
js 爬虫抓取网页数据
js 爬虫抓取网页数据(一下什么是Ajax全称为andXML,Ajax请求是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-01 17:09
文章目录
有时候,当我们使用requests爬取一个页面时,得到的结果可能与我们在浏览器中看到的不同:在浏览器中我们可以看到页面数据正常显示,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式。最初的页面不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口获取数据,然后对数据进行处理和渲染。对网页来说,这实际上是发送一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,让Web开发者可以将前后端分离,直接减少服务器带来的压力渲染页面。
所以如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
我们来看看什么是Ajax请求。什么是阿贾克斯
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
对于传统的网页,如果要更新其内容,就必须刷新整个页面,但是使用Ajax,可以在不刷新整个页面的情况下更新页面的内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
1.实例介绍
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如以微博为例,以徐嵩的主页为例:切换到微博页面,一直往下滑,你会发现往下滑几条微博后,它就消失了,而是出现了一个加载动画,并且然后下面继续出现新的微博内容,这个过程其实就是Ajax加载的过程:
我们注意到页面并没有完全刷新,也就是说页面上的链接没有变化,但是页面中出现了新的内容,也就是后来刷到的新微博。这就是通过 Ajax 获取新数据并呈现的内容。
2.基本原则
初步了解了Ajax之后,我们再来了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它也是由 JavaScript 实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest){
//code for IE7+,Firefox,Chrmoe,Opera,Safari
xmlhttp=new XMLHttpRequest();
}else{//code for IE5,IE6
xmlhttp=new ActiveXObject("Mircrosoft.XMLHTTP");
}
xmlhttp.onreadystatchange=function(){
if(xmlhttp.readyState==4 && xmlhttp.stutus == 200){
document.getElementById("myDiv").innerHTML = xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是由 JavaScript 实现的 Ajax 的最低级别。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open()和send()方法向一个链接(也就是服务器)发送请求。在前面的文章中,我们使用python发送请求后可以得到响应结果,但是这里请求的发送是通过JavaScript编程完成的。由于设置了监听器,当服务器返回时,会触发onreadystatechange对应的方法,然后可以在该方法中解析响应的内容。
解析内容
得到响应后,会启动onreadychange属性对应的方法,可以通过xmlhttp的responseText属性获取对应的内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。文档操作,如更改、删除等。
在上面的例子中,document.getElementById("myDiv").innerHTML = xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的新数据就是呈现在 myDiv 元素中。部分内容似乎已更新。
我们观察到这 3 个步骤实际上是由 JavaScript 完成的,它完成了请求、解析和渲染的整个过程。
回想一下微博的pull-to-refresh,这其实就是JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,渲染到网页中。
因此,我们知道,真正的数据实际上是一次又一次地从 Ajax 请求中获取的。如果你想捕获这些数据,你需要知道数据是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,我们可以在 Python 中模拟这个操作并得到结果。 查看全部
js 爬虫抓取网页数据(一下什么是Ajax全称为andXML,Ajax请求是什么)
文章目录
有时候,当我们使用requests爬取一个页面时,得到的结果可能与我们在浏览器中看到的不同:在浏览器中我们可以看到页面数据正常显示,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式。最初的页面不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口获取数据,然后对数据进行处理和渲染。对网页来说,这实际上是发送一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,让Web开发者可以将前后端分离,直接减少服务器带来的压力渲染页面。
所以如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
我们来看看什么是Ajax请求。什么是阿贾克斯
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
对于传统的网页,如果要更新其内容,就必须刷新整个页面,但是使用Ajax,可以在不刷新整个页面的情况下更新页面的内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
1.实例介绍
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如以微博为例,以徐嵩的主页为例:切换到微博页面,一直往下滑,你会发现往下滑几条微博后,它就消失了,而是出现了一个加载动画,并且然后下面继续出现新的微博内容,这个过程其实就是Ajax加载的过程:

我们注意到页面并没有完全刷新,也就是说页面上的链接没有变化,但是页面中出现了新的内容,也就是后来刷到的新微博。这就是通过 Ajax 获取新数据并呈现的内容。
2.基本原则
初步了解了Ajax之后,我们再来了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它也是由 JavaScript 实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest){
//code for IE7+,Firefox,Chrmoe,Opera,Safari
xmlhttp=new XMLHttpRequest();
}else{//code for IE5,IE6
xmlhttp=new ActiveXObject("Mircrosoft.XMLHTTP");
}
xmlhttp.onreadystatchange=function(){
if(xmlhttp.readyState==4 && xmlhttp.stutus == 200){
document.getElementById("myDiv").innerHTML = xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是由 JavaScript 实现的 Ajax 的最低级别。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open()和send()方法向一个链接(也就是服务器)发送请求。在前面的文章中,我们使用python发送请求后可以得到响应结果,但是这里请求的发送是通过JavaScript编程完成的。由于设置了监听器,当服务器返回时,会触发onreadystatechange对应的方法,然后可以在该方法中解析响应的内容。
解析内容
得到响应后,会启动onreadychange属性对应的方法,可以通过xmlhttp的responseText属性获取对应的内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。文档操作,如更改、删除等。
在上面的例子中,document.getElementById("myDiv").innerHTML = xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的新数据就是呈现在 myDiv 元素中。部分内容似乎已更新。
我们观察到这 3 个步骤实际上是由 JavaScript 完成的,它完成了请求、解析和渲染的整个过程。
回想一下微博的pull-to-refresh,这其实就是JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,渲染到网页中。
因此,我们知道,真正的数据实际上是一次又一次地从 Ajax 请求中获取的。如果你想捕获这些数据,你需要知道数据是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,我们可以在 Python 中模拟这个操作并得到结果。
js 爬虫抓取网页数据(如何用python来抓取页面中的JS动态加载的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-31 22:12
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是页面加载到浏览器后动态生成的,但之前并不存在。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8import urllibimport requestspost_param = {'action':'','start':'0','limit':'1'}return_data = requests.get("",data =post_param, verify = False)打印 return_data.text 查看全部
js 爬虫抓取网页数据(如何用python来抓取页面中的JS动态加载的数据)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是页面加载到浏览器后动态生成的,但之前并不存在。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8import urllibimport requestspost_param = {'action':'','start':'0','limit':'1'}return_data = requests.get("",data =post_param, verify = False)打印 return_data.text
js 爬虫抓取网页数据(Python的requests库不会像浏览器一样执行JS并生成网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-03-31 15:02
目前大部分网站使用JS动态加载内容,浏览器执行JS生成网页内容。因为 Python 的 requests 库不像浏览器那样执行 JS,所以抓取的内容并不是最终的页面渲染内容。这个问题的解决方法也很简单,我们用浏览器执行JS生成内容,然后提取需要的数据。
selenium webdriver简介
Selenium webdriver 是我们这里要使用的工具,用来控制浏览器执行 JS 生成的内容。WebDriver 通过调用浏览器的原生自动化 API 直接驱动浏览器。目前主流浏览器都提供了自动化API。因此,我们可以通过webdriver提供的API,方便地操纵浏览器访问网页生成内容和返回数据。
通过python的pip工具,我们可以很方便的安装selenium模块,pip install selenium。安装完成后,我们简单试试webdriver驱动浏览器打开网页。
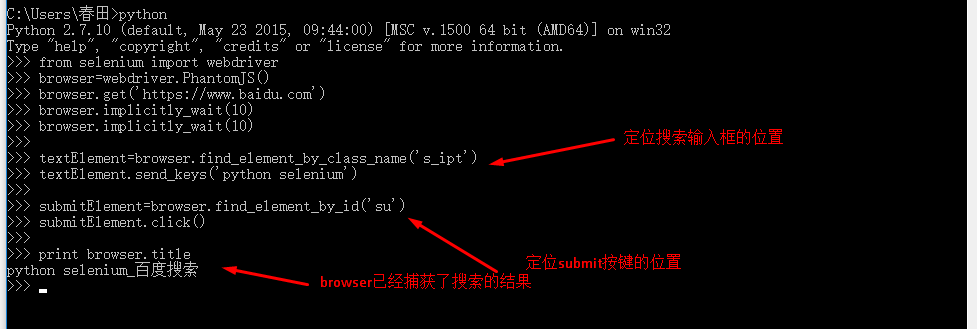
爬虫实例中的应用
现在回到我们的爬虫示例,我们使用 requests 库来爬取内容,现在我们使用 webdriver 驱动浏览器获取网页内容。这样就可以得到执行JS动态加载内容的网页了。
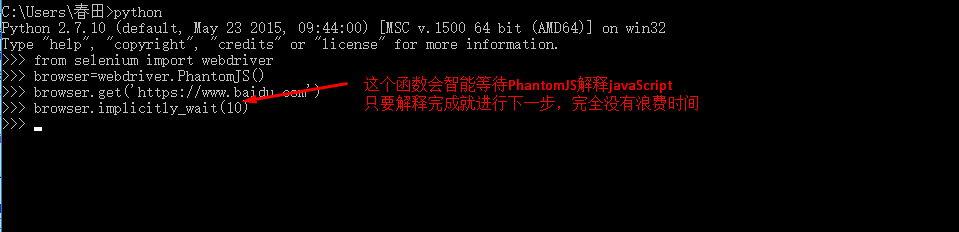
通常浏览器会打开一个窗口,但对于爬虫来说这不是必需的。幸运的是,我们可以使用 phantomjs 作为浏览器的替代品。PhantomJS 是一个没有 UI 的基于 webkit 的浏览器,几乎所有可以在浏览器上完成的事情也可以在 PhantomJs 上完成。PhantomJs 广泛用于网络监控、Web 测试和页面访问自动化。
使用的代码和我们之前使用的浏览器没有太大区别,唯一不同的是我们初始化浏览器的代码。
总结
这一部分我们简要讨论了如何使用 webdriver 来获取动态加载的网页内容。其实webdriver有很多非常有趣的应用,我们后面会看。继续下一节。 查看全部
js 爬虫抓取网页数据(Python的requests库不会像浏览器一样执行JS并生成网页内容)
目前大部分网站使用JS动态加载内容,浏览器执行JS生成网页内容。因为 Python 的 requests 库不像浏览器那样执行 JS,所以抓取的内容并不是最终的页面渲染内容。这个问题的解决方法也很简单,我们用浏览器执行JS生成内容,然后提取需要的数据。
selenium webdriver简介
Selenium webdriver 是我们这里要使用的工具,用来控制浏览器执行 JS 生成的内容。WebDriver 通过调用浏览器的原生自动化 API 直接驱动浏览器。目前主流浏览器都提供了自动化API。因此,我们可以通过webdriver提供的API,方便地操纵浏览器访问网页生成内容和返回数据。
通过python的pip工具,我们可以很方便的安装selenium模块,pip install selenium。安装完成后,我们简单试试webdriver驱动浏览器打开网页。
爬虫实例中的应用
现在回到我们的爬虫示例,我们使用 requests 库来爬取内容,现在我们使用 webdriver 驱动浏览器获取网页内容。这样就可以得到执行JS动态加载内容的网页了。
通常浏览器会打开一个窗口,但对于爬虫来说这不是必需的。幸运的是,我们可以使用 phantomjs 作为浏览器的替代品。PhantomJS 是一个没有 UI 的基于 webkit 的浏览器,几乎所有可以在浏览器上完成的事情也可以在 PhantomJs 上完成。PhantomJs 广泛用于网络监控、Web 测试和页面访问自动化。
使用的代码和我们之前使用的浏览器没有太大区别,唯一不同的是我们初始化浏览器的代码。
总结
这一部分我们简要讨论了如何使用 webdriver 来获取动态加载的网页内容。其实webdriver有很多非常有趣的应用,我们后面会看。继续下一节。
js 爬虫抓取网页数据(提取HTML页面内有用的数据定义匹配规则(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2022-03-31 14:34
在 HTML 页面中提取有用的数据:
一种。如果是需要的数据--保存
湾。如果还有其他 URL,继续步骤 2
4. Python爬虫的优点?
5. 学习路线
抓取 HTML 页面:
HTTP请求的处理:urllib、urllib2、requests
处理器的请求可以模拟浏览器发送请求并获取服务器响应的文件
解析服务器对应的内容:
re, xpath, BeautifulSoup(bs4), jsonpath, pyquery, 等等。
使用描述性语言为我们需要提取的数据定义一个匹配规则,匹配到这个规则的数据就会被匹配
采集动态HTML,验证码处理
Generic Dynamic Pages 采集: Selenium + PhantomJS: 模拟真实浏览器加载JS
验证码处理:Tesseract机器学习库、机器图像识别系统
Scrapy 框架:
高定制、高性能(异步网络框架扭曲)-> 快速数据下载
提供数据存储、数据下载、提取规则等组件
分布式策略:
scrapy redis:在scarpy的基础上增加了一套以redis数据库为中心的组件,主要用于redis中请求指纹去重、请求分配、临时数据存储
爬虫、反爬虫、反爬虫之间的斗争:
用户代理、代理、验证码、动态数据加载、加密数据
6. 爬虫分类
6.1 万能爬虫:
1.定义:搜索引擎爬虫系统
2.目标:爬取互联网上的所有网页,放到本地服务器上形成备份,对这些网页做相关处理(提取关键词,去除广告),最终为用户提供借口拜访
3.爬取过程:
a) 首先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中取出URL,然后解析NDS得到主机IP,然后到该IP对应的服务器下载HTML页面,保存到搜索引擎的本地服务器,然后把爬取的抓取队列中的 URL
c) 分析网页内容,找出网页中的其他URL连接,继续第二步,直到爬取结束
4.搜索引擎如何获得一个新的网站 URL:
主动向搜索引擎提交 URL:
在其他网站中设置网站的外部链接:其他网站之上的链接
搜索引擎将与DNS服务商合作,快速收录new网站
5.一般爬虫注意事项
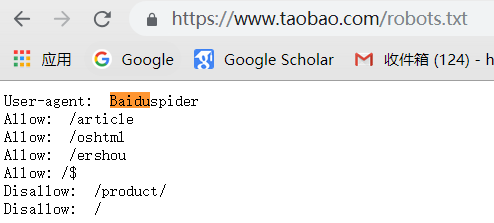
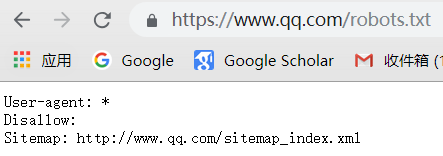
万能爬虫不是万物皆可爬,它必须遵守规则:
机器人协议:该协议将指定通用爬虫爬取网页的权限
我们可以在不同的网页上访问机器人权限
6.一般爬虫一般流程:
7.通用爬虫的缺点
只能提供文本相关的内容(HTML、WORD、PDF)等,但不能提供多媒体文件(msic、图片、视频)等二进制文件
提供相同的结果,不能针对不同背景领域的人收听不同的搜索结果
不理解人类语义的检索
专注于爬行动物的优势
DNS域名解析到IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员编写的针对某个内容的爬虫 -> 面向主题的爬虫,需要爬虫的爬虫 查看全部
js 爬虫抓取网页数据(提取HTML页面内有用的数据定义匹配规则(图))
在 HTML 页面中提取有用的数据:
一种。如果是需要的数据--保存
湾。如果还有其他 URL,继续步骤 2
4. Python爬虫的优点?

5. 学习路线
抓取 HTML 页面:
HTTP请求的处理:urllib、urllib2、requests
处理器的请求可以模拟浏览器发送请求并获取服务器响应的文件
解析服务器对应的内容:
re, xpath, BeautifulSoup(bs4), jsonpath, pyquery, 等等。
使用描述性语言为我们需要提取的数据定义一个匹配规则,匹配到这个规则的数据就会被匹配
采集动态HTML,验证码处理
Generic Dynamic Pages 采集: Selenium + PhantomJS: 模拟真实浏览器加载JS
验证码处理:Tesseract机器学习库、机器图像识别系统
Scrapy 框架:
高定制、高性能(异步网络框架扭曲)-> 快速数据下载
提供数据存储、数据下载、提取规则等组件
分布式策略:
scrapy redis:在scarpy的基础上增加了一套以redis数据库为中心的组件,主要用于redis中请求指纹去重、请求分配、临时数据存储
爬虫、反爬虫、反爬虫之间的斗争:
用户代理、代理、验证码、动态数据加载、加密数据
6. 爬虫分类
6.1 万能爬虫:
1.定义:搜索引擎爬虫系统
2.目标:爬取互联网上的所有网页,放到本地服务器上形成备份,对这些网页做相关处理(提取关键词,去除广告),最终为用户提供借口拜访
3.爬取过程:
a) 首先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中取出URL,然后解析NDS得到主机IP,然后到该IP对应的服务器下载HTML页面,保存到搜索引擎的本地服务器,然后把爬取的抓取队列中的 URL
c) 分析网页内容,找出网页中的其他URL连接,继续第二步,直到爬取结束
4.搜索引擎如何获得一个新的网站 URL:
主动向搜索引擎提交 URL:
在其他网站中设置网站的外部链接:其他网站之上的链接
搜索引擎将与DNS服务商合作,快速收录new网站
5.一般爬虫注意事项
万能爬虫不是万物皆可爬,它必须遵守规则:
机器人协议:该协议将指定通用爬虫爬取网页的权限
我们可以在不同的网页上访问机器人权限
6.一般爬虫一般流程:

7.通用爬虫的缺点
只能提供文本相关的内容(HTML、WORD、PDF)等,但不能提供多媒体文件(msic、图片、视频)等二进制文件
提供相同的结果,不能针对不同背景领域的人收听不同的搜索结果
不理解人类语义的检索
专注于爬行动物的优势
DNS域名解析到IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员编写的针对某个内容的爬虫 -> 面向主题的爬虫,需要爬虫的爬虫
js 爬虫抓取网页数据(别的项目组什么项目突然心血来潮想研究一下爬虫、分析的简单原型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-30 06:02
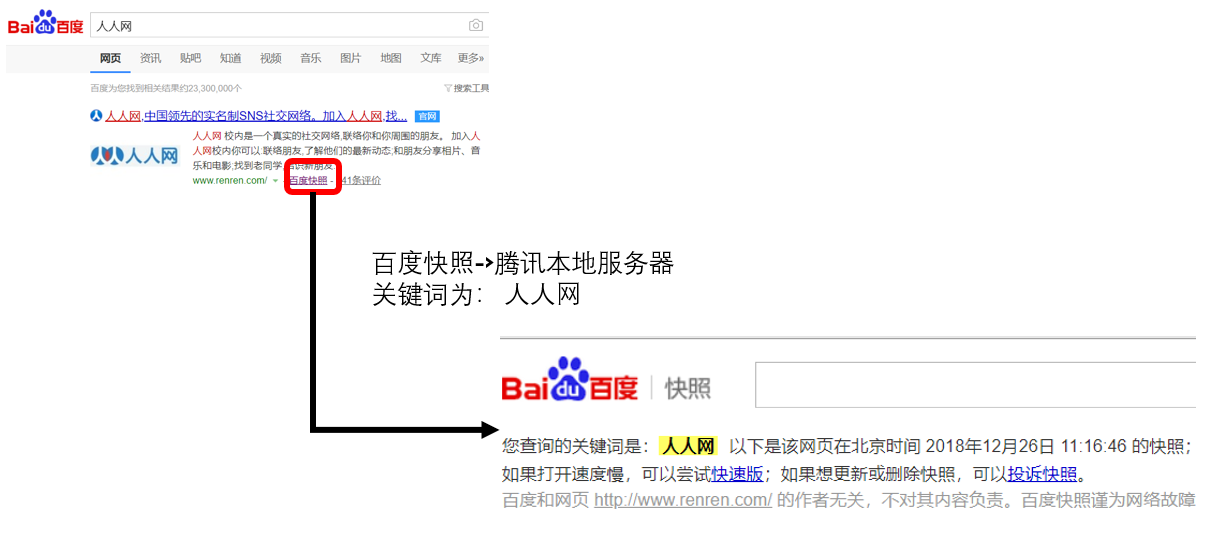
由于其他项目组都在做舆情预测项目,我只是手头没有项目,突然想研究一个简单的爬虫原型,一时兴起分析。网上有很多关于这方面的资料,看得我眼花缭乱。对于我这种新手,想做一个简单的爬虫程序,所以HttpClient + jsoup是个不错的选择。前者是用来管理请求的,后者是用来解析页面的,主要是后者的select语法和jquery很像,对我这个用js的人来说太方便了。
昨天和他们聊天时,他们使用了几个知名的开源框架。聊了几句,他们发现自己没有办法爬取动态网页,尤其是一些重要的数字,比如评论数和回复数。等等我有一个大致的了解。比如TRS的爬虫需要编写js脚本进行js调用,但分析量巨大。他们的技术人员告诉我们,如果他们匹配这样的模板,他们每天只能匹配2到3个。,更何况我们这些中途修士。碰巧这是一个相当大的挑战,所以我昨天答应他们,看看他们是否能找到一个相对简单的解决方案,当然,不管效率如何。
举个简单的例子,如下图
“我有话要说”后面的1307是后载的,但这些数字往往对舆情分析更重要。
对需求有了大致的了解后,我们来分析如何解决它们。通常,我们对请求得到的响应中收录js代码和html元素,所以像jsoup这样的html解析器很难在这里发挥优势,因为它所能得到的html,1307还没有生成。这时候就需要一个可以运行js的平台,运行js代码后的页面会被html解析,这样才能正确得到结果。
因为懒,一开始写脚本的方式被我抛弃了,因为分析一个页面太痛苦,代码乱成一锅粥,而且很多还用了压缩的方式,都是分别是 a(), b() 方法,太累了,看不下去了。所以我的首要任务是,为什么我不能让这个地址在某个浏览器中运行,然后将运行结果交给html解析器进行解析,那么整个问题就解决了。这样,我的临时解决方案是在爬虫服务器上打开一个后台浏览器,或者是带有浏览器内核的程序,将url地址交给它去请求,然后从浏览器中取出页面的元素并交给交给它吧。html 解析器进行解析以获取您想要的信息。
明天再说吧,先休息吧。 查看全部
js 爬虫抓取网页数据(别的项目组什么项目突然心血来潮想研究一下爬虫、分析的简单原型)
由于其他项目组都在做舆情预测项目,我只是手头没有项目,突然想研究一个简单的爬虫原型,一时兴起分析。网上有很多关于这方面的资料,看得我眼花缭乱。对于我这种新手,想做一个简单的爬虫程序,所以HttpClient + jsoup是个不错的选择。前者是用来管理请求的,后者是用来解析页面的,主要是后者的select语法和jquery很像,对我这个用js的人来说太方便了。
昨天和他们聊天时,他们使用了几个知名的开源框架。聊了几句,他们发现自己没有办法爬取动态网页,尤其是一些重要的数字,比如评论数和回复数。等等我有一个大致的了解。比如TRS的爬虫需要编写js脚本进行js调用,但分析量巨大。他们的技术人员告诉我们,如果他们匹配这样的模板,他们每天只能匹配2到3个。,更何况我们这些中途修士。碰巧这是一个相当大的挑战,所以我昨天答应他们,看看他们是否能找到一个相对简单的解决方案,当然,不管效率如何。
举个简单的例子,如下图

“我有话要说”后面的1307是后载的,但这些数字往往对舆情分析更重要。
对需求有了大致的了解后,我们来分析如何解决它们。通常,我们对请求得到的响应中收录js代码和html元素,所以像jsoup这样的html解析器很难在这里发挥优势,因为它所能得到的html,1307还没有生成。这时候就需要一个可以运行js的平台,运行js代码后的页面会被html解析,这样才能正确得到结果。
因为懒,一开始写脚本的方式被我抛弃了,因为分析一个页面太痛苦,代码乱成一锅粥,而且很多还用了压缩的方式,都是分别是 a(), b() 方法,太累了,看不下去了。所以我的首要任务是,为什么我不能让这个地址在某个浏览器中运行,然后将运行结果交给html解析器进行解析,那么整个问题就解决了。这样,我的临时解决方案是在爬虫服务器上打开一个后台浏览器,或者是带有浏览器内核的程序,将url地址交给它去请求,然后从浏览器中取出页面的元素并交给交给它吧。html 解析器进行解析以获取您想要的信息。
明天再说吧,先休息吧。
js 爬虫抓取网页数据( 这段文字是从哪里来的?文字是怎么抓取的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-30 04:05
这段文字是从哪里来的?文字是怎么抓取的)
我们来看一个网页,我们来思考一下如何使用 XPath 进行爬取。
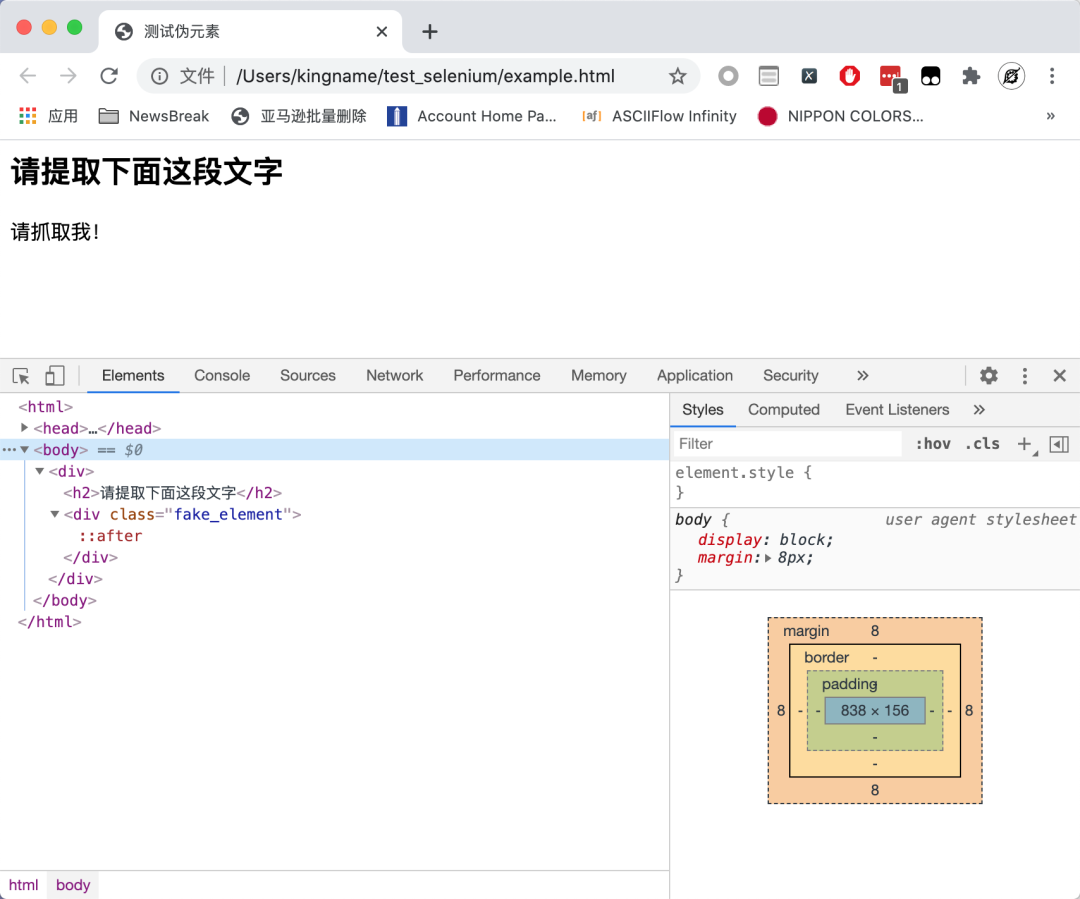
如您所见,没有请抓住我!此文本在源代码中。这个页面是异步加载的吗?我们现在看一下页面的请求:
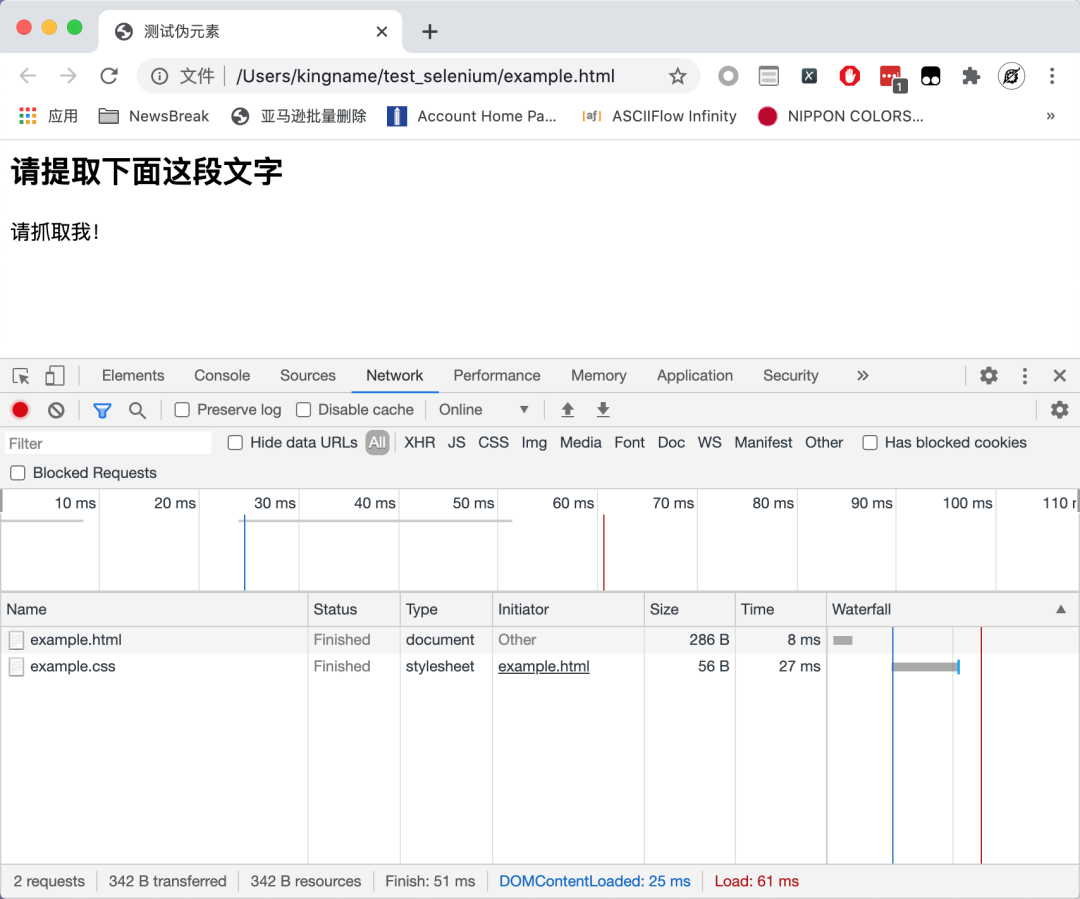
该网页也不发出任何 Ajax 请求。那么,这段文字是从哪里来的呢?
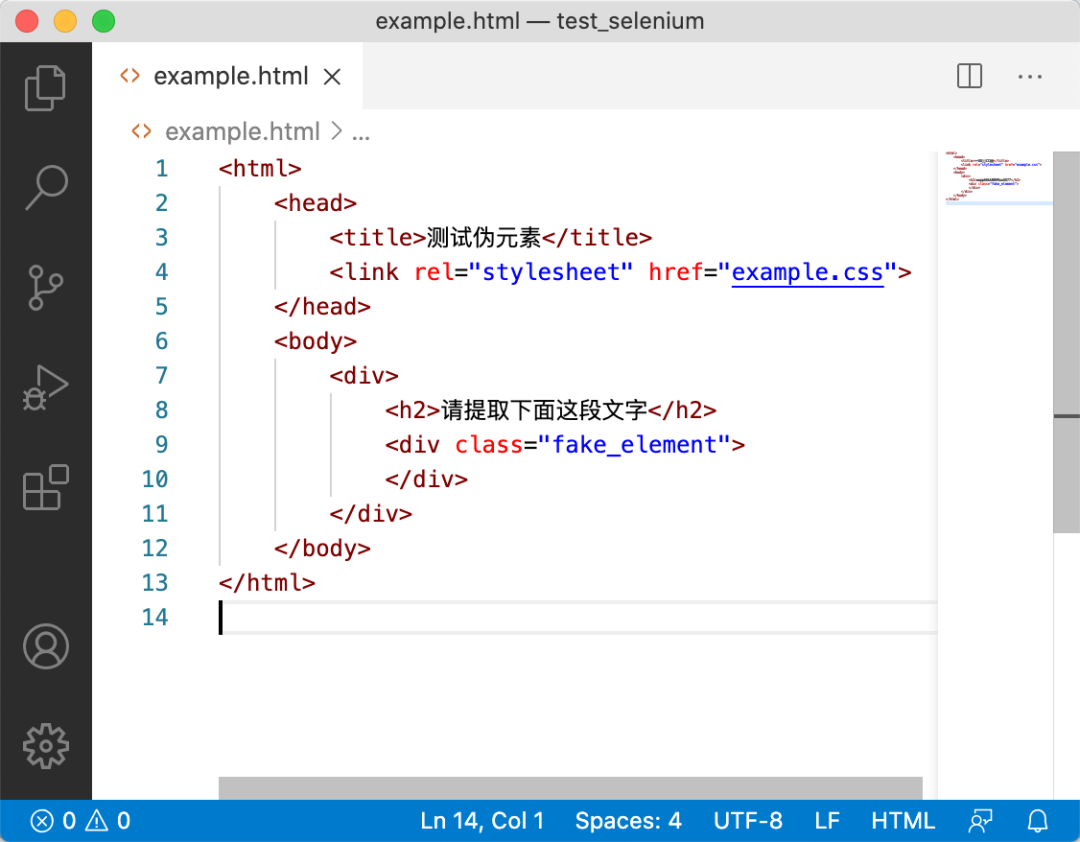
我们来看看这个页面对应的HTML:
整个 HTML 中甚至没有 JavaScript。那么这段文字是从哪里来的呢?
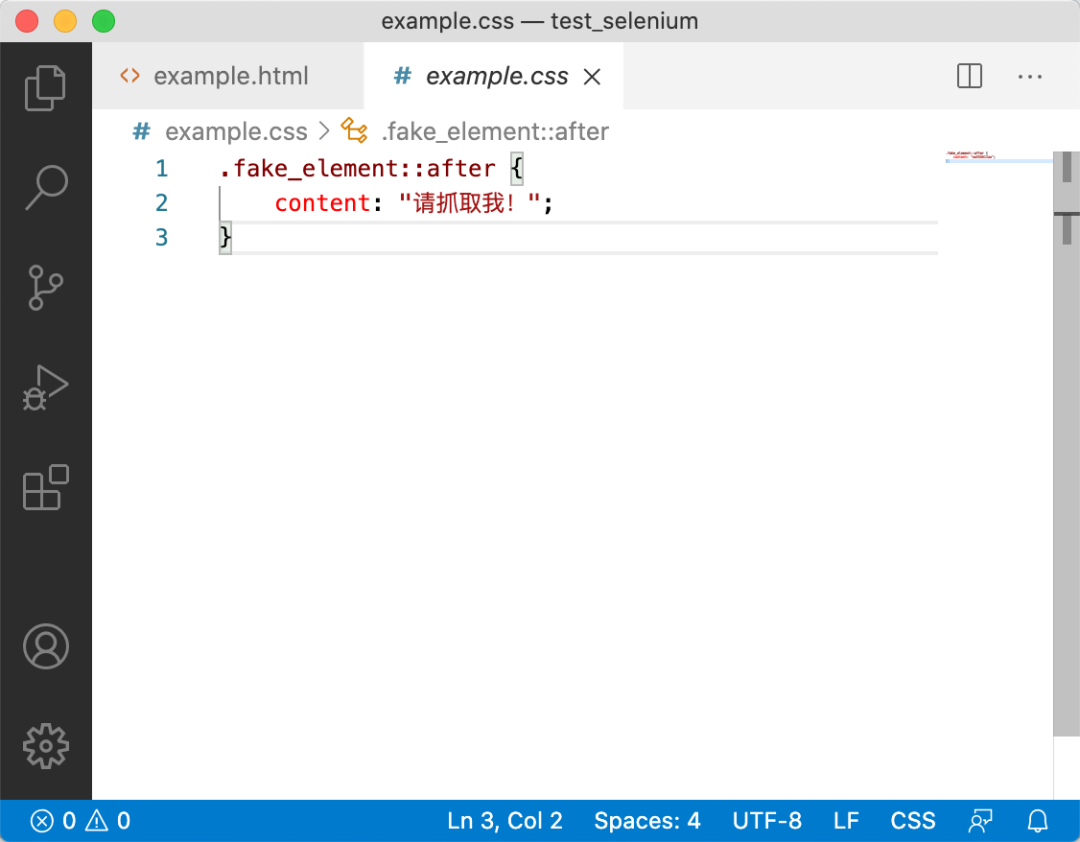
稍有经验的同学可能会想到看一下这个example.css文件,其内容如下:
是的,文本确实在那里。其中::after,我们称之为伪元素(Pseudo-element)[1]。
如何提取伪元素中的文本?当然也可以使用正则表达式来提取。但我们今天不打算谈论这个。
XPath 没有办法提取伪元素,因为 XPath 只能提取 Dom 树中的内容,而伪元素不属于 Dom 树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 不会做任何事情,因为数据根本不在其中。单独获取CSS,虽然有数据,但是如果不使用正则表达式,里面的数据是取不出来的。所以 BeautifulSoup4 的 CSS 选择器也不起作用。所以我们需要把 CSS 和 HTML 放在一起渲染,然后使用 JavaScript 的 CSS 选择器来查找要提取的内容。
首先我们来看看,为了提取这个伪元素的值,我们需要下面的Js代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表值为fake_element的类属性。第二个参数是伪元素:after。运行效果如下图所示:
为了能够运行此 JavaScript,我们需要使用模拟浏览器,Selenium 或 Puppeteer。这里以 Selenium 为例。
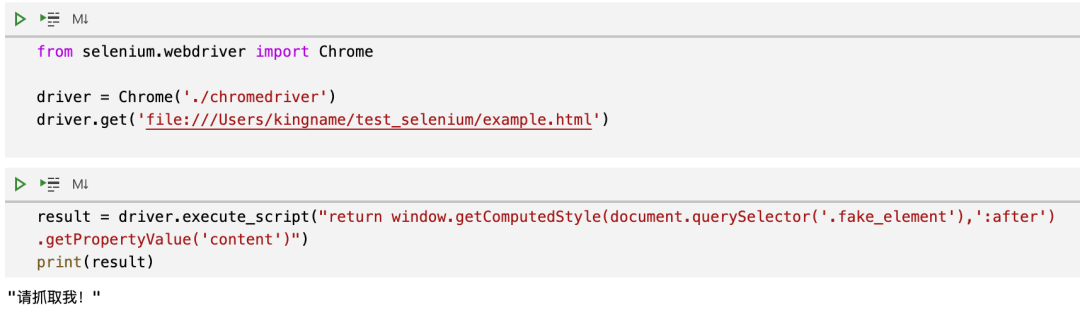
要在 Selenium 中执行 Js,需要使用 driver.execute_script() 方法。代码如下:
提取内容的最外层会用一对双引号包裹起来。拿到之后,去掉外面的双引号,就是我们在网页上看到的内容。
参考
[1] 伪元素: 查看全部
js 爬虫抓取网页数据(
这段文字是从哪里来的?文字是怎么抓取的)

