
输入关键字 抓取所有网页
输入关键字 抓取所有网页(如何在新浪搜索主页面中获取关键词的url链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-24 11:08
前段时间写了一个爬虫。在新浪主搜索页面,输入关键词,抓取关键词相关新闻的标题、发布时间、url、关键词和内容。并根据内容提取摘要,计算相似度。下面说明我自己的想法,并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取该页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词获取新的url,发送new url 请求,获取页面的源代码。缺点:对于动态网页,URL是这样获取的,发送请求获取的网页源码与搜索界面手动输入关键词获取的网页源码不一致.
2)动态爬取
模拟浏览器行为并抓取 关键词 新闻相关页面。有两种方法,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是使用浏览器来模拟没有界面的浏览器的行为。关键词 页面的 URL 和源代码。如图,进入搜索首页,输入关键词跳转到搜索结果页面。
2、分析关键词新闻页面信息
1)找到搜索到的新闻文章数,根据一页新闻数量计算出与关键词相关的新闻有多少页。找出不同页面的url之间的链接,生成翻页url。
如上图,新闻界面出现“7651条相关新闻”。使用正则匹配等方法得到'7651',根据新浪新闻搜索页面的一页出现的新闻m数计算相关新闻页数:Int(7651/m)。
2)在一个页面中,找到新闻的url。
查看页面源码,找到新闻对应的url。如上图所示,当新闻url出现时,同样的规则是"",所以可以按照这个规则提取页面源码中的所有url。
3、从新闻页面中提取信息
根据新闻url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取。需要注意的一件事是解码问题。网页的源代码有不同的编码格式,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方法。根据新闻内容,计算内容中的词频,用词频确定输出词为关键词;
2) 新闻中的抽象生成基于石木博客的代码(链接如下:)。
3)关键词 与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键词和标题
关键字和标题都收录与输入词相关的词,权重为kT_W=0.8;只有标题收录输入词,相关词被赋予权重kT_W=0.7;only the key 词收录与输入词相关的词,权重为kT_W=0.6;其他权重是 kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频content_P
c) 最终的相似度计算公式为:
4、代码(运行环境python)
代码链接:
安装好相关模块后,附上需要下载的文件和代码中需要的文件。并给出对应的python2和python3代码 查看全部
输入关键字 抓取所有网页(如何在新浪搜索主页面中获取关键词的url链接)
前段时间写了一个爬虫。在新浪主搜索页面,输入关键词,抓取关键词相关新闻的标题、发布时间、url、关键词和内容。并根据内容提取摘要,计算相似度。下面说明我自己的想法,并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取该页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词获取新的url,发送new url 请求,获取页面的源代码。缺点:对于动态网页,URL是这样获取的,发送请求获取的网页源码与搜索界面手动输入关键词获取的网页源码不一致.
2)动态爬取
模拟浏览器行为并抓取 关键词 新闻相关页面。有两种方法,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是使用浏览器来模拟没有界面的浏览器的行为。关键词 页面的 URL 和源代码。如图,进入搜索首页,输入关键词跳转到搜索结果页面。

2、分析关键词新闻页面信息
1)找到搜索到的新闻文章数,根据一页新闻数量计算出与关键词相关的新闻有多少页。找出不同页面的url之间的链接,生成翻页url。

如上图,新闻界面出现“7651条相关新闻”。使用正则匹配等方法得到'7651',根据新浪新闻搜索页面的一页出现的新闻m数计算相关新闻页数:Int(7651/m)。
2)在一个页面中,找到新闻的url。

查看页面源码,找到新闻对应的url。如上图所示,当新闻url出现时,同样的规则是"",所以可以按照这个规则提取页面源码中的所有url。
3、从新闻页面中提取信息
根据新闻url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取。需要注意的一件事是解码问题。网页的源代码有不同的编码格式,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方法。根据新闻内容,计算内容中的词频,用词频确定输出词为关键词;
2) 新闻中的抽象生成基于石木博客的代码(链接如下:)。
3)关键词 与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键词和标题
关键字和标题都收录与输入词相关的词,权重为kT_W=0.8;只有标题收录输入词,相关词被赋予权重kT_W=0.7;only the key 词收录与输入词相关的词,权重为kT_W=0.6;其他权重是 kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频content_P

c) 最终的相似度计算公式为:

4、代码(运行环境python)
代码链接:
安装好相关模块后,附上需要下载的文件和代码中需要的文件。并给出对应的python2和python3代码
输入关键字 抓取所有网页(一个神器之一selenium五年发表文章五年数量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-24 11:06
PubMed 是一个提供生物医学论文检索和摘要的数据库,可以免费检索。它是生物学中经常使用的文档搜索网站。最近在学习爬虫,包括urllib库、requests库、xpath表达式、scrapy框架等,刚想爬PubMed,作为一个实践,准备爬取过去5年在PubMed上发表的文章文章的数量根据搜索到的关键词,以此为基础来看看这个研究方向近五年的热度。
最初的想法是使用scrapy框架进行爬取和存储。于是打开PubMed,开始分析网页组成、源码等,发现NCBI使用的是动态网页,在进行翻页、关键字搜索等操作时,URL并没有发生变化。于是想到了爬虫神器之一的selenium模块,利用selenium模拟搜索、翻页等操作,然后分析源码,得到想要的信息。由于和selenium接触不多,所以暂时在网上搜索了一些功能。
1、 加载需要的模块
import urllib
import time
import matplotlib.pyplot as plt
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
2、使用关键字构造URL
手动输入几个关键字来分析 URL 的结构。
PubMed的原链接是``,当你输入搜索'cancer, TCGA, Breast'时,url变成''。所以不难分析,URL由两部分组成,一部分不变,另一部分由我们搜索的关键字串起来的字符串'%2C'组成。因此,对于传入的'keyword',我们可以做如下处理,拼接到搜索后返回的url中
keyword = '%2C'.join(keyword)
tart_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
url = start_url + keyword
这样我们就简单的拼接返回的url。
3、创建浏览器对象
下一步就是使用selenium模块打开我们的Chrome浏览器,跳转到url界面。这个操作相信大家都不陌生。因为后面会进行模拟点击翻页等操作,所以需要实例化一个WebDriverWait对象,方便后续调用
browser = webdriver.Chrome()
self.browser.get(url)
wait = WebDriverWait(browser, 10)
模拟点击网页
打开网页后,我们需要模拟点击网页。首先,我们需要找到过去五年的文章,所以我们需要模拟点击左边的5years按钮,改变单页显示的文章的数量。变成200,可以减少我们的翻页操作
QQ图片246.png
我们要等到网页上加载了相应的元素才可以点击,所以我们需要用到前面提到的WebDriverWait对象。代码显示如下
years =wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH,'//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
此处使用了 CSS 选择器和 Xpath 表达式。您使用哪一种取决于您的个人喜好。您可以使用任何您觉得方便的方式。EC.element_to_be_clickable 中的输入是一个元组,第一个元素是声明使用哪个选择器,第二个元素是一个表达式。这个函数的意思是等到你在表达式中传入的元素出现在网页上之后,才会在selenium中出现时才会进行后续的操作。在使用selenium的过程中,有很多地方需要用到presence_of_element_located、text_to_be_present_in_element等类似的操作,有兴趣的可以上网查查。
解析网页并提取信息
下一步是解析网页。我使用 lxml 来解析网页并从 Xpath 中提取信息。代码如下
html = self.browser.page_source
doc = etree.HTML(self.html)
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
这里主要是对网页中的年份进行Xpath提取和字符串切片处理,从而获取年份信息并保存到列表中。在实际操作中发现了少量其他不相关的元素。经过仔细排查,发现是网页源代码有问题。因此,遵循常规过程以删除不以“2”开头的元素。最终结果被检查是正确的。
这里我们提取了单个页面的信息。
翻页操作
我们还需要翻页以获取我们想要的所有信息。硒模块仍在使用。
status = True
def next_page():
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
status = False
while True:
if status:
next_page()
else:
break
这里我首先定义了一个函数来判断是否可以翻页,使用异常捕获,因为翻页动作要停在最后一页,不能再次点击翻页元素。因此,在进行点击操作时应先判断。如果无法点击,会因为超时而抛出异常。next_page 函数中的状态变量记录了“下一页”按钮是否可以被点击。接下来是一个 while True 循环。只有 next_page 变为 False 时,翻页动作才会停止。在循环中,我们继续解析网页来提取信息,就可以得到我们想要的所有信息。
可视化
爬取了所有年份信息的列表后,我们还需要进一步的可视化处理来直观的判断目标话题的研究趋势,所以使用matplotlib进行可视化操作,简单的画一个折线图。代码显示如下:
def plot_curve(yearlist):
counter = Counter(yearlist)
dic = dict(counter)
keys = sorted(list(dic.keys()))
curcount = 0
y = []
temp = [int(i) for i in keys]
for i in range(min(temp), max(temp)+1):
if str(i) in keys:
curcount += self.dic[str(i)]
y.append(self.curcount)
else:
y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.plot(np.arange(min(temp), max(temp)+1), np.array(y), 'r', marker='+', linewidth=2)
plt.show()
最后贴出完整代码:
import re
import urllib
import time
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
import matplotlib.pyplot as plt
class NcbiInfo(object):
browser = webdriver.Chrome()
start_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
wait = WebDriverWait(browser, 10)
def __init__(self, keywordlist):
self.temp = [urllib.parse.quote(i) for i in keywordlist]
self.keyword = '%2C'.join(self.temp)
self.title = ' AND '.join(self.temp)
self.url = NcbiInfo.start_url + self.keyword
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
self.file = open('information.txt', 'w')
self.status = True
self.yearlist = []
def click_yearandabstract(self, ):
self.browser.get(self.url)
years = self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
page_200.click()
def get_response(self):
self.html = self.browser.page_source
self.doc = etree.HTML(self.html)
def get_numof_article(self):
article_count_ = self.doc.xpath('//*[@id="maincontent"]/div/div[3]/div[1]/h3/text()')[0]
if 'of' not in article_count_:
print(article_count_.split(': ')[1])
else:
print(article_count_.split('of ')[1])
def get_info(self):
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
def next_page(self):
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
self.status = False
def plot_curve(self):
self.counter = Counter(self.yearlist)
self.dic = dict(self.counter)
self.keys = sorted(list(self.dic.keys()))
self.curcount = 0
self.y = []
temp = [int(i) for i in self.keys]
for i in range(min(temp), max(temp)+1):
if str(i) in self.keys:
self.curcount += self.dic[str(i)]
self.y.append(self.curcount)
else:
self.y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.title(self.title)
plt.plot(np.arange(min(temp), max(temp)+1), np.array(self.y), 'r', marker='+', linewidth=2)
plt.show()
def main(self):
self.click_yearandabstract()
time.sleep(3)
self.get_response()
self.get_numof_article()
while True:
self.get_info()
self.next_page()
if self.status:
self.nextpage.click()
self.get_response()
else:
break
self.plot_curve()
if __name__ == '__main__':
a = NcbiInfo(['TCGA', 'breast', 'cancer'])
a.main()
结果如下:
图片.png 查看全部
输入关键字 抓取所有网页(一个神器之一selenium五年发表文章五年数量)
PubMed 是一个提供生物医学论文检索和摘要的数据库,可以免费检索。它是生物学中经常使用的文档搜索网站。最近在学习爬虫,包括urllib库、requests库、xpath表达式、scrapy框架等,刚想爬PubMed,作为一个实践,准备爬取过去5年在PubMed上发表的文章文章的数量根据搜索到的关键词,以此为基础来看看这个研究方向近五年的热度。
最初的想法是使用scrapy框架进行爬取和存储。于是打开PubMed,开始分析网页组成、源码等,发现NCBI使用的是动态网页,在进行翻页、关键字搜索等操作时,URL并没有发生变化。于是想到了爬虫神器之一的selenium模块,利用selenium模拟搜索、翻页等操作,然后分析源码,得到想要的信息。由于和selenium接触不多,所以暂时在网上搜索了一些功能。
1、 加载需要的模块
import urllib
import time
import matplotlib.pyplot as plt
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
2、使用关键字构造URL
手动输入几个关键字来分析 URL 的结构。
PubMed的原链接是``,当你输入搜索'cancer, TCGA, Breast'时,url变成''。所以不难分析,URL由两部分组成,一部分不变,另一部分由我们搜索的关键字串起来的字符串'%2C'组成。因此,对于传入的'keyword',我们可以做如下处理,拼接到搜索后返回的url中
keyword = '%2C'.join(keyword)
tart_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
url = start_url + keyword
这样我们就简单的拼接返回的url。
3、创建浏览器对象
下一步就是使用selenium模块打开我们的Chrome浏览器,跳转到url界面。这个操作相信大家都不陌生。因为后面会进行模拟点击翻页等操作,所以需要实例化一个WebDriverWait对象,方便后续调用
browser = webdriver.Chrome()
self.browser.get(url)
wait = WebDriverWait(browser, 10)
模拟点击网页
打开网页后,我们需要模拟点击网页。首先,我们需要找到过去五年的文章,所以我们需要模拟点击左边的5years按钮,改变单页显示的文章的数量。变成200,可以减少我们的翻页操作

QQ图片246.png
我们要等到网页上加载了相应的元素才可以点击,所以我们需要用到前面提到的WebDriverWait对象。代码显示如下
years =wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH,'//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
此处使用了 CSS 选择器和 Xpath 表达式。您使用哪一种取决于您的个人喜好。您可以使用任何您觉得方便的方式。EC.element_to_be_clickable 中的输入是一个元组,第一个元素是声明使用哪个选择器,第二个元素是一个表达式。这个函数的意思是等到你在表达式中传入的元素出现在网页上之后,才会在selenium中出现时才会进行后续的操作。在使用selenium的过程中,有很多地方需要用到presence_of_element_located、text_to_be_present_in_element等类似的操作,有兴趣的可以上网查查。
解析网页并提取信息
下一步是解析网页。我使用 lxml 来解析网页并从 Xpath 中提取信息。代码如下
html = self.browser.page_source
doc = etree.HTML(self.html)
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
这里主要是对网页中的年份进行Xpath提取和字符串切片处理,从而获取年份信息并保存到列表中。在实际操作中发现了少量其他不相关的元素。经过仔细排查,发现是网页源代码有问题。因此,遵循常规过程以删除不以“2”开头的元素。最终结果被检查是正确的。
这里我们提取了单个页面的信息。
翻页操作
我们还需要翻页以获取我们想要的所有信息。硒模块仍在使用。
status = True
def next_page():
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
status = False
while True:
if status:
next_page()
else:
break
这里我首先定义了一个函数来判断是否可以翻页,使用异常捕获,因为翻页动作要停在最后一页,不能再次点击翻页元素。因此,在进行点击操作时应先判断。如果无法点击,会因为超时而抛出异常。next_page 函数中的状态变量记录了“下一页”按钮是否可以被点击。接下来是一个 while True 循环。只有 next_page 变为 False 时,翻页动作才会停止。在循环中,我们继续解析网页来提取信息,就可以得到我们想要的所有信息。
可视化
爬取了所有年份信息的列表后,我们还需要进一步的可视化处理来直观的判断目标话题的研究趋势,所以使用matplotlib进行可视化操作,简单的画一个折线图。代码显示如下:
def plot_curve(yearlist):
counter = Counter(yearlist)
dic = dict(counter)
keys = sorted(list(dic.keys()))
curcount = 0
y = []
temp = [int(i) for i in keys]
for i in range(min(temp), max(temp)+1):
if str(i) in keys:
curcount += self.dic[str(i)]
y.append(self.curcount)
else:
y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.plot(np.arange(min(temp), max(temp)+1), np.array(y), 'r', marker='+', linewidth=2)
plt.show()
最后贴出完整代码:
import re
import urllib
import time
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
import matplotlib.pyplot as plt
class NcbiInfo(object):
browser = webdriver.Chrome()
start_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
wait = WebDriverWait(browser, 10)
def __init__(self, keywordlist):
self.temp = [urllib.parse.quote(i) for i in keywordlist]
self.keyword = '%2C'.join(self.temp)
self.title = ' AND '.join(self.temp)
self.url = NcbiInfo.start_url + self.keyword
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
self.file = open('information.txt', 'w')
self.status = True
self.yearlist = []
def click_yearandabstract(self, ):
self.browser.get(self.url)
years = self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
page_200.click()
def get_response(self):
self.html = self.browser.page_source
self.doc = etree.HTML(self.html)
def get_numof_article(self):
article_count_ = self.doc.xpath('//*[@id="maincontent"]/div/div[3]/div[1]/h3/text()')[0]
if 'of' not in article_count_:
print(article_count_.split(': ')[1])
else:
print(article_count_.split('of ')[1])
def get_info(self):
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
def next_page(self):
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
self.status = False
def plot_curve(self):
self.counter = Counter(self.yearlist)
self.dic = dict(self.counter)
self.keys = sorted(list(self.dic.keys()))
self.curcount = 0
self.y = []
temp = [int(i) for i in self.keys]
for i in range(min(temp), max(temp)+1):
if str(i) in self.keys:
self.curcount += self.dic[str(i)]
self.y.append(self.curcount)
else:
self.y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.title(self.title)
plt.plot(np.arange(min(temp), max(temp)+1), np.array(self.y), 'r', marker='+', linewidth=2)
plt.show()
def main(self):
self.click_yearandabstract()
time.sleep(3)
self.get_response()
self.get_numof_article()
while True:
self.get_info()
self.next_page()
if self.status:
self.nextpage.click()
self.get_response()
else:
break
self.plot_curve()
if __name__ == '__main__':
a = NcbiInfo(['TCGA', 'breast', 'cancer'])
a.main()
结果如下:
图片.png
输入关键字 抓取所有网页(怎么才能让商品被搜到?蜘蛛抓取就很重要了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-23 08:03
在这个互联网时代,解决问题最常用的工具就是互联网。“不懂就找妈妈”;自然这个习惯被很多商家用来在网上销售自己的产品,也就是常说的SEO,那么,自己的产品怎么能被搜索到呢?如何在首页上排名?蜘蛛爬行非常重要。
一、蜘蛛爬行网站一个必不可少的因素?
1、关键词 设置;
关键词是网站的核心,可见关键词的重要性。
2、外部链接必不可少;
seo行业有句老话“内容为王,外链为王”,外链对网站的权重也有非常重要的影响。
3、页面权重;
重量越高,自然蜘蛛就越喜欢它。这也是在强调旧域名的重要性。一般网站的首页权重最高,所以一般都是最新的(或没有收录)文章首页的调用,因为权重越高,蜘蛛爬的越深。
4、服务器;
服务器是网站的基石。如果服务器出现故障,会直接导致网站访问受限,页面加载时间过长,直接导致用户体验自然无人访问;百度蜘蛛也是网站的访问者之一,那么百度蜘蛛自然不会抓取它。
5、网站的更新;
网站 抓取的页面将被存储。如果长时间不更新,百度蜘蛛存储的数据将持续相同的时间。百度蜘蛛自然不会来爬。定期更新是必要的。;当然,最好的更新内容是原创,至少是伪原创。百度蜘蛛非常喜欢原创的内容。
6、扁平的网站结构;
百度蜘蛛抓取有自己的线路。网站 结构不要太复杂,链接层次不要太深,链接最好是静态的。
7、内链建设;
蜘蛛的爬取是跟随链接的,所以合理的网站内链可以让蜘蛛抓取更多的页面,常见的内链一般都加载在文章中。
8、404页面;
404页面非常重要。404 告诉搜索引擎这是一个错误页面。一个好的 404 页面也可以阻止客户浏览。
9、 死链检测;
死链接过多会影响网站的权重。一旦发现死链接,必须及时处理。
10、检查robots文件;
很多网站有意无意地屏蔽了百度或网站robots文件中的部分页面,但他们正在寻找蜘蛛不抓取我的页面的原因。你能怪百度吗?让别人进来,百度收录你的网页是怎么做的?所以需要不时检查网站robots文件是否正常。
11、网站地图;
搜索引擎蜘蛛非常喜欢网站 地图。网站 地图是所有链接网站 的容器。很多网站链接都有很深的层次,蜘蛛很难捕捉。网站地图可以方便搜索引擎蜘蛛抓取网站页面。通过爬取网站页面,很清楚的了解了网站的结构,所以构建一张网站地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
12、 链接提交;
记得更新后主动提交链接,自动提交代码也是必不可少的。 查看全部
输入关键字 抓取所有网页(怎么才能让商品被搜到?蜘蛛抓取就很重要了)
在这个互联网时代,解决问题最常用的工具就是互联网。“不懂就找妈妈”;自然这个习惯被很多商家用来在网上销售自己的产品,也就是常说的SEO,那么,自己的产品怎么能被搜索到呢?如何在首页上排名?蜘蛛爬行非常重要。
一、蜘蛛爬行网站一个必不可少的因素?
1、关键词 设置;
关键词是网站的核心,可见关键词的重要性。
2、外部链接必不可少;
seo行业有句老话“内容为王,外链为王”,外链对网站的权重也有非常重要的影响。
3、页面权重;
重量越高,自然蜘蛛就越喜欢它。这也是在强调旧域名的重要性。一般网站的首页权重最高,所以一般都是最新的(或没有收录)文章首页的调用,因为权重越高,蜘蛛爬的越深。
4、服务器;
服务器是网站的基石。如果服务器出现故障,会直接导致网站访问受限,页面加载时间过长,直接导致用户体验自然无人访问;百度蜘蛛也是网站的访问者之一,那么百度蜘蛛自然不会抓取它。
5、网站的更新;
网站 抓取的页面将被存储。如果长时间不更新,百度蜘蛛存储的数据将持续相同的时间。百度蜘蛛自然不会来爬。定期更新是必要的。;当然,最好的更新内容是原创,至少是伪原创。百度蜘蛛非常喜欢原创的内容。
6、扁平的网站结构;
百度蜘蛛抓取有自己的线路。网站 结构不要太复杂,链接层次不要太深,链接最好是静态的。
7、内链建设;
蜘蛛的爬取是跟随链接的,所以合理的网站内链可以让蜘蛛抓取更多的页面,常见的内链一般都加载在文章中。
8、404页面;
404页面非常重要。404 告诉搜索引擎这是一个错误页面。一个好的 404 页面也可以阻止客户浏览。
9、 死链检测;
死链接过多会影响网站的权重。一旦发现死链接,必须及时处理。
10、检查robots文件;
很多网站有意无意地屏蔽了百度或网站robots文件中的部分页面,但他们正在寻找蜘蛛不抓取我的页面的原因。你能怪百度吗?让别人进来,百度收录你的网页是怎么做的?所以需要不时检查网站robots文件是否正常。
11、网站地图;
搜索引擎蜘蛛非常喜欢网站 地图。网站 地图是所有链接网站 的容器。很多网站链接都有很深的层次,蜘蛛很难捕捉。网站地图可以方便搜索引擎蜘蛛抓取网站页面。通过爬取网站页面,很清楚的了解了网站的结构,所以构建一张网站地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
12、 链接提交;
记得更新后主动提交链接,自动提交代码也是必不可少的。
输入关键字 抓取所有网页(TextRank提取的算法,用于提取短语和自动摘要的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-23 08:01
今天要介绍的TextRank是一种用于关键词提取的算法,也可以用于词组提取和自动摘要。因为TextRank是基于PageRank的,先简单介绍一下PageRank算法。
1.PageRank 算法
PageRank 最初是为谷歌的页面排名而设计的,以公司创始人拉里佩奇的名字命名。谷歌用它来反映网页的相关性和重要性,常用于评价网页优化在搜索引擎优化操作中的有效性。PageRank 使用互联网中的超链接关系来确定网页的排名。公式是由一个投票的想法设计的:如果我们要计算网页A的PageRank值(以下简称PR值),那么我们需要知道哪些网页如果链接到网页A,意味着得到先获取网页A的链接,然后通过链接投票给网页A,计算网页A的PR值。这样的设计可以保证实现这样的效果:当一些高质量的网页指向网页A时,那么网页A的PR值会因为这些高质量的投票而增加,网页A被较少的网页指向或者被一些PR值较低的网页指向时,A的PR值不会很大大,可以合理反映一个网页的质量水平。基于以上思路,Page设计了如下公式:
在这个公式中,Vi代表某个网页,Vj代表链接到Vi的网页(即Vi的in-link),S(Vi)代表网页Vi的PR值,In(Vi)代表集合在网页 Vi 的所有 in-link 中,Out(Vj) 代表网页,d 代表阻尼系数,用于克服该公式中“d *”后部分的固有缺陷:如果只有求和部分,那么公式将无法处理非链内网页的PR值,因为此时根据公式,这些网页的PR值为0,但实际情况并非如此。添加了阻尼系数,保证每个网页的PR值都大于0。 根据实验结果,在0.85的阻尼系数下,大约100次迭代后,PR值可以收敛到一个稳定值。当阻尼系数接近1时,需要的迭代次数会突然增加,排名不会稳定。公式中S(Vj)前面的分数是指Vj指向的所有网页都应该平均分享Vj的PR值,这样你就可以为你链接的网页统计你的票数。
2.1 TextRank算法提取关键词
TextRank 是由 PageRank 改进而来,其公式有很多相似之处。下面是 TextRank 的公式:
可以看出,这个公式只比PageRank多了一个权重项Wji,用于表示两个节点之间的边连接具有不同的重要程度。TextRank用于关键词提取的算法如下:
1) 根据完整的句子对给定的文本T进行切分,即
2)对于每个句子
, 进行分词和词性标注,过滤掉停用词,只保留指定的词性词,如名词、动词、形容词,即
, 其中ti,j 为保留后的候选关键词。
3)构造候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence) 在任意两点之间构造一条边。两个节点之间只有当它们对应的词在长度为K的窗口中共同出现时才存在边。K表示窗口大小,即在大多数 K 个词可以同时出现。
4)根据上面的公式,迭代传播每个节点的权重,直到收敛。
5) 将节点权重逆序排序,得到最重要的T字作为候选关键词。
6) 从5中找出最重要的T字,并在原文中做标记。如果形成相邻的短语,则将它们组合成多个词关键词。
2.2 TextRank算法提取关键词词组
提取关键词词组的方法基于关键词提取。可以简单地认为:如果提取出的几个关键词在文本中相邻,那么它们就构成了一个提取出的关键短语。
2.3TextRank 生成摘要
将文本中的每个句子视为一个节点。如果两个句子相似,则认为这两个句子对应的节点之间存在无向右边缘。检验句子相似度的方法是以下公式:
式中,Si和Sj分别代表两个句子,Wk代表句子中的词,那么分子部分表示两个句子中同时出现的同一个词的个数,分母为词的个数在句子中对数的总和。分母的这种设计可以抑制长句在相似度计算中的优势。
我们可以根据上述相似度公式循环计算任意两个节点之间的相似度,根据阈值去除两个节点之间相似度低的边连接,构建节点连接图,然后计算TextRank值,最后所有的 TextRank 按值排序,选取 TextRank 值最高的节点对应的句子作为汇总。
参考 查看全部
输入关键字 抓取所有网页(TextRank提取的算法,用于提取短语和自动摘要的方法)
今天要介绍的TextRank是一种用于关键词提取的算法,也可以用于词组提取和自动摘要。因为TextRank是基于PageRank的,先简单介绍一下PageRank算法。
1.PageRank 算法
PageRank 最初是为谷歌的页面排名而设计的,以公司创始人拉里佩奇的名字命名。谷歌用它来反映网页的相关性和重要性,常用于评价网页优化在搜索引擎优化操作中的有效性。PageRank 使用互联网中的超链接关系来确定网页的排名。公式是由一个投票的想法设计的:如果我们要计算网页A的PageRank值(以下简称PR值),那么我们需要知道哪些网页如果链接到网页A,意味着得到先获取网页A的链接,然后通过链接投票给网页A,计算网页A的PR值。这样的设计可以保证实现这样的效果:当一些高质量的网页指向网页A时,那么网页A的PR值会因为这些高质量的投票而增加,网页A被较少的网页指向或者被一些PR值较低的网页指向时,A的PR值不会很大大,可以合理反映一个网页的质量水平。基于以上思路,Page设计了如下公式:
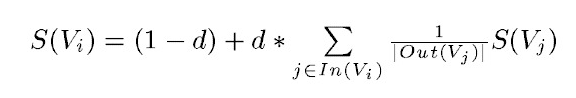
在这个公式中,Vi代表某个网页,Vj代表链接到Vi的网页(即Vi的in-link),S(Vi)代表网页Vi的PR值,In(Vi)代表集合在网页 Vi 的所有 in-link 中,Out(Vj) 代表网页,d 代表阻尼系数,用于克服该公式中“d *”后部分的固有缺陷:如果只有求和部分,那么公式将无法处理非链内网页的PR值,因为此时根据公式,这些网页的PR值为0,但实际情况并非如此。添加了阻尼系数,保证每个网页的PR值都大于0。 根据实验结果,在0.85的阻尼系数下,大约100次迭代后,PR值可以收敛到一个稳定值。当阻尼系数接近1时,需要的迭代次数会突然增加,排名不会稳定。公式中S(Vj)前面的分数是指Vj指向的所有网页都应该平均分享Vj的PR值,这样你就可以为你链接的网页统计你的票数。
2.1 TextRank算法提取关键词
TextRank 是由 PageRank 改进而来,其公式有很多相似之处。下面是 TextRank 的公式:
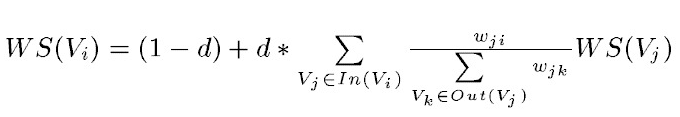
可以看出,这个公式只比PageRank多了一个权重项Wji,用于表示两个节点之间的边连接具有不同的重要程度。TextRank用于关键词提取的算法如下:
1) 根据完整的句子对给定的文本T进行切分,即

2)对于每个句子

, 进行分词和词性标注,过滤掉停用词,只保留指定的词性词,如名词、动词、形容词,即

, 其中ti,j 为保留后的候选关键词。
3)构造候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence) 在任意两点之间构造一条边。两个节点之间只有当它们对应的词在长度为K的窗口中共同出现时才存在边。K表示窗口大小,即在大多数 K 个词可以同时出现。
4)根据上面的公式,迭代传播每个节点的权重,直到收敛。
5) 将节点权重逆序排序,得到最重要的T字作为候选关键词。
6) 从5中找出最重要的T字,并在原文中做标记。如果形成相邻的短语,则将它们组合成多个词关键词。
2.2 TextRank算法提取关键词词组
提取关键词词组的方法基于关键词提取。可以简单地认为:如果提取出的几个关键词在文本中相邻,那么它们就构成了一个提取出的关键短语。
2.3TextRank 生成摘要
将文本中的每个句子视为一个节点。如果两个句子相似,则认为这两个句子对应的节点之间存在无向右边缘。检验句子相似度的方法是以下公式:
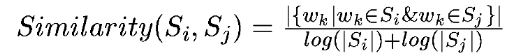
式中,Si和Sj分别代表两个句子,Wk代表句子中的词,那么分子部分表示两个句子中同时出现的同一个词的个数,分母为词的个数在句子中对数的总和。分母的这种设计可以抑制长句在相似度计算中的优势。
我们可以根据上述相似度公式循环计算任意两个节点之间的相似度,根据阈值去除两个节点之间相似度低的边连接,构建节点连接图,然后计算TextRank值,最后所有的 TextRank 按值排序,选取 TextRank 值最高的节点对应的句子作为汇总。
参考
输入关键字 抓取所有网页(从服务器打开文件的方法是使用URL请求它。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-23 07:14
从服务器打开文件的方法是使用 URL 请求它。从服务器打开文件的方法是使用 URL 请求它。事实上,在万维网诞生之初,这是获取内容的唯一途径:内容创建者将各种文件放在服务器上,而客户端将打开或下载这些文件。唯一的方法:内容创建者将各种文件放在服务器上,客户端打开或下载这些文件。 URI 和参数的动态处理是后来的发明。这就是评论者要求提供您使用的 URL 的原因。我们希望看到它并进行相应的修改,以帮助您了解需要更改哪些部分才能获得该特定文件。您可以省略密码,或将其替换为其他一些字母字符串。您可以省略密码,或将其替换为其他一些字母字符串。
通常,您想要的文件将在您使用的 url 下,但以文件名结尾。如果起始 URL 是,则此文件将位于。如果起始 URL 是,则此文件将位于。
请注意,任何参数都应该遵循路径,所以会变成 查看全部
输入关键字 抓取所有网页(从服务器打开文件的方法是使用URL请求它。。)
从服务器打开文件的方法是使用 URL 请求它。从服务器打开文件的方法是使用 URL 请求它。事实上,在万维网诞生之初,这是获取内容的唯一途径:内容创建者将各种文件放在服务器上,而客户端将打开或下载这些文件。唯一的方法:内容创建者将各种文件放在服务器上,客户端打开或下载这些文件。 URI 和参数的动态处理是后来的发明。这就是评论者要求提供您使用的 URL 的原因。我们希望看到它并进行相应的修改,以帮助您了解需要更改哪些部分才能获得该特定文件。您可以省略密码,或将其替换为其他一些字母字符串。您可以省略密码,或将其替换为其他一些字母字符串。
通常,您想要的文件将在您使用的 url 下,但以文件名结尾。如果起始 URL 是,则此文件将位于。如果起始 URL 是,则此文件将位于。
请注意,任何参数都应该遵循路径,所以会变成
输入关键字 抓取所有网页(关注回复“书籍”即可获赠Python从入门到进阶共10本电子书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-22 13:05
点击上方“Python爬虫与数据挖掘”关注
回复“books”即可领取Python入门到高级共10本电子书
今天
日
鸡肉
汤
有清明漫天,下有绿水波。
/前言/
在上一篇文章中:我们已经获得了文章详情页的链接,但是提取URL后,如何发送给Scrapy下载呢?下载完成后,我们如何调用自己定义的解析函数呢?这时候就需要Scrapy框架中的另一个类Request。具体教程如下。
/具体实现/
1、 这个Request存放在scrapy.http下,如下图,直接导入即可。
我们需要把这个Request对象交给Scrapy,然后Scrapy爬虫框架会帮我们下载。
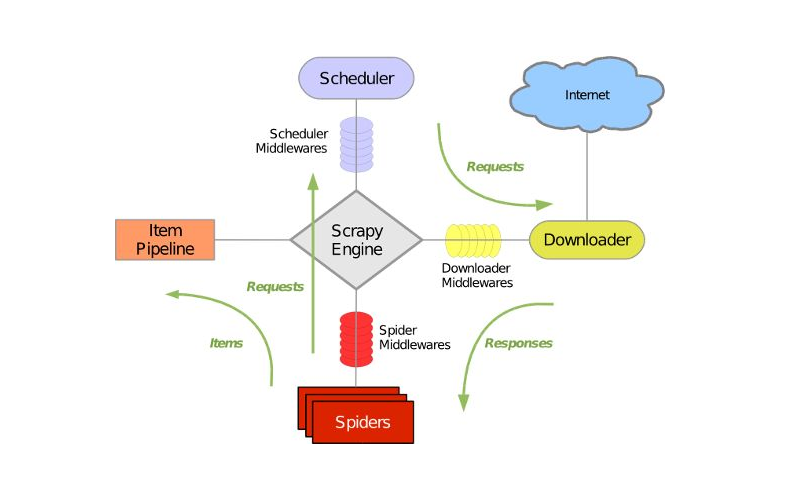
2、Request对象中,有初始化参数url和回调函数callback。当然,还有其他参数,这里就不解释了。我们将获取到的文章链接URL传递给这个初始化参数url,然后就可以构造Request了。这里需要注意的是,这个Request是文章的详情页,不是文章的列表页。对于文章详情页,那么我们需要提取每个文章的具体信息。
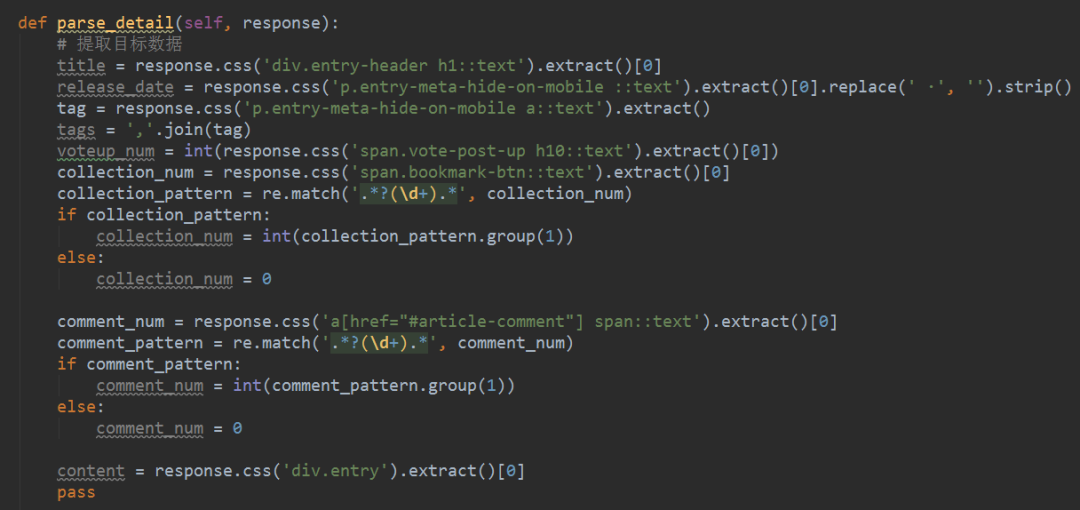
3、基于前面文章的铺垫,为了提取网页的目标信息,可以将提取的目标信息的表达部分封装成一个函数parse_detail(),作为提取文章特定字段的回调函数。下面是一个 CSS 选择器的例子,如下图所示。如果你想用 Xpath 选择器提取,没有问题。具体实现请参考文章历史文章中CSS和Xpath选择器的使用。具体实现过程这里不再赘述。
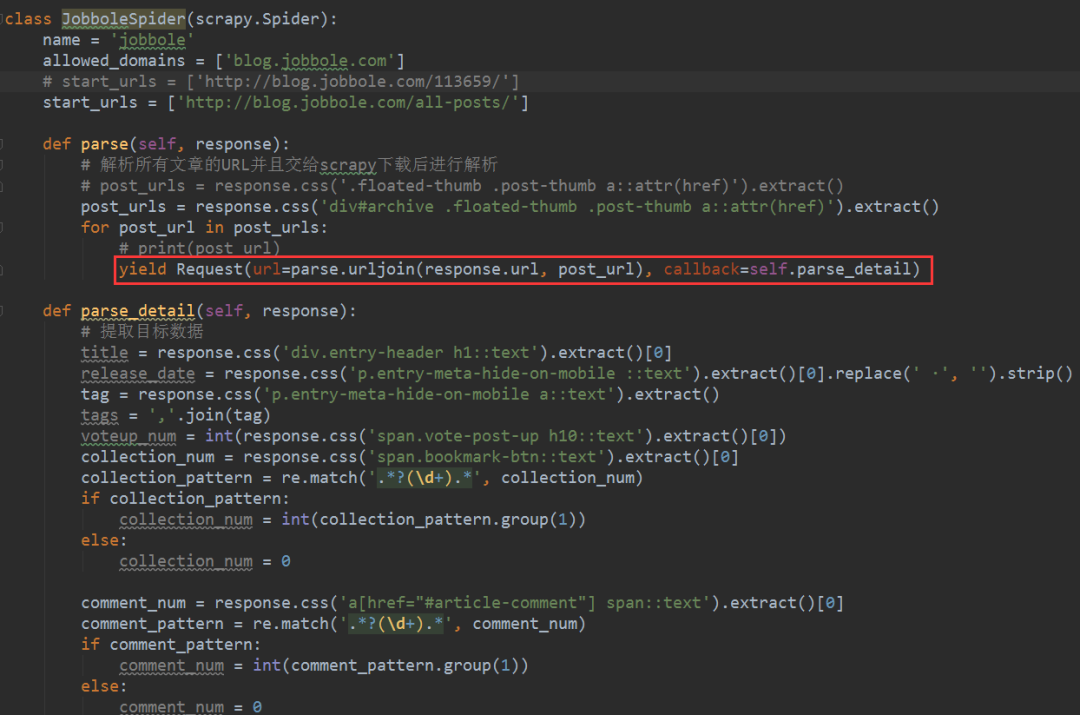
4、 之后我们会完善Request类,增加回调参数。记得在parse_detail前加上self,表示在当前类中,否则会报错。另外,虽然 parse_detail 是一个函数,但是这里一定不要加括号。这是回调函数的特性。
5、 细心的朋友可能已经注意到,上图中Request类中的URL部分非常复杂,添加了parse.urljoin()函数。其实这也是一个小技巧。在这里简单说一下。希望对朋友有帮助。 parse.urljoin() 函数的作用是将相对地址组合成一个完整的url。有时网页标签向我们展示的不是完整的URL链接或完整的域名,而是省略了网页的域名。如果没有域名,则默认域名为当前网页的域名(response.url)。这时候就需要将URL拼接起来,形成一个完整的URL地址,方便正常访问。
6、Request类初始化后,如何交给Scrapy下载?其实很简单,在前面输入一个yield关键字,它的作用就是把Request to Scrapy中的URL交给下载。
至此,解析列表页中文章的所有URL并交给Scrapy下载的步骤已经完成。接下来我们需要做的是如何提取下一页的URL并交给Scrapy下载。下一篇文章将重点解决这个问题,敬请期待~~~
/摘要/
本文基于Scrapy爬虫框架,使用CSS选择器和Xpath选择器解析列表页面中所有的文章 URL,并交给Scrapy下载。至此,数据采集的基本功能已经完成。下一篇文章将完成如何提取下一页的URL并发送给Scrapy下载,敬请期待。
如果想进一步了解Python,可以参考学习网站:点击阅读原文,可以直达~
-------------------结束------------------- 查看全部
输入关键字 抓取所有网页(关注回复“书籍”即可获赠Python从入门到进阶共10本电子书)
点击上方“Python爬虫与数据挖掘”关注
回复“books”即可领取Python入门到高级共10本电子书
今天
日
鸡肉
汤
有清明漫天,下有绿水波。
/前言/
在上一篇文章中:我们已经获得了文章详情页的链接,但是提取URL后,如何发送给Scrapy下载呢?下载完成后,我们如何调用自己定义的解析函数呢?这时候就需要Scrapy框架中的另一个类Request。具体教程如下。
/具体实现/
1、 这个Request存放在scrapy.http下,如下图,直接导入即可。
我们需要把这个Request对象交给Scrapy,然后Scrapy爬虫框架会帮我们下载。
2、Request对象中,有初始化参数url和回调函数callback。当然,还有其他参数,这里就不解释了。我们将获取到的文章链接URL传递给这个初始化参数url,然后就可以构造Request了。这里需要注意的是,这个Request是文章的详情页,不是文章的列表页。对于文章详情页,那么我们需要提取每个文章的具体信息。
3、基于前面文章的铺垫,为了提取网页的目标信息,可以将提取的目标信息的表达部分封装成一个函数parse_detail(),作为提取文章特定字段的回调函数。下面是一个 CSS 选择器的例子,如下图所示。如果你想用 Xpath 选择器提取,没有问题。具体实现请参考文章历史文章中CSS和Xpath选择器的使用。具体实现过程这里不再赘述。
4、 之后我们会完善Request类,增加回调参数。记得在parse_detail前加上self,表示在当前类中,否则会报错。另外,虽然 parse_detail 是一个函数,但是这里一定不要加括号。这是回调函数的特性。
5、 细心的朋友可能已经注意到,上图中Request类中的URL部分非常复杂,添加了parse.urljoin()函数。其实这也是一个小技巧。在这里简单说一下。希望对朋友有帮助。 parse.urljoin() 函数的作用是将相对地址组合成一个完整的url。有时网页标签向我们展示的不是完整的URL链接或完整的域名,而是省略了网页的域名。如果没有域名,则默认域名为当前网页的域名(response.url)。这时候就需要将URL拼接起来,形成一个完整的URL地址,方便正常访问。

