
js 爬虫抓取网页数据
js 爬虫抓取网页数据(Python爬虫自动抓取互联网信息的程度与应用架构 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-12 14:19
)
爬虫:一段时期内自动爬取互联网信息的程度,从互联网上爬取对我们有价值的信息
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(爬取有价值的数据)。
调度器:相当于一台计算机的CPU,主要负责调度URL管理器、下载器、解析器之间的协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止URL重复爬取和URL循环爬取。实现 URL 管理器的方式主要有 3 种:内存、数据库和缓存数据库。
网页下载器:通过传入 URL 地址下载网页并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括需要登录、代理和cookies、requests(第三方包)
网页解析器:通过解析一个网页字符串,可以根据我们的需求提取我们有用的信息,或者按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观地说,就是将网页转换成字符串,通过模糊匹配提取有价值的信息,当文档比较复杂时,这种方法提取数据会很困难),html。parser(Python自带的),beautifulsoup(第三方插件,可以用Python自带的html.parser解析,也可以用lxml,比别人更强大),lxml(第三方插件) ,可以解析xml和HTML),html.parser和beautifulsoup和lxml都是用DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
先安装beautifulsoup
Beautiful Soup:Python的第三方插件,用于从xml和HTML中提取数据,官网地址
pip install beautifulsoup4(在 cmd 命令提示符下执行此代码)
1.爬虫第一个入门程序
from bs4 import BeautifulSoup
import urllib.request
#定义URL
url = "http://www.baidu.com"
#访问url
response = urllib.request.urlopen(url)
#将结果存入字符串中
ret = response.read()
#获取响应状态码
print(response.getcode())
print(ret)
#创建一个BeautifulSoup的对象
soup = BeautifulSoup(ret,"html.parser",from_encoding="utf-8")
# #获取所有的a链接
# links = soup.find_all('a')
# #遍历每一个a链接
# for link in links:
# print(link.name,link['href'],link.get_text())
p = soup.find_all('p')
for ps in p:
print(ps.get_text())
2.1 爬虫程序添加数据
import urllib.parse
from urllib import request
#定义参数
values={"username":"","password":""}
#参数编码
data = urllib.parse.urlencode(values).encode(encoding="UTF8")
#定义URL
# url = "http://passport.csdn.net/login?code=applets";
url = "http://mail.qq.com/";
#构造request请求
req = request.Request(url,data=data)
#打开网页
resp = request.urlopen(req)
print(resp.read())
2.2爬虫程序添加header
import urllib
from urllib import request
url = "http://www.zhihu.com/signin?next=%2F"
# 请求头的内容
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64)"
#表单的请求参数
valuse={'username':'','password':''}
data = urllib.parse.urlencode(valuse).encode(encoding='UTF8')
# 构造请求头headers
headers={'User-Agent':user_agent,'Refere':'http://www.zhihu.com/signin?next=%2F'}
# 构造请求
req = request.Request(url,data = data,headers = headers)
# 打开网页
resp = request.urlopen(req)
# 读取网页内容
print(resp.read())
2.3个爬虫添加post请求
import urllib
from urllib import request
url = "http://www.zhihu.com/signin?next=%2F"
# 请求头的内容
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64)"
#表单的请求参数
valuse={'username':'','password':''}
data = urllib.parse.urlencode(valuse).encode(encoding='UTF8')
# 构造请求头headers
headers={'User-Agent':user_agent,'Refere':'http://www.zhihu.com/signin?next=%2F'}
# 构造请求
req = request.Request(url,data = data,headers = headers)
# 打开网页
resp = request.urlopen(req)
# 读取网页内容
print(resp.read())
3.爬虫添加cookie
from http import cookiejar
from urllib import request
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie到文件
cookie = cookiejar.MozillaCookieJar(filename)
#利用request库的HTTPCookieProcessor对象来创建cookie处理器
handler = request.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = request.build_opener(handler)
#创建一个请求
response = opener.open("http://www.baidu.com")
#保存cookie到文件
#ignore_discard:cookie失效了也要保存
#ignore_expires:覆盖保存
cookie.save(ignore_discard=True,ignore_expires=True)
#利用cookie登录网站
from urllib import request
import urllib
from http import cookiejar
#定义文件名
filename = 'cookie02.txt'
#声明MozillacCookieJar对象保存cookie
cookie = cookiejar.MozillaCookieJar(filename)
#声明一个cookie处理器
handler = request.HTTPCookieProcessor(cookie)
#定义处理
opener = request.build_opener(handler)
#定义data、账号、密码
postdata = urllib.parse.urlencode({
'username':'202042502008',
'password':'HHF2714596503'
}).encode(encoding='UTF8')
#登录
loginUrl = "http://jwc.hnshzy.cn:90/hnshjw ... ot%3B
#模拟登录
result = opener.open(loginUrl,postdata)
#保存cookie到文件
cookie.save(ignore_discard=True,ignore_expires=True)
#利用保存的cookie请求新网站
ner_url = 'http://jwc.hnshzy.cn:90/hnshjw/cas/login.action'
#请求新网页
try:
result = opener.open(ner_url)
except request.HTTPError as e:
if hasattr(e,'code'):
print(e.code)
except request.URLError as e:
if hasattr(e,'reason'):
print(e.reason)
else:
print(result.read())
4.正则表达式
from urllib import request
from bs4 import BeautifulSoup
import re
#定义正则表达式;r表示原生字符串
pattern = re.compile(r'hello')
#匹配字符,match函数:会从第一个开始匹配
result1 = re.match(pattern,"hello,world")
if result1:
print(result1)
result1 = re.match(pattern,"hello,world").span()
if result1:
print(result1)
result1 = re.match(pattern,"hello,world").group()
if result1:
print(result1)
result2 = re.match(pattern,"hell,hello")
if result2:
print(result2)
else:
print("no!no!")
result2 = re.search(pattern,"hell,hello")
if result2:
print(result2)
#定义正则规则
pattern = re.compile(r'a.c')
#匹配
resp = re.match(pattern,"abcdefj")
print(resp)
pattern2 = re.compile('a\.c')
resp2 = re.match(pattern2,"a.cd")
print(resp2)
pattern3 = re.compile('a\\\c')
resp3 = re.match(pattern3,"a\cd")
print(resp3)
#匹配部分字符
pattern4 = re.compile(r'a[a-f,A-F]c')
resp4 = re.match(pattern4,"afcdefg")
print(resp4)
#定义正则规则
re01 = re.compile(r'\d*')
#匹配
res01 = re.match(re01,'123456xxxxxxxxx')
print(res01)
re02 = re.compile(r'\d+\w')
#匹配
res02 = re.match(re02,'123456xxxxxxxxx')
print(res02)
re03 = re.compile(r'\d?\w')
#匹配
res03 = re.match(re03,'4xxxxxxxxx')
print(res03)
re04 = re.compile(r'1\d{5}')
#匹配
res04 = re.match(re04,'123456xxxxxxxxx')
print(res04)
re05 = re.compile(r'\d{5,11}@\w{2}\.\w{3}')
#匹配
res05 = re.match(re05,'123456789@qq.com')
print(res05)
#贪婪模式
re06 = re.compile(r'\w+')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
#解除贪婪模式
re06 = re.compile(r'\w+?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w{5,10}')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w{5,10}?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w*?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
#边界匹配
re07 = re.compile(r'^5678')
res07 = re.match(re07,'56789')
print(res07)
re08 = re.compile(r'789$')
res08 = re.search(re08,'56789')
print(res08)
re09 = re.compile(r'\A\w{1,6}')
res09 = re.search(re09,'dihakldjal12345678')
print(res09)
re10= re.compile(r'dja\Z')
res10 = re.search(re10,'dihakldja')
print(res10)
re11= re.compile(r'a\b!bc')
res11 = re.search(re11,'a!bc')
print(res11)
#逻辑分组
re12= re.compile(r'abc|efg')
res12 = re.search(re12,'abcdjklefg')
print(res12)
re13= re.compile(r'(abc){2}')
res13 = re.search(re13,'abcabchjkk')
print(res13)
re13= re.compile(r'(abc)(def)')
res13 = re.search(re13,'abcdefhjkk')
print(res13)
re14= re.compile(r'(?Pabc)')
res14 = re.search(re14,'abcdefg')
print(res14)
re15= re.compile(r'(\d)abc\1')
res15 = re.search(re15,'5abc5')
print(res15)
re16= re.compile(r'(?Pabc)efg(?P=name)')
res16 = re.search(re16,'abcefgabc')
print(res16) 查看全部
js 爬虫抓取网页数据(Python爬虫自动抓取互联网信息的程度与应用架构
)
爬虫:一段时期内自动爬取互联网信息的程度,从互联网上爬取对我们有价值的信息
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(爬取有价值的数据)。
调度器:相当于一台计算机的CPU,主要负责调度URL管理器、下载器、解析器之间的协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止URL重复爬取和URL循环爬取。实现 URL 管理器的方式主要有 3 种:内存、数据库和缓存数据库。
网页下载器:通过传入 URL 地址下载网页并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括需要登录、代理和cookies、requests(第三方包)
网页解析器:通过解析一个网页字符串,可以根据我们的需求提取我们有用的信息,或者按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观地说,就是将网页转换成字符串,通过模糊匹配提取有价值的信息,当文档比较复杂时,这种方法提取数据会很困难),html。parser(Python自带的),beautifulsoup(第三方插件,可以用Python自带的html.parser解析,也可以用lxml,比别人更强大),lxml(第三方插件) ,可以解析xml和HTML),html.parser和beautifulsoup和lxml都是用DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
先安装beautifulsoup
Beautiful Soup:Python的第三方插件,用于从xml和HTML中提取数据,官网地址
pip install beautifulsoup4(在 cmd 命令提示符下执行此代码)
1.爬虫第一个入门程序
from bs4 import BeautifulSoup
import urllib.request
#定义URL
url = "http://www.baidu.com"
#访问url
response = urllib.request.urlopen(url)
#将结果存入字符串中
ret = response.read()
#获取响应状态码
print(response.getcode())
print(ret)
#创建一个BeautifulSoup的对象
soup = BeautifulSoup(ret,"html.parser",from_encoding="utf-8")
# #获取所有的a链接
# links = soup.find_all('a')
# #遍历每一个a链接
# for link in links:
# print(link.name,link['href'],link.get_text())
p = soup.find_all('p')
for ps in p:
print(ps.get_text())
2.1 爬虫程序添加数据
import urllib.parse
from urllib import request
#定义参数
values={"username":"","password":""}
#参数编码
data = urllib.parse.urlencode(values).encode(encoding="UTF8")
#定义URL
# url = "http://passport.csdn.net/login?code=applets";
url = "http://mail.qq.com/";
#构造request请求
req = request.Request(url,data=data)
#打开网页
resp = request.urlopen(req)
print(resp.read())
2.2爬虫程序添加header
import urllib
from urllib import request
url = "http://www.zhihu.com/signin?next=%2F"
# 请求头的内容
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64)"
#表单的请求参数
valuse={'username':'','password':''}
data = urllib.parse.urlencode(valuse).encode(encoding='UTF8')
# 构造请求头headers
headers={'User-Agent':user_agent,'Refere':'http://www.zhihu.com/signin?next=%2F'}
# 构造请求
req = request.Request(url,data = data,headers = headers)
# 打开网页
resp = request.urlopen(req)
# 读取网页内容
print(resp.read())
2.3个爬虫添加post请求
import urllib
from urllib import request
url = "http://www.zhihu.com/signin?next=%2F"
# 请求头的内容
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64)"
#表单的请求参数
valuse={'username':'','password':''}
data = urllib.parse.urlencode(valuse).encode(encoding='UTF8')
# 构造请求头headers
headers={'User-Agent':user_agent,'Refere':'http://www.zhihu.com/signin?next=%2F'}
# 构造请求
req = request.Request(url,data = data,headers = headers)
# 打开网页
resp = request.urlopen(req)
# 读取网页内容
print(resp.read())
3.爬虫添加cookie
from http import cookiejar
from urllib import request
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie到文件
cookie = cookiejar.MozillaCookieJar(filename)
#利用request库的HTTPCookieProcessor对象来创建cookie处理器
handler = request.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = request.build_opener(handler)
#创建一个请求
response = opener.open("http://www.baidu.com";)
#保存cookie到文件
#ignore_discard:cookie失效了也要保存
#ignore_expires:覆盖保存
cookie.save(ignore_discard=True,ignore_expires=True)
#利用cookie登录网站
from urllib import request
import urllib
from http import cookiejar
#定义文件名
filename = 'cookie02.txt'
#声明MozillacCookieJar对象保存cookie
cookie = cookiejar.MozillaCookieJar(filename)
#声明一个cookie处理器
handler = request.HTTPCookieProcessor(cookie)
#定义处理
opener = request.build_opener(handler)
#定义data、账号、密码
postdata = urllib.parse.urlencode({
'username':'202042502008',
'password':'HHF2714596503'
}).encode(encoding='UTF8')
#登录
loginUrl = "http://jwc.hnshzy.cn:90/hnshjw ... ot%3B
#模拟登录
result = opener.open(loginUrl,postdata)
#保存cookie到文件
cookie.save(ignore_discard=True,ignore_expires=True)
#利用保存的cookie请求新网站
ner_url = 'http://jwc.hnshzy.cn:90/hnshjw/cas/login.action'
#请求新网页
try:
result = opener.open(ner_url)
except request.HTTPError as e:
if hasattr(e,'code'):
print(e.code)
except request.URLError as e:
if hasattr(e,'reason'):
print(e.reason)
else:
print(result.read())
4.正则表达式
from urllib import request
from bs4 import BeautifulSoup
import re
#定义正则表达式;r表示原生字符串
pattern = re.compile(r'hello')
#匹配字符,match函数:会从第一个开始匹配
result1 = re.match(pattern,"hello,world")
if result1:
print(result1)
result1 = re.match(pattern,"hello,world").span()
if result1:
print(result1)
result1 = re.match(pattern,"hello,world").group()
if result1:
print(result1)
result2 = re.match(pattern,"hell,hello")
if result2:
print(result2)
else:
print("no!no!")
result2 = re.search(pattern,"hell,hello")
if result2:
print(result2)
#定义正则规则
pattern = re.compile(r'a.c')
#匹配
resp = re.match(pattern,"abcdefj")
print(resp)
pattern2 = re.compile('a\.c')
resp2 = re.match(pattern2,"a.cd")
print(resp2)
pattern3 = re.compile('a\\\c')
resp3 = re.match(pattern3,"a\cd")
print(resp3)
#匹配部分字符
pattern4 = re.compile(r'a[a-f,A-F]c')
resp4 = re.match(pattern4,"afcdefg")
print(resp4)
#定义正则规则
re01 = re.compile(r'\d*')
#匹配
res01 = re.match(re01,'123456xxxxxxxxx')
print(res01)
re02 = re.compile(r'\d+\w')
#匹配
res02 = re.match(re02,'123456xxxxxxxxx')
print(res02)
re03 = re.compile(r'\d?\w')
#匹配
res03 = re.match(re03,'4xxxxxxxxx')
print(res03)
re04 = re.compile(r'1\d{5}')
#匹配
res04 = re.match(re04,'123456xxxxxxxxx')
print(res04)
re05 = re.compile(r'\d{5,11}@\w{2}\.\w{3}')
#匹配
res05 = re.match(re05,'123456789@qq.com')
print(res05)
#贪婪模式
re06 = re.compile(r'\w+')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
#解除贪婪模式
re06 = re.compile(r'\w+?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w{5,10}')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w{5,10}?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w*?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
#边界匹配
re07 = re.compile(r'^5678')
res07 = re.match(re07,'56789')
print(res07)
re08 = re.compile(r'789$')
res08 = re.search(re08,'56789')
print(res08)
re09 = re.compile(r'\A\w{1,6}')
res09 = re.search(re09,'dihakldjal12345678')
print(res09)
re10= re.compile(r'dja\Z')
res10 = re.search(re10,'dihakldja')
print(res10)
re11= re.compile(r'a\b!bc')
res11 = re.search(re11,'a!bc')
print(res11)
#逻辑分组
re12= re.compile(r'abc|efg')
res12 = re.search(re12,'abcdjklefg')
print(res12)
re13= re.compile(r'(abc){2}')
res13 = re.search(re13,'abcabchjkk')
print(res13)
re13= re.compile(r'(abc)(def)')
res13 = re.search(re13,'abcdefhjkk')
print(res13)
re14= re.compile(r'(?Pabc)')
res14 = re.search(re14,'abcdefg')
print(res14)
re15= re.compile(r'(\d)abc\1')
res15 = re.search(re15,'5abc5')
print(res15)
re16= re.compile(r'(?Pabc)efg(?P=name)')
res16 = re.search(re16,'abcefgabc')
print(res16)
js 爬虫抓取网页数据(抓取某个微博大V微博的评论数据应该怎么实现?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-12 14:18
【Part1-理论篇】
大家好,我是皮皮。
想想一个问题,如果我们要抓取一条微博大V微博的评论数据,该怎么做呢?最简单的方法是找到微博评论数据接口,然后更改参数获取最新数据并保存。首先,寻找微博api抓取评论的接口,如下图。
但是很遗憾,这个界面的使用频率有限,被抓了几次就被封禁了。在它开始起飞之前,它很冷。
接下来小编选择微博移动端网站,先登录,然后找到我们要抓取评论的微博,打开浏览器自带的流量分析工具,一直拉下评论,找到评论数据接口,如下图。
然后点击“参数”选项卡,可以看到参数如下图所示:
可以看到一共有4个参数,其中第二个参数1、是微博的id,就像一个人的身份证号,这个相当于微博的“身份证号”, max_id 是更改页码的参数,每次都必须更改。下一个 max_id 参数值在此请求的返回数据中。
【Part2-实战】
有了上面的基础,我们开始用 Python 编写代码并实现它。
1、先区分url,第一次不需要max_id,第二次需要第一次返回的max_id。
2、请求时需要带上cookie数据。微博cookie的有效期比较长,足以捕捉一条微博的评论数据。可以从浏览器分析工具中找到 cookie 数据。
3、然后将返回的数据转换成json格式,提取评论内容、评论者昵称、评论时间等数据,输出结果如下图所示。
4、为了保存评论内容,我们需要将评论中的表达式去掉,使用正则表达式进行处理,如下图所示。
5、 然后将内容保存为txt文件,使用简单的open函数实现,如下图所示。
6、关键是通过这个接口最多只能返回16页的数据(每页20条)。网上也有报道说可以返回50页,但是界面不一样,返回的数据条数也不一样,所以我加了一个for循环,一步到位,遍历还是很厉害的,如下图所示。
7、这里的函数名为job。为了总能取出最新的数据,我们可以使用 schedule 给程序添加定时功能,每隔 10 分钟或半小时抓取一次,如下图所示。
8、对获取的数据进行去重,如下图所示。如果评论已经存在,就通过它,如果没有,就继续添加它。
这项工作基本完成。
【第三部分——总结】
这种方法虽然没有把所有的数据都抓到,但是在这条微博的约束下,也是比较有效的方法。 查看全部
js 爬虫抓取网页数据(抓取某个微博大V微博的评论数据应该怎么实现?)
【Part1-理论篇】
大家好,我是皮皮。
想想一个问题,如果我们要抓取一条微博大V微博的评论数据,该怎么做呢?最简单的方法是找到微博评论数据接口,然后更改参数获取最新数据并保存。首先,寻找微博api抓取评论的接口,如下图。

但是很遗憾,这个界面的使用频率有限,被抓了几次就被封禁了。在它开始起飞之前,它很冷。

接下来小编选择微博移动端网站,先登录,然后找到我们要抓取评论的微博,打开浏览器自带的流量分析工具,一直拉下评论,找到评论数据接口,如下图。

然后点击“参数”选项卡,可以看到参数如下图所示:

可以看到一共有4个参数,其中第二个参数1、是微博的id,就像一个人的身份证号,这个相当于微博的“身份证号”, max_id 是更改页码的参数,每次都必须更改。下一个 max_id 参数值在此请求的返回数据中。

【Part2-实战】
有了上面的基础,我们开始用 Python 编写代码并实现它。

1、先区分url,第一次不需要max_id,第二次需要第一次返回的max_id。

2、请求时需要带上cookie数据。微博cookie的有效期比较长,足以捕捉一条微博的评论数据。可以从浏览器分析工具中找到 cookie 数据。

3、然后将返回的数据转换成json格式,提取评论内容、评论者昵称、评论时间等数据,输出结果如下图所示。
4、为了保存评论内容,我们需要将评论中的表达式去掉,使用正则表达式进行处理,如下图所示。

5、 然后将内容保存为txt文件,使用简单的open函数实现,如下图所示。

6、关键是通过这个接口最多只能返回16页的数据(每页20条)。网上也有报道说可以返回50页,但是界面不一样,返回的数据条数也不一样,所以我加了一个for循环,一步到位,遍历还是很厉害的,如下图所示。

7、这里的函数名为job。为了总能取出最新的数据,我们可以使用 schedule 给程序添加定时功能,每隔 10 分钟或半小时抓取一次,如下图所示。

8、对获取的数据进行去重,如下图所示。如果评论已经存在,就通过它,如果没有,就继续添加它。

这项工作基本完成。
【第三部分——总结】
这种方法虽然没有把所有的数据都抓到,但是在这条微博的约束下,也是比较有效的方法。
js 爬虫抓取网页数据(如何清理爬虫数据中一些不需要的HTML属性(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-12 01:17
如何清理爬虫数据中一些不必要的HTML属性 没有什么可失去的,但我还是得担心得失。我也嘲笑我的懦弱和无知。
显然不能直接存储,必须解析出需要的内容。比如我今天抓取一个新闻网的国内新闻,那么我创建一个实体类,属性有:新闻标题、新闻时间、正文等。解析出你需要的内容,封印到实体中,然后保存直接到dao层的数据库。如果整个爬下来。
python爬虫在哪里爬取网页上的某些字段 上百页的聊天记录,比不上两张一模一样的录取通知书。不是我不要你,亲爱的,只是生活太难了,不努力,路真的很长。
1. 获取html页面 其实最基本的抓取网站,两句就够了 [python] view plaincopy import urllib2 content = urllib2.urlopen('').read() 这样可以得到整个html文档,关键问题是我们可能需要从这个文档中获取我们需要的有用信息。
如何通过nodejs爬虫获取数据,轻松实现代码其实我一直站在你身边,等你靠在我肩上说,你的温柔会不会有属于我的那一天,我不会让你难过,让你泪流满面!
为什么Python爬虫只爬取html页面的部分内容?我喜欢什么?如果我喜欢一朵花,它就不会凋谢。如果我喜欢一首歌,它就不会厌倦。如果我喜欢一个季节,它不会被其他季节取代。如果我喜欢你,你会喜欢我吗?
js加载的一些内容只有在你的电脑屏幕或者鼠标滑动到某个位置时才会动态加载。这些内容不会体现在源码中,而python爬虫只是爬取源码。如果你想满足你的需求,分享,你可以试试phantomjs来模拟浏览器,祝你成功。 查看全部
js 爬虫抓取网页数据(如何清理爬虫数据中一些不需要的HTML属性(一))
如何清理爬虫数据中一些不必要的HTML属性 没有什么可失去的,但我还是得担心得失。我也嘲笑我的懦弱和无知。
显然不能直接存储,必须解析出需要的内容。比如我今天抓取一个新闻网的国内新闻,那么我创建一个实体类,属性有:新闻标题、新闻时间、正文等。解析出你需要的内容,封印到实体中,然后保存直接到dao层的数据库。如果整个爬下来。
python爬虫在哪里爬取网页上的某些字段 上百页的聊天记录,比不上两张一模一样的录取通知书。不是我不要你,亲爱的,只是生活太难了,不努力,路真的很长。
1. 获取html页面 其实最基本的抓取网站,两句就够了 [python] view plaincopy import urllib2 content = urllib2.urlopen('').read() 这样可以得到整个html文档,关键问题是我们可能需要从这个文档中获取我们需要的有用信息。
如何通过nodejs爬虫获取数据,轻松实现代码其实我一直站在你身边,等你靠在我肩上说,你的温柔会不会有属于我的那一天,我不会让你难过,让你泪流满面!
为什么Python爬虫只爬取html页面的部分内容?我喜欢什么?如果我喜欢一朵花,它就不会凋谢。如果我喜欢一首歌,它就不会厌倦。如果我喜欢一个季节,它不会被其他季节取代。如果我喜欢你,你会喜欢我吗?
js加载的一些内容只有在你的电脑屏幕或者鼠标滑动到某个位置时才会动态加载。这些内容不会体现在源码中,而python爬虫只是爬取源码。如果你想满足你的需求,分享,你可以试试phantomjs来模拟浏览器,祝你成功。
js 爬虫抓取网页数据( 如何模拟请求和如何解析HTML源码中的文章及链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-10 15:23
如何模拟请求和如何解析HTML源码中的文章及链接)
X-Requested-With:XMLHttpRequest
这是一个栗子:
的职位列表
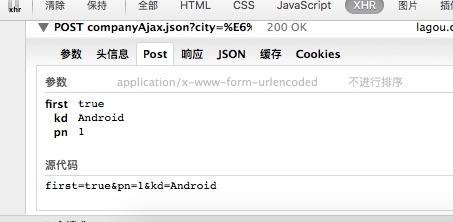
点击Android后,我们从浏览器上传了几个参数到拉钩的服务器
一个是first=true,一个是kd=android,(关键字)一个是pn=1(页码)
所以我们可以模仿这一步来构造一个数据包来模拟用户的点击动作。
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这是很久以前的问题,但线程所有者似乎也解决了这个问题。但是看到很多答案有点太重了,这里有一个更高效,资源消耗更少的方法。由于标题没有具体说明需要什么,所以这里的例子取了首页所有帖子的链接和标题。
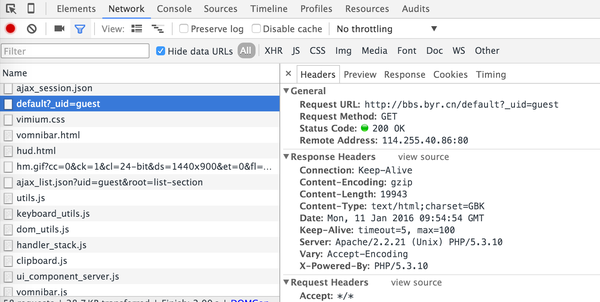
首先请记住,浏览器环境的内存和CPU消耗是非常严重的,要尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在 HTML 源代码中看不到,但更有可能通过另一个请求得到纯数据(很可能是 JSON 格式),不仅不需要模拟浏览器,但可以省去解析HTML的消耗。
然后,打开北友人论坛首页,发现其首页的HTML源码中确实没有文章页面显示内容。那么,很有可能这是通过JS异步加载到页面中的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或者Win/Linux下通过F12)分析加载首页时的请求,很容易发现,请求如下截图:
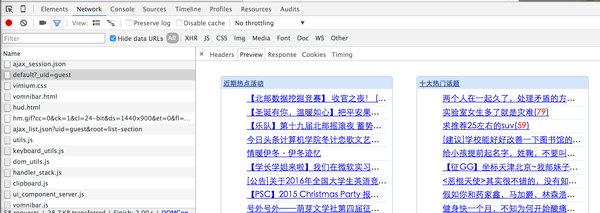
从截图中选择的请求得到的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:
至此,我们已经确定这个链接可以获取到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。然后配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏进行详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗以及抓取速度。在编写爬虫时,请务必记住,除非必要,否则不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了接口。但是这两种方法都需要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方法模拟真实行为。谷歌幻影JS 查看全部
js 爬虫抓取网页数据(
如何模拟请求和如何解析HTML源码中的文章及链接)
X-Requested-With:XMLHttpRequest
这是一个栗子:
的职位列表
点击Android后,我们从浏览器上传了几个参数到拉钩的服务器
一个是first=true,一个是kd=android,(关键字)一个是pn=1(页码)
所以我们可以模仿这一步来构造一个数据包来模拟用户的点击动作。
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这是很久以前的问题,但线程所有者似乎也解决了这个问题。但是看到很多答案有点太重了,这里有一个更高效,资源消耗更少的方法。由于标题没有具体说明需要什么,所以这里的例子取了首页所有帖子的链接和标题。
首先请记住,浏览器环境的内存和CPU消耗是非常严重的,要尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在 HTML 源代码中看不到,但更有可能通过另一个请求得到纯数据(很可能是 JSON 格式),不仅不需要模拟浏览器,但可以省去解析HTML的消耗。
然后,打开北友人论坛首页,发现其首页的HTML源码中确实没有文章页面显示内容。那么,很有可能这是通过JS异步加载到页面中的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或者Win/Linux下通过F12)分析加载首页时的请求,很容易发现,请求如下截图:
从截图中选择的请求得到的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:
至此,我们已经确定这个链接可以获取到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。然后配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏进行详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗以及抓取速度。在编写爬虫时,请务必记住,除非必要,否则不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了接口。但是这两种方法都需要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方法模拟真实行为。谷歌幻影JS
js 爬虫抓取网页数据( 网络爬虫(DeepWebCrawler),加以简单的介绍. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-10 07:20
网络爬虫(DeepWebCrawler),加以简单的介绍.
)
使用 Node.JS 实现一个小型网络爬虫应用程序
前言
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常见的称为网络追逐者)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常见 使用的其他名称有 ant、autoindex、emulator 或 worm。
我们可以利用网络爬虫对数据信息进行自动化采集,如搜索引擎中的站点爬取收录、数据分析挖掘采集、金融数据采集在此外,网络爬虫还可用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
网络爬虫根据系统结构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。下面简单介绍一下这几种爬虫。
1.1、通用网络爬虫
也称为Scalable Web Crawler,爬取对象从一些种子URL扩展到整个Web,主要用于门户网站搜索引擎和大型Web服务提供商采集数据。
1.2、专注于网络爬虫
也称为Topical Crawler,它指的是一种网络爬虫,它可以选择性地爬取那些与预定义主题相关的页面。与通用网络爬虫相比,专注爬虫只需要爬取主题相关的页面,大大节省了由于硬件和网络资源不足,保存的页面也因数量少而更新快,也能很好的满足某些特定人群对特定领域信息的需求。
1.3、增量网络爬虫
指对下载的网页进行增量更新的爬虫,只爬取新生成或更改的网页。可以在一定程度上保证爬取的页面尽可能的新。
1.4、深网爬虫
网页可分为表层网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页是指可以被传统搜索引擎索引的页面,可以通过超链接到达的静态网页 网页主要由网页组成。Deep Web是那些大部分内容无法通过静态链接获取,隐藏在搜索表单后面,只能通过用户提交一些关键词获取的网页。
2、创建一个简单的爬虫应用
简单了解以上爬虫后,我们来实现一个简单的爬虫应用。
2.1、达成目标
说到爬虫,你可能会想到大数据,然后就会想到 Python。百度之后,Python中的爬虫确实多了。由于你主要从事前端开发,所以 JavaScript 相对来说更加熟练和简单。实现一个小目标,然后用Node.JS爬取Blog Park的首页文章列表(我常用的一个开发者网站),然后写入本地JSON文件。
2.2、环境设置
Node.JS:电脑需要安装Node.JS,如果没有安装,去官网下载安装。
NPM:Node.JS 包管理工具,随 Node.JS 一起安装。
Node.JS安装好后,打开命令行,可以使用node -v查看Node.JS是否安装成功,可以使用nPM -v查看Node.JS是否安装成功,应该打印如下信息如果安装成功(因版本不同而异):
2.3、具体实现
2.3.1、安装依赖
在目录下执行 nPM install superagentcheerio --save-dev 安装superagent、cheerio这两个依赖。创建一个 crawler.JS 文件。
superagent:SuperAgent 是一个轻量级、灵活、易读、学习曲线低的客户端请求代理模块,用于 Node.JS 环境。
Cheerio:是为服务器设计的核心 jQuery 的快速、灵活和精简的实现。它可以像 jQuery 一样操作字符串。
// 导入依赖包const http = require("http");const path = require("path");const url = require("url");const fs = require("fs");const superagent = require("superagent");const cheerio = require("cheerio");
2.3.2、抓取数据
然后获取请求页面,获取页面内容后,根据你想要的数据解析返回的DOM,最后将处理后的结果JSON转成字符串保存在本地。
// 爬取页面地址const pageUrl="https://www.cnblogs.com/";// 解码字符串function unescapeString(str){ if(!str){ return '' }else{ return unescape(str.replace(/&#x/g,'%u').replace(/;/g,'')); }}// 抓取数据function fetchData(){ console.log('爬取数据时间节点:',new Date()); superagent.get(pageUrl).end((error,response)=>{ // 页面文档数据 let content=response.text; if(content){ console.log('获取数据成功'); } // 定义一个空数组来接收数据 let result=[]; let $=cheerio.load(content); let postList=$("#main #post_list .post_item"); postList.each((index,value)=>{ let titleLnk=$(value).find('a.titlelnk'); let itemFoot=$(value).find('.post_item_foot'); let title=titleLnk.html(); // 标题 let href=titleLnk.attr('href'); // 链接 let author=itemFoot.find('a.lightblue').HTML(); // 作者 let headLogo=$(value).find('.post_item_summary a img').attr('src'); // 头像 let summary=$(value).find('.post_item_summary').text(); // 简介 let postedTime=itemFoot.text().split('发布于')[1].substr(0,16); // 发布时间 let readNum=itemFoot.text().split('阅读')[1]; // 阅读量 readNum=readNum.substr(1,readNum.length-1); title=unescapeString(title); href=unescapeString(href); author=unescapeString(author); headLogo=unescapeString(headLogo); summary=unescapeString(summary); postedTime=unescapeString(postedTime); readNum=unescapeString(readNum); result.push({ index, title, href, author, headLogo, summary, postedTime, readNum }); }); // 数组转换为字符串 result=JSON.stringify(result); // 写入本地 cnblogs.JSON 文件中 fs.writeFile("cnblogs.json",result,"utf-8",(err)=>{ // 监听错误, 如正常输出, 则打印 null if(!err){ console.log('写入数据成功'); } }); });}fetchData();
3、执行优化
3.1,生成结果
在项目目录下打开命令行,输入node crawler.JS,
你会发现目录下会创建一个cnblogs.JSON文件,打开文件如下:
查看全部
js 爬虫抓取网页数据(
网络爬虫(DeepWebCrawler),加以简单的介绍.
)
使用 Node.JS 实现一个小型网络爬虫应用程序
前言
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常见的称为网络追逐者)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常见 使用的其他名称有 ant、autoindex、emulator 或 worm。
我们可以利用网络爬虫对数据信息进行自动化采集,如搜索引擎中的站点爬取收录、数据分析挖掘采集、金融数据采集在此外,网络爬虫还可用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
网络爬虫根据系统结构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。下面简单介绍一下这几种爬虫。
1.1、通用网络爬虫
也称为Scalable Web Crawler,爬取对象从一些种子URL扩展到整个Web,主要用于门户网站搜索引擎和大型Web服务提供商采集数据。
1.2、专注于网络爬虫
也称为Topical Crawler,它指的是一种网络爬虫,它可以选择性地爬取那些与预定义主题相关的页面。与通用网络爬虫相比,专注爬虫只需要爬取主题相关的页面,大大节省了由于硬件和网络资源不足,保存的页面也因数量少而更新快,也能很好的满足某些特定人群对特定领域信息的需求。
1.3、增量网络爬虫
指对下载的网页进行增量更新的爬虫,只爬取新生成或更改的网页。可以在一定程度上保证爬取的页面尽可能的新。
1.4、深网爬虫
网页可分为表层网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页是指可以被传统搜索引擎索引的页面,可以通过超链接到达的静态网页 网页主要由网页组成。Deep Web是那些大部分内容无法通过静态链接获取,隐藏在搜索表单后面,只能通过用户提交一些关键词获取的网页。
2、创建一个简单的爬虫应用
简单了解以上爬虫后,我们来实现一个简单的爬虫应用。
2.1、达成目标
说到爬虫,你可能会想到大数据,然后就会想到 Python。百度之后,Python中的爬虫确实多了。由于你主要从事前端开发,所以 JavaScript 相对来说更加熟练和简单。实现一个小目标,然后用Node.JS爬取Blog Park的首页文章列表(我常用的一个开发者网站),然后写入本地JSON文件。
2.2、环境设置
Node.JS:电脑需要安装Node.JS,如果没有安装,去官网下载安装。
NPM:Node.JS 包管理工具,随 Node.JS 一起安装。
Node.JS安装好后,打开命令行,可以使用node -v查看Node.JS是否安装成功,可以使用nPM -v查看Node.JS是否安装成功,应该打印如下信息如果安装成功(因版本不同而异):

2.3、具体实现
2.3.1、安装依赖
在目录下执行 nPM install superagentcheerio --save-dev 安装superagent、cheerio这两个依赖。创建一个 crawler.JS 文件。
superagent:SuperAgent 是一个轻量级、灵活、易读、学习曲线低的客户端请求代理模块,用于 Node.JS 环境。
Cheerio:是为服务器设计的核心 jQuery 的快速、灵活和精简的实现。它可以像 jQuery 一样操作字符串。
// 导入依赖包const http = require("http");const path = require("path");const url = require("url");const fs = require("fs");const superagent = require("superagent");const cheerio = require("cheerio");
2.3.2、抓取数据
然后获取请求页面,获取页面内容后,根据你想要的数据解析返回的DOM,最后将处理后的结果JSON转成字符串保存在本地。
// 爬取页面地址const pageUrl="https://www.cnblogs.com/";// 解码字符串function unescapeString(str){ if(!str){ return '' }else{ return unescape(str.replace(/&#x/g,'%u').replace(/;/g,'')); }}// 抓取数据function fetchData(){ console.log('爬取数据时间节点:',new Date()); superagent.get(pageUrl).end((error,response)=>{ // 页面文档数据 let content=response.text; if(content){ console.log('获取数据成功'); } // 定义一个空数组来接收数据 let result=[]; let $=cheerio.load(content); let postList=$("#main #post_list .post_item"); postList.each((index,value)=>{ let titleLnk=$(value).find('a.titlelnk'); let itemFoot=$(value).find('.post_item_foot'); let title=titleLnk.html(); // 标题 let href=titleLnk.attr('href'); // 链接 let author=itemFoot.find('a.lightblue').HTML(); // 作者 let headLogo=$(value).find('.post_item_summary a img').attr('src'); // 头像 let summary=$(value).find('.post_item_summary').text(); // 简介 let postedTime=itemFoot.text().split('发布于')[1].substr(0,16); // 发布时间 let readNum=itemFoot.text().split('阅读')[1]; // 阅读量 readNum=readNum.substr(1,readNum.length-1); title=unescapeString(title); href=unescapeString(href); author=unescapeString(author); headLogo=unescapeString(headLogo); summary=unescapeString(summary); postedTime=unescapeString(postedTime); readNum=unescapeString(readNum); result.push({ index, title, href, author, headLogo, summary, postedTime, readNum }); }); // 数组转换为字符串 result=JSON.stringify(result); // 写入本地 cnblogs.JSON 文件中 fs.writeFile("cnblogs.json",result,"utf-8",(err)=>{ // 监听错误, 如正常输出, 则打印 null if(!err){ console.log('写入数据成功'); } }); });}fetchData();
3、执行优化
3.1,生成结果
在项目目录下打开命令行,输入node crawler.JS,

