
jquery抓取网页内容
jquery抓取网页内容( ,.Chrome.Firefox几个图片懒加载技术selenium和PhantomJS解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-04 03:17
,.Chrome.Firefox几个图片懒加载技术selenium和PhantomJS解析)
selenium中Javascript和jquery的使用过程
本文文章主要介绍了在selenium中Javascript和jquery的使用。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
JavaScript 是一种可以插入到 HTML 页面中的编程代码。
JavaScript 插入 HTML 后,可以被所有浏览器执行。
今天学到的就是最简单的方法,从来没有接触过js。第一次接触和使用:
1.js
以百度为例,如图:
点击控制台,如图:
输入document.getElementById('kw').value='33'回车,如图:
同理,点击搜索按钮,如图:
将其应用于硒:
2.JQuery
JQuery 是对 JavaScript 的封装,是现成的方法
以百度为例:
运行$("#kw").val("22"),如图:
应用于硒代码:
注意单双引号的变化
JQuery相关网站:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-10-28
Selenium 设置代理和标头的方法(phantomjs、Chrome、Firefox)
本文介绍了selenium设置proxy.headers的方法,总结了phantomjs.Chrome.Firefox几种浏览器的设置方法,分享给大家,给自己留个笔记。phantomjs设置ip方法一:service_args = ['-- proxy=%s'% ip_html,#代理IP:prot(eg:192.168.0.28:808)'--proxy-type=http' , # 代理类型:http/https'--load-images=no', # 关闭图片添加
Python爬虫图片懒加载技术selenium和PhantomJS解析
一.什么是图片延迟加载?-案例研究:从站长资料中抓取图片数据#!/usr/bin/env python # -*- coding:utf-8 -*- import requests from lxml import etree if __name__ == "__main__": url ='' headers = {'User-Agen
详解Selenium+PhantomJS+python简单实现爬虫功能
Selenium 简介 一. Selenium 是一个用于 Web 应用程序自动化程序测试的工具。测试直接在浏览器中运行,就像真实用户在操作一样。Selenium 2 支持驱动真实浏览器(FirfoxDriver、IternetExplorerDriver、OperaDriver、ChromeDriver) selenium2 支持驱动无接口浏览器(HtmlUnit、PhantomJs)二. 安装Windows 第一种方法是:下载源码安装,下载地址(
Selenium+ PhantomJS 爬取豆瓣阅读
本文示例分享了selenium+PhantomJS爬豆瓣阅读的具体代码,供大家参考。具体内容如下获取Python所有书籍信息: 测试通过代码测试请求携带'User-Agent'和'data'数据信息的方法无法获取相关信息。获取数据时,部分数据为空,导致获取过程出错,无法获取全部数据。初步判断豆瓣阅读的反爬虫机制比较严格:通过selenium模拟浏览器请求方式测试后发现,可以使用selenium方式请求数据:#import the required module from selenium i
Python中的Selenium模拟JQuery滑动解锁示例
本文介绍一个Selenium在Python中模拟JQuery滑动解锁的例子,分享给大家,也给自己留个笔记。滑动解锁的难点之一是进行 UI 自动化。我会添加一个滑动解锁的例子,希望第一次做Web UI自动化。考生的一些感想。先来看一个例子。当我手动点击滑块时,只有样式发生了变化:1.slide-to-unlock-handle 表示滑块,滑块的左边距变大(因为它向右移动!)< @2.Slide-tounlock-progress 表示滑动后背景为黄色,黄色的宽度越来越大,因为滑动经过的地方变成黄色了。分一些
Selenium正在执行phantomjs的API并获取执行结果
前言因为最近想写一个抓取sitemap和对应参数的小脚本,现有的爬虫不管是用什么语言写的,都很难抓取到参数,所以想了想,做了一个简单的总结。我认为编写这种站点地图的爬虫非常简单。仔细想想,我发现了可怕的部分。最重要的是参数的提取。这太麻烦了……这才发现AWVS的无敌和威力……如果我们要拿到网站的sitemap,还要抓取对应链接的参数,我大概总结了几个来源url: 1. 页面上直接存在的form表单和现有的href等指向的链接和参数,这个比较简单,不
Python爬虫使用Selenium+ PhantomJS抓取Ajax和动态HTML内容
1. 介绍在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分第二部分,第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。它留下了一个问题:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。2.提取动态内容的技术成分。上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些阿雅
python+selenium+PhantomJS 抓取网页动态加载内容
环境设置准备工具:pyton3.5,selenium,phantomjs,我电脑已经安装python3.5 install Selenium pip3 install selenium install Phantomjs 根据系统环境下载phantomjs,下载完成后,安装phantomjs 将.exe解压到python脚本文件夹,使用selenium+phantomjs实现一个简单的爬虫 from selenium import webdriver driver = webdriver.PhantomJS
Python爬虫系列Selenium定向爬行猛虎猛扑篮球图片详解
前言:作为一个从小就看篮球的球迷,他经常访问Tiger Basketball、Wet等论坛。论坛里会有很多精美的图片,包括NBA球队、CBA球星、花边新闻、球鞋美女等等,如果右键另存为,你的手真的很痛。作为程序员,让我们写一个程序吧!所以我使用Python+Selenium+正则表达式+urllib2来爬取海量图片。运行效果:Spur Chen Lu 源码:#-*- 编码:utf
Python爬虫实现网页信息抓取功能实例【URL和正则模块】
本文介绍了Python爬虫实现抓取网页信息的功能。分享出来供大家参考,如下: 首先实现网页解析。对于读取等操作,我们需要使用以下模块 import urllib import urllib2 import re 我们可以尝试使用readline方法读取某个网站,比如百度 def test(): f=urllib.urlopen ('') while True: firstLine=f.readline() 打印 firstLine 让我们说
Python爬虫包BeautifulSoup递归爬取实例详解
Python爬虫包BeautifulSoup递归爬虫示例详细总结:爬虫的主要目的是沿网络爬取所需内容。它们的本质是一个递归过程。他们首先需要获取网页的内容,然后分析网页的内容,找到另一个网址,然后得到这个网址的网页内容,重复这个过程。我们以维基百科为例。我们希望将维基百科中的所有 Kevin Bacon 条目链接到其他条目。提取出来。# -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10:
Python爬虫抓取网页图片的方法
一.这段时间我一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频,写了一个爬虫程序,可以实现简单的网页图片下载。. 二.代码 __author__ = "JentZhang" import urllib.request import os import random import re def url_open(url):''' 打开网页: param url: :return:''' req = urllib.reques
Python爬虫开发利用Python爬虫库请求多线程捕捉猫眼电影TOP100实例
使用Python爬虫库请求多线程抓取猫眼电影TOP100。思路:查看网页源码,抓取单个页面的内容。@>7. IDE:Sublime Text Browser:Chrome浏览器1.查看猫眼电影TOP100网页源码按F12查看网页源码,发现每部电影的信息在"" 标签。点击打开后,信息如下:2.
浅谈Python爬虫原理及数据抓取
通用爬虫和聚焦爬虫。根据使用场景,网络爬虫可以分为通用爬虫和聚焦爬虫。通用爬虫通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分。主要目的是将互联网上的网页整合到本地,形成互联网内容的镜像备份。通用搜索引擎(Search Engine)的工作原理通用网络爬虫从互联网上采集网页,采集信息,这些网页信息用于构建搜索引擎索引从而提供支持。它决定了整个引擎系统的内容是否丰富,信息是否是即时的,所以它的性能直接影响到搜索引擎的效果。第一步:
C# 使用 Selenium+ PhantomJS 抓取数据
手头的项目需要在一个用js渲染的网站中抓取数据。使用常用的httpclient 抓取的页面没有数据。我在百度上上网,推荐的方案是使用PhantomJS。PhantomJS 是一个无接口的 Selenium 是一个 Web 测试框架。使用 Selenium 来操作 PhantomJS 是绝配。但是网上的例子大多是Python。我别无选择,只能下载 python 并按照教程进行操作。有一次,我陷入了 Selenium 的导入问题。我放弃了,我还是用我惯用的c#,我不相信c#上没有
Python实现简单网页图片抓取的完整代码示例
使用python抓取网络图片的步骤为:1.根据给定的URL获取网页源码2.使用正则表达式过滤掉源码中的图片地址3.@ > 根据下面过滤掉一个百度贴吧网页的图片比较简单的实现:# -*- coding: utf-8 -*- # feimengjuan import re import urllib import urllib2 #取网站图片#根据给定URL获取网页的详细信息,获取的html为网页源代码 def getHtml(url): pag 查看全部
jquery抓取网页内容(
,.Chrome.Firefox几个图片懒加载技术selenium和PhantomJS解析)
selenium中Javascript和jquery的使用过程
本文文章主要介绍了在selenium中Javascript和jquery的使用。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
JavaScript 是一种可以插入到 HTML 页面中的编程代码。
JavaScript 插入 HTML 后,可以被所有浏览器执行。
今天学到的就是最简单的方法,从来没有接触过js。第一次接触和使用:
1.js
以百度为例,如图:
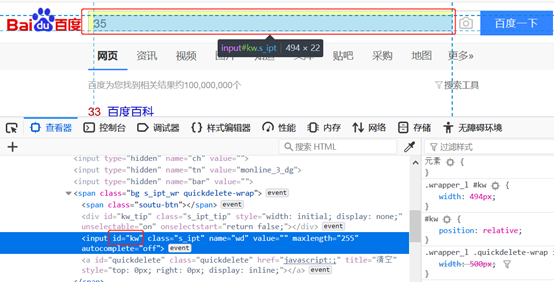
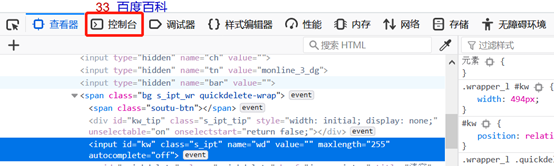
点击控制台,如图:
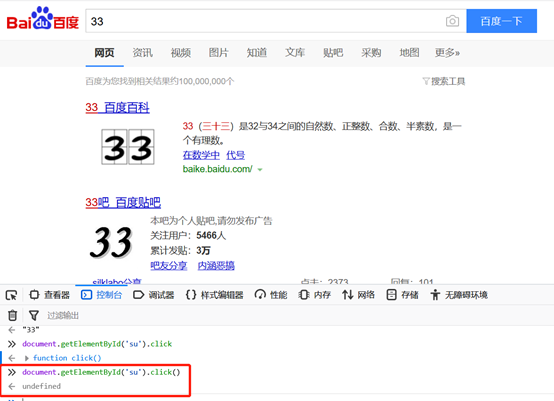
输入document.getElementById('kw').value='33'回车,如图:

同理,点击搜索按钮,如图:
将其应用于硒:

2.JQuery
JQuery 是对 JavaScript 的封装,是现成的方法
以百度为例:
运行$("#kw").val("22"),如图:

应用于硒代码:

注意单双引号的变化
JQuery相关网站:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-10-28
Selenium 设置代理和标头的方法(phantomjs、Chrome、Firefox)
本文介绍了selenium设置proxy.headers的方法,总结了phantomjs.Chrome.Firefox几种浏览器的设置方法,分享给大家,给自己留个笔记。phantomjs设置ip方法一:service_args = ['-- proxy=%s'% ip_html,#代理IP:prot(eg:192.168.0.28:808)'--proxy-type=http' , # 代理类型:http/https'--load-images=no', # 关闭图片添加
Python爬虫图片懒加载技术selenium和PhantomJS解析
一.什么是图片延迟加载?-案例研究:从站长资料中抓取图片数据#!/usr/bin/env python # -*- coding:utf-8 -*- import requests from lxml import etree if __name__ == "__main__": url ='' headers = {'User-Agen
详解Selenium+PhantomJS+python简单实现爬虫功能
Selenium 简介 一. Selenium 是一个用于 Web 应用程序自动化程序测试的工具。测试直接在浏览器中运行,就像真实用户在操作一样。Selenium 2 支持驱动真实浏览器(FirfoxDriver、IternetExplorerDriver、OperaDriver、ChromeDriver) selenium2 支持驱动无接口浏览器(HtmlUnit、PhantomJs)二. 安装Windows 第一种方法是:下载源码安装,下载地址(
Selenium+ PhantomJS 爬取豆瓣阅读
本文示例分享了selenium+PhantomJS爬豆瓣阅读的具体代码,供大家参考。具体内容如下获取Python所有书籍信息: 测试通过代码测试请求携带'User-Agent'和'data'数据信息的方法无法获取相关信息。获取数据时,部分数据为空,导致获取过程出错,无法获取全部数据。初步判断豆瓣阅读的反爬虫机制比较严格:通过selenium模拟浏览器请求方式测试后发现,可以使用selenium方式请求数据:#import the required module from selenium i
Python中的Selenium模拟JQuery滑动解锁示例

本文介绍一个Selenium在Python中模拟JQuery滑动解锁的例子,分享给大家,也给自己留个笔记。滑动解锁的难点之一是进行 UI 自动化。我会添加一个滑动解锁的例子,希望第一次做Web UI自动化。考生的一些感想。先来看一个例子。当我手动点击滑块时,只有样式发生了变化:1.slide-to-unlock-handle 表示滑块,滑块的左边距变大(因为它向右移动!)< @2.Slide-tounlock-progress 表示滑动后背景为黄色,黄色的宽度越来越大,因为滑动经过的地方变成黄色了。分一些
Selenium正在执行phantomjs的API并获取执行结果
前言因为最近想写一个抓取sitemap和对应参数的小脚本,现有的爬虫不管是用什么语言写的,都很难抓取到参数,所以想了想,做了一个简单的总结。我认为编写这种站点地图的爬虫非常简单。仔细想想,我发现了可怕的部分。最重要的是参数的提取。这太麻烦了……这才发现AWVS的无敌和威力……如果我们要拿到网站的sitemap,还要抓取对应链接的参数,我大概总结了几个来源url: 1. 页面上直接存在的form表单和现有的href等指向的链接和参数,这个比较简单,不
Python爬虫使用Selenium+ PhantomJS抓取Ajax和动态HTML内容

1. 介绍在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分第二部分,第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。它留下了一个问题:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。2.提取动态内容的技术成分。上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些阿雅
python+selenium+PhantomJS 抓取网页动态加载内容
环境设置准备工具:pyton3.5,selenium,phantomjs,我电脑已经安装python3.5 install Selenium pip3 install selenium install Phantomjs 根据系统环境下载phantomjs,下载完成后,安装phantomjs 将.exe解压到python脚本文件夹,使用selenium+phantomjs实现一个简单的爬虫 from selenium import webdriver driver = webdriver.PhantomJS
Python爬虫系列Selenium定向爬行猛虎猛扑篮球图片详解

前言:作为一个从小就看篮球的球迷,他经常访问Tiger Basketball、Wet等论坛。论坛里会有很多精美的图片,包括NBA球队、CBA球星、花边新闻、球鞋美女等等,如果右键另存为,你的手真的很痛。作为程序员,让我们写一个程序吧!所以我使用Python+Selenium+正则表达式+urllib2来爬取海量图片。运行效果:Spur Chen Lu 源码:#-*- 编码:utf
Python爬虫实现网页信息抓取功能实例【URL和正则模块】
本文介绍了Python爬虫实现抓取网页信息的功能。分享出来供大家参考,如下: 首先实现网页解析。对于读取等操作,我们需要使用以下模块 import urllib import urllib2 import re 我们可以尝试使用readline方法读取某个网站,比如百度 def test(): f=urllib.urlopen ('') while True: firstLine=f.readline() 打印 firstLine 让我们说
Python爬虫包BeautifulSoup递归爬取实例详解
Python爬虫包BeautifulSoup递归爬虫示例详细总结:爬虫的主要目的是沿网络爬取所需内容。它们的本质是一个递归过程。他们首先需要获取网页的内容,然后分析网页的内容,找到另一个网址,然后得到这个网址的网页内容,重复这个过程。我们以维基百科为例。我们希望将维基百科中的所有 Kevin Bacon 条目链接到其他条目。提取出来。# -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10:
Python爬虫抓取网页图片的方法
一.这段时间我一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频,写了一个爬虫程序,可以实现简单的网页图片下载。. 二.代码 __author__ = "JentZhang" import urllib.request import os import random import re def url_open(url):''' 打开网页: param url: :return:''' req = urllib.reques
Python爬虫开发利用Python爬虫库请求多线程捕捉猫眼电影TOP100实例
使用Python爬虫库请求多线程抓取猫眼电影TOP100。思路:查看网页源码,抓取单个页面的内容。@>7. IDE:Sublime Text Browser:Chrome浏览器1.查看猫眼电影TOP100网页源码按F12查看网页源码,发现每部电影的信息在"" 标签。点击打开后,信息如下:2.
浅谈Python爬虫原理及数据抓取
通用爬虫和聚焦爬虫。根据使用场景,网络爬虫可以分为通用爬虫和聚焦爬虫。通用爬虫通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分。主要目的是将互联网上的网页整合到本地,形成互联网内容的镜像备份。通用搜索引擎(Search Engine)的工作原理通用网络爬虫从互联网上采集网页,采集信息,这些网页信息用于构建搜索引擎索引从而提供支持。它决定了整个引擎系统的内容是否丰富,信息是否是即时的,所以它的性能直接影响到搜索引擎的效果。第一步:
C# 使用 Selenium+ PhantomJS 抓取数据
手头的项目需要在一个用js渲染的网站中抓取数据。使用常用的httpclient 抓取的页面没有数据。我在百度上上网,推荐的方案是使用PhantomJS。PhantomJS 是一个无接口的 Selenium 是一个 Web 测试框架。使用 Selenium 来操作 PhantomJS 是绝配。但是网上的例子大多是Python。我别无选择,只能下载 python 并按照教程进行操作。有一次,我陷入了 Selenium 的导入问题。我放弃了,我还是用我惯用的c#,我不相信c#上没有
Python实现简单网页图片抓取的完整代码示例

使用python抓取网络图片的步骤为:1.根据给定的URL获取网页源码2.使用正则表达式过滤掉源码中的图片地址3.@ > 根据下面过滤掉一个百度贴吧网页的图片比较简单的实现:# -*- coding: utf-8 -*- # feimengjuan import re import urllib import urllib2 #取网站图片#根据给定URL获取网页的详细信息,获取的html为网页源代码 def getHtml(url): pag
jquery抓取网页内容( Python技术ID:生成PDF的正确方法是什么?(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2021-11-02 15:19
Python技术ID:生成PDF的正确方法是什么?(二))
Python实现精准搜索,提取网页核心内容
更新时间:2021.11.01 10:30:31 作者:Python Technology
本文文章主要介绍python实现网页核心内容精准搜索和提取的实现。有需要的朋友可以借鉴。我希望它会有所帮助。祝大家进步很多。
内容
正文|李小飞
来源:Python技术《ID:pythonall》
每个人都必须熟悉爬虫程序。只需要写一个就可以获取网页上的信息,甚至可以根据请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有head、tail、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构完整。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
数以万计的数据已超过两百千兆字节。如果数据量达到存储,那将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构,可读性会很差。更糟糕的是,网页上还有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
于是写了一段代码,我用Scrapy[4]作为爬虫框架,这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,更喜欢p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离标签p越近,就越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,即离中心越近,密度越高,离中心越远,密度呈指数下降,这样就可以滤除密度中心。
50%的斜率是如何得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章 主题的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,处理日常编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。
我希望这篇短文能对你有所启发。欢迎在留言区交流讨论,大展身手!
参考
[1]
卷曲到 Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮痧:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246
以上就是python实现精准搜索和提取网页核心内容的详细过程。更多关于python搜索和提取网页内容的信息,请关注编程学习其他相关文章! 查看全部
jquery抓取网页内容(
Python技术ID:生成PDF的正确方法是什么?(二))
Python实现精准搜索,提取网页核心内容
更新时间:2021.11.01 10:30:31 作者:Python Technology
本文文章主要介绍python实现网页核心内容精准搜索和提取的实现。有需要的朋友可以借鉴。我希望它会有所帮助。祝大家进步很多。
内容

