
java爬虫抓取动态网页
java爬虫抓取动态网页(Java的Http协议客户端HttpClient来实现抓取网页数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-11-26 03:07
爬虫抓取网页上的数据,我们同样点击链接访问网页数据。就是使用Http协议访问网页。这里我们使用Java Http协议客户端HttpClient来实现网页数据的爬取。
你好,世界
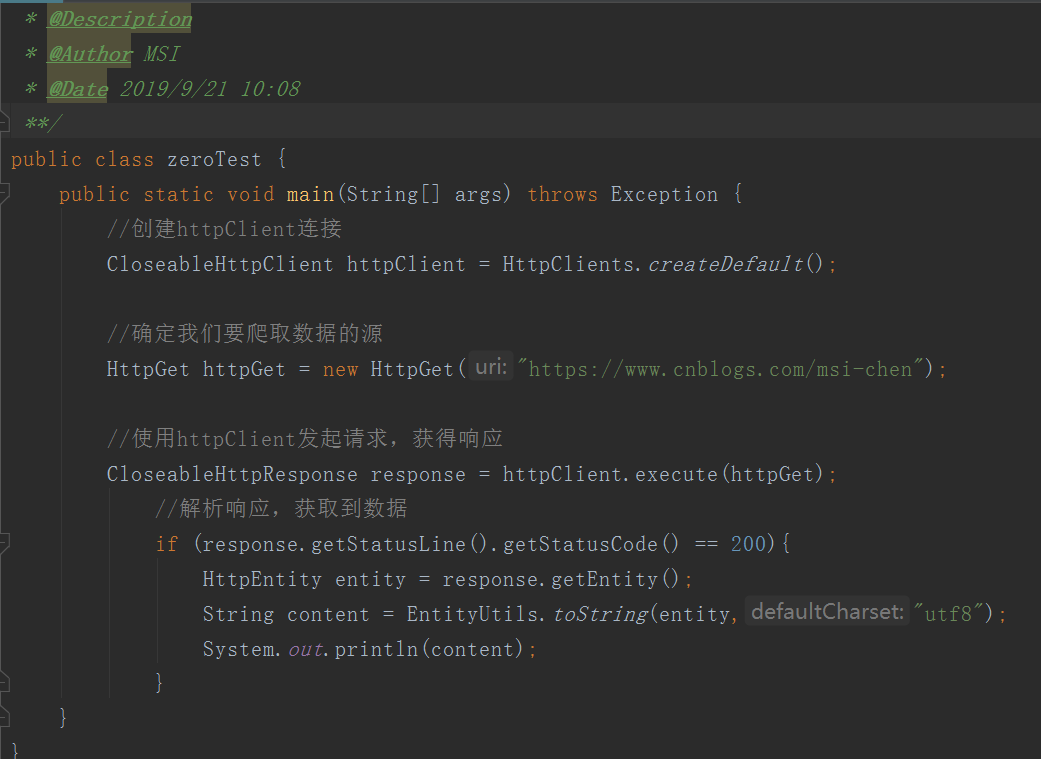
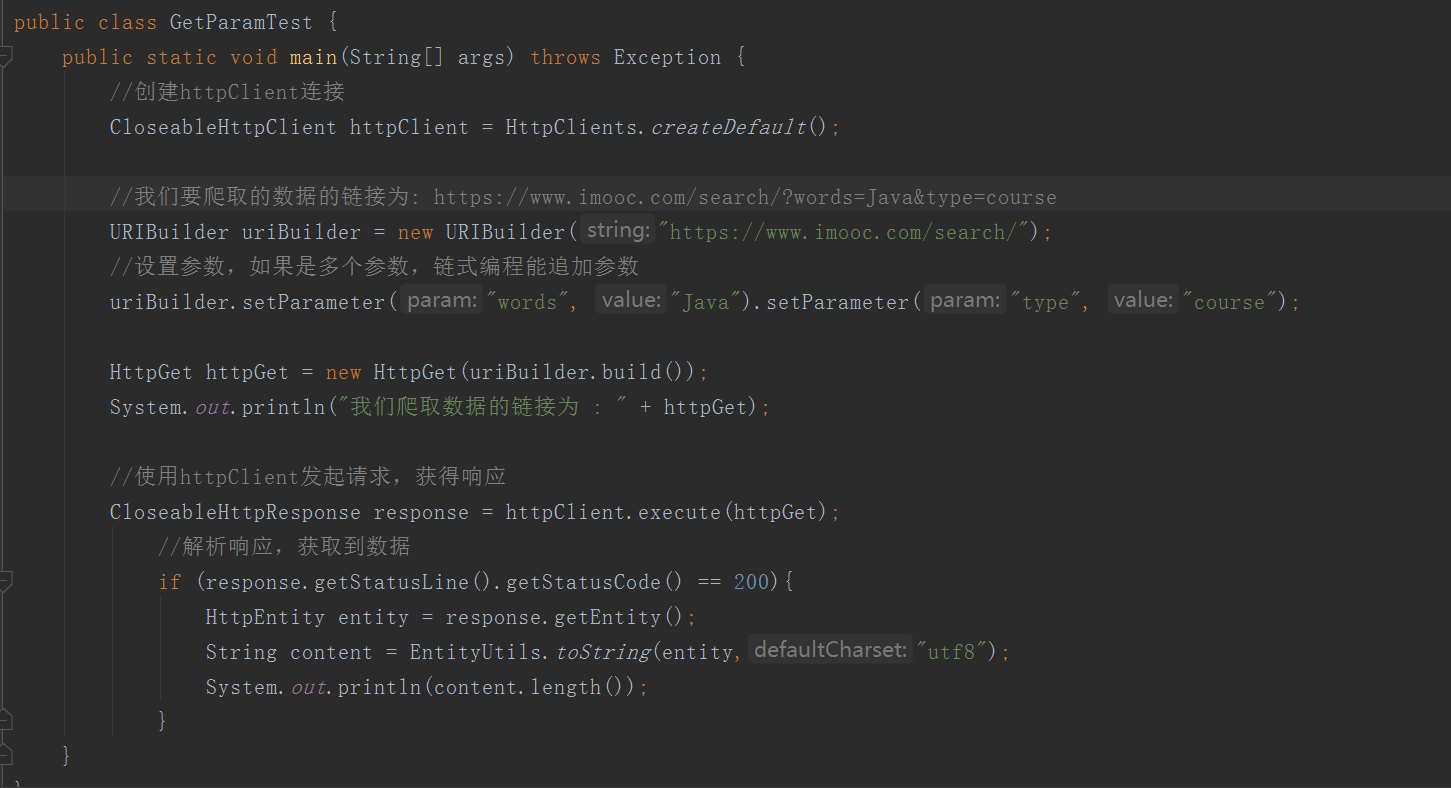
获取带参数的请求
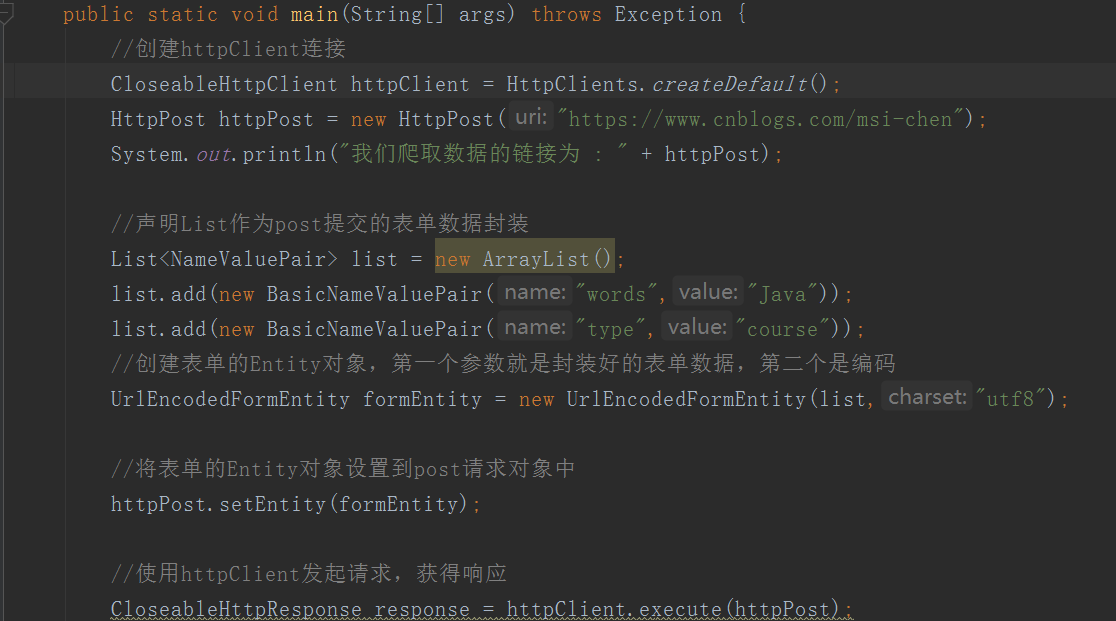
使用参数发布请求
帖子也很简单,和上面的差不多,只是改变了发起请求的方式,如下:
当然,如果没有参数,则不需要创建表单对象,只需一个HttpPost对象即可。
代码中对象的说明:
代码优化:连接池
在我们爬取数据的过程中,HttpClient连接对象的创建和销毁是非常频繁的,这里我们使用连接池进行优化
public class poolTest {
public static void main(String[] args) {
//创建连接池管理器
PoolingHttpClientConnectionManager pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(100); //设置池内最大连接数
pcm.setDefaultMaxPerRoute(10); //设置每个坠机的最大连接数
//从连接池中获取连接对象,而不是单独创建连接对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(pcm).build();
HttpGet httpGet = new HttpGet("https://www.cnblogs.com/msi-chen");
System.out.println(httpGet);
//使用httpClient发起请求,获得响应
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
//解析响应,获取到数据
if (response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity,"utf8");
System.out.println(content.length());
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if (response != null){
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
//因为我们是连接池中获取到的连接,所以这里不能再给他关闭了
//httpClient.close();
}
}
}
}
获取资源的相关时间配置
Jsoup 不是 Jsonp
经过我们上面的学习,我们已经可以通过HttpClient抓取页面了。抓取页面后,我们可以解析它。您可以使用字符串解析工具来解析页面,也可以使用正则表达式。用于分析,但是这两种方案的开发成本很高,不推荐使用,这里我们学习一个专门解析html页面的技术Jsonp
汤品介绍
jsonp 是一个 Java Html 解析器,可以自行解析 URL 地址和 html 文本内容。它有一组现成的 API 来删除和操作数据。
jsonp的作用:
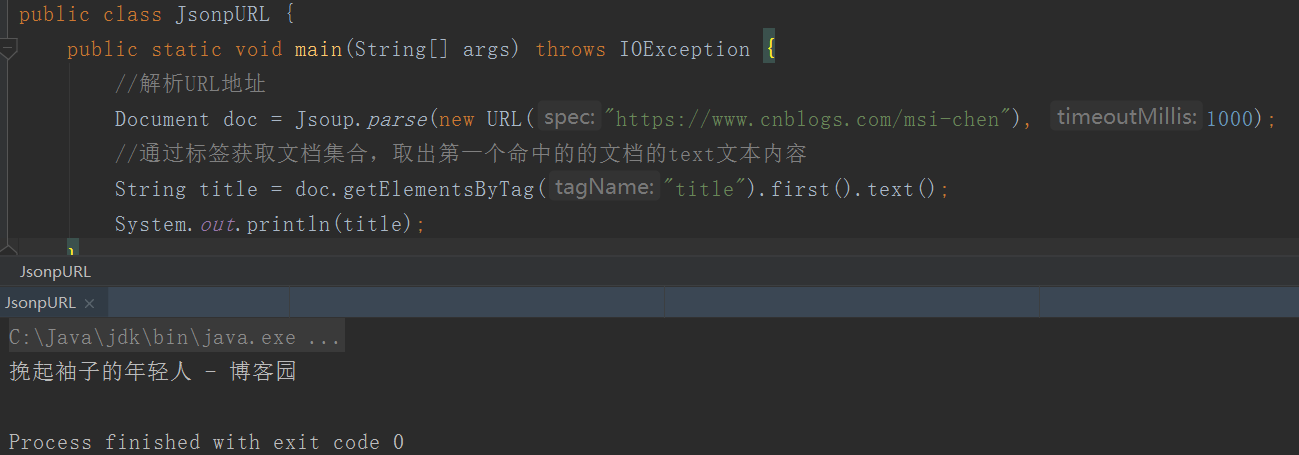
Jsoup 解析 URL
添加 Jsoup 依赖以使用 Jsoup
注意:Jsoup 只限于使用 Html 解析工具,而不是替代 HttpClient 来发起请求,因为 HttpClient 支持多线程、连接池、代理等技术,而 Jsoup 对此的支持并不理想。专业的事情交给专业的人,HttpClient发送请求抓取数据,Jsoup做解析
Jsoup 解析字符串
Jsoup解析文件
这是上面的静态页面。除了转换成String再解析,我们也可以直接解析文件
使用 Dom 遍历文档
记得还有一个sax解析,比较麻烦,现在差点忘了;
Dom解析,不知道大家有没有听过或者用过。反正我之前用过,但是解析的确实是XML。先简单介绍一个Dmo方法。
Dmo 解析会将目标文档视为一个对象。首先将整个文档加载到内存中。如果文档太大,内存可能会溢出(一般不会)。加载到内存后会构建一个Dom树,然后Just开始提供访问和修改操作
如果你之前没有学习过,我们通过一个小Demo来学习。如果您使用过它,我们有权对其进行审核:
Java代码如下: 我演示了几个常用的获取页面数据的API
从元素中获取属性
选择器
下面是上述always选择器的使用演示
选择器选择器组合使用
Hello World 类爬虫案例列表
在上面的学习中,我们已经知道HttpClient是用来爬取数据的,Jsoup是用来解析HttpClient爬取到的数据的。下面我们来练习一下这两个工具的使用。
搁浅,暂时……以后更新 查看全部
java爬虫抓取动态网页(Java的Http协议客户端HttpClient来实现抓取网页数据(组图))
爬虫抓取网页上的数据,我们同样点击链接访问网页数据。就是使用Http协议访问网页。这里我们使用Java Http协议客户端HttpClient来实现网页数据的爬取。
你好,世界
获取带参数的请求

使用参数发布请求
帖子也很简单,和上面的差不多,只是改变了发起请求的方式,如下:
当然,如果没有参数,则不需要创建表单对象,只需一个HttpPost对象即可。
代码中对象的说明:
代码优化:连接池
在我们爬取数据的过程中,HttpClient连接对象的创建和销毁是非常频繁的,这里我们使用连接池进行优化
public class poolTest {
public static void main(String[] args) {
//创建连接池管理器
PoolingHttpClientConnectionManager pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(100); //设置池内最大连接数
pcm.setDefaultMaxPerRoute(10); //设置每个坠机的最大连接数
//从连接池中获取连接对象,而不是单独创建连接对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(pcm).build();
HttpGet httpGet = new HttpGet("https://www.cnblogs.com/msi-chen";);
System.out.println(httpGet);
//使用httpClient发起请求,获得响应
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
//解析响应,获取到数据
if (response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity,"utf8");
System.out.println(content.length());
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if (response != null){
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
//因为我们是连接池中获取到的连接,所以这里不能再给他关闭了
//httpClient.close();
}
}
}
}
获取资源的相关时间配置

Jsoup 不是 Jsonp
经过我们上面的学习,我们已经可以通过HttpClient抓取页面了。抓取页面后,我们可以解析它。您可以使用字符串解析工具来解析页面,也可以使用正则表达式。用于分析,但是这两种方案的开发成本很高,不推荐使用,这里我们学习一个专门解析html页面的技术Jsonp
汤品介绍
jsonp 是一个 Java Html 解析器,可以自行解析 URL 地址和 html 文本内容。它有一组现成的 API 来删除和操作数据。
jsonp的作用:
Jsoup 解析 URL
添加 Jsoup 依赖以使用 Jsoup

注意:Jsoup 只限于使用 Html 解析工具,而不是替代 HttpClient 来发起请求,因为 HttpClient 支持多线程、连接池、代理等技术,而 Jsoup 对此的支持并不理想。专业的事情交给专业的人,HttpClient发送请求抓取数据,Jsoup做解析
Jsoup 解析字符串

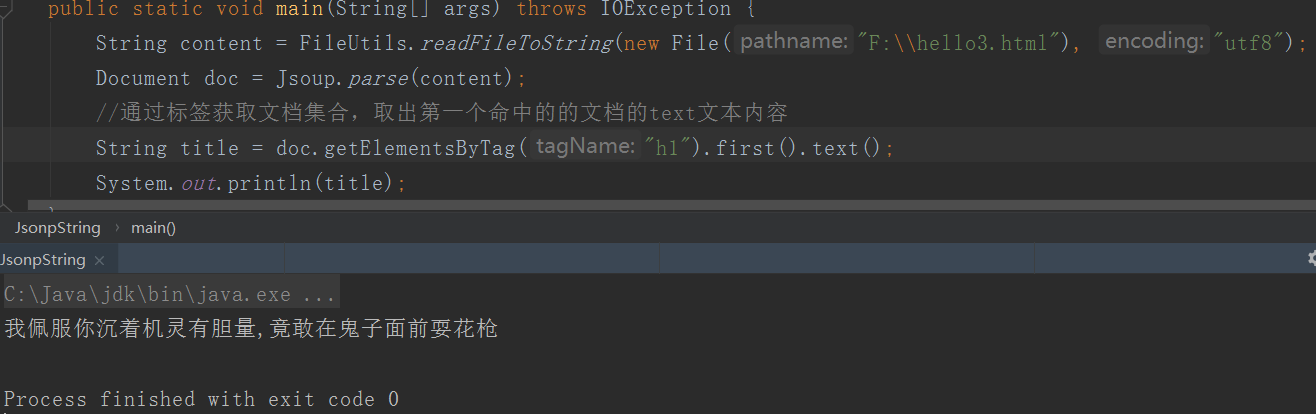
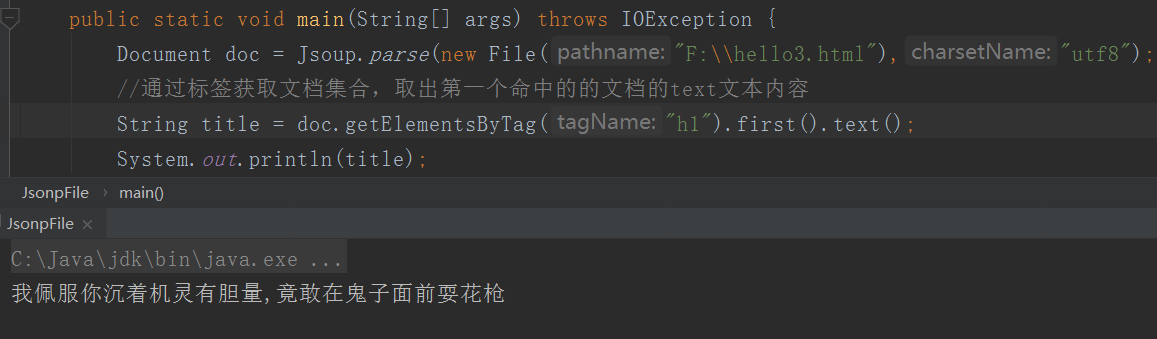
Jsoup解析文件
这是上面的静态页面。除了转换成String再解析,我们也可以直接解析文件
使用 Dom 遍历文档
记得还有一个sax解析,比较麻烦,现在差点忘了;
Dom解析,不知道大家有没有听过或者用过。反正我之前用过,但是解析的确实是XML。先简单介绍一个Dmo方法。
Dmo 解析会将目标文档视为一个对象。首先将整个文档加载到内存中。如果文档太大,内存可能会溢出(一般不会)。加载到内存后会构建一个Dom树,然后Just开始提供访问和修改操作
如果你之前没有学习过,我们通过一个小Demo来学习。如果您使用过它,我们有权对其进行审核:
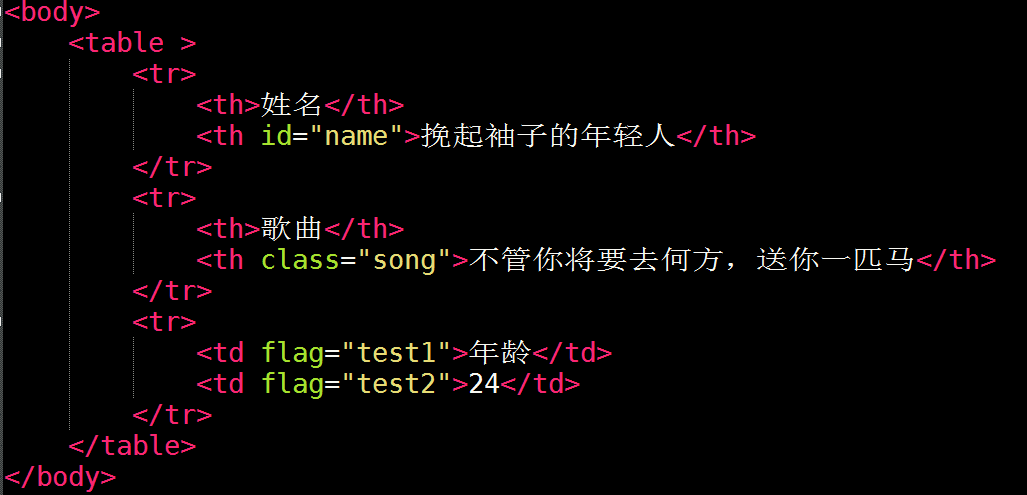
Java代码如下: 我演示了几个常用的获取页面数据的API

从元素中获取属性
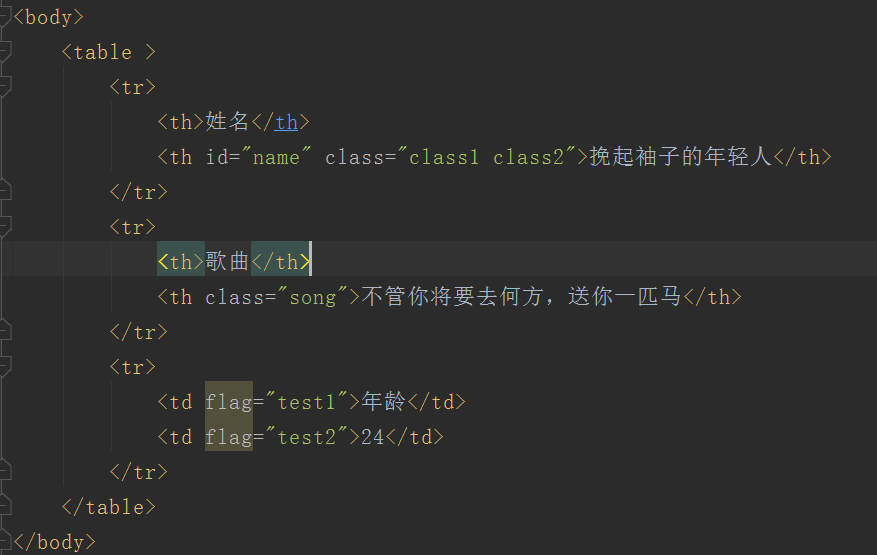
选择器
下面是上述always选择器的使用演示
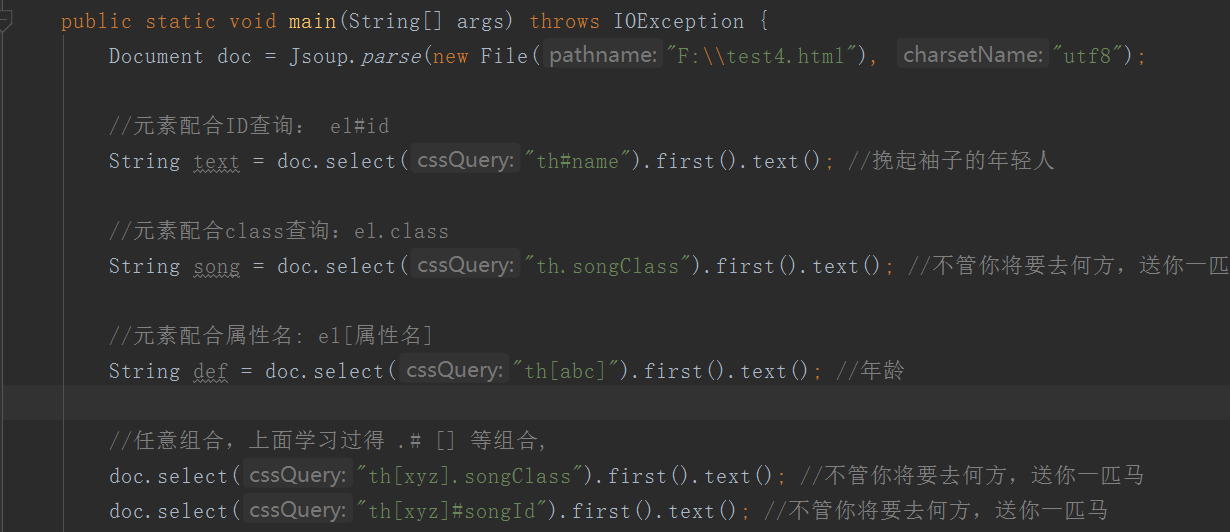
选择器选择器组合使用
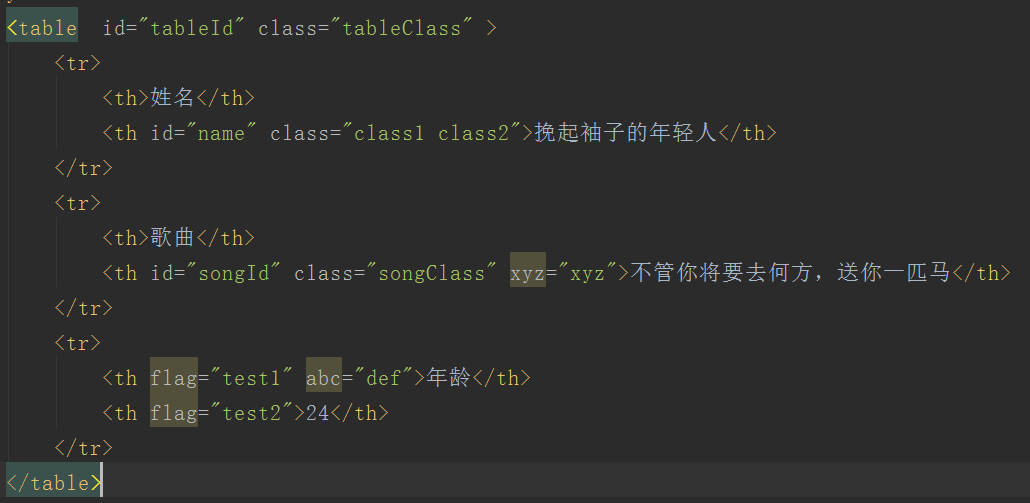
Hello World 类爬虫案例列表
在上面的学习中,我们已经知道HttpClient是用来爬取数据的,Jsoup是用来解析HttpClient爬取到的数据的。下面我们来练习一下这两个工具的使用。
搁浅,暂时……以后更新
java爬虫抓取动态网页(北京知名的房源网站python3.6怎么用解密?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-25 04:01
java爬虫抓取动态网页首先我们需要抓取这个动态网页的url,然后就是内容格式的解析了,我一直用python,简单的说就是生成下载列表url,item对象,并在python代码中处理解析,这里同一个网页的编码方式和url等等,因为技术原因,我的系统环境版本低了一版,没办法完美调用爬虫抓取。今天分享一个小案例,爬取北京知名的一些房源网站,我使用python3.6,先说效果吧:首先我们要有具体的数据,获取知名房源网站数据的网站网址,再就是提取出url,可以查看代码,保存url,最后写入url文件。
代码地址:-811144848.html,获取地址:,一旦确定数据要求,我们在不影响行为不影响项目不影响公司业务的前提下,什么code代码加密,java加密,vip代码加密,只能告诉代码的使用人无论懂不懂,都能看懂代码,你说好不好用。
我一般直接用google..
qq空间访问?
高德地图
电脑ai识别软件
小说下载器或者网页反爬技术
起点中文网很好用
会方便很多吧,有了页面的md5算法就可以猜出大部分主流网站的ip,因为他们的md5是标准的,baidu用ascii解密就能破解用md5解密用是以下这个网站的页面,很赞,ip验证码,直接应用于ip上了whois。icmp。com。phplar。qq。com。51。com。51。com。51。com。51。
com。51。com。51。com。51。com。51。com。51。com。还有无线网络的ip验证要去这个网站应该也可以访问。 查看全部
java爬虫抓取动态网页(北京知名的房源网站python3.6怎么用解密?)
java爬虫抓取动态网页首先我们需要抓取这个动态网页的url,然后就是内容格式的解析了,我一直用python,简单的说就是生成下载列表url,item对象,并在python代码中处理解析,这里同一个网页的编码方式和url等等,因为技术原因,我的系统环境版本低了一版,没办法完美调用爬虫抓取。今天分享一个小案例,爬取北京知名的一些房源网站,我使用python3.6,先说效果吧:首先我们要有具体的数据,获取知名房源网站数据的网站网址,再就是提取出url,可以查看代码,保存url,最后写入url文件。
代码地址:-811144848.html,获取地址:,一旦确定数据要求,我们在不影响行为不影响项目不影响公司业务的前提下,什么code代码加密,java加密,vip代码加密,只能告诉代码的使用人无论懂不懂,都能看懂代码,你说好不好用。
我一般直接用google..
qq空间访问?
高德地图
电脑ai识别软件
小说下载器或者网页反爬技术
起点中文网很好用
会方便很多吧,有了页面的md5算法就可以猜出大部分主流网站的ip,因为他们的md5是标准的,baidu用ascii解密就能破解用md5解密用是以下这个网站的页面,很赞,ip验证码,直接应用于ip上了whois。icmp。com。phplar。qq。com。51。com。51。com。51。com。51。
com。51。com。51。com。51。com。51。com。51。com。还有无线网络的ip验证要去这个网站应该也可以访问。
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-22 01:15
htmlunit 是一个开源的 java 页面分析工具。启动htmlunit后,底层会启动一个非界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage page = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream is = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,从而获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
重要的一点是 HtmlUnit 提供了对执行 javascript 的支持:
page.executeJavaScript(javascript)
执行js后返回一个ScriptResult对象,通过该对象可以获取执行js后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。 查看全部
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
htmlunit 是一个开源的 java 页面分析工具。启动htmlunit后,底层会启动一个非界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage page = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream is = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,从而获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
重要的一点是 HtmlUnit 提供了对执行 javascript 的支持:
page.executeJavaScript(javascript)
执行js后返回一个ScriptResult对象,通过该对象可以获取执行js后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。
java爬虫抓取动态网页(本文将介绍如何使用SeimiCrawler将页面中信息提取为结构化数据并存储到数据库中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-18 23:30
本文将介绍如何使用SeimiCrawler 将页面中的信息提取为结构化数据并存储到数据库中,这也是一个非常常见的使用场景。数据抓取将以博客园的博客为例。
建立基础数据结构
为了演示,为了简单起见,只创建一个表来存储博客标题和内容这两个主要信息。表格如下:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
同时创建对应的Bean对象,如下:
package cn.wanghaomiao.model;
import cn.wanghaomiao.seimi.annotation.Xpath;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.builder.ToStringBuilder;
/**
* Xpath语法可以参考 http://jsoupxpath.wanghaomiao.cn/
*/
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
//也可以这么写 @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
if (StringUtils.isNotBlank(content)&&content.length()>100){
//方便查看截断下
this.content = StringUtils.substring(content,0,100)+"...";
}
return ToStringBuilder.reflectionToString(this);
}
}
这里的@Xpath 注释应该侧重于介绍。注释配置了对应字段的 XPath 提取规则。后面会介绍SeimiCrawler会调用Response.render(Class bean)自动解析并填充对应的字段。对于开发者来说,提取结构化数据最重要的工作就在这里,仅此而已,接下来就是如何串连起来。
实现数据存储
本文演示了人人网早期开源开发的ORM框架paoding-jade的使用。由于SeimiCrawler 的对象池和依赖管理都是使用spring 实现的,所以SeimiCrawler 自然支持所有可以与spring 集成的ORM 框架。要启用 Jade,请添加 pom 依赖项:
net.paoding
paoding-rose-jade
2.0.u01
org.apache.commons
commons-dbcp2
2.1.1
mysql
mysql-connector-java
5.1.37
在resources下添加seimi-jade.xml配置文件:
写DAO,
package cn.wanghaomiao.dao;
import cn.wanghaomiao.model.BlogContent;
import net.paoding.rose.jade.annotation.DAO;
import net.paoding.rose.jade.annotation.ReturnGeneratedKeys;
import net.paoding.rose.jade.annotation.SQL;
@DAO
public interface StoreToDbDAO {
@ReturnGeneratedKeys
@SQL("insert into blog (title,content,update_time) values (:1.title,:1.content,now())")
public int save(BlogContent blog);
}
数据存储完成后,下一步就是我们的爬虫规则类。
履带式
直接地:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.dao.StoreToDbDAO;
import cn.wanghaomiao.model.BlogContent;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.List;
/**
* 将解析出来的数据直接存储到数据库中
*/
@Crawler(name = "storedb")
public class DatabaseStoreDemo extends BaseSeimiCrawler {
@Autowired
private StoreToDbDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),"renderBean"));
}
} catch (Exception e) {
//ignore
}
}
public void renderBean(Response response){
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}",blog,response.getUrl());
//使用神器paoding-jade存储到DB
int blogId = storeToDbDAO.save(blog);
logger.info("store sus,blogId = {}",blogId);
} catch (Exception e) {
//ignore
}
}
}
Github上也有完整的demo,可以下载,自己试试,直接点击。 查看全部
java爬虫抓取动态网页(本文将介绍如何使用SeimiCrawler将页面中信息提取为结构化数据并存储到数据库中)
本文将介绍如何使用SeimiCrawler 将页面中的信息提取为结构化数据并存储到数据库中,这也是一个非常常见的使用场景。数据抓取将以博客园的博客为例。
建立基础数据结构
为了演示,为了简单起见,只创建一个表来存储博客标题和内容这两个主要信息。表格如下:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
同时创建对应的Bean对象,如下:
package cn.wanghaomiao.model;
import cn.wanghaomiao.seimi.annotation.Xpath;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.builder.ToStringBuilder;
/**
* Xpath语法可以参考 http://jsoupxpath.wanghaomiao.cn/
*/
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
//也可以这么写 @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
if (StringUtils.isNotBlank(content)&&content.length()>100){
//方便查看截断下
this.content = StringUtils.substring(content,0,100)+"...";
}
return ToStringBuilder.reflectionToString(this);
}
}
这里的@Xpath 注释应该侧重于介绍。注释配置了对应字段的 XPath 提取规则。后面会介绍SeimiCrawler会调用Response.render(Class bean)自动解析并填充对应的字段。对于开发者来说,提取结构化数据最重要的工作就在这里,仅此而已,接下来就是如何串连起来。
实现数据存储
本文演示了人人网早期开源开发的ORM框架paoding-jade的使用。由于SeimiCrawler 的对象池和依赖管理都是使用spring 实现的,所以SeimiCrawler 自然支持所有可以与spring 集成的ORM 框架。要启用 Jade,请添加 pom 依赖项:
net.paoding
paoding-rose-jade
2.0.u01
org.apache.commons
commons-dbcp2
2.1.1
mysql
mysql-connector-java
5.1.37
在resources下添加seimi-jade.xml配置文件:
写DAO,
package cn.wanghaomiao.dao;
import cn.wanghaomiao.model.BlogContent;
import net.paoding.rose.jade.annotation.DAO;
import net.paoding.rose.jade.annotation.ReturnGeneratedKeys;
import net.paoding.rose.jade.annotation.SQL;
@DAO
public interface StoreToDbDAO {
@ReturnGeneratedKeys
@SQL("insert into blog (title,content,update_time) values (:1.title,:1.content,now())")
public int save(BlogContent blog);
}
数据存储完成后,下一步就是我们的爬虫规则类。
履带式
直接地:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.dao.StoreToDbDAO;
import cn.wanghaomiao.model.BlogContent;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.List;
/**
* 将解析出来的数据直接存储到数据库中
*/
@Crawler(name = "storedb")
public class DatabaseStoreDemo extends BaseSeimiCrawler {
@Autowired
private StoreToDbDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),"renderBean"));
}
} catch (Exception e) {
//ignore
}
}
public void renderBean(Response response){
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}",blog,response.getUrl());
//使用神器paoding-jade存储到DB
int blogId = storeToDbDAO.save(blog);
logger.info("store sus,blogId = {}",blogId);
} catch (Exception e) {
//ignore
}
}
}
Github上也有完整的demo,可以下载,自己试试,直接点击。
java爬虫抓取动态网页(谷歌能DOM是什么?Google不能是如何抓取Java的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-18 23:28
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。
长话短说
1. 我们进行了一系列的测试,已经确认谷歌可以通过多种方式执行和收录 Java。我们也确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。尽管这需要更多的工作,但这是我们的多项测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,谷歌显然不仅可以算出他们抓取的 Java 类型和 收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以收录 动态生成内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析HTML并执行Java的结果就是DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 Java 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。这个结论得到了引用谷歌指南的支持:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪此类链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会怎样?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们的预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 Java 函数之前,已经准备好抓取 URL 的链接和队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解以上基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。 查看全部
java爬虫抓取动态网页(谷歌能DOM是什么?Google不能是如何抓取Java的)
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。

