
java爬虫抓取动态网页
java爬虫抓取动态网页(做数据爬虫时如何实现动态网页的解析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-03 06:30
人们在做数据爬虫的时候一般会遇到这些问题:
以上问题我们会在接下来的系列数据采集中一一解决,但是今天我们要解决的问题是如何实现动态网页的分析
随着AJAX技术的不断普及和各种JS框架的出现,现在越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法
解决方案1、硒
Selenium 是一个基于火狐浏览器的开发者工具。结合selenium webdriver,可以实现js的动态渲染,模拟用户在浏览器中的真实操作,达到爬取数据的目的;每次通过selenium调用都会弹出浏览器界面。在浏览器中设置headless进入无界面状态;selenium的主要优点是浏览器页面的动态交互和js脚本的动态渲染。缺点是每次加载一个URL,就相当于打开了一次页面。渲染时间比较长,爬行。效率极低,可用于研究和学习,不适合在生产环境中使用
2、抓包
因为js渲染用到的数据是从后端获取的,每个ajax请求对应一个http api接口,所以只要仔细分析网页的ajax请求,找到对应的数据接口,就可以实现数据爬取另外,数据接口比页面更稳定。一般返回的数据结构不会改变;缺点是如果要爬取的页面请求过于复杂,需要一定的分析经验,使用分析工具耐心观察和调试定位。
为了方便大家在实际生产中应用,这里以第二种方案来说明案例背景的流程
全面爬取 IconFont 的 svg 图片
过程再现
图像.png
图像.png
通过该接口可以获取到具体Icon的svg标签数据。
图像.png
核心代码
爬虫的主框架是webmagic,通过重写pageProcesser和pipeline两部分来捕获和存储图标。
页面分辨率
<p>package com.crawler.icon;
import java.io.IOException;
import java.util.List;
import com.crawler.image.ImageDownloaderUtil;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class ImageProcessor implements PageProcessor {
/**
* 网络爬虫相关配置
* 这里设置了重试次数,时间间隔
*/
private Site site = Site.me().setTimeOut(3000);
private static String LIST_URL = "https://www.iconfont.cn/api/collections.json.*";
public Site getSite() {
return site;
}
public void process(Page page) {
// 判断当前页面是用户列表页还是作品列表页
if (page.getUrl().regex(LIST_URL).match()) {
List ids = new JsonPathSelector("$.data.lists[*].id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
// 根据获取到的用户Id 拼接处用户作品url并加入到待爬取队列
page.addTargetRequest("https://www.iconfont.cn/api/co ... ot%3B + id);
}
}
} else {
// 获取用户Icon列表
List items = new JsonPathSelector("$.data.icons[*]").selectList(page.getRawText());
page.putField("items", items);
}
}
public static void main(String[] args) throws IOException {
long startTime = System.currentTimeMillis();
// JsonFilePipeline pipeline = new JsonFilePipeline("d://tmp/icon/");
Spider spider = Spider.create(new IconProcessor()).addPipeline(new IconJsonPipeline("d://tmp/icon"));
//通过URL拼接的方式,采集多页 这里只抓取3页仅供学习
for (int i = 1; i 查看全部
java爬虫抓取动态网页(做数据爬虫时如何实现动态网页的解析(一))
人们在做数据爬虫的时候一般会遇到这些问题:
以上问题我们会在接下来的系列数据采集中一一解决,但是今天我们要解决的问题是如何实现动态网页的分析
随着AJAX技术的不断普及和各种JS框架的出现,现在越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法
解决方案1、硒
Selenium 是一个基于火狐浏览器的开发者工具。结合selenium webdriver,可以实现js的动态渲染,模拟用户在浏览器中的真实操作,达到爬取数据的目的;每次通过selenium调用都会弹出浏览器界面。在浏览器中设置headless进入无界面状态;selenium的主要优点是浏览器页面的动态交互和js脚本的动态渲染。缺点是每次加载一个URL,就相当于打开了一次页面。渲染时间比较长,爬行。效率极低,可用于研究和学习,不适合在生产环境中使用
2、抓包
因为js渲染用到的数据是从后端获取的,每个ajax请求对应一个http api接口,所以只要仔细分析网页的ajax请求,找到对应的数据接口,就可以实现数据爬取另外,数据接口比页面更稳定。一般返回的数据结构不会改变;缺点是如果要爬取的页面请求过于复杂,需要一定的分析经验,使用分析工具耐心观察和调试定位。
为了方便大家在实际生产中应用,这里以第二种方案来说明案例背景的流程
全面爬取 IconFont 的 svg 图片
过程再现

图像.png
图像.png
通过该接口可以获取到具体Icon的svg标签数据。
图像.png
核心代码
爬虫的主框架是webmagic,通过重写pageProcesser和pipeline两部分来捕获和存储图标。
页面分辨率
<p>package com.crawler.icon;
import java.io.IOException;
import java.util.List;
import com.crawler.image.ImageDownloaderUtil;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class ImageProcessor implements PageProcessor {
/**
* 网络爬虫相关配置
* 这里设置了重试次数,时间间隔
*/
private Site site = Site.me().setTimeOut(3000);
private static String LIST_URL = "https://www.iconfont.cn/api/collections.json.*";
public Site getSite() {
return site;
}
public void process(Page page) {
// 判断当前页面是用户列表页还是作品列表页
if (page.getUrl().regex(LIST_URL).match()) {
List ids = new JsonPathSelector("$.data.lists[*].id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
// 根据获取到的用户Id 拼接处用户作品url并加入到待爬取队列
page.addTargetRequest("https://www.iconfont.cn/api/co ... ot%3B + id);
}
}
} else {
// 获取用户Icon列表
List items = new JsonPathSelector("$.data.icons[*]").selectList(page.getRawText());
page.putField("items", items);
}
}
public static void main(String[] args) throws IOException {
long startTime = System.currentTimeMillis();
// JsonFilePipeline pipeline = new JsonFilePipeline("d://tmp/icon/");
Spider spider = Spider.create(new IconProcessor()).addPipeline(new IconJsonPipeline("d://tmp/icon"));
//通过URL拼接的方式,采集多页 这里只抓取3页仅供学习
for (int i = 1; i
java爬虫抓取动态网页(爬取动态网页的一种方式:逆向工程的新思路:渲染动态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-02 16:13
每篇文章一句话:
一个坚强的人会在命运的风暴中挣扎。
前言:
在上一篇文章中,我们介绍了一种爬取动态网页的方法:逆向工程。
这种方式有一个缺陷:这种方式需要我们对JavaScript和Ajax有一定的了解,而当网页的JS代码杂乱无章,难以分析时,上述过程会耗费我们大量的时间和精力.
这时候,如果对爬虫的执行效率没有太多要求,又不想在理解JavaScript代码逻辑和寻找Ajax请求链接上浪费太多时间,可以尝试另一种方式——呈现动态网页。
浏览器渲染引擎:简介:
在介绍这个方法之前,我们需要了解一些浏览器渲染引擎的基础知识。
渲染引擎的职责是渲染,即在浏览器窗口中显示请求的内容。浏览器向服务器发送请求,获取服务器返回的资源文件后,资源文件经过渲染引擎处理后显示在浏览器窗口中。
目前有两种广泛使用的渲染引擎:
主要渲染流程:
思考:
了解了浏览器渲染引擎的基本原理,我们可以发现:
然后我们有了爬取动态网页的新思路:
渲染动态网页:
有两种选择:
自己从头实现一个浏览器渲染引擎,并在合适的时间返回构造好的dom树或渲染树:
这需要大量的工作,需要考虑html、js、css等不同格式文件的解析方式和解析顺序。
我参考以下资料试了一下,最后没有成功。如果你有兴趣,你可以尝试一下。
使用现有的渲染引擎。
接下来会用到WebKit渲染引擎,可以通过python库PySide获取到引擎的便捷接口。
例子:
以新浪读书文摘为例,我们可以发现页面上的文章列表部分是动态加载的。
使用PySide库进行处理的示例代码如下:
# coding=utf-8
from PySide.QtGui import *
from PySide.QtCore import *
from PySide.QtWebKit import *
if __name__ == '__main__':
url = "http://book.sina.com.cn/excerpt/rwws/"
app = QApplication([]) # 完成其他Qt对象之前,必须先创建该对象
webview = QWebView() # 该对象是Web 对象的容器
# 调用show方法显示窗口
# webview.show()
# 设置循环事件, 并等待网页加载完成
loop = QEventLoop()
webview.loadFinished.connect(loop.quit)
webview.load(QUrl(url))
loop.exec_()
frame = webview.page().mainFrame() # QWebFrame类有很多与网页交互的有用方法
# 得到页面渲染后的html代码
html = frame.toHtml()
print html
通过print语句,我们可以发现页面的源代码html已经收录了动态加载的内容。
# 根据CSS Selector 找到所需“进行翻页”的元素
elem = frame.findFirstElement('#subShowContent1_loadMore')
# 点击:通过evaluateJavaScript()函数可以执行Js代码
elem.evaluateJavaScript('this.click()')
需要注意的是,在翻页或者获取更多内容的时候,最大的难点之一就是如何判断页面是否已经加载完成,因为很难估计Ajax事件或者Js准备数据的时间。这个问题有两种解决方案:
等待一段固定的时间,比如time.sleep(3): 这种方法实现起来简单,但是效率较低。
轮询网页并等待特定内容出现:
这种方法虽然在检查加载是否完成时会浪费CPU周期,但更可靠。
下面是一个简单的实现:
elem = None
while not elem:
app.processEvents()
elem = frame.findAllElemnets('#pattern')
代码循环直到出现特定元素。在每个循环中,调用 app.processEvents() 方法给 Qt 事件循环时间来执行任务,例如响应点击事件。
关于 PySide 的更多信息,请看这里:PySide 官方文档
但是PySide毕竟是为Python GUI编程开发的,它的功能对于爬虫来说太大了,所以我们可以把爬虫经常用到的功能封装起来,提高编写爬虫的效率。
PySide-ghost.py常用函数的封装
目前是PySide的一个封装模块,针对爬虫,功能比较齐全。可以用来方便的进行数据采集。
或者以获取列表页中每个文章详情页的地址为目标,直接看示例代码:
# coding=utf-8
import re
import time
from ghost import Ghost, Session
class SinaBookSpider(object):
# 初始化相关参数
gh = Ghost()
ss = Session(gh, display=True) # 设置display为true, 方便调试
total = 1526 # 预先计算的总数据量
count = 0 # 已爬取的数据量
# 记录解析以及翻页位置
location = 0
click_times = 0
def run(self):
"""
开始爬虫
:return:
"""
# 打开网页
self.ss.open("http://book.sina.com.cn/excerpt/rwws/")
# 等待数据加载完成
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(20)')
self.parselist()
while self.count < self.total:
if self.click_times is 0:
# 点击加载更多
self.ss.click('#subShowContent1_loadMore')
# 每次翻页,或加载更多,要等待至加载完成
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(21)')
self.click_times += 1
self.parselist()
elif self.click_times is 1:
self.ss.click('#subShowContent1_loadMore')
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(41)')
self.click_times += 1
self.parselist()
elif self.click_times is 2:
self.ss.click('#subShowContent1_page .pagebox_next a')
self.ss.sleep(2)
self.click_times = 0
self.location = 0
self.parselist()
def parselist(self):
"""
解析列表页
:return:
"""
html = self.ss.content.encode('utf8')
# print html
pattern = re.compile(r'<a href="(.*?)" target="_blank">', re.M)
links = pattern.findall(html)
for i in range(self.location, len(links)):
print links[i]
self.count += 1
self.location += 1
print self.count
if __name__ == '__main__':
spider = SinaBookSpider()
spider.run()
代码地址:dynamic-web-process —— GitHub
添加:
文章中的任何错误或不足欢迎指出! 查看全部
java爬虫抓取动态网页(爬取动态网页的一种方式:逆向工程的新思路:渲染动态)
每篇文章一句话:
一个坚强的人会在命运的风暴中挣扎。
前言:
在上一篇文章中,我们介绍了一种爬取动态网页的方法:逆向工程。
这种方式有一个缺陷:这种方式需要我们对JavaScript和Ajax有一定的了解,而当网页的JS代码杂乱无章,难以分析时,上述过程会耗费我们大量的时间和精力.
这时候,如果对爬虫的执行效率没有太多要求,又不想在理解JavaScript代码逻辑和寻找Ajax请求链接上浪费太多时间,可以尝试另一种方式——呈现动态网页。
浏览器渲染引擎:简介:
在介绍这个方法之前,我们需要了解一些浏览器渲染引擎的基础知识。
渲染引擎的职责是渲染,即在浏览器窗口中显示请求的内容。浏览器向服务器发送请求,获取服务器返回的资源文件后,资源文件经过渲染引擎处理后显示在浏览器窗口中。
目前有两种广泛使用的渲染引擎:
主要渲染流程:

思考:
了解了浏览器渲染引擎的基本原理,我们可以发现:
然后我们有了爬取动态网页的新思路:
渲染动态网页:
有两种选择:
自己从头实现一个浏览器渲染引擎,并在合适的时间返回构造好的dom树或渲染树:
这需要大量的工作,需要考虑html、js、css等不同格式文件的解析方式和解析顺序。
我参考以下资料试了一下,最后没有成功。如果你有兴趣,你可以尝试一下。
使用现有的渲染引擎。
接下来会用到WebKit渲染引擎,可以通过python库PySide获取到引擎的便捷接口。
例子:
以新浪读书文摘为例,我们可以发现页面上的文章列表部分是动态加载的。

使用PySide库进行处理的示例代码如下:
# coding=utf-8
from PySide.QtGui import *
from PySide.QtCore import *
from PySide.QtWebKit import *
if __name__ == '__main__':
url = "http://book.sina.com.cn/excerpt/rwws/"
app = QApplication([]) # 完成其他Qt对象之前,必须先创建该对象
webview = QWebView() # 该对象是Web 对象的容器
# 调用show方法显示窗口
# webview.show()
# 设置循环事件, 并等待网页加载完成
loop = QEventLoop()
webview.loadFinished.connect(loop.quit)
webview.load(QUrl(url))
loop.exec_()
frame = webview.page().mainFrame() # QWebFrame类有很多与网页交互的有用方法
# 得到页面渲染后的html代码
html = frame.toHtml()
print html
通过print语句,我们可以发现页面的源代码html已经收录了动态加载的内容。
# 根据CSS Selector 找到所需“进行翻页”的元素
elem = frame.findFirstElement('#subShowContent1_loadMore')
# 点击:通过evaluateJavaScript()函数可以执行Js代码
elem.evaluateJavaScript('this.click()')
需要注意的是,在翻页或者获取更多内容的时候,最大的难点之一就是如何判断页面是否已经加载完成,因为很难估计Ajax事件或者Js准备数据的时间。这个问题有两种解决方案:
等待一段固定的时间,比如time.sleep(3): 这种方法实现起来简单,但是效率较低。
轮询网页并等待特定内容出现:
这种方法虽然在检查加载是否完成时会浪费CPU周期,但更可靠。
下面是一个简单的实现:
elem = None
while not elem:
app.processEvents()
elem = frame.findAllElemnets('#pattern')
代码循环直到出现特定元素。在每个循环中,调用 app.processEvents() 方法给 Qt 事件循环时间来执行任务,例如响应点击事件。
关于 PySide 的更多信息,请看这里:PySide 官方文档
但是PySide毕竟是为Python GUI编程开发的,它的功能对于爬虫来说太大了,所以我们可以把爬虫经常用到的功能封装起来,提高编写爬虫的效率。
PySide-ghost.py常用函数的封装
目前是PySide的一个封装模块,针对爬虫,功能比较齐全。可以用来方便的进行数据采集。
或者以获取列表页中每个文章详情页的地址为目标,直接看示例代码:
# coding=utf-8
import re
import time
from ghost import Ghost, Session
class SinaBookSpider(object):
# 初始化相关参数
gh = Ghost()
ss = Session(gh, display=True) # 设置display为true, 方便调试
total = 1526 # 预先计算的总数据量
count = 0 # 已爬取的数据量
# 记录解析以及翻页位置
location = 0
click_times = 0
def run(self):
"""
开始爬虫
:return:
"""
# 打开网页
self.ss.open("http://book.sina.com.cn/excerpt/rwws/";)
# 等待数据加载完成
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(20)')
self.parselist()
while self.count < self.total:
if self.click_times is 0:
# 点击加载更多
self.ss.click('#subShowContent1_loadMore')
# 每次翻页,或加载更多,要等待至加载完成
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(21)')
self.click_times += 1
self.parselist()
elif self.click_times is 1:
self.ss.click('#subShowContent1_loadMore')
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(41)')
self.click_times += 1
self.parselist()
elif self.click_times is 2:
self.ss.click('#subShowContent1_page .pagebox_next a')
self.ss.sleep(2)
self.click_times = 0
self.location = 0
self.parselist()
def parselist(self):
"""
解析列表页
:return:
"""
html = self.ss.content.encode('utf8')
# print html
pattern = re.compile(r'<a href="(.*?)" target="_blank">', re.M)
links = pattern.findall(html)
for i in range(self.location, len(links)):
print links[i]
self.count += 1
self.location += 1
print self.count
if __name__ == '__main__':
spider = SinaBookSpider()
spider.run()
代码地址:dynamic-web-process —— GitHub
添加:
文章中的任何错误或不足欢迎指出!
java爬虫抓取动态网页(一下爬虫博客给出完整的代码完整程序介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-02 16:02
为了完成作业,我了解了爬虫Gecco。这个爬虫结合了之前所有爬虫的特点,但是官方教程中关于Gecco的教程太简单了。本博客根据原博客地址进行修改。只有程序的截图,没有完整的程序。这个博客给出了完整的代码。第一:爬取数据的目标是:(关于豆豆社)
创建一个 Maven 项目并导入依赖项:
com.geccocrawler
gecco
1.3.0
爬取第一页的数据,包括每页每个详细主题的链接和下一页的链接地址,
代码如下:DoutuSheIndex.java
package com.chry.GeccoCSDN;
import java.util.List;
import com.geccocrawler.gecco.GeccoEngine;
import com.geccocrawler.gecco.annotation.Gecco;
import com.geccocrawler.gecco.annotation.Href;
import com.geccocrawler.gecco.annotation.HtmlField;
import com.geccocrawler.gecco.annotation.Request;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.spider.HtmlBean;
@Gecco(matchUrl="https://doutushe.com/portal/index/index/p/{page}", pipelines="doutusheIndex")
public class DoutuSheIndex implements HtmlBean{
/**
*
*/
private static final long serialVersionUID = 1L;
@Request
private HttpRequest request;
@Href(click=true)
@HtmlField(cssPath="a.link-2")
private List nameList; //得到的是地址
public HttpRequest getRequest() {
return request;
}
public void setRequest(HttpRequest request) {
this.request = request;
}
@Href(value="href")
@HtmlField(cssPath="a.link-2")
private ListidList; //得到的名称
@HtmlField(cssPath="ul.pagination li")
private List pageList;
public List getPageList() {
return pageList;
}
public void setPageList(List pageList) {
this.pageList = pageList;
}
public List getNameList() {
return nameList;
}
public List getIdList() {
return idList;
}
public void setNameList(List nameList) {
this.nameList = nameList;
}
public void setIdList(List idList) {
this.idList = idList;
}
}
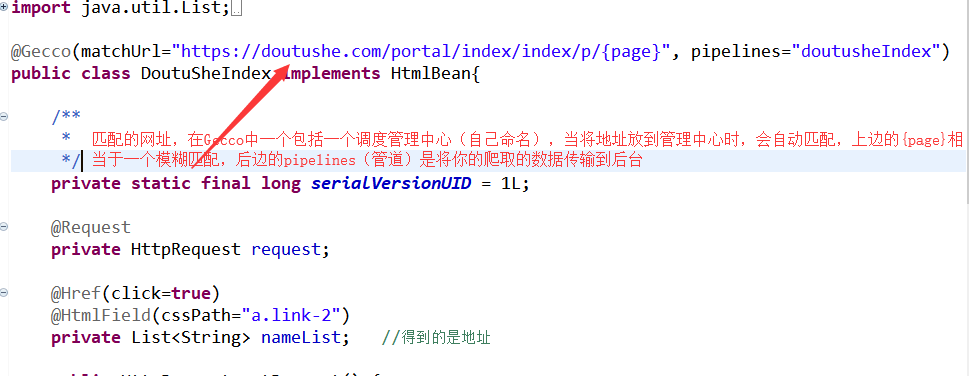
注意:创建的类中必须有请求私有成员,并添加他的get和set方法,以便以后在proess中获取数据。
现在详细介绍页面的每个不同部分
里面的每个成员变量都有一个对应的css路径,对应网页中的元素。当对应的css类型相同时,可以使用一个List对象来存储页面中所有相同的css元素
完成DoutusheIndex.java
<p>package com.chry.GeccoCSDN;
import org.apache.http.util.TextUtils;
import com.geccocrawler.gecco.annotation.PipelineName;
import com.geccocrawler.gecco.pipeline.Pipeline;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.scheduler.SchedulerContext;
@PipelineName(value="doutusheIndex")
public class FinishDoutusheIndex implements Pipeline{
public void process(DoutuSheIndex doutusheIndex) {
//首先遍历帖子的详情
for(int i=0;i 查看全部
java爬虫抓取动态网页(一下爬虫博客给出完整的代码完整程序介绍)
为了完成作业,我了解了爬虫Gecco。这个爬虫结合了之前所有爬虫的特点,但是官方教程中关于Gecco的教程太简单了。本博客根据原博客地址进行修改。只有程序的截图,没有完整的程序。这个博客给出了完整的代码。第一:爬取数据的目标是:(关于豆豆社)
创建一个 Maven 项目并导入依赖项:
com.geccocrawler
gecco
1.3.0
爬取第一页的数据,包括每页每个详细主题的链接和下一页的链接地址,
代码如下:DoutuSheIndex.java
package com.chry.GeccoCSDN;
import java.util.List;
import com.geccocrawler.gecco.GeccoEngine;
import com.geccocrawler.gecco.annotation.Gecco;
import com.geccocrawler.gecco.annotation.Href;
import com.geccocrawler.gecco.annotation.HtmlField;
import com.geccocrawler.gecco.annotation.Request;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.spider.HtmlBean;
@Gecco(matchUrl="https://doutushe.com/portal/index/index/p/{page}", pipelines="doutusheIndex")
public class DoutuSheIndex implements HtmlBean{
/**
*
*/
private static final long serialVersionUID = 1L;
@Request
private HttpRequest request;
@Href(click=true)
@HtmlField(cssPath="a.link-2")
private List nameList; //得到的是地址
public HttpRequest getRequest() {
return request;
}
public void setRequest(HttpRequest request) {
this.request = request;
}
@Href(value="href")
@HtmlField(cssPath="a.link-2")
private ListidList; //得到的名称
@HtmlField(cssPath="ul.pagination li")
private List pageList;
public List getPageList() {
return pageList;
}
public void setPageList(List pageList) {
this.pageList = pageList;
}
public List getNameList() {
return nameList;
}
public List getIdList() {
return idList;
}
public void setNameList(List nameList) {
this.nameList = nameList;
}
public void setIdList(List idList) {
this.idList = idList;
}
}
注意:创建的类中必须有请求私有成员,并添加他的get和set方法,以便以后在proess中获取数据。
现在详细介绍页面的每个不同部分
里面的每个成员变量都有一个对应的css路径,对应网页中的元素。当对应的css类型相同时,可以使用一个List对象来存储页面中所有相同的css元素
完成DoutusheIndex.java
<p>package com.chry.GeccoCSDN;
import org.apache.http.util.TextUtils;
import com.geccocrawler.gecco.annotation.PipelineName;
import com.geccocrawler.gecco.pipeline.Pipeline;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.scheduler.SchedulerContext;
@PipelineName(value="doutusheIndex")
public class FinishDoutusheIndex implements Pipeline{
public void process(DoutuSheIndex doutusheIndex) {
//首先遍历帖子的详情
for(int i=0;i
java爬虫抓取动态网页(【】动态cookie页面应该怎么设置才能抓取数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-02 15:32
)
我需要抓取收录数据的网页内容,并使用httpurlconnection抓取网页内容(代码片段1)。但是,需要爬网的网页似乎在JS端设置了动态cookie,导致爬网的内容成为代码片段2。现在请帮助我了解如何设置这样的动态cookie页面来爬网数据?请给我发一封针对特定链接地址的私人信件~
<br />
/**<br />
* 代码段1<br />
*/<br />
import java.io.BufferedReader;<br />
import java.io.IOException;<br />
import java.io.InputStream;<br />
import java.io.InputStreamReader;<br />
import java.net.CookieHandler;<br />
import java.net.CookieManager;<br />
import java.net.CookiePolicy;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
public class GetWebContent {<br />
public static String GetWebContent(String urlString, final String charset,int timeout) throws IOException {<br />
if (urlString == null || urlString.length() == 0) {<br />
return null;<br />
}<br />
urlString = (urlString.startsWith("http://") || urlString<br />
.startsWith("https://")) ? urlString : ("http://" + urlString)<br />
.intern();<br />
CookieHandler.setDefault(new CookieManager(null,<br />
CookiePolicy.ACCEPT_ALL));<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
conn.setDoOutput(true);<br />
conn.setRequestProperty("Pragma", "no-cache");<br />
conn.setRequestProperty("Cache-Control", "no-cache");<br />
// http://blog.csdn.net/yjflinchong<br />
int temp = Integer.parseInt(Math.round(Math.random() * 2) + "");<br />
conn.setRequestProperty("User-Agent", UserAgent[temp]); // 模拟手机系统<br />
System.out.println(UserAgent[temp]);<br />
conn.setRequestProperty("Accept",<br />
"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");// 只接受text/html类型,当然也可以接受图片,pdf,*/*任意,就是tomcat/conf/web里面定义那些<br />
conn.setConnectTimeout(timeout);<br />
<br />
try {<br />
if (conn.getResponseCode() != HttpURLConnection.HTTP_OK) {<br />
return null;<br />
}<br />
} catch (Exception e) {<br />
try {<br />
e.printStackTrace();<br />
} catch (Exception e2) {<br />
e2.printStackTrace();<br />
}<br />
return null;<br />
}<br />
InputStream input = conn.getInputStream();<br />
BufferedReader reader = new BufferedReader(new InputStreamReader(input,<br />
charset));<br />
String line = null;<br />
StringBuffer sb = new StringBuffer();<br />
while ((line = reader.readLine()) != null) {<br />
sb.append(line).append("\r\n");<br />
}<br />
<br />
if (reader != null) {<br />
reader.close();<br />
}<br />
if (conn != null) {<br />
conn.disconnect();<br />
}<br />
return sb.toString();<br />
}<br />
<br />
public static String[] UserAgent = {<br />
//"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.2",<br />
"Mozilla/5.0 (iPad; U; CPU OS 9_2_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Version/4.0.4 Mobile/7B500 Safari/531.21.11",<br />
<br />
// http://blog.csdn.net/yjflinchong<br />
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",//win10 chrome<br />
"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1" };//iphone X<br />
}
代码段2,抓取从网页获取的数据
<br />
<br />
<br />
<br />
<br />
<br />
var data = {<br />
'cookie' : "6a947161cfdda35d01f8c6c673653ffc",<br />
'uri' : "此处地址即为需要抓取的地址,如有需要请私信我"<br />
};<br />
<br />
function getCookie(c_name){<br />
if (document.cookie.length>0){ <br />
c_start=document.cookie.indexOf(c_name + "=")<br />
if (c_start!=-1){ <br />
c_start=c_start + c_name.length+1 <br />
c_end=document.cookie.indexOf(";",c_start)<br />
if (c_end==-1) c_end=document.cookie.length<br />
return unescape(document.cookie.substring(c_start,c_end))<br />
} <br />
}<br />
return "";<br />
}<br />
<br />
function setCookie(c_name,value,expiredays){<br />
var exdate=new Date();<br />
exdate.setDate(exdate.getDate()+expiredays);<br />
document.cookie=c_name+ "=" +escape(value)+((expiredays==null) ? "" : "; path=/; expires="+exdate.toGMTString());<br />
}<br />
<br />
function jump(){<br />
setCookie('elvaeye',data['cookie'],365);<br />
window.location = data['uri'];<br />
}<br />
<br />
<br />
<br />
<br />
<br /> 查看全部
java爬虫抓取动态网页(【】动态cookie页面应该怎么设置才能抓取数据?
)
我需要抓取收录数据的网页内容,并使用httpurlconnection抓取网页内容(代码片段1)。但是,需要爬网的网页似乎在JS端设置了动态cookie,导致爬网的内容成为代码片段2。现在请帮助我了解如何设置这样的动态cookie页面来爬网数据?请给我发一封针对特定链接地址的私人信件~
<br />
/**<br />
* 代码段1<br />
*/<br />
import java.io.BufferedReader;<br />
import java.io.IOException;<br />
import java.io.InputStream;<br />
import java.io.InputStreamReader;<br />
import java.net.CookieHandler;<br />
import java.net.CookieManager;<br />
import java.net.CookiePolicy;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
public class GetWebContent {<br />
public static String GetWebContent(String urlString, final String charset,int timeout) throws IOException {<br />
if (urlString == null || urlString.length() == 0) {<br />
return null;<br />
}<br />
urlString = (urlString.startsWith("http://";) || urlString<br />
.startsWith("https://";)) ? urlString : ("http://" + urlString)<br />
.intern();<br />
CookieHandler.setDefault(new CookieManager(null,<br />
CookiePolicy.ACCEPT_ALL));<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
conn.setDoOutput(true);<br />
conn.setRequestProperty("Pragma", "no-cache");<br />
conn.setRequestProperty("Cache-Control", "no-cache");<br />
// http://blog.csdn.net/yjflinchong<br />
int temp = Integer.parseInt(Math.round(Math.random() * 2) + "");<br />
conn.setRequestProperty("User-Agent", UserAgent[temp]); // 模拟手机系统<br />
System.out.println(UserAgent[temp]);<br />
conn.setRequestProperty("Accept",<br />
"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");// 只接受text/html类型,当然也可以接受图片,pdf,*/*任意,就是tomcat/conf/web里面定义那些<br />
conn.setConnectTimeout(timeout);<br />
<br />
try {<br />
if (conn.getResponseCode() != HttpURLConnection.HTTP_OK) {<br />
return null;<br />
}<br />
} catch (Exception e) {<br />
try {<br />
e.printStackTrace();<br />
} catch (Exception e2) {<br />
e2.printStackTrace();<br />
}<br />
return null;<br />
}<br />
InputStream input = conn.getInputStream();<br />
BufferedReader reader = new BufferedReader(new InputStreamReader(input,<br />
charset));<br />
String line = null;<br />
StringBuffer sb = new StringBuffer();<br />
while ((line = reader.readLine()) != null) {<br />
sb.append(line).append("\r\n");<br />
}<br />
<br />
if (reader != null) {<br />
reader.close();<br />
}<br />
if (conn != null) {<br />
conn.disconnect();<br />
}<br />
return sb.toString();<br />
}<br />
<br />
public static String[] UserAgent = {<br />
//"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.2",<br />
"Mozilla/5.0 (iPad; U; CPU OS 9_2_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Version/4.0.4 Mobile/7B500 Safari/531.21.11",<br />
<br />
// http://blog.csdn.net/yjflinchong<br />
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",//win10 chrome<br />
"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1" };//iphone X<br />
}
代码段2,抓取从网页获取的数据
<br />
<br />
<br />
<br />
<br />
<br />
var data = {<br />
'cookie' : "6a947161cfdda35d01f8c6c673653ffc",<br />
'uri' : "此处地址即为需要抓取的地址,如有需要请私信我"<br />
};<br />
<br />
function getCookie(c_name){<br />
if (document.cookie.length>0){ <br />
c_start=document.cookie.indexOf(c_name + "=")<br />
if (c_start!=-1){ <br />
c_start=c_start + c_name.length+1 <br />
c_end=document.cookie.indexOf(";",c_start)<br />
if (c_end==-1) c_end=document.cookie.length<br />
return unescape(document.cookie.substring(c_start,c_end))<br />
} <br />
}<br />
return "";<br />
}<br />
<br />
function setCookie(c_name,value,expiredays){<br />
var exdate=new Date();<br />
exdate.setDate(exdate.getDate()+expiredays);<br />
document.cookie=c_name+ "=" +escape(value)+((expiredays==null) ? "" : "; path=/; expires="+exdate.toGMTString());<br />
}<br />
<br />
function jump(){<br />
setCookie('elvaeye',data['cookie'],365);<br />
window.location = data['uri'];<br />
}<br />
<br />
<br />
<br />
<br />
<br />
java爬虫抓取动态网页( 什么是Python?Python是什么?(二)模糊)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-01 20:09
什么是Python?Python是什么?(二)模糊)
今天听到有人问:为什么Python叫爬虫?我脑子里的第一反应不是答案,而是为什么有人问这个问题。我觉得大家对Python的概念有点模糊,把Python和爬虫混为一谈,所以今天问请解释一下。
什么是 Python?什么是 Python?
如果你在英文字典里查Python,他会给你下Python是大蟒蛇的定义,读成这样:英语[ˈpaɪθən],美国[ˈpaɪθɑ:n],Python就是大名鼎鼎的“龟叔”Guido van Rossum在 1989 年圣诞节期间,为了度过无聊的圣诞节而编写的一种编程语言。Python 是一种计算机编程语言。是一种动态的、面向对象的脚本语言,最初是为编写自动化脚本(shell)而设计的,随着版本的不断更新和新语言功能的加入,越来越多的被用于独立的、大型的项目开发。
Python 是一种解释性脚本语言,可用于以下领域:
1、Web 和 Internet 开发
2、科学计算和统计
3、教育
4、桌面界面开发
5、软件开发
6、后端开发
什么是爬虫?什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。
搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。
(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
Python和爬虫有什么关系?
爬虫一般是指对网络资源的爬取。由于python的脚本特性,python易于配置,对字符的处理也非常灵活。另外python有丰富的网络捕捉模块,所以两者经常联系在一起。只需使用python自带的urllib库即可;使用python编写搜索引擎,搜索引擎是一个复杂的爬虫。从这里您将了解什么是 Python 爬虫。是一种基于Python编程创建的网络资源爬取方法。Python 不是爬虫。
为什么Python适合一些爬虫?
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
什么是爬虫代理?
在爬行的过程中,如果你的爬行频率过快,不符合人类的操作方式。一些网站反爬虫机制检测到你的IP异常,访问频率过高。您将被阻止 IP。目前,专门从事代理IP服务的第三方平台比较多。
【相关学习建议】
1. Python爬虫视频教程
2. Python爬虫入门教程
如果想尝试爬取数据实践,可以试试下面爬虫专用代理ip,支持https、http、socks5、地址: 查看全部
java爬虫抓取动态网页(
什么是Python?Python是什么?(二)模糊)

