
java爬虫抓取动态网页
java爬虫抓取动态网页(Selenium+Chrome:运用到爬虫中的思路是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-21 14:10
爬虫:动态网页的处理方法(第2部分)——模拟浏览器行为前言:
在上一个示例中,我们使用WebKit库自定义浏览器渲染引擎,以便完全控制要执行的行为。如果您不需要如此多的灵活性,那么有一个很好的替代方案来替代selenium,它提供了一个API接口来自动化浏览器
硒简介:
Selenium是一种用于测试web应用程序的工具。Selenium测试直接在浏览器中运行,就像真实用户一样。支持市场上几乎所有主流浏览器
最初,我打算使用selenium+phantom JS的组合,但我发现chrome和Firefox也相继推出了无头浏览器模式,我更喜欢chrome。本文采用硒+铬的组合
例如:
适用于爬行动物的想法是:
以新浪阅读图书节选网站为例。目标是获取列表中每个文章详细页面的地址。直接参见示例代码:
# coding=utf-8
import time
from selenium import webdriver
class SinaBookSpider(object):
# 创建可见的Chrome浏览器, 方便调试
driver = webdriver.Chrome()
# 创建Chrome的无头浏览器
# opt = webdriver.ChromeOptions()
# opt.set_headless()
# driver = webdriver.Chrome(options=opt)
driver.implicitly_wait(10)
total = 1526 # 预先计算的总数据量
count = 0 # 已爬取的数据量
# 记录解析以及翻页位置
location = 0
click_times = 0
def run(self):
"""
开始爬虫
:return:
"""
# get方式打开网页
self.driver.get("http://book.sina.com.cn/excerpt/rwws/")
self.parselist()
while self.count < self.total:
if self.click_times is 2:
self.driver.find_element_by_css_selector('#subShowContent1_page > span:nth-child(6) > a').click()
# 等待页面加载完成
time.sleep(5)
self.click_times = 0
self.location = 0
else:
self.driver.find_element_by_css_selector('#subShowContent1_loadMore').click()
# 等待页面加载完成
time.sleep(3)
self.click_times += 1
# 分析加载的新内容,从location开始
self.parselist()
self.driver.quit()
def parselist(self):
"""
解析列表
:return:
"""
divs = self.driver.find_elements_by_class_name("item")
for i in range(self.location, len(divs)):
link = divs[i].find_element_by_tag_name('a').get_attribute("href")
print link
self.location += 1
self.count += 1
print self.count
if __name__ == '__main__':
spider = SinaBookSpider()
spider.run()
代码地址:动态web进程--GitHub
如果要实际运行上述代码,请确保在运行之前安装了与浏览器版本对应的驱动程序,并将其正确添加到环境变量中
这里可以看到对这三种方法的解释:Python selenium——必须能够使用selenium进行等待,以及对这三种等待方法的解释——gray和blue博客
总结:
在这里,我们介绍两种动态页面处理方法:
做一个简单的比较:
使用哪种方法取决于爬行动物活动的具体情况:
就我个人而言,我认为应该尽可能避免模拟浏览器的方法,因为浏览器环境会消耗大量内存和CPU,这可以作为短期解决方案。此时,长期性能和可靠性并不重要;作为一个长期的解决方案,我将尽最大努力网站进行逆向工程
欢迎指出本文中的任何错误或不足之处 查看全部
java爬虫抓取动态网页(Selenium+Chrome:运用到爬虫中的思路是什么?)
爬虫:动态网页的处理方法(第2部分)——模拟浏览器行为前言:
在上一个示例中,我们使用WebKit库自定义浏览器渲染引擎,以便完全控制要执行的行为。如果您不需要如此多的灵活性,那么有一个很好的替代方案来替代selenium,它提供了一个API接口来自动化浏览器
硒简介:
Selenium是一种用于测试web应用程序的工具。Selenium测试直接在浏览器中运行,就像真实用户一样。支持市场上几乎所有主流浏览器
最初,我打算使用selenium+phantom JS的组合,但我发现chrome和Firefox也相继推出了无头浏览器模式,我更喜欢chrome。本文采用硒+铬的组合
例如:
适用于爬行动物的想法是:
以新浪阅读图书节选网站为例。目标是获取列表中每个文章详细页面的地址。直接参见示例代码:
# coding=utf-8
import time
from selenium import webdriver
class SinaBookSpider(object):
# 创建可见的Chrome浏览器, 方便调试
driver = webdriver.Chrome()
# 创建Chrome的无头浏览器
# opt = webdriver.ChromeOptions()
# opt.set_headless()
# driver = webdriver.Chrome(options=opt)
driver.implicitly_wait(10)
total = 1526 # 预先计算的总数据量
count = 0 # 已爬取的数据量
# 记录解析以及翻页位置
location = 0
click_times = 0
def run(self):
"""
开始爬虫
:return:
"""
# get方式打开网页
self.driver.get("http://book.sina.com.cn/excerpt/rwws/";)
self.parselist()
while self.count < self.total:
if self.click_times is 2:
self.driver.find_element_by_css_selector('#subShowContent1_page > span:nth-child(6) > a').click()
# 等待页面加载完成
time.sleep(5)
self.click_times = 0
self.location = 0
else:
self.driver.find_element_by_css_selector('#subShowContent1_loadMore').click()
# 等待页面加载完成
time.sleep(3)
self.click_times += 1
# 分析加载的新内容,从location开始
self.parselist()
self.driver.quit()
def parselist(self):
"""
解析列表
:return:
"""
divs = self.driver.find_elements_by_class_name("item")
for i in range(self.location, len(divs)):
link = divs[i].find_element_by_tag_name('a').get_attribute("href")
print link
self.location += 1
self.count += 1
print self.count
if __name__ == '__main__':
spider = SinaBookSpider()
spider.run()
代码地址:动态web进程--GitHub
如果要实际运行上述代码,请确保在运行之前安装了与浏览器版本对应的驱动程序,并将其正确添加到环境变量中
这里可以看到对这三种方法的解释:Python selenium——必须能够使用selenium进行等待,以及对这三种等待方法的解释——gray和blue博客
总结:
在这里,我们介绍两种动态页面处理方法:
做一个简单的比较:
使用哪种方法取决于爬行动物活动的具体情况:
就我个人而言,我认为应该尽可能避免模拟浏览器的方法,因为浏览器环境会消耗大量内存和CPU,这可以作为短期解决方案。此时,长期性能和可靠性并不重要;作为一个长期的解决方案,我将尽最大努力网站进行逆向工程
欢迎指出本文中的任何错误或不足之处
java爬虫抓取动态网页(关于Java使用PhantomJs的一些事儿,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-21 14:08
让我们先离题。当我刚开始学习爬行动物时,有一次一位大四的学生让我需要捕捉京东图书的相关信息。因为我刚刚开始学习爬行动物和练习豆瓣菜,所以我抓取了大约500篇电影评论并存储在MySQL中。当时,我觉得自己不够强壮,所以很容易就接受了这个要求
然后自信地开始工作。。首先查看网页源代码。。。???我需要的不是源代码!!!然后我去问大四。前辈告诉我这是由Ajax生成的数据。听了之后,我去检查数据。人们发现,互联网上的大量信息正在解释一个事实。对于动态页面,使用phantom JS进行捕获,但这种效率非常低。作为一名优秀的程序员,我当时看到了四个低效字,这在我心里是绝对不允许的,所以我使用捕获数据包的方式查看ajax数据所在的URL。模拟浏览器的方法一直被搁置至今
但是现在你知道了这件事,没有理由不去学习。因此,我花了一些时间阅读了有关在Java中使用phantom JS的信息,现在我将与您分享
顺便说一句,作为一个网络爬虫,页面上90%的数据可以通过捕获数据包获得。因此,我鼓励您直接请求所需数据的URL。毕竟,尽管这种方法很方便,但效率很低
JS渲染与ajax
在学习这件事之前,我们必须首先了解什么是JS渲染,什么是Ajax,以及为什么我们不能在web源代码中获取这两种数据
据我了解,JS渲染和Ajax是相辅相成的。AJAX负责从服务器异步获取数据,获取数据后用JS进行渲染,最后将数据呈现给用户。在Java中,httpclient只能请求简单的静态页面,不能在页面完全加载后请求JS调用相关代码生成的异步数据。因此,我们无法通过httpclient直接获取Ajax和JS渲染生成的数据。此时,建议您直接捕获网络数据包以获取ajax数据所在的URL,或者使用本文中描述的phantom JS呈现引擎
三种JS渲染引擎的比较
在互联网上查阅信息时,我们常常被各种各样的答案所淹没。此时,首先要保持平静的心情,其次,我们应该考虑搜索问题的相关姿势,我们需要在必要时科学地上网。
更不用说本文中提到的JS呈现引擎,Java爬虫中的HTTP请求库可以用多种方式描述。Java的本机httpurlconnection类、httpclient第三方库等等。。。当然,网络上有太多可用的方法,我们必须选择,因此我们当然希望选择一个功能强大且简单的类库。此时,我们应该在互联网上搜索并比较两个类库,以做出更好的选择,而不是仅仅选择一个来学习。这样,学习成本很可能与回报不成正比
所以我相信,当您准备使用JS引擎来模拟浏览器时,您不仅看到了phantom JS,还看到了selenium和htmlunit,它们具有相同的功能。那么我们如何选择呢?下图摘自其他网友的博客:
HtmlUnitSeleniumPhantomJs
内置rhinojs浏览器引擎,没有浏览器使用此内核,解析速度平均,解析JS/CSS较差,没有浏览器界面
Selenium+webdriver=Selenium基于本地安装的浏览器。需要打开浏览器,引用相应的webdriver,并正确配置webdriver的路径参数。在抓取大量JS呈现的页面时,这显然是不合适的
工件简短而简洁,可以在本地运行,也可以作为服务器运行。它基于WebKit内核,具有良好的性能和性能,能够完美解析大多数页面
这就是为什么我选择谈论幻影JS
在互联网上,phantom JS和selenium经常成对出现。原因是selenium封装了phantom JS的一些函数,并且selenium提供了Python接口模块。Selenium可以在Python语言中很好地使用,phantom JS可以间接使用。然而,是时候放弃selenium+phantom JS了。一个原因是封装的接口很长时间没有更新(没有人维护它)。另一个原因是selenium只实现了一些phantom JS函数,而且非常不完善
幻影JS的使用
我用Ubuntu16.04开发环境。关于phantom JS+selenium的环境部署,网络上有很多信息。我将在这里介绍一个链接。我不会详细解释:Ubuntu安装phantomjs
我不会详细介绍phantom JS和selenium的介绍。你可以直接去百度。让我们直接看看幻像JS应该如何在java
中使用
如果您不使用maven,请在Internet上下载第三方jar包。我们需要的Maven依赖项如下:
org.seleniumhq.selenium
selenium-java
2.53.1
com.github.detro.ghostdriver
phantomjsdriver
1.1.0
接下来,让我们看看程序应该如何编写:
1.set请求头
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径,使用whereis phantomjs可以查看)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY, "/usr/local/bin/phantomjs");
2.create phantomjs浏览器对象
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
3.set隐藏等待
//设置隐性等待
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
由于加载页面需要一段时间,如果在加载页面之前查找元素,则一定无法找到它们。最好的方法是设置默认等待时间。如果找不到页面元素,请等待一段时间,直到它超时
使用phantomjs时应注意以上三点。您可以查看一般的总体程序:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.concurrent.TimeUnit;
/**
* Created by hg_yi on 17-10-11.
*/
public class phantomjs {
public static void main(String[] args) {
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,
"/usr/bin/phantomjs-2.1.1-linux-x86_64/bin/phantomjs");
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
//设置隐性等待(作用于全局)
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
//打开页面
driver.get("--------------------------------");
//查找元素
WebElement element = driver.findElement(By.id("img_valiCode"));
System.out.println(element.getAttribute("src"));
}
}
我成功捕获了网页源代码中没有的数据~
对于上面使用的phantomjsdriver类的相关API,您可以直接查看此资料,它应该满足您的日常需要:webdriver API中文版(webdriver API也适用于phantomjsdriver)
phantom JS的性能优化
我们都知道,使用phantom JS等无头浏览器捕获web源代码非常耗时,因此当我们决定使用此工具并对捕获速度有一定要求时,我们需要掌握优化phantom JS性能的能力
1.设置参数
谷歌和百度已经阅读了很长时间的一些官方文档,但是他们仍然找不到与phantomjs相关的Java调用API文档。好吧,先抛出一篇python文章,然后找到这方面的内容并加以补充~~~
[phantom JS series]硒+phantom JS性能优化
旁白:事实上,对于java网络爬虫。。。真想吐槽,建议刚开始抱怨爬行动物或与Python爬虫搏斗的人~~对Java爬虫来说,只要说一句话:学习很难,学习周期很长,扔东西和收入不成正比!!!p> 查看全部
java爬虫抓取动态网页(关于Java使用PhantomJs的一些事儿,你了解多少?)
让我们先离题。当我刚开始学习爬行动物时,有一次一位大四的学生让我需要捕捉京东图书的相关信息。因为我刚刚开始学习爬行动物和练习豆瓣菜,所以我抓取了大约500篇电影评论并存储在MySQL中。当时,我觉得自己不够强壮,所以很容易就接受了这个要求
然后自信地开始工作。。首先查看网页源代码。。。???我需要的不是源代码!!!然后我去问大四。前辈告诉我这是由Ajax生成的数据。听了之后,我去检查数据。人们发现,互联网上的大量信息正在解释一个事实。对于动态页面,使用phantom JS进行捕获,但这种效率非常低。作为一名优秀的程序员,我当时看到了四个低效字,这在我心里是绝对不允许的,所以我使用捕获数据包的方式查看ajax数据所在的URL。模拟浏览器的方法一直被搁置至今
但是现在你知道了这件事,没有理由不去学习。因此,我花了一些时间阅读了有关在Java中使用phantom JS的信息,现在我将与您分享
顺便说一句,作为一个网络爬虫,页面上90%的数据可以通过捕获数据包获得。因此,我鼓励您直接请求所需数据的URL。毕竟,尽管这种方法很方便,但效率很低
JS渲染与ajax
在学习这件事之前,我们必须首先了解什么是JS渲染,什么是Ajax,以及为什么我们不能在web源代码中获取这两种数据
据我了解,JS渲染和Ajax是相辅相成的。AJAX负责从服务器异步获取数据,获取数据后用JS进行渲染,最后将数据呈现给用户。在Java中,httpclient只能请求简单的静态页面,不能在页面完全加载后请求JS调用相关代码生成的异步数据。因此,我们无法通过httpclient直接获取Ajax和JS渲染生成的数据。此时,建议您直接捕获网络数据包以获取ajax数据所在的URL,或者使用本文中描述的phantom JS呈现引擎
三种JS渲染引擎的比较
在互联网上查阅信息时,我们常常被各种各样的答案所淹没。此时,首先要保持平静的心情,其次,我们应该考虑搜索问题的相关姿势,我们需要在必要时科学地上网。
更不用说本文中提到的JS呈现引擎,Java爬虫中的HTTP请求库可以用多种方式描述。Java的本机httpurlconnection类、httpclient第三方库等等。。。当然,网络上有太多可用的方法,我们必须选择,因此我们当然希望选择一个功能强大且简单的类库。此时,我们应该在互联网上搜索并比较两个类库,以做出更好的选择,而不是仅仅选择一个来学习。这样,学习成本很可能与回报不成正比
所以我相信,当您准备使用JS引擎来模拟浏览器时,您不仅看到了phantom JS,还看到了selenium和htmlunit,它们具有相同的功能。那么我们如何选择呢?下图摘自其他网友的博客:
HtmlUnitSeleniumPhantomJs
内置rhinojs浏览器引擎,没有浏览器使用此内核,解析速度平均,解析JS/CSS较差,没有浏览器界面
Selenium+webdriver=Selenium基于本地安装的浏览器。需要打开浏览器,引用相应的webdriver,并正确配置webdriver的路径参数。在抓取大量JS呈现的页面时,这显然是不合适的
工件简短而简洁,可以在本地运行,也可以作为服务器运行。它基于WebKit内核,具有良好的性能和性能,能够完美解析大多数页面
这就是为什么我选择谈论幻影JS
在互联网上,phantom JS和selenium经常成对出现。原因是selenium封装了phantom JS的一些函数,并且selenium提供了Python接口模块。Selenium可以在Python语言中很好地使用,phantom JS可以间接使用。然而,是时候放弃selenium+phantom JS了。一个原因是封装的接口很长时间没有更新(没有人维护它)。另一个原因是selenium只实现了一些phantom JS函数,而且非常不完善
幻影JS的使用
我用Ubuntu16.04开发环境。关于phantom JS+selenium的环境部署,网络上有很多信息。我将在这里介绍一个链接。我不会详细解释:Ubuntu安装phantomjs
我不会详细介绍phantom JS和selenium的介绍。你可以直接去百度。让我们直接看看幻像JS应该如何在java
中使用
如果您不使用maven,请在Internet上下载第三方jar包。我们需要的Maven依赖项如下:
org.seleniumhq.selenium
selenium-java
2.53.1
com.github.detro.ghostdriver
phantomjsdriver
1.1.0
接下来,让我们看看程序应该如何编写:
1.set请求头
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径,使用whereis phantomjs可以查看)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY, "/usr/local/bin/phantomjs");
2.create phantomjs浏览器对象
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
3.set隐藏等待
//设置隐性等待
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
由于加载页面需要一段时间,如果在加载页面之前查找元素,则一定无法找到它们。最好的方法是设置默认等待时间。如果找不到页面元素,请等待一段时间,直到它超时
使用phantomjs时应注意以上三点。您可以查看一般的总体程序:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.concurrent.TimeUnit;
/**
* Created by hg_yi on 17-10-11.
*/
public class phantomjs {
public static void main(String[] args) {
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,
"/usr/bin/phantomjs-2.1.1-linux-x86_64/bin/phantomjs");
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
//设置隐性等待(作用于全局)
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
//打开页面
driver.get("--------------------------------");
//查找元素
WebElement element = driver.findElement(By.id("img_valiCode"));
System.out.println(element.getAttribute("src"));
}
}
我成功捕获了网页源代码中没有的数据~
对于上面使用的phantomjsdriver类的相关API,您可以直接查看此资料,它应该满足您的日常需要:webdriver API中文版(webdriver API也适用于phantomjsdriver)
phantom JS的性能优化
我们都知道,使用phantom JS等无头浏览器捕获web源代码非常耗时,因此当我们决定使用此工具并对捕获速度有一定要求时,我们需要掌握优化phantom JS性能的能力
1.设置参数
谷歌和百度已经阅读了很长时间的一些官方文档,但是他们仍然找不到与phantomjs相关的Java调用API文档。好吧,先抛出一篇python文章,然后找到这方面的内容并加以补充~~~
[phantom JS series]硒+phantom JS性能优化
旁白:事实上,对于java网络爬虫。。。真想吐槽,建议刚开始抱怨爬行动物或与Python爬虫搏斗的人~~对Java爬虫来说,只要说一句话:学习很难,学习周期很长,扔东西和收入不成正比!!!p>
java爬虫抓取动态网页(soup()需要爬取的网站数据及分析方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-09-21 14:07
参考原文:
需要爬网的网站数据:共165页,可通过将page=1改为其他数字进行访问
获取所有URL:URL=(“{}”。范围(1)中的I的格式(I),166))
使用Firefox浏览器打开要爬网的网页,右键单击查看页面源代码,Ctrl+F查找并输入293。此值在源代码中不存在,表示它是动态加载的数据
对于动态加载的数据,我熟悉两种方法:一种是使用selenium,另一种是分析网页元素,找出原创网页中的数据,提交表单,并获取不同的数据以达到爬行的目的
方法1:
#coding=utf-8
from bs4 import BeautifulSoup
from selenium import webdriver
urls = ('http://gkcx.eol.cn/soudaxue/qu ... ge%3D{}'.format(i) for i in range(1,166))
driver=webdriver.Firefox()
driver.maximize_window()
for url in urls:
#print ("正在访问{}".format(url))
driver.get(url)
data = driver.page_source
soup = BeautifulSoup(data, 'lxml')
grades = soup.find_all('tr')
for grade in grades:
if '' in str(grade):
print(grade.get_text())
代码说明:
从BS4导入Beauty soup使用Beauty soup解析网页数据
从selenium导入webdriver使用selenium抓取动态数据
URL=('{}'。范围(1)中的i的格式(i),166))收录需要爬网的所有数据的网站生成器
Driver=webdriver.Firefox()打开Firefox浏览器
Driver.maximize_window()最大化窗口
driver.get(URL)浏览器会自动跳转到URL链接
Data=driver.page\u source获取页面元素,其中收录要爬网的数据
soup=BeautifulSoup(数据'lxml')
等级=汤。查找所有('tr'))
按年级划分的年级:
如果str(年级)中有“”:
打印(grade.get_text())
通过分析数据并写出上述搜索方法,您可以获得所有数据
通过这种方法获取数据简单直观,但缺点是速度太慢
现在,第二种方法是获取数据
使用Firefox浏览器打开要爬网的网页,右键单击查看元素,然后选择“网络”。默认情况下,该功能正常
(一些旧版本的Firefox可能需要安装firebug插件)
单击第二页以查看加载了哪些页面和数据
分析如下:
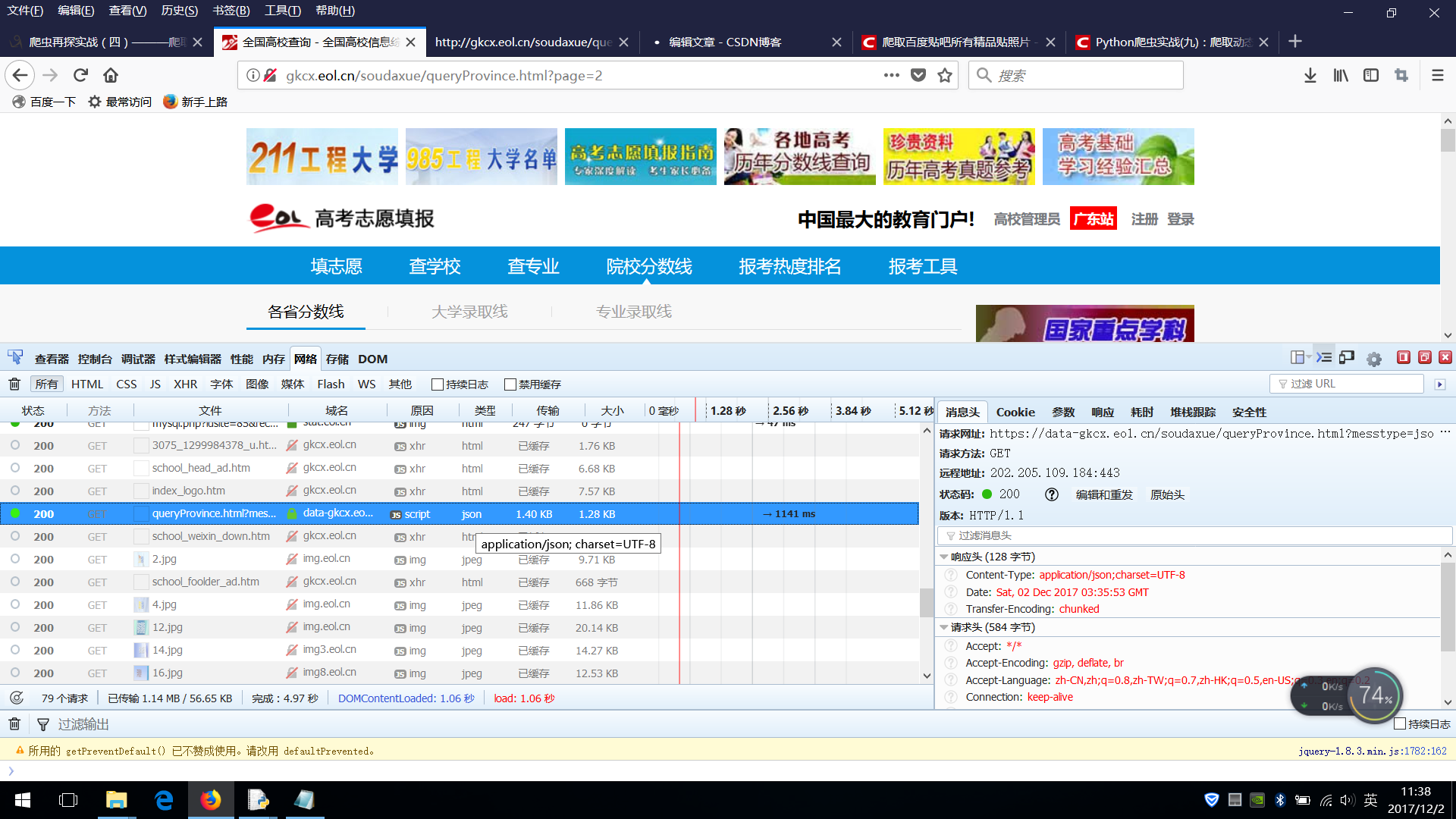
分析表明,JSON类型的列就是我们需要的数据
在消息头网站中查看请求@
实际请求网站
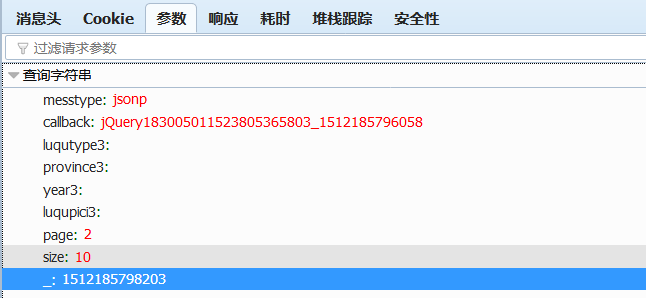
参数mestype=jsonp&;callback=jquery3805365803&;luqutype3=&;province3=&;year3=&;luqupici3=&;page=2&;size=10&;03
也可以单击右侧的参数栏以查看参数
Page表示当前的页数
大小表示每页显示的项目数
编写代码
#coding=utf-8
import requests
import json
from prettytable import PrettyTable
if __name__=='__main__':
url = 'https://data-gkcx.eol.cn/souda ... 39%3B
row = PrettyTable()
row.field_names = ["地区", "年份", "考生类别", "批次","分数线"]
for i in range(1,34):
data ={"messtype":"json",
"page":i,
"size":50,
"callback":
"jQuery1830426658582613074_1469201131959",
"_":"1469201133189",
}
school_datas = requests.post(url,data = data).json()
datas = school_datas["school"]
for data in datas:
row.add_row((data["province"] ,data["year"],data["bath"],data["type"], data["score"]))
print(row)
代码描述
对于范围(1,34):
共有1644个条目。每页上显示的最大条目数为50,1600/50=32,44个条目为33页,因此范围应为(1,34)
数据={“messtype”:“json”
“页面”:我
“尺寸”:50
“回调”:
“jQuery82613074_59”
":"89"
}
分析提交的数据并使用post方法 查看全部
java爬虫抓取动态网页(soup()需要爬取的网站数据及分析方法)
参考原文:
需要爬网的网站数据:共165页,可通过将page=1改为其他数字进行访问
获取所有URL:URL=(“{}”。范围(1)中的I的格式(I),166))
使用Firefox浏览器打开要爬网的网页,右键单击查看页面源代码,Ctrl+F查找并输入293。此值在源代码中不存在,表示它是动态加载的数据
对于动态加载的数据,我熟悉两种方法:一种是使用selenium,另一种是分析网页元素,找出原创网页中的数据,提交表单,并获取不同的数据以达到爬行的目的
方法1:
#coding=utf-8
from bs4 import BeautifulSoup
from selenium import webdriver
urls = ('http://gkcx.eol.cn/soudaxue/qu ... ge%3D{}'.format(i) for i in range(1,166))
driver=webdriver.Firefox()
driver.maximize_window()
for url in urls:
#print ("正在访问{}".format(url))
driver.get(url)
data = driver.page_source
soup = BeautifulSoup(data, 'lxml')
grades = soup.find_all('tr')
for grade in grades:
if '' in str(grade):
print(grade.get_text())
代码说明:
从BS4导入Beauty soup使用Beauty soup解析网页数据
从selenium导入webdriver使用selenium抓取动态数据
URL=('{}'。范围(1)中的i的格式(i),166))收录需要爬网的所有数据的网站生成器
Driver=webdriver.Firefox()打开Firefox浏览器
Driver.maximize_window()最大化窗口
driver.get(URL)浏览器会自动跳转到URL链接
Data=driver.page\u source获取页面元素,其中收录要爬网的数据
soup=BeautifulSoup(数据'lxml')
等级=汤。查找所有('tr'))
按年级划分的年级:
如果str(年级)中有“”:
打印(grade.get_text())
通过分析数据并写出上述搜索方法,您可以获得所有数据
通过这种方法获取数据简单直观,但缺点是速度太慢
现在,第二种方法是获取数据
使用Firefox浏览器打开要爬网的网页,右键单击查看元素,然后选择“网络”。默认情况下,该功能正常
(一些旧版本的Firefox可能需要安装firebug插件)
单击第二页以查看加载了哪些页面和数据
分析如下:
分析表明,JSON类型的列就是我们需要的数据
在消息头网站中查看请求@
实际请求网站
参数mestype=jsonp&;callback=jquery3805365803&;luqutype3=&;province3=&;year3=&;luqupici3=&;page=2&;size=10&;03
也可以单击右侧的参数栏以查看参数
Page表示当前的页数
大小表示每页显示的项目数
编写代码
#coding=utf-8
import requests
import json
from prettytable import PrettyTable
if __name__=='__main__':
url = 'https://data-gkcx.eol.cn/souda ... 39%3B
row = PrettyTable()
row.field_names = ["地区", "年份", "考生类别", "批次","分数线"]
for i in range(1,34):
data ={"messtype":"json",
"page":i,
"size":50,
"callback":
"jQuery1830426658582613074_1469201131959",
"_":"1469201133189",
}
school_datas = requests.post(url,data = data).json()
datas = school_datas["school"]
for data in datas:
row.add_row((data["province"] ,data["year"],data["bath"],data["type"], data["score"]))
print(row)
代码描述
对于范围(1,34):
共有1644个条目。每页上显示的最大条目数为50,1600/50=32,44个条目为33页,因此范围应为(1,34)
数据={“messtype”:“json”
“页面”:我
“尺寸”:50
“回调”:
“jQuery82613074_59”
":"89"
}
分析提交的数据并使用post方法
java爬虫抓取动态网页(豆瓣View:headlessbrowser网页抓取(网络爬虫)的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-21 14:05
CasperJS是一个导航脚本&;用于PhantomJS(WebKit)和SlimerJS(Gecko)无头浏览器的测试实用程序,用Javascript编写
Phantom JS是一款基于WebKit内核的无头浏览器
Slimerjs是一款基于gecko内核的无头浏览器
无头浏览器:没有界面显示的浏览器。它可以用于自动测试、网页截图、JS注入、DOM操作等。它是一个非常新的web应用工具。虽然该浏览器没有任何界面输出,但它可以在许多方面得到广泛的应用。整篇文章文章将介绍使用casperjs的web页面爬行(web crawler)的应用。这篇文章只是起到了吸引翡翠的作用。事实上,无头浏览器技术的应用将非常广泛,甚至可能会深刻地影响web前端和后端技术的发展
本文使用了著名的网站[]“operation”(仅供研究、学习和使用。我希望该站不会打扰我
),以测试功能强大的无头浏览器网页捕获技术的威力
第一步是安装casperjs,打开casperjs官网,下载并安装最新稳定版本的casperjs,官网上有非常详细的文档,这是学习casperjs最好的第一手资料,当然如果安装了NPM,也可以通过NPM直接安装。同时,这也是官方推荐的安装方法。关于安装的内容不多。官方文件非常详细
1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
视图代码
第二步是分析target网站.一般来说,内容类网站分为列表页和详细内容页。Douban也不例外。先看看豆瓣列表的页长。经过分析,发现豆瓣电影网站的列表页像T。他的。首先,你可以点击排序规则。翻页不像翻过传统的页码,而是点击最后一页来加载更多。对于这样一个页面,传统的爬虫程序通常会停止烹饪,或者实现非常复杂。但是,对于无头浏览器技术,这是一个很小的例子分析网页,你可以看到点击这个[load more]位置可以持续显示更多的电影信息
第三步是开始编写代码获取电影详情页面的链接信息。我们不礼貌。模拟点击此处采集超链接列表。以下代码是获取链接的代码。引用并创建casperjs对象。如果网页需要插入脚本,您可以引用要插入的脚本生成Casper对象时,注入到clientscript部分的网页中。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
视图代码
)
完成获取详细信息页面链接的代码。单击[load more]并循环50次。事实上,可以通过[判断while(而不是“loading more”)然后(stop)]来改进循环。获取后,使用require('utils')。Dump(…)要输出链接列表,请将以下代码另存为getdoublanlist.js,然后运行casperjs getdoublanlist.js以获取并输出该类别下的所有详细页面链接
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
GetAllUrls
引用的recordurl模块不是用mongodb编写的,您可以自己完成
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录URL
第四步是分析细节页面并编写细节页面捕获程序
在这一步中,您已经获得了要捕获的详细页面列表。现在让我们打开一个电影详细页面,看看结构如何,并分析如何捕获每个信息。对于信息捕获,我们必须综合使用DOM、文本处理、JS脚本和其他技术。我想获得这部分的信息,包括di校长、编剧、乐谱等等。我们在本文中不再重复。这里我们只提取一些信息项的示例
1.grab director list:domcss选择器'div#info span:nth child(1)span.Attrs a')的director列表。我们使用函数gettexcontent(strule,strmesg)方法来获取内容
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subject/25662329/', fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获得董事
2.使用CSS选择器很难捕捉生产国家和地区。分析网页后,我们可以发现,首先,信息没有放置在标签中,文本“America”直接位于标签中
在这个高级元素中。对于此类信息,我们使用另一种方法,文本分析和截取。首先,映射字符串模块var s=require(“字符串”);此模块也将单独安装。然后获取整个信息,然后用文本截取:
1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
GetCountry
其他信息也可以类似地获得
第五步:存储捕获的信息并将其作为分析源,建议使用NoSQL数据库存储,如mongodb,更适合存储此类非结构化数据,性能更好 查看全部
java爬虫抓取动态网页(豆瓣View:headlessbrowser网页抓取(网络爬虫)的应用)
CasperJS是一个导航脚本&;用于PhantomJS(WebKit)和SlimerJS(Gecko)无头浏览器的测试实用程序,用Javascript编写
Phantom JS是一款基于WebKit内核的无头浏览器
Slimerjs是一款基于gecko内核的无头浏览器
无头浏览器:没有界面显示的浏览器。它可以用于自动测试、网页截图、JS注入、DOM操作等。它是一个非常新的web应用工具。虽然该浏览器没有任何界面输出,但它可以在许多方面得到广泛的应用。整篇文章文章将介绍使用casperjs的web页面爬行(web crawler)的应用。这篇文章只是起到了吸引翡翠的作用。事实上,无头浏览器技术的应用将非常广泛,甚至可能会深刻地影响web前端和后端技术的发展
本文使用了著名的网站[]“operation”(仅供研究、学习和使用。我希望该站不会打扰我

