
excel自动抓取网页数据
excel自动抓取网页数据(excel自动抓取网页数据原理很简单具体步骤步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2022-02-19 16:02
excel自动抓取网页数据原理很简单,具体步骤如下:
1、添加工作表
2、在数据源区域点右键复制数据源,然后点另存为数据.
3、选中要抓取的网页信息,右键点条件格式,选择“新建规则”.
4、用鼠标在数据源单元格右键,
5、全选数据源,右键点“替换”---选择“值”,再点“替换为”.
6、最后点关闭即可.动图效果:***文章出自@阿文,原文链接:excel自动抓取网页数据_excel教程**欢迎大家关注我的微信公众号,彩云的机械整备间。公众号以浅显的语言讲解excel基础知识。
知乎上也有类似问题!请参考我的博客,时间充裕时都翻译完善了。excel2010抓取万网列表数据然后excel做出来的数据透视表以上是我在正则表达式中采用的方法,效果如下图所示。excel抓取万网列表数据-excelhome技术论坛,看完那个再有兴趣,
鼠标右键复制这个网页的内容,可以得到一个粘贴到excel表格的路径,粘贴到excel粘贴路径下的workbook选项,里面包含了这个网页的所有文本信息,找到文本所在位置,改成text,按下alt+f10,就复制成功啦,再点击文本再把字体大小调成可以读取的, 查看全部
excel自动抓取网页数据(excel自动抓取网页数据原理很简单具体步骤步骤)
excel自动抓取网页数据原理很简单,具体步骤如下:
1、添加工作表
2、在数据源区域点右键复制数据源,然后点另存为数据.
3、选中要抓取的网页信息,右键点条件格式,选择“新建规则”.
4、用鼠标在数据源单元格右键,
5、全选数据源,右键点“替换”---选择“值”,再点“替换为”.
6、最后点关闭即可.动图效果:***文章出自@阿文,原文链接:excel自动抓取网页数据_excel教程**欢迎大家关注我的微信公众号,彩云的机械整备间。公众号以浅显的语言讲解excel基础知识。
知乎上也有类似问题!请参考我的博客,时间充裕时都翻译完善了。excel2010抓取万网列表数据然后excel做出来的数据透视表以上是我在正则表达式中采用的方法,效果如下图所示。excel抓取万网列表数据-excelhome技术论坛,看完那个再有兴趣,
鼠标右键复制这个网页的内容,可以得到一个粘贴到excel表格的路径,粘贴到excel粘贴路径下的workbook选项,里面包含了这个网页的所有文本信息,找到文本所在位置,改成text,按下alt+f10,就复制成功啦,再点击文本再把字体大小调成可以读取的,
excel自动抓取网页数据(本文实例讲述Python实现抓取网页生成Excel文件的方法。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-11 02:06
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="https://www.yourwebname.com/%3 ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
接下来就是用Notepad++打开gongsi.csv,然后转换成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
excel自动抓取网页数据(本文实例讲述Python实现抓取网页生成Excel文件的方法。)
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="https://www.yourwebname.com/%3 ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
接下来就是用Notepad++打开gongsi.csv,然后转换成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。
excel自动抓取网页数据(excel自动抓取网页数据步骤(1)_抓取的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-09 21:04
excel自动抓取网页数据步骤1选择要抓取的数据步骤2选择要抓取的网页步骤3点击左上角的“抓取网页”步骤4等待计算完成,等待抓取完成步骤5单击文件,保存步骤6保存的时候,
可以用如下文件的插件进行,不过我在百度也没找到,
不用下载那个插件,直接找到url复制到word2016自动保存就可以了,
;cid=4545434700&cid=4545434700
别克社区有个“知网下载助手”,可以免费看论文,是本校图书馆开发的,有卖,包邮哦。
你只需要下载word2016版的wps,右键点击你要抓取的网页,上传文件。就可以自动抓取了。
"
自己用了将近半年才在我实习时候学会,是个很好用的插件,
话不多说,
最近对我的影响最大的就是他了
在知乎上第一次答题,这么认真为题主回答这个问题。
感谢wps的帮助,在word2016里应该能找到,
自己百度找找吧,
有一个叫百度学术的app可以下载
我也想知道我也想知道感觉这么多傻逼不如自己搞
看着知乎的各种广告下载了app,然后被制裁了, 查看全部
excel自动抓取网页数据(excel自动抓取网页数据步骤(1)_抓取的数据)
excel自动抓取网页数据步骤1选择要抓取的数据步骤2选择要抓取的网页步骤3点击左上角的“抓取网页”步骤4等待计算完成,等待抓取完成步骤5单击文件,保存步骤6保存的时候,
可以用如下文件的插件进行,不过我在百度也没找到,
不用下载那个插件,直接找到url复制到word2016自动保存就可以了,
;cid=4545434700&cid=4545434700
别克社区有个“知网下载助手”,可以免费看论文,是本校图书馆开发的,有卖,包邮哦。
你只需要下载word2016版的wps,右键点击你要抓取的网页,上传文件。就可以自动抓取了。
"
自己用了将近半年才在我实习时候学会,是个很好用的插件,
话不多说,
最近对我的影响最大的就是他了
在知乎上第一次答题,这么认真为题主回答这个问题。
感谢wps的帮助,在word2016里应该能找到,
自己百度找找吧,
有一个叫百度学术的app可以下载
我也想知道我也想知道感觉这么多傻逼不如自己搞
看着知乎的各种广告下载了app,然后被制裁了,
excel自动抓取网页数据(WebHarvy功能介绍智能识别模式WebHarvy网页中的文本及图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-09 14:21
WebHarvy 是一个网页数据捕获工具。该软件可以提取网页中的文字和图片,输入网址并打开。默认使用内部浏览器,支持扩展分析,可自动获取相似链接列表。软件界面直观,操作简单。
WebHarvy功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
WebHarvy 软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
WebHarvy 变更日志
修复了可能导致页面启动时禁用连接的错误
您可以为页面模式配置专用的连接方法
可以自动搜索 HTML 上的可配置资源 查看全部
excel自动抓取网页数据(WebHarvy功能介绍智能识别模式WebHarvy网页中的文本及图片)
WebHarvy 是一个网页数据捕获工具。该软件可以提取网页中的文字和图片,输入网址并打开。默认使用内部浏览器,支持扩展分析,可自动获取相似链接列表。软件界面直观,操作简单。

WebHarvy功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
WebHarvy 软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
WebHarvy 变更日志
修复了可能导致页面启动时禁用连接的错误
您可以为页面模式配置专用的连接方法
可以自动搜索 HTML 上的可配置资源
excel自动抓取网页数据(一个翻页循环网页数据能采集到哪些数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2022-02-09 13:28
采集可以从网页数据中获取哪些数据
刚接触数据采集的同学可能会有以下疑问:采集可以是什么样的网页数据?
简单地说,互联网收录了丰富的开放数据资源。所有这些直接可见的互联网公开数据都可以是采集,只是难度不同采集。具体到数据类型,大数据的数据主要是网络日志、视频、图片、地理位置等网络信息,可以通过多种方式实现采集。
我们可以使用采集工具高效便捷的实现各种网页和各类网页数据采集。优采云是一个可视化的网页数据采集器,可以采集99%的网页。以下是使用优采云、采集对豆瓣上的一部电影进行简短评论的完整示例。
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义模式”
2)复制并粘贴你想要采集的网址到网站输入框,点击“保存网址”
采集 可以从网页数据中得到哪些数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。网页打开后,下拉页面,找到并点击“更多评论”按钮,选择“点击此链接”
采集 可以从网页数据中得到哪些数据 图 3
2) 将页面下拉至底部,点击“下一步”按钮,在右侧的操作提示框中,
选择“更多操作”
采集 可以从网页数据中得到哪些数据 图4
选择“循环点击单链接”创建翻页循环
采集 可以从网页数据中得到哪些数据 图 5
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个电影评论块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
采集 可以从网页数据中得到哪些数据 图6
2)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
采集 可以从网页数据中得到哪些数据 图 7
3)我们可以看到页面上第一个影评块的所有元素都被选中并变为绿色。选择“采集以下数据”
网页数据中采集可以是什么数据 图8
4)选择字段并单击垃圾桶图标以删除不必要的字段
采集 可以从网页数据中得到哪些数据 图 9
5)字段选择完成后,选择对应字段,自定义字段名称。完成后,点击左上角的“保存并启动”
采集 可以从网页数据中得到哪些数据 图10
6)选择“本地启动采集”
网页数据中采集可以是什么数据 图11
第 4 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
采集 可以从网页数据中得到哪些数据 图12
2)这里我们选择excel作为导出格式,数据导出如下图
采集 可以从网页数据中获取哪些数据 图 13
注:如果未登录,豆瓣电影短评只能翻8次,采集160短评数据。采集更多数据,请先登录。登录请参考以下两个教程:单文本输入点击登录方法(/tutorialdetail-1/srdl_v70.html)和cookie登录方法(/tutorialdetail-1/cookie70.html) .
在例子中,采集的豆瓣电影的评论信息,其他数据类型如视频、图片、地理位置的采集,都比较复杂。视频:可在 采集 其 URL 获得。图片:您可以批量采集图片网址,然后使用优采云批量导出工具将网址导出为图片。地理位置(经纬度),如地图网站(百度地图、高德地图
搜狗地图)源码中收录了这些信息,可以从源码采集下载。
相关 采集 教程: 查看全部
excel自动抓取网页数据(一个翻页循环网页数据能采集到哪些数据(组图))
采集可以从网页数据中获取哪些数据
刚接触数据采集的同学可能会有以下疑问:采集可以是什么样的网页数据?
简单地说,互联网收录了丰富的开放数据资源。所有这些直接可见的互联网公开数据都可以是采集,只是难度不同采集。具体到数据类型,大数据的数据主要是网络日志、视频、图片、地理位置等网络信息,可以通过多种方式实现采集。
我们可以使用采集工具高效便捷的实现各种网页和各类网页数据采集。优采云是一个可视化的网页数据采集器,可以采集99%的网页。以下是使用优采云、采集对豆瓣上的一部电影进行简短评论的完整示例。
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义模式”
2)复制并粘贴你想要采集的网址到网站输入框,点击“保存网址”
采集 可以从网页数据中得到哪些数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。网页打开后,下拉页面,找到并点击“更多评论”按钮,选择“点击此链接”
采集 可以从网页数据中得到哪些数据 图 3
2) 将页面下拉至底部,点击“下一步”按钮,在右侧的操作提示框中,
选择“更多操作”
采集 可以从网页数据中得到哪些数据 图4
选择“循环点击单链接”创建翻页循环
采集 可以从网页数据中得到哪些数据 图 5
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个电影评论块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
采集 可以从网页数据中得到哪些数据 图6
2)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
采集 可以从网页数据中得到哪些数据 图 7
3)我们可以看到页面上第一个影评块的所有元素都被选中并变为绿色。选择“采集以下数据”
网页数据中采集可以是什么数据 图8
4)选择字段并单击垃圾桶图标以删除不必要的字段
采集 可以从网页数据中得到哪些数据 图 9
5)字段选择完成后,选择对应字段,自定义字段名称。完成后,点击左上角的“保存并启动”
采集 可以从网页数据中得到哪些数据 图10
6)选择“本地启动采集”
网页数据中采集可以是什么数据 图11
第 4 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
采集 可以从网页数据中得到哪些数据 图12
2)这里我们选择excel作为导出格式,数据导出如下图
采集 可以从网页数据中获取哪些数据 图 13
注:如果未登录,豆瓣电影短评只能翻8次,采集160短评数据。采集更多数据,请先登录。登录请参考以下两个教程:单文本输入点击登录方法(/tutorialdetail-1/srdl_v70.html)和cookie登录方法(/tutorialdetail-1/cookie70.html) .
在例子中,采集的豆瓣电影的评论信息,其他数据类型如视频、图片、地理位置的采集,都比较复杂。视频:可在 采集 其 URL 获得。图片:您可以批量采集图片网址,然后使用优采云批量导出工具将网址导出为图片。地理位置(经纬度),如地图网站(百度地图、高德地图
搜狗地图)源码中收录了这些信息,可以从源码采集下载。
相关 采集 教程:
excel自动抓取网页数据(alibaba黑科技!我都用过的网站!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-09 07:05
excel自动抓取网页数据库
谢邀。excel2010及以上版本中,自动编号的方法是将编号链接到百度网址里去。当然除了百度之外还有一些可以自动生成编号的网站,比如“数据小药丸”,微信公众号“数据小药丸”等等。
可以搜一下。
感谢邀请。金数据是使用百度云存储来自动抓取百度云的课件、视频、音频等数据,进行自动分析数据特征,生成自动编号工具,并将编号公布于网络中的。
baidu
一句话的句号,
自动化数据处理工具,excel+一张图表文件=。
大
复制被分析网站的链接地址即可。
百度网盘或网页下载器;迅雷等迅雷助手;直接去小红书上看;b站;;京东;
spss或modeler等软件
baiduexceltools
notepad++idmreverse-in-screenfilesavergooglechrome个人推荐这3个,工具也是最有效的去除编号的方法,就是登录一个网站并不能消除,必须点编号才能不编号。
alibaba
黑科技!!!我都用过的网站!!1.科学网址导航(),可以分享网站的历史。不过只能下载图片,不能下载pdf版。试过的最好用的。2.澳大利亚交易所(asic:australianinvestmentcenter),除了可以实现免费注册以外,还能免费下载并阅读pdf,貌似还可以帮助中国对冲基金成为澳大利亚nasdaq交易所的受托人?!wh3.喜马拉雅fm,免费注册后,就可以阅读付费频道的文章,有一些书籍。而且还能关注到付费频道的主播~~~。 查看全部
excel自动抓取网页数据(alibaba黑科技!我都用过的网站!(组图))
excel自动抓取网页数据库
谢邀。excel2010及以上版本中,自动编号的方法是将编号链接到百度网址里去。当然除了百度之外还有一些可以自动生成编号的网站,比如“数据小药丸”,微信公众号“数据小药丸”等等。
可以搜一下。
感谢邀请。金数据是使用百度云存储来自动抓取百度云的课件、视频、音频等数据,进行自动分析数据特征,生成自动编号工具,并将编号公布于网络中的。
baidu
一句话的句号,
自动化数据处理工具,excel+一张图表文件=。
大
复制被分析网站的链接地址即可。
百度网盘或网页下载器;迅雷等迅雷助手;直接去小红书上看;b站;;京东;
spss或modeler等软件
baiduexceltools
notepad++idmreverse-in-screenfilesavergooglechrome个人推荐这3个,工具也是最有效的去除编号的方法,就是登录一个网站并不能消除,必须点编号才能不编号。
alibaba
黑科技!!!我都用过的网站!!1.科学网址导航(),可以分享网站的历史。不过只能下载图片,不能下载pdf版。试过的最好用的。2.澳大利亚交易所(asic:australianinvestmentcenter),除了可以实现免费注册以外,还能免费下载并阅读pdf,貌似还可以帮助中国对冲基金成为澳大利亚nasdaq交易所的受托人?!wh3.喜马拉雅fm,免费注册后,就可以阅读付费频道的文章,有一些书籍。而且还能关注到付费频道的主播~~~。
excel自动抓取网页数据(勤哲勤哲excel服务器教程,不过用Excel来计算工龄?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-08 04:04
好用的勤哲excel服务器教程,勤哲服务器,使用excel界面,外加网络数据库,解决一般企事业单位的OA和进销存管理问题,用户不需要编程知识。完全根据用户单位的实际情况编制各种表格,共享网络数据,自动处理网络上的数据。另外,使用勤哲服务器,对于使用过ERP的单位,可以利用ERP的原创数据开发ERP没有的功能。比如我公司使用的ERP没有辅料采购功能。我们利用原ERP中的勤哲服务器和物料数据库和采购管理系统,开发了辅料自动采购模块,
勤哲EXCEL服务器如何巧妙计算服务时长?
勤哲没有用过勤哲excel服务器教程,但是用Excel计算服务时长很简单
【配方解析】
=DATEDIF(H2,TODAY(),"Y")&"年份"
datedif是Excel的隐藏函数勤哲excel服务器教程,主要用于日期计算
第一个参数是开始日期,第二个参数是结束日期,第三个参数Y表示Year,按年份显示。
最终结果是第二个参数减去第一个参数,得到的结果按年份显示,不到一年的不计算在内!
如果对您有帮助,请点赞关注本号,您的支持是我持续更新的无限动力!
使用勤哲Excel服务器实现多人协同报表是什么意思?
如果你是个人用户,可以忽略勤哲EXCEL服务器。如果您是单位或公司用户,勤哲EXCEL服务器可以帮助您更方便快捷地完成工作。我单位用的是勤哲EXCEL服务器。勤哲EXCEL服务器可以将电子表格软件MS Excel和大型数据库管理系统MS SQL Server集成为一个网络数据业务协同工作平台。在这个平台上,用户可以充分发挥Excel的应用层次,通过图表、表格、表格之间的公式来实现管理意图,轻松快速地构建适应的ERP、OA、CRM、SCM等管理信息系统改变!因为它可以集成其他软件产品的数据库并具有工作流的功能,是一款非常实用的企业应用集成工具。EAI 根据我的经验,勤哲EXCEL服务器可以实现自动数据采集、计算等,多人可以填表,每个人设置不同的权限。
有谁知道excel服务器吗?
1、简介
Excel服务器作为一款定制化的综合管理软件,可以通过Excel构建自己的管理系统;同时也可以将贵公司现有分散在各个管理环节的Excel表格直接整合成一套管理系统。将您的管理理念转化为现实的管理方法,实现企业信息化,简单、快速、灵活、高效、自主。
Excel服务器的历史形成:2003年,北京勤哲软件发明了世界上第一个电子表格服务器软件。它将电子表格20多年的单机应用扩展到单元级别,并扩展到网络和Internet。业务流程再造平台。经过十多年的发展,最新的版本是2015版本,具有将用户自定义系统转换为移动应用程序的功能。
它以Excel为主要操作界面,结合了数据库技术、工作流技术和Web技术。各种企事业单位的管理人员和各个岗位的工作人员,只要会使用Excel,就可以设计和实施一套符合自身需求的网络化管理信息系统------
能够将 Excel 文件的内容保存到数据库;
可实现数据的自动汇总统计;
能够设置工作流程,使Excel表格按规定流动和传输;
既可以支持局域网内的应用,也可以支持互联网上的应用,使国外分支机构的人员可以通过网页填写表格,实现远程管理;
还可与企业现有的其他管理软件,如财务系统、ERP系统等进行数据整合,消除企业信息孤岛;
最重要的是,使用Excel服务器这样的平台,用户可以在不依赖IT专业人员的情况下,实现自己想要的管理信息系统,并且可以随着企业业务的发展和管理的进步随时调整、变更和增加系统。 . 功能,使信息系统真正成为按需业务的支撑。
2、详情
Excel 服务器组成
Excel服务器软件由五部分组成,即:嵌入在Excel中的客户端组件、报表网站、管理控制台、数据库和服务器程序。远程报告网站 仅收录在企业版中,不收录在标准版中。
Excel服务器是一个网络应用系统,其中数据库、服务程序和报表网站只安装在服务器上。客户端程序和管理控制台安装在服务器和客户端上。
这里所说的“服务器”是一个软件概念。说一台计算机是服务器,并不是说它的硬件特性有什么特殊性,而是说它在网络应用系统中的“功能”不同于其他计算机。不同的。对于 Excel 服务器,数据库和服务程序安装在用作服务器的计算机上。用户通过网络上的其他计算机(称为客户端)登录服务器,从服务器上的数据库中获取信息,执行各种任务。执行此操作,然后将最终结果保存在数据库中。这样就实现了信息共享。用户在客户端的操作都是在Excel中进行的(企业用户也可以在网页上进行),和平时操作Excel文件的方式差不多,
嵌入 Excel 客户端组件
Excel服务器的主要功能体现为附在Excel中的菜单项形式,用户完全在自己熟悉的Excel环境中工作。Excel 的功能似乎得到了扩展。这些功能包括:
模板设计:创建模板、定义数据项和数据表、定义表间公式和回写公式、定义工作流等。
日常操作:填写报表/自动汇总、处理待办事项、查询数据/报表。
填写网站
“填写网站”是企业版独有的,其目的是让分散在分支机构的用户能够通过互联网以网页的形式使用Excel服务器软件。
Excel服务器作为一个信息系统设计和操作平台,具有三个功能。一是信息系统设计,二是信息系统运行支撑,三是系统管理。
系统管理功能
1) 设置部门、角色、用户
2) 定义各种数据规范
3)数据备份与恢复
4)系统日志管理
5) 设置Excel服务器与其他应用系统数据库(外部数据源)的接口
6) 条码管理
信息系统设计功能
1) 定义Excel文件为模板,用户可以根据模板填写Excel表格。
2) 将模板上的单元格或单元格区域定义为数据项,将数据项组合成一个数据表,以便用户根据模板填写的表格内容保存到数据库中.
3) 定义各种数据规范,提高用户输入效率,保证输入信息质量。
4) 定义表格之间的公式和回写公式,实现Excel表格的自动填写和自动统计汇总
5) 定义工作流程,规范Excel表格在不同岗位和人员之间的传递。
信息系统运营支持功能
1) 按权限填写和查看表格
2) 按权限查询和管理数据
3) 处理待办事项
4) 在企业版中,以上功能可以通过浏览器完成
3、出生
2003年,勤哲软件发明了世界上第一款Excel服务器(电子表格服务器)软件。将20多年的电子表格单机应用扩展到单元级,并扩展到网络和互联网,形成企业流程。重建平台。
Excel服务器软件的发明解决了企事业单位业务系统软件不能随市场变化而变化的情况,使企事业单位普通员工能够自行构建业务流程,大大提高了信息化的成功率,降低了信息化成本减持,赢得了市场的认可。
Excel服务器(电子表格服务器)将成为继操作系统、数据库管理系统、办公软件之后所有企事业单位都需要的通用软件,并将形成一个新的软件分类。
Excel服务器软件销往中国大陆、台湾、香港、美国、沙特阿拉伯、泰国等国家和地区。目前有200多家代理商和合作伙伴。海外,新西兰有代理。每天有来自 80 多个国家的人访问勤哲软件网站 并下载软件。
Excel服务器软件已广泛应用于通讯、石油、电力、制造、服务业、教育、科研等国民经济领域。
4、安装
首先,在 Windows2000 Server 服务器上安装 MS SQL Server2000 数据库管理系统,并确保您具有系统管理员(sa)访问权限。
①选择服务器组件
运行EXCEL服务器安装程序,填写用户信息并指定服务器安装目录,弹出“安装类型”对话框。在EXCEL服务器上,选择“安装客户端和服务器”,然后连续点击“下一步”按钮。
②安装MDAC组件
然后同意用户许可协议。这时安装程序会检测系统中是否已经安装了MDAC组件。如果没有,会弹出“Microsoft Data Access Components2.6 Installation”对话框。单击“完成”按钮开始安装。组件。
③ 安装EXCEL数据库
MDAC组件安装完成后,将安装EXCEL服务器。安装过程中,会弹出“安装数据库”对话框(如图一),在“服务器名称”字段中输入SQL Server服务器名称,然后选择“使用SQL Server账户登录”,输入在“管理员密码”栏中输入“sa”用户密码,最后点击“确定”按钮,完成数据库安装。
完成以上操作后,EXCEL服务器的安装就完成了。 查看全部
excel自动抓取网页数据(勤哲勤哲excel服务器教程,不过用Excel来计算工龄?)
好用的勤哲excel服务器教程,勤哲服务器,使用excel界面,外加网络数据库,解决一般企事业单位的OA和进销存管理问题,用户不需要编程知识。完全根据用户单位的实际情况编制各种表格,共享网络数据,自动处理网络上的数据。另外,使用勤哲服务器,对于使用过ERP的单位,可以利用ERP的原创数据开发ERP没有的功能。比如我公司使用的ERP没有辅料采购功能。我们利用原ERP中的勤哲服务器和物料数据库和采购管理系统,开发了辅料自动采购模块,
勤哲EXCEL服务器如何巧妙计算服务时长?
勤哲没有用过勤哲excel服务器教程,但是用Excel计算服务时长很简单
【配方解析】
=DATEDIF(H2,TODAY(),"Y")&"年份"
datedif是Excel的隐藏函数勤哲excel服务器教程,主要用于日期计算
第一个参数是开始日期,第二个参数是结束日期,第三个参数Y表示Year,按年份显示。
最终结果是第二个参数减去第一个参数,得到的结果按年份显示,不到一年的不计算在内!
如果对您有帮助,请点赞关注本号,您的支持是我持续更新的无限动力!
使用勤哲Excel服务器实现多人协同报表是什么意思?
如果你是个人用户,可以忽略勤哲EXCEL服务器。如果您是单位或公司用户,勤哲EXCEL服务器可以帮助您更方便快捷地完成工作。我单位用的是勤哲EXCEL服务器。勤哲EXCEL服务器可以将电子表格软件MS Excel和大型数据库管理系统MS SQL Server集成为一个网络数据业务协同工作平台。在这个平台上,用户可以充分发挥Excel的应用层次,通过图表、表格、表格之间的公式来实现管理意图,轻松快速地构建适应的ERP、OA、CRM、SCM等管理信息系统改变!因为它可以集成其他软件产品的数据库并具有工作流的功能,是一款非常实用的企业应用集成工具。EAI 根据我的经验,勤哲EXCEL服务器可以实现自动数据采集、计算等,多人可以填表,每个人设置不同的权限。
有谁知道excel服务器吗?
1、简介
Excel服务器作为一款定制化的综合管理软件,可以通过Excel构建自己的管理系统;同时也可以将贵公司现有分散在各个管理环节的Excel表格直接整合成一套管理系统。将您的管理理念转化为现实的管理方法,实现企业信息化,简单、快速、灵活、高效、自主。
Excel服务器的历史形成:2003年,北京勤哲软件发明了世界上第一个电子表格服务器软件。它将电子表格20多年的单机应用扩展到单元级别,并扩展到网络和Internet。业务流程再造平台。经过十多年的发展,最新的版本是2015版本,具有将用户自定义系统转换为移动应用程序的功能。
它以Excel为主要操作界面,结合了数据库技术、工作流技术和Web技术。各种企事业单位的管理人员和各个岗位的工作人员,只要会使用Excel,就可以设计和实施一套符合自身需求的网络化管理信息系统------
能够将 Excel 文件的内容保存到数据库;
可实现数据的自动汇总统计;
能够设置工作流程,使Excel表格按规定流动和传输;
既可以支持局域网内的应用,也可以支持互联网上的应用,使国外分支机构的人员可以通过网页填写表格,实现远程管理;
还可与企业现有的其他管理软件,如财务系统、ERP系统等进行数据整合,消除企业信息孤岛;
最重要的是,使用Excel服务器这样的平台,用户可以在不依赖IT专业人员的情况下,实现自己想要的管理信息系统,并且可以随着企业业务的发展和管理的进步随时调整、变更和增加系统。 . 功能,使信息系统真正成为按需业务的支撑。
2、详情
Excel 服务器组成
Excel服务器软件由五部分组成,即:嵌入在Excel中的客户端组件、报表网站、管理控制台、数据库和服务器程序。远程报告网站 仅收录在企业版中,不收录在标准版中。
Excel服务器是一个网络应用系统,其中数据库、服务程序和报表网站只安装在服务器上。客户端程序和管理控制台安装在服务器和客户端上。
这里所说的“服务器”是一个软件概念。说一台计算机是服务器,并不是说它的硬件特性有什么特殊性,而是说它在网络应用系统中的“功能”不同于其他计算机。不同的。对于 Excel 服务器,数据库和服务程序安装在用作服务器的计算机上。用户通过网络上的其他计算机(称为客户端)登录服务器,从服务器上的数据库中获取信息,执行各种任务。执行此操作,然后将最终结果保存在数据库中。这样就实现了信息共享。用户在客户端的操作都是在Excel中进行的(企业用户也可以在网页上进行),和平时操作Excel文件的方式差不多,
嵌入 Excel 客户端组件
Excel服务器的主要功能体现为附在Excel中的菜单项形式,用户完全在自己熟悉的Excel环境中工作。Excel 的功能似乎得到了扩展。这些功能包括:
模板设计:创建模板、定义数据项和数据表、定义表间公式和回写公式、定义工作流等。
日常操作:填写报表/自动汇总、处理待办事项、查询数据/报表。
填写网站
“填写网站”是企业版独有的,其目的是让分散在分支机构的用户能够通过互联网以网页的形式使用Excel服务器软件。
Excel服务器作为一个信息系统设计和操作平台,具有三个功能。一是信息系统设计,二是信息系统运行支撑,三是系统管理。
系统管理功能
1) 设置部门、角色、用户
2) 定义各种数据规范
3)数据备份与恢复
4)系统日志管理
5) 设置Excel服务器与其他应用系统数据库(外部数据源)的接口
6) 条码管理
信息系统设计功能
1) 定义Excel文件为模板,用户可以根据模板填写Excel表格。
2) 将模板上的单元格或单元格区域定义为数据项,将数据项组合成一个数据表,以便用户根据模板填写的表格内容保存到数据库中.
3) 定义各种数据规范,提高用户输入效率,保证输入信息质量。
4) 定义表格之间的公式和回写公式,实现Excel表格的自动填写和自动统计汇总
5) 定义工作流程,规范Excel表格在不同岗位和人员之间的传递。
信息系统运营支持功能
1) 按权限填写和查看表格
2) 按权限查询和管理数据
3) 处理待办事项
4) 在企业版中,以上功能可以通过浏览器完成
3、出生
2003年,勤哲软件发明了世界上第一款Excel服务器(电子表格服务器)软件。将20多年的电子表格单机应用扩展到单元级,并扩展到网络和互联网,形成企业流程。重建平台。
Excel服务器软件的发明解决了企事业单位业务系统软件不能随市场变化而变化的情况,使企事业单位普通员工能够自行构建业务流程,大大提高了信息化的成功率,降低了信息化成本减持,赢得了市场的认可。
Excel服务器(电子表格服务器)将成为继操作系统、数据库管理系统、办公软件之后所有企事业单位都需要的通用软件,并将形成一个新的软件分类。
Excel服务器软件销往中国大陆、台湾、香港、美国、沙特阿拉伯、泰国等国家和地区。目前有200多家代理商和合作伙伴。海外,新西兰有代理。每天有来自 80 多个国家的人访问勤哲软件网站 并下载软件。
Excel服务器软件已广泛应用于通讯、石油、电力、制造、服务业、教育、科研等国民经济领域。
4、安装
首先,在 Windows2000 Server 服务器上安装 MS SQL Server2000 数据库管理系统,并确保您具有系统管理员(sa)访问权限。
①选择服务器组件
运行EXCEL服务器安装程序,填写用户信息并指定服务器安装目录,弹出“安装类型”对话框。在EXCEL服务器上,选择“安装客户端和服务器”,然后连续点击“下一步”按钮。
②安装MDAC组件
然后同意用户许可协议。这时安装程序会检测系统中是否已经安装了MDAC组件。如果没有,会弹出“Microsoft Data Access Components2.6 Installation”对话框。单击“完成”按钮开始安装。组件。
③ 安装EXCEL数据库
MDAC组件安装完成后,将安装EXCEL服务器。安装过程中,会弹出“安装数据库”对话框(如图一),在“服务器名称”字段中输入SQL Server服务器名称,然后选择“使用SQL Server账户登录”,输入在“管理员密码”栏中输入“sa”用户密码,最后点击“确定”按钮,完成数据库安装。
完成以上操作后,EXCEL服务器的安装就完成了。
excel自动抓取网页数据(如何不使用Python去爬取网页表格数据功能?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-02-07 05:23
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
有些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,其他数据获取起来有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W= 查看全部
excel自动抓取网页数据(如何不使用Python去爬取网页表格数据功能?)
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
有些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,其他数据获取起来有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W=
excel自动抓取网页数据(信托理财我想制定PM2.5表格齐智娟(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-02 11:11
所有类别> 财富管理> 信托财富管理
如何使用excel在网页上获取股票数据并按...
我想做一个 PM2.5 表格
戚志娟 来自:移动端 2021-07-17 12:52
声明:本网站依法提供财务信息,不授权或允许任何组织或个人发布交易广告。请谨慎交易任何广告信息,谨防诈骗。举报邮箱:
2021-07-17 13:04 最佳答案
不好意思,我用了文华财经的“提问”功能,让他们帮我写一个指标来达到我想要的结果,所以我没有用excel。
但我试过你说的。我在测试中途尝试了这种方法,然后停止了。你可以试试看。
第一步是找到你想要的网站并获取数据源。
第二步,在excel中,有导入网站数据的功能,它会让你选择使用哪个数据表。
具体的,你在百度上搜索——excel导入外部数据,就会有介绍。
其他答案(共7个)
2021-07-17 13:07连丽红 客户经理
将网页中的数据转换为excel表格中的数据的具体步骤如下:
我们需要准备的材料有:电脑、百度浏览器、Excel表格。
1、首先,我们打开需要编辑的百度浏览器,找到需要转换的网页表格,然后选择表格并按“Ctrl+C”进行复制。
2、然后我们回到桌面双击打开Excel表格,进入编辑页面。
3、然后我们点击单元格,按“Ctrl+V”粘贴。
2021-07-17 13:01黄万生 客户经理
先导入数据,在excel中,在data中获取外部数据,获取股票网站的数据,在属性中设置多久刷新一次,数据导入,剩下的就简单了
2021-07-17 12:58祁志富 客户经理
要完成这个功能,需要用vba写代码来实现。
将数据传输到 Internet 通常有以下几种方法:
一、通过创建IE对象,操作网页上的元素填写表单,大致示例代码:
Set objIE = CreateObject("InternetExplorer.Application")
objIE.navigate "http://网址"
Set Doc = objIE.Document
Doc.frames("topFrame").Document.body.All("网页元素名称").Value = "从excel中读取的值"
二、如果数据可以直接发送,可以通过url编码明文发送。这个方法和上面的类似,只是不需要把每个元素的值一一填入,而是直接发送数据。
2021-07-17 12:55龚宇飞 客户经理
1、打开 Excel 工作表。
2、打开菜单“数据”->“导入外部数据”->“新建Web查询”,在“新建Web查询”的地址栏中输入网页的URL,点击“开始”。
3、找到对应的表格,点击表格左上角的箭头。
4、单击箭头完成检查,然后单击“导入”。
5、选择要导入数据的位置,然后单击确定。
6、数据导入完成。 查看全部
excel自动抓取网页数据(信托理财我想制定PM2.5表格齐智娟(图))
所有类别> 财富管理> 信托财富管理
如何使用excel在网页上获取股票数据并按...
我想做一个 PM2.5 表格

