
网页新闻抓取
网页新闻抓取( Python学习交流群:爬取前的准备:jsonJavascript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-10-17 19:13
Python学习交流群:爬取前的准备:jsonJavascript)
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
【前言】
Python学习交流群:834179111,群里有很多学习资料。欢迎大家前来交流学习。
爬行前的准备:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
json
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
Javascript 对象
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
使用请求获取网页信息
使用 BeautifulSoup 将网页信息转换为可操作的块
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
可以通过beautifulSoup中的select方法获取对应的元素,获取的元素为列表形式,可以用for循环一一解析出来
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取到html标签值后,可以使用['href']获取'href'属性的值,如
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻编号:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
re正则表达式的使用:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
使用 for 循环获取多页新闻
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻发布时间:
获取的信息可能收录不需要的成分,即可以获取其他我们不想要的元素,例如发布者。里面的元素可以用contents拆分成list形式,用contents[0]获取对应的元素
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
时间字符串转换
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻文章:
检查其类别后,根据上述选择获取新闻内容。获取的内容为列表形式。您可以使用 for 循环删除标签并将内容添加到您创建的列表中(例如 article = [])
*** 其中,可以使用''.join(article)将文章列表中的每一项用换行符''分隔开;**
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
上面获取单个消息的代码可以在一行中完成:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取评论数:(获取评论数后会发现评论是以js的形式发送给浏览器的,所以必须先将获取到的内容转换成json格式才能读取python字典):
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
完整代码(以新浪新闻为例):
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
存储的excel文件如下:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
问题:在jupyter notebook中导入pandas时可能会出现导入错误
解决方法:不要使用命令行打开jupyter notebook,直接找软件打开或者在Anocanda Navigator中打开即可 查看全部
网页新闻抓取(
Python学习交流群:爬取前的准备:jsonJavascript)
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
【前言】
Python学习交流群:834179111,群里有很多学习资料。欢迎大家前来交流学习。
爬行前的准备:

今天给大家分享一些新浪新闻的数据,用Python在网上爬取
json
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
Javascript 对象
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
使用请求获取网页信息
使用 BeautifulSoup 将网页信息转换为可操作的块
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
可以通过beautifulSoup中的select方法获取对应的元素,获取的元素为列表形式,可以用for循环一一解析出来
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取到html标签值后,可以使用['href']获取'href'属性的值,如
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻编号:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
re正则表达式的使用:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
使用 for 循环获取多页新闻
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻发布时间:
获取的信息可能收录不需要的成分,即可以获取其他我们不想要的元素,例如发布者。里面的元素可以用contents拆分成list形式,用contents[0]获取对应的元素
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
时间字符串转换
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻文章:
检查其类别后,根据上述选择获取新闻内容。获取的内容为列表形式。您可以使用 for 循环删除标签并将内容添加到您创建的列表中(例如 article = [])
*** 其中,可以使用''.join(article)将文章列表中的每一项用换行符''分隔开;**
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
上面获取单个消息的代码可以在一行中完成:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取评论数:(获取评论数后会发现评论是以js的形式发送给浏览器的,所以必须先将获取到的内容转换成json格式才能读取python字典):
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
完整代码(以新浪新闻为例):
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
存储的excel文件如下:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
问题:在jupyter notebook中导入pandas时可能会出现导入错误
解决方法:不要使用命令行打开jupyter notebook,直接找软件打开或者在Anocanda Navigator中打开即可
网页新闻抓取(网站title就是所谓的网站标题,百度上将其其称为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-15 04:08
#seo#网站title 就是所谓的网站title。百度称之为“网页标题是网页的高级概括”。它有多大用处?先来看看你有没有遇到过这样的情况。有些网站的 关键词 排名比你低,但他们的访问者比你多。网站建设周期时间差不多,但在网页易用性方面明显优于对方,但无论排名如何,都没有那么高。问题的根源不是你的网站内容不如人,可能是你的页面标题做的不好。这些排名靠前的网站都有一个共同点,就是网站的标题写得很好,相比之下,垃圾网站的标题写得往往很差!
那么如果我们按照较高的排名写标题网站?一开始对网站的优化也不是没有这么幼稚的想法,后来发现每个站点的权重不一样,所以titte上写的方法难免会不一样。那么学习别人的网站title就没有意义了。
特殊关键词的使用
比如标题中使用了“官网”这个词,如果放在一些普通的网站上,那么这些网站很可能会因为两个字而被降级。官网上的两个字是需要做官网认证,不是随便加的。如果大家都这样写,谁知道哪个网站才是真正的官网呢?
使用高权重关键词
关键词 用于酒店预订和旅游度假,这样写一个较低的权重网站怎么办?结果可能是这个网站没有可以排名的关键词。这是为什么?总之,你没有足够的重量来支撑你设置的关键词。就像“定一个小目标,赚他一亿”这句话的权威。王健林说的,显然比嘴上说的更有说服力。这也是标题的艺术。
现在,让我们回到正题,网站的标题应该怎么写?下面的网络优化问题为大家介绍几个重点,希望对各位朋友有所帮助:
标题长度
很多人在准备网站title时的想法通常是这样的:把你做的所有关键词都放在title上。不要想一想:搜索引擎能接受你的网站上这么多的关键词标题吗?每个站点都有权对配额进行加权。设置的关键字越多,单个关键词的权重越低,最终可能导致网站的所有关键词都上不来。
品牌词和流量词的选择
许多 网站 都是这种情况。网站标题搜搜搜,都是写的产品关键词或者流量关键词,从头到尾都没有网站名字。为了得到更多的关键词,放弃自己的品牌词,这样真的好吗?同样的产品,一个是名牌产品,一个是无品牌产品。相信不用我多说,大家都知道如何选择。其实搜索引擎蜘蛛也在思考。
疑问词的选择
很多网站在发布文章时,往往采取“XXX哪家公司强?”这样的做法。真的有用吗?在这里我想说的网络优化的事情是:这句话是可以的,但是搜索引擎识别这一套,就看你自己的实力了。如果将标题设置为“哪个挖掘机技术强?”,即使你的名字和别人很相似,第一个出来的可能是蓝翔。这个网站有发言权吗?这确实是一个值得思考的问题,否则,也许搜索引擎蜘蛛会不喜欢它。
网站title 就像我们微信里的描述,让陌生人一句话就能理解我们。网站title 就是用这句话让搜索引擎理解这个网站。如果第一印象好,搜索引擎愿意联系这个网站,自然会提升网站的排名和流量。所以,不要在这个问题上敷衍了事,说不定你会因此多得到几百w的订单。 查看全部
网页新闻抓取(网站title就是所谓的网站标题,百度上将其其称为)
#seo#网站title 就是所谓的网站title。百度称之为“网页标题是网页的高级概括”。它有多大用处?先来看看你有没有遇到过这样的情况。有些网站的 关键词 排名比你低,但他们的访问者比你多。网站建设周期时间差不多,但在网页易用性方面明显优于对方,但无论排名如何,都没有那么高。问题的根源不是你的网站内容不如人,可能是你的页面标题做的不好。这些排名靠前的网站都有一个共同点,就是网站的标题写得很好,相比之下,垃圾网站的标题写得往往很差!
那么如果我们按照较高的排名写标题网站?一开始对网站的优化也不是没有这么幼稚的想法,后来发现每个站点的权重不一样,所以titte上写的方法难免会不一样。那么学习别人的网站title就没有意义了。
特殊关键词的使用
比如标题中使用了“官网”这个词,如果放在一些普通的网站上,那么这些网站很可能会因为两个字而被降级。官网上的两个字是需要做官网认证,不是随便加的。如果大家都这样写,谁知道哪个网站才是真正的官网呢?
使用高权重关键词
关键词 用于酒店预订和旅游度假,这样写一个较低的权重网站怎么办?结果可能是这个网站没有可以排名的关键词。这是为什么?总之,你没有足够的重量来支撑你设置的关键词。就像“定一个小目标,赚他一亿”这句话的权威。王健林说的,显然比嘴上说的更有说服力。这也是标题的艺术。
现在,让我们回到正题,网站的标题应该怎么写?下面的网络优化问题为大家介绍几个重点,希望对各位朋友有所帮助:
标题长度
很多人在准备网站title时的想法通常是这样的:把你做的所有关键词都放在title上。不要想一想:搜索引擎能接受你的网站上这么多的关键词标题吗?每个站点都有权对配额进行加权。设置的关键字越多,单个关键词的权重越低,最终可能导致网站的所有关键词都上不来。
品牌词和流量词的选择
许多 网站 都是这种情况。网站标题搜搜搜,都是写的产品关键词或者流量关键词,从头到尾都没有网站名字。为了得到更多的关键词,放弃自己的品牌词,这样真的好吗?同样的产品,一个是名牌产品,一个是无品牌产品。相信不用我多说,大家都知道如何选择。其实搜索引擎蜘蛛也在思考。
疑问词的选择
很多网站在发布文章时,往往采取“XXX哪家公司强?”这样的做法。真的有用吗?在这里我想说的网络优化的事情是:这句话是可以的,但是搜索引擎识别这一套,就看你自己的实力了。如果将标题设置为“哪个挖掘机技术强?”,即使你的名字和别人很相似,第一个出来的可能是蓝翔。这个网站有发言权吗?这确实是一个值得思考的问题,否则,也许搜索引擎蜘蛛会不喜欢它。
网站title 就像我们微信里的描述,让陌生人一句话就能理解我们。网站title 就是用这句话让搜索引擎理解这个网站。如果第一印象好,搜索引擎愿意联系这个网站,自然会提升网站的排名和流量。所以,不要在这个问题上敷衍了事,说不定你会因此多得到几百w的订单。
网页新闻抓取( 爬取一个新闻网站为分析思路很简单(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-15 04:02
爬取一个新闻网站为分析思路很简单(图))
Python爬取新闻网站并破解反爬取
一开始我觉得爬一个新闻网站很容易,因为一般的新闻网站比较容易爬。
但是,当我开始分析和编写代码时,运行它之后,我发现它并没有那么简单。
需要爬取的消息网站是
分析
这个想法很简单:
分析网站-->找出每个页面的URL规则-->分析每个页面收录的新闻链接-->回收批量下载
看起来是不是很简单?现在我开始分析每个URL的页数
我分开开的
链接到第一页
链接到第二页
链接到第三页
可以通过观察发现
page=后面的数字是页码,然后我把页码改成其他数字打开用原来的页面跳转到其他页面看同样的内容,所以现在找到每个页面的URL模式,然后然后通过for循环。你可以继续爬
for i in range(1,3):
url="http://www.shxz.gov.cn/sites/C ... 2Bstr(i)+"&ctgId=fe188544-e1fe-4230-b754-40e8d70ae432&leftBarId=08f6f7e1-badb-49fd-8da9-009f8dcc14a0"
然后分析每个页面的URL,右击查看,然后直接复制一个新闻标题,在页面源码上按Ctr+F就可以找到第一条新闻的标题。下面有一段代码。我点进去发现直接跳到了第一个新闻界面,然后我试着查了一下这样的网址有多少,发现有17个,但是每页不重复的新闻是12个,剩下的5个旁边是推荐内容。
ViewCon2_pg.ashx?ctgId=fe188544-e1fe-4230-b754-40e8d70ae432&infId=7f2c956f-75b0-4a59-808b-fa72b3307db0&leftBarId=08f40df8df9da-f40df9dad
跳转后的网址是
只需要找出每个页面的12个ViewCon2_pg.ash······这个代码,然后在前面加上每个新闻的URL,所以我只需要过滤掉每个页面的12段代码
观察源码,选择正则表达式过滤
<p>pat=' 查看全部
网页新闻抓取(
爬取一个新闻网站为分析思路很简单(图))
Python爬取新闻网站并破解反爬取
一开始我觉得爬一个新闻网站很容易,因为一般的新闻网站比较容易爬。
但是,当我开始分析和编写代码时,运行它之后,我发现它并没有那么简单。
需要爬取的消息网站是
分析
这个想法很简单:
分析网站-->找出每个页面的URL规则-->分析每个页面收录的新闻链接-->回收批量下载
看起来是不是很简单?现在我开始分析每个URL的页数
我分开开的
链接到第一页
链接到第二页
链接到第三页
可以通过观察发现
page=后面的数字是页码,然后我把页码改成其他数字打开用原来的页面跳转到其他页面看同样的内容,所以现在找到每个页面的URL模式,然后然后通过for循环。你可以继续爬
for i in range(1,3):
url="http://www.shxz.gov.cn/sites/C ... 2Bstr(i)+"&ctgId=fe188544-e1fe-4230-b754-40e8d70ae432&leftBarId=08f6f7e1-badb-49fd-8da9-009f8dcc14a0"
然后分析每个页面的URL,右击查看,然后直接复制一个新闻标题,在页面源码上按Ctr+F就可以找到第一条新闻的标题。下面有一段代码。我点进去发现直接跳到了第一个新闻界面,然后我试着查了一下这样的网址有多少,发现有17个,但是每页不重复的新闻是12个,剩下的5个旁边是推荐内容。
ViewCon2_pg.ashx?ctgId=fe188544-e1fe-4230-b754-40e8d70ae432&infId=7f2c956f-75b0-4a59-808b-fa72b3307db0&leftBarId=08f40df8df9da-f40df9dad
跳转后的网址是
只需要找出每个页面的12个ViewCon2_pg.ash······这个代码,然后在前面加上每个新闻的URL,所以我只需要过滤掉每个页面的12段代码
观察源码,选择正则表达式过滤
<p>pat='
网页新闻抓取(2016.10.12河北邮币卡电子盘交易所每日一练)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-14 04:25
以这个文章为例,
抓取文章的内容时,不要抓取【今日直播】的模块内容
抓取文章的内容代码:
from pyquery import PyQuery as pq
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
}
url = 'https://finance.sina.com.cn/mo ... 39%3B
res = requests.get(url,headers=headers)
response = pq(bytes(res.text, res.encoding).decode('utf-8', 'ignore')) # 转码
content_1 = response("#artibody p").text() # 获取内容
print(content_1)
【注意】由于爬取时文章的内容是乱码,需要转码。转码请参考网页抓取时的文字乱码解决方法。
此时获取的内容收录【今日直播】
解析网页获取【今日直播】标签
利用代码
response("#artibody blockquote").remove()
删除【今日直播】标签模块
response("#artibody blockquote").remove()
content_2 = response("#artibody p").text()
print(content_2)
此时获取的内容中没有【今日直播】 查看全部
网页新闻抓取(2016.10.12河北邮币卡电子盘交易所每日一练)
以这个文章为例,
抓取文章的内容时,不要抓取【今日直播】的模块内容

抓取文章的内容代码:
from pyquery import PyQuery as pq
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
}
url = 'https://finance.sina.com.cn/mo ... 39%3B
res = requests.get(url,headers=headers)
response = pq(bytes(res.text, res.encoding).decode('utf-8', 'ignore')) # 转码
content_1 = response("#artibody p").text() # 获取内容
print(content_1)
【注意】由于爬取时文章的内容是乱码,需要转码。转码请参考网页抓取时的文字乱码解决方法。
此时获取的内容收录【今日直播】
解析网页获取【今日直播】标签
利用代码
response("#artibody blockquote").remove()
删除【今日直播】标签模块
response("#artibody blockquote").remove()
content_2 = response("#artibody p").text()
print(content_2)
此时获取的内容中没有【今日直播】
网页新闻抓取(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-13 16:19
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是由于论文只讲了算法原理,并没有具体的语言实现,所以我根据论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻对结果进行了测试,发现提取效果非常好,几乎100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面信息抽取。如果目标网站不是新闻页面,也不是今日头条中的相册类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者是空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
验证消息:GNE 查看全部
网页新闻抓取(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是由于论文只讲了算法原理,并没有具体的语言实现,所以我根据论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻对结果进行了测试,发现提取效果非常好,几乎100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:

目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。

在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图

from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面信息抽取。如果目标网站不是新闻页面,也不是今日头条中的相册类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者是空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通

验证消息:GNE
网页新闻抓取( 如何通过Python爬虫按关键词抓取相关的新闻(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-13 08:36
如何通过Python爬虫按关键词抓取相关的新闻(二)
)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
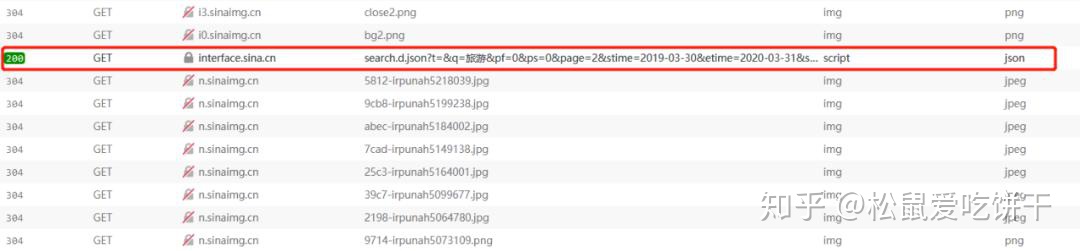
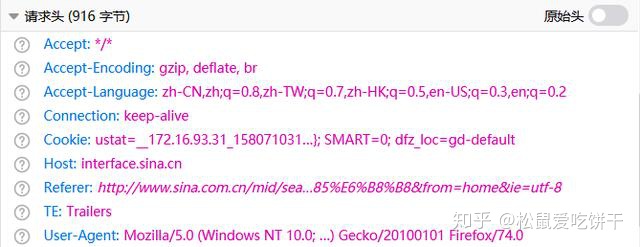
所以回到网站看看哪里出了问题
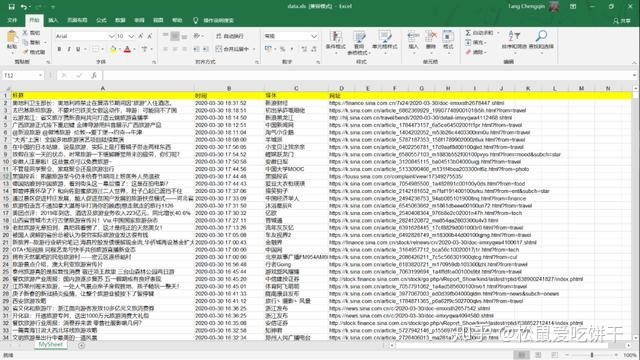
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果
查看全部
网页新闻抓取(
如何通过Python爬虫按关键词抓取相关的新闻(二)
)

前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。


网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:

恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:

所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。

完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果
网页新闻抓取(主权项:1.基于Ajax的新闻网页动态数据的抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-13 08:33
主权项:
1.基于Ajax的新闻网页动态数据抓取方法,其特点是以下步骤: 步骤(101):建立新闻网页抓取内容数据库,设置新闻网页抓取的编码内容库的方法;获取待爬取新闻页面的新闻列表页面的URL地址; 步骤(102):访问待爬取的新闻页面的新闻列表页面的URL地址,判断通过浏览器开发者工具新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具查找Ajax请求的数据源;如果没有,结束;步骤(103):确定数据源和Ajax请求的数据源) 步骤(101)是编码方式一致,如果不一致,则对数据源进行编码转换,然后转到步骤(104) ; 如果一致,直接进入步骤(104)@)>; 步骤(104): 解析数据格式:将数据源的格式解析成obj新闻列表页面后台语言处理的ect格式或数组格式;步骤(105):更改步骤(104)将解析后的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进入步骤(106)@) >; 否则,将数据作为字符串处理;完成后转步骤(106)@>; Step(106)@>:遍历数据对象或数组类型的输出列表;Step(107):使用网络爬虫采集 Step(106)@>得到Output list;Step(108):将采集的数据存入数据库。
展开 查看全部
网页新闻抓取(主权项:1.基于Ajax的新闻网页动态数据的抓取方法)
主权项:
1.基于Ajax的新闻网页动态数据抓取方法,其特点是以下步骤: 步骤(101):建立新闻网页抓取内容数据库,设置新闻网页抓取的编码内容库的方法;获取待爬取新闻页面的新闻列表页面的URL地址; 步骤(102):访问待爬取的新闻页面的新闻列表页面的URL地址,判断通过浏览器开发者工具新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具查找Ajax请求的数据源;如果没有,结束;步骤(103):确定数据源和Ajax请求的数据源) 步骤(101)是编码方式一致,如果不一致,则对数据源进行编码转换,然后转到步骤(104) ; 如果一致,直接进入步骤(104)@)>; 步骤(104): 解析数据格式:将数据源的格式解析成obj新闻列表页面后台语言处理的ect格式或数组格式;步骤(105):更改步骤(104)将解析后的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进入步骤(106)@) >; 否则,将数据作为字符串处理;完成后转步骤(106)@>; Step(106)@>:遍历数据对象或数组类型的输出列表;Step(107):使用网络爬虫采集 Step(106)@>得到Output list;Step(108):将采集的数据存入数据库。
展开
网页新闻抓取(Python开发简单爬虫,开始要爬取的澎湃新闻网页url )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-13 08:28
)
前言
因为学校的大数据课程需要获取数据,我们设置了爬虫实验。之前没怎么接触过爬虫,所以在网上找了个视频。这里推荐牧奇网的爬虫视频:Python开发一个简单的爬虫。短小精悍,实用。
开始
需要爬取的澎湃新闻网页的url为:按照基本爬虫写,需要:
图片
这里的写法比较简单,只选择了一条评论超过1k的新闻进行爬取。使用的主要库是 urllib.request(网络下载器)和 beautifulsoup(网络解析器)。因为澎湃新闻评论是通过下拉浏览器侧边栏自动刷新的,使用了自动工具,最后将数据写入txt文件,使用了python写文件的一些知识,所以这个主要流程爬虫是:
(刚开始爬,发现一条评论无法爬取……自闭……打开网页仔细查看后,发现评论信息被下拉刷新了。不知有没有是任何可以模拟网页自动下拉刷新的工具。我在网上搜索了资料,发现selenium是一个可以用ChromeDriver控制谷歌浏览器的自动化工具。)
还有一个坑。之前用beautifulsoup的时候,不知道可以递归调用find()和find_all()函数。我为如何找到子标签的问题苦苦挣扎了很长时间。这样看来,beautifulsoup还是蛮好用的。
我们来谈谈解析数据的问题。要分析网页的数据,您需要了解网页的内容。您只需要在要查看的网页内容上右击,查看元素,就可以看到该网页的内容(例如在这里查看昵称的网页结构):
图片
图片
结尾有坑。写入文件时,最好将字符集指定为utf-8,否则会出现乱码。
完整代码如下:
#-*-coding:utf-8-*-
# 解析html的
from bs4 import BeautifulSoup
# 模仿浏览器的
from selenium import webdriver
# 模仿键盘,操作下拉框的
from selenium.webdriver.common.keys import Keys
# 网页解析器BeautifulSoup
from bs4 import BeautifulSoup
import urllib.request
# 正则表达式
import re
# 找到的一则评论大于1k的有关校园暴力的url
# https://www.thepaper.cn/newsDetail_forward_3564808
url = "https://www.thepaper.cn/newsDe ... ot%3B
# 打开文件(指定编码,否则会出现乱码的情况)
with open('./my_data','wt',encoding='utf-8') as f:
# 爬取评论节点(评论如果不下拉刷新的话爬取不到,页面是下拉刷新的,需要使用自动化工具)
# 打开浏览器
driver = webdriver.Chrome(executable_path="D:\\chromedriver.exe")
# 打开你的访问地址
driver.get(url)
# 将页面最大化
driver.maximize_window()
# 循环下拉
# js="var q=document.documentElement.scrollTop=10000"为js脚本,页面下拉
js="var q=document.documentElement.scrollTop=250000"
for i in range(10000):
driver.execute_script(js)
driver.implicitly_wait(3)
# 创建beautifulsoup对象
html = BeautifulSoup(driver.page_source)
# 新闻标题:太原师范学院回应“女生自述遭室友的校园暴力”:正认真核查
title = html.find('h1',class_="news_title").get_text()
print("标题: {}".format(title), file=f)
# 新闻链接就是url
print("链接: {}".format(url), file=f)
# 获取评论数
comment_num_block = html.find('h2',id="comm_span")
comment = re.search(r'\d+[k]*', comment_num_block.get_text()).group()
print("评论数: {}".format(comment), file=f)
# 获取新闻发表时间
publish_time_block = html.find('div',class_="news_about")
# 匹配日期正则表达式
time = re.search(r'\d{4}-\d{1,2}-\d{1,2}', publish_time_block.get_text()).group()
print("时间: {}".format(time), file=f)
print("", file=f)
# 爬取评论节点
# 评论的节点为
comment_nodes = html.find_all('div', class_="comment_que")
count = 1
# print("开始打印评论:")
for node in comment_nodes:
# 获取昵称
nickname = node.find('div', class_="aqwright").find('h3').find('a').get_text().strip()
print("Nickname:{}".format(nickname), file=f)
# 获取评论主体内容
content = node.find('div', class_="aqwright").find('div', class_="ansright_cont").get_text().strip()
print("Content:{}".format(content), file=f)
count = count + 1
if (count < 1000):
# 在每一条评论间打印空行
print("",file=f)
print(count)
else:
break 查看全部
网页新闻抓取(Python开发简单爬虫,开始要爬取的澎湃新闻网页url
)
前言
因为学校的大数据课程需要获取数据,我们设置了爬虫实验。之前没怎么接触过爬虫,所以在网上找了个视频。这里推荐牧奇网的爬虫视频:Python开发一个简单的爬虫。短小精悍,实用。
开始
需要爬取的澎湃新闻网页的url为:按照基本爬虫写,需要:

图片
这里的写法比较简单,只选择了一条评论超过1k的新闻进行爬取。使用的主要库是 urllib.request(网络下载器)和 beautifulsoup(网络解析器)。因为澎湃新闻评论是通过下拉浏览器侧边栏自动刷新的,使用了自动工具,最后将数据写入txt文件,使用了python写文件的一些知识,所以这个主要流程爬虫是:
(刚开始爬,发现一条评论无法爬取……自闭……打开网页仔细查看后,发现评论信息被下拉刷新了。不知有没有是任何可以模拟网页自动下拉刷新的工具。我在网上搜索了资料,发现selenium是一个可以用ChromeDriver控制谷歌浏览器的自动化工具。)
还有一个坑。之前用beautifulsoup的时候,不知道可以递归调用find()和find_all()函数。我为如何找到子标签的问题苦苦挣扎了很长时间。这样看来,beautifulsoup还是蛮好用的。
我们来谈谈解析数据的问题。要分析网页的数据,您需要了解网页的内容。您只需要在要查看的网页内容上右击,查看元素,就可以看到该网页的内容(例如在这里查看昵称的网页结构):
图片
图片
结尾有坑。写入文件时,最好将字符集指定为utf-8,否则会出现乱码。
完整代码如下:
#-*-coding:utf-8-*-
# 解析html的
from bs4 import BeautifulSoup
# 模仿浏览器的
from selenium import webdriver
# 模仿键盘,操作下拉框的
from selenium.webdriver.common.keys import Keys
# 网页解析器BeautifulSoup
from bs4 import BeautifulSoup
import urllib.request
# 正则表达式
import re
# 找到的一则评论大于1k的有关校园暴力的url
# https://www.thepaper.cn/newsDetail_forward_3564808
url = "https://www.thepaper.cn/newsDe ... ot%3B
# 打开文件(指定编码,否则会出现乱码的情况)
with open('./my_data','wt',encoding='utf-8') as f:
# 爬取评论节点(评论如果不下拉刷新的话爬取不到,页面是下拉刷新的,需要使用自动化工具)
# 打开浏览器
driver = webdriver.Chrome(executable_path="D:\\chromedriver.exe")
# 打开你的访问地址
driver.get(url)
# 将页面最大化
driver.maximize_window()
# 循环下拉
# js="var q=document.documentElement.scrollTop=10000"为js脚本,页面下拉
js="var q=document.documentElement.scrollTop=250000"
for i in range(10000):
driver.execute_script(js)
driver.implicitly_wait(3)
# 创建beautifulsoup对象
html = BeautifulSoup(driver.page_source)
# 新闻标题:太原师范学院回应“女生自述遭室友的校园暴力”:正认真核查
title = html.find('h1',class_="news_title").get_text()
print("标题: {}".format(title), file=f)
# 新闻链接就是url
print("链接: {}".format(url), file=f)
# 获取评论数
comment_num_block = html.find('h2',id="comm_span")
comment = re.search(r'\d+[k]*', comment_num_block.get_text()).group()
print("评论数: {}".format(comment), file=f)
# 获取新闻发表时间
publish_time_block = html.find('div',class_="news_about")
# 匹配日期正则表达式
time = re.search(r'\d{4}-\d{1,2}-\d{1,2}', publish_time_block.get_text()).group()
print("时间: {}".format(time), file=f)
print("", file=f)
# 爬取评论节点
# 评论的节点为
comment_nodes = html.find_all('div', class_="comment_que")
count = 1
# print("开始打印评论:")
for node in comment_nodes:
# 获取昵称
nickname = node.find('div', class_="aqwright").find('h3').find('a').get_text().strip()
print("Nickname:{}".format(nickname), file=f)
# 获取评论主体内容
content = node.find('div', class_="aqwright").find('div', class_="ansright_cont").get_text().strip()
print("Content:{}".format(content), file=f)
count = count + 1
if (count < 1000):
# 在每一条评论间打印空行
print("",file=f)
print(count)
else:
break
网页新闻抓取(公司简介大渡河公司重构url流域已完成流域规划报告(咨询稿) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-13 08:23
)
一、公司简介
大渡河公司于2000年11月在成都高新区注册成立,主要任务是开发以公嘴和通街子为母电站,滚动开发大渡河流域水电站,是我国最大的水电开发、建设和国家能源集团的运营管理。综合性大型流域水电开发公司。
公司目前主要负责大渡河流域开发和西藏巴龙藏布河流域开发建设。拥有西藏大渡河干流和支流、巴隆藏布河流域水能资源约3000万千瓦。大渡河流域规划建设梯级电站28座,总装机容量约2340万千瓦。公司负责开发干流17座梯级电站,涉及四川省三州两市(甘孜州、阿坝州、凉山州、雅安市、乐山市)的12个县。总装机容量约1757万千瓦。, 准备构建稳步推进的可持续发展格局。巴龙藏布江流域已完成流域规划报告(征求意见稿),初步规划“一库九层”规划,规划装机容量1142万千瓦。截至目前,公司总资产910.68亿元,四川装机容量约占四川水电总装机容量的四分之一。
二、需求分析
分析网站新闻标题、作者、日期等统计数据,分析网站在线新闻有以上共性,即哪些类型的新闻更容易上传,也可以分析公司较高的稿件作者越多,稿件越多,一定程度上可以体现作者的水平。
三、具体实现
1、利用python爬虫技术获取公司新闻相关信息网站
第一步爬取url:重构url放入多线程队列
url = 'http://www.spddr.com/spddr/index.jsp?id=360'
base_url = 'http://www.spddr.com/spddr/'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
第二步解析url:在多线程队列中获取重构后的url,并进行解析,最后将解析后的信息放入线程队列
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
第三步,下载保存信息:将解析后的信息从队列中取出,执行下载保存操作
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
四、整个代码如下
from lxml import etree
import requests
import csv
import random
from headers_list import headers_list
import threading
from queue import Queue
headers = {
'User-Agent':random.choice(headers_list),
'Cookie': 'JSESSIONID=91AFDB0A74FDB3DE1011B2E59CF99993; JSESSIONID=DD7458D1055A53D464AE8DF68400DE1F',
'Referer': '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
}
#定义一个Producter类,类名通常是大写开头的单词,它继承的是threading.Thread
class Producter(threading.Thread):
# 用init方法绑定属性,比如定义一个人的类,那你可以再定义人的属性,比如有手、有脚
def __init__(self,page_queue,writer_queue,*args,**kwargs):
super(Producter,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
def run(self):
while True:
try:
url = '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
base_url = '[http://www.spddr.com/spddr/](http://www.spddr.com/spddr/)'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
except:
print("解析网页出错")
#定义一个Consumer类,类名通常是大写开头的单词,它继承的是threading.Thread
class Consumer(threading.Thread):
def __init__(self,page_queue,writer_queue,glock,writer,*args,**kwargs):
super(Consumer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
self.glock = glock
self.writer = writer
def run(self):
while True:
try:
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
except:
print("提取信息出错!")
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
if __name__ == '__main__':
# 创建FIFO队列
page_queue = Queue(1000)
writer_queue = Queue(1000)
# 创建线程锁
glock = threading.Lock()
#csv表头信息
head = ['title', 'author', 'department', 'time']
#打开csv文件
fp = open('daduhe.csv', 'a', newline='', errors='ignore', encoding='utf-8')
#用字典方式写入表头信息
writer = csv.DictWriter(fp, head)
writer.writeheader()
for i in range(1,207):
data = {
'nowPage': i,
'totalpage': 206,
'id': 360,
'pages': i,
}
page_queue.put(data)
for x in range(10):
t = Producter(page_queue,writer_queue)#根据Producter类创建一个实例t的线程
t.start()#开启线程
for x in range(10):
t = Consumer(page_queue,writer_queue,glock,writer)#根据Producter类创建一个实例t的线程
t.start() 查看全部
网页新闻抓取(公司简介大渡河公司重构url流域已完成流域规划报告(咨询稿)
)
一、公司简介
大渡河公司于2000年11月在成都高新区注册成立,主要任务是开发以公嘴和通街子为母电站,滚动开发大渡河流域水电站,是我国最大的水电开发、建设和国家能源集团的运营管理。综合性大型流域水电开发公司。
公司目前主要负责大渡河流域开发和西藏巴龙藏布河流域开发建设。拥有西藏大渡河干流和支流、巴隆藏布河流域水能资源约3000万千瓦。大渡河流域规划建设梯级电站28座,总装机容量约2340万千瓦。公司负责开发干流17座梯级电站,涉及四川省三州两市(甘孜州、阿坝州、凉山州、雅安市、乐山市)的12个县。总装机容量约1757万千瓦。, 准备构建稳步推进的可持续发展格局。巴龙藏布江流域已完成流域规划报告(征求意见稿),初步规划“一库九层”规划,规划装机容量1142万千瓦。截至目前,公司总资产910.68亿元,四川装机容量约占四川水电总装机容量的四分之一。
二、需求分析
分析网站新闻标题、作者、日期等统计数据,分析网站在线新闻有以上共性,即哪些类型的新闻更容易上传,也可以分析公司较高的稿件作者越多,稿件越多,一定程度上可以体现作者的水平。
三、具体实现
1、利用python爬虫技术获取公司新闻相关信息网站
第一步爬取url:重构url放入多线程队列
url = 'http://www.spddr.com/spddr/index.jsp?id=360'
base_url = 'http://www.spddr.com/spddr/'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
第二步解析url:在多线程队列中获取重构后的url,并进行解析,最后将解析后的信息放入线程队列
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
第三步,下载保存信息:将解析后的信息从队列中取出,执行下载保存操作
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
四、整个代码如下
from lxml import etree
import requests
import csv
import random
from headers_list import headers_list
import threading
from queue import Queue
headers = {
'User-Agent':random.choice(headers_list),
'Cookie': 'JSESSIONID=91AFDB0A74FDB3DE1011B2E59CF99993; JSESSIONID=DD7458D1055A53D464AE8DF68400DE1F',
'Referer': '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
}
#定义一个Producter类,类名通常是大写开头的单词,它继承的是threading.Thread
class Producter(threading.Thread):
# 用init方法绑定属性,比如定义一个人的类,那你可以再定义人的属性,比如有手、有脚
def __init__(self,page_queue,writer_queue,*args,**kwargs):
super(Producter,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
def run(self):
while True:
try:
url = '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
base_url = '[http://www.spddr.com/spddr/](http://www.spddr.com/spddr/)'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
except:
print("解析网页出错")
#定义一个Consumer类,类名通常是大写开头的单词,它继承的是threading.Thread
class Consumer(threading.Thread):
def __init__(self,page_queue,writer_queue,glock,writer,*args,**kwargs):
super(Consumer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
self.glock = glock
self.writer = writer
def run(self):
while True:
try:
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
except:
print("提取信息出错!")
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
if __name__ == '__main__':
# 创建FIFO队列
page_queue = Queue(1000)
writer_queue = Queue(1000)
# 创建线程锁
glock = threading.Lock()
#csv表头信息
head = ['title', 'author', 'department', 'time']
#打开csv文件
fp = open('daduhe.csv', 'a', newline='', errors='ignore', encoding='utf-8')
#用字典方式写入表头信息
writer = csv.DictWriter(fp, head)
writer.writeheader()
for i in range(1,207):
data = {
'nowPage': i,
'totalpage': 206,
'id': 360,
'pages': i,
}
page_queue.put(data)
for x in range(10):
t = Producter(page_queue,writer_queue)#根据Producter类创建一个实例t的线程
t.start()#开启线程
for x in range(10):
t = Consumer(page_queue,writer_queue,glock,writer)#根据Producter类创建一个实例t的线程
t.start()
网页新闻抓取(田朴珺否认与王石婚姻危机,怒怼网友:吃饱了撑的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-12 06:14
据说,大老王的妻子田朴君否认与王石有婚姻危机,被网友气愤:受够了。
王石
之后,大老王成了热搜名人。
再次成为网红
不少网友表示,怎么能这么说话呢?反正你也是个“贵族”……
今天,我们不讨论这个。我们专门讲解如何使用Python在海量新浪新闻中获取我们想认识的人的消息。我们以大老王的消息为例。本文只讨论技术问题。如果您有兴趣批量获取新浪新闻内容,建议您继续往下阅读。如果你通过这篇文章,你可以得到一个很好的工具。
获取新闻
情况总结
对于这个话题,我尝试了N种方法。如果只抓取新闻,比如首页展示的新闻,新浪没有实施反爬措施,或者反爬措施比较容易破解。但是,如果使用搜索功能,仍然很难抓取搜索到的内容......
今天,我们将教你如何降低这个难度。
简单的方法
刚开始的时候,我的想法是这样的。我先进入新闻搜索页面,然后搜索“王石”,出现了以下内容。
搜索王士后界面
可以看到,内容一共7页,有点小。第一页只有4条新闻,之后每页有20条新闻。(抱歉,我发现了一个bug,截至发帖时,文章的总数并不是我看到的132个,实际上只有116个,我们自己验证一下)
想法
分析网址信息
网址信息
我在使用requests库时,第一页信息正常,但是第二页无法获取。其实页面是由js代码控制的。每次点击页码都会出现相应的内容。如果使用修改后的 URL 传递参数,一般不会从第二页获取内容。
因此,分析网站地址的信息和内容应该是解决此类问题的重中之重。
那该怎么办呢?
我们知道,对于这种js加载页面问题,有两种方式:一种是使用Python中的相关模块来执行js代码,网上有很多教程,感兴趣的朋友可以参考学习;另一种是使用selenium或者PhantomJS等自动化模块模拟一个人打开一个网页,然后获取该网页的源代码(此时获取的代码就是执行js后的代码),然后分析内容。
怎么做?
想法
今天,我们重点用第二种方法来梳理一下新浪新闻中关于王石的新闻。我们的想法是直接打开这个搜索页面,首先获取第一页的内容,从中提取出我们需要的信息;那么你每次使用selenium点击下一页的内容时,都会得到下一页的源码,提取你需要的信息。最后,我们每个页面需要的信息通过一个列表返回。
准备环境
Python3.7 安装 selenium、requests、bs4 库
具体实施步骤
【获取单页内容】
准备开始
一、设置UA代理
header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome /63.0.3239.132 Safari/537.36'}
这里的UA代理是爬虫的基础。UA代理池可以自己搭建,这里不再赘述。
然后获取单页的内容。由于搜索URL的URL是经过编码的,这里应该设置一个URL处理函数
def parse_key(key):
返回 parse.quote(key, encoding='gb2312')
然后使用这个函数来获取单个页面的内容。
def get_text(key='王石'):
req = requests.get(url.format(parse_key(key)), headers=header).text
返回请求
这里没有异常处理,貌似不需要了,可以自己添加。
【使用selenium自动化处理】
自动化处理
定义一个函数,使用webdriver打开URL并返回webdriver对象,方便我们后续的操作
def in_url(url):
wb = webdriver.Ie()
wb.get(url)
返回 wb
然后,当我们点击一个页码时,就会显示每个页面的新闻内容并获取源代码。
def click_element(wb, el_no, total_no):
如果 el_no == 1:
e = wb.find_element_by_xpath('//*[@id="_function_code_page"]/a[1]')
e.click()
elif 1
e = wb.find_element_by_xpath('//*[@id="_function_code_page"]/a[{}]'.format(
el_no + 2))
e.click()
返回 wb.page_source
以上两步是重点。通过分析,我们知道每次点击“Next Page”,xpath变化范围为页码+2(因为网页中增加了“Previous Page”和“Next Page”选项),当el_no为1时,我们实际点击获取第二页的内容。以上内容不难理解。
【使用BeautifulSoup库获取有效信息】
汤不错,可以煮吗
下面是我们定义的获取信息的函数。它可以从单个页面的内容中搜索所有“h2”标签内容(包括新闻标题、作者、发布日期、新闻链接等),我们会从标签中一一获取关键内容出来。
def find_info_bs4(html):
r_lst = []
汤 = BeautifulSoup(html,'html.parser')
对于soup.find_all('h2') 中的项目:
tmp_dict = {}
tmp_dict['title'] = item.find('a').text
打印(tmp_dict['title'])
tmp_dict['author'] = item.find('span').text.split('')[0]
打印(tmp_dict['作者'])
tmp_dict['time'] = "".join(item.find('span').text.split('')[1:])
打印(tmp_dict['时间'])
tmp_dict['url'] = item.find('a').get('href')
打印(tmp_dict['url'])
r_lst.append(tmp_dict)
返回 r_lst
【整合流程】
资源整合
# 使用selenium输入网址
wb = in_url(url.format(parse_key('王石')))
# 最后结果
结果_lst = []
print('第一页')
# 首先将第一页新闻过滤器添加到result_lst
result_lst.extend(find_info_bs4(wb.page_source))
打印('{}'.format(len(find_info_bs4(wb.page_source))))
# 获取总页数,有多少分页元素就有多少页
n = len(wb.find_elements_by_xpath('//*[@id="_function_code_page"]/a'))
# 遍历每一页
对于范围内的 i (1, n):
print('第{}页'.format(i + 1))
# 点击获取源代码
html = click_element(wb, i, n)
# 提取有效信息并将字典添加到result_lst
result_lst.extend(find_info_bs4(html))
打印('添加记录{)项目'。格式(len(find_info_bs4(html))))
# 打印最终消息的数量
打印(len(result_lst))
执行结果显示
最后得到如下内容
程序运行结果显示
好了,今天就到此为止。这个怎么样?是不是很酷?有兴趣的小朋友可以试一试。如果修改关键字,则可以检索其他新闻内容。实际上,您可以更改 result_lst 来设置数据类型。当然,你也可以将这些函数封装成一个类来使用。你可以做更多的扩展,这取决于你。
欢迎大家关注我,更多有趣的内容稍后发布。 查看全部
网页新闻抓取(田朴珺否认与王石婚姻危机,怒怼网友:吃饱了撑的)
据说,大老王的妻子田朴君否认与王石有婚姻危机,被网友气愤:受够了。
王石
之后,大老王成了热搜名人。
再次成为网红
不少网友表示,怎么能这么说话呢?反正你也是个“贵族”……
今天,我们不讨论这个。我们专门讲解如何使用Python在海量新浪新闻中获取我们想认识的人的消息。我们以大老王的消息为例。本文只讨论技术问题。如果您有兴趣批量获取新浪新闻内容,建议您继续往下阅读。如果你通过这篇文章,你可以得到一个很好的工具。
获取新闻
情况总结
对于这个话题,我尝试了N种方法。如果只抓取新闻,比如首页展示的新闻,新浪没有实施反爬措施,或者反爬措施比较容易破解。但是,如果使用搜索功能,仍然很难抓取搜索到的内容......
今天,我们将教你如何降低这个难度。
简单的方法
刚开始的时候,我的想法是这样的。我先进入新闻搜索页面,然后搜索“王石”,出现了以下内容。
搜索王士后界面
可以看到,内容一共7页,有点小。第一页只有4条新闻,之后每页有20条新闻。(抱歉,我发现了一个bug,截至发帖时,文章的总数并不是我看到的132个,实际上只有116个,我们自己验证一下)
想法
分析网址信息
网址信息
我在使用requests库时,第一页信息正常,但是第二页无法获取。其实页面是由js代码控制的。每次点击页码都会出现相应的内容。如果使用修改后的 URL 传递参数,一般不会从第二页获取内容。
因此,分析网站地址的信息和内容应该是解决此类问题的重中之重。
那该怎么办呢?
我们知道,对于这种js加载页面问题,有两种方式:一种是使用Python中的相关模块来执行js代码,网上有很多教程,感兴趣的朋友可以参考学习;另一种是使用selenium或者PhantomJS等自动化模块模拟一个人打开一个网页,然后获取该网页的源代码(此时获取的代码就是执行js后的代码),然后分析内容。
怎么做?
想法
今天,我们重点用第二种方法来梳理一下新浪新闻中关于王石的新闻。我们的想法是直接打开这个搜索页面,首先获取第一页的内容,从中提取出我们需要的信息;那么你每次使用selenium点击下一页的内容时,都会得到下一页的源码,提取你需要的信息。最后,我们每个页面需要的信息通过一个列表返回。
准备环境
Python3.7 安装 selenium、requests、bs4 库
具体实施步骤
【获取单页内容】
准备开始
一、设置UA代理
header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome /63.0.3239.132 Safari/537.36'}
这里的UA代理是爬虫的基础。UA代理池可以自己搭建,这里不再赘述。
然后获取单页的内容。由于搜索URL的URL是经过编码的,这里应该设置一个URL处理函数
def parse_key(key):
返回 parse.quote(key, encoding='gb2312')
然后使用这个函数来获取单个页面的内容。
def get_text(key='王石'):
req = requests.get(url.format(parse_key(key)), headers=header).text
返回请求
这里没有异常处理,貌似不需要了,可以自己添加。
【使用selenium自动化处理】
自动化处理
定义一个函数,使用webdriver打开URL并返回webdriver对象,方便我们后续的操作
def in_url(url):
wb = webdriver.Ie()
wb.get(url)
返回 wb
然后,当我们点击一个页码时,就会显示每个页面的新闻内容并获取源代码。
def click_element(wb, el_no, total_no):
如果 el_no == 1:
e = wb.find_element_by_xpath('//*[@id="_function_code_page"]/a[1]')
e.click()
elif 1
e = wb.find_element_by_xpath('//*[@id="_function_code_page"]/a[{}]'.format(
el_no + 2))
e.click()
返回 wb.page_source
以上两步是重点。通过分析,我们知道每次点击“Next Page”,xpath变化范围为页码+2(因为网页中增加了“Previous Page”和“Next Page”选项),当el_no为1时,我们实际点击获取第二页的内容。以上内容不难理解。
【使用BeautifulSoup库获取有效信息】
汤不错,可以煮吗
下面是我们定义的获取信息的函数。它可以从单个页面的内容中搜索所有“h2”标签内容(包括新闻标题、作者、发布日期、新闻链接等),我们会从标签中一一获取关键内容出来。
def find_info_bs4(html):
r_lst = []
汤 = BeautifulSoup(html,'html.parser')
对于soup.find_all('h2') 中的项目:
tmp_dict = {}
tmp_dict['title'] = item.find('a').text
打印(tmp_dict['title'])
tmp_dict['author'] = item.find('span').text.split('')[0]
打印(tmp_dict['作者'])
tmp_dict['time'] = "".join(item.find('span').text.split('')[1:])
打印(tmp_dict['时间'])
tmp_dict['url'] = item.find('a').get('href')
打印(tmp_dict['url'])
r_lst.append(tmp_dict)
返回 r_lst
【整合流程】
资源整合
# 使用selenium输入网址
wb = in_url(url.format(parse_key('王石')))
# 最后结果
结果_lst = []
print('第一页')
# 首先将第一页新闻过滤器添加到result_lst
result_lst.extend(find_info_bs4(wb.page_source))
打印('{}'.format(len(find_info_bs4(wb.page_source))))
# 获取总页数,有多少分页元素就有多少页
n = len(wb.find_elements_by_xpath('//*[@id="_function_code_page"]/a'))
# 遍历每一页
对于范围内的 i (1, n):
print('第{}页'.format(i + 1))
# 点击获取源代码
html = click_element(wb, i, n)
# 提取有效信息并将字典添加到result_lst
result_lst.extend(find_info_bs4(html))
打印('添加记录{)项目'。格式(len(find_info_bs4(html))))
# 打印最终消息的数量
打印(len(result_lst))
执行结果显示
最后得到如下内容
程序运行结果显示
好了,今天就到此为止。这个怎么样?是不是很酷?有兴趣的小朋友可以试一试。如果修改关键字,则可以检索其他新闻内容。实际上,您可以更改 result_lst 来设置数据类型。当然,你也可以将这些函数封装成一个类来使用。你可以做更多的扩展,这取决于你。
欢迎大家关注我,更多有趣的内容稍后发布。
网页新闻抓取(爬虫课题中的需求如下的分析与分析方法(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-11 15:28
)
昨晚,我的朋友向我求助。他的一个主题需要爬取《人民日报》中的文章,方便后续的分词、词性标注、词频统计等一系列数据统计和分析。于是他找到了我。
对爬虫的一般要求如下。简单的看了一下这个网站还有他想爬的东西。难度不大,但涉及的知识相当全面。正好用来练手,所以就答应了。.
在写爬虫之前,回顾一下爬虫的思路。
首先你要清楚自己要爬取什么内容。需求明确了,就可以有目标了;那么,你必须分析目标网站,包括URL结构、HTML页面、网络请求和返回结果等,目的是找到我们网站中的爬取目标在哪里,怎么才能我们得到它,然后指定爬取策略;接下来是编码环节,利用编码发起网络请求,解析网页内容,提取目标数据,并进行数据存储;最后,对代码进行测试,对程序进行改进,比如增加一些输入输出交互使程序使用更方便,增加异常捕获和处理部分,使程序更加健壮。
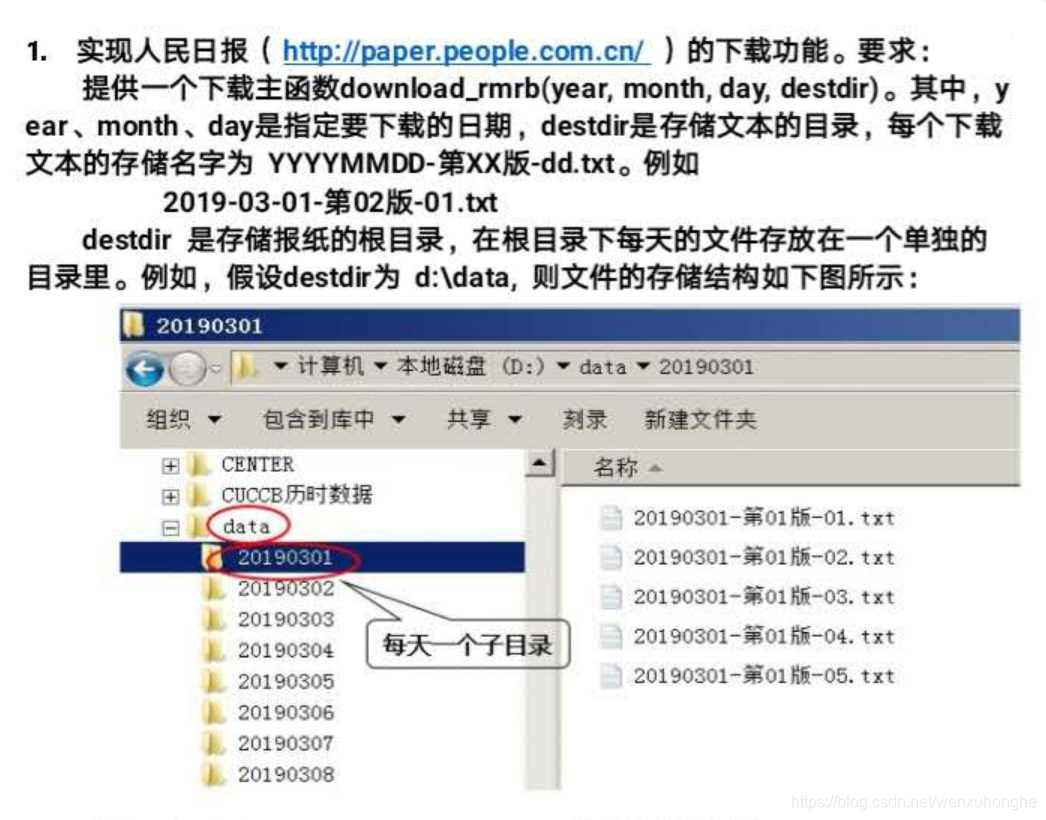
一、明确需求
他的需求其实很简单,就是人民日报每天有一份报纸,每份报纸有几页,每一页有几个文章。他希望将这些文章全部抓取并按照一定的规则存储在本地(具体要求如下图所示)。
二、分析目标网站
1. URL 组成结构
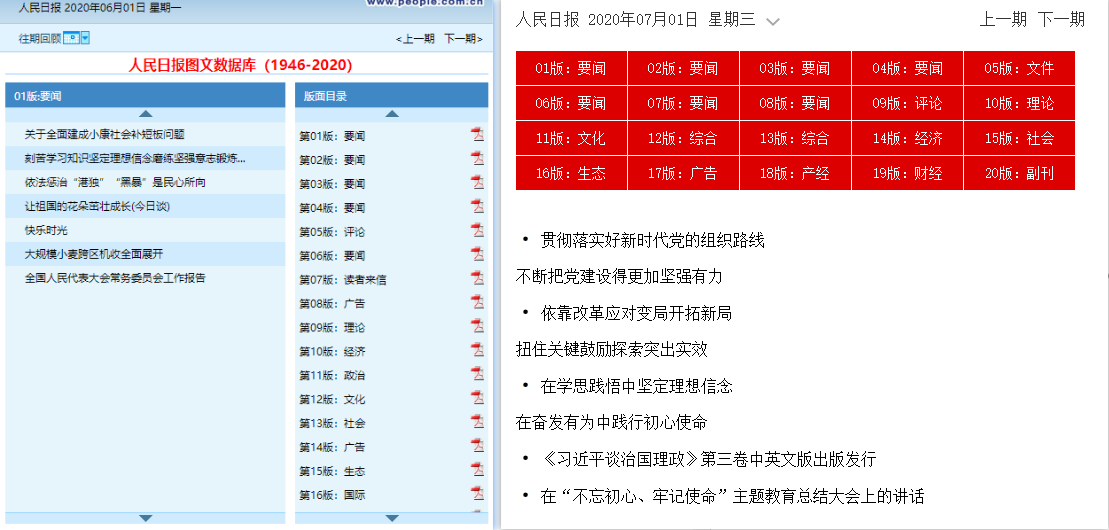
人民日报网站的网址结构比较直观。基本上重要的参数,比如日期、页码、文章号等,都反映在URL中,组成的规则也很简单,像这样
布局目录:
文章内容:
在页面目录的链接中,“/2019-05/06/”表示日期,后面的“_01”表示这是第一页的链接。
文章的内容链接中,“/2019-05/06/”表示日期,后面的“_20190506_5_01”表示这是5月6日该报第一版第五章, 2019文章
值得注意的是,如果日期的“月”、“日”和“页码”数小于10,则必须在日期前加上“0”,而文章@的文章编号> 没有必要。
知道了这一点之后,我们就可以按照这个规则构造一个链接到任何一天的报纸页面,以及一个链接到任何文章文章。
例如,2018 年 6 月 5 日第 4 版目录的链接是:
2018 年 6 月 1 日第 2 版第 3 部分的链接:文章:
点击访问,发现确实如此。至此,网站的URL组成结构分析完毕。
2. 分析网页的HTML结构
在URL分析中,我们也发现网站的页面跳转是通过改变URL来完成的,不涉及Ajax等动态加载方式。也就是说,它的所有数据都是从头开始加载的,我们只需要从html中提取相应的数据即可。
PS:如果使用Ajax的话,网站开头显示的数据是不完整的,只有在触发某些操作时,比如浏览到页面底部,或者点击查看更多按钮等,稍后,它将向服务器发送请求以获取剩余数据。如果是这种情况,我们的爬取策略不是从 HTML 中查找,而是直接向服务器发送请求,然后解析服务器返回的 json 文件。具体方法请参考《Python Web爬虫实战:爬取主题下知乎 18934响应数据》。
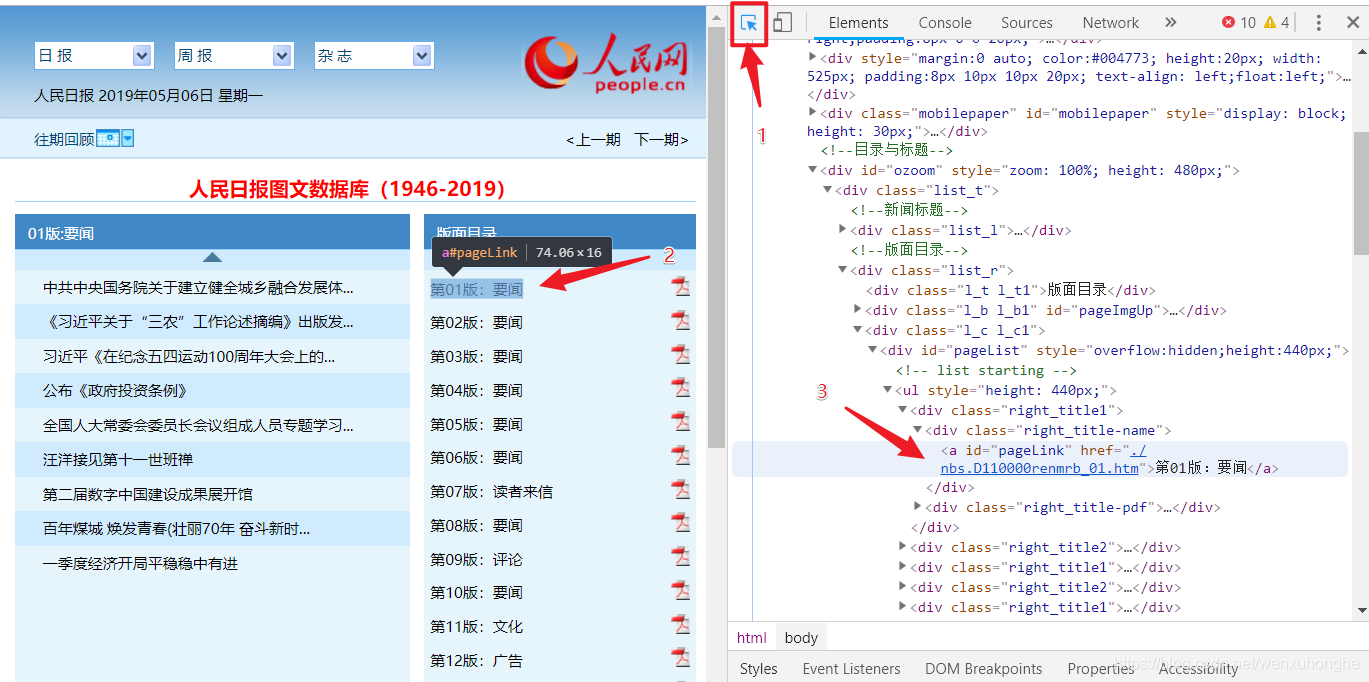
好的,让我们回到正题,让我们分析一下我们的目标网站。按F12调出开发者工具(点击图中1处的小箭头,再点击网页中的内容,可以在html源代码中快速找到对应的位置)。
这样我们就可以知道布局目录存放在一个id=“pageList”的div标签下,而在一个class=“right_title1”或“right_title2”的div标签中,每个div代表一个布局,链接布局在 id = "pageLink" 的标签中。
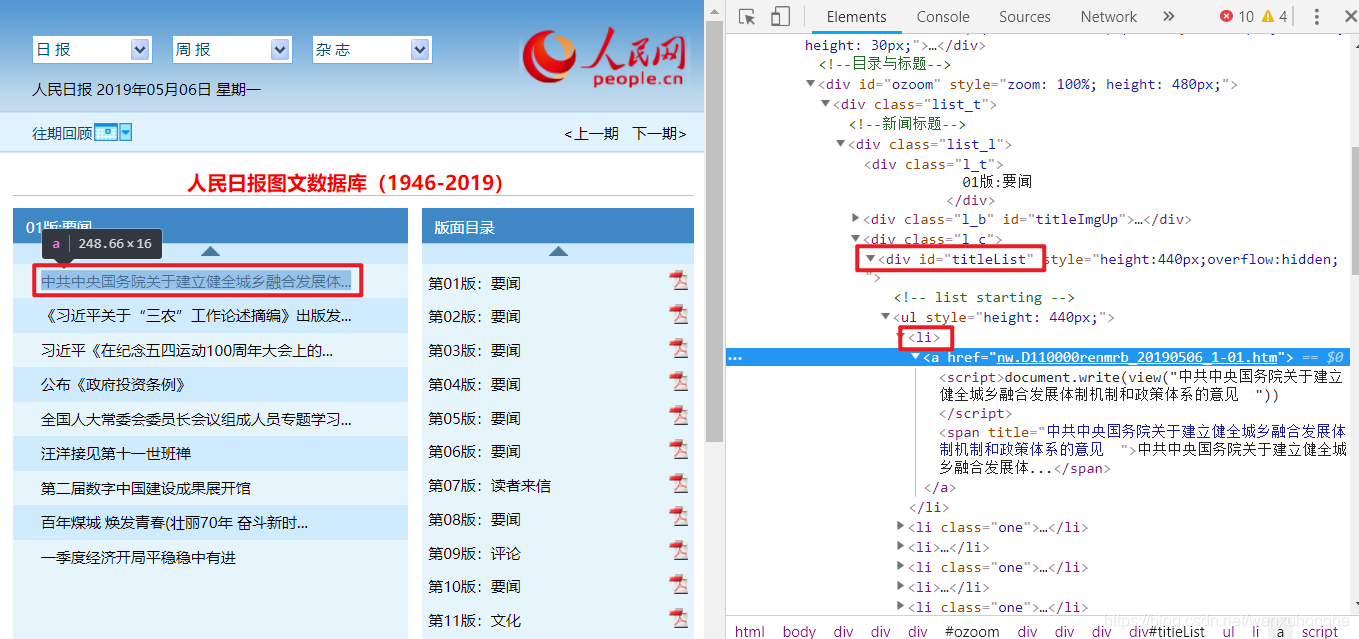
用同样的方法,我们可以知道文章目录存放在id=“titleList”的div标签下的ul标签中。每个li标签代表一块文章,而文章链接在li标签下的a标签中。
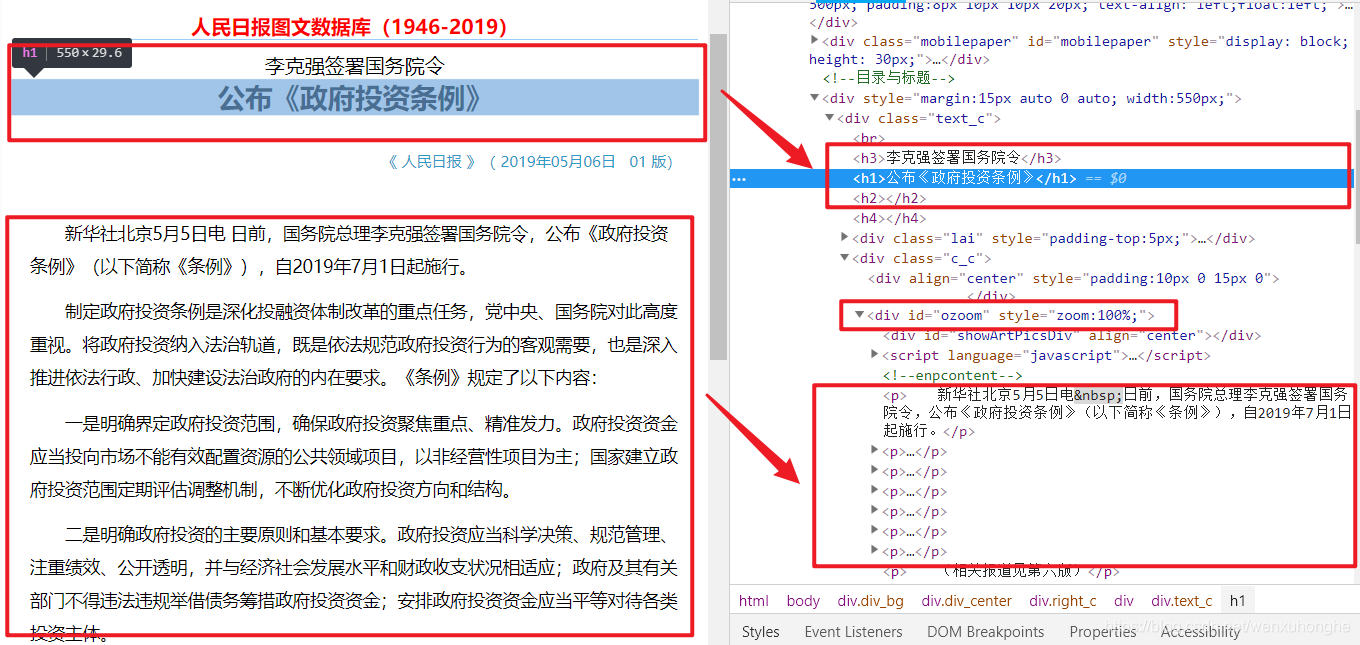
进入文章内容页面后,我们可以知道文章标题是存放在h1、h2、h3标签中的(有的文章标题只用到了h1标签,有的< @文章H2 或 h3 标签可能用于字幕),正文部分存储在 id = "ozoom" 的 div 标签下的 p 标签中。
至此,目标网站的HTML页面分析完成。
3. 制定爬取策略
通过分析目标网站的URL组成结构和HTML结构,我们完成了爬虫的初步研究工作。接下来,我们需要根据网站的特点制定相应的爬取策略,然后评估每种方法的性能优劣和难易程度,最后选择最优方案进行编码实现。
策略一:第一遍,先爬取页面目录,保存每个页面的链接;第二遍,依次访问各个页面的链接,并保存页面的文章链接;第三次,依次访问每个文章链接,将文章的标题和正文保存在本地。
策略二:既然我们已经知道文章链接是如何构建的,那么我们或许可以跳过目录的爬取,直接循环构建文章链接来爬取文章的内容文章。
经过一些比较和简单的编码测试,我决定使用策略一来完成这个爬虫。
主要原因是策略二的逻辑虽然比较简单方便,但有两个问题需要解决。1.每天的报纸页数都不一样,每一页的文章页数也不同。正在构建 URL。如何保证文章不重复或省略?2. 在某些特殊情况下,文章 的编号是不连续的。如何解决这个问题呢?
所以,综合考虑,我认为策略一可能更稳定,更安全(如果你想到解决策略二问题的方法,你可以尝试一下,或者如果你想到其他策略,请留言和我们将一起讨论)。
三、编码链接
接下来是实际的编码环节,不多说,直接开始。
首先导入本项目中用到的库:
import requests
import bs4
import os
import datetime
import time
其中,requests库主要用于发起网络请求,接收服务器返回的数据;bs4库主要用于解析html内容,是一个非常简单易用的库;os 库主要用于将数据输出存储在本地文件中。
def fetchUrl(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
fetchUrl函数用于发起网络请求,可以访问目标url,获取目标网页的html内容并返回。
事实上,异常捕获应该在这里完成(为了简单起见,我把它省略了,伸出我的舌头)。由于网络情况比较复杂,可能会因为各种原因导致访问失败。r.raise_for_status() 代码实际上是在判断访问是否成功。如果访问失败,返回的状态码不是200,执行到这里。会直接抛出相应的异常。
def getPageList(year, month, day):
'''
功能:获取当天报纸的各版面的链接列表
参数:年,月,日
'''
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/nbs.D110000renmrb_01.htm'
html = fetchUrl(url)
bsobj = bs4.BeautifulSoup(html,'html.parser')
pageList = bsobj.find('div', attrs = {'id': 'pageList'}).ul.find_all('div', attrs = {'class': 'right_title-name'})
linkList = []
for page in pageList:
link = page.a["href"]
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link
linkList.append(url)
return linkList
getPageList函数用于抓取当天报纸各版面的链接,保存为数组,返回。
def getTitleList(year, month, day, pageUrl):
'''
功能:获取报纸某一版面的文章链接列表
参数:年,月,日,该版面的链接
'''
html = fetchUrl(pageUrl)
bsobj = bs4.BeautifulSoup(html,'html.parser')
titleList = bsobj.find('div', attrs = {'id': 'titleList'}).ul.find_all('li')
linkList = []
for title in titleList:
tempList = title.find_all('a')
for temp in tempList:
link = temp["href"]
if 'nw.D110000renmrb' in link:
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link
linkList.append(url)
return linkList
getPageList函数用于抓取当日报纸某个页面中文章的所有链接,保存为数组,返回。
def getContent(html):
'''
功能:解析 HTML 网页,获取新闻的文章内容
参数:html 网页内容
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
# 获取文章 标题
title = bsobj.h3.text + '\n' + bsobj.h1.text + '\n' + bsobj.h2.text + '\n'
#print(title)
# 获取文章 内容
pList = bsobj.find('div', attrs = {'id': 'ozoom'}).find_all('p')
content = ''
for p in pList:
content += p.text + '\n'
#print(content)
# 返回结果 标题+内容
resp = title + content
return resp
getContent函数用于访问文章的内容页面,抓取文章的title和body,返回。
def saveFile(content, path, filename):
'''
功能:将文章内容 content 保存到本地文件中
参数:要保存的内容,路径,文件名
'''
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
# 保存文件
with open(path + filename, 'w', encoding='utf-8') as f:
f.write(content)
saveFile函数用于将文章的内容保存到指定的本地文件夹。
def download_rmrb(year, month, day, destdir):
'''
功能:爬取《人民日报》网站 某年 某月 某日 的新闻内容,并保存在 指定目录下
参数:年,月,日,文件保存的根目录
'''
pageList = getPageList(year, month, day)
for page in pageList:
titleList = getTitleList(year, month, day, page)
for url in titleList:
# 获取新闻文章内容
html = fetchUrl(url)
content = getContent(html)
# 生成保存的文件路径及文件名
temp = url.split('_')[2].split('.')[0].split('-')
pageNo = temp[1]
titleNo = temp[0] if int(temp[0]) >= 10 else '0' + temp[0]
path = destdir + '/' + year + month + day + '/'
fileName = year + month + day + '-' + pageNo + '-' + titleNo + '.txt'
# 保存文件
saveFile(content, path, fileName)
download_rmrb 函数是需求中需要的主要函数。根据年、月、日参数,可以将当天报纸文章的所有内容按规则下载并保存到指定路径destdir。
if __name__ == '__main__':
'''
主函数:程序入口
'''
year = "2019"
month = "05"
day = "06"
destdir = "D:/data"
download_rmrb(year, month, day, destdir)
print("爬取完成:" + year + month + day)
至此,程序的主要功能已经完成。
四、改进程序
通过上一章的编码,我们已经实现了通过调用download_rmrb函数,可以下载特定日期的所有文章内容。但同时我们也可以发现,在程序入口的main函数中,日期是硬编码在代码中的,也就是说,如果我们要爬取其他日期的报纸,就必须修改源代码。
很不方便,是不是,我们改进一下,日期是用户以交互方式输入的。
if __name__ == '__main__':
'''
主函数:程序入口
'''
# 爬取指定日期的新闻
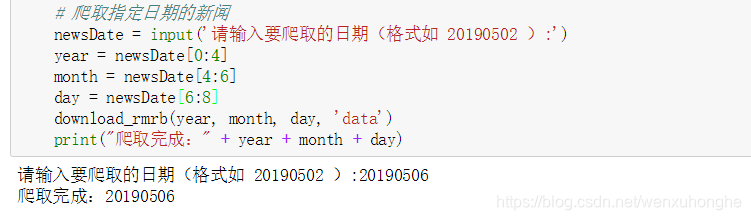
newsDate = input('请输入要爬取的日期(格式如 20190502 ):')
year = newsDate[0:4]
month = newsDate[4:6]
day = newsDate[6:8]
download_rmrb(year, month, day, 'D:/data')
print("爬取完成:" + year + month + day)
不是更方便吗?但问题又来了。如果我想一次攀登一个月或一年怎么办?不用我手动输入几十次或几百次吗?因此,我们可以改进程序。用户输入实际日期和结束日期,程序爬取期间的所有日期都是文章。
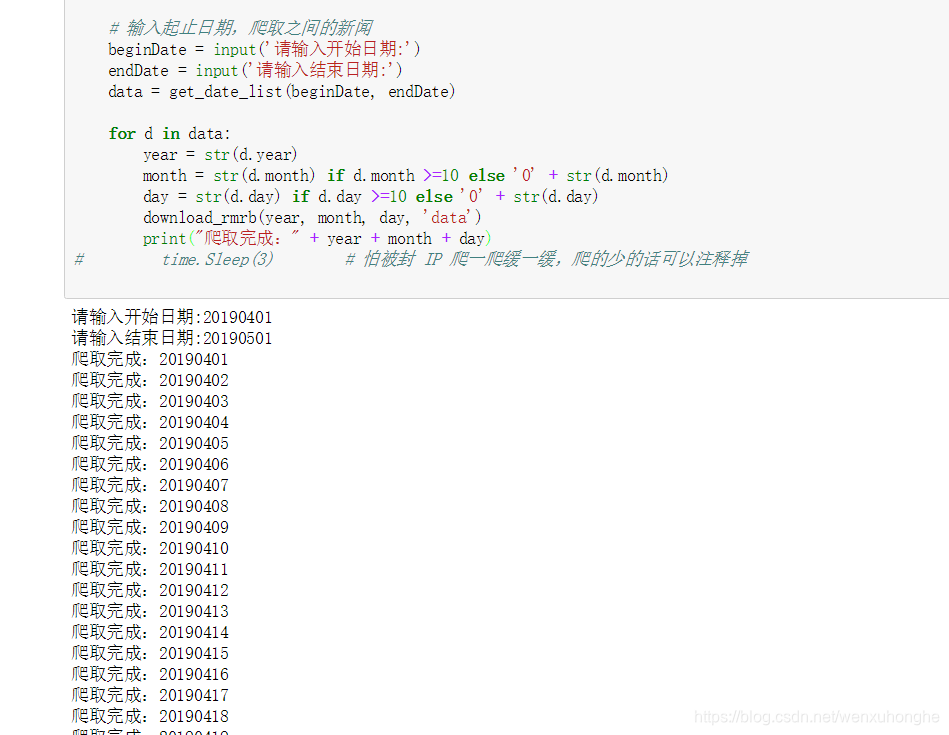
实际运行测试,假设我们要抓取2019年4月的所有报纸内容,那么我们开始日期输入20190401,结束日期输入20190501,回车运行。
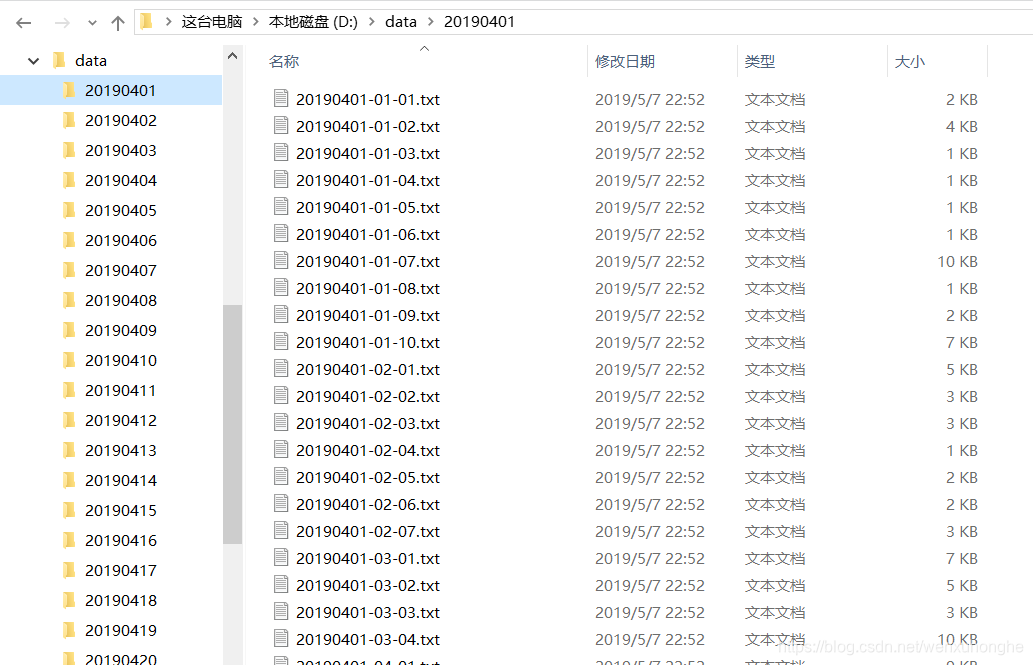
等待一段时间后,程序已经运行完成。我们去文件夹看看我们爬取了什么。
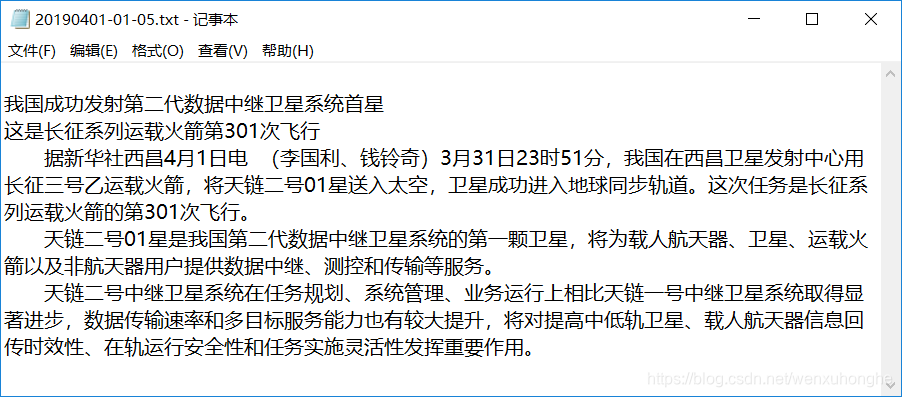
爬取的内容整齐地排列在文件夹中,真的很舒服。随便打开一个文件看看,没问题。
到这里这个爬虫就全部完成了。
写在后面的字
这次好久没有写新的爬虫文章了。一是因为我快毕业了,忙着做毕业设计;另一种是写教程文章,真的很辛苦。,需要整理思路和语言,重新整理代码,要求各种截图,让零基础或者刚入门的人都能看懂,写出来。第三,我找不到一个有趣的动机,因为爬虫总是为了使用而写的,你不能为了炫耀你的技能而写爬虫。那是没有意义的。
一开始就写了一个爬虫来记录自己的成长过程。如果我在学习过程中的这些记录能同时帮助到更多后来者,那就更好了。
2019 年 7 月 10 日更新
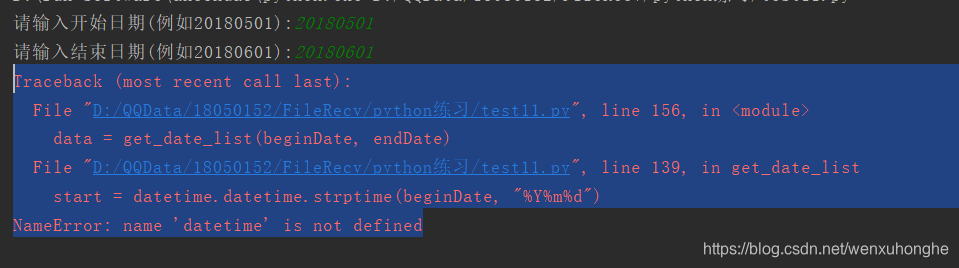
有读者在评论中反映,不能使用输入起止日期的方式来抓取一段时间内的新闻,运行时会报如下错误。
我查了一下,确实是我的疏忽。
这是因为计算日期的函数在datetime库中,在写博客整理代码的过程中,忽略了引用这个库,导致程序运行出错。
解决方法是在程序中添加两行代码:
import datetime
import time
我对博客的代码做了改动,请放心食用。
感谢weixin_42435870,宋心悦悦的朋友指出了问题,非常感谢!!
2020 年 7 月 26 日更新
通过读者朋友的反馈,我发现《人民日报》的网站近日进行了改版,7月1日的新闻版面采用了新的版式。这也导致无法使用原创代码抓取2020年7月1日之后的新闻。
所以这里有一个更新以兼容 网站 的新格式。
1. 在getPageList函数中,替换原来的
pageList = bsobj.find('div', attrs = {'id': 'pageList'}).ul.find_all('div', attrs = {'class': 'right_title-name'})
改成:
temp = bsobj.find('div', attrs = {'id': 'pageList'})
if temp:
pageList = temp.ul.find_all('div', attrs = {'class': 'right_title-name'})
else:
pageList = bsobj.find('div', attrs = {'class': 'swiper-container'}).find_all('div', attrs = {'class': 'swiper-slide'})
2. 在getTitleList函数中,替换原来的
titleList = bsobj.find('div', attrs = {'id': 'titleList'}).ul.find_all('li')
改成:
temp = bsobj.find('div', attrs = {'id': 'titleList'})
if temp:
titleList = temp.ul.find_all('li')
else:
titleList = bsobj.find('ul', attrs = {'class': 'news-list'}).find_all('li')
简单解释一下上面的变化,
1. 在原来的网站中,对布局列表和文章列表的标签进行了调整,所以我们需要使用新的标签和新的属性来获取它们。
2. 为了兼容,我们先获取之前版本的标签。如果有,就说明是改版前的接口。如果不可用,说明是改版后的接口。您需要使用新的标签属性来获取它。
如果文章有什么不明白的地方,或者解释有误,欢迎在评论区批评指正,或扫描下方二维码加我微信。让我们一起学习交流,共同进步。
查看全部
网页新闻抓取(爬虫课题中的需求如下的分析与分析方法(上)
)
昨晚,我的朋友向我求助。他的一个主题需要爬取《人民日报》中的文章,方便后续的分词、词性标注、词频统计等一系列数据统计和分析。于是他找到了我。
对爬虫的一般要求如下。简单的看了一下这个网站还有他想爬的东西。难度不大,但涉及的知识相当全面。正好用来练手,所以就答应了。.
在写爬虫之前,回顾一下爬虫的思路。
首先你要清楚自己要爬取什么内容。需求明确了,就可以有目标了;那么,你必须分析目标网站,包括URL结构、HTML页面、网络请求和返回结果等,目的是找到我们网站中的爬取目标在哪里,怎么才能我们得到它,然后指定爬取策略;接下来是编码环节,利用编码发起网络请求,解析网页内容,提取目标数据,并进行数据存储;最后,对代码进行测试,对程序进行改进,比如增加一些输入输出交互使程序使用更方便,增加异常捕获和处理部分,使程序更加健壮。
一、明确需求
他的需求其实很简单,就是人民日报每天有一份报纸,每份报纸有几页,每一页有几个文章。他希望将这些文章全部抓取并按照一定的规则存储在本地(具体要求如下图所示)。
二、分析目标网站
1. URL 组成结构
人民日报网站的网址结构比较直观。基本上重要的参数,比如日期、页码、文章号等,都反映在URL中,组成的规则也很简单,像这样
布局目录:
文章内容:
在页面目录的链接中,“/2019-05/06/”表示日期,后面的“_01”表示这是第一页的链接。
文章的内容链接中,“/2019-05/06/”表示日期,后面的“_20190506_5_01”表示这是5月6日该报第一版第五章, 2019文章
值得注意的是,如果日期的“月”、“日”和“页码”数小于10,则必须在日期前加上“0”,而文章@的文章编号> 没有必要。
知道了这一点之后,我们就可以按照这个规则构造一个链接到任何一天的报纸页面,以及一个链接到任何文章文章。
例如,2018 年 6 月 5 日第 4 版目录的链接是:
2018 年 6 月 1 日第 2 版第 3 部分的链接:文章:
点击访问,发现确实如此。至此,网站的URL组成结构分析完毕。
2. 分析网页的HTML结构
在URL分析中,我们也发现网站的页面跳转是通过改变URL来完成的,不涉及Ajax等动态加载方式。也就是说,它的所有数据都是从头开始加载的,我们只需要从html中提取相应的数据即可。
PS:如果使用Ajax的话,网站开头显示的数据是不完整的,只有在触发某些操作时,比如浏览到页面底部,或者点击查看更多按钮等,稍后,它将向服务器发送请求以获取剩余数据。如果是这种情况,我们的爬取策略不是从 HTML 中查找,而是直接向服务器发送请求,然后解析服务器返回的 json 文件。具体方法请参考《Python Web爬虫实战:爬取主题下知乎 18934响应数据》。
好的,让我们回到正题,让我们分析一下我们的目标网站。按F12调出开发者工具(点击图中1处的小箭头,再点击网页中的内容,可以在html源代码中快速找到对应的位置)。
这样我们就可以知道布局目录存放在一个id=“pageList”的div标签下,而在一个class=“right_title1”或“right_title2”的div标签中,每个div代表一个布局,链接布局在 id = "pageLink" 的标签中。
用同样的方法,我们可以知道文章目录存放在id=“titleList”的div标签下的ul标签中。每个li标签代表一块文章,而文章链接在li标签下的a标签中。
进入文章内容页面后,我们可以知道文章标题是存放在h1、h2、h3标签中的(有的文章标题只用到了h1标签,有的< @文章H2 或 h3 标签可能用于字幕),正文部分存储在 id = "ozoom" 的 div 标签下的 p 标签中。
至此,目标网站的HTML页面分析完成。
3. 制定爬取策略
通过分析目标网站的URL组成结构和HTML结构,我们完成了爬虫的初步研究工作。接下来,我们需要根据网站的特点制定相应的爬取策略,然后评估每种方法的性能优劣和难易程度,最后选择最优方案进行编码实现。
策略一:第一遍,先爬取页面目录,保存每个页面的链接;第二遍,依次访问各个页面的链接,并保存页面的文章链接;第三次,依次访问每个文章链接,将文章的标题和正文保存在本地。
策略二:既然我们已经知道文章链接是如何构建的,那么我们或许可以跳过目录的爬取,直接循环构建文章链接来爬取文章的内容文章。
经过一些比较和简单的编码测试,我决定使用策略一来完成这个爬虫。
主要原因是策略二的逻辑虽然比较简单方便,但有两个问题需要解决。1.每天的报纸页数都不一样,每一页的文章页数也不同。正在构建 URL。如何保证文章不重复或省略?2. 在某些特殊情况下,文章 的编号是不连续的。如何解决这个问题呢?
所以,综合考虑,我认为策略一可能更稳定,更安全(如果你想到解决策略二问题的方法,你可以尝试一下,或者如果你想到其他策略,请留言和我们将一起讨论)。
三、编码链接
接下来是实际的编码环节,不多说,直接开始。
首先导入本项目中用到的库:
import requests
import bs4
import os
import datetime
import time
其中,requests库主要用于发起网络请求,接收服务器返回的数据;bs4库主要用于解析html内容,是一个非常简单易用的库;os 库主要用于将数据输出存储在本地文件中。
def fetchUrl(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
fetchUrl函数用于发起网络请求,可以访问目标url,获取目标网页的html内容并返回。
事实上,异常捕获应该在这里完成(为了简单起见,我把它省略了,伸出我的舌头)。由于网络情况比较复杂,可能会因为各种原因导致访问失败。r.raise_for_status() 代码实际上是在判断访问是否成功。如果访问失败,返回的状态码不是200,执行到这里。会直接抛出相应的异常。
def getPageList(year, month, day):
'''
功能:获取当天报纸的各版面的链接列表
参数:年,月,日
'''
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/nbs.D110000renmrb_01.htm'
html = fetchUrl(url)
bsobj = bs4.BeautifulSoup(html,'html.parser')
pageList = bsobj.find('div', attrs = {'id': 'pageList'}).ul.find_all('div', attrs = {'class': 'right_title-name'})
linkList = []
for page in pageList:
link = page.a["href"]
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link
linkList.append(url)
return linkList
getPageList函数用于抓取当天报纸各版面的链接,保存为数组,返回。
def getTitleList(year, month, day, pageUrl):
'''
功能:获取报纸某一版面的文章链接列表
参数:年,月,日,该版面的链接
'''
html = fetchUrl(pageUrl)
bsobj = bs4.BeautifulSoup(html,'html.parser')
titleList = bsobj.find('div', attrs = {'id': 'titleList'}).ul.find_all('li')
linkList = []
for title in titleList:
tempList = title.find_all('a')
for temp in tempList:
link = temp["href"]
if 'nw.D110000renmrb' in link:
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link
linkList.append(url)
return linkList
getPageList函数用于抓取当日报纸某个页面中文章的所有链接,保存为数组,返回。
def getContent(html):
'''
功能:解析 HTML 网页,获取新闻的文章内容
参数:html 网页内容
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
# 获取文章 标题
title = bsobj.h3.text + '\n' + bsobj.h1.text + '\n' + bsobj.h2.text + '\n'
#print(title)
# 获取文章 内容
pList = bsobj.find('div', attrs = {'id': 'ozoom'}).find_all('p')
content = ''
for p in pList:
content += p.text + '\n'
#print(content)
# 返回结果 标题+内容
resp = title + content
return resp
getContent函数用于访问文章的内容页面,抓取文章的title和body,返回。
def saveFile(content, path, filename):
'''
功能:将文章内容 content 保存到本地文件中
参数:要保存的内容,路径,文件名
'''
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
# 保存文件
with open(path + filename, 'w', encoding='utf-8') as f:
f.write(content)
saveFile函数用于将文章的内容保存到指定的本地文件夹。
def download_rmrb(year, month, day, destdir):
'''
功能:爬取《人民日报》网站 某年 某月 某日 的新闻内容,并保存在 指定目录下
参数:年,月,日,文件保存的根目录
'''
pageList = getPageList(year, month, day)
for page in pageList:
titleList = getTitleList(year, month, day, page)
for url in titleList:
# 获取新闻文章内容
html = fetchUrl(url)
content = getContent(html)
# 生成保存的文件路径及文件名
temp = url.split('_')[2].split('.')[0].split('-')
pageNo = temp[1]
titleNo = temp[0] if int(temp[0]) >= 10 else '0' + temp[0]
path = destdir + '/' + year + month + day + '/'
fileName = year + month + day + '-' + pageNo + '-' + titleNo + '.txt'
# 保存文件
saveFile(content, path, fileName)
download_rmrb 函数是需求中需要的主要函数。根据年、月、日参数,可以将当天报纸文章的所有内容按规则下载并保存到指定路径destdir。
if __name__ == '__main__':
'''
主函数:程序入口
'''
year = "2019"
month = "05"
day = "06"
destdir = "D:/data"
download_rmrb(year, month, day, destdir)
print("爬取完成:" + year + month + day)
至此,程序的主要功能已经完成。
四、改进程序
通过上一章的编码,我们已经实现了通过调用download_rmrb函数,可以下载特定日期的所有文章内容。但同时我们也可以发现,在程序入口的main函数中,日期是硬编码在代码中的,也就是说,如果我们要爬取其他日期的报纸,就必须修改源代码。
很不方便,是不是,我们改进一下,日期是用户以交互方式输入的。
if __name__ == '__main__':
'''
主函数:程序入口
'''
# 爬取指定日期的新闻
newsDate = input('请输入要爬取的日期(格式如 20190502 ):')
year = newsDate[0:4]
month = newsDate[4:6]
day = newsDate[6:8]
download_rmrb(year, month, day, 'D:/data')
print("爬取完成:" + year + month + day)
不是更方便吗?但问题又来了。如果我想一次攀登一个月或一年怎么办?不用我手动输入几十次或几百次吗?因此,我们可以改进程序。用户输入实际日期和结束日期,程序爬取期间的所有日期都是文章。
实际运行测试,假设我们要抓取2019年4月的所有报纸内容,那么我们开始日期输入20190401,结束日期输入20190501,回车运行。
等待一段时间后,程序已经运行完成。我们去文件夹看看我们爬取了什么。
爬取的内容整齐地排列在文件夹中,真的很舒服。随便打开一个文件看看,没问题。
到这里这个爬虫就全部完成了。
写在后面的字
这次好久没有写新的爬虫文章了。一是因为我快毕业了,忙着做毕业设计;另一种是写教程文章,真的很辛苦。,需要整理思路和语言,重新整理代码,要求各种截图,让零基础或者刚入门的人都能看懂,写出来。第三,我找不到一个有趣的动机,因为爬虫总是为了使用而写的,你不能为了炫耀你的技能而写爬虫。那是没有意义的。
一开始就写了一个爬虫来记录自己的成长过程。如果我在学习过程中的这些记录能同时帮助到更多后来者,那就更好了。
2019 年 7 月 10 日更新
有读者在评论中反映,不能使用输入起止日期的方式来抓取一段时间内的新闻,运行时会报如下错误。
我查了一下,确实是我的疏忽。
这是因为计算日期的函数在datetime库中,在写博客整理代码的过程中,忽略了引用这个库,导致程序运行出错。
解决方法是在程序中添加两行代码:
import datetime
import time
我对博客的代码做了改动,请放心食用。
感谢weixin_42435870,宋心悦悦的朋友指出了问题,非常感谢!!
2020 年 7 月 26 日更新
通过读者朋友的反馈,我发现《人民日报》的网站近日进行了改版,7月1日的新闻版面采用了新的版式。这也导致无法使用原创代码抓取2020年7月1日之后的新闻。
所以这里有一个更新以兼容 网站 的新格式。
1. 在getPageList函数中,替换原来的
pageList = bsobj.find('div', attrs = {'id': 'pageList'}).ul.find_all('div', attrs = {'class': 'right_title-name'})
改成:
temp = bsobj.find('div', attrs = {'id': 'pageList'})
if temp:
pageList = temp.ul.find_all('div', attrs = {'class': 'right_title-name'})
else:
pageList = bsobj.find('div', attrs = {'class': 'swiper-container'}).find_all('div', attrs = {'class': 'swiper-slide'})
2. 在getTitleList函数中,替换原来的
titleList = bsobj.find('div', attrs = {'id': 'titleList'}).ul.find_all('li')
改成:
temp = bsobj.find('div', attrs = {'id': 'titleList'})
if temp:
titleList = temp.ul.find_all('li')
else:
titleList = bsobj.find('ul', attrs = {'class': 'news-list'}).find_all('li')
简单解释一下上面的变化,
1. 在原来的网站中,对布局列表和文章列表的标签进行了调整,所以我们需要使用新的标签和新的属性来获取它们。
2. 为了兼容,我们先获取之前版本的标签。如果有,就说明是改版前的接口。如果不可用,说明是改版后的接口。您需要使用新的标签属性来获取它。
如果文章有什么不明白的地方,或者解释有误,欢迎在评论区批评指正,或扫描下方二维码加我微信。让我们一起学习交流,共同进步。

