
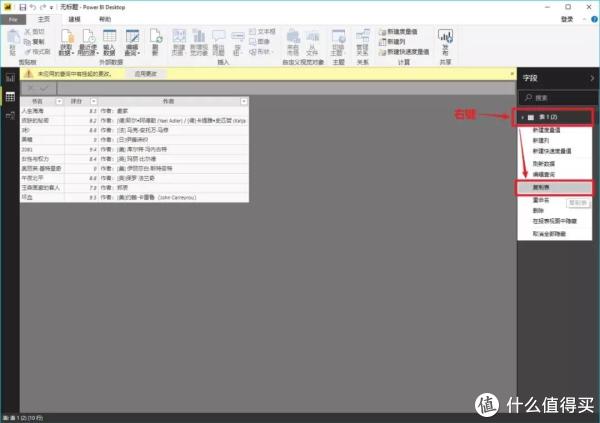
excel自动抓取网页数据
excel自动抓取网页数据(PowerAutomate从Excel中读取数据的操作,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 468 次浏览 • 2022-04-20 06:00
在使用Power Automate进行流程自动化的过程中,我们经常会遇到从Excel中读取数据的操作,所以我们首先需要学习的是:
废话不多说,干活吧!
Step-01 要获取读取的数据,首先在PAD中启动Excel并打开文件
Step-02 设置活动工作表
PAD 启动 Excel 打开文件时,默认使用 Excel 工作簿当前活动的工作表。因此,在读取Excel工作表的数据之前,一定要增加设置活动工作表的操作,避免Excel文件在最后Fetching wrong data with other worksheets activate (selected) on close时出现。
Step-03 从 Excel 工作表中读取数据
可以按需读取工作表中所有可用的值,带或不带标题(第一行收录列名)等。
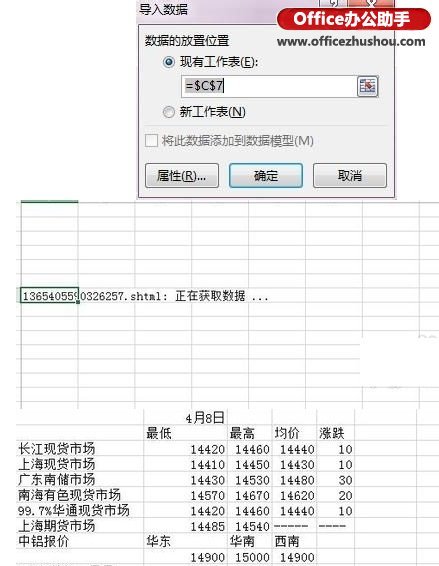
完成以上步骤后,即可运行流程,然后在“流变量”窗口中查看读取的数据:
检查读取的数据是否正确,然后进行后续操作——读取的数据表大致如下(第一行不收录列名):
读取数据后,我们可以根据需要提取行、列或单元格数据。
1、提取一行数据
选择从Excel中读取的数据表(ExcelData)变量,然后在方括号中手动输入行号。注意行号从0开始,即第一行的行号为0,以此类推。
2、从单元格中提取数据
提取单元格数据,可以在提取的行后面加上列名,即ExcelData后面跟两个方括号,分别代表行号和列名(注意单引号):
3、提取一列数据
对于ExcelData,无法通过之前的取行方式直接获取特定列的内容,但是Power Automate提供了“将数据列取回列表”的功能,直接填写列名(或索引)在步骤中。 ) 到:
最后,不要忘记关闭 Excel,以免打开的 Excel 运行时间过长,或者在另一个进程中再次打开此 Excel 文件时可能出现错误。
其实可以设置在读取数据的步骤之后立即关闭Excel的步骤,因为此时数据已经被读出,如果不需要读取其他数据或者对此做其他操作Excel文件稍后,不再需要。
以上是从Excel中读取数据的基本操作方法的介绍。结合循环和判断操作等步骤,将可以灵活读取Excel数据。流程自动化奠定了坚实的基础。 查看全部
excel自动抓取网页数据(PowerAutomate从Excel中读取数据的操作,你知道吗?)
在使用Power Automate进行流程自动化的过程中,我们经常会遇到从Excel中读取数据的操作,所以我们首先需要学习的是:
废话不多说,干活吧!
Step-01 要获取读取的数据,首先在PAD中启动Excel并打开文件
Step-02 设置活动工作表
PAD 启动 Excel 打开文件时,默认使用 Excel 工作簿当前活动的工作表。因此,在读取Excel工作表的数据之前,一定要增加设置活动工作表的操作,避免Excel文件在最后Fetching wrong data with other worksheets activate (selected) on close时出现。
Step-03 从 Excel 工作表中读取数据
可以按需读取工作表中所有可用的值,带或不带标题(第一行收录列名)等。
完成以上步骤后,即可运行流程,然后在“流变量”窗口中查看读取的数据:
检查读取的数据是否正确,然后进行后续操作——读取的数据表大致如下(第一行不收录列名):
读取数据后,我们可以根据需要提取行、列或单元格数据。
1、提取一行数据
选择从Excel中读取的数据表(ExcelData)变量,然后在方括号中手动输入行号。注意行号从0开始,即第一行的行号为0,以此类推。
2、从单元格中提取数据
提取单元格数据,可以在提取的行后面加上列名,即ExcelData后面跟两个方括号,分别代表行号和列名(注意单引号):
3、提取一列数据
对于ExcelData,无法通过之前的取行方式直接获取特定列的内容,但是Power Automate提供了“将数据列取回列表”的功能,直接填写列名(或索引)在步骤中。 ) 到:
最后,不要忘记关闭 Excel,以免打开的 Excel 运行时间过长,或者在另一个进程中再次打开此 Excel 文件时可能出现错误。
其实可以设置在读取数据的步骤之后立即关闭Excel的步骤,因为此时数据已经被读出,如果不需要读取其他数据或者对此做其他操作Excel文件稍后,不再需要。
以上是从Excel中读取数据的基本操作方法的介绍。结合循环和判断操作等步骤,将可以灵活读取Excel数据。流程自动化奠定了坚实的基础。
excel自动抓取网页数据(如何制作一个随网站自动同步的Excel表呢?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-04-20 00:02
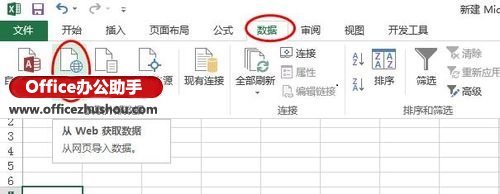
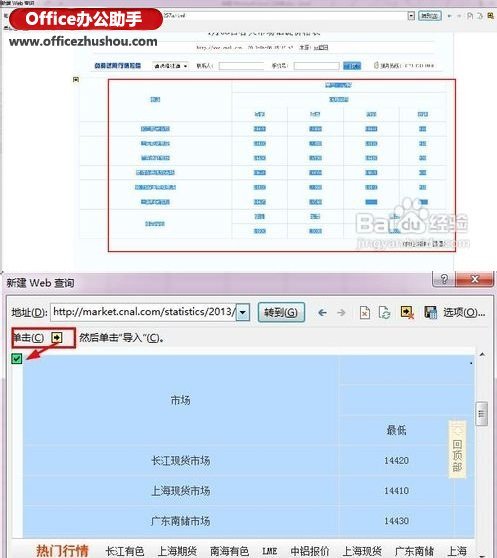
有时我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作一个自动与 网站 同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 函数。
1.打开网页
以下页面为中国地震台网()官方页面。每当发生地震时,都会在此处自动更新。由于要爬取,所以需要先打开页面。
▲先打开要爬取的网页
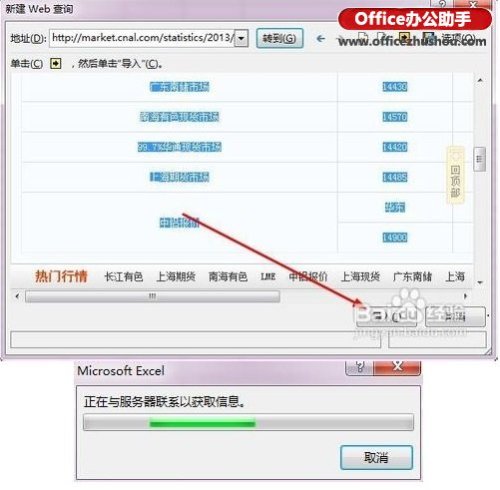
2. 确定从哪里获取
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要爬取的URL。此时,Power Query 会自动分析网页,然后在选取框内显示分析结果。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
▲创建查询以确定抓取范围
3.数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角“关闭并上传”即可上传Excel。
▲数据“预清洗”
4.格式化
数据上传到 Excel 后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的讲就是一些美化操作,最后得到下表。
▲美化餐桌
5.设置自动同步间隔
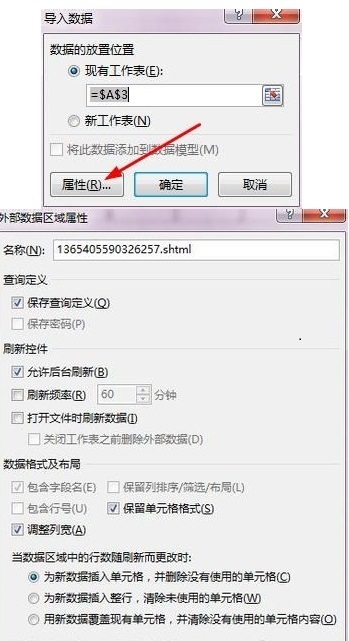
现在表格基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表格可以自动同步。
▲设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决此问题。
▲防止更新时破坏表格格式
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这是本期想和大家分享的一个小技巧,是不是很有用!
本文由 LinkNemo 爬虫 [Echo]采集from[]
创建 查看全部
excel自动抓取网页数据(如何制作一个随网站自动同步的Excel表呢?(组图))
有时我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作一个自动与 网站 同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 函数。
1.打开网页
以下页面为中国地震台网()官方页面。每当发生地震时,都会在此处自动更新。由于要爬取,所以需要先打开页面。
▲先打开要爬取的网页
2. 确定从哪里获取
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要爬取的URL。此时,Power Query 会自动分析网页,然后在选取框内显示分析结果。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
▲创建查询以确定抓取范围
3.数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角“关闭并上传”即可上传Excel。
▲数据“预清洗”
4.格式化
数据上传到 Excel 后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的讲就是一些美化操作,最后得到下表。
▲美化餐桌
5.设置自动同步间隔
现在表格基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表格可以自动同步。
▲设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决此问题。
▲防止更新时破坏表格格式
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这是本期想和大家分享的一个小技巧,是不是很有用!
本文由 LinkNemo 爬虫 [Echo]采集from[]
创建
excel自动抓取网页数据( Excel黑科技挖掘,Python小技巧(致力于)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-16 06:02
Excel黑科技挖掘,Python小技巧(致力于)(组图))
1、点击“获取数据”>“Web”,在弹出的对话框中输入网址,点击“确定”
2、在弹出的“Navigator”对话框中,选择左下角的“Add Table Using Example”
3、接下来我们需要做的就是提供一个表格,其中收录我们需要提取的数据示例。
以抓取书名为例,可以看到当我们提供两个书名时,Power BI会自动为我们抓取其余的书名。
4、用同样的方法分别抓取我们需要的其他字段。
单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。
二、将“示例中的列”添加到 Power Query
上面获取的数据收录无用的信息,除了正确的 [author] 和 [rating] 列。Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
其中,“示例中的列”可以根据用户提供的示例提取信息。
1、选择【作者】列,点击“添加列”>“示例中的列”,左下角的小三角,在弹出的下拉选项中选择“From Selection”
2、 在【第 1 列】中提供示例,Power BI 将智能识别我们需要的数据
点击右上角的“确定”后,作者的名字被提取到一个新的列中。
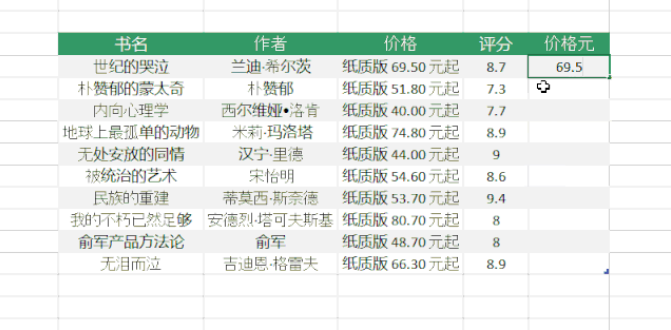
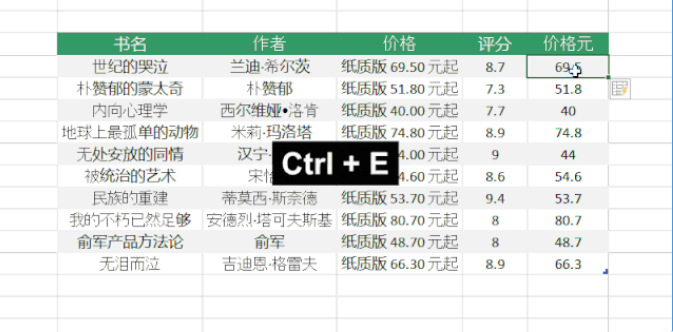
三、Excel 中的智能填充“Ctrl + E”
Excel 还提供了基于用户提供的示例智能提取数据的功能。例如,从列表数据中的价格列中提取数字。使用“Ctrl + E”快捷键从收录文本和数字的列中提取数字。
结尾。爱数据网专栏作者:Jary Yuan 专栏名称:Power BI 自动化与可视化专栏介绍:Excel、Power BI、Python 等学习交流领域。Excel黑科技挖掘,Python技巧。致力于办公自动化、工作场所效率提升、数据分析与视觉设计个人公众号:JaryYuan 查看全部
excel自动抓取网页数据(
Excel黑科技挖掘,Python小技巧(致力于)(组图))
1、点击“获取数据”>“Web”,在弹出的对话框中输入网址,点击“确定”

2、在弹出的“Navigator”对话框中,选择左下角的“Add Table Using Example”
3、接下来我们需要做的就是提供一个表格,其中收录我们需要提取的数据示例。
以抓取书名为例,可以看到当我们提供两个书名时,Power BI会自动为我们抓取其余的书名。
4、用同样的方法分别抓取我们需要的其他字段。

单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。

二、将“示例中的列”添加到 Power Query
上面获取的数据收录无用的信息,除了正确的 [author] 和 [rating] 列。Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
其中,“示例中的列”可以根据用户提供的示例提取信息。
1、选择【作者】列,点击“添加列”>“示例中的列”,左下角的小三角,在弹出的下拉选项中选择“From Selection”
2、 在【第 1 列】中提供示例,Power BI 将智能识别我们需要的数据
点击右上角的“确定”后,作者的名字被提取到一个新的列中。
三、Excel 中的智能填充“Ctrl + E”
Excel 还提供了基于用户提供的示例智能提取数据的功能。例如,从列表数据中的价格列中提取数字。使用“Ctrl + E”快捷键从收录文本和数字的列中提取数字。
结尾。爱数据网专栏作者:Jary Yuan 专栏名称:Power BI 自动化与可视化专栏介绍:Excel、Power BI、Python 等学习交流领域。Excel黑科技挖掘,Python技巧。致力于办公自动化、工作场所效率提升、数据分析与视觉设计个人公众号:JaryYuan
excel自动抓取网页数据(数据特征归一化(FeatureScaling)学习及实现_爱吃西瓜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-15 05:09
数据特征归一化(Feature Scaling)学习与实现 - 程序员大本营
为什么我们需要特征归一化?不同的特征指标往往有不同的维度和维度单位。这种情况会影响数据分析的结果。为了消除指标间的维度影响,需要进行数据标准化处理,解决指标间的可比性。原创数据标准化后,各项指标处于同一数量级,适合综合比较评价。两种常用的归一化方法是最值归一化方法(normaization):最值归一化方法将数据映射在0-1之间。适合分发...
DNS 域名解析流程
前言 本文来自《深入解析Java Web技术》这本书,因为我对DNS不是特别熟悉,而且本书中关于DNS的部分已经描述的比较详细,所以我直接使用了书。老规矩,不复制不粘贴,所有内容都是手写,边打字边学习理解。DNS域名解析我们知道,互联网通过URL发布和请求资源,需要将URL中的域名解析成IP地址才能与远程主机建立连接。如何将域名解析为IP地址属于DNS解析的范畴。毫不夸张的说,虽然我们平时上网时感觉不到DNS解析的存在,但是一旦DNS解析出了问题,
U盘分区合并_HelloBirthday的博客-程序员的秘密
USB存储:闪迪至尊操作系统:Winodws 7 64bit 问题:使用U盘制作linux镜像时,操作错误导致U盘被分成两个分区。linux下挂载两个分区是可以的,但是刷了固件。总是不成功。Windows下只能识别一个分区,分区大小只有8M(U盘8G)。Windows下将U盘的两个分区合并为一个分区,重新创建U盘。以下操作在wi中进行
Nutz表操作_一指流沙QQ博客-程序员秘籍
导入 java.util.Set;导入 org.nutz.dao.entity.annotation.ColDefine;导入 org.nutz.dao.entity.annotation.ColType;导入 org.nutz.dao.entity.annotation.Column;导入 org.nutz .dao.entity.anno...
Re sub 实现多次替换 - 程序员大本营
两种写法 1 | 表示或替换所有字母 result_content = re.sub('a|b|c|d|e|f|g|h|i|j|k|l|m|n|o |p|q|r|s| t|u|v|w|x|y|z','',result_content)2 将每个替换放在括号中,最后放在方括号中 & \ / ; 四个匹配替换 result_content
zookeeper实际应用场景案例
1、数据发布订阅/配置中心1、原理:发布者向zookeeper节点发布数据,订阅者获取节点上的数据,从而实现发布订阅的目的。实现配置信息集中管理和数据动态更新2、实现配置中心有两种模式:push(push:服务器端push)、pull(pull:客户端主动拉取)、client-side向服务客户端注册要关注的节点。一旦节点发生变化,服务器将向客户端发送通知。3、zookeeper 使用推和拉的组合。... 查看全部
excel自动抓取网页数据(数据特征归一化(FeatureScaling)学习及实现_爱吃西瓜)
数据特征归一化(Feature Scaling)学习与实现 - 程序员大本营
为什么我们需要特征归一化?不同的特征指标往往有不同的维度和维度单位。这种情况会影响数据分析的结果。为了消除指标间的维度影响,需要进行数据标准化处理,解决指标间的可比性。原创数据标准化后,各项指标处于同一数量级,适合综合比较评价。两种常用的归一化方法是最值归一化方法(normaization):最值归一化方法将数据映射在0-1之间。适合分发...
DNS 域名解析流程
前言 本文来自《深入解析Java Web技术》这本书,因为我对DNS不是特别熟悉,而且本书中关于DNS的部分已经描述的比较详细,所以我直接使用了书。老规矩,不复制不粘贴,所有内容都是手写,边打字边学习理解。DNS域名解析我们知道,互联网通过URL发布和请求资源,需要将URL中的域名解析成IP地址才能与远程主机建立连接。如何将域名解析为IP地址属于DNS解析的范畴。毫不夸张的说,虽然我们平时上网时感觉不到DNS解析的存在,但是一旦DNS解析出了问题,
U盘分区合并_HelloBirthday的博客-程序员的秘密
USB存储:闪迪至尊操作系统:Winodws 7 64bit 问题:使用U盘制作linux镜像时,操作错误导致U盘被分成两个分区。linux下挂载两个分区是可以的,但是刷了固件。总是不成功。Windows下只能识别一个分区,分区大小只有8M(U盘8G)。Windows下将U盘的两个分区合并为一个分区,重新创建U盘。以下操作在wi中进行
Nutz表操作_一指流沙QQ博客-程序员秘籍
导入 java.util.Set;导入 org.nutz.dao.entity.annotation.ColDefine;导入 org.nutz.dao.entity.annotation.ColType;导入 org.nutz.dao.entity.annotation.Column;导入 org.nutz .dao.entity.anno...
Re sub 实现多次替换 - 程序员大本营
两种写法 1 | 表示或替换所有字母 result_content = re.sub('a|b|c|d|e|f|g|h|i|j|k|l|m|n|o |p|q|r|s| t|u|v|w|x|y|z','',result_content)2 将每个替换放在括号中,最后放在方括号中 & \ / ; 四个匹配替换 result_content
zookeeper实际应用场景案例
1、数据发布订阅/配置中心1、原理:发布者向zookeeper节点发布数据,订阅者获取节点上的数据,从而实现发布订阅的目的。实现配置信息集中管理和数据动态更新2、实现配置中心有两种模式:push(push:服务器端push)、pull(pull:客户端主动拉取)、client-side向服务客户端注册要关注的节点。一旦节点发生变化,服务器将向客户端发送通知。3、zookeeper 使用推和拉的组合。...
excel自动抓取网页数据(如何使用Excel网络函数库的GetJsonSource()函数从财经网站提取股票交易数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-04-14 13:32
昨天小编给大家介绍了如何使用Excel网络函数库的GetJsonSource()和Split2Array()函数从Finance网站中提取股票交易数据。今天我们继续这个话题。
首先我们来了解一下什么是JSON?
JSON(JavaScript Object Notation,JS Object Short)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。易于人类读写,也易于机器解析生成,有效提高网络传输效率。
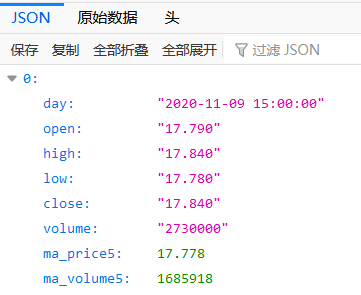
JSON 格式的数据是什么样的?比如我们打开某财经网站某只股票的网页,在火狐浏览器中会显示如下:
JSON格式广泛应用于各种APP或web系统,是APP程序交换数据的主要数据格式。 JSON格式的数据是结构化数据,易于程序读取。
接下来我们将分别通过GetJsonProperty()和GetJsonByPropertyName()公式提取Excel中的Json数据。
第一步,使用GetJsonSource(url)公式获取url对应的Json数据,如下图:
[{"day":"2020-11-10 15:00:00","open":"18.080","high":"18.110","low":"18.080","close":"18.110","volume":"1599186","ma_price5":18.116,"ma_volume5":1135977}]
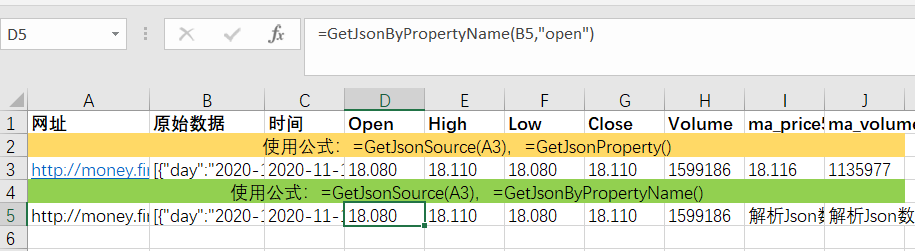
第二步,使用GetJsonProperty(Json_string, Property_name)提取Json数据的指定属性值。在Json数据中,一般由“属性名:属性值”组成,多个属性用英文逗号分隔。比如GetJsonProperty(B5, "day")函数会返回时间2020-11-1015:00:00"。如下图,依次获取每个属性的值。
从Json数据中提取属性值,除了GetJsonProperty()函数,还有GetJsonByPropertyName()函数,后者适用于标准格式的Json字符串,前者可以处理类似Json格式的数据如上所示,GetJsonByPropertyName() 函数无法处理 ma_price5 和 ma_volume5 属性。
如果你觉得这个技巧有用,请帮忙转发给你的朋友 查看全部
excel自动抓取网页数据(如何使用Excel网络函数库的GetJsonSource()函数从财经网站提取股票交易数据)
昨天小编给大家介绍了如何使用Excel网络函数库的GetJsonSource()和Split2Array()函数从Finance网站中提取股票交易数据。今天我们继续这个话题。
首先我们来了解一下什么是JSON?