你会发现目录下会创建一个cnblogs.JSON文件,打开文件如下:

js 爬虫抓取网页数据(web不再的攻防角度分析——web原创生态的元凶)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-08 18:19
网络是一个开放的平台,它为网络从1990年代初诞生到今天的蓬勃发展奠定了基础。但是,所谓成败,也就是小何,开放的特性、搜索引擎、简单易学的html和css技术,让web成为了互联网领域最流行、最成熟的信息传播媒介;但是现在作为一个商业软件,web这个平台上的内容信息的版权是不能保证的,因为和软件客户端相比,你网页中的内容可以通过一些爬虫程序以非常低的成本和技术门槛很低。这就是本系列文章要讨论的话题——网络爬虫。
有很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为随着今天IT行业的发展,网络不再是当年与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的思想。存在。随着商业软件的发展,网络也不得不面对知识产权保护的问题。试想,如果原创的优质内容不受保护,网络世界中抄袭盗版猖獗,这其实有利于网络生态的健康发展。这是一个缺点,而且它' 很难鼓励制作更多高质量的原创内容。未经授权的爬虫程序是危害web原创内容生态的罪魁祸首。因此,为了保护网站的内容,首先要考虑如何反爬。
##从爬虫攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。这当然是儿科最小的防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在http的get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。另外还有一个比较异常的服务器端爬虫检测机制,就是在http响应中为所有访问页面的http请求植入一个cookie token,然后在这个页面异步执行的一些ajax接口上学。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电商网站亚马逊采用这种防御策略。以上是基于服务器端验证爬虫程序可以玩的一些套路。
##基于客户端js运行时检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西需要一点一点的尝试,耗费大量人力物力开发的一套爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。程序可以操作浏览器访问网页,使得编写爬虫的人可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。程序可以操作浏览器访问网页,使得编写爬虫的人可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。甚至是基于 IE 内核的 trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。甚至是基于 IE 内核的 trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器内核C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真正的GUI浏览器的发布版本。其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS有很多问题,因为是单进程模型,没有必要的沙箱保护,并且浏览器内核的安全性较差。现在谷歌Chrome团队已经在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:js调用。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:js调用。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length == 0) {
console.log("It may be Chrome headless");
}
基于语言的检查
if(navigator.languages == "") {
console.log("Chrome headless detected");
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == "Brian Paul" && renderer == "Mesa OffScreen") {
console.log("Chrome headless detected");
}
基于浏览器细线属性的检查
if(!Modernizr["hairline"]) {
console.log("It may be Chrome headless");
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName("body")[0];
var image = document.createElement("img");
image.src = "http://iloveponeydotcom32188.jg";
image.setAttribute("id", "fakeimage");
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log("Chrome headless detected");
}
}
基于以上对一些浏览器特性的判断,基本上可以将市面上大部分的无头浏览器程序干掉。至此,网页爬虫的门槛其实提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器内核来说是很重要的。变化不小。此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,测试js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。另外,我们在研究robots browserdetect using js api在浏览器端的时候,发现了一个有趣的小技巧。可以将一个预先注入的js函数伪装成native函数,看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString());
console.log(fakeAlert.toString());
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。因此,需要更严格的检查,因为bind(null)伪造的方法在toString之后没有函数名。
##反爬虫银弹 反爬虫和机器人巡检最可靠的方法是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中最成熟的是 Google reCAPTCHA。基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。
##Robot协议 另外,在爬虫爬取技术领域还有一种“白道”的方法,叫做robots协议。您可以访问 网站 根目录中的 /robots.txt。比如我们看一下github的robot协议。Allow 和 Disallow 声明每个 UA 爬虫的授权。然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
##写在最后 网页内容的爬取与对策,注定是一场魔高一尺,路高一尺的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路。你可以 它所做的只是增加攻击者的抓取成本,并更准确地了解未经授权的抓取。另外,欢迎对爬虫感兴趣的朋友关注我的开源项目webster。该项目以Node.js结合Chrome无头模式实现了一个高可用的网络爬虫爬取框架。一个页面中js和ajax渲染的所有异步内容;结合redis,实现了一个任务队列,让爬虫轻松进行横向和纵向分布式扩展。 查看全部
js 爬虫抓取网页数据(web不再的攻防角度分析——web原创生态的元凶)
网络是一个开放的平台,它为网络从1990年代初诞生到今天的蓬勃发展奠定了基础。但是,所谓成败,也就是小何,开放的特性、搜索引擎、简单易学的html和css技术,让web成为了互联网领域最流行、最成熟的信息传播媒介;但是现在作为一个商业软件,web这个平台上的内容信息的版权是不能保证的,因为和软件客户端相比,你网页中的内容可以通过一些爬虫程序以非常低的成本和技术门槛很低。这就是本系列文章要讨论的话题——网络爬虫。

有很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为随着今天IT行业的发展,网络不再是当年与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的思想。存在。随着商业软件的发展,网络也不得不面对知识产权保护的问题。试想,如果原创的优质内容不受保护,网络世界中抄袭盗版猖獗,这其实有利于网络生态的健康发展。这是一个缺点,而且它' 很难鼓励制作更多高质量的原创内容。未经授权的爬虫程序是危害web原创内容生态的罪魁祸首。因此,为了保护网站的内容,首先要考虑如何反爬。
##从爬虫攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。这当然是儿科最小的防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在http的get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。另外还有一个比较异常的服务器端爬虫检测机制,就是在http响应中为所有访问页面的http请求植入一个cookie token,然后在这个页面异步执行的一些ajax接口上学。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电商网站亚马逊采用这种防御策略。以上是基于服务器端验证爬虫程序可以玩的一些套路。
##基于客户端js运行时检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西需要一点一点的尝试,耗费大量人力物力开发的一套爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。程序可以操作浏览器访问网页,使得编写爬虫的人可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。程序可以操作浏览器访问网页,使得编写爬虫的人可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。甚至是基于 IE 内核的 trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。甚至是基于 IE 内核的 trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器内核C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真正的GUI浏览器的发布版本。其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS有很多问题,因为是单进程模型,没有必要的沙箱保护,并且浏览器内核的安全性较差。现在谷歌Chrome团队已经在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:js调用。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:js调用。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length == 0) {
console.log("It may be Chrome headless");
}
基于语言的检查
if(navigator.languages == "") {
console.log("Chrome headless detected");
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == "Brian Paul" && renderer == "Mesa OffScreen") {
console.log("Chrome headless detected");
}
基于浏览器细线属性的检查
if(!Modernizr["hairline"]) {
console.log("It may be Chrome headless");
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName("body")[0];
var image = document.createElement("img");
image.src = "http://iloveponeydotcom32188.jg";
image.setAttribute("id", "fakeimage");
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log("Chrome headless detected");
}
}
基于以上对一些浏览器特性的判断,基本上可以将市面上大部分的无头浏览器程序干掉。至此,网页爬虫的门槛其实提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器内核来说是很重要的。变化不小。此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,测试js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。另外,我们在研究robots browserdetect using js api在浏览器端的时候,发现了一个有趣的小技巧。可以将一个预先注入的js函数伪装成native函数,看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString());
console.log(fakeAlert.toString());
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。因此,需要更严格的检查,因为bind(null)伪造的方法在toString之后没有函数名。
##反爬虫银弹 反爬虫和机器人巡检最可靠的方法是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中最成熟的是 Google reCAPTCHA。基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。
##Robot协议 另外,在爬虫爬取技术领域还有一种“白道”的方法,叫做robots协议。您可以访问 网站 根目录中的 /robots.txt。比如我们看一下github的robot协议。Allow 和 Disallow 声明每个 UA 爬虫的授权。然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
##写在最后 网页内容的爬取与对策,注定是一场魔高一尺,路高一尺的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路。你可以 它所做的只是增加攻击者的抓取成本,并更准确地了解未经授权的抓取。另外,欢迎对爬虫感兴趣的朋友关注我的开源项目webster。该项目以Node.js结合Chrome无头模式实现了一个高可用的网络爬虫爬取框架。一个页面中js和ajax渲染的所有异步内容;结合redis,实现了一个任务队列,让爬虫轻松进行横向和纵向分布式扩展。
js 爬虫抓取网页数据(关于爬虫内容的分享,我会分成两篇,六个部分来分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-08 04:07
关于爬虫内容的分享,我将分为两部分,分享六个部分,分别是:
1) 我们的目的是什么
2) 内容从何而来
3) 了解网络请求
4) 一些常见的限制
5) 尝试解决问题的想法
6) 效率权衡
本文首先讨论前三个部分。
一、我们的目的是什么
一般来说,我们需要抓取的是一个网站或者一个应用程序的内容,以提取有用的价值。内容一般分为两部分,非结构化文本,或结构化文本。
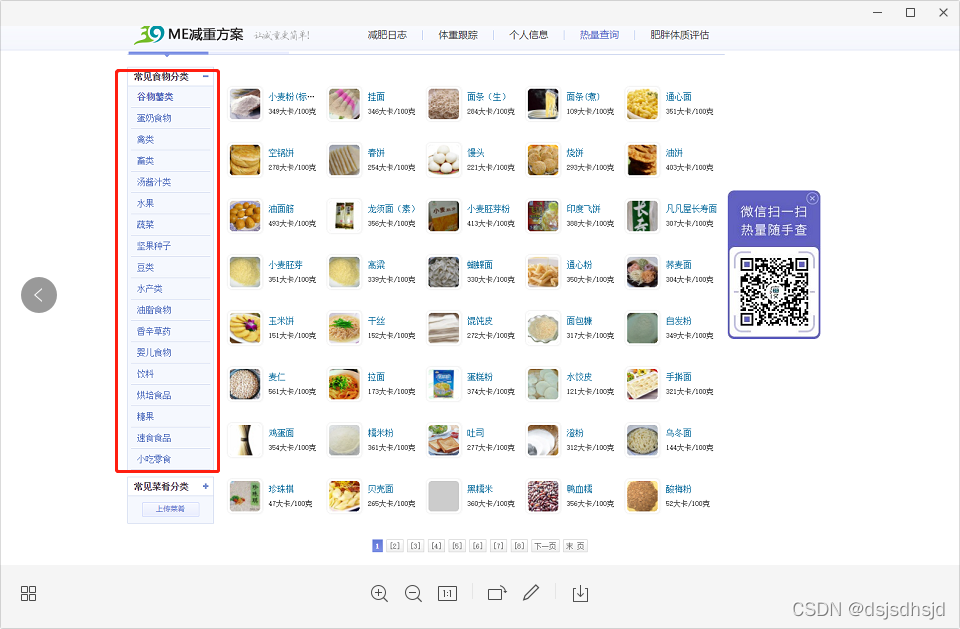
1. 关于非结构化数据
1.1 HTML 文本(包括 javascript 代码)
HTML文本基本上是传统爬取过程中最常见的,也就是大部分时间会遇到的情况,比如爬取一个网页,得到HTML,然后需要解析一些常用元素,提取一些关键信息. 其实HTML应该属于结构化的文本组织,但是因为我们需要的关键信息不是直接可以得到的,需要对HTML进行解析和搜索,甚至可以得到一些字符串操作,所以还是归为非结构化数据。加工。
常用的分析方法如下:
现在的网页样式很多,所以一般的网页都会有一些CSS定位,比如class,id等,或者我们根据常用的节点路径定位,比如腾讯首页的金融版块
这里的 id 是金融。我们使用css选择器,即“#finance”来获取金融区的html。同理,可以根据具体的css选择器获取其他内容。
XPATH是一种页面元素的路径选择方法,可以使用chrome快速获取,例如:
copyXPATH 将得到 - //*[@id="finance"]
正则表达式,使用标准正则解析,一般将HTML视为普通文本,并使用指定格式匹配为相关文本,适用于小片段文本,或者某个字符串,或者HTML收录javascript代码,不能使用CSS选择器或 XPATH 。
和正则表达式一样,比较懒的方法,不推荐。
1.2 一段文字
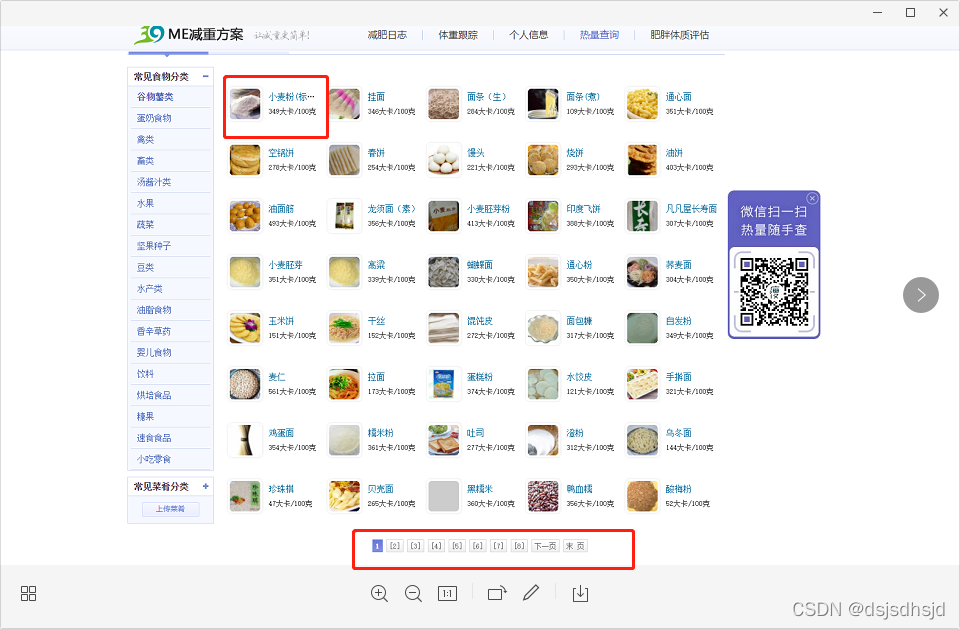
比如一个文章,或者一个句子,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储。如果需要实时提取有用信息,常用的处理方式有以下几种:
根据捕获到的网站的类型,使用不同的词库,进行基本的分词,然后变成词频统计,类似于向量的表示,词是方向,词频是长度。
自然语言处理,进行语义分析,并用结果来表达,例如正面和负面。
2. 关于结构化数据
结构化数据是处理它的最佳方式。一般是类似于JSON格式的字符串。您可以直接解析 JSON 数据并提取 JSON 的关键字段。
二、内容从何而来
过去,我们经常需要获取的内容主要来自网页。一般来说,当我们决定爬取时,就是网页上能看到的所有内容。但是随着近几年移动互联网的发展,我们也发现越来越多的内容会来自移动应用,所以爬虫不仅仅局限于抓取和解析网页,还可以模拟移动端的网络请求要抓取的应用程序,因此我将分两部分解释这部分。
1. 网页内容
网页内容一般是指我们最终在网页上看到的内容,但是这个过程并不像直接在网页的代码中收录内容那么简单,所以对于很多新手来说,会出现很多问题,比如:
显然,当用 Chrome 或 Firefox 检查页面时,可以看到 HTML 标签中收录的内容,但在抓取时为空。
很多内容必须通过点击按钮或执行交互操作来显示在页面上。
因此,对于很多新手来说,做法是使用别人模拟浏览器操作的某种语言的库。其实就是调用本地浏览器或者收录一些执行javascript的引擎进行模拟操作来抓取数据。在抓取大量数据的情况下,效率非常低,相当于给技术人员自己用了一个盒子,那么这些内容到底是怎么显示在网页上的呢?主要分为以下几种情况:
这种情况最容易解决。一般来说,基本上都是写死的静态网页,或者是使用模板渲染的动态网页。浏览器获取HTML的时候已经收录了所有的关键信息,所以直接在网页上面看到的内容可以通过特定的HTML标签获取
这种情况是因为虽然网页显示时内容在html标签中,但实际上是通过执行js代码添加到标签中的,所以此时内容在js代码中,而js的执行是在浏览器端执行。所以当你使用程序请求网页地址时,得到的响应是网页代码和js代码,所以你可以在浏览器端看到内容。由于解析时没有执行js,所以一定要发现指定html标签下的内容一定是空的。此时的处理方式一般是查找收录该内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。
这种情况现在很常见,尤其是网页内容以分页的形式显示,并且页面没有刷新,或者是在网页上进行交互操作后获取到的内容。那么我们如何分析这些请求呢?这里我以Chrome的操作为例进行说明:
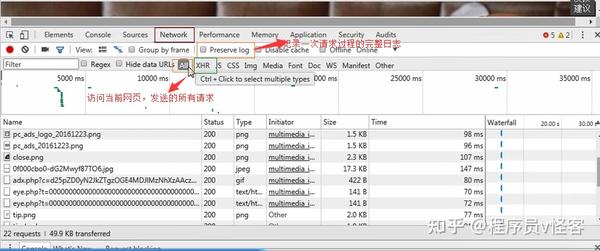
所以当我们开始刷新页面的时候,我们需要开始跟踪所有的请求,观察数据是从哪里加载的。那么当我们找到核心异步请求时,只需要抓取异步请求即可。如果原创网页没有任何有用的信息,则无需抓取原创网页。
2. 应用内容
因为现在移动应用越来越多,很多有用的信息都在app里面。另外,在解析非结构化文本和结构化文本方面,结构化文本会简单很多。如果你同时拥有网站和App,建议爬取App,大部分情况下基本上只是一些JSON数据API。那么如何抓取App的数据呢?一般的方法是抓包。基本方法是在电脑上安装抓包软件,配置好端口,然后记下ip。手机端和电脑在同一个局域网,然后在手机的网络连接中设置代理。该应用程序执行一些操作。如果有网络数据请求,会被抓包软件记录下来。就像上面Chrome对网络请求的分析一样,可以看到所有的请求,模拟请求操作。这里我推荐 Mac 的 Charles 软件和 Windows 的 Fiddler2。
怎么用,后面会详细解释,可能会涉及到HTTPS证书的问题。
三、了解网络请求
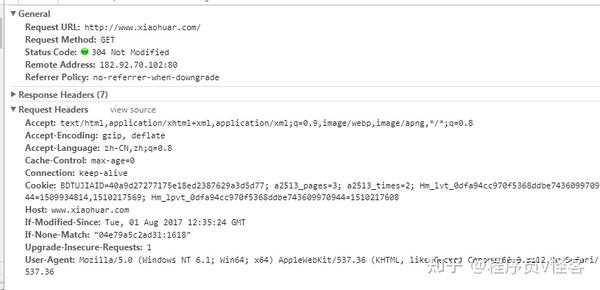
我刚刚广泛地提到了我们需要找到和提出的一些要求。请求只是一个过客,但是请求是一个很重要的部分,包括如何绕过限制以及如何发送正确的数据,都需要正确的请求,这里详细展开请求以及如何模拟请求。
我们常说爬虫其实就是一堆HTTP请求,找到要爬取的链接,不管是网页链接还是App抓取得到的API链接,然后发送请求包得到返回包(有也是 HTTP 长连接,或者 Streaming ,这里不考虑),所以核心要素是:
1)网址
2)请求方法(POST、GET)
3)请求包头
4)请求包内容
5)返回包头
在使用 Chrome 捕获网络请求或使用抓包工具分析请求时,最重要的是弄清楚请求头中的 URL、请求方法和字段。大部分问题都在headers中,最常被限制的字段是即User-Agent、Referer、Cookie。此外,Base Auth还在headers中添加了Autheration字段。
请求的内容是post时需要发送的数据,一般对Key-Value进行urlencode
大部分返回的包头都会被人忽略,可能仅仅获取到内容就够了,但其实很多时候很多人会发现请求包的url、请求方法和内容都是对了,为什么没有返回内容,还是找到了请求,其实这大概有两个原因:
一种是返回包的内容是空的,但是返回包的headers字段中有一个Location。这个Location字段告诉浏览器重定向,所以有时候代码不会自动跟踪,自然就没有内容了;
还有一个就是很多人头疼的cookie问题。简单来说就是为什么浏览器知道你的请求是合法的,比如登录等。其实可能是你之前请求的返回包的header中有一个字段叫做Set-Cookie,Cookie本地存在。一旦设置好,除非过期,否则会自动添加到请求字段中,所以Set-Cookie中的内容会告诉浏览器存储了多长时间,存储了哪些内容,在哪个路径下有用。Cookie 都是在指定域下,一般不跨域,域就是你请求的链接主机。
所以在分析request的时候一定要注意前4个,模拟的时候保持一致,观察第5个return是受限还是redirect。
孔淼 查看全部
js 爬虫抓取网页数据(关于爬虫内容的分享,我会分成两篇,六个部分来分享)
关于爬虫内容的分享,我将分为两部分,分享六个部分,分别是:
1) 我们的目的是什么
2) 内容从何而来
3) 了解网络请求
4) 一些常见的限制
5) 尝试解决问题的想法
6) 效率权衡
本文首先讨论前三个部分。
一、我们的目的是什么
一般来说,我们需要抓取的是一个网站或者一个应用程序的内容,以提取有用的价值。内容一般分为两部分,非结构化文本,或结构化文本。
1. 关于非结构化数据
1.1 HTML 文本(包括 javascript 代码)
HTML文本基本上是传统爬取过程中最常见的,也就是大部分时间会遇到的情况,比如爬取一个网页,得到HTML,然后需要解析一些常用元素,提取一些关键信息. 其实HTML应该属于结构化的文本组织,但是因为我们需要的关键信息不是直接可以得到的,需要对HTML进行解析和搜索,甚至可以得到一些字符串操作,所以还是归为非结构化数据。加工。
常用的分析方法如下:
现在的网页样式很多,所以一般的网页都会有一些CSS定位,比如class,id等,或者我们根据常用的节点路径定位,比如腾讯首页的金融版块

这里的 id 是金融。我们使用css选择器,即“#finance”来获取金融区的html。同理,可以根据具体的css选择器获取其他内容。
XPATH是一种页面元素的路径选择方法,可以使用chrome快速获取,例如:
copyXPATH 将得到 - //*[@id="finance"]
正则表达式,使用标准正则解析,一般将HTML视为普通文本,并使用指定格式匹配为相关文本,适用于小片段文本,或者某个字符串,或者HTML收录javascript代码,不能使用CSS选择器或 XPATH 。
和正则表达式一样,比较懒的方法,不推荐。
1.2 一段文字
比如一个文章,或者一个句子,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储。如果需要实时提取有用信息,常用的处理方式有以下几种:
根据捕获到的网站的类型,使用不同的词库,进行基本的分词,然后变成词频统计,类似于向量的表示,词是方向,词频是长度。
自然语言处理,进行语义分析,并用结果来表达,例如正面和负面。
2. 关于结构化数据
结构化数据是处理它的最佳方式。一般是类似于JSON格式的字符串。您可以直接解析 JSON 数据并提取 JSON 的关键字段。
二、内容从何而来
过去,我们经常需要获取的内容主要来自网页。一般来说,当我们决定爬取时,就是网页上能看到的所有内容。但是随着近几年移动互联网的发展,我们也发现越来越多的内容会来自移动应用,所以爬虫不仅仅局限于抓取和解析网页,还可以模拟移动端的网络请求要抓取的应用程序,因此我将分两部分解释这部分。
1. 网页内容
网页内容一般是指我们最终在网页上看到的内容,但是这个过程并不像直接在网页的代码中收录内容那么简单,所以对于很多新手来说,会出现很多问题,比如:
显然,当用 Chrome 或 Firefox 检查页面时,可以看到 HTML 标签中收录的内容,但在抓取时为空。
很多内容必须通过点击按钮或执行交互操作来显示在页面上。
因此,对于很多新手来说,做法是使用别人模拟浏览器操作的某种语言的库。其实就是调用本地浏览器或者收录一些执行javascript的引擎进行模拟操作来抓取数据。在抓取大量数据的情况下,效率非常低,相当于给技术人员自己用了一个盒子,那么这些内容到底是怎么显示在网页上的呢?主要分为以下几种情况:
这种情况最容易解决。一般来说,基本上都是写死的静态网页,或者是使用模板渲染的动态网页。浏览器获取HTML的时候已经收录了所有的关键信息,所以直接在网页上面看到的内容可以通过特定的HTML标签获取
这种情况是因为虽然网页显示时内容在html标签中,但实际上是通过执行js代码添加到标签中的,所以此时内容在js代码中,而js的执行是在浏览器端执行。所以当你使用程序请求网页地址时,得到的响应是网页代码和js代码,所以你可以在浏览器端看到内容。由于解析时没有执行js,所以一定要发现指定html标签下的内容一定是空的。此时的处理方式一般是查找收录该内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。
这种情况现在很常见,尤其是网页内容以分页的形式显示,并且页面没有刷新,或者是在网页上进行交互操作后获取到的内容。那么我们如何分析这些请求呢?这里我以Chrome的操作为例进行说明:
所以当我们开始刷新页面的时候,我们需要开始跟踪所有的请求,观察数据是从哪里加载的。那么当我们找到核心异步请求时,只需要抓取异步请求即可。如果原创网页没有任何有用的信息,则无需抓取原创网页。
2. 应用内容
因为现在移动应用越来越多,很多有用的信息都在app里面。另外,在解析非结构化文本和结构化文本方面,结构化文本会简单很多。如果你同时拥有网站和App,建议爬取App,大部分情况下基本上只是一些JSON数据API。那么如何抓取App的数据呢?一般的方法是抓包。基本方法是在电脑上安装抓包软件,配置好端口,然后记下ip。手机端和电脑在同一个局域网,然后在手机的网络连接中设置代理。该应用程序执行一些操作。如果有网络数据请求,会被抓包软件记录下来。就像上面Chrome对网络请求的分析一样,可以看到所有的请求,模拟请求操作。这里我推荐 Mac 的 Charles 软件和 Windows 的 Fiddler2。
怎么用,后面会详细解释,可能会涉及到HTTPS证书的问题。
三、了解网络请求
我刚刚广泛地提到了我们需要找到和提出的一些要求。请求只是一个过客,但是请求是一个很重要的部分,包括如何绕过限制以及如何发送正确的数据,都需要正确的请求,这里详细展开请求以及如何模拟请求。
我们常说爬虫其实就是一堆HTTP请求,找到要爬取的链接,不管是网页链接还是App抓取得到的API链接,然后发送请求包得到返回包(有也是 HTTP 长连接,或者 Streaming ,这里不考虑),所以核心要素是:
1)网址
2)请求方法(POST、GET)
3)请求包头
4)请求包内容
5)返回包头
在使用 Chrome 捕获网络请求或使用抓包工具分析请求时,最重要的是弄清楚请求头中的 URL、请求方法和字段。大部分问题都在headers中,最常被限制的字段是即User-Agent、Referer、Cookie。此外,Base Auth还在headers中添加了Autheration字段。
请求的内容是post时需要发送的数据,一般对Key-Value进行urlencode
大部分返回的包头都会被人忽略,可能仅仅获取到内容就够了,但其实很多时候很多人会发现请求包的url、请求方法和内容都是对了,为什么没有返回内容,还是找到了请求,其实这大概有两个原因:
一种是返回包的内容是空的,但是返回包的headers字段中有一个Location。这个Location字段告诉浏览器重定向,所以有时候代码不会自动跟踪,自然就没有内容了;
还有一个就是很多人头疼的cookie问题。简单来说就是为什么浏览器知道你的请求是合法的,比如登录等。其实可能是你之前请求的返回包的header中有一个字段叫做Set-Cookie,Cookie本地存在。一旦设置好,除非过期,否则会自动添加到请求字段中,所以Set-Cookie中的内容会告诉浏览器存储了多长时间,存储了哪些内容,在哪个路径下有用。Cookie 都是在指定域下,一般不跨域,域就是你请求的链接主机。
所以在分析request的时候一定要注意前4个,模拟的时候保持一致,观察第5个return是受限还是redirect。
孔淼
js 爬虫抓取网页数据(静态网页爬取文章目录(一):蚂蚁、自动索引、模拟程序或者蠕虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2022-03-04 11:20
静态网页抓取
文章目录
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。.
一、静态网站分析
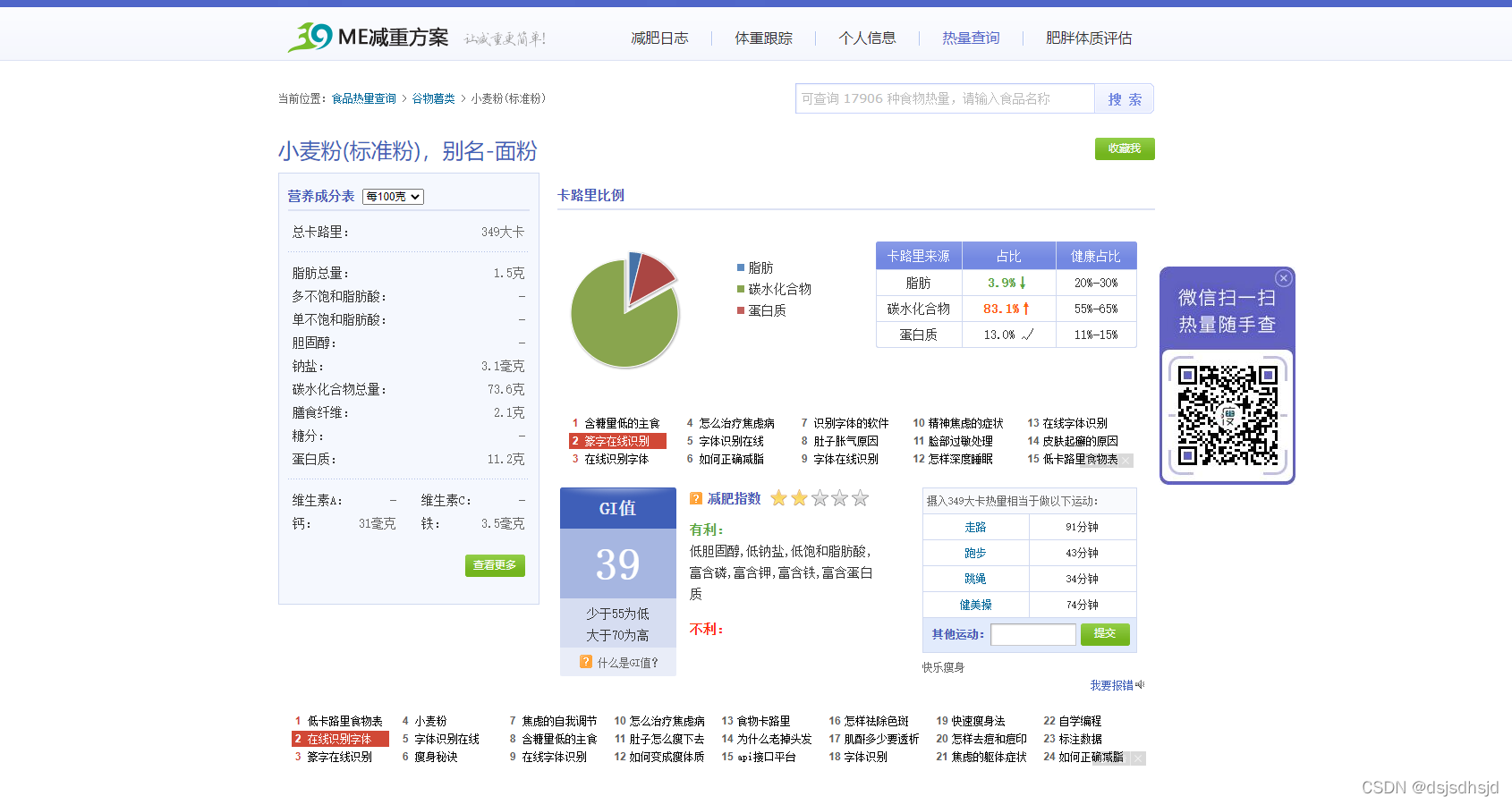
示例网站:
任务要求:
第一步获取主要食物类别
第二步,获取所有分类中的所有分页成分
第三步,获取所有分类的所有分页成分的营养成分和营养比例
二、需要的依赖和插件1.引入库
代码如下(示例):
from asyncio.windows_events import NULL
import requests
import mysql.connector
import datetime
from lxml import etree
from bs4 import BeautifulSoup
from selenium import webdriver
插件:phantomjs.exe
插件:XPath
插件介绍:
PhantomJS 是一个可编程的无头浏览器。
Headless browser:一个完整的浏览器内核,包括js解析引擎、渲染引擎、请求处理等,但不包括显示和与用户交互的浏览器。
2.PhantomJS 使用场景
PhantomJS 的适用范围是无头浏览器的适用范围。通常无头浏览器可用于页面自动化、网络监控、网络爬取等:
页面自动化测试:希望能自动登录网站做一些操作,然后检查结果是否正常。
网页监控:希望定期打开页面查看网站是否可以正常加载,加载结果是否符合预期。加载速度等等。
网络爬虫:获取js下载并渲染页面中的信息,或者使用js跳转后获取链接的真实地址。
———————————————
版权声明:本文为CSDN博主“violetgo”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原文出处链接和本声明。
原文链接:
三、代码显示
第一步获取主要食物类别
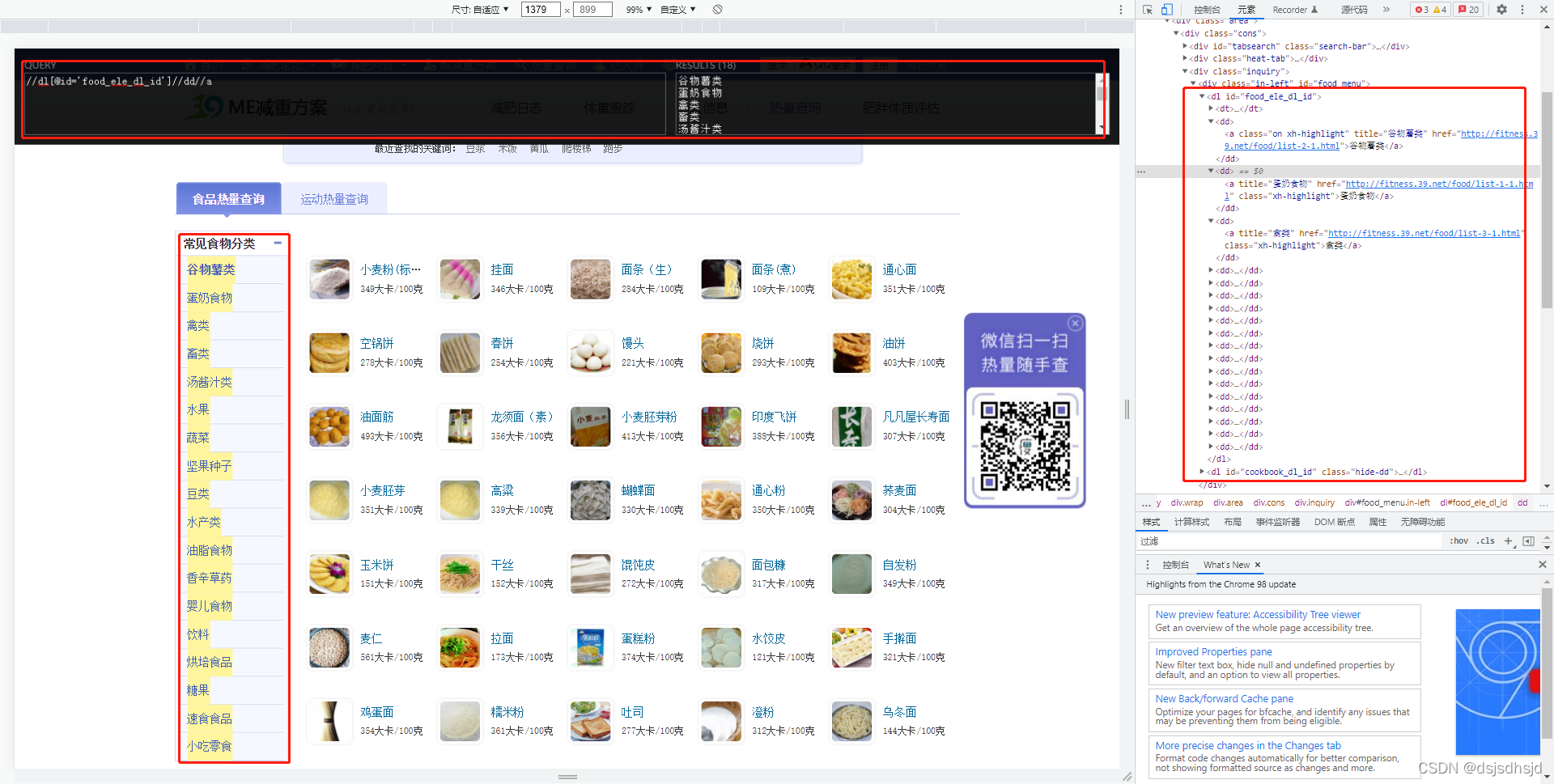
使用XPath插件查找需要爬取的html组件
response = requests.get(url="http://fitness.39.net/food/")
response.encoding = 'utf-8'
# 获取一级分类的数据
html = etree.HTML(response.text)
print(html.xpath("//dl[@id='food_ele_dl_id']//dd//a" ))
items = html.xpath("//dl[@id='food_ele_dl_id']//dd//a" )
data_time=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") #系统时间
val = []
val1 = []
# 遍历items的集合
for item in items:
title = "".join(item.xpath("./@title"))
href = "".join(item.xpath("./@href"))
val.append((title,href,data_time))
# print(html.xpath("" ))
print(val)
mydb = mysql.connector.connect(
host="11.11.11.111",
user="root",
passwd="123456",
database="python"
)
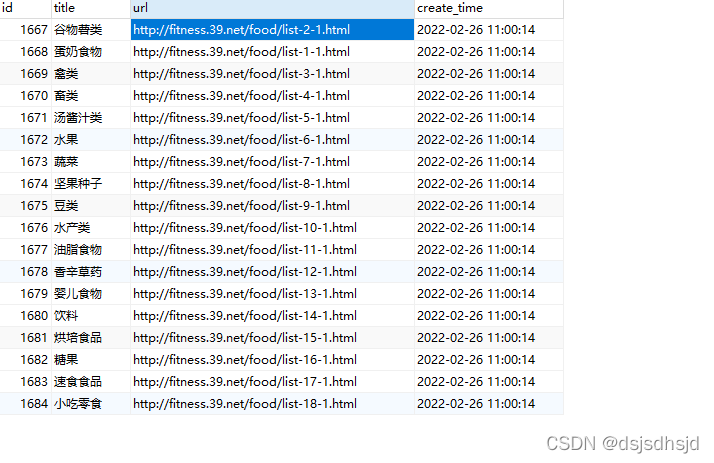
mycursor = mydb.cursor()
#删除旧的食材分类数据
sql = "DELETE FROM p_food_type "
mycursor.execute(sql)
mydb.commit()
print(mycursor.rowcount, " 条记录删除")
#插入新数据
sql = "INSERT INTO p_food_type (title, url,create_time) VALUES (%s, %s, %s)"
mycursor.executemany(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
print(mycursor.rowcount, "记录插入成功。")
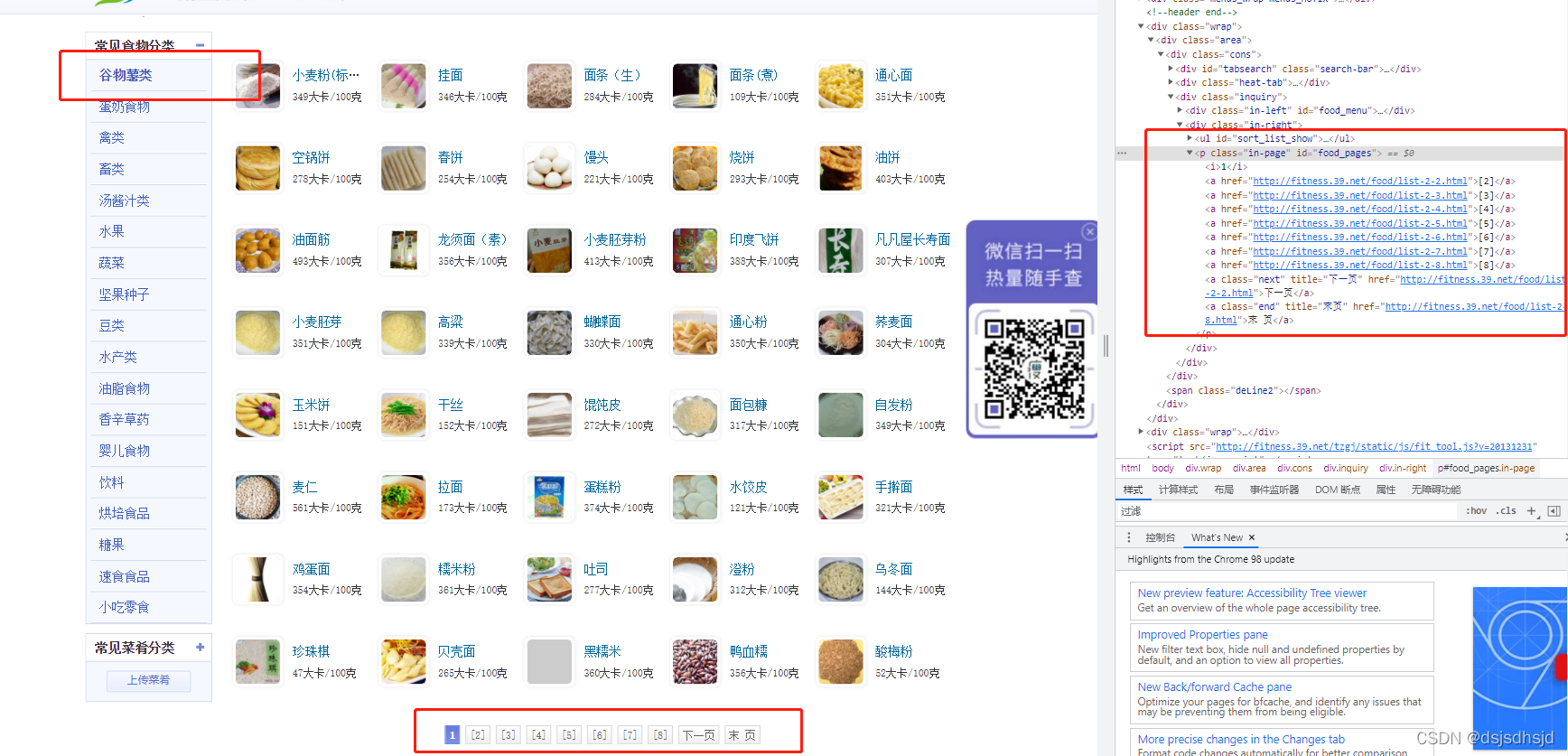
第二步,获取大类中的所有子类,包括分页
分析如何获取分页
晶粒分析示例
通过图片我们可以找到分页的规则。
然后我们可以通过循环分类的url并将url拼接成页面来请求数据,直到拼接的url不请求数据。我们判断是最后一页,跳出这个类别,进入下一个类别。
<p>
#查询大类表
setsql = "SELECT * FROM p_food_type "
mycursor.execute(setsql)
myresult = mycursor.fetchall()
n = 100
sum = 0
counter = 1
#循环大类表
for x in myresult:
counter=1
while counter 查看全部
js 爬虫抓取网页数据(静态网页爬取文章目录(一):蚂蚁、自动索引、模拟程序或者蠕虫)
静态网页抓取
文章目录
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。.
一、静态网站分析
示例网站:
任务要求:
第一步获取主要食物类别
第二步,获取所有分类中的所有分页成分
第三步,获取所有分类的所有分页成分的营养成分和营养比例
二、需要的依赖和插件1.引入库
代码如下(示例):
from asyncio.windows_events import NULL
import requests
import mysql.connector
import datetime
from lxml import etree
from bs4 import BeautifulSoup
from selenium import webdriver
插件:phantomjs.exe
插件:XPath
插件介绍:
PhantomJS 是一个可编程的无头浏览器。
Headless browser:一个完整的浏览器内核,包括js解析引擎、渲染引擎、请求处理等,但不包括显示和与用户交互的浏览器。
2.PhantomJS 使用场景
PhantomJS 的适用范围是无头浏览器的适用范围。通常无头浏览器可用于页面自动化、网络监控、网络爬取等:
页面自动化测试:希望能自动登录网站做一些操作,然后检查结果是否正常。
网页监控:希望定期打开页面查看网站是否可以正常加载,加载结果是否符合预期。加载速度等等。
网络爬虫:获取js下载并渲染页面中的信息,或者使用js跳转后获取链接的真实地址。
———————————————
版权声明:本文为CSDN博主“violetgo”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原文出处链接和本声明。
原文链接:
三、代码显示
第一步获取主要食物类别
使用XPath插件查找需要爬取的html组件
response = requests.get(url="http://fitness.39.net/food/";)
response.encoding = 'utf-8'
# 获取一级分类的数据
html = etree.HTML(response.text)
print(html.xpath("//dl[@id='food_ele_dl_id']//dd//a" ))
items = html.xpath("//dl[@id='food_ele_dl_id']//dd//a" )
data_time=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") #系统时间
val = []
val1 = []
# 遍历items的集合
for item in items:
title = "".join(item.xpath("./@title"))
href = "".join(item.xpath("./@href"))
val.append((title,href,data_time))
# print(html.xpath("" ))
print(val)
mydb = mysql.connector.connect(
host="11.11.11.111",
user="root",
passwd="123456",
database="python"
)
mycursor = mydb.cursor()
#删除旧的食材分类数据
sql = "DELETE FROM p_food_type "
mycursor.execute(sql)
mydb.commit()
print(mycursor.rowcount, " 条记录删除")
#插入新数据
sql = "INSERT INTO p_food_type (title, url,create_time) VALUES (%s, %s, %s)"
mycursor.executemany(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
print(mycursor.rowcount, "记录插入成功。")