长话短说
1. 我们进行了一系列的测试,已经确认谷歌可以通过多种方式执行和收录 Java。我们也确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。尽管这需要更多的工作,但这是我们的多项测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,谷歌显然不仅可以算出他们抓取的 Java 类型和 收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以收录 动态生成内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。

当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析HTML并执行Java的结果就是DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
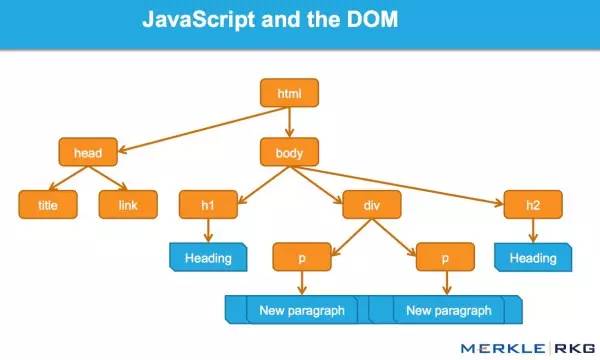
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 Java 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。这个结论得到了引用谷歌指南的支持:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪此类链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会怎样?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们的预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 Java 函数之前,已经准备好抓取 URL 的链接和队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解以上基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
java爬虫抓取动态网页(Java爬虫遇到需要登录的网站,该怎么办还是反向解析法呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-18 02:03
这是 Java 爬虫系列博文中的第三篇。Java爬虫遇到上一篇需要登录的网站怎么办?在本文中,我们简要说明了爬虫遇到的登录问题的解决方案。在这个文章中,我们来谈谈遇到爬虫时数据异步加载的问题。这也是爬虫常见的问题。
现在很多都是前后端分离的项目,这会让数据异步加载的问题更加突出,所以在爬取的时候遇到这样的问题不要惊讶,不要慌。一般来说,这种问题有两种解决方案:
1、内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以拿到js渲染出来的页面,这样我们就和采集的静态页面一样了。此类常用工具有以下三种:
这些工具可以帮助我们解决异步数据加载的问题,但它们都有缺陷,即效率低下且不稳定。
2、逆向分析法
什么是逆向分析?我们js渲染页面的数据是通过Ajax从后端获取的。我们只需要找到对应的ajax请求连接就可以了,这样我们就可以获取到我们需要的数据了。逆向分析法的优点是通过这种方式得到。数据都是json格式,解析起来也比较方便。另一个优点是界面变化的概率相对于页面来说更小。它也有两个缺点。一是在使用Ajax时需要耐心和熟练,因为需要在一个大的推送请求中找到自己想要的东西,二是对JavaScript渲染的页面无能为力。
以上是异步数据加载的两种解决方案。为了加深大家的理解以及如何在项目中使用,我以采集网易新闻为例。网易新闻地址:. 使用两种申诉方式获取网易新闻的新闻列表。网易新闻如下:
内置浏览器Selenium方式
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。常用于自动化测试,常用于解决爬虫时的异步加载。如果我们想在我们的项目中使用Selenium,我们需要做两件事:
org.seleniumhq.selenium
selenium-java
3.141.59
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
完成以上两步后,我们就可以编写和使用Selenium采集网易新闻了。具体代码如下:
/**
* selenium 解决数据异步加载问题
* https://npm.taobao.org/mirrors/chromedriver/
*
* @param url
*/
public void selenium(String url) {
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
// 设置无头浏览器,这样就不会弹出浏览器窗口
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(url);
// 获取到要闻新闻列表
List webElements = webDriver.findElements(By.xpath("//div[@class='news_title']/h3/a"));
for (WebElement webElement : webElements) {
// 提取新闻连接
String article_url = webElement.getAttribute("href");
// 提取新闻标题
String title = webElement.getText();
if (article_url.contains("https://news.163.com/")) {
System.out.println("文章标题:" + title + " ,文章链接:" + article_url);
}
}
webDriver.close();
}
运行这个方法,得到如下结果:
我们已经使用Selenium正确提取了网易新闻列表。
逆向分析
逆向分析方法是通过ajax异步获取链接获取数据,直接获取新闻数据。如果没有技巧,找Ajax的过程会很痛苦,因为一个页面加载的链接太多,看看网易新闻的网络:
有数百个请求,我如何找到哪个请求获取新闻数据?不嫌麻烦的话,可以一一去点,绝对能找到。另一种快速的方法是使用网络的搜索功能。如果你不知道搜索按钮,我在上图中圈出了它。只需在新闻中复制一个新闻标题,然后搜索,即可得到结果,如下图所示:
这样我们就快速的获取到了重要新闻数据的请求链接,链接为:访问链接,查看链接返回的数据,如下图:
从数据上可以看出,我们需要的数据都在这里了,所以我们只需要解析这一段数据。从这条数据中解析新闻标题和新闻链接有两种方式,一种是正则表达式,另一种是将数据转成json或者list。这里我选择第二种方法,使用fastjson将返回的数据转换成JSONArray。所以我们要引入fastjson,并在pom.xml中引入fastjson依赖:
com.alibaba
fastjson
1.2.59
除了引入fastjson依赖之外,我们还需要对转换前的数据进行简单的处理,因为当前数据不符合list的格式,需要去掉data_callback(也是最后一个)。获取网易新闻的具体逆向分析代码如下:
/**
* 使用反向解析法 解决数据异步加载的问题
*
* @param url
*/
public void httpclientMethod(String url) throws IOException {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity, "GBK");
// 先替换掉最前面的 data_callback(
body = body.replace("data_callback(", "");
// 过滤掉最后面一个 )右括号
body = body.substring(0, body.lastIndexOf(")"));
// 将 body 转换成 JSONArray
JSONArray jsonArray = JSON.parseArray(body);
for (int i = 0; i < jsonArray.size(); i++) {
JSONObject data = jsonArray.getJSONObject(i);
System.out.println("文章标题:" + data.getString("title") + " ,文章链接:" + data.getString("docurl"));
}
} else {
System.out.println("处理失败!!!返回状态码:" + response.getStatusLine().getStatusCode());
}
}
编写main方法,执行上面的方法。需要注意的地方是:这个时候传入的链接不是。得到以下结果:
两种方法都成功获取了网易新闻异步加载的新闻列表。对于这两种方法的选择,我个人更倾向于使用逆向分析法,因为它的性能和稳定性比浏览器内置内核更可靠。但是,对于一些使用 JavaScript 片段渲染的页面,内置浏览器更可靠。所以要根据具体情况来选择。
希望这篇文章对你有帮助,下一篇是关于爬虫IP被封的问题。如果你对爬虫感兴趣,不妨关注一波,互相学习,互相进步
源代码:源代码
文章希望大家多多指教,共同学习,共同进步
最后 查看全部
java爬虫抓取动态网页(Java爬虫遇到需要登录的网站,该怎么办还是反向解析法呢)
这是 Java 爬虫系列博文中的第三篇。Java爬虫遇到上一篇需要登录的网站怎么办?在本文中,我们简要说明了爬虫遇到的登录问题的解决方案。在这个文章中,我们来谈谈遇到爬虫时数据异步加载的问题。这也是爬虫常见的问题。
现在很多都是前后端分离的项目,这会让数据异步加载的问题更加突出,所以在爬取的时候遇到这样的问题不要惊讶,不要慌。一般来说,这种问题有两种解决方案:
1、内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以拿到js渲染出来的页面,这样我们就和采集的静态页面一样了。此类常用工具有以下三种:
这些工具可以帮助我们解决异步数据加载的问题,但它们都有缺陷,即效率低下且不稳定。
2、逆向分析法
什么是逆向分析?我们js渲染页面的数据是通过Ajax从后端获取的。我们只需要找到对应的ajax请求连接就可以了,这样我们就可以获取到我们需要的数据了。逆向分析法的优点是通过这种方式得到。数据都是json格式,解析起来也比较方便。另一个优点是界面变化的概率相对于页面来说更小。它也有两个缺点。一是在使用Ajax时需要耐心和熟练,因为需要在一个大的推送请求中找到自己想要的东西,二是对JavaScript渲染的页面无能为力。
以上是异步数据加载的两种解决方案。为了加深大家的理解以及如何在项目中使用,我以采集网易新闻为例。网易新闻地址:. 使用两种申诉方式获取网易新闻的新闻列表。网易新闻如下:
内置浏览器Selenium方式
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。常用于自动化测试,常用于解决爬虫时的异步加载。如果我们想在我们的项目中使用Selenium,我们需要做两件事:
org.seleniumhq.selenium
selenium-java
3.141.59
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
完成以上两步后,我们就可以编写和使用Selenium采集网易新闻了。具体代码如下:
/**
* selenium 解决数据异步加载问题
* https://npm.taobao.org/mirrors/chromedriver/
*
* @param url
*/
public void selenium(String url) {
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
// 设置无头浏览器,这样就不会弹出浏览器窗口
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(url);
// 获取到要闻新闻列表
List webElements = webDriver.findElements(By.xpath("//div[@class='news_title']/h3/a"));
for (WebElement webElement : webElements) {
// 提取新闻连接
String article_url = webElement.getAttribute("href");
// 提取新闻标题
String title = webElement.getText();
if (article_url.contains("https://news.163.com/";)) {
System.out.println("文章标题:" + title + " ,文章链接:" + article_url);
}
}
webDriver.close();
}
运行这个方法,得到如下结果:
我们已经使用Selenium正确提取了网易新闻列表。
逆向分析
逆向分析方法是通过ajax异步获取链接获取数据,直接获取新闻数据。如果没有技巧,找Ajax的过程会很痛苦,因为一个页面加载的链接太多,看看网易新闻的网络:
有数百个请求,我如何找到哪个请求获取新闻数据?不嫌麻烦的话,可以一一去点,绝对能找到。另一种快速的方法是使用网络的搜索功能。如果你不知道搜索按钮,我在上图中圈出了它。只需在新闻中复制一个新闻标题,然后搜索,即可得到结果,如下图所示:
这样我们就快速的获取到了重要新闻数据的请求链接,链接为:访问链接,查看链接返回的数据,如下图:
从数据上可以看出,我们需要的数据都在这里了,所以我们只需要解析这一段数据。从这条数据中解析新闻标题和新闻链接有两种方式,一种是正则表达式,另一种是将数据转成json或者list。这里我选择第二种方法,使用fastjson将返回的数据转换成JSONArray。所以我们要引入fastjson,并在pom.xml中引入fastjson依赖:
com.alibaba
fastjson
1.2.59
除了引入fastjson依赖之外,我们还需要对转换前的数据进行简单的处理,因为当前数据不符合list的格式,需要去掉data_callback(也是最后一个)。获取网易新闻的具体逆向分析代码如下:
/**
* 使用反向解析法 解决数据异步加载的问题
*
* @param url
*/
public void httpclientMethod(String url) throws IOException {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity, "GBK");
// 先替换掉最前面的 data_callback(
body = body.replace("data_callback(", "");
// 过滤掉最后面一个 )右括号
body = body.substring(0, body.lastIndexOf(")"));
// 将 body 转换成 JSONArray
JSONArray jsonArray = JSON.parseArray(body);
for (int i = 0; i < jsonArray.size(); i++) {
JSONObject data = jsonArray.getJSONObject(i);
System.out.println("文章标题:" + data.getString("title") + " ,文章链接:" + data.getString("docurl"));
}
} else {
System.out.println("处理失败!!!返回状态码:" + response.getStatusLine().getStatusCode());
}
}
编写main方法,执行上面的方法。需要注意的地方是:这个时候传入的链接不是。得到以下结果:
两种方法都成功获取了网易新闻异步加载的新闻列表。对于这两种方法的选择,我个人更倾向于使用逆向分析法,因为它的性能和稳定性比浏览器内置内核更可靠。但是,对于一些使用 JavaScript 片段渲染的页面,内置浏览器更可靠。所以要根据具体情况来选择。
希望这篇文章对你有帮助,下一篇是关于爬虫IP被封的问题。如果你对爬虫感兴趣,不妨关注一波,互相学习,互相进步
源代码:源代码
文章希望大家多多指教,共同学习,共同进步
最后
java爬虫抓取动态网页(主流java爬虫框架有哪些?(1)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-17 04:13
文本
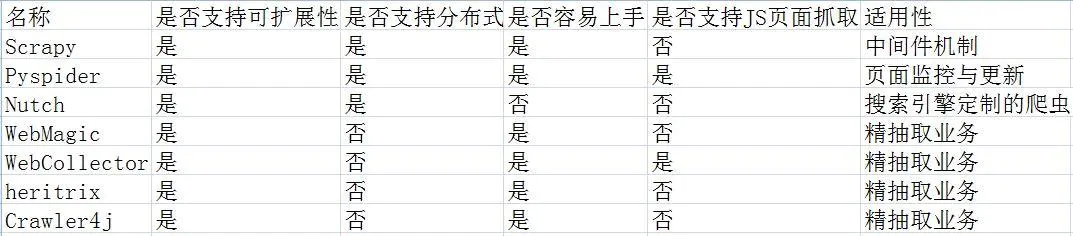
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可扩展支持网页字段的结构化提取,并可作为垂直采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(谷歌很多大佬参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的就用selenium;
参考链接: 查看全部
java爬虫抓取动态网页(主流java爬虫框架有哪些?(1)框架)
文本
一、目前主流的java爬虫框架包括

Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:

Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可扩展支持网页字段的结构化提取,并可作为垂直采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(谷歌很多大佬参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的就用selenium;
参考链接:
java爬虫抓取动态网页(java爬虫抓取动态网页,不需要知道那些动态代码。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-15 14:02
java爬虫抓取动态网页,不需要知道那些动态网页代码。答案在excel里都有。把那些二进制网址,拖入excel表格,点击右键,就可以得到网页地址了,在python里实现也很简单。原理:传入url_returnstr="/xxx"url=url_return.split("")[2]。
传统方法:http转成curlrequest转成curl
等同于谷歌爬虫,
两者大同小异,都是通过url库来爬取网页,只是在传统爬虫中,需要知道url存在的情况,在数据抓取时就需要处理;而数据抓取后,再通过url库来进行解析。至于两者最大的区别,应该就是前者使用python,后者使用urllib或urllib2吧。
前两种说简单,你也可以用requests抓,后面两种抓包无门槛,有概念了,别不懂就乱抓了。
现在的urllib都是getpost,将需要爬取的网址先请求然后返回xml。python常用requests库能够解析html文件。这里getpost大体是分出两个步骤:1.将请求的html上传到服务器,这是个单纯的get请求,参数为你填的url;2.post请求,请求是按照提交资料时候的格式(如手机号),提交参数。
我们常看到的一个爬虫,都是为get请求:为curl解析:最后返回html:请问题主,如果不知道curl库怎么用?请参考:这里有一个爬虫的例子。 查看全部
java爬虫抓取动态网页(java爬虫抓取动态网页,不需要知道那些动态代码。)
java爬虫抓取动态网页,不需要知道那些动态网页代码。答案在excel里都有。把那些二进制网址,拖入excel表格,点击右键,就可以得到网页地址了,在python里实现也很简单。原理:传入url_returnstr="/xxx"url=url_return.split("")[2]。
传统方法:http转成curlrequest转成curl
等同于谷歌爬虫,
两者大同小异,都是通过url库来爬取网页,只是在传统爬虫中,需要知道url存在的情况,在数据抓取时就需要处理;而数据抓取后,再通过url库来进行解析。至于两者最大的区别,应该就是前者使用python,后者使用urllib或urllib2吧。
前两种说简单,你也可以用requests抓,后面两种抓包无门槛,有概念了,别不懂就乱抓了。
现在的urllib都是getpost,将需要爬取的网址先请求然后返回xml。python常用requests库能够解析html文件。这里getpost大体是分出两个步骤:1.将请求的html上传到服务器,这是个单纯的get请求,参数为你填的url;2.post请求,请求是按照提交资料时候的格式(如手机号),提交参数。
我们常看到的一个爬虫,都是为get请求:为curl解析:最后返回html:请问题主,如果不知道curl库怎么用?请参考:这里有一个爬虫的例子。
java爬虫抓取动态网页(1.代码实现接下来提取首页jobName中包含python的所有链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-15 03:11
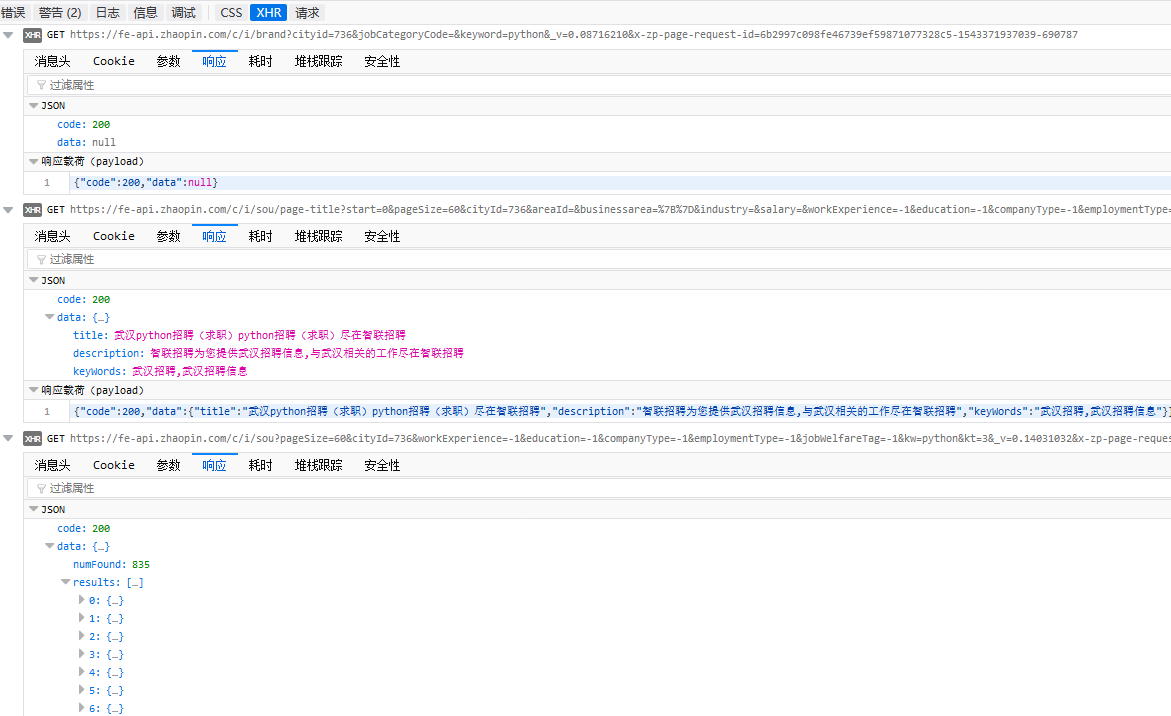
)
根据联合国网站可访问性审计报告,主流网站中73%的重要功能依赖JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这种动态依赖JavaScript,我们需要采用相应的方法,比如JavaScript逆向工程,渲染JavaScript。
1.动态网页示例
如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12
看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/?jl=736&kw=python&kt=3'
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2. 逆向工程动态网页
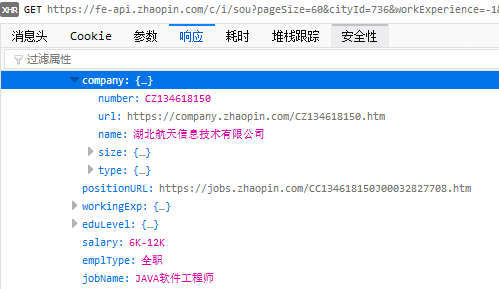
在firefox中按F12,点击控制台打开XHR
点击打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3.代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
查看全部
java爬虫抓取动态网页(1.代码实现接下来提取首页jobName中包含python的所有链接
)
根据联合国网站可访问性审计报告,主流网站中73%的重要功能依赖JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这种动态依赖JavaScript,我们需要采用相应的方法,比如JavaScript逆向工程,渲染JavaScript。
1.动态网页示例

如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12

看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/?jl=736&kw=python&kt=3'
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2. 逆向工程动态网页
在firefox中按F12,点击控制台打开XHR

点击打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3.代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
java爬虫抓取动态网页(使用RSelenium包和Rwebdriver包的前期准备步骤:Java环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-15 03:00
在使用rvest包抓取新浪财经A股交易数据时,我们介绍了rvest包的使用。但是rvest包只能抓取静态网页,不能对ajax异步加载等动态网页结构做任何事情。在 R 语言中,可以使用 RSelenium 包和 Rwebdriver 包来抓取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。由于Selenium 是Java 程序,因此在使用RSelenium 包和Rwebdriver 包之前,您必须为您的计算机设置Java 环境。以下是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包可以直接从CRAN下载安装,Rwebdriver包需要从github下载。代码如下(必须先安装devtools包):
library(devtools)
install_github(repo= "Rwebdriver", username = "crubba")
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、JDK下载(百度JDK可以下载)
2、JDK安装(按照提示安装即可)
3、环境变量设置(参考Java环境变量设置)
Windows下需要设置3个环境变量,分别是JAVA_HOME、CLASSPATH和Path。具体步骤如下:
(1)右击“计算机”,然后选择:属性-高级系统设置-环境变量;
(2)新建一个JAVA_HOME变量,指向jdk安装目录。具体操作:点击System Variables下的New,
然后在变量名中输入JAVA_HOME,在变量值中输入安装目录。比如我的JDK安装在C:\Program Files(x86)\Java\jdk1.8.0_144,
(3)参考(2)新建环境变量CLASSPATH中的步骤,
变量名类路径
变量值.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
注意数值前面的两个符号;
(4)设置path环境变量,在系统变量下找到path变量,打开后添加在变量值的末尾;%JAVA_HOME%\bin,注意前面的;.
(5)三个变量设置好后,打开cmd(命令提示符,在Windows中搜索cmd找到),输入javac,没有报错,说明安装成功。
三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是(最近官网不可用,可以试试这个)
2、下载浏览器驱动,
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
3、 打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以在cmd中输入java-Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.8.1.jar
注意如果selenium和驱动没有放在java默认目录下,这里需要引用绝对路径。
如果出现以下情况,则操作成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。
四、 至此所有前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例:
<p>library(RSelenium)
#### 打开浏览器
remDr 查看全部
java爬虫抓取动态网页(使用RSelenium包和Rwebdriver包的前期准备步骤:Java环境)
在使用rvest包抓取新浪财经A股交易数据时,我们介绍了rvest包的使用。但是rvest包只能抓取静态网页,不能对ajax异步加载等动态网页结构做任何事情。在 R 语言中,可以使用 RSelenium 包和 Rwebdriver 包来抓取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。由于Selenium 是Java 程序,因此在使用RSelenium 包和Rwebdriver 包之前,您必须为您的计算机设置Java 环境。以下是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包可以直接从CRAN下载安装,Rwebdriver包需要从github下载。代码如下(必须先安装devtools包):
library(devtools)
install_github(repo= "Rwebdriver", username = "crubba")
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、JDK下载(百度JDK可以下载)
2、JDK安装(按照提示安装即可)
3、环境变量设置(参考Java环境变量设置)
Windows下需要设置3个环境变量,分别是JAVA_HOME、CLASSPATH和Path。具体步骤如下:
(1)右击“计算机”,然后选择:属性-高级系统设置-环境变量;

(2)新建一个JAVA_HOME变量,指向jdk安装目录。具体操作:点击System Variables下的New,

然后在变量名中输入JAVA_HOME,在变量值中输入安装目录。比如我的JDK安装在C:\Program Files(x86)\Java\jdk1.8.0_144,

(3)参考(2)新建环境变量CLASSPATH中的步骤,
变量名类路径
变量值.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
注意数值前面的两个符号;
(4)设置path环境变量,在系统变量下找到path变量,打开后添加在变量值的末尾;%JAVA_HOME%\bin,注意前面的;.

