
jquery抓取网页内容
jquery抓取网页内容(jquery完数据后解析代码的操作方法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-02 07:08
jquery抓取网页内容,jquery解析网页,jquery加载数据等等等,jquery解析出来的是你要的,或者是ajax提交完数据后返回给后端的数据,或者是后端渲染的页面数据。jquery代码是一样的,你可以使用同一个jquery,但是渲染的数据不同,那么你渲染的代码的语法和js就要改,有一定兼容性的调整,最终数据结果也要改。
我没有做过后端的开发,以前看的大概是jquery加载完数据后解析并返回给后端的。有些场景下需要更多的实现数据之间的换算关系或者特殊方法计算数据值差值。没有详细去阅读这方面的知识,不敢妄加评论,
不同ajax回调里jquery接受值jquery。injectlist(x,y)example:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})这里要注意参数的同步更新jquery。
injectlist(x,y),$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})就不会执行这个方法了jquery。exec("ajax-on");这段代码是异步ajax的方法$。
ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})实际上就是同步ajax的方法更正:楼上是对的我用一段代码来解释这个答案吧intent传递参数的关系$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})实际上就是同步ajax的方法,依次调用$(intent)。
request('')。accept('http/1。1host:xxx',jsonp)`jsonp`这段代码是异步ajax请求的方法`jsonp`函数将两个请求参数直接绑定到数据库里面去执行`jsonp`请求的代码:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})//这个时候ajax方法只作用于:{username:'test',password:'test'}。
1。使用jsonp的时候用1个参数//数据存放在json里//解析函数也只能存放一个//2个参数,在后面只能传两个参数2。将一个参数的代码分为两段,一次是请求所得数据,一次是用请求和验证数据是否匹配`jsonp`函数把两个参数绑定到数据库里面去执行`jsonp`请求的代码:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})//一次传一个参数,只能传1个。 查看全部
jquery抓取网页内容(jquery完数据后解析代码的操作方法和方法)
jquery抓取网页内容,jquery解析网页,jquery加载数据等等等,jquery解析出来的是你要的,或者是ajax提交完数据后返回给后端的数据,或者是后端渲染的页面数据。jquery代码是一样的,你可以使用同一个jquery,但是渲染的数据不同,那么你渲染的代码的语法和js就要改,有一定兼容性的调整,最终数据结果也要改。
我没有做过后端的开发,以前看的大概是jquery加载完数据后解析并返回给后端的。有些场景下需要更多的实现数据之间的换算关系或者特殊方法计算数据值差值。没有详细去阅读这方面的知识,不敢妄加评论,
不同ajax回调里jquery接受值jquery。injectlist(x,y)example:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})这里要注意参数的同步更新jquery。
injectlist(x,y),$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})就不会执行这个方法了jquery。exec("ajax-on");这段代码是异步ajax的方法$。
ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})实际上就是同步ajax的方法更正:楼上是对的我用一段代码来解释这个答案吧intent传递参数的关系$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})实际上就是同步ajax的方法,依次调用$(intent)。
request('')。accept('http/1。1host:xxx',jsonp)`jsonp`这段代码是异步ajax请求的方法`jsonp`函数将两个请求参数直接绑定到数据库里面去执行`jsonp`请求的代码:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})//这个时候ajax方法只作用于:{username:'test',password:'test'}。
1。使用jsonp的时候用1个参数//数据存放在json里//解析函数也只能存放一个//2个参数,在后面只能传两个参数2。将一个参数的代码分为两段,一次是请求所得数据,一次是用请求和验证数据是否匹配`jsonp`函数把两个参数绑定到数据库里面去执行`jsonp`请求的代码:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})//一次传一个参数,只能传1个。
jquery抓取网页内容(网页设计是p2p建设网站必不可少的,那么你是否观察过)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-30 07:12
网页设计是p2p建设必不可少的网站,那么你观察过网页中代码的顺序吗?网页的代码顺序是可逆的吗?
头部元素排序
网页中的head元素,也称为head,通常收录文档的描述信息,一般包括网页代码、title标题、meta描述网页关键字、链接导入CSS文件、js文件等。
首先是标准的 DOCTYPE 声明,HTML 结构。
然后是元和标题部分,它们在网页中非常重要。浏览器用什么代码来解析网页,文章的标题是什么,文章的关键词是什么?文章 的描述是什么?这些对于 文章 的搜索引擎抓取和排名非常重要。
最后js部分,页面任意位置都可以添加js,但是js的加载速度很慢,而且对于搜索引擎来说,js是一个“陌生人”,所以一般建议放在页面底部.
正文中的元素顺序
浏览器的加载顺序是从上到下,而搜索引擎的一般习惯是从上到下,从左到右,所以在body中写代码时的重要思想是:重要的放在最上面,不重要的放在下面。
页面代码顺序是否可逆?
css代码元素的排序
Div和CSS是网页设计中常用的技术,使用起来非常方便。CSS中有很多元素,例如:背景颜色、长度、宽度、高度和字体样式。在 CSS 代码元素中,有些顺序会被忽略,但有些顺序必须正确书写。比如你想在CSS代码中写加粗字体和CSS reset reset,那么就必须先加载CSS reset,字体加粗。稍后加载,如果顺序颠倒,字体加粗后会重置,会覆盖加粗效果。
js代码顺序
如果要加载js代码,应该先调用jQuery库,再编写js文件。浏览器在先下载库后,只会识别依赖于jQuery库的js文件。
网页代码中有些元素的顺序是可以相互交换的,但是有些代码的顺序是必须要遵循的,所以在编写网页代码的时候要注意。
戴蒙p2p网贷系统开发商提醒您! 查看全部
jquery抓取网页内容(网页设计是p2p建设网站必不可少的,那么你是否观察过)
网页设计是p2p建设必不可少的网站,那么你观察过网页中代码的顺序吗?网页的代码顺序是可逆的吗?
头部元素排序
网页中的head元素,也称为head,通常收录文档的描述信息,一般包括网页代码、title标题、meta描述网页关键字、链接导入CSS文件、js文件等。
首先是标准的 DOCTYPE 声明,HTML 结构。
然后是元和标题部分,它们在网页中非常重要。浏览器用什么代码来解析网页,文章的标题是什么,文章的关键词是什么?文章 的描述是什么?这些对于 文章 的搜索引擎抓取和排名非常重要。
最后js部分,页面任意位置都可以添加js,但是js的加载速度很慢,而且对于搜索引擎来说,js是一个“陌生人”,所以一般建议放在页面底部.
正文中的元素顺序
浏览器的加载顺序是从上到下,而搜索引擎的一般习惯是从上到下,从左到右,所以在body中写代码时的重要思想是:重要的放在最上面,不重要的放在下面。
页面代码顺序是否可逆?
css代码元素的排序
Div和CSS是网页设计中常用的技术,使用起来非常方便。CSS中有很多元素,例如:背景颜色、长度、宽度、高度和字体样式。在 CSS 代码元素中,有些顺序会被忽略,但有些顺序必须正确书写。比如你想在CSS代码中写加粗字体和CSS reset reset,那么就必须先加载CSS reset,字体加粗。稍后加载,如果顺序颠倒,字体加粗后会重置,会覆盖加粗效果。
js代码顺序
如果要加载js代码,应该先调用jQuery库,再编写js文件。浏览器在先下载库后,只会识别依赖于jQuery库的js文件。
网页代码中有些元素的顺序是可以相互交换的,但是有些代码的顺序是必须要遵循的,所以在编写网页代码的时候要注意。
戴蒙p2p网贷系统开发商提醒您!
jquery抓取网页内容(自然要和http的request,get,post一些方法相关)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-29 10:17
Node.js Request+Cheerio实现小爬虫-基础功能实现1:内容抓取
Node.js Request+Cheerio实现小爬虫-基础功能实现2:文件写入
Node.js Request+Cheerio实现小爬虫-基础功能实现3:进程控制和并发控制
Node.js Request+Cheerio 实现小爬虫 - 额外部分:代理设置
前段时间碰巧有个小任务是爬虫。因为一直使用js和Node.js的兴起,所以我打算用Node来完成这个任务。当然,在实施过程中也遇到了很多问题。所以我打算把它写成评论和排序。
既然是爬虫,自然和http的request、get、post方法有关。至于这方面的知识,可以去问谷歌或者度娘。除了http相关的知识,我们还需要提取抓取到的内容。提取可以使用万能的正则表达式,当然我们也可以使用node丰富的包。下面是这个小项目用到的node包。
使用的包
要求
Request 模块是一个非常方便使用的 http 模块。具体用法请参考GitHub官方主页。
官方主页
切里奥
Cheerio 是一个可以使用 jQuery 语法来提取内容的模块。特别是对于从网络上抓取的东西。因为它使用与jQuery相同的语法,所以特别适合前端使用。
官方主页
现在您已经介绍了包和模块,是时候试用它们了。那我们把代码放在下面吧!
const request = require('request');
const cheerio = require('cheerio');
var shopLists = [];
var option = {
url: url,
// 不加入headers的话很可能会被拒绝访问
headers: {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.6',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Mobile Safari/537.36',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
};
request(option, function(error, response, body) {
if (!error && response.statusCode == 200) {
// 使用Cheerio对抓取到的内容进行解析
var $ = cheerio.load(body, {
ignoreWhitespace: true,
xmlMode: true
});
var shopInfo = {
pageNo: option.url.match(/g\d+p(\d+)/)[1],
pageURL: option.url,
info: []
};
var shopList = $('div#shop-all-list').find('a[data-hippo-type = "shop"]');
shopList.each(function(no, shop) {
let info = {};
info.no = no + 1;
info.name = $(shop).attr('title');
info.url = $(shop).attr('href');
shopInfo.info.push(info);
});
shopLists.push(shopInfo);
}
});
这样就可以抓取到想要的网站内容了。当然,问题自然会一个接一个地解决。现在您已经捕获了内容,您总是希望将其保存在一个地方。以本地保存为例,我们可以使用Node自带的fs模块来读取文件。fs模块的使用方法请参考官方文档或向谷歌渡娘咨询。
const fs = require('fs');
...
// 刚才的爬虫代码
...
fs.writeFile(FILE_PATH + FILE_NAME, shopLists, 'utf-8', function(err) {
if (err) {
console.error("文件生成时发生错误.");
throw err;
}
console.info('文件已经成功生成.');
});
好吧,看来问题已经解决了。所以不管它是否有效,都需要练习。运行它,问题就出现了。文件是0,那是怎么回事?只需在下一篇文章文章 中解决它。 查看全部
jquery抓取网页内容(自然要和http的request,get,post一些方法相关)
Node.js Request+Cheerio实现小爬虫-基础功能实现1:内容抓取
Node.js Request+Cheerio实现小爬虫-基础功能实现2:文件写入
Node.js Request+Cheerio实现小爬虫-基础功能实现3:进程控制和并发控制
Node.js Request+Cheerio 实现小爬虫 - 额外部分:代理设置
前段时间碰巧有个小任务是爬虫。因为一直使用js和Node.js的兴起,所以我打算用Node来完成这个任务。当然,在实施过程中也遇到了很多问题。所以我打算把它写成评论和排序。
既然是爬虫,自然和http的request、get、post方法有关。至于这方面的知识,可以去问谷歌或者度娘。除了http相关的知识,我们还需要提取抓取到的内容。提取可以使用万能的正则表达式,当然我们也可以使用node丰富的包。下面是这个小项目用到的node包。
使用的包
要求
Request 模块是一个非常方便使用的 http 模块。具体用法请参考GitHub官方主页。
官方主页
切里奥
Cheerio 是一个可以使用 jQuery 语法来提取内容的模块。特别是对于从网络上抓取的东西。因为它使用与jQuery相同的语法,所以特别适合前端使用。
官方主页
现在您已经介绍了包和模块,是时候试用它们了。那我们把代码放在下面吧!
const request = require('request');
const cheerio = require('cheerio');
var shopLists = [];
var option = {
url: url,
// 不加入headers的话很可能会被拒绝访问
headers: {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.6',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Mobile Safari/537.36',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
};
request(option, function(error, response, body) {
if (!error && response.statusCode == 200) {
// 使用Cheerio对抓取到的内容进行解析
var $ = cheerio.load(body, {
ignoreWhitespace: true,
xmlMode: true
});
var shopInfo = {
pageNo: option.url.match(/g\d+p(\d+)/)[1],
pageURL: option.url,
info: []
};
var shopList = $('div#shop-all-list').find('a[data-hippo-type = "shop"]');
shopList.each(function(no, shop) {
let info = {};
info.no = no + 1;
info.name = $(shop).attr('title');
info.url = $(shop).attr('href');
shopInfo.info.push(info);
});
shopLists.push(shopInfo);
}
});
这样就可以抓取到想要的网站内容了。当然,问题自然会一个接一个地解决。现在您已经捕获了内容,您总是希望将其保存在一个地方。以本地保存为例,我们可以使用Node自带的fs模块来读取文件。fs模块的使用方法请参考官方文档或向谷歌渡娘咨询。
const fs = require('fs');
...
// 刚才的爬虫代码
...
fs.writeFile(FILE_PATH + FILE_NAME, shopLists, 'utf-8', function(err) {
if (err) {
console.error("文件生成时发生错误.");
throw err;
}
console.info('文件已经成功生成.');
});
好吧,看来问题已经解决了。所以不管它是否有效,都需要练习。运行它,问题就出现了。文件是0,那是怎么回事?只需在下一篇文章文章 中解决它。
jquery抓取网页内容(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-27 19:00
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架
上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是爬取的页面数量、页面大小、爬取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是要爬取的URL数量巨大,爬虫是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人阅读后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,一段时间内没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。但是,存储大量历史信息对于搜索引擎来说是一种负担,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指根据网页显示的某些属性对许多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈! 查看全部
jquery抓取网页内容(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架

上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是爬取的页面数量、页面大小、爬取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是要爬取的URL数量巨大,爬虫是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略

宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人阅读后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,一段时间内没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。但是,存储大量历史信息对于搜索引擎来说是一种负担,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指根据网页显示的某些属性对许多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
jquery抓取网页内容(jquery抓取网页内容的一般步骤分为以下几个步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-26 06:04
jquery抓取网页内容的一般步骤分为以下几个步骤:一,分析抓取网页中需要爬取的部分,建立相关网页代码的二维表格。二,通过jquery框架将原始数据进行翻译三,将翻译后的数据进行解析工作,利用一些js框架四,利用js框架进行js解析工作,将页面返回给用户5.利用js框架解析出来的页面js内容存入对应的文件夹下面。
在jquery未对这个页面做处理时,通过javascript请求链接可以进行这样的操作。
首先你要知道request可以对接任何javascript网络请求。然后抓包看返回值的api是application/javascript,你懂的。另外这里其实只有ajax是抓包看到数据的,其他的都是自己写进去的javascript。
1.同时抓一个页面的ajax方法,再抓另一个页面的javascript需要的请求。2.post的方法应该在抓包时就可以捕捉到。3.jquery提供了接口(xmlhttprequest),但要使用这个接口前,需要先对页面进行处理,譬如一个javascript规定,如果前端页面已经包含javascript,那么javascript只能获取到varxxx;varxxx;xxx;中的部分javascript代码。
get是不行的,
<p>varxxx="accept";varxxx=[];for(vari=0;i 查看全部
jquery抓取网页内容(jquery抓取网页内容的一般步骤分为以下几个步骤)
jquery抓取网页内容的一般步骤分为以下几个步骤:一,分析抓取网页中需要爬取的部分,建立相关网页代码的二维表格。二,通过jquery框架将原始数据进行翻译三,将翻译后的数据进行解析工作,利用一些js框架四,利用js框架进行js解析工作,将页面返回给用户5.利用js框架解析出来的页面js内容存入对应的文件夹下面。
在jquery未对这个页面做处理时,通过javascript请求链接可以进行这样的操作。
首先你要知道request可以对接任何javascript网络请求。然后抓包看返回值的api是application/javascript,你懂的。另外这里其实只有ajax是抓包看到数据的,其他的都是自己写进去的javascript。
1.同时抓一个页面的ajax方法,再抓另一个页面的javascript需要的请求。2.post的方法应该在抓包时就可以捕捉到。3.jquery提供了接口(xmlhttprequest),但要使用这个接口前,需要先对页面进行处理,譬如一个javascript规定,如果前端页面已经包含javascript,那么javascript只能获取到varxxx;varxxx;xxx;中的部分javascript代码。
get是不行的,
<p>varxxx="accept";varxxx=[];for(vari=0;i
jquery抓取网页内容( JQuery插件Jqprint实现网页打印(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-23 17:13
JQuery插件Jqprint实现网页打印(图))
web各种前端打印方式的jquery打印插件jqprint实现网页打印
更新时间:2013-01-09 16:37:38 作者:
本文介绍JQuery插件Jqprint实现网页打印。不懂的同学可以借此机会学习一下,以防万一,话不多说,切入主题
我对网络打印方法的了解有:
1、JQuery插件Jqprint实现
2、JQery打印插件PrintArea实现网页打印
3、CSS 控制网页打印样式
JQuery插件Jqprint实现:
首先导入js文件:
jquery.jqprint.js 下载
复制代码代码如下:
html代码:
复制代码代码如下:
打印时显示
打印时隐藏。
javascript代码:
复制代码代码如下:
插件还提供了一些参数来配置:
debug: false,//如果为true,可以显示iframe查看效果(默认iframe的高宽都很小,可以在源码中增加),默认为false
importCSS: true, //true表示导入原页面的CSS,默认为true。 (如果为真则先查找$("link[media=print]"),否则先查找$("link")中的css文件)
printContainer: true,//表示最初选择的对象是否必须收录在打印中(注意:设置为false可能会破坏您的CSS规则)。
operaSupport: true//表示插件是否还必须支持opera浏览器,在这种情况下,它会提供创建一个临时打印选项卡。默认为真
我自己只使用importCSS:原创页面中的链接会被导入到iframe中。第一次media search=打印,如果没有,就会导入正常的css文件。
importCSS 示例:
复制代码代码如下:
$('.my_show').jqprint({
importCSS://CSS 样式文件
}); 查看全部
jquery抓取网页内容(
JQuery插件Jqprint实现网页打印(图))
web各种前端打印方式的jquery打印插件jqprint实现网页打印
更新时间:2013-01-09 16:37:38 作者:
本文介绍JQuery插件Jqprint实现网页打印。不懂的同学可以借此机会学习一下,以防万一,话不多说,切入主题
我对网络打印方法的了解有:
1、JQuery插件Jqprint实现
2、JQery打印插件PrintArea实现网页打印
3、CSS 控制网页打印样式
JQuery插件Jqprint实现:
首先导入js文件:
jquery.jqprint.js 下载
复制代码代码如下:
html代码:
复制代码代码如下:
打印时显示
打印时隐藏。
javascript代码:
复制代码代码如下:
插件还提供了一些参数来配置:
debug: false,//如果为true,可以显示iframe查看效果(默认iframe的高宽都很小,可以在源码中增加),默认为false
importCSS: true, //true表示导入原页面的CSS,默认为true。 (如果为真则先查找$("link[media=print]"),否则先查找$("link")中的css文件)
printContainer: true,//表示最初选择的对象是否必须收录在打印中(注意:设置为false可能会破坏您的CSS规则)。
operaSupport: true//表示插件是否还必须支持opera浏览器,在这种情况下,它会提供创建一个临时打印选项卡。默认为真
我自己只使用importCSS:原创页面中的链接会被导入到iframe中。第一次media search=打印,如果没有,就会导入正常的css文件。
importCSS 示例:
复制代码代码如下:
$('.my_show').jqprint({
importCSS://CSS 样式文件
});
jquery抓取网页内容(聊一聊Python与网络爬虫的主要框架及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-23 02:14
我们来谈谈 Python 和网络爬虫。
1、爬虫的定义
Crawler:自动抓取互联网数据的程序。
2、爬虫主要框架
爬虫程序的主框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中有需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的URL。网页,然后调用网页解析器解析网页,将网页中新的URL添加到URL管理器中,输出有价值的数据。
3、爬虫时序图
4、网址管理器
网址管理器管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。 URL管理器的主要功能如下图所示:
URL管理器的实现主要使用Python中的内存(set)和关系型数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,一般采用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用了urllib库,这是python自带的一个模块。对于2.x版本的urllib2库,在其request和其他子模块中集成到python3.x中的urllib中。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen函数的参数可以是url链接,也可以是请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页,带有反爬虫机制的网页,然后使用urlopen函数,需要添加http头。对于有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载的 url 数据中提取有价值的数据和新的 url。对于数据提取,可以使用正则表达式、BeautifulSoup等方法。正则表达式采用基于字符串的模糊匹配,对目标源gao@daima#com有较好的效果,特征比较鲜明(%code@#数据,但通用性不高。BeautifulSoup是第三个—— party模块,用于结构化解析url内容。下载的网页内容被解析成DOM树。下图是BeautifulSoup抓取的百度百科中的一个网页的部分输出。
BeautifulSoup的具体使用会在以后写文章。以下代码使用python抓取百度百科中其他英雄联盟相关条目,并将这些条目保存在新建的excel中。以上代码:
from bs4 import BeautifulSoup import re import xlrd import xlwt from urllib.request import urlopen excelFile=xlwt.Workbook() sheet=excelFile.add_sheet('league of legend') ## 百度百科:英雄联盟## html=urlopen("http://baike.baidu.com/subview ... 6quot;) bsObj=BeautifulSoup(html.read(),"html.parser") #print(bsObj.prettify()) row=0 for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}): links=node.findAll("a",href=re.compile("^(/view/)[0-9]+\.htm$")) for link in links: if 'href' in link.attrs: print(link.attrs['href'],link.get_text()) sheet.write(row,0,link.attrs['href']) sheet.write(row,1,link.get_text()) row=row+1 excelFile.save('E:\Project\Python\lol.xls')
部分输出截图如下:
excel部分截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。 查看全部
jquery抓取网页内容(聊一聊Python与网络爬虫的主要框架及应用)
我们来谈谈 Python 和网络爬虫。
1、爬虫的定义
Crawler:自动抓取互联网数据的程序。
2、爬虫主要框架
爬虫程序的主框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中有需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的URL。网页,然后调用网页解析器解析网页,将网页中新的URL添加到URL管理器中,输出有价值的数据。
3、爬虫时序图
4、网址管理器
网址管理器管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。 URL管理器的主要功能如下图所示:
URL管理器的实现主要使用Python中的内存(set)和关系型数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,一般采用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用了urllib库,这是python自带的一个模块。对于2.x版本的urllib2库,在其request和其他子模块中集成到python3.x中的urllib中。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen函数的参数可以是url链接,也可以是请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页,带有反爬虫机制的网页,然后使用urlopen函数,需要添加http头。对于有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载的 url 数据中提取有价值的数据和新的 url。对于数据提取,可以使用正则表达式、BeautifulSoup等方法。正则表达式采用基于字符串的模糊匹配,对目标源gao@daima#com有较好的效果,特征比较鲜明(%code@#数据,但通用性不高。BeautifulSoup是第三个—— party模块,用于结构化解析url内容。下载的网页内容被解析成DOM树。下图是BeautifulSoup抓取的百度百科中的一个网页的部分输出。
BeautifulSoup的具体使用会在以后写文章。以下代码使用python抓取百度百科中其他英雄联盟相关条目,并将这些条目保存在新建的excel中。以上代码:
from bs4 import BeautifulSoup import re import xlrd import xlwt from urllib.request import urlopen excelFile=xlwt.Workbook() sheet=excelFile.add_sheet('league of legend') ## 百度百科:英雄联盟## html=urlopen("http://baike.baidu.com/subview ... 6quot;) bsObj=BeautifulSoup(html.read(),"html.parser") #print(bsObj.prettify()) row=0 for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}): links=node.findAll("a",href=re.compile("^(/view/)[0-9]+\.htm$")) for link in links: if 'href' in link.attrs: print(link.attrs['href'],link.get_text()) sheet.write(row,0,link.attrs['href']) sheet.write(row,1,link.get_text()) row=row+1 excelFile.save('E:\Project\Python\lol.xls')
部分输出截图如下:
excel部分截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。
jquery抓取网页内容(PHP中CURL使用正则表达式抓取网站信息的如下操作相关技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-23 02:06
