
jquery抓取网页内容
jquery抓取网页内容(WOT全球技术创新大会2022,门票6折抢购中!购票立减2320元!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-14 23:36
WOT全球科技创新大会2022,门票40折抢购!购票立减2320元!
一:背景
1. 讲个故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢奇怪的东西,所以就需要如何瞄准和捕捉奇怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。我这个年纪的码农至少学了 5-6 年的 Jquery,所以我必须使用类似 Jquery 的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?哎,真的有全能的github。. .
二:CSQuery
1. 安装
github地址:然后直接在vs中点击nuget:
2. 举几个例子
万事俱备,如何使用?别急,我举两个博客园的例子。
1) 从首页提取友情链接到
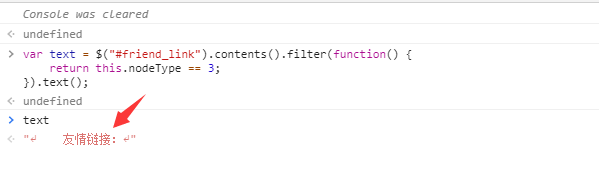
如上图所示,这里如果要获取友情链接的几个大字,直接用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
那怎么处理呢?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最后得到文本节点的内容,如下:
用js做的,用CSQuery代码怎么做?模仿一下,如下代码:
static void Main(string[] args) { var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com")); var content = jquery["#friend_link"].Contents().Filter((dom) => { return dom.NodeType == NodeType.TEXT_NODE; }).Text(); Console.WriteLine(content); }
不知道用xpath提取这样的内容是不是很麻烦,但是用jquery也不是很方便,但是熟悉。
2) 如何给html中的一些元素着色
有时需要为业务更改一些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:
如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args) { Config.HtmlEncoder = HtmlEncoders.None; var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com")); var html = jquery["#nav_left li"].Each(dom => { var self = jquery[dom]; var text = self.Text(); if (text == "博问" || text == "专区") { self.Find("a").CssSet(new { color = "red" }); } }).Render(); }
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等百种实用方法,本文当然不能一一介绍,有兴趣的可以下载到看看并玩弄小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以用CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到
3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args) { Config.HtmlEncoder = HtmlEncoders.None; var strlist = new string[2] { "1", "2" }; var path = Environment.CurrentDirectory + "\\2.html"; var jquery = CQ.CreateFromFile(path); var current = jquery.Find("#main"); foreach (var str in strlist) { current.Append($"{str}"); } var html = current.RenderSelection(); Console.WriteLine(html); } ------------- output ---------------- 12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!但是html5中也加入了querySelector和querySelectorAll来支持css3的选择器,非常强大,但是jquery不仅在选择器上灵活,而且在对节点的灵活操作方面,一般来说可以怀旧的时候它的交互性不是特别丰富。 查看全部
jquery抓取网页内容(WOT全球技术创新大会2022,门票6折抢购中!购票立减2320元!)
WOT全球科技创新大会2022,门票40折抢购!购票立减2320元!

一:背景
1. 讲个故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢奇怪的东西,所以就需要如何瞄准和捕捉奇怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。我这个年纪的码农至少学了 5-6 年的 Jquery,所以我必须使用类似 Jquery 的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?哎,真的有全能的github。. .
二:CSQuery
1. 安装
github地址:然后直接在vs中点击nuget:
2. 举几个例子
万事俱备,如何使用?别急,我举两个博客园的例子。
1) 从首页提取友情链接到

如上图所示,这里如果要获取友情链接的几个大字,直接用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:

那怎么处理呢?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最后得到文本节点的内容,如下:
用js做的,用CSQuery代码怎么做?模仿一下,如下代码:
static void Main(string[] args) { var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";)); var content = jquery["#friend_link"].Contents().Filter((dom) => { return dom.NodeType == NodeType.TEXT_NODE; }).Text(); Console.WriteLine(content); }
不知道用xpath提取这样的内容是不是很麻烦,但是用jquery也不是很方便,但是熟悉。
2) 如何给html中的一些元素着色
有时需要为业务更改一些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:

如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args) { Config.HtmlEncoder = HtmlEncoders.None; var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";)); var html = jquery["#nav_left li"].Each(dom => { var self = jquery[dom]; var text = self.Text(); if (text == "博问" || text == "专区") { self.Find("a").CssSet(new { color = "red" }); } }).Render(); }

3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等百种实用方法,本文当然不能一一介绍,有兴趣的可以下载到看看并玩弄小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以用CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到

3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args) { Config.HtmlEncoder = HtmlEncoders.None; var strlist = new string[2] { "1", "2" }; var path = Environment.CurrentDirectory + "\\2.html"; var jquery = CQ.CreateFromFile(path); var current = jquery.Find("#main"); foreach (var str in strlist) { current.Append($"{str}"); } var html = current.RenderSelection(); Console.WriteLine(html); } ------------- output ---------------- 12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!但是html5中也加入了querySelector和querySelectorAll来支持css3的选择器,非常强大,但是jquery不仅在选择器上灵活,而且在对节点的灵活操作方面,一般来说可以怀旧的时候它的交互性不是特别丰富。
jquery抓取网页内容(PythonWeb爬虫库Python是最常用的Web抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-13 22:06
您是否打算开始一个新的网页抓取项目并正在寻找可以使用的最佳网页抓取工具?现在发现最好的工具,包括非编码器专用的工具。
虽然您可以从头开发自己的网页抓取工具来执行网页抓取任务,但除非您有明显的原因,否则这样做是明智的,否则不仅会浪费您的时间,还会浪费您所有的投资其他资源。无需走那条路,您需要调查市场以使用现有解决方案。说到网络抓取工具,您需要知道市场上有很多工具。
然而,并非所有人都是平等的。事实证明,有些方法比其他方法更好。有些工具比其他工具更受欢迎,而且每种工具的学习曲线都不同。平台和编程语言支持及其含义也是如此。但是,我们仍然可以就市场上最好的网络抓取工具达成一致,下面将逐一讨论。该列表包括为具有编程技能的人和非编码人员开发的工具。
程序员的Web爬网工具
网页抓取最初是编码人员的任务,因为需要在抓取网站之前编写代码。因此,市场上有许多专门为编码人员创建的工具。供编码人员使用的 Web 抓取工具采用库和框架的形式,开发人员将这些库和框架合并到他们的代码中,以从他们的 Web 抓取中获得所需的行为。
Python 网络爬虫库
Python 是网络爬虫代码最常用的编程语言,因为它语法简单,学习曲线丰富,并且有大量可用的库,简化了开发者的工作。下面讨论了 Python 开发人员可以使用的一些网络抓取库和框架。
刮痧
Scrapy 是一个用 Python 为 Python 开发人员编写的网络爬虫和网络抓取框架。Scrapy 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面解析数据的模块。
它是开源的,可以免费使用。爬行还提供了一种保存数据的方法。但是,Scrapy 无法渲染 JavaScript,因此需要其他库的帮助。为此,您可以使用 Splash 或流行的 Selenium 浏览器自动化工具。
蜘蛛侠
PySpider 是另一种网页抓取工具,可用于在 Python 中编写脚本。与 Scrapy 不同的是,它可以渲染 JavaScript,因此无需使用 Selenium。然而,它不如 Scrapy 成熟,因为 Scrapy 自 2008 年就已经存在,并且拥有更好的文档和用户社区。这不会使 PySpider 劣等。事实上,PySpider 有一些无与伦比的功能,比如一个 Web UI 脚本编辑器。
要求
request 是一个可以轻松发送 HTTP 请求的 HTTP 库。它建立在 urllib 之上。它是一个强大的工具,可以帮助您创建更可靠的刮板。它易于使用并且需要更少的代码行。
非常重要的事实是,它可以帮助您处理 cookie 和会话以及身份验证和自动连接池。它是免费使用的,Python 开发者会在使用解析器解析所需数据之前使用它下载页面。
美汤
BeautifulSoup 使从网页解析数据的过程变得容易。它位于 HTML 或 XML 解析器之上,并为您提供 Python 方法来访问数据。由于其易于解析,BeautifulSoup 已成为市场上最重要的网页抓取工具之一。
事实上,大多数网页抓取教程都使用 BeautifulSoup 来教新手如何编写网页抓取工具。当与“发送HTTP请求”和“请求”一起使用时,网页抓取工具的开发变得比使用Scrapy或PySpider更容易。
硒
如果 网站 是 Ajaxified,Scrapy、Requests 和 BeautifulSoup 对你没有帮助——也就是说,它依赖 AJAX 请求通过 JavaScript 加载页面的某些部分。如果要访问这样的页面,则需要使用 Selenium,它是一种 Web 浏览器自动化工具。它可用于自动化浏览器,例如 Chrome 和 Firefox。老版本可以自动执行 PhantomJS。
Node.JS (JavaScript) 网页抓取工具
由于 JavaScript 的流行,Node.JS 也正在成为网络爬虫的流行平台。同样,它有许多用于网页抓取的工具,但不如 Python。下面讨论两个最流行的 Node.JS 运行时工具。
切里奥
对于 Node.JS,Cheerio 是 Python。它是一个解析库,用于解析标记并提供用于遍历和操作 Web 内容的 API。它没有渲染 JavaScript 的能力,所以你需要一个无头浏览器。它的唯一任务是为您提供一个 jQuery,例如用于解析网页数据的 API。它灵活、快速且易于使用。
傀儡师
Puppeteer 是 JavaScript 开发人员可以使用的最好的网络抓取工具之一。它是一个浏览器自动化工具,并提供用于控制 Chrome 的高级 API。Puppeteer 由 Google 开发,仅适用于 Chrome 浏览器和其他 Chromium 浏览器。与跨平台的 Selenium 不同,Puppeteer 仅用于 Node 环境。
网络采集API
没有使用代理爬取经验且难以爬取网站的编码者,或者不想担心代理管理和解决验证码问题的编码者,可以帮助他们从网站中提取通过仅使用 Web 抓取 API 数据或下载整个数据页面,以便他们可以抓取。最好的网页抓取 API 描述如下。
自动提取 API
AutoExtract API 是市场上最好的网页抓取 API 之一。它由 Scrapinghub、Crawlera 的创建者、代理 API 和主要维护者 Scrapy 开发,为 Python 程序员提供了一个流行的框架。
AutoExtract API 是一种 API 驱动的数据提取工具,可以帮助您从 网站 中提取特定数据,而无需事先了解 网站 - 这意味着不需要特定于站点的代码。AutoExtract API 支持提取新闻和博客、电子商务产品、招聘信息和车辆数据等。
刮蜂
ScrapingBee 是一个网页抓取 API,可以帮助您下载网页。使用 ScrapingBee,您不必考虑块,但是当作为响应返回给您时,ScrapingBee 会解析从下载的网页返回的数据。
ScrapingBee 使用方便,只需要调用一次 API。ScrapingBee 使用大量 IP 来路由您的请求并避免被禁止。它还有助于处理无头 Chrome,这不是一件容易的事,尤其是在扩展无头 Chrome 网格时。
爬虫API
Scraper API 每月处理超过 50 亿次 API 请求,因此在网页抓取 API 市场中不可忽视。其强大的系统可以帮助您处理大量任务,包括使用超过 4000 万个 IP 的代理池进行 IP 轮换。
除了 IP 轮换之外,Scraper API 还可以处理无头浏览器,并可以帮助您避免直接处理验证码。网页抓取 API 快速可靠,其客户名单中有许多财富 500 强公司。定价也很合理。
Zenscrape
Zenscrape 将帮助您以实惠的价格轻松地从 网站 中提取数据——他们甚至像其他人一样拥有免费试用计划,可以在做出财务承诺之前测试他们的服务。
Zenscrape 会为您下载普通用户看到的页面,并可以根据您选择的方案处理针对地理区域的内容。非常重要的一点是,由于所有请求都是在无头 Chrome 中执行的,因此它可以完美地处理 JavaScript。它甚至支持流行的 JavaScript 框架。
刮痧蚂蚁
使用严格的反垃圾邮件系统来抓取站点是一项艰巨的任务,因为您必须处理许多障碍。ScrapingAnt 可以帮助您处理所有障碍,轻松获取您需要的数据。
它使用无头 Chrome 浏览器来处理 JavaScript 执行、处理代理并帮助您避免验证码。ScrapingAnt 还处理自定义 cookie 和输出预处理。当你开始使用它的网页抓取 API 时,它的价格很友好,低至 9 美元。
最佳非编码器Web爬网工具
过去,网络抓取需要您编写代码。这不再是事实,因为一些网页抓取工具是专门为非编码人员开发的。使用这些工具,您可以在不编写代码的情况下从 Internet 获取所需的数据。这些工具可以采用可安装软件、基于云的解决方案或浏览器扩展的形式。
网页抓取软件
市场上有很多软件可以用来在线采集各种数据,而无需知道如何编写代码。以下是目前市场上的前 5 种选择。
八爪鱼
Octoparse 使每个人都可以轻松进行网络抓取。使用 Octoparse,您只需点击几下即可将整个 网站 快速转换为结构化的电子表格。Octoparse 不需要任何编码技能,因为您只需点击一下,您就会获得所需的数据。Octoparse可以使用严格的反爬技术从各种网站(包括Ajaxified网站)中抓取数据。它使用 IP 轮换来隐藏 IP 足迹。除了可安装的软件,他们还提供基于云的解决方案,您甚至可以享受 14 天的免费试用期。
氦气刮刀
Helium Scraper 是另一个可以抓取 网站 作为非编码器的软件。您可以通过为编码人员定义自己的操作来捕获复杂的数据;他们还可以运行自定义 JavaScript 文件。通过简单的工作流程,使用 Helium Scraper 不仅简单而且快速,因为它具有简单直观的界面。Helium Scraper也是一款具有多种功能(包括抓取计划、代理轮换、文本操作和API调用等)的网页抓取软件。
分析中心
ParseHub 有两个版本——一个免费使用的桌面应用程序和一个付费的基于云的爬虫解决方案,具有附加功能,无需安装即可使用。ParseHub 桌面应用程序允许您轻松获取所需的任何内容 网站 即使没有编码技能。这是因为该软件提供了一个点击式界面,该界面专为对要捕获的数据进行软件培训而设计。它非常适合现代网站,并允许您以流行的文件格式下载捕获的数据。
刮刮风
ScrapeStorm 与上述其他桌面应用的不同之处在于,它仅在无法自动识别所需数据时才使用点击界面。ScrapeStorm 使用 AI 智能识别网页上的特定数据点。ScrapeStorm 快速、可靠且易于使用。在操作系统支持方面,ScrapeStorm 提供了对 Windows、Mac 和 Linux 的支持。支持多种数据导出方式,可实现企业级爬取。有趣的是,它是由前 Google 爬虫团队构建的。
网络哈维
WebHarvy 是另一种网络抓取软件,您可以将其安装在您的计算机上,以帮助您处理抓取并从网页中提取数据。该软件允许您编写一行代码进行捕获,您可以选择将捕获的数据保存在文件或数据库系统中。它是一个强大的可视化工具,可用于从网页中抓取各种数据,例如电子邮件、链接、图像,甚至完整的 HTML 文件。它具有智能模式检测功能,可以抓取多个页面。
网络应用扩展
浏览器环境在网络爬虫中越来越流行,许多网络爬虫工具可以作为浏览器的扩展和插件安装,帮助你从网站中抓取数据,下面将讨论其中的一些。
网页抓取扩展
Webscraper.io 浏览器扩展(Chrome 和 Firefox)提供了最好的网页抓取工具之一,您可以使用它轻松地从网页中提取数据。超过 250,000 名用户安装了这个工具,他们发现它非常有用。这些浏览器扩展不需要点击编码,因为它们使用点击界面。有趣的是,它甚至可以通过许多 JavaScript 触发的操作来获取最现代的 网站。
数据挖掘器扩展
Data Miner 扩展仅适用于 Google Chrome 和 Microsoft Edge 浏览器。它可以帮助您从页面抓取数据并将抓取的数据保存在 CSV 或 Excel 电子表格中。与 Webscraper.io 提供的扩展程序免费的情况不同,Data Miner 扩展程序仅对一个月内抓取的前 500 页免费 - 之后,您需要订阅付费计划才能使用它。使用此扩展程序,您可以在不考虑块的情况下抓取任何页面 - 并且您的数据保持私密。
刮刀
Scraper 是一个 Chrome 扩展,可能由开发人员设计和管理 - 它甚至没有自己的 网站 像上面的另一个 网站 。Scraper 没有上面提到的其他浏览器扩展那么先进。但是,它是完全免费的。Scraper 的主要问题是它要求用户知道如何使用 XPath,因为这是您将要使用的 XPath。因此,它不是初学者友好的。
SimpleScraper
SimpleScraper 是另一种可用作 Chrome 扩展程序的网页抓取工具。通过在 Chrome 浏览器中安装此扩展程序,您可以将任何 网站 变成一个 API,让网络爬虫变得简单而自由。此扩展程序将帮助您从网页中快速提取结构化数据,适用于所有 网站,包括那些收录 JavaScript 网站 的内容。如果您需要更灵活的选择,您可以付费选择他们基于云的解决方案。
代理刮油剂
使用Agenty Scraping Agent,您可以不考虑障碍地继续操作和抓取网页中的数据。此工具不是免费的,但它们提供免费试用选项。这个浏览器扩展是为现代web开发的,所以爬很多JavaScript网站不会有问题。有趣的是,它也适用于旧的 网站。
网页抓取代理
事实是,除非您使用通常被认为昂贵的网络抓取 API,否则您必须使用代理。说到爬虫的代理,我会推荐用户使用带有住宅替换IP的代理提供商——这样可以减轻你的代理管理负担。以下是市场上 3 种最佳 IP 轮换服务。
发光体
Luminati可以说是市场上最好的代理服务商。它还拥有全球最大的代理网络,Luminati 代理池中拥有超过 7200 万个住宅 IP。它仍然是最安全、可靠和快速的工具之一。有趣的是,它兼容当今互联网上最流行的网站。Luminati 拥有最好的会话控制系统,因为它允许您决定何时维护会话——它还有一个高轮换代理,可以在每次请求后更改 IP。然而,它是昂贵的。
智能代理
Smartproxy拥有住宅代理池,收录超过1000万个住宅IP。由于会话控制系统,它们的代理对于网络抓取非常有效。他们的代理可以保持会话和相同IP 10分钟——这非常适合基于登录的爬取网站。对于常规的 网站,您可以使用其高轮换代理,它会在每次请求后更改 IP。他们在全球约195个国家和8个主要城市设有代理商。
爬虫
Crawlera 通过帮助您与代理打交道来帮助您专注于数据。与 Luminati 的情况不同,Crawlera 的系统中没有足够的 IP。
但是,与 Luminati 可能被 Captchas 攻击的情况不同,Crawlera 使用一些技巧来确保您请求的页面被返回——但是,与 Luminati 一样,它们在世界上所有国家和城市都没有代理。他们的定价基于请求的数量,而不是消耗的带宽。 查看全部
jquery抓取网页内容(PythonWeb爬虫库Python是最常用的Web抓取工具)
您是否打算开始一个新的网页抓取项目并正在寻找可以使用的最佳网页抓取工具?现在发现最好的工具,包括非编码器专用的工具。
虽然您可以从头开发自己的网页抓取工具来执行网页抓取任务,但除非您有明显的原因,否则这样做是明智的,否则不仅会浪费您的时间,还会浪费您所有的投资其他资源。无需走那条路,您需要调查市场以使用现有解决方案。说到网络抓取工具,您需要知道市场上有很多工具。
然而,并非所有人都是平等的。事实证明,有些方法比其他方法更好。有些工具比其他工具更受欢迎,而且每种工具的学习曲线都不同。平台和编程语言支持及其含义也是如此。但是,我们仍然可以就市场上最好的网络抓取工具达成一致,下面将逐一讨论。该列表包括为具有编程技能的人和非编码人员开发的工具。
程序员的Web爬网工具
网页抓取最初是编码人员的任务,因为需要在抓取网站之前编写代码。因此,市场上有许多专门为编码人员创建的工具。供编码人员使用的 Web 抓取工具采用库和框架的形式,开发人员将这些库和框架合并到他们的代码中,以从他们的 Web 抓取中获得所需的行为。
Python 网络爬虫库
Python 是网络爬虫代码最常用的编程语言,因为它语法简单,学习曲线丰富,并且有大量可用的库,简化了开发者的工作。下面讨论了 Python 开发人员可以使用的一些网络抓取库和框架。
刮痧
Scrapy 是一个用 Python 为 Python 开发人员编写的网络爬虫和网络抓取框架。Scrapy 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面解析数据的模块。
它是开源的,可以免费使用。爬行还提供了一种保存数据的方法。但是,Scrapy 无法渲染 JavaScript,因此需要其他库的帮助。为此,您可以使用 Splash 或流行的 Selenium 浏览器自动化工具。
蜘蛛侠
PySpider 是另一种网页抓取工具,可用于在 Python 中编写脚本。与 Scrapy 不同的是,它可以渲染 JavaScript,因此无需使用 Selenium。然而,它不如 Scrapy 成熟,因为 Scrapy 自 2008 年就已经存在,并且拥有更好的文档和用户社区。这不会使 PySpider 劣等。事实上,PySpider 有一些无与伦比的功能,比如一个 Web UI 脚本编辑器。
要求
request 是一个可以轻松发送 HTTP 请求的 HTTP 库。它建立在 urllib 之上。它是一个强大的工具,可以帮助您创建更可靠的刮板。它易于使用并且需要更少的代码行。
非常重要的事实是,它可以帮助您处理 cookie 和会话以及身份验证和自动连接池。它是免费使用的,Python 开发者会在使用解析器解析所需数据之前使用它下载页面。
美汤
BeautifulSoup 使从网页解析数据的过程变得容易。它位于 HTML 或 XML 解析器之上,并为您提供 Python 方法来访问数据。由于其易于解析,BeautifulSoup 已成为市场上最重要的网页抓取工具之一。
事实上,大多数网页抓取教程都使用 BeautifulSoup 来教新手如何编写网页抓取工具。当与“发送HTTP请求”和“请求”一起使用时,网页抓取工具的开发变得比使用Scrapy或PySpider更容易。
硒
如果 网站 是 Ajaxified,Scrapy、Requests 和 BeautifulSoup 对你没有帮助——也就是说,它依赖 AJAX 请求通过 JavaScript 加载页面的某些部分。如果要访问这样的页面,则需要使用 Selenium,它是一种 Web 浏览器自动化工具。它可用于自动化浏览器,例如 Chrome 和 Firefox。老版本可以自动执行 PhantomJS。
Node.JS (JavaScript) 网页抓取工具
由于 JavaScript 的流行,Node.JS 也正在成为网络爬虫的流行平台。同样,它有许多用于网页抓取的工具,但不如 Python。下面讨论两个最流行的 Node.JS 运行时工具。
切里奥
对于 Node.JS,Cheerio 是 Python。它是一个解析库,用于解析标记并提供用于遍历和操作 Web 内容的 API。它没有渲染 JavaScript 的能力,所以你需要一个无头浏览器。它的唯一任务是为您提供一个 jQuery,例如用于解析网页数据的 API。它灵活、快速且易于使用。
傀儡师
Puppeteer 是 JavaScript 开发人员可以使用的最好的网络抓取工具之一。它是一个浏览器自动化工具,并提供用于控制 Chrome 的高级 API。Puppeteer 由 Google 开发,仅适用于 Chrome 浏览器和其他 Chromium 浏览器。与跨平台的 Selenium 不同,Puppeteer 仅用于 Node 环境。
网络采集API
没有使用代理爬取经验且难以爬取网站的编码者,或者不想担心代理管理和解决验证码问题的编码者,可以帮助他们从网站中提取通过仅使用 Web 抓取 API 数据或下载整个数据页面,以便他们可以抓取。最好的网页抓取 API 描述如下。
自动提取 API
AutoExtract API 是市场上最好的网页抓取 API 之一。它由 Scrapinghub、Crawlera 的创建者、代理 API 和主要维护者 Scrapy 开发,为 Python 程序员提供了一个流行的框架。
AutoExtract API 是一种 API 驱动的数据提取工具,可以帮助您从 网站 中提取特定数据,而无需事先了解 网站 - 这意味着不需要特定于站点的代码。AutoExtract API 支持提取新闻和博客、电子商务产品、招聘信息和车辆数据等。
刮蜂
ScrapingBee 是一个网页抓取 API,可以帮助您下载网页。使用 ScrapingBee,您不必考虑块,但是当作为响应返回给您时,ScrapingBee 会解析从下载的网页返回的数据。
ScrapingBee 使用方便,只需要调用一次 API。ScrapingBee 使用大量 IP 来路由您的请求并避免被禁止。它还有助于处理无头 Chrome,这不是一件容易的事,尤其是在扩展无头 Chrome 网格时。
爬虫API
Scraper API 每月处理超过 50 亿次 API 请求,因此在网页抓取 API 市场中不可忽视。其强大的系统可以帮助您处理大量任务,包括使用超过 4000 万个 IP 的代理池进行 IP 轮换。
除了 IP 轮换之外,Scraper API 还可以处理无头浏览器,并可以帮助您避免直接处理验证码。网页抓取 API 快速可靠,其客户名单中有许多财富 500 强公司。定价也很合理。
Zenscrape
Zenscrape 将帮助您以实惠的价格轻松地从 网站 中提取数据——他们甚至像其他人一样拥有免费试用计划,可以在做出财务承诺之前测试他们的服务。
Zenscrape 会为您下载普通用户看到的页面,并可以根据您选择的方案处理针对地理区域的内容。非常重要的一点是,由于所有请求都是在无头 Chrome 中执行的,因此它可以完美地处理 JavaScript。它甚至支持流行的 JavaScript 框架。
刮痧蚂蚁
使用严格的反垃圾邮件系统来抓取站点是一项艰巨的任务,因为您必须处理许多障碍。ScrapingAnt 可以帮助您处理所有障碍,轻松获取您需要的数据。
它使用无头 Chrome 浏览器来处理 JavaScript 执行、处理代理并帮助您避免验证码。ScrapingAnt 还处理自定义 cookie 和输出预处理。当你开始使用它的网页抓取 API 时,它的价格很友好,低至 9 美元。
最佳非编码器Web爬网工具
过去,网络抓取需要您编写代码。这不再是事实,因为一些网页抓取工具是专门为非编码人员开发的。使用这些工具,您可以在不编写代码的情况下从 Internet 获取所需的数据。这些工具可以采用可安装软件、基于云的解决方案或浏览器扩展的形式。
网页抓取软件
市场上有很多软件可以用来在线采集各种数据,而无需知道如何编写代码。以下是目前市场上的前 5 种选择。
八爪鱼
Octoparse 使每个人都可以轻松进行网络抓取。使用 Octoparse,您只需点击几下即可将整个 网站 快速转换为结构化的电子表格。Octoparse 不需要任何编码技能,因为您只需点击一下,您就会获得所需的数据。Octoparse可以使用严格的反爬技术从各种网站(包括Ajaxified网站)中抓取数据。它使用 IP 轮换来隐藏 IP 足迹。除了可安装的软件,他们还提供基于云的解决方案,您甚至可以享受 14 天的免费试用期。
氦气刮刀
Helium Scraper 是另一个可以抓取 网站 作为非编码器的软件。您可以通过为编码人员定义自己的操作来捕获复杂的数据;他们还可以运行自定义 JavaScript 文件。通过简单的工作流程,使用 Helium Scraper 不仅简单而且快速,因为它具有简单直观的界面。Helium Scraper也是一款具有多种功能(包括抓取计划、代理轮换、文本操作和API调用等)的网页抓取软件。
分析中心
ParseHub 有两个版本——一个免费使用的桌面应用程序和一个付费的基于云的爬虫解决方案,具有附加功能,无需安装即可使用。ParseHub 桌面应用程序允许您轻松获取所需的任何内容 网站 即使没有编码技能。这是因为该软件提供了一个点击式界面,该界面专为对要捕获的数据进行软件培训而设计。它非常适合现代网站,并允许您以流行的文件格式下载捕获的数据。
刮刮风
ScrapeStorm 与上述其他桌面应用的不同之处在于,它仅在无法自动识别所需数据时才使用点击界面。ScrapeStorm 使用 AI 智能识别网页上的特定数据点。ScrapeStorm 快速、可靠且易于使用。在操作系统支持方面,ScrapeStorm 提供了对 Windows、Mac 和 Linux 的支持。支持多种数据导出方式,可实现企业级爬取。有趣的是,它是由前 Google 爬虫团队构建的。
网络哈维
WebHarvy 是另一种网络抓取软件,您可以将其安装在您的计算机上,以帮助您处理抓取并从网页中提取数据。该软件允许您编写一行代码进行捕获,您可以选择将捕获的数据保存在文件或数据库系统中。它是一个强大的可视化工具,可用于从网页中抓取各种数据,例如电子邮件、链接、图像,甚至完整的 HTML 文件。它具有智能模式检测功能,可以抓取多个页面。
网络应用扩展
浏览器环境在网络爬虫中越来越流行,许多网络爬虫工具可以作为浏览器的扩展和插件安装,帮助你从网站中抓取数据,下面将讨论其中的一些。
网页抓取扩展
Webscraper.io 浏览器扩展(Chrome 和 Firefox)提供了最好的网页抓取工具之一,您可以使用它轻松地从网页中提取数据。超过 250,000 名用户安装了这个工具,他们发现它非常有用。这些浏览器扩展不需要点击编码,因为它们使用点击界面。有趣的是,它甚至可以通过许多 JavaScript 触发的操作来获取最现代的 网站。
数据挖掘器扩展
Data Miner 扩展仅适用于 Google Chrome 和 Microsoft Edge 浏览器。它可以帮助您从页面抓取数据并将抓取的数据保存在 CSV 或 Excel 电子表格中。与 Webscraper.io 提供的扩展程序免费的情况不同,Data Miner 扩展程序仅对一个月内抓取的前 500 页免费 - 之后,您需要订阅付费计划才能使用它。使用此扩展程序,您可以在不考虑块的情况下抓取任何页面 - 并且您的数据保持私密。
刮刀
Scraper 是一个 Chrome 扩展,可能由开发人员设计和管理 - 它甚至没有自己的 网站 像上面的另一个 网站 。Scraper 没有上面提到的其他浏览器扩展那么先进。但是,它是完全免费的。Scraper 的主要问题是它要求用户知道如何使用 XPath,因为这是您将要使用的 XPath。因此,它不是初学者友好的。
SimpleScraper
SimpleScraper 是另一种可用作 Chrome 扩展程序的网页抓取工具。通过在 Chrome 浏览器中安装此扩展程序,您可以将任何 网站 变成一个 API,让网络爬虫变得简单而自由。此扩展程序将帮助您从网页中快速提取结构化数据,适用于所有 网站,包括那些收录 JavaScript 网站 的内容。如果您需要更灵活的选择,您可以付费选择他们基于云的解决方案。
代理刮油剂
使用Agenty Scraping Agent,您可以不考虑障碍地继续操作和抓取网页中的数据。此工具不是免费的,但它们提供免费试用选项。这个浏览器扩展是为现代web开发的,所以爬很多JavaScript网站不会有问题。有趣的是,它也适用于旧的 网站。
网页抓取代理
事实是,除非您使用通常被认为昂贵的网络抓取 API,否则您必须使用代理。说到爬虫的代理,我会推荐用户使用带有住宅替换IP的代理提供商——这样可以减轻你的代理管理负担。以下是市场上 3 种最佳 IP 轮换服务。
发光体
Luminati可以说是市场上最好的代理服务商。它还拥有全球最大的代理网络,Luminati 代理池中拥有超过 7200 万个住宅 IP。它仍然是最安全、可靠和快速的工具之一。有趣的是,它兼容当今互联网上最流行的网站。Luminati 拥有最好的会话控制系统,因为它允许您决定何时维护会话——它还有一个高轮换代理,可以在每次请求后更改 IP。然而,它是昂贵的。
智能代理
Smartproxy拥有住宅代理池,收录超过1000万个住宅IP。由于会话控制系统,它们的代理对于网络抓取非常有效。他们的代理可以保持会话和相同IP 10分钟——这非常适合基于登录的爬取网站。对于常规的 网站,您可以使用其高轮换代理,它会在每次请求后更改 IP。他们在全球约195个国家和8个主要城市设有代理商。
爬虫
Crawlera 通过帮助您与代理打交道来帮助您专注于数据。与 Luminati 的情况不同,Crawlera 的系统中没有足够的 IP。
但是,与 Luminati 可能被 Captchas 攻击的情况不同,Crawlera 使用一些技巧来确保您请求的页面被返回——但是,与 Luminati 一样,它们在世界上所有国家和城市都没有代理。他们的定价基于请求的数量,而不是消耗的带宽。
jquery抓取网页内容(WOT全球技术创新大会2022,门票6折抢购中!购票立减2320元!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-13 10:21
2022年Wot全球技术创新大会,门票以60%的折扣被抢购一空!门票减少了2320元
如果您在Python爬行过程中遇到问题,并且不知道如何解决这些问题,您可以通过以下文章>详细了解Python爬行。通过了解它,您可以在股票信息和其他信息中获得您想要查询的内容
您需要向python添加一些内容。这很容易做到。JQuery对于HTML内容提取和分析非常方便。Python做类似的工作有点麻烦。事实证明,我使用正则表达式或HTMLPasser。它们都不太好用。今天,我发现了一个好东西pyquery,一个类似于jQuery的python库
摘录一段说明:
from pyquery import PyQuery as pq from lxml import etree d = pq(" html>") d = pq(etree.fromstring(" html>")) d = pq(url='http://google.com/') d = pq(filename=path_to_html_file) Now d is like the $ in jquery: d("#hello") [ ] p = d("#hello") p.html() 'Hello world !' p.html("you know Python a> rocks") [ ] p.html() 'you know Python a> rocks' p.text() 'you know Python rocks'
这很容易。安装也很简单。解压缩Python安装程序Py-install就可以了。您可能需要安装ezsetup。目前的版本是0.3。还有一些jQuery函数尚未实现,如radio、password和一些Ajax函数。通过介绍,您可以更好地了解Python爬行的应用。快试试
[编者推荐]
Python列表内涵实用介绍中国IPTV研究项目及世界领先的Python列表内涵使用介绍Python抓取网页图片相关编码方法Python抓取网页内容应用代码分析Python抓取网页内容应用代码分析 查看全部
jquery抓取网页内容(WOT全球技术创新大会2022,门票6折抢购中!购票立减2320元!)