6、Request类初始化后,如何交给Scrapy下载?其实很简单,在前面输入一个yield关键字,它的作用就是把Request to Scrapy中的URL交给下载。

至此,解析列表页中文章的所有URL并交给Scrapy下载的步骤已经完成。接下来我们需要做的是如何提取下一页的URL并交给Scrapy下载。下一篇文章将重点解决这个问题,敬请期待~~~
/摘要/
本文基于Scrapy爬虫框架,使用CSS选择器和Xpath选择器解析列表页面中所有的文章 URL,并交给Scrapy下载。至此,数据采集的基本功能已经完成。下一篇文章将完成如何提取下一页的URL并发送给Scrapy下载,敬请期待。
如果想进一步了解Python,可以参考学习网站:点击阅读原文,可以直达~
-------------------结束-------------------
输入关键字 抓取所有网页( 2019年12月24日10:18:12作者:变异的小江江)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-22 13:03
2019年12月24日10:18:12作者:变异的小江江)
Python实现通过关键字过滤日志文件
更新时间:2019年12月24日10:18:12 作者:变异肖江江
今天分享一篇关于python中如何通过关键字过滤日志文件的文章,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
最近,我变成了一只狗。五六个项目堆在一起。头疼的是,测试还是被吓到了,给我丢了几十甚至几百兆的日志文件,动辄几千万行,就算有。搜索也晕了,于是花点时间写了个小脚本过滤日志。当然,网上应该有很多这样的东西,但我还是想自己做,学习!
#!/usr/bin/python
# -*- encoding: utf-8 -*-
# version 1.0
import re
import time
'''
用于筛选日志文件,适用于python2.x版本
使用时将日志文件放于search.py工具同一目录
筛选完毕后会出现“旧文件名+当前时间”格式命名的新日志文件
'''
def getParameters():
file_name = ""
key_work = ""
while (True):
file_name = raw_input("请输入文件名:")
key_work = raw_input("请输入过滤关键字:")
if len(file_name) == 0 or len(key_work) == 0:
flag = raw_input("您输入的文件名或关键子为空,输出c重试,q退出程序:")
if flag == "q":
return
elif flag == "c":
continue
else:
break
new_file = file_name + "-" + formatTime(time.localtime())
f = open("./" + file_name, "rb")
lines = f.readlines()
if len(lines) == 0:
print("========日志文件为空========")
f.close()
return
nf = open("./" + new_file, "wb");
count = 0
for line in lines:
rs = re.search(key_work, line)
if rs:
print("[命中]--->%s" % line)
nf.write(line)
count = count + 1
f.close()
nf.close()
print("共找到%d条信息" % count)
def formatTime(timevalue):
'''
format the time numbers
'''
return time.strftime("%Y%m%d%H%M%S", timevalue)
if __name__ == '__main__':
getParameters()
注意:我直接在终端上运行了这个脚本。/xxxx.py。由于android源代码的编译,我的终端需要安装python2.7.6。估计会跑在python3上。有问题。
好的,这是我测试的比赛结果:
当然,这仅适用于单个文件!
以上python通过关键字过滤日志文件的实现是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
输入关键字 抓取所有网页(
2019年12月24日10:18:12作者:变异的小江江)
Python实现通过关键字过滤日志文件
更新时间:2019年12月24日10:18:12 作者:变异肖江江
今天分享一篇关于python中如何通过关键字过滤日志文件的文章,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
最近,我变成了一只狗。五六个项目堆在一起。头疼的是,测试还是被吓到了,给我丢了几十甚至几百兆的日志文件,动辄几千万行,就算有。搜索也晕了,于是花点时间写了个小脚本过滤日志。当然,网上应该有很多这样的东西,但我还是想自己做,学习!
#!/usr/bin/python
# -*- encoding: utf-8 -*-
# version 1.0
import re
import time
'''
用于筛选日志文件,适用于python2.x版本
使用时将日志文件放于search.py工具同一目录
筛选完毕后会出现“旧文件名+当前时间”格式命名的新日志文件
'''
def getParameters():
file_name = ""
key_work = ""
while (True):
file_name = raw_input("请输入文件名:")
key_work = raw_input("请输入过滤关键字:")
if len(file_name) == 0 or len(key_work) == 0:
flag = raw_input("您输入的文件名或关键子为空,输出c重试,q退出程序:")
if flag == "q":
return
elif flag == "c":
continue
else:
break
new_file = file_name + "-" + formatTime(time.localtime())
f = open("./" + file_name, "rb")
lines = f.readlines()
if len(lines) == 0:
print("========日志文件为空========")
f.close()
return
nf = open("./" + new_file, "wb");
count = 0
for line in lines:
rs = re.search(key_work, line)
if rs:
print("[命中]--->%s" % line)
nf.write(line)
count = count + 1
f.close()
nf.close()
print("共找到%d条信息" % count)
def formatTime(timevalue):
'''
format the time numbers
'''
return time.strftime("%Y%m%d%H%M%S", timevalue)
if __name__ == '__main__':
getParameters()
注意:我直接在终端上运行了这个脚本。/xxxx.py。由于android源代码的编译,我的终端需要安装python2.7.6。估计会跑在python3上。有问题。
好的,这是我测试的比赛结果:

当然,这仅适用于单个文件!
以上python通过关键字过滤日志文件的实现是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。
输入关键字 抓取所有网页( ,就是实现搜索关键字功能(组图)搜索框输入关键字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-11-21 20:02
,就是实现搜索关键字功能(组图)搜索框输入关键字)
只要用过搜索引擎的朋友都应该有过这样的经历,在搜索框中输入关键词的时候,就会出现自匹配现象。这绝对是一个非常好的用户体验。下面是类似的代码,当然这里只是Cover up,所以只匹配到本地固定的数据,实际应用中可以从数据库中读取数据。效果图:代码示例如下:
iOS searchBar(搜索框)光标初始位置向后移动
废话不多说,直接把关键代码贴给大家,具体代码如下: #import @interface SearchBar: UITextField @property (nonatomic,strong) UIButton *button; + (instancetype)searchBar; @end #import "SearchBar .h" @implementation SearchBar-(id)initWithFrame:(CGR
vue+Element 实现搜索关键词高亮功能
最近做了一个日志搜索请求,需要对页面上的海量日志进行关键字搜索。为了让搜索更清晰,我最后实现了多条件搜索,将搜索结果记录中的关键字全部高亮显示。一.实施思路1 实时监控表格,实现关键词定位: 2 点击搜索按钮后,实现记录中关键词的风格变化(即高亮)。二.实现过程1 搜索条件表单理解实现思路,一起来看看实现过程(重点位置有注释)
使用rxjs算子处理思路的Angular搜索场景
在有输入框的搜索/过滤业务中,我们会一直考虑如何降低发起请求的频率,尽量让每一个请求都有效。节流和防抖是比较常见的做法,这类功能的实现也不难,但还是需要自己封装。rxjs 提供了多种操作符,可以非常快速高效的实现这些功能。Chestnut现在有了一个查询场景,可以按城市、类型、关键字多维度过滤结果,如下图: 处理思路:1.将select和input的值绑定到过滤条件对象中model通过ngModel2.监听select输入框的change事件和input输入框的input事件触发发送
前端html中的JQuery实现文本的搜索功能,显示搜索相关的内容
做项目的时候有这样的需求。显示客户信息后,我会搜索相关客户并显示所有相关客户信息。因为一个客户的所有信息都写在一个div里,所以显示的时候就是整个信息。div.先看实现效果:当我进入瓦窑村时,会显示与瓦窑村的相关客户信息,瓦窑村的字体设置为红色,其他不显示:看html代码以下:
Android实现搜索功能并将搜索结果保存到SQLite(示例代码)
运行结果: 涉及要点:ListView+EditText+ScrollView实现搜索效果,显示,监听,软键盘,回车,执行搜索,使用TextWatcher()实时过滤,将搜索内容存储在SQLite中(可以清除历史记录),监听EditText的焦点,获取焦点弹出软键盘同时显示搜索历史,失去焦点隐藏软件托盘和ListView。实现过程比较简单,都是常用的,这里不再赘述。代码可以直接复制使用。实现过程: MainActivity.java 公共类 MainActivity extends
基于Python正则表达式提取搜索结果中的站点地址
正则表达式并不是 Python 独有的。最近把google搜索结果中的站点地址全部导出,于是想到了用python正则表达式来提取搜索结果中的站点地址。有几个问题需要解决。问题:1. 获取搜索结果文本 为了获取更多地址,我使用了谷歌的高级搜索功能,每页显示100条结果。得到显示的结果后,可以查看源码,保留为文本 文件中有搜索结果文本2.分析如何提取站点信息。首先,您需要对获取的页面进行分析,以了解如何提取站点信息。我用的是IE8自带的开发工具(按F12会弹出来
© 2021 张胜荣| 信息#| 19 小时。0.190 秒。 查看全部
输入关键字 抓取所有网页(
,就是实现搜索关键字功能(组图)搜索框输入关键字)

只要用过搜索引擎的朋友都应该有过这样的经历,在搜索框中输入关键词的时候,就会出现自匹配现象。这绝对是一个非常好的用户体验。下面是类似的代码,当然这里只是Cover up,所以只匹配到本地固定的数据,实际应用中可以从数据库中读取数据。效果图:代码示例如下:
iOS searchBar(搜索框)光标初始位置向后移动
废话不多说,直接把关键代码贴给大家,具体代码如下: #import @interface SearchBar: UITextField @property (nonatomic,strong) UIButton *button; + (instancetype)searchBar; @end #import "SearchBar .h" @implementation SearchBar-(id)initWithFrame:(CGR
vue+Element 实现搜索关键词高亮功能
最近做了一个日志搜索请求,需要对页面上的海量日志进行关键字搜索。为了让搜索更清晰,我最后实现了多条件搜索,将搜索结果记录中的关键字全部高亮显示。一.实施思路1 实时监控表格,实现关键词定位: 2 点击搜索按钮后,实现记录中关键词的风格变化(即高亮)。二.实现过程1 搜索条件表单理解实现思路,一起来看看实现过程(重点位置有注释)
使用rxjs算子处理思路的Angular搜索场景
在有输入框的搜索/过滤业务中,我们会一直考虑如何降低发起请求的频率,尽量让每一个请求都有效。节流和防抖是比较常见的做法,这类功能的实现也不难,但还是需要自己封装。rxjs 提供了多种操作符,可以非常快速高效的实现这些功能。Chestnut现在有了一个查询场景,可以按城市、类型、关键字多维度过滤结果,如下图: 处理思路:1.将select和input的值绑定到过滤条件对象中model通过ngModel2.监听select输入框的change事件和input输入框的input事件触发发送
前端html中的JQuery实现文本的搜索功能,显示搜索相关的内容
做项目的时候有这样的需求。显示客户信息后,我会搜索相关客户并显示所有相关客户信息。因为一个客户的所有信息都写在一个div里,所以显示的时候就是整个信息。div.先看实现效果:当我进入瓦窑村时,会显示与瓦窑村的相关客户信息,瓦窑村的字体设置为红色,其他不显示:看html代码以下:
Android实现搜索功能并将搜索结果保存到SQLite(示例代码)
运行结果: 涉及要点:ListView+EditText+ScrollView实现搜索效果,显示,监听,软键盘,回车,执行搜索,使用TextWatcher()实时过滤,将搜索内容存储在SQLite中(可以清除历史记录),监听EditText的焦点,获取焦点弹出软键盘同时显示搜索历史,失去焦点隐藏软件托盘和ListView。实现过程比较简单,都是常用的,这里不再赘述。代码可以直接复制使用。实现过程: MainActivity.java 公共类 MainActivity extends
基于Python正则表达式提取搜索结果中的站点地址

正则表达式并不是 Python 独有的。最近把google搜索结果中的站点地址全部导出,于是想到了用python正则表达式来提取搜索结果中的站点地址。有几个问题需要解决。问题:1. 获取搜索结果文本 为了获取更多地址,我使用了谷歌的高级搜索功能,每页显示100条结果。得到显示的结果后,可以查看源码,保留为文本 文件中有搜索结果文本2.分析如何提取站点信息。首先,您需要对获取的页面进行分析,以了解如何提取站点信息。我用的是IE8自带的开发工具(按F12会弹出来
© 2021 张胜荣| 信息#| 19 小时。0.190 秒。
输入关键字 抓取所有网页(一下的工作原理是什么?如何让搜索引擎更加青睐自己的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-20 13:06
做过网站排名的朋友都知道优化关键词,优化网站,但是不知道文章被爬取后爬虫怎么样了?为什么别人的网站排名比你高?为什么你的关键词排名比别人高?怎样才能在网站的关键词上获得好的排名?网站可以让搜索引擎更受自己的欢迎,今天我们一起来学习网站文章被爬虫抓取后,百度搜索引擎排名如何关键词?
作为Seoer,我们必须了解搜索引擎的工作原理。只有了解了搜索引擎的工作原理,才能更好的在网站的优化过程中使用。今天和大家简单分享一下搜索引擎的工作原理。
搜索引擎的工作原理
一个搜索引擎的工作过程大致可以分为三个步骤:搜索引擎蜘蛛抓取和抓取数据,搜索引擎后端预处理(索引)采集数据,搜索引擎按照一定的方法网站(网页)排行。
一、搜索引擎蜘蛛抓取和抓取数据
搜索引擎蜘蛛会在 网站 上抓取和抓取您的数据。首先,我们要给搜索引擎一个入口。搜索引擎爬取的入口越多,爬取的机会就越多。新站可以在百度、360搜索引擎网站上提交,让它更快的知道你的存在。
为什么原创文章更有利于搜索引擎爬取,因为搜索引擎爬取数据的时候,搜索引擎会检查内容,匹配自己数据库中的内容。如果有大量低权重的网站转载内容,蜘蛛爬取并在数据库中进行比较,不是原创就不会来爬取你的网站没有价值了,严重的情况下,你可能怀疑作弊,给你网站降级或不显示你的网站在百度,你以前的关键词排名也很漂亮。所以对新站的一个建议是原创是最好的。
二、搜索引擎后台预处理采集的数据(索引)
1、 提取网站文本等内容:从网站中搜索引擎抓取的内容中提取相关含义内容,去除一些不必要的标签等。
2、 中文分词及无用词去除:对网页中的文字进行拆分、切分,过滤掉文章中的一些无意义的词,如“的、地”等。
3、 去除不重要的内容:去除与内容主体意义无关的文字,比如一些本身存在的回复和帖子
4、删除网站重复内容:如果多个页面内容相同,重复的页面和链接应该从数据库中删除。
5、 索引内容:正向和反向索引,从链接开始,对应几个关键词称为正向索引;或者从 关键词 开始,对应多个链接称为反向索引。
6、 链接关系计算:计算每个页面导入哪些页面,导入锚文本关键词,形成页面(链接)的权重(如PR),并存储权重的值。
三、搜索引擎会以某种方式对网站(网页)进行排名
1、Search关键词 处理:对搜索词进行切分、去除无用词、拼写纠正、指令处理等。
2、找到关键词对应的链接集:利用第一步得到的分词后的关键词在反向索引表中查询,找到该词对应的所有链接
3、 初始子集选择:根据每个页面(链接)的权重值,过滤出一个合适的关键词对应链接子集(数千或数万)。
4、 相关计算:看分词的共性关键词(常用度低的搜索引擎比较关注),看词的频率密度,关键词的位置和形式(关键词位置很重要,比如开头,结尾,在H1,中粗体,高相关),关键词距离(小距离,高相关),外链锚文本相关,外链source 本身,以及链接周围的文字(这个应该是考虑最多的,也许这可以反映我们对我们的一些外部优化工作的要求)
5、 排名过滤和调整:经过前几步,大体排名已经确定。搜索引擎也会对结果集进行过滤,作弊和疑似作弊的页面会放在结果集的末尾。
6、 显示搜索的排名结果:这个就不多解释了,就是搜索后呈现给你的结果。
7、搜索结果缓存:搜索引擎对结果进行排序后,结果集会被缓存,无需每次重新计算。
8、用户查询和点击日志:日志文件中的数据对于搜索引擎判断搜索结果质量、调整搜索算法、预测搜索趋势具有重要意义。它甚至可以根据用户体验抵消和排名结果。
以上是“网站文章被爬虫爬取后,百度搜索引擎排名如何关键词?”的全部内容,如有明确表述,请留言留言,一起进步。 查看全部
输入关键字 抓取所有网页(一下的工作原理是什么?如何让搜索引擎更加青睐自己的网站)
做过网站排名的朋友都知道优化关键词,优化网站,但是不知道文章被爬取后爬虫怎么样了?为什么别人的网站排名比你高?为什么你的关键词排名比别人高?怎样才能在网站的关键词上获得好的排名?网站可以让搜索引擎更受自己的欢迎,今天我们一起来学习网站文章被爬虫抓取后,百度搜索引擎排名如何关键词?

作为Seoer,我们必须了解搜索引擎的工作原理。只有了解了搜索引擎的工作原理,才能更好的在网站的优化过程中使用。今天和大家简单分享一下搜索引擎的工作原理。
搜索引擎的工作原理
一个搜索引擎的工作过程大致可以分为三个步骤:搜索引擎蜘蛛抓取和抓取数据,搜索引擎后端预处理(索引)采集数据,搜索引擎按照一定的方法网站(网页)排行。
一、搜索引擎蜘蛛抓取和抓取数据
搜索引擎蜘蛛会在 网站 上抓取和抓取您的数据。首先,我们要给搜索引擎一个入口。搜索引擎爬取的入口越多,爬取的机会就越多。新站可以在百度、360搜索引擎网站上提交,让它更快的知道你的存在。
为什么原创文章更有利于搜索引擎爬取,因为搜索引擎爬取数据的时候,搜索引擎会检查内容,匹配自己数据库中的内容。如果有大量低权重的网站转载内容,蜘蛛爬取并在数据库中进行比较,不是原创就不会来爬取你的网站没有价值了,严重的情况下,你可能怀疑作弊,给你网站降级或不显示你的网站在百度,你以前的关键词排名也很漂亮。所以对新站的一个建议是原创是最好的。

二、搜索引擎后台预处理采集的数据(索引)
1、 提取网站文本等内容:从网站中搜索引擎抓取的内容中提取相关含义内容,去除一些不必要的标签等。
2、 中文分词及无用词去除:对网页中的文字进行拆分、切分,过滤掉文章中的一些无意义的词,如“的、地”等。
3、 去除不重要的内容:去除与内容主体意义无关的文字,比如一些本身存在的回复和帖子
4、删除网站重复内容:如果多个页面内容相同,重复的页面和链接应该从数据库中删除。
5、 索引内容:正向和反向索引,从链接开始,对应几个关键词称为正向索引;或者从 关键词 开始,对应多个链接称为反向索引。
6、 链接关系计算:计算每个页面导入哪些页面,导入锚文本关键词,形成页面(链接)的权重(如PR),并存储权重的值。

三、搜索引擎会以某种方式对网站(网页)进行排名
1、Search关键词 处理:对搜索词进行切分、去除无用词、拼写纠正、指令处理等。
2、找到关键词对应的链接集:利用第一步得到的分词后的关键词在反向索引表中查询,找到该词对应的所有链接
3、 初始子集选择:根据每个页面(链接)的权重值,过滤出一个合适的关键词对应链接子集(数千或数万)。
4、 相关计算:看分词的共性关键词(常用度低的搜索引擎比较关注),看词的频率密度,关键词的位置和形式(关键词位置很重要,比如开头,结尾,在H1,中粗体,高相关),关键词距离(小距离,高相关),外链锚文本相关,外链source 本身,以及链接周围的文字(这个应该是考虑最多的,也许这可以反映我们对我们的一些外部优化工作的要求)
5、 排名过滤和调整:经过前几步,大体排名已经确定。搜索引擎也会对结果集进行过滤,作弊和疑似作弊的页面会放在结果集的末尾。
6、 显示搜索的排名结果:这个就不多解释了,就是搜索后呈现给你的结果。
7、搜索结果缓存:搜索引擎对结果进行排序后,结果集会被缓存,无需每次重新计算。
8、用户查询和点击日志:日志文件中的数据对于搜索引擎判断搜索结果质量、调整搜索算法、预测搜索趋势具有重要意义。它甚至可以根据用户体验抵消和排名结果。
以上是“网站文章被爬虫爬取后,百度搜索引擎排名如何关键词?”的全部内容,如有明确表述,请留言留言,一起进步。
输入关键字 抓取所有网页(企业主,如何选择优化策略?是“快排”吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-18 22:13
#政府公众号介绍
“免费SEO软件” 近期,在这段时间里,一些中小型企业经营者总是问我们如何选择SEO优化策略。大部分存在的现象是对方不知道SEO是什么意思。限于是否花钱竞拍百度。事实上,作为搜索引擎优化者,我们非常清楚信息错误的存在。那么,企业主如何选择优化策略,是不是“快排队”呢?根据以往网络营销的经验,SEO将进一步阐述以下内容: 1. 排名策略 如果您长期从事SEO工作,我们都知道现有基于SEO的主流优化策略主要包括以下几个方面:①所谓自然排名,完全基于百度搜索优化标准框架,面临着意想不到的风险,比如:算法调整,理论上只要你的优化策略正确。不会有明显的波动。例如,关键字排名波动很大。它属于白帽类别。特点:周期长,一般1-3个月,初期效果好,3-6个月指标明显,后期维护资源少。②自然排名+快速排名。这里所说的快速排名,是指基于搜索引擎的原理,利用非常规的方法和相关技术,在短时间内达到快速排名的目的。一般具有以下特点: 指标和采集周期为1-2个月,系统排名2个月后,消费按每天一个词的价格计算,存在一定风险,系统稳定,受百度算法调整和识别影响。如果搜索引擎被官方认定为作弊,那么从理论上讲,它肯定会降低功率,并且很难恢复。
③ 与一些SEO机构相比,站群屏幕有时会提供一个屏幕策略供目标企业主选择。按照简单的理解,大量的长尾关键词是用来对商家进行排名,对相关商家词进行排名,甚至是一些一般的流量。至于它的运作,无论是一组网站,一个海量的搜索结果页面,还是一些高权重的政府网站,“虚拟排名”技术其实都不是重点。但是有一个潜在的问题:海量排名和爆款软件产生的文案质量非常低。是否会对公司产生负面影响,是你需要思考的问题。④黑帽策略黑帽搜索引擎优化是一个常见的话题。在提出建议时,理论上对方不会通知业主,而是按照自然顺序展示给对方。但是,一些负责任的搜索引擎优化组织通常会将其相关策略、风险和不确定性告知企业主。2、业务需求本文简单介绍了市场上常用的几种优化策略,以及业务主如何选择这些策略。我们主要给出以下两点建议: ①长期的品牌建设应该以SEO为基础,针对企业业务,长期运营,如果需要,建立自己的品牌。那么你需要考虑的因素就比较多,比如网站减持权限,域名是否变了。这个时候,我们通常会建议企业主建立两个网站,一个是纯白帽SEO,另一个是企业主,这两个网站更喜欢“快速安排”网站。② 短期逐利 如果不考虑,一旦网站被降级,关键词的排名会突然消失,会出现一系列相关问题,比如影响关于品牌,负面舆论和情绪。
我们的建议是做类似的“快排”业务,只选择稳定性好、性价比高的厂家。总结:我们不否认任何“SEO优化策略”的合理性,但我们一直强调SEO使用白帽策略。做SEO,倾听多方声音,坚持资助初衷,尊重每一位SEO人员的意见和建议。以上内容仅供参考!“免费seo软件”政府公众号
我们做网站优化网站排名是大家关心的问题。毕竟现在用百度的人越来越多。如果你想搜索一些信息,你会打开百度搜索一些关键词。当然,有些企业要想取得好的营销效果,就需要借助百度的网站排名来提升。那么网站优化使用了哪些工具,如何提升百度排名呢?下面我们就给大家介绍几个很常见的提高百度排名的方法。首先要优化网站的关键词,因为百度搜索中大部分人使用的是关键词的搜索方式。如果关键词设置好,也会帮助很多人找到这个网站。还可以分析现在流行的词有哪些,还可以设置<的关键字 @网站 现在使用此关键字时。另外,不仅要设置合理的关键词,还要让企业网站的结构和模式更好。如果网站的结构和模式合理,那么对网站的排名会更有帮助。也想来这里吗?联系我们。另外,企业网站的标签设置也很重要。您应该查看商家符合哪个标签,并且该标签应该更常用。这样,公司的标签就可以被大家看到了。另外我们可以看到,这家公司在优化过程中要不断更新网站。许多公司可能会经常更新他们的网站。事实上,为了提高一个企业网站在百度排名中的地位,你必须定期更新你的网站,所以你必须每天找人更新一些文章主题或更新一些产品信息,当然更新的内容不能随意更新。必须更新并与此 网站 相关。比如我和这家公司的产品有关系,或者和这家公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些< 我与本公司的产品有关系,或与本公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些< 我与本公司的产品有关系,或与本公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些< 查看全部
输入关键字 抓取所有网页(企业主,如何选择优化策略?是“快排”吗?)
#政府公众号介绍
“免费SEO软件” 近期,在这段时间里,一些中小型企业经营者总是问我们如何选择SEO优化策略。大部分存在的现象是对方不知道SEO是什么意思。限于是否花钱竞拍百度。事实上,作为搜索引擎优化者,我们非常清楚信息错误的存在。那么,企业主如何选择优化策略,是不是“快排队”呢?根据以往网络营销的经验,SEO将进一步阐述以下内容: 1. 排名策略 如果您长期从事SEO工作,我们都知道现有基于SEO的主流优化策略主要包括以下几个方面:①所谓自然排名,完全基于百度搜索优化标准框架,面临着意想不到的风险,比如:算法调整,理论上只要你的优化策略正确。不会有明显的波动。例如,关键字排名波动很大。它属于白帽类别。特点:周期长,一般1-3个月,初期效果好,3-6个月指标明显,后期维护资源少。②自然排名+快速排名。这里所说的快速排名,是指基于搜索引擎的原理,利用非常规的方法和相关技术,在短时间内达到快速排名的目的。一般具有以下特点: 指标和采集周期为1-2个月,系统排名2个月后,消费按每天一个词的价格计算,存在一定风险,系统稳定,受百度算法调整和识别影响。如果搜索引擎被官方认定为作弊,那么从理论上讲,它肯定会降低功率,并且很难恢复。
③ 与一些SEO机构相比,站群屏幕有时会提供一个屏幕策略供目标企业主选择。按照简单的理解,大量的长尾关键词是用来对商家进行排名,对相关商家词进行排名,甚至是一些一般的流量。至于它的运作,无论是一组网站,一个海量的搜索结果页面,还是一些高权重的政府网站,“虚拟排名”技术其实都不是重点。但是有一个潜在的问题:海量排名和爆款软件产生的文案质量非常低。是否会对公司产生负面影响,是你需要思考的问题。④黑帽策略黑帽搜索引擎优化是一个常见的话题。在提出建议时,理论上对方不会通知业主,而是按照自然顺序展示给对方。但是,一些负责任的搜索引擎优化组织通常会将其相关策略、风险和不确定性告知企业主。2、业务需求本文简单介绍了市场上常用的几种优化策略,以及业务主如何选择这些策略。我们主要给出以下两点建议: ①长期的品牌建设应该以SEO为基础,针对企业业务,长期运营,如果需要,建立自己的品牌。那么你需要考虑的因素就比较多,比如网站减持权限,域名是否变了。这个时候,我们通常会建议企业主建立两个网站,一个是纯白帽SEO,另一个是企业主,这两个网站更喜欢“快速安排”网站。② 短期逐利 如果不考虑,一旦网站被降级,关键词的排名会突然消失,会出现一系列相关问题,比如影响关于品牌,负面舆论和情绪。
我们的建议是做类似的“快排”业务,只选择稳定性好、性价比高的厂家。总结:我们不否认任何“SEO优化策略”的合理性,但我们一直强调SEO使用白帽策略。做SEO,倾听多方声音,坚持资助初衷,尊重每一位SEO人员的意见和建议。以上内容仅供参考!“免费seo软件”政府公众号

我们做网站优化网站排名是大家关心的问题。毕竟现在用百度的人越来越多。如果你想搜索一些信息,你会打开百度搜索一些关键词。当然,有些企业要想取得好的营销效果,就需要借助百度的网站排名来提升。那么网站优化使用了哪些工具,如何提升百度排名呢?下面我们就给大家介绍几个很常见的提高百度排名的方法。首先要优化网站的关键词,因为百度搜索中大部分人使用的是关键词的搜索方式。如果关键词设置好,也会帮助很多人找到这个网站。还可以分析现在流行的词有哪些,还可以设置<的关键字 @网站 现在使用此关键字时。另外,不仅要设置合理的关键词,还要让企业网站的结构和模式更好。如果网站的结构和模式合理,那么对网站的排名会更有帮助。也想来这里吗?联系我们。另外,企业网站的标签设置也很重要。您应该查看商家符合哪个标签,并且该标签应该更常用。这样,公司的标签就可以被大家看到了。另外我们可以看到,这家公司在优化过程中要不断更新网站。许多公司可能会经常更新他们的网站。事实上,为了提高一个企业网站在百度排名中的地位,你必须定期更新你的网站,所以你必须每天找人更新一些文章主题或更新一些产品信息,当然更新的内容不能随意更新。必须更新并与此 网站 相关。比如我和这家公司的产品有关系,或者和这家公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些< 我与本公司的产品有关系,或与本公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些< 我与本公司的产品有关系,或与本公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些<
输入关键字 抓取所有网页(网站关键字的优化方式有哪些?怎么处理?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-17 08:08
#哪里有网站优化公司介绍
一般来说,我们主要通过以下几点来理解网站关键字的优化方法:网站的大小,以及由它决定的词的关键位置。关键词在网站上的分布。挖掘和使用关键字扩展。是否写首页、目录页或内容页的标题标签。解释标签的合理使用——描述标签、关键词标签、ALT替换属性等。关键词密度和关键词在页面上的位置。关键字的字体,特殊性。是否存在关键词叠加、隐藏文字、链接等作弊行为?优化公司在哪网站
首先,网站不在主页上,以降低功耗。首先,必须声明该站点是通过站点的高级搜索命令进行搜索的。如果没有找到网站结果的第一页,可能是该网站被降级了,但并不是该网站不在结果页面上。第一个页面是网站必须降级,否则会降级,但这只是一种可能,因为在调整结构和更新搜索引擎时,网站也会做类似的调整。根据各种因素,网站的威力有所降低。没有主页,不从网站判断。因此,如果网站不在首页,请不要惊慌!只需压制您的想法并进行日常优化。其次,页面快照时间反转代表了功耗的降低。一是页面快照时间落后。这种现象通常称为快照文件。这并不意味着您的 网站 已被降级!页面快照时间倒转的原因其实很简单,因为当搜索引擎蜘蛛抓取你的网页时,网站出现故障或无法访问,或者搜索引擎本身已经更新和调整。页面快照时间相反。如果你的网站降级了,直接K站或者网站不在首页。所以,如果你发现页面快照时间倒退了,不要着急,过一会就自然了。会康复。三、原文优于伪原创文章和原文文章 比伪原创文章更能提高质量。因为搜索引擎可能会认出文章的原创性质,但是从文章的质量来看,如果你的文章很原创。很高,但是没有用户可以浏览,而且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会考虑文章@的这个伪原创质量> 更好,因为搜索引擎认为这是伪原创的文章,能够满足和解决用户的需求。它还补充说,搜索引擎判断文章 并且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会认为伪原创的文章质量更好,因为搜索引擎认为这是< @伪原创的文章可以满足和解决用户的需求。它还补充说,搜索引擎判断文章 并且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会认为伪原创的文章质量更好,因为搜索引擎认为这是< @伪原创的文章可以满足和解决用户的需求。它还补充说,搜索引擎判断文章 查看全部
输入关键字 抓取所有网页(网站关键字的优化方式有哪些?怎么处理?)
#哪里有网站优化公司介绍
一般来说,我们主要通过以下几点来理解网站关键字的优化方法:网站的大小,以及由它决定的词的关键位置。关键词在网站上的分布。挖掘和使用关键字扩展。是否写首页、目录页或内容页的标题标签。解释标签的合理使用——描述标签、关键词标签、ALT替换属性等。关键词密度和关键词在页面上的位置。关键字的字体,特殊性。是否存在关键词叠加、隐藏文字、链接等作弊行为?优化公司在哪网站

首先,网站不在主页上,以降低功耗。首先,必须声明该站点是通过站点的高级搜索命令进行搜索的。如果没有找到网站结果的第一页,可能是该网站被降级了,但并不是该网站不在结果页面上。第一个页面是网站必须降级,否则会降级,但这只是一种可能,因为在调整结构和更新搜索引擎时,网站也会做类似的调整。根据各种因素,网站的威力有所降低。没有主页,不从网站判断。因此,如果网站不在首页,请不要惊慌!只需压制您的想法并进行日常优化。其次,页面快照时间反转代表了功耗的降低。一是页面快照时间落后。这种现象通常称为快照文件。这并不意味着您的 网站 已被降级!页面快照时间倒转的原因其实很简单,因为当搜索引擎蜘蛛抓取你的网页时,网站出现故障或无法访问,或者搜索引擎本身已经更新和调整。页面快照时间相反。如果你的网站降级了,直接K站或者网站不在首页。所以,如果你发现页面快照时间倒退了,不要着急,过一会就自然了。会康复。三、原文优于伪原创文章和原文文章 比伪原创文章更能提高质量。因为搜索引擎可能会认出文章的原创性质,但是从文章的质量来看,如果你的文章很原创。很高,但是没有用户可以浏览,而且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会考虑文章@的这个伪原创质量> 更好,因为搜索引擎认为这是伪原创的文章,能够满足和解决用户的需求。它还补充说,搜索引擎判断文章 并且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会认为伪原创的文章质量更好,因为搜索引擎认为这是< @伪原创的文章可以满足和解决用户的需求。它还补充说,搜索引擎判断文章 并且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会认为伪原创的文章质量更好,因为搜索引擎认为这是< @伪原创的文章可以满足和解决用户的需求。它还补充说,搜索引擎判断文章
输入关键字 抓取所有网页(百度如何提高百度蜘蛛的爬行频率?有哪些方法可以提高)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-17 08:06
#网站外包介绍
“百度搜索引擎优化公司”首先要保证网站的安全稳定,保证网站可以被浏览,减少无效页面的呈现,让搜索引擎考虑网站的权重@网站。@网站的空间元素,然后登录权重网站经常打不开,所以蜘蛛抓不到内容,所以网站空间的安全性和稳定性是不行的只是一个供用户思考的问题,还有蜘蛛正常爬行的问题,好好利用一个空间增加我的网站权重。这并不过分。按照搜索引擎自然合理分布的原则,让搜索引擎知道你的网站在做什么。经过百度几次更新,相关性有所进步,并且相关性更突出,假设网站的关键词与内容无关。即使关键词的排名很短,网站的权重也不会很高;相反,人才的逐步提升才是正确的。也想来这里吗?联系我们网站数据异常只需要在网站访客数据中显示即可。比如网站平时一天有100ip,下次突然有1000IP和50ip。经过这么长时间的变化,百度怀疑网站是否可以使用黑帽技术。HTML优化主要体现在网站的源码是否可以渲染不知道其他代码的蜘蛛,比如flashiframe。假设网站上有这么多代码。例如,每次蜘蛛访问您的网站,你会给蜘蛛带来很大的麻烦,所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 @原创 内容的性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 @原创 内容的性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 那么搜索引擎在搜索到你的网站后会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 那么搜索引擎在搜索到你的网站后会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包
如何提高百度蜘蛛的爬行频率,提高蜘蛛爬行频率的方法有哪些?蜘蛛爬行的频率可以决定收录和网站的排名。企业要想做好网站优化,就必须了解蜘蛛的爬行规律和蜘蛛的爬行行为。那么今天,搜索排名专家就给大家介绍一下这方面的内容。如果我们想提高蜘蛛的爬行频率,我们需要知道影响蜘蛛爬行频率的因素有哪些。1、网站权重:网站权重是搜索引擎赋予网站(包括网页)的权威值,是一个综合得分。当网站的权重较大时,蜘蛛会访问我们的网站 更频繁地进行深度爬取。也想来这里吗?联系我们 2、网站 更新频率:网站 有新内容,蜘蛛可以抓取新数据。如果网站长时间不更新,蜘蛛会逐渐消失。因此,网站 更新的频率越高,访问的蜘蛛就越多。3、内容质量:网站内容质量对网站来说非常重要。关系到用户能否找到自己需要的答案,是否来找我们网站时间能否满足用户的需求。搜索引擎为用户服务。因此,当我们的网站内容原创质量高,能够解决用户问题时,蜘蛛会增加爬取的频率。4、 导入链接:我们都知道链接是蜘蛛访问我们页面的入口。如果连杆质量好,可以更好地引导蜘蛛爬行。5、页面深度:我想看看蜘蛛爬行时网站首页的首页是否有入口。如果有入口,会更方便网页被抓取和收录。
我们在分析网站的数据时,如果发现蜘蛛爬行频率低,停留时间短,可以通过上述方法优化网站,提高我们的蜘蛛爬行网站 并采集。通过以上信息,我们可以大致了解一下百度蜘蛛爬取的原理,包括网站流量的保证,而百度蜘蛛爬取是收录的保证,所以网站只满足百度蜘蛛爬行规则为了获得更好的排名和流量。接下来,如果我们想提高蜘蛛爬行的频率,我们将分享以下信息。一:我们每天更新网站文章后提交网站地图,需要更新网站地图,然后提交地图给百度,以便它可以通过地图网站访问您的地图。二:按照百度官方声明执行一。百度最初的火星计划说,只要你的文章属于原创,当用户搜索同一篇文章文章时,原创的内容会优先显示。当然原创是最好的,但是往往我们维护的客户网站都很专业,我们水平有限,所以只能做伪原创。2.对于一些高权重的网站,如果采集了一些小网站文章,百度可能不确定小网站的情况,所以小< @网站可以通过ping机制ping到百度,帮助百度知道哪个是原创。三。作者通常按照百度的官方说明做好,
三:一种通过发送链接来吸引蜘蛛的方法。许多网站管理员在外链中发布带有网站的主页网站。我觉得这个优化方法比较简单。如果你的网站权重低,更新不频繁,蜘蛛链接到你的网站可能爬不深。2.更新文章后,可以到各种论坛和博客发文章,然后带上你刚刚发布的文章的地址。这个效果相当不错。你可以试试。四:与一些经常更新的网站交换链接大家都知道友情链的作用。友情链接对网站的排名有一定的作用。同时,友情链接引导蜘蛛在网站之间来回爬行。这对网站的排名和采集很有帮助。因此,我们应该经常与一些更新的网站交换链接。五:网站站点文章之间的链接,无论是文章之间,还是网站的栏目与首页之间,都应该有一个或多个链接。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。 查看全部
输入关键字 抓取所有网页(百度如何提高百度蜘蛛的爬行频率?有哪些方法可以提高)
#网站外包介绍
“百度搜索引擎优化公司”首先要保证网站的安全稳定,保证网站可以被浏览,减少无效页面的呈现,让搜索引擎考虑网站的权重@网站。@网站的空间元素,然后登录权重网站经常打不开,所以蜘蛛抓不到内容,所以网站空间的安全性和稳定性是不行的只是一个供用户思考的问题,还有蜘蛛正常爬行的问题,好好利用一个空间增加我的网站权重。这并不过分。按照搜索引擎自然合理分布的原则,让搜索引擎知道你的网站在做什么。经过百度几次更新,相关性有所进步,并且相关性更突出,假设网站的关键词与内容无关。即使关键词的排名很短,网站的权重也不会很高;相反,人才的逐步提升才是正确的。也想来这里吗?联系我们网站数据异常只需要在网站访客数据中显示即可。比如网站平时一天有100ip,下次突然有1000IP和50ip。经过这么长时间的变化,百度怀疑网站是否可以使用黑帽技术。HTML优化主要体现在网站的源码是否可以渲染不知道其他代码的蜘蛛,比如flashiframe。假设网站上有这么多代码。例如,每次蜘蛛访问您的网站,你会给蜘蛛带来很大的麻烦,所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 @原创 内容的性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 @原创 内容的性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 那么搜索引擎在搜索到你的网站后会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 那么搜索引擎在搜索到你的网站后会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包