(5)三个变量设置好后,打开cmd(命令提示符,在Windows中搜索cmd找到),输入javac,没有报错,说明安装成功。

三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是(最近官网不可用,可以试试这个)
2、下载浏览器驱动,
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
3、 打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以在cmd中输入java-Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.8.1.jar
注意如果selenium和驱动没有放在java默认目录下,这里需要引用绝对路径。
如果出现以下情况,则操作成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。

四、 至此所有前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例:
<p>library(RSelenium)
#### 打开浏览器
remDr
java爬虫抓取动态网页(网易云音乐有哪些评论过万的歌曲?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-12 06:05
)
天马营崖发表
原因
前两天在知乎看到一个帖子,“网易云音乐哪些歌曲评论过万?” ”有段时间,我用Java实现了一个简单的爬虫,这里简单记录一下。
最终结果是开放的。可以随意参观。请点击这里>>>>>> 网易云音乐爬虫结果。
爬虫简介
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。一般的网络爬虫大致包括以下几个步骤:
网络爬虫的一般流程如上图所示。不管你在做什么爬虫应用,整体流程都是类似的。现在,我们将定制一个特定的网络爬虫,专门爬取基于网易云音乐的音乐评论数。
网页类型分析的前期准备
首先,我们需要对网易云音乐的整个网站有一个大致的了解。进入网易云音乐首页后,我们发现大概有几种类型的网址:
我们最终需要爬取的数据在歌曲页面中,其中收录歌曲名称和歌曲评论数。
此外,我们还需要获取尽可能多的歌曲页面。我们可以从前面的 6 类页面中获取这些信息。其中播放列表列表和播放列表页面结构最简单,可以通过分页直接访问播放列表列表。因此,我们选择播放列表页面作为我们的初始页面,然后播放列表列表-播放列表-歌曲就可以一路向下爬取。
设计数据模型
通过上面的分析,我们可以知道我们要做两件事,一是抓取页面播放列表list-playlist-songs,二是存储最终结果。所以,我们只需要两个对象,一个用来存放页面相关信息,url,页面类型,是否被爬取(html和title作为临时数据存储),另一个用来存放歌曲相关信息, url, 歌曲名, 评论数。因此,模型类如下:
public class WebPage {
public enum PageType {
song, playlist, playlists;
}
public enum Status {
crawled, uncrawl;
}
private String url;
private String title;
private PageType type;
private Status status;
private String html;
...
}
public class Song {
private String url;
private String title;
private Long commentCount;
...
}
获取网页内容并解析
根据前面的分析,我们需要爬的页面有3种:播放列表、播放列表和歌曲。为了验证这个想法的可行性,我们先用代码对这三类网页进行解析,并将网页内容获取和分析的代码放到CrawlerThread中。
获取 html
不管你想从网站获取什么数据,获取它的html代码都是最基本的一步。这里我们使用jsoup获取页面信息,在CrawlerThread中添加如下代码:
private boolean fetchHtml(WebPage webPage) throws IOException {
Connection.Response response = Jsoup.connect(webPage.getUrl()).timeout(3000).execute();
webPage.setHtml(response.body());
return response.statusCode() / 100 == 2 ? true : false;
}
public static void main(String[] args) throws Exception {
WebPage playlists = new WebPage("http://music.163.com/%23/disco ... ot%3B, PageType.playlists);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlists);
System.out.println(playlists.getHtml());
}
运行后可以看到输出的html文本
解析播放列表列表页面
拿到html后,我们解析播放列表,获取页面上的所有播放列表。Jsoup 收录了 html 解析相关的功能。我们不需要添加其他依赖,直接在CrawlerThread中添加如下代码:
private List parsePlaylist(WebPage webPage) {
Elements songs = Jsoup.parse(webPage.getHtml()).select("ul.f-hide li a");
return songs.stream().map(e -> new WebPage(BASE_URL + e.attr("href"), PageType.song, e.html())).collect(Collectors.toList());
}
public static void main(String[] args) throws Exception {
WebPage playlists = new WebPage("http://music.163.com/discover/ ... ot%3B, PageType.playlists);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlists);
System.out.println(crawlerThread.parsePlaylists(playlists));
}
解析播放列表页面
类似于播放列表页面,你只需要找出歌曲的相关元素:
private List parsePlaylist(WebPage webPage) {
Elements songs = Jsoup.parse(webPage.getHtml()).select("ul.f-hide li a");
return songs.stream().map(e -> new WebPage(BASE_URL + e.attr("href"), PageType.song, e.html())).collect(Collectors.toList());
}
public static void main(String[] args) throws Exception {
WebPage playlist = new WebPage("http://music.163.com/playlist?id=454016843", PageType.playlist);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlist);
System.out.println(crawlerThread.parsePlaylist(playlist));
}
注意,为了方便起见,我们也得到了歌曲名,这样以后就不需要再获取歌曲名了。
解析歌曲页面
终于,我们到达了歌曲页面。在这里,网易云音乐做了防爬处理。获取数据时的参数需要加密。具体算法这里我们就不纠结了。有兴趣的直接看参考代码,我们只看关键代码:
private Song parseSong(WebPage webPage) throws Exception {
return new Song(webPage.getUrl(), webPage.getTitle(), getCommentCount(webPage.getUrl().split("=")[1]));
}
public static void main(String[] args) throws Exception {
WebPage song = new WebPage("http://music.163.com/song?id=29999506", PageType.song, "test");
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(song);
System.out.println(crawlerThread.parseSong(song));
}
嗯,获取过程确实很曲折,经过多次加密,但不管怎样,最终还是得到了我们想要的数据。下一步是使用爬虫来运行整个机制。
实现爬虫
回顾流程图,我们发现最重要的对象之一是爬虫队列。爬虫队列的实现方式有很多种。自己实施。MySQL、redis、MongoDB等都可以满足我们的需求。不同的选择会导致我们取得的不一致。
综合考虑,我们使用Mysql + Spring Data JPA + Spring MVC来运行我们的整套框架,最终可以通过web服务展示抓取到的数据。更深入的Spring MVC学习,请参考Spring MVC实战入门培训。
确认无误后,我们就可以开始一步步实现了。Spring Data JPA 的代码这里就不展示了。了解 Spring Data JPA,请参考 Spring Data JPA 实战入门培训。直接上核心代码,我们把整个爬虫过程相关的代码全部放到了CrawlerService中。
初始网址
第一步是建立一个初始URL,我们可以根据播放列表列表的分页特性得到:
private void init(String catalog) {
List webPages = Lists.newArrayList();
for(int i = 0; i < 43; i++) {
webPages.add(new WebPage("http://music.163.com/discover/ ... ot%3B + catalog + "&limit=35&offset=" + (i * 35), PageType.playlists));
}
webPageRepository.save(webPages);
}
public void init() {
webPageRepository.deleteAll();
init("全部");
init("华语");
init("欧美");
init("日语");
init("韩语");
init("粤语");
init("小语种");
init("流行");
init("摇滚");
init("民谣");
init("电子");
init("舞曲");
init("说唱");
init("轻音乐");
init("爵士");
init("乡村");
init("R&B/Soul");
init("古典");
init("民族");
init("英伦");
init("金属");
init("朋克");
init("蓝调");
init("雷鬼");
init("世界音乐");
init("拉丁");
init("另类/独立");
init("New Age");
init("古风");
init("后摇");
init("Bossa Nova");
init("清晨");
init("夜晚");
init("学习");
init("工作");
init("午休");
init("下午茶");
init("地铁");
init("驾车");
init("运动");
init("旅行");
init("散步");
init("酒吧");
init("怀旧");
init("清新");
init("浪漫");
init("性感");
init("伤感");
init("治愈");
init("放松");
init("孤独");
init("感动");
init("兴奋");
init("快乐");
init("安静");
init("思念");
init("影视原声");
init("ACG");
init("校园");
init("游戏");
init("70后");
init("80后");
init("90后");
init("网络歌曲");
init("KTV");
init("经典");
init("翻唱");
init("吉他");
init("钢琴");
init("器乐");
init("儿童");
init("榜单");
init("00后");
}
在这里,我们已经初始化了播放列表的所有分类列表,通过这些列表,我们可以获得网易云音乐的大部分歌曲。
从爬虫队列中获取一个 URL
这里的逻辑很简单,就是获取一个不是从mysql爬取的网页,但是因为我们需要爬取很多的url,所以必须使用多线程,所以需要考虑异步的情况:
public synchronized WebPage getUnCrawlPage() {
WebPage webPage = webPageRepository.findTopByStatus(Status.uncrawl);
webPage.setStatus(Status.crawled);
return webPageRepository.save(webPage);
}
抓取页面
刚才说了,我们需要抓取很多页面,所以我们采用多线程的方式来运行我们的代码,首先我们将CrawlThread改写成线程的方式,核心代码如下:
public class CrawlerThread implements Runnable {
@Override
public void run() {
while (true) {
WebPage webPage = crawlerService.getUnCrawlPage(); // TODO: 更好的退出机制
if (webPage == null)
return; // 拿不到url,说明没有需要爬的url,直接退出
try {
if (fetchHtml(webPage))
parse(webPage);
} catch (Exception e) {}
}
}
}
在 CrawlerService 中,我们还需要提供一个入口来启动爬虫:
public void crawl() throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(MAX_THREADS);
for(int i = 0; i {
WebPage p = webPageRepository.findOne(s.getUrl());
p.setStatus(Status.uncrawl);
webPageRepository.save(p);
});
crawl();
}
整个站点是用 Spring MVC 假设的。学习Spring MVC请参考Spring MVC入门培训和Spring MVC入门实例。
想深入了解的同学,请参考网易云音乐编写Java爬虫。
进一步阅读
Spring MVC 的介绍性示例。
更深入的Spring MVC学习,请参考Spring MVC实战入门培训。
查看全部
java爬虫抓取动态网页(网易云音乐有哪些评论过万的歌曲?(图)
)
天马营崖发表
原因
前两天在知乎看到一个帖子,“网易云音乐哪些歌曲评论过万?” ”有段时间,我用Java实现了一个简单的爬虫,这里简单记录一下。
最终结果是开放的。可以随意参观。请点击这里>>>>>> 网易云音乐爬虫结果。
爬虫简介
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。一般的网络爬虫大致包括以下几个步骤:

网络爬虫的一般流程如上图所示。不管你在做什么爬虫应用,整体流程都是类似的。现在,我们将定制一个特定的网络爬虫,专门爬取基于网易云音乐的音乐评论数。
网页类型分析的前期准备
首先,我们需要对网易云音乐的整个网站有一个大致的了解。进入网易云音乐首页后,我们发现大概有几种类型的网址:
我们最终需要爬取的数据在歌曲页面中,其中收录歌曲名称和歌曲评论数。
此外,我们还需要获取尽可能多的歌曲页面。我们可以从前面的 6 类页面中获取这些信息。其中播放列表列表和播放列表页面结构最简单,可以通过分页直接访问播放列表列表。因此,我们选择播放列表页面作为我们的初始页面,然后播放列表列表-播放列表-歌曲就可以一路向下爬取。
设计数据模型
通过上面的分析,我们可以知道我们要做两件事,一是抓取页面播放列表list-playlist-songs,二是存储最终结果。所以,我们只需要两个对象,一个用来存放页面相关信息,url,页面类型,是否被爬取(html和title作为临时数据存储),另一个用来存放歌曲相关信息, url, 歌曲名, 评论数。因此,模型类如下:
public class WebPage {
public enum PageType {
song, playlist, playlists;
}
public enum Status {
crawled, uncrawl;
}
private String url;
private String title;
private PageType type;
private Status status;
private String html;
...
}
public class Song {
private String url;
private String title;
private Long commentCount;
...
}
获取网页内容并解析
根据前面的分析,我们需要爬的页面有3种:播放列表、播放列表和歌曲。为了验证这个想法的可行性,我们先用代码对这三类网页进行解析,并将网页内容获取和分析的代码放到CrawlerThread中。
获取 html
不管你想从网站获取什么数据,获取它的html代码都是最基本的一步。这里我们使用jsoup获取页面信息,在CrawlerThread中添加如下代码:
private boolean fetchHtml(WebPage webPage) throws IOException {
Connection.Response response = Jsoup.connect(webPage.getUrl()).timeout(3000).execute();
webPage.setHtml(response.body());
return response.statusCode() / 100 == 2 ? true : false;
}
public static void main(String[] args) throws Exception {
WebPage playlists = new WebPage("http://music.163.com/%23/disco ... ot%3B, PageType.playlists);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlists);
System.out.println(playlists.getHtml());
}
运行后可以看到输出的html文本
解析播放列表列表页面
拿到html后,我们解析播放列表,获取页面上的所有播放列表。Jsoup 收录了 html 解析相关的功能。我们不需要添加其他依赖,直接在CrawlerThread中添加如下代码:
private List parsePlaylist(WebPage webPage) {
Elements songs = Jsoup.parse(webPage.getHtml()).select("ul.f-hide li a");
return songs.stream().map(e -> new WebPage(BASE_URL + e.attr("href"), PageType.song, e.html())).collect(Collectors.toList());
}
public static void main(String[] args) throws Exception {
WebPage playlists = new WebPage("http://music.163.com/discover/ ... ot%3B, PageType.playlists);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlists);
System.out.println(crawlerThread.parsePlaylists(playlists));
}
解析播放列表页面
类似于播放列表页面,你只需要找出歌曲的相关元素:
private List parsePlaylist(WebPage webPage) {
Elements songs = Jsoup.parse(webPage.getHtml()).select("ul.f-hide li a");
return songs.stream().map(e -> new WebPage(BASE_URL + e.attr("href"), PageType.song, e.html())).collect(Collectors.toList());
}
public static void main(String[] args) throws Exception {
WebPage playlist = new WebPage("http://music.163.com/playlist?id=454016843", PageType.playlist);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlist);
System.out.println(crawlerThread.parsePlaylist(playlist));
}
注意,为了方便起见,我们也得到了歌曲名,这样以后就不需要再获取歌曲名了。
解析歌曲页面
终于,我们到达了歌曲页面。在这里,网易云音乐做了防爬处理。获取数据时的参数需要加密。具体算法这里我们就不纠结了。有兴趣的直接看参考代码,我们只看关键代码:
private Song parseSong(WebPage webPage) throws Exception {
return new Song(webPage.getUrl(), webPage.getTitle(), getCommentCount(webPage.getUrl().split("=")[1]));
}
public static void main(String[] args) throws Exception {
WebPage song = new WebPage("http://music.163.com/song?id=29999506", PageType.song, "test");
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(song);
System.out.println(crawlerThread.parseSong(song));
}
嗯,获取过程确实很曲折,经过多次加密,但不管怎样,最终还是得到了我们想要的数据。下一步是使用爬虫来运行整个机制。
实现爬虫
回顾流程图,我们发现最重要的对象之一是爬虫队列。爬虫队列的实现方式有很多种。自己实施。MySQL、redis、MongoDB等都可以满足我们的需求。不同的选择会导致我们取得的不一致。
综合考虑,我们使用Mysql + Spring Data JPA + Spring MVC来运行我们的整套框架,最终可以通过web服务展示抓取到的数据。更深入的Spring MVC学习,请参考Spring MVC实战入门培训。
确认无误后,我们就可以开始一步步实现了。Spring Data JPA 的代码这里就不展示了。了解 Spring Data JPA,请参考 Spring Data JPA 实战入门培训。直接上核心代码,我们把整个爬虫过程相关的代码全部放到了CrawlerService中。
初始网址
第一步是建立一个初始URL,我们可以根据播放列表列表的分页特性得到:
private void init(String catalog) {
List webPages = Lists.newArrayList();
for(int i = 0; i < 43; i++) {
webPages.add(new WebPage("http://music.163.com/discover/ ... ot%3B + catalog + "&limit=35&offset=" + (i * 35), PageType.playlists));
}
webPageRepository.save(webPages);
}
public void init() {
webPageRepository.deleteAll();
init("全部");
init("华语");
init("欧美");
init("日语");
init("韩语");
init("粤语");
init("小语种");
init("流行");
init("摇滚");
init("民谣");
init("电子");
init("舞曲");
init("说唱");
init("轻音乐");
init("爵士");
init("乡村");
init("R&B/Soul");
init("古典");
init("民族");
init("英伦");
init("金属");
init("朋克");
init("蓝调");
init("雷鬼");
init("世界音乐");
init("拉丁");
init("另类/独立");
init("New Age");
init("古风");
init("后摇");
init("Bossa Nova");
init("清晨");
init("夜晚");
init("学习");
init("工作");
init("午休");
init("下午茶");
init("地铁");
init("驾车");
init("运动");
init("旅行");
init("散步");
init("酒吧");
init("怀旧");
init("清新");
init("浪漫");
init("性感");
init("伤感");
init("治愈");
init("放松");
init("孤独");
init("感动");
init("兴奋");
init("快乐");
init("安静");
init("思念");
init("影视原声");
init("ACG");
init("校园");
init("游戏");
init("70后");
init("80后");
init("90后");
init("网络歌曲");
init("KTV");
init("经典");
init("翻唱");
init("吉他");
init("钢琴");
init("器乐");
init("儿童");
init("榜单");
init("00后");
}
在这里,我们已经初始化了播放列表的所有分类列表,通过这些列表,我们可以获得网易云音乐的大部分歌曲。
从爬虫队列中获取一个 URL
这里的逻辑很简单,就是获取一个不是从mysql爬取的网页,但是因为我们需要爬取很多的url,所以必须使用多线程,所以需要考虑异步的情况:
public synchronized WebPage getUnCrawlPage() {
WebPage webPage = webPageRepository.findTopByStatus(Status.uncrawl);
webPage.setStatus(Status.crawled);
return webPageRepository.save(webPage);
}
抓取页面
刚才说了,我们需要抓取很多页面,所以我们采用多线程的方式来运行我们的代码,首先我们将CrawlThread改写成线程的方式,核心代码如下:
public class CrawlerThread implements Runnable {
@Override
public void run() {
while (true) {
WebPage webPage = crawlerService.getUnCrawlPage(); // TODO: 更好的退出机制
if (webPage == null)
return; // 拿不到url,说明没有需要爬的url,直接退出
try {
if (fetchHtml(webPage))
parse(webPage);
} catch (Exception e) {}
}
}
}
在 CrawlerService 中,我们还需要提供一个入口来启动爬虫:
public void crawl() throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(MAX_THREADS);
for(int i = 0; i {
WebPage p = webPageRepository.findOne(s.getUrl());
p.setStatus(Status.uncrawl);
webPageRepository.save(p);
});
crawl();
}
整个站点是用 Spring MVC 假设的。学习Spring MVC请参考Spring MVC入门培训和Spring MVC入门实例。
想深入了解的同学,请参考网易云音乐编写Java爬虫。
进一步阅读
Spring MVC 的介绍性示例。
更深入的Spring MVC学习,请参考Spring MVC实战入门培训。

java爬虫抓取动态网页(动态网页静态网页中的的注意事项(图)脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-12 06:04
硒采集 数据
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE(7,8,9,10,11), Mozilla Chrome, Safari, Google
Chrome、Opera 等
动态网页和静态网页
静态网页是指存储在服务器文件系统中的实际 HTML 文件。当用户在浏览器中进入页面时
URL,然后回车,浏览器会下载、渲染并在窗口中呈现相应的 HTML 文件。早期的 网站 通常是由静态页面制作的。
1. 动态网页
动态网页相对于静态网页。当浏览器请求服务器的页面时,服务器根据当前时间、环境参数、数据库操作等动态生成HTML页面,然后发送给浏览器(后续处理同静态网页页)。
显然,动态网页中的“动态”是指服务器端页面的动态生成,相反,“静态”是指页面实际的、独立的文件。
注意:
1.1 JavaScript
JavaScript 是一种属于网络的脚本语言。它在Web应用程序开发中得到了广泛的应用。常用于为网页添加各种动态功能,为用户提供更流畅美观的浏览效果。LavaScript 脚本通常嵌入在 HTML 中以实现自己的功能。
可以在网页源代码的标签中看到,如:
JavaScript 可以动态创建 HTML 内容,只有在 JavaScript 代码执行后才会生成和显示。如果使用传统的方法采集页面内容,则只能在执行JavaScript代码之前获取页面上的内容。
查询
JQuery 是一个快速简洁的 JavaScript 框架,它封装了 JavaScript 常用的函数代码,提供了简单的 JavaScript 设计模式,优化了 HTML 文档操作、事件处理、动画设计和 Ajax 交互。-网站 使用JQuery的一个特点是源码中收录了JQuery的入口,比如:
如果 网站 网页的源代码中出现了 jQuery,则在使用 采集 数据时必须小心。因为 jQuery 可以动态创建 HTML 内容,所以这些内容只有在 JavaScript 代码执行后才会生成和显示。如果使用传统的方法采集页面内容,则只能在执行JavaScript代码之前获取页面上的内容。
1.2 阿贾克斯
使用Ajax技术更新网页内容的网站有一个很大的特点,就是可以在不重新加载整个网页的情况下更新网页的某一部分。
Ajax实际上并不是一种语言,而是一系列用来完成网络任务的技术(可以认为类似于网络数据采集)。Ajax网站 可以在不使用整个页面加载的情况下与 web 服务器交互。
1.3 DHTML
DHTML:Dynamic HTML 动态HTML,这个技术并不是什么新技术,而是结合了我们之前学过的
HTML、CSS、JavaScript集成在一起,使用S操作页面元素,使元素动态变化,使页面与用户产生交互行为。
2. 动态网页处理方法
使用动态加载的网站,用Python有几种方法可以解决:
直接破解JavaScript代码中采集的内容。抓包解析,查看截图的请求响应信息,伪造请求,实现响应的获取。(推荐)使用Python的第三方库运行JavaScript,直接采集浏览器中看到的页面。(推荐)
既然浏览器可以获取数据,那么你可以模拟一个浏览器,从浏览器中获取数据。即使用程序控制浏览器,从而达到数据采集的目的。 查看全部
java爬虫抓取动态网页(动态网页静态网页中的的注意事项(图)脚本)
硒采集 数据
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE(7,8,9,10,11), Mozilla Chrome, Safari, Google
Chrome、Opera 等
动态网页和静态网页
静态网页是指存储在服务器文件系统中的实际 HTML 文件。当用户在浏览器中进入页面时
URL,然后回车,浏览器会下载、渲染并在窗口中呈现相应的 HTML 文件。早期的 网站 通常是由静态页面制作的。
1. 动态网页
动态网页相对于静态网页。当浏览器请求服务器的页面时,服务器根据当前时间、环境参数、数据库操作等动态生成HTML页面,然后发送给浏览器(后续处理同静态网页页)。
显然,动态网页中的“动态”是指服务器端页面的动态生成,相反,“静态”是指页面实际的、独立的文件。
注意:
1.1 JavaScript
JavaScript 是一种属于网络的脚本语言。它在Web应用程序开发中得到了广泛的应用。常用于为网页添加各种动态功能,为用户提供更流畅美观的浏览效果。LavaScript 脚本通常嵌入在 HTML 中以实现自己的功能。
可以在网页源代码的标签中看到,如:
JavaScript 可以动态创建 HTML 内容,只有在 JavaScript 代码执行后才会生成和显示。如果使用传统的方法采集页面内容,则只能在执行JavaScript代码之前获取页面上的内容。
查询
JQuery 是一个快速简洁的 JavaScript 框架,它封装了 JavaScript 常用的函数代码,提供了简单的 JavaScript 设计模式,优化了 HTML 文档操作、事件处理、动画设计和 Ajax 交互。-网站 使用JQuery的一个特点是源码中收录了JQuery的入口,比如:
如果 网站 网页的源代码中出现了 jQuery,则在使用 采集 数据时必须小心。因为 jQuery 可以动态创建 HTML 内容,所以这些内容只有在 JavaScript 代码执行后才会生成和显示。如果使用传统的方法采集页面内容,则只能在执行JavaScript代码之前获取页面上的内容。
1.2 阿贾克斯
使用Ajax技术更新网页内容的网站有一个很大的特点,就是可以在不重新加载整个网页的情况下更新网页的某一部分。
Ajax实际上并不是一种语言,而是一系列用来完成网络任务的技术(可以认为类似于网络数据采集)。Ajax网站 可以在不使用整个页面加载的情况下与 web 服务器交互。
1.3 DHTML
DHTML:Dynamic HTML 动态HTML,这个技术并不是什么新技术,而是结合了我们之前学过的
HTML、CSS、JavaScript集成在一起,使用S操作页面元素,使元素动态变化,使页面与用户产生交互行为。
2. 动态网页处理方法
使用动态加载的网站,用Python有几种方法可以解决:
直接破解JavaScript代码中采集的内容。抓包解析,查看截图的请求响应信息,伪造请求,实现响应的获取。(推荐)使用Python的第三方库运行JavaScript,直接采集浏览器中看到的页面。(推荐)
既然浏览器可以获取数据,那么你可以模拟一个浏览器,从浏览器中获取数据。即使用程序控制浏览器,从而达到数据采集的目的。
java爬虫抓取动态网页(18款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-10 09:05
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍18款Java开源网络爬虫,有需要的小伙伴赶紧采集吧。
赫里特克斯
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。它最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备工作,比如延迟和重新处理处理,否决后续操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取结果,这一步可以直接索引全文。Heritrix提供了ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。
Heritrix 系统框架图
Heritrix 处理一个 url 进程
网络SPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX包。
WebSPHINX-目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可以看:
/~rcm/websphinx/
网络学习
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是写爬虫的新手,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
/
特征:
1.开源,免费
2.代码纯Java编写,可以在任何支持Java的平台上运行
3.支持多线程下载网页
4. 可以维护网页之间的链接信息
5.强大的可配置性:网页的深度优先或宽度优先抓取;可自定义的 URL 过滤器,以便您可以根据需要抓取单个 Web 服务器、单个目录或抓取整个 WWW 网络;您可以设置网址的优先级,这样我们就可以抓取我们感兴趣或重要的网页;我们可以记录断点时程序的状态,重启的时候可以继续上次爬取。
阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
蜘蛛侠
JSpider:是一个完全可配置和可定制的Web Spider引擎,你可以用它来检查网站错误(内部服务器错误等)、网站内外部链接检查、分析网站结构(可以创建网站图),下载整个网站,也可以写一个JSpider插件扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略 ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。
JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的 网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的 网站 的结构(创建站点地图,...)
下载翻新网站
通过编写JSpider插件实现任意功能。
项目主页:
/
主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。Spindle 项目提供了一组JSP 标记库,以便那些基于JSP 的站点可以在不开发任何Java 类的情况下增加搜索功能。
蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,能够分析收录 HTML 内容的输入流。通过实现 Arachnid 子类,可以开发一个简单的网络蜘蛛,并在解析网站上的每个页面后添加几行代码调用。Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
/
警报器
LARM 可以为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
/
乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
Snoics-爬行动物
什么是snoics-reptile?
它是用纯Java开发的,用于捕获网站的图像。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取到的网站 所有资源都是本地抓取的,包括网页和各类文件。
如:图片、flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
既然有其他类似的软件,为什么还要开发snotics-reptile呢?
因为在爬取的过程中经常会出现一些文件出错,很多javascript控制的URL没有办法正确解析,snoics-reptile提供了外部接口和配置文件。对于特殊的URL,可以通过自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:
/snoics
网络收获
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现 text/xml 操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。
它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了使数据操作和复用更容易,Web-Harvest 还提供了上下变量用于存储声明的变量。
web-harvest启动,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。
第二种方法是切换到cmd下的web-harvest目录,输入命令“java-jar-Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:
真烂
ItSucks 是 Java Web 爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
多线程
正则表达式
保存/加载下载作业
网上帮助 查看全部
java爬虫抓取动态网页(18款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍18款Java开源网络爬虫,有需要的小伙伴赶紧采集吧。
赫里特克斯
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。它最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备工作,比如延迟和重新处理处理,否决后续操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取结果,这一步可以直接索引全文。Heritrix提供了ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。

