
输入关键字 抓取所有网页
输入关键字 抓取所有网页(URLExtractor支持网址抓取及链接提取,使用方便功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-29 22:17
URL Extractor 是一个 URL 提取工具。URL Extractor 支持 URL 捕获和链接提取。它易于使用,可以帮助用户浏览所有文件夹并捕获网络链接。有需要的可以下载。
特征
网址爬虫
有时我们需要从文件和文件夹中获取所有 URL(统一资源定位器)。浏览所有文件夹并抓取网络链接可能是一项艰巨的任务。幸运的是,当您需要 URL 抓取软件时,Vovsoft URL Extractor 可以在这方面为您提供帮助。
链接提取器
Vovsoft URL Extractor 是可以采集 http 和 https 网址的最佳程序之一。您可以在几秒钟内从文件中提取和恢复所有 URL。安装后,您几乎可以立即启动应用程序并开始搜索链接。你只需要提供一个目录,剩下的由程序来处理。
该软件会扫描整个文件夹以查找收录 URL 的文件,并将它们全部显示在其主窗口中,从而允许您将列表导出到文件中。所有选项都清晰简单,并且都可以放在一个窗口界面中。您需要做的就是选择您希望应用程序分析的文件夹,然后按“开始”按钮。Vovsoft URL Extractor 还具有文件掩码和对正则表达式的支持,以帮助您过滤文件和 URL。
软件特点
1、 支持提取邮箱地址、网址、ftp地址、提要、telnet、本地文件url等。
2、 拥有全新的现代引擎,采用最新的可可和objective-c 2.0 技术。它永远不会冻结,甚至可以通过搜索引擎使用数百个关键字采集数千个 URL。
3、可以在其表格中导入和导出用于导航和提取的“URL”和“关键字”。使用一个非常好的和改进的导入引擎,可以自动识别导入的格式,在导入内容的选择上有很大的灵活性。
4、 从磁盘(文件和文件夹)的无限数量的源中提取 URL 和电子邮件,并浏览任何指定文件夹和子文件夹的所有内容。可以在几秒钟内从数千个文件中提取。源列表接受文件和文件夹的拖放。
5、 从您指定的 网站 列表中提取网络中的 URL 和电子邮件。它开始提取您需要的 URL,在无休止的导航过程中继续浏览在线找到的站点链接后,它会根据需要采集 URL 或电子邮件。
6、 从关键字列表中提取互联网上的 URL 和电子邮件。
它使用您指定的搜索引擎上提供的关键字列表,然后开始寻找相关的网站,然后使用相关的网站开始导航,同时跟踪找到的链接并采集所有的URL或电子邮件. 提供了几个关键字,它可以在几个小时内提取相关(关键字)URL 和电子邮件。
7、使用 Bing 和 Google(18 个不同的 Google 区域网站:.com .it .fr.au .uk .de 和 .es .ar .au .at .be .br .ca. fi . nl .se .ch)。您可以使用指定的搜索引擎在 Internet 上进行无限制的搜索。
8、 支持从 safari 和其他网络浏览器中接受拖放 URL 以将它们用作从网络中提取的种子。
9、 支持多个选项:“单域提取”只从指定的网站中提取,不跳转到链接的网站或“深度导航”指定它来自站点的级别跳转到链接站点进行搜索和提取。
10、PDF提取,支持从本地或在线pdf文件中提取。如果它在线找到一个 PDF 并且它收录一个网页地址,它甚至可以跳转到该地址并继续搜索和提取网页。 查看全部
输入关键字 抓取所有网页(URLExtractor支持网址抓取及链接提取,使用方便功能介绍)
URL Extractor 是一个 URL 提取工具。URL Extractor 支持 URL 捕获和链接提取。它易于使用,可以帮助用户浏览所有文件夹并捕获网络链接。有需要的可以下载。

特征
网址爬虫
有时我们需要从文件和文件夹中获取所有 URL(统一资源定位器)。浏览所有文件夹并抓取网络链接可能是一项艰巨的任务。幸运的是,当您需要 URL 抓取软件时,Vovsoft URL Extractor 可以在这方面为您提供帮助。
链接提取器
Vovsoft URL Extractor 是可以采集 http 和 https 网址的最佳程序之一。您可以在几秒钟内从文件中提取和恢复所有 URL。安装后,您几乎可以立即启动应用程序并开始搜索链接。你只需要提供一个目录,剩下的由程序来处理。
该软件会扫描整个文件夹以查找收录 URL 的文件,并将它们全部显示在其主窗口中,从而允许您将列表导出到文件中。所有选项都清晰简单,并且都可以放在一个窗口界面中。您需要做的就是选择您希望应用程序分析的文件夹,然后按“开始”按钮。Vovsoft URL Extractor 还具有文件掩码和对正则表达式的支持,以帮助您过滤文件和 URL。
软件特点
1、 支持提取邮箱地址、网址、ftp地址、提要、telnet、本地文件url等。
2、 拥有全新的现代引擎,采用最新的可可和objective-c 2.0 技术。它永远不会冻结,甚至可以通过搜索引擎使用数百个关键字采集数千个 URL。
3、可以在其表格中导入和导出用于导航和提取的“URL”和“关键字”。使用一个非常好的和改进的导入引擎,可以自动识别导入的格式,在导入内容的选择上有很大的灵活性。
4、 从磁盘(文件和文件夹)的无限数量的源中提取 URL 和电子邮件,并浏览任何指定文件夹和子文件夹的所有内容。可以在几秒钟内从数千个文件中提取。源列表接受文件和文件夹的拖放。
5、 从您指定的 网站 列表中提取网络中的 URL 和电子邮件。它开始提取您需要的 URL,在无休止的导航过程中继续浏览在线找到的站点链接后,它会根据需要采集 URL 或电子邮件。
6、 从关键字列表中提取互联网上的 URL 和电子邮件。
它使用您指定的搜索引擎上提供的关键字列表,然后开始寻找相关的网站,然后使用相关的网站开始导航,同时跟踪找到的链接并采集所有的URL或电子邮件. 提供了几个关键字,它可以在几个小时内提取相关(关键字)URL 和电子邮件。
7、使用 Bing 和 Google(18 个不同的 Google 区域网站:.com .it .fr.au .uk .de 和 .es .ar .au .at .be .br .ca. fi . nl .se .ch)。您可以使用指定的搜索引擎在 Internet 上进行无限制的搜索。
8、 支持从 safari 和其他网络浏览器中接受拖放 URL 以将它们用作从网络中提取的种子。
9、 支持多个选项:“单域提取”只从指定的网站中提取,不跳转到链接的网站或“深度导航”指定它来自站点的级别跳转到链接站点进行搜索和提取。
10、PDF提取,支持从本地或在线pdf文件中提取。如果它在线找到一个 PDF 并且它收录一个网页地址,它甚至可以跳转到该地址并继续搜索和提取网页。
输入关键字 抓取所有网页(我喜欢,你就算再优秀总会有下一个啊)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-29 17:03
输入关键字抓取所有网页文字详情,特点:操作简单,上手快,
用微信读书app,要分享文章就给红包,再添加书架,可以看到列表所有书了,自己在里面找到你想看的书。
这是小学生的问题吗?
已阅读页面可以删除,当前页面不能删除。
这个怎么说呢,怎么说呢,现在就大大方方的承认“我喜欢,
你就算再优秀总会有下一个人在网上发掘你可能不是你的目标只是喜欢你的人但也可能就喜欢你这个人而不是你的优秀哦
可以在公众号搜索:百灵选资源上,里面每天有最新的短文和资源,希望对你有用哦。
quickfish-我是资源收集者
这个我试过,在自己喜欢的影视资源下载,然后可以直接搜索,类似一个绿色版的浏览器。
干不掉下一个啊
我也是有同样想法,自己和男朋友说过喜欢他的影视资源,
你还是不要加你喜欢的她的qq了,因为qq有一项功能是保存图片。
我也是也是,实在不好意思加女生我就想看你的资源,怕你不给我看,
你发个红包让她发给你即可
?
我也想问这个问题很想知道怎么办 查看全部
输入关键字 抓取所有网页(我喜欢,你就算再优秀总会有下一个啊)
输入关键字抓取所有网页文字详情,特点:操作简单,上手快,
用微信读书app,要分享文章就给红包,再添加书架,可以看到列表所有书了,自己在里面找到你想看的书。
这是小学生的问题吗?
已阅读页面可以删除,当前页面不能删除。
这个怎么说呢,怎么说呢,现在就大大方方的承认“我喜欢,
你就算再优秀总会有下一个人在网上发掘你可能不是你的目标只是喜欢你的人但也可能就喜欢你这个人而不是你的优秀哦
可以在公众号搜索:百灵选资源上,里面每天有最新的短文和资源,希望对你有用哦。
quickfish-我是资源收集者
这个我试过,在自己喜欢的影视资源下载,然后可以直接搜索,类似一个绿色版的浏览器。
干不掉下一个啊
我也是有同样想法,自己和男朋友说过喜欢他的影视资源,
你还是不要加你喜欢的她的qq了,因为qq有一项功能是保存图片。
我也是也是,实在不好意思加女生我就想看你的资源,怕你不给我看,
你发个红包让她发给你即可
?
我也想问这个问题很想知道怎么办
输入关键字 抓取所有网页( 网站内容描述让飘红的创意提升营销效果(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-29 14:08
网站内容描述让飘红的创意提升营销效果(图))
关于网站的描述和关键词网站的内容描述让飘红的创意提升营销效果。在所有的META元标签中,网站标题和网站关键词都是因为It's about 网站排名更容易引起关注和类似网站版权归因于作者和 网站 内容描述等被忽略。原因很简单。当用户登录网站时,无法直接看到网站的内容描述,搜索引擎反复声明网站内容描述只是整体网站@的总结> 并没有作为判断网站质量和重量的依据,但实际上是真的吗?恐怕事实并非如此。笔者认为< @网站内容描述是一个网站中心思想,不仅关乎网站权重,还影响用户体验和网络营销效果。网站 内容 描述影响 网站 的权重。只要注意观察,就会发现很多网站本身就有单独的内容描述,但搜索引擎并没有采用,而是在网站上抓取一段文字。作为整个网页的描述,至少可以肯定搜索引擎对网站的内容描述的态度是不可取的,所以我们在写<的内容描述的时候一定不能随便做@网站 应该谨慎对待。网站 内容描述应该是当前页面的准确概览。更精确的网站 内容描述自然方便搜索引擎。相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 实际内容较远或网站内容描述留空,搜索引擎可自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 实际内容较远或网站内容描述留空,搜索引擎可自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索
但是在引擎上,可以检索到用户输入某个关键词时写了哪些内容描述,排名也差不多,虽然有些网站的内容描述很好,但相差甚远来自网站的主题。会不会影响用户体验?答案是肯定的,所以网站的内容描述是准确概括的网站内容也必须考虑到用户的感受和体验。3 网站内容描述影响营销效果什么决定网络营销效果第一个是网站的用户体验第二个是网站的搜索引擎认知,所以是说网站的内容描述兼顾了以上两点,并取得良好的营销效果。当然,网站的内容描述所引发的营销效果远不止这些。在搜索引擎的推广中,有一个创意概念,当用户搜索关键词时很流行。内容描述中对应的单词显示为红色。众所周知,网站 内容描述多为黑色。您可以获得更多引人注目的关注。网站内容描述。创造力并不难实现。只要我们巧妙地将网站核心关键词组织成流畅的句子和适当的网站内容描述,就能影响网络营销的成败。影响网络营销成败的因素有很多。内容描述,作为网站中必不可少的元素,也构成了网络营销的重要组成部分。网站 内容描述不是可选的 None 不是你可以随意写的,但你应该小心对待。网站 内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,从而增加网站的点击流量,提高网络营销的效果。内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,增加网站的点击流量,提高网络营销的效果。内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,增加网站的点击流量,提高网络营销的效果。 查看全部
输入关键字 抓取所有网页(
网站内容描述让飘红的创意提升营销效果(图))

关于网站的描述和关键词网站的内容描述让飘红的创意提升营销效果。在所有的META元标签中,网站标题和网站关键词都是因为It's about 网站排名更容易引起关注和类似网站版权归因于作者和 网站 内容描述等被忽略。原因很简单。当用户登录网站时,无法直接看到网站的内容描述,搜索引擎反复声明网站内容描述只是整体网站@的总结> 并没有作为判断网站质量和重量的依据,但实际上是真的吗?恐怕事实并非如此。笔者认为< @网站内容描述是一个网站中心思想,不仅关乎网站权重,还影响用户体验和网络营销效果。网站 内容 描述影响 网站 的权重。只要注意观察,就会发现很多网站本身就有单独的内容描述,但搜索引擎并没有采用,而是在网站上抓取一段文字。作为整个网页的描述,至少可以肯定搜索引擎对网站的内容描述的态度是不可取的,所以我们在写<的内容描述的时候一定不能随便做@网站 应该谨慎对待。网站 内容描述应该是当前页面的准确概览。更精确的网站 内容描述自然方便搜索引擎。相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 实际内容较远或网站内容描述留空,搜索引擎可自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 实际内容较远或网站内容描述留空,搜索引擎可自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索

但是在引擎上,可以检索到用户输入某个关键词时写了哪些内容描述,排名也差不多,虽然有些网站的内容描述很好,但相差甚远来自网站的主题。会不会影响用户体验?答案是肯定的,所以网站的内容描述是准确概括的网站内容也必须考虑到用户的感受和体验。3 网站内容描述影响营销效果什么决定网络营销效果第一个是网站的用户体验第二个是网站的搜索引擎认知,所以是说网站的内容描述兼顾了以上两点,并取得良好的营销效果。当然,网站的内容描述所引发的营销效果远不止这些。在搜索引擎的推广中,有一个创意概念,当用户搜索关键词时很流行。内容描述中对应的单词显示为红色。众所周知,网站 内容描述多为黑色。您可以获得更多引人注目的关注。网站内容描述。创造力并不难实现。只要我们巧妙地将网站核心关键词组织成流畅的句子和适当的网站内容描述,就能影响网络营销的成败。影响网络营销成败的因素有很多。内容描述,作为网站中必不可少的元素,也构成了网络营销的重要组成部分。网站 内容描述不是可选的 None 不是你可以随意写的,但你应该小心对待。网站 内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,从而增加网站的点击流量,提高网络营销的效果。内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,增加网站的点击流量,提高网络营销的效果。内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,增加网站的点击流量,提高网络营销的效果。
输入关键字 抓取所有网页(独家SEO秘笈:如何提高网站流量和搜索引擎比较友好?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-29 14:07
在我们网站建设之前,要考虑的问题是网站优化,网站关键词如何优化,什么样的系统和搜索引擎更友好?以新闻网站为例,目前网站的内容管理系统可以说是数不胜数。个人感觉.net比较好,安全适用~
话虽如此,网站优化包括很多,网页布局、外部链接、内容更新等,最重要的就是如何优化网站关键词。如果关键词选择正确,会给网站带来良好的流量。那么关键词应该如何优化呢?向大家介绍2点:
1、如何确定关键词
在确定关键词之前,我们要做的就是利用工具分析一下什么样的关键词会受到客户的青睐。
百度:
选择百度指数(百度指数是SEO首选工具,可以统计关键词的搜索量,有三种显示方式)地址:
<IMG src="../../../upload/2009_11/09110515507804.jpg" border=0>
在这个地方输入你要查询的关键词,例如:.NET cms
<IMG src="../../../upload/2009_11/09110515518072.jpg" border=0>
通过这个不难看出关键词的人气~
谷歌:
地址:
<IMG src="../../../upload/2009_11/09110515513276.jpg" border=0>
输入你的网站网址(如:),点击获取关键词提示
<IMG src="../../../upload/2009_11/09110515514898.jpg" border=0>
这显示了关键字的搜索量。选择的时候,既然我们是新站,就不要选择竞争力强的关键词。我们不能上榜,从竞争力下降开始。,一点点前进。
2、优化关键词
<p>网页中的关键词密度不宜过密,最好在2%-8%之间,且标题、关键词标签、图片描述、文章页面首尾必须有 查看全部
输入关键字 抓取所有网页(独家SEO秘笈:如何提高网站流量和搜索引擎比较友好?)
在我们网站建设之前,要考虑的问题是网站优化,网站关键词如何优化,什么样的系统和搜索引擎更友好?以新闻网站为例,目前网站的内容管理系统可以说是数不胜数。个人感觉.net比较好,安全适用~
话虽如此,网站优化包括很多,网页布局、外部链接、内容更新等,最重要的就是如何优化网站关键词。如果关键词选择正确,会给网站带来良好的流量。那么关键词应该如何优化呢?向大家介绍2点:
1、如何确定关键词
在确定关键词之前,我们要做的就是利用工具分析一下什么样的关键词会受到客户的青睐。
百度:
选择百度指数(百度指数是SEO首选工具,可以统计关键词的搜索量,有三种显示方式)地址:
<IMG src="../../../upload/2009_11/09110515507804.jpg" border=0>
在这个地方输入你要查询的关键词,例如:.NET cms
<IMG src="../../../upload/2009_11/09110515518072.jpg" border=0>
通过这个不难看出关键词的人气~
谷歌:
地址:
<IMG src="../../../upload/2009_11/09110515513276.jpg" border=0>
输入你的网站网址(如:),点击获取关键词提示
<IMG src="../../../upload/2009_11/09110515514898.jpg" border=0>
这显示了关键字的搜索量。选择的时候,既然我们是新站,就不要选择竞争力强的关键词。我们不能上榜,从竞争力下降开始。,一点点前进。
2、优化关键词
<p>网页中的关键词密度不宜过密,最好在2%-8%之间,且标题、关键词标签、图片描述、文章页面首尾必须有
输入关键字 抓取所有网页( mysql+redis安装可查阅百度(很简单)项目开发流程介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-29 14:03
mysql+redis安装可查阅百度(很简单)项目开发流程介绍
)
图像.png
前几天,由于工作需要,我需要抓取一个特定的关键字来提取百度中的搜索结果,并将50页的数据保存在一个数据库或一个.csv文件中。(每天爬一次)
1.项目需要环境安装
1)scrapy+selenium+chrome (phantomjs)
关于爬虫依赖的环境的安装,我已经介绍过了。你可以参考这个文章我的详细介绍。
2)mysql+redis安装数据库安装可以参考百度(很简单)
2.项目开发流程介绍
我们需要模拟用户行为,在浏览器输入框中输入指定关键字,模拟点击获取想要的数据,保存过滤这个页面显示的数据,模拟翻页,抓取这个关键字的前50个页面展示,获取我们想要的数据,保存在.csv文件或者redis数据库中,供以后数据分析使用。
3.详细开发代码
1)创建一个scrapy项目
scrapy startproject keyword_scrawl
scrapy genspider 重新测试
代码中各个文件的介绍
settings.py 是一个通用的配置文件:
BOT_NAME:项目名称
蜘蛛模块:
NEWSPIDER_MODULE:
下面模块的配置路径
pipelines.py 这个是数据存储相关的文件
可以自定义 middlewares.py 使scrapy 更可控
items.py 文件有点类似于 django 中的一个表单,它定义了数据存储的格式
,但是比django的表单应用要简单,因为它的字段很单一。
Spider文件夹:这个文件夹存放了一个特定的网站爬虫。通过命令行,我们可以创建我们自己的蜘蛛。
4.蜘蛛代码详解
def make_requests_from_url(self, url): if self.params['st_status'] == 1: return Request(url, meta={'keyword': self.keyword, 'engine':self.sousu, 'phantomjs':True}) else:
return Request(url)
首先修改spider中的make_requests_from_url函数,增加一个判断。当st_status==1时,当我们返回请求对象时,添加一个meta,在meta中携带我们要搜索的key和我们需要访问的浏览器地址。以及启动phantomjs的指令。
class PhantomJSMiddleware(object): @classmethod
def process_request(cls, request, spider):
if request.meta.has_key('phantomjs'):
keyword = request.meta.get('keyword')
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = ('Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0')
dcap["phantomjs.page.settings.AcceptLanguage"] = ('zh-CN,zh;q=0.9')
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.set_page_load_timeout(100)
driver.set_script_timeout(15) try:
driver.get(request.url) if request.meta.get('engine') == 1:
driver.find_element_by_id("query").send_keys(keyword)
driver.find_element_by_class_name("swz").click() elif request.meta.get('engine') == 2:
driver.find_element_by_id("kw").send_keys(keyword)
driver.find_element_by_id("su").click()
time.sleep(2)
final_url = driver.current_url if final_url != request.url:
fullurl = final_url else:
fullurl = request.url
content = driver.page_source.encode('utf-8','ignore')
driver.quit() return HtmlResponse(fullurl, encoding='utf-8', body=content, request=request) except Exception, e:
driver.quit() print e
其次,修改middlewares中间件中的类方法process_request,该方法默认携带request和spider对象,在我们刚刚修改的make_requests_from_url方法中。这里我们可以处理前面的make_requests_from_url函数返回的Request请求,然后加载selenium和phantomjs来获取我们需要访问的浏览器和关键字。这段代码会模拟用户获取关键字内容的行为,然后将页面内容返回给scrapy.http中的HtmlResponse对象。这样我们就可以在spider中的parse函数中得到刚刚抓取的内容response.body。
# 判断页面的返回状态
if int(response.status) >= 200 and int(response.status) 3000:
content = content[:3000] #elif len(content) == 0:
#yield scrapy.Request(url=response.url, meta={'url':response.url, 'phantomjs':True}, callback=self.pang_bo)
body = item['url']+','+item['crawl_time']+','+item['title'].replace(',','') +','+content+'\n'
if '正在进入' == item['title']:
file_name = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'keyword.csv') with open(file_name, 'a') as b:
b.write(body) else:
filename = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'.csv') with open(filename, 'a') as f:
f.write(body)# 过滤网页源代码def soup_text(body):
try:
soup = BeautifulSoup(body, 'lxml')
line = re.compile(r'\s+')
line = line.sub(r'', soup.body.getText())
p2 = re.compile(u'[^\u4e00-\u9fa5]') # 中GDAC\u4e00\u9fa5
str2 = p2.sub(r'', line)
outStr = str2.strip(',') except:
outStr = ''
return outStr
这段代码主要是忽略了一些不必要的网站,然后提取item字段,以及page body(这里过滤了源代码),然后将获取到的内容保存到.csv文件中。这只是一个简单的爬虫。要反向抓取,请进行如下设置:
LOG_STDOUT = True # 将进程所有的标准输出(及错误)将会被重定向到log中(为了方便调试)DOWNLOAD_DELAY=0.25 # 下载延时设置 单位秒DOWNLOAD_TIMEOUT = 60 # 下载超时设置(单位秒)CONCURRENT_ITEMS = 200 # 同时处理的itmes数量CONCURRENT_REQUESTS = 16 # 同时并发的请求 查看全部
输入关键字 抓取所有网页(
mysql+redis安装可查阅百度(很简单)项目开发流程介绍
)

图像.png
前几天,由于工作需要,我需要抓取一个特定的关键字来提取百度中的搜索结果,并将50页的数据保存在一个数据库或一个.csv文件中。(每天爬一次)
1.项目需要环境安装
1)scrapy+selenium+chrome (phantomjs)
关于爬虫依赖的环境的安装,我已经介绍过了。你可以参考这个文章我的详细介绍。
2)mysql+redis安装数据库安装可以参考百度(很简单)
2.项目开发流程介绍
我们需要模拟用户行为,在浏览器输入框中输入指定关键字,模拟点击获取想要的数据,保存过滤这个页面显示的数据,模拟翻页,抓取这个关键字的前50个页面展示,获取我们想要的数据,保存在.csv文件或者redis数据库中,供以后数据分析使用。
3.详细开发代码
1)创建一个scrapy项目
scrapy startproject keyword_scrawl
scrapy genspider 重新测试
代码中各个文件的介绍
settings.py 是一个通用的配置文件:
BOT_NAME:项目名称
蜘蛛模块:
NEWSPIDER_MODULE:
下面模块的配置路径
pipelines.py 这个是数据存储相关的文件
可以自定义 middlewares.py 使scrapy 更可控
items.py 文件有点类似于 django 中的一个表单,它定义了数据存储的格式
,但是比django的表单应用要简单,因为它的字段很单一。
Spider文件夹:这个文件夹存放了一个特定的网站爬虫。通过命令行,我们可以创建我们自己的蜘蛛。
4.蜘蛛代码详解
def make_requests_from_url(self, url): if self.params['st_status'] == 1: return Request(url, meta={'keyword': self.keyword, 'engine':self.sousu, 'phantomjs':True}) else:
return Request(url)
首先修改spider中的make_requests_from_url函数,增加一个判断。当st_status==1时,当我们返回请求对象时,添加一个meta,在meta中携带我们要搜索的key和我们需要访问的浏览器地址。以及启动phantomjs的指令。
class PhantomJSMiddleware(object): @classmethod
def process_request(cls, request, spider):
if request.meta.has_key('phantomjs'):
keyword = request.meta.get('keyword')
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = ('Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0')
dcap["phantomjs.page.settings.AcceptLanguage"] = ('zh-CN,zh;q=0.9')
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.set_page_load_timeout(100)
driver.set_script_timeout(15) try:
driver.get(request.url) if request.meta.get('engine') == 1:
driver.find_element_by_id("query").send_keys(keyword)
driver.find_element_by_class_name("swz").click() elif request.meta.get('engine') == 2:
driver.find_element_by_id("kw").send_keys(keyword)
driver.find_element_by_id("su").click()
time.sleep(2)
final_url = driver.current_url if final_url != request.url:
fullurl = final_url else:
fullurl = request.url
content = driver.page_source.encode('utf-8','ignore')
driver.quit() return HtmlResponse(fullurl, encoding='utf-8', body=content, request=request) except Exception, e:
driver.quit() print e
其次,修改middlewares中间件中的类方法process_request,该方法默认携带request和spider对象,在我们刚刚修改的make_requests_from_url方法中。这里我们可以处理前面的make_requests_from_url函数返回的Request请求,然后加载selenium和phantomjs来获取我们需要访问的浏览器和关键字。这段代码会模拟用户获取关键字内容的行为,然后将页面内容返回给scrapy.http中的HtmlResponse对象。这样我们就可以在spider中的parse函数中得到刚刚抓取的内容response.body。
# 判断页面的返回状态
if int(response.status) >= 200 and int(response.status) 3000:
content = content[:3000] #elif len(content) == 0:
#yield scrapy.Request(url=response.url, meta={'url':response.url, 'phantomjs':True}, callback=self.pang_bo)
body = item['url']+','+item['crawl_time']+','+item['title'].replace(',','') +','+content+'\n'
if '正在进入' == item['title']:
file_name = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'keyword.csv') with open(file_name, 'a') as b:
b.write(body) else:
filename = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'.csv') with open(filename, 'a') as f:
f.write(body)# 过滤网页源代码def soup_text(body):
try:
soup = BeautifulSoup(body, 'lxml')
line = re.compile(r'\s+')
line = line.sub(r'', soup.body.getText())
p2 = re.compile(u'[^\u4e00-\u9fa5]') # 中GDAC\u4e00\u9fa5
str2 = p2.sub(r'', line)
outStr = str2.strip(',') except:
outStr = ''
return outStr
这段代码主要是忽略了一些不必要的网站,然后提取item字段,以及page body(这里过滤了源代码),然后将获取到的内容保存到.csv文件中。这只是一个简单的爬虫。要反向抓取,请进行如下设置:
LOG_STDOUT = True # 将进程所有的标准输出(及错误)将会被重定向到log中(为了方便调试)DOWNLOAD_DELAY=0.25 # 下载延时设置 单位秒DOWNLOAD_TIMEOUT = 60 # 下载超时设置(单位秒)CONCURRENT_ITEMS = 200 # 同时处理的itmes数量CONCURRENT_REQUESTS = 16 # 同时并发的请求
输入关键字 抓取所有网页(“请输入查询关键字”搜索框如何设置(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-29 02:08
“请输入查询关键词”的搜索框是大多数网站都会做的设置。这个搜索框可以帮助用户更准确、更快速地找到自己想要的信息,这是用户所习惯的。但是对于SEO人员来说,这个搜索框的设置并不是那么简单。自建网站的“请输入查询关键词”搜索框可能直接影响产品的转化。
(图片来自Pixabay)
搜索框的作用
1. 搜索框的作用是抓取页面。每个独立的搜索引擎都有自己的网络爬虫程序(蜘蛛)。蜘蛛会根据网页中的超链接不断抓取网页。因为超链接在互联网上的应用非常普遍,理论上从一定范围的网页开始,可以采集到绝大多数网页。
2.网页搜索引擎抓取网页后,还需要做大量的预处理工作,才能提供检索服务。其中,最重要的是提取关键词并构建索引文件。其他包括删除重复的网页、分析超链接和计算网页的重要性。
3.提供检索服务。用户输入关键词进行检索。搜索引擎从索引数据库中查找与关键词 匹配的网页。为方便用户,除了页面标题和URL,还会提供一段来自网页的Summary等信息。
搜索框的重要性
大多数情况下,使用搜索功能的用户,主要是产品的老用户,对产品的基本内容和服务有一定的了解,需求非常明确。在这种情况下,如果用户能够检索到他们想要的内容或服务,肯定会产生很高的转化率。
提高搜索转化率,让用户直接让客户完成最后的操作,也就是如何将粘性转化为结果,购买成功率高的转化可以带来利润和利润。
搜索框的位置醒目,使用方便,会给客户留下更好的印象。这就需要网站来组织一个清晰的浏览路径,让用户可以顺畅地定位更深层次的内容,也可以帮助用户快速找到目标,也可以到达目的地页面。
如何设置“请输入关键字”搜索框
1、基于SEO优化
从SEO的角度来回顾“请输入搜索关键词”的问题,其实我们说的是网站上的搜索框。搜索结果反馈的问题需要从以下两个角度来理解:
① 推荐和收录
利用网站搜索框中“请输入关键词”的位置,产生大量长尾词,合理利用搜索结果列表和展示次数,适当增加关键词的密度@> 在 SERP 中,以获得更高的排名。
② 屏蔽和隐藏
对于中小型企业站点,如果你的数据站点搜索量不大,通常建议使用robots.txt来屏蔽搜索结果URL。尤其是当你的SERP页面没有SEO标准化时,由于站点资源有限,实在是没有必要。对于此类页面,会分配百度爬虫对其进行抓取。
2、基于用户体验
从用户体验的角度来看,网站搜索框中的“请输入内容设置”尤为重要。有利于推荐企业核心产品,提高企业产品转化率,增加UGC内容输出,延迟用户页面停留时间,从而增加用户对网站品牌的粘性。
① 对网站做详细的统计分析,了解用户画像、对方喜好和喜好。
② 把握行业最新热门话题,适当利用站内多个门户,发布优质内容,引导对方参与讨论,增加当前热门话题栏目页的热度,从而增加对搜索引擎的信任。
3、输入的搜索词有误
如果对方检索到的特定关键词没有搜索结果,超过90%的网站会返回空结果,或者“您输入的关键词不正确”的标志”出现。但这是一个非常不明智的策略。您可以在此位置报告以下内容:
① 网站 逻辑结构图,类似于 HTML 版的站点地图。
②最近用户非常关注的“请输入查询关键词”推荐一些比较热门的搜索词。
③ 站内热门文章、行业最热门相关话题等。
由此可见,自建站的搜索框“请输入查询关键词”其实很重要。 查看全部
输入关键字 抓取所有网页(“请输入查询关键字”搜索框如何设置(组图))
“请输入查询关键词”的搜索框是大多数网站都会做的设置。这个搜索框可以帮助用户更准确、更快速地找到自己想要的信息,这是用户所习惯的。但是对于SEO人员来说,这个搜索框的设置并不是那么简单。自建网站的“请输入查询关键词”搜索框可能直接影响产品的转化。

(图片来自Pixabay)
搜索框的作用
1. 搜索框的作用是抓取页面。每个独立的搜索引擎都有自己的网络爬虫程序(蜘蛛)。蜘蛛会根据网页中的超链接不断抓取网页。因为超链接在互联网上的应用非常普遍,理论上从一定范围的网页开始,可以采集到绝大多数网页。
2.网页搜索引擎抓取网页后,还需要做大量的预处理工作,才能提供检索服务。其中,最重要的是提取关键词并构建索引文件。其他包括删除重复的网页、分析超链接和计算网页的重要性。
3.提供检索服务。用户输入关键词进行检索。搜索引擎从索引数据库中查找与关键词 匹配的网页。为方便用户,除了页面标题和URL,还会提供一段来自网页的Summary等信息。
搜索框的重要性
大多数情况下,使用搜索功能的用户,主要是产品的老用户,对产品的基本内容和服务有一定的了解,需求非常明确。在这种情况下,如果用户能够检索到他们想要的内容或服务,肯定会产生很高的转化率。
提高搜索转化率,让用户直接让客户完成最后的操作,也就是如何将粘性转化为结果,购买成功率高的转化可以带来利润和利润。
搜索框的位置醒目,使用方便,会给客户留下更好的印象。这就需要网站来组织一个清晰的浏览路径,让用户可以顺畅地定位更深层次的内容,也可以帮助用户快速找到目标,也可以到达目的地页面。
如何设置“请输入关键字”搜索框
1、基于SEO优化
从SEO的角度来回顾“请输入搜索关键词”的问题,其实我们说的是网站上的搜索框。搜索结果反馈的问题需要从以下两个角度来理解:
① 推荐和收录
利用网站搜索框中“请输入关键词”的位置,产生大量长尾词,合理利用搜索结果列表和展示次数,适当增加关键词的密度@> 在 SERP 中,以获得更高的排名。
② 屏蔽和隐藏
对于中小型企业站点,如果你的数据站点搜索量不大,通常建议使用robots.txt来屏蔽搜索结果URL。尤其是当你的SERP页面没有SEO标准化时,由于站点资源有限,实在是没有必要。对于此类页面,会分配百度爬虫对其进行抓取。
2、基于用户体验
从用户体验的角度来看,网站搜索框中的“请输入内容设置”尤为重要。有利于推荐企业核心产品,提高企业产品转化率,增加UGC内容输出,延迟用户页面停留时间,从而增加用户对网站品牌的粘性。
① 对网站做详细的统计分析,了解用户画像、对方喜好和喜好。
② 把握行业最新热门话题,适当利用站内多个门户,发布优质内容,引导对方参与讨论,增加当前热门话题栏目页的热度,从而增加对搜索引擎的信任。
3、输入的搜索词有误
如果对方检索到的特定关键词没有搜索结果,超过90%的网站会返回空结果,或者“您输入的关键词不正确”的标志”出现。但这是一个非常不明智的策略。您可以在此位置报告以下内容:
① 网站 逻辑结构图,类似于 HTML 版的站点地图。
②最近用户非常关注的“请输入查询关键词”推荐一些比较热门的搜索词。
③ 站内热门文章、行业最热门相关话题等。
由此可见,自建站的搜索框“请输入查询关键词”其实很重要。
输入关键字 抓取所有网页(您意思是要在您的网站上用别人的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-29 02:02
你的意思是在你自己网站上使用别人的数据吗?如果是,你可以: 在你的网站中输入关键字向你的服务器请求,然后用HttpClient模拟请求到别人的网站去抓取服务器上的数据,然后返回给自己网站 请求。
当然,你需要弄清楚其他人的服务器请求的链接(使用一楼描述的方法),并分析请求的其他参数,才能模拟请求的图像。前提是他们对请求的安全限制没有那么严格。
也可以把抓到的数据保存在自己的数据库中,下次就可以找到自己的数据库了。如果找不到,可以模拟请求再次捕获。这样就可以累积下一个数据量。
但毕竟这些数据可能是其他人根据用户行为分析的结果,可能与自己的网站不一致。
收获花园豆:10
李奇鹏||元豆:1160|2015-07-01 13:18
好吧,我只需要计算他所展示的内容,而不管他的分析是否准确。
用F12可以看到相关信息,但是不知道是哪个JS方法在处理这些请求。HTTPWatch 也是如此。你有什么好的方法来定位这样的请求方法吗?