今天听到有人问:为什么Python叫爬虫?我脑子里的第一反应不是答案,而是为什么有人问这个问题。我觉得大家对Python的概念有点模糊,把Python和爬虫混为一谈,所以今天问请解释一下。
什么是 Python?什么是 Python?
如果你在英文字典里查Python,他会给你下Python是大蟒蛇的定义,读成这样:英语[ˈpaɪθən],美国[ˈpaɪθɑ:n],Python就是大名鼎鼎的“龟叔”Guido van Rossum在 1989 年圣诞节期间,为了度过无聊的圣诞节而编写的一种编程语言。Python 是一种计算机编程语言。是一种动态的、面向对象的脚本语言,最初是为编写自动化脚本(shell)而设计的,随着版本的不断更新和新语言功能的加入,越来越多的被用于独立的、大型的项目开发。
Python 是一种解释性脚本语言,可用于以下领域:
1、Web 和 Internet 开发
2、科学计算和统计
3、教育
4、桌面界面开发
5、软件开发
6、后端开发
什么是爬虫?什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。
搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。
(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
Python和爬虫有什么关系?
爬虫一般是指对网络资源的爬取。由于python的脚本特性,python易于配置,对字符的处理也非常灵活。另外python有丰富的网络捕捉模块,所以两者经常联系在一起。只需使用python自带的urllib库即可;使用python编写搜索引擎,搜索引擎是一个复杂的爬虫。从这里您将了解什么是 Python 爬虫。是一种基于Python编程创建的网络资源爬取方法。Python 不是爬虫。
为什么Python适合一些爬虫?
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
什么是爬虫代理?
在爬行的过程中,如果你的爬行频率过快,不符合人类的操作方式。一些网站反爬虫机制检测到你的IP异常,访问频率过高。您将被阻止 IP。目前,专门从事代理IP服务的第三方平台比较多。
【相关学习建议】
1. Python爬虫视频教程
2. Python爬虫入门教程
如果想尝试爬取数据实践,可以试试下面爬虫专用代理ip,支持https、http、socks5、地址:
java爬虫抓取动态网页(体验Python版本的话-alpha版本示例代码介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-27 21:26
官方网站地址:。这是Java版本。如果您想体验python版本,请继续
其他介绍文章
不要说太多废话。直截了当地说。首先,使用Maven引入相关的依赖关系。目前,最新版本为2.73 alpha
cn.edu.hfut.dmic.webcollector
WebCollector
2.73-alpha
请参阅下面的示例代码了解如何使用它。它用于捕捉网站的图片。这网站不方便发放,我们自己试试吧
<p>import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.util.ExceptionUtils;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.MD5Utils;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
/**
* 继承 BreadthCrawler(广度爬虫)
* BreadthCrawler 是 WebCollector 最常用的爬取器之一
*
* @author hu
*/
public class DemoCrawler extends BreadthCrawler {
File baseDir = new File("images");
/**
* 构造一个基于伯克利DB的爬虫
* 伯克利DB文件夹为crawlPath,crawlPath中维护了历史URL等信息
* 不同任务不要使用相同的crawlPath
* 两个使用相同crawlPath的爬虫并行爬取会产生错误
*
* @param crawlPath 伯克利DB使用的文件夹
*/
public DemoCrawler(String crawlPath) {
//设置是否自动解析网页内容
super(crawlPath, true);
//只有在autoParse和autoDetectImg都为true的情况下
//爬虫才会自动解析图片链接
//getConf().setAutoDetectImg(true);
//如果使用默认的Requester,需要像下面这样设置一下网页大小上限
//否则可能会获得一个不完整的页面
//下面这行将页面大小上限设置为10M
//getConf().setMaxReceiveSize(1024 * 1024 * 10);
//添加种子URL
addSeed("http://www.xxx.com");
//限定爬取范围
addRegex("http://image.xxx.com/.*");
addRegex("-.*#.*");
addRegex("-.*\\?.*");
//设置线程数
setThreads(10);
}
@Override
public void visit(Page page, CrawlDatums next) {
//根据http头中的Content-Type信息来判断当前资源是网页还是图片
String contentType = page.contentType();
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
//如果是网页,则抽取其中包含图片的URL,放入后续任务
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
if (imgSrc.indexOf("thumb") 查看全部
java爬虫抓取动态网页(体验Python版本的话-alpha版本示例代码介绍)
官方网站地址:。这是Java版本。如果您想体验python版本,请继续
其他介绍文章
不要说太多废话。直截了当地说。首先,使用Maven引入相关的依赖关系。目前,最新版本为2.73 alpha
cn.edu.hfut.dmic.webcollector
WebCollector
2.73-alpha
请参阅下面的示例代码了解如何使用它。它用于捕捉网站的图片。这网站不方便发放,我们自己试试吧
<p>import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.util.ExceptionUtils;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.MD5Utils;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
/**
* 继承 BreadthCrawler(广度爬虫)
* BreadthCrawler 是 WebCollector 最常用的爬取器之一
*
* @author hu
*/
public class DemoCrawler extends BreadthCrawler {
File baseDir = new File("images");
/**
* 构造一个基于伯克利DB的爬虫
* 伯克利DB文件夹为crawlPath,crawlPath中维护了历史URL等信息
* 不同任务不要使用相同的crawlPath
* 两个使用相同crawlPath的爬虫并行爬取会产生错误
*
* @param crawlPath 伯克利DB使用的文件夹
*/
public DemoCrawler(String crawlPath) {
//设置是否自动解析网页内容
super(crawlPath, true);
//只有在autoParse和autoDetectImg都为true的情况下
//爬虫才会自动解析图片链接
//getConf().setAutoDetectImg(true);
//如果使用默认的Requester,需要像下面这样设置一下网页大小上限
//否则可能会获得一个不完整的页面
//下面这行将页面大小上限设置为10M
//getConf().setMaxReceiveSize(1024 * 1024 * 10);
//添加种子URL
addSeed("http://www.xxx.com";);
//限定爬取范围
addRegex("http://image.xxx.com/.*");
addRegex("-.*#.*");
addRegex("-.*\\?.*");
//设置线程数
setThreads(10);
}
@Override
public void visit(Page page, CrawlDatums next) {
//根据http头中的Content-Type信息来判断当前资源是网页还是图片
String contentType = page.contentType();
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
//如果是网页,则抽取其中包含图片的URL,放入后续任务
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
if (imgSrc.indexOf("thumb")
java爬虫抓取动态网页(爬虫遇到js动态数据时怎么办?漫画网站详解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-27 15:24
当爬虫遇到JS动态数据时,主要有两种解决方案:
使用一些库(如selenium)在模拟的浏览器环境中捕获数据。但是,这会消耗大量内存和CPU,并且爬虫效率较低,应尽量避免。手动分析JS请求并构造请求URL
接下来,我选择一幅卡通网站作为一个小例子来介绍第二种方法
我们的目标是获取卡通图片的URL并下载它
判断要爬网的数据是否动态加载
使用chrome打开网页,右键单击卡通图片->;检查
我们可以在里面看到图片的URL。右键单击此处(蓝色部分)->;复制->;复制XPath获取与图片对应的XPath,然后可以使用请求和XPath获取图片URL。当然,它最终失败了。因为这里的图片是由JS动态加载的
(当然,还有一种更简单的判断方法。直接安装chrome插件toggle JavaScript,它可以判断页面的哪个部分是由JS加载的)
获取与要爬网的数据相关的JS代码信息
我们可以查看网页源代码,Ctrl+F定位图像ID“curpic”:
如您所见,没有图片的URL,图片是由JS加载的。阅读JS代码,我们可以知道图片URL由以下代码行决定:
pic2.src = hosts[getHost()] + picAy[curIndex]
在源代码中查找hosts和picay,发现它们只出现在这里。这表明这两个数组可以由JS代码加载
查找与要爬网的数据相关的JS请求
回到卡通页面,我们打开chrome的F12,点击网络,检查JS,刷新网页,查看相关JS请求对应的预览,查看哪些收录主机和picay:
嗯,进展惊人地顺利。第一个JS收录我们想要查找的内容。从这个图中,我们可以看到,当我们进入卡通的第一页时,JS代码会请求卡通所有页面的图片URL。单击请求的标题,我们可以看到请求的URL,其中收录JS文件名
那么,在编写程序时,我们如何获得JS文件名呢
看看其他的漫画,我们可以发现,虽然这个JS代码的命名是不规则的,但它在网页源代码中通常位于第一个JS位置。这样,O(∩ ∩) O可以通过正则表达式提取。哈哈~
知道JS文件名后,我们就可以构造请求URL了,上图就是一个例子:
url = 'https' + '//comic.sfacg.com/Utility/1887/ZP/117.js'
总结
到目前为止,让我们总结一下如何下载网站动画片:
获取动画第一页的URL,获取URL响应的HTML,在HTML中找到第一个JS代码文件名,构造请求URL,获取JS的响应内容,并从中提取所有图片URL
总结本例中获取JS动态数据的想法:
判断数据是否是JS加载的,如果是JS加载的,则在网页源代码中检查要爬网的数据附近的JS代码,获取关键信息(如一些变量名),返回要爬网的网页,按F12(my chrome),单击网络,检查JS,刷新网页,获取JS请求,逐个检查每个请求的预览,查看是否有任何与要爬网的内容相关的信息。如果请求的响应内容收录我们需要的信息,请检查请求的标题和URL,并找到构造此类请求URL的方法 查看全部
java爬虫抓取动态网页(爬虫遇到js动态数据时怎么办?漫画网站详解(组图))
当爬虫遇到JS动态数据时,主要有两种解决方案:
使用一些库(如selenium)在模拟的浏览器环境中捕获数据。但是,这会消耗大量内存和CPU,并且爬虫效率较低,应尽量避免。手动分析JS请求并构造请求URL
接下来,我选择一幅卡通网站作为一个小例子来介绍第二种方法
我们的目标是获取卡通图片的URL并下载它
判断要爬网的数据是否动态加载
使用chrome打开网页,右键单击卡通图片->;检查

我们可以在里面看到图片的URL。右键单击此处(蓝色部分)->;复制->;复制XPath获取与图片对应的XPath,然后可以使用请求和XPath获取图片URL。当然,它最终失败了。因为这里的图片是由JS动态加载的
(当然,还有一种更简单的判断方法。直接安装chrome插件toggle JavaScript,它可以判断页面的哪个部分是由JS加载的)
获取与要爬网的数据相关的JS代码信息
我们可以查看网页源代码,Ctrl+F定位图像ID“curpic”:
如您所见,没有图片的URL,图片是由JS加载的。阅读JS代码,我们可以知道图片URL由以下代码行决定:
pic2.src = hosts[getHost()] + picAy[curIndex]
在源代码中查找hosts和picay,发现它们只出现在这里。这表明这两个数组可以由JS代码加载
查找与要爬网的数据相关的JS请求
回到卡通页面,我们打开chrome的F12,点击网络,检查JS,刷新网页,查看相关JS请求对应的预览,查看哪些收录主机和picay:
嗯,进展惊人地顺利。第一个JS收录我们想要查找的内容。从这个图中,我们可以看到,当我们进入卡通的第一页时,JS代码会请求卡通所有页面的图片URL。单击请求的标题,我们可以看到请求的URL,其中收录JS文件名
那么,在编写程序时,我们如何获得JS文件名呢
看看其他的漫画,我们可以发现,虽然这个JS代码的命名是不规则的,但它在网页源代码中通常位于第一个JS位置。这样,O(∩ ∩) O可以通过正则表达式提取。哈哈~
知道JS文件名后,我们就可以构造请求URL了,上图就是一个例子:
url = 'https' + '//comic.sfacg.com/Utility/1887/ZP/117.js'
总结
到目前为止,让我们总结一下如何下载网站动画片:
获取动画第一页的URL,获取URL响应的HTML,在HTML中找到第一个JS代码文件名,构造请求URL,获取JS的响应内容,并从中提取所有图片URL
总结本例中获取JS动态数据的想法:
判断数据是否是JS加载的,如果是JS加载的,则在网页源代码中检查要爬网的数据附近的JS代码,获取关键信息(如一些变量名),返回要爬网的网页,按F12(my chrome),单击网络,检查JS,刷新网页,获取JS请求,逐个检查每个请求的预览,查看是否有任何与要爬网的内容相关的信息。如果请求的响应内容收录我们需要的信息,请检查请求的标题和URL,并找到构造此类请求URL的方法
java爬虫抓取动态网页(Java爬虫Jsoup+httpclient获取动态生成的数据的相关内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-09-26 23:16
想知道Java爬虫Jsoup+httpclient获取动态生成数据的相关内容吗?在本文中,我将讲解Java爬虫的相关知识和一些代码示例。欢迎阅读和纠正我们。我们先重点介绍一下:Java爬虫Jsoup+httpclient获取动态生成的数据,Java爬虫,Java爬虫Jsoup一起来学习吧。
Java爬虫Jsoup+httpclient获取动态生成的数据
前面我们详细讲了Jsoup,发现这个东西其实是一样的,只要是可以访问的静态资源页面,就可以直接用它来获取自己需要的数据。>为了防止数据被恶意爬取,我们做了很多掩饰,比如加密和动态加载,无形中给我们写的爬虫程序带来了很多麻烦,那么我们如何突破这个梗获取我们急需的数据?
让我们详细说明如何获得
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
这时候整个页面的数据其实已经获取到了,但是商品的价格是通过回调函数获取然后填写的。 这就需要我们写爬虫的开发者耐心的找到页面的回调接口价格数据。我们直接访问这个接口。你可以直接拿到这个价格。这是一个演示:
通过这个截图可以看到,他传递的只是一个静态资源页面,根本没有价格参数,那么价格是怎么来的呢?继续找这个界面:
你会发现这个界面里面拼接了很多参数,那么我们要做的就是分析一下所有的参数是否都有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
可以尝试删除一些参数,发现这个接口需要的参数其实很简单:
https://p.3.cn/prices/mgets%3F ... em-pc
看到这里是不是很兴奋?你实际上可以更改一些其他的京东产品ID,以获得当前价格和最高价格。我不知道价格是多少。我们需要做的只是写一个Httpclient模拟请求接口
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是这样的:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
至于后者,如果直接解析JSON字符串,那么你想要的数据就是GET。
请注意
这是重新请求获取回调请求的数据。这只是对之前动态获取商品价格的补充。这种情况是价格本身不是通过主链接带到页面的,而是在加载过程中通过异步请求填写的。当时把数据带过来了,但是有相关的JS做相关处理。我们仍然无法得到它。这时候我们就得通过其他方式来获取这些数据,后面会解释。 查看全部
java爬虫抓取动态网页(Java爬虫Jsoup+httpclient获取动态生成的数据的相关内容)
想知道Java爬虫Jsoup+httpclient获取动态生成数据的相关内容吗?在本文中,我将讲解Java爬虫的相关知识和一些代码示例。欢迎阅读和纠正我们。我们先重点介绍一下:Java爬虫Jsoup+httpclient获取动态生成的数据,Java爬虫,Java爬虫Jsoup一起来学习吧。
Java爬虫Jsoup+httpclient获取动态生成的数据
前面我们详细讲了Jsoup,发现这个东西其实是一样的,只要是可以访问的静态资源页面,就可以直接用它来获取自己需要的数据。>为了防止数据被恶意爬取,我们做了很多掩饰,比如加密和动态加载,无形中给我们写的爬虫程序带来了很多麻烦,那么我们如何突破这个梗获取我们急需的数据?
让我们详细说明如何获得
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
这时候整个页面的数据其实已经获取到了,但是商品的价格是通过回调函数获取然后填写的。 这就需要我们写爬虫的开发者耐心的找到页面的回调接口价格数据。我们直接访问这个接口。你可以直接拿到这个价格。这是一个演示:

通过这个截图可以看到,他传递的只是一个静态资源页面,根本没有价格参数,那么价格是怎么来的呢?继续找这个界面:


你会发现这个界面里面拼接了很多参数,那么我们要做的就是分析一下所有的参数是否都有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
可以尝试删除一些参数,发现这个接口需要的参数其实很简单:
https://p.3.cn/prices/mgets%3F ... em-pc
看到这里是不是很兴奋?你实际上可以更改一些其他的京东产品ID,以获得当前价格和最高价格。我不知道价格是多少。我们需要做的只是写一个Httpclient模拟请求接口
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是这样的:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
至于后者,如果直接解析JSON字符串,那么你想要的数据就是GET。
请注意
这是重新请求获取回调请求的数据。这只是对之前动态获取商品价格的补充。这种情况是价格本身不是通过主链接带到页面的,而是在加载过程中通过异步请求填写的。当时把数据带过来了,但是有相关的JS做相关处理。我们仍然无法得到它。这时候我们就得通过其他方式来获取这些数据,后面会解释。
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-26 01:22
Htmlunit是一个开源Java页面分析工具。启动htmlunit后,底层将启动一个没有界面的浏览器。用户可以指定浏览器类型:Firefox、ie等。如果未指定,默认为Internet\uExplorer\u7:
WebClient WebClient=新的WebClient(BrowserVersion.FIREFOX\u36)
通过一个简单的电话:
HtmlPage=webClient.getPage(url)
可通过以下方式获取页面的HTML页面表示:
InputStream is=targetPage.getWebResponse().getContentAsStream()
您可以获取页面的输入流,从而获取页面的源代码,这对于web爬虫项目非常有用
当然,您也可以从页面中获取更多页面元素
htmlunit为执行javascript提供支持非常重要:
page.executeJavaScript(javascript)
执行JS后,返回一个scriptresult对象,通过该对象可以得到执行JS后的页面等信息,默认情况下,内部浏览器会跳转到执行JS后生成的新页面,如果执行JS失败,则不会执行页面跳转 查看全部
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
Htmlunit是一个开源Java页面分析工具。启动htmlunit后,底层将启动一个没有界面的浏览器。用户可以指定浏览器类型:Firefox、ie等。如果未指定,默认为Internet\uExplorer\u7:
WebClient WebClient=新的WebClient(BrowserVersion.FIREFOX\u36)
通过一个简单的电话:
HtmlPage=webClient.getPage(url)
可通过以下方式获取页面的HTML页面表示:
InputStream is=targetPage.getWebResponse().getContentAsStream()
您可以获取页面的输入流,从而获取页面的源代码,这对于web爬虫项目非常有用
当然,您也可以从页面中获取更多页面元素
htmlunit为执行javascript提供支持非常重要:
page.executeJavaScript(javascript)
执行JS后,返回一个scriptresult对象,通过该对象可以得到执行JS后的页面等信息,默认情况下,内部浏览器会跳转到执行JS后生成的新页面,如果执行JS失败,则不会执行页面跳转
java爬虫抓取动态网页(使用Python语言开发爬虫有什么优势?-Python培训分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-25 20:51
网络爬虫有很多种,Python爬虫就是其中之一。那么使用Python语言开发爬虫有哪些优势呢?看看下面的详细介绍。
Python培训分享:使用Python开发爬虫有哪些优势?到目前为止,网络爬虫的主要开发语言有Java、Python和C++。对于一般信息,各种开发语言之间几乎没有区别。详细情况如下:
C/C++
大多数搜索引擎使用C/C++来开发爬虫,可能是因为搜索引擎爬虫对于采集网站信息很重要,对页面解析要求不高。
Python
Python语言具有强大的网络功能,可以模拟登录,解析JavaScript。缺点是网页分析。Python编写程序非常方便,尤其是对于专注的爬虫。目标 网站 经常变化。使用Python根据目标的变化修改爬虫程序非常方便。
爪哇
Java中有很多解析器,对解析网页有很好的支持。缺点是网络部分支持较差。
对于一般需求,无论是Java还是Python都可以胜任。如果需要模拟登陆,选择Python来对抗反爬虫更方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者需要对网页内容进行细粒度分析,可以选择Java。
在本书中选择 Python 作为实现爬虫的语言的主要考虑是:
(1) 抓取网页本身的界面
与其他动态脚本语言(如Perl、Shell)相比,Python的urllib2包提供了更完整的网页文档访问API;与其他静态编程语言(如Java、C#、C++)相比,Python捕捉网页文档的界面更加简洁。
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这时候就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有出色的第三方包可以帮助您完成任务,例如 Requests 或 Mechanize。
(2) 网页爬取后的处理
抓取到的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python 的 Beautiful Soup 提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上的功能,但是Python可以做到最快最干净,就像那句话“人生苦短,你需要Python”。
(3) 开发效率高
因为爬虫的具体代码要根据网站进行修改,而Python这种灵活的脚本语言特别适合这个任务。
(4) 快速上手
网上Python教学资源很多,方便大家学习,遇到问题也很容易找到相关资料。此外,Python 拥有强大的成熟爬虫框架的支持,例如 Scrapy。
以上就是《Python培训分享:使用Python语言开发爬虫有什么优势?》的介绍。更多成都Python培训的具体课程,加入千峰教育Python交流群-790693323,群内会有专职老师为您解答。此外,群内不定期会有免费直播课,由活跃讲师授课。 查看全部
java爬虫抓取动态网页(使用Python语言开发爬虫有什么优势?-Python培训分享)
网络爬虫有很多种,Python爬虫就是其中之一。那么使用Python语言开发爬虫有哪些优势呢?看看下面的详细介绍。
Python培训分享:使用Python开发爬虫有哪些优势?到目前为止,网络爬虫的主要开发语言有Java、Python和C++。对于一般信息,各种开发语言之间几乎没有区别。详细情况如下:
C/C++
大多数搜索引擎使用C/C++来开发爬虫,可能是因为搜索引擎爬虫对于采集网站信息很重要,对页面解析要求不高。
Python
Python语言具有强大的网络功能,可以模拟登录,解析JavaScript。缺点是网页分析。Python编写程序非常方便,尤其是对于专注的爬虫。目标 网站 经常变化。使用Python根据目标的变化修改爬虫程序非常方便。
爪哇
Java中有很多解析器,对解析网页有很好的支持。缺点是网络部分支持较差。
对于一般需求,无论是Java还是Python都可以胜任。如果需要模拟登陆,选择Python来对抗反爬虫更方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者需要对网页内容进行细粒度分析,可以选择Java。
在本书中选择 Python 作为实现爬虫的语言的主要考虑是:
(1) 抓取网页本身的界面
与其他动态脚本语言(如Perl、Shell)相比,Python的urllib2包提供了更完整的网页文档访问API;与其他静态编程语言(如Java、C#、C++)相比,Python捕捉网页文档的界面更加简洁。
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这时候就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有出色的第三方包可以帮助您完成任务,例如 Requests 或 Mechanize。
(2) 网页爬取后的处理
抓取到的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python 的 Beautiful Soup 提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上的功能,但是Python可以做到最快最干净,就像那句话“人生苦短,你需要Python”。
(3) 开发效率高
因为爬虫的具体代码要根据网站进行修改,而Python这种灵活的脚本语言特别适合这个任务。
(4) 快速上手
网上Python教学资源很多,方便大家学习,遇到问题也很容易找到相关资料。此外,Python 拥有强大的成熟爬虫框架的支持,例如 Scrapy。
以上就是《Python培训分享:使用Python语言开发爬虫有什么优势?》的介绍。更多成都Python培训的具体课程,加入千峰教育Python交流群-790693323,群内会有专职老师为您解答。此外,群内不定期会有免费直播课,由活跃讲师授课。
java爬虫抓取动态网页(学习Java的同窗注意了!!(附学习源码))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-25 20:38
学习Java的同学注意啦!!!
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入Java学习交流群,群号:183993990,一起学Java吧!html
本文文章来自个人回答:GitHub上有哪些优秀的Java爬虫项目?但是在这个答案中,进行了一些更改并添加了一些项目。这些项目来自github和开源中国。希望这些开源的Java爬虫项目对你有所帮助。阅读源代码可以帮助您获得质的提升。
一、格科
github地址:xtuhcy/gecco
Gecco是一个用java语言开发的轻量级易用的网络爬虫。集成jsoup、httpclient、fastjson、spring、htmlunit、redission等框架,只需要配置一些jquery风格的选择器即可快速编写爬虫。Gecco 框架具有出色的可扩展性。框架按照开闭原则设计,封闭用于修改,开放用于扩展。
二、WebCollector
github地址:CrawlScript/WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需很少的代码即可实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
三、蜘蛛侠
码云地址:l-weiwei/Spiderman2-码云-开源中国
用例:展示垂直爬虫的能力——如风般自由
蜘蛛侠是一个基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法,将复杂的目标网页信息捕获并解析成它需要的业务数据。
四、WebMagic
码云地址:flashsword20/webmagic-码云-中国开源
webmagic是一个爬虫框架,不需要配置,方便二次开发。它提供了一个简单灵活的API,只需很少的代码就可以实现一个爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(连接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。
五、Heritrix
Github 地址:internetarchive/heritrix3 Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。
六、crawler4j
GitHub 地址:yasserg/crawler4j · GitHub crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,可以在几分钟内构建一个多线程的网络爬虫。
七、Nutchjava
github地址:apache/nutchjquery
Nutch 是一个用开源 Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
在 Nutch 的发展过程中,产生了四个 Java 开源项目,Hadoop、Tika、Gora 和 Crawler Commons。现在这四个项目发展迅速,非常火爆,尤其是Hadoop,已经成为大规模数据处理的事实标准。Tika 使用各种现有的开源内容分析项目从多种格式的文件中提取元数据和结构化文本。Gora 支持将大数据持久化到多个存储实现。Crawler Commons 是一个通用的网络爬虫组件。.
八、SeimiCrawlergit
github地址:zhegexiaohuozi/SeimiCrawlergithub
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望能最大程度的降低新手开发高可用、低性能的爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大多数人只需要关心编写爬行的业务逻辑,其他 Seimi 会为你做。在设计上,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy,同时融合了 Java 语言的特性和 Spring 的特性,希望在国内能更方便、更广泛地使用更多的 HTML 解析高效的XPath,所以SeimiCrawler的默认HTML解析器是JsoupXpath(独立的扩展项目,不收录在jsoup中),HTML数据的默认解析和提取是使用XPath完成的(当然数据处理也可以选择其他解析器)。并结合SeimiAgent,彻底解决复杂的动态页面渲染和爬取问题。
九、Jsoupweb
github地址:jhy/jsoupredis
中文指南:jsoup开发指南、jsoup中文文档spring
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。学习Java的同学注意啦!!!
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入Java学习交流群,群号:183993990,一起学Java吧! 查看全部
java爬虫抓取动态网页(学习Java的同窗注意了!!(附学习源码))
学习Java的同学注意啦!!!
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入Java学习交流群,群号:183993990,一起学Java吧!html
本文文章来自个人回答:GitHub上有哪些优秀的Java爬虫项目?但是在这个答案中,进行了一些更改并添加了一些项目。这些项目来自github和开源中国。希望这些开源的Java爬虫项目对你有所帮助。阅读源代码可以帮助您获得质的提升。
一、格科
github地址:xtuhcy/gecco
Gecco是一个用java语言开发的轻量级易用的网络爬虫。集成jsoup、httpclient、fastjson、spring、htmlunit、redission等框架,只需要配置一些jquery风格的选择器即可快速编写爬虫。Gecco 框架具有出色的可扩展性。框架按照开闭原则设计,封闭用于修改,开放用于扩展。
二、WebCollector
github地址:CrawlScript/WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需很少的代码即可实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
三、蜘蛛侠
码云地址:l-weiwei/Spiderman2-码云-开源中国
用例:展示垂直爬虫的能力——如风般自由
蜘蛛侠是一个基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法,将复杂的目标网页信息捕获并解析成它需要的业务数据。
四、WebMagic
码云地址:flashsword20/webmagic-码云-中国开源
webmagic是一个爬虫框架,不需要配置,方便二次开发。它提供了一个简单灵活的API,只需很少的代码就可以实现一个爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(连接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。