本篇文章主要介绍C#中使用正则表达式抓取网站信息,并结合实例分析C#对网页信息的正则爬取操作的相关技巧。@Code~Code$Net 参考值,有需要的朋友可以参考下面的例子,里面描述了C#使用正则表达式捕获网站信息的方法。分享给大家参考,具体如下: 这里以抓取京东商城商品详情为例。1、创建JdRobber.cs程序类public class JdRobber{ /// ///判断京东是否链接/// /// ///
1. C# 如何使用正则表达式捕获 网站 信息的代码示例
简介:本文章主要介绍了C#中使用正则表达式抓取网站信息,并结合实例分析了C#对网页信息正则爬取的相关技巧,具有一定的参考价值。朋友可以参考
2.使用python抓取求职网站信息
简介:本文章介绍使用python抓取求职网站信息
3. 创建数据库php代码,用PHP_PHP教程编写自己的博客系统
简介:创建数据库php代码,用PHP编写自己的BLOG系统。直接复制下面的代码:?php //date_default_timezone_set("Asia/Shanghai"); /* function create_siteinfo DONE:网站信息表作者:DATE:2010-3-
4. PHP中的CURL技术模拟登录并获取网站信息,并在微信公众平台查询结果_PHP教程
简介:PHP中的CURL技术模拟登录并获取网站信息,并在微信公众平台查询结果。随着微信的火爆,微信公众平台成为众多开发者的下一个目标。作者本人对这种新颖性并不那么有吸引力。但是最近有朋友帮忙开发
5.使用PHP curl模拟浏览器抓包网站信息_PHP教程
简介:使用PHP curl模拟浏览器对网站信息的抓取。官方解释 curl 是一个文件传输工具,使用 URL 语法在命令行模式下工作。curl 是一个文件传输工具,它使用 URL 语法从命令行工作。它非常支持
6. 关于 PHP 命名约定
简介:既然是web项目,难免会在配置文件中写入数据库连接信息,网站常量。我在 config.inc.php 中编写了以下代码: ?php //网站info $siteurl = ';; /*网站网址*/ $sitename = '春卷'; /*< @网站Name*/ //数据库配置 $hostnam
7. 网站添加RSS功能
简介:为方便用户定制网站内容而设置的各种RSS频道。通过订阅不同的RSS(可以同时订阅多个网站),观看者无需登录网站即可及时获取新闻信息,也可以避免网页上无用的广告和垃圾信息干涉。使用RSS将为观众节省大量时间,也将成为网站人性化设计的一大亮点,提升网站的档次。其实RSS技术并不太难。如果您的 网站 信息很大,您可以将此技术应用于您自己的站点。一、什么是RSSRSS是站点和站点
8. 如何通过网页判断用户机器上是否安装了这个软件
简介:如何通过网页判断用户机器上是否安装了这个软件我们为网站开发了一个小软件,它具有自己发消息和聊天的功能,包括阅读网站消息。现在想问一下,如何通过网页来判断用户机器上是否安装了这个软件?如果已安装,您可以启动该软件的消息窗口,如果没有,请进入下载安装页面。类似于QQ?在线/离线模仿- 解决办法 ——————–
9. php 网站信息查询站点
简介:php网站信息查询站点想开发一个与php类似的站点。大家给出一些想法。. . ——最佳方案————SEO下的一些内容可以抓取,有的内容叫界面。很多工具都是自己开发的,简单说几句
10. 没有数据库的空间怎么做动态网站
简介:没有数据库网站的空间怎么做动态?没有php环境,只能用html语言、css、javascript建站,还需要更新网站信息(例如:新闻、视频等)。求指点,谢谢大侠!分享给:
【相关问答推荐】:
requests - 有关 python 模拟登录捕获的信息 网站
[求助] PHP使用curl模拟post提交数据获取目标网站信息,解决? 查看全部
jquery抓取网页内容(PHP中CURL使用正则表达式抓取网站信息的如下操作相关技巧)
本篇文章主要介绍C#中使用正则表达式抓取网站信息,并结合实例分析C#对网页信息的正则爬取操作的相关技巧。@Code~Code$Net 参考值,有需要的朋友可以参考下面的例子,里面描述了C#使用正则表达式捕获网站信息的方法。分享给大家参考,具体如下: 这里以抓取京东商城商品详情为例。1、创建JdRobber.cs程序类public class JdRobber{ /// ///判断京东是否链接/// /// ///
1. C# 如何使用正则表达式捕获 网站 信息的代码示例
简介:本文章主要介绍了C#中使用正则表达式抓取网站信息,并结合实例分析了C#对网页信息正则爬取的相关技巧,具有一定的参考价值。朋友可以参考
2.使用python抓取求职网站信息
简介:本文章介绍使用python抓取求职网站信息
3. 创建数据库php代码,用PHP_PHP教程编写自己的博客系统
简介:创建数据库php代码,用PHP编写自己的BLOG系统。直接复制下面的代码:?php //date_default_timezone_set("Asia/Shanghai"); /* function create_siteinfo DONE:网站信息表作者:DATE:2010-3-
4. PHP中的CURL技术模拟登录并获取网站信息,并在微信公众平台查询结果_PHP教程
简介:PHP中的CURL技术模拟登录并获取网站信息,并在微信公众平台查询结果。随着微信的火爆,微信公众平台成为众多开发者的下一个目标。作者本人对这种新颖性并不那么有吸引力。但是最近有朋友帮忙开发
5.使用PHP curl模拟浏览器抓包网站信息_PHP教程
简介:使用PHP curl模拟浏览器对网站信息的抓取。官方解释 curl 是一个文件传输工具,使用 URL 语法在命令行模式下工作。curl 是一个文件传输工具,它使用 URL 语法从命令行工作。它非常支持
6. 关于 PHP 命名约定
简介:既然是web项目,难免会在配置文件中写入数据库连接信息,网站常量。我在 config.inc.php 中编写了以下代码: ?php //网站info $siteurl = ';; /*网站网址*/ $sitename = '春卷'; /*< @网站Name*/ //数据库配置 $hostnam
7. 网站添加RSS功能
简介:为方便用户定制网站内容而设置的各种RSS频道。通过订阅不同的RSS(可以同时订阅多个网站),观看者无需登录网站即可及时获取新闻信息,也可以避免网页上无用的广告和垃圾信息干涉。使用RSS将为观众节省大量时间,也将成为网站人性化设计的一大亮点,提升网站的档次。其实RSS技术并不太难。如果您的 网站 信息很大,您可以将此技术应用于您自己的站点。一、什么是RSSRSS是站点和站点
8. 如何通过网页判断用户机器上是否安装了这个软件
简介:如何通过网页判断用户机器上是否安装了这个软件我们为网站开发了一个小软件,它具有自己发消息和聊天的功能,包括阅读网站消息。现在想问一下,如何通过网页来判断用户机器上是否安装了这个软件?如果已安装,您可以启动该软件的消息窗口,如果没有,请进入下载安装页面。类似于QQ?在线/离线模仿- 解决办法 ——————–
9. php 网站信息查询站点
简介:php网站信息查询站点想开发一个与php类似的站点。大家给出一些想法。. . ——最佳方案————SEO下的一些内容可以抓取,有的内容叫界面。很多工具都是自己开发的,简单说几句
10. 没有数据库的空间怎么做动态网站
简介:没有数据库网站的空间怎么做动态?没有php环境,只能用html语言、css、javascript建站,还需要更新网站信息(例如:新闻、视频等)。求指点,谢谢大侠!分享给:
【相关问答推荐】:
requests - 有关 python 模拟登录捕获的信息 网站
[求助] PHP使用curl模拟post提交数据获取目标网站信息,解决?
jquery抓取网页内容(谷歌实际上是否会通过ajax呼叫来拉下/链接流量?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-19 09:18
概述 在我的 网站 主页上,我使用 JQuery 的 ajax 函数来下拉用户最近活动的列表。最近的活动显示在页面上,最近活动的每一行都收录一个指向执行该活动的用户的用户配置文件的链接。Google 是否真的通过 ajax 调用来提取这些信息并使用它来计算页面相关性/链接流量?我希望不是因为用户个人资料页面不太值得谷歌索引,我不希望所有这些链接到用户个人资料页面,使我的主页的链接流量远离其他更重要的链接
在我的 网站 主页上,我使用 JQuery 的 ajax 函数来下拉用户最近活动的列表。
最近的活动显示在页面上,最近活动的每一行都收录一个指向执行该活动的用户的用户配置文件的链接。
Google 是否真的通过 ajax 调用来提取这些信息并使用它来计算页面相关性/链接流量?
我希望这不是因为用户个人资料页面不太值得谷歌索引,我不希望所有这些链接到用户个人资料页面,使我的主页的链接流量远离其他更重要的链接。
解决方案
不,默认情况下不会抓取 AJAX 内容。
有关于如何使 AJAX 内容可抓取的说明,但这些是您需要采取的明确步骤,它不是自动的
总结
以上是编程之家为你采集的jquery——谷歌会抓取AJAX内容吗?全部内容,希望文章能对jquery有所帮助——谷歌会抓取AJAX内容吗?程序开发遇到的问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。 查看全部
jquery抓取网页内容(谷歌实际上是否会通过ajax呼叫来拉下/链接流量?(图))
概述 在我的 网站 主页上,我使用 JQuery 的 ajax 函数来下拉用户最近活动的列表。最近的活动显示在页面上,最近活动的每一行都收录一个指向执行该活动的用户的用户配置文件的链接。Google 是否真的通过 ajax 调用来提取这些信息并使用它来计算页面相关性/链接流量?我希望不是因为用户个人资料页面不太值得谷歌索引,我不希望所有这些链接到用户个人资料页面,使我的主页的链接流量远离其他更重要的链接
在我的 网站 主页上,我使用 JQuery 的 ajax 函数来下拉用户最近活动的列表。
最近的活动显示在页面上,最近活动的每一行都收录一个指向执行该活动的用户的用户配置文件的链接。
Google 是否真的通过 ajax 调用来提取这些信息并使用它来计算页面相关性/链接流量?
我希望这不是因为用户个人资料页面不太值得谷歌索引,我不希望所有这些链接到用户个人资料页面,使我的主页的链接流量远离其他更重要的链接。
解决方案
不,默认情况下不会抓取 AJAX 内容。
有关于如何使 AJAX 内容可抓取的说明,但这些是您需要采取的明确步骤,它不是自动的
总结
以上是编程之家为你采集的jquery——谷歌会抓取AJAX内容吗?全部内容,希望文章能对jquery有所帮助——谷歌会抓取AJAX内容吗?程序开发遇到的问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
jquery抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-16 13:00
需要思考的问题:
如何在一个网页的div中嵌套另一个网页(不使用include、iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套网页无法获取父页面)信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一个页面的一部分)
答案(想法):
使用jquery的ajax函数或者load函数可以获取网页的内容,从而实现网页的嵌套(获取的网页内容为html字符串)。如何从字符串中获取部分内容?
练习一:
index.html页面(获取本页内容页面的内容)
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题到这里就可以解决了,点击获取完整的content.html页面的内容
查看jquery的load方法可以发现load函数其实可以指定网页的内容
练习二:
更改index.html页面的ajax函数的url路径获取content.html页面div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url + ' #container',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + ' #container');
48 }
49
查看代码
至此我们解决了,文章一开始提出的问题。. . . . . 但这是一个静态页面(html页面),它可以工作吗?
答案是否定的,ajax函数或者load函数获取的页面内容是否收录title标签和两个
这是ajax获取的内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到,不仅获取到了div的内容,还多了两个div和一个title
上网查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行,下面是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: 'get',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + ' #container':获取url网页中container容器内的内容
41 url: url + ' #container',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find('div[id=container]').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + ' #container', '', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find('div[id=container]').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
这里还有一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个页面,使用母版页会导致标签id发生变化。我想要实现的是在不刷新页面的情况下点击菜单。
转载于: 查看全部
jquery抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
需要思考的问题:
如何在一个网页的div中嵌套另一个网页(不使用include、iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套网页无法获取父页面)信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一个页面的一部分)
答案(想法):
使用jquery的ajax函数或者load函数可以获取网页的内容,从而实现网页的嵌套(获取的网页内容为html字符串)。如何从字符串中获取部分内容?
练习一:
index.html页面(获取本页内容页面的内容)


1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题到这里就可以解决了,点击获取完整的content.html页面的内容
查看jquery的load方法可以发现load函数其实可以指定网页的内容
练习二:
更改index.html页面的ajax函数的url路径获取content.html页面div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url + ' #container',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + ' #container');
48 }
49
查看代码
至此我们解决了,文章一开始提出的问题。. . . . . 但这是一个静态页面(html页面),它可以工作吗?
答案是否定的,ajax函数或者load函数获取的页面内容是否收录title标签和两个
这是ajax获取的内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到,不仅获取到了div的内容,还多了两个div和一个title
上网查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行,下面是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: 'get',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + ' #container':获取url网页中container容器内的内容
41 url: url + ' #container',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find('div[id=container]').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + ' #container', '', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find('div[id=container]').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
这里还有一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个页面,使用母版页会导致标签id发生变化。我想要实现的是在不刷新页面的情况下点击菜单。
转载于:
jquery抓取网页内容(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-16 07:16
任何你想要的信息基本上都在网上存在,问题是如何组织成你需要的,比如抓取某个行业所有相关公司的名字网站,联系电话,Email,等,然后将其保存在 Excel 中进行分析。网页抓取变得越来越有用。
对于传统网页,web服务器直接返回Html。这种类型的网页很容易掌握。不管用什么方法,只要拿到html页面,然后做Dom解析。但是对于需要Javascript来生成的网页来说,就不是那么容易了。张宇还没有找到解决这个问题的好办法。欢迎有抓javascript网页经验的朋友指点。
那么今天我要讲的就是传统html网页的信息爬取。虽然如前所述,没有技术难度,但是有没有相对简单的方法呢?使用过 jQuery 等 js 框架的朋友可能会认为 javascript 就像是抓取网页信息的天然助手,为网页解析而生。当然,现在有更多的应用,比如服务器端的javascript应用,NodeJs。
如果能够在我们的应用程序中使用 jQuery 来抓取网页,例如 java 程序,那将是非常令人兴奋的。确实有现成的解决方案,Javascript引擎,可以支持jQuery运行的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import org.mozilla.javascript.Context;
import org.mozilla.javascript.ContextFactory;
import org.mozilla.javascript.Scriptable;
import org.mozilla.javascript.ScriptableObject;
/**
* @author MyBeautiful
* @Emal: zhangyu0182@sina.com
* @date Mar 7, 2012
*/
public class RhinoScaper {
private String url;
private String jsFile;
private Context cx;
private Scriptable scope;
public String getUrl() {
return url;
}
public String getJsFile() {
return jsFile;
}
public void setUrl(String url) {
this.url = url;
putObject("url", url);
}
public void setJsFile(String jsFile) {
this.jsFile = jsFile;
}
public void init() {
cx = ContextFactory.getGlobal().enterContext();
scope = cx.initStandardObjects(null);
cx.setOptimizationLevel(-1);
cx.setLanguageVersion(Context.VERSION_1_5);
String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" };
for (String f : file) {
evaluateJs(f);
}
try {
ScriptableObject.defineClass(scope, ExtendUtil.class);
} catch (IllegalAccessException e1) {
e1.printStackTrace();
} catch (InstantiationException e1) {
e1.printStackTrace();
} catch (InvocationTargetException e1) {
e1.printStackTrace();
}
ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util");
scope.put("util", scope, util);
}
protected void evaluateJs(String f) {
try {
FileReader in = null;
in = new FileReader(f);
cx.evaluateReader(scope, in, f, 1, null);
} catch (FileNotFoundException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
public void putObject(String name, Object o) {
scope.put(name, scope, o);
}
public void run() {
evaluateJs(this.jsFile);
}
}
测试代码:
package stony.zhang.scrape;
import java.util.HashMap;
import java.util.Map;
import junit.framework.TestCase;
public class RhinoScaperTest extends TestCase {
public RhinoScaperTest(String name) {
super(name);
}
public void testRun() {
RhinoScaper rs = new RhinoScaper();
rs.init();
rs.setUrl("http://www.baidu.com");
rs.setJsFile("test.js");
// Map o = new HashMap();
// rs.putObject("result", o);
rs.run();
// System.out.println(o.get("imgurl"));
}
}
test.js 文件,如下
$.ajax({
url: "http://www.baidu.com",
context: document.body,
success: function(data){
// util.log(data);
var result =parseHtml(data);
var $v= jQuery(result);
// util.log(result);
$v.find('#u a').each(function(index) {
util.log(index + ': ' + $(this).attr("href"));
// arr.add($(this).attr("href"));
});
}
});
function parseHtml(html) {
//Create an iFrame object that will be used to render the HTML in order to get the DOM objects
//created - this is a far quicker way of achieving the HTML to DOM conversion than trying
//to transform the HTML objects one-by-one
var oIframe = document.createElement('iframe');
//Hide the iFrame from view
oIframe.style.display = 'none';
if (document.body)
document.body.appendChild(oIframe);
else
document.documentElement.appendChild(oIframe);
//Open the iFrame DOM object and write in our HTML
oIframe.contentDocument.open();
oIframe.contentDocument.write(html);
oIframe.contentDocument.close();
//Return the document body object containing the HTML that was just
//added to the iFrame as DOM objects
var oBody = oIframe.contentDocument.body;
//TODO: Remove the iFrame object created to cleanup the DOM
return oBody;
}
当我们执行Unit Test的时候,会在控制台打印从网页抓取的三个百度连接,
0:
1:
2:
测试成功,证明在java程序中使用jQuery爬取网页是可行的。
----------------------------------- ---------- ------------
张宇,我的美丽, 查看全部
jquery抓取网页内容(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
任何你想要的信息基本上都在网上存在,问题是如何组织成你需要的,比如抓取某个行业所有相关公司的名字网站,联系电话,Email,等,然后将其保存在 Excel 中进行分析。网页抓取变得越来越有用。
对于传统网页,web服务器直接返回Html。这种类型的网页很容易掌握。不管用什么方法,只要拿到html页面,然后做Dom解析。但是对于需要Javascript来生成的网页来说,就不是那么容易了。张宇还没有找到解决这个问题的好办法。欢迎有抓javascript网页经验的朋友指点。
那么今天我要讲的就是传统html网页的信息爬取。虽然如前所述,没有技术难度,但是有没有相对简单的方法呢?使用过 jQuery 等 js 框架的朋友可能会认为 javascript 就像是抓取网页信息的天然助手,为网页解析而生。当然,现在有更多的应用,比如服务器端的javascript应用,NodeJs。
如果能够在我们的应用程序中使用 jQuery 来抓取网页,例如 java 程序,那将是非常令人兴奋的。确实有现成的解决方案,Javascript引擎,可以支持jQuery运行的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import org.mozilla.javascript.Context;
import org.mozilla.javascript.ContextFactory;
import org.mozilla.javascript.Scriptable;
import org.mozilla.javascript.ScriptableObject;
/**
* @author MyBeautiful
* @Emal: zhangyu0182@sina.com
* @date Mar 7, 2012
*/
public class RhinoScaper {
private String url;
private String jsFile;
private Context cx;
private Scriptable scope;
public String getUrl() {
return url;
}
public String getJsFile() {
return jsFile;
}
public void setUrl(String url) {
this.url = url;
putObject("url", url);
}
public void setJsFile(String jsFile) {
this.jsFile = jsFile;
}
public void init() {
cx = ContextFactory.getGlobal().enterContext();
scope = cx.initStandardObjects(null);
cx.setOptimizationLevel(-1);
cx.setLanguageVersion(Context.VERSION_1_5);
String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" };
for (String f : file) {
evaluateJs(f);
}
try {
ScriptableObject.defineClass(scope, ExtendUtil.class);
} catch (IllegalAccessException e1) {
e1.printStackTrace();
} catch (InstantiationException e1) {
e1.printStackTrace();
} catch (InvocationTargetException e1) {
e1.printStackTrace();
}
ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util");
scope.put("util", scope, util);
}
protected void evaluateJs(String f) {
try {
FileReader in = null;
in = new FileReader(f);
cx.evaluateReader(scope, in, f, 1, null);
} catch (FileNotFoundException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
public void putObject(String name, Object o) {
scope.put(name, scope, o);
}
public void run() {
evaluateJs(this.jsFile);
}
}
测试代码:
package stony.zhang.scrape;
import java.util.HashMap;
import java.util.Map;
import junit.framework.TestCase;
public class RhinoScaperTest extends TestCase {
public RhinoScaperTest(String name) {
super(name);
}
public void testRun() {
RhinoScaper rs = new RhinoScaper();
rs.init();
rs.setUrl("http://www.baidu.com";);
rs.setJsFile("test.js");
// Map o = new HashMap();
// rs.putObject("result", o);
rs.run();
// System.out.println(o.get("imgurl"));
}
}
test.js 文件,如下
$.ajax({
url: "http://www.baidu.com",
context: document.body,
success: function(data){
// util.log(data);
var result =parseHtml(data);
var $v= jQuery(result);
// util.log(result);
$v.find('#u a').each(function(index) {
util.log(index + ': ' + $(this).attr("href"));
// arr.add($(this).attr("href"));
});
}
});
function parseHtml(html) {
//Create an iFrame object that will be used to render the HTML in order to get the DOM objects
//created - this is a far quicker way of achieving the HTML to DOM conversion than trying
//to transform the HTML objects one-by-one
var oIframe = document.createElement('iframe');
//Hide the iFrame from view
oIframe.style.display = 'none';
if (document.body)
document.body.appendChild(oIframe);
else
document.documentElement.appendChild(oIframe);
//Open the iFrame DOM object and write in our HTML
oIframe.contentDocument.open();
oIframe.contentDocument.write(html);
oIframe.contentDocument.close();
//Return the document body object containing the HTML that was just
//added to the iFrame as DOM objects
var oBody = oIframe.contentDocument.body;
//TODO: Remove the iFrame object created to cleanup the DOM
return oBody;
}
当我们执行Unit Test的时候,会在控制台打印从网页抓取的三个百度连接,
0:
1:
2:
测试成功,证明在java程序中使用jQuery爬取网页是可行的。

----------------------------------- ---------- ------------
张宇,我的美丽,
jquery抓取网页内容( 什么是HTML?、Jquery、密码记性前端的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-15 08:04
什么是HTML?、Jquery、密码记性前端的区别)
jquery+Css+Html实现前端验证和用户登录功能的登录用户和密码
文章目录
前言
应用场景:可实现任意程序的登录,可对用户名、密码记忆或手机号、邮箱等信息进行前端验证。
温馨提示:以下为本文正文内容文章,以下案例供参考
一、什么是 jQuery?
jQuery 是免费的、开源的,并且在 MIT 许可下获得许可。jQuery 的语法旨在使开发人员更轻松,例如操作文档对象、选择 DOM 元素、制作动画、处理事件、使用 Ajax 和其他功能。此外,jQuery 还为开发人员提供了编写插件的 API。它的模块化使用允许开发人员轻松开发强大的静态或动态网页。(百度百科)。
二、什么是 CSS?
