jquery抓取网页内容( ,.Chrome.Firefox几个图片懒加载技术selenium和PhantomJS解析)
优采云 发布时间: 2021-11-04 03:17jquery抓取网页内容(
,.Chrome.Firefox几个图片懒加载技术selenium和PhantomJS解析)
selenium中Javascript和jquery的使用过程
本文文章主要介绍了在selenium中Javascript和jquery的使用。通过示例代码介绍非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
JavaScript 是一种可以插入到 HTML 页面中的编程代码。
JavaScript 插入 HTML 后,可以被所有浏览器执行。
今天学到的就是最简单的方法,从来没有接触过js。第一次接触和使用:
1.js
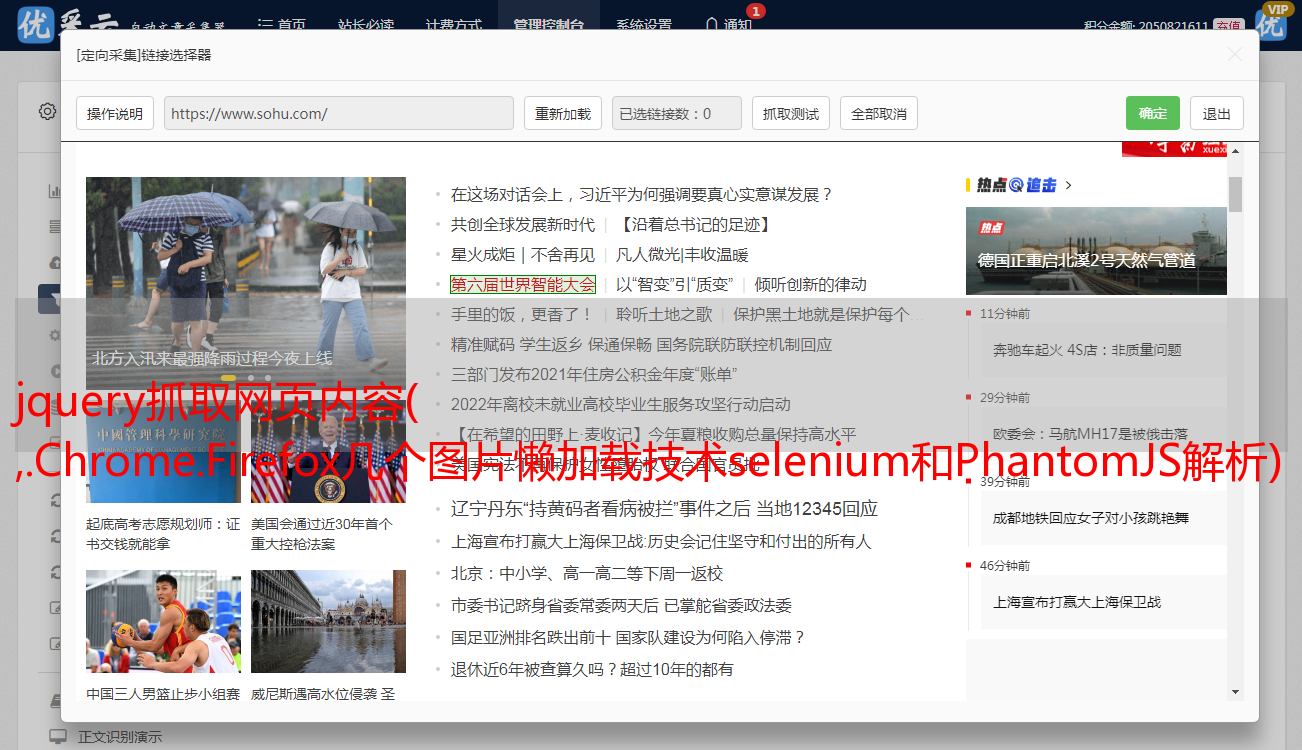
以百度为例,如图:

点击控制台,如图:
输入document.getElementById('kw').value='33'回车,如图:
同理,点击搜索按钮,如图:
将其应用于硒:
2.JQuery
JQuery 是对 JavaScript 的封装,是现成的方法
以百度为例:
运行$("#kw").val("22"),如图:
应用于硒代码:
注意单双引号的变化
JQuery相关网站:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-10-28
Selenium 设置代理和标头的方法(phantomjs、Chrome、Firefox)
本文介绍了selenium设置proxy.headers的方法,总结了phantomjs.Chrome.Firefox几种浏览器的设置方法,分享给大家,给自己留个笔记。phantomjs设置ip方法一:service_args = ['-- proxy=%s'% ip_html,#代理IP:prot(eg:192.168.0.28:808)'--proxy-type=http' , # 代理类型:http/https'--load-images=no', # 关闭图片添加
Python爬虫图片懒加载技术selenium和PhantomJS解析
一.什么是图片延迟加载?-案例研究:从站长资料中抓取图片数据#!/usr/bin/env python # -*- coding:utf-8 -*- import requests from lxml import etree if __name__ == "__main__": url ='' headers = {'User-Agen
详解Selenium+PhantomJS+python简单实现爬虫功能
Selenium 简介 一. Selenium 是一个用于 Web 应用程序自动化程序测试的工具。测试直接在浏览器中运行,就像真实用户在操作一样。Selenium 2 支持驱动真实浏览器(FirfoxDriver、IternetExplorerDriver、OperaDriver、ChromeDriver) selenium2 支持驱动无接口浏览器(HtmlUnit、PhantomJs)二. 安装Windows 第一种方法是:下载源码安装,下载地址(
Selenium+ PhantomJS 爬取豆瓣阅读
本文示例分享了selenium+PhantomJS爬豆瓣阅读的具体代码,供大家参考。具体内容如下获取Python所有书籍信息: 测试通过代码测试请求携带'User-Agent'和'data'数据信息的方法无法获取相关信息。获取数据时,部分数据为空,导致获取过程出错,无法获取全部数据。初步判断豆瓣阅读的反爬虫机制比较严格:通过selenium模拟浏览器请求方式测试后发现,可以使用selenium方式请求数据:#import the required module from selenium i