我们来看一个网页,我们来思考一下如何使用 XPath 进行爬取。
如您所见,没有请抓住我!此文本在源代码中。这个页面是异步加载的吗?我们现在看一下页面的请求:
该网页也不发出任何 Ajax 请求。那么,这段文字是从哪里来的呢?
我们来看看这个页面对应的HTML:
整个 HTML 中甚至没有 JavaScript。那么这段文字是从哪里来的呢?
稍有经验的同学可能会想到看一下这个example.css文件,其内容如下:
是的,文本确实在那里。其中::after,我们称之为伪元素(Pseudo-element)[1]。
如何提取伪元素中的文本?当然也可以使用正则表达式来提取。但我们今天不打算谈论这个。
XPath 没有办法提取伪元素,因为 XPath 只能提取 Dom 树中的内容,而伪元素不属于 Dom 树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 不会做任何事情,因为数据根本不在其中。单独获取CSS,虽然有数据,但是如果不使用正则表达式,里面的数据是取不出来的。所以 BeautifulSoup4 的 CSS 选择器也不起作用。所以我们需要把 CSS 和 HTML 放在一起渲染,然后使用 JavaScript 的 CSS 选择器来查找要提取的内容。
首先我们来看看,为了提取这个伪元素的值,我们需要下面的Js代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表值为fake_element的类属性。第二个参数是伪元素:after。运行效果如下图所示:
为了能够运行此 JavaScript,我们需要使用模拟浏览器,Selenium 或 Puppeteer。这里以 Selenium 为例。
要在 Selenium 中执行 Js,需要使用 driver.execute_script() 方法。代码如下:
提取内容的最外层会用一对双引号包裹起来。拿到之后,去掉外面的双引号,就是我们在网页上看到的内容。
参考
[1] 伪元素:
js 爬虫抓取网页数据(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-29 21:17
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人解决了困难和复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用模块之类的管道好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。 查看全部
js 爬虫抓取网页数据(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。

2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。

2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。

网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。


2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD

2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。

分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人解决了困难和复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用模块之类的管道好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。

上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
js 爬虫抓取网页数据(从爬虫的攻防角度来讲最简单的爬虫,是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-03-27 10:22
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。
这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。
另外还有一个比较异常的服务端爬虫检测机制,就是在http响应中种一个cookie token,让所有http请求访问页面,然后在这个异步执行的一些ajax接口上学页。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电子商务公司网站亚马逊采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时的检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序调用的API来实现复杂的爬取业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真实的GUI浏览器发行版运行稳定。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已经宣布他们将停止维护这个项目。
现在谷歌浏览器团队已经在 Chrome 59 发布版本中开放了 headless mode api,并开源了一个基于 Node.js 调用的 headless chromium dirver 库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless Chrome 可以说是 Headless Browser 中独一无二的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length === 0) {
console.log('It may be Chrome headless');
}
基于语言的检查
if(navigator.languages === '') {
console.log('Chrome headless detected');
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == 'Brian Paul' && renderer == 'Mesa OffScreen') {
console.log('Chrome headless detected');
}
基于浏览器细线属性的检查
if(!Modernizr['hairline']) {
console.log('It may be Chrome headless');
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName('body')[0];
var image = document.createElement('img');
image.src = 'http://iloveponeydotcom32188.jg';
image.setAttribute('id', 'fakeimage');
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log('Chrome headless detected');
}
}
基于以上一些浏览器特性的判断,它基本上可以秒杀市面上大部分的Headless Browser程序。在这个层面上,网页爬虫的门槛其实是提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器来说是很重要的。内核的改动其实不小,如果你尝试过编译Blink内核或者Gecko内核你就会明白对于一个“脚本小子”来说是多么的难了~
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本、型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察特性是否符合浏览器这个版本。设备应具备的功能。
这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
另外,在研究Robots Browser Detect using js api在浏览器端的时候,我们发现了一个有趣的trick。可以将预先注入的js函数伪装成Native Function,看一下下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString()); // function alert() { [native code] }
console.log(fakeAlert.toString()); // function () { [native code] }
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,784758214
群里有不错的学习视频教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null)fake方法在toString后面没有函数名,所以需要检查toString后面的函数名是否为空。
这个技巧有什么用?在这里延伸一下,反爬虫防御者有一个Robot Detect方法,就是在js运行的时候主动抛出一个alert。文案可以写一些业务逻辑相关的。当普通用户点击OK按钮时,肯定会有1s甚至是alert。对于更长的延迟,由于浏览器中的alert会阻塞js代码的运行(其实在v8中,他会以类似进程挂起的方式挂起isolate context的执行),所以爬虫作为攻击者可以选择使用上面的窍门,就是在页面所有js运行前预先注入一段js代码,伪造alert、prompt、confirm等所有弹窗方法。如果防御者在弹出代码之前检查他调用的alert方法是否仍然是原生的,则这种方式被阻止。
对付爬行动物的灵丹妙药
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中,最成熟的是基于机器学习的谷歌reCAPTCHA。区分用户和爬虫。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。Allow 和 Disallow 声明每个 UA 爬虫的爬取授权。
然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
写在最后
网页内容的爬取与反制,注定是一场魔高路高的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路,你能做的就是增加攻击。用户爬取的成本,以及关于未经授权的爬取行为的更准确信息。 查看全部
js 爬虫抓取网页数据(从爬虫的攻防角度来讲最简单的爬虫,是什么?)
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。
这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。
另外还有一个比较异常的服务端爬虫检测机制,就是在http响应中种一个cookie token,让所有http请求访问页面,然后在这个异步执行的一些ajax接口上学页。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电子商务公司网站亚马逊采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时的检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序调用的API来实现复杂的爬取业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真实的GUI浏览器发行版运行稳定。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已经宣布他们将停止维护这个项目。
现在谷歌浏览器团队已经在 Chrome 59 发布版本中开放了 headless mode api,并开源了一个基于 Node.js 调用的 headless chromium dirver 库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless Chrome 可以说是 Headless Browser 中独一无二的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length === 0) {
console.log('It may be Chrome headless');
}
基于语言的检查
if(navigator.languages === '') {
console.log('Chrome headless detected');
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == 'Brian Paul' && renderer == 'Mesa OffScreen') {
console.log('Chrome headless detected');
}
基于浏览器细线属性的检查
if(!Modernizr['hairline']) {
console.log('It may be Chrome headless');
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName('body')[0];
var image = document.createElement('img');
image.src = 'http://iloveponeydotcom32188.jg';
image.setAttribute('id', 'fakeimage');
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log('Chrome headless detected');
}
}
基于以上一些浏览器特性的判断,它基本上可以秒杀市面上大部分的Headless Browser程序。在这个层面上,网页爬虫的门槛其实是提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器来说是很重要的。内核的改动其实不小,如果你尝试过编译Blink内核或者Gecko内核你就会明白对于一个“脚本小子”来说是多么的难了~
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本、型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察特性是否符合浏览器这个版本。设备应具备的功能。
这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
另外,在研究Robots Browser Detect using js api在浏览器端的时候,我们发现了一个有趣的trick。可以将预先注入的js函数伪装成Native Function,看一下下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString()); // function alert() { [native code] }
console.log(fakeAlert.toString()); // function () { [native code] }
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,784758214
群里有不错的学习视频教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null)fake方法在toString后面没有函数名,所以需要检查toString后面的函数名是否为空。
这个技巧有什么用?在这里延伸一下,反爬虫防御者有一个Robot Detect方法,就是在js运行的时候主动抛出一个alert。文案可以写一些业务逻辑相关的。当普通用户点击OK按钮时,肯定会有1s甚至是alert。对于更长的延迟,由于浏览器中的alert会阻塞js代码的运行(其实在v8中,他会以类似进程挂起的方式挂起isolate context的执行),所以爬虫作为攻击者可以选择使用上面的窍门,就是在页面所有js运行前预先注入一段js代码,伪造alert、prompt、confirm等所有弹窗方法。如果防御者在弹出代码之前检查他调用的alert方法是否仍然是原生的,则这种方式被阻止。
对付爬行动物的灵丹妙药
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中,最成熟的是基于机器学习的谷歌reCAPTCHA。区分用户和爬虫。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。Allow 和 Disallow 声明每个 UA 爬虫的爬取授权。
然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
写在最后
网页内容的爬取与反制,注定是一场魔高路高的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路,你能做的就是增加攻击。用户爬取的成本,以及关于未经授权的爬取行为的更准确信息。
js 爬虫抓取网页数据(集搜客GooSeeker爬虫术语“主题”统一改为“任务” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-27 09:23
)
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在Sooke官网会员中心的“任务管理”中,您可以查看采集任务的执行状态,管理潜在客户的URL,进行调度设置。
一、什么时候需要自定义xpath?
二、为数据自定义 xpath采集 规则
XPath 是一串 html 节点,以 / 分隔,以便在 html 中定位信息节点。从XPath的第一个节点开始,在html的DOM树上一层一层的找到一个节点(参考MS牧手台的网页结构窗口),这个节点就是XPath的定位结果。一个XPath还可以定位一个节点或者多个节点的集合,还可以用一些函数计算布尔值。
排序框就像一个盒子,里面可以存放很多抓取的内容(见下图右侧)。代表这个盒子的容器节点是创建排序框时自动生成的第一个容器节点。在它下面你可以创建一个树状结构的爬取内容。排序框的作用是在网页上限定一个范围,所有爬取的内容都在这个范围内。例如下图左侧,顶部的 DIV 定义了网页的范围。该范围通常是自动生成的,但是可以通过定位容器节点或复制示例地图来更改所选网页范围。
定义范围的DIV是一个基点,在排序框内抓取内容的XPath表达式都是从这个基点开始定位的。所以内部XPath写成相对定位表达式,比如./div/... .or div/span/... or *//*[@class='title']/...,不写作为绝对定位表达式,比如/html/body/.....或者//div /span/....,因为这种格式是从网页的最高节点(html)开始的,简单来说就是开头不是 / 符号。
所以需要保证一个原则:自定义的xpath是相对于基点的,基点是容器节点的xpath,内部爬取内容的xpath路径是相对于它定义的。在编写自定义 XPath 时,尽量不要使用它。绝对 XPath 定位表达式(即以 / 或 // 开头的表达式)。
下面以百度新闻为例,讲解如何自定义xpath。点击下载本案例规则:百度新闻搜索结果
2.1 设置排序框,将抓取到的内容进行映射。最好映射定位标记,可以提高定位精度;这里我们需要采集 整个搜索结果列表,还需要容器。节点“列”用作样本复制图或锚图以捕获多个样本。至此,规则的定义已经完成。
2.2 点击测试,可以看到输出信息窗口中没有捕捉到部分结果的摘要信息,说明摘要有不同的网页结构。对于各种结构,我们可以按照以下步骤2.3、2.4、2.5、2.6个步骤。
2.3 查看数据规则,每个爬取的内容都会有几个可选的xpath路径。自定义 xpath 时,只需使用第一个 XPath 进行转换。将双引号之间的 xpath 路径复制到显示 xpath 搜索框中(不包括 *)。其中*表示任意节点,//表示从当前节点开始的任意级别节点,如果不明白请先掌握“xpath基础”。
2.4 XPath搜索框可用于获取节点的xpath,校验xpath语法,检查xpath是否定位准确等,当xpath语法正确且有节点时,点击搜索计算节点总数及其位置。点击下一项,一一查看节点信息。
2.5 上面只有15个digest节点,但实际上有20个digest,所以需要另找digest的节点结构。点击网页上没有抓取到的摘要信息会定位到一个dom节点,根据节点情况选择“显示XPath***”模式,然后生成节点的xpath,然后搜索那个只是碰巧错过了。5 个汇总节点,表明这是我们正在寻找的另一种结构。
注意:抓取内容的xpath是基于容器节点的相对路径。因此,不要选择绝对定位。最好生成一个较短的xpath路径,这样更适用。
2.6 经过上面的分析,abstract的两个结构是:没有graph的xpath是//*[@class='c-summary c-row'],有graph的xpath是//*[ @class='c-span18 c-span-last'] 或 //*[@class='c-summary c-row c-gap-top-small'],根据这两种结构的异同来write 定位20条摘要信息的xpath,这里写成 //*[contains(@class,'c-summary c-row ')] or //*[@class='c-summary c-row '] | // *[@class='c-span18 c-span-last'] ,然后搜索完成。
2.7 然后需要在抓取内容的高级设置中自定义xpath,操作:双击抓取内容“摘要”,勾选高级设置,选择自定义xpath,选择文本内容和专用定位,抓取内容用点填充表达式,然后粘贴上面写的xpath,用点填充定位表达式,最后保存。
注意:点号表示从当前路径开始。上述xpath收录在容器节点的基点范围内。添加点号可以使范围更准确。另外,定位方式通常不会选择网页片段,否则采集会下来带有html编码的信息,不利于后期处理和分析。
2.8保存规则,再次加载规则后报错,定位失败。由于百度搜索页面是实时变化的,所以第一个搜索结果缺少同新闻同新闻链接这两条信息,所以看到定位失败的提示,但是只要规则还是可以的采集@ > 到数据,会注意规则还是有效的,规则是不能修改的。如果想彻底解决这种网页变化导致某些信息丢失的情况,需要做一个自定义的xpath,否则会出现定位失败的情况,前提是找一个比较完整的示例页面信息作为一项规则。
2.9 点击同一条新闻的信息,找到它所在的页面节点,然后选择“Show XPath***”模式得到它的xpath表达式,然后点击搜索查看。
2.10 对于这种只存在于某些网页中的信息,自定义xpath时只能选择专用定位。将上面的 xpath 复制到抓取内容表达式中,并填写 . 在定位标志表达式中。
注意:如果设置了自定义xpath的抓取内容,并且还需要内容映射,可以选择排序框范围内的任意一个节点映射到它。
2.11 点击测试,如果正确,您将在输出信息窗口中看到数据。如果抓到空白信息,说明xpath没有以容器节点的xpath路径开始,需要重写。如果看到下图提示,说明xpath有语法错误,请检查xpath语法。
自定义xpath不仅有上述用法,还可以精确定位、过滤信息、拼接字符串等,具体请参考《Xpath常用功能用法》。
请看专用定位和两用定位的区别
三、自定义爬虫路由的xpath
爬虫路线通常用于设置下级线索和点击。常规爬虫路由只能一键设置。请看它与连续动作的区别。
遇到循环点击的情况,有两种解决方法,如下:
四、自定义 xpath 以实现连续动作
连续动作可以设置多个连续动作,包括点击、悬停、输入、滚动、提交、选择。信息采集”
注意:用于连续操作的 xpath 支持绝对路径和相对路径。请根据实际网页编写action对象的xpath。
如有疑问,您可以或
查看全部
js 爬虫抓取网页数据(集搜客GooSeeker爬虫术语“主题”统一改为“任务”
)
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在Sooke官网会员中心的“任务管理”中,您可以查看采集任务的执行状态,管理潜在客户的URL,进行调度设置。
一、什么时候需要自定义xpath?
二、为数据自定义 xpath采集 规则
XPath 是一串 html 节点,以 / 分隔,以便在 html 中定位信息节点。从XPath的第一个节点开始,在html的DOM树上一层一层的找到一个节点(参考MS牧手台的网页结构窗口),这个节点就是XPath的定位结果。一个XPath还可以定位一个节点或者多个节点的集合,还可以用一些函数计算布尔值。
排序框就像一个盒子,里面可以存放很多抓取的内容(见下图右侧)。代表这个盒子的容器节点是创建排序框时自动生成的第一个容器节点。在它下面你可以创建一个树状结构的爬取内容。排序框的作用是在网页上限定一个范围,所有爬取的内容都在这个范围内。例如下图左侧,顶部的 DIV 定义了网页的范围。该范围通常是自动生成的,但是可以通过定位容器节点或复制示例地图来更改所选网页范围。
定义范围的DIV是一个基点,在排序框内抓取内容的XPath表达式都是从这个基点开始定位的。所以内部XPath写成相对定位表达式,比如./div/... .or div/span/... or *//*[@class='title']/...,不写作为绝对定位表达式,比如/html/body/.....或者//div /span/....,因为这种格式是从网页的最高节点(html)开始的,简单来说就是开头不是 / 符号。
所以需要保证一个原则:自定义的xpath是相对于基点的,基点是容器节点的xpath,内部爬取内容的xpath路径是相对于它定义的。在编写自定义 XPath 时,尽量不要使用它。绝对 XPath 定位表达式(即以 / 或 // 开头的表达式)。
下面以百度新闻为例,讲解如何自定义xpath。点击下载本案例规则:百度新闻搜索结果

2.1 设置排序框,将抓取到的内容进行映射。最好映射定位标记,可以提高定位精度;这里我们需要采集 整个搜索结果列表,还需要容器。节点“列”用作样本复制图或锚图以捕获多个样本。至此,规则的定义已经完成。

2.2 点击测试,可以看到输出信息窗口中没有捕捉到部分结果的摘要信息,说明摘要有不同的网页结构。对于各种结构,我们可以按照以下步骤2.3、2.4、2.5、2.6个步骤。

2.3 查看数据规则,每个爬取的内容都会有几个可选的xpath路径。自定义 xpath 时,只需使用第一个 XPath 进行转换。将双引号之间的 xpath 路径复制到显示 xpath 搜索框中(不包括 *)。其中*表示任意节点,//表示从当前节点开始的任意级别节点,如果不明白请先掌握“xpath基础”。

2.4 XPath搜索框可用于获取节点的xpath,校验xpath语法,检查xpath是否定位准确等,当xpath语法正确且有节点时,点击搜索计算节点总数及其位置。点击下一项,一一查看节点信息。
2.5 上面只有15个digest节点,但实际上有20个digest,所以需要另找digest的节点结构。点击网页上没有抓取到的摘要信息会定位到一个dom节点,根据节点情况选择“显示XPath***”模式,然后生成节点的xpath,然后搜索那个只是碰巧错过了。5 个汇总节点,表明这是我们正在寻找的另一种结构。
注意:抓取内容的xpath是基于容器节点的相对路径。因此,不要选择绝对定位。最好生成一个较短的xpath路径,这样更适用。

2.6 经过上面的分析,abstract的两个结构是:没有graph的xpath是//*[@class='c-summary c-row'],有graph的xpath是//*[ @class='c-span18 c-span-last'] 或 //*[@class='c-summary c-row c-gap-top-small'],根据这两种结构的异同来write 定位20条摘要信息的xpath,这里写成 //*[contains(@class,'c-summary c-row ')] or //*[@class='c-summary c-row '] | // *[@class='c-span18 c-span-last'] ,然后搜索完成。


2.7 然后需要在抓取内容的高级设置中自定义xpath,操作:双击抓取内容“摘要”,勾选高级设置,选择自定义xpath,选择文本内容和专用定位,抓取内容用点填充表达式,然后粘贴上面写的xpath,用点填充定位表达式,最后保存。
注意:点号表示从当前路径开始。上述xpath收录在容器节点的基点范围内。添加点号可以使范围更准确。另外,定位方式通常不会选择网页片段,否则采集会下来带有html编码的信息,不利于后期处理和分析。

2.8保存规则,再次加载规则后报错,定位失败。由于百度搜索页面是实时变化的,所以第一个搜索结果缺少同新闻同新闻链接这两条信息,所以看到定位失败的提示,但是只要规则还是可以的采集@ > 到数据,会注意规则还是有效的,规则是不能修改的。如果想彻底解决这种网页变化导致某些信息丢失的情况,需要做一个自定义的xpath,否则会出现定位失败的情况,前提是找一个比较完整的示例页面信息作为一项规则。

2.9 点击同一条新闻的信息,找到它所在的页面节点,然后选择“Show XPath***”模式得到它的xpath表达式,然后点击搜索查看。

2.10 对于这种只存在于某些网页中的信息,自定义xpath时只能选择专用定位。将上面的 xpath 复制到抓取内容表达式中,并填写 . 在定位标志表达式中。
注意:如果设置了自定义xpath的抓取内容,并且还需要内容映射,可以选择排序框范围内的任意一个节点映射到它。

2.11 点击测试,如果正确,您将在输出信息窗口中看到数据。如果抓到空白信息,说明xpath没有以容器节点的xpath路径开始,需要重写。如果看到下图提示,说明xpath有语法错误,请检查xpath语法。

自定义xpath不仅有上述用法,还可以精确定位、过滤信息、拼接字符串等,具体请参考《Xpath常用功能用法》。
请看专用定位和两用定位的区别
三、自定义爬虫路由的xpath
爬虫路线通常用于设置下级线索和点击。常规爬虫路由只能一键设置。请看它与连续动作的区别。
遇到循环点击的情况,有两种解决方法,如下:
四、自定义 xpath 以实现连续动作
连续动作可以设置多个连续动作,包括点击、悬停、输入、滚动、提交、选择。信息采集”
注意:用于连续操作的 xpath 支持绝对路径和相对路径。请根据实际网页编写action对象的xpath。
如有疑问,您可以或

js 爬虫抓取网页数据(Python网络爬虫动态网页详解(一)(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-26 03:18
1.动态网页指的是几种可能:
1)需要用户交互,比如常见的登录操作;
2)网页是通过/AJAX动态生成的,比如在一个html中,由JS生成
啊啊啊
;
3)点击输入关键字进行查询,浏览器url地址不变
2.如果想在网站中使用Python获取JavaScript返回的数据,目前有两种方法:
第一种方法:直接url法
(1) 仔细分析页面结构,查看js响应的动作;
(2)借助firfox的firebug解析js点击动作发送的请求url;
(3)使用这个异步请求的url作为scrapy的start_url或者yield请求再次爬取。
第二种方法:借助硒
Selenium 基于并结合其 WebDriver 来模拟用户的真实操作。它具有很好的Ajax处理能力,支持多种浏览器(Safari、IE、Firefox、Chrome),可以在多种操作系统上运行。Selenium 可以调用浏览器的 API 接口,selenium 会打开一个浏览器,然后在新打开的浏览器中执行程序中模拟的动作。
如图所示:
3.在下面安装 Selenium 模块:
4.浏览器的选择:在编写Python网络爬虫时,主要使用Selenium的Webdriver。Selenium.Webdriver 不能支持所有的浏览器,也没有必要支持所有的浏览器。
Webdriver 支持列表:
5.安装 PhantomJS:
下载解压后,放到一个带有python的文件夹中:
windows下的PhantomJS环境配置好后,测试成功:
6.Selenium&PhantomJS 抓取数据:
(1)网站获取返回的数据
(2)定位“有效数据”的位置
(3)从定位中获取“有效数据”
7.以百度搜索为例,用百度搜索“python selenium”,保存搜索结果第一页的标题和链接:
(1)获取搜索结果:直接用Selenium&PhantomJS打开百度首页,然后模拟搜索关键字
(2)定位form frame或者“有效数据”位置可以通过import bs4来实现,也可以通过Selenium自带的功能来实现:一共有8个F方法可以定位返回数据中的“有效数据”:
可以看到文本框中有class、name、id属性,可以使用find_element_by_class_name、find_element_by_id、find_element_by_name来定位:
选择以下三种定位功能中的任何一种:
textElement=browser.find_element_by_class_name('s_ipt')
textElement=browser.find_element_by_id('kw')
textElement=browser.find_element_by_name('wd')
发送搜索关键字:
textElement.send_keys('python selenium')
定位提交按钮:
从图中可以看出,提交按钮有id和class属性,可以用find_element_by_class_name和find_element_by_id定位:
8.从哪里获取有效数据:首先定位搜索结果的标题和链接:查看搜索结果的源码:
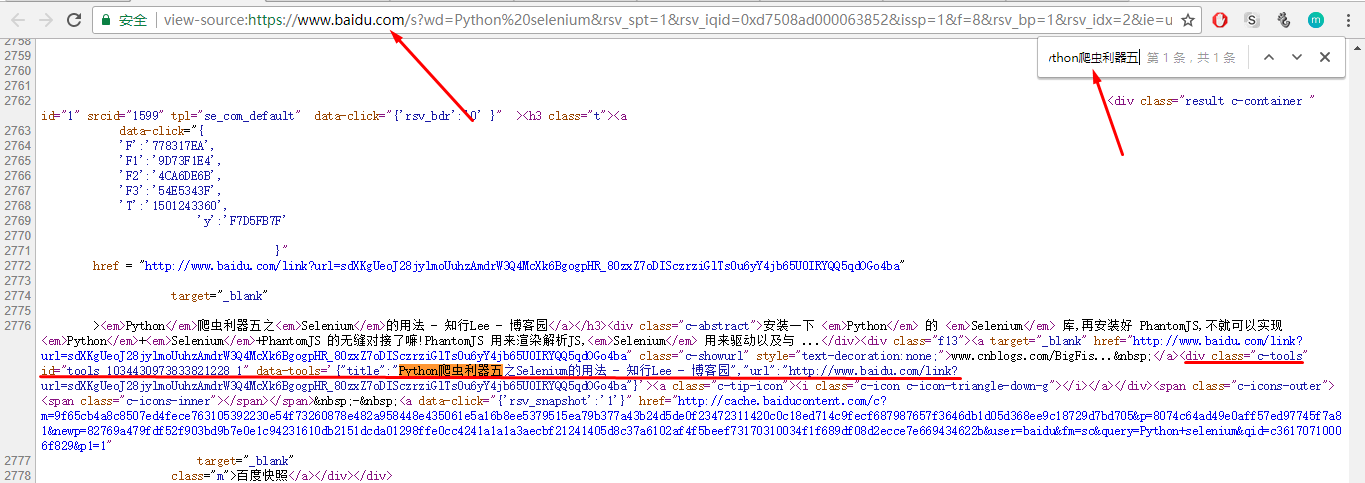
发现了一个特殊的属性:class="c-tools",搜索这个属性:
共找到12个,第二个搜索结果的标题与搜索页面中第二个搜索结果的标题相同,可以确定所有搜索结果都收录class="c-tools"标签
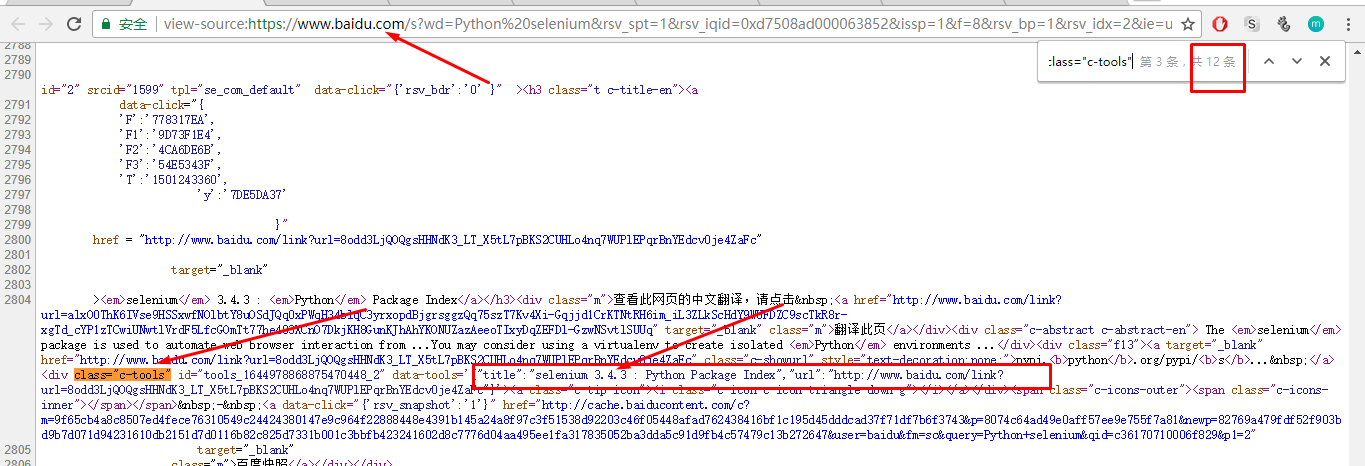
现在可以使用 find_element_by_class_name 定位所有搜索结果:
9.从位置获取有效数据:确定有效数据的位置后,如何从该位置过滤掉有效数据?
Selenium 有自己独特的方法:
元素.文本()
element.get_attribute(name)
所需的有效数据是 data-tools 属性的值:执行命令
遍历resultElements列表,获取所有搜索结果的title和url。
转载于: 查看全部
js 爬虫抓取网页数据(Python网络爬虫动态网页详解(一)(1))
1.动态网页指的是几种可能:
1)需要用户交互,比如常见的登录操作;
2)网页是通过/AJAX动态生成的,比如在一个html中,由JS生成
啊啊啊
;
3)点击输入关键字进行查询,浏览器url地址不变
2.如果想在网站中使用Python获取JavaScript返回的数据,目前有两种方法:
第一种方法:直接url法
(1) 仔细分析页面结构,查看js响应的动作;
(2)借助firfox的firebug解析js点击动作发送的请求url;
(3)使用这个异步请求的url作为scrapy的start_url或者yield请求再次爬取。
第二种方法:借助硒
Selenium 基于并结合其 WebDriver 来模拟用户的真实操作。它具有很好的Ajax处理能力,支持多种浏览器(Safari、IE、Firefox、Chrome),可以在多种操作系统上运行。Selenium 可以调用浏览器的 API 接口,selenium 会打开一个浏览器,然后在新打开的浏览器中执行程序中模拟的动作。
如图所示:

3.在下面安装 Selenium 模块:

4.浏览器的选择:在编写Python网络爬虫时,主要使用Selenium的Webdriver。Selenium.Webdriver 不能支持所有的浏览器,也没有必要支持所有的浏览器。
Webdriver 支持列表:
5.安装 PhantomJS:
下载解压后,放到一个带有python的文件夹中:
windows下的PhantomJS环境配置好后,测试成功:
6.Selenium&PhantomJS 抓取数据:
(1)网站获取返回的数据
(2)定位“有效数据”的位置
(3)从定位中获取“有效数据”
7.以百度搜索为例,用百度搜索“python selenium”,保存搜索结果第一页的标题和链接:
(1)获取搜索结果:直接用Selenium&PhantomJS打开百度首页,然后模拟搜索关键字
(2)定位form frame或者“有效数据”位置可以通过import bs4来实现,也可以通过Selenium自带的功能来实现:一共有8个F方法可以定位返回数据中的“有效数据”:

可以看到文本框中有class、name、id属性,可以使用find_element_by_class_name、find_element_by_id、find_element_by_name来定位:
选择以下三种定位功能中的任何一种:
textElement=browser.find_element_by_class_name('s_ipt')
textElement=browser.find_element_by_id('kw')
textElement=browser.find_element_by_name('wd')
发送搜索关键字:
textElement.send_keys('python selenium')
定位提交按钮:

从图中可以看出,提交按钮有id和class属性,可以用find_element_by_class_name和find_element_by_id定位:
8.从哪里获取有效数据:首先定位搜索结果的标题和链接:查看搜索结果的源码:
发现了一个特殊的属性:class="c-tools",搜索这个属性:
共找到12个,第二个搜索结果的标题与搜索页面中第二个搜索结果的标题相同,可以确定所有搜索结果都收录class="c-tools"标签
现在可以使用 find_element_by_class_name 定位所有搜索结果:

9.从位置获取有效数据:确定有效数据的位置后,如何从该位置过滤掉有效数据?
Selenium 有自己独特的方法:
元素.文本()
element.get_attribute(name)

所需的有效数据是 data-tools 属性的值:执行命令

遍历resultElements列表,获取所有搜索结果的title和url。
转载于:
js 爬虫抓取网页数据(如何用header来处理js页面,的数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2022-03-25 18:01
打开浏览器,以谷歌浏览器为例,在上面输入你的网址。然后按F12打开调试窗口,然后尝试勾选左边的选项之一,马上可以看到右边的调试窗口有输出。找到第一个输出行,点击表头,可以看到每一个都使用了post方式。所以你只需要构造相应的header并发布,就可以得到你想要的数据。
尝试每个请求并单击它
是你要构建的数据
FormData 是你要构造的数据
构造数据并使用 post 函数将其发送到 网站
这得到的是网页格式数据。
而这个分发返回json数据,然后编码成dict格式提取数据。
最好的方法是使用像 selenium 这样的库。selenium的简单介绍,它本身是一个网站自动测试库,所以它可以模拟所有的用户交互行为,包括输入、点击、拖动、滚动等。和用户完全一样的操作,所以它是也和真正的打开网页一样,可以响应Javascript的行为,可以加载JS异步加载的网页。Selenium 最好和 PhantomJS 一起使用,所以没有接口,完全自动化。
存储每次获取的结果并将其与之前的结果进行比较。
如何使用Python爬虫爬取JS动态过滤内容——可以使用splash处理js页面,然后解析处理后的页面内容。可以参考这个文档:9270/pages/viewpage.action?pageId=919763
如何使用python爬取js动态生成内容的页面——python 2.6 + selenium-2.53.6 + firefox45.0 + BeautifulSoup3.@ >2.1 或 python 2.6 + selenium-2.53.6 + phantomjs 2.1.1
如何使用python抓取js生成的数据?——如果对刮削性能没有要求,可以试试selenium或watir。Web 自动化测试脚本可以做很多事情。使用浏览器执行好js,然后从dom中获取数据。还有一种情况,如果知道js通过ajax或者api取数据,可以直接抓取数据源,获取json或者xml中的任意一个,然后对数据进行处理
爬虫怎么爬取js动态生成的数据——我用jsoup写爬虫,一般会遇到html没有返回的内容。但是,浏览器会显示一些内容。就是分析页面的http请求日志。分析页面的JS代码解决问题。1、部分页面元素被隐藏->更改选择器解决2、部分数据存放在js/json对象中->截取对应字符串,分析解决3、通过api接口调用->还有一种终极方法是伪造请求获取数据4、使用无头浏览器如phantomjs或casperjs
Python如何获取js动态加载的数据——使用WebBrowser控件获取js动态加载的数据: 首先需要在DocumentCompleted事件中完成内容获取,因为该控件是在文档加载后触发的。二、这个事件有一个问题,就是如果页面中有iframe框架之类的,如果加载了iframe也会触发这个事件,所以我们要做一个判断:if(wb. ReadyState == WebBrowserReadyState.Complete && e. Url.ToString() == wb.Url.ToString()) wb.Document.Body.InnerHtml;//这样获取数据
程序员如何使用网络爬虫获取js中的动态数据——如果你不会使用爬虫软件,我推荐使用在采集之前对网页进行嗅探的forespider数据采集系统中间需要js数据,操作简单直观,鼠标点击即可。它完全适合不会编程的人。希望采纳
如何使用python捕获js生成的数据 -- 一、查看对应的js代码,用python获取原创数据后,模仿js编写对应的python代码。二、通过接口api获取数据,直接使用python获取接口数据并处理。三.终极方法。使用selenium和phantomjs执行网页的js代码,然后获取数据。这种方法可以100%获取数据,但是速度太慢了。
Python爬虫在处理Javascript动态生成的页面时有哪些解决方案——我们一直在使用第二种思路中的方法1,即用一个浏览器内容运行JavaScript并解析动态内容,用python模拟人在浏览器上执行操作。这种实现是最自然的,虽然有人一直批评这种速度慢,但是在实际运行环境中,大多数情况下你会担心...
如何使用scrapy爬取js动态生成的数据——这个方法只是获取页面的源代码;您的要求是获取 DOM 结构;有一种使用lxml库的方法,先用selenium获取整个html的DOM,然后将DOM转储到lxml对象中,这样就可以得到正常的html Dom树,如下例子: def parse_from_unicode( unicode_str): #...
python如何抓取动态页面内容?- —— 1.了解网页抓取的逻辑流程请参考:【整理】关于抓取网页、分析网页内容、模拟登陆的逻辑/流程网站及注意事项2.重用工具分析所需内容是如何生成的【总结】浏览器中的开发者工具(IE9的F12和Chrome的Ctrl+Shift+I)——网页分析的强大工具 火狐的上述firebug也可以用过,不过我用过,觉得不如IE9的F12好用。3.已经分析过了,找出具体是哪个url生成了你需要的数据,然后用Python实现对应的代码.... 查看全部
js 爬虫抓取网页数据(如何用header来处理js页面,的数据(组图))
打开浏览器,以谷歌浏览器为例,在上面输入你的网址。然后按F12打开调试窗口,然后尝试勾选左边的选项之一,马上可以看到右边的调试窗口有输出。找到第一个输出行,点击表头,可以看到每一个都使用了post方式。所以你只需要构造相应的header并发布,就可以得到你想要的数据。
尝试每个请求并单击它
是你要构建的数据
FormData 是你要构造的数据
构造数据并使用 post 函数将其发送到 网站
这得到的是网页格式数据。
而这个分发返回json数据,然后编码成dict格式提取数据。
最好的方法是使用像 selenium 这样的库。selenium的简单介绍,它本身是一个网站自动测试库,所以它可以模拟所有的用户交互行为,包括输入、点击、拖动、滚动等。和用户完全一样的操作,所以它是也和真正的打开网页一样,可以响应Javascript的行为,可以加载JS异步加载的网页。Selenium 最好和 PhantomJS 一起使用,所以没有接口,完全自动化。
存储每次获取的结果并将其与之前的结果进行比较。
如何使用Python爬虫爬取JS动态过滤内容——可以使用splash处理js页面,然后解析处理后的页面内容。可以参考这个文档:9270/pages/viewpage.action?pageId=919763
如何使用python爬取js动态生成内容的页面——python 2.6 + selenium-2.53.6 + firefox45.0 + BeautifulSoup3.@ >2.1 或 python 2.6 + selenium-2.53.6 + phantomjs 2.1.1
如何使用python抓取js生成的数据?——如果对刮削性能没有要求,可以试试selenium或watir。Web 自动化测试脚本可以做很多事情。使用浏览器执行好js,然后从dom中获取数据。还有一种情况,如果知道js通过ajax或者api取数据,可以直接抓取数据源,获取json或者xml中的任意一个,然后对数据进行处理
爬虫怎么爬取js动态生成的数据——我用jsoup写爬虫,一般会遇到html没有返回的内容。但是,浏览器会显示一些内容。就是分析页面的http请求日志。分析页面的JS代码解决问题。1、部分页面元素被隐藏->更改选择器解决2、部分数据存放在js/json对象中->截取对应字符串,分析解决3、通过api接口调用->还有一种终极方法是伪造请求获取数据4、使用无头浏览器如phantomjs或casperjs
Python如何获取js动态加载的数据——使用WebBrowser控件获取js动态加载的数据: 首先需要在DocumentCompleted事件中完成内容获取,因为该控件是在文档加载后触发的。二、这个事件有一个问题,就是如果页面中有iframe框架之类的,如果加载了iframe也会触发这个事件,所以我们要做一个判断:if(wb. ReadyState == WebBrowserReadyState.Complete && e. Url.ToString() == wb.Url.ToString()) wb.Document.Body.InnerHtml;//这样获取数据
程序员如何使用网络爬虫获取js中的动态数据——如果你不会使用爬虫软件,我推荐使用在采集之前对网页进行嗅探的forespider数据采集系统中间需要js数据,操作简单直观,鼠标点击即可。它完全适合不会编程的人。希望采纳
如何使用python捕获js生成的数据 -- 一、查看对应的js代码,用python获取原创数据后,模仿js编写对应的python代码。二、通过接口api获取数据,直接使用python获取接口数据并处理。三.终极方法。使用selenium和phantomjs执行网页的js代码,然后获取数据。这种方法可以100%获取数据,但是速度太慢了。
Python爬虫在处理Javascript动态生成的页面时有哪些解决方案——我们一直在使用第二种思路中的方法1,即用一个浏览器内容运行JavaScript并解析动态内容,用python模拟人在浏览器上执行操作。这种实现是最自然的,虽然有人一直批评这种速度慢,但是在实际运行环境中,大多数情况下你会担心...
如何使用scrapy爬取js动态生成的数据——这个方法只是获取页面的源代码;您的要求是获取 DOM 结构;有一种使用lxml库的方法,先用selenium获取整个html的DOM,然后将DOM转储到lxml对象中,这样就可以得到正常的html Dom树,如下例子: def parse_from_unicode( unicode_str): #...
python如何抓取动态页面内容?- —— 1.了解网页抓取的逻辑流程请参考:【整理】关于抓取网页、分析网页内容、模拟登陆的逻辑/流程网站及注意事项2.重用工具分析所需内容是如何生成的【总结】浏览器中的开发者工具(IE9的F12和Chrome的Ctrl+Shift+I)——网页分析的强大工具 火狐的上述firebug也可以用过,不过我用过,觉得不如IE9的F12好用。3.已经分析过了,找出具体是哪个url生成了你需要的数据,然后用Python实现对应的代码....
js 爬虫抓取网页数据(AngularJSjs渲染出的页面越来越多如何判断前端渲染页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2022-03-25 05:28
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面使用js渲染。对于爬虫来说,这种页面比较烦人:只提取 HTML 内容,往往无法获取有效信息。那么如何处理这种页面呢?一般有两种方法:
爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面的相应工具是 Selenium、HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。优点是编写规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本上是通过AJAX获取的,所以分析AJAX请求,找到数据对应的请求也是可行的。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较大量的分析经验。
比较这两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更为可靠。对于某些网站,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,而第二种方法会很复杂。
对于第一种方法,webmagic-selenium就是这样一种尝试,它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,和平台和版本有关,没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。我希望你会发现解析一个前端渲染的页面并没有那么复杂。这里我们以AngularJS中文社区为例。
1 如何判断前端渲染
判断页面是否为js渲染的方式比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果没有找到有效信息,基本上就是js渲染了。
本例中在源码中找不到页面中的标题“优符计算机网-前端攻城师”,因此可以断定是js渲染,这个数据是通过AJAX获取的。
2 分析请求
现在我们到了最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是浏览器中的开发者工具查看网络请求。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是一个下拉页面,总之所有的操作你觉得可能会触发新的数据)),那就记得保留场景,一一分析请求!
这一步需要一点耐心,但不是随机的。首先可以帮助我们的是上面的分类过滤器(All、Document 和其他选项)。如果是普通的 AJAX,会显示在 XHR 标签下,而 JSONP 请求会显示在 Scripts 标签下。这是两种更常见的数据类型。
然后你可以根据数据的大小来判断。一般来说,较大的结果更有可能是返回数据的接口。其余的基本上都是凭经验。比如这里的“latest?p=1&s=20”,一看就很可疑……
对于可疑地址,此时可以查看响应正文的内容。在这里的开发者工具中并不清楚。我们把URL复制到地址栏再请求一次(如果你用Chrome推荐安装一个jsonviewer,查看AJAX结果很方便)。查看结果,看起来我们找到了我们想要的东西。
同样的方法,我们进入帖子详情页面,找到具体内容的请求:.
3 编写程序
回顾之前列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只不过换成了AJAX方法——AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们仍然可以使用最后一种方式,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求由一些固定的url加上这个id组成。所以在这一步中,我们手动构造URL,并将其添加到待爬取队列中。这里我们使用 JsonPath 选择语言来选择数据(webmagic-extension 包中提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了 URL,解析目标数据其实很简单,因为 JSON 数据是完全结构化的,所以我们省去了分析页面和编写 XPath 的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见 AngularJSProcessor.java
4 总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。事实上,动态网页抓取的最大区别在于它使链接发现更加困难。我们比较一下两种开发模式:
后端渲染页面
下载二级页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是在页面HTML中预先输出,也可能是通过AJAX请求,甚至可能是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点所在。
本节这个例子希望实现的是在分析请求后,为此类爬虫的编写提供一个模式,即发现辅助数据 => 构建链接 => 下载并分析目标 AJAX 模式。
PS:
WebMagic 0.5.0 稍后会为链式 API 添加 Json 支持,您可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析 AJAX 请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。 查看全部
js 爬虫抓取网页数据(AngularJSjs渲染出的页面越来越多如何判断前端渲染页面)
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面使用js渲染。对于爬虫来说,这种页面比较烦人:只提取 HTML 内容,往往无法获取有效信息。那么如何处理这种页面呢?一般有两种方法:
爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面的相应工具是 Selenium、HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。优点是编写规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本上是通过AJAX获取的,所以分析AJAX请求,找到数据对应的请求也是可行的。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较大量的分析经验。
比较这两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更为可靠。对于某些网站,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,而第二种方法会很复杂。
对于第一种方法,webmagic-selenium就是这样一种尝试,它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,和平台和版本有关,没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。我希望你会发现解析一个前端渲染的页面并没有那么复杂。这里我们以AngularJS中文社区为例。
1 如何判断前端渲染
判断页面是否为js渲染的方式比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果没有找到有效信息,基本上就是js渲染了。


本例中在源码中找不到页面中的标题“优符计算机网-前端攻城师”,因此可以断定是js渲染,这个数据是通过AJAX获取的。
2 分析请求
现在我们到了最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是浏览器中的开发者工具查看网络请求。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是一个下拉页面,总之所有的操作你觉得可能会触发新的数据)),那就记得保留场景,一一分析请求!
这一步需要一点耐心,但不是随机的。首先可以帮助我们的是上面的分类过滤器(All、Document 和其他选项)。如果是普通的 AJAX,会显示在 XHR 标签下,而 JSONP 请求会显示在 Scripts 标签下。这是两种更常见的数据类型。
然后你可以根据数据的大小来判断。一般来说,较大的结果更有可能是返回数据的接口。其余的基本上都是凭经验。比如这里的“latest?p=1&s=20”,一看就很可疑……

对于可疑地址,此时可以查看响应正文的内容。在这里的开发者工具中并不清楚。我们把URL复制到地址栏再请求一次(如果你用Chrome推荐安装一个jsonviewer,查看AJAX结果很方便)。查看结果,看起来我们找到了我们想要的东西。

同样的方法,我们进入帖子详情页面,找到具体内容的请求:.
3 编写程序
回顾之前列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只不过换成了AJAX方法——AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们仍然可以使用最后一种方式,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求由一些固定的url加上这个id组成。所以在这一步中,我们手动构造URL,并将其添加到待爬取队列中。这里我们使用 JsonPath 选择语言来选择数据(webmagic-extension 包中提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了 URL,解析目标数据其实很简单,因为 JSON 数据是完全结构化的,所以我们省去了分析页面和编写 XPath 的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见 AngularJSProcessor.java
4 总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。事实上,动态网页抓取的最大区别在于它使链接发现更加困难。我们比较一下两种开发模式:
后端渲染页面
下载二级页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是在页面HTML中预先输出,也可能是通过AJAX请求,甚至可能是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点所在。
本节这个例子希望实现的是在分析请求后,为此类爬虫的编写提供一个模式,即发现辅助数据 => 构建链接 => 下载并分析目标 AJAX 模式。
PS:
WebMagic 0.5.0 稍后会为链式 API 添加 Json 支持,您可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析 AJAX 请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。
js 爬虫抓取网页数据(未授权的爬虫是危害web原创内容生态的一大元凶)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-20 16:11
分享一篇文章文章,来自如果有人问你爬虫技术,请让他看这篇文章文章。
网络是一个开放的平台,它为网络从1990年代初诞生到今天的蓬勃发展奠定了基础。然而,作为所谓的成败,开放的特性、搜索引擎、简单易学的html和css技术,使得web成为了互联网领域最流行、最成熟的信息传播媒介;但是今天,作为一个商业软件,web这个平台上的内容信息的版权是不能保证的,因为和软件客户端相比,你网页中的内容可以通过一些爬虫程序以非常低的成本和技术门槛很低。这就是本系列文章要讨论的话题——网络爬虫。
有很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为随着今天IT行业的发展,网络不再是当年与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的思想。存在。随着商业软件的发展,网络也不得不面对知识产权保护的问题。试想,如果原创的优质内容不受保护,网络世界中抄袭盗版猖獗,这其实有利于网络生态的健康发展。这是一个缺点,而且它'
未经授权的爬虫程序是危害web原创内容生态的罪魁祸首。因此,为了保护网站的内容,首先要考虑如何反爬。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的http请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。
这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。
另外还有一个比较异常的服务器端爬虫检测机制,就是在所有访问页面的http请求的http响应中都种上一个cookie token,然后在这个页面异步执行的一些ajax接口上学. 检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电商网站amazon采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时的检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序调用的API来实现复杂的爬取业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真正的GUI浏览器的发布版本。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。
现在谷歌Chrome团队已经在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length == 0) {
console.log("It may be Chrome headless");
}
基于语言的检查
if(navigator.languages == "") {
console.log("Chrome headless detected");
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == "Brian Paul" && renderer == "Mesa OffScreen") {
console.log("Chrome headless detected");
}
基于浏览器细线属性的检查
if(!Modernizr["hairline"]) {
console.log("It may be Chrome headless");
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName("body")[0];
var image = document.createElement("img");
image.src = "http://iloveponeydotcom32188.jg";
image.setAttribute("id", "fakeimage");
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log("Chrome headless detected");
}
}
基于以上对一些浏览器特性的判断,基本上可以将市面上大部分的无头浏览器程序干掉。至此,网页爬虫的门槛其实提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器内核来说是很重要的。变化不小。
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。
这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
另外,我们在研究robots browserdetect using js api在浏览器端的时候,发现了一个有趣的小技巧。可以将一个预先注入的js函数伪装成native函数,看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString());
console.log(fakeAlert.toString());
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。因此,需要更严格的检查,因为bind(null)伪造的方法在toString之后没有函数名。
对付爬行动物的灵丹妙药
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中最成熟的是 Google reCAPTCHA。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。您可以访问 网站 根目录中的 /robots.txt。比如我们看一下github的robot协议。Allow 和 Disallow 声明每个 UA 爬虫的授权。
然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
写在最后
网页内容的爬取与反制,注定是一场魔高路高的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路,你能做的就是增加攻击。用户爬取的成本,以及关于未经授权的爬取行为的更准确信息。
这篇文章中提到的验证码攻防,其实是一个比较复杂的技术难点。我在这里留下一个悬念。有兴趣的可以多加关注,期待后续文章的详细阐述。
另外,欢迎对爬虫感兴趣的朋友关注我的开源项目webster。该项目以Node.js结合Chrome无头模式实现了一个高可用的网络爬虫爬取框架。一个页面中js和ajax渲染的所有异步内容;结合redis,实现了一个任务队列,让爬虫轻松进行横向和纵向分布式扩展。
如果你想进一步了解学习Python的知识体系,可以看一下我们花了一个多月时间整理了上百个小时的上百个知识点的内容:
【超全整理】《Python自动化全能开发从入门到精通》笔记完整发布 查看全部
js 爬虫抓取网页数据(未授权的爬虫是危害web原创内容生态的一大元凶)
分享一篇文章文章,来自如果有人问你爬虫技术,请让他看这篇文章文章。
网络是一个开放的平台,它为网络从1990年代初诞生到今天的蓬勃发展奠定了基础。然而,作为所谓的成败,开放的特性、搜索引擎、简单易学的html和css技术,使得web成为了互联网领域最流行、最成熟的信息传播媒介;但是今天,作为一个商业软件,web这个平台上的内容信息的版权是不能保证的,因为和软件客户端相比,你网页中的内容可以通过一些爬虫程序以非常低的成本和技术门槛很低。这就是本系列文章要讨论的话题——网络爬虫。

有很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为随着今天IT行业的发展,网络不再是当年与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的思想。存在。随着商业软件的发展,网络也不得不面对知识产权保护的问题。试想,如果原创的优质内容不受保护,网络世界中抄袭盗版猖獗,这其实有利于网络生态的健康发展。这是一个缺点,而且它'
未经授权的爬虫程序是危害web原创内容生态的罪魁祸首。因此,为了保护网站的内容,首先要考虑如何反爬。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的http请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。
这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。
另外还有一个比较异常的服务器端爬虫检测机制,就是在所有访问页面的http请求的http响应中都种上一个cookie token,然后在这个页面异步执行的一些ajax接口上学. 检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电商网站amazon采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时的检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序调用的API来实现复杂的爬取业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真正的GUI浏览器的发布版本。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。
现在谷歌Chrome团队已经在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length == 0) {
console.log("It may be Chrome headless");
}
基于语言的检查
if(navigator.languages == "") {
console.log("Chrome headless detected");
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == "Brian Paul" && renderer == "Mesa OffScreen") {
console.log("Chrome headless detected");
}
基于浏览器细线属性的检查
if(!Modernizr["hairline"]) {
console.log("It may be Chrome headless");
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName("body")[0];
var image = document.createElement("img");
image.src = "http://iloveponeydotcom32188.jg";
image.setAttribute("id", "fakeimage");
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log("Chrome headless detected");
}
}
基于以上对一些浏览器特性的判断,基本上可以将市面上大部分的无头浏览器程序干掉。至此,网页爬虫的门槛其实提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器内核来说是很重要的。变化不小。
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。
这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
另外,我们在研究robots browserdetect using js api在浏览器端的时候,发现了一个有趣的小技巧。可以将一个预先注入的js函数伪装成native函数,看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString());
console.log(fakeAlert.toString());
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。因此,需要更严格的检查,因为bind(null)伪造的方法在toString之后没有函数名。
对付爬行动物的灵丹妙药
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中最成熟的是 Google reCAPTCHA。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。您可以访问 网站 根目录中的 /robots.txt。比如我们看一下github的robot协议。Allow 和 Disallow 声明每个 UA 爬虫的授权。
然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
写在最后
网页内容的爬取与反制,注定是一场魔高路高的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路,你能做的就是增加攻击。用户爬取的成本,以及关于未经授权的爬取行为的更准确信息。
这篇文章中提到的验证码攻防,其实是一个比较复杂的技术难点。我在这里留下一个悬念。有兴趣的可以多加关注,期待后续文章的详细阐述。
另外,欢迎对爬虫感兴趣的朋友关注我的开源项目webster。该项目以Node.js结合Chrome无头模式实现了一个高可用的网络爬虫爬取框架。一个页面中js和ajax渲染的所有异步内容;结合redis,实现了一个任务队列,让爬虫轻松进行横向和纵向分布式扩展。
如果你想进一步了解学习Python的知识体系,可以看一下我们花了一个多月时间整理了上百个小时的上百个知识点的内容:
【超全整理】《Python自动化全能开发从入门到精通》笔记完整发布
js 爬虫抓取网页数据(应用宝应用搜索页面中的JS动态生成方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-19 01:17
1.1 Ajax异步加载生成网页内容
现在越来越多的网页使用Ajax异步加载方式,即网页中的一些内容是由前端JS动态生成的。由于网页上呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中看不到。
例如应用宝的搜索应用页面显示如下:
从上面可以看出,搜索到的应用列表信息在id="J_SearchDefaultListBox"的DOM树下。
查看当前网页的源码(使用快捷键“Ctrl+U”)如下:
源码中发现元素id="J_SearchDefaultListBox"下的内容为空,没有应用列表信息。
从上面的分析可以看出,应用宝的应用搜索页面显示的应用列表是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页内容呢?一般有两种方法:
(1)从网页响应中查找JS脚本返回的数据(多为json格式,也有xml格式);
(2)使用 Selenium 模拟对网页的访问。
下面我们将介绍第一种方法。第二种方法可以在这里找到。
1.2 从网页响应中找到JS脚本返回的数据由于网页内容是由JS动态生成并加载的,那么JS需要先调用一个接口,然后根据返回的数据进行加载和渲染界面。那么我们可以先找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。下面以应用宝的搜索应用页面为例进行说明。
1.2.1 找到JS请求的数据接口
按着这些次序:
您将看到以下信息:
在这里,我们看到只有一个请求(其他页面可能有多个)。点击这个请求,然后选择“预览”,可以看到如下数据:
在上述数据中,我们找到了“微信”、“多开助手”等信息,这些信息就是搜索到的应用列表信息。
通过以上分析可知,搜索到的应用列表信息就是通过这个请求获得的。这个请求对应的URL是%E5%BE%AE%E4%BF%A1&pns=&sid=(获取方法:鼠标移到这个请求上->然后右键->复制->复制链接地址)。
在浏览器中打开上述 URL 将返回一串数据。它看起来很乱,但实际上是 JSON 格式的数据。
这样,我们就找到了JS请求的数据接口。
1.2.2 URL编码上面我们找到的JS请求的数据接口是%E5%BE%AE%E4%BF%A1&pns=&sid=,但是%E5%BE%AE%E4是什么%BF%A1 是什么意思?
实际上 %E5%BE%AE%E4%BF%A1 是中文微信的 URL 编码。在Python中,可以使用urllib.parse.quote()获取,即'%E5%BE%AE%E4%BF%A1' = urllib.parse.quote('WeChat')。
根据标准,URL 中只允许使用英文字母、数字和一些符号。其他字符(如中文)不符合 URL 标准。这时候需要进行 URL 编码。
1.2.3 代码实现
请按照以下 4 个步骤来实施:
(1)介绍相关库;
(2)请求JS请求的数据接口; 查看全部
js 爬虫抓取网页数据(应用宝应用搜索页面中的JS动态生成方法)
1.1 Ajax异步加载生成网页内容
现在越来越多的网页使用Ajax异步加载方式,即网页中的一些内容是由前端JS动态生成的。由于网页上呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中看不到。
例如应用宝的搜索应用页面显示如下:

从上面可以看出,搜索到的应用列表信息在id="J_SearchDefaultListBox"的DOM树下。
查看当前网页的源码(使用快捷键“Ctrl+U”)如下:

源码中发现元素id="J_SearchDefaultListBox"下的内容为空,没有应用列表信息。
从上面的分析可以看出,应用宝的应用搜索页面显示的应用列表是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页内容呢?一般有两种方法:
(1)从网页响应中查找JS脚本返回的数据(多为json格式,也有xml格式);
(2)使用 Selenium 模拟对网页的访问。
下面我们将介绍第一种方法。第二种方法可以在这里找到。
1.2 从网页响应中找到JS脚本返回的数据由于网页内容是由JS动态生成并加载的,那么JS需要先调用一个接口,然后根据返回的数据进行加载和渲染界面。那么我们可以先找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。下面以应用宝的搜索应用页面为例进行说明。
1.2.1 找到JS请求的数据接口
按着这些次序:
您将看到以下信息:

在这里,我们看到只有一个请求(其他页面可能有多个)。点击这个请求,然后选择“预览”,可以看到如下数据:

在上述数据中,我们找到了“微信”、“多开助手”等信息,这些信息就是搜索到的应用列表信息。

通过以上分析可知,搜索到的应用列表信息就是通过这个请求获得的。这个请求对应的URL是%E5%BE%AE%E4%BF%A1&pns=&sid=(获取方法:鼠标移到这个请求上->然后右键->复制->复制链接地址)。
在浏览器中打开上述 URL 将返回一串数据。它看起来很乱,但实际上是 JSON 格式的数据。