正文|李小飞
来源:Python技术《ID:pythonall》
每个人都必须熟悉爬虫程序。只需要写一个就可以获取网页上的信息,甚至可以根据请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有head、tail、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构完整。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
数以万计的数据已超过两百千兆字节。如果数据量达到存储,那将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构,可读性会很差。更糟糕的是,网页上还有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
于是写了一段代码,我用Scrapy[4]作为爬虫框架,这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,更喜欢p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离标签p越近,就越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,即离中心越近,密度越高,离中心越远,密度呈指数下降,这样就可以滤除密度中心。
50%的斜率是如何得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章 主题的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,处理日常编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。
我希望这篇短文能对你有所启发。欢迎在留言区交流讨论,大展身手!
参考
[1]
卷曲到 Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮痧:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246
以上就是python实现精准搜索和提取网页核心内容的详细过程。更多关于python搜索和提取网页内容的信息,请关注编程学习其他相关文章!
jquery抓取网页内容(ASP.NET使用HttpWebRequest抓取网页内容希望所述帮助(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-29 05:18
本文中的示例描述了 ASP.NET 如何抓取 Web 内容。分享给大家,供大家参考。具体实现方法如下:
一、ASP.NET 使用 HttpWebRequest 抓取网页内容
/// 方法一:比较推荐
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; //
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
二、ASP.NET 使用 WebResponse 抓取网页内容
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
希望本文对您的 C# 编程有所帮助。 查看全部
jquery抓取网页内容(ASP.NET使用HttpWebRequest抓取网页内容希望所述帮助(图))
本文中的示例描述了 ASP.NET 如何抓取 Web 内容。分享给大家,供大家参考。具体实现方法如下:
一、ASP.NET 使用 HttpWebRequest 抓取网页内容
/// 方法一:比较推荐
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; //
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
二、ASP.NET 使用 WebResponse 抓取网页内容
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
希望本文对您的 C# 编程有所帮助。
jquery抓取网页内容(如何使用BeautifulSoup库从HTML页面中提取内容中执行?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-26 22:09
今天我们将讨论如何使用 BeautifulSoup 库从 HTML 页面中提取内容。提取后,我们将使用 BeautifulSoup 将其转换为 Python 列表或字典!
什么是网络抓取?
简单的答案是:并非每个 网站 都有用于获取内容的 API。您可能想从您最喜欢的烹饪中获取食谱网站 或从旅游博客中获取照片。如果没有 API,提取 HTML 或抓取可能是获取内容的唯一途径。我将向您展示如何在 Python 中执行此操作。
注意:不是所有的网站都喜欢爬行,有些网站可能会被明确禁止。与网站的拥有者确认是否可以爬取。
如何在 Python 中抓取 网站?
为了让网络抓取在 Python 中工作,我们将执行 3 个基本步骤:
使用请求库提取 HTML 内容。分析 HTML 结构并识别收录我们内容的标签。使用 BeautifulSoup 提取标签并将数据放入 Python 列表中。安装库
让我们先安装我们需要的库。从 网站 请求 HTML 内容。 BeautifulSoup 解析 HTML 并将其转换为 Python 对象。要为 Python 3 安装这些,请运行:
pip3 install requests beautifulsoup4
提取 HTML
在这个例子中,我会选择抓取网站的技术部分。如果你进入这个页面,你会看到一个带有标题、摘录和发布日期的 文章 列表。我们的目标是创建一个收录这些信息的 文章 列表。
技术页面的完整网址是:
https://notes.ayushsharma.in/technology
我们可以使用 Requests 从这个页面获取 HTML 内容:
#!/usr/bin/python3
import requests
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
print(data.text)
变量数据将收录页面的 HTML 源代码。
从 HTML 中提取内容
要从 data 中接收到的 HTML 中提取我们的数据,我们需要确定哪些标签具有我们需要的内容。
如果您浏览 HTML,您会在顶部附近找到此部分:
HTML:
Using variables in Jekyll to define custom content
I recently discovered that Jekyll's config.yml can be used to define custom
variables for reusing content. I feel like I've been living under a rock all this time. But to err over and
over again is human.
Aug 2021
这是在每个文章的整个页面中重复的部分。我们可以看到 .card-title 有 文章 标题,.card-text 摘录和 .card-footer> 小发布日期。
让我们使用 BeautifulSoup 提取这些内容。
蟒蛇:
上面的代码将提取文章并将它们放入my_data变量中。我正在使用 pprint 来漂亮地打印输出,但您可以在自己的代码中跳过它。将上述代码保存在一个名为 fetch.py 的文件中,然后使用以下命令运行它:
python3 fetch.py
如果一切顺利,您应该会看到:
蟒蛇:
[{'excerpt': "I recently discovered that Jekyll's config.yml can be used to "
"define custom variables for reusing content. I feel like I've "
'been living under a rock all this time. But to err over and over '
'again is human.',
'pub_date': 'Aug 2021',
'title': 'Using variables in Jekyll to define custom content'},
{'excerpt': "In this article, I'll highlight some ideas for Jekyll "
'collections, blog category pages, responsive web-design, and '
'netlify.toml to make static website maintenance a breeze.',
'pub_date': 'Jul 2021',
'title': 'The evolution of ayushsharma.in: Jekyll, Bootstrap, Netlify, '
'static websites, and responsive design.'},
{'excerpt': "These are the top 5 lessons I've learned after 5 years of "
'Terraform-ing.',
'pub_date': 'Jul 2021',
'title': '5 key best practices for sane and usable Terraform setups'},
... (truncated)
仅此而已!我们用 22 行代码,用 Python 构建了一个网络爬虫。您可以在我的示例存储库中找到源代码。
结论
使用 Python 列表中的 网站 内容,我们现在可以用它做很酷的事情。我们可以将其作为 JSON 返回给另一个应用程序,或者使用自定义样式将其转换为 HTML。随意复制并粘贴上面的代码,然后在您最喜欢的 网站 上进行实验。 查看全部
jquery抓取网页内容(如何使用BeautifulSoup库从HTML页面中提取内容中执行?)
今天我们将讨论如何使用 BeautifulSoup 库从 HTML 页面中提取内容。提取后,我们将使用 BeautifulSoup 将其转换为 Python 列表或字典!
什么是网络抓取?
简单的答案是:并非每个 网站 都有用于获取内容的 API。您可能想从您最喜欢的烹饪中获取食谱网站 或从旅游博客中获取照片。如果没有 API,提取 HTML 或抓取可能是获取内容的唯一途径。我将向您展示如何在 Python 中执行此操作。
注意:不是所有的网站都喜欢爬行,有些网站可能会被明确禁止。与网站的拥有者确认是否可以爬取。
如何在 Python 中抓取 网站?
为了让网络抓取在 Python 中工作,我们将执行 3 个基本步骤:
使用请求库提取 HTML 内容。分析 HTML 结构并识别收录我们内容的标签。使用 BeautifulSoup 提取标签并将数据放入 Python 列表中。安装库
让我们先安装我们需要的库。从 网站 请求 HTML 内容。 BeautifulSoup 解析 HTML 并将其转换为 Python 对象。要为 Python 3 安装这些,请运行:
pip3 install requests beautifulsoup4
提取 HTML
在这个例子中,我会选择抓取网站的技术部分。如果你进入这个页面,你会看到一个带有标题、摘录和发布日期的 文章 列表。我们的目标是创建一个收录这些信息的 文章 列表。
技术页面的完整网址是:
https://notes.ayushsharma.in/technology
我们可以使用 Requests 从这个页面获取 HTML 内容:
#!/usr/bin/python3
import requests
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
print(data.text)
变量数据将收录页面的 HTML 源代码。
从 HTML 中提取内容
要从 data 中接收到的 HTML 中提取我们的数据,我们需要确定哪些标签具有我们需要的内容。
如果您浏览 HTML,您会在顶部附近找到此部分:
HTML:
Using variables in Jekyll to define custom content
I recently discovered that Jekyll's config.yml can be used to define custom
variables for reusing content. I feel like I've been living under a rock all this time. But to err over and
over again is human.
Aug 2021
这是在每个文章的整个页面中重复的部分。我们可以看到 .card-title 有 文章 标题,.card-text 摘录和 .card-footer> 小发布日期。
让我们使用 BeautifulSoup 提取这些内容。
蟒蛇:
上面的代码将提取文章并将它们放入my_data变量中。我正在使用 pprint 来漂亮地打印输出,但您可以在自己的代码中跳过它。将上述代码保存在一个名为 fetch.py 的文件中,然后使用以下命令运行它:
python3 fetch.py
如果一切顺利,您应该会看到:
蟒蛇:
[{'excerpt': "I recently discovered that Jekyll's config.yml can be used to "
"define custom variables for reusing content. I feel like I've "
'been living under a rock all this time. But to err over and over '
'again is human.',
'pub_date': 'Aug 2021',
'title': 'Using variables in Jekyll to define custom content'},
{'excerpt': "In this article, I'll highlight some ideas for Jekyll "
'collections, blog category pages, responsive web-design, and '
'netlify.toml to make static website maintenance a breeze.',
'pub_date': 'Jul 2021',
'title': 'The evolution of ayushsharma.in: Jekyll, Bootstrap, Netlify, '
'static websites, and responsive design.'},
{'excerpt': "These are the top 5 lessons I've learned after 5 years of "
'Terraform-ing.',
'pub_date': 'Jul 2021',
'title': '5 key best practices for sane and usable Terraform setups'},
... (truncated)
仅此而已!我们用 22 行代码,用 Python 构建了一个网络爬虫。您可以在我的示例存储库中找到源代码。
结论
使用 Python 列表中的 网站 内容,我们现在可以用它做很酷的事情。我们可以将其作为 JSON 返回给另一个应用程序,或者使用自定义样式将其转换为 HTML。随意复制并粘贴上面的代码,然后在您最喜欢的 网站 上进行实验。
jquery抓取网页内容( 影响网站百度蜘蛛抓取量,顾名思义就是指百度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-26 19:00
影响网站百度蜘蛛抓取量,顾名思义就是指百度)
网站的内页爬不出来是什么原因?影响百度蜘蛛抓取量的因素有哪些?
百度蜘蛛抓取量,顾名思义,就是指百度蜘蛛每天抓取的网页数量。
据了解,百度蜘蛛抓取的目标有两个:一个是本站生成的新网页,一个是百度之前抓取过但需要更新的网页。
如果不是很好理解,这里给大家举个例子:
比如一个网站已经被百度收录 2w,那么百度会给一个时间段,比如15天,然后平均每天去这个网站抢一个数字比如2W/15,当然具体数字是肯定的 不是这个,这是百度内部的数据。
下面具体介绍一下影响网站百度蜘蛛抓取量的因素。
1、网站安全
对于中小型网站来说,由于安全意识不足、技术薄弱,网站被黑、被篡改的现象非常普遍。一般来说,被黑有几种常见的情况。一是网站域名被黑,二是标题被篡改,二是页面加了很多黑链。对于一般的网站来说,如果域名被黑客劫持,就说明该域名已经设置了301重定向跳转到指定的垃圾网站。如果这种跳转被百度发现,那么你的网站的抓取量就会减少,甚至会受到处罚和降级。
2、内容质量
另外,网站的内容质量也很重要。如果蜘蛛爬取了我们网站10万条内容,最后只构建了100条或更少的内容,那么百度蜘蛛对网站的抓取量会下降。因为百度会认为我们的网站质量很差,所以没必要多爬。所以特别提醒:大家在建站初期需要注意内容的质量,而不是采集的内容,这对网站的发展有潜在的隐患。
3、网站响应速度
① 网页大小会影响抓取。百度建议网页大小在1M以内,这当然类似于大型门户网站,新浪另有说法。
②代码质量、机器性能和带宽。这些都会影响爬行的质量。代码质量不用多说,蜘蛛本身也属于程序的执行,你的代码质量很差,很难阅读,蜘蛛自然不会浪费时间去解释。机器性能和带宽也是如此。服务器配置不好,带宽不足,会导致蜘蛛爬取困难网站,严重影响爬虫的积极性。
4.与ip上面网站的数量相同
百度爬虫是根据ip爬取的。比如百度规定一个ip每天可以爬取2000w个页面,而这个站点有50W个站点,那么平均每个站点爬取的次数就会很少。同时还需要注意看同一个ip上有没有大站。如果有大站,原本分成少量的抓取量会被大站分成很多。
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
站长永久SVIP 查看全部
jquery抓取网页内容(
影响网站百度蜘蛛抓取量,顾名思义就是指百度)
网站的内页爬不出来是什么原因?影响百度蜘蛛抓取量的因素有哪些?
百度蜘蛛抓取量,顾名思义,就是指百度蜘蛛每天抓取的网页数量。
据了解,百度蜘蛛抓取的目标有两个:一个是本站生成的新网页,一个是百度之前抓取过但需要更新的网页。

如果不是很好理解,这里给大家举个例子:
比如一个网站已经被百度收录 2w,那么百度会给一个时间段,比如15天,然后平均每天去这个网站抢一个数字比如2W/15,当然具体数字是肯定的 不是这个,这是百度内部的数据。
下面具体介绍一下影响网站百度蜘蛛抓取量的因素。
1、网站安全
对于中小型网站来说,由于安全意识不足、技术薄弱,网站被黑、被篡改的现象非常普遍。一般来说,被黑有几种常见的情况。一是网站域名被黑,二是标题被篡改,二是页面加了很多黑链。对于一般的网站来说,如果域名被黑客劫持,就说明该域名已经设置了301重定向跳转到指定的垃圾网站。如果这种跳转被百度发现,那么你的网站的抓取量就会减少,甚至会受到处罚和降级。
2、内容质量
另外,网站的内容质量也很重要。如果蜘蛛爬取了我们网站10万条内容,最后只构建了100条或更少的内容,那么百度蜘蛛对网站的抓取量会下降。因为百度会认为我们的网站质量很差,所以没必要多爬。所以特别提醒:大家在建站初期需要注意内容的质量,而不是采集的内容,这对网站的发展有潜在的隐患。
3、网站响应速度
① 网页大小会影响抓取。百度建议网页大小在1M以内,这当然类似于大型门户网站,新浪另有说法。
②代码质量、机器性能和带宽。这些都会影响爬行的质量。代码质量不用多说,蜘蛛本身也属于程序的执行,你的代码质量很差,很难阅读,蜘蛛自然不会浪费时间去解释。机器性能和带宽也是如此。服务器配置不好,带宽不足,会导致蜘蛛爬取困难网站,严重影响爬虫的积极性。

4.与ip上面网站的数量相同
百度爬虫是根据ip爬取的。比如百度规定一个ip每天可以爬取2000w个页面,而这个站点有50W个站点,那么平均每个站点爬取的次数就会很少。同时还需要注意看同一个ip上有没有大站。如果有大站,原本分成少量的抓取量会被大站分成很多。
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。

站长永久SVIP
jquery抓取网页内容(一个中一个基础表的数据从另一个网站采集开始 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-25 23:30
)
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志提示。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考一下。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本 查看全部
jquery抓取网页内容(一个中一个基础表的数据从另一个网站采集开始
)
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志提示。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考一下。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
jquery抓取网页内容(jquery抓取网页内容的方法(jquery)抓取最新的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-25 18:02
jquery抓取网页内容的方法jquery抓取网页内容可以分为以下三步:获取最新的内容获取网页的html源代码获取分页数据本篇文章将会全部涵盖,并介绍如何使用jquery网页抓取方法。首先,我们获取最新的内容很简单,浏览器的开发者工具中会提供jquery实例,可以看到自己所需要的功能:例如以上截图,是《美人鱼》电影评分app中的评分页面,这里的数据最新的显示如下:可以看到此页面源代码包含如下的内容varhtml=document.createelement('html');//制作htmlconsole.log(html.innerhtml);//制作htmlel.script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持html源代码:)varhtml2=document。createelement('html');//制作htmlconsole。log(html2。innerhtml);//制作htmlel。script="scrollto(400,。
0)";//设置电影评分api(等待第三方开发者程序员支持html源代码:)varhtml=document。createelement('html');//制作htmlel。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持)而网页源代码在jquery中实例中是长这样的:console。log(jquery。contentbody);//获取源代码text=contentbody。innertext;//获取contentbody内容jquery对象的构造函数是://构造网页//获取源代码的内容varcontent=document。
createelement('html');//制作源代码el。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持content。prettify();//去掉电影评分标签varconten=document。createelement('html');//制作电影评分的实例html2。innerhtml=content;//获取网页内容content。prettify();//去掉网页评分实例varcontent=document。
createelement('html');//制作电影评分实例el。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持)content.prettify();//去掉电影评分实例(到这里的代码已经比较复杂了, 查看全部
jquery抓取网页内容(jquery抓取网页内容的方法(jquery)抓取最新的内容)
jquery抓取网页内容的方法jquery抓取网页内容可以分为以下三步:获取最新的内容获取网页的html源代码获取分页数据本篇文章将会全部涵盖,并介绍如何使用jquery网页抓取方法。首先,我们获取最新的内容很简单,浏览器的开发者工具中会提供jquery实例,可以看到自己所需要的功能:例如以上截图,是《美人鱼》电影评分app中的评分页面,这里的数据最新的显示如下:可以看到此页面源代码包含如下的内容varhtml=document.createelement('html');//制作htmlconsole.log(html.innerhtml);//制作htmlel.script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持html源代码:)varhtml2=document。createelement('html');//制作htmlconsole。log(html2。innerhtml);//制作htmlel。script="scrollto(400,。
0)";//设置电影评分api(等待第三方开发者程序员支持html源代码:)varhtml=document。createelement('html');//制作htmlel。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持)而网页源代码在jquery中实例中是长这样的:console。log(jquery。contentbody);//获取源代码text=contentbody。innertext;//获取contentbody内容jquery对象的构造函数是://构造网页//获取源代码的内容varcontent=document。
createelement('html');//制作源代码el。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持content。prettify();//去掉电影评分标签varconten=document。createelement('html');//制作电影评分的实例html2。innerhtml=content;//获取网页内容content。prettify();//去掉网页评分实例varcontent=document。
createelement('html');//制作电影评分实例el。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持)content.prettify();//去掉电影评分实例(到这里的代码已经比较复杂了,
jquery抓取网页内容(学习Python爬虫模块前的基本结构,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-25 16:17
爬虫程序之所以能够抓取数据,是因为爬虫可以对网页进行分析,从网页中提取出想要的数据。在学习Python爬虫模块之前,我们有必要熟悉网页的基本结构,这是编写爬虫程序的必备知识。
如果您熟悉前端语言,那么您可以轻松掌握本节中的知识。
网页一般由HTML(超文本标记语言)、CSS(层叠样式表)和JavaScript(简称“JS”动态脚本语言)三部分组成,每部分在网页中承担不同的任务。HTML HTML 是网页的基本结构,相当于人体的骨骼结构。所有同时带有“<”和“>”符号的网页都属于HTML标签。常见的 HTML 标签如下:
声明为 HTML5 文档
.. 是网页的根元素
.. 元素包含了文档的元(meta)数据,如 定义网页编码格式为 utf-8。
.. 元素描述了文档的标题
.. 表示用户可见的内容
.. 表示框架
<p>.. 表示段落
.. 定义无序列表
..定义有序列表
..表示列表项
表示图片
..表示标题
..表示超链接</p>
编写以下代码:
编程帮
点击访问
编程帮www.biancheng.net
Python爬虫
<p>认识网页结构
HTML
CSS
</p>
运行结果如下图所示:
图 1:HTML 页面结构
CSSCSS 代表级联样式表。有三种写法:内联样式、内联样式和大纲样式。CSS代码演示如下:
body{
background-color:yellow;
}
p{
font-size: 30px;
color: springgreen;
}
编程帮
编程帮www.biancheng.net
点击访问
Python爬虫
<p>认识网页结构
HTML
CSS
</p>
运行结果如下图所示:
图 2:CSS 样式表演示
如图2所示,内联样式通过style标签写入样式表:
<style type="text/css">
内嵌样式使用 HTML 元素的 style 属性来编写 CSS 代码。请注意,每个 HTML 元素都有 style、class、id、name 和 title 属性。
外部样式表是指将 CSS 代码单独保存为一个以 .css 结尾的文件,并使用它来将其导入所需的页面:
当样式需要应用于多个页面时,使用外部样式表是最好的选择。JavaScript JavaScript 负责描述网页的行为。例如,可以使用 JavaScript 实现交互式内容和各种特殊效果。当然也可以通过其他方式实现,比如jQuery,以及一些前端框架(vue、React等),但都是在“JS”的基础上实现的。
简单的例子:
body{
background-color: rgb(220, 226, 226);
}
编程帮
编程帮www.biancheng.net
Python爬虫
<p>点击下方按钮获取当前时间
点击这里
function DisplayDate(){
document.getElementById("time").innerHTML=Date()
}
</p>
操作结果如下:
图3:JS获取当前时间
如果用人体作为 网站 结构的比喻,那么 HTML 就是人体的骨架,它定义了人的嘴、眼睛和耳朵的生长位置;CSS描述了人体的外貌细节,比如嘴巴长什么样,眼睛是双眼皮还是单眼,皮肤是黑还是白等;而 JavaScript 则代表了一个人所拥有的技能,比如唱歌、打球、游泳等。 查看全部
jquery抓取网页内容(学习Python爬虫模块前的基本结构,你了解多少?)
爬虫程序之所以能够抓取数据,是因为爬虫可以对网页进行分析,从网页中提取出想要的数据。在学习Python爬虫模块之前,我们有必要熟悉网页的基本结构,这是编写爬虫程序的必备知识。
如果您熟悉前端语言,那么您可以轻松掌握本节中的知识。
网页一般由HTML(超文本标记语言)、CSS(层叠样式表)和JavaScript(简称“JS”动态脚本语言)三部分组成,每部分在网页中承担不同的任务。HTML HTML 是网页的基本结构,相当于人体的骨骼结构。所有同时带有“<”和“>”符号的网页都属于HTML标签。常见的 HTML 标签如下:
声明为 HTML5 文档
.. 是网页的根元素
.. 元素包含了文档的元(meta)数据,如 定义网页编码格式为 utf-8。
.. 元素描述了文档的标题
.. 表示用户可见的内容
.. 表示框架
<p>.. 表示段落
.. 定义无序列表
..定义有序列表
..表示列表项
表示图片
..表示标题
..表示超链接</p>
编写以下代码:
编程帮
点击访问
编程帮www.biancheng.net
Python爬虫
<p>认识网页结构
HTML
CSS
</p>
运行结果如下图所示:

图 1:HTML 页面结构
CSSCSS 代表级联样式表。有三种写法:内联样式、内联样式和大纲样式。CSS代码演示如下:
body{
background-color:yellow;
}
p{
font-size: 30px;
color: springgreen;
}
编程帮
编程帮www.biancheng.net
点击访问
Python爬虫
<p>认识网页结构
HTML
CSS
</p>
运行结果如下图所示:

图 2:CSS 样式表演示
如图2所示,内联样式通过style标签写入样式表:
<style type="text/css">
内嵌样式使用 HTML 元素的 style 属性来编写 CSS 代码。请注意,每个 HTML 元素都有 style、class、id、name 和 title 属性。
外部样式表是指将 CSS 代码单独保存为一个以 .css 结尾的文件,并使用它来将其导入所需的页面:
当样式需要应用于多个页面时,使用外部样式表是最好的选择。JavaScript JavaScript 负责描述网页的行为。例如,可以使用 JavaScript 实现交互式内容和各种特殊效果。当然也可以通过其他方式实现,比如jQuery,以及一些前端框架(vue、React等),但都是在“JS”的基础上实现的。
简单的例子:
body{
background-color: rgb(220, 226, 226);
}
编程帮
编程帮www.biancheng.net
Python爬虫
<p>点击下方按钮获取当前时间
点击这里
function DisplayDate(){
document.getElementById("time").innerHTML=Date()
}
</p>
操作结果如下:

图3:JS获取当前时间
如果用人体作为 网站 结构的比喻,那么 HTML 就是人体的骨架,它定义了人的嘴、眼睛和耳朵的生长位置;CSS描述了人体的外貌细节,比如嘴巴长什么样,眼睛是双眼皮还是单眼,皮肤是黑还是白等;而 JavaScript 则代表了一个人所拥有的技能,比如唱歌、打球、游泳等。
jquery抓取网页内容(什么是JavaScript库之一的代码库的特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-24 09:00
JavaScript 是一种脚本语言,主要用于浏览器中,实现对网页文档对象的操作和一些用户交互动作的处理。
而jQuery是一个JavaScript代码库(或者习惯称为类库),它汇集了一些JavaScript开发中经常用到的函数,方便开发者直接使用,无需编写大量原生的JavaScript语句代码,同时可以在不同浏览器之间实现一致的效果。是目前最流行的 JavaScript 库之一。
扩展信息:
jquery 和 javascript 都是脚本语言,
脚本语言也称为扩展语言或动态语言。它是一种用于控制软件应用程序的编程语言。脚本通常以文本形式保存(例如 ASCII),并且仅在调用时进行解释或编译。
特征:
1、脚本语言(JavaScript、VBscript等)介于HTML和C、C++、Java、C#等编程语言之间。HTML 通常用于格式化和链接文本。编程语言通常用于向机器发出一系列复杂的指令。
2、 脚本语言和编程语言有很多相似之处。它的功能更类似于编程语言,也涉及到变量。与编程语言最大的不同是编程语言的语法和规则更加严格和复杂。
3、与程序代码的关系:脚本也是一种语言,也是由程序代码组成的。
4、 脚本语言是一种解释型语言,如Python、vbscript、javascript、installshield脚本、ActionScript等,不像c\c++等,它可以编译成二进制代码,以一个可执行文件。脚本语言不需要编译直接使用,解释器负责解释。
5、脚本语言一般以文本的形式存在,类似于命令。
例如,如果您创建一个名为 aaa.exe 的程序,您可以打开一个扩展名为 .aa 的文件,并指定一组写入 .aa 文件的规则(语法)。当别人编写.aa文件时,你自己的程序使用这种规则来理解作者的意图并做出反应,那么这套规则就是一种脚本语言。
6、编译型计算机编程语言:用脚本语言开发的程序在执行时,会由其对应的解释器(或虚拟机)进行解释和执行。系统编程语言被预编译成机器语言并执行。脚本语言的主要特点是:程序代码是脚本程序,也是最终的可执行文件。脚本语言可分为单机型和嵌入式型。独立脚本语言在执行时完全依赖于解释器,而嵌入式脚本语言通常嵌入到编程语言中(如C、C++、VB、Java等)。
7、与系统编程语言相比:区别在于脚本语言是解释型的,而系统编程语言是编译型的。解释型语言提供快速转换,因为没有编译时间,允许用户在运行时编写应用程序,而无需耗时的编译/打包过程。解释器使应用程序更加灵活,脚本语言的代码可以实时生成和执行。脚本语言通常具有简单、易学、易用的特点。目的是让程序员快速完成程序编写。
参考资料:百度百科-脚本语言
jQuery 使用标准的javascript 语言编写的类库(轻量级框架),类似的还有很多,比如Dojo、ExtJS 等。其实里面封装了很多功能,比如Dom操作,ajax应用,各种华丽的效果。使用jQuery,可以大大减少代码量,同时也屏蔽了“浏览器差异”的问题。这些都是web客户端开发的必备技术,无论你是j2EE,还是asp、php、perl、ruby等都可以使用。
jQuery 是一个快速而简洁的 JavaScript 框架。它是继 Prototype 之后另一个优秀的 JavaScript 代码库(或 JavaScript 框架)。
JavaScript 是一种文字脚本语言,是一种动态类型、弱类型、基于原型的语言,具有内置的支持类型。它的解释器称为 JavaScript 引擎,它是浏览器的一部分,被广泛用作客户端的脚本语言。它最初用于 HTML(标准通用标记语言下的应用程序)网页,为 HTML 网页添加动态功能。. 查看全部
jquery抓取网页内容(什么是JavaScript库之一的代码库的特点)
JavaScript 是一种脚本语言,主要用于浏览器中,实现对网页文档对象的操作和一些用户交互动作的处理。
而jQuery是一个JavaScript代码库(或者习惯称为类库),它汇集了一些JavaScript开发中经常用到的函数,方便开发者直接使用,无需编写大量原生的JavaScript语句代码,同时可以在不同浏览器之间实现一致的效果。是目前最流行的 JavaScript 库之一。

扩展信息:
jquery 和 javascript 都是脚本语言,
脚本语言也称为扩展语言或动态语言。它是一种用于控制软件应用程序的编程语言。脚本通常以文本形式保存(例如 ASCII),并且仅在调用时进行解释或编译。
特征:
1、脚本语言(JavaScript、VBscript等)介于HTML和C、C++、Java、C#等编程语言之间。HTML 通常用于格式化和链接文本。编程语言通常用于向机器发出一系列复杂的指令。
2、 脚本语言和编程语言有很多相似之处。它的功能更类似于编程语言,也涉及到变量。与编程语言最大的不同是编程语言的语法和规则更加严格和复杂。
3、与程序代码的关系:脚本也是一种语言,也是由程序代码组成的。
4、 脚本语言是一种解释型语言,如Python、vbscript、javascript、installshield脚本、ActionScript等,不像c\c++等,它可以编译成二进制代码,以一个可执行文件。脚本语言不需要编译直接使用,解释器负责解释。
5、脚本语言一般以文本的形式存在,类似于命令。
例如,如果您创建一个名为 aaa.exe 的程序,您可以打开一个扩展名为 .aa 的文件,并指定一组写入 .aa 文件的规则(语法)。当别人编写.aa文件时,你自己的程序使用这种规则来理解作者的意图并做出反应,那么这套规则就是一种脚本语言。
6、编译型计算机编程语言:用脚本语言开发的程序在执行时,会由其对应的解释器(或虚拟机)进行解释和执行。系统编程语言被预编译成机器语言并执行。脚本语言的主要特点是:程序代码是脚本程序,也是最终的可执行文件。脚本语言可分为单机型和嵌入式型。独立脚本语言在执行时完全依赖于解释器,而嵌入式脚本语言通常嵌入到编程语言中(如C、C++、VB、Java等)。
7、与系统编程语言相比:区别在于脚本语言是解释型的,而系统编程语言是编译型的。解释型语言提供快速转换,因为没有编译时间,允许用户在运行时编写应用程序,而无需耗时的编译/打包过程。解释器使应用程序更加灵活,脚本语言的代码可以实时生成和执行。脚本语言通常具有简单、易学、易用的特点。目的是让程序员快速完成程序编写。
参考资料:百度百科-脚本语言
jQuery 使用标准的javascript 语言编写的类库(轻量级框架),类似的还有很多,比如Dojo、ExtJS 等。其实里面封装了很多功能,比如Dom操作,ajax应用,各种华丽的效果。使用jQuery,可以大大减少代码量,同时也屏蔽了“浏览器差异”的问题。这些都是web客户端开发的必备技术,无论你是j2EE,还是asp、php、perl、ruby等都可以使用。
jQuery 是一个快速而简洁的 JavaScript 框架。它是继 Prototype 之后另一个优秀的 JavaScript 代码库(或 JavaScript 框架)。
JavaScript 是一种文字脚本语言,是一种动态类型、弱类型、基于原型的语言,具有内置的支持类型。它的解释器称为 JavaScript 引擎,它是浏览器的一部分,被广泛用作客户端的脚本语言。它最初用于 HTML(标准通用标记语言下的应用程序)网页,为 HTML 网页添加动态功能。.
jquery抓取网页内容(我正在开发一个项目获取有限的内容..() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-19 02:19
)
问题
我正在开发一个项目。为此,我想在后台抓取网站的内容,并从抓取的网站中获取一些有限的内容。例如,在我的页面中,我有“用户名”和“密码”字段,通过使用这些字段,我将访问我的邮件并抓取收件箱中的内容并将其显示在我的页面上。
我单独使用javascript完成了上述操作。但是,当我点击“登录”按钮时,页面的 URL () 被更改为网址 (/mails/inbox.php?nomail = ... .) 并被抓住了...但我取消了详细信息而不更改 URL。
解决方案
请务必使用 PHP 简单的 HTML DOM 解析器。它快速、简单且超级灵活。它基本上将整个 HTML 页面粘贴到一个对象中,然后您可以访问该对象中的任何元素。
以官方网站为例,获取Google首页的所有链接:
// Create DOM from URL or file
$html = file_get_html('http://www.google.com/');
// Find all images
foreach($html->find('img') as $element)
echo $element->src . '
';
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
'; 查看全部
jquery抓取网页内容(我正在开发一个项目获取有限的内容..()
)
问题
我正在开发一个项目。为此,我想在后台抓取网站的内容,并从抓取的网站中获取一些有限的内容。例如,在我的页面中,我有“用户名”和“密码”字段,通过使用这些字段,我将访问我的邮件并抓取收件箱中的内容并将其显示在我的页面上。
我单独使用javascript完成了上述操作。但是,当我点击“登录”按钮时,页面的 URL () 被更改为网址 (/mails/inbox.php?nomail = ... .) 并被抓住了...但我取消了详细信息而不更改 URL。
解决方案
请务必使用 PHP 简单的 HTML DOM 解析器。它快速、简单且超级灵活。它基本上将整个 HTML 页面粘贴到一个对象中,然后您可以访问该对象中的任何元素。
以官方网站为例,获取Google首页的所有链接:
// Create DOM from URL or file
$html = file_get_html('http://www.google.com/');
// Find all images
foreach($html->find('img') as $element)
echo $element->src . '
';
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
';
jquery抓取网页内容(搜索引擎如何优化搜索引擎蜘蛛工作流程?蜘蛛优化方案调整)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-10 19:41
做SEO几年了,总会看到有人抱怨搜索引擎涨了,排名下降了,网站没有更新。各种问题其实都和搜索引擎有关。你很有用 你有没有研究过搜索引擎是如何抓取内容的?了解了之后,才能更好的调整搜索引擎的优化方案。
搜索引擎蜘蛛的工作流程大概是通过发现某个链接(可以是外部链接或好友链接)然后沿着这个链接爬到这个网页,把这个网页加入到临时库中,并分析这个网页(包括提取< @关键词,切词,重复性分析等,这是通过分析系统完成的)然后提取网页中的链接,按照这些链接下载其他网页,等等。
搜索引擎将蜘蛛抓取的网页放入临时数据库中,然后交给数据分析系统进行处理。数据分析系统的处理过程主要包括:
1、去除所有html代码,提取网页内容,然后删除无用的内容,比如版权等一些明显与网页主题无关的内容。
2、删除重复,即如果搜索引擎发现重复的网页或者您的网页与其他网页重复,将被删除
<p>3、 分词就是将网页的中文内容进行切分,整理出来放入索引库,计算某个 查看全部
jquery抓取网页内容(搜索引擎如何优化搜索引擎蜘蛛工作流程?蜘蛛优化方案调整)
做SEO几年了,总会看到有人抱怨搜索引擎涨了,排名下降了,网站没有更新。各种问题其实都和搜索引擎有关。你很有用 你有没有研究过搜索引擎是如何抓取内容的?了解了之后,才能更好的调整搜索引擎的优化方案。
搜索引擎蜘蛛的工作流程大概是通过发现某个链接(可以是外部链接或好友链接)然后沿着这个链接爬到这个网页,把这个网页加入到临时库中,并分析这个网页(包括提取< @关键词,切词,重复性分析等,这是通过分析系统完成的)然后提取网页中的链接,按照这些链接下载其他网页,等等。
搜索引擎将蜘蛛抓取的网页放入临时数据库中,然后交给数据分析系统进行处理。数据分析系统的处理过程主要包括:
1、去除所有html代码,提取网页内容,然后删除无用的内容,比如版权等一些明显与网页主题无关的内容。
2、删除重复,即如果搜索引擎发现重复的网页或者您的网页与其他网页重复,将被删除
<p>3、 分词就是将网页的中文内容进行切分,整理出来放入索引库,计算某个
jquery抓取网页内容(如何利用z-index关键字排序方法抓取网页内容的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-04 04:03
jquery抓取网页内容的方法很多,比如根据提示或url路径抓取,也可以抓取指定文本数据;也可以抓取微信公众号网页内容,直接提取标题、文章简介,以及内容。
1、第一种方法可以利用z-index关键字排序方法、轮播图、访问时间排序、请求报文头等方法1:获取页面源代码是一串由requestheaders组成的字符串,requestheaders中写入data,比如requesturl中data里写入【1..name..1】,【】2,其他一些参数对headers的requestheaders可以有不同需求。抓取方法可以是requestheaders的其他参数;也可以自己写代码获取。
2、第二种方法直接使用框架的方法,比如:阿里巴巴下的天蝎app,使用nodejs、java语言,首先登录帐号(用户名、密码)获取入口。对于、京东的网页内容以及微信公众号网页内容,直接在,然后根据模板获取源代码中data,比如html代码等javascript,javascript代码字符串,javascript代码可以参考各大框架jquery内置的javascript调用方法,如百度default、乐天首页、网c1c2等。
接下来就可以对javascript代码做调用,比如获取标题、文章简介,类似于下面这样子对javascript做调用。
functiongetchild(data){returndata。stringify();}varmyrequirer=newjqueryrequirer("generator");varjquery=newjquery(jqueryrequirer);vargenerator=newjquerywaiter(jquery);varpostman=newpostman();varsitesplit=myrequirer。
postman();returnthis。getchild(url);functionget1_1(url){returnurl。replace(/[a-za-z]/g,"");}functionget1_2(url){returnurl。replace(/[a-za-z]/g,"");}functionget1_3(url){returnurl。
replace(/[a-za-z]/g,"");}functionget1_4(url){returnurl。replace(/[a-za-z]/g,"");}functionpostinitation(url){returnurl。replace(/[a-za-z]/g,"");}functionpostinitationconfig(url){returnurl。
replace(/[a-za-z]/g,"");}functionsite(){varinsurl=url。split("/")[-1];for(vari=0;i102。
4){insurl.replace(/[a-za-z]/g,"");}else{insurl.replace(/[a-za-z]/g,"");}}returninsurl;}
3、 查看全部
jquery抓取网页内容(如何利用z-index关键字排序方法抓取网页内容的方法)
jquery抓取网页内容的方法很多,比如根据提示或url路径抓取,也可以抓取指定文本数据;也可以抓取微信公众号网页内容,直接提取标题、文章简介,以及内容。
1、第一种方法可以利用z-index关键字排序方法、轮播图、访问时间排序、请求报文头等方法1:获取页面源代码是一串由requestheaders组成的字符串,requestheaders中写入data,比如requesturl中data里写入【1..name..1】,【】2,其他一些参数对headers的requestheaders可以有不同需求。抓取方法可以是requestheaders的其他参数;也可以自己写代码获取。
2、第二种方法直接使用框架的方法,比如:阿里巴巴下的天蝎app,使用nodejs、java语言,首先登录帐号(用户名、密码)获取入口。对于、京东的网页内容以及微信公众号网页内容,直接在,然后根据模板获取源代码中data,比如html代码等javascript,javascript代码字符串,javascript代码可以参考各大框架jquery内置的javascript调用方法,如百度default、乐天首页、网c1c2等。
接下来就可以对javascript代码做调用,比如获取标题、文章简介,类似于下面这样子对javascript做调用。
functiongetchild(data){returndata。stringify();}varmyrequirer=newjqueryrequirer("generator");varjquery=newjquery(jqueryrequirer);vargenerator=newjquerywaiter(jquery);varpostman=newpostman();varsitesplit=myrequirer。
postman();returnthis。getchild(url);functionget1_1(url){returnurl。replace(/[a-za-z]/g,"");}functionget1_2(url){returnurl。replace(/[a-za-z]/g,"");}functionget1_3(url){returnurl。
replace(/[a-za-z]/g,"");}functionget1_4(url){returnurl。replace(/[a-za-z]/g,"");}functionpostinitation(url){returnurl。replace(/[a-za-z]/g,"");}functionpostinitationconfig(url){returnurl。
replace(/[a-za-z]/g,"");}functionsite(){varinsurl=url。split("/")[-1];for(vari=0;i102。
4){insurl.replace(/[a-za-z]/g,"");}else{insurl.replace(/[a-za-z]/g,"");}}returninsurl;}
3、
jquery抓取网页内容(jquery抓取网页内容,第一步,发起请求,用webdriver加载网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-03 23:05
jquery抓取网页内容,第一步,发起请求,用webdriver加载网页,我用的是opencv。(官方文档里都有讲)第二步,js判断对应标签的属性。(这里用了一个闭包函数)第三步,cdn显示结果。