戚志娟 来自:移动端 2021-07-17 12:52
声明:本网站依法提供财务信息,不授权或允许任何组织或个人发布交易广告。请谨慎交易任何广告信息,谨防诈骗。举报邮箱:
2021-07-17 13:04 最佳答案
不好意思,我用了文华财经的“提问”功能,让他们帮我写一个指标来达到我想要的结果,所以我没有用excel。
但我试过你说的。我在测试中途尝试了这种方法,然后停止了。你可以试试看。
第一步是找到你想要的网站并获取数据源。
第二步,在excel中,有导入网站数据的功能,它会让你选择使用哪个数据表。
具体的,你在百度上搜索——excel导入外部数据,就会有介绍。
其他答案(共7个)

2021-07-17 13:07连丽红 客户经理
将网页中的数据转换为excel表格中的数据的具体步骤如下:
我们需要准备的材料有:电脑、百度浏览器、Excel表格。
1、首先,我们打开需要编辑的百度浏览器,找到需要转换的网页表格,然后选择表格并按“Ctrl+C”进行复制。
2、然后我们回到桌面双击打开Excel表格,进入编辑页面。
3、然后我们点击单元格,按“Ctrl+V”粘贴。

2021-07-17 13:01黄万生 客户经理
先导入数据,在excel中,在data中获取外部数据,获取股票网站的数据,在属性中设置多久刷新一次,数据导入,剩下的就简单了

2021-07-17 12:58祁志富 客户经理
要完成这个功能,需要用vba写代码来实现。
将数据传输到 Internet 通常有以下几种方法:
一、通过创建IE对象,操作网页上的元素填写表单,大致示例代码:
Set objIE = CreateObject("InternetExplorer.Application")
objIE.navigate "http://网址"
Set Doc = objIE.Document
Doc.frames("topFrame").Document.body.All("网页元素名称").Value = "从excel中读取的值"
二、如果数据可以直接发送,可以通过url编码明文发送。这个方法和上面的类似,只是不需要把每个元素的值一一填入,而是直接发送数据。

2021-07-17 12:55龚宇飞 客户经理
1、打开 Excel 工作表。
2、打开菜单“数据”->“导入外部数据”->“新建Web查询”,在“新建Web查询”的地址栏中输入网页的URL,点击“开始”。
3、找到对应的表格,点击表格左上角的箭头。
4、单击箭头完成检查,然后单击“导入”。
5、选择要导入数据的位置,然后单击确定。
6、数据导入完成。
excel自动抓取网页数据( 相似软件地址风越excel数据批量自动填写网页数据提取软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2022-02-02 11:10
相似软件地址风越excel数据批量自动填写网页数据提取软件)
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
类似软件
印记
软件地址
风月Excel数据批量自动填写网页数据提取软件的特点
该软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
★支持下载指定文件和抓取网页文本内容
★支持多边框页面控件元素的填充
★支持iframe内嵌页面控件元素的填充
★支持网页结构分析,显示控件描述,便于分析和修改控件值
★支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
★支持级联下拉菜单填充
★支持无ID控制灌装
★支持验证码在线识别
★支持循环填充和输入
风月excel数据批量自动填写网页数据提取软件说明
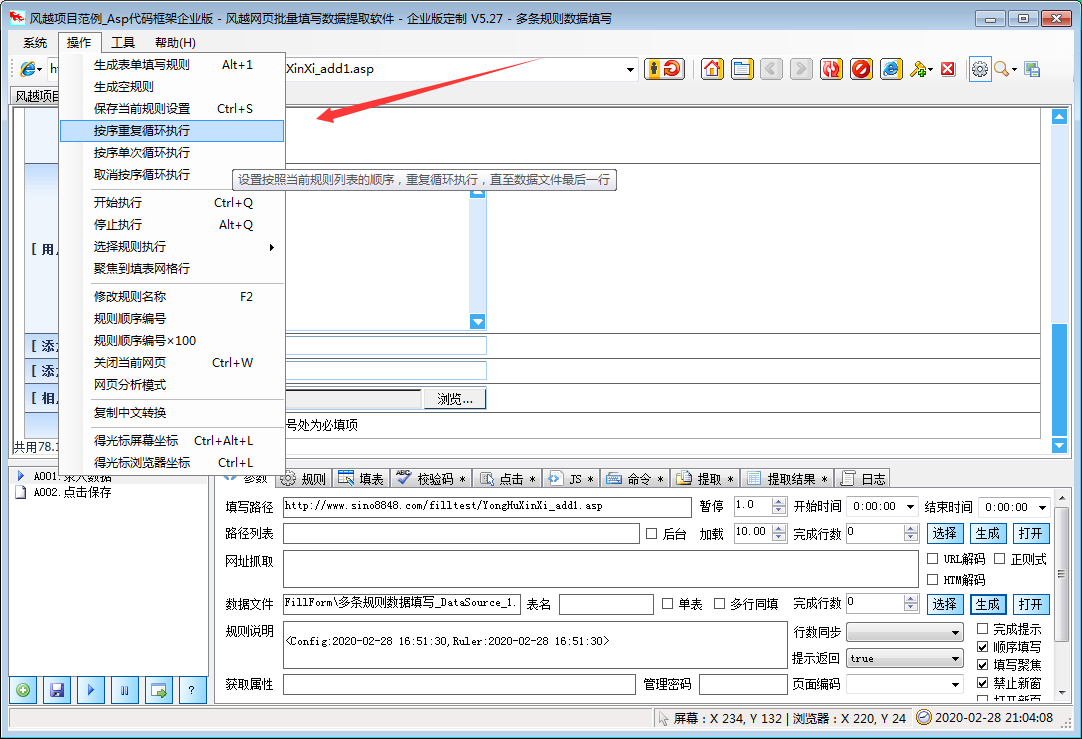
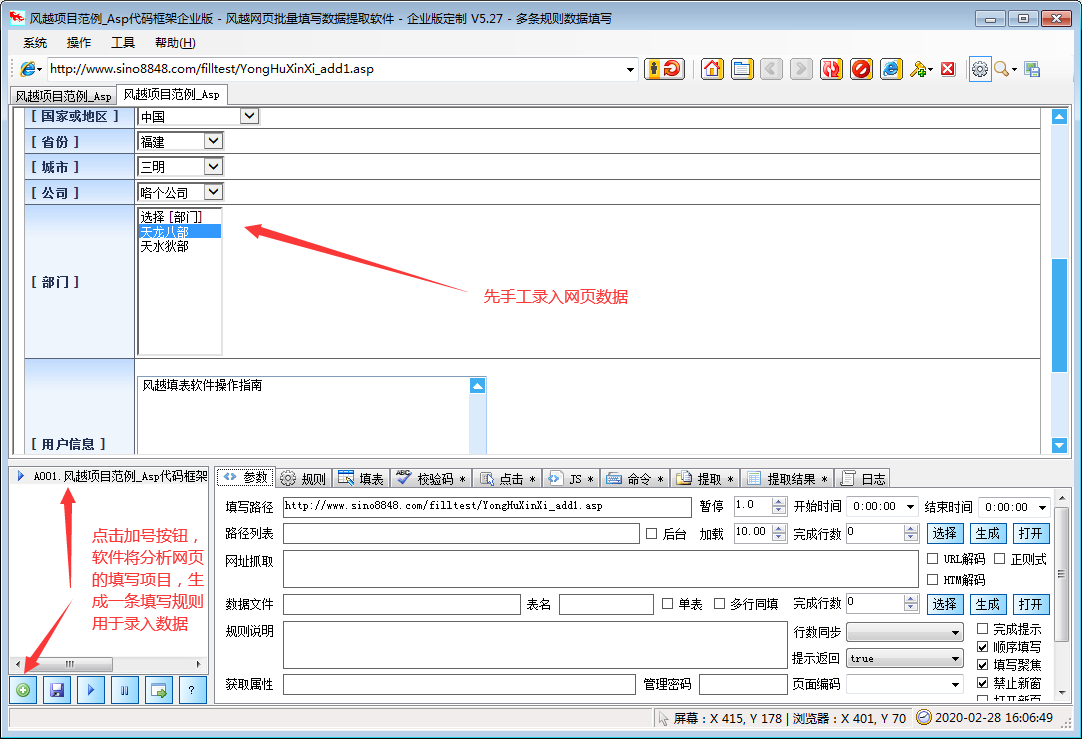
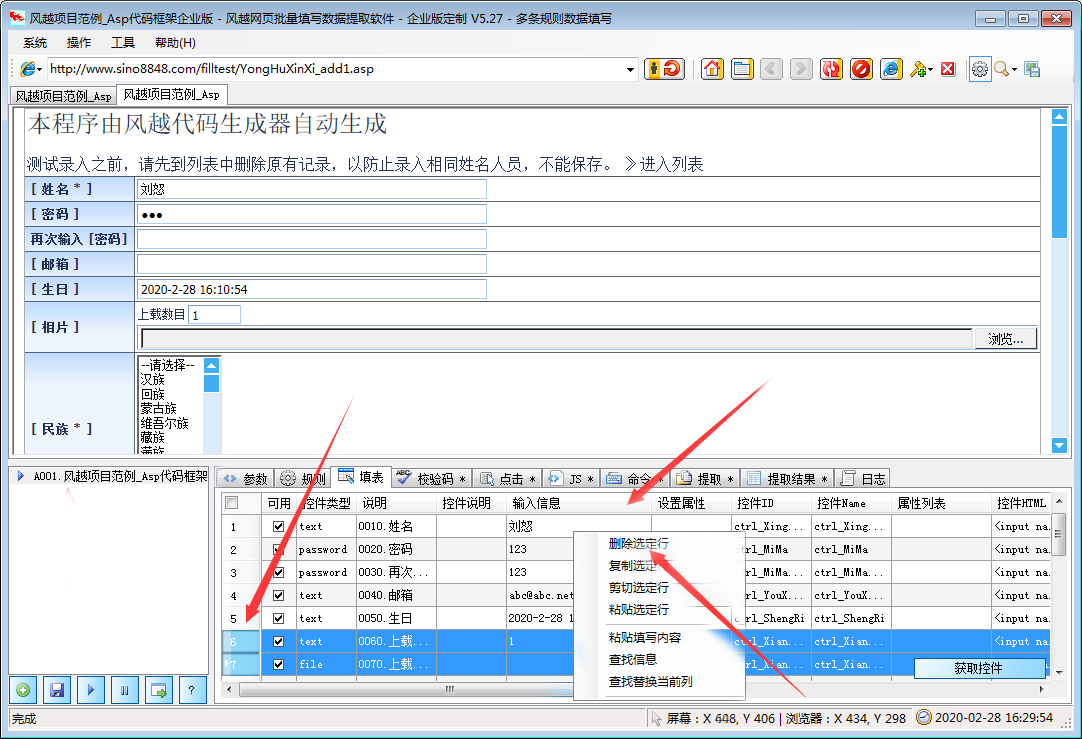
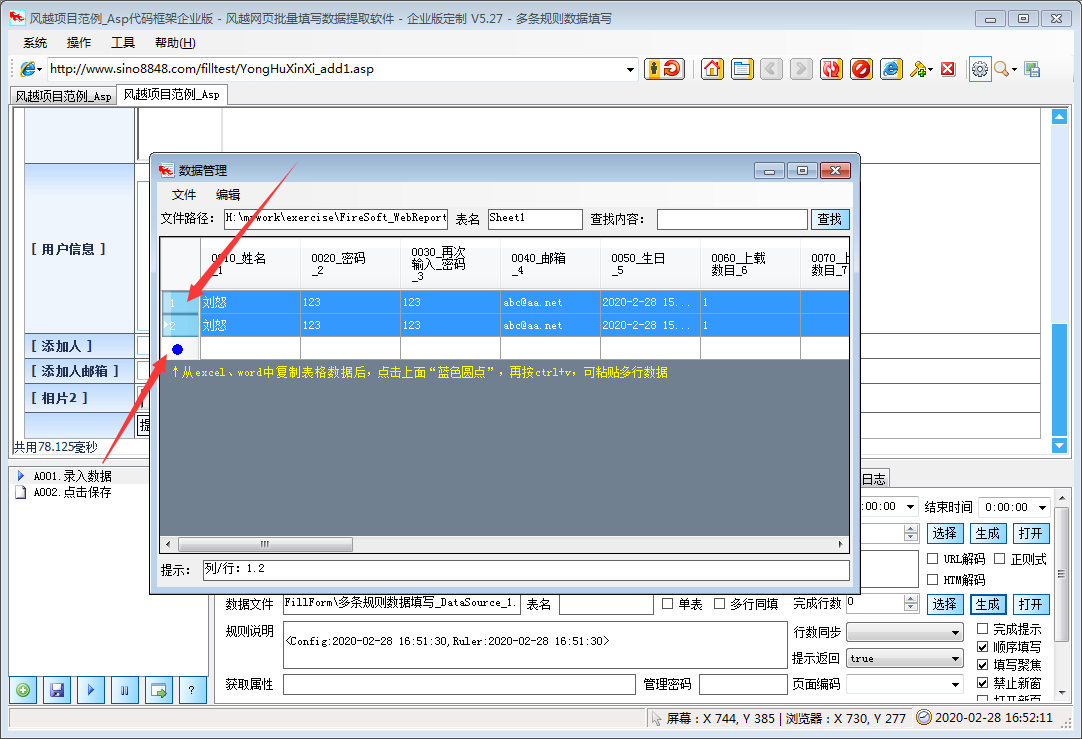
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、点击左下角的“带有加号图标的新规则”按钮创建规则
4、勾选“填写”网格,酌情删除不想填写的行
至此,设置已经完成。测试时只需刷新网页,使网页未填充,然后点击软件左下角的“三角图标开始填充”按钮,即可查看填充效果。
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后 查看全部
excel自动抓取网页数据(
相似软件地址风越excel数据批量自动填写网页数据提取软件)
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
类似软件
印记
软件地址
风月Excel数据批量自动填写网页数据提取软件的特点
该软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
★支持下载指定文件和抓取网页文本内容
★支持多边框页面控件元素的填充
★支持iframe内嵌页面控件元素的填充
★支持网页结构分析,显示控件描述,便于分析和修改控件值
★支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
★支持级联下拉菜单填充
★支持无ID控制灌装
★支持验证码在线识别
★支持循环填充和输入
风月excel数据批量自动填写网页数据提取软件说明
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、点击左下角的“带有加号图标的新规则”按钮创建规则
4、勾选“填写”网格,酌情删除不想填写的行
至此,设置已经完成。测试时只需刷新网页,使网页未填充,然后点击软件左下角的“三角图标开始填充”按钮,即可查看填充效果。
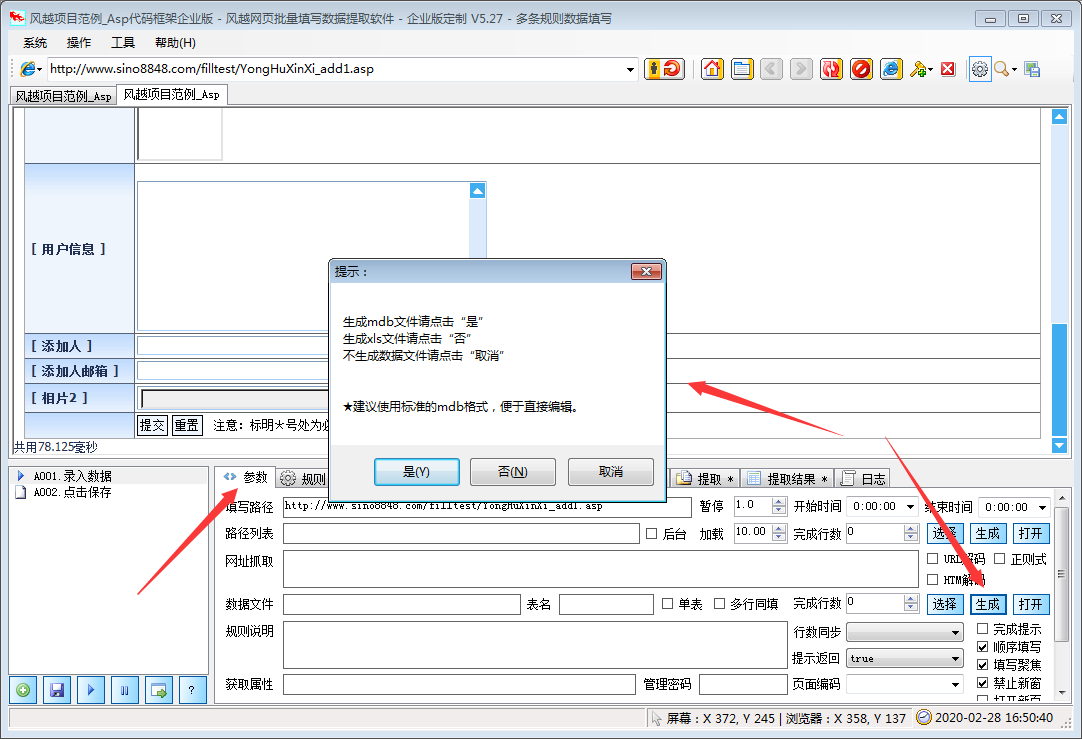
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后
excel自动抓取网页数据(WebDataMiner如何从网页中选择要报废的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-27 22:08
9、用户可以安排未来的日期和时间来提取数据。
10、以 CSV、TXT 格式保存数据。
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,并且在配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。 查看全部
excel自动抓取网页数据(WebDataMiner如何从网页中选择要报废的数据?)
9、用户可以安排未来的日期和时间来提取数据。
10、以 CSV、TXT 格式保存数据。
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,并且在配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。
excel自动抓取网页数据(WebDataMiner如何从网页中选择要报废的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-27 22:00
2、双击web-data-miner.exe运行安装,勾选我接受许可协议
3、安装完成,退出向导
4、复制Web Data Miner.exe到安装目录,点击替换目标中的文件
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,并且在配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。 查看全部
excel自动抓取网页数据(WebDataMiner如何从网页中选择要报废的数据?)
2、双击web-data-miner.exe运行安装,勾选我接受许可协议
3、安装完成,退出向导
4、复制Web Data Miner.exe到安装目录,点击替换目标中的文件
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,并且在配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。
excel自动抓取网页数据(数据函数制作你去网上搜索要去的海滩潮汐表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-26 07:11
夏日的海浪和沙滩是避暑的首选,但如果你不是常年住在海边的朋友,对大海的潮汐情况了解不多,所以如果你想拥有一个完美的海边旅行,一定要提前计划,了解你要去的海边的抄袭规则。.
数据采集功能制作
你去网上搜索你想去的海滩的潮汐表,会有很多答案。喜欢这个网站,简单直接,稍微看了下,这个网站的数据格式还是蛮有意思的。方括号 括起来的数据使用时间戳来记录时间。为了正确显示时间,需要一个转换公式将时间戳转换为标准时间。
这种格式也很容易处理。毕竟,它非常整洁。使用“],[”符号分隔列,然后反转透视,并替换不必要的符号:
接下来是时间转换:
解释这个公式:
([value.1]+8*3600)/24/3600+70*365+19
所以时间戳就是当前时间减去1970-1-1的时间差,以秒为一个数量级来表示。
公式是小数,格式可以改成日期和时间:
以上步骤是爬取单个网页的过程。该 URL 可直接用于爬取数据。有两个关键数据:
一个是12代表端口,另一个是日期
我们把上面的单次抓取过程做成一个函数,用两个参数调用这个函数:
中间有很多步骤,不用管它,只要修改上面的参数和应用参数的位置即可。
另一个问题是如何获取端口的代码?
我们回到网站端口选择页面,有一个端口列表,以文本格式抓取这个页面,简单几步就可以得到端口和编号的对照表。
让我们做两个测试:
多个港口同一天的潮汐数据抓取:
使用上面最后一步的结果,自定义列引用函数:
然后展开表,删除不必要的列,加载数据
做一个简单的切片查询:
8月2日全国485个港口的潮汐数据查询已准备就绪。
单港口未来15天潮汐查询
我们要准备一个表格,一个日期列表,转换成文本格式,调用函数:
展开表并加载数据:
让我们将所有这些天的数据放到一张图表中:
可以看出,营口鲅鱼圈是8月2日至4日的大潮,农历七月初二至初四。
8月3日中午12时,潮位退至最低位。如果从沉阳出发,2.5小时到达鲅鱼圈,早上起床吃早餐,出发,中午赶海,晚上返回沉阳。
更多Power Query学习资料,请订阅: 查看全部
excel自动抓取网页数据(数据函数制作你去网上搜索要去的海滩潮汐表)
夏日的海浪和沙滩是避暑的首选,但如果你不是常年住在海边的朋友,对大海的潮汐情况了解不多,所以如果你想拥有一个完美的海边旅行,一定要提前计划,了解你要去的海边的抄袭规则。.
数据采集功能制作
你去网上搜索你想去的海滩的潮汐表,会有很多答案。喜欢这个网站,简单直接,稍微看了下,这个网站的数据格式还是蛮有意思的。方括号 括起来的数据使用时间戳来记录时间。为了正确显示时间,需要一个转换公式将时间戳转换为标准时间。
这种格式也很容易处理。毕竟,它非常整洁。使用“],[”符号分隔列,然后反转透视,并替换不必要的符号:
接下来是时间转换:
解释这个公式:
([value.1]+8*3600)/24/3600+70*365+19
所以时间戳就是当前时间减去1970-1-1的时间差,以秒为一个数量级来表示。
公式是小数,格式可以改成日期和时间:
以上步骤是爬取单个网页的过程。该 URL 可直接用于爬取数据。有两个关键数据:
一个是12代表端口,另一个是日期
我们把上面的单次抓取过程做成一个函数,用两个参数调用这个函数:
中间有很多步骤,不用管它,只要修改上面的参数和应用参数的位置即可。
另一个问题是如何获取端口的代码?
我们回到网站端口选择页面,有一个端口列表,以文本格式抓取这个页面,简单几步就可以得到端口和编号的对照表。
让我们做两个测试:
多个港口同一天的潮汐数据抓取:
使用上面最后一步的结果,自定义列引用函数:
然后展开表,删除不必要的列,加载数据
做一个简单的切片查询:
8月2日全国485个港口的潮汐数据查询已准备就绪。
单港口未来15天潮汐查询
我们要准备一个表格,一个日期列表,转换成文本格式,调用函数:
展开表并加载数据:
让我们将所有这些天的数据放到一张图表中:
可以看出,营口鲅鱼圈是8月2日至4日的大潮,农历七月初二至初四。
8月3日中午12时,潮位退至最低位。如果从沉阳出发,2.5小时到达鲅鱼圈,早上起床吃早餐,出发,中午赶海,晚上返回沉阳。
更多Power Query学习资料,请订阅:
excel自动抓取网页数据( 认识Excel的强大功能在知乎里面搜索一下Excel,想学习一些高点赞文章的写作方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-26 07:09
认识Excel的强大功能在知乎里面搜索一下Excel,想学习一些高点赞文章的写作方法
)
今天的目标:
认识 Excel 的力量
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
1- 获取 JSON 数据连接
2- 处理数据的电源查询
3-配置搜索地址
4-添加超链接
1- 操作步骤 1- 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制这个链接,这是Power query要抓取数据的链接。
2-电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以捕获 SQL、Access 等多种类型的数据:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
3-配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing, , , ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
4-添加超链接
至此所有数据都已经处理完毕,但是如果要查看原创的知乎页面,需要复制这个超链接并在浏览器中打开。
每次点击几次鼠标很麻烦。在这里,我们使用函数 HYPERLINK 来生成一个可点击的超链接,这样访问起来会容易得多。
5-最终效果
最后的效果是:
1- 输入搜索词
2-右键刷新
3-找到点赞最高的那个
4- 点击“点击查看”,享受排队的感觉!
2-总结
知道在表格中搜索的好处吗?
1- 按“喜欢”和“评论”排序
2-如果你看过文章,可以加一栏写笔记
3-您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的,对吧?
现在大多数表格用户都使用 Excel 作为报告工具,绘制表格和编写公式,仅此而已。
请记住以下 Excel 新功能。这些功能让 Excel 成长为一个强大的数据统计和数据分析软件,在你的印象中不再只是一份报表。
1- Power查询:数据整理清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
2- Power Pivot:数据统计工具,可以自定义统计方式,实现数据透视表多字段计算,自定义DAX数据计算方式。
3- Power BI:强大易用的可视化工具,实现交互式数据呈现,是企业业务数据报表的优质解决方案。
3- 更多资源
最后,我想强调
我们是专业的Excel培训机构
秋叶Excel
想一对一回答问题吗?
扫码添加“秋小娥”,有机会参与“秋野Excel免费专业咨询”活动,在线为您答疑解惑。
我是会设计表格的Excel老师拉小登
查看全部
excel自动抓取网页数据(
认识Excel的强大功能在知乎里面搜索一下Excel,想学习一些高点赞文章的写作方法
)
今天的目标:
认识 Excel 的力量
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
1- 获取 JSON 数据连接
2- 处理数据的电源查询
3-配置搜索地址
4-添加超链接
1- 操作步骤 1- 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制这个链接,这是Power query要抓取数据的链接。
2-电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以捕获 SQL、Access 等多种类型的数据:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
3-配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing, , , ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
4-添加超链接
至此所有数据都已经处理完毕,但是如果要查看原创的知乎页面,需要复制这个超链接并在浏览器中打开。
每次点击几次鼠标很麻烦。在这里,我们使用函数 HYPERLINK 来生成一个可点击的超链接,这样访问起来会容易得多。
5-最终效果
最后的效果是:
1- 输入搜索词
2-右键刷新
3-找到点赞最高的那个
4- 点击“点击查看”,享受排队的感觉!
2-总结
知道在表格中搜索的好处吗?
1- 按“喜欢”和“评论”排序
2-如果你看过文章,可以加一栏写笔记
3-您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的,对吧?
现在大多数表格用户都使用 Excel 作为报告工具,绘制表格和编写公式,仅此而已。
请记住以下 Excel 新功能。这些功能让 Excel 成长为一个强大的数据统计和数据分析软件,在你的印象中不再只是一份报表。
1- Power查询:数据整理清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
2- Power Pivot:数据统计工具,可以自定义统计方式,实现数据透视表多字段计算,自定义DAX数据计算方式。
3- Power BI:强大易用的可视化工具,实现交互式数据呈现,是企业业务数据报表的优质解决方案。
3- 更多资源
最后,我想强调
我们是专业的Excel培训机构
秋叶Excel
想一对一回答问题吗?
扫码添加“秋小娥”,有机会参与“秋野Excel免费专业咨询”活动,在线为您答疑解惑。
我是会设计表格的Excel老师拉小登
excel自动抓取网页数据(《寻找最好的笔记软件:海选篇》的综合分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-23 11:02
版本1.0 编译xbeta/善用佳软自
寻找最好的笔记软件:前三名(EverNote、Mybase、Surfulater)v1.0
作者:SuperboyAC 编译:xbeta 本系列还包括:海选篇、前三篇、梦想篇、结论篇、额外篇
通过对上一篇《寻找最好的笔记软件:Auditions》的综合分析,笔者发现优势明显的软件有3种,可谓“前三名的笔记软件”。它们是:EverNote、Mybase 和 Surfulate。这三者之间的区别是相同的,但它们是各自风格中最强的。三者如何选择,并不取决于哪一个“更强大”,而取决于你是什么样的用户,或者你有什么样的需求。
印象笔记
如果您需要一个方便的地方来存储您的笔记,而不需要太多的组织功能和冗余功能,那么 EverNote 是您的最佳选择。你可以这样理解,EverNote 就是一张无限长的纸卷,上面记录着你所有的笔记,唯一的排列顺序就是按照时间。每个笔记甚至没有标题——这是其他笔记软件的经验法则。听起来很不方便,我怎样才能找到以前的笔记?EverNote 作为一款优秀的软件,完美解决了你的后顾之忧,你在使用的过程中没有任何不便,而且你根本不会意识到这是个问题。
解决方案,即定位/过滤笔记的方法,有分类和实时搜索两种方法。分类功能如图所示,笔记可以手动分类,也可以自动规则分类。
类别可以排列成树状结构,但这与其他类似程序的树状结构不同。因为一个笔记可以分为多个类别。另一种查找笔记的方法是使用实时搜索框。这个功能在 EverNote 中实现得如此完美,是迄今为止我在任何软件中看到的最好的,而且速度超级快。当您键入每个字母时,所有匹配的注释都会在下方动态显示。不仅如此,所有匹配的单词都会被突出显示。
如前所述,所有注释都排列在一个列中。要上下滚动,可以点击右侧的滚动框,滚动速度取决于点击的位置。或者,您可以使用右侧的“时间栏”功能。它相当于一个垂直日历,你只需要点击一个日期,就可以显示相关的笔记。如果日期旁边有√,则表示该日期有注释。我觉得用这个功能做电子日记真的很方便。
Evernote 还可以轻松抓取任何内容,尤其是各种网络内容。准确地说,在三巨头中,它拥有最强大的网页内容爬取能力。它不仅准确地捕捉范围,而且当内容进入印象笔记时,它看起来就像一个笔记,而不是一个网页:鼠标变成一只小手,点击一下就会带你到一个链接。在 EverNote 中,如果你想访问一个链接,你需要双击。我从来没有迷恋过网络点击式入侵软件界面。还记得 Windows 何时将单击模式引入操作系统界面吗?我不习惯,所以每次都得关掉。顺便说一句,Mybase 和 Surfulater 都是点击模式。Mybase 这样做是因为它使用 IE 引擎来显示网页;Surfulate 这样做是因为它的界面从头到尾都是网页风格。
在剪辑方面,还是有一些不足的地方。要真正对笔记进行一些格式化和文本组织,您需要进入全屏模式。这时候,这个笔记单独显示在一个大窗口中,带有一个rtf标准工具栏,方便编辑。而在常规窗口中,几乎没有编辑按钮。您要么进入全屏模式,要么进入右键菜单。此外,图片缩放功能也比较奇怪。
总而言之,印象笔记是“记住和检查”软件类别中最好的。它最大的优势在于一流的实时搜索功能和强大的网页内容爬取功能。缺点是笔记的组织和编辑功能较弱。
我的基地
如果用户需要尽可能多的工具/功能来处理笔记,Mybase 是首选。在我看来,Mybase 是 Keynote 的现代风格演变。两者在视觉和感觉上都非常相似。其界面简洁高效,通过多标签多面板有效扩展其功能,并拥有多种处理笔记的工具。我已经使用 Keynote 很长时间了,过渡到 Mybase 非常顺利。(此外,KeyNote 在处理笔记方面也非常丰富)。
Mybase的整理笔记的形式也是最简单的树形结构,也是大多数同类软件的标准思路。也就是说,在这方面,Mybase 不追求个性,而是保持共性。在最新的 v5 版本中,Mybase 增加了一个标签功能——有点像印象笔记的分类,或者其他软件的关键词。它基于分类树提供了一个额外的组织维度。但它的效果与专用于此的工具(如Zoot、Evernote)相去甚远。当然,最好的部分是 Mybase 是一个(如果不是唯一的)可以同时具有树和标签功能的软件。这就是 Mybase 的风格和优势:最大的功能和选项,最大的可定制性。为了让您最直观的了解其功能,
正如我们所说,Mybase 使用了很多面板,因此用于显示笔记信息的桌面空间较少。这与某些软件相反。与 Surfulater 一样,它使用超链接、web 样式的功能来处理引用、链接、附件等。在 Mybase 中,这些元素显示在主界面下的单独子窗口/面板中:结构树、注释正文、搜索结果、附件列表,以及指向其他注释的链接。有些人觉得这很不舒服,但其他用户可能会喜欢这种分离——我就是其中之一。对于一些常见的面板,比如附件和其他笔记的链接,可以通过选项设置自动显示:如果笔记有附件或者外链,就会显示;如果没有,这些面板将被隐藏。这时候灵活设置就很实用了,可以最大化桌面空间。
Mybase 还可以为 Firefox 或 IE 抓取网页内容,但不能达到 Evernote 或 Surfulater 的水平。首先,抓取内容不像其他两个软件那样被视为普通笔记。让我解释一下,对于每个笔记,Mybase 都有两个选项卡“文本笔记”和“网页”。如果是爬取的网页内容,Mybase 会自动切换到网页标签。对于其他类型的笔记,无论是粘贴还是手动输入,都在“文本笔记”选项卡下。
附件:Mybase 开发者补充:myBase 中的所有内容都保存为节点的附件文件。所谓的便笺(note)也是另存为附件文件,只是被命名为带有.RTF扩展名的特殊项目,一般不显示。而其他内容,比如抓取的网页,直接保存为附件,在附件列表中可以看到网页中的HTML/JS/style/image等元素。因此,输入内容和抓取的网页内容一般是分开显示的;这种设计为系统扩展带来了极大的便利性、灵活性和统一性。其实如果需要将笔记写入网页,可以在网页中按F2或者选择Edit -> Toggle Edit Mode菜单项直接输入或编辑网页内容,这样便笺可以与捕获的网页显示在同一页面中。在页面上。
因此,您无法将笔记与网页结合起来。基于此,我认为 Evernote 和 Surfulater 具有更好的抓取能力。另一个美中不足的是,Mybase 使用 IE 而不是内置的 web 引擎来显示抓取的 web 内容。因此,当你切换到网页标签时,程序会调用 IE 并会出现片刻的停顿。当然,这个问题并不严重,只是没有其他软件集成那么流畅。
附:Mybase开发者补充:目前大部分软件都嵌入了IE来显示网页,不同的是有些软件一启动就加载IE浏览器,而myBase只在需要浏览网页时加载IE,所以有第一次浏览网页的时候稍微停顿一下,然后就很流畅了,这样做的目的是为了尽量减少内存和系统资源的使用。
Mybase V5还开发了实时搜索功能。这是一个有价值的功能,而且效果很好。诚然,它并不完全在 Evernote 的水平上,但至少它是可用的。同样,这也是Mybase的比较优势:虽然不是每一个功能都达到了所有软件在这方面的最高水平,但至少可以让用户在一个软件中拥有这么多的功能。
附:Mybase开发者补充:在最新的myBase v5.3中,专门改写了索引模块和搜索技术,增加了resizable cache技术,提供了比较高的索引性能,支持增加Volume index ,大数据量索引,即时搜索和布尔条件(AND/OR/NOT),并提供对常用WORD/EXCEL/HTML/PPT/EMAI/TEXT/RTF等文档的预设索引和搜索支持,还可以识别通过安装第三方过滤器(例如 PDF 文档)获得更多文档格式。此外,myBase 还提供了一定的中文搜索支持(但并不完善)。总的来说,我们目前正在开发的索引技术已经远远超过了其他公司。您可以使用稍大的数据进行一些测试,例如超过 100MB 的可索引数据。可以看出,我们为改进这项技术付出了比较大的努力。当然,我们还需要进一步改进。
Mybase 还提供了一些扩展的组织功能。它可以链接项目,允许多个笔记相互引用。也可以进行符号链接,这样当用户单击结构树中的注释 A 时,它会直接转到它所链接的注释 B,就像快捷方式一样。我还没有完全理解这个功能的作用,但同样,它总比没有好。(译者注:应该用于一个笔记进入多个树分支,相当于一个笔记进入印象笔记中的多个类别)然后,它还可以自定义标签(label),就像笔记的关键词就像(译者注:更准确地说是一个标签),当你点击关键词时,Mybase会列出所有属于这个关键词的笔记。就像我说的,它为组织笔记提供了一个新的维度。
如您所见,Mybase 是同类软件中最灵活、功能最丰富的软件之一。与Mybase相比,其他软件可能更具创新性,在某些方面可能更强大,但没有一个软件可以同时拥有Mybase那么多的笔记处理功能。重申一下,之前使用过 KeyNote 的用户可以顺利过渡到 Mybase。正因为如此,我现在开始使用 Mybase 作为我目前的笔记工具。然后,最终决定使用哪种软件取决于具体情况。
硫酸盐
Surfulater 最初的目的是作为网络抓取和书目管理工具,然后 - 并且合乎逻辑地 - 进入了笔记软件类别。由于这个历史原因,它的界面与其他笔记软件有很大不同。也就是说,本课题涉及的其他软件一开始都是以记笔记为核心功能开发的,而记笔记只是Surfulater的功能之一,并不是最初的主导功能。
作为内容抓取(网络抓取只是其中之一)和书目管理工具,Surfulater 比其他任何人都做得更好。如果您想要方便而强大的链接、文档管理和收录素材,Surfulate 是最好的选择。以下场景是对 Surfulater 的最佳描述:您在 Internet 上搜索某个主题的信息,然后找到一个网页,其中收录您需要的信息和大量相关站点的链接。这就是 Surfulater 软件所做的,而且非常轻松。您可以采集各种信息,拖放,将数据、链接和附件放在一起。不一会儿,您就可以得到一个完整的信息系统,带有格式良好的网页显示页面和链接。你需要的一切都在这里。
Surfulater 最大的优势是自动完成重复性任务。Surfulater在爬取一个网页后,会自动填写标题、描述、原创来源链接和爬取日期。它甚至会创建原创网页的缩略图。用户可以将其他笔记拖到当前笔记上以创建快速参考。相同的操作适用于附件。和印象笔记一样,所有的笔记也是排成一排,一个接一个。不过,它的队列线程不像印象笔记那样受限于时间,所以灵活多了。
最让我感兴趣的是 Surfulater 的结构树。乍一看,似乎中规中矩,并没有什么出众之处。但事实上,它拥有目前所有软件中最好的后端引擎。它实际上是一个虚拟树结构,可以配置不同的选项。笔记可以根据用户需要显示为树状,也可以像印象笔记一样按时间顺序排列。您还可以使结构树不展开最后一个分支,使结构树只显示目录,而不显示注释条目。一个重要的消息是,开发者提到在新版本中,用户将被允许自定义树状结构,这意味着一个笔记可以进入多个类别。
另一个突出的特点是 Surfulater 可以克隆笔记项目。乍一看,它似乎与复制具有相同的效果。但实际上,它们是非常不同的。克隆出来的副本实际上是一种镜像:它不会重复占用存储空间,而是可以在逻辑上放到另一个类别中,并且实时保持一致。例如,修改其中任何一个,其他克隆将同时更新。最后,一个不错的功能是搜索结果在树结构的末尾列为虚拟树分支。用户可以浏览和滚动搜索结果,就像普通的树和注释一样。当然,命中 关键词 也像 Evernote 一样突出显示。对于搜索结果,印象笔记也是纵向分组的,但我觉得建立一个列表可以让用户更容易查阅。
接下来是一个小功能,为笔记或分支节点设置图标,Surfulater 在这方面做得很好,与其他软件相比它相形见绌。用户只需要在图标上单击鼠标右键,然后会弹出一个小窗口,显示所有可用的图标,然后单击他们想要选择的那个。(注意 1)
接下来说说Surfulater作为笔记软件的不足之处。造成这些缺点的主要原因是 Surfulater 的初衷不是做笔记。如果您想编辑笔记,在大多数笔记软件中,只需单击笔记并开始输入。但在 Surfulater,这条路已经死了。您必须在编辑模式和常规模式之间手动切换——这常常让新手感到困惑。进入编辑模式的一种方法是用鼠标点击输入框几秒钟,也就是不要像普通软件那样点击,而是按住。进入编辑模式的另一种方法是单击每个项目旁边的铅笔图标。值得庆幸的是,作者意识到了这个问题,并进行了改进,并承诺在未来进行进一步的改进。但是,我还是坚持这个原则:
另一个缺点是 Surfulater 中没有空格可以直接做笔记。Surfulater 中的任何 文章(又名笔记)都基于预定义的模板。这些模板有标题来保存标题、评论、评级、参考……。这些功能非常有利于学术研究的管理和组织;但是对于普通用户,特别是当他们只是想记下一些东西时,这是一个极其不方便的限制。现在可以做的是选择一个“笔记模板”,它只有一个标题信息,就是“笔记”,主体部分完全空白,用户在这里做笔记。如下所示:
Surfulat 成为真正的笔记工具的底线是在上述两个方面进行改进:提供默认启用或禁用编辑模式的选项,并提供完全空白的笔记区域。正是在这些方面,Surfulater 必须更接近标准——并且被证明是最有效的——笔记软件风格。
总体而言,Surfulater 功能丰富且风格独特,非常适合引用、导航和抓取大量笔记。以我的理解和判断,律师、学者可能非常欣赏。究其原因,想想其鲜明的特点就明白了。以下场景也可以说明谁最适合它:如果你现在正在使用 Evernote,但发现它在组织管理方面还不够强大,那么转向 Surfulater 是明智之举。或者,如果您正在使用任何其他基于最基本树结构的笔记软件,并且对链接和引用感到不知所措,您也可以求助于 Surfulater。
三强功能对照表
前三名的笔记软件的优缺点已经一一讨论过了,相信读者已经知道了。如果仍然不清楚,请参阅下表。俗话说,不怕不识货,只怕比货。此表并未涵盖所有功能,但可能会有所帮助。
笔记本三强功能对照表
印象笔记
我的基地
硫酸盐
同时打开多个数据库
√
√
实时搜索(输入后立即开始搜索)
√
√
基本树结构
√
√
标签/类别
√
√
滚动
√
√
加密
√
√
链接到其他笔记
√
√
按时间顺序显示
√
笔记2
√
超强大的导入/导出功能
√ 查看全部
excel自动抓取网页数据(《寻找最好的笔记软件:海选篇》的综合分析)
版本1.0 编译xbeta/善用佳软自
寻找最好的笔记软件:前三名(EverNote、Mybase、Surfulater)v1.0
作者:SuperboyAC 编译:xbeta 本系列还包括:海选篇、前三篇、梦想篇、结论篇、额外篇
通过对上一篇《寻找最好的笔记软件:Auditions》的综合分析,笔者发现优势明显的软件有3种,可谓“前三名的笔记软件”。它们是:EverNote、Mybase 和 Surfulate。这三者之间的区别是相同的,但它们是各自风格中最强的。三者如何选择,并不取决于哪一个“更强大”,而取决于你是什么样的用户,或者你有什么样的需求。
印象笔记
如果您需要一个方便的地方来存储您的笔记,而不需要太多的组织功能和冗余功能,那么 EverNote 是您的最佳选择。你可以这样理解,EverNote 就是一张无限长的纸卷,上面记录着你所有的笔记,唯一的排列顺序就是按照时间。每个笔记甚至没有标题——这是其他笔记软件的经验法则。听起来很不方便,我怎样才能找到以前的笔记?EverNote 作为一款优秀的软件,完美解决了你的后顾之忧,你在使用的过程中没有任何不便,而且你根本不会意识到这是个问题。
解决方案,即定位/过滤笔记的方法,有分类和实时搜索两种方法。分类功能如图所示,笔记可以手动分类,也可以自动规则分类。
类别可以排列成树状结构,但这与其他类似程序的树状结构不同。因为一个笔记可以分为多个类别。另一种查找笔记的方法是使用实时搜索框。这个功能在 EverNote 中实现得如此完美,是迄今为止我在任何软件中看到的最好的,而且速度超级快。当您键入每个字母时,所有匹配的注释都会在下方动态显示。不仅如此,所有匹配的单词都会被突出显示。
如前所述,所有注释都排列在一个列中。要上下滚动,可以点击右侧的滚动框,滚动速度取决于点击的位置。或者,您可以使用右侧的“时间栏”功能。它相当于一个垂直日历,你只需要点击一个日期,就可以显示相关的笔记。如果日期旁边有√,则表示该日期有注释。我觉得用这个功能做电子日记真的很方便。
Evernote 还可以轻松抓取任何内容,尤其是各种网络内容。准确地说,在三巨头中,它拥有最强大的网页内容爬取能力。它不仅准确地捕捉范围,而且当内容进入印象笔记时,它看起来就像一个笔记,而不是一个网页:鼠标变成一只小手,点击一下就会带你到一个链接。在 EverNote 中,如果你想访问一个链接,你需要双击。我从来没有迷恋过网络点击式入侵软件界面。还记得 Windows 何时将单击模式引入操作系统界面吗?我不习惯,所以每次都得关掉。顺便说一句,Mybase 和 Surfulater 都是点击模式。Mybase 这样做是因为它使用 IE 引擎来显示网页;Surfulate 这样做是因为它的界面从头到尾都是网页风格。
在剪辑方面,还是有一些不足的地方。要真正对笔记进行一些格式化和文本组织,您需要进入全屏模式。这时候,这个笔记单独显示在一个大窗口中,带有一个rtf标准工具栏,方便编辑。而在常规窗口中,几乎没有编辑按钮。您要么进入全屏模式,要么进入右键菜单。此外,图片缩放功能也比较奇怪。
总而言之,印象笔记是“记住和检查”软件类别中最好的。它最大的优势在于一流的实时搜索功能和强大的网页内容爬取功能。缺点是笔记的组织和编辑功能较弱。
我的基地
如果用户需要尽可能多的工具/功能来处理笔记,Mybase 是首选。在我看来,Mybase 是 Keynote 的现代风格演变。两者在视觉和感觉上都非常相似。其界面简洁高效,通过多标签多面板有效扩展其功能,并拥有多种处理笔记的工具。我已经使用 Keynote 很长时间了,过渡到 Mybase 非常顺利。(此外,KeyNote 在处理笔记方面也非常丰富)。
Mybase的整理笔记的形式也是最简单的树形结构,也是大多数同类软件的标准思路。也就是说,在这方面,Mybase 不追求个性,而是保持共性。在最新的 v5 版本中,Mybase 增加了一个标签功能——有点像印象笔记的分类,或者其他软件的关键词。它基于分类树提供了一个额外的组织维度。但它的效果与专用于此的工具(如Zoot、Evernote)相去甚远。当然,最好的部分是 Mybase 是一个(如果不是唯一的)可以同时具有树和标签功能的软件。这就是 Mybase 的风格和优势:最大的功能和选项,最大的可定制性。为了让您最直观的了解其功能,
正如我们所说,Mybase 使用了很多面板,因此用于显示笔记信息的桌面空间较少。这与某些软件相反。与 Surfulater 一样,它使用超链接、web 样式的功能来处理引用、链接、附件等。在 Mybase 中,这些元素显示在主界面下的单独子窗口/面板中:结构树、注释正文、搜索结果、附件列表,以及指向其他注释的链接。有些人觉得这很不舒服,但其他用户可能会喜欢这种分离——我就是其中之一。对于一些常见的面板,比如附件和其他笔记的链接,可以通过选项设置自动显示:如果笔记有附件或者外链,就会显示;如果没有,这些面板将被隐藏。这时候灵活设置就很实用了,可以最大化桌面空间。
Mybase 还可以为 Firefox 或 IE 抓取网页内容,但不能达到 Evernote 或 Surfulater 的水平。首先,抓取内容不像其他两个软件那样被视为普通笔记。让我解释一下,对于每个笔记,Mybase 都有两个选项卡“文本笔记”和“网页”。如果是爬取的网页内容,Mybase 会自动切换到网页标签。对于其他类型的笔记,无论是粘贴还是手动输入,都在“文本笔记”选项卡下。
附件:Mybase 开发者补充:myBase 中的所有内容都保存为节点的附件文件。所谓的便笺(note)也是另存为附件文件,只是被命名为带有.RTF扩展名的特殊项目,一般不显示。而其他内容,比如抓取的网页,直接保存为附件,在附件列表中可以看到网页中的HTML/JS/style/image等元素。因此,输入内容和抓取的网页内容一般是分开显示的;这种设计为系统扩展带来了极大的便利性、灵活性和统一性。其实如果需要将笔记写入网页,可以在网页中按F2或者选择Edit -> Toggle Edit Mode菜单项直接输入或编辑网页内容,这样便笺可以与捕获的网页显示在同一页面中。在页面上。
因此,您无法将笔记与网页结合起来。基于此,我认为 Evernote 和 Surfulater 具有更好的抓取能力。另一个美中不足的是,Mybase 使用 IE 而不是内置的 web 引擎来显示抓取的 web 内容。因此,当你切换到网页标签时,程序会调用 IE 并会出现片刻的停顿。当然,这个问题并不严重,只是没有其他软件集成那么流畅。
附:Mybase开发者补充:目前大部分软件都嵌入了IE来显示网页,不同的是有些软件一启动就加载IE浏览器,而myBase只在需要浏览网页时加载IE,所以有第一次浏览网页的时候稍微停顿一下,然后就很流畅了,这样做的目的是为了尽量减少内存和系统资源的使用。
Mybase V5还开发了实时搜索功能。这是一个有价值的功能,而且效果很好。诚然,它并不完全在 Evernote 的水平上,但至少它是可用的。同样,这也是Mybase的比较优势:虽然不是每一个功能都达到了所有软件在这方面的最高水平,但至少可以让用户在一个软件中拥有这么多的功能。
附:Mybase开发者补充:在最新的myBase v5.3中,专门改写了索引模块和搜索技术,增加了resizable cache技术,提供了比较高的索引性能,支持增加Volume index ,大数据量索引,即时搜索和布尔条件(AND/OR/NOT),并提供对常用WORD/EXCEL/HTML/PPT/EMAI/TEXT/RTF等文档的预设索引和搜索支持,还可以识别通过安装第三方过滤器(例如 PDF 文档)获得更多文档格式。此外,myBase 还提供了一定的中文搜索支持(但并不完善)。总的来说,我们目前正在开发的索引技术已经远远超过了其他公司。您可以使用稍大的数据进行一些测试,例如超过 100MB 的可索引数据。可以看出,我们为改进这项技术付出了比较大的努力。当然,我们还需要进一步改进。
Mybase 还提供了一些扩展的组织功能。它可以链接项目,允许多个笔记相互引用。也可以进行符号链接,这样当用户单击结构树中的注释 A 时,它会直接转到它所链接的注释 B,就像快捷方式一样。我还没有完全理解这个功能的作用,但同样,它总比没有好。(译者注:应该用于一个笔记进入多个树分支,相当于一个笔记进入印象笔记中的多个类别)然后,它还可以自定义标签(label),就像笔记的关键词就像(译者注:更准确地说是一个标签),当你点击关键词时,Mybase会列出所有属于这个关键词的笔记。就像我说的,它为组织笔记提供了一个新的维度。
如您所见,Mybase 是同类软件中最灵活、功能最丰富的软件之一。与Mybase相比,其他软件可能更具创新性,在某些方面可能更强大,但没有一个软件可以同时拥有Mybase那么多的笔记处理功能。重申一下,之前使用过 KeyNote 的用户可以顺利过渡到 Mybase。正因为如此,我现在开始使用 Mybase 作为我目前的笔记工具。然后,最终决定使用哪种软件取决于具体情况。
硫酸盐
Surfulater 最初的目的是作为网络抓取和书目管理工具,然后 - 并且合乎逻辑地 - 进入了笔记软件类别。由于这个历史原因,它的界面与其他笔记软件有很大不同。也就是说,本课题涉及的其他软件一开始都是以记笔记为核心功能开发的,而记笔记只是Surfulater的功能之一,并不是最初的主导功能。
作为内容抓取(网络抓取只是其中之一)和书目管理工具,Surfulater 比其他任何人都做得更好。如果您想要方便而强大的链接、文档管理和收录素材,Surfulate 是最好的选择。以下场景是对 Surfulater 的最佳描述:您在 Internet 上搜索某个主题的信息,然后找到一个网页,其中收录您需要的信息和大量相关站点的链接。这就是 Surfulater 软件所做的,而且非常轻松。您可以采集各种信息,拖放,将数据、链接和附件放在一起。不一会儿,您就可以得到一个完整的信息系统,带有格式良好的网页显示页面和链接。你需要的一切都在这里。
Surfulater 最大的优势是自动完成重复性任务。Surfulater在爬取一个网页后,会自动填写标题、描述、原创来源链接和爬取日期。它甚至会创建原创网页的缩略图。用户可以将其他笔记拖到当前笔记上以创建快速参考。相同的操作适用于附件。和印象笔记一样,所有的笔记也是排成一排,一个接一个。不过,它的队列线程不像印象笔记那样受限于时间,所以灵活多了。
最让我感兴趣的是 Surfulater 的结构树。乍一看,似乎中规中矩,并没有什么出众之处。但事实上,它拥有目前所有软件中最好的后端引擎。它实际上是一个虚拟树结构,可以配置不同的选项。笔记可以根据用户需要显示为树状,也可以像印象笔记一样按时间顺序排列。您还可以使结构树不展开最后一个分支,使结构树只显示目录,而不显示注释条目。一个重要的消息是,开发者提到在新版本中,用户将被允许自定义树状结构,这意味着一个笔记可以进入多个类别。