五、Heritrix
Github 地址:internetarchive/heritrix3 Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。
六、crawler4j
GitHub 地址:yasserg/crawler4j · GitHub crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,可以在几分钟内构建一个多线程的网络爬虫。
七、Nutchjava
github地址:apache/nutchjquery
Nutch 是一个用开源 Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
在 Nutch 的发展过程中,产生了四个 Java 开源项目,Hadoop、Tika、Gora 和 Crawler Commons。现在这四个项目发展迅速,非常火爆,尤其是Hadoop,已经成为大规模数据处理的事实标准。Tika 使用各种现有的开源内容分析项目从多种格式的文件中提取元数据和结构化文本。Gora 支持将大数据持久化到多个存储实现。Crawler Commons 是一个通用的网络爬虫组件。.
八、SeimiCrawlergit
github地址:zhegexiaohuozi/SeimiCrawlergithub
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望能最大程度的降低新手开发高可用、低性能的爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大多数人只需要关心编写爬行的业务逻辑,其他 Seimi 会为你做。在设计上,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy,同时融合了 Java 语言的特性和 Spring 的特性,希望在国内能更方便、更广泛地使用更多的 HTML 解析高效的XPath,所以SeimiCrawler的默认HTML解析器是JsoupXpath(独立的扩展项目,不收录在jsoup中),HTML数据的默认解析和提取是使用XPath完成的(当然数据处理也可以选择其他解析器)。并结合SeimiAgent,彻底解决复杂的动态页面渲染和爬取问题。
九、Jsoupweb
github地址:jhy/jsoupredis
中文指南:jsoup开发指南、jsoup中文文档spring
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。学习Java的同学注意啦!!!
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入Java学习交流群,群号:183993990,一起学Java吧!
java爬虫抓取动态网页(全球最大的中文社区,java爬虫抓取动态网页知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-24 13:06
java爬虫抓取动态网页知乎号称知乎是全球最大的中文社区,这个社区知乎不断的引进用户,用户很多是假装用户的,因此需要抓取用户信息,方便之后爬取正规的用户信息。实际上网页上的信息并不多,只抓取了一个页面里的基本信息,以及对照了知乎里面的信息,同时网页代码加密处理。所以从理论上而言可以实现爬取。注意的是,在抓取前使用javahttp库调用getshell函数,导致代码效率有问题,同时爬取完用户信息后使用websql库去读取,反而需要去读取一些java中基本的sql功能。
简单说下整个步骤。这个网页的地址是:keywords.github.io,可能由于浏览器兼容的问题,会下载不了这个页面。所以抓取首先需要借助javaweb开发框架,getshell需要jsp,没看懂这个getshell是干嘛的,可以使用浏览器开发工具运行,发现下载不成功,现在测试还可以用。抓取完成,使用浏览器的getshell,可以看到getshell工具的路径,是可以访问到知乎的地址的。
有了路径,也可以查看代码,看看是否如我们预期那样,从而完成获取。websql运行很慢,测试4s/min。目前知乎还没有清除所有爬虫内容的功能,我们手工逐页清除,并重新抓取新的页面。老代码在这里:armgit仓库地址:websql包名:getjavapyqueueheader替换为0为10为定义tag解释器apipagesplit获取到页面源码之后,需要使用websql做清除数据的工作,然后返回true。
清除数据api简单代码:frompyqueryimportqueryexecuteopen('paths.github.io',request,'users.ikd.py')#pyqueryconvertedtotheuserselectorrequest=query(executeopen('paths.github.io',request))#pyqueryconvertedtotheuserselector如果是单向爬虫爬取,userselector很简单,如果是双向爬虫爬取,userselector要写很多代码。
list=jsp(query,'user').list()#list要手工处理一下,对list修改jsp定义。asp(query).aggregate('user',list,list).range(0,。
4).range(0,
6).list()#"user.py"存储,也可以存储更多的,比如xianyuan,你喜欢就存。
解释器api最后清除结果api代码:
1、全部内容:users.ikd.py
2、如果是清除整页清除不了,会在返回true时,写入一个判断的attribute,否则清除不了。selector清除不了的话,每次调用都会接受一个payload并返回。定义payload的方法,初始attribute和payload进行匹配,返回结果类型,匹配的payload类型中有:selector\__。 查看全部
java爬虫抓取动态网页(全球最大的中文社区,java爬虫抓取动态网页知乎)
java爬虫抓取动态网页知乎号称知乎是全球最大的中文社区,这个社区知乎不断的引进用户,用户很多是假装用户的,因此需要抓取用户信息,方便之后爬取正规的用户信息。实际上网页上的信息并不多,只抓取了一个页面里的基本信息,以及对照了知乎里面的信息,同时网页代码加密处理。所以从理论上而言可以实现爬取。注意的是,在抓取前使用javahttp库调用getshell函数,导致代码效率有问题,同时爬取完用户信息后使用websql库去读取,反而需要去读取一些java中基本的sql功能。
简单说下整个步骤。这个网页的地址是:keywords.github.io,可能由于浏览器兼容的问题,会下载不了这个页面。所以抓取首先需要借助javaweb开发框架,getshell需要jsp,没看懂这个getshell是干嘛的,可以使用浏览器开发工具运行,发现下载不成功,现在测试还可以用。抓取完成,使用浏览器的getshell,可以看到getshell工具的路径,是可以访问到知乎的地址的。
有了路径,也可以查看代码,看看是否如我们预期那样,从而完成获取。websql运行很慢,测试4s/min。目前知乎还没有清除所有爬虫内容的功能,我们手工逐页清除,并重新抓取新的页面。老代码在这里:armgit仓库地址:websql包名:getjavapyqueueheader替换为0为10为定义tag解释器apipagesplit获取到页面源码之后,需要使用websql做清除数据的工作,然后返回true。
清除数据api简单代码:frompyqueryimportqueryexecuteopen('paths.github.io',request,'users.ikd.py')#pyqueryconvertedtotheuserselectorrequest=query(executeopen('paths.github.io',request))#pyqueryconvertedtotheuserselector如果是单向爬虫爬取,userselector很简单,如果是双向爬虫爬取,userselector要写很多代码。
list=jsp(query,'user').list()#list要手工处理一下,对list修改jsp定义。asp(query).aggregate('user',list,list).range(0,。
4).range(0,
6).list()#"user.py"存储,也可以存储更多的,比如xianyuan,你喜欢就存。
解释器api最后清除结果api代码:
1、全部内容:users.ikd.py
2、如果是清除整页清除不了,会在返回true时,写入一个判断的attribute,否则清除不了。selector清除不了的话,每次调用都会接受一个payload并返回。定义payload的方法,初始attribute和payload进行匹配,返回结果类型,匹配的payload类型中有:selector\__。
java爬虫抓取动态网页(HTML解析:Jsoup基本思路(组图)线程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-09-23 02:11
html分析:jsoup
基本思想
网络爬行动物的基本思想是爬网线程从URL队列中获取URL - &gt;模拟浏览器对目标URL的请求 - &gt;下载Web内容返回 - &gt;然后在页面上,请将目标数据获取到相应的存储 - &gt;然后获取将从当前抓取的网页中攀爬的URL,具有一定的规则。
当然,上述思想基于爬行过程。没有必要模拟登录,网站非常友好,而不是做一些“反攀爬”的工作,然而,在现实中,仿真登录有时非常重要(如新浪微博);没有反攀爬网站也少,当频繁访问时,可能是冻结的帐户,密封IP,返回“系统繁忙”“请慢慢访问”和其他信息。因此,有必要加强爬行动物来增强爬行动物:增加转世信息的处理,动态切换帐户/ IP,访问时间延迟等。
编程
由于模拟登录模块的复杂性,并且不同网站实现的机制不相同,这里只给出一个原理图,其中主要分析不需要登录的爬行动物。
工作者:每个工人都是一个爬网线程,由主线程蜘蛛网创建
登录:爬网程序模拟登录模块,您可以设置帐户队列。帐户冻结后,将其放入队列的末尾并从头开始新帐户。再次登录。队列的长度是必需的,gt; =帐户冻结时间/每个帐户可以支持连续攀爬时间
获取器:爬行动物模拟浏览器发出Get URL请求,下载页
处理程序:在获取器下载的页面上的初步处理,如果确定页面的返回状态代码是否正确,页面内容是反升温器等,以便为解析器付费的页面是正确
解析器:通过fetcher下载的页面内容的分辨率,获取目标数据
store:将解析器解析的目标数据放入本地存储,这可以是MySQL传统数据库或Redis等.KV存储
抓取队列:URL
需要放置
钳位:URL
已被捕获
程序流程图
以下是爬行动物实现的流程图。图中的绿色框位于同一模块中,模块名称由红色字符表示。
代码实现
将于明天开始上学,加上实验室的任务,没有时间写作,写一个比较水,蚀地点,可能意识到上面的流程图,许多地方都需要根据具体攀爬,真诚地实现方案来实现笔记,真诚的希望包装美丽的观点。
丑陋的妻子即将到来。点我很丑&gt; _ 查看全部
java爬虫抓取动态网页(HTML解析:Jsoup基本思路(组图)线程(图))
html分析:jsoup
基本思想
网络爬行动物的基本思想是爬网线程从URL队列中获取URL - &gt;模拟浏览器对目标URL的请求 - &gt;下载Web内容返回 - &gt;然后在页面上,请将目标数据获取到相应的存储 - &gt;然后获取将从当前抓取的网页中攀爬的URL,具有一定的规则。
当然,上述思想基于爬行过程。没有必要模拟登录,网站非常友好,而不是做一些“反攀爬”的工作,然而,在现实中,仿真登录有时非常重要(如新浪微博);没有反攀爬网站也少,当频繁访问时,可能是冻结的帐户,密封IP,返回“系统繁忙”“请慢慢访问”和其他信息。因此,有必要加强爬行动物来增强爬行动物:增加转世信息的处理,动态切换帐户/ IP,访问时间延迟等。
编程
由于模拟登录模块的复杂性,并且不同网站实现的机制不相同,这里只给出一个原理图,其中主要分析不需要登录的爬行动物。

工作者:每个工人都是一个爬网线程,由主线程蜘蛛网创建
登录:爬网程序模拟登录模块,您可以设置帐户队列。帐户冻结后,将其放入队列的末尾并从头开始新帐户。再次登录。队列的长度是必需的,gt; =帐户冻结时间/每个帐户可以支持连续攀爬时间
获取器:爬行动物模拟浏览器发出Get URL请求,下载页
处理程序:在获取器下载的页面上的初步处理,如果确定页面的返回状态代码是否正确,页面内容是反升温器等,以便为解析器付费的页面是正确
解析器:通过fetcher下载的页面内容的分辨率,获取目标数据
store:将解析器解析的目标数据放入本地存储,这可以是MySQL传统数据库或Redis等.KV存储
抓取队列:URL
需要放置
钳位:URL
已被捕获
程序流程图
以下是爬行动物实现的流程图。图中的绿色框位于同一模块中,模块名称由红色字符表示。

代码实现
将于明天开始上学,加上实验室的任务,没有时间写作,写一个比较水,蚀地点,可能意识到上面的流程图,许多地方都需要根据具体攀爬,真诚地实现方案来实现笔记,真诚的希望包装美丽的观点。
丑陋的妻子即将到来。点我很丑&gt; _
java爬虫抓取动态网页(高效学习Python爬虫技术的步骤及步骤技术介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-23 02:08
↑↑↑↑↑如何有效地学习Python爬行动物技术?大多数Python爬行动物被“发送请求 - 获取页面 - 分辨率页面 - 提取并保存内容”进程抓住,并模拟人们使用浏览器获取网页信息。
Python爬行动物技术的高效学习:
1、学位网上爬行动物基本知识
了解Python网络爬行动物,当您了解Python基本知识,变量,字符串,列表,词典,元组,手持句,语法等,这些都是PRUNIFIZE的,以及在做例时可以使用什么知识点。此外,还需要了解某些网络请求的基本原理,Web结构等。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
2、看tthon网络爬行动物视频教程学习
查看视频或找到专业网络爬行动物的书“用python写网络”,按照视频来学习爬行动物代码,敲门代码,了解每行代码进行个人练习,并学会学习快的。很多人都有误解,我觉得我不愿意采取行动,理解和学习是两个概念。当我真的这样做时,它是一种测试知识的有效方法。如果你有很多漏洞,你必须坚持经常点击代码。
开发建议Python3,2020 Python2被暂停,Python3是主流。 IDE选择Pycharm,Sublime或Jupyter等,小编建议使用Pychram,一些类似的Java的Eclipse非常聪明。浏览器学习使用Chrome或Firefox浏览器来检查元素,学会使用捕获。了解干流的爬行动物和库,例如URLLIB,请求,RE,BS 4、 XPath,JSON等,需要常用的爬行动物结构SCRAPY。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
3、用于实际练习
有一个爬行动物的想法,独立地设计爬行动物系统,找到一些网站钻。静态Web和动态网页抓取策略和方法需求,了解JS加载的网页,了解Selenium + PhantomJS模拟浏览器的方式,知道如何处理JSON模式。 Web Post请求,通过数据参数,并且此网页通常是动态加载的,并且需要掌握该方法。如果要提高爬行动物的电源,则必须考虑使用多线程,多流程解决方案或分布式操作。
4、学习数据库基本响应大规模数据存储
爬回的数据量,并且文档可以以文档的形式存储,数据量不可用。因此,您必须掌握数据库并学习当前主流MongoDB。方便地存储一些非结构化数据,数据库知识非常简单,主要是数据存储,提取,并在需要时学习。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
Python应用方向,可以在背景,web开发,科学计算等中,爬行动物可以为初学者实现基础爬行动物,简单,简单,简单,更好的学习经验。 查看全部
java爬虫抓取动态网页(高效学习Python爬虫技术的步骤及步骤技术介绍)
↑↑↑↑↑如何有效地学习Python爬行动物技术?大多数Python爬行动物被“发送请求 - 获取页面 - 分辨率页面 - 提取并保存内容”进程抓住,并模拟人们使用浏览器获取网页信息。
Python爬行动物技术的高效学习:
1、学位网上爬行动物基本知识
了解Python网络爬行动物,当您了解Python基本知识,变量,字符串,列表,词典,元组,手持句,语法等,这些都是PRUNIFIZE的,以及在做例时可以使用什么知识点。此外,还需要了解某些网络请求的基本原理,Web结构等。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
2、看tthon网络爬行动物视频教程学习
查看视频或找到专业网络爬行动物的书“用python写网络”,按照视频来学习爬行动物代码,敲门代码,了解每行代码进行个人练习,并学会学习快的。很多人都有误解,我觉得我不愿意采取行动,理解和学习是两个概念。当我真的这样做时,它是一种测试知识的有效方法。如果你有很多漏洞,你必须坚持经常点击代码。
开发建议Python3,2020 Python2被暂停,Python3是主流。 IDE选择Pycharm,Sublime或Jupyter等,小编建议使用Pychram,一些类似的Java的Eclipse非常聪明。浏览器学习使用Chrome或Firefox浏览器来检查元素,学会使用捕获。了解干流的爬行动物和库,例如URLLIB,请求,RE,BS 4、 XPath,JSON等,需要常用的爬行动物结构SCRAPY。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
3、用于实际练习
有一个爬行动物的想法,独立地设计爬行动物系统,找到一些网站钻。静态Web和动态网页抓取策略和方法需求,了解JS加载的网页,了解Selenium + PhantomJS模拟浏览器的方式,知道如何处理JSON模式。 Web Post请求,通过数据参数,并且此网页通常是动态加载的,并且需要掌握该方法。如果要提高爬行动物的电源,则必须考虑使用多线程,多流程解决方案或分布式操作。
4、学习数据库基本响应大规模数据存储
爬回的数据量,并且文档可以以文档的形式存储,数据量不可用。因此,您必须掌握数据库并学习当前主流MongoDB。方便地存储一些非结构化数据,数据库知识非常简单,主要是数据存储,提取,并在需要时学习。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
Python应用方向,可以在背景,web开发,科学计算等中,爬行动物可以为初学者实现基础爬行动物,简单,简单,简单,更好的学习经验。
java爬虫抓取动态网页(你知道Python爬虫是什么吗?用python语言写爬虫的缘由)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-22 10:22
1、你知道什么是python爬虫吗
在进入文章之前,我们首先需要知道爬行动物是什么。爬虫是一种网络爬虫。你可以把它理解为在互联网上爬行的蜘蛛。互联网就像一张大网,而爬行器就是一只在这张网上爬行的蜘蛛。如果它遇到自己的猎物(所需资源),它会抓住它。例如,它正在抓取网页。在这个网络中,他发现了一条路,这条路实际上是网页的超链接,因此它可以爬到另一个网页获取数据。html
由于Python的脚本特性,Python易于配置,并且字符处理灵活。此外,python具有丰富的网络捕获模块,因此这两个模块经常链接在一起。Python爬虫开发工程师从网站a页面(通常是主页)开始,阅读页面内容,在页面中找到其他连接地址,然后通过这些连接地址找到下一页。此循环将继续,直到捕获网站的所有页面。如果整个互联网被视为一个网站,那么网络蜘蛛就可以利用这一原理抓取互联网上的所有网页。爪哇
爬虫可以抓取网站或应用程序的内容并提取有用的价值。它还可以模拟用户在浏览器或应用程序上的操作,以实现自动程序。蟒蛇
爬虫通常是指对网络资源的爬虫。由于Python的脚本特性,它不仅易于配置,而且字符处理灵活,并且Python有丰富的网络爬虫模块,两者经常联系在一起。这就是Python被称为爬虫的原因。编程器
2、用Python1.编写爬虫程序的优点是什么2、简洁、清晰、高效
作为一种编程语言,Python是纯自由软件。它因其简洁明了的语法和强制使用空格进行句子缩进而深受程序员的喜爱。壳
用不同的编程语言完成一项任务:C语言需要编写1000行代码;Java需要写100行;Python只需要编写20行代码。如果使用Python来完成编程任务,那么编写的代码量就会减少,代码简洁易读,并且团队在开发时会更高效地编写代码。高开发效率使工作更高效
程序设计
2.grab网页自己的界面
与其他静态编程语言如Java、c#、c++、python相比,捕获web文档的界面更加简洁;与其他动态脚本语言(如Perl和shell)相比,Python的urlib2包为访问web文档提供了更完整的API
此外,爬行网页有时需要模拟浏览器的行为,许多用于刚性爬行器爬行的网站被阻止。我们需要模拟用户代理的行为来构造适当的请求,例如模拟用户登录和模拟会话/cookie的存储和设置。在Python中,有一些优秀的第三方软件包可以帮助您,例如requests和mechanizejson
3.web页面捕获处理
捕获的网页通常需要进行处理,例如过滤HTML标记、提取文本等。Python漂亮的soap提供了一个简洁的文档处理功能,可以用很短的代码完成大多数文档的处理。事实上,许多语言和工具都可以实现上述功能,但Python可以以最快、最干净的速度实现这些功能。c#
Python crawler的体系结构包括:
浏览者
爬虫架构:cookies
一、URL管理器:管理要爬网的URL集和爬网的URL集,并将要爬网的URL传输到网页下载器
2.. 网页下载器:抓取与URL对应的网页,将其存储为字符串,并将其发送给网页解析器
三、web页面解析器:解析有价值的数据,存储它,并将URL添加到URL管理器
Python的工作流程如下所示:
python爬虫程序通过URL管理器来确定是否对URL进行爬虫。如果要对URL进行爬网,则通过调度程序将其传输到下载程序,下载URL内容,并通过调度程序将其传输到解析器,解析URL内容,通过调度程序将值数据和新URL列表传递给应用程序,并输出值信息
Python是一种非常适合开发web爬虫的编程语言。它提供了urlib、re、JSON、pyquery等模块,同时也有很多形成的框架,如scripy框架、pyspider爬虫系统等,代码非常简洁方便。它是初学者学习网络爬虫的首选编程语言。爬虫是指捕获网络资源。由于python的脚本特性,python易于配置,并且字符处理灵活。此外,python具有丰富的网络捕获模块,因此这两个模块经常链接在一起。Python语言更适合初学者学习
Python回答。遇到问题时不要惊慌。过来~
基本学习资料,数据分析,爬虫和其他视频,来这里~
互相关爱、互相帮助的技术交流,Q组:943192807,过来~ 查看全部
java爬虫抓取动态网页(你知道Python爬虫是什么吗?用python语言写爬虫的缘由)
1、你知道什么是python爬虫吗
在进入文章之前,我们首先需要知道爬行动物是什么。爬虫是一种网络爬虫。你可以把它理解为在互联网上爬行的蜘蛛。互联网就像一张大网,而爬行器就是一只在这张网上爬行的蜘蛛。如果它遇到自己的猎物(所需资源),它会抓住它。例如,它正在抓取网页。在这个网络中,他发现了一条路,这条路实际上是网页的超链接,因此它可以爬到另一个网页获取数据。html

由于Python的脚本特性,Python易于配置,并且字符处理灵活。此外,python具有丰富的网络捕获模块,因此这两个模块经常链接在一起。Python爬虫开发工程师从网站a页面(通常是主页)开始,阅读页面内容,在页面中找到其他连接地址,然后通过这些连接地址找到下一页。此循环将继续,直到捕获网站的所有页面。如果整个互联网被视为一个网站,那么网络蜘蛛就可以利用这一原理抓取互联网上的所有网页。爪哇

爬虫可以抓取网站或应用程序的内容并提取有用的价值。它还可以模拟用户在浏览器或应用程序上的操作,以实现自动程序。蟒蛇
爬虫通常是指对网络资源的爬虫。由于Python的脚本特性,它不仅易于配置,而且字符处理灵活,并且Python有丰富的网络爬虫模块,两者经常联系在一起。这就是Python被称为爬虫的原因。编程器
2、用Python1.编写爬虫程序的优点是什么2、简洁、清晰、高效
作为一种编程语言,Python是纯自由软件。它因其简洁明了的语法和强制使用空格进行句子缩进而深受程序员的喜爱。壳
用不同的编程语言完成一项任务:C语言需要编写1000行代码;Java需要写100行;Python只需要编写20行代码。如果使用Python来完成编程任务,那么编写的代码量就会减少,代码简洁易读,并且团队在开发时会更高效地编写代码。高开发效率使工作更高效

程序设计
2.grab网页自己的界面
与其他静态编程语言如Java、c#、c++、python相比,捕获web文档的界面更加简洁;与其他动态脚本语言(如Perl和shell)相比,Python的urlib2包为访问web文档提供了更完整的API
此外,爬行网页有时需要模拟浏览器的行为,许多用于刚性爬行器爬行的网站被阻止。我们需要模拟用户代理的行为来构造适当的请求,例如模拟用户登录和模拟会话/cookie的存储和设置。在Python中,有一些优秀的第三方软件包可以帮助您,例如requests和mechanizejson
3.web页面捕获处理
捕获的网页通常需要进行处理,例如过滤HTML标记、提取文本等。Python漂亮的soap提供了一个简洁的文档处理功能,可以用很短的代码完成大多数文档的处理。事实上,许多语言和工具都可以实现上述功能,但Python可以以最快、最干净的速度实现这些功能。c#
Python crawler的体系结构包括:

浏览者
爬虫架构:cookies
一、URL管理器:管理要爬网的URL集和爬网的URL集,并将要爬网的URL传输到网页下载器
2.. 网页下载器:抓取与URL对应的网页,将其存储为字符串,并将其发送给网页解析器
三、web页面解析器:解析有价值的数据,存储它,并将URL添加到URL管理器
Python的工作流程如下所示:

python爬虫程序通过URL管理器来确定是否对URL进行爬虫。如果要对URL进行爬网,则通过调度程序将其传输到下载程序,下载URL内容,并通过调度程序将其传输到解析器,解析URL内容,通过调度程序将值数据和新URL列表传递给应用程序,并输出值信息
Python是一种非常适合开发web爬虫的编程语言。它提供了urlib、re、JSON、pyquery等模块,同时也有很多形成的框架,如scripy框架、pyspider爬虫系统等,代码非常简洁方便。它是初学者学习网络爬虫的首选编程语言。爬虫是指捕获网络资源。由于python的脚本特性,python易于配置,并且字符处理灵活。此外,python具有丰富的网络捕获模块,因此这两个模块经常链接在一起。Python语言更适合初学者学习
Python回答。遇到问题时不要惊慌。过来~
基本学习资料,数据分析,爬虫和其他视频,来这里~
互相关爱、互相帮助的技术交流,Q组:943192807,过来~
java爬虫抓取动态网页(Python3数据分析与机器学习实战(Python爬虫分析汇总))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-22 10:17
使用urllib模块,该模块提供了一个用于读取网页数据的接口,可以像读取本地文件一样读取WWW和FTP上的数据。Urllib是一个URL处理包,它采集一些用于处理URL的模块
Urllib。请求模块:用于打开和读取URL。Urllib。错误模块:收录由urllib生成的一些错误。请求,可通过try捕获和处理。Urllib。解析模块:收录一些解析URL的方法。Urllib.robot解析器:用于解析robots.txt文本文件。它通过该类提供的can提供一个单独的robotfileparser类。fetch()方法测试爬虫是否可以下载页面
以下代码是获取网页的代码:
import urllib.request
url = "https://www.douban.com/"
# 这边需要模拟浏览器才能进行抓取
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
data = response.read()
# 这边需要转码才能正常显示
print(str(data, 'utf-8'))
# 下面代码可以打印抓取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
2、grab收录关键词网页
代码如下:
import urllib.request
data = {'word': '海贼王'}
url_values = urllib.parse.urlencode(data)
url = "http://www.baidu.com/s?"
full_url = url + url_values
data = urllib.request.urlopen(full_url).read()
print(str(data, 'utf-8'))
3、下载贴吧中的图片@
代码如下:
import re
import urllib.request
# 获取网页源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
# 获取网页所有图片
def getImg(html):
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
return imglist
html = getHtml('https://tieba.baidu.com/p/3205263090')
html = html.decode('utf-8')
imgList = getImg(html)
imgName = 0
# 循环保存图片
for imgPath in imgList:
f = open(str(imgName) + ".jpg", 'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgName += 1
print('正在下载第 %s 张图片 ' % imgName)
print('该网站图片已经下载完')
4、stock数据捕获
代码如下:
<p>
import random
import re
import time
import urllib.request
# 抓取所需内容
user_agent = ["Mozilla/5.0 (Windows NT 10.0; WOW64)", 'Mozilla/5.0 (Windows NT 6.3; WOW64)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11']
stock_total = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
for page in range(1, 8):
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_' + str(page) + '.html'
request = urllib.request.Request(url=url, headers={"User-Agent": random.choice(user_agent)})
response = urllib.request.urlopen(request)
content = str(response.read(), 'gbk')
pattern = re.compile(' 查看全部
java爬虫抓取动态网页(Python3数据分析与机器学习实战(Python爬虫分析汇总))
使用urllib模块,该模块提供了一个用于读取网页数据的接口,可以像读取本地文件一样读取WWW和FTP上的数据。Urllib是一个URL处理包,它采集一些用于处理URL的模块
Urllib。请求模块:用于打开和读取URL。Urllib。错误模块:收录由urllib生成的一些错误。请求,可通过try捕获和处理。Urllib。解析模块:收录一些解析URL的方法。Urllib.robot解析器:用于解析robots.txt文本文件。它通过该类提供的can提供一个单独的robotfileparser类。fetch()方法测试爬虫是否可以下载页面
以下代码是获取网页的代码:
import urllib.request
url = "https://www.douban.com/"
# 这边需要模拟浏览器才能进行抓取
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
data = response.read()
# 这边需要转码才能正常显示
print(str(data, 'utf-8'))
# 下面代码可以打印抓取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
2、grab收录关键词网页
代码如下:
import urllib.request
data = {'word': '海贼王'}
url_values = urllib.parse.urlencode(data)
url = "http://www.baidu.com/s?"
full_url = url + url_values
data = urllib.request.urlopen(full_url).read()
print(str(data, 'utf-8'))
3、下载贴吧中的图片@
代码如下:
import re
import urllib.request
# 获取网页源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
# 获取网页所有图片
def getImg(html):
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
return imglist
html = getHtml('https://tieba.baidu.com/p/3205263090')
html = html.decode('utf-8')
imgList = getImg(html)
imgName = 0
# 循环保存图片
for imgPath in imgList:
f = open(str(imgName) + ".jpg", 'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgName += 1
print('正在下载第 %s 张图片 ' % imgName)
print('该网站图片已经下载完')
4、stock数据捕获
代码如下:
<p>
import random
import re
import time
import urllib.request
# 抓取所需内容
user_agent = ["Mozilla/5.0 (Windows NT 10.0; WOW64)", 'Mozilla/5.0 (Windows NT 6.3; WOW64)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11']
stock_total = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
for page in range(1, 8):
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_' + str(page) + '.html'
request = urllib.request.Request(url=url, headers={"User-Agent": random.choice(user_agent)})
response = urllib.request.urlopen(request)
content = str(response.read(), 'gbk')
pattern = re.compile('
java爬虫抓取动态网页(GitHub上有哪些优秀的Java爬虫项目?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-21 23:20
)
本文文章来自我的回答:GitHub上有哪些优秀的Java爬虫项目?但是,已经对该答案进行了一些修改,并添加了一些项目。这些项目来自GitHub和开源中国。我希望这些开源Java爬虫项目将对您有所帮助。阅读源代码可以帮助您获得质量上的改进
1、Gecco
GitHub地址:xtuhcy/GECCO
GECCO是一个用Java语言开发的轻量级且易于使用的web爬虫程序。它集成了jsoup、httpclient、fastjson、spring、htmlunit、再分配和其他框架。通过配置一些jQuery样式选择器,可以快速编写爬虫程序。GECCO框架具有良好的可扩展性。框架根据开闭原理设计,关闭修改,打开扩展
2、WebCollector
GitHub地址:crawlscript/webcollector
Webcollector是一个Java爬虫框架(内核),不需要配置,便于二次开发。它提供了一个简化的API,只需少量代码即可实现强大的爬虫程序。Webcollector Hadoop是Webcollector的Hadoop版本,支持分布式爬网
3、Spiderman
代码云地址:l-weiwei/spiderman2-代码云-开源中国
用例:演示垂直爬虫的能力-随风自由移动
蜘蛛侠是一种基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法捕获复杂的目标网页信息并将其解析为业务数据
4、WebMagic
代码云地址:flashsword20/webmagic-代码云-开源中国
Webmagic是一个无配置的爬虫框架,便于二次开发。它提供了一个简单灵活的API,只需少量代码即可实现爬虫程序。Webmagic采用全模块化设计,覆盖爬虫的整个生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬虫、分布式爬虫、自动重试、自定义UA/cookie等功能
5、Heritrix
GitHub地址:Internet Archive/heritrix 3 heritrix是一个开源和可扩展的web爬虫程序项目。用户可以使用它从互联网上获取所需的资源。Heritrix的设计严格遵循robots.txt文件和meta robots标签的排除说明。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
6、crawler4j
GitHub地址:yasserg/crawler4j·githubcrawler4j是一个用Java实现的开源web爬虫程序。提供一个易于使用的界面,以便在几分钟内创建多线程web爬虫程序
7、Nutch
GitHub地址:Apache/nutch
Nutch是一个用Java实现的开源搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫
在nutch的发展过程中,出现了四个Java开源项目,Hadoop、Tika、Gora和crawler commons。如今,这四个项目发展迅速,非常流行,尤其是Hadoop,它已经成为大规模数据处理的事实标准。Tika使用各种现有的开源内容解析项目从各种格式的文件中提取元数据和结构化文本。Gora支持将大数据持久化到各种存储实现中。Crawler Commons是一个通用的web爬虫组件
8、SeimiCrawler
GitHub地址:哲格晓霍兹/赛米克罗勒
Seimicrawler是一个灵活、独立部署和分布式Java爬虫框架。希望最大限度地降低新手开发高可用性、高性能爬虫系统的门槛,提高爬虫系统的开发效率。在seimi crawler的世界中,大多数人只需要关心编写捕获的业务逻辑,其余的seimi将帮助您。在设计理念上,seimicrawler受到Python的crawler框架scripy的启发,融合了Java语言和spring的特点,希望在中国使用更方便高效的XPath解析HTML。因此,seimicrawler的默认HTML解析器是JSOUPPATH(独立扩展项目,不是jsoup提供的),默认情况下,解析和提取HTML数据是使用XPath完成的(当然,数据处理也可以选择其他解析器)。它与seimiagent相结合,全面、完美地解决了复杂动态页面的渲染和抓取问题
9、Jsoup
GitHub地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
查看全部
java爬虫抓取动态网页(GitHub上有哪些优秀的Java爬虫项目?(一)
)
本文文章来自我的回答:GitHub上有哪些优秀的Java爬虫项目?但是,已经对该答案进行了一些修改,并添加了一些项目。这些项目来自GitHub和开源中国。我希望这些开源Java爬虫项目将对您有所帮助。阅读源代码可以帮助您获得质量上的改进
1、Gecco
GitHub地址:xtuhcy/GECCO
GECCO是一个用Java语言开发的轻量级且易于使用的web爬虫程序。它集成了jsoup、httpclient、fastjson、spring、htmlunit、再分配和其他框架。通过配置一些jQuery样式选择器,可以快速编写爬虫程序。GECCO框架具有良好的可扩展性。框架根据开闭原理设计,关闭修改,打开扩展
2、WebCollector
GitHub地址:crawlscript/webcollector
Webcollector是一个Java爬虫框架(内核),不需要配置,便于二次开发。它提供了一个简化的API,只需少量代码即可实现强大的爬虫程序。Webcollector Hadoop是Webcollector的Hadoop版本,支持分布式爬网
3、Spiderman
代码云地址:l-weiwei/spiderman2-代码云-开源中国
用例:演示垂直爬虫的能力-随风自由移动
蜘蛛侠是一种基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法捕获复杂的目标网页信息并将其解析为业务数据
4、WebMagic
代码云地址:flashsword20/webmagic-代码云-开源中国
Webmagic是一个无配置的爬虫框架,便于二次开发。它提供了一个简单灵活的API,只需少量代码即可实现爬虫程序。Webmagic采用全模块化设计,覆盖爬虫的整个生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬虫、分布式爬虫、自动重试、自定义UA/cookie等功能
5、Heritrix
GitHub地址:Internet Archive/heritrix 3 heritrix是一个开源和可扩展的web爬虫程序项目。用户可以使用它从互联网上获取所需的资源。Heritrix的设计严格遵循robots.txt文件和meta robots标签的排除说明。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
6、crawler4j
GitHub地址:yasserg/crawler4j·githubcrawler4j是一个用Java实现的开源web爬虫程序。提供一个易于使用的界面,以便在几分钟内创建多线程web爬虫程序
7、Nutch
GitHub地址:Apache/nutch
Nutch是一个用Java实现的开源搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫
在nutch的发展过程中,出现了四个Java开源项目,Hadoop、Tika、Gora和crawler commons。如今,这四个项目发展迅速,非常流行,尤其是Hadoop,它已经成为大规模数据处理的事实标准。Tika使用各种现有的开源内容解析项目从各种格式的文件中提取元数据和结构化文本。Gora支持将大数据持久化到各种存储实现中。Crawler Commons是一个通用的web爬虫组件
8、SeimiCrawler
GitHub地址:哲格晓霍兹/赛米克罗勒
Seimicrawler是一个灵活、独立部署和分布式Java爬虫框架。希望最大限度地降低新手开发高可用性、高性能爬虫系统的门槛,提高爬虫系统的开发效率。在seimi crawler的世界中,大多数人只需要关心编写捕获的业务逻辑,其余的seimi将帮助您。在设计理念上,seimicrawler受到Python的crawler框架scripy的启发,融合了Java语言和spring的特点,希望在中国使用更方便高效的XPath解析HTML。因此,seimicrawler的默认HTML解析器是JSOUPPATH(独立扩展项目,不是jsoup提供的),默认情况下,解析和提取HTML数据是使用XPath完成的(当然,数据处理也可以选择其他解析器)。它与seimiagent相结合,全面、完美地解决了复杂动态页面的渲染和抓取问题
9、Jsoup
GitHub地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据

java爬虫抓取动态网页(动态页面和Ajax渲染页面数据基础的基本流程介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-21 23:16
)
内容简介
本文介绍了动态页面和Ajax呈现页面数据的示例,以及相应的页面分析过程,您会发现我认为复杂的Web攀登实际上比那些非动态网页更简单。
虽然Python数据分析师没有敲门代码不是一个好的数据分析师,但你不是郑的开发人员,什么是使用代码敲门?学习点数据爬行动物基础可以使繁琐的数据CV工作(Ctrl + C,Ctrl + V)是肤浅的。
ajax划痕示例
现在越来越多的网页的原创HTML文档不包括任何数据,而是用Ajax均匀加载。发送Ajax请求道路更新过程:
打开浏览器的开发人员工具,转到NetworkK选项卡,使用XHR过滤工具。您需要建立一个相应的文件夹以修改此配置并根据相应的All_Config_File.py文件打开相关服务。
all_config_file.py
#coding=utf-8
__author__ = 'Mr数据杨'
__explain__ = '各目标网站爬虫脚本配置文件'
#加载引用模块
import time
import pymongo
import pandas as pd
def news_page_num():
page_num=input("输入每个网站页面爬取的页面数:")
return int(page_num)
def title_error_num():
title_error_num=input("输入错误标题爬取最大数:")
return int(title_error_num)
def body_error_num():
body_error_num=input("输入错误页面爬取最大数:")
return int(body_error_num)
def mongodb_client():
# 获取mongoClient对象
client = pymongo.MongoClient("localhost", 27017)
# 获取使用的database对象
db = client.news
print("加载MongoDB数据库完毕......")
return db
db=mongodb_client()
def time_today():
# 全局函数
time_today = time.strftime('%Y-%m-%d', time.localtime(time.time()))
print("加载全局日期函数完毕......")
return time_today
# 错误日志信息
def error_text_title(text,time_today):
print("加载错误信息日志完毕......")
with open("logs/" + time_today + " news_title_error.txt", "a") as f:
f.write(text + '\n')
# 错误日志信息
def error_text_body(text,time_today):
with open("logs/" + time_today + " news_body_error.txt", "a") as f:
f.write(text + '\n')
# 找到每个爬取网页的链接
def get_title_links_from_MongoDB(label, type):
result = []
for item in db.news_tmp.find({'label': label, 'type': type}, {'url': 1, '_id': 1}):
result.append(item)
result = pd.DataFrame(result, columns=['url', '_id'])
return result
主程序
<p>#加载引用模块
import urllib
import urllib.request
import requests
import datetime
from bs4 import BeautifulSoup
import all_config_file
from all_config_file import error_text_title
from all_config_file import error_text_body
from all_config_file import get_title_links_from_MongoDB
cqcoal = "http://news.cqcoal.com/manage/ ... ot%3B
print("加载目标网址完毕......")
db = all_config_file.mongodb_client()
time_today = all_config_file.time_today()
def cqcoal_title_start(num):
def start_type(url, label, typeid, pagenum, type):
try:
page_num = 1
while page_num 查看全部
java爬虫抓取动态网页(动态页面和Ajax渲染页面数据基础的基本流程介绍
)
内容简介
本文介绍了动态页面和Ajax呈现页面数据的示例,以及相应的页面分析过程,您会发现我认为复杂的Web攀登实际上比那些非动态网页更简单。
虽然Python数据分析师没有敲门代码不是一个好的数据分析师,但你不是郑的开发人员,什么是使用代码敲门?学习点数据爬行动物基础可以使繁琐的数据CV工作(Ctrl + C,Ctrl + V)是肤浅的。
ajax划痕示例
现在越来越多的网页的原创HTML文档不包括任何数据,而是用Ajax均匀加载。发送Ajax请求道路更新过程:
打开浏览器的开发人员工具,转到NetworkK选项卡,使用XHR过滤工具。您需要建立一个相应的文件夹以修改此配置并根据相应的All_Config_File.py文件打开相关服务。
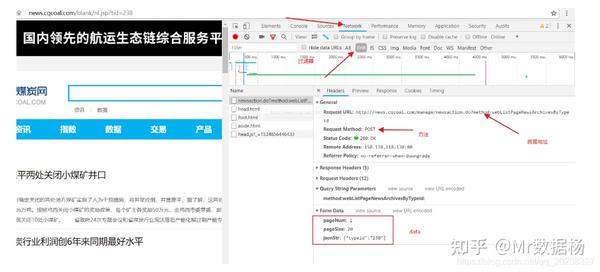
all_config_file.py
#coding=utf-8
__author__ = 'Mr数据杨'
__explain__ = '各目标网站爬虫脚本配置文件'
#加载引用模块
import time
import pymongo
import pandas as pd
def news_page_num():
page_num=input("输入每个网站页面爬取的页面数:")
return int(page_num)
def title_error_num():
title_error_num=input("输入错误标题爬取最大数:")
return int(title_error_num)
def body_error_num():
body_error_num=input("输入错误页面爬取最大数:")
return int(body_error_num)
def mongodb_client():
# 获取mongoClient对象
client = pymongo.MongoClient("localhost", 27017)
# 获取使用的database对象
db = client.news
print("加载MongoDB数据库完毕......")
return db
db=mongodb_client()
def time_today():
# 全局函数
time_today = time.strftime('%Y-%m-%d', time.localtime(time.time()))
print("加载全局日期函数完毕......")
return time_today
# 错误日志信息
def error_text_title(text,time_today):
print("加载错误信息日志完毕......")
with open("logs/" + time_today + " news_title_error.txt", "a") as f:
f.write(text + '\n')
# 错误日志信息
def error_text_body(text,time_today):
with open("logs/" + time_today + " news_body_error.txt", "a") as f:
f.write(text + '\n')
# 找到每个爬取网页的链接
def get_title_links_from_MongoDB(label, type):
result = []
for item in db.news_tmp.find({'label': label, 'type': type}, {'url': 1, '_id': 1}):
result.append(item)
result = pd.DataFrame(result, columns=['url', '_id'])
return result
主程序
<p>#加载引用模块
import urllib
import urllib.request
import requests
import datetime
from bs4 import BeautifulSoup
import all_config_file
from all_config_file import error_text_title
from all_config_file import error_text_body
from all_config_file import get_title_links_from_MongoDB
cqcoal = "http://news.cqcoal.com/manage/ ... ot%3B
print("加载目标网址完毕......")
db = all_config_file.mongodb_client()
time_today = all_config_file.time_today()
def cqcoal_title_start(num):
def start_type(url, label, typeid, pagenum, type):
try:
page_num = 1
while page_num
java爬虫抓取动态网页(目标网络爬虫的是做什么的?手动写一个简单的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-21 23:15
目标网络爬虫做什么?手动编写一个简单的网络爬虫1.webcrawler1.1.name1.2.short description@2.process
通过上面的流程图,我们可以大致了解网络爬虫的功能,并根据这些功能设计一个简单的网络爬虫
简单爬虫程序所需的功能:
发送请求和获取响应的功能;解析响应的功能;存储过滤后的数据的功能;处理解析后的URL路径@2.1.的函数涉及
3.分类
4.思维分析
首先,观察爬虫的起始页:
所有好消息信息的URL都用XPath表达式表示,即//div[@class='main_l']/UL/Li
相关数据
我们已经在上面的代码中找到了需要获得的关键信息的XPath表达式,然后我们可以正式编写代码来实现它
5.代码实现
代码实现部分采用webmagic框架,因为它比使用基本Java网络编程简单得多。注意:您可以看到以下关于webmagic框架的讲义
5.1.代码结构
5.@2.程序条目
Demo.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/")
// 启用的线程数
.thread(5).run();
}
}
5.3.爬行过程
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i 查看全部
java爬虫抓取动态网页(目标网络爬虫的是做什么的?手动写一个简单的)
目标网络爬虫做什么?手动编写一个简单的网络爬虫1.webcrawler1.1.name1.2.short description@2.process
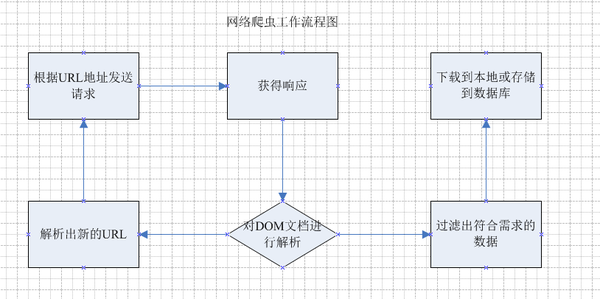
通过上面的流程图,我们可以大致了解网络爬虫的功能,并根据这些功能设计一个简单的网络爬虫
简单爬虫程序所需的功能:
发送请求和获取响应的功能;解析响应的功能;存储过滤后的数据的功能;处理解析后的URL路径@2.1.的函数涉及
3.分类
4.思维分析
首先,观察爬虫的起始页:
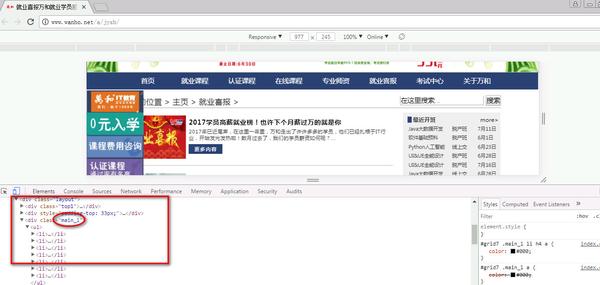
所有好消息信息的URL都用XPath表达式表示,即//div[@class='main_l']/UL/Li