2022年Wot全球技术创新大会,门票以60%的折扣被抢购一空!门票减少了2320元
如果您在Python爬行过程中遇到问题,并且不知道如何解决这些问题,您可以通过以下文章>详细了解Python爬行。通过了解它,您可以在股票信息和其他信息中获得您想要查询的内容
您需要向python添加一些内容。这很容易做到。JQuery对于HTML内容提取和分析非常方便。Python做类似的工作有点麻烦。事实证明,我使用正则表达式或HTMLPasser。它们都不太好用。今天,我发现了一个好东西pyquery,一个类似于jQuery的python库
摘录一段说明:
from pyquery import PyQuery as pq from lxml import etree d = pq(" html>") d = pq(etree.fromstring(" html>")) d = pq(url='http://google.com/') d = pq(filename=path_to_html_file) Now d is like the $ in jquery: d("#hello") [ ] p = d("#hello") p.html() 'Hello world !' p.html("you know Python a> rocks") [ ] p.html() 'you know Python a> rocks' p.text() 'you know Python rocks'
这很容易。安装也很简单。解压缩Python安装程序Py-install就可以了。您可能需要安装ezsetup。目前的版本是0.3。还有一些jQuery函数尚未实现,如radio、password和一些Ajax函数。通过介绍,您可以更好地了解Python爬行的应用。快试试
[编者推荐]
Python列表内涵实用介绍中国IPTV研究项目及世界领先的Python列表内涵使用介绍Python抓取网页图片相关编码方法Python抓取网页内容应用代码分析Python抓取网页内容应用代码分析
jquery抓取网页内容(jquery抓取页面内容可以忽略的jquery代码吗?代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-06 13:12
jquery抓取网页内容,js代码还是非常重要的,而且涉及到dom。mediaquery抓取页面内容可以忽略jquery代码。第一步:发布一个js脚本meta.js,第二步:firebug第三步:meta.js,要抓取哪页的内容,抓取哪页的,这里引用mediaquery。获取加载网页的view的元素一般是这页的后几页的内容,或者隐藏的内容就按需获取。
获取对应元素,一般用a标签。第四步:firebug或者js生成a标签可以直接获取elements.pagecontainer().tag,也可以函数继承global.inject_html()函数。newjs脚本().prototype.tagname=".js"。
用vscodeimportjqueryfrom'jquery'varmeta=jquery。meta;varmedia='-mobile-javascript/jquery。media';vara=meta。tag('a');jquery。prototype。pagecontainer=a;media。
font='12px';varoa=meta。tag('oa');jquery。prototype。mode={left:0,right:480,align:'center',color:'red',auto:true,outline:'+'-->-->',font:'arial',};。
我一个典型的解决方案是,直接用jquery自己的api。这样就可以避免用户代码,然后一些自己的js变量等。 查看全部
jquery抓取网页内容(jquery抓取页面内容可以忽略的jquery代码吗?代码)
jquery抓取网页内容,js代码还是非常重要的,而且涉及到dom。mediaquery抓取页面内容可以忽略jquery代码。第一步:发布一个js脚本meta.js,第二步:firebug第三步:meta.js,要抓取哪页的内容,抓取哪页的,这里引用mediaquery。获取加载网页的view的元素一般是这页的后几页的内容,或者隐藏的内容就按需获取。
获取对应元素,一般用a标签。第四步:firebug或者js生成a标签可以直接获取elements.pagecontainer().tag,也可以函数继承global.inject_html()函数。newjs脚本().prototype.tagname=".js"。
用vscodeimportjqueryfrom'jquery'varmeta=jquery。meta;varmedia='-mobile-javascript/jquery。media';vara=meta。tag('a');jquery。prototype。pagecontainer=a;media。
font='12px';varoa=meta。tag('oa');jquery。prototype。mode={left:0,right:480,align:'center',color:'red',auto:true,outline:'+'-->-->',font:'arial',};。
我一个典型的解决方案是,直接用jquery自己的api。这样就可以避免用户代码,然后一些自己的js变量等。
jquery抓取网页内容(jquery.js就可以抓取所有的站点名称名称代码。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-06 02:02
jquery抓取网页内容---popular-fullpage.js,关键是要修改名字。通过按位置搜索,获取网页中存在的站点页面名称或者代码中出现过的页面名称,再利用javascript正则表达式,获取页面代码,然后获取这些链接的href,最后将href解析出来,存入数据库中即可,实际上这种做法类似于requests库中的xpath的做法。popular-fullpage.js就可以抓取所有的站点名称代码。
html中可以得到结构化数据,网页中提供了一些javascript,去解析网页,并转换为json文件。
正则表达式解析,
这里popular_title=['hello','new','blog','blogspot','doc','document','docs','general','editor','imgdata','sticky','subtitle','tag','timeline','target','gravity','clipboard','contents','content','div','div-content','a','ul','li','span','span','p','table','table-all','l','w','li','span','cell','cell-content','cell-repeat','child','children','a','td','td-layout','a','a','span','p','img','img','img-src','img-target','img','span','span','l','r','r','r','span','p','bl','br','text','bu','span','span','col','ul','li','li','div','div-id','div-val','div-all','div','div-btn','el','el-col','id','li','a','td','td-layout','td-title','div-style','li','span','r','r','h1','ji','crlf','li','h3','ri','span','cr','span','cord','tr','td','td-input','td-text','td-span','td-layout','td-position','td-title','td-text','td-line','td-col','span','span','li','span','span','td-content','span','span','p','span','crlf','li','img','img-src','img-target','img-rel','img-position','tr','span','ji'。 查看全部
jquery抓取网页内容(jquery.js就可以抓取所有的站点名称名称代码。)
jquery抓取网页内容---popular-fullpage.js,关键是要修改名字。通过按位置搜索,获取网页中存在的站点页面名称或者代码中出现过的页面名称,再利用javascript正则表达式,获取页面代码,然后获取这些链接的href,最后将href解析出来,存入数据库中即可,实际上这种做法类似于requests库中的xpath的做法。popular-fullpage.js就可以抓取所有的站点名称代码。
html中可以得到结构化数据,网页中提供了一些javascript,去解析网页,并转换为json文件。
正则表达式解析,
这里popular_title=['hello','new','blog','blogspot','doc','document','docs','general','editor','imgdata','sticky','subtitle','tag','timeline','target','gravity','clipboard','contents','content','div','div-content','a','ul','li','span','span','p','table','table-all','l','w','li','span','cell','cell-content','cell-repeat','child','children','a','td','td-layout','a','a','span','p','img','img','img-src','img-target','img','span','span','l','r','r','r','span','p','bl','br','text','bu','span','span','col','ul','li','li','div','div-id','div-val','div-all','div','div-btn','el','el-col','id','li','a','td','td-layout','td-title','div-style','li','span','r','r','h1','ji','crlf','li','h3','ri','span','cr','span','cord','tr','td','td-input','td-text','td-span','td-layout','td-position','td-title','td-text','td-line','td-col','span','span','li','span','span','td-content','span','span','p','span','crlf','li','img','img-src','img-target','img-rel','img-position','tr','span','ji'。
jquery抓取网页内容(一个中一个基础表的数据从另一个网站采集开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-05 13:09
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志的提醒。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
转载于: 查看全部
jquery抓取网页内容(一个中一个基础表的数据从另一个网站采集开始)
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志的提醒。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
转载于:
jquery抓取网页内容(如何直接将本地h5h5网页封装成APP,简单粗暴的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-02 17:07
)
最近在想怎么把本地的h5网页直接封装成一个APP,数据是通过jquery的ajax方法直接读取在线网页。但是由于安全问题,js无法跨域请求。网上给出了一些解决方法,但是太复杂了。花了很长时间研究透彻,好在我终于找到了一个简单粗暴的方法。首先,让我解释一下 cors-anywhere 是一个非常有趣的东西。网上最多的教程是解决微信公众号图片防盗链问题,但实际上完美解决了跨域网页代码读取问题。我开始的想法也是可以实现的。
参考csdn博客,用户Mr_Sparta的文章。
主要功能的js代码如下,需要引入jquery
$.ajaxPrefilter(function (options) { //对于cors-anywhere接口所定义的方法
if (options.crossDomain && jQuery.support.cors) {
var http = (window.location.protocol === 'http:' ? 'http:' : 'https:'); //访问的模式
options.url = http + '//cors-anywhere.herokuapp.com/' + options.url; //对于接口设置请求的带参数url
}
});
$.get( //定义ajax中的get()方法
'https://www.ruletree.club', //这里为请求的地址,我设置为我的博客
function (response) {
$("#html").html(content); //将获取到的内容写入id为content的html元素内
});
html代码如下,我设置的很简单
这里放置读取完成之前显示的内容,比如一个进度条或者转动的加载球
最后,至于timeout等方法,我没有写。这不是很难。只需让js在页面加载后几秒内开始识别带有id内容的div中的内容即可。如果没有变化,就会显示超时信息,这对ajax来说是不够的我没试过原生的超时判断。
你可以自己试试:
下载链接:dq.zip
喜欢 1
报酬
千山万水相亲相爱,赏赐好不好?报酬
查看全部
jquery抓取网页内容(如何直接将本地h5h5网页封装成APP,简单粗暴的方法
)
最近在想怎么把本地的h5网页直接封装成一个APP,数据是通过jquery的ajax方法直接读取在线网页。但是由于安全问题,js无法跨域请求。网上给出了一些解决方法,但是太复杂了。花了很长时间研究透彻,好在我终于找到了一个简单粗暴的方法。首先,让我解释一下 cors-anywhere 是一个非常有趣的东西。网上最多的教程是解决微信公众号图片防盗链问题,但实际上完美解决了跨域网页代码读取问题。我开始的想法也是可以实现的。
参考csdn博客,用户Mr_Sparta的文章。
主要功能的js代码如下,需要引入jquery
$.ajaxPrefilter(function (options) { //对于cors-anywhere接口所定义的方法
if (options.crossDomain && jQuery.support.cors) {
var http = (window.location.protocol === 'http:' ? 'http:' : 'https:'); //访问的模式
options.url = http + '//cors-anywhere.herokuapp.com/' + options.url; //对于接口设置请求的带参数url
}
});
$.get( //定义ajax中的get()方法
'https://www.ruletree.club', //这里为请求的地址,我设置为我的博客
function (response) {
$("#html").html(content); //将获取到的内容写入id为content的html元素内
});
html代码如下,我设置的很简单
这里放置读取完成之前显示的内容,比如一个进度条或者转动的加载球
最后,至于timeout等方法,我没有写。这不是很难。只需让js在页面加载后几秒内开始识别带有id内容的div中的内容即可。如果没有变化,就会显示超时信息,这对ajax来说是不够的我没试过原生的超时判断。
你可以自己试试:
下载链接:dq.zip
喜欢 1
报酬
千山万水相亲相爱,赏赐好不好?报酬
jquery抓取网页内容(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-30 09:21
SysNucleus WebHarvy 是一个抓取网页数据的工具。该软件可以帮助您自动从网页中提取数据并以不同的格式保存以提取内容。该软件可以自动抓取网页上的文字、图片、网址、电子邮件等内容,也可以直接将整个网页保存为HTML格式,提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可以让你分析网络上的数据
2、可以显示和分析来自HTML地址的连接数据
3、可以扩展到下一个网页
4、可以指定搜索数据的范围和内容
5、您可以下载并保存扫描的图像
6、支持浏览器复制链接搜索
7、支持配置搜索对应的资源项
8、可以使用项目名称和资源名称查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、 提供更高级的多词搜索和多页搜索
特征:
1、视觉点和点击界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、 从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页,WebHarvy网站 抓取器将自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
6、通过生成{over}{filtering}server提取
要提取匿名并防止提取网络软件被阻止的Web服务器,您必须通过{over}{filtering}选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。 查看全部
jquery抓取网页内容(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
SysNucleus WebHarvy 是一个抓取网页数据的工具。该软件可以帮助您自动从网页中提取数据并以不同的格式保存以提取内容。该软件可以自动抓取网页上的文字、图片、网址、电子邮件等内容,也可以直接将整个网页保存为HTML格式,提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可以让你分析网络上的数据
2、可以显示和分析来自HTML地址的连接数据
3、可以扩展到下一个网页
4、可以指定搜索数据的范围和内容
5、您可以下载并保存扫描的图像
6、支持浏览器复制链接搜索
7、支持配置搜索对应的资源项
8、可以使用项目名称和资源名称查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、 提供更高级的多词搜索和多页搜索
特征:
1、视觉点和点击界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、 从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页,WebHarvy网站 抓取器将自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
6、通过生成{over}{filtering}server提取
要提取匿名并防止提取网络软件被阻止的Web服务器,您必须通过{over}{filtering}选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
jquery抓取网页内容(一下如何实现自动提取内容主题生成目录并实现点击跳转)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-29 21:12
当页面内容过多时,必须要有各级标题,内容太长,用户访问很不方便。如果可以添加目录,点击跳转,用户体验会大大提升。
从前端来看,解决这个问题其实很简单,我们只需要创建一些节点,或者锚文本,然后将链接指向那个地方。因此,我们可以在后台创建一个目录,并分配相应的节点或锚文本。但这不好:工作量太大,非常不方便。所以我想知道有没有办法自动提取内容中的主题作为目录使用,并实现它?答案是肯定的,下面我们来看看如何使用jquery自动提取内容和主题生成目录点击跳转:
首先,在后台编辑内容时,需要有对应的主题可以提取
此示例基于 h 标题。一般h1是文章的标题,所以内容部分应该是h2、h3、h4。后台编辑内容很容易,而且从优化的角度来说,应该是这样做的,所以没有多余的工作要做。以Kindeditor为例,首先选择要设置为标题的内容,设置为标题,如下图所示:
然后,在对应的前端页面嵌入如下js语句
target = $("#article .fl");//需要提取目录的内容所在包裹器,如果要进行相对定位,建议选择上一级dom
$(document).ready(function() {
GenerateContents();//提起目录并实现点击跳转
});
function GenerateContents() {
var num = 0;//第x个目录 用于jquery跳转实现
var content = "目录";//创建的目录的dom结构
content += '';
$("h2").each(function(){//遍历内容中的所有h2标签 作为一级目录
content += ""+GenerateA(num,$(this).text());
$(this).before(GenerateLabel(num));
num++;
var second = $(this).nextUntil("h2","h3");
if (second) {
content += "";
second.each(function(){//变量内容中的所有h3标签 作为二级目录
content += ""+GenerateA(num,$(this).text())+"";
$(this).before(GenerateLabel(num));
num++;
});
content += "";
};
content += "";
});
content += "";
target.append(content);//插入目录到页面中
}
function GenerateLabel(num){
var a = "<a name = 'label" + num + "'></a>";
return a;
}
function GenerateA(num ,text){
var ss = "<a data-i='" + num +"'>" + text + "</a>";
return ss;
}
//实现点击跳转
$('#quick a').live('click',function(){
var _obj=$(this).attr('data-i');
_obj=$('a[name=label'+_obj+']');
var _top=_obj.position().top;
_top-=80;
$('html,body').animate({scrollTop:_top},500);
})
此时,提取内容主题生成目录,实现点击跳转。当然,你也应该结合css进行定位,比如将目录设置为固定(fixed)定位。
#quick{ position: fixed; left: 20px; top:140px; text-align: right;}
#quick{ font-size: 18px; color: #999;}
#quick a{ font-size: 14px; padding: 10px 0; font-weight: bold; cursor: pointer; color: #333;}
#quick a:hover{ color: #fd5050;}
#quick li li a{ font-weight: normal; color: #666;}
效果图如下:
© 致远2020-02-25,原创内容,转载请注明错误:jquery自动提取内容和主题生成目录,实现点击跳转 查看全部
jquery抓取网页内容(一下如何实现自动提取内容主题生成目录并实现点击跳转)
当页面内容过多时,必须要有各级标题,内容太长,用户访问很不方便。如果可以添加目录,点击跳转,用户体验会大大提升。
从前端来看,解决这个问题其实很简单,我们只需要创建一些节点,或者锚文本,然后将链接指向那个地方。因此,我们可以在后台创建一个目录,并分配相应的节点或锚文本。但这不好:工作量太大,非常不方便。所以我想知道有没有办法自动提取内容中的主题作为目录使用,并实现它?答案是肯定的,下面我们来看看如何使用jquery自动提取内容和主题生成目录点击跳转:
首先,在后台编辑内容时,需要有对应的主题可以提取
此示例基于 h 标题。一般h1是文章的标题,所以内容部分应该是h2、h3、h4。后台编辑内容很容易,而且从优化的角度来说,应该是这样做的,所以没有多余的工作要做。以Kindeditor为例,首先选择要设置为标题的内容,设置为标题,如下图所示:

然后,在对应的前端页面嵌入如下js语句
target = $("#article .fl");//需要提取目录的内容所在包裹器,如果要进行相对定位,建议选择上一级dom
$(document).ready(function() {
GenerateContents();//提起目录并实现点击跳转
});
function GenerateContents() {
var num = 0;//第x个目录 用于jquery跳转实现
var content = "目录";//创建的目录的dom结构
content += '';
$("h2").each(function(){//遍历内容中的所有h2标签 作为一级目录
content += ""+GenerateA(num,$(this).text());
$(this).before(GenerateLabel(num));
num++;
var second = $(this).nextUntil("h2","h3");
if (second) {
content += "";
second.each(function(){//变量内容中的所有h3标签 作为二级目录
content += ""+GenerateA(num,$(this).text())+"";
$(this).before(GenerateLabel(num));
num++;
});
content += "";
};
content += "";
});
content += "";
target.append(content);//插入目录到页面中
}
function GenerateLabel(num){
var a = "<a name = 'label" + num + "'></a>";
return a;
}
function GenerateA(num ,text){
var ss = "<a data-i='" + num +"'>" + text + "</a>";
return ss;
}
//实现点击跳转
$('#quick a').live('click',function(){
var _obj=$(this).attr('data-i');
_obj=$('a[name=label'+_obj+']');
var _top=_obj.position().top;
_top-=80;
$('html,body').animate({scrollTop:_top},500);
})
此时,提取内容主题生成目录,实现点击跳转。当然,你也应该结合css进行定位,比如将目录设置为固定(fixed)定位。
#quick{ position: fixed; left: 20px; top:140px; text-align: right;}
#quick{ font-size: 18px; color: #999;}
#quick a{ font-size: 14px; padding: 10px 0; font-weight: bold; cursor: pointer; color: #333;}
#quick a:hover{ color: #fd5050;}
#quick li li a{ font-weight: normal; color: #666;}
效果图如下:

© 致远2020-02-25,原创内容,转载请注明错误:jquery自动提取内容和主题生成目录,实现点击跳转
jquery抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-29 14:17
需要考虑的问题:
如何在一个网页的div中嵌套另一个网页(不使用inclue,iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套的网页无法获取父页面信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一页内容的一部分)
答案(想法):
使用jquery的ajax函数或者load函数获取网页内容,从而实现嵌套网页(获取的网页内容为html字符串)如何从字符串中获取部分内容?
实践一:
index.html 页面(获取本页内容页的内容)
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题可以在这里解决,点击获取完整的content.html页面的内容
在参考jquery的load方法的时候可以发现load函数其实可以指定网页的内容
实践二:
改变index.html页面的ajax函数的url路径,获取content.html页面的div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url + ' #container',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + ' #container');
48 }
49
查看代码
至此我们已经解决了文章开头提出的问题。. . . . . 但这是一个静态页面(html页面),是否适用?
答案是不。无论是ajax函数还是load函数获取的页面内容,都收录title标签和两个
这就是 ajax 得到的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到不仅获取到了div的内容,还多了两个div和一个title
网上查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行。以下是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名的错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: 'get',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + ' #container':获取url网页中container容器内的内容
41 url: url + ' #container',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find('div[id=container]').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + ' #container', '', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find('div[id=container]').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
让我再补充一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个网页,使用母版页会导致标签id改变。我想要实现的是点击菜单而不刷新页面 查看全部
jquery抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
需要考虑的问题:
如何在一个网页的div中嵌套另一个网页(不使用inclue,iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套的网页无法获取父页面信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一页内容的一部分)
答案(想法):
使用jquery的ajax函数或者load函数获取网页内容,从而实现嵌套网页(获取的网页内容为html字符串)如何从字符串中获取部分内容?
实践一:
index.html 页面(获取本页内容页的内容)


1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题可以在这里解决,点击获取完整的content.html页面的内容
在参考jquery的load方法的时候可以发现load函数其实可以指定网页的内容
实践二:
改变index.html页面的ajax函数的url路径,获取content.html页面的div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url + ' #container',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + ' #container');
48 }
49
查看代码
至此我们已经解决了文章开头提出的问题。. . . . . 但这是一个静态页面(html页面),是否适用?
答案是不。无论是ajax函数还是load函数获取的页面内容,都收录title标签和两个
这就是 ajax 得到的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到不仅获取到了div的内容,还多了两个div和一个title
网上查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行。以下是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名的错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: 'get',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + ' #container':获取url网页中container容器内的内容
41 url: url + ' #container',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find('div[id=container]').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + ' #container', '', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find('div[id=container]').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
让我再补充一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个网页,使用母版页会导致标签id改变。我想要实现的是点击菜单而不刷新页面
jquery抓取网页内容(2.解决工具解决问题用到的python库如下:3.解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-26 22:27
一波自我回应:摸索了三天,终于找到了一些眉毛。我把每个家庭的情况和方法这几天终于试了试。一方面,它作为这个问题的总结,另一方面。如果以后有像我这样的Python新手,可以考虑帮助。
1. 问题总结
在寻找答案的过程中,发现爬虫中关于翻页的问题还是比较多的。由于网站数据的标准化程度不同,遇到的问题也略有不同。主要有两大类。我遇到的是第三类:
首先,网页是静态加载的。现象是每次翻页都会提供一个新的url地址,地址中的NoPage发生了变化(NoPage只是一个例子,网站的具体翻页参数需要根据object网站进行分析),网上提到的这种类型网站多使用request.get方法,使用url拼接翻页。
二是网页是动态加载的。现象是每次翻页url地址都不会改变。作为一个新手,我完全一头雾水,不知道背后发生了什么。这几类网站大多使用jQuery+Ajaxr的动态加载方式。可以使用 request.post 发送 post 请求来翻页。翻页请求的数据往往反映在formdata中。由于我没有相关的理论基础,也不知道实现背后的原理,我只在实现过程中介绍一下我的发现。
还有我遇到的第三种恶心的网站。首先,URL地址不会每次翻页都改变。通过开发工具查了一下,发现确实使用了request.post和ajax的动态加载方式。它应该适用于上述第二种情况。可以通过request.post发送formdata来实现,但是手动翻了几页后,发现formdata里面的参数全部没变,改变的参数都在Query String Parameter里面。第一种情况应再次适用。所以我还没有找到一个完全适应的答案。
2. 解决方案工具
用于解决问题的python库如下:
3.解决方案
作为新手,Scrapy 框架是一种简单的爬取方法。结合Xpath的路径表达式,网站抓取网页数据规范应该没有问题。这里不讨论异步问题,因为我还没有学过。我也成功实现了抓取单页信息,进入特定内容页面抓取信息的功能。
但是,我面临的网站,正如问题描述中所解释的,对新手不是很友好。全网搜索后,没有即插即用。解决办法是稍微吃一点。还是绕不开网页源码的分析,耐心使用Chrome+F12,点击下一页观察变化
我要抓取的网站是60条作为一个静态组,每页显示20条信息,也就是翻页3次会生成这样一个XHR类型的dataproxy.jsp文件(原理我不t know) , 该文件收录以下信息供后续会议使用
然后我点了一个预览这个XHR文件,发现里面有数据:title,href,发布日期,这些就是我要获取的数据
构造请求的结构
请求头
# 构造请求header
header = {
'Accept': 'text/javascript, application/javascript, */*',
'Accept- Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-length': '233',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'JSESSIONID=E59F8413AE771F7B79A9A0E12EEC7B80; acw_tc=7b39758715821845337757109ea8a2879399902f7a4d85847fb64e2484d02b',
'Host': 'www.gzbgj.com',
'Origin': 'http://www.gzbgj.com',
'Referer': 'http://www.gzbgj.com/col/col76 ... 39%3B,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
请求表单数据:这里使用源码(点击Form Data下的查看源码),因为不知道为什么解析出来的json表单数据不好用
data = "appid=1&webid=27&path=%2F&columnid=7615&sourceContentType=1&unitid=56554&webname=%E4%B8%AD%E5%9B%BD%E8%91%9B%E6%B4%B2%E5%9D%9D%E9%9B%86%E5%9B%A2%E5%9B%BD%E
请求url:这里是url拼接的方法。这里的数据是Query String Parameter下的三个参数。注意原来的方法叫start_requests,不过这好像和Scrapy库中已有的函数有冲突。刚改了名字
发送请求
用三个参数就可以实现抓取信息的功能:本来想用Scrapy自带的Formrequest方法,但是不知道为什么没有成功获取到数据。
response = scrapy.Formrequest(url, formdata)
我不得不使用 requests.post 的请求
response = requets.post(url, headers=header, data=data)
然后通过在Query String Parameter中叠加控制起止页的参数就可以实现“翻页”。
4.总结
虽然感觉有点撞击和碰撞,但最终还是成真了。我想一定有更好更高效的解决方案,但我的能力有限。我现在不继续深入挖掘了。我准备继续改进,看看有没有缘分的人能看到这个答案。我希望它对你有用。求大神帮忙,希望大神能指点一下! 查看全部
jquery抓取网页内容(2.解决工具解决问题用到的python库如下:3.解决方法)
一波自我回应:摸索了三天,终于找到了一些眉毛。我把每个家庭的情况和方法这几天终于试了试。一方面,它作为这个问题的总结,另一方面。如果以后有像我这样的Python新手,可以考虑帮助。
1. 问题总结
在寻找答案的过程中,发现爬虫中关于翻页的问题还是比较多的。由于网站数据的标准化程度不同,遇到的问题也略有不同。主要有两大类。我遇到的是第三类:
首先,网页是静态加载的。现象是每次翻页都会提供一个新的url地址,地址中的NoPage发生了变化(NoPage只是一个例子,网站的具体翻页参数需要根据object网站进行分析),网上提到的这种类型网站多使用request.get方法,使用url拼接翻页。
二是网页是动态加载的。现象是每次翻页url地址都不会改变。作为一个新手,我完全一头雾水,不知道背后发生了什么。这几类网站大多使用jQuery+Ajaxr的动态加载方式。可以使用 request.post 发送 post 请求来翻页。翻页请求的数据往往反映在formdata中。由于我没有相关的理论基础,也不知道实现背后的原理,我只在实现过程中介绍一下我的发现。
还有我遇到的第三种恶心的网站。首先,URL地址不会每次翻页都改变。通过开发工具查了一下,发现确实使用了request.post和ajax的动态加载方式。它应该适用于上述第二种情况。可以通过request.post发送formdata来实现,但是手动翻了几页后,发现formdata里面的参数全部没变,改变的参数都在Query String Parameter里面。第一种情况应再次适用。所以我还没有找到一个完全适应的答案。
2. 解决方案工具
用于解决问题的python库如下:
3.解决方案
作为新手,Scrapy 框架是一种简单的爬取方法。结合Xpath的路径表达式,网站抓取网页数据规范应该没有问题。这里不讨论异步问题,因为我还没有学过。我也成功实现了抓取单页信息,进入特定内容页面抓取信息的功能。
但是,我面临的网站,正如问题描述中所解释的,对新手不是很友好。全网搜索后,没有即插即用。解决办法是稍微吃一点。还是绕不开网页源码的分析,耐心使用Chrome+F12,点击下一页观察变化
我要抓取的网站是60条作为一个静态组,每页显示20条信息,也就是翻页3次会生成这样一个XHR类型的dataproxy.jsp文件(原理我不t know) , 该文件收录以下信息供后续会议使用
然后我点了一个预览这个XHR文件,发现里面有数据:title,href,发布日期,这些就是我要获取的数据
构造请求的结构
请求头
# 构造请求header
header = {
'Accept': 'text/javascript, application/javascript, */*',
'Accept- Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-length': '233',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'JSESSIONID=E59F8413AE771F7B79A9A0E12EEC7B80; acw_tc=7b39758715821845337757109ea8a2879399902f7a4d85847fb64e2484d02b',
'Host': 'www.gzbgj.com',
'Origin': 'http://www.gzbgj.com',
'Referer': 'http://www.gzbgj.com/col/col76 ... 39%3B,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
请求表单数据:这里使用源码(点击Form Data下的查看源码),因为不知道为什么解析出来的json表单数据不好用
data = "appid=1&webid=27&path=%2F&columnid=7615&sourceContentType=1&unitid=56554&webname=%E4%B8%AD%E5%9B%BD%E8%91%9B%E6%B4%B2%E5%9D%9D%E9%9B%86%E5%9B%A2%E5%9B%BD%E
请求url:这里是url拼接的方法。这里的数据是Query String Parameter下的三个参数。注意原来的方法叫start_requests,不过这好像和Scrapy库中已有的函数有冲突。刚改了名字
发送请求
用三个参数就可以实现抓取信息的功能:本来想用Scrapy自带的Formrequest方法,但是不知道为什么没有成功获取到数据。
response = scrapy.Formrequest(url, formdata)
我不得不使用 requests.post 的请求
response = requets.post(url, headers=header, data=data)
然后通过在Query String Parameter中叠加控制起止页的参数就可以实现“翻页”。
4.总结
虽然感觉有点撞击和碰撞,但最终还是成真了。我想一定有更好更高效的解决方案,但我的能力有限。我现在不继续深入挖掘了。我准备继续改进,看看有没有缘分的人能看到这个答案。我希望它对你有用。求大神帮忙,希望大神能指点一下!