JSON(JavaScript Object Notation,JS Object Short)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。易于人类读写,也易于机器解析生成,有效提高网络传输效率。
JSON 格式的数据是什么样的?比如我们打开某财经网站某只股票的网页,在火狐浏览器中会显示如下:
JSON格式广泛应用于各种APP或web系统,是APP程序交换数据的主要数据格式。 JSON格式的数据是结构化数据,易于程序读取。
接下来我们将分别通过GetJsonProperty()和GetJsonByPropertyName()公式提取Excel中的Json数据。
第一步,使用GetJsonSource(url)公式获取url对应的Json数据,如下图:
[{"day":"2020-11-10 15:00:00","open":"18.080","high":"18.110","low":"18.080","close":"18.110","volume":"1599186","ma_price5":18.116,"ma_volume5":1135977}]
第二步,使用GetJsonProperty(Json_string, Property_name)提取Json数据的指定属性值。在Json数据中,一般由“属性名:属性值”组成,多个属性用英文逗号分隔。比如GetJsonProperty(B5, "day")函数会返回时间2020-11-1015:00:00"。如下图,依次获取每个属性的值。
从Json数据中提取属性值,除了GetJsonProperty()函数,还有GetJsonByPropertyName()函数,后者适用于标准格式的Json字符串,前者可以处理类似Json格式的数据如上所示,GetJsonByPropertyName() 函数无法处理 ma_price5 和 ma_volume5 属性。
如果你觉得这个技巧有用,请帮忙转发给你的朋友
excel自动抓取网页数据(如何打造一款属于自己的邮箱客户端(图),Python基础之破解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-03 17:15
猜你在找什么 Python 相关文章
基于Python的数字大屏
在公司或前台,有时需要展示数字标牌来展示公司的业务信息。看着其他公司展示的炫酷数码屏,你羡慕吗?本文使用Pythonʿlask+jQuery⯬harts来简要介绍如何开发数字大屏
基于Python破解加密压缩包
在日常工作和生活中,经常会用到压缩文件,其中一些为了安全和保密还专门设置了密码。如果您忘记了密码,如何破解它,那么暴力破解将派上用场。本文使用一个简单的例子。描述如何通过Python中的zipfile模块进行破解
Python办公自动化的文件合并
如果公司需要统计每个员工的个人信息,制定模板后,由员工填写,然后发给综合部门汇总。这将是耗时、劳动密集且容易出错的
Python办公自动化的文档批量生成
在日常工作中,合同等文件通常都有固定的模板。例如,偶尔可以手动编辑一两个文档。如果需要为同一个模板生成一百个或更多文档怎么办?如果您手动逐个文档编辑和保存,不仅容易出错,而且是一项吃力不讨好的任务。
Python通过IMAP实现邮件客户端
在日常工作和生活中,我们使用个人或公司邮箱客户端收发邮件,那么如何创建自己的邮箱客户端呢?本文通过一个简单的例子来简要介绍如何使用 Pyhton 的 imaplib 和 email 模块来实现邮件接收。
基于Python的os模块介绍
在日常工作中,经常会用到操作系统和文件目录相关的内容,是系统运维相关的必备知识点。本文主要简单介绍Python中os模块和os.path模块相关的内容,仅供学习。分享使用,如有不足请指正。
基于Python爬取豆瓣图书信息
所谓爬虫,就是帮助我们从网上获取相关数据,提取有用信息。在大数据时代,爬虫是非常重要的数据手段采集。与手动查询相比,采集data 更加方便快捷。刚开始学爬虫的时候,一般都是从一个结构比较规范的静态网页开始。
Python基本语句语法
打好基础,练好基本功,我觉得这就是学习Python的“秘诀”。老子曾云:九层平台,起于大地。本文主要通过一些简单的例子来简要说明基于Python的语句语法的相关内容,仅供学习分享。 查看全部
excel自动抓取网页数据(如何打造一款属于自己的邮箱客户端(图),Python基础之破解(组图))
猜你在找什么 Python 相关文章
基于Python的数字大屏
在公司或前台,有时需要展示数字标牌来展示公司的业务信息。看着其他公司展示的炫酷数码屏,你羡慕吗?本文使用Pythonʿlask+jQuery⯬harts来简要介绍如何开发数字大屏
基于Python破解加密压缩包
在日常工作和生活中,经常会用到压缩文件,其中一些为了安全和保密还专门设置了密码。如果您忘记了密码,如何破解它,那么暴力破解将派上用场。本文使用一个简单的例子。描述如何通过Python中的zipfile模块进行破解
Python办公自动化的文件合并
如果公司需要统计每个员工的个人信息,制定模板后,由员工填写,然后发给综合部门汇总。这将是耗时、劳动密集且容易出错的
Python办公自动化的文档批量生成
在日常工作中,合同等文件通常都有固定的模板。例如,偶尔可以手动编辑一两个文档。如果需要为同一个模板生成一百个或更多文档怎么办?如果您手动逐个文档编辑和保存,不仅容易出错,而且是一项吃力不讨好的任务。
Python通过IMAP实现邮件客户端
在日常工作和生活中,我们使用个人或公司邮箱客户端收发邮件,那么如何创建自己的邮箱客户端呢?本文通过一个简单的例子来简要介绍如何使用 Pyhton 的 imaplib 和 email 模块来实现邮件接收。
基于Python的os模块介绍
在日常工作中,经常会用到操作系统和文件目录相关的内容,是系统运维相关的必备知识点。本文主要简单介绍Python中os模块和os.path模块相关的内容,仅供学习。分享使用,如有不足请指正。
基于Python爬取豆瓣图书信息
所谓爬虫,就是帮助我们从网上获取相关数据,提取有用信息。在大数据时代,爬虫是非常重要的数据手段采集。与手动查询相比,采集data 更加方便快捷。刚开始学爬虫的时候,一般都是从一个结构比较规范的静态网页开始。
Python基本语句语法
打好基础,练好基本功,我觉得这就是学习Python的“秘诀”。老子曾云:九层平台,起于大地。本文主要通过一些简单的例子来简要说明基于Python的语句语法的相关内容,仅供学习分享。
excel自动抓取网页数据(通过自动程序在Airbnb上花最少的钱住最好的酒店 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-03 17:14
)
站长之家注:在大数据时代,如何有效获取数据已成为驱动业务决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网页抓取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络爬虫赚钱的方法,只需几个小时,使用不到 50 行代码即可学会。
使用机器人在 Airbnb 上以最少的钱入住最好的酒店
机器人可用于执行特定操作,您可以将它们出售给没有技术技能的人以获取利润。
为了展示如何创建和销售机器人,Christopher Zita 创建了一个 Airbnb 机器人。该程序允许用户输入一个位置,它将抓取 Airbnb 为该位置的房屋提供的所有数据,包括价格、评级、允许进入的客人数量等。所有这些都是通过从 Airbnb 抓取数据来完成的。
为了演示该程序的实际效果,Christopher Zita 在程序中输入了 Rome,并在几秒钟内获得了 272 家 Airbnb 的数据:
查看所有家庭数据现在非常简单,过滤也更容易。以克里斯托弗·齐塔的四口之家为例。如果他们要去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床位的酒店。并且在得到这张表中的数据后,excel可以很方便的进行过滤。从这 272 条结果中,找到了 7 家符合要求的酒店。
在 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费61美元。选择所需链接后,只需将链接复制到浏览器并预订即可。
在度假旅行时,寻找酒店可能是一项艰巨的任务。为此,有人愿意为简化流程付费。使用此自动程序,您只需 5 分钟即可以低廉的价格预订让您满意的房间。
抓取特定商品的价格数据,以最低价格购买
网络抓取最常见的用途之一是从 网站 获取价格。创建一个程序来获取特定产品的价格数据,当价格低于某个水平时,它会在该产品售罄之前自动购买该产品。
接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时仍然赚钱的方法:
每个电子商务网站 都会有数量有限的特价商品。他们会显示产品的原价和折扣价,但一般不会显示在原价的基础上做了多少折扣。例如,一块原价350美元的手表,售价300美元,你会认为50美元的折扣是一大笔钱,但实际上只有14.2%的折扣。而如果一件 T 恤原价 50 美元,卖到 40 美元,你会认为它并没有便宜多少,但实际上比手表优惠了 20%。因此,您可以通过购买折扣率最高的产品来节省/赚钱。
我们以百货公司 Hudson's'Bay 为例进行数据采集实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
在抓取网站的数据后,我们获得了900多款产品的数据,其中只有一款产品Perry Ellis纯色衬衫的折扣率超过50%。
由于是限时优惠,这件衬衫的价格很快就会回到 90 美元左右。因此,如果您现在以 40 美元的价格购买它,并在限时优惠结束后以 60 美元的价格出售它,您仍然可以获得 20 美元。
如果您找到合适的利基市场,这是一种有可能赚很多钱的方法。
捕获宣传数据并将其可视化
网络上有数以百万计的数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有其他数据不易获取,需要大量时间才能可视化,这就是销售数据的演变方式。天眼查、企查查等公司专注于获取和可视化企业的业务和行业变化信息,然后以“采购员可查”的形式出售给用户。
一个类似的模型是这个体育数据网站BigDataBall,它通过出售球员的比赛数据和其他统计数据向用户收取每赛季30美元的费用。他们没有设定这个价格,因为他们网站拥有数据,但他们会抓取数据,将其组织成类别,并以易于阅读和清晰的结构呈现。
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,并将其放入结构化数据集中。BigDataBall 不是唯一的 网站 拥有这些数据,它具有相同的数据,但是 网站 没有结构化数据,使用户难以过滤和下载所需的数据集。Christopher Zita 使用网络抓取工具来抓取网络上的所有玩家数据。
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络抓取工具来查找手动难以获取的数据,让计算机完成工作,然后将数据可视化并出售给感兴趣的人。
总结
今天,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
每天一个超实用的创业案例,扫码关注【站长愿景】↓↓↓
查看全部
excel自动抓取网页数据(通过自动程序在Airbnb上花最少的钱住最好的酒店
)
站长之家注:在大数据时代,如何有效获取数据已成为驱动业务决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网页抓取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络爬虫赚钱的方法,只需几个小时,使用不到 50 行代码即可学会。
使用机器人在 Airbnb 上以最少的钱入住最好的酒店
机器人可用于执行特定操作,您可以将它们出售给没有技术技能的人以获取利润。
为了展示如何创建和销售机器人,Christopher Zita 创建了一个 Airbnb 机器人。该程序允许用户输入一个位置,它将抓取 Airbnb 为该位置的房屋提供的所有数据,包括价格、评级、允许进入的客人数量等。所有这些都是通过从 Airbnb 抓取数据来完成的。
为了演示该程序的实际效果,Christopher Zita 在程序中输入了 Rome,并在几秒钟内获得了 272 家 Airbnb 的数据:
查看所有家庭数据现在非常简单,过滤也更容易。以克里斯托弗·齐塔的四口之家为例。如果他们要去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床位的酒店。并且在得到这张表中的数据后,excel可以很方便的进行过滤。从这 272 条结果中,找到了 7 家符合要求的酒店。
在 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费61美元。选择所需链接后,只需将链接复制到浏览器并预订即可。
在度假旅行时,寻找酒店可能是一项艰巨的任务。为此,有人愿意为简化流程付费。使用此自动程序,您只需 5 分钟即可以低廉的价格预订让您满意的房间。
抓取特定商品的价格数据,以最低价格购买
网络抓取最常见的用途之一是从 网站 获取价格。创建一个程序来获取特定产品的价格数据,当价格低于某个水平时,它会在该产品售罄之前自动购买该产品。
接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时仍然赚钱的方法:
每个电子商务网站 都会有数量有限的特价商品。他们会显示产品的原价和折扣价,但一般不会显示在原价的基础上做了多少折扣。例如,一块原价350美元的手表,售价300美元,你会认为50美元的折扣是一大笔钱,但实际上只有14.2%的折扣。而如果一件 T 恤原价 50 美元,卖到 40 美元,你会认为它并没有便宜多少,但实际上比手表优惠了 20%。因此,您可以通过购买折扣率最高的产品来节省/赚钱。
我们以百货公司 Hudson's'Bay 为例进行数据采集实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
在抓取网站的数据后,我们获得了900多款产品的数据,其中只有一款产品Perry Ellis纯色衬衫的折扣率超过50%。
由于是限时优惠,这件衬衫的价格很快就会回到 90 美元左右。因此,如果您现在以 40 美元的价格购买它,并在限时优惠结束后以 60 美元的价格出售它,您仍然可以获得 20 美元。
如果您找到合适的利基市场,这是一种有可能赚很多钱的方法。
捕获宣传数据并将其可视化
网络上有数以百万计的数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有其他数据不易获取,需要大量时间才能可视化,这就是销售数据的演变方式。天眼查、企查查等公司专注于获取和可视化企业的业务和行业变化信息,然后以“采购员可查”的形式出售给用户。
一个类似的模型是这个体育数据网站BigDataBall,它通过出售球员的比赛数据和其他统计数据向用户收取每赛季30美元的费用。他们没有设定这个价格,因为他们网站拥有数据,但他们会抓取数据,将其组织成类别,并以易于阅读和清晰的结构呈现。
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,并将其放入结构化数据集中。BigDataBall 不是唯一的 网站 拥有这些数据,它具有相同的数据,但是 网站 没有结构化数据,使用户难以过滤和下载所需的数据集。Christopher Zita 使用网络抓取工具来抓取网络上的所有玩家数据。
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络抓取工具来查找手动难以获取的数据,让计算机完成工作,然后将数据可视化并出售给感兴趣的人。
总结
今天,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
每天一个超实用的创业案例,扫码关注【站长愿景】↓↓↓
excel自动抓取网页数据(excel自动抓取网页数据-精华帖讲解如何用excel抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-02 22:06
excel自动抓取网页数据-精华帖讲解如何用excel抓取网页数据-在线教育交流中心-中国计算机教育网excel自动抓取网页数据-精华帖
如果是文本类型的数据,可以用正则表达式+xpath,
excel自动抓取网页数据-精华帖我刚也问了一下,
python抓取网页数据:分享
也是刚刚学习,抓了一下微博数据,总共抓到一千五百多万条数据,感觉还挺好玩的,
推荐一个能抓取百度搜索结果的小工具,支持的浏览器有chrome,safari,opera,qq浏览器,ie,360,猎豹,uc,360极速,支持的操作系统有windows,linux,ios,
中国人民大学新闻学院的陈永兴教授组建了一个“站长在线工作室”,与站长进行长期分成,
如果是文本类数据,有效的方法是:1.很多站可以用spider+xpath,支持抓取大段网页。如:;2.手动撸,直接requests之类xml方式来请求网页。
方案一:爬虫+正则方案二:网页抓取+xpath大神或者产品自己脑补方案三:框架,
方案一:用爬虫
用jieba分词
如果你用的是windows或者mac系统,试试用软件高德地图网站抓包器,easytransprite,把url导入就可以抓取了。如果需要在excel中合并单元格,比如a2,a4,d2,d4这种,直接用xls,xlwt(xlsx)就可以操作好了。 查看全部
excel自动抓取网页数据(excel自动抓取网页数据-精华帖讲解如何用excel抓取)
excel自动抓取网页数据-精华帖讲解如何用excel抓取网页数据-在线教育交流中心-中国计算机教育网excel自动抓取网页数据-精华帖
如果是文本类型的数据,可以用正则表达式+xpath,
excel自动抓取网页数据-精华帖我刚也问了一下,
python抓取网页数据:分享
也是刚刚学习,抓了一下微博数据,总共抓到一千五百多万条数据,感觉还挺好玩的,
推荐一个能抓取百度搜索结果的小工具,支持的浏览器有chrome,safari,opera,qq浏览器,ie,360,猎豹,uc,360极速,支持的操作系统有windows,linux,ios,
中国人民大学新闻学院的陈永兴教授组建了一个“站长在线工作室”,与站长进行长期分成,
如果是文本类数据,有效的方法是:1.很多站可以用spider+xpath,支持抓取大段网页。如:;2.手动撸,直接requests之类xml方式来请求网页。
方案一:爬虫+正则方案二:网页抓取+xpath大神或者产品自己脑补方案三:框架,
方案一:用爬虫
用jieba分词
如果你用的是windows或者mac系统,试试用软件高德地图网站抓包器,easytransprite,把url导入就可以抓取了。如果需要在excel中合并单元格,比如a2,a4,d2,d4这种,直接用xls,xlwt(xlsx)就可以操作好了。
excel自动抓取网页数据( 什么是PowerBI?(图)的优势(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-04-01 06:14
什么是PowerBI?(图)的优势(组图))
火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
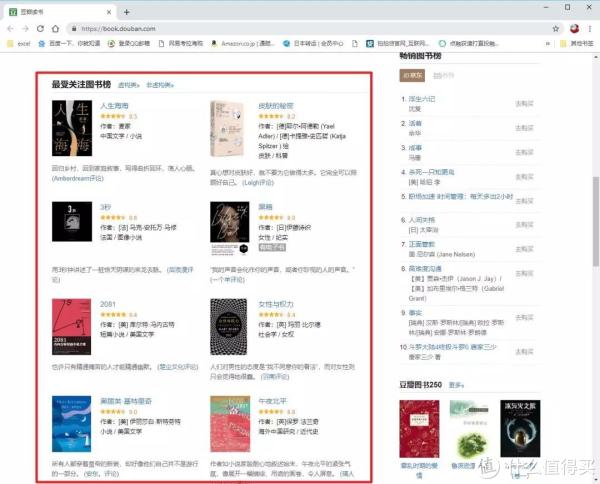
抢豆瓣“最受关注书单”
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
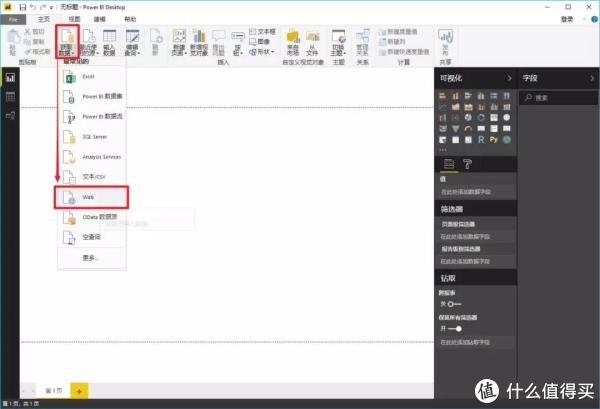
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址()并确认
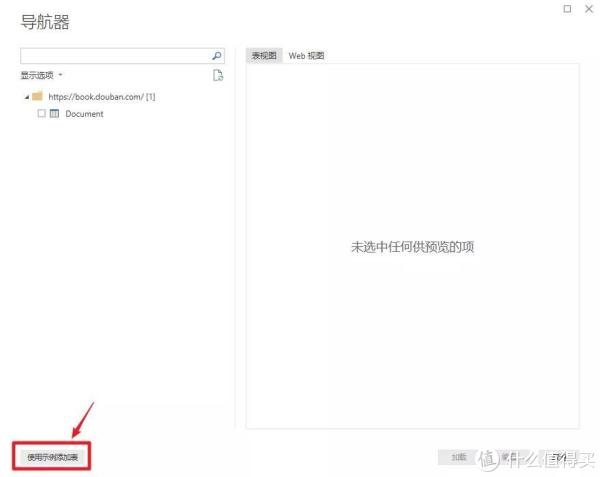
>>>第三步
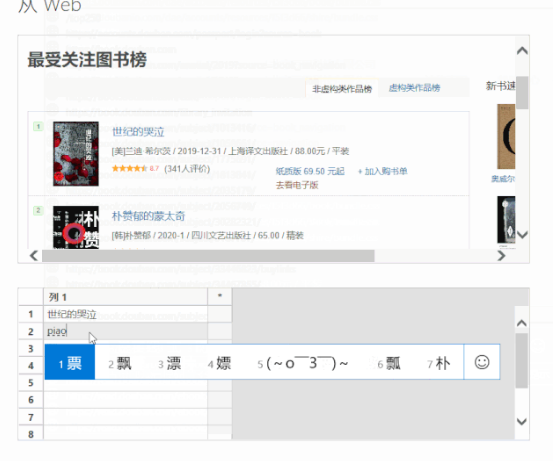
此时会弹出另一个导航器,选择“Add Table Using Example”。
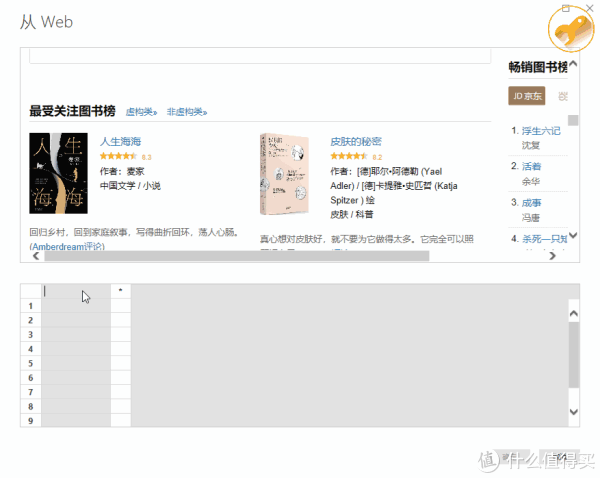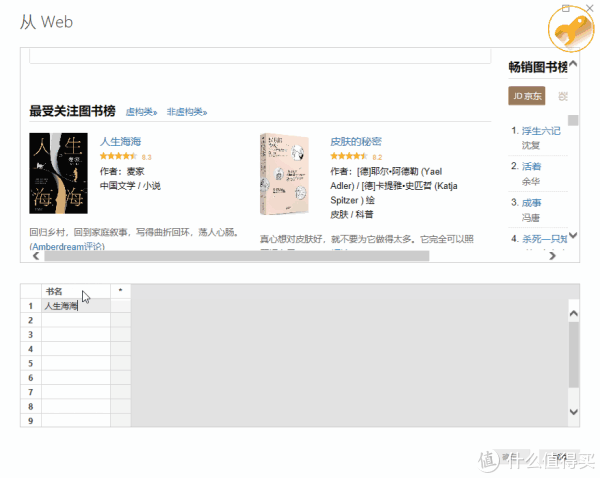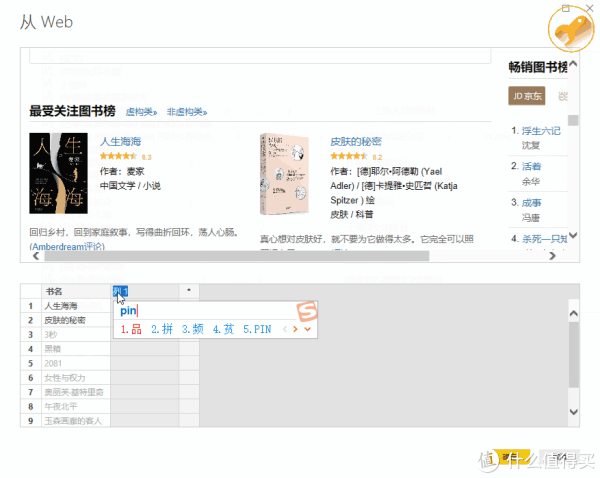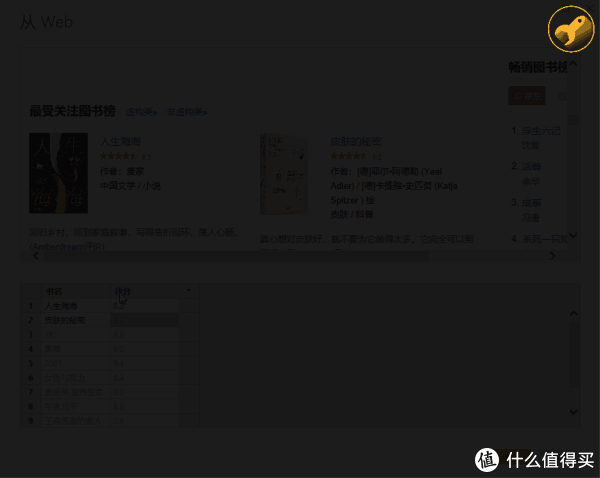
>>>第四步
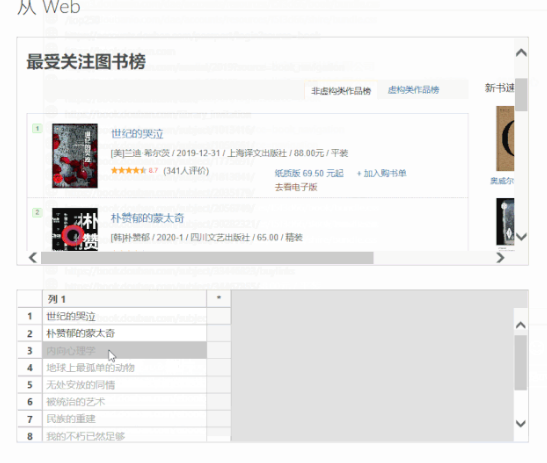
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果你说,“好吧,我还是想用 Excel 来最终处理或保存这些数据”,当然没问题。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
原文链接: 查看全部
excel自动抓取网页数据(
什么是PowerBI?(图)的优势(组图))
火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址()并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果你说,“好吧,我还是想用 Excel 来最终处理或保存这些数据”,当然没问题。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
原文链接:
excel自动抓取网页数据(一下用PowerBI爬取招聘网站信息实时刷新内容(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-26 02:22
在我们的概念中,爬虫都是由程序员完成的。今天给大家分享一下如何使用Power BI抓取招聘网站信息并实时刷新内容。
今天以一条招聘网站信息为例:
步骤如下:
STEP1:解析网址
因为有多个页面,所以我们提取前三个页面的URL进行分析:
第一页:
第二页:
第三页:
很简单,每页对应2个地方,需要换成对应的页码。
STEP2:采集数据
打开Power BI - 获取数据 - 选择高级 - 添加部分 - 将URL写成四部分,数字在单独的部分中
这里我们直接选择Table 1,点击加载数据。到这一步,我们可以看到我们已经获取到了第一页的数据。是不是很简单?
查看第一行信息,和网页内容完全一致!
STEP3:获取分页数据
①、点击首页-高级编辑器
②。在第一行输入以下代码: (p as number) as table =>
③。将对应的两个“1”修改为如下代码:(Number.ToText(p)),然后点击确定,得到一个函数公式,
我们将表 1 更改为 BOSS_ZP
④。右击表1下方空白处——创建空查询,输入={1..100},点击表创建1-10的表
⑤、调用自定义函数,这里我们使用gif图片来操作
至此,我们已经抓取到了第 1-10 页的数据。如果您想要更长的数据,请单击高级编辑器以修改页码。
【小陈说】
Power BI这几年越来越火了,小伙伴们可以学习一下。很适合表妹和表妹使用,而且非常好用! 查看全部
excel自动抓取网页数据(一下用PowerBI爬取招聘网站信息实时刷新内容(图))
在我们的概念中,爬虫都是由程序员完成的。今天给大家分享一下如何使用Power BI抓取招聘网站信息并实时刷新内容。
今天以一条招聘网站信息为例:
步骤如下:
STEP1:解析网址
因为有多个页面,所以我们提取前三个页面的URL进行分析:
第一页:
第二页:
第三页:
很简单,每页对应2个地方,需要换成对应的页码。
STEP2:采集数据
打开Power BI - 获取数据 - 选择高级 - 添加部分 - 将URL写成四部分,数字在单独的部分中
这里我们直接选择Table 1,点击加载数据。到这一步,我们可以看到我们已经获取到了第一页的数据。是不是很简单?
查看第一行信息,和网页内容完全一致!
STEP3:获取分页数据
①、点击首页-高级编辑器
②。在第一行输入以下代码: (p as number) as table =>
③。将对应的两个“1”修改为如下代码:(Number.ToText(p)),然后点击确定,得到一个函数公式,
我们将表 1 更改为 BOSS_ZP
④。右击表1下方空白处——创建空查询,输入={1..100},点击表创建1-10的表
⑤、调用自定义函数,这里我们使用gif图片来操作
至此,我们已经抓取到了第 1-10 页的数据。如果您想要更长的数据,请单击高级编辑器以修改页码。
【小陈说】
Power BI这几年越来越火了,小伙伴们可以学习一下。很适合表妹和表妹使用,而且非常好用!
excel自动抓取网页数据( 什么是PowerBI?(图)的优势(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-16 13:06
什么是PowerBI?(图)的优势(组图))
火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们想在豆瓣阅读页面抓取“最受欢迎图书榜”的相关信息:
书名
分数
作者
...
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
欢迎关注
我们是一个倡导“高效做事,尽情享受生活”的专栏。 查看全部
excel自动抓取网页数据(
什么是PowerBI?(图)的优势(组图))