),以测试功能强大的无头浏览器网页捕获技术的威力
第一步是安装casperjs,打开casperjs官网,下载并安装最新稳定版本的casperjs,官网上有非常详细的文档,这是学习casperjs最好的第一手资料,当然如果安装了NPM,也可以通过NPM直接安装。同时,这也是官方推荐的安装方法。关于安装的内容不多。官方文件非常详细


1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
视图代码
第二步是分析target网站.一般来说,内容类网站分为列表页和详细内容页。Douban也不例外。先看看豆瓣列表的页长。经过分析,发现豆瓣电影网站的列表页像T。他的。首先,你可以点击排序规则。翻页不像翻过传统的页码,而是点击最后一页来加载更多。对于这样一个页面,传统的爬虫程序通常会停止烹饪,或者实现非常复杂。但是,对于无头浏览器技术,这是一个很小的例子分析网页,你可以看到点击这个[load more]位置可以持续显示更多的电影信息

第三步是开始编写代码获取电影详情页面的链接信息。我们不礼貌。模拟点击此处采集超链接列表。以下代码是获取链接的代码。引用并创建casperjs对象。如果网页需要插入脚本,您可以引用要插入的脚本生成Casper对象时,注入到clientscript部分的网页中。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
视图代码
)
完成获取详细信息页面链接的代码。单击[load more]并循环50次。事实上,可以通过[判断while(而不是“loading more”)然后(stop)]来改进循环。获取后,使用require('utils')。Dump(…)要输出链接列表,请将以下代码另存为getdoublanlist.js,然后运行casperjs getdoublanlist.js以获取并输出该类别下的所有详细页面链接
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
GetAllUrls
引用的recordurl模块不是用mongodb编写的,您可以自己完成
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录URL
第四步是分析细节页面并编写细节页面捕获程序
在这一步中,您已经获得了要捕获的详细页面列表。现在让我们打开一个电影详细页面,看看结构如何,并分析如何捕获每个信息。对于信息捕获,我们必须综合使用DOM、文本处理、JS脚本和其他技术。我想获得这部分的信息,包括di校长、编剧、乐谱等等。我们在本文中不再重复。这里我们只提取一些信息项的示例

1.grab director list:domcss选择器'div#info span:nth child(1)span.Attrs a')的director列表。我们使用函数gettexcontent(strule,strmesg)方法来获取内容
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subject/25662329/', fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获得董事
2.使用CSS选择器很难捕捉生产国家和地区。分析网页后,我们可以发现,首先,信息没有放置在标签中,文本“America”直接位于标签中
在这个高级元素中。对于此类信息,我们使用另一种方法,文本分析和截取。首先,映射字符串模块var s=require(“字符串”);此模块也将单独安装。然后获取整个信息,然后用文本截取:

1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
GetCountry
其他信息也可以类似地获得
第五步:存储捕获的信息并将其作为分析源,建议使用NoSQL数据库存储,如mongodb,更适合存储此类非结构化数据,性能更好
java爬虫抓取动态网页(基于微内核+插件式架构的JAVA爬虫框架(内核))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-21 14:05
1、Gecco
GitHub地址:xtuhcy/GECCO
GECCO是一个用Java语言开发的轻量级且易于使用的web爬虫程序。它集成了jsoup、httpclient、fastjson、spring、htmlunit、再分配和其他框架。通过配置一些jQuery样式选择器,可以快速编写爬虫程序。GECCO框架具有良好的可扩展性。框架根据开闭原理设计,关闭修改,打开扩展
2、WebCollector
GitHub地址:crawlscript/webcollector
Webcollector是一个Java爬虫框架(内核),不需要配置,便于二次开发。它提供了一个简化的API,只需少量代码即可实现强大的爬虫程序。Webcollector Hadoop是Webcollector的Hadoop版本,支持分布式爬网
3、Spiderman
代码云地址:l-weiwei/spiderman2-代码云-开源中国
用例:演示垂直爬虫的能力–自由如风
蜘蛛侠是一种基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法捕获复杂的目标网页信息并将其解析为业务数据
4、WebMagic
代码云地址:flashsword20/webmagic-代码云-开源中国
Webmagic是一个无配置的爬虫框架,便于二次开发。它提供了一个简单灵活的API,只需少量代码即可实现爬虫程序。Webmagic采用全模块化设计,覆盖爬虫的整个生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬虫、分布式爬虫、自动重试、自定义UA/cookie等功能
5、Heritrix
GitHub地址:InternetArchive/Heritrix 3
Heritrix是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取所需的资源。Heritrix的设计严格遵循robots.txt文件和meta robots标签的排除说明。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
6、crawler4j
GitHub地址:yasserg/crawler4j·GitHub
Crawler4j是一个用Java实现的开源web爬虫程序。提供一个易于使用的界面,以便在几分钟内创建多线程web爬虫程序
7、Nutch
GitHub地址:Apache/nutch
Nutch是一个用Java实现的开源搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫
在nutch的发展过程中,出现了四个Java开源项目,Hadoop、Tika、Gora和crawler commons。如今,这四个项目发展迅速,非常流行,尤其是Hadoop,它已经成为大规模数据处理的事实标准。Tika使用各种现有的开源内容解析项目从各种格式的文件中提取元数据和结构化文本。Gora支持将大数据持久化到各种存储实现中。Crawler Commons是一个通用的web爬虫组件
8、SeimiCrawler
GitHub地址:哲格晓霍兹/赛米克罗勒
Seimicrawler是一个灵活、独立部署和分布式Java爬虫框架。希望最大限度地降低新手开发高可用性、高性能爬虫系统的门槛,提高爬虫系统的开发效率。在seimi crawler的世界中,大多数人只需要关心编写捕获的业务逻辑,其余的seimi将帮助您。在设计理念上,seimicrawler受到Python的crawler框架scripy的启发,融合了Java语言和spring的特点,希望在中国使用更方便高效的XPath解析HTML。因此,seimicrawler的默认HTML解析器是JSOUPPATH(独立扩展项目,不是jsoup提供的),默认情况下,解析和提取HTML数据是使用XPath完成的(当然,数据处理也可以选择其他解析器)。它与seimiagent相结合,全面、完美地解决了复杂动态页面的渲染和抓取问题
9、Jsoup
GitHub地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据 查看全部
java爬虫抓取动态网页(基于微内核+插件式架构的JAVA爬虫框架(内核))
1、Gecco
GitHub地址:xtuhcy/GECCO
GECCO是一个用Java语言开发的轻量级且易于使用的web爬虫程序。它集成了jsoup、httpclient、fastjson、spring、htmlunit、再分配和其他框架。通过配置一些jQuery样式选择器,可以快速编写爬虫程序。GECCO框架具有良好的可扩展性。框架根据开闭原理设计,关闭修改,打开扩展
2、WebCollector
GitHub地址:crawlscript/webcollector
Webcollector是一个Java爬虫框架(内核),不需要配置,便于二次开发。它提供了一个简化的API,只需少量代码即可实现强大的爬虫程序。Webcollector Hadoop是Webcollector的Hadoop版本,支持分布式爬网
3、Spiderman
代码云地址:l-weiwei/spiderman2-代码云-开源中国
用例:演示垂直爬虫的能力–自由如风
蜘蛛侠是一种基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法捕获复杂的目标网页信息并将其解析为业务数据
4、WebMagic
代码云地址:flashsword20/webmagic-代码云-开源中国
Webmagic是一个无配置的爬虫框架,便于二次开发。它提供了一个简单灵活的API,只需少量代码即可实现爬虫程序。Webmagic采用全模块化设计,覆盖爬虫的整个生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬虫、分布式爬虫、自动重试、自定义UA/cookie等功能
5、Heritrix
GitHub地址:InternetArchive/Heritrix 3
Heritrix是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取所需的资源。Heritrix的设计严格遵循robots.txt文件和meta robots标签的排除说明。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
6、crawler4j
GitHub地址:yasserg/crawler4j·GitHub
Crawler4j是一个用Java实现的开源web爬虫程序。提供一个易于使用的界面,以便在几分钟内创建多线程web爬虫程序
7、Nutch
GitHub地址:Apache/nutch
Nutch是一个用Java实现的开源搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫
在nutch的发展过程中,出现了四个Java开源项目,Hadoop、Tika、Gora和crawler commons。如今,这四个项目发展迅速,非常流行,尤其是Hadoop,它已经成为大规模数据处理的事实标准。Tika使用各种现有的开源内容解析项目从各种格式的文件中提取元数据和结构化文本。Gora支持将大数据持久化到各种存储实现中。Crawler Commons是一个通用的web爬虫组件
8、SeimiCrawler
GitHub地址:哲格晓霍兹/赛米克罗勒
Seimicrawler是一个灵活、独立部署和分布式Java爬虫框架。希望最大限度地降低新手开发高可用性、高性能爬虫系统的门槛,提高爬虫系统的开发效率。在seimi crawler的世界中,大多数人只需要关心编写捕获的业务逻辑,其余的seimi将帮助您。在设计理念上,seimicrawler受到Python的crawler框架scripy的启发,融合了Java语言和spring的特点,希望在中国使用更方便高效的XPath解析HTML。因此,seimicrawler的默认HTML解析器是JSOUPPATH(独立扩展项目,不是jsoup提供的),默认情况下,解析和提取HTML数据是使用XPath完成的(当然,数据处理也可以选择其他解析器)。它与seimiagent相结合,全面、完美地解决了复杂动态页面的渲染和抓取问题
9、Jsoup
GitHub地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
java爬虫抓取动态网页(Python编程修改程序函数式编程的实战二抓取您想要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-19 22:08
实战一
抓取所需的网页并将其保存到本地计算机
首先,我们简要分析了要编写的爬虫程序,它可以分为以下三个部分:
在澄清逻辑之后,我们可以正式编写爬虫程序
导入所需模块
from urllib import request, parse
拼接URL地址
定义URL变量和拼接URL地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
向URL发送请求
发送请求主要分为以下步骤:
代码如下:
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
另存为本地文件
将已爬网的照片保存到本地。这里需要使用python编程的文件IO操作。代码如下:
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
整个程序如下:
from urllib import request, parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
尝试运行该程序,进入riotian blog Park,确认搜索,然后您将在当前工作目录中找到“riotian blog Park.HTML”文件
函数式编程修改器
Python函数式编程可以使程序的思想更清晰、更容易理解。接下来,使用函数式编程的思想更改上述代码
定义相应的函数并通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
# 此处使用urlencode()进行编码
params = parse.urlencode({'wd': word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url, filename)
除了函数式编程外,还可以使用面向对象的编程方法(actual Combation二),将在后续内容中介绍)
实战二
抓取百度贴吧()页面,如Python爬虫栏和编程栏。只需抓取贴吧的前五页即可@
确定页面类型
通过简单的分析,我们可以知道要抓取的百度贴吧页面属于静态网页,分析方法非常简单:打开百度贴吧,搜索“Python爬虫”,复制页面中的任何部分信息,如“爬虫为什么需要HTTP代理”然后右键单击以查看源代码,并使用Ctrl+F搜索刚刚复制到源代码页上的数据,如下所示:
从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库中加载数据,因此该页面是一个静态页面
查找URL更改规则
接下来,找到要爬网的页面的URL规则,搜索“Python爬虫”后,贴吧first页面的URL如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后,您发现URL有两个查询参数kW和PN,PN参数是常规的,如下所示:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
URL地址可以缩写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
写爬虫
爬虫程序以类的形式编写,类下编写不同的函数,代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,爬网文件将保存到pychart当前工作目录,输出结果如下:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法编写爬虫程序时,思路简单,逻辑清晰易懂,以上代码主要包括四个功能,分别负责不同的功能,总结如下:
1)request函数
请求函数的最终结果是返回一个HTML对象,以方便后续函数调用
2)解析函数
解析功能用于解析HTML页面,常用的解析模块包括常规解析模块和BS4解析模块,通过对页面的分析提取所需的数据,在后续内容中详细描述
3)保存数据功能
此功能负责将捕获的数据保存到数据库中,如mysql、mongodb等,或以文件格式保存,如CSV、TXT、Excel等
4)entry函数
entry函数的主要任务是组织数据,例如要搜索的贴吧名称、编码URL参数、拼接URL地址以及定义文件保存路径
履带结构
采用面向对象方法编译爬虫程序时,逻辑结构相对固定,概括如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握上述编程逻辑有助于后续学习
爬虫随机睡眠
在输入功能代码中,包括以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问网站的速度非常快,这与正常人的点击行为非常不一致。因此,通过随机睡眠,爬虫可以像成年人一样点击网站,因此网站不容易被检测到是爬虫访问网站,但这样做的代价是影响程序的执行效率
聚焦爬虫(Focused crawler)是一种执行效率较低的程序,提高其性能一直是业界关注的问题,这也催生了高效的python爬虫框架scripy
程序员灯塔
转载请注明原链接:[网络爬虫学习]实战、抓取网页和贴吧数据 查看全部
java爬虫抓取动态网页(Python编程修改程序函数式编程的实战二抓取您想要的)
实战一
抓取所需的网页并将其保存到本地计算机
首先,我们简要分析了要编写的爬虫程序,它可以分为以下三个部分:
在澄清逻辑之后,我们可以正式编写爬虫程序
导入所需模块
from urllib import request, parse
拼接URL地址
定义URL变量和拼接URL地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
向URL发送请求
发送请求主要分为以下步骤:
代码如下:
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
另存为本地文件
将已爬网的照片保存到本地。这里需要使用python编程的文件IO操作。代码如下:
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
整个程序如下:
from urllib import request, parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
尝试运行该程序,进入riotian blog Park,确认搜索,然后您将在当前工作目录中找到“riotian blog Park.HTML”文件
函数式编程修改器
Python函数式编程可以使程序的思想更清晰、更容易理解。接下来,使用函数式编程的思想更改上述代码
定义相应的函数并通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
# 此处使用urlencode()进行编码
params = parse.urlencode({'wd': word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url, filename)
除了函数式编程外,还可以使用面向对象的编程方法(actual Combation二),将在后续内容中介绍)
实战二
抓取百度贴吧()页面,如Python爬虫栏和编程栏。只需抓取贴吧的前五页即可@
确定页面类型
通过简单的分析,我们可以知道要抓取的百度贴吧页面属于静态网页,分析方法非常简单:打开百度贴吧,搜索“Python爬虫”,复制页面中的任何部分信息,如“爬虫为什么需要HTTP代理”然后右键单击以查看源代码,并使用Ctrl+F搜索刚刚复制到源代码页上的数据,如下所示:
 https://cdn.jsdelivr.net/gh/Ri ... 49.png" />
https://cdn.jsdelivr.net/gh/Ri ... 49.png" />从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库中加载数据,因此该页面是一个静态页面
查找URL更改规则
接下来,找到要爬网的页面的URL规则,搜索“Python爬虫”后,贴吧first页面的URL如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后,您发现URL有两个查询参数kW和PN,PN参数是常规的,如下所示:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
URL地址可以缩写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
写爬虫
爬虫程序以类的形式编写,类下编写不同的函数,代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,爬网文件将保存到pychart当前工作目录,输出结果如下:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法编写爬虫程序时,思路简单,逻辑清晰易懂,以上代码主要包括四个功能,分别负责不同的功能,总结如下:
1)request函数
请求函数的最终结果是返回一个HTML对象,以方便后续函数调用
2)解析函数
解析功能用于解析HTML页面,常用的解析模块包括常规解析模块和BS4解析模块,通过对页面的分析提取所需的数据,在后续内容中详细描述
3)保存数据功能
此功能负责将捕获的数据保存到数据库中,如mysql、mongodb等,或以文件格式保存,如CSV、TXT、Excel等
4)entry函数
entry函数的主要任务是组织数据,例如要搜索的贴吧名称、编码URL参数、拼接URL地址以及定义文件保存路径
履带结构
采用面向对象方法编译爬虫程序时,逻辑结构相对固定,概括如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握上述编程逻辑有助于后续学习
爬虫随机睡眠
在输入功能代码中,包括以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问网站的速度非常快,这与正常人的点击行为非常不一致。因此,通过随机睡眠,爬虫可以像成年人一样点击网站,因此网站不容易被检测到是爬虫访问网站,但这样做的代价是影响程序的执行效率
聚焦爬虫(Focused crawler)是一种执行效率较低的程序,提高其性能一直是业界关注的问题,这也催生了高效的python爬虫框架scripy
程序员灯塔
转载请注明原链接:[网络爬虫学习]实战、抓取网页和贴吧数据
java爬虫抓取动态网页(Java爬虫Jsoup+httpclient获取动态生成的数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-09-19 22:05
您想知道Java爬虫jsup+httpclient获取动态生成数据的相关内容吗?在本文中,我们将仔细解释Java爬虫的相关知识和一些代码示例。欢迎阅读并更正。让我们首先关注:Java爬虫jsup+httpclient获取动态生成的数据,Java爬虫,Java爬虫jsup。让我们一起学习
Java爬虫程序jsup+httpclient获取动态生成的数据
我们之前详细讨论过,发现事情就是这样。只要它是一个可以访问的静态资源页面,您就可以直接使用它来获取所需的数据。细节跳跃——jsup爬虫的详细解释,但很多时候网站为了防止数据被恶意爬虫,有很多掩码,比如加密和动态加载,这实际上给我们编写的爬虫程序带来了很多麻烦,那么,我们如何突破这一限制,获得我们迫切需要的数据呢
让我们详细解释一下如何获得
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
此时,已经获取了整个页面的数据,但商品价格是通过回调函数获取并填写的。因此,编写爬虫程序的开发人员必须非常耐心地找到价格数据的回调接口。我们可以直接访问此界面获取价格。以下是一个演示:
从这个截图中,我们可以看到他传递的只是一个静态资源页面,根本没有价格参数。那么价格是怎么来的呢?继续查找此接口:
您会发现许多参数都拼接在这个接口中,所以我们需要做的是分析所有参数是否有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
您可以尝试删除一些参数,发现接口所需的参数其实非常简单:
https://p.3.cn/prices/mgets%3F ... em-pc
在这里看电影不是很刺激吗?事实上,您可以更改其他一些JD产品ID以获取当前价格和最高价格。我不知道价格是多少。我们需要做的就是编写一个httpclient模拟请求接口
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
对于以下内容,您可以直接解析JSON字符串,获得您想要的数据
注意
这是对回调请求的数据的重新请求获取,这只是对先前商品价格动态获取的补充。在这种情况下,价格本身不会通过主链接带到页面,而是在加载过程中由异步请求填写。有时候会带来数据,但是相关的JS处理后我们还是无法得到,这个时候我们要通过其他的方式来获得这个数据,后面会解释 查看全部
java爬虫抓取动态网页(Java爬虫Jsoup+httpclient获取动态生成的数据(组图))
您想知道Java爬虫jsup+httpclient获取动态生成数据的相关内容吗?在本文中,我们将仔细解释Java爬虫的相关知识和一些代码示例。欢迎阅读并更正。让我们首先关注:Java爬虫jsup+httpclient获取动态生成的数据,Java爬虫,Java爬虫jsup。让我们一起学习
Java爬虫程序jsup+httpclient获取动态生成的数据
我们之前详细讨论过,发现事情就是这样。只要它是一个可以访问的静态资源页面,您就可以直接使用它来获取所需的数据。细节跳跃——jsup爬虫的详细解释,但很多时候网站为了防止数据被恶意爬虫,有很多掩码,比如加密和动态加载,这实际上给我们编写的爬虫程序带来了很多麻烦,那么,我们如何突破这一限制,获得我们迫切需要的数据呢
让我们详细解释一下如何获得
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
此时,已经获取了整个页面的数据,但商品价格是通过回调函数获取并填写的。因此,编写爬虫程序的开发人员必须非常耐心地找到价格数据的回调接口。我们可以直接访问此界面获取价格。以下是一个演示:

从这个截图中,我们可以看到他传递的只是一个静态资源页面,根本没有价格参数。那么价格是怎么来的呢?继续查找此接口:


您会发现许多参数都拼接在这个接口中,所以我们需要做的是分析所有参数是否有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
您可以尝试删除一些参数,发现接口所需的参数其实非常简单:
https://p.3.cn/prices/mgets%3F ... em-pc
在这里看电影不是很刺激吗?事实上,您可以更改其他一些JD产品ID以获取当前价格和最高价格。我不知道价格是多少。我们需要做的就是编写一个httpclient模拟请求接口
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
对于以下内容,您可以直接解析JSON字符串,获得您想要的数据
注意
这是对回调请求的数据的重新请求获取,这只是对先前商品价格动态获取的补充。在这种情况下,价格本身不会通过主链接带到页面,而是在加载过程中由异步请求填写。有时候会带来数据,但是相关的JS处理后我们还是无法得到,这个时候我们要通过其他的方式来获得这个数据,后面会解释
java爬虫抓取动态网页(【学习】morestories模拟点击按钮行为比phantomjs更稳定)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-19 16:14
在上一期中,我们说过phantomjs可以模拟单击按钮的行为,并通过单击所有“加载更多”按钮来获取所有内容。例如,此网页
我们需要抓取红线标记的超链接,存储URL,然后单击“查看更多故事”以显示更多列表。但是,对于某些网页,“查看更多故事”按钮在所有隐藏内容出现后仍然存在,这使得很难判断模拟点击行为何时终止。也许聪明的朋友会说:“有什么困难?模拟单击行为,抓取网页,并从下到上获取列表项的URL。当URL与数据库中已捕获的URL重复时,停止获取。当从下到上获取的第一个URL与数据库中的URL重复时,这意味着整个网页的所有内容都已获取,模拟点击行为可以停止”。这确实是一种方法,但网页有很多判断和重复爬行。我们有一个更优雅的解决方案。为什么不呢??(此外,如果我们真的想模拟,selenium比phantomjs更稳定…)
你一定已经知道我接下来想通过标题说什么,所谓的更优雅的方式……没错
打开控制台的网络模块
单击“查看更多故事”按钮,将显示以下网络请求。请注意,此类型为XHR的网络请求是从后台请求更多列表项的原因。请观察请求标题
请求有两个参数,因此请尝试按如下方式拼接URL
我们得到了13个列表项,但是当我们点击load more按钮时,添加了15个新项,只缺少了两个列表项,这并不影响抓取的整体效果,所以我们使用这种方法抓取它们。当页面参数大于实际最大页数时,一些网页不会出现“查看更多故事”“按钮,某些按钮仍会出现,但会显示最大页数的页面内容。根据不同情况判断是否停止爬网。”
代码如下:(大部分基本代码已经在前面解释过了,所以我不再重复)
package edu.nju.opsource.vnexpress.linktype;
import java.io.InputStream;
import java.util.Date;
import java.util.LinkedList;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.onezetta.downloader.EasyHttpDownloader;
import edu.nju.opensource.common.beans.ELinkState;
import edu.nju.opensource.common.beans.Link;
import edu.nju.opensource.common.beans.LinkType;
import edu.nju.opensource.common.beans.Site;
import edu.nju.opsource.vnexpress.utils.IdXmlUtil;
public class LinkType_NewsList extends LinkType {
private Document doc = null;
private Site site = null;
private LinkedList newItems = null;
private Link nextPage = null;
public LinkType_NewsList() {
super();
// TODO Auto-generated constructor stub
}
public LinkType_NewsList(String linkTypeName) {
super.setLinkTypeName(linkTypeName);
}
public LinkType_NewsList(Site site) {
super.setLinkTypeName("vnexpress.newslist");
this.site = site;
}
public void get(String url) {
super.get(url);
String content = new EasyHttpDownloader(url).run();
if (content != null) {
this.doc = Jsoup.parse(content, this.site.getUrl().getUrl());
System.out.println(" ... has Crawled.");
} else {
setState(ELinkState.CRAWLFAILED);
System.out.println(" ... crawled failed.");
}
}
// 把新闻列表条目的链接插入表
// 在总项目中被调用的核心函数handle()
@Override
public boolean handle(Link parentlink) throws Exception {
if (getState() == ELinkState.CRAWLFAILED)
return false;
Elements news = this.doc.select("div.list_news_folder.col_720 h4.title_news_site");
this.newItems = new LinkedList();
boolean flag = false;
for (Element newItem : news) {
Elements tmp = newItem.select("a");
if ((tmp != null) && (tmp.size() != 0)) {
Link link = new Link(tmp.first().attr("abs:href"), new LinkType_News(), ELinkState.UNCRAWL, parentlink,
this.site).setLinkDate( new java.sql.Date(new Date().getTime()));
// System.out.println(tmp.first().attr("abs:href"));
int rst = link.insert();
if (rst == -1)
flag = true;// link exist
}
}
if (flag) {
setState(ELinkState.CRAWLED);
return false;
}
Elements nextPageE = this.doc.select("a#vnexpress_folder_load_more");
String url = getNextPageUrl();
if ((nextPageE != null) && (nextPageE.size() != 0)) {
System.out.println(url);
this.nextPage = new Link(url, new LinkType_NewsList(this.site), ELinkState.UNCRAWL, parentlink, this.site).setLinkDate( new java.sql.Date(new Date().getTime()));
this.nextPage.insert();
}
else {
IdXmlUtil.setIdByName("news", 2 + "");
}
setState(ELinkState.CRAWLED);
return true;
}
public static String getNextPageUrl() {
int id = IdXmlUtil.getIdByName("news");
// IdXmlUtil用来存储当前已抓取的pageid其实这个工具完全没必要,因为数据库的//url有此参数啊。。。当时脑抽没想到,搞麻烦了。。。
IdXmlUtil.setIdByName("news", (id + 1) + "");
//此文章的精髓
String url = "http://e.vnexpress.net/news/ne ... ot%3B + id;
return url;
}
@Override
public String getLinkTextData() {
// TODO Auto-generated method stub
return null;
}
@Override
public InputStream getLinkBinaryData() {
// TODO Auto-generated method stub
return null;
}
@Override
public String getLinkUniqeID(String paramString) {
// TODO Auto-generated method stub
return null;
}
@Override
public Date getLinkDate() {
// TODO Auto-generated method stub
return null;
}
public Site getSite() {
return this.site;
}
@Override
public void setSite(Site site) {
// TODO Auto-generated method stub
this.site = site;
}
public LinkedList getNewItems() {
return this.newItems;
}
public void setNewItems(LinkedList newItems) {
this.newItems = newItems;
}
public Link getNextPage() {
return this.nextPage;
}
public void setNextPage(Link nextPage) {
this.nextPage = nextPage;
}
@Override
public String toString() {
return "LinkType_newsList [doc=" + doc + ", site=" + site + ", newItems=" + newItems + ", nextPage="
+ nextPage + "]";
}
}
我原以为爬虫系列将在这里结束。事实上,另一个问题是我们在浏览器上尝试URL以查看效果。但是,一些网站尝试以这种方式看不到任何内容。这是因为浏览器将URL作为get请求输入,而一些网站后台内容不接受get请求。在这种情况下,我们如何处理ck拼接URL的效果如何
<p>期待下一期>0 查看全部
java爬虫抓取动态网页(【学习】morestories模拟点击按钮行为比phantomjs更稳定)
在上一期中,我们说过phantomjs可以模拟单击按钮的行为,并通过单击所有“加载更多”按钮来获取所有内容。例如,此网页
我们需要抓取红线标记的超链接,存储URL,然后单击“查看更多故事”以显示更多列表。但是,对于某些网页,“查看更多故事”按钮在所有隐藏内容出现后仍然存在,这使得很难判断模拟点击行为何时终止。也许聪明的朋友会说:“有什么困难?模拟单击行为,抓取网页,并从下到上获取列表项的URL。当URL与数据库中已捕获的URL重复时,停止获取。当从下到上获取的第一个URL与数据库中的URL重复时,这意味着整个网页的所有内容都已获取,模拟点击行为可以停止”。这确实是一种方法,但网页有很多判断和重复爬行。我们有一个更优雅的解决方案。为什么不呢??(此外,如果我们真的想模拟,selenium比phantomjs更稳定…)
你一定已经知道我接下来想通过标题说什么,所谓的更优雅的方式……没错
打开控制台的网络模块
单击“查看更多故事”按钮,将显示以下网络请求。请注意,此类型为XHR的网络请求是从后台请求更多列表项的原因。请观察请求标题
请求有两个参数,因此请尝试按如下方式拼接URL
我们得到了13个列表项,但是当我们点击load more按钮时,添加了15个新项,只缺少了两个列表项,这并不影响抓取的整体效果,所以我们使用这种方法抓取它们。当页面参数大于实际最大页数时,一些网页不会出现“查看更多故事”“按钮,某些按钮仍会出现,但会显示最大页数的页面内容。根据不同情况判断是否停止爬网。”
代码如下:(大部分基本代码已经在前面解释过了,所以我不再重复)
package edu.nju.opsource.vnexpress.linktype;
import java.io.InputStream;
import java.util.Date;
import java.util.LinkedList;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.onezetta.downloader.EasyHttpDownloader;
import edu.nju.opensource.common.beans.ELinkState;
import edu.nju.opensource.common.beans.Link;
import edu.nju.opensource.common.beans.LinkType;
import edu.nju.opensource.common.beans.Site;
import edu.nju.opsource.vnexpress.utils.IdXmlUtil;
public class LinkType_NewsList extends LinkType {
private Document doc = null;
private Site site = null;
private LinkedList newItems = null;
private Link nextPage = null;
public LinkType_NewsList() {
super();
// TODO Auto-generated constructor stub
}
public LinkType_NewsList(String linkTypeName) {
super.setLinkTypeName(linkTypeName);
}
public LinkType_NewsList(Site site) {
super.setLinkTypeName("vnexpress.newslist");
this.site = site;
}
public void get(String url) {
super.get(url);
String content = new EasyHttpDownloader(url).run();
if (content != null) {
this.doc = Jsoup.parse(content, this.site.getUrl().getUrl());
System.out.println(" ... has Crawled.");
} else {
setState(ELinkState.CRAWLFAILED);
System.out.println(" ... crawled failed.");
}
}
// 把新闻列表条目的链接插入表
// 在总项目中被调用的核心函数handle()
@Override
public boolean handle(Link parentlink) throws Exception {
if (getState() == ELinkState.CRAWLFAILED)
return false;
Elements news = this.doc.select("div.list_news_folder.col_720 h4.title_news_site");
this.newItems = new LinkedList();
boolean flag = false;
for (Element newItem : news) {
Elements tmp = newItem.select("a");
if ((tmp != null) && (tmp.size() != 0)) {
Link link = new Link(tmp.first().attr("abs:href"), new LinkType_News(), ELinkState.UNCRAWL, parentlink,
this.site).setLinkDate( new java.sql.Date(new Date().getTime()));
// System.out.println(tmp.first().attr("abs:href"));
int rst = link.insert();
if (rst == -1)
flag = true;// link exist
}
}
if (flag) {
setState(ELinkState.CRAWLED);
return false;
}
Elements nextPageE = this.doc.select("a#vnexpress_folder_load_more");
String url = getNextPageUrl();
if ((nextPageE != null) && (nextPageE.size() != 0)) {
System.out.println(url);
this.nextPage = new Link(url, new LinkType_NewsList(this.site), ELinkState.UNCRAWL, parentlink, this.site).setLinkDate( new java.sql.Date(new Date().getTime()));
this.nextPage.insert();
}
else {
IdXmlUtil.setIdByName("news", 2 + "");
}
setState(ELinkState.CRAWLED);
return true;
}
public static String getNextPageUrl() {
int id = IdXmlUtil.getIdByName("news");
// IdXmlUtil用来存储当前已抓取的pageid其实这个工具完全没必要,因为数据库的//url有此参数啊。。。当时脑抽没想到,搞麻烦了。。。
IdXmlUtil.setIdByName("news", (id + 1) + "");
//此文章的精髓
String url = "http://e.vnexpress.net/news/ne ... ot%3B + id;
return url;
}
@Override
public String getLinkTextData() {
// TODO Auto-generated method stub
return null;
}
@Override
public InputStream getLinkBinaryData() {
// TODO Auto-generated method stub
return null;
}
@Override
public String getLinkUniqeID(String paramString) {
// TODO Auto-generated method stub
return null;
}
@Override
public Date getLinkDate() {
// TODO Auto-generated method stub
return null;
}
public Site getSite() {
return this.site;
}
@Override
public void setSite(Site site) {
// TODO Auto-generated method stub
this.site = site;
}
public LinkedList getNewItems() {
return this.newItems;
}
public void setNewItems(LinkedList newItems) {
this.newItems = newItems;
}
public Link getNextPage() {
return this.nextPage;
}
public void setNextPage(Link nextPage) {
this.nextPage = nextPage;
}
@Override
public String toString() {
return "LinkType_newsList [doc=" + doc + ", site=" + site + ", newItems=" + newItems + ", nextPage="
+ nextPage + "]";
}
}
我原以为爬虫系列将在这里结束。事实上,另一个问题是我们在浏览器上尝试URL以查看效果。但是,一些网站尝试以这种方式看不到任何内容。这是因为浏览器将URL作为get请求输入,而一些网站后台内容不接受get请求。在这种情况下,我们如何处理ck拼接URL的效果如何
<p>期待下一期>0
java爬虫抓取动态网页(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-19 16:11
下面是一个案例,演示如何使用jsup进行解析。在这种情况下,将获得博客花园第一页的标题和第一页上的博客文章列表
请查看代码(在前面代码的基础上操作。如果您不知道如何使用httpclient,请跳转到页面阅读):
引入依赖关系
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,首先分析HTML结构。不用说,那么文章列表呢?按浏览器的F12键查看页面元素源代码。您会发现列表是一个大div,id=“post\u list”,而每个文章文章都是一个小div,class=“post\u item”
接下来,您可以启动代码。jsup的核心代码如下(整体源代码将在文章末尾给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,您会发现我通过jsup.parse(string HTML)方法解析httpclient获取的HTML内容来获取文档,然后文档可以通过两种方式获取其子元素:类似JS的getelementxxxx和类似jQuery选择器的select()。两种方法都可以。我个人建议使用select方法。对于元素中的属性,例如超链接地址,可以使用元素。Attr(string)方法获取,对于元素的文本内容,可以使用元素。要获取的Text()方法
执行代码并检查结果(我不得不感叹博客公园的朋友们真的很棒。从上面对主页HTML结构的分析到jsup分析的代码的执行,这段时间文章有这么多主页)
因为新的文章版本太快了,上面的屏幕截图与这里的输出有些不同
三、Jsoup其他用途
一、 jsup不仅可以在httpclient的工作成果中发挥作用,还可以独立工作,抓取页面,自己分析。分析能力已在上面显示。现在让我们展示如何抓取页面。事实上,这很简单。区别在于我直接获取文档,不需要通过jsup解析它。Parse()方法
除了直接访问在线资源外,我还可以解析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup另一个值得一提的特点
你一定有过这种经历。如果在页面文本框中输入HTML元素并在保存后查看它们,则页面布局很可能会混乱。如果你能过滤这些内容,它将是完美的
只是为了让我能做
通过jsup.clean方法使用白名单进行过滤。执行结果:
unsafe: <p>博客园
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,我相信我是非常强大的。我不仅可以解析httpclient捕获的HTML元素,还可以自己抓取页面DOM。我还可以加载和解析本地保存的HTML文件
此外,我可以通过白名单过滤字符串,以筛选出一些不安全的字符
最重要的是,上述所有函数的API调用都相对简单
===============华丽的分界线=============
编写代码并不容易。就像你走之前那样~~
最后,本案例中分析博客公园主页文章列表的完整源代码附于后文:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
视图代码 查看全部
java爬虫抓取动态网页(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页)
下面是一个案例,演示如何使用jsup进行解析。在这种情况下,将获得博客花园第一页的标题和第一页上的博客文章列表
请查看代码(在前面代码的基础上操作。如果您不知道如何使用httpclient,请跳转到页面阅读):
引入依赖关系
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,首先分析HTML结构。不用说,那么文章列表呢?按浏览器的F12键查看页面元素源代码。您会发现列表是一个大div,id=“post\u list”,而每个文章文章都是一个小div,class=“post\u item”
接下来,您可以启动代码。jsup的核心代码如下(整体源代码将在文章末尾给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,您会发现我通过jsup.parse(string HTML)方法解析httpclient获取的HTML内容来获取文档,然后文档可以通过两种方式获取其子元素:类似JS的getelementxxxx和类似jQuery选择器的select()。两种方法都可以。我个人建议使用select方法。对于元素中的属性,例如超链接地址,可以使用元素。Attr(string)方法获取,对于元素的文本内容,可以使用元素。要获取的Text()方法
执行代码并检查结果(我不得不感叹博客公园的朋友们真的很棒。从上面对主页HTML结构的分析到jsup分析的代码的执行,这段时间文章有这么多主页)
因为新的文章版本太快了,上面的屏幕截图与这里的输出有些不同
三、Jsoup其他用途
一、 jsup不仅可以在httpclient的工作成果中发挥作用,还可以独立工作,抓取页面,自己分析。分析能力已在上面显示。现在让我们展示如何抓取页面。事实上,这很简单。区别在于我直接获取文档,不需要通过jsup解析它。Parse()方法

