参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看它的官方文档:
个人觉得用lxml解析网页是最快的。对于lxml的使用,可以看这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
废话不多说,开始我们的爬虫之旅吧
首先找到我们的目标网址:
可以看到我们要获取的歌名和作者(专辑)页面有十页,每页有十行
所以我们可以使用for循环来获取目标:
然后使用 requests 请求网页:
1import requests
2
1headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
2
1data = requests.get(url, headers=headers).text
2
然后使用lxml解析网页:
1from lxml import etree
2
1s = etree.HTML(data)
2
然后我们就可以提取我们想要的数据了
最后,将获取的数据保存到我们想要放置的位置。
至此,我们基本大功告成,完整代码如下:
然后看看我们爬取的结果
总结:
爬虫流程:
1、提出请求
js 爬虫抓取网页数据(爬虫就是模拟人的访问操作来获取网页/App数据的一种程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2022-04-07 09:15
摘要:爬虫是一种模拟人类访问操作以获取网页/App数据的程序。什么是爬行动物?
简单来说,爬虫就是模拟人类访问操作来获取网页/App数据的程序。我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!??¤
QQ群:961562169
我们平时看到的搜索引擎、统计数据、旅游软件、聚合平台,都离不开网络爬虫。
爬虫的应用领域有哪些?
我们常见的应用场景的一个简单例子如下:
1.搜索引擎抓取网页
2.旅游软件通过爬虫抢票
3.论坛或微博舆情监测。利用数据采集技术监测搜索引擎、新闻门户、论坛、博客、微博、微信、报纸、视频的舆情。说白了就是用来实现实时发现某个行业或地区的热点事件,比如青博舆情、百度舆情等。
4.价格比较网站 应用。如今,各大电商平台针对活跃用户开展了各种秒杀活动和优惠券。同一种产品在不同的网购平台上可能会有不同的价格。那么这些网站是如何在几分钟甚至几秒内就知道某款产品在某站打折的呢?这就需要一个data采集系统(爬虫)来实时监控各个站的价格波动。首先采集商品的价格、型号、配置等,然后进行处理、分析和反馈。
为什么要学习爬行?
互联网的飞速发展带来了前所未有的便利,但也带来了许多以前没有遇到过的新问题。获取信息的成本越来越低,信息的种类和数量越来越多,但我们对信息的处理能力并没有提高,很难从信息中提取出我们感兴趣的东西。
学习爬虫可以自动高效地获取我们在互联网上感兴趣的内容,帮助我们快速建立自己的信息知识库。
如何完成一个轻量级爬虫
这里简要概述三个步骤:获取数据-解析数据-存储数据。以下是完成这些步骤所涉及的工具供您参考。
获取数据:urllib2、Requests、Selenium、aiohttp
获取数据的工具:Chrome、Fiddler、MitmProxy、Appium
解析数据:CSS 选择器、PyQuery、BeautifulSoup、Xpath、Re
存储数据:MySQL、MongoDB、Redis
工程爬行动物
工程爬虫项目推荐:Scrapy、PySpider
官方文档:,
Github地址:,
反爬虫措施和应对措施
1.网页反爬虫-字体反爬虫
开发者可以使用@font-face为网页指定字体,也可以调用自定义字体文件来渲染网页中的文字,网页中的文字就变成了对应的代码。这时候,通过一个简单的网页 采集 无法获取编码后的网页内容。
对策:字体反爬相比其他反爬,难度属于比较初级的阶段,主要是处理起来比较麻烦,防御型的网站往往不止一个网站. 设置不同的字体加密防御系统,比如135配A方案,246配B方案,这需要一定的耐心去分析字体的规则,用Python解析字体文件,找到映射规则来解决。
推荐工具:fontTools、百度字体编辑器()
2.网页反爬虫-验证码
验证码是一种公共的自动程序,用于区分用户是计算机还是人。常见的验证码包括:多位混合验证码、滑动验证码、点击验证码、旋转验证码等。
对策:如果项目预算充足,可以连接专业的编码平台,减少90%的工作量;如果预算不足,可以使用华为云ModelArts完成模型搭建,无需编写一行代码
推荐工具:华为云ModelArts、CC框架
3.网页反爬虫-JS加密/混淆
前端代码是公开的,那么加密有意义吗?是的,通过从代码中删除尽可能多的有意义的信息,例如注释、换行符、空格、代码减号、变量重命名、属性重命名(如果允许)以及无用的代码删除,以尽可能多地增加爬虫的数量可能 工程师阅读代码的成本。
对策:对于轻度到中度混淆或混淆代码,可以阅读混淆代码,梳理加密逻辑,扣除可运行的Js代码,使用Python库调用完成加密参数的生成;对于严重混淆,使用AST语法树恢复混淆代码,去除无意义的垃圾代码,恢复清晰的加密逻辑,并使用Python库调用完成加密参数的生成。
推荐工具:AST、PyExecJS
4.APP反爬虫
都2020年了,还有没有通过应用市场下载的不带壳的APP?除了外壳保护,常见的APP还应用单向或双向证书验证。简单的中间人攻击已经无法捕获APP数据包,学习APP逆向工程势在必行。
对策:APP逆向工程需要学习的内容很多。这里简单总结一下抓不到的APP包(推荐工具:Frida、Xposed、IDA、jadx、Charles):
【单向认证和双向认证】
在单向验证的情况下,客户端验证证书,如果验证失败,则无法访问。
在双向认证的情况下,当客户端验证证书时,服务器也会验证证书。如果证书的一端无法验证证书,则无法访问数据。缺点是服务器压力比较大
处理方式:一般使用JustTrustMe,原理是Xpose Hook验证的API。
【APP不走代理——如何保证APP不走代理?】
(1)关闭代理服务器(fiddler等代理抓包工具)(2)用手机访问浏览器网页访问失败,判断代理无效(3)使用APP访问,正常访问确认APP不工作)通过代理访问网络
处理方法:更换不基于代理类型的抓包工具(HTTP Analyzer V7--缺点不能在真机上使用,HTTP Debug Pro,基于手机的VPN上的HttpCanary);先hook-decompile看他是不是用的那个框架,然后针对性的hook-chicken劝说;iptables 强制拦截和转发
【代理检测应用】
附代理前APP访问正常。附加代理后,APP无法使用,显示网络错误。
(1)代理检测(钩子代理检测方法)(2)证书检测(使用JustTrustMe)
【双向认证APP】
在双向认证的情况下,当客户端验证证书时,服务器也会验证证书。如果证书的一端无法验证证书,则无法访问数据。
但是,要在双向认证APP中实现双向验证,一般应该在APP中配置服务器端的验证证书,所以我们可以在客户端找到一个服务器端的证书,我们只需要配置这个证书在提琴手。请求。
ps:证书一般都有密码。需要反编译找到密码,然后导入系统,再从系统导出为.cer证书格式,然后在FiddlerScript中配置。
什么是分布式爬虫?
如果你已经学会了如何编写一个工程爬虫并有一些经验,那么你已经开始对爬虫架构有了一些经验。
分布式爬虫的概念看起来很吓人。其实从简单的角度来说,就是将一个单机爬虫分布到多台机器上。主要关注消息阻塞处理、日志告警、数据完整性校验等问题。
1亿级别以下的舆情数据,可以尝试学习Scrapy + Redis + MQ + Celery的组合,应付自如。
如果是垂直领域的数据采集,可以专注于快速稳定的获取数据。毕竟在垂直领域的数据抓取中,爬虫与反爬虫的对抗最为激烈。 查看全部
js 爬虫抓取网页数据(爬虫就是模拟人的访问操作来获取网页/App数据的一种程序)
摘要:爬虫是一种模拟人类访问操作以获取网页/App数据的程序。什么是爬行动物?
简单来说,爬虫就是模拟人类访问操作来获取网页/App数据的程序。我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!??¤
QQ群:961562169
我们平时看到的搜索引擎、统计数据、旅游软件、聚合平台,都离不开网络爬虫。
爬虫的应用领域有哪些?
我们常见的应用场景的一个简单例子如下:
1.搜索引擎抓取网页
2.旅游软件通过爬虫抢票
3.论坛或微博舆情监测。利用数据采集技术监测搜索引擎、新闻门户、论坛、博客、微博、微信、报纸、视频的舆情。说白了就是用来实现实时发现某个行业或地区的热点事件,比如青博舆情、百度舆情等。

4.价格比较网站 应用。如今,各大电商平台针对活跃用户开展了各种秒杀活动和优惠券。同一种产品在不同的网购平台上可能会有不同的价格。那么这些网站是如何在几分钟甚至几秒内就知道某款产品在某站打折的呢?这就需要一个data采集系统(爬虫)来实时监控各个站的价格波动。首先采集商品的价格、型号、配置等,然后进行处理、分析和反馈。
为什么要学习爬行?
互联网的飞速发展带来了前所未有的便利,但也带来了许多以前没有遇到过的新问题。获取信息的成本越来越低,信息的种类和数量越来越多,但我们对信息的处理能力并没有提高,很难从信息中提取出我们感兴趣的东西。
学习爬虫可以自动高效地获取我们在互联网上感兴趣的内容,帮助我们快速建立自己的信息知识库。
如何完成一个轻量级爬虫
这里简要概述三个步骤:获取数据-解析数据-存储数据。以下是完成这些步骤所涉及的工具供您参考。
获取数据:urllib2、Requests、Selenium、aiohttp
获取数据的工具:Chrome、Fiddler、MitmProxy、Appium
解析数据:CSS 选择器、PyQuery、BeautifulSoup、Xpath、Re
存储数据:MySQL、MongoDB、Redis