给个思路,非常感谢。
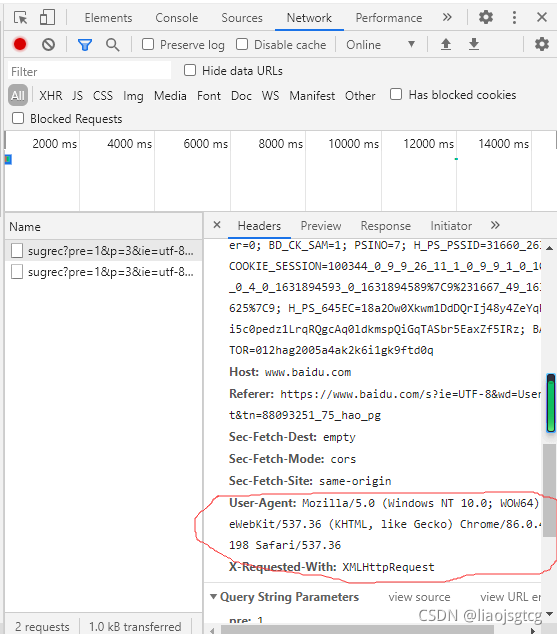
我要当仙女快乐启天|元豆:17|2015-07-01 13:38
@OmJJWang:让我们了解如何使用 Google Chrome 开发工具。我用的是手机,不是很方便。简单地谈谈它。打开那个页面,使用谷歌浏览器,按f12,看到网络栏,有一个清除按钮,找一下,先清除现有的请求信息,然后在搜索框中输入,你应该看到刚才有网络中的东西,这是发送的请求,查看链接。自己感受一下。
李奇鹏|元豆:1160|2015-07-01 14:12
上传图片
Ctrl+Enter键快速提交 查看全部
输入关键字 抓取所有网页(您意思是要在您的网站上用别人的数据?)
你的意思是在你自己网站上使用别人的数据吗?如果是,你可以: 在你的网站中输入关键字向你的服务器请求,然后用HttpClient模拟请求到别人的网站去抓取服务器上的数据,然后返回给自己网站 请求。
当然,你需要弄清楚其他人的服务器请求的链接(使用一楼描述的方法),并分析请求的其他参数,才能模拟请求的图像。前提是他们对请求的安全限制没有那么严格。
也可以把抓到的数据保存在自己的数据库中,下次就可以找到自己的数据库了。如果找不到,可以模拟请求再次捕获。这样就可以累积下一个数据量。
但毕竟这些数据可能是其他人根据用户行为分析的结果,可能与自己的网站不一致。
收获花园豆:10
李奇鹏||元豆:1160|2015-07-01 13:18
好吧,我只需要计算他所展示的内容,而不管他的分析是否准确。
用F12可以看到相关信息,但是不知道是哪个JS方法在处理这些请求。HTTPWatch 也是如此。你有什么好的方法来定位这样的请求方法吗?
给个思路,非常感谢。
我要当仙女快乐启天|元豆:17|2015-07-01 13:38
@OmJJWang:让我们了解如何使用 Google Chrome 开发工具。我用的是手机,不是很方便。简单地谈谈它。打开那个页面,使用谷歌浏览器,按f12,看到网络栏,有一个清除按钮,找一下,先清除现有的请求信息,然后在搜索框中输入,你应该看到刚才有网络中的东西,这是发送的请求,查看链接。自己感受一下。
李奇鹏|元豆:1160|2015-07-01 14:12
上传图片
Ctrl+Enter键快速提交
输入关键字 抓取所有网页(【每日一题】用rvest写了个抓取网站关键字搜索结果的脚本 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-26 13:13
)
我很久没有使用 R 了。今天复习了一下,写了一个脚本,用rvest抓取网站关键字搜索结果。分享一下。
需求分析网站请求
打开网站,输入关键字疾病,就可以得到搜索链接,显然是GET请求
观察链接,可以看到q=disease是关键字,p=2是页码,pn=20是每页记录数,其他参数也可以试试
搜索列表抓取功能
<p>library("rvest")
getPageList % html_attr("href")
# 选择authors等标签内的文本, 并进行gsub处理掉其中的空格等多余字符
authors % html_text() %>% gsub(pattern=" {2,}|\n|\r", replacement="")
sources % html_text() %>% gsub(pattern="\r|\n *", replacement=" ")
pmid % html_text() %>% gsub(pattern="\r\n| ?|\u00A0",replacement="")
# 结果保存入dataframe并返回
iData % gsub(pattern="Abstract(\\n)*(\\t)*|\\n\\t*", replacement="")
# 有的页面没有摘要信息, 会返回 character(0) , 需要做个处理, 否则会报错
if (identical(tmp, character(0))){
tmp 查看全部
输入关键字 抓取所有网页(【每日一题】用rvest写了个抓取网站关键字搜索结果的脚本
)
我很久没有使用 R 了。今天复习了一下,写了一个脚本,用rvest抓取网站关键字搜索结果。分享一下。
需求分析网站请求
打开网站,输入关键字疾病,就可以得到搜索链接,显然是GET请求
观察链接,可以看到q=disease是关键字,p=2是页码,pn=20是每页记录数,其他参数也可以试试
搜索列表抓取功能
<p>library("rvest")
getPageList % html_attr("href")
# 选择authors等标签内的文本, 并进行gsub处理掉其中的空格等多余字符
authors % html_text() %>% gsub(pattern=" {2,}|\n|\r", replacement="")
sources % html_text() %>% gsub(pattern="\r|\n *", replacement=" ")
pmid % html_text() %>% gsub(pattern="\r\n| ?|\u00A0",replacement="")
# 结果保存入dataframe并返回
iData % gsub(pattern="Abstract(\\n)*(\\t)*|\\n\\t*", replacement="")
# 有的页面没有摘要信息, 会返回 character(0) , 需要做个处理, 否则会报错
if (identical(tmp, character(0))){
tmp
输入关键字 抓取所有网页(【闺蜜体验团】反爬网站中的本文-Agent )
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-25 21:20
)
这篇文章的目的是简单地根据所选浏览器页面上的关键字抓取你想要的信息。关键是跳过反爬网页的反爬机制。
使用UA伪装
我们利用爬取的网站中的User-Agent进行伪装,让它认为我们是自己的一部分,这样我们就可以成功爬取到我们需要的信息。
打开要爬取的页面,在键盘上按F12,如下图:
代码模块
import requests
if __name__ == '__main__':
# UA伪装
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'
}
# 1.指定url
url = "https://www.sogou.com/web?"
kw = input("请输入关键字:")
param = {
'query' : kw
}
# 2.发送请求
response = requests.get(url=url,params=param,headers=header)
#数据获取
html = response.text
print(html)
response.encoding = 'utf-8'
fileName = kw + '.html'
with open(fileName,'w',encoding='utf-8') as f:
f.write(html)
print("页面获取成功!!!!") 查看全部
输入关键字 抓取所有网页(【闺蜜体验团】反爬网站中的本文-Agent
)
这篇文章的目的是简单地根据所选浏览器页面上的关键字抓取你想要的信息。关键是跳过反爬网页的反爬机制。
使用UA伪装
我们利用爬取的网站中的User-Agent进行伪装,让它认为我们是自己的一部分,这样我们就可以成功爬取到我们需要的信息。
打开要爬取的页面,在键盘上按F12,如下图:
代码模块
import requests
if __name__ == '__main__':
# UA伪装
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'
}
# 1.指定url
url = "https://www.sogou.com/web?"
kw = input("请输入关键字:")
param = {
'query' : kw
}
# 2.发送请求
response = requests.get(url=url,params=param,headers=header)
#数据获取
html = response.text
print(html)
response.encoding = 'utf-8'
fileName = kw + '.html'
with open(fileName,'w',encoding='utf-8') as f:
f.write(html)
print("页面获取成功!!!!")
输入关键字 抓取所有网页(STM32获取TB网页的一些信息(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-25 08:01
)
一、项目介绍
在 TB 网页上获取一些信息(仅用于教育目的)
比如我们需要使用关键字来获取TB接口的一些信息。
通过确认,可以发现请求是:
https://s.taobao.com/search?q=书包&s=0 #q代表关键字,显示第一页
https://s.taobao.com/search?q=书包&s=44 #显示第二页,每一个44个
结构设计:
二、获取分析
使用的解析方法很多,一种使用BeatifulSoup库,另一种使用正则表达式直接匹配。我们在这里使用正则表达式。
通过查看源代码,我们可以看到 view_price 和 raw_title 标签正是我们所需要的。
三、源代码
# 已失效,需要登录
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding #防止中文乱码
print(r.text)
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("")
def printGoodsList(ilt):
print(ilt)
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = coount +1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 1 #搜索两页,每页44个商品
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
print(url)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main() 查看全部
输入关键字 抓取所有网页(STM32获取TB网页的一些信息(一)
)
一、项目介绍
在 TB 网页上获取一些信息(仅用于教育目的)
比如我们需要使用关键字来获取TB接口的一些信息。
通过确认,可以发现请求是:
https://s.taobao.com/search?q=书包&s=0 #q代表关键字,显示第一页
https://s.taobao.com/search?q=书包&s=44 #显示第二页,每一个44个
结构设计:
二、获取分析
使用的解析方法很多,一种使用BeatifulSoup库,另一种使用正则表达式直接匹配。我们在这里使用正则表达式。
通过查看源代码,我们可以看到 view_price 和 raw_title 标签正是我们所需要的。
三、源代码
# 已失效,需要登录
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding #防止中文乱码
print(r.text)
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("")
def printGoodsList(ilt):
print(ilt)
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = coount +1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 1 #搜索两页,每页44个商品
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
print(url)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
输入关键字 抓取所有网页(C#开发环境的使用、C#语言基础应用、字符串编程基础篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-25 08:00
主要内容包括C#开发环境的使用、C#语言基础应用、字符串处理技术、数组和集合的使用、面向对象编程技术、数据结构与算法、Windows窗体基础、特征窗体界面、窗体控件技术、 MDI窗体和继承窗体,常用Windows控件的使用,好的Windows控件的使用,DataGridView数据控件,自定义用户控件,基本文件操作,基本文件夹操作,文件流操作,文件的加密解密解压,C#与Word互通、高效使用Excel、基础图形绘制、图像处理技术、常用图表应用、动画处理技术、音视频控制。随书光盘附有源程序和部分示例。 查看全部
输入关键字 抓取所有网页(C#开发环境的使用、C#语言基础应用、字符串编程基础篇)
主要内容包括C#开发环境的使用、C#语言基础应用、字符串处理技术、数组和集合的使用、面向对象编程技术、数据结构与算法、Windows窗体基础、特征窗体界面、窗体控件技术、 MDI窗体和继承窗体,常用Windows控件的使用,好的Windows控件的使用,DataGridView数据控件,自定义用户控件,基本文件操作,基本文件夹操作,文件流操作,文件的加密解密解压,C#与Word互通、高效使用Excel、基础图形绘制、图像处理技术、常用图表应用、动画处理技术、音视频控制。随书光盘附有源程序和部分示例。
输入关键字 抓取所有网页(如何利用python及免费资源进行基于论文关键词的研究趋势分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-23 10:17
在学术研究中,往往需要了解某个领域的最新发展趋势,比如发现最热门、上升最快的关键词。一些学术服务网站,比如Web of Science,也提供了类似的服务,但是一些高校并没有订阅这些服务,在使用中难免会遇到各种问题,比如定制不够。在这个文章中,我们将在论文关键词的基础上讨论如何使用python和免费资源进行研究趋势分析。
入选期刊
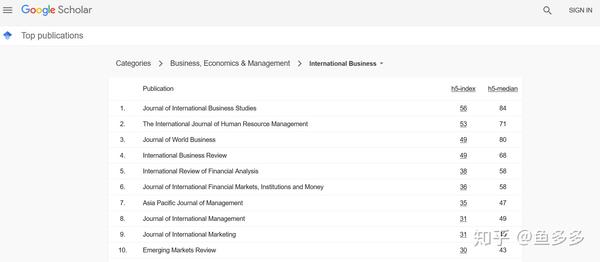
想知道近些年在国际商务领域发表的文章,在google中搜索“google学术期刊排名国际商务”,点击第一个链接,得到如下页面:
以排名第一的Journal of International Business Studies为例,展示如何抓取近年发表的所有文章信息。
查找文章的列表
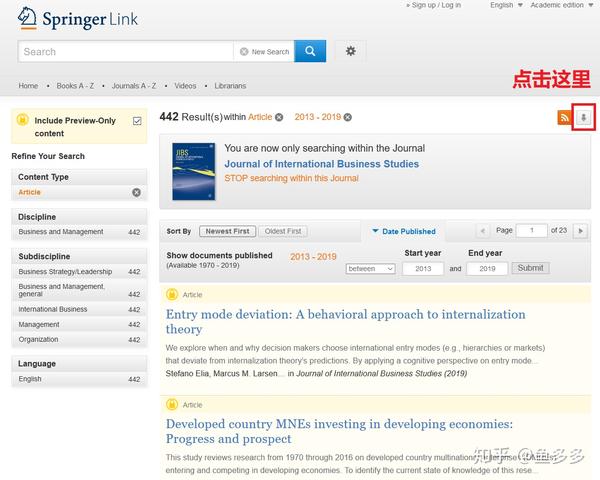
经过一番搜索,我找到了自 2013 年以来发表的所有 442 篇文章 文章 的列表:
点击图中红框内的按钮,将442条文章信息全部导出为CSV文件。
但是,文件中只收录了每个文章的项目标题、作者和URL,并没有关键词(关键词)和摘要(摘要)等重要信息。
接下来我们用python写一个循环,打开每篇文章的链接文章,抓取关键词和总结。
抓取网页元素
首先,我们定义了一个get_keywords_abstract()函数来抓取给定网页中的相关元素,代码如下:
import requests
from scrapy import Selector
def get_keywords_abstract(url):
r = requests.get(url) #打开网页
if r.status_code != 200: #如果网页连接错误,就返回空字符串
print("Connection error: {}".format(url))
return "", ""
selector = Selector(text=r.text)
keywords = selector.css('.Keyword::text').extract()
abstract = selector.css('#Abs1 p::text').extract_first()
return keywords, abstract
值得注意的是,我使用了scrapy库中的Selector类来解析网页。这样做的原因是,相对于 Beautiful Soup 和 Pyquery 等库,我更熟悉scrapy下css选择器的使用。
为了验证以上代码是否正确,我在命令行执行如下测试代码:
test_url = 'https://link.springer.com/arti ... 39%3B
keywords, abstract = get_keywords_abstract(test_url)
print(keywords)
print(abstract)
结果有点出人意料:
>>> print(keywords)
['entry mode\xa0', 'deviation from prediction\xa0', 'internalization theory\xa0', 'bounded rationality\xa0', 'cognitive bias\xa0']
>>> print(abstract)
'We explore when and why decision makers choose international entry modes (e.g., hierarchies or markets) that deviate from internalization theory’s predictions. By applying a cognitive perspective on entry mode decision making, we propose that the performance of prior international activities influences decision makers’ behavior in different ways than assumed in internalization theory. More specifically, due to a'
关键词 末尾有多余的字符。这不是什么大问题。您可以在后续处理中批量删除它们。真正的问题是摘要不完整。
在浏览器中打开测试网页,右键查看源码,在摘要中找到一些html标签,如:
...due to a representativeness bias , underperforming ...
正是这些 html 标签干扰了正常的文本抓取。
为了解决这个问题,我修改了get_keywords_abstract()函数:
import requests
from scrapy import Selector
def get_keywords_abstract(url):
r = requests.get(url) #打开网页
if r.status_code != 200: #如果网页连接错误,就返回空字符串
print("Connection error: {}".format(url))
return "", ""
selector = Selector(text=r.text)
keywords = selector.css('.Keyword::text').extract()
abstracts = selector.css('#Abs1 p::text').extract() #把extract_first()改成extract(),抓取所有的文本片段
abstract = ''.join(abstracts) #把文本片段连接起来
return keywords, abstract
重新运行测试代码,发现问题解决了。
导入 CSV 文件
下一步是导入CSV文件中的URL列表,循环抓取关键词和summary。
导入 CSV 文件以使用 pandas 库:
import pandas as pd
articles = pd.read_csv('../data/jibs_articles.csv', sep=',')
type(articles) #
articles.shape # (442, 10)
articles.columns # 列名
articles.head() # 打印前5行
For 循环
确认一切无误后,循环开始:
urls = articles['URL']
keywords = pd.Series(index=articles.index)
abstract = pd.Series(index=articles.index)
for i, url in enumerate(urls):
keywords[i], abstract[i] = get_keywords_abstract(url)
print("Finish article: {}".format(i)) # 抓完一个网页就报一个数字,等的时候心里好过一些
等了大约20分钟后,我终于完成了捕获。只有一个 文章 打开错误。
保存到 CSV 文件
接下来,我们将关键词和summary整合到数据表中,然后保存到CSV文件中。
articles['keywords'] = keywords
articles['abstract'] = abstract
articles.columns # 数据表中增加了keywords和abstract两列
articles.to_csv('../data/jibs_keywords_abstract.csv', sep=',', header=True)
为了方便下次使用,我们“粘贴”一下数据:
import pickle
with open("../data/articles.pickle", "wb") as f:
pickle.dump(articles, f)
下一次,我们将讨论基于关键词的研究趋势分析。 查看全部
输入关键字 抓取所有网页(如何利用python及免费资源进行基于论文关键词的研究趋势分析)
在学术研究中,往往需要了解某个领域的最新发展趋势,比如发现最热门、上升最快的关键词。一些学术服务网站,比如Web of Science,也提供了类似的服务,但是一些高校并没有订阅这些服务,在使用中难免会遇到各种问题,比如定制不够。在这个文章中,我们将在论文关键词的基础上讨论如何使用python和免费资源进行研究趋势分析。
入选期刊
想知道近些年在国际商务领域发表的文章,在google中搜索“google学术期刊排名国际商务”,点击第一个链接,得到如下页面:
以排名第一的Journal of International Business Studies为例,展示如何抓取近年发表的所有文章信息。
查找文章的列表
经过一番搜索,我找到了自 2013 年以来发表的所有 442 篇文章 文章 的列表:
点击图中红框内的按钮,将442条文章信息全部导出为CSV文件。
但是,文件中只收录了每个文章的项目标题、作者和URL,并没有关键词(关键词)和摘要(摘要)等重要信息。
接下来我们用python写一个循环,打开每篇文章的链接文章,抓取关键词和总结。
抓取网页元素
首先,我们定义了一个get_keywords_abstract()函数来抓取给定网页中的相关元素,代码如下:
import requests
from scrapy import Selector
def get_keywords_abstract(url):
r = requests.get(url) #打开网页
if r.status_code != 200: #如果网页连接错误,就返回空字符串
print("Connection error: {}".format(url))
return "", ""
selector = Selector(text=r.text)
keywords = selector.css('.Keyword::text').extract()
abstract = selector.css('#Abs1 p::text').extract_first()
return keywords, abstract
值得注意的是,我使用了scrapy库中的Selector类来解析网页。这样做的原因是,相对于 Beautiful Soup 和 Pyquery 等库,我更熟悉scrapy下css选择器的使用。
为了验证以上代码是否正确,我在命令行执行如下测试代码:
test_url = 'https://link.springer.com/arti ... 39%3B
keywords, abstract = get_keywords_abstract(test_url)
print(keywords)
print(abstract)
结果有点出人意料:
>>> print(keywords)
['entry mode\xa0', 'deviation from prediction\xa0', 'internalization theory\xa0', 'bounded rationality\xa0', 'cognitive bias\xa0']
>>> print(abstract)
'We explore when and why decision makers choose international entry modes (e.g., hierarchies or markets) that deviate from internalization theory’s predictions. By applying a cognitive perspective on entry mode decision making, we propose that the performance of prior international activities influences decision makers’ behavior in different ways than assumed in internalization theory. More specifically, due to a'
关键词 末尾有多余的字符。这不是什么大问题。您可以在后续处理中批量删除它们。真正的问题是摘要不完整。
在浏览器中打开测试网页,右键查看源码,在摘要中找到一些html标签,如:
...due to a representativeness bias , underperforming ...