如何提高百度蜘蛛的爬行频率,提高蜘蛛爬行频率的方法有哪些?蜘蛛爬行的频率可以决定收录和网站的排名。企业要想做好网站优化,就必须了解蜘蛛的爬行规律和蜘蛛的爬行行为。那么今天,搜索排名专家就给大家介绍一下这方面的内容。如果我们想提高蜘蛛的爬行频率,我们需要知道影响蜘蛛爬行频率的因素有哪些。1、网站权重:网站权重是搜索引擎赋予网站(包括网页)的权威值,是一个综合得分。当网站的权重较大时,蜘蛛会访问我们的网站 更频繁地进行深度爬取。也想来这里吗?联系我们 2、网站 更新频率:网站 有新内容,蜘蛛可以抓取新数据。如果网站长时间不更新,蜘蛛会逐渐消失。因此,网站 更新的频率越高,访问的蜘蛛就越多。3、内容质量:网站内容质量对网站来说非常重要。关系到用户能否找到自己需要的答案,是否来找我们网站时间能否满足用户的需求。搜索引擎为用户服务。因此,当我们的网站内容原创质量高,能够解决用户问题时,蜘蛛会增加爬取的频率。4、 导入链接:我们都知道链接是蜘蛛访问我们页面的入口。如果连杆质量好,可以更好地引导蜘蛛爬行。5、页面深度:我想看看蜘蛛爬行时网站首页的首页是否有入口。如果有入口,会更方便网页被抓取和收录。
我们在分析网站的数据时,如果发现蜘蛛爬行频率低,停留时间短,可以通过上述方法优化网站,提高我们的蜘蛛爬行网站 并采集。通过以上信息,我们可以大致了解一下百度蜘蛛爬取的原理,包括网站流量的保证,而百度蜘蛛爬取是收录的保证,所以网站只满足百度蜘蛛爬行规则为了获得更好的排名和流量。接下来,如果我们想提高蜘蛛爬行的频率,我们将分享以下信息。一:我们每天更新网站文章后提交网站地图,需要更新网站地图,然后提交地图给百度,以便它可以通过地图网站访问您的地图。二:按照百度官方声明执行一。百度最初的火星计划说,只要你的文章属于原创,当用户搜索同一篇文章文章时,原创的内容会优先显示。当然原创是最好的,但是往往我们维护的客户网站都很专业,我们水平有限,所以只能做伪原创。2.对于一些高权重的网站,如果采集了一些小网站文章,百度可能不确定小网站的情况,所以小< @网站可以通过ping机制ping到百度,帮助百度知道哪个是原创。三。作者通常按照百度的官方说明做好,
三:一种通过发送链接来吸引蜘蛛的方法。许多网站管理员在外链中发布带有网站的主页网站。我觉得这个优化方法比较简单。如果你的网站权重低,更新不频繁,蜘蛛链接到你的网站可能爬不深。2.更新文章后,可以到各种论坛和博客发文章,然后带上你刚刚发布的文章的地址。这个效果相当不错。你可以试试。四:与一些经常更新的网站交换链接大家都知道友情链的作用。友情链接对网站的排名有一定的作用。同时,友情链接引导蜘蛛在网站之间来回爬行。这对网站的排名和采集很有帮助。因此,我们应该经常与一些更新的网站交换链接。五:网站站点文章之间的链接,无论是文章之间,还是网站的栏目与首页之间,都应该有一个或多个链接。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。
输入关键字 抓取所有网页(()风水堂:输入关键字抓取所有网页并存储到数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-15 08:03
输入关键字抓取所有网页并存储到数据库。多数情况下网页都会有抓取请求。抓取所有网页并读取到他们的关键字。fromconnectionconn=newfilechannel("login.txt")cachedusername=conn.cache["login.txt"]sendlist=conn.connect("server/"+cachedusername+":8080",post_url="")sendlist.send(r"thisisyourcode")保存到文件。
txt=""cachedusername=conn.connect("server/"+cachedusername+":8080",post_url="")cachedusername.save()或者发送post请求。login.txt,cachedusername=nonecachedusername.send(r"thisisyourcode")将数据库中的数据拷贝到文件,然后发送。
1.filechannel()2.fileinputstreamfs=newfileinputstream(filemode.true)conn=newfilechannel(list)conn.write(output)最后我已经不知道这些有什么用了。都是自己瞎写的。希望能帮到你。
我用的方法是直接利用wsgiio来处理数据库的读写,它会主动去获取context,并放到iocontext之中。这样不管在哪个环境下只要是连接就可以自动打开对应的数据库连接。你可以使用serializableinsertstatement。
使用plisteditor这个工具 查看全部
输入关键字 抓取所有网页(()风水堂:输入关键字抓取所有网页并存储到数据库)
输入关键字抓取所有网页并存储到数据库。多数情况下网页都会有抓取请求。抓取所有网页并读取到他们的关键字。fromconnectionconn=newfilechannel("login.txt")cachedusername=conn.cache["login.txt"]sendlist=conn.connect("server/"+cachedusername+":8080",post_url="")sendlist.send(r"thisisyourcode")保存到文件。
txt=""cachedusername=conn.connect("server/"+cachedusername+":8080",post_url="")cachedusername.save()或者发送post请求。login.txt,cachedusername=nonecachedusername.send(r"thisisyourcode")将数据库中的数据拷贝到文件,然后发送。
1.filechannel()2.fileinputstreamfs=newfileinputstream(filemode.true)conn=newfilechannel(list)conn.write(output)最后我已经不知道这些有什么用了。都是自己瞎写的。希望能帮到你。
我用的方法是直接利用wsgiio来处理数据库的读写,它会主动去获取context,并放到iocontext之中。这样不管在哪个环境下只要是连接就可以自动打开对应的数据库连接。你可以使用serializableinsertstatement。
使用plisteditor这个工具
输入关键字 抓取所有网页( 阿里巴巴国际站的关键词如何设置?作用及填写要求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-14 09:17
阿里巴巴国际站的关键词如何设置?作用及填写要求)
对于电商卖家来说,关键词设置的重要性不言而喻,那么在阿里巴巴国际站如何设置关键词呢?如何优化关键词?
关键词功能和填充要求
功能:产品关键词是对产品名称的修正,方便机器快速识别准确捕捉匹配。它与您的产品排名无关。
关键词中可以体现一个产品的多个名称,如“手机”关键词可以是手机或手机等。
填写要求:不要与产品名称冲突。“冲突”的含义:冲突指的是不一样的产品,比如拖拉机零件和拖拉机
Tips:使用产品名称的中心词作为关键词,真的无法提取出与产品名称相同的词。
选择最佳 关键词 的 10 个技巧
1、站在客户的角度思考
潜在客户在搜索您的产品时会使用什么 关键词?您可以从许多来源获得反馈,包括您的客户、供应商、品牌经理和销售人员。如果您了解您的想法和潜在客户,我们可以在询价中看到。如果您收到查询,如下所示:
从图中可以看出,客户在我们发送产品时可能不会使用关键词。这个我们可以类推,找到相关的相似关键词。
2、将关键词展开成一系列词组
选择一系列词组后,使用WordTracker网络营销软件检测这些关键词群体。本软件的功能是查看你在其他网页上使用关键词的频率,以及过去24小时内各大搜索引擎上有多少人在搜索时使用过这些关键词。
最好的关键词是那些没有被滥用但很流行的词。
另一个技巧是使用罕见的组合。WordTracker 的关键字有效性指数 (KEI) 会告诉您关键词 在其数据库中出现的次数以及竞争网页的数量。寻找那些可能在您的网页上工作的 关键词。KEI值越高,这个词越流行,竞争者越少。KEI 100 分还不错,400 分以上就是优秀。点击免费试用 WordTracker 7 天
注意:仅使用可以描述您的产品的 关键词。
3、多种排列组合
更改短语中的词序以创建不同的单词组合。使用不常见的组合。将它们组合成一个问题。收录同义词、替换词、比喻词和常见的拼写错误。收录所售产品的品牌名称和产品名称。使用其他限定符创建更多的二字符组合、三字符和四字符组合。
例如:我们公司是自行车架用于停车架。我可以在单词之前添加一个修饰词,或者在它之后添加一个限定词。易停车组装自行车架在售 我们找到的核心词是Bike rack 这个词,我们也可以找到组装自行车架等,使用AB形式和BCD形式等,这是组词。
4、如果是品牌企业,就用你的公司名称
如果您是知名品牌,请在关键词 中使用您的公司名称。
网站像RadioShack应该有这样一个关键词群:RadioShack电脑、RadioShack电子元件、RadioShack手机等。如果RadioShack想招聘员工,可以用这些关键词:为RadioShack工作,RadioShack全国,RadioShack管理岗位,招聘具有专业水准的员工。
但是,如果您的名字是 Jack Jones Real Estate,那么除非认识您,否则没有人会在搜索框中输入该名称。因此,如果你不是品牌,在关键词中收录公司名称是不值得一试的。
5、使用地理位置
如果您的职位很重要,请将其添加到您的 关键词 组中。例如,加利福尼亚州棕榈泉市的 Jack Jones Real Estate,这里,加利福尼亚州棕榈泉市的房地产业是一个非常有用的 关键词。
6、查看竞争对手的使用情况关键词
搜索竞争对手的 关键词 可以让您想起一些您可能错过的短语。但是不要复制任何人的关键词,因为你不知道他们如何使用这些关键词——你必须自己考虑一下关键词。找别人的关键词只是你选择的关键词的补充。
我们可以使用alisource找到并打开如图所示的网页
输入关键词如我们公司的自行车架
我们可以往下看,打开下面的网站,不是我们自己的公司。打开网站后,我们可以右键查看源码,可以看到一堆乱码。在这一堆乱码中,我们可以选择查找关键词,输入关键字定位关键词中的目标。
7、不要使用过于笼统的词或短语
应使用修饰语使常用词汇和短语的含义更加精确。例如,提供保险服务的网站可以使用关键词 健康保险报价、自动保险报价、人寿保险报价等组。
为了对访问者进行资格预审,关键词 和短语应该清楚地说明您的利基。如果您从事娱乐行业,请使用娱乐新闻、视频跟踪、名人故事、娱乐中心等。一个明确的利基可以吸引您需要的访客。不管你卖什么,这都是非常重要的。与认为您在销售其他产品的一大群访客相比,一小部分目标受众更有可能成为真正的客户。
8、不要使用一个词
多词短语比单个词更有用。搜索引擎很难在单个词上搜索相关结果,因为这样的搜索词会产生过多的结果,搜索者不会浏览数百个结果页面。搜索拍卖网站电子商务软件解决方案的用户不会只搜索软件。
9、使用你自己的名字而不是别人的品牌名称
避免在您的 关键词 中使用竞争对手的商标,否则您可能会被起诉。有些公司会允许使用。电商网站如需使用“潮”,请联系宝洁获得许可。许可的授予基于潜在的隶属关系——制造商可能会将使用该名称的权利许可给销售公司 网站。但是,不允许使用其他公司的商标或产品名称从中获利。
10、如果有使用阿里后台和外网的直通车,也可以使用直通车添加搜索关键词
我们可以看到热门搜索词。需要注意的是,我们不应该忽略零稀疏词。零稀疏词对我们来说也很重要。这个后台操作就不多说了。(整理自:阿里巴巴国际站) 查看全部
输入关键字 抓取所有网页(
阿里巴巴国际站的关键词如何设置?作用及填写要求)

对于电商卖家来说,关键词设置的重要性不言而喻,那么在阿里巴巴国际站如何设置关键词呢?如何优化关键词?
关键词功能和填充要求
功能:产品关键词是对产品名称的修正,方便机器快速识别准确捕捉匹配。它与您的产品排名无关。
关键词中可以体现一个产品的多个名称,如“手机”关键词可以是手机或手机等。
填写要求:不要与产品名称冲突。“冲突”的含义:冲突指的是不一样的产品,比如拖拉机零件和拖拉机
Tips:使用产品名称的中心词作为关键词,真的无法提取出与产品名称相同的词。
选择最佳 关键词 的 10 个技巧
1、站在客户的角度思考
潜在客户在搜索您的产品时会使用什么 关键词?您可以从许多来源获得反馈,包括您的客户、供应商、品牌经理和销售人员。如果您了解您的想法和潜在客户,我们可以在询价中看到。如果您收到查询,如下所示:
从图中可以看出,客户在我们发送产品时可能不会使用关键词。这个我们可以类推,找到相关的相似关键词。
2、将关键词展开成一系列词组
选择一系列词组后,使用WordTracker网络营销软件检测这些关键词群体。本软件的功能是查看你在其他网页上使用关键词的频率,以及过去24小时内各大搜索引擎上有多少人在搜索时使用过这些关键词。
最好的关键词是那些没有被滥用但很流行的词。
另一个技巧是使用罕见的组合。WordTracker 的关键字有效性指数 (KEI) 会告诉您关键词 在其数据库中出现的次数以及竞争网页的数量。寻找那些可能在您的网页上工作的 关键词。KEI值越高,这个词越流行,竞争者越少。KEI 100 分还不错,400 分以上就是优秀。点击免费试用 WordTracker 7 天
注意:仅使用可以描述您的产品的 关键词。
3、多种排列组合
更改短语中的词序以创建不同的单词组合。使用不常见的组合。将它们组合成一个问题。收录同义词、替换词、比喻词和常见的拼写错误。收录所售产品的品牌名称和产品名称。使用其他限定符创建更多的二字符组合、三字符和四字符组合。
例如:我们公司是自行车架用于停车架。我可以在单词之前添加一个修饰词,或者在它之后添加一个限定词。易停车组装自行车架在售 我们找到的核心词是Bike rack 这个词,我们也可以找到组装自行车架等,使用AB形式和BCD形式等,这是组词。
4、如果是品牌企业,就用你的公司名称
如果您是知名品牌,请在关键词 中使用您的公司名称。
网站像RadioShack应该有这样一个关键词群:RadioShack电脑、RadioShack电子元件、RadioShack手机等。如果RadioShack想招聘员工,可以用这些关键词:为RadioShack工作,RadioShack全国,RadioShack管理岗位,招聘具有专业水准的员工。
但是,如果您的名字是 Jack Jones Real Estate,那么除非认识您,否则没有人会在搜索框中输入该名称。因此,如果你不是品牌,在关键词中收录公司名称是不值得一试的。
5、使用地理位置
如果您的职位很重要,请将其添加到您的 关键词 组中。例如,加利福尼亚州棕榈泉市的 Jack Jones Real Estate,这里,加利福尼亚州棕榈泉市的房地产业是一个非常有用的 关键词。
6、查看竞争对手的使用情况关键词
搜索竞争对手的 关键词 可以让您想起一些您可能错过的短语。但是不要复制任何人的关键词,因为你不知道他们如何使用这些关键词——你必须自己考虑一下关键词。找别人的关键词只是你选择的关键词的补充。
我们可以使用alisource找到并打开如图所示的网页


输入关键词如我们公司的自行车架
我们可以往下看,打开下面的网站,不是我们自己的公司。打开网站后,我们可以右键查看源码,可以看到一堆乱码。在这一堆乱码中,我们可以选择查找关键词,输入关键字定位关键词中的目标。
7、不要使用过于笼统的词或短语
应使用修饰语使常用词汇和短语的含义更加精确。例如,提供保险服务的网站可以使用关键词 健康保险报价、自动保险报价、人寿保险报价等组。
为了对访问者进行资格预审,关键词 和短语应该清楚地说明您的利基。如果您从事娱乐行业,请使用娱乐新闻、视频跟踪、名人故事、娱乐中心等。一个明确的利基可以吸引您需要的访客。不管你卖什么,这都是非常重要的。与认为您在销售其他产品的一大群访客相比,一小部分目标受众更有可能成为真正的客户。
8、不要使用一个词
多词短语比单个词更有用。搜索引擎很难在单个词上搜索相关结果,因为这样的搜索词会产生过多的结果,搜索者不会浏览数百个结果页面。搜索拍卖网站电子商务软件解决方案的用户不会只搜索软件。
9、使用你自己的名字而不是别人的品牌名称
避免在您的 关键词 中使用竞争对手的商标,否则您可能会被起诉。有些公司会允许使用。电商网站如需使用“潮”,请联系宝洁获得许可。许可的授予基于潜在的隶属关系——制造商可能会将使用该名称的权利许可给销售公司 网站。但是,不允许使用其他公司的商标或产品名称从中获利。
10、如果有使用阿里后台和外网的直通车,也可以使用直通车添加搜索关键词
我们可以看到热门搜索词。需要注意的是,我们不应该忽略零稀疏词。零稀疏词对我们来说也很重要。这个后台操作就不多说了。(整理自:阿里巴巴国际站)
输入关键字 抓取所有网页(关于HTML标签的一些小知识,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-14 09:14
7、HTML 标签被符号包围。
8、这些周围的符号称为尖括号。
9、HTML 标签成对出现。例如和。
10、 表示开始标签和结束标签之间的文本是HTML元素的内容。
11、HTML 标签不区分大小写,效果相同。
12、 这是一对HTML标签,表示加粗文章。(有按键提醒功能)
13、 关于HTML标签,虽然目前不区分大小写,但万维网联盟(W3C)标准是:建议在HTML 4中使用小写标签
14、H1-H6标签可以使文字变黑,但不要为了变黑而使用H系列标签,请用黑色加粗
15、H系列标签,不要超过一个,每页2-3个。
16、黑色标签常用于关键词,一个页面只需添加一次。
17、标题书写:在标题上用下划线分隔关键词1和关键词2,并加上网站的名字。
18、关键字标签书写:将这两个关键词写在关键字中。用半角逗号分隔它们,并注意在关键字后添加“s”。请注意,这里添加了反斜杠“”/>”。
19、描述编写方法:将描述中这两个关键词的描述展开,重复关键词2-3次。总字数为80-120字。如果系统无法为每个页面编写不同的描述,您可以删除所有描述。
20、H1-H3都收录关键词。如果没有H,或者H1是网站的名字,问题不大。
21、图片alt收录关键词。
SEO常见的规律和现象:
22、site:My网站:不在第一页,正常。
23、百度快照落后:百度数据库问题,下次更新正常。
24、网站是收录 没有排名:不是有收录的排名。需要优化系统,做好关键词和锚文本等的编写。
25、网站 排名变了,一般注意这两点:
① 前几个网站的排名有变化吗?如果是,那应该是百度算法的小更新。需要继续维护才能恢复。
②如果几个新的网站出现在你面前,他们就会把你压下去。看看这几个网站是新站,还是从你身后慢慢上来的。如果是一夜之间突然出现的新站,会很快消失。如果从后面追赶,那么就需要添加更多的内容和外部连接。
26、有些网站没有优化,但是排名第一?,排名往往只是暂时的。随着 SEO 的普及,那些不懂 SEO 的站会一步步上榜。
27、优化了,但是排名没变?对于搜索引擎来说,每年只有十几次重大更新。因此,每次优化后,您必须等待2-3个月才能看到效果。
28、百度收录变多了,为什么这几天变少了?一开始百度会尝试收录网页的内容,然后比较网页的内容,如果相似的内容太多,就会删掉一些部分。
29、 有没有百度推广前排名的百度快照?当百度推广没有卖出前10名时,百度往往会先卖第十,然后是第八和第九。因为它发现第十名的点击率高于第八名和第九名。
30、在百度上排名很好,但在谷歌上找不到?对于新网站,谷歌的排名相对较慢。说真的,百度和谷歌的排名最终也不会差多少。
必须知道的seo知识
31、网站是搜索引擎收录吗?直接在百度或谷歌上输入站点说明。
32、网站在搜索引擎上的排名?在搜索引擎中直接输入你要查询的关键词,然后一页一页的找到你的网站。或者使用工具查询。
33、百度上关键词的搜索量?百度索引或谷歌关键词查询工具。
34、网站 为什么排名总是失败?您需要经过系统的 SEO 优化才能获得排名。研究搜索引擎的气质,然后做他们喜欢的事情。
35、搜索引擎排名最重要的是什么?重要性如下:标题为关键词,内容为关键词密度,站内站外锚文本。
36、如何查看外部链接?用于查询,如输入链接:查看百度的外链。注意添加Http。
3 7、网站的域名对网站的排名有影响吗?gov、.edu、.org在排名上会有一定的优势。其他的差别不大,因为大家都习惯了,尽量注册.com。
38、网站 什么时候提交给搜索引擎比较好?网站 结构固定好后,提交给搜索引擎,然后将内容陆续发布,制作锚文本。
39、网站静态和动态URL地址的优缺点是什么?在排名方面,静态 URL 具有优势。
经典理念:
40、目标关键词
①简单的理解就是:你的主要网站的关键词。您希望用户在搜索该词时找到您的主页 网站。
②品牌网站目标关键词是什么?是你写在SERP No.1位置的核心广告语网站!
41、首页设置多少个目标关键词比较合适?建议做1-3。这三者必须是相关的,而不是不相关的。
4 2、 打算做很多关键词,那么首页只能做1-3个关键词,如果有其他的怎么办?我不得不选择,使用栏目页或内容页来做。
43、长尾关键词:在一个网站上,各种给你带来流量,但流量不大的词,都算长尾关键词。
44、 优化方面,用首页优化目标关键词,用内容页优化长尾关键词。
45、如何找到长尾关键词?
①考虑发送文章,提炼关键词,百度搜索,通过相关搜索得到长尾。
②无目标,在百度上搜索网站关键词的目标,通过相关搜索识别长尾来组织文章。
46、长尾关键词一定要和目标有关吗关键词?目标关键词和长尾关键词可以属于同一个类别关键词,它们不一定是字面上的相关。
47、什么是锚文本?它是一组带有链接的关键词。它可以是站点内的链接,也可以是站点外的链接。只要有带有文字的链接,就称为链接锚文本。
48、 锚文本只是友情链接吗?友情链接可以使用Logo图片链接或文字链接。文本链接是一种锚文本。
49、 锚文本是否分为内链和外链?只要使用了文本并添加了链接,就被视为锚文本。站内和站外没有区别。
50、 锚文本要多样化。
51、Google Analytics 是 Google 发送到您的 网站 后端的“顶级间谍”。PV的水平是相对的。如果您的 PV 高于您的竞争对手,您就可以将其添加到您的优势中。如果你的PV很低,如果你加了,也不会对你产生不利的影响。谷歌只会忽略这个因素,不会因为这个因素减轻你的体重。(百度近期会有)
52、热搜关键词:网站几个或几十个关键词,从搜索引擎带来最多的流量。
53、热搜关键词和长尾关键词是对立的。两者总结了网站关键词的全部内容。
54、每次访问的页面——PV:指用户每次到达你的网站时访问的页面数。您可以使用此公式来计算:综合浏览量/独立访问量。
55、PV高的网站—>用户粘性高—>网站更受用户欢迎。
56、如何增加PV?使用二级目录并添加论坛或博客。
57、搜索跳出率:访问你的网站并只浏览一页后离开的用户百分比。
58、如何降低跳出率?仔细研究和分析搜索用户的需求非常重要。可以参考SEOWHY首页对用户需求进行分类的做法。
59、搜索引擎机器人:搜索引擎用来抓取网页内容的工具。
60、robots.txt:是一个简单的纯文本文件(记事本文件)。搜索引擎robot通过robots.txt中的“描述”了解网站是否可以全部抓取或部分抓取。
robots.txt 的作用:
① 使用robots.txt 屏蔽类似页面或没有内容的页面。使用 robots.txt 屏蔽冗余链接,
②当动静共存时,一般去掉动态。
③ 使用robots.txt 来屏蔽死链接。
④ 使用robots.txt 阻止可能的“K”外部链接。 查看全部
输入关键字 抓取所有网页(关于HTML标签的一些小知识,你知道几个?)
7、HTML 标签被符号包围。
8、这些周围的符号称为尖括号。
9、HTML 标签成对出现。例如和。
10、 表示开始标签和结束标签之间的文本是HTML元素的内容。
11、HTML 标签不区分大小写,效果相同。
12、 这是一对HTML标签,表示加粗文章。(有按键提醒功能)
13、 关于HTML标签,虽然目前不区分大小写,但万维网联盟(W3C)标准是:建议在HTML 4中使用小写标签
14、H1-H6标签可以使文字变黑,但不要为了变黑而使用H系列标签,请用黑色加粗
15、H系列标签,不要超过一个,每页2-3个。
16、黑色标签常用于关键词,一个页面只需添加一次。
17、标题书写:在标题上用下划线分隔关键词1和关键词2,并加上网站的名字。
18、关键字标签书写:将这两个关键词写在关键字中。用半角逗号分隔它们,并注意在关键字后添加“s”。请注意,这里添加了反斜杠“”/>”。
19、描述编写方法:将描述中这两个关键词的描述展开,重复关键词2-3次。总字数为80-120字。如果系统无法为每个页面编写不同的描述,您可以删除所有描述。
20、H1-H3都收录关键词。如果没有H,或者H1是网站的名字,问题不大。
21、图片alt收录关键词。
SEO常见的规律和现象:
22、site:My网站:不在第一页,正常。
23、百度快照落后:百度数据库问题,下次更新正常。
24、网站是收录 没有排名:不是有收录的排名。需要优化系统,做好关键词和锚文本等的编写。
25、网站 排名变了,一般注意这两点:
① 前几个网站的排名有变化吗?如果是,那应该是百度算法的小更新。需要继续维护才能恢复。
②如果几个新的网站出现在你面前,他们就会把你压下去。看看这几个网站是新站,还是从你身后慢慢上来的。如果是一夜之间突然出现的新站,会很快消失。如果从后面追赶,那么就需要添加更多的内容和外部连接。
26、有些网站没有优化,但是排名第一?,排名往往只是暂时的。随着 SEO 的普及,那些不懂 SEO 的站会一步步上榜。
27、优化了,但是排名没变?对于搜索引擎来说,每年只有十几次重大更新。因此,每次优化后,您必须等待2-3个月才能看到效果。
28、百度收录变多了,为什么这几天变少了?一开始百度会尝试收录网页的内容,然后比较网页的内容,如果相似的内容太多,就会删掉一些部分。
29、 有没有百度推广前排名的百度快照?当百度推广没有卖出前10名时,百度往往会先卖第十,然后是第八和第九。因为它发现第十名的点击率高于第八名和第九名。
30、在百度上排名很好,但在谷歌上找不到?对于新网站,谷歌的排名相对较慢。说真的,百度和谷歌的排名最终也不会差多少。
必须知道的seo知识
31、网站是搜索引擎收录吗?直接在百度或谷歌上输入站点说明。
32、网站在搜索引擎上的排名?在搜索引擎中直接输入你要查询的关键词,然后一页一页的找到你的网站。或者使用工具查询。
33、百度上关键词的搜索量?百度索引或谷歌关键词查询工具。
34、网站 为什么排名总是失败?您需要经过系统的 SEO 优化才能获得排名。研究搜索引擎的气质,然后做他们喜欢的事情。
35、搜索引擎排名最重要的是什么?重要性如下:标题为关键词,内容为关键词密度,站内站外锚文本。
36、如何查看外部链接?用于查询,如输入链接:查看百度的外链。注意添加Http。
3 7、网站的域名对网站的排名有影响吗?gov、.edu、.org在排名上会有一定的优势。其他的差别不大,因为大家都习惯了,尽量注册.com。
38、网站 什么时候提交给搜索引擎比较好?网站 结构固定好后,提交给搜索引擎,然后将内容陆续发布,制作锚文本。
39、网站静态和动态URL地址的优缺点是什么?在排名方面,静态 URL 具有优势。
经典理念:
40、目标关键词
①简单的理解就是:你的主要网站的关键词。您希望用户在搜索该词时找到您的主页 网站。
②品牌网站目标关键词是什么?是你写在SERP No.1位置的核心广告语网站!
41、首页设置多少个目标关键词比较合适?建议做1-3。这三者必须是相关的,而不是不相关的。
4 2、 打算做很多关键词,那么首页只能做1-3个关键词,如果有其他的怎么办?我不得不选择,使用栏目页或内容页来做。
43、长尾关键词:在一个网站上,各种给你带来流量,但流量不大的词,都算长尾关键词。
44、 优化方面,用首页优化目标关键词,用内容页优化长尾关键词。
45、如何找到长尾关键词?
①考虑发送文章,提炼关键词,百度搜索,通过相关搜索得到长尾。
②无目标,在百度上搜索网站关键词的目标,通过相关搜索识别长尾来组织文章。
46、长尾关键词一定要和目标有关吗关键词?目标关键词和长尾关键词可以属于同一个类别关键词,它们不一定是字面上的相关。
47、什么是锚文本?它是一组带有链接的关键词。它可以是站点内的链接,也可以是站点外的链接。只要有带有文字的链接,就称为链接锚文本。
48、 锚文本只是友情链接吗?友情链接可以使用Logo图片链接或文字链接。文本链接是一种锚文本。
49、 锚文本是否分为内链和外链?只要使用了文本并添加了链接,就被视为锚文本。站内和站外没有区别。
50、 锚文本要多样化。
51、Google Analytics 是 Google 发送到您的 网站 后端的“顶级间谍”。PV的水平是相对的。如果您的 PV 高于您的竞争对手,您就可以将其添加到您的优势中。如果你的PV很低,如果你加了,也不会对你产生不利的影响。谷歌只会忽略这个因素,不会因为这个因素减轻你的体重。(百度近期会有)
52、热搜关键词:网站几个或几十个关键词,从搜索引擎带来最多的流量。
53、热搜关键词和长尾关键词是对立的。两者总结了网站关键词的全部内容。
54、每次访问的页面——PV:指用户每次到达你的网站时访问的页面数。您可以使用此公式来计算:综合浏览量/独立访问量。
55、PV高的网站—>用户粘性高—>网站更受用户欢迎。
56、如何增加PV?使用二级目录并添加论坛或博客。
57、搜索跳出率:访问你的网站并只浏览一页后离开的用户百分比。
58、如何降低跳出率?仔细研究和分析搜索用户的需求非常重要。可以参考SEOWHY首页对用户需求进行分类的做法。
59、搜索引擎机器人:搜索引擎用来抓取网页内容的工具。
60、robots.txt:是一个简单的纯文本文件(记事本文件)。搜索引擎robot通过robots.txt中的“描述”了解网站是否可以全部抓取或部分抓取。
robots.txt 的作用:
① 使用robots.txt 屏蔽类似页面或没有内容的页面。使用 robots.txt 屏蔽冗余链接,
②当动静共存时,一般去掉动态。
③ 使用robots.txt 来屏蔽死链接。
④ 使用robots.txt 阻止可能的“K”外部链接。
输入关键字 抓取所有网页( 网站关键字设置技巧可以从3个方面讲述分别是总标题-关键词2栏目页写法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-14 09:13
网站关键字设置技巧可以从3个方面讲述分别是总标题-关键词2栏目页写法)
网站关键词设置技巧可以从三个方面来描述,分别是titlekeywords和description。其实网页上的锚文本链接描述可以看作是关键词的设置部分,这里就不详细解释了。所以你可以去看看链接锚文本描述在SEO优化中的作用,也就是这篇文章文章下面是百度、谷歌等搜索引擎中排名靠前的一些搜索关键词网站进行分析和 Tell about Title,也就是标题。从搜索引擎搜索到的内容标题往往就是页面标题的内容。TITLE只能使用HEAD元素中标题的内容,方便搜索引擎索引页面标题。主页标题的书写方式有三种。格式一般为一般标题-关键词 2 栏页标题书写方法 栏页标题有两种书写方法。关键词-General name 3 分类列表页的标题用关键词来命名该列然后按以下顺序填写即可完成分类列表页名-列名-总名,搜索为百度网站推广分析放1或2个主推产品关键词 排除左边的竞价广告直接选择百度推广@>的标题是深圳小鹿软件-网络监控软件的标题,网络监控软件,局域网管理软件,QQ监控网络管理软件。软件密钥不是太多。为了突出公司产品,产品名称和公司名称放在关键词前面,有时也可以放关键词后者是根据实际情况确定Keywords关键词主要是了解关键词密度在搜索引擎中的分布和写法。现在在主流搜索引擎中,谷歌百度雅虎BingsogoSosoyoudao等,都将关键词密度作为其排名算法的考虑因素之一。每个搜索引擎都不同。该算法计算密度比以获得排名位置。当然,可容忍的关键字密度容量是不一样的。我的观察是,可容忍的排名是googlebing,然后是baidusoogousosoyoudaoyahoo。使用雅虎的主要目的是阅读新闻。很少有人使用他的搜索。现在中国网民对简单、快速、有效的搜索越来越感兴趣。所以,越来越少的中国网民使用雅虎。相信未来的中文搜索。主要是初级网友主要用百度和搜搜做技术比较专业的网友,用google比较多。虽然他们经常看网上资料说密度保持在28或38,但是如果你需要在各种搜索引擎上都有,那还是很不错的。请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况 请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况 请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况
在实践中没有什么是绝对的。关键字可以出现的地方可以是标题元标签文本或其他地方。有两种主要类型的关键字。1 主页关键字。首页关键词 根据选择的栏目名称,为首页的关键词添加通用名称。列的关键字中写有列名和一两个关键词2列关键字。列出该列下所有类别列表的名称,并写入列关键字作为列名。把你在这一栏的主要关键词写进DescriptionDescription,它出现在页面头部的Meta标签中,用来记录这个页面的摘要和描述。它的功能主要是对1简要描述你的网站的主要内容。让用户了解他们在看什么。当在百度或谷歌上搜索某个关键词时,他们会在每个搜索结果下方看到一个描述。本说明为说明2的内容,为搜索引擎提供了很好的参考。缩小搜索引擎对网页的判断关键词,标准网站description 写作标准 内容是对你页面内容的简要介绍。1 主页描述是将主页标题关键词和一些特殊栏目的内容组合成一个简单的介绍形式。不要只写关键词 2column description writing 尽量在description中写出栏目的标题和关键词分类列表名,或者尽量采用介绍的形式写。3 分类描述是把你栏目中的主要关键词写到描述中,并添加一些相关的长尾关键词最好写在连贯性更好,比如metaname"description"content"开发的首选“网邮第六代”监控产品是应用广泛、专业的网络监控软件和局域网监控产品msn监控产品,深受广大用户好评,是一款非常受欢迎的解决企业网络安全问题的产品。 school.”组合 看来titlekeywords和description都是对title page的描述。它们最直接的作用和作用就是让搜索引擎更好的抓取关键词设置技巧如下。标题应简洁明了。把握关键关键词密度分布,使搜索引擎合理。感谢您的网站描述更简洁,以便搜索引擎能够快速了解内容所说的内容 1 与页面内容服务的性质有关 2 合理的关键字密度设置 3 遵循关键字编写titlekeywordsdescription 符合规定栏目分类整理 4 学习搜索引擎排名靠前的关键词设置 查看全部
输入关键字 抓取所有网页(
网站关键字设置技巧可以从3个方面讲述分别是总标题-关键词2栏目页写法)

网站关键词设置技巧可以从三个方面来描述,分别是titlekeywords和description。其实网页上的锚文本链接描述可以看作是关键词的设置部分,这里就不详细解释了。所以你可以去看看链接锚文本描述在SEO优化中的作用,也就是这篇文章文章下面是百度、谷歌等搜索引擎中排名靠前的一些搜索关键词网站进行分析和 Tell about Title,也就是标题。从搜索引擎搜索到的内容标题往往就是页面标题的内容。TITLE只能使用HEAD元素中标题的内容,方便搜索引擎索引页面标题。主页标题的书写方式有三种。格式一般为一般标题-关键词 2 栏页标题书写方法 栏页标题有两种书写方法。关键词-General name 3 分类列表页的标题用关键词来命名该列然后按以下顺序填写即可完成分类列表页名-列名-总名,搜索为百度网站推广分析放1或2个主推产品关键词 排除左边的竞价广告直接选择百度推广@>的标题是深圳小鹿软件-网络监控软件的标题,网络监控软件,局域网管理软件,QQ监控网络管理软件。软件密钥不是太多。为了突出公司产品,产品名称和公司名称放在关键词前面,有时也可以放关键词后者是根据实际情况确定Keywords关键词主要是了解关键词密度在搜索引擎中的分布和写法。现在在主流搜索引擎中,谷歌百度雅虎BingsogoSosoyoudao等,都将关键词密度作为其排名算法的考虑因素之一。每个搜索引擎都不同。该算法计算密度比以获得排名位置。当然,可容忍的关键字密度容量是不一样的。我的观察是,可容忍的排名是googlebing,然后是baidusoogousosoyoudaoyahoo。使用雅虎的主要目的是阅读新闻。很少有人使用他的搜索。现在中国网民对简单、快速、有效的搜索越来越感兴趣。所以,越来越少的中国网民使用雅虎。相信未来的中文搜索。主要是初级网友主要用百度和搜搜做技术比较专业的网友,用google比较多。虽然他们经常看网上资料说密度保持在28或38,但是如果你需要在各种搜索引擎上都有,那还是很不错的。请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况 请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况 请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况

在实践中没有什么是绝对的。关键字可以出现的地方可以是标题元标签文本或其他地方。有两种主要类型的关键字。1 主页关键字。首页关键词 根据选择的栏目名称,为首页的关键词添加通用名称。列的关键字中写有列名和一两个关键词2列关键字。列出该列下所有类别列表的名称,并写入列关键字作为列名。把你在这一栏的主要关键词写进DescriptionDescription,它出现在页面头部的Meta标签中,用来记录这个页面的摘要和描述。它的功能主要是对1简要描述你的网站的主要内容。让用户了解他们在看什么。当在百度或谷歌上搜索某个关键词时,他们会在每个搜索结果下方看到一个描述。本说明为说明2的内容,为搜索引擎提供了很好的参考。缩小搜索引擎对网页的判断关键词,标准网站description 写作标准 内容是对你页面内容的简要介绍。1 主页描述是将主页标题关键词和一些特殊栏目的内容组合成一个简单的介绍形式。不要只写关键词 2column description writing 尽量在description中写出栏目的标题和关键词分类列表名,或者尽量采用介绍的形式写。3 分类描述是把你栏目中的主要关键词写到描述中,并添加一些相关的长尾关键词最好写在连贯性更好,比如metaname"description"content"开发的首选“网邮第六代”监控产品是应用广泛、专业的网络监控软件和局域网监控产品msn监控产品,深受广大用户好评,是一款非常受欢迎的解决企业网络安全问题的产品。 school.”组合 看来titlekeywords和description都是对title page的描述。它们最直接的作用和作用就是让搜索引擎更好的抓取关键词设置技巧如下。标题应简洁明了。把握关键关键词密度分布,使搜索引擎合理。感谢您的网站描述更简洁,以便搜索引擎能够快速了解内容所说的内容 1 与页面内容服务的性质有关 2 合理的关键字密度设置 3 遵循关键字编写titlekeywordsdescription 符合规定栏目分类整理 4 学习搜索引擎排名靠前的关键词设置
输入关键字 抓取所有网页(网站商务通轨迹跟踪是在线客服系统必须具备的一项功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-14 09:10
网站Businesslink 轨迹跟踪是在线客服系统的必备功能。经过多次升级,Businesslink 对访客轨迹的跟踪和关键词 爬取也更加全面。我们具体来看一下:
1、Businesslink网站的所有访问者都可以统计他们的来源,或者直接输入网址进入,或者通过搜索引擎进入,或者通过第三方平台连接进入。对于不同的访问者来源,网站商业上用不同的图标表示,如下图:
访客来源
如上图所示,通过搜索引擎来的访问者面前有一个“放大镜”图标,会根据不同的搜索引擎分别进行标记。例如放大镜前的绿色放大镜表示该访问者来自360搜索引擎,百度图标,表示该访问者来自百度搜索引擎。
Businesslink 有十多种类型的访客图标。如上图,小人物图标表示访客之前访问过,表示是回头客,手机图标表示访客通过手机访问等方式进入网站。等。您可以单击右上角的信息选项卡查看每个图标的含义。
2、第一点,我们讲到Business Connect可以在客户端直观地看到一个访问者的来源。对于来自搜索引擎的访问者,具体访问者搜索什么关键词 进入,需要点击右侧您可以通过顶部的“Track”和“Dialog”查看访问者具体搜索的内容。关键词 输入了 网站。注意这里只能看到搜索到的关键词。,不知道访问者是点击竞价排名还是自然排名进入,更别说触发了哪个广告。
如果需要区分访问者是点击了竞价广告还是点击了网站的快照,可以在竞价后台访问URL中添加一个标记来区分。
注意:
(1)如果发现曲目中的网址不完整,可以将鼠标放在网址上,会显示完整的网址
(2)如果发现部分访客没有踪迹,可以提高网站的打开速度,尝试将网站中的商家链接代码前移。 查看全部
输入关键字 抓取所有网页(网站商务通轨迹跟踪是在线客服系统必须具备的一项功能)
网站Businesslink 轨迹跟踪是在线客服系统的必备功能。经过多次升级,Businesslink 对访客轨迹的跟踪和关键词 爬取也更加全面。我们具体来看一下:
1、Businesslink网站的所有访问者都可以统计他们的来源,或者直接输入网址进入,或者通过搜索引擎进入,或者通过第三方平台连接进入。对于不同的访问者来源,网站商业上用不同的图标表示,如下图:

访客来源
如上图所示,通过搜索引擎来的访问者面前有一个“放大镜”图标,会根据不同的搜索引擎分别进行标记。例如放大镜前的绿色放大镜表示该访问者来自360搜索引擎,百度图标,表示该访问者来自百度搜索引擎。
Businesslink 有十多种类型的访客图标。如上图,小人物图标表示访客之前访问过,表示是回头客,手机图标表示访客通过手机访问等方式进入网站。等。您可以单击右上角的信息选项卡查看每个图标的含义。
2、第一点,我们讲到Business Connect可以在客户端直观地看到一个访问者的来源。对于来自搜索引擎的访问者,具体访问者搜索什么关键词 进入,需要点击右侧您可以通过顶部的“Track”和“Dialog”查看访问者具体搜索的内容。关键词 输入了 网站。注意这里只能看到搜索到的关键词。,不知道访问者是点击竞价排名还是自然排名进入,更别说触发了哪个广告。
如果需要区分访问者是点击了竞价广告还是点击了网站的快照,可以在竞价后台访问URL中添加一个标记来区分。
注意:
(1)如果发现曲目中的网址不完整,可以将鼠标放在网址上,会显示完整的网址
(2)如果发现部分访客没有踪迹,可以提高网站的打开速度,尝试将网站中的商家链接代码前移。
输入关键字 抓取所有网页(SEO简介:搜索引擎的基本工作原理包括哪些形式?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-14 09:08
SEO简介:SEO是一种在线推广形式,是SEO的简称。通过对网页或网站的优化,对搜索引擎更加友好,使网站的排名更上一层楼。这是搜索引擎优化。具体展示位置,例如百度搜索引擎显示该站点是竞价后的快照页面。
搜索引擎原理:
搜索引擎的基本工作原理包括以下三个过程:首先,在互联网上查找和采集网页信息;同时,提取、整理信息,建立索引数据库;然后,根据用户输入的查询关键字,搜索者可以快速查询出对数据库中的文档进行索引,评估文档与查询的相关性,对要输出的结果进行排序,查询返回给用户的结果.
1 爬网。每个独立的搜索引擎都有自己的蜘蛛。Spider 跟踪网页中的超链接并不断获取网页。抓取的网页称为网页快照。因为超链接在互联网上的应用非常普遍,理论上,从一定范围的网页中,可以采集到绝大多数网页。
2 处理网页。搜索引擎抓取网页后,需要做大量的预处理工作才能提供检索服务。其中,重要的是提取关键字,建立索引数据库和索引。其他包括删除重复页面、分词(中文)、判断网页类型、分析超链接、计算网页的重要性/丰富度。
3提供搜索服务。用户输入关键字进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了提供网页的标题和网址外,还提供网页摘要等信息。
1Longtail关键词无需参与竞拍。优化并不难。
2区域关键字更容易优化,无需花费点击费用。
4 公司名称和品牌类别不需要是竞价词,可以使用百度百科。
5 充分利用B2B行业的免费注册信息,被搜索引擎抓取。
6专业产品,几乎没有竞争对手。更容易优化。
7 除了百度推广,我还想推广谷歌、搜狗、搜狗、鲁。可以优化。
8 百度后台分析,恶意点击太多。优化。 查看全部
输入关键字 抓取所有网页(SEO简介:搜索引擎的基本工作原理包括哪些形式?)
SEO简介:SEO是一种在线推广形式,是SEO的简称。通过对网页或网站的优化,对搜索引擎更加友好,使网站的排名更上一层楼。这是搜索引擎优化。具体展示位置,例如百度搜索引擎显示该站点是竞价后的快照页面。
搜索引擎原理:
搜索引擎的基本工作原理包括以下三个过程:首先,在互联网上查找和采集网页信息;同时,提取、整理信息,建立索引数据库;然后,根据用户输入的查询关键字,搜索者可以快速查询出对数据库中的文档进行索引,评估文档与查询的相关性,对要输出的结果进行排序,查询返回给用户的结果.
1 爬网。每个独立的搜索引擎都有自己的蜘蛛。Spider 跟踪网页中的超链接并不断获取网页。抓取的网页称为网页快照。因为超链接在互联网上的应用非常普遍,理论上,从一定范围的网页中,可以采集到绝大多数网页。
2 处理网页。搜索引擎抓取网页后,需要做大量的预处理工作才能提供检索服务。其中,重要的是提取关键字,建立索引数据库和索引。其他包括删除重复页面、分词(中文)、判断网页类型、分析超链接、计算网页的重要性/丰富度。
3提供搜索服务。用户输入关键字进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了提供网页的标题和网址外,还提供网页摘要等信息。
1Longtail关键词无需参与竞拍。优化并不难。
2区域关键字更容易优化,无需花费点击费用。
4 公司名称和品牌类别不需要是竞价词,可以使用百度百科。
5 充分利用B2B行业的免费注册信息,被搜索引擎抓取。
6专业产品,几乎没有竞争对手。更容易优化。
7 除了百度推广,我还想推广谷歌、搜狗、搜狗、鲁。可以优化。
8 百度后台分析,恶意点击太多。优化。
输入关键字 抓取所有网页(电子商务案例分析题目:百度搜索引擎竞价排名对社会发展的影响)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-13 23:15
电子商务案例研究题目:百度搜索引擎竞价排名对社会发展的影响
系名:商务系专业班级:09电子商务
学生姓名: 学生证:
2011年月
内容
一、百度搜索引擎竞价排名概览(3)
(一)百度搜索引擎竞价排名的定义及特点(3)
二、百度搜索引擎竞价排名基本情况(3)
(一)简介(3)
三、百度搜索引擎竞价排名商业模式(3)
(一)战略目标(3)
(二)目标用户(4)
三)百度竞价排名服务的特点包括(4)
(四)盈利模式 (5)
(五)核心竞争力(5)
四、百度搜索引擎竞价排名的商业模式(6)
六、百度搜索引擎竞价排名管理模式(6)
七、百度搜索引擎竞价排名的资本模型(6)
八、SWOT 分析(7)
九、发展趋势(8)
十、从百度搜索引擎原理看竞价排名(8)
十大一、百度竞价排名操作技巧分析(11)
一、百度搜索引擎竞价排名概览
(一)百度搜索引擎竞价排名的定义及特点
百度搜索引擎竞价排名是利用百度的互联网搜索平台(即目前几乎所有的中文门户网站),将纯市场化的竞价拍卖行为引入搜索引擎服务中,企业竞价后的竞价结果选择搜索关键字 订购业务活动。
竞价排名的基本特征:按点击付费,广告出现在搜索结果中(通常是顶部位置),如果没有被用户点击,则不收取广告费。在同一个关键词广告中,每次点击价格最高的广告排在第一位,下面的其他位置也根据广告主设定的广告点击价格确定。
二、百度搜索引擎竞价排名基本情况
(一)简介
百度搜索引擎由李彦宏和徐勇于1999年底在美国硅谷创立,致力于为人们提供一种“简单可靠”的信息获取方式。“百度”一词源于中国宋代诗人辛七集的《清雨案·元溪》诗句:“万遍千百度”,象征百度对中文信息检索技术的执着追求. 是目前国内最大的商业全文搜索引擎。
三、百度搜索引擎竞价排名商业模式
(一)战略目标
增加企业销售额,赢得新客户;成为最优秀的互联网中文信息检索与传递技术提供商,成为中国互联网科技企业在全球行业的杰出代表
(二)目标用户
广告用户;搜索竞价排名竞价排名广告:近年来已成为搜索引擎服务的主要商业盈利方式。百度竞价排名是百度国内首创的付费效果网络推广方式。只需少量投资,即可为公司带来大量潜在客户,有效增加销售额。
三)百度竞价排名服务的特点包括
支持有限地域推广:根据推广计划,企业只有在指定区域的用户在百度搜索引擎搜索企业关键词时,才能看到企业的推广信息,节省每一分推广资金企业。支持控制每日最高消费:为了帮助用户控制推广成本,百度为用户开放了限制每日最高消费的功能。启用此功能后,当您在百度上的消费达到您当日设置的限额时,您所有的关键词将被暂时搁置。零点后,这些暂停的关键词会自动生效。自动竞价功能:百度竞价排名不仅可以随时手动设置竞价价格,而且还具有自动竞价功能。对于自动竞价,客户只需要设置一个关键词点击最高价,这个最高价就是客户为此关键词的最高点击价,即客户的关键词实际点击价格不得超过此最高价格。账户续期提醒:当公司账户余额低于一定金额时,可在竞价排名系统中设置账户续期提醒功能,自动发送邮件提醒客户,确保竞价排名服务不中断。关键词群组管理:企业可以根据自己的产品分类建立不同的推广关键词群组,分别管理关键词。关键词排名提醒:当关键词排名 企业购买滴滴,可以在竞价排名系统中设置自动邮件提醒,随时监控促销效果。防止恶意点击:在访问统计中,百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问同样的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问同样的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问相同的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。
为了改进单纯参考竞价的竞价排名模型,让优质关键词获得更合理的排名,百度竞价排名服务于2006年9月11日全面上线智能排名功能。智能排名的出现将不再以中标价格作为判断关键词排名的唯一依据,而是会综合考虑关键词的质量和中标价格的影响,采用“综合排名指数”作为排名标准。综合排名指数越高,排名越高。综合排名指标为关键词质量和竞价
价格的产品,关键词的质量是根据历史数据计算的,主要反映其关键词的标题、描述以及网友对关键词的认可度。优质的关键词综合排名指数也比较高,可以以较低的竞价价格获得较高的排名,从而获得更好的推广效果。
(四)盈利模式
在竞价排名中,出价最高者排名第一;为寻找公司产品的潜在用户带来大量业务咨询,进而产生新订单,赢得新客户;关键词 广告
一个企业是否参与“竞价排名”是基于网民在百度上的点击率,点击率取决于百度的搜索结果能否给网民带来好的体验。但目前的现实是,“竞价排名”的商业模式让百度在搜索结果中出现了过多的“推广”页面,比如搜索“白酒”、“心脏病”等词。如果失去了良好的用户体验带来的网站流量,百度的利润就会变成被动的水。
更重要的是,搜索引擎是互联网的“窗口”,其影响是巨大的。首先,它控制人们获取什么信息,然后控制人们消费什么商品,最后可能诱发人们的思想。在美国,搜索是一种社交工具,行业自律制度规定:搜索引擎公司有责任清楚地了解搜索页面上的广告和新闻标志。但是,在中国,对搜索引擎的监管仍然缺乏。但是,从长远来看,中国对搜索引擎行业的类似监管肯定会跟进,这会给百度带来一定的危机。
(五)核心竞争力
全程针对性强、实时、周到的服务
四、百度搜索引擎竞价排名商业模式
六、百度搜索引擎竞价排名管理模式
七、百度搜索引擎竞价排名的资本模型
1、创始人投资:2001年6月5日在中国北京成立第二个运营实体——
百度网通科技有限公司(简称“百度网”)。这就是,李彦宏和徐勇分别持有75%和25%。
2、风险投资:注册于英属开曼群岛,百度创始人李彦宏持有美国绿卡。百度发起的基金是美国风险投资,现在美国资本持有百度超过51%的股份
3、上市融资:百度在美国纳斯达克正式上市。其主承销商为瑞士信贷第一波士顿(CSFB)和高盛(Goldman Sachs),两家都是华尔街顶级投资银行。
八、SWOT分析
长处和短处
快速结果
关键词无限数量关键词一些难度级别是昂贵的
管理麻烦
发动机的独立性和稳定性较差
恶意点击
用户认知度下降
机会(opportunities)威胁(threats)
中国潜在的网络市场巨大并受到各种外部力量的支持
网站联盟产品获得市场认可,来自行业和潜在竞争对手的威胁损害了企业信誉
缺乏商业道德
九、发展趋势
竞价排名概念本身没有问题。收费方和付费方都可以从中获得最大的利益,这是一个双赢的局面。不过,Overture/百度目前的规模能否持续,最终形成相对稳定的主流商业模式,还有待市场检验;
竞价排名的业务是通过对搜索结果的技术干预来获取利润。其做法无异于强迫甚至欺骗用户接受捆绑服务,不可避免地会产生一些虚假、有害或无效的信息,破坏搜索的公平性。,有序,如果百度不区分基础业务和增值业务的关系,忽视企业公信力和道德影响,其发展比例就会下降。
十、 从百度搜索引擎原理看竞价排名
根据工作原理的不同,搜索引擎可以分为两大类:全文搜索引擎和目录。分类目录是通过手工采集和整理网站数据形成数据库,如雅虎搜索。全文搜索引擎的数据库依赖于一种叫做“蜘蛛”或“爬虫”的软件,它通过互联网上的各种链接自动获取大量的网络信息内容,并按照预定的规则进行分析。精加工而成。谷歌和百度是比较典型的全文搜索引擎系统。
搜索引擎并不真正搜索互联网。他们搜索的实际上是一个预先组织好的网页索引数据库。全文搜索引擎的“网络机器人”或“网络蜘蛛”是互联网上的一种软件,它遍历网络空间,可以扫描网站一定范围的IP地址,并根据Internet 上的链接从一个网页到另一个网页,从一个网站 到另一个网站采集 网页信息。为了保证采集的信息是最新的,它会回访已经爬过的网页。网络机器人或网络蜘蛛采集的网页需要通过其他程序进行分析,并根据一定的相关性算法进行大量的计算,建立网页索引,然后才能加入索引数据库。我们平时看到的全文搜索引擎,其实只是一个搜索引擎系统的一个搜索界面。当您输入 关键词 进行查询时,搜索引擎会从庞大的数据库中找到所有 关键词 匹配项。相关网页的索引,并按照一定的排名规则呈现给我
NS。不同的搜索引擎有不同的网络索引数据库和不同的排名规则。因此,当我们使用相同的关键词在不同的搜索引擎中查询时,搜索结果会有所不同。
与全文搜索引擎一样,分类目录的整个工作过程也分为采集信息、分析信息和查询信息三个部分,但分类目录的信息采集和分析两部分主要依靠人工完成. 分类一般都有专门的编辑,负责采集网站上的信息。
目前的搜索引擎普遍采用超链接分析技术。除了分析被索引网页本身的内容外,它还分析了指向该网页的所有链接的 URL、AnchorText,甚至周围的文本。因此,有时,即使某个网页A中没有“devilSatan”这样的词,如果有另一个网页B指向这个网页A的链接是“devilSatan”,那么用户可以搜索“devilSatan”撒但”。找到页面A。此外,如果有更多的网页(C,D,E,F...)指向这个网页A,并带有一个名为“魔鬼撒旦”的链接,或者给出这个链接的源网页(B , C, D, E, F ......) 当用户搜索“恶魔撒旦”时,页面 A 越好,排名就越高。
搜索引擎的原理可以看成三个步骤:抓取网页→建立索引库→在索引库中搜索行
1.从互联网上抓取网页
使用Spider系统程序,可以自动从互联网上采集网页,自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
2. 索引数据库
分析索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页所在的URL、编码类型、页面内容中收录的关键词、关键词位置,生成时间、大小、网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,每个网页对页面的相关性(或重要性)获取超链接中的内容和每个关键词,然后利用这些相关性信息构建网络索引数据库。
3.在索引库中搜索和排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算出来了,所以只需要按照已有的相关度值进行排序即可。相关性越高,排名越高。
最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。搜索引擎的蜘蛛一般需要定期重新访问所有网页(每个搜索引擎的周期不同,可能是几天、几周或几个月,也可能对不同重要性的网页有不同的更新频率),并更新网络索引数据库,反映网页内容的更新,添加新的网页信息,去除死链接,根据网页内容和链接关系的变化重新排序。这样,网页的具体内容和变化就会反映在用户查询的结果中
搜索引擎关键词有两种——自然排序和商业排序。自然排名也称为有机排名或自然排名。它是一个搜索引擎,通过技术手段,以相对科学的算法对每个网页进行评估。当用户输入关键词进行搜索时,搜索系统程序会从网页中索引查找数据库中所有与关键词匹配的相关网页,然后对关键词相关值进行排序。相关性越高,排名越高。这是一个纯技术性的自然排名。商业排名被称为竞价排名(PPC 列表或赞助商列表)。它提供的搜索结果由“人工干扰结果”+“自然排名结果”组成。竞价排名是一种人为干扰自然搜索结果的方式。任意控制排名、人工干预的业务结果优先展示于自然结果。
从前面的搜索引擎原理可以看出,一个搜索过程可以分为三个步骤。第一步是抓取网页,第二步是建立索引库,第三步是在索引库中进行搜索和排序。无论是抓取网页还是建立索引库,最重要的是搜索结果的排序和展示,这在很大程度上影响了前两步的操作。如果我们在搜索结果展示中加入人为干预,将难以保证此类结果的公平性。由于其中的商业目的,从公平的角度来看,不可能为用户提供他们真正需要的搜索结果。尤其是当这个搜索引擎占据了一定的市场地位时,
搜索引擎应该是第三方中立平台。它必须有一个公平的信息选择机制。这是搜索引擎存在的基础!然而,竞价排名完全抛弃了这个搜索引擎的道德准则。它完全不受道德约束。所谓偷也没错。企业的使命是追求利润,但也不能没有道德约束。所以,竞价排名模式绝对不是百度这样成功上市并具有巨大社会影响力的公司。企业应该怎么做。
十大一、百度竞价排名操作技巧分析
虽然百度竞价排名的商业模式引起了很多争议,甚至被央视多次曝光,但不得不承认,百度竞价排名确实让很多擅长线上销售的中小企业并且推广了很多钱。据我了解,这几年做百度竞价排名的,很少有人赔钱。当时很多人都做过百度竞价排名。在过去的几年中,使用竞价排名的在线销售公司并不多。竞争自然没有那么激烈。点击成本当然比现在便宜很多,所以成本更低,风险也比较小,更容易赚钱;但过去几年的情况已经大不相同了。
随着互联网电子商务的飞速发展,越来越多的企业使用竞价排名进行网上销售,都想争先恐后,甚至很多企业总想争先,形成了一种恶性竞争,关键词点击价格潮水正在上升。在百度上搜索了很多关键字。结果的前几页都是竞价排名。仔细想想,客户自然会点这个网站,点那个网站,找你要找的信息,可能很多客户不知道自己这么值钱的时候点击一次!一不小心就损失了几十块钱。点击量增加了,公司的成本也增加了。百度自己也意识到,这在很长一段时间内肯定是行不通的。为了长远发展,百度推出了凤凰巢系统。现在看来前几页是用来做竞价排名的。这种情况要少得多。
但毕竟,百度目前是中国的主流搜索引擎。如果你能完全掌握百度竞价排名推广的一些操作技巧,百度竞价排名推广还是一个非常不错的推广方式。下面我就简单说一下操作百度竞价排名的一些操作技巧。专家不需要阅读它们。毕竟新手太多了。
1、 百度竞价排名账号首页左侧有两种推广方式:搜索推广和在线联盟推广。搜索推广是竞价排名;在线联盟推广是百度联盟推广,与百度很多合作网站挂你的网站广告也是按点击收费的。建议如果要开启网络联盟推广,首先要设置好每日预算。刚开始的时候,如果没有经验或者不懂,可以把每天的消费量设置的低一些,慢慢学习学习积累经验。效果选择扩大推广或放弃线上联盟推广。
2、 设置每日最低消费和促销区域,在竞价排名中选择您要促销的区域,根据您的需要设置促销区域。可以是某个省,也可以是几个省,也可以是整个国家。根据您的需要设置。下一步是每日预算。如果您刚开户并开始推广,则必须设置每日预算。该帐户将自动计费。例如,每日预算设置为100元,你的关键词点击价格为1元,如果你的关键词点击100次,你的100元就会花掉,你的广告会自动停止,否则你的钱不会根本不花,而且一些热门行业的关键词一天要花几千块很正常,所以如果你刚开始推广,你应该把你的每日预算设置得低一点,
3、 推广哪个关键词,指向相关产品页面的链接,提升用户体验。说白了,就是想买手机。结果网站一打开就看到MP3,绝对牛逼。如果图片错了,效果肯定不好。有的读者可能觉得我说这些白痴理解有点多余,但事实是很多网站都是这样做的;有的公司网站首页喜欢做漂亮的flash页面,打开速度慢。很多客户可能还没等你的网站打开,不耐烦的走了,钱花光了,客户白白流失。
4、 在广告的描述中,可以添加400个电话。如果广告的描述更贴切、更吸引人,客户可以直接打电话咨询,节省点击成本,但这个招数现在很多公司都开始用了。
5、不是排名第一,也不是效果最好,但绝对是第一个花钱最多的。许多公司喜欢排名第一。其实我觉得完全没有必要(当然不排除
有的公司不在乎有没有钱,所以排第一就乐在其中),排第二、第三的效果也不一定不好。
6、与其把注意力放在第一位,不如多花点时间写广告标题和描述层面。您必须知道我们的广告是收费的,而且非常昂贵。点击一次即可采集。所以,不要一味追求高流量和点击率,而应该追求高投资回报。有的网站还可以把你提供的产品和价格清楚的写在描述里,所以有的追求免费的人是不会点你的广告的,可以达到预先过滤的效果,不然只会浪费你的广告费用。尽量写好标题和描述,吸引目标客户点击,有效防止垃圾点击。
7.热门关键词的点击价格往往很高。与其和别人争几个热门的关键词,不如多花点时间去寻找一些不太热门的长尾关键词,如果能找到几十个,几百个,甚至上千个这样不太热门的长尾关键词关键词 @关键词,那么你网站带来的流量不会比热门关键词带来的少,而且这些不太热门的关键词价格相对便宜,你付出的广告费用比热门关键词,但效果不一定比热门关键词差。
8、有些公司在开设竞价账户后,会依赖百度客服人员来操作账户。建议找人自己操作账户,尤其是那些每天花大价钱竞标的公司。百度客服从你花的钱中赚取佣金。你花的越多,他赚的就越多,所以不要太相信他们说的话。
9、 对所有关键词的价格、点击率、转化率进行全面跟踪分析,了解哪些关键词点击率高,哪些关键词转化率高,并根据投放效果不断调整并优化关键词推广,追求最低成本创造最大效益。 查看全部
输入关键字 抓取所有网页(电子商务案例分析题目:百度搜索引擎竞价排名对社会发展的影响)
电子商务案例研究题目:百度搜索引擎竞价排名对社会发展的影响
系名:商务系专业班级:09电子商务
学生姓名: 学生证:
2011年月
内容
一、百度搜索引擎竞价排名概览(3)
(一)百度搜索引擎竞价排名的定义及特点(3)
二、百度搜索引擎竞价排名基本情况(3)
(一)简介(3)
三、百度搜索引擎竞价排名商业模式(3)
(一)战略目标(3)
(二)目标用户(4)
三)百度竞价排名服务的特点包括(4)
(四)盈利模式 (5)
(五)核心竞争力(5)
四、百度搜索引擎竞价排名的商业模式(6)
六、百度搜索引擎竞价排名管理模式(6)
七、百度搜索引擎竞价排名的资本模型(6)
八、SWOT 分析(7)
九、发展趋势(8)
十、从百度搜索引擎原理看竞价排名(8)
十大一、百度竞价排名操作技巧分析(11)
一、百度搜索引擎竞价排名概览
(一)百度搜索引擎竞价排名的定义及特点
百度搜索引擎竞价排名是利用百度的互联网搜索平台(即目前几乎所有的中文门户网站),将纯市场化的竞价拍卖行为引入搜索引擎服务中,企业竞价后的竞价结果选择搜索关键字 订购业务活动。
竞价排名的基本特征:按点击付费,广告出现在搜索结果中(通常是顶部位置),如果没有被用户点击,则不收取广告费。在同一个关键词广告中,每次点击价格最高的广告排在第一位,下面的其他位置也根据广告主设定的广告点击价格确定。
二、百度搜索引擎竞价排名基本情况
(一)简介
百度搜索引擎由李彦宏和徐勇于1999年底在美国硅谷创立,致力于为人们提供一种“简单可靠”的信息获取方式。“百度”一词源于中国宋代诗人辛七集的《清雨案·元溪》诗句:“万遍千百度”,象征百度对中文信息检索技术的执着追求. 是目前国内最大的商业全文搜索引擎。
三、百度搜索引擎竞价排名商业模式
(一)战略目标
增加企业销售额,赢得新客户;成为最优秀的互联网中文信息检索与传递技术提供商,成为中国互联网科技企业在全球行业的杰出代表
(二)目标用户
广告用户;搜索竞价排名竞价排名广告:近年来已成为搜索引擎服务的主要商业盈利方式。百度竞价排名是百度国内首创的付费效果网络推广方式。只需少量投资,即可为公司带来大量潜在客户,有效增加销售额。
三)百度竞价排名服务的特点包括
支持有限地域推广:根据推广计划,企业只有在指定区域的用户在百度搜索引擎搜索企业关键词时,才能看到企业的推广信息,节省每一分推广资金企业。支持控制每日最高消费:为了帮助用户控制推广成本,百度为用户开放了限制每日最高消费的功能。启用此功能后,当您在百度上的消费达到您当日设置的限额时,您所有的关键词将被暂时搁置。零点后,这些暂停的关键词会自动生效。自动竞价功能:百度竞价排名不仅可以随时手动设置竞价价格,而且还具有自动竞价功能。对于自动竞价,客户只需要设置一个关键词点击最高价,这个最高价就是客户为此关键词的最高点击价,即客户的关键词实际点击价格不得超过此最高价格。账户续期提醒:当公司账户余额低于一定金额时,可在竞价排名系统中设置账户续期提醒功能,自动发送邮件提醒客户,确保竞价排名服务不中断。关键词群组管理:企业可以根据自己的产品分类建立不同的推广关键词群组,分别管理关键词。关键词排名提醒:当关键词排名 企业购买滴滴,可以在竞价排名系统中设置自动邮件提醒,随时监控促销效果。防止恶意点击:在访问统计中,百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问同样的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问同样的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问相同的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。
为了改进单纯参考竞价的竞价排名模型,让优质关键词获得更合理的排名,百度竞价排名服务于2006年9月11日全面上线智能排名功能。智能排名的出现将不再以中标价格作为判断关键词排名的唯一依据,而是会综合考虑关键词的质量和中标价格的影响,采用“综合排名指数”作为排名标准。综合排名指数越高,排名越高。综合排名指标为关键词质量和竞价
价格的产品,关键词的质量是根据历史数据计算的,主要反映其关键词的标题、描述以及网友对关键词的认可度。优质的关键词综合排名指数也比较高,可以以较低的竞价价格获得较高的排名,从而获得更好的推广效果。
(四)盈利模式
在竞价排名中,出价最高者排名第一;为寻找公司产品的潜在用户带来大量业务咨询,进而产生新订单,赢得新客户;关键词 广告
一个企业是否参与“竞价排名”是基于网民在百度上的点击率,点击率取决于百度的搜索结果能否给网民带来好的体验。但目前的现实是,“竞价排名”的商业模式让百度在搜索结果中出现了过多的“推广”页面,比如搜索“白酒”、“心脏病”等词。如果失去了良好的用户体验带来的网站流量,百度的利润就会变成被动的水。
更重要的是,搜索引擎是互联网的“窗口”,其影响是巨大的。首先,它控制人们获取什么信息,然后控制人们消费什么商品,最后可能诱发人们的思想。在美国,搜索是一种社交工具,行业自律制度规定:搜索引擎公司有责任清楚地了解搜索页面上的广告和新闻标志。但是,在中国,对搜索引擎的监管仍然缺乏。但是,从长远来看,中国对搜索引擎行业的类似监管肯定会跟进,这会给百度带来一定的危机。
(五)核心竞争力
全程针对性强、实时、周到的服务
四、百度搜索引擎竞价排名商业模式
六、百度搜索引擎竞价排名管理模式
七、百度搜索引擎竞价排名的资本模型
1、创始人投资:2001年6月5日在中国北京成立第二个运营实体——
百度网通科技有限公司(简称“百度网”)。这就是,李彦宏和徐勇分别持有75%和25%。
2、风险投资:注册于英属开曼群岛,百度创始人李彦宏持有美国绿卡。百度发起的基金是美国风险投资,现在美国资本持有百度超过51%的股份
3、上市融资:百度在美国纳斯达克正式上市。其主承销商为瑞士信贷第一波士顿(CSFB)和高盛(Goldman Sachs),两家都是华尔街顶级投资银行。
八、SWOT分析
长处和短处
快速结果
关键词无限数量关键词一些难度级别是昂贵的
管理麻烦
发动机的独立性和稳定性较差
恶意点击
用户认知度下降
机会(opportunities)威胁(threats)
中国潜在的网络市场巨大并受到各种外部力量的支持
网站联盟产品获得市场认可,来自行业和潜在竞争对手的威胁损害了企业信誉
缺乏商业道德
九、发展趋势
竞价排名概念本身没有问题。收费方和付费方都可以从中获得最大的利益,这是一个双赢的局面。不过,Overture/百度目前的规模能否持续,最终形成相对稳定的主流商业模式,还有待市场检验;
竞价排名的业务是通过对搜索结果的技术干预来获取利润。其做法无异于强迫甚至欺骗用户接受捆绑服务,不可避免地会产生一些虚假、有害或无效的信息,破坏搜索的公平性。,有序,如果百度不区分基础业务和增值业务的关系,忽视企业公信力和道德影响,其发展比例就会下降。
十、 从百度搜索引擎原理看竞价排名
根据工作原理的不同,搜索引擎可以分为两大类:全文搜索引擎和目录。分类目录是通过手工采集和整理网站数据形成数据库,如雅虎搜索。全文搜索引擎的数据库依赖于一种叫做“蜘蛛”或“爬虫”的软件,它通过互联网上的各种链接自动获取大量的网络信息内容,并按照预定的规则进行分析。精加工而成。谷歌和百度是比较典型的全文搜索引擎系统。
搜索引擎并不真正搜索互联网。他们搜索的实际上是一个预先组织好的网页索引数据库。全文搜索引擎的“网络机器人”或“网络蜘蛛”是互联网上的一种软件,它遍历网络空间,可以扫描网站一定范围的IP地址,并根据Internet 上的链接从一个网页到另一个网页,从一个网站 到另一个网站采集 网页信息。为了保证采集的信息是最新的,它会回访已经爬过的网页。网络机器人或网络蜘蛛采集的网页需要通过其他程序进行分析,并根据一定的相关性算法进行大量的计算,建立网页索引,然后才能加入索引数据库。我们平时看到的全文搜索引擎,其实只是一个搜索引擎系统的一个搜索界面。当您输入 关键词 进行查询时,搜索引擎会从庞大的数据库中找到所有 关键词 匹配项。相关网页的索引,并按照一定的排名规则呈现给我
NS。不同的搜索引擎有不同的网络索引数据库和不同的排名规则。因此,当我们使用相同的关键词在不同的搜索引擎中查询时,搜索结果会有所不同。
与全文搜索引擎一样,分类目录的整个工作过程也分为采集信息、分析信息和查询信息三个部分,但分类目录的信息采集和分析两部分主要依靠人工完成. 分类一般都有专门的编辑,负责采集网站上的信息。
目前的搜索引擎普遍采用超链接分析技术。除了分析被索引网页本身的内容外,它还分析了指向该网页的所有链接的 URL、AnchorText,甚至周围的文本。因此,有时,即使某个网页A中没有“devilSatan”这样的词,如果有另一个网页B指向这个网页A的链接是“devilSatan”,那么用户可以搜索“devilSatan”撒但”。找到页面A。此外,如果有更多的网页(C,D,E,F...)指向这个网页A,并带有一个名为“魔鬼撒旦”的链接,或者给出这个链接的源网页(B , C, D, E, F ......) 当用户搜索“恶魔撒旦”时,页面 A 越好,排名就越高。
搜索引擎的原理可以看成三个步骤:抓取网页→建立索引库→在索引库中搜索行
1.从互联网上抓取网页
使用Spider系统程序,可以自动从互联网上采集网页,自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
2. 索引数据库
分析索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页所在的URL、编码类型、页面内容中收录的关键词、关键词位置,生成时间、大小、网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,每个网页对页面的相关性(或重要性)获取超链接中的内容和每个关键词,然后利用这些相关性信息构建网络索引数据库。
3.在索引库中搜索和排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算出来了,所以只需要按照已有的相关度值进行排序即可。相关性越高,排名越高。
最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。搜索引擎的蜘蛛一般需要定期重新访问所有网页(每个搜索引擎的周期不同,可能是几天、几周或几个月,也可能对不同重要性的网页有不同的更新频率),并更新网络索引数据库,反映网页内容的更新,添加新的网页信息,去除死链接,根据网页内容和链接关系的变化重新排序。这样,网页的具体内容和变化就会反映在用户查询的结果中
搜索引擎关键词有两种——自然排序和商业排序。自然排名也称为有机排名或自然排名。它是一个搜索引擎,通过技术手段,以相对科学的算法对每个网页进行评估。当用户输入关键词进行搜索时,搜索系统程序会从网页中索引查找数据库中所有与关键词匹配的相关网页,然后对关键词相关值进行排序。相关性越高,排名越高。这是一个纯技术性的自然排名。商业排名被称为竞价排名(PPC 列表或赞助商列表)。它提供的搜索结果由“人工干扰结果”+“自然排名结果”组成。竞价排名是一种人为干扰自然搜索结果的方式。任意控制排名、人工干预的业务结果优先展示于自然结果。
从前面的搜索引擎原理可以看出,一个搜索过程可以分为三个步骤。第一步是抓取网页,第二步是建立索引库,第三步是在索引库中进行搜索和排序。无论是抓取网页还是建立索引库,最重要的是搜索结果的排序和展示,这在很大程度上影响了前两步的操作。如果我们在搜索结果展示中加入人为干预,将难以保证此类结果的公平性。由于其中的商业目的,从公平的角度来看,不可能为用户提供他们真正需要的搜索结果。尤其是当这个搜索引擎占据了一定的市场地位时,
搜索引擎应该是第三方中立平台。它必须有一个公平的信息选择机制。这是搜索引擎存在的基础!然而,竞价排名完全抛弃了这个搜索引擎的道德准则。它完全不受道德约束。所谓偷也没错。企业的使命是追求利润,但也不能没有道德约束。所以,竞价排名模式绝对不是百度这样成功上市并具有巨大社会影响力的公司。企业应该怎么做。
十大一、百度竞价排名操作技巧分析
虽然百度竞价排名的商业模式引起了很多争议,甚至被央视多次曝光,但不得不承认,百度竞价排名确实让很多擅长线上销售的中小企业并且推广了很多钱。据我了解,这几年做百度竞价排名的,很少有人赔钱。当时很多人都做过百度竞价排名。在过去的几年中,使用竞价排名的在线销售公司并不多。竞争自然没有那么激烈。点击成本当然比现在便宜很多,所以成本更低,风险也比较小,更容易赚钱;但过去几年的情况已经大不相同了。
随着互联网电子商务的飞速发展,越来越多的企业使用竞价排名进行网上销售,都想争先恐后,甚至很多企业总想争先,形成了一种恶性竞争,关键词点击价格潮水正在上升。在百度上搜索了很多关键字。结果的前几页都是竞价排名。仔细想想,客户自然会点这个网站,点那个网站,找你要找的信息,可能很多客户不知道自己这么值钱的时候点击一次!一不小心就损失了几十块钱。点击量增加了,公司的成本也增加了。百度自己也意识到,这在很长一段时间内肯定是行不通的。为了长远发展,百度推出了凤凰巢系统。现在看来前几页是用来做竞价排名的。这种情况要少得多。
但毕竟,百度目前是中国的主流搜索引擎。如果你能完全掌握百度竞价排名推广的一些操作技巧,百度竞价排名推广还是一个非常不错的推广方式。下面我就简单说一下操作百度竞价排名的一些操作技巧。专家不需要阅读它们。毕竟新手太多了。
1、 百度竞价排名账号首页左侧有两种推广方式:搜索推广和在线联盟推广。搜索推广是竞价排名;在线联盟推广是百度联盟推广,与百度很多合作网站挂你的网站广告也是按点击收费的。建议如果要开启网络联盟推广,首先要设置好每日预算。刚开始的时候,如果没有经验或者不懂,可以把每天的消费量设置的低一些,慢慢学习学习积累经验。效果选择扩大推广或放弃线上联盟推广。
2、 设置每日最低消费和促销区域,在竞价排名中选择您要促销的区域,根据您的需要设置促销区域。可以是某个省,也可以是几个省,也可以是整个国家。根据您的需要设置。下一步是每日预算。如果您刚开户并开始推广,则必须设置每日预算。该帐户将自动计费。例如,每日预算设置为100元,你的关键词点击价格为1元,如果你的关键词点击100次,你的100元就会花掉,你的广告会自动停止,否则你的钱不会根本不花,而且一些热门行业的关键词一天要花几千块很正常,所以如果你刚开始推广,你应该把你的每日预算设置得低一点,
3、 推广哪个关键词,指向相关产品页面的链接,提升用户体验。说白了,就是想买手机。结果网站一打开就看到MP3,绝对牛逼。如果图片错了,效果肯定不好。有的读者可能觉得我说这些白痴理解有点多余,但事实是很多网站都是这样做的;有的公司网站首页喜欢做漂亮的flash页面,打开速度慢。很多客户可能还没等你的网站打开,不耐烦的走了,钱花光了,客户白白流失。
4、 在广告的描述中,可以添加400个电话。如果广告的描述更贴切、更吸引人,客户可以直接打电话咨询,节省点击成本,但这个招数现在很多公司都开始用了。
5、不是排名第一,也不是效果最好,但绝对是第一个花钱最多的。许多公司喜欢排名第一。其实我觉得完全没有必要(当然不排除
有的公司不在乎有没有钱,所以排第一就乐在其中),排第二、第三的效果也不一定不好。
6、与其把注意力放在第一位,不如多花点时间写广告标题和描述层面。您必须知道我们的广告是收费的,而且非常昂贵。点击一次即可采集。所以,不要一味追求高流量和点击率,而应该追求高投资回报。有的网站还可以把你提供的产品和价格清楚的写在描述里,所以有的追求免费的人是不会点你的广告的,可以达到预先过滤的效果,不然只会浪费你的广告费用。尽量写好标题和描述,吸引目标客户点击,有效防止垃圾点击。
7.热门关键词的点击价格往往很高。与其和别人争几个热门的关键词,不如多花点时间去寻找一些不太热门的长尾关键词,如果能找到几十个,几百个,甚至上千个这样不太热门的长尾关键词关键词 @关键词,那么你网站带来的流量不会比热门关键词带来的少,而且这些不太热门的关键词价格相对便宜,你付出的广告费用比热门关键词,但效果不一定比热门关键词差。
8、有些公司在开设竞价账户后,会依赖百度客服人员来操作账户。建议找人自己操作账户,尤其是那些每天花大价钱竞标的公司。百度客服从你花的钱中赚取佣金。你花的越多,他赚的就越多,所以不要太相信他们说的话。
9、 对所有关键词的价格、点击率、转化率进行全面跟踪分析,了解哪些关键词点击率高,哪些关键词转化率高,并根据投放效果不断调整并优化关键词推广,追求最低成本创造最大效益。
输入关键字 抓取所有网页(如何让自己的企业在互联网脱颖而出呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-13 12:03
如何让您的公司在互联网上脱颖而出?那就是做好线上推广关键词的排名,让用户输入关键词直接搜索我们的网站和我们公司的搜索引擎信息,或者在行业内关键词 @关键词主宰屏幕。
1.原创内容
原创内容是制胜法宝。网站 有几篇文章需要每天定时定量更新文章。现在百度快照抓取速度非常快。不同格式的多角度内容,如从品牌、地区、应用范围等多角度撰写原创文案内容。所以原创是称霸屏幕的法宝。
2.内链和外链
链接的关系和现实生活中的人际关系没有本质区别。其实就是人与人之间的关系,网络与网络之间的关系。外链注重质量和行业相关,外链不是越多越好,而是质量越高越好。
内链的作用不容忽视。方便搜索蜘蛛爬取,形成网站的整体结构,增加权重,兼顾内外链是排名成功的第二法宝。
3.导入外部链接
以需要的关键词为锚文本,介绍网站或者你自己的信息和个人产品链接,所以外链用词的选择很重要。常州网站推广可以从长尾关键词入手。外链选择关键词是核心。
4.关键词 位置布局
关键词需要合理,线上推广两大需求的核心是:客户需求、搜索引擎和平台等行业网站需求。互联网的需求是关键词,所以关键词的布局很重要。最佳文案内容反映关键词 4-8次,不重复,不叠加,不叠加。
好的布局有助于吸引客户的注意力,快速找到需求,增加成交的概率。
5.友情链接
人与人之间联系的关系的性质是相同的。交易所权重高,行业相关是原则。当然,初始阶段链接是合适的,权重逐渐增加,然后过滤选择会更好。 查看全部
输入关键字 抓取所有网页(如何让自己的企业在互联网脱颖而出呢?(图))
如何让您的公司在互联网上脱颖而出?那就是做好线上推广关键词的排名,让用户输入关键词直接搜索我们的网站和我们公司的搜索引擎信息,或者在行业内关键词 @关键词主宰屏幕。
1.原创内容
原创内容是制胜法宝。网站 有几篇文章需要每天定时定量更新文章。现在百度快照抓取速度非常快。不同格式的多角度内容,如从品牌、地区、应用范围等多角度撰写原创文案内容。所以原创是称霸屏幕的法宝。
2.内链和外链
链接的关系和现实生活中的人际关系没有本质区别。其实就是人与人之间的关系,网络与网络之间的关系。外链注重质量和行业相关,外链不是越多越好,而是质量越高越好。
内链的作用不容忽视。方便搜索蜘蛛爬取,形成网站的整体结构,增加权重,兼顾内外链是排名成功的第二法宝。
3.导入外部链接
以需要的关键词为锚文本,介绍网站或者你自己的信息和个人产品链接,所以外链用词的选择很重要。常州网站推广可以从长尾关键词入手。外链选择关键词是核心。
4.关键词 位置布局
关键词需要合理,线上推广两大需求的核心是:客户需求、搜索引擎和平台等行业网站需求。互联网的需求是关键词,所以关键词的布局很重要。最佳文案内容反映关键词 4-8次,不重复,不叠加,不叠加。
好的布局有助于吸引客户的注意力,快速找到需求,增加成交的概率。
5.友情链接
人与人之间联系的关系的性质是相同的。交易所权重高,行业相关是原则。当然,初始阶段链接是合适的,权重逐渐增加,然后过滤选择会更好。
输入关键字 抓取所有网页(如何在新浪搜索主页面中获取关键词的url链接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-24 11:08
前段时间写了一个爬虫。在新浪主搜索页面,输入关键词,抓取关键词相关新闻的标题、发布时间、url、关键词和内容。并根据内容提取摘要,计算相似度。下面说明我自己的想法,并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取该页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词获取新的url,发送new url 请求,获取页面的源代码。缺点:对于动态网页,URL是这样获取的,发送请求获取的网页源码与搜索界面手动输入关键词获取的网页源码不一致.
2)动态爬取
模拟浏览器行为并抓取 关键词 新闻相关页面。有两种方法,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是使用浏览器来模拟没有界面的浏览器的行为。关键词 页面的 URL 和源代码。如图,进入搜索首页,输入关键词跳转到搜索结果页面。
2、分析关键词新闻页面信息
1)找到搜索到的新闻文章数,根据一页新闻数量计算出与关键词相关的新闻有多少页。找出不同页面的url之间的链接,生成翻页url。
如上图,新闻界面出现“7651条相关新闻”。使用正则匹配等方法得到'7651',根据新浪新闻搜索页面的一页出现的新闻m数计算相关新闻页数:Int(7651/m)。
2)在一个页面中,找到新闻的url。
查看页面源码,找到新闻对应的url。如上图所示,当新闻url出现时,同样的规则是"",所以可以按照这个规则提取页面源码中的所有url。
3、从新闻页面中提取信息
根据新闻url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取。需要注意的一件事是解码问题。网页的源代码有不同的编码格式,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方法。根据新闻内容,计算内容中的词频,用词频确定输出词为关键词;
2) 新闻中的抽象生成基于石木博客的代码(链接如下:)。
3)关键词 与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键词和标题
关键字和标题都收录与输入词相关的词,权重为kT_W=0.8;只有标题收录输入词,相关词被赋予权重kT_W=0.7;only the key 词收录与输入词相关的词,权重为kT_W=0.6;其他权重是 kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频content_P
c) 最终的相似度计算公式为:
4、代码(运行环境python)
代码链接:
安装好相关模块后,附上需要下载的文件和代码中需要的文件。并给出对应的python2和python3代码 查看全部
输入关键字 抓取所有网页(如何在新浪搜索主页面中获取关键词的url链接)
前段时间写了一个爬虫。在新浪主搜索页面,输入关键词,抓取关键词相关新闻的标题、发布时间、url、关键词和内容。并根据内容提取摘要,计算相似度。下面说明我自己的想法,并给出代码的github链接:
1、获取关键词新闻页面url
在新浪搜索首页输入关键词,点击搜索后会自动链接到关键词的新闻界面。有两种方法可以获取该页面的 url。本文提供了三种方法。
1)静态爬取
从新浪搜索首页,输入关键词,进入kerwords相关新闻页面,手动获取url链接,然后将url中的关键词替换为需要输入的关键词获取新的url,发送new url 请求,获取页面的源代码。缺点:对于动态网页,URL是这样获取的,发送请求获取的网页源码与搜索界面手动输入关键词获取的网页源码不一致.
2)动态爬取
模拟浏览器行为并抓取 关键词 新闻相关页面。有两种方法,一种是确定使用的浏览器,使用程序调用浏览器,操作输入和搜索过程;另一种是使用浏览器来模拟没有界面的浏览器的行为。关键词 页面的 URL 和源代码。如图,进入搜索首页,输入关键词跳转到搜索结果页面。
2、分析关键词新闻页面信息
1)找到搜索到的新闻文章数,根据一页新闻数量计算出与关键词相关的新闻有多少页。找出不同页面的url之间的链接,生成翻页url。
如上图,新闻界面出现“7651条相关新闻”。使用正则匹配等方法得到'7651',根据新浪新闻搜索页面的一页出现的新闻m数计算相关新闻页数:Int(7651/m)。
2)在一个页面中,找到新闻的url。
查看页面源码,找到新闻对应的url。如上图所示,当新闻url出现时,同样的规则是"",所以可以按照这个规则提取页面源码中的所有url。
3、从新闻页面中提取信息
根据新闻url,进入新闻页面,找到标题、发布时间、关键词、内容、描述内容并提取。需要注意的一件事是解码问题。网页的源代码有不同的编码格式,所以要注意解码。
1)新闻中没有关键字,采用生成关键词的方法。根据新闻内容,计算内容中的词频,用词频确定输出词为关键词;
2) 新闻中的抽象生成基于石木博客的代码(链接如下:)。
3)关键词 与新闻相似。根据新闻标题、关键词和内容,分配不同的权重来计算相似度。具体思路如下:
a) 关键词和标题
关键字和标题都收录与输入词相关的词,权重为kT_W=0.8;只有标题收录输入词,相关词被赋予权重kT_W=0.7;only the key 词收录与输入词相关的词,权重为kT_W=0.6;其他权重是 kT_W=0.6。
b) 在新闻内容中:新闻内容中自然语言相关词的词频content_P
c) 最终的相似度计算公式为:
4、代码(运行环境python)
代码链接:
安装好相关模块后,附上需要下载的文件和代码中需要的文件。并给出对应的python2和python3代码
输入关键字 抓取所有网页(一个神器之一selenium五年发表文章五年数量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-24 11:06
PubMed 是一个提供生物医学论文检索和摘要的数据库,可以免费检索。它是生物学中经常使用的文档搜索网站。最近在学习爬虫,包括urllib库、requests库、xpath表达式、scrapy框架等,刚想爬PubMed,作为一个实践,准备爬取过去5年在PubMed上发表的文章文章的数量根据搜索到的关键词,以此为基础来看看这个研究方向近五年的热度。
最初的想法是使用scrapy框架进行爬取和存储。于是打开PubMed,开始分析网页组成、源码等,发现NCBI使用的是动态网页,在进行翻页、关键字搜索等操作时,URL并没有发生变化。于是想到了爬虫神器之一的selenium模块,利用selenium模拟搜索、翻页等操作,然后分析源码,得到想要的信息。由于和selenium接触不多,所以暂时在网上搜索了一些功能。
1、 加载需要的模块
import urllib
import time
import matplotlib.pyplot as plt
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
2、使用关键字构造URL
手动输入几个关键字来分析 URL 的结构。
PubMed的原链接是``,当你输入搜索'cancer, TCGA, Breast'时,url变成''。所以不难分析,URL由两部分组成,一部分不变,另一部分由我们搜索的关键字串起来的字符串'%2C'组成。因此,对于传入的'keyword',我们可以做如下处理,拼接到搜索后返回的url中
keyword = '%2C'.join(keyword)
tart_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
url = start_url + keyword
这样我们就简单的拼接返回的url。
3、创建浏览器对象
下一步就是使用selenium模块打开我们的Chrome浏览器,跳转到url界面。这个操作相信大家都不陌生。因为后面会进行模拟点击翻页等操作,所以需要实例化一个WebDriverWait对象,方便后续调用
browser = webdriver.Chrome()
self.browser.get(url)
wait = WebDriverWait(browser, 10)
模拟点击网页
打开网页后,我们需要模拟点击网页。首先,我们需要找到过去五年的文章,所以我们需要模拟点击左边的5years按钮,改变单页显示的文章的数量。变成200,可以减少我们的翻页操作
QQ图片246.png
我们要等到网页上加载了相应的元素才可以点击,所以我们需要用到前面提到的WebDriverWait对象。代码显示如下
years =wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH,'//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
此处使用了 CSS 选择器和 Xpath 表达式。您使用哪一种取决于您的个人喜好。您可以使用任何您觉得方便的方式。EC.element_to_be_clickable 中的输入是一个元组,第一个元素是声明使用哪个选择器,第二个元素是一个表达式。这个函数的意思是等到你在表达式中传入的元素出现在网页上之后,才会在selenium中出现时才会进行后续的操作。在使用selenium的过程中,有很多地方需要用到presence_of_element_located、text_to_be_present_in_element等类似的操作,有兴趣的可以上网查查。
解析网页并提取信息
下一步是解析网页。我使用 lxml 来解析网页并从 Xpath 中提取信息。代码如下
html = self.browser.page_source
doc = etree.HTML(self.html)
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
这里主要是对网页中的年份进行Xpath提取和字符串切片处理,从而获取年份信息并保存到列表中。在实际操作中发现了少量其他不相关的元素。经过仔细排查,发现是网页源代码有问题。因此,遵循常规过程以删除不以“2”开头的元素。最终结果被检查是正确的。
这里我们提取了单个页面的信息。
翻页操作
我们还需要翻页以获取我们想要的所有信息。硒模块仍在使用。
status = True
def next_page():
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
status = False
while True:
if status:
next_page()
else:
break
这里我首先定义了一个函数来判断是否可以翻页,使用异常捕获,因为翻页动作要停在最后一页,不能再次点击翻页元素。因此,在进行点击操作时应先判断。如果无法点击,会因为超时而抛出异常。next_page 函数中的状态变量记录了“下一页”按钮是否可以被点击。接下来是一个 while True 循环。只有 next_page 变为 False 时,翻页动作才会停止。在循环中,我们继续解析网页来提取信息,就可以得到我们想要的所有信息。
可视化
爬取了所有年份信息的列表后,我们还需要进一步的可视化处理来直观的判断目标话题的研究趋势,所以使用matplotlib进行可视化操作,简单的画一个折线图。代码显示如下:
def plot_curve(yearlist):
counter = Counter(yearlist)
dic = dict(counter)
keys = sorted(list(dic.keys()))
curcount = 0
y = []
temp = [int(i) for i in keys]
for i in range(min(temp), max(temp)+1):
if str(i) in keys:
curcount += self.dic[str(i)]
y.append(self.curcount)
else:
y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.plot(np.arange(min(temp), max(temp)+1), np.array(y), 'r', marker='+', linewidth=2)
plt.show()
最后贴出完整代码:
import re
import urllib
import time
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
import matplotlib.pyplot as plt
class NcbiInfo(object):
browser = webdriver.Chrome()
start_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
wait = WebDriverWait(browser, 10)
def __init__(self, keywordlist):
self.temp = [urllib.parse.quote(i) for i in keywordlist]
self.keyword = '%2C'.join(self.temp)
self.title = ' AND '.join(self.temp)
self.url = NcbiInfo.start_url + self.keyword
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
self.file = open('information.txt', 'w')
self.status = True
self.yearlist = []
def click_yearandabstract(self, ):
self.browser.get(self.url)
years = self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
page_200.click()
def get_response(self):
self.html = self.browser.page_source
self.doc = etree.HTML(self.html)
def get_numof_article(self):
article_count_ = self.doc.xpath('//*[@id="maincontent"]/div/div[3]/div[1]/h3/text()')[0]
if 'of' not in article_count_:
print(article_count_.split(': ')[1])
else:
print(article_count_.split('of ')[1])
def get_info(self):
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
def next_page(self):
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
self.status = False
def plot_curve(self):
self.counter = Counter(self.yearlist)
self.dic = dict(self.counter)
self.keys = sorted(list(self.dic.keys()))
self.curcount = 0
self.y = []
temp = [int(i) for i in self.keys]
for i in range(min(temp), max(temp)+1):
if str(i) in self.keys:
self.curcount += self.dic[str(i)]
self.y.append(self.curcount)
else:
self.y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.title(self.title)
plt.plot(np.arange(min(temp), max(temp)+1), np.array(self.y), 'r', marker='+', linewidth=2)
plt.show()
def main(self):
self.click_yearandabstract()
time.sleep(3)
self.get_response()
self.get_numof_article()
while True:
self.get_info()
self.next_page()
if self.status:
self.nextpage.click()
self.get_response()
else:
break
self.plot_curve()
if __name__ == '__main__':
a = NcbiInfo(['TCGA', 'breast', 'cancer'])
a.main()
结果如下:
图片.png 查看全部
输入关键字 抓取所有网页(一个神器之一selenium五年发表文章五年数量)
PubMed 是一个提供生物医学论文检索和摘要的数据库,可以免费检索。它是生物学中经常使用的文档搜索网站。最近在学习爬虫,包括urllib库、requests库、xpath表达式、scrapy框架等,刚想爬PubMed,作为一个实践,准备爬取过去5年在PubMed上发表的文章文章的数量根据搜索到的关键词,以此为基础来看看这个研究方向近五年的热度。
最初的想法是使用scrapy框架进行爬取和存储。于是打开PubMed,开始分析网页组成、源码等,发现NCBI使用的是动态网页,在进行翻页、关键字搜索等操作时,URL并没有发生变化。于是想到了爬虫神器之一的selenium模块,利用selenium模拟搜索、翻页等操作,然后分析源码,得到想要的信息。由于和selenium接触不多,所以暂时在网上搜索了一些功能。
1、 加载需要的模块
import urllib
import time
import matplotlib.pyplot as plt
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
2、使用关键字构造URL
手动输入几个关键字来分析 URL 的结构。
PubMed的原链接是``,当你输入搜索'cancer, TCGA, Breast'时,url变成''。所以不难分析,URL由两部分组成,一部分不变,另一部分由我们搜索的关键字串起来的字符串'%2C'组成。因此,对于传入的'keyword',我们可以做如下处理,拼接到搜索后返回的url中
keyword = '%2C'.join(keyword)
tart_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
url = start_url + keyword
这样我们就简单的拼接返回的url。
3、创建浏览器对象
下一步就是使用selenium模块打开我们的Chrome浏览器,跳转到url界面。这个操作相信大家都不陌生。因为后面会进行模拟点击翻页等操作,所以需要实例化一个WebDriverWait对象,方便后续调用
browser = webdriver.Chrome()
self.browser.get(url)
wait = WebDriverWait(browser, 10)
模拟点击网页
打开网页后,我们需要模拟点击网页。首先,我们需要找到过去五年的文章,所以我们需要模拟点击左边的5years按钮,改变单页显示的文章的数量。变成200,可以减少我们的翻页操作
QQ图片246.png
我们要等到网页上加载了相应的元素才可以点击,所以我们需要用到前面提到的WebDriverWait对象。代码显示如下
years =wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH,'//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
此处使用了 CSS 选择器和 Xpath 表达式。您使用哪一种取决于您的个人喜好。您可以使用任何您觉得方便的方式。EC.element_to_be_clickable 中的输入是一个元组,第一个元素是声明使用哪个选择器,第二个元素是一个表达式。这个函数的意思是等到你在表达式中传入的元素出现在网页上之后,才会在selenium中出现时才会进行后续的操作。在使用selenium的过程中,有很多地方需要用到presence_of_element_located、text_to_be_present_in_element等类似的操作,有兴趣的可以上网查查。
解析网页并提取信息
下一步是解析网页。我使用 lxml 来解析网页并从 Xpath 中提取信息。代码如下
html = self.browser.page_source
doc = etree.HTML(self.html)
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
这里主要是对网页中的年份进行Xpath提取和字符串切片处理,从而获取年份信息并保存到列表中。在实际操作中发现了少量其他不相关的元素。经过仔细排查,发现是网页源代码有问题。因此,遵循常规过程以删除不以“2”开头的元素。最终结果被检查是正确的。
这里我们提取了单个页面的信息。
翻页操作
我们还需要翻页以获取我们想要的所有信息。硒模块仍在使用。
status = True
def next_page():
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
status = False
while True:
if status:
next_page()
else:
break
这里我首先定义了一个函数来判断是否可以翻页,使用异常捕获,因为翻页动作要停在最后一页,不能再次点击翻页元素。因此,在进行点击操作时应先判断。如果无法点击,会因为超时而抛出异常。next_page 函数中的状态变量记录了“下一页”按钮是否可以被点击。接下来是一个 while True 循环。只有 next_page 变为 False 时,翻页动作才会停止。在循环中,我们继续解析网页来提取信息,就可以得到我们想要的所有信息。
可视化
爬取了所有年份信息的列表后,我们还需要进一步的可视化处理来直观的判断目标话题的研究趋势,所以使用matplotlib进行可视化操作,简单的画一个折线图。代码显示如下:
def plot_curve(yearlist):
counter = Counter(yearlist)
dic = dict(counter)
keys = sorted(list(dic.keys()))
curcount = 0
y = []
temp = [int(i) for i in keys]
for i in range(min(temp), max(temp)+1):
if str(i) in keys:
curcount += self.dic[str(i)]
y.append(self.curcount)
else:
y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.plot(np.arange(min(temp), max(temp)+1), np.array(y), 'r', marker='+', linewidth=2)
plt.show()
最后贴出完整代码:
import re
import urllib
import time
import numpy as np
from lxml import etree
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from collections import Counter
import matplotlib.pyplot as plt
class NcbiInfo(object):
browser = webdriver.Chrome()
start_url = 'https://www.ncbi.nlm.nih.gov/pubmed/?term='
wait = WebDriverWait(browser, 10)
def __init__(self, keywordlist):
self.temp = [urllib.parse.quote(i) for i in keywordlist]
self.keyword = '%2C'.join(self.temp)
self.title = ' AND '.join(self.temp)
self.url = NcbiInfo.start_url + self.keyword
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
self.file = open('information.txt', 'w')
self.status = True
self.yearlist = []
def click_yearandabstract(self, ):
self.browser.get(self.url)
years = self.wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#_ds1 > li > ul > li:nth-child(1) > a')))
years.click()
perpage = self.wait.until(EC.element_to_be_clickable((By.XPATH, '//ul[@class="inline_list left display_settings"]/li[3]/a/span[4]')))
perpage.click()
page_200 = self.wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#display_settings_menu_ps > fieldset > ul > li:nth-child(6) > label')))
page_200.click()
def get_response(self):
self.html = self.browser.page_source
self.doc = etree.HTML(self.html)
def get_numof_article(self):
article_count_ = self.doc.xpath('//*[@id="maincontent"]/div/div[3]/div[1]/h3/text()')[0]
if 'of' not in article_count_:
print(article_count_.split(': ')[1])
else:
print(article_count_.split('of ')[1])
def get_info(self):
self.art_timeanddoi = self.doc.xpath('//div[@class="rprt"]/div[2]/div/p[@class="details"]/text()')
for i in self.art_timeanddoi:
self.yearlist.append(i[2:6])
for i in self.yearlist:
if re.match('2', i):
continue
else:
self.yearlist.remove(i)
def next_page(self):
try:
self.nextpage = self.wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@title="Next page of results"]')))
except TimeoutException:
self.status = False
def plot_curve(self):
self.counter = Counter(self.yearlist)
self.dic = dict(self.counter)
self.keys = sorted(list(self.dic.keys()))
self.curcount = 0
self.y = []
temp = [int(i) for i in self.keys]
for i in range(min(temp), max(temp)+1):
if str(i) in self.keys:
self.curcount += self.dic[str(i)]
self.y.append(self.curcount)
else:
self.y.append(self.curcount)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.xlabel('年份')
plt.ylabel('近五年文章数量')
plt.title(self.title)
plt.plot(np.arange(min(temp), max(temp)+1), np.array(self.y), 'r', marker='+', linewidth=2)
plt.show()
def main(self):
self.click_yearandabstract()
time.sleep(3)
self.get_response()
self.get_numof_article()
while True:
self.get_info()
self.next_page()
if self.status:
self.nextpage.click()
self.get_response()
else:
break
self.plot_curve()
if __name__ == '__main__':
a = NcbiInfo(['TCGA', 'breast', 'cancer'])
a.main()
结果如下:
图片.png
输入关键字 抓取所有网页(怎么才能让商品被搜到?蜘蛛抓取就很重要了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-23 08:03
在这个互联网时代,解决问题最常用的工具就是互联网。“不懂就找妈妈”;自然这个习惯被很多商家用来在网上销售自己的产品,也就是常说的SEO,那么,自己的产品怎么能被搜索到呢?如何在首页上排名?蜘蛛爬行非常重要。
一、蜘蛛爬行网站一个必不可少的因素?
1、关键词 设置;
关键词是网站的核心,可见关键词的重要性。
2、外部链接必不可少;
seo行业有句老话“内容为王,外链为王”,外链对网站的权重也有非常重要的影响。
3、页面权重;
重量越高,自然蜘蛛就越喜欢它。这也是在强调旧域名的重要性。一般网站的首页权重最高,所以一般都是最新的(或没有收录)文章首页的调用,因为权重越高,蜘蛛爬的越深。
4、服务器;
服务器是网站的基石。如果服务器出现故障,会直接导致网站访问受限,页面加载时间过长,直接导致用户体验自然无人访问;百度蜘蛛也是网站的访问者之一,那么百度蜘蛛自然不会抓取它。
5、网站的更新;
网站 抓取的页面将被存储。如果长时间不更新,百度蜘蛛存储的数据将持续相同的时间。百度蜘蛛自然不会来爬。定期更新是必要的。;当然,最好的更新内容是原创,至少是伪原创。百度蜘蛛非常喜欢原创的内容。
6、扁平的网站结构;
百度蜘蛛抓取有自己的线路。网站 结构不要太复杂,链接层次不要太深,链接最好是静态的。
7、内链建设;
蜘蛛的爬取是跟随链接的,所以合理的网站内链可以让蜘蛛抓取更多的页面,常见的内链一般都加载在文章中。
8、404页面;
404页面非常重要。404 告诉搜索引擎这是一个错误页面。一个好的 404 页面也可以阻止客户浏览。
9、 死链检测;
死链接过多会影响网站的权重。一旦发现死链接,必须及时处理。
10、检查robots文件;
很多网站有意无意地屏蔽了百度或网站robots文件中的部分页面,但他们正在寻找蜘蛛不抓取我的页面的原因。你能怪百度吗?让别人进来,百度收录你的网页是怎么做的?所以需要不时检查网站robots文件是否正常。
11、网站地图;
搜索引擎蜘蛛非常喜欢网站 地图。网站 地图是所有链接网站 的容器。很多网站链接都有很深的层次,蜘蛛很难捕捉。网站地图可以方便搜索引擎蜘蛛抓取网站页面。通过爬取网站页面,很清楚的了解了网站的结构,所以构建一张网站地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
12、 链接提交;
记得更新后主动提交链接,自动提交代码也是必不可少的。 查看全部
输入关键字 抓取所有网页(怎么才能让商品被搜到?蜘蛛抓取就很重要了)
在这个互联网时代,解决问题最常用的工具就是互联网。“不懂就找妈妈”;自然这个习惯被很多商家用来在网上销售自己的产品,也就是常说的SEO,那么,自己的产品怎么能被搜索到呢?如何在首页上排名?蜘蛛爬行非常重要。
一、蜘蛛爬行网站一个必不可少的因素?
1、关键词 设置;
关键词是网站的核心,可见关键词的重要性。
2、外部链接必不可少;
seo行业有句老话“内容为王,外链为王”,外链对网站的权重也有非常重要的影响。
3、页面权重;
重量越高,自然蜘蛛就越喜欢它。这也是在强调旧域名的重要性。一般网站的首页权重最高,所以一般都是最新的(或没有收录)文章首页的调用,因为权重越高,蜘蛛爬的越深。
4、服务器;
服务器是网站的基石。如果服务器出现故障,会直接导致网站访问受限,页面加载时间过长,直接导致用户体验自然无人访问;百度蜘蛛也是网站的访问者之一,那么百度蜘蛛自然不会抓取它。
5、网站的更新;
网站 抓取的页面将被存储。如果长时间不更新,百度蜘蛛存储的数据将持续相同的时间。百度蜘蛛自然不会来爬。定期更新是必要的。;当然,最好的更新内容是原创,至少是伪原创。百度蜘蛛非常喜欢原创的内容。
6、扁平的网站结构;
百度蜘蛛抓取有自己的线路。网站 结构不要太复杂,链接层次不要太深,链接最好是静态的。
7、内链建设;
蜘蛛的爬取是跟随链接的,所以合理的网站内链可以让蜘蛛抓取更多的页面,常见的内链一般都加载在文章中。
8、404页面;
404页面非常重要。404 告诉搜索引擎这是一个错误页面。一个好的 404 页面也可以阻止客户浏览。
9、 死链检测;
死链接过多会影响网站的权重。一旦发现死链接,必须及时处理。
10、检查robots文件;
很多网站有意无意地屏蔽了百度或网站robots文件中的部分页面,但他们正在寻找蜘蛛不抓取我的页面的原因。你能怪百度吗?让别人进来,百度收录你的网页是怎么做的?所以需要不时检查网站robots文件是否正常。
11、网站地图;
搜索引擎蜘蛛非常喜欢网站 地图。网站 地图是所有链接网站 的容器。很多网站链接都有很深的层次,蜘蛛很难捕捉。网站地图可以方便搜索引擎蜘蛛抓取网站页面。通过爬取网站页面,很清楚的了解了网站的结构,所以构建一张网站地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
12、 链接提交;
记得更新后主动提交链接,自动提交代码也是必不可少的。
输入关键字 抓取所有网页(TextRank提取的算法,用于提取短语和自动摘要的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-23 08:01
今天要介绍的TextRank是一种用于关键词提取的算法,也可以用于词组提取和自动摘要。因为TextRank是基于PageRank的,先简单介绍一下PageRank算法。
1.PageRank 算法
PageRank 最初是为谷歌的页面排名而设计的,以公司创始人拉里佩奇的名字命名。谷歌用它来反映网页的相关性和重要性,常用于评价网页优化在搜索引擎优化操作中的有效性。PageRank 使用互联网中的超链接关系来确定网页的排名。公式是由一个投票的想法设计的:如果我们要计算网页A的PageRank值(以下简称PR值),那么我们需要知道哪些网页如果链接到网页A,意味着得到先获取网页A的链接,然后通过链接投票给网页A,计算网页A的PR值。这样的设计可以保证实现这样的效果:当一些高质量的网页指向网页A时,那么网页A的PR值会因为这些高质量的投票而增加,网页A被较少的网页指向或者被一些PR值较低的网页指向时,A的PR值不会很大大,可以合理反映一个网页的质量水平。基于以上思路,Page设计了如下公式:
在这个公式中,Vi代表某个网页,Vj代表链接到Vi的网页(即Vi的in-link),S(Vi)代表网页Vi的PR值,In(Vi)代表集合在网页 Vi 的所有 in-link 中,Out(Vj) 代表网页,d 代表阻尼系数,用于克服该公式中“d *”后部分的固有缺陷:如果只有求和部分,那么公式将无法处理非链内网页的PR值,因为此时根据公式,这些网页的PR值为0,但实际情况并非如此。添加了阻尼系数,保证每个网页的PR值都大于0。 根据实验结果,在0.85的阻尼系数下,大约100次迭代后,PR值可以收敛到一个稳定值。当阻尼系数接近1时,需要的迭代次数会突然增加,排名不会稳定。公式中S(Vj)前面的分数是指Vj指向的所有网页都应该平均分享Vj的PR值,这样你就可以为你链接的网页统计你的票数。
2.1 TextRank算法提取关键词
TextRank 是由 PageRank 改进而来,其公式有很多相似之处。下面是 TextRank 的公式:
可以看出,这个公式只比PageRank多了一个权重项Wji,用于表示两个节点之间的边连接具有不同的重要程度。TextRank用于关键词提取的算法如下:
1) 根据完整的句子对给定的文本T进行切分,即
2)对于每个句子
, 进行分词和词性标注,过滤掉停用词,只保留指定的词性词,如名词、动词、形容词,即
, 其中ti,j 为保留后的候选关键词。
3)构造候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence) 在任意两点之间构造一条边。两个节点之间只有当它们对应的词在长度为K的窗口中共同出现时才存在边。K表示窗口大小,即在大多数 K 个词可以同时出现。
4)根据上面的公式,迭代传播每个节点的权重,直到收敛。
5) 将节点权重逆序排序,得到最重要的T字作为候选关键词。
6) 从5中找出最重要的T字,并在原文中做标记。如果形成相邻的短语,则将它们组合成多个词关键词。
2.2 TextRank算法提取关键词词组
提取关键词词组的方法基于关键词提取。可以简单地认为:如果提取出的几个关键词在文本中相邻,那么它们就构成了一个提取出的关键短语。
2.3TextRank 生成摘要
将文本中的每个句子视为一个节点。如果两个句子相似,则认为这两个句子对应的节点之间存在无向右边缘。检验句子相似度的方法是以下公式:
式中,Si和Sj分别代表两个句子,Wk代表句子中的词,那么分子部分表示两个句子中同时出现的同一个词的个数,分母为词的个数在句子中对数的总和。分母的这种设计可以抑制长句在相似度计算中的优势。
我们可以根据上述相似度公式循环计算任意两个节点之间的相似度,根据阈值去除两个节点之间相似度低的边连接,构建节点连接图,然后计算TextRank值,最后所有的 TextRank 按值排序,选取 TextRank 值最高的节点对应的句子作为汇总。
参考 查看全部
输入关键字 抓取所有网页(TextRank提取的算法,用于提取短语和自动摘要的方法)
今天要介绍的TextRank是一种用于关键词提取的算法,也可以用于词组提取和自动摘要。因为TextRank是基于PageRank的,先简单介绍一下PageRank算法。
1.PageRank 算法
PageRank 最初是为谷歌的页面排名而设计的,以公司创始人拉里佩奇的名字命名。谷歌用它来反映网页的相关性和重要性,常用于评价网页优化在搜索引擎优化操作中的有效性。PageRank 使用互联网中的超链接关系来确定网页的排名。公式是由一个投票的想法设计的:如果我们要计算网页A的PageRank值(以下简称PR值),那么我们需要知道哪些网页如果链接到网页A,意味着得到先获取网页A的链接,然后通过链接投票给网页A,计算网页A的PR值。这样的设计可以保证实现这样的效果:当一些高质量的网页指向网页A时,那么网页A的PR值会因为这些高质量的投票而增加,网页A被较少的网页指向或者被一些PR值较低的网页指向时,A的PR值不会很大大,可以合理反映一个网页的质量水平。基于以上思路,Page设计了如下公式:
在这个公式中,Vi代表某个网页,Vj代表链接到Vi的网页(即Vi的in-link),S(Vi)代表网页Vi的PR值,In(Vi)代表集合在网页 Vi 的所有 in-link 中,Out(Vj) 代表网页,d 代表阻尼系数,用于克服该公式中“d *”后部分的固有缺陷:如果只有求和部分,那么公式将无法处理非链内网页的PR值,因为此时根据公式,这些网页的PR值为0,但实际情况并非如此。添加了阻尼系数,保证每个网页的PR值都大于0。 根据实验结果,在0.85的阻尼系数下,大约100次迭代后,PR值可以收敛到一个稳定值。当阻尼系数接近1时,需要的迭代次数会突然增加,排名不会稳定。公式中S(Vj)前面的分数是指Vj指向的所有网页都应该平均分享Vj的PR值,这样你就可以为你链接的网页统计你的票数。
2.1 TextRank算法提取关键词
TextRank 是由 PageRank 改进而来,其公式有很多相似之处。下面是 TextRank 的公式:
可以看出,这个公式只比PageRank多了一个权重项Wji,用于表示两个节点之间的边连接具有不同的重要程度。TextRank用于关键词提取的算法如下:
1) 根据完整的句子对给定的文本T进行切分,即
2)对于每个句子
, 进行分词和词性标注,过滤掉停用词,只保留指定的词性词,如名词、动词、形容词,即
, 其中ti,j 为保留后的候选关键词。
3)构造候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence) 在任意两点之间构造一条边。两个节点之间只有当它们对应的词在长度为K的窗口中共同出现时才存在边。K表示窗口大小,即在大多数 K 个词可以同时出现。
4)根据上面的公式,迭代传播每个节点的权重,直到收敛。
5) 将节点权重逆序排序,得到最重要的T字作为候选关键词。
6) 从5中找出最重要的T字,并在原文中做标记。如果形成相邻的短语,则将它们组合成多个词关键词。
2.2 TextRank算法提取关键词词组
提取关键词词组的方法基于关键词提取。可以简单地认为:如果提取出的几个关键词在文本中相邻,那么它们就构成了一个提取出的关键短语。
2.3TextRank 生成摘要
将文本中的每个句子视为一个节点。如果两个句子相似,则认为这两个句子对应的节点之间存在无向右边缘。检验句子相似度的方法是以下公式:
式中,Si和Sj分别代表两个句子,Wk代表句子中的词,那么分子部分表示两个句子中同时出现的同一个词的个数,分母为词的个数在句子中对数的总和。分母的这种设计可以抑制长句在相似度计算中的优势。
我们可以根据上述相似度公式循环计算任意两个节点之间的相似度,根据阈值去除两个节点之间相似度低的边连接,构建节点连接图,然后计算TextRank值,最后所有的 TextRank 按值排序,选取 TextRank 值最高的节点对应的句子作为汇总。
参考
输入关键字 抓取所有网页(从服务器打开文件的方法是使用URL请求它。。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-23 07:14
从服务器打开文件的方法是使用 URL 请求它。从服务器打开文件的方法是使用 URL 请求它。事实上,在万维网诞生之初,这是获取内容的唯一途径:内容创建者将各种文件放在服务器上,而客户端将打开或下载这些文件。唯一的方法:内容创建者将各种文件放在服务器上,客户端打开或下载这些文件。 URI 和参数的动态处理是后来的发明。这就是评论者要求提供您使用的 URL 的原因。我们希望看到它并进行相应的修改,以帮助您了解需要更改哪些部分才能获得该特定文件。您可以省略密码,或将其替换为其他一些字母字符串。您可以省略密码,或将其替换为其他一些字母字符串。
通常,您想要的文件将在您使用的 url 下,但以文件名结尾。如果起始 URL 是,则此文件将位于。如果起始 URL 是,则此文件将位于。
请注意,任何参数都应该遵循路径,所以会变成 查看全部
输入关键字 抓取所有网页(从服务器打开文件的方法是使用URL请求它。。)
从服务器打开文件的方法是使用 URL 请求它。从服务器打开文件的方法是使用 URL 请求它。事实上,在万维网诞生之初,这是获取内容的唯一途径:内容创建者将各种文件放在服务器上,而客户端将打开或下载这些文件。唯一的方法:内容创建者将各种文件放在服务器上,客户端打开或下载这些文件。 URI 和参数的动态处理是后来的发明。这就是评论者要求提供您使用的 URL 的原因。我们希望看到它并进行相应的修改,以帮助您了解需要更改哪些部分才能获得该特定文件。您可以省略密码,或将其替换为其他一些字母字符串。您可以省略密码,或将其替换为其他一些字母字符串。
通常,您想要的文件将在您使用的 url 下,但以文件名结尾。如果起始 URL 是,则此文件将位于。如果起始 URL 是,则此文件将位于。
请注意,任何参数都应该遵循路径,所以会变成
输入关键字 抓取所有网页(关注回复“书籍”即可获赠Python从入门到进阶共10本电子书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-22 13:05
点击上方“Python爬虫与数据挖掘”关注
回复“books”即可领取Python入门到高级共10本电子书
今天
日
鸡肉
汤
有清明漫天,下有绿水波。
/前言/
在上一篇文章中:我们已经获得了文章详情页的链接,但是提取URL后,如何发送给Scrapy下载呢?下载完成后,我们如何调用自己定义的解析函数呢?这时候就需要Scrapy框架中的另一个类Request。具体教程如下。
/具体实现/
1、 这个Request存放在scrapy.http下,如下图,直接导入即可。
我们需要把这个Request对象交给Scrapy,然后Scrapy爬虫框架会帮我们下载。
2、Request对象中,有初始化参数url和回调函数callback。当然,还有其他参数,这里就不解释了。我们将获取到的文章链接URL传递给这个初始化参数url,然后就可以构造Request了。这里需要注意的是,这个Request是文章的详情页,不是文章的列表页。对于文章详情页,那么我们需要提取每个文章的具体信息。