工程爬行动物

工程爬虫项目推荐:Scrapy、PySpider
官方文档:,
Github地址:,
反爬虫措施和应对措施
1.网页反爬虫-字体反爬虫
开发者可以使用@font-face为网页指定字体,也可以调用自定义字体文件来渲染网页中的文字,网页中的文字就变成了对应的代码。这时候,通过一个简单的网页 采集 无法获取编码后的网页内容。
对策:字体反爬相比其他反爬,难度属于比较初级的阶段,主要是处理起来比较麻烦,防御型的网站往往不止一个网站. 设置不同的字体加密防御系统,比如135配A方案,246配B方案,这需要一定的耐心去分析字体的规则,用Python解析字体文件,找到映射规则来解决。
推荐工具:fontTools、百度字体编辑器()
2.网页反爬虫-验证码
验证码是一种公共的自动程序,用于区分用户是计算机还是人。常见的验证码包括:多位混合验证码、滑动验证码、点击验证码、旋转验证码等。
对策:如果项目预算充足,可以连接专业的编码平台,减少90%的工作量;如果预算不足,可以使用华为云ModelArts完成模型搭建,无需编写一行代码
推荐工具:华为云ModelArts、CC框架
3.网页反爬虫-JS加密/混淆
前端代码是公开的,那么加密有意义吗?是的,通过从代码中删除尽可能多的有意义的信息,例如注释、换行符、空格、代码减号、变量重命名、属性重命名(如果允许)以及无用的代码删除,以尽可能多地增加爬虫的数量可能 工程师阅读代码的成本。
对策:对于轻度到中度混淆或混淆代码,可以阅读混淆代码,梳理加密逻辑,扣除可运行的Js代码,使用Python库调用完成加密参数的生成;对于严重混淆,使用AST语法树恢复混淆代码,去除无意义的垃圾代码,恢复清晰的加密逻辑,并使用Python库调用完成加密参数的生成。
推荐工具:AST、PyExecJS
4.APP反爬虫
都2020年了,还有没有通过应用市场下载的不带壳的APP?除了外壳保护,常见的APP还应用单向或双向证书验证。简单的中间人攻击已经无法捕获APP数据包,学习APP逆向工程势在必行。
对策:APP逆向工程需要学习的内容很多。这里简单总结一下抓不到的APP包(推荐工具:Frida、Xposed、IDA、jadx、Charles):
【单向认证和双向认证】
在单向验证的情况下,客户端验证证书,如果验证失败,则无法访问。
在双向认证的情况下,当客户端验证证书时,服务器也会验证证书。如果证书的一端无法验证证书,则无法访问数据。缺点是服务器压力比较大
处理方式:一般使用JustTrustMe,原理是Xpose Hook验证的API。
【APP不走代理——如何保证APP不走代理?】
(1)关闭代理服务器(fiddler等代理抓包工具)(2)用手机访问浏览器网页访问失败,判断代理无效(3)使用APP访问,正常访问确认APP不工作)通过代理访问网络
处理方法:更换不基于代理类型的抓包工具(HTTP Analyzer V7--缺点不能在真机上使用,HTTP Debug Pro,基于手机的VPN上的HttpCanary);先hook-decompile看他是不是用的那个框架,然后针对性的hook-chicken劝说;iptables 强制拦截和转发
【代理检测应用】
附代理前APP访问正常。附加代理后,APP无法使用,显示网络错误。
(1)代理检测(钩子代理检测方法)(2)证书检测(使用JustTrustMe)
【双向认证APP】
在双向认证的情况下,当客户端验证证书时,服务器也会验证证书。如果证书的一端无法验证证书,则无法访问数据。
但是,要在双向认证APP中实现双向验证,一般应该在APP中配置服务器端的验证证书,所以我们可以在客户端找到一个服务器端的证书,我们只需要配置这个证书在提琴手。请求。
ps:证书一般都有密码。需要反编译找到密码,然后导入系统,再从系统导出为.cer证书格式,然后在FiddlerScript中配置。
什么是分布式爬虫?
如果你已经学会了如何编写一个工程爬虫并有一些经验,那么你已经开始对爬虫架构有了一些经验。
分布式爬虫的概念看起来很吓人。其实从简单的角度来说,就是将一个单机爬虫分布到多台机器上。主要关注消息阻塞处理、日志告警、数据完整性校验等问题。
1亿级别以下的舆情数据,可以尝试学习Scrapy + Redis + MQ + Celery的组合,应付自如。
如果是垂直领域的数据采集,可以专注于快速稳定的获取数据。毕竟在垂直领域的数据抓取中,爬虫与反爬虫的对抗最为激烈。
js 爬虫抓取网页数据(js爬虫抓取网页数据教程-js抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-07 03:02
js爬虫抓取网页数据教程说明一、调用工具和模拟发送请求不做任何修改,直接使用python模拟get请求对网页进行爬取和解析,获取页面数据,然后将代码发送到服务器。二、步骤文件目录说明/数据抓取的具体的结构文件/代码注释说明3.1:代码的开始文件example.py。3.2:数据抓取的链接example.pyfrombs4importbeautifulsoup3.3:data.text的保存文件example.pyfrombs4importbeautifulsoup//usersimulation//1抓取网页时使用重定向http协议与https协议保存的图片3.4:抓取网页时随机取样动态数据//2抓取网页时不使用随机取样3.5:抓取请求头data.parse('///images/data.jpg')3.6:抓取headers参数example.pyfrombs4importbeautifulsoupexample.pyfrombs4importbeautifulsoup3.7:http请求参数与源数据js文件的代码//data.html3.8:action参数代码//data.js3.9:js文件数据的抓取3.10:items对象的抓取3.11:调用模拟请求example.pyexample.pyfrombs4importbeautifulsoupexample.pyfrombs4importbeautifulsoupfromurllib.requestimporturlopenurlopen('/','w')3.12:抓取百度/谷歌/雅虎网站的数据(网页/浏览器)frombs4importbeautifulsoup,embedding3.13:抓取各类网站源代码的本地文件fromurllib.requestimporturlopenfrombs4importbeautifulsoupfromembeddingimportimage_from_listdirfromgzipimportgzipfromgzipimportencode_loaderfromgzipimporthttps_loaderdata.parse('//javascript-bin/example.py')3.14:抓取各类网站源代码的保存路径3.15:抓取调用本地文件,发送请求python代码请求网页中数据的具体代码python爬虫抓取各大主流网站数据教程说明。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据教程-js抓取数据)
js爬虫抓取网页数据教程说明一、调用工具和模拟发送请求不做任何修改,直接使用python模拟get请求对网页进行爬取和解析,获取页面数据,然后将代码发送到服务器。二、步骤文件目录说明/数据抓取的具体的结构文件/代码注释说明3.1:代码的开始文件example.py。3.2:数据抓取的链接example.pyfrombs4importbeautifulsoup3.3:data.text的保存文件example.pyfrombs4importbeautifulsoup//usersimulation//1抓取网页时使用重定向http协议与https协议保存的图片3.4:抓取网页时随机取样动态数据//2抓取网页时不使用随机取样3.5:抓取请求头data.parse('///images/data.jpg')3.6:抓取headers参数example.pyfrombs4importbeautifulsoupexample.pyfrombs4importbeautifulsoup3.7:http请求参数与源数据js文件的代码//data.html3.8:action参数代码//data.js3.9:js文件数据的抓取3.10:items对象的抓取3.11:调用模拟请求example.pyexample.pyfrombs4importbeautifulsoupexample.pyfrombs4importbeautifulsoupfromurllib.requestimporturlopenurlopen('/','w')3.12:抓取百度/谷歌/雅虎网站的数据(网页/浏览器)frombs4importbeautifulsoup,embedding3.13:抓取各类网站源代码的本地文件fromurllib.requestimporturlopenfrombs4importbeautifulsoupfromembeddingimportimage_from_listdirfromgzipimportgzipfromgzipimportencode_loaderfromgzipimporthttps_loaderdata.parse('//javascript-bin/example.py')3.14:抓取各类网站源代码的保存路径3.15:抓取调用本地文件,发送请求python代码请求网页中数据的具体代码python爬虫抓取各大主流网站数据教程说明。
js 爬虫抓取网页数据(就是用户爬虫的原理及原理模拟一个的配置介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-07 00:08
一、环境配置
1)做一个服务器,任何linux都可以,我用CentOS 6.5;
2)安装一个mysql数据库,5.5或者5.6都可以,可以直接用lnmp或者lamp安装比较省事,也可以直接查看日志返回时浏览器;
3)先搭建一个node.js环境,我用的是0.12.7,后面的版本没试过;
4)执行npm -g install forever,永远安装,让爬虫后台运行;
5)将所有代码集成到本地(integration=git clone);
6)在项目目录下执行npm install,安装依赖库;
7)在项目目录下创建两个空文件夹,json和avatar;
8)创建一个空的mysql数据库和一个全权限用户,依次执行代码中的setup.sql和startusers.sql,创建数据库结构并导入初始种子用户;
9)编辑config.js,标记为(必填)的配置项必须填写或修改,其余项可暂时不变:
exports.jsonPath = "./json/";//生成json文件的路径
exports.avatarPath = "./avatar/";//保存头像文件的路径
exports.dbconfig = {
host: 'localhost',//数据库服务器(必须)
user: 'dbuser',//数据库用户名(必须)
password: 'dbpassword',//数据库密码(必须)
database: 'dbname',//数据库名(必须)
port: 3306,//数据库服务器端口
poolSize: 20,
acquireTimeout: 30000
};
exports.urlpre = "https://www.jb51.net/";//脚本网址
exports.urlzhuanlanpre = "https://www.jb51.net/list/index_96.htm/";//脚本网址
exports.WPurl = "www.xxx.com";//要发布文章的wordpress网站地址
exports.WPusername = "publishuser";//发布文章的用户名
exports.WPpassword = "publishpassword";//发布文章用户的密码
exports.WPurlavatarpre = "http://www.xxx.com/avatar/";//发布文章中替代原始头像的url地址
exports.mailservice = "QQ";//邮件通知服务类型,也可以用Gmail,前提是你访问得了Gmail(必须)
exports.mailuser = "12345@qq.com";//邮箱用户名(必须)
exports.mailpass = "qqpassword";//邮箱密码(必须)
exports.mailfrom = "12345@qq.com";//发送邮件地址(必须,一般与用户名所属邮箱一致)
exports.mailto = "12345@qq.com";//接收通知邮件地址(必须)
保存并转到下一步。
二、爬虫用户
爬虫的原理其实就是模拟一个真实的知乎用户点击采集网站上的数据,所以我们需要一个真实的知乎用户。测试可以用自己的账号,但是长期来看还是注册一个专用账号比较好,一个就够了,目前爬虫只支持一个。我们的模拟不是像真实用户一样从主页登录,而是直接借用 cookie 值:
注册激活登录后,进入你的主页,使用任何有开发者模式的浏览器或查看cookie插件,在知乎中打开你自己的cookie。可能有一个非常复杂的列表,但我们只需要其中的一部分,即“z_c0”。复制您自己的 cookie 的 z_c0 部分,不要留下等号、引号和分号。最终的格式大致是这样的:
z_c0="LA8kJIJFdDSOA883wkUGJIRE8jVNKSOQfB9430=|1420113988|a6ea18bc1b23ea469e3b5fb2e33c2828439cb";
在mysql数据库的cookies表中插入一行记录,其中字段值为:
然后就可以正式开始运行了。如果cookie无效或者用户被屏蔽,可以直接修改该行记录的cookie字段。
三、跑
推荐使用forever来执行,不仅方便后台操作和记录,而且崩溃后自动重启。例子:
forever -l /var/www/log.txt index.js
-l 后面的地址是记录日志的地方。如果放在web服务器目录下,可以直接在浏览器中查看日志。在 index.js 后添加参数(以空格分隔),以执行不同的爬虫命令:
1、-i 立即执行,如果不加该参数,则默认在下一个指定时间执行,如每天凌晨0:05;
2、-ng 跳过获取新用户的阶段,即getnewuser;
3、-ns 跳过快照阶段,即usersnapshot;
4、-nf 跳过生成数据文件的阶段,即saveviewfile;
5、-db 显示调试日志。
每个阶段的功能将在下一节中描述。为了方便运行,这行命令可以写成sh脚本,例如:
#!/bin/bash
cd /usr/zhihuspider
rm -f /var/www/log.txt
forever -l /var/www/log.txt start index.js $*
请用您自己的替换具体路径。这样就可以通过在./知乎spider.sh中添加参数来启动爬虫:例如./知乎spider.sh -i -ng -nf 会立即启动任务,跳过新用户并保存文件阶段。停止爬虫的方式是forever stopall(或停止序号)。
四、原理概述
见知乎爬虫的入口文件是index.js。它每天在指定时间循环执行爬虫任务。每天要按顺序执行三项任务,即:
1)getnewuser.js:通过对比当前库中的用户关注列表获取新用户信息,并依靠该机制自动将知乎上值得关注的新人纳入库;
2)usersnapshot.js:循环抓取当前库中的用户数据和答案列表,并保存为每日快照。
3)saveviewfile.js:根据最新快照的内容,生成用户分析列表,过滤出昨天、近期和历史精华答案发布到“见知乎”网站@ >。
以上三个任务执行完毕后,主线程每隔几分钟就会刷新一次知乎主页,验证当前cookie是否还有效。,提醒您及时更换cookies。替换cookie的方法和初始化一样,只需要手动登录一次,然后取出cookie值即可。如果对具体的代码实现感兴趣,可以仔细阅读注释,调整一些配置,甚至尝试自己重构整个爬虫。
提示
1)getnewuser 的原理是通过比较快照前后两天用户的注意力来指定捕获,所以必须至少在两次快照后开始,甚至会自动跳过如果之前执行过。
2)可以中途恢复快照。如果程序因错误而崩溃,用forever stop停止它,然后添加参数-i -ng,立即执行并跳过新用户阶段从刚刚捕获的快照中途继续。
3)抓拍快照时不要轻易增加(伪)线程数,即usersnapshots中的maxthreadcount属性。线程过多会导致429错误,同时捕获的大量数据可能来不及写入数据库,造成内存溢出。因此,除非您的数据库在 SSD 上,否则不要使用超过 10 个线程。
4)从 saveviewfile 生成分析结果的工作需要至少 7 天的快照。如果快照内容少于 7 天,则会报告错误并跳过错误。以前的分析工作可以通过查询数据库手动执行。
5)考虑到大部分人不需要复制一个“look知乎”,自动发布wordpress文章功能入口已经被注释掉了。如果你搭建过wordpress,记得打开xmlrpc,然后设置一个专门发布文章的用户,在config.js中配置相应参数,在saveviewfile中取消注释相关代码。
6)因为知乎对头像做了防盗链处理,所以我们在抓取用户信息的时候也拿到了头像,保存在本地。在发布 文章 时,我们使用了本地头像地址。需要将url路径指向http服务器中保存头像的文件夹,或者将保存头像的文件夹直接放到网站目录下。
7)代码可能不容易阅读。除了node.js的回调结构混乱之外,部分原因是我刚开始写程序的时候才开始接触node.js,有很多不熟悉的地方导致结构混乱。拼凑中积累了很多丑陋的判断条件和重试规则。如果全部删除,代码量可能会减少三分之二。但是没有办法做到这一点。为了保证一个系统的稳定运行,这些都是必须要添加的。
8)本爬虫源码基于WTFPL协议,对修改和分发不做任何限制。 查看全部
js 爬虫抓取网页数据(就是用户爬虫的原理及原理模拟一个的配置介绍)
一、环境配置
1)做一个服务器,任何linux都可以,我用CentOS 6.5;
2)安装一个mysql数据库,5.5或者5.6都可以,可以直接用lnmp或者lamp安装比较省事,也可以直接查看日志返回时浏览器;
3)先搭建一个node.js环境,我用的是0.12.7,后面的版本没试过;
4)执行npm -g install forever,永远安装,让爬虫后台运行;
5)将所有代码集成到本地(integration=git clone);
6)在项目目录下执行npm install,安装依赖库;
7)在项目目录下创建两个空文件夹,json和avatar;
8)创建一个空的mysql数据库和一个全权限用户,依次执行代码中的setup.sql和startusers.sql,创建数据库结构并导入初始种子用户;
9)编辑config.js,标记为(必填)的配置项必须填写或修改,其余项可暂时不变:
exports.jsonPath = "./json/";//生成json文件的路径
exports.avatarPath = "./avatar/";//保存头像文件的路径
exports.dbconfig = {
host: 'localhost',//数据库服务器(必须)
user: 'dbuser',//数据库用户名(必须)
password: 'dbpassword',//数据库密码(必须)
database: 'dbname',//数据库名(必须)
port: 3306,//数据库服务器端口
poolSize: 20,
acquireTimeout: 30000
};
exports.urlpre = "https://www.jb51.net/";//脚本网址
exports.urlzhuanlanpre = "https://www.jb51.net/list/index_96.htm/";//脚本网址
exports.WPurl = "www.xxx.com";//要发布文章的wordpress网站地址
exports.WPusername = "publishuser";//发布文章的用户名
exports.WPpassword = "publishpassword";//发布文章用户的密码
exports.WPurlavatarpre = "http://www.xxx.com/avatar/";//发布文章中替代原始头像的url地址
exports.mailservice = "QQ";//邮件通知服务类型,也可以用Gmail,前提是你访问得了Gmail(必须)
exports.mailuser = "12345@qq.com";//邮箱用户名(必须)
exports.mailpass = "qqpassword";//邮箱密码(必须)
exports.mailfrom = "12345@qq.com";//发送邮件地址(必须,一般与用户名所属邮箱一致)
exports.mailto = "12345@qq.com";//接收通知邮件地址(必须)
保存并转到下一步。
二、爬虫用户
爬虫的原理其实就是模拟一个真实的知乎用户点击采集网站上的数据,所以我们需要一个真实的知乎用户。测试可以用自己的账号,但是长期来看还是注册一个专用账号比较好,一个就够了,目前爬虫只支持一个。我们的模拟不是像真实用户一样从主页登录,而是直接借用 cookie 值:
注册激活登录后,进入你的主页,使用任何有开发者模式的浏览器或查看cookie插件,在知乎中打开你自己的cookie。可能有一个非常复杂的列表,但我们只需要其中的一部分,即“z_c0”。复制您自己的 cookie 的 z_c0 部分,不要留下等号、引号和分号。最终的格式大致是这样的:
z_c0="LA8kJIJFdDSOA883wkUGJIRE8jVNKSOQfB9430=|1420113988|a6ea18bc1b23ea469e3b5fb2e33c2828439cb";
在mysql数据库的cookies表中插入一行记录,其中字段值为:
然后就可以正式开始运行了。如果cookie无效或者用户被屏蔽,可以直接修改该行记录的cookie字段。
三、跑
推荐使用forever来执行,不仅方便后台操作和记录,而且崩溃后自动重启。例子:
forever -l /var/www/log.txt index.js
-l 后面的地址是记录日志的地方。如果放在web服务器目录下,可以直接在浏览器中查看日志。在 index.js 后添加参数(以空格分隔),以执行不同的爬虫命令:
1、-i 立即执行,如果不加该参数,则默认在下一个指定时间执行,如每天凌晨0:05;
2、-ng 跳过获取新用户的阶段,即getnewuser;
3、-ns 跳过快照阶段,即usersnapshot;
4、-nf 跳过生成数据文件的阶段,即saveviewfile;
5、-db 显示调试日志。
每个阶段的功能将在下一节中描述。为了方便运行,这行命令可以写成sh脚本,例如:
#!/bin/bash
cd /usr/zhihuspider
rm -f /var/www/log.txt
forever -l /var/www/log.txt start index.js $*
请用您自己的替换具体路径。这样就可以通过在./知乎spider.sh中添加参数来启动爬虫:例如./知乎spider.sh -i -ng -nf 会立即启动任务,跳过新用户并保存文件阶段。停止爬虫的方式是forever stopall(或停止序号)。
四、原理概述
见知乎爬虫的入口文件是index.js。它每天在指定时间循环执行爬虫任务。每天要按顺序执行三项任务,即:
1)getnewuser.js:通过对比当前库中的用户关注列表获取新用户信息,并依靠该机制自动将知乎上值得关注的新人纳入库;
2)usersnapshot.js:循环抓取当前库中的用户数据和答案列表,并保存为每日快照。
3)saveviewfile.js:根据最新快照的内容,生成用户分析列表,过滤出昨天、近期和历史精华答案发布到“见知乎”网站@ >。
以上三个任务执行完毕后,主线程每隔几分钟就会刷新一次知乎主页,验证当前cookie是否还有效。,提醒您及时更换cookies。替换cookie的方法和初始化一样,只需要手动登录一次,然后取出cookie值即可。如果对具体的代码实现感兴趣,可以仔细阅读注释,调整一些配置,甚至尝试自己重构整个爬虫。
提示
1)getnewuser 的原理是通过比较快照前后两天用户的注意力来指定捕获,所以必须至少在两次快照后开始,甚至会自动跳过如果之前执行过。
2)可以中途恢复快照。如果程序因错误而崩溃,用forever stop停止它,然后添加参数-i -ng,立即执行并跳过新用户阶段从刚刚捕获的快照中途继续。
3)抓拍快照时不要轻易增加(伪)线程数,即usersnapshots中的maxthreadcount属性。线程过多会导致429错误,同时捕获的大量数据可能来不及写入数据库,造成内存溢出。因此,除非您的数据库在 SSD 上,否则不要使用超过 10 个线程。
4)从 saveviewfile 生成分析结果的工作需要至少 7 天的快照。如果快照内容少于 7 天,则会报告错误并跳过错误。以前的分析工作可以通过查询数据库手动执行。
5)考虑到大部分人不需要复制一个“look知乎”,自动发布wordpress文章功能入口已经被注释掉了。如果你搭建过wordpress,记得打开xmlrpc,然后设置一个专门发布文章的用户,在config.js中配置相应参数,在saveviewfile中取消注释相关代码。
6)因为知乎对头像做了防盗链处理,所以我们在抓取用户信息的时候也拿到了头像,保存在本地。在发布 文章 时,我们使用了本地头像地址。需要将url路径指向http服务器中保存头像的文件夹,或者将保存头像的文件夹直接放到网站目录下。
7)代码可能不容易阅读。除了node.js的回调结构混乱之外,部分原因是我刚开始写程序的时候才开始接触node.js,有很多不熟悉的地方导致结构混乱。拼凑中积累了很多丑陋的判断条件和重试规则。如果全部删除,代码量可能会减少三分之二。但是没有办法做到这一点。为了保证一个系统的稳定运行,这些都是必须要添加的。
8)本爬虫源码基于WTFPL协议,对修改和分发不做任何限制。
js 爬虫抓取网页数据(就是用户爬虫的原理及原理模拟一个的配置介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-04 18:01
一、环境配置
1)做一个服务器,任何linux都可以,我用CentOS 6.5;
2)安装一个mysql数据库,5.5或者5.6都可以,可以直接用lnmp或者lamp安装比较省事,也可以直接查看日志返回时浏览器;
3)先搭建一个node.js环境,我用的是0.12.7,后面的版本没试过;
4)执行npm -g install forever,永远安装,让爬虫后台运行;
5)将所有代码集成到本地(integration=git clone);
6)在项目目录下执行npm install,安装依赖库;
7)在项目目录下创建两个空文件夹,json和avatar;
8)创建一个空的mysql数据库和一个全权限用户,依次执行代码中的setup.sql和startusers.sql,创建数据库结构并导入初始种子用户;
9)编辑config.js,标记为(必填)的配置项必须填写或修改,其余项可暂时不变:
exports.jsonPath = "./json/";//生成json文件的路径
exports.avatarPath = "./avatar/";//保存头像文件的路径
exports.dbconfig = {
host: 'localhost',//数据库服务器(必须)
user: 'dbuser',//数据库用户名(必须)
password: 'dbpassword',//数据库密码(必须)
database: 'dbname',//数据库名(必须)
port: 3306,//数据库服务器端口
poolSize: 20,
acquireTimeout: 30000
};
exports.urlpre = "https://www.jb51.net/";//脚本网址
exports.urlzhuanlanpre = "https://www.jb51.net/list/index_96.htm/";//脚本网址
exports.WPurl = "www.xxx.com";//要发布文章的wordpress网站地址
exports.WPusername = "publishuser";//发布文章的用户名
exports.WPpassword = "publishpassword";//发布文章用户的密码
exports.WPurlavatarpre = "http://www.xxx.com/avatar/";//发布文章中替代原始头像的url地址
exports.mailservice = "QQ";//邮件通知服务类型,也可以用Gmail,前提是你访问得了Gmail(必须)
exports.mailuser = "12345@qq.com";//邮箱用户名(必须)
exports.mailpass = "qqpassword";//邮箱密码(必须)
exports.mailfrom = "12345@qq.com";//发送邮件地址(必须,一般与用户名所属邮箱一致)
exports.mailto = "12345@qq.com";//接收通知邮件地址(必须)
保存并转到下一步。
二、爬虫用户
爬虫的原理其实就是模拟一个真实的知乎用户点击采集网站上的数据,所以我们需要一个真实的知乎用户。测试可以用自己的账号,但是长期来看还是注册一个专用账号比较好,一个就够了,目前爬虫只支持一个。我们的模拟不是像真实用户一样从主页登录,而是直接借用 cookie 值:
注册激活登录后,进入你的主页,使用任何有开发者模式的浏览器或查看cookie插件,在知乎中打开你自己的cookie。可能有一个非常复杂的列表,但我们只需要其中的一部分,即“z_c0”。复制您自己的 cookie 的 z_c0 部分,不要留下等号、引号和分号。最终的格式大致是这样的:
z_c0="LA8kJIJFdDSOA883wkUGJIRE8jVNKSOQfB9430=|1420113988|a6ea18bc1b23ea469e3b5fb2e33c2828439cb";
在mysql数据库的cookies表中插入一行记录,其中字段值为:
然后就可以正式开始运行了。如果cookie无效或者用户被屏蔽,可以直接修改该行记录的cookie字段。
三、跑
推荐使用forever来执行,不仅方便后台操作和记录,而且崩溃后自动重启。例子:
forever -l /var/www/log.txt index.js
-l 后面的地址是记录日志的地方。如果放在web服务器目录下,可以直接在浏览器中查看日志。在 index.js 后添加参数(以空格分隔),以执行不同的爬虫命令:
1、-i 立即执行,如果不加该参数,则默认在下一个指定时间执行,如每天凌晨0:05;
2、-ng 跳过获取新用户的阶段,即getnewuser;
3、-ns 跳过快照阶段,即usersnapshot;
4、-nf 跳过生成数据文件的阶段,即saveviewfile;
5、-db 显示调试日志。
每个阶段的功能将在下一节中描述。为了方便运行,这行命令可以写成sh脚本,例如:
#!/bin/bash
cd /usr/zhihuspider
rm -f /var/www/log.txt
forever -l /var/www/log.txt start index.js $*
请用您自己的替换具体路径。这样就可以通过在./知乎spider.sh中添加参数来启动爬虫:例如./知乎spider.sh -i -ng -nf 会立即启动任务,跳过新用户并保存文件阶段。停止爬虫的方式是forever stopall(或停止序号)。
四、原理概述
见知乎爬虫的入口文件是index.js。它每天在指定时间循环执行爬虫任务。每天要按顺序执行三项任务,即:
1)getnewuser.js:通过对比当前库中的用户关注列表获取新用户信息,并依靠该机制自动将知乎上值得关注的新人纳入库;
2)usersnapshot.js:循环抓取当前库中的用户数据和答案列表,并保存为每日快照。
3)saveviewfile.js:根据最新快照的内容,生成用户分析列表,过滤出昨天、近期和历史精华答案发布到“见知乎”网站@ >。
以上三项任务完成后,主线程每隔几分钟就会刷新一次知乎主页,验证当前cookie是否还有效。,提醒您及时更换cookies。替换cookie的方法和初始化一样,只需要手动登录一次,然后取出cookie值即可。如果对具体的代码实现感兴趣,可以仔细阅读注释,调整一些配置,甚至尝试自己重构整个爬虫。
提示
1)getnewuser 的原理是通过比较前后两天快照中用户的注意力数量来指定抓包,所以必须至少在两个快照之后才开始,甚至会自动跳过如果之前执行过。
2)可以中途恢复快照。如果程序因错误而崩溃,用forever stop停止它,然后添加参数-i -ng,立即执行并跳过新用户阶段从刚刚捕获的快照中途继续。
3)抓拍快照时不要轻易增加(伪)线程数,即usersnapshots中的maxthreadcount属性。线程过多会导致429错误,同时捕获的大量数据可能来不及写入数据库,造成内存溢出。因此,除非您的数据库在 SSD 上,否则不要使用超过 10 个线程。
4)从 saveviewfile 生成分析结果的工作需要至少 7 天的快照。如果快照内容少于 7 天,则会报告错误并跳过错误。以前的分析工作可以通过查询数据库手动执行。
5)考虑到大部分人不需要复制一个“look知乎”,自动发布wordpress文章功能入口已经被注释掉了。如果你搭建过wordpress,记得打开xmlrpc,然后设置一个专门发布文章的用户,在config.js中配置相应参数,在saveviewfile中取消注释相关代码。
6)因为知乎对头像做了防盗链处理,所以我们在抓取用户信息的时候也拿到了头像,保存在本地。在发布 文章 时,我们使用了本地头像地址。需要将url路径指向http服务器中保存头像的文件夹,或者将保存头像的文件夹直接放到网站目录下。
7)代码可能不容易阅读。除了node.js本身的回调结构混乱之外,部分原因是我刚开始写程序的时候才开始接触node.js,有很多不熟悉的地方导致结构混乱并且没有来得及更正;另一部分是很多时候拼凑起来积累了很多丑陋的判断条件和重试规则。如果全部删除,代码量可能会减少三分之二。但是没有办法做到这一点。为了保证一个系统的稳定运行,这些都是必须要添加的。
8)本爬虫源码基于WTFPL协议,对修改和分发不做任何限制。 查看全部
js 爬虫抓取网页数据(就是用户爬虫的原理及原理模拟一个的配置介绍)
一、环境配置
1)做一个服务器,任何linux都可以,我用CentOS 6.5;
2)安装一个mysql数据库,5.5或者5.6都可以,可以直接用lnmp或者lamp安装比较省事,也可以直接查看日志返回时浏览器;
3)先搭建一个node.js环境,我用的是0.12.7,后面的版本没试过;
4)执行npm -g install forever,永远安装,让爬虫后台运行;
5)将所有代码集成到本地(integration=git clone);
6)在项目目录下执行npm install,安装依赖库;
7)在项目目录下创建两个空文件夹,json和avatar;
8)创建一个空的mysql数据库和一个全权限用户,依次执行代码中的setup.sql和startusers.sql,创建数据库结构并导入初始种子用户;
9)编辑config.js,标记为(必填)的配置项必须填写或修改,其余项可暂时不变:
exports.jsonPath = "./json/";//生成json文件的路径
exports.avatarPath = "./avatar/";//保存头像文件的路径
exports.dbconfig = {
host: 'localhost',//数据库服务器(必须)
user: 'dbuser',//数据库用户名(必须)
password: 'dbpassword',//数据库密码(必须)
database: 'dbname',//数据库名(必须)
port: 3306,//数据库服务器端口
poolSize: 20,
acquireTimeout: 30000
};
exports.urlpre = "https://www.jb51.net/";//脚本网址
exports.urlzhuanlanpre = "https://www.jb51.net/list/index_96.htm/";//脚本网址
exports.WPurl = "www.xxx.com";//要发布文章的wordpress网站地址
exports.WPusername = "publishuser";//发布文章的用户名
exports.WPpassword = "publishpassword";//发布文章用户的密码
exports.WPurlavatarpre = "http://www.xxx.com/avatar/";//发布文章中替代原始头像的url地址
exports.mailservice = "QQ";//邮件通知服务类型,也可以用Gmail,前提是你访问得了Gmail(必须)
exports.mailuser = "12345@qq.com";//邮箱用户名(必须)
exports.mailpass = "qqpassword";//邮箱密码(必须)
exports.mailfrom = "12345@qq.com";//发送邮件地址(必须,一般与用户名所属邮箱一致)
exports.mailto = "12345@qq.com";//接收通知邮件地址(必须)
保存并转到下一步。
二、爬虫用户
爬虫的原理其实就是模拟一个真实的知乎用户点击采集网站上的数据,所以我们需要一个真实的知乎用户。测试可以用自己的账号,但是长期来看还是注册一个专用账号比较好,一个就够了,目前爬虫只支持一个。我们的模拟不是像真实用户一样从主页登录,而是直接借用 cookie 值:
注册激活登录后,进入你的主页,使用任何有开发者模式的浏览器或查看cookie插件,在知乎中打开你自己的cookie。可能有一个非常复杂的列表,但我们只需要其中的一部分,即“z_c0”。复制您自己的 cookie 的 z_c0 部分,不要留下等号、引号和分号。最终的格式大致是这样的:
z_c0="LA8kJIJFdDSOA883wkUGJIRE8jVNKSOQfB9430=|1420113988|a6ea18bc1b23ea469e3b5fb2e33c2828439cb";
在mysql数据库的cookies表中插入一行记录,其中字段值为:
然后就可以正式开始运行了。如果cookie无效或者用户被屏蔽,可以直接修改该行记录的cookie字段。
三、跑
推荐使用forever来执行,不仅方便后台操作和记录,而且崩溃后自动重启。例子:
forever -l /var/www/log.txt index.js
-l 后面的地址是记录日志的地方。如果放在web服务器目录下,可以直接在浏览器中查看日志。在 index.js 后添加参数(以空格分隔),以执行不同的爬虫命令:
1、-i 立即执行,如果不加该参数,则默认在下一个指定时间执行,如每天凌晨0:05;
2、-ng 跳过获取新用户的阶段,即getnewuser;
3、-ns 跳过快照阶段,即usersnapshot;
4、-nf 跳过生成数据文件的阶段,即saveviewfile;
5、-db 显示调试日志。
每个阶段的功能将在下一节中描述。为了方便运行,这行命令可以写成sh脚本,例如:
#!/bin/bash
cd /usr/zhihuspider
rm -f /var/www/log.txt
forever -l /var/www/log.txt start index.js $*
请用您自己的替换具体路径。这样就可以通过在./知乎spider.sh中添加参数来启动爬虫:例如./知乎spider.sh -i -ng -nf 会立即启动任务,跳过新用户并保存文件阶段。停止爬虫的方式是forever stopall(或停止序号)。
四、原理概述
见知乎爬虫的入口文件是index.js。它每天在指定时间循环执行爬虫任务。每天要按顺序执行三项任务,即:
1)getnewuser.js:通过对比当前库中的用户关注列表获取新用户信息,并依靠该机制自动将知乎上值得关注的新人纳入库;
2)usersnapshot.js:循环抓取当前库中的用户数据和答案列表,并保存为每日快照。
3)saveviewfile.js:根据最新快照的内容,生成用户分析列表,过滤出昨天、近期和历史精华答案发布到“见知乎”网站@ >。
以上三项任务完成后,主线程每隔几分钟就会刷新一次知乎主页,验证当前cookie是否还有效。,提醒您及时更换cookies。替换cookie的方法和初始化一样,只需要手动登录一次,然后取出cookie值即可。如果对具体的代码实现感兴趣,可以仔细阅读注释,调整一些配置,甚至尝试自己重构整个爬虫。
提示
1)getnewuser 的原理是通过比较前后两天快照中用户的注意力数量来指定抓包,所以必须至少在两个快照之后才开始,甚至会自动跳过如果之前执行过。
2)可以中途恢复快照。如果程序因错误而崩溃,用forever stop停止它,然后添加参数-i -ng,立即执行并跳过新用户阶段从刚刚捕获的快照中途继续。
3)抓拍快照时不要轻易增加(伪)线程数,即usersnapshots中的maxthreadcount属性。线程过多会导致429错误,同时捕获的大量数据可能来不及写入数据库,造成内存溢出。因此,除非您的数据库在 SSD 上,否则不要使用超过 10 个线程。
4)从 saveviewfile 生成分析结果的工作需要至少 7 天的快照。如果快照内容少于 7 天,则会报告错误并跳过错误。以前的分析工作可以通过查询数据库手动执行。
5)考虑到大部分人不需要复制一个“look知乎”,自动发布wordpress文章功能入口已经被注释掉了。如果你搭建过wordpress,记得打开xmlrpc,然后设置一个专门发布文章的用户,在config.js中配置相应参数,在saveviewfile中取消注释相关代码。
6)因为知乎对头像做了防盗链处理,所以我们在抓取用户信息的时候也拿到了头像,保存在本地。在发布 文章 时,我们使用了本地头像地址。需要将url路径指向http服务器中保存头像的文件夹,或者将保存头像的文件夹直接放到网站目录下。
7)代码可能不容易阅读。除了node.js本身的回调结构混乱之外,部分原因是我刚开始写程序的时候才开始接触node.js,有很多不熟悉的地方导致结构混乱并且没有来得及更正;另一部分是很多时候拼凑起来积累了很多丑陋的判断条件和重试规则。如果全部删除,代码量可能会减少三分之二。但是没有办法做到这一点。为了保证一个系统的稳定运行,这些都是必须要添加的。
8)本爬虫源码基于WTFPL协议,对修改和分发不做任何限制。
js 爬虫抓取网页数据(个人浏览器上网原理图爬虫程序可以简单想象为替代浏览器的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-04 16:09
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。白话爬虫的官方定义:网络爬虫是按照一定的规则自动抓取全球信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。个人浏览器上网示意图 爬虫程序可以简单的想象为替代浏览器的功能,将获取的数据存储在数据库或文件中。同时,对于网站的反爬策略,它需要伪装自己,也就是跟着浏览器发送的信息Like,我是谁?,我来自哪里,我的浏览器型号,使用的方法,访问的信息。
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。这些数据来自哪里?正如我们通常在寻找“度娘”时遇到问题一样,重要的数据来源是互联网,而爬虫是获取互联网数据的手段。前端时间是数据分析的狮子。我做了两周的兼职爬虫工程师。今天给大家讲讲白话爬虫。事物。
白话爬行动物
爬虫的官方定义:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种按照一定的规则自动爬取全球信息的程序或脚本。规则。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
白话爬虫:利用程序模拟人们的上网行为进行网络索引,获取网页中的特定信息,实现对网络数据的短期、不间断、实时访问。
个人浏览器上网示意图
爬虫可以简单的想象成代替浏览器的功能【发送一个url请求,解析服务器返回的HTML文档】,将获取到的数据存储到数据库或者文件中。同时,对于网站的反爬策略,需要进行伪装,即携带浏览器发送的信息我是谁?(cookie信息),我来自哪里(IP地址,使用的代理IP),我的浏览器模型(User-Agent),使用的方法(get,post等),访问信息。
爬行动物示意图
Python爬虫代码案例
要求:网站百度前几页搜索结果的地址和主题(自定义)抓取一个关键字(自定义)
代码:
class crawler: '''按关键词爬取百度搜索页面内容''' url = '' urls = [] o_urls = [] html = '' total_pages = 5 current_page = 0 next_page_url = '' timeout = 60 headersParameters = { 'Connection': 'Keep-Alive', 'Accept': 'text/html, application/xhtml+xml, */*', 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3', 'Accept-Encoding': 'gzip, deflate', 'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko' } def __init__(self, keyword): self.keyword = keyword self.url = 'https://www.baidu.com/baidu?wd='+quote(keyword)+'&tn=monline_dg&ie=utf-8' self.url_df = pd.DataFrame(columns=["url"]) self.url_title_df = pd.DataFrame(columns=["url","title"]) def set_timeout(self, time): '''设置超时时间,单位:秒''' try: self.timeout = int(time) except: pass def set_total_pages(self, num): '''设置总共要爬取的页数''' try: self.total_pages = int(num) except: pass def set_current_url(self, url): '''设置当前url''' self.url = url def switch_url(self): '''切换当前url为下一页的url 若下一页为空,则退出程序''' if self.next_page_url == '': sys.exit() else: self.set_current_url(self.next_page_url) def is_finish(self): '''判断是否爬取完毕''' if self.current_page >= self.total_pages: return True else: return False def get_html(self): '''爬取当前url所指页面的内容,保存到html中''' r = requests.get(self.url ,timeout=self.timeout, headers=self.headersParameters) if r.status_code==200: self.html = r.text# print("-----------------------------------------------------------------------")# print("[当前页面链接]: ",self.url)# #print("[当前页面内容]: ",self.html)# print("-----------------------------------------------------------------------") self.current_page += 1 else: self.html = '' print('[ERROR]',self.url,'get此url返回的http状态码不是200') def get_urls(self): '''从当前html中解析出搜索结果的url,保存到o_urls''' o_urls = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\"', self.html) titles = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\".* data-tools=\'{"title":(.*?),"url"',self.html)# o_urls = list(set(o_urls)) #去重# titles = list(set(titles)) #去重 self.titles = titles self.o_urls = o_urls #取下一页地址 next = re.findall(' href\=\"(\/s\?wd\=[\w\d\%\&\=\_\-]*?)\" class\=\"n\"', self.html) if len(next) > 0: self.next_page_url = 'https://www.baidu.com'+next[-1] else: self.next_page_url = '' def get_real(self, o_url): '''获取重定向url指向的网址''' r = requests.get(o_url, allow_redirects = False) #禁止自动跳转 if r.status_code == 302: try: return r.headers['location'] #返回指向的地址 except: pass return o_url #返回源地址 def transformation(self): '''读取当前o_urls中的链接重定向的网址,并保存到urls中''' self.urls = [] for o_url in self.o_urls: self.urls.append(self.get_real(o_url)) def print_urls(self): '''输出当前urls中的url''' for url in self.urls: print(url) for title in self.titles: print(title[0]) def stock_data(self): url_df = pd.DataFrame(self.urls,columns=["url"]) o_url_df = pd.DataFrame([self.o_urls,self.urls],index=["o_url","url"]).T title_df = pd.DataFrame(self.titles,columns=["o_url","title"]) url_title_df = pd.merge(o_url_df,title_df,left_on="o_url",right_on="o_url",how="left") url_titles_df = url_title_df[["url","title"]] self.url_df = self.url_df.append(url_df,ignore_index=True) self.url_title_df = self.url_title_df.append(url_titles_df,ignore_index=True) self.url_title_df["keyword"] = len(self.url_title_df)* [self.keyword] def print_o_urls(self): '''输出当前o_urls中的url''' for url in self.o_urls: print(url) def run(self): while(not self.is_finish()): self.get_html() self.get_urls() self.transformation() c.print_urls() self.stock_data() time.sleep(10) self.switch_url()
API接口
## 爬取百度关键词timeout = 60totalpages=2 ##前两页baidu_url = pd.DataFrame(columns=["url","title","keyword"])keyword="数据分析"c = crawler(keyword)if timeout != None: c.set_timeout(timeout)if totalpages != None: c.set_total_pages(totalpages)c.run()# print(c.url_title_df)baidu_url=baidu_url.append(c.url_title_df,ignore_index=True)
获取关键词“数据分析”的百度搜索结果前两页信息
原创文章,作者:admin,如转载请注明出处: 查看全部
js 爬虫抓取网页数据(个人浏览器上网原理图爬虫程序可以简单想象为替代浏览器的功能)
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。白话爬虫的官方定义:网络爬虫是按照一定的规则自动抓取全球信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。个人浏览器上网示意图 爬虫程序可以简单的想象为替代浏览器的功能,将获取的数据存储在数据库或文件中。同时,对于网站的反爬策略,它需要伪装自己,也就是跟着浏览器发送的信息Like,我是谁?,我来自哪里,我的浏览器型号,使用的方法,访问的信息。
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。这些数据来自哪里?正如我们通常在寻找“度娘”时遇到问题一样,重要的数据来源是互联网,而爬虫是获取互联网数据的手段。前端时间是数据分析的狮子。我做了两周的兼职爬虫工程师。今天给大家讲讲白话爬虫。事物。
白话爬行动物
爬虫的官方定义:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种按照一定的规则自动爬取全球信息的程序或脚本。规则。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
白话爬虫:利用程序模拟人们的上网行为进行网络索引,获取网页中的特定信息,实现对网络数据的短期、不间断、实时访问。
个人浏览器上网示意图
爬虫可以简单的想象成代替浏览器的功能【发送一个url请求,解析服务器返回的HTML文档】,将获取到的数据存储到数据库或者文件中。同时,对于网站的反爬策略,需要进行伪装,即携带浏览器发送的信息我是谁?(cookie信息),我来自哪里(IP地址,使用的代理IP),我的浏览器模型(User-Agent),使用的方法(get,post等),访问信息。
爬行动物示意图
Python爬虫代码案例
要求:网站百度前几页搜索结果的地址和主题(自定义)抓取一个关键字(自定义)
代码:
class crawler: '''按关键词爬取百度搜索页面内容''' url = '' urls = [] o_urls = [] html = '' total_pages = 5 current_page = 0 next_page_url = '' timeout = 60 headersParameters = { 'Connection': 'Keep-Alive', 'Accept': 'text/html, application/xhtml+xml, */*', 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3', 'Accept-Encoding': 'gzip, deflate', 'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko' } def __init__(self, keyword): self.keyword = keyword self.url = 'https://www.baidu.com/baidu?wd='+quote(keyword)+'&tn=monline_dg&ie=utf-8' self.url_df = pd.DataFrame(columns=["url"]) self.url_title_df = pd.DataFrame(columns=["url","title"]) def set_timeout(self, time): '''设置超时时间,单位:秒''' try: self.timeout = int(time) except: pass def set_total_pages(self, num): '''设置总共要爬取的页数''' try: self.total_pages = int(num) except: pass def set_current_url(self, url): '''设置当前url''' self.url = url def switch_url(self): '''切换当前url为下一页的url 若下一页为空,则退出程序''' if self.next_page_url == '': sys.exit() else: self.set_current_url(self.next_page_url) def is_finish(self): '''判断是否爬取完毕''' if self.current_page >= self.total_pages: return True else: return False def get_html(self): '''爬取当前url所指页面的内容,保存到html中''' r = requests.get(self.url ,timeout=self.timeout, headers=self.headersParameters) if r.status_code==200: self.html = r.text# print("-----------------------------------------------------------------------")# print("[当前页面链接]: ",self.url)# #print("[当前页面内容]: ",self.html)# print("-----------------------------------------------------------------------") self.current_page += 1 else: self.html = '' print('[ERROR]',self.url,'get此url返回的http状态码不是200') def get_urls(self): '''从当前html中解析出搜索结果的url,保存到o_urls''' o_urls = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\"', self.html) titles = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\".* data-tools=\'{"title":(.*?),"url"',self.html)# o_urls = list(set(o_urls)) #去重# titles = list(set(titles)) #去重 self.titles = titles self.o_urls = o_urls #取下一页地址 next = re.findall(' href\=\"(\/s\?wd\=[\w\d\%\&\=\_\-]*?)\" class\=\"n\"', self.html) if len(next) > 0: self.next_page_url = 'https://www.baidu.com'+next[-1] else: self.next_page_url = '' def get_real(self, o_url): '''获取重定向url指向的网址''' r = requests.get(o_url, allow_redirects = False) #禁止自动跳转 if r.status_code == 302: try: return r.headers['location'] #返回指向的地址 except: pass return o_url #返回源地址 def transformation(self): '''读取当前o_urls中的链接重定向的网址,并保存到urls中''' self.urls = [] for o_url in self.o_urls: self.urls.append(self.get_real(o_url)) def print_urls(self): '''输出当前urls中的url''' for url in self.urls: print(url) for title in self.titles: print(title[0]) def stock_data(self): url_df = pd.DataFrame(self.urls,columns=["url"]) o_url_df = pd.DataFrame([self.o_urls,self.urls],index=["o_url","url"]).T title_df = pd.DataFrame(self.titles,columns=["o_url","title"]) url_title_df = pd.merge(o_url_df,title_df,left_on="o_url",right_on="o_url",how="left") url_titles_df = url_title_df[["url","title"]] self.url_df = self.url_df.append(url_df,ignore_index=True) self.url_title_df = self.url_title_df.append(url_titles_df,ignore_index=True) self.url_title_df["keyword"] = len(self.url_title_df)* [self.keyword] def print_o_urls(self): '''输出当前o_urls中的url''' for url in self.o_urls: print(url) def run(self): while(not self.is_finish()): self.get_html() self.get_urls() self.transformation() c.print_urls() self.stock_data() time.sleep(10) self.switch_url()
API接口
## 爬取百度关键词timeout = 60totalpages=2 ##前两页baidu_url = pd.DataFrame(columns=["url","title","keyword"])keyword="数据分析"c = crawler(keyword)if timeout != None: c.set_timeout(timeout)if totalpages != None: c.set_total_pages(totalpages)c.run()# print(c.url_title_df)baidu_url=baidu_url.append(c.url_title_df,ignore_index=True)
获取关键词“数据分析”的百度搜索结果前两页信息
原创文章,作者:admin,如转载请注明出处:
js 爬虫抓取网页数据(今日头条为例来尝试通过分析Ajax请求来网页数据的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2022-04-04 16:02
)
文章目录
在本文中,我们以今日头条为例,尝试通过分析Ajax请求来抓取网页数据。本次要抓拍的目标是今日头条的街拍,抓拍保存。本节代码参考了python3网络爬虫实战的6.4节,但是由于网页上的一些东西已经更新,所以本文中的代码也做了相应的修改,使其可以正常采集数据。1.准备
首先,确保已安装 requests 库。
2.爬取分析
在爬取之前,先分析一下爬取的逻辑。打开今日头条首页,如图
在搜索框中输入街拍,结果如图
点击图片切换图片分类
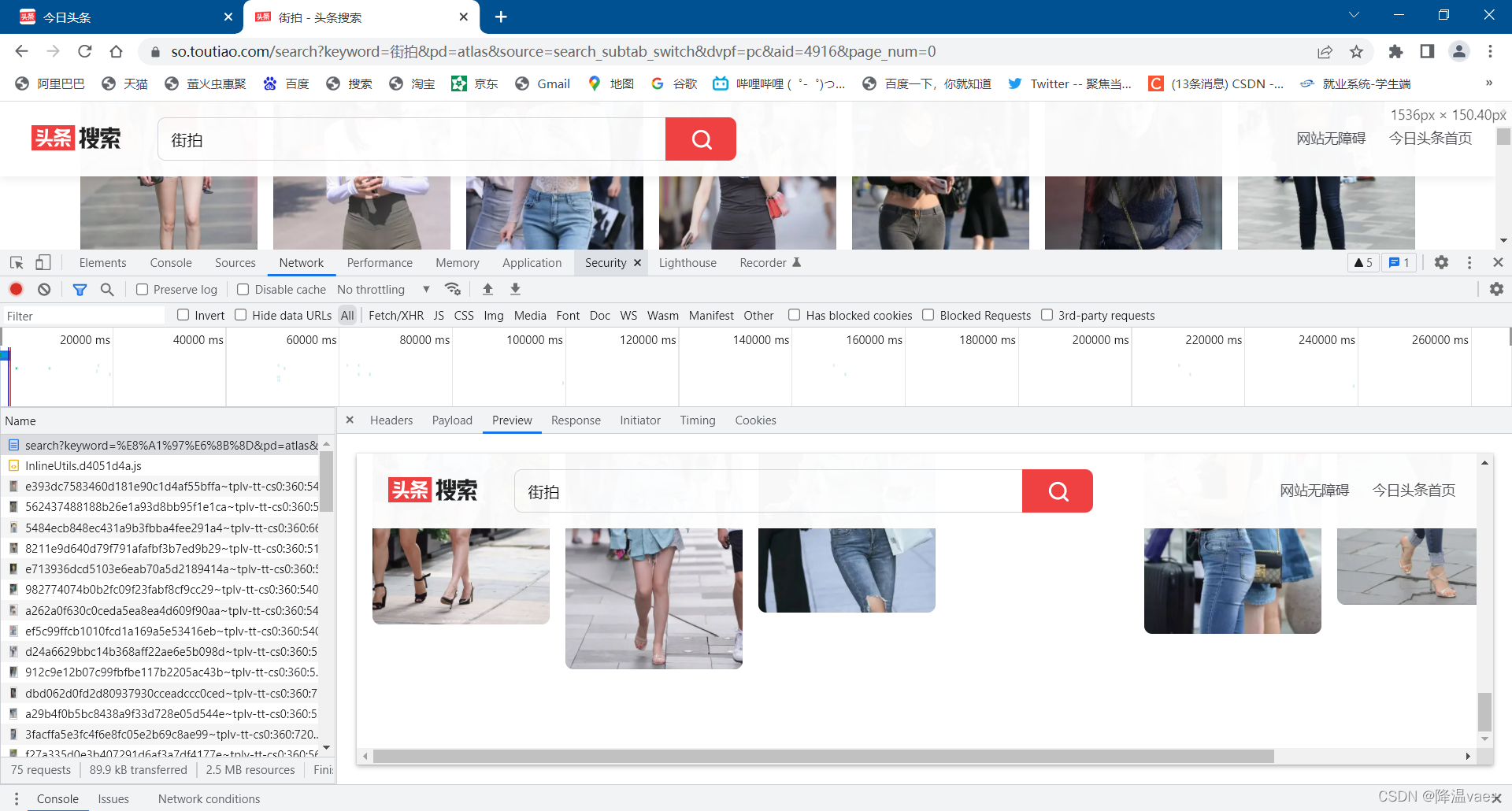
然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL是当前连接%E8%A1%97%E6%8B%8D&pd=atlas&source=search_subtab_switch&dvpf=pc&aid=4916&page_num=0,打开Preview标签查看Response Body。发现只有页面的一部分,如图。可以分析出下面的图片数据是通过Ajax加载,然后用JavaScript渲染出来的。
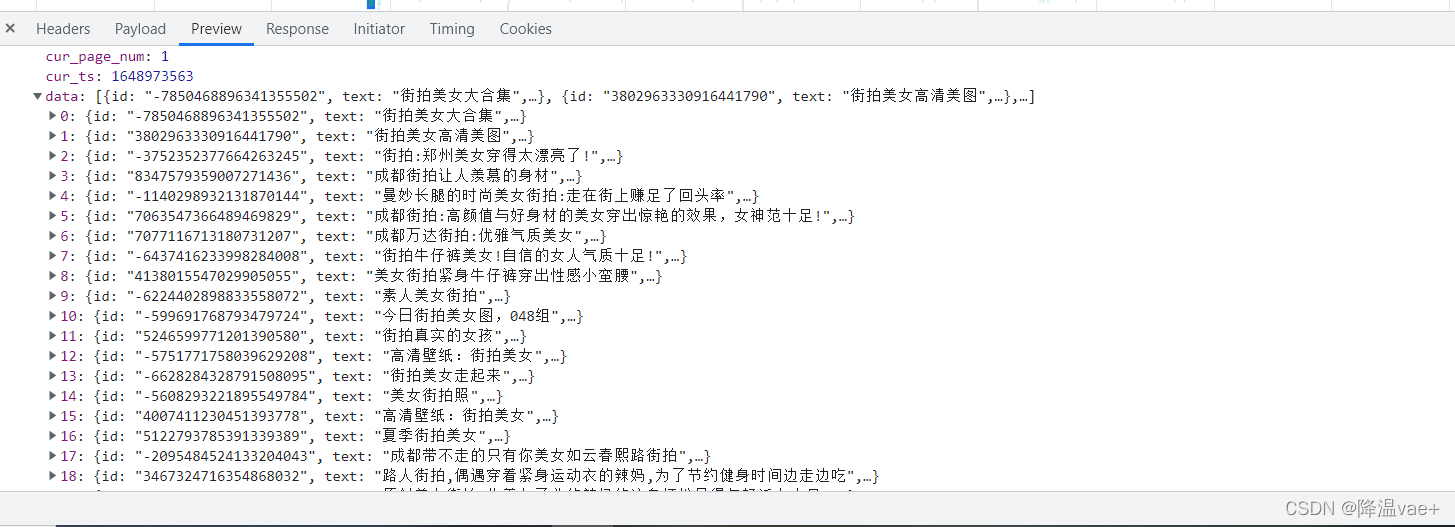
接下来,我们可以切换到 XHR 过滤选项卡,查看是否有任何 Ajax 请求。
果然有一个比较常规的ajax请求,看看它的结果是否收录页面中的相关数据。
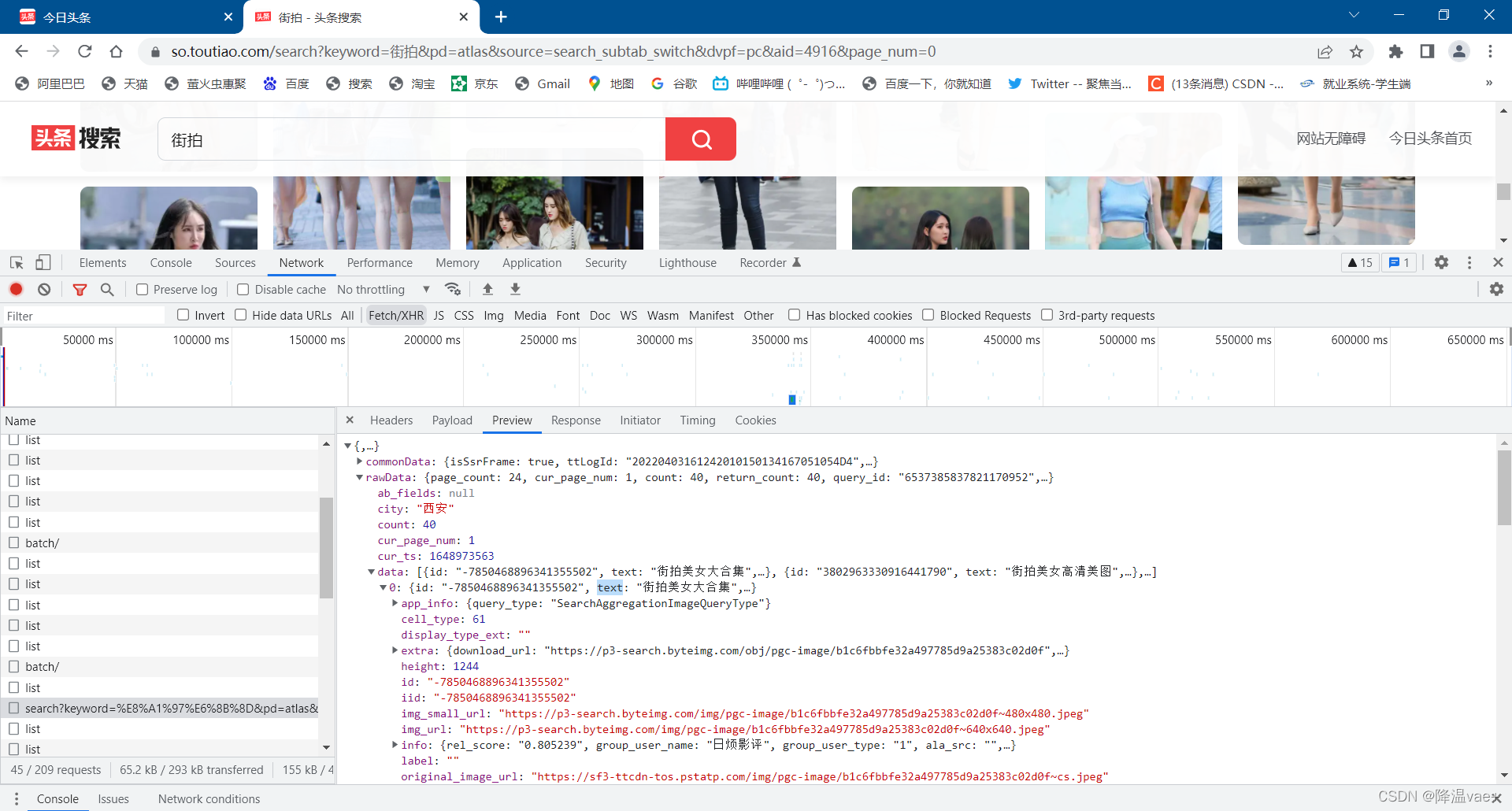
点击rawData字段展开,可以发现有一个data字段,count字段为40,表示本次请求收录40张图片,data字段收录40条记录,分别是图片的url等信息。
这证实了数据确实是由 Ajax 加载的。
我们的目的是抓取里面的图片,这里一组图片对应上一个数据域中的一条数据。如图所示
因此,我们只需要提取并下载data中每条数据的img_url字段即可。创建一个文件夹来保存这些图片。
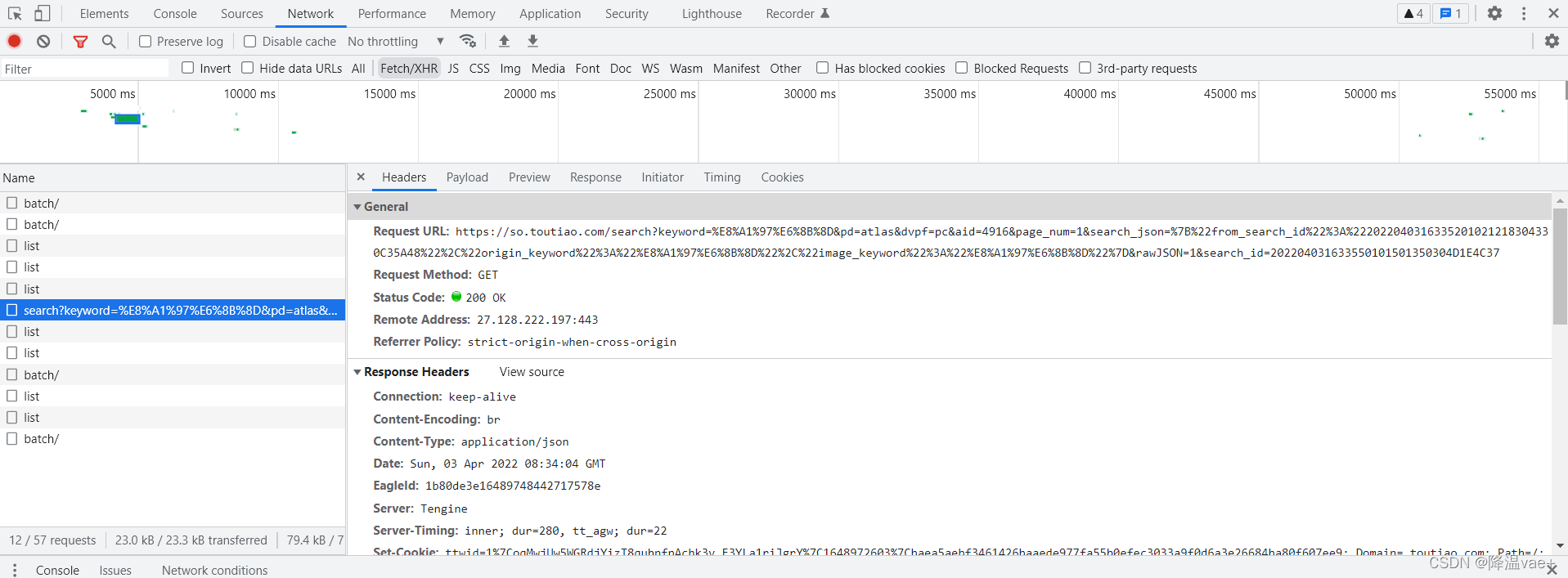
接下来,我们可以直接用Python来模拟这个Ajax请求,然后提取相关信息。但在此之前,我们还需要分析一下 URL 的规律。
切换回Headers选项卡,观察其请求URL和Headers信息,如图
可以看出这是一个GET请求。请求的参数有keyword、pd、source、dvpf、aid、page_num、search_json、rawJSON、search_id。我们需要找出这些参数的规则,因为这样可以方便地用程序构造请求。
接下来,滑动界面以加载更多结果。加载的时候可以发现NetWork中有很多Ajax请求,如图:
这里我们观察前后几个连接的请求变化,发现只有page_num参数在变化,每次变化都是1,所以可以找到规律,这个page_num就是偏移量,然后我们可以推断即count参数是一次得到的数据条数。所以我们可以使用page_num参数来控制分页。这样就可以通过接口批量获取数据,然后解析数据,下载图片。另外我们发现keyword参数使用的不是明文,而是加密的代码,可以借助python中的unquote包解决。
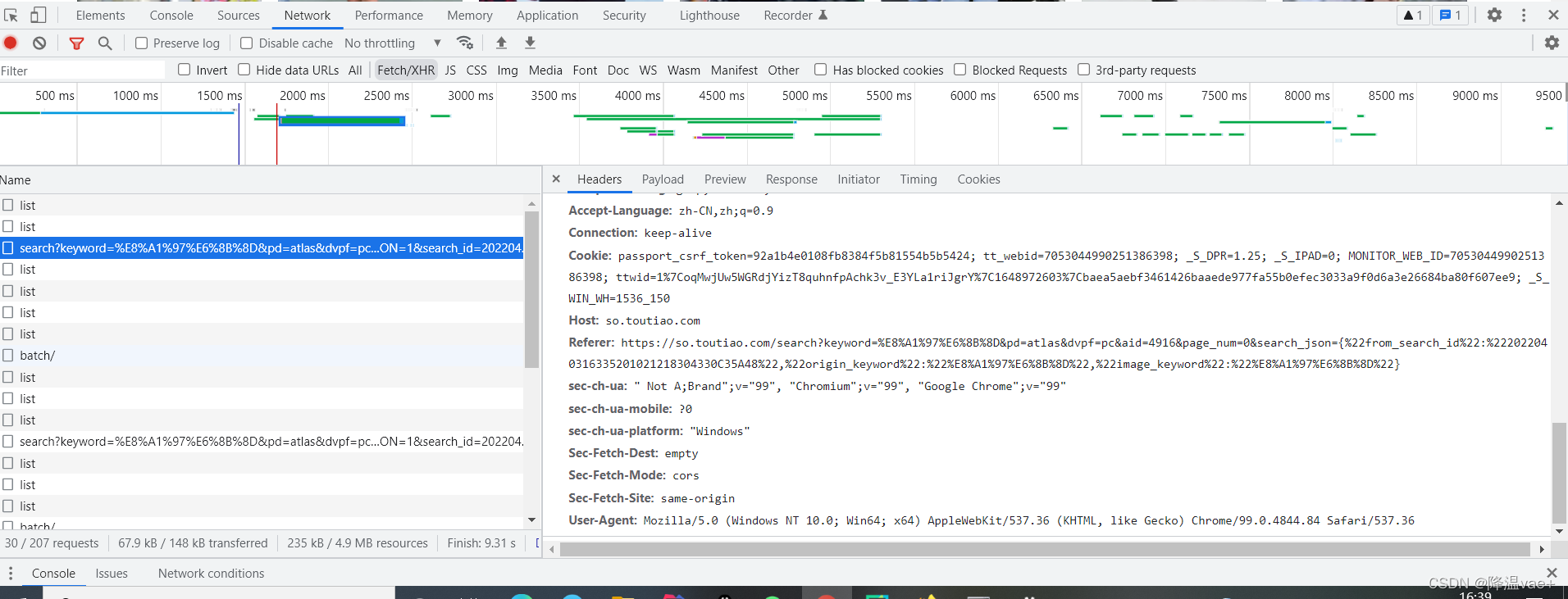
3.实战演练
我们刚刚分析了ajax请求的逻辑,下面使用程序来实现。
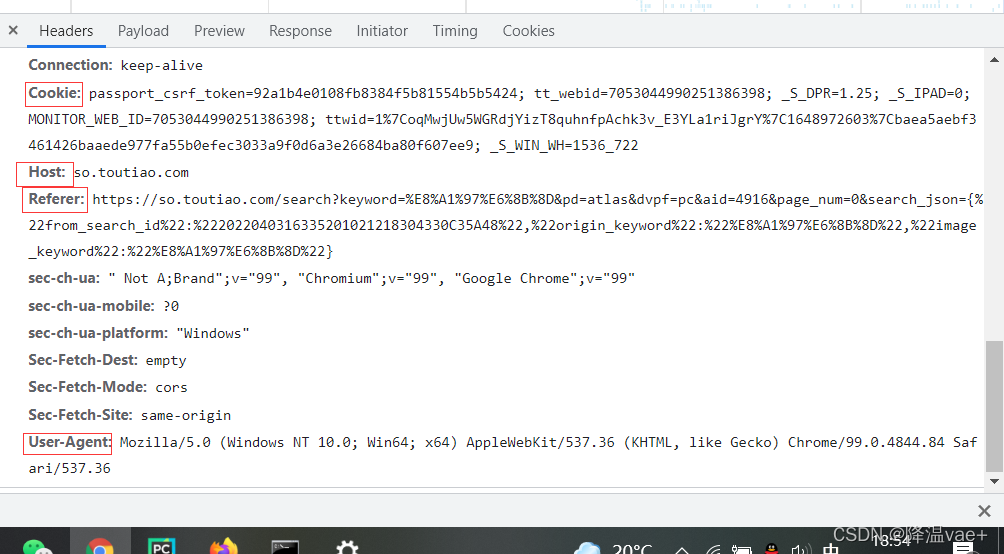
首先,实现方法 get_page() 来加载单个 Ajax 请求的结果。唯一的变化是参数page_num,所以它作为参数传递。另外需要注意的是,这里需要构造请求头,并且需要收录cooike,否则取不到Response。该信息可以在“标题”选项卡中找到:
构造参数可以在payload选项卡中找到
import requests
from urllib.parse import urlencode,quote,unquote
headers = {
'Host': 'so.toutiao.com',
'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%222022040316335201021218304330C35A48%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest', # Ajax请求需要手动设置这里
'Cookie': 'passport_csrf_token=92a1b4e0108fb8384f5b81554b5b5424; tt_webid=7053044990251386398; _S_DPR=1.25; _S_IPAD=0; MONITOR_WEB_ID=7053044990251386398; ttwid=1%7CoqMwjUw5WGRdjYizT8quhnfpAchk3v_E3YLa1riJgrY%7C1648972603%7Cbaea5aebf3461426baaede977fa55b0efec3033a9f0d6a3e26684ba80f607ee9; _S_WIN_WH=1536_722'
}
def get_page(page_num):
params = {
'keyword':unquote('%E8%A1%97%E6%8B%8D') ,
'pd':'atlas',
'dvpf':'pc',
'aid': '4916' ,
'page_num':page_num,
'search_json':{"from_search_id":"2022040316335201021218304330C35A48","origin_keyword":"街拍","image_keyword":"街拍"},
'rawJSON':'1',
'search_id':'2022040317334901015013503043241DAC'
}
url = 'https://so.toutiao.com/search/?'+urlencode(params,headers)
try:
response = requests.get(url,headers=headers,params=params)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
这里我们使用urlencode()方法构造请求的GET参数,然后使用requests请求链接。如果返回的状态码为 200,调用响应的 json() 方法将结果转换为 JSON 格式并返回。
接下来实现一个解析方法:提取每条数据的img_url字段中的图片链接,并返回图片链接。这时候就可以构建生成器了。实现代码如下:
def get_images(json):
if json.get('rawData'):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield {
'image':image.get('img_url'),
'title':"街拍",
'text':image.get('text')
}
接下来,实现一个用于保存图像的 save_image() 方法,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。代码显示如下:
import os
from hashlib import md5
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print('Failed to Save image')
最后,只需构造一个数组,遍历,提取图片链接,下载即可:
from multiprocessing.pool import Pool
def main(page_num):
json = get_page(page_num)
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 1
GROUP_END = 20
if __name__ == '__main__':
# pool = Pool()
# groups = ([x*20 for x in range(GROUP_START,GROUP_END+1)]) #使用这种方式启动出现bug,原因还没有找到
# pool.map(main,groups)
# pool.close()
# pool.join()
for i in range(1,10):
main(i)
因为博主在使用线程池有bug,一直没找到原因,所以先用for循环
结果如下:
最后,给出本文的代码地址:
参考
[1].Python3网络爬虫开发实战.崔庆才.——6.4 查看全部
js 爬虫抓取网页数据(今日头条为例来尝试通过分析Ajax请求来网页数据的方法
)
文章目录
在本文中,我们以今日头条为例,尝试通过分析Ajax请求来抓取网页数据。本次要抓拍的目标是今日头条的街拍,抓拍保存。本节代码参考了python3网络爬虫实战的6.4节,但是由于网页上的一些东西已经更新,所以本文中的代码也做了相应的修改,使其可以正常采集数据。1.准备
首先,确保已安装 requests 库。
2.爬取分析
在爬取之前,先分析一下爬取的逻辑。打开今日头条首页,如图
在搜索框中输入街拍,结果如图
点击图片切换图片分类
然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL是当前连接%E8%A1%97%E6%8B%8D&pd=atlas&source=search_subtab_switch&dvpf=pc&aid=4916&page_num=0,打开Preview标签查看Response Body。发现只有页面的一部分,如图。可以分析出下面的图片数据是通过Ajax加载,然后用JavaScript渲染出来的。
接下来,我们可以切换到 XHR 过滤选项卡,查看是否有任何 Ajax 请求。
果然有一个比较常规的ajax请求,看看它的结果是否收录页面中的相关数据。
点击rawData字段展开,可以发现有一个data字段,count字段为40,表示本次请求收录40张图片,data字段收录40条记录,分别是图片的url等信息。
这证实了数据确实是由 Ajax 加载的。
我们的目的是抓取里面的图片,这里一组图片对应上一个数据域中的一条数据。如图所示
因此,我们只需要提取并下载data中每条数据的img_url字段即可。创建一个文件夹来保存这些图片。
接下来,我们可以直接用Python来模拟这个Ajax请求,然后提取相关信息。但在此之前,我们还需要分析一下 URL 的规律。
切换回Headers选项卡,观察其请求URL和Headers信息,如图
可以看出这是一个GET请求。请求的参数有keyword、pd、source、dvpf、aid、page_num、search_json、rawJSON、search_id。我们需要找出这些参数的规则,因为这样可以方便地用程序构造请求。
接下来,滑动界面以加载更多结果。加载的时候可以发现NetWork中有很多Ajax请求,如图:
这里我们观察前后几个连接的请求变化,发现只有page_num参数在变化,每次变化都是1,所以可以找到规律,这个page_num就是偏移量,然后我们可以推断即count参数是一次得到的数据条数。所以我们可以使用page_num参数来控制分页。这样就可以通过接口批量获取数据,然后解析数据,下载图片。另外我们发现keyword参数使用的不是明文,而是加密的代码,可以借助python中的unquote包解决。
3.实战演练
我们刚刚分析了ajax请求的逻辑,下面使用程序来实现。
首先,实现方法 get_page() 来加载单个 Ajax 请求的结果。唯一的变化是参数page_num,所以它作为参数传递。另外需要注意的是,这里需要构造请求头,并且需要收录cooike,否则取不到Response。该信息可以在“标题”选项卡中找到:
构造参数可以在payload选项卡中找到
import requests
from urllib.parse import urlencode,quote,unquote
headers = {
'Host': 'so.toutiao.com',
'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%222022040316335201021218304330C35A48%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest', # Ajax请求需要手动设置这里
'Cookie': 'passport_csrf_token=92a1b4e0108fb8384f5b81554b5b5424; tt_webid=7053044990251386398; _S_DPR=1.25; _S_IPAD=0; MONITOR_WEB_ID=7053044990251386398; ttwid=1%7CoqMwjUw5WGRdjYizT8quhnfpAchk3v_E3YLa1riJgrY%7C1648972603%7Cbaea5aebf3461426baaede977fa55b0efec3033a9f0d6a3e26684ba80f607ee9; _S_WIN_WH=1536_722'
}
def get_page(page_num):
params = {
'keyword':unquote('%E8%A1%97%E6%8B%8D') ,
'pd':'atlas',
'dvpf':'pc',
'aid': '4916' ,
'page_num':page_num,
'search_json':{"from_search_id":"2022040316335201021218304330C35A48","origin_keyword":"街拍","image_keyword":"街拍"},
'rawJSON':'1',
'search_id':'2022040317334901015013503043241DAC'
}
url = 'https://so.toutiao.com/search/?'+urlencode(params,headers)
try:
response = requests.get(url,headers=headers,params=params)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
这里我们使用urlencode()方法构造请求的GET参数,然后使用requests请求链接。如果返回的状态码为 200,调用响应的 json() 方法将结果转换为 JSON 格式并返回。
接下来实现一个解析方法:提取每条数据的img_url字段中的图片链接,并返回图片链接。这时候就可以构建生成器了。实现代码如下:
def get_images(json):
if json.get('rawData'):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield {
'image':image.get('img_url'),
'title':"街拍",
'text':image.get('text')
}
接下来,实现一个用于保存图像的 save_image() 方法,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。代码显示如下:
import os
from hashlib import md5
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print('Failed to Save image')
最后,只需构造一个数组,遍历,提取图片链接,下载即可:
from multiprocessing.pool import Pool
def main(page_num):
json = get_page(page_num)
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 1
GROUP_END = 20
if __name__ == '__main__':
# pool = Pool()
# groups = ([x*20 for x in range(GROUP_START,GROUP_END+1)]) #使用这种方式启动出现bug,原因还没有找到
# pool.map(main,groups)
# pool.close()
# pool.join()
for i in range(1,10):
main(i)
因为博主在使用线程池有bug,一直没找到原因,所以先用for循环
结果如下:
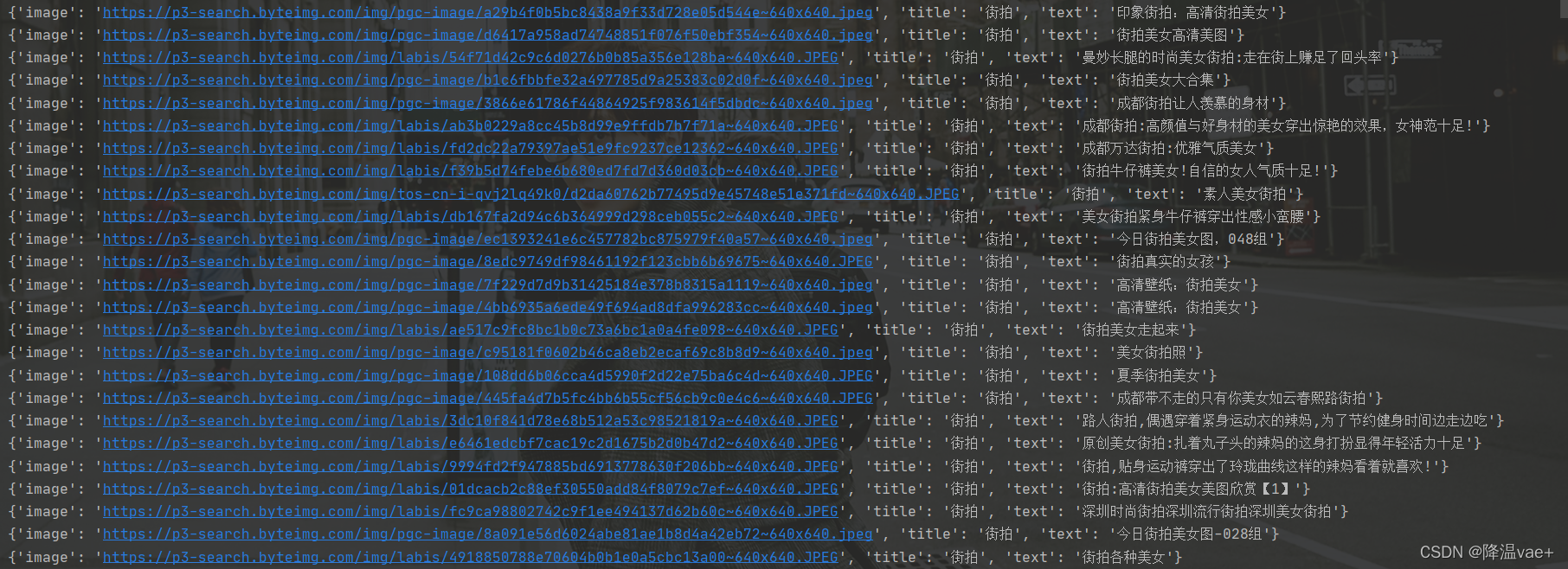
最后,给出本文的代码地址:
参考
[1].Python3网络爬虫开发实战.崔庆才.——6.4
js 爬虫抓取网页数据(盘点一下数据采集常见的几种网站类型(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-04-03 12:20
在学习爬虫之前,我们需要掌握网站的类型,这样才能根据网站的类型,使用适用的方法编写爬虫获取数据。
今天小编就以国内知名的ForeSpider爬虫软件采集可以使用的网站类型为例,盘点几种常见的网站数据类型采集@ >。
l 常用网站类型
1.js 页面
JavaScript是一种属于网络的脚本语言,广泛用于Web应用程序的开发。常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常 JavaScript 脚本嵌入在 HTML 中以实现自己的功能。
ForeSpider数据抓取工具可以自动解析JS,采集根据js页面中的数据,采集页面收录JS数据。
Ajax 是异步 JavaScript 和 XML。它不是一种编程语言,而是一种在不刷新页面和不改变页面链接的情况下,使用 JavaScript 与服务器交换数据并更新部分网页的技术。
我们在浏览网页时,经常会遇到这样的情况。浏览某个页面时,将页面向后拉,页面链接没有变化,但是网页中有新的内容,是通过ajax获取的。新数据和提出的过程。
ForeSpider数据采集系统支持Ajax技术,可以采集网页中的Ajax内容。
2.发布/获取请求
在 html 语言中,有两种方法可以将表单(您在网页中填写的一些数据)发送到服务器。一种是 POST,另一种是 GET。POST 将表单打包并隐藏在后台并发送给服务器;GET 包装表单并将其附加到 URL(网站)的后面,然后再发送。
ForeSpider采集器可以采集post/get请求中的网页内容中的数据,即采集post/get请求中的数据。
3.需要 cookie网站
Cookie是指存储在用户本地终端上用于识别用户身份和进行会话跟踪的一些数据。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。每当用户链接到服务器时,网站都可以访问 cookie 信息。
一般情况下,用户的账户信息都记录在 cookie 中。爬虫在爬取数据时,可以通过cookie模拟登录状态来获取数据。
ForeSpider数据采集分析引擎可以设置cookie来模拟登录,所以采集需要用到cookie的网站内容。
4. 采集需要OAuth认证的网页数据
OAUTH 协议为用户资源的授权提供了一个安全、开放、简单的标准。同时,任何第三方都可以使用OAUTH认证服务,任何服务提供商都可以实现自己的OAUTH认证服务,所以OAUTH是开放的。
业界提供PHP、Java Script、Java、Ruby等多种语言开发包的多种OAUTH实现,大大节省了程序员的时间,所以OAUTH简单。许多互联网服务如Open API,以及许多大公司如谷歌、雅虎、微软等都提供了OAUTH认证服务,这足以说明OAUTH标准已经逐渐成为开放资源授权的标准。
ForeSpider爬虫软件支持OAuth认证,可以采集需要OAuth认证的页面中的数据。
l 前嗅觉介绍
千秀大数据,国内领先的研发大数据专家,多年致力于大数据技术的研发,自主研发了一整套数据采集,分析、处理、管理、应用和营销。大数据产品。千秀致力于打造国内首个深度大数据平台! 查看全部
js 爬虫抓取网页数据(盘点一下数据采集常见的几种网站类型(一)(组图))
在学习爬虫之前,我们需要掌握网站的类型,这样才能根据网站的类型,使用适用的方法编写爬虫获取数据。
今天小编就以国内知名的ForeSpider爬虫软件采集可以使用的网站类型为例,盘点几种常见的网站数据类型采集@ >。
l 常用网站类型
1.js 页面
JavaScript是一种属于网络的脚本语言,广泛用于Web应用程序的开发。常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常 JavaScript 脚本嵌入在 HTML 中以实现自己的功能。
ForeSpider数据抓取工具可以自动解析JS,采集根据js页面中的数据,采集页面收录JS数据。
Ajax 是异步 JavaScript 和 XML。它不是一种编程语言,而是一种在不刷新页面和不改变页面链接的情况下,使用 JavaScript 与服务器交换数据并更新部分网页的技术。
我们在浏览网页时,经常会遇到这样的情况。浏览某个页面时,将页面向后拉,页面链接没有变化,但是网页中有新的内容,是通过ajax获取的。新数据和提出的过程。
ForeSpider数据采集系统支持Ajax技术,可以采集网页中的Ajax内容。
2.发布/获取请求
在 html 语言中,有两种方法可以将表单(您在网页中填写的一些数据)发送到服务器。一种是 POST,另一种是 GET。POST 将表单打包并隐藏在后台并发送给服务器;GET 包装表单并将其附加到 URL(网站)的后面,然后再发送。
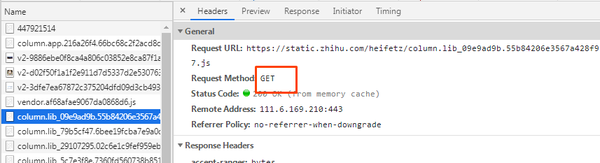
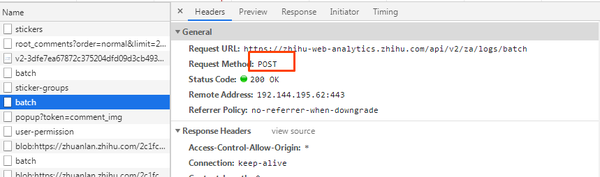
ForeSpider采集器可以采集post/get请求中的网页内容中的数据,即采集post/get请求中的数据。
3.需要 cookie网站
Cookie是指存储在用户本地终端上用于识别用户身份和进行会话跟踪的一些数据。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。每当用户链接到服务器时,网站都可以访问 cookie 信息。
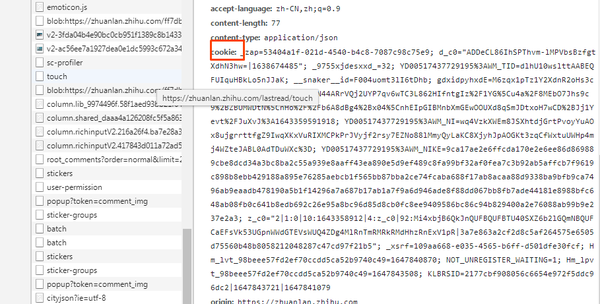
一般情况下,用户的账户信息都记录在 cookie 中。爬虫在爬取数据时,可以通过cookie模拟登录状态来获取数据。
ForeSpider数据采集分析引擎可以设置cookie来模拟登录,所以采集需要用到cookie的网站内容。
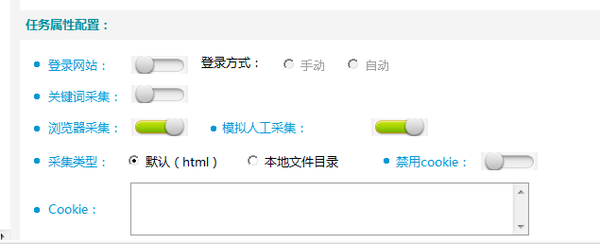
4. 采集需要OAuth认证的网页数据
OAUTH 协议为用户资源的授权提供了一个安全、开放、简单的标准。同时,任何第三方都可以使用OAUTH认证服务,任何服务提供商都可以实现自己的OAUTH认证服务,所以OAUTH是开放的。
业界提供PHP、Java Script、Java、Ruby等多种语言开发包的多种OAUTH实现,大大节省了程序员的时间,所以OAUTH简单。许多互联网服务如Open API,以及许多大公司如谷歌、雅虎、微软等都提供了OAUTH认证服务,这足以说明OAUTH标准已经逐渐成为开放资源授权的标准。
ForeSpider爬虫软件支持OAuth认证,可以采集需要OAuth认证的页面中的数据。
l 前嗅觉介绍
千秀大数据,国内领先的研发大数据专家,多年致力于大数据技术的研发,自主研发了一整套数据采集,分析、处理、管理、应用和营销。大数据产品。千秀致力于打造国内首个深度大数据平台!
js 爬虫抓取网页数据(Python3网络爬虫基本操作(二):静态网页抓取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-03 01:02
Python3网络爬虫基本操作(二):静态网页抓取
一.前言
Python版本:Python3.X
运行环境:Windows
IDE:PyCharm
上一篇博文之后,相信大家对爬虫有了一定的了解。在本文中,我们将系统地讲解如何抓取静态网页资源。(本人也是爬虫的初学者,只是把学到的知识总结一下,分享给大家,如有错误,请指出,谢谢!)
二.静态网页抓取1.安装请求库
打开cmd输入:(详细安装教程请参考上一篇博客)
pip install requests
2.获取网页对应的内容
在 Requests 中,常见的功能是获取网页的内容。现在我们以 Douban() 为例。
import requests
link = "https://movie.douban.com/chart"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
print("文本编码:", req.encoding)
print("响应体:", req.text)
这将返回一个名为 req 的响应对象,我们可以从中获取所需的信息。上述代码运行结果如图:
(1)req.status_code 用于检测响应状态码。
(所有状态码的详细信息:%E7%8A%B6%E6%80%81%E7%A0%81/5053660?fr=aladdin)
(2)req.encoding 是用于服务器内容的文本编码格式。
(3)req.text 是服务器响应内容。
(4)req.json() 是 Requests 中内置的 JSON 解码器。
3.自定义请求(1)获取请求
有时为了请求特定的数据,我们经常需要在 URL 中添加一些数据。在构建 URL 时,我们通常会在数据后面加上一个问号,并将其作为键/值放在 URL 中,例如。(这里是传递 start=0 到)
在 Requests 中,您可以将参数直接放入字典中,并使用 params 构建到 URL 中。
例如:
import requests
key = {'start': '0'}
req = requests.get('https://movie.douban.com/top250', params=key)
print("URL正确编码", req.url)
运行结果:
(2)自定义请求头
请求标头标头提供有关请求、响应或其他发送实体的信息。对于爬虫来说,请求头非常重要。如果没有指定请求头或请求头与实际网页不同,则可能无法得到正确的结果。我们如何获取网页的请求头呢?
我们以( )为例,进入网页检测页面。下图中箭头所指的部分就是网页的Requests Headers部分。
提取其中的重要部分并编写代码:
运行结果:
三.项目实践
我们以它为例进行实践,目的是获取起点中文网月票榜上的100本书的名字。
1.网站分析
打开起点中文网月票榜的网页,使用“检查”查看网页的请求头,写下我们的请求头。
请求头:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host': 'www.qidian.com'
}
第一个只有 20 本书,如果你想得到所有 100 本书,你需要总共得到 5 页。 查看全部
js 爬虫抓取网页数据(Python3网络爬虫基本操作(二):静态网页抓取(组图))
Python3网络爬虫基本操作(二):静态网页抓取
一.前言
Python版本:Python3.X
运行环境:Windows
IDE:PyCharm
上一篇博文之后,相信大家对爬虫有了一定的了解。在本文中,我们将系统地讲解如何抓取静态网页资源。(本人也是爬虫的初学者,只是把学到的知识总结一下,分享给大家,如有错误,请指出,谢谢!)
二.静态网页抓取1.安装请求库
打开cmd输入:(详细安装教程请参考上一篇博客)
pip install requests
2.获取网页对应的内容
在 Requests 中,常见的功能是获取网页的内容。现在我们以 Douban() 为例。
import requests
link = "https://movie.douban.com/chart"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
print("文本编码:", req.encoding)
print("响应体:", req.text)
这将返回一个名为 req 的响应对象,我们可以从中获取所需的信息。上述代码运行结果如图:
(1)req.status_code 用于检测响应状态码。
(所有状态码的详细信息:%E7%8A%B6%E6%80%81%E7%A0%81/5053660?fr=aladdin)
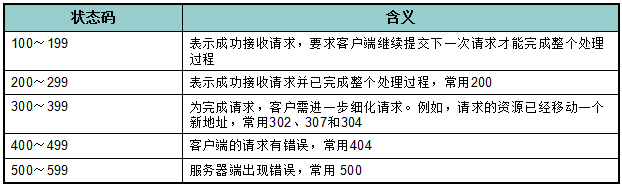
(2)req.encoding 是用于服务器内容的文本编码格式。
(3)req.text 是服务器响应内容。
(4)req.json() 是 Requests 中内置的 JSON 解码器。
3.自定义请求(1)获取请求
有时为了请求特定的数据,我们经常需要在 URL 中添加一些数据。在构建 URL 时,我们通常会在数据后面加上一个问号,并将其作为键/值放在 URL 中,例如。(这里是传递 start=0 到)
在 Requests 中,您可以将参数直接放入字典中,并使用 params 构建到 URL 中。
例如:
import requests
key = {'start': '0'}
req = requests.get('https://movie.douban.com/top250', params=key)
print("URL正确编码", req.url)
运行结果:
(2)自定义请求头
请求标头标头提供有关请求、响应或其他发送实体的信息。对于爬虫来说,请求头非常重要。如果没有指定请求头或请求头与实际网页不同,则可能无法得到正确的结果。我们如何获取网页的请求头呢?
我们以( )为例,进入网页检测页面。下图中箭头所指的部分就是网页的Requests Headers部分。
提取其中的重要部分并编写代码:
运行结果:

三.项目实践
我们以它为例进行实践,目的是获取起点中文网月票榜上的100本书的名字。
1.网站分析
打开起点中文网月票榜的网页,使用“检查”查看网页的请求头,写下我们的请求头。
请求头:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host': 'www.qidian.com'
}
第一个只有 20 本书,如果你想得到所有 100 本书,你需要总共得到 5 页。
js 爬虫抓取网页数据(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-04-02 00:19
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。返回搜狐,查看更多 查看全部
js 爬虫抓取网页数据(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。返回搜狐,查看更多
js 爬虫抓取网页数据(计算机学院大数据专业大三的错误出现,有纰漏恳请各位大佬不吝赐教)
网站优化 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2022-04-01 17:15
大家好,我是文部霍,计算机学院大数据专业三年级学生。我的昵称来自成语——不冷不热,意思是希望我有一个温柔的气质。博主作为互联网行业的新手,写博客一方面是为了记录自己的学习过程,另一方面是总结自己的错误,希望能帮助很多和自己一样处于起步阶段的新人。不过由于水平有限,博客难免会出现一些错误。如果有任何错误,请给我您的建议!.
内容
一、爬取策略
爬取策略是指在爬取过程中对从每个页面解析出来的超链接进行排列的方法,即按照什么顺序来爬取这些超链接。
1.1 爬取策略的设计需要考虑以下约束
(1)不要给web服务器压力太大
这些压力主要体现在:
①连接web服务器需要占用其网络带宽
②每请求一个页面,需要从硬盘读取一个文件
③ 对于动态页面,还需要执行脚本。如果启用了Session,大数据访问需要更多的内存消耗
(2)不要使用过多的客户端资源
当爬虫程序与 Web 服务器建立网络连接时,也会消耗本地网络资源和计算资源。如果同时运行的线程过多,特别是存在一些长期连接,或者网络连接的超时参数设置不当,很可能会导致客户端的网络资源消耗受限。
1.2 爬取策略设计的综合考虑
毕竟,不同网站上的网页链接图都有自己独特的特点。因此,在设计爬虫策略时,需要做出一定的权衡,并考虑各种影响因素,包括爬虫的网络连接消耗以及对服务器的影响。影响等等,一个好的爬虫需要不断的结合网页链接的一些特性来优化和调整。
对于爬虫来说,爬取的初始页面一般是比较重要的页面,比如公司首页、新闻首页网站等。
从爬虫管理多页超链接的效率来看,无论是基本的深度优先策略还是广度优先策略都具有较高的效率。
从页面优先级来看,虽然爬虫使用指定的页面作为初始页面进行爬取,但是在确定下一个要爬取的页面时,总是希望优先级较高的页面先被爬取。
因为页面之间的链接结构非常复杂,可能会出现双向链接、环形链接等情况。
爬虫在爬取WEB服务器上的页面时,需要先建立网络连接,占用主机和连接资源。合理分配这种资源占用是非常有必要的。
二、第一次尝试网络爬虫
互联网中的网络相互连接,形成一个巨大的网络图:
网络爬虫根据给定的策略从这个庞大而复杂的网络体中爬取所需的内容
import requests,re
# import time
# from collections import Counter
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'https://www.baidu.com/more/'
queue = [seed]
used = set() # 设置一个集合,保存已经抓取过的URL
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
我们可以感受下下一级页面到下一级页面可以有多少个链接
三、抓取策略
从网络爬虫的角度来看,整个互联网可以分为:
3.1、数据抓取策略不完善 PageRank 策略 OCIP 策略 大站优先策略 合作爬取策略 图遍历算法策略3.1.1、不完整的PageRank 策略
一般来说,一个网页的PageRank得分是这样计算的:
3.1.2、OPIC 政策
OPICOnline Page Importance Computation的缩写的时时时时以时时时彩平台网址OPIC
OPIC策略的基本思路
3.1.3、 大站点优先策略(粗略)
大站优先策略的思路简单明了:
“战斗”通常具有以下特点:
如何识别要抓取的目标网站是否是战争?
3.1.4、合作爬取策略(需要规范的URL地址)
为了提高爬取网页的速度,一个常见的选择是增加网络爬虫的数量
如何给这些爬虫分配不同的工作量,保证独立分工,避免重复爬取,这是协作爬取策略的目标
协作爬取策略通常使用以下两种方法:
3.1.5、图遍历算法策略(★)
图遍历算法主要分为两种:
1、深度优先
深度优先从根节点开始,沿着尽可能深的路径,直到遇到叶节点才回溯
2、广度优先
为什么要使用广度优先策略:
广度优先遍历策略的基本思想
广度优先策略从根节点开始,尽可能访问离根节点最近的节点
3、Python 实现
DFS和BFS具有高度的对称性,所以在实现Python的时候,不需要将两种数据结构分开,只需要构建一个数据结构
4、代码实现
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
queue = [seed]
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
stack = [seed]
storage = {}
while len(stack) > 0 and count > 0 :
try:
url = stack.pop(-1)
html = requests.get(url).text
new_urls = r.findall(html)
stack.extend(new_urls)
print(url+"下的url数量为:"+str(len(new_urls)))
storage[url] = len(new_urls)
count -= 1
except Exception as e :
print(url)
print(e)
BFS 和 DFS 各有优势,DFS 更容易陷入无限循环,而且通常有价值的网页不会隐藏得太深,因此 BFS 通常是更好的选择。上面的代码使用 list 来模拟堆栈或队列。Python中还有一个Queue模块,包括LifoQueue和PriorityQueue,使用起来比较方便。
3.2、数据更新政策
常见的更新策略如下:
集群策略的基本思想
美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!
一本好书读一百遍也不厌烦,熟了课才知道自己。而如果我想成为观众中最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证我的成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“[url=https://www.ucaiyun.com/]采集”!听说喜欢的人不会倒霉的,每天都精神抖擞!如果你真的想白嫖,那么祝你天天快乐,也欢迎经常光顾我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦! 查看全部
js 爬虫抓取网页数据(计算机学院大数据专业大三的错误出现,有纰漏恳请各位大佬不吝赐教)
大家好,我是文部霍,计算机学院大数据专业三年级学生。我的昵称来自成语——不冷不热,意思是希望我有一个温柔的气质。博主作为互联网行业的新手,写博客一方面是为了记录自己的学习过程,另一方面是总结自己的错误,希望能帮助很多和自己一样处于起步阶段的新人。不过由于水平有限,博客难免会出现一些错误。如果有任何错误,请给我您的建议!.
内容