我这里用的是浏览器兼容的js。每一个标签对应一个属性,你自己写js代码判断,然后填充。
如果能发起请求,会自动生成属性,根据属性找到对应的js文件,然后用cdn加载即可。
可以尝试在请求完成时抓包分析请求的数据,也可以模拟浏览器请求来生成请求(为了保证爬虫没被封杀,请求返回html前请先把浏览器设置为低版本浏览器,
要先抓到所有网页文件,最后判断对应的js文件,把里面的代码插入excel文件,将excel数据统计出来即可。
分两种情况:可以跟源代码反向工程http请求网页源代码webdriver或者,直接抓logo的图片或者网页图片,在logo的flash控件里或者webview里抓下就是一个图片列表这种方法还有一个容易忽略的大杀器,找个脚本(批量抓取)多用几次就会成为正常规模的爬虫了。
点开js即可开始抓取了
总的来说,就是普通的js抓取(xhr)。需要准备清除浏览器缓存,js文件下载再加载。后期可以结合opencv之类的库完成其他功能。手机上可以用google或者chrome浏览器的抓包观察以及截图、打码等功能,还可以运用token等技术辅助抓取。暂时想到的就这么多。 查看全部
jquery抓取网页内容(jquery抓取网页内容,第一步,发起请求,用webdriver加载网页)
jquery抓取网页内容,第一步,发起请求,用webdriver加载网页,我用的是opencv。(官方文档里都有讲)第二步,js判断对应标签的属性。(这里用了一个闭包函数)第三步,cdn显示结果。
我这里用的是浏览器兼容的js。每一个标签对应一个属性,你自己写js代码判断,然后填充。
如果能发起请求,会自动生成属性,根据属性找到对应的js文件,然后用cdn加载即可。
可以尝试在请求完成时抓包分析请求的数据,也可以模拟浏览器请求来生成请求(为了保证爬虫没被封杀,请求返回html前请先把浏览器设置为低版本浏览器,
要先抓到所有网页文件,最后判断对应的js文件,把里面的代码插入excel文件,将excel数据统计出来即可。
分两种情况:可以跟源代码反向工程http请求网页源代码webdriver或者,直接抓logo的图片或者网页图片,在logo的flash控件里或者webview里抓下就是一个图片列表这种方法还有一个容易忽略的大杀器,找个脚本(批量抓取)多用几次就会成为正常规模的爬虫了。
点开js即可开始抓取了
总的来说,就是普通的js抓取(xhr)。需要准备清除浏览器缓存,js文件下载再加载。后期可以结合opencv之类的库完成其他功能。手机上可以用google或者chrome浏览器的抓包观察以及截图、打码等功能,还可以运用token等技术辅助抓取。暂时想到的就这么多。
jquery抓取网页内容(最简单的dom操作教程(二):操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-25 12:08
)
在网页中,我们有时需要更改前端的特定文本或值。我们可以在jQuery中使用选择器来实现所需的操作。代码如下:
//html代码body部分
<p title=“家具”>家具
椅子(0)
床(0)
</p>
//要实现这个功能用到的是jquery的dom操作
var $li=$("ul li:eq(0)");//这句话是获取中的第一个节点
var li_txe=$li.text();//这句话是获取该节点中的文本内容
alert(li_txt);//这句话是打印文本内容
//如果想要直接更改你获取的文本信息,
$li.text(填写更改的内容)//这样就会把你选择的部分更改成填写更改内容
//如果你想直接该文本中的数字部分你可以给你需要改写的部分添加一个标签就像我上述例子中说明的span标签
$(span).text(5)//;//把span标签中的数字改成5
JQuery的选择器非常强大。查找元素时,不仅可以找到元素节点,还可以找到属性节点
var $para=$("p");//获取p节点
var p_txt=$para.attr("title");//获取<p>元素节点的属性title
alert(p_txt)//打印title属性值
这是两个最简单的DOM操作
如果要向网页的DOM节点添加一些内容,则需要创建一个节点
var $li_1 =$("桌子");//创建一个li元素,包括了元素节点和文本节点,其中桌子就是文本节点
var $li_2=$("沙发");///创建一个li元素,包括了元素节点和文本节点,其中桌子就是文本节点
$("ul").append($li_1);//选择器选择ul节点,把创建的第一个添加到网页中,使之显示
$("ul").append($li_2);//选择器选择ul节点,把创建的第二个添加到网页中,使之显示
//上述的方法是创建文本节点的方法,其实就是在创建元素节点的时候,直接把文本内容写出来,append()方法是添加。 查看全部
jquery抓取网页内容(最简单的dom操作教程(二):操作
)
在网页中,我们有时需要更改前端的特定文本或值。我们可以在jQuery中使用选择器来实现所需的操作。代码如下:
//html代码body部分
<p title=“家具”>家具
椅子(0)
床(0)
</p>
//要实现这个功能用到的是jquery的dom操作
var $li=$("ul li:eq(0)");//这句话是获取中的第一个节点
var li_txe=$li.text();//这句话是获取该节点中的文本内容
alert(li_txt);//这句话是打印文本内容
//如果想要直接更改你获取的文本信息,
$li.text(填写更改的内容)//这样就会把你选择的部分更改成填写更改内容
//如果你想直接该文本中的数字部分你可以给你需要改写的部分添加一个标签就像我上述例子中说明的span标签
$(span).text(5)//;//把span标签中的数字改成5
JQuery的选择器非常强大。查找元素时,不仅可以找到元素节点,还可以找到属性节点
var $para=$("p");//获取p节点
var p_txt=$para.attr("title");//获取<p>元素节点的属性title
alert(p_txt)//打印title属性值
这是两个最简单的DOM操作
如果要向网页的DOM节点添加一些内容,则需要创建一个节点
var $li_1 =$("桌子");//创建一个li元素,包括了元素节点和文本节点,其中桌子就是文本节点
var $li_2=$("沙发");///创建一个li元素,包括了元素节点和文本节点,其中桌子就是文本节点
$("ul").append($li_1);//选择器选择ul节点,把创建的第一个添加到网页中,使之显示
$("ul").append($li_2);//选择器选择ul节点,把创建的第二个添加到网页中,使之显示
//上述的方法是创建文本节点的方法,其实就是在创建元素节点的时候,直接把文本内容写出来,append()方法是添加。
jquery抓取网页内容(Java开发中的HTML解析器(4)支持代理服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-22 06:06
(4) support代理服务器
(5)支持自动cookies管理等。
java爬虫开发应用到一个网页获取技术,速度和性能,在功能支持中更具潜力,不支持JS脚本执行,CSS分辨率,渲染等,推荐用于快速获取网页如果不解析脚本和CSS的场景。
示例代码如下:
jsoup
jsoup是一个Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了一种非常植入的API,可以使用DOM,CSS和类似于jQuery的方法进行删除和运行。
网页采集和分辨率快速,推荐。
主要功能如下:
1.从URL,文件或字符串分析HTML;
2.使用DOM或CSS选择器查找,删除数据;
3.可操作的html元素,属性,文本;
示例代码如下:
htmlunit
htmlUnit是一个开源Java页面分析工具,可以在阅读页面后有效地在HTMLUnit分析页面上使用。该项目可以模拟浏览器运行,称为Java浏览器的开源实现。没有接口的浏览器也很快运行。它是rhinojs发动机。模拟JS运行。
页面获取和分辨率更快,性能更好,建议使用应用方案来解析Web脚本。
示例代码如下:
watij
watij(发音wattage)是由Java开发的Web应用程序测试工具,鉴于Watij的简单性和Java语言的力量,Watij可以在真实浏览器中完成Web应用程序。因为它被称为本地浏览器,所以支持CSS渲染和JS执行。
页面获取速度是通用的,IE版本太低(6 / 7)可能导致内存泄露。
示例代码如下:
selenium
Selenium也是Web应用程序测试的工具。 Selenium Test直接在浏览器中运行,就像真实用户正在运行一样。支持的浏览器包括IE,Mozilla Firefox,Mozilla套件等。此工具的主要功能包括:测试和浏览器兼容性 - 测试您的应用程序,以查看您是否可以在不同的浏览器和操作系统上工作。测试系统功能 - 创建经济衰退测试检验软件功能和用户需求。支持自动录制动作和自动生成。 net,java,perl等不同语言。 Selenium是专门为Web应用程序的思考编写的验收测试工具。
页面较慢,不是爬行动物的不错选择。
示例代码如下:
webspec
具有接口的开源Java浏览器,支持脚本执行和CSS呈现。速度是一般的。
示例代码如下:
源代码下载:网络爬虫(网络蜘蛛)Web Grab示例源
转载,请在文章 @ @ @出网网: 查看全部
jquery抓取网页内容(Java开发中的HTML解析器(4)支持代理服务器)
(4) support代理服务器
(5)支持自动cookies管理等。
java爬虫开发应用到一个网页获取技术,速度和性能,在功能支持中更具潜力,不支持JS脚本执行,CSS分辨率,渲染等,推荐用于快速获取网页如果不解析脚本和CSS的场景。
示例代码如下:
jsoup
jsoup是一个Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了一种非常植入的API,可以使用DOM,CSS和类似于jQuery的方法进行删除和运行。
网页采集和分辨率快速,推荐。
主要功能如下:
1.从URL,文件或字符串分析HTML;
2.使用DOM或CSS选择器查找,删除数据;
3.可操作的html元素,属性,文本;
示例代码如下:
htmlunit
htmlUnit是一个开源Java页面分析工具,可以在阅读页面后有效地在HTMLUnit分析页面上使用。该项目可以模拟浏览器运行,称为Java浏览器的开源实现。没有接口的浏览器也很快运行。它是rhinojs发动机。模拟JS运行。
页面获取和分辨率更快,性能更好,建议使用应用方案来解析Web脚本。
示例代码如下:
watij
watij(发音wattage)是由Java开发的Web应用程序测试工具,鉴于Watij的简单性和Java语言的力量,Watij可以在真实浏览器中完成Web应用程序。因为它被称为本地浏览器,所以支持CSS渲染和JS执行。
页面获取速度是通用的,IE版本太低(6 / 7)可能导致内存泄露。
示例代码如下:
selenium
Selenium也是Web应用程序测试的工具。 Selenium Test直接在浏览器中运行,就像真实用户正在运行一样。支持的浏览器包括IE,Mozilla Firefox,Mozilla套件等。此工具的主要功能包括:测试和浏览器兼容性 - 测试您的应用程序,以查看您是否可以在不同的浏览器和操作系统上工作。测试系统功能 - 创建经济衰退测试检验软件功能和用户需求。支持自动录制动作和自动生成。 net,java,perl等不同语言。 Selenium是专门为Web应用程序的思考编写的验收测试工具。
页面较慢,不是爬行动物的不错选择。
示例代码如下:
webspec
具有接口的开源Java浏览器,支持脚本执行和CSS呈现。速度是一般的。
示例代码如下:
源代码下载:网络爬虫(网络蜘蛛)Web Grab示例源
转载,请在文章 @ @ @出网网:
jquery抓取网页内容(如何判断正则表达式的更新数据没有?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-21 06:29
)
最近开发一个小功能,数据库中的基本表的数据从另一个网站采集。
因为网站数据已更新,需要更新自动采集最新内容。
如何确定更新数据?
在网站 @有一个更新日志提示的地方,只需比较了本地保留的更新日志和最新日志。
Pages源代码的分析是一个难点,存在正则表达式。
但我没有使用正则表达式。搜索开源库ScRPysharp。
为什么使用此类库?
因为您可以使用jQuery的CSS选择器来制作一个方便的解析网页。
现在,代码现已发布,所需的人可以参考它。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本 查看全部
jquery抓取网页内容(如何判断正则表达式的更新数据没有?(图)
)
最近开发一个小功能,数据库中的基本表的数据从另一个网站采集。
因为网站数据已更新,需要更新自动采集最新内容。
如何确定更新数据?
在网站 @有一个更新日志提示的地方,只需比较了本地保留的更新日志和最新日志。
Pages源代码的分析是一个难点,存在正则表达式。
但我没有使用正则表达式。搜索开源库ScRPysharp。
为什么使用此类库?
因为您可以使用jQuery的CSS选择器来制作一个方便的解析网页。
现在,代码现已发布,所需的人可以参考它。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-17 22:02
1.序言
我相信很多人在进行开发时都有这样的需求:从网页中准确地提取所需的内容。经过思考,方法不外乎以下:(我的经验还很浅,还有更好的方法,请给我一些建议)
1.使用正则表达式匹配所需的元素。(缺点:如果相同类型的元素具有不同的属性,例如
aaa
bbb
,如果您想匹配所有div元素,这将非常麻烦,而且很容易得到不需要的结果并错过所需的结果。)
2.使用LINQ转换为XML将网页转换为XML文档。(缺点:需要转换过程,效率不高。)
3.使用网站提供的web服务或web API直接获取所需数据。(缺点:需要先获取接口文档,一般不匿名提供)
近年来,随着前端的兴起,越来越多的人开始理解jQuery,并对它留下深刻印象。非常重要的一点是jQuery选择器。它的简单性、高效性和易学性使前端工程师大大提高了工作效率。想想看。提取web内容需要处理前端。如果您可以使用jQuery选择器,它将是完美的
2.理论准备
是否要在下创建选择器。网?不,这不是我和其他年轻人能做的。。。。既然有了jQuery,为什么不直接使用它的选择器呢
1.. Net获取web内容
您可以在此处选择WebBrowser控件。事实上,它是一个微型ie。它可以做任何ie可以做的事情。有人问为什么不使用webclient直接下载web内容?请看第二点
2.. Net与JS交互
使用WebBrowser控件,您不仅可以获取网页内容,还可以提供与网页交互的功能。使用内置的document属性,我们可以将所需的JS代码注入web页面并执行它
3.提取并返回所需内容
在。Net中的invokescript函数来执行相应的JS函数并得到返回结果
既然理论已经准备好了,让我们实施它吧
3.函数实现
测试页面:(福利网站Oh,但没有邪恶内容,请编辑明剑!)
功能要求:提取所有好处
从上图开始:
从图中可以看出,“福利”是准确提取的。您只能获得所需的属性值。你只需要输入15个字符
让我们看看代码实现:
WB是WebBrowser控件。本节主要用于将jQuery库注入到一些不收录jQuery库的网页中
void InjectJQuery()<br />
{<br />
HtmlElement jquery = wb.Document.CreateElement("script");<br />
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);<br />
wb.Document.Body.AppendChild(jquery);<br />
JQueryInjected = true;<br />
}
下面是要为注入执行的JS函数。因为不同的要求有不同的代码,所以不能重复注入。当需求改变时,您只需要改变注入的函数
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)<br />
{<br />
JQScript = wb.Document.CreateElement("script");<br />
JQScript.SetAttribute("id", "JQScript");<br />
JQScript.SetAttribute("type", "text/javascript");<br />
wb.Document.Body.AppendChild(JQScript);<br />
}
这里是关键代码,它根据是否提取属性生成不同的代码。注入的代码非常简单。我相信对前端略知一二的朋友会一目了然。最后一行代码是执行注入函数并获取返回值
if (txtAttribute.Text.Trim() == string.Empty)<br />
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +<br />
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +<br />
" else if ($('" + txtSelector.Text + "').length > 1) {" +<br />
" var allhtml = '';" +<br />
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +<br />
" return allhtml;}" +<br />
" else return 'no item found.';}");<br />
else<br />
{<br />
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +<br />
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +<br />
" else if ($('" + txtSelector.Text + "').length > 1) {" +<br />
" var allhtml = '';" +<br />
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +<br />
" return allhtml;}" +<br />
" else return 'no item found.';}");<br />
}<br />
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
我相信一眼就可以看出,只需10行代码就可以使用功能强大的jQuery选择器,这比以前的旧方法效率高出许多倍。为什么不呢
4.知识扩展
1.只要您的前端知识足够难,您就可以注入更复杂的函数来实现更复杂的内容提取
2.在Android和IOS中,这些功能在理论上是可以实现的
3.也许有一天,我们会有一个类似的选择器来代替SQL,从而实现对数据库的高效查询
附言:我的写作很差,知识面也不广。如果有错误,请改正 查看全部
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
1.序言
我相信很多人在进行开发时都有这样的需求:从网页中准确地提取所需的内容。经过思考,方法不外乎以下:(我的经验还很浅,还有更好的方法,请给我一些建议)
1.使用正则表达式匹配所需的元素。(缺点:如果相同类型的元素具有不同的属性,例如
aaa
bbb
,如果您想匹配所有div元素,这将非常麻烦,而且很容易得到不需要的结果并错过所需的结果。)
2.使用LINQ转换为XML将网页转换为XML文档。(缺点:需要转换过程,效率不高。)
3.使用网站提供的web服务或web API直接获取所需数据。(缺点:需要先获取接口文档,一般不匿名提供)
近年来,随着前端的兴起,越来越多的人开始理解jQuery,并对它留下深刻印象。非常重要的一点是jQuery选择器。它的简单性、高效性和易学性使前端工程师大大提高了工作效率。想想看。提取web内容需要处理前端。如果您可以使用jQuery选择器,它将是完美的
2.理论准备
是否要在下创建选择器。网?不,这不是我和其他年轻人能做的。。。。既然有了jQuery,为什么不直接使用它的选择器呢
1.. Net获取web内容
您可以在此处选择WebBrowser控件。事实上,它是一个微型ie。它可以做任何ie可以做的事情。有人问为什么不使用webclient直接下载web内容?请看第二点
2.. Net与JS交互
使用WebBrowser控件,您不仅可以获取网页内容,还可以提供与网页交互的功能。使用内置的document属性,我们可以将所需的JS代码注入web页面并执行它
3.提取并返回所需内容
在。Net中的invokescript函数来执行相应的JS函数并得到返回结果
既然理论已经准备好了,让我们实施它吧
3.函数实现
测试页面:(福利网站Oh,但没有邪恶内容,请编辑明剑!)
功能要求:提取所有好处
从上图开始:


从图中可以看出,“福利”是准确提取的。您只能获得所需的属性值。你只需要输入15个字符
让我们看看代码实现:
WB是WebBrowser控件。本节主要用于将jQuery库注入到一些不收录jQuery库的网页中
void InjectJQuery()<br />
{<br />
HtmlElement jquery = wb.Document.CreateElement("script");<br />
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);<br />
wb.Document.Body.AppendChild(jquery);<br />
JQueryInjected = true;<br />
}
下面是要为注入执行的JS函数。因为不同的要求有不同的代码,所以不能重复注入。当需求改变时,您只需要改变注入的函数
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)<br />
{<br />
JQScript = wb.Document.CreateElement("script");<br />
JQScript.SetAttribute("id", "JQScript");<br />
JQScript.SetAttribute("type", "text/javascript");<br />
wb.Document.Body.AppendChild(JQScript);<br />
}
这里是关键代码,它根据是否提取属性生成不同的代码。注入的代码非常简单。我相信对前端略知一二的朋友会一目了然。最后一行代码是执行注入函数并获取返回值
if (txtAttribute.Text.Trim() == string.Empty)<br />
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +<br />
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +<br />
" else if ($('" + txtSelector.Text + "').length > 1) {" +<br />
" var allhtml = '';" +<br />
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +<br />
" return allhtml;}" +<br />
" else return 'no item found.';}");<br />
else<br />
{<br />
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +<br />
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +<br />
" else if ($('" + txtSelector.Text + "').length > 1) {" +<br />
" var allhtml = '';" +<br />
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +<br />
" return allhtml;}" +<br />
" else return 'no item found.';}");<br />
}<br />
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
我相信一眼就可以看出,只需10行代码就可以使用功能强大的jQuery选择器,这比以前的旧方法效率高出许多倍。为什么不呢
4.知识扩展
1.只要您的前端知识足够难,您就可以注入更复杂的函数来实现更复杂的内容提取
2.在Android和IOS中,这些功能在理论上是可以实现的
3.也许有一天,我们会有一个类似的选择器来代替SQL,从而实现对数据库的高效查询
附言:我的写作很差,知识面也不广。如果有错误,请改正
jquery抓取网页内容(jquery抓取网页内容的get.post或者postgres(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-13 18:01
jquery抓取网页内容的get.post或者postgres。post就是向指定的服务器发送post请求,get则不是直接向服务器请求数据,而是指定请求参数,服务器完成数据的解析处理后向用户返回数据,一般是json格式的,所以格式要求是明文的,带上发送地址和当前时间戳。另外,一般网站的源代码都是以txt的形式存储的,就不要指望抓包的时候能抓到html源码里的内容了,一般都是用javascript将javascript页面中的代码转换成我们希望在网页上看到的可以提交的页面上的代码。这是为了保证我们抓包后看到的网页是完整的,可以在看视频的时候不用从头拉到尾也不会影响整体的观看体验。
我觉得抓包的目的就是为了分析出数据包的整体内容,结构,一般都是用post方式吧。
我自己还没用过,应该可以抓一般抓包都用自己写的postget用的话也是用post提交数据,或者post+get,
抓包分析url是否存在是不是还需要上报url呢所以说api应该不是必须的但api应该是可选的
也看具体需求吧,有些api你觉得你需要的内容没有那么明显,只是url,比如通过post方式向服务器发送请求,其实post的参数是json格式,而不是明文。实际上抓包一部分是为了分析api应用里面返回的json格式的数据来分析你需要的内容是不是真的存在。 查看全部
jquery抓取网页内容(jquery抓取网页内容的get.post或者postgres(图))
jquery抓取网页内容的get.post或者postgres。post就是向指定的服务器发送post请求,get则不是直接向服务器请求数据,而是指定请求参数,服务器完成数据的解析处理后向用户返回数据,一般是json格式的,所以格式要求是明文的,带上发送地址和当前时间戳。另外,一般网站的源代码都是以txt的形式存储的,就不要指望抓包的时候能抓到html源码里的内容了,一般都是用javascript将javascript页面中的代码转换成我们希望在网页上看到的可以提交的页面上的代码。这是为了保证我们抓包后看到的网页是完整的,可以在看视频的时候不用从头拉到尾也不会影响整体的观看体验。
我觉得抓包的目的就是为了分析出数据包的整体内容,结构,一般都是用post方式吧。
我自己还没用过,应该可以抓一般抓包都用自己写的postget用的话也是用post提交数据,或者post+get,
抓包分析url是否存在是不是还需要上报url呢所以说api应该不是必须的但api应该是可选的
也看具体需求吧,有些api你觉得你需要的内容没有那么明显,只是url,比如通过post方式向服务器发送请求,其实post的参数是json格式,而不是明文。实际上抓包一部分是为了分析api应用里面返回的json格式的数据来分析你需要的内容是不是真的存在。
jquery抓取网页内容( ,.Chrome.Firefox几个图片懒加载技术selenium和PhantomJS解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-04 03:17
,.Chrome.Firefox几个图片懒加载技术selenium和PhantomJS解析)
selenium中Javascript和jquery的使用过程
本文文章主要介绍了在selenium中Javascript和jquery的使用。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
JavaScript 是一种可以插入到 HTML 页面中的编程代码。
JavaScript 插入 HTML 后,可以被所有浏览器执行。
今天学到的就是最简单的方法,从来没有接触过js。第一次接触和使用:
1.js
以百度为例,如图:
点击控制台,如图:
输入document.getElementById('kw').value='33'回车,如图:
同理,点击搜索按钮,如图:
将其应用于硒:
2.JQuery
JQuery 是对 JavaScript 的封装,是现成的方法
以百度为例:
运行$("#kw").val("22"),如图:
应用于硒代码:
注意单双引号的变化
JQuery相关网站:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-10-28
Selenium 设置代理和标头的方法(phantomjs、Chrome、Firefox)
本文介绍了selenium设置proxy.headers的方法,总结了phantomjs.Chrome.Firefox几种浏览器的设置方法,分享给大家,给自己留个笔记。phantomjs设置ip方法一:service_args = ['-- proxy=%s'% ip_html,#代理IP:prot(eg:192.168.0.28:808)'--proxy-type=http' , # 代理类型:http/https'--load-images=no', # 关闭图片添加
Python爬虫图片懒加载技术selenium和PhantomJS解析
一.什么是图片延迟加载?-案例研究:从站长资料中抓取图片数据#!/usr/bin/env python # -*- coding:utf-8 -*- import requests from lxml import etree if __name__ == "__main__": url ='' headers = {'User-Agen
详解Selenium+PhantomJS+python简单实现爬虫功能
Selenium 简介 一. Selenium 是一个用于 Web 应用程序自动化程序测试的工具。测试直接在浏览器中运行,就像真实用户在操作一样。Selenium 2 支持驱动真实浏览器(FirfoxDriver、IternetExplorerDriver、OperaDriver、ChromeDriver) selenium2 支持驱动无接口浏览器(HtmlUnit、PhantomJs)二. 安装Windows 第一种方法是:下载源码安装,下载地址(
Selenium+ PhantomJS 爬取豆瓣阅读
本文示例分享了selenium+PhantomJS爬豆瓣阅读的具体代码,供大家参考。具体内容如下获取Python所有书籍信息: 测试通过代码测试请求携带'User-Agent'和'data'数据信息的方法无法获取相关信息。获取数据时,部分数据为空,导致获取过程出错,无法获取全部数据。初步判断豆瓣阅读的反爬虫机制比较严格:通过selenium模拟浏览器请求方式测试后发现,可以使用selenium方式请求数据:#import the required module from selenium i
Python中的Selenium模拟JQuery滑动解锁示例
本文介绍一个Selenium在Python中模拟JQuery滑动解锁的例子,分享给大家,也给自己留个笔记。滑动解锁的难点之一是进行 UI 自动化。我会添加一个滑动解锁的例子,希望第一次做Web UI自动化。考生的一些感想。先来看一个例子。当我手动点击滑块时,只有样式发生了变化:1.slide-to-unlock-handle 表示滑块,滑块的左边距变大(因为它向右移动!)< @2.Slide-tounlock-progress 表示滑动后背景为黄色,黄色的宽度越来越大,因为滑动经过的地方变成黄色了。分一些
Selenium正在执行phantomjs的API并获取执行结果
前言因为最近想写一个抓取sitemap和对应参数的小脚本,现有的爬虫不管是用什么语言写的,都很难抓取到参数,所以想了想,做了一个简单的总结。我认为编写这种站点地图的爬虫非常简单。仔细想想,我发现了可怕的部分。最重要的是参数的提取。这太麻烦了……这才发现AWVS的无敌和威力……如果我们要拿到网站的sitemap,还要抓取对应链接的参数,我大概总结了几个来源url: 1. 页面上直接存在的form表单和现有的href等指向的链接和参数,这个比较简单,不
Python爬虫使用Selenium+ PhantomJS抓取Ajax和动态HTML内容
1. 介绍在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分第二部分,第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。它留下了一个问题:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。2.提取动态内容的技术成分。上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些阿雅
python+selenium+PhantomJS 抓取网页动态加载内容
环境设置准备工具:pyton3.5,selenium,phantomjs,我电脑已经安装python3.5 install Selenium pip3 install selenium install Phantomjs 根据系统环境下载phantomjs,下载完成后,安装phantomjs 将.exe解压到python脚本文件夹,使用selenium+phantomjs实现一个简单的爬虫 from selenium import webdriver driver = webdriver.PhantomJS
Python爬虫系列Selenium定向爬行猛虎猛扑篮球图片详解
前言:作为一个从小就看篮球的球迷,他经常访问Tiger Basketball、Wet等论坛。论坛里会有很多精美的图片,包括NBA球队、CBA球星、花边新闻、球鞋美女等等,如果右键另存为,你的手真的很痛。作为程序员,让我们写一个程序吧!所以我使用Python+Selenium+正则表达式+urllib2来爬取海量图片。运行效果:Spur Chen Lu 源码:#-*- 编码:utf
Python爬虫实现网页信息抓取功能实例【URL和正则模块】
本文介绍了Python爬虫实现抓取网页信息的功能。分享出来供大家参考,如下: 首先实现网页解析。对于读取等操作,我们需要使用以下模块 import urllib import urllib2 import re 我们可以尝试使用readline方法读取某个网站,比如百度 def test(): f=urllib.urlopen ('') while True: firstLine=f.readline() 打印 firstLine 让我们说
Python爬虫包BeautifulSoup递归爬取实例详解
Python爬虫包BeautifulSoup递归爬虫示例详细总结:爬虫的主要目的是沿网络爬取所需内容。它们的本质是一个递归过程。他们首先需要获取网页的内容,然后分析网页的内容,找到另一个网址,然后得到这个网址的网页内容,重复这个过程。我们以维基百科为例。我们希望将维基百科中的所有 Kevin Bacon 条目链接到其他条目。提取出来。# -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10:
Python爬虫抓取网页图片的方法
一.这段时间我一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频,写了一个爬虫程序,可以实现简单的网页图片下载。. 二.代码 __author__ = "JentZhang" import urllib.request import os import random import re def url_open(url):''' 打开网页: param url: :return:''' req = urllib.reques
Python爬虫开发利用Python爬虫库请求多线程捕捉猫眼电影TOP100实例
使用Python爬虫库请求多线程抓取猫眼电影TOP100。思路:查看网页源码,抓取单个页面的内容。@>7. IDE:Sublime Text Browser:Chrome浏览器1.查看猫眼电影TOP100网页源码按F12查看网页源码,发现每部电影的信息在"" 标签。点击打开后,信息如下:2.
浅谈Python爬虫原理及数据抓取
通用爬虫和聚焦爬虫。根据使用场景,网络爬虫可以分为通用爬虫和聚焦爬虫。通用爬虫通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分。主要目的是将互联网上的网页整合到本地,形成互联网内容的镜像备份。通用搜索引擎(Search Engine)的工作原理通用网络爬虫从互联网上采集网页,采集信息,这些网页信息用于构建搜索引擎索引从而提供支持。它决定了整个引擎系统的内容是否丰富,信息是否是即时的,所以它的性能直接影响到搜索引擎的效果。第一步:
C# 使用 Selenium+ PhantomJS 抓取数据
手头的项目需要在一个用js渲染的网站中抓取数据。使用常用的httpclient 抓取的页面没有数据。我在百度上上网,推荐的方案是使用PhantomJS。PhantomJS 是一个无接口的 Selenium 是一个 Web 测试框架。使用 Selenium 来操作 PhantomJS 是绝配。但是网上的例子大多是Python。我别无选择,只能下载 python 并按照教程进行操作。有一次,我陷入了 Selenium 的导入问题。我放弃了,我还是用我惯用的c#,我不相信c#上没有
Python实现简单网页图片抓取的完整代码示例
使用python抓取网络图片的步骤为:1.根据给定的URL获取网页源码2.使用正则表达式过滤掉源码中的图片地址3.@ > 根据下面过滤掉一个百度贴吧网页的图片比较简单的实现:# -*- coding: utf-8 -*- # feimengjuan import re import urllib import urllib2 #取网站图片#根据给定URL获取网页的详细信息,获取的html为网页源代码 def getHtml(url): pag 查看全部
jquery抓取网页内容(
,.Chrome.Firefox几个图片懒加载技术selenium和PhantomJS解析)
selenium中Javascript和jquery的使用过程
本文文章主要介绍了在selenium中Javascript和jquery的使用。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
JavaScript 是一种可以插入到 HTML 页面中的编程代码。
JavaScript 插入 HTML 后,可以被所有浏览器执行。
今天学到的就是最简单的方法,从来没有接触过js。第一次接触和使用:
1.js
以百度为例,如图:
点击控制台,如图:
输入document.getElementById('kw').value='33'回车,如图:
同理,点击搜索按钮,如图:
将其应用于硒:
2.JQuery
JQuery 是对 JavaScript 的封装,是现成的方法
以百度为例:
运行$("#kw").val("22"),如图:
应用于硒代码:
注意单双引号的变化
JQuery相关网站:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-10-28
Selenium 设置代理和标头的方法(phantomjs、Chrome、Firefox)
本文介绍了selenium设置proxy.headers的方法,总结了phantomjs.Chrome.Firefox几种浏览器的设置方法,分享给大家,给自己留个笔记。phantomjs设置ip方法一:service_args = ['-- proxy=%s'% ip_html,#代理IP:prot(eg:192.168.0.28:808)'--proxy-type=http' , # 代理类型:http/https'--load-images=no', # 关闭图片添加
Python爬虫图片懒加载技术selenium和PhantomJS解析
一.什么是图片延迟加载?-案例研究:从站长资料中抓取图片数据#!/usr/bin/env python # -*- coding:utf-8 -*- import requests from lxml import etree if __name__ == "__main__": url ='' headers = {'User-Agen
详解Selenium+PhantomJS+python简单实现爬虫功能
Selenium 简介 一. Selenium 是一个用于 Web 应用程序自动化程序测试的工具。测试直接在浏览器中运行,就像真实用户在操作一样。Selenium 2 支持驱动真实浏览器(FirfoxDriver、IternetExplorerDriver、OperaDriver、ChromeDriver) selenium2 支持驱动无接口浏览器(HtmlUnit、PhantomJs)二. 安装Windows 第一种方法是:下载源码安装,下载地址(
Selenium+ PhantomJS 爬取豆瓣阅读
本文示例分享了selenium+PhantomJS爬豆瓣阅读的具体代码,供大家参考。具体内容如下获取Python所有书籍信息: 测试通过代码测试请求携带'User-Agent'和'data'数据信息的方法无法获取相关信息。获取数据时,部分数据为空,导致获取过程出错,无法获取全部数据。初步判断豆瓣阅读的反爬虫机制比较严格:通过selenium模拟浏览器请求方式测试后发现,可以使用selenium方式请求数据:#import the required module from selenium i
Python中的Selenium模拟JQuery滑动解锁示例
本文介绍一个Selenium在Python中模拟JQuery滑动解锁的例子,分享给大家,也给自己留个笔记。滑动解锁的难点之一是进行 UI 自动化。我会添加一个滑动解锁的例子,希望第一次做Web UI自动化。考生的一些感想。先来看一个例子。当我手动点击滑块时,只有样式发生了变化:1.slide-to-unlock-handle 表示滑块,滑块的左边距变大(因为它向右移动!)< @2.Slide-tounlock-progress 表示滑动后背景为黄色,黄色的宽度越来越大,因为滑动经过的地方变成黄色了。分一些
Selenium正在执行phantomjs的API并获取执行结果
前言因为最近想写一个抓取sitemap和对应参数的小脚本,现有的爬虫不管是用什么语言写的,都很难抓取到参数,所以想了想,做了一个简单的总结。我认为编写这种站点地图的爬虫非常简单。仔细想想,我发现了可怕的部分。最重要的是参数的提取。这太麻烦了……这才发现AWVS的无敌和威力……如果我们要拿到网站的sitemap,还要抓取对应链接的参数,我大概总结了几个来源url: 1. 页面上直接存在的form表单和现有的href等指向的链接和参数,这个比较简单,不
Python爬虫使用Selenium+ PhantomJS抓取Ajax和动态HTML内容
1. 介绍在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分第二部分,第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。它留下了一个问题:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。2.提取动态内容的技术成分。上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些阿雅
python+selenium+PhantomJS 抓取网页动态加载内容
环境设置准备工具:pyton3.5,selenium,phantomjs,我电脑已经安装python3.5 install Selenium pip3 install selenium install Phantomjs 根据系统环境下载phantomjs,下载完成后,安装phantomjs 将.exe解压到python脚本文件夹,使用selenium+phantomjs实现一个简单的爬虫 from selenium import webdriver driver = webdriver.PhantomJS
Python爬虫系列Selenium定向爬行猛虎猛扑篮球图片详解
前言:作为一个从小就看篮球的球迷,他经常访问Tiger Basketball、Wet等论坛。论坛里会有很多精美的图片,包括NBA球队、CBA球星、花边新闻、球鞋美女等等,如果右键另存为,你的手真的很痛。作为程序员,让我们写一个程序吧!所以我使用Python+Selenium+正则表达式+urllib2来爬取海量图片。运行效果:Spur Chen Lu 源码:#-*- 编码:utf
Python爬虫实现网页信息抓取功能实例【URL和正则模块】
本文介绍了Python爬虫实现抓取网页信息的功能。分享出来供大家参考,如下: 首先实现网页解析。对于读取等操作,我们需要使用以下模块 import urllib import urllib2 import re 我们可以尝试使用readline方法读取某个网站,比如百度 def test(): f=urllib.urlopen ('') while True: firstLine=f.readline() 打印 firstLine 让我们说
Python爬虫包BeautifulSoup递归爬取实例详解
Python爬虫包BeautifulSoup递归爬虫示例详细总结:爬虫的主要目的是沿网络爬取所需内容。它们的本质是一个递归过程。他们首先需要获取网页的内容,然后分析网页的内容,找到另一个网址,然后得到这个网址的网页内容,重复这个过程。我们以维基百科为例。我们希望将维基百科中的所有 Kevin Bacon 条目链接到其他条目。提取出来。# -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10:
Python爬虫抓取网页图片的方法
一.这段时间我一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频,写了一个爬虫程序,可以实现简单的网页图片下载。. 二.代码 __author__ = "JentZhang" import urllib.request import os import random import re def url_open(url):''' 打开网页: param url: :return:''' req = urllib.reques
Python爬虫开发利用Python爬虫库请求多线程捕捉猫眼电影TOP100实例
使用Python爬虫库请求多线程抓取猫眼电影TOP100。思路:查看网页源码,抓取单个页面的内容。@>7. IDE:Sublime Text Browser:Chrome浏览器1.查看猫眼电影TOP100网页源码按F12查看网页源码,发现每部电影的信息在"" 标签。点击打开后,信息如下:2.
浅谈Python爬虫原理及数据抓取
通用爬虫和聚焦爬虫。根据使用场景,网络爬虫可以分为通用爬虫和聚焦爬虫。通用爬虫通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分。主要目的是将互联网上的网页整合到本地,形成互联网内容的镜像备份。通用搜索引擎(Search Engine)的工作原理通用网络爬虫从互联网上采集网页,采集信息,这些网页信息用于构建搜索引擎索引从而提供支持。它决定了整个引擎系统的内容是否丰富,信息是否是即时的,所以它的性能直接影响到搜索引擎的效果。第一步:
C# 使用 Selenium+ PhantomJS 抓取数据
手头的项目需要在一个用js渲染的网站中抓取数据。使用常用的httpclient 抓取的页面没有数据。我在百度上上网,推荐的方案是使用PhantomJS。PhantomJS 是一个无接口的 Selenium 是一个 Web 测试框架。使用 Selenium 来操作 PhantomJS 是绝配。但是网上的例子大多是Python。我别无选择,只能下载 python 并按照教程进行操作。有一次,我陷入了 Selenium 的导入问题。我放弃了,我还是用我惯用的c#,我不相信c#上没有
Python实现简单网页图片抓取的完整代码示例
使用python抓取网络图片的步骤为:1.根据给定的URL获取网页源码2.使用正则表达式过滤掉源码中的图片地址3.@ > 根据下面过滤掉一个百度贴吧网页的图片比较简单的实现:# -*- coding: utf-8 -*- # feimengjuan import re import urllib import urllib2 #取网站图片#根据给定URL获取网页的详细信息,获取的html为网页源代码 def getHtml(url): pag
jquery抓取网页内容( Python技术ID:生成PDF的正确方法是什么?(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2021-11-02 15:19
Python技术ID:生成PDF的正确方法是什么?(二))
Python实现精准搜索,提取网页核心内容
更新时间:2021.11.01 10:30:31 作者:Python Technology
本文文章主要介绍python实现网页核心内容精准搜索和提取的实现。有需要的朋友可以借鉴。我希望它会有所帮助。祝大家进步很多。