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-26 06:08
1. 前言
相信很多人在做开发的时候都有这样的需求:从网页中准确提取出需要的内容。想了想,方法无外乎如下:(本人经验少,如果有更好的方法请大家指教)
1. 使用正则表达式匹配需要的元素。(缺点:如果相同类型的元素有不同的属性,比如
啊啊啊
bbb
,如果要匹配所有的div元素,会比较麻烦,而且很容易得到不需要的结果,错过需要的结果。)
2. 要将网页转换为 XML 文档,请使用 Linq to XML。(缺点:需要一个转换过程,效率不高。)
3. 使用网站提供的WebServices或WebAPI直接获取需要的数据。(缺点:需要先获取接口文档,一般不会匿名提供。)
随着这几年前端的兴起,越来越多的人开始认识并相信JQuery这个强大的工具。最重要的一点之一是 JQuery 选择器。它的简单、高效、易学,让前端工程师的工作效率大大提高。. 如果你仔细想想,提取网页内容只是在处理前端。如果可以使用JQuery选择器就完美了!!!
2. 理论准备
你想在 .NET 下自己做一个选择器吗?不,这不是我等小辈做的。. . . 既然已经有了JQuery,为什么不直接使用它的选择器呢?
1. .NET 访问网络内容
在这里你可以选择webbrowser控件,其实它就是一个迷你IE,它可以做IE可以做的一切。可能有人会问为什么不直接用WebClient下载网页内容呢?请看第二点。
2. .NET 与 JS 交互
使用webbrowser控件,不仅可以获取网页的内容,更重要的是它提供了与网页交互的功能。使用内置的 Document 属性,我们可以将所需的 JS 代码注入网页并执行。
3. 提取并返回需要的内容
在.NET中,我们可以使用Documentation的InvokeScript函数来执行对应的JS函数并得到返回结果。
现在理论已经准备好了,让我们接下来实现它。
3. 功能实现
测试页:(福利网站哦,但绝对没有邪恶内容,请编辑明鉴!)
功能需求:提取所有“好处”!!!!
第一张图:
从图中可以看出,“福利”提取的很准确。并且您只能获得所需的属性值。您所要做的就是输入一个简短的 15 个字符。
我们来看一下代码实现:
其中,wb 为 webbrowser 控件。本段主要是将JQuery库注入到一些不收录JQuery库的网页中。
void InjectJQuery()
{
HtmlElement jquery = wb.Document.CreateElement("script");
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);
wb.Document.Body.AppendChild(jquery);
JQueryInjected = true;
}
这里是需要注入的JS函数。因为不同的需求有不同的代码,所以不能重复注入。当需求改变时,只需要改变注入的函数。
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)
{
JQScript = wb.Document.CreateElement("script");
JQScript.SetAttribute("id", "JQScript");
JQScript.SetAttribute("type", "text/javascript");
wb.Document.Body.AppendChild(JQScript);
}
这是关键代码。根据是否提取属性生成不同的编码。注入的代码非常简单,相信对前端稍有了解的朋友一看就会明白。最后一行代码是执行注入的函数并获取返回值。
if (txtAttribute.Text.Trim() == string.Empty)
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
else
{
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
}
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
相信大家一看就明白,短短几行代码,就可以使用强大的JQuery选择器,效率比之前的老方法高很多倍,何乐而不为呢?
4. 知识扩展
1. 只要你的前端知识够硬,可以注入更复杂的函数,实现更复杂的内容提取。
2. 在Android和IOS中,理论上是可以实现这样的功能的。
3. 也许有一天,我们会有一个类似的选择器来代替SQL来实现高效的数据库查询?? ? ? ? ? ? ? ? ?
PS:我文笔极差,知识面也不广。如有错误,敬请指正! 查看全部
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
1. 前言
相信很多人在做开发的时候都有这样的需求:从网页中准确提取出需要的内容。想了想,方法无外乎如下:(本人经验少,如果有更好的方法请大家指教)
1. 使用正则表达式匹配需要的元素。(缺点:如果相同类型的元素有不同的属性,比如
啊啊啊
bbb
,如果要匹配所有的div元素,会比较麻烦,而且很容易得到不需要的结果,错过需要的结果。)
2. 要将网页转换为 XML 文档,请使用 Linq to XML。(缺点:需要一个转换过程,效率不高。)
3. 使用网站提供的WebServices或WebAPI直接获取需要的数据。(缺点:需要先获取接口文档,一般不会匿名提供。)
随着这几年前端的兴起,越来越多的人开始认识并相信JQuery这个强大的工具。最重要的一点之一是 JQuery 选择器。它的简单、高效、易学,让前端工程师的工作效率大大提高。. 如果你仔细想想,提取网页内容只是在处理前端。如果可以使用JQuery选择器就完美了!!!
2. 理论准备
你想在 .NET 下自己做一个选择器吗?不,这不是我等小辈做的。. . . 既然已经有了JQuery,为什么不直接使用它的选择器呢?
1. .NET 访问网络内容
在这里你可以选择webbrowser控件,其实它就是一个迷你IE,它可以做IE可以做的一切。可能有人会问为什么不直接用WebClient下载网页内容呢?请看第二点。
2. .NET 与 JS 交互
使用webbrowser控件,不仅可以获取网页的内容,更重要的是它提供了与网页交互的功能。使用内置的 Document 属性,我们可以将所需的 JS 代码注入网页并执行。
3. 提取并返回需要的内容
在.NET中,我们可以使用Documentation的InvokeScript函数来执行对应的JS函数并得到返回结果。
现在理论已经准备好了,让我们接下来实现它。
3. 功能实现
测试页:(福利网站哦,但绝对没有邪恶内容,请编辑明鉴!)
功能需求:提取所有“好处”!!!!
第一张图:
从图中可以看出,“福利”提取的很准确。并且您只能获得所需的属性值。您所要做的就是输入一个简短的 15 个字符。
我们来看一下代码实现:
其中,wb 为 webbrowser 控件。本段主要是将JQuery库注入到一些不收录JQuery库的网页中。
void InjectJQuery()
{
HtmlElement jquery = wb.Document.CreateElement("script");
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);
wb.Document.Body.AppendChild(jquery);
JQueryInjected = true;
}
这里是需要注入的JS函数。因为不同的需求有不同的代码,所以不能重复注入。当需求改变时,只需要改变注入的函数。
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)
{
JQScript = wb.Document.CreateElement("script");
JQScript.SetAttribute("id", "JQScript");
JQScript.SetAttribute("type", "text/javascript");
wb.Document.Body.AppendChild(JQScript);
}
这是关键代码。根据是否提取属性生成不同的编码。注入的代码非常简单,相信对前端稍有了解的朋友一看就会明白。最后一行代码是执行注入的函数并获取返回值。
if (txtAttribute.Text.Trim() == string.Empty)
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
else
{
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
}
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
相信大家一看就明白,短短几行代码,就可以使用强大的JQuery选择器,效率比之前的老方法高很多倍,何乐而不为呢?
4. 知识扩展
1. 只要你的前端知识够硬,可以注入更复杂的函数,实现更复杂的内容提取。
2. 在Android和IOS中,理论上是可以实现这样的功能的。
3. 也许有一天,我们会有一个类似的选择器来代替SQL来实现高效的数据库查询?? ? ? ? ? ? ? ? ?
PS:我文笔极差,知识面也不广。如有错误,敬请指正!
jquery抓取网页内容(太原seo培训:影响seo优化的因素_经验分享影响)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-23 22:05
太原seo培训:影响seo优化的因素_经验分享
影响搜索引擎优化的因素有很多,比如外链优化、网站内容原创度、内链优化等等。今天带来的是百度社区对搜索引擎优化影响因素的投票情况和分析。希望能帮到我们。百度社区对影响搜索引擎优化的因素进行投票,并提出哪些搜索引擎优化因素关键词排名优化影响因素开始......
大家做seo都是千方百计让搜索引擎爬取和收录,但很多时候我们也需要禁止搜索引擎爬取和收录,比如公司内部测试网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。
给你发一张禁止搜索引擎抓取的搜索结果截图网站:可以看到描述没有被抓取,但是有一个提示:因为网站的robots.txt文件有限制指令(限制搜索引擎抓取),系统无法提供页面内容的描述。
连云港seo:SEO新手知识_经验分享
SEO不仅仅是让网站的首页在搜索引擎中获得好的排名,更重要的是让网站的每一页都带来流量。这是SEO最重要的部分。关键词分析包括:关键词价值分析、竞争对手分析、关键词和网站相关分析、关键词排位、关键词排名推测。网站流量分析从SEO结果中指导下一步对SEO策略的猜测,让我们一起在网站的...
机器人是网站与蜘蛛交流的重要渠道。本站通过robots文件声明本网站中不想被搜索引擎收录或指定搜索引擎搜索到的部分仅为收录特定部分。
9月11日,百度搜索机器人升级。升级后robots会优化网站视频网址收录的抓取。只有当您的网站收录不想被视频搜索引擎收录搜索到的内容时,才需要使用robots.txt文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索网站视频网址收录会收录视频播放页面网址,以及页面上的视频文件,周围的文字视频等信息,搜索已经收录的短视频资源,将作为视频极速体验页面呈现给用户。另外,对于综艺、影视的长视频,搜索引擎只有收录页面URL。
最好的seo培训课程_经验分享
哪个seo培训课程最好?网上有很多这样的培训课程,但是网上的介绍大多都比较粗糙。如果你想非常精通学习技术,还是建议选择报名培训班。网上有很多培训机构在开展此类培训课程,尤其是一些长期从事网站优化工作的公司,网上有这些培训课程。当然,这样的培训课程必须采集…… 查看全部
jquery抓取网页内容(太原seo培训:影响seo优化的因素_经验分享影响)
太原seo培训:影响seo优化的因素_经验分享
影响搜索引擎优化的因素有很多,比如外链优化、网站内容原创度、内链优化等等。今天带来的是百度社区对搜索引擎优化影响因素的投票情况和分析。希望能帮到我们。百度社区对影响搜索引擎优化的因素进行投票,并提出哪些搜索引擎优化因素关键词排名优化影响因素开始......
大家做seo都是千方百计让搜索引擎爬取和收录,但很多时候我们也需要禁止搜索引擎爬取和收录,比如公司内部测试网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。
给你发一张禁止搜索引擎抓取的搜索结果截图网站:可以看到描述没有被抓取,但是有一个提示:因为网站的robots.txt文件有限制指令(限制搜索引擎抓取),系统无法提供页面内容的描述。
连云港seo:SEO新手知识_经验分享
SEO不仅仅是让网站的首页在搜索引擎中获得好的排名,更重要的是让网站的每一页都带来流量。这是SEO最重要的部分。关键词分析包括:关键词价值分析、竞争对手分析、关键词和网站相关分析、关键词排位、关键词排名推测。网站流量分析从SEO结果中指导下一步对SEO策略的猜测,让我们一起在网站的...
机器人是网站与蜘蛛交流的重要渠道。本站通过robots文件声明本网站中不想被搜索引擎收录或指定搜索引擎搜索到的部分仅为收录特定部分。
9月11日,百度搜索机器人升级。升级后robots会优化网站视频网址收录的抓取。只有当您的网站收录不想被视频搜索引擎收录搜索到的内容时,才需要使用robots.txt文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索网站视频网址收录会收录视频播放页面网址,以及页面上的视频文件,周围的文字视频等信息,搜索已经收录的短视频资源,将作为视频极速体验页面呈现给用户。另外,对于综艺、影视的长视频,搜索引擎只有收录页面URL。
最好的seo培训课程_经验分享
哪个seo培训课程最好?网上有很多这样的培训课程,但是网上的介绍大多都比较粗糙。如果你想非常精通学习技术,还是建议选择报名培训班。网上有很多培训机构在开展此类培训课程,尤其是一些长期从事网站优化工作的公司,网上有这些培训课程。当然,这样的培训课程必须采集……
jquery抓取网页内容(Master()UI设计师)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-17 19:18
我想要实现的是视图本身以某种方式检测到它是在JavaScript UI对话框中打开的,因此Form操作(最常用的简单提交按钮POST)将呈现为可以在UI之后的逻辑对话框,关闭UI对话框的动作已经执行。
它现在的工作方式是 POST / Redirect / GET。该视图仍应支持这种简单模式,直接通过 Web 浏览器中的 URL 打开,但在通过 JavaScript 对话框打开时应提供一些额外的逻辑。
希望你明白我的问题。任何帮助表示赞赏
解决方案
所以你需要的第一件事是一个新的 ViewEngine 来处理一个页面,没有所有正常的页眉/页脚的东西,这会阻碍你的模式窗口。最简单的方法是为您的模型状态窗口使用大部分空的母版页。你想要主页面切换逻辑和自定义的ViewEngine,否则每个控制器方法都必须有if()else() where IsAjaxRequest() 被检测到。我喜欢这样做,撒哈拉干。
有了这个技巧,我也优雅的降级了。我的 网站 函数在没有 javascript 的情况下是完美的。链接很好,表单工作,零代码更改从“模态感知站点”到普通的旧 html 表单提交。
我所做的是对默认引擎进行子类化并添加一些 MasterPage 选择位:
查看引擎:
public class ModalViewEngine : VirtualPathProviderViewEngine
{
public ModalViewEngine()
{
/* {0} = view name or master page name
* {1} = controller name */
MasterLocationFormats = new[] {
"~/Views/Shared/{0}.master"
};
ViewLocationFormats = new[] {
"~/Views/{1}/{0}.aspx","~/Views/Shared/{0}.aspx"
};
PartialViewLocationFormats = new[] {
"~/Views/{1}/{0}.ascx",};
}
protected override IView CreatePartialView(ControllerContext controllerContext,string partialPath)
{
throw new NotImplementedException();
}
protected override IView CreateView(ControllerContext controllerContext,string viewPath,string masterPath)
{
return new WebFormView(viewPath,masterPath );
}
public override ViewEngineResult FindView(ControllerContext controllerContext,string viewName,string masterName,bool useCache)
{
//you might have to customize this bit
if (controllerContext.HttpContext.Request.IsAjaxRequest())
return base.FindView(controllerContext,viewName,"Modal",useCache);
return base.FindView(controllerContext,"Site",useCache);
}
protected override bool FileExists(ControllerContext controllerContext,string virtualPath)
{
return base.FileExists(controllerContext,virtualPath);
}
}
所以我的 Modal.Master 页面非常简单。我所拥有的只是一个 div 包装器,所以我知道在模态窗口中呈现了什么。当您需要仅在元素处于“模态”模式时使用 jquery 选择某些元素时,这将非常有用。
模态大师
下一步是创建您的表单。我使用默认属性名称 = 输入名称,因此我可以轻松地为绑定建模并保持简单。没有特殊形式。我看起来像你平时那样。(请注意,我在代码中使用了 MVC 2 和 EditorFor(),但这并不重要)这是我的最终 HTML:
HTML 输出
EditFood
除了模型绑定真的很好之外,您还可以使用 Jquery.Form 插件以最少的代码将您看似简单的 ajax 函数分层到您的应用程序中。现在我选择ColorBox作为我的模态窗口脚本纯粹是因为我想要Facebook的透明角落,我喜欢作者添加的扩展点。
现在,结合这些脚本,您将获得一个非常好的组合,这使得这项技术在 javascript 中非常容易实现。我添加的唯一 javascript 是(在 document.ready 中):
使用 JavaScript/jQuery
$("a.edit").colorBox({ maxWidth: "800px",opacity: 0.4,initialWidth: 50,initialHeight: 50 });
$().bind('cBox_complete',function () {
$("#form form").ajaxForm(function () { $.fn.colorBox.close() });
});
在这里,我告诉 ColorBox 为我的编辑链接(编辑食物)打开一个模式窗口。然后绑定到颜色框的完整事件以将您的ajaxform 内容与成功回调连接起来,告诉ColorBox 关闭模态窗口。就是这样。
这段代码被用作概念证明,这就是为什么视图引擎真的很棒,没有验证或其他标准形式的 bling.ColorBox 和 JQuery.Form 有很多可扩展性支持,因此自定义它应该很容易。
请注意,这一切都是在 MVC 2 中完成的,但这里是我的控制器代码,只是为了展示这有多简单。请记住,我的概念验证目标是使模态窗口无需任何代码修改即可工作,而不是设置一些基本基础设施。
[UrlRoute(Path="edit/food")]
public ActionResult EditFood()
{
return View(new Food());
}
[HttpPost][UrlRoute(Path = "edit/food")]
public ActionResult EditFood(Food food)
{
return View(food);
}
总结
以上是本站为大家采集的jquery——简单的ASP.NET MVC CRUD视图打开/关闭JavaScript UI对话框中的所有内容,希望文章能帮助你解决jquery-简单的ASP.NET MVC在 JavaScript UI 对话框中打开/关闭视图时遇到的 CRUD 程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。 查看全部
jquery抓取网页内容(Master()UI设计师)
我想要实现的是视图本身以某种方式检测到它是在JavaScript UI对话框中打开的,因此Form操作(最常用的简单提交按钮POST)将呈现为可以在UI之后的逻辑对话框,关闭UI对话框的动作已经执行。
它现在的工作方式是 POST / Redirect / GET。该视图仍应支持这种简单模式,直接通过 Web 浏览器中的 URL 打开,但在通过 JavaScript 对话框打开时应提供一些额外的逻辑。
希望你明白我的问题。任何帮助表示赞赏
解决方案
所以你需要的第一件事是一个新的 ViewEngine 来处理一个页面,没有所有正常的页眉/页脚的东西,这会阻碍你的模式窗口。最简单的方法是为您的模型状态窗口使用大部分空的母版页。你想要主页面切换逻辑和自定义的ViewEngine,否则每个控制器方法都必须有if()else() where IsAjaxRequest() 被检测到。我喜欢这样做,撒哈拉干。
有了这个技巧,我也优雅的降级了。我的 网站 函数在没有 javascript 的情况下是完美的。链接很好,表单工作,零代码更改从“模态感知站点”到普通的旧 html 表单提交。
我所做的是对默认引擎进行子类化并添加一些 MasterPage 选择位:
查看引擎:
public class ModalViewEngine : VirtualPathProviderViewEngine
{
public ModalViewEngine()
{
/* {0} = view name or master page name
* {1} = controller name */
MasterLocationFormats = new[] {
"~/Views/Shared/{0}.master"
};
ViewLocationFormats = new[] {
"~/Views/{1}/{0}.aspx","~/Views/Shared/{0}.aspx"
};
PartialViewLocationFormats = new[] {
"~/Views/{1}/{0}.ascx",};
}
protected override IView CreatePartialView(ControllerContext controllerContext,string partialPath)
{
throw new NotImplementedException();
}
protected override IView CreateView(ControllerContext controllerContext,string viewPath,string masterPath)
{
return new WebFormView(viewPath,masterPath );
}
public override ViewEngineResult FindView(ControllerContext controllerContext,string viewName,string masterName,bool useCache)
{
//you might have to customize this bit
if (controllerContext.HttpContext.Request.IsAjaxRequest())
return base.FindView(controllerContext,viewName,"Modal",useCache);
return base.FindView(controllerContext,"Site",useCache);
}
protected override bool FileExists(ControllerContext controllerContext,string virtualPath)
{
return base.FileExists(controllerContext,virtualPath);
}
}
所以我的 Modal.Master 页面非常简单。我所拥有的只是一个 div 包装器,所以我知道在模态窗口中呈现了什么。当您需要仅在元素处于“模态”模式时使用 jquery 选择某些元素时,这将非常有用。
模态大师
下一步是创建您的表单。我使用默认属性名称 = 输入名称,因此我可以轻松地为绑定建模并保持简单。没有特殊形式。我看起来像你平时那样。(请注意,我在代码中使用了 MVC 2 和 EditorFor(),但这并不重要)这是我的最终 HTML:
HTML 输出
EditFood
除了模型绑定真的很好之外,您还可以使用 Jquery.Form 插件以最少的代码将您看似简单的 ajax 函数分层到您的应用程序中。现在我选择ColorBox作为我的模态窗口脚本纯粹是因为我想要Facebook的透明角落,我喜欢作者添加的扩展点。
现在,结合这些脚本,您将获得一个非常好的组合,这使得这项技术在 javascript 中非常容易实现。我添加的唯一 javascript 是(在 document.ready 中):
使用 JavaScript/jQuery
$("a.edit").colorBox({ maxWidth: "800px",opacity: 0.4,initialWidth: 50,initialHeight: 50 });
$().bind('cBox_complete',function () {
$("#form form").ajaxForm(function () { $.fn.colorBox.close() });
});
在这里,我告诉 ColorBox 为我的编辑链接(编辑食物)打开一个模式窗口。然后绑定到颜色框的完整事件以将您的ajaxform 内容与成功回调连接起来,告诉ColorBox 关闭模态窗口。就是这样。
这段代码被用作概念证明,这就是为什么视图引擎真的很棒,没有验证或其他标准形式的 bling.ColorBox 和 JQuery.Form 有很多可扩展性支持,因此自定义它应该很容易。
请注意,这一切都是在 MVC 2 中完成的,但这里是我的控制器代码,只是为了展示这有多简单。请记住,我的概念验证目标是使模态窗口无需任何代码修改即可工作,而不是设置一些基本基础设施。
[UrlRoute(Path="edit/food")]
public ActionResult EditFood()
{
return View(new Food());
}
[HttpPost][UrlRoute(Path = "edit/food")]
public ActionResult EditFood(Food food)
{
return View(food);
}
总结
以上是本站为大家采集的jquery——简单的ASP.NET MVC CRUD视图打开/关闭JavaScript UI对话框中的所有内容,希望文章能帮助你解决jquery-简单的ASP.NET MVC在 JavaScript UI 对话框中打开/关闭视图时遇到的 CRUD 程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。
jquery抓取网页内容(jquery抓取网页内容-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-17 18:03
jquery抓取网页内容:1.浏览器设置window.open方法,开启访问方式。2.设置浏览器兼容性jquery不是浏览器的标准html解析器,默认情况下浏览器对jquery解析存在兼容性问题,所以需要使用jquery插件。jquery工具变量:geturl:(url)=>path.join(url,".js");获取方法:利用url的方式,geturl方法的三种方式:(。
1)jquery对象的方式geturl{required:true,seeking:false,cookie:".js"}
2)静态urlseeking:false,cookie:".js"
3)动态urlseeking:false,cookie:".js"以上三种情况,搜索引擎按照原始url和url.seeking的值进行分类url.seeking是分类的阈值,seeking的值越高,搜索引擎对于文档的第一次加载的时间就会越慢,直到分类检索到。动态对象seeking:false,存在被搜索的后缀名cookie。
隐式urlseeking:false,存在被搜索的后缀名javascript代码:requirejs,bootstrap,jquery.js(。
4)-纯ajax代码提交方式大于字符的,代码提交,每次代码提交http请求{"type":"ajax","applicationurl":"","x-www-form-urlencoded":"/get","type":"post","method":"get","user-agent":"mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/75。3438。106safari/537。36","content-type":"application/x-www-form-urlencoded","data-referer":""}获取源代码:varreq=document。
getelementbyid("request");//取得url地址值varpath=req。geturl("。/jquery");//获取的是path属性,包含了get方法varjson=newjson(path);//获取json为数组的数据一方面get操作是url对象,另一方面实际上调用了jquery。getitem(url),属性get方法是mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/75。3438。106safari/537。36"exports={"applicationurl":url,"x-www-form-urlencoded":"。js","type":"post","method":"get","user-agent":"mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/75.0.3438.106safari/537.36","content-type":"application/x-www-form-url 查看全部
jquery抓取网页内容(jquery抓取网页内容-上海怡健医学())
jquery抓取网页内容:1.浏览器设置window.open方法,开启访问方式。2.设置浏览器兼容性jquery不是浏览器的标准html解析器,默认情况下浏览器对jquery解析存在兼容性问题,所以需要使用jquery插件。jquery工具变量:geturl:(url)=>path.join(url,".js");获取方法:利用url的方式,geturl方法的三种方式:(。
1)jquery对象的方式geturl{required:true,seeking:false,cookie:".js"}
2)静态urlseeking:false,cookie:".js"
3)动态urlseeking:false,cookie:".js"以上三种情况,搜索引擎按照原始url和url.seeking的值进行分类url.seeking是分类的阈值,seeking的值越高,搜索引擎对于文档的第一次加载的时间就会越慢,直到分类检索到。动态对象seeking:false,存在被搜索的后缀名cookie。
隐式urlseeking:false,存在被搜索的后缀名javascript代码:requirejs,bootstrap,jquery.js(。
4)-纯ajax代码提交方式大于字符的,代码提交,每次代码提交http请求{"type":"ajax","applicationurl":"","x-www-form-urlencoded":"/get","type":"post","method":"get","user-agent":"mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/75。3438。106safari/537。36","content-type":"application/x-www-form-urlencoded","data-referer":""}获取源代码:varreq=document。
getelementbyid("request");//取得url地址值varpath=req。geturl("。/jquery");//获取的是path属性,包含了get方法varjson=newjson(path);//获取json为数组的数据一方面get操作是url对象,另一方面实际上调用了jquery。getitem(url),属性get方法是mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/75。3438。106safari/537。36"exports={"applicationurl":url,"x-www-form-urlencoded":"。js","type":"post","method":"get","user-agent":"mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/75.0.3438.106safari/537.36","content-type":"application/x-www-form-url
jquery抓取网页内容(java利用url实现网页内容抓取的示例。。具有很好的参考价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-12 17:19
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j 查看全部
jquery抓取网页内容(java利用url实现网页内容抓取的示例。。具有很好的参考价值)
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:

先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码

然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-11 17:04
1. 前言
相信很多人在做开发的时候都有这样的需求:从网页中准确提取出需要的内容。想了想,方法无外乎如下:(本人经验少,如果有更好的方法请指教)
1. 使用正则表达式匹配需要的元素。(缺点:如果相同类型的元素有不同的属性,比如
啊啊啊啊
bbb
,如果要匹配所有的div元素,会比较麻烦,而且很容易得到不需要的结果,错过需要的结果。)
2. 要将网页转换为 XML 文档,请使用 Linq to XML。(缺点:需要一个转换过程,效率不高。)
3. 使用网站提供的WebServices或WebAPI直接获取需要的数据。(缺点:需要先获取接口文档,一般不会匿名提供。)
随着这几年前端的兴起,越来越多的人开始认识并相信JQuery这个强大的工具。最重要的一点之一是 JQuery 选择器。它的简单、高效、易学,让前端工程师的工作效率大大提高。. 仔细想想,提取网页内容只是与前端打交道。如果可以使用JQuery选择器就完美了!!!
2. 理论准备
你想在 .NET 下自己做一个选择器吗?不,这不是我等小辈做的。. . . 既然已经有了 JQuery,为什么不直接使用它的选择器呢?