网页新闻抓取(就是一条中去一条 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-11 15:16
)
第一次写小爬虫,python确实很强大,大概二十行代码抓取内容存成txt文本
直接编码
#coding = 'utf-8'
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = 'utf-8'
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select('.news-item')
#抓取需要的内容并且放入文件中
#抓取的内容有时间,内容文本,以及内容的链接
fname = "F:/asdf666.txt"
try:
f = open(fname, 'w')
for element in elements:
if len(element.select('h2')) > 0:
f.write(element.select('.time')[0].text)
f.write(element.select('h2')[0].text)
f.write(element.select('a')[0]['href'])
f.write('\n\n')
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为这是第一个小爬虫,功能很简单也很单一,就是直接抓取新闻页面上的部分新闻。
然后抓取新闻的时间和超链接
然后按照新闻的顺序整合,放到一个文本文件中存储
截图效果图,效果很简单,一一记录,时间,新闻内容,新闻链接(因为是今天写的,所以是今天的新闻)
查看全部
网页新闻抓取(就是一条中去一条
)
第一次写小爬虫,python确实很强大,大概二十行代码抓取内容存成txt文本
直接编码
#coding = 'utf-8'
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = 'utf-8'
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select('.news-item')
#抓取需要的内容并且放入文件中
#抓取的内容有时间,内容文本,以及内容的链接
fname = "F:/asdf666.txt"
try:
f = open(fname, 'w')
for element in elements:
if len(element.select('h2')) > 0:
f.write(element.select('.time')[0].text)
f.write(element.select('h2')[0].text)
f.write(element.select('a')[0]['href'])
f.write('\n\n')
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为这是第一个小爬虫,功能很简单也很单一,就是直接抓取新闻页面上的部分新闻。
然后抓取新闻的时间和超链接
然后按照新闻的顺序整合,放到一个文本文件中存储
截图效果图,效果很简单,一一记录,时间,新闻内容,新闻链接(因为是今天写的,所以是今天的新闻)