这样,我们就找到了JS请求的数据接口。
1.2.2 URL编码上面我们找到的JS请求的数据接口是%E5%BE%AE%E4%BF%A1&pns=&sid=,但是%E5%BE%AE%E4是什么%BF%A1 是什么意思?
实际上 %E5%BE%AE%E4%BF%A1 是中文微信的 URL 编码。在Python中,可以使用urllib.parse.quote()获取,即'%E5%BE%AE%E4%BF%A1' = urllib.parse.quote('WeChat')。
根据标准,URL 中只允许使用英文字母、数字和一些符号。其他字符(如中文)不符合 URL 标准。这时候需要进行 URL 编码。
1.2.3 代码实现
请按照以下 4 个步骤来实施:
(1)介绍相关库;
(2)请求JS请求的数据接口;
js 爬虫抓取网页数据(js爬虫抓取网页数据,pdf下载源码都是可以爬取的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-18 22:05
js爬虫抓取网页数据,pdf下载源码都是可以爬取的。
爬虫的话很多网站都有,常见的是,ie,chrome,firefox,只要看起来像个网站,基本就可以爬,可以百度“python爬虫”“java爬虫”,很多基础的学一下,基本就可以做很多事情,做爬虫这个东西最重要的是一定要熟悉cookie机制,毕竟所有网站本质上都是获取cookie,操作起来很方便,拿举例,的登录是通过useragent,你可以把这个当成一个安全问题,毕竟安全问题会大量降低登录效率和成功率,有了这个知识之后,你可以去翻翻这方面的资料,相信会对你有很大帮助,比如requests、beautifulsoup、python解析html、爬虫实战之家等,总之很多,下面列举几个效率很高的爬虫,百度jsonjson在现在也很火,可以看看,熟悉了这些之后,爬虫方面其实很简单,大量的小网站,都可以爬取,知乎也可以用来当爬虫爬取知乎,爬取github也不是不可以,这个先不说,估计题主是个高人,这个直接上手一个月就能做一个比较简单的爬虫,新鲜出炉的知乎爬虫,目前完成了几百万人看得了,哈哈哈,虽然大部分问题还是让人生气。
:下面是我整理的python爬虫框架,我写的爬虫框架其实不算很多,欢迎大家提出来,上面只是简单列举几个,其实随便用requests爬一下taobao,github就出来了,相信题主可以挖掘出其他更多牛逼的东西。:。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,pdf下载源码都是可以爬取的)
js爬虫抓取网页数据,pdf下载源码都是可以爬取的。
爬虫的话很多网站都有,常见的是,ie,chrome,firefox,只要看起来像个网站,基本就可以爬,可以百度“python爬虫”“java爬虫”,很多基础的学一下,基本就可以做很多事情,做爬虫这个东西最重要的是一定要熟悉cookie机制,毕竟所有网站本质上都是获取cookie,操作起来很方便,拿举例,的登录是通过useragent,你可以把这个当成一个安全问题,毕竟安全问题会大量降低登录效率和成功率,有了这个知识之后,你可以去翻翻这方面的资料,相信会对你有很大帮助,比如requests、beautifulsoup、python解析html、爬虫实战之家等,总之很多,下面列举几个效率很高的爬虫,百度jsonjson在现在也很火,可以看看,熟悉了这些之后,爬虫方面其实很简单,大量的小网站,都可以爬取,知乎也可以用来当爬虫爬取知乎,爬取github也不是不可以,这个先不说,估计题主是个高人,这个直接上手一个月就能做一个比较简单的爬虫,新鲜出炉的知乎爬虫,目前完成了几百万人看得了,哈哈哈,虽然大部分问题还是让人生气。
:下面是我整理的python爬虫框架,我写的爬虫框架其实不算很多,欢迎大家提出来,上面只是简单列举几个,其实随便用requests爬一下taobao,github就出来了,相信题主可以挖掘出其他更多牛逼的东西。:。
js 爬虫抓取网页数据(谷歌能DOM是什么?Google能读取动态生成的内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-16 18:01
)
(点击上方公众号快速关注)
编译:伯乐在线/刘建超-Jc
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。怎么做?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向,用不同的方式表达的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2. 测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果呢?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有相互冲突的信号时,哪一个获胜?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在此协议中,HTTP x-robots 响应标头作为另一个变量的行为如何?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要示例
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
认为这篇文章对您有帮助吗?请与更多人分享
关注“前端大全”提升前端技能
查看全部
js 爬虫抓取网页数据(谷歌能DOM是什么?Google能读取动态生成的内容
)
(点击上方公众号快速关注)
编译:伯乐在线/刘建超-Jc
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。

长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。怎么做?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。

当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例
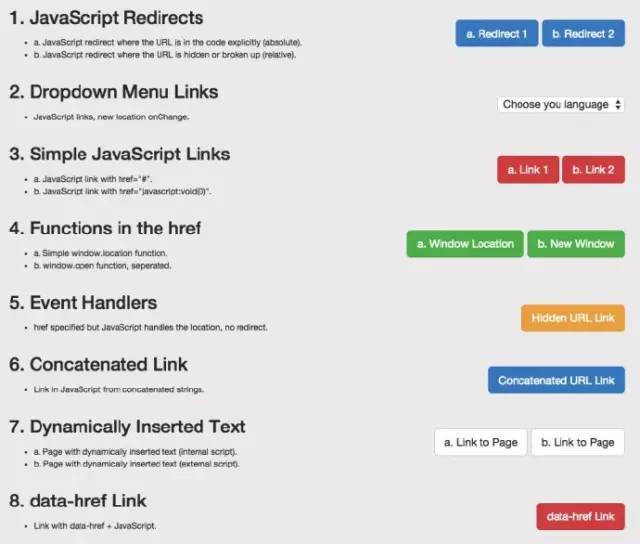
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向,用不同的方式表达的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
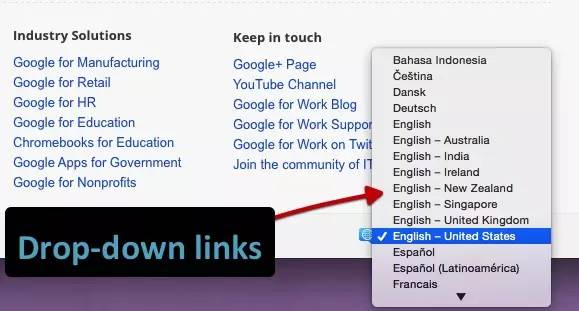
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2. 测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果呢?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有相互冲突的信号时,哪一个获胜?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在此协议中,HTTP x-robots 响应标头作为另一个变量的行为如何?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要示例
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
认为这篇文章对您有帮助吗?请与更多人分享
关注“前端大全”提升前端技能

js 爬虫抓取网页数据(摘:网络爬虫的12种常见词汇(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-16 17:20
《关于Python爬虫技术的网页数据采集与分析》为会员分享,可在线阅读。更多《关于Python爬虫技术的网页数据采集与分析(8页珍藏版)》,请访问人人图书馆在线搜索。
浅谈Python爬虫技术的Web数据抓取与分析 吴永聪 摘要:近年来,随着互联网的发展,如何有效地从互联网上获取所需的信息成为众多互联网公司竞争研究的新方向,而从互联网上获取数据最常用的手段是网络爬虫。网络爬虫,也称为网络蜘蛛和网络机器人,是一种根据特定规则和给定 URL 自动采集互联网数据和信息的程序。文章讨论了网络爬虫实现过程中的主要问题:如何使用python模拟登录、如何使用正则表达式匹配字符串获取信息、如何使用mysql存储数据等,并实现一个使用 python 的网络爬虫系统。关键词: 网络爬虫;Python; MySQL;正则表达式:TP311.11 文档代码:A:1006-8228(2019)08-94-03摘要:近年来,随着互联网的发展,如何有效地从互联网已经成为许多互联网公司争相研究的新方向,而最常见的从互联网获取数据的手段就是网络爬虫。网络爬虫也被称为网络蜘蛛或网络机器人,它是一种自动根据给定的 URL 和特定规则采集 Internet 数据和信息。如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段就是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段就是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。
于是,谷歌、百度、雅虎等搜索引擎应运而生。搜索引擎可以根据用户输入的关键字检索互联网上的网页,为用户查找与关键字相关或收录关键字的信息。网络爬虫作为搜索引擎的重要组成部分,在信息检索过程中发挥着重要作用。因此,网络爬虫的研究对搜索引擎的发展具有重要意义。对于编写网络爬虫,python有其独特的优势。比如python中有很多爬虫框架,使得网络爬虫爬取数据的效率更高。同时,Python 是一种面向对象的解释型高级编程语言。它的语法比其他高级编程语言更简单、更容易阅读和理解。所以,使用Python实现网络爬虫是一个不错的选择。1 网络爬虫概述1.1 网络爬虫原理 网络爬虫又称为网络蜘蛛、网络机器人,主要用于采集互联网上的各种资源。它是搜索引擎的重要组成部分,是一种自动提取 Internet 上特定页面内容的程序。通用搜索引擎网络爬虫工作流程1:将种子URL放入等待URL队列;将等待URL从等待URL队列中取出,进行读取URL、DNS解析、网页下载等操作;将下载的网页放入下载网页库;将下载的网页网址放入已抓取的网址队列中;分析爬取的URL队列中的URL,提取出新的URL,放入待爬取的URL队列中,
爬虫的工作流程:通过URL爬取页面代码;通过正则匹配获取页面的有用数据或页面上有用的URL;对获取的数据进行处理或通过获取的新URL进入下一轮爬取循环。1.2网络爬虫的分类网络爬虫大致可以分为通用网络爬虫和专注网络爬虫2.通用网络爬虫也称为全网爬虫,从一个或多个初始URL开始,获取初始页面的代码,同时从页面中提取相关的url放入队列中,直到满足程序停止条件。与一般网络爬虫相比,聚焦网络爬虫的工作流程更为复杂。它需要提前通过一定的网页分析算法过滤掉一些与主题无关的URL,以保证剩余的URL在一定程度上与主题相关。放入等待抓取的 URL 队列。然后根据搜索策略,从队列中选择下一步要爬取的URL,重复上述操作,直到满足程序的停止条件。专注的网络爬虫可以爬取与主题更相关的信息。例如,为了快速获取微博中的数据,我们可以开发一个利用聚焦爬虫技术抓取微博数据的工具3-5。在当今大数据时代,专注爬虫可以大海捞针,从网络数据的海洋中找到人们需要的信息,过滤掉那些“垃圾数据” (与检索主题无关的广告信息和其他数据)。2 Python Python的作者是荷兰人Guido von Rossum,他于1982年获得阿姆斯特丹大学数学与计算硕士学位6。
相比现在,在他那个年代,个人电脑的频率和内存都非常低,导致电脑的配置偏低。为了让程序在 PC 上运行,所有编译器都在其核心进行了优化,因为如果不进行优化,更大的数组可能会填满内存。Guido 想要编写一种全面、易于学习、易于使用和可扩展的新语言。1989 年,Guido 开始为 Python 语言编写编译器。3 系统分析 本系统是一个基于Python的网络爬虫系统,用于登录并爬取豆瓣网的相册、日记、主题、评论等一些动态数据信息。并且可以将关键字查询到的动态信息数据存入数据库,将部分数据存入数据库,存入本地txt文件,同时,它可以将相册中的图片动态下载到本地,还可以在每个页面上记录相册信息。操作完成后,可以翻页,选择页面继续操作。因此系统应满足以下要求。(1)可以通过验证码验证模拟登录豆瓣。即不用浏览器登录,输入用户名、密码和验证码即可登录豆瓣在控制台中(2)登录成功)之后就可以爬取豆瓣首页的代码了,也就是通过登录成功后的cookie,可以访问到游客无法访问的页面访问并可以捕获页面代码。(3)可以从页面代码中提取所需的信息。即,
图片的具体网址等信息都保存在txt文件中。(7) 将日记等动态信息存储在不同的本地文件中。数据信息的存储方式和存储路径不同。(8)在登录成功的情况下,可以进入个人中心,存储数据库表中当前用户关注的用户信息,该信息可能包括用户id、昵称、主页url、个性签名等。以上是本课程爬虫系统的一些基本要求,根据这些要求系统的功能可以说清楚了,由于本系统侧重于网络信息资源的爬取,所以在用户交互方面可能不是很好。漂亮,本系统没有写界面,所有操作都在 Eclipse 控制台中执行。例如:在控制台输入用户名、密码和验证码登录,登录成功后的页面选择,页面选择爬取后的数据等。
但是系统运行后爬取的数据可以在数据所在的本地txt文件或数据库中查看。因此,测试系统是否真的可以爬取数据,可以通过观察本地txt文件内容的变化或者数据库表中记录的变化来验证。该爬虫系统包括模拟登录、页面爬取、信息爬取、数据存储等主要功能。其中,页面爬取包括翻页爬取、页面选择爬取、个人页面爬取;信息爬取包括动态爬取和以用户为中心的爬取;数据存储包括写入文件、下载到本地和存储数据库,如图1所示。自动爬取互联网信息的程序称为爬虫。它主要由一个爬虫调度器组成,URL 管理器、网页下载器和网页解析器。爬虫调度器:程序的入口点,主要负责爬虫程序的控制。URL管理器:为要爬取的集合添加新的URL;判断要添加的URL是否已经存在;判断是否还有待爬取的URL,将URL从待爬取集合中移动到已经爬取的集合中。URL存储方式:Python内存是set()集合、关系数据库、缓存数据库。网页下载器:根据url获取网页内容,通过urllib2和request实现。网页解析器:从网页中提取有价值的数据。实现方式包括正则表达式、html.parser、BeautifulSoup、lxml。4 结论 爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页及其相关链接,以获取所需的信息。
本文爬虫旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源,实现网页数据的抓取和分析。参考文献: 1 曾小虎.基于话题的微博网络爬虫研究 D. 武汉理工大学, 2014.2 周丽珠, 林玲. 爬虫技术研究综述J.计算机应用,2005.25(9):1965-19693 周中华,张惠然,谢江。新浪微博数据爬虫在Python J.计算机应用,201 4.34 (11): 3131-31344 刘晶晶. 面向微博的网络爬虫研究与实现 D. 复旦大学, 2012.5 王晶, 朱可, 王斌强.基于信息数据分析的微博研究综述J.计算机应用,2012. 查看全部
js 爬虫抓取网页数据(摘:网络爬虫的12种常见词汇(一))
《关于Python爬虫技术的网页数据采集与分析》为会员分享,可在线阅读。更多《关于Python爬虫技术的网页数据采集与分析(8页珍藏版)》,请访问人人图书馆在线搜索。
浅谈Python爬虫技术的Web数据抓取与分析 吴永聪 摘要:近年来,随着互联网的发展,如何有效地从互联网上获取所需的信息成为众多互联网公司竞争研究的新方向,而从互联网上获取数据最常用的手段是网络爬虫。网络爬虫,也称为网络蜘蛛和网络机器人,是一种根据特定规则和给定 URL 自动采集互联网数据和信息的程序。文章讨论了网络爬虫实现过程中的主要问题:如何使用python模拟登录、如何使用正则表达式匹配字符串获取信息、如何使用mysql存储数据等,并实现一个使用 python 的网络爬虫系统。关键词: 网络爬虫;Python; MySQL;正则表达式:TP311.11 文档代码:A:1006-8228(2019)08-94-03摘要:近年来,随着互联网的发展,如何有效地从互联网已经成为许多互联网公司争相研究的新方向,而最常见的从互联网获取数据的手段就是网络爬虫。网络爬虫也被称为网络蜘蛛或网络机器人,它是一种自动根据给定的 URL 和特定规则采集 Internet 数据和信息。如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段就是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段就是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。
于是,谷歌、百度、雅虎等搜索引擎应运而生。搜索引擎可以根据用户输入的关键字检索互联网上的网页,为用户查找与关键字相关或收录关键字的信息。网络爬虫作为搜索引擎的重要组成部分,在信息检索过程中发挥着重要作用。因此,网络爬虫的研究对搜索引擎的发展具有重要意义。对于编写网络爬虫,python有其独特的优势。比如python中有很多爬虫框架,使得网络爬虫爬取数据的效率更高。同时,Python 是一种面向对象的解释型高级编程语言。它的语法比其他高级编程语言更简单、更容易阅读和理解。所以,使用Python实现网络爬虫是一个不错的选择。1 网络爬虫概述1.1 网络爬虫原理 网络爬虫又称为网络蜘蛛、网络机器人,主要用于采集互联网上的各种资源。它是搜索引擎的重要组成部分,是一种自动提取 Internet 上特定页面内容的程序。通用搜索引擎网络爬虫工作流程1:将种子URL放入等待URL队列;将等待URL从等待URL队列中取出,进行读取URL、DNS解析、网页下载等操作;将下载的网页放入下载网页库;将下载的网页网址放入已抓取的网址队列中;分析爬取的URL队列中的URL,提取出新的URL,放入待爬取的URL队列中,
爬虫的工作流程:通过URL爬取页面代码;通过正则匹配获取页面的有用数据或页面上有用的URL;对获取的数据进行处理或通过获取的新URL进入下一轮爬取循环。1.2网络爬虫的分类网络爬虫大致可以分为通用网络爬虫和专注网络爬虫2.通用网络爬虫也称为全网爬虫,从一个或多个初始URL开始,获取初始页面的代码,同时从页面中提取相关的url放入队列中,直到满足程序停止条件。与一般网络爬虫相比,聚焦网络爬虫的工作流程更为复杂。它需要提前通过一定的网页分析算法过滤掉一些与主题无关的URL,以保证剩余的URL在一定程度上与主题相关。放入等待抓取的 URL 队列。然后根据搜索策略,从队列中选择下一步要爬取的URL,重复上述操作,直到满足程序的停止条件。专注的网络爬虫可以爬取与主题更相关的信息。例如,为了快速获取微博中的数据,我们可以开发一个利用聚焦爬虫技术抓取微博数据的工具3-5。在当今大数据时代,专注爬虫可以大海捞针,从网络数据的海洋中找到人们需要的信息,过滤掉那些“垃圾数据” (与检索主题无关的广告信息和其他数据)。2 Python Python的作者是荷兰人Guido von Rossum,他于1982年获得阿姆斯特丹大学数学与计算硕士学位6。
相比现在,在他那个年代,个人电脑的频率和内存都非常低,导致电脑的配置偏低。为了让程序在 PC 上运行,所有编译器都在其核心进行了优化,因为如果不进行优化,更大的数组可能会填满内存。Guido 想要编写一种全面、易于学习、易于使用和可扩展的新语言。1989 年,Guido 开始为 Python 语言编写编译器。3 系统分析 本系统是一个基于Python的网络爬虫系统,用于登录并爬取豆瓣网的相册、日记、主题、评论等一些动态数据信息。并且可以将关键字查询到的动态信息数据存入数据库,将部分数据存入数据库,存入本地txt文件,同时,它可以将相册中的图片动态下载到本地,还可以在每个页面上记录相册信息。操作完成后,可以翻页,选择页面继续操作。因此系统应满足以下要求。(1)可以通过验证码验证模拟登录豆瓣。即不用浏览器登录,输入用户名、密码和验证码即可登录豆瓣在控制台中(2)登录成功)之后就可以爬取豆瓣首页的代码了,也就是通过登录成功后的cookie,可以访问到游客无法访问的页面访问并可以捕获页面代码。(3)可以从页面代码中提取所需的信息。即,
图片的具体网址等信息都保存在txt文件中。(7) 将日记等动态信息存储在不同的本地文件中。数据信息的存储方式和存储路径不同。(8)在登录成功的情况下,可以进入个人中心,存储数据库表中当前用户关注的用户信息,该信息可能包括用户id、昵称、主页url、个性签名等。以上是本课程爬虫系统的一些基本要求,根据这些要求系统的功能可以说清楚了,由于本系统侧重于网络信息资源的爬取,所以在用户交互方面可能不是很好。漂亮,本系统没有写界面,所有操作都在 Eclipse 控制台中执行。例如:在控制台输入用户名、密码和验证码登录,登录成功后的页面选择,页面选择爬取后的数据等。
但是系统运行后爬取的数据可以在数据所在的本地txt文件或数据库中查看。因此,测试系统是否真的可以爬取数据,可以通过观察本地txt文件内容的变化或者数据库表中记录的变化来验证。该爬虫系统包括模拟登录、页面爬取、信息爬取、数据存储等主要功能。其中,页面爬取包括翻页爬取、页面选择爬取、个人页面爬取;信息爬取包括动态爬取和以用户为中心的爬取;数据存储包括写入文件、下载到本地和存储数据库,如图1所示。自动爬取互联网信息的程序称为爬虫。它主要由一个爬虫调度器组成,URL 管理器、网页下载器和网页解析器。爬虫调度器:程序的入口点,主要负责爬虫程序的控制。URL管理器:为要爬取的集合添加新的URL;判断要添加的URL是否已经存在;判断是否还有待爬取的URL,将URL从待爬取集合中移动到已经爬取的集合中。URL存储方式:Python内存是set()集合、关系数据库、缓存数据库。网页下载器:根据url获取网页内容,通过urllib2和request实现。网页解析器:从网页中提取有价值的数据。实现方式包括正则表达式、html.parser、BeautifulSoup、lxml。4 结论 爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页及其相关链接,以获取所需的信息。
本文爬虫旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源,实现网页数据的抓取和分析。参考文献: 1 曾小虎.基于话题的微博网络爬虫研究 D. 武汉理工大学, 2014.2 周丽珠, 林玲. 爬虫技术研究综述J.计算机应用,2005.25(9):1965-19693 周中华,张惠然,谢江。新浪微博数据爬虫在Python J.计算机应用,201 4.34 (11): 3131-31344 刘晶晶. 面向微博的网络爬虫研究与实现 D. 复旦大学, 2012.5 王晶, 朱可, 王斌强.基于信息数据分析的微博研究综述J.计算机应用,2012.
js 爬虫抓取网页数据(js爬虫抓取网页数据-js获取页面上的所有链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-15 22:04
js爬虫抓取网页数据。目前在网上看到的第一个教程。js获取页面上所有链接,比如我要爬取某个视频网站截图的信息,会搜索该视频网站视频页面的url,获取url并通过页面代码中的href标签,得到页面所有文字信息。这里用到一个工具:googleanalytics.f12抓取url。url返回json格式。看下代码:{"pagespeed":1,"pageminute":8,"pagespeedtitle":"时刻","pagespeedyear":21}发现url请求参数个数是8,href标签后面会带一个"href"标签,这时候我们需要解析该标签,得到文字信息。
googleanalytics后台获取的url带有一个对应的cookie值,当用户登录时使用该cookie值登录。so从代码里我们可以很清楚的得到解析url变成:{"pagespeed":1,"pageminute":8,"pagespeedyear":21}通过cookie值,我们可以获取到对应的cookie值了,获取到cookie值有些困难,因为通过该工具可以通过cookie值预览登录的页面。
我们暂且说下http请求时,常用请求头:cookie_useragent:传递给googleanalytics的username或password,从这个useragent值我们可以知道一个人的真实信息。cookie_mimenegr:用于加密cookie值在网页上的传输,防止被篡改,篡改后网页将无法打开。
cookie_path:cookie传递的地址,指定文件存放路径。cookie_tmp_path:一次性将cookie存放到tmp文件中,比如说file.js文件也可以一次性写入。cookie_path':设置cookie保存在本地的路径,应该写入的路径是文件名(就是:a.js-目录-/a/b/c/d)a:用户登录名b:浏览器,浏览器登录信息是否加密c:浏览器的登录信息要加密d:参数传递给googleanalytics的参数cookie_text:cookie的内容cookie_name:cookie的名字cookie_type:cookie的类型,默认为aes-256cookie_assignr:加密方式加密方式是eph-key解密:转义后使用即可获取appid,appsecret,appidpassword,appidpasswordpassword,id,idfa,infodiv,httpsstr。
以及appsecret。property:传递给googleanalytics的值resulturl:传递给googleanalytics的返回值详细代码:/***1.js**@authoranton4*@date2019-3-31*///获取数据获取来源的url请求数据到wx.request.ajax。
可以在js配置中指定数据来源的urlres=requests.get(url(""),timeout=30)i=i+1print("%c"%res)data={'useragent':'','cookie_useragent':'c#..b。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据-js获取页面上的所有链接)
js爬虫抓取网页数据。目前在网上看到的第一个教程。js获取页面上所有链接,比如我要爬取某个视频网站截图的信息,会搜索该视频网站视频页面的url,获取url并通过页面代码中的href标签,得到页面所有文字信息。这里用到一个工具:googleanalytics.f12抓取url。url返回json格式。看下代码:{"pagespeed":1,"pageminute":8,"pagespeedtitle":"时刻","pagespeedyear":21}发现url请求参数个数是8,href标签后面会带一个"href"标签,这时候我们需要解析该标签,得到文字信息。
googleanalytics后台获取的url带有一个对应的cookie值,当用户登录时使用该cookie值登录。so从代码里我们可以很清楚的得到解析url变成:{"pagespeed":1,"pageminute":8,"pagespeedyear":21}通过cookie值,我们可以获取到对应的cookie值了,获取到cookie值有些困难,因为通过该工具可以通过cookie值预览登录的页面。
我们暂且说下http请求时,常用请求头:cookie_useragent:传递给googleanalytics的username或password,从这个useragent值我们可以知道一个人的真实信息。cookie_mimenegr:用于加密cookie值在网页上的传输,防止被篡改,篡改后网页将无法打开。
cookie_path:cookie传递的地址,指定文件存放路径。cookie_tmp_path:一次性将cookie存放到tmp文件中,比如说file.js文件也可以一次性写入。cookie_path':设置cookie保存在本地的路径,应该写入的路径是文件名(就是:a.js-目录-/a/b/c/d)a:用户登录名b:浏览器,浏览器登录信息是否加密c:浏览器的登录信息要加密d:参数传递给googleanalytics的参数cookie_text:cookie的内容cookie_name:cookie的名字cookie_type:cookie的类型,默认为aes-256cookie_assignr:加密方式加密方式是eph-key解密:转义后使用即可获取appid,appsecret,appidpassword,appidpasswordpassword,id,idfa,infodiv,httpsstr。
以及appsecret。property:传递给googleanalytics的值resulturl:传递给googleanalytics的返回值详细代码:/***1.js**@authoranton4*@date2019-3-31*///获取数据获取来源的url请求数据到wx.request.ajax。
可以在js配置中指定数据来源的urlres=requests.get(url(""),timeout=30)i=i+1print("%c"%res)data={'useragent':'','cookie_useragent':'c#..b。
js 爬虫抓取网页数据(聚焦爬虫技术聚焦网络爬虫(focusedcrawler)也就是全网爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-15 18:09
)
简介:网络爬虫是一种很好的自动化采集数据的通用手段。本文将介绍爬虫的种类。
01 专注于爬虫技术
聚焦网络爬虫(focused crawler)也是网络爬虫的主题。聚焦爬虫技术增加了链接评估和内容评估模块。其爬取策略的关键在于评估页面内容和链接的重要性。
基于链接评价的爬取策略主要使用网页作为半结构化文档,其中收录大量结构信息可用于评价链接的重要性。另一种方法是使用Web结构来评估链接的价值,即HITS方法,通过计算每个访问页面的Authority权重和Hub权重来确定链接访问的顺序。
基于内容评价的爬取策略主要应用类似于文本的计算方法,提出了以用户输入的查询词为主题的Fish-Search算法。随着算法的进一步改进,可以使用 Shark-Search 算法。用于计算页面和主题相关性大小的空间矢量模型。
面向主题的爬虫,面向需求的爬虫:会针对特定的内容爬取信息,并尽可能保证信息和需求相关。下面显示了如何使用简单的焦点爬虫的示例。
importurllib.request # 爬虫专用的包urllib,不同版本的Python需要下载不同的爬虫专用包importre # 正则用来规律爬取keyname=""# 想要爬取的内容key=urllib.request.quote(keyname) # 需要将你输入的keyname解码,从而让计算机读懂fori inrange(0,5): # (0,5)数字可以自己设置,是淘宝某产品的页数url="https://s.taobao.com/search%3F ... 2Bstr(i*44) # url后面加上你想爬取的网站名,然后你需要多开几个类似的网站以找到其规则# data是你爬取到的网站所有的内容要解码要读取内容pat='"pic_url":"//(.*?)"'# pat使用正则表达式从网页爬取图片# 将你爬取到的内容放在一个列表里面print(picturelist) # 可以不打印,也可以打印下来看看forj inrange(0,len(picturelist)): picture=picturelist[j] pictureurl="http://"+picture # 将列表里的内容遍历出来,并加上http://转到高清图片file="E:/pycharm/vscode文件/图片/"+str(i)+str(j)+".jpg"# 再把图片逐张编号,不然重复的名字将会被覆盖掉urllib.request.urlretrieve(pictureurl,filename=file) # 最后保存到文件夹
02 万能爬虫技术
通用网络爬虫是整个网络爬虫。实现过程如下。
通用爬虫技术的应用有不同的爬取策略,其中广度优先策略和深度优先策略更为关键。例如,深度优先策略的实现是按照深度从低到高的顺序访问下一级的网络链接。
如何使用通用爬虫的示例如下。
''' 爬取京东商品信息: 请求url:https://www.jd.com/ 提取商品信息: 1.商品详情页 2.商品名称 3.商品价格 4.评价人数 5.商品商家 '''fromselenium importwebdriver # 引入selenium中的webdriverfromselenium.webdriver.common.keys importKeys importtime defget_good(driver):try: # 通过JS控制滚轮滑动获取所有商品信息js_code = ''' window.scrollTo(0,5000); '''driver.execute_script(js_code) # 执行js代码# 等待数据加载time.sleep(2) # 查找所有商品div# good_div = driver.find_element_by_id('J_goodsList')good_list = driver.find_elements_by_class_name('gl-item') n = 1forgood ingood_list: # 根据属性选择器查找# 商品链接good_url = good.find_element_by_css_selector( '.p-img a').get_attribute('href') # 商品名称good_name = good.find_element_by_css_selector( '.p-name em').text.replace("n", "--") # 商品价格good_price = good.find_element_by_class_name( 'p-price').text.replace("n", ":") # 评价人数good_commit = good.find_element_by_class_name( 'p-commit').text.replace("n", " ") good_content = f''' 商品链接: {good_url}商品名称: {good_name}商品价格: {good_price}评价人数: {good_commit}n '''print(good_content) withopen('jd.txt', 'a', encoding='utf-8') asf: f.write(good_content) next_tag = driver.find_element_by_class_name('pn-next') next_tag.click() time.sleep(2) # 递归调用函数get_good(driver) time.sleep(10) finally: driver.close() if__name__ == '__main__': good_name = input('请输入爬取商品信息:').strip() driver = webdriver.Chrome() driver.implicitly_wait(10) # 往京东主页发送请求driver.get('https://www.jd.com/') # 输入商品名称,并回车搜索input_tag = driver.find_element_by_id('key') input_tag.send_keys(good_name) input_tag.send_keys(Keys.ENTER) time.sleep(2) get_good(driver)
03 增量爬虫技术
有的网站会根据原网页数据定期更新一批数据。比如一部电影网站会实时更新一批近期热门电影,一部小说网站会根据作者创作进度实时更新最新章节数据。当遇到类似的场景时,我们可以使用增量爬虫。
增量Web爬虫技术是通过爬虫程序监控某条网站数据的更新情况,以便对网站更新后的新数据进行爬取。
关于如何进行增量爬取工作,给出以下三种检测重复数据的思路:
发送请求前判断URL是否已经被爬取;解析内容后判断这部分内容是否被爬取;在写入存储介质时判断该内容是否已经存在于介质中。
不难发现,实现增量爬取的核心就是去重。目前有两种去重方法。
下面显示了如何使用增量爬虫的示例。
importscrapy fromscrapy.linkextractors importLinkExtractor fromscrapy.spiders importCrawlSpider, Rule fromredis importRedis fromincrementPro.items importIncrementproItem classMovieSpider(CrawlSpider):name = 'movie'# allowed_domains = ['www.xxx.com']start_urls = ['http://www.4567tv.tv/frim/index7-11.html'] rules = ( Rule(LinkExtractor(allow=r'/frim/index7-d+.html'), callback='parse_item', follow=True), ) # 创建Redis链接对象conn = Redis(host='127.0.0.1', port=6379) defparse_item(self, response):li_list = response.xpath('//li[@]') forli inli_list: # 获取详情页的urldetail_url = 'http://www.4567tv.tv'+ li.xpath('./a/@href').extract_first() # 将详情页的url存入Redis的set中ex = self.conn.sadd('urls', detail_url) ifex == 1: print('该url没有被爬取过,可以进行数据的爬取') yieldscrapy.Request(url=detail_url, callback=self.parst_detail) else: print('数据还没有更新,暂无新数据可爬取!') # 解析详情页中的电影名称和类型,进行持久化存储defparst_detail(self, response):item = IncrementproItem() item['name'] = response.xpath('//dt[@]/text()').extract_first() item['kind'] = response.xpath('//div[@]/dl/dt[4]//text()').extract() item['kind'] = ''.join(item['kind']) yieldit
管道文件:
from redis import Redis classIncrementproPipeline(object):conn = None defopen_spider(self,spider): self.conn = Redis(host='127.0.0.1',port=6379) defprocess_item(self, item, spider): dic = { 'name':item['name'], 'kind':item['kind'] } print(dic) self.conn.push('movieData',dic) # 如果push不进去,那么dic变成str(dic)或者改变redis版本 pip install -U redis==2.10.6returnitem
04 深网爬虫技术
在互联网中,网页按存在方式可分为表层网页和深层网页。
所谓表面网页,是指无需提交表单,使用静态链接即可到达的静态页面;而深层网页隐藏在表单后面,无法通过静态链接直接获取。需要提交一定数量的 关键词 深网爬虫最重要的部分就是表单填写部分。
在互联网中,深度网页的数量往往远远大于表面网页的数量,所以我们需要想办法爬取深度网页。
一个深网爬虫的基本组件:URL列表、LVS列表(LVS是指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器。
深度网络爬虫有两种类型的表单填写:
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。
查看全部
js 爬虫抓取网页数据(聚焦爬虫技术聚焦网络爬虫(focusedcrawler)也就是全网爬虫
)
简介:网络爬虫是一种很好的自动化采集数据的通用手段。本文将介绍爬虫的种类。