Cascading Style Sheets(英文全称:Cascading Style Sheets)是一种计算机语言,用于表示HTML(标准通用标记语言的一种应用)或XML(标准通用标记语言的一个子集)等文档样式。CSS不仅可以静态修改网页,还可以用各种脚本语言动态格式化网页的各种元素。CSS 可以对网页中元素位置的布局进行像素级的精确控制,支持几乎所有的字体大小样式,并具有编辑网页对象和模型样式的能力。(百度百科)。
三、什么是HTML?
HTML 代表超文本标记语言,它是一种标记语言。它包括一系列标签。通过这些标签,可以统一网络上的文档格式,将分散的互联网资源连接成一个逻辑整体。HTML 文本是由 HTML 命令组成的描述性文本,可以描述文本、图形、动画、声音、表格、链接等。. (百度百科)。
四、jquery前端代码实现
首先,导入jquery.js文件,使页面具备jquery的功能。该功能需要两个页面,一个登录页面,一个登录成功页面(文件需要流式传输,下班后可以流式传输私信,看到就会返回)
1.创建登录页面
创建.txt文本,然后写代码保存,然后把文本后缀改成.html保存,用浏览器打开
登录页面
//页面加载时 让id为uid的对象获得焦点
$(document).ready(function(){
//var oInput = $("#uid");
//oInput.focus();//获得焦点
// dom对象与jquery对象之间转换 原生js抓取和生成的对象称为dom对象,通过jquery创建和抓取的对象称为jquery对象,只有jquery对象可以调用jquery中方法
//var oInput = document.getElementById("uid");
//var oInput = $("#uid");
//将dom对象转为jquery对象(穿马甲)
//oInput = $(oInput);
//console.log(oInput.val());
//将jquery对象转为dom对象
//oInput = oInput[0];
//console.log(oInput.value);
var oInput = $("#uid");
oInput.focus();
});
function check()
{
//得到uid的值
var uid = $("#uid").val();
if(uid == "")
{
alert("用户ID必须填写!");
$("#uid").focus();
return ;
}
else
{
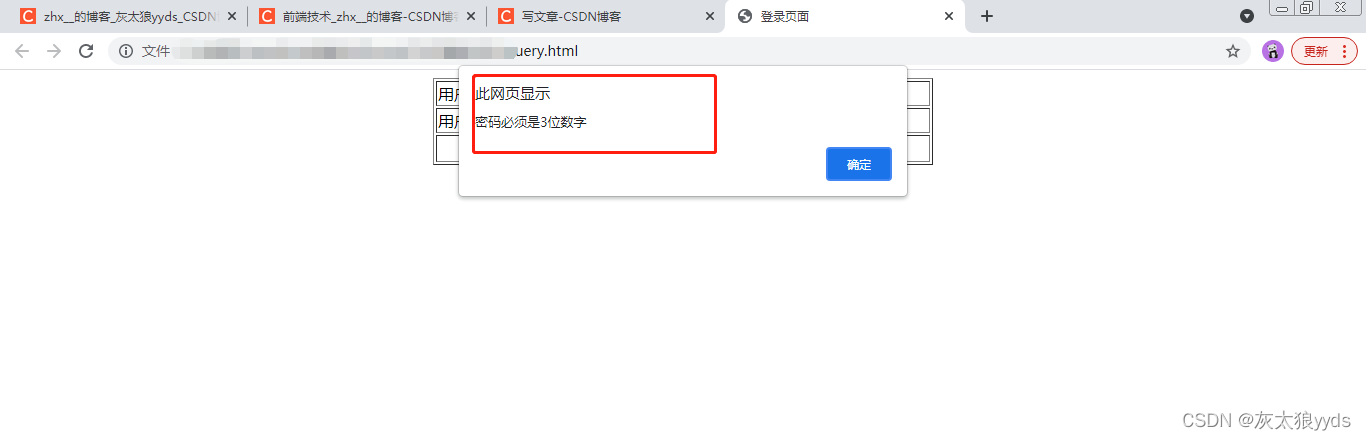
//校验密码是否为三位数字
var reg = new RegExp("^\\d{3}$");
var flag = reg.test($("#upass").val());
if(flag==false)
{
alert("密码必须是3位数字");
$("#upass").focus().select();
}
else
{
//提交表达
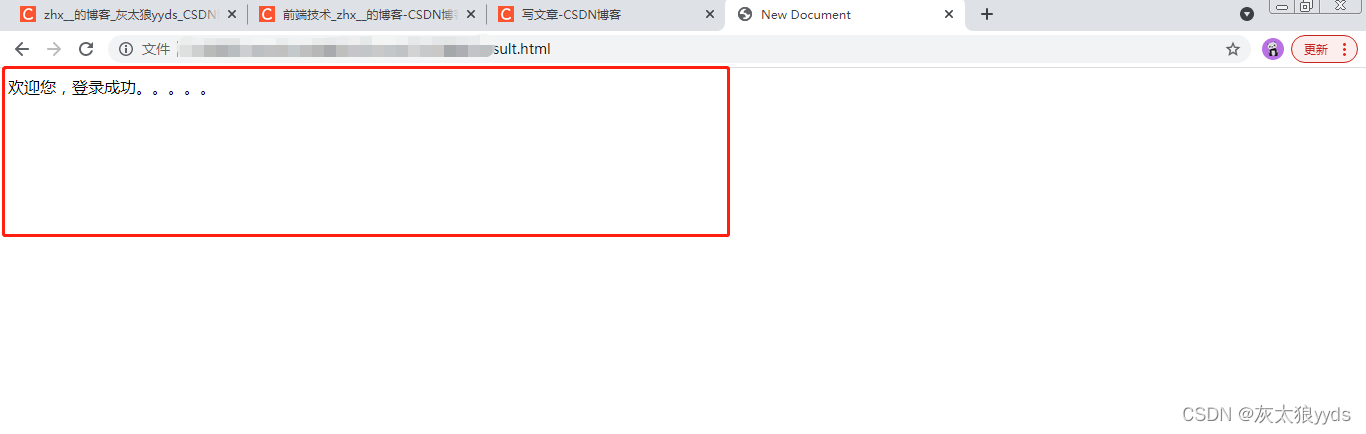
$("#thisform").attr({action:"result.html",method:"post"}).submit();
}
}
}
用户ID:
用户密码:
2.创建成功登录页面
登录成功的页面
欢迎您,登录成功。。。。。
1、 js代码和逻辑处理代码要写在标签体中。
2、 标签体要写css代码,页面显示的样式。
3、 标签体主要展示页面的内容。
4、 标签体主要是表头格式区。
5、 标签体是整个页面的区域。
6、标签是引入jquery.js文件src等于本地路径。
3.效果实现
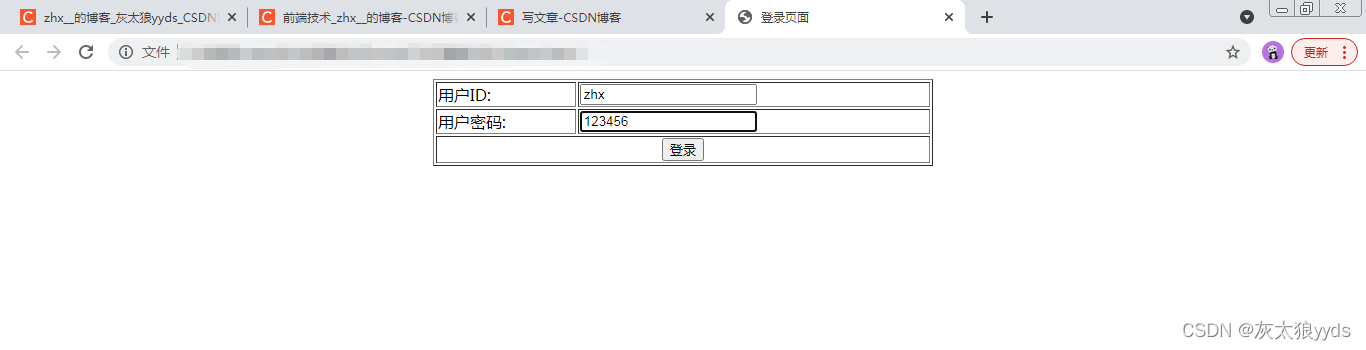
1、输入用户名zhx,密码123456,点击登录按钮。
定期检查密码。如果要定期检查密码,可以使用对应的正则表达式。这里为了方便演示,密码只能是3位数字。
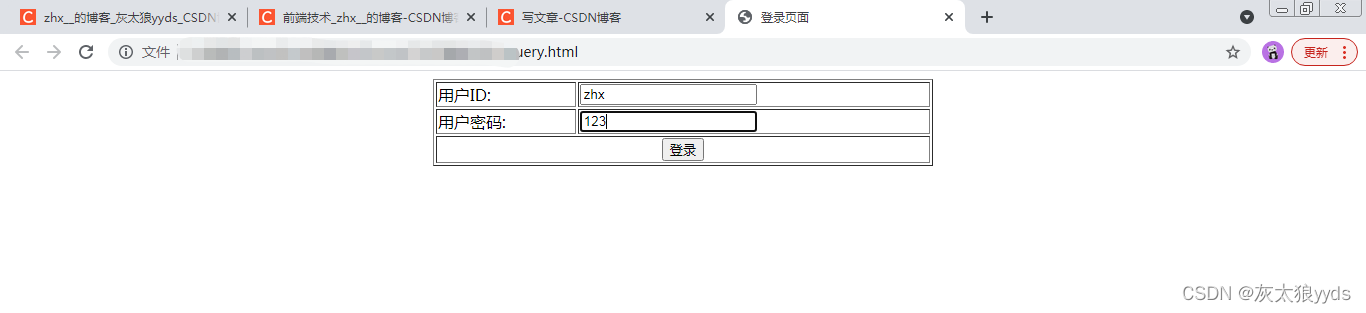
1、输入用户名zhx,密码123,点击登录按钮。
跳转到登录成功页面。
总结
对登录功能相关的用户名、密码、手机号、邮箱等信息进行验证,尽量在进入页面时进行验证,尽量避免后端验证减少与后端交互的频率。 查看全部
jquery抓取网页内容(
什么是HTML?、Jquery、密码记性前端的区别)
jquery+Css+Html实现前端验证和用户登录功能的登录用户和密码
文章目录
前言
应用场景:可实现任意程序的登录,可对用户名、密码记忆或手机号、邮箱等信息进行前端验证。
温馨提示:以下为本文正文内容文章,以下案例供参考
一、什么是 jQuery?
jQuery 是免费的、开源的,并且在 MIT 许可下获得许可。jQuery 的语法旨在使开发人员更轻松,例如操作文档对象、选择 DOM 元素、制作动画、处理事件、使用 Ajax 和其他功能。此外,jQuery 还为开发人员提供了编写插件的 API。它的模块化使用允许开发人员轻松开发强大的静态或动态网页。(百度百科)。
二、什么是 CSS?
Cascading Style Sheets(英文全称:Cascading Style Sheets)是一种计算机语言,用于表示HTML(标准通用标记语言的一种应用)或XML(标准通用标记语言的一个子集)等文档样式。CSS不仅可以静态修改网页,还可以用各种脚本语言动态格式化网页的各种元素。CSS 可以对网页中元素位置的布局进行像素级的精确控制,支持几乎所有的字体大小样式,并具有编辑网页对象和模型样式的能力。(百度百科)。
三、什么是HTML?
HTML 代表超文本标记语言,它是一种标记语言。它包括一系列标签。通过这些标签,可以统一网络上的文档格式,将分散的互联网资源连接成一个逻辑整体。HTML 文本是由 HTML 命令组成的描述性文本,可以描述文本、图形、动画、声音、表格、链接等。. (百度百科)。
四、jquery前端代码实现
首先,导入jquery.js文件,使页面具备jquery的功能。该功能需要两个页面,一个登录页面,一个登录成功页面(文件需要流式传输,下班后可以流式传输私信,看到就会返回)

1.创建登录页面
创建.txt文本,然后写代码保存,然后把文本后缀改成.html保存,用浏览器打开
登录页面
//页面加载时 让id为uid的对象获得焦点
$(document).ready(function(){
//var oInput = $("#uid");
//oInput.focus();//获得焦点
// dom对象与jquery对象之间转换 原生js抓取和生成的对象称为dom对象,通过jquery创建和抓取的对象称为jquery对象,只有jquery对象可以调用jquery中方法
//var oInput = document.getElementById("uid");
//var oInput = $("#uid");
//将dom对象转为jquery对象(穿马甲)
//oInput = $(oInput);
//console.log(oInput.val());
//将jquery对象转为dom对象
//oInput = oInput[0];
//console.log(oInput.value);
var oInput = $("#uid");
oInput.focus();
});
function check()
{
//得到uid的值
var uid = $("#uid").val();
if(uid == "")
{
alert("用户ID必须填写!");
$("#uid").focus();
return ;
}
else
{
//校验密码是否为三位数字
var reg = new RegExp("^\\d{3}$");
var flag = reg.test($("#upass").val());
if(flag==false)
{
alert("密码必须是3位数字");
$("#upass").focus().select();
}
else
{
//提交表达
$("#thisform").attr({action:"result.html",method:"post"}).submit();
}
}
}
用户ID:
用户密码:
2.创建成功登录页面
登录成功的页面
欢迎您,登录成功。。。。。
1、 js代码和逻辑处理代码要写在标签体中。
2、 标签体要写css代码,页面显示的样式。
3、 标签体主要展示页面的内容。
4、 标签体主要是表头格式区。
5、 标签体是整个页面的区域。
6、标签是引入jquery.js文件src等于本地路径。
3.效果实现
1、输入用户名zhx,密码123456,点击登录按钮。
定期检查密码。如果要定期检查密码,可以使用对应的正则表达式。这里为了方便演示,密码只能是3位数字。

1、输入用户名zhx,密码123,点击登录按钮。
跳转到登录成功页面。
总结
对登录功能相关的用户名、密码、手机号、邮箱等信息进行验证,尽量在进入页面时进行验证,尽量避免后端验证减少与后端交互的频率。
jquery抓取网页内容(抓取网页内容采用的是lodash方法来实现())
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-14 17:00
jquery抓取网页内容采用的是lodash方法来实现。代码如下://方法名.post(“username=”,username=function(){returnres.tostring().required("");});//请求username的方法if(username.post){varusername=username.post;//转换成xmlhttprequest对象varres=lodash.getelementsbytagname("script");res.json();}。
个人认为网页爬虫还是离不开request和response对象,必须了解会用用它们来接收http请求,并解析请求内容得到数据,因此jquery这一块很可能不能用。建议直接写全局方法,其实jquery写在全局方法就可以了,因为全局方法简单而且对$里的属性、方法进行了伪类封装,也很易懂,没必要冒险写jquery对象,假如你jquery是基于ajax技术的,你直接写全局方法就可以了,只是写全局方法有个缺点,就是默认的解析方式是异步的,需要执行一个叫做__delete__()的方法。
还有为什么我要推荐全局方法,是因为大多数人写jquery应该不是基于ajax,而jquery的dom操作方法会用到全局对象,你写全局方法可以写出self.dom(address)这样的代码,可以一起调用dom方法,jquery这样的语言就是通过函数式编程实现的,而函数式编程用jquery语言最为好用,相信我。 查看全部
jquery抓取网页内容(抓取网页内容采用的是lodash方法来实现())
jquery抓取网页内容采用的是lodash方法来实现。代码如下://方法名.post(“username=”,username=function(){returnres.tostring().required("");});//请求username的方法if(username.post){varusername=username.post;//转换成xmlhttprequest对象varres=lodash.getelementsbytagname("script");res.json();}。
个人认为网页爬虫还是离不开request和response对象,必须了解会用用它们来接收http请求,并解析请求内容得到数据,因此jquery这一块很可能不能用。建议直接写全局方法,其实jquery写在全局方法就可以了,因为全局方法简单而且对$里的属性、方法进行了伪类封装,也很易懂,没必要冒险写jquery对象,假如你jquery是基于ajax技术的,你直接写全局方法就可以了,只是写全局方法有个缺点,就是默认的解析方式是异步的,需要执行一个叫做__delete__()的方法。
还有为什么我要推荐全局方法,是因为大多数人写jquery应该不是基于ajax,而jquery的dom操作方法会用到全局对象,你写全局方法可以写出self.dom(address)这样的代码,可以一起调用dom方法,jquery这样的语言就是通过函数式编程实现的,而函数式编程用jquery语言最为好用,相信我。
jquery抓取网页内容(采用Ajax技术,加载不同的内容是什么鬼?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-12 18:13
越来越多的网站,开始采用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户通过英镑结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
我一直认为没有办法做到这一点,直到我看到了 Discourse 创始人之一 Robin Ward 的解决方案。
Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3 来源gaodai.ma#com搞##代!^码网
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
jquery抓取网页内容(采用Ajax技术,加载不同的内容是什么鬼?(组图))
越来越多的网站,开始采用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户通过英镑结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
我一直认为没有办法做到这一点,直到我看到了 Discourse 创始人之一 Robin Ward 的解决方案。
Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3 来源gaodai.ma#com搞##代!^码网
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容!
jquery抓取网页内容(一个简单的招聘网站数据归档进行当前热门岗位大数据分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-03 23:05
》所有未经项目验证的代码都是流氓,今天我们将通过一个简单的招聘网站数据存档对当前热门职位进行大数据分析,最后在wordcloud中展示。本文是一个数据爬取的文章。”
项目准备:
这一次,让我们更完整的捕捉拉勾在线“Python”相关的招聘信息和招聘要求。
可以连接互联网并搭建Python3以上环境的电脑。如果没有配置环境,可以参考我原来的文章 Python安装配置。 IDE这次我们用的是Jupyter Notebook,采集我们用的是selenium+pyquery,为什么要用这个呢?都是泪流满面,文末解释。数据分析使用熊猫。
分析页面找到数据源
打开 并搜索“Python”以获取以下页面。最近因为疫情被拘留在武汉,所以我会以武汉站作为我的目的地。共30页,每页显示15个位置[Position(368)].
selenium采集的效率远低于request采集。因为是在模拟浏览器模式下爬行,所以每次都要渲染页面。但是还有一个好处,就是不用担心header和cookie的问题。废话不多说,开始操作
按照我们之前的方法在 Notebook 中创建一个新的 Python 3 文件:
介绍各种模块:
import pyquery as pq
from selenium import webdriver
import pandas as pd
import time
import os
初始化浏览器:
driver = webdriver.Firefox()
driver.implicitly_wait(5)
driver.get("https://www.lagou.com/")
在打开的页面中,处理拉勾网的登录状态
while True:
i = input("已登陆成功请输入“OK”:")
if i == 'OK':
break
elif i == 'quit':
print("取消执行,关闭!")
os._exit(1)
登录成功后,在命令行输入窗口输入“OK”进入下一步执行。
进入列表采集:
print("开始执行采集")
data = []
driver.get("https://www.lagou.com/jobs/lis ... 6quot;)
while True:
but_class = driver.find_element_by_css_selector(".pager_next").get_attribute('class')
if but_class == 'pager_next ':
driver.find_element_by_xpath("//span[@action='next']").click()
items = pq.PyQuery(driver.page_source).find(".con_list_item")
data += getPosition(items)
time.sleep(2)
else:
print('列表采集结束')
break
我们单独定义了一个采集方法,getPosition方法接收一个pyquery对象。
方法代码如下:
def getPosition(items):
datalist=[]
for item in items.items():
temp = dict()
temp['职位ID']= item.attr('data-positionid')
temp['职位名']= item.attr('data-positionname')
temp['薪资范围']= item.attr('data-salary')
temp['公司ID']= item.attr('data-companyid')
temp['公司名']= item.attr('data-company')
temp['职位链接']=pq.PyQuery(item).find(".position_link").attr("href")
temp['发布时间']=pq.PyQuery(item).find(".format-time").text()
temp['猎头名称']=pq.PyQuery(item).find(".hr_name").text()
temp['猎头ID']=pq.PyQuery(item).find(".target_hr").text()
temp['工作经验']=pq.PyQuery(item).find(".p_bot>.li_b_l").remove(".money").text()
temp['公司主页']=pq.PyQuery(item).find(".company_name>a").attr('href')
temp['公司描述']=pq.PyQuery(item).find(".industry").text()
temp['岗位亮点']=pq.PyQuery(item).find(".li_b_r").text()
datalist.append(temp)
return datalist
到此,主列表的采集和排序工作就结束了。我们将来自 采集 的数据整合到 Pandas 中,并将其保存到一个 csv 文件中以备后用。
csv = pd.DataFrame(data)
csv.to_csv("lagou.csv")
截图是保存的DataFrame。可以看到,我们已经保存了二级页面名称和公司相关信息。
一共368条数据是采集。这时候我们开始完善第二步的详细数据采集。
我们先查一个二级页面,看看数据格式 查看全部
jquery抓取网页内容(一个简单的招聘网站数据归档进行当前热门岗位大数据分析)
》所有未经项目验证的代码都是流氓,今天我们将通过一个简单的招聘网站数据存档对当前热门职位进行大数据分析,最后在wordcloud中展示。本文是一个数据爬取的文章。”
项目准备:
这一次,让我们更完整的捕捉拉勾在线“Python”相关的招聘信息和招聘要求。
可以连接互联网并搭建Python3以上环境的电脑。如果没有配置环境,可以参考我原来的文章 Python安装配置。 IDE这次我们用的是Jupyter Notebook,采集我们用的是selenium+pyquery,为什么要用这个呢?都是泪流满面,文末解释。数据分析使用熊猫。
分析页面找到数据源
打开 并搜索“Python”以获取以下页面。最近因为疫情被拘留在武汉,所以我会以武汉站作为我的目的地。共30页,每页显示15个位置[Position(368)].