网页新闻抓取( 简单的来说,对于爬取网页的内容来说的一些介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-10-11 15:14
简单的来说,对于爬取网页的内容来说的一些介绍)
简单来说,对于爬取网页的内容:http在爬取过程中不需要输入账号密码,而https则需要输入账号和密码,以及密码带来的一系列问题帐户。因此,抓取https相对复杂。
二、选的框架scarpy 2.1 介绍scrapy
这里
有Scarpy的简单框架介绍
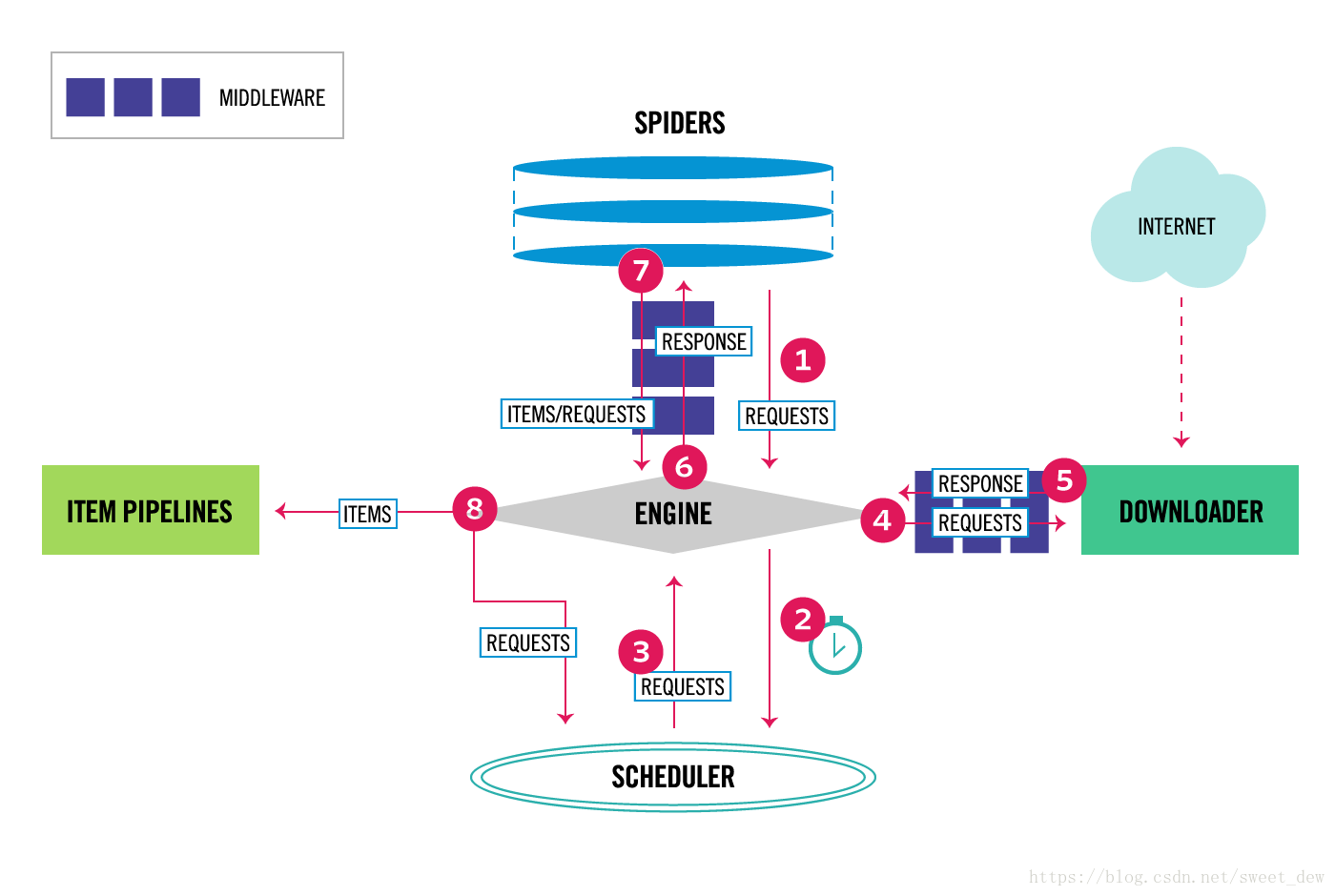
2.1.1 Scrapy结构2.1.2数据流
数据流向由执行引擎控制,如图中各个步骤所示。
* Step1:scrapy引擎首先获取初始URL(Requests)。
* Step2:然后交给Scheduler调度Requests,请求下一个URL。
* Step3:调度器将下一个请求返回给scrapy引擎
* Step4:scrapy引擎通过Downloader Middlewares向下载器Downloader(process_request())发送请求。
* Step5:Downloader Middlewares 完成网页下载后,会生成响应并通过 Downloader Middlewares 将其发送回scrapy 引擎(process_response())。
* Step6:scrapy引擎收到Response后,会通过Spider Middlewares发送给Spider做进一步处理。
* Step7:Spider 处理完响应后,会将抓取的项目和新请求(链接在下一页)返回给抓取引擎。
* Step8:crapy引擎将处理后的item发送到Item Pipelines,然后将Requests发送回Scheduler,请求下一个可能的URL进行爬取。
* Step9:从step1开始重复上面的操作,直到Scheduler中没有多余的URL可以请求
提示:解释第 7 步
Spider 分析的结果有两种:
* 一个是需要进一步爬取的链接,比如“下一页”的链接,会被发回给Scheduler;
* 另一个是需要保存的数据。它们被发送到 Item Pipeline 进行后期处理(详细分析、过滤、存储等)。
2.1.3 爬取过程第三部分,半年爬取中新网各种新闻
我的环境是Python3.6+Scrapy,Windows,IDE:PyCharm
3.1 创建一个scrapy项目**
在命令行输入scrapy startproject qqnews
会出现以下文件
3.1.1 在qqnew.py中编写我们的主要爬虫代码**
首先我们需要导入对应的文件
from scrapy.spiders import Spider
from qqnews.items import QqnewsItem
spider 会自动从 start_urls 抓取网页,可以收录多个 URL。
并且会默认调用parse函数,parse在蜘蛛抓取网页后会默认调用callback。
提示:因为我们要抓取半年的新闻数据,所以先通过start_urls获取半年每个月的网址,可以观察网址的规则。比如后面两天的网址,很容易看到规则。
我们可以通过拼接字符串来抓取每天的网址
* 每天:
* 每个月:
代码最后一句写的是scrapy.Request(url_month, callback=self.parse_month)
* url_month: 解析拼接后接下来要爬取的每一天的网址
* callback=self.parse_month:这句话的意思是,对于每一天的url,都会调用一个自定义的parse_month来解析每一天的网页内容
class QQNewsSpider(Spider):
name = 'qqnews'
start_urls=[#'http://www.chinanews.com/society.shtml',
#'http://www.chinanews.com/mil/news.shtml',
'http://finance.chinanews.com/it/gd.shtml',
]
def parse(self,response):
#找到所有连接的入口,一条一条的新闻做解析 //*[@id="news"] //*[@id="news"]/div[2]/div[1]/div[1]/em/a
for month in range(1,8):
for day in range(1,31):
if month is 2 and day>28 :
continue
elif month is 7 and day>6:
continue
else:
if day in range(1,10):
url_month='http://www.chinanews.com/scrol ... 2Bstr(month)+'0'+str(day)+'/news.shtml'
else:
url_month='http://www.chinanews.com/scrol ... 2Bstr(month)+str(day)+'/news.shtml'
yield scrapy.Request(url_month,callback=self.parse_month)
我们已经从前面的代码中得到了每天的新闻对应的链接地址,接下来我们要抓取对应页面的新闻标题和新闻内容。
是自定义def parse_month(self, response)处理的内容。
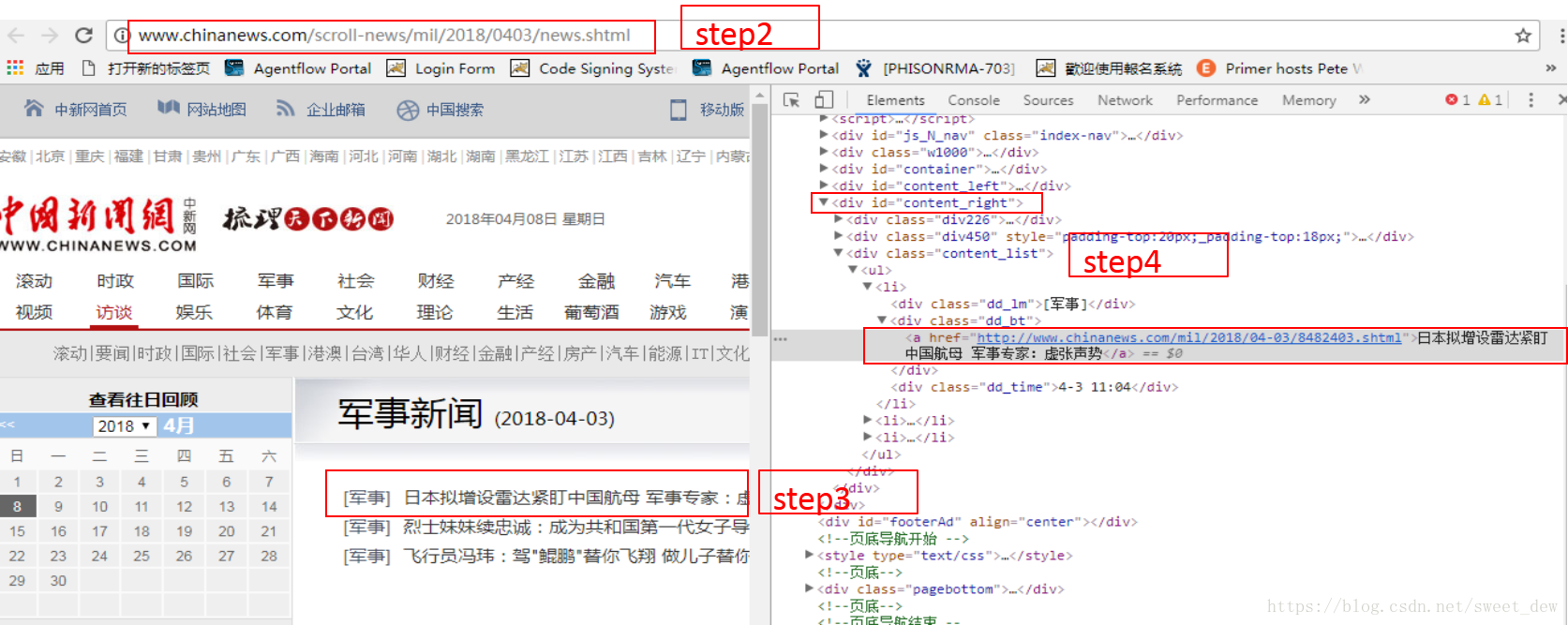
配合chrome浏览器右键“查看”,找到每天对应的新闻标题
Scrapy 提供了一种方便的方式来解析网页数据,文章 中使用 Xpath 进行分析。
提示:
* //ul/li 表示选择ul标签下的所有li标签
* a/@href 表示选择一个标签的所有 href 属性
* a/text() 表示选择标签文本
* div[@id="content_right"] 表示选择所有id属性为content_right的div标签
def parse_month(self,response):
#print(response.body)
#到了没一个月的页面下,提取每一天的url
urls=response.xpath('//div[@id="content_right"]/div[@class="content_list"]/ul/li/div[@class="dd_bt"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url,callback=self.parse_news)
找到新闻标题对应的新闻内容网址后,我们就可以抓取每日新闻标题和对应的新闻内容了。
然后通过self.parse_news,
在其中存储标题和内容。这是我们先导入的item=QqnewsItem()
def parse_news(self,response):
item=QqnewsItem()
item['title']=response.xpath('//div[@class="con_left"]/div[@id="cont_1_1_2"]/h1/text()').extract()
item['text']='\n'.join(response.xpath('//div[@class="left_zw"]/p/text()').extract())
yield item
在 items.py 中添加一些类
class QqnewsItem(scrapy.Item):
# define the fields for your item here like:
text=scrapy.Field()#新闻的内容
title=scrapy.Field()#新闻的标题
最后,如果要将抓取到的内容保存到文件中,可以新建一个begin.py,直接执行下面这句话。
在 begin.py
from scrapy import cmdline
cmdline.execute("scrapy crawl qqnews -o IT.csv".split())
然后我们就可以根据fastText将抓取到的数据处理成fastText格式,然后直接训练。
参考文章: 查看全部
网页新闻抓取(
简单的来说,对于爬取网页的内容来说的一些介绍)