01 专注于爬虫技术
聚焦网络爬虫(focused crawler)也是网络爬虫的主题。聚焦爬虫技术增加了链接评估和内容评估模块。其爬取策略的关键在于评估页面内容和链接的重要性。
基于链接评价的爬取策略主要使用网页作为半结构化文档,其中收录大量结构信息可用于评价链接的重要性。另一种方法是使用Web结构来评估链接的价值,即HITS方法,通过计算每个访问页面的Authority权重和Hub权重来确定链接访问的顺序。
基于内容评价的爬取策略主要应用类似于文本的计算方法,提出了以用户输入的查询词为主题的Fish-Search算法。随着算法的进一步改进,可以使用 Shark-Search 算法。用于计算页面和主题相关性大小的空间矢量模型。
面向主题的爬虫,面向需求的爬虫:会针对特定的内容爬取信息,并尽可能保证信息和需求相关。下面显示了如何使用简单的焦点爬虫的示例。
importurllib.request # 爬虫专用的包urllib,不同版本的Python需要下载不同的爬虫专用包importre # 正则用来规律爬取keyname=""# 想要爬取的内容key=urllib.request.quote(keyname) # 需要将你输入的keyname解码,从而让计算机读懂fori inrange(0,5): # (0,5)数字可以自己设置,是淘宝某产品的页数url="https://s.taobao.com/search%3F ... 2Bstr(i*44) # url后面加上你想爬取的网站名,然后你需要多开几个类似的网站以找到其规则# data是你爬取到的网站所有的内容要解码要读取内容pat='"pic_url":"//(.*?)"'# pat使用正则表达式从网页爬取图片# 将你爬取到的内容放在一个列表里面print(picturelist) # 可以不打印,也可以打印下来看看forj inrange(0,len(picturelist)): picture=picturelist[j] pictureurl="http://"+picture # 将列表里的内容遍历出来,并加上http://转到高清图片file="E:/pycharm/vscode文件/图片/"+str(i)+str(j)+".jpg"# 再把图片逐张编号,不然重复的名字将会被覆盖掉urllib.request.urlretrieve(pictureurl,filename=file) # 最后保存到文件夹
02 万能爬虫技术
通用网络爬虫是整个网络爬虫。实现过程如下。
通用爬虫技术的应用有不同的爬取策略,其中广度优先策略和深度优先策略更为关键。例如,深度优先策略的实现是按照深度从低到高的顺序访问下一级的网络链接。
如何使用通用爬虫的示例如下。
''' 爬取京东商品信息: 请求url:https://www.jd.com/ 提取商品信息: 1.商品详情页 2.商品名称 3.商品价格 4.评价人数 5.商品商家 '''fromselenium importwebdriver # 引入selenium中的webdriverfromselenium.webdriver.common.keys importKeys importtime defget_good(driver):try: # 通过JS控制滚轮滑动获取所有商品信息js_code = ''' window.scrollTo(0,5000); '''driver.execute_script(js_code) # 执行js代码# 等待数据加载time.sleep(2) # 查找所有商品div# good_div = driver.find_element_by_id('J_goodsList')good_list = driver.find_elements_by_class_name('gl-item') n = 1forgood ingood_list: # 根据属性选择器查找# 商品链接good_url = good.find_element_by_css_selector( '.p-img a').get_attribute('href') # 商品名称good_name = good.find_element_by_css_selector( '.p-name em').text.replace("n", "--") # 商品价格good_price = good.find_element_by_class_name( 'p-price').text.replace("n", ":") # 评价人数good_commit = good.find_element_by_class_name( 'p-commit').text.replace("n", " ") good_content = f''' 商品链接: {good_url}商品名称: {good_name}商品价格: {good_price}评价人数: {good_commit}n '''print(good_content) withopen('jd.txt', 'a', encoding='utf-8') asf: f.write(good_content) next_tag = driver.find_element_by_class_name('pn-next') next_tag.click() time.sleep(2) # 递归调用函数get_good(driver) time.sleep(10) finally: driver.close() if__name__ == '__main__': good_name = input('请输入爬取商品信息:').strip() driver = webdriver.Chrome() driver.implicitly_wait(10) # 往京东主页发送请求driver.get('https://www.jd.com/') # 输入商品名称,并回车搜索input_tag = driver.find_element_by_id('key') input_tag.send_keys(good_name) input_tag.send_keys(Keys.ENTER) time.sleep(2) get_good(driver)
03 增量爬虫技术
有的网站会根据原网页数据定期更新一批数据。比如一部电影网站会实时更新一批近期热门电影,一部小说网站会根据作者创作进度实时更新最新章节数据。当遇到类似的场景时,我们可以使用增量爬虫。
增量Web爬虫技术是通过爬虫程序监控某条网站数据的更新情况,以便对网站更新后的新数据进行爬取。
关于如何进行增量爬取工作,给出以下三种检测重复数据的思路:
发送请求前判断URL是否已经被爬取;解析内容后判断这部分内容是否被爬取;在写入存储介质时判断该内容是否已经存在于介质中。
不难发现,实现增量爬取的核心就是去重。目前有两种去重方法。
下面显示了如何使用增量爬虫的示例。
importscrapy fromscrapy.linkextractors importLinkExtractor fromscrapy.spiders importCrawlSpider, Rule fromredis importRedis fromincrementPro.items importIncrementproItem classMovieSpider(CrawlSpider):name = 'movie'# allowed_domains = ['www.xxx.com']start_urls = ['http://www.4567tv.tv/frim/index7-11.html'] rules = ( Rule(LinkExtractor(allow=r'/frim/index7-d+.html'), callback='parse_item', follow=True), ) # 创建Redis链接对象conn = Redis(host='127.0.0.1', port=6379) defparse_item(self, response):li_list = response.xpath('//li[@]') forli inli_list: # 获取详情页的urldetail_url = 'http://www.4567tv.tv'+ li.xpath('./a/@href').extract_first() # 将详情页的url存入Redis的set中ex = self.conn.sadd('urls', detail_url) ifex == 1: print('该url没有被爬取过,可以进行数据的爬取') yieldscrapy.Request(url=detail_url, callback=self.parst_detail) else: print('数据还没有更新,暂无新数据可爬取!') # 解析详情页中的电影名称和类型,进行持久化存储defparst_detail(self, response):item = IncrementproItem() item['name'] = response.xpath('//dt[@]/text()').extract_first() item['kind'] = response.xpath('//div[@]/dl/dt[4]//text()').extract() item['kind'] = ''.join(item['kind']) yieldit
管道文件:
from redis import Redis classIncrementproPipeline(object):conn = None defopen_spider(self,spider): self.conn = Redis(host='127.0.0.1',port=6379) defprocess_item(self, item, spider): dic = { 'name':item['name'], 'kind':item['kind'] } print(dic) self.conn.push('movieData',dic) # 如果push不进去,那么dic变成str(dic)或者改变redis版本 pip install -U redis==2.10.6returnitem
04 深网爬虫技术
在互联网中,网页按存在方式可分为表层网页和深层网页。
所谓表面网页,是指无需提交表单,使用静态链接即可到达的静态页面;而深层网页隐藏在表单后面,无法通过静态链接直接获取。需要提交一定数量的 关键词 深网爬虫最重要的部分就是表单填写部分。
在互联网中,深度网页的数量往往远远大于表面网页的数量,所以我们需要想办法爬取深度网页。
一个深网爬虫的基本组件:URL列表、LVS列表(LVS是指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器。
深度网络爬虫有两种类型的表单填写:
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。