正是这些 html 标签干扰了正常的文本抓取。
为了解决这个问题,我修改了get_keywords_abstract()函数:
import requests
from scrapy import Selector
def get_keywords_abstract(url):
r = requests.get(url) #打开网页
if r.status_code != 200: #如果网页连接错误,就返回空字符串
print("Connection error: {}".format(url))
return "", ""
selector = Selector(text=r.text)
keywords = selector.css('.Keyword::text').extract()
abstracts = selector.css('#Abs1 p::text').extract() #把extract_first()改成extract(),抓取所有的文本片段
abstract = ''.join(abstracts) #把文本片段连接起来
return keywords, abstract
重新运行测试代码,发现问题解决了。
导入 CSV 文件
下一步是导入CSV文件中的URL列表,循环抓取关键词和summary。
导入 CSV 文件以使用 pandas 库:
import pandas as pd
articles = pd.read_csv('../data/jibs_articles.csv', sep=',')
type(articles) #
articles.shape # (442, 10)
articles.columns # 列名
articles.head() # 打印前5行
For 循环
确认一切无误后,循环开始:
urls = articles['URL']
keywords = pd.Series(index=articles.index)
abstract = pd.Series(index=articles.index)
for i, url in enumerate(urls):
keywords[i], abstract[i] = get_keywords_abstract(url)
print("Finish article: {}".format(i)) # 抓完一个网页就报一个数字,等的时候心里好过一些
等了大约20分钟后,我终于完成了捕获。只有一个 文章 打开错误。
保存到 CSV 文件
接下来,我们将关键词和summary整合到数据表中,然后保存到CSV文件中。
articles['keywords'] = keywords
articles['abstract'] = abstract
articles.columns # 数据表中增加了keywords和abstract两列
articles.to_csv('../data/jibs_keywords_abstract.csv', sep=',', header=True)
为了方便下次使用,我们“粘贴”一下数据:
import pickle
with open("../data/articles.pickle", "wb") as f:
pickle.dump(articles, f)
下一次,我们将讨论基于关键词的研究趋势分析。
输入关键字 抓取所有网页( 安之若死)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-21 08:05
安之若死)
Python3获取一大段文本之间两个关键字之间的内容
更新时间:2018年10月11日14:47:19
今天小编就给大家分享一个Python3获取大段文本之间两个关键字之间内容的方法,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
使用 re 或 string.find。以下是重新代码
import re
#文本所在TXT文件
file = '123.txt'
#关键字1,2(修改引号间的内容)
w1 = '123'
w2 = '456'
f = open(file,'r')
buff = f.read()
#清除换行符,请取消下一行注释
#buff = buff.replace('\n','')
pat = re.compile(w1+'(.*?)'+w2,re.S)
result = pat.findall(buff)
print(result)
以上Python3获取一大段文本之间两个关键字之间的内容的方法就是编辑器共享的所有内容。希望能给大家一个参考,也希望大家多多支持剧本家。 查看全部
输入关键字 抓取所有网页(
安之若死)
Python3获取一大段文本之间两个关键字之间的内容
更新时间:2018年10月11日14:47:19
今天小编就给大家分享一个Python3获取大段文本之间两个关键字之间内容的方法,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
使用 re 或 string.find。以下是重新代码
import re
#文本所在TXT文件
file = '123.txt'
#关键字1,2(修改引号间的内容)
w1 = '123'
w2 = '456'
f = open(file,'r')
buff = f.read()
#清除换行符,请取消下一行注释
#buff = buff.replace('\n','')
pat = re.compile(w1+'(.*?)'+w2,re.S)
result = pat.findall(buff)
print(result)
以上Python3获取一大段文本之间两个关键字之间的内容的方法就是编辑器共享的所有内容。希望能给大家一个参考,也希望大家多多支持剧本家。
输入关键字 抓取所有网页(Node批量爬取头条视频地址A坑库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-21 08:04
需要
通过抖音的首页链接下载该用户的所有视频
想法
分析发现视频地址都是通过一个接口返回的,手动复制数据过滤掉需要的视频地址A
坑①:
地址A在浏览器的手机模式下只会跳转到真实的视频地址B
查资料发现神器Puppeteer的中文文档
Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。
您可以在浏览器中手动执行的大部分操作都可以使用 Puppeteer 完成!这里有些例子:
解决办法是:模仿iphone6打开页面,然后通过document.querySelector('source').src获取实际播放地址
getUrl.js
// 获取视频实际下载链接
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
const iPhone = devices['iPhone 6'];
const getUrl = async (item) => {
const browser = await puppeteer.launch(); //启动浏览器实例
const page = await browser.newPage(); //创建一个新页面
await page.emulate(iPhone); //模拟iphone6打开页面
await page.goto(item.url); //进入指定网页
const result = await page.evaluate((item) => {
let url = document.querySelector('source').src;
return {
title: item.title,
url
}
}, item);
await browser.close();
return result;
}
module.exports = getUrl
下载视频
这里直接参考Node对头条视频的批量抓取和保存方法的写法
download.js
// 下载视频
const fs = require('fs');
const http = require('http');
const config = require('./config');
function getVideoData(url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
function savefileToPath(fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
async function downloadVideo(video) {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.url, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
module.exports = downloadVideo
以上都可以实现后,研究如何获取所有视频链接
解决方案:仍然使用puppeteer获取请求完成事件并获取请求正文
注:为保证能拿到所有的视频,需要滚动到模拟页面底部,没有更多的视频,然后抓取数据
完成:
判断页面是否滚动到底部
let isScrollEnd = false
let scroll_timer = null
$(window).scroll(function () {
var scrollTop = $(this).scrollTop();
var scrollHeight = $(document).height();
var windowHeight = $(this).height();
// 防止滚动过快,接口较慢,500ms后再去判断
clearTimeout(scroll_timer)
scroll_timer = setTimeout(() => {
if (scrollTop + windowHeight >= scrollHeight) {
isScrollEnd = true
console.log("that.isScrollEnd", isScrollEnd)
}
}, 500)
});
操作浏览器滚动到底部时停止
坑评价范围
await page.evaluate(async (aa) => {
这里是node自己打开的浏览器作用域,无法直接取到外部的变量,需要通过参数传入,如aa
且无法传入this这类无法序列化的参数
},aa);
优化部分
通过config.js配置各种参数
module.exports = {
isShowChrome: false, //是否显示chrome浏览器
ajaxKey: 'v2/aweme/post',//接口的关键字,防止对所有接口都获取数据
ajaxPath: 'video.play_addr.url_list[0]',//视频在接口里的路径
inputUrl: 'https://v.douyin.com/qKDN9n/',//输入的链接,后期由页面传入吧
savePath: './output',//保存路径
isDownload: true,//是否下载视频
isSaveJsonData: false, //是否保存json数据,如获取到的接口数据和整理后的视频数据
}
全码地址
参考 查看全部
输入关键字 抓取所有网页(Node批量爬取头条视频地址A坑库)
需要
通过抖音的首页链接下载该用户的所有视频
想法
分析发现视频地址都是通过一个接口返回的,手动复制数据过滤掉需要的视频地址A
坑①:
地址A在浏览器的手机模式下只会跳转到真实的视频地址B
查资料发现神器Puppeteer的中文文档
Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。
您可以在浏览器中手动执行的大部分操作都可以使用 Puppeteer 完成!这里有些例子:
解决办法是:模仿iphone6打开页面,然后通过document.querySelector('source').src获取实际播放地址
getUrl.js
// 获取视频实际下载链接
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
const iPhone = devices['iPhone 6'];
const getUrl = async (item) => {
const browser = await puppeteer.launch(); //启动浏览器实例
const page = await browser.newPage(); //创建一个新页面
await page.emulate(iPhone); //模拟iphone6打开页面
await page.goto(item.url); //进入指定网页
const result = await page.evaluate((item) => {
let url = document.querySelector('source').src;
return {
title: item.title,
url
}
}, item);
await browser.close();
return result;
}
module.exports = getUrl
下载视频
这里直接参考Node对头条视频的批量抓取和保存方法的写法
download.js
// 下载视频
const fs = require('fs');
const http = require('http');
const config = require('./config');
function getVideoData(url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
function savefileToPath(fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
async function downloadVideo(video) {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.url, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
module.exports = downloadVideo
以上都可以实现后,研究如何获取所有视频链接
解决方案:仍然使用puppeteer获取请求完成事件并获取请求正文
注:为保证能拿到所有的视频,需要滚动到模拟页面底部,没有更多的视频,然后抓取数据
完成:
判断页面是否滚动到底部
let isScrollEnd = false
let scroll_timer = null
$(window).scroll(function () {
var scrollTop = $(this).scrollTop();
var scrollHeight = $(document).height();
var windowHeight = $(this).height();
// 防止滚动过快,接口较慢,500ms后再去判断
clearTimeout(scroll_timer)
scroll_timer = setTimeout(() => {
if (scrollTop + windowHeight >= scrollHeight) {
isScrollEnd = true
console.log("that.isScrollEnd", isScrollEnd)
}
}, 500)
});
操作浏览器滚动到底部时停止
坑评价范围
await page.evaluate(async (aa) => {
这里是node自己打开的浏览器作用域,无法直接取到外部的变量,需要通过参数传入,如aa
且无法传入this这类无法序列化的参数
},aa);
优化部分
通过config.js配置各种参数
module.exports = {
isShowChrome: false, //是否显示chrome浏览器
ajaxKey: 'v2/aweme/post',//接口的关键字,防止对所有接口都获取数据
ajaxPath: 'video.play_addr.url_list[0]',//视频在接口里的路径
inputUrl: 'https://v.douyin.com/qKDN9n/',//输入的链接,后期由页面传入吧
savePath: './output',//保存路径
isDownload: true,//是否下载视频
isSaveJsonData: false, //是否保存json数据,如获取到的接口数据和整理后的视频数据
}
全码地址
参考
输入关键字 抓取所有网页(京东商城关键字搜索商品的页面Url的参数为奇数(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-20 16:13
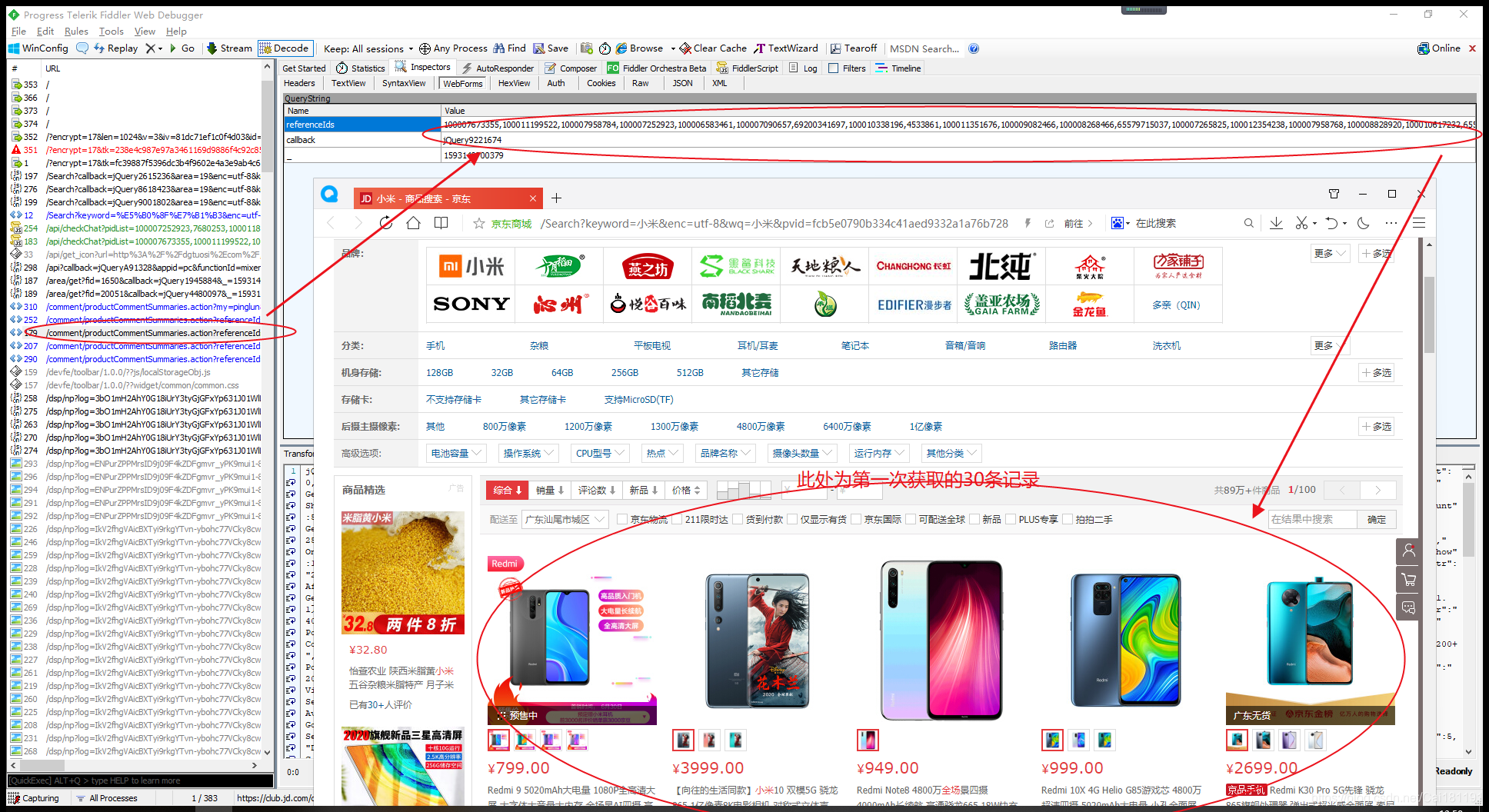
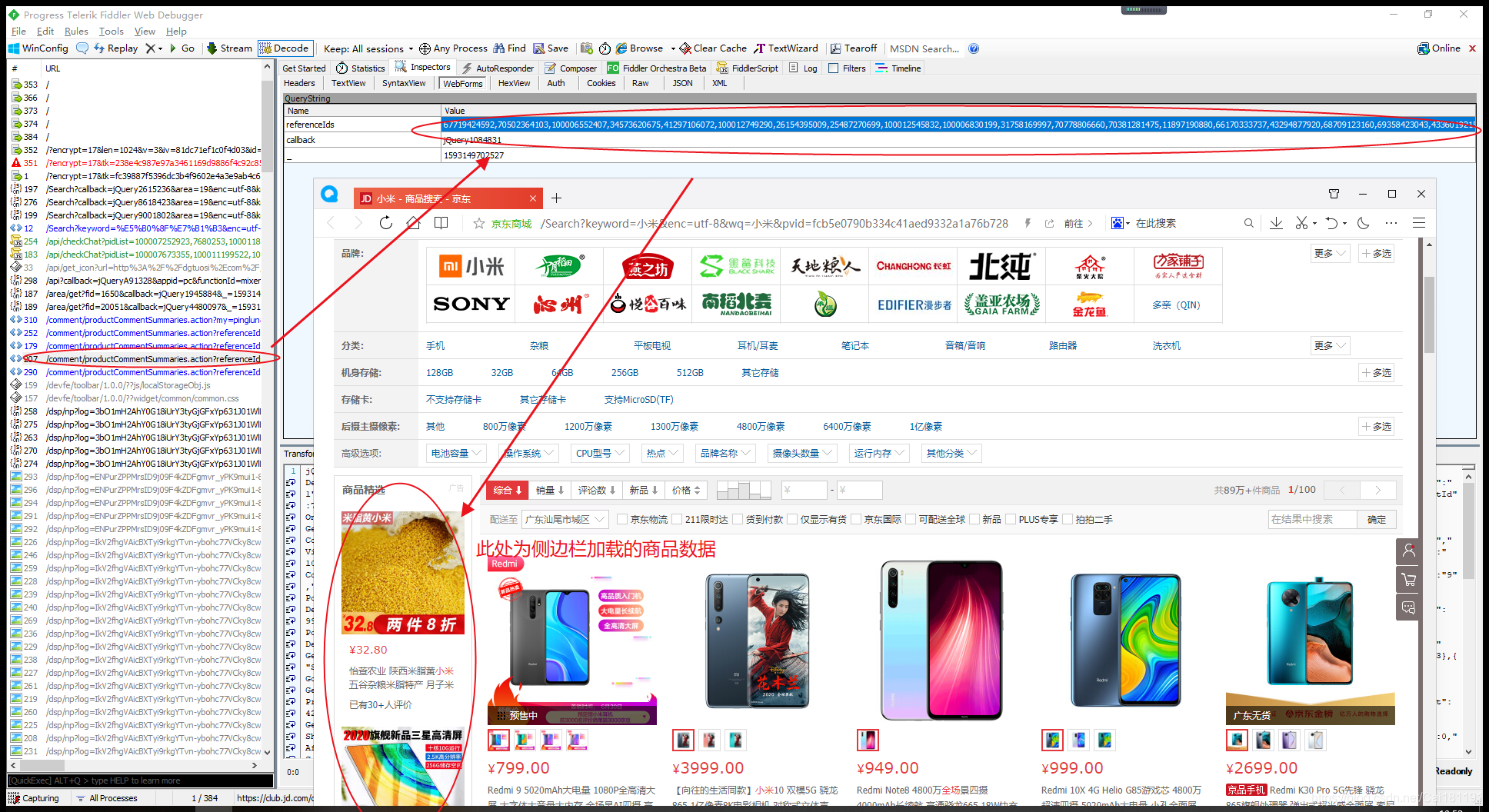
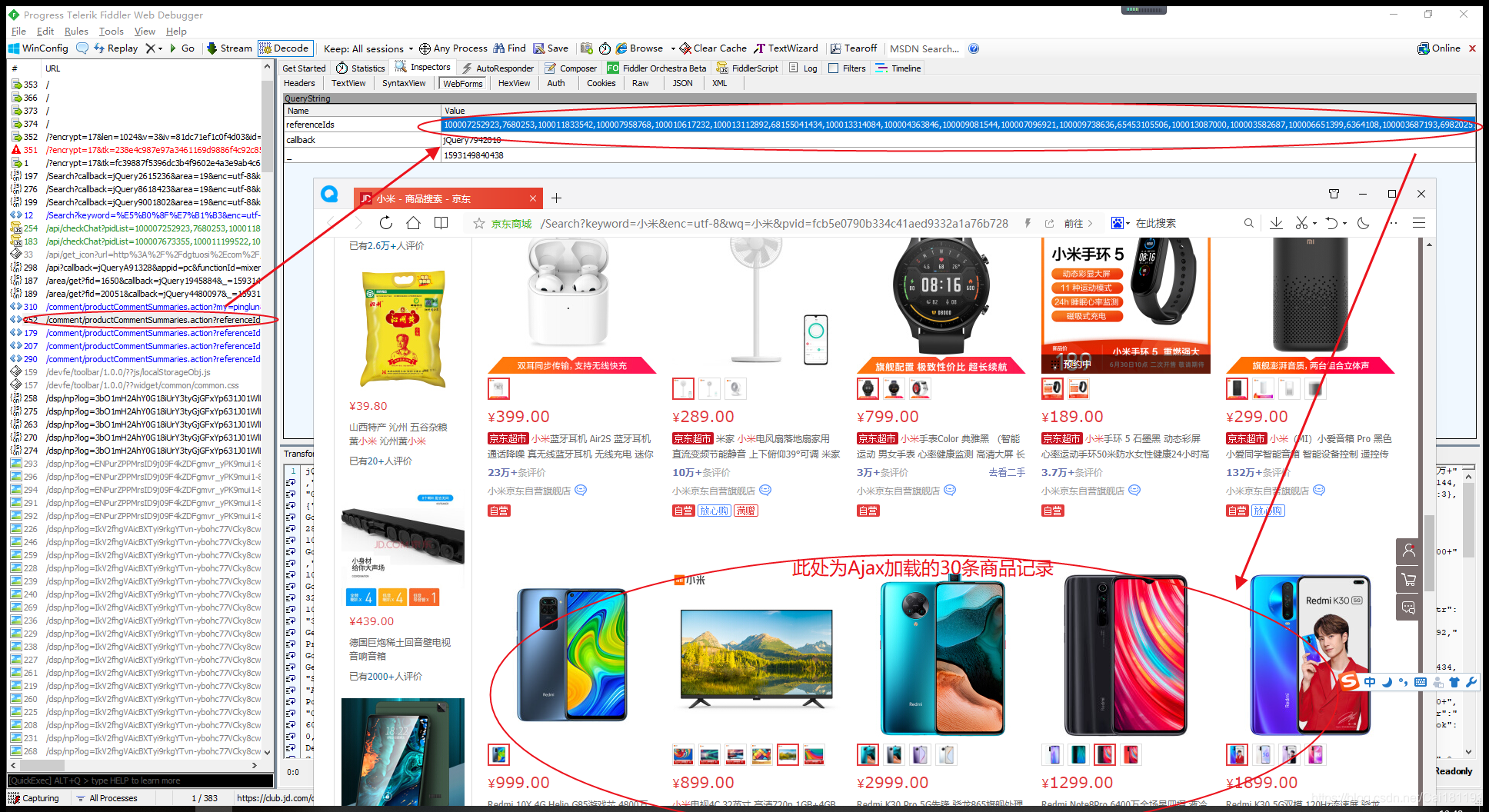
)
使用HttpClient可以创建浏览器对象,然后抓取页面数据,然后使用Jsoup库解析Html页面。因为Jsoup和JQuery通过selector获取元素的方式是一样的,所以抓取页面数据变得非常方便。
例如,此链接:%E5%B0%8F%E7%B1%B3&page=1&s=201&click=0
研究发现京东关键词搜索商品页面的page Url的page参数为奇数(1、3、5、7、9...),估计前30个产品数据其实是第一页,Ajax加载的后30个产品数据其实是第二页。第一页和第二页的数据合起来就是该页1页的数据。
另外,在京东商品的数据中,有两个字段很神奇,分别是spu和sku,spu代表商品集合的id,sku代表商品最小品类单元的id,意味着一个 spu 至少有一个或多个 sku 。每个 sku 代表一种商品。
例如这个链接:
现在可以爬取京东某关键词下的商品列表了。一个页面有60个产品,但是只能爬取30个,还有30个是通过ajax加载的,需要页面滚动。 Ajax请求是在第30条数据之后执行的,所以当前异步加载的30条商品数据是爬不出来的。如果要抓取完整的60条数据,可以使用Selenium库,在滚动页面中分析抓取网页数据,可以抓取Js动态生成数据。
使用 Fiddler 数据包捕获工具,有一些小的发现,如下所示。
这是一个简单的学习演示。基于SpringBoot+HttpClient+Jsoup框架,只能获取每个页面的前30条商品数据,后30条异步加载的商品数据暂时没有实现,仅供学习使用。
效果如下:
查看全部
输入关键字 抓取所有网页(京东商城关键字搜索商品的页面Url的参数为奇数(组图)
)
使用HttpClient可以创建浏览器对象,然后抓取页面数据,然后使用Jsoup库解析Html页面。因为Jsoup和JQuery通过selector获取元素的方式是一样的,所以抓取页面数据变得非常方便。
例如,此链接:%E5%B0%8F%E7%B1%B3&page=1&s=201&click=0
研究发现京东关键词搜索商品页面的page Url的page参数为奇数(1、3、5、7、9...),估计前30个产品数据其实是第一页,Ajax加载的后30个产品数据其实是第二页。第一页和第二页的数据合起来就是该页1页的数据。
另外,在京东商品的数据中,有两个字段很神奇,分别是spu和sku,spu代表商品集合的id,sku代表商品最小品类单元的id,意味着一个 spu 至少有一个或多个 sku 。每个 sku 代表一种商品。
例如这个链接:
现在可以爬取京东某关键词下的商品列表了。一个页面有60个产品,但是只能爬取30个,还有30个是通过ajax加载的,需要页面滚动。 Ajax请求是在第30条数据之后执行的,所以当前异步加载的30条商品数据是爬不出来的。如果要抓取完整的60条数据,可以使用Selenium库,在滚动页面中分析抓取网页数据,可以抓取Js动态生成数据。
使用 Fiddler 数据包捕获工具,有一些小的发现,如下所示。

这是一个简单的学习演示。基于SpringBoot+HttpClient+Jsoup框架,只能获取每个页面的前30条商品数据,后30条异步加载的商品数据暂时没有实现,仅供学习使用。
效果如下:

输入关键字 抓取所有网页(如何提炼和优化网站关键词将在搜索引擎中发挥重要作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 443 次浏览 • 2021-10-20 16:10
在搜索营销中,如何细化和优化网站关键词将在营销中发挥重要作用。那么关键词有多重要?比如我们在百度上搜索相关信息时,通常会在百度中输入一些关键词。搜索引擎会根据这些关键词搜索数据库。
如果我们找到匹配这些关键词的网页,我们会根据关键词的匹配程度、关键词的位置和频率以及网页中链接的质量,使用特殊的算法——。数字等。计算每个网页的相关性和排名级别,然后根据相关性将这些网页链接依次呈现给用户。可见,关键词提炼优化技术可以有效提高网页在搜索引擎中的排名。接下来,三兄弟介绍几种改进优化关键词的有效方法:
1.在做搜索引擎优化的时候,一定要选择好的网站关键词,先为网站选择好的关键词,提高营销的精准度。关键词 的数量不能太多。一般来说,我们应该选择三个关键词来获得收益。以“网络营销”为例。如果我们要从事的业务主要是“网络营销”,除了“网络营销”,我们还可以选择“网络营销”和“网络营销”作为关键词。这样,用户只能在搜索引擎中输入它们。这些关键词,当搜索引擎在数据库中搜索完毕后,因为我们的关键词设置满足了用户的需求,我们的网页信息被提供给用户的概率会增加。
2. 将关键词 URL 翻译成统一的资源定位符(也称为URL),是互联网上的标准资源地址。一般来说,在确定网站的位置后,域名可以使用行业关键词或者英文单词的double pinning,通常是比较理想的状态。我们以百度为例。在其域名中,“Baidu”是百度的全拼。不仅方便在线用户记忆,也方便搜索引擎采集,有利于提高搜索引擎的相关性排名。
3. 在网页内容中插入关键词就是网页应该呈现给用户的具体内容。它可以是产品信息或博客文章。这里有一个经典规则,“内容为王,链条为王”。换句话说,如果网站没有优质的内容,那么网站本身就会失败,更不用说优化网站,因为所有优化的推广只会吸引用户到网站@ > 的页面。至于用户体验,还是要看网站内容的质量。
4.在网页摘要中插入关键字搜索引擎向用户展示搜索结果时,会先显示网页的标题。这再次说明了sange强调在网页标题中插入关键词的重要性。其次,页面标题下方会显示50.70字的页面摘要。也可以是文章的总结。通常用户在阅读标题后会习惯性地查看网站摘要。如果在网站摘要中嵌入关键词,内容设计很吸引人,网站的点击率会增加,网站在搜索引擎中的排名也会增加也增加。
5.熟练使用现有的关键词,必要时创建自己的关键词。现有的关键词就是搜索引擎中常用的关键词。需要注意的是,关键词越热越好,因为热刺意味着用户太多,竞争力越强,所以一定要根据实际情况选择一些较弱的词,这样竞争力就会弱一些。
另外,尽量避免覆盖太多关键词,因为这样会增加优化的难度。边小建议使用百度索引搜索冷热关键词。在输入框中输入“网络营销”,点击索引查看如下结果: 当我们在现有的关键词中找不到满意的关键词时,我们可以自己创建关键词 通过测试。这时候,我们要么面对网站的推广,要么创建自己的关键词。
在这里,卞潇对他的关键词提出了三点建议:第一,这些关键词一定要特别;第二,要符合人们的语法习惯;第三,一定要有针对性,网站的项目与产品主题有关。简而言之,关于搜索引擎优化。关键词的正确提取和优化将在搜索引擎营销中发挥重要作用,值得我们关注。 查看全部
输入关键字 抓取所有网页(如何提炼和优化网站关键词将在搜索引擎中发挥重要作用)
在搜索营销中,如何细化和优化网站关键词将在营销中发挥重要作用。那么关键词有多重要?比如我们在百度上搜索相关信息时,通常会在百度中输入一些关键词。搜索引擎会根据这些关键词搜索数据库。
如果我们找到匹配这些关键词的网页,我们会根据关键词的匹配程度、关键词的位置和频率以及网页中链接的质量,使用特殊的算法——。数字等。计算每个网页的相关性和排名级别,然后根据相关性将这些网页链接依次呈现给用户。可见,关键词提炼优化技术可以有效提高网页在搜索引擎中的排名。接下来,三兄弟介绍几种改进优化关键词的有效方法:
1.在做搜索引擎优化的时候,一定要选择好的网站关键词,先为网站选择好的关键词,提高营销的精准度。关键词 的数量不能太多。一般来说,我们应该选择三个关键词来获得收益。以“网络营销”为例。如果我们要从事的业务主要是“网络营销”,除了“网络营销”,我们还可以选择“网络营销”和“网络营销”作为关键词。这样,用户只能在搜索引擎中输入它们。这些关键词,当搜索引擎在数据库中搜索完毕后,因为我们的关键词设置满足了用户的需求,我们的网页信息被提供给用户的概率会增加。
2. 将关键词 URL 翻译成统一的资源定位符(也称为URL),是互联网上的标准资源地址。一般来说,在确定网站的位置后,域名可以使用行业关键词或者英文单词的double pinning,通常是比较理想的状态。我们以百度为例。在其域名中,“Baidu”是百度的全拼。不仅方便在线用户记忆,也方便搜索引擎采集,有利于提高搜索引擎的相关性排名。

3. 在网页内容中插入关键词就是网页应该呈现给用户的具体内容。它可以是产品信息或博客文章。这里有一个经典规则,“内容为王,链条为王”。换句话说,如果网站没有优质的内容,那么网站本身就会失败,更不用说优化网站,因为所有优化的推广只会吸引用户到网站@ > 的页面。至于用户体验,还是要看网站内容的质量。
4.在网页摘要中插入关键字搜索引擎向用户展示搜索结果时,会先显示网页的标题。这再次说明了sange强调在网页标题中插入关键词的重要性。其次,页面标题下方会显示50.70字的页面摘要。也可以是文章的总结。通常用户在阅读标题后会习惯性地查看网站摘要。如果在网站摘要中嵌入关键词,内容设计很吸引人,网站的点击率会增加,网站在搜索引擎中的排名也会增加也增加。
5.熟练使用现有的关键词,必要时创建自己的关键词。现有的关键词就是搜索引擎中常用的关键词。需要注意的是,关键词越热越好,因为热刺意味着用户太多,竞争力越强,所以一定要根据实际情况选择一些较弱的词,这样竞争力就会弱一些。
另外,尽量避免覆盖太多关键词,因为这样会增加优化的难度。边小建议使用百度索引搜索冷热关键词。在输入框中输入“网络营销”,点击索引查看如下结果: 当我们在现有的关键词中找不到满意的关键词时,我们可以自己创建关键词 通过测试。这时候,我们要么面对网站的推广,要么创建自己的关键词。
在这里,卞潇对他的关键词提出了三点建议:第一,这些关键词一定要特别;第二,要符合人们的语法习惯;第三,一定要有针对性,网站的项目与产品主题有关。简而言之,关于搜索引擎优化。关键词的正确提取和优化将在搜索引擎营销中发挥重要作用,值得我们关注。
输入关键字 抓取所有网页(搜索引擎的搜索展现大部分为排序、索引、抓取三个步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-10-20 16:08
搜索引擎的搜索结果大多是排序、索引、爬行。其实原理很复杂。过程中需要抓取信息去重复、中文分词、关键词内容对比、页面链接关系等。、噪声消除、索引、搜索显示等,这些在下面详细描述。
搜索引擎优化的基本工作原理
1、获取
搜索引擎会抛出一种叫做“机器人、蜘蛛”的软件,按照一定的规则扫描互联网上的网站,按照网页的链接从一个页面到另一个,从一个网站去另一个网站获取页面的HTML代码并存入数据库。为了采集获取最新信息,我们会继续访问已爬取的网页。
2、索引
分析索引系统程序对采集到的网页进行分析,提取相关网页信息,并按照一定的相关性算法进行大量复杂的计算,得到页面文本和超链接中每个关键词的各个网页的相关性度,然后利用这些相关信息来构建网页索引数据库。
3、排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算出来了,所以只需要按照已有的相关度值进行排序即可。相关性越高,排名越高。最后还给了用户。
搜索引擎的工作原理大致分为三个步骤:爬行和爬行-索引-排序。
爬网:主要是数据采集。
索引/预处理:提取文本-中文分词-去除停用词-去除噪音-去除重复-索引。
排序:搜索词处理-匹配文件-初始子集选择-相关计算-过滤、调整-排名显示。
搜索引擎优化检索流程
1、 抓取信息去除重复项
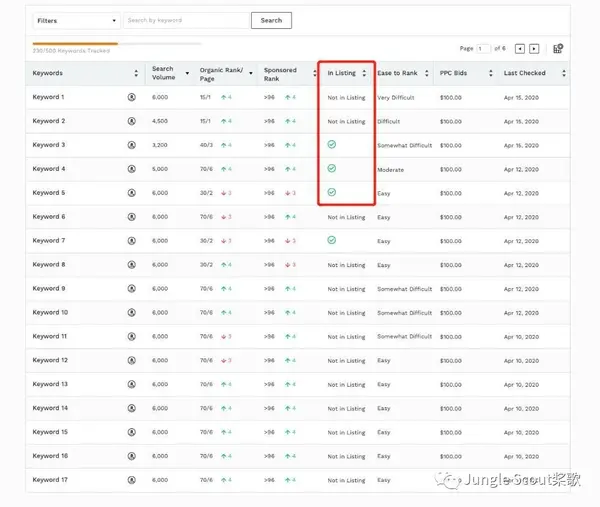
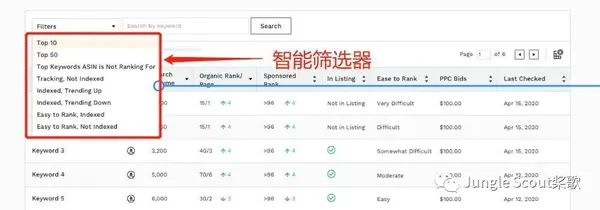
在搜索引擎优化的工作原理中,蜘蛛爬取信息后会进行一个去除数据库中杂质的过程。如果你的文章被蜘蛛抓到了,蜘蛛的内容和别人相似,那么蜘蛛就会认为你这种类型的内容毫无价值,很容易被丢弃。会有很多停用词,如:de、land、de、ah、ma等。
2、中文分词(分词)处理
搜索引擎会根据自己的字典切词,把你的标题和内容分成很多关键词。所以在创建内容时,必须在标题和内容中收录关键词。
3、提取网站的关键词并比较你的页面内容
计算页面关键词的密度是否合理。如果密度稀疏,说明你的关键词与内容不匹配,那么关键词一般没有很好的排名,不能重新分页关键词@ > 故意把页面堆在里面,导致密度很高,那么搜索引擎会认为你在作弊,只想测试关键词的累积进行排名。这种方法很容易被搜索到。引擎惩罚。
4、计算页面的链接关系
搜索引擎优化工作原理中的所谓页面链接关系,是指你的网站导出链接和导入链接的计算。所谓导出链接是指你的网站上指向其他网站的链接称为导出链接。导入链接,一个页面的导入链接越多,这个页面的分数越高,网站的页面排名就越好。导出的链接越多,页面的得分越低,不利于页面的排名。
5、降噪处理
搜索引擎优化工作原理中的所谓噪音,是指网页上弹出的大量广告。不相关的垃圾邮件页面。如果网站挂了很多弹窗广告,百度会认为你的网站严重影响用户体验。对于这些网站,百度会严厉打击,不会给你好的排名。. 百度冰桶算法对抗网站页面广告。
6、创建索引
根据上述处理结果,搜索引擎将网站的页面放入自己的索引库中。索引库中的内容实际上是百度排名的结果。当我们使用site命令查询网站的收录时,百度发布索引的内容。 查看全部
输入关键字 抓取所有网页(搜索引擎的搜索展现大部分为排序、索引、抓取三个步骤)
搜索引擎的搜索结果大多是排序、索引、爬行。其实原理很复杂。过程中需要抓取信息去重复、中文分词、关键词内容对比、页面链接关系等。、噪声消除、索引、搜索显示等,这些在下面详细描述。
搜索引擎优化的基本工作原理
1、获取
搜索引擎会抛出一种叫做“机器人、蜘蛛”的软件,按照一定的规则扫描互联网上的网站,按照网页的链接从一个页面到另一个,从一个网站去另一个网站获取页面的HTML代码并存入数据库。为了采集获取最新信息,我们会继续访问已爬取的网页。
2、索引
分析索引系统程序对采集到的网页进行分析,提取相关网页信息,并按照一定的相关性算法进行大量复杂的计算,得到页面文本和超链接中每个关键词的各个网页的相关性度,然后利用这些相关信息来构建网页索引数据库。
3、排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算出来了,所以只需要按照已有的相关度值进行排序即可。相关性越高,排名越高。最后还给了用户。
搜索引擎的工作原理大致分为三个步骤:爬行和爬行-索引-排序。
爬网:主要是数据采集。
索引/预处理:提取文本-中文分词-去除停用词-去除噪音-去除重复-索引。
排序:搜索词处理-匹配文件-初始子集选择-相关计算-过滤、调整-排名显示。
搜索引擎优化检索流程
1、 抓取信息去除重复项
在搜索引擎优化的工作原理中,蜘蛛爬取信息后会进行一个去除数据库中杂质的过程。如果你的文章被蜘蛛抓到了,蜘蛛的内容和别人相似,那么蜘蛛就会认为你这种类型的内容毫无价值,很容易被丢弃。会有很多停用词,如:de、land、de、ah、ma等。
2、中文分词(分词)处理
搜索引擎会根据自己的字典切词,把你的标题和内容分成很多关键词。所以在创建内容时,必须在标题和内容中收录关键词。
3、提取网站的关键词并比较你的页面内容
计算页面关键词的密度是否合理。如果密度稀疏,说明你的关键词与内容不匹配,那么关键词一般没有很好的排名,不能重新分页关键词@ > 故意把页面堆在里面,导致密度很高,那么搜索引擎会认为你在作弊,只想测试关键词的累积进行排名。这种方法很容易被搜索到。引擎惩罚。
4、计算页面的链接关系
搜索引擎优化工作原理中的所谓页面链接关系,是指你的网站导出链接和导入链接的计算。所谓导出链接是指你的网站上指向其他网站的链接称为导出链接。导入链接,一个页面的导入链接越多,这个页面的分数越高,网站的页面排名就越好。导出的链接越多,页面的得分越低,不利于页面的排名。
5、降噪处理
搜索引擎优化工作原理中的所谓噪音,是指网页上弹出的大量广告。不相关的垃圾邮件页面。如果网站挂了很多弹窗广告,百度会认为你的网站严重影响用户体验。对于这些网站,百度会严厉打击,不会给你好的排名。. 百度冰桶算法对抗网站页面广告。
6、创建索引
根据上述处理结果,搜索引擎将网站的页面放入自己的索引库中。索引库中的内容实际上是百度排名的结果。当我们使用site命令查询网站的收录时,百度发布索引的内容。
输入关键字 抓取所有网页(亚马逊运营的主要工作就是玩流量,做排名!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-18 06:14
一位接受小编采访的亚马逊资深运营商表示:运营的主要工作就是玩流量和排名!亚马逊发展到今天,除了是一个购物平台,还是一个强大的搜索引擎。
亚马逊网站流量的最大来源是 SEO,或搜索流量。最常见的购物习惯是通过关键词进行搜索。可以说,每一个关键词都是我们listing的入口。
“买家必须能够找到您的产品才能进行购买。买家可以通过输入关键词搜索您的产品,我们的系统会将买家输入的关键词与您匹配为产品提供要匹配的产品名称和描述等信息。”
监控关键词排名的重要性
关键词 排名越高,listing被点击转化的可能性越大;房源点击率和转化率越高,关键词的排名就越高。我们可以从亚马逊的营销飞轮中看到这一点:
这也是亚马逊运营一直追求“首页关键词”的原因。除非是蓝海市场的小众产品,否则新上架的Listings很难直接在首页上架,所以我们必须持续监控自己和竞品。关键词 排名,经过分析计算,再采取相应措施进行排名!