Heritrix 系统框架图
Heritrix 处理一个 url 进程
网络SPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX包。
WebSPHINX-目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可以看:
/~rcm/websphinx/
网络学习
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是写爬虫的新手,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
/
特征:
1.开源,免费
2.代码纯Java编写,可以在任何支持Java的平台上运行
3.支持多线程下载网页
4. 可以维护网页之间的链接信息
5.强大的可配置性:网页的深度优先或宽度优先抓取;可自定义的 URL 过滤器,以便您可以根据需要抓取单个 Web 服务器、单个目录或抓取整个 WWW 网络;您可以设置网址的优先级,这样我们就可以抓取我们感兴趣或重要的网页;我们可以记录断点时程序的状态,重启的时候可以继续上次爬取。
阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
蜘蛛侠
JSpider:是一个完全可配置和可定制的Web Spider引擎,你可以用它来检查网站错误(内部服务器错误等)、网站内外部链接检查、分析网站结构(可以创建网站图),下载整个网站,也可以写一个JSpider插件扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略 ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。
JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的 网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的 网站 的结构(创建站点地图,...)
下载翻新网站
通过编写JSpider插件实现任意功能。
项目主页:
/
主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。Spindle 项目提供了一组JSP 标记库,以便那些基于JSP 的站点可以在不开发任何Java 类的情况下增加搜索功能。
蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,能够分析收录 HTML 内容的输入流。通过实现 Arachnid 子类,可以开发一个简单的网络蜘蛛,并在解析网站上的每个页面后添加几行代码调用。Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
/
警报器
LARM 可以为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
/
乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
Snoics-爬行动物
什么是snoics-reptile?
它是用纯Java开发的,用于捕获网站的图像。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取到的网站 所有资源都是本地抓取的,包括网页和各类文件。
如:图片、flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
既然有其他类似的软件,为什么还要开发snotics-reptile呢?
因为在爬取的过程中经常会出现一些文件出错,很多javascript控制的URL没有办法正确解析,snoics-reptile提供了外部接口和配置文件。对于特殊的URL,可以通过自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:
/snoics
网络收获
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现 text/xml 操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。
它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了使数据操作和复用更容易,Web-Harvest 还提供了上下变量用于存储声明的变量。
web-harvest启动,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。
第二种方法是切换到cmd下的web-harvest目录,输入命令“java-jar-Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:
真烂
ItSucks 是 Java Web 爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
多线程
正则表达式
保存/加载下载作业
网上帮助
java爬虫抓取动态网页(本文爬虫:Java代码更多的关于robot.txt的具体)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-10 00:27
记得刚找工作的时候,隔壁的一个同学在面试的时候用大胆的文字认识了一个网络爬虫。后来在做图片搜索的时候,需要大量的测试图片,于是萌生了从亚马逊爬取书籍封面图片的想法,也从网上学习了一些之前的经验,一个简单但足够的爬虫系统实现了。
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。其基本结构如下图所示:
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。对于垂直搜索,聚焦爬虫,即针对特定主题抓取网页的爬虫更合适。
本文爬虫程序的核心代码如下:
Java代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java代码
private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
关于robot.txt更具体的写法,请参考以下文章:
getContent 使用apache的httpclient 4.1来获取网页的内容,具体代码如下:
Java代码
private String getContent(CrawlerUrl url) throws Throwable {
//HttpClient4.1的调用与之前的方式不同
HttpClient client = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url.getUrlString());
StringBuffer strBuf = new StringBuffer();
HttpResponse response = client.execute(httpGet);
if (HttpStatus.SC_OK == response.getStatusLine().getStatusCode()) {
HttpEntity entity = response.getEntity();
if (entity != null) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(entity.getContent(), "UTF-8"));
String line = null;
if (entity.getContentLength() > 0) {
strBuf = new StringBuffer((int) entity.getContentLength());
while ((line = reader.readLine()) != null) {
strBuf.append(line);
}
}
}
if (entity != null) {
entity.consumeContent();
}
}
//将url标记为已访问
markUrlAsVisited(url);
return strBuf.toString();
}
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是只采集与主题相关的数据,这就是isContentRelevant方法的作用。这里,可以使用分类预测技术。为简单起见,改为使用常规匹配。主要代码如下:
Java代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要功能是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样,一个简单的网络爬虫程序就搭建好了,可以使用如下程序进行测试:
Java代码
public static void main(String[] args) {
try {
String url = "http://www.amazon.com";
Queue urlQueue = new LinkedList();
String regexp = "java";
urlQueue.add(new CrawlerUrl(url, 0));
NaiveCrawler crawler = new NaiveCrawler(urlQueue, 100, 5, 1000L,
regexp);
// boolean allowCrawl = crawler.areWeAllowedToVisit(url);
// System.out.println("Allowed to crawl: " + url + " " +
// allowCrawl);
crawler.crawl();
} catch (Throwable t) {
System.out.println(t.toString());
t.printStackTrace();
}
}
当然,你可以赋予它更高级的特性,比如多线程、更智能的焦点、使用 Lucene 索引等等。对于更复杂的情况,可以考虑使用一些开源的spider程序,比如Nutch或者Heritrix等,这些都超出了本文的范围。 查看全部
java爬虫抓取动态网页(本文爬虫:Java代码更多的关于robot.txt的具体)
记得刚找工作的时候,隔壁的一个同学在面试的时候用大胆的文字认识了一个网络爬虫。后来在做图片搜索的时候,需要大量的测试图片,于是萌生了从亚马逊爬取书籍封面图片的想法,也从网上学习了一些之前的经验,一个简单但足够的爬虫系统实现了。
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。其基本结构如下图所示:

传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。对于垂直搜索,聚焦爬虫,即针对特定主题抓取网页的爬虫更合适。
本文爬虫程序的核心代码如下:
Java代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java代码
private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
关于robot.txt更具体的写法,请参考以下文章:
getContent 使用apache的httpclient 4.1来获取网页的内容,具体代码如下:
Java代码
private String getContent(CrawlerUrl url) throws Throwable {
//HttpClient4.1的调用与之前的方式不同
HttpClient client = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url.getUrlString());
StringBuffer strBuf = new StringBuffer();
HttpResponse response = client.execute(httpGet);
if (HttpStatus.SC_OK == response.getStatusLine().getStatusCode()) {
HttpEntity entity = response.getEntity();
if (entity != null) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(entity.getContent(), "UTF-8"));
String line = null;
if (entity.getContentLength() > 0) {
strBuf = new StringBuffer((int) entity.getContentLength());
while ((line = reader.readLine()) != null) {
strBuf.append(line);
}
}
}
if (entity != null) {
entity.consumeContent();
}
}
//将url标记为已访问
markUrlAsVisited(url);
return strBuf.toString();
}
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是只采集与主题相关的数据,这就是isContentRelevant方法的作用。这里,可以使用分类预测技术。为简单起见,改为使用常规匹配。主要代码如下:
Java代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要功能是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样,一个简单的网络爬虫程序就搭建好了,可以使用如下程序进行测试:
Java代码
public static void main(String[] args) {
try {
String url = "http://www.amazon.com";
Queue urlQueue = new LinkedList();
String regexp = "java";
urlQueue.add(new CrawlerUrl(url, 0));
NaiveCrawler crawler = new NaiveCrawler(urlQueue, 100, 5, 1000L,
regexp);
// boolean allowCrawl = crawler.areWeAllowedToVisit(url);
// System.out.println("Allowed to crawl: " + url + " " +
// allowCrawl);
crawler.crawl();
} catch (Throwable t) {
System.out.println(t.toString());
t.printStackTrace();
}
}
当然,你可以赋予它更高级的特性,比如多线程、更智能的焦点、使用 Lucene 索引等等。对于更复杂的情况,可以考虑使用一些开源的spider程序,比如Nutch或者Heritrix等,这些都超出了本文的范围。
java爬虫抓取动态网页(jdk1.8、win10、科学上网、eclipse一直想学下写爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-09 20:10
环境:jdk1.8、win10、科学上网,eclipse
一直想学习写爬虫,满足我的小愿望。刚好有过年的时间,所以研究了一下。网上的信息混杂,所以决定自己整理一份,按照我的步骤来。它必须是可能的。如果你成功了,记得回来喜欢它。
在这种情况下,抓取了一个小视频网站,最终的效果可以是自动下载网站的所有视频,并且每个视频都有自己的名字。
如果要爬取其他网站,代码中很多地方(比如url、url解析、字符串截取、下载位置)需要根据具体页面进行修改,我只能提供一个思路。,当然,如果你想爬这个网站,当然不用改。
一、 思路: 1、获取要爬取的网站首页url。2.对于分页网站(视频网站一般都会分页)分析url分页方式,找到规则3,在每个页面上找到视频页面的url,在视频页面上找到规则4 ,分析url,找出视频的实际下载地址,找到规则5,开始下载6,开始快乐!!!二、步骤:1.面函数,没什么好说的
public static void main(String[] args) throws Exception {
final String SCORE_URL = "https://www.xxxx/xxx";// 主页(手工打码)
final String DOWNLOAD_DIR = "F:/video/";// 下载目录
System.setProperty("https.protocols", "TLSv1,TLSv1.1,TLSv1.2,SSLv3");
System.err.println("爬取子页面...");
List allArticle = getAllVideoPage(SCORE_URL);
System.err.println("爬取视频...");
Map urlMap = getUrlInSource(allArticle);
System.err.println("本次下载文件数量:" + urlMap.size());
System.err.println("开始下载...");
downloadMovie(DOWNLOAD_DIR, urlMap);
}
2.这里网站的视频一般不会放在首页,视频网站一般会分页。所以你需要先分析页面的url,然后分析视频页面的url,然后将所有的视频页面url保存到一个列表中。难点在于页面的url解析
例如,这是一个分页 URL,这有明显的规则。我们只需要修改page=后面的数字就可以得到每个页面的url
然后我们需要分析进入每个视频页面的url,chrome F12,我们来看看
标记的那一行是进入视频页面的url。相信大家都会找到的,就不赘述了。
然后我们需要把href=后面双引号里面的东西剪掉,然后拼接成视频页面的完整url,具体看我的代码
最后,将所有视频页面的网址保存到一个列表中,下一步
<p> /**
* 爬所有视频页 存入一个list
*
* @param source 主页
* @return 视频页 列表
* @throws Exception
*/
private static List getAllVideoPage(String source) throws Exception {
List urls = new ArrayList();
for (int j = 1; j 查看全部
java爬虫抓取动态网页(jdk1.8、win10、科学上网、eclipse一直想学下写爬虫)
环境:jdk1.8、win10、科学上网,eclipse
一直想学习写爬虫,满足我的小愿望。刚好有过年的时间,所以研究了一下。网上的信息混杂,所以决定自己整理一份,按照我的步骤来。它必须是可能的。如果你成功了,记得回来喜欢它。
在这种情况下,抓取了一个小视频网站,最终的效果可以是自动下载网站的所有视频,并且每个视频都有自己的名字。
如果要爬取其他网站,代码中很多地方(比如url、url解析、字符串截取、下载位置)需要根据具体页面进行修改,我只能提供一个思路。,当然,如果你想爬这个网站,当然不用改。
一、 思路: 1、获取要爬取的网站首页url。2.对于分页网站(视频网站一般都会分页)分析url分页方式,找到规则3,在每个页面上找到视频页面的url,在视频页面上找到规则4 ,分析url,找出视频的实际下载地址,找到规则5,开始下载6,开始快乐!!!二、步骤:1.面函数,没什么好说的
public static void main(String[] args) throws Exception {
final String SCORE_URL = "https://www.xxxx/xxx";// 主页(手工打码)
final String DOWNLOAD_DIR = "F:/video/";// 下载目录
System.setProperty("https.protocols", "TLSv1,TLSv1.1,TLSv1.2,SSLv3");
System.err.println("爬取子页面...");
List allArticle = getAllVideoPage(SCORE_URL);
System.err.println("爬取视频...");
Map urlMap = getUrlInSource(allArticle);
System.err.println("本次下载文件数量:" + urlMap.size());
System.err.println("开始下载...");
downloadMovie(DOWNLOAD_DIR, urlMap);
}
2.这里网站的视频一般不会放在首页,视频网站一般会分页。所以你需要先分析页面的url,然后分析视频页面的url,然后将所有的视频页面url保存到一个列表中。难点在于页面的url解析
例如,这是一个分页 URL,这有明显的规则。我们只需要修改page=后面的数字就可以得到每个页面的url

然后我们需要分析进入每个视频页面的url,chrome F12,我们来看看
标记的那一行是进入视频页面的url。相信大家都会找到的,就不赘述了。
然后我们需要把href=后面双引号里面的东西剪掉,然后拼接成视频页面的完整url,具体看我的代码
最后,将所有视频页面的网址保存到一个列表中,下一步
<p> /**
* 爬所有视频页 存入一个list
*
* @param source 主页
* @return 视频页 列表
* @throws Exception
*/
private static List getAllVideoPage(String source) throws Exception {
List urls = new ArrayList();
for (int j = 1; j
java爬虫抓取动态网页(java调用、Firefox获取页面信息,以及Jsoup解析**)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-09 20:08
**
Java爬虫,调用Chrome、Firefox获取页面信息,Jsoup分析
**
前言:
某些 网站 具有反爬虫机制。在这种情况下,我们需要使用模拟真实浏览器来访问页面。在Linux环境下,我们需要设置浏览器headless模式。不过有一些网站反爬的比较好,会判断谷歌浏览器的headless模式,可以用火狐试试。
一、java调用Chrome(谷歌浏览器)抓取页面
1.本地安装的 Google Chrome 和 ChromeDriver
Chromedriver 地址:
注意:chromedriver的版本必须和谷歌浏览器的版本一致
2.chromedriver 需要配置环境变量,如果不配置环境变量需要调用
所需的依赖:
org.jsoup
jsoup
1.11.3
org.seleniumhq.selenium
selenium-java
public void ChromeDemo(){
//如果没有配置环境变量,需要调用
//第一个参数固定写法,第二个参数是chromedriver的安装位置
//System.setProperty("webdriver.chrome.driver", "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe");
try {
//设置不弹出浏览器
ChromeOptions options = new ChromeOptions();
options.addArguments("headless");
options.addArguments("disable-gpu");
//Chrome设置代理
// if (zsyzbConfig.proxyHost != null && !zsyzbConfig.proxyHost.equals("") && zsyzbConfig.proxyPort != null) {
// options.addArguments("--proxy-server=http://" + proxyIP);
//}
ChromeDriver driver = new ChromeDriver(options);
driver.get("要爬取的地址");
//获取页面源码
String content = driver.getPageSource();
//使用jsoup解析页面
Document document = Jsoup.parse(content);
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
} catch (Exception e) {
e.printStackTrace();
}
}
二、Java调用Firefox(火狐浏览器)抓取页面
1.火狐浏览器安装:
yum -y install firefox(安装火狐浏览器)
2.geckodriver 安装
(1) wget(下载浏览器对应的版本)
(2) tar -xvf geckodriver*.tar.bz2 (解压 geckodriver)
(3) mv geckodriver /user/local/bin/ (移动)
火狐浏览器已经安装好了,然后添加代码:
public void FirefoxDemo(){
try{
//调用geckodriver
System.setProperty("webdriver.gecko.driver", "geckodriver的路径");
//设置浏览器不弹出
FirefoxOptions firefoxOptions = new FirefoxOptions();
firefoxOptions.addArguments("--headless");
firefoxOptions.addArguments("--disable-gpu");
driver = new FirefoxDriver(firefoxOptions);
driver.get("需要爬取的网站");
//获得爬取的页面的源码
String content = driver.getPageSource();
//Jsoup解析页面
Document document = Jsoup.parse(content);
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
}catch (Exception e) {
e.printStackTrace();
}finally {
driver.close();
}
}
三、Jsoup 抓取简单页面
public void JsoupDemo(){
try{
//Jsoup发请求获取页面
Document document = Jsoup.connect(url).get();
//根据页面的结构,具体解析页面
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
for (Element e : content) {
//例如:<a href=“www.baidu.com”> 则这样写:e.attr("href");
e.attr("标签的属性");
}
}catch (Exception e){
e.printStackTrace();
}
}
JS选择器不会写,可以看这里: 查看全部
java爬虫抓取动态网页(java调用、Firefox获取页面信息,以及Jsoup解析**)
**
Java爬虫,调用Chrome、Firefox获取页面信息,Jsoup分析
**
前言:
某些 网站 具有反爬虫机制。在这种情况下,我们需要使用模拟真实浏览器来访问页面。在Linux环境下,我们需要设置浏览器headless模式。不过有一些网站反爬的比较好,会判断谷歌浏览器的headless模式,可以用火狐试试。
一、java调用Chrome(谷歌浏览器)抓取页面
1.本地安装的 Google Chrome 和 ChromeDriver
Chromedriver 地址:
注意:chromedriver的版本必须和谷歌浏览器的版本一致
2.chromedriver 需要配置环境变量,如果不配置环境变量需要调用
所需的依赖:
org.jsoup
jsoup
1.11.3
org.seleniumhq.selenium
selenium-java
public void ChromeDemo(){
//如果没有配置环境变量,需要调用
//第一个参数固定写法,第二个参数是chromedriver的安装位置
//System.setProperty("webdriver.chrome.driver", "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe");
try {
//设置不弹出浏览器
ChromeOptions options = new ChromeOptions();
options.addArguments("headless");
options.addArguments("disable-gpu");
//Chrome设置代理
// if (zsyzbConfig.proxyHost != null && !zsyzbConfig.proxyHost.equals("") && zsyzbConfig.proxyPort != null) {
// options.addArguments("--proxy-server=http://" + proxyIP);
//}
ChromeDriver driver = new ChromeDriver(options);
driver.get("要爬取的地址");
//获取页面源码
String content = driver.getPageSource();
//使用jsoup解析页面
Document document = Jsoup.parse(content);
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
} catch (Exception e) {
e.printStackTrace();
}
}
二、Java调用Firefox(火狐浏览器)抓取页面
1.火狐浏览器安装:
yum -y install firefox(安装火狐浏览器)
2.geckodriver 安装
(1) wget(下载浏览器对应的版本)
(2) tar -xvf geckodriver*.tar.bz2 (解压 geckodriver)
(3) mv geckodriver /user/local/bin/ (移动)
火狐浏览器已经安装好了,然后添加代码:
public void FirefoxDemo(){
try{
//调用geckodriver
System.setProperty("webdriver.gecko.driver", "geckodriver的路径");
//设置浏览器不弹出
FirefoxOptions firefoxOptions = new FirefoxOptions();
firefoxOptions.addArguments("--headless");
firefoxOptions.addArguments("--disable-gpu");
driver = new FirefoxDriver(firefoxOptions);
driver.get("需要爬取的网站");
//获得爬取的页面的源码
String content = driver.getPageSource();
//Jsoup解析页面
Document document = Jsoup.parse(content);
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
}catch (Exception e) {
e.printStackTrace();
}finally {
driver.close();
}
}
三、Jsoup 抓取简单页面
public void JsoupDemo(){
try{
//Jsoup发请求获取页面
Document document = Jsoup.connect(url).get();
//根据页面的结构,具体解析页面
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
for (Element e : content) {
//例如:<a href=“www.baidu.com”> 则这样写:e.attr("href");
e.attr("标签的属性");
}
}catch (Exception e){
e.printStackTrace();
}
}
JS选择器不会写,可以看这里:
java爬虫抓取动态网页(Java爬虫系列四:使用selenium-java爬取js异步请求的数据摘要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-07 06:18
Java爬虫系列四:使用selenium-java爬取js异步请求的数据
摘要:在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但有时无法正常捕获这两种方法。我们要的数据,例如看下面的例子。1. 需求场景:如果想抓取股票的最新价格,F12页面信息如下: 按照前面的方法,抓取代码如下:/阅读全文
发表于@2021-10-17 11:46 JAVA开发新手阅读(191)评论(0)推荐(1)编辑)
Java爬虫系列三:使用Jsoup解析HTML
摘要:在之前的文章《Java爬虫系列之二:使用HttpClient爬取页面HTML》中,介绍了如何使用HttpClient爬取第一步——爬取页面html,今天来看看爬虫第二步——分析捕获的 html。拜托了,第二步的主角:Jsoup上台了。接下来,我们将舞台交给 Jsoup,让他完成本文的其余部分。华读全文
发表于@2019-05-25 16:08 JAVA开发老菜鸟阅读(55842)评论(1)推荐(13)编辑)
Java爬虫系列2:使用HttpClient抓取页面HTML
摘要:爬虫要爬取到需要的信息,第一步就是抓取页面的html内容,然后对html进行分析,得到想要的内容。在上一篇《Java爬虫系列一:开始前的写作》中提到了HttpClient可以爬取页面内容。今天给大家介绍一个抓取html内容的工具:HttpClient。重点关注以下几点: 什么是HttpClie 阅读全文
发表于@2019-05-23 06:29 JAVA开发老菜鸟阅读(23582)评论(2)推荐(7)编辑)
Java爬虫系列1:开始之前先写
摘要:最近在研究Java爬虫,有所收获。我打算在学习的同时与大家分享。在干货开始之前,我想和你说几句话。一、首先来说说为什么要学习Java爬虫。Python 已经流行了很长时间。它功能强大,其中一个非常擅长的就是编写爬虫程序。作为一个Javaer,想写爬虫一定要学python吗?想到这个问题就去度娘了,其实看全文
发表于@2019-05-22 21:22 JAVA开发老菜鸟阅读(3768)评论(0)推荐(3)编辑) 查看全部
java爬虫抓取动态网页(Java爬虫系列四:使用selenium-java爬取js异步请求的数据摘要)
Java爬虫系列四:使用selenium-java爬取js异步请求的数据
摘要:在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但有时无法正常捕获这两种方法。我们要的数据,例如看下面的例子。1. 需求场景:如果想抓取股票的最新价格,F12页面信息如下: 按照前面的方法,抓取代码如下:/阅读全文
发表于@2021-10-17 11:46 JAVA开发新手阅读(191)评论(0)推荐(1)编辑)
Java爬虫系列三:使用Jsoup解析HTML
摘要:在之前的文章《Java爬虫系列之二:使用HttpClient爬取页面HTML》中,介绍了如何使用HttpClient爬取第一步——爬取页面html,今天来看看爬虫第二步——分析捕获的 html。拜托了,第二步的主角:Jsoup上台了。接下来,我们将舞台交给 Jsoup,让他完成本文的其余部分。华读全文
发表于@2019-05-25 16:08 JAVA开发老菜鸟阅读(55842)评论(1)推荐(13)编辑)
Java爬虫系列2:使用HttpClient抓取页面HTML
摘要:爬虫要爬取到需要的信息,第一步就是抓取页面的html内容,然后对html进行分析,得到想要的内容。在上一篇《Java爬虫系列一:开始前的写作》中提到了HttpClient可以爬取页面内容。今天给大家介绍一个抓取html内容的工具:HttpClient。重点关注以下几点: 什么是HttpClie 阅读全文
发表于@2019-05-23 06:29 JAVA开发老菜鸟阅读(23582)评论(2)推荐(7)编辑)
Java爬虫系列1:开始之前先写
摘要:最近在研究Java爬虫,有所收获。我打算在学习的同时与大家分享。在干货开始之前,我想和你说几句话。一、首先来说说为什么要学习Java爬虫。Python 已经流行了很长时间。它功能强大,其中一个非常擅长的就是编写爬虫程序。作为一个Javaer,想写爬虫一定要学python吗?想到这个问题就去度娘了,其实看全文
发表于@2019-05-22 21:22 JAVA开发老菜鸟阅读(3768)评论(0)推荐(3)编辑)
java爬虫抓取动态网页( 下一节:java如何爬取网页内容Java编程技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 509 次浏览 • 2021-11-06 17:15
下一节:java如何爬取网页内容Java编程技术)
java网络爬虫框架
爬虫是每个程序员都必须掌握的技能。与python爬虫的广泛应用相比,java爬虫也有着不可缺少的优势。Java爬虫现在也相当成熟。Python爬虫中的框架支持爬虫任务的进度,Java爬虫的框架也是如此。每个框架都扮演着不同的角色。本文介绍几个java网络常用的框架:Nutch、Crawler4j、WebMagic、WebCollecto。
1、Nutch:为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。
2、Crawler4j:是一款开源的Java爬虫网络爬虫,代码相当轻量,可以实现多线程爬取,上手难度低。
3、WebMagic:是一个简单灵活的Java爬虫框架。WebMagic 的结构分为四大组件:Downloader、pageProcessor、Scheduler、pipeline,它们以spliter 来组织。这四个组件分别对应爬虫生命周期中的下载、处理、管理和持久化功能。
4、WebCollector:致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。源代码中集成了Jsoup,用于准确的网页分析。
以上就是对java网络爬虫的简单介绍,希望对大家有所帮助~更多java学习推荐:java教程。
下一节:Java如何抓取网页内容Java编程技术
Java爬虫爬取网页内容:1、 网络爬虫按照一定的规则抓取网页上的信息,通常是在爬取一些网址后,再将这些网址放入队列中,反复搜索。2、Java抓取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,所以... 查看全部
java爬虫抓取动态网页(
下一节:java如何爬取网页内容Java编程技术)
java网络爬虫框架

爬虫是每个程序员都必须掌握的技能。与python爬虫的广泛应用相比,java爬虫也有着不可缺少的优势。Java爬虫现在也相当成熟。Python爬虫中的框架支持爬虫任务的进度,Java爬虫的框架也是如此。每个框架都扮演着不同的角色。本文介绍几个java网络常用的框架:Nutch、Crawler4j、WebMagic、WebCollecto。
1、Nutch:为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。
2、Crawler4j:是一款开源的Java爬虫网络爬虫,代码相当轻量,可以实现多线程爬取,上手难度低。
3、WebMagic:是一个简单灵活的Java爬虫框架。WebMagic 的结构分为四大组件:Downloader、pageProcessor、Scheduler、pipeline,它们以spliter 来组织。这四个组件分别对应爬虫生命周期中的下载、处理、管理和持久化功能。
4、WebCollector:致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。源代码中集成了Jsoup,用于准确的网页分析。
以上就是对java网络爬虫的简单介绍,希望对大家有所帮助~更多java学习推荐:java教程。
下一节:Java如何抓取网页内容Java编程技术
Java爬虫爬取网页内容:1、 网络爬虫按照一定的规则抓取网页上的信息,通常是在爬取一些网址后,再将这些网址放入队列中,反复搜索。2、Java抓取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,所以...
java爬虫抓取动态网页(Python语言Python爬虫程序之前知识准备工作会得心应手)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-06 17:13
在使用Python编写爬虫程序之前,需要提前做好一些准备工作,以便在后续的学习过程中得心应手。
知识准备1) Python语言Python爬虫作为Python编程的高级知识,要求学习者具备良好的Python编程基础。对于没有基础的同学,推荐阅读《Python基础教程》,这套教程通俗易懂,非常适合初学者学习,教程作者亲自解答问答,有帮助您可以快速开始使用 Python。
同时了解Python语言的多进程、多线程(可参考《Python并发编程》),熟悉正则表达式语法,对编写爬虫程序也有帮助。
注意:关于正则表达式,Python 提供了一个特殊的 re 模块。详情请参考“Python re模块”。
2) Web Front End 了解Web前端的基础知识,如HTML、CSS、JavaScript,可以帮助您分析网页结构,提取有效信息。推荐阅读《HTML教程》、《CSS教程》、《JS教程》。
3) HTTP协议掌握OSI七层网络模型,理解TCP/IP协议和HTTP协议。这些知识将帮助您了解网络请求(GET 请求、POST 请求)和网络传输的基本原理。同时,它也会帮助你理解编写爬虫程序的逻辑。推荐阅读这里的“TCP/IP协议简介”。
图 1:OSI 网络七层模型
环境准备在编写Python爬虫程序之前,需要准备相应的开发环境,非常简单。首先,您需要在您的计算机上安装 Python,然后下载并安装 Pycharm IDE(集成开发环境)工具。具体下载安装过程可以阅读《Python基础教程》。
本教程使用Windows 10系统讲解Python爬虫。当然,您也可以使用其他系统,例如 Linux 或 Mac。
注意:下载Python时,建议下载Python 3.5及以上版本(包括3.5版本),本教程使用Python 3.7.4版本。 查看全部
java爬虫抓取动态网页(Python语言Python爬虫程序之前知识准备工作会得心应手)
在使用Python编写爬虫程序之前,需要提前做好一些准备工作,以便在后续的学习过程中得心应手。
知识准备1) Python语言Python爬虫作为Python编程的高级知识,要求学习者具备良好的Python编程基础。对于没有基础的同学,推荐阅读《Python基础教程》,这套教程通俗易懂,非常适合初学者学习,教程作者亲自解答问答,有帮助您可以快速开始使用 Python。
同时了解Python语言的多进程、多线程(可参考《Python并发编程》),熟悉正则表达式语法,对编写爬虫程序也有帮助。
注意:关于正则表达式,Python 提供了一个特殊的 re 模块。详情请参考“Python re模块”。
2) Web Front End 了解Web前端的基础知识,如HTML、CSS、JavaScript,可以帮助您分析网页结构,提取有效信息。推荐阅读《HTML教程》、《CSS教程》、《JS教程》。
3) HTTP协议掌握OSI七层网络模型,理解TCP/IP协议和HTTP协议。这些知识将帮助您了解网络请求(GET 请求、POST 请求)和网络传输的基本原理。同时,它也会帮助你理解编写爬虫程序的逻辑。推荐阅读这里的“TCP/IP协议简介”。