火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:

Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们想在豆瓣阅读页面抓取“最受欢迎图书榜”的相关信息:
书名
分数
作者
...
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步

在弹窗复制豆瓣地址并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
欢迎关注
我们是一个倡导“高效做事,尽情享受生活”的专栏。
excel自动抓取网页数据(读取Excel今天我们要实现Excel转为html()!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2022-03-11 23:04
前言
说到用 Pandas 导出数据,应该想到 to.xxx 系列函数。
其中比较常用的是pd.to_csv()和pd.to_excel()。但其实也可以导入成Html网页格式,这里用到的函数是pd.to_html()!
读取 Excel
今天我们要将Excel转成html格式,首先需要读取Excel中的表格数据。
import paXvfKsHuFWkndas as pd
data = pd.read_excel('测试.xlsx')
查看数据
data.head()
让我们学习如何将 DataFrame 转换为 HTML 表格。
生成 HTML
to_html()函数只需一行代码就可以直接将DataFrame转换成HTML表格:
html_tahttp://www.cppcns.comble = dXvfKsHuFWkata.to_html('测试.html')
运行上述代码后,工作目录下多了一个test.html文件,用网络浏览器打开,内容如下
print(data.to_html())
通过打印可以看到DataFrame的内部结构自动转换成,,标签嵌入表格中,保留所有内部层次结构。
格式化
我们也可以自定义修改参数来调整生成的HTML的格式。
html_table = data.to_html('测试.html',header = True,index = False,justify='center')
再次打开新生成的test.html文件,发现格式变了。
如果要对格式做进一步的调整(添加标题、修改颜色等),需要一些HTML知识,可以在生成的测试.html文件中调整文本。
对于一些可能需要展示页面的小伙伴来说,需要结合Flask库使用XvfKsHuFWk。
总结
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常好用,一个可以轻松将DataFrame等复杂数据结构转换成HTML表格;另一个XvfKsHuFWk不需要复杂的爬虫,只需几行代码就可以抓取Table表数据,简直就是神器!
今天的篇幅很短,主要讲Pandas中的to_html()函数。使用这个功能最大的好处是我们可以在不了解HTML知识的情况下生成表格HTML。
总结
这是文章关于如何使用pandas将Excel转为html格式的介绍。更多相关pandas将Excel转html格式,请搜索我们之前的文章或继续浏览下方相关的文章,希望大家以后多多支持!
本文标题:如何使用pandas将Excel转为html格式 查看全部
excel自动抓取网页数据(读取Excel今天我们要实现Excel转为html()!!)
前言
说到用 Pandas 导出数据,应该想到 to.xxx 系列函数。
其中比较常用的是pd.to_csv()和pd.to_excel()。但其实也可以导入成Html网页格式,这里用到的函数是pd.to_html()!
读取 Excel
今天我们要将Excel转成html格式,首先需要读取Excel中的表格数据。
import paXvfKsHuFWkndas as pd
data = pd.read_excel('测试.xlsx')
查看数据
data.head()

让我们学习如何将 DataFrame 转换为 HTML 表格。
生成 HTML
to_html()函数只需一行代码就可以直接将DataFrame转换成HTML表格:
html_tahttp://www.cppcns.comble = dXvfKsHuFWkata.to_html('测试.html')
运行上述代码后,工作目录下多了一个test.html文件,用网络浏览器打开,内容如下

print(data.to_html())
通过打印可以看到DataFrame的内部结构自动转换成,,标签嵌入表格中,保留所有内部层次结构。

格式化
我们也可以自定义修改参数来调整生成的HTML的格式。
html_table = data.to_html('测试.html',header = True,index = False,justify='center')
再次打开新生成的test.html文件,发现格式变了。

如果要对格式做进一步的调整(添加标题、修改颜色等),需要一些HTML知识,可以在生成的测试.html文件中调整文本。
对于一些可能需要展示页面的小伙伴来说,需要结合Flask库使用XvfKsHuFWk。
总结
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常好用,一个可以轻松将DataFrame等复杂数据结构转换成HTML表格;另一个XvfKsHuFWk不需要复杂的爬虫,只需几行代码就可以抓取Table表数据,简直就是神器!
今天的篇幅很短,主要讲Pandas中的to_html()函数。使用这个功能最大的好处是我们可以在不了解HTML知识的情况下生成表格HTML。
总结
这是文章关于如何使用pandas将Excel转为html格式的介绍。更多相关pandas将Excel转html格式,请搜索我们之前的文章或继续浏览下方相关的文章,希望大家以后多多支持!
本文标题:如何使用pandas将Excel转为html格式
excel自动抓取网页数据(3个感兴趣的朋友可以尝试一下:速上采集和简易采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2022-03-08 22:22
导出网页上的数据,很明显是根据一定的规则或手段自动抓取特定网页的数据,然后转储到excel等文件中。至于说的话,有很多,很多都可以很容易的实现。3、感兴趣的朋友可以试试:
速商是纯国产的,专门做网页数据的,采集大部分网页数据不用写一行代码,支持自定义采集和简单的采集,对于小程序来说非常白话易掌握,只需输入网页地址,设计采集规则,然后一键采集,支持批量采集,数据导出(excel等) ,而且官方自带了很多现成的采集模板,可以轻松采集某宝等热门网站数据,是一款非常不错的日常数据工具和软件< @采集:
速商也是一款非常不错的网页数据data采集软件。与速商类似,速商支持更多平台,更灵活。目前支持智能采集和流程图采集两种模式,只要输入网页地址,软件就会自动启动采集进程,包括自动识别网页内容,自动翻页,当然也可以根据采集@>的内容自定义采集,规则都可以,支持数据导出,采集接收到的数据可以很方便的导出到excel、mysql等,也很方便后期的数据处理:
与速商、速商相比,data采集软件更专业、更强大。它整合了数据从采集、处理、分析到挖掘的全流程,并且规则设置更灵活,数据采集也更智能更快,对于网页等数据采集@ >,只需输入网页地址,自定义采集流程和步骤,软件会自动启动采集流程,如果你需要快速获取网页数据,但你不知道代码什么的,都可以用这个软件,整体效果很好:
当然,除了以上三个现成的网页采集软件,如果你熟悉代码或编程,也可以编写相关程序。基本原理是一样的(都是根据特定的规则来提取数据),但是实现起来会比较复杂和耗时。网上也有相关的教程和资料。介绍很详细。如果你有兴趣,你可以搜索它。希望以上分享的内容对您有所帮助。欢迎评论和留言补充。数据采集软件。 查看全部
excel自动抓取网页数据(3个感兴趣的朋友可以尝试一下:速上采集和简易采集)
导出网页上的数据,很明显是根据一定的规则或手段自动抓取特定网页的数据,然后转储到excel等文件中。至于说的话,有很多,很多都可以很容易的实现。3、感兴趣的朋友可以试试:
速商是纯国产的,专门做网页数据的,采集大部分网页数据不用写一行代码,支持自定义采集和简单的采集,对于小程序来说非常白话易掌握,只需输入网页地址,设计采集规则,然后一键采集,支持批量采集,数据导出(excel等) ,而且官方自带了很多现成的采集模板,可以轻松采集某宝等热门网站数据,是一款非常不错的日常数据工具和软件< @采集:
速商也是一款非常不错的网页数据data采集软件。与速商类似,速商支持更多平台,更灵活。目前支持智能采集和流程图采集两种模式,只要输入网页地址,软件就会自动启动采集进程,包括自动识别网页内容,自动翻页,当然也可以根据采集@>的内容自定义采集,规则都可以,支持数据导出,采集接收到的数据可以很方便的导出到excel、mysql等,也很方便后期的数据处理:
与速商、速商相比,data采集软件更专业、更强大。它整合了数据从采集、处理、分析到挖掘的全流程,并且规则设置更灵活,数据采集也更智能更快,对于网页等数据采集@ >,只需输入网页地址,自定义采集流程和步骤,软件会自动启动采集流程,如果你需要快速获取网页数据,但你不知道代码什么的,都可以用这个软件,整体效果很好:
当然,除了以上三个现成的网页采集软件,如果你熟悉代码或编程,也可以编写相关程序。基本原理是一样的(都是根据特定的规则来提取数据),但是实现起来会比较复杂和耗时。网上也有相关的教程和资料。介绍很详细。如果你有兴趣,你可以搜索它。希望以上分享的内容对您有所帮助。欢迎评论和留言补充。数据采集软件。
excel自动抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2022-03-01 17:19
)
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。
2、你会看到一个查询对话框打开,它会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、然后点击导入按钮,你会看到下图第二张,稍等几秒。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图,下图第二张,如果设置刷新频率,会看到Excel表格中的数据可以按照网页更新的数据,是不是很强大。
6、好的,这是我们导入的数据,现在是不是Excel 2013很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。
查看全部
excel自动抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据
)
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。
2、你会看到一个查询对话框打开,它会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、然后点击导入按钮,你会看到下图第二张,稍等几秒。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图,下图第二张,如果设置刷新频率,会看到Excel表格中的数据可以按照网页更新的数据,是不是很强大。
6、好的,这是我们导入的数据,现在是不是Excel 2013很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。

excel自动抓取网页数据(验证码100%,java能将验证码识别为数字吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-01 17:17
)
如何使用带有验证码的网站自动捕获数据?最近在做网站的数据抓取,但是这个网站有验证码,是不是需要去掉图片识别为4个数字,用httpclient加所有参数登录。是java有没有办法将图像解析为数字?网上百度说用ocr识别,不知道准确率是不是100%,java能把验证码识别为数字,用httpclient完成自动登录?验证码识别抓包数据--------编程问答--------orc肯定不是100%,这是毫无疑问的。你说的想法只能是做验证码识别。
抓取数据还有其他方式,比如绕过验证码/绕过登录等,访问实际数据所在的地址。这需要对您的业务和对该站点的请求进行一些测试和分析。
-------------------- 编程问答 -------------------- 你可以把一张图片反转成一个数字--------编程问答--------ORC的识别能力一般不弱,稍微扭曲的字体不起作用--------编程问答------ ——很难猜。--------------------编程问答--------------------喜欢这种验证码
, 不知道怎么解析成数字--------编程问答---- ----依赖 识别验证码的方法太难了,一般网站验证码要分开,可以想办法绕过------------ -------- 编程问答--------------------引用5楼萌兰香2的回复:就像这个验证码
,不知道怎么解析成数字
这种验证码过于规则,容易识别。先去除噪声,然后分成4个独立的数字,采集10个图片,分别比较每个部分的匹配度。
网上有相关的文章介绍。我曾经寻找文章,现在我不知道如何再次找到它。这是一个类似的 文章
补充:Java , Java EE 查看全部
excel自动抓取网页数据(验证码100%,java能将验证码识别为数字吗?
)
如何使用带有验证码的网站自动捕获数据?最近在做网站的数据抓取,但是这个网站有验证码,是不是需要去掉图片识别为4个数字,用httpclient加所有参数登录。是java有没有办法将图像解析为数字?网上百度说用ocr识别,不知道准确率是不是100%,java能把验证码识别为数字,用httpclient完成自动登录?验证码识别抓包数据--------编程问答--------orc肯定不是100%,这是毫无疑问的。你说的想法只能是做验证码识别。
抓取数据还有其他方式,比如绕过验证码/绕过登录等,访问实际数据所在的地址。这需要对您的业务和对该站点的请求进行一些测试和分析。
-------------------- 编程问答 -------------------- 你可以把一张图片反转成一个数字--------编程问答--------ORC的识别能力一般不弱,稍微扭曲的字体不起作用--------编程问答------ ——很难猜。--------------------编程问答--------------------喜欢这种验证码