相关数据
我们已经在上面的代码中找到了需要获得的关键信息的XPath表达式,然后我们可以正式编写代码来实现它
5.代码实现
代码实现部分采用webmagic框架,因为它比使用基本Java网络编程简单得多。注意:您可以看到以下关于webmagic框架的讲义
5.1.代码结构
5.@2.程序条目
Demo.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/";)
// 启用的线程数
.thread(5).run();
}
}
5.3.爬行过程
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i
java爬虫抓取动态网页(java中好用的爬虫框架java爬虫系列包含哪些内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-21 23:13
1.overview Java爬虫系列收录哪些内容?Java爬虫框架简介webmgic使用webmgic抓取爱情电影中的电影资源(动作电影列表页面、电影下载地址等)使用webmgic抓取极客时代的课程资源(文章系列课程和视频系列课程)
本文的文章主要内容是介绍Java中易于使用的爬虫框架。Java crawler框架webmatic介绍了webgic的使用,以抓取动作电影列表信息
2.如何判断爬虫框架在Java中是否优秀?它易于学习和使用。网络上有很多相应的学习资料,比较完善,被很多人使用。现有坑已由其他人填充。使用起来会更舒适。该框架将更快地更新,社区将更加活跃。您可以快速体验一些更好的功能,并与作者交流。该框架结构稳定,扩展方便
根据以上几点,我们推荐一个非常易于使用的Java爬虫框架webmgic
3.webmgic简介
4.使用webgic抓取动作电影列表
使用webgic抓取爱情电影列表的资源信息
示例源代码地址1.createanewspringboot项目javapachong
2.import-Maven配置
org.springframework.boot
spring-boot-starter
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
us.codecraft
webmagic-core
0.7.3
fastjson
com.alibaba
commons-io
commons-io
commons-io
commons-io
fastjson
com.alibaba
fastjson
com.alibaba
log4j
log4j
slf4j-log4j12
org.slf4j
us.codecraft
webmagic-extension
0.7.3
us.codecraft
webmagic-selenium
0.7.3
net.minidev
json-smart
2.2.1
com.alibaba
fastjson
1.2.49
commons-lang
commons-lang
2.6
commons-io
commons-io
2.6
commons-codec
commons-codec
1.11
commons-collections
commons-collections
3.2.2
3.编写代码以捕获电影数据
package com.ady01.demo1;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* description:第一个爬虫示例,爬去动作片列表信息
* <b>time:2019/4/20 10:58
* <b>author:ready likun_557@163.com
*/
@Slf4j
public class Ady01comPageProcessor implements PageProcessor {
@Override
public void process(Page page) {
log.info("爬取成功!");
log.info("爬取的内容:" + page.getRawText());
}
@Override
public Site getSite() {
return Site.me().setSleepTime(1000).setRetryTimes(3);
}
public static void main(String[] args) {
String url = "http://m.ady01.com/rs/film/lis ... 3B%3B
Spider.create(new Ady01comPageProcessor()).addUrl(url).thread(1).run();
}
}
4.runcrawler代码
在ady01compageprocessor中运行main方法,执行结果如下:
5.summary本文主要使用一个示例来说明webgic非常简单,可以完成数据捕获。从代码中可以看出,复杂的代码webmagic屏蔽了我们。我们只需要注意编写业务代码文章并没有详细说明如何使用webmagic。至于我为什么没有在文档中解释,主要是webigc提供了一个非常完美的学习文档。您可以转到webmagic的中文文档。如果您需要更深入的了解,可以学习webmagic的源代码,这对您编写爬虫程序非常有用。明天我们将抓取每一部动作片的详细页面信息,采集下载详细页面的页面地址代码,导入idea,idea需要Maven和Lombok支持,更多技术文章请注意官方账号:javacode2018 查看全部
java爬虫抓取动态网页(java中好用的爬虫框架java爬虫系列包含哪些内容?)
1.overview Java爬虫系列收录哪些内容?Java爬虫框架简介webmgic使用webmgic抓取爱情电影中的电影资源(动作电影列表页面、电影下载地址等)使用webmgic抓取极客时代的课程资源(文章系列课程和视频系列课程)
本文的文章主要内容是介绍Java中易于使用的爬虫框架。Java crawler框架webmatic介绍了webgic的使用,以抓取动作电影列表信息
2.如何判断爬虫框架在Java中是否优秀?它易于学习和使用。网络上有很多相应的学习资料,比较完善,被很多人使用。现有坑已由其他人填充。使用起来会更舒适。该框架将更快地更新,社区将更加活跃。您可以快速体验一些更好的功能,并与作者交流。该框架结构稳定,扩展方便
根据以上几点,我们推荐一个非常易于使用的Java爬虫框架webmgic
3.webmgic简介
4.使用webgic抓取动作电影列表
使用webgic抓取爱情电影列表的资源信息
示例源代码地址1.createanewspringboot项目javapachong
2.import-Maven配置
org.springframework.boot
spring-boot-starter
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
us.codecraft
webmagic-core
0.7.3
fastjson
com.alibaba
commons-io
commons-io
commons-io
commons-io
fastjson
com.alibaba
fastjson
com.alibaba
log4j
log4j
slf4j-log4j12
org.slf4j
us.codecraft
webmagic-extension
0.7.3
us.codecraft
webmagic-selenium
0.7.3
net.minidev
json-smart
2.2.1
com.alibaba
fastjson
1.2.49
commons-lang
commons-lang
2.6
commons-io
commons-io
2.6
commons-codec
commons-codec
1.11
commons-collections
commons-collections
3.2.2
3.编写代码以捕获电影数据
package com.ady01.demo1;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* description:第一个爬虫示例,爬去动作片列表信息
* <b>time:2019/4/20 10:58
* <b>author:ready likun_557@163.com
*/
@Slf4j
public class Ady01comPageProcessor implements PageProcessor {
@Override
public void process(Page page) {
log.info("爬取成功!");
log.info("爬取的内容:" + page.getRawText());
}
@Override
public Site getSite() {
return Site.me().setSleepTime(1000).setRetryTimes(3);
}
public static void main(String[] args) {
String url = "http://m.ady01.com/rs/film/lis ... 3B%3B
Spider.create(new Ady01comPageProcessor()).addUrl(url).thread(1).run();
}
}
4.runcrawler代码
在ady01compageprocessor中运行main方法,执行结果如下:
5.summary本文主要使用一个示例来说明webgic非常简单,可以完成数据捕获。从代码中可以看出,复杂的代码webmagic屏蔽了我们。我们只需要注意编写业务代码文章并没有详细说明如何使用webmagic。至于我为什么没有在文档中解释,主要是webigc提供了一个非常完美的学习文档。您可以转到webmagic的中文文档。如果您需要更深入的了解,可以学习webmagic的源代码,这对您编写爬虫程序非常有用。明天我们将抓取每一部动作片的详细页面信息,采集下载详细页面的页面地址代码,导入idea,idea需要Maven和Lombok支持,更多技术文章请注意官方账号:javacode2018
java爬虫抓取动态网页(做数据爬虫时如何实现动态网页的解析(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-03 06:30
人们在做数据爬虫的时候一般会遇到这些问题:
以上问题我们会在接下来的系列数据采集中一一解决,但是今天我们要解决的问题是如何实现动态网页的分析
随着AJAX技术的不断普及和各种JS框架的出现,现在越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法
解决方案1、硒
Selenium 是一个基于火狐浏览器的开发者工具。结合selenium webdriver,可以实现js的动态渲染,模拟用户在浏览器中的真实操作,达到爬取数据的目的;每次通过selenium调用都会弹出浏览器界面。在浏览器中设置headless进入无界面状态;selenium的主要优点是浏览器页面的动态交互和js脚本的动态渲染。缺点是每次加载一个URL,就相当于打开了一次页面。渲染时间比较长,爬行。效率极低,可用于研究和学习,不适合在生产环境中使用
2、抓包
因为js渲染用到的数据是从后端获取的,每个ajax请求对应一个http api接口,所以只要仔细分析网页的ajax请求,找到对应的数据接口,就可以实现数据爬取另外,数据接口比页面更稳定。一般返回的数据结构不会改变;缺点是如果要爬取的页面请求过于复杂,需要一定的分析经验,使用分析工具耐心观察和调试定位。
为了方便大家在实际生产中应用,这里以第二种方案来说明案例背景的流程
全面爬取 IconFont 的 svg 图片
过程再现
图像.png
图像.png
通过该接口可以获取到具体Icon的svg标签数据。
图像.png
核心代码
爬虫的主框架是webmagic,通过重写pageProcesser和pipeline两部分来捕获和存储图标。
页面分辨率
<p>package com.crawler.icon;
import java.io.IOException;
import java.util.List;
import com.crawler.image.ImageDownloaderUtil;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class ImageProcessor implements PageProcessor {
/**
* 网络爬虫相关配置
* 这里设置了重试次数,时间间隔
*/
private Site site = Site.me().setTimeOut(3000);
private static String LIST_URL = "https://www.iconfont.cn/api/collections.json.*";
public Site getSite() {
return site;
}
public void process(Page page) {
// 判断当前页面是用户列表页还是作品列表页
if (page.getUrl().regex(LIST_URL).match()) {
List ids = new JsonPathSelector("$.data.lists[*].id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
// 根据获取到的用户Id 拼接处用户作品url并加入到待爬取队列
page.addTargetRequest("https://www.iconfont.cn/api/co ... ot%3B + id);
}
}
} else {
// 获取用户Icon列表
List items = new JsonPathSelector("$.data.icons[*]").selectList(page.getRawText());
page.putField("items", items);
}
}
public static void main(String[] args) throws IOException {
long startTime = System.currentTimeMillis();
// JsonFilePipeline pipeline = new JsonFilePipeline("d://tmp/icon/");
Spider spider = Spider.create(new IconProcessor()).addPipeline(new IconJsonPipeline("d://tmp/icon"));
//通过URL拼接的方式,采集多页 这里只抓取3页仅供学习
for (int i = 1; i 查看全部
java爬虫抓取动态网页(做数据爬虫时如何实现动态网页的解析(一))
人们在做数据爬虫的时候一般会遇到这些问题:
以上问题我们会在接下来的系列数据采集中一一解决,但是今天我们要解决的问题是如何实现动态网页的分析
随着AJAX技术的不断普及和各种JS框架的出现,现在越来越多的页面由js渲染。对于爬虫来说,这种页面比较烦人:只提取HTML内容往往得不到有效信息。那么如何处理这种页面呢?一般来说,有两种方法
解决方案1、硒
Selenium 是一个基于火狐浏览器的开发者工具。结合selenium webdriver,可以实现js的动态渲染,模拟用户在浏览器中的真实操作,达到爬取数据的目的;每次通过selenium调用都会弹出浏览器界面。在浏览器中设置headless进入无界面状态;selenium的主要优点是浏览器页面的动态交互和js脚本的动态渲染。缺点是每次加载一个URL,就相当于打开了一次页面。渲染时间比较长,爬行。效率极低,可用于研究和学习,不适合在生产环境中使用
2、抓包
因为js渲染用到的数据是从后端获取的,每个ajax请求对应一个http api接口,所以只要仔细分析网页的ajax请求,找到对应的数据接口,就可以实现数据爬取另外,数据接口比页面更稳定。一般返回的数据结构不会改变;缺点是如果要爬取的页面请求过于复杂,需要一定的分析经验,使用分析工具耐心观察和调试定位。
为了方便大家在实际生产中应用,这里以第二种方案来说明案例背景的流程
全面爬取 IconFont 的 svg 图片
过程再现
图像.png
图像.png
通过该接口可以获取到具体Icon的svg标签数据。
图像.png
核心代码
爬虫的主框架是webmagic,通过重写pageProcesser和pipeline两部分来捕获和存储图标。
页面分辨率
<p>package com.crawler.icon;
import java.io.IOException;
import java.util.List;
import com.crawler.image.ImageDownloaderUtil;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
public class ImageProcessor implements PageProcessor {
/**
* 网络爬虫相关配置
* 这里设置了重试次数,时间间隔
*/
private Site site = Site.me().setTimeOut(3000);
private static String LIST_URL = "https://www.iconfont.cn/api/collections.json.*";
public Site getSite() {
return site;
}
public void process(Page page) {
// 判断当前页面是用户列表页还是作品列表页
if (page.getUrl().regex(LIST_URL).match()) {
List ids = new JsonPathSelector("$.data.lists[*].id").selectList(page.getRawText());
if (CollectionUtils.isNotEmpty(ids)) {
for (String id : ids) {
// 根据获取到的用户Id 拼接处用户作品url并加入到待爬取队列
page.addTargetRequest("https://www.iconfont.cn/api/co ... ot%3B + id);
}
}
} else {
// 获取用户Icon列表
List items = new JsonPathSelector("$.data.icons[*]").selectList(page.getRawText());
page.putField("items", items);
}
}
public static void main(String[] args) throws IOException {
long startTime = System.currentTimeMillis();
// JsonFilePipeline pipeline = new JsonFilePipeline("d://tmp/icon/");
Spider spider = Spider.create(new IconProcessor()).addPipeline(new IconJsonPipeline("d://tmp/icon"));
//通过URL拼接的方式,采集多页 这里只抓取3页仅供学习
for (int i = 1; i
java爬虫抓取动态网页(爬取动态网页的一种方式:逆向工程的新思路:渲染动态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-02 16:13
每篇文章一句话:
一个坚强的人会在命运的风暴中挣扎。
前言:
在上一篇文章中,我们介绍了一种爬取动态网页的方法:逆向工程。
这种方式有一个缺陷:这种方式需要我们对JavaScript和Ajax有一定的了解,而当网页的JS代码杂乱无章,难以分析时,上述过程会耗费我们大量的时间和精力.
这时候,如果对爬虫的执行效率没有太多要求,又不想在理解JavaScript代码逻辑和寻找Ajax请求链接上浪费太多时间,可以尝试另一种方式——呈现动态网页。
浏览器渲染引擎:简介:
在介绍这个方法之前,我们需要了解一些浏览器渲染引擎的基础知识。
渲染引擎的职责是渲染,即在浏览器窗口中显示请求的内容。浏览器向服务器发送请求,获取服务器返回的资源文件后,资源文件经过渲染引擎处理后显示在浏览器窗口中。
目前有两种广泛使用的渲染引擎:
主要渲染流程:
思考:
了解了浏览器渲染引擎的基本原理,我们可以发现:
然后我们有了爬取动态网页的新思路:
渲染动态网页:
有两种选择:
自己从头实现一个浏览器渲染引擎,并在合适的时间返回构造好的dom树或渲染树:
这需要大量的工作,需要考虑html、js、css等不同格式文件的解析方式和解析顺序。
我参考以下资料试了一下,最后没有成功。如果你有兴趣,你可以尝试一下。
使用现有的渲染引擎。
接下来会用到WebKit渲染引擎,可以通过python库PySide获取到引擎的便捷接口。
例子:
以新浪读书文摘为例,我们可以发现页面上的文章列表部分是动态加载的。
使用PySide库进行处理的示例代码如下:
# coding=utf-8
from PySide.QtGui import *
from PySide.QtCore import *
from PySide.QtWebKit import *
if __name__ == '__main__':
url = "http://book.sina.com.cn/excerpt/rwws/"
app = QApplication([]) # 完成其他Qt对象之前,必须先创建该对象
webview = QWebView() # 该对象是Web 对象的容器
# 调用show方法显示窗口
# webview.show()
# 设置循环事件, 并等待网页加载完成
loop = QEventLoop()
webview.loadFinished.connect(loop.quit)
webview.load(QUrl(url))
loop.exec_()
frame = webview.page().mainFrame() # QWebFrame类有很多与网页交互的有用方法
# 得到页面渲染后的html代码
html = frame.toHtml()
print html
通过print语句,我们可以发现页面的源代码html已经收录了动态加载的内容。
# 根据CSS Selector 找到所需“进行翻页”的元素
elem = frame.findFirstElement('#subShowContent1_loadMore')
# 点击:通过evaluateJavaScript()函数可以执行Js代码
elem.evaluateJavaScript('this.click()')
需要注意的是,在翻页或者获取更多内容的时候,最大的难点之一就是如何判断页面是否已经加载完成,因为很难估计Ajax事件或者Js准备数据的时间。这个问题有两种解决方案:
等待一段固定的时间,比如time.sleep(3): 这种方法实现起来简单,但是效率较低。
轮询网页并等待特定内容出现:
这种方法虽然在检查加载是否完成时会浪费CPU周期,但更可靠。
下面是一个简单的实现:
elem = None
while not elem:
app.processEvents()
elem = frame.findAllElemnets('#pattern')
代码循环直到出现特定元素。在每个循环中,调用 app.processEvents() 方法给 Qt 事件循环时间来执行任务,例如响应点击事件。
关于 PySide 的更多信息,请看这里:PySide 官方文档
但是PySide毕竟是为Python GUI编程开发的,它的功能对于爬虫来说太大了,所以我们可以把爬虫经常用到的功能封装起来,提高编写爬虫的效率。
PySide-ghost.py常用函数的封装
目前是PySide的一个封装模块,针对爬虫,功能比较齐全。可以用来方便的进行数据采集。
或者以获取列表页中每个文章详情页的地址为目标,直接看示例代码:
# coding=utf-8
import re
import time
from ghost import Ghost, Session
class SinaBookSpider(object):
# 初始化相关参数
gh = Ghost()
ss = Session(gh, display=True) # 设置display为true, 方便调试
total = 1526 # 预先计算的总数据量
count = 0 # 已爬取的数据量
# 记录解析以及翻页位置
location = 0
click_times = 0
def run(self):
"""
开始爬虫
:return:
"""
# 打开网页
self.ss.open("http://book.sina.com.cn/excerpt/rwws/")
# 等待数据加载完成
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(20)')
self.parselist()
while self.count < self.total:
if self.click_times is 0:
# 点击加载更多
self.ss.click('#subShowContent1_loadMore')
# 每次翻页,或加载更多,要等待至加载完成
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(21)')
self.click_times += 1
self.parselist()
elif self.click_times is 1:
self.ss.click('#subShowContent1_loadMore')
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(41)')
self.click_times += 1
self.parselist()
elif self.click_times is 2:
self.ss.click('#subShowContent1_page .pagebox_next a')
self.ss.sleep(2)
self.click_times = 0
self.location = 0
self.parselist()
def parselist(self):
"""
解析列表页
:return:
"""
html = self.ss.content.encode('utf8')
# print html
pattern = re.compile(r'<a href="(.*?)" target="_blank">', re.M)
links = pattern.findall(html)
for i in range(self.location, len(links)):
print links[i]
self.count += 1
self.location += 1
print self.count
if __name__ == '__main__':
spider = SinaBookSpider()
spider.run()
代码地址:dynamic-web-process —— GitHub
添加:
文章中的任何错误或不足欢迎指出! 查看全部
java爬虫抓取动态网页(爬取动态网页的一种方式:逆向工程的新思路:渲染动态)
每篇文章一句话:
一个坚强的人会在命运的风暴中挣扎。
前言:
在上一篇文章中,我们介绍了一种爬取动态网页的方法:逆向工程。
这种方式有一个缺陷:这种方式需要我们对JavaScript和Ajax有一定的了解,而当网页的JS代码杂乱无章,难以分析时,上述过程会耗费我们大量的时间和精力.
这时候,如果对爬虫的执行效率没有太多要求,又不想在理解JavaScript代码逻辑和寻找Ajax请求链接上浪费太多时间,可以尝试另一种方式——呈现动态网页。
浏览器渲染引擎:简介:
在介绍这个方法之前,我们需要了解一些浏览器渲染引擎的基础知识。
渲染引擎的职责是渲染,即在浏览器窗口中显示请求的内容。浏览器向服务器发送请求,获取服务器返回的资源文件后,资源文件经过渲染引擎处理后显示在浏览器窗口中。
目前有两种广泛使用的渲染引擎:
主要渲染流程:
思考:
了解了浏览器渲染引擎的基本原理,我们可以发现:
然后我们有了爬取动态网页的新思路:
渲染动态网页:
有两种选择:
自己从头实现一个浏览器渲染引擎,并在合适的时间返回构造好的dom树或渲染树:
这需要大量的工作,需要考虑html、js、css等不同格式文件的解析方式和解析顺序。
我参考以下资料试了一下,最后没有成功。如果你有兴趣,你可以尝试一下。
使用现有的渲染引擎。
接下来会用到WebKit渲染引擎,可以通过python库PySide获取到引擎的便捷接口。
例子:
以新浪读书文摘为例,我们可以发现页面上的文章列表部分是动态加载的。
使用PySide库进行处理的示例代码如下:
# coding=utf-8
from PySide.QtGui import *
from PySide.QtCore import *
from PySide.QtWebKit import *
if __name__ == '__main__':
url = "http://book.sina.com.cn/excerpt/rwws/"
app = QApplication([]) # 完成其他Qt对象之前,必须先创建该对象
webview = QWebView() # 该对象是Web 对象的容器
# 调用show方法显示窗口
# webview.show()
# 设置循环事件, 并等待网页加载完成
loop = QEventLoop()
webview.loadFinished.connect(loop.quit)
webview.load(QUrl(url))
loop.exec_()
frame = webview.page().mainFrame() # QWebFrame类有很多与网页交互的有用方法
# 得到页面渲染后的html代码
html = frame.toHtml()
print html
通过print语句,我们可以发现页面的源代码html已经收录了动态加载的内容。
# 根据CSS Selector 找到所需“进行翻页”的元素
elem = frame.findFirstElement('#subShowContent1_loadMore')
# 点击:通过evaluateJavaScript()函数可以执行Js代码
elem.evaluateJavaScript('this.click()')
需要注意的是,在翻页或者获取更多内容的时候,最大的难点之一就是如何判断页面是否已经加载完成,因为很难估计Ajax事件或者Js准备数据的时间。这个问题有两种解决方案:
等待一段固定的时间,比如time.sleep(3): 这种方法实现起来简单,但是效率较低。
轮询网页并等待特定内容出现:
这种方法虽然在检查加载是否完成时会浪费CPU周期,但更可靠。
下面是一个简单的实现:
elem = None
while not elem:
app.processEvents()
elem = frame.findAllElemnets('#pattern')
代码循环直到出现特定元素。在每个循环中,调用 app.processEvents() 方法给 Qt 事件循环时间来执行任务,例如响应点击事件。
关于 PySide 的更多信息,请看这里:PySide 官方文档
但是PySide毕竟是为Python GUI编程开发的,它的功能对于爬虫来说太大了,所以我们可以把爬虫经常用到的功能封装起来,提高编写爬虫的效率。
PySide-ghost.py常用函数的封装
目前是PySide的一个封装模块,针对爬虫,功能比较齐全。可以用来方便的进行数据采集。
或者以获取列表页中每个文章详情页的地址为目标,直接看示例代码:
# coding=utf-8
import re
import time
from ghost import Ghost, Session
class SinaBookSpider(object):
# 初始化相关参数
gh = Ghost()
ss = Session(gh, display=True) # 设置display为true, 方便调试
total = 1526 # 预先计算的总数据量
count = 0 # 已爬取的数据量
# 记录解析以及翻页位置
location = 0
click_times = 0
def run(self):
"""
开始爬虫
:return:
"""
# 打开网页
self.ss.open("http://book.sina.com.cn/excerpt/rwws/";)
# 等待数据加载完成
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(20)')
self.parselist()
while self.count < self.total:
if self.click_times is 0:
# 点击加载更多
self.ss.click('#subShowContent1_loadMore')
# 每次翻页,或加载更多,要等待至加载完成
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(21)')
self.click_times += 1
self.parselist()
elif self.click_times is 1:
self.ss.click('#subShowContent1_loadMore')
self.ss.wait_for_selector('#subShowContent1_static > div:nth-child(41)')
self.click_times += 1
self.parselist()
elif self.click_times is 2:
self.ss.click('#subShowContent1_page .pagebox_next a')
self.ss.sleep(2)
self.click_times = 0
self.location = 0
self.parselist()
def parselist(self):
"""
解析列表页
:return:
"""
html = self.ss.content.encode('utf8')
# print html
pattern = re.compile(r'<a href="(.*?)" target="_blank">', re.M)
links = pattern.findall(html)
for i in range(self.location, len(links)):
print links[i]
self.count += 1
self.location += 1
print self.count
if __name__ == '__main__':
spider = SinaBookSpider()
spider.run()
代码地址:dynamic-web-process —— GitHub
添加:
文章中的任何错误或不足欢迎指出!
java爬虫抓取动态网页(一下爬虫博客给出完整的代码完整程序介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-02 16:02
为了完成作业,我了解了爬虫Gecco。这个爬虫结合了之前所有爬虫的特点,但是官方教程中关于Gecco的教程太简单了。本博客根据原博客地址进行修改。只有程序的截图,没有完整的程序。这个博客给出了完整的代码。第一:爬取数据的目标是:(关于豆豆社)
创建一个 Maven 项目并导入依赖项:
com.geccocrawler
gecco
1.3.0
爬取第一页的数据,包括每页每个详细主题的链接和下一页的链接地址,
代码如下:DoutuSheIndex.java
package com.chry.GeccoCSDN;
import java.util.List;
import com.geccocrawler.gecco.GeccoEngine;
import com.geccocrawler.gecco.annotation.Gecco;
import com.geccocrawler.gecco.annotation.Href;
import com.geccocrawler.gecco.annotation.HtmlField;
import com.geccocrawler.gecco.annotation.Request;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.spider.HtmlBean;
@Gecco(matchUrl="https://doutushe.com/portal/index/index/p/{page}", pipelines="doutusheIndex")
public class DoutuSheIndex implements HtmlBean{
/**
*
*/
private static final long serialVersionUID = 1L;
@Request
private HttpRequest request;
@Href(click=true)
@HtmlField(cssPath="a.link-2")
private List nameList; //得到的是地址
public HttpRequest getRequest() {
return request;
}
public void setRequest(HttpRequest request) {
this.request = request;
}
@Href(value="href")
@HtmlField(cssPath="a.link-2")
private ListidList; //得到的名称
@HtmlField(cssPath="ul.pagination li")
private List pageList;
public List getPageList() {
return pageList;
}
public void setPageList(List pageList) {
this.pageList = pageList;
}
public List getNameList() {
return nameList;
}
public List getIdList() {
return idList;
}
public void setNameList(List nameList) {
this.nameList = nameList;
}
public void setIdList(List idList) {
this.idList = idList;
}
}
注意:创建的类中必须有请求私有成员,并添加他的get和set方法,以便以后在proess中获取数据。
现在详细介绍页面的每个不同部分
里面的每个成员变量都有一个对应的css路径,对应网页中的元素。当对应的css类型相同时,可以使用一个List对象来存储页面中所有相同的css元素
完成DoutusheIndex.java
<p>package com.chry.GeccoCSDN;
import org.apache.http.util.TextUtils;
import com.geccocrawler.gecco.annotation.PipelineName;
import com.geccocrawler.gecco.pipeline.Pipeline;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.scheduler.SchedulerContext;
@PipelineName(value="doutusheIndex")
public class FinishDoutusheIndex implements Pipeline{
public void process(DoutuSheIndex doutusheIndex) {
//首先遍历帖子的详情
for(int i=0;i 查看全部
java爬虫抓取动态网页(一下爬虫博客给出完整的代码完整程序介绍)
为了完成作业,我了解了爬虫Gecco。这个爬虫结合了之前所有爬虫的特点,但是官方教程中关于Gecco的教程太简单了。本博客根据原博客地址进行修改。只有程序的截图,没有完整的程序。这个博客给出了完整的代码。第一:爬取数据的目标是:(关于豆豆社)
创建一个 Maven 项目并导入依赖项:
com.geccocrawler
gecco
1.3.0
爬取第一页的数据,包括每页每个详细主题的链接和下一页的链接地址,
代码如下:DoutuSheIndex.java
package com.chry.GeccoCSDN;
import java.util.List;
import com.geccocrawler.gecco.GeccoEngine;
import com.geccocrawler.gecco.annotation.Gecco;
import com.geccocrawler.gecco.annotation.Href;
import com.geccocrawler.gecco.annotation.HtmlField;
import com.geccocrawler.gecco.annotation.Request;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.spider.HtmlBean;
@Gecco(matchUrl="https://doutushe.com/portal/index/index/p/{page}", pipelines="doutusheIndex")
public class DoutuSheIndex implements HtmlBean{
/**
*
*/
private static final long serialVersionUID = 1L;
@Request
private HttpRequest request;
@Href(click=true)
@HtmlField(cssPath="a.link-2")
private List nameList; //得到的是地址
public HttpRequest getRequest() {
return request;
}
public void setRequest(HttpRequest request) {
this.request = request;
}
@Href(value="href")
@HtmlField(cssPath="a.link-2")
private ListidList; //得到的名称
@HtmlField(cssPath="ul.pagination li")
private List pageList;
public List getPageList() {
return pageList;
}
public void setPageList(List pageList) {
this.pageList = pageList;
}
public List getNameList() {
return nameList;
}
public List getIdList() {
return idList;
}
public void setNameList(List nameList) {
this.nameList = nameList;
}
public void setIdList(List idList) {
this.idList = idList;
}
}
注意:创建的类中必须有请求私有成员,并添加他的get和set方法,以便以后在proess中获取数据。
现在详细介绍页面的每个不同部分
里面的每个成员变量都有一个对应的css路径,对应网页中的元素。当对应的css类型相同时,可以使用一个List对象来存储页面中所有相同的css元素
完成DoutusheIndex.java