图 1:OSI 网络七层模型
环境准备在编写Python爬虫程序之前,需要准备相应的开发环境,非常简单。首先,您需要在您的计算机上安装 Python,然后下载并安装 Pycharm IDE(集成开发环境)工具。具体下载安装过程可以阅读《Python基础教程》。
本教程使用Windows 10系统讲解Python爬虫。当然,您也可以使用其他系统,例如 Linux 或 Mac。
注意:下载Python时,建议下载Python 3.5及以上版本(包括3.5版本),本教程使用Python 3.7.4版本。
java爬虫抓取动态网页(自问自答一下可以用一个很牛逼的包,叫做selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-05 17:11
问你自己
你可以使用一个非常棒的名为 selenium 的包(官方文档 Selenium with Python)。简单地说,它模拟人们在浏览器上的动作。您可以用代码打开浏览器,然后像人一样操作,实现浏览器的自动化(打开网页、输入文本、提交表单等),安装等细节在官方文档中有介绍。
以爬取本页Food-Popular Questions and Answers的所有主要回答信息为例。正如我所描述的,这个页面需要向下滚动才能获得更多信息。但是requests库好像不能实现这个功能?我还是不知道。. 反正这个页面的爬取基本可以用selenium库来实现。
话不多说,直接贴代码(环境为python3.5)
先导入需要的库,打开知乎-与世界页面分享你的知识、经验和见解,先登录。
from selenium import webdriver
import time
from bs4 import BeautifulSoup
driver=webdriver.Chrome() #用chrome浏览器打开
driver.get("http://www.zhihu.com") #打开知乎我们要登录
time.sleep(2) #让操作稍微停一下
driver.find_element_by_link_text('登录').click() #找到‘登录’按钮并点击
time.sleep(2)
#找到输入账号的框,并自动输入账号 这里要替换为你的登录账号
driver.find_element_by_name('account').send_keys('你的账号')
time.sleep(2)
#密码,这里要替换为你的密码
driver.find_element_by_name('password').send_keys('你的密码')
time.sleep(2)
#输入浏览器中显示的验证码,这里如果知乎让你找烦人的倒立汉字,手动登录一下,再停止程序,退出#浏览器,然后重新启动程序,直到让你输入验证码
yanzhengma=input('验证码:')
driver.find_element_by_name('captcha').send_keys(yanzhengma)
#找到登录按钮,并点击
driver.find_element_by_css_selector('div.button-wrapper.command > button').click()
然后获取你的登录cookie并加载目标页面Food-Popular Q&A,因为用这个包打开浏览器不会记录你之前的浏览器会话(cookies、书签等),所以暂时只能用这个方法登录和然后进入目标页面。
cookie=driver.get_cookies()
time.sleep(3)
driver.get('https://www.zhihu.com/topic/19551137/hot')
time.sleep(5)
定义一个函数,实现将滚轮滑动到页面底部的功能。这是官方文档里的(为了让页面加载完成,每5秒向下移动一次,共10次)
def execute_times(times):
for i in range(times + 1):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)
execute_times(10)
接下来是页面解析,使用BeautifulSoup库,我就不多说了
html=driver.page_source
soup1=BeautifulSoup(html,'lxml')
authors=soup1.select('a.author-link')
authors_alls=[]
authors_hrefs=[]
for author in authors:
authors_alls.append(author.get_text())
authors_hrefs.append('http://www.zhihu.com'+author.get('href'))
authors_intros_urls=soup1.select('span.bio')
authors_intros=[]
for authors_intros_url in authors_intros_urls:
authors_intros.append(authors_intros_url.get_text())
for authors_all,authors_href,authors_intro in zip(authors_alls,authors_hrefs,authors_intros):
data={
'author':authors_all,
'href':authors_href,
'intro':authors_intro
}
print(data)
最后打印结果:
我这里只试了10页,程序没有问题,不知道数据多了会不会有问题 查看全部
java爬虫抓取动态网页(自问自答一下可以用一个很牛逼的包,叫做selenium)
问你自己
你可以使用一个非常棒的名为 selenium 的包(官方文档 Selenium with Python)。简单地说,它模拟人们在浏览器上的动作。您可以用代码打开浏览器,然后像人一样操作,实现浏览器的自动化(打开网页、输入文本、提交表单等),安装等细节在官方文档中有介绍。
以爬取本页Food-Popular Questions and Answers的所有主要回答信息为例。正如我所描述的,这个页面需要向下滚动才能获得更多信息。但是requests库好像不能实现这个功能?我还是不知道。. 反正这个页面的爬取基本可以用selenium库来实现。
话不多说,直接贴代码(环境为python3.5)
先导入需要的库,打开知乎-与世界页面分享你的知识、经验和见解,先登录。
from selenium import webdriver
import time
from bs4 import BeautifulSoup
driver=webdriver.Chrome() #用chrome浏览器打开
driver.get("http://www.zhihu.com";) #打开知乎我们要登录
time.sleep(2) #让操作稍微停一下
driver.find_element_by_link_text('登录').click() #找到‘登录’按钮并点击
time.sleep(2)
#找到输入账号的框,并自动输入账号 这里要替换为你的登录账号
driver.find_element_by_name('account').send_keys('你的账号')
time.sleep(2)
#密码,这里要替换为你的密码
driver.find_element_by_name('password').send_keys('你的密码')
time.sleep(2)
#输入浏览器中显示的验证码,这里如果知乎让你找烦人的倒立汉字,手动登录一下,再停止程序,退出#浏览器,然后重新启动程序,直到让你输入验证码
yanzhengma=input('验证码:')
driver.find_element_by_name('captcha').send_keys(yanzhengma)
#找到登录按钮,并点击
driver.find_element_by_css_selector('div.button-wrapper.command > button').click()
然后获取你的登录cookie并加载目标页面Food-Popular Q&A,因为用这个包打开浏览器不会记录你之前的浏览器会话(cookies、书签等),所以暂时只能用这个方法登录和然后进入目标页面。
cookie=driver.get_cookies()
time.sleep(3)
driver.get('https://www.zhihu.com/topic/19551137/hot')
time.sleep(5)
定义一个函数,实现将滚轮滑动到页面底部的功能。这是官方文档里的(为了让页面加载完成,每5秒向下移动一次,共10次)
def execute_times(times):
for i in range(times + 1):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)
execute_times(10)
接下来是页面解析,使用BeautifulSoup库,我就不多说了
html=driver.page_source
soup1=BeautifulSoup(html,'lxml')
authors=soup1.select('a.author-link')
authors_alls=[]
authors_hrefs=[]
for author in authors:
authors_alls.append(author.get_text())
authors_hrefs.append('http://www.zhihu.com'+author.get('href'))
authors_intros_urls=soup1.select('span.bio')
authors_intros=[]
for authors_intros_url in authors_intros_urls:
authors_intros.append(authors_intros_url.get_text())
for authors_all,authors_href,authors_intro in zip(authors_alls,authors_hrefs,authors_intros):
data={
'author':authors_all,
'href':authors_href,
'intro':authors_intro
}
print(data)
最后打印结果:
我这里只试了10页,程序没有问题,不知道数据多了会不会有问题
java爬虫抓取动态网页(Java的Http协议客户端HttpClient来实现抓取网页数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-11-26 03:07
爬虫抓取网页上的数据,我们同样点击链接访问网页数据。就是使用Http协议访问网页。这里我们使用Java Http协议客户端HttpClient来实现网页数据的爬取。
你好,世界
获取带参数的请求
使用参数发布请求
帖子也很简单,和上面的差不多,只是改变了发起请求的方式,如下:
当然,如果没有参数,则不需要创建表单对象,只需一个HttpPost对象即可。
代码中对象的说明:
代码优化:连接池
在我们爬取数据的过程中,HttpClient连接对象的创建和销毁是非常频繁的,这里我们使用连接池进行优化
public class poolTest {
public static void main(String[] args) {
//创建连接池管理器
PoolingHttpClientConnectionManager pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(100); //设置池内最大连接数
pcm.setDefaultMaxPerRoute(10); //设置每个坠机的最大连接数
//从连接池中获取连接对象,而不是单独创建连接对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(pcm).build();
HttpGet httpGet = new HttpGet("https://www.cnblogs.com/msi-chen");
System.out.println(httpGet);
//使用httpClient发起请求,获得响应
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
//解析响应,获取到数据
if (response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity,"utf8");
System.out.println(content.length());
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if (response != null){
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
//因为我们是连接池中获取到的连接,所以这里不能再给他关闭了
//httpClient.close();
}
}
}
}
获取资源的相关时间配置
Jsoup 不是 Jsonp
经过我们上面的学习,我们已经可以通过HttpClient抓取页面了。抓取页面后,我们可以解析它。您可以使用字符串解析工具来解析页面,也可以使用正则表达式。用于分析,但是这两种方案的开发成本很高,不推荐使用,这里我们学习一个专门解析html页面的技术Jsonp
汤品介绍
jsonp 是一个 Java Html 解析器,可以自行解析 URL 地址和 html 文本内容。它有一组现成的 API 来删除和操作数据。
jsonp的作用:
Jsoup 解析 URL
添加 Jsoup 依赖以使用 Jsoup
注意:Jsoup 只限于使用 Html 解析工具,而不是替代 HttpClient 来发起请求,因为 HttpClient 支持多线程、连接池、代理等技术,而 Jsoup 对此的支持并不理想。专业的事情交给专业的人,HttpClient发送请求抓取数据,Jsoup做解析
Jsoup 解析字符串
Jsoup解析文件
这是上面的静态页面。除了转换成String再解析,我们也可以直接解析文件
使用 Dom 遍历文档
记得还有一个sax解析,比较麻烦,现在差点忘了;
Dom解析,不知道大家有没有听过或者用过。反正我之前用过,但是解析的确实是XML。先简单介绍一个Dmo方法。
Dmo 解析会将目标文档视为一个对象。首先将整个文档加载到内存中。如果文档太大,内存可能会溢出(一般不会)。加载到内存后会构建一个Dom树,然后Just开始提供访问和修改操作
如果你之前没有学习过,我们通过一个小Demo来学习。如果您使用过它,我们有权对其进行审核:
Java代码如下: 我演示了几个常用的获取页面数据的API
从元素中获取属性
选择器
下面是上述always选择器的使用演示
选择器选择器组合使用
Hello World 类爬虫案例列表
在上面的学习中,我们已经知道HttpClient是用来爬取数据的,Jsoup是用来解析HttpClient爬取到的数据的。下面我们来练习一下这两个工具的使用。
搁浅,暂时……以后更新 查看全部
java爬虫抓取动态网页(Java的Http协议客户端HttpClient来实现抓取网页数据(组图))
爬虫抓取网页上的数据,我们同样点击链接访问网页数据。就是使用Http协议访问网页。这里我们使用Java Http协议客户端HttpClient来实现网页数据的爬取。
你好,世界
获取带参数的请求
使用参数发布请求
帖子也很简单,和上面的差不多,只是改变了发起请求的方式,如下:
当然,如果没有参数,则不需要创建表单对象,只需一个HttpPost对象即可。
代码中对象的说明:
代码优化:连接池
在我们爬取数据的过程中,HttpClient连接对象的创建和销毁是非常频繁的,这里我们使用连接池进行优化
public class poolTest {
public static void main(String[] args) {
//创建连接池管理器
PoolingHttpClientConnectionManager pcm = new PoolingHttpClientConnectionManager();
pcm.setMaxTotal(100); //设置池内最大连接数
pcm.setDefaultMaxPerRoute(10); //设置每个坠机的最大连接数
//从连接池中获取连接对象,而不是单独创建连接对象
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(pcm).build();
HttpGet httpGet = new HttpGet("https://www.cnblogs.com/msi-chen";);
System.out.println(httpGet);
//使用httpClient发起请求,获得响应
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
//解析响应,获取到数据
if (response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity,"utf8");
System.out.println(content.length());
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if (response != null){
try {
response.close();
} catch (IOException e) {
e.printStackTrace();
}
//因为我们是连接池中获取到的连接,所以这里不能再给他关闭了
//httpClient.close();
}
}
}
}
获取资源的相关时间配置
Jsoup 不是 Jsonp
经过我们上面的学习,我们已经可以通过HttpClient抓取页面了。抓取页面后,我们可以解析它。您可以使用字符串解析工具来解析页面,也可以使用正则表达式。用于分析,但是这两种方案的开发成本很高,不推荐使用,这里我们学习一个专门解析html页面的技术Jsonp
汤品介绍
jsonp 是一个 Java Html 解析器,可以自行解析 URL 地址和 html 文本内容。它有一组现成的 API 来删除和操作数据。
jsonp的作用:
Jsoup 解析 URL
添加 Jsoup 依赖以使用 Jsoup
注意:Jsoup 只限于使用 Html 解析工具,而不是替代 HttpClient 来发起请求,因为 HttpClient 支持多线程、连接池、代理等技术,而 Jsoup 对此的支持并不理想。专业的事情交给专业的人,HttpClient发送请求抓取数据,Jsoup做解析
Jsoup 解析字符串
Jsoup解析文件
这是上面的静态页面。除了转换成String再解析,我们也可以直接解析文件
使用 Dom 遍历文档
记得还有一个sax解析,比较麻烦,现在差点忘了;
Dom解析,不知道大家有没有听过或者用过。反正我之前用过,但是解析的确实是XML。先简单介绍一个Dmo方法。
Dmo 解析会将目标文档视为一个对象。首先将整个文档加载到内存中。如果文档太大,内存可能会溢出(一般不会)。加载到内存后会构建一个Dom树,然后Just开始提供访问和修改操作
如果你之前没有学习过,我们通过一个小Demo来学习。如果您使用过它,我们有权对其进行审核:
Java代码如下: 我演示了几个常用的获取页面数据的API
从元素中获取属性
选择器
下面是上述always选择器的使用演示
选择器选择器组合使用
Hello World 类爬虫案例列表
在上面的学习中,我们已经知道HttpClient是用来爬取数据的,Jsoup是用来解析HttpClient爬取到的数据的。下面我们来练习一下这两个工具的使用。
搁浅,暂时……以后更新
java爬虫抓取动态网页(北京知名的房源网站python3.6怎么用解密?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-25 04:01
java爬虫抓取动态网页首先我们需要抓取这个动态网页的url,然后就是内容格式的解析了,我一直用python,简单的说就是生成下载列表url,item对象,并在python代码中处理解析,这里同一个网页的编码方式和url等等,因为技术原因,我的系统环境版本低了一版,没办法完美调用爬虫抓取。今天分享一个小案例,爬取北京知名的一些房源网站,我使用python3.6,先说效果吧:首先我们要有具体的数据,获取知名房源网站数据的网站网址,再就是提取出url,可以查看代码,保存url,最后写入url文件。
代码地址:-811144848.html,获取地址:,一旦确定数据要求,我们在不影响行为不影响项目不影响公司业务的前提下,什么code代码加密,java加密,vip代码加密,只能告诉代码的使用人无论懂不懂,都能看懂代码,你说好不好用。
我一般直接用google..
qq空间访问?
高德地图
电脑ai识别软件
小说下载器或者网页反爬技术
起点中文网很好用
会方便很多吧,有了页面的md5算法就可以猜出大部分主流网站的ip,因为他们的md5是标准的,baidu用ascii解密就能破解用md5解密用是以下这个网站的页面,很赞,ip验证码,直接应用于ip上了whois。icmp。com。phplar。qq。com。51。com。51。com。51。com。51。
com。51。com。51。com。51。com。51。com。51。com。还有无线网络的ip验证要去这个网站应该也可以访问。 查看全部
java爬虫抓取动态网页(北京知名的房源网站python3.6怎么用解密?)
java爬虫抓取动态网页首先我们需要抓取这个动态网页的url,然后就是内容格式的解析了,我一直用python,简单的说就是生成下载列表url,item对象,并在python代码中处理解析,这里同一个网页的编码方式和url等等,因为技术原因,我的系统环境版本低了一版,没办法完美调用爬虫抓取。今天分享一个小案例,爬取北京知名的一些房源网站,我使用python3.6,先说效果吧:首先我们要有具体的数据,获取知名房源网站数据的网站网址,再就是提取出url,可以查看代码,保存url,最后写入url文件。
代码地址:-811144848.html,获取地址:,一旦确定数据要求,我们在不影响行为不影响项目不影响公司业务的前提下,什么code代码加密,java加密,vip代码加密,只能告诉代码的使用人无论懂不懂,都能看懂代码,你说好不好用。
我一般直接用google..
qq空间访问?
高德地图
电脑ai识别软件
小说下载器或者网页反爬技术
起点中文网很好用
会方便很多吧,有了页面的md5算法就可以猜出大部分主流网站的ip,因为他们的md5是标准的,baidu用ascii解密就能破解用md5解密用是以下这个网站的页面,很赞,ip验证码,直接应用于ip上了whois。icmp。com。phplar。qq。com。51。com。51。com。51。com。51。
com。51。com。51。com。51。com。51。com。51。com。还有无线网络的ip验证要去这个网站应该也可以访问。
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-22 01:15
htmlunit 是一个开源的 java 页面分析工具。启动htmlunit后,底层会启动一个非界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage page = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream is = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,从而获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
重要的一点是 HtmlUnit 提供了对执行 javascript 的支持:
page.executeJavaScript(javascript)
执行js后返回一个ScriptResult对象,通过该对象可以获取执行js后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。 查看全部
java爬虫抓取动态网页(开源java页面分析工具启动htmlunit之后会启动一个无界面浏览器)
htmlunit 是一个开源的 java 页面分析工具。启动htmlunit后,底层会启动一个非界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage page = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream is = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,从而获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
重要的一点是 HtmlUnit 提供了对执行 javascript 的支持:
page.executeJavaScript(javascript)
执行js后返回一个ScriptResult对象,通过该对象可以获取执行js后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。
java爬虫抓取动态网页(本文将介绍如何使用SeimiCrawler将页面中信息提取为结构化数据并存储到数据库中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-18 23:30
本文将介绍如何使用SeimiCrawler 将页面中的信息提取为结构化数据并存储到数据库中,这也是一个非常常见的使用场景。数据抓取将以博客园的博客为例。
建立基础数据结构
为了演示,为了简单起见,只创建一个表来存储博客标题和内容这两个主要信息。表格如下:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
同时创建对应的Bean对象,如下:
package cn.wanghaomiao.model;
import cn.wanghaomiao.seimi.annotation.Xpath;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.builder.ToStringBuilder;
/**
* Xpath语法可以参考 http://jsoupxpath.wanghaomiao.cn/
*/
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
//也可以这么写 @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
if (StringUtils.isNotBlank(content)&&content.length()>100){
//方便查看截断下
this.content = StringUtils.substring(content,0,100)+"...";
}
return ToStringBuilder.reflectionToString(this);
}
}
这里的@Xpath 注释应该侧重于介绍。注释配置了对应字段的 XPath 提取规则。后面会介绍SeimiCrawler会调用Response.render(Class bean)自动解析并填充对应的字段。对于开发者来说,提取结构化数据最重要的工作就在这里,仅此而已,接下来就是如何串连起来。
实现数据存储
本文演示了人人网早期开源开发的ORM框架paoding-jade的使用。由于SeimiCrawler 的对象池和依赖管理都是使用spring 实现的,所以SeimiCrawler 自然支持所有可以与spring 集成的ORM 框架。要启用 Jade,请添加 pom 依赖项:
net.paoding
paoding-rose-jade
2.0.u01
org.apache.commons
commons-dbcp2
2.1.1
mysql
mysql-connector-java
5.1.37
在resources下添加seimi-jade.xml配置文件:
写DAO,
package cn.wanghaomiao.dao;
import cn.wanghaomiao.model.BlogContent;
import net.paoding.rose.jade.annotation.DAO;
import net.paoding.rose.jade.annotation.ReturnGeneratedKeys;
import net.paoding.rose.jade.annotation.SQL;
@DAO
public interface StoreToDbDAO {
@ReturnGeneratedKeys
@SQL("insert into blog (title,content,update_time) values (:1.title,:1.content,now())")
public int save(BlogContent blog);
}
数据存储完成后,下一步就是我们的爬虫规则类。
履带式
直接地:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.dao.StoreToDbDAO;
import cn.wanghaomiao.model.BlogContent;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.List;
/**
* 将解析出来的数据直接存储到数据库中
*/
@Crawler(name = "storedb")
public class DatabaseStoreDemo extends BaseSeimiCrawler {
@Autowired
private StoreToDbDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),"renderBean"));
}
} catch (Exception e) {
//ignore
}
}
public void renderBean(Response response){
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}",blog,response.getUrl());
//使用神器paoding-jade存储到DB
int blogId = storeToDbDAO.save(blog);
logger.info("store sus,blogId = {}",blogId);
} catch (Exception e) {
//ignore
}
}
}
Github上也有完整的demo,可以下载,自己试试,直接点击。 查看全部
java爬虫抓取动态网页(本文将介绍如何使用SeimiCrawler将页面中信息提取为结构化数据并存储到数据库中)
本文将介绍如何使用SeimiCrawler 将页面中的信息提取为结构化数据并存储到数据库中,这也是一个非常常见的使用场景。数据抓取将以博客园的博客为例。
建立基础数据结构
为了演示,为了简单起见,只创建一个表来存储博客标题和内容这两个主要信息。表格如下:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
同时创建对应的Bean对象,如下:
package cn.wanghaomiao.model;
import cn.wanghaomiao.seimi.annotation.Xpath;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.builder.ToStringBuilder;
/**
* Xpath语法可以参考 http://jsoupxpath.wanghaomiao.cn/
*/
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
//也可以这么写 @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
if (StringUtils.isNotBlank(content)&&content.length()>100){
//方便查看截断下
this.content = StringUtils.substring(content,0,100)+"...";
}
return ToStringBuilder.reflectionToString(this);
}
}
这里的@Xpath 注释应该侧重于介绍。注释配置了对应字段的 XPath 提取规则。后面会介绍SeimiCrawler会调用Response.render(Class bean)自动解析并填充对应的字段。对于开发者来说,提取结构化数据最重要的工作就在这里,仅此而已,接下来就是如何串连起来。
实现数据存储
本文演示了人人网早期开源开发的ORM框架paoding-jade的使用。由于SeimiCrawler 的对象池和依赖管理都是使用spring 实现的,所以SeimiCrawler 自然支持所有可以与spring 集成的ORM 框架。要启用 Jade,请添加 pom 依赖项:
net.paoding
paoding-rose-jade
2.0.u01
org.apache.commons
commons-dbcp2
2.1.1
mysql
mysql-connector-java
5.1.37
在resources下添加seimi-jade.xml配置文件:
写DAO,
package cn.wanghaomiao.dao;
import cn.wanghaomiao.model.BlogContent;
import net.paoding.rose.jade.annotation.DAO;
import net.paoding.rose.jade.annotation.ReturnGeneratedKeys;
import net.paoding.rose.jade.annotation.SQL;
@DAO
public interface StoreToDbDAO {
@ReturnGeneratedKeys
@SQL("insert into blog (title,content,update_time) values (:1.title,:1.content,now())")
public int save(BlogContent blog);
}
数据存储完成后,下一步就是我们的爬虫规则类。
履带式
直接地:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.dao.StoreToDbDAO;
import cn.wanghaomiao.model.BlogContent;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.List;
/**
* 将解析出来的数据直接存储到数据库中
*/
@Crawler(name = "storedb")
public class DatabaseStoreDemo extends BaseSeimiCrawler {
@Autowired
private StoreToDbDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),"renderBean"));
}
} catch (Exception e) {
//ignore
}
}
public void renderBean(Response response){
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}",blog,response.getUrl());
//使用神器paoding-jade存储到DB
int blogId = storeToDbDAO.save(blog);
logger.info("store sus,blogId = {}",blogId);
} catch (Exception e) {
//ignore
}
}
}
Github上也有完整的demo,可以下载,自己试试,直接点击。
java爬虫抓取动态网页(谷歌能DOM是什么?Google不能是如何抓取Java的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-18 23:28
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。
长话短说
1. 我们进行了一系列的测试,已经确认谷歌可以通过多种方式执行和收录 Java。我们也确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。尽管这需要更多的工作,但这是我们的多项测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,谷歌显然不仅可以算出他们抓取的 Java 类型和 收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以收录 动态生成内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析HTML并执行Java的结果就是DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 Java 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。这个结论得到了引用谷歌指南的支持:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪此类链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会怎样?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们的预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 Java 函数之前,已经准备好抓取 URL 的链接和队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解以上基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。 查看全部
java爬虫抓取动态网页(谷歌能DOM是什么?Google不能是如何抓取Java的)
编译:伯乐在线/刘建超-Jc
我们测试了 Google 爬虫如何抓取 Java,这是我们从中学到的东西。
认为 Google 无法处理 Java?再想想。Audette Audette 分享了一系列测试结果,他和他的同事测试了 Google 和 收录 会抓取哪些类型的 Java 特性。
长话短说
1. 我们进行了一系列的测试,已经确认谷歌可以通过多种方式执行和收录 Java。我们也确认了 Google 可以渲染整个页面并读取 DOM,从而可以收录 动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都受到关注。动态插入DOM的内容也可以爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源代码语句。尽管这需要更多的工作,但这是我们的多项测试之一。
简介:Google 执行 Java 并读取 DOM
早在 2008 年,Google 就成功爬取了 Java,但很可能仅限于某种方式。
今天,谷歌显然不仅可以算出他们抓取的 Java 类型和 收录,而且在渲染整个网页方面也取得了重大进展(尤其是最近 12 到 18 个月)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaS 事件和 收录。经过研究,我们发现了惊人的结果,并确认 Google 不仅可以执行各种 Java 事件,还可以收录 动态生成内容。怎么做?Google 可以读取 DOM。
什么是DOM?
很多从事SEO的人不了解什么是文档对象模型(DOM)。
当浏览器请求一个页面时会发生什么,DOM 是如何参与的?
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和构建数据(例如 HTML 和 XML)。该接口允许 Web 浏览器将它们组合成一个文档。
DOM 还定义了如何获取和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 Java 和 Web 应用程序中的动态内容。
DOM 代表接口或“桥”,将网页与编程语言连接起来。解析HTML并执行Java的结果就是DOM。网页的内容不仅(不仅)是源代码,而且是 DOM。这使它变得非常重要。
Java 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM,并且可以解析信号和动态插入的内容,例如标题标签、页面文本、标题标签和元注释(例如:rel = canonical)。您可以阅读完整的详细信息。
这一系列的测试和结果
因为想知道会爬取什么Java特性和收录,所以分别在谷歌爬虫上创建了一系列测试。通过创建控件,确保可以独立理解 URL 活动。下面,让我们详细介绍一些有趣的测试结果。它们分为5类:
Java重定向
Java链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要例子
示例:用于测试 Google 爬虫理解 Java 能力的页面。
1. Java 重定向
我们首先测试了常见的 Java 重定向。以不同方式表达的 URL 会发生什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL URL 调用 window.location,而测试 B 使用相对路径。
结果:重定向很快就被谷歌跟踪了。从收录的角度来看,它们被解释为301——最终状态URL,而不是谷歌收录中的重定向URL。
在随后的测试中,我们在权威网页上使用完全相同的内容来完成使用 Java 重定向到同一站点的新页面。原创网址在 Google 热门查询的首页上排名。
结果:果然,重定向被谷歌跟踪了,但是原创页面不是收录。新的URL是收录,它立即在同一个查询页面的同一个位置上排名。这让我们感到惊讶。从排名的角度来看,Java 重定向行为(有时)与永久 301 重定向非常相似。
下次,您的客户想要为他们的 网站 完成 Java 重定向动作,您可能不需要回答,或者回答:“请不要”。因为这好像有转职排名信号的关系。这个结论得到了引用谷歌指南的支持:
使用 Java 重定向用户可能是一种合法的做法。例如,如果将登录用户重定向到内部页面,则可以使用 Java 来完成此操作。在仔细检查 Java 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,将 301 重定向重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以为此使用 Java 重定向。
2. Java 链接
我们使用多种编码方法测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。历史搜索引擎一直无法跟踪此类链接。我们要确定是否会跟踪 onchange 事件处理程序。重要的是,这只是特定类型的执行,而我们需要的是:其他变化的影响,而不是像上面Java重定向的强制操作。
示例:Google Work 页面上的语言选择下拉菜单。
结果:链接被完全抓取和跟踪。
我们还测试了常见的 Java 链接。以下是最常见的 Java 链接类型,而传统 SEO 推荐纯文本。这些测试包括 Java 链接代码:
结果:链接被完全抓取和跟踪。
我们接下来的测试是进一步测试事件处理程序,比如上面的onchange测试。具体来说,我们要使用鼠标移动的事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(在本例中为 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全抓取和跟踪。
构造链接:我们知道谷歌可以执行Java,但是我们想确认他们是否可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全抓取和跟踪。
3. 动态插入内容
显然,这些是要点:动态插入文本、图像、链接和导航。高质量的文本内容对于搜索引擎理解网页的主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以统计动态插入的文本,文本来自页面的HTML源代码。
2. 测试搜索引擎是否可以统计动态插入的文本,并且文本来自页面的HTML源代码之外(在外部Java文件中)。
结果:两种情况下都可以抓取文本和收录,页面根据内容排名。凉爽的!
为了深入了解,我们测试了一个用Java编写的客户端全局导航,导航中的链接是通过document.writeIn函数插入的,确认可以完全爬取和跟踪。需要指出的是,Google 可以解释网站 使用AngularJS 框架和HTML5 History API (pushState) 构建,可以渲染和收录 它,并且可以像传统的静态网页一样进行排名。这就是不禁止 Google 爬虫获取外部文件和 Java 的重要性,这可能也是 Google 将其从 Ajax Supporting SEO Guide 中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,结果都是一样的。比如图片加载到DOM后,会被抓取并收录。我们甚至做了这样一个测试:通过动态生成结构数据来制作面包屑(breadcrumb navigation),并插入到DOM中。结果呢?成功插入后的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在推荐使用 JSON-LD 标签来形成结构化数据。我相信未来会有更多基于此的东西。
4. 动态插入元数据和页面元素
我们动态地将各种对 SEO 至关重要的标签插入到 DOM 中:
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级的顺序。当出现相互矛盾的信号时,哪一个会获胜?如果源代码中没有index和nofollow标签,DOM中没有index和follow标签会怎样?在这个协议中,HTTP x-robots 响应头的行为如何作为另一个变量?这将是未来全面测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签并支持 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试谷歌如何响应出现在源代码和 DOM 链接级别的 nofollow 属性。我们还创建了一个没有 nofollow 的控件。