, 不知道怎么解析成数字--------编程问答---- ----依赖 识别验证码的方法太难了,一般网站验证码要分开,可以想办法绕过------------ -------- 编程问答--------------------引用5楼萌兰香2的回复:就像这个验证码
,不知道怎么解析成数字
这种验证码过于规则,容易识别。先去除噪声,然后分成4个独立的数字,采集10个图片,分别比较每个部分的匹配度。
网上有相关的文章介绍。我曾经寻找文章,现在我不知道如何再次找到它。这是一个类似的 文章
补充:Java , Java EE
excel自动抓取网页数据( 本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-27 02:07
本文就用Java给大家演示如何抓取网站的数据:(1))
Java爬取网页数据(原创网页+Javascript返回数据)
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在本例中,我们将从以下位置获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]查看纯副本
publicvoidcapturehtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml()的结果:查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建漳州移动
p>
二、获取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]查看纯副本
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
excel自动抓取网页数据(
本文就用Java给大家演示如何抓取网站的数据:(1))
Java爬取网页数据(原创网页+Javascript返回数据)
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在本例中,我们将从以下位置获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>

第二步:查看网页的源码,我们看到源码中有这么一段:

从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:

也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]查看纯副本
publicvoidcapturehtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml()的结果:查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建漳州移动
p>
二、获取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:

第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:

为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:

这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:


从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]查看纯副本
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
excel自动抓取网页数据(你能明白我一定要抓到表格里吗?Powerquery处理你可能不知道)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-24 10:18
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
获取JSON数据连接;
电源查询处理数据;
配置搜索地址;
添加超链接
01
脚步
获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=> let keywords = search term [search term]{0}, source = Json.Document(Web.Contents(""& keywords & "&correction=1&offset="& Text.From(page*2< @0) &"&limit=20&random=" & Text.From(Number.Random()))), data = source[data], jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, jsondata 中的 ExtraValues.Error),转换为 table = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
添加超链接
至此所有数据都已处理完毕,但如果要查看原创知乎页面,则需要复制此超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
最终效果
最后的效果是:
输入搜索词;
右键刷新;
找到点赞最多的;
点击【点击查看】,享受插队的感觉!
02
总结
知道在表格中搜索的好处吗?
按“喜欢”和“评论”排序;
如果你看过文章,可以加栏写笔记;
您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。 查看全部
excel自动抓取网页数据(你能明白我一定要抓到表格里吗?Powerquery处理你可能不知道)
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
获取JSON数据连接;
电源查询处理数据;
配置搜索地址;
添加超链接
01
脚步
获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=> let keywords = search term [search term]{0}, source = Json.Document(Web.Contents(""& keywords & "&correction=1&offset="& Text.From(page*2< @0) &"&limit=20&random=" & Text.From(Number.Random()))), data = source[data], jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, jsondata 中的 ExtraValues.Error),转换为 table = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
添加超链接
至此所有数据都已处理完毕,但如果要查看原创知乎页面,则需要复制此超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
最终效果
最后的效果是:
输入搜索词;
右键刷新;
找到点赞最多的;
点击【点击查看】,享受插队的感觉!
02
总结
知道在表格中搜索的好处吗?
按“喜欢”和“评论”排序;
如果你看过文章,可以加栏写笔记;
您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。
excel自动抓取网页数据(如何用Python构建一个带有GUI的爬虫小程序-之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2022-02-23 13:20
大家好,之前我们讲了如何使用Python构建一个带有GUI的爬虫小程序。很多文章会迎合热点,继续上一篇NBA爬虫GUI,讨论如何爬取虎扑NBA官网数据。并将数据写入Excel并自动生成折线图,主要有以下几个步骤
本文将分以下两部分进行讲解
项目涉及的主要 Python 模块:
** ** 爬虫部分
爬虫部分组织如下?
观察URL1的源码找到队名和对应的URL2 观察URL2的源码找到玩家对应的URL3 观察URL3的源码**** 找到对应的基本信息和比赛数据播放器并过滤和存储它们
其实爬虫是对html进行操作的,而html的结构很简单,只有一个,就是一个大框架协商一个小框架,小框架嵌套在小框架内,这样一层一层的层嵌套。
目标网址如下:
先引用模块
1from bs4 import BeautifulSoupimport requestsimport xlsxwriterimport os
2
查看URL1源码,可以看到团队名词及其对应的URL2在span标签下,然后找到它的父框和祖父框。下面的思路是一样的,如下图:
此时,可以使用 requests 模块和 bs4 模块进行有目的的索引以获取团队名称列表。
1def Teamlists(url):
2 TeamName=[]
3 TeamURL=[]
4 GET=requests.get(URL1)
5 soup=BeautifulSoup(GET.content,'lxml')
6 lables=soup.select('html body div div div ul li span a') for lable in lables:
7 ballname=lable.get_text()
8 TeamName.append(ballname)
9 print(ballname)
10 teamname=input("请输入想查询的球队名:")#此处可变为GUI界面中的按键值
11 c=TeamName.index(teamname)for item in lables:
12 HREF=item.get('href')
13 TeamURL.append(HREF)
14 URL2=TeamURL[c] return URL2
15
这样就得到了对应球队的URL2,然后观察URL2网页的内容,可以看到球员的名字在标签a下,对应球员的URL3也被存储了,如图下图:
此时,仍然使用requests模块和bs4模块的对应索引来获取播放器名称列表和对应的URL3。
1#自定义函数获取队员列表和对应的URLdef playerlists(URL2):
2 PlayerName=[]
3 PlayerURL=[]
4 GET2=requests.get(URL1)
5 soup2=BeautifulSoup(GET2.content,'lxml')
6 lables2=soup2.select('html body div div table tbody tr td b a')for lable2 in lables2:
7 playername=lable2.get_text()
8 PlayerName.append(playername)
9 print(playername)
10 name=input("请输入球员名:") #此处可变为GUI界面中的按键值
11 d=PlayerName.index(name)for item2 in lables2:
12 HREF2=item2.get('href')
13 PlayerURL.append(HREF2)
14 URL3=PlayerURL[d]return URL3,name
15
现在我们已经获得了对应队伍的URL3,然后观察URL3网页的内容。可以看到球员的基本信息在标签p下,球员常规赛生涯数据和季后赛生涯数据在标签td下,如下图:
同理,通过requests模块和bs4模块之间的对应索引,得到球员的基本信息和生涯数据,对球员常规赛和季后赛的生涯数据进行过滤存储,得到数据列表.
1def Competition(URL3):
2 data=[]
3 GET3=requests.get(URL3)
4 soup3=BeautifulSoup(GET3.content,'lxml')
5 lables3=soup3.select('html body div div div div div div div div p')
6 lables4=soup3.select('div div table tbody tr td')for lable3 in lables3:
7 introduction=lable3.get_text()
8 print(introduction) #球员基本信息for lable4 in lables4:
9 competition=lable4.get_text()
10 data.append(competition) for i in range(len(data)):if data[i]=='职业生涯常规赛平均数据':
11 a=data[i+31]
12 a=data.index(a)del(data[:a]) for x in range(len(data)):if data[x]=='职业生涯季后赛平均数据':
13 b=data[x]
14 b=data.index(b)del(data[b:])return data
15
通过上述网络爬虫获取以下数据,提供可视化数据,方便GUI界面按键事件的绑定:
** ** 可视化部分
**想法:创建文件夹**创建表格和折线图
自定义函数创建表,使用os模块编写,返回创建文件夹的路径。代码如下:
1def file_add(path): #此时的内函数path可与GUI界面的Statictext绑定
2 creatpath=path+'\\Basketball' try:if not os.path.isdir(creatpath):
3 os.makedirs(creatpath) except:
4 print("文件夹存在")return creatpath
5
使用xlsxwriter模块在creatpath路径下创建带有自定义函数的excel表格,同时放入数据和构造折线图。代码如下:
1def player_chart(name,data,creatpath):#此为表格名称——球员名称+chart
2 EXCEL=xlsxwriter.Workbook(creatpath+'\\'+name+'chart.xlsx')
3 worksheet=EXCEL.add_worksheet(name)
4 bold=EXCEL.add_format({'bold':1})
5 headings=data[:18]
6 worksheet.write_row('A1',headings,bold) #写入表头
7 num=(len(data))//18
8 a=0for i in range(num):
9 a=a+18
10 c=a+18
11 i=i+1
12 worksheet.write_row('A'+str(i+1),data[a:c]) #写入数据
13 chart_col = EXCEL.add_chart({'type': 'line'}) #创建一个折线图
14 chart_col.add_series({'name': '='+name+'!$R$1', #设置折线描述名称'categories':'='+name+'!$A$2:$A$'+str(num), #设置图表类别标签范围'values': '='+name+'!$R$2:$R$'+str(num-1), #设置图表数据范围'line': {'color': 'red'}, }) #设置图表线条属性#设置图标的标题和想x,y轴信息
15 chart_col.set_title({'name': name+'生涯常规赛平均得分'})
16 chart_col.set_x_axis({'name': '年份 (年)'})
17 chart_col.set_y_axis({'name': '平均得分(分)'})
18 chart_col.set_style(1) #设置图表风格
19 worksheet.insert_chart('A14', chart_col, {'x_offset':25, 'y_offset':3,}) #把图标插入工作台中并设置偏移
20 EXCEL.close()
21
数据表效果展示,以James为例如下
而此时打开自动生成的Excel,对应的折线图就会直接显示出来,不用再整理了!
现在结合任务1的网络爬虫和任务2的数据可视化,可以得到实时的球员常规赛数据和季后赛数据汇总,以及实时的球员生涯折线图。可以绑定上一个GUI界面任务设计中的“可视化”按钮事件,有兴趣的读者可以自行进一步研究! 查看全部
excel自动抓取网页数据(如何用Python构建一个带有GUI的爬虫小程序-之前)
大家好,之前我们讲了如何使用Python构建一个带有GUI的爬虫小程序。很多文章会迎合热点,继续上一篇NBA爬虫GUI,讨论如何爬取虎扑NBA官网数据。并将数据写入Excel并自动生成折线图,主要有以下几个步骤

本文将分以下两部分进行讲解
项目涉及的主要 Python 模块:
** ** 爬虫部分
爬虫部分组织如下?
观察URL1的源码找到队名和对应的URL2 观察URL2的源码找到玩家对应的URL3 观察URL3的源码**** 找到对应的基本信息和比赛数据播放器并过滤和存储它们
其实爬虫是对html进行操作的,而html的结构很简单,只有一个,就是一个大框架协商一个小框架,小框架嵌套在小框架内,这样一层一层的层嵌套。
目标网址如下:
先引用模块
1from bs4 import BeautifulSoupimport requestsimport xlsxwriterimport os
2
查看URL1源码,可以看到团队名词及其对应的URL2在span标签下,然后找到它的父框和祖父框。下面的思路是一样的,如下图:
此时,可以使用 requests 模块和 bs4 模块进行有目的的索引以获取团队名称列表。
1def Teamlists(url):
2 TeamName=[]
3 TeamURL=[]
4 GET=requests.get(URL1)
5 soup=BeautifulSoup(GET.content,'lxml')
6 lables=soup.select('html body div div div ul li span a') for lable in lables:
7 ballname=lable.get_text()
8 TeamName.append(ballname)
9 print(ballname)
10 teamname=input("请输入想查询的球队名:")#此处可变为GUI界面中的按键值
11 c=TeamName.index(teamname)for item in lables:
12 HREF=item.get('href')
13 TeamURL.append(HREF)
14 URL2=TeamURL[c] return URL2
15
这样就得到了对应球队的URL2,然后观察URL2网页的内容,可以看到球员的名字在标签a下,对应球员的URL3也被存储了,如图下图:
此时,仍然使用requests模块和bs4模块的对应索引来获取播放器名称列表和对应的URL3。
1#自定义函数获取队员列表和对应的URLdef playerlists(URL2):
2 PlayerName=[]
3 PlayerURL=[]
4 GET2=requests.get(URL1)
5 soup2=BeautifulSoup(GET2.content,'lxml')
6 lables2=soup2.select('html body div div table tbody tr td b a')for lable2 in lables2:
7 playername=lable2.get_text()
8 PlayerName.append(playername)
9 print(playername)
10 name=input("请输入球员名:") #此处可变为GUI界面中的按键值
11 d=PlayerName.index(name)for item2 in lables2:
12 HREF2=item2.get('href')
13 PlayerURL.append(HREF2)
14 URL3=PlayerURL[d]return URL3,name
15
现在我们已经获得了对应队伍的URL3,然后观察URL3网页的内容。可以看到球员的基本信息在标签p下,球员常规赛生涯数据和季后赛生涯数据在标签td下,如下图:
同理,通过requests模块和bs4模块之间的对应索引,得到球员的基本信息和生涯数据,对球员常规赛和季后赛的生涯数据进行过滤存储,得到数据列表.
1def Competition(URL3):
2 data=[]
3 GET3=requests.get(URL3)
4 soup3=BeautifulSoup(GET3.content,'lxml')
5 lables3=soup3.select('html body div div div div div div div div p')
6 lables4=soup3.select('div div table tbody tr td')for lable3 in lables3:
7 introduction=lable3.get_text()
8 print(introduction) #球员基本信息for lable4 in lables4:
9 competition=lable4.get_text()
10 data.append(competition) for i in range(len(data)):if data[i]=='职业生涯常规赛平均数据':
11 a=data[i+31]
12 a=data.index(a)del(data[:a]) for x in range(len(data)):if data[x]=='职业生涯季后赛平均数据':
13 b=data[x]
14 b=data.index(b)del(data[b:])return data
15
通过上述网络爬虫获取以下数据,提供可视化数据,方便GUI界面按键事件的绑定:
** ** 可视化部分
**想法:创建文件夹**创建表格和折线图
自定义函数创建表,使用os模块编写,返回创建文件夹的路径。代码如下:
1def file_add(path): #此时的内函数path可与GUI界面的Statictext绑定
2 creatpath=path+'\\Basketball' try:if not os.path.isdir(creatpath):
3 os.makedirs(creatpath) except:
4 print("文件夹存在")return creatpath
5
使用xlsxwriter模块在creatpath路径下创建带有自定义函数的excel表格,同时放入数据和构造折线图。代码如下:
1def player_chart(name,data,creatpath):#此为表格名称——球员名称+chart
2 EXCEL=xlsxwriter.Workbook(creatpath+'\\'+name+'chart.xlsx')
3 worksheet=EXCEL.add_worksheet(name)
4 bold=EXCEL.add_format({'bold':1})
5 headings=data[:18]
6 worksheet.write_row('A1',headings,bold) #写入表头
7 num=(len(data))//18
8 a=0for i in range(num):
9 a=a+18
10 c=a+18
11 i=i+1
12 worksheet.write_row('A'+str(i+1),data[a:c]) #写入数据
13 chart_col = EXCEL.add_chart({'type': 'line'}) #创建一个折线图
14 chart_col.add_series({'name': '='+name+'!$R$1', #设置折线描述名称'categories':'='+name+'!$A$2:$A$'+str(num), #设置图表类别标签范围'values': '='+name+'!$R$2:$R$'+str(num-1), #设置图表数据范围'line': {'color': 'red'}, }) #设置图表线条属性#设置图标的标题和想x,y轴信息
15 chart_col.set_title({'name': name+'生涯常规赛平均得分'})
16 chart_col.set_x_axis({'name': '年份 (年)'})
17 chart_col.set_y_axis({'name': '平均得分(分)'})
18 chart_col.set_style(1) #设置图表风格
19 worksheet.insert_chart('A14', chart_col, {'x_offset':25, 'y_offset':3,}) #把图标插入工作台中并设置偏移
20 EXCEL.close()
21
数据表效果展示,以James为例如下

而此时打开自动生成的Excel,对应的折线图就会直接显示出来,不用再整理了!
现在结合任务1的网络爬虫和任务2的数据可视化,可以得到实时的球员常规赛数据和季后赛数据汇总,以及实时的球员生涯折线图。可以绑定上一个GUI界面任务设计中的“可视化”按钮事件,有兴趣的读者可以自行进一步研究!
excel自动抓取网页数据( 神器PowerBI要怎么学?(一)PowerQuery )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-20 04:12
神器PowerBI要怎么学?(一)PowerQuery
)
您是否使用过 Power BI,它可能比 Excel 更简单但功能更强大?
Power BI 是微软最新的商业智能 (BI) 概念,其中包括一系列组件和工具。
废话不多说,先上图:
Power BI系列组件的功能你一眼就看懂了吗?其实Power BI的核心思想就是我们的用户不需要很强的技术背景,只需要掌握Excel等简单的工具就可以快速上手业务数据分析和可视化。
微软的Power BI主要收录四套插件,包括Power Query、Power Pivot、Power view和Power map。电力视图和电力地图需要另开一个界面,主要是基于交互式图表和地图可视化,与数据分析无关,相关内容自学也能满足需求。
1电源查询
Power Query 负责捕获和组织数据。它可以捕捉市面上几乎所有格式的源数据,然后按照我们需要的格式进行整理。通过PowerQuery,我们可以快速将来自多个数据源的数据合并和追加到一起,任意组合数据,分组数据,透视数据。而这些步骤以后会自动完成,也就是说以后你只需要点击刷新,所有的数据都会按照你的要求乖乖上碗,不再需要你手动调整数据……感动得想哭……
1.合并/追加表
2.数据包
3.透视/逆透视
2动力枢轴
Power Pivot 是微软 Power BI 系列工具的大脑,负责建模和分析。有人说这是过去 20 年来 Excel 中最好的新功能。它可以
1.易于处理各种量级的数据
2.快速创建多表关系,不再需要vlookup
3.查看生成的数据透视表:
那么,如何学习神器Power BI呢?
讲了半天,只是一点点Power BI毛皮,如果你想深入研究如何学习Power BI。
CDA 数据分析师
电子表格会议主席李奇先生
与你携手零基础入门商业智能分析
在这里,您可以学习快速提升数据分析技能,并在几分钟内制作出引人注目的数据分析报告。
一、课程表
北京&偏远:2017年8月19-20日(两个周末)
上海:2017年9月16-17日
深圳:2017年10月21~22日
课程费用:现场授课900元,远程授课500元
教学安排:
(1)教学方式:面对面直播、中文多媒体互动教学方式
(2)授课时间:上午9:00-12:00、下午13:30-16:30、16:30-17:00(答题)
(3)学习期:现场与视频相结合,长期学习加练习答题。
二、注册流程
1.在线填写报名信息
官方网站:
微信终端:
查看全部
excel自动抓取网页数据(
神器PowerBI要怎么学?(一)PowerQuery
)
您是否使用过 Power BI,它可能比 Excel 更简单但功能更强大?
Power BI 是微软最新的商业智能 (BI) 概念,其中包括一系列组件和工具。
废话不多说,先上图:

Power BI系列组件的功能你一眼就看懂了吗?其实Power BI的核心思想就是我们的用户不需要很强的技术背景,只需要掌握Excel等简单的工具就可以快速上手业务数据分析和可视化。
微软的Power BI主要收录四套插件,包括Power Query、Power Pivot、Power view和Power map。电力视图和电力地图需要另开一个界面,主要是基于交互式图表和地图可视化,与数据分析无关,相关内容自学也能满足需求。
1电源查询
Power Query 负责捕获和组织数据。它可以捕捉市面上几乎所有格式的源数据,然后按照我们需要的格式进行整理。通过PowerQuery,我们可以快速将来自多个数据源的数据合并和追加到一起,任意组合数据,分组数据,透视数据。而这些步骤以后会自动完成,也就是说以后你只需要点击刷新,所有的数据都会按照你的要求乖乖上碗,不再需要你手动调整数据……感动得想哭……
1.合并/追加表

2.数据包

3.透视/逆透视

2动力枢轴
Power Pivot 是微软 Power BI 系列工具的大脑,负责建模和分析。有人说这是过去 20 年来 Excel 中最好的新功能。它可以
1.易于处理各种量级的数据

2.快速创建多表关系,不再需要vlookup

3.查看生成的数据透视表:

那么,如何学习神器Power BI呢?
讲了半天,只是一点点Power BI毛皮,如果你想深入研究如何学习Power BI。
CDA 数据分析师
电子表格会议主席李奇先生
与你携手零基础入门商业智能分析
在这里,您可以学习快速提升数据分析技能,并在几分钟内制作出引人注目的数据分析报告。

一、课程表
北京&偏远:2017年8月19-20日(两个周末)
上海:2017年9月16-17日
深圳:2017年10月21~22日
课程费用:现场授课900元,远程授课500元
教学安排:
(1)教学方式:面对面直播、中文多媒体互动教学方式
(2)授课时间:上午9:00-12:00、下午13:30-16:30、16:30-17:00(答题)
(3)学习期:现场与视频相结合,长期学习加练习答题。
二、注册流程
1.在线填写报名信息
官方网站:

微信终端:

excel自动抓取网页数据( 抓取网络数据真实的数据挖掘项目,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-20 04:09
抓取网络数据真实的数据挖掘项目,你了解多少?)
1、爬虫爬取网络数据
一个真正的数据挖掘项目必须从数据采集开始。除了通过某些渠道购买或下载专业数据外,人们还经常需要自己爬取互联网数据。这时,爬虫就显得尤为重要。
Nutch爬虫的主要作用是从网络上爬取和索引网络数据。我们只需要指定 网站 的顶级 URL,例如爬虫可以自动检测页面内容中的新 URL,从而进一步爬取链接的网页数据。nutch 支持将捕获的数据转换为文本,例如(PDF、WORD、EXCEL、HTML、XML 等)转换为纯文本字符。
Nutch 与 Hadoop 集成,可以将下载的数据保存到 hdfs 以供后续离线分析。使用步骤如下:
$ hadoop fs -put urldir urldir
笔记:
第一个urldir是本地文件夹,存放url数据文件,每行一个url地址
第二个urldir是hdfs的存储路径。
$ bin/nutch crawlurldir --dir crawl -depth 3 --topN 10
命令执行成功后,会在hdfs中生成爬取目录。
2、MapReduce 预处理数据
下载的原创文本文档不能直接处理,需要对文本内容进行预处理,包括文档分词、文本分词、去除停用词(包括标点、数字、单词等无意义词)、文本特征提取、词频统计、文本向量化等操作。
一种常用的文本预处理算法是TF-IDF,其主要思想是如果一个词或短语在一个文章中出现频率很高,而在另一个文章中很少出现,则认为这个词或词组有很好的类别区分能力,适合分类。
再一次,似乎可可交付了......
hadoop jar $JAR SparseVectorsFromSequenceFiles …
9219:0.246 453:0.098 10322:0.21 11947:0.272 …
每列是单词及其权重,用冒号分隔。例如“9219:0.246”表示编号为9219的单词,对应原单词“Again”,其权重值为0.246。
3、Mahout 数据挖掘
预处理后的数据可用于数据挖掘。Mahout 是一个强大的数据挖掘工具和分布式机器学习算法的集合,包括:协同过滤、分类、聚类等。
以LDA算法为例,它可以将文档集中每个文档的主题以概率分布的形式给出。它是一种无监督学习算法,在训练时不需要对主题进行人工标注,只需要指定主题个数K即可。此外,LDA 的另一个优点是,对于每个主题,都可以找到一些词来描述它。
9219:0.246 453:0.098 …
mahout cvb –k 20…
topic1 {计算机、技术、系统、互联网、机器}
topic2 {戏剧、电影、电影、明星、导演、制作、舞台}
我们可以了解到哪些主题是用户的偏好,而这些主题是由一些关键词组成的。
4、Sqoop 导出到关系数据库
在某些场景下,需要将数据挖掘的结果导出到关系数据库中,以便及时响应外部应用程序的查询。
Sqoop 是用于在 hadoop 和关系数据库之间传输数据的工具。它可以将关系型数据库(如MySQL、Oracle等)的数据导入hadoop的hdfs,也可以将hdfs的数据导出到关系型数据库中:
sqoop export --connect jdbc:mysql://localhost:3306/zxtest --username root --password root --table result_test --export-dir /user/mr/lda/out
导出操作实现将hdfs目录/user/mr/lda/out中的数据导出到mysql的result_test表中。 查看全部
excel自动抓取网页数据(
抓取网络数据真实的数据挖掘项目,你了解多少?)