简单来说,对于爬取网页的内容:http在爬取过程中不需要输入账号密码,而https则需要输入账号和密码,以及密码带来的一系列问题帐户。因此,抓取https相对复杂。
二、选的框架scarpy 2.1 介绍scrapy
这里
有Scarpy的简单框架介绍
2.1.1 Scrapy结构2.1.2数据流
数据流向由执行引擎控制,如图中各个步骤所示。
* Step1:scrapy引擎首先获取初始URL(Requests)。
* Step2:然后交给Scheduler调度Requests,请求下一个URL。
* Step3:调度器将下一个请求返回给scrapy引擎
* Step4:scrapy引擎通过Downloader Middlewares向下载器Downloader(process_request())发送请求。
* Step5:Downloader Middlewares 完成网页下载后,会生成响应并通过 Downloader Middlewares 将其发送回scrapy 引擎(process_response())。
* Step6:scrapy引擎收到Response后,会通过Spider Middlewares发送给Spider做进一步处理。
* Step7:Spider 处理完响应后,会将抓取的项目和新请求(链接在下一页)返回给抓取引擎。
* Step8:crapy引擎将处理后的item发送到Item Pipelines,然后将Requests发送回Scheduler,请求下一个可能的URL进行爬取。
* Step9:从step1开始重复上面的操作,直到Scheduler中没有多余的URL可以请求
提示:解释第 7 步
Spider 分析的结果有两种:
* 一个是需要进一步爬取的链接,比如“下一页”的链接,会被发回给Scheduler;
* 另一个是需要保存的数据。它们被发送到 Item Pipeline 进行后期处理(详细分析、过滤、存储等)。
2.1.3 爬取过程第三部分,半年爬取中新网各种新闻
我的环境是Python3.6+Scrapy,Windows,IDE:PyCharm
3.1 创建一个scrapy项目**
在命令行输入scrapy startproject qqnews
会出现以下文件
3.1.1 在qqnew.py中编写我们的主要爬虫代码**
首先我们需要导入对应的文件
from scrapy.spiders import Spider
from qqnews.items import QqnewsItem
spider 会自动从 start_urls 抓取网页,可以收录多个 URL。
并且会默认调用parse函数,parse在蜘蛛抓取网页后会默认调用callback。
提示:因为我们要抓取半年的新闻数据,所以先通过start_urls获取半年每个月的网址,可以观察网址的规则。比如后面两天的网址,很容易看到规则。
我们可以通过拼接字符串来抓取每天的网址
* 每天:
* 每个月:
代码最后一句写的是scrapy.Request(url_month, callback=self.parse_month)
* url_month: 解析拼接后接下来要爬取的每一天的网址
* callback=self.parse_month:这句话的意思是,对于每一天的url,都会调用一个自定义的parse_month来解析每一天的网页内容
class QQNewsSpider(Spider):
name = 'qqnews'
start_urls=[#'http://www.chinanews.com/society.shtml',
#'http://www.chinanews.com/mil/news.shtml',
'http://finance.chinanews.com/it/gd.shtml',
]
def parse(self,response):
#找到所有连接的入口,一条一条的新闻做解析 //*[@id="news"] //*[@id="news"]/div[2]/div[1]/div[1]/em/a
for month in range(1,8):
for day in range(1,31):
if month is 2 and day>28 :
continue
elif month is 7 and day>6:
continue
else:
if day in range(1,10):
url_month='http://www.chinanews.com/scrol ... 2Bstr(month)+'0'+str(day)+'/news.shtml'
else:
url_month='http://www.chinanews.com/scrol ... 2Bstr(month)+str(day)+'/news.shtml'
yield scrapy.Request(url_month,callback=self.parse_month)
我们已经从前面的代码中得到了每天的新闻对应的链接地址,接下来我们要抓取对应页面的新闻标题和新闻内容。
是自定义def parse_month(self, response)处理的内容。
配合chrome浏览器右键“查看”,找到每天对应的新闻标题
Scrapy 提供了一种方便的方式来解析网页数据,文章 中使用 Xpath 进行分析。
提示:
* //ul/li 表示选择ul标签下的所有li标签
* a/@href 表示选择一个标签的所有 href 属性
* a/text() 表示选择标签文本
* div[@id="content_right"] 表示选择所有id属性为content_right的div标签
def parse_month(self,response):
#print(response.body)
#到了没一个月的页面下,提取每一天的url
urls=response.xpath('//div[@id="content_right"]/div[@class="content_list"]/ul/li/div[@class="dd_bt"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url,callback=self.parse_news)
找到新闻标题对应的新闻内容网址后,我们就可以抓取每日新闻标题和对应的新闻内容了。
然后通过self.parse_news,
在其中存储标题和内容。这是我们先导入的item=QqnewsItem()
def parse_news(self,response):
item=QqnewsItem()
item['title']=response.xpath('//div[@class="con_left"]/div[@id="cont_1_1_2"]/h1/text()').extract()
item['text']='\n'.join(response.xpath('//div[@class="left_zw"]/p/text()').extract())
yield item
在 items.py 中添加一些类
class QqnewsItem(scrapy.Item):
# define the fields for your item here like:
text=scrapy.Field()#新闻的内容
title=scrapy.Field()#新闻的标题
最后,如果要将抓取到的内容保存到文件中,可以新建一个begin.py,直接执行下面这句话。
在 begin.py
from scrapy import cmdline
cmdline.execute("scrapy crawl qqnews -o IT.csv".split())
然后我们就可以根据fastText将抓取到的数据处理成fastText格式,然后直接训练。
参考文章:
网页新闻抓取(1.图片优化有时候,由于网络太慢导致图片加载失败、或者浏览器禁止显示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-10 19:02
1.图片优化
有时因为网络太慢,图片加载失败,或者浏览器禁止显示图片,以及网站被病毒感染,这些情况都可能导致图片无法正常显示。这时候就需要设置图片的alt属性了。图片未显示出现的文字说明。搜索引擎蜘蛛可以根据替代文字读取图片的内容。图片的alt属性是图片优化中最重要的内容。图片在搜索引擎中的排名主要是根据alt优化的程度。设计alt时,要求每张图片都设置alt,尽量写关键词(但不要堆积关键词,否则搜索引擎会被视为作弊)。此外,图片也有标题属性。图片的title属性是鼠标在图片上移动时出现的图片说明。优化图片时,建议同时设置alt和title。
2.关键词优化
关键词优化是指对网站中关键词的选词和排版优化,达到优化网站排名的效果。相关关键词在搜索引擎排名中占据有利位置。出现在正文前50-100字的关键词权重比较高。通常建议第一段文字的第一句出现关键词,中间的文字,两三遍关键词,关键词在最后就足以达到优化的目的。在关键词的布局中,有一个概念“关键词密度”,即关键词出现的次数除以总词数,用百分比表示。关键词 频率越高,密度越大。一般来说,关键词 密度应该在 2% 到 8% 之间。
3. 精简代码
就搜索引擎的工作原理而言,搜索引擎工作的第一步是提取文本,即精简html代码。可以说html风格的代码对关键词来说是噪声,所以为了提高信号噪声比,必须对代码进行简化。常见的可以精简代码的地方如下:(1)页面的样式应该用CSS来设计。不要在html代码中再次定义CSS中定义的样式效果。(2)插入外部文件:将CSS和JavaScript分别做成一个文件,放在html代码之外,在html代码中添加一段insert代码即可。(3)删除注释:注释是解释代码,是的留给开发者,用户不需要理解。(4) 减少表的使用:使用 div 而不是表格。总之,页面中不应该有多余的代码。简化的代码有助于将*有意义的内容放在*之前,更容易被搜索引擎蜘蛛抓取,从而提高网站的排名。
4.标题优化
网页优化最重要的内容就是标题优化。Title 表示页面的标题。一般建议将标题放在标签之后,以便搜索引擎快速抓取标题。标题优化要注意以下问题:(1)唯一且不重复。每个页面必须有自己唯一的标题。如果同一网站中不同页面的标题相同,则标题优化会丢失 用户体验很差,用户无法从标题中一眼看出页面的具体内容;(2)字数限制。根据百度和谷歌字数要求,尽量不要标题超过30个字,超出部分,搜索引擎会自动剪掉,搜索引擎会减重,不会对排名产生任何影响;(3)不要堆砌关键词。一页*3到4多关键词就够了,不要太多,如:鼠标|鼠标批发|鼠标零售|鼠标批发和零售|鼠标网,这样的页面可以直接写成鼠标批发零售|页面的相关性有利于用户体验,用户可以一目了然地看到页面的大致内容。
5.元标签优化
元标签用于设计网页的属性。Meta标签优化主要包括描述标签和关键词(keyWords)标签。描述标签用于描述页面的主题。它描述了页面与什么相关以及它的用途。
在设计描述标签时,要注意以下几点:
(1)准确概括页面内容。设计描述时,需要提炼*页面的主要内容,准确描述页面内容,才能吸引用户点击。不要:描述标签内容与页面内容无关;
(2)为每个页面设置唯一的描述标签。这样的设计可以提高内部页面的相关性,在一定程度上可以引导用户和搜索引擎打开其他内部页面。另外,不要设置重复描述内容,keyWords标签用于设计页面的主题关键词。
设计keyWords标签时要注意:
(1)说明关键词是否出现在网页上。
(2)每个网页的关键词应该是不同的。
(3)关键词在每个网页上出现的次数不能超过5次,一般3到5次为宜。 查看全部
网页新闻抓取(1.图片优化有时候,由于网络太慢导致图片加载失败、或者浏览器禁止显示)
1.图片优化
有时因为网络太慢,图片加载失败,或者浏览器禁止显示图片,以及网站被病毒感染,这些情况都可能导致图片无法正常显示。这时候就需要设置图片的alt属性了。图片未显示出现的文字说明。搜索引擎蜘蛛可以根据替代文字读取图片的内容。图片的alt属性是图片优化中最重要的内容。图片在搜索引擎中的排名主要是根据alt优化的程度。设计alt时,要求每张图片都设置alt,尽量写关键词(但不要堆积关键词,否则搜索引擎会被视为作弊)。此外,图片也有标题属性。图片的title属性是鼠标在图片上移动时出现的图片说明。优化图片时,建议同时设置alt和title。
2.关键词优化
关键词优化是指对网站中关键词的选词和排版优化,达到优化网站排名的效果。相关关键词在搜索引擎排名中占据有利位置。出现在正文前50-100字的关键词权重比较高。通常建议第一段文字的第一句出现关键词,中间的文字,两三遍关键词,关键词在最后就足以达到优化的目的。在关键词的布局中,有一个概念“关键词密度”,即关键词出现的次数除以总词数,用百分比表示。关键词 频率越高,密度越大。一般来说,关键词 密度应该在 2% 到 8% 之间。
3. 精简代码
就搜索引擎的工作原理而言,搜索引擎工作的第一步是提取文本,即精简html代码。可以说html风格的代码对关键词来说是噪声,所以为了提高信号噪声比,必须对代码进行简化。常见的可以精简代码的地方如下:(1)页面的样式应该用CSS来设计。不要在html代码中再次定义CSS中定义的样式效果。(2)插入外部文件:将CSS和JavaScript分别做成一个文件,放在html代码之外,在html代码中添加一段insert代码即可。(3)删除注释:注释是解释代码,是的留给开发者,用户不需要理解。(4) 减少表的使用:使用 div 而不是表格。总之,页面中不应该有多余的代码。简化的代码有助于将*有意义的内容放在*之前,更容易被搜索引擎蜘蛛抓取,从而提高网站的排名。
4.标题优化
网页优化最重要的内容就是标题优化。Title 表示页面的标题。一般建议将标题放在标签之后,以便搜索引擎快速抓取标题。标题优化要注意以下问题:(1)唯一且不重复。每个页面必须有自己唯一的标题。如果同一网站中不同页面的标题相同,则标题优化会丢失 用户体验很差,用户无法从标题中一眼看出页面的具体内容;(2)字数限制。根据百度和谷歌字数要求,尽量不要标题超过30个字,超出部分,搜索引擎会自动剪掉,搜索引擎会减重,不会对排名产生任何影响;(3)不要堆砌关键词。一页*3到4多关键词就够了,不要太多,如:鼠标|鼠标批发|鼠标零售|鼠标批发和零售|鼠标网,这样的页面可以直接写成鼠标批发零售|页面的相关性有利于用户体验,用户可以一目了然地看到页面的大致内容。
5.元标签优化
元标签用于设计网页的属性。Meta标签优化主要包括描述标签和关键词(keyWords)标签。描述标签用于描述页面的主题。它描述了页面与什么相关以及它的用途。
在设计描述标签时,要注意以下几点:
(1)准确概括页面内容。设计描述时,需要提炼*页面的主要内容,准确描述页面内容,才能吸引用户点击。不要:描述标签内容与页面内容无关;
(2)为每个页面设置唯一的描述标签。这样的设计可以提高内部页面的相关性,在一定程度上可以引导用户和搜索引擎打开其他内部页面。另外,不要设置重复描述内容,keyWords标签用于设计页面的主题关键词。
设计keyWords标签时要注意:
(1)说明关键词是否出现在网页上。
(2)每个网页的关键词应该是不同的。
(3)关键词在每个网页上出现的次数不能超过5次,一般3到5次为宜。
网页新闻抓取( 【每日一题】新浪新闻为例(二):反爬机制 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-10-10 19:01
【每日一题】新浪新闻为例(二):反爬机制
)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=2')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第2页/spanspan style="color: #800000;""/span>2</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=3')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第3页/spanspan style="color: #800000;""/span>3</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=4')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第4页/spanspan style="color: #800000;""/span>4</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=5')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第5页/spanspan style="color: #800000;""/span>5</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=6')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第6页/spanspan style="color: #800000;""/span>6</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=7')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第7页/spanspan style="color: #800000;""/span>7</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=8')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第8页/spanspan style="color: #800000;""/span>8</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=9')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第9页/spanspan style="color: #800000;""/span>9</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=10')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第10页/spanspan style="color: #800000;""/span>10</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=2');/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"下一页/spanspan style="color: #800000;""/span>下一页</a>
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/homepage/search.d.json?q='+encodeURIComponent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果
查看全部
网页新闻抓取(
【每日一题】新浪新闻为例(二):反爬机制
)