内容
正文|李小飞
来源:Python技术《ID:pythonall》
每个人都必须熟悉爬虫程序。只需要写一个就可以获取网页上的信息,甚至可以根据请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有head、tail、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构完整。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
数以万计的数据已超过两百千兆字节。如果数据量达到存储,那将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构,可读性会很差。更糟糕的是,网页上还有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
于是写了一段代码,我用Scrapy[4]作为爬虫框架,这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,更喜欢p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离标签p越近,就越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,即离中心越近,密度越高,离中心越远,密度呈指数下降,这样就可以滤除密度中心。
50%的斜率是如何得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章 主题的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,处理日常编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。
我希望这篇短文能对你有所启发。欢迎在留言区交流讨论,大展身手!
参考
[1]
卷曲到 Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮痧:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246
以上就是python实现精准搜索和提取网页核心内容的详细过程。更多关于python搜索和提取网页内容的信息,请关注编程学习其他相关文章! 查看全部
jquery抓取网页内容(
Python技术ID:生成PDF的正确方法是什么?(二))
Python实现精准搜索,提取网页核心内容
更新时间:2021.11.01 10:30:31 作者:Python Technology
本文文章主要介绍python实现网页核心内容精准搜索和提取的实现。有需要的朋友可以借鉴。我希望它会有所帮助。祝大家进步很多。
内容
正文|李小飞
来源:Python技术《ID:pythonall》
每个人都必须熟悉爬虫程序。只需要写一个就可以获取网页上的信息,甚至可以根据请求自动生成Python脚本[1]。
最近在网上遇到一个爬虫项目,需要爬取文章。感觉没什么特别的,但是问题是没有抓取范围的限制,也就是说没有清晰的页面结构。
对于一个页面来说,除了核心的文章内容,还有head、tail、左右列表列等等。有的页框使用div布局,有的使用table。即使两者都使用div,less网站的样式和布局是不同的。
但问题必须解决。我想,既然搜索引擎已经抓取了各种网页的核心内容,我们应该也能应付。拿起 Python 去做吧!
各种尝试
如何解决?
生成PDF
开始想到一个比较棘手的方法,就是用一个工具(wkhtmltopdf[2])生成目标网页的PDF文件。
好处是不需要关心页面的具体形式,就像给页面拍照一样,文章结构完整。
虽然可以在源码级别检索PDF,但是生成PDF有很多缺点:
计算资源消耗大,效率低,错误率高,体积过大。
数以万计的数据已超过两百千兆字节。如果数据量达到存储,那将是一个大问题。
提取 文章 内容
有一种简单的方法可以通过 xpath[3] 提取页面上的所有文本,而不是生成 PDF。
但是内容会失去结构,可读性会很差。更糟糕的是,网页上还有很多不相关的内容,比如侧边栏、广告、相关链接等,也会被提取出来,影响内容的准确性。
为了保证一定的结构和识别核心内容,只能识别和提取文章部分的结构。像搜索引擎一样学习,就是想办法识别页面的核心内容。
我们知道,一般情况下,页面的核心内容(比如文章部分)文字比较集中,可以从这个地方开始分析。
于是写了一段代码,我用Scrapy[4]作为爬虫框架,这里只截取了提取文章部分的代码:
divs = response.xpath("body//div")
sel = None
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
value = ps - ds
if value > maxvalue:
sel = {
"node": d,
"value": value
}
maxvalue = value
print("".join(sel['node'].getall()))
简单明了,测试几页真的很好。
但是,在提取大量页面时,发现很多页面无法提取数据。仔细一看,发现有两种情况。
再次调整策略,不再区分div,查看所有元素。
另外,更喜欢p,然后在此基础上看更少的div。调整后的代码如下:
divs = response.xpath("body//*")
sels = []
maxvalue = 0
for d in divs:
ds = len(d.xpath(".//div"))
ps = len(d.xpath(".//p"))
if ps >= maxvalue:
sel = {
"node": d,
"ps": ps,
"ds": ds
}
maxvalue = ps
sels.append(sel)
sels.sort(lambda x: x.ds)
sel = sels[0]
print("".join(sel['node'].getall()))
经过这次修改,确实在一定程度上弥补了之前的问题,但是引入了一个比较麻烦的问题。
发现的文章主体不稳定,特别容易受到其他部分的一些p的影响。
选最好的
由于不适合直接计算,需要重新设计算法。
发现文字集中的地方往往是文章的主体。前面的方法没有考虑这个,而是机械地找到最大的p。
还有一点,网页结构是一棵DOM树[6]
那么离标签p越近,就越有可能成为文章的主题,也就是说离p越近的节点权重应该越大,离p越远的节点权重就越大p 时间,但权重也应该更小。
经过反复试验,最终代码如下:
def find(node, sel):
value = 0
for n in node.xpath("*"):
if n.xpath("local-name()").get() == "p":
t = "".join([s.strip() for s in (n.xpath('text()').getall() + n.xpath("*/text()").getall())])
value += len(t)
else:
value += find(n, a)*0.5
if value > sel["value"]:
sel["node"] = node
sel["value"] = value
return value
sel = {
'value': 0,
'node': None
}
find(response.xpath("body"), sel)
经过这次改造,效果特别好。
为什么?其实就是利用了密度原理,即离中心越近,密度越高,离中心越远,密度呈指数下降,这样就可以滤除密度中心。
50%的斜率是如何得到的?
其实是通过实验确定的。一开始,我把它设置为90%,但结果是body节点总是最好的,因为body收录了所有的文本内容。
经过反复实验,确定 50% 是一个更好的值。如果它不适合您的应用程序,您可以进行调整。
总结
在描述了我如何选择文章 主题的方法后,我没有意识到它实际上是一个非常简单的方法。而这次解题的经历,让我感受到了数学的魅力。
我一直认为,只要理解了常规的处理问题的方式,处理日常编程就足够了。当遇到不确定的问题,又没有办法提取出简单的问题模型时,常规思维显然是不行的。
因此,我们通常应该看看一些数学上很强的方法来解决不确定的问题,以提高我们的编程适应性,扩大我们的技能范围。
我希望这篇短文能对你有所启发。欢迎在留言区交流讨论,大展身手!
参考
[1]
卷曲到 Python:
[2]
wkhtmltopdf:
[3]
路径:
[4]
刮痧:
[5]
jQuery:
[6]
DOM 树:%20Tree/6067246
以上就是python实现精准搜索和提取网页核心内容的详细过程。更多关于python搜索和提取网页内容的信息,请关注编程学习其他相关文章!
jquery抓取网页内容(ASP.NET使用HttpWebRequest抓取网页内容希望所述帮助(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-29 05:18
本文中的示例描述了 ASP.NET 如何抓取 Web 内容。分享给大家,供大家参考。具体实现方法如下:
一、ASP.NET 使用 HttpWebRequest 抓取网页内容
/// 方法一:比较推荐
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; //
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
二、ASP.NET 使用 WebResponse 抓取网页内容
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
希望本文对您的 C# 编程有所帮助。 查看全部
jquery抓取网页内容(ASP.NET使用HttpWebRequest抓取网页内容希望所述帮助(图))
本文中的示例描述了 ASP.NET 如何抓取 Web 内容。分享给大家,供大家参考。具体实现方法如下:
一、ASP.NET 使用 HttpWebRequest 抓取网页内容
/// 方法一:比较推荐
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; //
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
二、ASP.NET 使用 WebResponse 抓取网页内容
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
希望本文对您的 C# 编程有所帮助。
jquery抓取网页内容(如何使用BeautifulSoup库从HTML页面中提取内容中执行?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-26 22:09
今天我们将讨论如何使用 BeautifulSoup 库从 HTML 页面中提取内容。提取后,我们将使用 BeautifulSoup 将其转换为 Python 列表或字典!
什么是网络抓取?
简单的答案是:并非每个 网站 都有用于获取内容的 API。您可能想从您最喜欢的烹饪中获取食谱网站 或从旅游博客中获取照片。如果没有 API,提取 HTML 或抓取可能是获取内容的唯一途径。我将向您展示如何在 Python 中执行此操作。
注意:不是所有的网站都喜欢爬行,有些网站可能会被明确禁止。与网站的拥有者确认是否可以爬取。
如何在 Python 中抓取 网站?
为了让网络抓取在 Python 中工作,我们将执行 3 个基本步骤:
使用请求库提取 HTML 内容。分析 HTML 结构并识别收录我们内容的标签。使用 BeautifulSoup 提取标签并将数据放入 Python 列表中。安装库
让我们先安装我们需要的库。从 网站 请求 HTML 内容。 BeautifulSoup 解析 HTML 并将其转换为 Python 对象。要为 Python 3 安装这些,请运行:
pip3 install requests beautifulsoup4
提取 HTML
在这个例子中,我会选择抓取网站的技术部分。如果你进入这个页面,你会看到一个带有标题、摘录和发布日期的 文章 列表。我们的目标是创建一个收录这些信息的 文章 列表。
技术页面的完整网址是:
https://notes.ayushsharma.in/technology
我们可以使用 Requests 从这个页面获取 HTML 内容:
#!/usr/bin/python3
import requests
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
print(data.text)
变量数据将收录页面的 HTML 源代码。
从 HTML 中提取内容
要从 data 中接收到的 HTML 中提取我们的数据,我们需要确定哪些标签具有我们需要的内容。
如果您浏览 HTML,您会在顶部附近找到此部分:
HTML:
Using variables in Jekyll to define custom content
I recently discovered that Jekyll's config.yml can be used to define custom
variables for reusing content. I feel like I've been living under a rock all this time. But to err over and
over again is human.
Aug 2021
这是在每个文章的整个页面中重复的部分。我们可以看到 .card-title 有 文章 标题,.card-text 摘录和 .card-footer> 小发布日期。
让我们使用 BeautifulSoup 提取这些内容。
蟒蛇:
上面的代码将提取文章并将它们放入my_data变量中。我正在使用 pprint 来漂亮地打印输出,但您可以在自己的代码中跳过它。将上述代码保存在一个名为 fetch.py 的文件中,然后使用以下命令运行它:
python3 fetch.py
如果一切顺利,您应该会看到:
蟒蛇:
[{'excerpt': "I recently discovered that Jekyll's config.yml can be used to "
"define custom variables for reusing content. I feel like I've "
'been living under a rock all this time. But to err over and over '
'again is human.',
'pub_date': 'Aug 2021',
'title': 'Using variables in Jekyll to define custom content'},
{'excerpt': "In this article, I'll highlight some ideas for Jekyll "
'collections, blog category pages, responsive web-design, and '
'netlify.toml to make static website maintenance a breeze.',
'pub_date': 'Jul 2021',
'title': 'The evolution of ayushsharma.in: Jekyll, Bootstrap, Netlify, '
'static websites, and responsive design.'},
{'excerpt': "These are the top 5 lessons I've learned after 5 years of "
'Terraform-ing.',
'pub_date': 'Jul 2021',
'title': '5 key best practices for sane and usable Terraform setups'},
... (truncated)
仅此而已!我们用 22 行代码,用 Python 构建了一个网络爬虫。您可以在我的示例存储库中找到源代码。
结论
使用 Python 列表中的 网站 内容,我们现在可以用它做很酷的事情。我们可以将其作为 JSON 返回给另一个应用程序,或者使用自定义样式将其转换为 HTML。随意复制并粘贴上面的代码,然后在您最喜欢的 网站 上进行实验。 查看全部
jquery抓取网页内容(如何使用BeautifulSoup库从HTML页面中提取内容中执行?)
今天我们将讨论如何使用 BeautifulSoup 库从 HTML 页面中提取内容。提取后,我们将使用 BeautifulSoup 将其转换为 Python 列表或字典!
什么是网络抓取?
简单的答案是:并非每个 网站 都有用于获取内容的 API。您可能想从您最喜欢的烹饪中获取食谱网站 或从旅游博客中获取照片。如果没有 API,提取 HTML 或抓取可能是获取内容的唯一途径。我将向您展示如何在 Python 中执行此操作。
注意:不是所有的网站都喜欢爬行,有些网站可能会被明确禁止。与网站的拥有者确认是否可以爬取。
如何在 Python 中抓取 网站?
为了让网络抓取在 Python 中工作,我们将执行 3 个基本步骤:
使用请求库提取 HTML 内容。分析 HTML 结构并识别收录我们内容的标签。使用 BeautifulSoup 提取标签并将数据放入 Python 列表中。安装库
让我们先安装我们需要的库。从 网站 请求 HTML 内容。 BeautifulSoup 解析 HTML 并将其转换为 Python 对象。要为 Python 3 安装这些,请运行:
pip3 install requests beautifulsoup4
提取 HTML
在这个例子中,我会选择抓取网站的技术部分。如果你进入这个页面,你会看到一个带有标题、摘录和发布日期的 文章 列表。我们的目标是创建一个收录这些信息的 文章 列表。
技术页面的完整网址是:
https://notes.ayushsharma.in/technology
我们可以使用 Requests 从这个页面获取 HTML 内容:
#!/usr/bin/python3
import requests
url = 'https://notes.ayushsharma.in/technology'
data = requests.get(url)
print(data.text)
变量数据将收录页面的 HTML 源代码。
从 HTML 中提取内容
要从 data 中接收到的 HTML 中提取我们的数据,我们需要确定哪些标签具有我们需要的内容。
如果您浏览 HTML,您会在顶部附近找到此部分:
HTML:
Using variables in Jekyll to define custom content
I recently discovered that Jekyll's config.yml can be used to define custom
variables for reusing content. I feel like I've been living under a rock all this time. But to err over and
over again is human.
Aug 2021
这是在每个文章的整个页面中重复的部分。我们可以看到 .card-title 有 文章 标题,.card-text 摘录和 .card-footer> 小发布日期。
让我们使用 BeautifulSoup 提取这些内容。
蟒蛇:
上面的代码将提取文章并将它们放入my_data变量中。我正在使用 pprint 来漂亮地打印输出,但您可以在自己的代码中跳过它。将上述代码保存在一个名为 fetch.py 的文件中,然后使用以下命令运行它:
python3 fetch.py
如果一切顺利,您应该会看到:
蟒蛇:
[{'excerpt': "I recently discovered that Jekyll's config.yml can be used to "
"define custom variables for reusing content. I feel like I've "
'been living under a rock all this time. But to err over and over '
'again is human.',
'pub_date': 'Aug 2021',
'title': 'Using variables in Jekyll to define custom content'},
{'excerpt': "In this article, I'll highlight some ideas for Jekyll "
'collections, blog category pages, responsive web-design, and '
'netlify.toml to make static website maintenance a breeze.',
'pub_date': 'Jul 2021',
'title': 'The evolution of ayushsharma.in: Jekyll, Bootstrap, Netlify, '
'static websites, and responsive design.'},
{'excerpt': "These are the top 5 lessons I've learned after 5 years of "
'Terraform-ing.',
'pub_date': 'Jul 2021',
'title': '5 key best practices for sane and usable Terraform setups'},
... (truncated)
仅此而已!我们用 22 行代码,用 Python 构建了一个网络爬虫。您可以在我的示例存储库中找到源代码。
结论
使用 Python 列表中的 网站 内容,我们现在可以用它做很酷的事情。我们可以将其作为 JSON 返回给另一个应用程序,或者使用自定义样式将其转换为 HTML。随意复制并粘贴上面的代码,然后在您最喜欢的 网站 上进行实验。
jquery抓取网页内容( 影响网站百度蜘蛛抓取量,顾名思义就是指百度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-26 19:00
影响网站百度蜘蛛抓取量,顾名思义就是指百度)
网站的内页爬不出来是什么原因?影响百度蜘蛛抓取量的因素有哪些?
百度蜘蛛抓取量,顾名思义,就是指百度蜘蛛每天抓取的网页数量。
据了解,百度蜘蛛抓取的目标有两个:一个是本站生成的新网页,一个是百度之前抓取过但需要更新的网页。
如果不是很好理解,这里给大家举个例子:
比如一个网站已经被百度收录 2w,那么百度会给一个时间段,比如15天,然后平均每天去这个网站抢一个数字比如2W/15,当然具体数字是肯定的 不是这个,这是百度内部的数据。
下面具体介绍一下影响网站百度蜘蛛抓取量的因素。
1、网站安全
对于中小型网站来说,由于安全意识不足、技术薄弱,网站被黑、被篡改的现象非常普遍。一般来说,被黑有几种常见的情况。一是网站域名被黑,二是标题被篡改,二是页面加了很多黑链。对于一般的网站来说,如果域名被黑客劫持,就说明该域名已经设置了301重定向跳转到指定的垃圾网站。如果这种跳转被百度发现,那么你的网站的抓取量就会减少,甚至会受到处罚和降级。
2、内容质量
另外,网站的内容质量也很重要。如果蜘蛛爬取了我们网站10万条内容,最后只构建了100条或更少的内容,那么百度蜘蛛对网站的抓取量会下降。因为百度会认为我们的网站质量很差,所以没必要多爬。所以特别提醒:大家在建站初期需要注意内容的质量,而不是采集的内容,这对网站的发展有潜在的隐患。
3、网站响应速度
① 网页大小会影响抓取。百度建议网页大小在1M以内,这当然类似于大型门户网站,新浪另有说法。
②代码质量、机器性能和带宽。这些都会影响爬行的质量。代码质量不用多说,蜘蛛本身也属于程序的执行,你的代码质量很差,很难阅读,蜘蛛自然不会浪费时间去解释。机器性能和带宽也是如此。服务器配置不好,带宽不足,会导致蜘蛛爬取困难网站,严重影响爬虫的积极性。
4.与ip上面网站的数量相同
百度爬虫是根据ip爬取的。比如百度规定一个ip每天可以爬取2000w个页面,而这个站点有50W个站点,那么平均每个站点爬取的次数就会很少。同时还需要注意看同一个ip上有没有大站。如果有大站,原本分成少量的抓取量会被大站分成很多。
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
站长永久SVIP 查看全部
jquery抓取网页内容(
影响网站百度蜘蛛抓取量,顾名思义就是指百度)
网站的内页爬不出来是什么原因?影响百度蜘蛛抓取量的因素有哪些?
百度蜘蛛抓取量,顾名思义,就是指百度蜘蛛每天抓取的网页数量。
据了解,百度蜘蛛抓取的目标有两个:一个是本站生成的新网页,一个是百度之前抓取过但需要更新的网页。
如果不是很好理解,这里给大家举个例子:
比如一个网站已经被百度收录 2w,那么百度会给一个时间段,比如15天,然后平均每天去这个网站抢一个数字比如2W/15,当然具体数字是肯定的 不是这个,这是百度内部的数据。
下面具体介绍一下影响网站百度蜘蛛抓取量的因素。
1、网站安全
对于中小型网站来说,由于安全意识不足、技术薄弱,网站被黑、被篡改的现象非常普遍。一般来说,被黑有几种常见的情况。一是网站域名被黑,二是标题被篡改,二是页面加了很多黑链。对于一般的网站来说,如果域名被黑客劫持,就说明该域名已经设置了301重定向跳转到指定的垃圾网站。如果这种跳转被百度发现,那么你的网站的抓取量就会减少,甚至会受到处罚和降级。
2、内容质量
另外,网站的内容质量也很重要。如果蜘蛛爬取了我们网站10万条内容,最后只构建了100条或更少的内容,那么百度蜘蛛对网站的抓取量会下降。因为百度会认为我们的网站质量很差,所以没必要多爬。所以特别提醒:大家在建站初期需要注意内容的质量,而不是采集的内容,这对网站的发展有潜在的隐患。
3、网站响应速度
① 网页大小会影响抓取。百度建议网页大小在1M以内,这当然类似于大型门户网站,新浪另有说法。
②代码质量、机器性能和带宽。这些都会影响爬行的质量。代码质量不用多说,蜘蛛本身也属于程序的执行,你的代码质量很差,很难阅读,蜘蛛自然不会浪费时间去解释。机器性能和带宽也是如此。服务器配置不好,带宽不足,会导致蜘蛛爬取困难网站,严重影响爬虫的积极性。
4.与ip上面网站的数量相同
百度爬虫是根据ip爬取的。比如百度规定一个ip每天可以爬取2000w个页面,而这个站点有50W个站点,那么平均每个站点爬取的次数就会很少。同时还需要注意看同一个ip上有没有大站。如果有大站,原本分成少量的抓取量会被大站分成很多。
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
站长永久SVIP
jquery抓取网页内容(一个中一个基础表的数据从另一个网站采集开始 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-25 23:30
)
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志提示。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考一下。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本 查看全部
jquery抓取网页内容(一个中一个基础表的数据从另一个网站采集开始
)
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志提示。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考一下。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
jquery抓取网页内容(jquery抓取网页内容的方法(jquery)抓取最新的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-25 18:02
jquery抓取网页内容的方法jquery抓取网页内容可以分为以下三步:获取最新的内容获取网页的html源代码获取分页数据本篇文章将会全部涵盖,并介绍如何使用jquery网页抓取方法。首先,我们获取最新的内容很简单,浏览器的开发者工具中会提供jquery实例,可以看到自己所需要的功能:例如以上截图,是《美人鱼》电影评分app中的评分页面,这里的数据最新的显示如下:可以看到此页面源代码包含如下的内容varhtml=document.createelement('html');//制作htmlconsole.log(html.innerhtml);//制作htmlel.script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持html源代码:)varhtml2=document。createelement('html');//制作htmlconsole。log(html2。innerhtml);//制作htmlel。script="scrollto(400,。