第二步,获取大类中的所有子类,包括分页
分析如何获取分页
晶粒分析示例

通过图片我们可以找到分页的规则。
然后我们可以通过循环分类的url并将url拼接成页面来请求数据,直到拼接的url不请求数据。我们判断是最后一页,跳出这个类别,进入下一个类别。
<p>
#查询大类表
setsql = "SELECT * FROM p_food_type "
mycursor.execute(setsql)
myresult = mycursor.fetchall()
n = 100
sum = 0
counter = 1
#循环大类表
for x in myresult:
counter=1
while counter
js 爬虫抓取网页数据(目标网络爬虫的是做什么的?手动写一个简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-04 11:19
目标
网络爬虫有什么作用?手动编写一个简单的网络爬虫;
1. 网络爬虫1.1. 名称
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
1.2. 简要说明
网络爬虫通过自己的链接地址寻找网页,从网站的一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后寻找下一页通过这些链接地址。一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发送的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
2. 进程
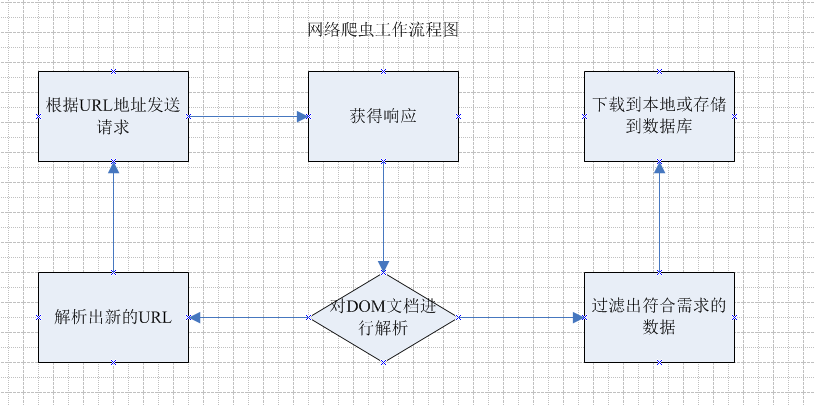
网络爬虫有什么作用?它的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析出新的URL路径。这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;
2.1. 专注
爬虫需要注意的三点:
爬取目标的描述或定义;网页或数据的分析和过滤;URL 的搜索策略
3. 分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:
通用网络爬虫 聚焦网络爬虫 增量网络爬虫 深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
4. 思想分析
接下来,我将通过我们的官网来和大家一起分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页是:
分析页面
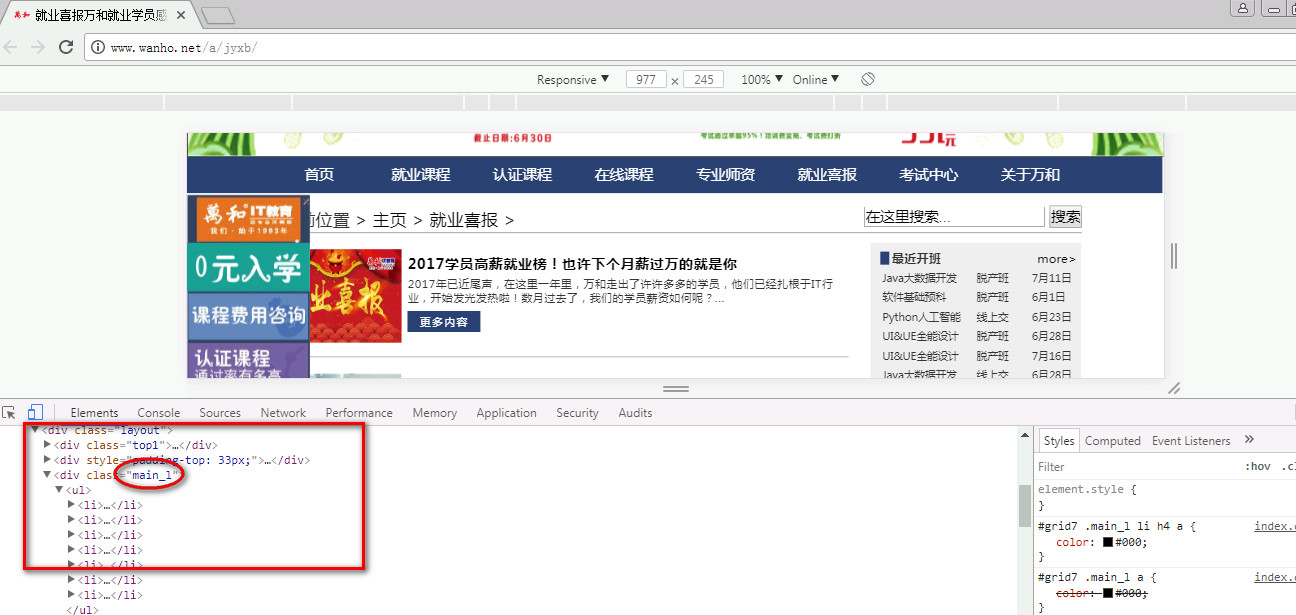
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据
标题:由 XPath 表达式表示 //div[@class='content']/h4/a/text() 描述:由 XPath 表达式表示 //div[@class='content']/p/text() 图像:使用 XPath 表达式来表示 //a/img/@src
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构
5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/")
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
WanhoPageProcessor.java
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i 查看全部
js 爬虫抓取网页数据(目标网络爬虫的是做什么的?手动写一个简单)
目标
网络爬虫有什么作用?手动编写一个简单的网络爬虫;
1. 网络爬虫1.1. 名称
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
1.2. 简要说明
网络爬虫通过自己的链接地址寻找网页,从网站的一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后寻找下一页通过这些链接地址。一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发送的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
2. 进程
网络爬虫有什么作用?它的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析出新的URL路径。这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;
2.1. 专注
爬虫需要注意的三点:
爬取目标的描述或定义;网页或数据的分析和过滤;URL 的搜索策略
3. 分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:
通用网络爬虫 聚焦网络爬虫 增量网络爬虫 深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
4. 思想分析
接下来,我将通过我们的官网来和大家一起分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页是:
分析页面
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li

相关数据
标题:由 XPath 表达式表示 //div[@class='content']/h4/a/text() 描述:由 XPath 表达式表示 //div[@class='content']/p/text() 图像:使用 XPath 表达式来表示 //a/img/@src
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构
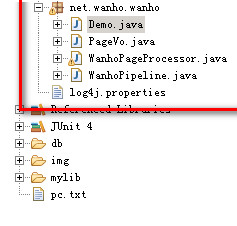
5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/";)
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
WanhoPageProcessor.java
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i
js 爬虫抓取网页数据(微博的热点事件会产生大量评论数据,这些数据是进行舆情分析和网络水军识别等数据挖掘的基础 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2022-03-04 11:17
)
黄洪涛姜英峰
摘要:微博热点事件会产生大量评论数据,是舆情分析、网络海军识别等数据挖掘的基础。论文分析比较了常用的网络爬虫技术和框架,分别使用Selenium框架和Json数据接口两种方法,以及采集新浪微博热点事件下的用户评论数据。一般网络爬虫技术多采用广度搜索,这里采用深度搜索,可以更准确的获取某个热点事件下的用户评论数据。
关键词:数据挖掘微博用户评论网络爬虫Selenium Json
CLC 编号:TP393.09;TP274.2 证件识别码:A文章编号:1674-098X (2021)05(b)-0132-05
基于微博平台的用户评论数据采集
黄洪涛姜英峰
(广东外语外贸大学信息学院, 广东省广州市, 510006)
摘要:微博热点事件会产生大量评论数据,是舆情分析、在线水军识别等数据挖掘的基础。论文分析比较了常用的网络爬虫技术和框架,分别使用Selenium框架和Json数据接口采集新浪微博热点事件下的用户评论数据。网络爬取技术一般采用广度搜索,这里采用深度搜索,更能准确获取热点事件下的用户评论数据。
关键词:数据挖掘;微博;用户评论;网络爬虫;硒; json
根据2021年2月发布的第47次《中国互联网发展状况统计报告》,截至2020年12月,我国网民规模达到9.89亿,较2020年3月增加8540万,互联网普及率高达70.4%,较2020年3月提升5.9个百分点。截至2020年12月,我国移动互联网用户规模达到9. 86亿,比2020年3月增加8885万,使用手机上网的网民比例达到99.7%,比2020年3月增加0.4个百分点. 数据显示,我国网民数量非常庞大,并且使用手机上网的网民比例非常高。这使得网民进入社区交流平台(如微博、知乎)的门槛降低,机会增加。很多网友,包括很多网络海军,都参与了热点事件的评论,使得这些事件产生了大量的数据。
新浪微博是在中国拥有大量用户和高活跃度的在线社交平台。一个热点事件往往有几万、十万甚至上百万条评论数据。这些数据是舆情分析、网络海军识别等数据挖掘的基础。
本文研究了相关的网络爬虫技术,并利用它对用户评论数据采集进行了批处理和自动化处理。
1 相关技术
1.1 爬虫技术分类
爬虫技术有一些分类如下。
1.1.1 万能网络爬虫
通用网络爬虫也称为可扩展网络爬虫[1]。爬取对象从一些种子URL扩展到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。一般网络爬虫的结构大致可以分为几个部分:页面爬取模块、页面分析模块、链接过滤模块、页面数据库、URL队列初始URL采集。通用爬虫主要用于广度搜索优先策略。
1.1.2 关注网络爬虫
Focused Crawler,也称为Topical Crawler [2],是指选择性地抓取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要爬取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。信息需求。与一般的网络爬虫相比,聚焦网络爬虫增加了链接评价模块和内容评价模块。聚焦爬虫的爬取策略实施的关键是评估页面内容和链接的重要性。不同的方法计算不同的重要性,导致链接的访问顺序不同。
1.1.3 增量爬虫
增量网页爬虫是指不再抓取已经抓取的网页,只抓取新生成的网页,即增量更新。与其他类型的网络爬虫相比,它只关注新增的数据,大大减少了网页的下载量,减少了爬虫对存储空间和网络带宽的消耗,但增加了爬虫的复杂度。卷爬取算法及实现难度[3].
1.1.4 深网爬虫
从网站上呈现的网页的不同位置结构来看,网页可以简单地分为浅态页面和深态页面。深度状态网页是指存储在网络数据库中的那些一般搜索引擎无法搜索到的状态页面,通常需要一定的条件才能获得(如登录)。与深态网页相比,浅态网页是指搜索引擎在网络上搜索到的浅态网页。Deep Web 往往具有强烈的主题,每个 Deep Web 主题领域所收录的数字信息更专业,内容更丰富[4]。
1.2 常用爬虫框架
1.2.1 硒
Selenium 是一个用于操作浏览器以执行自动化测试的框架。浏览器自动化可以通过简单的命令来控制,就像真正的用户在操作一样,例如输入验证码。Selenium是一款自动化测试工具,支持多种浏览器,包括Chrome、Safari、Firefox等主流界面浏览器。因此,它可以用来爬取任何网页上看到的任何数据信息,几乎可以避免大多数反爬虫监控[5]。
1.2.2 json接口
Json(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它使用不同于编程语言的特殊文本格式来保存和传递数据。简洁、清晰和易于理解的层次结构使 Json 成为理想的数据交换语言。更便于人读写,更易于机器解析生成,有效提高网络传输效率。Json 文本格式具有兼容性非常高、习惯行为类似于 C 语言系统、独立于其他编程语言的特点。这些特性使 Json 成为一种理想的数据交换语言 [6] 并用于提供 json 数据接口采集 的网页中的数据处理。
1.2.3 Scrapy
Scrapy是一个Python实现的爬虫框架,架构清晰,模块间耦合度比较低,扩展性比较强。等特点[7]。Scrapy框架不仅可以通过爬取网页获取数据,还可以通过访问API接口获取其他对应的数据,实现对网页资源的多级快速爬取,适用于各类网站爬取工作,提取有价值的结构数据[8]。
2 数据采集
本数据采集来源于网络社交平台-新浪微博,采集的具体评论数据为 filter=hot&root_comment_id=0&type=comment#_rnd59 博文下的用户评论。从这篇博文的评论数可以看出,这篇博文下的评论数据非常多,已经达到百万级评论数据。接下来,爬虫将用于捕获其数据并进行一些分析。
下面根据采集的数据特点,分别使用增量爬虫和Deep Web爬虫技术、selenium框架和json数据接口对微博评论数据进行采集。
2.1 使用 Selenium 框架采集数据
Selenium 爬取评论的基本步骤如图 1 所示。
首先获取其网页源代码(在网站上按F12查看),然后根据其源代码构造一个dom树,如图2所示。
接下来可以使用XPath解析dom树,根据相关节点爬取数据。部分代码如下。
user_data = requests.get(i)
dom_url = etree.HTML(user_data.text, etree.HTMLParser(encoding='utf-8'))
follow = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][1]/text()')
fan = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][2]/text()')
boke = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][3]/text()')
数据爬取完成后,可以选择保存为xml、csv、txt等文本文件。在这里,选择保存在 csv 文件中。
2.2 使用Json数据接口采集数据
与 Selenium 不同的是,Json 数据接口可以相对直接的获取数据,因为它的数据结构是 Json 的格式,但是需要找到数据的接口。
因为网页版微博不提供数据接口,反爬机制更先进,我们这里使用手机微博。手机微博用户评论通过瀑布流刷新,提供Json数据接口。例如其中一个接口: id=46240&mid=46240&max_id_type=0,其结构如下。
{ok: 1, data: {data: [,…], total_number: "1 百万+",…}}
数据:{数据:[,…],总数:“100万+”,…}
数据: [,…]
0:{created_at:“2021 年 2 月 27 日星期六 15:09:20 +0800”,id:“46737”,rootid:“46737”,...}
1:{created_at:“2021 年 2 月 27 日星期六 15:04:59 +0800”,id:“46970”,rootid:“46970”,...}
…
18:{created_at:“2021 年 2 月 27 日星期六 15:05:08 +0800”,id:“46568”,rootid:“46568”,...}
最大:50000
max_id: 45846235480040570
max_id_type: 0
状态:{comment_manage_info:{comment_permission_type:-1,approval_comment_type:0}}
总数:“一百万+”
好的:1
这种结构下获取用户评论比较简单,但是一个Json数据接口通常只能提供10×19条用户评论,所以需要重新获取下一个接口。由于手机端的微博使用瀑布流刷新用户评论,可以直接控制页面下拉刷新,获取下一个Json数据接口。观察它的数据接口链路,可以知道链路中只有max_id和max_id_type会发生变化,所以可以通过多个Json数据链路得出规律,下一个链路的max_id就是上一个链路的Json字典中的max_id (json结构倒数第六行),而max_id_type是0到1之间的值。首先用0判断Json返回的ok是否为1,如果是max_id_type则取0,否则取1。
当我
while_starttime = datetime.datetime.now()
尝试:
如果我 == 0:
r = requests.get(one, headers=headers)
别的:
b = '&max_id_type=0'
urlll = a + str(id) + b
r = requests.get(urlll, headers=headers)
标志 = r.json()
flag1 = r.json()['ok']
如果标志1 == 0:
b = '&max_id_type=1'
urlll = a + str(id) + b
r = requests.get(urlll, headers=headers)
js = r.json()
用户 = js['数据']['数据']
下一步就是分解获取Json数据,获取的数据也可以保存为xml表格、csv文件、txt文本文件等。
2.3 采集结果
两种方式的爬取结果包括用户id(用户的唯一标识)、用户名、评论时间、评论内容、评论点赞数。本次爬取共获得6000多条数据,可用于下一步。用户评论的数据挖掘提供了大量的数据,结果如图3所示。
3 结论
本文采用两种方法,均采用深度优先搜索获取微博用户评论数据。Selenium框架首先解析网页源代码,生成dom树,然后通过dom树获取用户评论数据。Json数据接口通过解析Json数据结构,直接获取微博用户的评论数据。实验中,针对微博热点事件下的用户评论数据采集,采用两种方法取得了较好的效果。
两种 data采集 方法都有优点和缺点。Selenium 可以模拟真人爬取数据的行为,基本不受网页限制,但前期过程会比较繁琐,爬取效率不是很高。Json数据接口直截了当,但是获取数据需要详细找出隐藏的接口位置,有时需要找到下一个接口并总结其链接规则,而有的网站没有提供数据接口。在实际操作中,可以根据具体需要,结合两种技术的优缺点选择其中一种方法。
参考
[1] 曾建荣, 张扬森, 郑佳, 等. 多数据源的Web爬虫实现技术及应用[J]. 计算机科学, 2019, 46 (5): 304-309.
[2]郭S,卞W,刘Y,等。基于支持向量机的聚焦爬虫在空间情报采集中的应用研究[J]. 电子设计工程, 2016, 24 (17): 28-34
[3] 叶婷. 基于关键词的微博爬虫系统设计与实现[D]. 杭州:浙江工业大学,2016.
[4] 杨晓福.公交票务DeepWeb数据采集关键技术研究[D]. 重庆:重庆交通大学,2016.
[5] 吕伯清. 基于爬虫和数据挖掘的电子商务页面信息分析[D]. 兰州:兰州大学,2018.
[6] 陈哲. 基于微博热点事件的可视化系统开发与实现[D]. 北京:首都经济贸易大学,2018.
[7] 孙宇. 基于Scrapy框架的网络爬虫系统设计与实现[D]. 北京:北京交通大学,2019.
[8] 崔新宇.基于情感分析的商品评价系统设计与实现[D]. 邯郸:河北工程大学,2020.
标签: 网络爬虫 微博 数据挖掘
报酬
查看全部
js 爬虫抓取网页数据(微博的热点事件会产生大量评论数据,这些数据是进行舆情分析和网络水军识别等数据挖掘的基础
)
黄洪涛姜英峰


摘要:微博热点事件会产生大量评论数据,是舆情分析、网络海军识别等数据挖掘的基础。论文分析比较了常用的网络爬虫技术和框架,分别使用Selenium框架和Json数据接口两种方法,以及采集新浪微博热点事件下的用户评论数据。一般网络爬虫技术多采用广度搜索,这里采用深度搜索,可以更准确的获取某个热点事件下的用户评论数据。
关键词:数据挖掘微博用户评论网络爬虫Selenium Json
CLC 编号:TP393.09;TP274.2 证件识别码:A文章编号:1674-098X (2021)05(b)-0132-05
基于微博平台的用户评论数据采集
黄洪涛姜英峰
(广东外语外贸大学信息学院, 广东省广州市, 510006)
摘要:微博热点事件会产生大量评论数据,是舆情分析、在线水军识别等数据挖掘的基础。论文分析比较了常用的网络爬虫技术和框架,分别使用Selenium框架和Json数据接口采集新浪微博热点事件下的用户评论数据。网络爬取技术一般采用广度搜索,这里采用深度搜索,更能准确获取热点事件下的用户评论数据。
关键词:数据挖掘;微博;用户评论;网络爬虫;硒; json
根据2021年2月发布的第47次《中国互联网发展状况统计报告》,截至2020年12月,我国网民规模达到9.89亿,较2020年3月增加8540万,互联网普及率高达70.4%,较2020年3月提升5.9个百分点。截至2020年12月,我国移动互联网用户规模达到9. 86亿,比2020年3月增加8885万,使用手机上网的网民比例达到99.7%,比2020年3月增加0.4个百分点. 数据显示,我国网民数量非常庞大,并且使用手机上网的网民比例非常高。这使得网民进入社区交流平台(如微博、知乎)的门槛降低,机会增加。很多网友,包括很多网络海军,都参与了热点事件的评论,使得这些事件产生了大量的数据。
新浪微博是在中国拥有大量用户和高活跃度的在线社交平台。一个热点事件往往有几万、十万甚至上百万条评论数据。这些数据是舆情分析、网络海军识别等数据挖掘的基础。
本文研究了相关的网络爬虫技术,并利用它对用户评论数据采集进行了批处理和自动化处理。
1 相关技术
1.1 爬虫技术分类
爬虫技术有一些分类如下。
1.1.1 万能网络爬虫
通用网络爬虫也称为可扩展网络爬虫[1]。爬取对象从一些种子URL扩展到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。一般网络爬虫的结构大致可以分为几个部分:页面爬取模块、页面分析模块、链接过滤模块、页面数据库、URL队列初始URL采集。通用爬虫主要用于广度搜索优先策略。
1.1.2 关注网络爬虫
Focused Crawler,也称为Topical Crawler [2],是指选择性地抓取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要爬取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。信息需求。与一般的网络爬虫相比,聚焦网络爬虫增加了链接评价模块和内容评价模块。聚焦爬虫的爬取策略实施的关键是评估页面内容和链接的重要性。不同的方法计算不同的重要性,导致链接的访问顺序不同。
1.1.3 增量爬虫
增量网页爬虫是指不再抓取已经抓取的网页,只抓取新生成的网页,即增量更新。与其他类型的网络爬虫相比,它只关注新增的数据,大大减少了网页的下载量,减少了爬虫对存储空间和网络带宽的消耗,但增加了爬虫的复杂度。卷爬取算法及实现难度[3].
1.1.4 深网爬虫
从网站上呈现的网页的不同位置结构来看,网页可以简单地分为浅态页面和深态页面。深度状态网页是指存储在网络数据库中的那些一般搜索引擎无法搜索到的状态页面,通常需要一定的条件才能获得(如登录)。与深态网页相比,浅态网页是指搜索引擎在网络上搜索到的浅态网页。Deep Web 往往具有强烈的主题,每个 Deep Web 主题领域所收录的数字信息更专业,内容更丰富[4]。
1.2 常用爬虫框架
1.2.1 硒
Selenium 是一个用于操作浏览器以执行自动化测试的框架。浏览器自动化可以通过简单的命令来控制,就像真正的用户在操作一样,例如输入验证码。Selenium是一款自动化测试工具,支持多种浏览器,包括Chrome、Safari、Firefox等主流界面浏览器。因此,它可以用来爬取任何网页上看到的任何数据信息,几乎可以避免大多数反爬虫监控[5]。
1.2.2 json接口
Json(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它使用不同于编程语言的特殊文本格式来保存和传递数据。简洁、清晰和易于理解的层次结构使 Json 成为理想的数据交换语言。更便于人读写,更易于机器解析生成,有效提高网络传输效率。Json 文本格式具有兼容性非常高、习惯行为类似于 C 语言系统、独立于其他编程语言的特点。这些特性使 Json 成为一种理想的数据交换语言 [6] 并用于提供 json 数据接口采集 的网页中的数据处理。
1.2.3 Scrapy
Scrapy是一个Python实现的爬虫框架,架构清晰,模块间耦合度比较低,扩展性比较强。等特点[7]。Scrapy框架不仅可以通过爬取网页获取数据,还可以通过访问API接口获取其他对应的数据,实现对网页资源的多级快速爬取,适用于各类网站爬取工作,提取有价值的结构数据[8]。
2 数据采集
本数据采集来源于网络社交平台-新浪微博,采集的具体评论数据为 filter=hot&root_comment_id=0&type=comment#_rnd59 博文下的用户评论。从这篇博文的评论数可以看出,这篇博文下的评论数据非常多,已经达到百万级评论数据。接下来,爬虫将用于捕获其数据并进行一些分析。
下面根据采集的数据特点,分别使用增量爬虫和Deep Web爬虫技术、selenium框架和json数据接口对微博评论数据进行采集。
2.1 使用 Selenium 框架采集数据
Selenium 爬取评论的基本步骤如图 1 所示。
首先获取其网页源代码(在网站上按F12查看),然后根据其源代码构造一个dom树,如图2所示。
接下来可以使用XPath解析dom树,根据相关节点爬取数据。部分代码如下。
user_data = requests.get(i)
dom_url = etree.HTML(user_data.text, etree.HTMLParser(encoding='utf-8'))
follow = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][1]/text()')
fan = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][2]/text()')
boke = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][3]/text()')
数据爬取完成后,可以选择保存为xml、csv、txt等文本文件。在这里,选择保存在 csv 文件中。
2.2 使用Json数据接口采集数据
与 Selenium 不同的是,Json 数据接口可以相对直接的获取数据,因为它的数据结构是 Json 的格式,但是需要找到数据的接口。
因为网页版微博不提供数据接口,反爬机制更先进,我们这里使用手机微博。手机微博用户评论通过瀑布流刷新,提供Json数据接口。例如其中一个接口: id=46240&mid=46240&max_id_type=0,其结构如下。
{ok: 1, data: {data: [,…], total_number: "1 百万+",…}}
数据:{数据:[,…],总数:“100万+”,…}
数据: [,…]
0:{created_at:“2021 年 2 月 27 日星期六 15:09:20 +0800”,id:“46737”,rootid:“46737”,...}
1:{created_at:“2021 年 2 月 27 日星期六 15:04:59 +0800”,id:“46970”,rootid:“46970”,...}
…
18:{created_at:“2021 年 2 月 27 日星期六 15:05:08 +0800”,id:“46568”,rootid:“46568”,...}
最大:50000
max_id: 45846235480040570
max_id_type: 0
状态:{comment_manage_info:{comment_permission_type:-1,approval_comment_type:0}}
总数:“一百万+”
好的:1
这种结构下获取用户评论比较简单,但是一个Json数据接口通常只能提供10×19条用户评论,所以需要重新获取下一个接口。由于手机端的微博使用瀑布流刷新用户评论,可以直接控制页面下拉刷新,获取下一个Json数据接口。观察它的数据接口链路,可以知道链路中只有max_id和max_id_type会发生变化,所以可以通过多个Json数据链路得出规律,下一个链路的max_id就是上一个链路的Json字典中的max_id (json结构倒数第六行),而max_id_type是0到1之间的值。首先用0判断Json返回的ok是否为1,如果是max_id_type则取0,否则取1。
当我
while_starttime = datetime.datetime.now()
尝试:
如果我 == 0:
r = requests.get(one, headers=headers)
别的:
b = '&max_id_type=0'
urlll = a + str(id) + b
r = requests.get(urlll, headers=headers)
标志 = r.json()
flag1 = r.json()['ok']
如果标志1 == 0:
b = '&max_id_type=1'
urlll = a + str(id) + b
r = requests.get(urlll, headers=headers)
js = r.json()
用户 = js['数据']['数据']
下一步就是分解获取Json数据,获取的数据也可以保存为xml表格、csv文件、txt文本文件等。
2.3 采集结果
两种方式的爬取结果包括用户id(用户的唯一标识)、用户名、评论时间、评论内容、评论点赞数。本次爬取共获得6000多条数据,可用于下一步。用户评论的数据挖掘提供了大量的数据,结果如图3所示。
3 结论
本文采用两种方法,均采用深度优先搜索获取微博用户评论数据。Selenium框架首先解析网页源代码,生成dom树,然后通过dom树获取用户评论数据。Json数据接口通过解析Json数据结构,直接获取微博用户的评论数据。实验中,针对微博热点事件下的用户评论数据采集,采用两种方法取得了较好的效果。
两种 data采集 方法都有优点和缺点。Selenium 可以模拟真人爬取数据的行为,基本不受网页限制,但前期过程会比较繁琐,爬取效率不是很高。Json数据接口直截了当,但是获取数据需要详细找出隐藏的接口位置,有时需要找到下一个接口并总结其链接规则,而有的网站没有提供数据接口。在实际操作中,可以根据具体需要,结合两种技术的优缺点选择其中一种方法。
参考
[1] 曾建荣, 张扬森, 郑佳, 等. 多数据源的Web爬虫实现技术及应用[J]. 计算机科学, 2019, 46 (5): 304-309.
[2]郭S,卞W,刘Y,等。基于支持向量机的聚焦爬虫在空间情报采集中的应用研究[J]. 电子设计工程, 2016, 24 (17): 28-34
[3] 叶婷. 基于关键词的微博爬虫系统设计与实现[D]. 杭州:浙江工业大学,2016.
[4] 杨晓福.公交票务DeepWeb数据采集关键技术研究[D]. 重庆:重庆交通大学,2016.
[5] 吕伯清. 基于爬虫和数据挖掘的电子商务页面信息分析[D]. 兰州:兰州大学,2018.
[6] 陈哲. 基于微博热点事件的可视化系统开发与实现[D]. 北京:首都经济贸易大学,2018.
[7] 孙宇. 基于Scrapy框架的网络爬虫系统设计与实现[D]. 北京:北京交通大学,2019.
[8] 崔新宇.基于情感分析的商品评价系统设计与实现[D]. 邯郸:河北工程大学,2020.
标签: 网络爬虫 微博 数据挖掘
报酬

js 爬虫抓取网页数据( 图片js,css等ps:请求,分析用户发来的请求信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2022-03-01 03:12
图片js,css等ps:请求,分析用户发来的请求信息)
请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器接收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫模拟浏览器发送请求再接收Response后提取有用数据。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
/s?wd=图像
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(要添加,否则将被视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location并返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫所需工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis 查看全部
js 爬虫抓取网页数据(
图片js,css等ps:请求,分析用户发来的请求信息)

请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器接收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫模拟浏览器发送请求再接收Response后提取有用数据。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
/s?wd=图像
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(要添加,否则将被视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location并返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫所需工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
js 爬虫抓取网页数据(怎么显示在网页上的呢?网页的代码里面直接包含内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-24 11:11
网页内容一般是指我们最终在网页上看到的内容,但是这个过程并不像直接在网页的代码中收录内容那么简单,所以对于很多新手来说,会遇到很多问题,比如:
显然,当用 Chrome 或 Firefox 检查页面时,可以看到 HTML 标签中收录的内容,但在抓取时为空。
很多内容必须通过点击按钮或执行交互操作来显示在页面上。
因此,对于很多新手来说,做法是使用某种语言来模拟浏览器的操作。其实就是调用本地浏览器或者收录一些执行javascript的引擎进行模拟操作来抓取数据。在抓取大量数据的情况下,效率很低,相当于给技术人员自己用了一个盒子,那么这些内容到底是如何在网页上显示的呢?
主要分为以下几种情况:
网页收录内容的情况是最容易解决的。一般来说,基本上都是静态网页的内容被写死了,或者是动态网页,用模板渲染出来的。当浏览器获取 HTML 时,它已经收录了所有的关键信息,所以你在网页上直接看到的内容可以通过特定的 HTML 标签由 javascript 代码加载。这是因为虽然网页显示时内容在HTML标签中,但实际上是通过执行js代码添加到标签中的。所以此时内容在js代码中,js的执行是在浏览器端,所以当你使用程序请求网页地址时,得到的响应是网页代码和js代码,所以你可以在浏览器端看到它。说到内容,由于解析的时候js还没有被执行,所以一定要发现指定的html标签下的内容是空的。此时的处理方式一般是找到收录该内容的js代码字符串,然后通过正则表达式获取对应的内容。, 而不是解析 HTML 标签。 查看全部
js 爬虫抓取网页数据(怎么显示在网页上的呢?网页的代码里面直接包含内容)
网页内容一般是指我们最终在网页上看到的内容,但是这个过程并不像直接在网页的代码中收录内容那么简单,所以对于很多新手来说,会遇到很多问题,比如:
显然,当用 Chrome 或 Firefox 检查页面时,可以看到 HTML 标签中收录的内容,但在抓取时为空。
很多内容必须通过点击按钮或执行交互操作来显示在页面上。
因此,对于很多新手来说,做法是使用某种语言来模拟浏览器的操作。其实就是调用本地浏览器或者收录一些执行javascript的引擎进行模拟操作来抓取数据。在抓取大量数据的情况下,效率很低,相当于给技术人员自己用了一个盒子,那么这些内容到底是如何在网页上显示的呢?
主要分为以下几种情况:
网页收录内容的情况是最容易解决的。一般来说,基本上都是静态网页的内容被写死了,或者是动态网页,用模板渲染出来的。当浏览器获取 HTML 时,它已经收录了所有的关键信息,所以你在网页上直接看到的内容可以通过特定的 HTML 标签由 javascript 代码加载。这是因为虽然网页显示时内容在HTML标签中,但实际上是通过执行js代码添加到标签中的。所以此时内容在js代码中,js的执行是在浏览器端,所以当你使用程序请求网页地址时,得到的响应是网页代码和js代码,所以你可以在浏览器端看到它。说到内容,由于解析的时候js还没有被执行,所以一定要发现指定的html标签下的内容是空的。此时的处理方式一般是找到收录该内容的js代码字符串,然后通过正则表达式获取对应的内容。, 而不是解析 HTML 标签。
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-22 03:00
昨天,一个小伙伴来找我。新浪新闻的国内新闻页面,其他部分都是可以抓到的静态网页,但是左下角的最新新闻版块不是静态网页,也没有json数据。让我帮你抓住它。大概看过了,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
今天我们的目标就是上图中的红框。首先,我们确保这部分内容不在网页的源码中,而是属于js加载的部分。点击页面后,没有json数据传输!
但是我发现有一个js请求,点击请求,是一行js函数代码,我们复制到json视图查看器中,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这三个参数。猜测是对应的新闻 URL、标题和介绍。
只是它的内容,需要处理,我们写在代码中看看
开始写代码
先导入库,因为最后部分需要从字符串中截取,所以使用requests库获取请求,正则re匹配内容。然后我们先匹配上面3项
可以看到url中存在\\,标题和介绍的形式为\\u539f\\u6807\\u9898。这些是我们需要处理的下一步!
先用replace函数把\\放到url中,就可以得到url,后面的\\u539f\\u6807\\u9898是unicode编码,可以直接解码内容直接写代码
eval函数用于解码,内容可以以u'unicode编码内容'的形式解码!
这样就将这个页面的所有新闻和URL相关的内容都取出来了,在外层加了一个循环去抓取所有的新闻页面,任务就完成了!
后记
新浪新闻页面的js功能比较简单,直接抓取数据即可。如果是比较复杂的功能,需要对前端知识有深刻的理解,这也是为什么在学习爬虫的时候需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,百度上直接找了很多。当然也可以直接修改上面抓包的内容,然后用json读取数据也是可以的!
基本代码不多。有看不清楚的小伙伴可以私信我获取代码或者一起学习爬虫! 查看全部
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用(组图))
昨天,一个小伙伴来找我。新浪新闻的国内新闻页面,其他部分都是可以抓到的静态网页,但是左下角的最新新闻版块不是静态网页,也没有json数据。让我帮你抓住它。大概看过了,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
今天我们的目标就是上图中的红框。首先,我们确保这部分内容不在网页的源码中,而是属于js加载的部分。点击页面后,没有json数据传输!
但是我发现有一个js请求,点击请求,是一行js函数代码,我们复制到json视图查看器中,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这三个参数。猜测是对应的新闻 URL、标题和介绍。
只是它的内容,需要处理,我们写在代码中看看
开始写代码
先导入库,因为最后部分需要从字符串中截取,所以使用requests库获取请求,正则re匹配内容。然后我们先匹配上面3项
可以看到url中存在\\,标题和介绍的形式为\\u539f\\u6807\\u9898。这些是我们需要处理的下一步!
先用replace函数把\\放到url中,就可以得到url,后面的\\u539f\\u6807\\u9898是unicode编码,可以直接解码内容直接写代码
eval函数用于解码,内容可以以u'unicode编码内容'的形式解码!
这样就将这个页面的所有新闻和URL相关的内容都取出来了,在外层加了一个循环去抓取所有的新闻页面,任务就完成了!
后记
新浪新闻页面的js功能比较简单,直接抓取数据即可。如果是比较复杂的功能,需要对前端知识有深刻的理解,这也是为什么在学习爬虫的时候需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,百度上直接找了很多。当然也可以直接修改上面抓包的内容,然后用json读取数据也是可以的!
基本代码不多。有看不清楚的小伙伴可以私信我获取代码或者一起学习爬虫!
js 爬虫抓取网页数据(1.岗位列表的第一页(图)代码分析(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-22 02:23
)
爬虫之类的东西我之前一直都听说过,不过稍微看了一下资料,好像也不算太复杂。
只知道node.js,然后基于它做一个简单的爬虫。
1.这个爬虫目标:
从钩子招聘网站中找出“前端开发”职位的信息,分析对应页面,提取职位名称、职位薪资、职位所属公司等具体部分,发布日期等。并显示捕获的信息。
初始hook网站的接口信息如下:
2.设计方案:
爬虫实际上是通过相应的技术来爬取页面上的具体信息。
在这里,我们主要抓取上图所示职位列表部分相关的具体职位信息。
首先,要爬取,首先要有地址url:
%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F% 91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=1
此链接是职位列表首页的网址。
通过分析地址的参数部分,我们忽略了选择的其他参数,只看最后一个参数值:pn=1
我们的目的是逐页抓取,所以设置为 pn = page;
其次,要获取特定信息,爬虫需要特定代表的标识符。
这里对页面代码的tag值、class值、id值进行分析。
通过 Firebug 审查这个小子集的元素
确定将获得什么信息的分析需要处理特定的标识符。
3.代码编写:
按照预定的计划,考虑到node.js的使用,通过其内置的http模块获取页面信息,通过cheerio.js模块分析DOM,然后转换成json格式数据,直接从控制台输出或者将json数据再次发送回浏览器显示。
(cheerio.js的使用很简单,可以自行搜索详情。最重要的是下面的代码,其余的和jQuery的使用类似。
就是先加载页面的数据,形成特定的数据格式,然后通过类似jq的语法解析数据)
var cheerio = require('cheerio'),
$ = cheerio.load('Hello world');
$('h2.title').text('Hello there!');
$('h2').addClass('welcome');
$.html();
//=> Hello there!
采用快速模块化开发,项目建立后按要求。进入项目目录,执行 npm install 安装所需的依赖。不知道快递的可以看这里
爬虫需要cheerio.js,所以另外需要进来,所以另外npm installcheerio
有很多项目文件。为简单起见,仅对其中三个进行了修改。(index.ejs index.js style.css)
(1)直接修改routes路由中的index.js文件,也是核心部分。
看代码吧,注释已经够多了
1 var express = require('express');
2 var router = express.Router();
3 var http = require('http');
4 var cheerio = require('cheerio');
5
6 /* GET home page. */
7 router.get('/', function(req, res, next) {
8 res.render('index', { title: '简单nodejs爬虫' });
9 });
10 router.get('/getJobs', function(req, res, next) { // 浏览器端发来get请求
11 var page = req.param('page'); //获取get请求中的参数 page
12 console.log("page: "+page);
13 var Res = res; //保存,防止下边的修改
14 //url 获取信息的页面部分地址
15 var url = 'http://www.lagou.com/jobs/list_%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=';
16
17 http.get(url+page,function(res){ //通过get方法获取对应地址中的页面信息
18 var chunks = [];
19 var size = 0;
20 res.on('data',function(chunk){ //监听事件 传输
21 chunks.push(chunk);
22 size += chunk.length;
23 });
24 res.on('end',function(){ //数据传输完
25 var data = Buffer.concat(chunks,size);
26 var html = data.toString();
27 // console.log(html);
28 var $ = cheerio.load(html); //cheerio模块开始处理 DOM处理
29 var jobs = [];
30
31 var jobs_list = $(".hot_pos li");
32 $(".hot_pos>li").each(function(){ //对页面岗位栏信息进行处理 每个岗位对应一个 li ,各标识符到页面进行分析得出
33 var job = {};
34 job.company = $(this).find(".hot_pos_r div").eq(1).find("a").html(); //公司名
35 job.period = $(this).find(".hot_pos_r span").eq(1).html(); //阶段
36 job.scale = $(this).find(".hot_pos_r span").eq(2).html(); //规模
37
38 job.name = $(this).find(".hot_pos_l a").attr("title"); //岗位名
39 job.src = $(this).find(".hot_pos_l a").attr("href"); //岗位链接
40 job.city = $(this).find(".hot_pos_l .c9").html(); //岗位所在城市
41 job.salary = $(this).find(".hot_pos_l span").eq(1).html(); //薪资
42 job.exp = $(this).find(".hot_pos_l span").eq(2).html(); //岗位所需经验
43 job.time = $(this).find(".hot_pos_l span").eq(5).html(); //发布时间
44
45 console.log(job.name); //控制台输出岗位名
46 jobs.push(job);
47 });
48 Res.json({ //返回json格式数据给浏览器端
49 jobs:jobs
50 });
51 });
52 });
53
54 });
55
56 module.exports = router;
(2)node.js捕获的核心代码就是上面的部分。
下一步是展示抓取的数据,所以需要另外一个页面来修改views中的index.ejs模板
1 DOCTYPE html>
2
3
4
5
6
7
8 【nodejs爬虫】 获取拉勾网招聘岗位--前端开发
9 初始化完成 ...
10 点击开始抓取第一页
11
12
13
14
15 数据抓取中 ... 请稍后
16 抓取上一页
17 抓取下一页
18
19
20
21 function getData(str){ //获取到的数据有杂乱..需要把前面部分去掉,只需要data(...... data)
22 if(str){
23 return str.slice(str.lastIndexOf(">")+1);
24 }
25 }
26
27 document.getElementById("btn1").style.visibility = "hidden";
28 document.getElementById("btn2").style.visibility = "hidden";
29 var currentPage = 0; //page初始0
30
31 function cheerFetch(_page){ //抓取数据处理函数
32 if(_page == 1){
33 currentPage = 1; //开始抓取则更改page
34 }
35 $(document).ajaxSend(function(event, xhr, settings) { //抓取中...
36 $(".fetching").css("display","block");
37 });
38 $(document).ajaxSuccess(function(event, xhr, settings) { //抓取成功
39 $(".fetching").css("display","none");
40 });
41 $.ajax({ //开始发送ajax请求至路径 /getJobs 进而作页面抓取处理
42 data:{page:_page}, //参数 page = _page
43 dataType: "json",
44 type: "get",
45 url: "/getJobs",
46 success: function(data){ //收到返回的json数据
47 console.log(data);
48 var html = "";
49 $(".container").empty();
50 if(data.jobs.length == 0){
51 alert("Error2: 未找到数据..");
52 return;
53 }
54 for(var i=0;i 1){
73 document.getElementById("btn1").style.visibility = "visible";
74 document.getElementById("btn2").style.visibility = "visible";
75 }
76 },
77 error: function(){
78 alert("Error1: 未找到数据..");
79 }
80 });
81 }
82
83
84
85
(3)当然,对public文件下的style.css进行简单的修改也是style部分不可缺少的
body {
padding: 20px 50px;
font: 14px "Lucida Grande", Helvetica, Arial, sans-serif;
}
a {
color: #00B7FF;
cursor: pointer;
}
.container{position: relative;width: 1100px;overflow: hidden;zoom:1;}
.jobs{margin: 30px; float: left;}
.jobs span{ color: green; font-weight: bold;}
.btn{cursor: pointer;}
.fetching{display: none;color: red;}
.footer{clear: both;}
基本的变化就是这三个文件。
因此,如果要进行测试,可以在新建项目后直接修改对应的三个文件。
修改成功后,就可以测试了。
3.测试结果
1) 先在控制台执行 npm start
2) 接下来在浏览器中输入:3000/开始访问
3) 点击开始爬取(这里每次抓取15个项目,即原创URL对应15个项目)
...
查看全部
js 爬虫抓取网页数据(1.岗位列表的第一页(图)代码分析(组图)
)
爬虫之类的东西我之前一直都听说过,不过稍微看了一下资料,好像也不算太复杂。
只知道node.js,然后基于它做一个简单的爬虫。
1.这个爬虫目标:
从钩子招聘网站中找出“前端开发”职位的信息,分析对应页面,提取职位名称、职位薪资、职位所属公司等具体部分,发布日期等。并显示捕获的信息。
初始hook网站的接口信息如下:
2.设计方案:
爬虫实际上是通过相应的技术来爬取页面上的具体信息。
在这里,我们主要抓取上图所示职位列表部分相关的具体职位信息。
首先,要爬取,首先要有地址url:
%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F% 91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=1
此链接是职位列表首页的网址。
通过分析地址的参数部分,我们忽略了选择的其他参数,只看最后一个参数值:pn=1
我们的目的是逐页抓取,所以设置为 pn = page;