1、爬虫爬取网络数据
一个真正的数据挖掘项目必须从数据采集开始。除了通过某些渠道购买或下载专业数据外,人们还经常需要自己爬取互联网数据。这时,爬虫就显得尤为重要。
Nutch爬虫的主要作用是从网络上爬取和索引网络数据。我们只需要指定 网站 的顶级 URL,例如爬虫可以自动检测页面内容中的新 URL,从而进一步爬取链接的网页数据。nutch 支持将捕获的数据转换为文本,例如(PDF、WORD、EXCEL、HTML、XML 等)转换为纯文本字符。
Nutch 与 Hadoop 集成,可以将下载的数据保存到 hdfs 以供后续离线分析。使用步骤如下:
$ hadoop fs -put urldir urldir
笔记:
第一个urldir是本地文件夹,存放url数据文件,每行一个url地址
第二个urldir是hdfs的存储路径。
$ bin/nutch crawlurldir --dir crawl -depth 3 --topN 10
命令执行成功后,会在hdfs中生成爬取目录。
2、MapReduce 预处理数据
下载的原创文本文档不能直接处理,需要对文本内容进行预处理,包括文档分词、文本分词、去除停用词(包括标点、数字、单词等无意义词)、文本特征提取、词频统计、文本向量化等操作。
一种常用的文本预处理算法是TF-IDF,其主要思想是如果一个词或短语在一个文章中出现频率很高,而在另一个文章中很少出现,则认为这个词或词组有很好的类别区分能力,适合分类。
再一次,似乎可可交付了......
hadoop jar $JAR SparseVectorsFromSequenceFiles …
9219:0.246 453:0.098 10322:0.21 11947:0.272 …
每列是单词及其权重,用冒号分隔。例如“9219:0.246”表示编号为9219的单词,对应原单词“Again”,其权重值为0.246。
3、Mahout 数据挖掘
预处理后的数据可用于数据挖掘。Mahout 是一个强大的数据挖掘工具和分布式机器学习算法的集合,包括:协同过滤、分类、聚类等。
以LDA算法为例,它可以将文档集中每个文档的主题以概率分布的形式给出。它是一种无监督学习算法,在训练时不需要对主题进行人工标注,只需要指定主题个数K即可。此外,LDA 的另一个优点是,对于每个主题,都可以找到一些词来描述它。
9219:0.246 453:0.098 …
mahout cvb –k 20…
topic1 {计算机、技术、系统、互联网、机器}
topic2 {戏剧、电影、电影、明星、导演、制作、舞台}
我们可以了解到哪些主题是用户的偏好,而这些主题是由一些关键词组成的。
4、Sqoop 导出到关系数据库
在某些场景下,需要将数据挖掘的结果导出到关系数据库中,以便及时响应外部应用程序的查询。
Sqoop 是用于在 hadoop 和关系数据库之间传输数据的工具。它可以将关系型数据库(如MySQL、Oracle等)的数据导入hadoop的hdfs,也可以将hdfs的数据导出到关系型数据库中:
sqoop export --connect jdbc:mysql://localhost:3306/zxtest --username root --password root --table result_test --export-dir /user/mr/lda/out
导出操作实现将hdfs目录/user/mr/lda/out中的数据导出到mysql的result_test表中。
excel自动抓取网页数据(PowerAutomate从Excel中读取数据的操作,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 468 次浏览 • 2022-04-20 06:00
在使用Power Automate进行流程自动化的过程中,我们经常会遇到从Excel中读取数据的操作,所以我们首先需要学习的是:
废话不多说,干活吧!
Step-01 要获取读取的数据,首先在PAD中启动Excel并打开文件
Step-02 设置活动工作表
PAD 启动 Excel 打开文件时,默认使用 Excel 工作簿当前活动的工作表。因此,在读取Excel工作表的数据之前,一定要增加设置活动工作表的操作,避免Excel文件在最后Fetching wrong data with other worksheets activate (selected) on close时出现。
Step-03 从 Excel 工作表中读取数据
可以按需读取工作表中所有可用的值,带或不带标题(第一行收录列名)等。
完成以上步骤后,即可运行流程,然后在“流变量”窗口中查看读取的数据:
检查读取的数据是否正确,然后进行后续操作——读取的数据表大致如下(第一行不收录列名):
读取数据后,我们可以根据需要提取行、列或单元格数据。
1、提取一行数据
选择从Excel中读取的数据表(ExcelData)变量,然后在方括号中手动输入行号。注意行号从0开始,即第一行的行号为0,以此类推。
2、从单元格中提取数据
提取单元格数据,可以在提取的行后面加上列名,即ExcelData后面跟两个方括号,分别代表行号和列名(注意单引号):
3、提取一列数据
对于ExcelData,无法通过之前的取行方式直接获取特定列的内容,但是Power Automate提供了“将数据列取回列表”的功能,直接填写列名(或索引)在步骤中。 ) 到:
最后,不要忘记关闭 Excel,以免打开的 Excel 运行时间过长,或者在另一个进程中再次打开此 Excel 文件时可能出现错误。
其实可以设置在读取数据的步骤之后立即关闭Excel的步骤,因为此时数据已经被读出,如果不需要读取其他数据或者对此做其他操作Excel文件稍后,不再需要。
以上是从Excel中读取数据的基本操作方法的介绍。结合循环和判断操作等步骤,将可以灵活读取Excel数据。流程自动化奠定了坚实的基础。 查看全部
excel自动抓取网页数据(PowerAutomate从Excel中读取数据的操作,你知道吗?)
在使用Power Automate进行流程自动化的过程中,我们经常会遇到从Excel中读取数据的操作,所以我们首先需要学习的是:
废话不多说,干活吧!
Step-01 要获取读取的数据,首先在PAD中启动Excel并打开文件
Step-02 设置活动工作表
PAD 启动 Excel 打开文件时,默认使用 Excel 工作簿当前活动的工作表。因此,在读取Excel工作表的数据之前,一定要增加设置活动工作表的操作,避免Excel文件在最后Fetching wrong data with other worksheets activate (selected) on close时出现。
Step-03 从 Excel 工作表中读取数据
可以按需读取工作表中所有可用的值,带或不带标题(第一行收录列名)等。
完成以上步骤后,即可运行流程,然后在“流变量”窗口中查看读取的数据:
检查读取的数据是否正确,然后进行后续操作——读取的数据表大致如下(第一行不收录列名):
读取数据后,我们可以根据需要提取行、列或单元格数据。
1、提取一行数据
选择从Excel中读取的数据表(ExcelData)变量,然后在方括号中手动输入行号。注意行号从0开始,即第一行的行号为0,以此类推。
2、从单元格中提取数据
提取单元格数据,可以在提取的行后面加上列名,即ExcelData后面跟两个方括号,分别代表行号和列名(注意单引号):
3、提取一列数据
对于ExcelData,无法通过之前的取行方式直接获取特定列的内容,但是Power Automate提供了“将数据列取回列表”的功能,直接填写列名(或索引)在步骤中。 ) 到:
最后,不要忘记关闭 Excel,以免打开的 Excel 运行时间过长,或者在另一个进程中再次打开此 Excel 文件时可能出现错误。
其实可以设置在读取数据的步骤之后立即关闭Excel的步骤,因为此时数据已经被读出,如果不需要读取其他数据或者对此做其他操作Excel文件稍后,不再需要。
以上是从Excel中读取数据的基本操作方法的介绍。结合循环和判断操作等步骤,将可以灵活读取Excel数据。流程自动化奠定了坚实的基础。
excel自动抓取网页数据(如何制作一个随网站自动同步的Excel表呢?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-04-20 00:02
有时我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作一个自动与 网站 同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 函数。
1.打开网页
以下页面为中国地震台网()官方页面。每当发生地震时,都会在此处自动更新。由于要爬取,所以需要先打开页面。
▲先打开要爬取的网页
2. 确定从哪里获取
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要爬取的URL。此时,Power Query 会自动分析网页,然后在选取框内显示分析结果。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
▲创建查询以确定抓取范围
3.数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角“关闭并上传”即可上传Excel。
▲数据“预清洗”
4.格式化
数据上传到 Excel 后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的讲就是一些美化操作,最后得到下表。
▲美化餐桌
5.设置自动同步间隔
现在表格基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表格可以自动同步。
▲设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决此问题。
▲防止更新时破坏表格格式
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这是本期想和大家分享的一个小技巧,是不是很有用!
本文由 LinkNemo 爬虫 [Echo]采集from[]
创建 查看全部
excel自动抓取网页数据(如何制作一个随网站自动同步的Excel表呢?(组图))
有时我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。我可以制作一个自动与 网站 同步的 Excel 工作表吗?答案是肯定的,这就是 Excel 中的 Power Query 函数。
1.打开网页
以下页面为中国地震台网()官方页面。每当发生地震时,都会在此处自动更新。由于要爬取,所以需要先打开页面。
▲先打开要爬取的网页
2. 确定从哪里获取
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要爬取的URL。此时,Power Query 会自动分析网页,然后在选取框内显示分析结果。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
▲创建查询以确定抓取范围
3.数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角“关闭并上传”即可上传Excel。
▲数据“预清洗”
4.格式化
数据上传到 Excel 后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的讲就是一些美化操作,最后得到下表。
▲美化餐桌
5.设置自动同步间隔
现在表格基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表格可以自动同步。
▲设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决此问题。
▲防止更新时破坏表格格式
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这是本期想和大家分享的一个小技巧,是不是很有用!
本文由 LinkNemo 爬虫 [Echo]采集from[]
创建
excel自动抓取网页数据( Excel黑科技挖掘,Python小技巧(致力于)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-16 06:02
Excel黑科技挖掘,Python小技巧(致力于)(组图))
1、点击“获取数据”>“Web”,在弹出的对话框中输入网址,点击“确定”
2、在弹出的“Navigator”对话框中,选择左下角的“Add Table Using Example”
3、接下来我们需要做的就是提供一个表格,其中收录我们需要提取的数据示例。
以抓取书名为例,可以看到当我们提供两个书名时,Power BI会自动为我们抓取其余的书名。
4、用同样的方法分别抓取我们需要的其他字段。
单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。
二、将“示例中的列”添加到 Power Query
上面获取的数据收录无用的信息,除了正确的 [author] 和 [rating] 列。Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
其中,“示例中的列”可以根据用户提供的示例提取信息。
1、选择【作者】列,点击“添加列”>“示例中的列”,左下角的小三角,在弹出的下拉选项中选择“From Selection”
2、 在【第 1 列】中提供示例,Power BI 将智能识别我们需要的数据
点击右上角的“确定”后,作者的名字被提取到一个新的列中。
三、Excel 中的智能填充“Ctrl + E”
Excel 还提供了基于用户提供的示例智能提取数据的功能。例如,从列表数据中的价格列中提取数字。使用“Ctrl + E”快捷键从收录文本和数字的列中提取数字。
结尾。爱数据网专栏作者:Jary Yuan 专栏名称:Power BI 自动化与可视化专栏介绍:Excel、Power BI、Python 等学习交流领域。Excel黑科技挖掘,Python技巧。致力于办公自动化、工作场所效率提升、数据分析与视觉设计个人公众号:JaryYuan 查看全部
excel自动抓取网页数据(
Excel黑科技挖掘,Python小技巧(致力于)(组图))
1、点击“获取数据”>“Web”,在弹出的对话框中输入网址,点击“确定”
2、在弹出的“Navigator”对话框中,选择左下角的“Add Table Using Example”
3、接下来我们需要做的就是提供一个表格,其中收录我们需要提取的数据示例。
以抓取书名为例,可以看到当我们提供两个书名时,Power BI会自动为我们抓取其余的书名。
4、用同样的方法分别抓取我们需要的其他字段。
单击“确定”>“转换数据”,我们已成功将数据捕获到 Power Query 查询编辑器中。
二、将“示例中的列”添加到 Power Query
上面获取的数据收录无用的信息,除了正确的 [author] 和 [rating] 列。Power Query 提供了丰富的数据清理功能,可以帮助我们从杂乱的数据中提取信息。
其中,“示例中的列”可以根据用户提供的示例提取信息。
1、选择【作者】列,点击“添加列”>“示例中的列”,左下角的小三角,在弹出的下拉选项中选择“From Selection”
2、 在【第 1 列】中提供示例,Power BI 将智能识别我们需要的数据
点击右上角的“确定”后,作者的名字被提取到一个新的列中。
三、Excel 中的智能填充“Ctrl + E”
Excel 还提供了基于用户提供的示例智能提取数据的功能。例如,从列表数据中的价格列中提取数字。使用“Ctrl + E”快捷键从收录文本和数字的列中提取数字。
结尾。爱数据网专栏作者:Jary Yuan 专栏名称:Power BI 自动化与可视化专栏介绍:Excel、Power BI、Python 等学习交流领域。Excel黑科技挖掘,Python技巧。致力于办公自动化、工作场所效率提升、数据分析与视觉设计个人公众号:JaryYuan
excel自动抓取网页数据(数据特征归一化(FeatureScaling)学习及实现_爱吃西瓜)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-15 05:09
数据特征归一化(Feature Scaling)学习与实现 - 程序员大本营
为什么我们需要特征归一化?不同的特征指标往往有不同的维度和维度单位。这种情况会影响数据分析的结果。为了消除指标间的维度影响,需要进行数据标准化处理,解决指标间的可比性。原创数据标准化后,各项指标处于同一数量级,适合综合比较评价。两种常用的归一化方法是最值归一化方法(normaization):最值归一化方法将数据映射在0-1之间。适合分发...
DNS 域名解析流程
前言 本文来自《深入解析Java Web技术》这本书,因为我对DNS不是特别熟悉,而且本书中关于DNS的部分已经描述的比较详细,所以我直接使用了书。老规矩,不复制不粘贴,所有内容都是手写,边打字边学习理解。DNS域名解析我们知道,互联网通过URL发布和请求资源,需要将URL中的域名解析成IP地址才能与远程主机建立连接。如何将域名解析为IP地址属于DNS解析的范畴。毫不夸张的说,虽然我们平时上网时感觉不到DNS解析的存在,但是一旦DNS解析出了问题,
U盘分区合并_HelloBirthday的博客-程序员的秘密
USB存储:闪迪至尊操作系统:Winodws 7 64bit 问题:使用U盘制作linux镜像时,操作错误导致U盘被分成两个分区。linux下挂载两个分区是可以的,但是刷了固件。总是不成功。Windows下只能识别一个分区,分区大小只有8M(U盘8G)。Windows下将U盘的两个分区合并为一个分区,重新创建U盘。以下操作在wi中进行
Nutz表操作_一指流沙QQ博客-程序员秘籍
导入 java.util.Set;导入 org.nutz.dao.entity.annotation.ColDefine;导入 org.nutz.dao.entity.annotation.ColType;导入 org.nutz.dao.entity.annotation.Column;导入 org.nutz .dao.entity.anno...
Re sub 实现多次替换 - 程序员大本营
两种写法 1 | 表示或替换所有字母 result_content = re.sub('a|b|c|d|e|f|g|h|i|j|k|l|m|n|o |p|q|r|s| t|u|v|w|x|y|z','',result_content)2 将每个替换放在括号中,最后放在方括号中 & \ / ; 四个匹配替换 result_content
zookeeper实际应用场景案例
1、数据发布订阅/配置中心1、原理:发布者向zookeeper节点发布数据,订阅者获取节点上的数据,从而实现发布订阅的目的。实现配置信息集中管理和数据动态更新2、实现配置中心有两种模式:push(push:服务器端push)、pull(pull:客户端主动拉取)、client-side向服务客户端注册要关注的节点。一旦节点发生变化,服务器将向客户端发送通知。3、zookeeper 使用推和拉的组合。... 查看全部
excel自动抓取网页数据(数据特征归一化(FeatureScaling)学习及实现_爱吃西瓜)
数据特征归一化(Feature Scaling)学习与实现 - 程序员大本营
为什么我们需要特征归一化?不同的特征指标往往有不同的维度和维度单位。这种情况会影响数据分析的结果。为了消除指标间的维度影响,需要进行数据标准化处理,解决指标间的可比性。原创数据标准化后,各项指标处于同一数量级,适合综合比较评价。两种常用的归一化方法是最值归一化方法(normaization):最值归一化方法将数据映射在0-1之间。适合分发...
DNS 域名解析流程
前言 本文来自《深入解析Java Web技术》这本书,因为我对DNS不是特别熟悉,而且本书中关于DNS的部分已经描述的比较详细,所以我直接使用了书。老规矩,不复制不粘贴,所有内容都是手写,边打字边学习理解。DNS域名解析我们知道,互联网通过URL发布和请求资源,需要将URL中的域名解析成IP地址才能与远程主机建立连接。如何将域名解析为IP地址属于DNS解析的范畴。毫不夸张的说,虽然我们平时上网时感觉不到DNS解析的存在,但是一旦DNS解析出了问题,
U盘分区合并_HelloBirthday的博客-程序员的秘密
USB存储:闪迪至尊操作系统:Winodws 7 64bit 问题:使用U盘制作linux镜像时,操作错误导致U盘被分成两个分区。linux下挂载两个分区是可以的,但是刷了固件。总是不成功。Windows下只能识别一个分区,分区大小只有8M(U盘8G)。Windows下将U盘的两个分区合并为一个分区,重新创建U盘。以下操作在wi中进行
Nutz表操作_一指流沙QQ博客-程序员秘籍
导入 java.util.Set;导入 org.nutz.dao.entity.annotation.ColDefine;导入 org.nutz.dao.entity.annotation.ColType;导入 org.nutz.dao.entity.annotation.Column;导入 org.nutz .dao.entity.anno...
Re sub 实现多次替换 - 程序员大本营
两种写法 1 | 表示或替换所有字母 result_content = re.sub('a|b|c|d|e|f|g|h|i|j|k|l|m|n|o |p|q|r|s| t|u|v|w|x|y|z','',result_content)2 将每个替换放在括号中,最后放在方括号中 & \ / ; 四个匹配替换 result_content
zookeeper实际应用场景案例
1、数据发布订阅/配置中心1、原理:发布者向zookeeper节点发布数据,订阅者获取节点上的数据,从而实现发布订阅的目的。实现配置信息集中管理和数据动态更新2、实现配置中心有两种模式:push(push:服务器端push)、pull(pull:客户端主动拉取)、client-side向服务客户端注册要关注的节点。一旦节点发生变化,服务器将向客户端发送通知。3、zookeeper 使用推和拉的组合。...
excel自动抓取网页数据(如何使用Excel网络函数库的GetJsonSource()函数从财经网站提取股票交易数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-04-14 13:32
昨天小编给大家介绍了如何使用Excel网络函数库的GetJsonSource()和Split2Array()函数从Finance网站中提取股票交易数据。今天我们继续这个话题。
首先我们来了解一下什么是JSON?
JSON(JavaScript Object Notation,JS Object Short)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。易于人类读写,也易于机器解析生成,有效提高网络传输效率。
JSON 格式的数据是什么样的?比如我们打开某财经网站某只股票的网页,在火狐浏览器中会显示如下:
JSON格式广泛应用于各种APP或web系统,是APP程序交换数据的主要数据格式。 JSON格式的数据是结构化数据,易于程序读取。
接下来我们将分别通过GetJsonProperty()和GetJsonByPropertyName()公式提取Excel中的Json数据。
第一步,使用GetJsonSource(url)公式获取url对应的Json数据,如下图:
[{"day":"2020-11-10 15:00:00","open":"18.080","high":"18.110","low":"18.080","close":"18.110","volume":"1599186","ma_price5":18.116,"ma_volume5":1135977}]
第二步,使用GetJsonProperty(Json_string, Property_name)提取Json数据的指定属性值。在Json数据中,一般由“属性名:属性值”组成,多个属性用英文逗号分隔。比如GetJsonProperty(B5, "day")函数会返回时间2020-11-1015:00:00"。如下图,依次获取每个属性的值。
从Json数据中提取属性值,除了GetJsonProperty()函数,还有GetJsonByPropertyName()函数,后者适用于标准格式的Json字符串,前者可以处理类似Json格式的数据如上所示,GetJsonByPropertyName() 函数无法处理 ma_price5 和 ma_volume5 属性。
如果你觉得这个技巧有用,请帮忙转发给你的朋友 查看全部
excel自动抓取网页数据(如何使用Excel网络函数库的GetJsonSource()函数从财经网站提取股票交易数据)
昨天小编给大家介绍了如何使用Excel网络函数库的GetJsonSource()和Split2Array()函数从Finance网站中提取股票交易数据。今天我们继续这个话题。
首先我们来了解一下什么是JSON?
JSON(JavaScript Object Notation,JS Object Short)是一种轻量级的数据交换格式。它基于 ECMAScript(欧洲计算机协会开发的 js 规范)的一个子集,使用完全独立于编程语言的文本格式来存储和表示数据。简洁明了的层次结构使 JSON 成为理想的数据交换语言。易于人类读写,也易于机器解析生成,有效提高网络传输效率。
JSON 格式的数据是什么样的?比如我们打开某财经网站某只股票的网页,在火狐浏览器中会显示如下:
JSON格式广泛应用于各种APP或web系统,是APP程序交换数据的主要数据格式。 JSON格式的数据是结构化数据,易于程序读取。
接下来我们将分别通过GetJsonProperty()和GetJsonByPropertyName()公式提取Excel中的Json数据。
第一步,使用GetJsonSource(url)公式获取url对应的Json数据,如下图:
[{"day":"2020-11-10 15:00:00","open":"18.080","high":"18.110","low":"18.080","close":"18.110","volume":"1599186","ma_price5":18.116,"ma_volume5":1135977}]
第二步,使用GetJsonProperty(Json_string, Property_name)提取Json数据的指定属性值。在Json数据中,一般由“属性名:属性值”组成,多个属性用英文逗号分隔。比如GetJsonProperty(B5, "day")函数会返回时间2020-11-1015:00:00"。如下图,依次获取每个属性的值。
从Json数据中提取属性值,除了GetJsonProperty()函数,还有GetJsonByPropertyName()函数,后者适用于标准格式的Json字符串,前者可以处理类似Json格式的数据如上所示,GetJsonByPropertyName() 函数无法处理 ma_price5 和 ma_volume5 属性。
如果你觉得这个技巧有用,请帮忙转发给你的朋友
excel自动抓取网页数据(如何打造一款属于自己的邮箱客户端(图),Python基础之破解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-03 17:15
猜你在找什么 Python 相关文章
基于Python的数字大屏
在公司或前台,有时需要展示数字标牌来展示公司的业务信息。看着其他公司展示的炫酷数码屏,你羡慕吗?本文使用Pythonʿlask+jQuery⯬harts来简要介绍如何开发数字大屏
基于Python破解加密压缩包
在日常工作和生活中,经常会用到压缩文件,其中一些为了安全和保密还专门设置了密码。如果您忘记了密码,如何破解它,那么暴力破解将派上用场。本文使用一个简单的例子。描述如何通过Python中的zipfile模块进行破解
Python办公自动化的文件合并
如果公司需要统计每个员工的个人信息,制定模板后,由员工填写,然后发给综合部门汇总。这将是耗时、劳动密集且容易出错的
Python办公自动化的文档批量生成
在日常工作中,合同等文件通常都有固定的模板。例如,偶尔可以手动编辑一两个文档。如果需要为同一个模板生成一百个或更多文档怎么办?如果您手动逐个文档编辑和保存,不仅容易出错,而且是一项吃力不讨好的任务。
Python通过IMAP实现邮件客户端
在日常工作和生活中,我们使用个人或公司邮箱客户端收发邮件,那么如何创建自己的邮箱客户端呢?本文通过一个简单的例子来简要介绍如何使用 Pyhton 的 imaplib 和 email 模块来实现邮件接收。
基于Python的os模块介绍
在日常工作中,经常会用到操作系统和文件目录相关的内容,是系统运维相关的必备知识点。本文主要简单介绍Python中os模块和os.path模块相关的内容,仅供学习。分享使用,如有不足请指正。
基于Python爬取豆瓣图书信息
所谓爬虫,就是帮助我们从网上获取相关数据,提取有用信息。在大数据时代,爬虫是非常重要的数据手段采集。与手动查询相比,采集data 更加方便快捷。刚开始学爬虫的时候,一般都是从一个结构比较规范的静态网页开始。
Python基本语句语法
打好基础,练好基本功,我觉得这就是学习Python的“秘诀”。老子曾云:九层平台,起于大地。本文主要通过一些简单的例子来简要说明基于Python的语句语法的相关内容,仅供学习分享。 查看全部
excel自动抓取网页数据(如何打造一款属于自己的邮箱客户端(图),Python基础之破解(组图))
猜你在找什么 Python 相关文章
基于Python的数字大屏
在公司或前台,有时需要展示数字标牌来展示公司的业务信息。看着其他公司展示的炫酷数码屏,你羡慕吗?本文使用Pythonʿlask+jQuery⯬harts来简要介绍如何开发数字大屏
基于Python破解加密压缩包
在日常工作和生活中,经常会用到压缩文件,其中一些为了安全和保密还专门设置了密码。如果您忘记了密码,如何破解它,那么暴力破解将派上用场。本文使用一个简单的例子。描述如何通过Python中的zipfile模块进行破解
Python办公自动化的文件合并
如果公司需要统计每个员工的个人信息,制定模板后,由员工填写,然后发给综合部门汇总。这将是耗时、劳动密集且容易出错的
Python办公自动化的文档批量生成
在日常工作中,合同等文件通常都有固定的模板。例如,偶尔可以手动编辑一两个文档。如果需要为同一个模板生成一百个或更多文档怎么办?如果您手动逐个文档编辑和保存,不仅容易出错,而且是一项吃力不讨好的任务。
Python通过IMAP实现邮件客户端
在日常工作和生活中,我们使用个人或公司邮箱客户端收发邮件,那么如何创建自己的邮箱客户端呢?本文通过一个简单的例子来简要介绍如何使用 Pyhton 的 imaplib 和 email 模块来实现邮件接收。
基于Python的os模块介绍
在日常工作中,经常会用到操作系统和文件目录相关的内容,是系统运维相关的必备知识点。本文主要简单介绍Python中os模块和os.path模块相关的内容,仅供学习。分享使用,如有不足请指正。
基于Python爬取豆瓣图书信息
所谓爬虫,就是帮助我们从网上获取相关数据,提取有用信息。在大数据时代,爬虫是非常重要的数据手段采集。与手动查询相比,采集data 更加方便快捷。刚开始学爬虫的时候,一般都是从一个结构比较规范的静态网页开始。
Python基本语句语法
打好基础,练好基本功,我觉得这就是学习Python的“秘诀”。老子曾云:九层平台,起于大地。本文主要通过一些简单的例子来简要说明基于Python的语句语法的相关内容,仅供学习分享。
excel自动抓取网页数据(通过自动程序在Airbnb上花最少的钱住最好的酒店 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-04-03 17:14
)
站长之家注:在大数据时代,如何有效获取数据已成为驱动业务决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网页抓取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络爬虫赚钱的方法,只需几个小时,使用不到 50 行代码即可学会。
使用机器人在 Airbnb 上以最少的钱入住最好的酒店
机器人可用于执行特定操作,您可以将它们出售给没有技术技能的人以获取利润。
为了展示如何创建和销售机器人,Christopher Zita 创建了一个 Airbnb 机器人。该程序允许用户输入一个位置,它将抓取 Airbnb 为该位置的房屋提供的所有数据,包括价格、评级、允许进入的客人数量等。所有这些都是通过从 Airbnb 抓取数据来完成的。
为了演示该程序的实际效果,Christopher Zita 在程序中输入了 Rome,并在几秒钟内获得了 272 家 Airbnb 的数据:
查看所有家庭数据现在非常简单,过滤也更容易。以克里斯托弗·齐塔的四口之家为例。如果他们要去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床位的酒店。并且在得到这张表中的数据后,excel可以很方便的进行过滤。从这 272 条结果中,找到了 7 家符合要求的酒店。
在 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费61美元。选择所需链接后,只需将链接复制到浏览器并预订即可。
在度假旅行时,寻找酒店可能是一项艰巨的任务。为此,有人愿意为简化流程付费。使用此自动程序,您只需 5 分钟即可以低廉的价格预订让您满意的房间。
抓取特定商品的价格数据,以最低价格购买
网络抓取最常见的用途之一是从 网站 获取价格。创建一个程序来获取特定产品的价格数据,当价格低于某个水平时,它会在该产品售罄之前自动购买该产品。
接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时仍然赚钱的方法:
每个电子商务网站 都会有数量有限的特价商品。他们会显示产品的原价和折扣价,但一般不会显示在原价的基础上做了多少折扣。例如,一块原价350美元的手表,售价300美元,你会认为50美元的折扣是一大笔钱,但实际上只有14.2%的折扣。而如果一件 T 恤原价 50 美元,卖到 40 美元,你会认为它并没有便宜多少,但实际上比手表优惠了 20%。因此,您可以通过购买折扣率最高的产品来节省/赚钱。
我们以百货公司 Hudson's'Bay 为例进行数据采集实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
在抓取网站的数据后,我们获得了900多款产品的数据,其中只有一款产品Perry Ellis纯色衬衫的折扣率超过50%。
由于是限时优惠,这件衬衫的价格很快就会回到 90 美元左右。因此,如果您现在以 40 美元的价格购买它,并在限时优惠结束后以 60 美元的价格出售它,您仍然可以获得 20 美元。
如果您找到合适的利基市场,这是一种有可能赚很多钱的方法。
捕获宣传数据并将其可视化
网络上有数以百万计的数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有其他数据不易获取,需要大量时间才能可视化,这就是销售数据的演变方式。天眼查、企查查等公司专注于获取和可视化企业的业务和行业变化信息,然后以“采购员可查”的形式出售给用户。
一个类似的模型是这个体育数据网站BigDataBall,它通过出售球员的比赛数据和其他统计数据向用户收取每赛季30美元的费用。他们没有设定这个价格,因为他们网站拥有数据,但他们会抓取数据,将其组织成类别,并以易于阅读和清晰的结构呈现。
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,并将其放入结构化数据集中。BigDataBall 不是唯一的 网站 拥有这些数据,它具有相同的数据,但是 网站 没有结构化数据,使用户难以过滤和下载所需的数据集。Christopher Zita 使用网络抓取工具来抓取网络上的所有玩家数据。
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络抓取工具来查找手动难以获取的数据,让计算机完成工作,然后将数据可视化并出售给感兴趣的人。
总结
今天,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
每天一个超实用的创业案例,扫码关注【站长愿景】↓↓↓
查看全部
excel自动抓取网页数据(通过自动程序在Airbnb上花最少的钱住最好的酒店
)
站长之家注:在大数据时代,如何有效获取数据已成为驱动业务决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。网页抓取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网络爬虫赚钱的方法,只需几个小时,使用不到 50 行代码即可学会。
使用机器人在 Airbnb 上以最少的钱入住最好的酒店
机器人可用于执行特定操作,您可以将它们出售给没有技术技能的人以获取利润。
为了展示如何创建和销售机器人,Christopher Zita 创建了一个 Airbnb 机器人。该程序允许用户输入一个位置,它将抓取 Airbnb 为该位置的房屋提供的所有数据,包括价格、评级、允许进入的客人数量等。所有这些都是通过从 Airbnb 抓取数据来完成的。
为了演示该程序的实际效果,Christopher Zita 在程序中输入了 Rome,并在几秒钟内获得了 272 家 Airbnb 的数据:
查看所有家庭数据现在非常简单,过滤也更容易。以克里斯托弗·齐塔的四口之家为例。如果他们要去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床位的酒店。并且在得到这张表中的数据后,excel可以很方便的进行过滤。从这 272 条结果中,找到了 7 家符合要求的酒店。
在 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费61美元。选择所需链接后,只需将链接复制到浏览器并预订即可。
在度假旅行时,寻找酒店可能是一项艰巨的任务。为此,有人愿意为简化流程付费。使用此自动程序,您只需 5 分钟即可以低廉的价格预订让您满意的房间。
抓取特定商品的价格数据,以最低价格购买
网络抓取最常见的用途之一是从 网站 获取价格。创建一个程序来获取特定产品的价格数据,当价格低于某个水平时,它会在该产品售罄之前自动购买该产品。
接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时仍然赚钱的方法:
每个电子商务网站 都会有数量有限的特价商品。他们会显示产品的原价和折扣价,但一般不会显示在原价的基础上做了多少折扣。例如,一块原价350美元的手表,售价300美元,你会认为50美元的折扣是一大笔钱,但实际上只有14.2%的折扣。而如果一件 T 恤原价 50 美元,卖到 40 美元,你会认为它并没有便宜多少,但实际上比手表优惠了 20%。因此,您可以通过购买折扣率最高的产品来节省/赚钱。
我们以百货公司 Hudson's'Bay 为例进行数据采集实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
在抓取网站的数据后,我们获得了900多款产品的数据,其中只有一款产品Perry Ellis纯色衬衫的折扣率超过50%。
由于是限时优惠,这件衬衫的价格很快就会回到 90 美元左右。因此,如果您现在以 40 美元的价格购买它,并在限时优惠结束后以 60 美元的价格出售它,您仍然可以获得 20 美元。
如果您找到合适的利基市场,这是一种有可能赚很多钱的方法。
捕获宣传数据并将其可视化
网络上有数以百万计的数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有其他数据不易获取,需要大量时间才能可视化,这就是销售数据的演变方式。天眼查、企查查等公司专注于获取和可视化企业的业务和行业变化信息,然后以“采购员可查”的形式出售给用户。
一个类似的模型是这个体育数据网站BigDataBall,它通过出售球员的比赛数据和其他统计数据向用户收取每赛季30美元的费用。他们没有设定这个价格,因为他们网站拥有数据,但他们会抓取数据,将其组织成类别,并以易于阅读和清晰的结构呈现。
现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,并将其放入结构化数据集中。BigDataBall 不是唯一的 网站 拥有这些数据,它具有相同的数据,但是 网站 没有结构化数据,使用户难以过滤和下载所需的数据集。Christopher Zita 使用网络抓取工具来抓取网络上的所有玩家数据。
所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过 16,000 份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络抓取工具来查找手动难以获取的数据,让计算机完成工作,然后将数据可视化并出售给感兴趣的人。
总结
今天,网络爬虫已经成为一种非常独特和新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
每天一个超实用的创业案例,扫码关注【站长愿景】↓↓↓
excel自动抓取网页数据(excel自动抓取网页数据-精华帖讲解如何用excel抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-02 22:06
excel自动抓取网页数据-精华帖讲解如何用excel抓取网页数据-在线教育交流中心-中国计算机教育网excel自动抓取网页数据-精华帖
如果是文本类型的数据,可以用正则表达式+xpath,
excel自动抓取网页数据-精华帖我刚也问了一下,
python抓取网页数据:分享
也是刚刚学习,抓了一下微博数据,总共抓到一千五百多万条数据,感觉还挺好玩的,
推荐一个能抓取百度搜索结果的小工具,支持的浏览器有chrome,safari,opera,qq浏览器,ie,360,猎豹,uc,360极速,支持的操作系统有windows,linux,ios,
中国人民大学新闻学院的陈永兴教授组建了一个“站长在线工作室”,与站长进行长期分成,
如果是文本类数据,有效的方法是:1.很多站可以用spider+xpath,支持抓取大段网页。如:;2.手动撸,直接requests之类xml方式来请求网页。
方案一:爬虫+正则方案二:网页抓取+xpath大神或者产品自己脑补方案三:框架,
方案一:用爬虫
用jieba分词
如果你用的是windows或者mac系统,试试用软件高德地图网站抓包器,easytransprite,把url导入就可以抓取了。如果需要在excel中合并单元格,比如a2,a4,d2,d4这种,直接用xls,xlwt(xlsx)就可以操作好了。 查看全部
excel自动抓取网页数据(excel自动抓取网页数据-精华帖讲解如何用excel抓取)
excel自动抓取网页数据-精华帖讲解如何用excel抓取网页数据-在线教育交流中心-中国计算机教育网excel自动抓取网页数据-精华帖
如果是文本类型的数据,可以用正则表达式+xpath,
excel自动抓取网页数据-精华帖我刚也问了一下,
python抓取网页数据:分享
也是刚刚学习,抓了一下微博数据,总共抓到一千五百多万条数据,感觉还挺好玩的,
推荐一个能抓取百度搜索结果的小工具,支持的浏览器有chrome,safari,opera,qq浏览器,ie,360,猎豹,uc,360极速,支持的操作系统有windows,linux,ios,
中国人民大学新闻学院的陈永兴教授组建了一个“站长在线工作室”,与站长进行长期分成,
如果是文本类数据,有效的方法是:1.很多站可以用spider+xpath,支持抓取大段网页。如:;2.手动撸,直接requests之类xml方式来请求网页。
方案一:爬虫+正则方案二:网页抓取+xpath大神或者产品自己脑补方案三:框架,
方案一:用爬虫
用jieba分词
如果你用的是windows或者mac系统,试试用软件高德地图网站抓包器,easytransprite,把url导入就可以抓取了。如果需要在excel中合并单元格,比如a2,a4,d2,d4这种,直接用xls,xlwt(xlsx)就可以操作好了。
excel自动抓取网页数据( 什么是PowerBI?(图)的优势(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-04-01 06:14
什么是PowerBI?(图)的优势(组图))
火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址()并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果你说,“好吧,我还是想用 Excel 来最终处理或保存这些数据”,当然没问题。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
原文链接: 查看全部
excel自动抓取网页数据(
什么是PowerBI?(图)的优势(组图))
火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址()并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果你说,“好吧,我还是想用 Excel 来最终处理或保存这些数据”,当然没问题。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
原文链接:
excel自动抓取网页数据(一下用PowerBI爬取招聘网站信息实时刷新内容(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-26 02:22
在我们的概念中,爬虫都是由程序员完成的。今天给大家分享一下如何使用Power BI抓取招聘网站信息并实时刷新内容。
今天以一条招聘网站信息为例:
步骤如下:
STEP1:解析网址
因为有多个页面,所以我们提取前三个页面的URL进行分析:
第一页:
第二页:
第三页:
很简单,每页对应2个地方,需要换成对应的页码。
STEP2:采集数据
打开Power BI - 获取数据 - 选择高级 - 添加部分 - 将URL写成四部分,数字在单独的部分中
这里我们直接选择Table 1,点击加载数据。到这一步,我们可以看到我们已经获取到了第一页的数据。是不是很简单?
查看第一行信息,和网页内容完全一致!
STEP3:获取分页数据
①、点击首页-高级编辑器
②。在第一行输入以下代码: (p as number) as table =>
③。将对应的两个“1”修改为如下代码:(Number.ToText(p)),然后点击确定,得到一个函数公式,
我们将表 1 更改为 BOSS_ZP
④。右击表1下方空白处——创建空查询,输入={1..100},点击表创建1-10的表
⑤、调用自定义函数,这里我们使用gif图片来操作
至此,我们已经抓取到了第 1-10 页的数据。如果您想要更长的数据,请单击高级编辑器以修改页码。
【小陈说】
Power BI这几年越来越火了,小伙伴们可以学习一下。很适合表妹和表妹使用,而且非常好用! 查看全部
excel自动抓取网页数据(一下用PowerBI爬取招聘网站信息实时刷新内容(图))
在我们的概念中,爬虫都是由程序员完成的。今天给大家分享一下如何使用Power BI抓取招聘网站信息并实时刷新内容。
今天以一条招聘网站信息为例:
步骤如下:
STEP1:解析网址
因为有多个页面,所以我们提取前三个页面的URL进行分析:
第一页:
第二页:
第三页:
很简单,每页对应2个地方,需要换成对应的页码。
STEP2:采集数据
打开Power BI - 获取数据 - 选择高级 - 添加部分 - 将URL写成四部分,数字在单独的部分中
这里我们直接选择Table 1,点击加载数据。到这一步,我们可以看到我们已经获取到了第一页的数据。是不是很简单?
查看第一行信息,和网页内容完全一致!
STEP3:获取分页数据
①、点击首页-高级编辑器
②。在第一行输入以下代码: (p as number) as table =>
③。将对应的两个“1”修改为如下代码:(Number.ToText(p)),然后点击确定,得到一个函数公式,
我们将表 1 更改为 BOSS_ZP
④。右击表1下方空白处——创建空查询,输入={1..100},点击表创建1-10的表
⑤、调用自定义函数,这里我们使用gif图片来操作
至此,我们已经抓取到了第 1-10 页的数据。如果您想要更长的数据,请单击高级编辑器以修改页码。
【小陈说】
Power BI这几年越来越火了,小伙伴们可以学习一下。很适合表妹和表妹使用,而且非常好用!
excel自动抓取网页数据( 什么是PowerBI?(图)的优势(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-16 13:06
什么是PowerBI?(图)的优势(组图))
火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们想在豆瓣阅读页面抓取“最受欢迎图书榜”的相关信息:
书名
分数
作者
...
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
欢迎关注
我们是一个倡导“高效做事,尽情享受生活”的专栏。 查看全部
excel自动抓取网页数据(
什么是PowerBI?(图)的优势(组图))
火箭君曾经介绍过使用Excel直接下载网页中的数据,但在实际使用中你会发现很多困难。它的另一款软件Power BI在这个时候表现出了无可比拟的优势。到底是什么,我们来看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们想在豆瓣阅读页面抓取“最受欢迎图书榜”的相关信息:
书名
分数
作者
...
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如“生命之海”和“皮肤的秘密”这两个标题,然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
欢迎关注
我们是一个倡导“高效做事,尽情享受生活”的专栏。
excel自动抓取网页数据(读取Excel今天我们要实现Excel转为html()!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 303 次浏览 • 2022-03-11 23:04
前言
说到用 Pandas 导出数据,应该想到 to.xxx 系列函数。
其中比较常用的是pd.to_csv()和pd.to_excel()。但其实也可以导入成Html网页格式,这里用到的函数是pd.to_html()!
读取 Excel
今天我们要将Excel转成html格式,首先需要读取Excel中的表格数据。
import paXvfKsHuFWkndas as pd
data = pd.read_excel('测试.xlsx')
查看数据
data.head()
让我们学习如何将 DataFrame 转换为 HTML 表格。
生成 HTML
to_html()函数只需一行代码就可以直接将DataFrame转换成HTML表格:
html_tahttp://www.cppcns.comble = dXvfKsHuFWkata.to_html('测试.html')
运行上述代码后,工作目录下多了一个test.html文件,用网络浏览器打开,内容如下
print(data.to_html())
通过打印可以看到DataFrame的内部结构自动转换成,,标签嵌入表格中,保留所有内部层次结构。
格式化
我们也可以自定义修改参数来调整生成的HTML的格式。
html_table = data.to_html('测试.html',header = True,index = False,justify='center')
再次打开新生成的test.html文件,发现格式变了。
如果要对格式做进一步的调整(添加标题、修改颜色等),需要一些HTML知识,可以在生成的测试.html文件中调整文本。
对于一些可能需要展示页面的小伙伴来说,需要结合Flask库使用XvfKsHuFWk。