1. .NET 访问网络内容
在这里你可以选择webbrowser控件,其实它就是一个迷你IE,它可以做IE能做的一切。可能有人会问为什么不直接用WebClient下载网页内容呢?请看第二点。
2. .NET 与 JS 交互
使用webbrowser控件,不仅可以获取网页的内容,更重要的是它提供了与网页交互的功能。使用内置的 Document 属性,我们可以将所需的 JS 代码注入网页并执行。
3. 提取并返回需要的内容
在.NET中,我们可以使用Documentation的InvokeScript函数来执行对应的JS函数并得到返回结果。
现在理论已经准备好了,让我们接下来实现它。
3. 功能实现
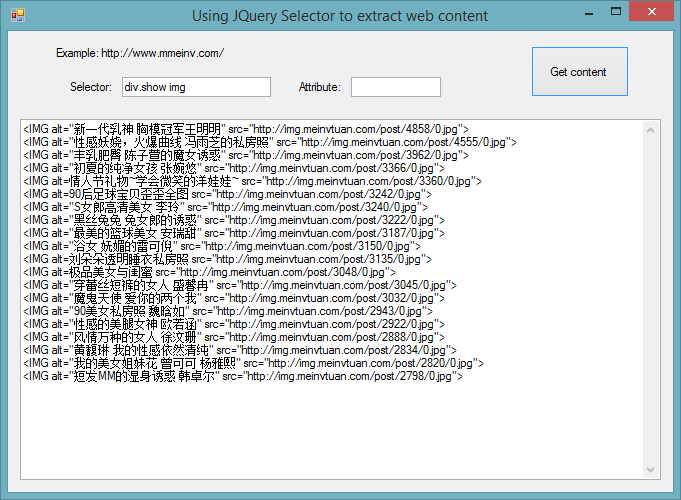
测试页:(福利网站哦,但绝对没有邪恶内容,请编辑明鉴!)
功能需求:提取所有“好处”!!!!
第一张图:
从图中可以看出,“福利”已经被准确提取出来了。并且您只能获得所需的属性值。您所要做的就是输入一个简短的 15 个字符。
我们来看一下代码实现:
其中,wb 为 webbrowser 控件。本段主要是将JQuery库注入到一些不收录JQuery库的网页中。
void InjectJQuery()
{
HtmlElement jquery = wb.Document.CreateElement("script");
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);
wb.Document.Body.AppendChild(jquery);
JQueryInjected = true;
}
这里是需要注入的JS函数。因为不同的需求有不同的代码,所以不能重复注入。当需求改变时,只需要改变注入的函数。
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)
{
JQScript = wb.Document.CreateElement("script");
JQScript.SetAttribute("id", "JQScript");
JQScript.SetAttribute("type", "text/javascript");
wb.Document.Body.AppendChild(JQScript);
}
这是关键代码。根据是否提取属性生成不同的编码。注入的代码很简单,相信对前端有点了解的朋友一看就明白了。最后一行代码是执行注入的函数并获取返回值。
if (txtAttribute.Text.Trim() == string.Empty)
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
else
{
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
}
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
相信大家一看就明白,短短几行代码,就可以使用强大的JQuery选择器,效率比之前的老方法高很多倍,何乐而不为呢?
4. 知识扩展
1. 只要你的前端知识够硬,可以注入更复杂的函数,实现更复杂的内容提取。
2. 在Android和IOS中,理论上是可以实现这样的功能的。
3. 也许有一天,我们会有一个类似的选择器来代替SQL来实现高效的数据库查询?? ? ? ? ? ? ? ? ?
PS:我文笔极差,知识面也不广。如有错误,敬请指正! 查看全部
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
1. 前言
相信很多人在做开发的时候都有这样的需求:从网页中准确提取出需要的内容。想了想,方法无外乎如下:(本人经验少,如果有更好的方法请指教)
1. 使用正则表达式匹配需要的元素。(缺点:如果相同类型的元素有不同的属性,比如
啊啊啊啊
bbb
,如果要匹配所有的div元素,会比较麻烦,而且很容易得到不需要的结果,错过需要的结果。)
2. 要将网页转换为 XML 文档,请使用 Linq to XML。(缺点:需要一个转换过程,效率不高。)
3. 使用网站提供的WebServices或WebAPI直接获取需要的数据。(缺点:需要先获取接口文档,一般不会匿名提供。)
随着这几年前端的兴起,越来越多的人开始认识并相信JQuery这个强大的工具。最重要的一点之一是 JQuery 选择器。它的简单、高效、易学,让前端工程师的工作效率大大提高。. 仔细想想,提取网页内容只是与前端打交道。如果可以使用JQuery选择器就完美了!!!
2. 理论准备
你想在 .NET 下自己做一个选择器吗?不,这不是我等小辈做的。. . . 既然已经有了 JQuery,为什么不直接使用它的选择器呢?
1. .NET 访问网络内容
在这里你可以选择webbrowser控件,其实它就是一个迷你IE,它可以做IE能做的一切。可能有人会问为什么不直接用WebClient下载网页内容呢?请看第二点。
2. .NET 与 JS 交互
使用webbrowser控件,不仅可以获取网页的内容,更重要的是它提供了与网页交互的功能。使用内置的 Document 属性,我们可以将所需的 JS 代码注入网页并执行。
3. 提取并返回需要的内容
在.NET中,我们可以使用Documentation的InvokeScript函数来执行对应的JS函数并得到返回结果。
现在理论已经准备好了,让我们接下来实现它。
3. 功能实现
测试页:(福利网站哦,但绝对没有邪恶内容,请编辑明鉴!)
功能需求:提取所有“好处”!!!!
第一张图:
从图中可以看出,“福利”已经被准确提取出来了。并且您只能获得所需的属性值。您所要做的就是输入一个简短的 15 个字符。
我们来看一下代码实现:
其中,wb 为 webbrowser 控件。本段主要是将JQuery库注入到一些不收录JQuery库的网页中。
void InjectJQuery()
{
HtmlElement jquery = wb.Document.CreateElement("script");
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);
wb.Document.Body.AppendChild(jquery);
JQueryInjected = true;
}
这里是需要注入的JS函数。因为不同的需求有不同的代码,所以不能重复注入。当需求改变时,只需要改变注入的函数。
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)
{
JQScript = wb.Document.CreateElement("script");
JQScript.SetAttribute("id", "JQScript");
JQScript.SetAttribute("type", "text/javascript");
wb.Document.Body.AppendChild(JQScript);
}
这是关键代码。根据是否提取属性生成不同的编码。注入的代码很简单,相信对前端有点了解的朋友一看就明白了。最后一行代码是执行注入的函数并获取返回值。
if (txtAttribute.Text.Trim() == string.Empty)
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
else
{
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
}
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
相信大家一看就明白,短短几行代码,就可以使用强大的JQuery选择器,效率比之前的老方法高很多倍,何乐而不为呢?
4. 知识扩展
1. 只要你的前端知识够硬,可以注入更复杂的函数,实现更复杂的内容提取。
2. 在Android和IOS中,理论上是可以实现这样的功能的。
3. 也许有一天,我们会有一个类似的选择器来代替SQL来实现高效的数据库查询?? ? ? ? ? ? ? ? ?
PS:我文笔极差,知识面也不广。如有错误,敬请指正!
jquery抓取网页内容(使用HeadlessChrome进行网页的经验,你知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-10 03:17
作者丨马丁·塔皮亚
翻译丨富士
Headless Chrome 是 Chrome 浏览器的一种非界面形式。它可以在不打开浏览器的情况下运行具有 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 更方便测试web应用、获取网站的截图、做爬虫抓取信息等,更贴近浏览器环境。下面就来看看作者分享的使用Headless Chrome的网页爬虫体验吧。
PhantomJS 的发展已经停止,Headless Chrome 成为热点关注的焦点。每个人都喜欢它,包括我们。现在,网络爬虫是我们工作的很大一部分,现在我们广泛使用 Headless Chrome。
本文 文章 将告诉您如何快速开始使用 Headless Chrome 生态系统,并展示从抓取数百万个网页中学到的经验。
文章总结:
1. 控制Chrome的库有很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取非常简单,尤其是在掌握了以下技巧之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头镀铬简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示将专注于该项目的研发,未来将继续维护。
这意味着对于网页抓取和自动化需求,您现在可以体验到 Chrome 的速度和功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,以及伟大的开发者工具 API。它是可怕的!
我应该使用哪个工具来控制 Headless Chrome?
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组由社区发布的其他语言的 C++ API 和库,例如 GO 语言。我们推荐使用 NodeJS 工具,因为它与 Web 解析语言相同(您将在下面看到它是多么方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
将饼干放回饼干罐中
使用全功能浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但有时登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
等待 nick.setCookie({
名称:“li_at”,
值:“从您的 DevTools 复制的会话 cookie 值”,
领域: ””
})
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当危险的,因为错误的信息会触发愤怒用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它来爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
等待 tab.open("")
await tab.untilVisible("#hnmain") // 确保我们已经加载了页面
await tab.inject("") // 我们将使用 jQuery 来抓取
consthackerNewsLinks = await tab.evaluate((arg, callback) => {
// 这里我们处于页面上下文中。就像在浏览器的检查器工具中一样
常量数据 = []
$(".athing").each((index, element) => {
数据推送({
标题:$(element).find(".storylink").text(),
url: $(element).find(".storylink").attr("href")
})
})
回调(空,数据)
})
印度、俄罗斯和巴基斯坦与屏蔽机器人的做法有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫机连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
如果(等待 tab.isVisible(“.captchaImage”)){
// 获取生成的 CAPTCHA 图片的 URL
// 请注意,我们也可以获取它的 -encoded 值并对其进行求解
const captchaImageLink = await tab.evaluate((arg, callback) => {
回调(空,$(“.captchaImage”)。attr(“src”))
})
// 调用 CAPTCHA 解决服务
const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink)
// 用我们的解决方案填写表单
等待 tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })
}
等待DOM元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
等待 tab.open("")
// await Promise.delay(5000) // 不要这样做!
等待 tab.waitUntilVisible(".permalinkPost .UFILikeLink")
// 您现在可以安全地单击“喜欢”按钮...
等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延迟。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它拥有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 的时候已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈,然后运行它。
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截
因为使用了DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null
tab.driver.client.Network.responseReceived((e) => {
if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {
cvRequestId = e.requestId
}
})
tab.driver.client.Network.loadingFinished((e) => {
如果(e.requestId === cvRequestId){
tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {
require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded?'':'utf8')))
})
}
})
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截
const 尼克 = 新尼克({
加载图像:假,
白名单: [
/.*.aspx/,
/.*axd.*/,
/.*.html.*/,
/.*.js.*/
],
黑名单:[
/*fsispin360.js/,
/.*fsitouchzoom.js/,
/.*.ashx.*/,
/。*谷歌。*/
]
})
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。返回搜狐查看更多 查看全部
jquery抓取网页内容(使用HeadlessChrome进行网页的经验,你知道吗?(上))
作者丨马丁·塔皮亚
翻译丨富士
Headless Chrome 是 Chrome 浏览器的一种非界面形式。它可以在不打开浏览器的情况下运行具有 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 更方便测试web应用、获取网站的截图、做爬虫抓取信息等,更贴近浏览器环境。下面就来看看作者分享的使用Headless Chrome的网页爬虫体验吧。
PhantomJS 的发展已经停止,Headless Chrome 成为热点关注的焦点。每个人都喜欢它,包括我们。现在,网络爬虫是我们工作的很大一部分,现在我们广泛使用 Headless Chrome。
本文 文章 将告诉您如何快速开始使用 Headless Chrome 生态系统,并展示从抓取数百万个网页中学到的经验。
文章总结:
1. 控制Chrome的库有很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取非常简单,尤其是在掌握了以下技巧之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头镀铬简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示将专注于该项目的研发,未来将继续维护。
这意味着对于网页抓取和自动化需求,您现在可以体验到 Chrome 的速度和功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,以及伟大的开发者工具 API。它是可怕的!
我应该使用哪个工具来控制 Headless Chrome?
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组由社区发布的其他语言的 C++ API 和库,例如 GO 语言。我们推荐使用 NodeJS 工具,因为它与 Web 解析语言相同(您将在下面看到它是多么方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
将饼干放回饼干罐中
使用全功能浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但有时登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
等待 nick.setCookie({
名称:“li_at”,
值:“从您的 DevTools 复制的会话 cookie 值”,
领域: ””
})
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当危险的,因为错误的信息会触发愤怒用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它来爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
等待 tab.open("")
await tab.untilVisible("#hnmain") // 确保我们已经加载了页面
await tab.inject("") // 我们将使用 jQuery 来抓取
consthackerNewsLinks = await tab.evaluate((arg, callback) => {
// 这里我们处于页面上下文中。就像在浏览器的检查器工具中一样
常量数据 = []
$(".athing").each((index, element) => {
数据推送({
标题:$(element).find(".storylink").text(),
url: $(element).find(".storylink").attr("href")
})
})
回调(空,数据)
})
印度、俄罗斯和巴基斯坦与屏蔽机器人的做法有什么共同点?

答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫机连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
如果(等待 tab.isVisible(“.captchaImage”)){
// 获取生成的 CAPTCHA 图片的 URL
// 请注意,我们也可以获取它的 -encoded 值并对其进行求解
const captchaImageLink = await tab.evaluate((arg, callback) => {
回调(空,$(“.captchaImage”)。attr(“src”))
})
// 调用 CAPTCHA 解决服务
const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink)
// 用我们的解决方案填写表单
等待 tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })
}
等待DOM元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
等待 tab.open("")
// await Promise.delay(5000) // 不要这样做!
等待 tab.waitUntilVisible(".permalinkPost .UFILikeLink")
// 您现在可以安全地单击“喜欢”按钮...
等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延迟。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它拥有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 的时候已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈,然后运行它。
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截
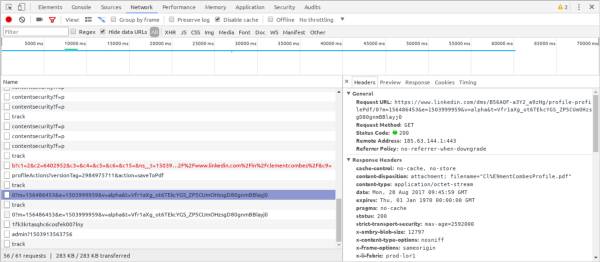
因为使用了DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null
tab.driver.client.Network.responseReceived((e) => {
if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {
cvRequestId = e.requestId
}
})
tab.driver.client.Network.loadingFinished((e) => {
如果(e.requestId === cvRequestId){
tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {
require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded?'':'utf8')))
})
}
})
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截
const 尼克 = 新尼克({
加载图像:假,
白名单: [
/.*.aspx/,
/.*axd.*/,
/.*.html.*/,
/.*.js.*/
],
黑名单:[
/*fsispin360.js/,
/.*fsitouchzoom.js/,
/.*.ashx.*/,
/。*谷歌。*/
]
})
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。返回搜狐查看更多
jquery抓取网页内容( ,前端资源1.什么是robots.txt文件搜索引擎教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-05 14:09
,前端资源1.什么是robots.txt文件搜索引擎教程)
robots.txt 如何禁止搜索引擎抓取
2013-3-3 分类:seo文章、wordpress教程、前端资源
1.robots.txt 文件是什么
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索的部分或指定那个搜索引擎只是收录的特定部分。
请注意,只有当您的 网站 收录您不想被 收录 搜索的内容时,您才需要使用 robots.txt 文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
2.robots.txt文件在哪里
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站网址
对应robots.txt的URL
:80/
:80/robots.txt
: 1234/
:1234/robots.txt
3.我在robots.txt中设置了禁止百度收录我网站,为什么它仍然出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
4.禁止搜索引擎跟踪网页链接,只索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放在页面的
部分:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写上这个标记:
登入
要允许其他搜索引擎跟踪,但只阻止百度跟踪指向您页面的链接,请将此元标记放在页面的一部分中:
5.禁止搜索引擎在搜索结果中显示网页快照,只能索引网页
为防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的
部分:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
6.我要禁止百度图片搜索收录一些图片,如何设置
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
7.Robots.txt 文件格式
“robots.txt”文件收录一条或多条记录,以空行分隔(以CR、CR/NL或NL为终止符)。每条记录的格式如下:
":"
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行。详细情况如下:
User-agent:此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。如果在“robots.txt”文件中添加“User-agent: SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”后的禁止和允许行限制。
Disallow:此项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,但不是访问 /help/index.html。“Disallow:”表示允许机器人访问网站的所有URL,并且“/robots.txt”文件中必须至少有一条Disallow记录。如果“/robots.txt”不存在或者是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
允许:此项的值用于描述一组您希望访问的 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。以 Allow 项的值开头的 URL 允许机器人访问。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认都是 Allow 的,所以 Allow 通常与 Disallow 结合使用,允许访问某些网页,同时禁止访问所有其他 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
注:我们将严格遵守机器人的相关协议。请注意区分您不想被抓取的目录或收录 的情况。我们会处理robots中写入的文件,你不想被爬取和收录的目录做精确匹配,否则robots协议不会生效。
8.URL 匹配示例
允许或禁止值
网址
比赛结果
/tmp
/tmp
是的
/tmp
/tmp.html
是的
/tmp
/tmp/a.html
是的
/tmp
/tmhoho
不
/你好*
/你好.html
是的
/He*lo
/你好,哈哈
是的
/堆*lo
/你好,哈哈
不
html$
/tmpa.html
是的
/a.html$
/a.html
是的
htm$
/a.html
不
9.Robots.txt 文件使用示例
示例 1. 禁止所有搜索引擎访问 网站 的任何部分
用户代理:*
不允许:/
示例 2. 允许所有机器人访问
(或者你可以创建一个空文件“/robots.txt”)
用户代理:*
允许:/
示例 3. 仅禁止百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
不允许:/
示例 4. 只允许百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
允许:/用户代理:*
不允许:/
示例 5. 只允许百度蜘蛛和谷歌机器人访问
用户代理:百度蜘蛛
允许:/用户代理:Googlebot
允许:/
用户代理:*
不允许:/
示例 6. 禁止蜘蛛访问特定目录
本例中网站有3个目录限制搜索引擎访问,即robot不会访问这3个目录。需要注意的是,每个目录必须单独声明,不能写成“Disallow:/cgi-bin//tmp/”。
用户代理:*
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 7. 允许访问特定目录中的某些 URL
用户代理:*
允许:/cgi-bin/见
允许:/tmp/hi
允许:/~joe/look
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 8. 使用“*”限制对 url 的访问
禁止访问/cgi-bin/目录下所有后缀为“.htm”的URL(包括子目录)。
用户代理:*
禁止:/cgi-bin/*.htm
示例 9. 使用“$”限制对 url 的访问
只允许访问带有“.htm”后缀的 URL。
用户代理:*
允许:/*.htm$
不允许:/
示例1 0.禁止访问网站中的所有动态页面
用户代理:*
不允许:/*?*
示例1 1.禁止百度蜘蛛抓取网站上的所有图片
只允许抓取网页,不允许抓取图片。
用户代理:百度蜘蛛
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.gif$
禁止:/*.png$
禁止:/*.bmp$
示例1 2.只允许百度蜘蛛抓取.gif格式的网页和图片
允许抓取网页和gif格式的图片,但不允许抓取其他格式的图片
用户代理:百度蜘蛛
允许:/*.gif$
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.png$
禁止:/*.bmp$
示例1 3. 只禁止百度蜘蛛抓取.jpg格式的图片
用户代理:百度蜘蛛
禁止:/*.jpg$ 查看全部
jquery抓取网页内容(
,前端资源1.什么是robots.txt文件搜索引擎教程)
robots.txt 如何禁止搜索引擎抓取
2013-3-3 分类:seo文章、wordpress教程、前端资源
1.robots.txt 文件是什么
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索的部分或指定那个搜索引擎只是收录的特定部分。
请注意,只有当您的 网站 收录您不想被 收录 搜索的内容时,您才需要使用 robots.txt 文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
2.robots.txt文件在哪里
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站网址
对应robots.txt的URL
:80/
:80/robots.txt
: 1234/
:1234/robots.txt
3.我在robots.txt中设置了禁止百度收录我网站,为什么它仍然出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
4.禁止搜索引擎跟踪网页链接,只索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放在页面的
部分:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写上这个标记:
登入
要允许其他搜索引擎跟踪,但只阻止百度跟踪指向您页面的链接,请将此元标记放在页面的一部分中:
5.禁止搜索引擎在搜索结果中显示网页快照,只能索引网页
为防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的
部分:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
6.我要禁止百度图片搜索收录一些图片,如何设置
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
7.Robots.txt 文件格式
“robots.txt”文件收录一条或多条记录,以空行分隔(以CR、CR/NL或NL为终止符)。每条记录的格式如下:
":"
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行。详细情况如下:
User-agent:此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。如果在“robots.txt”文件中添加“User-agent: SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”后的禁止和允许行限制。
Disallow:此项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,但不是访问 /help/index.html。“Disallow:”表示允许机器人访问网站的所有URL,并且“/robots.txt”文件中必须至少有一条Disallow记录。如果“/robots.txt”不存在或者是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
允许:此项的值用于描述一组您希望访问的 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。以 Allow 项的值开头的 URL 允许机器人访问。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认都是 Allow 的,所以 Allow 通常与 Disallow 结合使用,允许访问某些网页,同时禁止访问所有其他 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
注:我们将严格遵守机器人的相关协议。请注意区分您不想被抓取的目录或收录 的情况。我们会处理robots中写入的文件,你不想被爬取和收录的目录做精确匹配,否则robots协议不会生效。
8.URL 匹配示例
允许或禁止值
网址
比赛结果
/tmp
/tmp
是的
/tmp
/tmp.html
是的
/tmp
/tmp/a.html
是的
/tmp
/tmhoho
不
/你好*
/你好.html
是的
/He*lo
/你好,哈哈
是的
/堆*lo
/你好,哈哈
不
html$
/tmpa.html
是的
/a.html$
/a.html
是的
htm$
/a.html
不
9.Robots.txt 文件使用示例
示例 1. 禁止所有搜索引擎访问 网站 的任何部分
用户代理:*
不允许:/
示例 2. 允许所有机器人访问
(或者你可以创建一个空文件“/robots.txt”)
用户代理:*
允许:/
示例 3. 仅禁止百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
不允许:/
示例 4. 只允许百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
允许:/用户代理:*
不允许:/
示例 5. 只允许百度蜘蛛和谷歌机器人访问
用户代理:百度蜘蛛
允许:/用户代理:Googlebot
允许:/
用户代理:*
不允许:/
示例 6. 禁止蜘蛛访问特定目录
本例中网站有3个目录限制搜索引擎访问,即robot不会访问这3个目录。需要注意的是,每个目录必须单独声明,不能写成“Disallow:/cgi-bin//tmp/”。
用户代理:*
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 7. 允许访问特定目录中的某些 URL
用户代理:*
允许:/cgi-bin/见
允许:/tmp/hi
允许:/~joe/look
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 8. 使用“*”限制对 url 的访问
禁止访问/cgi-bin/目录下所有后缀为“.htm”的URL(包括子目录)。
用户代理:*
禁止:/cgi-bin/*.htm
示例 9. 使用“$”限制对 url 的访问
只允许访问带有“.htm”后缀的 URL。
用户代理:*
允许:/*.htm$
不允许:/
示例1 0.禁止访问网站中的所有动态页面
用户代理:*
不允许:/*?*
示例1 1.禁止百度蜘蛛抓取网站上的所有图片
只允许抓取网页,不允许抓取图片。
用户代理:百度蜘蛛
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.gif$
禁止:/*.png$
禁止:/*.bmp$
示例1 2.只允许百度蜘蛛抓取.gif格式的网页和图片
允许抓取网页和gif格式的图片,但不允许抓取其他格式的图片
用户代理:百度蜘蛛
允许:/*.gif$
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.png$
禁止:/*.bmp$
示例1 3. 只禁止百度蜘蛛抓取.jpg格式的图片
用户代理:百度蜘蛛
禁止:/*.jpg$
jquery抓取网页内容(我尝试使用c#.net3.5应用程序抓取网页,但我无法抓取整个页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-04 15:16
问题
我尝试使用c#.net 3.5 应用程序抓取网页,但无法抓取整个页面,因为部分内容是通过jquery Ajax 显示的。
如果你使用 Chrome 作为你的网络浏览器,你可以打开开发者工具(F12) 并检查“网络”选项卡以查看页面加载后请求的资源。上面的 URL 是我注意到的 URL 之一,好像带来了一些结果,如果你知道或者可以解析date和meeting_id,你或许可以像使用主页一样直接拨打电话。
另一种可能的选择是使用实际的 Web 浏览器控件并在加载所有内容后扫描 DOM。
其他解决方案
我认为您需要使用 System.Net 命名空间。
你需要做的是在这个的帮助下创建一个 HttpRequest
WebRequest webRequest = WebRequest.Create("http://www.racingpost.com/grey ... 6quot;);
WebResponse webResp = webRequest.GetResponse();
我认为这也将提供对 Ajax 数据的完整响应。 查看全部
jquery抓取网页内容(我尝试使用c#.net3.5应用程序抓取网页,但我无法抓取整个页面)
问题
我尝试使用c#.net 3.5 应用程序抓取网页,但无法抓取整个页面,因为部分内容是通过jquery Ajax 显示的。
如果你使用 Chrome 作为你的网络浏览器,你可以打开开发者工具(F12) 并检查“网络”选项卡以查看页面加载后请求的资源。上面的 URL 是我注意到的 URL 之一,好像带来了一些结果,如果你知道或者可以解析date和meeting_id,你或许可以像使用主页一样直接拨打电话。
另一种可能的选择是使用实际的 Web 浏览器控件并在加载所有内容后扫描 DOM。
其他解决方案
我认为您需要使用 System.Net 命名空间。
你需要做的是在这个的帮助下创建一个 HttpRequest
WebRequest webRequest = WebRequest.Create("http://www.racingpost.com/grey ... 6quot;);
WebResponse webResp = webRequest.GetResponse();
我认为这也将提供对 Ajax 数据的完整响应。
jquery抓取网页内容(WOT全球技术创新大会2022,门票6折抢购中!购票立减2320元!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-14 23:36
WOT全球科技创新大会2022,门票40折抢购!购票立减2320元!
一:背景
1. 讲个故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢奇怪的东西,所以就需要如何瞄准和捕捉奇怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。我这个年纪的码农至少学了 5-6 年的 Jquery,所以我必须使用类似 Jquery 的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?哎,真的有全能的github。. .
二:CSQuery
1. 安装
github地址:然后直接在vs中点击nuget:
2. 举几个例子
万事俱备,如何使用?别急,我举两个博客园的例子。
1) 从首页提取友情链接到
如上图所示,这里如果要获取友情链接的几个大字,直接用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
那怎么处理呢?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最后得到文本节点的内容,如下:
用js做的,用CSQuery代码怎么做?模仿一下,如下代码:
static void Main(string[] args) { var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com")); var content = jquery["#friend_link"].Contents().Filter((dom) => { return dom.NodeType == NodeType.TEXT_NODE; }).Text(); Console.WriteLine(content); }
不知道用xpath提取这样的内容是不是很麻烦,但是用jquery也不是很方便,但是熟悉。
2) 如何给html中的一些元素着色
有时需要为业务更改一些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:
如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args) { Config.HtmlEncoder = HtmlEncoders.None; var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com")); var html = jquery["#nav_left li"].Each(dom => { var self = jquery[dom]; var text = self.Text(); if (text == "博问" || text == "专区") { self.Find("a").CssSet(new { color = "red" }); } }).Render(); }
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等百种实用方法,本文当然不能一一介绍,有兴趣的可以下载到看看并玩弄小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以用CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到
3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args) { Config.HtmlEncoder = HtmlEncoders.None; var strlist = new string[2] { "1", "2" }; var path = Environment.CurrentDirectory + "\\2.html"; var jquery = CQ.CreateFromFile(path); var current = jquery.Find("#main"); foreach (var str in strlist) { current.Append($"{str}"); } var html = current.RenderSelection(); Console.WriteLine(html); } ------------- output ---------------- 12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!但是html5中也加入了querySelector和querySelectorAll来支持css3的选择器,非常强大,但是jquery不仅在选择器上灵活,而且在对节点的灵活操作方面,一般来说可以怀旧的时候它的交互性不是特别丰富。 查看全部
jquery抓取网页内容(WOT全球技术创新大会2022,门票6折抢购中!购票立减2320元!)
WOT全球科技创新大会2022,门票40折抢购!购票立减2320元!
一:背景
1. 讲个故事
前段时间,我创建了一个当地民生信息账号。我复制了你的信息。你复制了官方媒体。市民喜欢奇怪的东西,所以就需要如何瞄准和捕捉奇怪的东西。账号上的消息其实做起来很简单,用logistic回归就可以了。本文主要讨论如何爬取。在C#中,大家都知道抓取的通用库是HtmlAgilityPack,但是这个库的主流方法是使用xpath来提取网页的内容,让我很不爽。毕竟,我不熟悉莫名的抵抗。我这个年纪的码农至少学了 5-6 年的 Jquery,所以我必须使用类似 Jquery 的方法。python中有pyquery。在 C# 中是否有类似的方法可以做到这一点?哎,真的有全能的github。. .