另一个突出的特点是 Surfulater 可以克隆笔记项目。乍一看,它似乎与复制具有相同的效果。但实际上,它们是非常不同的。克隆出来的副本实际上是一种镜像:它不会重复占用存储空间,而是可以在逻辑上放到另一个类别中,并且实时保持一致。例如,修改其中任何一个,其他克隆将同时更新。最后,一个不错的功能是搜索结果在树结构的末尾列为虚拟树分支。用户可以浏览和滚动搜索结果,就像普通的树和注释一样。当然,命中 关键词 也像 Evernote 一样突出显示。对于搜索结果,印象笔记也是纵向分组的,但我觉得建立一个列表可以让用户更容易查阅。
接下来是一个小功能,为笔记或分支节点设置图标,Surfulater 在这方面做得很好,与其他软件相比它相形见绌。用户只需要在图标上单击鼠标右键,然后会弹出一个小窗口,显示所有可用的图标,然后单击他们想要选择的那个。(注意 1)
接下来说说Surfulater作为笔记软件的不足之处。造成这些缺点的主要原因是 Surfulater 的初衷不是做笔记。如果您想编辑笔记,在大多数笔记软件中,只需单击笔记并开始输入。但在 Surfulater,这条路已经死了。您必须在编辑模式和常规模式之间手动切换——这常常让新手感到困惑。进入编辑模式的一种方法是用鼠标点击输入框几秒钟,也就是不要像普通软件那样点击,而是按住。进入编辑模式的另一种方法是单击每个项目旁边的铅笔图标。值得庆幸的是,作者意识到了这个问题,并进行了改进,并承诺在未来进行进一步的改进。但是,我还是坚持这个原则:
另一个缺点是 Surfulater 中没有空格可以直接做笔记。Surfulater 中的任何 文章(又名笔记)都基于预定义的模板。这些模板有标题来保存标题、评论、评级、参考……。这些功能非常有利于学术研究的管理和组织;但是对于普通用户,特别是当他们只是想记下一些东西时,这是一个极其不方便的限制。现在可以做的是选择一个“笔记模板”,它只有一个标题信息,就是“笔记”,主体部分完全空白,用户在这里做笔记。如下所示:
Surfulat 成为真正的笔记工具的底线是在上述两个方面进行改进:提供默认启用或禁用编辑模式的选项,并提供完全空白的笔记区域。正是在这些方面,Surfulater 必须更接近标准——并且被证明是最有效的——笔记软件风格。
总体而言,Surfulater 功能丰富且风格独特,非常适合引用、导航和抓取大量笔记。以我的理解和判断,律师、学者可能非常欣赏。究其原因,想想其鲜明的特点就明白了。以下场景也可以说明谁最适合它:如果你现在正在使用 Evernote,但发现它在组织管理方面还不够强大,那么转向 Surfulater 是明智之举。或者,如果您正在使用任何其他基于最基本树结构的笔记软件,并且对链接和引用感到不知所措,您也可以求助于 Surfulater。
三强功能对照表
前三名的笔记软件的优缺点已经一一讨论过了,相信读者已经知道了。如果仍然不清楚,请参阅下表。俗话说,不怕不识货,只怕比货。此表并未涵盖所有功能,但可能会有所帮助。
笔记本三强功能对照表
印象笔记
我的基地
硫酸盐
同时打开多个数据库
√
√
实时搜索(输入后立即开始搜索)
√
√
基本树结构
√
√
标签/类别
√
√
滚动
√
√
加密
√
√
链接到其他笔记
√
√
按时间顺序显示
√
笔记2
√
超强大的导入/导出功能
√
excel自动抓取网页数据(把DataFrame转换成HTML表格的方法,读取Excel中的表格数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-23 01:23
前言
说到用 Pandas 导出数据,应该想到 to.xxx 系列函数。
其中比较常用的是pd.to_csv()和pd.to_excel()。但其实也可以导入成Html网页格式,这里用到的函数是pd.to_html()!
读取 Excel
今天我们要将Excel转成html格式,首先需要读取Excel中的表格数据。
import pandas as pd
data = pd.read_excel("测试.xlsx")
查看数据
data.head()
让我们学习如何将 DataFrame 转换为 HTML 表格。
生成 HTML
to_html()函数只需一行代码就可以直接将DataFrame转换成HTML表格:
html_table = data.to_html("测试.html")
运行上述代码后,工作目录下多了一个test.html文件,用浏览器打开,内容如下
print(data.to_html())
通过打印可以看到DataFrame的内部结构自动转换成,,标签嵌入表格中,保留所有内部层次结构。
格式化
我们也可以自定义修改参数来调整生成的HTML的格式。
html_table = data.to_html("测试.html",header = True,index = False,justify="center")
再次打开新生成的test.html文件,发现格式变了。
如果要对格式做进一步的调整(添加标题、修改颜色等),需要一些HTML知识,可以在生成的测试.html文件中调整文本。
对于一些可能需要展示页面的小伙伴来说,使用Flask库是很有必要的。
总结
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常有用。一种很容易将复杂的数据结构(例如 DataFrames)转换为 HTML 表格;另一种不需要复杂的爬虫,只需几行代码就可以抓取Table表数据,简直就是神器!
今天的篇幅很短,主要讲Pandas中的to_html()函数。使用这个功能最大的好处是我们可以在不了解HTML知识的情况下生成表格HTML。
总结
这里是文章关于如何使用pandas将Excel转为html格式的介绍。更多相关pandas将Excel转html格式,请在云海天教程前搜索文章或继续浏览以下相关文章希望大家以后多多支持云海天教程! 查看全部
excel自动抓取网页数据(把DataFrame转换成HTML表格的方法,读取Excel中的表格数据)
前言
说到用 Pandas 导出数据,应该想到 to.xxx 系列函数。
其中比较常用的是pd.to_csv()和pd.to_excel()。但其实也可以导入成Html网页格式,这里用到的函数是pd.to_html()!
读取 Excel
今天我们要将Excel转成html格式,首先需要读取Excel中的表格数据。
import pandas as pd
data = pd.read_excel("测试.xlsx")
查看数据
data.head()

让我们学习如何将 DataFrame 转换为 HTML 表格。
生成 HTML
to_html()函数只需一行代码就可以直接将DataFrame转换成HTML表格:
html_table = data.to_html("测试.html")
运行上述代码后,工作目录下多了一个test.html文件,用浏览器打开,内容如下

print(data.to_html())
通过打印可以看到DataFrame的内部结构自动转换成,,标签嵌入表格中,保留所有内部层次结构。

格式化
我们也可以自定义修改参数来调整生成的HTML的格式。
html_table = data.to_html("测试.html",header = True,index = False,justify="center")
再次打开新生成的test.html文件,发现格式变了。