前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。



网页结构分析
1
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=2')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第2页/spanspan style="color: #800000;""/span>2</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=3')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第3页/spanspan style="color: #800000;""/span>3</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=4')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第4页/spanspan style="color: #800000;""/span>4</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=5')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第5页/spanspan style="color: #800000;""/span>5</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=6')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第6页/spanspan style="color: #800000;""/span>6</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=7')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第7页/spanspan style="color: #800000;""/span>7</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=8')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第8页/spanspan style="color: #800000;""/span>8</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=9')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第9页/spanspan style="color: #800000;""/span>9</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=10')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第10页/spanspan style="color: #800000;""/span>10</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=2');/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"下一页/spanspan style="color: #800000;""/span>下一页</a>
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:

恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/homepage/search.d.json?q='+encodeURIComponent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:

所以回到网站看看哪里出了问题


在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。

完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果

网页新闻抓取(优采云中如何判断网页是否需要设置页面滚动的设置 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-09 13:14
)
网站有很多,页面中的数据需要向下滚动才能加载出来。相应的,还需要在优采云中设置【页面滚动】。
如何判断一个网页是否需要设置为【页面滚动】?【页面滚动】如何设置滚动方式、滚动次数、每次间隔?
本教程将讲解【页面滚动】的设置方法和常见应用场景。
一、【直接滚动到底部】
如果直接将滚动条拖到底部,出现类似【Loading】的字样,很快又出现新数据,滚动条变短反弹,需要设置【直接滚动到底部】,【Scrolling】次]根据网页根据自身情况和采集要求设置。[每个间隔]时间需要比数据加载时间稍长,这与网络速度等因素有关。
常见应用场景一:没有翻页按钮,需要不断向下滚动才能加载新数据。常见的网页有:今日头条首页、百度图片搜索、新浪微博首页。
以今日头条首页为例。, 我们需要采集 新闻列表数据。首先按照之前列出数据采集的方法配置采集的任务。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
观察网页,发现这个网页没有翻页按钮。将滚动条直接拉到底部,出现“Loading”字样。新数据很快就会出现,滚动条会变短并反弹回来。
这也可以在 优采云 中验证。网页默认打开,【循环列表】中有6条新闻。滚动到底部一次,加载新数据,【循环列表】中的新闻增加到24条。再次滚动到底部,[循环列表]中的新闻增加到34条。
因此,我们需要在优采云中设置【页面滚动】。选择【打开网页】的步骤,打开【高级选项】,勾选【页面加载后向下滚动】,设置【滚动次数】5次,【每次间隔时间】2秒,【滚动方式】为【滚动】到末】部】。然后点击【确定】保存。
启动采集,看看采集的结果。优采云自动执行【直接滚动到底部】5次,然后采集5次后滚动数据。
特别说明:
一种。此网页无限向下滚动加载数据,优采云 无法采集 一次获取所有数据。上面的例子设置滚动5次,在实际采集过程中可以按需,建议不要超过x次。
湾 这类网页常用于数据实时性较高的新闻网站,可以设置定时启动优采云,少量次采集最新数据。
C。有时候网页速度很快,像【加载中】这样的提示不明显。【是否有新数据】和【观察滚动条的反弹次数】是比较有用的判断标准。
二、【向下滚动一屏】
其他数据需要在当前屏幕上显示一段时间才能完全加载,然后被采集接收。需要设置【向下滚动一屏】,【滚动次数】根据网页本身和采集要求设置,【每次间隔】时间需要略大于数据加载时间,这与网速等因素。
常见应用场景一:数据需要在当前屏幕上显示一段时间才能完全加载,然后才可以采集。
以京东商品列表为例。%E6%89%8B%E6%9C%BA&enc=utf-8&suggest=1.his.0.0&wq=&pvid=1b312c8afe2845bd94fe55ff1b6165a8,我们想要一份所有产品的清单。首先按照之前列出数据采集的方法配置采集的任务。下面是一个配置好的任务,需要特别注意【主图片链接】字段。
启动采集,看看采集的结果。我们发现【主图链接】字段没有采集到达。
返回流程,手动执行采集流程。我们发现当主图显示在当前屏幕上时(循环中的item1、2、3),它的链接可以通过采集到达。当主图像未显示在当前屏幕上时(循环后面的项目),其链接 采集 不可用。
我们还需要在 优采云 中进行相同的设置。选择【打开网页】的步骤,打开【高级选项】,勾选【页面加载后向下滚动】,设置【滚动次数】10次,【每次间隔】2秒,【滚动模式】为【向下滚动】一屏]。
重新开始采集看看。优采云【向下滚动一屏】自动执行了10次。60个产品列表的主图在当前屏幕上显示2秒,主图链接也正常采集down。
特别说明:
一种。如果某个字段或某些数据项没有采集到达,您可以手动执行规则进行检查。很有可能需要设置【向下滚动一屏】。
湾 本例中设置滚动次数为10次,可以在当前屏幕上显示所有列表。在采集的实际过程中,根据网页的情况设置采集的数量。
C。[向下滚动一屏]的一屏与运行采集任务时的窗口显示区域有关。如下图,左边的滚动画面>右边的滚动画面。
查看全部
网页新闻抓取(优采云中如何判断网页是否需要设置页面滚动的设置
)
网站有很多,页面中的数据需要向下滚动才能加载出来。相应的,还需要在优采云中设置【页面滚动】。
如何判断一个网页是否需要设置为【页面滚动】?【页面滚动】如何设置滚动方式、滚动次数、每次间隔?
本教程将讲解【页面滚动】的设置方法和常见应用场景。
一、【直接滚动到底部】
如果直接将滚动条拖到底部,出现类似【Loading】的字样,很快又出现新数据,滚动条变短反弹,需要设置【直接滚动到底部】,【Scrolling】次]根据网页根据自身情况和采集要求设置。[每个间隔]时间需要比数据加载时间稍长,这与网络速度等因素有关。
常见应用场景一:没有翻页按钮,需要不断向下滚动才能加载新数据。常见的网页有:今日头条首页、百度图片搜索、新浪微博首页。
以今日头条首页为例。, 我们需要采集 新闻列表数据。首先按照之前列出数据采集的方法配置采集的任务。
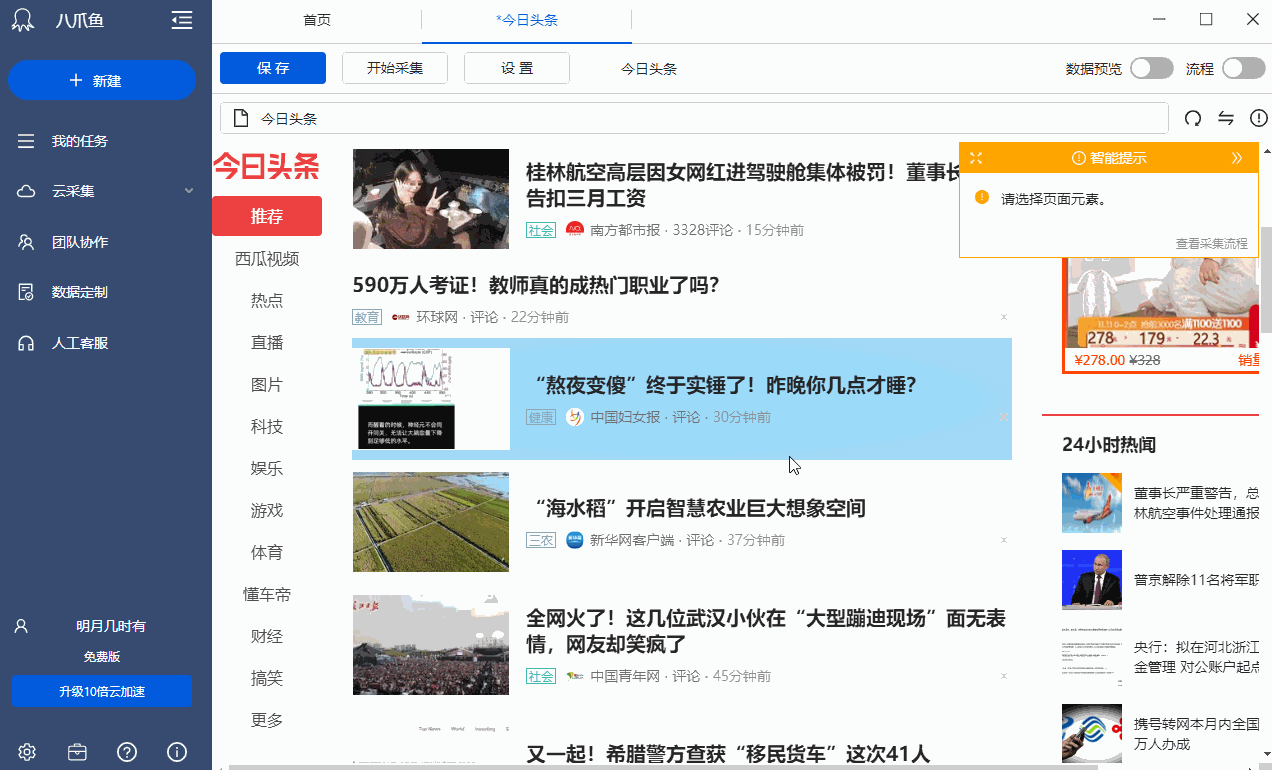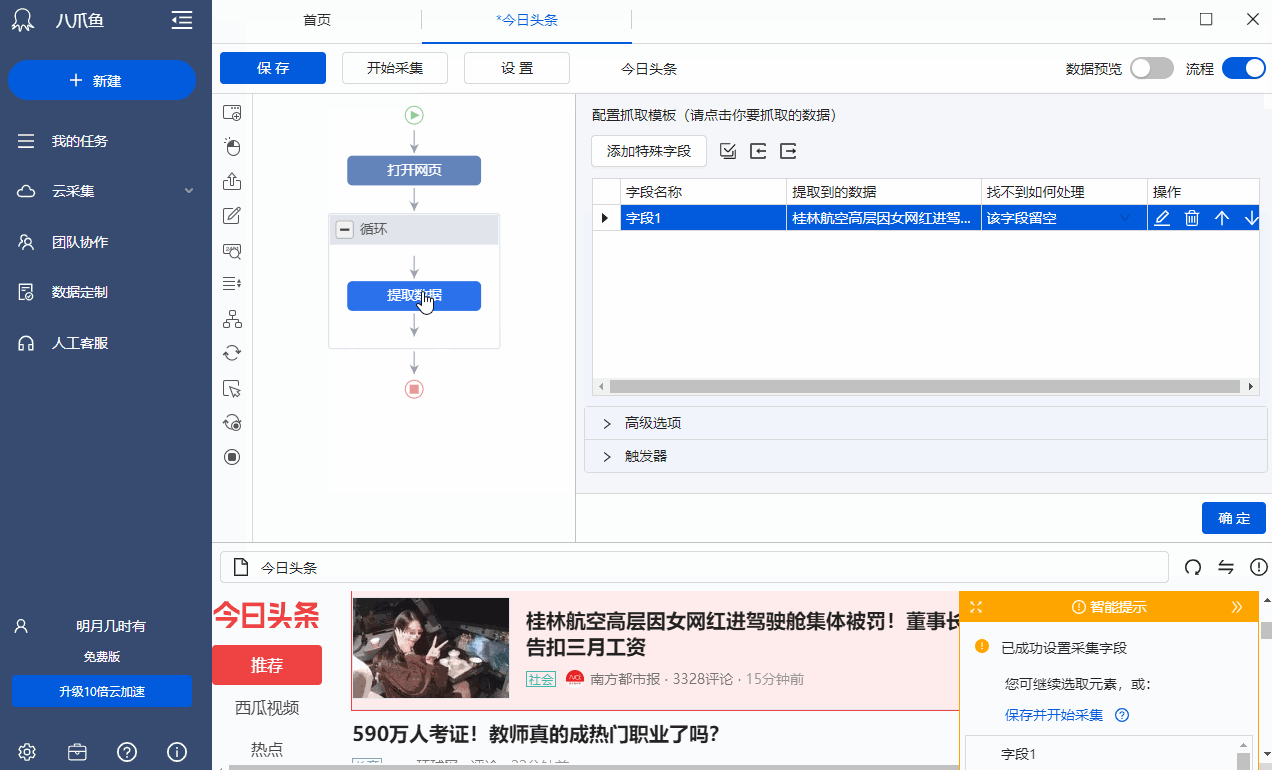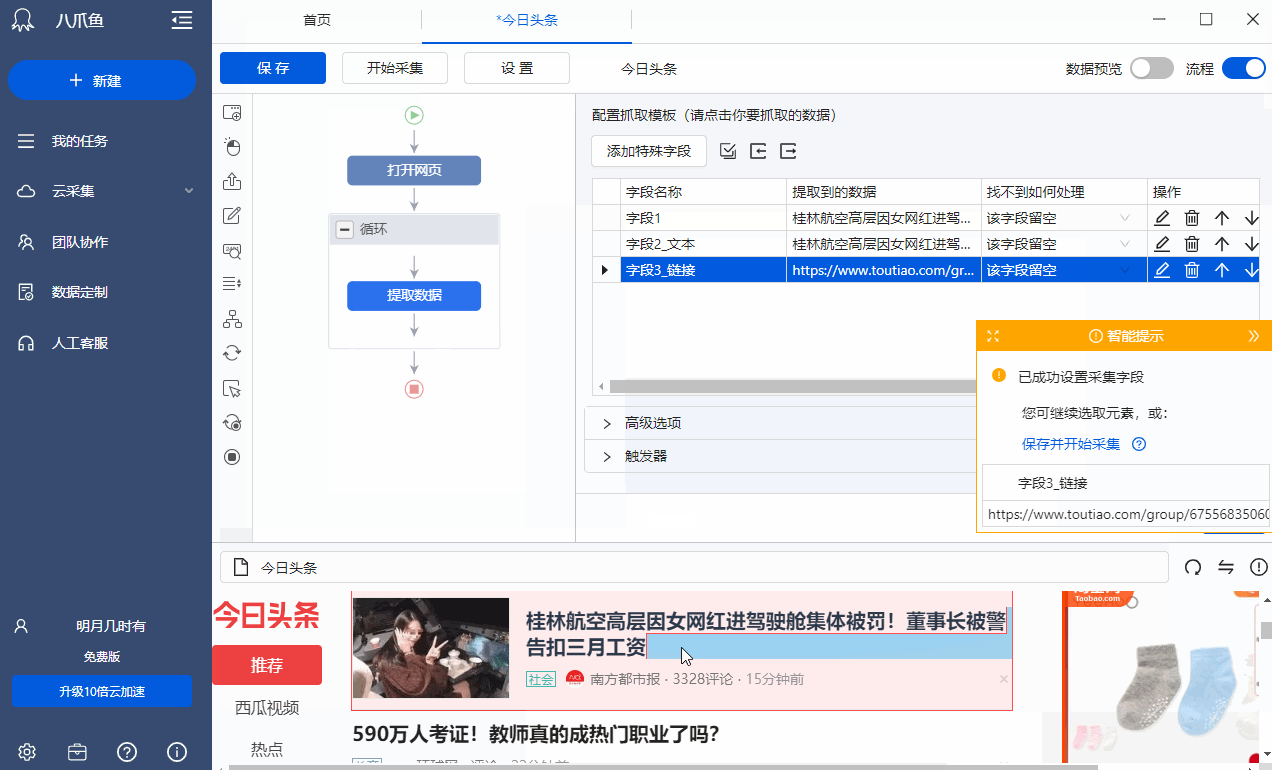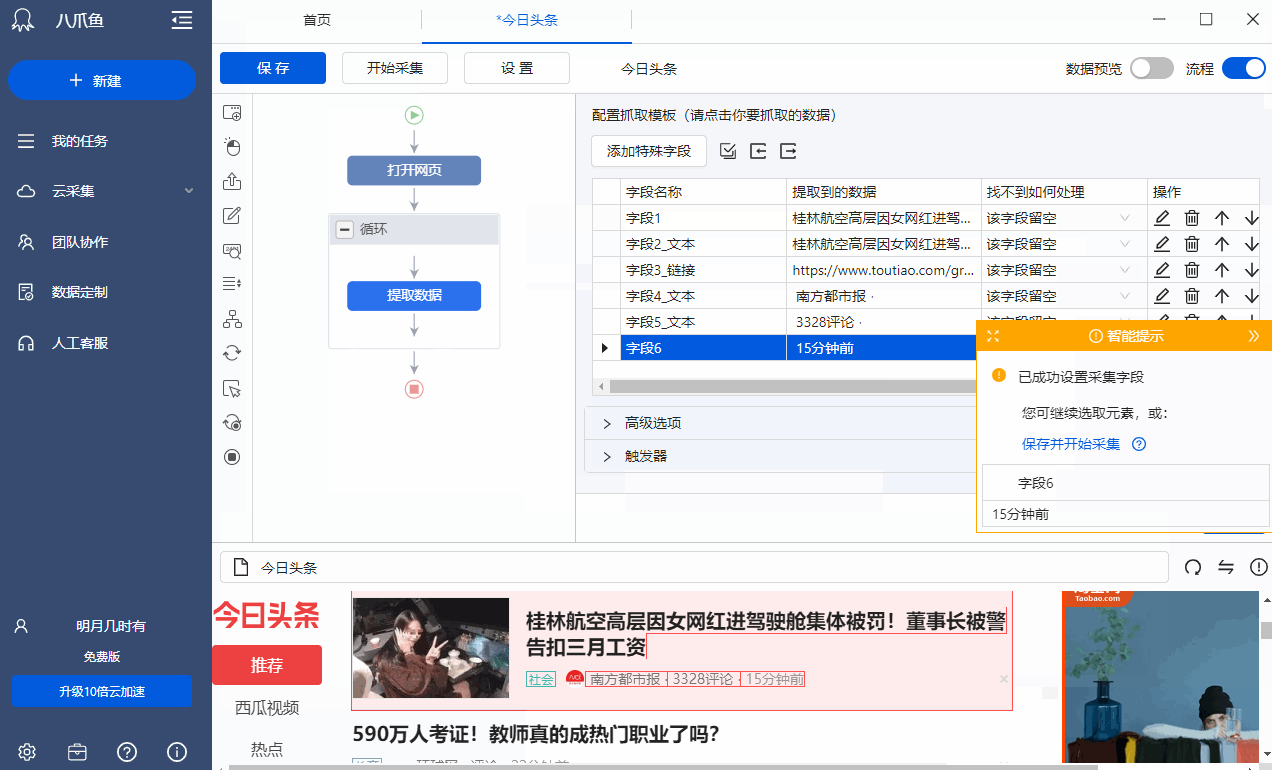
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
观察网页,发现这个网页没有翻页按钮。将滚动条直接拉到底部,出现“Loading”字样。新数据很快就会出现,滚动条会变短并反弹回来。