作为运营,每天必须完成的任务之一就是监控自己和竞品的关键词排名。如何监控?
首先:
在亚马逊前台输入关键词,在搜索结果页面找到你的listing,然后记录下来和之前的数据对比。同样的方法用于监控竞争产品。
如果你的 关键词 排名低,有更多的 ASIN 和更多的竞争产品,监控你的 关键词 排名,同时监控竞争产品 关键词。这个工作量堪比单个订单的大量操作,每个订单手动点击“请求评论”!
第二种:
使用工具-JS网页版的关键词排名监控,智能监控自己和竞品的关键词动态,告别繁琐的手工步骤,不错过竞品的任何变化。
关键词排名监控的升级
01
多渠道添加产品和关键词
多渠道添加产品
进入关键词排名监控页面,点击【添加商品】,我们有3种方式添加我们要跟踪的商品:
多通道加法关键词
我们可以通过以下3种方法添加关键词:
如果我们选择手动录入竞品,一次可以录入9个竞品ASIN,基本可以涵盖我们要监控的竞品范围。
自动生成关键词库
进入商品后,系统会立即抓取ASIN排名TOP 50的关键词并填入关键词库。最多可同时显示前500名竞品关键词。
02
关键词性能可视化
添加产品和关键词后,点击【保存】,图形化的关键词跟踪数据会立即返回。
一次可以查看10个关键词的排名,可以选择10个关键词,按搜索量或字母排序,选择关键词进行分析。
03
多维度高品质筛选关键词
在可视化图表下方,还有表格化的精准数据供查看和分析,自带过滤器,根据条件过滤出合格的关键词:
根据排名、PPC出价和搜索量过滤条件,更快了解流量分布,不错过任何流量入口。
您可以在标题、五点和描述中嵌入选定的核心关键词。然后继续监测关键词在这个ASIN下的排名,判断Listing优化的效果。
根据关键词的趋势,竞品的首页流量词,以及对应的PPC推荐出价,找出最适合的PPC关键词和关键词的最佳出价你! 查看全部
输入关键字 抓取所有网页(亚马逊运营的主要工作就是玩流量,做排名!(组图))
一位接受小编采访的亚马逊资深运营商表示:运营的主要工作就是玩流量和排名!亚马逊发展到今天,除了是一个购物平台,还是一个强大的搜索引擎。
亚马逊网站流量的最大来源是 SEO,或搜索流量。最常见的购物习惯是通过关键词进行搜索。可以说,每一个关键词都是我们listing的入口。
“买家必须能够找到您的产品才能进行购买。买家可以通过输入关键词搜索您的产品,我们的系统会将买家输入的关键词与您匹配为产品提供要匹配的产品名称和描述等信息。”
监控关键词排名的重要性
关键词 排名越高,listing被点击转化的可能性越大;房源点击率和转化率越高,关键词的排名就越高。我们可以从亚马逊的营销飞轮中看到这一点:

这也是亚马逊运营一直追求“首页关键词”的原因。除非是蓝海市场的小众产品,否则新上架的Listings很难直接在首页上架,所以我们必须持续监控自己和竞品。关键词 排名,经过分析计算,再采取相应措施进行排名!
作为运营,每天必须完成的任务之一就是监控自己和竞品的关键词排名。如何监控?
首先:
在亚马逊前台输入关键词,在搜索结果页面找到你的listing,然后记录下来和之前的数据对比。同样的方法用于监控竞争产品。
如果你的 关键词 排名低,有更多的 ASIN 和更多的竞争产品,监控你的 关键词 排名,同时监控竞争产品 关键词。这个工作量堪比单个订单的大量操作,每个订单手动点击“请求评论”!
第二种:
使用工具-JS网页版的关键词排名监控,智能监控自己和竞品的关键词动态,告别繁琐的手工步骤,不错过竞品的任何变化。
关键词排名监控的升级
01
多渠道添加产品和关键词
多渠道添加产品
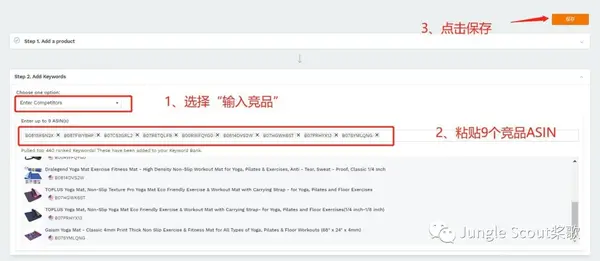
进入关键词排名监控页面,点击【添加商品】,我们有3种方式添加我们要跟踪的商品:
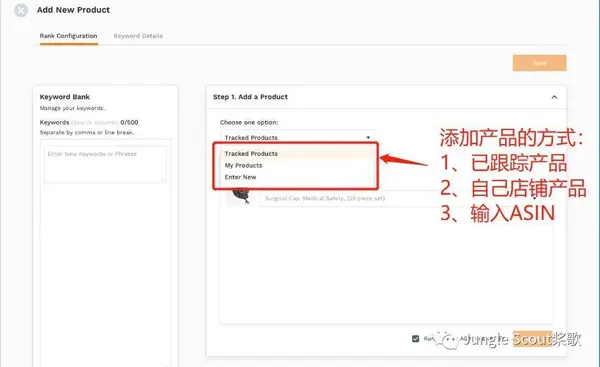
多通道加法关键词
我们可以通过以下3种方法添加关键词:
如果我们选择手动录入竞品,一次可以录入9个竞品ASIN,基本可以涵盖我们要监控的竞品范围。
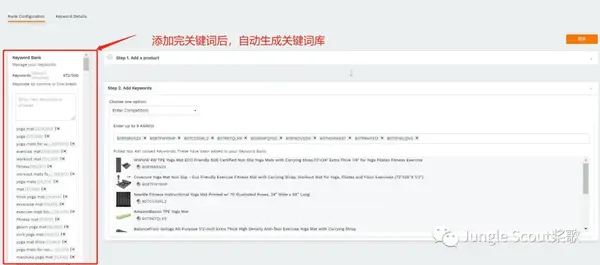
自动生成关键词库
进入商品后,系统会立即抓取ASIN排名TOP 50的关键词并填入关键词库。最多可同时显示前500名竞品关键词。
02
关键词性能可视化
添加产品和关键词后,点击【保存】,图形化的关键词跟踪数据会立即返回。
一次可以查看10个关键词的排名,可以选择10个关键词,按搜索量或字母排序,选择关键词进行分析。
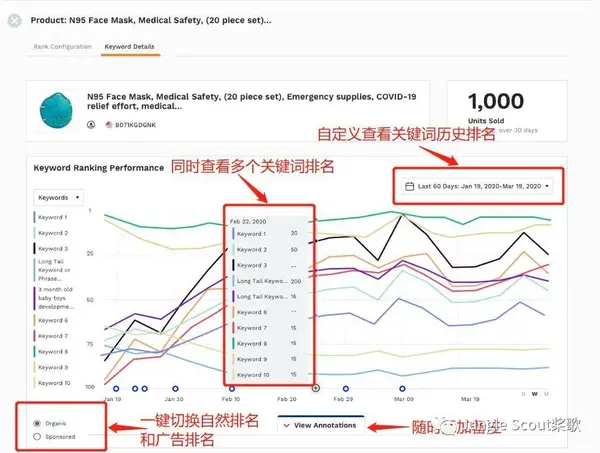
03
多维度高品质筛选关键词
在可视化图表下方,还有表格化的精准数据供查看和分析,自带过滤器,根据条件过滤出合格的关键词:
根据排名、PPC出价和搜索量过滤条件,更快了解流量分布,不错过任何流量入口。
您可以在标题、五点和描述中嵌入选定的核心关键词。然后继续监测关键词在这个ASIN下的排名,判断Listing优化的效果。
根据关键词的趋势,竞品的首页流量词,以及对应的PPC推荐出价,找出最适合的PPC关键词和关键词的最佳出价你!
输入关键字 抓取所有网页(超级排名系统原文链接:学会分析网站页面的索引库-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-18 06:13
原文出处:超级排位系统
原文链接:学习分析网站页面-超级排名系统的索引库
搜索引擎检索页面。下一步是分析页面内容,主要包括确定页面类型、提取页面主题、去除页面噪声、去除停用词、中文分词、注册统计、重建关键词索引数据库. 超级排名系统编辑器编译发布。
判断页面是普通页面还是特殊页面,如PDF、WPS、PPT、TXT等;区分文字、图片、视频等内容形式,识别页面网站论坛、视频站、文字站等。
目前搜索引擎基本不识别JS、AJAX、flash、图片、视频、frame和iframe框架结构的内容,主要是利用文本关键词抓取文本处理和搜索信息。提取页面级功能内容,例如标题、关键字和描述。这些特征占网页内容相关性的很大比例。一般情况下,它还表示网页的主题。
剔除无关广告、登录框、版权声明等噪音内容,提取主题内容。这部分不是很严谨,每个搜索引擎的处理都不一样。一般推荐的内容,锚文本,导航等还是很有价值的。
分词是中文搜索引擎的一个独特步骤。搜索引擎需要识别哪些词可以组合成词。每个搜索引擎都有自己庞大的词汇量。根据词典匹配,对网页内容进行切分。中文分词主要有两种方法:基于字典的匹配和基于统计的分词。他们有自己的优点和缺点。在实际应用中,他们混合了这种方法,不仅快速有效,而且可以识别生词,消除歧义。
百度搜索引擎可以通过快照页面查看输入的文本分为哪些关键词,如下图:
分词的目的是了解网页的内容。会先删除“de”、“de”、“ah”、“ba”等停用词,使页面文字的主题更加突出。当然,虚词不是很好。例如,新华字典页介绍了“啊”主题词的读音、意义和用法。“啊”是主题关键词。关键词 排名优化是对搜索引擎条目和历史数据的持续跟踪和分析。
分词后,搜索引擎会统计每个词在页面上出现的次数并计算密度,以便搜索引擎识别页面内容的相关性。建议关键词的布局密度在2%-8%之间。如果太低,很容易被认为是主题内容的相关性低,如果太高,则可能被认为是关键词堆砌,容易被处罚。
内容相关性:除了页面标题、关键词、描述、词密度,H标签(H1标签也很重,一般用于文章标题,H2、H3标签也有一定的效果,一般用来分割话题,但不是H4之后),加粗标签的内容明显会比其他常见标签更受关注。另外,核心关键词最好出现在页面的前面而不是后面。锚文本链接的相关性作为重要数据被采集和分析。
搜索引擎喜欢原创 内容,但不喜欢很多重复的内容页面。完成以上步骤后,他们就可以识别页面的内容功能,再次重复内容页面。
经过上述处理后,记录了页面关键字集,记录了词频、位置、格式(H标签、粗体、锚文本)等权重因素。搜索引擎创建页面的索引结构和关键字表。该指标有两种结构:正向指标结构和反向指标结构。在正向索引结构中,每个文件对应一个文件ID,文件的内容用一组关键字表示。
搜索引擎用户通过关键字进行搜索。正索引不利于查询效率,搜索引擎会将正索引变成倒排索引。倒排索引结构是关键字到文件集的映射。用户将只检索索引页。
收录:只要能被搜索引擎蜘蛛抓取,经过分析,有价值的页面就会被收录。
索引:搜索引擎已经收录页面,用户认为有意义的会议内容,可能会创建索引,可能会有流量。网站 排名优化基于网页已被索引的事实。
超级排名系统小编提醒大家,只要网站结构清晰,内容有价值,并且网站定期更新,那么站长平台提交链接和外链提高搜索引擎识别网站 以采集量和索引量,2-7天优化首页做SEO是非常有可能的。
百度蜘蛛爬了多少页不是很重要,重要的是索引数据库建立了多少页。搜索引擎的索引数据库是分层的。优质的网页会分配到重要的索引库,普通的网页会留在普通的数据库中,较差的网页会分配到低级别的数据库作为补充材料。目前60%的搜索需求只能通过使用重要的索引库来满足。这也是一些网站合集太高,但流量不理想的原因。
进入优质索引库的前提是对用户的价值。包括但不仅限于:
其实网上的大部分网站根本就不是百度的收录。不是百度没找到,而是建库前的筛选过程被过滤掉了。过滤的初始阶段:
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX、flash、图片、视频等。 查看全部
输入关键字 抓取所有网页(超级排名系统原文链接:学会分析网站页面的索引库-)
原文出处:超级排位系统
原文链接:学习分析网站页面-超级排名系统的索引库
搜索引擎检索页面。下一步是分析页面内容,主要包括确定页面类型、提取页面主题、去除页面噪声、去除停用词、中文分词、注册统计、重建关键词索引数据库. 超级排名系统编辑器编译发布。

判断页面是普通页面还是特殊页面,如PDF、WPS、PPT、TXT等;区分文字、图片、视频等内容形式,识别页面网站论坛、视频站、文字站等。
目前搜索引擎基本不识别JS、AJAX、flash、图片、视频、frame和iframe框架结构的内容,主要是利用文本关键词抓取文本处理和搜索信息。提取页面级功能内容,例如标题、关键字和描述。这些特征占网页内容相关性的很大比例。一般情况下,它还表示网页的主题。
剔除无关广告、登录框、版权声明等噪音内容,提取主题内容。这部分不是很严谨,每个搜索引擎的处理都不一样。一般推荐的内容,锚文本,导航等还是很有价值的。
分词是中文搜索引擎的一个独特步骤。搜索引擎需要识别哪些词可以组合成词。每个搜索引擎都有自己庞大的词汇量。根据词典匹配,对网页内容进行切分。中文分词主要有两种方法:基于字典的匹配和基于统计的分词。他们有自己的优点和缺点。在实际应用中,他们混合了这种方法,不仅快速有效,而且可以识别生词,消除歧义。
百度搜索引擎可以通过快照页面查看输入的文本分为哪些关键词,如下图:
分词的目的是了解网页的内容。会先删除“de”、“de”、“ah”、“ba”等停用词,使页面文字的主题更加突出。当然,虚词不是很好。例如,新华字典页介绍了“啊”主题词的读音、意义和用法。“啊”是主题关键词。关键词 排名优化是对搜索引擎条目和历史数据的持续跟踪和分析。
分词后,搜索引擎会统计每个词在页面上出现的次数并计算密度,以便搜索引擎识别页面内容的相关性。建议关键词的布局密度在2%-8%之间。如果太低,很容易被认为是主题内容的相关性低,如果太高,则可能被认为是关键词堆砌,容易被处罚。
内容相关性:除了页面标题、关键词、描述、词密度,H标签(H1标签也很重,一般用于文章标题,H2、H3标签也有一定的效果,一般用来分割话题,但不是H4之后),加粗标签的内容明显会比其他常见标签更受关注。另外,核心关键词最好出现在页面的前面而不是后面。锚文本链接的相关性作为重要数据被采集和分析。
搜索引擎喜欢原创 内容,但不喜欢很多重复的内容页面。完成以上步骤后,他们就可以识别页面的内容功能,再次重复内容页面。
经过上述处理后,记录了页面关键字集,记录了词频、位置、格式(H标签、粗体、锚文本)等权重因素。搜索引擎创建页面的索引结构和关键字表。该指标有两种结构:正向指标结构和反向指标结构。在正向索引结构中,每个文件对应一个文件ID,文件的内容用一组关键字表示。
搜索引擎用户通过关键字进行搜索。正索引不利于查询效率,搜索引擎会将正索引变成倒排索引。倒排索引结构是关键字到文件集的映射。用户将只检索索引页。
收录:只要能被搜索引擎蜘蛛抓取,经过分析,有价值的页面就会被收录。
索引:搜索引擎已经收录页面,用户认为有意义的会议内容,可能会创建索引,可能会有流量。网站 排名优化基于网页已被索引的事实。
超级排名系统小编提醒大家,只要网站结构清晰,内容有价值,并且网站定期更新,那么站长平台提交链接和外链提高搜索引擎识别网站 以采集量和索引量,2-7天优化首页做SEO是非常有可能的。
百度蜘蛛爬了多少页不是很重要,重要的是索引数据库建立了多少页。搜索引擎的索引数据库是分层的。优质的网页会分配到重要的索引库,普通的网页会留在普通的数据库中,较差的网页会分配到低级别的数据库作为补充材料。目前60%的搜索需求只能通过使用重要的索引库来满足。这也是一些网站合集太高,但流量不理想的原因。
进入优质索引库的前提是对用户的价值。包括但不仅限于:
其实网上的大部分网站根本就不是百度的收录。不是百度没找到,而是建库前的筛选过程被过滤掉了。过滤的初始阶段:
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX、flash、图片、视频等。
输入关键字 抓取所有网页( 文献获取葵花plus,让你写论文不用愁(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-17 15:08
文献获取葵花plus,让你写论文不用愁(上)
)
很多学生已经在毕业的路上,他们不得不面对一个难题,那就是写论文。很多学生为了写论文,得了黑眼圈,但还是一无所获。他们被散文折磨得死去活来,又爱又恨,写散文必不可少的一步就是查资料。古人云:“一本书百读百读。” 或许你在知网多翻翻,就知道怎么写论文了。所以小编今天整理了文献给你搞定Sunflower Plus,让你不用再为写论文发愁了。
写在前面:
先看爬取的效果
知网的反爬虫方法很强。反正我在PC端爬取的时候,用selenium爬取的时候是拿不到源码的。这真的很烦人。后来换了手机端就搞定了。爬取移动终端的操作如下。首先,进入知网后,选择开发工具,建议放在右边,然后点击图片中的红框,然后刷新网页切换到移动端。
进入手机端界面如下图(注意:记得刷新网页):
这是网址
在调用selenium之前先设置一些参数
from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byimport timeimport jsonimport csv# 设置谷歌驱动器的环境options = webdriver.ChromeOptions()# 设置chrome不加载图片,提高速度options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})# 创建一个谷歌驱动器browser = webdriver.Chrome(options=options)url = 'http://wap.cnki.net/touch/web/guide'
既然使用了selenium,那么我们需要获取输入框的id来自动输入关键字,输入关键字然后获取搜索按钮,然后点击
代码如下(输入的关键字是python):
# 请求urlbrowser.get(url)# 显示等待输入框是否加载完成WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.ID, 'keyword') ))# 找到输入框的id,并输入python关键字browser.find_element_by_id('keyword').send_keys('python')# 输入关键字之后点击搜索browser.find_element_by_id('btnSearch ').click()
搜索关键字后跳转到这个界面
通过selenium的显示和等待,我们可以等待其中的一些信息加载完毕,然后进行爬取,这样就可以避免因为元素没有加载而报错。如下图,我们可以知道这个信息在这个div标签中,所以我们可以等待这个元素加载
# 显示等待文献是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'g-search-body') ) )
向下滚动页面,您可以看到加载更多。可以通过显示和等待来判断按钮是否加载。如果在没有加载的情况下点击它,那么会报错。
代码,等待按钮加载并获取按钮
# 显示等待加载更多按钮加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'c-company__body-item-more') ) ) # 获取加载更多按钮 Btn = browser.find_element_by_class_name('c-company__body-item-more')
基础基本搞定,下一步就是开始获取信息了
获取信息是爬虫的基本能力,这里就不多说了,下图代码见注释
我上面说的就是这样。看图,正好我们需要的信息标签是1、3、5、7、9等等,所以是2*count-1
没什么好说的,代码注释基本都写好了,附上完整代码
from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byimport timeimport jsonimport csv# 设置谷歌驱动器的环境options = webdriver.ChromeOptions()# 设置chrome不加载图片,提高速度options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})# 创建一个谷歌驱动器browser = webdriver.Chrome(options=options)url = 'http://wap.cnki.net/touch/web/guide'# 声明一个全局列表,用来存储字典data_list = []def start_spider(page): # 请求url browser.get(url) # 显示等待输入框是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.ID, 'keyword') ) ) # 找到输入框的id,并输入python关键字 browser.find_element_by_id('keyword').click() browser.find_element_by_id('keyword_ordinary').send_keys('python') # 输入关键字之后点击搜索 browser.find_element_by_class_name('btn-search ').click() # print(browser.page_source) # 显示等待文献是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'g-search-body') ) ) # 声明一个标记,用来标记翻页几页 count = 1 while True: # 显示等待加载更多按钮加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'c-company__body-item-more') ) ) # 获取加载更多按钮 Btn = browser.find_element_by_class_name('c-company__body-item-more') # 显示等待该信息加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.XPATH, '//div[@id="searchlist_div"]/div[{}]/div[@]'.format(2*count-1)) ) ) # 获取在div标签的信息,其中format(2*count-1)是因为加载的时候有显示多少条 # 简单的说就是这些div的信息都是奇数 divs = browser.find_elements_by_xpath('//div[@id="searchlist_div"]/div[{}]/div[@]'.format(2*count-1)) # 遍历循环 for div in divs: # 获取文献的题目 name = div.find_element_by_class_name('c-company__body-title').text # 获取文献的作者 author = div.find_element_by_class_name('c-company__body-author').text # 获取文献的摘要 content = div.find_element_by_class_name('c-company__body-content').text # 获取文献的来源和日期、文献类型等 text = div.find_element_by_class_name('c-company__body-name').text.split() if (len(text) == 3 and text[-1] == '优先') or len(text) == 2: # 来源 source = text[0] # 日期 datetime = text[1] # 文献类型 literature_type = None else: source = text[0] datetime = text[2] literature_type = text[1] # 获取下载数和被引数 temp = div.find_element_by_class_name('c-company__body-info').text.split() # 下载数 download = temp[0].split(':')[-1] # 被引数 cite = temp[1].split(':')[-1] # 声明一个字典存储数据 data_dict = {} data_dict['name'] = name data_dict['author'] = author data_dict['content'] = content data_dict['source'] = source data_dict['datetime'] = datetime data_dict['literature_type'] = literature_type data_dict['download'] = download data_dict['cite'] = cite data_list.append(data_dict) print(data_dict) # 如果Btn按钮(就是加载更多这个按钮)没有找到(就是已经到底了),就退出 if not Btn: break else: Btn.click() # 如果到了爬取的页数就退出 if count == page: break count += 1 # 延迟两秒,我们不是在攻击服务器 time.sleep(2)def main(): start_spider(eval(input('请输入要爬取的页数(如果需要全部爬取请输入0):'))) # 将数据写入json文件中 with open('data_json.json', 'a+', encoding='utf-8') as f: json.dump(data_list, f, ensure_ascii=False, indent=4) print('json文件写入完成') # 将数据写入csv文件 with open('data_csv.csv', 'w', encoding='utf-8', newline='') as f: # 表头 title = data_list[0].keys() # 声明writer对象 writer = csv.DictWriter(f, title) # 写入表头 writer.writeheader() # 批量写入数据 writer.writerows(data_list) print('csv文件写入完成')if __name__ == '__main__': main()
概括:
学术之路艰难而漫长。希望编辑器中的这个程序可以帮助你在学术道路上走得更轻松一些。希望大家多多阅读文献,多发表文献,让自己的学术工作做得更好!