对于nofollow,我们分别测试了源代码和DOM生成的注解。
源代码中的 nofollow 按我们的预期工作(不跟踪链接)。但是DOM中的nofollow无效(链接被跟踪,页面为收录)。为什么?因为修改 DOM 中 href 元素的操作发生得太晚了:谷歌在执行添加 rel="nofollow" 的 Java 函数之前,已经准备好抓取 URL 的链接和队列。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,nofollow 和链接将被跟踪,因为它们是同时插入的。
结果
从历史的角度来看,各种 SEO 建议都尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 Java 链接会损害主流搜索引擎的 SEO。显然,这对谷歌来说不再是问题。Java 链接的操作方式类似于普通的 HTML 链接(这只是表面,我们不知道程序在幕后做了什么)。
对于SEO,不了解以上基本概念和谷歌技术的人应该学习学习,以追赶当前的技术。如果你不考虑 DOM,你可能会失去一半的份额。
java爬虫抓取动态网页(Java爬虫遇到需要登录的网站,该怎么办还是反向解析法呢)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-18 02:03
这是 Java 爬虫系列博文中的第三篇。Java爬虫遇到上一篇需要登录的网站怎么办?在本文中,我们简要说明了爬虫遇到的登录问题的解决方案。在这个文章中,我们来谈谈遇到爬虫时数据异步加载的问题。这也是爬虫常见的问题。
现在很多都是前后端分离的项目,这会让数据异步加载的问题更加突出,所以在爬取的时候遇到这样的问题不要惊讶,不要慌。一般来说,这种问题有两种解决方案:
1、内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以拿到js渲染出来的页面,这样我们就和采集的静态页面一样了。此类常用工具有以下三种:
这些工具可以帮助我们解决异步数据加载的问题,但它们都有缺陷,即效率低下且不稳定。
2、逆向分析法
什么是逆向分析?我们js渲染页面的数据是通过Ajax从后端获取的。我们只需要找到对应的ajax请求连接就可以了,这样我们就可以获取到我们需要的数据了。逆向分析法的优点是通过这种方式得到。数据都是json格式,解析起来也比较方便。另一个优点是界面变化的概率相对于页面来说更小。它也有两个缺点。一是在使用Ajax时需要耐心和熟练,因为需要在一个大的推送请求中找到自己想要的东西,二是对JavaScript渲染的页面无能为力。
以上是异步数据加载的两种解决方案。为了加深大家的理解以及如何在项目中使用,我以采集网易新闻为例。网易新闻地址:. 使用两种申诉方式获取网易新闻的新闻列表。网易新闻如下:
内置浏览器Selenium方式
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。常用于自动化测试,常用于解决爬虫时的异步加载。如果我们想在我们的项目中使用Selenium,我们需要做两件事:
org.seleniumhq.selenium
selenium-java
3.141.59
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
完成以上两步后,我们就可以编写和使用Selenium采集网易新闻了。具体代码如下:
/**
* selenium 解决数据异步加载问题
* https://npm.taobao.org/mirrors/chromedriver/
*
* @param url
*/
public void selenium(String url) {
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
// 设置无头浏览器,这样就不会弹出浏览器窗口
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(url);
// 获取到要闻新闻列表
List webElements = webDriver.findElements(By.xpath("//div[@class='news_title']/h3/a"));
for (WebElement webElement : webElements) {
// 提取新闻连接
String article_url = webElement.getAttribute("href");
// 提取新闻标题
String title = webElement.getText();
if (article_url.contains("https://news.163.com/")) {
System.out.println("文章标题:" + title + " ,文章链接:" + article_url);
}
}
webDriver.close();
}
运行这个方法,得到如下结果:
我们已经使用Selenium正确提取了网易新闻列表。
逆向分析
逆向分析方法是通过ajax异步获取链接获取数据,直接获取新闻数据。如果没有技巧,找Ajax的过程会很痛苦,因为一个页面加载的链接太多,看看网易新闻的网络:
有数百个请求,我如何找到哪个请求获取新闻数据?不嫌麻烦的话,可以一一去点,绝对能找到。另一种快速的方法是使用网络的搜索功能。如果你不知道搜索按钮,我在上图中圈出了它。只需在新闻中复制一个新闻标题,然后搜索,即可得到结果,如下图所示:
这样我们就快速的获取到了重要新闻数据的请求链接,链接为:访问链接,查看链接返回的数据,如下图:
从数据上可以看出,我们需要的数据都在这里了,所以我们只需要解析这一段数据。从这条数据中解析新闻标题和新闻链接有两种方式,一种是正则表达式,另一种是将数据转成json或者list。这里我选择第二种方法,使用fastjson将返回的数据转换成JSONArray。所以我们要引入fastjson,并在pom.xml中引入fastjson依赖:
com.alibaba
fastjson
1.2.59
除了引入fastjson依赖之外,我们还需要对转换前的数据进行简单的处理,因为当前数据不符合list的格式,需要去掉data_callback(也是最后一个)。获取网易新闻的具体逆向分析代码如下:
/**
* 使用反向解析法 解决数据异步加载的问题
*
* @param url
*/
public void httpclientMethod(String url) throws IOException {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity, "GBK");
// 先替换掉最前面的 data_callback(
body = body.replace("data_callback(", "");
// 过滤掉最后面一个 )右括号
body = body.substring(0, body.lastIndexOf(")"));
// 将 body 转换成 JSONArray
JSONArray jsonArray = JSON.parseArray(body);
for (int i = 0; i < jsonArray.size(); i++) {
JSONObject data = jsonArray.getJSONObject(i);
System.out.println("文章标题:" + data.getString("title") + " ,文章链接:" + data.getString("docurl"));
}
} else {
System.out.println("处理失败!!!返回状态码:" + response.getStatusLine().getStatusCode());
}
}
编写main方法,执行上面的方法。需要注意的地方是:这个时候传入的链接不是。得到以下结果:
两种方法都成功获取了网易新闻异步加载的新闻列表。对于这两种方法的选择,我个人更倾向于使用逆向分析法,因为它的性能和稳定性比浏览器内置内核更可靠。但是,对于一些使用 JavaScript 片段渲染的页面,内置浏览器更可靠。所以要根据具体情况来选择。
希望这篇文章对你有帮助,下一篇是关于爬虫IP被封的问题。如果你对爬虫感兴趣,不妨关注一波,互相学习,互相进步
源代码:源代码
文章希望大家多多指教,共同学习,共同进步
最后 查看全部
java爬虫抓取动态网页(Java爬虫遇到需要登录的网站,该怎么办还是反向解析法呢)
这是 Java 爬虫系列博文中的第三篇。Java爬虫遇到上一篇需要登录的网站怎么办?在本文中,我们简要说明了爬虫遇到的登录问题的解决方案。在这个文章中,我们来谈谈遇到爬虫时数据异步加载的问题。这也是爬虫常见的问题。
现在很多都是前后端分离的项目,这会让数据异步加载的问题更加突出,所以在爬取的时候遇到这样的问题不要惊讶,不要慌。一般来说,这种问题有两种解决方案:
1、内置浏览器内核
内置浏览器就是在爬虫程序中启动一个浏览器内核,这样我们就可以拿到js渲染出来的页面,这样我们就和采集的静态页面一样了。此类常用工具有以下三种:
这些工具可以帮助我们解决异步数据加载的问题,但它们都有缺陷,即效率低下且不稳定。
2、逆向分析法
什么是逆向分析?我们js渲染页面的数据是通过Ajax从后端获取的。我们只需要找到对应的ajax请求连接就可以了,这样我们就可以获取到我们需要的数据了。逆向分析法的优点是通过这种方式得到。数据都是json格式,解析起来也比较方便。另一个优点是界面变化的概率相对于页面来说更小。它也有两个缺点。一是在使用Ajax时需要耐心和熟练,因为需要在一个大的推送请求中找到自己想要的东西,二是对JavaScript渲染的页面无能为力。
以上是异步数据加载的两种解决方案。为了加深大家的理解以及如何在项目中使用,我以采集网易新闻为例。网易新闻地址:. 使用两种申诉方式获取网易新闻的新闻列表。网易新闻如下:
内置浏览器Selenium方式
Selenium 是一种模拟浏览器进行自动化测试的工具。它提供了一组 API 来与真正的浏览器内核进行交互。常用于自动化测试,常用于解决爬虫时的异步加载。如果我们想在我们的项目中使用Selenium,我们需要做两件事:
org.seleniumhq.selenium
selenium-java
3.141.59
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
完成以上两步后,我们就可以编写和使用Selenium采集网易新闻了。具体代码如下:
/**
* selenium 解决数据异步加载问题
* https://npm.taobao.org/mirrors/chromedriver/
*
* @param url
*/
public void selenium(String url) {
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "chromedriver.exe");
// 设置无头浏览器,这样就不会弹出浏览器窗口
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--headless");
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(url);
// 获取到要闻新闻列表
List webElements = webDriver.findElements(By.xpath("//div[@class='news_title']/h3/a"));
for (WebElement webElement : webElements) {
// 提取新闻连接
String article_url = webElement.getAttribute("href");
// 提取新闻标题
String title = webElement.getText();
if (article_url.contains("https://news.163.com/";)) {
System.out.println("文章标题:" + title + " ,文章链接:" + article_url);
}
}
webDriver.close();
}
运行这个方法,得到如下结果:
我们已经使用Selenium正确提取了网易新闻列表。
逆向分析
逆向分析方法是通过ajax异步获取链接获取数据,直接获取新闻数据。如果没有技巧,找Ajax的过程会很痛苦,因为一个页面加载的链接太多,看看网易新闻的网络:
有数百个请求,我如何找到哪个请求获取新闻数据?不嫌麻烦的话,可以一一去点,绝对能找到。另一种快速的方法是使用网络的搜索功能。如果你不知道搜索按钮,我在上图中圈出了它。只需在新闻中复制一个新闻标题,然后搜索,即可得到结果,如下图所示:
这样我们就快速的获取到了重要新闻数据的请求链接,链接为:访问链接,查看链接返回的数据,如下图:
从数据上可以看出,我们需要的数据都在这里了,所以我们只需要解析这一段数据。从这条数据中解析新闻标题和新闻链接有两种方式,一种是正则表达式,另一种是将数据转成json或者list。这里我选择第二种方法,使用fastjson将返回的数据转换成JSONArray。所以我们要引入fastjson,并在pom.xml中引入fastjson依赖:
com.alibaba
fastjson
1.2.59
除了引入fastjson依赖之外,我们还需要对转换前的数据进行简单的处理,因为当前数据不符合list的格式,需要去掉data_callback(也是最后一个)。获取网易新闻的具体逆向分析代码如下:
/**
* 使用反向解析法 解决数据异步加载的问题
*
* @param url
*/
public void httpclientMethod(String url) throws IOException {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet(url);
CloseableHttpResponse response = httpclient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
HttpEntity entity = response.getEntity();
String body = EntityUtils.toString(entity, "GBK");
// 先替换掉最前面的 data_callback(
body = body.replace("data_callback(", "");
// 过滤掉最后面一个 )右括号
body = body.substring(0, body.lastIndexOf(")"));
// 将 body 转换成 JSONArray
JSONArray jsonArray = JSON.parseArray(body);
for (int i = 0; i < jsonArray.size(); i++) {
JSONObject data = jsonArray.getJSONObject(i);
System.out.println("文章标题:" + data.getString("title") + " ,文章链接:" + data.getString("docurl"));
}
} else {
System.out.println("处理失败!!!返回状态码:" + response.getStatusLine().getStatusCode());
}
}
编写main方法,执行上面的方法。需要注意的地方是:这个时候传入的链接不是。得到以下结果:
两种方法都成功获取了网易新闻异步加载的新闻列表。对于这两种方法的选择,我个人更倾向于使用逆向分析法,因为它的性能和稳定性比浏览器内置内核更可靠。但是,对于一些使用 JavaScript 片段渲染的页面,内置浏览器更可靠。所以要根据具体情况来选择。
希望这篇文章对你有帮助,下一篇是关于爬虫IP被封的问题。如果你对爬虫感兴趣,不妨关注一波,互相学习,互相进步
源代码:源代码
文章希望大家多多指教,共同学习,共同进步
最后
java爬虫抓取动态网页(主流java爬虫框架有哪些?(1)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-17 04:13
文本
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可扩展支持网页字段的结构化提取,并可作为垂直采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(谷歌很多大佬参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的就用selenium;
参考链接: 查看全部
java爬虫抓取动态网页(主流java爬虫框架有哪些?(1)框架)
文本
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。它可以在浏览器界面上实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可扩展支持网页字段的结构化提取,并可作为垂直采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(谷歌很多大佬参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
[Github 存储库]
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的就用selenium;
参考链接:
java爬虫抓取动态网页(java爬虫抓取动态网页,不需要知道那些动态代码。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-15 14:02
java爬虫抓取动态网页,不需要知道那些动态网页代码。答案在excel里都有。把那些二进制网址,拖入excel表格,点击右键,就可以得到网页地址了,在python里实现也很简单。原理:传入url_returnstr="/xxx"url=url_return.split("")[2]。
传统方法:http转成curlrequest转成curl
等同于谷歌爬虫,
两者大同小异,都是通过url库来爬取网页,只是在传统爬虫中,需要知道url存在的情况,在数据抓取时就需要处理;而数据抓取后,再通过url库来进行解析。至于两者最大的区别,应该就是前者使用python,后者使用urllib或urllib2吧。
前两种说简单,你也可以用requests抓,后面两种抓包无门槛,有概念了,别不懂就乱抓了。
现在的urllib都是getpost,将需要爬取的网址先请求然后返回xml。python常用requests库能够解析html文件。这里getpost大体是分出两个步骤:1.将请求的html上传到服务器,这是个单纯的get请求,参数为你填的url;2.post请求,请求是按照提交资料时候的格式(如手机号),提交参数。
我们常看到的一个爬虫,都是为get请求:为curl解析:最后返回html:请问题主,如果不知道curl库怎么用?请参考:这里有一个爬虫的例子。 查看全部
java爬虫抓取动态网页(java爬虫抓取动态网页,不需要知道那些动态代码。)
java爬虫抓取动态网页,不需要知道那些动态网页代码。答案在excel里都有。把那些二进制网址,拖入excel表格,点击右键,就可以得到网页地址了,在python里实现也很简单。原理:传入url_returnstr="/xxx"url=url_return.split("")[2]。
传统方法:http转成curlrequest转成curl
等同于谷歌爬虫,
两者大同小异,都是通过url库来爬取网页,只是在传统爬虫中,需要知道url存在的情况,在数据抓取时就需要处理;而数据抓取后,再通过url库来进行解析。至于两者最大的区别,应该就是前者使用python,后者使用urllib或urllib2吧。
前两种说简单,你也可以用requests抓,后面两种抓包无门槛,有概念了,别不懂就乱抓了。
现在的urllib都是getpost,将需要爬取的网址先请求然后返回xml。python常用requests库能够解析html文件。这里getpost大体是分出两个步骤:1.将请求的html上传到服务器,这是个单纯的get请求,参数为你填的url;2.post请求,请求是按照提交资料时候的格式(如手机号),提交参数。
我们常看到的一个爬虫,都是为get请求:为curl解析:最后返回html:请问题主,如果不知道curl库怎么用?请参考:这里有一个爬虫的例子。
java爬虫抓取动态网页(1.代码实现接下来提取首页jobName中包含python的所有链接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-15 03:11
)
根据联合国网站可访问性审计报告,主流网站中73%的重要功能依赖JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这种动态依赖JavaScript,我们需要采用相应的方法,比如JavaScript逆向工程,渲染JavaScript。
1.动态网页示例
如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12
看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/?jl=736&kw=python&kt=3'
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2. 逆向工程动态网页
在firefox中按F12,点击控制台打开XHR
点击打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3.代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
查看全部
java爬虫抓取动态网页(1.代码实现接下来提取首页jobName中包含python的所有链接
)
根据联合国网站可访问性审计报告,主流网站中73%的重要功能依赖JavaScript。它不适用于单页应用程序的简单表单事件。使用 JavaScript 时,加载后不再立即下载所有页面内容。这将导致许多网页中显示的内容不会出现在 HTML 源代码中。对于这种动态依赖JavaScript,我们需要采用相应的方法,比如JavaScript逆向工程,渲染JavaScript。
1.动态网页示例
如上图,打开兆联招聘首页,输入python,搜索就会出现上图页面,现在我们抓取上图中红色标记的链接地址
首先分析网页,获取该位置的div元素信息。我这里用的是firefox浏览器,按F12
看上图,红色标记是我们要获取的链接地址,现在用代码获取链接试试
import requests
from bs4 import BeautifulSoup as bs
url = 'https://sou.zhaopin.com/?jl=736&kw=python&kt=3'
reponse = requests.get(url)
soup = bs(reponse.text,"lxml")
print(soup.select('span[title="JAVA软件工程师"]'))
print(soup.select('a[class~="contentpile__content__wrapper__item__info"]'))
输出结果为:[][]
这意味着这个示例爬虫失败了。查看源码会发现我们抓取的元素其实是空的,但是firefox给我们展示的是网页的当前状态,也就是使用JavaScript动态加载搜索结果后的网页。 .
2. 逆向工程动态网页
在firefox中按F12,点击控制台打开XHR
点击打开,查看回复内容
你会发现最后一行有我们想要的内容,继续点击结果的index 0
很好,这就是我们要找的信息
接下来我们可以爬取第三行的网址,得到我们想要的json信息。
3.代码实现
接下来,提取首页jobName中所有收录python的链接:
import requests
import urllib
import http
import json
def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1,
education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1,
kw="python",kt=3):
url = url.format(start,pagesize,cityid,workEXperience,education,companyType,\
employmentType,jobWelfareTag,kw,kt)
return url;
def ParseUrlToHtml(url,headers):
cjar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar))
headers_list = []
for key,value in headers.items():
headers_list.append(key)
headers_list.append(value)
opener.add_headers = [headers_list]
html = None
try:
urllib.request.install_opener(opener)
request = urllib.request.Request(url)
reponse = opener.open(request)
html = reponse.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e, 'code'):
print ("HTTPErro:", e.code)
elif hasattr(e, 'reason'):
print ("URLErro:", e.reason)
return opener,reponse,html
'''print(ajax)
with open("zlzp.txt", "w") as pf:
pf.write(json.dumps(ajax,indent=4))'''
if __name__ == "__main__":
url = 'https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}'\
'&workExperience={}&education={}&companyType={}&employmentType={}'\
'&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497'\
'&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400'
headers = {"Connection":"keep-alive",
"Accept":"application/json, text/plain, */*",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0'}
opener,reponse,html = ParseUrlToHtml(format_url(url), headers)
if reponse.code == 200:
try:
ajax = json.loads(html)
except ValueError as e:
print(e)
ajax = None
else:
results = ajax["data"]["results"]
for result in results:
if -1 != result["jobName"].lower().find("python"):
print(result["jobName"],":",result["positionURL"])
输出:
java爬虫抓取动态网页(使用RSelenium包和Rwebdriver包的前期准备步骤:Java环境)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-15 03:00
在使用rvest包抓取新浪财经A股交易数据时,我们介绍了rvest包的使用。但是rvest包只能抓取静态网页,不能对ajax异步加载等动态网页结构做任何事情。在 R 语言中,可以使用 RSelenium 包和 Rwebdriver 包来抓取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。由于Selenium 是Java 程序,因此在使用RSelenium 包和Rwebdriver 包之前,您必须为您的计算机设置Java 环境。以下是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包可以直接从CRAN下载安装,Rwebdriver包需要从github下载。代码如下(必须先安装devtools包):
library(devtools)
install_github(repo= "Rwebdriver", username = "crubba")
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、JDK下载(百度JDK可以下载)
2、JDK安装(按照提示安装即可)
3、环境变量设置(参考Java环境变量设置)
Windows下需要设置3个环境变量,分别是JAVA_HOME、CLASSPATH和Path。具体步骤如下:
(1)右击“计算机”,然后选择:属性-高级系统设置-环境变量;
(2)新建一个JAVA_HOME变量,指向jdk安装目录。具体操作:点击System Variables下的New,
然后在变量名中输入JAVA_HOME,在变量值中输入安装目录。比如我的JDK安装在C:\Program Files(x86)\Java\jdk1.8.0_144,
(3)参考(2)新建环境变量CLASSPATH中的步骤,
变量名类路径
变量值.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
注意数值前面的两个符号;
(4)设置path环境变量,在系统变量下找到path变量,打开后添加在变量值的末尾;%JAVA_HOME%\bin,注意前面的;.
(5)三个变量设置好后,打开cmd(命令提示符,在Windows中搜索cmd找到),输入javac,没有报错,说明安装成功。
三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是(最近官网不可用,可以试试这个)
2、下载浏览器驱动,
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
3、 打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以在cmd中输入java-Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.8.1.jar
注意如果selenium和驱动没有放在java默认目录下,这里需要引用绝对路径。
如果出现以下情况,则操作成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。
四、 至此所有前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例:
<p>library(RSelenium)
#### 打开浏览器
remDr 查看全部
java爬虫抓取动态网页(使用RSelenium包和Rwebdriver包的前期准备步骤:Java环境)
在使用rvest包抓取新浪财经A股交易数据时,我们介绍了rvest包的使用。但是rvest包只能抓取静态网页,不能对ajax异步加载等动态网页结构做任何事情。在 R 语言中,可以使用 RSelenium 包和 Rwebdriver 包来抓取此类网页。
RSelenium 包和 Rwebdriver 包都通过调用 Selenium Server 来模拟浏览器环境。其中Selenium是一款用于网页测试的Java开源软件,可以模拟浏览器的点击、滚动、滑动、文本输入等操作。由于Selenium 是Java 程序,因此在使用RSelenium 包和Rwebdriver 包之前,您必须为您的计算机设置Java 环境。以下是使用RSelenium包和Rwebdriver包的准备步骤:
一、下载并安装RSelenium包和Rwebdriver包
RSelenium包可以直接从CRAN下载安装,Rwebdriver包需要从github下载。代码如下(必须先安装devtools包):
library(devtools)
install_github(repo= "Rwebdriver", username = "crubba")
二、Java 环境设置
理论上是调用Java程序安装JRE(Java Runtime Environment),但本文推荐安装JDK(Java Development Kit)。 JDK收录JRE模块,网上找到的Java环境变量设置教程大多是针对JDK的。
1、JDK下载(百度JDK可以下载)
2、JDK安装(按照提示安装即可)
3、环境变量设置(参考Java环境变量设置)
Windows下需要设置3个环境变量,分别是JAVA_HOME、CLASSPATH和Path。具体步骤如下:
(1)右击“计算机”,然后选择:属性-高级系统设置-环境变量;
(2)新建一个JAVA_HOME变量,指向jdk安装目录。具体操作:点击System Variables下的New,
然后在变量名中输入JAVA_HOME,在变量值中输入安装目录。比如我的JDK安装在C:\Program Files(x86)\Java\jdk1.8.0_144,
(3)参考(2)新建环境变量CLASSPATH中的步骤,
变量名类路径
变量值.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
注意数值前面的两个符号;
(4)设置path环境变量,在系统变量下找到path变量,打开后添加在变量值的末尾;%JAVA_HOME%\bin,注意前面的;.
(5)三个变量设置好后,打开cmd(命令提示符,在Windows中搜索cmd找到),输入javac,没有报错,说明安装成功。
三、Selenium 及浏览器驱动下载及运行
1、下载selenium,网址是(最近官网不可用,可以试试这个)
2、下载浏览器驱动,
Chrome 驱动程序:
火狐驱动程序:
下载时请注意浏览器的版本。如果使用Chrome浏览器,请参考selenium的chromedriver与chrome版本映射表(更新为v2.34).
3、 打开cmd运行selenium和浏览器驱动。比如我用的是Chrome浏览器,所以在cmd中输入java-Dwebdriver.chrome.driver="E:\Selenium\chromedriver.exe"-jarE:\Selenium\selenium-server-standalone-3.8.1.jar
注意如果selenium和驱动没有放在java默认目录下,这里需要引用绝对路径。
如果出现以下情况,则操作成功(R语言调用RSelenium包和Rwebdriver包时,cmd不应关闭)。
四、 至此所有前期准备工作已经完成,可以使用RSelenium包和Rwebdriver包了。
以RSelenium包为例:
<p>library(RSelenium)
#### 打开浏览器
remDr
java爬虫抓取动态网页(网易云音乐有哪些评论过万的歌曲?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-12 06:05
)
天马营崖发表
原因
前两天在知乎看到一个帖子,“网易云音乐哪些歌曲评论过万?” ”有段时间,我用Java实现了一个简单的爬虫,这里简单记录一下。
最终结果是开放的。可以随意参观。请点击这里>>>>>> 网易云音乐爬虫结果。
爬虫简介
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。一般的网络爬虫大致包括以下几个步骤:
网络爬虫的一般流程如上图所示。不管你在做什么爬虫应用,整体流程都是类似的。现在,我们将定制一个特定的网络爬虫,专门爬取基于网易云音乐的音乐评论数。
网页类型分析的前期准备
首先,我们需要对网易云音乐的整个网站有一个大致的了解。进入网易云音乐首页后,我们发现大概有几种类型的网址:
我们最终需要爬取的数据在歌曲页面中,其中收录歌曲名称和歌曲评论数。
此外,我们还需要获取尽可能多的歌曲页面。我们可以从前面的 6 类页面中获取这些信息。其中播放列表列表和播放列表页面结构最简单,可以通过分页直接访问播放列表列表。因此,我们选择播放列表页面作为我们的初始页面,然后播放列表列表-播放列表-歌曲就可以一路向下爬取。
设计数据模型
通过上面的分析,我们可以知道我们要做两件事,一是抓取页面播放列表list-playlist-songs,二是存储最终结果。所以,我们只需要两个对象,一个用来存放页面相关信息,url,页面类型,是否被爬取(html和title作为临时数据存储),另一个用来存放歌曲相关信息, url, 歌曲名, 评论数。因此,模型类如下:
public class WebPage {
public enum PageType {
song, playlist, playlists;
}
public enum Status {
crawled, uncrawl;
}
private String url;
private String title;
private PageType type;
private Status status;
private String html;
...
}
public class Song {
private String url;
private String title;
private Long commentCount;
...
}
获取网页内容并解析
根据前面的分析,我们需要爬的页面有3种:播放列表、播放列表和歌曲。为了验证这个想法的可行性,我们先用代码对这三类网页进行解析,并将网页内容获取和分析的代码放到CrawlerThread中。
获取 html
不管你想从网站获取什么数据,获取它的html代码都是最基本的一步。这里我们使用jsoup获取页面信息,在CrawlerThread中添加如下代码:
private boolean fetchHtml(WebPage webPage) throws IOException {
Connection.Response response = Jsoup.connect(webPage.getUrl()).timeout(3000).execute();
webPage.setHtml(response.body());
return response.statusCode() / 100 == 2 ? true : false;
}
public static void main(String[] args) throws Exception {
WebPage playlists = new WebPage("http://music.163.com/%23/disco ... ot%3B, PageType.playlists);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlists);
System.out.println(playlists.getHtml());
}
运行后可以看到输出的html文本
解析播放列表列表页面
拿到html后,我们解析播放列表,获取页面上的所有播放列表。Jsoup 收录了 html 解析相关的功能。我们不需要添加其他依赖,直接在CrawlerThread中添加如下代码:
private List parsePlaylist(WebPage webPage) {
Elements songs = Jsoup.parse(webPage.getHtml()).select("ul.f-hide li a");
return songs.stream().map(e -> new WebPage(BASE_URL + e.attr("href"), PageType.song, e.html())).collect(Collectors.toList());
}
public static void main(String[] args) throws Exception {
WebPage playlists = new WebPage("http://music.163.com/discover/ ... ot%3B, PageType.playlists);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlists);
System.out.println(crawlerThread.parsePlaylists(playlists));
}
解析播放列表页面
类似于播放列表页面,你只需要找出歌曲的相关元素:
private List parsePlaylist(WebPage webPage) {
Elements songs = Jsoup.parse(webPage.getHtml()).select("ul.f-hide li a");
return songs.stream().map(e -> new WebPage(BASE_URL + e.attr("href"), PageType.song, e.html())).collect(Collectors.toList());
}
public static void main(String[] args) throws Exception {
WebPage playlist = new WebPage("http://music.163.com/playlist?id=454016843", PageType.playlist);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlist);
System.out.println(crawlerThread.parsePlaylist(playlist));
}
注意,为了方便起见,我们也得到了歌曲名,这样以后就不需要再获取歌曲名了。
解析歌曲页面
终于,我们到达了歌曲页面。在这里,网易云音乐做了防爬处理。获取数据时的参数需要加密。具体算法这里我们就不纠结了。有兴趣的直接看参考代码,我们只看关键代码:
private Song parseSong(WebPage webPage) throws Exception {
return new Song(webPage.getUrl(), webPage.getTitle(), getCommentCount(webPage.getUrl().split("=")[1]));
}
public static void main(String[] args) throws Exception {
WebPage song = new WebPage("http://music.163.com/song?id=29999506", PageType.song, "test");
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(song);
System.out.println(crawlerThread.parseSong(song));
}
嗯,获取过程确实很曲折,经过多次加密,但不管怎样,最终还是得到了我们想要的数据。下一步是使用爬虫来运行整个机制。
实现爬虫
回顾流程图,我们发现最重要的对象之一是爬虫队列。爬虫队列的实现方式有很多种。自己实施。MySQL、redis、MongoDB等都可以满足我们的需求。不同的选择会导致我们取得的不一致。
综合考虑,我们使用Mysql + Spring Data JPA + Spring MVC来运行我们的整套框架,最终可以通过web服务展示抓取到的数据。更深入的Spring MVC学习,请参考Spring MVC实战入门培训。
确认无误后,我们就可以开始一步步实现了。Spring Data JPA 的代码这里就不展示了。了解 Spring Data JPA,请参考 Spring Data JPA 实战入门培训。直接上核心代码,我们把整个爬虫过程相关的代码全部放到了CrawlerService中。
初始网址
第一步是建立一个初始URL,我们可以根据播放列表列表的分页特性得到:
private void init(String catalog) {
List webPages = Lists.newArrayList();
for(int i = 0; i < 43; i++) {
webPages.add(new WebPage("http://music.163.com/discover/ ... ot%3B + catalog + "&limit=35&offset=" + (i * 35), PageType.playlists));
}
webPageRepository.save(webPages);
}
public void init() {
webPageRepository.deleteAll();
init("全部");
init("华语");
init("欧美");
init("日语");
init("韩语");
init("粤语");
init("小语种");
init("流行");
init("摇滚");
init("民谣");
init("电子");
init("舞曲");
init("说唱");
init("轻音乐");
init("爵士");
init("乡村");
init("R&B/Soul");
init("古典");
init("民族");
init("英伦");
init("金属");
init("朋克");
init("蓝调");
init("雷鬼");
init("世界音乐");
init("拉丁");
init("另类/独立");
init("New Age");
init("古风");
init("后摇");
init("Bossa Nova");
init("清晨");
init("夜晚");
init("学习");
init("工作");
init("午休");
init("下午茶");
init("地铁");
init("驾车");
init("运动");
init("旅行");
init("散步");
init("酒吧");
init("怀旧");
init("清新");
init("浪漫");
init("性感");
init("伤感");
init("治愈");
init("放松");