一、爬取策略
爬取策略是指在爬取过程中对从每个页面解析出来的超链接进行排列的方法,即按照什么顺序来爬取这些超链接。
1.1 爬取策略的设计需要考虑以下约束
(1)不要给web服务器压力太大
这些压力主要体现在:
①连接web服务器需要占用其网络带宽
②每请求一个页面,需要从硬盘读取一个文件
③ 对于动态页面,还需要执行脚本。如果启用了Session,大数据访问需要更多的内存消耗
(2)不要使用过多的客户端资源
当爬虫程序与 Web 服务器建立网络连接时,也会消耗本地网络资源和计算资源。如果同时运行的线程过多,特别是存在一些长期连接,或者网络连接的超时参数设置不当,很可能会导致客户端的网络资源消耗受限。
1.2 爬取策略设计的综合考虑
毕竟,不同网站上的网页链接图都有自己独特的特点。因此,在设计爬虫策略时,需要做出一定的权衡,并考虑各种影响因素,包括爬虫的网络连接消耗以及对服务器的影响。影响等等,一个好的爬虫需要不断的结合网页链接的一些特性来优化和调整。
对于爬虫来说,爬取的初始页面一般是比较重要的页面,比如公司首页、新闻首页网站等。
从爬虫管理多页超链接的效率来看,无论是基本的深度优先策略还是广度优先策略都具有较高的效率。
从页面优先级来看,虽然爬虫使用指定的页面作为初始页面进行爬取,但是在确定下一个要爬取的页面时,总是希望优先级较高的页面先被爬取。
因为页面之间的链接结构非常复杂,可能会出现双向链接、环形链接等情况。
爬虫在爬取WEB服务器上的页面时,需要先建立网络连接,占用主机和连接资源。合理分配这种资源占用是非常有必要的。
二、第一次尝试网络爬虫
互联网中的网络相互连接,形成一个巨大的网络图:

网络爬虫根据给定的策略从这个庞大而复杂的网络体中爬取所需的内容
import requests,re
# import time
# from collections import Counter
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'https://www.baidu.com/more/'
queue = [seed]
used = set() # 设置一个集合,保存已经抓取过的URL
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
我们可以感受下下一级页面到下一级页面可以有多少个链接

三、抓取策略
从网络爬虫的角度来看,整个互联网可以分为:

3.1、数据抓取策略不完善 PageRank 策略 OCIP 策略 大站优先策略 合作爬取策略 图遍历算法策略3.1.1、不完整的PageRank 策略
一般来说,一个网页的PageRank得分是这样计算的:

3.1.2、OPIC 政策
OPICOnline Page Importance Computation的缩写的时时时时以时时时彩平台网址OPIC
OPIC策略的基本思路
3.1.3、 大站点优先策略(粗略)
大站优先策略的思路简单明了:
“战斗”通常具有以下特点:
如何识别要抓取的目标网站是否是战争?
3.1.4、合作爬取策略(需要规范的URL地址)
为了提高爬取网页的速度,一个常见的选择是增加网络爬虫的数量
如何给这些爬虫分配不同的工作量,保证独立分工,避免重复爬取,这是协作爬取策略的目标
协作爬取策略通常使用以下两种方法:
3.1.5、图遍历算法策略(★)
图遍历算法主要分为两种:
1、深度优先
深度优先从根节点开始,沿着尽可能深的路径,直到遇到叶节点才回溯

2、广度优先
为什么要使用广度优先策略:
广度优先遍历策略的基本思想
广度优先策略从根节点开始,尽可能访问离根节点最近的节点

3、Python 实现
DFS和BFS具有高度的对称性,所以在实现Python的时候,不需要将两种数据结构分开,只需要构建一个数据结构
4、代码实现
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
queue = [seed]
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)

import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
stack = [seed]
storage = {}
while len(stack) > 0 and count > 0 :
try:
url = stack.pop(-1)
html = requests.get(url).text
new_urls = r.findall(html)
stack.extend(new_urls)
print(url+"下的url数量为:"+str(len(new_urls)))
storage[url] = len(new_urls)
count -= 1
except Exception as e :
print(url)
print(e)

BFS 和 DFS 各有优势,DFS 更容易陷入无限循环,而且通常有价值的网页不会隐藏得太深,因此 BFS 通常是更好的选择。上面的代码使用 list 来模拟堆栈或队列。Python中还有一个Queue模块,包括LifoQueue和PriorityQueue,使用起来比较方便。
3.2、数据更新政策
常见的更新策略如下:
集群策略的基本思想


美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!