其次,要获取特定信息,爬虫需要特定代表的标识符。
这里对页面代码的tag值、class值、id值进行分析。
通过 Firebug 审查这个小子集的元素


确定将获得什么信息的分析需要处理特定的标识符。
3.代码编写:
按照预定的计划,考虑到node.js的使用,通过其内置的http模块获取页面信息,通过cheerio.js模块分析DOM,然后转换成json格式数据,直接从控制台输出或者将json数据再次发送回浏览器显示。
(cheerio.js的使用很简单,可以自行搜索详情。最重要的是下面的代码,其余的和jQuery的使用类似。
就是先加载页面的数据,形成特定的数据格式,然后通过类似jq的语法解析数据)
var cheerio = require('cheerio'),
$ = cheerio.load('Hello world');
$('h2.title').text('Hello there!');
$('h2').addClass('welcome');
$.html();
//=> Hello there!
采用快速模块化开发,项目建立后按要求。进入项目目录,执行 npm install 安装所需的依赖。不知道快递的可以看这里
爬虫需要cheerio.js,所以另外需要进来,所以另外npm installcheerio
有很多项目文件。为简单起见,仅对其中三个进行了修改。(index.ejs index.js style.css)
(1)直接修改routes路由中的index.js文件,也是核心部分。
看代码吧,注释已经够多了
1 var express = require('express');
2 var router = express.Router();
3 var http = require('http');
4 var cheerio = require('cheerio');
5
6 /* GET home page. */
7 router.get('/', function(req, res, next) {
8 res.render('index', { title: '简单nodejs爬虫' });
9 });
10 router.get('/getJobs', function(req, res, next) { // 浏览器端发来get请求
11 var page = req.param('page'); //获取get请求中的参数 page
12 console.log("page: "+page);
13 var Res = res; //保存,防止下边的修改
14 //url 获取信息的页面部分地址
15 var url = 'http://www.lagou.com/jobs/list_%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=';
16
17 http.get(url+page,function(res){ //通过get方法获取对应地址中的页面信息
18 var chunks = [];
19 var size = 0;
20 res.on('data',function(chunk){ //监听事件 传输
21 chunks.push(chunk);
22 size += chunk.length;
23 });
24 res.on('end',function(){ //数据传输完
25 var data = Buffer.concat(chunks,size);
26 var html = data.toString();
27 // console.log(html);
28 var $ = cheerio.load(html); //cheerio模块开始处理 DOM处理
29 var jobs = [];
30
31 var jobs_list = $(".hot_pos li");
32 $(".hot_pos>li").each(function(){ //对页面岗位栏信息进行处理 每个岗位对应一个 li ,各标识符到页面进行分析得出
33 var job = {};
34 job.company = $(this).find(".hot_pos_r div").eq(1).find("a").html(); //公司名
35 job.period = $(this).find(".hot_pos_r span").eq(1).html(); //阶段
36 job.scale = $(this).find(".hot_pos_r span").eq(2).html(); //规模
37
38 job.name = $(this).find(".hot_pos_l a").attr("title"); //岗位名
39 job.src = $(this).find(".hot_pos_l a").attr("href"); //岗位链接
40 job.city = $(this).find(".hot_pos_l .c9").html(); //岗位所在城市
41 job.salary = $(this).find(".hot_pos_l span").eq(1).html(); //薪资
42 job.exp = $(this).find(".hot_pos_l span").eq(2).html(); //岗位所需经验
43 job.time = $(this).find(".hot_pos_l span").eq(5).html(); //发布时间
44
45 console.log(job.name); //控制台输出岗位名
46 jobs.push(job);
47 });
48 Res.json({ //返回json格式数据给浏览器端
49 jobs:jobs
50 });
51 });
52 });
53
54 });
55
56 module.exports = router;
(2)node.js捕获的核心代码就是上面的部分。
下一步是展示抓取的数据,所以需要另外一个页面来修改views中的index.ejs模板
1 DOCTYPE html>
2
3
4
5
6
7
8 【nodejs爬虫】 获取拉勾网招聘岗位--前端开发
9 初始化完成 ...
10 点击开始抓取第一页
11
12
13
14
15 数据抓取中 ... 请稍后
16 抓取上一页
17 抓取下一页
18
19
20
21 function getData(str){ //获取到的数据有杂乱..需要把前面部分去掉,只需要data(...... data)
22 if(str){
23 return str.slice(str.lastIndexOf(">")+1);
24 }
25 }
26
27 document.getElementById("btn1").style.visibility = "hidden";
28 document.getElementById("btn2").style.visibility = "hidden";
29 var currentPage = 0; //page初始0
30
31 function cheerFetch(_page){ //抓取数据处理函数
32 if(_page == 1){
33 currentPage = 1; //开始抓取则更改page
34 }
35 $(document).ajaxSend(function(event, xhr, settings) { //抓取中...
36 $(".fetching").css("display","block");
37 });
38 $(document).ajaxSuccess(function(event, xhr, settings) { //抓取成功
39 $(".fetching").css("display","none");
40 });
41 $.ajax({ //开始发送ajax请求至路径 /getJobs 进而作页面抓取处理
42 data:{page:_page}, //参数 page = _page
43 dataType: "json",
44 type: "get",
45 url: "/getJobs",
46 success: function(data){ //收到返回的json数据
47 console.log(data);
48 var html = "";
49 $(".container").empty();
50 if(data.jobs.length == 0){
51 alert("Error2: 未找到数据..");
52 return;
53 }
54 for(var i=0;i 1){
73 document.getElementById("btn1").style.visibility = "visible";
74 document.getElementById("btn2").style.visibility = "visible";
75 }
76 },
77 error: function(){
78 alert("Error1: 未找到数据..");
79 }
80 });
81 }
82
83
84
85
(3)当然,对public文件下的style.css进行简单的修改也是style部分不可缺少的
body {
padding: 20px 50px;
font: 14px "Lucida Grande", Helvetica, Arial, sans-serif;
}
a {
color: #00B7FF;
cursor: pointer;
}
.container{position: relative;width: 1100px;overflow: hidden;zoom:1;}
.jobs{margin: 30px; float: left;}
.jobs span{ color: green; font-weight: bold;}
.btn{cursor: pointer;}
.fetching{display: none;color: red;}
.footer{clear: both;}
基本的变化就是这三个文件。
因此,如果要进行测试,可以在新建项目后直接修改对应的三个文件。
修改成功后,就可以测试了。
3.测试结果
1) 先在控制台执行 npm start
2) 接下来在浏览器中输入:3000/开始访问
3) 点击开始爬取(这里每次抓取15个项目,即原创URL对应15个项目)

...

js 爬虫抓取网页数据(js爬虫抓取网页数据采用的抓包软件网上就有很多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-02-21 23:02
js爬虫抓取网页数据采用的抓包软件网上就有很多可以自己尝试着搞我给你推荐个专门下载二手的网站地址:,然后在爬虫里面找到这个网站,把它的url拖进去浏览器就会自动下载此文件了另外,在编写爬虫时,也需要注意写一下它爬取这个网站的流程。
python实现下单,可关注我的知乎专栏,
三种方式,仅供参考。
1、二手交易平台上在线购买,你在一个月内不用任何操作就能出售。
2、二手转转等类似的商城购买,然后线下配送。
3、团购,跟实体店一样,按人头算服务费。
在知乎上搜搜下单教程可能会有点用
可以用邮箱登录京东二手交易市场,商品详情在这儿:京东二手_京东商城()我还是比较喜欢去二手平台买哈哈,物美价廉。
千万别去官方给出的图示。在前面说这个的网站看到的。以及在外链抓到的一条。在京东购物的详情页后面有隐藏单价说明。我也在想有用。我一共买了5次东西。然后京东赠了单独的app的一个id让我在其他app上改。
我是写个爬虫爬下来在手机上直接导入页面地址,
在手机上,我用了urllib比较方便。还有一种爬虫是在一些网站上爬,要做很大的页面,可以利用chrome的firebug,实时抓包。我也在思考,下单这么大的一个网站,能不能像邮箱一样给你人工建议。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据采用的抓包软件网上就有很多)
js爬虫抓取网页数据采用的抓包软件网上就有很多可以自己尝试着搞我给你推荐个专门下载二手的网站地址:,然后在爬虫里面找到这个网站,把它的url拖进去浏览器就会自动下载此文件了另外,在编写爬虫时,也需要注意写一下它爬取这个网站的流程。
python实现下单,可关注我的知乎专栏,
三种方式,仅供参考。
1、二手交易平台上在线购买,你在一个月内不用任何操作就能出售。
2、二手转转等类似的商城购买,然后线下配送。
3、团购,跟实体店一样,按人头算服务费。
在知乎上搜搜下单教程可能会有点用
可以用邮箱登录京东二手交易市场,商品详情在这儿:京东二手_京东商城()我还是比较喜欢去二手平台买哈哈,物美价廉。
千万别去官方给出的图示。在前面说这个的网站看到的。以及在外链抓到的一条。在京东购物的详情页后面有隐藏单价说明。我也在想有用。我一共买了5次东西。然后京东赠了单独的app的一个id让我在其他app上改。
我是写个爬虫爬下来在手机上直接导入页面地址,
在手机上,我用了urllib比较方便。还有一种爬虫是在一些网站上爬,要做很大的页面,可以利用chrome的firebug,实时抓包。我也在思考,下单这么大的一个网站,能不能像邮箱一样给你人工建议。
js 爬虫抓取网页数据(JS逆向方法论-反爬虫的四种常见方式(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2022-02-20 11:21
如今,网页的代码越来越复杂。除了使用vue等前端框架让开发更简单外,主要是为了防止爬虫,所以越来越多的精力投入到编写爬虫上。攻防双方在交锋中结下了不好的关系,但也互相促进。
本文讨论了JS反爬虫的策略,看看如何破解它们。
JS 逆向方法论——四种常见的反爬方式
1.JS写cookies
如果我们要写爬虫来抓取某个网页中的数据,无非就是打开网页看源码。如果html中有我们想要的数据,那就简单了。使用requests请求URL获取网页源代码,然后解析提取。
等等!requests得到的网页是一对JS,和浏览器看到的网页源码完全不一样!在这种情况下,浏览器运行这个 JS 来生成一个(或多个)cookie,然后用这个 cookie 发出第二个请求。当服务器接收到这个cookie时,它认为您的访问是通过浏览器的合法访问。
事实上,你可以在浏览器(chrome、Firefox)中看到这个过程。首先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox为“Persist logs”),刷新网页,这样我们就可以看到历史了网络请求记录。例如下图:
js写cookie
第一次打开“index.html”页面时,返回521,内容为一段JS代码;第二次请求页面时,获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实是JS生成的。
对策是研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
二、JS加密ajax请求参数
编写爬虫爬取网页中的数据,发现网页源代码中没有我们想要的数据,有点麻烦。这些数据通常是通过 ajax 请求获得的。不过不要害怕,按F12打开Network窗口,刷新网页看看加载这个网页的时候已经下载了哪些URL,我们要的数据在一个URL请求的结果中。Chrome 网络中此类 URL 的大多数类型都是 XHR。通过观察他们的“Response”,我们可以找到我们想要的数据。
然而,事情往往并不顺利。URL 收录很多参数,其中一个参数是一串看似无意义的字符串。这个字符串很可能是JS通过加密算法得到的,服务器也会通过同样的算法进行验证。验证通过后,它认为你是从浏览器请求。我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
对于这样的加密参数,对策就是调试JS找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
三、JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。这个方法用的太多了,网站加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。它看起来像这样:
无论我们点击多少次继续运行,它总是在这个“调试器”中,而且每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用. 这个“调试器”让我们无法调试 JS。但是当F12窗口关闭时,网页正常加载。
解决这种JS反调试的方法叫做“反反调试”,它的策略是通过“调用栈”找到让我们陷入死循环的函数并重新定义。
这样的功能几乎没有其他功能,但对我们来说是一个陷阱。我们可以在“Console”中重新定义这个函数,比如把它重新定义为一个空函数,这样当我们再次运行它的时候,它什么也不做,不会把我们引入陷阱。在调用此函数的位置放置一个“断点”。因为我们已经陷进去了,要刷新页面,JS的运行应该停在设置的断点处。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
四、JS 发送鼠标点击事件
还有一些网站,其反爬不是上面的方法。您可以从浏览器打开普通页面,但在请求中您需要输入验证码或重定向其他页面。一开始你可能会感到困惑,但不要害怕,仔细看看“网络”可能会发现一些线索。例如,以下网络流中的信息:
仔细观察后发现,每次点击页面的链接,都会发出“cl.gif”请求,貌似下载的是gif图片,其实不然。它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先梳理一下它的逻辑。JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
了解了这个过程,我们想出对策就不难了,几乎不用研究JS内容(JS也可能修改点击的链接)绕过这个反爬策略,访问cl. gif 就可以了。关键是研究一下cl.gif之后的参数,把这些参数都带上就万事大吉了。
结尾
爬行动物和 网站 是一对敌人,他们彼此生活在一起。如果爬虫知道反爬策略,可以做出响应式反反爬策略;网站 知道了爬虫的防反爬策略,就可以制定“防反反爬”策略了……道高一尺高一丈,二人争斗将没有结束。 查看全部
js 爬虫抓取网页数据(JS逆向方法论-反爬虫的四种常见方式(组图))
如今,网页的代码越来越复杂。除了使用vue等前端框架让开发更简单外,主要是为了防止爬虫,所以越来越多的精力投入到编写爬虫上。攻防双方在交锋中结下了不好的关系,但也互相促进。
本文讨论了JS反爬虫的策略,看看如何破解它们。

JS 逆向方法论——四种常见的反爬方式
1.JS写cookies
如果我们要写爬虫来抓取某个网页中的数据,无非就是打开网页看源码。如果html中有我们想要的数据,那就简单了。使用requests请求URL获取网页源代码,然后解析提取。
等等!requests得到的网页是一对JS,和浏览器看到的网页源码完全不一样!在这种情况下,浏览器运行这个 JS 来生成一个(或多个)cookie,然后用这个 cookie 发出第二个请求。当服务器接收到这个cookie时,它认为您的访问是通过浏览器的合法访问。
事实上,你可以在浏览器(chrome、Firefox)中看到这个过程。首先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox为“Persist logs”),刷新网页,这样我们就可以看到历史了网络请求记录。例如下图:
js写cookie
第一次打开“index.html”页面时,返回521,内容为一段JS代码;第二次请求页面时,获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实是JS生成的。
对策是研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
二、JS加密ajax请求参数
编写爬虫爬取网页中的数据,发现网页源代码中没有我们想要的数据,有点麻烦。这些数据通常是通过 ajax 请求获得的。不过不要害怕,按F12打开Network窗口,刷新网页看看加载这个网页的时候已经下载了哪些URL,我们要的数据在一个URL请求的结果中。Chrome 网络中此类 URL 的大多数类型都是 XHR。通过观察他们的“Response”,我们可以找到我们想要的数据。
然而,事情往往并不顺利。URL 收录很多参数,其中一个参数是一串看似无意义的字符串。这个字符串很可能是JS通过加密算法得到的,服务器也会通过同样的算法进行验证。验证通过后,它认为你是从浏览器请求。我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
对于这样的加密参数,对策就是调试JS找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
三、JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。这个方法用的太多了,网站加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。它看起来像这样:
无论我们点击多少次继续运行,它总是在这个“调试器”中,而且每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用. 这个“调试器”让我们无法调试 JS。但是当F12窗口关闭时,网页正常加载。
解决这种JS反调试的方法叫做“反反调试”,它的策略是通过“调用栈”找到让我们陷入死循环的函数并重新定义。
这样的功能几乎没有其他功能,但对我们来说是一个陷阱。我们可以在“Console”中重新定义这个函数,比如把它重新定义为一个空函数,这样当我们再次运行它的时候,它什么也不做,不会把我们引入陷阱。在调用此函数的位置放置一个“断点”。因为我们已经陷进去了,要刷新页面,JS的运行应该停在设置的断点处。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
四、JS 发送鼠标点击事件
还有一些网站,其反爬不是上面的方法。您可以从浏览器打开普通页面,但在请求中您需要输入验证码或重定向其他页面。一开始你可能会感到困惑,但不要害怕,仔细看看“网络”可能会发现一些线索。例如,以下网络流中的信息:
仔细观察后发现,每次点击页面的链接,都会发出“cl.gif”请求,貌似下载的是gif图片,其实不然。它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先梳理一下它的逻辑。JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
了解了这个过程,我们想出对策就不难了,几乎不用研究JS内容(JS也可能修改点击的链接)绕过这个反爬策略,访问cl. gif 就可以了。关键是研究一下cl.gif之后的参数,把这些参数都带上就万事大吉了。
结尾
爬行动物和 网站 是一对敌人,他们彼此生活在一起。如果爬虫知道反爬策略,可以做出响应式反反爬策略;网站 知道了爬虫的防反爬策略,就可以制定“防反反爬”策略了……道高一尺高一丈,二人争斗将没有结束。
js 爬虫抓取网页数据(js爬虫抓取网页数据的实现方法及实现技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-20 09:13
js爬虫抓取网页数据的,如果需要修改成批量的功能,看一下这个文章可以帮到你h5随便批量修改web前端开发,把这两个给他们看。一个是抓取网页数据的,一个是修改banner图片的。多看两遍,
推荐一个简单高效的实现方法1使用scrapy:基于框架的快速批量抓取scrapy。scrapy是一个开源框架,存在于nodejs上,相当于scrapycore的增强版,通过它来实现批量抓取是一件很方便的事情。网站抓取的问题在于定制化操作,这篇博客正是解决这些问题的办法之一。scrapycore是通过从scrapyspider的基本代码中继承来实现的,通过它可以快速的完成数据的抓取工作,其实现方法采用请求的思想。
首先,当你向scrapycore发送一个请求时,获取结果的方法就是,构造另一个spider,继承scrapycore.request并返回结果。接下来就是编写正确的spider了,在这篇博客中可以看到scrapycore中通过phantomjs和selenium写出实时网站抓取程序的方法。首先有这样一个case:everythingintheresourceisabouttradeoffrelationsanddelivery.everycoiniscalculatedtobetradedoffasanone-coinsets.soallcoinsaretradedatparticularcostoftrade.[root](analysisbasedonrequests,spiders,andblog)这段代码中有2个feature。
1.phantomjs的多页抓取可以实现爬虫,2.在我们爬取时,遍历相应的元素来获取原始数据。因为我们在爬取时为了确定必须要爬取的页面,必须事先爬取,所以我们通过phantomjs获取页面,以确定我们要爬取的页面。获取到页面后就是要遍历元素,来获取我们想要的原始数据了。因为原始数据是一个二进制值,所以一般采用python的“正则表达式”来匹配提取我们想要的数据。
通过phantomjs这个特殊的库进行批量抓取时是使用正则表达式来获取网页元素,通过正则表达式匹配元素来获取原始数据。正则表达式匹配一个对象时,一定是匹配当前对象包含的所有内容,而且具有一一对应关系,返回值一定是包含元素的内容,不包含内容的内容返回0。例如:匹配当前元素包含的内容是(0,),返回内容是一个结果字符串,那么返回值是['productid','verificationid']。
例如:匹配当前元素包含的内容是['areavailable','availablelist'],返回内容是一个结果字符串,那么返回值是['availableset','id']。基于正则表达式,获取元素时可以通过正则表达式匹配元素的一些特征如size,type,name,empty,default等等。正则表达式要匹配的内容一般。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据的实现方法及实现技巧)
js爬虫抓取网页数据的,如果需要修改成批量的功能,看一下这个文章可以帮到你h5随便批量修改web前端开发,把这两个给他们看。一个是抓取网页数据的,一个是修改banner图片的。多看两遍,
推荐一个简单高效的实现方法1使用scrapy:基于框架的快速批量抓取scrapy。scrapy是一个开源框架,存在于nodejs上,相当于scrapycore的增强版,通过它来实现批量抓取是一件很方便的事情。网站抓取的问题在于定制化操作,这篇博客正是解决这些问题的办法之一。scrapycore是通过从scrapyspider的基本代码中继承来实现的,通过它可以快速的完成数据的抓取工作,其实现方法采用请求的思想。
首先,当你向scrapycore发送一个请求时,获取结果的方法就是,构造另一个spider,继承scrapycore.request并返回结果。接下来就是编写正确的spider了,在这篇博客中可以看到scrapycore中通过phantomjs和selenium写出实时网站抓取程序的方法。首先有这样一个case:everythingintheresourceisabouttradeoffrelationsanddelivery.everycoiniscalculatedtobetradedoffasanone-coinsets.soallcoinsaretradedatparticularcostoftrade.[root](analysisbasedonrequests,spiders,andblog)这段代码中有2个feature。
1.phantomjs的多页抓取可以实现爬虫,2.在我们爬取时,遍历相应的元素来获取原始数据。因为我们在爬取时为了确定必须要爬取的页面,必须事先爬取,所以我们通过phantomjs获取页面,以确定我们要爬取的页面。获取到页面后就是要遍历元素,来获取我们想要的原始数据了。因为原始数据是一个二进制值,所以一般采用python的“正则表达式”来匹配提取我们想要的数据。
通过phantomjs这个特殊的库进行批量抓取时是使用正则表达式来获取网页元素,通过正则表达式匹配元素来获取原始数据。正则表达式匹配一个对象时,一定是匹配当前对象包含的所有内容,而且具有一一对应关系,返回值一定是包含元素的内容,不包含内容的内容返回0。例如:匹配当前元素包含的内容是(0,),返回内容是一个结果字符串,那么返回值是['productid','verificationid']。
例如:匹配当前元素包含的内容是['areavailable','availablelist'],返回内容是一个结果字符串,那么返回值是['availableset','id']。基于正则表达式,获取元素时可以通过正则表达式匹配元素的一些特征如size,type,name,empty,default等等。正则表达式要匹配的内容一般。
js 爬虫抓取网页数据(1.爬虫概述可能上面的说明还是难以具体地描述爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-15 19:26
爬虫,也就是网络爬虫,我们可以把互联网比作一个大网,而爬虫就是在网上爬行的蜘蛛,我们可以把网络的节点比作网页,爬它就相当于访问了page 获取其信息后,可以将节点之间的连接比作网页之间的链接关系,这样蜘蛛就可以在经过一个节点后继续沿着该节点连接爬行到下一个节点,即继续获取后续网页通过一个网页,让蜘蛛爬取整个网络的节点,从而抓取网站的数据。
1. 爬虫概述
在上面的描述中可能很难描述爬虫是什么。简而言之,爬虫是获取网页并提取和保存信息的自动化程序。接下来,我们将解释每一点:
获取网页
爬虫要做的第一个工作就是获取网页。这里,获取网页就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站的服务器发送一个Request,返回的Response的Body就是网页的源代码。所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。这个过程如何实施?不能手动截取网页源代码?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如Urllib、Requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。Request 和 Response 可以用类库提供的数据结构来表示。得到Response后,我们只需要解析数据结构的Body部分,即得到网页的源代码,这样就可以使用程序来实现获取网页的过程了。
行
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
保存数据
提取信息后,我们一般将提取的数据保存在某处,以供后续数据处理。保存有多种形式,比如简单的保存为TXT文本或者Json文本,或者保存到数据库,比如MySQL、MongoDB等,或者保存到远程服务器,比如使用Sftp操作。
自动化程序
谈到自动化,这意味着爬虫可以代替人类执行这些操作。首先,我们可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。因此,爬虫是一个自动化的程序,它代表我们完成爬取数据的工作。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们都对应着HTML代码,而最常见的爬取就是爬取HTML源代码。
此外,某些网页可能会返回 Json 字符串而不是 HTML 代码。大多数API接口都采用这种形式,方便数据传输和分析。这种数据也可以抓取,数据提取更方便。
此外,我们还可以看到各种二进制数据,比如图片、视频、音频等,我们可以使用爬虫抓取它们的二进制数据,并保存为对应的文件名。
此外,我们还可以看到各种扩展名的文件,比如CSS、JavaScript、配置文件等,这些其实是最常见的文件,只要在浏览器中访问,我们就可以抓取。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据爬虫,都可以爬取。
3. JavaScript 渲染页面
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。例如:
This is a Demo
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
body节点中只有一个id为container的节点,但是注意在body节点之后引入了一个app.js,负责渲染整个网站。
浏览器在打开这个页面的时候会先加载html内容,然后浏览器会发现里面已经引入了一个app.js文件,然后浏览器就会请求这个文件,获取到后执行文件。JavaScript 代码,而 JavaScript 会改变 HTML 中的节点,向内添加内容,最终得到完整的页面。
但是当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,所以我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。在这种情况下,我们可以分析它的后台 Ajax 接口,或者使用 Selenium 和 Splash 等库来模拟 JavaScript 渲染,这样我们就可以爬取 JavaScript 渲染的网页内容。
稍后我们将详细介绍 JavaScript 渲染页面的 采集 方法。
4. 结论
本节介绍爬虫的一些基本原理,了解以上内容可以帮助我们以后编写爬虫时更加得心应手。 查看全部
js 爬虫抓取网页数据(1.爬虫概述可能上面的说明还是难以具体地描述爬虫)
爬虫,也就是网络爬虫,我们可以把互联网比作一个大网,而爬虫就是在网上爬行的蜘蛛,我们可以把网络的节点比作网页,爬它就相当于访问了page 获取其信息后,可以将节点之间的连接比作网页之间的链接关系,这样蜘蛛就可以在经过一个节点后继续沿着该节点连接爬行到下一个节点,即继续获取后续网页通过一个网页,让蜘蛛爬取整个网络的节点,从而抓取网站的数据。
1. 爬虫概述
在上面的描述中可能很难描述爬虫是什么。简而言之,爬虫是获取网页并提取和保存信息的自动化程序。接下来,我们将解释每一点:
获取网页
爬虫要做的第一个工作就是获取网页。这里,获取网页就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站的服务器发送一个Request,返回的Response的Body就是网页的源代码。所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。这个过程如何实施?不能手动截取网页源代码?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如Urllib、Requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。Request 和 Response 可以用类库提供的数据结构来表示。得到Response后,我们只需要解析数据结构的Body部分,即得到网页的源代码,这样就可以使用程序来实现获取网页的过程了。
行
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
保存数据
提取信息后,我们一般将提取的数据保存在某处,以供后续数据处理。保存有多种形式,比如简单的保存为TXT文本或者Json文本,或者保存到数据库,比如MySQL、MongoDB等,或者保存到远程服务器,比如使用Sftp操作。
自动化程序
谈到自动化,这意味着爬虫可以代替人类执行这些操作。首先,我们可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。因此,爬虫是一个自动化的程序,它代表我们完成爬取数据的工作。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们都对应着HTML代码,而最常见的爬取就是爬取HTML源代码。
此外,某些网页可能会返回 Json 字符串而不是 HTML 代码。大多数API接口都采用这种形式,方便数据传输和分析。这种数据也可以抓取,数据提取更方便。
此外,我们还可以看到各种二进制数据,比如图片、视频、音频等,我们可以使用爬虫抓取它们的二进制数据,并保存为对应的文件名。
此外,我们还可以看到各种扩展名的文件,比如CSS、JavaScript、配置文件等,这些其实是最常见的文件,只要在浏览器中访问,我们就可以抓取。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据爬虫,都可以爬取。
3. JavaScript 渲染页面
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。例如:
This is a Demo
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
body节点中只有一个id为container的节点,但是注意在body节点之后引入了一个app.js,负责渲染整个网站。
浏览器在打开这个页面的时候会先加载html内容,然后浏览器会发现里面已经引入了一个app.js文件,然后浏览器就会请求这个文件,获取到后执行文件。JavaScript 代码,而 JavaScript 会改变 HTML 中的节点,向内添加内容,最终得到完整的页面。
但是当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,所以我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。在这种情况下,我们可以分析它的后台 Ajax 接口,或者使用 Selenium 和 Splash 等库来模拟 JavaScript 渲染,这样我们就可以爬取 JavaScript 渲染的网页内容。
稍后我们将详细介绍 JavaScript 渲染页面的 采集 方法。
4. 结论
本节介绍爬虫的一些基本原理,了解以上内容可以帮助我们以后编写爬虫时更加得心应手。
js 爬虫抓取网页数据(如何使用httpclient抓取页面以及如何用jsoup分析html内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-15 15:22
在之前的系列文章中介绍了如何使用httpclient抓取页面html以及如何使用jsoup分析html源文件的内容得到我们想要的数据,但是有时候这两种方法都不能使用捕获我们想要的数据。所需数据,例如,请参见以下示例。
1.需求场景:
如果要抢到股票的最新价格,F12页信息如下:
按照前面的方法,爬取的代码如下:
1/**
2 * @description: 爬取股票的最新股价
3 * @author: JAVA开发老菜鸟
4 * @date: 2021-10-16 21:47
5 */
6public class StockPriceSpider {
7
8 Logger logger = LoggerFactory.getLogger(this.getClass());
9
10 public static void main(String[] args) {
11
12 StockPriceSpider stockPriceSpider = new StockPriceSpider();
13 String html = stockPriceSpider.httpClientProcess();
14 stockPriceSpider.jsoupProcess(html);
15 }
16
17 private String httpClientProcess() {
18 String html = "";
19 String uri = "http://quote.eastmoney.com/sh600036.html";
20 //1.生成httpclient,相当于该打开一个浏览器
21 CloseableHttpClient httpClient = HttpClients.createDefault();
22 CloseableHttpResponse response = null;
23 //2.创建get请求,相当于在浏览器地址栏输入 网址
24 HttpGet request = new HttpGet(uri);
25 try {
26 request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
27 request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
28
29// HttpHost proxy = new HttpHost("3.211.17.212", 80);
30// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
31// request.setConfig(config);
32
33 //3.执行get请求,相当于在输入地址栏后敲回车键
34 response = httpClient.execute(request);
35
36 //4.判断响应状态为200,进行处理
37 if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
38 //5.获取响应内容
39 HttpEntity httpEntity = response.getEntity();
40 html = EntityUtils.toString(httpEntity, "utf-8");
41 logger.info("访问{} 成功,返回页面数据{}", uri, html);
42 } else {
43 //如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
44 logger.info("访问{},返回状态不是200", uri);
45 logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
46 }
47 } catch (ClientProtocolException e) {
48 e.printStackTrace();
49 } catch (IOException e) {
50 e.printStackTrace();
51 } finally {
52 //6.关闭
53 HttpClientUtils.closeQuietly(response);
54 HttpClientUtils.closeQuietly(httpClient);
55 }
56 return html;
57 }
58
59 private void jsoupProcess(String html) {
60 Document document = Jsoup.parse(html);
61 Element price = document.getElementById("price9");
62 logger.info("股价为:>>> {}", price.text());
63 }
64
65}
66
运行结果:
纳尼,股价是“-”?不可能的。
无法爬取正确结果的原因是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.爬取异步加载数据的java方法
如何爬取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,让js渲染出来的页面和静态页面一样。常用的内核有
这里我选择了 Selenium,它是一个模拟浏览器和自动化测试工具。它提供了一组 API 来与真正的浏览器内核交互。当然,爬虫也可以使用它。
具体方法如下:
1
2 org.seleniumhq.selenium
3 selenium-java
4 3.141.59
5
6
要使用 selenium,您需要下载浏览器的驱动程序。根据浏览器的不同,需要下载的驱动也不同。下载地址为:ChromeDriver Mirror
我用的是谷歌浏览器,所以我下载了对应版本的windows和linux驱动。
下载后需要配置到java环境变量中,并指定驱动目录:
System.getProperties().setProperty("webdriver.chrome.driver", "F:/download/chromedriver_win32_1/chromedriver.exe");
1Logger logger = LoggerFactory.getLogger(this.getClass());
2
3 public static void main(String[] args) {
4
5 StockPriceSpider stockPriceSpider = new StockPriceSpider();
6 stockPriceSpider.seleniumProcess();
7 }
8
9 private void seleniumProcess() {
10
11 String uri = "http://quote.eastmoney.com/sh600036.html";
12
13 // 设置 chromedirver 的存放位置
14 System.getProperties().setProperty("webdriver.chrome.driver", "F:/download/chromedriver_win32_1/chromedriver.exe");
15
16 // 设置浏览器参数
17 ChromeOptions chromeOptions = new ChromeOptions();
18 chromeOptions.addArguments("--no-sandbox");//禁用沙箱
19 chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
20 chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
21 WebDriver webDriver = new ChromeDriver(chromeOptions);
22
23 webDriver.get(uri);
24 WebElement webElements = webDriver.findElement(By.id("price9"));
25 String stockPrice = webElements.getText();
26 logger.info("最新股价为 >>> {}", stockPrice);
27 webDriver.close();
28 }
29
结果:
爬取成功!
2.2 逆向分析法
反向解析的方法是通过F12找到Ajax异步数据获取的链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
此方法的关键是找到 Ajax 链接。这个方法我没研究过,有兴趣可以百度下载。稍微在这里。
3.结束语
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:仓位市值通知系统,每天会根据自己的仓位配置自动计算账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以看看。 查看全部
js 爬虫抓取网页数据(如何使用httpclient抓取页面以及如何用jsoup分析html内容)
在之前的系列文章中介绍了如何使用httpclient抓取页面html以及如何使用jsoup分析html源文件的内容得到我们想要的数据,但是有时候这两种方法都不能使用捕获我们想要的数据。所需数据,例如,请参见以下示例。
1.需求场景:
如果要抢到股票的最新价格,F12页信息如下:
按照前面的方法,爬取的代码如下:
1/**
2 * @description: 爬取股票的最新股价
3 * @author: JAVA开发老菜鸟
4 * @date: 2021-10-16 21:47
5 */
6public class StockPriceSpider {
7
8 Logger logger = LoggerFactory.getLogger(this.getClass());
9
10 public static void main(String[] args) {
11
12 StockPriceSpider stockPriceSpider = new StockPriceSpider();
13 String html = stockPriceSpider.httpClientProcess();
14 stockPriceSpider.jsoupProcess(html);
15 }
16
17 private String httpClientProcess() {
18 String html = "";
19 String uri = "http://quote.eastmoney.com/sh600036.html";
20 //1.生成httpclient,相当于该打开一个浏览器
21 CloseableHttpClient httpClient = HttpClients.createDefault();
22 CloseableHttpResponse response = null;
23 //2.创建get请求,相当于在浏览器地址栏输入 网址
24 HttpGet request = new HttpGet(uri);
25 try {
26 request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
27 request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
28
29// HttpHost proxy = new HttpHost("3.211.17.212", 80);
30// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
31// request.setConfig(config);
32
33 //3.执行get请求,相当于在输入地址栏后敲回车键
34 response = httpClient.execute(request);
35
36 //4.判断响应状态为200,进行处理
37 if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
38 //5.获取响应内容
39 HttpEntity httpEntity = response.getEntity();
40 html = EntityUtils.toString(httpEntity, "utf-8");
41 logger.info("访问{} 成功,返回页面数据{}", uri, html);
42 } else {
43 //如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
44 logger.info("访问{},返回状态不是200", uri);
45 logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
46 }
47 } catch (ClientProtocolException e) {
48 e.printStackTrace();
49 } catch (IOException e) {
50 e.printStackTrace();
51 } finally {
52 //6.关闭
53 HttpClientUtils.closeQuietly(response);
54 HttpClientUtils.closeQuietly(httpClient);
55 }
56 return html;
57 }
58
59 private void jsoupProcess(String html) {
60 Document document = Jsoup.parse(html);
61 Element price = document.getElementById("price9");
62 logger.info("股价为:>>> {}", price.text());
63 }
64
65}
66
运行结果:
纳尼,股价是“-”?不可能的。
无法爬取正确结果的原因是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.爬取异步加载数据的java方法
如何爬取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,让js渲染出来的页面和静态页面一样。常用的内核有
这里我选择了 Selenium,它是一个模拟浏览器和自动化测试工具。它提供了一组 API 来与真正的浏览器内核交互。当然,爬虫也可以使用它。
具体方法如下:
1
2 org.seleniumhq.selenium
3 selenium-java
4 3.141.59
5
6
要使用 selenium,您需要下载浏览器的驱动程序。根据浏览器的不同,需要下载的驱动也不同。下载地址为:ChromeDriver Mirror
我用的是谷歌浏览器,所以我下载了对应版本的windows和linux驱动。