0)";//设置电影评分api(等待第三方开发者程序员支持html源代码:)varhtml=document。createelement('html');//制作htmlel。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持)而网页源代码在jquery中实例中是长这样的:console。log(jquery。contentbody);//获取源代码text=contentbody。innertext;//获取contentbody内容jquery对象的构造函数是://构造网页//获取源代码的内容varcontent=document。
createelement('html');//制作源代码el。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持content。prettify();//去掉电影评分标签varconten=document。createelement('html');//制作电影评分的实例html2。innerhtml=content;//获取网页内容content。prettify();//去掉网页评分实例varcontent=document。
createelement('html');//制作电影评分实例el。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持)content.prettify();//去掉电影评分实例(到这里的代码已经比较复杂了, 查看全部
jquery抓取网页内容(jquery抓取网页内容的方法(jquery)抓取最新的内容)
jquery抓取网页内容的方法jquery抓取网页内容可以分为以下三步:获取最新的内容获取网页的html源代码获取分页数据本篇文章将会全部涵盖,并介绍如何使用jquery网页抓取方法。首先,我们获取最新的内容很简单,浏览器的开发者工具中会提供jquery实例,可以看到自己所需要的功能:例如以上截图,是《美人鱼》电影评分app中的评分页面,这里的数据最新的显示如下:可以看到此页面源代码包含如下的内容varhtml=document.createelement('html');//制作htmlconsole.log(html.innerhtml);//制作htmlel.script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持html源代码:)varhtml2=document。createelement('html');//制作htmlconsole。log(html2。innerhtml);//制作htmlel。script="scrollto(400,。
0)";//设置电影评分api(等待第三方开发者程序员支持html源代码:)varhtml=document。createelement('html');//制作htmlel。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持)而网页源代码在jquery中实例中是长这样的:console。log(jquery。contentbody);//获取源代码text=contentbody。innertext;//获取contentbody内容jquery对象的构造函数是://构造网页//获取源代码的内容varcontent=document。
createelement('html');//制作源代码el。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持content。prettify();//去掉电影评分标签varconten=document。createelement('html');//制作电影评分的实例html2。innerhtml=content;//获取网页内容content。prettify();//去掉网页评分实例varcontent=document。
createelement('html');//制作电影评分实例el。script="scrollto(400,-70。
0)";//设置电影评分api(等待第三方开发者程序员支持)content.prettify();//去掉电影评分实例(到这里的代码已经比较复杂了,
jquery抓取网页内容(学习Python爬虫模块前的基本结构,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-25 16:17
爬虫程序之所以能够抓取数据,是因为爬虫可以对网页进行分析,从网页中提取出想要的数据。在学习Python爬虫模块之前,我们有必要熟悉网页的基本结构,这是编写爬虫程序的必备知识。
如果您熟悉前端语言,那么您可以轻松掌握本节中的知识。
网页一般由HTML(超文本标记语言)、CSS(层叠样式表)和JavaScript(简称“JS”动态脚本语言)三部分组成,每部分在网页中承担不同的任务。HTML HTML 是网页的基本结构,相当于人体的骨骼结构。所有同时带有“<”和“>”符号的网页都属于HTML标签。常见的 HTML 标签如下:
声明为 HTML5 文档
.. 是网页的根元素
.. 元素包含了文档的元(meta)数据,如 定义网页编码格式为 utf-8。
.. 元素描述了文档的标题
.. 表示用户可见的内容
.. 表示框架
<p>.. 表示段落
.. 定义无序列表
..定义有序列表
..表示列表项
表示图片
..表示标题
..表示超链接</p>
编写以下代码:
编程帮
点击访问
编程帮www.biancheng.net
Python爬虫
<p>认识网页结构
HTML
CSS
</p>
运行结果如下图所示:
图 1:HTML 页面结构
CSSCSS 代表级联样式表。有三种写法:内联样式、内联样式和大纲样式。CSS代码演示如下:
body{
background-color:yellow;
}
p{
font-size: 30px;
color: springgreen;
}
编程帮
编程帮www.biancheng.net
点击访问
Python爬虫
<p>认识网页结构
HTML
CSS
</p>
运行结果如下图所示:
图 2:CSS 样式表演示
如图2所示,内联样式通过style标签写入样式表:
<style type="text/css">
内嵌样式使用 HTML 元素的 style 属性来编写 CSS 代码。请注意,每个 HTML 元素都有 style、class、id、name 和 title 属性。
外部样式表是指将 CSS 代码单独保存为一个以 .css 结尾的文件,并使用它来将其导入所需的页面:
当样式需要应用于多个页面时,使用外部样式表是最好的选择。JavaScript JavaScript 负责描述网页的行为。例如,可以使用 JavaScript 实现交互式内容和各种特殊效果。当然也可以通过其他方式实现,比如jQuery,以及一些前端框架(vue、React等),但都是在“JS”的基础上实现的。
简单的例子:
body{
background-color: rgb(220, 226, 226);
}
编程帮
编程帮www.biancheng.net
Python爬虫
<p>点击下方按钮获取当前时间
点击这里
function DisplayDate(){
document.getElementById("time").innerHTML=Date()
}
</p>
操作结果如下:
图3:JS获取当前时间
如果用人体作为 网站 结构的比喻,那么 HTML 就是人体的骨架,它定义了人的嘴、眼睛和耳朵的生长位置;CSS描述了人体的外貌细节,比如嘴巴长什么样,眼睛是双眼皮还是单眼,皮肤是黑还是白等;而 JavaScript 则代表了一个人所拥有的技能,比如唱歌、打球、游泳等。 查看全部
jquery抓取网页内容(学习Python爬虫模块前的基本结构,你了解多少?)
爬虫程序之所以能够抓取数据,是因为爬虫可以对网页进行分析,从网页中提取出想要的数据。在学习Python爬虫模块之前,我们有必要熟悉网页的基本结构,这是编写爬虫程序的必备知识。
如果您熟悉前端语言,那么您可以轻松掌握本节中的知识。
网页一般由HTML(超文本标记语言)、CSS(层叠样式表)和JavaScript(简称“JS”动态脚本语言)三部分组成,每部分在网页中承担不同的任务。HTML HTML 是网页的基本结构,相当于人体的骨骼结构。所有同时带有“<”和“>”符号的网页都属于HTML标签。常见的 HTML 标签如下:
声明为 HTML5 文档
.. 是网页的根元素
.. 元素包含了文档的元(meta)数据,如 定义网页编码格式为 utf-8。
.. 元素描述了文档的标题
.. 表示用户可见的内容
.. 表示框架
<p>.. 表示段落
.. 定义无序列表
..定义有序列表
..表示列表项
表示图片
..表示标题
..表示超链接</p>
编写以下代码:
编程帮
点击访问
编程帮www.biancheng.net
Python爬虫
<p>认识网页结构
HTML
CSS
</p>
运行结果如下图所示:
图 1:HTML 页面结构
CSSCSS 代表级联样式表。有三种写法:内联样式、内联样式和大纲样式。CSS代码演示如下:
body{
background-color:yellow;
}
p{
font-size: 30px;
color: springgreen;
}
编程帮
编程帮www.biancheng.net
点击访问
Python爬虫
<p>认识网页结构
HTML
CSS
</p>
运行结果如下图所示:
图 2:CSS 样式表演示
如图2所示,内联样式通过style标签写入样式表:
<style type="text/css">
内嵌样式使用 HTML 元素的 style 属性来编写 CSS 代码。请注意,每个 HTML 元素都有 style、class、id、name 和 title 属性。
外部样式表是指将 CSS 代码单独保存为一个以 .css 结尾的文件,并使用它来将其导入所需的页面:
当样式需要应用于多个页面时,使用外部样式表是最好的选择。JavaScript JavaScript 负责描述网页的行为。例如,可以使用 JavaScript 实现交互式内容和各种特殊效果。当然也可以通过其他方式实现,比如jQuery,以及一些前端框架(vue、React等),但都是在“JS”的基础上实现的。
简单的例子:
body{
background-color: rgb(220, 226, 226);
}
编程帮
编程帮www.biancheng.net
Python爬虫
<p>点击下方按钮获取当前时间
点击这里
function DisplayDate(){
document.getElementById("time").innerHTML=Date()
}
</p>
操作结果如下:
图3:JS获取当前时间
如果用人体作为 网站 结构的比喻,那么 HTML 就是人体的骨架,它定义了人的嘴、眼睛和耳朵的生长位置;CSS描述了人体的外貌细节,比如嘴巴长什么样,眼睛是双眼皮还是单眼,皮肤是黑还是白等;而 JavaScript 则代表了一个人所拥有的技能,比如唱歌、打球、游泳等。
jquery抓取网页内容(什么是JavaScript库之一的代码库的特点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-10-24 09:00
JavaScript 是一种脚本语言,主要用于浏览器中,实现对网页文档对象的操作和一些用户交互动作的处理。
而jQuery是一个JavaScript代码库(或者习惯称为类库),它汇集了一些JavaScript开发中经常用到的函数,方便开发者直接使用,无需编写大量原生的JavaScript语句代码,同时可以在不同浏览器之间实现一致的效果。是目前最流行的 JavaScript 库之一。
扩展信息:
jquery 和 javascript 都是脚本语言,
脚本语言也称为扩展语言或动态语言。它是一种用于控制软件应用程序的编程语言。脚本通常以文本形式保存(例如 ASCII),并且仅在调用时进行解释或编译。
特征:
1、脚本语言(JavaScript、VBscript等)介于HTML和C、C++、Java、C#等编程语言之间。HTML 通常用于格式化和链接文本。编程语言通常用于向机器发出一系列复杂的指令。
2、 脚本语言和编程语言有很多相似之处。它的功能更类似于编程语言,也涉及到变量。与编程语言最大的不同是编程语言的语法和规则更加严格和复杂。
3、与程序代码的关系:脚本也是一种语言,也是由程序代码组成的。
4、 脚本语言是一种解释型语言,如Python、vbscript、javascript、installshield脚本、ActionScript等,不像c\c++等,它可以编译成二进制代码,以一个可执行文件。脚本语言不需要编译直接使用,解释器负责解释。
5、脚本语言一般以文本的形式存在,类似于命令。
例如,如果您创建一个名为 aaa.exe 的程序,您可以打开一个扩展名为 .aa 的文件,并指定一组写入 .aa 文件的规则(语法)。当别人编写.aa文件时,你自己的程序使用这种规则来理解作者的意图并做出反应,那么这套规则就是一种脚本语言。
6、编译型计算机编程语言:用脚本语言开发的程序在执行时,会由其对应的解释器(或虚拟机)进行解释和执行。系统编程语言被预编译成机器语言并执行。脚本语言的主要特点是:程序代码是脚本程序,也是最终的可执行文件。脚本语言可分为单机型和嵌入式型。独立脚本语言在执行时完全依赖于解释器,而嵌入式脚本语言通常嵌入到编程语言中(如C、C++、VB、Java等)。
7、与系统编程语言相比:区别在于脚本语言是解释型的,而系统编程语言是编译型的。解释型语言提供快速转换,因为没有编译时间,允许用户在运行时编写应用程序,而无需耗时的编译/打包过程。解释器使应用程序更加灵活,脚本语言的代码可以实时生成和执行。脚本语言通常具有简单、易学、易用的特点。目的是让程序员快速完成程序编写。
参考资料:百度百科-脚本语言
jQuery 使用标准的javascript 语言编写的类库(轻量级框架),类似的还有很多,比如Dojo、ExtJS 等。其实里面封装了很多功能,比如Dom操作,ajax应用,各种华丽的效果。使用jQuery,可以大大减少代码量,同时也屏蔽了“浏览器差异”的问题。这些都是web客户端开发的必备技术,无论你是j2EE,还是asp、php、perl、ruby等都可以使用。
jQuery 是一个快速而简洁的 JavaScript 框架。它是继 Prototype 之后另一个优秀的 JavaScript 代码库(或 JavaScript 框架)。
JavaScript 是一种文字脚本语言,是一种动态类型、弱类型、基于原型的语言,具有内置的支持类型。它的解释器称为 JavaScript 引擎,它是浏览器的一部分,被广泛用作客户端的脚本语言。它最初用于 HTML(标准通用标记语言下的应用程序)网页,为 HTML 网页添加动态功能。. 查看全部
jquery抓取网页内容(什么是JavaScript库之一的代码库的特点)
JavaScript 是一种脚本语言,主要用于浏览器中,实现对网页文档对象的操作和一些用户交互动作的处理。
而jQuery是一个JavaScript代码库(或者习惯称为类库),它汇集了一些JavaScript开发中经常用到的函数,方便开发者直接使用,无需编写大量原生的JavaScript语句代码,同时可以在不同浏览器之间实现一致的效果。是目前最流行的 JavaScript 库之一。
扩展信息:
jquery 和 javascript 都是脚本语言,
脚本语言也称为扩展语言或动态语言。它是一种用于控制软件应用程序的编程语言。脚本通常以文本形式保存(例如 ASCII),并且仅在调用时进行解释或编译。
特征:
1、脚本语言(JavaScript、VBscript等)介于HTML和C、C++、Java、C#等编程语言之间。HTML 通常用于格式化和链接文本。编程语言通常用于向机器发出一系列复杂的指令。
2、 脚本语言和编程语言有很多相似之处。它的功能更类似于编程语言,也涉及到变量。与编程语言最大的不同是编程语言的语法和规则更加严格和复杂。
3、与程序代码的关系:脚本也是一种语言,也是由程序代码组成的。
4、 脚本语言是一种解释型语言,如Python、vbscript、javascript、installshield脚本、ActionScript等,不像c\c++等,它可以编译成二进制代码,以一个可执行文件。脚本语言不需要编译直接使用,解释器负责解释。
5、脚本语言一般以文本的形式存在,类似于命令。
例如,如果您创建一个名为 aaa.exe 的程序,您可以打开一个扩展名为 .aa 的文件,并指定一组写入 .aa 文件的规则(语法)。当别人编写.aa文件时,你自己的程序使用这种规则来理解作者的意图并做出反应,那么这套规则就是一种脚本语言。
6、编译型计算机编程语言:用脚本语言开发的程序在执行时,会由其对应的解释器(或虚拟机)进行解释和执行。系统编程语言被预编译成机器语言并执行。脚本语言的主要特点是:程序代码是脚本程序,也是最终的可执行文件。脚本语言可分为单机型和嵌入式型。独立脚本语言在执行时完全依赖于解释器,而嵌入式脚本语言通常嵌入到编程语言中(如C、C++、VB、Java等)。
7、与系统编程语言相比:区别在于脚本语言是解释型的,而系统编程语言是编译型的。解释型语言提供快速转换,因为没有编译时间,允许用户在运行时编写应用程序,而无需耗时的编译/打包过程。解释器使应用程序更加灵活,脚本语言的代码可以实时生成和执行。脚本语言通常具有简单、易学、易用的特点。目的是让程序员快速完成程序编写。
参考资料:百度百科-脚本语言
jQuery 使用标准的javascript 语言编写的类库(轻量级框架),类似的还有很多,比如Dojo、ExtJS 等。其实里面封装了很多功能,比如Dom操作,ajax应用,各种华丽的效果。使用jQuery,可以大大减少代码量,同时也屏蔽了“浏览器差异”的问题。这些都是web客户端开发的必备技术,无论你是j2EE,还是asp、php、perl、ruby等都可以使用。
jQuery 是一个快速而简洁的 JavaScript 框架。它是继 Prototype 之后另一个优秀的 JavaScript 代码库(或 JavaScript 框架)。
JavaScript 是一种文字脚本语言,是一种动态类型、弱类型、基于原型的语言,具有内置的支持类型。它的解释器称为 JavaScript 引擎,它是浏览器的一部分,被广泛用作客户端的脚本语言。它最初用于 HTML(标准通用标记语言下的应用程序)网页,为 HTML 网页添加动态功能。.
jquery抓取网页内容(我正在开发一个项目获取有限的内容..() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-19 02:19
)
问题
我正在开发一个项目。为此,我想在后台抓取网站的内容,并从抓取的网站中获取一些有限的内容。例如,在我的页面中,我有“用户名”和“密码”字段,通过使用这些字段,我将访问我的邮件并抓取收件箱中的内容并将其显示在我的页面上。
我单独使用javascript完成了上述操作。但是,当我点击“登录”按钮时,页面的 URL () 被更改为网址 (/mails/inbox.php?nomail = ... .) 并被抓住了...但我取消了详细信息而不更改 URL。
解决方案
请务必使用 PHP 简单的 HTML DOM 解析器。它快速、简单且超级灵活。它基本上将整个 HTML 页面粘贴到一个对象中,然后您可以访问该对象中的任何元素。
以官方网站为例,获取Google首页的所有链接:
// Create DOM from URL or file
$html = file_get_html('http://www.google.com/');
// Find all images
foreach($html->find('img') as $element)
echo $element->src . '
';
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
'; 查看全部
jquery抓取网页内容(我正在开发一个项目获取有限的内容..()
)
问题
我正在开发一个项目。为此,我想在后台抓取网站的内容,并从抓取的网站中获取一些有限的内容。例如,在我的页面中,我有“用户名”和“密码”字段,通过使用这些字段,我将访问我的邮件并抓取收件箱中的内容并将其显示在我的页面上。
我单独使用javascript完成了上述操作。但是,当我点击“登录”按钮时,页面的 URL () 被更改为网址 (/mails/inbox.php?nomail = ... .) 并被抓住了...但我取消了详细信息而不更改 URL。
解决方案
请务必使用 PHP 简单的 HTML DOM 解析器。它快速、简单且超级灵活。它基本上将整个 HTML 页面粘贴到一个对象中,然后您可以访问该对象中的任何元素。
以官方网站为例,获取Google首页的所有链接:
// Create DOM from URL or file
$html = file_get_html('http://www.google.com/');
// Find all images
foreach($html->find('img') as $element)
echo $element->src . '
';
// Find all links
foreach($html->find('a') as $element)
echo $element->href . '
';
jquery抓取网页内容(搜索引擎如何优化搜索引擎蜘蛛工作流程?蜘蛛优化方案调整)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-10 19:41
做SEO几年了,总会看到有人抱怨搜索引擎涨了,排名下降了,网站没有更新。各种问题其实都和搜索引擎有关。你很有用 你有没有研究过搜索引擎是如何抓取内容的?了解了之后,才能更好的调整搜索引擎的优化方案。
搜索引擎蜘蛛的工作流程大概是通过发现某个链接(可以是外部链接或好友链接)然后沿着这个链接爬到这个网页,把这个网页加入到临时库中,并分析这个网页(包括提取< @关键词,切词,重复性分析等,这是通过分析系统完成的)然后提取网页中的链接,按照这些链接下载其他网页,等等。
搜索引擎将蜘蛛抓取的网页放入临时数据库中,然后交给数据分析系统进行处理。数据分析系统的处理过程主要包括:
1、去除所有html代码,提取网页内容,然后删除无用的内容,比如版权等一些明显与网页主题无关的内容。
2、删除重复,即如果搜索引擎发现重复的网页或者您的网页与其他网页重复,将被删除
<p>3、 分词就是将网页的中文内容进行切分,整理出来放入索引库,计算某个 查看全部
jquery抓取网页内容(搜索引擎如何优化搜索引擎蜘蛛工作流程?蜘蛛优化方案调整)
做SEO几年了,总会看到有人抱怨搜索引擎涨了,排名下降了,网站没有更新。各种问题其实都和搜索引擎有关。你很有用 你有没有研究过搜索引擎是如何抓取内容的?了解了之后,才能更好的调整搜索引擎的优化方案。
搜索引擎蜘蛛的工作流程大概是通过发现某个链接(可以是外部链接或好友链接)然后沿着这个链接爬到这个网页,把这个网页加入到临时库中,并分析这个网页(包括提取< @关键词,切词,重复性分析等,这是通过分析系统完成的)然后提取网页中的链接,按照这些链接下载其他网页,等等。
搜索引擎将蜘蛛抓取的网页放入临时数据库中,然后交给数据分析系统进行处理。数据分析系统的处理过程主要包括:
1、去除所有html代码,提取网页内容,然后删除无用的内容,比如版权等一些明显与网页主题无关的内容。
2、删除重复,即如果搜索引擎发现重复的网页或者您的网页与其他网页重复,将被删除
<p>3、 分词就是将网页的中文内容进行切分,整理出来放入索引库,计算某个
jquery抓取网页内容(如何利用z-index关键字排序方法抓取网页内容的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-04 04:03
jquery抓取网页内容的方法很多,比如根据提示或url路径抓取,也可以抓取指定文本数据;也可以抓取微信公众号网页内容,直接提取标题、文章简介,以及内容。
1、第一种方法可以利用z-index关键字排序方法、轮播图、访问时间排序、请求报文头等方法1:获取页面源代码是一串由requestheaders组成的字符串,requestheaders中写入data,比如requesturl中data里写入【1..name..1】,【】2,其他一些参数对headers的requestheaders可以有不同需求。抓取方法可以是requestheaders的其他参数;也可以自己写代码获取。
2、第二种方法直接使用框架的方法,比如:阿里巴巴下的天蝎app,使用nodejs、java语言,首先登录帐号(用户名、密码)获取入口。对于、京东的网页内容以及微信公众号网页内容,直接在,然后根据模板获取源代码中data,比如html代码等javascript,javascript代码字符串,javascript代码可以参考各大框架jquery内置的javascript调用方法,如百度default、乐天首页、网c1c2等。
接下来就可以对javascript代码做调用,比如获取标题、文章简介,类似于下面这样子对javascript做调用。
functiongetchild(data){returndata。stringify();}varmyrequirer=newjqueryrequirer("generator");varjquery=newjquery(jqueryrequirer);vargenerator=newjquerywaiter(jquery);varpostman=newpostman();varsitesplit=myrequirer。
postman();returnthis。getchild(url);functionget1_1(url){returnurl。replace(/[a-za-z]/g,"");}functionget1_2(url){returnurl。replace(/[a-za-z]/g,"");}functionget1_3(url){returnurl。
replace(/[a-za-z]/g,"");}functionget1_4(url){returnurl。replace(/[a-za-z]/g,"");}functionpostinitation(url){returnurl。replace(/[a-za-z]/g,"");}functionpostinitationconfig(url){returnurl。
replace(/[a-za-z]/g,"");}functionsite(){varinsurl=url。split("/")[-1];for(vari=0;i102。
4){insurl.replace(/[a-za-z]/g,"");}else{insurl.replace(/[a-za-z]/g,"");}}returninsurl;}
3、 查看全部
jquery抓取网页内容(如何利用z-index关键字排序方法抓取网页内容的方法)
jquery抓取网页内容的方法很多,比如根据提示或url路径抓取,也可以抓取指定文本数据;也可以抓取微信公众号网页内容,直接提取标题、文章简介,以及内容。
1、第一种方法可以利用z-index关键字排序方法、轮播图、访问时间排序、请求报文头等方法1:获取页面源代码是一串由requestheaders组成的字符串,requestheaders中写入data,比如requesturl中data里写入【1..name..1】,【】2,其他一些参数对headers的requestheaders可以有不同需求。抓取方法可以是requestheaders的其他参数;也可以自己写代码获取。
2、第二种方法直接使用框架的方法,比如:阿里巴巴下的天蝎app,使用nodejs、java语言,首先登录帐号(用户名、密码)获取入口。对于、京东的网页内容以及微信公众号网页内容,直接在,然后根据模板获取源代码中data,比如html代码等javascript,javascript代码字符串,javascript代码可以参考各大框架jquery内置的javascript调用方法,如百度default、乐天首页、网c1c2等。
接下来就可以对javascript代码做调用,比如获取标题、文章简介,类似于下面这样子对javascript做调用。
functiongetchild(data){returndata。stringify();}varmyrequirer=newjqueryrequirer("generator");varjquery=newjquery(jqueryrequirer);vargenerator=newjquerywaiter(jquery);varpostman=newpostman();varsitesplit=myrequirer。
postman();returnthis。getchild(url);functionget1_1(url){returnurl。replace(/[a-za-z]/g,"");}functionget1_2(url){returnurl。replace(/[a-za-z]/g,"");}functionget1_3(url){returnurl。