总结
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常好用,一个可以轻松将DataFrame等复杂数据结构转换成HTML表格;另一个XvfKsHuFWk不需要复杂的爬虫,只需几行代码就可以抓取Table表数据,简直就是神器!
今天的篇幅很短,主要讲Pandas中的to_html()函数。使用这个功能最大的好处是我们可以在不了解HTML知识的情况下生成表格HTML。
总结
这是文章关于如何使用pandas将Excel转为html格式的介绍。更多相关pandas将Excel转html格式,请搜索我们之前的文章或继续浏览下方相关的文章,希望大家以后多多支持!
本文标题:如何使用pandas将Excel转为html格式 查看全部
excel自动抓取网页数据(读取Excel今天我们要实现Excel转为html()!!)
前言
说到用 Pandas 导出数据,应该想到 to.xxx 系列函数。
其中比较常用的是pd.to_csv()和pd.to_excel()。但其实也可以导入成Html网页格式,这里用到的函数是pd.to_html()!
读取 Excel
今天我们要将Excel转成html格式,首先需要读取Excel中的表格数据。
import paXvfKsHuFWkndas as pd
data = pd.read_excel('测试.xlsx')
查看数据
data.head()
让我们学习如何将 DataFrame 转换为 HTML 表格。
生成 HTML
to_html()函数只需一行代码就可以直接将DataFrame转换成HTML表格:
html_tahttp://www.cppcns.comble = dXvfKsHuFWkata.to_html('测试.html')
运行上述代码后,工作目录下多了一个test.html文件,用网络浏览器打开,内容如下
print(data.to_html())
通过打印可以看到DataFrame的内部结构自动转换成,,标签嵌入表格中,保留所有内部层次结构。
格式化
我们也可以自定义修改参数来调整生成的HTML的格式。
html_table = data.to_html('测试.html',header = True,index = False,justify='center')
再次打开新生成的test.html文件,发现格式变了。
如果要对格式做进一步的调整(添加标题、修改颜色等),需要一些HTML知识,可以在生成的测试.html文件中调整文本。
对于一些可能需要展示页面的小伙伴来说,需要结合Flask库使用XvfKsHuFWk。
总结
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常好用,一个可以轻松将DataFrame等复杂数据结构转换成HTML表格;另一个XvfKsHuFWk不需要复杂的爬虫,只需几行代码就可以抓取Table表数据,简直就是神器!
今天的篇幅很短,主要讲Pandas中的to_html()函数。使用这个功能最大的好处是我们可以在不了解HTML知识的情况下生成表格HTML。
总结
这是文章关于如何使用pandas将Excel转为html格式的介绍。更多相关pandas将Excel转html格式,请搜索我们之前的文章或继续浏览下方相关的文章,希望大家以后多多支持!
本文标题:如何使用pandas将Excel转为html格式
excel自动抓取网页数据(3个感兴趣的朋友可以尝试一下:速上采集和简易采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 292 次浏览 • 2022-03-08 22:22
导出网页上的数据,很明显是根据一定的规则或手段自动抓取特定网页的数据,然后转储到excel等文件中。至于说的话,有很多,很多都可以很容易的实现。3、感兴趣的朋友可以试试:
速商是纯国产的,专门做网页数据的,采集大部分网页数据不用写一行代码,支持自定义采集和简单的采集,对于小程序来说非常白话易掌握,只需输入网页地址,设计采集规则,然后一键采集,支持批量采集,数据导出(excel等) ,而且官方自带了很多现成的采集模板,可以轻松采集某宝等热门网站数据,是一款非常不错的日常数据工具和软件< @采集:
速商也是一款非常不错的网页数据data采集软件。与速商类似,速商支持更多平台,更灵活。目前支持智能采集和流程图采集两种模式,只要输入网页地址,软件就会自动启动采集进程,包括自动识别网页内容,自动翻页,当然也可以根据采集@>的内容自定义采集,规则都可以,支持数据导出,采集接收到的数据可以很方便的导出到excel、mysql等,也很方便后期的数据处理:
与速商、速商相比,data采集软件更专业、更强大。它整合了数据从采集、处理、分析到挖掘的全流程,并且规则设置更灵活,数据采集也更智能更快,对于网页等数据采集@ >,只需输入网页地址,自定义采集流程和步骤,软件会自动启动采集流程,如果你需要快速获取网页数据,但你不知道代码什么的,都可以用这个软件,整体效果很好:
当然,除了以上三个现成的网页采集软件,如果你熟悉代码或编程,也可以编写相关程序。基本原理是一样的(都是根据特定的规则来提取数据),但是实现起来会比较复杂和耗时。网上也有相关的教程和资料。介绍很详细。如果你有兴趣,你可以搜索它。希望以上分享的内容对您有所帮助。欢迎评论和留言补充。数据采集软件。 查看全部
excel自动抓取网页数据(3个感兴趣的朋友可以尝试一下:速上采集和简易采集)
导出网页上的数据,很明显是根据一定的规则或手段自动抓取特定网页的数据,然后转储到excel等文件中。至于说的话,有很多,很多都可以很容易的实现。3、感兴趣的朋友可以试试:
速商是纯国产的,专门做网页数据的,采集大部分网页数据不用写一行代码,支持自定义采集和简单的采集,对于小程序来说非常白话易掌握,只需输入网页地址,设计采集规则,然后一键采集,支持批量采集,数据导出(excel等) ,而且官方自带了很多现成的采集模板,可以轻松采集某宝等热门网站数据,是一款非常不错的日常数据工具和软件< @采集:
速商也是一款非常不错的网页数据data采集软件。与速商类似,速商支持更多平台,更灵活。目前支持智能采集和流程图采集两种模式,只要输入网页地址,软件就会自动启动采集进程,包括自动识别网页内容,自动翻页,当然也可以根据采集@>的内容自定义采集,规则都可以,支持数据导出,采集接收到的数据可以很方便的导出到excel、mysql等,也很方便后期的数据处理:
与速商、速商相比,data采集软件更专业、更强大。它整合了数据从采集、处理、分析到挖掘的全流程,并且规则设置更灵活,数据采集也更智能更快,对于网页等数据采集@ >,只需输入网页地址,自定义采集流程和步骤,软件会自动启动采集流程,如果你需要快速获取网页数据,但你不知道代码什么的,都可以用这个软件,整体效果很好:
当然,除了以上三个现成的网页采集软件,如果你熟悉代码或编程,也可以编写相关程序。基本原理是一样的(都是根据特定的规则来提取数据),但是实现起来会比较复杂和耗时。网上也有相关的教程和资料。介绍很详细。如果你有兴趣,你可以搜索它。希望以上分享的内容对您有所帮助。欢迎评论和留言补充。数据采集软件。
excel自动抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2022-03-01 17:19
)
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。
2、你会看到一个查询对话框打开,它会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、然后点击导入按钮,你会看到下图第二张,稍等几秒。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图,下图第二张,如果设置刷新频率,会看到Excel表格中的数据可以按照网页更新的数据,是不是很强大。
6、好的,这是我们导入的数据,现在是不是Excel 2013很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。
查看全部
excel自动抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010自带工具--从网页获取数据
)
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。
2、你会看到一个查询对话框打开,它会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、然后点击导入按钮,你会看到下图第二张,稍等几秒。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图,下图第二张,如果设置刷新频率,会看到Excel表格中的数据可以按照网页更新的数据,是不是很强大。
6、好的,这是我们导入的数据,现在是不是Excel 2013很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。
excel自动抓取网页数据(验证码100%,java能将验证码识别为数字吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-03-01 17:17
)
如何使用带有验证码的网站自动捕获数据?最近在做网站的数据抓取,但是这个网站有验证码,是不是需要去掉图片识别为4个数字,用httpclient加所有参数登录。是java有没有办法将图像解析为数字?网上百度说用ocr识别,不知道准确率是不是100%,java能把验证码识别为数字,用httpclient完成自动登录?验证码识别抓包数据--------编程问答--------orc肯定不是100%,这是毫无疑问的。你说的想法只能是做验证码识别。
抓取数据还有其他方式,比如绕过验证码/绕过登录等,访问实际数据所在的地址。这需要对您的业务和对该站点的请求进行一些测试和分析。
-------------------- 编程问答 -------------------- 你可以把一张图片反转成一个数字--------编程问答--------ORC的识别能力一般不弱,稍微扭曲的字体不起作用--------编程问答------ ——很难猜。--------------------编程问答--------------------喜欢这种验证码
, 不知道怎么解析成数字--------编程问答---- ----依赖 识别验证码的方法太难了,一般网站验证码要分开,可以想办法绕过------------ -------- 编程问答--------------------引用5楼萌兰香2的回复:就像这个验证码
,不知道怎么解析成数字
这种验证码过于规则,容易识别。先去除噪声,然后分成4个独立的数字,采集10个图片,分别比较每个部分的匹配度。
网上有相关的文章介绍。我曾经寻找文章,现在我不知道如何再次找到它。这是一个类似的 文章
补充:Java , Java EE 查看全部
excel自动抓取网页数据(验证码100%,java能将验证码识别为数字吗?
)
如何使用带有验证码的网站自动捕获数据?最近在做网站的数据抓取,但是这个网站有验证码,是不是需要去掉图片识别为4个数字,用httpclient加所有参数登录。是java有没有办法将图像解析为数字?网上百度说用ocr识别,不知道准确率是不是100%,java能把验证码识别为数字,用httpclient完成自动登录?验证码识别抓包数据--------编程问答--------orc肯定不是100%,这是毫无疑问的。你说的想法只能是做验证码识别。
抓取数据还有其他方式,比如绕过验证码/绕过登录等,访问实际数据所在的地址。这需要对您的业务和对该站点的请求进行一些测试和分析。
-------------------- 编程问答 -------------------- 你可以把一张图片反转成一个数字--------编程问答--------ORC的识别能力一般不弱,稍微扭曲的字体不起作用--------编程问答------ ——很难猜。--------------------编程问答--------------------喜欢这种验证码
, 不知道怎么解析成数字--------编程问答---- ----依赖 识别验证码的方法太难了,一般网站验证码要分开,可以想办法绕过------------ -------- 编程问答--------------------引用5楼萌兰香2的回复:就像这个验证码
,不知道怎么解析成数字
这种验证码过于规则,容易识别。先去除噪声,然后分成4个独立的数字,采集10个图片,分别比较每个部分的匹配度。
网上有相关的文章介绍。我曾经寻找文章,现在我不知道如何再次找到它。这是一个类似的 文章
补充:Java , Java EE
excel自动抓取网页数据( 本文就用Java给大家演示如何抓取网站的数据:(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-27 02:07
本文就用Java给大家演示如何抓取网站的数据:(1))
Java爬取网页数据(原创网页+Javascript返回数据)
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在本例中,我们将从以下位置获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]查看纯副本
publicvoidcapturehtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml()的结果:查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建漳州移动
p>
二、获取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]查看纯副本
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载! 查看全部
excel自动抓取网页数据(
本文就用Java给大家演示如何抓取网站的数据:(1))
Java爬取网页数据(原创网页+Javascript返回数据)
有时候,由于各种原因,我们需要某个网站的采集的数据,但是由于网站的不同,数据的显示方式略有不同!
本文用Java给大家展示如何抓取网站的数据:(1)抓取网页原创数据;(2)抓取网页Javascript返回的数据.
一、 抓取原创页面。
在本例中,我们将从以下位置获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
p>
第二步:查看网页的源码,我们看到源码中有这么一段:
从这里可以看出,重新请求一个网页后,显示查询的结果。
查询后查看网址:
也就是说,我们只要访问这样一个URL,就可以得到ip查询的结果,然后看代码:
[java]查看纯副本
publicvoidcapturehtml(Stringip)throwsException{StringstrURL=""+ip;URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream(),"utf-8") ;BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);}Stringbuf=contentBuf.toString() ;intbeginIx=buf.indexOf("查询结果[");intendIx=buf.indexOf("以上四项依次显示");Stringresult=buf.substring(beginIx,endIx);System.out.println(" captureHtml() 结果:\n"+result);}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml()的结果:查询结果[1]:111.142.55.73 ==>> 1871591241 ==>>福建漳州移动
p>
二、获取网页的JavaScript返回的结果。
有时网站为了保护自己的数据,不是直接在网页源码中返回数据,而是采用异步方式,用JS返回数据,可以避开搜索引擎和其他工具来网站数据捕获。
先看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为是通过JS获取结果的。
但是有时候我们需要获取JS数据,这个时候我们应该怎么做呢?
这时候,我们需要用到一个工具:HTTP Analyzer。这个工具可以拦截Http的交互内容。我们使用这个工具来实现我们的目的。
第一次点击开始按钮后,开始监控网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,即只需要访问JS请求的网页地址就可以获取数据,当然前提是数据没有加密,我们记下JS请求的URL:
那就让程序请求这个网页的结果吧!
代码如下:
[java]查看纯副本
publicvoidcaptureJavascript(Stringpostid)throwsException{StringstrURL=""+postid+"&channel=&rnd=0";URLurl=newURL(strURL);HttpURLConnectionhttpConn=(HttpURLConnection)url.openConnection();InputStreamReaderinput=newInputStreamReader(httpConn.getInputStream() ,"utf-8");BufferedReaderbufReader=newBufferedReader(input);Stringline="";StringBuildercontentBuf=newStringBuilder();while((line=bufReader.readLine())!=null){contentBuf.append(line);} System.out.println("captureJavascript()的结果:\n"+contentBuf.toString());}
你看,爬取JS的方式和之前爬取原创网页的代码一模一样,我们只是做了一个解析JS的过程。
以下是程序执行的结果:
captureJavascript() 的结果:
运单追踪信息【7】
这些数据是JS返回的结果,我们的目的已经达到了!
希望这篇文章可以对需要的朋友有所帮助。如需程序源代码,请点击这里下载!
excel自动抓取网页数据(你能明白我一定要抓到表格里吗?Powerquery处理你可能不知道)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-24 10:18
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
获取JSON数据连接;
电源查询处理数据;
配置搜索地址;
添加超链接
01
脚步
获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=> let keywords = search term [search term]{0}, source = Json.Document(Web.Contents(""& keywords & "&correction=1&offset="& Text.From(page*2< @0) &"&limit=20&random=" & Text.From(Number.Random()))), data = source[data], jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, jsondata 中的 ExtraValues.Error),转换为 table = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
添加超链接
至此所有数据都已处理完毕,但如果要查看原创知乎页面,则需要复制此超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
最终效果
最后的效果是:
输入搜索词;
右键刷新;
找到点赞最多的;
点击【点击查看】,享受插队的感觉!
02
总结
知道在表格中搜索的好处吗?
按“喜欢”和“评论”排序;
如果你看过文章,可以加栏写笔记;
您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。 查看全部
excel自动抓取网页数据(你能明白我一定要抓到表格里吗?Powerquery处理你可能不知道)
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
获取JSON数据连接;
电源查询处理数据;
配置搜索地址;
添加超链接
01
脚步
获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=> let keywords = search term [search term]{0}, source = Json.Document(Web.Contents(""& keywords & "&correction=1&offset="& Text.From(page*2< @0) &"&limit=20&random=" & Text.From(Number.Random()))), data = source[data], jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, jsondata 中的 ExtraValues.Error),转换为 table = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
添加超链接
至此所有数据都已处理完毕,但如果要查看原创知乎页面,则需要复制此超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
最终效果
最后的效果是:
输入搜索词;
右键刷新;
找到点赞最多的;
点击【点击查看】,享受插队的感觉!
02
总结
知道在表格中搜索的好处吗?
按“喜欢”和“评论”排序;
如果你看过文章,可以加栏写笔记;
您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。
excel自动抓取网页数据(如何用Python构建一个带有GUI的爬虫小程序-之前)
网站优化 • 优采云 发表了文章 • 0 个评论 • 331 次浏览 • 2022-02-23 13:20
大家好,之前我们讲了如何使用Python构建一个带有GUI的爬虫小程序。很多文章会迎合热点,继续上一篇NBA爬虫GUI,讨论如何爬取虎扑NBA官网数据。并将数据写入Excel并自动生成折线图,主要有以下几个步骤
本文将分以下两部分进行讲解
项目涉及的主要 Python 模块:
** ** 爬虫部分
爬虫部分组织如下?
观察URL1的源码找到队名和对应的URL2 观察URL2的源码找到玩家对应的URL3 观察URL3的源码**** 找到对应的基本信息和比赛数据播放器并过滤和存储它们
其实爬虫是对html进行操作的,而html的结构很简单,只有一个,就是一个大框架协商一个小框架,小框架嵌套在小框架内,这样一层一层的层嵌套。
目标网址如下:
先引用模块
1from bs4 import BeautifulSoupimport requestsimport xlsxwriterimport os
2
查看URL1源码,可以看到团队名词及其对应的URL2在span标签下,然后找到它的父框和祖父框。下面的思路是一样的,如下图:
此时,可以使用 requests 模块和 bs4 模块进行有目的的索引以获取团队名称列表。
1def Teamlists(url):
2 TeamName=[]
3 TeamURL=[]
4 GET=requests.get(URL1)
5 soup=BeautifulSoup(GET.content,'lxml')
6 lables=soup.select('html body div div div ul li span a') for lable in lables:
7 ballname=lable.get_text()
8 TeamName.append(ballname)
9 print(ballname)
10 teamname=input("请输入想查询的球队名:")#此处可变为GUI界面中的按键值
11 c=TeamName.index(teamname)for item in lables:
12 HREF=item.get('href')
13 TeamURL.append(HREF)
14 URL2=TeamURL[c] return URL2
15
这样就得到了对应球队的URL2,然后观察URL2网页的内容,可以看到球员的名字在标签a下,对应球员的URL3也被存储了,如图下图:
此时,仍然使用requests模块和bs4模块的对应索引来获取播放器名称列表和对应的URL3。
1#自定义函数获取队员列表和对应的URLdef playerlists(URL2):
2 PlayerName=[]
3 PlayerURL=[]
4 GET2=requests.get(URL1)
5 soup2=BeautifulSoup(GET2.content,'lxml')
6 lables2=soup2.select('html body div div table tbody tr td b a')for lable2 in lables2:
7 playername=lable2.get_text()
8 PlayerName.append(playername)
9 print(playername)
10 name=input("请输入球员名:") #此处可变为GUI界面中的按键值
11 d=PlayerName.index(name)for item2 in lables2:
12 HREF2=item2.get('href')
13 PlayerURL.append(HREF2)
14 URL3=PlayerURL[d]return URL3,name
15