一本好书读一百遍也不厌烦,熟了课才知道自己。而如果我想成为观众中最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证我的成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“[url=https://www.ucaiyun.com/]采集”!听说喜欢的人不会倒霉的,每天都精神抖擞!如果你真的想白嫖,那么祝你天天快乐,也欢迎经常光顾我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦!
js 爬虫抓取网页数据(网站快速收录,网站怎么做才会快速收录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-16 18:04
网站快收录,网站怎么做才能快收录?首先,要想网站快收录,必须保证网站的质量。然后主动提交给搜索引擎。无论是百度、360还是搜狗等搜索引擎,所有搜索引擎都需要主动向搜索引擎提交链接。只有提交链接后,搜索引擎才能更快地发现网站链接。网站 时效性内容建议尽快提交,推送数据实时搜索。可以加快爬取速度,促进更快收录。
只有两种方法可以使搜索引擎 收录 快速。一个是做好站内优化和文章原创优化等搜索引擎主动爬取你的网站,另一个第一是你主动提交给搜索引擎并告诉它抓取。第一个周期太长,所以这篇文章讲第二个
1.准备就绪网站:
首先,想做SEO的同学需要考虑自己选择的前端框架。现在主流的angularJs、Vue.js、react.js,这些动态渲染数据的框架,对爬虫非常不友好,但是这些框架都有对应的后端渲染方案,或者曲线的方案就是专门写一套静态页面搜索引擎优化。当然,只想收录的同学可以忽略这些,可以通过bind的形式绑定数据,这样百度搜索结果至少不会出现{{}}这样的乱码。
标题标签是关键标签,它不仅是你的页面名称,也是百度搜索结果中的重要参考。如:
元标签的关键词和描述:谷歌和百度不再使用这两个标签作为排名因素,但描述对网站的流量还是有帮助的,因为描述是直接在谷歌搜索结果中使用的。页面的描述,当用户搜索看到描述好的时候,更容易找到你的网站,而关键词基本是无效的,有时会适得其反,百度会认为你过分了搜索引擎优化。怀疑。
2、加速网站收录:
虽然搜索引擎的爬虫不能实时爬取你的网站,但是爬到它并不代表它就是收录。一般百度会在一定期限内收录你的网站。您可以通过其他方式加速百度收录。提交sitemap,或者代码自动推送,提交网站的sitemap文件,让爬虫一一抓取页面。或者在页面插入自动推送代码,每个搜索引擎资源管理平台都会有自动推送代码。
这样,您的页面将在您每次访问时被抓取。
通过其他的网站名字,最常见的引导百度爬的就是网站下面的很多链接,在一些高权重的网站下面加一个你的链接,百度也会爬你的网站 沿着页面;或者把你的网站网址放在高权重的网站上发布文章,也会吸引百度进来。这大大增加了 收录 的机会。
3、改进网站收录方法
做好网站内部链接。在这方面,很多网站都没有做好。一开始他们以为内页需要正常收录才可以做内链,但是文章没有做内链。现在想想,如果文章里面没有内链,那么搜索引擎蜘蛛只会爬一页就走了,太浪费了。所以,文章页面的相关推荐和头条推荐是非常重要的,我们不得不用它们来进行SEO优化。
总结:很多朋友对网站的投稿知之甚少。这里给大家分享一个SEO人员正在使用的网站收录工具,包括:百度/搜狗/360/今日头条/神马/谷歌/等。只需导入自动提交的链接,还附带一个站点地图网站地图生成器。如果您想网站快速收录,请务必进行这些主动提交收录。返回搜狐,查看更多 查看全部
js 爬虫抓取网页数据(网站快速收录,网站怎么做才会快速收录?)
网站快收录,网站怎么做才能快收录?首先,要想网站快收录,必须保证网站的质量。然后主动提交给搜索引擎。无论是百度、360还是搜狗等搜索引擎,所有搜索引擎都需要主动向搜索引擎提交链接。只有提交链接后,搜索引擎才能更快地发现网站链接。网站 时效性内容建议尽快提交,推送数据实时搜索。可以加快爬取速度,促进更快收录。
只有两种方法可以使搜索引擎 收录 快速。一个是做好站内优化和文章原创优化等搜索引擎主动爬取你的网站,另一个第一是你主动提交给搜索引擎并告诉它抓取。第一个周期太长,所以这篇文章讲第二个
1.准备就绪网站:
首先,想做SEO的同学需要考虑自己选择的前端框架。现在主流的angularJs、Vue.js、react.js,这些动态渲染数据的框架,对爬虫非常不友好,但是这些框架都有对应的后端渲染方案,或者曲线的方案就是专门写一套静态页面搜索引擎优化。当然,只想收录的同学可以忽略这些,可以通过bind的形式绑定数据,这样百度搜索结果至少不会出现{{}}这样的乱码。
标题标签是关键标签,它不仅是你的页面名称,也是百度搜索结果中的重要参考。如:
元标签的关键词和描述:谷歌和百度不再使用这两个标签作为排名因素,但描述对网站的流量还是有帮助的,因为描述是直接在谷歌搜索结果中使用的。页面的描述,当用户搜索看到描述好的时候,更容易找到你的网站,而关键词基本是无效的,有时会适得其反,百度会认为你过分了搜索引擎优化。怀疑。
2、加速网站收录:
虽然搜索引擎的爬虫不能实时爬取你的网站,但是爬到它并不代表它就是收录。一般百度会在一定期限内收录你的网站。您可以通过其他方式加速百度收录。提交sitemap,或者代码自动推送,提交网站的sitemap文件,让爬虫一一抓取页面。或者在页面插入自动推送代码,每个搜索引擎资源管理平台都会有自动推送代码。
这样,您的页面将在您每次访问时被抓取。
通过其他的网站名字,最常见的引导百度爬的就是网站下面的很多链接,在一些高权重的网站下面加一个你的链接,百度也会爬你的网站 沿着页面;或者把你的网站网址放在高权重的网站上发布文章,也会吸引百度进来。这大大增加了 收录 的机会。
3、改进网站收录方法
做好网站内部链接。在这方面,很多网站都没有做好。一开始他们以为内页需要正常收录才可以做内链,但是文章没有做内链。现在想想,如果文章里面没有内链,那么搜索引擎蜘蛛只会爬一页就走了,太浪费了。所以,文章页面的相关推荐和头条推荐是非常重要的,我们不得不用它们来进行SEO优化。
总结:很多朋友对网站的投稿知之甚少。这里给大家分享一个SEO人员正在使用的网站收录工具,包括:百度/搜狗/360/今日头条/神马/谷歌/等。只需导入自动提交的链接,还附带一个站点地图网站地图生成器。如果您想网站快速收录,请务必进行这些主动提交收录。返回搜狐,查看更多
js 爬虫抓取网页数据(快速采集高质量文章的织梦采集文章方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-16 17:46
)
经常听到站长抱怨织梦网站跑了一段时间网站not收录关键词优化不排名或者只有收录首页,这个真的很烦人。事实上,网站 内容的收录 情况很大程度上取决于搜索引擎蜘蛛所花费的时间。抓取时间越长,深圳SEO针对这个问题总结了以下方法:
一、优化网站导航结构
1.添加内链:如及时出现的描述性文字,如网页右侧或底部出现的相关链接和相关文章,这些内链可以吸引用户的注意力,点击量,以及用户最喜欢的 网站 ,自然搜索引擎也会关注。
2. 降低目录层次或减少首页间隔:目录有条理,蜘蛛喜欢的越少,距离首页越远,页面的权重越低。
二、代码和图片优化
对于太多的js或者动态页面,应该优化网页的代码,即使网页是静态页面,提高网页对于搜索引擎的可读性。对于图片过多的网站,应结合图文并添加alt图片标签。毕竟像笔墨这样的搜索引擎的识别度要比图片高很多。
三、制作网站地图
网站地图在文章收录中起到了很大的作用,它可以为搜索引擎爬虫提供网站各个地方的链接,有效减少爬虫的工作量,可以有效的减少爬虫的工作量。增加搜索引擎的数量收录文章。
四、静态化 网站 URL
网站如果不是静态的,会导致动态URL过长,动态页面访问速度太慢,出现重复页面。实际上,您可以使整个站点保持静态。如果不能生成静态,可以使用伪静态。
五、上传原创或高质量伪原创文章定期更新
不得不说,新网站往往内容太少,不断更新会引起搜索引擎关注网站。像 原创 的 文章 这样的搜索引擎,尤其是定期定量发布 原创文章 的 网站。每天坚持战斗,用不了多久,你的网站快照和收录s就会快速增加。今天给大家分享一个快速采集高品质文章织梦采集插件(所有网站通用插件)。
这个织梦采集插件不需要学习更多的专业技能,只需要简单几步就可以轻松搞定采集内容数据,用户只需要添加织梦采集 在插件上进行了简单的设置。完成后,织梦采集插件会根据用户设置的关键词,对内容和图片进行高精度匹配。您可以选择保存在本地,也可以选择伪原创发布后,提供方便快捷的内容采集伪原创发布服务!!
和其他织梦采集插件相比,这个织梦采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟上手,只需要输入关键词即可实现采集(织梦采集插件也自带关键词 采集 函数)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO方面采集伪原创。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面的原创度,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
六、主动向搜索引擎提交链接
做SEO优化的人都知道,很多时候,我们基于百度搜索引擎对网站的SEO进行优化,研究如何让网站在百度获得排名。现在百度站长平台上有一个链接提交工具,可以让新的网站更快的被收录和网站被搜索引擎更快的抓取。网站只有在收录的时候才能被索引,只有被索引了才能显示出来,而且还有一个网站被点击的概率。因此,网站收录是seo优化的基础。只有打好基础,网站优化才能成功。因此,我们希望做出符合用户需求的内容,并尽可能地改进收录。
如何利用搜索引擎站长平台提升网站收录,这里以百度站长平台为例,加速新的网站收录链接工具?在站长平台上验证新的网站有三种方式:
注册百度站长平台账号,在站点管理中点击添加网站,输入你的网站,添加站点属性,然后验证网站。验证方式有文件验证、HTML标签验证、CNAME验证三种。每种网站验证方式都有对应的说明,可以根据自己的情况选择合适的方式进行验证。
加速新的网站收录有两个关键步骤,这里是加速新的网站收录的关键步骤。提交链接有两种方式,一种是自动提交,包括主动推送(实时)、自动推送和站点地图,另一种是手动提交。在经过验证的百度站长后台,每种提交方式都有详细的说明,大家可以按需操作。使用更高效的推送方式来实现收录的效果。建议使用带实时功能的主动推送功能,优点是速度最快;同时使用自动推送,通过用户行为将网站页面推送到搜索引擎,节省站长操作时间。
需要强调的是,我们将新的网站提交给百度,让搜索引擎抓取我们的网站,无论是收录,还是收录@的时间>,还受网站上线时间长短、网站内容质量等多重因素影响。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
查看全部
js 爬虫抓取网页数据(快速采集高质量文章的织梦采集文章方法
)
经常听到站长抱怨织梦网站跑了一段时间网站not收录关键词优化不排名或者只有收录首页,这个真的很烦人。事实上,网站 内容的收录 情况很大程度上取决于搜索引擎蜘蛛所花费的时间。抓取时间越长,深圳SEO针对这个问题总结了以下方法:
一、优化网站导航结构
1.添加内链:如及时出现的描述性文字,如网页右侧或底部出现的相关链接和相关文章,这些内链可以吸引用户的注意力,点击量,以及用户最喜欢的 网站 ,自然搜索引擎也会关注。
2. 降低目录层次或减少首页间隔:目录有条理,蜘蛛喜欢的越少,距离首页越远,页面的权重越低。
二、代码和图片优化
对于太多的js或者动态页面,应该优化网页的代码,即使网页是静态页面,提高网页对于搜索引擎的可读性。对于图片过多的网站,应结合图文并添加alt图片标签。毕竟像笔墨这样的搜索引擎的识别度要比图片高很多。
三、制作网站地图
网站地图在文章收录中起到了很大的作用,它可以为搜索引擎爬虫提供网站各个地方的链接,有效减少爬虫的工作量,可以有效的减少爬虫的工作量。增加搜索引擎的数量收录文章。
四、静态化 网站 URL
网站如果不是静态的,会导致动态URL过长,动态页面访问速度太慢,出现重复页面。实际上,您可以使整个站点保持静态。如果不能生成静态,可以使用伪静态。
五、上传原创或高质量伪原创文章定期更新
不得不说,新网站往往内容太少,不断更新会引起搜索引擎关注网站。像 原创 的 文章 这样的搜索引擎,尤其是定期定量发布 原创文章 的 网站。每天坚持战斗,用不了多久,你的网站快照和收录s就会快速增加。今天给大家分享一个快速采集高品质文章织梦采集插件(所有网站通用插件)。
这个织梦采集插件不需要学习更多的专业技能,只需要简单几步就可以轻松搞定采集内容数据,用户只需要添加织梦采集 在插件上进行了简单的设置。完成后,织梦采集插件会根据用户设置的关键词,对内容和图片进行高精度匹配。您可以选择保存在本地,也可以选择伪原创发布后,提供方便快捷的内容采集伪原创发布服务!!
和其他织梦采集插件相比,这个织梦采集插件基本没有门槛,不需要花很多时间学习正则表达式或者html标签,一分钟上手,只需要输入关键词即可实现采集(织梦采集插件也自带关键词 采集 函数)。一路挂断!设置任务自动执行采集伪原创发布和推送任务。
几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类dede采集发布插件工具也配备了很多SEO功能,通过软件发布也可以提升很多SEO方面采集伪原创。
例如:设置自动下载图片保存在本地或第三方(使内容不再有对方的外链)。自动内链(让搜索引擎更深入地抓取你的链接)、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“高原创 ”。
这些SEO小功能不仅提高了网站页面的原创度,还间接提升了网站的收录排名。您可以通过软件工具上的监控管理直接查看文章采集的发布状态,不再需要每天登录网站后台查看。目前博主亲测软件是免费的,可以直接下载使用!
六、主动向搜索引擎提交链接
做SEO优化的人都知道,很多时候,我们基于百度搜索引擎对网站的SEO进行优化,研究如何让网站在百度获得排名。现在百度站长平台上有一个链接提交工具,可以让新的网站更快的被收录和网站被搜索引擎更快的抓取。网站只有在收录的时候才能被索引,只有被索引了才能显示出来,而且还有一个网站被点击的概率。因此,网站收录是seo优化的基础。只有打好基础,网站优化才能成功。因此,我们希望做出符合用户需求的内容,并尽可能地改进收录。
如何利用搜索引擎站长平台提升网站收录,这里以百度站长平台为例,加速新的网站收录链接工具?在站长平台上验证新的网站有三种方式:
注册百度站长平台账号,在站点管理中点击添加网站,输入你的网站,添加站点属性,然后验证网站。验证方式有文件验证、HTML标签验证、CNAME验证三种。每种网站验证方式都有对应的说明,可以根据自己的情况选择合适的方式进行验证。
加速新的网站收录有两个关键步骤,这里是加速新的网站收录的关键步骤。提交链接有两种方式,一种是自动提交,包括主动推送(实时)、自动推送和站点地图,另一种是手动提交。在经过验证的百度站长后台,每种提交方式都有详细的说明,大家可以按需操作。使用更高效的推送方式来实现收录的效果。建议使用带实时功能的主动推送功能,优点是速度最快;同时使用自动推送,通过用户行为将网站页面推送到搜索引擎,节省站长操作时间。
需要强调的是,我们将新的网站提交给百度,让搜索引擎抓取我们的网站,无论是收录,还是收录@的时间>,还受网站上线时间长短、网站内容质量等多重因素影响。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天为你展示各种SEO经验,打通你的二线任命和主管!
js 爬虫抓取网页数据(联想虚拟货币爬取这是酷安老哥找我做的一个项目)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-16 05:20
在此期间总共制作了三种爬行动物:
我使用了两种不同的技术。前两个是我自己的想法。我使用 nodejs+express+superagent。说实话,nodejs对后台的数据真的很友好。然后我使用 Sequelize 进行 ORM 对象映射,确实非常好。方便。
这也是要熟悉express的架构,以后再补坑,虽然坑的不多。
我还为 Sequelize 文档做了一个镜像仓库,方便访问。
但是,在 JavaScript 中编写程序时,有一点是无法避免的,那就是异步操作。
JavaScript作为浏览器的主要逻辑实现语言,对于支持网络操作是必不可少的。如果浏览器不使用异步获取数据,就会出现页面加载慢等问题,用JavaScript编写的后端也无法避免处理异步操作。,比较头疼的是循环异步操作。我在网上查了很多文件。主要的解决方案是递归地循环嵌套promise,然后确保获取到最后一个promise对象,然后等待他的resolve或者reject。
让我们详细谈谈这些项目。
丁香园数据爬取
这个项目我是自发开始的,大概用了三四天的时间。
分析页面数据
打开丁香园的网站,右键查看网页源代码,可以看到丁香园的数据是后端渲染出来的,所有需要的数据都嵌入到了JavaScript中json 格式的 HTML。
事实上,最初的丁香园页面并不是这样的。一开始不是很直观,都是用html标签写的。
估计是为了方便网友抓取它的数据吧?毕竟写html+JavaScript对爬虫很有好处
而且里面几乎所有的数据都是完美而严格的json格式,用JSON.parse()就行了。后台没什么好说的,写个定时器,定时爬取。公开一些接口可以在 GitHub ⭐ 上收获。
联想虚拟货币爬行
这是关弟兄让我做的一个项目。毕竟,这是我人生中的第一次外包。我犹豫了两分钟,立刻开始了。第一天,我花了半天时间研究页面并分析困难。
第一点是我在这部分遇到的第一个坑。因为我之前做的是一个不需要登录的页面,只能直接分析得到的html数据,所以上网查了一些资料。
其实解决方法很简单。就是模拟登录操作,获取联想服务器返回的cookie数据,然后带着这个cookie访问币种查询页面。
以下是我对网络安全的一些看法:
网页安全吗?
不,没有网页是安全的,纯网页几乎不可能完全安全,所以很多网上银行都需要外挂一些硬件工具来保证安全。
那么一个网页可以相对安全吗?
是的,而且应该是。
使用 session 或 cookie 或 token 区分用户属性,防止未登录的未知用户查看敏感页面,并添加过期功能,确保数据安全。
使用不可逆加密来保护用户输入的密码。只有这样,后台才能在不知道用户真实密码的情况下确认用户的登录状态。个人认为MD5加密对于我这个级别来说是比较好的用户信息加密方式。
在分析联想的登录界面时,我发现了一个让我哭笑不得的地方。
百度百科
Base64 是 Internet 上传输 8Bit 字节码最常见的编码方法之一。Base64 是一种基于 64 个可打印字符表示二进制数据的方法。可以查看RFC2045~RFC2049,里面有MIME的详细规范。
Base64 编码是一种二进制到字符的过程,可用于在 HTTP 环境中传送更长的标识信息。使用 Base64 编码是不可读的,需要先解码才能读取。
连联想的一些登录页面,密码都是明文传输的……联想的技术水平我真的无语,具体是哪些页面就不说了。
解决了登录问题后,基本搞定了大半。
然后是运维和调优。这段时间,当IP被封时,我设置了爬取时间间隔,基本没有问题。
如何获取信息
有两种主要类型的网页
后端渲染SSR页面,或者prerender预渲染单页应用,前端请求数据前端渲染
第二种对爬虫不友好。只能手动找前端接口,然后看运气能不能请求对应的数据,比较随机。
在第一种情况下,我现在主要使用正则表达式。JavaScript对正则表达式比较友好,操作DOM也很方便。基本流程是
在使用正则表达式之前,您可以使用 DOM 操作工具来缩小搜索范围以方便匹配。 查看全部
js 爬虫抓取网页数据(联想虚拟货币爬取这是酷安老哥找我做的一个项目)
在此期间总共制作了三种爬行动物:
我使用了两种不同的技术。前两个是我自己的想法。我使用 nodejs+express+superagent。说实话,nodejs对后台的数据真的很友好。然后我使用 Sequelize 进行 ORM 对象映射,确实非常好。方便。
这也是要熟悉express的架构,以后再补坑,虽然坑的不多。
我还为 Sequelize 文档做了一个镜像仓库,方便访问。
但是,在 JavaScript 中编写程序时,有一点是无法避免的,那就是异步操作。
JavaScript作为浏览器的主要逻辑实现语言,对于支持网络操作是必不可少的。如果浏览器不使用异步获取数据,就会出现页面加载慢等问题,用JavaScript编写的后端也无法避免处理异步操作。,比较头疼的是循环异步操作。我在网上查了很多文件。主要的解决方案是递归地循环嵌套promise,然后确保获取到最后一个promise对象,然后等待他的resolve或者reject。
让我们详细谈谈这些项目。
丁香园数据爬取
这个项目我是自发开始的,大概用了三四天的时间。
分析页面数据
打开丁香园的网站,右键查看网页源代码,可以看到丁香园的数据是后端渲染出来的,所有需要的数据都嵌入到了JavaScript中json 格式的 HTML。
事实上,最初的丁香园页面并不是这样的。一开始不是很直观,都是用html标签写的。
估计是为了方便网友抓取它的数据吧?毕竟写html+JavaScript对爬虫很有好处
而且里面几乎所有的数据都是完美而严格的json格式,用JSON.parse()就行了。后台没什么好说的,写个定时器,定时爬取。公开一些接口可以在 GitHub ⭐ 上收获。
联想虚拟货币爬行
这是关弟兄让我做的一个项目。毕竟,这是我人生中的第一次外包。我犹豫了两分钟,立刻开始了。第一天,我花了半天时间研究页面并分析困难。
第一点是我在这部分遇到的第一个坑。因为我之前做的是一个不需要登录的页面,只能直接分析得到的html数据,所以上网查了一些资料。
其实解决方法很简单。就是模拟登录操作,获取联想服务器返回的cookie数据,然后带着这个cookie访问币种查询页面。
以下是我对网络安全的一些看法:
网页安全吗?
不,没有网页是安全的,纯网页几乎不可能完全安全,所以很多网上银行都需要外挂一些硬件工具来保证安全。
那么一个网页可以相对安全吗?
是的,而且应该是。
使用 session 或 cookie 或 token 区分用户属性,防止未登录的未知用户查看敏感页面,并添加过期功能,确保数据安全。
使用不可逆加密来保护用户输入的密码。只有这样,后台才能在不知道用户真实密码的情况下确认用户的登录状态。个人认为MD5加密对于我这个级别来说是比较好的用户信息加密方式。
在分析联想的登录界面时,我发现了一个让我哭笑不得的地方。
百度百科
Base64 是 Internet 上传输 8Bit 字节码最常见的编码方法之一。Base64 是一种基于 64 个可打印字符表示二进制数据的方法。可以查看RFC2045~RFC2049,里面有MIME的详细规范。
Base64 编码是一种二进制到字符的过程,可用于在 HTTP 环境中传送更长的标识信息。使用 Base64 编码是不可读的,需要先解码才能读取。
连联想的一些登录页面,密码都是明文传输的……联想的技术水平我真的无语,具体是哪些页面就不说了。
解决了登录问题后,基本搞定了大半。
然后是运维和调优。这段时间,当IP被封时,我设置了爬取时间间隔,基本没有问题。
如何获取信息
有两种主要类型的网页
后端渲染SSR页面,或者prerender预渲染单页应用,前端请求数据前端渲染
第二种对爬虫不友好。只能手动找前端接口,然后看运气能不能请求对应的数据,比较随机。
在第一种情况下,我现在主要使用正则表达式。JavaScript对正则表达式比较友好,操作DOM也很方便。基本流程是
在使用正则表达式之前,您可以使用 DOM 操作工具来缩小搜索范围以方便匹配。
js 爬虫抓取网页数据(本文接上文分享:pyspider界面pyspider模拟登录渲染爬取AJAX异步加载网页pyspider)
网站优化 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2022-04-15 13:40
这篇文章继续上面的内容,继续聊聊python爬虫的相关知识。上一篇是关于各种爬虫库的。本文主要介绍一个好用的框架pyspider,标题如下:
pyspider简介Pyspider接口pyspider脚本模拟登录JS渲染爬取AJAX异步加载网页pyspider简介
Pyspider 是 Binux 制作的爬虫架构的开源实现。主要功能有:
Pyspider使用去重调度、队列抓取、异常处理、监控等功能作为框架,只需要提供抓取脚本,保证灵活性即可。最后,web的编辑调试环境和web任务的监控成为框架。pyspider的设计基础是:一个python脚本驱动的抓环模型爬虫
pyspider 接口
在终端输入pyspider all运行pyspider服务,然后在浏览器中输入localhost:5000就可以看到pyspider的界面,rate用来控制每秒爬取的页面数,burst可以看做是并发控制。
点击create创建项目
点击新建项目,打开脚本编辑界面
我们可以在这里编写和调试脚本。网络可以在测试期间显示网页。网页左侧的按钮是css选择器,html是网页的源代码,followers显示可以爬取的url。具体调试,亲身体验就知道了。
pyspider 脚本
但是当你创建一个新项目时,你会看到这些默认的脚本模板。接下来简单介绍一下pyspider脚本的编写。
from pyspider.libs.base_handler import *class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60) def on_start(self):
self.crawl('__START_URL__', callback=self.index_page)
@config(age=10 * 24 * 60 * 60) def index_page(self, response): for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2) def detail_page(self, response): return { "url": response.url, "title": response.doc('title').text(),
}
更多参数用法可以查看官方文档。
index_page 和 detail_page 只是初始脚本中的回调函数。除了on_start,其他函数名可以自定义@every(minutes=24 * 60)来设置执行频率(24*60是一天一次,所以可以每天执行一次) 爬取一次获取数据) @config 模拟登录
有很多网站用户需要登录才能浏览更多内容,所以我们的爬虫需要实现模拟登录的功能,我们可以使用selenium来实现模拟登录。
Selenium 是一个 Web 应用测试的工具,我们也可以通过 selenium 来实现登录功能。以微博为例
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://weibo.com/")
username = driver.find_element_by_css_selector("input#loginname")
username.clear()
username.send_keys('your_username')
password = driver.find_element_by_css_selector('span.enter_psw')
password.clear()
password.send_keys('your_password')
输入帐号和密码后,最大的问题来了。验证码都是图片。一般我们需要使用图像识别来识别验证码,但是由于验证码的种类很多(英文、数字、中文或者它们的混合),而且验证码也可能会被旋转、扭曲甚至附着在每个其他,以至于人眼不能很好的识别,所以大部分模型的通用性和准确率都不是很高。因此,最有效的方法是在selenium打开浏览器后手动登录(过程中调用time.sleep()暂停程序)。由于爬虫最重要的不是解决登录问题,这样就节省了很多时间和代码,虽然笨但很有用。
登录后,使用代码获取cookie,并在pyspider全局参数中将cookie_dict传递给cookies。
cookies_dict = {}
cookies = driver.get_cookies()for cookie in cookies:
cookies_dict[cookie['name']] = cookie['value']
JS渲染
普通请求只能爬取静态的HTML页面,但是大部分网站都是混着JS数据加载的,数据是懒加载的。如果要爬取这些内容,可以使用 selenium + PhantomJS 将网页完整渲染,然后再进行网页分析。PhantomJS 是一个非接口、可编写脚本的 WebKit 浏览器引擎。使用方法类似于使用 selenium + Chrome 模拟登录,但由于 PhantomJS 没有接口,内存消耗会少很多。
爬取 AJAX 以异步加载网页
AJAX 是一种用于创建快速和动态网页的技术。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。要爬取AJAX异步加载的网页,我们需要分析网页的请求和返回信息。具体来说,我们需要使用谷歌浏览器的开发者工具(火狐等浏览器也有这个)查看网络的XHR,但是当网页部分更新时,浏览器发出了什么请求,返回了什么通过浏览器。
在我们微博登录的首页,只要将滚动条移到最下方,就会发现刷新了一条新的微博。这是我们打开开发者工具一直往下滚动,然后你会发现,但是你刷出来的时候有新的信息,总是发出新的请求,返回的json中的数据就是刷新微博的html .
仔细观察发现pagebar的变化是有规律的,id减15,对应新刷新的15微博。因此,可以推测pagebar应该是刷新微博的关键。在此之前,我们需要给爬虫添加请求头,否则很可能被服务器识别为机器人,无法成功访问。请求标头也可以在开发者工具中找到。
def on_start(self): for i in range(10):
url = 'https://weibo.com/aj/mblog/fse ... B%25i
self.crawl(url, callback=self.index_page)
发现微博内容被成功抓取并返回。然后只需处理您需要的信息。 查看全部
js 爬虫抓取网页数据(本文接上文分享:pyspider界面pyspider模拟登录渲染爬取AJAX异步加载网页pyspider)
这篇文章继续上面的内容,继续聊聊python爬虫的相关知识。上一篇是关于各种爬虫库的。本文主要介绍一个好用的框架pyspider,标题如下:
pyspider简介Pyspider接口pyspider脚本模拟登录JS渲染爬取AJAX异步加载网页pyspider简介
Pyspider 是 Binux 制作的爬虫架构的开源实现。主要功能有:
Pyspider使用去重调度、队列抓取、异常处理、监控等功能作为框架,只需要提供抓取脚本,保证灵活性即可。最后,web的编辑调试环境和web任务的监控成为框架。pyspider的设计基础是:一个python脚本驱动的抓环模型爬虫
pyspider 接口
在终端输入pyspider all运行pyspider服务,然后在浏览器中输入localhost:5000就可以看到pyspider的界面,rate用来控制每秒爬取的页面数,burst可以看做是并发控制。
点击create创建项目
点击新建项目,打开脚本编辑界面
我们可以在这里编写和调试脚本。网络可以在测试期间显示网页。网页左侧的按钮是css选择器,html是网页的源代码,followers显示可以爬取的url。具体调试,亲身体验就知道了。
pyspider 脚本
但是当你创建一个新项目时,你会看到这些默认的脚本模板。接下来简单介绍一下pyspider脚本的编写。
from pyspider.libs.base_handler import *class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60) def on_start(self):
self.crawl('__START_URL__', callback=self.index_page)
@config(age=10 * 24 * 60 * 60) def index_page(self, response): for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2) def detail_page(self, response): return { "url": response.url, "title": response.doc('title').text(),
}
更多参数用法可以查看官方文档。
index_page 和 detail_page 只是初始脚本中的回调函数。除了on_start,其他函数名可以自定义@every(minutes=24 * 60)来设置执行频率(24*60是一天一次,所以可以每天执行一次) 爬取一次获取数据) @config 模拟登录
有很多网站用户需要登录才能浏览更多内容,所以我们的爬虫需要实现模拟登录的功能,我们可以使用selenium来实现模拟登录。
Selenium 是一个 Web 应用测试的工具,我们也可以通过 selenium 来实现登录功能。以微博为例
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://weibo.com/";)
username = driver.find_element_by_css_selector("input#loginname")
username.clear()
username.send_keys('your_username')
password = driver.find_element_by_css_selector('span.enter_psw')
password.clear()
password.send_keys('your_password')
输入帐号和密码后,最大的问题来了。验证码都是图片。一般我们需要使用图像识别来识别验证码,但是由于验证码的种类很多(英文、数字、中文或者它们的混合),而且验证码也可能会被旋转、扭曲甚至附着在每个其他,以至于人眼不能很好的识别,所以大部分模型的通用性和准确率都不是很高。因此,最有效的方法是在selenium打开浏览器后手动登录(过程中调用time.sleep()暂停程序)。由于爬虫最重要的不是解决登录问题,这样就节省了很多时间和代码,虽然笨但很有用。
登录后,使用代码获取cookie,并在pyspider全局参数中将cookie_dict传递给cookies。
cookies_dict = {}
cookies = driver.get_cookies()for cookie in cookies:
cookies_dict[cookie['name']] = cookie['value']
JS渲染
普通请求只能爬取静态的HTML页面,但是大部分网站都是混着JS数据加载的,数据是懒加载的。如果要爬取这些内容,可以使用 selenium + PhantomJS 将网页完整渲染,然后再进行网页分析。PhantomJS 是一个非接口、可编写脚本的 WebKit 浏览器引擎。使用方法类似于使用 selenium + Chrome 模拟登录,但由于 PhantomJS 没有接口,内存消耗会少很多。
爬取 AJAX 以异步加载网页
AJAX 是一种用于创建快速和动态网页的技术。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。要爬取AJAX异步加载的网页,我们需要分析网页的请求和返回信息。具体来说,我们需要使用谷歌浏览器的开发者工具(火狐等浏览器也有这个)查看网络的XHR,但是当网页部分更新时,浏览器发出了什么请求,返回了什么通过浏览器。
在我们微博登录的首页,只要将滚动条移到最下方,就会发现刷新了一条新的微博。这是我们打开开发者工具一直往下滚动,然后你会发现,但是你刷出来的时候有新的信息,总是发出新的请求,返回的json中的数据就是刷新微博的html .
仔细观察发现pagebar的变化是有规律的,id减15,对应新刷新的15微博。因此,可以推测pagebar应该是刷新微博的关键。在此之前,我们需要给爬虫添加请求头,否则很可能被服务器识别为机器人,无法成功访问。请求标头也可以在开发者工具中找到。
def on_start(self): for i in range(10):
url = 'https://weibo.com/aj/mblog/fse ... B%25i
self.crawl(url, callback=self.index_page)
发现微博内容被成功抓取并返回。然后只需处理您需要的信息。
js 爬虫抓取网页数据(js爬虫抓取网页数据,其实也是需要构建数据库的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-15 02:00
js爬虫抓取网页数据,其实也是需要构建网页数据库的,然后将抓取的数据放入数据库进行数据的存储。最常见的数据库是mysql。而javaredis这些应用,只是会使用java语言来实现一个容器,然后将数据进行读写操作,并不会直接提供数据库功能。因此可以通过使用spring+mybatis等框架对于数据库进行操作。
这里面使用spring作为核心,可以轻松实现一个spring中的数据库操作对象,并且提供mybatis标准类库,来封装其他同类型的开发接口。不要觉得这里列举的东西很简单,其实背后需要用到的资料很多,比如利用druid轻松实现批量加载数据。按f5键提取数据并按enter回车查询,不要给sql语句加上#,#或等符号,会报错。
如果字符串允许标点符号,还要使用一个formitem去解析。index.sql从新建数据库或webserver中导入数据源,保存至spring的配置文件当中importjava.io.file;importjava.io.filereader;importjava.io.filewriter;importjava.io.filewriterlistener;importorg.springframework.beans.factory.annotation.annotationmethod;importorg.springframework.beans.factory.annotation.annotation;importjava.lang.string;importjava.lang.stringbuffer;importjava.util.list;importjava.util.listener;importorg.springframework.stereotype.scope.scoped;importorg.springframework.stereotype.scope.wrapper;importjava.util.list;importjava.util.listener;importjava.util.filesystem;importorg.springframework.annotation.windowshooks.bindinputwithobjectwithunimmediatewithfileinputwithobject(windowsize_inches);importjava.util.filesystem;importjava.util.filesystem;importjava.util.filesystem;importjava.util.filesystem;importorg.springframework.web.filesystem;importorg.springframework.web.filesystem;importorg.springframework.web.filesystem;/***@author小琪**/@webmvcconfigurationpublicclasswebmvcconfig{privatestaticspringapplicationcontextcontext=newspringapplicationcontext();@beanpublicindivisiblewebmodeviewmockviewmodeview(webmvcconfigcontext){indivisiblewebmodeviewmyviewmodeview=newindivisiblewebmodeview(context);myviewmodeview.init();returnmyviewmodeview;}@beanpublicthepredefineds。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,其实也是需要构建数据库的)
js爬虫抓取网页数据,其实也是需要构建网页数据库的,然后将抓取的数据放入数据库进行数据的存储。最常见的数据库是mysql。而javaredis这些应用,只是会使用java语言来实现一个容器,然后将数据进行读写操作,并不会直接提供数据库功能。因此可以通过使用spring+mybatis等框架对于数据库进行操作。
这里面使用spring作为核心,可以轻松实现一个spring中的数据库操作对象,并且提供mybatis标准类库,来封装其他同类型的开发接口。不要觉得这里列举的东西很简单,其实背后需要用到的资料很多,比如利用druid轻松实现批量加载数据。按f5键提取数据并按enter回车查询,不要给sql语句加上#,#或等符号,会报错。
如果字符串允许标点符号,还要使用一个formitem去解析。index.sql从新建数据库或webserver中导入数据源,保存至spring的配置文件当中importjava.io.file;importjava.io.filereader;importjava.io.filewriter;importjava.io.filewriterlistener;importorg.springframework.beans.factory.annotation.annotationmethod;importorg.springframework.beans.factory.annotation.annotation;importjava.lang.string;importjava.lang.stringbuffer;importjava.util.list;importjava.util.listener;importorg.springframework.stereotype.scope.scoped;importorg.springframework.stereotype.scope.wrapper;importjava.util.list;importjava.util.listener;importjava.util.filesystem;importorg.springframework.annotation.windowshooks.bindinputwithobjectwithunimmediatewithfileinputwithobject(windowsize_inches);importjava.util.filesystem;importjava.util.filesystem;importjava.util.filesystem;importjava.util.filesystem;importorg.springframework.web.filesystem;importorg.springframework.web.filesystem;importorg.springframework.web.filesystem;/***@author小琪**/@webmvcconfigurationpublicclasswebmvcconfig{privatestaticspringapplicationcontextcontext=newspringapplicationcontext();@beanpublicindivisiblewebmodeviewmockviewmodeview(webmvcconfigcontext){indivisiblewebmodeviewmyviewmodeview=newindivisiblewebmodeview(context);myviewmodeview.init();returnmyviewmodeview;}@beanpublicthepredefineds。
js 爬虫抓取网页数据(网络爬虫的三个优点代码简单明了适合python的语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-14 14:24
一、爬虫介绍
根据百度百科的定义:网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常被称为网络追逐者),是根据一定的规则或脚本自动爬取万维网上信息的程序. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
二、适合爬虫的几种语言1.phantomjs
2017 年 4 月,该语言的核心开发者之一 Vitaly 辞去维护工作,表示不再维护。其原话如下:
我看不到 PhantomJS 的未来,作为一个单独的开发者在 PhantomJS 2 和 2.5 上工作简直就是地狱。即使最近发布了带有新的、闪亮的 QtWebKit 的 2.5 Beta 版本,我仍然不能真正支持 3 个平台。我们没有其他势力支持!
并且 Vitaly 发帖称 Chrome 59 将支持无头模式,用户最终会转向它。Chrome 比 PhantomJS 更快更稳定,不会像 PhantomJS 那样吃内存,但不代表语言结束,语言还是可以用的
2.casperJS
CasperJs 是基于 PhantomJs 的工具,可以比 PhantomJs 更方便的导航。就个人而言,我对这门语言了解不多,也没有过多阐述。
3.nodejs
nodejs适合垂直爬取,分布式爬取难度较大,对部分功能支持较弱,不推荐使用
4.Python
我喜欢python的语言,强烈推荐使用python,尤其是它的语言爬虫框架scrapy特别值得学习。支持xpath,可以定义多个爬虫,支持多线程爬取等,以后我会一步步入手。流程发给大家,附上源码
ps:另外可以使用c++、PHP、java等语言爬取网页。爬虫因人而异。我推荐的不一定是最好的。
三、python爬虫的优点
代码简洁明了,适合根据实际情况快速修改代码。网络的内容和布局会随时变化。python的快速发展是有优势的。如果不加修改或者少加修改写得好,其他高性能语言更有优势。(来自 知乎)
1)相比其他静态编程语言,如java、c#、C++、python,爬取网页的界面更加简洁;与其他动态脚本语言相比,如perl、shell、python urllib2 包提供了比较完整的访问web 文档的API。(当然,ruby 也是一个不错的选择。)另外,爬取网页有时需要模拟浏览器的行为,很多网站都被屏蔽了用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理 抓取的网页通常需要进行处理,例如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。(摘自博客园)
以上就是前人为我们总结的诸多优势。我整理了其中两个供大家参考。
四、后续安排 查看全部
js 爬虫抓取网页数据(网络爬虫的三个优点代码简单明了适合python的语言)
一、爬虫介绍
根据百度百科的定义:网络爬虫(又名网络蜘蛛、网络机器人,在FOAF社区,更常被称为网络追逐者),是根据一定的规则或脚本自动爬取万维网上信息的程序. 其他不太常用的名称是 ant、autoindex、emulator 或 worm。随着大数据的不断发展,爬虫技术逐渐进入了人们的视野。可以说爬虫是大数据的产物。至少我在去除大数据后了解了爬虫的技术。
二、适合爬虫的几种语言1.phantomjs
2017 年 4 月,该语言的核心开发者之一 Vitaly 辞去维护工作,表示不再维护。其原话如下:
我看不到 PhantomJS 的未来,作为一个单独的开发者在 PhantomJS 2 和 2.5 上工作简直就是地狱。即使最近发布了带有新的、闪亮的 QtWebKit 的 2.5 Beta 版本,我仍然不能真正支持 3 个平台。我们没有其他势力支持!
并且 Vitaly 发帖称 Chrome 59 将支持无头模式,用户最终会转向它。Chrome 比 PhantomJS 更快更稳定,不会像 PhantomJS 那样吃内存,但不代表语言结束,语言还是可以用的
2.casperJS
CasperJs 是基于 PhantomJs 的工具,可以比 PhantomJs 更方便的导航。就个人而言,我对这门语言了解不多,也没有过多阐述。
3.nodejs
nodejs适合垂直爬取,分布式爬取难度较大,对部分功能支持较弱,不推荐使用
4.Python
我喜欢python的语言,强烈推荐使用python,尤其是它的语言爬虫框架scrapy特别值得学习。支持xpath,可以定义多个爬虫,支持多线程爬取等,以后我会一步步入手。流程发给大家,附上源码
ps:另外可以使用c++、PHP、java等语言爬取网页。爬虫因人而异。我推荐的不一定是最好的。
三、python爬虫的优点
代码简洁明了,适合根据实际情况快速修改代码。网络的内容和布局会随时变化。python的快速发展是有优势的。如果不加修改或者少加修改写得好,其他高性能语言更有优势。(来自 知乎)
1)相比其他静态编程语言,如java、c#、C++、python,爬取网页的界面更加简洁;与其他动态脚本语言相比,如perl、shell、python urllib2 包提供了比较完整的访问web 文档的API。(当然,ruby 也是一个不错的选择。)另外,爬取网页有时需要模拟浏览器的行为,很多网站都被屏蔽了用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理 抓取的网页通常需要进行处理,例如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。(摘自博客园)
以上就是前人为我们总结的诸多优势。我整理了其中两个供大家参考。
四、后续安排
js 爬虫抓取网页数据(从爬虫抓取到索引期间到底经过了哪些步骤,为什么网页但不收录?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-04-13 23:16
从爬取到索引的步骤是什么,为什么是网页爬取而不是收录?今天我就结合SEO数据,说说为什么你的页面爬虫爬了1000次,却不是收录!
从之前优化的页面中取出一个案例详情页面(/35950345.html),我将描述普通页面收录的路径:
99高级爬虫抓取IP段:111.206.221.27————111.206.198.125Finally完成收录,抓取IP段:220.181.108.99 Advanced UA的IP:111.206.221.27————111.206. 198.125(截图时间) 注:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密; 还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)@1.108.99 高级UA的IP:111.206.221.27————111.206. 198.125(快照时间) 注意:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密;还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)@1.108.99 高级UA的IP:111.206.221.27————111.206. 198.125(快照时间) 注意:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密;还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)
如果不了解爬虫蜘蛛的UA和IP段,可以看看国内主流搜索引擎的UA和对应的蜘蛛IP段。
说完了正例,再来说说为什么页面还是爬不上1000次收录,我们先来看下面的优化案例: URLpathname:/news/t-35950346.html
二级目录文章详情页,内链非常丰富,百度蜘蛛总共爬取816次(平均每天100次),IP段和爬取路径没有问题,但是结果不是 收录@ >。
爬虫爬到收录的日志分析
问题分析一:把标题放在百度上搜索,搜索结果都是网站内详情页链接的锚文本,但是在内容页找不到锚文本,所以打开百度快照,问题部分解决
分析结果1:由于爬虫第一次爬取的内容与第二次爬取的内容页面不一致(多见于网站detail页面,内部链接数不足),可以查看PC页面与M站页面收录综合对比(PC收录,M站不接受)。
解决方案一:优化内部链接以匹配站点内的更新频率(有时可能需要更改子目录,常用于大型站点)
--------------华丽的分割线-------------
问题分析2:同样的问题,如果没有页面不一致,分析高级爬虫UA看页面是否收录动态参数或者JS渲染隐藏数据,导致页面不一致,可以通过请求数据的大小来判断
分析结果2:看页面JS对页面主要内容的具体影响。动态 URL 参数优化同样重要。PC端和M端数据分开比较也比较好。
方案二:优化页面JS或者爬虫显示优化。
大展页面不收录详细分析——也有可能出现问题:页面主要内容的布局,内容的可读性。
如果觉得有点难,可以看一个简单的逻辑分析:蜘蛛爬还是不爬收录原因 查看全部
js 爬虫抓取网页数据(从爬虫抓取到索引期间到底经过了哪些步骤,为什么网页但不收录?)
从爬取到索引的步骤是什么,为什么是网页爬取而不是收录?今天我就结合SEO数据,说说为什么你的页面爬虫爬了1000次,却不是收录!
从之前优化的页面中取出一个案例详情页面(/35950345.html),我将描述普通页面收录的路径:
99高级爬虫抓取IP段:111.206.221.27————111.206.198.125Finally完成收录,抓取IP段:220.181.108.99 Advanced UA的IP:111.206.221.27————111.206. 198.125(截图时间) 注:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密; 还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)@1.108.99 高级UA的IP:111.206.221.27————111.206. 198.125(快照时间) 注意:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密;还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)@1.108.99 高级UA的IP:111.206.221.27————111.206. 198.125(快照时间) 注意:由于页面涉及到加密JS,所以多一步:百度高级蜘蛛解密;还说明了三层目录的详情页,后台主动提交页面即可快速完成收录(页面内容可能为采集内容)
如果不了解爬虫蜘蛛的UA和IP段,可以看看国内主流搜索引擎的UA和对应的蜘蛛IP段。
说完了正例,再来说说为什么页面还是爬不上1000次收录,我们先来看下面的优化案例: URLpathname:/news/t-35950346.html
二级目录文章详情页,内链非常丰富,百度蜘蛛总共爬取816次(平均每天100次),IP段和爬取路径没有问题,但是结果不是 收录@ >。
爬虫爬到收录的日志分析
问题分析一:把标题放在百度上搜索,搜索结果都是网站内详情页链接的锚文本,但是在内容页找不到锚文本,所以打开百度快照,问题部分解决
分析结果1:由于爬虫第一次爬取的内容与第二次爬取的内容页面不一致(多见于网站detail页面,内部链接数不足),可以查看PC页面与M站页面收录综合对比(PC收录,M站不接受)。
解决方案一:优化内部链接以匹配站点内的更新频率(有时可能需要更改子目录,常用于大型站点)
--------------华丽的分割线-------------
问题分析2:同样的问题,如果没有页面不一致,分析高级爬虫UA看页面是否收录动态参数或者JS渲染隐藏数据,导致页面不一致,可以通过请求数据的大小来判断
分析结果2:看页面JS对页面主要内容的具体影响。动态 URL 参数优化同样重要。PC端和M端数据分开比较也比较好。
方案二:优化页面JS或者爬虫显示优化。
大展页面不收录详细分析——也有可能出现问题:页面主要内容的布局,内容的可读性。
如果觉得有点难,可以看一个简单的逻辑分析:蜘蛛爬还是不爬收录原因
js 爬虫抓取网页数据(Python调用Phantomjs搭一个代理的部分拆了出来的模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-11 10:29
最近需要爬取某个网站,可惜页面都是JS渲染后生成的,普通爬虫框架处理不了,于是想到了用Phantomjs搭建代理。
貌似没有现成的Python调用Phantomjs的第三方库(如果有,请告知小编)。逛了一圈,发现只有pyspider提供了现成的解决方案。
简单试用了一下,感觉pyspider更像是新手的爬虫工具,像个老妈妈,时而细致,时而喋喋不休。轻量级的小工具应该更受欢迎。我也有一点自私。可以一起使用我最喜欢的BeautifulSoup,而不用学习PyQuery(pyspider是用来解析HTML的),也不必忍受浏览器写Python。糟糕的经历(窃笑)。
于是花了一个下午把pyspider实现Phantomjs代理的部分拆解,做成一个小的爬虫模块。我希望每个人都会喜欢它(感谢 binux!)。
准备好工作了
当然你有 Phantomjs,废话!(Linux下最好使用supervisord来守护,爬取时必须保持打开Phantomjs)
以项目路径中的 phantomjs_fetcher.js 开头:phantomjs phantomjs_fetcher.js [port]
安装 tornado 依赖项(使用 tornado 的 httpclient 模块)
调用超级简单
from tornado_fetcher import Fetcher
# 创建一个爬虫
>>> fetcher=Fetcher(
user_agent='phantomjs', # 模拟浏览器的User-Agent
phantomjs_proxy='http://localhost:12306', # phantomjs的地址
poolsize=10, # 最大的httpclient数量
async=False # 同步还是异步
)
# 开始连接Phantomjs的代码,可以渲染JS!
>>> fetcher.fetch(url)
# 渲染成功后执行额外的JS脚本(注意用function包起来!)
>>> fetcher.fetch(url, js_script='function(){setTimeout("window.scrollTo(0,100000)}", 1000)')
代码 查看全部
js 爬虫抓取网页数据(Python调用Phantomjs搭一个代理的部分拆了出来的模块)
最近需要爬取某个网站,可惜页面都是JS渲染后生成的,普通爬虫框架处理不了,于是想到了用Phantomjs搭建代理。
貌似没有现成的Python调用Phantomjs的第三方库(如果有,请告知小编)。逛了一圈,发现只有pyspider提供了现成的解决方案。
简单试用了一下,感觉pyspider更像是新手的爬虫工具,像个老妈妈,时而细致,时而喋喋不休。轻量级的小工具应该更受欢迎。我也有一点自私。可以一起使用我最喜欢的BeautifulSoup,而不用学习PyQuery(pyspider是用来解析HTML的),也不必忍受浏览器写Python。糟糕的经历(窃笑)。
于是花了一个下午把pyspider实现Phantomjs代理的部分拆解,做成一个小的爬虫模块。我希望每个人都会喜欢它(感谢 binux!)。
准备好工作了
当然你有 Phantomjs,废话!(Linux下最好使用supervisord来守护,爬取时必须保持打开Phantomjs)
以项目路径中的 phantomjs_fetcher.js 开头:phantomjs phantomjs_fetcher.js [port]
安装 tornado 依赖项(使用 tornado 的 httpclient 模块)
调用超级简单
from tornado_fetcher import Fetcher
# 创建一个爬虫
>>> fetcher=Fetcher(
user_agent='phantomjs', # 模拟浏览器的User-Agent
phantomjs_proxy='http://localhost:12306', # phantomjs的地址
poolsize=10, # 最大的httpclient数量
async=False # 同步还是异步
)
# 开始连接Phantomjs的代码,可以渲染JS!
>>> fetcher.fetch(url)
# 渲染成功后执行额外的JS脚本(注意用function包起来!)
>>> fetcher.fetch(url, js_script='function(){setTimeout("window.scrollTo(0,100000)}", 1000)')
代码
js 爬虫抓取网页数据( 学爬虫的流程简单来说获取网页并提取和保存信息程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-10 04:15
学爬虫的流程简单来说获取网页并提取和保存信息程序)
总之,爬虫可以帮助我们快速提取并保存网站上的信息。
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬虫爬到这个页面就相当于访问了这个页面,它可以提取网页上的信息。我们可以将节点之间的连接比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着该节点连接爬行到达下一个节点,即继续获取后续web页面通过一个网页,这样整个web的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫是干什么用的?
通过以上的话,大家可能对爬虫是做什么的有了初步的了解,但是一般我们要学一件事,我们要知道怎么处理它,对吧?
事实上,爬行动物更有用。
此外,还有很多其他的技术,比如黄牛抢票、自助抢课、网站排名等技术也离不开爬虫。爬虫的用处可以说是非常大了。可以说大家应该都知道点击爬虫了。
另外,学习爬虫也可以顺便帮助我们学习Python。要学习爬虫,我的第一个建议是 Python 语言。如果对 Python 不熟悉也没关系,爬虫作为学习 Python 的一种方式非常适合。你可以同时学习爬虫和Python。
不仅如此,爬虫技术和其他领域几乎都有交集,比如前端和后端web开发、数据库、数据分析、人工智能、运维、安全等领域都和爬虫有关,所以学好爬虫相当于它也为其他领域铺平了一步,以后如果想进入其他领域,可以更轻松的连接。Python爬虫是学习计算机的很好的入门方向之一。
2. 爬虫进程
简单来说,爬虫是一个自动程序,它获取网页并提取和保存信息,如下所述。
(1) 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
当我们用浏览器浏览网页时,浏览器实际上为我们模拟了这个过程。浏览器一一向服务器发送请求,返回的响应体就是网页的源代码,然后由浏览器解析和渲染。所以,我们要做的爬虫其实和浏览器差不多。获取网页的源代码并解析内容是好的,但是我们使用的不是浏览器,而是Python。
刚才说了,最关键的部分是构造一个请求并发送给服务器,然后接收并解析响应,那么如何在Python中实现这个过程呢?
Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以使用这些库来实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的body部分,即得到网页的源代码,这样我们就可以使用程序来实现获取网页的过程。
(2) 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫中非常重要的一个环节,它可以让杂乱的数据变得有条不紊、清晰明了,方便我们后期对数据进行处理和分析。