二:CSQuery
1. 安装
github地址:然后直接在vs中点击nuget:
2. 举几个例子
万事俱备,如何使用?别急,我举两个博客园的例子。
1) 从首页提取友情链接到
如上图所示,这里如果要获取友情链接的几个大字,直接用text()肯定是不行的。默认情况下,它还会捕获所有子节点的文本,如下图所示:
那怎么处理呢?可以使用jquery提供的contents方法,然后判断获取到的所有子节点中是否有文本节点,最后得到文本节点的内容,如下:
用js做的,用CSQuery代码怎么做?模仿一下,如下代码:
static void Main(string[] args) { var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";)); var content = jquery["#friend_link"].Contents().Filter((dom) => { return dom.NodeType == NodeType.TEXT_NODE; }).Text(); Console.WriteLine(content); }
不知道用xpath提取这样的内容是不是很麻烦,但是用jquery也不是很方便,但是熟悉。
2) 如何给html中的一些元素着色
有时需要为业务更改一些html标签的颜色,例如将首页tabmenu中的博客和区域更改为红色,如下图所示:
如何处理CSQuery?如果你玩过jquery,一般来说步骤如下:
有了步骤,C#代码如下:
static void Main(string[] args) { Config.HtmlEncoder = HtmlEncoders.None; var jquery = CQ.CreateDocument(new WebClient().DownloadString("http://cnblogs.com";)); var html = jquery["#nav_left li"].Each(dom => { var self = jquery[dom]; var text = self.Text(); if (text == "博问" || text == "专区") { self.Find("a").CssSet(new { color = "red" }); } }).Render(); }
3) 其他操作方法
除了以上两种操作方法,还可以使用after、before、replaceAll、IS等百种实用方法,本文当然不能一一介绍,有兴趣的可以下载到看看并玩弄小提琴。
三:其他用途
除了抓取html中的元素,我觉得这个东西还可以用来在发邮件的时候操作邮件模板。毕竟很久以前大家都是用jquery来画html的,所以用CSQuery也是可以的。使用 xslt 有优点也有缺点。, 举个例子:
1. 生成html模板
2. 使用 CSQuery 将 li 附加到 ul
您可以使用 Append 将内容附加到
3. 局部渲染RenderSelection
Render方法是将整个Dom渲染成html,但是有时候你只需要获取你修改的那部分内容而不是整个html,这涉及到部分渲染,可以使用RenderSelection方法,代码如下:
static void Main(string[] args) { Config.HtmlEncoder = HtmlEncoders.None; var strlist = new string[2] { "1", "2" }; var path = Environment.CurrentDirectory + "\\2.html"; var jquery = CQ.CreateFromFile(path); var current = jquery.Find("#main"); foreach (var str in strlist) { current.Append($"{str}"); } var html = current.RenderSelection(); Console.WriteLine(html); } ------------- output ---------------- 12
四:总结
Jquery的这种操作方式对我个人来说还是比较舒服的,毕竟我很熟悉!但是html5中也加入了querySelector和querySelectorAll来支持css3的选择器,非常强大,但是jquery不仅在选择器上灵活,而且在对节点的灵活操作方面,一般来说可以怀旧的时候它的交互性不是特别丰富。
jquery抓取网页内容(PythonWeb爬虫库Python是最常用的Web抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-13 22:06
您是否打算开始一个新的网页抓取项目并正在寻找可以使用的最佳网页抓取工具?现在发现最好的工具,包括非编码器专用的工具。
虽然您可以从头开发自己的网页抓取工具来执行网页抓取任务,但除非您有明显的原因,否则这样做是明智的,否则不仅会浪费您的时间,还会浪费您所有的投资其他资源。无需走那条路,您需要调查市场以使用现有解决方案。说到网络抓取工具,您需要知道市场上有很多工具。
然而,并非所有人都是平等的。事实证明,有些方法比其他方法更好。有些工具比其他工具更受欢迎,而且每种工具的学习曲线都不同。平台和编程语言支持及其含义也是如此。但是,我们仍然可以就市场上最好的网络抓取工具达成一致,下面将逐一讨论。该列表包括为具有编程技能的人和非编码人员开发的工具。
程序员的Web爬网工具
网页抓取最初是编码人员的任务,因为需要在抓取网站之前编写代码。因此,市场上有许多专门为编码人员创建的工具。供编码人员使用的 Web 抓取工具采用库和框架的形式,开发人员将这些库和框架合并到他们的代码中,以从他们的 Web 抓取中获得所需的行为。
Python 网络爬虫库
Python 是网络爬虫代码最常用的编程语言,因为它语法简单,学习曲线丰富,并且有大量可用的库,简化了开发者的工作。下面讨论了 Python 开发人员可以使用的一些网络抓取库和框架。
刮痧
Scrapy 是一个用 Python 为 Python 开发人员编写的网络爬虫和网络抓取框架。Scrapy 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面解析数据的模块。
它是开源的,可以免费使用。爬行还提供了一种保存数据的方法。但是,Scrapy 无法渲染 JavaScript,因此需要其他库的帮助。为此,您可以使用 Splash 或流行的 Selenium 浏览器自动化工具。
蜘蛛侠
PySpider 是另一种网页抓取工具,可用于在 Python 中编写脚本。与 Scrapy 不同的是,它可以渲染 JavaScript,因此无需使用 Selenium。然而,它不如 Scrapy 成熟,因为 Scrapy 自 2008 年就已经存在,并且拥有更好的文档和用户社区。这不会使 PySpider 劣等。事实上,PySpider 有一些无与伦比的功能,比如一个 Web UI 脚本编辑器。
要求
request 是一个可以轻松发送 HTTP 请求的 HTTP 库。它建立在 urllib 之上。它是一个强大的工具,可以帮助您创建更可靠的刮板。它易于使用并且需要更少的代码行。
非常重要的事实是,它可以帮助您处理 cookie 和会话以及身份验证和自动连接池。它是免费使用的,Python 开发者会在使用解析器解析所需数据之前使用它下载页面。
美汤
BeautifulSoup 使从网页解析数据的过程变得容易。它位于 HTML 或 XML 解析器之上,并为您提供 Python 方法来访问数据。由于其易于解析,BeautifulSoup 已成为市场上最重要的网页抓取工具之一。
事实上,大多数网页抓取教程都使用 BeautifulSoup 来教新手如何编写网页抓取工具。当与“发送HTTP请求”和“请求”一起使用时,网页抓取工具的开发变得比使用Scrapy或PySpider更容易。
硒
如果 网站 是 Ajaxified,Scrapy、Requests 和 BeautifulSoup 对你没有帮助——也就是说,它依赖 AJAX 请求通过 JavaScript 加载页面的某些部分。如果要访问这样的页面,则需要使用 Selenium,它是一种 Web 浏览器自动化工具。它可用于自动化浏览器,例如 Chrome 和 Firefox。老版本可以自动执行 PhantomJS。
Node.JS (JavaScript) 网页抓取工具
由于 JavaScript 的流行,Node.JS 也正在成为网络爬虫的流行平台。同样,它有许多用于网页抓取的工具,但不如 Python。下面讨论两个最流行的 Node.JS 运行时工具。
切里奥
对于 Node.JS,Cheerio 是 Python。它是一个解析库,用于解析标记并提供用于遍历和操作 Web 内容的 API。它没有渲染 JavaScript 的能力,所以你需要一个无头浏览器。它的唯一任务是为您提供一个 jQuery,例如用于解析网页数据的 API。它灵活、快速且易于使用。
傀儡师
Puppeteer 是 JavaScript 开发人员可以使用的最好的网络抓取工具之一。它是一个浏览器自动化工具,并提供用于控制 Chrome 的高级 API。Puppeteer 由 Google 开发,仅适用于 Chrome 浏览器和其他 Chromium 浏览器。与跨平台的 Selenium 不同,Puppeteer 仅用于 Node 环境。
网络采集API
没有使用代理爬取经验且难以爬取网站的编码者,或者不想担心代理管理和解决验证码问题的编码者,可以帮助他们从网站中提取通过仅使用 Web 抓取 API 数据或下载整个数据页面,以便他们可以抓取。最好的网页抓取 API 描述如下。
自动提取 API
AutoExtract API 是市场上最好的网页抓取 API 之一。它由 Scrapinghub、Crawlera 的创建者、代理 API 和主要维护者 Scrapy 开发,为 Python 程序员提供了一个流行的框架。
AutoExtract API 是一种 API 驱动的数据提取工具,可以帮助您从 网站 中提取特定数据,而无需事先了解 网站 - 这意味着不需要特定于站点的代码。AutoExtract API 支持提取新闻和博客、电子商务产品、招聘信息和车辆数据等。
刮蜂
ScrapingBee 是一个网页抓取 API,可以帮助您下载网页。使用 ScrapingBee,您不必考虑块,但是当作为响应返回给您时,ScrapingBee 会解析从下载的网页返回的数据。
ScrapingBee 使用方便,只需要调用一次 API。ScrapingBee 使用大量 IP 来路由您的请求并避免被禁止。它还有助于处理无头 Chrome,这不是一件容易的事,尤其是在扩展无头 Chrome 网格时。
爬虫API
Scraper API 每月处理超过 50 亿次 API 请求,因此在网页抓取 API 市场中不可忽视。其强大的系统可以帮助您处理大量任务,包括使用超过 4000 万个 IP 的代理池进行 IP 轮换。
除了 IP 轮换之外,Scraper API 还可以处理无头浏览器,并可以帮助您避免直接处理验证码。网页抓取 API 快速可靠,其客户名单中有许多财富 500 强公司。定价也很合理。
Zenscrape
Zenscrape 将帮助您以实惠的价格轻松地从 网站 中提取数据——他们甚至像其他人一样拥有免费试用计划,可以在做出财务承诺之前测试他们的服务。
Zenscrape 会为您下载普通用户看到的页面,并可以根据您选择的方案处理针对地理区域的内容。非常重要的一点是,由于所有请求都是在无头 Chrome 中执行的,因此它可以完美地处理 JavaScript。它甚至支持流行的 JavaScript 框架。
刮痧蚂蚁
使用严格的反垃圾邮件系统来抓取站点是一项艰巨的任务,因为您必须处理许多障碍。ScrapingAnt 可以帮助您处理所有障碍,轻松获取您需要的数据。
它使用无头 Chrome 浏览器来处理 JavaScript 执行、处理代理并帮助您避免验证码。ScrapingAnt 还处理自定义 cookie 和输出预处理。当你开始使用它的网页抓取 API 时,它的价格很友好,低至 9 美元。
最佳非编码器Web爬网工具
过去,网络抓取需要您编写代码。这不再是事实,因为一些网页抓取工具是专门为非编码人员开发的。使用这些工具,您可以在不编写代码的情况下从 Internet 获取所需的数据。这些工具可以采用可安装软件、基于云的解决方案或浏览器扩展的形式。
网页抓取软件
市场上有很多软件可以用来在线采集各种数据,而无需知道如何编写代码。以下是目前市场上的前 5 种选择。
八爪鱼
Octoparse 使每个人都可以轻松进行网络抓取。使用 Octoparse,您只需点击几下即可将整个 网站 快速转换为结构化的电子表格。Octoparse 不需要任何编码技能,因为您只需点击一下,您就会获得所需的数据。Octoparse可以使用严格的反爬技术从各种网站(包括Ajaxified网站)中抓取数据。它使用 IP 轮换来隐藏 IP 足迹。除了可安装的软件,他们还提供基于云的解决方案,您甚至可以享受 14 天的免费试用期。
氦气刮刀
Helium Scraper 是另一个可以抓取 网站 作为非编码器的软件。您可以通过为编码人员定义自己的操作来捕获复杂的数据;他们还可以运行自定义 JavaScript 文件。通过简单的工作流程,使用 Helium Scraper 不仅简单而且快速,因为它具有简单直观的界面。Helium Scraper也是一款具有多种功能(包括抓取计划、代理轮换、文本操作和API调用等)的网页抓取软件。
分析中心
ParseHub 有两个版本——一个免费使用的桌面应用程序和一个付费的基于云的爬虫解决方案,具有附加功能,无需安装即可使用。ParseHub 桌面应用程序允许您轻松获取所需的任何内容 网站 即使没有编码技能。这是因为该软件提供了一个点击式界面,该界面专为对要捕获的数据进行软件培训而设计。它非常适合现代网站,并允许您以流行的文件格式下载捕获的数据。
刮刮风
ScrapeStorm 与上述其他桌面应用的不同之处在于,它仅在无法自动识别所需数据时才使用点击界面。ScrapeStorm 使用 AI 智能识别网页上的特定数据点。ScrapeStorm 快速、可靠且易于使用。在操作系统支持方面,ScrapeStorm 提供了对 Windows、Mac 和 Linux 的支持。支持多种数据导出方式,可实现企业级爬取。有趣的是,它是由前 Google 爬虫团队构建的。
网络哈维
WebHarvy 是另一种网络抓取软件,您可以将其安装在您的计算机上,以帮助您处理抓取并从网页中提取数据。该软件允许您编写一行代码进行捕获,您可以选择将捕获的数据保存在文件或数据库系统中。它是一个强大的可视化工具,可用于从网页中抓取各种数据,例如电子邮件、链接、图像,甚至完整的 HTML 文件。它具有智能模式检测功能,可以抓取多个页面。
网络应用扩展
浏览器环境在网络爬虫中越来越流行,许多网络爬虫工具可以作为浏览器的扩展和插件安装,帮助你从网站中抓取数据,下面将讨论其中的一些。
网页抓取扩展
Webscraper.io 浏览器扩展(Chrome 和 Firefox)提供了最好的网页抓取工具之一,您可以使用它轻松地从网页中提取数据。超过 250,000 名用户安装了这个工具,他们发现它非常有用。这些浏览器扩展不需要点击编码,因为它们使用点击界面。有趣的是,它甚至可以通过许多 JavaScript 触发的操作来获取最现代的 网站。
数据挖掘器扩展
Data Miner 扩展仅适用于 Google Chrome 和 Microsoft Edge 浏览器。它可以帮助您从页面抓取数据并将抓取的数据保存在 CSV 或 Excel 电子表格中。与 Webscraper.io 提供的扩展程序免费的情况不同,Data Miner 扩展程序仅对一个月内抓取的前 500 页免费 - 之后,您需要订阅付费计划才能使用它。使用此扩展程序,您可以在不考虑块的情况下抓取任何页面 - 并且您的数据保持私密。
刮刀
Scraper 是一个 Chrome 扩展,可能由开发人员设计和管理 - 它甚至没有自己的 网站 像上面的另一个 网站 。Scraper 没有上面提到的其他浏览器扩展那么先进。但是,它是完全免费的。Scraper 的主要问题是它要求用户知道如何使用 XPath,因为这是您将要使用的 XPath。因此,它不是初学者友好的。
SimpleScraper
SimpleScraper 是另一种可用作 Chrome 扩展程序的网页抓取工具。通过在 Chrome 浏览器中安装此扩展程序,您可以将任何 网站 变成一个 API,让网络爬虫变得简单而自由。此扩展程序将帮助您从网页中快速提取结构化数据,适用于所有 网站,包括那些收录 JavaScript 网站 的内容。如果您需要更灵活的选择,您可以付费选择他们基于云的解决方案。
代理刮油剂
使用Agenty Scraping Agent,您可以不考虑障碍地继续操作和抓取网页中的数据。此工具不是免费的,但它们提供免费试用选项。这个浏览器扩展是为现代web开发的,所以爬很多JavaScript网站不会有问题。有趣的是,它也适用于旧的 网站。
网页抓取代理
事实是,除非您使用通常被认为昂贵的网络抓取 API,否则您必须使用代理。说到爬虫的代理,我会推荐用户使用带有住宅替换IP的代理提供商——这样可以减轻你的代理管理负担。以下是市场上 3 种最佳 IP 轮换服务。
发光体
Luminati可以说是市场上最好的代理服务商。它还拥有全球最大的代理网络,Luminati 代理池中拥有超过 7200 万个住宅 IP。它仍然是最安全、可靠和快速的工具之一。有趣的是,它兼容当今互联网上最流行的网站。Luminati 拥有最好的会话控制系统,因为它允许您决定何时维护会话——它还有一个高轮换代理,可以在每次请求后更改 IP。然而,它是昂贵的。
智能代理
Smartproxy拥有住宅代理池,收录超过1000万个住宅IP。由于会话控制系统,它们的代理对于网络抓取非常有效。他们的代理可以保持会话和相同IP 10分钟——这非常适合基于登录的爬取网站。对于常规的 网站,您可以使用其高轮换代理,它会在每次请求后更改 IP。他们在全球约195个国家和8个主要城市设有代理商。
爬虫
Crawlera 通过帮助您与代理打交道来帮助您专注于数据。与 Luminati 的情况不同,Crawlera 的系统中没有足够的 IP。
但是,与 Luminati 可能被 Captchas 攻击的情况不同,Crawlera 使用一些技巧来确保您请求的页面被返回——但是,与 Luminati 一样,它们在世界上所有国家和城市都没有代理。他们的定价基于请求的数量,而不是消耗的带宽。 查看全部
jquery抓取网页内容(PythonWeb爬虫库Python是最常用的Web抓取工具)
您是否打算开始一个新的网页抓取项目并正在寻找可以使用的最佳网页抓取工具?现在发现最好的工具,包括非编码器专用的工具。
虽然您可以从头开发自己的网页抓取工具来执行网页抓取任务,但除非您有明显的原因,否则这样做是明智的,否则不仅会浪费您的时间,还会浪费您所有的投资其他资源。无需走那条路,您需要调查市场以使用现有解决方案。说到网络抓取工具,您需要知道市场上有很多工具。
然而,并非所有人都是平等的。事实证明,有些方法比其他方法更好。有些工具比其他工具更受欢迎,而且每种工具的学习曲线都不同。平台和编程语言支持及其含义也是如此。但是,我们仍然可以就市场上最好的网络抓取工具达成一致,下面将逐一讨论。该列表包括为具有编程技能的人和非编码人员开发的工具。
程序员的Web爬网工具
网页抓取最初是编码人员的任务,因为需要在抓取网站之前编写代码。因此,市场上有许多专门为编码人员创建的工具。供编码人员使用的 Web 抓取工具采用库和框架的形式,开发人员将这些库和框架合并到他们的代码中,以从他们的 Web 抓取中获得所需的行为。
Python 网络爬虫库
Python 是网络爬虫代码最常用的编程语言,因为它语法简单,学习曲线丰富,并且有大量可用的库,简化了开发者的工作。下面讨论了 Python 开发人员可以使用的一些网络抓取库和框架。
刮痧
Scrapy 是一个用 Python 为 Python 开发人员编写的网络爬虫和网络抓取框架。Scrapy 是一个完整的框架,因此它收录了 Web 抓取所需的一切,包括用于发送 HTTP 请求和从下载的 HTML 页面解析数据的模块。
它是开源的,可以免费使用。爬行还提供了一种保存数据的方法。但是,Scrapy 无法渲染 JavaScript,因此需要其他库的帮助。为此,您可以使用 Splash 或流行的 Selenium 浏览器自动化工具。
蜘蛛侠
PySpider 是另一种网页抓取工具,可用于在 Python 中编写脚本。与 Scrapy 不同的是,它可以渲染 JavaScript,因此无需使用 Selenium。然而,它不如 Scrapy 成熟,因为 Scrapy 自 2008 年就已经存在,并且拥有更好的文档和用户社区。这不会使 PySpider 劣等。事实上,PySpider 有一些无与伦比的功能,比如一个 Web UI 脚本编辑器。
要求
request 是一个可以轻松发送 HTTP 请求的 HTTP 库。它建立在 urllib 之上。它是一个强大的工具,可以帮助您创建更可靠的刮板。它易于使用并且需要更少的代码行。
非常重要的事实是,它可以帮助您处理 cookie 和会话以及身份验证和自动连接池。它是免费使用的,Python 开发者会在使用解析器解析所需数据之前使用它下载页面。
美汤
BeautifulSoup 使从网页解析数据的过程变得容易。它位于 HTML 或 XML 解析器之上,并为您提供 Python 方法来访问数据。由于其易于解析,BeautifulSoup 已成为市场上最重要的网页抓取工具之一。
事实上,大多数网页抓取教程都使用 BeautifulSoup 来教新手如何编写网页抓取工具。当与“发送HTTP请求”和“请求”一起使用时,网页抓取工具的开发变得比使用Scrapy或PySpider更容易。
硒
如果 网站 是 Ajaxified,Scrapy、Requests 和 BeautifulSoup 对你没有帮助——也就是说,它依赖 AJAX 请求通过 JavaScript 加载页面的某些部分。如果要访问这样的页面,则需要使用 Selenium,它是一种 Web 浏览器自动化工具。它可用于自动化浏览器,例如 Chrome 和 Firefox。老版本可以自动执行 PhantomJS。
Node.JS (JavaScript) 网页抓取工具
由于 JavaScript 的流行,Node.JS 也正在成为网络爬虫的流行平台。同样,它有许多用于网页抓取的工具,但不如 Python。下面讨论两个最流行的 Node.JS 运行时工具。
切里奥
对于 Node.JS,Cheerio 是 Python。它是一个解析库,用于解析标记并提供用于遍历和操作 Web 内容的 API。它没有渲染 JavaScript 的能力,所以你需要一个无头浏览器。它的唯一任务是为您提供一个 jQuery,例如用于解析网页数据的 API。它灵活、快速且易于使用。
傀儡师
Puppeteer 是 JavaScript 开发人员可以使用的最好的网络抓取工具之一。它是一个浏览器自动化工具,并提供用于控制 Chrome 的高级 API。Puppeteer 由 Google 开发,仅适用于 Chrome 浏览器和其他 Chromium 浏览器。与跨平台的 Selenium 不同,Puppeteer 仅用于 Node 环境。
网络采集API
没有使用代理爬取经验且难以爬取网站的编码者,或者不想担心代理管理和解决验证码问题的编码者,可以帮助他们从网站中提取通过仅使用 Web 抓取 API 数据或下载整个数据页面,以便他们可以抓取。最好的网页抓取 API 描述如下。
自动提取 API
AutoExtract API 是市场上最好的网页抓取 API 之一。它由 Scrapinghub、Crawlera 的创建者、代理 API 和主要维护者 Scrapy 开发,为 Python 程序员提供了一个流行的框架。
AutoExtract API 是一种 API 驱动的数据提取工具,可以帮助您从 网站 中提取特定数据,而无需事先了解 网站 - 这意味着不需要特定于站点的代码。AutoExtract API 支持提取新闻和博客、电子商务产品、招聘信息和车辆数据等。
刮蜂
ScrapingBee 是一个网页抓取 API,可以帮助您下载网页。使用 ScrapingBee,您不必考虑块,但是当作为响应返回给您时,ScrapingBee 会解析从下载的网页返回的数据。
ScrapingBee 使用方便,只需要调用一次 API。ScrapingBee 使用大量 IP 来路由您的请求并避免被禁止。它还有助于处理无头 Chrome,这不是一件容易的事,尤其是在扩展无头 Chrome 网格时。
爬虫API
Scraper API 每月处理超过 50 亿次 API 请求,因此在网页抓取 API 市场中不可忽视。其强大的系统可以帮助您处理大量任务,包括使用超过 4000 万个 IP 的代理池进行 IP 轮换。
除了 IP 轮换之外,Scraper API 还可以处理无头浏览器,并可以帮助您避免直接处理验证码。网页抓取 API 快速可靠,其客户名单中有许多财富 500 强公司。定价也很合理。
Zenscrape
Zenscrape 将帮助您以实惠的价格轻松地从 网站 中提取数据——他们甚至像其他人一样拥有免费试用计划,可以在做出财务承诺之前测试他们的服务。
Zenscrape 会为您下载普通用户看到的页面,并可以根据您选择的方案处理针对地理区域的内容。非常重要的一点是,由于所有请求都是在无头 Chrome 中执行的,因此它可以完美地处理 JavaScript。它甚至支持流行的 JavaScript 框架。
刮痧蚂蚁
使用严格的反垃圾邮件系统来抓取站点是一项艰巨的任务,因为您必须处理许多障碍。ScrapingAnt 可以帮助您处理所有障碍,轻松获取您需要的数据。
它使用无头 Chrome 浏览器来处理 JavaScript 执行、处理代理并帮助您避免验证码。ScrapingAnt 还处理自定义 cookie 和输出预处理。当你开始使用它的网页抓取 API 时,它的价格很友好,低至 9 美元。
最佳非编码器Web爬网工具
过去,网络抓取需要您编写代码。这不再是事实,因为一些网页抓取工具是专门为非编码人员开发的。使用这些工具,您可以在不编写代码的情况下从 Internet 获取所需的数据。这些工具可以采用可安装软件、基于云的解决方案或浏览器扩展的形式。
网页抓取软件
市场上有很多软件可以用来在线采集各种数据,而无需知道如何编写代码。以下是目前市场上的前 5 种选择。
八爪鱼
Octoparse 使每个人都可以轻松进行网络抓取。使用 Octoparse,您只需点击几下即可将整个 网站 快速转换为结构化的电子表格。Octoparse 不需要任何编码技能,因为您只需点击一下,您就会获得所需的数据。Octoparse可以使用严格的反爬技术从各种网站(包括Ajaxified网站)中抓取数据。它使用 IP 轮换来隐藏 IP 足迹。除了可安装的软件,他们还提供基于云的解决方案,您甚至可以享受 14 天的免费试用期。
氦气刮刀
Helium Scraper 是另一个可以抓取 网站 作为非编码器的软件。您可以通过为编码人员定义自己的操作来捕获复杂的数据;他们还可以运行自定义 JavaScript 文件。通过简单的工作流程,使用 Helium Scraper 不仅简单而且快速,因为它具有简单直观的界面。Helium Scraper也是一款具有多种功能(包括抓取计划、代理轮换、文本操作和API调用等)的网页抓取软件。
分析中心
ParseHub 有两个版本——一个免费使用的桌面应用程序和一个付费的基于云的爬虫解决方案,具有附加功能,无需安装即可使用。ParseHub 桌面应用程序允许您轻松获取所需的任何内容 网站 即使没有编码技能。这是因为该软件提供了一个点击式界面,该界面专为对要捕获的数据进行软件培训而设计。它非常适合现代网站,并允许您以流行的文件格式下载捕获的数据。
刮刮风
ScrapeStorm 与上述其他桌面应用的不同之处在于,它仅在无法自动识别所需数据时才使用点击界面。ScrapeStorm 使用 AI 智能识别网页上的特定数据点。ScrapeStorm 快速、可靠且易于使用。在操作系统支持方面,ScrapeStorm 提供了对 Windows、Mac 和 Linux 的支持。支持多种数据导出方式,可实现企业级爬取。有趣的是,它是由前 Google 爬虫团队构建的。
网络哈维
WebHarvy 是另一种网络抓取软件,您可以将其安装在您的计算机上,以帮助您处理抓取并从网页中提取数据。该软件允许您编写一行代码进行捕获,您可以选择将捕获的数据保存在文件或数据库系统中。它是一个强大的可视化工具,可用于从网页中抓取各种数据,例如电子邮件、链接、图像,甚至完整的 HTML 文件。它具有智能模式检测功能,可以抓取多个页面。
网络应用扩展
浏览器环境在网络爬虫中越来越流行,许多网络爬虫工具可以作为浏览器的扩展和插件安装,帮助你从网站中抓取数据,下面将讨论其中的一些。
网页抓取扩展
Webscraper.io 浏览器扩展(Chrome 和 Firefox)提供了最好的网页抓取工具之一,您可以使用它轻松地从网页中提取数据。超过 250,000 名用户安装了这个工具,他们发现它非常有用。这些浏览器扩展不需要点击编码,因为它们使用点击界面。有趣的是,它甚至可以通过许多 JavaScript 触发的操作来获取最现代的 网站。
数据挖掘器扩展
Data Miner 扩展仅适用于 Google Chrome 和 Microsoft Edge 浏览器。它可以帮助您从页面抓取数据并将抓取的数据保存在 CSV 或 Excel 电子表格中。与 Webscraper.io 提供的扩展程序免费的情况不同,Data Miner 扩展程序仅对一个月内抓取的前 500 页免费 - 之后,您需要订阅付费计划才能使用它。使用此扩展程序,您可以在不考虑块的情况下抓取任何页面 - 并且您的数据保持私密。
刮刀
Scraper 是一个 Chrome 扩展,可能由开发人员设计和管理 - 它甚至没有自己的 网站 像上面的另一个 网站 。Scraper 没有上面提到的其他浏览器扩展那么先进。但是,它是完全免费的。Scraper 的主要问题是它要求用户知道如何使用 XPath,因为这是您将要使用的 XPath。因此,它不是初学者友好的。
SimpleScraper
SimpleScraper 是另一种可用作 Chrome 扩展程序的网页抓取工具。通过在 Chrome 浏览器中安装此扩展程序,您可以将任何 网站 变成一个 API,让网络爬虫变得简单而自由。此扩展程序将帮助您从网页中快速提取结构化数据,适用于所有 网站,包括那些收录 JavaScript 网站 的内容。如果您需要更灵活的选择,您可以付费选择他们基于云的解决方案。
代理刮油剂
使用Agenty Scraping Agent,您可以不考虑障碍地继续操作和抓取网页中的数据。此工具不是免费的,但它们提供免费试用选项。这个浏览器扩展是为现代web开发的,所以爬很多JavaScript网站不会有问题。有趣的是,它也适用于旧的 网站。
网页抓取代理
事实是,除非您使用通常被认为昂贵的网络抓取 API,否则您必须使用代理。说到爬虫的代理,我会推荐用户使用带有住宅替换IP的代理提供商——这样可以减轻你的代理管理负担。以下是市场上 3 种最佳 IP 轮换服务。
发光体
Luminati可以说是市场上最好的代理服务商。它还拥有全球最大的代理网络,Luminati 代理池中拥有超过 7200 万个住宅 IP。它仍然是最安全、可靠和快速的工具之一。有趣的是,它兼容当今互联网上最流行的网站。Luminati 拥有最好的会话控制系统,因为它允许您决定何时维护会话——它还有一个高轮换代理,可以在每次请求后更改 IP。然而,它是昂贵的。
智能代理
Smartproxy拥有住宅代理池,收录超过1000万个住宅IP。由于会话控制系统,它们的代理对于网络抓取非常有效。他们的代理可以保持会话和相同IP 10分钟——这非常适合基于登录的爬取网站。对于常规的 网站,您可以使用其高轮换代理,它会在每次请求后更改 IP。他们在全球约195个国家和8个主要城市设有代理商。
爬虫
Crawlera 通过帮助您与代理打交道来帮助您专注于数据。与 Luminati 的情况不同,Crawlera 的系统中没有足够的 IP。
但是,与 Luminati 可能被 Captchas 攻击的情况不同,Crawlera 使用一些技巧来确保您请求的页面被返回——但是,与 Luminati 一样,它们在世界上所有国家和城市都没有代理。他们的定价基于请求的数量,而不是消耗的带宽。
jquery抓取网页内容(WOT全球技术创新大会2022,门票6折抢购中!购票立减2320元!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-13 10:21
2022年Wot全球技术创新大会,门票以60%的折扣被抢购一空!门票减少了2320元
如果您在Python爬行过程中遇到问题,并且不知道如何解决这些问题,您可以通过以下文章>详细了解Python爬行。通过了解它,您可以在股票信息和其他信息中获得您想要查询的内容
您需要向python添加一些内容。这很容易做到。JQuery对于HTML内容提取和分析非常方便。Python做类似的工作有点麻烦。事实证明,我使用正则表达式或HTMLPasser。它们都不太好用。今天,我发现了一个好东西pyquery,一个类似于jQuery的python库
摘录一段说明:
from pyquery import PyQuery as pq from lxml import etree d = pq(" html>") d = pq(etree.fromstring(" html>")) d = pq(url='http://google.com/') d = pq(filename=path_to_html_file) Now d is like the $ in jquery: d("#hello") [ ] p = d("#hello") p.html() 'Hello world !' p.html("you know Python a> rocks") [ ] p.html() 'you know Python a> rocks' p.text() 'you know Python rocks'
这很容易。安装也很简单。解压缩Python安装程序Py-install就可以了。您可能需要安装ezsetup。目前的版本是0.3。还有一些jQuery函数尚未实现,如radio、password和一些Ajax函数。通过介绍,您可以更好地了解Python爬行的应用。快试试
[编者推荐]
Python列表内涵实用介绍中国IPTV研究项目及世界领先的Python列表内涵使用介绍Python抓取网页图片相关编码方法Python抓取网页内容应用代码分析Python抓取网页内容应用代码分析 查看全部
jquery抓取网页内容(WOT全球技术创新大会2022,门票6折抢购中!购票立减2320元!)