3、基于前面文章的铺垫,为了提取网页的目标信息,可以将提取的目标信息的表达部分封装成一个函数parse_detail(),作为提取文章特定字段的回调函数。下面是一个 CSS 选择器的例子,如下图所示。如果你想用 Xpath 选择器提取,没有问题。具体实现请参考文章历史文章中CSS和Xpath选择器的使用。具体实现过程这里不再赘述。
4、 之后我们会完善Request类,增加回调参数。记得在parse_detail前加上self,表示在当前类中,否则会报错。另外,虽然 parse_detail 是一个函数,但是这里一定不要加括号。这是回调函数的特性。
5、 细心的朋友可能已经注意到,上图中Request类中的URL部分非常复杂,添加了parse.urljoin()函数。其实这也是一个小技巧。在这里简单说一下。希望对朋友有帮助。 parse.urljoin() 函数的作用是将相对地址组合成一个完整的url。有时网页标签向我们展示的不是完整的URL链接或完整的域名,而是省略了网页的域名。如果没有域名,则默认域名为当前网页的域名(response.url)。这时候就需要将URL拼接起来,形成一个完整的URL地址,方便正常访问。
6、Request类初始化后,如何交给Scrapy下载?其实很简单,在前面输入一个yield关键字,它的作用就是把Request to Scrapy中的URL交给下载。
至此,解析列表页中文章的所有URL并交给Scrapy下载的步骤已经完成。接下来我们需要做的是如何提取下一页的URL并交给Scrapy下载。下一篇文章将重点解决这个问题,敬请期待~~~
/摘要/
本文基于Scrapy爬虫框架,使用CSS选择器和Xpath选择器解析列表页面中所有的文章 URL,并交给Scrapy下载。至此,数据采集的基本功能已经完成。下一篇文章将完成如何提取下一页的URL并发送给Scrapy下载,敬请期待。
如果想进一步了解Python,可以参考学习网站:点击阅读原文,可以直达~
-------------------结束------------------- 查看全部
输入关键字 抓取所有网页(关注回复“书籍”即可获赠Python从入门到进阶共10本电子书)
点击上方“Python爬虫与数据挖掘”关注
回复“books”即可领取Python入门到高级共10本电子书
今天
日
鸡肉
汤
有清明漫天,下有绿水波。
/前言/
在上一篇文章中:我们已经获得了文章详情页的链接,但是提取URL后,如何发送给Scrapy下载呢?下载完成后,我们如何调用自己定义的解析函数呢?这时候就需要Scrapy框架中的另一个类Request。具体教程如下。
/具体实现/
1、 这个Request存放在scrapy.http下,如下图,直接导入即可。
我们需要把这个Request对象交给Scrapy,然后Scrapy爬虫框架会帮我们下载。
2、Request对象中,有初始化参数url和回调函数callback。当然,还有其他参数,这里就不解释了。我们将获取到的文章链接URL传递给这个初始化参数url,然后就可以构造Request了。这里需要注意的是,这个Request是文章的详情页,不是文章的列表页。对于文章详情页,那么我们需要提取每个文章的具体信息。
3、基于前面文章的铺垫,为了提取网页的目标信息,可以将提取的目标信息的表达部分封装成一个函数parse_detail(),作为提取文章特定字段的回调函数。下面是一个 CSS 选择器的例子,如下图所示。如果你想用 Xpath 选择器提取,没有问题。具体实现请参考文章历史文章中CSS和Xpath选择器的使用。具体实现过程这里不再赘述。
4、 之后我们会完善Request类,增加回调参数。记得在parse_detail前加上self,表示在当前类中,否则会报错。另外,虽然 parse_detail 是一个函数,但是这里一定不要加括号。这是回调函数的特性。
5、 细心的朋友可能已经注意到,上图中Request类中的URL部分非常复杂,添加了parse.urljoin()函数。其实这也是一个小技巧。在这里简单说一下。希望对朋友有帮助。 parse.urljoin() 函数的作用是将相对地址组合成一个完整的url。有时网页标签向我们展示的不是完整的URL链接或完整的域名,而是省略了网页的域名。如果没有域名,则默认域名为当前网页的域名(response.url)。这时候就需要将URL拼接起来,形成一个完整的URL地址,方便正常访问。
6、Request类初始化后,如何交给Scrapy下载?其实很简单,在前面输入一个yield关键字,它的作用就是把Request to Scrapy中的URL交给下载。
至此,解析列表页中文章的所有URL并交给Scrapy下载的步骤已经完成。接下来我们需要做的是如何提取下一页的URL并交给Scrapy下载。下一篇文章将重点解决这个问题,敬请期待~~~
/摘要/
本文基于Scrapy爬虫框架,使用CSS选择器和Xpath选择器解析列表页面中所有的文章 URL,并交给Scrapy下载。至此,数据采集的基本功能已经完成。下一篇文章将完成如何提取下一页的URL并发送给Scrapy下载,敬请期待。
如果想进一步了解Python,可以参考学习网站:点击阅读原文,可以直达~
-------------------结束-------------------
输入关键字 抓取所有网页( 2019年12月24日10:18:12作者:变异的小江江)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-22 13:03
2019年12月24日10:18:12作者:变异的小江江)
Python实现通过关键字过滤日志文件
更新时间:2019年12月24日10:18:12 作者:变异肖江江
今天分享一篇关于python中如何通过关键字过滤日志文件的文章,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
最近,我变成了一只狗。五六个项目堆在一起。头疼的是,测试还是被吓到了,给我丢了几十甚至几百兆的日志文件,动辄几千万行,就算有。搜索也晕了,于是花点时间写了个小脚本过滤日志。当然,网上应该有很多这样的东西,但我还是想自己做,学习!
#!/usr/bin/python
# -*- encoding: utf-8 -*-
# version 1.0
import re
import time
'''
用于筛选日志文件,适用于python2.x版本
使用时将日志文件放于search.py工具同一目录
筛选完毕后会出现“旧文件名+当前时间”格式命名的新日志文件
'''
def getParameters():
file_name = ""
key_work = ""
while (True):
file_name = raw_input("请输入文件名:")
key_work = raw_input("请输入过滤关键字:")
if len(file_name) == 0 or len(key_work) == 0:
flag = raw_input("您输入的文件名或关键子为空,输出c重试,q退出程序:")
if flag == "q":
return
elif flag == "c":
continue
else:
break
new_file = file_name + "-" + formatTime(time.localtime())
f = open("./" + file_name, "rb")
lines = f.readlines()
if len(lines) == 0:
print("========日志文件为空========")
f.close()
return
nf = open("./" + new_file, "wb");
count = 0
for line in lines:
rs = re.search(key_work, line)
if rs:
print("[命中]--->%s" % line)
nf.write(line)
count = count + 1
f.close()
nf.close()
print("共找到%d条信息" % count)
def formatTime(timevalue):
'''
format the time numbers
'''
return time.strftime("%Y%m%d%H%M%S", timevalue)
if __name__ == '__main__':
getParameters()
注意:我直接在终端上运行了这个脚本。/xxxx.py。由于android源代码的编译,我的终端需要安装python2.7.6。估计会跑在python3上。有问题。
好的,这是我测试的比赛结果:
当然,这仅适用于单个文件!
以上python通过关键字过滤日志文件的实现是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
输入关键字 抓取所有网页(
2019年12月24日10:18:12作者:变异的小江江)
Python实现通过关键字过滤日志文件
更新时间:2019年12月24日10:18:12 作者:变异肖江江
今天分享一篇关于python中如何通过关键字过滤日志文件的文章,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
最近,我变成了一只狗。五六个项目堆在一起。头疼的是,测试还是被吓到了,给我丢了几十甚至几百兆的日志文件,动辄几千万行,就算有。搜索也晕了,于是花点时间写了个小脚本过滤日志。当然,网上应该有很多这样的东西,但我还是想自己做,学习!
#!/usr/bin/python
# -*- encoding: utf-8 -*-
# version 1.0
import re
import time
'''
用于筛选日志文件,适用于python2.x版本
使用时将日志文件放于search.py工具同一目录
筛选完毕后会出现“旧文件名+当前时间”格式命名的新日志文件
'''
def getParameters():
file_name = ""
key_work = ""
while (True):
file_name = raw_input("请输入文件名:")
key_work = raw_input("请输入过滤关键字:")
if len(file_name) == 0 or len(key_work) == 0:
flag = raw_input("您输入的文件名或关键子为空,输出c重试,q退出程序:")
if flag == "q":
return
elif flag == "c":
continue
else:
break
new_file = file_name + "-" + formatTime(time.localtime())
f = open("./" + file_name, "rb")
lines = f.readlines()
if len(lines) == 0:
print("========日志文件为空========")
f.close()
return
nf = open("./" + new_file, "wb");
count = 0
for line in lines:
rs = re.search(key_work, line)
if rs:
print("[命中]--->%s" % line)
nf.write(line)
count = count + 1
f.close()
nf.close()
print("共找到%d条信息" % count)
def formatTime(timevalue):
'''
format the time numbers
'''
return time.strftime("%Y%m%d%H%M%S", timevalue)
if __name__ == '__main__':
getParameters()
注意:我直接在终端上运行了这个脚本。/xxxx.py。由于android源代码的编译,我的终端需要安装python2.7.6。估计会跑在python3上。有问题。
好的,这是我测试的比赛结果:
当然,这仅适用于单个文件!
以上python通过关键字过滤日志文件的实现是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。
输入关键字 抓取所有网页( ,就是实现搜索关键字功能(组图)搜索框输入关键字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-11-21 20:02
,就是实现搜索关键字功能(组图)搜索框输入关键字)
只要用过搜索引擎的朋友都应该有过这样的经历,在搜索框中输入关键词的时候,就会出现自匹配现象。这绝对是一个非常好的用户体验。下面是类似的代码,当然这里只是Cover up,所以只匹配到本地固定的数据,实际应用中可以从数据库中读取数据。效果图:代码示例如下:
iOS searchBar(搜索框)光标初始位置向后移动
废话不多说,直接把关键代码贴给大家,具体代码如下: #import @interface SearchBar: UITextField @property (nonatomic,strong) UIButton *button; + (instancetype)searchBar; @end #import "SearchBar .h" @implementation SearchBar-(id)initWithFrame:(CGR
vue+Element 实现搜索关键词高亮功能
最近做了一个日志搜索请求,需要对页面上的海量日志进行关键字搜索。为了让搜索更清晰,我最后实现了多条件搜索,将搜索结果记录中的关键字全部高亮显示。一.实施思路1 实时监控表格,实现关键词定位: 2 点击搜索按钮后,实现记录中关键词的风格变化(即高亮)。二.实现过程1 搜索条件表单理解实现思路,一起来看看实现过程(重点位置有注释)
使用rxjs算子处理思路的Angular搜索场景
在有输入框的搜索/过滤业务中,我们会一直考虑如何降低发起请求的频率,尽量让每一个请求都有效。节流和防抖是比较常见的做法,这类功能的实现也不难,但还是需要自己封装。rxjs 提供了多种操作符,可以非常快速高效的实现这些功能。Chestnut现在有了一个查询场景,可以按城市、类型、关键字多维度过滤结果,如下图: 处理思路:1.将select和input的值绑定到过滤条件对象中model通过ngModel2.监听select输入框的change事件和input输入框的input事件触发发送
前端html中的JQuery实现文本的搜索功能,显示搜索相关的内容
做项目的时候有这样的需求。显示客户信息后,我会搜索相关客户并显示所有相关客户信息。因为一个客户的所有信息都写在一个div里,所以显示的时候就是整个信息。div.先看实现效果:当我进入瓦窑村时,会显示与瓦窑村的相关客户信息,瓦窑村的字体设置为红色,其他不显示:看html代码以下:
Android实现搜索功能并将搜索结果保存到SQLite(示例代码)
运行结果: 涉及要点:ListView+EditText+ScrollView实现搜索效果,显示,监听,软键盘,回车,执行搜索,使用TextWatcher()实时过滤,将搜索内容存储在SQLite中(可以清除历史记录),监听EditText的焦点,获取焦点弹出软键盘同时显示搜索历史,失去焦点隐藏软件托盘和ListView。实现过程比较简单,都是常用的,这里不再赘述。代码可以直接复制使用。实现过程: MainActivity.java 公共类 MainActivity extends
基于Python正则表达式提取搜索结果中的站点地址
正则表达式并不是 Python 独有的。最近把google搜索结果中的站点地址全部导出,于是想到了用python正则表达式来提取搜索结果中的站点地址。有几个问题需要解决。问题:1. 获取搜索结果文本 为了获取更多地址,我使用了谷歌的高级搜索功能,每页显示100条结果。得到显示的结果后,可以查看源码,保留为文本 文件中有搜索结果文本2.分析如何提取站点信息。首先,您需要对获取的页面进行分析,以了解如何提取站点信息。我用的是IE8自带的开发工具(按F12会弹出来
© 2021 张胜荣| 信息#| 19 小时。0.190 秒。 查看全部
输入关键字 抓取所有网页(
,就是实现搜索关键字功能(组图)搜索框输入关键字)
只要用过搜索引擎的朋友都应该有过这样的经历,在搜索框中输入关键词的时候,就会出现自匹配现象。这绝对是一个非常好的用户体验。下面是类似的代码,当然这里只是Cover up,所以只匹配到本地固定的数据,实际应用中可以从数据库中读取数据。效果图:代码示例如下:
iOS searchBar(搜索框)光标初始位置向后移动
废话不多说,直接把关键代码贴给大家,具体代码如下: #import @interface SearchBar: UITextField @property (nonatomic,strong) UIButton *button; + (instancetype)searchBar; @end #import "SearchBar .h" @implementation SearchBar-(id)initWithFrame:(CGR
vue+Element 实现搜索关键词高亮功能
最近做了一个日志搜索请求,需要对页面上的海量日志进行关键字搜索。为了让搜索更清晰,我最后实现了多条件搜索,将搜索结果记录中的关键字全部高亮显示。一.实施思路1 实时监控表格,实现关键词定位: 2 点击搜索按钮后,实现记录中关键词的风格变化(即高亮)。二.实现过程1 搜索条件表单理解实现思路,一起来看看实现过程(重点位置有注释)
使用rxjs算子处理思路的Angular搜索场景
在有输入框的搜索/过滤业务中,我们会一直考虑如何降低发起请求的频率,尽量让每一个请求都有效。节流和防抖是比较常见的做法,这类功能的实现也不难,但还是需要自己封装。rxjs 提供了多种操作符,可以非常快速高效的实现这些功能。Chestnut现在有了一个查询场景,可以按城市、类型、关键字多维度过滤结果,如下图: 处理思路:1.将select和input的值绑定到过滤条件对象中model通过ngModel2.监听select输入框的change事件和input输入框的input事件触发发送
前端html中的JQuery实现文本的搜索功能,显示搜索相关的内容
做项目的时候有这样的需求。显示客户信息后,我会搜索相关客户并显示所有相关客户信息。因为一个客户的所有信息都写在一个div里,所以显示的时候就是整个信息。div.先看实现效果:当我进入瓦窑村时,会显示与瓦窑村的相关客户信息,瓦窑村的字体设置为红色,其他不显示:看html代码以下:
Android实现搜索功能并将搜索结果保存到SQLite(示例代码)
运行结果: 涉及要点:ListView+EditText+ScrollView实现搜索效果,显示,监听,软键盘,回车,执行搜索,使用TextWatcher()实时过滤,将搜索内容存储在SQLite中(可以清除历史记录),监听EditText的焦点,获取焦点弹出软键盘同时显示搜索历史,失去焦点隐藏软件托盘和ListView。实现过程比较简单,都是常用的,这里不再赘述。代码可以直接复制使用。实现过程: MainActivity.java 公共类 MainActivity extends
基于Python正则表达式提取搜索结果中的站点地址
正则表达式并不是 Python 独有的。最近把google搜索结果中的站点地址全部导出,于是想到了用python正则表达式来提取搜索结果中的站点地址。有几个问题需要解决。问题:1. 获取搜索结果文本 为了获取更多地址,我使用了谷歌的高级搜索功能,每页显示100条结果。得到显示的结果后,可以查看源码,保留为文本 文件中有搜索结果文本2.分析如何提取站点信息。首先,您需要对获取的页面进行分析,以了解如何提取站点信息。我用的是IE8自带的开发工具(按F12会弹出来
© 2021 张胜荣| 信息#| 19 小时。0.190 秒。
输入关键字 抓取所有网页(一下的工作原理是什么?如何让搜索引擎更加青睐自己的网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-20 13:06
做过网站排名的朋友都知道优化关键词,优化网站,但是不知道文章被爬取后爬虫怎么样了?为什么别人的网站排名比你高?为什么你的关键词排名比别人高?怎样才能在网站的关键词上获得好的排名?网站可以让搜索引擎更受自己的欢迎,今天我们一起来学习网站文章被爬虫抓取后,百度搜索引擎排名如何关键词?
作为Seoer,我们必须了解搜索引擎的工作原理。只有了解了搜索引擎的工作原理,才能更好的在网站的优化过程中使用。今天和大家简单分享一下搜索引擎的工作原理。
搜索引擎的工作原理
一个搜索引擎的工作过程大致可以分为三个步骤:搜索引擎蜘蛛抓取和抓取数据,搜索引擎后端预处理(索引)采集数据,搜索引擎按照一定的方法网站(网页)排行。
一、搜索引擎蜘蛛抓取和抓取数据
搜索引擎蜘蛛会在 网站 上抓取和抓取您的数据。首先,我们要给搜索引擎一个入口。搜索引擎爬取的入口越多,爬取的机会就越多。新站可以在百度、360搜索引擎网站上提交,让它更快的知道你的存在。
为什么原创文章更有利于搜索引擎爬取,因为搜索引擎爬取数据的时候,搜索引擎会检查内容,匹配自己数据库中的内容。如果有大量低权重的网站转载内容,蜘蛛爬取并在数据库中进行比较,不是原创就不会来爬取你的网站没有价值了,严重的情况下,你可能怀疑作弊,给你网站降级或不显示你的网站在百度,你以前的关键词排名也很漂亮。所以对新站的一个建议是原创是最好的。
二、搜索引擎后台预处理采集的数据(索引)
1、 提取网站文本等内容:从网站中搜索引擎抓取的内容中提取相关含义内容,去除一些不必要的标签等。
2、 中文分词及无用词去除:对网页中的文字进行拆分、切分,过滤掉文章中的一些无意义的词,如“的、地”等。
3、 去除不重要的内容:去除与内容主体意义无关的文字,比如一些本身存在的回复和帖子
4、删除网站重复内容:如果多个页面内容相同,重复的页面和链接应该从数据库中删除。
5、 索引内容:正向和反向索引,从链接开始,对应几个关键词称为正向索引;或者从 关键词 开始,对应多个链接称为反向索引。
6、 链接关系计算:计算每个页面导入哪些页面,导入锚文本关键词,形成页面(链接)的权重(如PR),并存储权重的值。
三、搜索引擎会以某种方式对网站(网页)进行排名
1、Search关键词 处理:对搜索词进行切分、去除无用词、拼写纠正、指令处理等。
2、找到关键词对应的链接集:利用第一步得到的分词后的关键词在反向索引表中查询,找到该词对应的所有链接
3、 初始子集选择:根据每个页面(链接)的权重值,过滤出一个合适的关键词对应链接子集(数千或数万)。
4、 相关计算:看分词的共性关键词(常用度低的搜索引擎比较关注),看词的频率密度,关键词的位置和形式(关键词位置很重要,比如开头,结尾,在H1,中粗体,高相关),关键词距离(小距离,高相关),外链锚文本相关,外链source 本身,以及链接周围的文字(这个应该是考虑最多的,也许这可以反映我们对我们的一些外部优化工作的要求)
5、 排名过滤和调整:经过前几步,大体排名已经确定。搜索引擎也会对结果集进行过滤,作弊和疑似作弊的页面会放在结果集的末尾。
6、 显示搜索的排名结果:这个就不多解释了,就是搜索后呈现给你的结果。
7、搜索结果缓存:搜索引擎对结果进行排序后,结果集会被缓存,无需每次重新计算。
8、用户查询和点击日志:日志文件中的数据对于搜索引擎判断搜索结果质量、调整搜索算法、预测搜索趋势具有重要意义。它甚至可以根据用户体验抵消和排名结果。
以上是“网站文章被爬虫爬取后,百度搜索引擎排名如何关键词?”的全部内容,如有明确表述,请留言留言,一起进步。 查看全部
输入关键字 抓取所有网页(一下的工作原理是什么?如何让搜索引擎更加青睐自己的网站)
做过网站排名的朋友都知道优化关键词,优化网站,但是不知道文章被爬取后爬虫怎么样了?为什么别人的网站排名比你高?为什么你的关键词排名比别人高?怎样才能在网站的关键词上获得好的排名?网站可以让搜索引擎更受自己的欢迎,今天我们一起来学习网站文章被爬虫抓取后,百度搜索引擎排名如何关键词?
作为Seoer,我们必须了解搜索引擎的工作原理。只有了解了搜索引擎的工作原理,才能更好的在网站的优化过程中使用。今天和大家简单分享一下搜索引擎的工作原理。
搜索引擎的工作原理
一个搜索引擎的工作过程大致可以分为三个步骤:搜索引擎蜘蛛抓取和抓取数据,搜索引擎后端预处理(索引)采集数据,搜索引擎按照一定的方法网站(网页)排行。
一、搜索引擎蜘蛛抓取和抓取数据
搜索引擎蜘蛛会在 网站 上抓取和抓取您的数据。首先,我们要给搜索引擎一个入口。搜索引擎爬取的入口越多,爬取的机会就越多。新站可以在百度、360搜索引擎网站上提交,让它更快的知道你的存在。
为什么原创文章更有利于搜索引擎爬取,因为搜索引擎爬取数据的时候,搜索引擎会检查内容,匹配自己数据库中的内容。如果有大量低权重的网站转载内容,蜘蛛爬取并在数据库中进行比较,不是原创就不会来爬取你的网站没有价值了,严重的情况下,你可能怀疑作弊,给你网站降级或不显示你的网站在百度,你以前的关键词排名也很漂亮。所以对新站的一个建议是原创是最好的。
二、搜索引擎后台预处理采集的数据(索引)
1、 提取网站文本等内容:从网站中搜索引擎抓取的内容中提取相关含义内容,去除一些不必要的标签等。
2、 中文分词及无用词去除:对网页中的文字进行拆分、切分,过滤掉文章中的一些无意义的词,如“的、地”等。
3、 去除不重要的内容:去除与内容主体意义无关的文字,比如一些本身存在的回复和帖子
4、删除网站重复内容:如果多个页面内容相同,重复的页面和链接应该从数据库中删除。
5、 索引内容:正向和反向索引,从链接开始,对应几个关键词称为正向索引;或者从 关键词 开始,对应多个链接称为反向索引。
6、 链接关系计算:计算每个页面导入哪些页面,导入锚文本关键词,形成页面(链接)的权重(如PR),并存储权重的值。
三、搜索引擎会以某种方式对网站(网页)进行排名
1、Search关键词 处理:对搜索词进行切分、去除无用词、拼写纠正、指令处理等。
2、找到关键词对应的链接集:利用第一步得到的分词后的关键词在反向索引表中查询,找到该词对应的所有链接
3、 初始子集选择:根据每个页面(链接)的权重值,过滤出一个合适的关键词对应链接子集(数千或数万)。
4、 相关计算:看分词的共性关键词(常用度低的搜索引擎比较关注),看词的频率密度,关键词的位置和形式(关键词位置很重要,比如开头,结尾,在H1,中粗体,高相关),关键词距离(小距离,高相关),外链锚文本相关,外链source 本身,以及链接周围的文字(这个应该是考虑最多的,也许这可以反映我们对我们的一些外部优化工作的要求)
5、 排名过滤和调整:经过前几步,大体排名已经确定。搜索引擎也会对结果集进行过滤,作弊和疑似作弊的页面会放在结果集的末尾。
6、 显示搜索的排名结果:这个就不多解释了,就是搜索后呈现给你的结果。
7、搜索结果缓存:搜索引擎对结果进行排序后,结果集会被缓存,无需每次重新计算。
8、用户查询和点击日志:日志文件中的数据对于搜索引擎判断搜索结果质量、调整搜索算法、预测搜索趋势具有重要意义。它甚至可以根据用户体验抵消和排名结果。
以上是“网站文章被爬虫爬取后,百度搜索引擎排名如何关键词?”的全部内容,如有明确表述,请留言留言,一起进步。
输入关键字 抓取所有网页(企业主,如何选择优化策略?是“快排”吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-18 22:13
#政府公众号介绍
“免费SEO软件” 近期,在这段时间里,一些中小型企业经营者总是问我们如何选择SEO优化策略。大部分存在的现象是对方不知道SEO是什么意思。限于是否花钱竞拍百度。事实上,作为搜索引擎优化者,我们非常清楚信息错误的存在。那么,企业主如何选择优化策略,是不是“快排队”呢?根据以往网络营销的经验,SEO将进一步阐述以下内容: 1. 排名策略 如果您长期从事SEO工作,我们都知道现有基于SEO的主流优化策略主要包括以下几个方面:①所谓自然排名,完全基于百度搜索优化标准框架,面临着意想不到的风险,比如:算法调整,理论上只要你的优化策略正确。不会有明显的波动。例如,关键字排名波动很大。它属于白帽类别。特点:周期长,一般1-3个月,初期效果好,3-6个月指标明显,后期维护资源少。②自然排名+快速排名。这里所说的快速排名,是指基于搜索引擎的原理,利用非常规的方法和相关技术,在短时间内达到快速排名的目的。一般具有以下特点: 指标和采集周期为1-2个月,系统排名2个月后,消费按每天一个词的价格计算,存在一定风险,系统稳定,受百度算法调整和识别影响。如果搜索引擎被官方认定为作弊,那么从理论上讲,它肯定会降低功率,并且很难恢复。
③ 与一些SEO机构相比,站群屏幕有时会提供一个屏幕策略供目标企业主选择。按照简单的理解,大量的长尾关键词是用来对商家进行排名,对相关商家词进行排名,甚至是一些一般的流量。至于它的运作,无论是一组网站,一个海量的搜索结果页面,还是一些高权重的政府网站,“虚拟排名”技术其实都不是重点。但是有一个潜在的问题:海量排名和爆款软件产生的文案质量非常低。是否会对公司产生负面影响,是你需要思考的问题。④黑帽策略黑帽搜索引擎优化是一个常见的话题。在提出建议时,理论上对方不会通知业主,而是按照自然顺序展示给对方。但是,一些负责任的搜索引擎优化组织通常会将其相关策略、风险和不确定性告知企业主。2、业务需求本文简单介绍了市场上常用的几种优化策略,以及业务主如何选择这些策略。我们主要给出以下两点建议: ①长期的品牌建设应该以SEO为基础,针对企业业务,长期运营,如果需要,建立自己的品牌。那么你需要考虑的因素就比较多,比如网站减持权限,域名是否变了。这个时候,我们通常会建议企业主建立两个网站,一个是纯白帽SEO,另一个是企业主,这两个网站更喜欢“快速安排”网站。② 短期逐利 如果不考虑,一旦网站被降级,关键词的排名会突然消失,会出现一系列相关问题,比如影响关于品牌,负面舆论和情绪。
我们的建议是做类似的“快排”业务,只选择稳定性好、性价比高的厂家。总结:我们不否认任何“SEO优化策略”的合理性,但我们一直强调SEO使用白帽策略。做SEO,倾听多方声音,坚持资助初衷,尊重每一位SEO人员的意见和建议。以上内容仅供参考!“免费seo软件”政府公众号
我们做网站优化网站排名是大家关心的问题。毕竟现在用百度的人越来越多。如果你想搜索一些信息,你会打开百度搜索一些关键词。当然,有些企业要想取得好的营销效果,就需要借助百度的网站排名来提升。那么网站优化使用了哪些工具,如何提升百度排名呢?下面我们就给大家介绍几个很常见的提高百度排名的方法。首先要优化网站的关键词,因为百度搜索中大部分人使用的是关键词的搜索方式。如果关键词设置好,也会帮助很多人找到这个网站。还可以分析现在流行的词有哪些,还可以设置<的关键字 @网站 现在使用此关键字时。另外,不仅要设置合理的关键词,还要让企业网站的结构和模式更好。如果网站的结构和模式合理,那么对网站的排名会更有帮助。也想来这里吗?联系我们。另外,企业网站的标签设置也很重要。您应该查看商家符合哪个标签,并且该标签应该更常用。这样,公司的标签就可以被大家看到了。另外我们可以看到,这家公司在优化过程中要不断更新网站。许多公司可能会经常更新他们的网站。事实上,为了提高一个企业网站在百度排名中的地位,你必须定期更新你的网站,所以你必须每天找人更新一些文章主题或更新一些产品信息,当然更新的内容不能随意更新。必须更新并与此 网站 相关。比如我和这家公司的产品有关系,或者和这家公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些< 我与本公司的产品有关系,或与本公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些< 我与本公司的产品有关系,或与本公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些< 查看全部
输入关键字 抓取所有网页(企业主,如何选择优化策略?是“快排”吗?)
#政府公众号介绍
“免费SEO软件” 近期,在这段时间里,一些中小型企业经营者总是问我们如何选择SEO优化策略。大部分存在的现象是对方不知道SEO是什么意思。限于是否花钱竞拍百度。事实上,作为搜索引擎优化者,我们非常清楚信息错误的存在。那么,企业主如何选择优化策略,是不是“快排队”呢?根据以往网络营销的经验,SEO将进一步阐述以下内容: 1. 排名策略 如果您长期从事SEO工作,我们都知道现有基于SEO的主流优化策略主要包括以下几个方面:①所谓自然排名,完全基于百度搜索优化标准框架,面临着意想不到的风险,比如:算法调整,理论上只要你的优化策略正确。不会有明显的波动。例如,关键字排名波动很大。它属于白帽类别。特点:周期长,一般1-3个月,初期效果好,3-6个月指标明显,后期维护资源少。②自然排名+快速排名。这里所说的快速排名,是指基于搜索引擎的原理,利用非常规的方法和相关技术,在短时间内达到快速排名的目的。一般具有以下特点: 指标和采集周期为1-2个月,系统排名2个月后,消费按每天一个词的价格计算,存在一定风险,系统稳定,受百度算法调整和识别影响。如果搜索引擎被官方认定为作弊,那么从理论上讲,它肯定会降低功率,并且很难恢复。
③ 与一些SEO机构相比,站群屏幕有时会提供一个屏幕策略供目标企业主选择。按照简单的理解,大量的长尾关键词是用来对商家进行排名,对相关商家词进行排名,甚至是一些一般的流量。至于它的运作,无论是一组网站,一个海量的搜索结果页面,还是一些高权重的政府网站,“虚拟排名”技术其实都不是重点。但是有一个潜在的问题:海量排名和爆款软件产生的文案质量非常低。是否会对公司产生负面影响,是你需要思考的问题。④黑帽策略黑帽搜索引擎优化是一个常见的话题。在提出建议时,理论上对方不会通知业主,而是按照自然顺序展示给对方。但是,一些负责任的搜索引擎优化组织通常会将其相关策略、风险和不确定性告知企业主。2、业务需求本文简单介绍了市场上常用的几种优化策略,以及业务主如何选择这些策略。我们主要给出以下两点建议: ①长期的品牌建设应该以SEO为基础,针对企业业务,长期运营,如果需要,建立自己的品牌。那么你需要考虑的因素就比较多,比如网站减持权限,域名是否变了。这个时候,我们通常会建议企业主建立两个网站,一个是纯白帽SEO,另一个是企业主,这两个网站更喜欢“快速安排”网站。② 短期逐利 如果不考虑,一旦网站被降级,关键词的排名会突然消失,会出现一系列相关问题,比如影响关于品牌,负面舆论和情绪。
我们的建议是做类似的“快排”业务,只选择稳定性好、性价比高的厂家。总结:我们不否认任何“SEO优化策略”的合理性,但我们一直强调SEO使用白帽策略。做SEO,倾听多方声音,坚持资助初衷,尊重每一位SEO人员的意见和建议。以上内容仅供参考!“免费seo软件”政府公众号
我们做网站优化网站排名是大家关心的问题。毕竟现在用百度的人越来越多。如果你想搜索一些信息,你会打开百度搜索一些关键词。当然,有些企业要想取得好的营销效果,就需要借助百度的网站排名来提升。那么网站优化使用了哪些工具,如何提升百度排名呢?下面我们就给大家介绍几个很常见的提高百度排名的方法。首先要优化网站的关键词,因为百度搜索中大部分人使用的是关键词的搜索方式。如果关键词设置好,也会帮助很多人找到这个网站。还可以分析现在流行的词有哪些,还可以设置<的关键字 @网站 现在使用此关键字时。另外,不仅要设置合理的关键词,还要让企业网站的结构和模式更好。如果网站的结构和模式合理,那么对网站的排名会更有帮助。也想来这里吗?联系我们。另外,企业网站的标签设置也很重要。您应该查看商家符合哪个标签,并且该标签应该更常用。这样,公司的标签就可以被大家看到了。另外我们可以看到,这家公司在优化过程中要不断更新网站。许多公司可能会经常更新他们的网站。事实上,为了提高一个企业网站在百度排名中的地位,你必须定期更新你的网站,所以你必须每天找人更新一些文章主题或更新一些产品信息,当然更新的内容不能随意更新。必须更新并与此 网站 相关。比如我和这家公司的产品有关系,或者和这家公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些< 我与本公司的产品有关系,或与本公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些< 我与本公司的产品有关系,或与本公司的内容有关系。您还必须选择一些更重要的内容进行更新。当然,更新后的文章也有一定的要求。不是所有的文章都可以更新,但有些<
输入关键字 抓取所有网页(网站关键字的优化方式有哪些?怎么处理?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-17 08:08
#哪里有网站优化公司介绍
一般来说,我们主要通过以下几点来理解网站关键字的优化方法:网站的大小,以及由它决定的词的关键位置。关键词在网站上的分布。挖掘和使用关键字扩展。是否写首页、目录页或内容页的标题标签。解释标签的合理使用——描述标签、关键词标签、ALT替换属性等。关键词密度和关键词在页面上的位置。关键字的字体,特殊性。是否存在关键词叠加、隐藏文字、链接等作弊行为?优化公司在哪网站
首先,网站不在主页上,以降低功耗。首先,必须声明该站点是通过站点的高级搜索命令进行搜索的。如果没有找到网站结果的第一页,可能是该网站被降级了,但并不是该网站不在结果页面上。第一个页面是网站必须降级,否则会降级,但这只是一种可能,因为在调整结构和更新搜索引擎时,网站也会做类似的调整。根据各种因素,网站的威力有所降低。没有主页,不从网站判断。因此,如果网站不在首页,请不要惊慌!只需压制您的想法并进行日常优化。其次,页面快照时间反转代表了功耗的降低。一是页面快照时间落后。这种现象通常称为快照文件。这并不意味着您的 网站 已被降级!页面快照时间倒转的原因其实很简单,因为当搜索引擎蜘蛛抓取你的网页时,网站出现故障或无法访问,或者搜索引擎本身已经更新和调整。页面快照时间相反。如果你的网站降级了,直接K站或者网站不在首页。所以,如果你发现页面快照时间倒退了,不要着急,过一会就自然了。会康复。三、原文优于伪原创文章和原文文章 比伪原创文章更能提高质量。因为搜索引擎可能会认出文章的原创性质,但是从文章的质量来看,如果你的文章很原创。很高,但是没有用户可以浏览,而且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会考虑文章@的这个伪原创质量> 更好,因为搜索引擎认为这是伪原创的文章,能够满足和解决用户的需求。它还补充说,搜索引擎判断文章 并且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会认为伪原创的文章质量更好,因为搜索引擎认为这是< @伪原创的文章可以满足和解决用户的需求。它还补充说,搜索引擎判断文章 并且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会认为伪原创的文章质量更好,因为搜索引擎认为这是< @伪原创的文章可以满足和解决用户的需求。它还补充说,搜索引擎判断文章 查看全部
输入关键字 抓取所有网页(网站关键字的优化方式有哪些?怎么处理?)
#哪里有网站优化公司介绍
一般来说,我们主要通过以下几点来理解网站关键字的优化方法:网站的大小,以及由它决定的词的关键位置。关键词在网站上的分布。挖掘和使用关键字扩展。是否写首页、目录页或内容页的标题标签。解释标签的合理使用——描述标签、关键词标签、ALT替换属性等。关键词密度和关键词在页面上的位置。关键字的字体,特殊性。是否存在关键词叠加、隐藏文字、链接等作弊行为?优化公司在哪网站
首先,网站不在主页上,以降低功耗。首先,必须声明该站点是通过站点的高级搜索命令进行搜索的。如果没有找到网站结果的第一页,可能是该网站被降级了,但并不是该网站不在结果页面上。第一个页面是网站必须降级,否则会降级,但这只是一种可能,因为在调整结构和更新搜索引擎时,网站也会做类似的调整。根据各种因素,网站的威力有所降低。没有主页,不从网站判断。因此,如果网站不在首页,请不要惊慌!只需压制您的想法并进行日常优化。其次,页面快照时间反转代表了功耗的降低。一是页面快照时间落后。这种现象通常称为快照文件。这并不意味着您的 网站 已被降级!页面快照时间倒转的原因其实很简单,因为当搜索引擎蜘蛛抓取你的网页时,网站出现故障或无法访问,或者搜索引擎本身已经更新和调整。页面快照时间相反。如果你的网站降级了,直接K站或者网站不在首页。所以,如果你发现页面快照时间倒退了,不要着急,过一会就自然了。会康复。三、原文优于伪原创文章和原文文章 比伪原创文章更能提高质量。因为搜索引擎可能会认出文章的原创性质,但是从文章的质量来看,如果你的文章很原创。很高,但是没有用户可以浏览,而且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会考虑文章@的这个伪原创质量> 更好,因为搜索引擎认为这是伪原创的文章,能够满足和解决用户的需求。它还补充说,搜索引擎判断文章 并且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会认为伪原创的文章质量更好,因为搜索引擎认为这是< @伪原创的文章可以满足和解决用户的需求。它还补充说,搜索引擎判断文章 并且有很多用户可以浏览相同的内容文章伪原创,那么搜索引擎会认为伪原创的文章质量更好,因为搜索引擎认为这是< @伪原创的文章可以满足和解决用户的需求。它还补充说,搜索引擎判断文章
输入关键字 抓取所有网页(百度如何提高百度蜘蛛的爬行频率?有哪些方法可以提高)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-17 08:06
#网站外包介绍
“百度搜索引擎优化公司”首先要保证网站的安全稳定,保证网站可以被浏览,减少无效页面的呈现,让搜索引擎考虑网站的权重@网站。@网站的空间元素,然后登录权重网站经常打不开,所以蜘蛛抓不到内容,所以网站空间的安全性和稳定性是不行的只是一个供用户思考的问题,还有蜘蛛正常爬行的问题,好好利用一个空间增加我的网站权重。这并不过分。按照搜索引擎自然合理分布的原则,让搜索引擎知道你的网站在做什么。经过百度几次更新,相关性有所进步,并且相关性更突出,假设网站的关键词与内容无关。即使关键词的排名很短,网站的权重也不会很高;相反,人才的逐步提升才是正确的。也想来这里吗?联系我们网站数据异常只需要在网站访客数据中显示即可。比如网站平时一天有100ip,下次突然有1000IP和50ip。经过这么长时间的变化,百度怀疑网站是否可以使用黑帽技术。HTML优化主要体现在网站的源码是否可以渲染不知道其他代码的蜘蛛,比如flashiframe。假设网站上有这么多代码。例如,每次蜘蛛访问您的网站,你会给蜘蛛带来很大的麻烦,所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 @原创 内容的性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 @原创 内容的性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 那么搜索引擎在搜索到你的网站后会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 那么搜索引擎在搜索到你的网站后会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包