下载后需要配置到java环境变量中,并指定驱动目录:
System.getProperties().setProperty("webdriver.chrome.driver", "F:/download/chromedriver_win32_1/chromedriver.exe");
1Logger logger = LoggerFactory.getLogger(this.getClass());
2
3 public static void main(String[] args) {
4
5 StockPriceSpider stockPriceSpider = new StockPriceSpider();
6 stockPriceSpider.seleniumProcess();
7 }
8
9 private void seleniumProcess() {
10
11 String uri = "http://quote.eastmoney.com/sh600036.html";
12
13 // 设置 chromedirver 的存放位置
14 System.getProperties().setProperty("webdriver.chrome.driver", "F:/download/chromedriver_win32_1/chromedriver.exe");
15
16 // 设置浏览器参数
17 ChromeOptions chromeOptions = new ChromeOptions();
18 chromeOptions.addArguments("--no-sandbox");//禁用沙箱
19 chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
20 chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
21 WebDriver webDriver = new ChromeDriver(chromeOptions);
22
23 webDriver.get(uri);
24 WebElement webElements = webDriver.findElement(By.id("price9"));
25 String stockPrice = webElements.getText();
26 logger.info("最新股价为 >>> {}", stockPrice);
27 webDriver.close();
28 }
29
结果:
爬取成功!
2.2 逆向分析法
反向解析的方法是通过F12找到Ajax异步数据获取的链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
此方法的关键是找到 Ajax 链接。这个方法我没研究过,有兴趣可以百度下载。稍微在这里。
3.结束语
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:仓位市值通知系统,每天会根据自己的仓位配置自动计算账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以看看。
js 爬虫抓取网页数据(越过亚马逊的反爬虫机制,成功越过反爬机制(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 714 次浏览 • 2022-02-13 02:10
您的浏览器不支持音频标签。
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等
反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-import urllib.requestreq = urllib.request.urlopen('https://www.amazon.com')print(req.code)复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
代码如下↓ ↓ ↓
import requestsurl='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'web_header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate, br','Connection': 'keep-alive','Cookie': '你的cookie值','TE': 'Trailers'}r = requests.get(url,headers=web_header)print(r.status_code)复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。
我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium复制代码
在代码中引入 selenium 并设置相关参数
import osfrom requests.api import optionsfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Options#selenium配置参数options = Options()#配置无头参数,即不打开浏览器options.add_argument('--headless')#配置Chrome浏览器的selenium驱动 chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"os.environ["webdriver.chrome.driver"] = chromedriver#将参数设置+浏览器驱动组合browser = webdriver.Chrome(chromedriver,chrome_options=options)复制代码
测试访问
url = "https://www.amazon.com"print(url)#通过selenium来访问亚马逊browser.get(url)复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件fw=open('E:/amzon.html','w',encoding='utf-8')fw.write(str(browser.page_source))browser.close()fw.close()复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页
结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。 查看全部
js 爬虫抓取网页数据(越过亚马逊的反爬虫机制,成功越过反爬机制(组图))
您的浏览器不支持音频标签。
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等

反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-import urllib.requestreq = urllib.request.urlopen('https://www.amazon.com')print(req.code)复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。

以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200

分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问

代码如下↓ ↓ ↓
import requestsurl='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'web_header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate, br','Connection': 'keep-alive','Cookie': '你的cookie值','TE': 'Trailers'}r = requests.get(url,headers=web_header)print(r.status_code)复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。
我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium复制代码
在代码中引入 selenium 并设置相关参数
import osfrom requests.api import optionsfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Options#selenium配置参数options = Options()#配置无头参数,即不打开浏览器options.add_argument('--headless')#配置Chrome浏览器的selenium驱动 chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"os.environ["webdriver.chrome.driver"] = chromedriver#将参数设置+浏览器驱动组合browser = webdriver.Chrome(chromedriver,chrome_options=options)复制代码
测试访问
url = "https://www.amazon.com"print(url)#通过selenium来访问亚马逊browser.get(url)复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件fw=open('E:/amzon.html','w',encoding='utf-8')fw.write(str(browser.page_source))browser.close()fw.close()复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页