2022年Wot全球技术创新大会,门票以60%的折扣被抢购一空!门票减少了2320元
如果您在Python爬行过程中遇到问题,并且不知道如何解决这些问题,您可以通过以下文章>详细了解Python爬行。通过了解它,您可以在股票信息和其他信息中获得您想要查询的内容
您需要向python添加一些内容。这很容易做到。JQuery对于HTML内容提取和分析非常方便。Python做类似的工作有点麻烦。事实证明,我使用正则表达式或HTMLPasser。它们都不太好用。今天,我发现了一个好东西pyquery,一个类似于jQuery的python库
摘录一段说明:
from pyquery import PyQuery as pq from lxml import etree d = pq(" html>") d = pq(etree.fromstring(" html>")) d = pq(url='http://google.com/') d = pq(filename=path_to_html_file) Now d is like the $ in jquery: d("#hello") [ ] p = d("#hello") p.html() 'Hello world !' p.html("you know Python a> rocks") [ ] p.html() 'you know Python a> rocks' p.text() 'you know Python rocks'
这很容易。安装也很简单。解压缩Python安装程序Py-install就可以了。您可能需要安装ezsetup。目前的版本是0.3。还有一些jQuery函数尚未实现,如radio、password和一些Ajax函数。通过介绍,您可以更好地了解Python爬行的应用。快试试
[编者推荐]
Python列表内涵实用介绍中国IPTV研究项目及世界领先的Python列表内涵使用介绍Python抓取网页图片相关编码方法Python抓取网页内容应用代码分析Python抓取网页内容应用代码分析
jquery抓取网页内容(jquery抓取页面内容可以忽略的jquery代码吗?代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-06 13:12
jquery抓取网页内容,js代码还是非常重要的,而且涉及到dom。mediaquery抓取页面内容可以忽略jquery代码。第一步:发布一个js脚本meta.js,第二步:firebug第三步:meta.js,要抓取哪页的内容,抓取哪页的,这里引用mediaquery。获取加载网页的view的元素一般是这页的后几页的内容,或者隐藏的内容就按需获取。
获取对应元素,一般用a标签。第四步:firebug或者js生成a标签可以直接获取elements.pagecontainer().tag,也可以函数继承global.inject_html()函数。newjs脚本().prototype.tagname=".js"。
用vscodeimportjqueryfrom'jquery'varmeta=jquery。meta;varmedia='-mobile-javascript/jquery。media';vara=meta。tag('a');jquery。prototype。pagecontainer=a;media。
font='12px';varoa=meta。tag('oa');jquery。prototype。mode={left:0,right:480,align:'center',color:'red',auto:true,outline:'+'-->-->',font:'arial',};。
我一个典型的解决方案是,直接用jquery自己的api。这样就可以避免用户代码,然后一些自己的js变量等。 查看全部
jquery抓取网页内容(jquery抓取页面内容可以忽略的jquery代码吗?代码)
jquery抓取网页内容,js代码还是非常重要的,而且涉及到dom。mediaquery抓取页面内容可以忽略jquery代码。第一步:发布一个js脚本meta.js,第二步:firebug第三步:meta.js,要抓取哪页的内容,抓取哪页的,这里引用mediaquery。获取加载网页的view的元素一般是这页的后几页的内容,或者隐藏的内容就按需获取。
获取对应元素,一般用a标签。第四步:firebug或者js生成a标签可以直接获取elements.pagecontainer().tag,也可以函数继承global.inject_html()函数。newjs脚本().prototype.tagname=".js"。
用vscodeimportjqueryfrom'jquery'varmeta=jquery。meta;varmedia='-mobile-javascript/jquery。media';vara=meta。tag('a');jquery。prototype。pagecontainer=a;media。
font='12px';varoa=meta。tag('oa');jquery。prototype。mode={left:0,right:480,align:'center',color:'red',auto:true,outline:'+'-->-->',font:'arial',};。
我一个典型的解决方案是,直接用jquery自己的api。这样就可以避免用户代码,然后一些自己的js变量等。
jquery抓取网页内容(jquery.js就可以抓取所有的站点名称名称代码。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-12-06 02:02
jquery抓取网页内容---popular-fullpage.js,关键是要修改名字。通过按位置搜索,获取网页中存在的站点页面名称或者代码中出现过的页面名称,再利用javascript正则表达式,获取页面代码,然后获取这些链接的href,最后将href解析出来,存入数据库中即可,实际上这种做法类似于requests库中的xpath的做法。popular-fullpage.js就可以抓取所有的站点名称代码。
html中可以得到结构化数据,网页中提供了一些javascript,去解析网页,并转换为json文件。
正则表达式解析,
这里popular_title=['hello','new','blog','blogspot','doc','document','docs','general','editor','imgdata','sticky','subtitle','tag','timeline','target','gravity','clipboard','contents','content','div','div-content','a','ul','li','span','span','p','table','table-all','l','w','li','span','cell','cell-content','cell-repeat','child','children','a','td','td-layout','a','a','span','p','img','img','img-src','img-target','img','span','span','l','r','r','r','span','p','bl','br','text','bu','span','span','col','ul','li','li','div','div-id','div-val','div-all','div','div-btn','el','el-col','id','li','a','td','td-layout','td-title','div-style','li','span','r','r','h1','ji','crlf','li','h3','ri','span','cr','span','cord','tr','td','td-input','td-text','td-span','td-layout','td-position','td-title','td-text','td-line','td-col','span','span','li','span','span','td-content','span','span','p','span','crlf','li','img','img-src','img-target','img-rel','img-position','tr','span','ji'。 查看全部
jquery抓取网页内容(jquery.js就可以抓取所有的站点名称名称代码。)
jquery抓取网页内容---popular-fullpage.js,关键是要修改名字。通过按位置搜索,获取网页中存在的站点页面名称或者代码中出现过的页面名称,再利用javascript正则表达式,获取页面代码,然后获取这些链接的href,最后将href解析出来,存入数据库中即可,实际上这种做法类似于requests库中的xpath的做法。popular-fullpage.js就可以抓取所有的站点名称代码。
html中可以得到结构化数据,网页中提供了一些javascript,去解析网页,并转换为json文件。
正则表达式解析,
这里popular_title=['hello','new','blog','blogspot','doc','document','docs','general','editor','imgdata','sticky','subtitle','tag','timeline','target','gravity','clipboard','contents','content','div','div-content','a','ul','li','span','span','p','table','table-all','l','w','li','span','cell','cell-content','cell-repeat','child','children','a','td','td-layout','a','a','span','p','img','img','img-src','img-target','img','span','span','l','r','r','r','span','p','bl','br','text','bu','span','span','col','ul','li','li','div','div-id','div-val','div-all','div','div-btn','el','el-col','id','li','a','td','td-layout','td-title','div-style','li','span','r','r','h1','ji','crlf','li','h3','ri','span','cr','span','cord','tr','td','td-input','td-text','td-span','td-layout','td-position','td-title','td-text','td-line','td-col','span','span','li','span','span','td-content','span','span','p','span','crlf','li','img','img-src','img-target','img-rel','img-position','tr','span','ji'。
jquery抓取网页内容(一个中一个基础表的数据从另一个网站采集开始)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-05 13:09
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志的提醒。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
转载于: 查看全部
jquery抓取网页内容(一个中一个基础表的数据从另一个网站采集开始)
最近开发了一个小函数,数据库中一个基础表的数据来自另一个网站采集。
因为网站的数据会不时更新,所以需要自动更新采集最新的内容。
如何判断数据是否更新?
好在网站中有更新日志的提醒。您只需要比较本地保留的更新日志与最新日志是否一致即可。
解析网页的源代码是一个难点,有的使用正则表达式。
但我不经常使用正则表达式。网上搜了一下,找到了一个开源库ScrapySharp。
为什么要使用这个库?
因为您可以使用 JQuery 的 css 选择器轻松解析网页。
现在贴出这段代码,有需要的可以参考。
var browser = new ScrapingBrowser();
browser.Encoding = System.Text.Encoding.UTF8;
string html = browser.DownloadString(new Uri("urlAddress"));//获取网页的源码
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(html);
var docNode = doc.DocumentNode;
IEnumerable nodes = docNode.CssSelect(".className");//使用css类选择器获取节点
string text = row_0_s.ElementAt(0).InnerText;//获取标签的文本
转载于:
jquery抓取网页内容(如何直接将本地h5h5网页封装成APP,简单粗暴的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-02 17:07
)
最近在想怎么把本地的h5网页直接封装成一个APP,数据是通过jquery的ajax方法直接读取在线网页。但是由于安全问题,js无法跨域请求。网上给出了一些解决方法,但是太复杂了。花了很长时间研究透彻,好在我终于找到了一个简单粗暴的方法。首先,让我解释一下 cors-anywhere 是一个非常有趣的东西。网上最多的教程是解决微信公众号图片防盗链问题,但实际上完美解决了跨域网页代码读取问题。我开始的想法也是可以实现的。
参考csdn博客,用户Mr_Sparta的文章。
主要功能的js代码如下,需要引入jquery
$.ajaxPrefilter(function (options) { //对于cors-anywhere接口所定义的方法
if (options.crossDomain && jQuery.support.cors) {
var http = (window.location.protocol === 'http:' ? 'http:' : 'https:'); //访问的模式
options.url = http + '//cors-anywhere.herokuapp.com/' + options.url; //对于接口设置请求的带参数url
}
});
$.get( //定义ajax中的get()方法
'https://www.ruletree.club', //这里为请求的地址,我设置为我的博客
function (response) {
$("#html").html(content); //将获取到的内容写入id为content的html元素内
});
html代码如下,我设置的很简单
这里放置读取完成之前显示的内容,比如一个进度条或者转动的加载球
最后,至于timeout等方法,我没有写。这不是很难。只需让js在页面加载后几秒内开始识别带有id内容的div中的内容即可。如果没有变化,就会显示超时信息,这对ajax来说是不够的我没试过原生的超时判断。
你可以自己试试:
下载链接:dq.zip
喜欢 1
报酬
千山万水相亲相爱,赏赐好不好?报酬
查看全部
jquery抓取网页内容(如何直接将本地h5h5网页封装成APP,简单粗暴的方法
)
最近在想怎么把本地的h5网页直接封装成一个APP,数据是通过jquery的ajax方法直接读取在线网页。但是由于安全问题,js无法跨域请求。网上给出了一些解决方法,但是太复杂了。花了很长时间研究透彻,好在我终于找到了一个简单粗暴的方法。首先,让我解释一下 cors-anywhere 是一个非常有趣的东西。网上最多的教程是解决微信公众号图片防盗链问题,但实际上完美解决了跨域网页代码读取问题。我开始的想法也是可以实现的。
参考csdn博客,用户Mr_Sparta的文章。
主要功能的js代码如下,需要引入jquery
$.ajaxPrefilter(function (options) { //对于cors-anywhere接口所定义的方法
if (options.crossDomain && jQuery.support.cors) {
var http = (window.location.protocol === 'http:' ? 'http:' : 'https:'); //访问的模式
options.url = http + '//cors-anywhere.herokuapp.com/' + options.url; //对于接口设置请求的带参数url
}
});
$.get( //定义ajax中的get()方法
'https://www.ruletree.club', //这里为请求的地址,我设置为我的博客
function (response) {
$("#html").html(content); //将获取到的内容写入id为content的html元素内
});
html代码如下,我设置的很简单
这里放置读取完成之前显示的内容,比如一个进度条或者转动的加载球
最后,至于timeout等方法,我没有写。这不是很难。只需让js在页面加载后几秒内开始识别带有id内容的div中的内容即可。如果没有变化,就会显示超时信息,这对ajax来说是不够的我没试过原生的超时判断。
你可以自己试试:
下载链接:dq.zip
喜欢 1
报酬
千山万水相亲相爱,赏赐好不好?报酬
jquery抓取网页内容(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-30 09:21
SysNucleus WebHarvy 是一个抓取网页数据的工具。该软件可以帮助您自动从网页中提取数据并以不同的格式保存以提取内容。该软件可以自动抓取网页上的文字、图片、网址、电子邮件等内容,也可以直接将整个网页保存为HTML格式,提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可以让你分析网络上的数据
2、可以显示和分析来自HTML地址的连接数据
3、可以扩展到下一个网页
4、可以指定搜索数据的范围和内容
5、您可以下载并保存扫描的图像
6、支持浏览器复制链接搜索
7、支持配置搜索对应的资源项
8、可以使用项目名称和资源名称查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、 提供更高级的多词搜索和多页搜索
特征:
1、视觉点和点击界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、 从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页,WebHarvy网站 抓取器将自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
6、通过生成{over}{filtering}server提取
要提取匿名并防止提取网络软件被阻止的Web服务器,您必须通过{over}{filtering}选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。 查看全部
jquery抓取网页内容(SysNucleusWebHarvy可以自动从网页中提取数据的工具介绍介绍)
SysNucleus WebHarvy 是一个抓取网页数据的工具。该软件可以帮助您自动从网页中提取数据并以不同的格式保存以提取内容。该软件可以自动抓取网页上的文字、图片、网址、电子邮件等内容,也可以直接将整个网页保存为HTML格式,提取网页中的所有文字和图标内容。
软件特点:
1、SysNucleus WebHarvy 可以让你分析网络上的数据
2、可以显示和分析来自HTML地址的连接数据
3、可以扩展到下一个网页
4、可以指定搜索数据的范围和内容
5、您可以下载并保存扫描的图像
6、支持浏览器复制链接搜索
7、支持配置搜索对应的资源项
8、可以使用项目名称和资源名称查找
9、SysNucleus WebHarvy 可以轻松提取数据
10、 提供更高级的多词搜索和多页搜索
特征:
1、视觉点和点击界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 WebHarvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
2、智能识别模式
自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
3、导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
4、 从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。刚刚指出“链接到下一页,WebHarvy网站 抓取器将自动从所有页面抓取数据。
5、基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
6、通过生成{over}{filtering}server提取
要提取匿名并防止提取网络软件被阻止的Web服务器,您必须通过{over}{filtering}选项才能访问目标网站。您可以使用单个代理服务器地址或代理服务器地址列表。
7、提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
8、使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
jquery抓取网页内容(一下如何实现自动提取内容主题生成目录并实现点击跳转)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-29 21:12
当页面内容过多时,必须要有各级标题,内容太长,用户访问很不方便。如果可以添加目录,点击跳转,用户体验会大大提升。
从前端来看,解决这个问题其实很简单,我们只需要创建一些节点,或者锚文本,然后将链接指向那个地方。因此,我们可以在后台创建一个目录,并分配相应的节点或锚文本。但这不好:工作量太大,非常不方便。所以我想知道有没有办法自动提取内容中的主题作为目录使用,并实现它?答案是肯定的,下面我们来看看如何使用jquery自动提取内容和主题生成目录点击跳转:
首先,在后台编辑内容时,需要有对应的主题可以提取
此示例基于 h 标题。一般h1是文章的标题,所以内容部分应该是h2、h3、h4。后台编辑内容很容易,而且从优化的角度来说,应该是这样做的,所以没有多余的工作要做。以Kindeditor为例,首先选择要设置为标题的内容,设置为标题,如下图所示:
然后,在对应的前端页面嵌入如下js语句
target = $("#article .fl");//需要提取目录的内容所在包裹器,如果要进行相对定位,建议选择上一级dom
$(document).ready(function() {
GenerateContents();//提起目录并实现点击跳转
});
function GenerateContents() {
var num = 0;//第x个目录 用于jquery跳转实现
var content = "目录";//创建的目录的dom结构
content += '';
$("h2").each(function(){//遍历内容中的所有h2标签 作为一级目录
content += ""+GenerateA(num,$(this).text());
$(this).before(GenerateLabel(num));
num++;
var second = $(this).nextUntil("h2","h3");
if (second) {
content += "";
second.each(function(){//变量内容中的所有h3标签 作为二级目录
content += ""+GenerateA(num,$(this).text())+"";
$(this).before(GenerateLabel(num));
num++;
});
content += "";
};
content += "";
});
content += "";
target.append(content);//插入目录到页面中
}
function GenerateLabel(num){
var a = "<a name = 'label" + num + "'></a>";
return a;
}
function GenerateA(num ,text){
var ss = "<a data-i='" + num +"'>" + text + "</a>";
return ss;
}
//实现点击跳转
$('#quick a').live('click',function(){
var _obj=$(this).attr('data-i');
_obj=$('a[name=label'+_obj+']');
var _top=_obj.position().top;
_top-=80;
$('html,body').animate({scrollTop:_top},500);
})
此时,提取内容主题生成目录,实现点击跳转。当然,你也应该结合css进行定位,比如将目录设置为固定(fixed)定位。
#quick{ position: fixed; left: 20px; top:140px; text-align: right;}
#quick{ font-size: 18px; color: #999;}
#quick a{ font-size: 14px; padding: 10px 0; font-weight: bold; cursor: pointer; color: #333;}
#quick a:hover{ color: #fd5050;}
#quick li li a{ font-weight: normal; color: #666;}
效果图如下:
© 致远2020-02-25,原创内容,转载请注明错误:jquery自动提取内容和主题生成目录,实现点击跳转 查看全部
jquery抓取网页内容(一下如何实现自动提取内容主题生成目录并实现点击跳转)
当页面内容过多时,必须要有各级标题,内容太长,用户访问很不方便。如果可以添加目录,点击跳转,用户体验会大大提升。
从前端来看,解决这个问题其实很简单,我们只需要创建一些节点,或者锚文本,然后将链接指向那个地方。因此,我们可以在后台创建一个目录,并分配相应的节点或锚文本。但这不好:工作量太大,非常不方便。所以我想知道有没有办法自动提取内容中的主题作为目录使用,并实现它?答案是肯定的,下面我们来看看如何使用jquery自动提取内容和主题生成目录点击跳转:
首先,在后台编辑内容时,需要有对应的主题可以提取
此示例基于 h 标题。一般h1是文章的标题,所以内容部分应该是h2、h3、h4。后台编辑内容很容易,而且从优化的角度来说,应该是这样做的,所以没有多余的工作要做。以Kindeditor为例,首先选择要设置为标题的内容,设置为标题,如下图所示:
然后,在对应的前端页面嵌入如下js语句
target = $("#article .fl");//需要提取目录的内容所在包裹器,如果要进行相对定位,建议选择上一级dom
$(document).ready(function() {
GenerateContents();//提起目录并实现点击跳转
});
function GenerateContents() {
var num = 0;//第x个目录 用于jquery跳转实现
var content = "目录";//创建的目录的dom结构
content += '';
$("h2").each(function(){//遍历内容中的所有h2标签 作为一级目录
content += ""+GenerateA(num,$(this).text());
$(this).before(GenerateLabel(num));
num++;
var second = $(this).nextUntil("h2","h3");
if (second) {
content += "";
second.each(function(){//变量内容中的所有h3标签 作为二级目录
content += ""+GenerateA(num,$(this).text())+"";
$(this).before(GenerateLabel(num));
num++;
});
content += "";
};
content += "";
});
content += "";
target.append(content);//插入目录到页面中
}
function GenerateLabel(num){
var a = "<a name = 'label" + num + "'></a>";
return a;
}
function GenerateA(num ,text){
var ss = "<a data-i='" + num +"'>" + text + "</a>";
return ss;
}
//实现点击跳转
$('#quick a').live('click',function(){
var _obj=$(this).attr('data-i');
_obj=$('a[name=label'+_obj+']');
var _top=_obj.position().top;
_top-=80;
$('html,body').animate({scrollTop:_top},500);
})
此时,提取内容主题生成目录,实现点击跳转。当然,你也应该结合css进行定位,比如将目录设置为固定(fixed)定位。
#quick{ position: fixed; left: 20px; top:140px; text-align: right;}
#quick{ font-size: 18px; color: #999;}
#quick a{ font-size: 14px; padding: 10px 0; font-weight: bold; cursor: pointer; color: #333;}
#quick a:hover{ color: #fd5050;}
#quick li li a{ font-weight: normal; color: #666;}
效果图如下:
© 致远2020-02-25,原创内容,转载请注明错误:jquery自动提取内容和主题生成目录,实现点击跳转
jquery抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-29 14:17
需要考虑的问题:
如何在一个网页的div中嵌套另一个网页(不使用inclue,iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套的网页无法获取父页面信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一页内容的一部分)
答案(想法):
使用jquery的ajax函数或者load函数获取网页内容,从而实现嵌套网页(获取的网页内容为html字符串)如何从字符串中获取部分内容?
实践一:
index.html 页面(获取本页内容页的内容)
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题可以在这里解决,点击获取完整的content.html页面的内容
在参考jquery的load方法的时候可以发现load函数其实可以指定网页的内容
实践二:
改变index.html页面的ajax函数的url路径,获取content.html页面的div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url + ' #container',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + ' #container');
48 }
49
查看代码
至此我们已经解决了文章开头提出的问题。. . . . . 但这是一个静态页面(html页面),是否适用?
答案是不。无论是ajax函数还是load函数获取的页面内容,都收录title标签和两个
这就是 ajax 得到的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到不仅获取到了div的内容,还多了两个div和一个title
网上查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行。以下是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名的错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: 'get',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + ' #container':获取url网页中container容器内的内容
41 url: url + ' #container',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find('div[id=container]').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + ' #container', '', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find('div[id=container]').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
让我再补充一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个网页,使用母版页会导致标签id改变。我想要实现的是点击菜单而不刷新页面 查看全部
jquery抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
需要考虑的问题:
如何在一个网页的div中嵌套另一个网页(不使用inclue,iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套的网页无法获取父页面信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一页内容的一部分)
答案(想法):
使用jquery的ajax函数或者load函数获取网页内容,从而实现嵌套网页(获取的网页内容为html字符串)如何从字符串中获取部分内容?
实践一:
index.html 页面(获取本页内容页的内容)
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题可以在这里解决,点击获取完整的content.html页面的内容
在参考jquery的load方法的时候可以发现load函数其实可以指定网页的内容
实践二:
改变index.html页面的ajax函数的url路径,获取content.html页面的div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url + ' #container',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + ' #container');
48 }
49
查看代码
至此我们已经解决了文章开头提出的问题。. . . . . 但这是一个静态页面(html页面),是否适用?
答案是不。无论是ajax函数还是load函数获取的页面内容,都收录title标签和两个
这就是 ajax 得到的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到不仅获取到了div的内容,还多了两个div和一个title
网上查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行。以下是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名的错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: 'get',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + ' #container':获取url网页中container容器内的内容
41 url: url + ' #container',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find('div[id=container]').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + ' #container', '', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find('div[id=container]').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
让我再补充一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个网页,使用母版页会导致标签id改变。我想要实现的是点击菜单而不刷新页面
jquery抓取网页内容(2.解决工具解决问题用到的python库如下:3.解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-26 22:27
一波自我回应:摸索了三天,终于找到了一些眉毛。我把每个家庭的情况和方法这几天终于试了试。一方面,它作为这个问题的总结,另一方面。如果以后有像我这样的Python新手,可以考虑帮助。
1. 问题总结
在寻找答案的过程中,发现爬虫中关于翻页的问题还是比较多的。由于网站数据的标准化程度不同,遇到的问题也略有不同。主要有两大类。我遇到的是第三类:
首先,网页是静态加载的。现象是每次翻页都会提供一个新的url地址,地址中的NoPage发生了变化(NoPage只是一个例子,网站的具体翻页参数需要根据object网站进行分析),网上提到的这种类型网站多使用request.get方法,使用url拼接翻页。
二是网页是动态加载的。现象是每次翻页url地址都不会改变。作为一个新手,我完全一头雾水,不知道背后发生了什么。这几类网站大多使用jQuery+Ajaxr的动态加载方式。可以使用 request.post 发送 post 请求来翻页。翻页请求的数据往往反映在formdata中。由于我没有相关的理论基础,也不知道实现背后的原理,我只在实现过程中介绍一下我的发现。
还有我遇到的第三种恶心的网站。首先,URL地址不会每次翻页都改变。通过开发工具查了一下,发现确实使用了request.post和ajax的动态加载方式。它应该适用于上述第二种情况。可以通过request.post发送formdata来实现,但是手动翻了几页后,发现formdata里面的参数全部没变,改变的参数都在Query String Parameter里面。第一种情况应再次适用。所以我还没有找到一个完全适应的答案。
2. 解决方案工具
用于解决问题的python库如下:
3.解决方案
作为新手,Scrapy 框架是一种简单的爬取方法。结合Xpath的路径表达式,网站抓取网页数据规范应该没有问题。这里不讨论异步问题,因为我还没有学过。我也成功实现了抓取单页信息,进入特定内容页面抓取信息的功能。
但是,我面临的网站,正如问题描述中所解释的,对新手不是很友好。全网搜索后,没有即插即用。解决办法是稍微吃一点。还是绕不开网页源码的分析,耐心使用Chrome+F12,点击下一页观察变化
我要抓取的网站是60条作为一个静态组,每页显示20条信息,也就是翻页3次会生成这样一个XHR类型的dataproxy.jsp文件(原理我不t know) , 该文件收录以下信息供后续会议使用
然后我点了一个预览这个XHR文件,发现里面有数据:title,href,发布日期,这些就是我要获取的数据
构造请求的结构
请求头
# 构造请求header
header = {
'Accept': 'text/javascript, application/javascript, */*',
'Accept- Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-length': '233',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'JSESSIONID=E59F8413AE771F7B79A9A0E12EEC7B80; acw_tc=7b39758715821845337757109ea8a2879399902f7a4d85847fb64e2484d02b',
'Host': 'www.gzbgj.com',
'Origin': 'http://www.gzbgj.com',
'Referer': 'http://www.gzbgj.com/col/col76 ... 39%3B,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
请求表单数据:这里使用源码(点击Form Data下的查看源码),因为不知道为什么解析出来的json表单数据不好用
data = "appid=1&webid=27&path=%2F&columnid=7615&sourceContentType=1&unitid=56554&webname=%E4%B8%AD%E5%9B%BD%E8%91%9B%E6%B4%B2%E5%9D%9D%E9%9B%86%E5%9B%A2%E5%9B%BD%E
请求url:这里是url拼接的方法。这里的数据是Query String Parameter下的三个参数。注意原来的方法叫start_requests,不过这好像和Scrapy库中已有的函数有冲突。刚改了名字
发送请求
用三个参数就可以实现抓取信息的功能:本来想用Scrapy自带的Formrequest方法,但是不知道为什么没有成功获取到数据。
response = scrapy.Formrequest(url, formdata)
我不得不使用 requests.post 的请求
response = requets.post(url, headers=header, data=data)
然后通过在Query String Parameter中叠加控制起止页的参数就可以实现“翻页”。
4.总结
虽然感觉有点撞击和碰撞,但最终还是成真了。我想一定有更好更高效的解决方案,但我的能力有限。我现在不继续深入挖掘了。我准备继续改进,看看有没有缘分的人能看到这个答案。我希望它对你有用。求大神帮忙,希望大神能指点一下! 查看全部
jquery抓取网页内容(2.解决工具解决问题用到的python库如下:3.解决方法)
一波自我回应:摸索了三天,终于找到了一些眉毛。我把每个家庭的情况和方法这几天终于试了试。一方面,它作为这个问题的总结,另一方面。如果以后有像我这样的Python新手,可以考虑帮助。
1. 问题总结
在寻找答案的过程中,发现爬虫中关于翻页的问题还是比较多的。由于网站数据的标准化程度不同,遇到的问题也略有不同。主要有两大类。我遇到的是第三类:
首先,网页是静态加载的。现象是每次翻页都会提供一个新的url地址,地址中的NoPage发生了变化(NoPage只是一个例子,网站的具体翻页参数需要根据object网站进行分析),网上提到的这种类型网站多使用request.get方法,使用url拼接翻页。
二是网页是动态加载的。现象是每次翻页url地址都不会改变。作为一个新手,我完全一头雾水,不知道背后发生了什么。这几类网站大多使用jQuery+Ajaxr的动态加载方式。可以使用 request.post 发送 post 请求来翻页。翻页请求的数据往往反映在formdata中。由于我没有相关的理论基础,也不知道实现背后的原理,我只在实现过程中介绍一下我的发现。
还有我遇到的第三种恶心的网站。首先,URL地址不会每次翻页都改变。通过开发工具查了一下,发现确实使用了request.post和ajax的动态加载方式。它应该适用于上述第二种情况。可以通过request.post发送formdata来实现,但是手动翻了几页后,发现formdata里面的参数全部没变,改变的参数都在Query String Parameter里面。第一种情况应再次适用。所以我还没有找到一个完全适应的答案。
2. 解决方案工具
用于解决问题的python库如下:
3.解决方案
作为新手,Scrapy 框架是一种简单的爬取方法。结合Xpath的路径表达式,网站抓取网页数据规范应该没有问题。这里不讨论异步问题,因为我还没有学过。我也成功实现了抓取单页信息,进入特定内容页面抓取信息的功能。
但是,我面临的网站,正如问题描述中所解释的,对新手不是很友好。全网搜索后,没有即插即用。解决办法是稍微吃一点。还是绕不开网页源码的分析,耐心使用Chrome+F12,点击下一页观察变化
我要抓取的网站是60条作为一个静态组,每页显示20条信息,也就是翻页3次会生成这样一个XHR类型的dataproxy.jsp文件(原理我不t know) , 该文件收录以下信息供后续会议使用
然后我点了一个预览这个XHR文件,发现里面有数据:title,href,发布日期,这些就是我要获取的数据
构造请求的结构
请求头
# 构造请求header
header = {
'Accept': 'text/javascript, application/javascript, */*',
'Accept- Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-length': '233',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'JSESSIONID=E59F8413AE771F7B79A9A0E12EEC7B80; acw_tc=7b39758715821845337757109ea8a2879399902f7a4d85847fb64e2484d02b',
'Host': 'www.gzbgj.com',
'Origin': 'http://www.gzbgj.com',
'Referer': 'http://www.gzbgj.com/col/col76 ... 39%3B,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
请求表单数据:这里使用源码(点击Form Data下的查看源码),因为不知道为什么解析出来的json表单数据不好用
data = "appid=1&webid=27&path=%2F&columnid=7615&sourceContentType=1&unitid=56554&webname=%E4%B8%AD%E5%9B%BD%E8%91%9B%E6%B4%B2%E5%9D%9D%E9%9B%86%E5%9B%A2%E5%9B%BD%E
请求url:这里是url拼接的方法。这里的数据是Query String Parameter下的三个参数。注意原来的方法叫start_requests,不过这好像和Scrapy库中已有的函数有冲突。刚改了名字
发送请求
用三个参数就可以实现抓取信息的功能:本来想用Scrapy自带的Formrequest方法,但是不知道为什么没有成功获取到数据。
response = scrapy.Formrequest(url, formdata)
我不得不使用 requests.post 的请求
response = requets.post(url, headers=header, data=data)
然后通过在Query String Parameter中叠加控制起止页的参数就可以实现“翻页”。
4.总结
虽然感觉有点撞击和碰撞,但最终还是成真了。我想一定有更好更高效的解决方案,但我的能力有限。我现在不继续深入挖掘了。我准备继续改进,看看有没有缘分的人能看到这个答案。我希望它对你有用。求大神帮忙,希望大神能指点一下!