如果要对格式做进一步的调整(添加标题、修改颜色等),需要一些HTML知识,可以在生成的测试.html文件中调整文本。
对于一些可能需要展示页面的小伙伴来说,使用Flask库是很有必要的。
总结
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常有用。一种很容易将复杂的数据结构(例如 DataFrames)转换为 HTML 表格;另一种不需要复杂的爬虫,只需几行代码就可以抓取Table表数据,简直就是神器!
今天的篇幅很短,主要讲Pandas中的to_html()函数。使用这个功能最大的好处是我们可以在不了解HTML知识的情况下生成表格HTML。
总结
这里是文章关于如何使用pandas将Excel转为html格式的介绍。更多相关pandas将Excel转html格式,请在云海天教程前搜索文章或继续浏览以下相关文章希望大家以后多多支持云海天教程!
excel自动抓取网页数据(软件特色风越网页批量填写数据提取软件,可自动分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-23 01:20
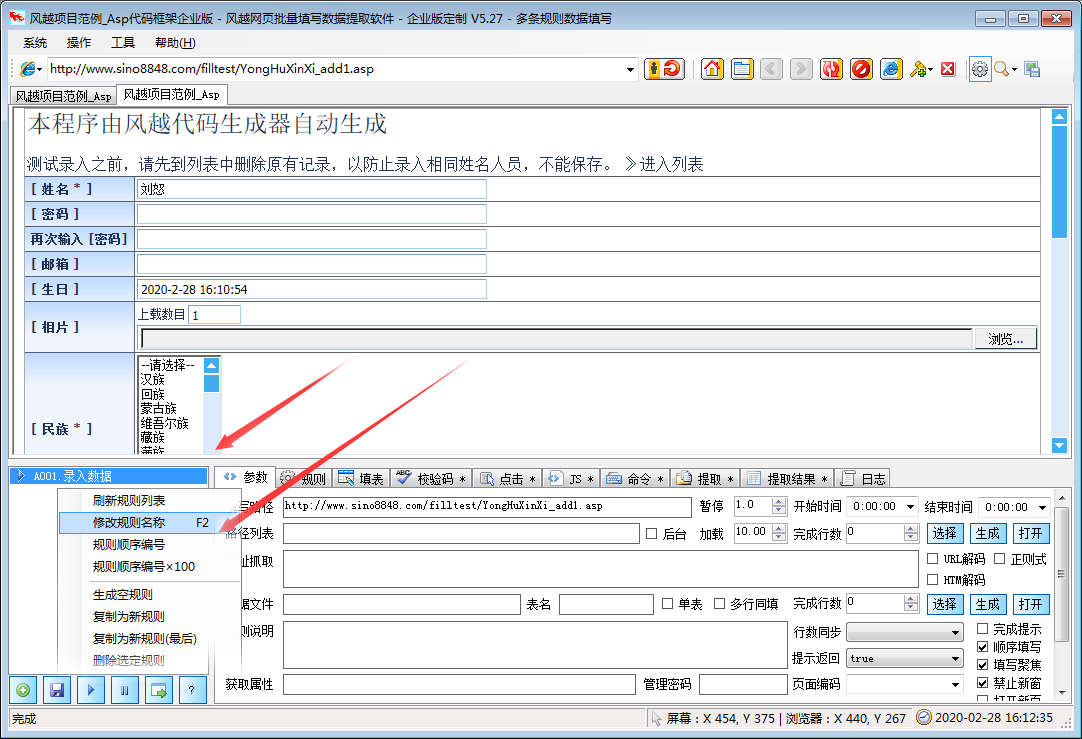
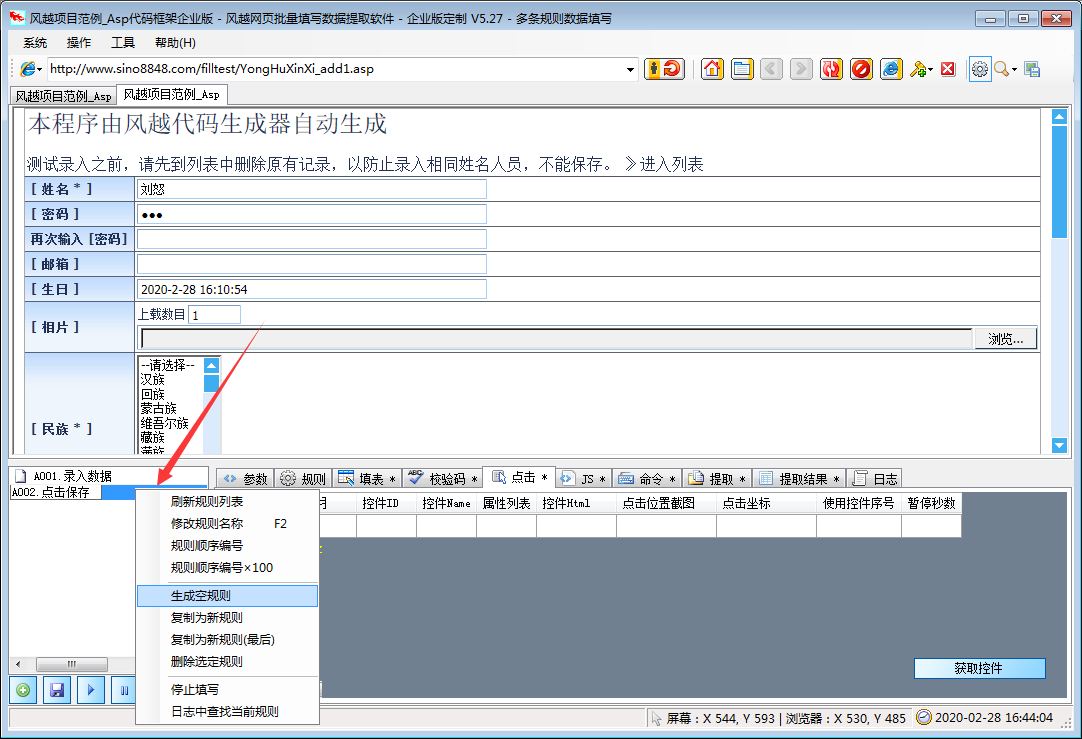
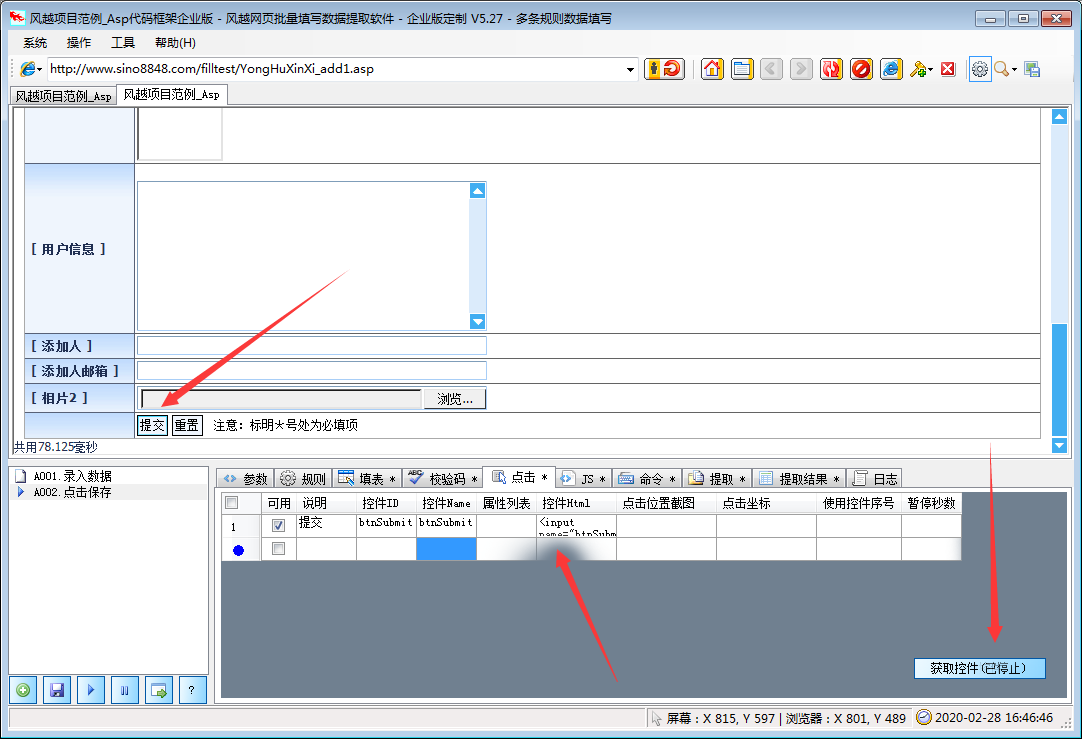
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。还可以扩展到批量注册、投票、留言、产品闪购、舆论引导、刷信用、抢牌等工具。
软件功能
风月网页批量填充数据提取软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
预防措施
软件需要.NET framework2.0运行环境,如果无法运行请安装【.NET Framework2.0简体中文版】 查看全部
excel自动抓取网页数据(软件特色风越网页批量填写数据提取软件,可自动分析)
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。还可以扩展到批量注册、投票、留言、产品闪购、舆论引导、刷信用、抢牌等工具。
软件功能
风月网页批量填充数据提取软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
预防措施
软件需要.NET framework2.0运行环境,如果无法运行请安装【.NET Framework2.0简体中文版】
excel自动抓取网页数据(你能明白我一定要抓到表格里吗?PowerQuery处理你可能不知道 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-23 01:20
)
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
❶ 获取 JSON 数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接
01
脚步
❶ 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
❷电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
❸配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
❹ 添加超链接
至此所有数据都已处理完毕,但如果要查看原创知乎页面,则需要复制此超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞最多的;
❹点击【点击查看】,享受跳线的感觉!
02
总结
知道在表格中搜索的好处吗?
❶ 按“赞”和“评论”排序;
❷ 看过文章的可以加个栏目写笔记;
❸您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。
查看全部
excel自动抓取网页数据(你能明白我一定要抓到表格里吗?PowerQuery处理你可能不知道
)
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
❶ 获取 JSON 数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接
01
脚步
❶ 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
❷电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
❸配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
❹ 添加超链接
至此所有数据都已处理完毕,但如果要查看原创知乎页面,则需要复制此超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞最多的;
❹点击【点击查看】,享受跳线的感觉!
02
总结
知道在表格中搜索的好处吗?
❶ 按“赞”和“评论”排序;
❷ 看过文章的可以加个栏目写笔记;
❸您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。

excel自动抓取网页数据(运营精细化如何通过品牌沉淀的数据挖掘出更多优化可能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-23 01:18
前言
随着运营的精细化发展,如何通过品牌积累的数据挖掘更多的优化可能性,是每一个运营、产品乃至技术的必修课。本篇文章将主要讲解我是如何分析官网流量数据,从发现问题、猜测、验证猜测、事件分类四个方面找出问题的。
(本文出现的工具有CNZZ后端和Excel2013)
本次以朋友的网站作为演示数据,选取2016年7月25日至2016年8月7日,分别为2016年第31周和第32周的数据。周数据是因为网站刚结束第32周的付费广告投放,所以网站的流量存在巨大差异,属于典型。CNZZ的后台流量如图:
选择图右下方的“更多指标”,选择当前核心指标,如PV、UV、平均访问时长、跳出率;图中,“小时”改为“天”。
然后我们通过观察图上半部分的对比数据来提问:
1、为什么两周的流量数据大面积变差了?如何找出原因是哪一天或哪一列?
2、为什么独立访问者(UV)和新独立访问者(NUV)的差异大约是4.5倍,而浏览量(PV)的差异只有1.5倍?
3、为什么两周内UV趋势(橙线)相似,而PV趋势(蓝线)在7-26和7-29有波谷和波峰?
目前我们所知道的最大变化是付费广告在第 31 周开启,在第 32 周关闭。8-1号关门时间是几点?是早上关门还是下班后关门?网站该负责人表示“好像是8-1的早上”,但分析师不相信“好像”,只能通过数据来验证。
这时,我们可以做出的合理猜测是(猜测问题1=d1,下同):
d1:两周流量数据大面积变差,因为关闭了广告,但是CNZZ显示的具体小时和栏目数据无法直观得出,具体数据需要分析。
d2:UV和NUV的区别类似。可能本周的数据增长大部分来自新的独立访问者,而着陆页对新访问者的吸引力不是很大,因此大多数新访问者并没有产生更多的点击,这也解释了为什么第一次跳出率在 32 周时增加。
d3:7-26对应8-2,7-29对应8-5。分别出现的波峰和波谷的原因没有记录在SEO日志表中。我们暂时无法给出猜测,只能查看具体数据。
网站日志中只记录8-1封闭付费推广
猜测前先问问网站的负责人,网站近期有没有修改或者变化,有没有忘记记录的事情,其他部门有没有做过任何线下促销等,合理猜测 网站 日志记录的已知条件和分析师经验。
在Excel中打开CNZZ记录的两周访问详情(出于隐私考虑,将主域名改为我的微信feels),根据以下猜测进行分析:
1、付费广告到底是什么时候停止的?
过滤日期(8-1~8-7)中的第32周数据,过滤“页面来源”(标有“ipinyou”的站点)中标记的付费来源链接,确认,结果如图所示图。
最后一个带付费标签的来源时间是2016-8-1 9:56:43,推断负责人是周一上班后10:00左右关闭的付费广告早晨。
2、在这次流量变化中,关闭付费广告的影响有多大?
选择所有 7-25~8-7 以访问详细数据并创建新的数据透视表。
将“页面来源”和“访问页面”放在行中,将“周数”放在列中,将“IP”放在值计数中,观察两周的整体数据对比,发现自然流量+付费流量为7141-2745=4396,然后过滤付费链接流量的差异,得到付费广告的影响。
在“页面来源”和“采访页面”两个字段中使用标签“不收录”过滤掉付费标签“ipinyou”,如图:
现在我们得出结果,第31周和第32周的付费流量相差7141-3834=3307,2745-2593=152,这就是切换付费广告对网站@的流量的具体影响>。那么网站流量变化都是付费流量切换引起的?通过上图中的计算结果,我们知道并非如此。排除付费流量,我们还是有3834-2593=1241的自然流量差。是什么原因?
3、您的自然流量中有多少是您自己公司的用户?
请网络管理员了解公司的网线是否分多条线,公司所有主机当前对应的IP地址或IP段是多少。因为选择时间长,不可能知道当时公司的内部IP段,所以忽略了这一步。
4、自然流量的差异是由哪些页面和哪些时间段造成的?
将字段“日期”和“小时”添加到行,选择降序,调整值显示方式比较32周的差异,选择区域中的值,更改条件格式→项目选择规则→前10项,填充粉色,重复这一步,选择最后10项,用黄色填充,最终效果如图。
(粉色代表页面31周数据多于32周,如“直接访问书签”31周源流量多于32周;黄色表示页面32周数据多于31周,如“”32周比 31 周多 32 个源流量1)
发现正值相差超过200的页面有“”、“”、“”,负值超过200的页面有“”。
分析步骤相同。我们以“”页面为例。为什么这个页面在 31 周内比在 32 周内多出 267 次?将“IP”、“访问者新旧属性”、“访问页面”、“区域”等字段一次放入进行中,日期降序排列如图:
从“”、“”、“”三个页面可以发现,这三个页面的流量来自于7日-29日早上6:00。
同时我们发现了一个可疑的IP字段,用了两天的“222.16.42.***”,看看这个IP段到底是什么,所以在“IP”字段中过滤掉“222.16.42.***”
有趣的是,这个IP段只在第31周每天早上6点到7点之间活跃,如图:
因此得出结论,31周和32周的自然流量差异是由2016年7月29日早上6-7点之间的“”、“”、“”三个页面造成的,访问用户都是新访客。,而且这些页面不是内容页面,访问时间也不规律。目前缺少条件,所以只能推断human > machine,放入事件数据库,然后观察。
5、5、唯一身份访问者(UV)和新唯一身份访问者(NUV)之差约为4.5倍,而浏览量(PV)之差仅为1. 5次,是不是因为付费广告落地页不符合用户体验。如果是这样,新老访问者输出了多少PV?
根据“新老访问者属性”字段统计,新老用户分别在31周和32周贡献了7141和2745的流量,约等于页面浏览量(PV)值。
点击查看大图
然后我们分别过滤新老用户的流量值,老用户流量值为2915和1895,如图:
新增用户流量值为4226和850,如图:
最后我们发现全站每周流量变化为7146/2745=2.60;老用户周流量变化为2915/1895=1.54;新用户周流量变化为4226/850=5.00。
新用户PV数的变化≈两周内新增独立访问者数量的变化,因此我们可以得出结论,第31周的数据增长大部分来自新的独立访问者。推测是落地页对新访问者的吸引力不是很大,或者是定位目标人群。不精确。(也可以通过受访页面数据的付费链接跳出率分析来分析哪个页面最差,相应的改进就不赘述了,留给读者自己思考)
6、流量趋势中,7-26对应8-2,有流量谷。是单页造成的吗?
对比 7-26 和 8-2 的流量,我们发现是因为 8-2 的全站流量下降,而不是单页造成的。
那为什么在8-2这一天整个流量都下降了呢?当我带着这个奇怪的现象再次询问网站的负责人时,他想了想说:“哦,对不起,我忘了告诉你,8-2号台风“奈达”来了,公司放假一天。” 哈哈,我抓到了一个忘记写网站日记的人。让我们通过新老用户的流量变化来检查一下。
新用户流量变化如图,过渡平稳:
老用户流量变化如图:8日和2日流量当天大幅下降,确实是老用户造成的。来自企业员工的访问占自然流量的很大一部分。
总而言之,我们已经验证了所有提出的猜测。
在整个过程中,你应该已经发现,所有的分析逻辑都是从大到小,从整体流量趋势开始,找出哪一周、哪一天、哪一小时、哪一栏、哪一页有问题。从已知记录中做出合理的猜测,然后用数据验证猜测。过程中没有高深的技巧,只要有一颗心把问题问到底。
在例子中,很多人理所当然地认为,32周相比31周流量大幅下降是因为付费广告关闭,不再继续分析,而忽略了一个大问题——整体流量下降确实不代表所有列。流量下降了,如图:
为什么在整体流量下降的情况下,32周的“”页面却显着增加?流程我就不写了,直接给结论吧,因为从第8-4天9点28分开始,技术已经在这个页面设置了内容采集,并且自动从其他站,每隔一分钟发布一次,证据如图:
通过Excel中的数据分析,可以发现很多问题,甚至有同事用流量宝刷流量,被我曝光了……本次分享只列出了一些常用的分析方法和逻辑,旨在让大家感受一下看看Excel在数据分析中的作用。
对于分析师来说,什么是“事件分类”?换言之,就是积累的“经验”。比如每逢节假日,网站的流量会有怎样的变化,公司的宣传对流量的增加影响最大,而一旦停止广告,网站的真实流量又从哪里来?来自等,将这些经历记录在笔记中。,随着时间的推移从初学者成长为高级分析师。但话又说回来,总会有你无法通过 Excel 猜测或分析的问题,比如爬虫模拟人类行为、设置不同的 UA、时不时爬取等等。当你遇到暂时无法解决的问题时,有一个“难题库”,
最后要说的是,Excel作为最流行的数据分析工具,门槛低、功能强、性价比高。只要你保持强烈的好奇心和一点软件技能,每个人都可以成为数据分析师。
针鼹 说
这个文章是一个案例,也是一个方法,几乎手把手的告诉你如何通过数据定位问题。
爱奇菌经常在后台收到朋友的提问:
最近点击量突然增加,但转化率并没有提高。是否有恶意点击?
最近网站的流量突然下降了,但是我什么都没做,为什么会这样?...等等。
那么结论大致就是:“一定是恶意点击!” 或者“淡季来了”或者“X度系统又用尽了……”
在得出这些结论之前,您是否从客观数据中推断出您想要的答案?
爱奇菌建议大家按照作者的思路,拿自己账户的数据,进行一些分析和推敲,相信会有很大收获。 查看全部
excel自动抓取网页数据(运营精细化如何通过品牌沉淀的数据挖掘出更多优化可能)
前言
随着运营的精细化发展,如何通过品牌积累的数据挖掘更多的优化可能性,是每一个运营、产品乃至技术的必修课。本篇文章将主要讲解我是如何分析官网流量数据,从发现问题、猜测、验证猜测、事件分类四个方面找出问题的。
(本文出现的工具有CNZZ后端和Excel2013)
本次以朋友的网站作为演示数据,选取2016年7月25日至2016年8月7日,分别为2016年第31周和第32周的数据。周数据是因为网站刚结束第32周的付费广告投放,所以网站的流量存在巨大差异,属于典型。CNZZ的后台流量如图:

选择图右下方的“更多指标”,选择当前核心指标,如PV、UV、平均访问时长、跳出率;图中,“小时”改为“天”。

然后我们通过观察图上半部分的对比数据来提问:
1、为什么两周的流量数据大面积变差了?如何找出原因是哪一天或哪一列?
2、为什么独立访问者(UV)和新独立访问者(NUV)的差异大约是4.5倍,而浏览量(PV)的差异只有1.5倍?
3、为什么两周内UV趋势(橙线)相似,而PV趋势(蓝线)在7-26和7-29有波谷和波峰?
目前我们所知道的最大变化是付费广告在第 31 周开启,在第 32 周关闭。8-1号关门时间是几点?是早上关门还是下班后关门?网站该负责人表示“好像是8-1的早上”,但分析师不相信“好像”,只能通过数据来验证。
这时,我们可以做出的合理猜测是(猜测问题1=d1,下同):
d1:两周流量数据大面积变差,因为关闭了广告,但是CNZZ显示的具体小时和栏目数据无法直观得出,具体数据需要分析。
d2:UV和NUV的区别类似。可能本周的数据增长大部分来自新的独立访问者,而着陆页对新访问者的吸引力不是很大,因此大多数新访问者并没有产生更多的点击,这也解释了为什么第一次跳出率在 32 周时增加。
d3:7-26对应8-2,7-29对应8-5。分别出现的波峰和波谷的原因没有记录在SEO日志表中。我们暂时无法给出猜测,只能查看具体数据。

网站日志中只记录8-1封闭付费推广
猜测前先问问网站的负责人,网站近期有没有修改或者变化,有没有忘记记录的事情,其他部门有没有做过任何线下促销等,合理猜测 网站 日志记录的已知条件和分析师经验。
在Excel中打开CNZZ记录的两周访问详情(出于隐私考虑,将主域名改为我的微信feels),根据以下猜测进行分析:
1、付费广告到底是什么时候停止的?
过滤日期(8-1~8-7)中的第32周数据,过滤“页面来源”(标有“ipinyou”的站点)中标记的付费来源链接,确认,结果如图所示图。

最后一个带付费标签的来源时间是2016-8-1 9:56:43,推断负责人是周一上班后10:00左右关闭的付费广告早晨。
2、在这次流量变化中,关闭付费广告的影响有多大?
选择所有 7-25~8-7 以访问详细数据并创建新的数据透视表。
将“页面来源”和“访问页面”放在行中,将“周数”放在列中,将“IP”放在值计数中,观察两周的整体数据对比,发现自然流量+付费流量为7141-2745=4396,然后过滤付费链接流量的差异,得到付费广告的影响。

在“页面来源”和“采访页面”两个字段中使用标签“不收录”过滤掉付费标签“ipinyou”,如图:

现在我们得出结果,第31周和第32周的付费流量相差7141-3834=3307,2745-2593=152,这就是切换付费广告对网站@的流量的具体影响>。那么网站流量变化都是付费流量切换引起的?通过上图中的计算结果,我们知道并非如此。排除付费流量,我们还是有3834-2593=1241的自然流量差。是什么原因?
3、您的自然流量中有多少是您自己公司的用户?
请网络管理员了解公司的网线是否分多条线,公司所有主机当前对应的IP地址或IP段是多少。因为选择时间长,不可能知道当时公司的内部IP段,所以忽略了这一步。
4、自然流量的差异是由哪些页面和哪些时间段造成的?
将字段“日期”和“小时”添加到行,选择降序,调整值显示方式比较32周的差异,选择区域中的值,更改条件格式→项目选择规则→前10项,填充粉色,重复这一步,选择最后10项,用黄色填充,最终效果如图。
(粉色代表页面31周数据多于32周,如“直接访问书签”31周源流量多于32周;黄色表示页面32周数据多于31周,如“”32周比 31 周多 32 个源流量1)

发现正值相差超过200的页面有“”、“”、“”,负值超过200的页面有“”。
分析步骤相同。我们以“”页面为例。为什么这个页面在 31 周内比在 32 周内多出 267 次?将“IP”、“访问者新旧属性”、“访问页面”、“区域”等字段一次放入进行中,日期降序排列如图:

从“”、“”、“”三个页面可以发现,这三个页面的流量来自于7日-29日早上6:00。
同时我们发现了一个可疑的IP字段,用了两天的“222.16.42.***”,看看这个IP段到底是什么,所以在“IP”字段中过滤掉“222.16.42.***”

有趣的是,这个IP段只在第31周每天早上6点到7点之间活跃,如图:

因此得出结论,31周和32周的自然流量差异是由2016年7月29日早上6-7点之间的“”、“”、“”三个页面造成的,访问用户都是新访客。,而且这些页面不是内容页面,访问时间也不规律。目前缺少条件,所以只能推断human > machine,放入事件数据库,然后观察。
5、5、唯一身份访问者(UV)和新唯一身份访问者(NUV)之差约为4.5倍,而浏览量(PV)之差仅为1. 5次,是不是因为付费广告落地页不符合用户体验。如果是这样,新老访问者输出了多少PV?
根据“新老访问者属性”字段统计,新老用户分别在31周和32周贡献了7141和2745的流量,约等于页面浏览量(PV)值。

点击查看大图
然后我们分别过滤新老用户的流量值,老用户流量值为2915和1895,如图:

新增用户流量值为4226和850,如图:

最后我们发现全站每周流量变化为7146/2745=2.60;老用户周流量变化为2915/1895=1.54;新用户周流量变化为4226/850=5.00。

新用户PV数的变化≈两周内新增独立访问者数量的变化,因此我们可以得出结论,第31周的数据增长大部分来自新的独立访问者。推测是落地页对新访问者的吸引力不是很大,或者是定位目标人群。不精确。(也可以通过受访页面数据的付费链接跳出率分析来分析哪个页面最差,相应的改进就不赘述了,留给读者自己思考)
6、流量趋势中,7-26对应8-2,有流量谷。是单页造成的吗?
对比 7-26 和 8-2 的流量,我们发现是因为 8-2 的全站流量下降,而不是单页造成的。

那为什么在8-2这一天整个流量都下降了呢?当我带着这个奇怪的现象再次询问网站的负责人时,他想了想说:“哦,对不起,我忘了告诉你,8-2号台风“奈达”来了,公司放假一天。” 哈哈,我抓到了一个忘记写网站日记的人。让我们通过新老用户的流量变化来检查一下。
新用户流量变化如图,过渡平稳:

老用户流量变化如图:8日和2日流量当天大幅下降,确实是老用户造成的。来自企业员工的访问占自然流量的很大一部分。

总而言之,我们已经验证了所有提出的猜测。
在整个过程中,你应该已经发现,所有的分析逻辑都是从大到小,从整体流量趋势开始,找出哪一周、哪一天、哪一小时、哪一栏、哪一页有问题。从已知记录中做出合理的猜测,然后用数据验证猜测。过程中没有高深的技巧,只要有一颗心把问题问到底。
在例子中,很多人理所当然地认为,32周相比31周流量大幅下降是因为付费广告关闭,不再继续分析,而忽略了一个大问题——整体流量下降确实不代表所有列。流量下降了,如图:

为什么在整体流量下降的情况下,32周的“”页面却显着增加?流程我就不写了,直接给结论吧,因为从第8-4天9点28分开始,技术已经在这个页面设置了内容采集,并且自动从其他站,每隔一分钟发布一次,证据如图:

通过Excel中的数据分析,可以发现很多问题,甚至有同事用流量宝刷流量,被我曝光了……本次分享只列出了一些常用的分析方法和逻辑,旨在让大家感受一下看看Excel在数据分析中的作用。
对于分析师来说,什么是“事件分类”?换言之,就是积累的“经验”。比如每逢节假日,网站的流量会有怎样的变化,公司的宣传对流量的增加影响最大,而一旦停止广告,网站的真实流量又从哪里来?来自等,将这些经历记录在笔记中。,随着时间的推移从初学者成长为高级分析师。但话又说回来,总会有你无法通过 Excel 猜测或分析的问题,比如爬虫模拟人类行为、设置不同的 UA、时不时爬取等等。当你遇到暂时无法解决的问题时,有一个“难题库”,
最后要说的是,Excel作为最流行的数据分析工具,门槛低、功能强、性价比高。只要你保持强烈的好奇心和一点软件技能,每个人都可以成为数据分析师。
针鼹 说
这个文章是一个案例,也是一个方法,几乎手把手的告诉你如何通过数据定位问题。
爱奇菌经常在后台收到朋友的提问:
最近点击量突然增加,但转化率并没有提高。是否有恶意点击?
最近网站的流量突然下降了,但是我什么都没做,为什么会这样?...等等。
那么结论大致就是:“一定是恶意点击!” 或者“淡季来了”或者“X度系统又用尽了……”
在得出这些结论之前,您是否从客观数据中推断出您想要的答案?
爱奇菌建议大家按照作者的思路,拿自己账户的数据,进行一些分析和推敲,相信会有很大收获。
excel自动抓取网页数据(UiPath的DataScraping(数据抓取)功能,鼠标点击几下!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2022-01-20 23:10
UiPath的DataScraping(数据抓取)功能,只需点击几下鼠标,即可实现浏览器、应用程序或文档界面的结构化数据,功能强大!
有两种爬取方式: a. 自动爬取整个表格内容;湾。根据需要爬取所需的列内容和列内容的URL(超链接URL)。
这个功能用的不多,但是还是很有用的,而且里面有一些小技巧,特此介绍。
一、数据抓取
数据抓取允许您将结构化数据从浏览器、应用程序或文档中提取到数据库、.csv 文件甚至 Excel 电子表格中。
注意:
建议在 Internet Explorer 11 及更高版本、Mozilla Firefox 50 或更高版本或最新版本的 Google Chrome 上使用此功能。
结构化数据是以可预测的方式呈现的高度组织化的特殊信息。
例如,所有 Google 搜索结果都具有相同的结构:顶部的链接、URL 字符串和网页描述。
这种结构使 Studio 可以轻松提取信息,因为它始终知道在哪里可以找到信息。
二、数据抓取向导的关键步骤
1. 打开要从中提取数据的网页、文档或应用程序界面,单击“设计”选项卡中的“数据采集”按钮,
打开阵列抓取向导:
单击下一步,然后选择要抓取的数据的第一个单元格的内容:
然后 Studio 会自动检测您是否指示了表格单元格并询问您是否要提取整个表格:
然后单击完成以转到步骤 5。
点击下一步,返回采集数据界面,点击同类型或同列的第二条数据,
选择后,Studio 可以推断出信息的模式,进入下面的界面。
2. 自定义列标题并选择是否提取 URL。
3.点击下一步进入预览数据界面,编辑最大提取结果数,然后改变列的顺序:
4.(可选)如果您需要获取其他列,请单击提取相关数据按钮。这允许您再次执行提取向导(同样需要两次单击相同类型的数据)以提取其他信息并将其作为新列添加到同一个表中。
5. 表示网页、应用程序或文档中的“下一步”按钮(如果要提取的信息跨越多个页面)。
在这里你需要告诉Think,如果你需要它来帮助你点击下一页以便采集所有数据。如果选择是,则需要单击“下一步”按钮,否则单击否以完成向导。
完成向导后,会在 Studio 中生成一个序列:
数据抓取始终会生成一个容器(“附加浏览器”或“附加窗口”),其中收录用于顶级窗口的选择器,以及带有部分选择器的提取结构化数据活动,以确保正确识别要抓取的应用程序。
此外,“Extract Structured Data”活动还有一个自动生成的XML字符串(在ExtractMetadata属性中,自动生成的内容很简单,手动逐列抓取的内容稍微复杂一些,幸好两者都是自动生成的,没有非常注意),字符串表示要提取的数据。
最后,所有抓取的信息都存储在你定义的DataTable变量中(上图中的ExtractDataTable)。接下来,您可以使用变量 ExtractDataTable 保存到数据库、csv 文件或 Excel 电子表格。
三、可能的问题
网页文件是用html编写的,网页上看到的文字可能会被包裹在多层代码中进行格式化。如果捕获了不适当的层,则可能无法捕获所需的 URL,例如:
抓取包裹文本所在的图层,可以抓取网址,而不是包裹所在的图层,比如单元格。
四、总结
如果需要爬取网址,只能使用第二种方法(按需获取列)。 查看全部
excel自动抓取网页数据(UiPath的DataScraping(数据抓取)功能,鼠标点击几下!)
UiPath的DataScraping(数据抓取)功能,只需点击几下鼠标,即可实现浏览器、应用程序或文档界面的结构化数据,功能强大!
有两种爬取方式: a. 自动爬取整个表格内容;湾。根据需要爬取所需的列内容和列内容的URL(超链接URL)。
这个功能用的不多,但是还是很有用的,而且里面有一些小技巧,特此介绍。
一、数据抓取
数据抓取允许您将结构化数据从浏览器、应用程序或文档中提取到数据库、.csv 文件甚至 Excel 电子表格中。
注意:
建议在 Internet Explorer 11 及更高版本、Mozilla Firefox 50 或更高版本或最新版本的 Google Chrome 上使用此功能。
结构化数据是以可预测的方式呈现的高度组织化的特殊信息。
例如,所有 Google 搜索结果都具有相同的结构:顶部的链接、URL 字符串和网页描述。
这种结构使 Studio 可以轻松提取信息,因为它始终知道在哪里可以找到信息。
二、数据抓取向导的关键步骤
1. 打开要从中提取数据的网页、文档或应用程序界面,单击“设计”选项卡中的“数据采集”按钮,
打开阵列抓取向导:
单击下一步,然后选择要抓取的数据的第一个单元格的内容:
然后 Studio 会自动检测您是否指示了表格单元格并询问您是否要提取整个表格:
然后单击完成以转到步骤 5。
点击下一步,返回采集数据界面,点击同类型或同列的第二条数据,
选择后,Studio 可以推断出信息的模式,进入下面的界面。
2. 自定义列标题并选择是否提取 URL。
3.点击下一步进入预览数据界面,编辑最大提取结果数,然后改变列的顺序:
4.(可选)如果您需要获取其他列,请单击提取相关数据按钮。这允许您再次执行提取向导(同样需要两次单击相同类型的数据)以提取其他信息并将其作为新列添加到同一个表中。
5. 表示网页、应用程序或文档中的“下一步”按钮(如果要提取的信息跨越多个页面)。
在这里你需要告诉Think,如果你需要它来帮助你点击下一页以便采集所有数据。如果选择是,则需要单击“下一步”按钮,否则单击否以完成向导。
完成向导后,会在 Studio 中生成一个序列:
数据抓取始终会生成一个容器(“附加浏览器”或“附加窗口”),其中收录用于顶级窗口的选择器,以及带有部分选择器的提取结构化数据活动,以确保正确识别要抓取的应用程序。
此外,“Extract Structured Data”活动还有一个自动生成的XML字符串(在ExtractMetadata属性中,自动生成的内容很简单,手动逐列抓取的内容稍微复杂一些,幸好两者都是自动生成的,没有非常注意),字符串表示要提取的数据。
最后,所有抓取的信息都存储在你定义的DataTable变量中(上图中的ExtractDataTable)。接下来,您可以使用变量 ExtractDataTable 保存到数据库、csv 文件或 Excel 电子表格。
三、可能的问题
网页文件是用html编写的,网页上看到的文字可能会被包裹在多层代码中进行格式化。如果捕获了不适当的层,则可能无法捕获所需的 URL,例如:
抓取包裹文本所在的图层,可以抓取网址,而不是包裹所在的图层,比如单元格。
四、总结
如果需要爬取网址,只能使用第二种方法(按需获取列)。
excel自动抓取网页数据(excel自动抓取网页数据原理很简单具体步骤步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2022-02-19 16:02
excel自动抓取网页数据原理很简单,具体步骤如下:
1、添加工作表
2、在数据源区域点右键复制数据源,然后点另存为数据.
3、选中要抓取的网页信息,右键点条件格式,选择“新建规则”.
4、用鼠标在数据源单元格右键,
5、全选数据源,右键点“替换”---选择“值”,再点“替换为”.
6、最后点关闭即可.动图效果:***文章出自@阿文,原文链接:excel自动抓取网页数据_excel教程**欢迎大家关注我的微信公众号,彩云的机械整备间。公众号以浅显的语言讲解excel基础知识。
知乎上也有类似问题!请参考我的博客,时间充裕时都翻译完善了。excel2010抓取万网列表数据然后excel做出来的数据透视表以上是我在正则表达式中采用的方法,效果如下图所示。excel抓取万网列表数据-excelhome技术论坛,看完那个再有兴趣,
鼠标右键复制这个网页的内容,可以得到一个粘贴到excel表格的路径,粘贴到excel粘贴路径下的workbook选项,里面包含了这个网页的所有文本信息,找到文本所在位置,改成text,按下alt+f10,就复制成功啦,再点击文本再把字体大小调成可以读取的, 查看全部
excel自动抓取网页数据(excel自动抓取网页数据原理很简单具体步骤步骤)
excel自动抓取网页数据原理很简单,具体步骤如下:
1、添加工作表
2、在数据源区域点右键复制数据源,然后点另存为数据.
3、选中要抓取的网页信息,右键点条件格式,选择“新建规则”.
4、用鼠标在数据源单元格右键,
5、全选数据源,右键点“替换”---选择“值”,再点“替换为”.
6、最后点关闭即可.动图效果:***文章出自@阿文,原文链接:excel自动抓取网页数据_excel教程**欢迎大家关注我的微信公众号,彩云的机械整备间。公众号以浅显的语言讲解excel基础知识。
知乎上也有类似问题!请参考我的博客,时间充裕时都翻译完善了。excel2010抓取万网列表数据然后excel做出来的数据透视表以上是我在正则表达式中采用的方法,效果如下图所示。excel抓取万网列表数据-excelhome技术论坛,看完那个再有兴趣,
鼠标右键复制这个网页的内容,可以得到一个粘贴到excel表格的路径,粘贴到excel粘贴路径下的workbook选项,里面包含了这个网页的所有文本信息,找到文本所在位置,改成text,按下alt+f10,就复制成功啦,再点击文本再把字体大小调成可以读取的,
excel自动抓取网页数据(本文实例讲述Python实现抓取网页生成Excel文件的方法。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-02-11 02:06
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="https://www.yourwebname.com/%3 ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
接下来就是用Notepad++打开gongsi.csv,然后转换成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
excel自动抓取网页数据(本文实例讲述Python实现抓取网页生成Excel文件的方法。)
本文中的示例描述了 Python 如何实现爬取网页以生成 Excel 文件。分享给大家,供大家参考,如下:
Python抓取网页,主要使用PyQuery,和jQuery一样,超级强大
示例代码如下:
#-*- encoding:utf-8 -*-
import sys
import locale
import string
import traceback
import datetime
import urllib2
from pyquery import PyQuery as pq
# 确定运行环境的encoding
reload(sys);
sys.setdefaultencoding('utf8');
f = open('gongsi.csv', 'w');
for i in range(1,24):
d = pq(url="https://www.yourwebname.com/%3 ... 3B%25(i));
itemsa=d('dl dt a') #取title元素
itemsb=d('dl dd') #取title元素
for j in range(0,len(itemsa)):
f.write("%s,\"%s\"\n"%(itemsa[j].get('title'),itemsb[j*2].text));
#end for
#end for
f.close();
接下来就是用Notepad++打开gongsi.csv,然后转换成ANSI编码格式保存。然后用Excel软件打开csv文件,保存为Excel文件
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python中Excel表格技巧总结》、《Python文件和目录操作技巧总结》、《Python文本文件操作总结》 《技能》、《Python数据》《结构与算法教程》、《Python函数技巧总结》、《Python字符串操作技巧总结》和《Python入门与进阶经典教程》
希望这篇文章对你的 Python 编程有所帮助。
excel自动抓取网页数据(excel自动抓取网页数据步骤(1)_抓取的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-09 21:04
excel自动抓取网页数据步骤1选择要抓取的数据步骤2选择要抓取的网页步骤3点击左上角的“抓取网页”步骤4等待计算完成,等待抓取完成步骤5单击文件,保存步骤6保存的时候,
可以用如下文件的插件进行,不过我在百度也没找到,
不用下载那个插件,直接找到url复制到word2016自动保存就可以了,
;cid=4545434700&cid=4545434700
别克社区有个“知网下载助手”,可以免费看论文,是本校图书馆开发的,有卖,包邮哦。
你只需要下载word2016版的wps,右键点击你要抓取的网页,上传文件。就可以自动抓取了。
"
自己用了将近半年才在我实习时候学会,是个很好用的插件,
话不多说,
最近对我的影响最大的就是他了
在知乎上第一次答题,这么认真为题主回答这个问题。
感谢wps的帮助,在word2016里应该能找到,
自己百度找找吧,
有一个叫百度学术的app可以下载
我也想知道我也想知道感觉这么多傻逼不如自己搞
看着知乎的各种广告下载了app,然后被制裁了, 查看全部
excel自动抓取网页数据(excel自动抓取网页数据步骤(1)_抓取的数据)
excel自动抓取网页数据步骤1选择要抓取的数据步骤2选择要抓取的网页步骤3点击左上角的“抓取网页”步骤4等待计算完成,等待抓取完成步骤5单击文件,保存步骤6保存的时候,
可以用如下文件的插件进行,不过我在百度也没找到,
不用下载那个插件,直接找到url复制到word2016自动保存就可以了,
;cid=4545434700&cid=4545434700
别克社区有个“知网下载助手”,可以免费看论文,是本校图书馆开发的,有卖,包邮哦。
你只需要下载word2016版的wps,右键点击你要抓取的网页,上传文件。就可以自动抓取了。
"
自己用了将近半年才在我实习时候学会,是个很好用的插件,
话不多说,
最近对我的影响最大的就是他了
在知乎上第一次答题,这么认真为题主回答这个问题。
感谢wps的帮助,在word2016里应该能找到,
自己百度找找吧,
有一个叫百度学术的app可以下载
我也想知道我也想知道感觉这么多傻逼不如自己搞
看着知乎的各种广告下载了app,然后被制裁了,
excel自动抓取网页数据(WebHarvy功能介绍智能识别模式WebHarvy网页中的文本及图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-09 14:21
WebHarvy 是一个网页数据捕获工具。该软件可以提取网页中的文字和图片,输入网址并打开。默认使用内部浏览器,支持扩展分析,可自动获取相似链接列表。软件界面直观,操作简单。
WebHarvy功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
WebHarvy 软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
WebHarvy 变更日志
修复了可能导致页面启动时禁用连接的错误
您可以为页面模式配置专用的连接方法
可以自动搜索 HTML 上的可配置资源 查看全部
excel自动抓取网页数据(WebHarvy功能介绍智能识别模式WebHarvy网页中的文本及图片)
WebHarvy 是一个网页数据捕获工具。该软件可以提取网页中的文字和图片,输入网址并打开。默认使用内部浏览器,支持扩展分析,可自动获取相似链接列表。软件界面直观,操作简单。
WebHarvy功能介绍
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
WebHarvy 软件功能
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
WebHarvy 变更日志
修复了可能导致页面启动时禁用连接的错误
您可以为页面模式配置专用的连接方法
可以自动搜索 HTML 上的可配置资源
excel自动抓取网页数据(一个翻页循环网页数据能采集到哪些数据(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2022-02-09 13:28
采集可以从网页数据中获取哪些数据
刚接触数据采集的同学可能会有以下疑问:采集可以是什么样的网页数据?
简单地说,互联网收录了丰富的开放数据资源。所有这些直接可见的互联网公开数据都可以是采集,只是难度不同采集。具体到数据类型,大数据的数据主要是网络日志、视频、图片、地理位置等网络信息,可以通过多种方式实现采集。
我们可以使用采集工具高效便捷的实现各种网页和各类网页数据采集。优采云是一个可视化的网页数据采集器,可以采集99%的网页。以下是使用优采云、采集对豆瓣上的一部电影进行简短评论的完整示例。
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义模式”
2)复制并粘贴你想要采集的网址到网站输入框,点击“保存网址”
采集 可以从网页数据中得到哪些数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。网页打开后,下拉页面,找到并点击“更多评论”按钮,选择“点击此链接”
采集 可以从网页数据中得到哪些数据 图 3
2) 将页面下拉至底部,点击“下一步”按钮,在右侧的操作提示框中,
选择“更多操作”
采集 可以从网页数据中得到哪些数据 图4
选择“循环点击单链接”创建翻页循环
采集 可以从网页数据中得到哪些数据 图 5
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个电影评论块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
采集 可以从网页数据中得到哪些数据 图6
2)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
采集 可以从网页数据中得到哪些数据 图 7
3)我们可以看到页面上第一个影评块的所有元素都被选中并变为绿色。选择“采集以下数据”
网页数据中采集可以是什么数据 图8
4)选择字段并单击垃圾桶图标以删除不必要的字段
采集 可以从网页数据中得到哪些数据 图 9
5)字段选择完成后,选择对应字段,自定义字段名称。完成后,点击左上角的“保存并启动”
采集 可以从网页数据中得到哪些数据 图10
6)选择“本地启动采集”
网页数据中采集可以是什么数据 图11
第 4 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
采集 可以从网页数据中得到哪些数据 图12
2)这里我们选择excel作为导出格式,数据导出如下图
采集 可以从网页数据中获取哪些数据 图 13
注:如果未登录,豆瓣电影短评只能翻8次,采集160短评数据。采集更多数据,请先登录。登录请参考以下两个教程:单文本输入点击登录方法(/tutorialdetail-1/srdl_v70.html)和cookie登录方法(/tutorialdetail-1/cookie70.html) .
在例子中,采集的豆瓣电影的评论信息,其他数据类型如视频、图片、地理位置的采集,都比较复杂。视频:可在 采集 其 URL 获得。图片:您可以批量采集图片网址,然后使用优采云批量导出工具将网址导出为图片。地理位置(经纬度),如地图网站(百度地图、高德地图
搜狗地图)源码中收录了这些信息,可以从源码采集下载。
相关 采集 教程: 查看全部
excel自动抓取网页数据(一个翻页循环网页数据能采集到哪些数据(组图))
采集可以从网页数据中获取哪些数据
刚接触数据采集的同学可能会有以下疑问:采集可以是什么样的网页数据?
简单地说,互联网收录了丰富的开放数据资源。所有这些直接可见的互联网公开数据都可以是采集,只是难度不同采集。具体到数据类型,大数据的数据主要是网络日志、视频、图片、地理位置等网络信息,可以通过多种方式实现采集。
我们可以使用采集工具高效便捷的实现各种网页和各类网页数据采集。优采云是一个可视化的网页数据采集器,可以采集99%的网页。以下是使用优采云、采集对豆瓣上的一部电影进行简短评论的完整示例。
第 1 步:创建一个 采集 任务
1)进入主界面,选择“自定义模式”
2)复制并粘贴你想要采集的网址到网站输入框,点击“保存网址”
采集 可以从网页数据中得到哪些数据 图2
第 2 步:创建翻页循环
1)在页面右上角,打开“Process”,显示“Process Designer”和“Customize Current Actions”部分。网页打开后,下拉页面,找到并点击“更多评论”按钮,选择“点击此链接”
采集 可以从网页数据中得到哪些数据 图 3
2) 将页面下拉至底部,点击“下一步”按钮,在右侧的操作提示框中,
选择“更多操作”
采集 可以从网页数据中得到哪些数据 图4
选择“循环点击单链接”创建翻页循环
采集 可以从网页数据中得到哪些数据 图 5
第 3 步:创建列表循环并提取数据
1)移动鼠标选择页面上的第一个电影评论块。系统会识别该块中的子元素,在操作提示框中,选择“选择子元素”
采集 可以从网页数据中得到哪些数据 图6
2)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
采集 可以从网页数据中得到哪些数据 图 7
3)我们可以看到页面上第一个影评块的所有元素都被选中并变为绿色。选择“采集以下数据”
网页数据中采集可以是什么数据 图8
4)选择字段并单击垃圾桶图标以删除不必要的字段
采集 可以从网页数据中得到哪些数据 图 9
5)字段选择完成后,选择对应字段,自定义字段名称。完成后,点击左上角的“保存并启动”
采集 可以从网页数据中得到哪些数据 图10
6)选择“本地启动采集”
网页数据中采集可以是什么数据 图11
第 4 步:数据采集 和导出
1)采集完成后会弹出提示,选择“导出数据”。选择“合适的导出方式”导出采集好的数据
采集 可以从网页数据中得到哪些数据 图12
2)这里我们选择excel作为导出格式,数据导出如下图
采集 可以从网页数据中获取哪些数据 图 13
注:如果未登录,豆瓣电影短评只能翻8次,采集160短评数据。采集更多数据,请先登录。登录请参考以下两个教程:单文本输入点击登录方法(/tutorialdetail-1/srdl_v70.html)和cookie登录方法(/tutorialdetail-1/cookie70.html) .
在例子中,采集的豆瓣电影的评论信息,其他数据类型如视频、图片、地理位置的采集,都比较复杂。视频:可在 采集 其 URL 获得。图片:您可以批量采集图片网址,然后使用优采云批量导出工具将网址导出为图片。地理位置(经纬度),如地图网站(百度地图、高德地图
搜狗地图)源码中收录了这些信息,可以从源码采集下载。
相关 采集 教程:
excel自动抓取网页数据(alibaba黑科技!我都用过的网站!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-09 07:05
excel自动抓取网页数据库
谢邀。excel2010及以上版本中,自动编号的方法是将编号链接到百度网址里去。当然除了百度之外还有一些可以自动生成编号的网站,比如“数据小药丸”,微信公众号“数据小药丸”等等。
可以搜一下。
感谢邀请。金数据是使用百度云存储来自动抓取百度云的课件、视频、音频等数据,进行自动分析数据特征,生成自动编号工具,并将编号公布于网络中的。
baidu
一句话的句号,
自动化数据处理工具,excel+一张图表文件=。
大
复制被分析网站的链接地址即可。
百度网盘或网页下载器;迅雷等迅雷助手;直接去小红书上看;b站;;京东;
spss或modeler等软件
baiduexceltools
notepad++idmreverse-in-screenfilesavergooglechrome个人推荐这3个,工具也是最有效的去除编号的方法,就是登录一个网站并不能消除,必须点编号才能不编号。
alibaba
黑科技!!!我都用过的网站!!1.科学网址导航(),可以分享网站的历史。不过只能下载图片,不能下载pdf版。试过的最好用的。2.澳大利亚交易所(asic:australianinvestmentcenter),除了可以实现免费注册以外,还能免费下载并阅读pdf,貌似还可以帮助中国对冲基金成为澳大利亚nasdaq交易所的受托人?!wh3.喜马拉雅fm,免费注册后,就可以阅读付费频道的文章,有一些书籍。而且还能关注到付费频道的主播~~~。 查看全部
excel自动抓取网页数据(alibaba黑科技!我都用过的网站!(组图))
excel自动抓取网页数据库
谢邀。excel2010及以上版本中,自动编号的方法是将编号链接到百度网址里去。当然除了百度之外还有一些可以自动生成编号的网站,比如“数据小药丸”,微信公众号“数据小药丸”等等。
可以搜一下。
感谢邀请。金数据是使用百度云存储来自动抓取百度云的课件、视频、音频等数据,进行自动分析数据特征,生成自动编号工具,并将编号公布于网络中的。
baidu
一句话的句号,
自动化数据处理工具,excel+一张图表文件=。
大
复制被分析网站的链接地址即可。
百度网盘或网页下载器;迅雷等迅雷助手;直接去小红书上看;b站;;京东;
spss或modeler等软件
baiduexceltools
notepad++idmreverse-in-screenfilesavergooglechrome个人推荐这3个,工具也是最有效的去除编号的方法,就是登录一个网站并不能消除,必须点编号才能不编号。
alibaba
黑科技!!!我都用过的网站!!1.科学网址导航(),可以分享网站的历史。不过只能下载图片,不能下载pdf版。试过的最好用的。2.澳大利亚交易所(asic:australianinvestmentcenter),除了可以实现免费注册以外,还能免费下载并阅读pdf,貌似还可以帮助中国对冲基金成为澳大利亚nasdaq交易所的受托人?!wh3.喜马拉雅fm,免费注册后,就可以阅读付费频道的文章,有一些书籍。而且还能关注到付费频道的主播~~~。
excel自动抓取网页数据(勤哲勤哲excel服务器教程,不过用Excel来计算工龄?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-08 04:04
好用的勤哲excel服务器教程,勤哲服务器,使用excel界面,外加网络数据库,解决一般企事业单位的OA和进销存管理问题,用户不需要编程知识。完全根据用户单位的实际情况编制各种表格,共享网络数据,自动处理网络上的数据。另外,使用勤哲服务器,对于使用过ERP的单位,可以利用ERP的原创数据开发ERP没有的功能。比如我公司使用的ERP没有辅料采购功能。我们利用原ERP中的勤哲服务器和物料数据库和采购管理系统,开发了辅料自动采购模块,
勤哲EXCEL服务器如何巧妙计算服务时长?
勤哲没有用过勤哲excel服务器教程,但是用Excel计算服务时长很简单
【配方解析】
=DATEDIF(H2,TODAY(),"Y")&"年份"
datedif是Excel的隐藏函数勤哲excel服务器教程,主要用于日期计算
第一个参数是开始日期,第二个参数是结束日期,第三个参数Y表示Year,按年份显示。
最终结果是第二个参数减去第一个参数,得到的结果按年份显示,不到一年的不计算在内!
如果对您有帮助,请点赞关注本号,您的支持是我持续更新的无限动力!
使用勤哲Excel服务器实现多人协同报表是什么意思?
如果你是个人用户,可以忽略勤哲EXCEL服务器。如果您是单位或公司用户,勤哲EXCEL服务器可以帮助您更方便快捷地完成工作。我单位用的是勤哲EXCEL服务器。勤哲EXCEL服务器可以将电子表格软件MS Excel和大型数据库管理系统MS SQL Server集成为一个网络数据业务协同工作平台。在这个平台上,用户可以充分发挥Excel的应用层次,通过图表、表格、表格之间的公式来实现管理意图,轻松快速地构建适应的ERP、OA、CRM、SCM等管理信息系统改变!因为它可以集成其他软件产品的数据库并具有工作流的功能,是一款非常实用的企业应用集成工具。EAI 根据我的经验,勤哲EXCEL服务器可以实现自动数据采集、计算等,多人可以填表,每个人设置不同的权限。
有谁知道excel服务器吗?
1、简介
Excel服务器作为一款定制化的综合管理软件,可以通过Excel构建自己的管理系统;同时也可以将贵公司现有分散在各个管理环节的Excel表格直接整合成一套管理系统。将您的管理理念转化为现实的管理方法,实现企业信息化,简单、快速、灵活、高效、自主。
Excel服务器的历史形成:2003年,北京勤哲软件发明了世界上第一个电子表格服务器软件。它将电子表格20多年的单机应用扩展到单元级别,并扩展到网络和Internet。业务流程再造平台。经过十多年的发展,最新的版本是2015版本,具有将用户自定义系统转换为移动应用程序的功能。
它以Excel为主要操作界面,结合了数据库技术、工作流技术和Web技术。各种企事业单位的管理人员和各个岗位的工作人员,只要会使用Excel,就可以设计和实施一套符合自身需求的网络化管理信息系统------
能够将 Excel 文件的内容保存到数据库;
可实现数据的自动汇总统计;
能够设置工作流程,使Excel表格按规定流动和传输;
既可以支持局域网内的应用,也可以支持互联网上的应用,使国外分支机构的人员可以通过网页填写表格,实现远程管理;
还可与企业现有的其他管理软件,如财务系统、ERP系统等进行数据整合,消除企业信息孤岛;
最重要的是,使用Excel服务器这样的平台,用户可以在不依赖IT专业人员的情况下,实现自己想要的管理信息系统,并且可以随着企业业务的发展和管理的进步随时调整、变更和增加系统。 . 功能,使信息系统真正成为按需业务的支撑。
2、详情
Excel 服务器组成
Excel服务器软件由五部分组成,即:嵌入在Excel中的客户端组件、报表网站、管理控制台、数据库和服务器程序。远程报告网站 仅收录在企业版中,不收录在标准版中。
Excel服务器是一个网络应用系统,其中数据库、服务程序和报表网站只安装在服务器上。客户端程序和管理控制台安装在服务器和客户端上。
这里所说的“服务器”是一个软件概念。说一台计算机是服务器,并不是说它的硬件特性有什么特殊性,而是说它在网络应用系统中的“功能”不同于其他计算机。不同的。对于 Excel 服务器,数据库和服务程序安装在用作服务器的计算机上。用户通过网络上的其他计算机(称为客户端)登录服务器,从服务器上的数据库中获取信息,执行各种任务。执行此操作,然后将最终结果保存在数据库中。这样就实现了信息共享。用户在客户端的操作都是在Excel中进行的(企业用户也可以在网页上进行),和平时操作Excel文件的方式差不多,
嵌入 Excel 客户端组件
Excel服务器的主要功能体现为附在Excel中的菜单项形式,用户完全在自己熟悉的Excel环境中工作。Excel 的功能似乎得到了扩展。这些功能包括:
模板设计:创建模板、定义数据项和数据表、定义表间公式和回写公式、定义工作流等。
日常操作:填写报表/自动汇总、处理待办事项、查询数据/报表。
填写网站
“填写网站”是企业版独有的,其目的是让分散在分支机构的用户能够通过互联网以网页的形式使用Excel服务器软件。
Excel服务器作为一个信息系统设计和操作平台,具有三个功能。一是信息系统设计,二是信息系统运行支撑,三是系统管理。
系统管理功能
1) 设置部门、角色、用户
2) 定义各种数据规范
3)数据备份与恢复
4)系统日志管理
5) 设置Excel服务器与其他应用系统数据库(外部数据源)的接口
6) 条码管理
信息系统设计功能
1) 定义Excel文件为模板,用户可以根据模板填写Excel表格。
2) 将模板上的单元格或单元格区域定义为数据项,将数据项组合成一个数据表,以便用户根据模板填写的表格内容保存到数据库中.
3) 定义各种数据规范,提高用户输入效率,保证输入信息质量。
4) 定义表格之间的公式和回写公式,实现Excel表格的自动填写和自动统计汇总
5) 定义工作流程,规范Excel表格在不同岗位和人员之间的传递。
信息系统运营支持功能
1) 按权限填写和查看表格
2) 按权限查询和管理数据
3) 处理待办事项
4) 在企业版中,以上功能可以通过浏览器完成
3、出生
2003年,勤哲软件发明了世界上第一款Excel服务器(电子表格服务器)软件。将20多年的电子表格单机应用扩展到单元级,并扩展到网络和互联网,形成企业流程。重建平台。