selenium采集的效率远低于request采集。因为是在模拟浏览器模式下爬行,所以每次都要渲染页面。但是还有一个好处,就是不用担心header和cookie的问题。废话不多说,开始操作
按照我们之前的方法在 Notebook 中创建一个新的 Python 3 文件:
介绍各种模块:
import pyquery as pq
from selenium import webdriver
import pandas as pd
import time
import os
初始化浏览器:
driver = webdriver.Firefox()
driver.implicitly_wait(5)
driver.get("https://www.lagou.com/";)
在打开的页面中,处理拉勾网的登录状态
while True:
i = input("已登陆成功请输入“OK”:")
if i == 'OK':
break
elif i == 'quit':
print("取消执行,关闭!")
os._exit(1)
登录成功后,在命令行输入窗口输入“OK”进入下一步执行。
进入列表采集:
print("开始执行采集")
data = []
driver.get("https://www.lagou.com/jobs/lis ... 6quot;)
while True:
but_class = driver.find_element_by_css_selector(".pager_next").get_attribute('class')
if but_class == 'pager_next ':
driver.find_element_by_xpath("//span[@action='next']").click()
items = pq.PyQuery(driver.page_source).find(".con_list_item")
data += getPosition(items)
time.sleep(2)
else:
print('列表采集结束')
break
我们单独定义了一个采集方法,getPosition方法接收一个pyquery对象。
方法代码如下:
def getPosition(items):
datalist=[]
for item in items.items():
temp = dict()
temp['职位ID']= item.attr('data-positionid')
temp['职位名']= item.attr('data-positionname')
temp['薪资范围']= item.attr('data-salary')
temp['公司ID']= item.attr('data-companyid')
temp['公司名']= item.attr('data-company')
temp['职位链接']=pq.PyQuery(item).find(".position_link").attr("href")
temp['发布时间']=pq.PyQuery(item).find(".format-time").text()
temp['猎头名称']=pq.PyQuery(item).find(".hr_name").text()
temp['猎头ID']=pq.PyQuery(item).find(".target_hr").text()
temp['工作经验']=pq.PyQuery(item).find(".p_bot>.li_b_l").remove(".money").text()
temp['公司主页']=pq.PyQuery(item).find(".company_name>a").attr('href')
temp['公司描述']=pq.PyQuery(item).find(".industry").text()
temp['岗位亮点']=pq.PyQuery(item).find(".li_b_r").text()
datalist.append(temp)
return datalist
到此,主列表的采集和排序工作就结束了。我们将来自 采集 的数据整合到 Pandas 中,并将其保存到一个 csv 文件中以备后用。
csv = pd.DataFrame(data)
csv.to_csv("lagou.csv")
截图是保存的DataFrame。可以看到,我们已经保存了二级页面名称和公司相关信息。
一共368条数据是采集。这时候我们开始完善第二步的详细数据采集。
我们先查一个二级页面,看看数据格式
jquery抓取网页内容(一下JS下常见的HTML解析库--HTML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-12-30 04:04
HTML 就是一切,每个打算做 Web 编程的人都应该熟悉 HTML 并了解如何解析 HTML。这尤其是前端工程师的基础。在本文中,我们将介绍 JS 下常见的 HTML 解析库。
DOM解析器
JavaScript 和 jQuery 的 DOM 操作函数非常适合分析简单的 HTML 片段。在实际编程中,如果要以编程方式解析DOM完整的HTML或XML,则需要一个更好的解决方案,DOMParser,这是所有现代数字浏览器都支持的功能。
通过使用 DOMParser,您可以轻松解析 HTML 文档。但是,通常需要欺骗浏览器来实现解析,例如通过向当前文档添加新元素。
DOMParser 的使用非常简单明了:
let domParser = new DOMParser();
let doc = domParser.parseFromString(stringContainingXMLSource, "application/xml");
domParser = new DOMParser();
doc = domParser.parseFromString(stringContainingSVGSource, "image/svg+xml");
domParser = new DOMParser();
doc = domParser.parseFromString(stringContainingHTMLSource, "text/html");
切里奥
为服务器设计的核心 jQuery 的快速、灵活和精致的实现。
Cheerio 看起来像 jQuery,但它不支持浏览器。Cheerio 可以解析 HTML 并使其易于操作,但它不会像在浏览器中那样解析 HTML,解析出与浏览器不同的内容,并且不会将解析结果直接发送给用户。
Cheerio 实现了 jQuery 的一个子集,去除了 jQuery 中所有与 DOM 不一致或用于填充浏览器的东西,再现了 jQuery 最漂亮的 API
得益于极其简洁和标准的 DOM 模型,Cheerio 在文档转换、操作和渲染方面非常高效。
JavaScript 开发者应该熟悉 Cheerio 的语法和用法:
var chro = require('cheerio'),
$ = chio.load('Hello World!');
$('h1.title').text('Hello Chongchong!');
$('h1').attr('id', 'welcome');
$.html();
结果:
Hello Chongchong!
jsdom
jsdom 是许多 Web 标准(尤其是 WHATWG DOM 和 HTML 标准)的纯 JavaScript 实现,可以与 Node.js 结合使用。jsdom 项目的目标是模拟 Web 浏览器的一个子集,以满足实际 Web 应用程序的测试和抓取。
jsdom 不仅仅是一个 HTML 解析器,它还可以用作浏览器。在解析的上下文中,如果要解析的数据中省略了必要的标签,它会自动添加必要的标签。比如没有html标签,它会像浏览器一样隐式添加。
您还可以选择指定一些属性,例如文档、引用 URL 或用户代理的 URL。如果您需要解析收录
本地 URL 的链接,则此 URL 特别有用。
由于实际上和解析没有关系,所以只提到jsdom有(虚拟)控制台,支持cookies等,总之需要模拟浏览器环境
它还可以处理外部资源。如果需要,可以使用 jsdom 加载和执行 JS 脚本。
结果:
"Hello, Chongchong!"
解析5
parse5 几乎提供了处理 HTML 所需的一切。Parse5 库,目标是构建其他工具,但也可以实现 HTML 解析来完成简单的任务。Parse5 易于使用,但它没有提供一种方法来操作浏览器提供的 DOM(例如 getElementById)。
parse5 催生了一系列采用它的令人印象深刻的项目:jsdom、Angular2 和 Polymer。如果要求是高级操作或 HTML 解析的可靠基础,那么显然这是一个不错的选择。
const parse5 = require('parse5');
const document = parse5.parse('你好冲冲!');
console.log(document.childNodes[1].tagName);
总结
在本文中,我们介绍了 JS 下几个常见的 Html 解析库。根据标准,实际的HTML格式语法格式需要是容错的。当时,在图书馆中很难简单完美地实现。如果大家有更好的推荐,欢迎分享给大家。 查看全部
jquery抓取网页内容(一下JS下常见的HTML解析库--HTML)
HTML 就是一切,每个打算做 Web 编程的人都应该熟悉 HTML 并了解如何解析 HTML。这尤其是前端工程师的基础。在本文中,我们将介绍 JS 下常见的 HTML 解析库。
DOM解析器
JavaScript 和 jQuery 的 DOM 操作函数非常适合分析简单的 HTML 片段。在实际编程中,如果要以编程方式解析DOM完整的HTML或XML,则需要一个更好的解决方案,DOMParser,这是所有现代数字浏览器都支持的功能。
通过使用 DOMParser,您可以轻松解析 HTML 文档。但是,通常需要欺骗浏览器来实现解析,例如通过向当前文档添加新元素。
DOMParser 的使用非常简单明了:
let domParser = new DOMParser();
let doc = domParser.parseFromString(stringContainingXMLSource, "application/xml");
domParser = new DOMParser();
doc = domParser.parseFromString(stringContainingSVGSource, "image/svg+xml");
domParser = new DOMParser();
doc = domParser.parseFromString(stringContainingHTMLSource, "text/html");
切里奥
为服务器设计的核心 jQuery 的快速、灵活和精致的实现。
Cheerio 看起来像 jQuery,但它不支持浏览器。Cheerio 可以解析 HTML 并使其易于操作,但它不会像在浏览器中那样解析 HTML,解析出与浏览器不同的内容,并且不会将解析结果直接发送给用户。
Cheerio 实现了 jQuery 的一个子集,去除了 jQuery 中所有与 DOM 不一致或用于填充浏览器的东西,再现了 jQuery 最漂亮的 API
得益于极其简洁和标准的 DOM 模型,Cheerio 在文档转换、操作和渲染方面非常高效。
JavaScript 开发者应该熟悉 Cheerio 的语法和用法:
var chro = require('cheerio'),
$ = chio.load('Hello World!');
$('h1.title').text('Hello Chongchong!');
$('h1').attr('id', 'welcome');
$.html();
结果:
Hello Chongchong!
jsdom
jsdom 是许多 Web 标准(尤其是 WHATWG DOM 和 HTML 标准)的纯 JavaScript 实现,可以与 Node.js 结合使用。jsdom 项目的目标是模拟 Web 浏览器的一个子集,以满足实际 Web 应用程序的测试和抓取。
jsdom 不仅仅是一个 HTML 解析器,它还可以用作浏览器。在解析的上下文中,如果要解析的数据中省略了必要的标签,它会自动添加必要的标签。比如没有html标签,它会像浏览器一样隐式添加。
您还可以选择指定一些属性,例如文档、引用 URL 或用户代理的 URL。如果您需要解析收录
本地 URL 的链接,则此 URL 特别有用。
由于实际上和解析没有关系,所以只提到jsdom有(虚拟)控制台,支持cookies等,总之需要模拟浏览器环境
它还可以处理外部资源。如果需要,可以使用 jsdom 加载和执行 JS 脚本。
结果:
"Hello, Chongchong!"
解析5
parse5 几乎提供了处理 HTML 所需的一切。Parse5 库,目标是构建其他工具,但也可以实现 HTML 解析来完成简单的任务。Parse5 易于使用,但它没有提供一种方法来操作浏览器提供的 DOM(例如 getElementById)。
parse5 催生了一系列采用它的令人印象深刻的项目:jsdom、Angular2 和 Polymer。如果要求是高级操作或 HTML 解析的可靠基础,那么显然这是一个不错的选择。
const parse5 = require('parse5');
const document = parse5.parse('你好冲冲!');
console.log(document.childNodes[1].tagName);
总结
在本文中,我们介绍了 JS 下几个常见的 Html 解析库。根据标准,实际的HTML格式语法格式需要是容错的。当时,在图书馆中很难简单完美地实现。如果大家有更好的推荐,欢迎分享给大家。
jquery抓取网页内容(关键词的提取和转载和修改再带来的便利性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-29 20:03
当搜索引擎抓取大量原创
网页时,会对其进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一样,不做任何修改)或“转载网页”“(Near-replicas,主题内容基本相同但可能会有一些额外的编辑信息等,转载网页也称为“近似镜像网页”)消除,链接分析和重要性的计算网页的。
1. 提取关键词,取一个网页的源文件(比如通过浏览器的“查看源文件”功能),可以看出情况是乱七八糟的。从知识和实践的角度来看,所收录
的关键词就是这个特性的最好代表。因此,作为预处理阶段的一项基本任务,就是提取网页源文件内容部分收录
的关键词。对于中文来说,需要使用所谓的“切词软件”,根据字典Σ从网页文本中切出Σ中收录
的词。之后,一个网页主要由一组词表示,p = {t1, t2, ..., tn}。一般来说,我们可能会得到很多词,而同一个词可能会在一个网页中出现多次。
2. 消除网页的复制或重印,固有的数字化和网络化为网页的复制、重印、修改和重新发布带来了便利。因此,我们在网络上看到了大量的重复信息。这种现象对广大网民具有积极意义,因为有更多的信息获取机会。但对于搜索引擎来说,主要是负面的;它不仅在采集网页时消耗机器时间和网络带宽资源,而且如果出现在查询结果中,会毫无意义地消耗计算机显示资源,而且还会引起用户抱怨,“这么多重复,就给我一个。” 所以,
3、 链接分析,大量的HTML标签不仅给网页的预处理带来了一些麻烦,也带来了一些新的机会。从信息检索的角度来看,如果系统只面对内容的文本,我们可以依据的是“共享词袋”,即内容中收录
的关键词的集合,加上at大多数统计信息,例如词在文档集合中出现的词频(term frequency 或 tf, TF)和文档频率(document frequency or df, DF)。TF、DF等频率信息可以在一定程度上表明单词在文档中的相对重要性或某些内容的相关性,是有意义的。有了 HTML 标记,这种情况可能会得到进一步改善。例如,在同一个文档中,和之间的信息可能比和之间的信息更重要。尤其是HTML文档中收录
的指向其他文档的链接信息是近年来特别关注的对象。他们认为他们不仅给出了网页之间的关系,而且在判断网页内容方面也起着非常重要的作用。
4、 在计算网页的重要性时,搜索引擎实际上追求的是统计意义上的满意度。人们认为谷歌优于百度或百度优于谷歌。在大多数情况下,引用依赖于前者返回的内容来满足用户的需求,但并非在所有情况下都是如此。如何对查询结果进行排序有很多因素需要考虑。如何说一个网页比另一个网页更重要?人们参考科技文献重要性的评价方法,核心思想是“被引用最多的就是重要的”。“引用”的概念恰好通过 HTML 超链接在网页之间得到很好的体现。PageRank作为谷歌创造的核心技术,就是这一理念的成功体现。此外,人们还注意到网页和文档的不同特点,即有的网页主要是大量的外部链接,本身基本没有明确的主题内容,而有的网页则是由大量的其他链接。网页。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。而其他网页由大量其他网页链接。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。而其他网页由大量其他网页链接。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。
本文链接地址: 查看全部
jquery抓取网页内容(关键词的提取和转载和修改再带来的便利性)
当搜索引擎抓取大量原创
网页时,会对其进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一样,不做任何修改)或“转载网页”“(Near-replicas,主题内容基本相同但可能会有一些额外的编辑信息等,转载网页也称为“近似镜像网页”)消除,链接分析和重要性的计算网页的。
1. 提取关键词,取一个网页的源文件(比如通过浏览器的“查看源文件”功能),可以看出情况是乱七八糟的。从知识和实践的角度来看,所收录
的关键词就是这个特性的最好代表。因此,作为预处理阶段的一项基本任务,就是提取网页源文件内容部分收录
的关键词。对于中文来说,需要使用所谓的“切词软件”,根据字典Σ从网页文本中切出Σ中收录
的词。之后,一个网页主要由一组词表示,p = {t1, t2, ..., tn}。一般来说,我们可能会得到很多词,而同一个词可能会在一个网页中出现多次。
2. 消除网页的复制或重印,固有的数字化和网络化为网页的复制、重印、修改和重新发布带来了便利。因此,我们在网络上看到了大量的重复信息。这种现象对广大网民具有积极意义,因为有更多的信息获取机会。但对于搜索引擎来说,主要是负面的;它不仅在采集网页时消耗机器时间和网络带宽资源,而且如果出现在查询结果中,会毫无意义地消耗计算机显示资源,而且还会引起用户抱怨,“这么多重复,就给我一个。” 所以,
3、 链接分析,大量的HTML标签不仅给网页的预处理带来了一些麻烦,也带来了一些新的机会。从信息检索的角度来看,如果系统只面对内容的文本,我们可以依据的是“共享词袋”,即内容中收录
的关键词的集合,加上at大多数统计信息,例如词在文档集合中出现的词频(term frequency 或 tf, TF)和文档频率(document frequency or df, DF)。TF、DF等频率信息可以在一定程度上表明单词在文档中的相对重要性或某些内容的相关性,是有意义的。有了 HTML 标记,这种情况可能会得到进一步改善。例如,在同一个文档中,和之间的信息可能比和之间的信息更重要。尤其是HTML文档中收录
的指向其他文档的链接信息是近年来特别关注的对象。他们认为他们不仅给出了网页之间的关系,而且在判断网页内容方面也起着非常重要的作用。
4、 在计算网页的重要性时,搜索引擎实际上追求的是统计意义上的满意度。人们认为谷歌优于百度或百度优于谷歌。在大多数情况下,引用依赖于前者返回的内容来满足用户的需求,但并非在所有情况下都是如此。如何对查询结果进行排序有很多因素需要考虑。如何说一个网页比另一个网页更重要?人们参考科技文献重要性的评价方法,核心思想是“被引用最多的就是重要的”。“引用”的概念恰好通过 HTML 超链接在网页之间得到很好的体现。PageRank作为谷歌创造的核心技术,就是这一理念的成功体现。此外,人们还注意到网页和文档的不同特点,即有的网页主要是大量的外部链接,本身基本没有明确的主题内容,而有的网页则是由大量的其他链接。网页。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。而其他网页由大量其他网页链接。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。而其他网页由大量其他网页链接。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。
本文链接地址:
jquery抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-28 06:14
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的获取方式是:
Java 代码
URL url = 新的 URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br .readLine()) != null) {i++; sb.append(s+"\r\n"); }
URL url = new URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { i++; sb.append(s+"\r\n"); }
这种方法抓取一般网页应该没有问题,但是当某些网页中存在一些嵌套的重定向连接时,它会报类似服务器重定向次数过多的错误。这是因为这个网页里面有错误。部分代码重定向到其他网页,循环过多导致程序错误。如果只想抓取该网址中网页的内容,而不想将其重定向到其他网页,则可以使用以下代码。
Java 代码
URL urlmy = 新 URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false);连接(); BufferedReader br = new BufferedReader( new InputStreamReader(con.getInputStream(),"UTF-8"));字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) {sb .append(s+"\r\n"); }
URL urlmy = new URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); con.connect(); BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8")); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { sb.append(s+"\r\n"); }
这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。 Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java 代码
System.getProperties().setProperty("http.proxyHost", proxyName); System.getProperties().setProperty( "http.proxyPort", port );
System.getProperties().setProperty( "http.proxyHost", proxyName ); System.getProperties().setProperty( "http.proxyPort", port );
这样,您就可以在内部网中,从互联网上获取您想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这真是太棒了! ! 查看全部
jquery抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的获取方式是:
Java 代码
URL url = 新的 URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br .readLine()) != null) {i++; sb.append(s+"\r\n"); }
URL url = new URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { i++; sb.append(s+"\r\n"); }
这种方法抓取一般网页应该没有问题,但是当某些网页中存在一些嵌套的重定向连接时,它会报类似服务器重定向次数过多的错误。这是因为这个网页里面有错误。部分代码重定向到其他网页,循环过多导致程序错误。如果只想抓取该网址中网页的内容,而不想将其重定向到其他网页,则可以使用以下代码。
Java 代码
URL urlmy = 新 URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false);连接(); BufferedReader br = new BufferedReader( new InputStreamReader(con.getInputStream(),"UTF-8"));字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) {sb .append(s+"\r\n"); }
URL urlmy = new URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); con.connect(); BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8")); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { sb.append(s+"\r\n"); }
这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。 Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java 代码
System.getProperties().setProperty("http.proxyHost", proxyName); System.getProperties().setProperty( "http.proxyPort", port );
System.getProperties().setProperty( "http.proxyHost", proxyName ); System.getProperties().setProperty( "http.proxyPort", port );
这样,您就可以在内部网中,从互联网上获取您想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这真是太棒了! !
jquery抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-26 02:25
越来越多的网站开始采用“单页应用程序”(Single-page application)。
整个网站只有一个网页,使用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是AJAX内容无法被搜索引擎抓取。例如,您有一个网站。
http://example.com
用户可以通过具有哈希结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“哈希+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,谷歌就会收录
它。但问题是“哈希+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须被 Google 收录。它的解决方案是放弃hash结构,使用History API。
所谓History API,就是在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
对 History API 的详细介绍超出了本文的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先用History API替换hash结构,让每一个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户点击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
如果你仔细看上面的代码,你会发现里面有一个 noscript 标签。这就是秘密。
我们将所有要被搜索引擎收录的内容放在 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下执行 AJAX 操作,但是搜索引擎会收录
每个页面的主要内容! 查看全部
jquery抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
越来越多的网站开始采用“单页应用程序”(Single-page application)。
整个网站只有一个网页,使用Ajax技术根据用户的输入加载不同的内容。

这种方式的优点是用户体验好,节省流量。缺点是AJAX内容无法被搜索引擎抓取。例如,您有一个网站。
http://example.com
用户可以通过具有哈希结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“哈希+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,谷歌就会收录
它。但问题是“哈希+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。

Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须被 Google 收录。它的解决方案是放弃hash结构,使用History API。
所谓History API,就是在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?

地址栏中的网址已更改,但音乐播放并未中断!