除了直接访问在线资源外,我还可以解析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup另一个值得一提的特点
你一定有过这种经历。如果在页面文本框中输入HTML元素并在保存后查看它们,则页面布局很可能会混乱。如果你能过滤这些内容,它将是完美的
只是为了让我能做
通过jsup.clean方法使用白名单进行过滤。执行结果:
unsafe: <p>博客园
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,我相信我是非常强大的。我不仅可以解析httpclient捕获的HTML元素,还可以自己抓取页面DOM。我还可以加载和解析本地保存的HTML文件
此外,我可以通过白名单过滤字符串,以筛选出一些不安全的字符
最重要的是,上述所有函数的API调用都相对简单
===============华丽的分界线=============
编写代码并不容易。就像你走之前那样~~
最后,本案例中分析博客公园主页文章列表的完整源代码附于后文:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/";);
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
视图代码
java爬虫抓取动态网页(大数据时代爬虫工作者开发框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-19 15:15
如今,在大数据时代,爬虫已经成为互联网数据公司的关键位置。他们不仅要精通数据采集和分析,还要熟悉搜索引擎和相关检索算法,并对各种算法有一定的了解。合理安排工作流程
爬虫有很多种方式,但是Java爬虫是开发中应用最广泛的一种网页获取技术。它具有一流的速度和性能,功能支持水平相对较低。Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
对于爬虫行业,我们推出了用于动态转发的高质量代理IP解决方案,完美解决了爬虫行业的难点。动态转发使用简单方便,不限制机器的使用,更适合项目的快速启动。最简单的方法如下:
import java.io.IOException;
import java.net.Authenticator;
import java.net.InetSocketAddress;
import java.net.PasswordAuthentication;
import java.net.Proxy;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Demo
{
// 代理验证信息
final static String ProxyUser = "16MNWZCB";
final static String ProxyPass = "365090";
// 代理服务器(产品官网 www.16yun.cn)
final static String ProxyHost = "t.16yun.cn";
final static Integer ProxyPort = 31111;
// 设置IP切换头
final static String ProxyHeadKey = "Proxy-Tunnel";
public static String getUrlProxyContent(String url)
{
Authenticator.setDefault(new Authenticator() {
public PasswordAuthentication getPasswordAuthentication()
{
return new PasswordAuthentication(ProxyUser, ProxyPass.toCharArray());
}
});
// 设置Proxy-Tunnel
Random random = new Random();
int tunnel = random.nextInt(10000);
String ProxyHeadVal = String.valueOf(tunnel);
Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress(ProxyHost, ProxyPort));
try
{
// 处理异常、其他参数
Document doc = Jsoup.connect(url).timeout(3000).header(ProxyHeadKey, ProxyHeadVal).proxy(proxy).get();
if(doc != null) {
System.out.println(doc.body().html());
}
}
catch (IOException e)
{
e.printStackTrace();
}
return null;
}
public static void main(String[] args) throws Exception
{
// 要访问的目标页面
String targetUrl = "https://weibo.com/";
getUrlProxyContent(targetUrl);
}
}
如果您需要,也可以理解许多爬虫开发框架 查看全部
java爬虫抓取动态网页(大数据时代爬虫工作者开发框架)
如今,在大数据时代,爬虫已经成为互联网数据公司的关键位置。他们不仅要精通数据采集和分析,还要熟悉搜索引擎和相关检索算法,并对各种算法有一定的了解。合理安排工作流程
爬虫有很多种方式,但是Java爬虫是开发中应用最广泛的一种网页获取技术。它具有一流的速度和性能,功能支持水平相对较低。Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
对于爬虫行业,我们推出了用于动态转发的高质量代理IP解决方案,完美解决了爬虫行业的难点。动态转发使用简单方便,不限制机器的使用,更适合项目的快速启动。最简单的方法如下:
import java.io.IOException;
import java.net.Authenticator;
import java.net.InetSocketAddress;
import java.net.PasswordAuthentication;
import java.net.Proxy;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Demo
{
// 代理验证信息
final static String ProxyUser = "16MNWZCB";
final static String ProxyPass = "365090";
// 代理服务器(产品官网 www.16yun.cn)
final static String ProxyHost = "t.16yun.cn";
final static Integer ProxyPort = 31111;
// 设置IP切换头
final static String ProxyHeadKey = "Proxy-Tunnel";
public static String getUrlProxyContent(String url)
{
Authenticator.setDefault(new Authenticator() {
public PasswordAuthentication getPasswordAuthentication()
{
return new PasswordAuthentication(ProxyUser, ProxyPass.toCharArray());
}
});
// 设置Proxy-Tunnel
Random random = new Random();
int tunnel = random.nextInt(10000);
String ProxyHeadVal = String.valueOf(tunnel);
Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress(ProxyHost, ProxyPort));
try
{
// 处理异常、其他参数
Document doc = Jsoup.connect(url).timeout(3000).header(ProxyHeadKey, ProxyHeadVal).proxy(proxy).get();
if(doc != null) {
System.out.println(doc.body().html());
}
}
catch (IOException e)
{
e.printStackTrace();
}
return null;
}
public static void main(String[] args) throws Exception
{
// 要访问的目标页面
String targetUrl = "https://weibo.com/";
getUrlProxyContent(targetUrl);
}
}
如果您需要,也可以理解许多爬虫开发框架
java爬虫抓取动态网页(爬虫科普一下对爬虫的误区、原理以及实现(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-19 15:11
爬行动物?我相信很多人都熟悉这个词。简而言之,就是使用工具来抓取网页上的数据,并对其进行分类和分析。像往常一样,向小白询问爬行动物的误解、原理和实施情况
爬虫的常见误解:python=crawler
许多白人把蟒蛇等同于爬虫。实际上,Python是一种计算机编程语言。它不仅可以是一个爬虫程序,还可以构建web应用程序。最近火灾的人工智能也可以通过使用python语言来实现
爬虫的本质是抓取服务器响应浏览器的数据(下面将详细介绍其原理)。不同的计算机编程语言,如Java和c#可以实现爬虫程序
概要:Python≠ 爬虫。Python的功能远比我们想象的强大。爬虫程序不能仅由python实现
爬行动物原理
让我们回忆一下我们对百度的访问:
1.在地址栏中输入URL:
有些人会说我以前从来没有这样做过。我使用浏览器导航到百度
其实,这样进入百度,只需在浏览器中为你输入访问百度的链接即可
2.浏览器刷新,百度的搜索框出现在我们面前
当然,不考虑网络速度无法刷新的情况
在此期间,浏览器和服务器之间发生了什么
1.浏览器向服务器发送URL,即请求地址
2.服务器接收来自浏览器的网络请求,并开始响应浏览器的数据
3.browser接收服务器发送的数据,对其进行分析并显示
如果您感兴趣,可以清除浏览器缓存,使用FN+F12打开浏览器控制台,选择网络菜单,在刷新页面时可以看到具体的响应过程
爬虫的实现机制
1.由于浏览器可以向服务器发送请求地址,我们也可以使用程序向服务器发送请求
2.由于浏览器可以接收服务器发送的数据,我们可以模拟浏览器解析过程,通过筛选得到我们想要的数据
小结:通过我们自己的程序,我们不需要重复整理我们想要的数据。所有这些都留给我们的爬虫程序
Java爬虫的具体案例
目标:抓取动态模块显示的最新新闻,并将新闻内容以文件形式本地保存
爬网资源1
爬网资源2
(一)需求分析)
1.分析新闻网主页,捕捉部门动态模块内容
2.simulate jump,进入每个新闻页面并抓取新闻的具体内容
3.将新闻的详细信息保存在文件中
(二)代码实现)
1.使用Maven工具在pom.xml中导入我们的爬虫程序所依赖的jar包
org.apache.httpcomponents
httpclient
4.5.3
org.jsoup
jsoup
1.8.3
log4j
log4j
1.2.16
junit
junit
4.10
2.make一个用于发送请求的简单类
package com.sxau.example;
import java.io.IOException;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.conn.params.ConnRouteParams;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.params.CoreConnectionPNames;
import org.apache.http.util.EntityUtils;
public class MyClient {
public String getContent(String url) throws ClientProtocolException, IOException {
// 创建httpclient对象
HttpClient hClient = new DefaultHttpClient();
// 设置连接超时时间,响应超时时间,以及代理服务器
hClient.getParams().setParameter(CoreConnectionPNames.CONNECTION_TIMEOUT, 5000)
.setParameter(CoreConnectionPNames.SO_TIMEOUT, 5000)
.setParameter(ConnRouteParams.DEFAULT_PROXY, new HttpHost("117.191.11.71", 8080));
// 创建get请求对象
HttpGet hGet = new HttpGet(url);
// 模拟请求,获得服务器响应的源码
HttpResponse response = hClient.execute(hGet);
// 将源码转换为字符串
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
// 返回转化后的字符串
return content;
}
}
3.make一个用于解析服务器数据的类
package com.sxau.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class MyJsoup {
public Elements getTarget(
String htmlResource,String selectCondition) {
//解析服务器发来的数据
Document doc = Jsoup.parse(htmlResource);
//对解析后的数据通过条件筛选
Elements elements = doc.select(selectCondition);
return elements;
}
}
4.make一个本地存储文件的类
package com.sxau.example;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class MyFileIO {
public void makeFile(String title,String txtContent) throws IOException {
//将标题左右多余的空格去掉
title = title.trim();
//拿到当前应用所在路径
String property = System.getProperty("user.dir");
//设置生成文件的路径与名称
String filePath = property + "\\src\\main\\webapp\\spidertxt\\" + title + ".txt";
//生成新文件
File txt = new File(filePath);
//将文件输入器定位到刚刚生成的新文件
FileWriter writer = new FileWriter(txt);
//将已经匹配的字符串写入文件中
writer.write(txtContent);
//刷新并关闭流
writer.flush();
writer.close();
}
}
5.为了提高效率,制作了一个线程进行并发处理
package com.sxau.example;
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
import org.jsoup.select.Elements;
/**
* 实现Runable接口
* @author Administrator
*
*/
public class MyThread implements Runnable{
private String mainUrl;
private String singleUrl;
//提供有参数的构造方法,确保进入页面时url不为空
public MyThread(String mainUrl, String singleUrl) {
this.mainUrl = mainUrl;
this.singleUrl = singleUrl;
}
/**
* 实现接口未实现的run()方法
* 通过httpclient发送请求并接收数据
* 观察html页面,使用jsoup中便捷的仿css/js选择器语法得到我们需要的内容
* 对匹配好的字符串进行优化,并进行本地存储
*/
@Override
public void run() {
// TODO 自动生成的方法存根
MyClient myClient = new MyClient();
String url=mainUrl+singleUrl;
String content;
try {
content = myClient.getContent(url);
String selectCondition1=".arti_title";
String selectCondition2=".wp_articlecontent";
MyJsoup jsoup = new MyJsoup();
Elements elements1 = jsoup.getTarget(content, selectCondition1);
Elements elements2 = jsoup.getTarget(content, selectCondition2);
String html1 = elements1.get(0).html();
String title = html1.replaceAll("", "");
String html2 = elements2.get(0).html();
html2 = html2.replaceAll("<p>", "");
String word = html2.replaceAll("", "");
MyFileIO fileIO=new MyFileIO();
fileIO.makeFile(title, word);
} catch (ClientProtocolException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
</p>
6.making主程序
package com.sxau.example;
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class MySpider {
public static void main(String[] args) throws ClientProtocolException, IOException {
MyClient myClient = new MyClient();
String url="http://news.sxau.edu.cn/";
String content = myClient.getContent(url);
String selectCondition="a[href][title~=(|)]";
MyJsoup jsoup = new MyJsoup();
Elements elements = jsoup.getTarget(content, selectCondition);
for (Element element : elements) {
String attr = element.attr("href");
new Thread(new MyThread(url, attr)).start();
}
System.out.println("文件爬虫成功!");
}
}
6.运行main方法并等待片刻。刚烤好的文件一直静静地放在文件夹里
log4j:WARN No appenders could be found for logger (org.apache.http.impl.conn.BasicClientConnectionManager).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4 ... onfig for more info.
文件爬虫成功!
最终效果
到目前为止,一个简单的爬虫功能已经实现。新手正在路上。如果您有任何问题,请毫不犹豫地提出建议,相互讨论,共同进步 查看全部
java爬虫抓取动态网页(爬虫科普一下对爬虫的误区、原理以及实现(组图))
爬行动物?我相信很多人都熟悉这个词。简而言之,就是使用工具来抓取网页上的数据,并对其进行分类和分析。像往常一样,向小白询问爬行动物的误解、原理和实施情况
爬虫的常见误解:python=crawler
许多白人把蟒蛇等同于爬虫。实际上,Python是一种计算机编程语言。它不仅可以是一个爬虫程序,还可以构建web应用程序。最近火灾的人工智能也可以通过使用python语言来实现
爬虫的本质是抓取服务器响应浏览器的数据(下面将详细介绍其原理)。不同的计算机编程语言,如Java和c#可以实现爬虫程序
概要:Python≠ 爬虫。Python的功能远比我们想象的强大。爬虫程序不能仅由python实现
爬行动物原理
让我们回忆一下我们对百度的访问:
1.在地址栏中输入URL:
有些人会说我以前从来没有这样做过。我使用浏览器导航到百度
其实,这样进入百度,只需在浏览器中为你输入访问百度的链接即可
2.浏览器刷新,百度的搜索框出现在我们面前
当然,不考虑网络速度无法刷新的情况
在此期间,浏览器和服务器之间发生了什么
1.浏览器向服务器发送URL,即请求地址
2.服务器接收来自浏览器的网络请求,并开始响应浏览器的数据
3.browser接收服务器发送的数据,对其进行分析并显示
如果您感兴趣,可以清除浏览器缓存,使用FN+F12打开浏览器控制台,选择网络菜单,在刷新页面时可以看到具体的响应过程
爬虫的实现机制
1.由于浏览器可以向服务器发送请求地址,我们也可以使用程序向服务器发送请求
2.由于浏览器可以接收服务器发送的数据,我们可以模拟浏览器解析过程,通过筛选得到我们想要的数据
小结:通过我们自己的程序,我们不需要重复整理我们想要的数据。所有这些都留给我们的爬虫程序
Java爬虫的具体案例
目标:抓取动态模块显示的最新新闻,并将新闻内容以文件形式本地保存