Excel服务器软件的发明解决了企事业单位业务系统软件不能随市场变化而变化的情况,使企事业单位普通员工能够自行构建业务流程,大大提高了信息化的成功率,降低了信息化成本减持,赢得了市场的认可。
Excel服务器(电子表格服务器)将成为继操作系统、数据库管理系统、办公软件之后所有企事业单位都需要的通用软件,并将形成一个新的软件分类。
Excel服务器软件销往中国大陆、台湾、香港、美国、沙特阿拉伯、泰国等国家和地区。目前有200多家代理商和合作伙伴。海外,新西兰有代理。每天有来自 80 多个国家的人访问勤哲软件网站 并下载软件。
Excel服务器软件已广泛应用于通讯、石油、电力、制造、服务业、教育、科研等国民经济领域。
4、安装
首先,在 Windows2000 Server 服务器上安装 MS SQL Server2000 数据库管理系统,并确保您具有系统管理员(sa)访问权限。
①选择服务器组件
运行EXCEL服务器安装程序,填写用户信息并指定服务器安装目录,弹出“安装类型”对话框。在EXCEL服务器上,选择“安装客户端和服务器”,然后连续点击“下一步”按钮。
②安装MDAC组件
然后同意用户许可协议。这时安装程序会检测系统中是否已经安装了MDAC组件。如果没有,会弹出“Microsoft Data Access Components2.6 Installation”对话框。单击“完成”按钮开始安装。组件。
③ 安装EXCEL数据库
MDAC组件安装完成后,将安装EXCEL服务器。安装过程中,会弹出“安装数据库”对话框(如图一),在“服务器名称”字段中输入SQL Server服务器名称,然后选择“使用SQL Server账户登录”,输入在“管理员密码”栏中输入“sa”用户密码,最后点击“确定”按钮,完成数据库安装。
完成以上操作后,EXCEL服务器的安装就完成了。 查看全部
excel自动抓取网页数据(勤哲勤哲excel服务器教程,不过用Excel来计算工龄?)
好用的勤哲excel服务器教程,勤哲服务器,使用excel界面,外加网络数据库,解决一般企事业单位的OA和进销存管理问题,用户不需要编程知识。完全根据用户单位的实际情况编制各种表格,共享网络数据,自动处理网络上的数据。另外,使用勤哲服务器,对于使用过ERP的单位,可以利用ERP的原创数据开发ERP没有的功能。比如我公司使用的ERP没有辅料采购功能。我们利用原ERP中的勤哲服务器和物料数据库和采购管理系统,开发了辅料自动采购模块,
勤哲EXCEL服务器如何巧妙计算服务时长?
勤哲没有用过勤哲excel服务器教程,但是用Excel计算服务时长很简单
【配方解析】
=DATEDIF(H2,TODAY(),"Y")&"年份"
datedif是Excel的隐藏函数勤哲excel服务器教程,主要用于日期计算
第一个参数是开始日期,第二个参数是结束日期,第三个参数Y表示Year,按年份显示。
最终结果是第二个参数减去第一个参数,得到的结果按年份显示,不到一年的不计算在内!
如果对您有帮助,请点赞关注本号,您的支持是我持续更新的无限动力!
使用勤哲Excel服务器实现多人协同报表是什么意思?
如果你是个人用户,可以忽略勤哲EXCEL服务器。如果您是单位或公司用户,勤哲EXCEL服务器可以帮助您更方便快捷地完成工作。我单位用的是勤哲EXCEL服务器。勤哲EXCEL服务器可以将电子表格软件MS Excel和大型数据库管理系统MS SQL Server集成为一个网络数据业务协同工作平台。在这个平台上,用户可以充分发挥Excel的应用层次,通过图表、表格、表格之间的公式来实现管理意图,轻松快速地构建适应的ERP、OA、CRM、SCM等管理信息系统改变!因为它可以集成其他软件产品的数据库并具有工作流的功能,是一款非常实用的企业应用集成工具。EAI 根据我的经验,勤哲EXCEL服务器可以实现自动数据采集、计算等,多人可以填表,每个人设置不同的权限。
有谁知道excel服务器吗?
1、简介
Excel服务器作为一款定制化的综合管理软件,可以通过Excel构建自己的管理系统;同时也可以将贵公司现有分散在各个管理环节的Excel表格直接整合成一套管理系统。将您的管理理念转化为现实的管理方法,实现企业信息化,简单、快速、灵活、高效、自主。
Excel服务器的历史形成:2003年,北京勤哲软件发明了世界上第一个电子表格服务器软件。它将电子表格20多年的单机应用扩展到单元级别,并扩展到网络和Internet。业务流程再造平台。经过十多年的发展,最新的版本是2015版本,具有将用户自定义系统转换为移动应用程序的功能。
它以Excel为主要操作界面,结合了数据库技术、工作流技术和Web技术。各种企事业单位的管理人员和各个岗位的工作人员,只要会使用Excel,就可以设计和实施一套符合自身需求的网络化管理信息系统------
能够将 Excel 文件的内容保存到数据库;
可实现数据的自动汇总统计;
能够设置工作流程,使Excel表格按规定流动和传输;
既可以支持局域网内的应用,也可以支持互联网上的应用,使国外分支机构的人员可以通过网页填写表格,实现远程管理;
还可与企业现有的其他管理软件,如财务系统、ERP系统等进行数据整合,消除企业信息孤岛;
最重要的是,使用Excel服务器这样的平台,用户可以在不依赖IT专业人员的情况下,实现自己想要的管理信息系统,并且可以随着企业业务的发展和管理的进步随时调整、变更和增加系统。 . 功能,使信息系统真正成为按需业务的支撑。
2、详情
Excel 服务器组成
Excel服务器软件由五部分组成,即:嵌入在Excel中的客户端组件、报表网站、管理控制台、数据库和服务器程序。远程报告网站 仅收录在企业版中,不收录在标准版中。
Excel服务器是一个网络应用系统,其中数据库、服务程序和报表网站只安装在服务器上。客户端程序和管理控制台安装在服务器和客户端上。
这里所说的“服务器”是一个软件概念。说一台计算机是服务器,并不是说它的硬件特性有什么特殊性,而是说它在网络应用系统中的“功能”不同于其他计算机。不同的。对于 Excel 服务器,数据库和服务程序安装在用作服务器的计算机上。用户通过网络上的其他计算机(称为客户端)登录服务器,从服务器上的数据库中获取信息,执行各种任务。执行此操作,然后将最终结果保存在数据库中。这样就实现了信息共享。用户在客户端的操作都是在Excel中进行的(企业用户也可以在网页上进行),和平时操作Excel文件的方式差不多,
嵌入 Excel 客户端组件
Excel服务器的主要功能体现为附在Excel中的菜单项形式,用户完全在自己熟悉的Excel环境中工作。Excel 的功能似乎得到了扩展。这些功能包括:
模板设计:创建模板、定义数据项和数据表、定义表间公式和回写公式、定义工作流等。
日常操作:填写报表/自动汇总、处理待办事项、查询数据/报表。
填写网站
“填写网站”是企业版独有的,其目的是让分散在分支机构的用户能够通过互联网以网页的形式使用Excel服务器软件。
Excel服务器作为一个信息系统设计和操作平台,具有三个功能。一是信息系统设计,二是信息系统运行支撑,三是系统管理。
系统管理功能
1) 设置部门、角色、用户
2) 定义各种数据规范
3)数据备份与恢复
4)系统日志管理
5) 设置Excel服务器与其他应用系统数据库(外部数据源)的接口
6) 条码管理
信息系统设计功能
1) 定义Excel文件为模板,用户可以根据模板填写Excel表格。
2) 将模板上的单元格或单元格区域定义为数据项,将数据项组合成一个数据表,以便用户根据模板填写的表格内容保存到数据库中.
3) 定义各种数据规范,提高用户输入效率,保证输入信息质量。
4) 定义表格之间的公式和回写公式,实现Excel表格的自动填写和自动统计汇总
5) 定义工作流程,规范Excel表格在不同岗位和人员之间的传递。
信息系统运营支持功能
1) 按权限填写和查看表格
2) 按权限查询和管理数据
3) 处理待办事项
4) 在企业版中,以上功能可以通过浏览器完成
3、出生
2003年,勤哲软件发明了世界上第一款Excel服务器(电子表格服务器)软件。将20多年的电子表格单机应用扩展到单元级,并扩展到网络和互联网,形成企业流程。重建平台。
Excel服务器软件的发明解决了企事业单位业务系统软件不能随市场变化而变化的情况,使企事业单位普通员工能够自行构建业务流程,大大提高了信息化的成功率,降低了信息化成本减持,赢得了市场的认可。
Excel服务器(电子表格服务器)将成为继操作系统、数据库管理系统、办公软件之后所有企事业单位都需要的通用软件,并将形成一个新的软件分类。
Excel服务器软件销往中国大陆、台湾、香港、美国、沙特阿拉伯、泰国等国家和地区。目前有200多家代理商和合作伙伴。海外,新西兰有代理。每天有来自 80 多个国家的人访问勤哲软件网站 并下载软件。
Excel服务器软件已广泛应用于通讯、石油、电力、制造、服务业、教育、科研等国民经济领域。
4、安装
首先,在 Windows2000 Server 服务器上安装 MS SQL Server2000 数据库管理系统,并确保您具有系统管理员(sa)访问权限。
①选择服务器组件
运行EXCEL服务器安装程序,填写用户信息并指定服务器安装目录,弹出“安装类型”对话框。在EXCEL服务器上,选择“安装客户端和服务器”,然后连续点击“下一步”按钮。
②安装MDAC组件
然后同意用户许可协议。这时安装程序会检测系统中是否已经安装了MDAC组件。如果没有,会弹出“Microsoft Data Access Components2.6 Installation”对话框。单击“完成”按钮开始安装。组件。
③ 安装EXCEL数据库
MDAC组件安装完成后,将安装EXCEL服务器。安装过程中,会弹出“安装数据库”对话框(如图一),在“服务器名称”字段中输入SQL Server服务器名称,然后选择“使用SQL Server账户登录”,输入在“管理员密码”栏中输入“sa”用户密码,最后点击“确定”按钮,完成数据库安装。
完成以上操作后,EXCEL服务器的安装就完成了。
excel自动抓取网页数据(如何不使用Python去爬取网页表格数据功能?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-02-07 05:23
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
有些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,其他数据获取起来有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W= 查看全部
excel自动抓取网页数据(如何不使用Python去爬取网页表格数据功能?)
现在很多朋友都知道Python可以用来爬取数据,但是如果你想从零基础开始学习Python爬虫,还是需要一些时间来学习Python的。但是,如果是为了一些简单的网页表格数据爬取,就没有必要使用Python了。
所以今天我将教大家如何在不使用 Python 的情况下抓取网页数据。
Excel的通用方法之一就是Excel,Excel表格可以帮你实现简单的网页表格数据爬取功能。
首先找到你要爬取的数据表
比如今天爬中国天气网的广东天气预报~
然后我们从 网站 复制链接,打开 Excel,在菜单栏上找到:Data – From 网站
然后将刚才复制的链接粘贴到刚刚打开的链接中:New Web Query
点击Go打开网站,在这里预览中找到你要导入的数据表,勾选左上角
选择好后点击右下角的导入,将选中的表格数据导入Excel
数据导入...
接下来就可以在Excel表格中一一看到想要呈现的数据了~
有些朋友有疑问。这样导出的数据是固定的。如果网页数据更新了,是否需要重新导入?
其实不是,Excel还自带数据刷新功能。我们还是在菜单栏中找到:data-refresh all下的link properties
在链接属性处,选择刷新条件、刷新频率、时间等,然后Excel会根据你设置的刷新属性自动更新数据~
以上就是一个自动抓取刷新数据的Excel表格的完成啦~~
当然,使用 Excel 表格爬取数据有利有弊。优点是利用Excel自带的函数来采集和更新数据,简单方便,不涉及编程等繁琐操作。缺点是Excel网页数据抓取只能抓取表格数据,其他数据获取起来有些困难。
所以如果你想获得更多样化的网页数据,不妨学习一下Python,它是目前爬虫中最容易学习的。一波安利~
如果还想知道更多实用的小技巧,可以关注一下,下次更新及时通知 W=
excel自动抓取网页数据(信托理财我想制定PM2.5表格齐智娟(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-02 11:11
所有类别> 财富管理> 信托财富管理
如何使用excel在网页上获取股票数据并按...
我想做一个 PM2.5 表格
戚志娟 来自:移动端 2021-07-17 12:52
声明:本网站依法提供财务信息,不授权或允许任何组织或个人发布交易广告。请谨慎交易任何广告信息,谨防诈骗。举报邮箱:
2021-07-17 13:04 最佳答案
不好意思,我用了文华财经的“提问”功能,让他们帮我写一个指标来达到我想要的结果,所以我没有用excel。
但我试过你说的。我在测试中途尝试了这种方法,然后停止了。你可以试试看。
第一步是找到你想要的网站并获取数据源。
第二步,在excel中,有导入网站数据的功能,它会让你选择使用哪个数据表。
具体的,你在百度上搜索——excel导入外部数据,就会有介绍。
其他答案(共7个)
2021-07-17 13:07连丽红 客户经理
将网页中的数据转换为excel表格中的数据的具体步骤如下:
我们需要准备的材料有:电脑、百度浏览器、Excel表格。
1、首先,我们打开需要编辑的百度浏览器,找到需要转换的网页表格,然后选择表格并按“Ctrl+C”进行复制。
2、然后我们回到桌面双击打开Excel表格,进入编辑页面。
3、然后我们点击单元格,按“Ctrl+V”粘贴。
2021-07-17 13:01黄万生 客户经理
先导入数据,在excel中,在data中获取外部数据,获取股票网站的数据,在属性中设置多久刷新一次,数据导入,剩下的就简单了
2021-07-17 12:58祁志富 客户经理
要完成这个功能,需要用vba写代码来实现。
将数据传输到 Internet 通常有以下几种方法:
一、通过创建IE对象,操作网页上的元素填写表单,大致示例代码:
Set objIE = CreateObject("InternetExplorer.Application")
objIE.navigate "http://网址"
Set Doc = objIE.Document
Doc.frames("topFrame").Document.body.All("网页元素名称").Value = "从excel中读取的值"
二、如果数据可以直接发送,可以通过url编码明文发送。这个方法和上面的类似,只是不需要把每个元素的值一一填入,而是直接发送数据。
2021-07-17 12:55龚宇飞 客户经理
1、打开 Excel 工作表。
2、打开菜单“数据”->“导入外部数据”->“新建Web查询”,在“新建Web查询”的地址栏中输入网页的URL,点击“开始”。
3、找到对应的表格,点击表格左上角的箭头。
4、单击箭头完成检查,然后单击“导入”。
5、选择要导入数据的位置,然后单击确定。
6、数据导入完成。 查看全部
excel自动抓取网页数据(信托理财我想制定PM2.5表格齐智娟(图))
所有类别> 财富管理> 信托财富管理
如何使用excel在网页上获取股票数据并按...
我想做一个 PM2.5 表格
戚志娟 来自:移动端 2021-07-17 12:52
声明:本网站依法提供财务信息,不授权或允许任何组织或个人发布交易广告。请谨慎交易任何广告信息,谨防诈骗。举报邮箱:
2021-07-17 13:04 最佳答案
不好意思,我用了文华财经的“提问”功能,让他们帮我写一个指标来达到我想要的结果,所以我没有用excel。
但我试过你说的。我在测试中途尝试了这种方法,然后停止了。你可以试试看。
第一步是找到你想要的网站并获取数据源。
第二步,在excel中,有导入网站数据的功能,它会让你选择使用哪个数据表。
具体的,你在百度上搜索——excel导入外部数据,就会有介绍。
其他答案(共7个)
2021-07-17 13:07连丽红 客户经理
将网页中的数据转换为excel表格中的数据的具体步骤如下:
我们需要准备的材料有:电脑、百度浏览器、Excel表格。
1、首先,我们打开需要编辑的百度浏览器,找到需要转换的网页表格,然后选择表格并按“Ctrl+C”进行复制。
2、然后我们回到桌面双击打开Excel表格,进入编辑页面。
3、然后我们点击单元格,按“Ctrl+V”粘贴。
2021-07-17 13:01黄万生 客户经理
先导入数据,在excel中,在data中获取外部数据,获取股票网站的数据,在属性中设置多久刷新一次,数据导入,剩下的就简单了
2021-07-17 12:58祁志富 客户经理
要完成这个功能,需要用vba写代码来实现。
将数据传输到 Internet 通常有以下几种方法:
一、通过创建IE对象,操作网页上的元素填写表单,大致示例代码:
Set objIE = CreateObject("InternetExplorer.Application")
objIE.navigate "http://网址"
Set Doc = objIE.Document
Doc.frames("topFrame").Document.body.All("网页元素名称").Value = "从excel中读取的值"
二、如果数据可以直接发送,可以通过url编码明文发送。这个方法和上面的类似,只是不需要把每个元素的值一一填入,而是直接发送数据。
2021-07-17 12:55龚宇飞 客户经理
1、打开 Excel 工作表。
2、打开菜单“数据”->“导入外部数据”->“新建Web查询”,在“新建Web查询”的地址栏中输入网页的URL,点击“开始”。
3、找到对应的表格,点击表格左上角的箭头。
4、单击箭头完成检查,然后单击“导入”。
5、选择要导入数据的位置,然后单击确定。
6、数据导入完成。
excel自动抓取网页数据( 相似软件地址风越excel数据批量自动填写网页数据提取软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2022-02-02 11:10
相似软件地址风越excel数据批量自动填写网页数据提取软件)
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
类似软件
印记
软件地址
风月Excel数据批量自动填写网页数据提取软件的特点
该软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
★支持下载指定文件和抓取网页文本内容
★支持多边框页面控件元素的填充
★支持iframe内嵌页面控件元素的填充
★支持网页结构分析,显示控件描述,便于分析和修改控件值
★支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
★支持级联下拉菜单填充
★支持无ID控制灌装
★支持验证码在线识别
★支持循环填充和输入
风月excel数据批量自动填写网页数据提取软件说明
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、点击左下角的“带有加号图标的新规则”按钮创建规则
4、勾选“填写”网格,酌情删除不想填写的行
至此,设置已经完成。测试时只需刷新网页,使网页未填充,然后点击软件左下角的“三角图标开始填充”按钮,即可查看填充效果。
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后 查看全部
excel自动抓取网页数据(
相似软件地址风越excel数据批量自动填写网页数据提取软件)
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。
类似软件
印记
软件地址
风月Excel数据批量自动填写网页数据提取软件的特点
该软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。
本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
★支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量输入
★支持下载指定文件和抓取网页文本内容
★支持多边框页面控件元素的填充
★支持iframe内嵌页面控件元素的填充
★支持网页结构分析,显示控件描述,便于分析和修改控件值
★支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
★支持级联下拉菜单填充
★支持无ID控制灌装
★支持验证码在线识别
★支持循环填充和输入
风月excel数据批量自动填写网页数据提取软件说明
1、点击菜单“系统”>“新建配置文件”
2、在软件中打开网页,手动填写需要输入的内容
3、点击左下角的“带有加号图标的新规则”按钮创建规则
4、勾选“填写”网格,酌情删除不想填写的行
至此,设置已经完成。测试时只需刷新网页,使网页未填充,然后点击软件左下角的“三角图标开始填充”按钮,即可查看填充效果。
风月excel数据批量自动填写网页数据提取软件更新日志
把bug扫到最后
excel自动抓取网页数据(WebDataMiner如何从网页中选择要报废的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-01-27 22:08
9、用户可以安排未来的日期和时间来提取数据。
10、以 CSV、TXT 格式保存数据。
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,并且在配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。 查看全部
excel自动抓取网页数据(WebDataMiner如何从网页中选择要报废的数据?)
9、用户可以安排未来的日期和时间来提取数据。
10、以 CSV、TXT 格式保存数据。
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,并且在配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。
excel自动抓取网页数据(WebDataMiner如何从网页中选择要报废的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-27 22:00
2、双击web-data-miner.exe运行安装,勾选我接受许可协议
3、安装完成,退出向导
4、复制Web Data Miner.exe到安装目录,点击替换目标中的文件
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,并且在配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。 查看全部
excel自动抓取网页数据(WebDataMiner如何从网页中选择要报废的数据?)
2、双击web-data-miner.exe运行安装,勾选我接受许可协议
3、安装完成,退出向导
4、复制Web Data Miner.exe到安装目录,点击替换目标中的文件
常见问题
1、如何开始记录配置过程?
输入 网站 URL 并等待浏览器加载。打开 网站 来抓取数据后,必须单击“开始配置”按钮。
输入 网站 URL 并等待浏览器加载。为 After star 配置 网站 后,您必须单击要从网页中删除的项目。Web Data Miner 工具从打开的网页中删除单击的项目或类似项目。
2、如何从网页中选择要报废的数据?
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 具有很好的从网页剪辑文本、html、图像和链接的功能,在 Captured Data Toolbox 窗口中,您可以选择剪辑数据类型的选项。例如,我们选择 Capture Text 并单击 Capture Text 按钮。
Web Data Miner 会自动识别相似的项目并将它们添加到给定列名中捕获的数据的预览列表中。通过类似的过程,您可以从网页中抓取更多数据。
3、如何从下一个后续链接中提取数据?
追踪链接:
如果要从网页中存在的另一个链接中删除更多数据,则必须选择“关注链接”选项。当您点击“关注链接”按钮时,智能数据抓取器将导航到点击项目链接,页面加载后,您可以通过相同的过程从导航页面抓取更多数据。
网络数据挖掘器 网络数据挖掘器 网络数据挖掘器 网络数据挖掘器
停止捕获:
捕获后,您只需停止即可开始挖矿。
4、如何根据您记录的配置从 网站 开始挖掘数据?
开始挖掘
当所有数据都通过单击开始挖掘按钮配置后,可以从网页中挖掘数据。
5、从多个页面抓取数据
要从多个页面抓取数据,您必须配置“设置下一页链接”。在设置下一页链接时,可以让智能数据抓取器从所有页面或页数中挖掘数据进行挖掘。
6、如何暂停、停止和保存提取的数据?
您可以在采矿时暂停和停止该过程。挖掘完成后,您可以将挖掘数据保存为 Excel (.csv) 文件或文本文件。
7、如何从外部链接中提取数据,可以是自定义链接和链表?
使用外部链接
自定义链接:在自定义链接选项中,您可以提供将字段更改为数字的链接。它还有助于从多个页面中抓取数据。在此选项中,您将链接分为三个部分。Link before change field 如果收录,change field before change field 和 field after change field (last commit) 如果收录,您还可以设置要挖掘的页数。更改字段将以 1 为增量进行更改。
链接列表:在此列表中,您可以提供多个链接或加载链接,其中收录来自文本文件的相似数据,并且在配置第一个链接后,智能数据抓取器会从所有链接中挖掘数据。
8、如何更改自动暂停、自动保存和页面加载超时的设置?
设定值
自动保存矿工数据:当您通过设置“页面后保存”和“保存位置”允许Smart Data Scraper自动保存数据时,它会在挖掘时自动将数据保存在给定位置。
自动暂停:您还可以通过在给定分钟后和给定分钟数内设置暂停来设置自动暂停。此设置可防止矿工被某些 网站s 阻止。
超时:您还可以设置网页加载超时。
9、如何安排任务以自动化流程?
在“计划程序”窗口中,您可以看到可以编辑、删除和计划新任务的计划任务列表。
您可以通过使用给定任务名称安排时间配置文件来安排新任务并保存文件。
10、如何采集你最喜欢的网站?
通过使用书签按钮,您可以为自己喜欢的 网站 添加书签。
excel自动抓取网页数据(数据函数制作你去网上搜索要去的海滩潮汐表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-01-26 07:11
夏日的海浪和沙滩是避暑的首选,但如果你不是常年住在海边的朋友,对大海的潮汐情况了解不多,所以如果你想拥有一个完美的海边旅行,一定要提前计划,了解你要去的海边的抄袭规则。.
数据采集功能制作
你去网上搜索你想去的海滩的潮汐表,会有很多答案。喜欢这个网站,简单直接,稍微看了下,这个网站的数据格式还是蛮有意思的。方括号 括起来的数据使用时间戳来记录时间。为了正确显示时间,需要一个转换公式将时间戳转换为标准时间。
这种格式也很容易处理。毕竟,它非常整洁。使用“],[”符号分隔列,然后反转透视,并替换不必要的符号:
接下来是时间转换:
解释这个公式:
([value.1]+8*3600)/24/3600+70*365+19
所以时间戳就是当前时间减去1970-1-1的时间差,以秒为一个数量级来表示。
公式是小数,格式可以改成日期和时间:
以上步骤是爬取单个网页的过程。该 URL 可直接用于爬取数据。有两个关键数据:
一个是12代表端口,另一个是日期
我们把上面的单次抓取过程做成一个函数,用两个参数调用这个函数:
中间有很多步骤,不用管它,只要修改上面的参数和应用参数的位置即可。
另一个问题是如何获取端口的代码?
我们回到网站端口选择页面,有一个端口列表,以文本格式抓取这个页面,简单几步就可以得到端口和编号的对照表。
让我们做两个测试:
多个港口同一天的潮汐数据抓取:
使用上面最后一步的结果,自定义列引用函数:
然后展开表,删除不必要的列,加载数据
做一个简单的切片查询:
8月2日全国485个港口的潮汐数据查询已准备就绪。
单港口未来15天潮汐查询
我们要准备一个表格,一个日期列表,转换成文本格式,调用函数:
展开表并加载数据:
让我们将所有这些天的数据放到一张图表中:
可以看出,营口鲅鱼圈是8月2日至4日的大潮,农历七月初二至初四。
8月3日中午12时,潮位退至最低位。如果从沉阳出发,2.5小时到达鲅鱼圈,早上起床吃早餐,出发,中午赶海,晚上返回沉阳。
更多Power Query学习资料,请订阅: 查看全部
excel自动抓取网页数据(数据函数制作你去网上搜索要去的海滩潮汐表)
夏日的海浪和沙滩是避暑的首选,但如果你不是常年住在海边的朋友,对大海的潮汐情况了解不多,所以如果你想拥有一个完美的海边旅行,一定要提前计划,了解你要去的海边的抄袭规则。.
数据采集功能制作
你去网上搜索你想去的海滩的潮汐表,会有很多答案。喜欢这个网站,简单直接,稍微看了下,这个网站的数据格式还是蛮有意思的。方括号 括起来的数据使用时间戳来记录时间。为了正确显示时间,需要一个转换公式将时间戳转换为标准时间。
这种格式也很容易处理。毕竟,它非常整洁。使用“],[”符号分隔列,然后反转透视,并替换不必要的符号:
接下来是时间转换:
解释这个公式:
([value.1]+8*3600)/24/3600+70*365+19
所以时间戳就是当前时间减去1970-1-1的时间差,以秒为一个数量级来表示。
公式是小数,格式可以改成日期和时间:
以上步骤是爬取单个网页的过程。该 URL 可直接用于爬取数据。有两个关键数据:
一个是12代表端口,另一个是日期
我们把上面的单次抓取过程做成一个函数,用两个参数调用这个函数:
中间有很多步骤,不用管它,只要修改上面的参数和应用参数的位置即可。
另一个问题是如何获取端口的代码?
我们回到网站端口选择页面,有一个端口列表,以文本格式抓取这个页面,简单几步就可以得到端口和编号的对照表。
让我们做两个测试:
多个港口同一天的潮汐数据抓取:
使用上面最后一步的结果,自定义列引用函数:
然后展开表,删除不必要的列,加载数据
做一个简单的切片查询:
8月2日全国485个港口的潮汐数据查询已准备就绪。
单港口未来15天潮汐查询
我们要准备一个表格,一个日期列表,转换成文本格式,调用函数:
展开表并加载数据:
让我们将所有这些天的数据放到一张图表中:
可以看出,营口鲅鱼圈是8月2日至4日的大潮,农历七月初二至初四。
8月3日中午12时,潮位退至最低位。如果从沉阳出发,2.5小时到达鲅鱼圈,早上起床吃早餐,出发,中午赶海,晚上返回沉阳。
更多Power Query学习资料,请订阅:
excel自动抓取网页数据( 认识Excel的强大功能在知乎里面搜索一下Excel,想学习一些高点赞文章的写作方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-26 07:09
认识Excel的强大功能在知乎里面搜索一下Excel,想学习一些高点赞文章的写作方法
)
今天的目标:
认识 Excel 的力量
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
1- 获取 JSON 数据连接
2- 处理数据的电源查询
3-配置搜索地址
4-添加超链接
1- 操作步骤 1- 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制这个链接,这是Power query要抓取数据的链接。
2-电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以捕获 SQL、Access 等多种类型的数据:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
3-配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing, , , ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
4-添加超链接
至此所有数据都已经处理完毕,但是如果要查看原创的知乎页面,需要复制这个超链接并在浏览器中打开。
每次点击几次鼠标很麻烦。在这里,我们使用函数 HYPERLINK 来生成一个可点击的超链接,这样访问起来会容易得多。
5-最终效果
最后的效果是:
1- 输入搜索词
2-右键刷新
3-找到点赞最高的那个
4- 点击“点击查看”,享受排队的感觉!
2-总结
知道在表格中搜索的好处吗?
1- 按“喜欢”和“评论”排序
2-如果你看过文章,可以加一栏写笔记
3-您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的,对吧?
现在大多数表格用户都使用 Excel 作为报告工具,绘制表格和编写公式,仅此而已。
请记住以下 Excel 新功能。这些功能让 Excel 成长为一个强大的数据统计和数据分析软件,在你的印象中不再只是一份报表。
1- Power查询:数据整理清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
2- Power Pivot:数据统计工具,可以自定义统计方式,实现数据透视表多字段计算,自定义DAX数据计算方式。
3- Power BI:强大易用的可视化工具,实现交互式数据呈现,是企业业务数据报表的优质解决方案。
3- 更多资源
最后,我想强调
我们是专业的Excel培训机构
秋叶Excel
想一对一回答问题吗?
扫码添加“秋小娥”,有机会参与“秋野Excel免费专业咨询”活动,在线为您答疑解惑。
我是会设计表格的Excel老师拉小登
查看全部
excel自动抓取网页数据(
认识Excel的强大功能在知乎里面搜索一下Excel,想学习一些高点赞文章的写作方法
)
今天的目标:
认识 Excel 的力量
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