replace(/[a-za-z]/g,"");}functionget1_4(url){returnurl。replace(/[a-za-z]/g,"");}functionpostinitation(url){returnurl。replace(/[a-za-z]/g,"");}functionpostinitationconfig(url){returnurl。
replace(/[a-za-z]/g,"");}functionsite(){varinsurl=url。split("/")[-1];for(vari=0;i102。
4){insurl.replace(/[a-za-z]/g,"");}else{insurl.replace(/[a-za-z]/g,"");}}returninsurl;}
3、
jquery抓取网页内容(jquery抓取网页内容,第一步,发起请求,用webdriver加载网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-03 23:05
jquery抓取网页内容,第一步,发起请求,用webdriver加载网页,我用的是opencv。(官方文档里都有讲)第二步,js判断对应标签的属性。(这里用了一个闭包函数)第三步,cdn显示结果。
我这里用的是浏览器兼容的js。每一个标签对应一个属性,你自己写js代码判断,然后填充。
如果能发起请求,会自动生成属性,根据属性找到对应的js文件,然后用cdn加载即可。
可以尝试在请求完成时抓包分析请求的数据,也可以模拟浏览器请求来生成请求(为了保证爬虫没被封杀,请求返回html前请先把浏览器设置为低版本浏览器,
要先抓到所有网页文件,最后判断对应的js文件,把里面的代码插入excel文件,将excel数据统计出来即可。
分两种情况:可以跟源代码反向工程http请求网页源代码webdriver或者,直接抓logo的图片或者网页图片,在logo的flash控件里或者webview里抓下就是一个图片列表这种方法还有一个容易忽略的大杀器,找个脚本(批量抓取)多用几次就会成为正常规模的爬虫了。
点开js即可开始抓取了
总的来说,就是普通的js抓取(xhr)。需要准备清除浏览器缓存,js文件下载再加载。后期可以结合opencv之类的库完成其他功能。手机上可以用google或者chrome浏览器的抓包观察以及截图、打码等功能,还可以运用token等技术辅助抓取。暂时想到的就这么多。 查看全部
jquery抓取网页内容(jquery抓取网页内容,第一步,发起请求,用webdriver加载网页)
jquery抓取网页内容,第一步,发起请求,用webdriver加载网页,我用的是opencv。(官方文档里都有讲)第二步,js判断对应标签的属性。(这里用了一个闭包函数)第三步,cdn显示结果。
我这里用的是浏览器兼容的js。每一个标签对应一个属性,你自己写js代码判断,然后填充。
如果能发起请求,会自动生成属性,根据属性找到对应的js文件,然后用cdn加载即可。
可以尝试在请求完成时抓包分析请求的数据,也可以模拟浏览器请求来生成请求(为了保证爬虫没被封杀,请求返回html前请先把浏览器设置为低版本浏览器,
要先抓到所有网页文件,最后判断对应的js文件,把里面的代码插入excel文件,将excel数据统计出来即可。
分两种情况:可以跟源代码反向工程http请求网页源代码webdriver或者,直接抓logo的图片或者网页图片,在logo的flash控件里或者webview里抓下就是一个图片列表这种方法还有一个容易忽略的大杀器,找个脚本(批量抓取)多用几次就会成为正常规模的爬虫了。
点开js即可开始抓取了
总的来说,就是普通的js抓取(xhr)。需要准备清除浏览器缓存,js文件下载再加载。后期可以结合opencv之类的库完成其他功能。手机上可以用google或者chrome浏览器的抓包观察以及截图、打码等功能,还可以运用token等技术辅助抓取。暂时想到的就这么多。
jquery抓取网页内容(最简单的dom操作教程(二):操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-09-25 12:08
)
在网页中,我们有时需要更改前端的特定文本或值。我们可以在jQuery中使用选择器来实现所需的操作。代码如下:
//html代码body部分
<p title=“家具”>家具
椅子(0)
床(0)
</p>
//要实现这个功能用到的是jquery的dom操作
var $li=$("ul li:eq(0)");//这句话是获取中的第一个节点
var li_txe=$li.text();//这句话是获取该节点中的文本内容
alert(li_txt);//这句话是打印文本内容
//如果想要直接更改你获取的文本信息,
$li.text(填写更改的内容)//这样就会把你选择的部分更改成填写更改内容
//如果你想直接该文本中的数字部分你可以给你需要改写的部分添加一个标签就像我上述例子中说明的span标签
$(span).text(5)//;//把span标签中的数字改成5
JQuery的选择器非常强大。查找元素时,不仅可以找到元素节点,还可以找到属性节点
var $para=$("p");//获取p节点
var p_txt=$para.attr("title");//获取<p>元素节点的属性title
alert(p_txt)//打印title属性值
这是两个最简单的DOM操作
如果要向网页的DOM节点添加一些内容,则需要创建一个节点
var $li_1 =$("桌子");//创建一个li元素,包括了元素节点和文本节点,其中桌子就是文本节点
var $li_2=$("沙发");///创建一个li元素,包括了元素节点和文本节点,其中桌子就是文本节点
$("ul").append($li_1);//选择器选择ul节点,把创建的第一个添加到网页中,使之显示
$("ul").append($li_2);//选择器选择ul节点,把创建的第二个添加到网页中,使之显示
//上述的方法是创建文本节点的方法,其实就是在创建元素节点的时候,直接把文本内容写出来,append()方法是添加。 查看全部
jquery抓取网页内容(最简单的dom操作教程(二):操作
)
在网页中,我们有时需要更改前端的特定文本或值。我们可以在jQuery中使用选择器来实现所需的操作。代码如下:
//html代码body部分
<p title=“家具”>家具
椅子(0)
床(0)
</p>
//要实现这个功能用到的是jquery的dom操作
var $li=$("ul li:eq(0)");//这句话是获取中的第一个节点
var li_txe=$li.text();//这句话是获取该节点中的文本内容
alert(li_txt);//这句话是打印文本内容
//如果想要直接更改你获取的文本信息,
$li.text(填写更改的内容)//这样就会把你选择的部分更改成填写更改内容
//如果你想直接该文本中的数字部分你可以给你需要改写的部分添加一个标签就像我上述例子中说明的span标签
$(span).text(5)//;//把span标签中的数字改成5
JQuery的选择器非常强大。查找元素时,不仅可以找到元素节点,还可以找到属性节点
var $para=$("p");//获取p节点
var p_txt=$para.attr("title");//获取<p>元素节点的属性title
alert(p_txt)//打印title属性值
这是两个最简单的DOM操作
如果要向网页的DOM节点添加一些内容,则需要创建一个节点
var $li_1 =$("桌子");//创建一个li元素,包括了元素节点和文本节点,其中桌子就是文本节点
var $li_2=$("沙发");///创建一个li元素,包括了元素节点和文本节点,其中桌子就是文本节点
$("ul").append($li_1);//选择器选择ul节点,把创建的第一个添加到网页中,使之显示
$("ul").append($li_2);//选择器选择ul节点,把创建的第二个添加到网页中,使之显示
//上述的方法是创建文本节点的方法,其实就是在创建元素节点的时候,直接把文本内容写出来,append()方法是添加。
jquery抓取网页内容(Java开发中的HTML解析器(4)支持代理服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-22 06:06
(4) support代理服务器
(5)支持自动cookies管理等。
java爬虫开发应用到一个网页获取技术,速度和性能,在功能支持中更具潜力,不支持JS脚本执行,CSS分辨率,渲染等,推荐用于快速获取网页如果不解析脚本和CSS的场景。
示例代码如下:
jsoup
jsoup是一个Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了一种非常植入的API,可以使用DOM,CSS和类似于jQuery的方法进行删除和运行。
网页采集和分辨率快速,推荐。
主要功能如下:
1.从URL,文件或字符串分析HTML;
2.使用DOM或CSS选择器查找,删除数据;
3.可操作的html元素,属性,文本;
示例代码如下:
htmlunit
htmlUnit是一个开源Java页面分析工具,可以在阅读页面后有效地在HTMLUnit分析页面上使用。该项目可以模拟浏览器运行,称为Java浏览器的开源实现。没有接口的浏览器也很快运行。它是rhinojs发动机。模拟JS运行。
页面获取和分辨率更快,性能更好,建议使用应用方案来解析Web脚本。
示例代码如下:
watij
watij(发音wattage)是由Java开发的Web应用程序测试工具,鉴于Watij的简单性和Java语言的力量,Watij可以在真实浏览器中完成Web应用程序。因为它被称为本地浏览器,所以支持CSS渲染和JS执行。
页面获取速度是通用的,IE版本太低(6 / 7)可能导致内存泄露。
示例代码如下:
selenium
Selenium也是Web应用程序测试的工具。 Selenium Test直接在浏览器中运行,就像真实用户正在运行一样。支持的浏览器包括IE,Mozilla Firefox,Mozilla套件等。此工具的主要功能包括:测试和浏览器兼容性 - 测试您的应用程序,以查看您是否可以在不同的浏览器和操作系统上工作。测试系统功能 - 创建经济衰退测试检验软件功能和用户需求。支持自动录制动作和自动生成。 net,java,perl等不同语言。 Selenium是专门为Web应用程序的思考编写的验收测试工具。
页面较慢,不是爬行动物的不错选择。
示例代码如下:
webspec
具有接口的开源Java浏览器,支持脚本执行和CSS呈现。速度是一般的。
示例代码如下:
源代码下载:网络爬虫(网络蜘蛛)Web Grab示例源
转载,请在文章 @ @ @出网网: 查看全部
jquery抓取网页内容(Java开发中的HTML解析器(4)支持代理服务器)
(4) support代理服务器
(5)支持自动cookies管理等。
java爬虫开发应用到一个网页获取技术,速度和性能,在功能支持中更具潜力,不支持JS脚本执行,CSS分辨率,渲染等,推荐用于快速获取网页如果不解析脚本和CSS的场景。
示例代码如下:
jsoup
jsoup是一个Java HTML解析器,可以直接解析URL地址和HTML文本内容。它提供了一种非常植入的API,可以使用DOM,CSS和类似于jQuery的方法进行删除和运行。
网页采集和分辨率快速,推荐。
主要功能如下:
1.从URL,文件或字符串分析HTML;
2.使用DOM或CSS选择器查找,删除数据;
3.可操作的html元素,属性,文本;
示例代码如下:
htmlunit
htmlUnit是一个开源Java页面分析工具,可以在阅读页面后有效地在HTMLUnit分析页面上使用。该项目可以模拟浏览器运行,称为Java浏览器的开源实现。没有接口的浏览器也很快运行。它是rhinojs发动机。模拟JS运行。
页面获取和分辨率更快,性能更好,建议使用应用方案来解析Web脚本。
示例代码如下:
watij
watij(发音wattage)是由Java开发的Web应用程序测试工具,鉴于Watij的简单性和Java语言的力量,Watij可以在真实浏览器中完成Web应用程序。因为它被称为本地浏览器,所以支持CSS渲染和JS执行。
页面获取速度是通用的,IE版本太低(6 / 7)可能导致内存泄露。
示例代码如下:
selenium
Selenium也是Web应用程序测试的工具。 Selenium Test直接在浏览器中运行,就像真实用户正在运行一样。支持的浏览器包括IE,Mozilla Firefox,Mozilla套件等。此工具的主要功能包括:测试和浏览器兼容性 - 测试您的应用程序,以查看您是否可以在不同的浏览器和操作系统上工作。测试系统功能 - 创建经济衰退测试检验软件功能和用户需求。支持自动录制动作和自动生成。 net,java,perl等不同语言。 Selenium是专门为Web应用程序的思考编写的验收测试工具。
页面较慢,不是爬行动物的不错选择。
示例代码如下:
webspec
具有接口的开源Java浏览器,支持脚本执行和CSS呈现。速度是一般的。
示例代码如下:
源代码下载:网络爬虫(网络蜘蛛)Web Grab示例源
转载,请在文章 @ @ @出网网:
jquery抓取网页内容(如何判断正则表达式的更新数据没有?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-21 06:29
)
最近开发一个小功能,数据库中的基本表的数据从另一个网站采集。
因为网站数据已更新,需要更新自动采集最新内容。
如何确定更新数据?
在网站 @有一个更新日志提示的地方,只需比较了本地保留的更新日志和最新日志。
Pages源代码的分析是一个难点,存在正则表达式。
但我没有使用正则表达式。搜索开源库ScRPysharp。
为什么使用此类库?
因为您可以使用jQuery的CSS选择器来制作一个方便的解析网页。
现在,代码现已发布,所需的人可以参考它。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本 查看全部
jquery抓取网页内容(如何判断正则表达式的更新数据没有?(图)
)
最近开发一个小功能,数据库中的基本表的数据从另一个网站采集。
因为网站数据已更新,需要更新自动采集最新内容。
如何确定更新数据?
在网站 @有一个更新日志提示的地方,只需比较了本地保留的更新日志和最新日志。
Pages源代码的分析是一个难点,存在正则表达式。
但我没有使用正则表达式。搜索开源库ScRPysharp。
为什么使用此类库?
因为您可以使用jQuery的CSS选择器来制作一个方便的解析网页。
现在,代码现已发布,所需的人可以参考它。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-17 22:02
1.序言
我相信很多人在进行开发时都有这样的需求:从网页中准确地提取所需的内容。经过思考,方法不外乎以下:(我的经验还很浅,还有更好的方法,请给我一些建议)
1.使用正则表达式匹配所需的元素。(缺点:如果相同类型的元素具有不同的属性,例如
aaa
bbb
,如果您想匹配所有div元素,这将非常麻烦,而且很容易得到不需要的结果并错过所需的结果。)
2.使用LINQ转换为XML将网页转换为XML文档。(缺点:需要转换过程,效率不高。)
3.使用网站提供的web服务或web API直接获取所需数据。(缺点:需要先获取接口文档,一般不匿名提供)
近年来,随着前端的兴起,越来越多的人开始理解jQuery,并对它留下深刻印象。非常重要的一点是jQuery选择器。它的简单性、高效性和易学性使前端工程师大大提高了工作效率。想想看。提取web内容需要处理前端。如果您可以使用jQuery选择器,它将是完美的
2.理论准备
是否要在下创建选择器。网?不,这不是我和其他年轻人能做的。。。。既然有了jQuery,为什么不直接使用它的选择器呢
1.. Net获取web内容
您可以在此处选择WebBrowser控件。事实上,它是一个微型ie。它可以做任何ie可以做的事情。有人问为什么不使用webclient直接下载web内容?请看第二点
2.. Net与JS交互
使用WebBrowser控件,您不仅可以获取网页内容,还可以提供与网页交互的功能。使用内置的document属性,我们可以将所需的JS代码注入web页面并执行它
3.提取并返回所需内容
在。Net中的invokescript函数来执行相应的JS函数并得到返回结果
既然理论已经准备好了,让我们实施它吧
3.函数实现
测试页面:(福利网站Oh,但没有邪恶内容,请编辑明剑!)
功能要求:提取所有好处
从上图开始:
从图中可以看出,“福利”是准确提取的。您只能获得所需的属性值。你只需要输入15个字符
让我们看看代码实现:
WB是WebBrowser控件。本节主要用于将jQuery库注入到一些不收录jQuery库的网页中
void InjectJQuery()<br />
{<br />
HtmlElement jquery = wb.Document.CreateElement("script");<br />
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);<br />
wb.Document.Body.AppendChild(jquery);<br />
JQueryInjected = true;<br />
}
下面是要为注入执行的JS函数。因为不同的要求有不同的代码,所以不能重复注入。当需求改变时,您只需要改变注入的函数
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)<br />
{<br />
JQScript = wb.Document.CreateElement("script");<br />
JQScript.SetAttribute("id", "JQScript");<br />
JQScript.SetAttribute("type", "text/javascript");<br />
wb.Document.Body.AppendChild(JQScript);<br />
}
这里是关键代码,它根据是否提取属性生成不同的代码。注入的代码非常简单。我相信对前端略知一二的朋友会一目了然。最后一行代码是执行注入函数并获取返回值
if (txtAttribute.Text.Trim() == string.Empty)<br />
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +<br />
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +<br />
" else if ($('" + txtSelector.Text + "').length > 1) {" +<br />
" var allhtml = '';" +<br />
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +<br />
" return allhtml;}" +<br />
" else return 'no item found.';}");<br />
else<br />
{<br />
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +<br />
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +<br />
" else if ($('" + txtSelector.Text + "').length > 1) {" +<br />
" var allhtml = '';" +<br />
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +<br />
" return allhtml;}" +<br />
" else return 'no item found.';}");<br />
}<br />
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
我相信一眼就可以看出,只需10行代码就可以使用功能强大的jQuery选择器,这比以前的旧方法效率高出许多倍。为什么不呢
4.知识扩展
1.只要您的前端知识足够难,您就可以注入更复杂的函数来实现更复杂的内容提取
2.在Android和IOS中,这些功能在理论上是可以实现的
3.也许有一天,我们会有一个类似的选择器来代替SQL,从而实现对数据库的高效查询
附言:我的写作很差,知识面也不广。如果有错误,请改正 查看全部
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
1.序言
我相信很多人在进行开发时都有这样的需求:从网页中准确地提取所需的内容。经过思考,方法不外乎以下:(我的经验还很浅,还有更好的方法,请给我一些建议)
1.使用正则表达式匹配所需的元素。(缺点:如果相同类型的元素具有不同的属性,例如
aaa
bbb
,如果您想匹配所有div元素,这将非常麻烦,而且很容易得到不需要的结果并错过所需的结果。)
2.使用LINQ转换为XML将网页转换为XML文档。(缺点:需要转换过程,效率不高。)
3.使用网站提供的web服务或web API直接获取所需数据。(缺点:需要先获取接口文档,一般不匿名提供)
近年来,随着前端的兴起,越来越多的人开始理解jQuery,并对它留下深刻印象。非常重要的一点是jQuery选择器。它的简单性、高效性和易学性使前端工程师大大提高了工作效率。想想看。提取web内容需要处理前端。如果您可以使用jQuery选择器,它将是完美的
2.理论准备
是否要在下创建选择器。网?不,这不是我和其他年轻人能做的。。。。既然有了jQuery,为什么不直接使用它的选择器呢
1.. Net获取web内容
您可以在此处选择WebBrowser控件。事实上,它是一个微型ie。它可以做任何ie可以做的事情。有人问为什么不使用webclient直接下载web内容?请看第二点
2.. Net与JS交互
使用WebBrowser控件,您不仅可以获取网页内容,还可以提供与网页交互的功能。使用内置的document属性,我们可以将所需的JS代码注入web页面并执行它
3.提取并返回所需内容
在。Net中的invokescript函数来执行相应的JS函数并得到返回结果
既然理论已经准备好了,让我们实施它吧
3.函数实现
测试页面:(福利网站Oh,但没有邪恶内容,请编辑明剑!)
功能要求:提取所有好处
从上图开始:
从图中可以看出,“福利”是准确提取的。您只能获得所需的属性值。你只需要输入15个字符
让我们看看代码实现:
WB是WebBrowser控件。本节主要用于将jQuery库注入到一些不收录jQuery库的网页中
void InjectJQuery()<br />
{<br />
HtmlElement jquery = wb.Document.CreateElement("script");<br />
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);<br />
wb.Document.Body.AppendChild(jquery);<br />
JQueryInjected = true;<br />
}
下面是要为注入执行的JS函数。因为不同的要求有不同的代码,所以不能重复注入。当需求改变时,您只需要改变注入的函数
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)<br />
{<br />
JQScript = wb.Document.CreateElement("script");<br />
JQScript.SetAttribute("id", "JQScript");<br />
JQScript.SetAttribute("type", "text/javascript");<br />
wb.Document.Body.AppendChild(JQScript);<br />
}
这里是关键代码,它根据是否提取属性生成不同的代码。注入的代码非常简单。我相信对前端略知一二的朋友会一目了然。最后一行代码是执行注入函数并获取返回值
if (txtAttribute.Text.Trim() == string.Empty)<br />
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +<br />
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +<br />
" else if ($('" + txtSelector.Text + "').length > 1) {" +<br />
" var allhtml = '';" +<br />
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +<br />
" return allhtml;}" +<br />
" else return 'no item found.';}");<br />
else<br />
{<br />
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +<br />
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +<br />
" else if ($('" + txtSelector.Text + "').length > 1) {" +<br />
" var allhtml = '';" +<br />
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +<br />
" return allhtml;}" +<br />
" else return 'no item found.';}");<br />
}<br />
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
我相信一眼就可以看出,只需10行代码就可以使用功能强大的jQuery选择器,这比以前的旧方法效率高出许多倍。为什么不呢
4.知识扩展
1.只要您的前端知识足够难,您就可以注入更复杂的函数来实现更复杂的内容提取
2.在Android和IOS中,这些功能在理论上是可以实现的
3.也许有一天,我们会有一个类似的选择器来代替SQL,从而实现对数据库的高效查询
附言:我的写作很差,知识面也不广。如果有错误,请改正
jquery抓取网页内容(jquery抓取网页内容的get.post或者postgres(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-13 18:01
jquery抓取网页内容的get.post或者postgres。post就是向指定的服务器发送post请求,get则不是直接向服务器请求数据,而是指定请求参数,服务器完成数据的解析处理后向用户返回数据,一般是json格式的,所以格式要求是明文的,带上发送地址和当前时间戳。另外,一般网站的源代码都是以txt的形式存储的,就不要指望抓包的时候能抓到html源码里的内容了,一般都是用javascript将javascript页面中的代码转换成我们希望在网页上看到的可以提交的页面上的代码。这是为了保证我们抓包后看到的网页是完整的,可以在看视频的时候不用从头拉到尾也不会影响整体的观看体验。
我觉得抓包的目的就是为了分析出数据包的整体内容,结构,一般都是用post方式吧。
我自己还没用过,应该可以抓一般抓包都用自己写的postget用的话也是用post提交数据,或者post+get,
抓包分析url是否存在是不是还需要上报url呢所以说api应该不是必须的但api应该是可选的
也看具体需求吧,有些api你觉得你需要的内容没有那么明显,只是url,比如通过post方式向服务器发送请求,其实post的参数是json格式,而不是明文。实际上抓包一部分是为了分析api应用里面返回的json格式的数据来分析你需要的内容是不是真的存在。 查看全部
jquery抓取网页内容(jquery抓取网页内容的get.post或者postgres(图))
jquery抓取网页内容的get.post或者postgres。post就是向指定的服务器发送post请求,get则不是直接向服务器请求数据,而是指定请求参数,服务器完成数据的解析处理后向用户返回数据,一般是json格式的,所以格式要求是明文的,带上发送地址和当前时间戳。另外,一般网站的源代码都是以txt的形式存储的,就不要指望抓包的时候能抓到html源码里的内容了,一般都是用javascript将javascript页面中的代码转换成我们希望在网页上看到的可以提交的页面上的代码。这是为了保证我们抓包后看到的网页是完整的,可以在看视频的时候不用从头拉到尾也不会影响整体的观看体验。
我觉得抓包的目的就是为了分析出数据包的整体内容,结构,一般都是用post方式吧。
我自己还没用过,应该可以抓一般抓包都用自己写的postget用的话也是用post提交数据,或者post+get,
抓包分析url是否存在是不是还需要上报url呢所以说api应该不是必须的但api应该是可选的
也看具体需求吧,有些api你觉得你需要的内容没有那么明显,只是url,比如通过post方式向服务器发送请求,其实post的参数是json格式,而不是明文。实际上抓包一部分是为了分析api应用里面返回的json格式的数据来分析你需要的内容是不是真的存在。