<p>package com.chry.GeccoCSDN;
import org.apache.http.util.TextUtils;
import com.geccocrawler.gecco.annotation.PipelineName;
import com.geccocrawler.gecco.pipeline.Pipeline;
import com.geccocrawler.gecco.request.HttpRequest;
import com.geccocrawler.gecco.scheduler.SchedulerContext;
@PipelineName(value="doutusheIndex")
public class FinishDoutusheIndex implements Pipeline{
public void process(DoutuSheIndex doutusheIndex) {
//首先遍历帖子的详情
for(int i=0;i
java爬虫抓取动态网页(【】动态cookie页面应该怎么设置才能抓取数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-02 15:32
)
我需要抓取收录数据的网页内容,并使用httpurlconnection抓取网页内容(代码片段1)。但是,需要爬网的网页似乎在JS端设置了动态cookie,导致爬网的内容成为代码片段2。现在请帮助我了解如何设置这样的动态cookie页面来爬网数据?请给我发一封针对特定链接地址的私人信件~
<br />
/**<br />
* 代码段1<br />
*/<br />
import java.io.BufferedReader;<br />
import java.io.IOException;<br />
import java.io.InputStream;<br />
import java.io.InputStreamReader;<br />
import java.net.CookieHandler;<br />
import java.net.CookieManager;<br />
import java.net.CookiePolicy;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
public class GetWebContent {<br />
public static String GetWebContent(String urlString, final String charset,int timeout) throws IOException {<br />
if (urlString == null || urlString.length() == 0) {<br />
return null;<br />
}<br />
urlString = (urlString.startsWith("http://") || urlString<br />
.startsWith("https://")) ? urlString : ("http://" + urlString)<br />
.intern();<br />
CookieHandler.setDefault(new CookieManager(null,<br />
CookiePolicy.ACCEPT_ALL));<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
conn.setDoOutput(true);<br />
conn.setRequestProperty("Pragma", "no-cache");<br />
conn.setRequestProperty("Cache-Control", "no-cache");<br />
// http://blog.csdn.net/yjflinchong<br />
int temp = Integer.parseInt(Math.round(Math.random() * 2) + "");<br />
conn.setRequestProperty("User-Agent", UserAgent[temp]); // 模拟手机系统<br />
System.out.println(UserAgent[temp]);<br />
conn.setRequestProperty("Accept",<br />
"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");// 只接受text/html类型,当然也可以接受图片,pdf,*/*任意,就是tomcat/conf/web里面定义那些<br />
conn.setConnectTimeout(timeout);<br />
<br />
try {<br />
if (conn.getResponseCode() != HttpURLConnection.HTTP_OK) {<br />
return null;<br />
}<br />
} catch (Exception e) {<br />
try {<br />
e.printStackTrace();<br />
} catch (Exception e2) {<br />
e2.printStackTrace();<br />
}<br />
return null;<br />
}<br />
InputStream input = conn.getInputStream();<br />
BufferedReader reader = new BufferedReader(new InputStreamReader(input,<br />
charset));<br />
String line = null;<br />
StringBuffer sb = new StringBuffer();<br />
while ((line = reader.readLine()) != null) {<br />
sb.append(line).append("\r\n");<br />
}<br />
<br />
if (reader != null) {<br />
reader.close();<br />
}<br />
if (conn != null) {<br />
conn.disconnect();<br />
}<br />
return sb.toString();<br />
}<br />
<br />
public static String[] UserAgent = {<br />
//"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.2",<br />
"Mozilla/5.0 (iPad; U; CPU OS 9_2_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Version/4.0.4 Mobile/7B500 Safari/531.21.11",<br />
<br />
// http://blog.csdn.net/yjflinchong<br />
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",//win10 chrome<br />
"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1" };//iphone X<br />
}
代码段2,抓取从网页获取的数据
<br />
<br />
<br />
<br />
<br />
<br />
var data = {<br />
'cookie' : "6a947161cfdda35d01f8c6c673653ffc",<br />
'uri' : "此处地址即为需要抓取的地址,如有需要请私信我"<br />
};<br />
<br />
function getCookie(c_name){<br />
if (document.cookie.length>0){ <br />
c_start=document.cookie.indexOf(c_name + "=")<br />
if (c_start!=-1){ <br />
c_start=c_start + c_name.length+1 <br />
c_end=document.cookie.indexOf(";",c_start)<br />
if (c_end==-1) c_end=document.cookie.length<br />
return unescape(document.cookie.substring(c_start,c_end))<br />
} <br />
}<br />
return "";<br />
}<br />
<br />
function setCookie(c_name,value,expiredays){<br />
var exdate=new Date();<br />
exdate.setDate(exdate.getDate()+expiredays);<br />
document.cookie=c_name+ "=" +escape(value)+((expiredays==null) ? "" : "; path=/; expires="+exdate.toGMTString());<br />
}<br />
<br />
function jump(){<br />
setCookie('elvaeye',data['cookie'],365);<br />
window.location = data['uri'];<br />
}<br />
<br />
<br />
<br />
<br />
<br /> 查看全部
java爬虫抓取动态网页(【】动态cookie页面应该怎么设置才能抓取数据?
)
我需要抓取收录数据的网页内容,并使用httpurlconnection抓取网页内容(代码片段1)。但是,需要爬网的网页似乎在JS端设置了动态cookie,导致爬网的内容成为代码片段2。现在请帮助我了解如何设置这样的动态cookie页面来爬网数据?请给我发一封针对特定链接地址的私人信件~
<br />
/**<br />
* 代码段1<br />
*/<br />
import java.io.BufferedReader;<br />
import java.io.IOException;<br />
import java.io.InputStream;<br />
import java.io.InputStreamReader;<br />
import java.net.CookieHandler;<br />
import java.net.CookieManager;<br />
import java.net.CookiePolicy;<br />
import java.net.HttpURLConnection;<br />
import java.net.URL;<br />
public class GetWebContent {<br />
public static String GetWebContent(String urlString, final String charset,int timeout) throws IOException {<br />
if (urlString == null || urlString.length() == 0) {<br />
return null;<br />
}<br />
urlString = (urlString.startsWith("http://";) || urlString<br />
.startsWith("https://";)) ? urlString : ("http://" + urlString)<br />
.intern();<br />
CookieHandler.setDefault(new CookieManager(null,<br />
CookiePolicy.ACCEPT_ALL));<br />
URL url = new URL(urlString);<br />
HttpURLConnection conn = (HttpURLConnection) url.openConnection();<br />
conn.setDoOutput(true);<br />
conn.setRequestProperty("Pragma", "no-cache");<br />
conn.setRequestProperty("Cache-Control", "no-cache");<br />
// http://blog.csdn.net/yjflinchong<br />
int temp = Integer.parseInt(Math.round(Math.random() * 2) + "");<br />
conn.setRequestProperty("User-Agent", UserAgent[temp]); // 模拟手机系统<br />
System.out.println(UserAgent[temp]);<br />
conn.setRequestProperty("Accept",<br />
"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");// 只接受text/html类型,当然也可以接受图片,pdf,*/*任意,就是tomcat/conf/web里面定义那些<br />
conn.setConnectTimeout(timeout);<br />
<br />
try {<br />
if (conn.getResponseCode() != HttpURLConnection.HTTP_OK) {<br />
return null;<br />
}<br />
} catch (Exception e) {<br />
try {<br />
e.printStackTrace();<br />
} catch (Exception e2) {<br />
e2.printStackTrace();<br />
}<br />
return null;<br />
}<br />
InputStream input = conn.getInputStream();<br />
BufferedReader reader = new BufferedReader(new InputStreamReader(input,<br />
charset));<br />
String line = null;<br />
StringBuffer sb = new StringBuffer();<br />
while ((line = reader.readLine()) != null) {<br />
sb.append(line).append("\r\n");<br />
}<br />
<br />
if (reader != null) {<br />
reader.close();<br />
}<br />
if (conn != null) {<br />
conn.disconnect();<br />
}<br />
return sb.toString();<br />
}<br />
<br />
public static String[] UserAgent = {<br />
//"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.2",<br />
"Mozilla/5.0 (iPad; U; CPU OS 9_2_2 like Mac OS X; en-us) AppleWebKit/531.21.10 (KHTML, like Gecko) Version/4.0.4 Mobile/7B500 Safari/531.21.11",<br />
<br />
// http://blog.csdn.net/yjflinchong<br />
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",//win10 chrome<br />
"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1" };//iphone X<br />
}
代码段2,抓取从网页获取的数据
<br />
<br />
<br />
<br />
<br />
<br />
var data = {<br />
'cookie' : "6a947161cfdda35d01f8c6c673653ffc",<br />
'uri' : "此处地址即为需要抓取的地址,如有需要请私信我"<br />
};<br />
<br />
function getCookie(c_name){<br />
if (document.cookie.length>0){ <br />
c_start=document.cookie.indexOf(c_name + "=")<br />
if (c_start!=-1){ <br />
c_start=c_start + c_name.length+1 <br />
c_end=document.cookie.indexOf(";",c_start)<br />
if (c_end==-1) c_end=document.cookie.length<br />
return unescape(document.cookie.substring(c_start,c_end))<br />
} <br />
}<br />
return "";<br />
}<br />
<br />
function setCookie(c_name,value,expiredays){<br />
var exdate=new Date();<br />
exdate.setDate(exdate.getDate()+expiredays);<br />
document.cookie=c_name+ "=" +escape(value)+((expiredays==null) ? "" : "; path=/; expires="+exdate.toGMTString());<br />
}<br />
<br />
function jump(){<br />
setCookie('elvaeye',data['cookie'],365);<br />
window.location = data['uri'];<br />
}<br />
<br />
<br />
<br />
<br />
<br />
java爬虫抓取动态网页( 什么是Python?Python是什么?(二)模糊)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-01 20:09
什么是Python?Python是什么?(二)模糊)
今天听到有人问:为什么Python叫爬虫?我脑子里的第一反应不是答案,而是为什么有人问这个问题。我觉得大家对Python的概念有点模糊,把Python和爬虫混为一谈,所以今天问请解释一下。
什么是 Python?什么是 Python?
如果你在英文字典里查Python,他会给你下Python是大蟒蛇的定义,读成这样:英语[ˈpaɪθən],美国[ˈpaɪθɑ:n],Python就是大名鼎鼎的“龟叔”Guido van Rossum在 1989 年圣诞节期间,为了度过无聊的圣诞节而编写的一种编程语言。Python 是一种计算机编程语言。是一种动态的、面向对象的脚本语言,最初是为编写自动化脚本(shell)而设计的,随着版本的不断更新和新语言功能的加入,越来越多的被用于独立的、大型的项目开发。
Python 是一种解释性脚本语言,可用于以下领域:
1、Web 和 Internet 开发
2、科学计算和统计
3、教育
4、桌面界面开发
5、软件开发
6、后端开发
什么是爬虫?什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。
搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。
(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
Python和爬虫有什么关系?
爬虫一般是指对网络资源的爬取。由于python的脚本特性,python易于配置,对字符的处理也非常灵活。另外python有丰富的网络捕捉模块,所以两者经常联系在一起。只需使用python自带的urllib库即可;使用python编写搜索引擎,搜索引擎是一个复杂的爬虫。从这里您将了解什么是 Python 爬虫。是一种基于Python编程创建的网络资源爬取方法。Python 不是爬虫。
为什么Python适合一些爬虫?
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
什么是爬虫代理?
在爬行的过程中,如果你的爬行频率过快,不符合人类的操作方式。一些网站反爬虫机制检测到你的IP异常,访问频率过高。您将被阻止 IP。目前,专门从事代理IP服务的第三方平台比较多。
【相关学习建议】
1. Python爬虫视频教程
2. Python爬虫入门教程
如果想尝试爬取数据实践,可以试试下面爬虫专用代理ip,支持https、http、socks5、地址: 查看全部
java爬虫抓取动态网页(
什么是Python?Python是什么?(二)模糊)
今天听到有人问:为什么Python叫爬虫?我脑子里的第一反应不是答案,而是为什么有人问这个问题。我觉得大家对Python的概念有点模糊,把Python和爬虫混为一谈,所以今天问请解释一下。
什么是 Python?什么是 Python?
如果你在英文字典里查Python,他会给你下Python是大蟒蛇的定义,读成这样:英语[ˈpaɪθən],美国[ˈpaɪθɑ:n],Python就是大名鼎鼎的“龟叔”Guido van Rossum在 1989 年圣诞节期间,为了度过无聊的圣诞节而编写的一种编程语言。Python 是一种计算机编程语言。是一种动态的、面向对象的脚本语言,最初是为编写自动化脚本(shell)而设计的,随着版本的不断更新和新语言功能的加入,越来越多的被用于独立的、大型的项目开发。
Python 是一种解释性脚本语言,可用于以下领域:
1、Web 和 Internet 开发
2、科学计算和统计
3、教育
4、桌面界面开发
5、软件开发
6、后端开发
什么是爬虫?什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。
搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。
(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
Python和爬虫有什么关系?
爬虫一般是指对网络资源的爬取。由于python的脚本特性,python易于配置,对字符的处理也非常灵活。另外python有丰富的网络捕捉模块,所以两者经常联系在一起。只需使用python自带的urllib库即可;使用python编写搜索引擎,搜索引擎是一个复杂的爬虫。从这里您将了解什么是 Python 爬虫。是一种基于Python编程创建的网络资源爬取方法。Python 不是爬虫。
为什么Python适合一些爬虫?
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
什么是爬虫代理?
在爬行的过程中,如果你的爬行频率过快,不符合人类的操作方式。一些网站反爬虫机制检测到你的IP异常,访问频率过高。您将被阻止 IP。目前,专门从事代理IP服务的第三方平台比较多。
【相关学习建议】
1. Python爬虫视频教程
2. Python爬虫入门教程
如果想尝试爬取数据实践,可以试试下面爬虫专用代理ip,支持https、http、socks5、地址:
java爬虫抓取动态网页(体验Python版本的话-alpha版本示例代码介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-27 21:26
官方网站地址:。这是Java版本。如果您想体验python版本,请继续
其他介绍文章
不要说太多废话。直截了当地说。首先,使用Maven引入相关的依赖关系。目前,最新版本为2.73 alpha
cn.edu.hfut.dmic.webcollector
WebCollector
2.73-alpha
请参阅下面的示例代码了解如何使用它。它用于捕捉网站的图片。这网站不方便发放,我们自己试试吧
<p>import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.util.ExceptionUtils;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.MD5Utils;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
/**
* 继承 BreadthCrawler(广度爬虫)
* BreadthCrawler 是 WebCollector 最常用的爬取器之一
*
* @author hu
*/
public class DemoCrawler extends BreadthCrawler {
File baseDir = new File("images");
/**
* 构造一个基于伯克利DB的爬虫
* 伯克利DB文件夹为crawlPath,crawlPath中维护了历史URL等信息
* 不同任务不要使用相同的crawlPath
* 两个使用相同crawlPath的爬虫并行爬取会产生错误
*
* @param crawlPath 伯克利DB使用的文件夹
*/
public DemoCrawler(String crawlPath) {
//设置是否自动解析网页内容
super(crawlPath, true);
//只有在autoParse和autoDetectImg都为true的情况下
//爬虫才会自动解析图片链接
//getConf().setAutoDetectImg(true);
//如果使用默认的Requester,需要像下面这样设置一下网页大小上限
//否则可能会获得一个不完整的页面
//下面这行将页面大小上限设置为10M
//getConf().setMaxReceiveSize(1024 * 1024 * 10);
//添加种子URL
addSeed("http://www.xxx.com");
//限定爬取范围
addRegex("http://image.xxx.com/.*");
addRegex("-.*#.*");
addRegex("-.*\\?.*");
//设置线程数
setThreads(10);
}
@Override
public void visit(Page page, CrawlDatums next) {
//根据http头中的Content-Type信息来判断当前资源是网页还是图片
String contentType = page.contentType();
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
//如果是网页,则抽取其中包含图片的URL,放入后续任务
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
if (imgSrc.indexOf("thumb") 查看全部
java爬虫抓取动态网页(体验Python版本的话-alpha版本示例代码介绍)
官方网站地址:。这是Java版本。如果您想体验python版本,请继续
其他介绍文章
不要说太多废话。直截了当地说。首先,使用Maven引入相关的依赖关系。目前,最新版本为2.73 alpha
cn.edu.hfut.dmic.webcollector
WebCollector
2.73-alpha
请参阅下面的示例代码了解如何使用它。它用于捕捉网站的图片。这网站不方便发放,我们自己试试吧
<p>import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler;
import cn.edu.hfut.dmic.webcollector.util.ExceptionUtils;
import cn.edu.hfut.dmic.webcollector.util.FileUtils;
import cn.edu.hfut.dmic.webcollector.util.MD5Utils;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
/**
* 继承 BreadthCrawler(广度爬虫)
* BreadthCrawler 是 WebCollector 最常用的爬取器之一
*
* @author hu
*/
public class DemoCrawler extends BreadthCrawler {
File baseDir = new File("images");
/**
* 构造一个基于伯克利DB的爬虫
* 伯克利DB文件夹为crawlPath,crawlPath中维护了历史URL等信息
* 不同任务不要使用相同的crawlPath
* 两个使用相同crawlPath的爬虫并行爬取会产生错误
*
* @param crawlPath 伯克利DB使用的文件夹
*/
public DemoCrawler(String crawlPath) {
//设置是否自动解析网页内容
super(crawlPath, true);
//只有在autoParse和autoDetectImg都为true的情况下
//爬虫才会自动解析图片链接
//getConf().setAutoDetectImg(true);
//如果使用默认的Requester,需要像下面这样设置一下网页大小上限
//否则可能会获得一个不完整的页面
//下面这行将页面大小上限设置为10M
//getConf().setMaxReceiveSize(1024 * 1024 * 10);
//添加种子URL
addSeed("http://www.xxx.com";);
//限定爬取范围
addRegex("http://image.xxx.com/.*");
addRegex("-.*#.*");
addRegex("-.*\\?.*");
//设置线程数
setThreads(10);
}
@Override
public void visit(Page page, CrawlDatums next) {
//根据http头中的Content-Type信息来判断当前资源是网页还是图片
String contentType = page.contentType();
if (contentType == null) {
return;
} else if (contentType.contains("html")) {
//如果是网页,则抽取其中包含图片的URL,放入后续任务
Elements imgs = page.select("img[src]");
for (Element img : imgs) {
String imgSrc = img.attr("abs:src");
if (imgSrc.indexOf("thumb")
java爬虫抓取动态网页(爬虫遇到js动态数据时怎么办?漫画网站详解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-09-27 15:24
当爬虫遇到JS动态数据时,主要有两种解决方案:
使用一些库(如selenium)在模拟的浏览器环境中捕获数据。但是,这会消耗大量内存和CPU,并且爬虫效率较低,应尽量避免。手动分析JS请求并构造请求URL
接下来,我选择一幅卡通网站作为一个小例子来介绍第二种方法
我们的目标是获取卡通图片的URL并下载它
判断要爬网的数据是否动态加载
使用chrome打开网页,右键单击卡通图片->;检查
我们可以在里面看到图片的URL。右键单击此处(蓝色部分)->;复制->;复制XPath获取与图片对应的XPath,然后可以使用请求和XPath获取图片URL。当然,它最终失败了。因为这里的图片是由JS动态加载的
(当然,还有一种更简单的判断方法。直接安装chrome插件toggle JavaScript,它可以判断页面的哪个部分是由JS加载的)
获取与要爬网的数据相关的JS代码信息
我们可以查看网页源代码,Ctrl+F定位图像ID“curpic”:
如您所见,没有图片的URL,图片是由JS加载的。阅读JS代码,我们可以知道图片URL由以下代码行决定:
pic2.src = hosts[getHost()] + picAy[curIndex]
在源代码中查找hosts和picay,发现它们只出现在这里。这表明这两个数组可以由JS代码加载
查找与要爬网的数据相关的JS请求
回到卡通页面,我们打开chrome的F12,点击网络,检查JS,刷新网页,查看相关JS请求对应的预览,查看哪些收录主机和picay:
嗯,进展惊人地顺利。第一个JS收录我们想要查找的内容。从这个图中,我们可以看到,当我们进入卡通的第一页时,JS代码会请求卡通所有页面的图片URL。单击请求的标题,我们可以看到请求的URL,其中收录JS文件名
那么,在编写程序时,我们如何获得JS文件名呢
看看其他的漫画,我们可以发现,虽然这个JS代码的命名是不规则的,但它在网页源代码中通常位于第一个JS位置。这样,O(∩ ∩) O可以通过正则表达式提取。哈哈~
知道JS文件名后,我们就可以构造请求URL了,上图就是一个例子:
url = 'https' + '//comic.sfacg.com/Utility/1887/ZP/117.js'
总结
到目前为止,让我们总结一下如何下载网站动画片:
获取动画第一页的URL,获取URL响应的HTML,在HTML中找到第一个JS代码文件名,构造请求URL,获取JS的响应内容,并从中提取所有图片URL
总结本例中获取JS动态数据的想法:
判断数据是否是JS加载的,如果是JS加载的,则在网页源代码中检查要爬网的数据附近的JS代码,获取关键信息(如一些变量名),返回要爬网的网页,按F12(my chrome),单击网络,检查JS,刷新网页,获取JS请求,逐个检查每个请求的预览,查看是否有任何与要爬网的内容相关的信息。如果请求的响应内容收录我们需要的信息,请检查请求的标题和URL,并找到构造此类请求URL的方法 查看全部
java爬虫抓取动态网页(爬虫遇到js动态数据时怎么办?漫画网站详解(组图))
当爬虫遇到JS动态数据时,主要有两种解决方案:
使用一些库(如selenium)在模拟的浏览器环境中捕获数据。但是,这会消耗大量内存和CPU,并且爬虫效率较低,应尽量避免。手动分析JS请求并构造请求URL
接下来,我选择一幅卡通网站作为一个小例子来介绍第二种方法
我们的目标是获取卡通图片的URL并下载它
判断要爬网的数据是否动态加载
使用chrome打开网页,右键单击卡通图片->;检查
我们可以在里面看到图片的URL。右键单击此处(蓝色部分)->;复制->;复制XPath获取与图片对应的XPath,然后可以使用请求和XPath获取图片URL。当然,它最终失败了。因为这里的图片是由JS动态加载的
(当然,还有一种更简单的判断方法。直接安装chrome插件toggle JavaScript,它可以判断页面的哪个部分是由JS加载的)
获取与要爬网的数据相关的JS代码信息
我们可以查看网页源代码,Ctrl+F定位图像ID“curpic”:
如您所见,没有图片的URL,图片是由JS加载的。阅读JS代码,我们可以知道图片URL由以下代码行决定:
pic2.src = hosts[getHost()] + picAy[curIndex]
在源代码中查找hosts和picay,发现它们只出现在这里。这表明这两个数组可以由JS代码加载
查找与要爬网的数据相关的JS请求
回到卡通页面,我们打开chrome的F12,点击网络,检查JS,刷新网页,查看相关JS请求对应的预览,查看哪些收录主机和picay:
嗯,进展惊人地顺利。第一个JS收录我们想要查找的内容。从这个图中,我们可以看到,当我们进入卡通的第一页时,JS代码会请求卡通所有页面的图片URL。单击请求的标题,我们可以看到请求的URL,其中收录JS文件名
那么,在编写程序时,我们如何获得JS文件名呢
看看其他的漫画,我们可以发现,虽然这个JS代码的命名是不规则的,但它在网页源代码中通常位于第一个JS位置。这样,O(∩ ∩) O可以通过正则表达式提取。哈哈~
知道JS文件名后,我们就可以构造请求URL了,上图就是一个例子:
url = 'https' + '//comic.sfacg.com/Utility/1887/ZP/117.js'
总结
到目前为止,让我们总结一下如何下载网站动画片:
获取动画第一页的URL,获取URL响应的HTML,在HTML中找到第一个JS代码文件名,构造请求URL,获取JS的响应内容,并从中提取所有图片URL
总结本例中获取JS动态数据的想法:
判断数据是否是JS加载的,如果是JS加载的,则在网页源代码中检查要爬网的数据附近的JS代码,获取关键信息(如一些变量名),返回要爬网的网页,按F12(my chrome),单击网络,检查JS,刷新网页,获取JS请求,逐个检查每个请求的预览,查看是否有任何与要爬网的内容相关的信息。如果请求的响应内容收录我们需要的信息,请检查请求的标题和URL,并找到构造此类请求URL的方法
java爬虫抓取动态网页(Java爬虫Jsoup+httpclient获取动态生成的数据的相关内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-09-26 23:16
想知道Java爬虫Jsoup+httpclient获取动态生成数据的相关内容吗?在本文中,我将讲解Java爬虫的相关知识和一些代码示例。欢迎阅读和纠正我们。我们先重点介绍一下:Java爬虫Jsoup+httpclient获取动态生成的数据,Java爬虫,Java爬虫Jsoup一起来学习吧。
Java爬虫Jsoup+httpclient获取动态生成的数据
前面我们详细讲了Jsoup,发现这个东西其实是一样的,只要是可以访问的静态资源页面,就可以直接用它来获取自己需要的数据。>为了防止数据被恶意爬取,我们做了很多掩饰,比如加密和动态加载,无形中给我们写的爬虫程序带来了很多麻烦,那么我们如何突破这个梗获取我们急需的数据?
让我们详细说明如何获得
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
这时候整个页面的数据其实已经获取到了,但是商品的价格是通过回调函数获取然后填写的。 这就需要我们写爬虫的开发者耐心的找到页面的回调接口价格数据。我们直接访问这个接口。你可以直接拿到这个价格。这是一个演示:
通过这个截图可以看到,他传递的只是一个静态资源页面,根本没有价格参数,那么价格是怎么来的呢?继续找这个界面:
你会发现这个界面里面拼接了很多参数,那么我们要做的就是分析一下所有的参数是否都有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
可以尝试删除一些参数,发现这个接口需要的参数其实很简单:
https://p.3.cn/prices/mgets%3F ... em-pc
看到这里是不是很兴奋?你实际上可以更改一些其他的京东产品ID,以获得当前价格和最高价格。我不知道价格是多少。我们需要做的只是写一个Httpclient模拟请求接口
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是这样的:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
至于后者,如果直接解析JSON字符串,那么你想要的数据就是GET。
请注意
这是重新请求获取回调请求的数据。这只是对之前动态获取商品价格的补充。这种情况是价格本身不是通过主链接带到页面的,而是在加载过程中通过异步请求填写的。当时把数据带过来了,但是有相关的JS做相关处理。我们仍然无法得到它。这时候我们就得通过其他方式来获取这些数据,后面会解释。 查看全部
java爬虫抓取动态网页(Java爬虫Jsoup+httpclient获取动态生成的数据的相关内容)
想知道Java爬虫Jsoup+httpclient获取动态生成数据的相关内容吗?在本文中,我将讲解Java爬虫的相关知识和一些代码示例。欢迎阅读和纠正我们。我们先重点介绍一下:Java爬虫Jsoup+httpclient获取动态生成的数据,Java爬虫,Java爬虫Jsoup一起来学习吧。
Java爬虫Jsoup+httpclient获取动态生成的数据
前面我们详细讲了Jsoup,发现这个东西其实是一样的,只要是可以访问的静态资源页面,就可以直接用它来获取自己需要的数据。>为了防止数据被恶意爬取,我们做了很多掩饰,比如加密和动态加载,无形中给我们写的爬虫程序带来了很多麻烦,那么我们如何突破这个梗获取我们急需的数据?
让我们详细说明如何获得
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
这时候整个页面的数据其实已经获取到了,但是商品的价格是通过回调函数获取然后填写的。 这就需要我们写爬虫的开发者耐心的找到页面的回调接口价格数据。我们直接访问这个接口。你可以直接拿到这个价格。这是一个演示:
通过这个截图可以看到,他传递的只是一个静态资源页面,根本没有价格参数,那么价格是怎么来的呢?继续找这个界面:
你会发现这个界面里面拼接了很多参数,那么我们要做的就是分析一下所有的参数是否都有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
可以尝试删除一些参数,发现这个接口需要的参数其实很简单:
https://p.3.cn/prices/mgets%3F ... em-pc
看到这里是不是很兴奋?你实际上可以更改一些其他的京东产品ID,以获得当前价格和最高价格。我不知道价格是多少。我们需要做的只是写一个Httpclient模拟请求接口
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是这样的:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
至于后者,如果直接解析JSON字符串,那么你想要的数据就是GET。
请注意
这是重新请求获取回调请求的数据。这只是对之前动态获取商品价格的补充。这种情况是价格本身不是通过主链接带到页面的,而是在加载过程中通过异步请求填写的。当时把数据带过来了,但是有相关的JS做相关处理。我们仍然无法得到它。这时候我们就得通过其他方式来获取这些数据,后面会解释。
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-26 01:22
Htmlunit是一个开源Java页面分析工具。启动htmlunit后,底层将启动一个没有界面的浏览器。用户可以指定浏览器类型:Firefox、ie等。如果未指定,默认为Internet\uExplorer\u7:
WebClient WebClient=新的WebClient(BrowserVersion.FIREFOX\u36)
通过一个简单的电话:
HtmlPage=webClient.getPage(url)
可通过以下方式获取页面的HTML页面表示:
InputStream is=targetPage.getWebResponse().getContentAsStream()
您可以获取页面的输入流,从而获取页面的源代码,这对于web爬虫项目非常有用
当然,您也可以从页面中获取更多页面元素
htmlunit为执行javascript提供支持非常重要:
page.executeJavaScript(javascript)
执行JS后,返回一个scriptresult对象,通过该对象可以得到执行JS后的页面等信息,默认情况下,内部浏览器会跳转到执行JS后生成的新页面,如果执行JS失败,则不会执行页面跳转 查看全部
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
Htmlunit是一个开源Java页面分析工具。启动htmlunit后,底层将启动一个没有界面的浏览器。用户可以指定浏览器类型:Firefox、ie等。如果未指定,默认为Internet\uExplorer\u7:
WebClient WebClient=新的WebClient(BrowserVersion.FIREFOX\u36)
通过一个简单的电话:
HtmlPage=webClient.getPage(url)
可通过以下方式获取页面的HTML页面表示:
InputStream is=targetPage.getWebResponse().getContentAsStream()
您可以获取页面的输入流,从而获取页面的源代码,这对于web爬虫项目非常有用
当然,您也可以从页面中获取更多页面元素
htmlunit为执行javascript提供支持非常重要:
page.executeJavaScript(javascript)
执行JS后,返回一个scriptresult对象,通过该对象可以得到执行JS后的页面等信息,默认情况下,内部浏览器会跳转到执行JS后生成的新页面,如果执行JS失败,则不会执行页面跳转
java爬虫抓取动态网页(使用Python语言开发爬虫有什么优势?-Python培训分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-25 20:51
网络爬虫有很多种,Python爬虫就是其中之一。那么使用Python语言开发爬虫有哪些优势呢?看看下面的详细介绍。
Python培训分享:使用Python开发爬虫有哪些优势?到目前为止,网络爬虫的主要开发语言有Java、Python和C++。对于一般信息,各种开发语言之间几乎没有区别。详细情况如下:
C/C++
大多数搜索引擎使用C/C++来开发爬虫,可能是因为搜索引擎爬虫对于采集网站信息很重要,对页面解析要求不高。
Python
Python语言具有强大的网络功能,可以模拟登录,解析JavaScript。缺点是网页分析。Python编写程序非常方便,尤其是对于专注的爬虫。目标 网站 经常变化。使用Python根据目标的变化修改爬虫程序非常方便。
爪哇
Java中有很多解析器,对解析网页有很好的支持。缺点是网络部分支持较差。
对于一般需求,无论是Java还是Python都可以胜任。如果需要模拟登陆,选择Python来对抗反爬虫更方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者需要对网页内容进行细粒度分析,可以选择Java。
在本书中选择 Python 作为实现爬虫的语言的主要考虑是:
(1) 抓取网页本身的界面
与其他动态脚本语言(如Perl、Shell)相比,Python的urllib2包提供了更完整的网页文档访问API;与其他静态编程语言(如Java、C#、C++)相比,Python捕捉网页文档的界面更加简洁。
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这时候就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有出色的第三方包可以帮助您完成任务,例如 Requests 或 Mechanize。
(2) 网页爬取后的处理
抓取到的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python 的 Beautiful Soup 提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上的功能,但是Python可以做到最快最干净,就像那句话“人生苦短,你需要Python”。
(3) 开发效率高
因为爬虫的具体代码要根据网站进行修改,而Python这种灵活的脚本语言特别适合这个任务。
(4) 快速上手
网上Python教学资源很多,方便大家学习,遇到问题也很容易找到相关资料。此外,Python 拥有强大的成熟爬虫框架的支持,例如 Scrapy。
以上就是《Python培训分享:使用Python语言开发爬虫有什么优势?》的介绍。更多成都Python培训的具体课程,加入千峰教育Python交流群-790693323,群内会有专职老师为您解答。此外,群内不定期会有免费直播课,由活跃讲师授课。 查看全部
java爬虫抓取动态网页(使用Python语言开发爬虫有什么优势?-Python培训分享)
网络爬虫有很多种,Python爬虫就是其中之一。那么使用Python语言开发爬虫有哪些优势呢?看看下面的详细介绍。
Python培训分享:使用Python开发爬虫有哪些优势?到目前为止,网络爬虫的主要开发语言有Java、Python和C++。对于一般信息,各种开发语言之间几乎没有区别。详细情况如下:
C/C++
大多数搜索引擎使用C/C++来开发爬虫,可能是因为搜索引擎爬虫对于采集网站信息很重要,对页面解析要求不高。
Python
Python语言具有强大的网络功能,可以模拟登录,解析JavaScript。缺点是网页分析。Python编写程序非常方便,尤其是对于专注的爬虫。目标 网站 经常变化。使用Python根据目标的变化修改爬虫程序非常方便。
爪哇
Java中有很多解析器,对解析网页有很好的支持。缺点是网络部分支持较差。
对于一般需求,无论是Java还是Python都可以胜任。如果需要模拟登陆,选择Python来对抗反爬虫更方便。如果需要处理复杂的网页,解析网页内容生成结构化数据,或者需要对网页内容进行细粒度分析,可以选择Java。
在本书中选择 Python 作为实现爬虫的语言的主要考虑是:
(1) 抓取网页本身的界面
与其他动态脚本语言(如Perl、Shell)相比,Python的urllib2包提供了更完整的网页文档访问API;与其他静态编程语言(如Java、C#、C++)相比,Python捕捉网页文档的界面更加简洁。
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这时候就需要模拟User Agent的行为来构造合适的请求,比如模拟用户登录,模拟Session/Cookie的存储和设置。Python 中有出色的第三方包可以帮助您完成任务,例如 Requests 或 Mechanize。
(2) 网页爬取后的处理
抓取到的网页通常需要进行处理,例如过滤Html标签、提取文本等。Python 的 Beautiful Soup 提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上的功能,但是Python可以做到最快最干净,就像那句话“人生苦短,你需要Python”。
(3) 开发效率高
因为爬虫的具体代码要根据网站进行修改,而Python这种灵活的脚本语言特别适合这个任务。
(4) 快速上手
网上Python教学资源很多,方便大家学习,遇到问题也很容易找到相关资料。此外,Python 拥有强大的成熟爬虫框架的支持,例如 Scrapy。
以上就是《Python培训分享:使用Python语言开发爬虫有什么优势?》的介绍。更多成都Python培训的具体课程,加入千峰教育Python交流群-790693323,群内会有专职老师为您解答。此外,群内不定期会有免费直播课,由活跃讲师授课。
java爬虫抓取动态网页(学习Java的同窗注意了!!(附学习源码))
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-25 20:38
学习Java的同学注意啦!!!
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入Java学习交流群,群号:183993990,一起学Java吧!html
本文文章来自个人回答:GitHub上有哪些优秀的Java爬虫项目?但是在这个答案中,进行了一些更改并添加了一些项目。这些项目来自github和开源中国。希望这些开源的Java爬虫项目对你有所帮助。阅读源代码可以帮助您获得质的提升。
一、格科
github地址:xtuhcy/gecco
Gecco是一个用java语言开发的轻量级易用的网络爬虫。集成jsoup、httpclient、fastjson、spring、htmlunit、redission等框架,只需要配置一些jquery风格的选择器即可快速编写爬虫。Gecco 框架具有出色的可扩展性。框架按照开闭原则设计,封闭用于修改,开放用于扩展。
二、WebCollector
github地址:CrawlScript/WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需很少的代码即可实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
三、蜘蛛侠
码云地址:l-weiwei/Spiderman2-码云-开源中国
用例:展示垂直爬虫的能力——如风般自由
蜘蛛侠是一个基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法,将复杂的目标网页信息捕获并解析成它需要的业务数据。
四、WebMagic
码云地址:flashsword20/webmagic-码云-中国开源
webmagic是一个爬虫框架,不需要配置,方便二次开发。它提供了一个简单灵活的API,只需很少的代码就可以实现一个爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(连接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。
五、Heritrix
Github 地址:internetarchive/heritrix3 Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。
六、crawler4j
GitHub 地址:yasserg/crawler4j · GitHub crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,可以在几分钟内构建一个多线程的网络爬虫。
七、Nutchjava
github地址:apache/nutchjquery
Nutch 是一个用开源 Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
在 Nutch 的发展过程中,产生了四个 Java 开源项目,Hadoop、Tika、Gora 和 Crawler Commons。现在这四个项目发展迅速,非常火爆,尤其是Hadoop,已经成为大规模数据处理的事实标准。Tika 使用各种现有的开源内容分析项目从多种格式的文件中提取元数据和结构化文本。Gora 支持将大数据持久化到多个存储实现。Crawler Commons 是一个通用的网络爬虫组件。.
八、SeimiCrawlergit
github地址:zhegexiaohuozi/SeimiCrawlergithub
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望能最大程度的降低新手开发高可用、低性能的爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大多数人只需要关心编写爬行的业务逻辑,其他 Seimi 会为你做。在设计上,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy,同时融合了 Java 语言的特性和 Spring 的特性,希望在国内能更方便、更广泛地使用更多的 HTML 解析高效的XPath,所以SeimiCrawler的默认HTML解析器是JsoupXpath(独立的扩展项目,不收录在jsoup中),HTML数据的默认解析和提取是使用XPath完成的(当然数据处理也可以选择其他解析器)。并结合SeimiAgent,彻底解决复杂的动态页面渲染和爬取问题。
九、Jsoupweb
github地址:jhy/jsoupredis
中文指南:jsoup开发指南、jsoup中文文档spring
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。学习Java的同学注意啦!!!
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入Java学习交流群,群号:183993990,一起学Java吧! 查看全部
java爬虫抓取动态网页(学习Java的同窗注意了!!(附学习源码))
学习Java的同学注意啦!!!
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入Java学习交流群,群号:183993990,一起学Java吧!html
本文文章来自个人回答:GitHub上有哪些优秀的Java爬虫项目?但是在这个答案中,进行了一些更改并添加了一些项目。这些项目来自github和开源中国。希望这些开源的Java爬虫项目对你有所帮助。阅读源代码可以帮助您获得质的提升。
一、格科
github地址:xtuhcy/gecco
Gecco是一个用java语言开发的轻量级易用的网络爬虫。集成jsoup、httpclient、fastjson、spring、htmlunit、redission等框架,只需要配置一些jquery风格的选择器即可快速编写爬虫。Gecco 框架具有出色的可扩展性。框架按照开闭原则设计,封闭用于修改,开放用于扩展。
二、WebCollector
github地址:CrawlScript/WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需很少的代码即可实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
三、蜘蛛侠
码云地址:l-weiwei/Spiderman2-码云-开源中国
用例:展示垂直爬虫的能力——如风般自由
蜘蛛侠是一个基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法,将复杂的目标网页信息捕获并解析成它需要的业务数据。
四、WebMagic
码云地址:flashsword20/webmagic-码云-中国开源
webmagic是一个爬虫框架,不需要配置,方便二次开发。它提供了一个简单灵活的API,只需很少的代码就可以实现一个爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(连接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。
五、Heritrix
Github 地址:internetarchive/heritrix3 Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。
六、crawler4j
GitHub 地址:yasserg/crawler4j · GitHub crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,可以在几分钟内构建一个多线程的网络爬虫。
七、Nutchjava
github地址:apache/nutchjquery
Nutch 是一个用开源 Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
在 Nutch 的发展过程中,产生了四个 Java 开源项目,Hadoop、Tika、Gora 和 Crawler Commons。现在这四个项目发展迅速,非常火爆,尤其是Hadoop,已经成为大规模数据处理的事实标准。Tika 使用各种现有的开源内容分析项目从多种格式的文件中提取元数据和结构化文本。Gora 支持将大数据持久化到多个存储实现。Crawler Commons 是一个通用的网络爬虫组件。.
八、SeimiCrawlergit
github地址:zhegexiaohuozi/SeimiCrawlergithub
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望能最大程度的降低新手开发高可用、低性能的爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大多数人只需要关心编写爬行的业务逻辑,其他 Seimi 会为你做。在设计上,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy,同时融合了 Java 语言的特性和 Spring 的特性,希望在国内能更方便、更广泛地使用更多的 HTML 解析高效的XPath,所以SeimiCrawler的默认HTML解析器是JsoupXpath(独立的扩展项目,不收录在jsoup中),HTML数据的默认解析和提取是使用XPath完成的(当然数据处理也可以选择其他解析器)。并结合SeimiAgent,彻底解决复杂的动态页面渲染和爬取问题。
九、Jsoupweb
github地址:jhy/jsoupredis
中文指南:jsoup开发指南、jsoup中文文档spring
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。学习Java的同学注意啦!!!
如果您在学习过程中遇到任何问题或者想获取学习资源,欢迎加入Java学习交流群,群号:183993990,一起学Java吧!
java爬虫抓取动态网页(全球最大的中文社区,java爬虫抓取动态网页知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-24 13:06
java爬虫抓取动态网页知乎号称知乎是全球最大的中文社区,这个社区知乎不断的引进用户,用户很多是假装用户的,因此需要抓取用户信息,方便之后爬取正规的用户信息。实际上网页上的信息并不多,只抓取了一个页面里的基本信息,以及对照了知乎里面的信息,同时网页代码加密处理。所以从理论上而言可以实现爬取。注意的是,在抓取前使用javahttp库调用getshell函数,导致代码效率有问题,同时爬取完用户信息后使用websql库去读取,反而需要去读取一些java中基本的sql功能。
简单说下整个步骤。这个网页的地址是:keywords.github.io,可能由于浏览器兼容的问题,会下载不了这个页面。所以抓取首先需要借助javaweb开发框架,getshell需要jsp,没看懂这个getshell是干嘛的,可以使用浏览器开发工具运行,发现下载不成功,现在测试还可以用。抓取完成,使用浏览器的getshell,可以看到getshell工具的路径,是可以访问到知乎的地址的。
有了路径,也可以查看代码,看看是否如我们预期那样,从而完成获取。websql运行很慢,测试4s/min。目前知乎还没有清除所有爬虫内容的功能,我们手工逐页清除,并重新抓取新的页面。老代码在这里:armgit仓库地址:websql包名:getjavapyqueueheader替换为0为10为定义tag解释器apipagesplit获取到页面源码之后,需要使用websql做清除数据的工作,然后返回true。
清除数据api简单代码:frompyqueryimportqueryexecuteopen('paths.github.io',request,'users.ikd.py')#pyqueryconvertedtotheuserselectorrequest=query(executeopen('paths.github.io',request))#pyqueryconvertedtotheuserselector如果是单向爬虫爬取,userselector很简单,如果是双向爬虫爬取,userselector要写很多代码。
list=jsp(query,'user').list()#list要手工处理一下,对list修改jsp定义。asp(query).aggregate('user',list,list).range(0,。
4).range(0,
6).list()#"user.py"存储,也可以存储更多的,比如xianyuan,你喜欢就存。
解释器api最后清除结果api代码:
1、全部内容:users.ikd.py
2、如果是清除整页清除不了,会在返回true时,写入一个判断的attribute,否则清除不了。selector清除不了的话,每次调用都会接受一个payload并返回。定义payload的方法,初始attribute和payload进行匹配,返回结果类型,匹配的payload类型中有:selector\__。 查看全部
java爬虫抓取动态网页(全球最大的中文社区,java爬虫抓取动态网页知乎)
java爬虫抓取动态网页知乎号称知乎是全球最大的中文社区,这个社区知乎不断的引进用户,用户很多是假装用户的,因此需要抓取用户信息,方便之后爬取正规的用户信息。实际上网页上的信息并不多,只抓取了一个页面里的基本信息,以及对照了知乎里面的信息,同时网页代码加密处理。所以从理论上而言可以实现爬取。注意的是,在抓取前使用javahttp库调用getshell函数,导致代码效率有问题,同时爬取完用户信息后使用websql库去读取,反而需要去读取一些java中基本的sql功能。
简单说下整个步骤。这个网页的地址是:keywords.github.io,可能由于浏览器兼容的问题,会下载不了这个页面。所以抓取首先需要借助javaweb开发框架,getshell需要jsp,没看懂这个getshell是干嘛的,可以使用浏览器开发工具运行,发现下载不成功,现在测试还可以用。抓取完成,使用浏览器的getshell,可以看到getshell工具的路径,是可以访问到知乎的地址的。
有了路径,也可以查看代码,看看是否如我们预期那样,从而完成获取。websql运行很慢,测试4s/min。目前知乎还没有清除所有爬虫内容的功能,我们手工逐页清除,并重新抓取新的页面。老代码在这里:armgit仓库地址:websql包名:getjavapyqueueheader替换为0为10为定义tag解释器apipagesplit获取到页面源码之后,需要使用websql做清除数据的工作,然后返回true。
清除数据api简单代码:frompyqueryimportqueryexecuteopen('paths.github.io',request,'users.ikd.py')#pyqueryconvertedtotheuserselectorrequest=query(executeopen('paths.github.io',request))#pyqueryconvertedtotheuserselector如果是单向爬虫爬取,userselector很简单,如果是双向爬虫爬取,userselector要写很多代码。
list=jsp(query,'user').list()#list要手工处理一下,对list修改jsp定义。asp(query).aggregate('user',list,list).range(0,。
4).range(0,
6).list()#"user.py"存储,也可以存储更多的,比如xianyuan,你喜欢就存。
解释器api最后清除结果api代码:
1、全部内容:users.ikd.py
2、如果是清除整页清除不了,会在返回true时,写入一个判断的attribute,否则清除不了。selector清除不了的话,每次调用都会接受一个payload并返回。定义payload的方法,初始attribute和payload进行匹配,返回结果类型,匹配的payload类型中有:selector\__。
java爬虫抓取动态网页(HTML解析:Jsoup基本思路(组图)线程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-09-23 02:11
html分析:jsoup
基本思想
网络爬行动物的基本思想是爬网线程从URL队列中获取URL - &gt;模拟浏览器对目标URL的请求 - &gt;下载Web内容返回 - &gt;然后在页面上,请将目标数据获取到相应的存储 - &gt;然后获取将从当前抓取的网页中攀爬的URL,具有一定的规则。
当然,上述思想基于爬行过程。没有必要模拟登录,网站非常友好,而不是做一些“反攀爬”的工作,然而,在现实中,仿真登录有时非常重要(如新浪微博);没有反攀爬网站也少,当频繁访问时,可能是冻结的帐户,密封IP,返回“系统繁忙”“请慢慢访问”和其他信息。因此,有必要加强爬行动物来增强爬行动物:增加转世信息的处理,动态切换帐户/ IP,访问时间延迟等。
编程
由于模拟登录模块的复杂性,并且不同网站实现的机制不相同,这里只给出一个原理图,其中主要分析不需要登录的爬行动物。
工作者:每个工人都是一个爬网线程,由主线程蜘蛛网创建
登录:爬网程序模拟登录模块,您可以设置帐户队列。帐户冻结后,将其放入队列的末尾并从头开始新帐户。再次登录。队列的长度是必需的,gt; =帐户冻结时间/每个帐户可以支持连续攀爬时间
获取器:爬行动物模拟浏览器发出Get URL请求,下载页
处理程序:在获取器下载的页面上的初步处理,如果确定页面的返回状态代码是否正确,页面内容是反升温器等,以便为解析器付费的页面是正确
解析器:通过fetcher下载的页面内容的分辨率,获取目标数据
store:将解析器解析的目标数据放入本地存储,这可以是MySQL传统数据库或Redis等.KV存储
抓取队列:URL
需要放置
钳位:URL
已被捕获
程序流程图
以下是爬行动物实现的流程图。图中的绿色框位于同一模块中,模块名称由红色字符表示。
代码实现
将于明天开始上学,加上实验室的任务,没有时间写作,写一个比较水,蚀地点,可能意识到上面的流程图,许多地方都需要根据具体攀爬,真诚地实现方案来实现笔记,真诚的希望包装美丽的观点。
丑陋的妻子即将到来。点我很丑&gt; _ 查看全部
java爬虫抓取动态网页(HTML解析:Jsoup基本思路(组图)线程(图))
html分析:jsoup
基本思想
网络爬行动物的基本思想是爬网线程从URL队列中获取URL - &gt;模拟浏览器对目标URL的请求 - &gt;下载Web内容返回 - &gt;然后在页面上,请将目标数据获取到相应的存储 - &gt;然后获取将从当前抓取的网页中攀爬的URL,具有一定的规则。
当然,上述思想基于爬行过程。没有必要模拟登录,网站非常友好,而不是做一些“反攀爬”的工作,然而,在现实中,仿真登录有时非常重要(如新浪微博);没有反攀爬网站也少,当频繁访问时,可能是冻结的帐户,密封IP,返回“系统繁忙”“请慢慢访问”和其他信息。因此,有必要加强爬行动物来增强爬行动物:增加转世信息的处理,动态切换帐户/ IP,访问时间延迟等。
编程
由于模拟登录模块的复杂性,并且不同网站实现的机制不相同,这里只给出一个原理图,其中主要分析不需要登录的爬行动物。
工作者:每个工人都是一个爬网线程,由主线程蜘蛛网创建
登录:爬网程序模拟登录模块,您可以设置帐户队列。帐户冻结后,将其放入队列的末尾并从头开始新帐户。再次登录。队列的长度是必需的,gt; =帐户冻结时间/每个帐户可以支持连续攀爬时间
获取器:爬行动物模拟浏览器发出Get URL请求,下载页
处理程序:在获取器下载的页面上的初步处理,如果确定页面的返回状态代码是否正确,页面内容是反升温器等,以便为解析器付费的页面是正确
解析器:通过fetcher下载的页面内容的分辨率,获取目标数据
store:将解析器解析的目标数据放入本地存储,这可以是MySQL传统数据库或Redis等.KV存储
抓取队列:URL
需要放置
钳位:URL
已被捕获
程序流程图
以下是爬行动物实现的流程图。图中的绿色框位于同一模块中,模块名称由红色字符表示。
代码实现
将于明天开始上学,加上实验室的任务,没有时间写作,写一个比较水,蚀地点,可能意识到上面的流程图,许多地方都需要根据具体攀爬,真诚地实现方案来实现笔记,真诚的希望包装美丽的观点。
丑陋的妻子即将到来。点我很丑&gt; _
java爬虫抓取动态网页(高效学习Python爬虫技术的步骤及步骤技术介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-23 02:08
↑↑↑↑↑如何有效地学习Python爬行动物技术?大多数Python爬行动物被“发送请求 - 获取页面 - 分辨率页面 - 提取并保存内容”进程抓住,并模拟人们使用浏览器获取网页信息。
Python爬行动物技术的高效学习:
1、学位网上爬行动物基本知识
了解Python网络爬行动物,当您了解Python基本知识,变量,字符串,列表,词典,元组,手持句,语法等,这些都是PRUNIFIZE的,以及在做例时可以使用什么知识点。此外,还需要了解某些网络请求的基本原理,Web结构等。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
2、看tthon网络爬行动物视频教程学习
查看视频或找到专业网络爬行动物的书“用python写网络”,按照视频来学习爬行动物代码,敲门代码,了解每行代码进行个人练习,并学会学习快的。很多人都有误解,我觉得我不愿意采取行动,理解和学习是两个概念。当我真的这样做时,它是一种测试知识的有效方法。如果你有很多漏洞,你必须坚持经常点击代码。
开发建议Python3,2020 Python2被暂停,Python3是主流。 IDE选择Pycharm,Sublime或Jupyter等,小编建议使用Pychram,一些类似的Java的Eclipse非常聪明。浏览器学习使用Chrome或Firefox浏览器来检查元素,学会使用捕获。了解干流的爬行动物和库,例如URLLIB,请求,RE,BS 4、 XPath,JSON等,需要常用的爬行动物结构SCRAPY。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
3、用于实际练习
有一个爬行动物的想法,独立地设计爬行动物系统,找到一些网站钻。静态Web和动态网页抓取策略和方法需求,了解JS加载的网页,了解Selenium + PhantomJS模拟浏览器的方式,知道如何处理JSON模式。 Web Post请求,通过数据参数,并且此网页通常是动态加载的,并且需要掌握该方法。如果要提高爬行动物的电源,则必须考虑使用多线程,多流程解决方案或分布式操作。
4、学习数据库基本响应大规模数据存储
爬回的数据量,并且文档可以以文档的形式存储,数据量不可用。因此,您必须掌握数据库并学习当前主流MongoDB。方便地存储一些非结构化数据,数据库知识非常简单,主要是数据存储,提取,并在需要时学习。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
Python应用方向,可以在背景,web开发,科学计算等中,爬行动物可以为初学者实现基础爬行动物,简单,简单,简单,更好的学习经验。 查看全部
java爬虫抓取动态网页(高效学习Python爬虫技术的步骤及步骤技术介绍)
↑↑↑↑↑如何有效地学习Python爬行动物技术?大多数Python爬行动物被“发送请求 - 获取页面 - 分辨率页面 - 提取并保存内容”进程抓住,并模拟人们使用浏览器获取网页信息。
Python爬行动物技术的高效学习:
1、学位网上爬行动物基本知识
了解Python网络爬行动物,当您了解Python基本知识,变量,字符串,列表,词典,元组,手持句,语法等,这些都是PRUNIFIZE的,以及在做例时可以使用什么知识点。此外,还需要了解某些网络请求的基本原理,Web结构等。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
2、看tthon网络爬行动物视频教程学习
查看视频或找到专业网络爬行动物的书“用python写网络”,按照视频来学习爬行动物代码,敲门代码,了解每行代码进行个人练习,并学会学习快的。很多人都有误解,我觉得我不愿意采取行动,理解和学习是两个概念。当我真的这样做时,它是一种测试知识的有效方法。如果你有很多漏洞,你必须坚持经常点击代码。
开发建议Python3,2020 Python2被暂停,Python3是主流。 IDE选择Pycharm,Sublime或Jupyter等,小编建议使用Pychram,一些类似的Java的Eclipse非常聪明。浏览器学习使用Chrome或Firefox浏览器来检查元素,学会使用捕获。了解干流的爬行动物和库,例如URLLIB,请求,RE,BS 4、 XPath,JSON等,需要常用的爬行动物结构SCRAPY。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
3、用于实际练习
有一个爬行动物的想法,独立地设计爬行动物系统,找到一些网站钻。静态Web和动态网页抓取策略和方法需求,了解JS加载的网页,了解Selenium + PhantomJS模拟浏览器的方式,知道如何处理JSON模式。 Web Post请求,通过数据参数,并且此网页通常是动态加载的,并且需要掌握该方法。如果要提高爬行动物的电源,则必须考虑使用多线程,多流程解决方案或分布式操作。
4、学习数据库基本响应大规模数据存储
爬回的数据量,并且文档可以以文档的形式存储,数据量不可用。因此,您必须掌握数据库并学习当前主流MongoDB。方便地存储一些非结构化数据,数据库知识非常简单,主要是数据存储,提取,并在需要时学习。主级签订了大学考试所需的考试信息,专业考试材料,软件和教程。
Python应用方向,可以在背景,web开发,科学计算等中,爬行动物可以为初学者实现基础爬行动物,简单,简单,简单,更好的学习经验。
java爬虫抓取动态网页(你知道Python爬虫是什么吗?用python语言写爬虫的缘由)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-22 10:22
1、你知道什么是python爬虫吗
在进入文章之前,我们首先需要知道爬行动物是什么。爬虫是一种网络爬虫。你可以把它理解为在互联网上爬行的蜘蛛。互联网就像一张大网,而爬行器就是一只在这张网上爬行的蜘蛛。如果它遇到自己的猎物(所需资源),它会抓住它。例如,它正在抓取网页。在这个网络中,他发现了一条路,这条路实际上是网页的超链接,因此它可以爬到另一个网页获取数据。html
由于Python的脚本特性,Python易于配置,并且字符处理灵活。此外,python具有丰富的网络捕获模块,因此这两个模块经常链接在一起。Python爬虫开发工程师从网站a页面(通常是主页)开始,阅读页面内容,在页面中找到其他连接地址,然后通过这些连接地址找到下一页。此循环将继续,直到捕获网站的所有页面。如果整个互联网被视为一个网站,那么网络蜘蛛就可以利用这一原理抓取互联网上的所有网页。爪哇
爬虫可以抓取网站或应用程序的内容并提取有用的价值。它还可以模拟用户在浏览器或应用程序上的操作,以实现自动程序。蟒蛇
爬虫通常是指对网络资源的爬虫。由于Python的脚本特性,它不仅易于配置,而且字符处理灵活,并且Python有丰富的网络爬虫模块,两者经常联系在一起。这就是Python被称为爬虫的原因。编程器
2、用Python1.编写爬虫程序的优点是什么2、简洁、清晰、高效
作为一种编程语言,Python是纯自由软件。它因其简洁明了的语法和强制使用空格进行句子缩进而深受程序员的喜爱。壳
用不同的编程语言完成一项任务:C语言需要编写1000行代码;Java需要写100行;Python只需要编写20行代码。如果使用Python来完成编程任务,那么编写的代码量就会减少,代码简洁易读,并且团队在开发时会更高效地编写代码。高开发效率使工作更高效
程序设计
2.grab网页自己的界面
与其他静态编程语言如Java、c#、c++、python相比,捕获web文档的界面更加简洁;与其他动态脚本语言(如Perl和shell)相比,Python的urlib2包为访问web文档提供了更完整的API
此外,爬行网页有时需要模拟浏览器的行为,许多用于刚性爬行器爬行的网站被阻止。我们需要模拟用户代理的行为来构造适当的请求,例如模拟用户登录和模拟会话/cookie的存储和设置。在Python中,有一些优秀的第三方软件包可以帮助您,例如requests和mechanizejson
3.web页面捕获处理
捕获的网页通常需要进行处理,例如过滤HTML标记、提取文本等。Python漂亮的soap提供了一个简洁的文档处理功能,可以用很短的代码完成大多数文档的处理。事实上,许多语言和工具都可以实现上述功能,但Python可以以最快、最干净的速度实现这些功能。c#
Python crawler的体系结构包括:
浏览者
爬虫架构:cookies
一、URL管理器:管理要爬网的URL集和爬网的URL集,并将要爬网的URL传输到网页下载器
2.. 网页下载器:抓取与URL对应的网页,将其存储为字符串,并将其发送给网页解析器
三、web页面解析器:解析有价值的数据,存储它,并将URL添加到URL管理器
Python的工作流程如下所示:
python爬虫程序通过URL管理器来确定是否对URL进行爬虫。如果要对URL进行爬网,则通过调度程序将其传输到下载程序,下载URL内容,并通过调度程序将其传输到解析器,解析URL内容,通过调度程序将值数据和新URL列表传递给应用程序,并输出值信息
Python是一种非常适合开发web爬虫的编程语言。它提供了urlib、re、JSON、pyquery等模块,同时也有很多形成的框架,如scripy框架、pyspider爬虫系统等,代码非常简洁方便。它是初学者学习网络爬虫的首选编程语言。爬虫是指捕获网络资源。由于python的脚本特性,python易于配置,并且字符处理灵活。此外,python具有丰富的网络捕获模块,因此这两个模块经常链接在一起。Python语言更适合初学者学习
Python回答。遇到问题时不要惊慌。过来~
基本学习资料,数据分析,爬虫和其他视频,来这里~
互相关爱、互相帮助的技术交流,Q组:943192807,过来~ 查看全部
java爬虫抓取动态网页(你知道Python爬虫是什么吗?用python语言写爬虫的缘由)
1、你知道什么是python爬虫吗
在进入文章之前,我们首先需要知道爬行动物是什么。爬虫是一种网络爬虫。你可以把它理解为在互联网上爬行的蜘蛛。互联网就像一张大网,而爬行器就是一只在这张网上爬行的蜘蛛。如果它遇到自己的猎物(所需资源),它会抓住它。例如,它正在抓取网页。在这个网络中,他发现了一条路,这条路实际上是网页的超链接,因此它可以爬到另一个网页获取数据。html
由于Python的脚本特性,Python易于配置,并且字符处理灵活。此外,python具有丰富的网络捕获模块,因此这两个模块经常链接在一起。Python爬虫开发工程师从网站a页面(通常是主页)开始,阅读页面内容,在页面中找到其他连接地址,然后通过这些连接地址找到下一页。此循环将继续,直到捕获网站的所有页面。如果整个互联网被视为一个网站,那么网络蜘蛛就可以利用这一原理抓取互联网上的所有网页。爪哇
爬虫可以抓取网站或应用程序的内容并提取有用的价值。它还可以模拟用户在浏览器或应用程序上的操作,以实现自动程序。蟒蛇
爬虫通常是指对网络资源的爬虫。由于Python的脚本特性,它不仅易于配置,而且字符处理灵活,并且Python有丰富的网络爬虫模块,两者经常联系在一起。这就是Python被称为爬虫的原因。编程器
2、用Python1.编写爬虫程序的优点是什么2、简洁、清晰、高效
作为一种编程语言,Python是纯自由软件。它因其简洁明了的语法和强制使用空格进行句子缩进而深受程序员的喜爱。壳
用不同的编程语言完成一项任务:C语言需要编写1000行代码;Java需要写100行;Python只需要编写20行代码。如果使用Python来完成编程任务,那么编写的代码量就会减少,代码简洁易读,并且团队在开发时会更高效地编写代码。高开发效率使工作更高效
程序设计
2.grab网页自己的界面
与其他静态编程语言如Java、c#、c++、python相比,捕获web文档的界面更加简洁;与其他动态脚本语言(如Perl和shell)相比,Python的urlib2包为访问web文档提供了更完整的API
此外,爬行网页有时需要模拟浏览器的行为,许多用于刚性爬行器爬行的网站被阻止。我们需要模拟用户代理的行为来构造适当的请求,例如模拟用户登录和模拟会话/cookie的存储和设置。在Python中,有一些优秀的第三方软件包可以帮助您,例如requests和mechanizejson
3.web页面捕获处理
捕获的网页通常需要进行处理,例如过滤HTML标记、提取文本等。Python漂亮的soap提供了一个简洁的文档处理功能,可以用很短的代码完成大多数文档的处理。事实上,许多语言和工具都可以实现上述功能,但Python可以以最快、最干净的速度实现这些功能。c#
Python crawler的体系结构包括:
浏览者
爬虫架构:cookies
一、URL管理器:管理要爬网的URL集和爬网的URL集,并将要爬网的URL传输到网页下载器
2.. 网页下载器:抓取与URL对应的网页,将其存储为字符串,并将其发送给网页解析器
三、web页面解析器:解析有价值的数据,存储它,并将URL添加到URL管理器
Python的工作流程如下所示:
python爬虫程序通过URL管理器来确定是否对URL进行爬虫。如果要对URL进行爬网,则通过调度程序将其传输到下载程序,下载URL内容,并通过调度程序将其传输到解析器,解析URL内容,通过调度程序将值数据和新URL列表传递给应用程序,并输出值信息
Python是一种非常适合开发web爬虫的编程语言。它提供了urlib、re、JSON、pyquery等模块,同时也有很多形成的框架,如scripy框架、pyspider爬虫系统等,代码非常简洁方便。它是初学者学习网络爬虫的首选编程语言。爬虫是指捕获网络资源。由于python的脚本特性,python易于配置,并且字符处理灵活。此外,python具有丰富的网络捕获模块,因此这两个模块经常链接在一起。Python语言更适合初学者学习
Python回答。遇到问题时不要惊慌。过来~
基本学习资料,数据分析,爬虫和其他视频,来这里~
互相关爱、互相帮助的技术交流,Q组:943192807,过来~
java爬虫抓取动态网页(Python3数据分析与机器学习实战(Python爬虫分析汇总))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-22 10:17
使用urllib模块,该模块提供了一个用于读取网页数据的接口,可以像读取本地文件一样读取WWW和FTP上的数据。Urllib是一个URL处理包,它采集一些用于处理URL的模块
Urllib。请求模块:用于打开和读取URL。Urllib。错误模块:收录由urllib生成的一些错误。请求,可通过try捕获和处理。Urllib。解析模块:收录一些解析URL的方法。Urllib.robot解析器:用于解析robots.txt文本文件。它通过该类提供的can提供一个单独的robotfileparser类。fetch()方法测试爬虫是否可以下载页面
以下代码是获取网页的代码:
import urllib.request
url = "https://www.douban.com/"
# 这边需要模拟浏览器才能进行抓取
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
data = response.read()
# 这边需要转码才能正常显示
print(str(data, 'utf-8'))
# 下面代码可以打印抓取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
2、grab收录关键词网页
代码如下:
import urllib.request
data = {'word': '海贼王'}
url_values = urllib.parse.urlencode(data)
url = "http://www.baidu.com/s?"
full_url = url + url_values
data = urllib.request.urlopen(full_url).read()