爬网资源1
爬网资源2
(一)需求分析)
1.分析新闻网主页,捕捉部门动态模块内容
2.simulate jump,进入每个新闻页面并抓取新闻的具体内容
3.将新闻的详细信息保存在文件中
(二)代码实现)
1.使用Maven工具在pom.xml中导入我们的爬虫程序所依赖的jar包
org.apache.httpcomponents
httpclient
4.5.3
org.jsoup
jsoup
1.8.3
log4j
log4j
1.2.16
junit
junit
4.10
2.make一个用于发送请求的简单类
package com.sxau.example;
import java.io.IOException;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.conn.params.ConnRouteParams;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.params.CoreConnectionPNames;
import org.apache.http.util.EntityUtils;
public class MyClient {
public String getContent(String url) throws ClientProtocolException, IOException {
// 创建httpclient对象
HttpClient hClient = new DefaultHttpClient();
// 设置连接超时时间,响应超时时间,以及代理服务器
hClient.getParams().setParameter(CoreConnectionPNames.CONNECTION_TIMEOUT, 5000)
.setParameter(CoreConnectionPNames.SO_TIMEOUT, 5000)
.setParameter(ConnRouteParams.DEFAULT_PROXY, new HttpHost("117.191.11.71", 8080));
// 创建get请求对象
HttpGet hGet = new HttpGet(url);
// 模拟请求,获得服务器响应的源码
HttpResponse response = hClient.execute(hGet);
// 将源码转换为字符串
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
// 返回转化后的字符串
return content;
}
}
3.make一个用于解析服务器数据的类
package com.sxau.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class MyJsoup {
public Elements getTarget(
String htmlResource,String selectCondition) {
//解析服务器发来的数据
Document doc = Jsoup.parse(htmlResource);
//对解析后的数据通过条件筛选
Elements elements = doc.select(selectCondition);
return elements;
}
}
4.make一个本地存储文件的类
package com.sxau.example;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class MyFileIO {
public void makeFile(String title,String txtContent) throws IOException {
//将标题左右多余的空格去掉
title = title.trim();
//拿到当前应用所在路径
String property = System.getProperty("user.dir");
//设置生成文件的路径与名称
String filePath = property + "\\src\\main\\webapp\\spidertxt\\" + title + ".txt";
//生成新文件
File txt = new File(filePath);
//将文件输入器定位到刚刚生成的新文件
FileWriter writer = new FileWriter(txt);
//将已经匹配的字符串写入文件中
writer.write(txtContent);
//刷新并关闭流
writer.flush();
writer.close();
}
}
5.为了提高效率,制作了一个线程进行并发处理
package com.sxau.example;
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
import org.jsoup.select.Elements;
/**
* 实现Runable接口
* @author Administrator
*
*/
public class MyThread implements Runnable{
private String mainUrl;
private String singleUrl;
//提供有参数的构造方法,确保进入页面时url不为空
public MyThread(String mainUrl, String singleUrl) {
this.mainUrl = mainUrl;
this.singleUrl = singleUrl;
}
/**
* 实现接口未实现的run()方法
* 通过httpclient发送请求并接收数据
* 观察html页面,使用jsoup中便捷的仿css/js选择器语法得到我们需要的内容
* 对匹配好的字符串进行优化,并进行本地存储
*/
@Override
public void run() {
// TODO 自动生成的方法存根
MyClient myClient = new MyClient();
String url=mainUrl+singleUrl;
String content;
try {
content = myClient.getContent(url);
String selectCondition1=".arti_title";
String selectCondition2=".wp_articlecontent";
MyJsoup jsoup = new MyJsoup();
Elements elements1 = jsoup.getTarget(content, selectCondition1);
Elements elements2 = jsoup.getTarget(content, selectCondition2);
String html1 = elements1.get(0).html();
String title = html1.replaceAll("", "");
String html2 = elements2.get(0).html();
html2 = html2.replaceAll("<p>", "");
String word = html2.replaceAll("", "");
MyFileIO fileIO=new MyFileIO();
fileIO.makeFile(title, word);
} catch (ClientProtocolException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
</p>
6.making主程序
package com.sxau.example;
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class MySpider {
public static void main(String[] args) throws ClientProtocolException, IOException {
MyClient myClient = new MyClient();
String url="http://news.sxau.edu.cn/";
String content = myClient.getContent(url);
String selectCondition="a[href][title~=(|)]";
MyJsoup jsoup = new MyJsoup();
Elements elements = jsoup.getTarget(content, selectCondition);
for (Element element : elements) {
String attr = element.attr("href");
new Thread(new MyThread(url, attr)).start();
}
System.out.println("文件爬虫成功!");
}
}
6.运行main方法并等待片刻。刚烤好的文件一直静静地放在文件夹里
log4j:WARN No appenders could be found for logger (org.apache.http.impl.conn.BasicClientConnectionManager).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4 ... onfig for more info.
文件爬虫成功!
最终效果
到目前为止,一个简单的爬虫功能已经实现。新手正在路上。如果您有任何问题,请毫不犹豫地提出建议,相互讨论,共同进步
java爬虫抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-19 10:10
Python爬虫4.2-Ajax[动态网页数据]使用教程
概述
本系列文档用于学习Python爬虫技术的简单教程。在巩固你的技术知识的同时,如果它碰巧对你有用,那就更好了
python版本为3.7.4
有时,当我们抓取收录请求的页面时,结果可能与在浏览器中看到的结果不同。您可以在浏览器中看到正常显示的页面数据,但通过使用请求获得的结果不显示。这是因为请求获取原创HTML文档,而浏览器中的页面是在JavaScript处理数据后生成的。这些数据来自各种来源,可以通过Ajax加载,收录在HTML文档中,也可以通过JavaScript和特定算法计算
因此,如果您遇到这样的页面,您无法通过直接使用请求和其他库获取原创页面来获得有效的数据。此时,您需要分析web页面后台发送到接口的Ajax请求。如果可以使用请求来模拟Ajax请求,就可以成功地捕获它们
因此,在本文中,我们主要了解什么是AJAX以及如何分析和获取AJAX请求
Ajax介绍了Ajax是什么
Ajax(异步JavaScript和XML)异步JavaScript和XML。通过与后台服务器的数据交换,AJAX可以实现web页面的异步更新,这意味着可以在不重新加载整个web页面的情况下更新部分web页面。如果一个传统的网页(没有Ajax)需要更新内容,它必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。事实上,受限数据交互基本上使用JSON和Ajax加载的数据。即使使用JS将数据呈现给浏览器,在查看网页源代码时也无法看到通过Ajax加载的数据,只能看到使用此URL加载的HTML代码
示例说明
浏览网页时,我们会发现许多网页有更多的选择。例如,微博、今日头条以及其他内容都是根据鼠标下拉菜单自动加载的。这些实际上是Ajax加载的过程。我们可以看到,页面尚未完全刷新,这意味着页面的链接没有变化,但网页中有更多的新内容,这意味着获取新数据并通过Ajax呈现的过程
请求分析
使用ChromeDeveloper工具的过滤功能过滤掉所有Ajax请求,这里不再详细解释
fiddler数据包捕获工具也可用于数据包捕获分析。这里不解释fiddler工具的使用。您可以在Internet上搜索和查看它
Ajax的响应结果通常是JSON数据格式
采集方法直接分析Ajax使用的接口,然后请求该接口通过代码获取数据(下面的示例就是这样一种方法)。使用selenium+chromedriver模拟浏览器行为并获取数据(稍后将文章继续)。这种方法的优点和缺点
分析接口
可以直接请求数据,而无需进行一些解析。代码量小,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一定的JS知识,这很容易被爬虫发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,也可以使用selenium请求。爬虫更稳定
大量代码和低性能
示例说明
让我们以知乎对“作为一名高价值程序员的经历是什么?”这个问题的所有答案为例。示例代码如下所示:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset 查看全部
java爬虫抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
Python爬虫4.2-Ajax[动态网页数据]使用教程
概述
本系列文档用于学习Python爬虫技术的简单教程。在巩固你的技术知识的同时,如果它碰巧对你有用,那就更好了
python版本为3.7.4
有时,当我们抓取收录请求的页面时,结果可能与在浏览器中看到的结果不同。您可以在浏览器中看到正常显示的页面数据,但通过使用请求获得的结果不显示。这是因为请求获取原创HTML文档,而浏览器中的页面是在JavaScript处理数据后生成的。这些数据来自各种来源,可以通过Ajax加载,收录在HTML文档中,也可以通过JavaScript和特定算法计算
因此,如果您遇到这样的页面,您无法通过直接使用请求和其他库获取原创页面来获得有效的数据。此时,您需要分析web页面后台发送到接口的Ajax请求。如果可以使用请求来模拟Ajax请求,就可以成功地捕获它们
因此,在本文中,我们主要了解什么是AJAX以及如何分析和获取AJAX请求
Ajax介绍了Ajax是什么
Ajax(异步JavaScript和XML)异步JavaScript和XML。通过与后台服务器的数据交换,AJAX可以实现web页面的异步更新,这意味着可以在不重新加载整个web页面的情况下更新部分web页面。如果一个传统的网页(没有Ajax)需要更新内容,它必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。事实上,受限数据交互基本上使用JSON和Ajax加载的数据。即使使用JS将数据呈现给浏览器,在查看网页源代码时也无法看到通过Ajax加载的数据,只能看到使用此URL加载的HTML代码
示例说明
浏览网页时,我们会发现许多网页有更多的选择。例如,微博、今日头条以及其他内容都是根据鼠标下拉菜单自动加载的。这些实际上是Ajax加载的过程。我们可以看到,页面尚未完全刷新,这意味着页面的链接没有变化,但网页中有更多的新内容,这意味着获取新数据并通过Ajax呈现的过程
请求分析
使用ChromeDeveloper工具的过滤功能过滤掉所有Ajax请求,这里不再详细解释
fiddler数据包捕获工具也可用于数据包捕获分析。这里不解释fiddler工具的使用。您可以在Internet上搜索和查看它
Ajax的响应结果通常是JSON数据格式
采集方法直接分析Ajax使用的接口,然后请求该接口通过代码获取数据(下面的示例就是这样一种方法)。使用selenium+chromedriver模拟浏览器行为并获取数据(稍后将文章继续)。这种方法的优点和缺点
分析接口
可以直接请求数据,而无需进行一些解析。代码量小,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一定的JS知识,这很容易被爬虫发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,也可以使用selenium请求。爬虫更稳定
大量代码和低性能
示例说明
让我们以知乎对“作为一名高价值程序员的经历是什么?”这个问题的所有答案为例。示例代码如下所示:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-19 09:17
Htmlunit是一个开源Java页面分析工具。启动htmlunit后,底层将启动一个没有界面的浏览器。用户可以指定浏览器类型:Firefox、ie等。如果未指定,默认为Internet\uExplorer\u7:
WebClient WebClient=新的WebClient(BrowserVersion.FIREFOX_3_6))
通过一个简单的电话:
HtmlPage=webClient.getPage(url)
可通过以下方式获取页面的HTML页面表示:
InputStream is=targetPage.getWebResponse().getContentAsStream()
您可以获取页面的输入流,从而获取页面的源代码,这对于web爬虫项目非常有用
当然,您也可以从页面中获取更多页面元素
htmlunit为执行javascript提供支持非常重要:
page.executeJavaScript(javascript)
执行JS后,返回一个scriptresult对象,通过该对象可以得到执行JS后的页面等信息,默认情况下,内部浏览器会跳转到执行JS后生成的新页面,如果执行JS失败,则不会执行页面跳转 查看全部
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
Htmlunit是一个开源Java页面分析工具。启动htmlunit后,底层将启动一个没有界面的浏览器。用户可以指定浏览器类型:Firefox、ie等。如果未指定,默认为Internet\uExplorer\u7:
WebClient WebClient=新的WebClient(BrowserVersion.FIREFOX_3_6))
通过一个简单的电话:
HtmlPage=webClient.getPage(url)
可通过以下方式获取页面的HTML页面表示:
InputStream is=targetPage.getWebResponse().getContentAsStream()
您可以获取页面的输入流,从而获取页面的源代码,这对于web爬虫项目非常有用
当然,您也可以从页面中获取更多页面元素
htmlunit为执行javascript提供支持非常重要:
page.executeJavaScript(javascript)
执行JS后,返回一个scriptresult对象,通过该对象可以得到执行JS后的页面等信息,默认情况下,内部浏览器会跳转到执行JS后生成的新页面,如果执行JS失败,则不会执行页面跳转
java爬虫抓取动态网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-19 09:12
最近,在做一个项目时,有一个需求:要从网页中获取数据,需要首先获取整个网页的HTML源代码(将在以后的更新中使用)。首先,我看了一下这个简单的,然后我敲了敲代码(nutch,一个以前使用Hadoop平台的分布式爬虫框架,使用起来非常方便,但最终由于速度原因放弃了,但生成的统计数据用于以后的爬虫)。很快,holder.html和finance.html页面被成功下载,然后,在解析holder.html页面之后,我解析了finance.html。然后我很沮丧地发现我在这个页面中需要的数据不在HTML源代码中。我去浏览器查看源代码。果然,源代码中没有我需要的数据。看来我的程序并没有写错,接下来就是让人筋疲力尽的事情——获取收录动态内容的HTML页面
在中国所谓最强的搜索引擎百度上走了很长一段时间后,我发现大多数人会使用webdriver和httpUnit(事实上,前者已经包括后者)。我很高兴,终于找到了解决办法。非常激动地使用webdriver,我发誓
下面对WebDriver的Tucao进行投诉
Webdriver是一个测试框架。它最初不是为爬虫服务的,但我想说的是:它几乎是一种浏览。你不能再向前迈一步吗?为什么这么多人在互联网上推荐webdriver?我不认为这些人是从现实出发的。有些人甚至吹嘘webdriver可以解析完成的页面,并将其返回给想要浏览整个页面的人(包括动态生成的内容)。是的,webdriver可以完成这个任务,但是当我看到作者编写的代码时,我想说的是:伙计,你的代码太有限了。解析自己编写的JS代码,JS代码很简单,因此webdriver肯定会在没有压力的情况下完成任务。当webdriver解析动态内容时,它取决于JS代码的复杂性和多样性
什么是复杂性
先发布一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是,我相信每个人都能理解上面使用的IE内核,当然是Firefox驱动程序、chrome驱动程序和htmlunitdriver。这些驱动程序的使用原则是相同的。首先打开浏览器(这需要时间),然后加载URL并完成动态解析,然后通过页面获得完整的HTML页面。作为xml(),htmlunitdriver模拟没有接口的浏览器。有一个rhino引擎在Java中执行JS。htmlunitdriver使用rhino解析JS。由于htmlunitdriver不会使用界面启动浏览器,因此它的速度比前三个版本快。不管是什么驱动程序,解析JS都是不可避免的,这需要时间,并且未使用的内核对JS的支持程序是不同的。例如,htmlunitdriver对带有滚动的JS代码的支持较差,并且会在执行过程中报告错误(亲身经历)。JS代码的复杂性意味着不同内核支持的JS并不完全相同。这要根据具体情况来确定。我已经很长时间没有学习JS了,所以我不会谈论内部检查JS的支持
什么是多样性
如前所述,浏览器解析JS需要时间。对于只有少量嵌入JS代码的页面,通过页面获取完整页面是没有问题的。Asxml()。但是,对于收录更多嵌入式JS代码的页面,解析JS需要很多时间(对于JVM)。此时,大部分页面都是通过页面获取的。Asxml()不收录动态生成的内容。问题是,为什么你说webdriver可以获得收录动态内容的HTML页面?网上有人说,开车后。Get(URL),当前线程需要等待以获取完成的页面,这类似于下面的表单
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
根据这个想法,我尝试了以下方法。啊,真的有可能。但这不是问题所在吗?如何确定等待时间?与数据挖掘中确定阈值的经验方法类似,或尽可能长。我认为这些不是很好的方法。时间成本相对较高。我认为驱动程序应该能够在解析JS后捕获状态,所以我去寻找,寻找,但根本没有这样的方法,所以我说为什么webdriver的设计者不进一步,以便我们可以在程序中获取驱动程序解析JS后的状态,所以我们不需要使用thread.sleep( 2000)很遗憾,我找不到这样不确定的代码,这让我很伤心。Firefox驱动程序、chrome驱动程序和htmlunitdriver也有同样的问题。可以说,使用webdriver帮助爬升动态生成的网页所获得的结果非常不稳定。我对此有深刻的理解。使用iedriver时,两个pages在同一页上,每次爬网的结果都不一样,有时ie会直接挂断。你敢在爬网程序中使用这些东西吗?我不敢
此外,有人建议使用httpUnit。事实上,httpUnit是由webdirver中的htmlunitdriver内部使用的,所以使用httpUnit时也会遇到同样的问题。我还进行了实验,这是正确的。通过thread.sleep( 2000)我认为等待JS解析是不明智的。有太多的不确定性,尤其是在大规模爬网中
综上所述,webdriver是一个专门为测试而设计的框架。虽然根据其原理,它在理论上可以用来帮助爬虫获取收录动态内容的HTML页面,但在实际应用中却没有被采用。不确定性太大,稳定性太差,速度太慢。让框架来完成它的best,不要损害他们的优势
我还没有完成我的工作,所以我需要找到一种上网的方式。这次,我找到了一个稳定且具有高度确定性的辅助工具phantomjs。目前,我不完全了解这个工具。但是,它已经被用来实现我想要的功能。在Java中,我使用runtime.exec(ARG)在解析JS后调用phantomjs获取页面。我最好发布代码
要在phantom JS端执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在Java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
通过这种方式,解析后的HTML页面可以在Java端获得,而不是使用thread.Sleep()在webdriver中,这种不确定的代码用于获取可能完成的代码。需要注意的一点是:phantomjs端的JS代码不能有语法错误,否则Java端会一直等待,如果JS代码的编译方式不同,Java端不会抛出异常。另一个原因是,在使用phantomjs.exe时side每次都要启动一个phantomjs进程,消耗的时间比较大,但至少结果是稳定的,当然最后我没有使用phantomjs,直接下载需要的数据,没有抓取整个页面,主要是速度问题(事实上,我不敢使用它,因为phantomjs是不熟悉的,所以我谨慎使用)
经过几天的辗转反侧,我没有解决我的问题,但我学到了很多知识。在后期,我熟悉phantomjs,看看我是否可以提高速度。如果我能打破速度框架,我将来爬到网页时会很方便。另外,nutch框架。我很佩服我哥哥的方便使用时,有必要在后期研究如何在Hadoop上优化nutch的爬行速度?此外,nutch的原创功能不会爬行动态生成的页面内容,但可以使用nutch和webdirver的组合。也许爬行结果是稳定的。哈哈,这些只是想法,但是你怎么知道你不要尝试
如果您对使用webdriver帮助爬虫获得的结果的稳定性有什么看法,欢迎您,因为我确实没有找到稳定结果的相关信息 查看全部
java爬虫抓取动态网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近,在做一个项目时,有一个需求:要从网页中获取数据,需要首先获取整个网页的HTML源代码(将在以后的更新中使用)。首先,我看了一下这个简单的,然后我敲了敲代码(nutch,一个以前使用Hadoop平台的分布式爬虫框架,使用起来非常方便,但最终由于速度原因放弃了,但生成的统计数据用于以后的爬虫)。很快,holder.html和finance.html页面被成功下载,然后,在解析holder.html页面之后,我解析了finance.html。然后我很沮丧地发现我在这个页面中需要的数据不在HTML源代码中。我去浏览器查看源代码。果然,源代码中没有我需要的数据。看来我的程序并没有写错,接下来就是让人筋疲力尽的事情——获取收录动态内容的HTML页面
在中国所谓最强的搜索引擎百度上走了很长一段时间后,我发现大多数人会使用webdriver和httpUnit(事实上,前者已经包括后者)。我很高兴,终于找到了解决办法。非常激动地使用webdriver,我发誓
下面对WebDriver的Tucao进行投诉
Webdriver是一个测试框架。它最初不是为爬虫服务的,但我想说的是:它几乎是一种浏览。你不能再向前迈一步吗?为什么这么多人在互联网上推荐webdriver?我不认为这些人是从现实出发的。有些人甚至吹嘘webdriver可以解析完成的页面,并将其返回给想要浏览整个页面的人(包括动态生成的内容)。是的,webdriver可以完成这个任务,但是当我看到作者编写的代码时,我想说的是:伙计,你的代码太有限了。解析自己编写的JS代码,JS代码很简单,因此webdriver肯定会在没有压力的情况下完成任务。当webdriver解析动态内容时,它取决于JS代码的复杂性和多样性
什么是复杂性
先发布一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是,我相信每个人都能理解上面使用的IE内核,当然是Firefox驱动程序、chrome驱动程序和htmlunitdriver。这些驱动程序的使用原则是相同的。首先打开浏览器(这需要时间),然后加载URL并完成动态解析,然后通过页面获得完整的HTML页面。作为xml(),htmlunitdriver模拟没有接口的浏览器。有一个rhino引擎在Java中执行JS。htmlunitdriver使用rhino解析JS。由于htmlunitdriver不会使用界面启动浏览器,因此它的速度比前三个版本快。不管是什么驱动程序,解析JS都是不可避免的,这需要时间,并且未使用的内核对JS的支持程序是不同的。例如,htmlunitdriver对带有滚动的JS代码的支持较差,并且会在执行过程中报告错误(亲身经历)。JS代码的复杂性意味着不同内核支持的JS并不完全相同。这要根据具体情况来确定。我已经很长时间没有学习JS了,所以我不会谈论内部检查JS的支持
什么是多样性
如前所述,浏览器解析JS需要时间。对于只有少量嵌入JS代码的页面,通过页面获取完整页面是没有问题的。Asxml()。但是,对于收录更多嵌入式JS代码的页面,解析JS需要很多时间(对于JVM)。此时,大部分页面都是通过页面获取的。Asxml()不收录动态生成的内容。问题是,为什么你说webdriver可以获得收录动态内容的HTML页面?网上有人说,开车后。Get(URL),当前线程需要等待以获取完成的页面,这类似于下面的表单
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
根据这个想法,我尝试了以下方法。啊,真的有可能。但这不是问题所在吗?如何确定等待时间?与数据挖掘中确定阈值的经验方法类似,或尽可能长。我认为这些不是很好的方法。时间成本相对较高。我认为驱动程序应该能够在解析JS后捕获状态,所以我去寻找,寻找,但根本没有这样的方法,所以我说为什么webdriver的设计者不进一步,以便我们可以在程序中获取驱动程序解析JS后的状态,所以我们不需要使用thread.sleep( 2000)很遗憾,我找不到这样不确定的代码,这让我很伤心。Firefox驱动程序、chrome驱动程序和htmlunitdriver也有同样的问题。可以说,使用webdriver帮助爬升动态生成的网页所获得的结果非常不稳定。我对此有深刻的理解。使用iedriver时,两个pages在同一页上,每次爬网的结果都不一样,有时ie会直接挂断。你敢在爬网程序中使用这些东西吗?我不敢
此外,有人建议使用httpUnit。事实上,httpUnit是由webdirver中的htmlunitdriver内部使用的,所以使用httpUnit时也会遇到同样的问题。我还进行了实验,这是正确的。通过thread.sleep( 2000)我认为等待JS解析是不明智的。有太多的不确定性,尤其是在大规模爬网中
综上所述,webdriver是一个专门为测试而设计的框架。虽然根据其原理,它在理论上可以用来帮助爬虫获取收录动态内容的HTML页面,但在实际应用中却没有被采用。不确定性太大,稳定性太差,速度太慢。让框架来完成它的best,不要损害他们的优势
我还没有完成我的工作,所以我需要找到一种上网的方式。这次,我找到了一个稳定且具有高度确定性的辅助工具phantomjs。目前,我不完全了解这个工具。但是,它已经被用来实现我想要的功能。在Java中,我使用runtime.exec(ARG)在解析JS后调用phantomjs获取页面。我最好发布代码
要在phantom JS端执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在Java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
通过这种方式,解析后的HTML页面可以在Java端获得,而不是使用thread.Sleep()在webdriver中,这种不确定的代码用于获取可能完成的代码。需要注意的一点是:phantomjs端的JS代码不能有语法错误,否则Java端会一直等待,如果JS代码的编译方式不同,Java端不会抛出异常。另一个原因是,在使用phantomjs.exe时side每次都要启动一个phantomjs进程,消耗的时间比较大,但至少结果是稳定的,当然最后我没有使用phantomjs,直接下载需要的数据,没有抓取整个页面,主要是速度问题(事实上,我不敢使用它,因为phantomjs是不熟悉的,所以我谨慎使用)
经过几天的辗转反侧,我没有解决我的问题,但我学到了很多知识。在后期,我熟悉phantomjs,看看我是否可以提高速度。如果我能打破速度框架,我将来爬到网页时会很方便。另外,nutch框架。我很佩服我哥哥的方便使用时,有必要在后期研究如何在Hadoop上优化nutch的爬行速度?此外,nutch的原创功能不会爬行动态生成的页面内容,但可以使用nutch和webdirver的组合。也许爬行结果是稳定的。哈哈,这些只是想法,但是你怎么知道你不要尝试
如果您对使用webdriver帮助爬虫获得的结果的稳定性有什么看法,欢迎您,因为我确实没有找到稳定结果的相关信息
java爬虫抓取动态网页(如何利用Webkit从JS渲染网页中实现浏览器非常有趣)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-19 09:11
当我们进行网络爬虫时,我们将使用某些规则从返回的HTML数据中提取有效信息。但是,如果web页面收录java代码,则必须经过渲染处理才能获得原创数据。在这一点上,如果我们仍然使用传统的方法从中获取数据,我们将一无所获。浏览器知道如何处理和显示这些代码,但是我们的程序应该如何处理这些代码呢?接下来,我将介绍一种简单而粗糙的方法来获取收录java代码的网页信息
大多数人使用lxml和漂亮的soup包来提取数据。在本文中我不会介绍任何爬虫框架,因为我只使用最基本的lxml包来处理数据。也许你会想知道为什么我更喜欢lxml。这是因为lxml使用元素遍历方法来处理数据,而不是像Beauty soup那样使用正则表达式来提取数据。在本文中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的pycoders周刊147期上,所以我想抓取pycoders周刊中所有文件的链接
显然,这是一个带有Java呈现的网页。我想捕获网页中的所有文件信息和相应的链接信息。那我该怎么办?首先,我们无法使用HTTP方法获取任何信息
导入请求
从lxml导入html
#存储响应
响应=请求。获取(“”)
#从响应体创建lxml树
tree=html.fromstring(response.text)
#查找响应中的所有锚定标记
print tree.xpath('//div[@class=“campaign”]/a/@href')
当我们运行上述代码时,我们无法获得任何信息。这怎么可能?网页清楚地显示了如此多的文件信息。其次,我们需要考虑如何解决这个问题。
如何获取内容信息
接下来,我将介绍如何使用web工具包从JS呈现的web页面获取数据。什么是网络工具包?Web kit可以实现浏览器可以处理的任何功能。对于某些浏览器,WebKit是底层网页呈现工具。Web工具包是Qt库的一部分,所以如果您已经安装了Qt和PyQt4库,则可以直接运行它们
您可以使用命令行安装软件库:
sudo apt get安装python-qt4
现在所有的准备工作已经完成,我们将使用一种新的方法来提取信息
解决方案
我们首先通过web工具包发送请求信息,然后在web页面完全加载后将其分配给变量。接下来,我们使用lxml从HTML数据中提取有效信息。这个过程需要一点时间,但是你会惊讶地发现整个网页都被完全加载了
导入系统
从PyQt4.QtGui导入*
从PyQt4.Qtcore导入*
从PyQt4.QtWebKit导入*
类呈现(QWeb页面):
定义初始化(self,url):
self.app=QApplication(sys.argv)
QWebPage._____;初始化(自)
self.loadFinished.connect(self.\u loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec()
def_uu加载完成(自身、结果):
self.frame=self.mainFrame()
self.app.quit()
类render可用于呈现网页。当我们创建一个新的呈现类时,它可以加载URL中的所有信息,并在一个新的框架中共存 查看全部
java爬虫抓取动态网页(如何利用Webkit从JS渲染网页中实现浏览器非常有趣)
当我们进行网络爬虫时,我们将使用某些规则从返回的HTML数据中提取有效信息。但是,如果web页面收录java代码,则必须经过渲染处理才能获得原创数据。在这一点上,如果我们仍然使用传统的方法从中获取数据,我们将一无所获。浏览器知道如何处理和显示这些代码,但是我们的程序应该如何处理这些代码呢?接下来,我将介绍一种简单而粗糙的方法来获取收录java代码的网页信息
大多数人使用lxml和漂亮的soup包来提取数据。在本文中我不会介绍任何爬虫框架,因为我只使用最基本的lxml包来处理数据。也许你会想知道为什么我更喜欢lxml。这是因为lxml使用元素遍历方法来处理数据,而不是像Beauty soup那样使用正则表达式来提取数据。在本文中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的pycoders周刊147期上,所以我想抓取pycoders周刊中所有文件的链接
显然,这是一个带有Java呈现的网页。我想捕获网页中的所有文件信息和相应的链接信息。那我该怎么办?首先,我们无法使用HTTP方法获取任何信息
导入请求
从lxml导入html
#存储响应
响应=请求。获取(“”)
#从响应体创建lxml树
tree=html.fromstring(response.text)
#查找响应中的所有锚定标记
print tree.xpath('//div[@class=“campaign”]/a/@href')
当我们运行上述代码时,我们无法获得任何信息。这怎么可能?网页清楚地显示了如此多的文件信息。其次,我们需要考虑如何解决这个问题。
如何获取内容信息
接下来,我将介绍如何使用web工具包从JS呈现的web页面获取数据。什么是网络工具包?Web kit可以实现浏览器可以处理的任何功能。对于某些浏览器,WebKit是底层网页呈现工具。Web工具包是Qt库的一部分,所以如果您已经安装了Qt和PyQt4库,则可以直接运行它们
您可以使用命令行安装软件库:
sudo apt get安装python-qt4
现在所有的准备工作已经完成,我们将使用一种新的方法来提取信息
解决方案
我们首先通过web工具包发送请求信息,然后在web页面完全加载后将其分配给变量。接下来,我们使用lxml从HTML数据中提取有效信息。这个过程需要一点时间,但是你会惊讶地发现整个网页都被完全加载了
导入系统
从PyQt4.QtGui导入*
从PyQt4.Qtcore导入*
从PyQt4.QtWebKit导入*
类呈现(QWeb页面):
定义初始化(self,url):
self.app=QApplication(sys.argv)
QWebPage._____;初始化(自)
self.loadFinished.connect(self.\u loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec()
def_uu加载完成(自身、结果):
self.frame=self.mainFrame()
self.app.quit()
类render可用于呈现网页。当我们创建一个新的呈现类时,它可以加载URL中的所有信息,并在一个新的框架中共存
java爬虫抓取动态网页(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和chromedriver)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-16 06:18
什么是Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:
1、直接分析Ajax调用的接口。然后通过代码请求这个接口
2、使用selenium+chromedriver模拟浏览器行为并获取数据
Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
1、Chrome:/a//chromedriver/下载
2、Firefox:/mozilla/geckodriver/releases
3、Edge:/en us/microsoft edge/tools/webdriver/
4、Safari:/blog/6900/webdriver-support-in-safari-10/
要安装selenium和chromedriver:
安装selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本
pip安装selenium
安装chromedriver:下载后,未经许可将其放入纯英文目录
快速启动:
现在让我们举一个简单的例子,让百度的主页告诉你如何快速启动硒和ChrimEdvor:
Selenium常见操作:
关闭页面:
1、driver.close():关闭当前页面
2、driver.quit():退出整个浏览器
定位元素:
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
作为表单元素:
1、操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag=driver.find u元素uu按u id('kw')查找
inputTag.send ukeys('python'))
使用“清除”方法清除输入框的内容。示例代码如下所示:
输入ag.clear()
2、operate checkbox:因为要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag=driver.find uu元素uu按名称(“rememberMe”)
记住标记。单击()
3、select:无法直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:
4、操作按钮:有多种方式操作按钮。例如,单击、右键单击、双击等。这里是最常用的方法之一。点击一下。直接调用click函数即可。示例代码如下所示:
inputTag=driver.find u元素uu按id('su')查找
输入ag。单击()行为链:
有时,页面中的操作可能有许多步骤,因此您可以使用鼠标行为链类actionchains来完成它。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下所示:
还有更多与鼠标相关的操作
1、click_按住(元素):单击但不要释放鼠标
2、context_单击(图元):单击鼠标右键
3、double_单击(图元):双击。有关更多方法,请参阅selenium-python.readthedocs.io/api.html
Cookie操作:
获取所有cookies:
对于driver.get\cookies()中的cookie:
打印(cookie)
根据cookie的键获取值:
value=driver.get uuCookie(键)
删除所有cookie:
driver.delete uu所有uu cookies()
删除cookie:
driver.delete\ucookie(密钥)
页面等待:
现在越来越多的网页使用ajax技术,因此程序无法确定元素何时完全加载。如果实际的页面等待时间太长,导致DOM元素无法出现,但您的代码直接使用此webelement,它将抛出空指针异常。解决这个问题。因此,selenium提供了两种等待方法:隐式等待和显式等待
隐式等待:调用driver.implicitly uuwait。然后它将等待10秒钟,然后才能获取不可用的元素。示例代码如下所示:
显示等待:显示等待指示仅在建立条件后执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。显示等待应使用selenium.webdriver.support.excluded uu条件预期条件和selenium.webdriver.support.ui.webdriverwait一起完成。示例代码如下所示:
其他一些等候条件:
1、presence_元素的位置:元素已加载
2、presence_位于的所有元素中:已加载网页中所有符合条件的元素
3、element_可点击:可以点击元素
切换页面:
有时窗口中有许多子选项卡页。此时必须切换。Selenium提供了一个名为“切换到”的窗口。您可以从句柄中的driver.window切换到哪个页面。示例代码如下所示:
self.driver.switch_uuu到uu窗口(self.driver.window_u句柄[1])
设置代理IP:
有时我经常抓取一些网页。当服务器发现您是爬虫程序时,它将阻止您的IP地址。此时,我们可以更改代理IP。改变代理IP,不同的浏览器有不同的实现方法。这里,以Chrome浏览器为例说明:
Webelement元素:
从selenium.webdriver.remote.webelement导入webelement类是每个获取的元素所属的类
有一些共同的属性:
1、get_属性:此标记的属性值
2、screentshot:获取当前页面的屏幕截图。此方法只能在驱动程序上使用
驱动程序的对象类也继承自webelement 查看全部
java爬虫抓取动态网页(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和chromedriver)
什么是Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:
1、直接分析Ajax调用的接口。然后通过代码请求这个接口
2、使用selenium+chromedriver模拟浏览器行为并获取数据

Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
1、Chrome:/a//chromedriver/下载
2、Firefox:/mozilla/geckodriver/releases
3、Edge:/en us/microsoft edge/tools/webdriver/
4、Safari:/blog/6900/webdriver-support-in-safari-10/
要安装selenium和chromedriver:
安装selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本
pip安装selenium
安装chromedriver:下载后,未经许可将其放入纯英文目录
快速启动:
现在让我们举一个简单的例子,让百度的主页告诉你如何快速启动硒和ChrimEdvor:
Selenium常见操作:
关闭页面:
1、driver.close():关闭当前页面
2、driver.quit():退出整个浏览器
定位元素:
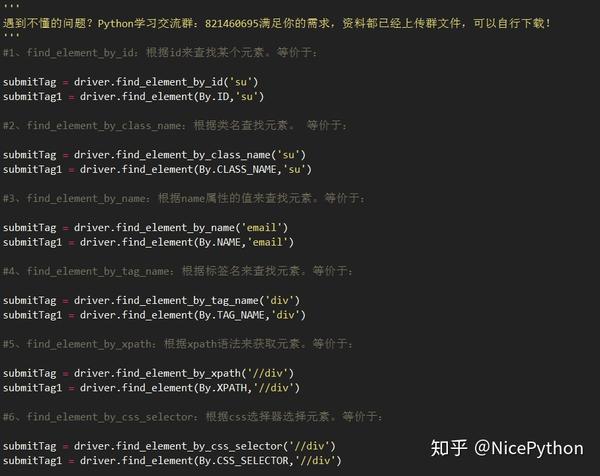
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
作为表单元素:
1、操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag=driver.find u元素uu按u id('kw')查找
inputTag.send ukeys('python'))
使用“清除”方法清除输入框的内容。示例代码如下所示:
输入ag.clear()
2、operate checkbox:因为要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag=driver.find uu元素uu按名称(“rememberMe”)
记住标记。单击()
3、select:无法直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:

4、操作按钮:有多种方式操作按钮。例如,单击、右键单击、双击等。这里是最常用的方法之一。点击一下。直接调用click函数即可。示例代码如下所示:
inputTag=driver.find u元素uu按id('su')查找
输入ag。单击()行为链:
有时,页面中的操作可能有许多步骤,因此您可以使用鼠标行为链类actionchains来完成它。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下所示:

还有更多与鼠标相关的操作
1、click_按住(元素):单击但不要释放鼠标
2、context_单击(图元):单击鼠标右键
3、double_单击(图元):双击。有关更多方法,请参阅selenium-python.readthedocs.io/api.html
Cookie操作:
获取所有cookies:
对于driver.get\cookies()中的cookie:
打印(cookie)
根据cookie的键获取值:
value=driver.get uuCookie(键)
删除所有cookie:
driver.delete uu所有uu cookies()
删除cookie:
driver.delete\ucookie(密钥)
页面等待:
现在越来越多的网页使用ajax技术,因此程序无法确定元素何时完全加载。如果实际的页面等待时间太长,导致DOM元素无法出现,但您的代码直接使用此webelement,它将抛出空指针异常。解决这个问题。因此,selenium提供了两种等待方法:隐式等待和显式等待
隐式等待:调用driver.implicitly uuwait。然后它将等待10秒钟,然后才能获取不可用的元素。示例代码如下所示:

显示等待:显示等待指示仅在建立条件后执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。显示等待应使用selenium.webdriver.support.excluded uu条件预期条件和selenium.webdriver.support.ui.webdriverwait一起完成。示例代码如下所示:

其他一些等候条件:
1、presence_元素的位置:元素已加载
2、presence_位于的所有元素中:已加载网页中所有符合条件的元素
3、element_可点击:可以点击元素
切换页面:
有时窗口中有许多子选项卡页。此时必须切换。Selenium提供了一个名为“切换到”的窗口。您可以从句柄中的driver.window切换到哪个页面。示例代码如下所示:
self.driver.switch_uuu到uu窗口(self.driver.window_u句柄[1])
设置代理IP:
有时我经常抓取一些网页。当服务器发现您是爬虫程序时,它将阻止您的IP地址。此时,我们可以更改代理IP。改变代理IP,不同的浏览器有不同的实现方法。这里,以Chrome浏览器为例说明:

Webelement元素:
从selenium.webdriver.remote.webelement导入webelement类是每个获取的元素所属的类
有一些共同的属性:
1、get_属性:此标记的属性值
2、screentshot:获取当前页面的屏幕截图。此方法只能在驱动程序上使用
驱动程序的对象类也继承自webelement
java爬虫抓取动态网页(本文插件模拟浏览器如何获得网页上的动态加载数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-14 05:02
本文讲如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。步骤如下:一、找到正确的网址。 二、填写URL对应的参数。 三、参数转换成urllib可以识别的字符串数据。 四、 初始化请求对象。 五、urlopen 这个Request对象获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
以下步骤相同,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计诊断、累计死亡等数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面来谈谈如何用火狐浏览器获取这两个数据。
在肺炎页面右击,在出现的菜单中选择勾选元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
这里会有很多网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。通常,动态加载的数据量大于其他页面元素的数据量。 ,与其他基于字节的数据相比,119kb 被认为是非常大的数据。当然,网页上的一些装修图片也是很大的。这个需要根据文件类型栏区分。
然后点击域名一栏对应的行,如下
在消息头中可以看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,则
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data) 查看全部
java爬虫抓取动态网页(本文插件模拟浏览器如何获得网页上的动态加载数据?)
本文讲如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。步骤如下:一、找到正确的网址。 二、填写URL对应的参数。 三、参数转换成urllib可以识别的字符串数据。 四、 初始化请求对象。 五、urlopen 这个Request对象获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
以下步骤相同,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计诊断、累计死亡等数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面来谈谈如何用火狐浏览器获取这两个数据。
在肺炎页面右击,在出现的菜单中选择勾选元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
这里会有很多网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。通常,动态加载的数据量大于其他页面元素的数据量。 ,与其他基于字节的数据相比,119kb 被认为是非常大的数据。当然,网页上的一些装修图片也是很大的。这个需要根据文件类型栏区分。
然后点击域名一栏对应的行,如下
在消息头中可以看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,则
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data)
java爬虫抓取动态网页(1.代码实现接下来提取首页jobName中包含python的所有链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-14 05:00
)
根据 UN网站accessibility 审计报告,主流网站 73% 的重要功能依赖 JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这个依赖JavaScript的动态网站,我们需要采取相应的方法,比如JavaScript逆向工程,渲染JavaScript等
1.动态网页示例
如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12
看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/?jl=736&kw=python&kt=3'
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2.逆向工程动态网页
在firefox中按F12,点击控制台打开XHR
点击一一打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3. 代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
查看全部
java爬虫抓取动态网页(1.代码实现接下来提取首页jobName中包含python的所有链接
)
根据 UN网站accessibility 审计报告,主流网站 73% 的重要功能依赖 JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这个依赖JavaScript的动态网站,我们需要采取相应的方法,比如JavaScript逆向工程,渲染JavaScript等
1.动态网页示例

如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12

看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/?jl=736&kw=python&kt=3'
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2.逆向工程动态网页
在firefox中按F12,点击控制台打开XHR