对 History API 的详细介绍超出了本文的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先用History API替换hash结构,让每一个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户点击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
如果你仔细看上面的代码,你会发现里面有一个 noscript 标签。这就是秘密。
我们将所有要被搜索引擎收录的内容放在 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下执行 AJAX 操作,但是搜索引擎会收录
每个页面的主要内容!
jquery抓取网页内容(封装lst转换成单词对分词jieba解析整个prototxt,直接上代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-18 15:01
jquery抓取网页内容,dom元素,执行ajax请求,解析,传输给caffe执行,封装lst转换成单词对;分词jieba解析整个prototxt,
直接上代码吧:test。js。box{background:#ff8df;}。middle{background:#31f34;}。radius{background:#131616;}$(function(){varwd=$('#wd');$('#block')。innerhtml='aaa</img>';varprice=$('#price');//activatethepriceitem$('#radius')。
activate(price);$('#text')。click(function(){$('#text')。text(wd+'');});exportdefault{width:2000px,height:2000px,margin:0auto;}}nodejs:nodejs。js。
jieba:在分词阶段完成词性识别,读取整个prototxt,读取html,进行分词, 查看全部
jquery抓取网页内容(封装lst转换成单词对分词jieba解析整个prototxt,直接上代码)
jquery抓取网页内容,dom元素,执行ajax请求,解析,传输给caffe执行,封装lst转换成单词对;分词jieba解析整个prototxt,
直接上代码吧:test。js。box{background:#ff8df;}。middle{background:#31f34;}。radius{background:#131616;}$(function(){varwd=$('#wd');$('#block')。innerhtml='aaa</img>';varprice=$('#price');//activatethepriceitem$('#radius')。
activate(price);$('#text')。click(function(){$('#text')。text(wd+'');});exportdefault{width:2000px,height:2000px,margin:0auto;}}nodejs:nodejs。js。
jieba:在分词阶段完成词性识别,读取整个prototxt,读取html,进行分词,
jquery抓取网页内容(jquery完数据后解析代码的操作方法和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-02 07:08
jquery抓取网页内容,jquery解析网页,jquery加载数据等等等,jquery解析出来的是你要的,或者是ajax提交完数据后返回给后端的数据,或者是后端渲染的页面数据。jquery代码是一样的,你可以使用同一个jquery,但是渲染的数据不同,那么你渲染的代码的语法和js就要改,有一定兼容性的调整,最终数据结果也要改。
我没有做过后端的开发,以前看的大概是jquery加载完数据后解析并返回给后端的。有些场景下需要更多的实现数据之间的换算关系或者特殊方法计算数据值差值。没有详细去阅读这方面的知识,不敢妄加评论,
不同ajax回调里jquery接受值jquery。injectlist(x,y)example:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})这里要注意参数的同步更新jquery。
injectlist(x,y),$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})就不会执行这个方法了jquery。exec("ajax-on");这段代码是异步ajax的方法$。
ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})实际上就是同步ajax的方法更正:楼上是对的我用一段代码来解释这个答案吧intent传递参数的关系$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})实际上就是同步ajax的方法,依次调用$(intent)。
request('')。accept('http/1。1host:xxx',jsonp)`jsonp`这段代码是异步ajax请求的方法`jsonp`函数将两个请求参数直接绑定到数据库里面去执行`jsonp`请求的代码:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})//这个时候ajax方法只作用于:{username:'test',password:'test'}。
1。使用jsonp的时候用1个参数//数据存放在json里//解析函数也只能存放一个//2个参数,在后面只能传两个参数2。将一个参数的代码分为两段,一次是请求所得数据,一次是用请求和验证数据是否匹配`jsonp`函数把两个参数绑定到数据库里面去执行`jsonp`请求的代码:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})//一次传一个参数,只能传1个。 查看全部
jquery抓取网页内容(jquery完数据后解析代码的操作方法和方法)
jquery抓取网页内容,jquery解析网页,jquery加载数据等等等,jquery解析出来的是你要的,或者是ajax提交完数据后返回给后端的数据,或者是后端渲染的页面数据。jquery代码是一样的,你可以使用同一个jquery,但是渲染的数据不同,那么你渲染的代码的语法和js就要改,有一定兼容性的调整,最终数据结果也要改。
我没有做过后端的开发,以前看的大概是jquery加载完数据后解析并返回给后端的。有些场景下需要更多的实现数据之间的换算关系或者特殊方法计算数据值差值。没有详细去阅读这方面的知识,不敢妄加评论,
不同ajax回调里jquery接受值jquery。injectlist(x,y)example:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})这里要注意参数的同步更新jquery。
injectlist(x,y),$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})就不会执行这个方法了jquery。exec("ajax-on");这段代码是异步ajax的方法$。
ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})实际上就是同步ajax的方法更正:楼上是对的我用一段代码来解释这个答案吧intent传递参数的关系$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})实际上就是同步ajax的方法,依次调用$(intent)。
request('')。accept('http/1。1host:xxx',jsonp)`jsonp`这段代码是异步ajax请求的方法`jsonp`函数将两个请求参数直接绑定到数据库里面去执行`jsonp`请求的代码:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})//这个时候ajax方法只作用于:{username:'test',password:'test'}。
1。使用jsonp的时候用1个参数//数据存放在json里//解析函数也只能存放一个//2个参数,在后面只能传两个参数2。将一个参数的代码分为两段,一次是请求所得数据,一次是用请求和验证数据是否匹配`jsonp`函数把两个参数绑定到数据库里面去执行`jsonp`请求的代码:$。ajax({url:'/somedir/api/username?name=test',params:{username:'test',password:'test'}})//一次传一个参数,只能传1个。
jquery抓取网页内容(网页设计是p2p建设网站必不可少的,那么你是否观察过)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-30 07:12
网页设计是p2p建设必不可少的网站,那么你观察过网页中代码的顺序吗?网页的代码顺序是可逆的吗?
头部元素排序
网页中的head元素,也称为head,通常收录文档的描述信息,一般包括网页代码、title标题、meta描述网页关键字、链接导入CSS文件、js文件等。
首先是标准的 DOCTYPE 声明,HTML 结构。
然后是元和标题部分,它们在网页中非常重要。浏览器用什么代码来解析网页,文章的标题是什么,文章的关键词是什么?文章 的描述是什么?这些对于 文章 的搜索引擎抓取和排名非常重要。
最后js部分,页面任意位置都可以添加js,但是js的加载速度很慢,而且对于搜索引擎来说,js是一个“陌生人”,所以一般建议放在页面底部.
正文中的元素顺序
浏览器的加载顺序是从上到下,而搜索引擎的一般习惯是从上到下,从左到右,所以在body中写代码时的重要思想是:重要的放在最上面,不重要的放在下面。
页面代码顺序是否可逆?
css代码元素的排序
Div和CSS是网页设计中常用的技术,使用起来非常方便。CSS中有很多元素,例如:背景颜色、长度、宽度、高度和字体样式。在 CSS 代码元素中,有些顺序会被忽略,但有些顺序必须正确书写。比如你想在CSS代码中写加粗字体和CSS reset reset,那么就必须先加载CSS reset,字体加粗。稍后加载,如果顺序颠倒,字体加粗后会重置,会覆盖加粗效果。
js代码顺序
如果要加载js代码,应该先调用jQuery库,再编写js文件。浏览器在先下载库后,只会识别依赖于jQuery库的js文件。
网页代码中有些元素的顺序是可以相互交换的,但是有些代码的顺序是必须要遵循的,所以在编写网页代码的时候要注意。
戴蒙p2p网贷系统开发商提醒您! 查看全部
jquery抓取网页内容(网页设计是p2p建设网站必不可少的,那么你是否观察过)
网页设计是p2p建设必不可少的网站,那么你观察过网页中代码的顺序吗?网页的代码顺序是可逆的吗?
头部元素排序
网页中的head元素,也称为head,通常收录文档的描述信息,一般包括网页代码、title标题、meta描述网页关键字、链接导入CSS文件、js文件等。
首先是标准的 DOCTYPE 声明,HTML 结构。
然后是元和标题部分,它们在网页中非常重要。浏览器用什么代码来解析网页,文章的标题是什么,文章的关键词是什么?文章 的描述是什么?这些对于 文章 的搜索引擎抓取和排名非常重要。
最后js部分,页面任意位置都可以添加js,但是js的加载速度很慢,而且对于搜索引擎来说,js是一个“陌生人”,所以一般建议放在页面底部.
正文中的元素顺序
浏览器的加载顺序是从上到下,而搜索引擎的一般习惯是从上到下,从左到右,所以在body中写代码时的重要思想是:重要的放在最上面,不重要的放在下面。
页面代码顺序是否可逆?
css代码元素的排序
Div和CSS是网页设计中常用的技术,使用起来非常方便。CSS中有很多元素,例如:背景颜色、长度、宽度、高度和字体样式。在 CSS 代码元素中,有些顺序会被忽略,但有些顺序必须正确书写。比如你想在CSS代码中写加粗字体和CSS reset reset,那么就必须先加载CSS reset,字体加粗。稍后加载,如果顺序颠倒,字体加粗后会重置,会覆盖加粗效果。
js代码顺序
如果要加载js代码,应该先调用jQuery库,再编写js文件。浏览器在先下载库后,只会识别依赖于jQuery库的js文件。
网页代码中有些元素的顺序是可以相互交换的,但是有些代码的顺序是必须要遵循的,所以在编写网页代码的时候要注意。
戴蒙p2p网贷系统开发商提醒您!
jquery抓取网页内容(自然要和http的request,get,post一些方法相关)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-29 10:17
Node.js Request+Cheerio实现小爬虫-基础功能实现1:内容抓取
Node.js Request+Cheerio实现小爬虫-基础功能实现2:文件写入
Node.js Request+Cheerio实现小爬虫-基础功能实现3:进程控制和并发控制
Node.js Request+Cheerio 实现小爬虫 - 额外部分:代理设置
前段时间碰巧有个小任务是爬虫。因为一直使用js和Node.js的兴起,所以我打算用Node来完成这个任务。当然,在实施过程中也遇到了很多问题。所以我打算把它写成评论和排序。
既然是爬虫,自然和http的request、get、post方法有关。至于这方面的知识,可以去问谷歌或者度娘。除了http相关的知识,我们还需要提取抓取到的内容。提取可以使用万能的正则表达式,当然我们也可以使用node丰富的包。下面是这个小项目用到的node包。
使用的包
要求
Request 模块是一个非常方便使用的 http 模块。具体用法请参考GitHub官方主页。
官方主页
切里奥
Cheerio 是一个可以使用 jQuery 语法来提取内容的模块。特别是对于从网络上抓取的东西。因为它使用与jQuery相同的语法,所以特别适合前端使用。
官方主页
现在您已经介绍了包和模块,是时候试用它们了。那我们把代码放在下面吧!
const request = require('request');
const cheerio = require('cheerio');
var shopLists = [];
var option = {
url: url,
// 不加入headers的话很可能会被拒绝访问
headers: {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.6',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Mobile Safari/537.36',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
};
request(option, function(error, response, body) {
if (!error && response.statusCode == 200) {
// 使用Cheerio对抓取到的内容进行解析
var $ = cheerio.load(body, {
ignoreWhitespace: true,
xmlMode: true
});
var shopInfo = {
pageNo: option.url.match(/g\d+p(\d+)/)[1],
pageURL: option.url,
info: []
};
var shopList = $('div#shop-all-list').find('a[data-hippo-type = "shop"]');
shopList.each(function(no, shop) {
let info = {};
info.no = no + 1;
info.name = $(shop).attr('title');
info.url = $(shop).attr('href');
shopInfo.info.push(info);
});
shopLists.push(shopInfo);
}
});
这样就可以抓取到想要的网站内容了。当然,问题自然会一个接一个地解决。现在您已经捕获了内容,您总是希望将其保存在一个地方。以本地保存为例,我们可以使用Node自带的fs模块来读取文件。fs模块的使用方法请参考官方文档或向谷歌渡娘咨询。
const fs = require('fs');
...
// 刚才的爬虫代码
...
fs.writeFile(FILE_PATH + FILE_NAME, shopLists, 'utf-8', function(err) {
if (err) {
console.error("文件生成时发生错误.");
throw err;
}
console.info('文件已经成功生成.');
});
好吧,看来问题已经解决了。所以不管它是否有效,都需要练习。运行它,问题就出现了。文件是0,那是怎么回事?只需在下一篇文章文章 中解决它。 查看全部
jquery抓取网页内容(自然要和http的request,get,post一些方法相关)
Node.js Request+Cheerio实现小爬虫-基础功能实现1:内容抓取
Node.js Request+Cheerio实现小爬虫-基础功能实现2:文件写入
Node.js Request+Cheerio实现小爬虫-基础功能实现3:进程控制和并发控制
Node.js Request+Cheerio 实现小爬虫 - 额外部分:代理设置
前段时间碰巧有个小任务是爬虫。因为一直使用js和Node.js的兴起,所以我打算用Node来完成这个任务。当然,在实施过程中也遇到了很多问题。所以我打算把它写成评论和排序。
既然是爬虫,自然和http的request、get、post方法有关。至于这方面的知识,可以去问谷歌或者度娘。除了http相关的知识,我们还需要提取抓取到的内容。提取可以使用万能的正则表达式,当然我们也可以使用node丰富的包。下面是这个小项目用到的node包。
使用的包
要求
Request 模块是一个非常方便使用的 http 模块。具体用法请参考GitHub官方主页。
官方主页
切里奥
Cheerio 是一个可以使用 jQuery 语法来提取内容的模块。特别是对于从网络上抓取的东西。因为它使用与jQuery相同的语法,所以特别适合前端使用。
官方主页
现在您已经介绍了包和模块,是时候试用它们了。那我们把代码放在下面吧!
const request = require('request');
const cheerio = require('cheerio');
var shopLists = [];
var option = {
url: url,
// 不加入headers的话很可能会被拒绝访问
headers: {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.6',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Mobile Safari/537.36',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}
};
request(option, function(error, response, body) {
if (!error && response.statusCode == 200) {
// 使用Cheerio对抓取到的内容进行解析
var $ = cheerio.load(body, {
ignoreWhitespace: true,
xmlMode: true
});
var shopInfo = {
pageNo: option.url.match(/g\d+p(\d+)/)[1],
pageURL: option.url,
info: []
};
var shopList = $('div#shop-all-list').find('a[data-hippo-type = "shop"]');
shopList.each(function(no, shop) {
let info = {};
info.no = no + 1;
info.name = $(shop).attr('title');
info.url = $(shop).attr('href');
shopInfo.info.push(info);
});
shopLists.push(shopInfo);
}
});
这样就可以抓取到想要的网站内容了。当然,问题自然会一个接一个地解决。现在您已经捕获了内容,您总是希望将其保存在一个地方。以本地保存为例,我们可以使用Node自带的fs模块来读取文件。fs模块的使用方法请参考官方文档或向谷歌渡娘咨询。
const fs = require('fs');
...
// 刚才的爬虫代码
...
fs.writeFile(FILE_PATH + FILE_NAME, shopLists, 'utf-8', function(err) {
if (err) {
console.error("文件生成时发生错误.");
throw err;
}
console.info('文件已经成功生成.');
});
好吧,看来问题已经解决了。所以不管它是否有效,都需要练习。运行它,问题就出现了。文件是0,那是怎么回事?只需在下一篇文章文章 中解决它。
jquery抓取网页内容(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-27 19:00
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架
上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是爬取的页面数量、页面大小、爬取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是要爬取的URL数量巨大,爬虫是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人阅读后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,一段时间内没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。但是,存储大量历史信息对于搜索引擎来说是一种负担,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指根据网页显示的某些属性对许多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈! 查看全部
jquery抓取网页内容(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
搜索引擎正面临着互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架
上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是爬取的页面数量、页面大小、爬取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是要爬取的URL数量巨大,爬虫是如何确定爬取顺序的呢?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人阅读后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,一段时间内没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。但是,存储大量历史信息对于搜索引擎来说是一种负担,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指根据网页显示的某些属性对许多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
jquery抓取网页内容(jquery抓取网页内容的一般步骤分为以下几个步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-26 06:04
jquery抓取网页内容的一般步骤分为以下几个步骤:一,分析抓取网页中需要爬取的部分,建立相关网页代码的二维表格。二,通过jquery框架将原始数据进行翻译三,将翻译后的数据进行解析工作,利用一些js框架四,利用js框架进行js解析工作,将页面返回给用户5.利用js框架解析出来的页面js内容存入对应的文件夹下面。
在jquery未对这个页面做处理时,通过javascript请求链接可以进行这样的操作。
首先你要知道request可以对接任何javascript网络请求。然后抓包看返回值的api是application/javascript,你懂的。另外这里其实只有ajax是抓包看到数据的,其他的都是自己写进去的javascript。
1.同时抓一个页面的ajax方法,再抓另一个页面的javascript需要的请求。2.post的方法应该在抓包时就可以捕捉到。3.jquery提供了接口(xmlhttprequest),但要使用这个接口前,需要先对页面进行处理,譬如一个javascript规定,如果前端页面已经包含javascript,那么javascript只能获取到varxxx;varxxx;xxx;中的部分javascript代码。
get是不行的,
<p>varxxx="accept";varxxx=[];for(vari=0;i 查看全部
jquery抓取网页内容(jquery抓取网页内容的一般步骤分为以下几个步骤)
jquery抓取网页内容的一般步骤分为以下几个步骤:一,分析抓取网页中需要爬取的部分,建立相关网页代码的二维表格。二,通过jquery框架将原始数据进行翻译三,将翻译后的数据进行解析工作,利用一些js框架四,利用js框架进行js解析工作,将页面返回给用户5.利用js框架解析出来的页面js内容存入对应的文件夹下面。
在jquery未对这个页面做处理时,通过javascript请求链接可以进行这样的操作。
首先你要知道request可以对接任何javascript网络请求。然后抓包看返回值的api是application/javascript,你懂的。另外这里其实只有ajax是抓包看到数据的,其他的都是自己写进去的javascript。
1.同时抓一个页面的ajax方法,再抓另一个页面的javascript需要的请求。2.post的方法应该在抓包时就可以捕捉到。3.jquery提供了接口(xmlhttprequest),但要使用这个接口前,需要先对页面进行处理,譬如一个javascript规定,如果前端页面已经包含javascript,那么javascript只能获取到varxxx;varxxx;xxx;中的部分javascript代码。
get是不行的,
<p>varxxx="accept";varxxx=[];for(vari=0;i
jquery抓取网页内容( JQuery插件Jqprint实现网页打印(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-23 17:13
JQuery插件Jqprint实现网页打印(图))
web各种前端打印方式的jquery打印插件jqprint实现网页打印
更新时间:2013-01-09 16:37:38 作者:
本文介绍JQuery插件Jqprint实现网页打印。不懂的同学可以借此机会学习一下,以防万一,话不多说,切入主题
我对网络打印方法的了解有:
1、JQuery插件Jqprint实现
2、JQery打印插件PrintArea实现网页打印
3、CSS 控制网页打印样式
JQuery插件Jqprint实现:
首先导入js文件:
jquery.jqprint.js 下载
复制代码代码如下:
html代码:
复制代码代码如下:
打印时显示
打印时隐藏。
javascript代码:
复制代码代码如下:
插件还提供了一些参数来配置:
debug: false,//如果为true,可以显示iframe查看效果(默认iframe的高宽都很小,可以在源码中增加),默认为false
importCSS: true, //true表示导入原页面的CSS,默认为true。 (如果为真则先查找$("link[media=print]"),否则先查找$("link")中的css文件)
printContainer: true,//表示最初选择的对象是否必须收录在打印中(注意:设置为false可能会破坏您的CSS规则)。
operaSupport: true//表示插件是否还必须支持opera浏览器,在这种情况下,它会提供创建一个临时打印选项卡。默认为真
我自己只使用importCSS:原创页面中的链接会被导入到iframe中。第一次media search=打印,如果没有,就会导入正常的css文件。
importCSS 示例:
复制代码代码如下:
$('.my_show').jqprint({
importCSS://CSS 样式文件
}); 查看全部
jquery抓取网页内容(
JQuery插件Jqprint实现网页打印(图))
web各种前端打印方式的jquery打印插件jqprint实现网页打印
更新时间:2013-01-09 16:37:38 作者:
本文介绍JQuery插件Jqprint实现网页打印。不懂的同学可以借此机会学习一下,以防万一,话不多说,切入主题
我对网络打印方法的了解有:
1、JQuery插件Jqprint实现
2、JQery打印插件PrintArea实现网页打印
3、CSS 控制网页打印样式
JQuery插件Jqprint实现:
首先导入js文件:
jquery.jqprint.js 下载
复制代码代码如下:
html代码:
复制代码代码如下:
打印时显示
打印时隐藏。
javascript代码:
复制代码代码如下:
插件还提供了一些参数来配置:
debug: false,//如果为true,可以显示iframe查看效果(默认iframe的高宽都很小,可以在源码中增加),默认为false
importCSS: true, //true表示导入原页面的CSS,默认为true。 (如果为真则先查找$("link[media=print]"),否则先查找$("link")中的css文件)
printContainer: true,//表示最初选择的对象是否必须收录在打印中(注意:设置为false可能会破坏您的CSS规则)。
operaSupport: true//表示插件是否还必须支持opera浏览器,在这种情况下,它会提供创建一个临时打印选项卡。默认为真
我自己只使用importCSS:原创页面中的链接会被导入到iframe中。第一次media search=打印,如果没有,就会导入正常的css文件。
importCSS 示例:
复制代码代码如下:
$('.my_show').jqprint({
importCSS://CSS 样式文件
});
jquery抓取网页内容(聊一聊Python与网络爬虫的主要框架及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-23 02:14
我们来谈谈 Python 和网络爬虫。
1、爬虫的定义
Crawler:自动抓取互联网数据的程序。
2、爬虫主要框架
爬虫程序的主框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中有需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的URL。网页,然后调用网页解析器解析网页,将网页中新的URL添加到URL管理器中,输出有价值的数据。
3、爬虫时序图
4、网址管理器
网址管理器管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。 URL管理器的主要功能如下图所示:
URL管理器的实现主要使用Python中的内存(set)和关系型数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,一般采用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用了urllib库,这是python自带的一个模块。对于2.x版本的urllib2库,在其request和其他子模块中集成到python3.x中的urllib中。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen函数的参数可以是url链接,也可以是请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页,带有反爬虫机制的网页,然后使用urlopen函数,需要添加http头。对于有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载的 url 数据中提取有价值的数据和新的 url。对于数据提取,可以使用正则表达式、BeautifulSoup等方法。正则表达式采用基于字符串的模糊匹配,对目标源gao@daima#com有较好的效果,特征比较鲜明(%code@#数据,但通用性不高。BeautifulSoup是第三个—— party模块,用于结构化解析url内容。下载的网页内容被解析成DOM树。下图是BeautifulSoup抓取的百度百科中的一个网页的部分输出。
BeautifulSoup的具体使用会在以后写文章。以下代码使用python抓取百度百科中其他英雄联盟相关条目,并将这些条目保存在新建的excel中。以上代码:
from bs4 import BeautifulSoup import re import xlrd import xlwt from urllib.request import urlopen excelFile=xlwt.Workbook() sheet=excelFile.add_sheet('league of legend') ## 百度百科:英雄联盟## html=urlopen("http://baike.baidu.com/subview ... 6quot;) bsObj=BeautifulSoup(html.read(),"html.parser") #print(bsObj.prettify()) row=0 for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}): links=node.findAll("a",href=re.compile("^(/view/)[0-9]+\.htm$")) for link in links: if 'href' in link.attrs: print(link.attrs['href'],link.get_text()) sheet.write(row,0,link.attrs['href']) sheet.write(row,1,link.get_text()) row=row+1 excelFile.save('E:\Project\Python\lol.xls')
部分输出截图如下:
excel部分截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。 查看全部
jquery抓取网页内容(聊一聊Python与网络爬虫的主要框架及应用)
我们来谈谈 Python 和网络爬虫。
1、爬虫的定义
Crawler:自动抓取互联网数据的程序。
2、爬虫主要框架
爬虫程序的主框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中有需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的URL。网页,然后调用网页解析器解析网页,将网页中新的URL添加到URL管理器中,输出有价值的数据。
3、爬虫时序图
4、网址管理器
网址管理器管理要爬取的URL集合和已经爬取的URL集合,防止重复爬取和循环爬取。 URL管理器的主要功能如下图所示:
URL管理器的实现主要使用Python中的内存(set)和关系型数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,一般采用数据库来实现。
5、网页下载器
Python中的网页下载器主要使用了urllib库,这是python自带的一个模块。对于2.x版本的urllib2库,在其request和其他子模块中集成到python3.x中的urllib中。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen函数的参数可以是url链接,也可以是请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页,带有反爬虫机制的网页,然后使用urlopen函数,需要添加http头。对于有登录机制的网页,需要设置cookie。
6、网页解析器
网页解析器从网页下载器下载的 url 数据中提取有价值的数据和新的 url。对于数据提取,可以使用正则表达式、BeautifulSoup等方法。正则表达式采用基于字符串的模糊匹配,对目标源gao@daima#com有较好的效果,特征比较鲜明(%code@#数据,但通用性不高。BeautifulSoup是第三个—— party模块,用于结构化解析url内容。下载的网页内容被解析成DOM树。下图是BeautifulSoup抓取的百度百科中的一个网页的部分输出。
BeautifulSoup的具体使用会在以后写文章。以下代码使用python抓取百度百科中其他英雄联盟相关条目,并将这些条目保存在新建的excel中。以上代码:
from bs4 import BeautifulSoup import re import xlrd import xlwt from urllib.request import urlopen excelFile=xlwt.Workbook() sheet=excelFile.add_sheet('league of legend') ## 百度百科:英雄联盟## html=urlopen("http://baike.baidu.com/subview ... 6quot;) bsObj=BeautifulSoup(html.read(),"html.parser") #print(bsObj.prettify()) row=0 for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}): links=node.findAll("a",href=re.compile("^(/view/)[0-9]+\.htm$")) for link in links: if 'href' in link.attrs: print(link.attrs['href'],link.get_text()) sheet.write(row,0,link.attrs['href']) sheet.write(row,1,link.get_text()) row=row+1 excelFile.save('E:\Project\Python\lol.xls')
部分输出截图如下:
excel部分截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。