如果您对此案有任何进一步的问题或意见,请告诉我,我很乐意跟进并提出建议。
查看全部
输入关键字 抓取所有网页(
文献获取葵花plus,让你写论文不用愁(上)
)

很多学生已经在毕业的路上,他们不得不面对一个难题,那就是写论文。很多学生为了写论文,得了黑眼圈,但还是一无所获。他们被散文折磨得死去活来,又爱又恨,写散文必不可少的一步就是查资料。古人云:“一本书百读百读。” 或许你在知网多翻翻,就知道怎么写论文了。所以小编今天整理了文献给你搞定Sunflower Plus,让你不用再为写论文发愁了。
写在前面:
先看爬取的效果
知网的反爬虫方法很强。反正我在PC端爬取的时候,用selenium爬取的时候是拿不到源码的。这真的很烦人。后来换了手机端就搞定了。爬取移动终端的操作如下。首先,进入知网后,选择开发工具,建议放在右边,然后点击图片中的红框,然后刷新网页切换到移动端。
进入手机端界面如下图(注意:记得刷新网页):
这是网址
在调用selenium之前先设置一些参数
from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byimport timeimport jsonimport csv# 设置谷歌驱动器的环境options = webdriver.ChromeOptions()# 设置chrome不加载图片,提高速度options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})# 创建一个谷歌驱动器browser = webdriver.Chrome(options=options)url = 'http://wap.cnki.net/touch/web/guide'
既然使用了selenium,那么我们需要获取输入框的id来自动输入关键字,输入关键字然后获取搜索按钮,然后点击

代码如下(输入的关键字是python):
# 请求urlbrowser.get(url)# 显示等待输入框是否加载完成WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.ID, 'keyword') ))# 找到输入框的id,并输入python关键字browser.find_element_by_id('keyword').send_keys('python')# 输入关键字之后点击搜索browser.find_element_by_id('btnSearch ').click()
搜索关键字后跳转到这个界面
通过selenium的显示和等待,我们可以等待其中的一些信息加载完毕,然后进行爬取,这样就可以避免因为元素没有加载而报错。如下图,我们可以知道这个信息在这个div标签中,所以我们可以等待这个元素加载
# 显示等待文献是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'g-search-body') ) )
向下滚动页面,您可以看到加载更多。可以通过显示和等待来判断按钮是否加载。如果在没有加载的情况下点击它,那么会报错。
代码,等待按钮加载并获取按钮
# 显示等待加载更多按钮加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'c-company__body-item-more') ) ) # 获取加载更多按钮 Btn = browser.find_element_by_class_name('c-company__body-item-more')
基础基本搞定,下一步就是开始获取信息了
获取信息是爬虫的基本能力,这里就不多说了,下图代码见注释

我上面说的就是这样。看图,正好我们需要的信息标签是1、3、5、7、9等等,所以是2*count-1
没什么好说的,代码注释基本都写好了,附上完整代码
from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byimport timeimport jsonimport csv# 设置谷歌驱动器的环境options = webdriver.ChromeOptions()# 设置chrome不加载图片,提高速度options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})# 创建一个谷歌驱动器browser = webdriver.Chrome(options=options)url = 'http://wap.cnki.net/touch/web/guide'# 声明一个全局列表,用来存储字典data_list = []def start_spider(page): # 请求url browser.get(url) # 显示等待输入框是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.ID, 'keyword') ) ) # 找到输入框的id,并输入python关键字 browser.find_element_by_id('keyword').click() browser.find_element_by_id('keyword_ordinary').send_keys('python') # 输入关键字之后点击搜索 browser.find_element_by_class_name('btn-search ').click() # print(browser.page_source) # 显示等待文献是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'g-search-body') ) ) # 声明一个标记,用来标记翻页几页 count = 1 while True: # 显示等待加载更多按钮加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'c-company__body-item-more') ) ) # 获取加载更多按钮 Btn = browser.find_element_by_class_name('c-company__body-item-more') # 显示等待该信息加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.XPATH, '//div[@id="searchlist_div"]/div[{}]/div[@]'.format(2*count-1)) ) ) # 获取在div标签的信息,其中format(2*count-1)是因为加载的时候有显示多少条 # 简单的说就是这些div的信息都是奇数 divs = browser.find_elements_by_xpath('//div[@id="searchlist_div"]/div[{}]/div[@]'.format(2*count-1)) # 遍历循环 for div in divs: # 获取文献的题目 name = div.find_element_by_class_name('c-company__body-title').text # 获取文献的作者 author = div.find_element_by_class_name('c-company__body-author').text # 获取文献的摘要 content = div.find_element_by_class_name('c-company__body-content').text # 获取文献的来源和日期、文献类型等 text = div.find_element_by_class_name('c-company__body-name').text.split() if (len(text) == 3 and text[-1] == '优先') or len(text) == 2: # 来源 source = text[0] # 日期 datetime = text[1] # 文献类型 literature_type = None else: source = text[0] datetime = text[2] literature_type = text[1] # 获取下载数和被引数 temp = div.find_element_by_class_name('c-company__body-info').text.split() # 下载数 download = temp[0].split(':')[-1] # 被引数 cite = temp[1].split(':')[-1] # 声明一个字典存储数据 data_dict = {} data_dict['name'] = name data_dict['author'] = author data_dict['content'] = content data_dict['source'] = source data_dict['datetime'] = datetime data_dict['literature_type'] = literature_type data_dict['download'] = download data_dict['cite'] = cite data_list.append(data_dict) print(data_dict) # 如果Btn按钮(就是加载更多这个按钮)没有找到(就是已经到底了),就退出 if not Btn: break else: Btn.click() # 如果到了爬取的页数就退出 if count == page: break count += 1 # 延迟两秒,我们不是在攻击服务器 time.sleep(2)def main(): start_spider(eval(input('请输入要爬取的页数(如果需要全部爬取请输入0):'))) # 将数据写入json文件中 with open('data_json.json', 'a+', encoding='utf-8') as f: json.dump(data_list, f, ensure_ascii=False, indent=4) print('json文件写入完成') # 将数据写入csv文件 with open('data_csv.csv', 'w', encoding='utf-8', newline='') as f: # 表头 title = data_list[0].keys() # 声明writer对象 writer = csv.DictWriter(f, title) # 写入表头 writer.writeheader() # 批量写入数据 writer.writerows(data_list) print('csv文件写入完成')if __name__ == '__main__': main()
概括:
学术之路艰难而漫长。希望编辑器中的这个程序可以帮助你在学术道路上走得更轻松一些。希望大家多多阅读文献,多发表文献,让自己的学术工作做得更好!
如果您对此案有任何进一步的问题或意见,请告诉我,我很乐意跟进并提出建议。
 https://res.wx.qq.com/mpres/ht ... 21.png" />
https://res.wx.qq.com/mpres/ht ... 21.png" />
输入关键字 抓取所有网页(URLExtractor支持网址抓取及链接提取,使用方便功能介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-29 22:17
URL Extractor 是一个 URL 提取工具。URL Extractor 支持 URL 捕获和链接提取。它易于使用,可以帮助用户浏览所有文件夹并捕获网络链接。有需要的可以下载。
特征
网址爬虫
有时我们需要从文件和文件夹中获取所有 URL(统一资源定位器)。浏览所有文件夹并抓取网络链接可能是一项艰巨的任务。幸运的是,当您需要 URL 抓取软件时,Vovsoft URL Extractor 可以在这方面为您提供帮助。
链接提取器
Vovsoft URL Extractor 是可以采集 http 和 https 网址的最佳程序之一。您可以在几秒钟内从文件中提取和恢复所有 URL。安装后,您几乎可以立即启动应用程序并开始搜索链接。你只需要提供一个目录,剩下的由程序来处理。
该软件会扫描整个文件夹以查找收录 URL 的文件,并将它们全部显示在其主窗口中,从而允许您将列表导出到文件中。所有选项都清晰简单,并且都可以放在一个窗口界面中。您需要做的就是选择您希望应用程序分析的文件夹,然后按“开始”按钮。Vovsoft URL Extractor 还具有文件掩码和对正则表达式的支持,以帮助您过滤文件和 URL。
软件特点
1、 支持提取邮箱地址、网址、ftp地址、提要、telnet、本地文件url等。
2、 拥有全新的现代引擎,采用最新的可可和objective-c 2.0 技术。它永远不会冻结,甚至可以通过搜索引擎使用数百个关键字采集数千个 URL。
3、可以在其表格中导入和导出用于导航和提取的“URL”和“关键字”。使用一个非常好的和改进的导入引擎,可以自动识别导入的格式,在导入内容的选择上有很大的灵活性。
4、 从磁盘(文件和文件夹)的无限数量的源中提取 URL 和电子邮件,并浏览任何指定文件夹和子文件夹的所有内容。可以在几秒钟内从数千个文件中提取。源列表接受文件和文件夹的拖放。
5、 从您指定的 网站 列表中提取网络中的 URL 和电子邮件。它开始提取您需要的 URL,在无休止的导航过程中继续浏览在线找到的站点链接后,它会根据需要采集 URL 或电子邮件。
6、 从关键字列表中提取互联网上的 URL 和电子邮件。
它使用您指定的搜索引擎上提供的关键字列表,然后开始寻找相关的网站,然后使用相关的网站开始导航,同时跟踪找到的链接并采集所有的URL或电子邮件. 提供了几个关键字,它可以在几个小时内提取相关(关键字)URL 和电子邮件。
7、使用 Bing 和 Google(18 个不同的 Google 区域网站:.com .it .fr.au .uk .de 和 .es .ar .au .at .be .br .ca. fi . nl .se .ch)。您可以使用指定的搜索引擎在 Internet 上进行无限制的搜索。
8、 支持从 safari 和其他网络浏览器中接受拖放 URL 以将它们用作从网络中提取的种子。
9、 支持多个选项:“单域提取”只从指定的网站中提取,不跳转到链接的网站或“深度导航”指定它来自站点的级别跳转到链接站点进行搜索和提取。
10、PDF提取,支持从本地或在线pdf文件中提取。如果它在线找到一个 PDF 并且它收录一个网页地址,它甚至可以跳转到该地址并继续搜索和提取网页。 查看全部
输入关键字 抓取所有网页(URLExtractor支持网址抓取及链接提取,使用方便功能介绍)
URL Extractor 是一个 URL 提取工具。URL Extractor 支持 URL 捕获和链接提取。它易于使用,可以帮助用户浏览所有文件夹并捕获网络链接。有需要的可以下载。
特征
网址爬虫
有时我们需要从文件和文件夹中获取所有 URL(统一资源定位器)。浏览所有文件夹并抓取网络链接可能是一项艰巨的任务。幸运的是,当您需要 URL 抓取软件时,Vovsoft URL Extractor 可以在这方面为您提供帮助。
链接提取器
Vovsoft URL Extractor 是可以采集 http 和 https 网址的最佳程序之一。您可以在几秒钟内从文件中提取和恢复所有 URL。安装后,您几乎可以立即启动应用程序并开始搜索链接。你只需要提供一个目录,剩下的由程序来处理。
该软件会扫描整个文件夹以查找收录 URL 的文件,并将它们全部显示在其主窗口中,从而允许您将列表导出到文件中。所有选项都清晰简单,并且都可以放在一个窗口界面中。您需要做的就是选择您希望应用程序分析的文件夹,然后按“开始”按钮。Vovsoft URL Extractor 还具有文件掩码和对正则表达式的支持,以帮助您过滤文件和 URL。
软件特点
1、 支持提取邮箱地址、网址、ftp地址、提要、telnet、本地文件url等。
2、 拥有全新的现代引擎,采用最新的可可和objective-c 2.0 技术。它永远不会冻结,甚至可以通过搜索引擎使用数百个关键字采集数千个 URL。
3、可以在其表格中导入和导出用于导航和提取的“URL”和“关键字”。使用一个非常好的和改进的导入引擎,可以自动识别导入的格式,在导入内容的选择上有很大的灵活性。
4、 从磁盘(文件和文件夹)的无限数量的源中提取 URL 和电子邮件,并浏览任何指定文件夹和子文件夹的所有内容。可以在几秒钟内从数千个文件中提取。源列表接受文件和文件夹的拖放。
5、 从您指定的 网站 列表中提取网络中的 URL 和电子邮件。它开始提取您需要的 URL,在无休止的导航过程中继续浏览在线找到的站点链接后,它会根据需要采集 URL 或电子邮件。
6、 从关键字列表中提取互联网上的 URL 和电子邮件。
它使用您指定的搜索引擎上提供的关键字列表,然后开始寻找相关的网站,然后使用相关的网站开始导航,同时跟踪找到的链接并采集所有的URL或电子邮件. 提供了几个关键字,它可以在几个小时内提取相关(关键字)URL 和电子邮件。
7、使用 Bing 和 Google(18 个不同的 Google 区域网站:.com .it .fr.au .uk .de 和 .es .ar .au .at .be .br .ca. fi . nl .se .ch)。您可以使用指定的搜索引擎在 Internet 上进行无限制的搜索。
8、 支持从 safari 和其他网络浏览器中接受拖放 URL 以将它们用作从网络中提取的种子。
9、 支持多个选项:“单域提取”只从指定的网站中提取,不跳转到链接的网站或“深度导航”指定它来自站点的级别跳转到链接站点进行搜索和提取。
10、PDF提取,支持从本地或在线pdf文件中提取。如果它在线找到一个 PDF 并且它收录一个网页地址,它甚至可以跳转到该地址并继续搜索和提取网页。
输入关键字 抓取所有网页(我喜欢,你就算再优秀总会有下一个啊)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-29 17:03
输入关键字抓取所有网页文字详情,特点:操作简单,上手快,
用微信读书app,要分享文章就给红包,再添加书架,可以看到列表所有书了,自己在里面找到你想看的书。
这是小学生的问题吗?
已阅读页面可以删除,当前页面不能删除。
这个怎么说呢,怎么说呢,现在就大大方方的承认“我喜欢,
你就算再优秀总会有下一个人在网上发掘你可能不是你的目标只是喜欢你的人但也可能就喜欢你这个人而不是你的优秀哦
可以在公众号搜索:百灵选资源上,里面每天有最新的短文和资源,希望对你有用哦。
quickfish-我是资源收集者
这个我试过,在自己喜欢的影视资源下载,然后可以直接搜索,类似一个绿色版的浏览器。
干不掉下一个啊
我也是有同样想法,自己和男朋友说过喜欢他的影视资源,
你还是不要加你喜欢的她的qq了,因为qq有一项功能是保存图片。
我也是也是,实在不好意思加女生我就想看你的资源,怕你不给我看,
你发个红包让她发给你即可
?
我也想问这个问题很想知道怎么办 查看全部
输入关键字 抓取所有网页(我喜欢,你就算再优秀总会有下一个啊)
输入关键字抓取所有网页文字详情,特点:操作简单,上手快,
用微信读书app,要分享文章就给红包,再添加书架,可以看到列表所有书了,自己在里面找到你想看的书。
这是小学生的问题吗?
已阅读页面可以删除,当前页面不能删除。
这个怎么说呢,怎么说呢,现在就大大方方的承认“我喜欢,
你就算再优秀总会有下一个人在网上发掘你可能不是你的目标只是喜欢你的人但也可能就喜欢你这个人而不是你的优秀哦
可以在公众号搜索:百灵选资源上,里面每天有最新的短文和资源,希望对你有用哦。
quickfish-我是资源收集者
这个我试过,在自己喜欢的影视资源下载,然后可以直接搜索,类似一个绿色版的浏览器。
干不掉下一个啊
我也是有同样想法,自己和男朋友说过喜欢他的影视资源,
你还是不要加你喜欢的她的qq了,因为qq有一项功能是保存图片。
我也是也是,实在不好意思加女生我就想看你的资源,怕你不给我看,
你发个红包让她发给你即可
?
我也想问这个问题很想知道怎么办
输入关键字 抓取所有网页( 网站内容描述让飘红的创意提升营销效果(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-29 14:08
网站内容描述让飘红的创意提升营销效果(图))
关于网站的描述和关键词网站的内容描述让飘红的创意提升营销效果。在所有的META元标签中,网站标题和网站关键词都是因为It's about 网站排名更容易引起关注和类似网站版权归因于作者和 网站 内容描述等被忽略。原因很简单。当用户登录网站时,无法直接看到网站的内容描述,搜索引擎反复声明网站内容描述只是整体网站@的总结> 并没有作为判断网站质量和重量的依据,但实际上是真的吗?恐怕事实并非如此。笔者认为< @网站内容描述是一个网站中心思想,不仅关乎网站权重,还影响用户体验和网络营销效果。网站 内容 描述影响 网站 的权重。只要注意观察,就会发现很多网站本身就有单独的内容描述,但搜索引擎并没有采用,而是在网站上抓取一段文字。作为整个网页的描述,至少可以肯定搜索引擎对网站的内容描述的态度是不可取的,所以我们在写<的内容描述的时候一定不能随便做@网站 应该谨慎对待。网站 内容描述应该是当前页面的准确概览。更精确的网站 内容描述自然方便搜索引擎。相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 实际内容较远或网站内容描述留空,搜索引擎可自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 实际内容较远或网站内容描述留空,搜索引擎可自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索
但是在引擎上,可以检索到用户输入某个关键词时写了哪些内容描述,排名也差不多,虽然有些网站的内容描述很好,但相差甚远来自网站的主题。会不会影响用户体验?答案是肯定的,所以网站的内容描述是准确概括的网站内容也必须考虑到用户的感受和体验。3 网站内容描述影响营销效果什么决定网络营销效果第一个是网站的用户体验第二个是网站的搜索引擎认知,所以是说网站的内容描述兼顾了以上两点,并取得良好的营销效果。当然,网站的内容描述所引发的营销效果远不止这些。在搜索引擎的推广中,有一个创意概念,当用户搜索关键词时很流行。内容描述中对应的单词显示为红色。众所周知,网站 内容描述多为黑色。您可以获得更多引人注目的关注。网站内容描述。创造力并不难实现。只要我们巧妙地将网站核心关键词组织成流畅的句子和适当的网站内容描述,就能影响网络营销的成败。影响网络营销成败的因素有很多。内容描述,作为网站中必不可少的元素,也构成了网络营销的重要组成部分。网站 内容描述不是可选的 None 不是你可以随意写的,但你应该小心对待。网站 内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,从而增加网站的点击流量,提高网络营销的效果。内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,增加网站的点击流量,提高网络营销的效果。内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,增加网站的点击流量,提高网络营销的效果。 查看全部
输入关键字 抓取所有网页(
网站内容描述让飘红的创意提升营销效果(图))
关于网站的描述和关键词网站的内容描述让飘红的创意提升营销效果。在所有的META元标签中,网站标题和网站关键词都是因为It's about 网站排名更容易引起关注和类似网站版权归因于作者和 网站 内容描述等被忽略。原因很简单。当用户登录网站时,无法直接看到网站的内容描述,搜索引擎反复声明网站内容描述只是整体网站@的总结> 并没有作为判断网站质量和重量的依据,但实际上是真的吗?恐怕事实并非如此。笔者认为< @网站内容描述是一个网站中心思想,不仅关乎网站权重,还影响用户体验和网络营销效果。网站 内容 描述影响 网站 的权重。只要注意观察,就会发现很多网站本身就有单独的内容描述,但搜索引擎并没有采用,而是在网站上抓取一段文字。作为整个网页的描述,至少可以肯定搜索引擎对网站的内容描述的态度是不可取的,所以我们在写<的内容描述的时候一定不能随便做@网站 应该谨慎对待。网站 内容描述应该是当前页面的准确概览。更精确的网站 内容描述自然方便搜索引擎。相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 相反,如果网站上很多页面的内容描述与网站@网站实际内容相距甚远或网站内容描述为空,搜索引擎可以自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 实际内容较远或网站内容描述留空,搜索引擎可自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索 实际内容较远或网站内容描述留空,搜索引擎可自行提取。至少基于此,可以认为这对搜索引擎不友好,当然会在一定程度上影响网站重重二网站 内容描述影响用户体验,如果你说网站内容描述对搜索引擎很重要,所以对用户来说更重要,因为网站最终是让用户看到的,虽然网站的内容描述不能直接看到from 网站 但是从搜索
但是在引擎上,可以检索到用户输入某个关键词时写了哪些内容描述,排名也差不多,虽然有些网站的内容描述很好,但相差甚远来自网站的主题。会不会影响用户体验?答案是肯定的,所以网站的内容描述是准确概括的网站内容也必须考虑到用户的感受和体验。3 网站内容描述影响营销效果什么决定网络营销效果第一个是网站的用户体验第二个是网站的搜索引擎认知,所以是说网站的内容描述兼顾了以上两点,并取得良好的营销效果。当然,网站的内容描述所引发的营销效果远不止这些。在搜索引擎的推广中,有一个创意概念,当用户搜索关键词时很流行。内容描述中对应的单词显示为红色。众所周知,网站 内容描述多为黑色。您可以获得更多引人注目的关注。网站内容描述。创造力并不难实现。只要我们巧妙地将网站核心关键词组织成流畅的句子和适当的网站内容描述,就能影响网络营销的成败。影响网络营销成败的因素有很多。内容描述,作为网站中必不可少的元素,也构成了网络营销的重要组成部分。网站 内容描述不是可选的 None 不是你可以随意写的,但你应该小心对待。网站 内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,从而增加网站的点击流量,提高网络营销的效果。内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,增加网站的点击流量,提高网络营销的效果。内容描述其实是一条捷径,也是最大化搜索引擎营销的好方法,因为毕竟排名差别不大。更多有创意的网站内容可以吸引更多的关注,增加网站的点击流量,提高网络营销的效果。
输入关键字 抓取所有网页(独家SEO秘笈:如何提高网站流量和搜索引擎比较友好?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-29 14:07
在我们网站建设之前,要考虑的问题是网站优化,网站关键词如何优化,什么样的系统和搜索引擎更友好?以新闻网站为例,目前网站的内容管理系统可以说是数不胜数。个人感觉.net比较好,安全适用~
话虽如此,网站优化包括很多,网页布局、外部链接、内容更新等,最重要的就是如何优化网站关键词。如果关键词选择正确,会给网站带来良好的流量。那么关键词应该如何优化呢?向大家介绍2点:
1、如何确定关键词
在确定关键词之前,我们要做的就是利用工具分析一下什么样的关键词会受到客户的青睐。
百度:
选择百度指数(百度指数是SEO首选工具,可以统计关键词的搜索量,有三种显示方式)地址:
<IMG src="../../../upload/2009_11/09110515507804.jpg" border=0>
在这个地方输入你要查询的关键词,例如:.NET cms
<IMG src="../../../upload/2009_11/09110515518072.jpg" border=0>
通过这个不难看出关键词的人气~
谷歌:
地址:
<IMG src="../../../upload/2009_11/09110515513276.jpg" border=0>
输入你的网站网址(如:),点击获取关键词提示
<IMG src="../../../upload/2009_11/09110515514898.jpg" border=0>
这显示了关键字的搜索量。选择的时候,既然我们是新站,就不要选择竞争力强的关键词。我们不能上榜,从竞争力下降开始。,一点点前进。
2、优化关键词
<p>网页中的关键词密度不宜过密,最好在2%-8%之间,且标题、关键词标签、图片描述、文章页面首尾必须有 查看全部
输入关键字 抓取所有网页(独家SEO秘笈:如何提高网站流量和搜索引擎比较友好?)