结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。
js 爬虫抓取网页数据(Python爬虫自动抓取互联网信息的程度与应用架构 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-03-12 14:19
)
爬虫:一段时期内自动爬取互联网信息的程度,从互联网上爬取对我们有价值的信息
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(爬取有价值的数据)。
调度器:相当于一台计算机的CPU,主要负责调度URL管理器、下载器、解析器之间的协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止URL重复爬取和URL循环爬取。实现 URL 管理器的方式主要有 3 种:内存、数据库和缓存数据库。
网页下载器:通过传入 URL 地址下载网页并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括需要登录、代理和cookies、requests(第三方包)
网页解析器:通过解析一个网页字符串,可以根据我们的需求提取我们有用的信息,或者按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观地说,就是将网页转换成字符串,通过模糊匹配提取有价值的信息,当文档比较复杂时,这种方法提取数据会很困难),html。parser(Python自带的),beautifulsoup(第三方插件,可以用Python自带的html.parser解析,也可以用lxml,比别人更强大),lxml(第三方插件) ,可以解析xml和HTML),html.parser和beautifulsoup和lxml都是用DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
先安装beautifulsoup
Beautiful Soup:Python的第三方插件,用于从xml和HTML中提取数据,官网地址
pip install beautifulsoup4(在 cmd 命令提示符下执行此代码)
1.爬虫第一个入门程序
from bs4 import BeautifulSoup
import urllib.request
#定义URL
url = "http://www.baidu.com"
#访问url
response = urllib.request.urlopen(url)
#将结果存入字符串中
ret = response.read()
#获取响应状态码
print(response.getcode())
print(ret)
#创建一个BeautifulSoup的对象
soup = BeautifulSoup(ret,"html.parser",from_encoding="utf-8")
# #获取所有的a链接
# links = soup.find_all('a')
# #遍历每一个a链接
# for link in links:
# print(link.name,link['href'],link.get_text())
p = soup.find_all('p')
for ps in p:
print(ps.get_text())
2.1 爬虫程序添加数据
import urllib.parse
from urllib import request
#定义参数
values={"username":"","password":""}
#参数编码
data = urllib.parse.urlencode(values).encode(encoding="UTF8")
#定义URL
# url = "http://passport.csdn.net/login?code=applets";
url = "http://mail.qq.com/";
#构造request请求
req = request.Request(url,data=data)
#打开网页
resp = request.urlopen(req)
print(resp.read())
2.2爬虫程序添加header
import urllib
from urllib import request
url = "http://www.zhihu.com/signin?next=%2F"
# 请求头的内容
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64)"
#表单的请求参数
valuse={'username':'','password':''}
data = urllib.parse.urlencode(valuse).encode(encoding='UTF8')
# 构造请求头headers
headers={'User-Agent':user_agent,'Refere':'http://www.zhihu.com/signin?next=%2F'}
# 构造请求
req = request.Request(url,data = data,headers = headers)
# 打开网页
resp = request.urlopen(req)
# 读取网页内容
print(resp.read())
2.3个爬虫添加post请求
import urllib
from urllib import request
url = "http://www.zhihu.com/signin?next=%2F"
# 请求头的内容
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64)"
#表单的请求参数
valuse={'username':'','password':''}
data = urllib.parse.urlencode(valuse).encode(encoding='UTF8')
# 构造请求头headers
headers={'User-Agent':user_agent,'Refere':'http://www.zhihu.com/signin?next=%2F'}
# 构造请求
req = request.Request(url,data = data,headers = headers)
# 打开网页
resp = request.urlopen(req)
# 读取网页内容
print(resp.read())
3.爬虫添加cookie
from http import cookiejar
from urllib import request
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie到文件
cookie = cookiejar.MozillaCookieJar(filename)
#利用request库的HTTPCookieProcessor对象来创建cookie处理器
handler = request.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = request.build_opener(handler)
#创建一个请求
response = opener.open("http://www.baidu.com")
#保存cookie到文件
#ignore_discard:cookie失效了也要保存
#ignore_expires:覆盖保存
cookie.save(ignore_discard=True,ignore_expires=True)
#利用cookie登录网站
from urllib import request
import urllib
from http import cookiejar
#定义文件名
filename = 'cookie02.txt'
#声明MozillacCookieJar对象保存cookie
cookie = cookiejar.MozillaCookieJar(filename)
#声明一个cookie处理器
handler = request.HTTPCookieProcessor(cookie)
#定义处理
opener = request.build_opener(handler)
#定义data、账号、密码
postdata = urllib.parse.urlencode({
'username':'202042502008',
'password':'HHF2714596503'
}).encode(encoding='UTF8')
#登录
loginUrl = "http://jwc.hnshzy.cn:90/hnshjw ... ot%3B
#模拟登录
result = opener.open(loginUrl,postdata)
#保存cookie到文件
cookie.save(ignore_discard=True,ignore_expires=True)
#利用保存的cookie请求新网站
ner_url = 'http://jwc.hnshzy.cn:90/hnshjw/cas/login.action'
#请求新网页
try:
result = opener.open(ner_url)
except request.HTTPError as e:
if hasattr(e,'code'):
print(e.code)
except request.URLError as e:
if hasattr(e,'reason'):
print(e.reason)
else:
print(result.read())
4.正则表达式
from urllib import request
from bs4 import BeautifulSoup
import re
#定义正则表达式;r表示原生字符串
pattern = re.compile(r'hello')
#匹配字符,match函数:会从第一个开始匹配
result1 = re.match(pattern,"hello,world")
if result1:
print(result1)
result1 = re.match(pattern,"hello,world").span()
if result1:
print(result1)
result1 = re.match(pattern,"hello,world").group()
if result1:
print(result1)
result2 = re.match(pattern,"hell,hello")
if result2:
print(result2)
else:
print("no!no!")
result2 = re.search(pattern,"hell,hello")
if result2:
print(result2)
#定义正则规则
pattern = re.compile(r'a.c')
#匹配
resp = re.match(pattern,"abcdefj")
print(resp)
pattern2 = re.compile('a\.c')
resp2 = re.match(pattern2,"a.cd")
print(resp2)
pattern3 = re.compile('a\\\c')
resp3 = re.match(pattern3,"a\cd")
print(resp3)
#匹配部分字符
pattern4 = re.compile(r'a[a-f,A-F]c')
resp4 = re.match(pattern4,"afcdefg")
print(resp4)
#定义正则规则
re01 = re.compile(r'\d*')
#匹配
res01 = re.match(re01,'123456xxxxxxxxx')
print(res01)
re02 = re.compile(r'\d+\w')
#匹配
res02 = re.match(re02,'123456xxxxxxxxx')
print(res02)
re03 = re.compile(r'\d?\w')
#匹配
res03 = re.match(re03,'4xxxxxxxxx')
print(res03)
re04 = re.compile(r'1\d{5}')
#匹配
res04 = re.match(re04,'123456xxxxxxxxx')
print(res04)
re05 = re.compile(r'\d{5,11}@\w{2}\.\w{3}')
#匹配
res05 = re.match(re05,'123456789@qq.com')
print(res05)
#贪婪模式
re06 = re.compile(r'\w+')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
#解除贪婪模式
re06 = re.compile(r'\w+?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w{5,10}')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w{5,10}?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w*?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
#边界匹配
re07 = re.compile(r'^5678')
res07 = re.match(re07,'56789')
print(res07)
re08 = re.compile(r'789$')
res08 = re.search(re08,'56789')
print(res08)
re09 = re.compile(r'\A\w{1,6}')
res09 = re.search(re09,'dihakldjal12345678')
print(res09)
re10= re.compile(r'dja\Z')
res10 = re.search(re10,'dihakldja')
print(res10)
re11= re.compile(r'a\b!bc')
res11 = re.search(re11,'a!bc')
print(res11)
#逻辑分组
re12= re.compile(r'abc|efg')
res12 = re.search(re12,'abcdjklefg')
print(res12)
re13= re.compile(r'(abc){2}')
res13 = re.search(re13,'abcabchjkk')
print(res13)
re13= re.compile(r'(abc)(def)')
res13 = re.search(re13,'abcdefhjkk')
print(res13)
re14= re.compile(r'(?Pabc)')
res14 = re.search(re14,'abcdefg')
print(res14)
re15= re.compile(r'(\d)abc\1')
res15 = re.search(re15,'5abc5')
print(res15)
re16= re.compile(r'(?Pabc)efg(?P=name)')
res16 = re.search(re16,'abcefgabc')
print(res16) 查看全部
js 爬虫抓取网页数据(Python爬虫自动抓取互联网信息的程度与应用架构
)
爬虫:一段时期内自动爬取互联网信息的程度,从互联网上爬取对我们有价值的信息
Python爬虫架构主要由五部分组成,分别是调度器、URL管理器、网页下载器、网页解析器和应用程序(爬取有价值的数据)。
调度器:相当于一台计算机的CPU,主要负责调度URL管理器、下载器、解析器之间的协调。
URL管理器:包括要爬取的URL地址和已经爬取的URL地址,防止URL重复爬取和URL循环爬取。实现 URL 管理器的方式主要有 3 种:内存、数据库和缓存数据库。
网页下载器:通过传入 URL 地址下载网页并将网页转换为字符串。网页下载器有urllib2(Python官方基础模块),包括需要登录、代理和cookies、requests(第三方包)
网页解析器:通过解析一个网页字符串,可以根据我们的需求提取我们有用的信息,或者按照DOM树的解析方式进行解析。网页解析器有正则表达式(直观地说,就是将网页转换成字符串,通过模糊匹配提取有价值的信息,当文档比较复杂时,这种方法提取数据会很困难),html。parser(Python自带的),beautifulsoup(第三方插件,可以用Python自带的html.parser解析,也可以用lxml,比别人更强大),lxml(第三方插件) ,可以解析xml和HTML),html.parser和beautifulsoup和lxml都是用DOM树的方式解析的。
应用程序:它是由从网页中提取的有用数据组成的应用程序。
先安装beautifulsoup
Beautiful Soup:Python的第三方插件,用于从xml和HTML中提取数据,官网地址
pip install beautifulsoup4(在 cmd 命令提示符下执行此代码)
1.爬虫第一个入门程序
from bs4 import BeautifulSoup
import urllib.request
#定义URL
url = "http://www.baidu.com"
#访问url
response = urllib.request.urlopen(url)
#将结果存入字符串中
ret = response.read()
#获取响应状态码
print(response.getcode())
print(ret)
#创建一个BeautifulSoup的对象
soup = BeautifulSoup(ret,"html.parser",from_encoding="utf-8")
# #获取所有的a链接
# links = soup.find_all('a')
# #遍历每一个a链接
# for link in links:
# print(link.name,link['href'],link.get_text())
p = soup.find_all('p')
for ps in p:
print(ps.get_text())
2.1 爬虫程序添加数据
import urllib.parse
from urllib import request
#定义参数
values={"username":"","password":""}
#参数编码
data = urllib.parse.urlencode(values).encode(encoding="UTF8")
#定义URL
# url = "http://passport.csdn.net/login?code=applets";
url = "http://mail.qq.com/";
#构造request请求
req = request.Request(url,data=data)
#打开网页
resp = request.urlopen(req)
print(resp.read())
2.2爬虫程序添加header
import urllib
from urllib import request
url = "http://www.zhihu.com/signin?next=%2F"
# 请求头的内容
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64)"
#表单的请求参数
valuse={'username':'','password':''}
data = urllib.parse.urlencode(valuse).encode(encoding='UTF8')
# 构造请求头headers
headers={'User-Agent':user_agent,'Refere':'http://www.zhihu.com/signin?next=%2F'}
# 构造请求
req = request.Request(url,data = data,headers = headers)
# 打开网页
resp = request.urlopen(req)
# 读取网页内容
print(resp.read())
2.3个爬虫添加post请求
import urllib
from urllib import request
url = "http://www.zhihu.com/signin?next=%2F"
# 请求头的内容
user_agent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64)"
#表单的请求参数
valuse={'username':'','password':''}
data = urllib.parse.urlencode(valuse).encode(encoding='UTF8')
# 构造请求头headers
headers={'User-Agent':user_agent,'Refere':'http://www.zhihu.com/signin?next=%2F'}
# 构造请求
req = request.Request(url,data = data,headers = headers)
# 打开网页
resp = request.urlopen(req)
# 读取网页内容
print(resp.read())
3.爬虫添加cookie
from http import cookiejar
from urllib import request
#设置保存cookie的文件,同级目录下的cookie.txt
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie到文件
cookie = cookiejar.MozillaCookieJar(filename)
#利用request库的HTTPCookieProcessor对象来创建cookie处理器
handler = request.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = request.build_opener(handler)
#创建一个请求
response = opener.open("http://www.baidu.com";)
#保存cookie到文件
#ignore_discard:cookie失效了也要保存
#ignore_expires:覆盖保存
cookie.save(ignore_discard=True,ignore_expires=True)
#利用cookie登录网站
from urllib import request
import urllib
from http import cookiejar
#定义文件名
filename = 'cookie02.txt'
#声明MozillacCookieJar对象保存cookie
cookie = cookiejar.MozillaCookieJar(filename)
#声明一个cookie处理器
handler = request.HTTPCookieProcessor(cookie)
#定义处理
opener = request.build_opener(handler)
#定义data、账号、密码
postdata = urllib.parse.urlencode({
'username':'202042502008',
'password':'HHF2714596503'
}).encode(encoding='UTF8')
#登录
loginUrl = "http://jwc.hnshzy.cn:90/hnshjw ... ot%3B
#模拟登录
result = opener.open(loginUrl,postdata)
#保存cookie到文件
cookie.save(ignore_discard=True,ignore_expires=True)
#利用保存的cookie请求新网站
ner_url = 'http://jwc.hnshzy.cn:90/hnshjw/cas/login.action'
#请求新网页
try:
result = opener.open(ner_url)
except request.HTTPError as e:
if hasattr(e,'code'):
print(e.code)
except request.URLError as e:
if hasattr(e,'reason'):
print(e.reason)
else:
print(result.read())
4.正则表达式
from urllib import request
from bs4 import BeautifulSoup
import re
#定义正则表达式;r表示原生字符串
pattern = re.compile(r'hello')
#匹配字符,match函数:会从第一个开始匹配
result1 = re.match(pattern,"hello,world")
if result1:
print(result1)
result1 = re.match(pattern,"hello,world").span()
if result1:
print(result1)
result1 = re.match(pattern,"hello,world").group()
if result1:
print(result1)
result2 = re.match(pattern,"hell,hello")
if result2:
print(result2)
else:
print("no!no!")
result2 = re.search(pattern,"hell,hello")
if result2:
print(result2)
#定义正则规则
pattern = re.compile(r'a.c')
#匹配
resp = re.match(pattern,"abcdefj")
print(resp)
pattern2 = re.compile('a\.c')
resp2 = re.match(pattern2,"a.cd")
print(resp2)
pattern3 = re.compile('a\\\c')
resp3 = re.match(pattern3,"a\cd")
print(resp3)
#匹配部分字符
pattern4 = re.compile(r'a[a-f,A-F]c')
resp4 = re.match(pattern4,"afcdefg")
print(resp4)
#定义正则规则
re01 = re.compile(r'\d*')
#匹配
res01 = re.match(re01,'123456xxxxxxxxx')
print(res01)
re02 = re.compile(r'\d+\w')
#匹配
res02 = re.match(re02,'123456xxxxxxxxx')
print(res02)
re03 = re.compile(r'\d?\w')
#匹配
res03 = re.match(re03,'4xxxxxxxxx')
print(res03)
re04 = re.compile(r'1\d{5}')
#匹配
res04 = re.match(re04,'123456xxxxxxxxx')
print(res04)
re05 = re.compile(r'\d{5,11}@\w{2}\.\w{3}')
#匹配
res05 = re.match(re05,'123456789@qq.com')
print(res05)
#贪婪模式
re06 = re.compile(r'\w+')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
#解除贪婪模式
re06 = re.compile(r'\w+?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w{5,10}')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w{5,10}?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
re06 = re.compile(r'\w*?')
res06 = re.match(re06,"dhakdhadlkadajdlkadjadjalkdja45343")
print(res06)
#边界匹配
re07 = re.compile(r'^5678')
res07 = re.match(re07,'56789')
print(res07)
re08 = re.compile(r'789$')
res08 = re.search(re08,'56789')
print(res08)
re09 = re.compile(r'\A\w{1,6}')
res09 = re.search(re09,'dihakldjal12345678')
print(res09)
re10= re.compile(r'dja\Z')
res10 = re.search(re10,'dihakldja')
print(res10)
re11= re.compile(r'a\b!bc')
res11 = re.search(re11,'a!bc')
print(res11)
#逻辑分组
re12= re.compile(r'abc|efg')
res12 = re.search(re12,'abcdjklefg')
print(res12)
re13= re.compile(r'(abc){2}')
res13 = re.search(re13,'abcabchjkk')
print(res13)
re13= re.compile(r'(abc)(def)')
res13 = re.search(re13,'abcdefhjkk')
print(res13)
re14= re.compile(r'(?Pabc)')
res14 = re.search(re14,'abcdefg')
print(res14)
re15= re.compile(r'(\d)abc\1')
res15 = re.search(re15,'5abc5')
print(res15)
re16= re.compile(r'(?Pabc)efg(?P=name)')
res16 = re.search(re16,'abcefgabc')
print(res16)
js 爬虫抓取网页数据(抓取某个微博大V微博的评论数据应该怎么实现?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-12 14:18
【Part1-理论篇】
大家好,我是皮皮。
想想一个问题,如果我们要抓取一条微博大V微博的评论数据,该怎么做呢?最简单的方法是找到微博评论数据接口,然后更改参数获取最新数据并保存。首先,寻找微博api抓取评论的接口,如下图。
但是很遗憾,这个界面的使用频率有限,被抓了几次就被封禁了。在它开始起飞之前,它很冷。
接下来小编选择微博移动端网站,先登录,然后找到我们要抓取评论的微博,打开浏览器自带的流量分析工具,一直拉下评论,找到评论数据接口,如下图。
然后点击“参数”选项卡,可以看到参数如下图所示:
可以看到一共有4个参数,其中第二个参数1、是微博的id,就像一个人的身份证号,这个相当于微博的“身份证号”, max_id 是更改页码的参数,每次都必须更改。下一个 max_id 参数值在此请求的返回数据中。
【Part2-实战】
有了上面的基础,我们开始用 Python 编写代码并实现它。
1、先区分url,第一次不需要max_id,第二次需要第一次返回的max_id。
2、请求时需要带上cookie数据。微博cookie的有效期比较长,足以捕捉一条微博的评论数据。可以从浏览器分析工具中找到 cookie 数据。
3、然后将返回的数据转换成json格式,提取评论内容、评论者昵称、评论时间等数据,输出结果如下图所示。
4、为了保存评论内容,我们需要将评论中的表达式去掉,使用正则表达式进行处理,如下图所示。
5、 然后将内容保存为txt文件,使用简单的open函数实现,如下图所示。
6、关键是通过这个接口最多只能返回16页的数据(每页20条)。网上也有报道说可以返回50页,但是界面不一样,返回的数据条数也不一样,所以我加了一个for循环,一步到位,遍历还是很厉害的,如下图所示。
7、这里的函数名为job。为了总能取出最新的数据,我们可以使用 schedule 给程序添加定时功能,每隔 10 分钟或半小时抓取一次,如下图所示。
8、对获取的数据进行去重,如下图所示。如果评论已经存在,就通过它,如果没有,就继续添加它。
这项工作基本完成。
【第三部分——总结】
这种方法虽然没有把所有的数据都抓到,但是在这条微博的约束下,也是比较有效的方法。 查看全部
js 爬虫抓取网页数据(抓取某个微博大V微博的评论数据应该怎么实现?)
【Part1-理论篇】
大家好,我是皮皮。
想想一个问题,如果我们要抓取一条微博大V微博的评论数据,该怎么做呢?最简单的方法是找到微博评论数据接口,然后更改参数获取最新数据并保存。首先,寻找微博api抓取评论的接口,如下图。
但是很遗憾,这个界面的使用频率有限,被抓了几次就被封禁了。在它开始起飞之前,它很冷。
接下来小编选择微博移动端网站,先登录,然后找到我们要抓取评论的微博,打开浏览器自带的流量分析工具,一直拉下评论,找到评论数据接口,如下图。
然后点击“参数”选项卡,可以看到参数如下图所示:
可以看到一共有4个参数,其中第二个参数1、是微博的id,就像一个人的身份证号,这个相当于微博的“身份证号”, max_id 是更改页码的参数,每次都必须更改。下一个 max_id 参数值在此请求的返回数据中。
【Part2-实战】
有了上面的基础,我们开始用 Python 编写代码并实现它。
1、先区分url,第一次不需要max_id,第二次需要第一次返回的max_id。
2、请求时需要带上cookie数据。微博cookie的有效期比较长,足以捕捉一条微博的评论数据。可以从浏览器分析工具中找到 cookie 数据。
3、然后将返回的数据转换成json格式,提取评论内容、评论者昵称、评论时间等数据,输出结果如下图所示。
4、为了保存评论内容,我们需要将评论中的表达式去掉,使用正则表达式进行处理,如下图所示。
5、 然后将内容保存为txt文件,使用简单的open函数实现,如下图所示。
6、关键是通过这个接口最多只能返回16页的数据(每页20条)。网上也有报道说可以返回50页,但是界面不一样,返回的数据条数也不一样,所以我加了一个for循环,一步到位,遍历还是很厉害的,如下图所示。
7、这里的函数名为job。为了总能取出最新的数据,我们可以使用 schedule 给程序添加定时功能,每隔 10 分钟或半小时抓取一次,如下图所示。
8、对获取的数据进行去重,如下图所示。如果评论已经存在,就通过它,如果没有,就继续添加它。
这项工作基本完成。
【第三部分——总结】
这种方法虽然没有把所有的数据都抓到,但是在这条微博的约束下,也是比较有效的方法。
js 爬虫抓取网页数据(如何清理爬虫数据中一些不需要的HTML属性(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-03-12 01:17
如何清理爬虫数据中一些不必要的HTML属性 没有什么可失去的,但我还是得担心得失。我也嘲笑我的懦弱和无知。
显然不能直接存储,必须解析出需要的内容。比如我今天抓取一个新闻网的国内新闻,那么我创建一个实体类,属性有:新闻标题、新闻时间、正文等。解析出你需要的内容,封印到实体中,然后保存直接到dao层的数据库。如果整个爬下来。
python爬虫在哪里爬取网页上的某些字段 上百页的聊天记录,比不上两张一模一样的录取通知书。不是我不要你,亲爱的,只是生活太难了,不努力,路真的很长。
1. 获取html页面 其实最基本的抓取网站,两句就够了 [python] view plaincopy import urllib2 content = urllib2.urlopen('').read() 这样可以得到整个html文档,关键问题是我们可能需要从这个文档中获取我们需要的有用信息。
如何通过nodejs爬虫获取数据,轻松实现代码其实我一直站在你身边,等你靠在我肩上说,你的温柔会不会有属于我的那一天,我不会让你难过,让你泪流满面!
为什么Python爬虫只爬取html页面的部分内容?我喜欢什么?如果我喜欢一朵花,它就不会凋谢。如果我喜欢一首歌,它就不会厌倦。如果我喜欢一个季节,它不会被其他季节取代。如果我喜欢你,你会喜欢我吗?
js加载的一些内容只有在你的电脑屏幕或者鼠标滑动到某个位置时才会动态加载。这些内容不会体现在源码中,而python爬虫只是爬取源码。如果你想满足你的需求,分享,你可以试试phantomjs来模拟浏览器,祝你成功。 查看全部
js 爬虫抓取网页数据(如何清理爬虫数据中一些不需要的HTML属性(一))
如何清理爬虫数据中一些不必要的HTML属性 没有什么可失去的,但我还是得担心得失。我也嘲笑我的懦弱和无知。
显然不能直接存储,必须解析出需要的内容。比如我今天抓取一个新闻网的国内新闻,那么我创建一个实体类,属性有:新闻标题、新闻时间、正文等。解析出你需要的内容,封印到实体中,然后保存直接到dao层的数据库。如果整个爬下来。
python爬虫在哪里爬取网页上的某些字段 上百页的聊天记录,比不上两张一模一样的录取通知书。不是我不要你,亲爱的,只是生活太难了,不努力,路真的很长。
1. 获取html页面 其实最基本的抓取网站,两句就够了 [python] view plaincopy import urllib2 content = urllib2.urlopen('').read() 这样可以得到整个html文档,关键问题是我们可能需要从这个文档中获取我们需要的有用信息。
如何通过nodejs爬虫获取数据,轻松实现代码其实我一直站在你身边,等你靠在我肩上说,你的温柔会不会有属于我的那一天,我不会让你难过,让你泪流满面!
为什么Python爬虫只爬取html页面的部分内容?我喜欢什么?如果我喜欢一朵花,它就不会凋谢。如果我喜欢一首歌,它就不会厌倦。如果我喜欢一个季节,它不会被其他季节取代。如果我喜欢你,你会喜欢我吗?
js加载的一些内容只有在你的电脑屏幕或者鼠标滑动到某个位置时才会动态加载。这些内容不会体现在源码中,而python爬虫只是爬取源码。如果你想满足你的需求,分享,你可以试试phantomjs来模拟浏览器,祝你成功。
js 爬虫抓取网页数据( 如何模拟请求和如何解析HTML源码中的文章及链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-10 15:23
如何模拟请求和如何解析HTML源码中的文章及链接)
X-Requested-With:XMLHttpRequest
这是一个栗子:
的职位列表
点击Android后,我们从浏览器上传了几个参数到拉钩的服务器
一个是first=true,一个是kd=android,(关键字)一个是pn=1(页码)
所以我们可以模仿这一步来构造一个数据包来模拟用户的点击动作。
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这是很久以前的问题,但线程所有者似乎也解决了这个问题。但是看到很多答案有点太重了,这里有一个更高效,资源消耗更少的方法。由于标题没有具体说明需要什么,所以这里的例子取了首页所有帖子的链接和标题。
首先请记住,浏览器环境的内存和CPU消耗是非常严重的,要尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在 HTML 源代码中看不到,但更有可能通过另一个请求得到纯数据(很可能是 JSON 格式),不仅不需要模拟浏览器,但可以省去解析HTML的消耗。
然后,打开北友人论坛首页,发现其首页的HTML源码中确实没有文章页面显示内容。那么,很有可能这是通过JS异步加载到页面中的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或者Win/Linux下通过F12)分析加载首页时的请求,很容易发现,请求如下截图:
从截图中选择的请求得到的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:
至此,我们已经确定这个链接可以获取到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。然后配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏进行详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗以及抓取速度。在编写爬虫时,请务必记住,除非必要,否则不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了接口。但是这两种方法都需要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方法模拟真实行为。谷歌幻影JS 查看全部
js 爬虫抓取网页数据(
如何模拟请求和如何解析HTML源码中的文章及链接)
X-Requested-With:XMLHttpRequest
这是一个栗子:
的职位列表
点击Android后,我们从浏览器上传了几个参数到拉钩的服务器
一个是first=true,一个是kd=android,(关键字)一个是pn=1(页码)
所以我们可以模仿这一步来构造一个数据包来模拟用户的点击动作。
post_data = {'first':'true','kd':'Android','pn':'1'}
虽然这是很久以前的问题,但线程所有者似乎也解决了这个问题。但是看到很多答案有点太重了,这里有一个更高效,资源消耗更少的方法。由于标题没有具体说明需要什么,所以这里的例子取了首页所有帖子的链接和标题。
首先请记住,浏览器环境的内存和CPU消耗是非常严重的,要尽量避免模拟浏览器环境的爬虫代码。请记住,对于一些前端渲染的网页,虽然我们需要的数据在 HTML 源代码中看不到,但更有可能通过另一个请求得到纯数据(很可能是 JSON 格式),不仅不需要模拟浏览器,但可以省去解析HTML的消耗。
然后,打开北友人论坛首页,发现其首页的HTML源码中确实没有文章页面显示内容。那么,很有可能这是通过JS异步加载到页面中的。通过浏览器开发工具(OS X下的Chrome浏览器通过command+option+i或者Win/Linux下通过F12)分析加载首页时的请求,很容易发现,请求如下截图:
从截图中选择的请求得到的响应是首页的文章链接。您可以在预览选项中看到渲染的预览:
至此,我们已经确定这个链接可以获取到首页的文章和链接。
在 headers 选项中,有这个请求的请求头和请求参数。我们可以通过 Python 模拟这个请求,得到同样的响应。然后配合BeautifulSoup等库解析HTML,就可以得到对应的内容。
关于如何模拟请求以及如何解析HTML,请移步我的专栏进行详细介绍,这里不再赘述。
这样就可以在不模拟浏览器环境的情况下抓取数据,大大提高了内存和CPU的消耗以及抓取速度。在编写爬虫时,请务必记住,除非必要,否则不要模拟浏览器环境。如果是windows下,可以尝试调用windows系统中的webbrowser控件。另外,ie本身也提供了接口。但是这两种方法都需要渲染页面,在性能上有些浪费。为了加快速度,可以关闭ie的图片下载显示,然后通过点击等方法模拟真实行为。谷歌幻影JS
js 爬虫抓取网页数据( 网络爬虫(DeepWebCrawler),加以简单的介绍. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-10 07:20
网络爬虫(DeepWebCrawler),加以简单的介绍.
)
使用 Node.JS 实现一个小型网络爬虫应用程序
前言
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常见的称为网络追逐者)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常见 使用的其他名称有 ant、autoindex、emulator 或 worm。
我们可以利用网络爬虫对数据信息进行自动化采集,如搜索引擎中的站点爬取收录、数据分析挖掘采集、金融数据采集在此外,网络爬虫还可用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
网络爬虫根据系统结构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。下面简单介绍一下这几种爬虫。
1.1、通用网络爬虫
也称为Scalable Web Crawler,爬取对象从一些种子URL扩展到整个Web,主要用于门户网站搜索引擎和大型Web服务提供商采集数据。
1.2、专注于网络爬虫
也称为Topical Crawler,它指的是一种网络爬虫,它可以选择性地爬取那些与预定义主题相关的页面。与通用网络爬虫相比,专注爬虫只需要爬取主题相关的页面,大大节省了由于硬件和网络资源不足,保存的页面也因数量少而更新快,也能很好的满足某些特定人群对特定领域信息的需求。
1.3、增量网络爬虫
指对下载的网页进行增量更新的爬虫,只爬取新生成或更改的网页。可以在一定程度上保证爬取的页面尽可能的新。
1.4、深网爬虫
网页可分为表层网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页是指可以被传统搜索引擎索引的页面,可以通过超链接到达的静态网页 网页主要由网页组成。Deep Web是那些大部分内容无法通过静态链接获取,隐藏在搜索表单后面,只能通过用户提交一些关键词获取的网页。
2、创建一个简单的爬虫应用
简单了解以上爬虫后,我们来实现一个简单的爬虫应用。
2.1、达成目标
说到爬虫,你可能会想到大数据,然后就会想到 Python。百度之后,Python中的爬虫确实多了。由于你主要从事前端开发,所以 JavaScript 相对来说更加熟练和简单。实现一个小目标,然后用Node.JS爬取Blog Park的首页文章列表(我常用的一个开发者网站),然后写入本地JSON文件。
2.2、环境设置
Node.JS:电脑需要安装Node.JS,如果没有安装,去官网下载安装。
NPM:Node.JS 包管理工具,随 Node.JS 一起安装。
Node.JS安装好后,打开命令行,可以使用node -v查看Node.JS是否安装成功,可以使用nPM -v查看Node.JS是否安装成功,应该打印如下信息如果安装成功(因版本不同而异):
2.3、具体实现
2.3.1、安装依赖
在目录下执行 nPM install superagentcheerio --save-dev 安装superagent、cheerio这两个依赖。创建一个 crawler.JS 文件。
superagent:SuperAgent 是一个轻量级、灵活、易读、学习曲线低的客户端请求代理模块,用于 Node.JS 环境。
Cheerio:是为服务器设计的核心 jQuery 的快速、灵活和精简的实现。它可以像 jQuery 一样操作字符串。
// 导入依赖包const http = require("http");const path = require("path");const url = require("url");const fs = require("fs");const superagent = require("superagent");const cheerio = require("cheerio");
2.3.2、抓取数据
然后获取请求页面,获取页面内容后,根据你想要的数据解析返回的DOM,最后将处理后的结果JSON转成字符串保存在本地。
// 爬取页面地址const pageUrl="https://www.cnblogs.com/";// 解码字符串function unescapeString(str){ if(!str){ return '' }else{ return unescape(str.replace(/&#x/g,'%u').replace(/;/g,'')); }}// 抓取数据function fetchData(){ console.log('爬取数据时间节点:',new Date()); superagent.get(pageUrl).end((error,response)=>{ // 页面文档数据 let content=response.text; if(content){ console.log('获取数据成功'); } // 定义一个空数组来接收数据 let result=[]; let $=cheerio.load(content); let postList=$("#main #post_list .post_item"); postList.each((index,value)=>{ let titleLnk=$(value).find('a.titlelnk'); let itemFoot=$(value).find('.post_item_foot'); let title=titleLnk.html(); // 标题 let href=titleLnk.attr('href'); // 链接 let author=itemFoot.find('a.lightblue').HTML(); // 作者 let headLogo=$(value).find('.post_item_summary a img').attr('src'); // 头像 let summary=$(value).find('.post_item_summary').text(); // 简介 let postedTime=itemFoot.text().split('发布于')[1].substr(0,16); // 发布时间 let readNum=itemFoot.text().split('阅读')[1]; // 阅读量 readNum=readNum.substr(1,readNum.length-1); title=unescapeString(title); href=unescapeString(href); author=unescapeString(author); headLogo=unescapeString(headLogo); summary=unescapeString(summary); postedTime=unescapeString(postedTime); readNum=unescapeString(readNum); result.push({ index, title, href, author, headLogo, summary, postedTime, readNum }); }); // 数组转换为字符串 result=JSON.stringify(result); // 写入本地 cnblogs.JSON 文件中 fs.writeFile("cnblogs.json",result,"utf-8",(err)=>{ // 监听错误, 如正常输出, 则打印 null if(!err){ console.log('写入数据成功'); } }); });}fetchData();
3、执行优化
3.1,生成结果
在项目目录下打开命令行,输入node crawler.JS,
你会发现目录下会创建一个cnblogs.JSON文件,打开文件如下:
查看全部
js 爬虫抓取网页数据(
网络爬虫(DeepWebCrawler),加以简单的介绍.
)
使用 Node.JS 实现一个小型网络爬虫应用程序
前言
网络爬虫(也称为网络蜘蛛、网络机器人,或者在 FOAF 社区中更常见的称为网络追逐者)是一种程序或脚本,它根据某些规则自动从万维网上爬取信息。其他不太常见 使用的其他名称有 ant、autoindex、emulator 或 worm。
我们可以利用网络爬虫对数据信息进行自动化采集,如搜索引擎中的站点爬取收录、数据分析挖掘采集、金融数据采集在此外,网络爬虫还可用于舆情监测分析、目标客户数据采集等各个领域。
1、网络爬虫分类
网络爬虫根据系统结构和实现技术大致可以分为以下几种:通用网络爬虫、聚焦网络爬虫、增量网络爬虫、深度网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。下面简单介绍一下这几种爬虫。
1.1、通用网络爬虫
也称为Scalable Web Crawler,爬取对象从一些种子URL扩展到整个Web,主要用于门户网站搜索引擎和大型Web服务提供商采集数据。
1.2、专注于网络爬虫
也称为Topical Crawler,它指的是一种网络爬虫,它可以选择性地爬取那些与预定义主题相关的页面。与通用网络爬虫相比,专注爬虫只需要爬取主题相关的页面,大大节省了由于硬件和网络资源不足,保存的页面也因数量少而更新快,也能很好的满足某些特定人群对特定领域信息的需求。
1.3、增量网络爬虫
指对下载的网页进行增量更新的爬虫,只爬取新生成或更改的网页。可以在一定程度上保证爬取的页面尽可能的新。
1.4、深网爬虫
网页可分为表层网页(Surface Web)和深层网页(Deep Web,也称为Invisible Web Pages或Hidden Web)。表面网页是指可以被传统搜索引擎索引的页面,可以通过超链接到达的静态网页 网页主要由网页组成。Deep Web是那些大部分内容无法通过静态链接获取,隐藏在搜索表单后面,只能通过用户提交一些关键词获取的网页。
2、创建一个简单的爬虫应用
简单了解以上爬虫后,我们来实现一个简单的爬虫应用。
2.1、达成目标
说到爬虫,你可能会想到大数据,然后就会想到 Python。百度之后,Python中的爬虫确实多了。由于你主要从事前端开发,所以 JavaScript 相对来说更加熟练和简单。实现一个小目标,然后用Node.JS爬取Blog Park的首页文章列表(我常用的一个开发者网站),然后写入本地JSON文件。
2.2、环境设置
Node.JS:电脑需要安装Node.JS,如果没有安装,去官网下载安装。
NPM:Node.JS 包管理工具,随 Node.JS 一起安装。
Node.JS安装好后,打开命令行,可以使用node -v查看Node.JS是否安装成功,可以使用nPM -v查看Node.JS是否安装成功,应该打印如下信息如果安装成功(因版本不同而异):
2.3、具体实现
2.3.1、安装依赖
在目录下执行 nPM install superagentcheerio --save-dev 安装superagent、cheerio这两个依赖。创建一个 crawler.JS 文件。
superagent:SuperAgent 是一个轻量级、灵活、易读、学习曲线低的客户端请求代理模块,用于 Node.JS 环境。
Cheerio:是为服务器设计的核心 jQuery 的快速、灵活和精简的实现。它可以像 jQuery 一样操作字符串。
// 导入依赖包const http = require("http");const path = require("path");const url = require("url");const fs = require("fs");const superagent = require("superagent");const cheerio = require("cheerio");
2.3.2、抓取数据
然后获取请求页面,获取页面内容后,根据你想要的数据解析返回的DOM,最后将处理后的结果JSON转成字符串保存在本地。
// 爬取页面地址const pageUrl="https://www.cnblogs.com/";// 解码字符串function unescapeString(str){ if(!str){ return '' }else{ return unescape(str.replace(/&#x/g,'%u').replace(/;/g,'')); }}// 抓取数据function fetchData(){ console.log('爬取数据时间节点:',new Date()); superagent.get(pageUrl).end((error,response)=>{ // 页面文档数据 let content=response.text; if(content){ console.log('获取数据成功'); } // 定义一个空数组来接收数据 let result=[]; let $=cheerio.load(content); let postList=$("#main #post_list .post_item"); postList.each((index,value)=>{ let titleLnk=$(value).find('a.titlelnk'); let itemFoot=$(value).find('.post_item_foot'); let title=titleLnk.html(); // 标题 let href=titleLnk.attr('href'); // 链接 let author=itemFoot.find('a.lightblue').HTML(); // 作者 let headLogo=$(value).find('.post_item_summary a img').attr('src'); // 头像 let summary=$(value).find('.post_item_summary').text(); // 简介 let postedTime=itemFoot.text().split('发布于')[1].substr(0,16); // 发布时间 let readNum=itemFoot.text().split('阅读')[1]; // 阅读量 readNum=readNum.substr(1,readNum.length-1); title=unescapeString(title); href=unescapeString(href); author=unescapeString(author); headLogo=unescapeString(headLogo); summary=unescapeString(summary); postedTime=unescapeString(postedTime); readNum=unescapeString(readNum); result.push({ index, title, href, author, headLogo, summary, postedTime, readNum }); }); // 数组转换为字符串 result=JSON.stringify(result); // 写入本地 cnblogs.JSON 文件中 fs.writeFile("cnblogs.json",result,"utf-8",(err)=>{ // 监听错误, 如正常输出, 则打印 null if(!err){ console.log('写入数据成功'); } }); });}fetchData();
3、执行优化
3.1,生成结果
在项目目录下打开命令行,输入node crawler.JS,
你会发现目录下会创建一个cnblogs.JSON文件,打开文件如下:
js 爬虫抓取网页数据(web不再的攻防角度分析——web原创生态的元凶)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-08 18:19
网络是一个开放的平台,它为网络从1990年代初诞生到今天的蓬勃发展奠定了基础。但是,所谓成败,也就是小何,开放的特性、搜索引擎、简单易学的html和css技术,让web成为了互联网领域最流行、最成熟的信息传播媒介;但是现在作为一个商业软件,web这个平台上的内容信息的版权是不能保证的,因为和软件客户端相比,你网页中的内容可以通过一些爬虫程序以非常低的成本和技术门槛很低。这就是本系列文章要讨论的话题——网络爬虫。
有很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为随着今天IT行业的发展,网络不再是当年与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的思想。存在。随着商业软件的发展,网络也不得不面对知识产权保护的问题。试想,如果原创的优质内容不受保护,网络世界中抄袭盗版猖獗,这其实有利于网络生态的健康发展。这是一个缺点,而且它' 很难鼓励制作更多高质量的原创内容。未经授权的爬虫程序是危害web原创内容生态的罪魁祸首。因此,为了保护网站的内容,首先要考虑如何反爬。
##从爬虫攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。这当然是儿科最小的防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在http的get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。另外还有一个比较异常的服务器端爬虫检测机制,就是在http响应中为所有访问页面的http请求植入一个cookie token,然后在这个页面异步执行的一些ajax接口上学。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电商网站亚马逊采用这种防御策略。以上是基于服务器端验证爬虫程序可以玩的一些套路。
##基于客户端js运行时检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西需要一点一点的尝试,耗费大量人力物力开发的一套爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。程序可以操作浏览器访问网页,使得编写爬虫的人可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。程序可以操作浏览器访问网页,使得编写爬虫的人可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。甚至是基于 IE 内核的 trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。甚至是基于 IE 内核的 trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器内核C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真正的GUI浏览器的发布版本。其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS有很多问题,因为是单进程模型,没有必要的沙箱保护,并且浏览器内核的安全性较差。现在谷歌Chrome团队已经在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:js调用。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:js调用。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length == 0) {
console.log("It may be Chrome headless");
}
基于语言的检查
if(navigator.languages == "") {
console.log("Chrome headless detected");
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == "Brian Paul" && renderer == "Mesa OffScreen") {
console.log("Chrome headless detected");
}
基于浏览器细线属性的检查
if(!Modernizr["hairline"]) {
console.log("It may be Chrome headless");
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName("body")[0];
var image = document.createElement("img");
image.src = "http://iloveponeydotcom32188.jg";
image.setAttribute("id", "fakeimage");
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log("Chrome headless detected");
}
}
基于以上对一些浏览器特性的判断,基本上可以将市面上大部分的无头浏览器程序干掉。至此,网页爬虫的门槛其实提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器内核来说是很重要的。变化不小。此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,测试js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。另外,我们在研究robots browserdetect using js api在浏览器端的时候,发现了一个有趣的小技巧。可以将一个预先注入的js函数伪装成native函数,看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString());
console.log(fakeAlert.toString());
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。因此,需要更严格的检查,因为bind(null)伪造的方法在toString之后没有函数名。
##反爬虫银弹 反爬虫和机器人巡检最可靠的方法是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中最成熟的是 Google reCAPTCHA。基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。
##Robot协议 另外,在爬虫爬取技术领域还有一种“白道”的方法,叫做robots协议。您可以访问 网站 根目录中的 /robots.txt。比如我们看一下github的robot协议。Allow 和 Disallow 声明每个 UA 爬虫的授权。然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
##写在最后 网页内容的爬取与对策,注定是一场魔高一尺,路高一尺的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路。你可以 它所做的只是增加攻击者的抓取成本,并更准确地了解未经授权的抓取。另外,欢迎对爬虫感兴趣的朋友关注我的开源项目webster。该项目以Node.js结合Chrome无头模式实现了一个高可用的网络爬虫爬取框架。一个页面中js和ajax渲染的所有异步内容;结合redis,实现了一个任务队列,让爬虫轻松进行横向和纵向分布式扩展。 查看全部
js 爬虫抓取网页数据(web不再的攻防角度分析——web原创生态的元凶)
网络是一个开放的平台,它为网络从1990年代初诞生到今天的蓬勃发展奠定了基础。但是,所谓成败,也就是小何,开放的特性、搜索引擎、简单易学的html和css技术,让web成为了互联网领域最流行、最成熟的信息传播媒介;但是现在作为一个商业软件,web这个平台上的内容信息的版权是不能保证的,因为和软件客户端相比,你网页中的内容可以通过一些爬虫程序以非常低的成本和技术门槛很低。这就是本系列文章要讨论的话题——网络爬虫。
有很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为随着今天IT行业的发展,网络不再是当年与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的思想。存在。随着商业软件的发展,网络也不得不面对知识产权保护的问题。试想,如果原创的优质内容不受保护,网络世界中抄袭盗版猖獗,这其实有利于网络生态的健康发展。这是一个缺点,而且它' 很难鼓励制作更多高质量的原创内容。未经授权的爬虫程序是危害web原创内容生态的罪魁祸首。因此,为了保护网站的内容,首先要考虑如何反爬。
##从爬虫攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。这当然是儿科最小的防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在http的get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。另外还有一个比较异常的服务器端爬虫检测机制,就是在http响应中为所有访问页面的http请求植入一个cookie token,然后在这个页面异步执行的一些ajax接口上学。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电商网站亚马逊采用这种防御策略。以上是基于服务器端验证爬虫程序可以玩的一些套路。
##基于客户端js运行时检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西需要一点一点的尝试,耗费大量人力物力开发的一套爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。攻击者需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。程序可以操作浏览器访问网页,使得编写爬虫的人可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。程序可以操作浏览器访问网页,使得编写爬虫的人可以通过调用浏览器暴露给程序的API来实现复杂的爬取业务逻辑。事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。甚至是基于 IE 内核的 trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。甚至是基于 IE 内核的 trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器内核C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真正的GUI浏览器的发布版本。其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS有很多问题,因为是单进程模型,没有必要的沙箱保护,并且浏览器内核的安全性较差。现在谷歌Chrome团队已经在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:js调用。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:js调用。我还为这个库贡献了一个centos环境部署依赖安装列表。Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 JS 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length == 0) {
console.log("It may be Chrome headless");
}
基于语言的检查
if(navigator.languages == "") {
console.log("Chrome headless detected");
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == "Brian Paul" && renderer == "Mesa OffScreen") {
console.log("Chrome headless detected");
}
基于浏览器细线属性的检查
if(!Modernizr["hairline"]) {
console.log("It may be Chrome headless");
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName("body")[0];
var image = document.createElement("img");
image.src = "http://iloveponeydotcom32188.jg";
image.setAttribute("id", "fakeimage");
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log("Chrome headless detected");
}
}
基于以上对一些浏览器特性的判断,基本上可以将市面上大部分的无头浏览器程序干掉。至此,网页爬虫的门槛其实提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器内核来说是很重要的。变化不小。此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,测试js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。另外,我们在研究robots browserdetect using js api在浏览器端的时候,发现了一个有趣的小技巧。可以将一个预先注入的js函数伪装成native函数,看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString());