点击一一打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3. 代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
java爬虫抓取动态网页(一个爬虫动态生成的网页是什么?一般来说怎么办 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-14 04:17
)
最近公司想写一个爬虫项目。遇到一些js或者ajax动态生成的网页。我在网上搜索,发现webdriver更可靠。至于htmlunit,有的网站直接抛出异常。对js的支持不是特别好。
一般来说,WebDriver 有两种方式:本地 diver 和远程 diver。由于爬虫最终会部署到Linux服务器上,只能在命令行上运行,看来浏览器是装不了的,所以本地驱动的进程就不行了,只能尝试远程驱动了。幸运的是,我找到了一个phantomjs webdriver,它可以在没有界面的情况下在Linux下运行,所以我选择了它作为从js动态生成网页的解决方案。
到官网下载:,找到对应的版本下载。解压并安装它。进入bin目录,执行phantomjs,需要带启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
driver.get("http://www.iteye.com"); 查看全部
java爬虫抓取动态网页(一个爬虫动态生成的网页是什么?一般来说怎么办
)
最近公司想写一个爬虫项目。遇到一些js或者ajax动态生成的网页。我在网上搜索,发现webdriver更可靠。至于htmlunit,有的网站直接抛出异常。对js的支持不是特别好。
一般来说,WebDriver 有两种方式:本地 diver 和远程 diver。由于爬虫最终会部署到Linux服务器上,只能在命令行上运行,看来浏览器是装不了的,所以本地驱动的进程就不行了,只能尝试远程驱动了。幸运的是,我找到了一个phantomjs webdriver,它可以在没有界面的情况下在Linux下运行,所以我选择了它作为从js动态生成网页的解决方案。
到官网下载:,找到对应的版本下载。解压并安装它。进入bin目录,执行phantomjs,需要带启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
driver.get("http://www.iteye.com";);
java爬虫抓取动态网页(代码不好使怎么获取后台js完后的完整页面?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-14 04:15
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上的HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,但是不行。
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,这段代码不能很好地工作。
对于答案,典型的是此链接的页面。 java程序中如何获取数据? 查看全部
java爬虫抓取动态网页(代码不好使怎么获取后台js完后的完整页面?)
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上的HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,但是不行。
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,这段代码不能很好地工作。
对于答案,典型的是此链接的页面。 java程序中如何获取数据?
java爬虫抓取动态网页(Selenium+Chrome:运用到爬虫中的思路是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-21 14:10
爬虫:动态网页的处理方法(第2部分)——模拟浏览器行为前言:
在上一个示例中,我们使用WebKit库自定义浏览器渲染引擎,以便完全控制要执行的行为。如果您不需要如此多的灵活性,那么有一个很好的替代方案来替代selenium,它提供了一个API接口来自动化浏览器
硒简介:
Selenium是一种用于测试web应用程序的工具。Selenium测试直接在浏览器中运行,就像真实用户一样。支持市场上几乎所有主流浏览器
最初,我打算使用selenium+phantom JS的组合,但我发现chrome和Firefox也相继推出了无头浏览器模式,我更喜欢chrome。本文采用硒+铬的组合
例如:
适用于爬行动物的想法是:
以新浪阅读图书节选网站为例。目标是获取列表中每个文章详细页面的地址。直接参见示例代码:
# coding=utf-8
import time
from selenium import webdriver
class SinaBookSpider(object):
# 创建可见的Chrome浏览器, 方便调试
driver = webdriver.Chrome()
# 创建Chrome的无头浏览器
# opt = webdriver.ChromeOptions()
# opt.set_headless()
# driver = webdriver.Chrome(options=opt)
driver.implicitly_wait(10)
total = 1526 # 预先计算的总数据量
count = 0 # 已爬取的数据量
# 记录解析以及翻页位置
location = 0
click_times = 0
def run(self):
"""
开始爬虫
:return:
"""
# get方式打开网页
self.driver.get("http://book.sina.com.cn/excerpt/rwws/")
self.parselist()
while self.count < self.total:
if self.click_times is 2:
self.driver.find_element_by_css_selector('#subShowContent1_page > span:nth-child(6) > a').click()
# 等待页面加载完成
time.sleep(5)
self.click_times = 0
self.location = 0
else:
self.driver.find_element_by_css_selector('#subShowContent1_loadMore').click()
# 等待页面加载完成
time.sleep(3)
self.click_times += 1
# 分析加载的新内容,从location开始
self.parselist()
self.driver.quit()
def parselist(self):
"""
解析列表
:return:
"""
divs = self.driver.find_elements_by_class_name("item")
for i in range(self.location, len(divs)):
link = divs[i].find_element_by_tag_name('a').get_attribute("href")
print link
self.location += 1
self.count += 1
print self.count
if __name__ == '__main__':
spider = SinaBookSpider()
spider.run()
代码地址:动态web进程--GitHub
如果要实际运行上述代码,请确保在运行之前安装了与浏览器版本对应的驱动程序,并将其正确添加到环境变量中
这里可以看到对这三种方法的解释:Python selenium——必须能够使用selenium进行等待,以及对这三种等待方法的解释——gray和blue博客
总结:
在这里,我们介绍两种动态页面处理方法:
做一个简单的比较:
使用哪种方法取决于爬行动物活动的具体情况:
就我个人而言,我认为应该尽可能避免模拟浏览器的方法,因为浏览器环境会消耗大量内存和CPU,这可以作为短期解决方案。此时,长期性能和可靠性并不重要;作为一个长期的解决方案,我将尽最大努力网站进行逆向工程
欢迎指出本文中的任何错误或不足之处 查看全部
java爬虫抓取动态网页(Selenium+Chrome:运用到爬虫中的思路是什么?)
爬虫:动态网页的处理方法(第2部分)——模拟浏览器行为前言:
在上一个示例中,我们使用WebKit库自定义浏览器渲染引擎,以便完全控制要执行的行为。如果您不需要如此多的灵活性,那么有一个很好的替代方案来替代selenium,它提供了一个API接口来自动化浏览器
硒简介:
Selenium是一种用于测试web应用程序的工具。Selenium测试直接在浏览器中运行,就像真实用户一样。支持市场上几乎所有主流浏览器
最初,我打算使用selenium+phantom JS的组合,但我发现chrome和Firefox也相继推出了无头浏览器模式,我更喜欢chrome。本文采用硒+铬的组合
例如:
适用于爬行动物的想法是:
以新浪阅读图书节选网站为例。目标是获取列表中每个文章详细页面的地址。直接参见示例代码:
# coding=utf-8
import time
from selenium import webdriver
class SinaBookSpider(object):
# 创建可见的Chrome浏览器, 方便调试
driver = webdriver.Chrome()
# 创建Chrome的无头浏览器
# opt = webdriver.ChromeOptions()
# opt.set_headless()
# driver = webdriver.Chrome(options=opt)
driver.implicitly_wait(10)
total = 1526 # 预先计算的总数据量
count = 0 # 已爬取的数据量
# 记录解析以及翻页位置
location = 0
click_times = 0
def run(self):
"""
开始爬虫
:return:
"""
# get方式打开网页
self.driver.get("http://book.sina.com.cn/excerpt/rwws/";)
self.parselist()
while self.count < self.total:
if self.click_times is 2:
self.driver.find_element_by_css_selector('#subShowContent1_page > span:nth-child(6) > a').click()
# 等待页面加载完成
time.sleep(5)
self.click_times = 0
self.location = 0
else:
self.driver.find_element_by_css_selector('#subShowContent1_loadMore').click()
# 等待页面加载完成
time.sleep(3)
self.click_times += 1
# 分析加载的新内容,从location开始
self.parselist()
self.driver.quit()
def parselist(self):
"""
解析列表
:return:
"""
divs = self.driver.find_elements_by_class_name("item")
for i in range(self.location, len(divs)):
link = divs[i].find_element_by_tag_name('a').get_attribute("href")
print link
self.location += 1
self.count += 1
print self.count
if __name__ == '__main__':
spider = SinaBookSpider()
spider.run()
代码地址:动态web进程--GitHub
如果要实际运行上述代码,请确保在运行之前安装了与浏览器版本对应的驱动程序,并将其正确添加到环境变量中
这里可以看到对这三种方法的解释:Python selenium——必须能够使用selenium进行等待,以及对这三种等待方法的解释——gray和blue博客
总结:
在这里,我们介绍两种动态页面处理方法:
做一个简单的比较:
使用哪种方法取决于爬行动物活动的具体情况:
就我个人而言,我认为应该尽可能避免模拟浏览器的方法,因为浏览器环境会消耗大量内存和CPU,这可以作为短期解决方案。此时,长期性能和可靠性并不重要;作为一个长期的解决方案,我将尽最大努力网站进行逆向工程
欢迎指出本文中的任何错误或不足之处
java爬虫抓取动态网页(关于Java使用PhantomJs的一些事儿,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-21 14:08
让我们先离题。当我刚开始学习爬行动物时,有一次一位大四的学生让我需要捕捉京东图书的相关信息。因为我刚刚开始学习爬行动物和练习豆瓣菜,所以我抓取了大约500篇电影评论并存储在MySQL中。当时,我觉得自己不够强壮,所以很容易就接受了这个要求
然后自信地开始工作。。首先查看网页源代码。。。???我需要的不是源代码!!!然后我去问大四。前辈告诉我这是由Ajax生成的数据。听了之后,我去检查数据。人们发现,互联网上的大量信息正在解释一个事实。对于动态页面,使用phantom JS进行捕获,但这种效率非常低。作为一名优秀的程序员,我当时看到了四个低效字,这在我心里是绝对不允许的,所以我使用捕获数据包的方式查看ajax数据所在的URL。模拟浏览器的方法一直被搁置至今
但是现在你知道了这件事,没有理由不去学习。因此,我花了一些时间阅读了有关在Java中使用phantom JS的信息,现在我将与您分享
顺便说一句,作为一个网络爬虫,页面上90%的数据可以通过捕获数据包获得。因此,我鼓励您直接请求所需数据的URL。毕竟,尽管这种方法很方便,但效率很低
JS渲染与ajax
在学习这件事之前,我们必须首先了解什么是JS渲染,什么是Ajax,以及为什么我们不能在web源代码中获取这两种数据
据我了解,JS渲染和Ajax是相辅相成的。AJAX负责从服务器异步获取数据,获取数据后用JS进行渲染,最后将数据呈现给用户。在Java中,httpclient只能请求简单的静态页面,不能在页面完全加载后请求JS调用相关代码生成的异步数据。因此,我们无法通过httpclient直接获取Ajax和JS渲染生成的数据。此时,建议您直接捕获网络数据包以获取ajax数据所在的URL,或者使用本文中描述的phantom JS呈现引擎
三种JS渲染引擎的比较
在互联网上查阅信息时,我们常常被各种各样的答案所淹没。此时,首先要保持平静的心情,其次,我们应该考虑搜索问题的相关姿势,我们需要在必要时科学地上网。
更不用说本文中提到的JS呈现引擎,Java爬虫中的HTTP请求库可以用多种方式描述。Java的本机httpurlconnection类、httpclient第三方库等等。。。当然,网络上有太多可用的方法,我们必须选择,因此我们当然希望选择一个功能强大且简单的类库。此时,我们应该在互联网上搜索并比较两个类库,以做出更好的选择,而不是仅仅选择一个来学习。这样,学习成本很可能与回报不成正比
所以我相信,当您准备使用JS引擎来模拟浏览器时,您不仅看到了phantom JS,还看到了selenium和htmlunit,它们具有相同的功能。那么我们如何选择呢?下图摘自其他网友的博客:
HtmlUnitSeleniumPhantomJs
内置rhinojs浏览器引擎,没有浏览器使用此内核,解析速度平均,解析JS/CSS较差,没有浏览器界面
Selenium+webdriver=Selenium基于本地安装的浏览器。需要打开浏览器,引用相应的webdriver,并正确配置webdriver的路径参数。在抓取大量JS呈现的页面时,这显然是不合适的
工件简短而简洁,可以在本地运行,也可以作为服务器运行。它基于WebKit内核,具有良好的性能和性能,能够完美解析大多数页面
这就是为什么我选择谈论幻影JS
在互联网上,phantom JS和selenium经常成对出现。原因是selenium封装了phantom JS的一些函数,并且selenium提供了Python接口模块。Selenium可以在Python语言中很好地使用,phantom JS可以间接使用。然而,是时候放弃selenium+phantom JS了。一个原因是封装的接口很长时间没有更新(没有人维护它)。另一个原因是selenium只实现了一些phantom JS函数,而且非常不完善
幻影JS的使用
我用Ubuntu16.04开发环境。关于phantom JS+selenium的环境部署,网络上有很多信息。我将在这里介绍一个链接。我不会详细解释:Ubuntu安装phantomjs
我不会详细介绍phantom JS和selenium的介绍。你可以直接去百度。让我们直接看看幻像JS应该如何在java
中使用
如果您不使用maven,请在Internet上下载第三方jar包。我们需要的Maven依赖项如下:
org.seleniumhq.selenium
selenium-java
2.53.1
com.github.detro.ghostdriver
phantomjsdriver
1.1.0
接下来,让我们看看程序应该如何编写:
1.set请求头
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径,使用whereis phantomjs可以查看)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY, "/usr/local/bin/phantomjs");
2.create phantomjs浏览器对象
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
3.set隐藏等待
//设置隐性等待
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
由于加载页面需要一段时间,如果在加载页面之前查找元素,则一定无法找到它们。最好的方法是设置默认等待时间。如果找不到页面元素,请等待一段时间,直到它超时
使用phantomjs时应注意以上三点。您可以查看一般的总体程序:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.concurrent.TimeUnit;
/**
* Created by hg_yi on 17-10-11.
*/
public class phantomjs {
public static void main(String[] args) {
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,
"/usr/bin/phantomjs-2.1.1-linux-x86_64/bin/phantomjs");
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
//设置隐性等待(作用于全局)
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
//打开页面
driver.get("--------------------------------");
//查找元素
WebElement element = driver.findElement(By.id("img_valiCode"));
System.out.println(element.getAttribute("src"));
}
}
我成功捕获了网页源代码中没有的数据~
对于上面使用的phantomjsdriver类的相关API,您可以直接查看此资料,它应该满足您的日常需要:webdriver API中文版(webdriver API也适用于phantomjsdriver)
phantom JS的性能优化
我们都知道,使用phantom JS等无头浏览器捕获web源代码非常耗时,因此当我们决定使用此工具并对捕获速度有一定要求时,我们需要掌握优化phantom JS性能的能力
1.设置参数
谷歌和百度已经阅读了很长时间的一些官方文档,但是他们仍然找不到与phantomjs相关的Java调用API文档。好吧,先抛出一篇python文章,然后找到这方面的内容并加以补充~~~
[phantom JS series]硒+phantom JS性能优化
旁白:事实上,对于java网络爬虫。。。真想吐槽,建议刚开始抱怨爬行动物或与Python爬虫搏斗的人~~对Java爬虫来说,只要说一句话:学习很难,学习周期很长,扔东西和收入不成正比!!!p> 查看全部
java爬虫抓取动态网页(关于Java使用PhantomJs的一些事儿,你了解多少?)
让我们先离题。当我刚开始学习爬行动物时,有一次一位大四的学生让我需要捕捉京东图书的相关信息。因为我刚刚开始学习爬行动物和练习豆瓣菜,所以我抓取了大约500篇电影评论并存储在MySQL中。当时,我觉得自己不够强壮,所以很容易就接受了这个要求
然后自信地开始工作。。首先查看网页源代码。。。???我需要的不是源代码!!!然后我去问大四。前辈告诉我这是由Ajax生成的数据。听了之后,我去检查数据。人们发现,互联网上的大量信息正在解释一个事实。对于动态页面,使用phantom JS进行捕获,但这种效率非常低。作为一名优秀的程序员,我当时看到了四个低效字,这在我心里是绝对不允许的,所以我使用捕获数据包的方式查看ajax数据所在的URL。模拟浏览器的方法一直被搁置至今
但是现在你知道了这件事,没有理由不去学习。因此,我花了一些时间阅读了有关在Java中使用phantom JS的信息,现在我将与您分享
顺便说一句,作为一个网络爬虫,页面上90%的数据可以通过捕获数据包获得。因此,我鼓励您直接请求所需数据的URL。毕竟,尽管这种方法很方便,但效率很低
JS渲染与ajax
在学习这件事之前,我们必须首先了解什么是JS渲染,什么是Ajax,以及为什么我们不能在web源代码中获取这两种数据
据我了解,JS渲染和Ajax是相辅相成的。AJAX负责从服务器异步获取数据,获取数据后用JS进行渲染,最后将数据呈现给用户。在Java中,httpclient只能请求简单的静态页面,不能在页面完全加载后请求JS调用相关代码生成的异步数据。因此,我们无法通过httpclient直接获取Ajax和JS渲染生成的数据。此时,建议您直接捕获网络数据包以获取ajax数据所在的URL,或者使用本文中描述的phantom JS呈现引擎
三种JS渲染引擎的比较
在互联网上查阅信息时,我们常常被各种各样的答案所淹没。此时,首先要保持平静的心情,其次,我们应该考虑搜索问题的相关姿势,我们需要在必要时科学地上网。
更不用说本文中提到的JS呈现引擎,Java爬虫中的HTTP请求库可以用多种方式描述。Java的本机httpurlconnection类、httpclient第三方库等等。。。当然,网络上有太多可用的方法,我们必须选择,因此我们当然希望选择一个功能强大且简单的类库。此时,我们应该在互联网上搜索并比较两个类库,以做出更好的选择,而不是仅仅选择一个来学习。这样,学习成本很可能与回报不成正比
所以我相信,当您准备使用JS引擎来模拟浏览器时,您不仅看到了phantom JS,还看到了selenium和htmlunit,它们具有相同的功能。那么我们如何选择呢?下图摘自其他网友的博客:
HtmlUnitSeleniumPhantomJs
内置rhinojs浏览器引擎,没有浏览器使用此内核,解析速度平均,解析JS/CSS较差,没有浏览器界面
Selenium+webdriver=Selenium基于本地安装的浏览器。需要打开浏览器,引用相应的webdriver,并正确配置webdriver的路径参数。在抓取大量JS呈现的页面时,这显然是不合适的
工件简短而简洁,可以在本地运行,也可以作为服务器运行。它基于WebKit内核,具有良好的性能和性能,能够完美解析大多数页面
这就是为什么我选择谈论幻影JS
在互联网上,phantom JS和selenium经常成对出现。原因是selenium封装了phantom JS的一些函数,并且selenium提供了Python接口模块。Selenium可以在Python语言中很好地使用,phantom JS可以间接使用。然而,是时候放弃selenium+phantom JS了。一个原因是封装的接口很长时间没有更新(没有人维护它)。另一个原因是selenium只实现了一些phantom JS函数,而且非常不完善
幻影JS的使用
我用Ubuntu16.04开发环境。关于phantom JS+selenium的环境部署,网络上有很多信息。我将在这里介绍一个链接。我不会详细解释:Ubuntu安装phantomjs
我不会详细介绍phantom JS和selenium的介绍。你可以直接去百度。让我们直接看看幻像JS应该如何在java
中使用
如果您不使用maven,请在Internet上下载第三方jar包。我们需要的Maven依赖项如下:
org.seleniumhq.selenium
selenium-java
2.53.1
com.github.detro.ghostdriver
phantomjsdriver
1.1.0
接下来,让我们看看程序应该如何编写:
1.set请求头
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径,使用whereis phantomjs可以查看)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY, "/usr/local/bin/phantomjs");
2.create phantomjs浏览器对象
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
3.set隐藏等待
//设置隐性等待
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
由于加载页面需要一段时间,如果在加载页面之前查找元素,则一定无法找到它们。最好的方法是设置默认等待时间。如果找不到页面元素,请等待一段时间,直到它超时
使用phantomjs时应注意以上三点。您可以查看一般的总体程序:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import java.util.concurrent.TimeUnit;
/**
* Created by hg_yi on 17-10-11.
*/
public class phantomjs {
public static void main(String[] args) {
//设置必要参数
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持(第二参数表明的是你的phantomjs引擎所在的路径)
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,
"/usr/bin/phantomjs-2.1.1-linux-x86_64/bin/phantomjs");
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(dcaps);
//设置隐性等待(作用于全局)
driver.manage().timeouts().implicitlyWait(1, TimeUnit.SECONDS);
//打开页面
driver.get("--------------------------------");
//查找元素
WebElement element = driver.findElement(By.id("img_valiCode"));
System.out.println(element.getAttribute("src"));
}
}
我成功捕获了网页源代码中没有的数据~
对于上面使用的phantomjsdriver类的相关API,您可以直接查看此资料,它应该满足您的日常需要:webdriver API中文版(webdriver API也适用于phantomjsdriver)
phantom JS的性能优化
我们都知道,使用phantom JS等无头浏览器捕获web源代码非常耗时,因此当我们决定使用此工具并对捕获速度有一定要求时,我们需要掌握优化phantom JS性能的能力
1.设置参数
谷歌和百度已经阅读了很长时间的一些官方文档,但是他们仍然找不到与phantomjs相关的Java调用API文档。好吧,先抛出一篇python文章,然后找到这方面的内容并加以补充~~~
[phantom JS series]硒+phantom JS性能优化
旁白:事实上,对于java网络爬虫。。。真想吐槽,建议刚开始抱怨爬行动物或与Python爬虫搏斗的人~~对Java爬虫来说,只要说一句话:学习很难,学习周期很长,扔东西和收入不成正比!!!p>
java爬虫抓取动态网页(soup()需要爬取的网站数据及分析方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-09-21 14:07
参考原文:
需要爬网的网站数据:共165页,可通过将page=1改为其他数字进行访问
获取所有URL:URL=(“{}”。范围(1)中的I的格式(I),166))
使用Firefox浏览器打开要爬网的网页,右键单击查看页面源代码,Ctrl+F查找并输入293。此值在源代码中不存在,表示它是动态加载的数据
对于动态加载的数据,我熟悉两种方法:一种是使用selenium,另一种是分析网页元素,找出原创网页中的数据,提交表单,并获取不同的数据以达到爬行的目的
方法1:
#coding=utf-8
from bs4 import BeautifulSoup
from selenium import webdriver
urls = ('http://gkcx.eol.cn/soudaxue/qu ... ge%3D{}'.format(i) for i in range(1,166))
driver=webdriver.Firefox()
driver.maximize_window()
for url in urls:
#print ("正在访问{}".format(url))
driver.get(url)
data = driver.page_source
soup = BeautifulSoup(data, 'lxml')
grades = soup.find_all('tr')
for grade in grades:
if '' in str(grade):
print(grade.get_text())
代码说明:
从BS4导入Beauty soup使用Beauty soup解析网页数据
从selenium导入webdriver使用selenium抓取动态数据
URL=('{}'。范围(1)中的i的格式(i),166))收录需要爬网的所有数据的网站生成器
Driver=webdriver.Firefox()打开Firefox浏览器
Driver.maximize_window()最大化窗口
driver.get(URL)浏览器会自动跳转到URL链接
Data=driver.page\u source获取页面元素,其中收录要爬网的数据
soup=BeautifulSoup(数据'lxml')
等级=汤。查找所有('tr'))
按年级划分的年级:
如果str(年级)中有“”:
打印(grade.get_text())
通过分析数据并写出上述搜索方法,您可以获得所有数据
通过这种方法获取数据简单直观,但缺点是速度太慢
现在,第二种方法是获取数据
使用Firefox浏览器打开要爬网的网页,右键单击查看元素,然后选择“网络”。默认情况下,该功能正常
(一些旧版本的Firefox可能需要安装firebug插件)
单击第二页以查看加载了哪些页面和数据
分析如下:
分析表明,JSON类型的列就是我们需要的数据
在消息头网站中查看请求@
实际请求网站
参数mestype=jsonp&;callback=jquery3805365803&;luqutype3=&;province3=&;year3=&;luqupici3=&;page=2&;size=10&;03
也可以单击右侧的参数栏以查看参数
Page表示当前的页数
大小表示每页显示的项目数
编写代码
#coding=utf-8
import requests
import json
from prettytable import PrettyTable
if __name__=='__main__':
url = 'https://data-gkcx.eol.cn/souda ... 39%3B
row = PrettyTable()
row.field_names = ["地区", "年份", "考生类别", "批次","分数线"]
for i in range(1,34):
data ={"messtype":"json",
"page":i,
"size":50,
"callback":
"jQuery1830426658582613074_1469201131959",
"_":"1469201133189",
}
school_datas = requests.post(url,data = data).json()
datas = school_datas["school"]
for data in datas:
row.add_row((data["province"] ,data["year"],data["bath"],data["type"], data["score"]))
print(row)
代码描述
对于范围(1,34):
共有1644个条目。每页上显示的最大条目数为50,1600/50=32,44个条目为33页,因此范围应为(1,34)
数据={“messtype”:“json”
“页面”:我
“尺寸”:50
“回调”:
“jQuery82613074_59”
":"89"
}
分析提交的数据并使用post方法 查看全部
java爬虫抓取动态网页(soup()需要爬取的网站数据及分析方法)
参考原文:
需要爬网的网站数据:共165页,可通过将page=1改为其他数字进行访问
获取所有URL:URL=(“{}”。范围(1)中的I的格式(I),166))
使用Firefox浏览器打开要爬网的网页,右键单击查看页面源代码,Ctrl+F查找并输入293。此值在源代码中不存在,表示它是动态加载的数据
对于动态加载的数据,我熟悉两种方法:一种是使用selenium,另一种是分析网页元素,找出原创网页中的数据,提交表单,并获取不同的数据以达到爬行的目的
方法1:
#coding=utf-8
from bs4 import BeautifulSoup
from selenium import webdriver
urls = ('http://gkcx.eol.cn/soudaxue/qu ... ge%3D{}'.format(i) for i in range(1,166))
driver=webdriver.Firefox()
driver.maximize_window()
for url in urls:
#print ("正在访问{}".format(url))
driver.get(url)
data = driver.page_source
soup = BeautifulSoup(data, 'lxml')
grades = soup.find_all('tr')
for grade in grades:
if '' in str(grade):
print(grade.get_text())
代码说明:
从BS4导入Beauty soup使用Beauty soup解析网页数据
从selenium导入webdriver使用selenium抓取动态数据
URL=('{}'。范围(1)中的i的格式(i),166))收录需要爬网的所有数据的网站生成器
Driver=webdriver.Firefox()打开Firefox浏览器
Driver.maximize_window()最大化窗口
driver.get(URL)浏览器会自动跳转到URL链接
Data=driver.page\u source获取页面元素,其中收录要爬网的数据
soup=BeautifulSoup(数据'lxml')
等级=汤。查找所有('tr'))
按年级划分的年级:
如果str(年级)中有“”:
打印(grade.get_text())
通过分析数据并写出上述搜索方法,您可以获得所有数据
通过这种方法获取数据简单直观,但缺点是速度太慢
现在,第二种方法是获取数据
使用Firefox浏览器打开要爬网的网页,右键单击查看元素,然后选择“网络”。默认情况下,该功能正常
(一些旧版本的Firefox可能需要安装firebug插件)
单击第二页以查看加载了哪些页面和数据
分析如下:
分析表明,JSON类型的列就是我们需要的数据
在消息头网站中查看请求@
实际请求网站
参数mestype=jsonp&;callback=jquery3805365803&;luqutype3=&;province3=&;year3=&;luqupici3=&;page=2&;size=10&;03
也可以单击右侧的参数栏以查看参数
Page表示当前的页数
大小表示每页显示的项目数
编写代码
#coding=utf-8
import requests
import json
from prettytable import PrettyTable
if __name__=='__main__':
url = 'https://data-gkcx.eol.cn/souda ... 39%3B
row = PrettyTable()
row.field_names = ["地区", "年份", "考生类别", "批次","分数线"]
for i in range(1,34):
data ={"messtype":"json",
"page":i,
"size":50,
"callback":
"jQuery1830426658582613074_1469201131959",
"_":"1469201133189",
}
school_datas = requests.post(url,data = data).json()
datas = school_datas["school"]
for data in datas:
row.add_row((data["province"] ,data["year"],data["bath"],data["type"], data["score"]))
print(row)
代码描述
对于范围(1,34):
共有1644个条目。每页上显示的最大条目数为50,1600/50=32,44个条目为33页,因此范围应为(1,34)
数据={“messtype”:“json”
“页面”:我
“尺寸”:50
“回调”:
“jQuery82613074_59”
":"89"
}
分析提交的数据并使用post方法
java爬虫抓取动态网页(豆瓣View:headlessbrowser网页抓取(网络爬虫)的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-09-21 14:05
CasperJS是一个导航脚本&;用于PhantomJS(WebKit)和SlimerJS(Gecko)无头浏览器的测试实用程序,用Javascript编写
Phantom JS是一款基于WebKit内核的无头浏览器
Slimerjs是一款基于gecko内核的无头浏览器
无头浏览器:没有界面显示的浏览器。它可以用于自动测试、网页截图、JS注入、DOM操作等。它是一个非常新的web应用工具。虽然该浏览器没有任何界面输出,但它可以在许多方面得到广泛的应用。整篇文章文章将介绍使用casperjs的web页面爬行(web crawler)的应用。这篇文章只是起到了吸引翡翠的作用。事实上,无头浏览器技术的应用将非常广泛,甚至可能会深刻地影响web前端和后端技术的发展
本文使用了著名的网站[]“operation”(仅供研究、学习和使用。我希望该站不会打扰我
),以测试功能强大的无头浏览器网页捕获技术的威力
第一步是安装casperjs,打开casperjs官网,下载并安装最新稳定版本的casperjs,官网上有非常详细的文档,这是学习casperjs最好的第一手资料,当然如果安装了NPM,也可以通过NPM直接安装。同时,这也是官方推荐的安装方法。关于安装的内容不多。官方文件非常详细
1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
视图代码
第二步是分析target网站.一般来说,内容类网站分为列表页和详细内容页。Douban也不例外。先看看豆瓣列表的页长。经过分析,发现豆瓣电影网站的列表页像T。他的。首先,你可以点击排序规则。翻页不像翻过传统的页码,而是点击最后一页来加载更多。对于这样一个页面,传统的爬虫程序通常会停止烹饪,或者实现非常复杂。但是,对于无头浏览器技术,这是一个很小的例子分析网页,你可以看到点击这个[load more]位置可以持续显示更多的电影信息
第三步是开始编写代码获取电影详情页面的链接信息。我们不礼貌。模拟点击此处采集超链接列表。以下代码是获取链接的代码。引用并创建casperjs对象。如果网页需要插入脚本,您可以引用要插入的脚本生成Casper对象时,注入到clientscript部分的网页中。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
视图代码
)
完成获取详细信息页面链接的代码。单击[load more]并循环50次。事实上,可以通过[判断while(而不是“loading more”)然后(stop)]来改进循环。获取后,使用require('utils')。Dump(…)要输出链接列表,请将以下代码另存为getdoublanlist.js,然后运行casperjs getdoublanlist.js以获取并输出该类别下的所有详细页面链接
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
GetAllUrls
引用的recordurl模块不是用mongodb编写的,您可以自己完成
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录URL
第四步是分析细节页面并编写细节页面捕获程序
在这一步中,您已经获得了要捕获的详细页面列表。现在让我们打开一个电影详细页面,看看结构如何,并分析如何捕获每个信息。对于信息捕获,我们必须综合使用DOM、文本处理、JS脚本和其他技术。我想获得这部分的信息,包括di校长、编剧、乐谱等等。我们在本文中不再重复。这里我们只提取一些信息项的示例
1.grab director list:domcss选择器'div#info span:nth child(1)span.Attrs a')的director列表。我们使用函数gettexcontent(strule,strmesg)方法来获取内容
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subject/25662329/', fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获得董事
2.使用CSS选择器很难捕捉生产国家和地区。分析网页后,我们可以发现,首先,信息没有放置在标签中,文本“America”直接位于标签中
在这个高级元素中。对于此类信息,我们使用另一种方法,文本分析和截取。首先,映射字符串模块var s=require(“字符串”);此模块也将单独安装。然后获取整个信息,然后用文本截取:
1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
GetCountry
其他信息也可以类似地获得
第五步:存储捕获的信息并将其作为分析源,建议使用NoSQL数据库存储,如mongodb,更适合存储此类非结构化数据,性能更好 查看全部
java爬虫抓取动态网页(豆瓣View:headlessbrowser网页抓取(网络爬虫)的应用)
CasperJS是一个导航脚本&;用于PhantomJS(WebKit)和SlimerJS(Gecko)无头浏览器的测试实用程序,用Javascript编写
Phantom JS是一款基于WebKit内核的无头浏览器
Slimerjs是一款基于gecko内核的无头浏览器
无头浏览器:没有界面显示的浏览器。它可以用于自动测试、网页截图、JS注入、DOM操作等。它是一个非常新的web应用工具。虽然该浏览器没有任何界面输出,但它可以在许多方面得到广泛的应用。整篇文章文章将介绍使用casperjs的web页面爬行(web crawler)的应用。这篇文章只是起到了吸引翡翠的作用。事实上,无头浏览器技术的应用将非常广泛,甚至可能会深刻地影响web前端和后端技术的发展
本文使用了著名的网站[]“operation”(仅供研究、学习和使用。我希望该站不会打扰我
),以测试功能强大的无头浏览器网页捕获技术的威力
第一步是安装casperjs,打开casperjs官网,下载并安装最新稳定版本的casperjs,官网上有非常详细的文档,这是学习casperjs最好的第一手资料,当然如果安装了NPM,也可以通过NPM直接安装。同时,这也是官方推荐的安装方法。关于安装的内容不多。官方文件非常详细
1 npm install casperjs
2 node_modules/casperjs/bin/casperjs selftest
视图代码
第二步是分析target网站.一般来说,内容类网站分为列表页和详细内容页。Douban也不例外。先看看豆瓣列表的页长。经过分析,发现豆瓣电影网站的列表页像T。他的。首先,你可以点击排序规则。翻页不像翻过传统的页码,而是点击最后一页来加载更多。对于这样一个页面,传统的爬虫程序通常会停止烹饪,或者实现非常复杂。但是,对于无头浏览器技术,这是一个很小的例子分析网页,你可以看到点击这个[load more]位置可以持续显示更多的电影信息
第三步是开始编写代码获取电影详情页面的链接信息。我们不礼貌。模拟点击此处采集超链接列表。以下代码是获取链接的代码。引用并创建casperjs对象。如果网页需要插入脚本,您可以引用要插入的脚本生成Casper对象时,注入到clientscript部分的网页中。为了加快网页的加载速度,我们禁止下载图片和插件:
1 pageSettings: {
2 loadImages: false, // The WebPage instance used by Casper will
3 loadPlugins: false // use these settings
4 },
视图代码
)
完成获取详细信息页面链接的代码。单击[load more]并循环50次。事实上,可以通过[判断while(而不是“loading more”)然后(stop)]来改进循环。获取后,使用require('utils')。Dump(…)要输出链接列表,请将以下代码另存为getdoublanlist.js,然后运行casperjs getdoublanlist.js以获取并输出该类别下的所有详细页面链接
1 1 phantom.outputEncoding="uft8";
2 var casper = require('casper').create({
3 // clientScripts: [
4 // 'includes/jquery.js', // These two scripts will be injected in remote
5 // 'includes/underscore.js' // DOM on every request
6 // ],
7 pageSettings: {
8 loadImages: false, // The WebPage instance used by Casper will
9 loadPlugins: false // use these settings
10 },
11 logLevel: "info", // Only "info" level messages will be logged
12 verbose: false // log messages will be printed out to the console
13 });
14
15 casper.start("https://movie.douban.com/explo ... ot%3B, function () {
16 this.capture("1.png");
17 });
18
19 casper.then(function () {
20 this.click("a.more",10,10);
21 var i = 0;
22 do
23 {
24 i ++;
25 casper.waitForText('加载更多', function() {
26 this.click("a.more",10,10);//this.capture("2.png"); // read data from popup