jquery抓取网页内容(PHP中CURL使用正则表达式抓取网站信息的如下操作相关技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-23 02:06
本篇文章主要介绍C#中使用正则表达式抓取网站信息,并结合实例分析C#对网页信息的正则爬取操作的相关技巧。@Code~Code$Net 参考值,有需要的朋友可以参考下面的例子,里面描述了C#使用正则表达式捕获网站信息的方法。分享给大家参考,具体如下: 这里以抓取京东商城商品详情为例。1、创建JdRobber.cs程序类public class JdRobber{ /// ///判断京东是否链接/// /// ///
1. C# 如何使用正则表达式捕获 网站 信息的代码示例
简介:本文章主要介绍了C#中使用正则表达式抓取网站信息,并结合实例分析了C#对网页信息正则爬取的相关技巧,具有一定的参考价值。朋友可以参考
2.使用python抓取求职网站信息
简介:本文章介绍使用python抓取求职网站信息
3. 创建数据库php代码,用PHP_PHP教程编写自己的博客系统
简介:创建数据库php代码,用PHP编写自己的BLOG系统。直接复制下面的代码:?php //date_default_timezone_set("Asia/Shanghai"); /* function create_siteinfo DONE:网站信息表作者:DATE:2010-3-
4. PHP中的CURL技术模拟登录并获取网站信息,并在微信公众平台查询结果_PHP教程
简介:PHP中的CURL技术模拟登录并获取网站信息,并在微信公众平台查询结果。随着微信的火爆,微信公众平台成为众多开发者的下一个目标。作者本人对这种新颖性并不那么有吸引力。但是最近有朋友帮忙开发
5.使用PHP curl模拟浏览器抓包网站信息_PHP教程
简介:使用PHP curl模拟浏览器对网站信息的抓取。官方解释 curl 是一个文件传输工具,使用 URL 语法在命令行模式下工作。curl 是一个文件传输工具,它使用 URL 语法从命令行工作。它非常支持
6. 关于 PHP 命名约定
简介:既然是web项目,难免会在配置文件中写入数据库连接信息,网站常量。我在 config.inc.php 中编写了以下代码: ?php //网站info $siteurl = ';; /*网站网址*/ $sitename = '春卷'; /*< @网站Name*/ //数据库配置 $hostnam
7. 网站添加RSS功能
简介:为方便用户定制网站内容而设置的各种RSS频道。通过订阅不同的RSS(可以同时订阅多个网站),观看者无需登录网站即可及时获取新闻信息,也可以避免网页上无用的广告和垃圾信息干涉。使用RSS将为观众节省大量时间,也将成为网站人性化设计的一大亮点,提升网站的档次。其实RSS技术并不太难。如果您的 网站 信息很大,您可以将此技术应用于您自己的站点。一、什么是RSSRSS是站点和站点
8. 如何通过网页判断用户机器上是否安装了这个软件
简介:如何通过网页判断用户机器上是否安装了这个软件我们为网站开发了一个小软件,它具有自己发消息和聊天的功能,包括阅读网站消息。现在想问一下,如何通过网页来判断用户机器上是否安装了这个软件?如果已安装,您可以启动该软件的消息窗口,如果没有,请进入下载安装页面。类似于QQ?在线/离线模仿- 解决办法 ——————–
9. php 网站信息查询站点
简介:php网站信息查询站点想开发一个与php类似的站点。大家给出一些想法。. . ——最佳方案————SEO下的一些内容可以抓取,有的内容叫界面。很多工具都是自己开发的,简单说几句
10. 没有数据库的空间怎么做动态网站
简介:没有数据库网站的空间怎么做动态?没有php环境,只能用html语言、css、javascript建站,还需要更新网站信息(例如:新闻、视频等)。求指点,谢谢大侠!分享给:
【相关问答推荐】:
requests - 有关 python 模拟登录捕获的信息 网站
[求助] PHP使用curl模拟post提交数据获取目标网站信息,解决? 查看全部
jquery抓取网页内容(PHP中CURL使用正则表达式抓取网站信息的如下操作相关技巧)
本篇文章主要介绍C#中使用正则表达式抓取网站信息,并结合实例分析C#对网页信息的正则爬取操作的相关技巧。@Code~Code$Net 参考值,有需要的朋友可以参考下面的例子,里面描述了C#使用正则表达式捕获网站信息的方法。分享给大家参考,具体如下: 这里以抓取京东商城商品详情为例。1、创建JdRobber.cs程序类public class JdRobber{ /// ///判断京东是否链接/// /// ///
1. C# 如何使用正则表达式捕获 网站 信息的代码示例
简介:本文章主要介绍了C#中使用正则表达式抓取网站信息,并结合实例分析了C#对网页信息正则爬取的相关技巧,具有一定的参考价值。朋友可以参考
2.使用python抓取求职网站信息
简介:本文章介绍使用python抓取求职网站信息
3. 创建数据库php代码,用PHP_PHP教程编写自己的博客系统
简介:创建数据库php代码,用PHP编写自己的BLOG系统。直接复制下面的代码:?php //date_default_timezone_set("Asia/Shanghai"); /* function create_siteinfo DONE:网站信息表作者:DATE:2010-3-
4. PHP中的CURL技术模拟登录并获取网站信息,并在微信公众平台查询结果_PHP教程
简介:PHP中的CURL技术模拟登录并获取网站信息,并在微信公众平台查询结果。随着微信的火爆,微信公众平台成为众多开发者的下一个目标。作者本人对这种新颖性并不那么有吸引力。但是最近有朋友帮忙开发
5.使用PHP curl模拟浏览器抓包网站信息_PHP教程
简介:使用PHP curl模拟浏览器对网站信息的抓取。官方解释 curl 是一个文件传输工具,使用 URL 语法在命令行模式下工作。curl 是一个文件传输工具,它使用 URL 语法从命令行工作。它非常支持
6. 关于 PHP 命名约定
简介:既然是web项目,难免会在配置文件中写入数据库连接信息,网站常量。我在 config.inc.php 中编写了以下代码: ?php //网站info $siteurl = ';; /*网站网址*/ $sitename = '春卷'; /*< @网站Name*/ //数据库配置 $hostnam
7. 网站添加RSS功能
简介:为方便用户定制网站内容而设置的各种RSS频道。通过订阅不同的RSS(可以同时订阅多个网站),观看者无需登录网站即可及时获取新闻信息,也可以避免网页上无用的广告和垃圾信息干涉。使用RSS将为观众节省大量时间,也将成为网站人性化设计的一大亮点,提升网站的档次。其实RSS技术并不太难。如果您的 网站 信息很大,您可以将此技术应用于您自己的站点。一、什么是RSSRSS是站点和站点
8. 如何通过网页判断用户机器上是否安装了这个软件
简介:如何通过网页判断用户机器上是否安装了这个软件我们为网站开发了一个小软件,它具有自己发消息和聊天的功能,包括阅读网站消息。现在想问一下,如何通过网页来判断用户机器上是否安装了这个软件?如果已安装,您可以启动该软件的消息窗口,如果没有,请进入下载安装页面。类似于QQ?在线/离线模仿- 解决办法 ——————–
9. php 网站信息查询站点
简介:php网站信息查询站点想开发一个与php类似的站点。大家给出一些想法。. . ——最佳方案————SEO下的一些内容可以抓取,有的内容叫界面。很多工具都是自己开发的,简单说几句
10. 没有数据库的空间怎么做动态网站
简介:没有数据库网站的空间怎么做动态?没有php环境,只能用html语言、css、javascript建站,还需要更新网站信息(例如:新闻、视频等)。求指点,谢谢大侠!分享给:
【相关问答推荐】:
requests - 有关 python 模拟登录捕获的信息 网站
[求助] PHP使用curl模拟post提交数据获取目标网站信息,解决?
jquery抓取网页内容(谷歌实际上是否会通过ajax呼叫来拉下/链接流量?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-19 09:18
概述 在我的 网站 主页上,我使用 JQuery 的 ajax 函数来下拉用户最近活动的列表。最近的活动显示在页面上,最近活动的每一行都收录一个指向执行该活动的用户的用户配置文件的链接。Google 是否真的通过 ajax 调用来提取这些信息并使用它来计算页面相关性/链接流量?我希望不是因为用户个人资料页面不太值得谷歌索引,我不希望所有这些链接到用户个人资料页面,使我的主页的链接流量远离其他更重要的链接
在我的 网站 主页上,我使用 JQuery 的 ajax 函数来下拉用户最近活动的列表。
最近的活动显示在页面上,最近活动的每一行都收录一个指向执行该活动的用户的用户配置文件的链接。
Google 是否真的通过 ajax 调用来提取这些信息并使用它来计算页面相关性/链接流量?
我希望这不是因为用户个人资料页面不太值得谷歌索引,我不希望所有这些链接到用户个人资料页面,使我的主页的链接流量远离其他更重要的链接。
解决方案
不,默认情况下不会抓取 AJAX 内容。
有关于如何使 AJAX 内容可抓取的说明,但这些是您需要采取的明确步骤,它不是自动的
总结
以上是编程之家为你采集的jquery——谷歌会抓取AJAX内容吗?全部内容,希望文章能对jquery有所帮助——谷歌会抓取AJAX内容吗?程序开发遇到的问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。 查看全部
jquery抓取网页内容(谷歌实际上是否会通过ajax呼叫来拉下/链接流量?(图))
概述 在我的 网站 主页上,我使用 JQuery 的 ajax 函数来下拉用户最近活动的列表。最近的活动显示在页面上,最近活动的每一行都收录一个指向执行该活动的用户的用户配置文件的链接。Google 是否真的通过 ajax 调用来提取这些信息并使用它来计算页面相关性/链接流量?我希望不是因为用户个人资料页面不太值得谷歌索引,我不希望所有这些链接到用户个人资料页面,使我的主页的链接流量远离其他更重要的链接
在我的 网站 主页上,我使用 JQuery 的 ajax 函数来下拉用户最近活动的列表。
最近的活动显示在页面上,最近活动的每一行都收录一个指向执行该活动的用户的用户配置文件的链接。
Google 是否真的通过 ajax 调用来提取这些信息并使用它来计算页面相关性/链接流量?
我希望这不是因为用户个人资料页面不太值得谷歌索引,我不希望所有这些链接到用户个人资料页面,使我的主页的链接流量远离其他更重要的链接。
解决方案
不,默认情况下不会抓取 AJAX 内容。
有关于如何使 AJAX 内容可抓取的说明,但这些是您需要采取的明确步骤,它不是自动的
总结
以上是编程之家为你采集的jquery——谷歌会抓取AJAX内容吗?全部内容,希望文章能对jquery有所帮助——谷歌会抓取AJAX内容吗?程序开发遇到的问题。
如果你觉得编程之家网站的内容还不错,欢迎你把编程之家网站推荐给你的程序员朋友。
jquery抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-16 13:00
需要思考的问题:
如何在一个网页的div中嵌套另一个网页(不使用include、iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套网页无法获取父页面)信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一个页面的一部分)
答案(想法):
使用jquery的ajax函数或者load函数可以获取网页的内容,从而实现网页的嵌套(获取的网页内容为html字符串)。如何从字符串中获取部分内容?
练习一:
index.html页面(获取本页内容页面的内容)
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题到这里就可以解决了,点击获取完整的content.html页面的内容
查看jquery的load方法可以发现load函数其实可以指定网页的内容
练习二:
更改index.html页面的ajax函数的url路径获取content.html页面div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url + ' #container',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + ' #container');
48 }
49
查看代码
至此我们解决了,文章一开始提出的问题。. . . . . 但这是一个静态页面(html页面),它可以工作吗?
答案是否定的,ajax函数或者load函数获取的页面内容是否收录title标签和两个
这是ajax获取的内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到,不仅获取到了div的内容,还多了两个div和一个title
上网查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行,下面是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: 'get',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + ' #container':获取url网页中container容器内的内容
41 url: url + ' #container',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find('div[id=container]').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + ' #container', '', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find('div[id=container]').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
这里还有一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个页面,使用母版页会导致标签id发生变化。我想要实现的是在不刷新页面的情况下点击菜单。
转载于: 查看全部
jquery抓取网页内容(思考的问题:怎么在一个网页的div中获取部分内容)
需要思考的问题:
如何在一个网页的div中嵌套另一个网页(不使用include、iframe和frame,不使用的原因,include只能嵌套静态网页,iframe影响网络爬虫,frame嵌套网页无法获取父页面)信息,不够灵活)如果您不想嵌套整个网页怎么办?(只是嵌套另一个页面的一部分)
答案(想法):
使用jquery的ajax函数或者load函数可以获取网页的内容,从而实现网页的嵌套(获取的网页内容为html字符串)。如何从字符串中获取部分内容?
练习一:
index.html页面(获取本页内容页面的内容)
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url,
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url);
48 }
49
查看代码
content.html 页面
1
2
3 内容页
4
5
6
7
8 This is Content Page;
9
10
11
12
查看代码
第一个问题到这里就可以解决了,点击获取完整的content.html页面的内容
查看jquery的load方法可以发现load函数其实可以指定网页的内容
练习二:
更改index.html页面的ajax函数的url路径获取content.html页面div的id=container的内容
1
2
3
4 使用jquery的ajax函数获取网页内容
5
6 div{
7 display: block;
8 }
9
10
11
12
13
14
15
16
17
18 This is index.html;
19
20
21
22
23
24
25
26
27 /*
28 * 使用ajax方式获取网页内容(也可以使用load方式获取)
29 * */
30 //解决方案一
31 function GetPageContent1(url) {
32 $.ajax({
33 type: 'get',
34 url: url + ' #container',
35 async: true,
36 success: function(html) {
37 $("#content").html(html);
38 },
39 error: function(errorMsg){
40 alert(errorMsg);
41 }
42 })
43 }
44 //解决方案二
45 function GetPageContent2(url){
46 /* 想知道更多的load方法信息,请查阅jquery api */
47 $("#content").load(url + ' #container');
48 }
49
查看代码
至此我们解决了,文章一开始提出的问题。. . . . . 但这是一个静态页面(html页面),它可以工作吗?
答案是否定的,ajax函数或者load函数获取的页面内容是否收录title标签和两个
这是ajax获取的内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 Welcome to Content Page!
17
18
查看代码
我们可以看到,不仅获取到了div的内容,还多了两个div和一个title
上网查了一些资料,有人说用$(html).find("#container").html(); 可以解决,但是实践后还是不行,下面是我的最终解决方案
这是Test1.aspx页面,相当于之前的index.html(是我命名错误,请见谅)
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9 div{
10 display: block;
11 }
12
13
14
15
16
17
18
19
20
21
22 This is index.html;
23
24
25
26
27
28
29
30
31
32 /*
33 * 使用ajax方式获取网页内容(也可以使用load方式获取)
34 * */
35 //解决方案一
36 function GetPageContent1(url) {
37 $.ajax({
38 type: 'get',
39 //url:直接使用url将会获取到整个网页的内容
40 //url + ' #container':获取url网页中container容器内的内容
41 url: url + ' #container',
42 async: true,
43 success: function (html) {
44 $("#content").html($(html).find('div[id=container]').html());
45
46 //$("#content").html(html);
47 },
48 error: function(errorMsg) {
49 alert(errorMsg);
50 }
51 });
52 }
53 //解决方案二(缺点是content容器会被两次赋值,如不在加载完成之后的函数中进行数据处理,讲含有title、asp.net隐藏内容等标签)
54 function GetPageContent2(url) {
55 /* 想知道更多的load方法信息,请查阅jquery api */
56 $("#content").load(url + ' #container', '', function (response, status, xhr) {
57 //response#是获取到的所有数据(未被截取),status#状态,成功或者失败,xhr#包含 XMLHttpRequest 对象
58 $("#content").html($(response).find('div[id=container]').html());
59 });
60 }
61
62
查看代码
内容页面.aspx
1
2
3 DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DT ... gt%3B
4
5
6
7
8
9
10
11
12 Welcome to Content Page!
13
14
15
16
17
查看代码
注意:如果直接复制代码,请修改jquery文件路径
这里还有一点,为什么不使用母版页
使用母版页,点击菜单会刷新整个页面,使用母版页会导致标签id发生变化。我想要实现的是在不刷新页面的情况下点击菜单。
转载于:
jquery抓取网页内容(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-16 07:16
任何你想要的信息基本上都在网上存在,问题是如何组织成你需要的,比如抓取某个行业所有相关公司的名字网站,联系电话,Email,等,然后将其保存在 Excel 中进行分析。网页抓取变得越来越有用。
对于传统网页,web服务器直接返回Html。这种类型的网页很容易掌握。不管用什么方法,只要拿到html页面,然后做Dom解析。但是对于需要Javascript来生成的网页来说,就不是那么容易了。张宇还没有找到解决这个问题的好办法。欢迎有抓javascript网页经验的朋友指点。
那么今天我要讲的就是传统html网页的信息爬取。虽然如前所述,没有技术难度,但是有没有相对简单的方法呢?使用过 jQuery 等 js 框架的朋友可能会认为 javascript 就像是抓取网页信息的天然助手,为网页解析而生。当然,现在有更多的应用,比如服务器端的javascript应用,NodeJs。
如果能够在我们的应用程序中使用 jQuery 来抓取网页,例如 java 程序,那将是非常令人兴奋的。确实有现成的解决方案,Javascript引擎,可以支持jQuery运行的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import org.mozilla.javascript.Context;
import org.mozilla.javascript.ContextFactory;
import org.mozilla.javascript.Scriptable;
import org.mozilla.javascript.ScriptableObject;
/**
* @author MyBeautiful
* @Emal: zhangyu0182@sina.com
* @date Mar 7, 2012
*/
public class RhinoScaper {
private String url;
private String jsFile;
private Context cx;
private Scriptable scope;
public String getUrl() {
return url;
}
public String getJsFile() {
return jsFile;
}
public void setUrl(String url) {
this.url = url;
putObject("url", url);
}
public void setJsFile(String jsFile) {
this.jsFile = jsFile;
}
public void init() {
cx = ContextFactory.getGlobal().enterContext();
scope = cx.initStandardObjects(null);
cx.setOptimizationLevel(-1);
cx.setLanguageVersion(Context.VERSION_1_5);
String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" };
for (String f : file) {
evaluateJs(f);
}
try {
ScriptableObject.defineClass(scope, ExtendUtil.class);
} catch (IllegalAccessException e1) {
e1.printStackTrace();
} catch (InstantiationException e1) {
e1.printStackTrace();
} catch (InvocationTargetException e1) {
e1.printStackTrace();
}
ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util");
scope.put("util", scope, util);
}
protected void evaluateJs(String f) {
try {
FileReader in = null;
in = new FileReader(f);
cx.evaluateReader(scope, in, f, 1, null);
} catch (FileNotFoundException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
public void putObject(String name, Object o) {
scope.put(name, scope, o);
}
public void run() {
evaluateJs(this.jsFile);
}
}
测试代码:
package stony.zhang.scrape;
import java.util.HashMap;
import java.util.Map;
import junit.framework.TestCase;
public class RhinoScaperTest extends TestCase {
public RhinoScaperTest(String name) {
super(name);
}
public void testRun() {
RhinoScaper rs = new RhinoScaper();
rs.init();
rs.setUrl("http://www.baidu.com");
rs.setJsFile("test.js");
// Map o = new HashMap();
// rs.putObject("result", o);
rs.run();
// System.out.println(o.get("imgurl"));
}
}
test.js 文件,如下
$.ajax({
url: "http://www.baidu.com",
context: document.body,
success: function(data){
// util.log(data);
var result =parseHtml(data);
var $v= jQuery(result);
// util.log(result);
$v.find('#u a').each(function(index) {
util.log(index + ': ' + $(this).attr("href"));
// arr.add($(this).attr("href"));
});
}
});
function parseHtml(html) {
//Create an iFrame object that will be used to render the HTML in order to get the DOM objects
//created - this is a far quicker way of achieving the HTML to DOM conversion than trying
//to transform the HTML objects one-by-one
var oIframe = document.createElement('iframe');
//Hide the iFrame from view
oIframe.style.display = 'none';
if (document.body)
document.body.appendChild(oIframe);
else
document.documentElement.appendChild(oIframe);
//Open the iFrame DOM object and write in our HTML
oIframe.contentDocument.open();
oIframe.contentDocument.write(html);
oIframe.contentDocument.close();
//Return the document body object containing the HTML that was just
//added to the iFrame as DOM objects
var oBody = oIframe.contentDocument.body;
//TODO: Remove the iFrame object created to cleanup the DOM
return oBody;
}
当我们执行Unit Test的时候,会在控制台打印从网页抓取的三个百度连接,
0:
1:
2:
测试成功,证明在java程序中使用jQuery爬取网页是可行的。
----------------------------------- ---------- ------------
张宇,我的美丽, 查看全部
jquery抓取网页内容(基本上在互联网上存在了问题是如何把它们整理成你所需要的)
任何你想要的信息基本上都在网上存在,问题是如何组织成你需要的,比如抓取某个行业所有相关公司的名字网站,联系电话,Email,等,然后将其保存在 Excel 中进行分析。网页抓取变得越来越有用。
对于传统网页,web服务器直接返回Html。这种类型的网页很容易掌握。不管用什么方法,只要拿到html页面,然后做Dom解析。但是对于需要Javascript来生成的网页来说,就不是那么容易了。张宇还没有找到解决这个问题的好办法。欢迎有抓javascript网页经验的朋友指点。
那么今天我要讲的就是传统html网页的信息爬取。虽然如前所述,没有技术难度,但是有没有相对简单的方法呢?使用过 jQuery 等 js 框架的朋友可能会认为 javascript 就像是抓取网页信息的天然助手,为网页解析而生。当然,现在有更多的应用,比如服务器端的javascript应用,NodeJs。
如果能够在我们的应用程序中使用 jQuery 来抓取网页,例如 java 程序,那将是非常令人兴奋的。确实有现成的解决方案,Javascript引擎,可以支持jQuery运行的环境。
工具:java、Rhino、envJs。其中Rhino是Mozzila提供的开源Javascript引擎,envJs是模拟浏览器环境,比如Window。代码如下,
package stony.zhang.scrape;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import org.mozilla.javascript.Context;
import org.mozilla.javascript.ContextFactory;
import org.mozilla.javascript.Scriptable;
import org.mozilla.javascript.ScriptableObject;
/**
* @author MyBeautiful
* @Emal: zhangyu0182@sina.com
* @date Mar 7, 2012
*/
public class RhinoScaper {
private String url;
private String jsFile;
private Context cx;
private Scriptable scope;
public String getUrl() {
return url;
}
public String getJsFile() {
return jsFile;
}
public void setUrl(String url) {
this.url = url;
putObject("url", url);
}
public void setJsFile(String jsFile) {
this.jsFile = jsFile;
}
public void init() {
cx = ContextFactory.getGlobal().enterContext();
scope = cx.initStandardObjects(null);
cx.setOptimizationLevel(-1);
cx.setLanguageVersion(Context.VERSION_1_5);
String[] file = { "./lib/env.rhino.1.2.js", "./lib/jquery.js" };
for (String f : file) {
evaluateJs(f);
}
try {
ScriptableObject.defineClass(scope, ExtendUtil.class);
} catch (IllegalAccessException e1) {
e1.printStackTrace();
} catch (InstantiationException e1) {
e1.printStackTrace();
} catch (InvocationTargetException e1) {
e1.printStackTrace();
}
ExtendUtil util = (ExtendUtil) cx.newObject(scope, "util");
scope.put("util", scope, util);
}
protected void evaluateJs(String f) {
try {
FileReader in = null;
in = new FileReader(f);
cx.evaluateReader(scope, in, f, 1, null);
} catch (FileNotFoundException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
}
public void putObject(String name, Object o) {
scope.put(name, scope, o);
}
public void run() {
evaluateJs(this.jsFile);
}
}
测试代码:
package stony.zhang.scrape;
import java.util.HashMap;
import java.util.Map;
import junit.framework.TestCase;
public class RhinoScaperTest extends TestCase {
public RhinoScaperTest(String name) {
super(name);
}
public void testRun() {
RhinoScaper rs = new RhinoScaper();
rs.init();
rs.setUrl("http://www.baidu.com";);
rs.setJsFile("test.js");
// Map o = new HashMap();
// rs.putObject("result", o);
rs.run();
// System.out.println(o.get("imgurl"));
}
}
test.js 文件,如下
$.ajax({
url: "http://www.baidu.com",
context: document.body,
success: function(data){
// util.log(data);
var result =parseHtml(data);
var $v= jQuery(result);
// util.log(result);
$v.find('#u a').each(function(index) {
util.log(index + ': ' + $(this).attr("href"));
// arr.add($(this).attr("href"));
});
}
});
function parseHtml(html) {
//Create an iFrame object that will be used to render the HTML in order to get the DOM objects
//created - this is a far quicker way of achieving the HTML to DOM conversion than trying
//to transform the HTML objects one-by-one
var oIframe = document.createElement('iframe');
//Hide the iFrame from view
oIframe.style.display = 'none';
if (document.body)
document.body.appendChild(oIframe);
else
document.documentElement.appendChild(oIframe);
//Open the iFrame DOM object and write in our HTML
oIframe.contentDocument.open();
oIframe.contentDocument.write(html);
oIframe.contentDocument.close();
//Return the document body object containing the HTML that was just
//added to the iFrame as DOM objects
var oBody = oIframe.contentDocument.body;
//TODO: Remove the iFrame object created to cleanup the DOM
return oBody;
}
当我们执行Unit Test的时候,会在控制台打印从网页抓取的三个百度连接,
0:
1:
2:
测试成功,证明在java程序中使用jQuery爬取网页是可行的。
----------------------------------- ---------- ------------
张宇,我的美丽,
jquery抓取网页内容( 什么是HTML?、Jquery、密码记性前端的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-15 08:04
什么是HTML?、Jquery、密码记性前端的区别)
jquery+Css+Html实现前端验证和用户登录功能的登录用户和密码
文章目录
前言
应用场景:可实现任意程序的登录,可对用户名、密码记忆或手机号、邮箱等信息进行前端验证。
温馨提示:以下为本文正文内容文章,以下案例供参考
一、什么是 jQuery?