console.log(fakeAlert.toString());
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。因此,需要更严格的检查,因为bind(null)伪造的方法在toString之后没有函数名。
##反爬虫银弹 反爬虫和机器人巡检最可靠的方法是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中最成熟的是 Google reCAPTCHA。基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。
##Robot协议 另外,在爬虫爬取技术领域还有一种“白道”的方法,叫做robots协议。您可以访问 网站 根目录中的 /robots.txt。比如我们看一下github的robot协议。Allow 和 Disallow 声明每个 UA 爬虫的授权。然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
##写在最后 网页内容的爬取与对策,注定是一场魔高一尺,路高一尺的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路。你可以 它所做的只是增加攻击者的抓取成本,并更准确地了解未经授权的抓取。另外,欢迎对爬虫感兴趣的朋友关注我的开源项目webster。该项目以Node.js结合Chrome无头模式实现了一个高可用的网络爬虫爬取框架。一个页面中js和ajax渲染的所有异步内容;结合redis,实现了一个任务队列,让爬虫轻松进行横向和纵向分布式扩展。
js 爬虫抓取网页数据(关于爬虫内容的分享,我会分成两篇,六个部分来分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-08 04:07
关于爬虫内容的分享,我将分为两部分,分享六个部分,分别是:
1) 我们的目的是什么
2) 内容从何而来
3) 了解网络请求
4) 一些常见的限制
5) 尝试解决问题的想法
6) 效率权衡
本文首先讨论前三个部分。
一、我们的目的是什么
一般来说,我们需要抓取的是一个网站或者一个应用程序的内容,以提取有用的价值。内容一般分为两部分,非结构化文本,或结构化文本。
1. 关于非结构化数据
1.1 HTML 文本(包括 javascript 代码)
HTML文本基本上是传统爬取过程中最常见的,也就是大部分时间会遇到的情况,比如爬取一个网页,得到HTML,然后需要解析一些常用元素,提取一些关键信息. 其实HTML应该属于结构化的文本组织,但是因为我们需要的关键信息不是直接可以得到的,需要对HTML进行解析和搜索,甚至可以得到一些字符串操作,所以还是归为非结构化数据。加工。
常用的分析方法如下:
现在的网页样式很多,所以一般的网页都会有一些CSS定位,比如class,id等,或者我们根据常用的节点路径定位,比如腾讯首页的金融版块
这里的 id 是金融。我们使用css选择器,即“#finance”来获取金融区的html。同理,可以根据具体的css选择器获取其他内容。
XPATH是一种页面元素的路径选择方法,可以使用chrome快速获取,例如:
copyXPATH 将得到 - //*[@id="finance"]
正则表达式,使用标准正则解析,一般将HTML视为普通文本,并使用指定格式匹配为相关文本,适用于小片段文本,或者某个字符串,或者HTML收录javascript代码,不能使用CSS选择器或 XPATH 。
和正则表达式一样,比较懒的方法,不推荐。
1.2 一段文字
比如一个文章,或者一个句子,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储。如果需要实时提取有用信息,常用的处理方式有以下几种:
根据捕获到的网站的类型,使用不同的词库,进行基本的分词,然后变成词频统计,类似于向量的表示,词是方向,词频是长度。
自然语言处理,进行语义分析,并用结果来表达,例如正面和负面。
2. 关于结构化数据
结构化数据是处理它的最佳方式。一般是类似于JSON格式的字符串。您可以直接解析 JSON 数据并提取 JSON 的关键字段。
二、内容从何而来
过去,我们经常需要获取的内容主要来自网页。一般来说,当我们决定爬取时,就是网页上能看到的所有内容。但是随着近几年移动互联网的发展,我们也发现越来越多的内容会来自移动应用,所以爬虫不仅仅局限于抓取和解析网页,还可以模拟移动端的网络请求要抓取的应用程序,因此我将分两部分解释这部分。
1. 网页内容
网页内容一般是指我们最终在网页上看到的内容,但是这个过程并不像直接在网页的代码中收录内容那么简单,所以对于很多新手来说,会出现很多问题,比如:
显然,当用 Chrome 或 Firefox 检查页面时,可以看到 HTML 标签中收录的内容,但在抓取时为空。
很多内容必须通过点击按钮或执行交互操作来显示在页面上。
因此,对于很多新手来说,做法是使用别人模拟浏览器操作的某种语言的库。其实就是调用本地浏览器或者收录一些执行javascript的引擎进行模拟操作来抓取数据。在抓取大量数据的情况下,效率非常低,相当于给技术人员自己用了一个盒子,那么这些内容到底是怎么显示在网页上的呢?主要分为以下几种情况:
这种情况最容易解决。一般来说,基本上都是写死的静态网页,或者是使用模板渲染的动态网页。浏览器获取HTML的时候已经收录了所有的关键信息,所以直接在网页上面看到的内容可以通过特定的HTML标签获取
这种情况是因为虽然网页显示时内容在html标签中,但实际上是通过执行js代码添加到标签中的,所以此时内容在js代码中,而js的执行是在浏览器端执行。所以当你使用程序请求网页地址时,得到的响应是网页代码和js代码,所以你可以在浏览器端看到内容。由于解析时没有执行js,所以一定要发现指定html标签下的内容一定是空的。此时的处理方式一般是查找收录该内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。
这种情况现在很常见,尤其是网页内容以分页的形式显示,并且页面没有刷新,或者是在网页上进行交互操作后获取到的内容。那么我们如何分析这些请求呢?这里我以Chrome的操作为例进行说明:
所以当我们开始刷新页面的时候,我们需要开始跟踪所有的请求,观察数据是从哪里加载的。那么当我们找到核心异步请求时,只需要抓取异步请求即可。如果原创网页没有任何有用的信息,则无需抓取原创网页。
2. 应用内容
因为现在移动应用越来越多,很多有用的信息都在app里面。另外,在解析非结构化文本和结构化文本方面,结构化文本会简单很多。如果你同时拥有网站和App,建议爬取App,大部分情况下基本上只是一些JSON数据API。那么如何抓取App的数据呢?一般的方法是抓包。基本方法是在电脑上安装抓包软件,配置好端口,然后记下ip。手机端和电脑在同一个局域网,然后在手机的网络连接中设置代理。该应用程序执行一些操作。如果有网络数据请求,会被抓包软件记录下来。就像上面Chrome对网络请求的分析一样,可以看到所有的请求,模拟请求操作。这里我推荐 Mac 的 Charles 软件和 Windows 的 Fiddler2。
怎么用,后面会详细解释,可能会涉及到HTTPS证书的问题。
三、了解网络请求
我刚刚广泛地提到了我们需要找到和提出的一些要求。请求只是一个过客,但是请求是一个很重要的部分,包括如何绕过限制以及如何发送正确的数据,都需要正确的请求,这里详细展开请求以及如何模拟请求。
我们常说爬虫其实就是一堆HTTP请求,找到要爬取的链接,不管是网页链接还是App抓取得到的API链接,然后发送请求包得到返回包(有也是 HTTP 长连接,或者 Streaming ,这里不考虑),所以核心要素是:
1)网址
2)请求方法(POST、GET)
3)请求包头
4)请求包内容
5)返回包头
在使用 Chrome 捕获网络请求或使用抓包工具分析请求时,最重要的是弄清楚请求头中的 URL、请求方法和字段。大部分问题都在headers中,最常被限制的字段是即User-Agent、Referer、Cookie。此外,Base Auth还在headers中添加了Autheration字段。
请求的内容是post时需要发送的数据,一般对Key-Value进行urlencode
大部分返回的包头都会被人忽略,可能仅仅获取到内容就够了,但其实很多时候很多人会发现请求包的url、请求方法和内容都是对了,为什么没有返回内容,还是找到了请求,其实这大概有两个原因:
一种是返回包的内容是空的,但是返回包的headers字段中有一个Location。这个Location字段告诉浏览器重定向,所以有时候代码不会自动跟踪,自然就没有内容了;
还有一个就是很多人头疼的cookie问题。简单来说就是为什么浏览器知道你的请求是合法的,比如登录等。其实可能是你之前请求的返回包的header中有一个字段叫做Set-Cookie,Cookie本地存在。一旦设置好,除非过期,否则会自动添加到请求字段中,所以Set-Cookie中的内容会告诉浏览器存储了多长时间,存储了哪些内容,在哪个路径下有用。Cookie 都是在指定域下,一般不跨域,域就是你请求的链接主机。
所以在分析request的时候一定要注意前4个,模拟的时候保持一致,观察第5个return是受限还是redirect。
孔淼 查看全部
js 爬虫抓取网页数据(关于爬虫内容的分享,我会分成两篇,六个部分来分享)
关于爬虫内容的分享,我将分为两部分,分享六个部分,分别是:
1) 我们的目的是什么
2) 内容从何而来
3) 了解网络请求
4) 一些常见的限制
5) 尝试解决问题的想法
6) 效率权衡
本文首先讨论前三个部分。
一、我们的目的是什么
一般来说,我们需要抓取的是一个网站或者一个应用程序的内容,以提取有用的价值。内容一般分为两部分,非结构化文本,或结构化文本。
1. 关于非结构化数据
1.1 HTML 文本(包括 javascript 代码)
HTML文本基本上是传统爬取过程中最常见的,也就是大部分时间会遇到的情况,比如爬取一个网页,得到HTML,然后需要解析一些常用元素,提取一些关键信息. 其实HTML应该属于结构化的文本组织,但是因为我们需要的关键信息不是直接可以得到的,需要对HTML进行解析和搜索,甚至可以得到一些字符串操作,所以还是归为非结构化数据。加工。
常用的分析方法如下:
现在的网页样式很多,所以一般的网页都会有一些CSS定位,比如class,id等,或者我们根据常用的节点路径定位,比如腾讯首页的金融版块
这里的 id 是金融。我们使用css选择器,即“#finance”来获取金融区的html。同理,可以根据具体的css选择器获取其他内容。
XPATH是一种页面元素的路径选择方法,可以使用chrome快速获取,例如:
copyXPATH 将得到 - //*[@id="finance"]
正则表达式,使用标准正则解析,一般将HTML视为普通文本,并使用指定格式匹配为相关文本,适用于小片段文本,或者某个字符串,或者HTML收录javascript代码,不能使用CSS选择器或 XPATH 。
和正则表达式一样,比较懒的方法,不推荐。
1.2 一段文字
比如一个文章,或者一个句子,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储。如果需要实时提取有用信息,常用的处理方式有以下几种:
根据捕获到的网站的类型,使用不同的词库,进行基本的分词,然后变成词频统计,类似于向量的表示,词是方向,词频是长度。
自然语言处理,进行语义分析,并用结果来表达,例如正面和负面。
2. 关于结构化数据
结构化数据是处理它的最佳方式。一般是类似于JSON格式的字符串。您可以直接解析 JSON 数据并提取 JSON 的关键字段。
二、内容从何而来
过去,我们经常需要获取的内容主要来自网页。一般来说,当我们决定爬取时,就是网页上能看到的所有内容。但是随着近几年移动互联网的发展,我们也发现越来越多的内容会来自移动应用,所以爬虫不仅仅局限于抓取和解析网页,还可以模拟移动端的网络请求要抓取的应用程序,因此我将分两部分解释这部分。
1. 网页内容
网页内容一般是指我们最终在网页上看到的内容,但是这个过程并不像直接在网页的代码中收录内容那么简单,所以对于很多新手来说,会出现很多问题,比如:
显然,当用 Chrome 或 Firefox 检查页面时,可以看到 HTML 标签中收录的内容,但在抓取时为空。
很多内容必须通过点击按钮或执行交互操作来显示在页面上。
因此,对于很多新手来说,做法是使用别人模拟浏览器操作的某种语言的库。其实就是调用本地浏览器或者收录一些执行javascript的引擎进行模拟操作来抓取数据。在抓取大量数据的情况下,效率非常低,相当于给技术人员自己用了一个盒子,那么这些内容到底是怎么显示在网页上的呢?主要分为以下几种情况:
这种情况最容易解决。一般来说,基本上都是写死的静态网页,或者是使用模板渲染的动态网页。浏览器获取HTML的时候已经收录了所有的关键信息,所以直接在网页上面看到的内容可以通过特定的HTML标签获取
这种情况是因为虽然网页显示时内容在html标签中,但实际上是通过执行js代码添加到标签中的,所以此时内容在js代码中,而js的执行是在浏览器端执行。所以当你使用程序请求网页地址时,得到的响应是网页代码和js代码,所以你可以在浏览器端看到内容。由于解析时没有执行js,所以一定要发现指定html标签下的内容一定是空的。此时的处理方式一般是查找收录该内容的js代码字符串,然后通过正则表达式获取对应的内容,而不是解析HTML标签。
这种情况现在很常见,尤其是网页内容以分页的形式显示,并且页面没有刷新,或者是在网页上进行交互操作后获取到的内容。那么我们如何分析这些请求呢?这里我以Chrome的操作为例进行说明:
所以当我们开始刷新页面的时候,我们需要开始跟踪所有的请求,观察数据是从哪里加载的。那么当我们找到核心异步请求时,只需要抓取异步请求即可。如果原创网页没有任何有用的信息,则无需抓取原创网页。
2. 应用内容
因为现在移动应用越来越多,很多有用的信息都在app里面。另外,在解析非结构化文本和结构化文本方面,结构化文本会简单很多。如果你同时拥有网站和App,建议爬取App,大部分情况下基本上只是一些JSON数据API。那么如何抓取App的数据呢?一般的方法是抓包。基本方法是在电脑上安装抓包软件,配置好端口,然后记下ip。手机端和电脑在同一个局域网,然后在手机的网络连接中设置代理。该应用程序执行一些操作。如果有网络数据请求,会被抓包软件记录下来。就像上面Chrome对网络请求的分析一样,可以看到所有的请求,模拟请求操作。这里我推荐 Mac 的 Charles 软件和 Windows 的 Fiddler2。
怎么用,后面会详细解释,可能会涉及到HTTPS证书的问题。
三、了解网络请求
我刚刚广泛地提到了我们需要找到和提出的一些要求。请求只是一个过客,但是请求是一个很重要的部分,包括如何绕过限制以及如何发送正确的数据,都需要正确的请求,这里详细展开请求以及如何模拟请求。
我们常说爬虫其实就是一堆HTTP请求,找到要爬取的链接,不管是网页链接还是App抓取得到的API链接,然后发送请求包得到返回包(有也是 HTTP 长连接,或者 Streaming ,这里不考虑),所以核心要素是:
1)网址
2)请求方法(POST、GET)
3)请求包头
4)请求包内容
5)返回包头
在使用 Chrome 捕获网络请求或使用抓包工具分析请求时,最重要的是弄清楚请求头中的 URL、请求方法和字段。大部分问题都在headers中,最常被限制的字段是即User-Agent、Referer、Cookie。此外,Base Auth还在headers中添加了Autheration字段。
请求的内容是post时需要发送的数据,一般对Key-Value进行urlencode
大部分返回的包头都会被人忽略,可能仅仅获取到内容就够了,但其实很多时候很多人会发现请求包的url、请求方法和内容都是对了,为什么没有返回内容,还是找到了请求,其实这大概有两个原因:
一种是返回包的内容是空的,但是返回包的headers字段中有一个Location。这个Location字段告诉浏览器重定向,所以有时候代码不会自动跟踪,自然就没有内容了;
还有一个就是很多人头疼的cookie问题。简单来说就是为什么浏览器知道你的请求是合法的,比如登录等。其实可能是你之前请求的返回包的header中有一个字段叫做Set-Cookie,Cookie本地存在。一旦设置好,除非过期,否则会自动添加到请求字段中,所以Set-Cookie中的内容会告诉浏览器存储了多长时间,存储了哪些内容,在哪个路径下有用。Cookie 都是在指定域下,一般不跨域,域就是你请求的链接主机。
所以在分析request的时候一定要注意前4个,模拟的时候保持一致,观察第5个return是受限还是redirect。
孔淼
js 爬虫抓取网页数据(静态网页爬取文章目录(一):蚂蚁、自动索引、模拟程序或者蠕虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2022-03-04 11:20
静态网页抓取
文章目录
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。.
一、静态网站分析
示例网站:
任务要求:
第一步获取主要食物类别
第二步,获取所有分类中的所有分页成分
第三步,获取所有分类的所有分页成分的营养成分和营养比例
二、需要的依赖和插件1.引入库
代码如下(示例):
from asyncio.windows_events import NULL
import requests
import mysql.connector
import datetime
from lxml import etree
from bs4 import BeautifulSoup
from selenium import webdriver
插件:phantomjs.exe
插件:XPath
插件介绍:
PhantomJS 是一个可编程的无头浏览器。
Headless browser:一个完整的浏览器内核,包括js解析引擎、渲染引擎、请求处理等,但不包括显示和与用户交互的浏览器。
2.PhantomJS 使用场景
PhantomJS 的适用范围是无头浏览器的适用范围。通常无头浏览器可用于页面自动化、网络监控、网络爬取等:
页面自动化测试:希望能自动登录网站做一些操作,然后检查结果是否正常。
网页监控:希望定期打开页面查看网站是否可以正常加载,加载结果是否符合预期。加载速度等等。
网络爬虫:获取js下载并渲染页面中的信息,或者使用js跳转后获取链接的真实地址。
———————————————
版权声明:本文为CSDN博主“violetgo”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原文出处链接和本声明。
原文链接:
三、代码显示
第一步获取主要食物类别
使用XPath插件查找需要爬取的html组件
response = requests.get(url="http://fitness.39.net/food/")
response.encoding = 'utf-8'
# 获取一级分类的数据
html = etree.HTML(response.text)
print(html.xpath("//dl[@id='food_ele_dl_id']//dd//a" ))
items = html.xpath("//dl[@id='food_ele_dl_id']//dd//a" )
data_time=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") #系统时间
val = []
val1 = []
# 遍历items的集合
for item in items:
title = "".join(item.xpath("./@title"))
href = "".join(item.xpath("./@href"))
val.append((title,href,data_time))
# print(html.xpath("" ))
print(val)
mydb = mysql.connector.connect(
host="11.11.11.111",
user="root",
passwd="123456",
database="python"
)
mycursor = mydb.cursor()
#删除旧的食材分类数据
sql = "DELETE FROM p_food_type "
mycursor.execute(sql)
mydb.commit()
print(mycursor.rowcount, " 条记录删除")
#插入新数据
sql = "INSERT INTO p_food_type (title, url,create_time) VALUES (%s, %s, %s)"
mycursor.executemany(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
print(mycursor.rowcount, "记录插入成功。")
第二步,获取大类中的所有子类,包括分页
分析如何获取分页
晶粒分析示例
通过图片我们可以找到分页的规则。
然后我们可以通过循环分类的url并将url拼接成页面来请求数据,直到拼接的url不请求数据。我们判断是最后一页,跳出这个类别,进入下一个类别。
<p>
#查询大类表
setsql = "SELECT * FROM p_food_type "
mycursor.execute(setsql)
myresult = mycursor.fetchall()
n = 100
sum = 0
counter = 1
#循环大类表
for x in myresult:
counter=1
while counter 查看全部
js 爬虫抓取网页数据(静态网页爬取文章目录(一):蚂蚁、自动索引、模拟程序或者蠕虫)
静态网页抓取
文章目录
前言
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中更常称为网络追逐者)是根据一定规则自动从万维网上爬取信息的程序或脚本。其他不太常用的名称是 ant、autoindex、emulator 或 worm。.
一、静态网站分析
示例网站:
任务要求:
第一步获取主要食物类别
第二步,获取所有分类中的所有分页成分
第三步,获取所有分类的所有分页成分的营养成分和营养比例
二、需要的依赖和插件1.引入库
代码如下(示例):
from asyncio.windows_events import NULL
import requests
import mysql.connector
import datetime
from lxml import etree
from bs4 import BeautifulSoup
from selenium import webdriver
插件:phantomjs.exe
插件:XPath
插件介绍:
PhantomJS 是一个可编程的无头浏览器。
Headless browser:一个完整的浏览器内核,包括js解析引擎、渲染引擎、请求处理等,但不包括显示和与用户交互的浏览器。
2.PhantomJS 使用场景
PhantomJS 的适用范围是无头浏览器的适用范围。通常无头浏览器可用于页面自动化、网络监控、网络爬取等:
页面自动化测试:希望能自动登录网站做一些操作,然后检查结果是否正常。
网页监控:希望定期打开页面查看网站是否可以正常加载,加载结果是否符合预期。加载速度等等。
网络爬虫:获取js下载并渲染页面中的信息,或者使用js跳转后获取链接的真实地址。
———————————————
版权声明:本文为CSDN博主“violetgo”的原创文章,遵循CC4.0 BY-SA版权协议。转载请附上原文出处链接和本声明。
原文链接:
三、代码显示
第一步获取主要食物类别
使用XPath插件查找需要爬取的html组件
response = requests.get(url="http://fitness.39.net/food/";)
response.encoding = 'utf-8'
# 获取一级分类的数据
html = etree.HTML(response.text)
print(html.xpath("//dl[@id='food_ele_dl_id']//dd//a" ))
items = html.xpath("//dl[@id='food_ele_dl_id']//dd//a" )
data_time=datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") #系统时间
val = []
val1 = []
# 遍历items的集合
for item in items:
title = "".join(item.xpath("./@title"))
href = "".join(item.xpath("./@href"))
val.append((title,href,data_time))
# print(html.xpath("" ))
print(val)
mydb = mysql.connector.connect(
host="11.11.11.111",
user="root",
passwd="123456",
database="python"
)
mycursor = mydb.cursor()
#删除旧的食材分类数据
sql = "DELETE FROM p_food_type "
mycursor.execute(sql)
mydb.commit()
print(mycursor.rowcount, " 条记录删除")
#插入新数据
sql = "INSERT INTO p_food_type (title, url,create_time) VALUES (%s, %s, %s)"
mycursor.executemany(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
print(mycursor.rowcount, "记录插入成功。")
第二步,获取大类中的所有子类,包括分页
分析如何获取分页
晶粒分析示例
通过图片我们可以找到分页的规则。
然后我们可以通过循环分类的url并将url拼接成页面来请求数据,直到拼接的url不请求数据。我们判断是最后一页,跳出这个类别,进入下一个类别。
<p>
#查询大类表
setsql = "SELECT * FROM p_food_type "
mycursor.execute(setsql)
myresult = mycursor.fetchall()
n = 100
sum = 0
counter = 1
#循环大类表
for x in myresult:
counter=1
while counter
js 爬虫抓取网页数据(目标网络爬虫的是做什么的?手动写一个简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-04 11:19
目标
网络爬虫有什么作用?手动编写一个简单的网络爬虫;
1. 网络爬虫1.1. 名称
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
1.2. 简要说明
网络爬虫通过自己的链接地址寻找网页,从网站的一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后寻找下一页通过这些链接地址。一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发送的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
2. 进程
网络爬虫有什么作用?它的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析出新的URL路径。这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;
2.1. 专注
爬虫需要注意的三点:
爬取目标的描述或定义;网页或数据的分析和过滤;URL 的搜索策略
3. 分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:
通用网络爬虫 聚焦网络爬虫 增量网络爬虫 深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
4. 思想分析
接下来,我将通过我们的官网来和大家一起分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页是:
分析页面
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据
标题:由 XPath 表达式表示 //div[@class='content']/h4/a/text() 描述:由 XPath 表达式表示 //div[@class='content']/p/text() 图像:使用 XPath 表达式来表示 //a/img/@src
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构
5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/")
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
WanhoPageProcessor.java
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i 查看全部
js 爬虫抓取网页数据(目标网络爬虫的是做什么的?手动写一个简单)
目标
网络爬虫有什么作用?手动编写一个简单的网络爬虫;
1. 网络爬虫1.1. 名称
网络爬虫(也称为网络蜘蛛或网络机器人)是一种程序或脚本,它根据一定的规则自动爬取万维网上的信息。其他不太常用的名称是 ant、autoindex、emulator 或 worm。
1.2. 简要说明
网络爬虫通过自己的链接地址寻找网页,从网站的一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后寻找下一页通过这些链接地址。一个网页,以此类推,直到这个网站的所有网页都被爬取完毕。如果把整个互联网看成一个网站,那么网络蜘蛛就可以利用这个原理爬取互联网上的所有网页。因此,为了抓取网络上的数据,不仅是爬虫程序,还有一个服务器,它可以接受“爬虫”发送的数据,并对其进行处理和过滤。爬虫爬取的数据量越大,对服务器的性能要求就越高。.
2. 进程
网络爬虫有什么作用?它的主要工作是根据指定的url地址发送请求,得到响应,然后解析响应。新的URL路径,然后继续访问,继续解析;继续寻找需要的数据,继续解析出新的URL路径。这是网络爬虫的主要工作。以下是流程图:
通过上面的流程图,可以大致了解网络爬虫是做什么的,基于这些,就可以设计一个简单的网络爬虫了。
简单爬虫所需:
发送请求和获取响应的功能;解析响应的功能;存储过滤数据的功能;处理解析后的URL路径的功能;
2.1. 专注
爬虫需要注意的三点:
爬取目标的描述或定义;网页或数据的分析和过滤;URL 的搜索策略
3. 分类
根据系统结构和实现技术,网络爬虫大致可以分为以下几种:
通用网络爬虫 聚焦网络爬虫 增量网络爬虫 深度网络爬虫。实际的网络爬虫系统通常是通过结合几种爬虫技术来实现的。
4. 思想分析
接下来,我将通过我们的官网来和大家一起分析一下如何实现这样的爬虫:
首先观察我们爬虫的起始页是:
分析页面
所有好消息 URL 都由 XPath 表达式表示://div[@class='main_l']/ul/li
相关数据
标题:由 XPath 表达式表示 //div[@class='content']/h4/a/text() 描述:由 XPath 表达式表示 //div[@class='content']/p/text() 图像:使用 XPath 表达式来表示 //a/img/@src
好了,我们在上面的代码中找到了需要获取的关键信息的XPath表达式,接下来就可以正式写代码实现了
5. 代码实现
代码实现部分使用了webmagic框架,因为它比使用基础Java网络编程要简单很多注:webmagic框架可以看下面的讲义
5.1. 代码结构
5.2. 程序入口
演示.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/";)
// 启用的线程数
.thread(5).run();
}
}
5.3. 爬取过程
WanhoPageProcessor.java
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i
js 爬虫抓取网页数据(微博的热点事件会产生大量评论数据,这些数据是进行舆情分析和网络水军识别等数据挖掘的基础 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2022-03-04 11:17
)
黄洪涛姜英峰
摘要:微博热点事件会产生大量评论数据,是舆情分析、网络海军识别等数据挖掘的基础。论文分析比较了常用的网络爬虫技术和框架,分别使用Selenium框架和Json数据接口两种方法,以及采集新浪微博热点事件下的用户评论数据。一般网络爬虫技术多采用广度搜索,这里采用深度搜索,可以更准确的获取某个热点事件下的用户评论数据。
关键词:数据挖掘微博用户评论网络爬虫Selenium Json
CLC 编号:TP393.09;TP274.2 证件识别码:A文章编号:1674-098X (2021)05(b)-0132-05
基于微博平台的用户评论数据采集
黄洪涛姜英峰
(广东外语外贸大学信息学院, 广东省广州市, 510006)
摘要:微博热点事件会产生大量评论数据,是舆情分析、在线水军识别等数据挖掘的基础。论文分析比较了常用的网络爬虫技术和框架,分别使用Selenium框架和Json数据接口采集新浪微博热点事件下的用户评论数据。网络爬取技术一般采用广度搜索,这里采用深度搜索,更能准确获取热点事件下的用户评论数据。
关键词:数据挖掘;微博;用户评论;网络爬虫;硒; json
根据2021年2月发布的第47次《中国互联网发展状况统计报告》,截至2020年12月,我国网民规模达到9.89亿,较2020年3月增加8540万,互联网普及率高达70.4%,较2020年3月提升5.9个百分点。截至2020年12月,我国移动互联网用户规模达到9. 86亿,比2020年3月增加8885万,使用手机上网的网民比例达到99.7%,比2020年3月增加0.4个百分点. 数据显示,我国网民数量非常庞大,并且使用手机上网的网民比例非常高。这使得网民进入社区交流平台(如微博、知乎)的门槛降低,机会增加。很多网友,包括很多网络海军,都参与了热点事件的评论,使得这些事件产生了大量的数据。
新浪微博是在中国拥有大量用户和高活跃度的在线社交平台。一个热点事件往往有几万、十万甚至上百万条评论数据。这些数据是舆情分析、网络海军识别等数据挖掘的基础。
本文研究了相关的网络爬虫技术,并利用它对用户评论数据采集进行了批处理和自动化处理。
1 相关技术
1.1 爬虫技术分类
爬虫技术有一些分类如下。
1.1.1 万能网络爬虫
通用网络爬虫也称为可扩展网络爬虫[1]。爬取对象从一些种子URL扩展到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。一般网络爬虫的结构大致可以分为几个部分:页面爬取模块、页面分析模块、链接过滤模块、页面数据库、URL队列初始URL采集。通用爬虫主要用于广度搜索优先策略。
1.1.2 关注网络爬虫
Focused Crawler,也称为Topical Crawler [2],是指选择性地抓取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要爬取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。信息需求。与一般的网络爬虫相比,聚焦网络爬虫增加了链接评价模块和内容评价模块。聚焦爬虫的爬取策略实施的关键是评估页面内容和链接的重要性。不同的方法计算不同的重要性,导致链接的访问顺序不同。
1.1.3 增量爬虫
增量网页爬虫是指不再抓取已经抓取的网页,只抓取新生成的网页,即增量更新。与其他类型的网络爬虫相比,它只关注新增的数据,大大减少了网页的下载量,减少了爬虫对存储空间和网络带宽的消耗,但增加了爬虫的复杂度。卷爬取算法及实现难度[3].
1.1.4 深网爬虫
从网站上呈现的网页的不同位置结构来看,网页可以简单地分为浅态页面和深态页面。深度状态网页是指存储在网络数据库中的那些一般搜索引擎无法搜索到的状态页面,通常需要一定的条件才能获得(如登录)。与深态网页相比,浅态网页是指搜索引擎在网络上搜索到的浅态网页。Deep Web 往往具有强烈的主题,每个 Deep Web 主题领域所收录的数字信息更专业,内容更丰富[4]。
1.2 常用爬虫框架
1.2.1 硒
Selenium 是一个用于操作浏览器以执行自动化测试的框架。浏览器自动化可以通过简单的命令来控制,就像真正的用户在操作一样,例如输入验证码。Selenium是一款自动化测试工具,支持多种浏览器,包括Chrome、Safari、Firefox等主流界面浏览器。因此,它可以用来爬取任何网页上看到的任何数据信息,几乎可以避免大多数反爬虫监控[5]。
1.2.2 json接口
Json(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它使用不同于编程语言的特殊文本格式来保存和传递数据。简洁、清晰和易于理解的层次结构使 Json 成为理想的数据交换语言。更便于人读写,更易于机器解析生成,有效提高网络传输效率。Json 文本格式具有兼容性非常高、习惯行为类似于 C 语言系统、独立于其他编程语言的特点。这些特性使 Json 成为一种理想的数据交换语言 [6] 并用于提供 json 数据接口采集 的网页中的数据处理。
1.2.3 Scrapy
Scrapy是一个Python实现的爬虫框架,架构清晰,模块间耦合度比较低,扩展性比较强。等特点[7]。Scrapy框架不仅可以通过爬取网页获取数据,还可以通过访问API接口获取其他对应的数据,实现对网页资源的多级快速爬取,适用于各类网站爬取工作,提取有价值的结构数据[8]。
2 数据采集
本数据采集来源于网络社交平台-新浪微博,采集的具体评论数据为 filter=hot&root_comment_id=0&type=comment#_rnd59 博文下的用户评论。从这篇博文的评论数可以看出,这篇博文下的评论数据非常多,已经达到百万级评论数据。接下来,爬虫将用于捕获其数据并进行一些分析。
下面根据采集的数据特点,分别使用增量爬虫和Deep Web爬虫技术、selenium框架和json数据接口对微博评论数据进行采集。
2.1 使用 Selenium 框架采集数据
Selenium 爬取评论的基本步骤如图 1 所示。
首先获取其网页源代码(在网站上按F12查看),然后根据其源代码构造一个dom树,如图2所示。
接下来可以使用XPath解析dom树,根据相关节点爬取数据。部分代码如下。
user_data = requests.get(i)
dom_url = etree.HTML(user_data.text, etree.HTMLParser(encoding='utf-8'))
follow = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][1]/text()')
fan = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][2]/text()')
boke = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][3]/text()')
数据爬取完成后,可以选择保存为xml、csv、txt等文本文件。在这里,选择保存在 csv 文件中。
2.2 使用Json数据接口采集数据
与 Selenium 不同的是,Json 数据接口可以相对直接的获取数据,因为它的数据结构是 Json 的格式,但是需要找到数据的接口。
因为网页版微博不提供数据接口,反爬机制更先进,我们这里使用手机微博。手机微博用户评论通过瀑布流刷新,提供Json数据接口。例如其中一个接口: id=46240&mid=46240&max_id_type=0,其结构如下。
{ok: 1, data: {data: [,…], total_number: "1 百万+",…}}
数据:{数据:[,…],总数:“100万+”,…}
数据: [,…]
0:{created_at:“2021 年 2 月 27 日星期六 15:09:20 +0800”,id:“46737”,rootid:“46737”,...}
1:{created_at:“2021 年 2 月 27 日星期六 15:04:59 +0800”,id:“46970”,rootid:“46970”,...}
…
18:{created_at:“2021 年 2 月 27 日星期六 15:05:08 +0800”,id:“46568”,rootid:“46568”,...}
最大:50000
max_id: 45846235480040570
max_id_type: 0
状态:{comment_manage_info:{comment_permission_type:-1,approval_comment_type:0}}
总数:“一百万+”
好的:1
这种结构下获取用户评论比较简单,但是一个Json数据接口通常只能提供10×19条用户评论,所以需要重新获取下一个接口。由于手机端的微博使用瀑布流刷新用户评论,可以直接控制页面下拉刷新,获取下一个Json数据接口。观察它的数据接口链路,可以知道链路中只有max_id和max_id_type会发生变化,所以可以通过多个Json数据链路得出规律,下一个链路的max_id就是上一个链路的Json字典中的max_id (json结构倒数第六行),而max_id_type是0到1之间的值。首先用0判断Json返回的ok是否为1,如果是max_id_type则取0,否则取1。
当我
while_starttime = datetime.datetime.now()
尝试:
如果我 == 0:
r = requests.get(one, headers=headers)
别的:
b = '&max_id_type=0'
urlll = a + str(id) + b
r = requests.get(urlll, headers=headers)
标志 = r.json()
flag1 = r.json()['ok']
如果标志1 == 0:
b = '&max_id_type=1'
urlll = a + str(id) + b
r = requests.get(urlll, headers=headers)
js = r.json()
用户 = js['数据']['数据']
下一步就是分解获取Json数据,获取的数据也可以保存为xml表格、csv文件、txt文本文件等。
2.3 采集结果
两种方式的爬取结果包括用户id(用户的唯一标识)、用户名、评论时间、评论内容、评论点赞数。本次爬取共获得6000多条数据,可用于下一步。用户评论的数据挖掘提供了大量的数据,结果如图3所示。
3 结论
本文采用两种方法,均采用深度优先搜索获取微博用户评论数据。Selenium框架首先解析网页源代码,生成dom树,然后通过dom树获取用户评论数据。Json数据接口通过解析Json数据结构,直接获取微博用户的评论数据。实验中,针对微博热点事件下的用户评论数据采集,采用两种方法取得了较好的效果。
两种 data采集 方法都有优点和缺点。Selenium 可以模拟真人爬取数据的行为,基本不受网页限制,但前期过程会比较繁琐,爬取效率不是很高。Json数据接口直截了当,但是获取数据需要详细找出隐藏的接口位置,有时需要找到下一个接口并总结其链接规则,而有的网站没有提供数据接口。在实际操作中,可以根据具体需要,结合两种技术的优缺点选择其中一种方法。
参考
[1] 曾建荣, 张扬森, 郑佳, 等. 多数据源的Web爬虫实现技术及应用[J]. 计算机科学, 2019, 46 (5): 304-309.
[2]郭S,卞W,刘Y,等。基于支持向量机的聚焦爬虫在空间情报采集中的应用研究[J]. 电子设计工程, 2016, 24 (17): 28-34
[3] 叶婷. 基于关键词的微博爬虫系统设计与实现[D]. 杭州:浙江工业大学,2016.
[4] 杨晓福.公交票务DeepWeb数据采集关键技术研究[D]. 重庆:重庆交通大学,2016.
[5] 吕伯清. 基于爬虫和数据挖掘的电子商务页面信息分析[D]. 兰州:兰州大学,2018.
[6] 陈哲. 基于微博热点事件的可视化系统开发与实现[D]. 北京:首都经济贸易大学,2018.
[7] 孙宇. 基于Scrapy框架的网络爬虫系统设计与实现[D]. 北京:北京交通大学,2019.
[8] 崔新宇.基于情感分析的商品评价系统设计与实现[D]. 邯郸:河北工程大学,2020.
标签: 网络爬虫 微博 数据挖掘
报酬
查看全部
js 爬虫抓取网页数据(微博的热点事件会产生大量评论数据,这些数据是进行舆情分析和网络水军识别等数据挖掘的基础
)
黄洪涛姜英峰
摘要:微博热点事件会产生大量评论数据,是舆情分析、网络海军识别等数据挖掘的基础。论文分析比较了常用的网络爬虫技术和框架,分别使用Selenium框架和Json数据接口两种方法,以及采集新浪微博热点事件下的用户评论数据。一般网络爬虫技术多采用广度搜索,这里采用深度搜索,可以更准确的获取某个热点事件下的用户评论数据。
关键词:数据挖掘微博用户评论网络爬虫Selenium Json
CLC 编号:TP393.09;TP274.2 证件识别码:A文章编号:1674-098X (2021)05(b)-0132-05
基于微博平台的用户评论数据采集
黄洪涛姜英峰
(广东外语外贸大学信息学院, 广东省广州市, 510006)
摘要:微博热点事件会产生大量评论数据,是舆情分析、在线水军识别等数据挖掘的基础。论文分析比较了常用的网络爬虫技术和框架,分别使用Selenium框架和Json数据接口采集新浪微博热点事件下的用户评论数据。网络爬取技术一般采用广度搜索,这里采用深度搜索,更能准确获取热点事件下的用户评论数据。
关键词:数据挖掘;微博;用户评论;网络爬虫;硒; json
根据2021年2月发布的第47次《中国互联网发展状况统计报告》,截至2020年12月,我国网民规模达到9.89亿,较2020年3月增加8540万,互联网普及率高达70.4%,较2020年3月提升5.9个百分点。截至2020年12月,我国移动互联网用户规模达到9. 86亿,比2020年3月增加8885万,使用手机上网的网民比例达到99.7%,比2020年3月增加0.4个百分点. 数据显示,我国网民数量非常庞大,并且使用手机上网的网民比例非常高。这使得网民进入社区交流平台(如微博、知乎)的门槛降低,机会增加。很多网友,包括很多网络海军,都参与了热点事件的评论,使得这些事件产生了大量的数据。
新浪微博是在中国拥有大量用户和高活跃度的在线社交平台。一个热点事件往往有几万、十万甚至上百万条评论数据。这些数据是舆情分析、网络海军识别等数据挖掘的基础。
本文研究了相关的网络爬虫技术,并利用它对用户评论数据采集进行了批处理和自动化处理。
1 相关技术
1.1 爬虫技术分类
爬虫技术有一些分类如下。
1.1.1 万能网络爬虫
通用网络爬虫也称为可扩展网络爬虫[1]。爬取对象从一些种子URL扩展到整个Web,主要针对门户网站搜索引擎和大型Web服务提供商采集数据。一般网络爬虫的结构大致可以分为几个部分:页面爬取模块、页面分析模块、链接过滤模块、页面数据库、URL队列初始URL采集。通用爬虫主要用于广度搜索优先策略。
1.1.2 关注网络爬虫
Focused Crawler,也称为Topical Crawler [2],是指选择性地抓取与预定义主题相关的页面的网络爬虫。与一般的网络爬虫相比,专注爬虫只需要爬取与主题相关的页面,大大节省了硬件和网络资源,而且由于页面数量少,保存的页面更新也很快。信息需求。与一般的网络爬虫相比,聚焦网络爬虫增加了链接评价模块和内容评价模块。聚焦爬虫的爬取策略实施的关键是评估页面内容和链接的重要性。不同的方法计算不同的重要性,导致链接的访问顺序不同。
1.1.3 增量爬虫
增量网页爬虫是指不再抓取已经抓取的网页,只抓取新生成的网页,即增量更新。与其他类型的网络爬虫相比,它只关注新增的数据,大大减少了网页的下载量,减少了爬虫对存储空间和网络带宽的消耗,但增加了爬虫的复杂度。卷爬取算法及实现难度[3].
1.1.4 深网爬虫
从网站上呈现的网页的不同位置结构来看,网页可以简单地分为浅态页面和深态页面。深度状态网页是指存储在网络数据库中的那些一般搜索引擎无法搜索到的状态页面,通常需要一定的条件才能获得(如登录)。与深态网页相比,浅态网页是指搜索引擎在网络上搜索到的浅态网页。Deep Web 往往具有强烈的主题,每个 Deep Web 主题领域所收录的数字信息更专业,内容更丰富[4]。
1.2 常用爬虫框架
1.2.1 硒
Selenium 是一个用于操作浏览器以执行自动化测试的框架。浏览器自动化可以通过简单的命令来控制,就像真正的用户在操作一样,例如输入验证码。Selenium是一款自动化测试工具,支持多种浏览器,包括Chrome、Safari、Firefox等主流界面浏览器。因此,它可以用来爬取任何网页上看到的任何数据信息,几乎可以避免大多数反爬虫监控[5]。
1.2.2 json接口
Json(JavaScript Object Notation,JS Object Notation)是一种轻量级的数据交换格式。它使用不同于编程语言的特殊文本格式来保存和传递数据。简洁、清晰和易于理解的层次结构使 Json 成为理想的数据交换语言。更便于人读写,更易于机器解析生成,有效提高网络传输效率。Json 文本格式具有兼容性非常高、习惯行为类似于 C 语言系统、独立于其他编程语言的特点。这些特性使 Json 成为一种理想的数据交换语言 [6] 并用于提供 json 数据接口采集 的网页中的数据处理。
1.2.3 Scrapy
Scrapy是一个Python实现的爬虫框架,架构清晰,模块间耦合度比较低,扩展性比较强。等特点[7]。Scrapy框架不仅可以通过爬取网页获取数据,还可以通过访问API接口获取其他对应的数据,实现对网页资源的多级快速爬取,适用于各类网站爬取工作,提取有价值的结构数据[8]。
2 数据采集
本数据采集来源于网络社交平台-新浪微博,采集的具体评论数据为 filter=hot&root_comment_id=0&type=comment#_rnd59 博文下的用户评论。从这篇博文的评论数可以看出,这篇博文下的评论数据非常多,已经达到百万级评论数据。接下来,爬虫将用于捕获其数据并进行一些分析。
下面根据采集的数据特点,分别使用增量爬虫和Deep Web爬虫技术、selenium框架和json数据接口对微博评论数据进行采集。
2.1 使用 Selenium 框架采集数据
Selenium 爬取评论的基本步骤如图 1 所示。
首先获取其网页源代码(在网站上按F12查看),然后根据其源代码构造一个dom树,如图2所示。
接下来可以使用XPath解析dom树,根据相关节点爬取数据。部分代码如下。
user_data = requests.get(i)
dom_url = etree.HTML(user_data.text, etree.HTMLParser(encoding='utf-8'))
follow = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][1]/text()')
fan = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][2]/text()')
boke = dom_url.xpath('//div[@class="WB_innerwrap"]//strong[@class="W_f18"][3]/text()')
数据爬取完成后,可以选择保存为xml、csv、txt等文本文件。在这里,选择保存在 csv 文件中。
2.2 使用Json数据接口采集数据
与 Selenium 不同的是,Json 数据接口可以相对直接的获取数据,因为它的数据结构是 Json 的格式,但是需要找到数据的接口。
因为网页版微博不提供数据接口,反爬机制更先进,我们这里使用手机微博。手机微博用户评论通过瀑布流刷新,提供Json数据接口。例如其中一个接口: id=46240&mid=46240&max_id_type=0,其结构如下。
{ok: 1, data: {data: [,…], total_number: "1 百万+",…}}
数据:{数据:[,…],总数:“100万+”,…}
数据: [,…]
0:{created_at:“2021 年 2 月 27 日星期六 15:09:20 +0800”,id:“46737”,rootid:“46737”,...}
1:{created_at:“2021 年 2 月 27 日星期六 15:04:59 +0800”,id:“46970”,rootid:“46970”,...}
…
18:{created_at:“2021 年 2 月 27 日星期六 15:05:08 +0800”,id:“46568”,rootid:“46568”,...}
最大:50000
max_id: 45846235480040570
max_id_type: 0
状态:{comment_manage_info:{comment_permission_type:-1,approval_comment_type:0}}
总数:“一百万+”
好的:1
这种结构下获取用户评论比较简单,但是一个Json数据接口通常只能提供10×19条用户评论,所以需要重新获取下一个接口。由于手机端的微博使用瀑布流刷新用户评论,可以直接控制页面下拉刷新,获取下一个Json数据接口。观察它的数据接口链路,可以知道链路中只有max_id和max_id_type会发生变化,所以可以通过多个Json数据链路得出规律,下一个链路的max_id就是上一个链路的Json字典中的max_id (json结构倒数第六行),而max_id_type是0到1之间的值。首先用0判断Json返回的ok是否为1,如果是max_id_type则取0,否则取1。
当我
while_starttime = datetime.datetime.now()
尝试:
如果我 == 0:
r = requests.get(one, headers=headers)
别的:
b = '&max_id_type=0'
urlll = a + str(id) + b
r = requests.get(urlll, headers=headers)
标志 = r.json()
flag1 = r.json()['ok']
如果标志1 == 0:
b = '&max_id_type=1'
urlll = a + str(id) + b
r = requests.get(urlll, headers=headers)
js = r.json()
用户 = js['数据']['数据']
下一步就是分解获取Json数据,获取的数据也可以保存为xml表格、csv文件、txt文本文件等。
2.3 采集结果
两种方式的爬取结果包括用户id(用户的唯一标识)、用户名、评论时间、评论内容、评论点赞数。本次爬取共获得6000多条数据,可用于下一步。用户评论的数据挖掘提供了大量的数据,结果如图3所示。
3 结论
本文采用两种方法,均采用深度优先搜索获取微博用户评论数据。Selenium框架首先解析网页源代码,生成dom树,然后通过dom树获取用户评论数据。Json数据接口通过解析Json数据结构,直接获取微博用户的评论数据。实验中,针对微博热点事件下的用户评论数据采集,采用两种方法取得了较好的效果。
两种 data采集 方法都有优点和缺点。Selenium 可以模拟真人爬取数据的行为,基本不受网页限制,但前期过程会比较繁琐,爬取效率不是很高。Json数据接口直截了当,但是获取数据需要详细找出隐藏的接口位置,有时需要找到下一个接口并总结其链接规则,而有的网站没有提供数据接口。在实际操作中,可以根据具体需要,结合两种技术的优缺点选择其中一种方法。
参考
[1] 曾建荣, 张扬森, 郑佳, 等. 多数据源的Web爬虫实现技术及应用[J]. 计算机科学, 2019, 46 (5): 304-309.
[2]郭S,卞W,刘Y,等。基于支持向量机的聚焦爬虫在空间情报采集中的应用研究[J]. 电子设计工程, 2016, 24 (17): 28-34
[3] 叶婷. 基于关键词的微博爬虫系统设计与实现[D]. 杭州:浙江工业大学,2016.
[4] 杨晓福.公交票务DeepWeb数据采集关键技术研究[D]. 重庆:重庆交通大学,2016.
[5] 吕伯清. 基于爬虫和数据挖掘的电子商务页面信息分析[D]. 兰州:兰州大学,2018.
[6] 陈哲. 基于微博热点事件的可视化系统开发与实现[D]. 北京:首都经济贸易大学,2018.
[7] 孙宇. 基于Scrapy框架的网络爬虫系统设计与实现[D]. 北京:北京交通大学,2019.
[8] 崔新宇.基于情感分析的商品评价系统设计与实现[D]. 邯郸:河北工程大学,2020.
标签: 网络爬虫 微博 数据挖掘
报酬
js 爬虫抓取网页数据( 图片js,css等ps:请求,分析用户发来的请求信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2022-03-01 03:12
图片js,css等ps:请求,分析用户发来的请求信息)
请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器接收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫模拟浏览器发送请求再接收Response后提取有用数据。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
/s?wd=图像
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(要添加,否则将被视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location并返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫所需工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis 查看全部
js 爬虫抓取网页数据(
图片js,css等ps:请求,分析用户发来的请求信息)
请求:用户通过浏览器(socket client)将自己的信息发送到服务器(socket server)
响应:服务器接收到请求,分析用户发送的请求信息,然后返回数据(返回的数据可能收录其他链接,如:图片、js、css等)
ps:浏览器收到Response后会解析其内容展示给用户,爬虫模拟浏览器发送请求再接收Response后提取有用数据。
四、 请求
1、请求方法:
常见的请求方式:GET / POST
2、请求的网址
url 全局统一资源定位器,用于定义互联网上唯一的资源 例如:图片、文件、视频都可以通过url唯一标识
网址编码
/s?wd=图像
图像将被编码(见示例代码)
一个网页的加载过程是:
加载网页通常会先加载文档,
在解析document文档时,如果遇到链接,则对该超链接发起图片下载请求
3、请求头
User-agent:如果请求头中没有user-agent客户端配置,服务器可能会将你视为非法用户主机;
cookies:cookies用于存储登录信息
注意:一般爬虫会添加请求头
请求头中需要注意的参数:
(1)Referrer:访问源从哪里来(有些大的网站,会使用Referrer做防盗链策略;所有爬虫也要注意模拟)
(2)User-Agent: 访问的浏览器(要添加,否则将被视为爬虫)
(3)cookie: 请注意请求头
4、请求正文
请求体
如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到)
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
五、 响应
1、响应状态码
200:代表成功
301:代表跳转
404: 文件不存在
403:未经授权的访问
502:服务器错误
2、响应头
响应头中需要注意的参数:
(1)Set-Cookie:BDSVRTM=0; path=/: 可能有多个,告诉浏览器保存cookie
(2)Content-Location:服务器响应头收录Location并返回浏览器后,浏览器会重新访问另一个页面
3、预览是网页的源代码
JSO 数据
如网页html、图片
二进制数据等
六、总结
1、爬虫流程总结:
爬取--->解析--->存储
2、爬虫所需工具:
请求库:requests、selenium(可以驱动浏览器解析和渲染CSS和JS,但有性能劣势(会加载有用和无用的网页);)
解析库:regular、beautifulsoup、pyquery
存储库:文件、MySQL、Mongodb、Redis
js 爬虫抓取网页数据(怎么显示在网页上的呢?网页的代码里面直接包含内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-24 11:11
网页内容一般是指我们最终在网页上看到的内容,但是这个过程并不像直接在网页的代码中收录内容那么简单,所以对于很多新手来说,会遇到很多问题,比如:
显然,当用 Chrome 或 Firefox 检查页面时,可以看到 HTML 标签中收录的内容,但在抓取时为空。
很多内容必须通过点击按钮或执行交互操作来显示在页面上。
因此,对于很多新手来说,做法是使用某种语言来模拟浏览器的操作。其实就是调用本地浏览器或者收录一些执行javascript的引擎进行模拟操作来抓取数据。在抓取大量数据的情况下,效率很低,相当于给技术人员自己用了一个盒子,那么这些内容到底是如何在网页上显示的呢?
主要分为以下几种情况:
网页收录内容的情况是最容易解决的。一般来说,基本上都是静态网页的内容被写死了,或者是动态网页,用模板渲染出来的。当浏览器获取 HTML 时,它已经收录了所有的关键信息,所以你在网页上直接看到的内容可以通过特定的 HTML 标签由 javascript 代码加载。这是因为虽然网页显示时内容在HTML标签中,但实际上是通过执行js代码添加到标签中的。所以此时内容在js代码中,js的执行是在浏览器端,所以当你使用程序请求网页地址时,得到的响应是网页代码和js代码,所以你可以在浏览器端看到它。说到内容,由于解析的时候js还没有被执行,所以一定要发现指定的html标签下的内容是空的。此时的处理方式一般是找到收录该内容的js代码字符串,然后通过正则表达式获取对应的内容。, 而不是解析 HTML 标签。 查看全部
js 爬虫抓取网页数据(怎么显示在网页上的呢?网页的代码里面直接包含内容)
网页内容一般是指我们最终在网页上看到的内容,但是这个过程并不像直接在网页的代码中收录内容那么简单,所以对于很多新手来说,会遇到很多问题,比如:
显然,当用 Chrome 或 Firefox 检查页面时,可以看到 HTML 标签中收录的内容,但在抓取时为空。
很多内容必须通过点击按钮或执行交互操作来显示在页面上。
因此,对于很多新手来说,做法是使用某种语言来模拟浏览器的操作。其实就是调用本地浏览器或者收录一些执行javascript的引擎进行模拟操作来抓取数据。在抓取大量数据的情况下,效率很低,相当于给技术人员自己用了一个盒子,那么这些内容到底是如何在网页上显示的呢?
主要分为以下几种情况:
网页收录内容的情况是最容易解决的。一般来说,基本上都是静态网页的内容被写死了,或者是动态网页,用模板渲染出来的。当浏览器获取 HTML 时,它已经收录了所有的关键信息,所以你在网页上直接看到的内容可以通过特定的 HTML 标签由 javascript 代码加载。这是因为虽然网页显示时内容在HTML标签中,但实际上是通过执行js代码添加到标签中的。所以此时内容在js代码中,js的执行是在浏览器端,所以当你使用程序请求网页地址时,得到的响应是网页代码和js代码,所以你可以在浏览器端看到它。说到内容,由于解析的时候js还没有被执行,所以一定要发现指定的html标签下的内容是空的。此时的处理方式一般是找到收录该内容的js代码字符串,然后通过正则表达式获取对应的内容。, 而不是解析 HTML 标签。
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-22 03:00
昨天,一个小伙伴来找我。新浪新闻的国内新闻页面,其他部分都是可以抓到的静态网页,但是左下角的最新新闻版块不是静态网页,也没有json数据。让我帮你抓住它。大概看过了,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
今天我们的目标就是上图中的红框。首先,我们确保这部分内容不在网页的源码中,而是属于js加载的部分。点击页面后,没有json数据传输!
但是我发现有一个js请求,点击请求,是一行js函数代码,我们复制到json视图查看器中,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这三个参数。猜测是对应的新闻 URL、标题和介绍。
只是它的内容,需要处理,我们写在代码中看看
开始写代码
先导入库,因为最后部分需要从字符串中截取,所以使用requests库获取请求,正则re匹配内容。然后我们先匹配上面3项
可以看到url中存在\\,标题和介绍的形式为\\u539f\\u6807\\u9898。这些是我们需要处理的下一步!
先用replace函数把\\放到url中,就可以得到url,后面的\\u539f\\u6807\\u9898是unicode编码,可以直接解码内容直接写代码
eval函数用于解码,内容可以以u'unicode编码内容'的形式解码!
这样就将这个页面的所有新闻和URL相关的内容都取出来了,在外层加了一个循环去抓取所有的新闻页面,任务就完成了!
后记
新浪新闻页面的js功能比较简单,直接抓取数据即可。如果是比较复杂的功能,需要对前端知识有深刻的理解,这也是为什么在学习爬虫的时候需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,百度上直接找了很多。当然也可以直接修改上面抓包的内容,然后用json读取数据也是可以的!
基本代码不多。有看不清楚的小伙伴可以私信我获取代码或者一起学习爬虫! 查看全部
js 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用(组图))
昨天,一个小伙伴来找我。新浪新闻的国内新闻页面,其他部分都是可以抓到的静态网页,但是左下角的最新新闻版块不是静态网页,也没有json数据。让我帮你抓住它。大概看过了,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
今天我们的目标就是上图中的红框。首先,我们确保这部分内容不在网页的源码中,而是属于js加载的部分。点击页面后,没有json数据传输!
但是我发现有一个js请求,点击请求,是一行js函数代码,我们复制到json视图查看器中,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这三个参数。猜测是对应的新闻 URL、标题和介绍。
只是它的内容,需要处理,我们写在代码中看看
开始写代码
先导入库,因为最后部分需要从字符串中截取,所以使用requests库获取请求,正则re匹配内容。然后我们先匹配上面3项
可以看到url中存在\\,标题和介绍的形式为\\u539f\\u6807\\u9898。这些是我们需要处理的下一步!
先用replace函数把\\放到url中,就可以得到url,后面的\\u539f\\u6807\\u9898是unicode编码,可以直接解码内容直接写代码
eval函数用于解码,内容可以以u'unicode编码内容'的形式解码!
这样就将这个页面的所有新闻和URL相关的内容都取出来了,在外层加了一个循环去抓取所有的新闻页面,任务就完成了!
后记
新浪新闻页面的js功能比较简单,直接抓取数据即可。如果是比较复杂的功能,需要对前端知识有深刻的理解,这也是为什么在学习爬虫的时候需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,百度上直接找了很多。当然也可以直接修改上面抓包的内容,然后用json读取数据也是可以的!
基本代码不多。有看不清楚的小伙伴可以私信我获取代码或者一起学习爬虫!
js 爬虫抓取网页数据(1.岗位列表的第一页(图)代码分析(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-22 02:23
)
爬虫之类的东西我之前一直都听说过,不过稍微看了一下资料,好像也不算太复杂。
只知道node.js,然后基于它做一个简单的爬虫。
1.这个爬虫目标:
从钩子招聘网站中找出“前端开发”职位的信息,分析对应页面,提取职位名称、职位薪资、职位所属公司等具体部分,发布日期等。并显示捕获的信息。
初始hook网站的接口信息如下:
2.设计方案:
爬虫实际上是通过相应的技术来爬取页面上的具体信息。
在这里,我们主要抓取上图所示职位列表部分相关的具体职位信息。
首先,要爬取,首先要有地址url:
%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F% 91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=1
此链接是职位列表首页的网址。
通过分析地址的参数部分,我们忽略了选择的其他参数,只看最后一个参数值:pn=1
我们的目的是逐页抓取,所以设置为 pn = page;
其次,要获取特定信息,爬虫需要特定代表的标识符。
这里对页面代码的tag值、class值、id值进行分析。
通过 Firebug 审查这个小子集的元素
确定将获得什么信息的分析需要处理特定的标识符。
3.代码编写:
按照预定的计划,考虑到node.js的使用,通过其内置的http模块获取页面信息,通过cheerio.js模块分析DOM,然后转换成json格式数据,直接从控制台输出或者将json数据再次发送回浏览器显示。
(cheerio.js的使用很简单,可以自行搜索详情。最重要的是下面的代码,其余的和jQuery的使用类似。
就是先加载页面的数据,形成特定的数据格式,然后通过类似jq的语法解析数据)
var cheerio = require('cheerio'),
$ = cheerio.load('Hello world');
$('h2.title').text('Hello there!');
$('h2').addClass('welcome');
$.html();
//=> Hello there!
采用快速模块化开发,项目建立后按要求。进入项目目录,执行 npm install 安装所需的依赖。不知道快递的可以看这里
爬虫需要cheerio.js,所以另外需要进来,所以另外npm installcheerio
有很多项目文件。为简单起见,仅对其中三个进行了修改。(index.ejs index.js style.css)
(1)直接修改routes路由中的index.js文件,也是核心部分。
看代码吧,注释已经够多了
1 var express = require('express');
2 var router = express.Router();
3 var http = require('http');
4 var cheerio = require('cheerio');
5
6 /* GET home page. */
7 router.get('/', function(req, res, next) {
8 res.render('index', { title: '简单nodejs爬虫' });
9 });
10 router.get('/getJobs', function(req, res, next) { // 浏览器端发来get请求
11 var page = req.param('page'); //获取get请求中的参数 page
12 console.log("page: "+page);
13 var Res = res; //保存,防止下边的修改
14 //url 获取信息的页面部分地址
15 var url = 'http://www.lagou.com/jobs/list_%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=';
16
17 http.get(url+page,function(res){ //通过get方法获取对应地址中的页面信息
18 var chunks = [];
19 var size = 0;
20 res.on('data',function(chunk){ //监听事件 传输
21 chunks.push(chunk);
22 size += chunk.length;
23 });
24 res.on('end',function(){ //数据传输完
25 var data = Buffer.concat(chunks,size);
26 var html = data.toString();
27 // console.log(html);
28 var $ = cheerio.load(html); //cheerio模块开始处理 DOM处理
29 var jobs = [];
30