如何提高百度蜘蛛的爬行频率,提高蜘蛛爬行频率的方法有哪些?蜘蛛爬行的频率可以决定收录和网站的排名。企业要想做好网站优化,就必须了解蜘蛛的爬行规律和蜘蛛的爬行行为。那么今天,搜索排名专家就给大家介绍一下这方面的内容。如果我们想提高蜘蛛的爬行频率,我们需要知道影响蜘蛛爬行频率的因素有哪些。1、网站权重:网站权重是搜索引擎赋予网站(包括网页)的权威值,是一个综合得分。当网站的权重较大时,蜘蛛会访问我们的网站 更频繁地进行深度爬取。也想来这里吗?联系我们 2、网站 更新频率:网站 有新内容,蜘蛛可以抓取新数据。如果网站长时间不更新,蜘蛛会逐渐消失。因此,网站 更新的频率越高,访问的蜘蛛就越多。3、内容质量:网站内容质量对网站来说非常重要。关系到用户能否找到自己需要的答案,是否来找我们网站时间能否满足用户的需求。搜索引擎为用户服务。因此,当我们的网站内容原创质量高,能够解决用户问题时,蜘蛛会增加爬取的频率。4、 导入链接:我们都知道链接是蜘蛛访问我们页面的入口。如果连杆质量好,可以更好地引导蜘蛛爬行。5、页面深度:我想看看蜘蛛爬行时网站首页的首页是否有入口。如果有入口,会更方便网页被抓取和收录。
我们在分析网站的数据时,如果发现蜘蛛爬行频率低,停留时间短,可以通过上述方法优化网站,提高我们的蜘蛛爬行网站 并采集。通过以上信息,我们可以大致了解一下百度蜘蛛爬取的原理,包括网站流量的保证,而百度蜘蛛爬取是收录的保证,所以网站只满足百度蜘蛛爬行规则为了获得更好的排名和流量。接下来,如果我们想提高蜘蛛爬行的频率,我们将分享以下信息。一:我们每天更新网站文章后提交网站地图,需要更新网站地图,然后提交地图给百度,以便它可以通过地图网站访问您的地图。二:按照百度官方声明执行一。百度最初的火星计划说,只要你的文章属于原创,当用户搜索同一篇文章文章时,原创的内容会优先显示。当然原创是最好的,但是往往我们维护的客户网站都很专业,我们水平有限,所以只能做伪原创。2.对于一些高权重的网站,如果采集了一些小网站文章,百度可能不确定小网站的情况,所以小< @网站可以通过ping机制ping到百度,帮助百度知道哪个是原创。三。作者通常按照百度的官方说明做好,
三:一种通过发送链接来吸引蜘蛛的方法。许多网站管理员在外链中发布带有网站的主页网站。我觉得这个优化方法比较简单。如果你的网站权重低,更新不频繁,蜘蛛链接到你的网站可能爬不深。2.更新文章后,可以到各种论坛和博客发文章,然后带上你刚刚发布的文章的地址。这个效果相当不错。你可以试试。四:与一些经常更新的网站交换链接大家都知道友情链的作用。友情链接对网站的排名有一定的作用。同时,友情链接引导蜘蛛在网站之间来回爬行。这对网站的排名和采集很有帮助。因此,我们应该经常与一些更新的网站交换链接。五:网站站点文章之间的链接,无论是文章之间,还是网站的栏目与首页之间,都应该有一个或多个链接。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。 查看全部
输入关键字 抓取所有网页(百度如何提高百度蜘蛛的爬行频率?有哪些方法可以提高)
#网站外包介绍
“百度搜索引擎优化公司”首先要保证网站的安全稳定,保证网站可以被浏览,减少无效页面的呈现,让搜索引擎考虑网站的权重@网站。@网站的空间元素,然后登录权重网站经常打不开,所以蜘蛛抓不到内容,所以网站空间的安全性和稳定性是不行的只是一个供用户思考的问题,还有蜘蛛正常爬行的问题,好好利用一个空间增加我的网站权重。这并不过分。按照搜索引擎自然合理分布的原则,让搜索引擎知道你的网站在做什么。经过百度几次更新,相关性有所进步,并且相关性更突出,假设网站的关键词与内容无关。即使关键词的排名很短,网站的权重也不会很高;相反,人才的逐步提升才是正确的。也想来这里吗?联系我们网站数据异常只需要在网站访客数据中显示即可。比如网站平时一天有100ip,下次突然有1000IP和50ip。经过这么长时间的变化,百度怀疑网站是否可以使用黑帽技术。HTML优化主要体现在网站的源码是否可以渲染不知道其他代码的蜘蛛,比如flashiframe。假设网站上有这么多代码。例如,每次蜘蛛访问您的网站,你会给蜘蛛带来很大的麻烦,所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 所以蜘蛛不喜欢你的网站,那么信任就会下降。除了相关性,内容的原创性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 @原创 内容的性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 @原创 内容的性质也是影响网页权重的重要因素。假设你的大部分网站内容都是模仿的,那么搜索引擎搜索到你的网站后就会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 那么搜索引擎在搜索到你的网站后会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包 那么搜索引擎在搜索到你的网站后会给出一些不好的评论。渐渐地,搜索引擎不会对你的网站感兴趣而信任你的网站,自然不会再给任何更详细的权重来停止给你的网站页面打分,彻底原创得到10分,所有模仿得0分。积累后原站积分会越来越高,而模拟站只有0分“百度”网站外包
如何提高百度蜘蛛的爬行频率,提高蜘蛛爬行频率的方法有哪些?蜘蛛爬行的频率可以决定收录和网站的排名。企业要想做好网站优化,就必须了解蜘蛛的爬行规律和蜘蛛的爬行行为。那么今天,搜索排名专家就给大家介绍一下这方面的内容。如果我们想提高蜘蛛的爬行频率,我们需要知道影响蜘蛛爬行频率的因素有哪些。1、网站权重:网站权重是搜索引擎赋予网站(包括网页)的权威值,是一个综合得分。当网站的权重较大时,蜘蛛会访问我们的网站 更频繁地进行深度爬取。也想来这里吗?联系我们 2、网站 更新频率:网站 有新内容,蜘蛛可以抓取新数据。如果网站长时间不更新,蜘蛛会逐渐消失。因此,网站 更新的频率越高,访问的蜘蛛就越多。3、内容质量:网站内容质量对网站来说非常重要。关系到用户能否找到自己需要的答案,是否来找我们网站时间能否满足用户的需求。搜索引擎为用户服务。因此,当我们的网站内容原创质量高,能够解决用户问题时,蜘蛛会增加爬取的频率。4、 导入链接:我们都知道链接是蜘蛛访问我们页面的入口。如果连杆质量好,可以更好地引导蜘蛛爬行。5、页面深度:我想看看蜘蛛爬行时网站首页的首页是否有入口。如果有入口,会更方便网页被抓取和收录。
我们在分析网站的数据时,如果发现蜘蛛爬行频率低,停留时间短,可以通过上述方法优化网站,提高我们的蜘蛛爬行网站 并采集。通过以上信息,我们可以大致了解一下百度蜘蛛爬取的原理,包括网站流量的保证,而百度蜘蛛爬取是收录的保证,所以网站只满足百度蜘蛛爬行规则为了获得更好的排名和流量。接下来,如果我们想提高蜘蛛爬行的频率,我们将分享以下信息。一:我们每天更新网站文章后提交网站地图,需要更新网站地图,然后提交地图给百度,以便它可以通过地图网站访问您的地图。二:按照百度官方声明执行一。百度最初的火星计划说,只要你的文章属于原创,当用户搜索同一篇文章文章时,原创的内容会优先显示。当然原创是最好的,但是往往我们维护的客户网站都很专业,我们水平有限,所以只能做伪原创。2.对于一些高权重的网站,如果采集了一些小网站文章,百度可能不确定小网站的情况,所以小< @网站可以通过ping机制ping到百度,帮助百度知道哪个是原创。三。作者通常按照百度的官方说明做好,
三:一种通过发送链接来吸引蜘蛛的方法。许多网站管理员在外链中发布带有网站的主页网站。我觉得这个优化方法比较简单。如果你的网站权重低,更新不频繁,蜘蛛链接到你的网站可能爬不深。2.更新文章后,可以到各种论坛和博客发文章,然后带上你刚刚发布的文章的地址。这个效果相当不错。你可以试试。四:与一些经常更新的网站交换链接大家都知道友情链的作用。友情链接对网站的排名有一定的作用。同时,友情链接引导蜘蛛在网站之间来回爬行。这对网站的排名和采集很有帮助。因此,我们应该经常与一些更新的网站交换链接。五:网站站点文章之间的链接,无论是文章之间,还是网站的栏目与首页之间,都应该有一个或多个链接。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。这个路径是蜘蛛在你的网站上爬取的一种链接。同时,用户还可以点击链接,有利于提高网站的采集、排名和权重。
输入关键字 抓取所有网页(()风水堂:输入关键字抓取所有网页并存储到数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-15 08:03
输入关键字抓取所有网页并存储到数据库。多数情况下网页都会有抓取请求。抓取所有网页并读取到他们的关键字。fromconnectionconn=newfilechannel("login.txt")cachedusername=conn.cache["login.txt"]sendlist=conn.connect("server/"+cachedusername+":8080",post_url="")sendlist.send(r"thisisyourcode")保存到文件。
txt=""cachedusername=conn.connect("server/"+cachedusername+":8080",post_url="")cachedusername.save()或者发送post请求。login.txt,cachedusername=nonecachedusername.send(r"thisisyourcode")将数据库中的数据拷贝到文件,然后发送。
1.filechannel()2.fileinputstreamfs=newfileinputstream(filemode.true)conn=newfilechannel(list)conn.write(output)最后我已经不知道这些有什么用了。都是自己瞎写的。希望能帮到你。
我用的方法是直接利用wsgiio来处理数据库的读写,它会主动去获取context,并放到iocontext之中。这样不管在哪个环境下只要是连接就可以自动打开对应的数据库连接。你可以使用serializableinsertstatement。
使用plisteditor这个工具 查看全部
输入关键字 抓取所有网页(()风水堂:输入关键字抓取所有网页并存储到数据库)
输入关键字抓取所有网页并存储到数据库。多数情况下网页都会有抓取请求。抓取所有网页并读取到他们的关键字。fromconnectionconn=newfilechannel("login.txt")cachedusername=conn.cache["login.txt"]sendlist=conn.connect("server/"+cachedusername+":8080",post_url="")sendlist.send(r"thisisyourcode")保存到文件。
txt=""cachedusername=conn.connect("server/"+cachedusername+":8080",post_url="")cachedusername.save()或者发送post请求。login.txt,cachedusername=nonecachedusername.send(r"thisisyourcode")将数据库中的数据拷贝到文件,然后发送。
1.filechannel()2.fileinputstreamfs=newfileinputstream(filemode.true)conn=newfilechannel(list)conn.write(output)最后我已经不知道这些有什么用了。都是自己瞎写的。希望能帮到你。
我用的方法是直接利用wsgiio来处理数据库的读写,它会主动去获取context,并放到iocontext之中。这样不管在哪个环境下只要是连接就可以自动打开对应的数据库连接。你可以使用serializableinsertstatement。
使用plisteditor这个工具
输入关键字 抓取所有网页( 阿里巴巴国际站的关键词如何设置?作用及填写要求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-11-14 09:17
阿里巴巴国际站的关键词如何设置?作用及填写要求)
对于电商卖家来说,关键词设置的重要性不言而喻,那么在阿里巴巴国际站如何设置关键词呢?如何优化关键词?
关键词功能和填充要求
功能:产品关键词是对产品名称的修正,方便机器快速识别准确捕捉匹配。它与您的产品排名无关。
关键词中可以体现一个产品的多个名称,如“手机”关键词可以是手机或手机等。
填写要求:不要与产品名称冲突。“冲突”的含义:冲突指的是不一样的产品,比如拖拉机零件和拖拉机
Tips:使用产品名称的中心词作为关键词,真的无法提取出与产品名称相同的词。
选择最佳 关键词 的 10 个技巧
1、站在客户的角度思考
潜在客户在搜索您的产品时会使用什么 关键词?您可以从许多来源获得反馈,包括您的客户、供应商、品牌经理和销售人员。如果您了解您的想法和潜在客户,我们可以在询价中看到。如果您收到查询,如下所示:
从图中可以看出,客户在我们发送产品时可能不会使用关键词。这个我们可以类推,找到相关的相似关键词。
2、将关键词展开成一系列词组
选择一系列词组后,使用WordTracker网络营销软件检测这些关键词群体。本软件的功能是查看你在其他网页上使用关键词的频率,以及过去24小时内各大搜索引擎上有多少人在搜索时使用过这些关键词。
最好的关键词是那些没有被滥用但很流行的词。
另一个技巧是使用罕见的组合。WordTracker 的关键字有效性指数 (KEI) 会告诉您关键词 在其数据库中出现的次数以及竞争网页的数量。寻找那些可能在您的网页上工作的 关键词。KEI值越高,这个词越流行,竞争者越少。KEI 100 分还不错,400 分以上就是优秀。点击免费试用 WordTracker 7 天
注意:仅使用可以描述您的产品的 关键词。
3、多种排列组合
更改短语中的词序以创建不同的单词组合。使用不常见的组合。将它们组合成一个问题。收录同义词、替换词、比喻词和常见的拼写错误。收录所售产品的品牌名称和产品名称。使用其他限定符创建更多的二字符组合、三字符和四字符组合。
例如:我们公司是自行车架用于停车架。我可以在单词之前添加一个修饰词,或者在它之后添加一个限定词。易停车组装自行车架在售 我们找到的核心词是Bike rack 这个词,我们也可以找到组装自行车架等,使用AB形式和BCD形式等,这是组词。
4、如果是品牌企业,就用你的公司名称
如果您是知名品牌,请在关键词 中使用您的公司名称。
网站像RadioShack应该有这样一个关键词群:RadioShack电脑、RadioShack电子元件、RadioShack手机等。如果RadioShack想招聘员工,可以用这些关键词:为RadioShack工作,RadioShack全国,RadioShack管理岗位,招聘具有专业水准的员工。
但是,如果您的名字是 Jack Jones Real Estate,那么除非认识您,否则没有人会在搜索框中输入该名称。因此,如果你不是品牌,在关键词中收录公司名称是不值得一试的。
5、使用地理位置
如果您的职位很重要,请将其添加到您的 关键词 组中。例如,加利福尼亚州棕榈泉市的 Jack Jones Real Estate,这里,加利福尼亚州棕榈泉市的房地产业是一个非常有用的 关键词。
6、查看竞争对手的使用情况关键词
搜索竞争对手的 关键词 可以让您想起一些您可能错过的短语。但是不要复制任何人的关键词,因为你不知道他们如何使用这些关键词——你必须自己考虑一下关键词。找别人的关键词只是你选择的关键词的补充。
我们可以使用alisource找到并打开如图所示的网页
输入关键词如我们公司的自行车架
我们可以往下看,打开下面的网站,不是我们自己的公司。打开网站后,我们可以右键查看源码,可以看到一堆乱码。在这一堆乱码中,我们可以选择查找关键词,输入关键字定位关键词中的目标。
7、不要使用过于笼统的词或短语
应使用修饰语使常用词汇和短语的含义更加精确。例如,提供保险服务的网站可以使用关键词 健康保险报价、自动保险报价、人寿保险报价等组。
为了对访问者进行资格预审,关键词 和短语应该清楚地说明您的利基。如果您从事娱乐行业,请使用娱乐新闻、视频跟踪、名人故事、娱乐中心等。一个明确的利基可以吸引您需要的访客。不管你卖什么,这都是非常重要的。与认为您在销售其他产品的一大群访客相比,一小部分目标受众更有可能成为真正的客户。
8、不要使用一个词
多词短语比单个词更有用。搜索引擎很难在单个词上搜索相关结果,因为这样的搜索词会产生过多的结果,搜索者不会浏览数百个结果页面。搜索拍卖网站电子商务软件解决方案的用户不会只搜索软件。
9、使用你自己的名字而不是别人的品牌名称
避免在您的 关键词 中使用竞争对手的商标,否则您可能会被起诉。有些公司会允许使用。电商网站如需使用“潮”,请联系宝洁获得许可。许可的授予基于潜在的隶属关系——制造商可能会将使用该名称的权利许可给销售公司 网站。但是,不允许使用其他公司的商标或产品名称从中获利。
10、如果有使用阿里后台和外网的直通车,也可以使用直通车添加搜索关键词
我们可以看到热门搜索词。需要注意的是,我们不应该忽略零稀疏词。零稀疏词对我们来说也很重要。这个后台操作就不多说了。(整理自:阿里巴巴国际站) 查看全部
输入关键字 抓取所有网页(
阿里巴巴国际站的关键词如何设置?作用及填写要求)
对于电商卖家来说,关键词设置的重要性不言而喻,那么在阿里巴巴国际站如何设置关键词呢?如何优化关键词?
关键词功能和填充要求
功能:产品关键词是对产品名称的修正,方便机器快速识别准确捕捉匹配。它与您的产品排名无关。
关键词中可以体现一个产品的多个名称,如“手机”关键词可以是手机或手机等。
填写要求:不要与产品名称冲突。“冲突”的含义:冲突指的是不一样的产品,比如拖拉机零件和拖拉机
Tips:使用产品名称的中心词作为关键词,真的无法提取出与产品名称相同的词。
选择最佳 关键词 的 10 个技巧
1、站在客户的角度思考
潜在客户在搜索您的产品时会使用什么 关键词?您可以从许多来源获得反馈,包括您的客户、供应商、品牌经理和销售人员。如果您了解您的想法和潜在客户,我们可以在询价中看到。如果您收到查询,如下所示:
从图中可以看出,客户在我们发送产品时可能不会使用关键词。这个我们可以类推,找到相关的相似关键词。
2、将关键词展开成一系列词组
选择一系列词组后,使用WordTracker网络营销软件检测这些关键词群体。本软件的功能是查看你在其他网页上使用关键词的频率,以及过去24小时内各大搜索引擎上有多少人在搜索时使用过这些关键词。
最好的关键词是那些没有被滥用但很流行的词。
另一个技巧是使用罕见的组合。WordTracker 的关键字有效性指数 (KEI) 会告诉您关键词 在其数据库中出现的次数以及竞争网页的数量。寻找那些可能在您的网页上工作的 关键词。KEI值越高,这个词越流行,竞争者越少。KEI 100 分还不错,400 分以上就是优秀。点击免费试用 WordTracker 7 天
注意:仅使用可以描述您的产品的 关键词。
3、多种排列组合
更改短语中的词序以创建不同的单词组合。使用不常见的组合。将它们组合成一个问题。收录同义词、替换词、比喻词和常见的拼写错误。收录所售产品的品牌名称和产品名称。使用其他限定符创建更多的二字符组合、三字符和四字符组合。
例如:我们公司是自行车架用于停车架。我可以在单词之前添加一个修饰词,或者在它之后添加一个限定词。易停车组装自行车架在售 我们找到的核心词是Bike rack 这个词,我们也可以找到组装自行车架等,使用AB形式和BCD形式等,这是组词。
4、如果是品牌企业,就用你的公司名称
如果您是知名品牌,请在关键词 中使用您的公司名称。
网站像RadioShack应该有这样一个关键词群:RadioShack电脑、RadioShack电子元件、RadioShack手机等。如果RadioShack想招聘员工,可以用这些关键词:为RadioShack工作,RadioShack全国,RadioShack管理岗位,招聘具有专业水准的员工。
但是,如果您的名字是 Jack Jones Real Estate,那么除非认识您,否则没有人会在搜索框中输入该名称。因此,如果你不是品牌,在关键词中收录公司名称是不值得一试的。
5、使用地理位置
如果您的职位很重要,请将其添加到您的 关键词 组中。例如,加利福尼亚州棕榈泉市的 Jack Jones Real Estate,这里,加利福尼亚州棕榈泉市的房地产业是一个非常有用的 关键词。
6、查看竞争对手的使用情况关键词
搜索竞争对手的 关键词 可以让您想起一些您可能错过的短语。但是不要复制任何人的关键词,因为你不知道他们如何使用这些关键词——你必须自己考虑一下关键词。找别人的关键词只是你选择的关键词的补充。
我们可以使用alisource找到并打开如图所示的网页
输入关键词如我们公司的自行车架
我们可以往下看,打开下面的网站,不是我们自己的公司。打开网站后,我们可以右键查看源码,可以看到一堆乱码。在这一堆乱码中,我们可以选择查找关键词,输入关键字定位关键词中的目标。
7、不要使用过于笼统的词或短语
应使用修饰语使常用词汇和短语的含义更加精确。例如,提供保险服务的网站可以使用关键词 健康保险报价、自动保险报价、人寿保险报价等组。
为了对访问者进行资格预审,关键词 和短语应该清楚地说明您的利基。如果您从事娱乐行业,请使用娱乐新闻、视频跟踪、名人故事、娱乐中心等。一个明确的利基可以吸引您需要的访客。不管你卖什么,这都是非常重要的。与认为您在销售其他产品的一大群访客相比,一小部分目标受众更有可能成为真正的客户。
8、不要使用一个词
多词短语比单个词更有用。搜索引擎很难在单个词上搜索相关结果,因为这样的搜索词会产生过多的结果,搜索者不会浏览数百个结果页面。搜索拍卖网站电子商务软件解决方案的用户不会只搜索软件。
9、使用你自己的名字而不是别人的品牌名称
避免在您的 关键词 中使用竞争对手的商标,否则您可能会被起诉。有些公司会允许使用。电商网站如需使用“潮”,请联系宝洁获得许可。许可的授予基于潜在的隶属关系——制造商可能会将使用该名称的权利许可给销售公司 网站。但是,不允许使用其他公司的商标或产品名称从中获利。
10、如果有使用阿里后台和外网的直通车,也可以使用直通车添加搜索关键词
我们可以看到热门搜索词。需要注意的是,我们不应该忽略零稀疏词。零稀疏词对我们来说也很重要。这个后台操作就不多说了。(整理自:阿里巴巴国际站)
输入关键字 抓取所有网页(关于HTML标签的一些小知识,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-14 09:14
7、HTML 标签被符号包围。
8、这些周围的符号称为尖括号。
9、HTML 标签成对出现。例如和。
10、 表示开始标签和结束标签之间的文本是HTML元素的内容。
11、HTML 标签不区分大小写,效果相同。
12、 这是一对HTML标签,表示加粗文章。(有按键提醒功能)
13、 关于HTML标签,虽然目前不区分大小写,但万维网联盟(W3C)标准是:建议在HTML 4中使用小写标签
14、H1-H6标签可以使文字变黑,但不要为了变黑而使用H系列标签,请用黑色加粗
15、H系列标签,不要超过一个,每页2-3个。
16、黑色标签常用于关键词,一个页面只需添加一次。
17、标题书写:在标题上用下划线分隔关键词1和关键词2,并加上网站的名字。
18、关键字标签书写:将这两个关键词写在关键字中。用半角逗号分隔它们,并注意在关键字后添加“s”。请注意,这里添加了反斜杠“”/>”。
19、描述编写方法:将描述中这两个关键词的描述展开,重复关键词2-3次。总字数为80-120字。如果系统无法为每个页面编写不同的描述,您可以删除所有描述。
20、H1-H3都收录关键词。如果没有H,或者H1是网站的名字,问题不大。
21、图片alt收录关键词。
SEO常见的规律和现象:
22、site:My网站:不在第一页,正常。
23、百度快照落后:百度数据库问题,下次更新正常。
24、网站是收录 没有排名:不是有收录的排名。需要优化系统,做好关键词和锚文本等的编写。
25、网站 排名变了,一般注意这两点:
① 前几个网站的排名有变化吗?如果是,那应该是百度算法的小更新。需要继续维护才能恢复。
②如果几个新的网站出现在你面前,他们就会把你压下去。看看这几个网站是新站,还是从你身后慢慢上来的。如果是一夜之间突然出现的新站,会很快消失。如果从后面追赶,那么就需要添加更多的内容和外部连接。
26、有些网站没有优化,但是排名第一?,排名往往只是暂时的。随着 SEO 的普及,那些不懂 SEO 的站会一步步上榜。
27、优化了,但是排名没变?对于搜索引擎来说,每年只有十几次重大更新。因此,每次优化后,您必须等待2-3个月才能看到效果。
28、百度收录变多了,为什么这几天变少了?一开始百度会尝试收录网页的内容,然后比较网页的内容,如果相似的内容太多,就会删掉一些部分。
29、 有没有百度推广前排名的百度快照?当百度推广没有卖出前10名时,百度往往会先卖第十,然后是第八和第九。因为它发现第十名的点击率高于第八名和第九名。
30、在百度上排名很好,但在谷歌上找不到?对于新网站,谷歌的排名相对较慢。说真的,百度和谷歌的排名最终也不会差多少。
必须知道的seo知识
31、网站是搜索引擎收录吗?直接在百度或谷歌上输入站点说明。
32、网站在搜索引擎上的排名?在搜索引擎中直接输入你要查询的关键词,然后一页一页的找到你的网站。或者使用工具查询。
33、百度上关键词的搜索量?百度索引或谷歌关键词查询工具。
34、网站 为什么排名总是失败?您需要经过系统的 SEO 优化才能获得排名。研究搜索引擎的气质,然后做他们喜欢的事情。
35、搜索引擎排名最重要的是什么?重要性如下:标题为关键词,内容为关键词密度,站内站外锚文本。
36、如何查看外部链接?用于查询,如输入链接:查看百度的外链。注意添加Http。
3 7、网站的域名对网站的排名有影响吗?gov、.edu、.org在排名上会有一定的优势。其他的差别不大,因为大家都习惯了,尽量注册.com。
38、网站 什么时候提交给搜索引擎比较好?网站 结构固定好后,提交给搜索引擎,然后将内容陆续发布,制作锚文本。
39、网站静态和动态URL地址的优缺点是什么?在排名方面,静态 URL 具有优势。
经典理念:
40、目标关键词
①简单的理解就是:你的主要网站的关键词。您希望用户在搜索该词时找到您的主页 网站。
②品牌网站目标关键词是什么?是你写在SERP No.1位置的核心广告语网站!
41、首页设置多少个目标关键词比较合适?建议做1-3。这三者必须是相关的,而不是不相关的。
4 2、 打算做很多关键词,那么首页只能做1-3个关键词,如果有其他的怎么办?我不得不选择,使用栏目页或内容页来做。
43、长尾关键词:在一个网站上,各种给你带来流量,但流量不大的词,都算长尾关键词。
44、 优化方面,用首页优化目标关键词,用内容页优化长尾关键词。
45、如何找到长尾关键词?
①考虑发送文章,提炼关键词,百度搜索,通过相关搜索得到长尾。
②无目标,在百度上搜索网站关键词的目标,通过相关搜索识别长尾来组织文章。
46、长尾关键词一定要和目标有关吗关键词?目标关键词和长尾关键词可以属于同一个类别关键词,它们不一定是字面上的相关。
47、什么是锚文本?它是一组带有链接的关键词。它可以是站点内的链接,也可以是站点外的链接。只要有带有文字的链接,就称为链接锚文本。
48、 锚文本只是友情链接吗?友情链接可以使用Logo图片链接或文字链接。文本链接是一种锚文本。
49、 锚文本是否分为内链和外链?只要使用了文本并添加了链接,就被视为锚文本。站内和站外没有区别。
50、 锚文本要多样化。
51、Google Analytics 是 Google 发送到您的 网站 后端的“顶级间谍”。PV的水平是相对的。如果您的 PV 高于您的竞争对手,您就可以将其添加到您的优势中。如果你的PV很低,如果你加了,也不会对你产生不利的影响。谷歌只会忽略这个因素,不会因为这个因素减轻你的体重。(百度近期会有)
52、热搜关键词:网站几个或几十个关键词,从搜索引擎带来最多的流量。
53、热搜关键词和长尾关键词是对立的。两者总结了网站关键词的全部内容。
54、每次访问的页面——PV:指用户每次到达你的网站时访问的页面数。您可以使用此公式来计算:综合浏览量/独立访问量。
55、PV高的网站—>用户粘性高—>网站更受用户欢迎。
56、如何增加PV?使用二级目录并添加论坛或博客。
57、搜索跳出率:访问你的网站并只浏览一页后离开的用户百分比。
58、如何降低跳出率?仔细研究和分析搜索用户的需求非常重要。可以参考SEOWHY首页对用户需求进行分类的做法。
59、搜索引擎机器人:搜索引擎用来抓取网页内容的工具。
60、robots.txt:是一个简单的纯文本文件(记事本文件)。搜索引擎robot通过robots.txt中的“描述”了解网站是否可以全部抓取或部分抓取。
robots.txt 的作用:
① 使用robots.txt 屏蔽类似页面或没有内容的页面。使用 robots.txt 屏蔽冗余链接,
②当动静共存时,一般去掉动态。
③ 使用robots.txt 来屏蔽死链接。
④ 使用robots.txt 阻止可能的“K”外部链接。 查看全部
输入关键字 抓取所有网页(关于HTML标签的一些小知识,你知道几个?)
7、HTML 标签被符号包围。
8、这些周围的符号称为尖括号。
9、HTML 标签成对出现。例如和。
10、 表示开始标签和结束标签之间的文本是HTML元素的内容。
11、HTML 标签不区分大小写,效果相同。
12、 这是一对HTML标签,表示加粗文章。(有按键提醒功能)
13、 关于HTML标签,虽然目前不区分大小写,但万维网联盟(W3C)标准是:建议在HTML 4中使用小写标签
14、H1-H6标签可以使文字变黑,但不要为了变黑而使用H系列标签,请用黑色加粗
15、H系列标签,不要超过一个,每页2-3个。
16、黑色标签常用于关键词,一个页面只需添加一次。
17、标题书写:在标题上用下划线分隔关键词1和关键词2,并加上网站的名字。
18、关键字标签书写:将这两个关键词写在关键字中。用半角逗号分隔它们,并注意在关键字后添加“s”。请注意,这里添加了反斜杠“”/>”。
19、描述编写方法:将描述中这两个关键词的描述展开,重复关键词2-3次。总字数为80-120字。如果系统无法为每个页面编写不同的描述,您可以删除所有描述。
20、H1-H3都收录关键词。如果没有H,或者H1是网站的名字,问题不大。
21、图片alt收录关键词。
SEO常见的规律和现象:
22、site:My网站:不在第一页,正常。
23、百度快照落后:百度数据库问题,下次更新正常。
24、网站是收录 没有排名:不是有收录的排名。需要优化系统,做好关键词和锚文本等的编写。
25、网站 排名变了,一般注意这两点:
① 前几个网站的排名有变化吗?如果是,那应该是百度算法的小更新。需要继续维护才能恢复。
②如果几个新的网站出现在你面前,他们就会把你压下去。看看这几个网站是新站,还是从你身后慢慢上来的。如果是一夜之间突然出现的新站,会很快消失。如果从后面追赶,那么就需要添加更多的内容和外部连接。
26、有些网站没有优化,但是排名第一?,排名往往只是暂时的。随着 SEO 的普及,那些不懂 SEO 的站会一步步上榜。
27、优化了,但是排名没变?对于搜索引擎来说,每年只有十几次重大更新。因此,每次优化后,您必须等待2-3个月才能看到效果。
28、百度收录变多了,为什么这几天变少了?一开始百度会尝试收录网页的内容,然后比较网页的内容,如果相似的内容太多,就会删掉一些部分。
29、 有没有百度推广前排名的百度快照?当百度推广没有卖出前10名时,百度往往会先卖第十,然后是第八和第九。因为它发现第十名的点击率高于第八名和第九名。
30、在百度上排名很好,但在谷歌上找不到?对于新网站,谷歌的排名相对较慢。说真的,百度和谷歌的排名最终也不会差多少。
必须知道的seo知识
31、网站是搜索引擎收录吗?直接在百度或谷歌上输入站点说明。
32、网站在搜索引擎上的排名?在搜索引擎中直接输入你要查询的关键词,然后一页一页的找到你的网站。或者使用工具查询。
33、百度上关键词的搜索量?百度索引或谷歌关键词查询工具。
34、网站 为什么排名总是失败?您需要经过系统的 SEO 优化才能获得排名。研究搜索引擎的气质,然后做他们喜欢的事情。
35、搜索引擎排名最重要的是什么?重要性如下:标题为关键词,内容为关键词密度,站内站外锚文本。
36、如何查看外部链接?用于查询,如输入链接:查看百度的外链。注意添加Http。
3 7、网站的域名对网站的排名有影响吗?gov、.edu、.org在排名上会有一定的优势。其他的差别不大,因为大家都习惯了,尽量注册.com。
38、网站 什么时候提交给搜索引擎比较好?网站 结构固定好后,提交给搜索引擎,然后将内容陆续发布,制作锚文本。
39、网站静态和动态URL地址的优缺点是什么?在排名方面,静态 URL 具有优势。
经典理念:
40、目标关键词
①简单的理解就是:你的主要网站的关键词。您希望用户在搜索该词时找到您的主页 网站。
②品牌网站目标关键词是什么?是你写在SERP No.1位置的核心广告语网站!
41、首页设置多少个目标关键词比较合适?建议做1-3。这三者必须是相关的,而不是不相关的。
4 2、 打算做很多关键词,那么首页只能做1-3个关键词,如果有其他的怎么办?我不得不选择,使用栏目页或内容页来做。
43、长尾关键词:在一个网站上,各种给你带来流量,但流量不大的词,都算长尾关键词。
44、 优化方面,用首页优化目标关键词,用内容页优化长尾关键词。
45、如何找到长尾关键词?
①考虑发送文章,提炼关键词,百度搜索,通过相关搜索得到长尾。
②无目标,在百度上搜索网站关键词的目标,通过相关搜索识别长尾来组织文章。
46、长尾关键词一定要和目标有关吗关键词?目标关键词和长尾关键词可以属于同一个类别关键词,它们不一定是字面上的相关。
47、什么是锚文本?它是一组带有链接的关键词。它可以是站点内的链接,也可以是站点外的链接。只要有带有文字的链接,就称为链接锚文本。
48、 锚文本只是友情链接吗?友情链接可以使用Logo图片链接或文字链接。文本链接是一种锚文本。
49、 锚文本是否分为内链和外链?只要使用了文本并添加了链接,就被视为锚文本。站内和站外没有区别。
50、 锚文本要多样化。
51、Google Analytics 是 Google 发送到您的 网站 后端的“顶级间谍”。PV的水平是相对的。如果您的 PV 高于您的竞争对手,您就可以将其添加到您的优势中。如果你的PV很低,如果你加了,也不会对你产生不利的影响。谷歌只会忽略这个因素,不会因为这个因素减轻你的体重。(百度近期会有)
52、热搜关键词:网站几个或几十个关键词,从搜索引擎带来最多的流量。
53、热搜关键词和长尾关键词是对立的。两者总结了网站关键词的全部内容。
54、每次访问的页面——PV:指用户每次到达你的网站时访问的页面数。您可以使用此公式来计算:综合浏览量/独立访问量。
55、PV高的网站—>用户粘性高—>网站更受用户欢迎。
56、如何增加PV?使用二级目录并添加论坛或博客。
57、搜索跳出率:访问你的网站并只浏览一页后离开的用户百分比。
58、如何降低跳出率?仔细研究和分析搜索用户的需求非常重要。可以参考SEOWHY首页对用户需求进行分类的做法。
59、搜索引擎机器人:搜索引擎用来抓取网页内容的工具。
60、robots.txt:是一个简单的纯文本文件(记事本文件)。搜索引擎robot通过robots.txt中的“描述”了解网站是否可以全部抓取或部分抓取。
robots.txt 的作用:
① 使用robots.txt 屏蔽类似页面或没有内容的页面。使用 robots.txt 屏蔽冗余链接,
②当动静共存时,一般去掉动态。
③ 使用robots.txt 来屏蔽死链接。
④ 使用robots.txt 阻止可能的“K”外部链接。
输入关键字 抓取所有网页( 网站关键字设置技巧可以从3个方面讲述分别是总标题-关键词2栏目页写法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-14 09:13
网站关键字设置技巧可以从3个方面讲述分别是总标题-关键词2栏目页写法)
网站关键词设置技巧可以从三个方面来描述,分别是titlekeywords和description。其实网页上的锚文本链接描述可以看作是关键词的设置部分,这里就不详细解释了。所以你可以去看看链接锚文本描述在SEO优化中的作用,也就是这篇文章文章下面是百度、谷歌等搜索引擎中排名靠前的一些搜索关键词网站进行分析和 Tell about Title,也就是标题。从搜索引擎搜索到的内容标题往往就是页面标题的内容。TITLE只能使用HEAD元素中标题的内容,方便搜索引擎索引页面标题。主页标题的书写方式有三种。格式一般为一般标题-关键词 2 栏页标题书写方法 栏页标题有两种书写方法。关键词-General name 3 分类列表页的标题用关键词来命名该列然后按以下顺序填写即可完成分类列表页名-列名-总名,搜索为百度网站推广分析放1或2个主推产品关键词 排除左边的竞价广告直接选择百度推广@>的标题是深圳小鹿软件-网络监控软件的标题,网络监控软件,局域网管理软件,QQ监控网络管理软件。软件密钥不是太多。为了突出公司产品,产品名称和公司名称放在关键词前面,有时也可以放关键词后者是根据实际情况确定Keywords关键词主要是了解关键词密度在搜索引擎中的分布和写法。现在在主流搜索引擎中,谷歌百度雅虎BingsogoSosoyoudao等,都将关键词密度作为其排名算法的考虑因素之一。每个搜索引擎都不同。该算法计算密度比以获得排名位置。当然,可容忍的关键字密度容量是不一样的。我的观察是,可容忍的排名是googlebing,然后是baidusoogousosoyoudaoyahoo。使用雅虎的主要目的是阅读新闻。很少有人使用他的搜索。现在中国网民对简单、快速、有效的搜索越来越感兴趣。所以,越来越少的中国网民使用雅虎。相信未来的中文搜索。主要是初级网友主要用百度和搜搜做技术比较专业的网友,用google比较多。虽然他们经常看网上资料说密度保持在28或38,但是如果你需要在各种搜索引擎上都有,那还是很不错的。请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况 请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况 请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况
在实践中没有什么是绝对的。关键字可以出现的地方可以是标题元标签文本或其他地方。有两种主要类型的关键字。1 主页关键字。首页关键词 根据选择的栏目名称,为首页的关键词添加通用名称。列的关键字中写有列名和一两个关键词2列关键字。列出该列下所有类别列表的名称,并写入列关键字作为列名。把你在这一栏的主要关键词写进DescriptionDescription,它出现在页面头部的Meta标签中,用来记录这个页面的摘要和描述。它的功能主要是对1简要描述你的网站的主要内容。让用户了解他们在看什么。当在百度或谷歌上搜索某个关键词时,他们会在每个搜索结果下方看到一个描述。本说明为说明2的内容,为搜索引擎提供了很好的参考。缩小搜索引擎对网页的判断关键词,标准网站description 写作标准 内容是对你页面内容的简要介绍。1 主页描述是将主页标题关键词和一些特殊栏目的内容组合成一个简单的介绍形式。不要只写关键词 2column description writing 尽量在description中写出栏目的标题和关键词分类列表名,或者尽量采用介绍的形式写。3 分类描述是把你栏目中的主要关键词写到描述中,并添加一些相关的长尾关键词最好写在连贯性更好,比如metaname"description"content"开发的首选“网邮第六代”监控产品是应用广泛、专业的网络监控软件和局域网监控产品msn监控产品,深受广大用户好评,是一款非常受欢迎的解决企业网络安全问题的产品。 school.”组合 看来titlekeywords和description都是对title page的描述。它们最直接的作用和作用就是让搜索引擎更好的抓取关键词设置技巧如下。标题应简洁明了。把握关键关键词密度分布,使搜索引擎合理。感谢您的网站描述更简洁,以便搜索引擎能够快速了解内容所说的内容 1 与页面内容服务的性质有关 2 合理的关键字密度设置 3 遵循关键字编写titlekeywordsdescription 符合规定栏目分类整理 4 学习搜索引擎排名靠前的关键词设置 查看全部
输入关键字 抓取所有网页(
网站关键字设置技巧可以从3个方面讲述分别是总标题-关键词2栏目页写法)
网站关键词设置技巧可以从三个方面来描述,分别是titlekeywords和description。其实网页上的锚文本链接描述可以看作是关键词的设置部分,这里就不详细解释了。所以你可以去看看链接锚文本描述在SEO优化中的作用,也就是这篇文章文章下面是百度、谷歌等搜索引擎中排名靠前的一些搜索关键词网站进行分析和 Tell about Title,也就是标题。从搜索引擎搜索到的内容标题往往就是页面标题的内容。TITLE只能使用HEAD元素中标题的内容,方便搜索引擎索引页面标题。主页标题的书写方式有三种。格式一般为一般标题-关键词 2 栏页标题书写方法 栏页标题有两种书写方法。关键词-General name 3 分类列表页的标题用关键词来命名该列然后按以下顺序填写即可完成分类列表页名-列名-总名,搜索为百度网站推广分析放1或2个主推产品关键词 排除左边的竞价广告直接选择百度推广@>的标题是深圳小鹿软件-网络监控软件的标题,网络监控软件,局域网管理软件,QQ监控网络管理软件。软件密钥不是太多。为了突出公司产品,产品名称和公司名称放在关键词前面,有时也可以放关键词后者是根据实际情况确定Keywords关键词主要是了解关键词密度在搜索引擎中的分布和写法。现在在主流搜索引擎中,谷歌百度雅虎BingsogoSosoyoudao等,都将关键词密度作为其排名算法的考虑因素之一。每个搜索引擎都不同。该算法计算密度比以获得排名位置。当然,可容忍的关键字密度容量是不一样的。我的观察是,可容忍的排名是googlebing,然后是baidusoogousosoyoudaoyahoo。使用雅虎的主要目的是阅读新闻。很少有人使用他的搜索。现在中国网民对简单、快速、有效的搜索越来越感兴趣。所以,越来越少的中国网民使用雅虎。相信未来的中文搜索。主要是初级网友主要用百度和搜搜做技术比较专业的网友,用google比较多。虽然他们经常看网上资料说密度保持在28或38,但是如果你需要在各种搜索引擎上都有,那还是很不错的。请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况 请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况 请将关键字密度控制在5个左右。有时这不是唯一的。根据大家的实际情况
在实践中没有什么是绝对的。关键字可以出现的地方可以是标题元标签文本或其他地方。有两种主要类型的关键字。1 主页关键字。首页关键词 根据选择的栏目名称,为首页的关键词添加通用名称。列的关键字中写有列名和一两个关键词2列关键字。列出该列下所有类别列表的名称,并写入列关键字作为列名。把你在这一栏的主要关键词写进DescriptionDescription,它出现在页面头部的Meta标签中,用来记录这个页面的摘要和描述。它的功能主要是对1简要描述你的网站的主要内容。让用户了解他们在看什么。当在百度或谷歌上搜索某个关键词时,他们会在每个搜索结果下方看到一个描述。本说明为说明2的内容,为搜索引擎提供了很好的参考。缩小搜索引擎对网页的判断关键词,标准网站description 写作标准 内容是对你页面内容的简要介绍。1 主页描述是将主页标题关键词和一些特殊栏目的内容组合成一个简单的介绍形式。不要只写关键词 2column description writing 尽量在description中写出栏目的标题和关键词分类列表名,或者尽量采用介绍的形式写。3 分类描述是把你栏目中的主要关键词写到描述中,并添加一些相关的长尾关键词最好写在连贯性更好,比如metaname"description"content"开发的首选“网邮第六代”监控产品是应用广泛、专业的网络监控软件和局域网监控产品msn监控产品,深受广大用户好评,是一款非常受欢迎的解决企业网络安全问题的产品。 school.”组合 看来titlekeywords和description都是对title page的描述。它们最直接的作用和作用就是让搜索引擎更好的抓取关键词设置技巧如下。标题应简洁明了。把握关键关键词密度分布,使搜索引擎合理。感谢您的网站描述更简洁,以便搜索引擎能够快速了解内容所说的内容 1 与页面内容服务的性质有关 2 合理的关键字密度设置 3 遵循关键字编写titlekeywordsdescription 符合规定栏目分类整理 4 学习搜索引擎排名靠前的关键词设置