js 爬虫抓取网页数据(一个爬虫动态生成的网页是什么?一般来说怎么办 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-14 07:01
)
最近公司准备写一个爬虫项目,遇到了一些js或者ajax动态生成的网页。在网上找了下,发现webdriver比较靠谱。至于htmlunit测试了一些网站直接抛出异常,可能对js支持不是特别好。
WebDriver一般有两种模式:本地驱动和远程驱动。由于爬虫最终会部署到linux服务器上,所以只能命令行运行,而且好像不能安装浏览器,所以本地驱动的进程无法工作,只能尝试远程驱动好在找了一个phantomjs的webdriver,在linux下可以不带接口运行,所以选择了它作为处理js动态生成网页的解决方案。
下载 去官网:,找到对应的版本下载。解压并安装。进入bin目录执行phantomjs,需要带上启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
1WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
2driver.get("http://www.iteye.com");
3 查看全部
js 爬虫抓取网页数据(一个爬虫动态生成的网页是什么?一般来说怎么办
)
最近公司准备写一个爬虫项目,遇到了一些js或者ajax动态生成的网页。在网上找了下,发现webdriver比较靠谱。至于htmlunit测试了一些网站直接抛出异常,可能对js支持不是特别好。
WebDriver一般有两种模式:本地驱动和远程驱动。由于爬虫最终会部署到linux服务器上,所以只能命令行运行,而且好像不能安装浏览器,所以本地驱动的进程无法工作,只能尝试远程驱动好在找了一个phantomjs的webdriver,在linux下可以不带接口运行,所以选择了它作为处理js动态生成网页的解决方案。
下载 去官网:,找到对应的版本下载。解压并安装。进入bin目录执行phantomjs,需要带上启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
1WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
2driver.get("http://www.iteye.com";);
3
js 爬虫抓取网页数据(一下什么是Ajax全称为andXML,Ajax请求是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-01 17:09
文章目录
有时候,当我们使用requests爬取一个页面时,得到的结果可能与我们在浏览器中看到的不同:在浏览器中我们可以看到页面数据正常显示,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式。最初的页面不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口获取数据,然后对数据进行处理和渲染。对网页来说,这实际上是发送一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,让Web开发者可以将前后端分离,直接减少服务器带来的压力渲染页面。
所以如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
我们来看看什么是Ajax请求。什么是阿贾克斯
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
对于传统的网页,如果要更新其内容,就必须刷新整个页面,但是使用Ajax,可以在不刷新整个页面的情况下更新页面的内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
1.实例介绍
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如以微博为例,以徐嵩的主页为例:切换到微博页面,一直往下滑,你会发现往下滑几条微博后,它就消失了,而是出现了一个加载动画,并且然后下面继续出现新的微博内容,这个过程其实就是Ajax加载的过程:
我们注意到页面并没有完全刷新,也就是说页面上的链接没有变化,但是页面中出现了新的内容,也就是后来刷到的新微博。这就是通过 Ajax 获取新数据并呈现的内容。
2.基本原则
初步了解了Ajax之后,我们再来了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它也是由 JavaScript 实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest){
//code for IE7+,Firefox,Chrmoe,Opera,Safari
xmlhttp=new XMLHttpRequest();
}else{//code for IE5,IE6
xmlhttp=new ActiveXObject("Mircrosoft.XMLHTTP");
}
xmlhttp.onreadystatchange=function(){
if(xmlhttp.readyState==4 && xmlhttp.stutus == 200){
document.getElementById("myDiv").innerHTML = xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是由 JavaScript 实现的 Ajax 的最低级别。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open()和send()方法向一个链接(也就是服务器)发送请求。在前面的文章中,我们使用python发送请求后可以得到响应结果,但是这里请求的发送是通过JavaScript编程完成的。由于设置了监听器,当服务器返回时,会触发onreadystatechange对应的方法,然后可以在该方法中解析响应的内容。
解析内容
得到响应后,会启动onreadychange属性对应的方法,可以通过xmlhttp的responseText属性获取对应的内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。文档操作,如更改、删除等。
在上面的例子中,document.getElementById("myDiv").innerHTML = xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的新数据就是呈现在 myDiv 元素中。部分内容似乎已更新。
我们观察到这 3 个步骤实际上是由 JavaScript 完成的,它完成了请求、解析和渲染的整个过程。
回想一下微博的pull-to-refresh,这其实就是JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,渲染到网页中。
因此,我们知道,真正的数据实际上是一次又一次地从 Ajax 请求中获取的。如果你想捕获这些数据,你需要知道数据是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,我们可以在 Python 中模拟这个操作并得到结果。 查看全部
js 爬虫抓取网页数据(一下什么是Ajax全称为andXML,Ajax请求是什么)
文章目录
有时候,当我们使用requests爬取一个页面时,得到的结果可能与我们在浏览器中看到的不同:在浏览器中我们可以看到页面数据正常显示,但是使用requests得到的结果却不是。这是因为请求获取的是原创的 HTML 文档,而浏览器中的页面是通过 JavaScript 处理数据的结果。这些数据有多种来源,可以通过 Ajax 加载或收录在 HTML 中。在文档中,也可能是通过 JavaScript 和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式。最初的页面不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口获取数据,然后对数据进行处理和渲染。对网页来说,这实际上是发送一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页原创HTML文档不收录任何数据,通过Ajax统一加载后呈现数据,让Web开发者可以将前后端分离,直接减少服务器带来的压力渲染页面。
所以如果遇到这样的页面,直接使用requests之类的库爬取原创页面是无法获取有效数据的。这时候就需要分析网页后端向接口发送的Ajax请求了。如果可以使用requests来模拟ajax请求,那么就可以成功抓取了。
我们来看看什么是Ajax请求。什么是阿贾克斯
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新网页的部分内容而不刷新页面且页面链接不改变的技术。
对于传统的网页,如果要更新其内容,就必须刷新整个页面,但是使用Ajax,可以在不刷新整个页面的情况下更新页面的内容。在这个过程中,页面实际上是在后台与服务器交互的。获取到数据后,使用 JavaScript 改变网页,从而更新网页的内容。
1.实例介绍
在浏览网页的时候,我们会发现很多网页已经向下滚动,可以查看更多选项。比如以微博为例,以徐嵩的主页为例:切换到微博页面,一直往下滑,你会发现往下滑几条微博后,它就消失了,而是出现了一个加载动画,并且然后下面继续出现新的微博内容,这个过程其实就是Ajax加载的过程:
我们注意到页面并没有完全刷新,也就是说页面上的链接没有变化,但是页面中出现了新的内容,也就是后来刷到的新微博。这就是通过 Ajax 获取新数据并呈现的内容。
2.基本原则
初步了解了Ajax之后,我们再来了解一下它的基本原理。向网页更新发送 Ajax 请求的过程可以简单分为以下 3 个步骤:
发送请求
我们知道JavaScript可以实现页面的各种交互功能,Ajax也不例外。它也是由 JavaScript 实现的,实际执行如下代码:
var xmlhttp;
if (window.XMLHttpRequest){
//code for IE7+,Firefox,Chrmoe,Opera,Safari
xmlhttp=new XMLHttpRequest();
}else{//code for IE5,IE6
xmlhttp=new ActiveXObject("Mircrosoft.XMLHTTP");
}
xmlhttp.onreadystatchange=function(){
if(xmlhttp.readyState==4 && xmlhttp.stutus == 200){
document.getElementById("myDiv").innerHTML = xmlhttp.responseText;
}
}
xmlhttp.open("POST","/ajax/",true);
xmlhttp.send();
这是由 JavaScript 实现的 Ajax 的最低级别。其实就是新建一个XMLHttpRequest对象,然后调用onreadystatechange属性设置监听,然后调用open()和send()方法向一个链接(也就是服务器)发送请求。在前面的文章中,我们使用python发送请求后可以得到响应结果,但是这里请求的发送是通过JavaScript编程完成的。由于设置了监听器,当服务器返回时,会触发onreadystatechange对应的方法,然后可以在该方法中解析响应的内容。
解析内容
得到响应后,会启动onreadychange属性对应的方法,可以通过xmlhttp的responseText属性获取对应的内容。这类似于 Python 中使用 requests 向服务器发起请求,然后得到响应的过程。那么返回的内容可能是 HTML,也可能是 JSON,然后你只需要在方法中使用 JavaScript 进行进一步处理即可。例如,如果是JSON,则可以进行解析和转换。
呈现网页
JavaScript 具有更改网页内容的能力。解析响应内容后,可以调用 JavaScript 对网页进行解析处理。例如,通过document.getElementById().innerHTML的操作,可以改变一个元素中的源代码,从而改变网页上显示的内容。文档操作,如更改、删除等。
在上面的例子中,document.getElementById("myDiv").innerHTML = xmlhttp.responseText 会将ID为myDiv的节点内部的HTML代码改成服务器返回的内容,这样服务器返回的新数据就是呈现在 myDiv 元素中。部分内容似乎已更新。
我们观察到这 3 个步骤实际上是由 JavaScript 完成的,它完成了请求、解析和渲染的整个过程。
回想一下微博的pull-to-refresh,这其实就是JavaScript向服务器发送Ajax请求,然后获取新的微博数据,解析,渲染到网页中。
因此,我们知道,真正的数据实际上是一次又一次地从 Ajax 请求中获取的。如果你想捕获这些数据,你需要知道数据是如何发送的,发送到哪里,发送了什么参数。如果我们知道这一点,我们可以在 Python 中模拟这个操作并得到结果。
js 爬虫抓取网页数据(如何用python来抓取页面中的JS动态加载的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-31 22:12
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是页面加载到浏览器后动态生成的,但之前并不存在。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8import urllibimport requestspost_param = {'action':'','start':'0','limit':'1'}return_data = requests.get("",data =post_param, verify = False)打印 return_data.text 查看全部
js 爬虫抓取网页数据(如何用python来抓取页面中的JS动态加载的数据)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是页面加载到浏览器后动态生成的,但之前并不存在。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8import urllibimport requestspost_param = {'action':'','start':'0','limit':'1'}return_data = requests.get("",data =post_param, verify = False)打印 return_data.text
js 爬虫抓取网页数据(Python的requests库不会像浏览器一样执行JS并生成网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-03-31 15:02
目前大部分网站使用JS动态加载内容,浏览器执行JS生成网页内容。因为 Python 的 requests 库不像浏览器那样执行 JS,所以抓取的内容并不是最终的页面渲染内容。这个问题的解决方法也很简单,我们用浏览器执行JS生成内容,然后提取需要的数据。
selenium webdriver简介
Selenium webdriver 是我们这里要使用的工具,用来控制浏览器执行 JS 生成的内容。WebDriver 通过调用浏览器的原生自动化 API 直接驱动浏览器。目前主流浏览器都提供了自动化API。因此,我们可以通过webdriver提供的API,方便地操纵浏览器访问网页生成内容和返回数据。
通过python的pip工具,我们可以很方便的安装selenium模块,pip install selenium。安装完成后,我们简单试试webdriver驱动浏览器打开网页。
爬虫实例中的应用
现在回到我们的爬虫示例,我们使用 requests 库来爬取内容,现在我们使用 webdriver 驱动浏览器获取网页内容。这样就可以得到执行JS动态加载内容的网页了。
通常浏览器会打开一个窗口,但对于爬虫来说这不是必需的。幸运的是,我们可以使用 phantomjs 作为浏览器的替代品。PhantomJS 是一个没有 UI 的基于 webkit 的浏览器,几乎所有可以在浏览器上完成的事情也可以在 PhantomJs 上完成。PhantomJs 广泛用于网络监控、Web 测试和页面访问自动化。
使用的代码和我们之前使用的浏览器没有太大区别,唯一不同的是我们初始化浏览器的代码。
总结
这一部分我们简要讨论了如何使用 webdriver 来获取动态加载的网页内容。其实webdriver有很多非常有趣的应用,我们后面会看。继续下一节。 查看全部
js 爬虫抓取网页数据(Python的requests库不会像浏览器一样执行JS并生成网页内容)
目前大部分网站使用JS动态加载内容,浏览器执行JS生成网页内容。因为 Python 的 requests 库不像浏览器那样执行 JS,所以抓取的内容并不是最终的页面渲染内容。这个问题的解决方法也很简单,我们用浏览器执行JS生成内容,然后提取需要的数据。
selenium webdriver简介
Selenium webdriver 是我们这里要使用的工具,用来控制浏览器执行 JS 生成的内容。WebDriver 通过调用浏览器的原生自动化 API 直接驱动浏览器。目前主流浏览器都提供了自动化API。因此,我们可以通过webdriver提供的API,方便地操纵浏览器访问网页生成内容和返回数据。
通过python的pip工具,我们可以很方便的安装selenium模块,pip install selenium。安装完成后,我们简单试试webdriver驱动浏览器打开网页。
爬虫实例中的应用
现在回到我们的爬虫示例,我们使用 requests 库来爬取内容,现在我们使用 webdriver 驱动浏览器获取网页内容。这样就可以得到执行JS动态加载内容的网页了。
通常浏览器会打开一个窗口,但对于爬虫来说这不是必需的。幸运的是,我们可以使用 phantomjs 作为浏览器的替代品。PhantomJS 是一个没有 UI 的基于 webkit 的浏览器,几乎所有可以在浏览器上完成的事情也可以在 PhantomJs 上完成。PhantomJs 广泛用于网络监控、Web 测试和页面访问自动化。
使用的代码和我们之前使用的浏览器没有太大区别,唯一不同的是我们初始化浏览器的代码。
总结
这一部分我们简要讨论了如何使用 webdriver 来获取动态加载的网页内容。其实webdriver有很多非常有趣的应用,我们后面会看。继续下一节。
js 爬虫抓取网页数据(提取HTML页面内有用的数据定义匹配规则(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2022-03-31 14:34
在 HTML 页面中提取有用的数据:
一种。如果是需要的数据--保存
湾。如果还有其他 URL,继续步骤 2
4. Python爬虫的优点?
5. 学习路线
抓取 HTML 页面:
HTTP请求的处理:urllib、urllib2、requests
处理器的请求可以模拟浏览器发送请求并获取服务器响应的文件
解析服务器对应的内容:
re, xpath, BeautifulSoup(bs4), jsonpath, pyquery, 等等。
使用描述性语言为我们需要提取的数据定义一个匹配规则,匹配到这个规则的数据就会被匹配
采集动态HTML,验证码处理
Generic Dynamic Pages 采集: Selenium + PhantomJS: 模拟真实浏览器加载JS
验证码处理:Tesseract机器学习库、机器图像识别系统
Scrapy 框架:
高定制、高性能(异步网络框架扭曲)-> 快速数据下载
提供数据存储、数据下载、提取规则等组件
分布式策略:
scrapy redis:在scarpy的基础上增加了一套以redis数据库为中心的组件,主要用于redis中请求指纹去重、请求分配、临时数据存储
爬虫、反爬虫、反爬虫之间的斗争:
用户代理、代理、验证码、动态数据加载、加密数据
6. 爬虫分类
6.1 万能爬虫:
1.定义:搜索引擎爬虫系统
2.目标:爬取互联网上的所有网页,放到本地服务器上形成备份,对这些网页做相关处理(提取关键词,去除广告),最终为用户提供借口拜访
3.爬取过程:
a) 首先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中取出URL,然后解析NDS得到主机IP,然后到该IP对应的服务器下载HTML页面,保存到搜索引擎的本地服务器,然后把爬取的抓取队列中的 URL
c) 分析网页内容,找出网页中的其他URL连接,继续第二步,直到爬取结束
4.搜索引擎如何获得一个新的网站 URL:
主动向搜索引擎提交 URL:
在其他网站中设置网站的外部链接:其他网站之上的链接
搜索引擎将与DNS服务商合作,快速收录new网站
5.一般爬虫注意事项
万能爬虫不是万物皆可爬,它必须遵守规则:
机器人协议:该协议将指定通用爬虫爬取网页的权限
我们可以在不同的网页上访问机器人权限
6.一般爬虫一般流程:
7.通用爬虫的缺点
只能提供文本相关的内容(HTML、WORD、PDF)等,但不能提供多媒体文件(msic、图片、视频)等二进制文件
提供相同的结果,不能针对不同背景领域的人收听不同的搜索结果
不理解人类语义的检索
专注于爬行动物的优势
DNS域名解析到IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员编写的针对某个内容的爬虫 -> 面向主题的爬虫,需要爬虫的爬虫 查看全部
js 爬虫抓取网页数据(提取HTML页面内有用的数据定义匹配规则(图))
在 HTML 页面中提取有用的数据:
一种。如果是需要的数据--保存
湾。如果还有其他 URL,继续步骤 2
4. Python爬虫的优点?
5. 学习路线
抓取 HTML 页面:
HTTP请求的处理:urllib、urllib2、requests
处理器的请求可以模拟浏览器发送请求并获取服务器响应的文件
解析服务器对应的内容:
re, xpath, BeautifulSoup(bs4), jsonpath, pyquery, 等等。
使用描述性语言为我们需要提取的数据定义一个匹配规则,匹配到这个规则的数据就会被匹配
采集动态HTML,验证码处理
Generic Dynamic Pages 采集: Selenium + PhantomJS: 模拟真实浏览器加载JS
验证码处理:Tesseract机器学习库、机器图像识别系统
Scrapy 框架:
高定制、高性能(异步网络框架扭曲)-> 快速数据下载
提供数据存储、数据下载、提取规则等组件
分布式策略:
scrapy redis:在scarpy的基础上增加了一套以redis数据库为中心的组件,主要用于redis中请求指纹去重、请求分配、临时数据存储
爬虫、反爬虫、反爬虫之间的斗争:
用户代理、代理、验证码、动态数据加载、加密数据
6. 爬虫分类
6.1 万能爬虫:
1.定义:搜索引擎爬虫系统
2.目标:爬取互联网上的所有网页,放到本地服务器上形成备份,对这些网页做相关处理(提取关键词,去除广告),最终为用户提供借口拜访
3.爬取过程:
a) 首先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中取出URL,然后解析NDS得到主机IP,然后到该IP对应的服务器下载HTML页面,保存到搜索引擎的本地服务器,然后把爬取的抓取队列中的 URL
c) 分析网页内容,找出网页中的其他URL连接,继续第二步,直到爬取结束
4.搜索引擎如何获得一个新的网站 URL:
主动向搜索引擎提交 URL:
在其他网站中设置网站的外部链接:其他网站之上的链接
搜索引擎将与DNS服务商合作,快速收录new网站
5.一般爬虫注意事项
万能爬虫不是万物皆可爬,它必须遵守规则:
机器人协议:该协议将指定通用爬虫爬取网页的权限
我们可以在不同的网页上访问机器人权限
6.一般爬虫一般流程:
7.通用爬虫的缺点
只能提供文本相关的内容(HTML、WORD、PDF)等,但不能提供多媒体文件(msic、图片、视频)等二进制文件
提供相同的结果,不能针对不同背景领域的人收听不同的搜索结果
不理解人类语义的检索
专注于爬行动物的优势
DNS域名解析到IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员编写的针对某个内容的爬虫 -> 面向主题的爬虫,需要爬虫的爬虫
js 爬虫抓取网页数据(别的项目组什么项目突然心血来潮想研究一下爬虫、分析的简单原型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-30 06:02
由于其他项目组都在做舆情预测项目,我只是手头没有项目,突然想研究一个简单的爬虫原型,一时兴起分析。网上有很多关于这方面的资料,看得我眼花缭乱。对于我这种新手,想做一个简单的爬虫程序,所以HttpClient + jsoup是个不错的选择。前者是用来管理请求的,后者是用来解析页面的,主要是后者的select语法和jquery很像,对我这个用js的人来说太方便了。
昨天和他们聊天时,他们使用了几个知名的开源框架。聊了几句,他们发现自己没有办法爬取动态网页,尤其是一些重要的数字,比如评论数和回复数。等等我有一个大致的了解。比如TRS的爬虫需要编写js脚本进行js调用,但分析量巨大。他们的技术人员告诉我们,如果他们匹配这样的模板,他们每天只能匹配2到3个。,更何况我们这些中途修士。碰巧这是一个相当大的挑战,所以我昨天答应他们,看看他们是否能找到一个相对简单的解决方案,当然,不管效率如何。
举个简单的例子,如下图
“我有话要说”后面的1307是后载的,但这些数字往往对舆情分析更重要。
对需求有了大致的了解后,我们来分析如何解决它们。通常,我们对请求得到的响应中收录js代码和html元素,所以像jsoup这样的html解析器很难在这里发挥优势,因为它所能得到的html,1307还没有生成。这时候就需要一个可以运行js的平台,运行js代码后的页面会被html解析,这样才能正确得到结果。
因为懒,一开始写脚本的方式被我抛弃了,因为分析一个页面太痛苦,代码乱成一锅粥,而且很多还用了压缩的方式,都是分别是 a(), b() 方法,太累了,看不下去了。所以我的首要任务是,为什么我不能让这个地址在某个浏览器中运行,然后将运行结果交给html解析器进行解析,那么整个问题就解决了。这样,我的临时解决方案是在爬虫服务器上打开一个后台浏览器,或者是带有浏览器内核的程序,将url地址交给它去请求,然后从浏览器中取出页面的元素并交给交给它吧。html 解析器进行解析以获取您想要的信息。
明天再说吧,先休息吧。 查看全部
js 爬虫抓取网页数据(别的项目组什么项目突然心血来潮想研究一下爬虫、分析的简单原型)
由于其他项目组都在做舆情预测项目,我只是手头没有项目,突然想研究一个简单的爬虫原型,一时兴起分析。网上有很多关于这方面的资料,看得我眼花缭乱。对于我这种新手,想做一个简单的爬虫程序,所以HttpClient + jsoup是个不错的选择。前者是用来管理请求的,后者是用来解析页面的,主要是后者的select语法和jquery很像,对我这个用js的人来说太方便了。
昨天和他们聊天时,他们使用了几个知名的开源框架。聊了几句,他们发现自己没有办法爬取动态网页,尤其是一些重要的数字,比如评论数和回复数。等等我有一个大致的了解。比如TRS的爬虫需要编写js脚本进行js调用,但分析量巨大。他们的技术人员告诉我们,如果他们匹配这样的模板,他们每天只能匹配2到3个。,更何况我们这些中途修士。碰巧这是一个相当大的挑战,所以我昨天答应他们,看看他们是否能找到一个相对简单的解决方案,当然,不管效率如何。
举个简单的例子,如下图
“我有话要说”后面的1307是后载的,但这些数字往往对舆情分析更重要。
对需求有了大致的了解后,我们来分析如何解决它们。通常,我们对请求得到的响应中收录js代码和html元素,所以像jsoup这样的html解析器很难在这里发挥优势,因为它所能得到的html,1307还没有生成。这时候就需要一个可以运行js的平台,运行js代码后的页面会被html解析,这样才能正确得到结果。
因为懒,一开始写脚本的方式被我抛弃了,因为分析一个页面太痛苦,代码乱成一锅粥,而且很多还用了压缩的方式,都是分别是 a(), b() 方法,太累了,看不下去了。所以我的首要任务是,为什么我不能让这个地址在某个浏览器中运行,然后将运行结果交给html解析器进行解析,那么整个问题就解决了。这样,我的临时解决方案是在爬虫服务器上打开一个后台浏览器,或者是带有浏览器内核的程序,将url地址交给它去请求,然后从浏览器中取出页面的元素并交给交给它吧。html 解析器进行解析以获取您想要的信息。
明天再说吧,先休息吧。
js 爬虫抓取网页数据( 这段文字是从哪里来的?文字是怎么抓取的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-03-30 04:05
这段文字是从哪里来的?文字是怎么抓取的)
我们来看一个网页,我们来思考一下如何使用 XPath 进行爬取。
如您所见,没有请抓住我!此文本在源代码中。这个页面是异步加载的吗?我们现在看一下页面的请求:
该网页也不发出任何 Ajax 请求。那么,这段文字是从哪里来的呢?
我们来看看这个页面对应的HTML:
整个 HTML 中甚至没有 JavaScript。那么这段文字是从哪里来的呢?
稍有经验的同学可能会想到看一下这个example.css文件,其内容如下:
是的,文本确实在那里。其中::after,我们称之为伪元素(Pseudo-element)[1]。
如何提取伪元素中的文本?当然也可以使用正则表达式来提取。但我们今天不打算谈论这个。
XPath 没有办法提取伪元素,因为 XPath 只能提取 Dom 树中的内容,而伪元素不属于 Dom 树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 不会做任何事情,因为数据根本不在其中。单独获取CSS,虽然有数据,但是如果不使用正则表达式,里面的数据是取不出来的。所以 BeautifulSoup4 的 CSS 选择器也不起作用。所以我们需要把 CSS 和 HTML 放在一起渲染,然后使用 JavaScript 的 CSS 选择器来查找要提取的内容。
首先我们来看看,为了提取这个伪元素的值,我们需要下面的Js代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表值为fake_element的类属性。第二个参数是伪元素:after。运行效果如下图所示:
为了能够运行此 JavaScript,我们需要使用模拟浏览器,Selenium 或 Puppeteer。这里以 Selenium 为例。
要在 Selenium 中执行 Js,需要使用 driver.execute_script() 方法。代码如下:
提取内容的最外层会用一对双引号包裹起来。拿到之后,去掉外面的双引号,就是我们在网页上看到的内容。
参考
[1] 伪元素: 查看全部
js 爬虫抓取网页数据(
这段文字是从哪里来的?文字是怎么抓取的)
我们来看一个网页,我们来思考一下如何使用 XPath 进行爬取。
如您所见,没有请抓住我!此文本在源代码中。这个页面是异步加载的吗?我们现在看一下页面的请求:
该网页也不发出任何 Ajax 请求。那么,这段文字是从哪里来的呢?
我们来看看这个页面对应的HTML:
整个 HTML 中甚至没有 JavaScript。那么这段文字是从哪里来的呢?
稍有经验的同学可能会想到看一下这个example.css文件,其内容如下:
是的,文本确实在那里。其中::after,我们称之为伪元素(Pseudo-element)[1]。
如何提取伪元素中的文本?当然也可以使用正则表达式来提取。但我们今天不打算谈论这个。
XPath 没有办法提取伪元素,因为 XPath 只能提取 Dom 树中的内容,而伪元素不属于 Dom 树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 不会做任何事情,因为数据根本不在其中。单独获取CSS,虽然有数据,但是如果不使用正则表达式,里面的数据是取不出来的。所以 BeautifulSoup4 的 CSS 选择器也不起作用。所以我们需要把 CSS 和 HTML 放在一起渲染,然后使用 JavaScript 的 CSS 选择器来查找要提取的内容。
首先我们来看看,为了提取这个伪元素的值,我们需要下面的Js代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表值为fake_element的类属性。第二个参数是伪元素:after。运行效果如下图所示:
为了能够运行此 JavaScript,我们需要使用模拟浏览器,Selenium 或 Puppeteer。这里以 Selenium 为例。
要在 Selenium 中执行 Js,需要使用 driver.execute_script() 方法。代码如下:
提取内容的最外层会用一对双引号包裹起来。拿到之后,去掉外面的双引号,就是我们在网页上看到的内容。
参考
[1] 伪元素:
js 爬虫抓取网页数据(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-29 21:17
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人解决了困难和复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用模块之类的管道好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。 查看全部
js 爬虫抓取网页数据(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过Nutch的二次开发使其适合提取业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并且有能力修改Nutch,还不如自己写一个新的. 分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发非常简单,前人解决了困难和复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重),可以据说没有技术含量。. 包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用模块之类的管道好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力较差,经常会循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测Headers的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往很容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大多出现在静态页面中,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
js 爬虫抓取网页数据(从爬虫的攻防角度来讲最简单的爬虫,是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-03-27 10:22
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。
这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。
另外还有一个比较异常的服务端爬虫检测机制,就是在http响应中种一个cookie token,让所有http请求访问页面,然后在这个异步执行的一些ajax接口上学页。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电子商务公司网站亚马逊采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时的检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序调用的API来实现复杂的爬取业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真实的GUI浏览器发行版运行稳定。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已经宣布他们将停止维护这个项目。
现在谷歌浏览器团队已经在 Chrome 59 发布版本中开放了 headless mode api,并开源了一个基于 Node.js 调用的 headless chromium dirver 库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless Chrome 可以说是 Headless Browser 中独一无二的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length === 0) {
console.log('It may be Chrome headless');
}
基于语言的检查
if(navigator.languages === '') {
console.log('Chrome headless detected');
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == 'Brian Paul' && renderer == 'Mesa OffScreen') {
console.log('Chrome headless detected');
}
基于浏览器细线属性的检查
if(!Modernizr['hairline']) {
console.log('It may be Chrome headless');
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName('body')[0];
var image = document.createElement('img');
image.src = 'http://iloveponeydotcom32188.jg';
image.setAttribute('id', 'fakeimage');
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log('Chrome headless detected');
}
}
基于以上一些浏览器特性的判断,它基本上可以秒杀市面上大部分的Headless Browser程序。在这个层面上,网页爬虫的门槛其实是提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器来说是很重要的。内核的改动其实不小,如果你尝试过编译Blink内核或者Gecko内核你就会明白对于一个“脚本小子”来说是多么的难了~
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本、型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察特性是否符合浏览器这个版本。设备应具备的功能。
这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
另外,在研究Robots Browser Detect using js api在浏览器端的时候,我们发现了一个有趣的trick。可以将预先注入的js函数伪装成Native Function,看一下下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString()); // function alert() { [native code] }
console.log(fakeAlert.toString()); // function () { [native code] }
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,784758214
群里有不错的学习视频教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null)fake方法在toString后面没有函数名,所以需要检查toString后面的函数名是否为空。
这个技巧有什么用?在这里延伸一下,反爬虫防御者有一个Robot Detect方法,就是在js运行的时候主动抛出一个alert。文案可以写一些业务逻辑相关的。当普通用户点击OK按钮时,肯定会有1s甚至是alert。对于更长的延迟,由于浏览器中的alert会阻塞js代码的运行(其实在v8中,他会以类似进程挂起的方式挂起isolate context的执行),所以爬虫作为攻击者可以选择使用上面的窍门,就是在页面所有js运行前预先注入一段js代码,伪造alert、prompt、confirm等所有弹窗方法。如果防御者在弹出代码之前检查他调用的alert方法是否仍然是原生的,则这种方式被阻止。
对付爬行动物的灵丹妙药
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中,最成熟的是基于机器学习的谷歌reCAPTCHA。区分用户和爬虫。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。Allow 和 Disallow 声明每个 UA 爬虫的爬取授权。
然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
写在最后
网页内容的爬取与反制,注定是一场魔高路高的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路,你能做的就是增加攻击。用户爬取的成本,以及关于未经授权的爬取行为的更准确信息。 查看全部
js 爬虫抓取网页数据(从爬虫的攻防角度来讲最简单的爬虫,是什么?)
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。
这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。
另外还有一个比较异常的服务端爬虫检测机制,就是在http响应中种一个cookie token,让所有http请求访问页面,然后在这个异步执行的一些ajax接口上学页。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电子商务公司网站亚马逊采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时的检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序调用的API来实现复杂的爬取业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真实的GUI浏览器发行版运行稳定。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已经宣布他们将停止维护这个项目。
现在谷歌浏览器团队已经在 Chrome 59 发布版本中开放了 headless mode api,并开源了一个基于 Node.js 调用的 headless chromium dirver 库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless Chrome 可以说是 Headless Browser 中独一无二的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length === 0) {
console.log('It may be Chrome headless');
}
基于语言的检查
if(navigator.languages === '') {
console.log('Chrome headless detected');
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == 'Brian Paul' && renderer == 'Mesa OffScreen') {
console.log('Chrome headless detected');
}
基于浏览器细线属性的检查
if(!Modernizr['hairline']) {
console.log('It may be Chrome headless');
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName('body')[0];
var image = document.createElement('img');
image.src = 'http://iloveponeydotcom32188.jg';
image.setAttribute('id', 'fakeimage');
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log('Chrome headless detected');
}
}
基于以上一些浏览器特性的判断,它基本上可以秒杀市面上大部分的Headless Browser程序。在这个层面上,网页爬虫的门槛其实是提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器来说是很重要的。内核的改动其实不小,如果你尝试过编译Blink内核或者Gecko内核你就会明白对于一个“脚本小子”来说是多么的难了~
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本、型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察特性是否符合浏览器这个版本。设备应具备的功能。
这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
另外,在研究Robots Browser Detect using js api在浏览器端的时候,我们发现了一个有趣的trick。可以将预先注入的js函数伪装成Native Function,看一下下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString()); // function alert() { [native code] }
console.log(fakeAlert.toString()); // function () { [native code] }
在学习过程中有什么不懂得可以加我的
python学习交流扣扣qun,784758214
群里有不错的学习视频教程、开发工具与电子书籍。
与你分享python企业当下人才需求及怎么从零基础学习好python,和学习什么内容
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null)fake方法在toString后面没有函数名,所以需要检查toString后面的函数名是否为空。
这个技巧有什么用?在这里延伸一下,反爬虫防御者有一个Robot Detect方法,就是在js运行的时候主动抛出一个alert。文案可以写一些业务逻辑相关的。当普通用户点击OK按钮时,肯定会有1s甚至是alert。对于更长的延迟,由于浏览器中的alert会阻塞js代码的运行(其实在v8中,他会以类似进程挂起的方式挂起isolate context的执行),所以爬虫作为攻击者可以选择使用上面的窍门,就是在页面所有js运行前预先注入一段js代码,伪造alert、prompt、confirm等所有弹窗方法。如果防御者在弹出代码之前检查他调用的alert方法是否仍然是原生的,则这种方式被阻止。
对付爬行动物的灵丹妙药
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中,最成熟的是基于机器学习的谷歌reCAPTCHA。区分用户和爬虫。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。Allow 和 Disallow 声明每个 UA 爬虫的爬取授权。
然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
写在最后
网页内容的爬取与反制,注定是一场魔高路高的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路,你能做的就是增加攻击。用户爬取的成本,以及关于未经授权的爬取行为的更准确信息。
js 爬虫抓取网页数据(集搜客GooSeeker爬虫术语“主题”统一改为“任务” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-27 09:23
)
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在Sooke官网会员中心的“任务管理”中,您可以查看采集任务的执行状态,管理潜在客户的URL,进行调度设置。
一、什么时候需要自定义xpath?
二、为数据自定义 xpath采集 规则
XPath 是一串 html 节点,以 / 分隔,以便在 html 中定位信息节点。从XPath的第一个节点开始,在html的DOM树上一层一层的找到一个节点(参考MS牧手台的网页结构窗口),这个节点就是XPath的定位结果。一个XPath还可以定位一个节点或者多个节点的集合,还可以用一些函数计算布尔值。
排序框就像一个盒子,里面可以存放很多抓取的内容(见下图右侧)。代表这个盒子的容器节点是创建排序框时自动生成的第一个容器节点。在它下面你可以创建一个树状结构的爬取内容。排序框的作用是在网页上限定一个范围,所有爬取的内容都在这个范围内。例如下图左侧,顶部的 DIV 定义了网页的范围。该范围通常是自动生成的,但是可以通过定位容器节点或复制示例地图来更改所选网页范围。
定义范围的DIV是一个基点,在排序框内抓取内容的XPath表达式都是从这个基点开始定位的。所以内部XPath写成相对定位表达式,比如./div/... .or div/span/... or *//*[@class='title']/...,不写作为绝对定位表达式,比如/html/body/.....或者//div /span/....,因为这种格式是从网页的最高节点(html)开始的,简单来说就是开头不是 / 符号。
所以需要保证一个原则:自定义的xpath是相对于基点的,基点是容器节点的xpath,内部爬取内容的xpath路径是相对于它定义的。在编写自定义 XPath 时,尽量不要使用它。绝对 XPath 定位表达式(即以 / 或 // 开头的表达式)。
下面以百度新闻为例,讲解如何自定义xpath。点击下载本案例规则:百度新闻搜索结果
2.1 设置排序框,将抓取到的内容进行映射。最好映射定位标记,可以提高定位精度;这里我们需要采集 整个搜索结果列表,还需要容器。节点“列”用作样本复制图或锚图以捕获多个样本。至此,规则的定义已经完成。
2.2 点击测试,可以看到输出信息窗口中没有捕捉到部分结果的摘要信息,说明摘要有不同的网页结构。对于各种结构,我们可以按照以下步骤2.3、2.4、2.5、2.6个步骤。
2.3 查看数据规则,每个爬取的内容都会有几个可选的xpath路径。自定义 xpath 时,只需使用第一个 XPath 进行转换。将双引号之间的 xpath 路径复制到显示 xpath 搜索框中(不包括 *)。其中*表示任意节点,//表示从当前节点开始的任意级别节点,如果不明白请先掌握“xpath基础”。
2.4 XPath搜索框可用于获取节点的xpath,校验xpath语法,检查xpath是否定位准确等,当xpath语法正确且有节点时,点击搜索计算节点总数及其位置。点击下一项,一一查看节点信息。
2.5 上面只有15个digest节点,但实际上有20个digest,所以需要另找digest的节点结构。点击网页上没有抓取到的摘要信息会定位到一个dom节点,根据节点情况选择“显示XPath***”模式,然后生成节点的xpath,然后搜索那个只是碰巧错过了。5 个汇总节点,表明这是我们正在寻找的另一种结构。
注意:抓取内容的xpath是基于容器节点的相对路径。因此,不要选择绝对定位。最好生成一个较短的xpath路径,这样更适用。
2.6 经过上面的分析,abstract的两个结构是:没有graph的xpath是//*[@class='c-summary c-row'],有graph的xpath是//*[ @class='c-span18 c-span-last'] 或 //*[@class='c-summary c-row c-gap-top-small'],根据这两种结构的异同来write 定位20条摘要信息的xpath,这里写成 //*[contains(@class,'c-summary c-row ')] or //*[@class='c-summary c-row '] | // *[@class='c-span18 c-span-last'] ,然后搜索完成。
2.7 然后需要在抓取内容的高级设置中自定义xpath,操作:双击抓取内容“摘要”,勾选高级设置,选择自定义xpath,选择文本内容和专用定位,抓取内容用点填充表达式,然后粘贴上面写的xpath,用点填充定位表达式,最后保存。
注意:点号表示从当前路径开始。上述xpath收录在容器节点的基点范围内。添加点号可以使范围更准确。另外,定位方式通常不会选择网页片段,否则采集会下来带有html编码的信息,不利于后期处理和分析。
2.8保存规则,再次加载规则后报错,定位失败。由于百度搜索页面是实时变化的,所以第一个搜索结果缺少同新闻同新闻链接这两条信息,所以看到定位失败的提示,但是只要规则还是可以的采集@ > 到数据,会注意规则还是有效的,规则是不能修改的。如果想彻底解决这种网页变化导致某些信息丢失的情况,需要做一个自定义的xpath,否则会出现定位失败的情况,前提是找一个比较完整的示例页面信息作为一项规则。
2.9 点击同一条新闻的信息,找到它所在的页面节点,然后选择“Show XPath***”模式得到它的xpath表达式,然后点击搜索查看。
2.10 对于这种只存在于某些网页中的信息,自定义xpath时只能选择专用定位。将上面的 xpath 复制到抓取内容表达式中,并填写 . 在定位标志表达式中。
注意:如果设置了自定义xpath的抓取内容,并且还需要内容映射,可以选择排序框范围内的任意一个节点映射到它。
2.11 点击测试,如果正确,您将在输出信息窗口中看到数据。如果抓到空白信息,说明xpath没有以容器节点的xpath路径开始,需要重写。如果看到下图提示,说明xpath有语法错误,请检查xpath语法。
自定义xpath不仅有上述用法,还可以精确定位、过滤信息、拼接字符串等,具体请参考《Xpath常用功能用法》。
请看专用定位和两用定位的区别
三、自定义爬虫路由的xpath
爬虫路线通常用于设置下级线索和点击。常规爬虫路由只能一键设置。请看它与连续动作的区别。
遇到循环点击的情况,有两种解决方法,如下:
四、自定义 xpath 以实现连续动作
连续动作可以设置多个连续动作,包括点击、悬停、输入、滚动、提交、选择。信息采集”