在我们网站建设之前,要考虑的问题是网站优化,网站关键词如何优化,什么样的系统和搜索引擎更友好?以新闻网站为例,目前网站的内容管理系统可以说是数不胜数。个人感觉.net比较好,安全适用~
话虽如此,网站优化包括很多,网页布局、外部链接、内容更新等,最重要的就是如何优化网站关键词。如果关键词选择正确,会给网站带来良好的流量。那么关键词应该如何优化呢?向大家介绍2点:
1、如何确定关键词
在确定关键词之前,我们要做的就是利用工具分析一下什么样的关键词会受到客户的青睐。
百度:
选择百度指数(百度指数是SEO首选工具,可以统计关键词的搜索量,有三种显示方式)地址:
<IMG src="../../../upload/2009_11/09110515507804.jpg" border=0>
在这个地方输入你要查询的关键词,例如:.NET cms
<IMG src="../../../upload/2009_11/09110515518072.jpg" border=0>
通过这个不难看出关键词的人气~
谷歌:
地址:
<IMG src="../../../upload/2009_11/09110515513276.jpg" border=0>
输入你的网站网址(如:),点击获取关键词提示
<IMG src="../../../upload/2009_11/09110515514898.jpg" border=0>
这显示了关键字的搜索量。选择的时候,既然我们是新站,就不要选择竞争力强的关键词。我们不能上榜,从竞争力下降开始。,一点点前进。
2、优化关键词
<p>网页中的关键词密度不宜过密,最好在2%-8%之间,且标题、关键词标签、图片描述、文章页面首尾必须有
输入关键字 抓取所有网页( mysql+redis安装可查阅百度(很简单)项目开发流程介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-29 14:03
mysql+redis安装可查阅百度(很简单)项目开发流程介绍
)
图像.png
前几天,由于工作需要,我需要抓取一个特定的关键字来提取百度中的搜索结果,并将50页的数据保存在一个数据库或一个.csv文件中。(每天爬一次)
1.项目需要环境安装
1)scrapy+selenium+chrome (phantomjs)
关于爬虫依赖的环境的安装,我已经介绍过了。你可以参考这个文章我的详细介绍。
2)mysql+redis安装数据库安装可以参考百度(很简单)
2.项目开发流程介绍
我们需要模拟用户行为,在浏览器输入框中输入指定关键字,模拟点击获取想要的数据,保存过滤这个页面显示的数据,模拟翻页,抓取这个关键字的前50个页面展示,获取我们想要的数据,保存在.csv文件或者redis数据库中,供以后数据分析使用。
3.详细开发代码
1)创建一个scrapy项目
scrapy startproject keyword_scrawl
scrapy genspider 重新测试
代码中各个文件的介绍
settings.py 是一个通用的配置文件:
BOT_NAME:项目名称
蜘蛛模块:
NEWSPIDER_MODULE:
下面模块的配置路径
pipelines.py 这个是数据存储相关的文件
可以自定义 middlewares.py 使scrapy 更可控
items.py 文件有点类似于 django 中的一个表单,它定义了数据存储的格式
,但是比django的表单应用要简单,因为它的字段很单一。
Spider文件夹:这个文件夹存放了一个特定的网站爬虫。通过命令行,我们可以创建我们自己的蜘蛛。
4.蜘蛛代码详解
def make_requests_from_url(self, url): if self.params['st_status'] == 1: return Request(url, meta={'keyword': self.keyword, 'engine':self.sousu, 'phantomjs':True}) else:
return Request(url)
首先修改spider中的make_requests_from_url函数,增加一个判断。当st_status==1时,当我们返回请求对象时,添加一个meta,在meta中携带我们要搜索的key和我们需要访问的浏览器地址。以及启动phantomjs的指令。
class PhantomJSMiddleware(object): @classmethod
def process_request(cls, request, spider):
if request.meta.has_key('phantomjs'):
keyword = request.meta.get('keyword')
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = ('Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0')
dcap["phantomjs.page.settings.AcceptLanguage"] = ('zh-CN,zh;q=0.9')
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.set_page_load_timeout(100)
driver.set_script_timeout(15) try:
driver.get(request.url) if request.meta.get('engine') == 1:
driver.find_element_by_id("query").send_keys(keyword)
driver.find_element_by_class_name("swz").click() elif request.meta.get('engine') == 2:
driver.find_element_by_id("kw").send_keys(keyword)
driver.find_element_by_id("su").click()
time.sleep(2)
final_url = driver.current_url if final_url != request.url:
fullurl = final_url else:
fullurl = request.url
content = driver.page_source.encode('utf-8','ignore')
driver.quit() return HtmlResponse(fullurl, encoding='utf-8', body=content, request=request) except Exception, e:
driver.quit() print e
其次,修改middlewares中间件中的类方法process_request,该方法默认携带request和spider对象,在我们刚刚修改的make_requests_from_url方法中。这里我们可以处理前面的make_requests_from_url函数返回的Request请求,然后加载selenium和phantomjs来获取我们需要访问的浏览器和关键字。这段代码会模拟用户获取关键字内容的行为,然后将页面内容返回给scrapy.http中的HtmlResponse对象。这样我们就可以在spider中的parse函数中得到刚刚抓取的内容response.body。
# 判断页面的返回状态
if int(response.status) >= 200 and int(response.status) 3000:
content = content[:3000] #elif len(content) == 0:
#yield scrapy.Request(url=response.url, meta={'url':response.url, 'phantomjs':True}, callback=self.pang_bo)
body = item['url']+','+item['crawl_time']+','+item['title'].replace(',','') +','+content+'\n'
if '正在进入' == item['title']:
file_name = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'keyword.csv') with open(file_name, 'a') as b:
b.write(body) else:
filename = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'.csv') with open(filename, 'a') as f:
f.write(body)# 过滤网页源代码def soup_text(body):
try:
soup = BeautifulSoup(body, 'lxml')
line = re.compile(r'\s+')
line = line.sub(r'', soup.body.getText())
p2 = re.compile(u'[^\u4e00-\u9fa5]') # 中GDAC\u4e00\u9fa5
str2 = p2.sub(r'', line)
outStr = str2.strip(',') except:
outStr = ''
return outStr
这段代码主要是忽略了一些不必要的网站,然后提取item字段,以及page body(这里过滤了源代码),然后将获取到的内容保存到.csv文件中。这只是一个简单的爬虫。要反向抓取,请进行如下设置:
LOG_STDOUT = True # 将进程所有的标准输出(及错误)将会被重定向到log中(为了方便调试)DOWNLOAD_DELAY=0.25 # 下载延时设置 单位秒DOWNLOAD_TIMEOUT = 60 # 下载超时设置(单位秒)CONCURRENT_ITEMS = 200 # 同时处理的itmes数量CONCURRENT_REQUESTS = 16 # 同时并发的请求 查看全部
输入关键字 抓取所有网页(
mysql+redis安装可查阅百度(很简单)项目开发流程介绍
)
图像.png
前几天,由于工作需要,我需要抓取一个特定的关键字来提取百度中的搜索结果,并将50页的数据保存在一个数据库或一个.csv文件中。(每天爬一次)
1.项目需要环境安装
1)scrapy+selenium+chrome (phantomjs)
关于爬虫依赖的环境的安装,我已经介绍过了。你可以参考这个文章我的详细介绍。
2)mysql+redis安装数据库安装可以参考百度(很简单)
2.项目开发流程介绍
我们需要模拟用户行为,在浏览器输入框中输入指定关键字,模拟点击获取想要的数据,保存过滤这个页面显示的数据,模拟翻页,抓取这个关键字的前50个页面展示,获取我们想要的数据,保存在.csv文件或者redis数据库中,供以后数据分析使用。
3.详细开发代码
1)创建一个scrapy项目
scrapy startproject keyword_scrawl
scrapy genspider 重新测试
代码中各个文件的介绍
settings.py 是一个通用的配置文件:
BOT_NAME:项目名称
蜘蛛模块:
NEWSPIDER_MODULE:
下面模块的配置路径
pipelines.py 这个是数据存储相关的文件
可以自定义 middlewares.py 使scrapy 更可控
items.py 文件有点类似于 django 中的一个表单,它定义了数据存储的格式
,但是比django的表单应用要简单,因为它的字段很单一。
Spider文件夹:这个文件夹存放了一个特定的网站爬虫。通过命令行,我们可以创建我们自己的蜘蛛。
4.蜘蛛代码详解
def make_requests_from_url(self, url): if self.params['st_status'] == 1: return Request(url, meta={'keyword': self.keyword, 'engine':self.sousu, 'phantomjs':True}) else:
return Request(url)
首先修改spider中的make_requests_from_url函数,增加一个判断。当st_status==1时,当我们返回请求对象时,添加一个meta,在meta中携带我们要搜索的key和我们需要访问的浏览器地址。以及启动phantomjs的指令。
class PhantomJSMiddleware(object): @classmethod
def process_request(cls, request, spider):
if request.meta.has_key('phantomjs'):
keyword = request.meta.get('keyword')
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = ('Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:60.0) Gecko/20100101 Firefox/60.0')
dcap["phantomjs.page.settings.AcceptLanguage"] = ('zh-CN,zh;q=0.9')
driver = webdriver.PhantomJS(desired_capabilities=dcap)
driver.set_page_load_timeout(100)
driver.set_script_timeout(15) try:
driver.get(request.url) if request.meta.get('engine') == 1:
driver.find_element_by_id("query").send_keys(keyword)
driver.find_element_by_class_name("swz").click() elif request.meta.get('engine') == 2:
driver.find_element_by_id("kw").send_keys(keyword)
driver.find_element_by_id("su").click()
time.sleep(2)
final_url = driver.current_url if final_url != request.url:
fullurl = final_url else:
fullurl = request.url
content = driver.page_source.encode('utf-8','ignore')
driver.quit() return HtmlResponse(fullurl, encoding='utf-8', body=content, request=request) except Exception, e:
driver.quit() print e
其次,修改middlewares中间件中的类方法process_request,该方法默认携带request和spider对象,在我们刚刚修改的make_requests_from_url方法中。这里我们可以处理前面的make_requests_from_url函数返回的Request请求,然后加载selenium和phantomjs来获取我们需要访问的浏览器和关键字。这段代码会模拟用户获取关键字内容的行为,然后将页面内容返回给scrapy.http中的HtmlResponse对象。这样我们就可以在spider中的parse函数中得到刚刚抓取的内容response.body。
# 判断页面的返回状态
if int(response.status) >= 200 and int(response.status) 3000:
content = content[:3000] #elif len(content) == 0:
#yield scrapy.Request(url=response.url, meta={'url':response.url, 'phantomjs':True}, callback=self.pang_bo)
body = item['url']+','+item['crawl_time']+','+item['title'].replace(',','') +','+content+'\n'
if '正在进入' == item['title']:
file_name = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'keyword.csv') with open(file_name, 'a') as b:
b.write(body) else:
filename = os.path.join(self.filetxt,time.strftime('%Y%m%d%H')+'.csv') with open(filename, 'a') as f:
f.write(body)# 过滤网页源代码def soup_text(body):
try:
soup = BeautifulSoup(body, 'lxml')
line = re.compile(r'\s+')
line = line.sub(r'', soup.body.getText())
p2 = re.compile(u'[^\u4e00-\u9fa5]') # 中GDAC\u4e00\u9fa5
str2 = p2.sub(r'', line)
outStr = str2.strip(',') except:
outStr = ''
return outStr
这段代码主要是忽略了一些不必要的网站,然后提取item字段,以及page body(这里过滤了源代码),然后将获取到的内容保存到.csv文件中。这只是一个简单的爬虫。要反向抓取,请进行如下设置:
LOG_STDOUT = True # 将进程所有的标准输出(及错误)将会被重定向到log中(为了方便调试)DOWNLOAD_DELAY=0.25 # 下载延时设置 单位秒DOWNLOAD_TIMEOUT = 60 # 下载超时设置(单位秒)CONCURRENT_ITEMS = 200 # 同时处理的itmes数量CONCURRENT_REQUESTS = 16 # 同时并发的请求
输入关键字 抓取所有网页(“请输入查询关键字”搜索框如何设置(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-10-29 02:08
“请输入查询关键词”的搜索框是大多数网站都会做的设置。这个搜索框可以帮助用户更准确、更快速地找到自己想要的信息,这是用户所习惯的。但是对于SEO人员来说,这个搜索框的设置并不是那么简单。自建网站的“请输入查询关键词”搜索框可能直接影响产品的转化。
(图片来自Pixabay)
搜索框的作用
1. 搜索框的作用是抓取页面。每个独立的搜索引擎都有自己的网络爬虫程序(蜘蛛)。蜘蛛会根据网页中的超链接不断抓取网页。因为超链接在互联网上的应用非常普遍,理论上从一定范围的网页开始,可以采集到绝大多数网页。
2.网页搜索引擎抓取网页后,还需要做大量的预处理工作,才能提供检索服务。其中,最重要的是提取关键词并构建索引文件。其他包括删除重复的网页、分析超链接和计算网页的重要性。
3.提供检索服务。用户输入关键词进行检索。搜索引擎从索引数据库中查找与关键词 匹配的网页。为方便用户,除了页面标题和URL,还会提供一段来自网页的Summary等信息。
搜索框的重要性
大多数情况下,使用搜索功能的用户,主要是产品的老用户,对产品的基本内容和服务有一定的了解,需求非常明确。在这种情况下,如果用户能够检索到他们想要的内容或服务,肯定会产生很高的转化率。
提高搜索转化率,让用户直接让客户完成最后的操作,也就是如何将粘性转化为结果,购买成功率高的转化可以带来利润和利润。
搜索框的位置醒目,使用方便,会给客户留下更好的印象。这就需要网站来组织一个清晰的浏览路径,让用户可以顺畅地定位更深层次的内容,也可以帮助用户快速找到目标,也可以到达目的地页面。
如何设置“请输入关键字”搜索框
1、基于SEO优化
从SEO的角度来回顾“请输入搜索关键词”的问题,其实我们说的是网站上的搜索框。搜索结果反馈的问题需要从以下两个角度来理解:
① 推荐和收录
利用网站搜索框中“请输入关键词”的位置,产生大量长尾词,合理利用搜索结果列表和展示次数,适当增加关键词的密度@> 在 SERP 中,以获得更高的排名。
② 屏蔽和隐藏
对于中小型企业站点,如果你的数据站点搜索量不大,通常建议使用robots.txt来屏蔽搜索结果URL。尤其是当你的SERP页面没有SEO标准化时,由于站点资源有限,实在是没有必要。对于此类页面,会分配百度爬虫对其进行抓取。
2、基于用户体验
从用户体验的角度来看,网站搜索框中的“请输入内容设置”尤为重要。有利于推荐企业核心产品,提高企业产品转化率,增加UGC内容输出,延迟用户页面停留时间,从而增加用户对网站品牌的粘性。
① 对网站做详细的统计分析,了解用户画像、对方喜好和喜好。
② 把握行业最新热门话题,适当利用站内多个门户,发布优质内容,引导对方参与讨论,增加当前热门话题栏目页的热度,从而增加对搜索引擎的信任。
3、输入的搜索词有误
如果对方检索到的特定关键词没有搜索结果,超过90%的网站会返回空结果,或者“您输入的关键词不正确”的标志”出现。但这是一个非常不明智的策略。您可以在此位置报告以下内容:
① 网站 逻辑结构图,类似于 HTML 版的站点地图。
②最近用户非常关注的“请输入查询关键词”推荐一些比较热门的搜索词。
③ 站内热门文章、行业最热门相关话题等。
由此可见,自建站的搜索框“请输入查询关键词”其实很重要。 查看全部
输入关键字 抓取所有网页(“请输入查询关键字”搜索框如何设置(组图))
“请输入查询关键词”的搜索框是大多数网站都会做的设置。这个搜索框可以帮助用户更准确、更快速地找到自己想要的信息,这是用户所习惯的。但是对于SEO人员来说,这个搜索框的设置并不是那么简单。自建网站的“请输入查询关键词”搜索框可能直接影响产品的转化。
(图片来自Pixabay)
搜索框的作用
1. 搜索框的作用是抓取页面。每个独立的搜索引擎都有自己的网络爬虫程序(蜘蛛)。蜘蛛会根据网页中的超链接不断抓取网页。因为超链接在互联网上的应用非常普遍,理论上从一定范围的网页开始,可以采集到绝大多数网页。
2.网页搜索引擎抓取网页后,还需要做大量的预处理工作,才能提供检索服务。其中,最重要的是提取关键词并构建索引文件。其他包括删除重复的网页、分析超链接和计算网页的重要性。
3.提供检索服务。用户输入关键词进行检索。搜索引擎从索引数据库中查找与关键词 匹配的网页。为方便用户,除了页面标题和URL,还会提供一段来自网页的Summary等信息。
搜索框的重要性
大多数情况下,使用搜索功能的用户,主要是产品的老用户,对产品的基本内容和服务有一定的了解,需求非常明确。在这种情况下,如果用户能够检索到他们想要的内容或服务,肯定会产生很高的转化率。
提高搜索转化率,让用户直接让客户完成最后的操作,也就是如何将粘性转化为结果,购买成功率高的转化可以带来利润和利润。
搜索框的位置醒目,使用方便,会给客户留下更好的印象。这就需要网站来组织一个清晰的浏览路径,让用户可以顺畅地定位更深层次的内容,也可以帮助用户快速找到目标,也可以到达目的地页面。
如何设置“请输入关键字”搜索框
1、基于SEO优化
从SEO的角度来回顾“请输入搜索关键词”的问题,其实我们说的是网站上的搜索框。搜索结果反馈的问题需要从以下两个角度来理解:
① 推荐和收录
利用网站搜索框中“请输入关键词”的位置,产生大量长尾词,合理利用搜索结果列表和展示次数,适当增加关键词的密度@> 在 SERP 中,以获得更高的排名。
② 屏蔽和隐藏
对于中小型企业站点,如果你的数据站点搜索量不大,通常建议使用robots.txt来屏蔽搜索结果URL。尤其是当你的SERP页面没有SEO标准化时,由于站点资源有限,实在是没有必要。对于此类页面,会分配百度爬虫对其进行抓取。
2、基于用户体验
从用户体验的角度来看,网站搜索框中的“请输入内容设置”尤为重要。有利于推荐企业核心产品,提高企业产品转化率,增加UGC内容输出,延迟用户页面停留时间,从而增加用户对网站品牌的粘性。
① 对网站做详细的统计分析,了解用户画像、对方喜好和喜好。
② 把握行业最新热门话题,适当利用站内多个门户,发布优质内容,引导对方参与讨论,增加当前热门话题栏目页的热度,从而增加对搜索引擎的信任。
3、输入的搜索词有误
如果对方检索到的特定关键词没有搜索结果,超过90%的网站会返回空结果,或者“您输入的关键词不正确”的标志”出现。但这是一个非常不明智的策略。您可以在此位置报告以下内容:
① 网站 逻辑结构图,类似于 HTML 版的站点地图。
②最近用户非常关注的“请输入查询关键词”推荐一些比较热门的搜索词。
③ 站内热门文章、行业最热门相关话题等。
由此可见,自建站的搜索框“请输入查询关键词”其实很重要。
输入关键字 抓取所有网页(您意思是要在您的网站上用别人的数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-29 02:02
你的意思是在你自己网站上使用别人的数据吗?如果是,你可以: 在你的网站中输入关键字向你的服务器请求,然后用HttpClient模拟请求到别人的网站去抓取服务器上的数据,然后返回给自己网站 请求。
当然,你需要弄清楚其他人的服务器请求的链接(使用一楼描述的方法),并分析请求的其他参数,才能模拟请求的图像。前提是他们对请求的安全限制没有那么严格。
也可以把抓到的数据保存在自己的数据库中,下次就可以找到自己的数据库了。如果找不到,可以模拟请求再次捕获。这样就可以累积下一个数据量。
但毕竟这些数据可能是其他人根据用户行为分析的结果,可能与自己的网站不一致。
收获花园豆:10
李奇鹏||元豆:1160|2015-07-01 13:18
好吧,我只需要计算他所展示的内容,而不管他的分析是否准确。
用F12可以看到相关信息,但是不知道是哪个JS方法在处理这些请求。HTTPWatch 也是如此。你有什么好的方法来定位这样的请求方法吗?
给个思路,非常感谢。
我要当仙女快乐启天|元豆:17|2015-07-01 13:38
@OmJJWang:让我们了解如何使用 Google Chrome 开发工具。我用的是手机,不是很方便。简单地谈谈它。打开那个页面,使用谷歌浏览器,按f12,看到网络栏,有一个清除按钮,找一下,先清除现有的请求信息,然后在搜索框中输入,你应该看到刚才有网络中的东西,这是发送的请求,查看链接。自己感受一下。
李奇鹏|元豆:1160|2015-07-01 14:12
上传图片
Ctrl+Enter键快速提交 查看全部
输入关键字 抓取所有网页(您意思是要在您的网站上用别人的数据?)
你的意思是在你自己网站上使用别人的数据吗?如果是,你可以: 在你的网站中输入关键字向你的服务器请求,然后用HttpClient模拟请求到别人的网站去抓取服务器上的数据,然后返回给自己网站 请求。
当然,你需要弄清楚其他人的服务器请求的链接(使用一楼描述的方法),并分析请求的其他参数,才能模拟请求的图像。前提是他们对请求的安全限制没有那么严格。
也可以把抓到的数据保存在自己的数据库中,下次就可以找到自己的数据库了。如果找不到,可以模拟请求再次捕获。这样就可以累积下一个数据量。
但毕竟这些数据可能是其他人根据用户行为分析的结果,可能与自己的网站不一致。
收获花园豆:10
李奇鹏||元豆:1160|2015-07-01 13:18
好吧,我只需要计算他所展示的内容,而不管他的分析是否准确。
用F12可以看到相关信息,但是不知道是哪个JS方法在处理这些请求。HTTPWatch 也是如此。你有什么好的方法来定位这样的请求方法吗?
给个思路,非常感谢。
我要当仙女快乐启天|元豆:17|2015-07-01 13:38
@OmJJWang:让我们了解如何使用 Google Chrome 开发工具。我用的是手机,不是很方便。简单地谈谈它。打开那个页面,使用谷歌浏览器,按f12,看到网络栏,有一个清除按钮,找一下,先清除现有的请求信息,然后在搜索框中输入,你应该看到刚才有网络中的东西,这是发送的请求,查看链接。自己感受一下。
李奇鹏|元豆:1160|2015-07-01 14:12
上传图片
Ctrl+Enter键快速提交
输入关键字 抓取所有网页(【每日一题】用rvest写了个抓取网站关键字搜索结果的脚本 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-26 13:13
)
我很久没有使用 R 了。今天复习了一下,写了一个脚本,用rvest抓取网站关键字搜索结果。分享一下。
需求分析网站请求
打开网站,输入关键字疾病,就可以得到搜索链接,显然是GET请求
观察链接,可以看到q=disease是关键字,p=2是页码,pn=20是每页记录数,其他参数也可以试试
搜索列表抓取功能
<p>library("rvest")
getPageList % html_attr("href")
# 选择authors等标签内的文本, 并进行gsub处理掉其中的空格等多余字符
authors % html_text() %>% gsub(pattern=" {2,}|\n|\r", replacement="")
sources % html_text() %>% gsub(pattern="\r|\n *", replacement=" ")
pmid % html_text() %>% gsub(pattern="\r\n| ?|\u00A0",replacement="")
# 结果保存入dataframe并返回
iData % gsub(pattern="Abstract(\\n)*(\\t)*|\\n\\t*", replacement="")
# 有的页面没有摘要信息, 会返回 character(0) , 需要做个处理, 否则会报错
if (identical(tmp, character(0))){
tmp 查看全部
输入关键字 抓取所有网页(【每日一题】用rvest写了个抓取网站关键字搜索结果的脚本
)
我很久没有使用 R 了。今天复习了一下,写了一个脚本,用rvest抓取网站关键字搜索结果。分享一下。
需求分析网站请求
打开网站,输入关键字疾病,就可以得到搜索链接,显然是GET请求
观察链接,可以看到q=disease是关键字,p=2是页码,pn=20是每页记录数,其他参数也可以试试
搜索列表抓取功能
<p>library("rvest")
getPageList % html_attr("href")
# 选择authors等标签内的文本, 并进行gsub处理掉其中的空格等多余字符
authors % html_text() %>% gsub(pattern=" {2,}|\n|\r", replacement="")
sources % html_text() %>% gsub(pattern="\r|\n *", replacement=" ")
pmid % html_text() %>% gsub(pattern="\r\n| ?|\u00A0",replacement="")
# 结果保存入dataframe并返回
iData % gsub(pattern="Abstract(\\n)*(\\t)*|\\n\\t*", replacement="")
# 有的页面没有摘要信息, 会返回 character(0) , 需要做个处理, 否则会报错
if (identical(tmp, character(0))){
tmp
输入关键字 抓取所有网页(【闺蜜体验团】反爬网站中的本文-Agent )
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-10-25 21:20
)
这篇文章的目的是简单地根据所选浏览器页面上的关键字抓取你想要的信息。关键是跳过反爬网页的反爬机制。
使用UA伪装
我们利用爬取的网站中的User-Agent进行伪装,让它认为我们是自己的一部分,这样我们就可以成功爬取到我们需要的信息。
打开要爬取的页面,在键盘上按F12,如下图:
代码模块
import requests
if __name__ == '__main__':
# UA伪装
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'
}
# 1.指定url
url = "https://www.sogou.com/web?"
kw = input("请输入关键字:")
param = {
'query' : kw
}
# 2.发送请求
response = requests.get(url=url,params=param,headers=header)
#数据获取
html = response.text
print(html)
response.encoding = 'utf-8'
fileName = kw + '.html'
with open(fileName,'w',encoding='utf-8') as f:
f.write(html)
print("页面获取成功!!!!") 查看全部
输入关键字 抓取所有网页(【闺蜜体验团】反爬网站中的本文-Agent
)
这篇文章的目的是简单地根据所选浏览器页面上的关键字抓取你想要的信息。关键是跳过反爬网页的反爬机制。
使用UA伪装
我们利用爬取的网站中的User-Agent进行伪装,让它认为我们是自己的一部分,这样我们就可以成功爬取到我们需要的信息。
打开要爬取的页面,在键盘上按F12,如下图:
代码模块
import requests
if __name__ == '__main__':
# UA伪装
header = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'
}
# 1.指定url
url = "https://www.sogou.com/web?"
kw = input("请输入关键字:")
param = {
'query' : kw
}
# 2.发送请求
response = requests.get(url=url,params=param,headers=header)
#数据获取
html = response.text
print(html)
response.encoding = 'utf-8'
fileName = kw + '.html'
with open(fileName,'w',encoding='utf-8') as f:
f.write(html)
print("页面获取成功!!!!")
输入关键字 抓取所有网页(STM32获取TB网页的一些信息(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-25 08:01
)
一、项目介绍
在 TB 网页上获取一些信息(仅用于教育目的)
比如我们需要使用关键字来获取TB接口的一些信息。
通过确认,可以发现请求是:
https://s.taobao.com/search?q=书包&s=0 #q代表关键字,显示第一页
https://s.taobao.com/search?q=书包&s=44 #显示第二页,每一个44个
结构设计:
二、获取分析
使用的解析方法很多,一种使用BeatifulSoup库,另一种使用正则表达式直接匹配。我们在这里使用正则表达式。
通过查看源代码,我们可以看到 view_price 和 raw_title 标签正是我们所需要的。
三、源代码
# 已失效,需要登录
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding #防止中文乱码
print(r.text)
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("")
def printGoodsList(ilt):
print(ilt)
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = coount +1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 1 #搜索两页,每页44个商品
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
print(url)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main() 查看全部
输入关键字 抓取所有网页(STM32获取TB网页的一些信息(一)
)
一、项目介绍
在 TB 网页上获取一些信息(仅用于教育目的)
比如我们需要使用关键字来获取TB接口的一些信息。
通过确认,可以发现请求是:
https://s.taobao.com/search?q=书包&s=0 #q代表关键字,显示第一页
https://s.taobao.com/search?q=书包&s=44 #显示第二页,每一个44个
结构设计:
二、获取分析
使用的解析方法很多,一种使用BeatifulSoup库,另一种使用正则表达式直接匹配。我们在这里使用正则表达式。
通过查看源代码,我们可以看到 view_price 和 raw_title 标签正是我们所需要的。
三、源代码
# 已失效,需要登录
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding #防止中文乱码
print(r.text)
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("")
def printGoodsList(ilt):
print(ilt)
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = coount +1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 1 #搜索两页,每页44个商品
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
print(url)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
输入关键字 抓取所有网页(C#开发环境的使用、C#语言基础应用、字符串编程基础篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-25 08:00
主要内容包括C#开发环境的使用、C#语言基础应用、字符串处理技术、数组和集合的使用、面向对象编程技术、数据结构与算法、Windows窗体基础、特征窗体界面、窗体控件技术、 MDI窗体和继承窗体,常用Windows控件的使用,好的Windows控件的使用,DataGridView数据控件,自定义用户控件,基本文件操作,基本文件夹操作,文件流操作,文件的加密解密解压,C#与Word互通、高效使用Excel、基础图形绘制、图像处理技术、常用图表应用、动画处理技术、音视频控制。随书光盘附有源程序和部分示例。 查看全部
输入关键字 抓取所有网页(C#开发环境的使用、C#语言基础应用、字符串编程基础篇)
主要内容包括C#开发环境的使用、C#语言基础应用、字符串处理技术、数组和集合的使用、面向对象编程技术、数据结构与算法、Windows窗体基础、特征窗体界面、窗体控件技术、 MDI窗体和继承窗体,常用Windows控件的使用,好的Windows控件的使用,DataGridView数据控件,自定义用户控件,基本文件操作,基本文件夹操作,文件流操作,文件的加密解密解压,C#与Word互通、高效使用Excel、基础图形绘制、图像处理技术、常用图表应用、动画处理技术、音视频控制。随书光盘附有源程序和部分示例。
输入关键字 抓取所有网页(如何利用python及免费资源进行基于论文关键词的研究趋势分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-10-23 10:17
在学术研究中,往往需要了解某个领域的最新发展趋势,比如发现最热门、上升最快的关键词。一些学术服务网站,比如Web of Science,也提供了类似的服务,但是一些高校并没有订阅这些服务,在使用中难免会遇到各种问题,比如定制不够。在这个文章中,我们将在论文关键词的基础上讨论如何使用python和免费资源进行研究趋势分析。
入选期刊
想知道近些年在国际商务领域发表的文章,在google中搜索“google学术期刊排名国际商务”,点击第一个链接,得到如下页面:
以排名第一的Journal of International Business Studies为例,展示如何抓取近年发表的所有文章信息。
查找文章的列表
经过一番搜索,我找到了自 2013 年以来发表的所有 442 篇文章 文章 的列表:
点击图中红框内的按钮,将442条文章信息全部导出为CSV文件。
但是,文件中只收录了每个文章的项目标题、作者和URL,并没有关键词(关键词)和摘要(摘要)等重要信息。
接下来我们用python写一个循环,打开每篇文章的链接文章,抓取关键词和总结。
抓取网页元素
首先,我们定义了一个get_keywords_abstract()函数来抓取给定网页中的相关元素,代码如下:
import requests
from scrapy import Selector
def get_keywords_abstract(url):
r = requests.get(url) #打开网页
if r.status_code != 200: #如果网页连接错误,就返回空字符串
print("Connection error: {}".format(url))
return "", ""
selector = Selector(text=r.text)
keywords = selector.css('.Keyword::text').extract()
abstract = selector.css('#Abs1 p::text').extract_first()
return keywords, abstract
值得注意的是,我使用了scrapy库中的Selector类来解析网页。这样做的原因是,相对于 Beautiful Soup 和 Pyquery 等库,我更熟悉scrapy下css选择器的使用。
为了验证以上代码是否正确,我在命令行执行如下测试代码:
test_url = 'https://link.springer.com/arti ... 39%3B
keywords, abstract = get_keywords_abstract(test_url)
print(keywords)
print(abstract)
结果有点出人意料:
>>> print(keywords)
['entry mode\xa0', 'deviation from prediction\xa0', 'internalization theory\xa0', 'bounded rationality\xa0', 'cognitive bias\xa0']
>>> print(abstract)
'We explore when and why decision makers choose international entry modes (e.g., hierarchies or markets) that deviate from internalization theory’s predictions. By applying a cognitive perspective on entry mode decision making, we propose that the performance of prior international activities influences decision makers’ behavior in different ways than assumed in internalization theory. More specifically, due to a'
关键词 末尾有多余的字符。这不是什么大问题。您可以在后续处理中批量删除它们。真正的问题是摘要不完整。
在浏览器中打开测试网页,右键查看源码,在摘要中找到一些html标签,如:
...due to a representativeness bias , underperforming ...