现在我们已经获得了对应队伍的URL3,然后观察URL3网页的内容。可以看到球员的基本信息在标签p下,球员常规赛生涯数据和季后赛生涯数据在标签td下,如下图:
同理,通过requests模块和bs4模块之间的对应索引,得到球员的基本信息和生涯数据,对球员常规赛和季后赛的生涯数据进行过滤存储,得到数据列表.
1def Competition(URL3):
2 data=[]
3 GET3=requests.get(URL3)
4 soup3=BeautifulSoup(GET3.content,'lxml')
5 lables3=soup3.select('html body div div div div div div div div p')
6 lables4=soup3.select('div div table tbody tr td')for lable3 in lables3:
7 introduction=lable3.get_text()
8 print(introduction) #球员基本信息for lable4 in lables4:
9 competition=lable4.get_text()
10 data.append(competition) for i in range(len(data)):if data[i]=='职业生涯常规赛平均数据':
11 a=data[i+31]
12 a=data.index(a)del(data[:a]) for x in range(len(data)):if data[x]=='职业生涯季后赛平均数据':
13 b=data[x]
14 b=data.index(b)del(data[b:])return data
15
通过上述网络爬虫获取以下数据,提供可视化数据,方便GUI界面按键事件的绑定:
** ** 可视化部分
**想法:创建文件夹**创建表格和折线图
自定义函数创建表,使用os模块编写,返回创建文件夹的路径。代码如下:
1def file_add(path): #此时的内函数path可与GUI界面的Statictext绑定
2 creatpath=path+'\\Basketball' try:if not os.path.isdir(creatpath):
3 os.makedirs(creatpath) except:
4 print("文件夹存在")return creatpath
5
使用xlsxwriter模块在creatpath路径下创建带有自定义函数的excel表格,同时放入数据和构造折线图。代码如下:
1def player_chart(name,data,creatpath):#此为表格名称——球员名称+chart
2 EXCEL=xlsxwriter.Workbook(creatpath+'\\'+name+'chart.xlsx')
3 worksheet=EXCEL.add_worksheet(name)
4 bold=EXCEL.add_format({'bold':1})
5 headings=data[:18]
6 worksheet.write_row('A1',headings,bold) #写入表头
7 num=(len(data))//18
8 a=0for i in range(num):
9 a=a+18
10 c=a+18
11 i=i+1
12 worksheet.write_row('A'+str(i+1),data[a:c]) #写入数据
13 chart_col = EXCEL.add_chart({'type': 'line'}) #创建一个折线图
14 chart_col.add_series({'name': '='+name+'!$R$1', #设置折线描述名称'categories':'='+name+'!$A$2:$A$'+str(num), #设置图表类别标签范围'values': '='+name+'!$R$2:$R$'+str(num-1), #设置图表数据范围'line': {'color': 'red'}, }) #设置图表线条属性#设置图标的标题和想x,y轴信息
15 chart_col.set_title({'name': name+'生涯常规赛平均得分'})
16 chart_col.set_x_axis({'name': '年份 (年)'})
17 chart_col.set_y_axis({'name': '平均得分(分)'})
18 chart_col.set_style(1) #设置图表风格
19 worksheet.insert_chart('A14', chart_col, {'x_offset':25, 'y_offset':3,}) #把图标插入工作台中并设置偏移
20 EXCEL.close()
21
数据表效果展示,以James为例如下
而此时打开自动生成的Excel,对应的折线图就会直接显示出来,不用再整理了!
现在结合任务1的网络爬虫和任务2的数据可视化,可以得到实时的球员常规赛数据和季后赛数据汇总,以及实时的球员生涯折线图。可以绑定上一个GUI界面任务设计中的“可视化”按钮事件,有兴趣的读者可以自行进一步研究! 查看全部
excel自动抓取网页数据(如何用Python构建一个带有GUI的爬虫小程序-之前)
大家好,之前我们讲了如何使用Python构建一个带有GUI的爬虫小程序。很多文章会迎合热点,继续上一篇NBA爬虫GUI,讨论如何爬取虎扑NBA官网数据。并将数据写入Excel并自动生成折线图,主要有以下几个步骤
本文将分以下两部分进行讲解
项目涉及的主要 Python 模块:
** ** 爬虫部分
爬虫部分组织如下?
观察URL1的源码找到队名和对应的URL2 观察URL2的源码找到玩家对应的URL3 观察URL3的源码**** 找到对应的基本信息和比赛数据播放器并过滤和存储它们
其实爬虫是对html进行操作的,而html的结构很简单,只有一个,就是一个大框架协商一个小框架,小框架嵌套在小框架内,这样一层一层的层嵌套。
目标网址如下:
先引用模块
1from bs4 import BeautifulSoupimport requestsimport xlsxwriterimport os
2
查看URL1源码,可以看到团队名词及其对应的URL2在span标签下,然后找到它的父框和祖父框。下面的思路是一样的,如下图:
此时,可以使用 requests 模块和 bs4 模块进行有目的的索引以获取团队名称列表。
1def Teamlists(url):
2 TeamName=[]
3 TeamURL=[]
4 GET=requests.get(URL1)
5 soup=BeautifulSoup(GET.content,'lxml')
6 lables=soup.select('html body div div div ul li span a') for lable in lables:
7 ballname=lable.get_text()
8 TeamName.append(ballname)
9 print(ballname)
10 teamname=input("请输入想查询的球队名:")#此处可变为GUI界面中的按键值
11 c=TeamName.index(teamname)for item in lables:
12 HREF=item.get('href')
13 TeamURL.append(HREF)
14 URL2=TeamURL[c] return URL2
15
这样就得到了对应球队的URL2,然后观察URL2网页的内容,可以看到球员的名字在标签a下,对应球员的URL3也被存储了,如图下图:
此时,仍然使用requests模块和bs4模块的对应索引来获取播放器名称列表和对应的URL3。
1#自定义函数获取队员列表和对应的URLdef playerlists(URL2):
2 PlayerName=[]
3 PlayerURL=[]
4 GET2=requests.get(URL1)
5 soup2=BeautifulSoup(GET2.content,'lxml')
6 lables2=soup2.select('html body div div table tbody tr td b a')for lable2 in lables2:
7 playername=lable2.get_text()
8 PlayerName.append(playername)
9 print(playername)
10 name=input("请输入球员名:") #此处可变为GUI界面中的按键值
11 d=PlayerName.index(name)for item2 in lables2:
12 HREF2=item2.get('href')
13 PlayerURL.append(HREF2)
14 URL3=PlayerURL[d]return URL3,name
15
现在我们已经获得了对应队伍的URL3,然后观察URL3网页的内容。可以看到球员的基本信息在标签p下,球员常规赛生涯数据和季后赛生涯数据在标签td下,如下图:
同理,通过requests模块和bs4模块之间的对应索引,得到球员的基本信息和生涯数据,对球员常规赛和季后赛的生涯数据进行过滤存储,得到数据列表.
1def Competition(URL3):
2 data=[]
3 GET3=requests.get(URL3)
4 soup3=BeautifulSoup(GET3.content,'lxml')
5 lables3=soup3.select('html body div div div div div div div div p')
6 lables4=soup3.select('div div table tbody tr td')for lable3 in lables3:
7 introduction=lable3.get_text()
8 print(introduction) #球员基本信息for lable4 in lables4:
9 competition=lable4.get_text()
10 data.append(competition) for i in range(len(data)):if data[i]=='职业生涯常规赛平均数据':
11 a=data[i+31]
12 a=data.index(a)del(data[:a]) for x in range(len(data)):if data[x]=='职业生涯季后赛平均数据':
13 b=data[x]
14 b=data.index(b)del(data[b:])return data
15
通过上述网络爬虫获取以下数据,提供可视化数据,方便GUI界面按键事件的绑定:
** ** 可视化部分
**想法:创建文件夹**创建表格和折线图
自定义函数创建表,使用os模块编写,返回创建文件夹的路径。代码如下:
1def file_add(path): #此时的内函数path可与GUI界面的Statictext绑定
2 creatpath=path+'\\Basketball' try:if not os.path.isdir(creatpath):
3 os.makedirs(creatpath) except:
4 print("文件夹存在")return creatpath
5
使用xlsxwriter模块在creatpath路径下创建带有自定义函数的excel表格,同时放入数据和构造折线图。代码如下:
1def player_chart(name,data,creatpath):#此为表格名称——球员名称+chart
2 EXCEL=xlsxwriter.Workbook(creatpath+'\\'+name+'chart.xlsx')
3 worksheet=EXCEL.add_worksheet(name)
4 bold=EXCEL.add_format({'bold':1})
5 headings=data[:18]
6 worksheet.write_row('A1',headings,bold) #写入表头
7 num=(len(data))//18
8 a=0for i in range(num):
9 a=a+18
10 c=a+18
11 i=i+1
12 worksheet.write_row('A'+str(i+1),data[a:c]) #写入数据
13 chart_col = EXCEL.add_chart({'type': 'line'}) #创建一个折线图
14 chart_col.add_series({'name': '='+name+'!$R$1', #设置折线描述名称'categories':'='+name+'!$A$2:$A$'+str(num), #设置图表类别标签范围'values': '='+name+'!$R$2:$R$'+str(num-1), #设置图表数据范围'line': {'color': 'red'}, }) #设置图表线条属性#设置图标的标题和想x,y轴信息
15 chart_col.set_title({'name': name+'生涯常规赛平均得分'})
16 chart_col.set_x_axis({'name': '年份 (年)'})
17 chart_col.set_y_axis({'name': '平均得分(分)'})
18 chart_col.set_style(1) #设置图表风格
19 worksheet.insert_chart('A14', chart_col, {'x_offset':25, 'y_offset':3,}) #把图标插入工作台中并设置偏移
20 EXCEL.close()
21
数据表效果展示,以James为例如下
而此时打开自动生成的Excel,对应的折线图就会直接显示出来,不用再整理了!
现在结合任务1的网络爬虫和任务2的数据可视化,可以得到实时的球员常规赛数据和季后赛数据汇总,以及实时的球员生涯折线图。可以绑定上一个GUI界面任务设计中的“可视化”按钮事件,有兴趣的读者可以自行进一步研究!
excel自动抓取网页数据( 神器PowerBI要怎么学?(一)PowerQuery )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-20 04:12
神器PowerBI要怎么学?(一)PowerQuery
)
您是否使用过 Power BI,它可能比 Excel 更简单但功能更强大?
Power BI 是微软最新的商业智能 (BI) 概念,其中包括一系列组件和工具。
废话不多说,先上图:
Power BI系列组件的功能你一眼就看懂了吗?其实Power BI的核心思想就是我们的用户不需要很强的技术背景,只需要掌握Excel等简单的工具就可以快速上手业务数据分析和可视化。
微软的Power BI主要收录四套插件,包括Power Query、Power Pivot、Power view和Power map。电力视图和电力地图需要另开一个界面,主要是基于交互式图表和地图可视化,与数据分析无关,相关内容自学也能满足需求。
1电源查询
Power Query 负责捕获和组织数据。它可以捕捉市面上几乎所有格式的源数据,然后按照我们需要的格式进行整理。通过PowerQuery,我们可以快速将来自多个数据源的数据合并和追加到一起,任意组合数据,分组数据,透视数据。而这些步骤以后会自动完成,也就是说以后你只需要点击刷新,所有的数据都会按照你的要求乖乖上碗,不再需要你手动调整数据……感动得想哭……
1.合并/追加表
2.数据包
3.透视/逆透视
2动力枢轴
Power Pivot 是微软 Power BI 系列工具的大脑,负责建模和分析。有人说这是过去 20 年来 Excel 中最好的新功能。它可以
1.易于处理各种量级的数据
2.快速创建多表关系,不再需要vlookup
3.查看生成的数据透视表:
那么,如何学习神器Power BI呢?
讲了半天,只是一点点Power BI毛皮,如果你想深入研究如何学习Power BI。
CDA 数据分析师
电子表格会议主席李奇先生
与你携手零基础入门商业智能分析
在这里,您可以学习快速提升数据分析技能,并在几分钟内制作出引人注目的数据分析报告。
一、课程表
北京&偏远:2017年8月19-20日(两个周末)
上海:2017年9月16-17日
深圳:2017年10月21~22日
课程费用:现场授课900元,远程授课500元
教学安排:
(1)教学方式:面对面直播、中文多媒体互动教学方式
(2)授课时间:上午9:00-12:00、下午13:30-16:30、16:30-17:00(答题)
(3)学习期:现场与视频相结合,长期学习加练习答题。
二、注册流程
1.在线填写报名信息
官方网站:
微信终端:
查看全部
excel自动抓取网页数据(
神器PowerBI要怎么学?(一)PowerQuery
)
您是否使用过 Power BI,它可能比 Excel 更简单但功能更强大?
Power BI 是微软最新的商业智能 (BI) 概念,其中包括一系列组件和工具。
废话不多说,先上图:
Power BI系列组件的功能你一眼就看懂了吗?其实Power BI的核心思想就是我们的用户不需要很强的技术背景,只需要掌握Excel等简单的工具就可以快速上手业务数据分析和可视化。
微软的Power BI主要收录四套插件,包括Power Query、Power Pivot、Power view和Power map。电力视图和电力地图需要另开一个界面,主要是基于交互式图表和地图可视化,与数据分析无关,相关内容自学也能满足需求。
1电源查询
Power Query 负责捕获和组织数据。它可以捕捉市面上几乎所有格式的源数据,然后按照我们需要的格式进行整理。通过PowerQuery,我们可以快速将来自多个数据源的数据合并和追加到一起,任意组合数据,分组数据,透视数据。而这些步骤以后会自动完成,也就是说以后你只需要点击刷新,所有的数据都会按照你的要求乖乖上碗,不再需要你手动调整数据……感动得想哭……
1.合并/追加表
2.数据包
3.透视/逆透视
2动力枢轴
Power Pivot 是微软 Power BI 系列工具的大脑,负责建模和分析。有人说这是过去 20 年来 Excel 中最好的新功能。它可以
1.易于处理各种量级的数据
2.快速创建多表关系,不再需要vlookup
3.查看生成的数据透视表:
那么,如何学习神器Power BI呢?
讲了半天,只是一点点Power BI毛皮,如果你想深入研究如何学习Power BI。
CDA 数据分析师
电子表格会议主席李奇先生
与你携手零基础入门商业智能分析
在这里,您可以学习快速提升数据分析技能,并在几分钟内制作出引人注目的数据分析报告。
一、课程表
北京&偏远:2017年8月19-20日(两个周末)
上海:2017年9月16-17日
深圳:2017年10月21~22日
课程费用:现场授课900元,远程授课500元
教学安排:
(1)教学方式:面对面直播、中文多媒体互动教学方式
(2)授课时间:上午9:00-12:00、下午13:30-16:30、16:30-17:00(答题)
(3)学习期:现场与视频相结合,长期学习加练习答题。
二、注册流程
1.在线填写报名信息
官方网站:
微信终端:
excel自动抓取网页数据( 抓取网络数据真实的数据挖掘项目,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-20 04:09
抓取网络数据真实的数据挖掘项目,你了解多少?)
1、爬虫爬取网络数据
一个真正的数据挖掘项目必须从数据采集开始。除了通过某些渠道购买或下载专业数据外,人们还经常需要自己爬取互联网数据。这时,爬虫就显得尤为重要。
Nutch爬虫的主要作用是从网络上爬取和索引网络数据。我们只需要指定 网站 的顶级 URL,例如爬虫可以自动检测页面内容中的新 URL,从而进一步爬取链接的网页数据。nutch 支持将捕获的数据转换为文本,例如(PDF、WORD、EXCEL、HTML、XML 等)转换为纯文本字符。
Nutch 与 Hadoop 集成,可以将下载的数据保存到 hdfs 以供后续离线分析。使用步骤如下:
$ hadoop fs -put urldir urldir
笔记:
第一个urldir是本地文件夹,存放url数据文件,每行一个url地址
第二个urldir是hdfs的存储路径。
$ bin/nutch crawlurldir --dir crawl -depth 3 --topN 10
命令执行成功后,会在hdfs中生成爬取目录。
2、MapReduce 预处理数据
下载的原创文本文档不能直接处理,需要对文本内容进行预处理,包括文档分词、文本分词、去除停用词(包括标点、数字、单词等无意义词)、文本特征提取、词频统计、文本向量化等操作。
一种常用的文本预处理算法是TF-IDF,其主要思想是如果一个词或短语在一个文章中出现频率很高,而在另一个文章中很少出现,则认为这个词或词组有很好的类别区分能力,适合分类。
再一次,似乎可可交付了......
hadoop jar $JAR SparseVectorsFromSequenceFiles …
9219:0.246 453:0.098 10322:0.21 11947:0.272 …
每列是单词及其权重,用冒号分隔。例如“9219:0.246”表示编号为9219的单词,对应原单词“Again”,其权重值为0.246。
3、Mahout 数据挖掘
预处理后的数据可用于数据挖掘。Mahout 是一个强大的数据挖掘工具和分布式机器学习算法的集合,包括:协同过滤、分类、聚类等。
以LDA算法为例,它可以将文档集中每个文档的主题以概率分布的形式给出。它是一种无监督学习算法,在训练时不需要对主题进行人工标注,只需要指定主题个数K即可。此外,LDA 的另一个优点是,对于每个主题,都可以找到一些词来描述它。
9219:0.246 453:0.098 …
mahout cvb –k 20…
topic1 {计算机、技术、系统、互联网、机器}
topic2 {戏剧、电影、电影、明星、导演、制作、舞台}
我们可以了解到哪些主题是用户的偏好,而这些主题是由一些关键词组成的。
4、Sqoop 导出到关系数据库
在某些场景下,需要将数据挖掘的结果导出到关系数据库中,以便及时响应外部应用程序的查询。
Sqoop 是用于在 hadoop 和关系数据库之间传输数据的工具。它可以将关系型数据库(如MySQL、Oracle等)的数据导入hadoop的hdfs,也可以将hdfs的数据导出到关系型数据库中:
sqoop export --connect jdbc:mysql://localhost:3306/zxtest --username root --password root --table result_test --export-dir /user/mr/lda/out
导出操作实现将hdfs目录/user/mr/lda/out中的数据导出到mysql的result_test表中。 查看全部
excel自动抓取网页数据(
抓取网络数据真实的数据挖掘项目,你了解多少?)
1、爬虫爬取网络数据
一个真正的数据挖掘项目必须从数据采集开始。除了通过某些渠道购买或下载专业数据外,人们还经常需要自己爬取互联网数据。这时,爬虫就显得尤为重要。
Nutch爬虫的主要作用是从网络上爬取和索引网络数据。我们只需要指定 网站 的顶级 URL,例如爬虫可以自动检测页面内容中的新 URL,从而进一步爬取链接的网页数据。nutch 支持将捕获的数据转换为文本,例如(PDF、WORD、EXCEL、HTML、XML 等)转换为纯文本字符。
Nutch 与 Hadoop 集成,可以将下载的数据保存到 hdfs 以供后续离线分析。使用步骤如下:
$ hadoop fs -put urldir urldir
笔记:
第一个urldir是本地文件夹,存放url数据文件,每行一个url地址
第二个urldir是hdfs的存储路径。
$ bin/nutch crawlurldir --dir crawl -depth 3 --topN 10
命令执行成功后,会在hdfs中生成爬取目录。
2、MapReduce 预处理数据
下载的原创文本文档不能直接处理,需要对文本内容进行预处理,包括文档分词、文本分词、去除停用词(包括标点、数字、单词等无意义词)、文本特征提取、词频统计、文本向量化等操作。
一种常用的文本预处理算法是TF-IDF,其主要思想是如果一个词或短语在一个文章中出现频率很高,而在另一个文章中很少出现,则认为这个词或词组有很好的类别区分能力,适合分类。
再一次,似乎可可交付了......
hadoop jar $JAR SparseVectorsFromSequenceFiles …
9219:0.246 453:0.098 10322:0.21 11947:0.272 …
每列是单词及其权重,用冒号分隔。例如“9219:0.246”表示编号为9219的单词,对应原单词“Again”,其权重值为0.246。
3、Mahout 数据挖掘
预处理后的数据可用于数据挖掘。Mahout 是一个强大的数据挖掘工具和分布式机器学习算法的集合,包括:协同过滤、分类、聚类等。
以LDA算法为例,它可以将文档集中每个文档的主题以概率分布的形式给出。它是一种无监督学习算法,在训练时不需要对主题进行人工标注,只需要指定主题个数K即可。此外,LDA 的另一个优点是,对于每个主题,都可以找到一些词来描述它。
9219:0.246 453:0.098 …
mahout cvb –k 20…
topic1 {计算机、技术、系统、互联网、机器}
topic2 {戏剧、电影、电影、明星、导演、制作、舞台}
我们可以了解到哪些主题是用户的偏好,而这些主题是由一些关键词组成的。
4、Sqoop 导出到关系数据库
在某些场景下,需要将数据挖掘的结果导出到关系数据库中,以便及时响应外部应用程序的查询。
Sqoop 是用于在 hadoop 和关系数据库之间传输数据的工具。它可以将关系型数据库(如MySQL、Oracle等)的数据导入hadoop的hdfs,也可以将hdfs的数据导出到关系型数据库中:
sqoop export --connect jdbc:mysql://localhost:3306/zxtest --username root --password root --table result_test --export-dir /user/mr/lda/out
导出操作实现将hdfs目录/user/mr/lda/out中的数据导出到mysql的result_test表中。