jQuery 是免费的、开源的,并且在 MIT 许可下获得许可。jQuery 的语法旨在使开发人员更轻松,例如操作文档对象、选择 DOM 元素、制作动画、处理事件、使用 Ajax 和其他功能。此外,jQuery 还为开发人员提供了编写插件的 API。它的模块化使用允许开发人员轻松开发强大的静态或动态网页。(百度百科)。
二、什么是 CSS?
Cascading Style Sheets(英文全称:Cascading Style Sheets)是一种计算机语言,用于表示HTML(标准通用标记语言的一种应用)或XML(标准通用标记语言的一个子集)等文档样式。CSS不仅可以静态修改网页,还可以用各种脚本语言动态格式化网页的各种元素。CSS 可以对网页中元素位置的布局进行像素级的精确控制,支持几乎所有的字体大小样式,并具有编辑网页对象和模型样式的能力。(百度百科)。
三、什么是HTML?
HTML 代表超文本标记语言,它是一种标记语言。它包括一系列标签。通过这些标签,可以统一网络上的文档格式,将分散的互联网资源连接成一个逻辑整体。HTML 文本是由 HTML 命令组成的描述性文本,可以描述文本、图形、动画、声音、表格、链接等。. (百度百科)。
四、jquery前端代码实现
首先,导入jquery.js文件,使页面具备jquery的功能。该功能需要两个页面,一个登录页面,一个登录成功页面(文件需要流式传输,下班后可以流式传输私信,看到就会返回)
1.创建登录页面
创建.txt文本,然后写代码保存,然后把文本后缀改成.html保存,用浏览器打开
登录页面
//页面加载时 让id为uid的对象获得焦点
$(document).ready(function(){
//var oInput = $("#uid");
//oInput.focus();//获得焦点
// dom对象与jquery对象之间转换 原生js抓取和生成的对象称为dom对象,通过jquery创建和抓取的对象称为jquery对象,只有jquery对象可以调用jquery中方法
//var oInput = document.getElementById("uid");
//var oInput = $("#uid");
//将dom对象转为jquery对象(穿马甲)
//oInput = $(oInput);
//console.log(oInput.val());
//将jquery对象转为dom对象
//oInput = oInput[0];
//console.log(oInput.value);
var oInput = $("#uid");
oInput.focus();
});
function check()
{
//得到uid的值
var uid = $("#uid").val();
if(uid == "")
{
alert("用户ID必须填写!");
$("#uid").focus();
return ;
}
else
{
//校验密码是否为三位数字
var reg = new RegExp("^\\d{3}$");
var flag = reg.test($("#upass").val());
if(flag==false)
{
alert("密码必须是3位数字");
$("#upass").focus().select();
}
else
{
//提交表达
$("#thisform").attr({action:"result.html",method:"post"}).submit();
}
}
}
用户ID:
用户密码:
2.创建成功登录页面
登录成功的页面
欢迎您,登录成功。。。。。
1、 js代码和逻辑处理代码要写在标签体中。
2、 标签体要写css代码,页面显示的样式。
3、 标签体主要展示页面的内容。
4、 标签体主要是表头格式区。
5、 标签体是整个页面的区域。
6、标签是引入jquery.js文件src等于本地路径。
3.效果实现
1、输入用户名zhx,密码123456,点击登录按钮。
定期检查密码。如果要定期检查密码,可以使用对应的正则表达式。这里为了方便演示,密码只能是3位数字。
1、输入用户名zhx,密码123,点击登录按钮。
跳转到登录成功页面。
总结
对登录功能相关的用户名、密码、手机号、邮箱等信息进行验证,尽量在进入页面时进行验证,尽量避免后端验证减少与后端交互的频率。 查看全部
jquery抓取网页内容(
什么是HTML?、Jquery、密码记性前端的区别)
jquery+Css+Html实现前端验证和用户登录功能的登录用户和密码
文章目录
前言
应用场景:可实现任意程序的登录,可对用户名、密码记忆或手机号、邮箱等信息进行前端验证。
温馨提示:以下为本文正文内容文章,以下案例供参考
一、什么是 jQuery?
jQuery 是免费的、开源的,并且在 MIT 许可下获得许可。jQuery 的语法旨在使开发人员更轻松,例如操作文档对象、选择 DOM 元素、制作动画、处理事件、使用 Ajax 和其他功能。此外,jQuery 还为开发人员提供了编写插件的 API。它的模块化使用允许开发人员轻松开发强大的静态或动态网页。(百度百科)。
二、什么是 CSS?
Cascading Style Sheets(英文全称:Cascading Style Sheets)是一种计算机语言,用于表示HTML(标准通用标记语言的一种应用)或XML(标准通用标记语言的一个子集)等文档样式。CSS不仅可以静态修改网页,还可以用各种脚本语言动态格式化网页的各种元素。CSS 可以对网页中元素位置的布局进行像素级的精确控制,支持几乎所有的字体大小样式,并具有编辑网页对象和模型样式的能力。(百度百科)。
三、什么是HTML?
HTML 代表超文本标记语言,它是一种标记语言。它包括一系列标签。通过这些标签,可以统一网络上的文档格式,将分散的互联网资源连接成一个逻辑整体。HTML 文本是由 HTML 命令组成的描述性文本,可以描述文本、图形、动画、声音、表格、链接等。. (百度百科)。
四、jquery前端代码实现
首先,导入jquery.js文件,使页面具备jquery的功能。该功能需要两个页面,一个登录页面,一个登录成功页面(文件需要流式传输,下班后可以流式传输私信,看到就会返回)
1.创建登录页面
创建.txt文本,然后写代码保存,然后把文本后缀改成.html保存,用浏览器打开
登录页面
//页面加载时 让id为uid的对象获得焦点
$(document).ready(function(){
//var oInput = $("#uid");
//oInput.focus();//获得焦点
// dom对象与jquery对象之间转换 原生js抓取和生成的对象称为dom对象,通过jquery创建和抓取的对象称为jquery对象,只有jquery对象可以调用jquery中方法
//var oInput = document.getElementById("uid");
//var oInput = $("#uid");
//将dom对象转为jquery对象(穿马甲)
//oInput = $(oInput);
//console.log(oInput.val());
//将jquery对象转为dom对象
//oInput = oInput[0];
//console.log(oInput.value);
var oInput = $("#uid");
oInput.focus();
});
function check()
{
//得到uid的值
var uid = $("#uid").val();
if(uid == "")
{
alert("用户ID必须填写!");
$("#uid").focus();
return ;
}
else
{
//校验密码是否为三位数字
var reg = new RegExp("^\\d{3}$");
var flag = reg.test($("#upass").val());
if(flag==false)
{
alert("密码必须是3位数字");
$("#upass").focus().select();
}
else
{
//提交表达
$("#thisform").attr({action:"result.html",method:"post"}).submit();
}
}
}
用户ID:
用户密码:
2.创建成功登录页面
登录成功的页面
欢迎您,登录成功。。。。。
1、 js代码和逻辑处理代码要写在标签体中。
2、 标签体要写css代码,页面显示的样式。
3、 标签体主要展示页面的内容。
4、 标签体主要是表头格式区。
5、 标签体是整个页面的区域。
6、标签是引入jquery.js文件src等于本地路径。
3.效果实现
1、输入用户名zhx,密码123456,点击登录按钮。
定期检查密码。如果要定期检查密码,可以使用对应的正则表达式。这里为了方便演示,密码只能是3位数字。
1、输入用户名zhx,密码123,点击登录按钮。
跳转到登录成功页面。
总结
对登录功能相关的用户名、密码、手机号、邮箱等信息进行验证,尽量在进入页面时进行验证,尽量避免后端验证减少与后端交互的频率。
jquery抓取网页内容(抓取网页内容采用的是lodash方法来实现())
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-14 17:00
jquery抓取网页内容采用的是lodash方法来实现。代码如下://方法名.post(“username=”,username=function(){returnres.tostring().required("");});//请求username的方法if(username.post){varusername=username.post;//转换成xmlhttprequest对象varres=lodash.getelementsbytagname("script");res.json();}。
个人认为网页爬虫还是离不开request和response对象,必须了解会用用它们来接收http请求,并解析请求内容得到数据,因此jquery这一块很可能不能用。建议直接写全局方法,其实jquery写在全局方法就可以了,因为全局方法简单而且对$里的属性、方法进行了伪类封装,也很易懂,没必要冒险写jquery对象,假如你jquery是基于ajax技术的,你直接写全局方法就可以了,只是写全局方法有个缺点,就是默认的解析方式是异步的,需要执行一个叫做__delete__()的方法。
还有为什么我要推荐全局方法,是因为大多数人写jquery应该不是基于ajax,而jquery的dom操作方法会用到全局对象,你写全局方法可以写出self.dom(address)这样的代码,可以一起调用dom方法,jquery这样的语言就是通过函数式编程实现的,而函数式编程用jquery语言最为好用,相信我。 查看全部
jquery抓取网页内容(抓取网页内容采用的是lodash方法来实现())
jquery抓取网页内容采用的是lodash方法来实现。代码如下://方法名.post(“username=”,username=function(){returnres.tostring().required("");});//请求username的方法if(username.post){varusername=username.post;//转换成xmlhttprequest对象varres=lodash.getelementsbytagname("script");res.json();}。
个人认为网页爬虫还是离不开request和response对象,必须了解会用用它们来接收http请求,并解析请求内容得到数据,因此jquery这一块很可能不能用。建议直接写全局方法,其实jquery写在全局方法就可以了,因为全局方法简单而且对$里的属性、方法进行了伪类封装,也很易懂,没必要冒险写jquery对象,假如你jquery是基于ajax技术的,你直接写全局方法就可以了,只是写全局方法有个缺点,就是默认的解析方式是异步的,需要执行一个叫做__delete__()的方法。
还有为什么我要推荐全局方法,是因为大多数人写jquery应该不是基于ajax,而jquery的dom操作方法会用到全局对象,你写全局方法可以写出self.dom(address)这样的代码,可以一起调用dom方法,jquery这样的语言就是通过函数式编程实现的,而函数式编程用jquery语言最为好用,相信我。
jquery抓取网页内容(采用Ajax技术,加载不同的内容是什么鬼?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-12 18:13
越来越多的网站,开始采用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户通过英镑结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
我一直认为没有办法做到这一点,直到我看到了 Discourse 创始人之一 Robin Ward 的解决方案。
Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3 来源gaodai.ma#com搞##代!^码网
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
jquery抓取网页内容(采用Ajax技术,加载不同的内容是什么鬼?(组图))
越来越多的网站,开始采用“单页结构”(Single-page application)。
整个网站只有一个网页,它使用Ajax技术根据用户的输入加载不同的内容。
这种方式的好处是用户体验好,节省了流量。缺点是AJAX内容不能被搜索引擎抓取。例如,您有一个 网站。
http://example.com
用户通过英镑结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只抓取和忽略主题标签,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“井号+感叹号”的结构。
http://example.com#!1
当 Google 找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是,“英镑+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户投诉连连,仅半年就被废止。
那么,有没有什么方法可以让搜索引擎在抓取 AJAX 内容的同时保持更直观的 URL?
我一直认为没有办法做到这一点,直到我看到了 Discourse 创始人之一 Robin Ward 的解决方案。
Discourse 是一个严重依赖 Ajax 的论坛程序,但必须使用 Google收录 内容。它的解决方案是放弃英镑符号结构并使用 History API。
所谓History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏的网址变了,但音乐播放没有中断!
History API 的详细介绍超出了本文章 的范围。这里简单说一下,它的作用是在浏览器的History对象中添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以使新的 URL 出现在地址栏中。History对象的pushState方法接受三个参数,新的URL是第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前所有主流浏览器都支持这种方法:Chrome (26.0+), Firefox (20.0+), IE (10.0+), Safari (0.0+) @5.1+),歌剧 (12.1+)。
以下是罗宾·沃德 (Robin Ward) 的做法。
首先,用History API替换hashtag结构,让每个hashtag变成一个正常路径的URL,这样搜索引擎就会爬取每一个网页。
example.com/1 example.com/2 example.com/3 来源gaodai.ma#com搞##代!^码网
然后,定义一个处理 Ajax 部分并基于 URL 获取内容的 JavaScript 函数(假设是 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑到用户单击浏览器的“前进/后退”按钮。此时触发了History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义完以上三段代码后,就可以在不刷新页面的情况下显示正常的路径URL和AJAX内容了。
最后,设置服务器端。
因为没有使用主题标签结构,所以每个 URL 都是不同的请求。因此,服务器需要为所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
如果你仔细看上面的代码,你会发现有一个noscript标签,这就是秘密。
我们将搜索引擎应该为 收录 的所有内容放在 noscript 标记中。在这种情况下,用户仍然可以在不刷新页面的情况下进行 AJAX 操作,但是搜索引擎会收录每个页面的主要内容!
jquery抓取网页内容(一个简单的招聘网站数据归档进行当前热门岗位大数据分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-03 23:05
》所有未经项目验证的代码都是流氓,今天我们将通过一个简单的招聘网站数据存档对当前热门职位进行大数据分析,最后在wordcloud中展示。本文是一个数据爬取的文章。”
项目准备:
这一次,让我们更完整的捕捉拉勾在线“Python”相关的招聘信息和招聘要求。
可以连接互联网并搭建Python3以上环境的电脑。如果没有配置环境,可以参考我原来的文章 Python安装配置。 IDE这次我们用的是Jupyter Notebook,采集我们用的是selenium+pyquery,为什么要用这个呢?都是泪流满面,文末解释。数据分析使用熊猫。
分析页面找到数据源
打开 并搜索“Python”以获取以下页面。最近因为疫情被拘留在武汉,所以我会以武汉站作为我的目的地。共30页,每页显示15个位置[Position(368)].
selenium采集的效率远低于request采集。因为是在模拟浏览器模式下爬行,所以每次都要渲染页面。但是还有一个好处,就是不用担心header和cookie的问题。废话不多说,开始操作
按照我们之前的方法在 Notebook 中创建一个新的 Python 3 文件:
介绍各种模块:
import pyquery as pq
from selenium import webdriver
import pandas as pd
import time
import os
初始化浏览器:
driver = webdriver.Firefox()
driver.implicitly_wait(5)
driver.get("https://www.lagou.com/")
在打开的页面中,处理拉勾网的登录状态
while True:
i = input("已登陆成功请输入“OK”:")
if i == 'OK':
break
elif i == 'quit':
print("取消执行,关闭!")
os._exit(1)
登录成功后,在命令行输入窗口输入“OK”进入下一步执行。
进入列表采集:
print("开始执行采集")
data = []
driver.get("https://www.lagou.com/jobs/lis ... 6quot;)
while True:
but_class = driver.find_element_by_css_selector(".pager_next").get_attribute('class')
if but_class == 'pager_next ':
driver.find_element_by_xpath("//span[@action='next']").click()
items = pq.PyQuery(driver.page_source).find(".con_list_item")
data += getPosition(items)
time.sleep(2)
else:
print('列表采集结束')
break
我们单独定义了一个采集方法,getPosition方法接收一个pyquery对象。
方法代码如下:
def getPosition(items):
datalist=[]
for item in items.items():
temp = dict()
temp['职位ID']= item.attr('data-positionid')
temp['职位名']= item.attr('data-positionname')
temp['薪资范围']= item.attr('data-salary')
temp['公司ID']= item.attr('data-companyid')
temp['公司名']= item.attr('data-company')
temp['职位链接']=pq.PyQuery(item).find(".position_link").attr("href")
temp['发布时间']=pq.PyQuery(item).find(".format-time").text()
temp['猎头名称']=pq.PyQuery(item).find(".hr_name").text()
temp['猎头ID']=pq.PyQuery(item).find(".target_hr").text()
temp['工作经验']=pq.PyQuery(item).find(".p_bot>.li_b_l").remove(".money").text()
temp['公司主页']=pq.PyQuery(item).find(".company_name>a").attr('href')
temp['公司描述']=pq.PyQuery(item).find(".industry").text()
temp['岗位亮点']=pq.PyQuery(item).find(".li_b_r").text()
datalist.append(temp)
return datalist
到此,主列表的采集和排序工作就结束了。我们将来自 采集 的数据整合到 Pandas 中,并将其保存到一个 csv 文件中以备后用。
csv = pd.DataFrame(data)
csv.to_csv("lagou.csv")
截图是保存的DataFrame。可以看到,我们已经保存了二级页面名称和公司相关信息。
一共368条数据是采集。这时候我们开始完善第二步的详细数据采集。
我们先查一个二级页面,看看数据格式 查看全部
jquery抓取网页内容(一个简单的招聘网站数据归档进行当前热门岗位大数据分析)
》所有未经项目验证的代码都是流氓,今天我们将通过一个简单的招聘网站数据存档对当前热门职位进行大数据分析,最后在wordcloud中展示。本文是一个数据爬取的文章。”
项目准备:
这一次,让我们更完整的捕捉拉勾在线“Python”相关的招聘信息和招聘要求。
可以连接互联网并搭建Python3以上环境的电脑。如果没有配置环境,可以参考我原来的文章 Python安装配置。 IDE这次我们用的是Jupyter Notebook,采集我们用的是selenium+pyquery,为什么要用这个呢?都是泪流满面,文末解释。数据分析使用熊猫。
分析页面找到数据源
打开 并搜索“Python”以获取以下页面。最近因为疫情被拘留在武汉,所以我会以武汉站作为我的目的地。共30页,每页显示15个位置[Position(368)].
selenium采集的效率远低于request采集。因为是在模拟浏览器模式下爬行,所以每次都要渲染页面。但是还有一个好处,就是不用担心header和cookie的问题。废话不多说,开始操作
按照我们之前的方法在 Notebook 中创建一个新的 Python 3 文件:
介绍各种模块:
import pyquery as pq
from selenium import webdriver
import pandas as pd
import time
import os
初始化浏览器:
driver = webdriver.Firefox()
driver.implicitly_wait(5)
driver.get("https://www.lagou.com/";)
在打开的页面中,处理拉勾网的登录状态
while True:
i = input("已登陆成功请输入“OK”:")
if i == 'OK':
break
elif i == 'quit':
print("取消执行,关闭!")