注意:用于连续操作的 xpath 支持绝对路径和相对路径。请根据实际网页编写action对象的xpath。
如有疑问,您可以或
查看全部
js 爬虫抓取网页数据(集搜客GooSeeker爬虫术语“主题”统一改为“任务”
)
注:GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”改为“任务”。在爬虫浏览器中,先命名任务,然后创建规则,然后登录集合。在Sooke官网会员中心的“任务管理”中,您可以查看采集任务的执行状态,管理潜在客户的URL,进行调度设置。
一、什么时候需要自定义xpath?
二、为数据自定义 xpath采集 规则
XPath 是一串 html 节点,以 / 分隔,以便在 html 中定位信息节点。从XPath的第一个节点开始,在html的DOM树上一层一层的找到一个节点(参考MS牧手台的网页结构窗口),这个节点就是XPath的定位结果。一个XPath还可以定位一个节点或者多个节点的集合,还可以用一些函数计算布尔值。
排序框就像一个盒子,里面可以存放很多抓取的内容(见下图右侧)。代表这个盒子的容器节点是创建排序框时自动生成的第一个容器节点。在它下面你可以创建一个树状结构的爬取内容。排序框的作用是在网页上限定一个范围,所有爬取的内容都在这个范围内。例如下图左侧,顶部的 DIV 定义了网页的范围。该范围通常是自动生成的,但是可以通过定位容器节点或复制示例地图来更改所选网页范围。
定义范围的DIV是一个基点,在排序框内抓取内容的XPath表达式都是从这个基点开始定位的。所以内部XPath写成相对定位表达式,比如./div/... .or div/span/... or *//*[@class='title']/...,不写作为绝对定位表达式,比如/html/body/.....或者//div /span/....,因为这种格式是从网页的最高节点(html)开始的,简单来说就是开头不是 / 符号。
所以需要保证一个原则:自定义的xpath是相对于基点的,基点是容器节点的xpath,内部爬取内容的xpath路径是相对于它定义的。在编写自定义 XPath 时,尽量不要使用它。绝对 XPath 定位表达式(即以 / 或 // 开头的表达式)。
下面以百度新闻为例,讲解如何自定义xpath。点击下载本案例规则:百度新闻搜索结果
2.1 设置排序框,将抓取到的内容进行映射。最好映射定位标记,可以提高定位精度;这里我们需要采集 整个搜索结果列表,还需要容器。节点“列”用作样本复制图或锚图以捕获多个样本。至此,规则的定义已经完成。
2.2 点击测试,可以看到输出信息窗口中没有捕捉到部分结果的摘要信息,说明摘要有不同的网页结构。对于各种结构,我们可以按照以下步骤2.3、2.4、2.5、2.6个步骤。
2.3 查看数据规则,每个爬取的内容都会有几个可选的xpath路径。自定义 xpath 时,只需使用第一个 XPath 进行转换。将双引号之间的 xpath 路径复制到显示 xpath 搜索框中(不包括 *)。其中*表示任意节点,//表示从当前节点开始的任意级别节点,如果不明白请先掌握“xpath基础”。
2.4 XPath搜索框可用于获取节点的xpath,校验xpath语法,检查xpath是否定位准确等,当xpath语法正确且有节点时,点击搜索计算节点总数及其位置。点击下一项,一一查看节点信息。
2.5 上面只有15个digest节点,但实际上有20个digest,所以需要另找digest的节点结构。点击网页上没有抓取到的摘要信息会定位到一个dom节点,根据节点情况选择“显示XPath***”模式,然后生成节点的xpath,然后搜索那个只是碰巧错过了。5 个汇总节点,表明这是我们正在寻找的另一种结构。
注意:抓取内容的xpath是基于容器节点的相对路径。因此,不要选择绝对定位。最好生成一个较短的xpath路径,这样更适用。
2.6 经过上面的分析,abstract的两个结构是:没有graph的xpath是//*[@class='c-summary c-row'],有graph的xpath是//*[ @class='c-span18 c-span-last'] 或 //*[@class='c-summary c-row c-gap-top-small'],根据这两种结构的异同来write 定位20条摘要信息的xpath,这里写成 //*[contains(@class,'c-summary c-row ')] or //*[@class='c-summary c-row '] | // *[@class='c-span18 c-span-last'] ,然后搜索完成。
2.7 然后需要在抓取内容的高级设置中自定义xpath,操作:双击抓取内容“摘要”,勾选高级设置,选择自定义xpath,选择文本内容和专用定位,抓取内容用点填充表达式,然后粘贴上面写的xpath,用点填充定位表达式,最后保存。
注意:点号表示从当前路径开始。上述xpath收录在容器节点的基点范围内。添加点号可以使范围更准确。另外,定位方式通常不会选择网页片段,否则采集会下来带有html编码的信息,不利于后期处理和分析。
2.8保存规则,再次加载规则后报错,定位失败。由于百度搜索页面是实时变化的,所以第一个搜索结果缺少同新闻同新闻链接这两条信息,所以看到定位失败的提示,但是只要规则还是可以的采集@ > 到数据,会注意规则还是有效的,规则是不能修改的。如果想彻底解决这种网页变化导致某些信息丢失的情况,需要做一个自定义的xpath,否则会出现定位失败的情况,前提是找一个比较完整的示例页面信息作为一项规则。
2.9 点击同一条新闻的信息,找到它所在的页面节点,然后选择“Show XPath***”模式得到它的xpath表达式,然后点击搜索查看。
2.10 对于这种只存在于某些网页中的信息,自定义xpath时只能选择专用定位。将上面的 xpath 复制到抓取内容表达式中,并填写 . 在定位标志表达式中。
注意:如果设置了自定义xpath的抓取内容,并且还需要内容映射,可以选择排序框范围内的任意一个节点映射到它。
2.11 点击测试,如果正确,您将在输出信息窗口中看到数据。如果抓到空白信息,说明xpath没有以容器节点的xpath路径开始,需要重写。如果看到下图提示,说明xpath有语法错误,请检查xpath语法。
自定义xpath不仅有上述用法,还可以精确定位、过滤信息、拼接字符串等,具体请参考《Xpath常用功能用法》。
请看专用定位和两用定位的区别
三、自定义爬虫路由的xpath
爬虫路线通常用于设置下级线索和点击。常规爬虫路由只能一键设置。请看它与连续动作的区别。
遇到循环点击的情况,有两种解决方法,如下:
四、自定义 xpath 以实现连续动作
连续动作可以设置多个连续动作,包括点击、悬停、输入、滚动、提交、选择。信息采集”
注意:用于连续操作的 xpath 支持绝对路径和相对路径。请根据实际网页编写action对象的xpath。
如有疑问,您可以或
js 爬虫抓取网页数据(Python网络爬虫动态网页详解(一)(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-26 03:18
1.动态网页指的是几种可能:
1)需要用户交互,比如常见的登录操作;
2)网页是通过/AJAX动态生成的,比如在一个html中,由JS生成
啊啊啊
;
3)点击输入关键字进行查询,浏览器url地址不变
2.如果想在网站中使用Python获取JavaScript返回的数据,目前有两种方法:
第一种方法:直接url法
(1) 仔细分析页面结构,查看js响应的动作;
(2)借助firfox的firebug解析js点击动作发送的请求url;
(3)使用这个异步请求的url作为scrapy的start_url或者yield请求再次爬取。
第二种方法:借助硒
Selenium 基于并结合其 WebDriver 来模拟用户的真实操作。它具有很好的Ajax处理能力,支持多种浏览器(Safari、IE、Firefox、Chrome),可以在多种操作系统上运行。Selenium 可以调用浏览器的 API 接口,selenium 会打开一个浏览器,然后在新打开的浏览器中执行程序中模拟的动作。
如图所示:
3.在下面安装 Selenium 模块:
4.浏览器的选择:在编写Python网络爬虫时,主要使用Selenium的Webdriver。Selenium.Webdriver 不能支持所有的浏览器,也没有必要支持所有的浏览器。
Webdriver 支持列表:
5.安装 PhantomJS:
下载解压后,放到一个带有python的文件夹中:
windows下的PhantomJS环境配置好后,测试成功:
6.Selenium&PhantomJS 抓取数据:
(1)网站获取返回的数据
(2)定位“有效数据”的位置
(3)从定位中获取“有效数据”
7.以百度搜索为例,用百度搜索“python selenium”,保存搜索结果第一页的标题和链接:
(1)获取搜索结果:直接用Selenium&PhantomJS打开百度首页,然后模拟搜索关键字
(2)定位form frame或者“有效数据”位置可以通过import bs4来实现,也可以通过Selenium自带的功能来实现:一共有8个F方法可以定位返回数据中的“有效数据”:
可以看到文本框中有class、name、id属性,可以使用find_element_by_class_name、find_element_by_id、find_element_by_name来定位:
选择以下三种定位功能中的任何一种:
textElement=browser.find_element_by_class_name('s_ipt')
textElement=browser.find_element_by_id('kw')
textElement=browser.find_element_by_name('wd')
发送搜索关键字:
textElement.send_keys('python selenium')
定位提交按钮:
从图中可以看出,提交按钮有id和class属性,可以用find_element_by_class_name和find_element_by_id定位:
8.从哪里获取有效数据:首先定位搜索结果的标题和链接:查看搜索结果的源码:
发现了一个特殊的属性:class="c-tools",搜索这个属性:
共找到12个,第二个搜索结果的标题与搜索页面中第二个搜索结果的标题相同,可以确定所有搜索结果都收录class="c-tools"标签
现在可以使用 find_element_by_class_name 定位所有搜索结果:
9.从位置获取有效数据:确定有效数据的位置后,如何从该位置过滤掉有效数据?
Selenium 有自己独特的方法:
元素.文本()
element.get_attribute(name)
所需的有效数据是 data-tools 属性的值:执行命令
遍历resultElements列表,获取所有搜索结果的title和url。
转载于: 查看全部
js 爬虫抓取网页数据(Python网络爬虫动态网页详解(一)(1))
1.动态网页指的是几种可能:
1)需要用户交互,比如常见的登录操作;
2)网页是通过/AJAX动态生成的,比如在一个html中,由JS生成
啊啊啊
;
3)点击输入关键字进行查询,浏览器url地址不变
2.如果想在网站中使用Python获取JavaScript返回的数据,目前有两种方法:
第一种方法:直接url法
(1) 仔细分析页面结构,查看js响应的动作;
(2)借助firfox的firebug解析js点击动作发送的请求url;
(3)使用这个异步请求的url作为scrapy的start_url或者yield请求再次爬取。
第二种方法:借助硒
Selenium 基于并结合其 WebDriver 来模拟用户的真实操作。它具有很好的Ajax处理能力,支持多种浏览器(Safari、IE、Firefox、Chrome),可以在多种操作系统上运行。Selenium 可以调用浏览器的 API 接口,selenium 会打开一个浏览器,然后在新打开的浏览器中执行程序中模拟的动作。
如图所示:
3.在下面安装 Selenium 模块:
4.浏览器的选择:在编写Python网络爬虫时,主要使用Selenium的Webdriver。Selenium.Webdriver 不能支持所有的浏览器,也没有必要支持所有的浏览器。
Webdriver 支持列表:
5.安装 PhantomJS:
下载解压后,放到一个带有python的文件夹中:
windows下的PhantomJS环境配置好后,测试成功:
6.Selenium&PhantomJS 抓取数据:
(1)网站获取返回的数据
(2)定位“有效数据”的位置
(3)从定位中获取“有效数据”
7.以百度搜索为例,用百度搜索“python selenium”,保存搜索结果第一页的标题和链接:
(1)获取搜索结果:直接用Selenium&PhantomJS打开百度首页,然后模拟搜索关键字
(2)定位form frame或者“有效数据”位置可以通过import bs4来实现,也可以通过Selenium自带的功能来实现:一共有8个F方法可以定位返回数据中的“有效数据”:
可以看到文本框中有class、name、id属性,可以使用find_element_by_class_name、find_element_by_id、find_element_by_name来定位:
选择以下三种定位功能中的任何一种:
textElement=browser.find_element_by_class_name('s_ipt')
textElement=browser.find_element_by_id('kw')
textElement=browser.find_element_by_name('wd')
发送搜索关键字:
textElement.send_keys('python selenium')
定位提交按钮:
从图中可以看出,提交按钮有id和class属性,可以用find_element_by_class_name和find_element_by_id定位:
8.从哪里获取有效数据:首先定位搜索结果的标题和链接:查看搜索结果的源码:
发现了一个特殊的属性:class="c-tools",搜索这个属性:
共找到12个,第二个搜索结果的标题与搜索页面中第二个搜索结果的标题相同,可以确定所有搜索结果都收录class="c-tools"标签
现在可以使用 find_element_by_class_name 定位所有搜索结果:
9.从位置获取有效数据:确定有效数据的位置后,如何从该位置过滤掉有效数据?
Selenium 有自己独特的方法:
元素.文本()
element.get_attribute(name)
所需的有效数据是 data-tools 属性的值:执行命令
遍历resultElements列表,获取所有搜索结果的title和url。
转载于:
js 爬虫抓取网页数据(如何用header来处理js页面,的数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2022-03-25 18:01
打开浏览器,以谷歌浏览器为例,在上面输入你的网址。然后按F12打开调试窗口,然后尝试勾选左边的选项之一,马上可以看到右边的调试窗口有输出。找到第一个输出行,点击表头,可以看到每一个都使用了post方式。所以你只需要构造相应的header并发布,就可以得到你想要的数据。
尝试每个请求并单击它
是你要构建的数据
FormData 是你要构造的数据
构造数据并使用 post 函数将其发送到 网站
这得到的是网页格式数据。
而这个分发返回json数据,然后编码成dict格式提取数据。
最好的方法是使用像 selenium 这样的库。selenium的简单介绍,它本身是一个网站自动测试库,所以它可以模拟所有的用户交互行为,包括输入、点击、拖动、滚动等。和用户完全一样的操作,所以它是也和真正的打开网页一样,可以响应Javascript的行为,可以加载JS异步加载的网页。Selenium 最好和 PhantomJS 一起使用,所以没有接口,完全自动化。
存储每次获取的结果并将其与之前的结果进行比较。
如何使用Python爬虫爬取JS动态过滤内容——可以使用splash处理js页面,然后解析处理后的页面内容。可以参考这个文档:9270/pages/viewpage.action?pageId=919763
如何使用python爬取js动态生成内容的页面——python 2.6 + selenium-2.53.6 + firefox45.0 + BeautifulSoup3.@ >2.1 或 python 2.6 + selenium-2.53.6 + phantomjs 2.1.1
如何使用python抓取js生成的数据?——如果对刮削性能没有要求,可以试试selenium或watir。Web 自动化测试脚本可以做很多事情。使用浏览器执行好js,然后从dom中获取数据。还有一种情况,如果知道js通过ajax或者api取数据,可以直接抓取数据源,获取json或者xml中的任意一个,然后对数据进行处理
爬虫怎么爬取js动态生成的数据——我用jsoup写爬虫,一般会遇到html没有返回的内容。但是,浏览器会显示一些内容。就是分析页面的http请求日志。分析页面的JS代码解决问题。1、部分页面元素被隐藏->更改选择器解决2、部分数据存放在js/json对象中->截取对应字符串,分析解决3、通过api接口调用->还有一种终极方法是伪造请求获取数据4、使用无头浏览器如phantomjs或casperjs
Python如何获取js动态加载的数据——使用WebBrowser控件获取js动态加载的数据: 首先需要在DocumentCompleted事件中完成内容获取,因为该控件是在文档加载后触发的。二、这个事件有一个问题,就是如果页面中有iframe框架之类的,如果加载了iframe也会触发这个事件,所以我们要做一个判断:if(wb. ReadyState == WebBrowserReadyState.Complete && e. Url.ToString() == wb.Url.ToString()) wb.Document.Body.InnerHtml;//这样获取数据
程序员如何使用网络爬虫获取js中的动态数据——如果你不会使用爬虫软件,我推荐使用在采集之前对网页进行嗅探的forespider数据采集系统中间需要js数据,操作简单直观,鼠标点击即可。它完全适合不会编程的人。希望采纳
如何使用python捕获js生成的数据 -- 一、查看对应的js代码,用python获取原创数据后,模仿js编写对应的python代码。二、通过接口api获取数据,直接使用python获取接口数据并处理。三.终极方法。使用selenium和phantomjs执行网页的js代码,然后获取数据。这种方法可以100%获取数据,但是速度太慢了。
Python爬虫在处理Javascript动态生成的页面时有哪些解决方案——我们一直在使用第二种思路中的方法1,即用一个浏览器内容运行JavaScript并解析动态内容,用python模拟人在浏览器上执行操作。这种实现是最自然的,虽然有人一直批评这种速度慢,但是在实际运行环境中,大多数情况下你会担心...
如何使用scrapy爬取js动态生成的数据——这个方法只是获取页面的源代码;您的要求是获取 DOM 结构;有一种使用lxml库的方法,先用selenium获取整个html的DOM,然后将DOM转储到lxml对象中,这样就可以得到正常的html Dom树,如下例子: def parse_from_unicode( unicode_str): #...
python如何抓取动态页面内容?- —— 1.了解网页抓取的逻辑流程请参考:【整理】关于抓取网页、分析网页内容、模拟登陆的逻辑/流程网站及注意事项2.重用工具分析所需内容是如何生成的【总结】浏览器中的开发者工具(IE9的F12和Chrome的Ctrl+Shift+I)——网页分析的强大工具 火狐的上述firebug也可以用过,不过我用过,觉得不如IE9的F12好用。3.已经分析过了,找出具体是哪个url生成了你需要的数据,然后用Python实现对应的代码.... 查看全部
js 爬虫抓取网页数据(如何用header来处理js页面,的数据(组图))
打开浏览器,以谷歌浏览器为例,在上面输入你的网址。然后按F12打开调试窗口,然后尝试勾选左边的选项之一,马上可以看到右边的调试窗口有输出。找到第一个输出行,点击表头,可以看到每一个都使用了post方式。所以你只需要构造相应的header并发布,就可以得到你想要的数据。
尝试每个请求并单击它
是你要构建的数据
FormData 是你要构造的数据
构造数据并使用 post 函数将其发送到 网站
这得到的是网页格式数据。
而这个分发返回json数据,然后编码成dict格式提取数据。
最好的方法是使用像 selenium 这样的库。selenium的简单介绍,它本身是一个网站自动测试库,所以它可以模拟所有的用户交互行为,包括输入、点击、拖动、滚动等。和用户完全一样的操作,所以它是也和真正的打开网页一样,可以响应Javascript的行为,可以加载JS异步加载的网页。Selenium 最好和 PhantomJS 一起使用,所以没有接口,完全自动化。
存储每次获取的结果并将其与之前的结果进行比较。
如何使用Python爬虫爬取JS动态过滤内容——可以使用splash处理js页面,然后解析处理后的页面内容。可以参考这个文档:9270/pages/viewpage.action?pageId=919763
如何使用python爬取js动态生成内容的页面——python 2.6 + selenium-2.53.6 + firefox45.0 + BeautifulSoup3.@ >2.1 或 python 2.6 + selenium-2.53.6 + phantomjs 2.1.1
如何使用python抓取js生成的数据?——如果对刮削性能没有要求,可以试试selenium或watir。Web 自动化测试脚本可以做很多事情。使用浏览器执行好js,然后从dom中获取数据。还有一种情况,如果知道js通过ajax或者api取数据,可以直接抓取数据源,获取json或者xml中的任意一个,然后对数据进行处理
爬虫怎么爬取js动态生成的数据——我用jsoup写爬虫,一般会遇到html没有返回的内容。但是,浏览器会显示一些内容。就是分析页面的http请求日志。分析页面的JS代码解决问题。1、部分页面元素被隐藏->更改选择器解决2、部分数据存放在js/json对象中->截取对应字符串,分析解决3、通过api接口调用->还有一种终极方法是伪造请求获取数据4、使用无头浏览器如phantomjs或casperjs
Python如何获取js动态加载的数据——使用WebBrowser控件获取js动态加载的数据: 首先需要在DocumentCompleted事件中完成内容获取,因为该控件是在文档加载后触发的。二、这个事件有一个问题,就是如果页面中有iframe框架之类的,如果加载了iframe也会触发这个事件,所以我们要做一个判断:if(wb. ReadyState == WebBrowserReadyState.Complete && e. Url.ToString() == wb.Url.ToString()) wb.Document.Body.InnerHtml;//这样获取数据
程序员如何使用网络爬虫获取js中的动态数据——如果你不会使用爬虫软件,我推荐使用在采集之前对网页进行嗅探的forespider数据采集系统中间需要js数据,操作简单直观,鼠标点击即可。它完全适合不会编程的人。希望采纳
如何使用python捕获js生成的数据 -- 一、查看对应的js代码,用python获取原创数据后,模仿js编写对应的python代码。二、通过接口api获取数据,直接使用python获取接口数据并处理。三.终极方法。使用selenium和phantomjs执行网页的js代码,然后获取数据。这种方法可以100%获取数据,但是速度太慢了。
Python爬虫在处理Javascript动态生成的页面时有哪些解决方案——我们一直在使用第二种思路中的方法1,即用一个浏览器内容运行JavaScript并解析动态内容,用python模拟人在浏览器上执行操作。这种实现是最自然的,虽然有人一直批评这种速度慢,但是在实际运行环境中,大多数情况下你会担心...
如何使用scrapy爬取js动态生成的数据——这个方法只是获取页面的源代码;您的要求是获取 DOM 结构;有一种使用lxml库的方法,先用selenium获取整个html的DOM,然后将DOM转储到lxml对象中,这样就可以得到正常的html Dom树,如下例子: def parse_from_unicode( unicode_str): #...
python如何抓取动态页面内容?- —— 1.了解网页抓取的逻辑流程请参考:【整理】关于抓取网页、分析网页内容、模拟登陆的逻辑/流程网站及注意事项2.重用工具分析所需内容是如何生成的【总结】浏览器中的开发者工具(IE9的F12和Chrome的Ctrl+Shift+I)——网页分析的强大工具 火狐的上述firebug也可以用过,不过我用过,觉得不如IE9的F12好用。3.已经分析过了,找出具体是哪个url生成了你需要的数据,然后用Python实现对应的代码....
js 爬虫抓取网页数据(AngularJSjs渲染出的页面越来越多如何判断前端渲染页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2022-03-25 05:28
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面使用js渲染。对于爬虫来说,这种页面比较烦人:只提取 HTML 内容,往往无法获取有效信息。那么如何处理这种页面呢?一般有两种方法:
爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面的相应工具是 Selenium、HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。优点是编写规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本上是通过AJAX获取的,所以分析AJAX请求,找到数据对应的请求也是可行的。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较大量的分析经验。
比较这两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更为可靠。对于某些网站,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,而第二种方法会很复杂。
对于第一种方法,webmagic-selenium就是这样一种尝试,它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,和平台和版本有关,没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。我希望你会发现解析一个前端渲染的页面并没有那么复杂。这里我们以AngularJS中文社区为例。
1 如何判断前端渲染
判断页面是否为js渲染的方式比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果没有找到有效信息,基本上就是js渲染了。
本例中在源码中找不到页面中的标题“优符计算机网-前端攻城师”,因此可以断定是js渲染,这个数据是通过AJAX获取的。
2 分析请求
现在我们到了最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是浏览器中的开发者工具查看网络请求。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是一个下拉页面,总之所有的操作你觉得可能会触发新的数据)),那就记得保留场景,一一分析请求!
这一步需要一点耐心,但不是随机的。首先可以帮助我们的是上面的分类过滤器(All、Document 和其他选项)。如果是普通的 AJAX,会显示在 XHR 标签下,而 JSONP 请求会显示在 Scripts 标签下。这是两种更常见的数据类型。
然后你可以根据数据的大小来判断。一般来说,较大的结果更有可能是返回数据的接口。其余的基本上都是凭经验。比如这里的“latest?p=1&s=20”,一看就很可疑……
对于可疑地址,此时可以查看响应正文的内容。在这里的开发者工具中并不清楚。我们把URL复制到地址栏再请求一次(如果你用Chrome推荐安装一个jsonviewer,查看AJAX结果很方便)。查看结果,看起来我们找到了我们想要的东西。
同样的方法,我们进入帖子详情页面,找到具体内容的请求:.
3 编写程序
回顾之前列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只不过换成了AJAX方法——AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们仍然可以使用最后一种方式,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求由一些固定的url加上这个id组成。所以在这一步中,我们手动构造URL,并将其添加到待爬取队列中。这里我们使用 JsonPath 选择语言来选择数据(webmagic-extension 包中提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了 URL,解析目标数据其实很简单,因为 JSON 数据是完全结构化的,所以我们省去了分析页面和编写 XPath 的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见 AngularJSProcessor.java
4 总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。事实上,动态网页抓取的最大区别在于它使链接发现更加困难。我们比较一下两种开发模式:
后端渲染页面
下载二级页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是在页面HTML中预先输出,也可能是通过AJAX请求,甚至可能是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点所在。
本节这个例子希望实现的是在分析请求后,为此类爬虫的编写提供一个模式,即发现辅助数据 => 构建链接 => 下载并分析目标 AJAX 模式。
PS:
WebMagic 0.5.0 稍后会为链式 API 添加 Json 支持,您可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析 AJAX 请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。 查看全部
js 爬虫抓取网页数据(AngularJSjs渲染出的页面越来越多如何判断前端渲染页面)
随着AJAX技术的不断普及和AngularJS等单页应用框架的出现,越来越多的页面使用js渲染。对于爬虫来说,这种页面比较烦人:只提取 HTML 内容,往往无法获取有效信息。那么如何处理这种页面呢?一般有两种方法:
爬取阶段,爬虫内置浏览器内核,爬取前执行js渲染页面。这方面的相应工具是 Selenium、HtmlUnit 或 PhantomJs。但这些工具都存在一定的效率问题,同时也不是那么稳定。优点是编写规则与静态页面相同。因为js渲染页面的数据也是从后端获取的,而且基本上是通过AJAX获取的,所以分析AJAX请求,找到数据对应的请求也是可行的。而且相对于页面样式,这个界面是不太可能改变的。缺点是找到这个请求并模拟它是一个比较困难的过程,需要比较大量的分析经验。
比较这两种方法,我的观点是,对于一次性或小规模的需求,第一种方法省时省力。但对于长期、大规模的需求,第二种更为可靠。对于某些网站,甚至还有一些 js 混淆技术。这时候第一种方法基本上是万能的,而第二种方法会很复杂。
对于第一种方法,webmagic-selenium就是这样一种尝试,它定义了一个Downloader,它在下载页面时使用浏览器内核进行渲染。selenium的配置比较复杂,和平台和版本有关,没有稳定的解决方案。有兴趣可以看我的博客:使用Selenium爬取动态加载的页面
这里我主要介绍第二种方法。我希望你会发现解析一个前端渲染的页面并没有那么复杂。这里我们以AngularJS中文社区为例。
1 如何判断前端渲染
判断页面是否为js渲染的方式比较简单。可以直接在浏览器中查看源码(Windows下Ctrl+U,Mac下command+alt+u)。如果没有找到有效信息,基本上就是js渲染了。
本例中在源码中找不到页面中的标题“优符计算机网-前端攻城师”,因此可以断定是js渲染,这个数据是通过AJAX获取的。
2 分析请求
现在我们到了最难的部分:找到这个数据请求。这一步可以帮助我们的工具,主要是浏览器中的开发者工具查看网络请求。
以Chome为例,我们打开“开发者工具”(Windows下F12,Mac下command+alt+i),然后刷新页面(也可能是一个下拉页面,总之所有的操作你觉得可能会触发新的数据)),那就记得保留场景,一一分析请求!
这一步需要一点耐心,但不是随机的。首先可以帮助我们的是上面的分类过滤器(All、Document 和其他选项)。如果是普通的 AJAX,会显示在 XHR 标签下,而 JSONP 请求会显示在 Scripts 标签下。这是两种更常见的数据类型。
然后你可以根据数据的大小来判断。一般来说,较大的结果更有可能是返回数据的接口。其余的基本上都是凭经验。比如这里的“latest?p=1&s=20”,一看就很可疑……
对于可疑地址,此时可以查看响应正文的内容。在这里的开发者工具中并不清楚。我们把URL复制到地址栏再请求一次(如果你用Chrome推荐安装一个jsonviewer,查看AJAX结果很方便)。查看结果,看起来我们找到了我们想要的东西。
同样的方法,我们进入帖子详情页面,找到具体内容的请求:.
3 编写程序
回顾之前列表+目标页面的例子,你会发现我们这次的需求和之前的差不多,只不过换成了AJAX方法——AJAX方法列表,AJAX方法数据,返回的数据变成了JSON。那么,我们仍然可以使用最后一种方式,分成两页来写:
数据表
在这个列表页面上,我们需要找到有效的信息来帮助我们构建目标 AJAX URL。这里我们看到这个_id应该是我们想要的帖子的id,帖子详情请求由一些固定的url加上这个id组成。所以在这一步中,我们手动构造URL,并将其添加到待爬取队列中。这里我们使用 JsonPath 选择语言来选择数据(webmagic-extension 包中提供了 JsonPathSelector 来支持它)。
if (page.getUrl().regex(LIST_URL).match()) {
//这里我们使用JSONPATH这种选择语言来选择数据
List ids = new JsonPathSelector("$.data[*]._id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
page.addTargetRequest("http://angularjs.cn/api/article/"+id);
}
}
}
目标数据
有了 URL,解析目标数据其实很简单,因为 JSON 数据是完全结构化的,所以我们省去了分析页面和编写 XPath 的过程。这里我们仍然使用 JsonPath 来获取标题和内容。
page.putField("title", new JsonPathSelector("$.data.title").select(page.getRawText()));
page.putField("content", new JsonPathSelector("$.data.content").select(page.getRawText()));
本示例的完整代码请参见 AngularJSProcessor.java
4 总结
在这个例子中,我们分析了一个比较经典的动态页面的爬取过程。事实上,动态网页抓取的最大区别在于它使链接发现更加困难。我们比较一下两种开发模式:
后端渲染页面
下载二级页面 => 发现链接 => 下载并分析目标 HTML
前端渲染页面
发现辅助数据 => 构建链接 => 下载并分析目标 AJAX
对于不同的站点,这个辅助数据可能是在页面HTML中预先输出,也可能是通过AJAX请求,甚至可能是多个数据请求的过程,但这种模式基本是固定的。
但是这些数据请求的分析还是比页面分析复杂的多,所以这其实就是动态页面爬取的难点所在。
本节这个例子希望实现的是在分析请求后,为此类爬虫的编写提供一个模式,即发现辅助数据 => 构建链接 => 下载并分析目标 AJAX 模式。
PS:
WebMagic 0.5.0 稍后会为链式 API 添加 Json 支持,您可以使用:
page.getJson().jsonPath("$.name").get();
这种方式来解析 AJAX 请求。
还支持
page.getJson().removePadding("callback").jsonPath("$.name").get();
这种方式来解析 JSONP 请求。
js 爬虫抓取网页数据(未授权的爬虫是危害web原创内容生态的一大元凶)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-20 16:11
分享一篇文章文章,来自如果有人问你爬虫技术,请让他看这篇文章文章。
网络是一个开放的平台,它为网络从1990年代初诞生到今天的蓬勃发展奠定了基础。然而,作为所谓的成败,开放的特性、搜索引擎、简单易学的html和css技术,使得web成为了互联网领域最流行、最成熟的信息传播媒介;但是今天,作为一个商业软件,web这个平台上的内容信息的版权是不能保证的,因为和软件客户端相比,你网页中的内容可以通过一些爬虫程序以非常低的成本和技术门槛很低。这就是本系列文章要讨论的话题——网络爬虫。
有很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为随着今天IT行业的发展,网络不再是当年与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的思想。存在。随着商业软件的发展,网络也不得不面对知识产权保护的问题。试想,如果原创的优质内容不受保护,网络世界中抄袭盗版猖獗,这其实有利于网络生态的健康发展。这是一个缺点,而且它'
未经授权的爬虫程序是危害web原创内容生态的罪魁祸首。因此,为了保护网站的内容,首先要考虑如何反爬。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的http请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。
这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。
另外还有一个比较异常的服务器端爬虫检测机制,就是在所有访问页面的http请求的http响应中都种上一个cookie token,然后在这个页面异步执行的一些ajax接口上学. 检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电商网站amazon采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时的检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序调用的API来实现复杂的爬取业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真正的GUI浏览器的发布版本。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。
现在谷歌Chrome团队已经在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length == 0) {
console.log("It may be Chrome headless");
}
基于语言的检查
if(navigator.languages == "") {
console.log("Chrome headless detected");
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == "Brian Paul" && renderer == "Mesa OffScreen") {
console.log("Chrome headless detected");
}
基于浏览器细线属性的检查
if(!Modernizr["hairline"]) {
console.log("It may be Chrome headless");
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName("body")[0];
var image = document.createElement("img");
image.src = "http://iloveponeydotcom32188.jg";
image.setAttribute("id", "fakeimage");
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log("Chrome headless detected");
}
}
基于以上对一些浏览器特性的判断,基本上可以将市面上大部分的无头浏览器程序干掉。至此,网页爬虫的门槛其实提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器内核来说是很重要的。变化不小。
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。
这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
另外,我们在研究robots browserdetect using js api在浏览器端的时候,发现了一个有趣的小技巧。可以将一个预先注入的js函数伪装成native函数,看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString());
console.log(fakeAlert.toString());
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。因此,需要更严格的检查,因为bind(null)伪造的方法在toString之后没有函数名。
对付爬行动物的灵丹妙药
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中最成熟的是 Google reCAPTCHA。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。您可以访问 网站 根目录中的 /robots.txt。比如我们看一下github的robot协议。Allow 和 Disallow 声明每个 UA 爬虫的授权。
然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
写在最后
网页内容的爬取与反制,注定是一场魔高路高的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路,你能做的就是增加攻击。用户爬取的成本,以及关于未经授权的爬取行为的更准确信息。
这篇文章中提到的验证码攻防,其实是一个比较复杂的技术难点。我在这里留下一个悬念。有兴趣的可以多加关注,期待后续文章的详细阐述。
另外,欢迎对爬虫感兴趣的朋友关注我的开源项目webster。该项目以Node.js结合Chrome无头模式实现了一个高可用的网络爬虫爬取框架。一个页面中js和ajax渲染的所有异步内容;结合redis,实现了一个任务队列,让爬虫轻松进行横向和纵向分布式扩展。
如果你想进一步了解学习Python的知识体系,可以看一下我们花了一个多月时间整理了上百个小时的上百个知识点的内容:
【超全整理】《Python自动化全能开发从入门到精通》笔记完整发布 查看全部
js 爬虫抓取网页数据(未授权的爬虫是危害web原创内容生态的一大元凶)
分享一篇文章文章,来自如果有人问你爬虫技术,请让他看这篇文章文章。
网络是一个开放的平台,它为网络从1990年代初诞生到今天的蓬勃发展奠定了基础。然而,作为所谓的成败,开放的特性、搜索引擎、简单易学的html和css技术,使得web成为了互联网领域最流行、最成熟的信息传播媒介;但是今天,作为一个商业软件,web这个平台上的内容信息的版权是不能保证的,因为和软件客户端相比,你网页中的内容可以通过一些爬虫程序以非常低的成本和技术门槛很低。这就是本系列文章要讨论的话题——网络爬虫。
有很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为随着今天IT行业的发展,网络不再是当年与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的思想。存在。随着商业软件的发展,网络也不得不面对知识产权保护的问题。试想,如果原创的优质内容不受保护,网络世界中抄袭盗版猖獗,这其实有利于网络生态的健康发展。这是一个缺点,而且它'
未经授权的爬虫程序是危害web原创内容生态的罪魁祸首。因此,为了保护网站的内容,首先要考虑如何反爬。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的http请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。
这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以服务器直接识别。并被拦截。
另外还有一个比较异常的服务器端爬虫检测机制,就是在所有访问页面的http请求的http响应中都种上一个cookie token,然后在这个页面异步执行的一些ajax接口上学. 检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电商网站amazon采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
基于客户端js运行时的检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。
此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序调用的API来实现复杂的爬取业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里和这里有两个无头浏览器采集列表。
这些无头浏览器程序的原理其实就是对一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如真正的GUI浏览器的发布版本。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。
现在谷歌Chrome团队已经在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless chrome 可以说是无头浏览器中独树一帜的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。
基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length == 0) {
console.log("It may be Chrome headless");
}
基于语言的检查
if(navigator.languages == "") {
console.log("Chrome headless detected");
}
基于 webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == "Brian Paul" && renderer == "Mesa OffScreen") {
console.log("Chrome headless detected");
}
基于浏览器细线属性的检查
if(!Modernizr["hairline"]) {
console.log("It may be Chrome headless");
}
检查基于错误的img src属性生成的img对象
var body = document.getElementsByTagName("body")[0];
var image = document.createElement("img");
image.src = "http://iloveponeydotcom32188.jg";
image.setAttribute("id", "fakeimage");
body.appendChild(image);
image.onerror = function(){
if(image.width == 0 && image.height == 0) {
console.log("Chrome headless detected");
}
}
基于以上对一些浏览器特性的判断,基本上可以将市面上大部分的无头浏览器程序干掉。至此,网页爬虫的门槛其实提高了,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器内核来说是很重要的。变化不小。
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本和型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。
这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
另外,我们在研究robots browserdetect using js api在浏览器端的时候,发现了一个有趣的小技巧。可以将一个预先注入的js函数伪装成native函数,看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString());
console.log(fakeAlert.toString());
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。因此,需要更严格的检查,因为bind(null)伪造的方法在toString之后没有函数名。
对付爬行动物的灵丹妙药
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中最成熟的是 Google reCAPTCHA。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。您可以访问 网站 根目录中的 /robots.txt。比如我们看一下github的robot协议。Allow 和 Disallow 声明每个 UA 爬虫的授权。
然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
写在最后
网页内容的爬取与反制,注定是一场魔高路高的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路,你能做的就是增加攻击。用户爬取的成本,以及关于未经授权的爬取行为的更准确信息。
这篇文章中提到的验证码攻防,其实是一个比较复杂的技术难点。我在这里留下一个悬念。有兴趣的可以多加关注,期待后续文章的详细阐述。
另外,欢迎对爬虫感兴趣的朋友关注我的开源项目webster。该项目以Node.js结合Chrome无头模式实现了一个高可用的网络爬虫爬取框架。一个页面中js和ajax渲染的所有异步内容;结合redis,实现了一个任务队列,让爬虫轻松进行横向和纵向分布式扩展。
如果你想进一步了解学习Python的知识体系,可以看一下我们花了一个多月时间整理了上百个小时的上百个知识点的内容:
【超全整理】《Python自动化全能开发从入门到精通》笔记完整发布
js 爬虫抓取网页数据(应用宝应用搜索页面中的JS动态生成方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-19 01:17
1.1 Ajax异步加载生成网页内容
现在越来越多的网页使用Ajax异步加载方式,即网页中的一些内容是由前端JS动态生成的。由于网页上呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中看不到。
例如应用宝的搜索应用页面显示如下:
从上面可以看出,搜索到的应用列表信息在id="J_SearchDefaultListBox"的DOM树下。
查看当前网页的源码(使用快捷键“Ctrl+U”)如下:
源码中发现元素id="J_SearchDefaultListBox"下的内容为空,没有应用列表信息。
从上面的分析可以看出,应用宝的应用搜索页面显示的应用列表是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页内容呢?一般有两种方法:
(1)从网页响应中查找JS脚本返回的数据(多为json格式,也有xml格式);
(2)使用 Selenium 模拟对网页的访问。
下面我们将介绍第一种方法。第二种方法可以在这里找到。
1.2 从网页响应中找到JS脚本返回的数据由于网页内容是由JS动态生成并加载的,那么JS需要先调用一个接口,然后根据返回的数据进行加载和渲染界面。那么我们可以先找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。下面以应用宝的搜索应用页面为例进行说明。
1.2.1 找到JS请求的数据接口
按着这些次序:
您将看到以下信息:
在这里,我们看到只有一个请求(其他页面可能有多个)。点击这个请求,然后选择“预览”,可以看到如下数据:
在上述数据中,我们找到了“微信”、“多开助手”等信息,这些信息就是搜索到的应用列表信息。
通过以上分析可知,搜索到的应用列表信息就是通过这个请求获得的。这个请求对应的URL是%E5%BE%AE%E4%BF%A1&pns=&sid=(获取方法:鼠标移到这个请求上->然后右键->复制->复制链接地址)。
在浏览器中打开上述 URL 将返回一串数据。它看起来很乱,但实际上是 JSON 格式的数据。
这样,我们就找到了JS请求的数据接口。
1.2.2 URL编码上面我们找到的JS请求的数据接口是%E5%BE%AE%E4%BF%A1&pns=&sid=,但是%E5%BE%AE%E4是什么%BF%A1 是什么意思?
实际上 %E5%BE%AE%E4%BF%A1 是中文微信的 URL 编码。在Python中,可以使用urllib.parse.quote()获取,即'%E5%BE%AE%E4%BF%A1' = urllib.parse.quote('WeChat')。
根据标准,URL 中只允许使用英文字母、数字和一些符号。其他字符(如中文)不符合 URL 标准。这时候需要进行 URL 编码。
1.2.3 代码实现
请按照以下 4 个步骤来实施:
(1)介绍相关库;
(2)请求JS请求的数据接口; 查看全部
js 爬虫抓取网页数据(应用宝应用搜索页面中的JS动态生成方法)
1.1 Ajax异步加载生成网页内容
现在越来越多的网页使用Ajax异步加载方式,即网页中的一些内容是由前端JS动态生成的。由于网页上呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中看不到。