print(str(data, 'utf-8'))
3、下载贴吧中的图片@
代码如下:
import re
import urllib.request
# 获取网页源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
# 获取网页所有图片
def getImg(html):
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
return imglist
html = getHtml('https://tieba.baidu.com/p/3205263090')
html = html.decode('utf-8')
imgList = getImg(html)
imgName = 0
# 循环保存图片
for imgPath in imgList:
f = open(str(imgName) + ".jpg", 'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgName += 1
print('正在下载第 %s 张图片 ' % imgName)
print('该网站图片已经下载完')
4、stock数据捕获
代码如下:
<p>
import random
import re
import time
import urllib.request
# 抓取所需内容
user_agent = ["Mozilla/5.0 (Windows NT 10.0; WOW64)", 'Mozilla/5.0 (Windows NT 6.3; WOW64)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11']
stock_total = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
for page in range(1, 8):
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_' + str(page) + '.html'
request = urllib.request.Request(url=url, headers={"User-Agent": random.choice(user_agent)})
response = urllib.request.urlopen(request)
content = str(response.read(), 'gbk')
pattern = re.compile(' 查看全部
java爬虫抓取动态网页(Python3数据分析与机器学习实战(Python爬虫分析汇总))
使用urllib模块,该模块提供了一个用于读取网页数据的接口,可以像读取本地文件一样读取WWW和FTP上的数据。Urllib是一个URL处理包,它采集一些用于处理URL的模块
Urllib。请求模块:用于打开和读取URL。Urllib。错误模块:收录由urllib生成的一些错误。请求,可通过try捕获和处理。Urllib。解析模块:收录一些解析URL的方法。Urllib.robot解析器:用于解析robots.txt文本文件。它通过该类提供的can提供一个单独的robotfileparser类。fetch()方法测试爬虫是否可以下载页面
以下代码是获取网页的代码:
import urllib.request
url = "https://www.douban.com/"
# 这边需要模拟浏览器才能进行抓取
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
request = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(request)
data = response.read()
# 这边需要转码才能正常显示
print(str(data, 'utf-8'))
# 下面代码可以打印抓取网页的各类信息
print(type(response))
print(response.geturl())
print(response.info())
print(response.getcode())
2、grab收录关键词网页
代码如下:
import urllib.request
data = {'word': '海贼王'}
url_values = urllib.parse.urlencode(data)
url = "http://www.baidu.com/s?"
full_url = url + url_values
data = urllib.request.urlopen(full_url).read()
print(str(data, 'utf-8'))
3、下载贴吧中的图片@
代码如下:
import re
import urllib.request
# 获取网页源代码
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
# 获取网页所有图片
def getImg(html):
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
return imglist
html = getHtml('https://tieba.baidu.com/p/3205263090')
html = html.decode('utf-8')
imgList = getImg(html)
imgName = 0
# 循环保存图片
for imgPath in imgList:
f = open(str(imgName) + ".jpg", 'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgName += 1
print('正在下载第 %s 张图片 ' % imgName)
print('该网站图片已经下载完')
4、stock数据捕获
代码如下:
<p>
import random
import re
import time
import urllib.request
# 抓取所需内容
user_agent = ["Mozilla/5.0 (Windows NT 10.0; WOW64)", 'Mozilla/5.0 (Windows NT 6.3; WOW64)',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; rv:11.0) like Gecko)',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) Gecko/2008070208 Firefox/3.0.1',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070309 Firefox/2.0.0.3',
'Mozilla/5.0 (Windows; U; Windows NT 5.1) Gecko/20070803 Firefox/1.5.0.12',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0',
'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.12) Gecko/20080219 Firefox/2.0.0.12 Navigator/9.0.0.6',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Win64; x64; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0)',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Maxthon/4.0.6.2000 Chrome/26.0.1410.43 Safari/537.1 ',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.2; .NET4.0C; .NET4.0E; QQBrowser/7.3.9825.400)',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.92 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; BIDUBrowser 2.x)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/3.0 Safari/536.11']
stock_total = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}
for page in range(1, 8):
url = 'http://quote.stockstar.com/stock/ranklist_a_3_1_' + str(page) + '.html'
request = urllib.request.Request(url=url, headers={"User-Agent": random.choice(user_agent)})
response = urllib.request.urlopen(request)
content = str(response.read(), 'gbk')
pattern = re.compile('
java爬虫抓取动态网页(GitHub上有哪些优秀的Java爬虫项目?(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-21 23:20
)
本文文章来自我的回答:GitHub上有哪些优秀的Java爬虫项目?但是,已经对该答案进行了一些修改,并添加了一些项目。这些项目来自GitHub和开源中国。我希望这些开源Java爬虫项目将对您有所帮助。阅读源代码可以帮助您获得质量上的改进
1、Gecco
GitHub地址:xtuhcy/GECCO
GECCO是一个用Java语言开发的轻量级且易于使用的web爬虫程序。它集成了jsoup、httpclient、fastjson、spring、htmlunit、再分配和其他框架。通过配置一些jQuery样式选择器,可以快速编写爬虫程序。GECCO框架具有良好的可扩展性。框架根据开闭原理设计,关闭修改,打开扩展
2、WebCollector
GitHub地址:crawlscript/webcollector
Webcollector是一个Java爬虫框架(内核),不需要配置,便于二次开发。它提供了一个简化的API,只需少量代码即可实现强大的爬虫程序。Webcollector Hadoop是Webcollector的Hadoop版本,支持分布式爬网
3、Spiderman
代码云地址:l-weiwei/spiderman2-代码云-开源中国
用例:演示垂直爬虫的能力-随风自由移动
蜘蛛侠是一种基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法捕获复杂的目标网页信息并将其解析为业务数据
4、WebMagic
代码云地址:flashsword20/webmagic-代码云-开源中国
Webmagic是一个无配置的爬虫框架,便于二次开发。它提供了一个简单灵活的API,只需少量代码即可实现爬虫程序。Webmagic采用全模块化设计,覆盖爬虫的整个生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬虫、分布式爬虫、自动重试、自定义UA/cookie等功能
5、Heritrix
GitHub地址:Internet Archive/heritrix 3 heritrix是一个开源和可扩展的web爬虫程序项目。用户可以使用它从互联网上获取所需的资源。Heritrix的设计严格遵循robots.txt文件和meta robots标签的排除说明。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
6、crawler4j
GitHub地址:yasserg/crawler4j·githubcrawler4j是一个用Java实现的开源web爬虫程序。提供一个易于使用的界面,以便在几分钟内创建多线程web爬虫程序
7、Nutch
GitHub地址:Apache/nutch
Nutch是一个用Java实现的开源搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫
在nutch的发展过程中,出现了四个Java开源项目,Hadoop、Tika、Gora和crawler commons。如今,这四个项目发展迅速,非常流行,尤其是Hadoop,它已经成为大规模数据处理的事实标准。Tika使用各种现有的开源内容解析项目从各种格式的文件中提取元数据和结构化文本。Gora支持将大数据持久化到各种存储实现中。Crawler Commons是一个通用的web爬虫组件
8、SeimiCrawler
GitHub地址:哲格晓霍兹/赛米克罗勒
Seimicrawler是一个灵活、独立部署和分布式Java爬虫框架。希望最大限度地降低新手开发高可用性、高性能爬虫系统的门槛,提高爬虫系统的开发效率。在seimi crawler的世界中,大多数人只需要关心编写捕获的业务逻辑,其余的seimi将帮助您。在设计理念上,seimicrawler受到Python的crawler框架scripy的启发,融合了Java语言和spring的特点,希望在中国使用更方便高效的XPath解析HTML。因此,seimicrawler的默认HTML解析器是JSOUPPATH(独立扩展项目,不是jsoup提供的),默认情况下,解析和提取HTML数据是使用XPath完成的(当然,数据处理也可以选择其他解析器)。它与seimiagent相结合,全面、完美地解决了复杂动态页面的渲染和抓取问题
9、Jsoup
GitHub地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
查看全部
java爬虫抓取动态网页(GitHub上有哪些优秀的Java爬虫项目?(一)
)
本文文章来自我的回答:GitHub上有哪些优秀的Java爬虫项目?但是,已经对该答案进行了一些修改,并添加了一些项目。这些项目来自GitHub和开源中国。我希望这些开源Java爬虫项目将对您有所帮助。阅读源代码可以帮助您获得质量上的改进
1、Gecco
GitHub地址:xtuhcy/GECCO
GECCO是一个用Java语言开发的轻量级且易于使用的web爬虫程序。它集成了jsoup、httpclient、fastjson、spring、htmlunit、再分配和其他框架。通过配置一些jQuery样式选择器,可以快速编写爬虫程序。GECCO框架具有良好的可扩展性。框架根据开闭原理设计,关闭修改,打开扩展
2、WebCollector
GitHub地址:crawlscript/webcollector
Webcollector是一个Java爬虫框架(内核),不需要配置,便于二次开发。它提供了一个简化的API,只需少量代码即可实现强大的爬虫程序。Webcollector Hadoop是Webcollector的Hadoop版本,支持分布式爬网
3、Spiderman
代码云地址:l-weiwei/spiderman2-代码云-开源中国
用例:演示垂直爬虫的能力-随风自由移动
蜘蛛侠是一种基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法捕获复杂的目标网页信息并将其解析为业务数据
4、WebMagic
代码云地址:flashsword20/webmagic-代码云-开源中国
Webmagic是一个无配置的爬虫框架,便于二次开发。它提供了一个简单灵活的API,只需少量代码即可实现爬虫程序。Webmagic采用全模块化设计,覆盖爬虫的整个生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬虫、分布式爬虫、自动重试、自定义UA/cookie等功能
5、Heritrix
GitHub地址:Internet Archive/heritrix 3 heritrix是一个开源和可扩展的web爬虫程序项目。用户可以使用它从互联网上获取所需的资源。Heritrix的设计严格遵循robots.txt文件和meta robots标签的排除说明。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
6、crawler4j
GitHub地址:yasserg/crawler4j·githubcrawler4j是一个用Java实现的开源web爬虫程序。提供一个易于使用的界面,以便在几分钟内创建多线程web爬虫程序
7、Nutch
GitHub地址:Apache/nutch
Nutch是一个用Java实现的开源搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫
在nutch的发展过程中,出现了四个Java开源项目,Hadoop、Tika、Gora和crawler commons。如今,这四个项目发展迅速,非常流行,尤其是Hadoop,它已经成为大规模数据处理的事实标准。Tika使用各种现有的开源内容解析项目从各种格式的文件中提取元数据和结构化文本。Gora支持将大数据持久化到各种存储实现中。Crawler Commons是一个通用的web爬虫组件
8、SeimiCrawler
GitHub地址:哲格晓霍兹/赛米克罗勒
Seimicrawler是一个灵活、独立部署和分布式Java爬虫框架。希望最大限度地降低新手开发高可用性、高性能爬虫系统的门槛,提高爬虫系统的开发效率。在seimi crawler的世界中,大多数人只需要关心编写捕获的业务逻辑,其余的seimi将帮助您。在设计理念上,seimicrawler受到Python的crawler框架scripy的启发,融合了Java语言和spring的特点,希望在中国使用更方便高效的XPath解析HTML。因此,seimicrawler的默认HTML解析器是JSOUPPATH(独立扩展项目,不是jsoup提供的),默认情况下,解析和提取HTML数据是使用XPath完成的(当然,数据处理也可以选择其他解析器)。它与seimiagent相结合,全面、完美地解决了复杂动态页面的渲染和抓取问题
9、Jsoup
GitHub地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
java爬虫抓取动态网页(动态页面和Ajax渲染页面数据基础的基本流程介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-21 23:16
)
内容简介
本文介绍了动态页面和Ajax呈现页面数据的示例,以及相应的页面分析过程,您会发现我认为复杂的Web攀登实际上比那些非动态网页更简单。
虽然Python数据分析师没有敲门代码不是一个好的数据分析师,但你不是郑的开发人员,什么是使用代码敲门?学习点数据爬行动物基础可以使繁琐的数据CV工作(Ctrl + C,Ctrl + V)是肤浅的。
ajax划痕示例
现在越来越多的网页的原创HTML文档不包括任何数据,而是用Ajax均匀加载。发送Ajax请求道路更新过程:
打开浏览器的开发人员工具,转到NetworkK选项卡,使用XHR过滤工具。您需要建立一个相应的文件夹以修改此配置并根据相应的All_Config_File.py文件打开相关服务。
all_config_file.py
#coding=utf-8
__author__ = 'Mr数据杨'
__explain__ = '各目标网站爬虫脚本配置文件'
#加载引用模块
import time
import pymongo
import pandas as pd
def news_page_num():
page_num=input("输入每个网站页面爬取的页面数:")
return int(page_num)
def title_error_num():
title_error_num=input("输入错误标题爬取最大数:")
return int(title_error_num)
def body_error_num():
body_error_num=input("输入错误页面爬取最大数:")
return int(body_error_num)
def mongodb_client():
# 获取mongoClient对象
client = pymongo.MongoClient("localhost", 27017)
# 获取使用的database对象
db = client.news
print("加载MongoDB数据库完毕......")
return db
db=mongodb_client()
def time_today():
# 全局函数
time_today = time.strftime('%Y-%m-%d', time.localtime(time.time()))
print("加载全局日期函数完毕......")
return time_today
# 错误日志信息
def error_text_title(text,time_today):
print("加载错误信息日志完毕......")
with open("logs/" + time_today + " news_title_error.txt", "a") as f:
f.write(text + '\n')
# 错误日志信息
def error_text_body(text,time_today):
with open("logs/" + time_today + " news_body_error.txt", "a") as f:
f.write(text + '\n')
# 找到每个爬取网页的链接
def get_title_links_from_MongoDB(label, type):
result = []
for item in db.news_tmp.find({'label': label, 'type': type}, {'url': 1, '_id': 1}):
result.append(item)
result = pd.DataFrame(result, columns=['url', '_id'])
return result
主程序
<p>#加载引用模块
import urllib
import urllib.request
import requests
import datetime
from bs4 import BeautifulSoup
import all_config_file
from all_config_file import error_text_title
from all_config_file import error_text_body
from all_config_file import get_title_links_from_MongoDB
cqcoal = "http://news.cqcoal.com/manage/ ... ot%3B
print("加载目标网址完毕......")
db = all_config_file.mongodb_client()
time_today = all_config_file.time_today()
def cqcoal_title_start(num):
def start_type(url, label, typeid, pagenum, type):
try:
page_num = 1
while page_num 查看全部
java爬虫抓取动态网页(动态页面和Ajax渲染页面数据基础的基本流程介绍
)
内容简介
本文介绍了动态页面和Ajax呈现页面数据的示例,以及相应的页面分析过程,您会发现我认为复杂的Web攀登实际上比那些非动态网页更简单。
虽然Python数据分析师没有敲门代码不是一个好的数据分析师,但你不是郑的开发人员,什么是使用代码敲门?学习点数据爬行动物基础可以使繁琐的数据CV工作(Ctrl + C,Ctrl + V)是肤浅的。
ajax划痕示例
现在越来越多的网页的原创HTML文档不包括任何数据,而是用Ajax均匀加载。发送Ajax请求道路更新过程:
打开浏览器的开发人员工具,转到NetworkK选项卡,使用XHR过滤工具。您需要建立一个相应的文件夹以修改此配置并根据相应的All_Config_File.py文件打开相关服务。
all_config_file.py
#coding=utf-8
__author__ = 'Mr数据杨'
__explain__ = '各目标网站爬虫脚本配置文件'
#加载引用模块
import time
import pymongo
import pandas as pd
def news_page_num():
page_num=input("输入每个网站页面爬取的页面数:")
return int(page_num)
def title_error_num():
title_error_num=input("输入错误标题爬取最大数:")
return int(title_error_num)
def body_error_num():
body_error_num=input("输入错误页面爬取最大数:")
return int(body_error_num)
def mongodb_client():
# 获取mongoClient对象
client = pymongo.MongoClient("localhost", 27017)
# 获取使用的database对象
db = client.news
print("加载MongoDB数据库完毕......")
return db
db=mongodb_client()
def time_today():
# 全局函数
time_today = time.strftime('%Y-%m-%d', time.localtime(time.time()))
print("加载全局日期函数完毕......")
return time_today
# 错误日志信息
def error_text_title(text,time_today):
print("加载错误信息日志完毕......")
with open("logs/" + time_today + " news_title_error.txt", "a") as f:
f.write(text + '\n')
# 错误日志信息
def error_text_body(text,time_today):
with open("logs/" + time_today + " news_body_error.txt", "a") as f:
f.write(text + '\n')
# 找到每个爬取网页的链接
def get_title_links_from_MongoDB(label, type):
result = []
for item in db.news_tmp.find({'label': label, 'type': type}, {'url': 1, '_id': 1}):
result.append(item)
result = pd.DataFrame(result, columns=['url', '_id'])
return result
主程序
<p>#加载引用模块
import urllib
import urllib.request
import requests
import datetime
from bs4 import BeautifulSoup
import all_config_file
from all_config_file import error_text_title
from all_config_file import error_text_body
from all_config_file import get_title_links_from_MongoDB
cqcoal = "http://news.cqcoal.com/manage/ ... ot%3B
print("加载目标网址完毕......")
db = all_config_file.mongodb_client()
time_today = all_config_file.time_today()
def cqcoal_title_start(num):
def start_type(url, label, typeid, pagenum, type):
try:
page_num = 1
while page_num
java爬虫抓取动态网页(目标网络爬虫的是做什么的?手动写一个简单的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-21 23:15
目标网络爬虫做什么?手动编写一个简单的网络爬虫1.webcrawler1.1.name1.2.short description@2.process
通过上面的流程图,我们可以大致了解网络爬虫的功能,并根据这些功能设计一个简单的网络爬虫
简单爬虫程序所需的功能:
发送请求和获取响应的功能;解析响应的功能;存储过滤后的数据的功能;处理解析后的URL路径@2.1.的函数涉及
3.分类
4.思维分析
首先,观察爬虫的起始页:
所有好消息信息的URL都用XPath表达式表示,即//div[@class='main_l']/UL/Li
相关数据
我们已经在上面的代码中找到了需要获得的关键信息的XPath表达式,然后我们可以正式编写代码来实现它
5.代码实现
代码实现部分采用webmagic框架,因为它比使用基本Java网络编程简单得多。注意:您可以看到以下关于webmagic框架的讲义
5.1.代码结构
5.@2.程序条目
Demo.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/")
// 启用的线程数
.thread(5).run();
}
}
5.3.爬行过程
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i 查看全部
java爬虫抓取动态网页(目标网络爬虫的是做什么的?手动写一个简单的)
目标网络爬虫做什么?手动编写一个简单的网络爬虫1.webcrawler1.1.name1.2.short description@2.process
通过上面的流程图,我们可以大致了解网络爬虫的功能,并根据这些功能设计一个简单的网络爬虫
简单爬虫程序所需的功能:
发送请求和获取响应的功能;解析响应的功能;存储过滤后的数据的功能;处理解析后的URL路径@2.1.的函数涉及
3.分类
4.思维分析
首先,观察爬虫的起始页:
所有好消息信息的URL都用XPath表达式表示,即//div[@class='main_l']/UL/Li
相关数据
我们已经在上面的代码中找到了需要获得的关键信息的XPath表达式,然后我们可以正式编写代码来实现它
5.代码实现
代码实现部分采用webmagic框架,因为它比使用基本Java网络编程简单得多。注意:您可以看到以下关于webmagic框架的讲义
5.1.代码结构
5.@2.程序条目
Demo.java
/**
* 程序入口
*/
public class Demo {
public static void main(String[] args) {
// 爬取开始
Spider
// 爬取过程
.create(new WanhoPageProcessor())
// 爬取结果保存
.addPipeline(new WanhoPipeline())
// 爬取的第一个页面
.addUrl("http://www.wanho.net/a/jyxb/";)
// 启用的线程数
.thread(5).run();
}
}
5.3.爬行过程
<p>package net.wanho.wanhosite;
import java.util.ArrayList;
import java.util.List;
import java.util.Vector;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
public class WanhoPageProcessor implements PageProcessor {
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site
.me()
.setTimeOut(10000)
.setRetryTimes(3)
.setSleepTime(1000)
.setCharset("UTF-8");
// 獲得站點
@Override
public Site getSite() {
return site;
}
//爬取過程
@Override
public void process(Page page) {
//获取当前页的所有喜报
List list = page.getHtml().xpath("//div[@class='main_l']/ul/li").all();
//要保存喜报的集合
Vector voLst = new Vector();
//遍历喜报
String title;
String content;
String img;
for (String item : list) {
Html tmp = Html.create(item);
//标题
title = tmp.xpath("//div[@class='content']/h4/a/text()").toString();
//内容
content = tmp.xpath("//div[@class='content']/p/text()").toString();
//图片路径
img = tmp.xpath("//a/img/@src").toString();
//加入集合
ArticleVo vo = new ArticleVo(title, content, img);
voLst.add(vo);
}
//保存数据至page中,后续进行持久化
page.putField("e_list", voLst);
//加载其它页
page.addTargetRequests( getOtherUrls());
}
//其它页
public List getOtherUrls(){
List urlLsts = new ArrayList();
for(int i=2;i
java爬虫抓取动态网页(java中好用的爬虫框架java爬虫系列包含哪些内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-09-21 23:13
1.overview Java爬虫系列收录哪些内容?Java爬虫框架简介webmgic使用webmgic抓取爱情电影中的电影资源(动作电影列表页面、电影下载地址等)使用webmgic抓取极客时代的课程资源(文章系列课程和视频系列课程)
本文的文章主要内容是介绍Java中易于使用的爬虫框架。Java crawler框架webmatic介绍了webgic的使用,以抓取动作电影列表信息
2.如何判断爬虫框架在Java中是否优秀?它易于学习和使用。网络上有很多相应的学习资料,比较完善,被很多人使用。现有坑已由其他人填充。使用起来会更舒适。该框架将更快地更新,社区将更加活跃。您可以快速体验一些更好的功能,并与作者交流。该框架结构稳定,扩展方便
根据以上几点,我们推荐一个非常易于使用的Java爬虫框架webmgic
3.webmgic简介
4.使用webgic抓取动作电影列表
使用webgic抓取爱情电影列表的资源信息
示例源代码地址1.createanewspringboot项目javapachong
2.import-Maven配置
org.springframework.boot
spring-boot-starter
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
us.codecraft
webmagic-core
0.7.3
fastjson
com.alibaba
commons-io
commons-io
commons-io
commons-io
fastjson
com.alibaba
fastjson
com.alibaba
log4j
log4j
slf4j-log4j12
org.slf4j
us.codecraft
webmagic-extension
0.7.3
us.codecraft
webmagic-selenium
0.7.3
net.minidev
json-smart
2.2.1
com.alibaba
fastjson
1.2.49
commons-lang
commons-lang
2.6
commons-io
commons-io
2.6
commons-codec
commons-codec
1.11
commons-collections
commons-collections
3.2.2
3.编写代码以捕获电影数据
package com.ady01.demo1;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* description:第一个爬虫示例,爬去动作片列表信息
* <b>time:2019/4/20 10:58
* <b>author:ready likun_557@163.com
*/
@Slf4j
public class Ady01comPageProcessor implements PageProcessor {
@Override
public void process(Page page) {
log.info("爬取成功!");
log.info("爬取的内容:" + page.getRawText());
}
@Override
public Site getSite() {
return Site.me().setSleepTime(1000).setRetryTimes(3);
}
public static void main(String[] args) {
String url = "http://m.ady01.com/rs/film/lis ... 3B%3B
Spider.create(new Ady01comPageProcessor()).addUrl(url).thread(1).run();
}
}
4.runcrawler代码
在ady01compageprocessor中运行main方法,执行结果如下:
5.summary本文主要使用一个示例来说明webgic非常简单,可以完成数据捕获。从代码中可以看出,复杂的代码webmagic屏蔽了我们。我们只需要注意编写业务代码文章并没有详细说明如何使用webmagic。至于我为什么没有在文档中解释,主要是webigc提供了一个非常完美的学习文档。您可以转到webmagic的中文文档。如果您需要更深入的了解,可以学习webmagic的源代码,这对您编写爬虫程序非常有用。明天我们将抓取每一部动作片的详细页面信息,采集下载详细页面的页面地址代码,导入idea,idea需要Maven和Lombok支持,更多技术文章请注意官方账号:javacode2018 查看全部
java爬虫抓取动态网页(java中好用的爬虫框架java爬虫系列包含哪些内容?)
1.overview Java爬虫系列收录哪些内容?Java爬虫框架简介webmgic使用webmgic抓取爱情电影中的电影资源(动作电影列表页面、电影下载地址等)使用webmgic抓取极客时代的课程资源(文章系列课程和视频系列课程)
本文的文章主要内容是介绍Java中易于使用的爬虫框架。Java crawler框架webmatic介绍了webgic的使用,以抓取动作电影列表信息
2.如何判断爬虫框架在Java中是否优秀?它易于学习和使用。网络上有很多相应的学习资料,比较完善,被很多人使用。现有坑已由其他人填充。使用起来会更舒适。该框架将更快地更新,社区将更加活跃。您可以快速体验一些更好的功能,并与作者交流。该框架结构稳定,扩展方便
根据以上几点,我们推荐一个非常易于使用的Java爬虫框架webmgic
3.webmgic简介
4.使用webgic抓取动作电影列表
使用webgic抓取爱情电影列表的资源信息
示例源代码地址1.createanewspringboot项目javapachong
2.import-Maven配置
org.springframework.boot
spring-boot-starter
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
us.codecraft
webmagic-core
0.7.3
fastjson
com.alibaba
commons-io
commons-io
commons-io
commons-io
fastjson
com.alibaba
fastjson
com.alibaba
log4j
log4j
slf4j-log4j12
org.slf4j
us.codecraft
webmagic-extension
0.7.3
us.codecraft
webmagic-selenium
0.7.3
net.minidev
json-smart
2.2.1
com.alibaba
fastjson
1.2.49
commons-lang
commons-lang
2.6
commons-io
commons-io
2.6
commons-codec
commons-codec
1.11
commons-collections
commons-collections
3.2.2
3.编写代码以捕获电影数据
package com.ady01.demo1;
import lombok.extern.slf4j.Slf4j;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
/**
* description:第一个爬虫示例,爬去动作片列表信息
* <b>time:2019/4/20 10:58
* <b>author:ready likun_557@163.com
*/
@Slf4j
public class Ady01comPageProcessor implements PageProcessor {
@Override
public void process(Page page) {
log.info("爬取成功!");
log.info("爬取的内容:" + page.getRawText());
}
@Override
public Site getSite() {
return Site.me().setSleepTime(1000).setRetryTimes(3);
}
public static void main(String[] args) {
String url = "http://m.ady01.com/rs/film/lis ... 3B%3B
Spider.create(new Ady01comPageProcessor()).addUrl(url).thread(1).run();
}
}
4.runcrawler代码
在ady01compageprocessor中运行main方法,执行结果如下:
5.summary本文主要使用一个示例来说明webgic非常简单,可以完成数据捕获。从代码中可以看出,复杂的代码webmagic屏蔽了我们。我们只需要注意编写业务代码文章并没有详细说明如何使用webmagic。至于我为什么没有在文档中解释,主要是webigc提供了一个非常完美的学习文档。您可以转到webmagic的中文文档。如果您需要更深入的了解,可以学习webmagic的源代码,这对您编写爬虫程序非常有用。明天我们将抓取每一部动作片的详细页面信息,采集下载详细页面的页面地址代码,导入idea,idea需要Maven和Lombok支持,更多技术文章请注意官方账号:javacode2018