输入关键字 抓取所有网页(网站商务通轨迹跟踪是在线客服系统必须具备的一项功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-14 09:10
网站Businesslink 轨迹跟踪是在线客服系统的必备功能。经过多次升级,Businesslink 对访客轨迹的跟踪和关键词 爬取也更加全面。我们具体来看一下:
1、Businesslink网站的所有访问者都可以统计他们的来源,或者直接输入网址进入,或者通过搜索引擎进入,或者通过第三方平台连接进入。对于不同的访问者来源,网站商业上用不同的图标表示,如下图:
访客来源
如上图所示,通过搜索引擎来的访问者面前有一个“放大镜”图标,会根据不同的搜索引擎分别进行标记。例如放大镜前的绿色放大镜表示该访问者来自360搜索引擎,百度图标,表示该访问者来自百度搜索引擎。
Businesslink 有十多种类型的访客图标。如上图,小人物图标表示访客之前访问过,表示是回头客,手机图标表示访客通过手机访问等方式进入网站。等。您可以单击右上角的信息选项卡查看每个图标的含义。
2、第一点,我们讲到Business Connect可以在客户端直观地看到一个访问者的来源。对于来自搜索引擎的访问者,具体访问者搜索什么关键词 进入,需要点击右侧您可以通过顶部的“Track”和“Dialog”查看访问者具体搜索的内容。关键词 输入了 网站。注意这里只能看到搜索到的关键词。,不知道访问者是点击竞价排名还是自然排名进入,更别说触发了哪个广告。
如果需要区分访问者是点击了竞价广告还是点击了网站的快照,可以在竞价后台访问URL中添加一个标记来区分。
注意:
(1)如果发现曲目中的网址不完整,可以将鼠标放在网址上,会显示完整的网址
(2)如果发现部分访客没有踪迹,可以提高网站的打开速度,尝试将网站中的商家链接代码前移。 查看全部
输入关键字 抓取所有网页(网站商务通轨迹跟踪是在线客服系统必须具备的一项功能)
网站Businesslink 轨迹跟踪是在线客服系统的必备功能。经过多次升级,Businesslink 对访客轨迹的跟踪和关键词 爬取也更加全面。我们具体来看一下:
1、Businesslink网站的所有访问者都可以统计他们的来源,或者直接输入网址进入,或者通过搜索引擎进入,或者通过第三方平台连接进入。对于不同的访问者来源,网站商业上用不同的图标表示,如下图:
访客来源
如上图所示,通过搜索引擎来的访问者面前有一个“放大镜”图标,会根据不同的搜索引擎分别进行标记。例如放大镜前的绿色放大镜表示该访问者来自360搜索引擎,百度图标,表示该访问者来自百度搜索引擎。
Businesslink 有十多种类型的访客图标。如上图,小人物图标表示访客之前访问过,表示是回头客,手机图标表示访客通过手机访问等方式进入网站。等。您可以单击右上角的信息选项卡查看每个图标的含义。
2、第一点,我们讲到Business Connect可以在客户端直观地看到一个访问者的来源。对于来自搜索引擎的访问者,具体访问者搜索什么关键词 进入,需要点击右侧您可以通过顶部的“Track”和“Dialog”查看访问者具体搜索的内容。关键词 输入了 网站。注意这里只能看到搜索到的关键词。,不知道访问者是点击竞价排名还是自然排名进入,更别说触发了哪个广告。
如果需要区分访问者是点击了竞价广告还是点击了网站的快照,可以在竞价后台访问URL中添加一个标记来区分。
注意:
(1)如果发现曲目中的网址不完整,可以将鼠标放在网址上,会显示完整的网址
(2)如果发现部分访客没有踪迹,可以提高网站的打开速度,尝试将网站中的商家链接代码前移。
输入关键字 抓取所有网页(SEO简介:搜索引擎的基本工作原理包括哪些形式?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-14 09:08
SEO简介:SEO是一种在线推广形式,是SEO的简称。通过对网页或网站的优化,对搜索引擎更加友好,使网站的排名更上一层楼。这是搜索引擎优化。具体展示位置,例如百度搜索引擎显示该站点是竞价后的快照页面。
搜索引擎原理:
搜索引擎的基本工作原理包括以下三个过程:首先,在互联网上查找和采集网页信息;同时,提取、整理信息,建立索引数据库;然后,根据用户输入的查询关键字,搜索者可以快速查询出对数据库中的文档进行索引,评估文档与查询的相关性,对要输出的结果进行排序,查询返回给用户的结果.
1 爬网。每个独立的搜索引擎都有自己的蜘蛛。Spider 跟踪网页中的超链接并不断获取网页。抓取的网页称为网页快照。因为超链接在互联网上的应用非常普遍,理论上,从一定范围的网页中,可以采集到绝大多数网页。
2 处理网页。搜索引擎抓取网页后,需要做大量的预处理工作才能提供检索服务。其中,重要的是提取关键字,建立索引数据库和索引。其他包括删除重复页面、分词(中文)、判断网页类型、分析超链接、计算网页的重要性/丰富度。
3提供搜索服务。用户输入关键字进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了提供网页的标题和网址外,还提供网页摘要等信息。
1Longtail关键词无需参与竞拍。优化并不难。
2区域关键字更容易优化,无需花费点击费用。
4 公司名称和品牌类别不需要是竞价词,可以使用百度百科。
5 充分利用B2B行业的免费注册信息,被搜索引擎抓取。
6专业产品,几乎没有竞争对手。更容易优化。
7 除了百度推广,我还想推广谷歌、搜狗、搜狗、鲁。可以优化。
8 百度后台分析,恶意点击太多。优化。 查看全部
输入关键字 抓取所有网页(SEO简介:搜索引擎的基本工作原理包括哪些形式?)
SEO简介:SEO是一种在线推广形式,是SEO的简称。通过对网页或网站的优化,对搜索引擎更加友好,使网站的排名更上一层楼。这是搜索引擎优化。具体展示位置,例如百度搜索引擎显示该站点是竞价后的快照页面。
搜索引擎原理:
搜索引擎的基本工作原理包括以下三个过程:首先,在互联网上查找和采集网页信息;同时,提取、整理信息,建立索引数据库;然后,根据用户输入的查询关键字,搜索者可以快速查询出对数据库中的文档进行索引,评估文档与查询的相关性,对要输出的结果进行排序,查询返回给用户的结果.
1 爬网。每个独立的搜索引擎都有自己的蜘蛛。Spider 跟踪网页中的超链接并不断获取网页。抓取的网页称为网页快照。因为超链接在互联网上的应用非常普遍,理论上,从一定范围的网页中,可以采集到绝大多数网页。
2 处理网页。搜索引擎抓取网页后,需要做大量的预处理工作才能提供检索服务。其中,重要的是提取关键字,建立索引数据库和索引。其他包括删除重复页面、分词(中文)、判断网页类型、分析超链接、计算网页的重要性/丰富度。
3提供搜索服务。用户输入关键字进行搜索,搜索引擎从索引库中找到与关键词匹配的网页;为方便用户,除了提供网页的标题和网址外,还提供网页摘要等信息。
1Longtail关键词无需参与竞拍。优化并不难。
2区域关键字更容易优化,无需花费点击费用。
4 公司名称和品牌类别不需要是竞价词,可以使用百度百科。
5 充分利用B2B行业的免费注册信息,被搜索引擎抓取。
6专业产品,几乎没有竞争对手。更容易优化。
7 除了百度推广,我还想推广谷歌、搜狗、搜狗、鲁。可以优化。
8 百度后台分析,恶意点击太多。优化。
输入关键字 抓取所有网页(电子商务案例分析题目:百度搜索引擎竞价排名对社会发展的影响)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-13 23:15
电子商务案例研究题目:百度搜索引擎竞价排名对社会发展的影响
系名:商务系专业班级:09电子商务
学生姓名: 学生证:
2011年月
内容
一、百度搜索引擎竞价排名概览(3)
(一)百度搜索引擎竞价排名的定义及特点(3)
二、百度搜索引擎竞价排名基本情况(3)
(一)简介(3)
三、百度搜索引擎竞价排名商业模式(3)
(一)战略目标(3)
(二)目标用户(4)
三)百度竞价排名服务的特点包括(4)
(四)盈利模式 (5)
(五)核心竞争力(5)
四、百度搜索引擎竞价排名的商业模式(6)
六、百度搜索引擎竞价排名管理模式(6)
七、百度搜索引擎竞价排名的资本模型(6)
八、SWOT 分析(7)
九、发展趋势(8)
十、从百度搜索引擎原理看竞价排名(8)
十大一、百度竞价排名操作技巧分析(11)
一、百度搜索引擎竞价排名概览
(一)百度搜索引擎竞价排名的定义及特点
百度搜索引擎竞价排名是利用百度的互联网搜索平台(即目前几乎所有的中文门户网站),将纯市场化的竞价拍卖行为引入搜索引擎服务中,企业竞价后的竞价结果选择搜索关键字 订购业务活动。
竞价排名的基本特征:按点击付费,广告出现在搜索结果中(通常是顶部位置),如果没有被用户点击,则不收取广告费。在同一个关键词广告中,每次点击价格最高的广告排在第一位,下面的其他位置也根据广告主设定的广告点击价格确定。
二、百度搜索引擎竞价排名基本情况
(一)简介
百度搜索引擎由李彦宏和徐勇于1999年底在美国硅谷创立,致力于为人们提供一种“简单可靠”的信息获取方式。“百度”一词源于中国宋代诗人辛七集的《清雨案·元溪》诗句:“万遍千百度”,象征百度对中文信息检索技术的执着追求. 是目前国内最大的商业全文搜索引擎。
三、百度搜索引擎竞价排名商业模式
(一)战略目标
增加企业销售额,赢得新客户;成为最优秀的互联网中文信息检索与传递技术提供商,成为中国互联网科技企业在全球行业的杰出代表
(二)目标用户
广告用户;搜索竞价排名竞价排名广告:近年来已成为搜索引擎服务的主要商业盈利方式。百度竞价排名是百度国内首创的付费效果网络推广方式。只需少量投资,即可为公司带来大量潜在客户,有效增加销售额。
三)百度竞价排名服务的特点包括
支持有限地域推广:根据推广计划,企业只有在指定区域的用户在百度搜索引擎搜索企业关键词时,才能看到企业的推广信息,节省每一分推广资金企业。支持控制每日最高消费:为了帮助用户控制推广成本,百度为用户开放了限制每日最高消费的功能。启用此功能后,当您在百度上的消费达到您当日设置的限额时,您所有的关键词将被暂时搁置。零点后,这些暂停的关键词会自动生效。自动竞价功能:百度竞价排名不仅可以随时手动设置竞价价格,而且还具有自动竞价功能。对于自动竞价,客户只需要设置一个关键词点击最高价,这个最高价就是客户为此关键词的最高点击价,即客户的关键词实际点击价格不得超过此最高价格。账户续期提醒:当公司账户余额低于一定金额时,可在竞价排名系统中设置账户续期提醒功能,自动发送邮件提醒客户,确保竞价排名服务不中断。关键词群组管理:企业可以根据自己的产品分类建立不同的推广关键词群组,分别管理关键词。关键词排名提醒:当关键词排名 企业购买滴滴,可以在竞价排名系统中设置自动邮件提醒,随时监控促销效果。防止恶意点击:在访问统计中,百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问同样的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问同样的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问相同的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。
为了改进单纯参考竞价的竞价排名模型,让优质关键词获得更合理的排名,百度竞价排名服务于2006年9月11日全面上线智能排名功能。智能排名的出现将不再以中标价格作为判断关键词排名的唯一依据,而是会综合考虑关键词的质量和中标价格的影响,采用“综合排名指数”作为排名标准。综合排名指数越高,排名越高。综合排名指标为关键词质量和竞价
价格的产品,关键词的质量是根据历史数据计算的,主要反映其关键词的标题、描述以及网友对关键词的认可度。优质的关键词综合排名指数也比较高,可以以较低的竞价价格获得较高的排名,从而获得更好的推广效果。
(四)盈利模式
在竞价排名中,出价最高者排名第一;为寻找公司产品的潜在用户带来大量业务咨询,进而产生新订单,赢得新客户;关键词 广告
一个企业是否参与“竞价排名”是基于网民在百度上的点击率,点击率取决于百度的搜索结果能否给网民带来好的体验。但目前的现实是,“竞价排名”的商业模式让百度在搜索结果中出现了过多的“推广”页面,比如搜索“白酒”、“心脏病”等词。如果失去了良好的用户体验带来的网站流量,百度的利润就会变成被动的水。
更重要的是,搜索引擎是互联网的“窗口”,其影响是巨大的。首先,它控制人们获取什么信息,然后控制人们消费什么商品,最后可能诱发人们的思想。在美国,搜索是一种社交工具,行业自律制度规定:搜索引擎公司有责任清楚地了解搜索页面上的广告和新闻标志。但是,在中国,对搜索引擎的监管仍然缺乏。但是,从长远来看,中国对搜索引擎行业的类似监管肯定会跟进,这会给百度带来一定的危机。
(五)核心竞争力
全程针对性强、实时、周到的服务
四、百度搜索引擎竞价排名商业模式
六、百度搜索引擎竞价排名管理模式
七、百度搜索引擎竞价排名的资本模型
1、创始人投资:2001年6月5日在中国北京成立第二个运营实体——
百度网通科技有限公司(简称“百度网”)。这就是,李彦宏和徐勇分别持有75%和25%。
2、风险投资:注册于英属开曼群岛,百度创始人李彦宏持有美国绿卡。百度发起的基金是美国风险投资,现在美国资本持有百度超过51%的股份
3、上市融资:百度在美国纳斯达克正式上市。其主承销商为瑞士信贷第一波士顿(CSFB)和高盛(Goldman Sachs),两家都是华尔街顶级投资银行。
八、SWOT分析
长处和短处
快速结果
关键词无限数量关键词一些难度级别是昂贵的
管理麻烦
发动机的独立性和稳定性较差
恶意点击
用户认知度下降
机会(opportunities)威胁(threats)
中国潜在的网络市场巨大并受到各种外部力量的支持
网站联盟产品获得市场认可,来自行业和潜在竞争对手的威胁损害了企业信誉
缺乏商业道德
九、发展趋势
竞价排名概念本身没有问题。收费方和付费方都可以从中获得最大的利益,这是一个双赢的局面。不过,Overture/百度目前的规模能否持续,最终形成相对稳定的主流商业模式,还有待市场检验;
竞价排名的业务是通过对搜索结果的技术干预来获取利润。其做法无异于强迫甚至欺骗用户接受捆绑服务,不可避免地会产生一些虚假、有害或无效的信息,破坏搜索的公平性。,有序,如果百度不区分基础业务和增值业务的关系,忽视企业公信力和道德影响,其发展比例就会下降。
十、 从百度搜索引擎原理看竞价排名
根据工作原理的不同,搜索引擎可以分为两大类:全文搜索引擎和目录。分类目录是通过手工采集和整理网站数据形成数据库,如雅虎搜索。全文搜索引擎的数据库依赖于一种叫做“蜘蛛”或“爬虫”的软件,它通过互联网上的各种链接自动获取大量的网络信息内容,并按照预定的规则进行分析。精加工而成。谷歌和百度是比较典型的全文搜索引擎系统。
搜索引擎并不真正搜索互联网。他们搜索的实际上是一个预先组织好的网页索引数据库。全文搜索引擎的“网络机器人”或“网络蜘蛛”是互联网上的一种软件,它遍历网络空间,可以扫描网站一定范围的IP地址,并根据Internet 上的链接从一个网页到另一个网页,从一个网站 到另一个网站采集 网页信息。为了保证采集的信息是最新的,它会回访已经爬过的网页。网络机器人或网络蜘蛛采集的网页需要通过其他程序进行分析,并根据一定的相关性算法进行大量的计算,建立网页索引,然后才能加入索引数据库。我们平时看到的全文搜索引擎,其实只是一个搜索引擎系统的一个搜索界面。当您输入 关键词 进行查询时,搜索引擎会从庞大的数据库中找到所有 关键词 匹配项。相关网页的索引,并按照一定的排名规则呈现给我
NS。不同的搜索引擎有不同的网络索引数据库和不同的排名规则。因此,当我们使用相同的关键词在不同的搜索引擎中查询时,搜索结果会有所不同。
与全文搜索引擎一样,分类目录的整个工作过程也分为采集信息、分析信息和查询信息三个部分,但分类目录的信息采集和分析两部分主要依靠人工完成. 分类一般都有专门的编辑,负责采集网站上的信息。
目前的搜索引擎普遍采用超链接分析技术。除了分析被索引网页本身的内容外,它还分析了指向该网页的所有链接的 URL、AnchorText,甚至周围的文本。因此,有时,即使某个网页A中没有“devilSatan”这样的词,如果有另一个网页B指向这个网页A的链接是“devilSatan”,那么用户可以搜索“devilSatan”撒但”。找到页面A。此外,如果有更多的网页(C,D,E,F...)指向这个网页A,并带有一个名为“魔鬼撒旦”的链接,或者给出这个链接的源网页(B , C, D, E, F ......) 当用户搜索“恶魔撒旦”时,页面 A 越好,排名就越高。
搜索引擎的原理可以看成三个步骤:抓取网页→建立索引库→在索引库中搜索行
1.从互联网上抓取网页
使用Spider系统程序,可以自动从互联网上采集网页,自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
2. 索引数据库
分析索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页所在的URL、编码类型、页面内容中收录的关键词、关键词位置,生成时间、大小、网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,每个网页对页面的相关性(或重要性)获取超链接中的内容和每个关键词,然后利用这些相关性信息构建网络索引数据库。
3.在索引库中搜索和排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算出来了,所以只需要按照已有的相关度值进行排序即可。相关性越高,排名越高。
最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。搜索引擎的蜘蛛一般需要定期重新访问所有网页(每个搜索引擎的周期不同,可能是几天、几周或几个月,也可能对不同重要性的网页有不同的更新频率),并更新网络索引数据库,反映网页内容的更新,添加新的网页信息,去除死链接,根据网页内容和链接关系的变化重新排序。这样,网页的具体内容和变化就会反映在用户查询的结果中
搜索引擎关键词有两种——自然排序和商业排序。自然排名也称为有机排名或自然排名。它是一个搜索引擎,通过技术手段,以相对科学的算法对每个网页进行评估。当用户输入关键词进行搜索时,搜索系统程序会从网页中索引查找数据库中所有与关键词匹配的相关网页,然后对关键词相关值进行排序。相关性越高,排名越高。这是一个纯技术性的自然排名。商业排名被称为竞价排名(PPC 列表或赞助商列表)。它提供的搜索结果由“人工干扰结果”+“自然排名结果”组成。竞价排名是一种人为干扰自然搜索结果的方式。任意控制排名、人工干预的业务结果优先展示于自然结果。
从前面的搜索引擎原理可以看出,一个搜索过程可以分为三个步骤。第一步是抓取网页,第二步是建立索引库,第三步是在索引库中进行搜索和排序。无论是抓取网页还是建立索引库,最重要的是搜索结果的排序和展示,这在很大程度上影响了前两步的操作。如果我们在搜索结果展示中加入人为干预,将难以保证此类结果的公平性。由于其中的商业目的,从公平的角度来看,不可能为用户提供他们真正需要的搜索结果。尤其是当这个搜索引擎占据了一定的市场地位时,
搜索引擎应该是第三方中立平台。它必须有一个公平的信息选择机制。这是搜索引擎存在的基础!然而,竞价排名完全抛弃了这个搜索引擎的道德准则。它完全不受道德约束。所谓偷也没错。企业的使命是追求利润,但也不能没有道德约束。所以,竞价排名模式绝对不是百度这样成功上市并具有巨大社会影响力的公司。企业应该怎么做。
十大一、百度竞价排名操作技巧分析
虽然百度竞价排名的商业模式引起了很多争议,甚至被央视多次曝光,但不得不承认,百度竞价排名确实让很多擅长线上销售的中小企业并且推广了很多钱。据我了解,这几年做百度竞价排名的,很少有人赔钱。当时很多人都做过百度竞价排名。在过去的几年中,使用竞价排名的在线销售公司并不多。竞争自然没有那么激烈。点击成本当然比现在便宜很多,所以成本更低,风险也比较小,更容易赚钱;但过去几年的情况已经大不相同了。
随着互联网电子商务的飞速发展,越来越多的企业使用竞价排名进行网上销售,都想争先恐后,甚至很多企业总想争先,形成了一种恶性竞争,关键词点击价格潮水正在上升。在百度上搜索了很多关键字。结果的前几页都是竞价排名。仔细想想,客户自然会点这个网站,点那个网站,找你要找的信息,可能很多客户不知道自己这么值钱的时候点击一次!一不小心就损失了几十块钱。点击量增加了,公司的成本也增加了。百度自己也意识到,这在很长一段时间内肯定是行不通的。为了长远发展,百度推出了凤凰巢系统。现在看来前几页是用来做竞价排名的。这种情况要少得多。
但毕竟,百度目前是中国的主流搜索引擎。如果你能完全掌握百度竞价排名推广的一些操作技巧,百度竞价排名推广还是一个非常不错的推广方式。下面我就简单说一下操作百度竞价排名的一些操作技巧。专家不需要阅读它们。毕竟新手太多了。
1、 百度竞价排名账号首页左侧有两种推广方式:搜索推广和在线联盟推广。搜索推广是竞价排名;在线联盟推广是百度联盟推广,与百度很多合作网站挂你的网站广告也是按点击收费的。建议如果要开启网络联盟推广,首先要设置好每日预算。刚开始的时候,如果没有经验或者不懂,可以把每天的消费量设置的低一些,慢慢学习学习积累经验。效果选择扩大推广或放弃线上联盟推广。
2、 设置每日最低消费和促销区域,在竞价排名中选择您要促销的区域,根据您的需要设置促销区域。可以是某个省,也可以是几个省,也可以是整个国家。根据您的需要设置。下一步是每日预算。如果您刚开户并开始推广,则必须设置每日预算。该帐户将自动计费。例如,每日预算设置为100元,你的关键词点击价格为1元,如果你的关键词点击100次,你的100元就会花掉,你的广告会自动停止,否则你的钱不会根本不花,而且一些热门行业的关键词一天要花几千块很正常,所以如果你刚开始推广,你应该把你的每日预算设置得低一点,
3、 推广哪个关键词,指向相关产品页面的链接,提升用户体验。说白了,就是想买手机。结果网站一打开就看到MP3,绝对牛逼。如果图片错了,效果肯定不好。有的读者可能觉得我说这些白痴理解有点多余,但事实是很多网站都是这样做的;有的公司网站首页喜欢做漂亮的flash页面,打开速度慢。很多客户可能还没等你的网站打开,不耐烦的走了,钱花光了,客户白白流失。
4、 在广告的描述中,可以添加400个电话。如果广告的描述更贴切、更吸引人,客户可以直接打电话咨询,节省点击成本,但这个招数现在很多公司都开始用了。
5、不是排名第一,也不是效果最好,但绝对是第一个花钱最多的。许多公司喜欢排名第一。其实我觉得完全没有必要(当然不排除
有的公司不在乎有没有钱,所以排第一就乐在其中),排第二、第三的效果也不一定不好。
6、与其把注意力放在第一位,不如多花点时间写广告标题和描述层面。您必须知道我们的广告是收费的,而且非常昂贵。点击一次即可采集。所以,不要一味追求高流量和点击率,而应该追求高投资回报。有的网站还可以把你提供的产品和价格清楚的写在描述里,所以有的追求免费的人是不会点你的广告的,可以达到预先过滤的效果,不然只会浪费你的广告费用。尽量写好标题和描述,吸引目标客户点击,有效防止垃圾点击。
7.热门关键词的点击价格往往很高。与其和别人争几个热门的关键词,不如多花点时间去寻找一些不太热门的长尾关键词,如果能找到几十个,几百个,甚至上千个这样不太热门的长尾关键词关键词 @关键词,那么你网站带来的流量不会比热门关键词带来的少,而且这些不太热门的关键词价格相对便宜,你付出的广告费用比热门关键词,但效果不一定比热门关键词差。
8、有些公司在开设竞价账户后,会依赖百度客服人员来操作账户。建议找人自己操作账户,尤其是那些每天花大价钱竞标的公司。百度客服从你花的钱中赚取佣金。你花的越多,他赚的就越多,所以不要太相信他们说的话。
9、 对所有关键词的价格、点击率、转化率进行全面跟踪分析,了解哪些关键词点击率高,哪些关键词转化率高,并根据投放效果不断调整并优化关键词推广,追求最低成本创造最大效益。 查看全部
输入关键字 抓取所有网页(电子商务案例分析题目:百度搜索引擎竞价排名对社会发展的影响)
电子商务案例研究题目:百度搜索引擎竞价排名对社会发展的影响
系名:商务系专业班级:09电子商务
学生姓名: 学生证:
2011年月
内容
一、百度搜索引擎竞价排名概览(3)
(一)百度搜索引擎竞价排名的定义及特点(3)
二、百度搜索引擎竞价排名基本情况(3)
(一)简介(3)
三、百度搜索引擎竞价排名商业模式(3)
(一)战略目标(3)
(二)目标用户(4)
三)百度竞价排名服务的特点包括(4)
(四)盈利模式 (5)
(五)核心竞争力(5)
四、百度搜索引擎竞价排名的商业模式(6)
六、百度搜索引擎竞价排名管理模式(6)
七、百度搜索引擎竞价排名的资本模型(6)
八、SWOT 分析(7)
九、发展趋势(8)
十、从百度搜索引擎原理看竞价排名(8)
十大一、百度竞价排名操作技巧分析(11)
一、百度搜索引擎竞价排名概览
(一)百度搜索引擎竞价排名的定义及特点
百度搜索引擎竞价排名是利用百度的互联网搜索平台(即目前几乎所有的中文门户网站),将纯市场化的竞价拍卖行为引入搜索引擎服务中,企业竞价后的竞价结果选择搜索关键字 订购业务活动。
竞价排名的基本特征:按点击付费,广告出现在搜索结果中(通常是顶部位置),如果没有被用户点击,则不收取广告费。在同一个关键词广告中,每次点击价格最高的广告排在第一位,下面的其他位置也根据广告主设定的广告点击价格确定。
二、百度搜索引擎竞价排名基本情况
(一)简介
百度搜索引擎由李彦宏和徐勇于1999年底在美国硅谷创立,致力于为人们提供一种“简单可靠”的信息获取方式。“百度”一词源于中国宋代诗人辛七集的《清雨案·元溪》诗句:“万遍千百度”,象征百度对中文信息检索技术的执着追求. 是目前国内最大的商业全文搜索引擎。
三、百度搜索引擎竞价排名商业模式
(一)战略目标
增加企业销售额,赢得新客户;成为最优秀的互联网中文信息检索与传递技术提供商,成为中国互联网科技企业在全球行业的杰出代表
(二)目标用户
广告用户;搜索竞价排名竞价排名广告:近年来已成为搜索引擎服务的主要商业盈利方式。百度竞价排名是百度国内首创的付费效果网络推广方式。只需少量投资,即可为公司带来大量潜在客户,有效增加销售额。
三)百度竞价排名服务的特点包括
支持有限地域推广:根据推广计划,企业只有在指定区域的用户在百度搜索引擎搜索企业关键词时,才能看到企业的推广信息,节省每一分推广资金企业。支持控制每日最高消费:为了帮助用户控制推广成本,百度为用户开放了限制每日最高消费的功能。启用此功能后,当您在百度上的消费达到您当日设置的限额时,您所有的关键词将被暂时搁置。零点后,这些暂停的关键词会自动生效。自动竞价功能:百度竞价排名不仅可以随时手动设置竞价价格,而且还具有自动竞价功能。对于自动竞价,客户只需要设置一个关键词点击最高价,这个最高价就是客户为此关键词的最高点击价,即客户的关键词实际点击价格不得超过此最高价格。账户续期提醒:当公司账户余额低于一定金额时,可在竞价排名系统中设置账户续期提醒功能,自动发送邮件提醒客户,确保竞价排名服务不中断。关键词群组管理:企业可以根据自己的产品分类建立不同的推广关键词群组,分别管理关键词。关键词排名提醒:当关键词排名 企业购买滴滴,可以在竞价排名系统中设置自动邮件提醒,随时监控促销效果。防止恶意点击:在访问统计中,百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问同样的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问同样的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。百度竞价排名系统有几十个参数来判断一次访问是否真实有效。如果有人一直访问相同的结果,进入企业的网站,无论访问多少次,都只会统计。一次,防止恶意访问或自动程序访问,最大程度保证科学合理的访问统计。
为了改进单纯参考竞价的竞价排名模型,让优质关键词获得更合理的排名,百度竞价排名服务于2006年9月11日全面上线智能排名功能。智能排名的出现将不再以中标价格作为判断关键词排名的唯一依据,而是会综合考虑关键词的质量和中标价格的影响,采用“综合排名指数”作为排名标准。综合排名指数越高,排名越高。综合排名指标为关键词质量和竞价
价格的产品,关键词的质量是根据历史数据计算的,主要反映其关键词的标题、描述以及网友对关键词的认可度。优质的关键词综合排名指数也比较高,可以以较低的竞价价格获得较高的排名,从而获得更好的推广效果。
(四)盈利模式
在竞价排名中,出价最高者排名第一;为寻找公司产品的潜在用户带来大量业务咨询,进而产生新订单,赢得新客户;关键词 广告
一个企业是否参与“竞价排名”是基于网民在百度上的点击率,点击率取决于百度的搜索结果能否给网民带来好的体验。但目前的现实是,“竞价排名”的商业模式让百度在搜索结果中出现了过多的“推广”页面,比如搜索“白酒”、“心脏病”等词。如果失去了良好的用户体验带来的网站流量,百度的利润就会变成被动的水。
更重要的是,搜索引擎是互联网的“窗口”,其影响是巨大的。首先,它控制人们获取什么信息,然后控制人们消费什么商品,最后可能诱发人们的思想。在美国,搜索是一种社交工具,行业自律制度规定:搜索引擎公司有责任清楚地了解搜索页面上的广告和新闻标志。但是,在中国,对搜索引擎的监管仍然缺乏。但是,从长远来看,中国对搜索引擎行业的类似监管肯定会跟进,这会给百度带来一定的危机。
(五)核心竞争力
全程针对性强、实时、周到的服务
四、百度搜索引擎竞价排名商业模式
六、百度搜索引擎竞价排名管理模式
七、百度搜索引擎竞价排名的资本模型
1、创始人投资:2001年6月5日在中国北京成立第二个运营实体——
百度网通科技有限公司(简称“百度网”)。这就是,李彦宏和徐勇分别持有75%和25%。
2、风险投资:注册于英属开曼群岛,百度创始人李彦宏持有美国绿卡。百度发起的基金是美国风险投资,现在美国资本持有百度超过51%的股份
3、上市融资:百度在美国纳斯达克正式上市。其主承销商为瑞士信贷第一波士顿(CSFB)和高盛(Goldman Sachs),两家都是华尔街顶级投资银行。
八、SWOT分析
长处和短处
快速结果
关键词无限数量关键词一些难度级别是昂贵的
管理麻烦
发动机的独立性和稳定性较差
恶意点击
用户认知度下降
机会(opportunities)威胁(threats)
中国潜在的网络市场巨大并受到各种外部力量的支持
网站联盟产品获得市场认可,来自行业和潜在竞争对手的威胁损害了企业信誉
缺乏商业道德
九、发展趋势
竞价排名概念本身没有问题。收费方和付费方都可以从中获得最大的利益,这是一个双赢的局面。不过,Overture/百度目前的规模能否持续,最终形成相对稳定的主流商业模式,还有待市场检验;
竞价排名的业务是通过对搜索结果的技术干预来获取利润。其做法无异于强迫甚至欺骗用户接受捆绑服务,不可避免地会产生一些虚假、有害或无效的信息,破坏搜索的公平性。,有序,如果百度不区分基础业务和增值业务的关系,忽视企业公信力和道德影响,其发展比例就会下降。
十、 从百度搜索引擎原理看竞价排名
根据工作原理的不同,搜索引擎可以分为两大类:全文搜索引擎和目录。分类目录是通过手工采集和整理网站数据形成数据库,如雅虎搜索。全文搜索引擎的数据库依赖于一种叫做“蜘蛛”或“爬虫”的软件,它通过互联网上的各种链接自动获取大量的网络信息内容,并按照预定的规则进行分析。精加工而成。谷歌和百度是比较典型的全文搜索引擎系统。
搜索引擎并不真正搜索互联网。他们搜索的实际上是一个预先组织好的网页索引数据库。全文搜索引擎的“网络机器人”或“网络蜘蛛”是互联网上的一种软件,它遍历网络空间,可以扫描网站一定范围的IP地址,并根据Internet 上的链接从一个网页到另一个网页,从一个网站 到另一个网站采集 网页信息。为了保证采集的信息是最新的,它会回访已经爬过的网页。网络机器人或网络蜘蛛采集的网页需要通过其他程序进行分析,并根据一定的相关性算法进行大量的计算,建立网页索引,然后才能加入索引数据库。我们平时看到的全文搜索引擎,其实只是一个搜索引擎系统的一个搜索界面。当您输入 关键词 进行查询时,搜索引擎会从庞大的数据库中找到所有 关键词 匹配项。相关网页的索引,并按照一定的排名规则呈现给我
NS。不同的搜索引擎有不同的网络索引数据库和不同的排名规则。因此,当我们使用相同的关键词在不同的搜索引擎中查询时,搜索结果会有所不同。
与全文搜索引擎一样,分类目录的整个工作过程也分为采集信息、分析信息和查询信息三个部分,但分类目录的信息采集和分析两部分主要依靠人工完成. 分类一般都有专门的编辑,负责采集网站上的信息。
目前的搜索引擎普遍采用超链接分析技术。除了分析被索引网页本身的内容外,它还分析了指向该网页的所有链接的 URL、AnchorText,甚至周围的文本。因此,有时,即使某个网页A中没有“devilSatan”这样的词,如果有另一个网页B指向这个网页A的链接是“devilSatan”,那么用户可以搜索“devilSatan”撒但”。找到页面A。此外,如果有更多的网页(C,D,E,F...)指向这个网页A,并带有一个名为“魔鬼撒旦”的链接,或者给出这个链接的源网页(B , C, D, E, F ......) 当用户搜索“恶魔撒旦”时,页面 A 越好,排名就越高。
搜索引擎的原理可以看成三个步骤:抓取网页→建立索引库→在索引库中搜索行
1.从互联网上抓取网页
使用Spider系统程序,可以自动从互联网上采集网页,自动上网,沿着任意一个网页中的所有网址爬到其他网页,重复这个过程,把已经爬回来的网页全部采集回来。
2. 索引数据库
分析索引系统程序对采集到的网页进行分析,提取相关网页信息(包括网页所在的URL、编码类型、页面内容中收录的关键词、关键词位置,生成时间、大小、网页的链接关系等),根据一定的相关性算法进行大量复杂的计算,每个网页对页面的相关性(或重要性)获取超链接中的内容和每个关键词,然后利用这些相关性信息构建网络索引数据库。
3.在索引库中搜索和排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算出来了,所以只需要按照已有的相关度值进行排序即可。相关性越高,排名越高。
最后,页面生成系统将搜索结果的链接地址和页面的内容摘要进行整理并返回给用户。搜索引擎的蜘蛛一般需要定期重新访问所有网页(每个搜索引擎的周期不同,可能是几天、几周或几个月,也可能对不同重要性的网页有不同的更新频率),并更新网络索引数据库,反映网页内容的更新,添加新的网页信息,去除死链接,根据网页内容和链接关系的变化重新排序。这样,网页的具体内容和变化就会反映在用户查询的结果中
搜索引擎关键词有两种——自然排序和商业排序。自然排名也称为有机排名或自然排名。它是一个搜索引擎,通过技术手段,以相对科学的算法对每个网页进行评估。当用户输入关键词进行搜索时,搜索系统程序会从网页中索引查找数据库中所有与关键词匹配的相关网页,然后对关键词相关值进行排序。相关性越高,排名越高。这是一个纯技术性的自然排名。商业排名被称为竞价排名(PPC 列表或赞助商列表)。它提供的搜索结果由“人工干扰结果”+“自然排名结果”组成。竞价排名是一种人为干扰自然搜索结果的方式。任意控制排名、人工干预的业务结果优先展示于自然结果。
从前面的搜索引擎原理可以看出,一个搜索过程可以分为三个步骤。第一步是抓取网页,第二步是建立索引库,第三步是在索引库中进行搜索和排序。无论是抓取网页还是建立索引库,最重要的是搜索结果的排序和展示,这在很大程度上影响了前两步的操作。如果我们在搜索结果展示中加入人为干预,将难以保证此类结果的公平性。由于其中的商业目的,从公平的角度来看,不可能为用户提供他们真正需要的搜索结果。尤其是当这个搜索引擎占据了一定的市场地位时,
搜索引擎应该是第三方中立平台。它必须有一个公平的信息选择机制。这是搜索引擎存在的基础!然而,竞价排名完全抛弃了这个搜索引擎的道德准则。它完全不受道德约束。所谓偷也没错。企业的使命是追求利润,但也不能没有道德约束。所以,竞价排名模式绝对不是百度这样成功上市并具有巨大社会影响力的公司。企业应该怎么做。
十大一、百度竞价排名操作技巧分析
虽然百度竞价排名的商业模式引起了很多争议,甚至被央视多次曝光,但不得不承认,百度竞价排名确实让很多擅长线上销售的中小企业并且推广了很多钱。据我了解,这几年做百度竞价排名的,很少有人赔钱。当时很多人都做过百度竞价排名。在过去的几年中,使用竞价排名的在线销售公司并不多。竞争自然没有那么激烈。点击成本当然比现在便宜很多,所以成本更低,风险也比较小,更容易赚钱;但过去几年的情况已经大不相同了。
随着互联网电子商务的飞速发展,越来越多的企业使用竞价排名进行网上销售,都想争先恐后,甚至很多企业总想争先,形成了一种恶性竞争,关键词点击价格潮水正在上升。在百度上搜索了很多关键字。结果的前几页都是竞价排名。仔细想想,客户自然会点这个网站,点那个网站,找你要找的信息,可能很多客户不知道自己这么值钱的时候点击一次!一不小心就损失了几十块钱。点击量增加了,公司的成本也增加了。百度自己也意识到,这在很长一段时间内肯定是行不通的。为了长远发展,百度推出了凤凰巢系统。现在看来前几页是用来做竞价排名的。这种情况要少得多。
但毕竟,百度目前是中国的主流搜索引擎。如果你能完全掌握百度竞价排名推广的一些操作技巧,百度竞价排名推广还是一个非常不错的推广方式。下面我就简单说一下操作百度竞价排名的一些操作技巧。专家不需要阅读它们。毕竟新手太多了。
1、 百度竞价排名账号首页左侧有两种推广方式:搜索推广和在线联盟推广。搜索推广是竞价排名;在线联盟推广是百度联盟推广,与百度很多合作网站挂你的网站广告也是按点击收费的。建议如果要开启网络联盟推广,首先要设置好每日预算。刚开始的时候,如果没有经验或者不懂,可以把每天的消费量设置的低一些,慢慢学习学习积累经验。效果选择扩大推广或放弃线上联盟推广。
2、 设置每日最低消费和促销区域,在竞价排名中选择您要促销的区域,根据您的需要设置促销区域。可以是某个省,也可以是几个省,也可以是整个国家。根据您的需要设置。下一步是每日预算。如果您刚开户并开始推广,则必须设置每日预算。该帐户将自动计费。例如,每日预算设置为100元,你的关键词点击价格为1元,如果你的关键词点击100次,你的100元就会花掉,你的广告会自动停止,否则你的钱不会根本不花,而且一些热门行业的关键词一天要花几千块很正常,所以如果你刚开始推广,你应该把你的每日预算设置得低一点,
3、 推广哪个关键词,指向相关产品页面的链接,提升用户体验。说白了,就是想买手机。结果网站一打开就看到MP3,绝对牛逼。如果图片错了,效果肯定不好。有的读者可能觉得我说这些白痴理解有点多余,但事实是很多网站都是这样做的;有的公司网站首页喜欢做漂亮的flash页面,打开速度慢。很多客户可能还没等你的网站打开,不耐烦的走了,钱花光了,客户白白流失。
4、 在广告的描述中,可以添加400个电话。如果广告的描述更贴切、更吸引人,客户可以直接打电话咨询,节省点击成本,但这个招数现在很多公司都开始用了。
5、不是排名第一,也不是效果最好,但绝对是第一个花钱最多的。许多公司喜欢排名第一。其实我觉得完全没有必要(当然不排除
有的公司不在乎有没有钱,所以排第一就乐在其中),排第二、第三的效果也不一定不好。
6、与其把注意力放在第一位,不如多花点时间写广告标题和描述层面。您必须知道我们的广告是收费的,而且非常昂贵。点击一次即可采集。所以,不要一味追求高流量和点击率,而应该追求高投资回报。有的网站还可以把你提供的产品和价格清楚的写在描述里,所以有的追求免费的人是不会点你的广告的,可以达到预先过滤的效果,不然只会浪费你的广告费用。尽量写好标题和描述,吸引目标客户点击,有效防止垃圾点击。
7.热门关键词的点击价格往往很高。与其和别人争几个热门的关键词,不如多花点时间去寻找一些不太热门的长尾关键词,如果能找到几十个,几百个,甚至上千个这样不太热门的长尾关键词关键词 @关键词,那么你网站带来的流量不会比热门关键词带来的少,而且这些不太热门的关键词价格相对便宜,你付出的广告费用比热门关键词,但效果不一定比热门关键词差。
8、有些公司在开设竞价账户后,会依赖百度客服人员来操作账户。建议找人自己操作账户,尤其是那些每天花大价钱竞标的公司。百度客服从你花的钱中赚取佣金。你花的越多,他赚的就越多,所以不要太相信他们说的话。
9、 对所有关键词的价格、点击率、转化率进行全面跟踪分析,了解哪些关键词点击率高,哪些关键词转化率高,并根据投放效果不断调整并优化关键词推广,追求最低成本创造最大效益。
输入关键字 抓取所有网页(如何让自己的企业在互联网脱颖而出呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-13 12:03
如何让您的公司在互联网上脱颖而出?那就是做好线上推广关键词的排名,让用户输入关键词直接搜索我们的网站和我们公司的搜索引擎信息,或者在行业内关键词 @关键词主宰屏幕。
1.原创内容
原创内容是制胜法宝。网站 有几篇文章需要每天定时定量更新文章。现在百度快照抓取速度非常快。不同格式的多角度内容,如从品牌、地区、应用范围等多角度撰写原创文案内容。所以原创是称霸屏幕的法宝。
2.内链和外链
链接的关系和现实生活中的人际关系没有本质区别。其实就是人与人之间的关系,网络与网络之间的关系。外链注重质量和行业相关,外链不是越多越好,而是质量越高越好。
内链的作用不容忽视。方便搜索蜘蛛爬取,形成网站的整体结构,增加权重,兼顾内外链是排名成功的第二法宝。
3.导入外部链接
以需要的关键词为锚文本,介绍网站或者你自己的信息和个人产品链接,所以外链用词的选择很重要。常州网站推广可以从长尾关键词入手。外链选择关键词是核心。
4.关键词 位置布局
关键词需要合理,线上推广两大需求的核心是:客户需求、搜索引擎和平台等行业网站需求。互联网的需求是关键词,所以关键词的布局很重要。最佳文案内容反映关键词 4-8次,不重复,不叠加,不叠加。
好的布局有助于吸引客户的注意力,快速找到需求,增加成交的概率。
5.友情链接
人与人之间联系的关系的性质是相同的。交易所权重高,行业相关是原则。当然,初始阶段链接是合适的,权重逐渐增加,然后过滤选择会更好。 查看全部
输入关键字 抓取所有网页(如何让自己的企业在互联网脱颖而出呢?(图))
如何让您的公司在互联网上脱颖而出?那就是做好线上推广关键词的排名,让用户输入关键词直接搜索我们的网站和我们公司的搜索引擎信息,或者在行业内关键词 @关键词主宰屏幕。
1.原创内容
原创内容是制胜法宝。网站 有几篇文章需要每天定时定量更新文章。现在百度快照抓取速度非常快。不同格式的多角度内容,如从品牌、地区、应用范围等多角度撰写原创文案内容。所以原创是称霸屏幕的法宝。
2.内链和外链
链接的关系和现实生活中的人际关系没有本质区别。其实就是人与人之间的关系,网络与网络之间的关系。外链注重质量和行业相关,外链不是越多越好,而是质量越高越好。
内链的作用不容忽视。方便搜索蜘蛛爬取,形成网站的整体结构,增加权重,兼顾内外链是排名成功的第二法宝。
3.导入外部链接
以需要的关键词为锚文本,介绍网站或者你自己的信息和个人产品链接,所以外链用词的选择很重要。常州网站推广可以从长尾关键词入手。外链选择关键词是核心。
4.关键词 位置布局
关键词需要合理,线上推广两大需求的核心是:客户需求、搜索引擎和平台等行业网站需求。互联网的需求是关键词,所以关键词的布局很重要。最佳文案内容反映关键词 4-8次,不重复,不叠加,不叠加。
好的布局有助于吸引客户的注意力,快速找到需求,增加成交的概率。
5.友情链接
人与人之间联系的关系的性质是相同的。交易所权重高,行业相关是原则。当然,初始阶段链接是合适的,权重逐渐增加,然后过滤选择会更好。