例如应用宝的搜索应用页面显示如下:
从上面可以看出,搜索到的应用列表信息在id="J_SearchDefaultListBox"的DOM树下。
查看当前网页的源码(使用快捷键“Ctrl+U”)如下:
源码中发现元素id="J_SearchDefaultListBox"下的内容为空,没有应用列表信息。
从上面的分析可以看出,应用宝的应用搜索页面显示的应用列表是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页内容呢?一般有两种方法:
(1)从网页响应中查找JS脚本返回的数据(多为json格式,也有xml格式);
(2)使用 Selenium 模拟对网页的访问。
下面我们将介绍第一种方法。第二种方法可以在这里找到。
1.2 从网页响应中找到JS脚本返回的数据由于网页内容是由JS动态生成并加载的,那么JS需要先调用一个接口,然后根据返回的数据进行加载和渲染界面。那么我们可以先找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。下面以应用宝的搜索应用页面为例进行说明。
1.2.1 找到JS请求的数据接口
按着这些次序:
您将看到以下信息:
在这里,我们看到只有一个请求(其他页面可能有多个)。点击这个请求,然后选择“预览”,可以看到如下数据:
在上述数据中,我们找到了“微信”、“多开助手”等信息,这些信息就是搜索到的应用列表信息。
通过以上分析可知,搜索到的应用列表信息就是通过这个请求获得的。这个请求对应的URL是%E5%BE%AE%E4%BF%A1&pns=&sid=(获取方法:鼠标移到这个请求上->然后右键->复制->复制链接地址)。
在浏览器中打开上述 URL 将返回一串数据。它看起来很乱,但实际上是 JSON 格式的数据。
这样,我们就找到了JS请求的数据接口。
1.2.2 URL编码上面我们找到的JS请求的数据接口是%E5%BE%AE%E4%BF%A1&pns=&sid=,但是%E5%BE%AE%E4是什么%BF%A1 是什么意思?
实际上 %E5%BE%AE%E4%BF%A1 是中文微信的 URL 编码。在Python中,可以使用urllib.parse.quote()获取,即'%E5%BE%AE%E4%BF%A1' = urllib.parse.quote('WeChat')。
根据标准,URL 中只允许使用英文字母、数字和一些符号。其他字符(如中文)不符合 URL 标准。这时候需要进行 URL 编码。
1.2.3 代码实现
请按照以下 4 个步骤来实施:
(1)介绍相关库;
(2)请求JS请求的数据接口;
js 爬虫抓取网页数据(js爬虫抓取网页数据,pdf下载源码都是可以爬取的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-18 22:05
js爬虫抓取网页数据,pdf下载源码都是可以爬取的。
爬虫的话很多网站都有,常见的是,ie,chrome,firefox,只要看起来像个网站,基本就可以爬,可以百度“python爬虫”“java爬虫”,很多基础的学一下,基本就可以做很多事情,做爬虫这个东西最重要的是一定要熟悉cookie机制,毕竟所有网站本质上都是获取cookie,操作起来很方便,拿举例,的登录是通过useragent,你可以把这个当成一个安全问题,毕竟安全问题会大量降低登录效率和成功率,有了这个知识之后,你可以去翻翻这方面的资料,相信会对你有很大帮助,比如requests、beautifulsoup、python解析html、爬虫实战之家等,总之很多,下面列举几个效率很高的爬虫,百度jsonjson在现在也很火,可以看看,熟悉了这些之后,爬虫方面其实很简单,大量的小网站,都可以爬取,知乎也可以用来当爬虫爬取知乎,爬取github也不是不可以,这个先不说,估计题主是个高人,这个直接上手一个月就能做一个比较简单的爬虫,新鲜出炉的知乎爬虫,目前完成了几百万人看得了,哈哈哈,虽然大部分问题还是让人生气。
:下面是我整理的python爬虫框架,我写的爬虫框架其实不算很多,欢迎大家提出来,上面只是简单列举几个,其实随便用requests爬一下taobao,github就出来了,相信题主可以挖掘出其他更多牛逼的东西。:。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据,pdf下载源码都是可以爬取的)
js爬虫抓取网页数据,pdf下载源码都是可以爬取的。
爬虫的话很多网站都有,常见的是,ie,chrome,firefox,只要看起来像个网站,基本就可以爬,可以百度“python爬虫”“java爬虫”,很多基础的学一下,基本就可以做很多事情,做爬虫这个东西最重要的是一定要熟悉cookie机制,毕竟所有网站本质上都是获取cookie,操作起来很方便,拿举例,的登录是通过useragent,你可以把这个当成一个安全问题,毕竟安全问题会大量降低登录效率和成功率,有了这个知识之后,你可以去翻翻这方面的资料,相信会对你有很大帮助,比如requests、beautifulsoup、python解析html、爬虫实战之家等,总之很多,下面列举几个效率很高的爬虫,百度jsonjson在现在也很火,可以看看,熟悉了这些之后,爬虫方面其实很简单,大量的小网站,都可以爬取,知乎也可以用来当爬虫爬取知乎,爬取github也不是不可以,这个先不说,估计题主是个高人,这个直接上手一个月就能做一个比较简单的爬虫,新鲜出炉的知乎爬虫,目前完成了几百万人看得了,哈哈哈,虽然大部分问题还是让人生气。
:下面是我整理的python爬虫框架,我写的爬虫框架其实不算很多,欢迎大家提出来,上面只是简单列举几个,其实随便用requests爬一下taobao,github就出来了,相信题主可以挖掘出其他更多牛逼的东西。:。
js 爬虫抓取网页数据(谷歌能DOM是什么?Google能读取动态生成的内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-16 18:01
)
(点击上方公众号快速关注)
编译:伯乐在线/刘建超-Jc
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。怎么做?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向,用不同的方式表达的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2. 测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果呢?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有相互冲突的信号时,哪一个获胜?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在此协议中,HTTP x-robots 响应标头作为另一个变量的行为如何?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要示例
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
认为这篇文章对您有帮助吗?请与更多人分享
关注“前端大全”提升前端技能
查看全部
js 爬虫抓取网页数据(谷歌能DOM是什么?Google能读取动态生成的内容
)
(点击上方公众号快速关注)
编译:伯乐在线/刘建超-Jc
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。怎么做?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向,用不同的方式表达的 URL 会产生什么结果?我们为两个测试选择了 window.location 对象:测试 A 使用绝对路径 URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2. 测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果呢?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有相互冲突的信号时,哪一个获胜?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在此协议中,HTTP x-robots 响应标头作为另一个变量的行为如何?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要示例
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎 网站)提供,部分观点由客座作者提供。所有作者的名单。
认为这篇文章对您有帮助吗?请与更多人分享
关注“前端大全”提升前端技能
js 爬虫抓取网页数据(摘:网络爬虫的12种常见词汇(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-16 17:20
《关于Python爬虫技术的网页数据采集与分析》为会员分享,可在线阅读。更多《关于Python爬虫技术的网页数据采集与分析(8页珍藏版)》,请访问人人图书馆在线搜索。
浅谈Python爬虫技术的Web数据抓取与分析 吴永聪 摘要:近年来,随着互联网的发展,如何有效地从互联网上获取所需的信息成为众多互联网公司竞争研究的新方向,而从互联网上获取数据最常用的手段是网络爬虫。网络爬虫,也称为网络蜘蛛和网络机器人,是一种根据特定规则和给定 URL 自动采集互联网数据和信息的程序。文章讨论了网络爬虫实现过程中的主要问题:如何使用python模拟登录、如何使用正则表达式匹配字符串获取信息、如何使用mysql存储数据等,并实现一个使用 python 的网络爬虫系统。关键词: 网络爬虫;Python; MySQL;正则表达式:TP311.11 文档代码:A:1006-8228(2019)08-94-03摘要:近年来,随着互联网的发展,如何有效地从互联网已经成为许多互联网公司争相研究的新方向,而最常见的从互联网获取数据的手段就是网络爬虫。网络爬虫也被称为网络蜘蛛或网络机器人,它是一种自动根据给定的 URL 和特定规则采集 Internet 数据和信息。如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段就是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段就是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。
于是,谷歌、百度、雅虎等搜索引擎应运而生。搜索引擎可以根据用户输入的关键字检索互联网上的网页,为用户查找与关键字相关或收录关键字的信息。网络爬虫作为搜索引擎的重要组成部分,在信息检索过程中发挥着重要作用。因此,网络爬虫的研究对搜索引擎的发展具有重要意义。对于编写网络爬虫,python有其独特的优势。比如python中有很多爬虫框架,使得网络爬虫爬取数据的效率更高。同时,Python 是一种面向对象的解释型高级编程语言。它的语法比其他高级编程语言更简单、更容易阅读和理解。所以,使用Python实现网络爬虫是一个不错的选择。1 网络爬虫概述1.1 网络爬虫原理 网络爬虫又称为网络蜘蛛、网络机器人,主要用于采集互联网上的各种资源。它是搜索引擎的重要组成部分,是一种自动提取 Internet 上特定页面内容的程序。通用搜索引擎网络爬虫工作流程1:将种子URL放入等待URL队列;将等待URL从等待URL队列中取出,进行读取URL、DNS解析、网页下载等操作;将下载的网页放入下载网页库;将下载的网页网址放入已抓取的网址队列中;分析爬取的URL队列中的URL,提取出新的URL,放入待爬取的URL队列中,
爬虫的工作流程:通过URL爬取页面代码;通过正则匹配获取页面的有用数据或页面上有用的URL;对获取的数据进行处理或通过获取的新URL进入下一轮爬取循环。1.2网络爬虫的分类网络爬虫大致可以分为通用网络爬虫和专注网络爬虫2.通用网络爬虫也称为全网爬虫,从一个或多个初始URL开始,获取初始页面的代码,同时从页面中提取相关的url放入队列中,直到满足程序停止条件。与一般网络爬虫相比,聚焦网络爬虫的工作流程更为复杂。它需要提前通过一定的网页分析算法过滤掉一些与主题无关的URL,以保证剩余的URL在一定程度上与主题相关。放入等待抓取的 URL 队列。然后根据搜索策略,从队列中选择下一步要爬取的URL,重复上述操作,直到满足程序的停止条件。专注的网络爬虫可以爬取与主题更相关的信息。例如,为了快速获取微博中的数据,我们可以开发一个利用聚焦爬虫技术抓取微博数据的工具3-5。在当今大数据时代,专注爬虫可以大海捞针,从网络数据的海洋中找到人们需要的信息,过滤掉那些“垃圾数据” (与检索主题无关的广告信息和其他数据)。2 Python Python的作者是荷兰人Guido von Rossum,他于1982年获得阿姆斯特丹大学数学与计算硕士学位6。
相比现在,在他那个年代,个人电脑的频率和内存都非常低,导致电脑的配置偏低。为了让程序在 PC 上运行,所有编译器都在其核心进行了优化,因为如果不进行优化,更大的数组可能会填满内存。Guido 想要编写一种全面、易于学习、易于使用和可扩展的新语言。1989 年,Guido 开始为 Python 语言编写编译器。3 系统分析 本系统是一个基于Python的网络爬虫系统,用于登录并爬取豆瓣网的相册、日记、主题、评论等一些动态数据信息。并且可以将关键字查询到的动态信息数据存入数据库,将部分数据存入数据库,存入本地txt文件,同时,它可以将相册中的图片动态下载到本地,还可以在每个页面上记录相册信息。操作完成后,可以翻页,选择页面继续操作。因此系统应满足以下要求。(1)可以通过验证码验证模拟登录豆瓣。即不用浏览器登录,输入用户名、密码和验证码即可登录豆瓣在控制台中(2)登录成功)之后就可以爬取豆瓣首页的代码了,也就是通过登录成功后的cookie,可以访问到游客无法访问的页面访问并可以捕获页面代码。(3)可以从页面代码中提取所需的信息。即,
图片的具体网址等信息都保存在txt文件中。(7) 将日记等动态信息存储在不同的本地文件中。数据信息的存储方式和存储路径不同。(8)在登录成功的情况下,可以进入个人中心,存储数据库表中当前用户关注的用户信息,该信息可能包括用户id、昵称、主页url、个性签名等。以上是本课程爬虫系统的一些基本要求,根据这些要求系统的功能可以说清楚了,由于本系统侧重于网络信息资源的爬取,所以在用户交互方面可能不是很好。漂亮,本系统没有写界面,所有操作都在 Eclipse 控制台中执行。例如:在控制台输入用户名、密码和验证码登录,登录成功后的页面选择,页面选择爬取后的数据等。
但是系统运行后爬取的数据可以在数据所在的本地txt文件或数据库中查看。因此,测试系统是否真的可以爬取数据,可以通过观察本地txt文件内容的变化或者数据库表中记录的变化来验证。该爬虫系统包括模拟登录、页面爬取、信息爬取、数据存储等主要功能。其中,页面爬取包括翻页爬取、页面选择爬取、个人页面爬取;信息爬取包括动态爬取和以用户为中心的爬取;数据存储包括写入文件、下载到本地和存储数据库,如图1所示。自动爬取互联网信息的程序称为爬虫。它主要由一个爬虫调度器组成,URL 管理器、网页下载器和网页解析器。爬虫调度器:程序的入口点,主要负责爬虫程序的控制。URL管理器:为要爬取的集合添加新的URL;判断要添加的URL是否已经存在;判断是否还有待爬取的URL,将URL从待爬取集合中移动到已经爬取的集合中。URL存储方式:Python内存是set()集合、关系数据库、缓存数据库。网页下载器:根据url获取网页内容,通过urllib2和request实现。网页解析器:从网页中提取有价值的数据。实现方式包括正则表达式、html.parser、BeautifulSoup、lxml。4 结论 爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页及其相关链接,以获取所需的信息。
本文爬虫旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源,实现网页数据的抓取和分析。参考文献: 1 曾小虎.基于话题的微博网络爬虫研究 D. 武汉理工大学, 2014.2 周丽珠, 林玲. 爬虫技术研究综述J.计算机应用,2005.25(9):1965-19693 周中华,张惠然,谢江。新浪微博数据爬虫在Python J.计算机应用,201 4.34 (11): 3131-31344 刘晶晶. 面向微博的网络爬虫研究与实现 D. 复旦大学, 2012.5 王晶, 朱可, 王斌强.基于信息数据分析的微博研究综述J.计算机应用,2012. 查看全部
js 爬虫抓取网页数据(摘:网络爬虫的12种常见词汇(一))
《关于Python爬虫技术的网页数据采集与分析》为会员分享,可在线阅读。更多《关于Python爬虫技术的网页数据采集与分析(8页珍藏版)》,请访问人人图书馆在线搜索。
浅谈Python爬虫技术的Web数据抓取与分析 吴永聪 摘要:近年来,随着互联网的发展,如何有效地从互联网上获取所需的信息成为众多互联网公司竞争研究的新方向,而从互联网上获取数据最常用的手段是网络爬虫。网络爬虫,也称为网络蜘蛛和网络机器人,是一种根据特定规则和给定 URL 自动采集互联网数据和信息的程序。文章讨论了网络爬虫实现过程中的主要问题:如何使用python模拟登录、如何使用正则表达式匹配字符串获取信息、如何使用mysql存储数据等,并实现一个使用 python 的网络爬虫系统。关键词: 网络爬虫;Python; MySQL;正则表达式:TP311.11 文档代码:A:1006-8228(2019)08-94-03摘要:近年来,随着互联网的发展,如何有效地从互联网已经成为许多互联网公司争相研究的新方向,而最常见的从互联网获取数据的手段就是网络爬虫。网络爬虫也被称为网络蜘蛛或网络机器人,它是一种自动根据给定的 URL 和特定规则采集 Internet 数据和信息。如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段就是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。如何有效地从互联网上获取所需的信息成为众多互联网公司争相研究的新方向,而最常见的从互联网上获取数据的手段就是网络爬虫。网络爬虫也称为网络蜘蛛或网络机器人,它是根据给定的 URL 和特定规则自动采集互联网数据和信息的程序。
于是,谷歌、百度、雅虎等搜索引擎应运而生。搜索引擎可以根据用户输入的关键字检索互联网上的网页,为用户查找与关键字相关或收录关键字的信息。网络爬虫作为搜索引擎的重要组成部分,在信息检索过程中发挥着重要作用。因此,网络爬虫的研究对搜索引擎的发展具有重要意义。对于编写网络爬虫,python有其独特的优势。比如python中有很多爬虫框架,使得网络爬虫爬取数据的效率更高。同时,Python 是一种面向对象的解释型高级编程语言。它的语法比其他高级编程语言更简单、更容易阅读和理解。所以,使用Python实现网络爬虫是一个不错的选择。1 网络爬虫概述1.1 网络爬虫原理 网络爬虫又称为网络蜘蛛、网络机器人,主要用于采集互联网上的各种资源。它是搜索引擎的重要组成部分,是一种自动提取 Internet 上特定页面内容的程序。通用搜索引擎网络爬虫工作流程1:将种子URL放入等待URL队列;将等待URL从等待URL队列中取出,进行读取URL、DNS解析、网页下载等操作;将下载的网页放入下载网页库;将下载的网页网址放入已抓取的网址队列中;分析爬取的URL队列中的URL,提取出新的URL,放入待爬取的URL队列中,
爬虫的工作流程:通过URL爬取页面代码;通过正则匹配获取页面的有用数据或页面上有用的URL;对获取的数据进行处理或通过获取的新URL进入下一轮爬取循环。1.2网络爬虫的分类网络爬虫大致可以分为通用网络爬虫和专注网络爬虫2.通用网络爬虫也称为全网爬虫,从一个或多个初始URL开始,获取初始页面的代码,同时从页面中提取相关的url放入队列中,直到满足程序停止条件。与一般网络爬虫相比,聚焦网络爬虫的工作流程更为复杂。它需要提前通过一定的网页分析算法过滤掉一些与主题无关的URL,以保证剩余的URL在一定程度上与主题相关。放入等待抓取的 URL 队列。然后根据搜索策略,从队列中选择下一步要爬取的URL,重复上述操作,直到满足程序的停止条件。专注的网络爬虫可以爬取与主题更相关的信息。例如,为了快速获取微博中的数据,我们可以开发一个利用聚焦爬虫技术抓取微博数据的工具3-5。在当今大数据时代,专注爬虫可以大海捞针,从网络数据的海洋中找到人们需要的信息,过滤掉那些“垃圾数据” (与检索主题无关的广告信息和其他数据)。2 Python Python的作者是荷兰人Guido von Rossum,他于1982年获得阿姆斯特丹大学数学与计算硕士学位6。
相比现在,在他那个年代,个人电脑的频率和内存都非常低,导致电脑的配置偏低。为了让程序在 PC 上运行,所有编译器都在其核心进行了优化,因为如果不进行优化,更大的数组可能会填满内存。Guido 想要编写一种全面、易于学习、易于使用和可扩展的新语言。1989 年,Guido 开始为 Python 语言编写编译器。3 系统分析 本系统是一个基于Python的网络爬虫系统,用于登录并爬取豆瓣网的相册、日记、主题、评论等一些动态数据信息。并且可以将关键字查询到的动态信息数据存入数据库,将部分数据存入数据库,存入本地txt文件,同时,它可以将相册中的图片动态下载到本地,还可以在每个页面上记录相册信息。操作完成后,可以翻页,选择页面继续操作。因此系统应满足以下要求。(1)可以通过验证码验证模拟登录豆瓣。即不用浏览器登录,输入用户名、密码和验证码即可登录豆瓣在控制台中(2)登录成功)之后就可以爬取豆瓣首页的代码了,也就是通过登录成功后的cookie,可以访问到游客无法访问的页面访问并可以捕获页面代码。(3)可以从页面代码中提取所需的信息。即,
图片的具体网址等信息都保存在txt文件中。(7) 将日记等动态信息存储在不同的本地文件中。数据信息的存储方式和存储路径不同。(8)在登录成功的情况下,可以进入个人中心,存储数据库表中当前用户关注的用户信息,该信息可能包括用户id、昵称、主页url、个性签名等。以上是本课程爬虫系统的一些基本要求,根据这些要求系统的功能可以说清楚了,由于本系统侧重于网络信息资源的爬取,所以在用户交互方面可能不是很好。漂亮,本系统没有写界面,所有操作都在 Eclipse 控制台中执行。例如:在控制台输入用户名、密码和验证码登录,登录成功后的页面选择,页面选择爬取后的数据等。
但是系统运行后爬取的数据可以在数据所在的本地txt文件或数据库中查看。因此,测试系统是否真的可以爬取数据,可以通过观察本地txt文件内容的变化或者数据库表中记录的变化来验证。该爬虫系统包括模拟登录、页面爬取、信息爬取、数据存储等主要功能。其中,页面爬取包括翻页爬取、页面选择爬取、个人页面爬取;信息爬取包括动态爬取和以用户为中心的爬取;数据存储包括写入文件、下载到本地和存储数据库,如图1所示。自动爬取互联网信息的程序称为爬虫。它主要由一个爬虫调度器组成,URL 管理器、网页下载器和网页解析器。爬虫调度器:程序的入口点,主要负责爬虫程序的控制。URL管理器:为要爬取的集合添加新的URL;判断要添加的URL是否已经存在;判断是否还有待爬取的URL,将URL从待爬取集合中移动到已经爬取的集合中。URL存储方式:Python内存是set()集合、关系数据库、缓存数据库。网页下载器:根据url获取网页内容,通过urllib2和request实现。网页解析器:从网页中提取有价值的数据。实现方式包括正则表达式、html.parser、BeautifulSoup、lxml。4 结论 爬虫是一种自动下载网页的程序。它根据给定的爬取目标有选择地访问万维网上的网页及其相关链接,以获取所需的信息。
本文爬虫旨在爬取与特定主题内容相关的网页,为面向主题的用户查询准备数据资源,实现网页数据的抓取和分析。参考文献: 1 曾小虎.基于话题的微博网络爬虫研究 D. 武汉理工大学, 2014.2 周丽珠, 林玲. 爬虫技术研究综述J.计算机应用,2005.25(9):1965-19693 周中华,张惠然,谢江。新浪微博数据爬虫在Python J.计算机应用,201 4.34 (11): 3131-31344 刘晶晶. 面向微博的网络爬虫研究与实现 D. 复旦大学, 2012.5 王晶, 朱可, 王斌强.基于信息数据分析的微博研究综述J.计算机应用,2012.
js 爬虫抓取网页数据(js爬虫抓取网页数据-js获取页面上的所有链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-15 22:04
js爬虫抓取网页数据。目前在网上看到的第一个教程。js获取页面上所有链接,比如我要爬取某个视频网站截图的信息,会搜索该视频网站视频页面的url,获取url并通过页面代码中的href标签,得到页面所有文字信息。这里用到一个工具:googleanalytics.f12抓取url。url返回json格式。看下代码:{"pagespeed":1,"pageminute":8,"pagespeedtitle":"时刻","pagespeedyear":21}发现url请求参数个数是8,href标签后面会带一个"href"标签,这时候我们需要解析该标签,得到文字信息。
googleanalytics后台获取的url带有一个对应的cookie值,当用户登录时使用该cookie值登录。so从代码里我们可以很清楚的得到解析url变成:{"pagespeed":1,"pageminute":8,"pagespeedyear":21}通过cookie值,我们可以获取到对应的cookie值了,获取到cookie值有些困难,因为通过该工具可以通过cookie值预览登录的页面。
我们暂且说下http请求时,常用请求头:cookie_useragent:传递给googleanalytics的username或password,从这个useragent值我们可以知道一个人的真实信息。cookie_mimenegr:用于加密cookie值在网页上的传输,防止被篡改,篡改后网页将无法打开。
cookie_path:cookie传递的地址,指定文件存放路径。cookie_tmp_path:一次性将cookie存放到tmp文件中,比如说file.js文件也可以一次性写入。cookie_path':设置cookie保存在本地的路径,应该写入的路径是文件名(就是:a.js-目录-/a/b/c/d)a:用户登录名b:浏览器,浏览器登录信息是否加密c:浏览器的登录信息要加密d:参数传递给googleanalytics的参数cookie_text:cookie的内容cookie_name:cookie的名字cookie_type:cookie的类型,默认为aes-256cookie_assignr:加密方式加密方式是eph-key解密:转义后使用即可获取appid,appsecret,appidpassword,appidpasswordpassword,id,idfa,infodiv,httpsstr。
以及appsecret。property:传递给googleanalytics的值resulturl:传递给googleanalytics的返回值详细代码:/***1.js**@authoranton4*@date2019-3-31*///获取数据获取来源的url请求数据到wx.request.ajax。
可以在js配置中指定数据来源的urlres=requests.get(url(""),timeout=30)i=i+1print("%c"%res)data={'useragent':'','cookie_useragent':'c#..b。 查看全部
js 爬虫抓取网页数据(js爬虫抓取网页数据-js获取页面上的所有链接)
js爬虫抓取网页数据。目前在网上看到的第一个教程。js获取页面上所有链接,比如我要爬取某个视频网站截图的信息,会搜索该视频网站视频页面的url,获取url并通过页面代码中的href标签,得到页面所有文字信息。这里用到一个工具:googleanalytics.f12抓取url。url返回json格式。看下代码:{"pagespeed":1,"pageminute":8,"pagespeedtitle":"时刻","pagespeedyear":21}发现url请求参数个数是8,href标签后面会带一个"href"标签,这时候我们需要解析该标签,得到文字信息。
googleanalytics后台获取的url带有一个对应的cookie值,当用户登录时使用该cookie值登录。so从代码里我们可以很清楚的得到解析url变成:{"pagespeed":1,"pageminute":8,"pagespeedyear":21}通过cookie值,我们可以获取到对应的cookie值了,获取到cookie值有些困难,因为通过该工具可以通过cookie值预览登录的页面。
我们暂且说下http请求时,常用请求头:cookie_useragent:传递给googleanalytics的username或password,从这个useragent值我们可以知道一个人的真实信息。cookie_mimenegr:用于加密cookie值在网页上的传输,防止被篡改,篡改后网页将无法打开。
cookie_path:cookie传递的地址,指定文件存放路径。cookie_tmp_path:一次性将cookie存放到tmp文件中,比如说file.js文件也可以一次性写入。cookie_path':设置cookie保存在本地的路径,应该写入的路径是文件名(就是:a.js-目录-/a/b/c/d)a:用户登录名b:浏览器,浏览器登录信息是否加密c:浏览器的登录信息要加密d:参数传递给googleanalytics的参数cookie_text:cookie的内容cookie_name:cookie的名字cookie_type:cookie的类型,默认为aes-256cookie_assignr:加密方式加密方式是eph-key解密:转义后使用即可获取appid,appsecret,appidpassword,appidpasswordpassword,id,idfa,infodiv,httpsstr。
以及appsecret。property:传递给googleanalytics的值resulturl:传递给googleanalytics的返回值详细代码:/***1.js**@authoranton4*@date2019-3-31*///获取数据获取来源的url请求数据到wx.request.ajax。
可以在js配置中指定数据来源的urlres=requests.get(url(""),timeout=30)i=i+1print("%c"%res)data={'useragent':'','cookie_useragent':'c#..b。
js 爬虫抓取网页数据(聚焦爬虫技术聚焦网络爬虫(focusedcrawler)也就是全网爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-15 18:09
)
简介:网络爬虫是一种很好的自动化采集数据的通用手段。本文将介绍爬虫的种类。
01 专注于爬虫技术
聚焦网络爬虫(focused crawler)也是网络爬虫的主题。聚焦爬虫技术增加了链接评估和内容评估模块。其爬取策略的关键在于评估页面内容和链接的重要性。
基于链接评价的爬取策略主要使用网页作为半结构化文档,其中收录大量结构信息可用于评价链接的重要性。另一种方法是使用Web结构来评估链接的价值,即HITS方法,通过计算每个访问页面的Authority权重和Hub权重来确定链接访问的顺序。
基于内容评价的爬取策略主要应用类似于文本的计算方法,提出了以用户输入的查询词为主题的Fish-Search算法。随着算法的进一步改进,可以使用 Shark-Search 算法。用于计算页面和主题相关性大小的空间矢量模型。
面向主题的爬虫,面向需求的爬虫:会针对特定的内容爬取信息,并尽可能保证信息和需求相关。下面显示了如何使用简单的焦点爬虫的示例。
importurllib.request # 爬虫专用的包urllib,不同版本的Python需要下载不同的爬虫专用包importre # 正则用来规律爬取keyname=""# 想要爬取的内容key=urllib.request.quote(keyname) # 需要将你输入的keyname解码,从而让计算机读懂fori inrange(0,5): # (0,5)数字可以自己设置,是淘宝某产品的页数url="https://s.taobao.com/search%3F ... 2Bstr(i*44) # url后面加上你想爬取的网站名,然后你需要多开几个类似的网站以找到其规则# data是你爬取到的网站所有的内容要解码要读取内容pat='"pic_url":"//(.*?)"'# pat使用正则表达式从网页爬取图片# 将你爬取到的内容放在一个列表里面print(picturelist) # 可以不打印,也可以打印下来看看forj inrange(0,len(picturelist)): picture=picturelist[j] pictureurl="http://"+picture # 将列表里的内容遍历出来,并加上http://转到高清图片file="E:/pycharm/vscode文件/图片/"+str(i)+str(j)+".jpg"# 再把图片逐张编号,不然重复的名字将会被覆盖掉urllib.request.urlretrieve(pictureurl,filename=file) # 最后保存到文件夹
02 万能爬虫技术
通用网络爬虫是整个网络爬虫。实现过程如下。
通用爬虫技术的应用有不同的爬取策略,其中广度优先策略和深度优先策略更为关键。例如,深度优先策略的实现是按照深度从低到高的顺序访问下一级的网络链接。
如何使用通用爬虫的示例如下。
''' 爬取京东商品信息: 请求url:https://www.jd.com/ 提取商品信息: 1.商品详情页 2.商品名称 3.商品价格 4.评价人数 5.商品商家 '''fromselenium importwebdriver # 引入selenium中的webdriverfromselenium.webdriver.common.keys importKeys importtime defget_good(driver):try: # 通过JS控制滚轮滑动获取所有商品信息js_code = ''' window.scrollTo(0,5000); '''driver.execute_script(js_code) # 执行js代码# 等待数据加载time.sleep(2) # 查找所有商品div# good_div = driver.find_element_by_id('J_goodsList')good_list = driver.find_elements_by_class_name('gl-item') n = 1forgood ingood_list: # 根据属性选择器查找# 商品链接good_url = good.find_element_by_css_selector( '.p-img a').get_attribute('href') # 商品名称good_name = good.find_element_by_css_selector( '.p-name em').text.replace("n", "--") # 商品价格good_price = good.find_element_by_class_name( 'p-price').text.replace("n", ":") # 评价人数good_commit = good.find_element_by_class_name( 'p-commit').text.replace("n", " ") good_content = f''' 商品链接: {good_url}商品名称: {good_name}商品价格: {good_price}评价人数: {good_commit}n '''print(good_content) withopen('jd.txt', 'a', encoding='utf-8') asf: f.write(good_content) next_tag = driver.find_element_by_class_name('pn-next') next_tag.click() time.sleep(2) # 递归调用函数get_good(driver) time.sleep(10) finally: driver.close() if__name__ == '__main__': good_name = input('请输入爬取商品信息:').strip() driver = webdriver.Chrome() driver.implicitly_wait(10) # 往京东主页发送请求driver.get('https://www.jd.com/') # 输入商品名称,并回车搜索input_tag = driver.find_element_by_id('key') input_tag.send_keys(good_name) input_tag.send_keys(Keys.ENTER) time.sleep(2) get_good(driver)
03 增量爬虫技术
有的网站会根据原网页数据定期更新一批数据。比如一部电影网站会实时更新一批近期热门电影,一部小说网站会根据作者创作进度实时更新最新章节数据。当遇到类似的场景时,我们可以使用增量爬虫。
增量Web爬虫技术是通过爬虫程序监控某条网站数据的更新情况,以便对网站更新后的新数据进行爬取。
关于如何进行增量爬取工作,给出以下三种检测重复数据的思路:
发送请求前判断URL是否已经被爬取;解析内容后判断这部分内容是否被爬取;在写入存储介质时判断该内容是否已经存在于介质中。
不难发现,实现增量爬取的核心就是去重。目前有两种去重方法。
下面显示了如何使用增量爬虫的示例。
importscrapy fromscrapy.linkextractors importLinkExtractor fromscrapy.spiders importCrawlSpider, Rule fromredis importRedis fromincrementPro.items importIncrementproItem classMovieSpider(CrawlSpider):name = 'movie'# allowed_domains = ['www.xxx.com']start_urls = ['http://www.4567tv.tv/frim/index7-11.html'] rules = ( Rule(LinkExtractor(allow=r'/frim/index7-d+.html'), callback='parse_item', follow=True), ) # 创建Redis链接对象conn = Redis(host='127.0.0.1', port=6379) defparse_item(self, response):li_list = response.xpath('//li[@]') forli inli_list: # 获取详情页的urldetail_url = 'http://www.4567tv.tv'+ li.xpath('./a/@href').extract_first() # 将详情页的url存入Redis的set中ex = self.conn.sadd('urls', detail_url) ifex == 1: print('该url没有被爬取过,可以进行数据的爬取') yieldscrapy.Request(url=detail_url, callback=self.parst_detail) else: print('数据还没有更新,暂无新数据可爬取!') # 解析详情页中的电影名称和类型,进行持久化存储defparst_detail(self, response):item = IncrementproItem() item['name'] = response.xpath('//dt[@]/text()').extract_first() item['kind'] = response.xpath('//div[@]/dl/dt[4]//text()').extract() item['kind'] = ''.join(item['kind']) yieldit
管道文件:
from redis import Redis classIncrementproPipeline(object):conn = None defopen_spider(self,spider): self.conn = Redis(host='127.0.0.1',port=6379) defprocess_item(self, item, spider): dic = { 'name':item['name'], 'kind':item['kind'] } print(dic) self.conn.push('movieData',dic) # 如果push不进去,那么dic变成str(dic)或者改变redis版本 pip install -U redis==2.10.6returnitem
04 深网爬虫技术
在互联网中,网页按存在方式可分为表层网页和深层网页。
所谓表面网页,是指无需提交表单,使用静态链接即可到达的静态页面;而深层网页隐藏在表单后面,无法通过静态链接直接获取。需要提交一定数量的 关键词 深网爬虫最重要的部分就是表单填写部分。
在互联网中,深度网页的数量往往远远大于表面网页的数量,所以我们需要想办法爬取深度网页。
一个深网爬虫的基本组件:URL列表、LVS列表(LVS是指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器。
深度网络爬虫有两种类型的表单填写:
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。
查看全部
js 爬虫抓取网页数据(聚焦爬虫技术聚焦网络爬虫(focusedcrawler)也就是全网爬虫
)
简介:网络爬虫是一种很好的自动化采集数据的通用手段。本文将介绍爬虫的种类。
01 专注于爬虫技术
聚焦网络爬虫(focused crawler)也是网络爬虫的主题。聚焦爬虫技术增加了链接评估和内容评估模块。其爬取策略的关键在于评估页面内容和链接的重要性。
基于链接评价的爬取策略主要使用网页作为半结构化文档,其中收录大量结构信息可用于评价链接的重要性。另一种方法是使用Web结构来评估链接的价值,即HITS方法,通过计算每个访问页面的Authority权重和Hub权重来确定链接访问的顺序。
基于内容评价的爬取策略主要应用类似于文本的计算方法,提出了以用户输入的查询词为主题的Fish-Search算法。随着算法的进一步改进,可以使用 Shark-Search 算法。用于计算页面和主题相关性大小的空间矢量模型。
面向主题的爬虫,面向需求的爬虫:会针对特定的内容爬取信息,并尽可能保证信息和需求相关。下面显示了如何使用简单的焦点爬虫的示例。
importurllib.request # 爬虫专用的包urllib,不同版本的Python需要下载不同的爬虫专用包importre # 正则用来规律爬取keyname=""# 想要爬取的内容key=urllib.request.quote(keyname) # 需要将你输入的keyname解码,从而让计算机读懂fori inrange(0,5): # (0,5)数字可以自己设置,是淘宝某产品的页数url="https://s.taobao.com/search%3F ... 2Bstr(i*44) # url后面加上你想爬取的网站名,然后你需要多开几个类似的网站以找到其规则# data是你爬取到的网站所有的内容要解码要读取内容pat='"pic_url":"//(.*?)"'# pat使用正则表达式从网页爬取图片# 将你爬取到的内容放在一个列表里面print(picturelist) # 可以不打印,也可以打印下来看看forj inrange(0,len(picturelist)): picture=picturelist[j] pictureurl="http://"+picture # 将列表里的内容遍历出来,并加上http://转到高清图片file="E:/pycharm/vscode文件/图片/"+str(i)+str(j)+".jpg"# 再把图片逐张编号,不然重复的名字将会被覆盖掉urllib.request.urlretrieve(pictureurl,filename=file) # 最后保存到文件夹
02 万能爬虫技术
通用网络爬虫是整个网络爬虫。实现过程如下。
通用爬虫技术的应用有不同的爬取策略,其中广度优先策略和深度优先策略更为关键。例如,深度优先策略的实现是按照深度从低到高的顺序访问下一级的网络链接。
如何使用通用爬虫的示例如下。
''' 爬取京东商品信息: 请求url:https://www.jd.com/ 提取商品信息: 1.商品详情页 2.商品名称 3.商品价格 4.评价人数 5.商品商家 '''fromselenium importwebdriver # 引入selenium中的webdriverfromselenium.webdriver.common.keys importKeys importtime defget_good(driver):try: # 通过JS控制滚轮滑动获取所有商品信息js_code = ''' window.scrollTo(0,5000); '''driver.execute_script(js_code) # 执行js代码# 等待数据加载time.sleep(2) # 查找所有商品div# good_div = driver.find_element_by_id('J_goodsList')good_list = driver.find_elements_by_class_name('gl-item') n = 1forgood ingood_list: # 根据属性选择器查找# 商品链接good_url = good.find_element_by_css_selector( '.p-img a').get_attribute('href') # 商品名称good_name = good.find_element_by_css_selector( '.p-name em').text.replace("n", "--") # 商品价格good_price = good.find_element_by_class_name( 'p-price').text.replace("n", ":") # 评价人数good_commit = good.find_element_by_class_name( 'p-commit').text.replace("n", " ") good_content = f''' 商品链接: {good_url}商品名称: {good_name}商品价格: {good_price}评价人数: {good_commit}n '''print(good_content) withopen('jd.txt', 'a', encoding='utf-8') asf: f.write(good_content) next_tag = driver.find_element_by_class_name('pn-next') next_tag.click() time.sleep(2) # 递归调用函数get_good(driver) time.sleep(10) finally: driver.close() if__name__ == '__main__': good_name = input('请输入爬取商品信息:').strip() driver = webdriver.Chrome() driver.implicitly_wait(10) # 往京东主页发送请求driver.get('https://www.jd.com/') # 输入商品名称,并回车搜索input_tag = driver.find_element_by_id('key') input_tag.send_keys(good_name) input_tag.send_keys(Keys.ENTER) time.sleep(2) get_good(driver)
03 增量爬虫技术
有的网站会根据原网页数据定期更新一批数据。比如一部电影网站会实时更新一批近期热门电影,一部小说网站会根据作者创作进度实时更新最新章节数据。当遇到类似的场景时,我们可以使用增量爬虫。
增量Web爬虫技术是通过爬虫程序监控某条网站数据的更新情况,以便对网站更新后的新数据进行爬取。
关于如何进行增量爬取工作,给出以下三种检测重复数据的思路:
发送请求前判断URL是否已经被爬取;解析内容后判断这部分内容是否被爬取;在写入存储介质时判断该内容是否已经存在于介质中。
不难发现,实现增量爬取的核心就是去重。目前有两种去重方法。
下面显示了如何使用增量爬虫的示例。
importscrapy fromscrapy.linkextractors importLinkExtractor fromscrapy.spiders importCrawlSpider, Rule fromredis importRedis fromincrementPro.items importIncrementproItem classMovieSpider(CrawlSpider):name = 'movie'# allowed_domains = ['www.xxx.com']start_urls = ['http://www.4567tv.tv/frim/index7-11.html'] rules = ( Rule(LinkExtractor(allow=r'/frim/index7-d+.html'), callback='parse_item', follow=True), ) # 创建Redis链接对象conn = Redis(host='127.0.0.1', port=6379) defparse_item(self, response):li_list = response.xpath('//li[@]') forli inli_list: # 获取详情页的urldetail_url = 'http://www.4567tv.tv'+ li.xpath('./a/@href').extract_first() # 将详情页的url存入Redis的set中ex = self.conn.sadd('urls', detail_url) ifex == 1: print('该url没有被爬取过,可以进行数据的爬取') yieldscrapy.Request(url=detail_url, callback=self.parst_detail) else: print('数据还没有更新,暂无新数据可爬取!') # 解析详情页中的电影名称和类型,进行持久化存储defparst_detail(self, response):item = IncrementproItem() item['name'] = response.xpath('//dt[@]/text()').extract_first() item['kind'] = response.xpath('//div[@]/dl/dt[4]//text()').extract() item['kind'] = ''.join(item['kind']) yieldit
管道文件:
from redis import Redis classIncrementproPipeline(object):conn = None defopen_spider(self,spider): self.conn = Redis(host='127.0.0.1',port=6379) defprocess_item(self, item, spider): dic = { 'name':item['name'], 'kind':item['kind'] } print(dic) self.conn.push('movieData',dic) # 如果push不进去,那么dic变成str(dic)或者改变redis版本 pip install -U redis==2.10.6returnitem
04 深网爬虫技术
在互联网中,网页按存在方式可分为表层网页和深层网页。
所谓表面网页,是指无需提交表单,使用静态链接即可到达的静态页面;而深层网页隐藏在表单后面,无法通过静态链接直接获取。需要提交一定数量的 关键词 深网爬虫最重要的部分就是表单填写部分。
在互联网中,深度网页的数量往往远远大于表面网页的数量,所以我们需要想办法爬取深度网页。
一个深网爬虫的基本组件:URL列表、LVS列表(LVS是指标签/值集合,即填充表单的数据源)、爬取控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器。
深度网络爬虫有两种类型的表单填写:
作者简介:赵国胜,哈尔滨师范大学教授,工学博士,硕士生导师,黑龙江省网络安全技术领域特殊人才。主要从事可信网络、入侵容忍、认知计算、物联网安全等领域的教学和科研工作。
本文摘自《Python网络爬虫技术与实践》,经出版社授权发布。
js 爬虫抓取网页数据(一个爬虫动态生成的网页是什么?一般来说怎么办 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-14 07:01
)
最近公司准备写一个爬虫项目,遇到了一些js或者ajax动态生成的网页。在网上找了下,发现webdriver比较靠谱。至于htmlunit测试了一些网站直接抛出异常,可能对js支持不是特别好。
WebDriver一般有两种模式:本地驱动和远程驱动。由于爬虫最终会部署到linux服务器上,所以只能命令行运行,而且好像不能安装浏览器,所以本地驱动的进程无法工作,只能尝试远程驱动好在找了一个phantomjs的webdriver,在linux下可以不带接口运行,所以选择了它作为处理js动态生成网页的解决方案。
下载 去官网:,找到对应的版本下载。解压并安装。进入bin目录执行phantomjs,需要带上启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
1WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
2driver.get("http://www.iteye.com");
3 查看全部
js 爬虫抓取网页数据(一个爬虫动态生成的网页是什么?一般来说怎么办
)
最近公司准备写一个爬虫项目,遇到了一些js或者ajax动态生成的网页。在网上找了下,发现webdriver比较靠谱。至于htmlunit测试了一些网站直接抛出异常,可能对js支持不是特别好。
WebDriver一般有两种模式:本地驱动和远程驱动。由于爬虫最终会部署到linux服务器上,所以只能命令行运行,而且好像不能安装浏览器,所以本地驱动的进程无法工作,只能尝试远程驱动好在找了一个phantomjs的webdriver,在linux下可以不带接口运行,所以选择了它作为处理js动态生成网页的解决方案。
下载 去官网:,找到对应的版本下载。解压并安装。进入bin目录执行phantomjs,需要带上启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
1WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
2driver.get("http://www.iteye.com";);
3