正是这些 html 标签干扰了正常的文本抓取。
为了解决这个问题,我修改了get_keywords_abstract()函数:
import requests
from scrapy import Selector
def get_keywords_abstract(url):
r = requests.get(url) #打开网页
if r.status_code != 200: #如果网页连接错误,就返回空字符串
print("Connection error: {}".format(url))
return "", ""
selector = Selector(text=r.text)
keywords = selector.css('.Keyword::text').extract()
abstracts = selector.css('#Abs1 p::text').extract() #把extract_first()改成extract(),抓取所有的文本片段
abstract = ''.join(abstracts) #把文本片段连接起来
return keywords, abstract
重新运行测试代码,发现问题解决了。
导入 CSV 文件
下一步是导入CSV文件中的URL列表,循环抓取关键词和summary。
导入 CSV 文件以使用 pandas 库:
import pandas as pd
articles = pd.read_csv('../data/jibs_articles.csv', sep=',')
type(articles) #
articles.shape # (442, 10)
articles.columns # 列名
articles.head() # 打印前5行
For 循环
确认一切无误后,循环开始:
urls = articles['URL']
keywords = pd.Series(index=articles.index)
abstract = pd.Series(index=articles.index)
for i, url in enumerate(urls):
keywords[i], abstract[i] = get_keywords_abstract(url)
print("Finish article: {}".format(i)) # 抓完一个网页就报一个数字,等的时候心里好过一些
等了大约20分钟后,我终于完成了捕获。只有一个 文章 打开错误。
保存到 CSV 文件
接下来,我们将关键词和summary整合到数据表中,然后保存到CSV文件中。
articles['keywords'] = keywords
articles['abstract'] = abstract
articles.columns # 数据表中增加了keywords和abstract两列
articles.to_csv('../data/jibs_keywords_abstract.csv', sep=',', header=True)
为了方便下次使用,我们“粘贴”一下数据:
import pickle
with open("../data/articles.pickle", "wb") as f:
pickle.dump(articles, f)
下一次,我们将讨论基于关键词的研究趋势分析。 查看全部
输入关键字 抓取所有网页(如何利用python及免费资源进行基于论文关键词的研究趋势分析)
在学术研究中,往往需要了解某个领域的最新发展趋势,比如发现最热门、上升最快的关键词。一些学术服务网站,比如Web of Science,也提供了类似的服务,但是一些高校并没有订阅这些服务,在使用中难免会遇到各种问题,比如定制不够。在这个文章中,我们将在论文关键词的基础上讨论如何使用python和免费资源进行研究趋势分析。
入选期刊
想知道近些年在国际商务领域发表的文章,在google中搜索“google学术期刊排名国际商务”,点击第一个链接,得到如下页面:
以排名第一的Journal of International Business Studies为例,展示如何抓取近年发表的所有文章信息。
查找文章的列表
经过一番搜索,我找到了自 2013 年以来发表的所有 442 篇文章 文章 的列表:
点击图中红框内的按钮,将442条文章信息全部导出为CSV文件。
但是,文件中只收录了每个文章的项目标题、作者和URL,并没有关键词(关键词)和摘要(摘要)等重要信息。
接下来我们用python写一个循环,打开每篇文章的链接文章,抓取关键词和总结。
抓取网页元素
首先,我们定义了一个get_keywords_abstract()函数来抓取给定网页中的相关元素,代码如下:
import requests
from scrapy import Selector
def get_keywords_abstract(url):
r = requests.get(url) #打开网页
if r.status_code != 200: #如果网页连接错误,就返回空字符串
print("Connection error: {}".format(url))
return "", ""
selector = Selector(text=r.text)
keywords = selector.css('.Keyword::text').extract()
abstract = selector.css('#Abs1 p::text').extract_first()
return keywords, abstract
值得注意的是,我使用了scrapy库中的Selector类来解析网页。这样做的原因是,相对于 Beautiful Soup 和 Pyquery 等库,我更熟悉scrapy下css选择器的使用。
为了验证以上代码是否正确,我在命令行执行如下测试代码:
test_url = 'https://link.springer.com/arti ... 39%3B
keywords, abstract = get_keywords_abstract(test_url)
print(keywords)
print(abstract)
结果有点出人意料:
>>> print(keywords)
['entry mode\xa0', 'deviation from prediction\xa0', 'internalization theory\xa0', 'bounded rationality\xa0', 'cognitive bias\xa0']
>>> print(abstract)
'We explore when and why decision makers choose international entry modes (e.g., hierarchies or markets) that deviate from internalization theory’s predictions. By applying a cognitive perspective on entry mode decision making, we propose that the performance of prior international activities influences decision makers’ behavior in different ways than assumed in internalization theory. More specifically, due to a'
关键词 末尾有多余的字符。这不是什么大问题。您可以在后续处理中批量删除它们。真正的问题是摘要不完整。
在浏览器中打开测试网页,右键查看源码,在摘要中找到一些html标签,如:
...due to a representativeness bias , underperforming ...
正是这些 html 标签干扰了正常的文本抓取。
为了解决这个问题,我修改了get_keywords_abstract()函数:
import requests
from scrapy import Selector
def get_keywords_abstract(url):
r = requests.get(url) #打开网页
if r.status_code != 200: #如果网页连接错误,就返回空字符串
print("Connection error: {}".format(url))
return "", ""
selector = Selector(text=r.text)
keywords = selector.css('.Keyword::text').extract()
abstracts = selector.css('#Abs1 p::text').extract() #把extract_first()改成extract(),抓取所有的文本片段
abstract = ''.join(abstracts) #把文本片段连接起来
return keywords, abstract
重新运行测试代码,发现问题解决了。
导入 CSV 文件
下一步是导入CSV文件中的URL列表,循环抓取关键词和summary。
导入 CSV 文件以使用 pandas 库:
import pandas as pd
articles = pd.read_csv('../data/jibs_articles.csv', sep=',')
type(articles) #
articles.shape # (442, 10)
articles.columns # 列名
articles.head() # 打印前5行
For 循环
确认一切无误后,循环开始:
urls = articles['URL']
keywords = pd.Series(index=articles.index)
abstract = pd.Series(index=articles.index)
for i, url in enumerate(urls):
keywords[i], abstract[i] = get_keywords_abstract(url)
print("Finish article: {}".format(i)) # 抓完一个网页就报一个数字,等的时候心里好过一些
等了大约20分钟后,我终于完成了捕获。只有一个 文章 打开错误。
保存到 CSV 文件
接下来,我们将关键词和summary整合到数据表中,然后保存到CSV文件中。
articles['keywords'] = keywords
articles['abstract'] = abstract
articles.columns # 数据表中增加了keywords和abstract两列
articles.to_csv('../data/jibs_keywords_abstract.csv', sep=',', header=True)
为了方便下次使用,我们“粘贴”一下数据:
import pickle
with open("../data/articles.pickle", "wb") as f:
pickle.dump(articles, f)
下一次,我们将讨论基于关键词的研究趋势分析。
输入关键字 抓取所有网页( 安之若死)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-21 08:05
安之若死)
Python3获取一大段文本之间两个关键字之间的内容
更新时间:2018年10月11日14:47:19
今天小编就给大家分享一个Python3获取大段文本之间两个关键字之间内容的方法,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
使用 re 或 string.find。以下是重新代码
import re
#文本所在TXT文件
file = '123.txt'
#关键字1,2(修改引号间的内容)
w1 = '123'
w2 = '456'
f = open(file,'r')
buff = f.read()
#清除换行符,请取消下一行注释
#buff = buff.replace('\n','')
pat = re.compile(w1+'(.*?)'+w2,re.S)
result = pat.findall(buff)
print(result)
以上Python3获取一大段文本之间两个关键字之间的内容的方法就是编辑器共享的所有内容。希望能给大家一个参考,也希望大家多多支持剧本家。 查看全部
输入关键字 抓取所有网页(
安之若死)
Python3获取一大段文本之间两个关键字之间的内容
更新时间:2018年10月11日14:47:19
今天小编就给大家分享一个Python3获取大段文本之间两个关键字之间内容的方法,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
使用 re 或 string.find。以下是重新代码
import re
#文本所在TXT文件
file = '123.txt'
#关键字1,2(修改引号间的内容)
w1 = '123'
w2 = '456'
f = open(file,'r')
buff = f.read()
#清除换行符,请取消下一行注释
#buff = buff.replace('\n','')
pat = re.compile(w1+'(.*?)'+w2,re.S)
result = pat.findall(buff)
print(result)
以上Python3获取一大段文本之间两个关键字之间的内容的方法就是编辑器共享的所有内容。希望能给大家一个参考,也希望大家多多支持剧本家。
输入关键字 抓取所有网页(Node批量爬取头条视频地址A坑库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-10-21 08:04
需要
通过抖音的首页链接下载该用户的所有视频
想法
分析发现视频地址都是通过一个接口返回的,手动复制数据过滤掉需要的视频地址A
坑①:
地址A在浏览器的手机模式下只会跳转到真实的视频地址B
查资料发现神器Puppeteer的中文文档
Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。
您可以在浏览器中手动执行的大部分操作都可以使用 Puppeteer 完成!这里有些例子:
解决办法是:模仿iphone6打开页面,然后通过document.querySelector('source').src获取实际播放地址
getUrl.js
// 获取视频实际下载链接
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
const iPhone = devices['iPhone 6'];
const getUrl = async (item) => {
const browser = await puppeteer.launch(); //启动浏览器实例
const page = await browser.newPage(); //创建一个新页面
await page.emulate(iPhone); //模拟iphone6打开页面
await page.goto(item.url); //进入指定网页
const result = await page.evaluate((item) => {
let url = document.querySelector('source').src;
return {
title: item.title,
url
}
}, item);
await browser.close();
return result;
}
module.exports = getUrl
下载视频
这里直接参考Node对头条视频的批量抓取和保存方法的写法
download.js
// 下载视频
const fs = require('fs');
const http = require('http');
const config = require('./config');
function getVideoData(url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
function savefileToPath(fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
async function downloadVideo(video) {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.url, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
module.exports = downloadVideo
以上都可以实现后,研究如何获取所有视频链接
解决方案:仍然使用puppeteer获取请求完成事件并获取请求正文
注:为保证能拿到所有的视频,需要滚动到模拟页面底部,没有更多的视频,然后抓取数据
完成:
判断页面是否滚动到底部
let isScrollEnd = false
let scroll_timer = null
$(window).scroll(function () {
var scrollTop = $(this).scrollTop();
var scrollHeight = $(document).height();
var windowHeight = $(this).height();
// 防止滚动过快,接口较慢,500ms后再去判断
clearTimeout(scroll_timer)
scroll_timer = setTimeout(() => {
if (scrollTop + windowHeight >= scrollHeight) {
isScrollEnd = true
console.log("that.isScrollEnd", isScrollEnd)
}
}, 500)
});
操作浏览器滚动到底部时停止
坑评价范围
await page.evaluate(async (aa) => {
这里是node自己打开的浏览器作用域,无法直接取到外部的变量,需要通过参数传入,如aa
且无法传入this这类无法序列化的参数
},aa);
优化部分
通过config.js配置各种参数
module.exports = {
isShowChrome: false, //是否显示chrome浏览器
ajaxKey: 'v2/aweme/post',//接口的关键字,防止对所有接口都获取数据
ajaxPath: 'video.play_addr.url_list[0]',//视频在接口里的路径
inputUrl: 'https://v.douyin.com/qKDN9n/',//输入的链接,后期由页面传入吧
savePath: './output',//保存路径
isDownload: true,//是否下载视频
isSaveJsonData: false, //是否保存json数据,如获取到的接口数据和整理后的视频数据
}
全码地址
参考 查看全部
输入关键字 抓取所有网页(Node批量爬取头条视频地址A坑库)
需要
通过抖音的首页链接下载该用户的所有视频
想法
分析发现视频地址都是通过一个接口返回的,手动复制数据过滤掉需要的视频地址A
坑①:
地址A在浏览器的手机模式下只会跳转到真实的视频地址B
查资料发现神器Puppeteer的中文文档
Puppeteer 是一个 Node 库,它提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。
您可以在浏览器中手动执行的大部分操作都可以使用 Puppeteer 完成!这里有些例子:
解决办法是:模仿iphone6打开页面,然后通过document.querySelector('source').src获取实际播放地址
getUrl.js
// 获取视频实际下载链接
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
const iPhone = devices['iPhone 6'];
const getUrl = async (item) => {
const browser = await puppeteer.launch(); //启动浏览器实例
const page = await browser.newPage(); //创建一个新页面
await page.emulate(iPhone); //模拟iphone6打开页面
await page.goto(item.url); //进入指定网页
const result = await page.evaluate((item) => {
let url = document.querySelector('source').src;
return {
title: item.title,
url
}
}, item);
await browser.close();
return result;
}
module.exports = getUrl
下载视频
这里直接参考Node对头条视频的批量抓取和保存方法的写法
download.js
// 下载视频
const fs = require('fs');
const http = require('http');
const config = require('./config');
function getVideoData(url, encoding) {
return new Promise((resolve, reject) => {
let req = http.get(url, function (res) {
let result = ''
encoding && res.setEncoding(encoding)
res.on('data', function (d) {
result += d
})
res.on('end', function () {
resolve(result)
})
res.on('error', function (e) {
reject(e)
})
})
req.end()
})
}
function savefileToPath(fileName, fileData) {
let fileFullName = `${config.savePath}/${fileName}.mp4`
return new Promise((resolve, reject) => {
fs.writeFile(fileFullName, fileData, 'binary', function (err) {
if (err) {
console.log('savefileToPath error:', err)
}
resolve('已下载')
})
})
}
async function downloadVideo(video) {
// 判断视频文件是否已经下载
if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) {
await getVideoData(video.url, 'binary').then(fileData => {
console.log('下载视频中:', video.title)
savefileToPath(video.title, fileData).then(res =>
console.log(`${res}: ${video.title}`)
)
})
} else {
console.log(`视频文件已存在:${video.title}`)
}
}
module.exports = downloadVideo
以上都可以实现后,研究如何获取所有视频链接
解决方案:仍然使用puppeteer获取请求完成事件并获取请求正文
注:为保证能拿到所有的视频,需要滚动到模拟页面底部,没有更多的视频,然后抓取数据
完成:
判断页面是否滚动到底部
let isScrollEnd = false
let scroll_timer = null
$(window).scroll(function () {
var scrollTop = $(this).scrollTop();
var scrollHeight = $(document).height();
var windowHeight = $(this).height();
// 防止滚动过快,接口较慢,500ms后再去判断
clearTimeout(scroll_timer)
scroll_timer = setTimeout(() => {
if (scrollTop + windowHeight >= scrollHeight) {
isScrollEnd = true
console.log("that.isScrollEnd", isScrollEnd)
}
}, 500)
});
操作浏览器滚动到底部时停止
坑评价范围
await page.evaluate(async (aa) => {
这里是node自己打开的浏览器作用域,无法直接取到外部的变量,需要通过参数传入,如aa
且无法传入this这类无法序列化的参数
},aa);
优化部分
通过config.js配置各种参数
module.exports = {
isShowChrome: false, //是否显示chrome浏览器
ajaxKey: 'v2/aweme/post',//接口的关键字,防止对所有接口都获取数据
ajaxPath: 'video.play_addr.url_list[0]',//视频在接口里的路径
inputUrl: 'https://v.douyin.com/qKDN9n/',//输入的链接,后期由页面传入吧
savePath: './output',//保存路径
isDownload: true,//是否下载视频
isSaveJsonData: false, //是否保存json数据,如获取到的接口数据和整理后的视频数据
}
全码地址
参考
输入关键字 抓取所有网页(京东商城关键字搜索商品的页面Url的参数为奇数(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-20 16:13
)
使用HttpClient可以创建浏览器对象,然后抓取页面数据,然后使用Jsoup库解析Html页面。因为Jsoup和JQuery通过selector获取元素的方式是一样的,所以抓取页面数据变得非常方便。
例如,此链接:%E5%B0%8F%E7%B1%B3&page=1&s=201&click=0
研究发现京东关键词搜索商品页面的page Url的page参数为奇数(1、3、5、7、9...),估计前30个产品数据其实是第一页,Ajax加载的后30个产品数据其实是第二页。第一页和第二页的数据合起来就是该页1页的数据。
另外,在京东商品的数据中,有两个字段很神奇,分别是spu和sku,spu代表商品集合的id,sku代表商品最小品类单元的id,意味着一个 spu 至少有一个或多个 sku 。每个 sku 代表一种商品。
例如这个链接:
现在可以爬取京东某关键词下的商品列表了。一个页面有60个产品,但是只能爬取30个,还有30个是通过ajax加载的,需要页面滚动。 Ajax请求是在第30条数据之后执行的,所以当前异步加载的30条商品数据是爬不出来的。如果要抓取完整的60条数据,可以使用Selenium库,在滚动页面中分析抓取网页数据,可以抓取Js动态生成数据。
使用 Fiddler 数据包捕获工具,有一些小的发现,如下所示。
这是一个简单的学习演示。基于SpringBoot+HttpClient+Jsoup框架,只能获取每个页面的前30条商品数据,后30条异步加载的商品数据暂时没有实现,仅供学习使用。
效果如下:
查看全部
输入关键字 抓取所有网页(京东商城关键字搜索商品的页面Url的参数为奇数(组图)
)
使用HttpClient可以创建浏览器对象,然后抓取页面数据,然后使用Jsoup库解析Html页面。因为Jsoup和JQuery通过selector获取元素的方式是一样的,所以抓取页面数据变得非常方便。
例如,此链接:%E5%B0%8F%E7%B1%B3&page=1&s=201&click=0
研究发现京东关键词搜索商品页面的page Url的page参数为奇数(1、3、5、7、9...),估计前30个产品数据其实是第一页,Ajax加载的后30个产品数据其实是第二页。第一页和第二页的数据合起来就是该页1页的数据。
另外,在京东商品的数据中,有两个字段很神奇,分别是spu和sku,spu代表商品集合的id,sku代表商品最小品类单元的id,意味着一个 spu 至少有一个或多个 sku 。每个 sku 代表一种商品。
例如这个链接:
现在可以爬取京东某关键词下的商品列表了。一个页面有60个产品,但是只能爬取30个,还有30个是通过ajax加载的,需要页面滚动。 Ajax请求是在第30条数据之后执行的,所以当前异步加载的30条商品数据是爬不出来的。如果要抓取完整的60条数据,可以使用Selenium库,在滚动页面中分析抓取网页数据,可以抓取Js动态生成数据。
使用 Fiddler 数据包捕获工具,有一些小的发现,如下所示。
这是一个简单的学习演示。基于SpringBoot+HttpClient+Jsoup框架,只能获取每个页面的前30条商品数据,后30条异步加载的商品数据暂时没有实现,仅供学习使用。
效果如下:
输入关键字 抓取所有网页(如何提炼和优化网站关键词将在搜索引擎中发挥重要作用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 443 次浏览 • 2021-10-20 16:10
在搜索营销中,如何细化和优化网站关键词将在营销中发挥重要作用。那么关键词有多重要?比如我们在百度上搜索相关信息时,通常会在百度中输入一些关键词。搜索引擎会根据这些关键词搜索数据库。
如果我们找到匹配这些关键词的网页,我们会根据关键词的匹配程度、关键词的位置和频率以及网页中链接的质量,使用特殊的算法——。数字等。计算每个网页的相关性和排名级别,然后根据相关性将这些网页链接依次呈现给用户。可见,关键词提炼优化技术可以有效提高网页在搜索引擎中的排名。接下来,三兄弟介绍几种改进优化关键词的有效方法:
1.在做搜索引擎优化的时候,一定要选择好的网站关键词,先为网站选择好的关键词,提高营销的精准度。关键词 的数量不能太多。一般来说,我们应该选择三个关键词来获得收益。以“网络营销”为例。如果我们要从事的业务主要是“网络营销”,除了“网络营销”,我们还可以选择“网络营销”和“网络营销”作为关键词。这样,用户只能在搜索引擎中输入它们。这些关键词,当搜索引擎在数据库中搜索完毕后,因为我们的关键词设置满足了用户的需求,我们的网页信息被提供给用户的概率会增加。
2. 将关键词 URL 翻译成统一的资源定位符(也称为URL),是互联网上的标准资源地址。一般来说,在确定网站的位置后,域名可以使用行业关键词或者英文单词的double pinning,通常是比较理想的状态。我们以百度为例。在其域名中,“Baidu”是百度的全拼。不仅方便在线用户记忆,也方便搜索引擎采集,有利于提高搜索引擎的相关性排名。
3. 在网页内容中插入关键词就是网页应该呈现给用户的具体内容。它可以是产品信息或博客文章。这里有一个经典规则,“内容为王,链条为王”。换句话说,如果网站没有优质的内容,那么网站本身就会失败,更不用说优化网站,因为所有优化的推广只会吸引用户到网站@ > 的页面。至于用户体验,还是要看网站内容的质量。
4.在网页摘要中插入关键字搜索引擎向用户展示搜索结果时,会先显示网页的标题。这再次说明了sange强调在网页标题中插入关键词的重要性。其次,页面标题下方会显示50.70字的页面摘要。也可以是文章的总结。通常用户在阅读标题后会习惯性地查看网站摘要。如果在网站摘要中嵌入关键词,内容设计很吸引人,网站的点击率会增加,网站在搜索引擎中的排名也会增加也增加。
5.熟练使用现有的关键词,必要时创建自己的关键词。现有的关键词就是搜索引擎中常用的关键词。需要注意的是,关键词越热越好,因为热刺意味着用户太多,竞争力越强,所以一定要根据实际情况选择一些较弱的词,这样竞争力就会弱一些。
另外,尽量避免覆盖太多关键词,因为这样会增加优化的难度。边小建议使用百度索引搜索冷热关键词。在输入框中输入“网络营销”,点击索引查看如下结果: 当我们在现有的关键词中找不到满意的关键词时,我们可以自己创建关键词 通过测试。这时候,我们要么面对网站的推广,要么创建自己的关键词。
在这里,卞潇对他的关键词提出了三点建议:第一,这些关键词一定要特别;第二,要符合人们的语法习惯;第三,一定要有针对性,网站的项目与产品主题有关。简而言之,关于搜索引擎优化。关键词的正确提取和优化将在搜索引擎营销中发挥重要作用,值得我们关注。 查看全部
输入关键字 抓取所有网页(如何提炼和优化网站关键词将在搜索引擎中发挥重要作用)
在搜索营销中,如何细化和优化网站关键词将在营销中发挥重要作用。那么关键词有多重要?比如我们在百度上搜索相关信息时,通常会在百度中输入一些关键词。搜索引擎会根据这些关键词搜索数据库。
如果我们找到匹配这些关键词的网页,我们会根据关键词的匹配程度、关键词的位置和频率以及网页中链接的质量,使用特殊的算法——。数字等。计算每个网页的相关性和排名级别,然后根据相关性将这些网页链接依次呈现给用户。可见,关键词提炼优化技术可以有效提高网页在搜索引擎中的排名。接下来,三兄弟介绍几种改进优化关键词的有效方法:
1.在做搜索引擎优化的时候,一定要选择好的网站关键词,先为网站选择好的关键词,提高营销的精准度。关键词 的数量不能太多。一般来说,我们应该选择三个关键词来获得收益。以“网络营销”为例。如果我们要从事的业务主要是“网络营销”,除了“网络营销”,我们还可以选择“网络营销”和“网络营销”作为关键词。这样,用户只能在搜索引擎中输入它们。这些关键词,当搜索引擎在数据库中搜索完毕后,因为我们的关键词设置满足了用户的需求,我们的网页信息被提供给用户的概率会增加。
2. 将关键词 URL 翻译成统一的资源定位符(也称为URL),是互联网上的标准资源地址。一般来说,在确定网站的位置后,域名可以使用行业关键词或者英文单词的double pinning,通常是比较理想的状态。我们以百度为例。在其域名中,“Baidu”是百度的全拼。不仅方便在线用户记忆,也方便搜索引擎采集,有利于提高搜索引擎的相关性排名。
3. 在网页内容中插入关键词就是网页应该呈现给用户的具体内容。它可以是产品信息或博客文章。这里有一个经典规则,“内容为王,链条为王”。换句话说,如果网站没有优质的内容,那么网站本身就会失败,更不用说优化网站,因为所有优化的推广只会吸引用户到网站@ > 的页面。至于用户体验,还是要看网站内容的质量。
4.在网页摘要中插入关键字搜索引擎向用户展示搜索结果时,会先显示网页的标题。这再次说明了sange强调在网页标题中插入关键词的重要性。其次,页面标题下方会显示50.70字的页面摘要。也可以是文章的总结。通常用户在阅读标题后会习惯性地查看网站摘要。如果在网站摘要中嵌入关键词,内容设计很吸引人,网站的点击率会增加,网站在搜索引擎中的排名也会增加也增加。
5.熟练使用现有的关键词,必要时创建自己的关键词。现有的关键词就是搜索引擎中常用的关键词。需要注意的是,关键词越热越好,因为热刺意味着用户太多,竞争力越强,所以一定要根据实际情况选择一些较弱的词,这样竞争力就会弱一些。
另外,尽量避免覆盖太多关键词,因为这样会增加优化的难度。边小建议使用百度索引搜索冷热关键词。在输入框中输入“网络营销”,点击索引查看如下结果: 当我们在现有的关键词中找不到满意的关键词时,我们可以自己创建关键词 通过测试。这时候,我们要么面对网站的推广,要么创建自己的关键词。
在这里,卞潇对他的关键词提出了三点建议:第一,这些关键词一定要特别;第二,要符合人们的语法习惯;第三,一定要有针对性,网站的项目与产品主题有关。简而言之,关于搜索引擎优化。关键词的正确提取和优化将在搜索引擎营销中发挥重要作用,值得我们关注。
输入关键字 抓取所有网页(搜索引擎的搜索展现大部分为排序、索引、抓取三个步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-10-20 16:08
搜索引擎的搜索结果大多是排序、索引、爬行。其实原理很复杂。过程中需要抓取信息去重复、中文分词、关键词内容对比、页面链接关系等。、噪声消除、索引、搜索显示等,这些在下面详细描述。
搜索引擎优化的基本工作原理
1、获取
搜索引擎会抛出一种叫做“机器人、蜘蛛”的软件,按照一定的规则扫描互联网上的网站,按照网页的链接从一个页面到另一个,从一个网站去另一个网站获取页面的HTML代码并存入数据库。为了采集获取最新信息,我们会继续访问已爬取的网页。
2、索引
分析索引系统程序对采集到的网页进行分析,提取相关网页信息,并按照一定的相关性算法进行大量复杂的计算,得到页面文本和超链接中每个关键词的各个网页的相关性度,然后利用这些相关信息来构建网页索引数据库。
3、排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算出来了,所以只需要按照已有的相关度值进行排序即可。相关性越高,排名越高。最后还给了用户。
搜索引擎的工作原理大致分为三个步骤:爬行和爬行-索引-排序。
爬网:主要是数据采集。
索引/预处理:提取文本-中文分词-去除停用词-去除噪音-去除重复-索引。
排序:搜索词处理-匹配文件-初始子集选择-相关计算-过滤、调整-排名显示。
搜索引擎优化检索流程
1、 抓取信息去除重复项
在搜索引擎优化的工作原理中,蜘蛛爬取信息后会进行一个去除数据库中杂质的过程。如果你的文章被蜘蛛抓到了,蜘蛛的内容和别人相似,那么蜘蛛就会认为你这种类型的内容毫无价值,很容易被丢弃。会有很多停用词,如:de、land、de、ah、ma等。
2、中文分词(分词)处理
搜索引擎会根据自己的字典切词,把你的标题和内容分成很多关键词。所以在创建内容时,必须在标题和内容中收录关键词。
3、提取网站的关键词并比较你的页面内容
计算页面关键词的密度是否合理。如果密度稀疏,说明你的关键词与内容不匹配,那么关键词一般没有很好的排名,不能重新分页关键词@ > 故意把页面堆在里面,导致密度很高,那么搜索引擎会认为你在作弊,只想测试关键词的累积进行排名。这种方法很容易被搜索到。引擎惩罚。
4、计算页面的链接关系
搜索引擎优化工作原理中的所谓页面链接关系,是指你的网站导出链接和导入链接的计算。所谓导出链接是指你的网站上指向其他网站的链接称为导出链接。导入链接,一个页面的导入链接越多,这个页面的分数越高,网站的页面排名就越好。导出的链接越多,页面的得分越低,不利于页面的排名。
5、降噪处理
搜索引擎优化工作原理中的所谓噪音,是指网页上弹出的大量广告。不相关的垃圾邮件页面。如果网站挂了很多弹窗广告,百度会认为你的网站严重影响用户体验。对于这些网站,百度会严厉打击,不会给你好的排名。. 百度冰桶算法对抗网站页面广告。
6、创建索引
根据上述处理结果,搜索引擎将网站的页面放入自己的索引库中。索引库中的内容实际上是百度排名的结果。当我们使用site命令查询网站的收录时,百度发布索引的内容。 查看全部
输入关键字 抓取所有网页(搜索引擎的搜索展现大部分为排序、索引、抓取三个步骤)
搜索引擎的搜索结果大多是排序、索引、爬行。其实原理很复杂。过程中需要抓取信息去重复、中文分词、关键词内容对比、页面链接关系等。、噪声消除、索引、搜索显示等,这些在下面详细描述。
搜索引擎优化的基本工作原理
1、获取
搜索引擎会抛出一种叫做“机器人、蜘蛛”的软件,按照一定的规则扫描互联网上的网站,按照网页的链接从一个页面到另一个,从一个网站去另一个网站获取页面的HTML代码并存入数据库。为了采集获取最新信息,我们会继续访问已爬取的网页。
2、索引
分析索引系统程序对采集到的网页进行分析,提取相关网页信息,并按照一定的相关性算法进行大量复杂的计算,得到页面文本和超链接中每个关键词的各个网页的相关性度,然后利用这些相关信息来构建网页索引数据库。
3、排序
当用户输入关键词进行搜索时,搜索系统程序会从网页索引数据库中查找所有与关键词匹配的相关网页。因为这个关键词的所有相关网页的相关度已经计算出来了,所以只需要按照已有的相关度值进行排序即可。相关性越高,排名越高。最后还给了用户。
搜索引擎的工作原理大致分为三个步骤:爬行和爬行-索引-排序。
爬网:主要是数据采集。
索引/预处理:提取文本-中文分词-去除停用词-去除噪音-去除重复-索引。
排序:搜索词处理-匹配文件-初始子集选择-相关计算-过滤、调整-排名显示。
搜索引擎优化检索流程
1、 抓取信息去除重复项
在搜索引擎优化的工作原理中,蜘蛛爬取信息后会进行一个去除数据库中杂质的过程。如果你的文章被蜘蛛抓到了,蜘蛛的内容和别人相似,那么蜘蛛就会认为你这种类型的内容毫无价值,很容易被丢弃。会有很多停用词,如:de、land、de、ah、ma等。
2、中文分词(分词)处理
搜索引擎会根据自己的字典切词,把你的标题和内容分成很多关键词。所以在创建内容时,必须在标题和内容中收录关键词。
3、提取网站的关键词并比较你的页面内容
计算页面关键词的密度是否合理。如果密度稀疏,说明你的关键词与内容不匹配,那么关键词一般没有很好的排名,不能重新分页关键词@ > 故意把页面堆在里面,导致密度很高,那么搜索引擎会认为你在作弊,只想测试关键词的累积进行排名。这种方法很容易被搜索到。引擎惩罚。
4、计算页面的链接关系
搜索引擎优化工作原理中的所谓页面链接关系,是指你的网站导出链接和导入链接的计算。所谓导出链接是指你的网站上指向其他网站的链接称为导出链接。导入链接,一个页面的导入链接越多,这个页面的分数越高,网站的页面排名就越好。导出的链接越多,页面的得分越低,不利于页面的排名。
5、降噪处理
搜索引擎优化工作原理中的所谓噪音,是指网页上弹出的大量广告。不相关的垃圾邮件页面。如果网站挂了很多弹窗广告,百度会认为你的网站严重影响用户体验。对于这些网站,百度会严厉打击,不会给你好的排名。. 百度冰桶算法对抗网站页面广告。
6、创建索引
根据上述处理结果,搜索引擎将网站的页面放入自己的索引库中。索引库中的内容实际上是百度排名的结果。当我们使用site命令查询网站的收录时,百度发布索引的内容。
输入关键字 抓取所有网页(亚马逊运营的主要工作就是玩流量,做排名!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-18 06:14
一位接受小编采访的亚马逊资深运营商表示:运营的主要工作就是玩流量和排名!亚马逊发展到今天,除了是一个购物平台,还是一个强大的搜索引擎。
亚马逊网站流量的最大来源是 SEO,或搜索流量。最常见的购物习惯是通过关键词进行搜索。可以说,每一个关键词都是我们listing的入口。
“买家必须能够找到您的产品才能进行购买。买家可以通过输入关键词搜索您的产品,我们的系统会将买家输入的关键词与您匹配为产品提供要匹配的产品名称和描述等信息。”
监控关键词排名的重要性
关键词 排名越高,listing被点击转化的可能性越大;房源点击率和转化率越高,关键词的排名就越高。我们可以从亚马逊的营销飞轮中看到这一点:
这也是亚马逊运营一直追求“首页关键词”的原因。除非是蓝海市场的小众产品,否则新上架的Listings很难直接在首页上架,所以我们必须持续监控自己和竞品。关键词 排名,经过分析计算,再采取相应措施进行排名!