Python中的Selenium模拟JQuery滑动解锁示例
本文介绍一个Selenium在Python中模拟JQuery滑动解锁的例子,分享给大家,也给自己留个笔记。滑动解锁的难点之一是进行 UI 自动化。我会添加一个滑动解锁的例子,希望第一次做Web UI自动化。考生的一些感想。先来看一个例子。当我手动点击滑块时,只有样式发生了变化:1.slide-to-unlock-handle 表示滑块,滑块的左边距变大(因为它向右移动!)< @2.Slide-tounlock-progress 表示滑动后背景为*敏*感*词*,*敏*感*词*的宽度越来越大,因为滑动经过的地方变成*敏*感*词*了。分一些
Selenium正在执行phantomjs的API并获取执行结果
前言因为最近想写一个抓取sitemap和对应参数的小脚本,现有的爬虫不管是用什么语言写的,都很难抓取到参数,所以想了想,做了一个简单的总结。我认为编写这种站点地图的爬虫非常简单。仔细想想,我发现了可怕的部分。最重要的是参数的提取。这太麻烦了……这才发现AWVS的无敌和威力……如果我们要拿到网站的sitemap,还要抓取对应链接的参数,我大概总结了几个来源url: 1. 页面上直接存在的form表单和现有的href等指向的链接和参数,这个比较简单,不
Python爬虫使用Selenium+ PhantomJS抓取Ajax和动态HTML内容
1. 介绍在Python网络爬虫内容提取器一文中,我们详细讲解了核心组件:可插拔内容提取器类gsExtractor。本文记录了在确定gsExtractor技术路线过程中所做的编程实验。这是第一部分第二部分,第一部分是使用xslt一次性提取静态网页内容并转换成xml格式的实验。它留下了一个问题:如何提取由 javascript 管理的动态内容?那么这篇文章就回答了这个问题。2.提取动态内容的技术成分。上一篇Python使用xslt提取网页数据,提取的内容直接从网页源码中获取。但是有些阿雅
python+selenium+PhantomJS 抓取网页动态加载内容
环境设置准备工具:pyton3.5,selenium,phantomjs,我电脑已经安装python3.5 install Selenium pip3 install selenium install Phantomjs 根据系统环境下载phantomjs,下载完成后,安装phantomjs 将.exe解压到python脚本文件夹,使用selenium+phantomjs实现一个简单的爬虫 from selenium import webdriver driver = webdriver.PhantomJS
Python爬虫系列Selenium定向爬行猛虎猛扑篮球图片详解
前言:作为一个从小就看篮球的球迷,他经常访问Tiger Basketball、Wet等论坛。论坛里会有很多精美的图片,包括NBA球队、CBA球星、花边新闻、球鞋美女等等,如果右键另存为,你的手真的很痛。作为程序员,让我们写一个程序吧!所以我使用Python+Selenium+正则表达式+urllib2来爬取海量图片。运行效果:Spur Chen Lu 源码:#-*- 编码:utf
Python爬虫实现网页信息抓取功能实例【URL和正则模块】