1- 获取 JSON 数据连接
2- 处理数据的电源查询
3-配置搜索地址
4-添加超链接
1- 操作步骤 1- 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制这个链接,这是Power query要抓取数据的链接。
2-电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以捕获 SQL、Access 等多种类型的数据:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
3-配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing, , , ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
4-添加超链接
至此所有数据都已经处理完毕,但是如果要查看原创的知乎页面,需要复制这个超链接并在浏览器中打开。
每次点击几次鼠标很麻烦。在这里,我们使用函数 HYPERLINK 来生成一个可点击的超链接,这样访问起来会容易得多。
5-最终效果
最后的效果是:
1- 输入搜索词
2-右键刷新
3-找到点赞最高的那个
4- 点击“点击查看”,享受排队的感觉!
2-总结
知道在表格中搜索的好处吗?
1- 按“喜欢”和“评论”排序
2-如果你看过文章,可以加一栏写笔记
3-您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的,对吧?
现在大多数表格用户都使用 Excel 作为报告工具,绘制表格和编写公式,仅此而已。
请记住以下 Excel 新功能。这些功能让 Excel 成长为一个强大的数据统计和数据分析软件,在你的印象中不再只是一份报表。
1- Power查询:数据整理清理工具,搭载M强大的M语言,可以实现多表合并,也是本文的主要技术。
2- Power Pivot:数据统计工具,可以自定义统计方式,实现数据透视表多字段计算,自定义DAX数据计算方式。
3- Power BI:强大易用的可视化工具,实现交互式数据呈现,是企业业务数据报表的优质解决方案。
3- 更多资源
最后,我想强调
我们是专业的Excel培训机构
秋叶Excel
想一对一回答问题吗?
扫码添加“秋小娥”,有机会参与“秋野Excel免费专业咨询”活动,在线为您答疑解惑。
我是会设计表格的Excel老师拉小登
excel自动抓取网页数据(《寻找最好的笔记软件:海选篇》的综合分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-01-23 11:02
版本1.0 编译xbeta/善用佳软自
寻找最好的笔记软件:前三名(EverNote、Mybase、Surfulater)v1.0
作者:SuperboyAC 编译:xbeta 本系列还包括:海选篇、前三篇、梦想篇、结论篇、额外篇
通过对上一篇《寻找最好的笔记软件:Auditions》的综合分析,笔者发现优势明显的软件有3种,可谓“前三名的笔记软件”。它们是:EverNote、Mybase 和 Surfulate。这三者之间的区别是相同的,但它们是各自风格中最强的。三者如何选择,并不取决于哪一个“更强大”,而取决于你是什么样的用户,或者你有什么样的需求。
印象笔记
如果您需要一个方便的地方来存储您的笔记,而不需要太多的组织功能和冗余功能,那么 EverNote 是您的最佳选择。你可以这样理解,EverNote 就是一张无限长的纸卷,上面记录着你所有的笔记,唯一的排列顺序就是按照时间。每个笔记甚至没有标题——这是其他笔记软件的经验法则。听起来很不方便,我怎样才能找到以前的笔记?EverNote 作为一款优秀的软件,完美解决了你的后顾之忧,你在使用的过程中没有任何不便,而且你根本不会意识到这是个问题。
解决方案,即定位/过滤笔记的方法,有分类和实时搜索两种方法。分类功能如图所示,笔记可以手动分类,也可以自动规则分类。
类别可以排列成树状结构,但这与其他类似程序的树状结构不同。因为一个笔记可以分为多个类别。另一种查找笔记的方法是使用实时搜索框。这个功能在 EverNote 中实现得如此完美,是迄今为止我在任何软件中看到的最好的,而且速度超级快。当您键入每个字母时,所有匹配的注释都会在下方动态显示。不仅如此,所有匹配的单词都会被突出显示。
如前所述,所有注释都排列在一个列中。要上下滚动,可以点击右侧的滚动框,滚动速度取决于点击的位置。或者,您可以使用右侧的“时间栏”功能。它相当于一个垂直日历,你只需要点击一个日期,就可以显示相关的笔记。如果日期旁边有√,则表示该日期有注释。我觉得用这个功能做电子日记真的很方便。
Evernote 还可以轻松抓取任何内容,尤其是各种网络内容。准确地说,在三巨头中,它拥有最强大的网页内容爬取能力。它不仅准确地捕捉范围,而且当内容进入印象笔记时,它看起来就像一个笔记,而不是一个网页:鼠标变成一只小手,点击一下就会带你到一个链接。在 EverNote 中,如果你想访问一个链接,你需要双击。我从来没有迷恋过网络点击式入侵软件界面。还记得 Windows 何时将单击模式引入操作系统界面吗?我不习惯,所以每次都得关掉。顺便说一句,Mybase 和 Surfulater 都是点击模式。Mybase 这样做是因为它使用 IE 引擎来显示网页;Surfulate 这样做是因为它的界面从头到尾都是网页风格。
在剪辑方面,还是有一些不足的地方。要真正对笔记进行一些格式化和文本组织,您需要进入全屏模式。这时候,这个笔记单独显示在一个大窗口中,带有一个rtf标准工具栏,方便编辑。而在常规窗口中,几乎没有编辑按钮。您要么进入全屏模式,要么进入右键菜单。此外,图片缩放功能也比较奇怪。
总而言之,印象笔记是“记住和检查”软件类别中最好的。它最大的优势在于一流的实时搜索功能和强大的网页内容爬取功能。缺点是笔记的组织和编辑功能较弱。
我的基地
如果用户需要尽可能多的工具/功能来处理笔记,Mybase 是首选。在我看来,Mybase 是 Keynote 的现代风格演变。两者在视觉和感觉上都非常相似。其界面简洁高效,通过多标签多面板有效扩展其功能,并拥有多种处理笔记的工具。我已经使用 Keynote 很长时间了,过渡到 Mybase 非常顺利。(此外,KeyNote 在处理笔记方面也非常丰富)。
Mybase的整理笔记的形式也是最简单的树形结构,也是大多数同类软件的标准思路。也就是说,在这方面,Mybase 不追求个性,而是保持共性。在最新的 v5 版本中,Mybase 增加了一个标签功能——有点像印象笔记的分类,或者其他软件的关键词。它基于分类树提供了一个额外的组织维度。但它的效果与专用于此的工具(如Zoot、Evernote)相去甚远。当然,最好的部分是 Mybase 是一个(如果不是唯一的)可以同时具有树和标签功能的软件。这就是 Mybase 的风格和优势:最大的功能和选项,最大的可定制性。为了让您最直观的了解其功能,
正如我们所说,Mybase 使用了很多面板,因此用于显示笔记信息的桌面空间较少。这与某些软件相反。与 Surfulater 一样,它使用超链接、web 样式的功能来处理引用、链接、附件等。在 Mybase 中,这些元素显示在主界面下的单独子窗口/面板中:结构树、注释正文、搜索结果、附件列表,以及指向其他注释的链接。有些人觉得这很不舒服,但其他用户可能会喜欢这种分离——我就是其中之一。对于一些常见的面板,比如附件和其他笔记的链接,可以通过选项设置自动显示:如果笔记有附件或者外链,就会显示;如果没有,这些面板将被隐藏。这时候灵活设置就很实用了,可以最大化桌面空间。
Mybase 还可以为 Firefox 或 IE 抓取网页内容,但不能达到 Evernote 或 Surfulater 的水平。首先,抓取内容不像其他两个软件那样被视为普通笔记。让我解释一下,对于每个笔记,Mybase 都有两个选项卡“文本笔记”和“网页”。如果是爬取的网页内容,Mybase 会自动切换到网页标签。对于其他类型的笔记,无论是粘贴还是手动输入,都在“文本笔记”选项卡下。
附件:Mybase 开发者补充:myBase 中的所有内容都保存为节点的附件文件。所谓的便笺(note)也是另存为附件文件,只是被命名为带有.RTF扩展名的特殊项目,一般不显示。而其他内容,比如抓取的网页,直接保存为附件,在附件列表中可以看到网页中的HTML/JS/style/image等元素。因此,输入内容和抓取的网页内容一般是分开显示的;这种设计为系统扩展带来了极大的便利性、灵活性和统一性。其实如果需要将笔记写入网页,可以在网页中按F2或者选择Edit -> Toggle Edit Mode菜单项直接输入或编辑网页内容,这样便笺可以与捕获的网页显示在同一页面中。在页面上。
因此,您无法将笔记与网页结合起来。基于此,我认为 Evernote 和 Surfulater 具有更好的抓取能力。另一个美中不足的是,Mybase 使用 IE 而不是内置的 web 引擎来显示抓取的 web 内容。因此,当你切换到网页标签时,程序会调用 IE 并会出现片刻的停顿。当然,这个问题并不严重,只是没有其他软件集成那么流畅。
附:Mybase开发者补充:目前大部分软件都嵌入了IE来显示网页,不同的是有些软件一启动就加载IE浏览器,而myBase只在需要浏览网页时加载IE,所以有第一次浏览网页的时候稍微停顿一下,然后就很流畅了,这样做的目的是为了尽量减少内存和系统资源的使用。
Mybase V5还开发了实时搜索功能。这是一个有价值的功能,而且效果很好。诚然,它并不完全在 Evernote 的水平上,但至少它是可用的。同样,这也是Mybase的比较优势:虽然不是每一个功能都达到了所有软件在这方面的最高水平,但至少可以让用户在一个软件中拥有这么多的功能。
附:Mybase开发者补充:在最新的myBase v5.3中,专门改写了索引模块和搜索技术,增加了resizable cache技术,提供了比较高的索引性能,支持增加Volume index ,大数据量索引,即时搜索和布尔条件(AND/OR/NOT),并提供对常用WORD/EXCEL/HTML/PPT/EMAI/TEXT/RTF等文档的预设索引和搜索支持,还可以识别通过安装第三方过滤器(例如 PDF 文档)获得更多文档格式。此外,myBase 还提供了一定的中文搜索支持(但并不完善)。总的来说,我们目前正在开发的索引技术已经远远超过了其他公司。您可以使用稍大的数据进行一些测试,例如超过 100MB 的可索引数据。可以看出,我们为改进这项技术付出了比较大的努力。当然,我们还需要进一步改进。
Mybase 还提供了一些扩展的组织功能。它可以链接项目,允许多个笔记相互引用。也可以进行符号链接,这样当用户单击结构树中的注释 A 时,它会直接转到它所链接的注释 B,就像快捷方式一样。我还没有完全理解这个功能的作用,但同样,它总比没有好。(译者注:应该用于一个笔记进入多个树分支,相当于一个笔记进入印象笔记中的多个类别)然后,它还可以自定义标签(label),就像笔记的关键词就像(译者注:更准确地说是一个标签),当你点击关键词时,Mybase会列出所有属于这个关键词的笔记。就像我说的,它为组织笔记提供了一个新的维度。
如您所见,Mybase 是同类软件中最灵活、功能最丰富的软件之一。与Mybase相比,其他软件可能更具创新性,在某些方面可能更强大,但没有一个软件可以同时拥有Mybase那么多的笔记处理功能。重申一下,之前使用过 KeyNote 的用户可以顺利过渡到 Mybase。正因为如此,我现在开始使用 Mybase 作为我目前的笔记工具。然后,最终决定使用哪种软件取决于具体情况。
硫酸盐
Surfulater 最初的目的是作为网络抓取和书目管理工具,然后 - 并且合乎逻辑地 - 进入了笔记软件类别。由于这个历史原因,它的界面与其他笔记软件有很大不同。也就是说,本课题涉及的其他软件一开始都是以记笔记为核心功能开发的,而记笔记只是Surfulater的功能之一,并不是最初的主导功能。
作为内容抓取(网络抓取只是其中之一)和书目管理工具,Surfulater 比其他任何人都做得更好。如果您想要方便而强大的链接、文档管理和收录素材,Surfulate 是最好的选择。以下场景是对 Surfulater 的最佳描述:您在 Internet 上搜索某个主题的信息,然后找到一个网页,其中收录您需要的信息和大量相关站点的链接。这就是 Surfulater 软件所做的,而且非常轻松。您可以采集各种信息,拖放,将数据、链接和附件放在一起。不一会儿,您就可以得到一个完整的信息系统,带有格式良好的网页显示页面和链接。你需要的一切都在这里。
Surfulater 最大的优势是自动完成重复性任务。Surfulater在爬取一个网页后,会自动填写标题、描述、原创来源链接和爬取日期。它甚至会创建原创网页的缩略图。用户可以将其他笔记拖到当前笔记上以创建快速参考。相同的操作适用于附件。和印象笔记一样,所有的笔记也是排成一排,一个接一个。不过,它的队列线程不像印象笔记那样受限于时间,所以灵活多了。
最让我感兴趣的是 Surfulater 的结构树。乍一看,似乎中规中矩,并没有什么出众之处。但事实上,它拥有目前所有软件中最好的后端引擎。它实际上是一个虚拟树结构,可以配置不同的选项。笔记可以根据用户需要显示为树状,也可以像印象笔记一样按时间顺序排列。您还可以使结构树不展开最后一个分支,使结构树只显示目录,而不显示注释条目。一个重要的消息是,开发者提到在新版本中,用户将被允许自定义树状结构,这意味着一个笔记可以进入多个类别。
另一个突出的特点是 Surfulater 可以克隆笔记项目。乍一看,它似乎与复制具有相同的效果。但实际上,它们是非常不同的。克隆出来的副本实际上是一种镜像:它不会重复占用存储空间,而是可以在逻辑上放到另一个类别中,并且实时保持一致。例如,修改其中任何一个,其他克隆将同时更新。最后,一个不错的功能是搜索结果在树结构的末尾列为虚拟树分支。用户可以浏览和滚动搜索结果,就像普通的树和注释一样。当然,命中 关键词 也像 Evernote 一样突出显示。对于搜索结果,印象笔记也是纵向分组的,但我觉得建立一个列表可以让用户更容易查阅。
接下来是一个小功能,为笔记或分支节点设置图标,Surfulater 在这方面做得很好,与其他软件相比它相形见绌。用户只需要在图标上单击鼠标右键,然后会弹出一个小窗口,显示所有可用的图标,然后单击他们想要选择的那个。(注意 1)
接下来说说Surfulater作为笔记软件的不足之处。造成这些缺点的主要原因是 Surfulater 的初衷不是做笔记。如果您想编辑笔记,在大多数笔记软件中,只需单击笔记并开始输入。但在 Surfulater,这条路已经死了。您必须在编辑模式和常规模式之间手动切换——这常常让新手感到困惑。进入编辑模式的一种方法是用鼠标点击输入框几秒钟,也就是不要像普通软件那样点击,而是按住。进入编辑模式的另一种方法是单击每个项目旁边的铅笔图标。值得庆幸的是,作者意识到了这个问题,并进行了改进,并承诺在未来进行进一步的改进。但是,我还是坚持这个原则:
另一个缺点是 Surfulater 中没有空格可以直接做笔记。Surfulater 中的任何 文章(又名笔记)都基于预定义的模板。这些模板有标题来保存标题、评论、评级、参考……。这些功能非常有利于学术研究的管理和组织;但是对于普通用户,特别是当他们只是想记下一些东西时,这是一个极其不方便的限制。现在可以做的是选择一个“笔记模板”,它只有一个标题信息,就是“笔记”,主体部分完全空白,用户在这里做笔记。如下所示:
Surfulat 成为真正的笔记工具的底线是在上述两个方面进行改进:提供默认启用或禁用编辑模式的选项,并提供完全空白的笔记区域。正是在这些方面,Surfulater 必须更接近标准——并且被证明是最有效的——笔记软件风格。
总体而言,Surfulater 功能丰富且风格独特,非常适合引用、导航和抓取大量笔记。以我的理解和判断,律师、学者可能非常欣赏。究其原因,想想其鲜明的特点就明白了。以下场景也可以说明谁最适合它:如果你现在正在使用 Evernote,但发现它在组织管理方面还不够强大,那么转向 Surfulater 是明智之举。或者,如果您正在使用任何其他基于最基本树结构的笔记软件,并且对链接和引用感到不知所措,您也可以求助于 Surfulater。
三强功能对照表
前三名的笔记软件的优缺点已经一一讨论过了,相信读者已经知道了。如果仍然不清楚,请参阅下表。俗话说,不怕不识货,只怕比货。此表并未涵盖所有功能,但可能会有所帮助。
笔记本三强功能对照表
印象笔记
我的基地
硫酸盐
同时打开多个数据库
√
√
实时搜索(输入后立即开始搜索)
√
√
基本树结构
√
√
标签/类别
√
√
滚动
√
√
加密
√
√
链接到其他笔记
√
√
按时间顺序显示
√
笔记2
√
超强大的导入/导出功能
√ 查看全部
excel自动抓取网页数据(《寻找最好的笔记软件:海选篇》的综合分析)
版本1.0 编译xbeta/善用佳软自
寻找最好的笔记软件:前三名(EverNote、Mybase、Surfulater)v1.0
作者:SuperboyAC 编译:xbeta 本系列还包括:海选篇、前三篇、梦想篇、结论篇、额外篇
通过对上一篇《寻找最好的笔记软件:Auditions》的综合分析,笔者发现优势明显的软件有3种,可谓“前三名的笔记软件”。它们是:EverNote、Mybase 和 Surfulate。这三者之间的区别是相同的,但它们是各自风格中最强的。三者如何选择,并不取决于哪一个“更强大”,而取决于你是什么样的用户,或者你有什么样的需求。
印象笔记
如果您需要一个方便的地方来存储您的笔记,而不需要太多的组织功能和冗余功能,那么 EverNote 是您的最佳选择。你可以这样理解,EverNote 就是一张无限长的纸卷,上面记录着你所有的笔记,唯一的排列顺序就是按照时间。每个笔记甚至没有标题——这是其他笔记软件的经验法则。听起来很不方便,我怎样才能找到以前的笔记?EverNote 作为一款优秀的软件,完美解决了你的后顾之忧,你在使用的过程中没有任何不便,而且你根本不会意识到这是个问题。
解决方案,即定位/过滤笔记的方法,有分类和实时搜索两种方法。分类功能如图所示,笔记可以手动分类,也可以自动规则分类。
类别可以排列成树状结构,但这与其他类似程序的树状结构不同。因为一个笔记可以分为多个类别。另一种查找笔记的方法是使用实时搜索框。这个功能在 EverNote 中实现得如此完美,是迄今为止我在任何软件中看到的最好的,而且速度超级快。当您键入每个字母时,所有匹配的注释都会在下方动态显示。不仅如此,所有匹配的单词都会被突出显示。
如前所述,所有注释都排列在一个列中。要上下滚动,可以点击右侧的滚动框,滚动速度取决于点击的位置。或者,您可以使用右侧的“时间栏”功能。它相当于一个垂直日历,你只需要点击一个日期,就可以显示相关的笔记。如果日期旁边有√,则表示该日期有注释。我觉得用这个功能做电子日记真的很方便。
Evernote 还可以轻松抓取任何内容,尤其是各种网络内容。准确地说,在三巨头中,它拥有最强大的网页内容爬取能力。它不仅准确地捕捉范围,而且当内容进入印象笔记时,它看起来就像一个笔记,而不是一个网页:鼠标变成一只小手,点击一下就会带你到一个链接。在 EverNote 中,如果你想访问一个链接,你需要双击。我从来没有迷恋过网络点击式入侵软件界面。还记得 Windows 何时将单击模式引入操作系统界面吗?我不习惯,所以每次都得关掉。顺便说一句,Mybase 和 Surfulater 都是点击模式。Mybase 这样做是因为它使用 IE 引擎来显示网页;Surfulate 这样做是因为它的界面从头到尾都是网页风格。
在剪辑方面,还是有一些不足的地方。要真正对笔记进行一些格式化和文本组织,您需要进入全屏模式。这时候,这个笔记单独显示在一个大窗口中,带有一个rtf标准工具栏,方便编辑。而在常规窗口中,几乎没有编辑按钮。您要么进入全屏模式,要么进入右键菜单。此外,图片缩放功能也比较奇怪。
总而言之,印象笔记是“记住和检查”软件类别中最好的。它最大的优势在于一流的实时搜索功能和强大的网页内容爬取功能。缺点是笔记的组织和编辑功能较弱。
我的基地
如果用户需要尽可能多的工具/功能来处理笔记,Mybase 是首选。在我看来,Mybase 是 Keynote 的现代风格演变。两者在视觉和感觉上都非常相似。其界面简洁高效,通过多标签多面板有效扩展其功能,并拥有多种处理笔记的工具。我已经使用 Keynote 很长时间了,过渡到 Mybase 非常顺利。(此外,KeyNote 在处理笔记方面也非常丰富)。
Mybase的整理笔记的形式也是最简单的树形结构,也是大多数同类软件的标准思路。也就是说,在这方面,Mybase 不追求个性,而是保持共性。在最新的 v5 版本中,Mybase 增加了一个标签功能——有点像印象笔记的分类,或者其他软件的关键词。它基于分类树提供了一个额外的组织维度。但它的效果与专用于此的工具(如Zoot、Evernote)相去甚远。当然,最好的部分是 Mybase 是一个(如果不是唯一的)可以同时具有树和标签功能的软件。这就是 Mybase 的风格和优势:最大的功能和选项,最大的可定制性。为了让您最直观的了解其功能,
正如我们所说,Mybase 使用了很多面板,因此用于显示笔记信息的桌面空间较少。这与某些软件相反。与 Surfulater 一样,它使用超链接、web 样式的功能来处理引用、链接、附件等。在 Mybase 中,这些元素显示在主界面下的单独子窗口/面板中:结构树、注释正文、搜索结果、附件列表,以及指向其他注释的链接。有些人觉得这很不舒服,但其他用户可能会喜欢这种分离——我就是其中之一。对于一些常见的面板,比如附件和其他笔记的链接,可以通过选项设置自动显示:如果笔记有附件或者外链,就会显示;如果没有,这些面板将被隐藏。这时候灵活设置就很实用了,可以最大化桌面空间。
Mybase 还可以为 Firefox 或 IE 抓取网页内容,但不能达到 Evernote 或 Surfulater 的水平。首先,抓取内容不像其他两个软件那样被视为普通笔记。让我解释一下,对于每个笔记,Mybase 都有两个选项卡“文本笔记”和“网页”。如果是爬取的网页内容,Mybase 会自动切换到网页标签。对于其他类型的笔记,无论是粘贴还是手动输入,都在“文本笔记”选项卡下。
附件:Mybase 开发者补充:myBase 中的所有内容都保存为节点的附件文件。所谓的便笺(note)也是另存为附件文件,只是被命名为带有.RTF扩展名的特殊项目,一般不显示。而其他内容,比如抓取的网页,直接保存为附件,在附件列表中可以看到网页中的HTML/JS/style/image等元素。因此,输入内容和抓取的网页内容一般是分开显示的;这种设计为系统扩展带来了极大的便利性、灵活性和统一性。其实如果需要将笔记写入网页,可以在网页中按F2或者选择Edit -> Toggle Edit Mode菜单项直接输入或编辑网页内容,这样便笺可以与捕获的网页显示在同一页面中。在页面上。
因此,您无法将笔记与网页结合起来。基于此,我认为 Evernote 和 Surfulater 具有更好的抓取能力。另一个美中不足的是,Mybase 使用 IE 而不是内置的 web 引擎来显示抓取的 web 内容。因此,当你切换到网页标签时,程序会调用 IE 并会出现片刻的停顿。当然,这个问题并不严重,只是没有其他软件集成那么流畅。
附:Mybase开发者补充:目前大部分软件都嵌入了IE来显示网页,不同的是有些软件一启动就加载IE浏览器,而myBase只在需要浏览网页时加载IE,所以有第一次浏览网页的时候稍微停顿一下,然后就很流畅了,这样做的目的是为了尽量减少内存和系统资源的使用。
Mybase V5还开发了实时搜索功能。这是一个有价值的功能,而且效果很好。诚然,它并不完全在 Evernote 的水平上,但至少它是可用的。同样,这也是Mybase的比较优势:虽然不是每一个功能都达到了所有软件在这方面的最高水平,但至少可以让用户在一个软件中拥有这么多的功能。
附:Mybase开发者补充:在最新的myBase v5.3中,专门改写了索引模块和搜索技术,增加了resizable cache技术,提供了比较高的索引性能,支持增加Volume index ,大数据量索引,即时搜索和布尔条件(AND/OR/NOT),并提供对常用WORD/EXCEL/HTML/PPT/EMAI/TEXT/RTF等文档的预设索引和搜索支持,还可以识别通过安装第三方过滤器(例如 PDF 文档)获得更多文档格式。此外,myBase 还提供了一定的中文搜索支持(但并不完善)。总的来说,我们目前正在开发的索引技术已经远远超过了其他公司。您可以使用稍大的数据进行一些测试,例如超过 100MB 的可索引数据。可以看出,我们为改进这项技术付出了比较大的努力。当然,我们还需要进一步改进。
Mybase 还提供了一些扩展的组织功能。它可以链接项目,允许多个笔记相互引用。也可以进行符号链接,这样当用户单击结构树中的注释 A 时,它会直接转到它所链接的注释 B,就像快捷方式一样。我还没有完全理解这个功能的作用,但同样,它总比没有好。(译者注:应该用于一个笔记进入多个树分支,相当于一个笔记进入印象笔记中的多个类别)然后,它还可以自定义标签(label),就像笔记的关键词就像(译者注:更准确地说是一个标签),当你点击关键词时,Mybase会列出所有属于这个关键词的笔记。就像我说的,它为组织笔记提供了一个新的维度。
如您所见,Mybase 是同类软件中最灵活、功能最丰富的软件之一。与Mybase相比,其他软件可能更具创新性,在某些方面可能更强大,但没有一个软件可以同时拥有Mybase那么多的笔记处理功能。重申一下,之前使用过 KeyNote 的用户可以顺利过渡到 Mybase。正因为如此,我现在开始使用 Mybase 作为我目前的笔记工具。然后,最终决定使用哪种软件取决于具体情况。
硫酸盐
Surfulater 最初的目的是作为网络抓取和书目管理工具,然后 - 并且合乎逻辑地 - 进入了笔记软件类别。由于这个历史原因,它的界面与其他笔记软件有很大不同。也就是说,本课题涉及的其他软件一开始都是以记笔记为核心功能开发的,而记笔记只是Surfulater的功能之一,并不是最初的主导功能。
作为内容抓取(网络抓取只是其中之一)和书目管理工具,Surfulater 比其他任何人都做得更好。如果您想要方便而强大的链接、文档管理和收录素材,Surfulate 是最好的选择。以下场景是对 Surfulater 的最佳描述:您在 Internet 上搜索某个主题的信息,然后找到一个网页,其中收录您需要的信息和大量相关站点的链接。这就是 Surfulater 软件所做的,而且非常轻松。您可以采集各种信息,拖放,将数据、链接和附件放在一起。不一会儿,您就可以得到一个完整的信息系统,带有格式良好的网页显示页面和链接。你需要的一切都在这里。
Surfulater 最大的优势是自动完成重复性任务。Surfulater在爬取一个网页后,会自动填写标题、描述、原创来源链接和爬取日期。它甚至会创建原创网页的缩略图。用户可以将其他笔记拖到当前笔记上以创建快速参考。相同的操作适用于附件。和印象笔记一样,所有的笔记也是排成一排,一个接一个。不过,它的队列线程不像印象笔记那样受限于时间,所以灵活多了。
最让我感兴趣的是 Surfulater 的结构树。乍一看,似乎中规中矩,并没有什么出众之处。但事实上,它拥有目前所有软件中最好的后端引擎。它实际上是一个虚拟树结构,可以配置不同的选项。笔记可以根据用户需要显示为树状,也可以像印象笔记一样按时间顺序排列。您还可以使结构树不展开最后一个分支,使结构树只显示目录,而不显示注释条目。一个重要的消息是,开发者提到在新版本中,用户将被允许自定义树状结构,这意味着一个笔记可以进入多个类别。
另一个突出的特点是 Surfulater 可以克隆笔记项目。乍一看,它似乎与复制具有相同的效果。但实际上,它们是非常不同的。克隆出来的副本实际上是一种镜像:它不会重复占用存储空间,而是可以在逻辑上放到另一个类别中,并且实时保持一致。例如,修改其中任何一个,其他克隆将同时更新。最后,一个不错的功能是搜索结果在树结构的末尾列为虚拟树分支。用户可以浏览和滚动搜索结果,就像普通的树和注释一样。当然,命中 关键词 也像 Evernote 一样突出显示。对于搜索结果,印象笔记也是纵向分组的,但我觉得建立一个列表可以让用户更容易查阅。
接下来是一个小功能,为笔记或分支节点设置图标,Surfulater 在这方面做得很好,与其他软件相比它相形见绌。用户只需要在图标上单击鼠标右键,然后会弹出一个小窗口,显示所有可用的图标,然后单击他们想要选择的那个。(注意 1)
接下来说说Surfulater作为笔记软件的不足之处。造成这些缺点的主要原因是 Surfulater 的初衷不是做笔记。如果您想编辑笔记,在大多数笔记软件中,只需单击笔记并开始输入。但在 Surfulater,这条路已经死了。您必须在编辑模式和常规模式之间手动切换——这常常让新手感到困惑。进入编辑模式的一种方法是用鼠标点击输入框几秒钟,也就是不要像普通软件那样点击,而是按住。进入编辑模式的另一种方法是单击每个项目旁边的铅笔图标。值得庆幸的是,作者意识到了这个问题,并进行了改进,并承诺在未来进行进一步的改进。但是,我还是坚持这个原则:
另一个缺点是 Surfulater 中没有空格可以直接做笔记。Surfulater 中的任何 文章(又名笔记)都基于预定义的模板。这些模板有标题来保存标题、评论、评级、参考……。这些功能非常有利于学术研究的管理和组织;但是对于普通用户,特别是当他们只是想记下一些东西时,这是一个极其不方便的限制。现在可以做的是选择一个“笔记模板”,它只有一个标题信息,就是“笔记”,主体部分完全空白,用户在这里做笔记。如下所示:
Surfulat 成为真正的笔记工具的底线是在上述两个方面进行改进:提供默认启用或禁用编辑模式的选项,并提供完全空白的笔记区域。正是在这些方面,Surfulater 必须更接近标准——并且被证明是最有效的——笔记软件风格。
总体而言,Surfulater 功能丰富且风格独特,非常适合引用、导航和抓取大量笔记。以我的理解和判断,律师、学者可能非常欣赏。究其原因,想想其鲜明的特点就明白了。以下场景也可以说明谁最适合它:如果你现在正在使用 Evernote,但发现它在组织管理方面还不够强大,那么转向 Surfulater 是明智之举。或者,如果您正在使用任何其他基于最基本树结构的笔记软件,并且对链接和引用感到不知所措,您也可以求助于 Surfulater。
三强功能对照表
前三名的笔记软件的优缺点已经一一讨论过了,相信读者已经知道了。如果仍然不清楚,请参阅下表。俗话说,不怕不识货,只怕比货。此表并未涵盖所有功能,但可能会有所帮助。
笔记本三强功能对照表
印象笔记
我的基地
硫酸盐
同时打开多个数据库
√
√
实时搜索(输入后立即开始搜索)
√
√
基本树结构
√
√
标签/类别
√
√
滚动
√
√
加密
√
√
链接到其他笔记
√
√
按时间顺序显示
√
笔记2
√
超强大的导入/导出功能
√
excel自动抓取网页数据(把DataFrame转换成HTML表格的方法,读取Excel中的表格数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-23 01:23
前言
说到用 Pandas 导出数据,应该想到 to.xxx 系列函数。
其中比较常用的是pd.to_csv()和pd.to_excel()。但其实也可以导入成Html网页格式,这里用到的函数是pd.to_html()!
读取 Excel
今天我们要将Excel转成html格式,首先需要读取Excel中的表格数据。
import pandas as pd
data = pd.read_excel("测试.xlsx")
查看数据
data.head()
让我们学习如何将 DataFrame 转换为 HTML 表格。
生成 HTML
to_html()函数只需一行代码就可以直接将DataFrame转换成HTML表格:
html_table = data.to_html("测试.html")
运行上述代码后,工作目录下多了一个test.html文件,用浏览器打开,内容如下
print(data.to_html())
通过打印可以看到DataFrame的内部结构自动转换成,,标签嵌入表格中,保留所有内部层次结构。
格式化
我们也可以自定义修改参数来调整生成的HTML的格式。
html_table = data.to_html("测试.html",header = True,index = False,justify="center")
再次打开新生成的test.html文件,发现格式变了。
如果要对格式做进一步的调整(添加标题、修改颜色等),需要一些HTML知识,可以在生成的测试.html文件中调整文本。
对于一些可能需要展示页面的小伙伴来说,使用Flask库是很有必要的。
总结
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常有用。一种很容易将复杂的数据结构(例如 DataFrames)转换为 HTML 表格;另一种不需要复杂的爬虫,只需几行代码就可以抓取Table表数据,简直就是神器!
今天的篇幅很短,主要讲Pandas中的to_html()函数。使用这个功能最大的好处是我们可以在不了解HTML知识的情况下生成表格HTML。
总结
这里是文章关于如何使用pandas将Excel转为html格式的介绍。更多相关pandas将Excel转html格式,请在云海天教程前搜索文章或继续浏览以下相关文章希望大家以后多多支持云海天教程! 查看全部
excel自动抓取网页数据(把DataFrame转换成HTML表格的方法,读取Excel中的表格数据)
前言
说到用 Pandas 导出数据,应该想到 to.xxx 系列函数。
其中比较常用的是pd.to_csv()和pd.to_excel()。但其实也可以导入成Html网页格式,这里用到的函数是pd.to_html()!
读取 Excel
今天我们要将Excel转成html格式,首先需要读取Excel中的表格数据。
import pandas as pd
data = pd.read_excel("测试.xlsx")
查看数据
data.head()
让我们学习如何将 DataFrame 转换为 HTML 表格。
生成 HTML
to_html()函数只需一行代码就可以直接将DataFrame转换成HTML表格:
html_table = data.to_html("测试.html")
运行上述代码后,工作目录下多了一个test.html文件,用浏览器打开,内容如下
print(data.to_html())