作为运营,每天必须完成的任务之一就是监控自己和竞品的关键词排名。如何监控?
首先:
在亚马逊前台输入关键词,在搜索结果页面找到你的listing,然后记录下来和之前的数据对比。同样的方法用于监控竞争产品。
如果你的 关键词 排名低,有更多的 ASIN 和更多的竞争产品,监控你的 关键词 排名,同时监控竞争产品 关键词。这个工作量堪比单个订单的大量操作,每个订单手动点击“请求评论”!
第二种:
使用工具-JS网页版的关键词排名监控,智能监控自己和竞品的关键词动态,告别繁琐的手工步骤,不错过竞品的任何变化。
关键词排名监控的升级
01
多渠道添加产品和关键词
多渠道添加产品
进入关键词排名监控页面,点击【添加商品】,我们有3种方式添加我们要跟踪的商品:
多通道加法关键词
我们可以通过以下3种方法添加关键词:
如果我们选择手动录入竞品,一次可以录入9个竞品ASIN,基本可以涵盖我们要监控的竞品范围。
自动生成关键词库
进入商品后,系统会立即抓取ASIN排名TOP 50的关键词并填入关键词库。最多可同时显示前500名竞品关键词。
02
关键词性能可视化
添加产品和关键词后,点击【保存】,图形化的关键词跟踪数据会立即返回。
一次可以查看10个关键词的排名,可以选择10个关键词,按搜索量或字母排序,选择关键词进行分析。
03
多维度高品质筛选关键词
在可视化图表下方,还有表格化的精准数据供查看和分析,自带过滤器,根据条件过滤出合格的关键词:
根据排名、PPC出价和搜索量过滤条件,更快了解流量分布,不错过任何流量入口。
您可以在标题、五点和描述中嵌入选定的核心关键词。然后继续监测关键词在这个ASIN下的排名,判断Listing优化的效果。
根据关键词的趋势,竞品的首页流量词,以及对应的PPC推荐出价,找出最适合的PPC关键词和关键词的最佳出价你! 查看全部
输入关键字 抓取所有网页(亚马逊运营的主要工作就是玩流量,做排名!(组图))
一位接受小编采访的亚马逊资深运营商表示:运营的主要工作就是玩流量和排名!亚马逊发展到今天,除了是一个购物平台,还是一个强大的搜索引擎。
亚马逊网站流量的最大来源是 SEO,或搜索流量。最常见的购物习惯是通过关键词进行搜索。可以说,每一个关键词都是我们listing的入口。
“买家必须能够找到您的产品才能进行购买。买家可以通过输入关键词搜索您的产品,我们的系统会将买家输入的关键词与您匹配为产品提供要匹配的产品名称和描述等信息。”
监控关键词排名的重要性
关键词 排名越高,listing被点击转化的可能性越大;房源点击率和转化率越高,关键词的排名就越高。我们可以从亚马逊的营销飞轮中看到这一点:
这也是亚马逊运营一直追求“首页关键词”的原因。除非是蓝海市场的小众产品,否则新上架的Listings很难直接在首页上架,所以我们必须持续监控自己和竞品。关键词 排名,经过分析计算,再采取相应措施进行排名!
作为运营,每天必须完成的任务之一就是监控自己和竞品的关键词排名。如何监控?
首先:
在亚马逊前台输入关键词,在搜索结果页面找到你的listing,然后记录下来和之前的数据对比。同样的方法用于监控竞争产品。
如果你的 关键词 排名低,有更多的 ASIN 和更多的竞争产品,监控你的 关键词 排名,同时监控竞争产品 关键词。这个工作量堪比单个订单的大量操作,每个订单手动点击“请求评论”!
第二种:
使用工具-JS网页版的关键词排名监控,智能监控自己和竞品的关键词动态,告别繁琐的手工步骤,不错过竞品的任何变化。
关键词排名监控的升级
01
多渠道添加产品和关键词
多渠道添加产品
进入关键词排名监控页面,点击【添加商品】,我们有3种方式添加我们要跟踪的商品:
多通道加法关键词
我们可以通过以下3种方法添加关键词:
如果我们选择手动录入竞品,一次可以录入9个竞品ASIN,基本可以涵盖我们要监控的竞品范围。
自动生成关键词库
进入商品后,系统会立即抓取ASIN排名TOP 50的关键词并填入关键词库。最多可同时显示前500名竞品关键词。
02
关键词性能可视化
添加产品和关键词后,点击【保存】,图形化的关键词跟踪数据会立即返回。
一次可以查看10个关键词的排名,可以选择10个关键词,按搜索量或字母排序,选择关键词进行分析。
03
多维度高品质筛选关键词
在可视化图表下方,还有表格化的精准数据供查看和分析,自带过滤器,根据条件过滤出合格的关键词:
根据排名、PPC出价和搜索量过滤条件,更快了解流量分布,不错过任何流量入口。
您可以在标题、五点和描述中嵌入选定的核心关键词。然后继续监测关键词在这个ASIN下的排名,判断Listing优化的效果。
根据关键词的趋势,竞品的首页流量词,以及对应的PPC推荐出价,找出最适合的PPC关键词和关键词的最佳出价你!
输入关键字 抓取所有网页(超级排名系统原文链接:学会分析网站页面的索引库-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-18 06:13
原文出处:超级排位系统
原文链接:学习分析网站页面-超级排名系统的索引库
搜索引擎检索页面。下一步是分析页面内容,主要包括确定页面类型、提取页面主题、去除页面噪声、去除停用词、中文分词、注册统计、重建关键词索引数据库. 超级排名系统编辑器编译发布。
判断页面是普通页面还是特殊页面,如PDF、WPS、PPT、TXT等;区分文字、图片、视频等内容形式,识别页面网站论坛、视频站、文字站等。
目前搜索引擎基本不识别JS、AJAX、flash、图片、视频、frame和iframe框架结构的内容,主要是利用文本关键词抓取文本处理和搜索信息。提取页面级功能内容,例如标题、关键字和描述。这些特征占网页内容相关性的很大比例。一般情况下,它还表示网页的主题。
剔除无关广告、登录框、版权声明等噪音内容,提取主题内容。这部分不是很严谨,每个搜索引擎的处理都不一样。一般推荐的内容,锚文本,导航等还是很有价值的。
分词是中文搜索引擎的一个独特步骤。搜索引擎需要识别哪些词可以组合成词。每个搜索引擎都有自己庞大的词汇量。根据词典匹配,对网页内容进行切分。中文分词主要有两种方法:基于字典的匹配和基于统计的分词。他们有自己的优点和缺点。在实际应用中,他们混合了这种方法,不仅快速有效,而且可以识别生词,消除歧义。
百度搜索引擎可以通过快照页面查看输入的文本分为哪些关键词,如下图:
分词的目的是了解网页的内容。会先删除“de”、“de”、“ah”、“ba”等停用词,使页面文字的主题更加突出。当然,虚词不是很好。例如,新华字典页介绍了“啊”主题词的读音、意义和用法。“啊”是主题关键词。关键词 排名优化是对搜索引擎条目和历史数据的持续跟踪和分析。
分词后,搜索引擎会统计每个词在页面上出现的次数并计算密度,以便搜索引擎识别页面内容的相关性。建议关键词的布局密度在2%-8%之间。如果太低,很容易被认为是主题内容的相关性低,如果太高,则可能被认为是关键词堆砌,容易被处罚。
内容相关性:除了页面标题、关键词、描述、词密度,H标签(H1标签也很重,一般用于文章标题,H2、H3标签也有一定的效果,一般用来分割话题,但不是H4之后),加粗标签的内容明显会比其他常见标签更受关注。另外,核心关键词最好出现在页面的前面而不是后面。锚文本链接的相关性作为重要数据被采集和分析。
搜索引擎喜欢原创 内容,但不喜欢很多重复的内容页面。完成以上步骤后,他们就可以识别页面的内容功能,再次重复内容页面。
经过上述处理后,记录了页面关键字集,记录了词频、位置、格式(H标签、粗体、锚文本)等权重因素。搜索引擎创建页面的索引结构和关键字表。该指标有两种结构:正向指标结构和反向指标结构。在正向索引结构中,每个文件对应一个文件ID,文件的内容用一组关键字表示。
搜索引擎用户通过关键字进行搜索。正索引不利于查询效率,搜索引擎会将正索引变成倒排索引。倒排索引结构是关键字到文件集的映射。用户将只检索索引页。
收录:只要能被搜索引擎蜘蛛抓取,经过分析,有价值的页面就会被收录。
索引:搜索引擎已经收录页面,用户认为有意义的会议内容,可能会创建索引,可能会有流量。网站 排名优化基于网页已被索引的事实。
超级排名系统小编提醒大家,只要网站结构清晰,内容有价值,并且网站定期更新,那么站长平台提交链接和外链提高搜索引擎识别网站 以采集量和索引量,2-7天优化首页做SEO是非常有可能的。
百度蜘蛛爬了多少页不是很重要,重要的是索引数据库建立了多少页。搜索引擎的索引数据库是分层的。优质的网页会分配到重要的索引库,普通的网页会留在普通的数据库中,较差的网页会分配到低级别的数据库作为补充材料。目前60%的搜索需求只能通过使用重要的索引库来满足。这也是一些网站合集太高,但流量不理想的原因。
进入优质索引库的前提是对用户的价值。包括但不仅限于:
其实网上的大部分网站根本就不是百度的收录。不是百度没找到,而是建库前的筛选过程被过滤掉了。过滤的初始阶段:
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX、flash、图片、视频等。 查看全部
输入关键字 抓取所有网页(超级排名系统原文链接:学会分析网站页面的索引库-)
原文出处:超级排位系统
原文链接:学习分析网站页面-超级排名系统的索引库
搜索引擎检索页面。下一步是分析页面内容,主要包括确定页面类型、提取页面主题、去除页面噪声、去除停用词、中文分词、注册统计、重建关键词索引数据库. 超级排名系统编辑器编译发布。
判断页面是普通页面还是特殊页面,如PDF、WPS、PPT、TXT等;区分文字、图片、视频等内容形式,识别页面网站论坛、视频站、文字站等。
目前搜索引擎基本不识别JS、AJAX、flash、图片、视频、frame和iframe框架结构的内容,主要是利用文本关键词抓取文本处理和搜索信息。提取页面级功能内容,例如标题、关键字和描述。这些特征占网页内容相关性的很大比例。一般情况下,它还表示网页的主题。
剔除无关广告、登录框、版权声明等噪音内容,提取主题内容。这部分不是很严谨,每个搜索引擎的处理都不一样。一般推荐的内容,锚文本,导航等还是很有价值的。
分词是中文搜索引擎的一个独特步骤。搜索引擎需要识别哪些词可以组合成词。每个搜索引擎都有自己庞大的词汇量。根据词典匹配,对网页内容进行切分。中文分词主要有两种方法:基于字典的匹配和基于统计的分词。他们有自己的优点和缺点。在实际应用中,他们混合了这种方法,不仅快速有效,而且可以识别生词,消除歧义。
百度搜索引擎可以通过快照页面查看输入的文本分为哪些关键词,如下图:
分词的目的是了解网页的内容。会先删除“de”、“de”、“ah”、“ba”等停用词,使页面文字的主题更加突出。当然,虚词不是很好。例如,新华字典页介绍了“啊”主题词的读音、意义和用法。“啊”是主题关键词。关键词 排名优化是对搜索引擎条目和历史数据的持续跟踪和分析。
分词后,搜索引擎会统计每个词在页面上出现的次数并计算密度,以便搜索引擎识别页面内容的相关性。建议关键词的布局密度在2%-8%之间。如果太低,很容易被认为是主题内容的相关性低,如果太高,则可能被认为是关键词堆砌,容易被处罚。
内容相关性:除了页面标题、关键词、描述、词密度,H标签(H1标签也很重,一般用于文章标题,H2、H3标签也有一定的效果,一般用来分割话题,但不是H4之后),加粗标签的内容明显会比其他常见标签更受关注。另外,核心关键词最好出现在页面的前面而不是后面。锚文本链接的相关性作为重要数据被采集和分析。
搜索引擎喜欢原创 内容,但不喜欢很多重复的内容页面。完成以上步骤后,他们就可以识别页面的内容功能,再次重复内容页面。
经过上述处理后,记录了页面关键字集,记录了词频、位置、格式(H标签、粗体、锚文本)等权重因素。搜索引擎创建页面的索引结构和关键字表。该指标有两种结构:正向指标结构和反向指标结构。在正向索引结构中,每个文件对应一个文件ID,文件的内容用一组关键字表示。
搜索引擎用户通过关键字进行搜索。正索引不利于查询效率,搜索引擎会将正索引变成倒排索引。倒排索引结构是关键字到文件集的映射。用户将只检索索引页。
收录:只要能被搜索引擎蜘蛛抓取,经过分析,有价值的页面就会被收录。
索引:搜索引擎已经收录页面,用户认为有意义的会议内容,可能会创建索引,可能会有流量。网站 排名优化基于网页已被索引的事实。
超级排名系统小编提醒大家,只要网站结构清晰,内容有价值,并且网站定期更新,那么站长平台提交链接和外链提高搜索引擎识别网站 以采集量和索引量,2-7天优化首页做SEO是非常有可能的。
百度蜘蛛爬了多少页不是很重要,重要的是索引数据库建立了多少页。搜索引擎的索引数据库是分层的。优质的网页会分配到重要的索引库,普通的网页会留在普通的数据库中,较差的网页会分配到低级别的数据库作为补充材料。目前60%的搜索需求只能通过使用重要的索引库来满足。这也是一些网站合集太高,但流量不理想的原因。
进入优质索引库的前提是对用户的价值。包括但不仅限于:
其实网上的大部分网站根本就不是百度的收录。不是百度没找到,而是建库前的筛选过程被过滤掉了。过滤的初始阶段:
部分内容使用了百度蜘蛛无法解析的技术,如JS、AJAX、flash、图片、视频等。
输入关键字 抓取所有网页( 文献获取葵花plus,让你写论文不用愁(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-17 15:08
文献获取葵花plus,让你写论文不用愁(上)
)
很多学生已经在毕业的路上,他们不得不面对一个难题,那就是写论文。很多学生为了写论文,得了黑眼圈,但还是一无所获。他们被散文折磨得死去活来,又爱又恨,写散文必不可少的一步就是查资料。古人云:“一本书百读百读。” 或许你在知网多翻翻,就知道怎么写论文了。所以小编今天整理了文献给你搞定Sunflower Plus,让你不用再为写论文发愁了。
写在前面:
先看爬取的效果
知网的反爬虫方法很强。反正我在PC端爬取的时候,用selenium爬取的时候是拿不到源码的。这真的很烦人。后来换了手机端就搞定了。爬取移动终端的操作如下。首先,进入知网后,选择开发工具,建议放在右边,然后点击图片中的红框,然后刷新网页切换到移动端。
进入手机端界面如下图(注意:记得刷新网页):
这是网址
在调用selenium之前先设置一些参数
from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byimport timeimport jsonimport csv# 设置谷歌驱动器的环境options = webdriver.ChromeOptions()# 设置chrome不加载图片,提高速度options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})# 创建一个谷歌驱动器browser = webdriver.Chrome(options=options)url = 'http://wap.cnki.net/touch/web/guide'
既然使用了selenium,那么我们需要获取输入框的id来自动输入关键字,输入关键字然后获取搜索按钮,然后点击
代码如下(输入的关键字是python):
# 请求urlbrowser.get(url)# 显示等待输入框是否加载完成WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.ID, 'keyword') ))# 找到输入框的id,并输入python关键字browser.find_element_by_id('keyword').send_keys('python')# 输入关键字之后点击搜索browser.find_element_by_id('btnSearch ').click()
搜索关键字后跳转到这个界面
通过selenium的显示和等待,我们可以等待其中的一些信息加载完毕,然后进行爬取,这样就可以避免因为元素没有加载而报错。如下图,我们可以知道这个信息在这个div标签中,所以我们可以等待这个元素加载
# 显示等待文献是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'g-search-body') ) )
向下滚动页面,您可以看到加载更多。可以通过显示和等待来判断按钮是否加载。如果在没有加载的情况下点击它,那么会报错。
代码,等待按钮加载并获取按钮
# 显示等待加载更多按钮加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'c-company__body-item-more') ) ) # 获取加载更多按钮 Btn = browser.find_element_by_class_name('c-company__body-item-more')
基础基本搞定,下一步就是开始获取信息了
获取信息是爬虫的基本能力,这里就不多说了,下图代码见注释
我上面说的就是这样。看图,正好我们需要的信息标签是1、3、5、7、9等等,所以是2*count-1
没什么好说的,代码注释基本都写好了,附上完整代码
from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byimport timeimport jsonimport csv# 设置谷歌驱动器的环境options = webdriver.ChromeOptions()# 设置chrome不加载图片,提高速度options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})# 创建一个谷歌驱动器browser = webdriver.Chrome(options=options)url = 'http://wap.cnki.net/touch/web/guide'# 声明一个全局列表,用来存储字典data_list = []def start_spider(page): # 请求url browser.get(url) # 显示等待输入框是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.ID, 'keyword') ) ) # 找到输入框的id,并输入python关键字 browser.find_element_by_id('keyword').click() browser.find_element_by_id('keyword_ordinary').send_keys('python') # 输入关键字之后点击搜索 browser.find_element_by_class_name('btn-search ').click() # print(browser.page_source) # 显示等待文献是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'g-search-body') ) ) # 声明一个标记,用来标记翻页几页 count = 1 while True: # 显示等待加载更多按钮加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'c-company__body-item-more') ) ) # 获取加载更多按钮 Btn = browser.find_element_by_class_name('c-company__body-item-more') # 显示等待该信息加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.XPATH, '//div[@id="searchlist_div"]/div[{}]/div[@]'.format(2*count-1)) ) ) # 获取在div标签的信息,其中format(2*count-1)是因为加载的时候有显示多少条 # 简单的说就是这些div的信息都是奇数 divs = browser.find_elements_by_xpath('//div[@id="searchlist_div"]/div[{}]/div[@]'.format(2*count-1)) # 遍历循环 for div in divs: # 获取文献的题目 name = div.find_element_by_class_name('c-company__body-title').text # 获取文献的作者 author = div.find_element_by_class_name('c-company__body-author').text # 获取文献的摘要 content = div.find_element_by_class_name('c-company__body-content').text # 获取文献的来源和日期、文献类型等 text = div.find_element_by_class_name('c-company__body-name').text.split() if (len(text) == 3 and text[-1] == '优先') or len(text) == 2: # 来源 source = text[0] # 日期 datetime = text[1] # 文献类型 literature_type = None else: source = text[0] datetime = text[2] literature_type = text[1] # 获取下载数和被引数 temp = div.find_element_by_class_name('c-company__body-info').text.split() # 下载数 download = temp[0].split(':')[-1] # 被引数 cite = temp[1].split(':')[-1] # 声明一个字典存储数据 data_dict = {} data_dict['name'] = name data_dict['author'] = author data_dict['content'] = content data_dict['source'] = source data_dict['datetime'] = datetime data_dict['literature_type'] = literature_type data_dict['download'] = download data_dict['cite'] = cite data_list.append(data_dict) print(data_dict) # 如果Btn按钮(就是加载更多这个按钮)没有找到(就是已经到底了),就退出 if not Btn: break else: Btn.click() # 如果到了爬取的页数就退出 if count == page: break count += 1 # 延迟两秒,我们不是在攻击服务器 time.sleep(2)def main(): start_spider(eval(input('请输入要爬取的页数(如果需要全部爬取请输入0):'))) # 将数据写入json文件中 with open('data_json.json', 'a+', encoding='utf-8') as f: json.dump(data_list, f, ensure_ascii=False, indent=4) print('json文件写入完成') # 将数据写入csv文件 with open('data_csv.csv', 'w', encoding='utf-8', newline='') as f: # 表头 title = data_list[0].keys() # 声明writer对象 writer = csv.DictWriter(f, title) # 写入表头 writer.writeheader() # 批量写入数据 writer.writerows(data_list) print('csv文件写入完成')if __name__ == '__main__': main()
概括:
学术之路艰难而漫长。希望编辑器中的这个程序可以帮助你在学术道路上走得更轻松一些。希望大家多多阅读文献,多发表文献,让自己的学术工作做得更好!
如果您对此案有任何进一步的问题或意见,请告诉我,我很乐意跟进并提出建议。
查看全部
输入关键字 抓取所有网页(
文献获取葵花plus,让你写论文不用愁(上)
)
很多学生已经在毕业的路上,他们不得不面对一个难题,那就是写论文。很多学生为了写论文,得了黑眼圈,但还是一无所获。他们被散文折磨得死去活来,又爱又恨,写散文必不可少的一步就是查资料。古人云:“一本书百读百读。” 或许你在知网多翻翻,就知道怎么写论文了。所以小编今天整理了文献给你搞定Sunflower Plus,让你不用再为写论文发愁了。
写在前面:
先看爬取的效果
知网的反爬虫方法很强。反正我在PC端爬取的时候,用selenium爬取的时候是拿不到源码的。这真的很烦人。后来换了手机端就搞定了。爬取移动终端的操作如下。首先,进入知网后,选择开发工具,建议放在右边,然后点击图片中的红框,然后刷新网页切换到移动端。
进入手机端界面如下图(注意:记得刷新网页):
这是网址
在调用selenium之前先设置一些参数
from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byimport timeimport jsonimport csv# 设置谷歌驱动器的环境options = webdriver.ChromeOptions()# 设置chrome不加载图片,提高速度options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})# 创建一个谷歌驱动器browser = webdriver.Chrome(options=options)url = 'http://wap.cnki.net/touch/web/guide'
既然使用了selenium,那么我们需要获取输入框的id来自动输入关键字,输入关键字然后获取搜索按钮,然后点击
代码如下(输入的关键字是python):
# 请求urlbrowser.get(url)# 显示等待输入框是否加载完成WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.ID, 'keyword') ))# 找到输入框的id,并输入python关键字browser.find_element_by_id('keyword').send_keys('python')# 输入关键字之后点击搜索browser.find_element_by_id('btnSearch ').click()
搜索关键字后跳转到这个界面
通过selenium的显示和等待,我们可以等待其中的一些信息加载完毕,然后进行爬取,这样就可以避免因为元素没有加载而报错。如下图,我们可以知道这个信息在这个div标签中,所以我们可以等待这个元素加载
# 显示等待文献是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'g-search-body') ) )
向下滚动页面,您可以看到加载更多。可以通过显示和等待来判断按钮是否加载。如果在没有加载的情况下点击它,那么会报错。
代码,等待按钮加载并获取按钮
# 显示等待加载更多按钮加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'c-company__body-item-more') ) ) # 获取加载更多按钮 Btn = browser.find_element_by_class_name('c-company__body-item-more')
基础基本搞定,下一步就是开始获取信息了
获取信息是爬虫的基本能力,这里就不多说了,下图代码见注释
我上面说的就是这样。看图,正好我们需要的信息标签是1、3、5、7、9等等,所以是2*count-1
没什么好说的,代码注释基本都写好了,附上完整代码
from selenium import webdriverfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byimport timeimport jsonimport csv# 设置谷歌驱动器的环境options = webdriver.ChromeOptions()# 设置chrome不加载图片,提高速度options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})# 创建一个谷歌驱动器browser = webdriver.Chrome(options=options)url = 'http://wap.cnki.net/touch/web/guide'# 声明一个全局列表,用来存储字典data_list = []def start_spider(page): # 请求url browser.get(url) # 显示等待输入框是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.ID, 'keyword') ) ) # 找到输入框的id,并输入python关键字 browser.find_element_by_id('keyword').click() browser.find_element_by_id('keyword_ordinary').send_keys('python') # 输入关键字之后点击搜索 browser.find_element_by_class_name('btn-search ').click() # print(browser.page_source) # 显示等待文献是否加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'g-search-body') ) ) # 声明一个标记,用来标记翻页几页 count = 1 while True: # 显示等待加载更多按钮加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.CLASS_NAME, 'c-company__body-item-more') ) ) # 获取加载更多按钮 Btn = browser.find_element_by_class_name('c-company__body-item-more') # 显示等待该信息加载完成 WebDriverWait(browser, 1000).until( EC.presence_of_all_elements_located( (By.XPATH, '//div[@id="searchlist_div"]/div[{}]/div[@]'.format(2*count-1)) ) ) # 获取在div标签的信息,其中format(2*count-1)是因为加载的时候有显示多少条 # 简单的说就是这些div的信息都是奇数 divs = browser.find_elements_by_xpath('//div[@id="searchlist_div"]/div[{}]/div[@]'.format(2*count-1)) # 遍历循环 for div in divs: # 获取文献的题目 name = div.find_element_by_class_name('c-company__body-title').text # 获取文献的作者 author = div.find_element_by_class_name('c-company__body-author').text # 获取文献的摘要 content = div.find_element_by_class_name('c-company__body-content').text # 获取文献的来源和日期、文献类型等 text = div.find_element_by_class_name('c-company__body-name').text.split() if (len(text) == 3 and text[-1] == '优先') or len(text) == 2: # 来源 source = text[0] # 日期 datetime = text[1] # 文献类型 literature_type = None else: source = text[0] datetime = text[2] literature_type = text[1] # 获取下载数和被引数 temp = div.find_element_by_class_name('c-company__body-info').text.split() # 下载数 download = temp[0].split(':')[-1] # 被引数 cite = temp[1].split(':')[-1] # 声明一个字典存储数据 data_dict = {} data_dict['name'] = name data_dict['author'] = author data_dict['content'] = content data_dict['source'] = source data_dict['datetime'] = datetime data_dict['literature_type'] = literature_type data_dict['download'] = download data_dict['cite'] = cite data_list.append(data_dict) print(data_dict) # 如果Btn按钮(就是加载更多这个按钮)没有找到(就是已经到底了),就退出 if not Btn: break else: Btn.click() # 如果到了爬取的页数就退出 if count == page: break count += 1 # 延迟两秒,我们不是在攻击服务器 time.sleep(2)def main(): start_spider(eval(input('请输入要爬取的页数(如果需要全部爬取请输入0):'))) # 将数据写入json文件中 with open('data_json.json', 'a+', encoding='utf-8') as f: json.dump(data_list, f, ensure_ascii=False, indent=4) print('json文件写入完成') # 将数据写入csv文件 with open('data_csv.csv', 'w', encoding='utf-8', newline='') as f: # 表头 title = data_list[0].keys() # 声明writer对象 writer = csv.DictWriter(f, title) # 写入表头 writer.writeheader() # 批量写入数据 writer.writerows(data_list) print('csv文件写入完成')if __name__ == '__main__': main()
概括:
学术之路艰难而漫长。希望编辑器中的这个程序可以帮助你在学术道路上走得更轻松一些。希望大家多多阅读文献,多发表文献,让自己的学术工作做得更好!
如果您对此案有任何进一步的问题或意见,请告诉我,我很乐意跟进并提出建议。
https://res.wx.qq.com/mpres/ht ... 21.png" /> 