本文介绍了Python爬虫实现抓取网页信息的功能。分享出来供大家参考,如下: 首先实现网页解析。对于读取等操作,我们需要使用以下模块 import urllib import urllib2 import re 我们可以尝试使用readline方法读取某个网站,比如百度 def test(): f=urllib.urlopen ('') while True: firstLine=f.readline() 打印 firstLine 让我们说
Python爬虫包BeautifulSoup递归爬取实例详解
Python爬虫包BeautifulSoup递归爬虫示例详细总结:爬虫的主要目的是沿网络爬取所需内容。它们的本质是一个递归过程。他们首先需要获取网页的内容,然后分析网页的内容,找到另一个网址,然后得到这个网址的网页内容,重复这个过程。我们以维基百科为例。我们希望将维基百科中的所有 Kevin Bacon 条目链接到其他条目。提取出来。# -*- coding: utf-8 -*- # @Author: HaonanWu # @Date: 2016-12-25 10:
Python爬虫抓取网页图片的方法
一.这段时间我一直在学习Python。我听说过 Python 爬虫有多强大。我现在才在这里学习。跟着小乌龟的Python视频,写了一个爬虫程序,可以实现简单的网页图片下载。. 二.代码 __author__ = "JentZhang" import urllib.request import os import random import re def url_open(url):''' 打开网页: param url: :return:''' req = urllib.reques
Python爬虫开发利用Python爬虫库请求多线程捕捉猫眼电影TOP100实例
使用Python爬虫库请求多线程抓取猫眼电影TOP100。思路:查看网页源码,抓取单个页面的内容。@>7. IDE:Sublime Text Browser:Chrome浏览器1.查看猫眼电影TOP100网页源码按F12查看网页源码,发现每部电影的信息在"" 标签。点击打开后,信息如下:2.
浅谈Python爬虫原理及数据抓取
通用爬虫和聚焦爬虫。根据使用场景,网络爬虫可以分为通用爬虫和聚焦爬虫。通用爬虫通用网络爬虫是搜索引擎爬虫系统(百度、谷歌、雅虎等)的重要组成部分。主要目的是将互联网上的网页整合到本地,形成互联网内容的镜像备份。通用搜索引擎(Search Engine)的工作原理通用网络爬虫从互联网上采集网页,采集信息,这些网页信息用于构建搜索引擎索引从而提供支持。它决定了整个引擎系统的内容是否丰富,信息是否是即时的,所以它的性能直接影响到搜索引擎的效果。第一步:
C# 使用 Selenium+ PhantomJS 抓取数据
手头的项目需要在一个用js渲染的网站中抓取数据。使用常用的httpclient 抓取的页面没有数据。我在百度上上网,推荐的方案是使用PhantomJS。PhantomJS 是一个无接口的 Selenium 是一个 Web 测试框架。使用 Selenium 来操作 PhantomJS 是绝配。但是网上的例子大多是Python。我别无选择,只能下载 python 并按照教程进行操作。有一次,我陷入了 Selenium 的导入问题。我放弃了,我还是用我惯用的c#,我不相信c#上没有
Python实现简单网页图片抓取的完整代码示例
使用python抓取网络图片的步骤为:1.根据给定的URL获取网页源码2.使用正则表达式过滤掉源码中的图片地址3.@ > 根据下面过滤掉一个*敏*感*词*网页的图片比较简单的实现:# -*- coding: utf-8 -*- # feimengjuan import re import urllib import urllib2 #取网站图片#根据给定URL获取网页的详细信息,获取的html为网页源代码 def getHtml(url): pag