31 var jobs_list = $(".hot_pos li");
32 $(".hot_pos>li").each(function(){ //对页面岗位栏信息进行处理 每个岗位对应一个 li ,各标识符到页面进行分析得出
33 var job = {};
34 job.company = $(this).find(".hot_pos_r div").eq(1).find("a").html(); //公司名
35 job.period = $(this).find(".hot_pos_r span").eq(1).html(); //阶段
36 job.scale = $(this).find(".hot_pos_r span").eq(2).html(); //规模
37
38 job.name = $(this).find(".hot_pos_l a").attr("title"); //岗位名
39 job.src = $(this).find(".hot_pos_l a").attr("href"); //岗位链接
40 job.city = $(this).find(".hot_pos_l .c9").html(); //岗位所在城市
41 job.salary = $(this).find(".hot_pos_l span").eq(1).html(); //薪资
42 job.exp = $(this).find(".hot_pos_l span").eq(2).html(); //岗位所需经验
43 job.time = $(this).find(".hot_pos_l span").eq(5).html(); //发布时间
44
45 console.log(job.name); //控制台输出岗位名
46 jobs.push(job);
47 });
48 Res.json({ //返回json格式数据给浏览器端
49 jobs:jobs
50 });
51 });
52 });
53
54 });
55
56 module.exports = router;
(2)node.js捕获的核心代码就是上面的部分。
下一步是展示抓取的数据,所以需要另外一个页面来修改views中的index.ejs模板
1 DOCTYPE html>
2
3
4
5
6
7
8 【nodejs爬虫】 获取拉勾网招聘岗位--前端开发
9 初始化完成 ...
10 点击开始抓取第一页
11
12
13
14
15 数据抓取中 ... 请稍后
16 抓取上一页
17 抓取下一页
18
19
20
21 function getData(str){ //获取到的数据有杂乱..需要把前面部分去掉,只需要data(...... data)
22 if(str){
23 return str.slice(str.lastIndexOf(">")+1);
24 }
25 }
26
27 document.getElementById("btn1").style.visibility = "hidden";
28 document.getElementById("btn2").style.visibility = "hidden";
29 var currentPage = 0; //page初始0
30
31 function cheerFetch(_page){ //抓取数据处理函数
32 if(_page == 1){
33 currentPage = 1; //开始抓取则更改page
34 }
35 $(document).ajaxSend(function(event, xhr, settings) { //抓取中...
36 $(".fetching").css("display","block");
37 });
38 $(document).ajaxSuccess(function(event, xhr, settings) { //抓取成功
39 $(".fetching").css("display","none");
40 });
41 $.ajax({ //开始发送ajax请求至路径 /getJobs 进而作页面抓取处理
42 data:{page:_page}, //参数 page = _page
43 dataType: "json",
44 type: "get",
45 url: "/getJobs",
46 success: function(data){ //收到返回的json数据
47 console.log(data);
48 var html = "";
49 $(".container").empty();
50 if(data.jobs.length == 0){
51 alert("Error2: 未找到数据..");
52 return;
53 }
54 for(var i=0;i 1){
73 document.getElementById("btn1").style.visibility = "visible";
74 document.getElementById("btn2").style.visibility = "visible";
75 }
76 },
77 error: function(){
78 alert("Error1: 未找到数据..");
79 }
80 });
81 }
82
83
84
85
(3)当然,对public文件下的style.css进行简单的修改也是style部分不可缺少的
body {
padding: 20px 50px;
font: 14px "Lucida Grande", Helvetica, Arial, sans-serif;
}
a {
color: #00B7FF;
cursor: pointer;
}
.container{position: relative;width: 1100px;overflow: hidden;zoom:1;}
.jobs{margin: 30px; float: left;}
.jobs span{ color: green; font-weight: bold;}
.btn{cursor: pointer;}
.fetching{display: none;color: red;}
.footer{clear: both;}
基本的变化就是这三个文件。
因此,如果要进行测试,可以在新建项目后直接修改对应的三个文件。
修改成功后,就可以测试了。
3.测试结果
1) 先在控制台执行 npm start
2) 接下来在浏览器中输入:3000/开始访问
3) 点击开始爬取(这里每次抓取15个项目,即原创URL对应15个项目)
...
查看全部
js 爬虫抓取网页数据(1.岗位列表的第一页(图)代码分析(组图)
)
爬虫之类的东西我之前一直都听说过,不过稍微看了一下资料,好像也不算太复杂。
只知道node.js,然后基于它做一个简单的爬虫。
1.这个爬虫目标:
从钩子招聘网站中找出“前端开发”职位的信息,分析对应页面,提取职位名称、职位薪资、职位所属公司等具体部分,发布日期等。并显示捕获的信息。
初始hook网站的接口信息如下:
2.设计方案:
爬虫实际上是通过相应的技术来爬取页面上的具体信息。
在这里,我们主要抓取上图所示职位列表部分相关的具体职位信息。
首先,要爬取,首先要有地址url:
%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F% 91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=1
此链接是职位列表首页的网址。
通过分析地址的参数部分,我们忽略了选择的其他参数,只看最后一个参数值:pn=1
我们的目的是逐页抓取,所以设置为 pn = page;
其次,要获取特定信息,爬虫需要特定代表的标识符。
这里对页面代码的tag值、class值、id值进行分析。
通过 Firebug 审查这个小子集的元素
确定将获得什么信息的分析需要处理特定的标识符。
3.代码编写:
按照预定的计划,考虑到node.js的使用,通过其内置的http模块获取页面信息,通过cheerio.js模块分析DOM,然后转换成json格式数据,直接从控制台输出或者将json数据再次发送回浏览器显示。
(cheerio.js的使用很简单,可以自行搜索详情。最重要的是下面的代码,其余的和jQuery的使用类似。
就是先加载页面的数据,形成特定的数据格式,然后通过类似jq的语法解析数据)
var cheerio = require('cheerio'),
$ = cheerio.load('Hello world');
$('h2.title').text('Hello there!');
$('h2').addClass('welcome');
$.html();
//=> Hello there!
采用快速模块化开发,项目建立后按要求。进入项目目录,执行 npm install 安装所需的依赖。不知道快递的可以看这里
爬虫需要cheerio.js,所以另外需要进来,所以另外npm installcheerio
有很多项目文件。为简单起见,仅对其中三个进行了修改。(index.ejs index.js style.css)
(1)直接修改routes路由中的index.js文件,也是核心部分。
看代码吧,注释已经够多了
1 var express = require('express');
2 var router = express.Router();
3 var http = require('http');
4 var cheerio = require('cheerio');
5
6 /* GET home page. */
7 router.get('/', function(req, res, next) {
8 res.render('index', { title: '简单nodejs爬虫' });
9 });
10 router.get('/getJobs', function(req, res, next) { // 浏览器端发来get请求
11 var page = req.param('page'); //获取get请求中的参数 page
12 console.log("page: "+page);
13 var Res = res; //保存,防止下边的修改
14 //url 获取信息的页面部分地址
15 var url = 'http://www.lagou.com/jobs/list_%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91?kd=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91&spc=1&pl=&gj=&xl=&yx=&gx=&st=&labelWords=label&lc=&workAddress=&city=%E5%85%A8%E5%9B%BD&requestId=&pn=';
16
17 http.get(url+page,function(res){ //通过get方法获取对应地址中的页面信息
18 var chunks = [];
19 var size = 0;
20 res.on('data',function(chunk){ //监听事件 传输
21 chunks.push(chunk);
22 size += chunk.length;
23 });
24 res.on('end',function(){ //数据传输完
25 var data = Buffer.concat(chunks,size);
26 var html = data.toString();
27 // console.log(html);
28 var $ = cheerio.load(html); //cheerio模块开始处理 DOM处理
29 var jobs = [];
30
31 var jobs_list = $(".hot_pos li");
32 $(".hot_pos>li").each(function(){ //对页面岗位栏信息进行处理 每个岗位对应一个 li ,各标识符到页面进行分析得出
33 var job = {};
34 job.company = $(this).find(".hot_pos_r div").eq(1).find("a").html(); //公司名
35 job.period = $(this).find(".hot_pos_r span").eq(1).html(); //阶段
36 job.scale = $(this).find(".hot_pos_r span").eq(2).html(); //规模
37
38 job.name = $(this).find(".hot_pos_l a").attr("title"); //岗位名
39 job.src = $(this).find(".hot_pos_l a").attr("href"); //岗位链接
40 job.city = $(this).find(".hot_pos_l .c9").html(); //岗位所在城市
41 job.salary = $(this).find(".hot_pos_l span").eq(1).html(); //薪资
42 job.exp = $(this).find(".hot_pos_l span").eq(2).html(); //岗位所需经验
43 job.time = $(this).find(".hot_pos_l span").eq(5).html(); //发布时间
44
45 console.log(job.name); //控制台输出岗位名
46 jobs.push(job);
47 });
48 Res.json({ //返回json格式数据给浏览器端
49 jobs:jobs
50 });
51 });
52 });
53
54 });
55
56 module.exports = router;
(2)node.js捕获的核心代码就是上面的部分。
下一步是展示抓取的数据,所以需要另外一个页面来修改views中的index.ejs模板
1 DOCTYPE html>
2
3
4
5
6
7
8 【nodejs爬虫】 获取拉勾网招聘岗位--前端开发
9 初始化完成 ...
10 点击开始抓取第一页
11
12
13
14
15 数据抓取中 ... 请稍后
16 抓取上一页
17 抓取下一页
18
19
20
21 function getData(str){ //获取到的数据有杂乱..需要把前面部分去掉,只需要data(...... data)
22 if(str){
23 return str.slice(str.lastIndexOf(">")+1);
24 }
25 }
26
27 document.getElementById("btn1").style.visibility = "hidden";
28 document.getElementById("btn2").style.visibility = "hidden";
29 var currentPage = 0; //page初始0
30
31 function cheerFetch(_page){ //抓取数据处理函数
32 if(_page == 1){
33 currentPage = 1; //开始抓取则更改page
34 }
35 $(document).ajaxSend(function(event, xhr, settings) { //抓取中...
36 $(".fetching").css("display","block");
37 });
38 $(document).ajaxSuccess(function(event, xhr, settings) { //抓取成功
39 $(".fetching").css("display","none");
40 });
41 $.ajax({ //开始发送ajax请求至路径 /getJobs 进而作页面抓取处理
42 data:{page:_page}, //参数 page = _page
43 dataType: "json",
44 type: "get",
45 url: "/getJobs",
46 success: function(data){ //收到返回的json数据
47 console.log(data);
48 var html = "";
49 $(".container").empty();
50 if(data.jobs.length == 0){
51 alert("Error2: 未找到数据..");
52 return;
53 }
54 for(var i=0;i 1){
73 document.getElementById("btn1").style.visibility = "visible";
74 document.getElementById("btn2").style.visibility = "visible";
75 }
76 },
77 error: function(){
78 alert("Error1: 未找到数据..");
79 }
80 });
81 }
82
83
84
85
(3)当然,对public文件下的style.css进行简单的修改也是style部分不可缺少的
body {
padding: 20px 50px;
font: 14px "Lucida Grande", Helvetica, Arial, sans-serif;
}
a {
color: #00B7FF;
cursor: pointer;
}
.container{position: relative;width: 1100px;overflow: hidden;zoom:1;}
.jobs{margin: 30px; float: left;}
.jobs span{ color: green; font-weight: bold;}
.btn{cursor: pointer;}
.fetching{display: none;color: red;}
.footer{clear: both;}
基本的变化就是这三个文件。
因此,如果要进行测试,可以在新建项目后直接修改对应的三个文件。
修改成功后,就可以测试了。
3.测试结果
1) 先在控制台执行 npm start
2) 接下来在浏览器中输入:3000/开始访问
3) 点击开始爬取(这里每次抓取15个项目,即原创URL对应15个项目)
...
js 爬虫抓取网页数据(js爬虫抓取网页数据采用的抓包软件网上就有很多)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-02-21 23:02
js爬虫抓取网页数据采用的抓包软件网上就有很多可以自己尝试着搞我给你推荐个专门下载二手的网站地址:,然后在爬虫里面找到这个网站,把它的url拖进去浏览器就会自动下载此文件了另外,在编写爬虫时,也需要注意写一下它爬取这个网站的流程。
python实现下单,可关注我的知乎专栏,
三种方式,仅供参考。
1、二手交易平台上在线购买,你在一个月内不用任何操作就能出售。
2、二手转转等类似的商城购买,然后线下配送。
3、团购,跟实体店一样,按人头算服务费。
在知乎上搜搜下单教程可能会有点用
可以用邮箱登录京东二手交易市场,商品详情在这儿:京东二手_京东商城()我还是比较喜欢去二手平台买哈哈,物美价廉。
千万别去官方给出的图示。在前面说这个的网站看到的。以及在外链抓到的一条。在京东购物的详情页后面有隐藏单价说明。我也在想有用。我一共买了5次东西。然后京东赠了单独的app的一个id让我在其他app上改。
我是写个爬虫爬下来在手机上直接导入页面地址,
在手机上,我用了urllib比较方便。还有一种爬虫是在一些网站上爬,要做很大的页面,可以利用chrome的firebug,实时抓包。我也在思考,下单这么大的一个网站,能不能像邮箱一样给你人工建议。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据采用的抓包软件网上就有很多)
js爬虫抓取网页数据采用的抓包软件网上就有很多可以自己尝试着搞我给你推荐个专门下载二手的网站地址:,然后在爬虫里面找到这个网站,把它的url拖进去浏览器就会自动下载此文件了另外,在编写爬虫时,也需要注意写一下它爬取这个网站的流程。
python实现下单,可关注我的知乎专栏,
三种方式,仅供参考。
1、二手交易平台上在线购买,你在一个月内不用任何操作就能出售。
2、二手转转等类似的商城购买,然后线下配送。
3、团购,跟实体店一样,按人头算服务费。
在知乎上搜搜下单教程可能会有点用
可以用邮箱登录京东二手交易市场,商品详情在这儿:京东二手_京东商城()我还是比较喜欢去二手平台买哈哈,物美价廉。
千万别去官方给出的图示。在前面说这个的网站看到的。以及在外链抓到的一条。在京东购物的详情页后面有隐藏单价说明。我也在想有用。我一共买了5次东西。然后京东赠了单独的app的一个id让我在其他app上改。
我是写个爬虫爬下来在手机上直接导入页面地址,
在手机上,我用了urllib比较方便。还有一种爬虫是在一些网站上爬,要做很大的页面,可以利用chrome的firebug,实时抓包。我也在思考,下单这么大的一个网站,能不能像邮箱一样给你人工建议。
js 爬虫抓取网页数据(JS逆向方法论-反爬虫的四种常见方式(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2022-02-20 11:21
如今,网页的代码越来越复杂。除了使用vue等前端框架让开发更简单外,主要是为了防止爬虫,所以越来越多的精力投入到编写爬虫上。攻防双方在交锋中结下了不好的关系,但也互相促进。
本文讨论了JS反爬虫的策略,看看如何破解它们。
JS 逆向方法论——四种常见的反爬方式
1.JS写cookies
如果我们要写爬虫来抓取某个网页中的数据,无非就是打开网页看源码。如果html中有我们想要的数据,那就简单了。使用requests请求URL获取网页源代码,然后解析提取。
等等!requests得到的网页是一对JS,和浏览器看到的网页源码完全不一样!在这种情况下,浏览器运行这个 JS 来生成一个(或多个)cookie,然后用这个 cookie 发出第二个请求。当服务器接收到这个cookie时,它认为您的访问是通过浏览器的合法访问。
事实上,你可以在浏览器(chrome、Firefox)中看到这个过程。首先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox为“Persist logs”),刷新网页,这样我们就可以看到历史了网络请求记录。例如下图:
js写cookie
第一次打开“index.html”页面时,返回521,内容为一段JS代码;第二次请求页面时,获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实是JS生成的。
对策是研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
二、JS加密ajax请求参数
编写爬虫爬取网页中的数据,发现网页源代码中没有我们想要的数据,有点麻烦。这些数据通常是通过 ajax 请求获得的。不过不要害怕,按F12打开Network窗口,刷新网页看看加载这个网页的时候已经下载了哪些URL,我们要的数据在一个URL请求的结果中。Chrome 网络中此类 URL 的大多数类型都是 XHR。通过观察他们的“Response”,我们可以找到我们想要的数据。
然而,事情往往并不顺利。URL 收录很多参数,其中一个参数是一串看似无意义的字符串。这个字符串很可能是JS通过加密算法得到的,服务器也会通过同样的算法进行验证。验证通过后,它认为你是从浏览器请求。我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
对于这样的加密参数,对策就是调试JS找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
三、JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。这个方法用的太多了,网站加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。它看起来像这样:
无论我们点击多少次继续运行,它总是在这个“调试器”中,而且每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用. 这个“调试器”让我们无法调试 JS。但是当F12窗口关闭时,网页正常加载。
解决这种JS反调试的方法叫做“反反调试”,它的策略是通过“调用栈”找到让我们陷入死循环的函数并重新定义。
这样的功能几乎没有其他功能,但对我们来说是一个陷阱。我们可以在“Console”中重新定义这个函数,比如把它重新定义为一个空函数,这样当我们再次运行它的时候,它什么也不做,不会把我们引入陷阱。在调用此函数的位置放置一个“断点”。因为我们已经陷进去了,要刷新页面,JS的运行应该停在设置的断点处。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
四、JS 发送鼠标点击事件
还有一些网站,其反爬不是上面的方法。您可以从浏览器打开普通页面,但在请求中您需要输入验证码或重定向其他页面。一开始你可能会感到困惑,但不要害怕,仔细看看“网络”可能会发现一些线索。例如,以下网络流中的信息:
仔细观察后发现,每次点击页面的链接,都会发出“cl.gif”请求,貌似下载的是gif图片,其实不然。它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先梳理一下它的逻辑。JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
了解了这个过程,我们想出对策就不难了,几乎不用研究JS内容(JS也可能修改点击的链接)绕过这个反爬策略,访问cl. gif 就可以了。关键是研究一下cl.gif之后的参数,把这些参数都带上就万事大吉了。
结尾
爬行动物和 网站 是一对敌人,他们彼此生活在一起。如果爬虫知道反爬策略,可以做出响应式反反爬策略;网站 知道了爬虫的防反爬策略,就可以制定“防反反爬”策略了……道高一尺高一丈,二人争斗将没有结束。 查看全部
js 爬虫抓取网页数据(JS逆向方法论-反爬虫的四种常见方式(组图))
如今,网页的代码越来越复杂。除了使用vue等前端框架让开发更简单外,主要是为了防止爬虫,所以越来越多的精力投入到编写爬虫上。攻防双方在交锋中结下了不好的关系,但也互相促进。
本文讨论了JS反爬虫的策略,看看如何破解它们。
JS 逆向方法论——四种常见的反爬方式
1.JS写cookies
如果我们要写爬虫来抓取某个网页中的数据,无非就是打开网页看源码。如果html中有我们想要的数据,那就简单了。使用requests请求URL获取网页源代码,然后解析提取。
等等!requests得到的网页是一对JS,和浏览器看到的网页源码完全不一样!在这种情况下,浏览器运行这个 JS 来生成一个(或多个)cookie,然后用这个 cookie 发出第二个请求。当服务器接收到这个cookie时,它认为您的访问是通过浏览器的合法访问。
事实上,你可以在浏览器(chrome、Firefox)中看到这个过程。首先删除Chrome浏览器保存的网站的cookie,按F12到Network窗口,选择“preserve log”(Firefox为“Persist logs”),刷新网页,这样我们就可以看到历史了网络请求记录。例如下图:
js写cookie
第一次打开“index.html”页面时,返回521,内容为一段JS代码;第二次请求页面时,获得正常的 HTML。查看这两个请求的cookie,可以发现第二个请求中带了一个cookie,而这个cookie并不是第一个请求时服务器发送的。其实是JS生成的。
对策是研究JS,找到生成cookie的算法,爬虫可以解决这个问题。
二、JS加密ajax请求参数
编写爬虫爬取网页中的数据,发现网页源代码中没有我们想要的数据,有点麻烦。这些数据通常是通过 ajax 请求获得的。不过不要害怕,按F12打开Network窗口,刷新网页看看加载这个网页的时候已经下载了哪些URL,我们要的数据在一个URL请求的结果中。Chrome 网络中此类 URL 的大多数类型都是 XHR。通过观察他们的“Response”,我们可以找到我们想要的数据。
然而,事情往往并不顺利。URL 收录很多参数,其中一个参数是一串看似无意义的字符串。这个字符串很可能是JS通过加密算法得到的,服务器也会通过同样的算法进行验证。验证通过后,它认为你是从浏览器请求。我们可以把这个URL复制到地址栏,把参数改成任意字母,访问看看能不能得到正确的结果,从而验证它是否是一个重要的加密参数。
对于这样的加密参数,对策就是调试JS找到对应的JS加密算法。关键是在 Chrome 中设置“XHR/fetch Breakpoints”。
三、JS反调试(反调试)
之前大家都是用Chrome的F12来查看网页加载的过程,或者调试JS的运行过程。这个方法用的太多了,网站加了反调试策略。只要我们打开F12,它就会停在一个“调试器”代码行,无论如何也不会跳出来。它看起来像这样:
无论我们点击多少次继续运行,它总是在这个“调试器”中,而且每次都会多出一个VMxx标签,观察“调用栈”发现似乎陷入了递归函数调用. 这个“调试器”让我们无法调试 JS。但是当F12窗口关闭时,网页正常加载。
解决这种JS反调试的方法叫做“反反调试”,它的策略是通过“调用栈”找到让我们陷入死循环的函数并重新定义。
这样的功能几乎没有其他功能,但对我们来说是一个陷阱。我们可以在“Console”中重新定义这个函数,比如把它重新定义为一个空函数,这样当我们再次运行它的时候,它什么也不做,不会把我们引入陷阱。在调用此函数的位置放置一个“断点”。因为我们已经陷进去了,要刷新页面,JS的运行应该停在设置的断点处。此时,该功能尚未运行。我们在Console中重新定义,继续运行跳过陷阱。
四、JS 发送鼠标点击事件
还有一些网站,其反爬不是上面的方法。您可以从浏览器打开普通页面,但在请求中您需要输入验证码或重定向其他页面。一开始你可能会感到困惑,但不要害怕,仔细看看“网络”可能会发现一些线索。例如,以下网络流中的信息:
仔细观察后发现,每次点击页面的链接,都会发出“cl.gif”请求,貌似下载的是gif图片,其实不然。它在请求的时候会发送很多参数,这些参数就是当前页面的信息。例如,它收录点击的链接等。
我们先梳理一下它的逻辑。JS 会响应链接被点击的事件。在打开链接之前,它会先访问cl.gif,将当前信息发送到服务器,然后再打开点击的链接。当服务器收到点击链接的请求时,会检查之前是否通过cl.gif发送过相应的信息。
因为请求没有鼠标事件响应,所以直接访问链接,没有访问cl.gif的过程,服务器拒绝服务。
了解了这个过程,我们想出对策就不难了,几乎不用研究JS内容(JS也可能修改点击的链接)绕过这个反爬策略,访问cl. gif 就可以了。关键是研究一下cl.gif之后的参数,把这些参数都带上就万事大吉了。
结尾
爬行动物和 网站 是一对敌人,他们彼此生活在一起。如果爬虫知道反爬策略,可以做出响应式反反爬策略;网站 知道了爬虫的防反爬策略,就可以制定“防反反爬”策略了……道高一尺高一丈,二人争斗将没有结束。
js 爬虫抓取网页数据(js爬虫抓取网页数据的实现方法及实现技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-20 09:13
js爬虫抓取网页数据的,如果需要修改成批量的功能,看一下这个文章可以帮到你h5随便批量修改web前端开发,把这两个给他们看。一个是抓取网页数据的,一个是修改banner图片的。多看两遍,
推荐一个简单高效的实现方法1使用scrapy:基于框架的快速批量抓取scrapy。scrapy是一个开源框架,存在于nodejs上,相当于scrapycore的增强版,通过它来实现批量抓取是一件很方便的事情。网站抓取的问题在于定制化操作,这篇博客正是解决这些问题的办法之一。scrapycore是通过从scrapyspider的基本代码中继承来实现的,通过它可以快速的完成数据的抓取工作,其实现方法采用请求的思想。
首先,当你向scrapycore发送一个请求时,获取结果的方法就是,构造另一个spider,继承scrapycore.request并返回结果。接下来就是编写正确的spider了,在这篇博客中可以看到scrapycore中通过phantomjs和selenium写出实时网站抓取程序的方法。首先有这样一个case:everythingintheresourceisabouttradeoffrelationsanddelivery.everycoiniscalculatedtobetradedoffasanone-coinsets.soallcoinsaretradedatparticularcostoftrade.[root](analysisbasedonrequests,spiders,andblog)这段代码中有2个feature。
1.phantomjs的多页抓取可以实现爬虫,2.在我们爬取时,遍历相应的元素来获取原始数据。因为我们在爬取时为了确定必须要爬取的页面,必须事先爬取,所以我们通过phantomjs获取页面,以确定我们要爬取的页面。获取到页面后就是要遍历元素,来获取我们想要的原始数据了。因为原始数据是一个二进制值,所以一般采用python的“正则表达式”来匹配提取我们想要的数据。
通过phantomjs这个特殊的库进行批量抓取时是使用正则表达式来获取网页元素,通过正则表达式匹配元素来获取原始数据。正则表达式匹配一个对象时,一定是匹配当前对象包含的所有内容,而且具有一一对应关系,返回值一定是包含元素的内容,不包含内容的内容返回0。例如:匹配当前元素包含的内容是(0,),返回内容是一个结果字符串,那么返回值是['productid','verificationid']。
例如:匹配当前元素包含的内容是['areavailable','availablelist'],返回内容是一个结果字符串,那么返回值是['availableset','id']。基于正则表达式,获取元素时可以通过正则表达式匹配元素的一些特征如size,type,name,empty,default等等。正则表达式要匹配的内容一般。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据的实现方法及实现技巧)
js爬虫抓取网页数据的,如果需要修改成批量的功能,看一下这个文章可以帮到你h5随便批量修改web前端开发,把这两个给他们看。一个是抓取网页数据的,一个是修改banner图片的。多看两遍,
推荐一个简单高效的实现方法1使用scrapy:基于框架的快速批量抓取scrapy。scrapy是一个开源框架,存在于nodejs上,相当于scrapycore的增强版,通过它来实现批量抓取是一件很方便的事情。网站抓取的问题在于定制化操作,这篇博客正是解决这些问题的办法之一。scrapycore是通过从scrapyspider的基本代码中继承来实现的,通过它可以快速的完成数据的抓取工作,其实现方法采用请求的思想。
首先,当你向scrapycore发送一个请求时,获取结果的方法就是,构造另一个spider,继承scrapycore.request并返回结果。接下来就是编写正确的spider了,在这篇博客中可以看到scrapycore中通过phantomjs和selenium写出实时网站抓取程序的方法。首先有这样一个case:everythingintheresourceisabouttradeoffrelationsanddelivery.everycoiniscalculatedtobetradedoffasanone-coinsets.soallcoinsaretradedatparticularcostoftrade.[root](analysisbasedonrequests,spiders,andblog)这段代码中有2个feature。
1.phantomjs的多页抓取可以实现爬虫,2.在我们爬取时,遍历相应的元素来获取原始数据。因为我们在爬取时为了确定必须要爬取的页面,必须事先爬取,所以我们通过phantomjs获取页面,以确定我们要爬取的页面。获取到页面后就是要遍历元素,来获取我们想要的原始数据了。因为原始数据是一个二进制值,所以一般采用python的“正则表达式”来匹配提取我们想要的数据。
通过phantomjs这个特殊的库进行批量抓取时是使用正则表达式来获取网页元素,通过正则表达式匹配元素来获取原始数据。正则表达式匹配一个对象时,一定是匹配当前对象包含的所有内容,而且具有一一对应关系,返回值一定是包含元素的内容,不包含内容的内容返回0。例如:匹配当前元素包含的内容是(0,),返回内容是一个结果字符串,那么返回值是['productid','verificationid']。
例如:匹配当前元素包含的内容是['areavailable','availablelist'],返回内容是一个结果字符串,那么返回值是['availableset','id']。基于正则表达式,获取元素时可以通过正则表达式匹配元素的一些特征如size,type,name,empty,default等等。正则表达式要匹配的内容一般。
js 爬虫抓取网页数据(1.爬虫概述可能上面的说明还是难以具体地描述爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-15 19:26
爬虫,也就是网络爬虫,我们可以把互联网比作一个大网,而爬虫就是在网上爬行的蜘蛛,我们可以把网络的节点比作网页,爬它就相当于访问了page 获取其信息后,可以将节点之间的连接比作网页之间的链接关系,这样蜘蛛就可以在经过一个节点后继续沿着该节点连接爬行到下一个节点,即继续获取后续网页通过一个网页,让蜘蛛爬取整个网络的节点,从而抓取网站的数据。
1. 爬虫概述
在上面的描述中可能很难描述爬虫是什么。简而言之,爬虫是获取网页并提取和保存信息的自动化程序。接下来,我们将解释每一点:
获取网页
爬虫要做的第一个工作就是获取网页。这里,获取网页就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站的服务器发送一个Request,返回的Response的Body就是网页的源代码。所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。这个过程如何实施?不能手动截取网页源代码?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如Urllib、Requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。Request 和 Response 可以用类库提供的数据结构来表示。得到Response后,我们只需要解析数据结构的Body部分,即得到网页的源代码,这样就可以使用程序来实现获取网页的过程了。
行
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
保存数据
提取信息后,我们一般将提取的数据保存在某处,以供后续数据处理。保存有多种形式,比如简单的保存为TXT文本或者Json文本,或者保存到数据库,比如MySQL、MongoDB等,或者保存到远程服务器,比如使用Sftp操作。
自动化程序
谈到自动化,这意味着爬虫可以代替人类执行这些操作。首先,我们可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。因此,爬虫是一个自动化的程序,它代表我们完成爬取数据的工作。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们都对应着HTML代码,而最常见的爬取就是爬取HTML源代码。
此外,某些网页可能会返回 Json 字符串而不是 HTML 代码。大多数API接口都采用这种形式,方便数据传输和分析。这种数据也可以抓取,数据提取更方便。
此外,我们还可以看到各种二进制数据,比如图片、视频、音频等,我们可以使用爬虫抓取它们的二进制数据,并保存为对应的文件名。
此外,我们还可以看到各种扩展名的文件,比如CSS、JavaScript、配置文件等,这些其实是最常见的文件,只要在浏览器中访问,我们就可以抓取。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据爬虫,都可以爬取。
3. JavaScript 渲染页面
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。例如:
This is a Demo
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
body节点中只有一个id为container的节点,但是注意在body节点之后引入了一个app.js,负责渲染整个网站。
浏览器在打开这个页面的时候会先加载html内容,然后浏览器会发现里面已经引入了一个app.js文件,然后浏览器就会请求这个文件,获取到后执行文件。JavaScript 代码,而 JavaScript 会改变 HTML 中的节点,向内添加内容,最终得到完整的页面。
但是当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,所以我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。在这种情况下,我们可以分析它的后台 Ajax 接口,或者使用 Selenium 和 Splash 等库来模拟 JavaScript 渲染,这样我们就可以爬取 JavaScript 渲染的网页内容。
稍后我们将详细介绍 JavaScript 渲染页面的 采集 方法。
4. 结论
本节介绍爬虫的一些基本原理,了解以上内容可以帮助我们以后编写爬虫时更加得心应手。 查看全部
js 爬虫抓取网页数据(1.爬虫概述可能上面的说明还是难以具体地描述爬虫)
爬虫,也就是网络爬虫,我们可以把互联网比作一个大网,而爬虫就是在网上爬行的蜘蛛,我们可以把网络的节点比作网页,爬它就相当于访问了page 获取其信息后,可以将节点之间的连接比作网页之间的链接关系,这样蜘蛛就可以在经过一个节点后继续沿着该节点连接爬行到下一个节点,即继续获取后续网页通过一个网页,让蜘蛛爬取整个网络的节点,从而抓取网站的数据。
1. 爬虫概述
在上面的描述中可能很难描述爬虫是什么。简而言之,爬虫是获取网页并提取和保存信息的自动化程序。接下来,我们将解释每一点:
获取网页
爬虫要做的第一个工作就是获取网页。这里,获取网页就是获取网页的源代码。源代码中一定收录了网页的一些有用信息,所以只要得到源代码,我们就可以从中提取出我们想要的东西。信息。
前面我们谈到了请求和响应的概念。我们向网站的服务器发送一个Request,返回的Response的Body就是网页的源代码。所以最关键的部分就是构造一个Request并发送给服务器,然后接收Response并解析出来。这个过程如何实施?不能手动截取网页源代码?
不用担心,Python提供了很多库来帮助我们实现这个操作,比如Urllib、Requests等,我们可以利用这些库来帮助我们实现HTTP请求操作。Request 和 Response 可以用类库提供的数据结构来表示。得到Response后,我们只需要解析数据结构的Body部分,即得到网页的源代码,这样就可以使用程序来实现获取网页的过程了。
行
我们在第一步得到了网页的源代码后,接下来的工作就是分析网页的源代码,提取出我们想要的数据。最常用的方法是使用正则表达式进行提取,这是一种通用的方法。但是构造正则表达式是复杂且容易出错的。
另外,由于网页的结构有一定的规则,也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如BeautifulSoup、PyQuery、LXML等,这些库都可以使用高效快速地提取网页。信息,例如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以让杂乱无章的数据变得清晰有条理,方便我们后期对数据进行处理和分析。
保存数据
提取信息后,我们一般将提取的数据保存在某处,以供后续数据处理。保存有多种形式,比如简单的保存为TXT文本或者Json文本,或者保存到数据库,比如MySQL、MongoDB等,或者保存到远程服务器,比如使用Sftp操作。
自动化程序
谈到自动化,这意味着爬虫可以代替人类执行这些操作。首先,我们可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。因此,爬虫是一个自动化的程序,它代表我们完成爬取数据的工作。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们都对应着HTML代码,而最常见的爬取就是爬取HTML源代码。
此外,某些网页可能会返回 Json 字符串而不是 HTML 代码。大多数API接口都采用这种形式,方便数据传输和分析。这种数据也可以抓取,数据提取更方便。
此外,我们还可以看到各种二进制数据,比如图片、视频、音频等,我们可以使用爬虫抓取它们的二进制数据,并保存为对应的文件名。
此外,我们还可以看到各种扩展名的文件,比如CSS、JavaScript、配置文件等,这些其实是最常见的文件,只要在浏览器中访问,我们就可以抓取。
以上内容其实是对应各自的URL,是基于HTTP或HTTPS协议的。只要是这种数据爬虫,都可以爬取。
3. JavaScript 渲染页面
有时当我们用 Urllib 或 Requests 抓取网页时,我们得到的源代码实际上与我们在浏览器中看到的不同。
这个问题是一个非常普遍的问题。现在越来越多的网页使用Ajax和前端模块化工具来构建网页。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码是一个空壳。例如:
This is a Demo
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
body节点中只有一个id为container的节点,但是注意在body节点之后引入了一个app.js,负责渲染整个网站。
浏览器在打开这个页面的时候会先加载html内容,然后浏览器会发现里面已经引入了一个app.js文件,然后浏览器就会请求这个文件,获取到后执行文件。JavaScript 代码,而 JavaScript 会改变 HTML 中的节点,向内添加内容,最终得到完整的页面。
但是当使用 Urllib 或 Requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,所以我们不会在浏览器中看到我们看到的内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
所以使用基本的HTTP请求库得到的结果源代码可能与浏览器中的页面源代码不一样。在这种情况下,我们可以分析它的后台 Ajax 接口,或者使用 Selenium 和 Splash 等库来模拟 JavaScript 渲染,这样我们就可以爬取 JavaScript 渲染的网页内容。
稍后我们将详细介绍 JavaScript 渲染页面的 采集 方法。
4. 结论
本节介绍爬虫的一些基本原理,了解以上内容可以帮助我们以后编写爬虫时更加得心应手。
js 爬虫抓取网页数据(如何使用httpclient抓取页面以及如何用jsoup分析html内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-15 15:22
在之前的系列文章中介绍了如何使用httpclient抓取页面html以及如何使用jsoup分析html源文件的内容得到我们想要的数据,但是有时候这两种方法都不能使用捕获我们想要的数据。所需数据,例如,请参见以下示例。
1.需求场景:
如果要抢到股票的最新价格,F12页信息如下:
按照前面的方法,爬取的代码如下:
1/**
2 * @description: 爬取股票的最新股价
3 * @author: JAVA开发老菜鸟
4 * @date: 2021-10-16 21:47
5 */
6public class StockPriceSpider {
7
8 Logger logger = LoggerFactory.getLogger(this.getClass());
9
10 public static void main(String[] args) {
11
12 StockPriceSpider stockPriceSpider = new StockPriceSpider();
13 String html = stockPriceSpider.httpClientProcess();
14 stockPriceSpider.jsoupProcess(html);
15 }
16
17 private String httpClientProcess() {
18 String html = "";
19 String uri = "http://quote.eastmoney.com/sh600036.html";
20 //1.生成httpclient,相当于该打开一个浏览器
21 CloseableHttpClient httpClient = HttpClients.createDefault();
22 CloseableHttpResponse response = null;
23 //2.创建get请求,相当于在浏览器地址栏输入 网址
24 HttpGet request = new HttpGet(uri);
25 try {
26 request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
27 request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
28
29// HttpHost proxy = new HttpHost("3.211.17.212", 80);
30// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
31// request.setConfig(config);
32
33 //3.执行get请求,相当于在输入地址栏后敲回车键
34 response = httpClient.execute(request);
35
36 //4.判断响应状态为200,进行处理
37 if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
38 //5.获取响应内容
39 HttpEntity httpEntity = response.getEntity();
40 html = EntityUtils.toString(httpEntity, "utf-8");
41 logger.info("访问{} 成功,返回页面数据{}", uri, html);
42 } else {
43 //如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
44 logger.info("访问{},返回状态不是200", uri);
45 logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
46 }
47 } catch (ClientProtocolException e) {
48 e.printStackTrace();
49 } catch (IOException e) {
50 e.printStackTrace();
51 } finally {
52 //6.关闭
53 HttpClientUtils.closeQuietly(response);
54 HttpClientUtils.closeQuietly(httpClient);
55 }
56 return html;
57 }
58
59 private void jsoupProcess(String html) {
60 Document document = Jsoup.parse(html);
61 Element price = document.getElementById("price9");
62 logger.info("股价为:>>> {}", price.text());
63 }
64
65}
66
运行结果:
纳尼,股价是“-”?不可能的。
无法爬取正确结果的原因是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.爬取异步加载数据的java方法
如何爬取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,让js渲染出来的页面和静态页面一样。常用的内核有
这里我选择了 Selenium,它是一个模拟浏览器和自动化测试工具。它提供了一组 API 来与真正的浏览器内核交互。当然,爬虫也可以使用它。
具体方法如下:
1
2 org.seleniumhq.selenium
3 selenium-java
4 3.141.59
5
6
要使用 selenium,您需要下载浏览器的驱动程序。根据浏览器的不同,需要下载的驱动也不同。下载地址为:ChromeDriver Mirror
我用的是谷歌浏览器,所以我下载了对应版本的windows和linux驱动。
下载后需要配置到java环境变量中,并指定驱动目录:
System.getProperties().setProperty("webdriver.chrome.driver", "F:/download/chromedriver_win32_1/chromedriver.exe");
1Logger logger = LoggerFactory.getLogger(this.getClass());
2
3 public static void main(String[] args) {
4
5 StockPriceSpider stockPriceSpider = new StockPriceSpider();
6 stockPriceSpider.seleniumProcess();
7 }
8
9 private void seleniumProcess() {
10
11 String uri = "http://quote.eastmoney.com/sh600036.html";
12
13 // 设置 chromedirver 的存放位置
14 System.getProperties().setProperty("webdriver.chrome.driver", "F:/download/chromedriver_win32_1/chromedriver.exe");
15
16 // 设置浏览器参数
17 ChromeOptions chromeOptions = new ChromeOptions();
18 chromeOptions.addArguments("--no-sandbox");//禁用沙箱
19 chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
20 chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
21 WebDriver webDriver = new ChromeDriver(chromeOptions);
22
23 webDriver.get(uri);
24 WebElement webElements = webDriver.findElement(By.id("price9"));
25 String stockPrice = webElements.getText();
26 logger.info("最新股价为 >>> {}", stockPrice);
27 webDriver.close();
28 }
29
结果:
爬取成功!
2.2 逆向分析法
反向解析的方法是通过F12找到Ajax异步数据获取的链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
此方法的关键是找到 Ajax 链接。这个方法我没研究过,有兴趣可以百度下载。稍微在这里。
3.结束语
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:仓位市值通知系统,每天会根据自己的仓位配置自动计算账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以看看。 查看全部
js 爬虫抓取网页数据(如何使用httpclient抓取页面以及如何用jsoup分析html内容)
在之前的系列文章中介绍了如何使用httpclient抓取页面html以及如何使用jsoup分析html源文件的内容得到我们想要的数据,但是有时候这两种方法都不能使用捕获我们想要的数据。所需数据,例如,请参见以下示例。
1.需求场景:
如果要抢到股票的最新价格,F12页信息如下:
按照前面的方法,爬取的代码如下:
1/**
2 * @description: 爬取股票的最新股价
3 * @author: JAVA开发老菜鸟
4 * @date: 2021-10-16 21:47
5 */
6public class StockPriceSpider {
7
8 Logger logger = LoggerFactory.getLogger(this.getClass());
9
10 public static void main(String[] args) {
11
12 StockPriceSpider stockPriceSpider = new StockPriceSpider();
13 String html = stockPriceSpider.httpClientProcess();
14 stockPriceSpider.jsoupProcess(html);
15 }
16
17 private String httpClientProcess() {
18 String html = "";
19 String uri = "http://quote.eastmoney.com/sh600036.html";
20 //1.生成httpclient,相当于该打开一个浏览器
21 CloseableHttpClient httpClient = HttpClients.createDefault();
22 CloseableHttpResponse response = null;
23 //2.创建get请求,相当于在浏览器地址栏输入 网址
24 HttpGet request = new HttpGet(uri);
25 try {
26 request.setHeader("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36");
27 request.setHeader("accept", "application/json, text/javascript, */*; q=0.01");
28
29// HttpHost proxy = new HttpHost("3.211.17.212", 80);
30// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
31// request.setConfig(config);
32
33 //3.执行get请求,相当于在输入地址栏后敲回车键
34 response = httpClient.execute(request);
35
36 //4.判断响应状态为200,进行处理
37 if (response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
38 //5.获取响应内容
39 HttpEntity httpEntity = response.getEntity();
40 html = EntityUtils.toString(httpEntity, "utf-8");
41 logger.info("访问{} 成功,返回页面数据{}", uri, html);
42 } else {
43 //如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
44 logger.info("访问{},返回状态不是200", uri);
45 logger.info(EntityUtils.toString(response.getEntity(), "utf-8"));
46 }
47 } catch (ClientProtocolException e) {
48 e.printStackTrace();
49 } catch (IOException e) {
50 e.printStackTrace();
51 } finally {
52 //6.关闭
53 HttpClientUtils.closeQuietly(response);
54 HttpClientUtils.closeQuietly(httpClient);
55 }
56 return html;
57 }
58
59 private void jsoupProcess(String html) {
60 Document document = Jsoup.parse(html);
61 Element price = document.getElementById("price9");
62 logger.info("股价为:>>> {}", price.text());
63 }
64
65}
66
运行结果:
纳尼,股价是“-”?不可能的。
无法爬取正确结果的原因是因为这个值是在网站上异步加载渲染的,所以无法正常获取。
2.爬取异步加载数据的java方法
如何爬取异步加载的数据?通常有两种方法:
2.1 内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,让js渲染出来的页面和静态页面一样。常用的内核有
这里我选择了 Selenium,它是一个模拟浏览器和自动化测试工具。它提供了一组 API 来与真正的浏览器内核交互。当然,爬虫也可以使用它。
具体方法如下:
1
2 org.seleniumhq.selenium
3 selenium-java
4 3.141.59
5
6
要使用 selenium,您需要下载浏览器的驱动程序。根据浏览器的不同,需要下载的驱动也不同。下载地址为:ChromeDriver Mirror
我用的是谷歌浏览器,所以我下载了对应版本的windows和linux驱动。
下载后需要配置到java环境变量中,并指定驱动目录:
System.getProperties().setProperty("webdriver.chrome.driver", "F:/download/chromedriver_win32_1/chromedriver.exe");
1Logger logger = LoggerFactory.getLogger(this.getClass());
2
3 public static void main(String[] args) {
4
5 StockPriceSpider stockPriceSpider = new StockPriceSpider();
6 stockPriceSpider.seleniumProcess();
7 }
8
9 private void seleniumProcess() {
10
11 String uri = "http://quote.eastmoney.com/sh600036.html";
12
13 // 设置 chromedirver 的存放位置
14 System.getProperties().setProperty("webdriver.chrome.driver", "F:/download/chromedriver_win32_1/chromedriver.exe");
15
16 // 设置浏览器参数
17 ChromeOptions chromeOptions = new ChromeOptions();
18 chromeOptions.addArguments("--no-sandbox");//禁用沙箱
19 chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
20 chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
21 WebDriver webDriver = new ChromeDriver(chromeOptions);
22
23 webDriver.get(uri);
24 WebElement webElements = webDriver.findElement(By.id("price9"));
25 String stockPrice = webElements.getText();
26 logger.info("最新股价为 >>> {}", stockPrice);
27 webDriver.close();
28 }
29
结果:
爬取成功!
2.2 逆向分析法
反向解析的方法是通过F12找到Ajax异步数据获取的链接,直接调用链接得到json结果,然后直接解析json结果得到想要的数据。
此方法的关键是找到 Ajax 链接。这个方法我没研究过,有兴趣可以百度下载。稍微在这里。
3.结束语
以上就是如何通过selenium-java爬取异步加载的数据。通过这个方法,我写了一个小工具:仓位市值通知系统,每天会根据自己的仓位配置自动计算账户总市值,并发送邮件通知到指定邮箱。
使用的技术如下:
相关代码已经上传到我的码云,有兴趣的可以看看。
js 爬虫抓取网页数据(越过亚马逊的反爬虫机制,成功越过反爬机制(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 714 次浏览 • 2022-02-13 02:10
您的浏览器不支持音频标签。
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等
反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-import urllib.requestreq = urllib.request.urlopen('https://www.amazon.com')print(req.code)复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
代码如下↓ ↓ ↓
import requestsurl='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'web_header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate, br','Connection': 'keep-alive','Cookie': '你的cookie值','TE': 'Trailers'}r = requests.get(url,headers=web_header)print(r.status_code)复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。
我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium复制代码
在代码中引入 selenium 并设置相关参数
import osfrom requests.api import optionsfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Options#selenium配置参数options = Options()#配置无头参数,即不打开浏览器options.add_argument('--headless')#配置Chrome浏览器的selenium驱动 chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"os.environ["webdriver.chrome.driver"] = chromedriver#将参数设置+浏览器驱动组合browser = webdriver.Chrome(chromedriver,chrome_options=options)复制代码
测试访问
url = "https://www.amazon.com"print(url)#通过selenium来访问亚马逊browser.get(url)复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件fw=open('E:/amzon.html','w',encoding='utf-8')fw.write(str(browser.page_source))browser.close()fw.close()复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页
结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。 查看全部
js 爬虫抓取网页数据(越过亚马逊的反爬虫机制,成功越过反爬机制(组图))
您的浏览器不支持音频标签。
事情是这样的
亚马逊是全球最大的购物平台
很多产品信息、用户评论等都是最丰富的。
今天就带大家一起来穿越亚马逊的反爬虫机制吧
抓取您想要的有用信息,例如产品、评论等
反爬虫机制
但是,当我们想使用爬虫爬取相关数据信息时
亚马逊、TBO、京东等大型购物中心
为了保护他们的数据信息,他们都有一套完整的反爬虫机制。
先试试亚马逊的反爬机制
我们使用几个不同的python爬虫模块来一步步测试
最终,防爬机制顺利通过。
一、urllib 模块
代码显示如下:
# -*- coding:utf-8 -*-import urllib.requestreq = urllib.request.urlopen('https://www.amazon.com')print(req.code)复制代码
返回结果:状态码:503。
分析:亚马逊将你的请求识别为爬虫,拒绝提供服务。
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
以科学严谨的态度,来试试千人之首的百度吧。
返回结果:状态码200
分析:正常访问
代码如下↓ ↓ ↓
import requestsurl='https://www.amazon.com/KAVU-Rope-Bag-Denim-Size/product-reviews/xxxxxxx'web_header={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0','Accept': '*/*','Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2','Accept-Encoding': 'gzip, deflate, br','Connection': 'keep-alive','Cookie': '你的cookie值','TE': 'Trailers'}r = requests.get(url,headers=web_header)print(r.status_code)复制代码
返回结果:状态码:200
分析:返回状态码为200,属于正常。它闻起来像爬虫。
3、查看返回页面
通过requests+cookie的方法,我们得到的状态码是200
至少它目前由亚马逊的服务器提供服务。
我们将爬取的页面写入文本并在浏览器中打开。
我在骑马……返回状态正常,但是返回了反爬虫验证码页面。
仍然被亚马逊屏蔽。
三、硒自动化模块
相关硒模块的安装
pip install selenium复制代码
在代码中引入 selenium 并设置相关参数
import osfrom requests.api import optionsfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Options#selenium配置参数options = Options()#配置无头参数,即不打开浏览器options.add_argument('--headless')#配置Chrome浏览器的selenium驱动 chromedriver="C:/Users/pacer/AppData/Local/Google/Chrome/Application/chromedriver.exe"os.environ["webdriver.chrome.driver"] = chromedriver#将参数设置+浏览器驱动组合browser = webdriver.Chrome(chromedriver,chrome_options=options)复制代码
测试访问
url = "https://www.amazon.com"print(url)#通过selenium来访问亚马逊browser.get(url)复制代码
返回结果:状态码:200
分析:返回状态码为200,访问状态正常。我们来看看爬取的网页上的信息。
将网页源代码保存到本地
#将爬取到的网页信息,写入到本地文件fw=open('E:/amzon.html','w',encoding='utf-8')fw.write(str(browser.page_source))browser.close()fw.close()复制代码
打开我们爬取的本地文件查看,
我们已经成功绕过反爬机制,进入亚马逊首页
结尾
通过selenium模块,我们可以成功穿越
亚马逊的反爬虫机制。