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-26 06:08
1. 前言
相信很多人在做开发的时候都有这样的需求:从网页中准确提取出需要的内容。想了想,方法无外乎如下:(本人经验少,如果有更好的方法请大家指教)
1. 使用正则表达式匹配需要的元素。(缺点:如果相同类型的元素有不同的属性,比如
啊啊啊
bbb
,如果要匹配所有的div元素,会比较麻烦,而且很容易得到不需要的结果,错过需要的结果。)
2. 要将网页转换为 XML 文档,请使用 Linq to XML。(缺点:需要一个转换过程,效率不高。)
3. 使用网站提供的WebServices或WebAPI直接获取需要的数据。(缺点:需要先获取接口文档,一般不会匿名提供。)
随着这几年前端的兴起,越来越多的人开始认识并相信JQuery这个强大的工具。最重要的一点之一是 JQuery 选择器。它的简单、高效、易学,让前端工程师的工作效率大大提高。. 如果你仔细想想,提取网页内容只是在处理前端。如果可以使用JQuery选择器就完美了!!!
2. 理论准备
你想在 .NET 下自己做一个选择器吗?不,这不是我等小辈做的。. . . 既然已经有了JQuery,为什么不直接使用它的选择器呢?
1. .NET 访问网络内容
在这里你可以选择webbrowser控件,其实它就是一个迷你IE,它可以做IE可以做的一切。可能有人会问为什么不直接用WebClient下载网页内容呢?请看第二点。
2. .NET 与 JS 交互
使用webbrowser控件,不仅可以获取网页的内容,更重要的是它提供了与网页交互的功能。使用内置的 Document 属性,我们可以将所需的 JS 代码注入网页并执行。
3. 提取并返回需要的内容
在.NET中,我们可以使用Documentation的InvokeScript函数来执行对应的JS函数并得到返回结果。
现在理论已经准备好了,让我们接下来实现它。
3. 功能实现
测试页:(福利网站哦,但绝对没有邪恶内容,请编辑明鉴!)
功能需求:提取所有“好处”!!!!
第一张图:
从图中可以看出,“福利”提取的很准确。并且您只能获得所需的属性值。您所要做的就是输入一个简短的 15 个字符。
我们来看一下代码实现:
其中,wb 为 webbrowser 控件。本段主要是将JQuery库注入到一些不收录JQuery库的网页中。
void InjectJQuery()
{
HtmlElement jquery = wb.Document.CreateElement("script");
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);
wb.Document.Body.AppendChild(jquery);
JQueryInjected = true;
}
这里是需要注入的JS函数。因为不同的需求有不同的代码,所以不能重复注入。当需求改变时,只需要改变注入的函数。
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)
{
JQScript = wb.Document.CreateElement("script");
JQScript.SetAttribute("id", "JQScript");
JQScript.SetAttribute("type", "text/javascript");
wb.Document.Body.AppendChild(JQScript);
}
这是关键代码。根据是否提取属性生成不同的编码。注入的代码非常简单,相信对前端稍有了解的朋友一看就会明白。最后一行代码是执行注入的函数并获取返回值。
if (txtAttribute.Text.Trim() == string.Empty)
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
else
{
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
}
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
相信大家一看就明白,短短几行代码,就可以使用强大的JQuery选择器,效率比之前的老方法高很多倍,何乐而不为呢?
4. 知识扩展
1. 只要你的前端知识够硬,可以注入更复杂的函数,实现更复杂的内容提取。
2. 在Android和IOS中,理论上是可以实现这样的功能的。
3. 也许有一天,我们会有一个类似的选择器来代替SQL来实现高效的数据库查询?? ? ? ? ? ? ? ? ?
PS:我文笔极差,知识面也不广。如有错误,敬请指正! 查看全部
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
1. 前言
相信很多人在做开发的时候都有这样的需求:从网页中准确提取出需要的内容。想了想,方法无外乎如下:(本人经验少,如果有更好的方法请大家指教)
1. 使用正则表达式匹配需要的元素。(缺点:如果相同类型的元素有不同的属性,比如
啊啊啊
bbb
,如果要匹配所有的div元素,会比较麻烦,而且很容易得到不需要的结果,错过需要的结果。)
2. 要将网页转换为 XML 文档,请使用 Linq to XML。(缺点:需要一个转换过程,效率不高。)
3. 使用网站提供的WebServices或WebAPI直接获取需要的数据。(缺点:需要先获取接口文档,一般不会匿名提供。)
随着这几年前端的兴起,越来越多的人开始认识并相信JQuery这个强大的工具。最重要的一点之一是 JQuery 选择器。它的简单、高效、易学,让前端工程师的工作效率大大提高。. 如果你仔细想想,提取网页内容只是在处理前端。如果可以使用JQuery选择器就完美了!!!
2. 理论准备
你想在 .NET 下自己做一个选择器吗?不,这不是我等小辈做的。. . . 既然已经有了JQuery,为什么不直接使用它的选择器呢?
1. .NET 访问网络内容
在这里你可以选择webbrowser控件,其实它就是一个迷你IE,它可以做IE可以做的一切。可能有人会问为什么不直接用WebClient下载网页内容呢?请看第二点。
2. .NET 与 JS 交互
使用webbrowser控件,不仅可以获取网页的内容,更重要的是它提供了与网页交互的功能。使用内置的 Document 属性,我们可以将所需的 JS 代码注入网页并执行。
3. 提取并返回需要的内容
在.NET中,我们可以使用Documentation的InvokeScript函数来执行对应的JS函数并得到返回结果。
现在理论已经准备好了,让我们接下来实现它。
3. 功能实现
测试页:(福利网站哦,但绝对没有邪恶内容,请编辑明鉴!)
功能需求:提取所有“好处”!!!!
第一张图:
从图中可以看出,“福利”提取的很准确。并且您只能获得所需的属性值。您所要做的就是输入一个简短的 15 个字符。
我们来看一下代码实现:
其中,wb 为 webbrowser 控件。本段主要是将JQuery库注入到一些不收录JQuery库的网页中。
void InjectJQuery()
{
HtmlElement jquery = wb.Document.CreateElement("script");
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);
wb.Document.Body.AppendChild(jquery);
JQueryInjected = true;
}
这里是需要注入的JS函数。因为不同的需求有不同的代码,所以不能重复注入。当需求改变时,只需要改变注入的函数。
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)
{
JQScript = wb.Document.CreateElement("script");
JQScript.SetAttribute("id", "JQScript");
JQScript.SetAttribute("type", "text/javascript");
wb.Document.Body.AppendChild(JQScript);
}
这是关键代码。根据是否提取属性生成不同的编码。注入的代码非常简单,相信对前端稍有了解的朋友一看就会明白。最后一行代码是执行注入的函数并获取返回值。
if (txtAttribute.Text.Trim() == string.Empty)
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
else
{
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
}
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
相信大家一看就明白,短短几行代码,就可以使用强大的JQuery选择器,效率比之前的老方法高很多倍,何乐而不为呢?
4. 知识扩展
1. 只要你的前端知识够硬,可以注入更复杂的函数,实现更复杂的内容提取。
2. 在Android和IOS中,理论上是可以实现这样的功能的。
3. 也许有一天,我们会有一个类似的选择器来代替SQL来实现高效的数据库查询?? ? ? ? ? ? ? ? ?
PS:我文笔极差,知识面也不广。如有错误,敬请指正!
jquery抓取网页内容(太原seo培训:影响seo优化的因素_经验分享影响)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-23 22:05
太原seo培训:影响seo优化的因素_经验分享
影响搜索引擎优化的因素有很多,比如外链优化、网站内容原创度、内链优化等等。今天带来的是百度社区对搜索引擎优化影响因素的投票情况和分析。希望能帮到我们。百度社区对影响搜索引擎优化的因素进行投票,并提出哪些搜索引擎优化因素关键词排名优化影响因素开始......
大家做seo都是千方百计让搜索引擎爬取和收录,但很多时候我们也需要禁止搜索引擎爬取和收录,比如公司内部测试网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。
给你发一张禁止搜索引擎抓取的搜索结果截图网站:可以看到描述没有被抓取,但是有一个提示:因为网站的robots.txt文件有限制指令(限制搜索引擎抓取),系统无法提供页面内容的描述。
连云港seo:SEO新手知识_经验分享
SEO不仅仅是让网站的首页在搜索引擎中获得好的排名,更重要的是让网站的每一页都带来流量。这是SEO最重要的部分。关键词分析包括:关键词价值分析、竞争对手分析、关键词和网站相关分析、关键词排位、关键词排名推测。网站流量分析从SEO结果中指导下一步对SEO策略的猜测,让我们一起在网站的...
机器人是网站与蜘蛛交流的重要渠道。本站通过robots文件声明本网站中不想被搜索引擎收录或指定搜索引擎搜索到的部分仅为收录特定部分。
9月11日,百度搜索机器人升级。升级后robots会优化网站视频网址收录的抓取。只有当您的网站收录不想被视频搜索引擎收录搜索到的内容时,才需要使用robots.txt文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索网站视频网址收录会收录视频播放页面网址,以及页面上的视频文件,周围的文字视频等信息,搜索已经收录的短视频资源,将作为视频极速体验页面呈现给用户。另外,对于综艺、影视的长视频,搜索引擎只有收录页面URL。
最好的seo培训课程_经验分享
哪个seo培训课程最好?网上有很多这样的培训课程,但是网上的介绍大多都比较粗糙。如果你想非常精通学习技术,还是建议选择报名培训班。网上有很多培训机构在开展此类培训课程,尤其是一些长期从事网站优化工作的公司,网上有这些培训课程。当然,这样的培训课程必须采集…… 查看全部
jquery抓取网页内容(太原seo培训:影响seo优化的因素_经验分享影响)
太原seo培训:影响seo优化的因素_经验分享
影响搜索引擎优化的因素有很多,比如外链优化、网站内容原创度、内链优化等等。今天带来的是百度社区对搜索引擎优化影响因素的投票情况和分析。希望能帮到我们。百度社区对影响搜索引擎优化的因素进行投票,并提出哪些搜索引擎优化因素关键词排名优化影响因素开始......
大家做seo都是千方百计让搜索引擎爬取和收录,但很多时候我们也需要禁止搜索引擎爬取和收录,比如公司内部测试网站,或者内网,或者后台登录页面,肯定不想被外人搜索到,所以应该禁止搜索引擎抓取。
给你发一张禁止搜索引擎抓取的搜索结果截图网站:可以看到描述没有被抓取,但是有一个提示:因为网站的robots.txt文件有限制指令(限制搜索引擎抓取),系统无法提供页面内容的描述。
连云港seo:SEO新手知识_经验分享
SEO不仅仅是让网站的首页在搜索引擎中获得好的排名,更重要的是让网站的每一页都带来流量。这是SEO最重要的部分。关键词分析包括:关键词价值分析、竞争对手分析、关键词和网站相关分析、关键词排位、关键词排名推测。网站流量分析从SEO结果中指导下一步对SEO策略的猜测,让我们一起在网站的...
机器人是网站与蜘蛛交流的重要渠道。本站通过robots文件声明本网站中不想被搜索引擎收录或指定搜索引擎搜索到的部分仅为收录特定部分。
9月11日,百度搜索机器人升级。升级后robots会优化网站视频网址收录的抓取。只有当您的网站收录不想被视频搜索引擎收录搜索到的内容时,才需要使用robots.txt文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
如果你的网站没有设置robots协议,百度搜索网站视频网址收录会收录视频播放页面网址,以及页面上的视频文件,周围的文字视频等信息,搜索已经收录的短视频资源,将作为视频极速体验页面呈现给用户。另外,对于综艺、影视的长视频,搜索引擎只有收录页面URL。
最好的seo培训课程_经验分享
哪个seo培训课程最好?网上有很多这样的培训课程,但是网上的介绍大多都比较粗糙。如果你想非常精通学习技术,还是建议选择报名培训班。网上有很多培训机构在开展此类培训课程,尤其是一些长期从事网站优化工作的公司,网上有这些培训课程。当然,这样的培训课程必须采集……
jquery抓取网页内容(Master()UI设计师)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-17 19:18
我想要实现的是视图本身以某种方式检测到它是在JavaScript UI对话框中打开的,因此Form操作(最常用的简单提交按钮POST)将呈现为可以在UI之后的逻辑对话框,关闭UI对话框的动作已经执行。
它现在的工作方式是 POST / Redirect / GET。该视图仍应支持这种简单模式,直接通过 Web 浏览器中的 URL 打开,但在通过 JavaScript 对话框打开时应提供一些额外的逻辑。
希望你明白我的问题。任何帮助表示赞赏
解决方案
所以你需要的第一件事是一个新的 ViewEngine 来处理一个页面,没有所有正常的页眉/页脚的东西,这会阻碍你的模式窗口。最简单的方法是为您的模型状态窗口使用大部分空的母版页。你想要主页面切换逻辑和自定义的ViewEngine,否则每个控制器方法都必须有if()else() where IsAjaxRequest() 被检测到。我喜欢这样做,撒哈拉干。
有了这个技巧,我也优雅的降级了。我的 网站 函数在没有 javascript 的情况下是完美的。链接很好,表单工作,零代码更改从“模态感知站点”到普通的旧 html 表单提交。
我所做的是对默认引擎进行子类化并添加一些 MasterPage 选择位:
查看引擎:
public class ModalViewEngine : VirtualPathProviderViewEngine
{
public ModalViewEngine()
{
/* {0} = view name or master page name
* {1} = controller name */
MasterLocationFormats = new[] {
"~/Views/Shared/{0}.master"
};
ViewLocationFormats = new[] {
"~/Views/{1}/{0}.aspx","~/Views/Shared/{0}.aspx"
};
PartialViewLocationFormats = new[] {
"~/Views/{1}/{0}.ascx",};
}
protected override IView CreatePartialView(ControllerContext controllerContext,string partialPath)
{
throw new NotImplementedException();
}
protected override IView CreateView(ControllerContext controllerContext,string viewPath,string masterPath)
{
return new WebFormView(viewPath,masterPath );
}
public override ViewEngineResult FindView(ControllerContext controllerContext,string viewName,string masterName,bool useCache)
{
//you might have to customize this bit
if (controllerContext.HttpContext.Request.IsAjaxRequest())
return base.FindView(controllerContext,viewName,"Modal",useCache);
return base.FindView(controllerContext,"Site",useCache);
}
protected override bool FileExists(ControllerContext controllerContext,string virtualPath)
{
return base.FileExists(controllerContext,virtualPath);
}
}
所以我的 Modal.Master 页面非常简单。我所拥有的只是一个 div 包装器,所以我知道在模态窗口中呈现了什么。当您需要仅在元素处于“模态”模式时使用 jquery 选择某些元素时,这将非常有用。
模态大师
下一步是创建您的表单。我使用默认属性名称 = 输入名称,因此我可以轻松地为绑定建模并保持简单。没有特殊形式。我看起来像你平时那样。(请注意,我在代码中使用了 MVC 2 和 EditorFor(),但这并不重要)这是我的最终 HTML:
HTML 输出
EditFood
除了模型绑定真的很好之外,您还可以使用 Jquery.Form 插件以最少的代码将您看似简单的 ajax 函数分层到您的应用程序中。现在我选择ColorBox作为我的模态窗口脚本纯粹是因为我想要Facebook的透明角落,我喜欢作者添加的扩展点。
现在,结合这些脚本,您将获得一个非常好的组合,这使得这项技术在 javascript 中非常容易实现。我添加的唯一 javascript 是(在 document.ready 中):
使用 JavaScript/jQuery
$("a.edit").colorBox({ maxWidth: "800px",opacity: 0.4,initialWidth: 50,initialHeight: 50 });
$().bind('cBox_complete',function () {
$("#form form").ajaxForm(function () { $.fn.colorBox.close() });
});
在这里,我告诉 ColorBox 为我的编辑链接(编辑食物)打开一个模式窗口。然后绑定到颜色框的完整事件以将您的ajaxform 内容与成功回调连接起来,告诉ColorBox 关闭模态窗口。就是这样。
这段代码被用作概念证明,这就是为什么视图引擎真的很棒,没有验证或其他标准形式的 bling.ColorBox 和 JQuery.Form 有很多可扩展性支持,因此自定义它应该很容易。
请注意,这一切都是在 MVC 2 中完成的,但这里是我的控制器代码,只是为了展示这有多简单。请记住,我的概念验证目标是使模态窗口无需任何代码修改即可工作,而不是设置一些基本基础设施。
[UrlRoute(Path="edit/food")]
public ActionResult EditFood()
{
return View(new Food());
}
[HttpPost][UrlRoute(Path = "edit/food")]
public ActionResult EditFood(Food food)
{
return View(food);
}
总结
以上是本站为大家采集的jquery——简单的ASP.NET MVC CRUD视图打开/关闭JavaScript UI对话框中的所有内容,希望文章能帮助你解决jquery-简单的ASP.NET MVC在 JavaScript UI 对话框中打开/关闭视图时遇到的 CRUD 程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。 查看全部
jquery抓取网页内容(Master()UI设计师)
我想要实现的是视图本身以某种方式检测到它是在JavaScript UI对话框中打开的,因此Form操作(最常用的简单提交按钮POST)将呈现为可以在UI之后的逻辑对话框,关闭UI对话框的动作已经执行。
它现在的工作方式是 POST / Redirect / GET。该视图仍应支持这种简单模式,直接通过 Web 浏览器中的 URL 打开,但在通过 JavaScript 对话框打开时应提供一些额外的逻辑。
希望你明白我的问题。任何帮助表示赞赏
解决方案
所以你需要的第一件事是一个新的 ViewEngine 来处理一个页面,没有所有正常的页眉/页脚的东西,这会阻碍你的模式窗口。最简单的方法是为您的模型状态窗口使用大部分空的母版页。你想要主页面切换逻辑和自定义的ViewEngine,否则每个控制器方法都必须有if()else() where IsAjaxRequest() 被检测到。我喜欢这样做,撒哈拉干。
有了这个技巧,我也优雅的降级了。我的 网站 函数在没有 javascript 的情况下是完美的。链接很好,表单工作,零代码更改从“模态感知站点”到普通的旧 html 表单提交。
我所做的是对默认引擎进行子类化并添加一些 MasterPage 选择位:
查看引擎:
public class ModalViewEngine : VirtualPathProviderViewEngine
{
public ModalViewEngine()
{
/* {0} = view name or master page name
* {1} = controller name */
MasterLocationFormats = new[] {
"~/Views/Shared/{0}.master"
};
ViewLocationFormats = new[] {
"~/Views/{1}/{0}.aspx","~/Views/Shared/{0}.aspx"
};
PartialViewLocationFormats = new[] {
"~/Views/{1}/{0}.ascx",};
}
protected override IView CreatePartialView(ControllerContext controllerContext,string partialPath)
{
throw new NotImplementedException();
}
protected override IView CreateView(ControllerContext controllerContext,string viewPath,string masterPath)
{
return new WebFormView(viewPath,masterPath );
}
public override ViewEngineResult FindView(ControllerContext controllerContext,string viewName,string masterName,bool useCache)
{
//you might have to customize this bit
if (controllerContext.HttpContext.Request.IsAjaxRequest())
return base.FindView(controllerContext,viewName,"Modal",useCache);
return base.FindView(controllerContext,"Site",useCache);
}
protected override bool FileExists(ControllerContext controllerContext,string virtualPath)
{
return base.FileExists(controllerContext,virtualPath);
}
}
所以我的 Modal.Master 页面非常简单。我所拥有的只是一个 div 包装器,所以我知道在模态窗口中呈现了什么。当您需要仅在元素处于“模态”模式时使用 jquery 选择某些元素时,这将非常有用。
模态大师
下一步是创建您的表单。我使用默认属性名称 = 输入名称,因此我可以轻松地为绑定建模并保持简单。没有特殊形式。我看起来像你平时那样。(请注意,我在代码中使用了 MVC 2 和 EditorFor(),但这并不重要)这是我的最终 HTML:
HTML 输出
EditFood
除了模型绑定真的很好之外,您还可以使用 Jquery.Form 插件以最少的代码将您看似简单的 ajax 函数分层到您的应用程序中。现在我选择ColorBox作为我的模态窗口脚本纯粹是因为我想要Facebook的透明角落,我喜欢作者添加的扩展点。
现在,结合这些脚本,您将获得一个非常好的组合,这使得这项技术在 javascript 中非常容易实现。我添加的唯一 javascript 是(在 document.ready 中):
使用 JavaScript/jQuery
$("a.edit").colorBox({ maxWidth: "800px",opacity: 0.4,initialWidth: 50,initialHeight: 50 });
$().bind('cBox_complete',function () {
$("#form form").ajaxForm(function () { $.fn.colorBox.close() });
});
在这里,我告诉 ColorBox 为我的编辑链接(编辑食物)打开一个模式窗口。然后绑定到颜色框的完整事件以将您的ajaxform 内容与成功回调连接起来,告诉ColorBox 关闭模态窗口。就是这样。
这段代码被用作概念证明,这就是为什么视图引擎真的很棒,没有验证或其他标准形式的 bling.ColorBox 和 JQuery.Form 有很多可扩展性支持,因此自定义它应该很容易。
请注意,这一切都是在 MVC 2 中完成的,但这里是我的控制器代码,只是为了展示这有多简单。请记住,我的概念验证目标是使模态窗口无需任何代码修改即可工作,而不是设置一些基本基础设施。
[UrlRoute(Path="edit/food")]
public ActionResult EditFood()
{
return View(new Food());
}
[HttpPost][UrlRoute(Path = "edit/food")]
public ActionResult EditFood(Food food)
{
return View(food);
}
总结
以上是本站为大家采集的jquery——简单的ASP.NET MVC CRUD视图打开/关闭JavaScript UI对话框中的所有内容,希望文章能帮助你解决jquery-简单的ASP.NET MVC在 JavaScript UI 对话框中打开/关闭视图时遇到的 CRUD 程序开发问题。
如果您觉得本站网站的内容还不错,欢迎向程序员朋友推荐本站网站。
jquery抓取网页内容(jquery抓取网页内容-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-17 18:03
jquery抓取网页内容:1.浏览器设置window.open方法,开启访问方式。2.设置浏览器兼容性jquery不是浏览器的标准html解析器,默认情况下浏览器对jquery解析存在兼容性问题,所以需要使用jquery插件。jquery工具变量:geturl:(url)=>path.join(url,".js");获取方法:利用url的方式,geturl方法的三种方式:(。
1)jquery对象的方式geturl{required:true,seeking:false,cookie:".js"}
2)静态urlseeking:false,cookie:".js"
3)动态urlseeking:false,cookie:".js"以上三种情况,搜索引擎按照原始url和url.seeking的值进行分类url.seeking是分类的阈值,seeking的值越高,搜索引擎对于文档的第一次加载的时间就会越慢,直到分类检索到。动态对象seeking:false,存在被搜索的后缀名cookie。
隐式urlseeking:false,存在被搜索的后缀名javascript代码:requirejs,bootstrap,jquery.js(。
4)-纯ajax代码提交方式大于字符的,代码提交,每次代码提交http请求{"type":"ajax","applicationurl":"","x-www-form-urlencoded":"/get","type":"post","method":"get","user-agent":"mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/75。3438。106safari/537。36","content-type":"application/x-www-form-urlencoded","data-referer":""}获取源代码:varreq=document。
getelementbyid("request");//取得url地址值varpath=req。geturl("。/jquery");//获取的是path属性,包含了get方法varjson=newjson(path);//获取json为数组的数据一方面get操作是url对象,另一方面实际上调用了jquery。getitem(url),属性get方法是mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/75。3438。106safari/537。36"exports={"applicationurl":url,"x-www-form-urlencoded":"。js","type":"post","method":"get","user-agent":"mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/75.0.3438.106safari/537.36","content-type":"application/x-www-form-url 查看全部
jquery抓取网页内容(jquery抓取网页内容-上海怡健医学())
jquery抓取网页内容:1.浏览器设置window.open方法,开启访问方式。2.设置浏览器兼容性jquery不是浏览器的标准html解析器,默认情况下浏览器对jquery解析存在兼容性问题,所以需要使用jquery插件。jquery工具变量:geturl:(url)=>path.join(url,".js");获取方法:利用url的方式,geturl方法的三种方式:(。
1)jquery对象的方式geturl{required:true,seeking:false,cookie:".js"}
2)静态urlseeking:false,cookie:".js"
3)动态urlseeking:false,cookie:".js"以上三种情况,搜索引擎按照原始url和url.seeking的值进行分类url.seeking是分类的阈值,seeking的值越高,搜索引擎对于文档的第一次加载的时间就会越慢,直到分类检索到。动态对象seeking:false,存在被搜索的后缀名cookie。
隐式urlseeking:false,存在被搜索的后缀名javascript代码:requirejs,bootstrap,jquery.js(。
4)-纯ajax代码提交方式大于字符的,代码提交,每次代码提交http请求{"type":"ajax","applicationurl":"","x-www-form-urlencoded":"/get","type":"post","method":"get","user-agent":"mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/75。3438。106safari/537。36","content-type":"application/x-www-form-urlencoded","data-referer":""}获取源代码:varreq=document。
getelementbyid("request");//取得url地址值varpath=req。geturl("。/jquery");//获取的是path属性,包含了get方法varjson=newjson(path);//获取json为数组的数据一方面get操作是url对象,另一方面实际上调用了jquery。getitem(url),属性get方法是mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537。36(khtml,likegecko)chrome/75。3438。106safari/537。36"exports={"applicationurl":url,"x-www-form-urlencoded":"。js","type":"post","method":"get","user-agent":"mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/75.0.3438.106safari/537.36","content-type":"application/x-www-form-url
jquery抓取网页内容(java利用url实现网页内容抓取的示例。。具有很好的参考价值)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-12 17:19
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j 查看全部
jquery抓取网页内容(java利用url实现网页内容抓取的示例。。具有很好的参考价值)
本文主要介绍一个java使用url实现网页内容爬取的例子。有很好的参考价值。跟小编一起来看看吧
无事可做,刚学会了将git部署到远程服务器上,无事可做,就简单的做了个抓取网页信息的小工具。如果将其中的一些值设置为参数,扩展性能会更好!我希望这是一个好的开始,也让我更熟练地阅读字符串。值得注意的是JAVA1.8在使用String拼接字符串时会自动询问你。拼接后的字符串由StringBulider处理,极大的优化了String的性能。废话不多说,晒出我的XXX码~
运行结果:
先打开百度百科,搜索一个词条,比如“演员”,然后按F12查看源码
然后抓取你想要的标签并将其注入到 LinkedHashMap 中。这很容易,对吧?看代码
<p> import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; import java.util.*; /** * Created by chunmiao on 17-3-10. */ public class ReadBaiduSearch { //储存返回结果 private LinkedHashMap mapOfBaike; //获取搜索信息 public LinkedHashMap getInfomationOfBaike(String infomationWords) throws IOException { mapOfBaike = getResult(infomationWords); return mapOfBaike; } //通过网络链接获取信息 private static LinkedHashMap getResult(String keywords) throws IOException { //搜索的url String keyUrl = "http://baike.baidu.com/search?word=" + keywords; //搜索词条的节点 String startNode = ""; //词条的链接关键字 String keyOfHref = "href=\""; //词条的标题关键字 String keyOfTitle = "target=\"_blank\">"; String endNode = ""; boolean isNode = false; String title; String href; String rLine; LinkedHashMap keyMap = new LinkedHashMap(); //开始网络请求 URL url = new URL(keyUrl); HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection(); InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容 while ((rLine = bufferedReader.readLine()) != null){ //判断目标节点是否出现 if(rLine.contains(startNode)){ isNode = true; } //若目标节点出现,则开始抓取数据 if (isNode){ //若目标结束节点出现,则结束读取,节省读取时间 if (rLine.contains(endNode)) { //关闭读取流 bufferedReader.close(); inputStreamReader.close(); break; } //若值为空则不读取 if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){ keyMap.put(title,href); } } } return keyMap; } //获取词条对应的url private static String getHref(String rLine,String keyOfHref){ String baikeUrl = "http://baike.baidu.com"; String result = ""; if(rLine.contains(keyOfHref)){ //获取url for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-11-11 17:04
1. 前言
相信很多人在做开发的时候都有这样的需求:从网页中准确提取出需要的内容。想了想,方法无外乎如下:(本人经验少,如果有更好的方法请指教)
1. 使用正则表达式匹配需要的元素。(缺点:如果相同类型的元素有不同的属性,比如
啊啊啊啊
bbb
,如果要匹配所有的div元素,会比较麻烦,而且很容易得到不需要的结果,错过需要的结果。)
2. 要将网页转换为 XML 文档,请使用 Linq to XML。(缺点:需要一个转换过程,效率不高。)
3. 使用网站提供的WebServices或WebAPI直接获取需要的数据。(缺点:需要先获取接口文档,一般不会匿名提供。)
随着这几年前端的兴起,越来越多的人开始认识并相信JQuery这个强大的工具。最重要的一点之一是 JQuery 选择器。它的简单、高效、易学,让前端工程师的工作效率大大提高。. 仔细想想,提取网页内容只是与前端打交道。如果可以使用JQuery选择器就完美了!!!