init("孤独");
init("感动");
init("兴奋");
init("快乐");
init("安静");
init("思念");
init("影视原声");
init("ACG");
init("校园");
init("游戏");
init("70后");
init("80后");
init("90后");
init("网络歌曲");
init("KTV");
init("经典");
init("翻唱");
init("吉他");
init("钢琴");
init("器乐");
init("儿童");
init("榜单");
init("00后");
}
在这里,我们已经初始化了播放列表的所有分类列表,通过这些列表,我们可以获得网易云音乐的大部分歌曲。
从爬虫队列中获取一个 URL
这里的逻辑很简单,就是获取一个不是从mysql爬取的网页,但是因为我们需要爬取很多的url,所以必须使用多线程,所以需要考虑异步的情况:
public synchronized WebPage getUnCrawlPage() {
WebPage webPage = webPageRepository.findTopByStatus(Status.uncrawl);
webPage.setStatus(Status.crawled);
return webPageRepository.save(webPage);
}
抓取页面
刚才说了,我们需要抓取很多页面,所以我们采用多线程的方式来运行我们的代码,首先我们将CrawlThread改写成线程的方式,核心代码如下:
public class CrawlerThread implements Runnable {
@Override
public void run() {
while (true) {
WebPage webPage = crawlerService.getUnCrawlPage(); // TODO: 更好的退出机制
if (webPage == null)
return; // 拿不到url,说明没有需要爬的url,直接退出
try {
if (fetchHtml(webPage))
parse(webPage);
} catch (Exception e) {}
}
}
}
在 CrawlerService 中,我们还需要提供一个入口来启动爬虫:
public void crawl() throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(MAX_THREADS);
for(int i = 0; i {
WebPage p = webPageRepository.findOne(s.getUrl());
p.setStatus(Status.uncrawl);
webPageRepository.save(p);
});
crawl();
}
整个站点是用 Spring MVC 假设的。学习Spring MVC请参考Spring MVC入门培训和Spring MVC入门实例。
想深入了解的同学,请参考网易云音乐编写Java爬虫。
进一步阅读
Spring MVC 的介绍性示例。
更深入的Spring MVC学习,请参考Spring MVC实战入门培训。
查看全部
java爬虫抓取动态网页(网易云音乐有哪些评论过万的歌曲?(图)
)
天马营崖发表
原因
前两天在知乎看到一个帖子,“网易云音乐哪些歌曲评论过万?” ”有段时间,我用Java实现了一个简单的爬虫,这里简单记录一下。
最终结果是开放的。可以随意参观。请点击这里>>>>>> 网易云音乐爬虫结果。
爬虫简介
网络爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。一般的网络爬虫大致包括以下几个步骤:
网络爬虫的一般流程如上图所示。不管你在做什么爬虫应用,整体流程都是类似的。现在,我们将定制一个特定的网络爬虫,专门爬取基于网易云音乐的音乐评论数。
网页类型分析的前期准备
首先,我们需要对网易云音乐的整个网站有一个大致的了解。进入网易云音乐首页后,我们发现大概有几种类型的网址:
我们最终需要爬取的数据在歌曲页面中,其中收录歌曲名称和歌曲评论数。
此外,我们还需要获取尽可能多的歌曲页面。我们可以从前面的 6 类页面中获取这些信息。其中播放列表列表和播放列表页面结构最简单,可以通过分页直接访问播放列表列表。因此,我们选择播放列表页面作为我们的初始页面,然后播放列表列表-播放列表-歌曲就可以一路向下爬取。
设计数据模型
通过上面的分析,我们可以知道我们要做两件事,一是抓取页面播放列表list-playlist-songs,二是存储最终结果。所以,我们只需要两个对象,一个用来存放页面相关信息,url,页面类型,是否被爬取(html和title作为临时数据存储),另一个用来存放歌曲相关信息, url, 歌曲名, 评论数。因此,模型类如下:
public class WebPage {
public enum PageType {
song, playlist, playlists;
}
public enum Status {
crawled, uncrawl;
}
private String url;
private String title;
private PageType type;
private Status status;
private String html;
...
}
public class Song {
private String url;
private String title;
private Long commentCount;
...
}
获取网页内容并解析
根据前面的分析,我们需要爬的页面有3种:播放列表、播放列表和歌曲。为了验证这个想法的可行性,我们先用代码对这三类网页进行解析,并将网页内容获取和分析的代码放到CrawlerThread中。
获取 html
不管你想从网站获取什么数据,获取它的html代码都是最基本的一步。这里我们使用jsoup获取页面信息,在CrawlerThread中添加如下代码:
private boolean fetchHtml(WebPage webPage) throws IOException {
Connection.Response response = Jsoup.connect(webPage.getUrl()).timeout(3000).execute();
webPage.setHtml(response.body());
return response.statusCode() / 100 == 2 ? true : false;
}
public static void main(String[] args) throws Exception {
WebPage playlists = new WebPage("http://music.163.com/%23/disco ... ot%3B, PageType.playlists);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlists);
System.out.println(playlists.getHtml());
}
运行后可以看到输出的html文本
解析播放列表列表页面
拿到html后,我们解析播放列表,获取页面上的所有播放列表。Jsoup 收录了 html 解析相关的功能。我们不需要添加其他依赖,直接在CrawlerThread中添加如下代码:
private List parsePlaylist(WebPage webPage) {
Elements songs = Jsoup.parse(webPage.getHtml()).select("ul.f-hide li a");
return songs.stream().map(e -> new WebPage(BASE_URL + e.attr("href"), PageType.song, e.html())).collect(Collectors.toList());
}
public static void main(String[] args) throws Exception {
WebPage playlists = new WebPage("http://music.163.com/discover/ ... ot%3B, PageType.playlists);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlists);
System.out.println(crawlerThread.parsePlaylists(playlists));
}
解析播放列表页面
类似于播放列表页面,你只需要找出歌曲的相关元素:
private List parsePlaylist(WebPage webPage) {
Elements songs = Jsoup.parse(webPage.getHtml()).select("ul.f-hide li a");
return songs.stream().map(e -> new WebPage(BASE_URL + e.attr("href"), PageType.song, e.html())).collect(Collectors.toList());
}
public static void main(String[] args) throws Exception {
WebPage playlist = new WebPage("http://music.163.com/playlist?id=454016843", PageType.playlist);
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(playlist);
System.out.println(crawlerThread.parsePlaylist(playlist));
}
注意,为了方便起见,我们也得到了歌曲名,这样以后就不需要再获取歌曲名了。
解析歌曲页面
终于,我们到达了歌曲页面。在这里,网易云音乐做了防爬处理。获取数据时的参数需要加密。具体算法这里我们就不纠结了。有兴趣的直接看参考代码,我们只看关键代码:
private Song parseSong(WebPage webPage) throws Exception {
return new Song(webPage.getUrl(), webPage.getTitle(), getCommentCount(webPage.getUrl().split("=")[1]));
}
public static void main(String[] args) throws Exception {
WebPage song = new WebPage("http://music.163.com/song?id=29999506", PageType.song, "test");
CrawlerThread crawlerThread = new CrawlerThread();
crawlerThread.fetchHtml(song);
System.out.println(crawlerThread.parseSong(song));
}
嗯,获取过程确实很曲折,经过多次加密,但不管怎样,最终还是得到了我们想要的数据。下一步是使用爬虫来运行整个机制。
实现爬虫
回顾流程图,我们发现最重要的对象之一是爬虫队列。爬虫队列的实现方式有很多种。自己实施。MySQL、redis、MongoDB等都可以满足我们的需求。不同的选择会导致我们取得的不一致。
综合考虑,我们使用Mysql + Spring Data JPA + Spring MVC来运行我们的整套框架,最终可以通过web服务展示抓取到的数据。更深入的Spring MVC学习,请参考Spring MVC实战入门培训。
确认无误后,我们就可以开始一步步实现了。Spring Data JPA 的代码这里就不展示了。了解 Spring Data JPA,请参考 Spring Data JPA 实战入门培训。直接上核心代码,我们把整个爬虫过程相关的代码全部放到了CrawlerService中。
初始网址
第一步是建立一个初始URL,我们可以根据播放列表列表的分页特性得到:
private void init(String catalog) {
List webPages = Lists.newArrayList();
for(int i = 0; i < 43; i++) {
webPages.add(new WebPage("http://music.163.com/discover/ ... ot%3B + catalog + "&limit=35&offset=" + (i * 35), PageType.playlists));
}
webPageRepository.save(webPages);
}
public void init() {
webPageRepository.deleteAll();
init("全部");
init("华语");
init("欧美");
init("日语");
init("韩语");
init("粤语");
init("小语种");
init("流行");
init("摇滚");
init("民谣");
init("电子");
init("舞曲");
init("说唱");
init("轻音乐");
init("爵士");
init("乡村");
init("R&B/Soul");
init("古典");
init("民族");
init("英伦");
init("金属");
init("朋克");
init("蓝调");
init("雷鬼");
init("世界音乐");
init("拉丁");
init("另类/独立");
init("New Age");
init("古风");
init("后摇");
init("Bossa Nova");
init("清晨");
init("夜晚");
init("学习");
init("工作");
init("午休");
init("下午茶");
init("地铁");
init("驾车");
init("运动");
init("旅行");
init("散步");
init("酒吧");
init("怀旧");
init("清新");
init("浪漫");
init("性感");
init("伤感");
init("治愈");
init("放松");
init("孤独");
init("感动");
init("兴奋");
init("快乐");
init("安静");
init("思念");
init("影视原声");
init("ACG");
init("校园");
init("游戏");
init("70后");
init("80后");
init("90后");
init("网络歌曲");
init("KTV");
init("经典");
init("翻唱");
init("吉他");
init("钢琴");
init("器乐");
init("儿童");
init("榜单");
init("00后");
}
在这里,我们已经初始化了播放列表的所有分类列表,通过这些列表,我们可以获得网易云音乐的大部分歌曲。
从爬虫队列中获取一个 URL
这里的逻辑很简单,就是获取一个不是从mysql爬取的网页,但是因为我们需要爬取很多的url,所以必须使用多线程,所以需要考虑异步的情况:
public synchronized WebPage getUnCrawlPage() {
WebPage webPage = webPageRepository.findTopByStatus(Status.uncrawl);
webPage.setStatus(Status.crawled);
return webPageRepository.save(webPage);
}
抓取页面
刚才说了,我们需要抓取很多页面,所以我们采用多线程的方式来运行我们的代码,首先我们将CrawlThread改写成线程的方式,核心代码如下:
public class CrawlerThread implements Runnable {
@Override
public void run() {
while (true) {
WebPage webPage = crawlerService.getUnCrawlPage(); // TODO: 更好的退出机制
if (webPage == null)
return; // 拿不到url,说明没有需要爬的url,直接退出
try {
if (fetchHtml(webPage))
parse(webPage);
} catch (Exception e) {}
}
}
}
在 CrawlerService 中,我们还需要提供一个入口来启动爬虫:
public void crawl() throws InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(MAX_THREADS);
for(int i = 0; i {
WebPage p = webPageRepository.findOne(s.getUrl());
p.setStatus(Status.uncrawl);
webPageRepository.save(p);
});
crawl();
}
整个站点是用 Spring MVC 假设的。学习Spring MVC请参考Spring MVC入门培训和Spring MVC入门实例。
想深入了解的同学,请参考网易云音乐编写Java爬虫。
进一步阅读
Spring MVC 的介绍性示例。
更深入的Spring MVC学习,请参考Spring MVC实战入门培训。
java爬虫抓取动态网页(动态网页静态网页中的的注意事项(图)脚本)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-12 06:04
硒采集 数据
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE(7,8,9,10,11), Mozilla Chrome, Safari, Google
Chrome、Opera 等
动态网页和静态网页
静态网页是指存储在服务器文件系统中的实际 HTML 文件。当用户在浏览器中进入页面时
URL,然后回车,浏览器会下载、渲染并在窗口中呈现相应的 HTML 文件。早期的 网站 通常是由静态页面制作的。
1. 动态网页
动态网页相对于静态网页。当浏览器请求服务器的页面时,服务器根据当前时间、环境参数、数据库操作等动态生成HTML页面,然后发送给浏览器(后续处理同静态网页页)。
显然,动态网页中的“动态”是指服务器端页面的动态生成,相反,“静态”是指页面实际的、独立的文件。
注意:
1.1 JavaScript
JavaScript 是一种属于网络的脚本语言。它在Web应用程序开发中得到了广泛的应用。常用于为网页添加各种动态功能,为用户提供更流畅美观的浏览效果。LavaScript 脚本通常嵌入在 HTML 中以实现自己的功能。
可以在网页源代码的标签中看到,如:
JavaScript 可以动态创建 HTML 内容,只有在 JavaScript 代码执行后才会生成和显示。如果使用传统的方法采集页面内容,则只能在执行JavaScript代码之前获取页面上的内容。
查询
JQuery 是一个快速简洁的 JavaScript 框架,它封装了 JavaScript 常用的函数代码,提供了简单的 JavaScript 设计模式,优化了 HTML 文档操作、事件处理、动画设计和 Ajax 交互。-网站 使用JQuery的一个特点是源码中收录了JQuery的入口,比如:
如果 网站 网页的源代码中出现了 jQuery,则在使用 采集 数据时必须小心。因为 jQuery 可以动态创建 HTML 内容,所以这些内容只有在 JavaScript 代码执行后才会生成和显示。如果使用传统的方法采集页面内容,则只能在执行JavaScript代码之前获取页面上的内容。
1.2 阿贾克斯
使用Ajax技术更新网页内容的网站有一个很大的特点,就是可以在不重新加载整个网页的情况下更新网页的某一部分。
Ajax实际上并不是一种语言,而是一系列用来完成网络任务的技术(可以认为类似于网络数据采集)。Ajax网站 可以在不使用整个页面加载的情况下与 web 服务器交互。
1.3 DHTML
DHTML:Dynamic HTML 动态HTML,这个技术并不是什么新技术,而是结合了我们之前学过的
HTML、CSS、JavaScript集成在一起,使用S操作页面元素,使元素动态变化,使页面与用户产生交互行为。
2. 动态网页处理方法
使用动态加载的网站,用Python有几种方法可以解决:
直接破解JavaScript代码中采集的内容。抓包解析,查看截图的请求响应信息,伪造请求,实现响应的获取。(推荐)使用Python的第三方库运行JavaScript,直接采集浏览器中看到的页面。(推荐)
既然浏览器可以获取数据,那么你可以模拟一个浏览器,从浏览器中获取数据。即使用程序控制浏览器,从而达到数据采集的目的。 查看全部
java爬虫抓取动态网页(动态网页静态网页中的的注意事项(图)脚本)
硒采集 数据
Selenium 是一种用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户在操作一样。支持的浏览器包括 IE(7,8,9,10,11), Mozilla Chrome, Safari, Google
Chrome、Opera 等
动态网页和静态网页
静态网页是指存储在服务器文件系统中的实际 HTML 文件。当用户在浏览器中进入页面时
URL,然后回车,浏览器会下载、渲染并在窗口中呈现相应的 HTML 文件。早期的 网站 通常是由静态页面制作的。
1. 动态网页
动态网页相对于静态网页。当浏览器请求服务器的页面时,服务器根据当前时间、环境参数、数据库操作等动态生成HTML页面,然后发送给浏览器(后续处理同静态网页页)。
显然,动态网页中的“动态”是指服务器端页面的动态生成,相反,“静态”是指页面实际的、独立的文件。
注意:
1.1 JavaScript
JavaScript 是一种属于网络的脚本语言。它在Web应用程序开发中得到了广泛的应用。常用于为网页添加各种动态功能,为用户提供更流畅美观的浏览效果。LavaScript 脚本通常嵌入在 HTML 中以实现自己的功能。
可以在网页源代码的标签中看到,如:
JavaScript 可以动态创建 HTML 内容,只有在 JavaScript 代码执行后才会生成和显示。如果使用传统的方法采集页面内容,则只能在执行JavaScript代码之前获取页面上的内容。
查询
JQuery 是一个快速简洁的 JavaScript 框架,它封装了 JavaScript 常用的函数代码,提供了简单的 JavaScript 设计模式,优化了 HTML 文档操作、事件处理、动画设计和 Ajax 交互。-网站 使用JQuery的一个特点是源码中收录了JQuery的入口,比如:
如果 网站 网页的源代码中出现了 jQuery,则在使用 采集 数据时必须小心。因为 jQuery 可以动态创建 HTML 内容,所以这些内容只有在 JavaScript 代码执行后才会生成和显示。如果使用传统的方法采集页面内容,则只能在执行JavaScript代码之前获取页面上的内容。
1.2 阿贾克斯
使用Ajax技术更新网页内容的网站有一个很大的特点,就是可以在不重新加载整个网页的情况下更新网页的某一部分。
Ajax实际上并不是一种语言,而是一系列用来完成网络任务的技术(可以认为类似于网络数据采集)。Ajax网站 可以在不使用整个页面加载的情况下与 web 服务器交互。
1.3 DHTML
DHTML:Dynamic HTML 动态HTML,这个技术并不是什么新技术,而是结合了我们之前学过的
HTML、CSS、JavaScript集成在一起,使用S操作页面元素,使元素动态变化,使页面与用户产生交互行为。
2. 动态网页处理方法
使用动态加载的网站,用Python有几种方法可以解决:
直接破解JavaScript代码中采集的内容。抓包解析,查看截图的请求响应信息,伪造请求,实现响应的获取。(推荐)使用Python的第三方库运行JavaScript,直接采集浏览器中看到的页面。(推荐)
既然浏览器可以获取数据,那么你可以模拟一个浏览器,从浏览器中获取数据。即使用程序控制浏览器,从而达到数据采集的目的。
java爬虫抓取动态网页(18款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-10 09:05
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍18款Java开源网络爬虫,有需要的小伙伴赶紧采集吧。
赫里特克斯
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。它最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备工作,比如延迟和重新处理处理,否决后续操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取结果,这一步可以直接索引全文。Heritrix提供了ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。
Heritrix 系统框架图
Heritrix 处理一个 url 进程
网络SPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX包。
WebSPHINX-目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可以看:
/~rcm/websphinx/
网络学习
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是写爬虫的新手,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
/
特征:
1.开源,免费
2.代码纯Java编写,可以在任何支持Java的平台上运行
3.支持多线程下载网页
4. 可以维护网页之间的链接信息
5.强大的可配置性:网页的深度优先或宽度优先抓取;可自定义的 URL 过滤器,以便您可以根据需要抓取单个 Web 服务器、单个目录或抓取整个 WWW 网络;您可以设置网址的优先级,这样我们就可以抓取我们感兴趣或重要的网页;我们可以记录断点时程序的状态,重启的时候可以继续上次爬取。
阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
蜘蛛侠
JSpider:是一个完全可配置和可定制的Web Spider引擎,你可以用它来检查网站错误(内部服务器错误等)、网站内外部链接检查、分析网站结构(可以创建网站图),下载整个网站,也可以写一个JSpider插件扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略 ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。
JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的 网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的 网站 的结构(创建站点地图,...)
下载翻新网站
通过编写JSpider插件实现任意功能。
项目主页:
/
主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。Spindle 项目提供了一组JSP 标记库,以便那些基于JSP 的站点可以在不开发任何Java 类的情况下增加搜索功能。
蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,能够分析收录 HTML 内容的输入流。通过实现 Arachnid 子类,可以开发一个简单的网络蜘蛛,并在解析网站上的每个页面后添加几行代码调用。Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
/
警报器
LARM 可以为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
/
乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
Snoics-爬行动物
什么是snoics-reptile?
它是用纯Java开发的,用于捕获网站的图像。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取到的网站 所有资源都是本地抓取的,包括网页和各类文件。
如:图片、flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
既然有其他类似的软件,为什么还要开发snotics-reptile呢?
因为在爬取的过程中经常会出现一些文件出错,很多javascript控制的URL没有办法正确解析,snoics-reptile提供了外部接口和配置文件。对于特殊的URL,可以通过自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:
/snoics
网络收获
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现 text/xml 操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。
它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了使数据操作和复用更容易,Web-Harvest 还提供了上下变量用于存储声明的变量。
web-harvest启动,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。
第二种方法是切换到cmd下的web-harvest目录,输入命令“java-jar-Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:
真烂
ItSucks 是 Java Web 爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
多线程
正则表达式
保存/加载下载作业
网上帮助 查看全部
java爬虫抓取动态网页(18款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍18款Java开源网络爬虫,有需要的小伙伴赶紧采集吧。
赫里特克斯
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。它最突出的特点是良好的扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。Teo 线程为每个 URL 执行 URL 处理器链。URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备工作,比如延迟和重新处理处理,否决后续操作。
(2) 提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3) 提取链:提取完成后,提取感兴趣的 HTML 和 JavaScript,通常会有新的 URL 需要爬取。
(4)写链:存储爬取结果,这一步可以直接索引全文。Heritrix提供了ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)提交链:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外,DNS缓存信息也会更新。
Heritrix 系统框架图
Heritrix 处理一个 url 进程
网络SPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX包。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX包。
WebSPHINX-目的
1.可视化展示页面集合
2.将页面下载到本地磁盘进行离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用Java或Javascript开发自定义爬虫
详细介绍可以看:
/~rcm/websphinx/
网络学习
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
WebLech 是一款功能强大的免费开源工具,用于下载和镜像网站。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是写爬虫的新手,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
/
特征:
1.开源,免费
2.代码纯Java编写,可以在任何支持Java的平台上运行
3.支持多线程下载网页
4. 可以维护网页之间的链接信息
5.强大的可配置性:网页的深度优先或宽度优先抓取;可自定义的 URL 过滤器,以便您可以根据需要抓取单个 Web 服务器、单个目录或抓取整个 WWW 网络;您可以设置网址的优先级,这样我们就可以抓取我们感兴趣或重要的网页;我们可以记录断点时程序的状态,重启的时候可以继续上次爬取。
阿拉蕾
Arale 主要是为个人使用而设计的,不像其他爬虫那样专注于页面索引。Arale 可以下载整个网站或网站上的部分资源。Arale 还可以将动态页面映射到静态页面。
蜘蛛侠
JSpider:是一个完全可配置和可定制的Web Spider引擎,你可以用它来检查网站错误(内部服务器错误等)、网站内外部链接检查、分析网站结构(可以创建网站图),下载整个网站,也可以写一个JSpider插件扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。JSpider的执行格式如下:
jspider [URL] [ConfigName]
URL必须加上协议名,如:,否则会报错。如果省略 ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。
JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以将其用于:
检查您的 网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的 网站 的结构(创建站点地图,...)
下载翻新网站
通过编写JSpider插件实现任意功能。
项目主页:
/
主轴
Spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。Spindle 项目提供了一组JSP 标记库,以便那些基于JSP 的站点可以在不开发任何Java 类的情况下增加搜索功能。
蛛形纲动物
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,能够分析收录 HTML 内容的输入流。通过实现 Arachnid 子类,可以开发一个简单的网络蜘蛛,并在解析网站上的每个页面后添加几行代码调用。Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
/
警报器
LARM 可以为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
/
乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。JoBo 还具有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
Snoics-爬行动物
什么是snoics-reptile?
它是用纯Java开发的,用于捕获网站的图像。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取到的网站 所有资源都是本地抓取的,包括网页和各类文件。
如:图片、flash、mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
既然有其他类似的软件,为什么还要开发snotics-reptile呢?
因为在爬取的过程中经常会出现一些文件出错,很多javascript控制的URL没有办法正确解析,snoics-reptile提供了外部接口和配置文件。对于特殊的URL,可以通过自由扩展外部提供的接口,通过配置文件注入的方式,基本上可以正确解析和抓取所有网页。
项目主页:
/snoics
网络收获
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现 text/xml 操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取功能。
Web-Harvest 的主要目的是加强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。
它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了使数据操作和复用更容易,Web-Harvest 还提供了上下变量用于存储声明的变量。
web-harvest启动,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。
第二种方法是切换到cmd下的web-harvest目录,输入命令“java-jar-Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:
真烂
ItSucks 是 Java Web 爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和 Swing GUI 操作界面。
特征:
多线程
正则表达式
保存/加载下载作业
网上帮助
java爬虫抓取动态网页(本文爬虫:Java代码更多的关于robot.txt的具体)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-11-10 00:27
记得刚找工作的时候,隔壁的一个同学在面试的时候用大胆的文字认识了一个网络爬虫。后来在做图片搜索的时候,需要大量的测试图片,于是萌生了从亚马逊爬取书籍封面图片的想法,也从网上学习了一些之前的经验,一个简单但足够的爬虫系统实现了。
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。其基本结构如下图所示:
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。对于垂直搜索,聚焦爬虫,即针对特定主题抓取网页的爬虫更合适。
本文爬虫程序的核心代码如下:
Java代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java代码
private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
关于robot.txt更具体的写法,请参考以下文章:
getContent 使用apache的httpclient 4.1来获取网页的内容,具体代码如下:
Java代码
private String getContent(CrawlerUrl url) throws Throwable {
//HttpClient4.1的调用与之前的方式不同
HttpClient client = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url.getUrlString());
StringBuffer strBuf = new StringBuffer();
HttpResponse response = client.execute(httpGet);
if (HttpStatus.SC_OK == response.getStatusLine().getStatusCode()) {
HttpEntity entity = response.getEntity();
if (entity != null) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(entity.getContent(), "UTF-8"));
String line = null;
if (entity.getContentLength() > 0) {
strBuf = new StringBuffer((int) entity.getContentLength());
while ((line = reader.readLine()) != null) {
strBuf.append(line);
}
}
}
if (entity != null) {
entity.consumeContent();
}
}
//将url标记为已访问
markUrlAsVisited(url);
return strBuf.toString();
}
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是只采集与主题相关的数据,这就是isContentRelevant方法的作用。这里,可以使用分类预测技术。为简单起见,改为使用常规匹配。主要代码如下:
Java代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要功能是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样,一个简单的网络爬虫程序就搭建好了,可以使用如下程序进行测试:
Java代码
public static void main(String[] args) {
try {
String url = "http://www.amazon.com";
Queue urlQueue = new LinkedList();
String regexp = "java";
urlQueue.add(new CrawlerUrl(url, 0));
NaiveCrawler crawler = new NaiveCrawler(urlQueue, 100, 5, 1000L,
regexp);
// boolean allowCrawl = crawler.areWeAllowedToVisit(url);
// System.out.println("Allowed to crawl: " + url + " " +
// allowCrawl);
crawler.crawl();
} catch (Throwable t) {
System.out.println(t.toString());
t.printStackTrace();
}
}
当然,你可以赋予它更高级的特性,比如多线程、更智能的焦点、使用 Lucene 索引等等。对于更复杂的情况,可以考虑使用一些开源的spider程序,比如Nutch或者Heritrix等,这些都超出了本文的范围。 查看全部
java爬虫抓取动态网页(本文爬虫:Java代码更多的关于robot.txt的具体)
记得刚找工作的时候,隔壁的一个同学在面试的时候用大胆的文字认识了一个网络爬虫。后来在做图片搜索的时候,需要大量的测试图片,于是萌生了从亚马逊爬取书籍封面图片的想法,也从网上学习了一些之前的经验,一个简单但足够的爬虫系统实现了。
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。其基本结构如下图所示:
传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。对于垂直搜索,聚焦爬虫,即针对特定主题抓取网页的爬虫更合适。
本文爬虫程序的核心代码如下:
Java代码
public void crawl() throws Throwable {
while (continueCrawling()) {
CrawlerUrl url = getNextUrl(); //获取待爬取队列中的下一个URL
if (url != null) {
printCrawlInfo();
String content = getContent(url); //获取URL的文本信息
//聚焦爬虫只爬取与主题内容相关的网页,这里采用正则匹配简单处理
if (isContentRelevant(content, this.regexpSearchPattern)) {
saveContent(url, content); //保存网页至本地
//获取网页内容中的链接,并放入待爬取队列中
Collection urlStrings = extractUrls(content, url);
addUrlsToUrlQueue(url, urlStrings);
} else {
System.out.println(url + " is not relevant ignoring ...");
}
//延时防止被对方屏蔽
Thread.sleep(this.delayBetweenUrls);
}
}
closeOutputStream();
}
整个函数由getNextUrl、getContent、isContentRelevant、extractUrls、addUrlsToUrlQueue等几个核心方法组成,下面将一一介绍。先看getNextUrl:
Java代码
private CrawlerUrl getNextUrl() throws Throwable {
CrawlerUrl nextUrl = null;
while ((nextUrl == null) && (!urlQueue.isEmpty())) {
CrawlerUrl crawlerUrl = this.urlQueue.remove();
//doWeHavePermissionToVisit:是否有权限访问该URL,友好的爬虫会根据网站提供的"Robot.txt"中配置的规则进行爬取
//isUrlAlreadyVisited:URL是否访问过,大型的搜索引擎往往采用BloomFilter进行排重,这里简单使用HashMap
//isDepthAcceptable:是否达到指定的深度上限。爬虫一般采取广度优先的方式。一些网站会构建爬虫陷阱(自动生成一些无效链接使爬虫陷入死循环),采用深度限制加以避免
if (doWeHavePermissionToVisit(crawlerUrl)
&& (!isUrlAlreadyVisited(crawlerUrl))
&& isDepthAcceptable(crawlerUrl)) {
nextUrl = crawlerUrl;
// System.out.println("Next url to be visited is " + nextUrl);