27 });
28 }
29 while (i {
15 console.log(data.toString());
16 strUrls = strUrls + data.toString();
17
18 });
19
20 urllist.stderr.on('data', (data) => {
21 console.log(data);
22 });
23
24 urllist.on('exit', (code) => {
25 console.log(`Child exited with code ${code}`);
26 var urlData = JSON.parse(strUrls);
27 var content2 = "";
28 for(var key in urlData){
29 if (content2 != "") {
30 content2 = content2 + "\r\n" + urlData[key];
31 }
32 else {
33 content2 = urlData[key];
34 }
35 }
36 var recordurl = new record.RecordAllUrl();
37 recordurl.RecordUrlInText(content2);
38 console.log(content2);
39 });
40
GetAllUrls
引用的recordurl模块不是用mongodb编写的,您可以自己完成
1 exports.RecordAllUrl = RecordUrl;
2 var fs = require('fs');
3 function RecordUrl() {
4 var file = "d:/urllog.txt";
5 var RecordUrlInFile = function(theurl) {
6
9 fs.appendFile(file, theurl, function(err){
10 if(err)
11 console.log("fail " + err);
12 else
13 console.log("写入文件ok");
14 });
15 };
16 var RecordUrlInMongo = function() {
17 console.log('Hello ' + name);
18 };
19 return {
20 RecordUrlInDB: RecordUrlInMongo,
21 RecordUrlInText: RecordUrlInFile
22 } ;
23 };
记录URL
第四步是分析细节页面并编写细节页面捕获程序
在这一步中,您已经获得了要捕获的详细页面列表。现在让我们打开一个电影详细页面,看看结构如何,并分析如何捕获每个信息。对于信息捕获,我们必须综合使用DOM、文本处理、JS脚本和其他技术。我想获得这部分的信息,包括di校长、编剧、乐谱等等。我们在本文中不再重复。这里我们只提取一些信息项的示例
1.grab director list:domcss选择器'div#info span:nth child(1)span.Attrs a')的director列表。我们使用函数gettexcontent(strule,strmesg)方法来获取内容
1 phantom.outputEncoding="GBK";
2 var S = require("string");
3 var casper = require('casper').create({
4 clientScripts: [
5 'includes/jquery.js', // These two scripts will be injected in remote
6 'includes/underscore.js' // DOM on every request
7 ],
8 pageSettings: {
9 loadImages: false, // The WebPage instance used by Casper will
10 loadPlugins: false // use these settings
11 },
12 logLevel: "info", // Only "info" level messages will be logged
13 verbose: false // log messages will be printed out to the console
14 });
15
16 //casper.echo(casper.cli.get(0));
17 var fetchUrl='https://movie.douban.com/subject/25662329/', fetchNumber;
18 if(casper.cli.has('url'))
19 fetchUrl = casper.cli.get('url');
20 else if(casper.cli.has('number'))
21 fetchNumber = casper.cli.get('number');
22 casper.echo(fetchUrl);
23
24 casper.start(fetchUrl, function () {
25 this.capture("1.png");
26 //this.echo("启动程序....");
27 //this.echo(this.getHTML('div#info span:nth-child(3) a'));
28 //this.echo(this.fetchText('div#info span:nth-child(1) a'));
29
30 //抓取导演
31 getTextContent('div#info span:nth-child(1) span.attrs a','抓取导演');
32
33
34 });
35
36 //get the text content of tag
37 function getTextContent(strRule, strMesg)
38 {
39 //给evaluate传入参数
40 var textinfo = casper.evaluate(function(rule) {
41 var valArr = '';
42 $(rule).each(function(index,item){
43 valArr = valArr + $(this).text() + ',';
44 });
45 return valArr.substring(0,valArr.length-1);
46 }, strRule);
47 casper.echo(strMesg);
48 require('utils').dump(textinfo.split(','));
49 return textinfo.split(',');
50 };
51
52 //get the attribute content of tag
53 function getAttrContent(strRule, strMesg, Attr)
54 {
55 //给evaluate传入参数
56 var textinfo = casper.evaluate(function(rule, attrname) {
57 var valArr = '';
58 $(rule).each(function(index,item){
59 valArr = valArr + $(this).attr(attrname) + ',';
60 });
61 return valArr.substring(0,valArr.length-1);
62 }, strRule, Attr);
63 casper.echo(strMesg);
64 require('utils').dump(textinfo.split(','));
65 return textinfo.split(',');
66 };
67
68 casper.run();
获得董事
2.使用CSS选择器很难捕捉生产国家和地区。分析网页后,我们可以发现,首先,信息没有放置在标签中,文本“America”直接位于标签中
在这个高级元素中。对于此类信息,我们使用另一种方法,文本分析和截取。首先,映射字符串模块var s=require(“字符串”);此模块也将单独安装。然后获取整个信息,然后用文本截取:
1 //影片信息全文字抓取
2 nameCount = casper.evaluate(function() {
3 var valArr = '';
4 $('div#info').each(function(index,item){
5 valArr = valArr + $(this).text() + ',';
6 });
7 return valArr.substring(0,valArr.length-1);
8 });
9 this.echo("影片信息全文字抓取");
10 this.echo(nameCount);
11 //this.echo(nameCount.indexOf("制片国家/地区:"));
12
13 //抓取国家
14 this.echo(S(nameCount).between("制片国家/地区:","\n"));
GetCountry
其他信息也可以类似地获得
第五步:存储捕获的信息并将其作为分析源,建议使用NoSQL数据库存储,如mongodb,更适合存储此类非结构化数据,性能更好
java爬虫抓取动态网页(基于微内核+插件式架构的JAVA爬虫框架(内核))
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-09-21 14:05
1、Gecco
GitHub地址:xtuhcy/GECCO
GECCO是一个用Java语言开发的轻量级且易于使用的web爬虫程序。它集成了jsoup、httpclient、fastjson、spring、htmlunit、再分配和其他框架。通过配置一些jQuery样式选择器,可以快速编写爬虫程序。GECCO框架具有良好的可扩展性。框架根据开闭原理设计,关闭修改,打开扩展
2、WebCollector
GitHub地址:crawlscript/webcollector
Webcollector是一个Java爬虫框架(内核),不需要配置,便于二次开发。它提供了一个简化的API,只需少量代码即可实现强大的爬虫程序。Webcollector Hadoop是Webcollector的Hadoop版本,支持分布式爬网
3、Spiderman
代码云地址:l-weiwei/spiderman2-代码云-开源中国
用例:演示垂直爬虫的能力–自由如风
蜘蛛侠是一种基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法捕获复杂的目标网页信息并将其解析为业务数据
4、WebMagic
代码云地址:flashsword20/webmagic-代码云-开源中国
Webmagic是一个无配置的爬虫框架,便于二次开发。它提供了一个简单灵活的API,只需少量代码即可实现爬虫程序。Webmagic采用全模块化设计,覆盖爬虫的整个生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬虫、分布式爬虫、自动重试、自定义UA/cookie等功能
5、Heritrix
GitHub地址:InternetArchive/Heritrix 3
Heritrix是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取所需的资源。Heritrix的设计严格遵循robots.txt文件和meta robots标签的排除说明。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
6、crawler4j
GitHub地址:yasserg/crawler4j·GitHub
Crawler4j是一个用Java实现的开源web爬虫程序。提供一个易于使用的界面,以便在几分钟内创建多线程web爬虫程序
7、Nutch
GitHub地址:Apache/nutch
Nutch是一个用Java实现的开源搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫
在nutch的发展过程中,出现了四个Java开源项目,Hadoop、Tika、Gora和crawler commons。如今,这四个项目发展迅速,非常流行,尤其是Hadoop,它已经成为大规模数据处理的事实标准。Tika使用各种现有的开源内容解析项目从各种格式的文件中提取元数据和结构化文本。Gora支持将大数据持久化到各种存储实现中。Crawler Commons是一个通用的web爬虫组件
8、SeimiCrawler
GitHub地址:哲格晓霍兹/赛米克罗勒
Seimicrawler是一个灵活、独立部署和分布式Java爬虫框架。希望最大限度地降低新手开发高可用性、高性能爬虫系统的门槛,提高爬虫系统的开发效率。在seimi crawler的世界中,大多数人只需要关心编写捕获的业务逻辑,其余的seimi将帮助您。在设计理念上,seimicrawler受到Python的crawler框架scripy的启发,融合了Java语言和spring的特点,希望在中国使用更方便高效的XPath解析HTML。因此,seimicrawler的默认HTML解析器是JSOUPPATH(独立扩展项目,不是jsoup提供的),默认情况下,解析和提取HTML数据是使用XPath完成的(当然,数据处理也可以选择其他解析器)。它与seimiagent相结合,全面、完美地解决了复杂动态页面的渲染和抓取问题
9、Jsoup
GitHub地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据 查看全部
java爬虫抓取动态网页(基于微内核+插件式架构的JAVA爬虫框架(内核))
1、Gecco
GitHub地址:xtuhcy/GECCO
GECCO是一个用Java语言开发的轻量级且易于使用的web爬虫程序。它集成了jsoup、httpclient、fastjson、spring、htmlunit、再分配和其他框架。通过配置一些jQuery样式选择器,可以快速编写爬虫程序。GECCO框架具有良好的可扩展性。框架根据开闭原理设计,关闭修改,打开扩展
2、WebCollector
GitHub地址:crawlscript/webcollector
Webcollector是一个Java爬虫框架(内核),不需要配置,便于二次开发。它提供了一个简化的API,只需少量代码即可实现强大的爬虫程序。Webcollector Hadoop是Webcollector的Hadoop版本,支持分布式爬网
3、Spiderman
代码云地址:l-weiwei/spiderman2-代码云-开源中国
用例:演示垂直爬虫的能力–自由如风
蜘蛛侠是一种基于微内核+插件架构的网络蜘蛛。它的目标是通过简单的方法捕获复杂的目标网页信息并将其解析为业务数据
4、WebMagic
代码云地址:flashsword20/webmagic-代码云-开源中国
Webmagic是一个无配置的爬虫框架,便于二次开发。它提供了一个简单灵活的API,只需少量代码即可实现爬虫程序。Webmagic采用全模块化设计,覆盖爬虫的整个生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬虫、分布式爬虫、自动重试、自定义UA/cookie等功能
5、Heritrix
GitHub地址:InternetArchive/Heritrix 3
Heritrix是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取所需的资源。Heritrix的设计严格遵循robots.txt文件和meta robots标签的排除说明。其最大的特点是具有良好的可扩展性,方便用户实现自己的爬网逻辑
6、crawler4j
GitHub地址:yasserg/crawler4j·GitHub
Crawler4j是一个用Java实现的开源web爬虫程序。提供一个易于使用的界面,以便在几分钟内创建多线程web爬虫程序
7、Nutch
GitHub地址:Apache/nutch
Nutch是一个用Java实现的开源搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫
在nutch的发展过程中,出现了四个Java开源项目,Hadoop、Tika、Gora和crawler commons。如今,这四个项目发展迅速,非常流行,尤其是Hadoop,它已经成为大规模数据处理的事实标准。Tika使用各种现有的开源内容解析项目从各种格式的文件中提取元数据和结构化文本。Gora支持将大数据持久化到各种存储实现中。Crawler Commons是一个通用的web爬虫组件
8、SeimiCrawler
GitHub地址:哲格晓霍兹/赛米克罗勒
Seimicrawler是一个灵活、独立部署和分布式Java爬虫框架。希望最大限度地降低新手开发高可用性、高性能爬虫系统的门槛,提高爬虫系统的开发效率。在seimi crawler的世界中,大多数人只需要关心编写捕获的业务逻辑,其余的seimi将帮助您。在设计理念上,seimicrawler受到Python的crawler框架scripy的启发,融合了Java语言和spring的特点,希望在中国使用更方便高效的XPath解析HTML。因此,seimicrawler的默认HTML解析器是JSOUPPATH(独立扩展项目,不是jsoup提供的),默认情况下,解析和提取HTML数据是使用XPath完成的(当然,数据处理也可以选择其他解析器)。它与seimiagent相结合,全面、完美地解决了复杂动态页面的渲染和抓取问题
9、Jsoup
GitHub地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
java爬虫抓取动态网页(Python编程修改程序函数式编程的实战二抓取您想要的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-19 22:08
实战一
抓取所需的网页并将其保存到本地计算机
首先,我们简要分析了要编写的爬虫程序,它可以分为以下三个部分:
在澄清逻辑之后,我们可以正式编写爬虫程序
导入所需模块
from urllib import request, parse
拼接URL地址
定义URL变量和拼接URL地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
向URL发送请求
发送请求主要分为以下步骤:
代码如下:
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
另存为本地文件
将已爬网的照片保存到本地。这里需要使用python编程的文件IO操作。代码如下:
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
整个程序如下:
from urllib import request, parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
尝试运行该程序,进入riotian blog Park,确认搜索,然后您将在当前工作目录中找到“riotian blog Park.HTML”文件
函数式编程修改器
Python函数式编程可以使程序的思想更清晰、更容易理解。接下来,使用函数式编程的思想更改上述代码
定义相应的函数并通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
# 此处使用urlencode()进行编码
params = parse.urlencode({'wd': word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url, filename)
除了函数式编程外,还可以使用面向对象的编程方法(actual Combation二),将在后续内容中介绍)
实战二
抓取百度贴吧()页面,如Python爬虫栏和编程栏。只需抓取贴吧的前五页即可@
确定页面类型
通过简单的分析,我们可以知道要抓取的百度贴吧页面属于静态网页,分析方法非常简单:打开百度贴吧,搜索“Python爬虫”,复制页面中的任何部分信息,如“爬虫为什么需要HTTP代理”然后右键单击以查看源代码,并使用Ctrl+F搜索刚刚复制到源代码页上的数据,如下所示:
从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库中加载数据,因此该页面是一个静态页面
查找URL更改规则
接下来,找到要爬网的页面的URL规则,搜索“Python爬虫”后,贴吧first页面的URL如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后,您发现URL有两个查询参数kW和PN,PN参数是常规的,如下所示:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
URL地址可以缩写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
写爬虫
爬虫程序以类的形式编写,类下编写不同的函数,代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,爬网文件将保存到pychart当前工作目录,输出结果如下:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法编写爬虫程序时,思路简单,逻辑清晰易懂,以上代码主要包括四个功能,分别负责不同的功能,总结如下:
1)request函数
请求函数的最终结果是返回一个HTML对象,以方便后续函数调用
2)解析函数
解析功能用于解析HTML页面,常用的解析模块包括常规解析模块和BS4解析模块,通过对页面的分析提取所需的数据,在后续内容中详细描述
3)保存数据功能
此功能负责将捕获的数据保存到数据库中,如mysql、mongodb等,或以文件格式保存,如CSV、TXT、Excel等
4)entry函数
entry函数的主要任务是组织数据,例如要搜索的贴吧名称、编码URL参数、拼接URL地址以及定义文件保存路径
履带结构
采用面向对象方法编译爬虫程序时,逻辑结构相对固定,概括如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握上述编程逻辑有助于后续学习
爬虫随机睡眠
在输入功能代码中,包括以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问网站的速度非常快,这与正常人的点击行为非常不一致。因此,通过随机睡眠,爬虫可以像成年人一样点击网站,因此网站不容易被检测到是爬虫访问网站,但这样做的代价是影响程序的执行效率
聚焦爬虫(Focused crawler)是一种执行效率较低的程序,提高其性能一直是业界关注的问题,这也催生了高效的python爬虫框架scripy
程序员灯塔
转载请注明原链接:[网络爬虫学习]实战、抓取网页和贴吧数据 查看全部
java爬虫抓取动态网页(Python编程修改程序函数式编程的实战二抓取您想要的)
实战一
抓取所需的网页并将其保存到本地计算机
首先,我们简要分析了要编写的爬虫程序,它可以分为以下三个部分:
在澄清逻辑之后,我们可以正式编写爬虫程序
导入所需模块
from urllib import request, parse
拼接URL地址
定义URL变量和拼接URL地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
向URL发送请求
发送请求主要分为以下步骤:
代码如下:
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
另存为本地文件
将已爬网的照片保存到本地。这里需要使用python编程的文件IO操作。代码如下:
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
整个程序如下:
from urllib import request, parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入想要搜索的内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
# 重构请求头
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 创建请求对应
req = request.Request(url=full_url, headers=headers)
# 获取响应对象
res = request.urlopen(req)
# 获取响应内容
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
尝试运行该程序,进入riotian blog Park,确认搜索,然后您将在当前工作目录中找到“riotian blog Park.HTML”文件
函数式编程修改器
Python函数式编程可以使程序的思想更清晰、更容易理解。接下来,使用函数式编程的思想更改上述代码
定义相应的函数并通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request, parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
# 此处使用urlencode()进行编码
params = parse.urlencode({'wd': word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url, filename):
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'
}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename, 'w', encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url, filename)
除了函数式编程外,还可以使用面向对象的编程方法(actual Combation二),将在后续内容中介绍)
实战二
抓取百度贴吧()页面,如Python爬虫栏和编程栏。只需抓取贴吧的前五页即可@
确定页面类型
通过简单的分析,我们可以知道要抓取的百度贴吧页面属于静态网页,分析方法非常简单:打开百度贴吧,搜索“Python爬虫”,复制页面中的任何部分信息,如“爬虫为什么需要HTTP代理”然后右键单击以查看源代码,并使用Ctrl+F搜索刚刚复制到源代码页上的数据,如下所示:
https://cdn.jsdelivr.net/gh/Ri ... 49.png" />从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库中加载数据,因此该页面是一个静态页面
查找URL更改规则
接下来,找到要爬网的页面的URL规则,搜索“Python爬虫”后,贴吧first页面的URL如下:
https://tieba.baidu.com/f?ie=utf-8&kw=python爬虫&fr=search
点击第二页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=50
点击第三页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=100
再次点击第一页,URL信息如下:
https://tieba.baidu.com/f?kw=python爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后,您发现URL有两个查询参数kW和PN,PN参数是常规的,如下所示:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
URL地址可以缩写为:
https://tieba.baidu.com/f?kw=python爬虫&pn=450
写爬虫
爬虫程序以类的形式编写,类下编写不同的函数,代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,爬网文件将保存到pychart当前工作目录,输出结果如下:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法编写爬虫程序时,思路简单,逻辑清晰易懂,以上代码主要包括四个功能,分别负责不同的功能,总结如下:
1)request函数
请求函数的最终结果是返回一个HTML对象,以方便后续函数调用
2)解析函数
解析功能用于解析HTML页面,常用的解析模块包括常规解析模块和BS4解析模块,通过对页面的分析提取所需的数据,在后续内容中详细描述
3)保存数据功能
此功能负责将捕获的数据保存到数据库中,如mysql、mongodb等,或以文件格式保存,如CSV、TXT、Excel等
4)entry函数
entry函数的主要任务是组织数据,例如要搜索的贴吧名称、编码URL参数、拼接URL地址以及定义文件保存路径
履带结构
采用面向对象方法编译爬虫程序时,逻辑结构相对固定,概括如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注意:掌握上述编程逻辑有助于后续学习
爬虫随机睡眠
在输入功能代码中,包括以下代码:
# 每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问网站的速度非常快,这与正常人的点击行为非常不一致。因此,通过随机睡眠,爬虫可以像成年人一样点击网站,因此网站不容易被检测到是爬虫访问网站,但这样做的代价是影响程序的执行效率
聚焦爬虫(Focused crawler)是一种执行效率较低的程序,提高其性能一直是业界关注的问题,这也催生了高效的python爬虫框架scripy
程序员灯塔
转载请注明原链接:[网络爬虫学习]实战、抓取网页和贴吧数据
java爬虫抓取动态网页(Java爬虫Jsoup+httpclient获取动态生成的数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2021-09-19 22:05
您想知道Java爬虫jsup+httpclient获取动态生成数据的相关内容吗?在本文中,我们将仔细解释Java爬虫的相关知识和一些代码示例。欢迎阅读并更正。让我们首先关注:Java爬虫jsup+httpclient获取动态生成的数据,Java爬虫,Java爬虫jsup。让我们一起学习
Java爬虫程序jsup+httpclient获取动态生成的数据
我们之前详细讨论过,发现事情就是这样。只要它是一个可以访问的静态资源页面,您就可以直接使用它来获取所需的数据。细节跳跃——jsup爬虫的详细解释,但很多时候网站为了防止数据被恶意爬虫,有很多掩码,比如加密和动态加载,这实际上给我们编写的爬虫程序带来了很多麻烦,那么,我们如何突破这一限制,获得我们迫切需要的数据呢
让我们详细解释一下如何获得
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
此时,已经获取了整个页面的数据,但商品价格是通过回调函数获取并填写的。因此,编写爬虫程序的开发人员必须非常耐心地找到价格数据的回调接口。我们可以直接访问此界面获取价格。以下是一个演示:
从这个截图中,我们可以看到他传递的只是一个静态资源页面,根本没有价格参数。那么价格是怎么来的呢?继续查找此接口:
您会发现许多参数都拼接在这个接口中,所以我们需要做的是分析所有参数是否有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
您可以尝试删除一些参数,发现接口所需的参数其实非常简单:
https://p.3.cn/prices/mgets%3F ... em-pc
在这里看电影不是很刺激吗?事实上,您可以更改其他一些JD产品ID以获取当前价格和最高价格。我不知道价格是多少。我们需要做的就是编写一个httpclient模拟请求接口
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
对于以下内容,您可以直接解析JSON字符串,获得您想要的数据
注意
这是对回调请求的数据的重新请求获取,这只是对先前商品价格动态获取的补充。在这种情况下,价格本身不会通过主链接带到页面,而是在加载过程中由异步请求填写。有时候会带来数据,但是相关的JS处理后我们还是无法得到,这个时候我们要通过其他的方式来获得这个数据,后面会解释 查看全部
java爬虫抓取动态网页(Java爬虫Jsoup+httpclient获取动态生成的数据(组图))
您想知道Java爬虫jsup+httpclient获取动态生成数据的相关内容吗?在本文中,我们将仔细解释Java爬虫的相关知识和一些代码示例。欢迎阅读并更正。让我们首先关注:Java爬虫jsup+httpclient获取动态生成的数据,Java爬虫,Java爬虫jsup。让我们一起学习
Java爬虫程序jsup+httpclient获取动态生成的数据
我们之前详细讨论过,发现事情就是这样。只要它是一个可以访问的静态资源页面,您就可以直接使用它来获取所需的数据。细节跳跃——jsup爬虫的详细解释,但很多时候网站为了防止数据被恶意爬虫,有很多掩码,比如加密和动态加载,这实际上给我们编写的爬虫程序带来了很多麻烦,那么,我们如何突破这一限制,获得我们迫切需要的数据呢
让我们详细解释一下如何获得
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
此时,已经获取了整个页面的数据,但商品价格是通过回调函数获取并填写的。因此,编写爬虫程序的开发人员必须非常耐心地找到价格数据的回调接口。我们可以直接访问此界面获取价格。以下是一个演示:
从这个截图中,我们可以看到他传递的只是一个静态资源页面,根本没有价格参数。那么价格是怎么来的呢?继续查找此接口:
您会发现许多参数都拼接在这个接口中,所以我们需要做的是分析所有参数是否有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
您可以尝试删除一些参数,发现接口所需的参数其实非常简单:
https://p.3.cn/prices/mgets%3F ... em-pc
在这里看电影不是很刺激吗?事实上,您可以更改其他一些JD产品ID以获取当前价格和最高价格。我不知道价格是多少。我们需要做的就是编写一个httpclient模拟请求接口
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
对于以下内容,您可以直接解析JSON字符串,获得您想要的数据
注意
这是对回调请求的数据的重新请求获取,这只是对先前商品价格动态获取的补充。在这种情况下,价格本身不会通过主链接带到页面,而是在加载过程中由异步请求填写。有时候会带来数据,但是相关的JS处理后我们还是无法得到,这个时候我们要通过其他的方式来获得这个数据,后面会解释
java爬虫抓取动态网页(【学习】morestories模拟点击按钮行为比phantomjs更稳定)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-19 16:14
在上一期中,我们说过phantomjs可以模拟单击按钮的行为,并通过单击所有“加载更多”按钮来获取所有内容。例如,此网页
我们需要抓取红线标记的超链接,存储URL,然后单击“查看更多故事”以显示更多列表。但是,对于某些网页,“查看更多故事”按钮在所有隐藏内容出现后仍然存在,这使得很难判断模拟点击行为何时终止。也许聪明的朋友会说:“有什么困难?模拟单击行为,抓取网页,并从下到上获取列表项的URL。当URL与数据库中已捕获的URL重复时,停止获取。当从下到上获取的第一个URL与数据库中的URL重复时,这意味着整个网页的所有内容都已获取,模拟点击行为可以停止”。这确实是一种方法,但网页有很多判断和重复爬行。我们有一个更优雅的解决方案。为什么不呢??(此外,如果我们真的想模拟,selenium比phantomjs更稳定…)
你一定已经知道我接下来想通过标题说什么,所谓的更优雅的方式……没错
打开控制台的网络模块
单击“查看更多故事”按钮,将显示以下网络请求。请注意,此类型为XHR的网络请求是从后台请求更多列表项的原因。请观察请求标题
请求有两个参数,因此请尝试按如下方式拼接URL
我们得到了13个列表项,但是当我们点击load more按钮时,添加了15个新项,只缺少了两个列表项,这并不影响抓取的整体效果,所以我们使用这种方法抓取它们。当页面参数大于实际最大页数时,一些网页不会出现“查看更多故事”“按钮,某些按钮仍会出现,但会显示最大页数的页面内容。根据不同情况判断是否停止爬网。”
代码如下:(大部分基本代码已经在前面解释过了,所以我不再重复)
package edu.nju.opsource.vnexpress.linktype;
import java.io.InputStream;
import java.util.Date;
import java.util.LinkedList;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.onezetta.downloader.EasyHttpDownloader;
import edu.nju.opensource.common.beans.ELinkState;
import edu.nju.opensource.common.beans.Link;
import edu.nju.opensource.common.beans.LinkType;
import edu.nju.opensource.common.beans.Site;
import edu.nju.opsource.vnexpress.utils.IdXmlUtil;
public class LinkType_NewsList extends LinkType {
private Document doc = null;
private Site site = null;
private LinkedList newItems = null;
private Link nextPage = null;
public LinkType_NewsList() {
super();
// TODO Auto-generated constructor stub
}
public LinkType_NewsList(String linkTypeName) {
super.setLinkTypeName(linkTypeName);
}
public LinkType_NewsList(Site site) {
super.setLinkTypeName("vnexpress.newslist");
this.site = site;
}
public void get(String url) {
super.get(url);
String content = new EasyHttpDownloader(url).run();
if (content != null) {
this.doc = Jsoup.parse(content, this.site.getUrl().getUrl());
System.out.println(" ... has Crawled.");
} else {
setState(ELinkState.CRAWLFAILED);
System.out.println(" ... crawled failed.");
}
}
// 把新闻列表条目的链接插入表
// 在总项目中被调用的核心函数handle()
@Override
public boolean handle(Link parentlink) throws Exception {
if (getState() == ELinkState.CRAWLFAILED)
return false;
Elements news = this.doc.select("div.list_news_folder.col_720 h4.title_news_site");
this.newItems = new LinkedList();
boolean flag = false;
for (Element newItem : news) {
Elements tmp = newItem.select("a");
if ((tmp != null) && (tmp.size() != 0)) {
Link link = new Link(tmp.first().attr("abs:href"), new LinkType_News(), ELinkState.UNCRAWL, parentlink,
this.site).setLinkDate( new java.sql.Date(new Date().getTime()));
// System.out.println(tmp.first().attr("abs:href"));
int rst = link.insert();
if (rst == -1)
flag = true;// link exist
}
}
if (flag) {
setState(ELinkState.CRAWLED);
return false;
}
Elements nextPageE = this.doc.select("a#vnexpress_folder_load_more");
String url = getNextPageUrl();
if ((nextPageE != null) && (nextPageE.size() != 0)) {
System.out.println(url);
this.nextPage = new Link(url, new LinkType_NewsList(this.site), ELinkState.UNCRAWL, parentlink, this.site).setLinkDate( new java.sql.Date(new Date().getTime()));
this.nextPage.insert();
}
else {
IdXmlUtil.setIdByName("news", 2 + "");
}
setState(ELinkState.CRAWLED);
return true;
}
public static String getNextPageUrl() {
int id = IdXmlUtil.getIdByName("news");
// IdXmlUtil用来存储当前已抓取的pageid其实这个工具完全没必要,因为数据库的//url有此参数啊。。。当时脑抽没想到,搞麻烦了。。。
IdXmlUtil.setIdByName("news", (id + 1) + "");
//此文章的精髓
String url = "http://e.vnexpress.net/news/ne ... ot%3B + id;
return url;
}
@Override
public String getLinkTextData() {
// TODO Auto-generated method stub
return null;
}
@Override
public InputStream getLinkBinaryData() {
// TODO Auto-generated method stub
return null;
}
@Override
public String getLinkUniqeID(String paramString) {
// TODO Auto-generated method stub
return null;
}
@Override
public Date getLinkDate() {
// TODO Auto-generated method stub
return null;
}
public Site getSite() {
return this.site;
}
@Override
public void setSite(Site site) {
// TODO Auto-generated method stub
this.site = site;
}
public LinkedList getNewItems() {
return this.newItems;
}
public void setNewItems(LinkedList newItems) {
this.newItems = newItems;
}
public Link getNextPage() {
return this.nextPage;
}
public void setNextPage(Link nextPage) {
this.nextPage = nextPage;
}
@Override
public String toString() {
return "LinkType_newsList [doc=" + doc + ", site=" + site + ", newItems=" + newItems + ", nextPage="
+ nextPage + "]";
}
}
我原以为爬虫系列将在这里结束。事实上,另一个问题是我们在浏览器上尝试URL以查看效果。但是,一些网站尝试以这种方式看不到任何内容。这是因为浏览器将URL作为get请求输入,而一些网站后台内容不接受get请求。在这种情况下,我们如何处理ck拼接URL的效果如何
<p>期待下一期>0 查看全部
java爬虫抓取动态网页(【学习】morestories模拟点击按钮行为比phantomjs更稳定)
在上一期中,我们说过phantomjs可以模拟单击按钮的行为,并通过单击所有“加载更多”按钮来获取所有内容。例如,此网页
我们需要抓取红线标记的超链接,存储URL,然后单击“查看更多故事”以显示更多列表。但是,对于某些网页,“查看更多故事”按钮在所有隐藏内容出现后仍然存在,这使得很难判断模拟点击行为何时终止。也许聪明的朋友会说:“有什么困难?模拟单击行为,抓取网页,并从下到上获取列表项的URL。当URL与数据库中已捕获的URL重复时,停止获取。当从下到上获取的第一个URL与数据库中的URL重复时,这意味着整个网页的所有内容都已获取,模拟点击行为可以停止”。这确实是一种方法,但网页有很多判断和重复爬行。我们有一个更优雅的解决方案。为什么不呢??(此外,如果我们真的想模拟,selenium比phantomjs更稳定…)
你一定已经知道我接下来想通过标题说什么,所谓的更优雅的方式……没错
打开控制台的网络模块
单击“查看更多故事”按钮,将显示以下网络请求。请注意,此类型为XHR的网络请求是从后台请求更多列表项的原因。请观察请求标题
请求有两个参数,因此请尝试按如下方式拼接URL
我们得到了13个列表项,但是当我们点击load more按钮时,添加了15个新项,只缺少了两个列表项,这并不影响抓取的整体效果,所以我们使用这种方法抓取它们。当页面参数大于实际最大页数时,一些网页不会出现“查看更多故事”“按钮,某些按钮仍会出现,但会显示最大页数的页面内容。根据不同情况判断是否停止爬网。”
代码如下:(大部分基本代码已经在前面解释过了,所以我不再重复)
package edu.nju.opsource.vnexpress.linktype;
import java.io.InputStream;
import java.util.Date;
import java.util.LinkedList;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.onezetta.downloader.EasyHttpDownloader;
import edu.nju.opensource.common.beans.ELinkState;
import edu.nju.opensource.common.beans.Link;
import edu.nju.opensource.common.beans.LinkType;
import edu.nju.opensource.common.beans.Site;
import edu.nju.opsource.vnexpress.utils.IdXmlUtil;
public class LinkType_NewsList extends LinkType {
private Document doc = null;
private Site site = null;
private LinkedList newItems = null;
private Link nextPage = null;
public LinkType_NewsList() {
super();
// TODO Auto-generated constructor stub
}
public LinkType_NewsList(String linkTypeName) {
super.setLinkTypeName(linkTypeName);
}