2. 理论准备
你想在 .NET 下自己做一个选择器吗?不,这不是我等小辈做的。. . . 既然已经有了 JQuery,为什么不直接使用它的选择器呢?
1. .NET 访问网络内容
在这里你可以选择webbrowser控件,其实它就是一个迷你IE,它可以做IE能做的一切。可能有人会问为什么不直接用WebClient下载网页内容呢?请看第二点。
2. .NET 与 JS 交互
使用webbrowser控件,不仅可以获取网页的内容,更重要的是它提供了与网页交互的功能。使用内置的 Document 属性,我们可以将所需的 JS 代码注入网页并执行。
3. 提取并返回需要的内容
在.NET中,我们可以使用Documentation的InvokeScript函数来执行对应的JS函数并得到返回结果。
现在理论已经准备好了,让我们接下来实现它。
3. 功能实现
测试页:(福利网站哦,但绝对没有邪恶内容,请编辑明鉴!)
功能需求:提取所有“好处”!!!!
第一张图:
从图中可以看出,“福利”已经被准确提取出来了。并且您只能获得所需的属性值。您所要做的就是输入一个简短的 15 个字符。
我们来看一下代码实现:
其中,wb 为 webbrowser 控件。本段主要是将JQuery库注入到一些不收录JQuery库的网页中。
void InjectJQuery()
{
HtmlElement jquery = wb.Document.CreateElement("script");
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);
wb.Document.Body.AppendChild(jquery);
JQueryInjected = true;
}
这里是需要注入的JS函数。因为不同的需求有不同的代码,所以不能重复注入。当需求改变时,只需要改变注入的函数。
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)
{
JQScript = wb.Document.CreateElement("script");
JQScript.SetAttribute("id", "JQScript");
JQScript.SetAttribute("type", "text/javascript");
wb.Document.Body.AppendChild(JQScript);
}
这是关键代码。根据是否提取属性生成不同的编码。注入的代码很简单,相信对前端有点了解的朋友一看就明白了。最后一行代码是执行注入的函数并获取返回值。
if (txtAttribute.Text.Trim() == string.Empty)
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
else
{
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
}
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
相信大家一看就明白,短短几行代码,就可以使用强大的JQuery选择器,效率比之前的老方法高很多倍,何乐而不为呢?
4. 知识扩展
1. 只要你的前端知识够硬,可以注入更复杂的函数,实现更复杂的内容提取。
2. 在Android和IOS中,理论上是可以实现这样的功能的。
3. 也许有一天,我们会有一个类似的选择器来代替SQL来实现高效的数据库查询?? ? ? ? ? ? ? ? ?
PS:我文笔极差,知识面也不广。如有错误,敬请指正! 查看全部
jquery抓取网页内容(从网页中准确提取所需的内容,你知道吗?)
1. 前言
相信很多人在做开发的时候都有这样的需求:从网页中准确提取出需要的内容。想了想,方法无外乎如下:(本人经验少,如果有更好的方法请指教)
1. 使用正则表达式匹配需要的元素。(缺点:如果相同类型的元素有不同的属性,比如
啊啊啊啊
bbb
,如果要匹配所有的div元素,会比较麻烦,而且很容易得到不需要的结果,错过需要的结果。)
2. 要将网页转换为 XML 文档,请使用 Linq to XML。(缺点:需要一个转换过程,效率不高。)
3. 使用网站提供的WebServices或WebAPI直接获取需要的数据。(缺点:需要先获取接口文档,一般不会匿名提供。)
随着这几年前端的兴起,越来越多的人开始认识并相信JQuery这个强大的工具。最重要的一点之一是 JQuery 选择器。它的简单、高效、易学,让前端工程师的工作效率大大提高。. 仔细想想,提取网页内容只是与前端打交道。如果可以使用JQuery选择器就完美了!!!
2. 理论准备
你想在 .NET 下自己做一个选择器吗?不,这不是我等小辈做的。. . . 既然已经有了 JQuery,为什么不直接使用它的选择器呢?
1. .NET 访问网络内容
在这里你可以选择webbrowser控件,其实它就是一个迷你IE,它可以做IE能做的一切。可能有人会问为什么不直接用WebClient下载网页内容呢?请看第二点。
2. .NET 与 JS 交互
使用webbrowser控件,不仅可以获取网页的内容,更重要的是它提供了与网页交互的功能。使用内置的 Document 属性,我们可以将所需的 JS 代码注入网页并执行。
3. 提取并返回需要的内容
在.NET中,我们可以使用Documentation的InvokeScript函数来执行对应的JS函数并得到返回结果。
现在理论已经准备好了,让我们接下来实现它。
3. 功能实现
测试页:(福利网站哦,但绝对没有邪恶内容,请编辑明鉴!)
功能需求:提取所有“好处”!!!!
第一张图:
从图中可以看出,“福利”已经被准确提取出来了。并且您只能获得所需的属性值。您所要做的就是输入一个简短的 15 个字符。
我们来看一下代码实现:
其中,wb 为 webbrowser 控件。本段主要是将JQuery库注入到一些不收录JQuery库的网页中。
void InjectJQuery()
{
HtmlElement jquery = wb.Document.CreateElement("script");
jquery.SetAttribute("src", "http://ajax.googleapis.com/aja ... 6quot;);
wb.Document.Body.AppendChild(jquery);
JQueryInjected = true;
}
这里是需要注入的JS函数。因为不同的需求有不同的代码,所以不能重复注入。当需求改变时,只需要改变注入的函数。
JQScript = wb.Document.GetElementById("JQScript");
if (JQScript == null)
{
JQScript = wb.Document.CreateElement("script");
JQScript.SetAttribute("id", "JQScript");
JQScript.SetAttribute("type", "text/javascript");
wb.Document.Body.AppendChild(JQScript);
}
这是关键代码。根据是否提取属性生成不同的编码。注入的代码很简单,相信对前端有点了解的朋友一看就明白了。最后一行代码是执行注入的函数并获取返回值。
if (txtAttribute.Text.Trim() == string.Empty)
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "')[0].outerHTML; }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this)[0].outerHTML+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
else
{
JQScript.SetAttribute("text", "function GetJQValue() { if ($('" + txtSelector.Text + "').length == 1) {" +
"return $('" + txtSelector.Text + "').attr('" + txtAttribute.Text + "'); }" +
" else if ($('" + txtSelector.Text + "').length > 1) {" +
" var allhtml = '';" +
" $('" + txtSelector.Text + "').each(function() {allhtml=allhtml+$(this).attr('" + txtAttribute.Text + "')+'\\r\\n';});" +
" return allhtml;}" +
" else return 'no item found.';}");
}
textBox2.Text = wb.Document.InvokeScript("GetJQValue").ToString();
相信大家一看就明白,短短几行代码,就可以使用强大的JQuery选择器,效率比之前的老方法高很多倍,何乐而不为呢?
4. 知识扩展
1. 只要你的前端知识够硬,可以注入更复杂的函数,实现更复杂的内容提取。
2. 在Android和IOS中,理论上是可以实现这样的功能的。
3. 也许有一天,我们会有一个类似的选择器来代替SQL来实现高效的数据库查询?? ? ? ? ? ? ? ? ?
PS:我文笔极差,知识面也不广。如有错误,敬请指正!
jquery抓取网页内容(使用HeadlessChrome进行网页的经验,你知道吗?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-11-10 03:17
作者丨马丁·塔皮亚
翻译丨富士
Headless Chrome 是 Chrome 浏览器的一种非界面形式。它可以在不打开浏览器的情况下运行具有 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 更方便测试web应用、获取网站的截图、做爬虫抓取信息等,更贴近浏览器环境。下面就来看看作者分享的使用Headless Chrome的网页爬虫体验吧。
PhantomJS 的发展已经停止,Headless Chrome 成为热点关注的焦点。每个人都喜欢它,包括我们。现在,网络爬虫是我们工作的很大一部分,现在我们广泛使用 Headless Chrome。
本文 文章 将告诉您如何快速开始使用 Headless Chrome 生态系统,并展示从抓取数百万个网页中学到的经验。
文章总结:
1. 控制Chrome的库有很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取非常简单,尤其是在掌握了以下技巧之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头镀铬简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示将专注于该项目的研发,未来将继续维护。
这意味着对于网页抓取和自动化需求,您现在可以体验到 Chrome 的速度和功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,以及伟大的开发者工具 API。它是可怕的!
我应该使用哪个工具来控制 Headless Chrome?
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组由社区发布的其他语言的 C++ API 和库,例如 GO 语言。我们推荐使用 NodeJS 工具,因为它与 Web 解析语言相同(您将在下面看到它是多么方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
将饼干放回饼干罐中
使用全功能浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但有时登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
等待 nick.setCookie({
名称:“li_at”,
值:“从您的 DevTools 复制的会话 cookie 值”,
领域: ””
})
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当危险的,因为错误的信息会触发愤怒用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它来爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
等待 tab.open("")
await tab.untilVisible("#hnmain") // 确保我们已经加载了页面
await tab.inject("") // 我们将使用 jQuery 来抓取
consthackerNewsLinks = await tab.evaluate((arg, callback) => {
// 这里我们处于页面上下文中。就像在浏览器的检查器工具中一样
常量数据 = []
$(".athing").each((index, element) => {
数据推送({
标题:$(element).find(".storylink").text(),
url: $(element).find(".storylink").attr("href")
})
})
回调(空,数据)
})
印度、俄罗斯和巴基斯坦与屏蔽机器人的做法有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫机连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
如果(等待 tab.isVisible(“.captchaImage”)){
// 获取生成的 CAPTCHA 图片的 URL
// 请注意,我们也可以获取它的 -encoded 值并对其进行求解
const captchaImageLink = await tab.evaluate((arg, callback) => {
回调(空,$(“.captchaImage”)。attr(“src”))
})
// 调用 CAPTCHA 解决服务
const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink)
// 用我们的解决方案填写表单
等待 tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })
}
等待DOM元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
等待 tab.open("")
// await Promise.delay(5000) // 不要这样做!
等待 tab.waitUntilVisible(".permalinkPost .UFILikeLink")
// 您现在可以安全地单击“喜欢”按钮...
等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延迟。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它拥有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 的时候已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈,然后运行它。
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截
因为使用了DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null
tab.driver.client.Network.responseReceived((e) => {
if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {
cvRequestId = e.requestId
}
})
tab.driver.client.Network.loadingFinished((e) => {
如果(e.requestId === cvRequestId){
tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {
require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded?'':'utf8')))
})
}
})
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截
const 尼克 = 新尼克({
加载图像:假,
白名单: [
/.*.aspx/,
/.*axd.*/,
/.*.html.*/,
/.*.js.*/
],
黑名单:[
/*fsispin360.js/,
/.*fsitouchzoom.js/,
/.*.ashx.*/,
/。*谷歌。*/
]
})
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。返回搜狐查看更多 查看全部
jquery抓取网页内容(使用HeadlessChrome进行网页的经验,你知道吗?(上))
作者丨马丁·塔皮亚
翻译丨富士
Headless Chrome 是 Chrome 浏览器的一种非界面形式。它可以在不打开浏览器的情况下运行具有 Chrome 支持的所有功能的程序。与现代浏览器相比,Headless Chrome 更方便测试web应用、获取网站的截图、做爬虫抓取信息等,更贴近浏览器环境。下面就来看看作者分享的使用Headless Chrome的网页爬虫体验吧。
PhantomJS 的发展已经停止,Headless Chrome 成为热点关注的焦点。每个人都喜欢它,包括我们。现在,网络爬虫是我们工作的很大一部分,现在我们广泛使用 Headless Chrome。
本文 文章 将告诉您如何快速开始使用 Headless Chrome 生态系统,并展示从抓取数百万个网页中学到的经验。
文章总结:
1. 控制Chrome的库有很多,大家可以根据自己的喜好选择。
2. 使用 Headless Chrome 进行网页抓取非常简单,尤其是在掌握了以下技巧之后。
3. 可以检测到无头浏览器访问者,但没有人可以检测到。
无头镀铬简介
Headless Chrome 基于 Google Chrome 团队开发的 PhantomJS(QtWebKit 内核)。团队表示将专注于该项目的研发,未来将继续维护。
这意味着对于网页抓取和自动化需求,您现在可以体验到 Chrome 的速度和功能,因为它具有世界上最常用的浏览器的特性:支持所有 网站,支持 JS 引擎,以及伟大的开发者工具 API。它是可怕的!
我应该使用哪个工具来控制 Headless Chrome?
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组由社区发布的其他语言的 C++ API 和库,例如 GO 语言。我们推荐使用 NodeJS 工具,因为它与 Web 解析语言相同(您将在下面看到它是多么方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
将饼干放回饼干罐中
使用全功能浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但有时登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
等待 nick.setCookie({
名称:“li_at”,
值:“从您的 DevTools 复制的会话 cookie 值”,
领域: ””
})
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当危险的,因为错误的信息会触发愤怒用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它来爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
等待 tab.open("")
await tab.untilVisible("#hnmain") // 确保我们已经加载了页面
await tab.inject("") // 我们将使用 jQuery 来抓取
consthackerNewsLinks = await tab.evaluate((arg, callback) => {
// 这里我们处于页面上下文中。就像在浏览器的检查器工具中一样
常量数据 = []
$(".athing").each((index, element) => {
数据推送({
标题:$(element).find(".storylink").text(),
url: $(element).find(".storylink").attr("href")
})
})
回调(空,数据)
})
印度、俄罗斯和巴基斯坦与屏蔽机器人的做法有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫机连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
如果(等待 tab.isVisible(“.captchaImage”)){
// 获取生成的 CAPTCHA 图片的 URL
// 请注意,我们也可以获取它的 -encoded 值并对其进行求解
const captchaImageLink = await tab.evaluate((arg, callback) => {
回调(空,$(“.captchaImage”)。attr(“src”))
})
// 调用 CAPTCHA 解决服务
const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink)
// 用我们的解决方案填写表单
等待 tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })
}
等待DOM元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
等待 tab.open("")
// await Promise.delay(5000) // 不要这样做!
等待 tab.waitUntilVisible(".permalinkPost .UFILikeLink")
// 您现在可以安全地单击“喜欢”按钮...
等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延迟。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它拥有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 的时候已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈,然后运行它。
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截
因为使用了DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null
tab.driver.client.Network.responseReceived((e) => {
if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {
cvRequestId = e.requestId
}
})
tab.driver.client.Network.loadingFinished((e) => {
如果(e.requestId === cvRequestId){
tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {
require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.Encoded?'':'utf8')))
})
}
})
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截
const 尼克 = 新尼克({
加载图像:假,
白名单: [
/.*.aspx/,
/.*axd.*/,
/.*.html.*/,
/.*.js.*/
],
黑名单:[
/*fsispin360.js/,
/.*fsitouchzoom.js/,
/.*.ashx.*/,
/。*谷歌。*/
]
})
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。返回搜狐查看更多
jquery抓取网页内容( ,前端资源1.什么是robots.txt文件搜索引擎教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-05 14:09
,前端资源1.什么是robots.txt文件搜索引擎教程)
robots.txt 如何禁止搜索引擎抓取
2013-3-3 分类:seo文章、wordpress教程、前端资源
1.robots.txt 文件是什么
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索的部分或指定那个搜索引擎只是收录的特定部分。
请注意,只有当您的 网站 收录您不想被 收录 搜索的内容时,您才需要使用 robots.txt 文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
2.robots.txt文件在哪里
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站网址
对应robots.txt的URL
:80/
:80/robots.txt
: 1234/
:1234/robots.txt
3.我在robots.txt中设置了禁止百度收录我网站,为什么它仍然出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
4.禁止搜索引擎跟踪网页链接,只索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放在页面的
部分:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写上这个标记:
登入
要允许其他搜索引擎跟踪,但只阻止百度跟踪指向您页面的链接,请将此元标记放在页面的一部分中:
5.禁止搜索引擎在搜索结果中显示网页快照,只能索引网页
为防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的
部分:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
6.我要禁止百度图片搜索收录一些图片,如何设置
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
7.Robots.txt 文件格式
“robots.txt”文件收录一条或多条记录,以空行分隔(以CR、CR/NL或NL为终止符)。每条记录的格式如下:
":"
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行。详细情况如下:
User-agent:此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。如果在“robots.txt”文件中添加“User-agent: SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”后的禁止和允许行限制。
Disallow:此项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,但不是访问 /help/index.html。“Disallow:”表示允许机器人访问网站的所有URL,并且“/robots.txt”文件中必须至少有一条Disallow记录。如果“/robots.txt”不存在或者是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
允许:此项的值用于描述一组您希望访问的 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。以 Allow 项的值开头的 URL 允许机器人访问。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认都是 Allow 的,所以 Allow 通常与 Disallow 结合使用,允许访问某些网页,同时禁止访问所有其他 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
注:我们将严格遵守机器人的相关协议。请注意区分您不想被抓取的目录或收录 的情况。我们会处理robots中写入的文件,你不想被爬取和收录的目录做精确匹配,否则robots协议不会生效。
8.URL 匹配示例
允许或禁止值
网址
比赛结果
/tmp
/tmp
是的
/tmp
/tmp.html
是的
/tmp
/tmp/a.html
是的
/tmp
/tmhoho
不
/你好*
/你好.html
是的
/He*lo
/你好,哈哈
是的
/堆*lo
/你好,哈哈
不
html$
/tmpa.html
是的
/a.html$
/a.html
是的
htm$
/a.html
不
9.Robots.txt 文件使用示例
示例 1. 禁止所有搜索引擎访问 网站 的任何部分
用户代理:*
不允许:/
示例 2. 允许所有机器人访问
(或者你可以创建一个空文件“/robots.txt”)
用户代理:*
允许:/
示例 3. 仅禁止百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
不允许:/
示例 4. 只允许百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
允许:/用户代理:*
不允许:/
示例 5. 只允许百度蜘蛛和谷歌机器人访问
用户代理:百度蜘蛛
允许:/用户代理:Googlebot
允许:/
用户代理:*
不允许:/
示例 6. 禁止蜘蛛访问特定目录
本例中网站有3个目录限制搜索引擎访问,即robot不会访问这3个目录。需要注意的是,每个目录必须单独声明,不能写成“Disallow:/cgi-bin//tmp/”。
用户代理:*
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 7. 允许访问特定目录中的某些 URL
用户代理:*
允许:/cgi-bin/见
允许:/tmp/hi
允许:/~joe/look
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 8. 使用“*”限制对 url 的访问
禁止访问/cgi-bin/目录下所有后缀为“.htm”的URL(包括子目录)。
用户代理:*
禁止:/cgi-bin/*.htm
示例 9. 使用“$”限制对 url 的访问
只允许访问带有“.htm”后缀的 URL。
用户代理:*
允许:/*.htm$
不允许:/
示例1 0.禁止访问网站中的所有动态页面
用户代理:*
不允许:/*?*
示例1 1.禁止百度蜘蛛抓取网站上的所有图片
只允许抓取网页,不允许抓取图片。
用户代理:百度蜘蛛
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.gif$
禁止:/*.png$
禁止:/*.bmp$
示例1 2.只允许百度蜘蛛抓取.gif格式的网页和图片
允许抓取网页和gif格式的图片,但不允许抓取其他格式的图片
用户代理:百度蜘蛛
允许:/*.gif$
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.png$
禁止:/*.bmp$
示例1 3. 只禁止百度蜘蛛抓取.jpg格式的图片
用户代理:百度蜘蛛
禁止:/*.jpg$ 查看全部
jquery抓取网页内容(
,前端资源1.什么是robots.txt文件搜索引擎教程)
robots.txt 如何禁止搜索引擎抓取
2013-3-3 分类:seo文章、wordpress教程、前端资源
1.robots.txt 文件是什么
搜索引擎使用蜘蛛程序自动访问互联网上的网页并获取网页信息。当蜘蛛访问一个网站时,它会首先检查网站的根域下是否有一个名为robots.txt的纯文本文件。这个文件是用来指定蜘蛛在你的网站 爬取范围上的。您可以在您的网站中创建一个robots.txt,并在文件中声明网站中不想被搜索引擎收录搜索的部分或指定那个搜索引擎只是收录的特定部分。
请注意,只有当您的 网站 收录您不想被 收录 搜索的内容时,您才需要使用 robots.txt 文件。如果您想要搜索引擎收录网站 上的所有内容,请不要创建robots.txt 文件。
2.robots.txt文件在哪里
robots.txt文件应该放在网站的根目录下。例如,当蜘蛛访问一个网站(例如)时,它会首先检查网站中是否存在该文件。如果蜘蛛找到该文件,它会根据文件的内容确定其访问权限的范围。
网站网址
对应robots.txt的URL
:80/
:80/robots.txt
: 1234/
:1234/robots.txt
3.我在robots.txt中设置了禁止百度收录我网站,为什么它仍然出现在百度搜索结果中?
如果您的robots.txt文件中设置了禁止收录的其他网站链接,这些网页可能仍会出现在百度的搜索结果中,但您网页上的内容将不会被抓取,索引和显示,百度搜索结果中显示的只是您相关网页的其他网站描述。
4.禁止搜索引擎跟踪网页链接,只索引网页
如果您不希望搜索引擎跟踪此页面上的链接并且不传递链接的权重,请将此元标记放在页面的
部分:
如果您不想让百度跟踪特定链接,百度也支持更精确的控制,请直接在链接上写上这个标记:
登入
要允许其他搜索引擎跟踪,但只阻止百度跟踪指向您页面的链接,请将此元标记放在页面的一部分中:
5.禁止搜索引擎在搜索结果中显示网页快照,只能索引网页
为防止所有搜索引擎显示您的 网站 快照,请将此元标记放在页面的
部分:
要允许其他搜索引擎显示快照,但只阻止百度显示,请使用以下标签:
注意:此标签仅禁止百度显示网页快照。百度将继续对网页进行索引,并在搜索结果中显示网页摘要。
6.我要禁止百度图片搜索收录一些图片,如何设置
禁止百度蜘蛛抓取网站上的所有图片,禁止或允许百度蜘蛛抓取网站上特定格式的图片文件可以通过设置robots实现,请参考“robots.txt文件使用示例”示例10、11、12。
7.Robots.txt 文件格式
“robots.txt”文件收录一条或多条记录,以空行分隔(以CR、CR/NL或NL为终止符)。每条记录的格式如下:
":"
可以在这个文件中使用#做注释,具体用法同UNIX中的约定。此文件中的记录通常以一行或多行 User-agent 开头,后跟几行 Disallow 和 Allow 行。详细情况如下:
User-agent:此项的值用于描述搜索引擎机器人的名称。在“robots.txt”文件中,如果有多个User-agent记录,表示多个robots会被“robots.txt”限制。对于此文件,必须至少有一个用户代理记录。如果此项的值设置为*,则对任何机器人都有效。在“robots.txt”文件中,只能有“User-agent:*”这样的一条记录。如果在“robots.txt”文件中添加“User-agent: SomeBot”和几行禁止和允许行,则名称“SomeBot”仅受“User-agent: SomeBot”后的禁止和允许行限制。
Disallow:此项的值用于描述一组不想被访问的 URL。该值可以是完整路径或路径的非空前缀。机器人不会访问以 Disallow 项的值开头的 URL。例如,“Disallow:/help”禁止机器人访问/help.html、/helpabc.html、/help/index.html,而“Disallow:/help/”则允许机器人访问/help.html、/helpabc。 html,但不是访问 /help/index.html。“Disallow:”表示允许机器人访问网站的所有URL,并且“/robots.txt”文件中必须至少有一条Disallow记录。如果“/robots.txt”不存在或者是一个空文件,这个网站 对所有搜索引擎机器人都是开放的。
允许:此项的值用于描述一组您希望访问的 URL。与 Disallow 项类似,该值可以是完整路径或路径前缀。以 Allow 项的值开头的 URL 允许机器人访问。例如,“Allow:/hibaidu”允许机器人访问/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。网站 的所有 URL 默认都是 Allow 的,所以 Allow 通常与 Disallow 结合使用,允许访问某些网页,同时禁止访问所有其他 URL。
使用“*”和“$”:
百度蜘蛛支持使用通配符“*”和“$”来模糊匹配URL。
"$" 匹配行尾。
“*”匹配 0 个或多个任意字符。
注:我们将严格遵守机器人的相关协议。请注意区分您不想被抓取的目录或收录 的情况。我们会处理robots中写入的文件,你不想被爬取和收录的目录做精确匹配,否则robots协议不会生效。
8.URL 匹配示例
允许或禁止值
网址
比赛结果
/tmp
/tmp
是的
/tmp
/tmp.html
是的
/tmp
/tmp/a.html
是的
/tmp
/tmhoho
不
/你好*
/你好.html
是的
/He*lo
/你好,哈哈
是的
/堆*lo
/你好,哈哈
不
html$
/tmpa.html
是的
/a.html$
/a.html
是的
htm$
/a.html
不
9.Robots.txt 文件使用示例
示例 1. 禁止所有搜索引擎访问 网站 的任何部分
用户代理:*
不允许:/
示例 2. 允许所有机器人访问
(或者你可以创建一个空文件“/robots.txt”)
用户代理:*
允许:/
示例 3. 仅禁止百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
不允许:/
示例 4. 只允许百度蜘蛛访问您的 网站
用户代理:百度蜘蛛
允许:/用户代理:*
不允许:/
示例 5. 只允许百度蜘蛛和谷歌机器人访问
用户代理:百度蜘蛛
允许:/用户代理:Googlebot
允许:/
用户代理:*
不允许:/
示例 6. 禁止蜘蛛访问特定目录
本例中网站有3个目录限制搜索引擎访问,即robot不会访问这3个目录。需要注意的是,每个目录必须单独声明,不能写成“Disallow:/cgi-bin//tmp/”。
用户代理:*
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 7. 允许访问特定目录中的某些 URL
用户代理:*
允许:/cgi-bin/见
允许:/tmp/hi
允许:/~joe/look
禁止:/cgi-bin/
禁止:/tmp/
禁止:/~joe/
示例 8. 使用“*”限制对 url 的访问
禁止访问/cgi-bin/目录下所有后缀为“.htm”的URL(包括子目录)。
用户代理:*
禁止:/cgi-bin/*.htm
示例 9. 使用“$”限制对 url 的访问
只允许访问带有“.htm”后缀的 URL。
用户代理:*
允许:/*.htm$
不允许:/
示例1 0.禁止访问网站中的所有动态页面
用户代理:*
不允许:/*?*
示例1 1.禁止百度蜘蛛抓取网站上的所有图片
只允许抓取网页,不允许抓取图片。
用户代理:百度蜘蛛
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.gif$
禁止:/*.png$
禁止:/*.bmp$
示例1 2.只允许百度蜘蛛抓取.gif格式的网页和图片
允许抓取网页和gif格式的图片,但不允许抓取其他格式的图片
用户代理:百度蜘蛛
允许:/*.gif$
禁止:/*.jpg$
禁止:/*.jpeg$
禁止:/*.png$
禁止:/*.bmp$
示例1 3. 只禁止百度蜘蛛抓取.jpg格式的图片
用户代理:百度蜘蛛
禁止:/*.jpg$
jquery抓取网页内容(我尝试使用c#.net3.5应用程序抓取网页,但我无法抓取整个页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-04 15:16
问题
我尝试使用c#.net 3.5 应用程序抓取网页,但无法抓取整个页面,因为部分内容是通过jquery Ajax 显示的。
如果你使用 Chrome 作为你的网络浏览器,你可以打开开发者工具(F12) 并检查“网络”选项卡以查看页面加载后请求的资源。上面的 URL 是我注意到的 URL 之一,好像带来了一些结果,如果你知道或者可以解析date和meeting_id,你或许可以像使用主页一样直接拨打电话。
另一种可能的选择是使用实际的 Web 浏览器控件并在加载所有内容后扫描 DOM。
其他解决方案
我认为您需要使用 System.Net 命名空间。
你需要做的是在这个的帮助下创建一个 HttpRequest
WebRequest webRequest = WebRequest.Create("http://www.racingpost.com/grey ... 6quot;);
WebResponse webResp = webRequest.GetResponse();
我认为这也将提供对 Ajax 数据的完整响应。 查看全部
jquery抓取网页内容(我尝试使用c#.net3.5应用程序抓取网页,但我无法抓取整个页面)
问题
我尝试使用c#.net 3.5 应用程序抓取网页,但无法抓取整个页面,因为部分内容是通过jquery Ajax 显示的。
如果你使用 Chrome 作为你的网络浏览器,你可以打开开发者工具(F12) 并检查“网络”选项卡以查看页面加载后请求的资源。上面的 URL 是我注意到的 URL 之一,好像带来了一些结果,如果你知道或者可以解析date和meeting_id,你或许可以像使用主页一样直接拨打电话。
另一种可能的选择是使用实际的 Web 浏览器控件并在加载所有内容后扫描 DOM。
其他解决方案
我认为您需要使用 System.Net 命名空间。
你需要做的是在这个的帮助下创建一个 HttpRequest
WebRequest webRequest = WebRequest.Create("http://www.racingpost.com/grey ... 6quot;);
WebResponse webResp = webRequest.GetResponse();
我认为这也将提供对 Ajax 数据的完整响应。