}
}
return nextUrl;
}
关于robot.txt更具体的写法,请参考以下文章:
getContent 使用apache的httpclient 4.1来获取网页的内容,具体代码如下:
Java代码
private String getContent(CrawlerUrl url) throws Throwable {
//HttpClient4.1的调用与之前的方式不同
HttpClient client = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url.getUrlString());
StringBuffer strBuf = new StringBuffer();
HttpResponse response = client.execute(httpGet);
if (HttpStatus.SC_OK == response.getStatusLine().getStatusCode()) {
HttpEntity entity = response.getEntity();
if (entity != null) {
BufferedReader reader = new BufferedReader(
new InputStreamReader(entity.getContent(), "UTF-8"));
String line = null;
if (entity.getContentLength() > 0) {
strBuf = new StringBuffer((int) entity.getContentLength());
while ((line = reader.readLine()) != null) {
strBuf.append(line);
}
}
}
if (entity != null) {
entity.consumeContent();
}
}
//将url标记为已访问
markUrlAsVisited(url);
return strBuf.toString();
}
对于垂直应用,数据准确性通常更为重要。聚焦爬虫的主要特点是只采集与主题相关的数据,这就是isContentRelevant方法的作用。这里,可以使用分类预测技术。为简单起见,改为使用常规匹配。主要代码如下:
Java代码
public static boolean isContentRelevant(String content,
Pattern regexpPattern) {
boolean retValue = false;
if (content != null) {
//是否符合正则表达式的条件
Matcher m = regexpPattern.matcher(content.toLowerCase());
retValue = m.find();
}
return retValue;
}
extractUrls 的主要功能是从网页中获取更多的 URL,包括内部链接和外部链接。代码如下:
Java代码
public List extractUrls(String text, CrawlerUrl crawlerUrl) {
Map urlMap = new HashMap();
extractHttpUrls(urlMap, text);
extractRelativeUrls(urlMap, text, crawlerUrl);
return new ArrayList(urlMap.keySet());
}
//处理外部链接
private void extractHttpUrls(Map urlMap, String text) {
Matcher m = httpRegexp.matcher(text);
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
// System.out.println("Term = " + term);
if (term.startsWith("http")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
urlMap.put(term, term);
System.out.println("Hyperlink: " + term);
}
}
}
}
//处理内部链接
private void extractRelativeUrls(Map urlMap, String text,
CrawlerUrl crawlerUrl) {
Matcher m = relativeRegexp.matcher(text);
URL textURL = crawlerUrl.getURL();
String host = textURL.getHost();
while (m.find()) {
String url = m.group();
String[] terms = url.split("a href=\"");
for (String term : terms) {
if (term.startsWith("/")) {
int index = term.indexOf("\"");
if (index > 0) {
term = term.substring(0, index);
}
String s = "http://" + host + term;
urlMap.put(s, s);
System.out.println("Relative url: " + s);
}
}
}
}
这样,一个简单的网络爬虫程序就搭建好了,可以使用如下程序进行测试:
Java代码
public static void main(String[] args) {
try {
String url = "http://www.amazon.com";
Queue urlQueue = new LinkedList();
String regexp = "java";
urlQueue.add(new CrawlerUrl(url, 0));
NaiveCrawler crawler = new NaiveCrawler(urlQueue, 100, 5, 1000L,
regexp);
// boolean allowCrawl = crawler.areWeAllowedToVisit(url);
// System.out.println("Allowed to crawl: " + url + " " +
// allowCrawl);
crawler.crawl();
} catch (Throwable t) {
System.out.println(t.toString());
t.printStackTrace();
}
}
当然,你可以赋予它更高级的特性,比如多线程、更智能的焦点、使用 Lucene 索引等等。对于更复杂的情况,可以考虑使用一些开源的spider程序,比如Nutch或者Heritrix等,这些都超出了本文的范围。
java爬虫抓取动态网页(jdk1.8、win10、科学上网、eclipse一直想学下写爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-09 20:10
环境:jdk1.8、win10、科学上网,eclipse
一直想学习写爬虫,满足我的小愿望。刚好有过年的时间,所以研究了一下。网上的信息混杂,所以决定自己整理一份,按照我的步骤来。它必须是可能的。如果你成功了,记得回来喜欢它。
在这种情况下,抓取了一个小视频网站,最终的效果可以是自动下载网站的所有视频,并且每个视频都有自己的名字。
如果要爬取其他网站,代码中很多地方(比如url、url解析、字符串截取、下载位置)需要根据具体页面进行修改,我只能提供一个思路。,当然,如果你想爬这个网站,当然不用改。
一、 思路: 1、获取要爬取的网站首页url。2.对于分页网站(视频网站一般都会分页)分析url分页方式,找到规则3,在每个页面上找到视频页面的url,在视频页面上找到规则4 ,分析url,找出视频的实际下载地址,找到规则5,开始下载6,开始快乐!!!二、步骤:1.面函数,没什么好说的
public static void main(String[] args) throws Exception {
final String SCORE_URL = "https://www.xxxx/xxx";// 主页(手工打码)
final String DOWNLOAD_DIR = "F:/video/";// 下载目录
System.setProperty("https.protocols", "TLSv1,TLSv1.1,TLSv1.2,SSLv3");
System.err.println("爬取子页面...");
List allArticle = getAllVideoPage(SCORE_URL);
System.err.println("爬取视频...");
Map urlMap = getUrlInSource(allArticle);
System.err.println("本次下载文件数量:" + urlMap.size());
System.err.println("开始下载...");
downloadMovie(DOWNLOAD_DIR, urlMap);
}
2.这里网站的视频一般不会放在首页,视频网站一般会分页。所以你需要先分析页面的url,然后分析视频页面的url,然后将所有的视频页面url保存到一个列表中。难点在于页面的url解析
例如,这是一个分页 URL,这有明显的规则。我们只需要修改page=后面的数字就可以得到每个页面的url
然后我们需要分析进入每个视频页面的url,chrome F12,我们来看看
标记的那一行是进入视频页面的url。相信大家都会找到的,就不赘述了。
然后我们需要把href=后面双引号里面的东西剪掉,然后拼接成视频页面的完整url,具体看我的代码
最后,将所有视频页面的网址保存到一个列表中,下一步
<p> /**
* 爬所有视频页 存入一个list
*
* @param source 主页
* @return 视频页 列表
* @throws Exception
*/
private static List getAllVideoPage(String source) throws Exception {
List urls = new ArrayList();
for (int j = 1; j 查看全部
java爬虫抓取动态网页(jdk1.8、win10、科学上网、eclipse一直想学下写爬虫)
环境:jdk1.8、win10、科学上网,eclipse
一直想学习写爬虫,满足我的小愿望。刚好有过年的时间,所以研究了一下。网上的信息混杂,所以决定自己整理一份,按照我的步骤来。它必须是可能的。如果你成功了,记得回来喜欢它。
在这种情况下,抓取了一个小视频网站,最终的效果可以是自动下载网站的所有视频,并且每个视频都有自己的名字。
如果要爬取其他网站,代码中很多地方(比如url、url解析、字符串截取、下载位置)需要根据具体页面进行修改,我只能提供一个思路。,当然,如果你想爬这个网站,当然不用改。
一、 思路: 1、获取要爬取的网站首页url。2.对于分页网站(视频网站一般都会分页)分析url分页方式,找到规则3,在每个页面上找到视频页面的url,在视频页面上找到规则4 ,分析url,找出视频的实际下载地址,找到规则5,开始下载6,开始快乐!!!二、步骤:1.面函数,没什么好说的
public static void main(String[] args) throws Exception {
final String SCORE_URL = "https://www.xxxx/xxx";// 主页(手工打码)
final String DOWNLOAD_DIR = "F:/video/";// 下载目录
System.setProperty("https.protocols", "TLSv1,TLSv1.1,TLSv1.2,SSLv3");
System.err.println("爬取子页面...");
List allArticle = getAllVideoPage(SCORE_URL);
System.err.println("爬取视频...");
Map urlMap = getUrlInSource(allArticle);
System.err.println("本次下载文件数量:" + urlMap.size());
System.err.println("开始下载...");
downloadMovie(DOWNLOAD_DIR, urlMap);
}
2.这里网站的视频一般不会放在首页,视频网站一般会分页。所以你需要先分析页面的url,然后分析视频页面的url,然后将所有的视频页面url保存到一个列表中。难点在于页面的url解析
例如,这是一个分页 URL,这有明显的规则。我们只需要修改page=后面的数字就可以得到每个页面的url
然后我们需要分析进入每个视频页面的url,chrome F12,我们来看看
标记的那一行是进入视频页面的url。相信大家都会找到的,就不赘述了。
然后我们需要把href=后面双引号里面的东西剪掉,然后拼接成视频页面的完整url,具体看我的代码
最后,将所有视频页面的网址保存到一个列表中,下一步
<p> /**
* 爬所有视频页 存入一个list
*
* @param source 主页
* @return 视频页 列表
* @throws Exception
*/
private static List getAllVideoPage(String source) throws Exception {
List urls = new ArrayList();
for (int j = 1; j
java爬虫抓取动态网页(java调用、Firefox获取页面信息,以及Jsoup解析**)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-09 20:08
**
Java爬虫,调用Chrome、Firefox获取页面信息,Jsoup分析
**
前言:
某些 网站 具有反爬虫机制。在这种情况下,我们需要使用模拟真实浏览器来访问页面。在Linux环境下,我们需要设置浏览器headless模式。不过有一些网站反爬的比较好,会判断谷歌浏览器的headless模式,可以用火狐试试。
一、java调用Chrome(谷歌浏览器)抓取页面
1.本地安装的 Google Chrome 和 ChromeDriver
Chromedriver 地址:
注意:chromedriver的版本必须和谷歌浏览器的版本一致
2.chromedriver 需要配置环境变量,如果不配置环境变量需要调用
所需的依赖:
org.jsoup
jsoup
1.11.3
org.seleniumhq.selenium
selenium-java
public void ChromeDemo(){
//如果没有配置环境变量,需要调用
//第一个参数固定写法,第二个参数是chromedriver的安装位置
//System.setProperty("webdriver.chrome.driver", "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe");
try {
//设置不弹出浏览器
ChromeOptions options = new ChromeOptions();
options.addArguments("headless");
options.addArguments("disable-gpu");
//Chrome设置代理
// if (zsyzbConfig.proxyHost != null && !zsyzbConfig.proxyHost.equals("") && zsyzbConfig.proxyPort != null) {
// options.addArguments("--proxy-server=http://" + proxyIP);
//}
ChromeDriver driver = new ChromeDriver(options);
driver.get("要爬取的地址");
//获取页面源码
String content = driver.getPageSource();
//使用jsoup解析页面
Document document = Jsoup.parse(content);
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
} catch (Exception e) {
e.printStackTrace();
}
}
二、Java调用Firefox(火狐浏览器)抓取页面
1.火狐浏览器安装:
yum -y install firefox(安装火狐浏览器)
2.geckodriver 安装
(1) wget(下载浏览器对应的版本)
(2) tar -xvf geckodriver*.tar.bz2 (解压 geckodriver)
(3) mv geckodriver /user/local/bin/ (移动)
火狐浏览器已经安装好了,然后添加代码:
public void FirefoxDemo(){
try{
//调用geckodriver
System.setProperty("webdriver.gecko.driver", "geckodriver的路径");
//设置浏览器不弹出
FirefoxOptions firefoxOptions = new FirefoxOptions();
firefoxOptions.addArguments("--headless");
firefoxOptions.addArguments("--disable-gpu");
driver = new FirefoxDriver(firefoxOptions);
driver.get("需要爬取的网站");
//获得爬取的页面的源码
String content = driver.getPageSource();
//Jsoup解析页面
Document document = Jsoup.parse(content);
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
}catch (Exception e) {
e.printStackTrace();
}finally {
driver.close();
}
}
三、Jsoup 抓取简单页面
public void JsoupDemo(){
try{
//Jsoup发请求获取页面
Document document = Jsoup.connect(url).get();
//根据页面的结构,具体解析页面
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
for (Element e : content) {
//例如:<a href=“www.baidu.com”> 则这样写:e.attr("href");
e.attr("标签的属性");
}
}catch (Exception e){
e.printStackTrace();
}
}
JS选择器不会写,可以看这里: 查看全部
java爬虫抓取动态网页(java调用、Firefox获取页面信息,以及Jsoup解析**)
**
Java爬虫,调用Chrome、Firefox获取页面信息,Jsoup分析
**
前言:
某些 网站 具有反爬虫机制。在这种情况下,我们需要使用模拟真实浏览器来访问页面。在Linux环境下,我们需要设置浏览器headless模式。不过有一些网站反爬的比较好,会判断谷歌浏览器的headless模式,可以用火狐试试。
一、java调用Chrome(谷歌浏览器)抓取页面
1.本地安装的 Google Chrome 和 ChromeDriver
Chromedriver 地址:
注意:chromedriver的版本必须和谷歌浏览器的版本一致
2.chromedriver 需要配置环境变量,如果不配置环境变量需要调用
所需的依赖:
org.jsoup
jsoup
1.11.3
org.seleniumhq.selenium
selenium-java
public void ChromeDemo(){
//如果没有配置环境变量,需要调用
//第一个参数固定写法,第二个参数是chromedriver的安装位置
//System.setProperty("webdriver.chrome.driver", "C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe");
try {
//设置不弹出浏览器
ChromeOptions options = new ChromeOptions();
options.addArguments("headless");
options.addArguments("disable-gpu");
//Chrome设置代理
// if (zsyzbConfig.proxyHost != null && !zsyzbConfig.proxyHost.equals("") && zsyzbConfig.proxyPort != null) {
// options.addArguments("--proxy-server=http://" + proxyIP);
//}
ChromeDriver driver = new ChromeDriver(options);
driver.get("要爬取的地址");
//获取页面源码
String content = driver.getPageSource();
//使用jsoup解析页面
Document document = Jsoup.parse(content);
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
} catch (Exception e) {
e.printStackTrace();
}
}
二、Java调用Firefox(火狐浏览器)抓取页面
1.火狐浏览器安装:
yum -y install firefox(安装火狐浏览器)
2.geckodriver 安装
(1) wget(下载浏览器对应的版本)
(2) tar -xvf geckodriver*.tar.bz2 (解压 geckodriver)
(3) mv geckodriver /user/local/bin/ (移动)
火狐浏览器已经安装好了,然后添加代码:
public void FirefoxDemo(){
try{
//调用geckodriver
System.setProperty("webdriver.gecko.driver", "geckodriver的路径");
//设置浏览器不弹出
FirefoxOptions firefoxOptions = new FirefoxOptions();
firefoxOptions.addArguments("--headless");
firefoxOptions.addArguments("--disable-gpu");
driver = new FirefoxDriver(firefoxOptions);
driver.get("需要爬取的网站");
//获得爬取的页面的源码
String content = driver.getPageSource();
//Jsoup解析页面
Document document = Jsoup.parse(content);
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
}catch (Exception e) {
e.printStackTrace();
}finally {
driver.close();
}
}
三、Jsoup 抓取简单页面
public void JsoupDemo(){
try{
//Jsoup发请求获取页面
Document document = Jsoup.connect(url).get();
//根据页面的结构,具体解析页面
String classTxt = document.getElementsByClass("Class属性").txt;
Elements content = document.getElementById("ID属性").select("js选择器");
for (Element e : content) {
//例如:<a href=“www.baidu.com”> 则这样写:e.attr("href");
e.attr("标签的属性");
}
}catch (Exception e){
e.printStackTrace();
}
}
JS选择器不会写,可以看这里:
java爬虫抓取动态网页(Java爬虫系列四:使用selenium-java爬取js异步请求的数据摘要)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-07 06:18
Java爬虫系列四:使用selenium-java爬取js异步请求的数据
摘要:在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但有时无法正常捕获这两种方法。我们要的数据,例如看下面的例子。1. 需求场景:如果想抓取股票的最新价格,F12页面信息如下: 按照前面的方法,抓取代码如下:/阅读全文
发表于@2021-10-17 11:46 JAVA开发新手阅读(191)评论(0)推荐(1)编辑)
Java爬虫系列三:使用Jsoup解析HTML
摘要:在之前的文章《Java爬虫系列之二:使用HttpClient爬取页面HTML》中,介绍了如何使用HttpClient爬取第一步——爬取页面html,今天来看看爬虫第二步——分析捕获的 html。拜托了,第二步的主角:Jsoup上台了。接下来,我们将舞台交给 Jsoup,让他完成本文的其余部分。华读全文
发表于@2019-05-25 16:08 JAVA开发老菜鸟阅读(55842)评论(1)推荐(13)编辑)
Java爬虫系列2:使用HttpClient抓取页面HTML
摘要:爬虫要爬取到需要的信息,第一步就是抓取页面的html内容,然后对html进行分析,得到想要的内容。在上一篇《Java爬虫系列一:开始前的写作》中提到了HttpClient可以爬取页面内容。今天给大家介绍一个抓取html内容的工具:HttpClient。重点关注以下几点: 什么是HttpClie 阅读全文
发表于@2019-05-23 06:29 JAVA开发老菜鸟阅读(23582)评论(2)推荐(7)编辑)
Java爬虫系列1:开始之前先写
摘要:最近在研究Java爬虫,有所收获。我打算在学习的同时与大家分享。在干货开始之前,我想和你说几句话。一、首先来说说为什么要学习Java爬虫。Python 已经流行了很长时间。它功能强大,其中一个非常擅长的就是编写爬虫程序。作为一个Javaer,想写爬虫一定要学python吗?想到这个问题就去度娘了,其实看全文
发表于@2019-05-22 21:22 JAVA开发老菜鸟阅读(3768)评论(0)推荐(3)编辑) 查看全部
java爬虫抓取动态网页(Java爬虫系列四:使用selenium-java爬取js异步请求的数据摘要)
Java爬虫系列四:使用selenium-java爬取js异步请求的数据
摘要:在之前的系列文章中,我们介绍了如何使用httpclient捕获页面html,以及如何使用jsoup分析html源文件的内容来获取我们想要的数据,但有时无法正常捕获这两种方法。我们要的数据,例如看下面的例子。1. 需求场景:如果想抓取股票的最新价格,F12页面信息如下: 按照前面的方法,抓取代码如下:/阅读全文
发表于@2021-10-17 11:46 JAVA开发新手阅读(191)评论(0)推荐(1)编辑)
Java爬虫系列三:使用Jsoup解析HTML
摘要:在之前的文章《Java爬虫系列之二:使用HttpClient爬取页面HTML》中,介绍了如何使用HttpClient爬取第一步——爬取页面html,今天来看看爬虫第二步——分析捕获的 html。拜托了,第二步的主角:Jsoup上台了。接下来,我们将舞台交给 Jsoup,让他完成本文的其余部分。华读全文
发表于@2019-05-25 16:08 JAVA开发老菜鸟阅读(55842)评论(1)推荐(13)编辑)
Java爬虫系列2:使用HttpClient抓取页面HTML
摘要:爬虫要爬取到需要的信息,第一步就是抓取页面的html内容,然后对html进行分析,得到想要的内容。在上一篇《Java爬虫系列一:开始前的写作》中提到了HttpClient可以爬取页面内容。今天给大家介绍一个抓取html内容的工具:HttpClient。重点关注以下几点: 什么是HttpClie 阅读全文
发表于@2019-05-23 06:29 JAVA开发老菜鸟阅读(23582)评论(2)推荐(7)编辑)
Java爬虫系列1:开始之前先写
摘要:最近在研究Java爬虫,有所收获。我打算在学习的同时与大家分享。在干货开始之前,我想和你说几句话。一、首先来说说为什么要学习Java爬虫。Python 已经流行了很长时间。它功能强大,其中一个非常擅长的就是编写爬虫程序。作为一个Javaer,想写爬虫一定要学python吗?想到这个问题就去度娘了,其实看全文
发表于@2019-05-22 21:22 JAVA开发老菜鸟阅读(3768)评论(0)推荐(3)编辑)
java爬虫抓取动态网页( 下一节:java如何爬取网页内容Java编程技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 509 次浏览 • 2021-11-06 17:15
下一节:java如何爬取网页内容Java编程技术)
java网络爬虫框架
爬虫是每个程序员都必须掌握的技能。与python爬虫的广泛应用相比,java爬虫也有着不可缺少的优势。Java爬虫现在也相当成熟。Python爬虫中的框架支持爬虫任务的进度,Java爬虫的框架也是如此。每个框架都扮演着不同的角色。本文介绍几个java网络常用的框架:Nutch、Crawler4j、WebMagic、WebCollecto。
1、Nutch:为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。
2、Crawler4j:是一款开源的Java爬虫网络爬虫,代码相当轻量,可以实现多线程爬取,上手难度低。
3、WebMagic:是一个简单灵活的Java爬虫框架。WebMagic 的结构分为四大组件:Downloader、pageProcessor、Scheduler、pipeline,它们以spliter 来组织。这四个组件分别对应爬虫生命周期中的下载、处理、管理和持久化功能。
4、WebCollector:致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。源代码中集成了Jsoup,用于准确的网页分析。
以上就是对java网络爬虫的简单介绍,希望对大家有所帮助~更多java学习推荐:java教程。
下一节:Java如何抓取网页内容Java编程技术
Java爬虫爬取网页内容:1、 网络爬虫按照一定的规则抓取网页上的信息,通常是在爬取一些网址后,再将这些网址放入队列中,反复搜索。2、Java抓取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,所以... 查看全部
java爬虫抓取动态网页(
下一节:java如何爬取网页内容Java编程技术)
java网络爬虫框架
爬虫是每个程序员都必须掌握的技能。与python爬虫的广泛应用相比,java爬虫也有着不可缺少的优势。Java爬虫现在也相当成熟。Python爬虫中的框架支持爬虫任务的进度,Java爬虫的框架也是如此。每个框架都扮演着不同的角色。本文介绍几个java网络常用的框架:Nutch、Crawler4j、WebMagic、WebCollecto。
1、Nutch:为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。
2、Crawler4j:是一款开源的Java爬虫网络爬虫,代码相当轻量,可以实现多线程爬取,上手难度低。
3、WebMagic:是一个简单灵活的Java爬虫框架。WebMagic 的结构分为四大组件:Downloader、pageProcessor、Scheduler、pipeline,它们以spliter 来组织。这四个组件分别对应爬虫生命周期中的下载、处理、管理和持久化功能。
4、WebCollector:致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。源代码中集成了Jsoup,用于准确的网页分析。
以上就是对java网络爬虫的简单介绍,希望对大家有所帮助~更多java学习推荐:java教程。
下一节:Java如何抓取网页内容Java编程技术
Java爬虫爬取网页内容:1、 网络爬虫按照一定的规则抓取网页上的信息,通常是在爬取一些网址后,再将这些网址放入队列中,反复搜索。2、Java抓取网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,所以...
java爬虫抓取动态网页(Python语言Python爬虫程序之前知识准备工作会得心应手)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-06 17:13
在使用Python编写爬虫程序之前,需要提前做好一些准备工作,以便在后续的学习过程中得心应手。
知识准备1) Python语言Python爬虫作为Python编程的高级知识,要求学习者具备良好的Python编程基础。对于没有基础的同学,推荐阅读《Python基础教程》,这套教程通俗易懂,非常适合初学者学习,教程作者亲自解答问答,有帮助您可以快速开始使用 Python。
同时了解Python语言的多进程、多线程(可参考《Python并发编程》),熟悉正则表达式语法,对编写爬虫程序也有帮助。
注意:关于正则表达式,Python 提供了一个特殊的 re 模块。详情请参考“Python re模块”。
2) Web Front End 了解Web前端的基础知识,如HTML、CSS、JavaScript,可以帮助您分析网页结构,提取有效信息。推荐阅读《HTML教程》、《CSS教程》、《JS教程》。
3) HTTP协议掌握OSI七层网络模型,理解TCP/IP协议和HTTP协议。这些知识将帮助您了解网络请求(GET 请求、POST 请求)和网络传输的基本原理。同时,它也会帮助你理解编写爬虫程序的逻辑。推荐阅读这里的“TCP/IP协议简介”。
图 1:OSI 网络七层模型
环境准备在编写Python爬虫程序之前,需要准备相应的开发环境,非常简单。首先,您需要在您的计算机上安装 Python,然后下载并安装 Pycharm IDE(集成开发环境)工具。具体下载安装过程可以阅读《Python基础教程》。
本教程使用Windows 10系统讲解Python爬虫。当然,您也可以使用其他系统,例如 Linux 或 Mac。
注意:下载Python时,建议下载Python 3.5及以上版本(包括3.5版本),本教程使用Python 3.7.4版本。 查看全部
java爬虫抓取动态网页(Python语言Python爬虫程序之前知识准备工作会得心应手)
在使用Python编写爬虫程序之前,需要提前做好一些准备工作,以便在后续的学习过程中得心应手。
知识准备1) Python语言Python爬虫作为Python编程的高级知识,要求学习者具备良好的Python编程基础。对于没有基础的同学,推荐阅读《Python基础教程》,这套教程通俗易懂,非常适合初学者学习,教程作者亲自解答问答,有帮助您可以快速开始使用 Python。
同时了解Python语言的多进程、多线程(可参考《Python并发编程》),熟悉正则表达式语法,对编写爬虫程序也有帮助。
注意:关于正则表达式,Python 提供了一个特殊的 re 模块。详情请参考“Python re模块”。
2) Web Front End 了解Web前端的基础知识,如HTML、CSS、JavaScript,可以帮助您分析网页结构,提取有效信息。推荐阅读《HTML教程》、《CSS教程》、《JS教程》。
3) HTTP协议掌握OSI七层网络模型,理解TCP/IP协议和HTTP协议。这些知识将帮助您了解网络请求(GET 请求、POST 请求)和网络传输的基本原理。同时,它也会帮助你理解编写爬虫程序的逻辑。推荐阅读这里的“TCP/IP协议简介”。
图 1:OSI 网络七层模型
环境准备在编写Python爬虫程序之前,需要准备相应的开发环境,非常简单。首先,您需要在您的计算机上安装 Python,然后下载并安装 Pycharm IDE(集成开发环境)工具。具体下载安装过程可以阅读《Python基础教程》。
本教程使用Windows 10系统讲解Python爬虫。当然,您也可以使用其他系统,例如 Linux 或 Mac。
注意:下载Python时,建议下载Python 3.5及以上版本(包括3.5版本),本教程使用Python 3.7.4版本。
java爬虫抓取动态网页(自问自答一下可以用一个很牛逼的包,叫做selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-05 17:11
问你自己
你可以使用一个非常棒的名为 selenium 的包(官方文档 Selenium with Python)。简单地说,它模拟人们在浏览器上的动作。您可以用代码打开浏览器,然后像人一样操作,实现浏览器的自动化(打开网页、输入文本、提交表单等),安装等细节在官方文档中有介绍。
以爬取本页Food-Popular Questions and Answers的所有主要回答信息为例。正如我所描述的,这个页面需要向下滚动才能获得更多信息。但是requests库好像不能实现这个功能?我还是不知道。. 反正这个页面的爬取基本可以用selenium库来实现。
话不多说,直接贴代码(环境为python3.5)
先导入需要的库,打开知乎-与世界页面分享你的知识、经验和见解,先登录。
from selenium import webdriver
import time
from bs4 import BeautifulSoup
driver=webdriver.Chrome() #用chrome浏览器打开
driver.get("http://www.zhihu.com") #打开知乎我们要登录
time.sleep(2) #让操作稍微停一下
driver.find_element_by_link_text('登录').click() #找到‘登录’按钮并点击
time.sleep(2)
#找到输入账号的框,并自动输入账号 这里要替换为你的登录账号
driver.find_element_by_name('account').send_keys('你的账号')
time.sleep(2)
#密码,这里要替换为你的密码
driver.find_element_by_name('password').send_keys('你的密码')
time.sleep(2)
#输入浏览器中显示的验证码,这里如果知乎让你找烦人的倒立汉字,手动登录一下,再停止程序,退出#浏览器,然后重新启动程序,直到让你输入验证码
yanzhengma=input('验证码:')
driver.find_element_by_name('captcha').send_keys(yanzhengma)
#找到登录按钮,并点击
driver.find_element_by_css_selector('div.button-wrapper.command > button').click()
然后获取你的登录cookie并加载目标页面Food-Popular Q&A,因为用这个包打开浏览器不会记录你之前的浏览器会话(cookies、书签等),所以暂时只能用这个方法登录和然后进入目标页面。
cookie=driver.get_cookies()
time.sleep(3)
driver.get('https://www.zhihu.com/topic/19551137/hot')
time.sleep(5)
定义一个函数,实现将滚轮滑动到页面底部的功能。这是官方文档里的(为了让页面加载完成,每5秒向下移动一次,共10次)
def execute_times(times):
for i in range(times + 1):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)
execute_times(10)
接下来是页面解析,使用BeautifulSoup库,我就不多说了
html=driver.page_source
soup1=BeautifulSoup(html,'lxml')
authors=soup1.select('a.author-link')
authors_alls=[]
authors_hrefs=[]
for author in authors:
authors_alls.append(author.get_text())
authors_hrefs.append('http://www.zhihu.com'+author.get('href'))
authors_intros_urls=soup1.select('span.bio')
authors_intros=[]
for authors_intros_url in authors_intros_urls:
authors_intros.append(authors_intros_url.get_text())
for authors_all,authors_href,authors_intro in zip(authors_alls,authors_hrefs,authors_intros):
data={
'author':authors_all,
'href':authors_href,
'intro':authors_intro
}
print(data)
最后打印结果:
我这里只试了10页,程序没有问题,不知道数据多了会不会有问题 查看全部
java爬虫抓取动态网页(自问自答一下可以用一个很牛逼的包,叫做selenium)
问你自己
你可以使用一个非常棒的名为 selenium 的包(官方文档 Selenium with Python)。简单地说,它模拟人们在浏览器上的动作。您可以用代码打开浏览器,然后像人一样操作,实现浏览器的自动化(打开网页、输入文本、提交表单等),安装等细节在官方文档中有介绍。
以爬取本页Food-Popular Questions and Answers的所有主要回答信息为例。正如我所描述的,这个页面需要向下滚动才能获得更多信息。但是requests库好像不能实现这个功能?我还是不知道。. 反正这个页面的爬取基本可以用selenium库来实现。
话不多说,直接贴代码(环境为python3.5)
先导入需要的库,打开知乎-与世界页面分享你的知识、经验和见解,先登录。
from selenium import webdriver
import time
from bs4 import BeautifulSoup
driver=webdriver.Chrome() #用chrome浏览器打开
driver.get("http://www.zhihu.com";) #打开知乎我们要登录
time.sleep(2) #让操作稍微停一下
driver.find_element_by_link_text('登录').click() #找到‘登录’按钮并点击
time.sleep(2)
#找到输入账号的框,并自动输入账号 这里要替换为你的登录账号
driver.find_element_by_name('account').send_keys('你的账号')
time.sleep(2)
#密码,这里要替换为你的密码
driver.find_element_by_name('password').send_keys('你的密码')
time.sleep(2)
#输入浏览器中显示的验证码,这里如果知乎让你找烦人的倒立汉字,手动登录一下,再停止程序,退出#浏览器,然后重新启动程序,直到让你输入验证码
yanzhengma=input('验证码:')
driver.find_element_by_name('captcha').send_keys(yanzhengma)
#找到登录按钮,并点击
driver.find_element_by_css_selector('div.button-wrapper.command > button').click()
然后获取你的登录cookie并加载目标页面Food-Popular Q&A,因为用这个包打开浏览器不会记录你之前的浏览器会话(cookies、书签等),所以暂时只能用这个方法登录和然后进入目标页面。
cookie=driver.get_cookies()
time.sleep(3)
driver.get('https://www.zhihu.com/topic/19551137/hot')
time.sleep(5)
定义一个函数,实现将滚轮滑动到页面底部的功能。这是官方文档里的(为了让页面加载完成,每5秒向下移动一次,共10次)
def execute_times(times):
for i in range(times + 1):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)
execute_times(10)
接下来是页面解析,使用BeautifulSoup库,我就不多说了
html=driver.page_source
soup1=BeautifulSoup(html,'lxml')
authors=soup1.select('a.author-link')
authors_alls=[]
authors_hrefs=[]
for author in authors:
authors_alls.append(author.get_text())
authors_hrefs.append('http://www.zhihu.com'+author.get('href'))
authors_intros_urls=soup1.select('span.bio')
authors_intros=[]
for authors_intros_url in authors_intros_urls:
authors_intros.append(authors_intros_url.get_text())
for authors_all,authors_href,authors_intro in zip(authors_alls,authors_hrefs,authors_intros):
data={
'author':authors_all,
'href':authors_href,
'intro':authors_intro
}
print(data)
最后打印结果:
我这里只试了10页,程序没有问题,不知道数据多了会不会有问题