os._exit(1)
登录成功后,在命令行输入窗口输入“OK”进入下一步执行。
进入列表采集:
print("开始执行采集")
data = []
driver.get("https://www.lagou.com/jobs/lis ... 6quot;)
while True:
but_class = driver.find_element_by_css_selector(".pager_next").get_attribute('class')
if but_class == 'pager_next ':
driver.find_element_by_xpath("//span[@action='next']").click()
items = pq.PyQuery(driver.page_source).find(".con_list_item")
data += getPosition(items)
time.sleep(2)
else:
print('列表采集结束')
break
我们单独定义了一个采集方法,getPosition方法接收一个pyquery对象。
方法代码如下:
def getPosition(items):
datalist=[]
for item in items.items():
temp = dict()
temp['职位ID']= item.attr('data-positionid')
temp['职位名']= item.attr('data-positionname')
temp['薪资范围']= item.attr('data-salary')
temp['公司ID']= item.attr('data-companyid')
temp['公司名']= item.attr('data-company')
temp['职位链接']=pq.PyQuery(item).find(".position_link").attr("href")
temp['发布时间']=pq.PyQuery(item).find(".format-time").text()
temp['猎头名称']=pq.PyQuery(item).find(".hr_name").text()
temp['猎头ID']=pq.PyQuery(item).find(".target_hr").text()
temp['工作经验']=pq.PyQuery(item).find(".p_bot>.li_b_l").remove(".money").text()
temp['公司主页']=pq.PyQuery(item).find(".company_name>a").attr('href')
temp['公司描述']=pq.PyQuery(item).find(".industry").text()
temp['岗位亮点']=pq.PyQuery(item).find(".li_b_r").text()
datalist.append(temp)
return datalist
到此,主列表的采集和排序工作就结束了。我们将来自 采集 的数据整合到 Pandas 中,并将其保存到一个 csv 文件中以备后用。
csv = pd.DataFrame(data)
csv.to_csv("lagou.csv")
截图是保存的DataFrame。可以看到,我们已经保存了二级页面名称和公司相关信息。
一共368条数据是采集。这时候我们开始完善第二步的详细数据采集。
我们先查一个二级页面,看看数据格式
jquery抓取网页内容(一下JS下常见的HTML解析库--HTML)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-12-30 04:04
HTML 就是一切,每个打算做 Web 编程的人都应该熟悉 HTML 并了解如何解析 HTML。这尤其是前端工程师的基础。在本文中,我们将介绍 JS 下常见的 HTML 解析库。
DOM解析器
JavaScript 和 jQuery 的 DOM 操作函数非常适合分析简单的 HTML 片段。在实际编程中,如果要以编程方式解析DOM完整的HTML或XML,则需要一个更好的解决方案,DOMParser,这是所有现代数字浏览器都支持的功能。
通过使用 DOMParser,您可以轻松解析 HTML 文档。但是,通常需要欺骗浏览器来实现解析,例如通过向当前文档添加新元素。
DOMParser 的使用非常简单明了:
let domParser = new DOMParser();
let doc = domParser.parseFromString(stringContainingXMLSource, "application/xml");
domParser = new DOMParser();
doc = domParser.parseFromString(stringContainingSVGSource, "image/svg+xml");
domParser = new DOMParser();
doc = domParser.parseFromString(stringContainingHTMLSource, "text/html");
切里奥
为服务器设计的核心 jQuery 的快速、灵活和精致的实现。
Cheerio 看起来像 jQuery,但它不支持浏览器。Cheerio 可以解析 HTML 并使其易于操作,但它不会像在浏览器中那样解析 HTML,解析出与浏览器不同的内容,并且不会将解析结果直接发送给用户。
Cheerio 实现了 jQuery 的一个子集,去除了 jQuery 中所有与 DOM 不一致或用于填充浏览器的东西,再现了 jQuery 最漂亮的 API
得益于极其简洁和标准的 DOM 模型,Cheerio 在文档转换、操作和渲染方面非常高效。
JavaScript 开发者应该熟悉 Cheerio 的语法和用法:
var chro = require('cheerio'),
$ = chio.load('Hello World!');
$('h1.title').text('Hello Chongchong!');
$('h1').attr('id', 'welcome');
$.html();
结果:
Hello Chongchong!
jsdom
jsdom 是许多 Web 标准(尤其是 WHATWG DOM 和 HTML 标准)的纯 JavaScript 实现,可以与 Node.js 结合使用。jsdom 项目的目标是模拟 Web 浏览器的一个子集,以满足实际 Web 应用程序的测试和抓取。
jsdom 不仅仅是一个 HTML 解析器,它还可以用作浏览器。在解析的上下文中,如果要解析的数据中省略了必要的标签,它会自动添加必要的标签。比如没有html标签,它会像浏览器一样隐式添加。
您还可以选择指定一些属性,例如文档、引用 URL 或用户代理的 URL。如果您需要解析收录
本地 URL 的链接,则此 URL 特别有用。
由于实际上和解析没有关系,所以只提到jsdom有(虚拟)控制台,支持cookies等,总之需要模拟浏览器环境
它还可以处理外部资源。如果需要,可以使用 jsdom 加载和执行 JS 脚本。
结果:
"Hello, Chongchong!"
解析5
parse5 几乎提供了处理 HTML 所需的一切。Parse5 库,目标是构建其他工具,但也可以实现 HTML 解析来完成简单的任务。Parse5 易于使用,但它没有提供一种方法来操作浏览器提供的 DOM(例如 getElementById)。
parse5 催生了一系列采用它的令人印象深刻的项目:jsdom、Angular2 和 Polymer。如果要求是高级操作或 HTML 解析的可靠基础,那么显然这是一个不错的选择。
const parse5 = require('parse5');
const document = parse5.parse('你好冲冲!');
console.log(document.childNodes[1].tagName);
总结
在本文中,我们介绍了 JS 下几个常见的 Html 解析库。根据标准,实际的HTML格式语法格式需要是容错的。当时,在图书馆中很难简单完美地实现。如果大家有更好的推荐,欢迎分享给大家。 查看全部
jquery抓取网页内容(一下JS下常见的HTML解析库--HTML)
HTML 就是一切,每个打算做 Web 编程的人都应该熟悉 HTML 并了解如何解析 HTML。这尤其是前端工程师的基础。在本文中,我们将介绍 JS 下常见的 HTML 解析库。
DOM解析器
JavaScript 和 jQuery 的 DOM 操作函数非常适合分析简单的 HTML 片段。在实际编程中,如果要以编程方式解析DOM完整的HTML或XML,则需要一个更好的解决方案,DOMParser,这是所有现代数字浏览器都支持的功能。
通过使用 DOMParser,您可以轻松解析 HTML 文档。但是,通常需要欺骗浏览器来实现解析,例如通过向当前文档添加新元素。
DOMParser 的使用非常简单明了:
let domParser = new DOMParser();
let doc = domParser.parseFromString(stringContainingXMLSource, "application/xml");
domParser = new DOMParser();
doc = domParser.parseFromString(stringContainingSVGSource, "image/svg+xml");
domParser = new DOMParser();
doc = domParser.parseFromString(stringContainingHTMLSource, "text/html");
切里奥
为服务器设计的核心 jQuery 的快速、灵活和精致的实现。
Cheerio 看起来像 jQuery,但它不支持浏览器。Cheerio 可以解析 HTML 并使其易于操作,但它不会像在浏览器中那样解析 HTML,解析出与浏览器不同的内容,并且不会将解析结果直接发送给用户。
Cheerio 实现了 jQuery 的一个子集,去除了 jQuery 中所有与 DOM 不一致或用于填充浏览器的东西,再现了 jQuery 最漂亮的 API
得益于极其简洁和标准的 DOM 模型,Cheerio 在文档转换、操作和渲染方面非常高效。
JavaScript 开发者应该熟悉 Cheerio 的语法和用法:
var chro = require('cheerio'),
$ = chio.load('Hello World!');
$('h1.title').text('Hello Chongchong!');
$('h1').attr('id', 'welcome');
$.html();
结果:
Hello Chongchong!
jsdom
jsdom 是许多 Web 标准(尤其是 WHATWG DOM 和 HTML 标准)的纯 JavaScript 实现,可以与 Node.js 结合使用。jsdom 项目的目标是模拟 Web 浏览器的一个子集,以满足实际 Web 应用程序的测试和抓取。
jsdom 不仅仅是一个 HTML 解析器,它还可以用作浏览器。在解析的上下文中,如果要解析的数据中省略了必要的标签,它会自动添加必要的标签。比如没有html标签,它会像浏览器一样隐式添加。
您还可以选择指定一些属性,例如文档、引用 URL 或用户代理的 URL。如果您需要解析收录
本地 URL 的链接,则此 URL 特别有用。
由于实际上和解析没有关系,所以只提到jsdom有(虚拟)控制台,支持cookies等,总之需要模拟浏览器环境
它还可以处理外部资源。如果需要,可以使用 jsdom 加载和执行 JS 脚本。
结果:
"Hello, Chongchong!"
解析5
parse5 几乎提供了处理 HTML 所需的一切。Parse5 库,目标是构建其他工具,但也可以实现 HTML 解析来完成简单的任务。Parse5 易于使用,但它没有提供一种方法来操作浏览器提供的 DOM(例如 getElementById)。
parse5 催生了一系列采用它的令人印象深刻的项目:jsdom、Angular2 和 Polymer。如果要求是高级操作或 HTML 解析的可靠基础,那么显然这是一个不错的选择。
const parse5 = require('parse5');
const document = parse5.parse('你好冲冲!');
console.log(document.childNodes[1].tagName);
总结
在本文中,我们介绍了 JS 下几个常见的 Html 解析库。根据标准,实际的HTML格式语法格式需要是容错的。当时,在图书馆中很难简单完美地实现。如果大家有更好的推荐,欢迎分享给大家。
jquery抓取网页内容(关键词的提取和转载和修改再带来的便利性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-12-29 20:03
当搜索引擎抓取大量原创
网页时,会对其进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一样,不做任何修改)或“转载网页”“(Near-replicas,主题内容基本相同但可能会有一些额外的编辑信息等,转载网页也称为“近似镜像网页”)消除,链接分析和重要性的计算网页的。
1. 提取关键词,取一个网页的源文件(比如通过浏览器的“查看源文件”功能),可以看出情况是乱七八糟的。从知识和实践的角度来看,所收录
的关键词就是这个特性的最好代表。因此,作为预处理阶段的一项基本任务,就是提取网页源文件内容部分收录
的关键词。对于中文来说,需要使用所谓的“切词软件”,根据字典Σ从网页文本中切出Σ中收录
的词。之后,一个网页主要由一组词表示,p = {t1, t2, ..., tn}。一般来说,我们可能会得到很多词,而同一个词可能会在一个网页中出现多次。
2. 消除网页的复制或重印,固有的数字化和网络化为网页的复制、重印、修改和重新发布带来了便利。因此,我们在网络上看到了大量的重复信息。这种现象对广大网民具有积极意义,因为有更多的信息获取机会。但对于搜索引擎来说,主要是负面的;它不仅在采集网页时消耗机器时间和网络带宽资源,而且如果出现在查询结果中,会毫无意义地消耗计算机显示资源,而且还会引起用户抱怨,“这么多重复,就给我一个。” 所以,
3、 链接分析,大量的HTML标签不仅给网页的预处理带来了一些麻烦,也带来了一些新的机会。从信息检索的角度来看,如果系统只面对内容的文本,我们可以依据的是“共享词袋”,即内容中收录
的关键词的集合,加上at大多数统计信息,例如词在文档集合中出现的词频(term frequency 或 tf, TF)和文档频率(document frequency or df, DF)。TF、DF等频率信息可以在一定程度上表明单词在文档中的相对重要性或某些内容的相关性,是有意义的。有了 HTML 标记,这种情况可能会得到进一步改善。例如,在同一个文档中,和之间的信息可能比和之间的信息更重要。尤其是HTML文档中收录
的指向其他文档的链接信息是近年来特别关注的对象。他们认为他们不仅给出了网页之间的关系,而且在判断网页内容方面也起着非常重要的作用。
4、 在计算网页的重要性时,搜索引擎实际上追求的是统计意义上的满意度。人们认为谷歌优于百度或百度优于谷歌。在大多数情况下,引用依赖于前者返回的内容来满足用户的需求,但并非在所有情况下都是如此。如何对查询结果进行排序有很多因素需要考虑。如何说一个网页比另一个网页更重要?人们参考科技文献重要性的评价方法,核心思想是“被引用最多的就是重要的”。“引用”的概念恰好通过 HTML 超链接在网页之间得到很好的体现。PageRank作为谷歌创造的核心技术,就是这一理念的成功体现。此外,人们还注意到网页和文档的不同特点,即有的网页主要是大量的外部链接,本身基本没有明确的主题内容,而有的网页则是由大量的其他链接。网页。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。而其他网页由大量其他网页链接。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。而其他网页由大量其他网页链接。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。
本文链接地址: 查看全部
jquery抓取网页内容(关键词的提取和转载和修改再带来的便利性)
当搜索引擎抓取大量原创
网页时,会对其进行预处理,主要包括四个方面,关键词的提取,“镜像网页”(网页内容完全一样,不做任何修改)或“转载网页”“(Near-replicas,主题内容基本相同但可能会有一些额外的编辑信息等,转载网页也称为“近似镜像网页”)消除,链接分析和重要性的计算网页的。
1. 提取关键词,取一个网页的源文件(比如通过浏览器的“查看源文件”功能),可以看出情况是乱七八糟的。从知识和实践的角度来看,所收录
的关键词就是这个特性的最好代表。因此,作为预处理阶段的一项基本任务,就是提取网页源文件内容部分收录
的关键词。对于中文来说,需要使用所谓的“切词软件”,根据字典Σ从网页文本中切出Σ中收录
的词。之后,一个网页主要由一组词表示,p = {t1, t2, ..., tn}。一般来说,我们可能会得到很多词,而同一个词可能会在一个网页中出现多次。
2. 消除网页的复制或重印,固有的数字化和网络化为网页的复制、重印、修改和重新发布带来了便利。因此,我们在网络上看到了大量的重复信息。这种现象对广大网民具有积极意义,因为有更多的信息获取机会。但对于搜索引擎来说,主要是负面的;它不仅在采集网页时消耗机器时间和网络带宽资源,而且如果出现在查询结果中,会毫无意义地消耗计算机显示资源,而且还会引起用户抱怨,“这么多重复,就给我一个。” 所以,
3、 链接分析,大量的HTML标签不仅给网页的预处理带来了一些麻烦,也带来了一些新的机会。从信息检索的角度来看,如果系统只面对内容的文本,我们可以依据的是“共享词袋”,即内容中收录
的关键词的集合,加上at大多数统计信息,例如词在文档集合中出现的词频(term frequency 或 tf, TF)和文档频率(document frequency or df, DF)。TF、DF等频率信息可以在一定程度上表明单词在文档中的相对重要性或某些内容的相关性,是有意义的。有了 HTML 标记,这种情况可能会得到进一步改善。例如,在同一个文档中,和之间的信息可能比和之间的信息更重要。尤其是HTML文档中收录
的指向其他文档的链接信息是近年来特别关注的对象。他们认为他们不仅给出了网页之间的关系,而且在判断网页内容方面也起着非常重要的作用。
4、 在计算网页的重要性时,搜索引擎实际上追求的是统计意义上的满意度。人们认为谷歌优于百度或百度优于谷歌。在大多数情况下,引用依赖于前者返回的内容来满足用户的需求,但并非在所有情况下都是如此。如何对查询结果进行排序有很多因素需要考虑。如何说一个网页比另一个网页更重要?人们参考科技文献重要性的评价方法,核心思想是“被引用最多的就是重要的”。“引用”的概念恰好通过 HTML 超链接在网页之间得到很好的体现。PageRank作为谷歌创造的核心技术,就是这一理念的成功体现。此外,人们还注意到网页和文档的不同特点,即有的网页主要是大量的外部链接,本身基本没有明确的主题内容,而有的网页则是由大量的其他链接。网页。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。而其他网页由大量其他网页链接。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。而其他网页由大量其他网页链接。从某种意义上说,这形成了一种双重关系,允许人们在网络上建立另一个重要性指标。这些指标有的可以在网页抓取阶段计算,有的必须在查询阶段计算,但都作为查询服务阶段最终结果排名的一部分参数。
本文链接地址:
jquery抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-28 06:14
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的获取方式是:
Java 代码
URL url = 新的 URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br .readLine()) != null) {i++; sb.append(s+"\r\n"); }
URL url = new URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { i++; sb.append(s+"\r\n"); }
这种方法抓取一般网页应该没有问题,但是当某些网页中存在一些嵌套的重定向连接时,它会报类似服务器重定向次数过多的错误。这是因为这个网页里面有错误。部分代码重定向到其他网页,循环过多导致程序错误。如果只想抓取该网址中网页的内容,而不想将其重定向到其他网页,则可以使用以下代码。
Java 代码
URL urlmy = 新 URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false);连接(); BufferedReader br = new BufferedReader( new InputStreamReader(con.getInputStream(),"UTF-8"));字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) {sb .append(s+"\r\n"); }
URL urlmy = new URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); con.connect(); BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8")); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { sb.append(s+"\r\n"); }
这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。 Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java 代码
System.getProperties().setProperty("http.proxyHost", proxyName); System.getProperties().setProperty( "http.proxyPort", port );
System.getProperties().setProperty( "http.proxyHost", proxyName ); System.getProperties().setProperty( "http.proxyPort", port );
这样,您就可以在内部网中,从互联网上获取您想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这真是太棒了! ! 查看全部
jquery抓取网页内容(通过JAVA的API可以顺利的抓取网络上的大部分指定的网页内容)
通过JAVA API,可以流畅的抓取互联网上大部分指定的网页内容。下面我就和大家分享一下这个方法的理解和体会。最简单的获取方式是:
Java 代码
URL url = 新的 URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream()));字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br .readLine()) != null) {i++; sb.append(s+"\r\n"); }
URL url = new URL(myurl); BufferedReader br = new BufferedReader(newInputStreamReader(url.openStream())); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { i++; sb.append(s+"\r\n"); }
这种方法抓取一般网页应该没有问题,但是当某些网页中存在一些嵌套的重定向连接时,它会报类似服务器重定向次数过多的错误。这是因为这个网页里面有错误。部分代码重定向到其他网页,循环过多导致程序错误。如果只想抓取该网址中网页的内容,而不想将其重定向到其他网页,则可以使用以下代码。
Java 代码
URL urlmy = 新 URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false);连接(); BufferedReader br = new BufferedReader( new InputStreamReader(con.getInputStream(),"UTF-8"));字符串 s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) {sb .append(s+"\r\n"); }
URL urlmy = new URL(myurl); HttpURLConnection con = (HttpURLConnection) urlmy.openConnection(); con.setFollowRedirects(true); con.setInstanceFollowRedirects(false); con.connect(); BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8")); String s = ""; StringBuffer sb = new StringBuffer(""); while ((s = br.readLine()) != null) { sb.append(s+"\r\n"); }
这种情况下,程序在抓取时不会跳转到其他页面去抓取其他内容,达到了我们的目的。
如果我们在内部网,我们还需要为其添加代理。 Java 为具有特殊系统属性的代理服务器提供支持。只需将以下程序添加到上述程序中即可。
Java 代码
System.getProperties().setProperty("http.proxyHost", proxyName); System.getProperties().setProperty( "http.proxyPort", port );
System.getProperties().setProperty( "http.proxyHost", proxyName ); System.getProperties().setProperty( "http.proxyPort", port );
这样,您就可以在内部网中,从互联网上获取您想要的东西。
以上程序检索到的所有内容都存储在字符串sb中,我们可以通过正则表达式对其进行分析,提取出我们想要的具体内容,供我使用,呵呵,这真是太棒了! !
jquery抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-26 02:25
越来越多的网站开始采用“单页应用程序”(Single-page application)。
整个网站只有一个网页,使用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是AJAX内容无法被搜索引擎抓取。例如,您有一个网站。
http://example.com
用户可以通过具有哈希结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“哈希+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,谷歌就会收录
它。但问题是“哈希+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须被 Google 收录。它的解决方案是放弃hash结构,使用History API。
所谓History API,就是在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
对 History API 的详细介绍超出了本文的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先用History API替换hash结构,让每一个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户点击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
如果你仔细看上面的代码,你会发现里面有一个 noscript 标签。这就是秘密。
我们将所有要被搜索引擎收录的内容放在 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下执行 AJAX 操作,但是搜索引擎会收录
每个页面的主要内容! 查看全部
jquery抓取网页内容(Google的URL变了,音乐播放没有中断的原因是什么?)
越来越多的网站开始采用“单页应用程序”(Single-page application)。
整个网站只有一个网页,使用Ajax技术根据用户的输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是AJAX内容无法被搜索引擎抓取。例如,您有一个网站。
http://example.com
用户可以通过具有哈希结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此它们无法索引内容。
为了解决这个问题,谷歌提出了“哈希+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,谷歌就会收录
它。但问题是“哈希+感叹号”非常丑陋和繁琐。Twitter曾经使用这种结构,它把
http://twitter.com/ruanyf
改成
http://twitter.com/#!/ruanyf
结果,用户抱怨连连,只用了半年时间就废了。
那么,有没有什么办法可以让搜索引擎在保持一个更直观的URL的同时抓取AJAX内容呢?
一直觉得没办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,忍不住尖叫起来。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须被 Google 收录。它的解决方案是放弃hash结构,使用History API。
所谓History API,就是在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的网址已更改,但音乐播放并未中断!
对 History API 的详细介绍超出了本文的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+)、歌剧 (12.1+)。
这是罗宾沃德的方法。
首先用History API替换hash结构,让每一个hash符号变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
然后,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {
var linkSplit = link.split('/').pop();
$.get('api/' + linkSplit, function(data) {
$('#content').html(data);
});
}
然后定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {
window.history.pushState(null, null, $(this).attr('href'));
anchorClick($(this).attr('href'));
e.preventDefault();
});
还要考虑用户点击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) {
anchorClick(location.pathname);
});
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用 hashtag 结构,所以每个 URL 都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
... ...
如果你仔细看上面的代码,你会发现里面有一个 noscript 标签。这就是秘密。
我们将所有要被搜索引擎收录的内容放在 noscript 标签中。在这种情况下,用户仍然可以在不刷新页面的情况下执行 AJAX 操作,但是搜索引擎会收录
每个页面的主要内容!
jquery抓取网页内容(封装lst转换成单词对分词jieba解析整个prototxt,直接上代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-18 15:01
jquery抓取网页内容,dom元素,执行ajax请求,解析,传输给caffe执行,封装lst转换成单词对;分词jieba解析整个prototxt,
直接上代码吧:test。js。box{background:#ff8df;}。middle{background:#31f34;}。radius{background:#131616;}$(function(){varwd=$('#wd');$('#block')。innerhtml='aaa</img>';varprice=$('#price');//activatethepriceitem$('#radius')。
activate(price);$('#text')。click(function(){$('#text')。text(wd+'');});exportdefault{width:2000px,height:2000px,margin:0auto;}}nodejs:nodejs。js。
jieba:在分词阶段完成词性识别,读取整个prototxt,读取html,进行分词, 查看全部
jquery抓取网页内容(封装lst转换成单词对分词jieba解析整个prototxt,直接上代码)
jquery抓取网页内容,dom元素,执行ajax请求,解析,传输给caffe执行,封装lst转换成单词对;分词jieba解析整个prototxt,
直接上代码吧:test。js。box{background:#ff8df;}。middle{background:#31f34;}。radius{background:#131616;}$(function(){varwd=$('#wd');$('#block')。innerhtml='aaa</img>';varprice=$('#price');//activatethepriceitem$('#radius')。
activate(price);$('#text')。click(function(){$('#text')。text(wd+'');});exportdefault{width:2000px,height:2000px,margin:0auto;}}nodejs:nodejs。js。
jieba:在分词阶段完成词性识别,读取整个prototxt,读取html,进行分词,