public LinkType_NewsList(Site site) {
super.setLinkTypeName("vnexpress.newslist");
this.site = site;
}
public void get(String url) {
super.get(url);
String content = new EasyHttpDownloader(url).run();
if (content != null) {
this.doc = Jsoup.parse(content, this.site.getUrl().getUrl());
System.out.println(" ... has Crawled.");
} else {
setState(ELinkState.CRAWLFAILED);
System.out.println(" ... crawled failed.");
}
}
// 把新闻列表条目的链接插入表
// 在总项目中被调用的核心函数handle()
@Override
public boolean handle(Link parentlink) throws Exception {
if (getState() == ELinkState.CRAWLFAILED)
return false;
Elements news = this.doc.select("div.list_news_folder.col_720 h4.title_news_site");
this.newItems = new LinkedList();
boolean flag = false;
for (Element newItem : news) {
Elements tmp = newItem.select("a");
if ((tmp != null) && (tmp.size() != 0)) {
Link link = new Link(tmp.first().attr("abs:href"), new LinkType_News(), ELinkState.UNCRAWL, parentlink,
this.site).setLinkDate( new java.sql.Date(new Date().getTime()));
// System.out.println(tmp.first().attr("abs:href"));
int rst = link.insert();
if (rst == -1)
flag = true;// link exist
}
}
if (flag) {
setState(ELinkState.CRAWLED);
return false;
}
Elements nextPageE = this.doc.select("a#vnexpress_folder_load_more");
String url = getNextPageUrl();
if ((nextPageE != null) && (nextPageE.size() != 0)) {
System.out.println(url);
this.nextPage = new Link(url, new LinkType_NewsList(this.site), ELinkState.UNCRAWL, parentlink, this.site).setLinkDate( new java.sql.Date(new Date().getTime()));
this.nextPage.insert();
}
else {
IdXmlUtil.setIdByName("news", 2 + "");
}
setState(ELinkState.CRAWLED);
return true;
}
public static String getNextPageUrl() {
int id = IdXmlUtil.getIdByName("news");
// IdXmlUtil用来存储当前已抓取的pageid其实这个工具完全没必要,因为数据库的//url有此参数啊。。。当时脑抽没想到,搞麻烦了。。。
IdXmlUtil.setIdByName("news", (id + 1) + "");
//此文章的精髓
String url = "http://e.vnexpress.net/news/ne ... ot%3B + id;
return url;
}
@Override
public String getLinkTextData() {
// TODO Auto-generated method stub
return null;
}
@Override
public InputStream getLinkBinaryData() {
// TODO Auto-generated method stub
return null;
}
@Override
public String getLinkUniqeID(String paramString) {
// TODO Auto-generated method stub
return null;
}
@Override
public Date getLinkDate() {
// TODO Auto-generated method stub
return null;
}
public Site getSite() {
return this.site;
}
@Override
public void setSite(Site site) {
// TODO Auto-generated method stub
this.site = site;
}
public LinkedList getNewItems() {
return this.newItems;
}
public void setNewItems(LinkedList newItems) {
this.newItems = newItems;
}
public Link getNextPage() {
return this.nextPage;
}
public void setNextPage(Link nextPage) {
this.nextPage = nextPage;
}
@Override
public String toString() {
return "LinkType_newsList [doc=" + doc + ", site=" + site + ", newItems=" + newItems + ", nextPage="
+ nextPage + "]";
}
}
我原以为爬虫系列将在这里结束。事实上,另一个问题是我们在浏览器上尝试URL以查看效果。但是,一些网站尝试以这种方式看不到任何内容。这是因为浏览器将URL作为get请求输入,而一些网站后台内容不接受get请求。在这种情况下,我们如何处理ck拼接URL的效果如何
<p>期待下一期>0
java爬虫抓取动态网页(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-09-19 16:11
下面是一个案例,演示如何使用jsup进行解析。在这种情况下,将获得博客花园第一页的标题和第一页上的博客文章列表
请查看代码(在前面代码的基础上操作。如果您不知道如何使用httpclient,请跳转到页面阅读):
引入依赖关系
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,首先分析HTML结构。不用说,那么文章列表呢?按浏览器的F12键查看页面元素源代码。您会发现列表是一个大div,id=“post\u list”,而每个文章文章都是一个小div,class=“post\u item”
接下来,您可以启动代码。jsup的核心代码如下(整体源代码将在文章末尾给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,您会发现我通过jsup.parse(string HTML)方法解析httpclient获取的HTML内容来获取文档,然后文档可以通过两种方式获取其子元素:类似JS的getelementxxxx和类似jQuery选择器的select()。两种方法都可以。我个人建议使用select方法。对于元素中的属性,例如超链接地址,可以使用元素。Attr(string)方法获取,对于元素的文本内容,可以使用元素。要获取的Text()方法
执行代码并检查结果(我不得不感叹博客公园的朋友们真的很棒。从上面对主页HTML结构的分析到jsup分析的代码的执行,这段时间文章有这么多主页)
因为新的文章版本太快了,上面的屏幕截图与这里的输出有些不同
三、Jsoup其他用途
一、 jsup不仅可以在httpclient的工作成果中发挥作用,还可以独立工作,抓取页面,自己分析。分析能力已在上面显示。现在让我们展示如何抓取页面。事实上,这很简单。区别在于我直接获取文档,不需要通过jsup解析它。Parse()方法
除了直接访问在线资源外,我还可以解析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup另一个值得一提的特点
你一定有过这种经历。如果在页面文本框中输入HTML元素并在保存后查看它们,则页面布局很可能会混乱。如果你能过滤这些内容,它将是完美的
只是为了让我能做
通过jsup.clean方法使用白名单进行过滤。执行结果:
unsafe: <p>博客园
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,我相信我是非常强大的。我不仅可以解析httpclient捕获的HTML元素,还可以自己抓取页面DOM。我还可以加载和解析本地保存的HTML文件
此外,我可以通过白名单过滤字符串,以筛选出一些不安全的字符
最重要的是,上述所有函数的API调用都相对简单
===============华丽的分界线=============
编写代码并不容易。就像你走之前那样~~
最后,本案例中分析博客公园主页文章列表的完整源代码附于后文:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
视图代码 查看全部
java爬虫抓取动态网页(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页)
下面是一个案例,演示如何使用jsup进行解析。在这种情况下,将获得博客花园第一页的标题和第一页上的博客文章列表
请查看代码(在前面代码的基础上操作。如果您不知道如何使用httpclient,请跳转到页面阅读):
引入依赖关系
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,首先分析HTML结构。不用说,那么文章列表呢?按浏览器的F12键查看页面元素源代码。您会发现列表是一个大div,id=“post\u list”,而每个文章文章都是一个小div,class=“post\u item”
接下来,您可以启动代码。jsup的核心代码如下(整体源代码将在文章末尾给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,您会发现我通过jsup.parse(string HTML)方法解析httpclient获取的HTML内容来获取文档,然后文档可以通过两种方式获取其子元素:类似JS的getelementxxxx和类似jQuery选择器的select()。两种方法都可以。我个人建议使用select方法。对于元素中的属性,例如超链接地址,可以使用元素。Attr(string)方法获取,对于元素的文本内容,可以使用元素。要获取的Text()方法
执行代码并检查结果(我不得不感叹博客公园的朋友们真的很棒。从上面对主页HTML结构的分析到jsup分析的代码的执行,这段时间文章有这么多主页)
因为新的文章版本太快了,上面的屏幕截图与这里的输出有些不同
三、Jsoup其他用途
一、 jsup不仅可以在httpclient的工作成果中发挥作用,还可以独立工作,抓取页面,自己分析。分析能力已在上面显示。现在让我们展示如何抓取页面。事实上,这很简单。区别在于我直接获取文档,不需要通过jsup解析它。Parse()方法
除了直接访问在线资源外,我还可以解析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup另一个值得一提的特点
你一定有过这种经历。如果在页面文本框中输入HTML元素并在保存后查看它们,则页面布局很可能会混乱。如果你能过滤这些内容,它将是完美的
只是为了让我能做
通过jsup.clean方法使用白名单进行过滤。执行结果:
unsafe: <p>博客园
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,我相信我是非常强大的。我不仅可以解析httpclient捕获的HTML元素,还可以自己抓取页面DOM。我还可以加载和解析本地保存的HTML文件
此外,我可以通过白名单过滤字符串,以筛选出一些不安全的字符
最重要的是,上述所有函数的API调用都相对简单
===============华丽的分界线=============
编写代码并不容易。就像你走之前那样~~
最后,本案例中分析博客公园主页文章列表的完整源代码附于后文:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/";);
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
视图代码
java爬虫抓取动态网页(大数据时代爬虫工作者开发框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-19 15:15
如今,在大数据时代,爬虫已经成为互联网数据公司的关键位置。他们不仅要精通数据采集和分析,还要熟悉搜索引擎和相关检索算法,并对各种算法有一定的了解。合理安排工作流程
爬虫有很多种方式,但是Java爬虫是开发中应用最广泛的一种网页获取技术。它具有一流的速度和性能,功能支持水平相对较低。Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
对于爬虫行业,我们推出了用于动态转发的高质量代理IP解决方案,完美解决了爬虫行业的难点。动态转发使用简单方便,不限制机器的使用,更适合项目的快速启动。最简单的方法如下:
import java.io.IOException;
import java.net.Authenticator;
import java.net.InetSocketAddress;
import java.net.PasswordAuthentication;
import java.net.Proxy;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Demo
{
// 代理验证信息
final static String ProxyUser = "16MNWZCB";
final static String ProxyPass = "365090";
// 代理服务器(产品官网 www.16yun.cn)
final static String ProxyHost = "t.16yun.cn";
final static Integer ProxyPort = 31111;
// 设置IP切换头
final static String ProxyHeadKey = "Proxy-Tunnel";
public static String getUrlProxyContent(String url)
{
Authenticator.setDefault(new Authenticator() {
public PasswordAuthentication getPasswordAuthentication()
{
return new PasswordAuthentication(ProxyUser, ProxyPass.toCharArray());
}
});
// 设置Proxy-Tunnel
Random random = new Random();
int tunnel = random.nextInt(10000);
String ProxyHeadVal = String.valueOf(tunnel);
Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress(ProxyHost, ProxyPort));
try
{
// 处理异常、其他参数
Document doc = Jsoup.connect(url).timeout(3000).header(ProxyHeadKey, ProxyHeadVal).proxy(proxy).get();
if(doc != null) {
System.out.println(doc.body().html());
}
}
catch (IOException e)
{
e.printStackTrace();
}
return null;
}
public static void main(String[] args) throws Exception
{
// 要访问的目标页面
String targetUrl = "https://weibo.com/";
getUrlProxyContent(targetUrl);
}
}
如果您需要,也可以理解许多爬虫开发框架 查看全部
java爬虫抓取动态网页(大数据时代爬虫工作者开发框架)
如今,在大数据时代,爬虫已经成为互联网数据公司的关键位置。他们不仅要精通数据采集和分析,还要熟悉搜索引擎和相关检索算法,并对各种算法有一定的了解。合理安排工作流程
爬虫有很多种方式,但是Java爬虫是开发中应用最广泛的一种网页获取技术。它具有一流的速度和性能,功能支持水平相对较低。Jsoup是一个Java HTML解析器,它可以直接解析URL地址和HTML文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似于jQuery的操作方法获取和操作数据
对于爬虫行业,我们推出了用于动态转发的高质量代理IP解决方案,完美解决了爬虫行业的难点。动态转发使用简单方便,不限制机器的使用,更适合项目的快速启动。最简单的方法如下:
import java.io.IOException;
import java.net.Authenticator;
import java.net.InetSocketAddress;
import java.net.PasswordAuthentication;
import java.net.Proxy;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Demo
{
// 代理验证信息
final static String ProxyUser = "16MNWZCB";
final static String ProxyPass = "365090";
// 代理服务器(产品官网 www.16yun.cn)
final static String ProxyHost = "t.16yun.cn";
final static Integer ProxyPort = 31111;
// 设置IP切换头
final static String ProxyHeadKey = "Proxy-Tunnel";
public static String getUrlProxyContent(String url)
{
Authenticator.setDefault(new Authenticator() {
public PasswordAuthentication getPasswordAuthentication()
{
return new PasswordAuthentication(ProxyUser, ProxyPass.toCharArray());
}
});
// 设置Proxy-Tunnel
Random random = new Random();
int tunnel = random.nextInt(10000);
String ProxyHeadVal = String.valueOf(tunnel);
Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress(ProxyHost, ProxyPort));
try
{
// 处理异常、其他参数
Document doc = Jsoup.connect(url).timeout(3000).header(ProxyHeadKey, ProxyHeadVal).proxy(proxy).get();
if(doc != null) {
System.out.println(doc.body().html());
}
}
catch (IOException e)
{
e.printStackTrace();
}
return null;
}
public static void main(String[] args) throws Exception
{
// 要访问的目标页面
String targetUrl = "https://weibo.com/";
getUrlProxyContent(targetUrl);
}
}
如果您需要,也可以理解许多爬虫开发框架
java爬虫抓取动态网页(爬虫科普一下对爬虫的误区、原理以及实现(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-19 15:11
爬行动物?我相信很多人都熟悉这个词。简而言之,就是使用工具来抓取网页上的数据,并对其进行分类和分析。像往常一样,向小白询问爬行动物的误解、原理和实施情况
爬虫的常见误解:python=crawler
许多白人把蟒蛇等同于爬虫。实际上,Python是一种计算机编程语言。它不仅可以是一个爬虫程序,还可以构建web应用程序。最近火灾的人工智能也可以通过使用python语言来实现
爬虫的本质是抓取服务器响应浏览器的数据(下面将详细介绍其原理)。不同的计算机编程语言,如Java和c#可以实现爬虫程序
概要:Python≠ 爬虫。Python的功能远比我们想象的强大。爬虫程序不能仅由python实现
爬行动物原理
让我们回忆一下我们对百度的访问:
1.在地址栏中输入URL:
有些人会说我以前从来没有这样做过。我使用浏览器导航到百度
其实,这样进入百度,只需在浏览器中为你输入访问百度的链接即可
2.浏览器刷新,百度的搜索框出现在我们面前
当然,不考虑网络速度无法刷新的情况
在此期间,浏览器和服务器之间发生了什么
1.浏览器向服务器发送URL,即请求地址
2.服务器接收来自浏览器的网络请求,并开始响应浏览器的数据
3.browser接收服务器发送的数据,对其进行分析并显示
如果您感兴趣,可以清除浏览器缓存,使用FN+F12打开浏览器控制台,选择网络菜单,在刷新页面时可以看到具体的响应过程
爬虫的实现机制
1.由于浏览器可以向服务器发送请求地址,我们也可以使用程序向服务器发送请求
2.由于浏览器可以接收服务器发送的数据,我们可以模拟浏览器解析过程,通过筛选得到我们想要的数据
小结:通过我们自己的程序,我们不需要重复整理我们想要的数据。所有这些都留给我们的爬虫程序
Java爬虫的具体案例
目标:抓取动态模块显示的最新新闻,并将新闻内容以文件形式本地保存
爬网资源1
爬网资源2
(一)需求分析)
1.分析新闻网主页,捕捉部门动态模块内容
2.simulate jump,进入每个新闻页面并抓取新闻的具体内容
3.将新闻的详细信息保存在文件中
(二)代码实现)
1.使用Maven工具在pom.xml中导入我们的爬虫程序所依赖的jar包
org.apache.httpcomponents
httpclient
4.5.3
org.jsoup
jsoup
1.8.3
log4j
log4j
1.2.16
junit
junit
4.10
2.make一个用于发送请求的简单类
package com.sxau.example;
import java.io.IOException;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.conn.params.ConnRouteParams;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.params.CoreConnectionPNames;
import org.apache.http.util.EntityUtils;
public class MyClient {
public String getContent(String url) throws ClientProtocolException, IOException {
// 创建httpclient对象
HttpClient hClient = new DefaultHttpClient();
// 设置连接超时时间,响应超时时间,以及代理服务器
hClient.getParams().setParameter(CoreConnectionPNames.CONNECTION_TIMEOUT, 5000)
.setParameter(CoreConnectionPNames.SO_TIMEOUT, 5000)
.setParameter(ConnRouteParams.DEFAULT_PROXY, new HttpHost("117.191.11.71", 8080));
// 创建get请求对象
HttpGet hGet = new HttpGet(url);
// 模拟请求,获得服务器响应的源码
HttpResponse response = hClient.execute(hGet);
// 将源码转换为字符串
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
// 返回转化后的字符串
return content;
}
}
3.make一个用于解析服务器数据的类
package com.sxau.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class MyJsoup {
public Elements getTarget(
String htmlResource,String selectCondition) {
//解析服务器发来的数据
Document doc = Jsoup.parse(htmlResource);
//对解析后的数据通过条件筛选
Elements elements = doc.select(selectCondition);
return elements;
}
}
4.make一个本地存储文件的类
package com.sxau.example;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class MyFileIO {
public void makeFile(String title,String txtContent) throws IOException {
//将标题左右多余的空格去掉
title = title.trim();
//拿到当前应用所在路径
String property = System.getProperty("user.dir");
//设置生成文件的路径与名称
String filePath = property + "\\src\\main\\webapp\\spidertxt\\" + title + ".txt";
//生成新文件
File txt = new File(filePath);
//将文件输入器定位到刚刚生成的新文件
FileWriter writer = new FileWriter(txt);
//将已经匹配的字符串写入文件中
writer.write(txtContent);
//刷新并关闭流
writer.flush();
writer.close();
}
}
5.为了提高效率,制作了一个线程进行并发处理
package com.sxau.example;
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
import org.jsoup.select.Elements;
/**
* 实现Runable接口
* @author Administrator
*
*/
public class MyThread implements Runnable{
private String mainUrl;
private String singleUrl;
//提供有参数的构造方法,确保进入页面时url不为空
public MyThread(String mainUrl, String singleUrl) {
this.mainUrl = mainUrl;
this.singleUrl = singleUrl;
}
/**
* 实现接口未实现的run()方法
* 通过httpclient发送请求并接收数据
* 观察html页面,使用jsoup中便捷的仿css/js选择器语法得到我们需要的内容
* 对匹配好的字符串进行优化,并进行本地存储
*/
@Override
public void run() {
// TODO 自动生成的方法存根
MyClient myClient = new MyClient();
String url=mainUrl+singleUrl;
String content;
try {
content = myClient.getContent(url);
String selectCondition1=".arti_title";
String selectCondition2=".wp_articlecontent";
MyJsoup jsoup = new MyJsoup();
Elements elements1 = jsoup.getTarget(content, selectCondition1);
Elements elements2 = jsoup.getTarget(content, selectCondition2);
String html1 = elements1.get(0).html();
String title = html1.replaceAll("", "");
String html2 = elements2.get(0).html();
html2 = html2.replaceAll("<p>", "");
String word = html2.replaceAll("", "");
MyFileIO fileIO=new MyFileIO();
fileIO.makeFile(title, word);
} catch (ClientProtocolException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
</p>
6.making主程序
package com.sxau.example;
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class MySpider {
public static void main(String[] args) throws ClientProtocolException, IOException {
MyClient myClient = new MyClient();
String url="http://news.sxau.edu.cn/";
String content = myClient.getContent(url);
String selectCondition="a[href][title~=(|)]";
MyJsoup jsoup = new MyJsoup();
Elements elements = jsoup.getTarget(content, selectCondition);
for (Element element : elements) {
String attr = element.attr("href");
new Thread(new MyThread(url, attr)).start();
}
System.out.println("文件爬虫成功!");
}
}
6.运行main方法并等待片刻。刚烤好的文件一直静静地放在文件夹里
log4j:WARN No appenders could be found for logger (org.apache.http.impl.conn.BasicClientConnectionManager).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4 ... onfig for more info.
文件爬虫成功!
最终效果
到目前为止,一个简单的爬虫功能已经实现。新手正在路上。如果您有任何问题,请毫不犹豫地提出建议,相互讨论,共同进步 查看全部
java爬虫抓取动态网页(爬虫科普一下对爬虫的误区、原理以及实现(组图))
爬行动物?我相信很多人都熟悉这个词。简而言之,就是使用工具来抓取网页上的数据,并对其进行分类和分析。像往常一样,向小白询问爬行动物的误解、原理和实施情况
爬虫的常见误解:python=crawler
许多白人把蟒蛇等同于爬虫。实际上,Python是一种计算机编程语言。它不仅可以是一个爬虫程序,还可以构建web应用程序。最近火灾的人工智能也可以通过使用python语言来实现
爬虫的本质是抓取服务器响应浏览器的数据(下面将详细介绍其原理)。不同的计算机编程语言,如Java和c#可以实现爬虫程序
概要:Python≠ 爬虫。Python的功能远比我们想象的强大。爬虫程序不能仅由python实现
爬行动物原理
让我们回忆一下我们对百度的访问:
1.在地址栏中输入URL:
有些人会说我以前从来没有这样做过。我使用浏览器导航到百度
其实,这样进入百度,只需在浏览器中为你输入访问百度的链接即可
2.浏览器刷新,百度的搜索框出现在我们面前
当然,不考虑网络速度无法刷新的情况
在此期间,浏览器和服务器之间发生了什么
1.浏览器向服务器发送URL,即请求地址
2.服务器接收来自浏览器的网络请求,并开始响应浏览器的数据
3.browser接收服务器发送的数据,对其进行分析并显示
如果您感兴趣,可以清除浏览器缓存,使用FN+F12打开浏览器控制台,选择网络菜单,在刷新页面时可以看到具体的响应过程
爬虫的实现机制
1.由于浏览器可以向服务器发送请求地址,我们也可以使用程序向服务器发送请求
2.由于浏览器可以接收服务器发送的数据,我们可以模拟浏览器解析过程,通过筛选得到我们想要的数据
小结:通过我们自己的程序,我们不需要重复整理我们想要的数据。所有这些都留给我们的爬虫程序
Java爬虫的具体案例
目标:抓取动态模块显示的最新新闻,并将新闻内容以文件形式本地保存
爬网资源1
爬网资源2
(一)需求分析)
1.分析新闻网主页,捕捉部门动态模块内容
2.simulate jump,进入每个新闻页面并抓取新闻的具体内容
3.将新闻的详细信息保存在文件中
(二)代码实现)
1.使用Maven工具在pom.xml中导入我们的爬虫程序所依赖的jar包
org.apache.httpcomponents
httpclient
4.5.3
org.jsoup
jsoup
1.8.3
log4j
log4j
1.2.16
junit
junit
4.10
2.make一个用于发送请求的简单类
package com.sxau.example;
import java.io.IOException;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.conn.params.ConnRouteParams;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.params.CoreConnectionPNames;
import org.apache.http.util.EntityUtils;
public class MyClient {
public String getContent(String url) throws ClientProtocolException, IOException {
// 创建httpclient对象
HttpClient hClient = new DefaultHttpClient();
// 设置连接超时时间,响应超时时间,以及代理服务器
hClient.getParams().setParameter(CoreConnectionPNames.CONNECTION_TIMEOUT, 5000)
.setParameter(CoreConnectionPNames.SO_TIMEOUT, 5000)
.setParameter(ConnRouteParams.DEFAULT_PROXY, new HttpHost("117.191.11.71", 8080));
// 创建get请求对象
HttpGet hGet = new HttpGet(url);
// 模拟请求,获得服务器响应的源码
HttpResponse response = hClient.execute(hGet);
// 将源码转换为字符串
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
// 返回转化后的字符串
return content;
}
}
3.make一个用于解析服务器数据的类
package com.sxau.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
public class MyJsoup {
public Elements getTarget(
String htmlResource,String selectCondition) {
//解析服务器发来的数据
Document doc = Jsoup.parse(htmlResource);
//对解析后的数据通过条件筛选
Elements elements = doc.select(selectCondition);
return elements;
}
}
4.make一个本地存储文件的类
package com.sxau.example;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class MyFileIO {
public void makeFile(String title,String txtContent) throws IOException {
//将标题左右多余的空格去掉
title = title.trim();
//拿到当前应用所在路径
String property = System.getProperty("user.dir");
//设置生成文件的路径与名称
String filePath = property + "\\src\\main\\webapp\\spidertxt\\" + title + ".txt";
//生成新文件
File txt = new File(filePath);
//将文件输入器定位到刚刚生成的新文件
FileWriter writer = new FileWriter(txt);
//将已经匹配的字符串写入文件中
writer.write(txtContent);
//刷新并关闭流
writer.flush();
writer.close();
}
}
5.为了提高效率,制作了一个线程进行并发处理
package com.sxau.example;
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
import org.jsoup.select.Elements;
/**
* 实现Runable接口
* @author Administrator
*
*/
public class MyThread implements Runnable{
private String mainUrl;
private String singleUrl;
//提供有参数的构造方法,确保进入页面时url不为空
public MyThread(String mainUrl, String singleUrl) {
this.mainUrl = mainUrl;
this.singleUrl = singleUrl;
}
/**
* 实现接口未实现的run()方法
* 通过httpclient发送请求并接收数据
* 观察html页面,使用jsoup中便捷的仿css/js选择器语法得到我们需要的内容
* 对匹配好的字符串进行优化,并进行本地存储
*/
@Override
public void run() {
// TODO 自动生成的方法存根
MyClient myClient = new MyClient();
String url=mainUrl+singleUrl;
String content;
try {
content = myClient.getContent(url);
String selectCondition1=".arti_title";
String selectCondition2=".wp_articlecontent";
MyJsoup jsoup = new MyJsoup();
Elements elements1 = jsoup.getTarget(content, selectCondition1);
Elements elements2 = jsoup.getTarget(content, selectCondition2);
String html1 = elements1.get(0).html();
String title = html1.replaceAll("", "");
String html2 = elements2.get(0).html();
html2 = html2.replaceAll("<p>", "");
String word = html2.replaceAll("", "");
MyFileIO fileIO=new MyFileIO();
fileIO.makeFile(title, word);
} catch (ClientProtocolException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
</p>
6.making主程序
package com.sxau.example;
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class MySpider {
public static void main(String[] args) throws ClientProtocolException, IOException {
MyClient myClient = new MyClient();
String url="http://news.sxau.edu.cn/";
String content = myClient.getContent(url);
String selectCondition="a[href][title~=(|)]";
MyJsoup jsoup = new MyJsoup();
Elements elements = jsoup.getTarget(content, selectCondition);
for (Element element : elements) {
String attr = element.attr("href");
new Thread(new MyThread(url, attr)).start();
}
System.out.println("文件爬虫成功!");
}
}
6.运行main方法并等待片刻。刚烤好的文件一直静静地放在文件夹里
log4j:WARN No appenders could be found for logger (org.apache.http.impl.conn.BasicClientConnectionManager).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4 ... onfig for more info.
文件爬虫成功!
最终效果
到目前为止,一个简单的爬虫功能已经实现。新手正在路上。如果您有任何问题,请毫不犹豫地提出建议,相互讨论,共同进步
java爬虫抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-19 10:10
Python爬虫4.2-Ajax[动态网页数据]使用教程
概述
本系列文档用于学习Python爬虫技术的简单教程。在巩固你的技术知识的同时,如果它碰巧对你有用,那就更好了
python版本为3.7.4
有时,当我们抓取收录请求的页面时,结果可能与在浏览器中看到的结果不同。您可以在浏览器中看到正常显示的页面数据,但通过使用请求获得的结果不显示。这是因为请求获取原创HTML文档,而浏览器中的页面是在JavaScript处理数据后生成的。这些数据来自各种来源,可以通过Ajax加载,收录在HTML文档中,也可以通过JavaScript和特定算法计算
因此,如果您遇到这样的页面,您无法通过直接使用请求和其他库获取原创页面来获得有效的数据。此时,您需要分析web页面后台发送到接口的Ajax请求。如果可以使用请求来模拟Ajax请求,就可以成功地捕获它们
因此,在本文中,我们主要了解什么是AJAX以及如何分析和获取AJAX请求
Ajax介绍了Ajax是什么
Ajax(异步JavaScript和XML)异步JavaScript和XML。通过与后台服务器的数据交换,AJAX可以实现web页面的异步更新,这意味着可以在不重新加载整个web页面的情况下更新部分web页面。如果一个传统的网页(没有Ajax)需要更新内容,它必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。事实上,受限数据交互基本上使用JSON和Ajax加载的数据。即使使用JS将数据呈现给浏览器,在查看网页源代码时也无法看到通过Ajax加载的数据,只能看到使用此URL加载的HTML代码
示例说明
浏览网页时,我们会发现许多网页有更多的选择。例如,微博、今日头条以及其他内容都是根据鼠标下拉菜单自动加载的。这些实际上是Ajax加载的过程。我们可以看到,页面尚未完全刷新,这意味着页面的链接没有变化,但网页中有更多的新内容,这意味着获取新数据并通过Ajax呈现的过程
请求分析
使用ChromeDeveloper工具的过滤功能过滤掉所有Ajax请求,这里不再详细解释
fiddler数据包捕获工具也可用于数据包捕获分析。这里不解释fiddler工具的使用。您可以在Internet上搜索和查看它
Ajax的响应结果通常是JSON数据格式
采集方法直接分析Ajax使用的接口,然后请求该接口通过代码获取数据(下面的示例就是这样一种方法)。使用selenium+chromedriver模拟浏览器行为并获取数据(稍后将文章继续)。这种方法的优点和缺点
分析接口
可以直接请求数据,而无需进行一些解析。代码量小,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一定的JS知识,这很容易被爬虫发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,也可以使用selenium请求。爬虫更稳定
大量代码和低性能
示例说明
让我们以知乎对“作为一名高价值程序员的经历是什么?”这个问题的所有答案为例。示例代码如下所示:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset 查看全部
java爬虫抓取动态网页(Python爬虫4.2—ajax[动态网页数据]用法教程综述)
Python爬虫4.2-Ajax[动态网页数据]使用教程
概述
本系列文档用于学习Python爬虫技术的简单教程。在巩固你的技术知识的同时,如果它碰巧对你有用,那就更好了
python版本为3.7.4
有时,当我们抓取收录请求的页面时,结果可能与在浏览器中看到的结果不同。您可以在浏览器中看到正常显示的页面数据,但通过使用请求获得的结果不显示。这是因为请求获取原创HTML文档,而浏览器中的页面是在JavaScript处理数据后生成的。这些数据来自各种来源,可以通过Ajax加载,收录在HTML文档中,也可以通过JavaScript和特定算法计算
因此,如果您遇到这样的页面,您无法通过直接使用请求和其他库获取原创页面来获得有效的数据。此时,您需要分析web页面后台发送到接口的Ajax请求。如果可以使用请求来模拟Ajax请求,就可以成功地捕获它们
因此,在本文中,我们主要了解什么是AJAX以及如何分析和获取AJAX请求
Ajax介绍了Ajax是什么
Ajax(异步JavaScript和XML)异步JavaScript和XML。通过与后台服务器的数据交换,AJAX可以实现web页面的异步更新,这意味着可以在不重新加载整个web页面的情况下更新部分web页面。如果一个传统的网页(没有Ajax)需要更新内容,它必须重新加载整个网页,因为传统的数据传输格式使用XML语法,所以称为Ajax。事实上,受限数据交互基本上使用JSON和Ajax加载的数据。即使使用JS将数据呈现给浏览器,在查看网页源代码时也无法看到通过Ajax加载的数据,只能看到使用此URL加载的HTML代码