通过打印可以看到DataFrame的内部结构自动转换成,,标签嵌入表格中,保留所有内部层次结构。
格式化
我们也可以自定义修改参数来调整生成的HTML的格式。
html_table = data.to_html("测试.html",header = True,index = False,justify="center")
再次打开新生成的test.html文件,发现格式变了。
如果要对格式做进一步的调整(添加标题、修改颜色等),需要一些HTML知识,可以在生成的测试.html文件中调整文本。
对于一些可能需要展示页面的小伙伴来说,使用Flask库是很有必要的。
总结
Pandas 提供 read_html() 和 to_html() 函数用于读取和写入 html 文件。这两个功能非常有用。一种很容易将复杂的数据结构(例如 DataFrames)转换为 HTML 表格;另一种不需要复杂的爬虫,只需几行代码就可以抓取Table表数据,简直就是神器!
今天的篇幅很短,主要讲Pandas中的to_html()函数。使用这个功能最大的好处是我们可以在不了解HTML知识的情况下生成表格HTML。
总结
这里是文章关于如何使用pandas将Excel转为html格式的介绍。更多相关pandas将Excel转html格式,请在云海天教程前搜索文章或继续浏览以下相关文章希望大家以后多多支持云海天教程!
excel自动抓取网页数据(软件特色风越网页批量填写数据提取软件,可自动分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-23 01:20
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。还可以扩展到批量注册、投票、留言、产品闪购、舆论引导、刷信用、抢牌等工具。
软件功能
风月网页批量填充数据提取软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
预防措施
软件需要.NET framework2.0运行环境,如果无法运行请安装【.NET Framework2.0简体中文版】 查看全部
excel自动抓取网页数据(软件特色风越网页批量填写数据提取软件,可自动分析)
风月网页批量填表数据提取软件可以自动分析网页中已经填好的内容,并保存为填表规则。下载指定的网页链接文件。还可以扩展到批量注册、投票、留言、产品闪购、舆论引导、刷信用、抢牌等工具。
软件功能
风月网页批量填充数据提取软件支持更多类型的页面填充和控制元素,精度更高。其他表单填写工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于普通办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆论引导、刷信、抢牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量输入
支持下载指定文件和抓取网页文本内容
在支持多帧框架的页面中填充控件元素
在支持嵌入框架 iframe 的页面中填充控件元素
支持网页结构分析,显示控件描述,便于分析修改控件值
支持填写各种页面控制元素:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框单选
支持单选框
支持填充级联下拉菜单
支持无ID控件填写
预防措施
软件需要.NET framework2.0运行环境,如果无法运行请安装【.NET Framework2.0简体中文版】
excel自动抓取网页数据(你能明白我一定要抓到表格里吗?PowerQuery处理你可能不知道 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-23 01:20
)
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
❶ 获取 JSON 数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接
01
脚步
❶ 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
❷电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
❸配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
❹ 添加超链接
至此所有数据都已处理完毕,但如果要查看原创知乎页面,则需要复制此超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞最多的;
❹点击【点击查看】,享受跳线的感觉!
02
总结
知道在表格中搜索的好处吗?
❶ 按“赞”和“评论”排序;
❷ 看过文章的可以加个栏目写笔记;
❸您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。
查看全部
excel自动抓取网页数据(你能明白我一定要抓到表格里吗?PowerQuery处理你可能不知道
)
一时兴起,在知乎中搜索了Excel,想学习一些好评文章的写作方法。
看到这些标题,完结了,顿时激起了下载采集的欲望!
如何捕获所有 文章 高度喜欢的?
当我开始时,我考虑过使用 Python。
想了想,好像可以用Power query来实现,于是做了如下效果。
在表单中输入搜索词,然后右键刷新,即可得到搜索结果。
你明白我必须拿表格吗?
因为Excel可以直接按照“点赞数”排序!
那种感觉就像在排队。无论我在哪里排队,我都会是第一个并选择最好的!
好了,废话不多说,我们来看看这个表格是怎么做出来的。
大致可以分为4个步骤:
❶ 获取 JSON 数据连接;
❷ 电源查询处理数据;
❸ 配置搜索地址;
❹ 添加超链接
01
脚步
❶ 获取 JSON 数据连接
通常在浏览网页时,它是一个简单的网址。
网页中看到的数据其实有一个单独的数据链接,可以在浏览器中找到。
我们需要的数据链接对应的是JSON格式的数据,如下所示。
找到方法需要进入开发者模式,然后查看数据的网络变化,找到xhr类型的链接,其中之一就是数据传输连接。
复制此链接,这是 Power 查询将获取数据的链接。
❷电源查询处理
你可能不知道,除了在 Excel 中捕获数据,Power Query 还可以
您还可以抓取多种类型的数据,例如 SQL 和 Access:
网站Data 也是其中之一:
将我们之前获取的链接粘贴到PQ中,链接就可以抓取数据了。
然后得到网页的数据格式。如何获取具体的 文章 数据?
Power Query的强大之处在于它可以自动识别json数据格式,并解析提取具体内容。
整个过程,我们不需要做任何操作,只需点击鼠标即可完成。
这时候我们获取的数据会有一些不必要的冗余数据。
例如:thumbnail_info(缩略图信息)、relationship、question、id.1等。
只需删除它们并仅保留所需的 文章 标题、作者、超链接等。
数据处理完成后,在开始选项卡中,点击“关闭并上传”即可完成数据抓取,非常简单。
❸配置搜索地址
但是,此时我们抓取的数据是固定的,没有办法根据我们输入的关键词进行更新。
这是因为数据超链接中收录的搜索词没有更新。
所以在这一步中,我们需要配置这个数据链接,实现基于搜索词的动态更新。
在表中创建一个新数据,然后将其加载到 Power 查询中。
然后获取搜索词,以变量的形式放入搜索地址中,完成搜索地址的配置。
修改后的地址码如下:
getdata = (page)=>
let
keywords = 搜索词[ 搜索词]{0},
源 = Json.Document(Web.Contents("https://www.zhihu.com/api/v4/s ... mp%3B keywords & "&correction=1&offset="& Text.From(page*20) &"&limit=20&random=" & Text.From(Number.Random()))),
data = 源[data],
jsondata = Table.FromList(data, Splitter.SplitByNothing(), null, null, ExtraValues.Error)
in
jsondata,
转换为表 = Table.Combine(List.Transform({1..10}, getdata)),
▲ 左右滑动查看
❹ 添加超链接
至此所有数据都已处理完毕,但如果要查看原创知乎页面,则需要复制此超链接并在浏览器中打开。
每次点击几次鼠标很麻烦;
这里我们使用 HYPERLINK 函数来生成一个可点击的超链接,这使得访问变得更加容易。
❺ 最终效果
最后的效果是:
❶ 输入搜索词;
❷ 右键刷新;
❸ 找到点赞最多的;
❹点击【点击查看】,享受跳线的感觉!
02
总结
知道在表格中搜索的好处吗?
❶ 按“赞”和“评论”排序;
❷ 看过文章的可以加个栏目写笔记;
❸您可以过滤您喜欢的“作者”等。
明白为什么,精英都是Excel控制的吧?
大多数电子表格用户仍然使用 Excel 作为报告工具、绘制表格和编写公式。
请记住以下 Excel 新功能。这些功能让Excel成为了一个强大的数据统计和数据分析软件,不再只是你印象中的报表。
excel自动抓取网页数据(运营精细化如何通过品牌沉淀的数据挖掘出更多优化可能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-23 01:18
前言
随着运营的精细化发展,如何通过品牌积累的数据挖掘更多的优化可能性,是每一个运营、产品乃至技术的必修课。本篇文章将主要讲解我是如何分析官网流量数据,从发现问题、猜测、验证猜测、事件分类四个方面找出问题的。
(本文出现的工具有CNZZ后端和Excel2013)
本次以朋友的网站作为演示数据,选取2016年7月25日至2016年8月7日,分别为2016年第31周和第32周的数据。周数据是因为网站刚结束第32周的付费广告投放,所以网站的流量存在巨大差异,属于典型。CNZZ的后台流量如图:
选择图右下方的“更多指标”,选择当前核心指标,如PV、UV、平均访问时长、跳出率;图中,“小时”改为“天”。
然后我们通过观察图上半部分的对比数据来提问:
1、为什么两周的流量数据大面积变差了?如何找出原因是哪一天或哪一列?
2、为什么独立访问者(UV)和新独立访问者(NUV)的差异大约是4.5倍,而浏览量(PV)的差异只有1.5倍?
3、为什么两周内UV趋势(橙线)相似,而PV趋势(蓝线)在7-26和7-29有波谷和波峰?
目前我们所知道的最大变化是付费广告在第 31 周开启,在第 32 周关闭。8-1号关门时间是几点?是早上关门还是下班后关门?网站该负责人表示“好像是8-1的早上”,但分析师不相信“好像”,只能通过数据来验证。
这时,我们可以做出的合理猜测是(猜测问题1=d1,下同):
d1:两周流量数据大面积变差,因为关闭了广告,但是CNZZ显示的具体小时和栏目数据无法直观得出,具体数据需要分析。
d2:UV和NUV的区别类似。可能本周的数据增长大部分来自新的独立访问者,而着陆页对新访问者的吸引力不是很大,因此大多数新访问者并没有产生更多的点击,这也解释了为什么第一次跳出率在 32 周时增加。
d3:7-26对应8-2,7-29对应8-5。分别出现的波峰和波谷的原因没有记录在SEO日志表中。我们暂时无法给出猜测,只能查看具体数据。
网站日志中只记录8-1封闭付费推广
猜测前先问问网站的负责人,网站近期有没有修改或者变化,有没有忘记记录的事情,其他部门有没有做过任何线下促销等,合理猜测 网站 日志记录的已知条件和分析师经验。
在Excel中打开CNZZ记录的两周访问详情(出于隐私考虑,将主域名改为我的微信feels),根据以下猜测进行分析:
1、付费广告到底是什么时候停止的?
过滤日期(8-1~8-7)中的第32周数据,过滤“页面来源”(标有“ipinyou”的站点)中标记的付费来源链接,确认,结果如图所示图。
最后一个带付费标签的来源时间是2016-8-1 9:56:43,推断负责人是周一上班后10:00左右关闭的付费广告早晨。
2、在这次流量变化中,关闭付费广告的影响有多大?
选择所有 7-25~8-7 以访问详细数据并创建新的数据透视表。
将“页面来源”和“访问页面”放在行中,将“周数”放在列中,将“IP”放在值计数中,观察两周的整体数据对比,发现自然流量+付费流量为7141-2745=4396,然后过滤付费链接流量的差异,得到付费广告的影响。
在“页面来源”和“采访页面”两个字段中使用标签“不收录”过滤掉付费标签“ipinyou”,如图:
现在我们得出结果,第31周和第32周的付费流量相差7141-3834=3307,2745-2593=152,这就是切换付费广告对网站@的流量的具体影响>。那么网站流量变化都是付费流量切换引起的?通过上图中的计算结果,我们知道并非如此。排除付费流量,我们还是有3834-2593=1241的自然流量差。是什么原因?
3、您的自然流量中有多少是您自己公司的用户?
请网络管理员了解公司的网线是否分多条线,公司所有主机当前对应的IP地址或IP段是多少。因为选择时间长,不可能知道当时公司的内部IP段,所以忽略了这一步。
4、自然流量的差异是由哪些页面和哪些时间段造成的?
将字段“日期”和“小时”添加到行,选择降序,调整值显示方式比较32周的差异,选择区域中的值,更改条件格式→项目选择规则→前10项,填充粉色,重复这一步,选择最后10项,用黄色填充,最终效果如图。
(粉色代表页面31周数据多于32周,如“直接访问书签”31周源流量多于32周;黄色表示页面32周数据多于31周,如“”32周比 31 周多 32 个源流量1)
发现正值相差超过200的页面有“”、“”、“”,负值超过200的页面有“”。
分析步骤相同。我们以“”页面为例。为什么这个页面在 31 周内比在 32 周内多出 267 次?将“IP”、“访问者新旧属性”、“访问页面”、“区域”等字段一次放入进行中,日期降序排列如图:
从“”、“”、“”三个页面可以发现,这三个页面的流量来自于7日-29日早上6:00。
同时我们发现了一个可疑的IP字段,用了两天的“222.16.42.***”,看看这个IP段到底是什么,所以在“IP”字段中过滤掉“222.16.42.***”
有趣的是,这个IP段只在第31周每天早上6点到7点之间活跃,如图:
因此得出结论,31周和32周的自然流量差异是由2016年7月29日早上6-7点之间的“”、“”、“”三个页面造成的,访问用户都是新访客。,而且这些页面不是内容页面,访问时间也不规律。目前缺少条件,所以只能推断human > machine,放入事件数据库,然后观察。
5、5、唯一身份访问者(UV)和新唯一身份访问者(NUV)之差约为4.5倍,而浏览量(PV)之差仅为1. 5次,是不是因为付费广告落地页不符合用户体验。如果是这样,新老访问者输出了多少PV?
根据“新老访问者属性”字段统计,新老用户分别在31周和32周贡献了7141和2745的流量,约等于页面浏览量(PV)值。
点击查看大图
然后我们分别过滤新老用户的流量值,老用户流量值为2915和1895,如图:
新增用户流量值为4226和850,如图:
最后我们发现全站每周流量变化为7146/2745=2.60;老用户周流量变化为2915/1895=1.54;新用户周流量变化为4226/850=5.00。
新用户PV数的变化≈两周内新增独立访问者数量的变化,因此我们可以得出结论,第31周的数据增长大部分来自新的独立访问者。推测是落地页对新访问者的吸引力不是很大,或者是定位目标人群。不精确。(也可以通过受访页面数据的付费链接跳出率分析来分析哪个页面最差,相应的改进就不赘述了,留给读者自己思考)
6、流量趋势中,7-26对应8-2,有流量谷。是单页造成的吗?
对比 7-26 和 8-2 的流量,我们发现是因为 8-2 的全站流量下降,而不是单页造成的。
那为什么在8-2这一天整个流量都下降了呢?当我带着这个奇怪的现象再次询问网站的负责人时,他想了想说:“哦,对不起,我忘了告诉你,8-2号台风“奈达”来了,公司放假一天。” 哈哈,我抓到了一个忘记写网站日记的人。让我们通过新老用户的流量变化来检查一下。
新用户流量变化如图,过渡平稳:
老用户流量变化如图:8日和2日流量当天大幅下降,确实是老用户造成的。来自企业员工的访问占自然流量的很大一部分。
总而言之,我们已经验证了所有提出的猜测。
在整个过程中,你应该已经发现,所有的分析逻辑都是从大到小,从整体流量趋势开始,找出哪一周、哪一天、哪一小时、哪一栏、哪一页有问题。从已知记录中做出合理的猜测,然后用数据验证猜测。过程中没有高深的技巧,只要有一颗心把问题问到底。
在例子中,很多人理所当然地认为,32周相比31周流量大幅下降是因为付费广告关闭,不再继续分析,而忽略了一个大问题——整体流量下降确实不代表所有列。流量下降了,如图:
为什么在整体流量下降的情况下,32周的“”页面却显着增加?流程我就不写了,直接给结论吧,因为从第8-4天9点28分开始,技术已经在这个页面设置了内容采集,并且自动从其他站,每隔一分钟发布一次,证据如图:
通过Excel中的数据分析,可以发现很多问题,甚至有同事用流量宝刷流量,被我曝光了……本次分享只列出了一些常用的分析方法和逻辑,旨在让大家感受一下看看Excel在数据分析中的作用。
对于分析师来说,什么是“事件分类”?换言之,就是积累的“经验”。比如每逢节假日,网站的流量会有怎样的变化,公司的宣传对流量的增加影响最大,而一旦停止广告,网站的真实流量又从哪里来?来自等,将这些经历记录在笔记中。,随着时间的推移从初学者成长为高级分析师。但话又说回来,总会有你无法通过 Excel 猜测或分析的问题,比如爬虫模拟人类行为、设置不同的 UA、时不时爬取等等。当你遇到暂时无法解决的问题时,有一个“难题库”,
最后要说的是,Excel作为最流行的数据分析工具,门槛低、功能强、性价比高。只要你保持强烈的好奇心和一点软件技能,每个人都可以成为数据分析师。
针鼹 说
这个文章是一个案例,也是一个方法,几乎手把手的告诉你如何通过数据定位问题。
爱奇菌经常在后台收到朋友的提问:
最近点击量突然增加,但转化率并没有提高。是否有恶意点击?
最近网站的流量突然下降了,但是我什么都没做,为什么会这样?...等等。
那么结论大致就是:“一定是恶意点击!” 或者“淡季来了”或者“X度系统又用尽了……”
在得出这些结论之前,您是否从客观数据中推断出您想要的答案?
爱奇菌建议大家按照作者的思路,拿自己账户的数据,进行一些分析和推敲,相信会有很大收获。 查看全部
excel自动抓取网页数据(运营精细化如何通过品牌沉淀的数据挖掘出更多优化可能)
前言
随着运营的精细化发展,如何通过品牌积累的数据挖掘更多的优化可能性,是每一个运营、产品乃至技术的必修课。本篇文章将主要讲解我是如何分析官网流量数据,从发现问题、猜测、验证猜测、事件分类四个方面找出问题的。
(本文出现的工具有CNZZ后端和Excel2013)
本次以朋友的网站作为演示数据,选取2016年7月25日至2016年8月7日,分别为2016年第31周和第32周的数据。周数据是因为网站刚结束第32周的付费广告投放,所以网站的流量存在巨大差异,属于典型。CNZZ的后台流量如图:
选择图右下方的“更多指标”,选择当前核心指标,如PV、UV、平均访问时长、跳出率;图中,“小时”改为“天”。
然后我们通过观察图上半部分的对比数据来提问:
1、为什么两周的流量数据大面积变差了?如何找出原因是哪一天或哪一列?
2、为什么独立访问者(UV)和新独立访问者(NUV)的差异大约是4.5倍,而浏览量(PV)的差异只有1.5倍?
3、为什么两周内UV趋势(橙线)相似,而PV趋势(蓝线)在7-26和7-29有波谷和波峰?
目前我们所知道的最大变化是付费广告在第 31 周开启,在第 32 周关闭。8-1号关门时间是几点?是早上关门还是下班后关门?网站该负责人表示“好像是8-1的早上”,但分析师不相信“好像”,只能通过数据来验证。
这时,我们可以做出的合理猜测是(猜测问题1=d1,下同):
d1:两周流量数据大面积变差,因为关闭了广告,但是CNZZ显示的具体小时和栏目数据无法直观得出,具体数据需要分析。
d2:UV和NUV的区别类似。可能本周的数据增长大部分来自新的独立访问者,而着陆页对新访问者的吸引力不是很大,因此大多数新访问者并没有产生更多的点击,这也解释了为什么第一次跳出率在 32 周时增加。
d3:7-26对应8-2,7-29对应8-5。分别出现的波峰和波谷的原因没有记录在SEO日志表中。我们暂时无法给出猜测,只能查看具体数据。
网站日志中只记录8-1封闭付费推广
猜测前先问问网站的负责人,网站近期有没有修改或者变化,有没有忘记记录的事情,其他部门有没有做过任何线下促销等,合理猜测 网站 日志记录的已知条件和分析师经验。
在Excel中打开CNZZ记录的两周访问详情(出于隐私考虑,将主域名改为我的微信feels),根据以下猜测进行分析:
1、付费广告到底是什么时候停止的?
过滤日期(8-1~8-7)中的第32周数据,过滤“页面来源”(标有“ipinyou”的站点)中标记的付费来源链接,确认,结果如图所示图。
最后一个带付费标签的来源时间是2016-8-1 9:56:43,推断负责人是周一上班后10:00左右关闭的付费广告早晨。
2、在这次流量变化中,关闭付费广告的影响有多大?
选择所有 7-25~8-7 以访问详细数据并创建新的数据透视表。
将“页面来源”和“访问页面”放在行中,将“周数”放在列中,将“IP”放在值计数中,观察两周的整体数据对比,发现自然流量+付费流量为7141-2745=4396,然后过滤付费链接流量的差异,得到付费广告的影响。
在“页面来源”和“采访页面”两个字段中使用标签“不收录”过滤掉付费标签“ipinyou”,如图:
现在我们得出结果,第31周和第32周的付费流量相差7141-3834=3307,2745-2593=152,这就是切换付费广告对网站@的流量的具体影响>。那么网站流量变化都是付费流量切换引起的?通过上图中的计算结果,我们知道并非如此。排除付费流量,我们还是有3834-2593=1241的自然流量差。是什么原因?
3、您的自然流量中有多少是您自己公司的用户?
请网络管理员了解公司的网线是否分多条线,公司所有主机当前对应的IP地址或IP段是多少。因为选择时间长,不可能知道当时公司的内部IP段,所以忽略了这一步。
4、自然流量的差异是由哪些页面和哪些时间段造成的?
将字段“日期”和“小时”添加到行,选择降序,调整值显示方式比较32周的差异,选择区域中的值,更改条件格式→项目选择规则→前10项,填充粉色,重复这一步,选择最后10项,用黄色填充,最终效果如图。
(粉色代表页面31周数据多于32周,如“直接访问书签”31周源流量多于32周;黄色表示页面32周数据多于31周,如“”32周比 31 周多 32 个源流量1)
发现正值相差超过200的页面有“”、“”、“”,负值超过200的页面有“”。
分析步骤相同。我们以“”页面为例。为什么这个页面在 31 周内比在 32 周内多出 267 次?将“IP”、“访问者新旧属性”、“访问页面”、“区域”等字段一次放入进行中,日期降序排列如图:
从“”、“”、“”三个页面可以发现,这三个页面的流量来自于7日-29日早上6:00。
同时我们发现了一个可疑的IP字段,用了两天的“222.16.42.***”,看看这个IP段到底是什么,所以在“IP”字段中过滤掉“222.16.42.***”
有趣的是,这个IP段只在第31周每天早上6点到7点之间活跃,如图:
因此得出结论,31周和32周的自然流量差异是由2016年7月29日早上6-7点之间的“”、“”、“”三个页面造成的,访问用户都是新访客。,而且这些页面不是内容页面,访问时间也不规律。目前缺少条件,所以只能推断human > machine,放入事件数据库,然后观察。
5、5、唯一身份访问者(UV)和新唯一身份访问者(NUV)之差约为4.5倍,而浏览量(PV)之差仅为1. 5次,是不是因为付费广告落地页不符合用户体验。如果是这样,新老访问者输出了多少PV?
根据“新老访问者属性”字段统计,新老用户分别在31周和32周贡献了7141和2745的流量,约等于页面浏览量(PV)值。
点击查看大图
然后我们分别过滤新老用户的流量值,老用户流量值为2915和1895,如图:
新增用户流量值为4226和850,如图:
最后我们发现全站每周流量变化为7146/2745=2.60;老用户周流量变化为2915/1895=1.54;新用户周流量变化为4226/850=5.00。
新用户PV数的变化≈两周内新增独立访问者数量的变化,因此我们可以得出结论,第31周的数据增长大部分来自新的独立访问者。推测是落地页对新访问者的吸引力不是很大,或者是定位目标人群。不精确。(也可以通过受访页面数据的付费链接跳出率分析来分析哪个页面最差,相应的改进就不赘述了,留给读者自己思考)
6、流量趋势中,7-26对应8-2,有流量谷。是单页造成的吗?
对比 7-26 和 8-2 的流量,我们发现是因为 8-2 的全站流量下降,而不是单页造成的。
那为什么在8-2这一天整个流量都下降了呢?当我带着这个奇怪的现象再次询问网站的负责人时,他想了想说:“哦,对不起,我忘了告诉你,8-2号台风“奈达”来了,公司放假一天。” 哈哈,我抓到了一个忘记写网站日记的人。让我们通过新老用户的流量变化来检查一下。
新用户流量变化如图,过渡平稳:
老用户流量变化如图:8日和2日流量当天大幅下降,确实是老用户造成的。来自企业员工的访问占自然流量的很大一部分。
总而言之,我们已经验证了所有提出的猜测。
在整个过程中,你应该已经发现,所有的分析逻辑都是从大到小,从整体流量趋势开始,找出哪一周、哪一天、哪一小时、哪一栏、哪一页有问题。从已知记录中做出合理的猜测,然后用数据验证猜测。过程中没有高深的技巧,只要有一颗心把问题问到底。
在例子中,很多人理所当然地认为,32周相比31周流量大幅下降是因为付费广告关闭,不再继续分析,而忽略了一个大问题——整体流量下降确实不代表所有列。流量下降了,如图:
为什么在整体流量下降的情况下,32周的“”页面却显着增加?流程我就不写了,直接给结论吧,因为从第8-4天9点28分开始,技术已经在这个页面设置了内容采集,并且自动从其他站,每隔一分钟发布一次,证据如图:
通过Excel中的数据分析,可以发现很多问题,甚至有同事用流量宝刷流量,被我曝光了……本次分享只列出了一些常用的分析方法和逻辑,旨在让大家感受一下看看Excel在数据分析中的作用。
对于分析师来说,什么是“事件分类”?换言之,就是积累的“经验”。比如每逢节假日,网站的流量会有怎样的变化,公司的宣传对流量的增加影响最大,而一旦停止广告,网站的真实流量又从哪里来?来自等,将这些经历记录在笔记中。,随着时间的推移从初学者成长为高级分析师。但话又说回来,总会有你无法通过 Excel 猜测或分析的问题,比如爬虫模拟人类行为、设置不同的 UA、时不时爬取等等。当你遇到暂时无法解决的问题时,有一个“难题库”,
最后要说的是,Excel作为最流行的数据分析工具,门槛低、功能强、性价比高。只要你保持强烈的好奇心和一点软件技能,每个人都可以成为数据分析师。
针鼹 说
这个文章是一个案例,也是一个方法,几乎手把手的告诉你如何通过数据定位问题。
爱奇菌经常在后台收到朋友的提问:
最近点击量突然增加,但转化率并没有提高。是否有恶意点击?
最近网站的流量突然下降了,但是我什么都没做,为什么会这样?...等等。
那么结论大致就是:“一定是恶意点击!” 或者“淡季来了”或者“X度系统又用尽了……”
在得出这些结论之前,您是否从客观数据中推断出您想要的答案?
爱奇菌建议大家按照作者的思路,拿自己账户的数据,进行一些分析和推敲,相信会有很大收获。
excel自动抓取网页数据(UiPath的DataScraping(数据抓取)功能,鼠标点击几下!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2022-01-20 23:10
UiPath的DataScraping(数据抓取)功能,只需点击几下鼠标,即可实现浏览器、应用程序或文档界面的结构化数据,功能强大!
有两种爬取方式: a. 自动爬取整个表格内容;湾。根据需要爬取所需的列内容和列内容的URL(超链接URL)。
这个功能用的不多,但是还是很有用的,而且里面有一些小技巧,特此介绍。
一、数据抓取
数据抓取允许您将结构化数据从浏览器、应用程序或文档中提取到数据库、.csv 文件甚至 Excel 电子表格中。
注意:
建议在 Internet Explorer 11 及更高版本、Mozilla Firefox 50 或更高版本或最新版本的 Google Chrome 上使用此功能。
结构化数据是以可预测的方式呈现的高度组织化的特殊信息。
例如,所有 Google 搜索结果都具有相同的结构:顶部的链接、URL 字符串和网页描述。
这种结构使 Studio 可以轻松提取信息,因为它始终知道在哪里可以找到信息。
二、数据抓取向导的关键步骤
1. 打开要从中提取数据的网页、文档或应用程序界面,单击“设计”选项卡中的“数据采集”按钮,
打开阵列抓取向导:
单击下一步,然后选择要抓取的数据的第一个单元格的内容:
然后 Studio 会自动检测您是否指示了表格单元格并询问您是否要提取整个表格:
然后单击完成以转到步骤 5。
点击下一步,返回采集数据界面,点击同类型或同列的第二条数据,
选择后,Studio 可以推断出信息的模式,进入下面的界面。
2. 自定义列标题并选择是否提取 URL。
3.点击下一步进入预览数据界面,编辑最大提取结果数,然后改变列的顺序:
4.(可选)如果您需要获取其他列,请单击提取相关数据按钮。这允许您再次执行提取向导(同样需要两次单击相同类型的数据)以提取其他信息并将其作为新列添加到同一个表中。
5. 表示网页、应用程序或文档中的“下一步”按钮(如果要提取的信息跨越多个页面)。
在这里你需要告诉Think,如果你需要它来帮助你点击下一页以便采集所有数据。如果选择是,则需要单击“下一步”按钮,否则单击否以完成向导。
完成向导后,会在 Studio 中生成一个序列:
数据抓取始终会生成一个容器(“附加浏览器”或“附加窗口”),其中收录用于顶级窗口的选择器,以及带有部分选择器的提取结构化数据活动,以确保正确识别要抓取的应用程序。
此外,“Extract Structured Data”活动还有一个自动生成的XML字符串(在ExtractMetadata属性中,自动生成的内容很简单,手动逐列抓取的内容稍微复杂一些,幸好两者都是自动生成的,没有非常注意),字符串表示要提取的数据。
最后,所有抓取的信息都存储在你定义的DataTable变量中(上图中的ExtractDataTable)。接下来,您可以使用变量 ExtractDataTable 保存到数据库、csv 文件或 Excel 电子表格。
三、可能的问题
网页文件是用html编写的,网页上看到的文字可能会被包裹在多层代码中进行格式化。如果捕获了不适当的层,则可能无法捕获所需的 URL,例如:
抓取包裹文本所在的图层,可以抓取网址,而不是包裹所在的图层,比如单元格。
四、总结
如果需要爬取网址,只能使用第二种方法(按需获取列)。 查看全部
excel自动抓取网页数据(UiPath的DataScraping(数据抓取)功能,鼠标点击几下!)
UiPath的DataScraping(数据抓取)功能,只需点击几下鼠标,即可实现浏览器、应用程序或文档界面的结构化数据,功能强大!
有两种爬取方式: a. 自动爬取整个表格内容;湾。根据需要爬取所需的列内容和列内容的URL(超链接URL)。
这个功能用的不多,但是还是很有用的,而且里面有一些小技巧,特此介绍。
一、数据抓取
数据抓取允许您将结构化数据从浏览器、应用程序或文档中提取到数据库、.csv 文件甚至 Excel 电子表格中。
注意:
建议在 Internet Explorer 11 及更高版本、Mozilla Firefox 50 或更高版本或最新版本的 Google Chrome 上使用此功能。
结构化数据是以可预测的方式呈现的高度组织化的特殊信息。
例如,所有 Google 搜索结果都具有相同的结构:顶部的链接、URL 字符串和网页描述。
这种结构使 Studio 可以轻松提取信息,因为它始终知道在哪里可以找到信息。
二、数据抓取向导的关键步骤
1. 打开要从中提取数据的网页、文档或应用程序界面,单击“设计”选项卡中的“数据采集”按钮,
打开阵列抓取向导:
单击下一步,然后选择要抓取的数据的第一个单元格的内容:
然后 Studio 会自动检测您是否指示了表格单元格并询问您是否要提取整个表格:
然后单击完成以转到步骤 5。
点击下一步,返回采集数据界面,点击同类型或同列的第二条数据,
选择后,Studio 可以推断出信息的模式,进入下面的界面。
2. 自定义列标题并选择是否提取 URL。
3.点击下一步进入预览数据界面,编辑最大提取结果数,然后改变列的顺序:
4.(可选)如果您需要获取其他列,请单击提取相关数据按钮。这允许您再次执行提取向导(同样需要两次单击相同类型的数据)以提取其他信息并将其作为新列添加到同一个表中。
5. 表示网页、应用程序或文档中的“下一步”按钮(如果要提取的信息跨越多个页面)。
在这里你需要告诉Think,如果你需要它来帮助你点击下一页以便采集所有数据。如果选择是,则需要单击“下一步”按钮,否则单击否以完成向导。
完成向导后,会在 Studio 中生成一个序列:
数据抓取始终会生成一个容器(“附加浏览器”或“附加窗口”),其中收录用于顶级窗口的选择器,以及带有部分选择器的提取结构化数据活动,以确保正确识别要抓取的应用程序。
此外,“Extract Structured Data”活动还有一个自动生成的XML字符串(在ExtractMetadata属性中,自动生成的内容很简单,手动逐列抓取的内容稍微复杂一些,幸好两者都是自动生成的,没有非常注意),字符串表示要提取的数据。
最后,所有抓取的信息都存储在你定义的DataTable变量中(上图中的ExtractDataTable)。接下来,您可以使用变量 ExtractDataTable 保存到数据库、csv 文件或 Excel 电子表格。
三、可能的问题
网页文件是用html编写的,网页上看到的文字可能会被包裹在多层代码中进行格式化。如果捕获了不适当的层,则可能无法捕获所需的 URL,例如:
抓取包裹文本所在的图层,可以抓取网址,而不是包裹所在的图层,比如单元格。
四、总结
如果需要爬取网址,只能使用第二种方法(按需获取列)。