(3) 保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
(4) 自动化
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
3. 我可以爬取什么样的数据?
我们可以在网页中看到各种信息,最常见的是常规网页,它们对应的是HTML代码,最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
4. 总结
本节结束,我们对爬虫有了基本的了解,让我们一起走进爬虫学习的世界吧! 查看全部
js 爬虫抓取网页数据(
学爬虫的流程简单来说获取网页并提取和保存信息程序)
总之,爬虫可以帮助我们快速提取并保存网站上的信息。
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬虫爬到这个页面就相当于访问了这个页面,它可以提取网页上的信息。我们可以将节点之间的连接比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着该节点连接爬行到达下一个节点,即继续获取后续web页面通过一个网页,这样整个web的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫是干什么用的?
通过以上的话,大家可能对爬虫是做什么的有了初步的了解,但是一般我们要学一件事,我们要知道怎么处理它,对吧?
事实上,爬行动物更有用。
此外,还有很多其他的技术,比如黄牛抢票、自助抢课、网站排名等技术也离不开爬虫。爬虫的用处可以说是非常大了。可以说大家应该都知道点击爬虫了。
另外,学习爬虫也可以顺便帮助我们学习Python。要学习爬虫,我的第一个建议是 Python 语言。如果对 Python 不熟悉也没关系,爬虫作为学习 Python 的一种方式非常适合。你可以同时学习爬虫和Python。
不仅如此,爬虫技术和其他领域几乎都有交集,比如前端和后端web开发、数据库、数据分析、人工智能、运维、安全等领域都和爬虫有关,所以学好爬虫相当于它也为其他领域铺平了一步,以后如果想进入其他领域,可以更轻松的连接。Python爬虫是学习计算机的很好的入门方向之一。
2. 爬虫进程
简单来说,爬虫是一个自动程序,它获取网页并提取和保存信息,如下所述。
(1) 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
当我们用浏览器浏览网页时,浏览器实际上为我们模拟了这个过程。浏览器一一向服务器发送请求,返回的响应体就是网页的源代码,然后由浏览器解析和渲染。所以,我们要做的爬虫其实和浏览器差不多。获取网页的源代码并解析内容是好的,但是我们使用的不是浏览器,而是Python。
刚才说了,最关键的部分是构造一个请求并发送给服务器,然后接收并解析响应,那么如何在Python中实现这个过程呢?
Python提供了很多库来帮助我们实现这个操作,比如urllib、requests等,我们可以使用这些库来实现HTTP请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的body部分,即得到网页的源代码,这样我们就可以使用程序来实现获取网页的过程。
(2) 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规则,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫中非常重要的一个环节,它可以让杂乱的数据变得有条不紊、清晰明了,方便我们后期对数据进行处理和分析。
(3) 保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
(4) 自动化
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
3. 我可以爬取什么样的数据?
我们可以在网页中看到各种信息,最常见的是常规网页,它们对应的是HTML代码,最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
4. 总结
本节结束,我们对爬虫有了基本的了解,让我们一起走进爬虫学习的世界吧!
js 爬虫抓取网页数据(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-04-09 20:36
概述:
这是pycharm在phthon环境下做的一个简单的爬虫分享。主要通过爬取豆瓣音乐top250的歌名和作者(专辑)来分析爬虫原理
什么是爬行动物?
要想学爬虫,首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
中文名网络爬虫,外文名网络爬虫,网络蜘蛛的别称,目的是根据需要从万维网获取信息
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
准备好工作了:
我们使用的是pycharm,可以参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看它的官方文档:
个人觉得用lxml解析网页是最快的。对于lxml的使用,可以看这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
废话不多说,开始我们的爬虫之旅吧
首先找到我们的目标网址:
可以看到我们要获取的歌名和作者(专辑)页面有十页,每页有十行
所以我们可以使用for循环来获取目标:
然后使用 requests 请求网页:
1import requests
2
1headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
2
1data = requests.get(url, headers=headers).text
2
然后使用lxml解析网页:
1from lxml import etree
2
1s = etree.HTML(data)
2
然后我们就可以提取我们想要的数据了
最后,将获取的数据保存到我们想要放置的位置。
至此,我们基本大功告成,完整代码如下:
然后看看我们爬取的结果
总结:
爬虫流程:
1、提出请求 查看全部
js 爬虫抓取网页数据(这是一个利用pycharm简单爬虫分享的工作流程及使用方法)
概述:
这是pycharm在phthon环境下做的一个简单的爬虫分享。主要通过爬取豆瓣音乐top250的歌名和作者(专辑)来分析爬虫原理
什么是爬行动物?
要想学爬虫,首先要知道什么是爬虫。
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常被称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
中文名网络爬虫,外文名网络爬虫,网络蜘蛛的别称,目的是根据需要从万维网获取信息
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在对网页进行爬取的过程中,不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到系统达到一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
准备好工作了:
我们使用的是pycharm,可以参考pycharm的安装和使用
使用工具:requests、lxml、xpath
关于requests的使用,可以看它的官方文档:
个人觉得用lxml解析网页是最快的。对于lxml的使用,可以看这个:
xpath 是一种用于在 xml 文档中查找信息的语言。xpath 可用于遍历 xml 文档中的元素和属性。xpath的使用可以参考他的教程:
废话不多说,开始我们的爬虫之旅吧
首先找到我们的目标网址:
可以看到我们要获取的歌名和作者(专辑)页面有十页,每页有十行
所以我们可以使用for循环来获取目标:
然后使用 requests 请求网页:
1import requests
2
1headers = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
2
1data = requests.get(url, headers=headers).text
2
然后使用lxml解析网页:
1from lxml import etree
2
1s = etree.HTML(data)
2
然后我们就可以提取我们想要的数据了
最后,将获取的数据保存到我们想要放置的位置。
至此,我们基本大功告成,完整代码如下:
然后看看我们爬取的结果
总结:
爬虫流程:
1、提出请求
js 爬虫抓取网页数据(爬虫就是模拟人的访问操作来获取网页/App数据的一种程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 354 次浏览 • 2022-04-07 09:15
摘要:爬虫是一种模拟人类访问操作以获取网页/App数据的程序。什么是爬行动物?
简单来说,爬虫就是模拟人类访问操作来获取网页/App数据的程序。我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!??¤
QQ群:961562169
我们平时看到的搜索引擎、统计数据、旅游软件、聚合平台,都离不开网络爬虫。
爬虫的应用领域有哪些?
我们常见的应用场景的一个简单例子如下:
1.搜索引擎抓取网页
2.旅游软件通过爬虫抢票
3.论坛或微博舆情监测。利用数据采集技术监测搜索引擎、新闻门户、论坛、博客、微博、微信、报纸、视频的舆情。说白了就是用来实现实时发现某个行业或地区的热点事件,比如青博舆情、百度舆情等。
4.价格比较网站 应用。如今,各大电商平台针对活跃用户开展了各种秒杀活动和优惠券。同一种产品在不同的网购平台上可能会有不同的价格。那么这些网站是如何在几分钟甚至几秒内就知道某款产品在某站打折的呢?这就需要一个data采集系统(爬虫)来实时监控各个站的价格波动。首先采集商品的价格、型号、配置等,然后进行处理、分析和反馈。
为什么要学习爬行?
互联网的飞速发展带来了前所未有的便利,但也带来了许多以前没有遇到过的新问题。获取信息的成本越来越低,信息的种类和数量越来越多,但我们对信息的处理能力并没有提高,很难从信息中提取出我们感兴趣的东西。
学习爬虫可以自动高效地获取我们在互联网上感兴趣的内容,帮助我们快速建立自己的信息知识库。
如何完成一个轻量级爬虫
这里简要概述三个步骤:获取数据-解析数据-存储数据。以下是完成这些步骤所涉及的工具供您参考。
获取数据:urllib2、Requests、Selenium、aiohttp
获取数据的工具:Chrome、Fiddler、MitmProxy、Appium
解析数据:CSS 选择器、PyQuery、BeautifulSoup、Xpath、Re
存储数据:MySQL、MongoDB、Redis
工程爬行动物
工程爬虫项目推荐:Scrapy、PySpider
官方文档:,
Github地址:,
反爬虫措施和应对措施
1.网页反爬虫-字体反爬虫
开发者可以使用@font-face为网页指定字体,也可以调用自定义字体文件来渲染网页中的文字,网页中的文字就变成了对应的代码。这时候,通过一个简单的网页 采集 无法获取编码后的网页内容。
对策:字体反爬相比其他反爬,难度属于比较初级的阶段,主要是处理起来比较麻烦,防御型的网站往往不止一个网站. 设置不同的字体加密防御系统,比如135配A方案,246配B方案,这需要一定的耐心去分析字体的规则,用Python解析字体文件,找到映射规则来解决。
推荐工具:fontTools、百度字体编辑器()
2.网页反爬虫-验证码
验证码是一种公共的自动程序,用于区分用户是计算机还是人。常见的验证码包括:多位混合验证码、滑动验证码、点击验证码、旋转验证码等。
对策:如果项目预算充足,可以连接专业的编码平台,减少90%的工作量;如果预算不足,可以使用华为云ModelArts完成模型搭建,无需编写一行代码
推荐工具:华为云ModelArts、CC框架
3.网页反爬虫-JS加密/混淆
前端代码是公开的,那么加密有意义吗?是的,通过从代码中删除尽可能多的有意义的信息,例如注释、换行符、空格、代码减号、变量重命名、属性重命名(如果允许)以及无用的代码删除,以尽可能多地增加爬虫的数量可能 工程师阅读代码的成本。
对策:对于轻度到中度混淆或混淆代码,可以阅读混淆代码,梳理加密逻辑,扣除可运行的Js代码,使用Python库调用完成加密参数的生成;对于严重混淆,使用AST语法树恢复混淆代码,去除无意义的垃圾代码,恢复清晰的加密逻辑,并使用Python库调用完成加密参数的生成。
推荐工具:AST、PyExecJS
4.APP反爬虫
都2020年了,还有没有通过应用市场下载的不带壳的APP?除了外壳保护,常见的APP还应用单向或双向证书验证。简单的中间人攻击已经无法捕获APP数据包,学习APP逆向工程势在必行。
对策:APP逆向工程需要学习的内容很多。这里简单总结一下抓不到的APP包(推荐工具:Frida、Xposed、IDA、jadx、Charles):
【单向认证和双向认证】
在单向验证的情况下,客户端验证证书,如果验证失败,则无法访问。
在双向认证的情况下,当客户端验证证书时,服务器也会验证证书。如果证书的一端无法验证证书,则无法访问数据。缺点是服务器压力比较大
处理方式:一般使用JustTrustMe,原理是Xpose Hook验证的API。
【APP不走代理——如何保证APP不走代理?】
(1)关闭代理服务器(fiddler等代理抓包工具)(2)用手机访问浏览器网页访问失败,判断代理无效(3)使用APP访问,正常访问确认APP不工作)通过代理访问网络
处理方法:更换不基于代理类型的抓包工具(HTTP Analyzer V7--缺点不能在真机上使用,HTTP Debug Pro,基于手机的VPN上的HttpCanary);先hook-decompile看他是不是用的那个框架,然后针对性的hook-chicken劝说;iptables 强制拦截和转发
【代理检测应用】
附代理前APP访问正常。附加代理后,APP无法使用,显示网络错误。
(1)代理检测(钩子代理检测方法)(2)证书检测(使用JustTrustMe)
【双向认证APP】
在双向认证的情况下,当客户端验证证书时,服务器也会验证证书。如果证书的一端无法验证证书,则无法访问数据。
但是,要在双向认证APP中实现双向验证,一般应该在APP中配置服务器端的验证证书,所以我们可以在客户端找到一个服务器端的证书,我们只需要配置这个证书在提琴手。请求。
ps:证书一般都有密码。需要反编译找到密码,然后导入系统,再从系统导出为.cer证书格式,然后在FiddlerScript中配置。
什么是分布式爬虫?
如果你已经学会了如何编写一个工程爬虫并有一些经验,那么你已经开始对爬虫架构有了一些经验。
分布式爬虫的概念看起来很吓人。其实从简单的角度来说,就是将一个单机爬虫分布到多台机器上。主要关注消息阻塞处理、日志告警、数据完整性校验等问题。
1亿级别以下的舆情数据,可以尝试学习Scrapy + Redis + MQ + Celery的组合,应付自如。
如果是垂直领域的数据采集,可以专注于快速稳定的获取数据。毕竟在垂直领域的数据抓取中,爬虫与反爬虫的对抗最为激烈。 查看全部
js 爬虫抓取网页数据(爬虫就是模拟人的访问操作来获取网页/App数据的一种程序)
摘要:爬虫是一种模拟人类访问操作以获取网页/App数据的程序。什么是爬行动物?
简单来说,爬虫就是模拟人类访问操作来获取网页/App数据的程序。我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。将网络的节点比作网页,爬取它相当于访问该页面并获取其信息。节点之间的连接可以比作网页与网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
很多人学习python,不知道从哪里开始。
很多人学了python,掌握了基本的语法之后,都不知道去哪里找case入门了。
许多做过案例研究的人不知道如何学习更高级的知识。
所以针对这三类人,我会为大家提供一个很好的学习平台,免费的视频教程,电子书,还有课程的源码!??¤
QQ群:961562169
我们平时看到的搜索引擎、统计数据、旅游软件、聚合平台,都离不开网络爬虫。
爬虫的应用领域有哪些?
我们常见的应用场景的一个简单例子如下:
1.搜索引擎抓取网页
2.旅游软件通过爬虫抢票
3.论坛或微博舆情监测。利用数据采集技术监测搜索引擎、新闻门户、论坛、博客、微博、微信、报纸、视频的舆情。说白了就是用来实现实时发现某个行业或地区的热点事件,比如青博舆情、百度舆情等。
4.价格比较网站 应用。如今,各大电商平台针对活跃用户开展了各种秒杀活动和优惠券。同一种产品在不同的网购平台上可能会有不同的价格。那么这些网站是如何在几分钟甚至几秒内就知道某款产品在某站打折的呢?这就需要一个data采集系统(爬虫)来实时监控各个站的价格波动。首先采集商品的价格、型号、配置等,然后进行处理、分析和反馈。
为什么要学习爬行?
互联网的飞速发展带来了前所未有的便利,但也带来了许多以前没有遇到过的新问题。获取信息的成本越来越低,信息的种类和数量越来越多,但我们对信息的处理能力并没有提高,很难从信息中提取出我们感兴趣的东西。
学习爬虫可以自动高效地获取我们在互联网上感兴趣的内容,帮助我们快速建立自己的信息知识库。
如何完成一个轻量级爬虫
这里简要概述三个步骤:获取数据-解析数据-存储数据。以下是完成这些步骤所涉及的工具供您参考。
获取数据:urllib2、Requests、Selenium、aiohttp
获取数据的工具:Chrome、Fiddler、MitmProxy、Appium
解析数据:CSS 选择器、PyQuery、BeautifulSoup、Xpath、Re
存储数据:MySQL、MongoDB、Redis
工程爬行动物
工程爬虫项目推荐:Scrapy、PySpider
官方文档:,
Github地址:,
反爬虫措施和应对措施
1.网页反爬虫-字体反爬虫
开发者可以使用@font-face为网页指定字体,也可以调用自定义字体文件来渲染网页中的文字,网页中的文字就变成了对应的代码。这时候,通过一个简单的网页 采集 无法获取编码后的网页内容。
对策:字体反爬相比其他反爬,难度属于比较初级的阶段,主要是处理起来比较麻烦,防御型的网站往往不止一个网站. 设置不同的字体加密防御系统,比如135配A方案,246配B方案,这需要一定的耐心去分析字体的规则,用Python解析字体文件,找到映射规则来解决。
推荐工具:fontTools、百度字体编辑器()
2.网页反爬虫-验证码
验证码是一种公共的自动程序,用于区分用户是计算机还是人。常见的验证码包括:多位混合验证码、滑动验证码、点击验证码、旋转验证码等。
对策:如果项目预算充足,可以连接专业的编码平台,减少90%的工作量;如果预算不足,可以使用华为云ModelArts完成模型搭建,无需编写一行代码
推荐工具:华为云ModelArts、CC框架
3.网页反爬虫-JS加密/混淆
前端代码是公开的,那么加密有意义吗?是的,通过从代码中删除尽可能多的有意义的信息,例如注释、换行符、空格、代码减号、变量重命名、属性重命名(如果允许)以及无用的代码删除,以尽可能多地增加爬虫的数量可能 工程师阅读代码的成本。
对策:对于轻度到中度混淆或混淆代码,可以阅读混淆代码,梳理加密逻辑,扣除可运行的Js代码,使用Python库调用完成加密参数的生成;对于严重混淆,使用AST语法树恢复混淆代码,去除无意义的垃圾代码,恢复清晰的加密逻辑,并使用Python库调用完成加密参数的生成。
推荐工具:AST、PyExecJS
4.APP反爬虫
都2020年了,还有没有通过应用市场下载的不带壳的APP?除了外壳保护,常见的APP还应用单向或双向证书验证。简单的中间人攻击已经无法捕获APP数据包,学习APP逆向工程势在必行。
对策:APP逆向工程需要学习的内容很多。这里简单总结一下抓不到的APP包(推荐工具:Frida、Xposed、IDA、jadx、Charles):
【单向认证和双向认证】
在单向验证的情况下,客户端验证证书,如果验证失败,则无法访问。
在双向认证的情况下,当客户端验证证书时,服务器也会验证证书。如果证书的一端无法验证证书,则无法访问数据。缺点是服务器压力比较大
处理方式:一般使用JustTrustMe,原理是Xpose Hook验证的API。
【APP不走代理——如何保证APP不走代理?】
(1)关闭代理服务器(fiddler等代理抓包工具)(2)用手机访问浏览器网页访问失败,判断代理无效(3)使用APP访问,正常访问确认APP不工作)通过代理访问网络
处理方法:更换不基于代理类型的抓包工具(HTTP Analyzer V7--缺点不能在真机上使用,HTTP Debug Pro,基于手机的VPN上的HttpCanary);先hook-decompile看他是不是用的那个框架,然后针对性的hook-chicken劝说;iptables 强制拦截和转发
【代理检测应用】
附代理前APP访问正常。附加代理后,APP无法使用,显示网络错误。
(1)代理检测(钩子代理检测方法)(2)证书检测(使用JustTrustMe)
【双向认证APP】
在双向认证的情况下,当客户端验证证书时,服务器也会验证证书。如果证书的一端无法验证证书,则无法访问数据。
但是,要在双向认证APP中实现双向验证,一般应该在APP中配置服务器端的验证证书,所以我们可以在客户端找到一个服务器端的证书,我们只需要配置这个证书在提琴手。请求。
ps:证书一般都有密码。需要反编译找到密码,然后导入系统,再从系统导出为.cer证书格式,然后在FiddlerScript中配置。
什么是分布式爬虫?
如果你已经学会了如何编写一个工程爬虫并有一些经验,那么你已经开始对爬虫架构有了一些经验。
分布式爬虫的概念看起来很吓人。其实从简单的角度来说,就是将一个单机爬虫分布到多台机器上。主要关注消息阻塞处理、日志告警、数据完整性校验等问题。
1亿级别以下的舆情数据,可以尝试学习Scrapy + Redis + MQ + Celery的组合,应付自如。
如果是垂直领域的数据采集,可以专注于快速稳定的获取数据。毕竟在垂直领域的数据抓取中,爬虫与反爬虫的对抗最为激烈。
js 爬虫抓取网页数据(js爬虫抓取网页数据教程-js抓取数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-07 03:02
js爬虫抓取网页数据教程说明一、调用工具和模拟发送请求不做任何修改,直接使用python模拟get请求对网页进行爬取和解析,获取页面数据,然后将代码发送到服务器。二、步骤文件目录说明/数据抓取的具体的结构文件/代码注释说明3.1:代码的开始文件example.py。3.2:数据抓取的链接example.pyfrombs4importbeautifulsoup3.3:data.text的保存文件example.pyfrombs4importbeautifulsoup//usersimulation//1抓取网页时使用重定向http协议与https协议保存的图片3.4:抓取网页时随机取样动态数据//2抓取网页时不使用随机取样3.5:抓取请求头data.parse('///images/data.jpg')3.6:抓取headers参数example.pyfrombs4importbeautifulsoupexample.pyfrombs4importbeautifulsoup3.7:http请求参数与源数据js文件的代码//data.html3.8:action参数代码//data.js3.9:js文件数据的抓取3.10:items对象的抓取3.11:调用模拟请求example.pyexample.pyfrombs4importbeautifulsoupexample.pyfrombs4importbeautifulsoupfromurllib.requestimporturlopenurlopen('/','w')3.12:抓取百度/谷歌/雅虎网站的数据(网页/浏览器)frombs4importbeautifulsoup,embedding3.13:抓取各类网站源代码的本地文件fromurllib.requestimporturlopenfrombs4importbeautifulsoupfromembeddingimportimage_from_listdirfromgzipimportgzipfromgzipimportencode_loaderfromgzipimporthttps_loaderdata.parse('//javascript-bin/example.py')3.14:抓取各类网站源代码的保存路径3.15:抓取调用本地文件,发送请求python代码请求网页中数据的具体代码python爬虫抓取各大主流网站数据教程说明。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据教程-js抓取数据)
js爬虫抓取网页数据教程说明一、调用工具和模拟发送请求不做任何修改,直接使用python模拟get请求对网页进行爬取和解析,获取页面数据,然后将代码发送到服务器。二、步骤文件目录说明/数据抓取的具体的结构文件/代码注释说明3.1:代码的开始文件example.py。3.2:数据抓取的链接example.pyfrombs4importbeautifulsoup3.3:data.text的保存文件example.pyfrombs4importbeautifulsoup//usersimulation//1抓取网页时使用重定向http协议与https协议保存的图片3.4:抓取网页时随机取样动态数据//2抓取网页时不使用随机取样3.5:抓取请求头data.parse('///images/data.jpg')3.6:抓取headers参数example.pyfrombs4importbeautifulsoupexample.pyfrombs4importbeautifulsoup3.7:http请求参数与源数据js文件的代码//data.html3.8:action参数代码//data.js3.9:js文件数据的抓取3.10:items对象的抓取3.11:调用模拟请求example.pyexample.pyfrombs4importbeautifulsoupexample.pyfrombs4importbeautifulsoupfromurllib.requestimporturlopenurlopen('/','w')3.12:抓取百度/谷歌/雅虎网站的数据(网页/浏览器)frombs4importbeautifulsoup,embedding3.13:抓取各类网站源代码的本地文件fromurllib.requestimporturlopenfrombs4importbeautifulsoupfromembeddingimportimage_from_listdirfromgzipimportgzipfromgzipimportencode_loaderfromgzipimporthttps_loaderdata.parse('//javascript-bin/example.py')3.14:抓取各类网站源代码的保存路径3.15:抓取调用本地文件,发送请求python代码请求网页中数据的具体代码python爬虫抓取各大主流网站数据教程说明。
js 爬虫抓取网页数据(就是用户爬虫的原理及原理模拟一个的配置介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-07 00:08
一、环境配置
1)做一个服务器,任何linux都可以,我用CentOS 6.5;
2)安装一个mysql数据库,5.5或者5.6都可以,可以直接用lnmp或者lamp安装比较省事,也可以直接查看日志返回时浏览器;
3)先搭建一个node.js环境,我用的是0.12.7,后面的版本没试过;
4)执行npm -g install forever,永远安装,让爬虫后台运行;
5)将所有代码集成到本地(integration=git clone);
6)在项目目录下执行npm install,安装依赖库;
7)在项目目录下创建两个空文件夹,json和avatar;
8)创建一个空的mysql数据库和一个全权限用户,依次执行代码中的setup.sql和startusers.sql,创建数据库结构并导入初始种子用户;
9)编辑config.js,标记为(必填)的配置项必须填写或修改,其余项可暂时不变:
exports.jsonPath = "./json/";//生成json文件的路径
exports.avatarPath = "./avatar/";//保存头像文件的路径
exports.dbconfig = {
host: 'localhost',//数据库服务器(必须)
user: 'dbuser',//数据库用户名(必须)
password: 'dbpassword',//数据库密码(必须)
database: 'dbname',//数据库名(必须)
port: 3306,//数据库服务器端口
poolSize: 20,
acquireTimeout: 30000
};
exports.urlpre = "https://www.jb51.net/";//脚本网址
exports.urlzhuanlanpre = "https://www.jb51.net/list/index_96.htm/";//脚本网址
exports.WPurl = "www.xxx.com";//要发布文章的wordpress网站地址
exports.WPusername = "publishuser";//发布文章的用户名
exports.WPpassword = "publishpassword";//发布文章用户的密码
exports.WPurlavatarpre = "http://www.xxx.com/avatar/";//发布文章中替代原始头像的url地址
exports.mailservice = "QQ";//邮件通知服务类型,也可以用Gmail,前提是你访问得了Gmail(必须)
exports.mailuser = "12345@qq.com";//邮箱用户名(必须)
exports.mailpass = "qqpassword";//邮箱密码(必须)
exports.mailfrom = "12345@qq.com";//发送邮件地址(必须,一般与用户名所属邮箱一致)
exports.mailto = "12345@qq.com";//接收通知邮件地址(必须)
保存并转到下一步。
二、爬虫用户
爬虫的原理其实就是模拟一个真实的知乎用户点击采集网站上的数据,所以我们需要一个真实的知乎用户。测试可以用自己的账号,但是长期来看还是注册一个专用账号比较好,一个就够了,目前爬虫只支持一个。我们的模拟不是像真实用户一样从主页登录,而是直接借用 cookie 值:
注册激活登录后,进入你的主页,使用任何有开发者模式的浏览器或查看cookie插件,在知乎中打开你自己的cookie。可能有一个非常复杂的列表,但我们只需要其中的一部分,即“z_c0”。复制您自己的 cookie 的 z_c0 部分,不要留下等号、引号和分号。最终的格式大致是这样的:
z_c0="LA8kJIJFdDSOA883wkUGJIRE8jVNKSOQfB9430=|1420113988|a6ea18bc1b23ea469e3b5fb2e33c2828439cb";
在mysql数据库的cookies表中插入一行记录,其中字段值为:
然后就可以正式开始运行了。如果cookie无效或者用户被屏蔽,可以直接修改该行记录的cookie字段。
三、跑
推荐使用forever来执行,不仅方便后台操作和记录,而且崩溃后自动重启。例子:
forever -l /var/www/log.txt index.js
-l 后面的地址是记录日志的地方。如果放在web服务器目录下,可以直接在浏览器中查看日志。在 index.js 后添加参数(以空格分隔),以执行不同的爬虫命令:
1、-i 立即执行,如果不加该参数,则默认在下一个指定时间执行,如每天凌晨0:05;
2、-ng 跳过获取新用户的阶段,即getnewuser;
3、-ns 跳过快照阶段,即usersnapshot;
4、-nf 跳过生成数据文件的阶段,即saveviewfile;
5、-db 显示调试日志。
每个阶段的功能将在下一节中描述。为了方便运行,这行命令可以写成sh脚本,例如:
#!/bin/bash
cd /usr/zhihuspider
rm -f /var/www/log.txt
forever -l /var/www/log.txt start index.js $*
请用您自己的替换具体路径。这样就可以通过在./知乎spider.sh中添加参数来启动爬虫:例如./知乎spider.sh -i -ng -nf 会立即启动任务,跳过新用户并保存文件阶段。停止爬虫的方式是forever stopall(或停止序号)。
四、原理概述
见知乎爬虫的入口文件是index.js。它每天在指定时间循环执行爬虫任务。每天要按顺序执行三项任务,即:
1)getnewuser.js:通过对比当前库中的用户关注列表获取新用户信息,并依靠该机制自动将知乎上值得关注的新人纳入库;
2)usersnapshot.js:循环抓取当前库中的用户数据和答案列表,并保存为每日快照。
3)saveviewfile.js:根据最新快照的内容,生成用户分析列表,过滤出昨天、近期和历史精华答案发布到“见知乎”网站@ >。
以上三个任务执行完毕后,主线程每隔几分钟就会刷新一次知乎主页,验证当前cookie是否还有效。,提醒您及时更换cookies。替换cookie的方法和初始化一样,只需要手动登录一次,然后取出cookie值即可。如果对具体的代码实现感兴趣,可以仔细阅读注释,调整一些配置,甚至尝试自己重构整个爬虫。
提示
1)getnewuser 的原理是通过比较快照前后两天用户的注意力来指定捕获,所以必须至少在两次快照后开始,甚至会自动跳过如果之前执行过。
2)可以中途恢复快照。如果程序因错误而崩溃,用forever stop停止它,然后添加参数-i -ng,立即执行并跳过新用户阶段从刚刚捕获的快照中途继续。
3)抓拍快照时不要轻易增加(伪)线程数,即usersnapshots中的maxthreadcount属性。线程过多会导致429错误,同时捕获的大量数据可能来不及写入数据库,造成内存溢出。因此,除非您的数据库在 SSD 上,否则不要使用超过 10 个线程。
4)从 saveviewfile 生成分析结果的工作需要至少 7 天的快照。如果快照内容少于 7 天,则会报告错误并跳过错误。以前的分析工作可以通过查询数据库手动执行。
5)考虑到大部分人不需要复制一个“look知乎”,自动发布wordpress文章功能入口已经被注释掉了。如果你搭建过wordpress,记得打开xmlrpc,然后设置一个专门发布文章的用户,在config.js中配置相应参数,在saveviewfile中取消注释相关代码。
6)因为知乎对头像做了防盗链处理,所以我们在抓取用户信息的时候也拿到了头像,保存在本地。在发布 文章 时,我们使用了本地头像地址。需要将url路径指向http服务器中保存头像的文件夹,或者将保存头像的文件夹直接放到网站目录下。
7)代码可能不容易阅读。除了node.js的回调结构混乱之外,部分原因是我刚开始写程序的时候才开始接触node.js,有很多不熟悉的地方导致结构混乱。拼凑中积累了很多丑陋的判断条件和重试规则。如果全部删除,代码量可能会减少三分之二。但是没有办法做到这一点。为了保证一个系统的稳定运行,这些都是必须要添加的。
8)本爬虫源码基于WTFPL协议,对修改和分发不做任何限制。 查看全部
js 爬虫抓取网页数据(就是用户爬虫的原理及原理模拟一个的配置介绍)
一、环境配置
1)做一个服务器,任何linux都可以,我用CentOS 6.5;
2)安装一个mysql数据库,5.5或者5.6都可以,可以直接用lnmp或者lamp安装比较省事,也可以直接查看日志返回时浏览器;
3)先搭建一个node.js环境,我用的是0.12.7,后面的版本没试过;
4)执行npm -g install forever,永远安装,让爬虫后台运行;
5)将所有代码集成到本地(integration=git clone);
6)在项目目录下执行npm install,安装依赖库;
7)在项目目录下创建两个空文件夹,json和avatar;
8)创建一个空的mysql数据库和一个全权限用户,依次执行代码中的setup.sql和startusers.sql,创建数据库结构并导入初始种子用户;
9)编辑config.js,标记为(必填)的配置项必须填写或修改,其余项可暂时不变:
exports.jsonPath = "./json/";//生成json文件的路径
exports.avatarPath = "./avatar/";//保存头像文件的路径
exports.dbconfig = {
host: 'localhost',//数据库服务器(必须)
user: 'dbuser',//数据库用户名(必须)
password: 'dbpassword',//数据库密码(必须)
database: 'dbname',//数据库名(必须)
port: 3306,//数据库服务器端口
poolSize: 20,
acquireTimeout: 30000
};
exports.urlpre = "https://www.jb51.net/";//脚本网址
exports.urlzhuanlanpre = "https://www.jb51.net/list/index_96.htm/";//脚本网址
exports.WPurl = "www.xxx.com";//要发布文章的wordpress网站地址
exports.WPusername = "publishuser";//发布文章的用户名
exports.WPpassword = "publishpassword";//发布文章用户的密码
exports.WPurlavatarpre = "http://www.xxx.com/avatar/";//发布文章中替代原始头像的url地址
exports.mailservice = "QQ";//邮件通知服务类型,也可以用Gmail,前提是你访问得了Gmail(必须)
exports.mailuser = "12345@qq.com";//邮箱用户名(必须)
exports.mailpass = "qqpassword";//邮箱密码(必须)
exports.mailfrom = "12345@qq.com";//发送邮件地址(必须,一般与用户名所属邮箱一致)
exports.mailto = "12345@qq.com";//接收通知邮件地址(必须)
保存并转到下一步。
二、爬虫用户
爬虫的原理其实就是模拟一个真实的知乎用户点击采集网站上的数据,所以我们需要一个真实的知乎用户。测试可以用自己的账号,但是长期来看还是注册一个专用账号比较好,一个就够了,目前爬虫只支持一个。我们的模拟不是像真实用户一样从主页登录,而是直接借用 cookie 值:
注册激活登录后,进入你的主页,使用任何有开发者模式的浏览器或查看cookie插件,在知乎中打开你自己的cookie。可能有一个非常复杂的列表,但我们只需要其中的一部分,即“z_c0”。复制您自己的 cookie 的 z_c0 部分,不要留下等号、引号和分号。最终的格式大致是这样的:
z_c0="LA8kJIJFdDSOA883wkUGJIRE8jVNKSOQfB9430=|1420113988|a6ea18bc1b23ea469e3b5fb2e33c2828439cb";
在mysql数据库的cookies表中插入一行记录,其中字段值为:
然后就可以正式开始运行了。如果cookie无效或者用户被屏蔽,可以直接修改该行记录的cookie字段。
三、跑
推荐使用forever来执行,不仅方便后台操作和记录,而且崩溃后自动重启。例子:
forever -l /var/www/log.txt index.js
-l 后面的地址是记录日志的地方。如果放在web服务器目录下,可以直接在浏览器中查看日志。在 index.js 后添加参数(以空格分隔),以执行不同的爬虫命令:
1、-i 立即执行,如果不加该参数,则默认在下一个指定时间执行,如每天凌晨0:05;
2、-ng 跳过获取新用户的阶段,即getnewuser;
3、-ns 跳过快照阶段,即usersnapshot;
4、-nf 跳过生成数据文件的阶段,即saveviewfile;
5、-db 显示调试日志。
每个阶段的功能将在下一节中描述。为了方便运行,这行命令可以写成sh脚本,例如:
#!/bin/bash
cd /usr/zhihuspider
rm -f /var/www/log.txt
forever -l /var/www/log.txt start index.js $*
请用您自己的替换具体路径。这样就可以通过在./知乎spider.sh中添加参数来启动爬虫:例如./知乎spider.sh -i -ng -nf 会立即启动任务,跳过新用户并保存文件阶段。停止爬虫的方式是forever stopall(或停止序号)。
四、原理概述
见知乎爬虫的入口文件是index.js。它每天在指定时间循环执行爬虫任务。每天要按顺序执行三项任务,即:
1)getnewuser.js:通过对比当前库中的用户关注列表获取新用户信息,并依靠该机制自动将知乎上值得关注的新人纳入库;
2)usersnapshot.js:循环抓取当前库中的用户数据和答案列表,并保存为每日快照。
3)saveviewfile.js:根据最新快照的内容,生成用户分析列表,过滤出昨天、近期和历史精华答案发布到“见知乎”网站@ >。
以上三个任务执行完毕后,主线程每隔几分钟就会刷新一次知乎主页,验证当前cookie是否还有效。,提醒您及时更换cookies。替换cookie的方法和初始化一样,只需要手动登录一次,然后取出cookie值即可。如果对具体的代码实现感兴趣,可以仔细阅读注释,调整一些配置,甚至尝试自己重构整个爬虫。
提示
1)getnewuser 的原理是通过比较快照前后两天用户的注意力来指定捕获,所以必须至少在两次快照后开始,甚至会自动跳过如果之前执行过。
2)可以中途恢复快照。如果程序因错误而崩溃,用forever stop停止它,然后添加参数-i -ng,立即执行并跳过新用户阶段从刚刚捕获的快照中途继续。
3)抓拍快照时不要轻易增加(伪)线程数,即usersnapshots中的maxthreadcount属性。线程过多会导致429错误,同时捕获的大量数据可能来不及写入数据库,造成内存溢出。因此,除非您的数据库在 SSD 上,否则不要使用超过 10 个线程。
4)从 saveviewfile 生成分析结果的工作需要至少 7 天的快照。如果快照内容少于 7 天,则会报告错误并跳过错误。以前的分析工作可以通过查询数据库手动执行。
5)考虑到大部分人不需要复制一个“look知乎”,自动发布wordpress文章功能入口已经被注释掉了。如果你搭建过wordpress,记得打开xmlrpc,然后设置一个专门发布文章的用户,在config.js中配置相应参数,在saveviewfile中取消注释相关代码。
6)因为知乎对头像做了防盗链处理,所以我们在抓取用户信息的时候也拿到了头像,保存在本地。在发布 文章 时,我们使用了本地头像地址。需要将url路径指向http服务器中保存头像的文件夹,或者将保存头像的文件夹直接放到网站目录下。
7)代码可能不容易阅读。除了node.js的回调结构混乱之外,部分原因是我刚开始写程序的时候才开始接触node.js,有很多不熟悉的地方导致结构混乱。拼凑中积累了很多丑陋的判断条件和重试规则。如果全部删除,代码量可能会减少三分之二。但是没有办法做到这一点。为了保证一个系统的稳定运行,这些都是必须要添加的。
8)本爬虫源码基于WTFPL协议,对修改和分发不做任何限制。
js 爬虫抓取网页数据(就是用户爬虫的原理及原理模拟一个的配置介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-04 18:01
一、环境配置
1)做一个服务器,任何linux都可以,我用CentOS 6.5;
2)安装一个mysql数据库,5.5或者5.6都可以,可以直接用lnmp或者lamp安装比较省事,也可以直接查看日志返回时浏览器;
3)先搭建一个node.js环境,我用的是0.12.7,后面的版本没试过;
4)执行npm -g install forever,永远安装,让爬虫后台运行;
5)将所有代码集成到本地(integration=git clone);
6)在项目目录下执行npm install,安装依赖库;
7)在项目目录下创建两个空文件夹,json和avatar;
8)创建一个空的mysql数据库和一个全权限用户,依次执行代码中的setup.sql和startusers.sql,创建数据库结构并导入初始种子用户;
9)编辑config.js,标记为(必填)的配置项必须填写或修改,其余项可暂时不变:
exports.jsonPath = "./json/";//生成json文件的路径
exports.avatarPath = "./avatar/";//保存头像文件的路径
exports.dbconfig = {
host: 'localhost',//数据库服务器(必须)
user: 'dbuser',//数据库用户名(必须)
password: 'dbpassword',//数据库密码(必须)
database: 'dbname',//数据库名(必须)
port: 3306,//数据库服务器端口
poolSize: 20,
acquireTimeout: 30000
};
exports.urlpre = "https://www.jb51.net/";//脚本网址
exports.urlzhuanlanpre = "https://www.jb51.net/list/index_96.htm/";//脚本网址
exports.WPurl = "www.xxx.com";//要发布文章的wordpress网站地址
exports.WPusername = "publishuser";//发布文章的用户名
exports.WPpassword = "publishpassword";//发布文章用户的密码
exports.WPurlavatarpre = "http://www.xxx.com/avatar/";//发布文章中替代原始头像的url地址
exports.mailservice = "QQ";//邮件通知服务类型,也可以用Gmail,前提是你访问得了Gmail(必须)
exports.mailuser = "12345@qq.com";//邮箱用户名(必须)
exports.mailpass = "qqpassword";//邮箱密码(必须)
exports.mailfrom = "12345@qq.com";//发送邮件地址(必须,一般与用户名所属邮箱一致)
exports.mailto = "12345@qq.com";//接收通知邮件地址(必须)
保存并转到下一步。
二、爬虫用户
爬虫的原理其实就是模拟一个真实的知乎用户点击采集网站上的数据,所以我们需要一个真实的知乎用户。测试可以用自己的账号,但是长期来看还是注册一个专用账号比较好,一个就够了,目前爬虫只支持一个。我们的模拟不是像真实用户一样从主页登录,而是直接借用 cookie 值:
注册激活登录后,进入你的主页,使用任何有开发者模式的浏览器或查看cookie插件,在知乎中打开你自己的cookie。可能有一个非常复杂的列表,但我们只需要其中的一部分,即“z_c0”。复制您自己的 cookie 的 z_c0 部分,不要留下等号、引号和分号。最终的格式大致是这样的:
z_c0="LA8kJIJFdDSOA883wkUGJIRE8jVNKSOQfB9430=|1420113988|a6ea18bc1b23ea469e3b5fb2e33c2828439cb";
在mysql数据库的cookies表中插入一行记录,其中字段值为:
然后就可以正式开始运行了。如果cookie无效或者用户被屏蔽,可以直接修改该行记录的cookie字段。
三、跑
推荐使用forever来执行,不仅方便后台操作和记录,而且崩溃后自动重启。例子:
forever -l /var/www/log.txt index.js
-l 后面的地址是记录日志的地方。如果放在web服务器目录下,可以直接在浏览器中查看日志。在 index.js 后添加参数(以空格分隔),以执行不同的爬虫命令:
1、-i 立即执行,如果不加该参数,则默认在下一个指定时间执行,如每天凌晨0:05;
2、-ng 跳过获取新用户的阶段,即getnewuser;
3、-ns 跳过快照阶段,即usersnapshot;
4、-nf 跳过生成数据文件的阶段,即saveviewfile;
5、-db 显示调试日志。
每个阶段的功能将在下一节中描述。为了方便运行,这行命令可以写成sh脚本,例如:
#!/bin/bash
cd /usr/zhihuspider
rm -f /var/www/log.txt
forever -l /var/www/log.txt start index.js $*
请用您自己的替换具体路径。这样就可以通过在./知乎spider.sh中添加参数来启动爬虫:例如./知乎spider.sh -i -ng -nf 会立即启动任务,跳过新用户并保存文件阶段。停止爬虫的方式是forever stopall(或停止序号)。
四、原理概述
见知乎爬虫的入口文件是index.js。它每天在指定时间循环执行爬虫任务。每天要按顺序执行三项任务,即:
1)getnewuser.js:通过对比当前库中的用户关注列表获取新用户信息,并依靠该机制自动将知乎上值得关注的新人纳入库;
2)usersnapshot.js:循环抓取当前库中的用户数据和答案列表,并保存为每日快照。
3)saveviewfile.js:根据最新快照的内容,生成用户分析列表,过滤出昨天、近期和历史精华答案发布到“见知乎”网站@ >。
以上三项任务完成后,主线程每隔几分钟就会刷新一次知乎主页,验证当前cookie是否还有效。,提醒您及时更换cookies。替换cookie的方法和初始化一样,只需要手动登录一次,然后取出cookie值即可。如果对具体的代码实现感兴趣,可以仔细阅读注释,调整一些配置,甚至尝试自己重构整个爬虫。
提示
1)getnewuser 的原理是通过比较前后两天快照中用户的注意力数量来指定抓包,所以必须至少在两个快照之后才开始,甚至会自动跳过如果之前执行过。
2)可以中途恢复快照。如果程序因错误而崩溃,用forever stop停止它,然后添加参数-i -ng,立即执行并跳过新用户阶段从刚刚捕获的快照中途继续。
3)抓拍快照时不要轻易增加(伪)线程数,即usersnapshots中的maxthreadcount属性。线程过多会导致429错误,同时捕获的大量数据可能来不及写入数据库,造成内存溢出。因此,除非您的数据库在 SSD 上,否则不要使用超过 10 个线程。
4)从 saveviewfile 生成分析结果的工作需要至少 7 天的快照。如果快照内容少于 7 天,则会报告错误并跳过错误。以前的分析工作可以通过查询数据库手动执行。
5)考虑到大部分人不需要复制一个“look知乎”,自动发布wordpress文章功能入口已经被注释掉了。如果你搭建过wordpress,记得打开xmlrpc,然后设置一个专门发布文章的用户,在config.js中配置相应参数,在saveviewfile中取消注释相关代码。
6)因为知乎对头像做了防盗链处理,所以我们在抓取用户信息的时候也拿到了头像,保存在本地。在发布 文章 时,我们使用了本地头像地址。需要将url路径指向http服务器中保存头像的文件夹,或者将保存头像的文件夹直接放到网站目录下。
7)代码可能不容易阅读。除了node.js本身的回调结构混乱之外,部分原因是我刚开始写程序的时候才开始接触node.js,有很多不熟悉的地方导致结构混乱并且没有来得及更正;另一部分是很多时候拼凑起来积累了很多丑陋的判断条件和重试规则。如果全部删除,代码量可能会减少三分之二。但是没有办法做到这一点。为了保证一个系统的稳定运行,这些都是必须要添加的。
8)本爬虫源码基于WTFPL协议,对修改和分发不做任何限制。 查看全部
js 爬虫抓取网页数据(就是用户爬虫的原理及原理模拟一个的配置介绍)
一、环境配置
1)做一个服务器,任何linux都可以,我用CentOS 6.5;
2)安装一个mysql数据库,5.5或者5.6都可以,可以直接用lnmp或者lamp安装比较省事,也可以直接查看日志返回时浏览器;
3)先搭建一个node.js环境,我用的是0.12.7,后面的版本没试过;
4)执行npm -g install forever,永远安装,让爬虫后台运行;
5)将所有代码集成到本地(integration=git clone);
6)在项目目录下执行npm install,安装依赖库;
7)在项目目录下创建两个空文件夹,json和avatar;
8)创建一个空的mysql数据库和一个全权限用户,依次执行代码中的setup.sql和startusers.sql,创建数据库结构并导入初始种子用户;
9)编辑config.js,标记为(必填)的配置项必须填写或修改,其余项可暂时不变:
exports.jsonPath = "./json/";//生成json文件的路径
exports.avatarPath = "./avatar/";//保存头像文件的路径
exports.dbconfig = {
host: 'localhost',//数据库服务器(必须)
user: 'dbuser',//数据库用户名(必须)
password: 'dbpassword',//数据库密码(必须)
database: 'dbname',//数据库名(必须)
port: 3306,//数据库服务器端口
poolSize: 20,
acquireTimeout: 30000
};
exports.urlpre = "https://www.jb51.net/";//脚本网址
exports.urlzhuanlanpre = "https://www.jb51.net/list/index_96.htm/";//脚本网址
exports.WPurl = "www.xxx.com";//要发布文章的wordpress网站地址
exports.WPusername = "publishuser";//发布文章的用户名
exports.WPpassword = "publishpassword";//发布文章用户的密码
exports.WPurlavatarpre = "http://www.xxx.com/avatar/";//发布文章中替代原始头像的url地址
exports.mailservice = "QQ";//邮件通知服务类型,也可以用Gmail,前提是你访问得了Gmail(必须)
exports.mailuser = "12345@qq.com";//邮箱用户名(必须)
exports.mailpass = "qqpassword";//邮箱密码(必须)
exports.mailfrom = "12345@qq.com";//发送邮件地址(必须,一般与用户名所属邮箱一致)
exports.mailto = "12345@qq.com";//接收通知邮件地址(必须)
保存并转到下一步。
二、爬虫用户
爬虫的原理其实就是模拟一个真实的知乎用户点击采集网站上的数据,所以我们需要一个真实的知乎用户。测试可以用自己的账号,但是长期来看还是注册一个专用账号比较好,一个就够了,目前爬虫只支持一个。我们的模拟不是像真实用户一样从主页登录,而是直接借用 cookie 值:
注册激活登录后,进入你的主页,使用任何有开发者模式的浏览器或查看cookie插件,在知乎中打开你自己的cookie。可能有一个非常复杂的列表,但我们只需要其中的一部分,即“z_c0”。复制您自己的 cookie 的 z_c0 部分,不要留下等号、引号和分号。最终的格式大致是这样的:
z_c0="LA8kJIJFdDSOA883wkUGJIRE8jVNKSOQfB9430=|1420113988|a6ea18bc1b23ea469e3b5fb2e33c2828439cb";
在mysql数据库的cookies表中插入一行记录,其中字段值为:
然后就可以正式开始运行了。如果cookie无效或者用户被屏蔽,可以直接修改该行记录的cookie字段。
三、跑
推荐使用forever来执行,不仅方便后台操作和记录,而且崩溃后自动重启。例子:
forever -l /var/www/log.txt index.js
-l 后面的地址是记录日志的地方。如果放在web服务器目录下,可以直接在浏览器中查看日志。在 index.js 后添加参数(以空格分隔),以执行不同的爬虫命令:
1、-i 立即执行,如果不加该参数,则默认在下一个指定时间执行,如每天凌晨0:05;
2、-ng 跳过获取新用户的阶段,即getnewuser;
3、-ns 跳过快照阶段,即usersnapshot;
4、-nf 跳过生成数据文件的阶段,即saveviewfile;
5、-db 显示调试日志。
每个阶段的功能将在下一节中描述。为了方便运行,这行命令可以写成sh脚本,例如:
#!/bin/bash
cd /usr/zhihuspider
rm -f /var/www/log.txt
forever -l /var/www/log.txt start index.js $*
请用您自己的替换具体路径。这样就可以通过在./知乎spider.sh中添加参数来启动爬虫:例如./知乎spider.sh -i -ng -nf 会立即启动任务,跳过新用户并保存文件阶段。停止爬虫的方式是forever stopall(或停止序号)。
四、原理概述
见知乎爬虫的入口文件是index.js。它每天在指定时间循环执行爬虫任务。每天要按顺序执行三项任务,即:
1)getnewuser.js:通过对比当前库中的用户关注列表获取新用户信息,并依靠该机制自动将知乎上值得关注的新人纳入库;
2)usersnapshot.js:循环抓取当前库中的用户数据和答案列表,并保存为每日快照。
3)saveviewfile.js:根据最新快照的内容,生成用户分析列表,过滤出昨天、近期和历史精华答案发布到“见知乎”网站@ >。
以上三项任务完成后,主线程每隔几分钟就会刷新一次知乎主页,验证当前cookie是否还有效。,提醒您及时更换cookies。替换cookie的方法和初始化一样,只需要手动登录一次,然后取出cookie值即可。如果对具体的代码实现感兴趣,可以仔细阅读注释,调整一些配置,甚至尝试自己重构整个爬虫。
提示
1)getnewuser 的原理是通过比较前后两天快照中用户的注意力数量来指定抓包,所以必须至少在两个快照之后才开始,甚至会自动跳过如果之前执行过。
2)可以中途恢复快照。如果程序因错误而崩溃,用forever stop停止它,然后添加参数-i -ng,立即执行并跳过新用户阶段从刚刚捕获的快照中途继续。
3)抓拍快照时不要轻易增加(伪)线程数,即usersnapshots中的maxthreadcount属性。线程过多会导致429错误,同时捕获的大量数据可能来不及写入数据库,造成内存溢出。因此,除非您的数据库在 SSD 上,否则不要使用超过 10 个线程。
4)从 saveviewfile 生成分析结果的工作需要至少 7 天的快照。如果快照内容少于 7 天,则会报告错误并跳过错误。以前的分析工作可以通过查询数据库手动执行。
5)考虑到大部分人不需要复制一个“look知乎”,自动发布wordpress文章功能入口已经被注释掉了。如果你搭建过wordpress,记得打开xmlrpc,然后设置一个专门发布文章的用户,在config.js中配置相应参数,在saveviewfile中取消注释相关代码。
6)因为知乎对头像做了防盗链处理,所以我们在抓取用户信息的时候也拿到了头像,保存在本地。在发布 文章 时,我们使用了本地头像地址。需要将url路径指向http服务器中保存头像的文件夹,或者将保存头像的文件夹直接放到网站目录下。
7)代码可能不容易阅读。除了node.js本身的回调结构混乱之外,部分原因是我刚开始写程序的时候才开始接触node.js,有很多不熟悉的地方导致结构混乱并且没有来得及更正;另一部分是很多时候拼凑起来积累了很多丑陋的判断条件和重试规则。如果全部删除,代码量可能会减少三分之二。但是没有办法做到这一点。为了保证一个系统的稳定运行,这些都是必须要添加的。
8)本爬虫源码基于WTFPL协议,对修改和分发不做任何限制。
js 爬虫抓取网页数据(个人浏览器上网原理图爬虫程序可以简单想象为替代浏览器的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-04 16:09
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。白话爬虫的官方定义:网络爬虫是按照一定的规则自动抓取全球信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。个人浏览器上网示意图 爬虫程序可以简单的想象为替代浏览器的功能,将获取的数据存储在数据库或文件中。同时,对于网站的反爬策略,它需要伪装自己,也就是跟着浏览器发送的信息Like,我是谁?,我来自哪里,我的浏览器型号,使用的方法,访问的信息。
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。这些数据来自哪里?正如我们通常在寻找“度娘”时遇到问题一样,重要的数据来源是互联网,而爬虫是获取互联网数据的手段。前端时间是数据分析的狮子。我做了两周的兼职爬虫工程师。今天给大家讲讲白话爬虫。事物。
白话爬行动物
爬虫的官方定义:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种按照一定的规则自动爬取全球信息的程序或脚本。规则。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
白话爬虫:利用程序模拟人们的上网行为进行网络索引,获取网页中的特定信息,实现对网络数据的短期、不间断、实时访问。
个人浏览器上网示意图
爬虫可以简单的想象成代替浏览器的功能【发送一个url请求,解析服务器返回的HTML文档】,将获取到的数据存储到数据库或者文件中。同时,对于网站的反爬策略,需要进行伪装,即携带浏览器发送的信息我是谁?(cookie信息),我来自哪里(IP地址,使用的代理IP),我的浏览器模型(User-Agent),使用的方法(get,post等),访问信息。
爬行动物示意图
Python爬虫代码案例
要求:网站百度前几页搜索结果的地址和主题(自定义)抓取一个关键字(自定义)
代码:
class crawler: '''按关键词爬取百度搜索页面内容''' url = '' urls = [] o_urls = [] html = '' total_pages = 5 current_page = 0 next_page_url = '' timeout = 60 headersParameters = { 'Connection': 'Keep-Alive', 'Accept': 'text/html, application/xhtml+xml, */*', 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3', 'Accept-Encoding': 'gzip, deflate', 'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko' } def __init__(self, keyword): self.keyword = keyword self.url = 'https://www.baidu.com/baidu?wd='+quote(keyword)+'&tn=monline_dg&ie=utf-8' self.url_df = pd.DataFrame(columns=["url"]) self.url_title_df = pd.DataFrame(columns=["url","title"]) def set_timeout(self, time): '''设置超时时间,单位:秒''' try: self.timeout = int(time) except: pass def set_total_pages(self, num): '''设置总共要爬取的页数''' try: self.total_pages = int(num) except: pass def set_current_url(self, url): '''设置当前url''' self.url = url def switch_url(self): '''切换当前url为下一页的url 若下一页为空,则退出程序''' if self.next_page_url == '': sys.exit() else: self.set_current_url(self.next_page_url) def is_finish(self): '''判断是否爬取完毕''' if self.current_page >= self.total_pages: return True else: return False def get_html(self): '''爬取当前url所指页面的内容,保存到html中''' r = requests.get(self.url ,timeout=self.timeout, headers=self.headersParameters) if r.status_code==200: self.html = r.text# print("-----------------------------------------------------------------------")# print("[当前页面链接]: ",self.url)# #print("[当前页面内容]: ",self.html)# print("-----------------------------------------------------------------------") self.current_page += 1 else: self.html = '' print('[ERROR]',self.url,'get此url返回的http状态码不是200') def get_urls(self): '''从当前html中解析出搜索结果的url,保存到o_urls''' o_urls = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\"', self.html) titles = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\".* data-tools=\'{"title":(.*?),"url"',self.html)# o_urls = list(set(o_urls)) #去重# titles = list(set(titles)) #去重 self.titles = titles self.o_urls = o_urls #取下一页地址 next = re.findall(' href\=\"(\/s\?wd\=[\w\d\%\&\=\_\-]*?)\" class\=\"n\"', self.html) if len(next) > 0: self.next_page_url = 'https://www.baidu.com'+next[-1] else: self.next_page_url = '' def get_real(self, o_url): '''获取重定向url指向的网址''' r = requests.get(o_url, allow_redirects = False) #禁止自动跳转 if r.status_code == 302: try: return r.headers['location'] #返回指向的地址 except: pass return o_url #返回源地址 def transformation(self): '''读取当前o_urls中的链接重定向的网址,并保存到urls中''' self.urls = [] for o_url in self.o_urls: self.urls.append(self.get_real(o_url)) def print_urls(self): '''输出当前urls中的url''' for url in self.urls: print(url) for title in self.titles: print(title[0]) def stock_data(self): url_df = pd.DataFrame(self.urls,columns=["url"]) o_url_df = pd.DataFrame([self.o_urls,self.urls],index=["o_url","url"]).T title_df = pd.DataFrame(self.titles,columns=["o_url","title"]) url_title_df = pd.merge(o_url_df,title_df,left_on="o_url",right_on="o_url",how="left") url_titles_df = url_title_df[["url","title"]] self.url_df = self.url_df.append(url_df,ignore_index=True) self.url_title_df = self.url_title_df.append(url_titles_df,ignore_index=True) self.url_title_df["keyword"] = len(self.url_title_df)* [self.keyword] def print_o_urls(self): '''输出当前o_urls中的url''' for url in self.o_urls: print(url) def run(self): while(not self.is_finish()): self.get_html() self.get_urls() self.transformation() c.print_urls() self.stock_data() time.sleep(10) self.switch_url()
API接口
## 爬取百度关键词timeout = 60totalpages=2 ##前两页baidu_url = pd.DataFrame(columns=["url","title","keyword"])keyword="数据分析"c = crawler(keyword)if timeout != None: c.set_timeout(timeout)if totalpages != None: c.set_total_pages(totalpages)c.run()# print(c.url_title_df)baidu_url=baidu_url.append(c.url_title_df,ignore_index=True)
获取关键词“数据分析”的百度搜索结果前两页信息
原创文章,作者:admin,如转载请注明出处: 查看全部
js 爬虫抓取网页数据(个人浏览器上网原理图爬虫程序可以简单想象为替代浏览器的功能)
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。白话爬虫的官方定义:网络爬虫是按照一定的规则自动抓取全球信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。个人浏览器上网示意图 爬虫程序可以简单的想象为替代浏览器的功能,将获取的数据存储在数据库或文件中。同时,对于网站的反爬策略,它需要伪装自己,也就是跟着浏览器发送的信息Like,我是谁?,我来自哪里,我的浏览器型号,使用的方法,访问的信息。
在大数据时代,企业和个人都希望通过数据分析获取信息,了解行业和竞争,解决业务问题。这些数据来自哪里?正如我们通常在寻找“度娘”时遇到问题一样,重要的数据来源是互联网,而爬虫是获取互联网数据的手段。前端时间是数据分析的狮子。我做了两周的兼职爬虫工程师。今天给大家讲讲白话爬虫。事物。
白话爬行动物
爬虫的官方定义:网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种按照一定的规则自动爬取全球信息的程序或脚本。规则。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
白话爬虫:利用程序模拟人们的上网行为进行网络索引,获取网页中的特定信息,实现对网络数据的短期、不间断、实时访问。
个人浏览器上网示意图
爬虫可以简单的想象成代替浏览器的功能【发送一个url请求,解析服务器返回的HTML文档】,将获取到的数据存储到数据库或者文件中。同时,对于网站的反爬策略,需要进行伪装,即携带浏览器发送的信息我是谁?(cookie信息),我来自哪里(IP地址,使用的代理IP),我的浏览器模型(User-Agent),使用的方法(get,post等),访问信息。
爬行动物示意图
Python爬虫代码案例
要求:网站百度前几页搜索结果的地址和主题(自定义)抓取一个关键字(自定义)
代码:
class crawler: '''按关键词爬取百度搜索页面内容''' url = '' urls = [] o_urls = [] html = '' total_pages = 5 current_page = 0 next_page_url = '' timeout = 60 headersParameters = { 'Connection': 'Keep-Alive', 'Accept': 'text/html, application/xhtml+xml, */*', 'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3', 'Accept-Encoding': 'gzip, deflate', 'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko' } def __init__(self, keyword): self.keyword = keyword self.url = 'https://www.baidu.com/baidu?wd='+quote(keyword)+'&tn=monline_dg&ie=utf-8' self.url_df = pd.DataFrame(columns=["url"]) self.url_title_df = pd.DataFrame(columns=["url","title"]) def set_timeout(self, time): '''设置超时时间,单位:秒''' try: self.timeout = int(time) except: pass def set_total_pages(self, num): '''设置总共要爬取的页数''' try: self.total_pages = int(num) except: pass def set_current_url(self, url): '''设置当前url''' self.url = url def switch_url(self): '''切换当前url为下一页的url 若下一页为空,则退出程序''' if self.next_page_url == '': sys.exit() else: self.set_current_url(self.next_page_url) def is_finish(self): '''判断是否爬取完毕''' if self.current_page >= self.total_pages: return True else: return False def get_html(self): '''爬取当前url所指页面的内容,保存到html中''' r = requests.get(self.url ,timeout=self.timeout, headers=self.headersParameters) if r.status_code==200: self.html = r.text# print("-----------------------------------------------------------------------")# print("[当前页面链接]: ",self.url)# #print("[当前页面内容]: ",self.html)# print("-----------------------------------------------------------------------") self.current_page += 1 else: self.html = '' print('[ERROR]',self.url,'get此url返回的http状态码不是200') def get_urls(self): '''从当前html中解析出搜索结果的url,保存到o_urls''' o_urls = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\"', self.html) titles = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\".* data-tools=\'{"title":(.*?),"url"',self.html)# o_urls = list(set(o_urls)) #去重# titles = list(set(titles)) #去重 self.titles = titles self.o_urls = o_urls #取下一页地址 next = re.findall(' href\=\"(\/s\?wd\=[\w\d\%\&\=\_\-]*?)\" class\=\"n\"', self.html) if len(next) > 0: self.next_page_url = 'https://www.baidu.com'+next[-1] else: self.next_page_url = '' def get_real(self, o_url): '''获取重定向url指向的网址''' r = requests.get(o_url, allow_redirects = False) #禁止自动跳转 if r.status_code == 302: try: return r.headers['location'] #返回指向的地址 except: pass return o_url #返回源地址 def transformation(self): '''读取当前o_urls中的链接重定向的网址,并保存到urls中''' self.urls = [] for o_url in self.o_urls: self.urls.append(self.get_real(o_url)) def print_urls(self): '''输出当前urls中的url''' for url in self.urls: print(url) for title in self.titles: print(title[0]) def stock_data(self): url_df = pd.DataFrame(self.urls,columns=["url"]) o_url_df = pd.DataFrame([self.o_urls,self.urls],index=["o_url","url"]).T title_df = pd.DataFrame(self.titles,columns=["o_url","title"]) url_title_df = pd.merge(o_url_df,title_df,left_on="o_url",right_on="o_url",how="left") url_titles_df = url_title_df[["url","title"]] self.url_df = self.url_df.append(url_df,ignore_index=True) self.url_title_df = self.url_title_df.append(url_titles_df,ignore_index=True) self.url_title_df["keyword"] = len(self.url_title_df)* [self.keyword] def print_o_urls(self): '''输出当前o_urls中的url''' for url in self.o_urls: print(url) def run(self): while(not self.is_finish()): self.get_html() self.get_urls() self.transformation() c.print_urls() self.stock_data() time.sleep(10) self.switch_url()
API接口
## 爬取百度关键词timeout = 60totalpages=2 ##前两页baidu_url = pd.DataFrame(columns=["url","title","keyword"])keyword="数据分析"c = crawler(keyword)if timeout != None: c.set_timeout(timeout)if totalpages != None: c.set_total_pages(totalpages)c.run()# print(c.url_title_df)baidu_url=baidu_url.append(c.url_title_df,ignore_index=True)
获取关键词“数据分析”的百度搜索结果前两页信息
原创文章,作者:admin,如转载请注明出处:
js 爬虫抓取网页数据(今日头条为例来尝试通过分析Ajax请求来网页数据的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 372 次浏览 • 2022-04-04 16:02
)
文章目录
在本文中,我们以今日头条为例,尝试通过分析Ajax请求来抓取网页数据。本次要抓拍的目标是今日头条的街拍,抓拍保存。本节代码参考了python3网络爬虫实战的6.4节,但是由于网页上的一些东西已经更新,所以本文中的代码也做了相应的修改,使其可以正常采集数据。1.准备
首先,确保已安装 requests 库。
2.爬取分析
在爬取之前,先分析一下爬取的逻辑。打开今日头条首页,如图
在搜索框中输入街拍,结果如图
点击图片切换图片分类
然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL是当前连接%E8%A1%97%E6%8B%8D&pd=atlas&source=search_subtab_switch&dvpf=pc&aid=4916&page_num=0,打开Preview标签查看Response Body。发现只有页面的一部分,如图。可以分析出下面的图片数据是通过Ajax加载,然后用JavaScript渲染出来的。
接下来,我们可以切换到 XHR 过滤选项卡,查看是否有任何 Ajax 请求。
果然有一个比较常规的ajax请求,看看它的结果是否收录页面中的相关数据。
点击rawData字段展开,可以发现有一个data字段,count字段为40,表示本次请求收录40张图片,data字段收录40条记录,分别是图片的url等信息。
这证实了数据确实是由 Ajax 加载的。
我们的目的是抓取里面的图片,这里一组图片对应上一个数据域中的一条数据。如图所示
因此,我们只需要提取并下载data中每条数据的img_url字段即可。创建一个文件夹来保存这些图片。
接下来,我们可以直接用Python来模拟这个Ajax请求,然后提取相关信息。但在此之前,我们还需要分析一下 URL 的规律。
切换回Headers选项卡,观察其请求URL和Headers信息,如图
可以看出这是一个GET请求。请求的参数有keyword、pd、source、dvpf、aid、page_num、search_json、rawJSON、search_id。我们需要找出这些参数的规则,因为这样可以方便地用程序构造请求。
接下来,滑动界面以加载更多结果。加载的时候可以发现NetWork中有很多Ajax请求,如图:
这里我们观察前后几个连接的请求变化,发现只有page_num参数在变化,每次变化都是1,所以可以找到规律,这个page_num就是偏移量,然后我们可以推断即count参数是一次得到的数据条数。所以我们可以使用page_num参数来控制分页。这样就可以通过接口批量获取数据,然后解析数据,下载图片。另外我们发现keyword参数使用的不是明文,而是加密的代码,可以借助python中的unquote包解决。
3.实战演练
我们刚刚分析了ajax请求的逻辑,下面使用程序来实现。
首先,实现方法 get_page() 来加载单个 Ajax 请求的结果。唯一的变化是参数page_num,所以它作为参数传递。另外需要注意的是,这里需要构造请求头,并且需要收录cooike,否则取不到Response。该信息可以在“标题”选项卡中找到:
构造参数可以在payload选项卡中找到
import requests
from urllib.parse import urlencode,quote,unquote
headers = {
'Host': 'so.toutiao.com',
'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%222022040316335201021218304330C35A48%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest', # Ajax请求需要手动设置这里
'Cookie': 'passport_csrf_token=92a1b4e0108fb8384f5b81554b5b5424; tt_webid=7053044990251386398; _S_DPR=1.25; _S_IPAD=0; MONITOR_WEB_ID=7053044990251386398; ttwid=1%7CoqMwjUw5WGRdjYizT8quhnfpAchk3v_E3YLa1riJgrY%7C1648972603%7Cbaea5aebf3461426baaede977fa55b0efec3033a9f0d6a3e26684ba80f607ee9; _S_WIN_WH=1536_722'
}
def get_page(page_num):
params = {
'keyword':unquote('%E8%A1%97%E6%8B%8D') ,
'pd':'atlas',
'dvpf':'pc',
'aid': '4916' ,
'page_num':page_num,
'search_json':{"from_search_id":"2022040316335201021218304330C35A48","origin_keyword":"街拍","image_keyword":"街拍"},
'rawJSON':'1',
'search_id':'2022040317334901015013503043241DAC'
}
url = 'https://so.toutiao.com/search/?'+urlencode(params,headers)
try:
response = requests.get(url,headers=headers,params=params)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
这里我们使用urlencode()方法构造请求的GET参数,然后使用requests请求链接。如果返回的状态码为 200,调用响应的 json() 方法将结果转换为 JSON 格式并返回。
接下来实现一个解析方法:提取每条数据的img_url字段中的图片链接,并返回图片链接。这时候就可以构建生成器了。实现代码如下:
def get_images(json):
if json.get('rawData'):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield {
'image':image.get('img_url'),
'title':"街拍",
'text':image.get('text')
}
接下来,实现一个用于保存图像的 save_image() 方法,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。代码显示如下:
import os
from hashlib import md5
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print('Failed to Save image')
最后,只需构造一个数组,遍历,提取图片链接,下载即可:
from multiprocessing.pool import Pool
def main(page_num):
json = get_page(page_num)
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 1
GROUP_END = 20
if __name__ == '__main__':
# pool = Pool()
# groups = ([x*20 for x in range(GROUP_START,GROUP_END+1)]) #使用这种方式启动出现bug,原因还没有找到
# pool.map(main,groups)
# pool.close()
# pool.join()
for i in range(1,10):
main(i)
因为博主在使用线程池有bug,一直没找到原因,所以先用for循环
结果如下:
最后,给出本文的代码地址:
参考
[1].Python3网络爬虫开发实战.崔庆才.——6.4 查看全部
js 爬虫抓取网页数据(今日头条为例来尝试通过分析Ajax请求来网页数据的方法
)
文章目录
在本文中,我们以今日头条为例,尝试通过分析Ajax请求来抓取网页数据。本次要抓拍的目标是今日头条的街拍,抓拍保存。本节代码参考了python3网络爬虫实战的6.4节,但是由于网页上的一些东西已经更新,所以本文中的代码也做了相应的修改,使其可以正常采集数据。1.准备
首先,确保已安装 requests 库。
2.爬取分析
在爬取之前,先分析一下爬取的逻辑。打开今日头条首页,如图
在搜索框中输入街拍,结果如图
点击图片切换图片分类
然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL是当前连接%E8%A1%97%E6%8B%8D&pd=atlas&source=search_subtab_switch&dvpf=pc&aid=4916&page_num=0,打开Preview标签查看Response Body。发现只有页面的一部分,如图。可以分析出下面的图片数据是通过Ajax加载,然后用JavaScript渲染出来的。
接下来,我们可以切换到 XHR 过滤选项卡,查看是否有任何 Ajax 请求。
果然有一个比较常规的ajax请求,看看它的结果是否收录页面中的相关数据。
点击rawData字段展开,可以发现有一个data字段,count字段为40,表示本次请求收录40张图片,data字段收录40条记录,分别是图片的url等信息。
这证实了数据确实是由 Ajax 加载的。
我们的目的是抓取里面的图片,这里一组图片对应上一个数据域中的一条数据。如图所示
因此,我们只需要提取并下载data中每条数据的img_url字段即可。创建一个文件夹来保存这些图片。
接下来,我们可以直接用Python来模拟这个Ajax请求,然后提取相关信息。但在此之前,我们还需要分析一下 URL 的规律。
切换回Headers选项卡,观察其请求URL和Headers信息,如图
可以看出这是一个GET请求。请求的参数有keyword、pd、source、dvpf、aid、page_num、search_json、rawJSON、search_id。我们需要找出这些参数的规则,因为这样可以方便地用程序构造请求。
接下来,滑动界面以加载更多结果。加载的时候可以发现NetWork中有很多Ajax请求,如图:
这里我们观察前后几个连接的请求变化,发现只有page_num参数在变化,每次变化都是1,所以可以找到规律,这个page_num就是偏移量,然后我们可以推断即count参数是一次得到的数据条数。所以我们可以使用page_num参数来控制分页。这样就可以通过接口批量获取数据,然后解析数据,下载图片。另外我们发现keyword参数使用的不是明文,而是加密的代码,可以借助python中的unquote包解决。
3.实战演练
我们刚刚分析了ajax请求的逻辑,下面使用程序来实现。
首先,实现方法 get_page() 来加载单个 Ajax 请求的结果。唯一的变化是参数page_num,所以它作为参数传递。另外需要注意的是,这里需要构造请求头,并且需要收录cooike,否则取不到Response。该信息可以在“标题”选项卡中找到:
构造参数可以在payload选项卡中找到
import requests
from urllib.parse import urlencode,quote,unquote
headers = {
'Host': 'so.toutiao.com',
'Referer': 'https://so.toutiao.com/search% ... on%3D{%22from_search_id%22:%222022040316335201021218304330C35A48%22,%22origin_keyword%22:%22%E8%A1%97%E6%8B%8D%22,%22image_keyword%22:%22%E8%A1%97%E6%8B%8D%22}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest', # Ajax请求需要手动设置这里
'Cookie': 'passport_csrf_token=92a1b4e0108fb8384f5b81554b5b5424; tt_webid=7053044990251386398; _S_DPR=1.25; _S_IPAD=0; MONITOR_WEB_ID=7053044990251386398; ttwid=1%7CoqMwjUw5WGRdjYizT8quhnfpAchk3v_E3YLa1riJgrY%7C1648972603%7Cbaea5aebf3461426baaede977fa55b0efec3033a9f0d6a3e26684ba80f607ee9; _S_WIN_WH=1536_722'
}
def get_page(page_num):
params = {
'keyword':unquote('%E8%A1%97%E6%8B%8D') ,
'pd':'atlas',
'dvpf':'pc',
'aid': '4916' ,
'page_num':page_num,
'search_json':{"from_search_id":"2022040316335201021218304330C35A48","origin_keyword":"街拍","image_keyword":"街拍"},
'rawJSON':'1',
'search_id':'2022040317334901015013503043241DAC'
}
url = 'https://so.toutiao.com/search/?'+urlencode(params,headers)
try:
response = requests.get(url,headers=headers,params=params)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
这里我们使用urlencode()方法构造请求的GET参数,然后使用requests请求链接。如果返回的状态码为 200,调用响应的 json() 方法将结果转换为 JSON 格式并返回。
接下来实现一个解析方法:提取每条数据的img_url字段中的图片链接,并返回图片链接。这时候就可以构建生成器了。实现代码如下:
def get_images(json):
if json.get('rawData'):
images = json.get('rawData').get('data')
for image in images:
link = image.get('img_url')
yield {
'image':image.get('img_url'),
'title':"街拍",
'text':image.get('text')
}
接下来,实现一个用于保存图像的 save_image() 方法,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。代码显示如下:
import os
from hashlib import md5
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'),md5(response.content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(response.content)
else:
print("Already Downloaded",file_path)
except requests.ConnectionError:
print('Failed to Save image')
最后,只需构造一个数组,遍历,提取图片链接,下载即可:
from multiprocessing.pool import Pool
def main(page_num):
json = get_page(page_num)
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 1
GROUP_END = 20
if __name__ == '__main__':
# pool = Pool()
# groups = ([x*20 for x in range(GROUP_START,GROUP_END+1)]) #使用这种方式启动出现bug,原因还没有找到
# pool.map(main,groups)
# pool.close()
# pool.join()
for i in range(1,10):
main(i)
因为博主在使用线程池有bug,一直没找到原因,所以先用for循环
结果如下:
最后,给出本文的代码地址:
参考
[1].Python3网络爬虫开发实战.崔庆才.——6.4
js 爬虫抓取网页数据(盘点一下数据采集常见的几种网站类型(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-04-03 12:20
在学习爬虫之前,我们需要掌握网站的类型,这样才能根据网站的类型,使用适用的方法编写爬虫获取数据。
今天小编就以国内知名的ForeSpider爬虫软件采集可以使用的网站类型为例,盘点几种常见的网站数据类型采集@ >。
l 常用网站类型
1.js 页面
JavaScript是一种属于网络的脚本语言,广泛用于Web应用程序的开发。常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常 JavaScript 脚本嵌入在 HTML 中以实现自己的功能。
ForeSpider数据抓取工具可以自动解析JS,采集根据js页面中的数据,采集页面收录JS数据。
Ajax 是异步 JavaScript 和 XML。它不是一种编程语言,而是一种在不刷新页面和不改变页面链接的情况下,使用 JavaScript 与服务器交换数据并更新部分网页的技术。
我们在浏览网页时,经常会遇到这样的情况。浏览某个页面时,将页面向后拉,页面链接没有变化,但是网页中有新的内容,是通过ajax获取的。新数据和提出的过程。
ForeSpider数据采集系统支持Ajax技术,可以采集网页中的Ajax内容。
2.发布/获取请求
在 html 语言中,有两种方法可以将表单(您在网页中填写的一些数据)发送到服务器。一种是 POST,另一种是 GET。POST 将表单打包并隐藏在后台并发送给服务器;GET 包装表单并将其附加到 URL(网站)的后面,然后再发送。
ForeSpider采集器可以采集post/get请求中的网页内容中的数据,即采集post/get请求中的数据。
3.需要 cookie网站
Cookie是指存储在用户本地终端上用于识别用户身份和进行会话跟踪的一些数据。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。每当用户链接到服务器时,网站都可以访问 cookie 信息。
一般情况下,用户的账户信息都记录在 cookie 中。爬虫在爬取数据时,可以通过cookie模拟登录状态来获取数据。
ForeSpider数据采集分析引擎可以设置cookie来模拟登录,所以采集需要用到cookie的网站内容。
4. 采集需要OAuth认证的网页数据
OAUTH 协议为用户资源的授权提供了一个安全、开放、简单的标准。同时,任何第三方都可以使用OAUTH认证服务,任何服务提供商都可以实现自己的OAUTH认证服务,所以OAUTH是开放的。
业界提供PHP、Java Script、Java、Ruby等多种语言开发包的多种OAUTH实现,大大节省了程序员的时间,所以OAUTH简单。许多互联网服务如Open API,以及许多大公司如谷歌、雅虎、微软等都提供了OAUTH认证服务,这足以说明OAUTH标准已经逐渐成为开放资源授权的标准。
ForeSpider爬虫软件支持OAuth认证,可以采集需要OAuth认证的页面中的数据。
l 前嗅觉介绍
千秀大数据,国内领先的研发大数据专家,多年致力于大数据技术的研发,自主研发了一整套数据采集,分析、处理、管理、应用和营销。大数据产品。千秀致力于打造国内首个深度大数据平台! 查看全部
js 爬虫抓取网页数据(盘点一下数据采集常见的几种网站类型(一)(组图))
在学习爬虫之前,我们需要掌握网站的类型,这样才能根据网站的类型,使用适用的方法编写爬虫获取数据。
今天小编就以国内知名的ForeSpider爬虫软件采集可以使用的网站类型为例,盘点几种常见的网站数据类型采集@ >。
l 常用网站类型
1.js 页面
JavaScript是一种属于网络的脚本语言,广泛用于Web应用程序的开发。常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常 JavaScript 脚本嵌入在 HTML 中以实现自己的功能。
ForeSpider数据抓取工具可以自动解析JS,采集根据js页面中的数据,采集页面收录JS数据。
Ajax 是异步 JavaScript 和 XML。它不是一种编程语言,而是一种在不刷新页面和不改变页面链接的情况下,使用 JavaScript 与服务器交换数据并更新部分网页的技术。
我们在浏览网页时,经常会遇到这样的情况。浏览某个页面时,将页面向后拉,页面链接没有变化,但是网页中有新的内容,是通过ajax获取的。新数据和提出的过程。
ForeSpider数据采集系统支持Ajax技术,可以采集网页中的Ajax内容。
2.发布/获取请求
在 html 语言中,有两种方法可以将表单(您在网页中填写的一些数据)发送到服务器。一种是 POST,另一种是 GET。POST 将表单打包并隐藏在后台并发送给服务器;GET 包装表单并将其附加到 URL(网站)的后面,然后再发送。
ForeSpider采集器可以采集post/get请求中的网页内容中的数据,即采集post/get请求中的数据。
3.需要 cookie网站
Cookie是指存储在用户本地终端上用于识别用户身份和进行会话跟踪的一些数据。Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。每当用户链接到服务器时,网站都可以访问 cookie 信息。
一般情况下,用户的账户信息都记录在 cookie 中。爬虫在爬取数据时,可以通过cookie模拟登录状态来获取数据。
ForeSpider数据采集分析引擎可以设置cookie来模拟登录,所以采集需要用到cookie的网站内容。
4. 采集需要OAuth认证的网页数据
OAUTH 协议为用户资源的授权提供了一个安全、开放、简单的标准。同时,任何第三方都可以使用OAUTH认证服务,任何服务提供商都可以实现自己的OAUTH认证服务,所以OAUTH是开放的。
业界提供PHP、Java Script、Java、Ruby等多种语言开发包的多种OAUTH实现,大大节省了程序员的时间,所以OAUTH简单。许多互联网服务如Open API,以及许多大公司如谷歌、雅虎、微软等都提供了OAUTH认证服务,这足以说明OAUTH标准已经逐渐成为开放资源授权的标准。
ForeSpider爬虫软件支持OAuth认证,可以采集需要OAuth认证的页面中的数据。
l 前嗅觉介绍
千秀大数据,国内领先的研发大数据专家,多年致力于大数据技术的研发,自主研发了一整套数据采集,分析、处理、管理、应用和营销。大数据产品。千秀致力于打造国内首个深度大数据平台!
js 爬虫抓取网页数据(Python3网络爬虫基本操作(二):静态网页抓取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-03 01:02
Python3网络爬虫基本操作(二):静态网页抓取
一.前言
Python版本:Python3.X
运行环境:Windows
IDE:PyCharm
上一篇博文之后,相信大家对爬虫有了一定的了解。在本文中,我们将系统地讲解如何抓取静态网页资源。(本人也是爬虫的初学者,只是把学到的知识总结一下,分享给大家,如有错误,请指出,谢谢!)
二.静态网页抓取1.安装请求库
打开cmd输入:(详细安装教程请参考上一篇博客)
pip install requests
2.获取网页对应的内容
在 Requests 中,常见的功能是获取网页的内容。现在我们以 Douban() 为例。
import requests
link = "https://movie.douban.com/chart"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
print("文本编码:", req.encoding)
print("响应体:", req.text)
这将返回一个名为 req 的响应对象,我们可以从中获取所需的信息。上述代码运行结果如图:
(1)req.status_code 用于检测响应状态码。
(所有状态码的详细信息:%E7%8A%B6%E6%80%81%E7%A0%81/5053660?fr=aladdin)
(2)req.encoding 是用于服务器内容的文本编码格式。
(3)req.text 是服务器响应内容。
(4)req.json() 是 Requests 中内置的 JSON 解码器。
3.自定义请求(1)获取请求
有时为了请求特定的数据,我们经常需要在 URL 中添加一些数据。在构建 URL 时,我们通常会在数据后面加上一个问号,并将其作为键/值放在 URL 中,例如。(这里是传递 start=0 到)
在 Requests 中,您可以将参数直接放入字典中,并使用 params 构建到 URL 中。
例如:
import requests
key = {'start': '0'}
req = requests.get('https://movie.douban.com/top250', params=key)
print("URL正确编码", req.url)
运行结果:
(2)自定义请求头
请求标头标头提供有关请求、响应或其他发送实体的信息。对于爬虫来说,请求头非常重要。如果没有指定请求头或请求头与实际网页不同,则可能无法得到正确的结果。我们如何获取网页的请求头呢?
我们以( )为例,进入网页检测页面。下图中箭头所指的部分就是网页的Requests Headers部分。
提取其中的重要部分并编写代码:
运行结果:
三.项目实践
我们以它为例进行实践,目的是获取起点中文网月票榜上的100本书的名字。
1.网站分析
打开起点中文网月票榜的网页,使用“检查”查看网页的请求头,写下我们的请求头。
请求头:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host': 'www.qidian.com'
}
第一个只有 20 本书,如果你想得到所有 100 本书,你需要总共得到 5 页。 查看全部
js 爬虫抓取网页数据(Python3网络爬虫基本操作(二):静态网页抓取(组图))
Python3网络爬虫基本操作(二):静态网页抓取
一.前言
Python版本:Python3.X
运行环境:Windows
IDE:PyCharm
上一篇博文之后,相信大家对爬虫有了一定的了解。在本文中,我们将系统地讲解如何抓取静态网页资源。(本人也是爬虫的初学者,只是把学到的知识总结一下,分享给大家,如有错误,请指出,谢谢!)
二.静态网页抓取1.安装请求库
打开cmd输入:(详细安装教程请参考上一篇博客)
pip install requests
2.获取网页对应的内容
在 Requests 中,常见的功能是获取网页的内容。现在我们以 Douban() 为例。
import requests
link = "https://movie.douban.com/chart"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
print("文本编码:", req.encoding)
print("响应体:", req.text)
这将返回一个名为 req 的响应对象,我们可以从中获取所需的信息。上述代码运行结果如图:
(1)req.status_code 用于检测响应状态码。
(所有状态码的详细信息:%E7%8A%B6%E6%80%81%E7%A0%81/5053660?fr=aladdin)
(2)req.encoding 是用于服务器内容的文本编码格式。
(3)req.text 是服务器响应内容。
(4)req.json() 是 Requests 中内置的 JSON 解码器。
3.自定义请求(1)获取请求
有时为了请求特定的数据,我们经常需要在 URL 中添加一些数据。在构建 URL 时,我们通常会在数据后面加上一个问号,并将其作为键/值放在 URL 中,例如。(这里是传递 start=0 到)
在 Requests 中,您可以将参数直接放入字典中,并使用 params 构建到 URL 中。
例如:
import requests
key = {'start': '0'}
req = requests.get('https://movie.douban.com/top250', params=key)
print("URL正确编码", req.url)
运行结果:
(2)自定义请求头
请求标头标头提供有关请求、响应或其他发送实体的信息。对于爬虫来说,请求头非常重要。如果没有指定请求头或请求头与实际网页不同,则可能无法得到正确的结果。我们如何获取网页的请求头呢?
我们以( )为例,进入网页检测页面。下图中箭头所指的部分就是网页的Requests Headers部分。
提取其中的重要部分并编写代码:
运行结果:
三.项目实践
我们以它为例进行实践,目的是获取起点中文网月票榜上的100本书的名字。
1.网站分析
打开起点中文网月票榜的网页,使用“检查”查看网页的请求头,写下我们的请求头。
请求头:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host': 'www.qidian.com'
}
第一个只有 20 本书,如果你想得到所有 100 本书,你需要总共得到 5 页。
js 爬虫抓取网页数据(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-04-02 00:19
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。返回搜狐,查看更多 查看全部
js 爬虫抓取网页数据(网站抓取是一个用Python编写的Web爬虫和Web框架)
网站Crawling 是一个用 Python 编写的网络爬虫和网络抓取框架。网站Scraping 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面中解析数据的模块。它可以渲染 JavaScript,网站从网页中抓取和解析数据变得容易。它位于 HTML 或 XML 解析器之上,为网站管理员提供了一种 Python 方式来访问数据。所以网站爬取是站长需要了解的采集文章填充网站内容的工具。
网页抓取是一种从网页中获取页面内容的技术。通常通过 网站 抓取,使用低级超文本传输协议来模拟正常的人类访问。网络抓取与网络索引非常相似,其中网络索引是指大多数搜索引擎使用的机器人或网络爬虫等技术。相比之下,网络抓取更侧重于将网络上的非结构化数据(通常为 HTML 格式)转换为可以在中央数据库和电子表格中存储和分析的结构化数据。网络抓取还涉及网络自动化,它使用计算机软件来模拟人类浏览。
网页抓取文本搜索和正则表达式:文本搜索和正则表达式可以有效地从页面中提取所需的内容。网页抓取可以在基于UNIX的系统上使用grep,在其他平台或其他编程语言(如Perl、Python)中都有对应的命令或语法。网页抓取是基于HTTP编程的:无论是静态网页还是动态网页,都可以通过向服务器发送HTTP请求来获取,所以可以通过直接socket编程来实现。
网站爬取的HTML解析器:很多网站使用数据库来存储自己的数据,当用户访问时,由程序按照指定的格式自动生成。因此,可以使用语法分析器对网站爬取得到的HTML页面进行解析,然后使用HTML标签提取出需要的内容。使用 HTML 解析器比文本搜索和正则表达式更健壮,并且避免构造复杂的正则表达式。
网站爬虫应用,从搜索引擎优化(SEO)分析到搜索引擎索引、一般性能监控等,它的一些应用可能还包括爬取网页。网站抓取只需要提交网站首页URL,其他页面(如列表页、内容页)会自动抓取。网站抓取的模板收录HTML、CSS、图片、JS、Flash等目录并保存在原站点结构中,替换对应的cms标签即可使用。
网站 掌握最新海量网络信息采集、处理、存储、全文检索、中文处理和文本挖掘技术,可实时监控最新新闻、论坛、博客、微博和视频。舆情信息帮助站长及时、全面、准确地掌握网络动态,自动采集到自己网站,用户填写网站的内容。
网站爬虫使用自然语言处理技术,保证抓取信息的准确性、分类的准确性和否定判断的准确性。网站抓取相似文章识别,准确识别出内容相似的文章,可用于文章的去重和识别。网站爬取无需模板,方便随时添加采集源,不受网页修改影响。网站捕捉全方位的数据分析展示功能,多角度多层次展示内容特征,揭示数据规律,帮助站长更好的管理和维护网站。返回搜狐,查看更多
js 爬虫抓取网页数据(计算机学院大数据专业大三的错误出现,有纰漏恳请各位大佬不吝赐教)
网站优化 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2022-04-01 17:15
大家好,我是文部霍,计算机学院大数据专业三年级学生。我的昵称来自成语——不冷不热,意思是希望我有一个温柔的气质。博主作为互联网行业的新手,写博客一方面是为了记录自己的学习过程,另一方面是总结自己的错误,希望能帮助很多和自己一样处于起步阶段的新人。不过由于水平有限,博客难免会出现一些错误。如果有任何错误,请给我您的建议!.
内容
一、爬取策略
爬取策略是指在爬取过程中对从每个页面解析出来的超链接进行排列的方法,即按照什么顺序来爬取这些超链接。
1.1 爬取策略的设计需要考虑以下约束
(1)不要给web服务器压力太大
这些压力主要体现在:
①连接web服务器需要占用其网络带宽
②每请求一个页面,需要从硬盘读取一个文件
③ 对于动态页面,还需要执行脚本。如果启用了Session,大数据访问需要更多的内存消耗
(2)不要使用过多的客户端资源
当爬虫程序与 Web 服务器建立网络连接时,也会消耗本地网络资源和计算资源。如果同时运行的线程过多,特别是存在一些长期连接,或者网络连接的超时参数设置不当,很可能会导致客户端的网络资源消耗受限。
1.2 爬取策略设计的综合考虑
毕竟,不同网站上的网页链接图都有自己独特的特点。因此,在设计爬虫策略时,需要做出一定的权衡,并考虑各种影响因素,包括爬虫的网络连接消耗以及对服务器的影响。影响等等,一个好的爬虫需要不断的结合网页链接的一些特性来优化和调整。
对于爬虫来说,爬取的初始页面一般是比较重要的页面,比如公司首页、新闻首页网站等。
从爬虫管理多页超链接的效率来看,无论是基本的深度优先策略还是广度优先策略都具有较高的效率。
从页面优先级来看,虽然爬虫使用指定的页面作为初始页面进行爬取,但是在确定下一个要爬取的页面时,总是希望优先级较高的页面先被爬取。
因为页面之间的链接结构非常复杂,可能会出现双向链接、环形链接等情况。
爬虫在爬取WEB服务器上的页面时,需要先建立网络连接,占用主机和连接资源。合理分配这种资源占用是非常有必要的。
二、第一次尝试网络爬虫
互联网中的网络相互连接,形成一个巨大的网络图:
网络爬虫根据给定的策略从这个庞大而复杂的网络体中爬取所需的内容
import requests,re
# import time
# from collections import Counter
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'https://www.baidu.com/more/'
queue = [seed]
used = set() # 设置一个集合,保存已经抓取过的URL
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
我们可以感受下下一级页面到下一级页面可以有多少个链接
三、抓取策略
从网络爬虫的角度来看,整个互联网可以分为:
3.1、数据抓取策略不完善 PageRank 策略 OCIP 策略 大站优先策略 合作爬取策略 图遍历算法策略3.1.1、不完整的PageRank 策略
一般来说,一个网页的PageRank得分是这样计算的:
3.1.2、OPIC 政策
OPICOnline Page Importance Computation的缩写的时时时时以时时时彩平台网址OPIC
OPIC策略的基本思路
3.1.3、 大站点优先策略(粗略)
大站优先策略的思路简单明了:
“战斗”通常具有以下特点:
如何识别要抓取的目标网站是否是战争?
3.1.4、合作爬取策略(需要规范的URL地址)
为了提高爬取网页的速度,一个常见的选择是增加网络爬虫的数量
如何给这些爬虫分配不同的工作量,保证独立分工,避免重复爬取,这是协作爬取策略的目标
协作爬取策略通常使用以下两种方法:
3.1.5、图遍历算法策略(★)
图遍历算法主要分为两种:
1、深度优先
深度优先从根节点开始,沿着尽可能深的路径,直到遇到叶节点才回溯
2、广度优先
为什么要使用广度优先策略:
广度优先遍历策略的基本思想
广度优先策略从根节点开始,尽可能访问离根节点最近的节点
3、Python 实现
DFS和BFS具有高度的对称性,所以在实现Python的时候,不需要将两种数据结构分开,只需要构建一个数据结构
4、代码实现
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
queue = [seed]
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
stack = [seed]
storage = {}
while len(stack) > 0 and count > 0 :
try:
url = stack.pop(-1)
html = requests.get(url).text
new_urls = r.findall(html)
stack.extend(new_urls)
print(url+"下的url数量为:"+str(len(new_urls)))
storage[url] = len(new_urls)
count -= 1
except Exception as e :
print(url)
print(e)
BFS 和 DFS 各有优势,DFS 更容易陷入无限循环,而且通常有价值的网页不会隐藏得太深,因此 BFS 通常是更好的选择。上面的代码使用 list 来模拟堆栈或队列。Python中还有一个Queue模块,包括LifoQueue和PriorityQueue,使用起来比较方便。
3.2、数据更新政策
常见的更新策略如下:
集群策略的基本思想
美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!
一本好书读一百遍也不厌烦,熟了课才知道自己。而如果我想成为观众中最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证我的成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“[url=https://www.ucaiyun.com/]采集”!听说喜欢的人不会倒霉的,每天都精神抖擞!如果你真的想白嫖,那么祝你天天快乐,也欢迎经常光顾我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦! 查看全部
js 爬虫抓取网页数据(计算机学院大数据专业大三的错误出现,有纰漏恳请各位大佬不吝赐教)
大家好,我是文部霍,计算机学院大数据专业三年级学生。我的昵称来自成语——不冷不热,意思是希望我有一个温柔的气质。博主作为互联网行业的新手,写博客一方面是为了记录自己的学习过程,另一方面是总结自己的错误,希望能帮助很多和自己一样处于起步阶段的新人。不过由于水平有限,博客难免会出现一些错误。如果有任何错误,请给我您的建议!.
内容
一、爬取策略
爬取策略是指在爬取过程中对从每个页面解析出来的超链接进行排列的方法,即按照什么顺序来爬取这些超链接。
1.1 爬取策略的设计需要考虑以下约束
(1)不要给web服务器压力太大
这些压力主要体现在:
①连接web服务器需要占用其网络带宽
②每请求一个页面,需要从硬盘读取一个文件
③ 对于动态页面,还需要执行脚本。如果启用了Session,大数据访问需要更多的内存消耗
(2)不要使用过多的客户端资源
当爬虫程序与 Web 服务器建立网络连接时,也会消耗本地网络资源和计算资源。如果同时运行的线程过多,特别是存在一些长期连接,或者网络连接的超时参数设置不当,很可能会导致客户端的网络资源消耗受限。
1.2 爬取策略设计的综合考虑
毕竟,不同网站上的网页链接图都有自己独特的特点。因此,在设计爬虫策略时,需要做出一定的权衡,并考虑各种影响因素,包括爬虫的网络连接消耗以及对服务器的影响。影响等等,一个好的爬虫需要不断的结合网页链接的一些特性来优化和调整。
对于爬虫来说,爬取的初始页面一般是比较重要的页面,比如公司首页、新闻首页网站等。
从爬虫管理多页超链接的效率来看,无论是基本的深度优先策略还是广度优先策略都具有较高的效率。
从页面优先级来看,虽然爬虫使用指定的页面作为初始页面进行爬取,但是在确定下一个要爬取的页面时,总是希望优先级较高的页面先被爬取。
因为页面之间的链接结构非常复杂,可能会出现双向链接、环形链接等情况。
爬虫在爬取WEB服务器上的页面时,需要先建立网络连接,占用主机和连接资源。合理分配这种资源占用是非常有必要的。
二、第一次尝试网络爬虫
互联网中的网络相互连接,形成一个巨大的网络图:
网络爬虫根据给定的策略从这个庞大而复杂的网络体中爬取所需的内容
import requests,re
# import time
# from collections import Counter
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'https://www.baidu.com/more/'
queue = [seed]
used = set() # 设置一个集合,保存已经抓取过的URL
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
我们可以感受下下一级页面到下一级页面可以有多少个链接
三、抓取策略
从网络爬虫的角度来看,整个互联网可以分为:
3.1、数据抓取策略不完善 PageRank 策略 OCIP 策略 大站优先策略 合作爬取策略 图遍历算法策略3.1.1、不完整的PageRank 策略
一般来说,一个网页的PageRank得分是这样计算的:
3.1.2、OPIC 政策
OPICOnline Page Importance Computation的缩写的时时时时以时时时彩平台网址OPIC
OPIC策略的基本思路
3.1.3、 大站点优先策略(粗略)
大站优先策略的思路简单明了:
“战斗”通常具有以下特点:
如何识别要抓取的目标网站是否是战争?
3.1.4、合作爬取策略(需要规范的URL地址)
为了提高爬取网页的速度,一个常见的选择是增加网络爬虫的数量
如何给这些爬虫分配不同的工作量,保证独立分工,避免重复爬取,这是协作爬取策略的目标
协作爬取策略通常使用以下两种方法:
3.1.5、图遍历算法策略(★)
图遍历算法主要分为两种:
1、深度优先
深度优先从根节点开始,沿着尽可能深的路径,直到遇到叶节点才回溯
2、广度优先
为什么要使用广度优先策略:
广度优先遍历策略的基本思想
广度优先策略从根节点开始,尽可能访问离根节点最近的节点
3、Python 实现
DFS和BFS具有高度的对称性,所以在实现Python的时候,不需要将两种数据结构分开,只需要构建一个数据结构
4、代码实现
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
queue = [seed]
storage = {}
while len(queue) > 0 and count > 0 :
try:
url = queue.pop(0)
html = requests.get(url).text
storage[url] = html #将已经抓取过的URL存入used集合中
used.add(url)
new_urls = r.findall(html) # 将新发行未抓取的URL添加到queue中
print(url+"下的url数量为:"+str(len(new_urls)))
for new_url in new_urls:
if new_url not in used and new_url not in queue:
queue.append(new_url)
count -= 1
except Exception as e :
print(url)
print(e)
import requests,re
count = 20
r = re.compile(r'href=[\'"]?(http[^\'">]+)')
seed = 'http://httpbin.org/'
stack = [seed]
storage = {}
while len(stack) > 0 and count > 0 :
try:
url = stack.pop(-1)
html = requests.get(url).text
new_urls = r.findall(html)
stack.extend(new_urls)
print(url+"下的url数量为:"+str(len(new_urls)))
storage[url] = len(new_urls)
count -= 1
except Exception as e :
print(url)
print(e)
BFS 和 DFS 各有优势,DFS 更容易陷入无限循环,而且通常有价值的网页不会隐藏得太深,因此 BFS 通常是更好的选择。上面的代码使用 list 来模拟堆栈或队列。Python中还有一个Queue模块,包括LifoQueue和PriorityQueue,使用起来比较方便。
3.2、数据更新政策
常见的更新策略如下:
集群策略的基本思想
美好的日子总是短暂的。虽然我想继续和你聊天,但是这篇博文已经结束了。如果还不够好玩,别着急,我们下期再见!
一本好书读一百遍也不厌烦,熟了课才知道自己。而如果我想成为观众中最漂亮的男孩,我必须坚持通过学习获得更多的知识,用知识改变命运,用博客见证我的成长,用行动证明我在努力。
如果我的博客对你有帮助,如果你喜欢我的博客内容,请一键“点赞”“评论”“[url=https://www.ucaiyun.com/]采集”!听说喜欢的人不会倒霉的,每天都精神抖擞!如果你真的想白嫖,那么祝你天天快乐,也欢迎经常光顾我的博客。
码字不易,大家的支持是我坚持下去的动力。喜欢后别忘了关注我哦!