示例说明
浏览网页时,我们会发现许多网页有更多的选择。例如,微博、今日头条以及其他内容都是根据鼠标下拉菜单自动加载的。这些实际上是Ajax加载的过程。我们可以看到,页面尚未完全刷新,这意味着页面的链接没有变化,但网页中有更多的新内容,这意味着获取新数据并通过Ajax呈现的过程
请求分析
使用ChromeDeveloper工具的过滤功能过滤掉所有Ajax请求,这里不再详细解释
fiddler数据包捕获工具也可用于数据包捕获分析。这里不解释fiddler工具的使用。您可以在Internet上搜索和查看它
Ajax的响应结果通常是JSON数据格式
采集方法直接分析Ajax使用的接口,然后请求该接口通过代码获取数据(下面的示例就是这样一种方法)。使用selenium+chromedriver模拟浏览器行为并获取数据(稍后将文章继续)。这种方法的优点和缺点
分析接口
可以直接请求数据,而无需进行一些解析。代码量小,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一定的JS知识,这很容易被爬虫发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,也可以使用selenium请求。爬虫更稳定
大量代码和低性能
示例说明
让我们以知乎对“作为一名高价值程序员的经历是什么?”这个问题的所有答案为例。示例代码如下所示:
<p># 引入所需库
import json
import requests
# 声明定义请求头
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/67.0.3396.99 '
'Safari/537.36',
'Host': "www.zhihu.com",
'Referer': "https://www.zhihu.com/question/37787176"
}
def answer(url_):
"""
获取问题答案
:param url_:
:return:
"""
r = requests.get(url_, headers=header)
data = r.text
jsonobj = json.loads(data)
return jsonobj
# 问题答案接口地址
url = "https://www.zhihu.com/api/v4/q ... ot%3B
# 获取回答总数
answer_total = int(answer(url)['paging']['totals'])
offset = 0
while offset
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-19 09:17
Htmlunit是一个开源Java页面分析工具。启动htmlunit后,底层将启动一个没有界面的浏览器。用户可以指定浏览器类型:Firefox、ie等。如果未指定,默认为Internet\uExplorer\u7:
WebClient WebClient=新的WebClient(BrowserVersion.FIREFOX_3_6))
通过一个简单的电话:
HtmlPage=webClient.getPage(url)
可通过以下方式获取页面的HTML页面表示:
InputStream is=targetPage.getWebResponse().getContentAsStream()
您可以获取页面的输入流,从而获取页面的源代码,这对于web爬虫项目非常有用
当然,您也可以从页面中获取更多页面元素
htmlunit为执行javascript提供支持非常重要:
page.executeJavaScript(javascript)
执行JS后,返回一个scriptresult对象,通过该对象可以得到执行JS后的页面等信息,默认情况下,内部浏览器会跳转到执行JS后生成的新页面,如果执行JS失败,则不会执行页面跳转 查看全部
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
Htmlunit是一个开源Java页面分析工具。启动htmlunit后,底层将启动一个没有界面的浏览器。用户可以指定浏览器类型:Firefox、ie等。如果未指定,默认为Internet\uExplorer\u7:
WebClient WebClient=新的WebClient(BrowserVersion.FIREFOX_3_6))
通过一个简单的电话:
HtmlPage=webClient.getPage(url)
可通过以下方式获取页面的HTML页面表示:
InputStream is=targetPage.getWebResponse().getContentAsStream()
您可以获取页面的输入流,从而获取页面的源代码,这对于web爬虫项目非常有用
当然,您也可以从页面中获取更多页面元素
htmlunit为执行javascript提供支持非常重要:
page.executeJavaScript(javascript)
执行JS后,返回一个scriptresult对象,通过该对象可以得到执行JS后的页面等信息,默认情况下,内部浏览器会跳转到执行JS后生成的新页面,如果执行JS失败,则不会执行页面跳转
java爬虫抓取动态网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-19 09:12
最近,在做一个项目时,有一个需求:要从网页中获取数据,需要首先获取整个网页的HTML源代码(将在以后的更新中使用)。首先,我看了一下这个简单的,然后我敲了敲代码(nutch,一个以前使用Hadoop平台的分布式爬虫框架,使用起来非常方便,但最终由于速度原因放弃了,但生成的统计数据用于以后的爬虫)。很快,holder.html和finance.html页面被成功下载,然后,在解析holder.html页面之后,我解析了finance.html。然后我很沮丧地发现我在这个页面中需要的数据不在HTML源代码中。我去浏览器查看源代码。果然,源代码中没有我需要的数据。看来我的程序并没有写错,接下来就是让人筋疲力尽的事情——获取收录动态内容的HTML页面
在中国所谓最强的搜索引擎百度上走了很长一段时间后,我发现大多数人会使用webdriver和httpUnit(事实上,前者已经包括后者)。我很高兴,终于找到了解决办法。非常激动地使用webdriver,我发誓
下面对WebDriver的Tucao进行投诉
Webdriver是一个测试框架。它最初不是为爬虫服务的,但我想说的是:它几乎是一种浏览。你不能再向前迈一步吗?为什么这么多人在互联网上推荐webdriver?我不认为这些人是从现实出发的。有些人甚至吹嘘webdriver可以解析完成的页面,并将其返回给想要浏览整个页面的人(包括动态生成的内容)。是的,webdriver可以完成这个任务,但是当我看到作者编写的代码时,我想说的是:伙计,你的代码太有限了。解析自己编写的JS代码,JS代码很简单,因此webdriver肯定会在没有压力的情况下完成任务。当webdriver解析动态内容时,它取决于JS代码的复杂性和多样性
什么是复杂性
先发布一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是,我相信每个人都能理解上面使用的IE内核,当然是Firefox驱动程序、chrome驱动程序和htmlunitdriver。这些驱动程序的使用原则是相同的。首先打开浏览器(这需要时间),然后加载URL并完成动态解析,然后通过页面获得完整的HTML页面。作为xml(),htmlunitdriver模拟没有接口的浏览器。有一个rhino引擎在Java中执行JS。htmlunitdriver使用rhino解析JS。由于htmlunitdriver不会使用界面启动浏览器,因此它的速度比前三个版本快。不管是什么驱动程序,解析JS都是不可避免的,这需要时间,并且未使用的内核对JS的支持程序是不同的。例如,htmlunitdriver对带有滚动的JS代码的支持较差,并且会在执行过程中报告错误(亲身经历)。JS代码的复杂性意味着不同内核支持的JS并不完全相同。这要根据具体情况来确定。我已经很长时间没有学习JS了,所以我不会谈论内部检查JS的支持
什么是多样性
如前所述,浏览器解析JS需要时间。对于只有少量嵌入JS代码的页面,通过页面获取完整页面是没有问题的。Asxml()。但是,对于收录更多嵌入式JS代码的页面,解析JS需要很多时间(对于JVM)。此时,大部分页面都是通过页面获取的。Asxml()不收录动态生成的内容。问题是,为什么你说webdriver可以获得收录动态内容的HTML页面?网上有人说,开车后。Get(URL),当前线程需要等待以获取完成的页面,这类似于下面的表单
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
根据这个想法,我尝试了以下方法。啊,真的有可能。但这不是问题所在吗?如何确定等待时间?与数据挖掘中确定阈值的经验方法类似,或尽可能长。我认为这些不是很好的方法。时间成本相对较高。我认为驱动程序应该能够在解析JS后捕获状态,所以我去寻找,寻找,但根本没有这样的方法,所以我说为什么webdriver的设计者不进一步,以便我们可以在程序中获取驱动程序解析JS后的状态,所以我们不需要使用thread.sleep( 2000)很遗憾,我找不到这样不确定的代码,这让我很伤心。Firefox驱动程序、chrome驱动程序和htmlunitdriver也有同样的问题。可以说,使用webdriver帮助爬升动态生成的网页所获得的结果非常不稳定。我对此有深刻的理解。使用iedriver时,两个pages在同一页上,每次爬网的结果都不一样,有时ie会直接挂断。你敢在爬网程序中使用这些东西吗?我不敢
此外,有人建议使用httpUnit。事实上,httpUnit是由webdirver中的htmlunitdriver内部使用的,所以使用httpUnit时也会遇到同样的问题。我还进行了实验,这是正确的。通过thread.sleep( 2000)我认为等待JS解析是不明智的。有太多的不确定性,尤其是在大规模爬网中
综上所述,webdriver是一个专门为测试而设计的框架。虽然根据其原理,它在理论上可以用来帮助爬虫获取收录动态内容的HTML页面,但在实际应用中却没有被采用。不确定性太大,稳定性太差,速度太慢。让框架来完成它的best,不要损害他们的优势
我还没有完成我的工作,所以我需要找到一种上网的方式。这次,我找到了一个稳定且具有高度确定性的辅助工具phantomjs。目前,我不完全了解这个工具。但是,它已经被用来实现我想要的功能。在Java中,我使用runtime.exec(ARG)在解析JS后调用phantomjs获取页面。我最好发布代码
要在phantom JS端执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在Java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
通过这种方式,解析后的HTML页面可以在Java端获得,而不是使用thread.Sleep()在webdriver中,这种不确定的代码用于获取可能完成的代码。需要注意的一点是:phantomjs端的JS代码不能有语法错误,否则Java端会一直等待,如果JS代码的编译方式不同,Java端不会抛出异常。另一个原因是,在使用phantomjs.exe时side每次都要启动一个phantomjs进程,消耗的时间比较大,但至少结果是稳定的,当然最后我没有使用phantomjs,直接下载需要的数据,没有抓取整个页面,主要是速度问题(事实上,我不敢使用它,因为phantomjs是不熟悉的,所以我谨慎使用)
经过几天的辗转反侧,我没有解决我的问题,但我学到了很多知识。在后期,我熟悉phantomjs,看看我是否可以提高速度。如果我能打破速度框架,我将来爬到网页时会很方便。另外,nutch框架。我很佩服我哥哥的方便使用时,有必要在后期研究如何在Hadoop上优化nutch的爬行速度?此外,nutch的原创功能不会爬行动态生成的页面内容,但可以使用nutch和webdirver的组合。也许爬行结果是稳定的。哈哈,这些只是想法,但是你怎么知道你不要尝试
如果您对使用webdriver帮助爬虫获得的结果的稳定性有什么看法,欢迎您,因为我确实没有找到稳定结果的相关信息 查看全部
java爬虫抓取动态网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近,在做一个项目时,有一个需求:要从网页中获取数据,需要首先获取整个网页的HTML源代码(将在以后的更新中使用)。首先,我看了一下这个简单的,然后我敲了敲代码(nutch,一个以前使用Hadoop平台的分布式爬虫框架,使用起来非常方便,但最终由于速度原因放弃了,但生成的统计数据用于以后的爬虫)。很快,holder.html和finance.html页面被成功下载,然后,在解析holder.html页面之后,我解析了finance.html。然后我很沮丧地发现我在这个页面中需要的数据不在HTML源代码中。我去浏览器查看源代码。果然,源代码中没有我需要的数据。看来我的程序并没有写错,接下来就是让人筋疲力尽的事情——获取收录动态内容的HTML页面
在中国所谓最强的搜索引擎百度上走了很长一段时间后,我发现大多数人会使用webdriver和httpUnit(事实上,前者已经包括后者)。我很高兴,终于找到了解决办法。非常激动地使用webdriver,我发誓
下面对WebDriver的Tucao进行投诉
Webdriver是一个测试框架。它最初不是为爬虫服务的,但我想说的是:它几乎是一种浏览。你不能再向前迈一步吗?为什么这么多人在互联网上推荐webdriver?我不认为这些人是从现实出发的。有些人甚至吹嘘webdriver可以解析完成的页面,并将其返回给想要浏览整个页面的人(包括动态生成的内容)。是的,webdriver可以完成这个任务,但是当我看到作者编写的代码时,我想说的是:伙计,你的代码太有限了。解析自己编写的JS代码,JS代码很简单,因此webdriver肯定会在没有压力的情况下完成任务。当webdriver解析动态内容时,它取决于JS代码的复杂性和多样性
什么是复杂性
先发布一段代码
WebDriver driver = newInternetExplorerDriver ();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是,我相信每个人都能理解上面使用的IE内核,当然是Firefox驱动程序、chrome驱动程序和htmlunitdriver。这些驱动程序的使用原则是相同的。首先打开浏览器(这需要时间),然后加载URL并完成动态解析,然后通过页面获得完整的HTML页面。作为xml(),htmlunitdriver模拟没有接口的浏览器。有一个rhino引擎在Java中执行JS。htmlunitdriver使用rhino解析JS。由于htmlunitdriver不会使用界面启动浏览器,因此它的速度比前三个版本快。不管是什么驱动程序,解析JS都是不可避免的,这需要时间,并且未使用的内核对JS的支持程序是不同的。例如,htmlunitdriver对带有滚动的JS代码的支持较差,并且会在执行过程中报告错误(亲身经历)。JS代码的复杂性意味着不同内核支持的JS并不完全相同。这要根据具体情况来确定。我已经很长时间没有学习JS了,所以我不会谈论内部检查JS的支持
什么是多样性
如前所述,浏览器解析JS需要时间。对于只有少量嵌入JS代码的页面,通过页面获取完整页面是没有问题的。Asxml()。但是,对于收录更多嵌入式JS代码的页面,解析JS需要很多时间(对于JVM)。此时,大部分页面都是通过页面获取的。Asxml()不收录动态生成的内容。问题是,为什么你说webdriver可以获得收录动态内容的HTML页面?网上有人说,开车后。Get(URL),当前线程需要等待以获取完成的页面,这类似于下面的表单
WebDriver driver = new InternetExplorerDriver();
HtmlPage page = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
根据这个想法,我尝试了以下方法。啊,真的有可能。但这不是问题所在吗?如何确定等待时间?与数据挖掘中确定阈值的经验方法类似,或尽可能长。我认为这些不是很好的方法。时间成本相对较高。我认为驱动程序应该能够在解析JS后捕获状态,所以我去寻找,寻找,但根本没有这样的方法,所以我说为什么webdriver的设计者不进一步,以便我们可以在程序中获取驱动程序解析JS后的状态,所以我们不需要使用thread.sleep( 2000)很遗憾,我找不到这样不确定的代码,这让我很伤心。Firefox驱动程序、chrome驱动程序和htmlunitdriver也有同样的问题。可以说,使用webdriver帮助爬升动态生成的网页所获得的结果非常不稳定。我对此有深刻的理解。使用iedriver时,两个pages在同一页上,每次爬网的结果都不一样,有时ie会直接挂断。你敢在爬网程序中使用这些东西吗?我不敢
此外,有人建议使用httpUnit。事实上,httpUnit是由webdirver中的htmlunitdriver内部使用的,所以使用httpUnit时也会遇到同样的问题。我还进行了实验,这是正确的。通过thread.sleep( 2000)我认为等待JS解析是不明智的。有太多的不确定性,尤其是在大规模爬网中
综上所述,webdriver是一个专门为测试而设计的框架。虽然根据其原理,它在理论上可以用来帮助爬虫获取收录动态内容的HTML页面,但在实际应用中却没有被采用。不确定性太大,稳定性太差,速度太慢。让框架来完成它的best,不要损害他们的优势
我还没有完成我的工作,所以我需要找到一种上网的方式。这次,我找到了一个稳定且具有高度确定性的辅助工具phantomjs。目前,我不完全了解这个工具。但是,它已经被用来实现我想要的功能。在Java中,我使用runtime.exec(ARG)在解析JS后调用phantomjs获取页面。我最好发布代码
要在phantom JS端执行的代码
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
//console.log('Loading a web page');
var page = require('webpage').create();
var url = address;
//console.log(url);
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('Unable to post!');
} else {
//此处的打印,是将结果一流的形式output到java中,java通过InputStream可以获取该输出内容
console.log(page.content);
}
phantom.exit();
});
在Java端执行的代码
public void getParseredHtml(){
String url = "www.bai.com";
Runtime runtime = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js "+url);
InputStream in = runtime.getInputStream();
//后面的代码省略,得到了InputStream就好说了
}
通过这种方式,解析后的HTML页面可以在Java端获得,而不是使用thread.Sleep()在webdriver中,这种不确定的代码用于获取可能完成的代码。需要注意的一点是:phantomjs端的JS代码不能有语法错误,否则Java端会一直等待,如果JS代码的编译方式不同,Java端不会抛出异常。另一个原因是,在使用phantomjs.exe时side每次都要启动一个phantomjs进程,消耗的时间比较大,但至少结果是稳定的,当然最后我没有使用phantomjs,直接下载需要的数据,没有抓取整个页面,主要是速度问题(事实上,我不敢使用它,因为phantomjs是不熟悉的,所以我谨慎使用)
经过几天的辗转反侧,我没有解决我的问题,但我学到了很多知识。在后期,我熟悉phantomjs,看看我是否可以提高速度。如果我能打破速度框架,我将来爬到网页时会很方便。另外,nutch框架。我很佩服我哥哥的方便使用时,有必要在后期研究如何在Hadoop上优化nutch的爬行速度?此外,nutch的原创功能不会爬行动态生成的页面内容,但可以使用nutch和webdirver的组合。也许爬行结果是稳定的。哈哈,这些只是想法,但是你怎么知道你不要尝试
如果您对使用webdriver帮助爬虫获得的结果的稳定性有什么看法,欢迎您,因为我确实没有找到稳定结果的相关信息
java爬虫抓取动态网页(如何利用Webkit从JS渲染网页中实现浏览器非常有趣)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-19 09:11
当我们进行网络爬虫时,我们将使用某些规则从返回的HTML数据中提取有效信息。但是,如果web页面收录java代码,则必须经过渲染处理才能获得原创数据。在这一点上,如果我们仍然使用传统的方法从中获取数据,我们将一无所获。浏览器知道如何处理和显示这些代码,但是我们的程序应该如何处理这些代码呢?接下来,我将介绍一种简单而粗糙的方法来获取收录java代码的网页信息
大多数人使用lxml和漂亮的soup包来提取数据。在本文中我不会介绍任何爬虫框架,因为我只使用最基本的lxml包来处理数据。也许你会想知道为什么我更喜欢lxml。这是因为lxml使用元素遍历方法来处理数据,而不是像Beauty soup那样使用正则表达式来提取数据。在本文中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的pycoders周刊147期上,所以我想抓取pycoders周刊中所有文件的链接
显然,这是一个带有Java呈现的网页。我想捕获网页中的所有文件信息和相应的链接信息。那我该怎么办?首先,我们无法使用HTTP方法获取任何信息
导入请求
从lxml导入html
#存储响应
响应=请求。获取(“”)
#从响应体创建lxml树
tree=html.fromstring(response.text)
#查找响应中的所有锚定标记
print tree.xpath('//div[@class=“campaign”]/a/@href')
当我们运行上述代码时,我们无法获得任何信息。这怎么可能?网页清楚地显示了如此多的文件信息。其次,我们需要考虑如何解决这个问题。
如何获取内容信息
接下来,我将介绍如何使用web工具包从JS呈现的web页面获取数据。什么是网络工具包?Web kit可以实现浏览器可以处理的任何功能。对于某些浏览器,WebKit是底层网页呈现工具。Web工具包是Qt库的一部分,所以如果您已经安装了Qt和PyQt4库,则可以直接运行它们
您可以使用命令行安装软件库:
sudo apt get安装python-qt4
现在所有的准备工作已经完成,我们将使用一种新的方法来提取信息
解决方案
我们首先通过web工具包发送请求信息,然后在web页面完全加载后将其分配给变量。接下来,我们使用lxml从HTML数据中提取有效信息。这个过程需要一点时间,但是你会惊讶地发现整个网页都被完全加载了
导入系统
从PyQt4.QtGui导入*
从PyQt4.Qtcore导入*
从PyQt4.QtWebKit导入*
类呈现(QWeb页面):
定义初始化(self,url):
self.app=QApplication(sys.argv)
QWebPage._____;初始化(自)
self.loadFinished.connect(self.\u loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec()
def_uu加载完成(自身、结果):
self.frame=self.mainFrame()
self.app.quit()
类render可用于呈现网页。当我们创建一个新的呈现类时,它可以加载URL中的所有信息,并在一个新的框架中共存 查看全部
java爬虫抓取动态网页(如何利用Webkit从JS渲染网页中实现浏览器非常有趣)
当我们进行网络爬虫时,我们将使用某些规则从返回的HTML数据中提取有效信息。但是,如果web页面收录java代码,则必须经过渲染处理才能获得原创数据。在这一点上,如果我们仍然使用传统的方法从中获取数据,我们将一无所获。浏览器知道如何处理和显示这些代码,但是我们的程序应该如何处理这些代码呢?接下来,我将介绍一种简单而粗糙的方法来获取收录java代码的网页信息
大多数人使用lxml和漂亮的soup包来提取数据。在本文中我不会介绍任何爬虫框架,因为我只使用最基本的lxml包来处理数据。也许你会想知道为什么我更喜欢lxml。这是因为lxml使用元素遍历方法来处理数据,而不是像Beauty soup那样使用正则表达式来提取数据。在本文中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的pycoders周刊147期上,所以我想抓取pycoders周刊中所有文件的链接
显然,这是一个带有Java呈现的网页。我想捕获网页中的所有文件信息和相应的链接信息。那我该怎么办?首先,我们无法使用HTTP方法获取任何信息
导入请求
从lxml导入html
#存储响应
响应=请求。获取(“”)
#从响应体创建lxml树
tree=html.fromstring(response.text)
#查找响应中的所有锚定标记
print tree.xpath('//div[@class=“campaign”]/a/@href')
当我们运行上述代码时,我们无法获得任何信息。这怎么可能?网页清楚地显示了如此多的文件信息。其次,我们需要考虑如何解决这个问题。
如何获取内容信息
接下来,我将介绍如何使用web工具包从JS呈现的web页面获取数据。什么是网络工具包?Web kit可以实现浏览器可以处理的任何功能。对于某些浏览器,WebKit是底层网页呈现工具。Web工具包是Qt库的一部分,所以如果您已经安装了Qt和PyQt4库,则可以直接运行它们
您可以使用命令行安装软件库:
sudo apt get安装python-qt4
现在所有的准备工作已经完成,我们将使用一种新的方法来提取信息
解决方案
我们首先通过web工具包发送请求信息,然后在web页面完全加载后将其分配给变量。接下来,我们使用lxml从HTML数据中提取有效信息。这个过程需要一点时间,但是你会惊讶地发现整个网页都被完全加载了
导入系统
从PyQt4.QtGui导入*
从PyQt4.Qtcore导入*
从PyQt4.QtWebKit导入*
类呈现(QWeb页面):
定义初始化(self,url):
self.app=QApplication(sys.argv)
QWebPage._____;初始化(自)
self.loadFinished.connect(self.\u loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec()
def_uu加载完成(自身、结果):
self.frame=self.mainFrame()
self.app.quit()
类render可用于呈现网页。当我们创建一个新的呈现类时,它可以加载URL中的所有信息,并在一个新的框架中共存
java爬虫抓取动态网页(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和chromedriver)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-16 06:18
什么是Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:
1、直接分析Ajax调用的接口。然后通过代码请求这个接口
2、使用selenium+chromedriver模拟浏览器行为并获取数据
Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
1、Chrome:/a//chromedriver/下载
2、Firefox:/mozilla/geckodriver/releases
3、Edge:/en us/microsoft edge/tools/webdriver/
4、Safari:/blog/6900/webdriver-support-in-safari-10/
要安装selenium和chromedriver:
安装selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本
pip安装selenium
安装chromedriver:下载后,未经许可将其放入纯英文目录
快速启动:
现在让我们举一个简单的例子,让百度的主页告诉你如何快速启动硒和ChrimEdvor:
Selenium常见操作:
关闭页面:
1、driver.close():关闭当前页面
2、driver.quit():退出整个浏览器
定位元素:
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
作为表单元素:
1、操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag=driver.find u元素uu按u id('kw')查找
inputTag.send ukeys('python'))
使用“清除”方法清除输入框的内容。示例代码如下所示:
输入ag.clear()
2、operate checkbox:因为要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag=driver.find uu元素uu按名称(“rememberMe”)
记住标记。单击()
3、select:无法直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:
4、操作按钮:有多种方式操作按钮。例如,单击、右键单击、双击等。这里是最常用的方法之一。点击一下。直接调用click函数即可。示例代码如下所示:
inputTag=driver.find u元素uu按id('su')查找
输入ag。单击()行为链:
有时,页面中的操作可能有许多步骤,因此您可以使用鼠标行为链类actionchains来完成它。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下所示:
还有更多与鼠标相关的操作
1、click_按住(元素):单击但不要释放鼠标
2、context_单击(图元):单击鼠标右键
3、double_单击(图元):双击。有关更多方法,请参阅selenium-python.readthedocs.io/api.html
Cookie操作:
获取所有cookies:
对于driver.get\cookies()中的cookie:
打印(cookie)
根据cookie的键获取值:
value=driver.get uuCookie(键)
删除所有cookie:
driver.delete uu所有uu cookies()
删除cookie:
driver.delete\ucookie(密钥)
页面等待:
现在越来越多的网页使用ajax技术,因此程序无法确定元素何时完全加载。如果实际的页面等待时间太长,导致DOM元素无法出现,但您的代码直接使用此webelement,它将抛出空指针异常。解决这个问题。因此,selenium提供了两种等待方法:隐式等待和显式等待
隐式等待:调用driver.implicitly uuwait。然后它将等待10秒钟,然后才能获取不可用的元素。示例代码如下所示:
显示等待:显示等待指示仅在建立条件后执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。显示等待应使用selenium.webdriver.support.excluded uu条件预期条件和selenium.webdriver.support.ui.webdriverwait一起完成。示例代码如下所示:
其他一些等候条件:
1、presence_元素的位置:元素已加载
2、presence_位于的所有元素中:已加载网页中所有符合条件的元素
3、element_可点击:可以点击元素
切换页面:
有时窗口中有许多子选项卡页。此时必须切换。Selenium提供了一个名为“切换到”的窗口。您可以从句柄中的driver.window切换到哪个页面。示例代码如下所示:
self.driver.switch_uuu到uu窗口(self.driver.window_u句柄[1])
设置代理IP:
有时我经常抓取一些网页。当服务器发现您是爬虫程序时,它将阻止您的IP地址。此时,我们可以更改代理IP。改变代理IP,不同的浏览器有不同的实现方法。这里,以Chrome浏览器为例说明:
Webelement元素:
从selenium.webdriver.remote.webelement导入webelement类是每个获取的元素所属的类
有一些共同的属性:
1、get_属性:此标记的属性值
2、screentshot:获取当前页面的屏幕截图。此方法只能在驱动程序上使用
驱动程序的对象类也继承自webelement 查看全部
java爬虫抓取动态网页(什么是Ajax:Ajax(AsynchronouseJavaScript)异步JavaScript和chromedriver)
什么是Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:
1、直接分析Ajax调用的接口。然后通过代码请求这个接口
2、使用selenium+chromedriver模拟浏览器行为并获取数据
Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
1、Chrome:/a//chromedriver/下载
2、Firefox:/mozilla/geckodriver/releases
3、Edge:/en us/microsoft edge/tools/webdriver/
4、Safari:/blog/6900/webdriver-support-in-safari-10/
要安装selenium和chromedriver:
安装selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本
pip安装selenium
安装chromedriver:下载后,未经许可将其放入纯英文目录
快速启动:
现在让我们举一个简单的例子,让百度的主页告诉你如何快速启动硒和ChrimEdvor:
Selenium常见操作:
关闭页面:
1、driver.close():关闭当前页面
2、driver.quit():退出整个浏览器
定位元素:
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
作为表单元素:
1、操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag=driver.find u元素uu按u id('kw')查找
inputTag.send ukeys('python'))
使用“清除”方法清除输入框的内容。示例代码如下所示:
输入ag.clear()
2、operate checkbox:因为要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag=driver.find uu元素uu按名称(“rememberMe”)
记住标记。单击()
3、select:无法直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:
4、操作按钮:有多种方式操作按钮。例如,单击、右键单击、双击等。这里是最常用的方法之一。点击一下。直接调用click函数即可。示例代码如下所示:
inputTag=driver.find u元素uu按id('su')查找
输入ag。单击()行为链:
有时,页面中的操作可能有许多步骤,因此您可以使用鼠标行为链类actionchains来完成它。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下所示:
还有更多与鼠标相关的操作
1、click_按住(元素):单击但不要释放鼠标
2、context_单击(图元):单击鼠标右键
3、double_单击(图元):双击。有关更多方法,请参阅selenium-python.readthedocs.io/api.html
Cookie操作:
获取所有cookies:
对于driver.get\cookies()中的cookie:
打印(cookie)
根据cookie的键获取值:
value=driver.get uuCookie(键)
删除所有cookie:
driver.delete uu所有uu cookies()
删除cookie:
driver.delete\ucookie(密钥)
页面等待:
现在越来越多的网页使用ajax技术,因此程序无法确定元素何时完全加载。如果实际的页面等待时间太长,导致DOM元素无法出现,但您的代码直接使用此webelement,它将抛出空指针异常。解决这个问题。因此,selenium提供了两种等待方法:隐式等待和显式等待
隐式等待:调用driver.implicitly uuwait。然后它将等待10秒钟,然后才能获取不可用的元素。示例代码如下所示:
显示等待:显示等待指示仅在建立条件后执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。显示等待应使用selenium.webdriver.support.excluded uu条件预期条件和selenium.webdriver.support.ui.webdriverwait一起完成。示例代码如下所示:
其他一些等候条件:
1、presence_元素的位置:元素已加载
2、presence_位于的所有元素中:已加载网页中所有符合条件的元素
3、element_可点击:可以点击元素
切换页面:
有时窗口中有许多子选项卡页。此时必须切换。Selenium提供了一个名为“切换到”的窗口。您可以从句柄中的driver.window切换到哪个页面。示例代码如下所示:
self.driver.switch_uuu到uu窗口(self.driver.window_u句柄[1])
设置代理IP:
有时我经常抓取一些网页。当服务器发现您是爬虫程序时,它将阻止您的IP地址。此时,我们可以更改代理IP。改变代理IP,不同的浏览器有不同的实现方法。这里,以Chrome浏览器为例说明:
Webelement元素:
从selenium.webdriver.remote.webelement导入webelement类是每个获取的元素所属的类
有一些共同的属性:
1、get_属性:此标记的属性值
2、screentshot:获取当前页面的屏幕截图。此方法只能在驱动程序上使用
驱动程序的对象类也继承自webelement
java爬虫抓取动态网页(本文插件模拟浏览器如何获得网页上的动态加载数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-09-14 05:02
本文讲如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。步骤如下:一、找到正确的网址。 二、填写URL对应的参数。 三、参数转换成urllib可以识别的字符串数据。 四、 初始化请求对象。 五、urlopen 这个Request对象获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
以下步骤相同,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计诊断、累计死亡等数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面来谈谈如何用火狐浏览器获取这两个数据。
在肺炎页面右击,在出现的菜单中选择勾选元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
这里会有很多网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。通常,动态加载的数据量大于其他页面元素的数据量。 ,与其他基于字节的数据相比,119kb 被认为是非常大的数据。当然,网页上的一些装修图片也是很大的。这个需要根据文件类型栏区分。
然后点击域名一栏对应的行,如下
在消息头中可以看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,则
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data) 查看全部
java爬虫抓取动态网页(本文插件模拟浏览器如何获得网页上的动态加载数据?)
本文讲如何在不使用selenium插件模拟浏览器的情况下获取网页的动态加载数据。步骤如下:一、找到正确的网址。 二、填写URL对应的参数。 三、参数转换成urllib可以识别的字符串数据。 四、 初始化请求对象。 五、urlopen 这个Request对象获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
以下步骤相同,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计诊断、累计死亡等数据。因为这个页面上的数据是动态加载的,不是静态的html页面。需要按照我上面写的步骤来获取数据,关键是获取URL和对应的参数formdata。下面来谈谈如何用火狐浏览器获取这两个数据。
在肺炎页面右击,在出现的菜单中选择勾选元素。
点击上图中红色箭头的网络选项,然后刷新页面。如下,
这里会有很多网络传输记录。观察最右侧红色框中的“尺寸”列。此列表示此 http 请求传输的数据量。通常,动态加载的数据量大于其他页面元素的数据量。 ,与其他基于字节的数据相比,119kb 被认为是非常大的数据。当然,网页上的一些装修图片也是很大的。这个需要根据文件类型栏区分。
然后点击域名一栏对应的行,如下
在消息头中可以看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?后面的参数已经写好了。
如果我们使用带参数的 URL,则
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url,data = data)
java爬虫抓取动态网页(1.代码实现接下来提取首页jobName中包含python的所有链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-14 05:00
)
根据 UN网站accessibility 审计报告,主流网站 73% 的重要功能依赖 JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这个依赖JavaScript的动态网站,我们需要采取相应的方法,比如JavaScript逆向工程,渲染JavaScript等
1.动态网页示例
如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12
看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/?jl=736&kw=python&kt=3'
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2.逆向工程动态网页
在firefox中按F12,点击控制台打开XHR
点击一一打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3. 代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
查看全部
java爬虫抓取动态网页(1.代码实现接下来提取首页jobName中包含python的所有链接
)
根据 UN网站accessibility 审计报告,主流网站 73% 的重要功能依赖 JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这个依赖JavaScript的动态网站,我们需要采取相应的方法,比如JavaScript逆向工程,渲染JavaScript等
1.动态网页示例
如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12
看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/?jl=736&kw=python&kt=3'
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2.逆向工程动态网页
在firefox中按F12,点击控制台打开XHR
点击一一打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3. 代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
java爬虫抓取动态网页(一个爬虫动态生成的网页是什么?一般来说怎么办 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-09-14 04:17
)
最近公司想写一个爬虫项目。遇到一些js或者ajax动态生成的网页。我在网上搜索,发现webdriver更可靠。至于htmlunit,有的网站直接抛出异常。对js的支持不是特别好。
一般来说,WebDriver 有两种方式:本地 diver 和远程 diver。由于爬虫最终会部署到Linux服务器上,只能在命令行上运行,看来浏览器是装不了的,所以本地驱动的进程就不行了,只能尝试远程驱动了。幸运的是,我找到了一个phantomjs webdriver,它可以在没有界面的情况下在Linux下运行,所以我选择了它作为从js动态生成网页的解决方案。
到官网下载:,找到对应的版本下载。解压并安装它。进入bin目录,执行phantomjs,需要带启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
driver.get("http://www.iteye.com"); 查看全部
java爬虫抓取动态网页(一个爬虫动态生成的网页是什么?一般来说怎么办
)
最近公司想写一个爬虫项目。遇到一些js或者ajax动态生成的网页。我在网上搜索,发现webdriver更可靠。至于htmlunit,有的网站直接抛出异常。对js的支持不是特别好。
一般来说,WebDriver 有两种方式:本地 diver 和远程 diver。由于爬虫最终会部署到Linux服务器上,只能在命令行上运行,看来浏览器是装不了的,所以本地驱动的进程就不行了,只能尝试远程驱动了。幸运的是,我找到了一个phantomjs webdriver,它可以在没有界面的情况下在Linux下运行,所以我选择了它作为从js动态生成网页的解决方案。
到官网下载:,找到对应的版本下载。解压并安装它。进入bin目录,执行phantomjs,需要带启动参数,执行远程驱动的地址和端口。 phantomjs --webdriver 127.0.0.1:10025.
java 连接:
WebDriver driver = new RemoteWebDriver("http://127.0.0.1:10025", DesiredCapabilities.phantomjs());
driver.get("http://www.iteye.com";);
java爬虫抓取动态网页(代码不好使怎么获取后台js完后的完整页面?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-14 04:15
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上的HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,但是不行。
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,这段代码不能很好地工作。
对于答案,典型的是此链接的页面。 java程序中如何获取数据? 查看全部
java爬虫抓取动态网页(代码不好使怎么获取后台js完后的完整页面?)
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上的HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,但是不行。
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,这段代码不能很好地工作。
对于答案,典型的是此链接的页面。 java程序中如何获取数据?