这也可以在 优采云 中验证。网页默认打开,【循环列表】中有6条新闻。滚动到底部一次,加载新数据,【循环列表】中的新闻增加到24条。再次滚动到底部,[循环列表]中的新闻增加到34条。
因此,我们需要在优采云中设置【页面滚动】。选择【打开网页】的步骤,打开【高级选项】,勾选【页面加载后向下滚动】,设置【滚动次数】5次,【每次间隔时间】2秒,【滚动方式】为【滚动】到末】部】。然后点击【确定】保存。
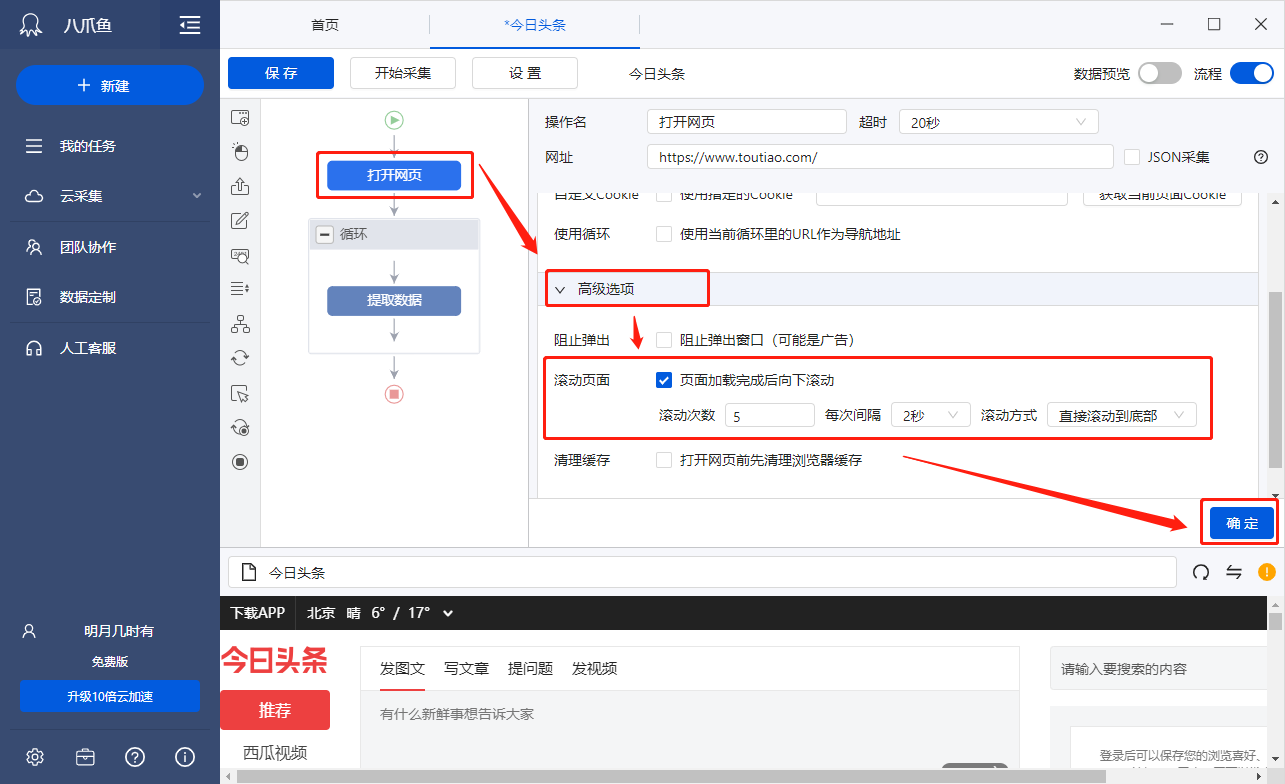
启动采集,看看采集的结果。优采云自动执行【直接滚动到底部】5次,然后采集5次后滚动数据。
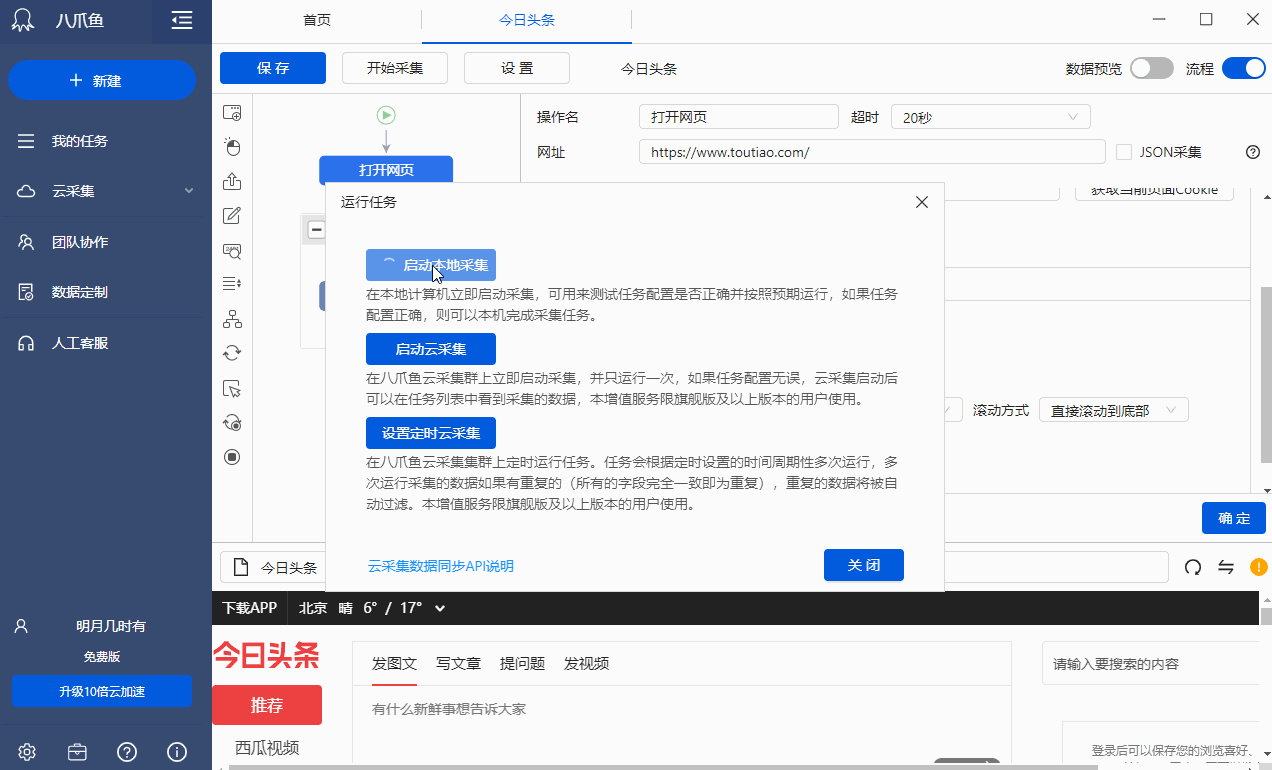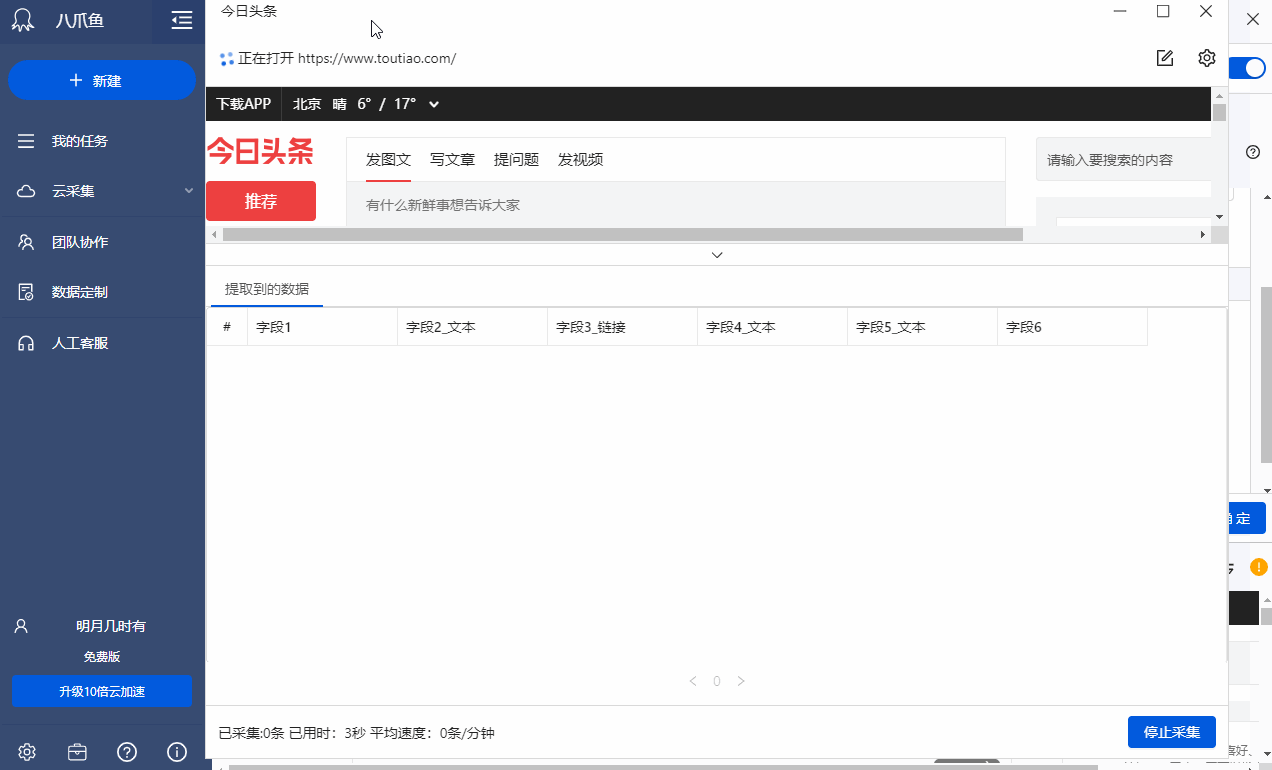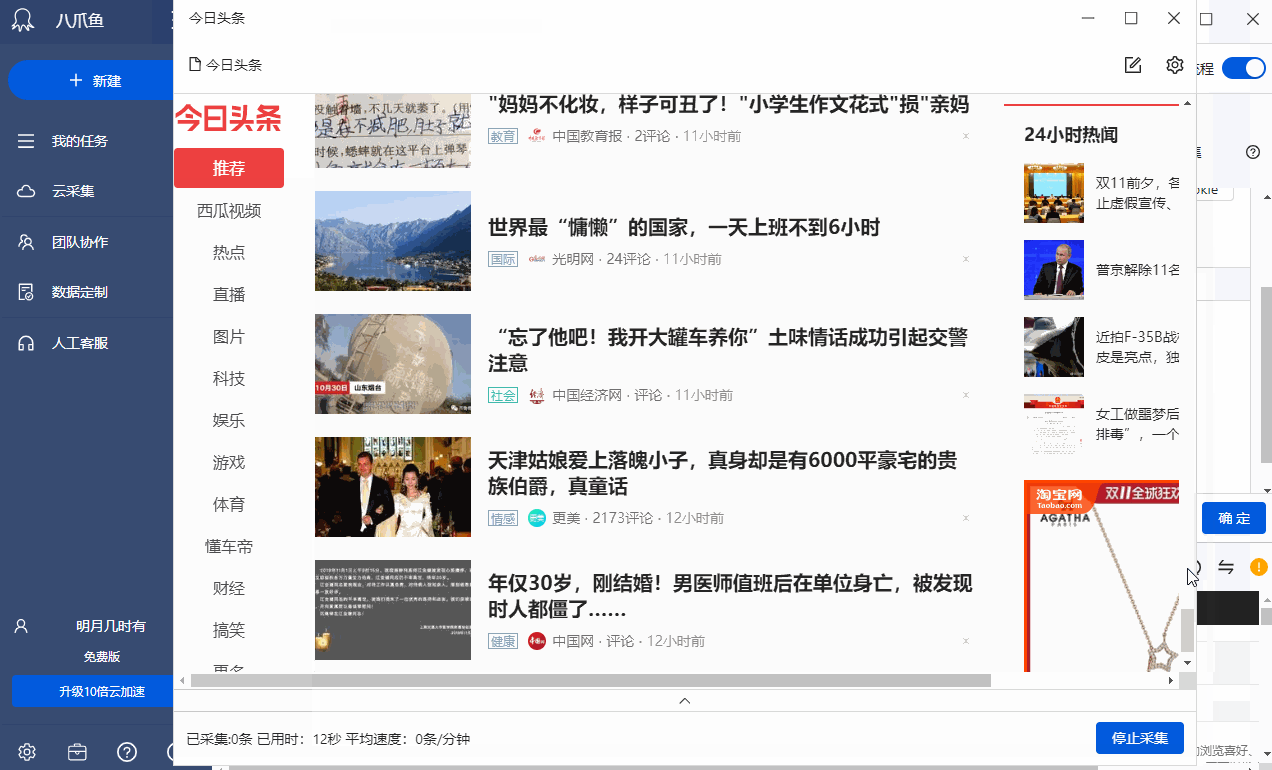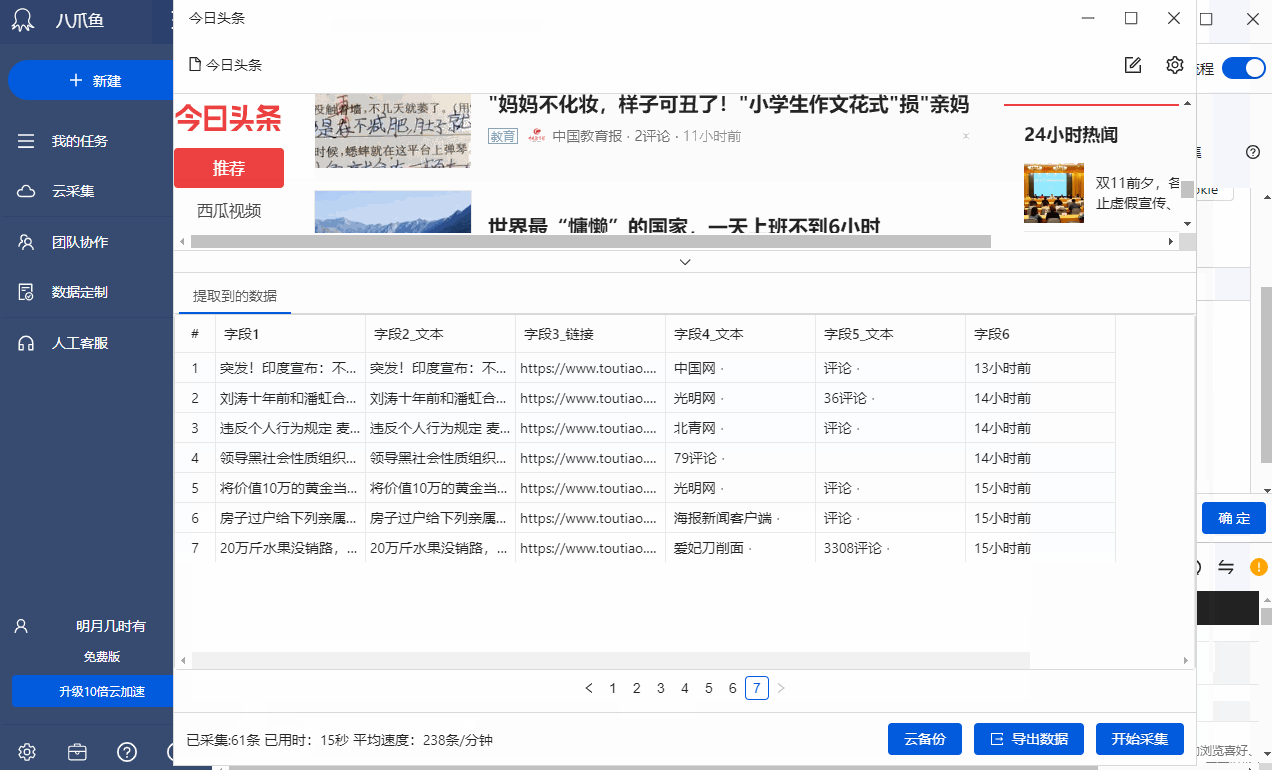
特别说明:
一种。此网页无限向下滚动加载数据,优采云 无法采集 一次获取所有数据。上面的例子设置滚动5次,在实际采集过程中可以按需,建议不要超过x次。
湾 这类网页常用于数据实时性较高的新闻网站,可以设置定时启动优采云,少量次采集最新数据。
C。有时候网页速度很快,像【加载中】这样的提示不明显。【是否有新数据】和【观察滚动条的反弹次数】是比较有用的判断标准。
二、【向下滚动一屏】
其他数据需要在当前屏幕上显示一段时间才能完全加载,然后被采集接收。需要设置【向下滚动一屏】,【滚动次数】根据网页本身和采集要求设置,【每次间隔】时间需要略大于数据加载时间,这与网速等因素。
常见应用场景一:数据需要在当前屏幕上显示一段时间才能完全加载,然后才可以采集。
以京东商品列表为例。%E6%89%8B%E6%9C%BA&enc=utf-8&suggest=1.his.0.0&wq=&pvid=1b312c8afe2845bd94fe55ff1b6165a8,我们想要一份所有产品的清单。首先按照之前列出数据采集的方法配置采集的任务。下面是一个配置好的任务,需要特别注意【主图片链接】字段。
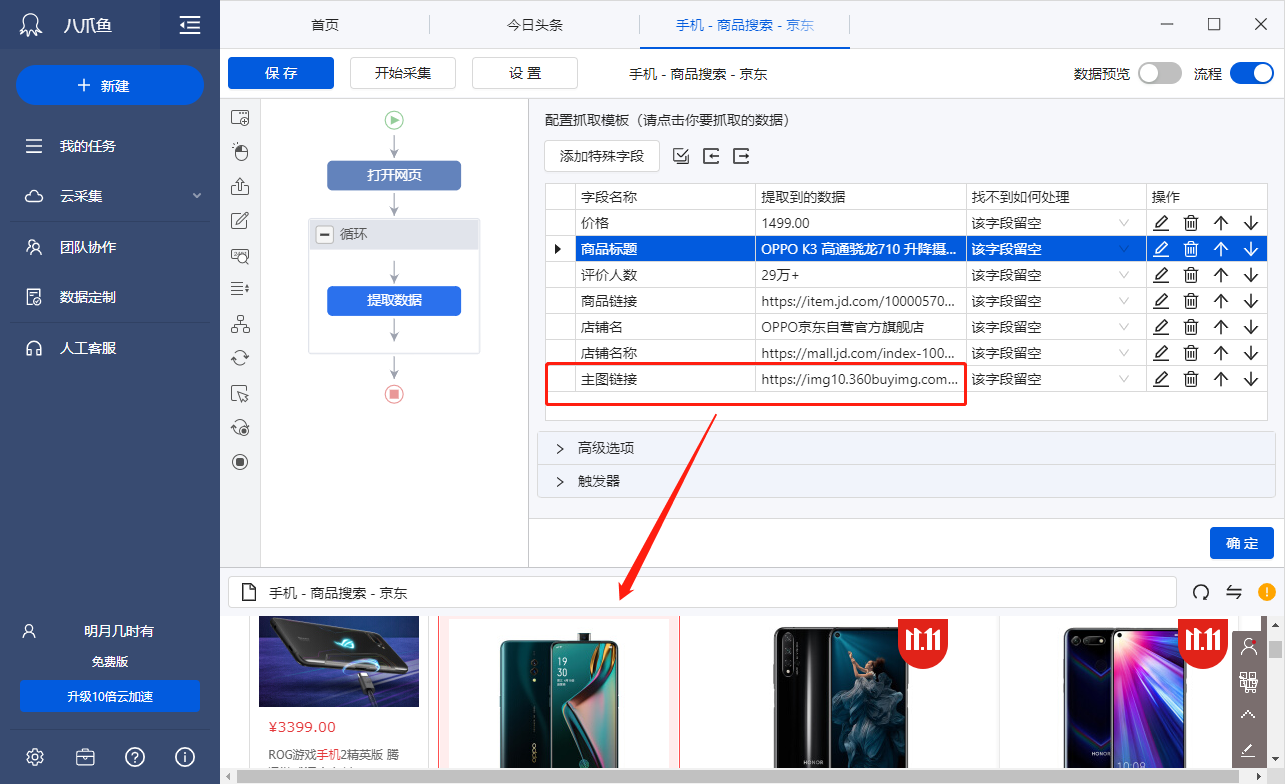
启动采集,看看采集的结果。我们发现【主图链接】字段没有采集到达。
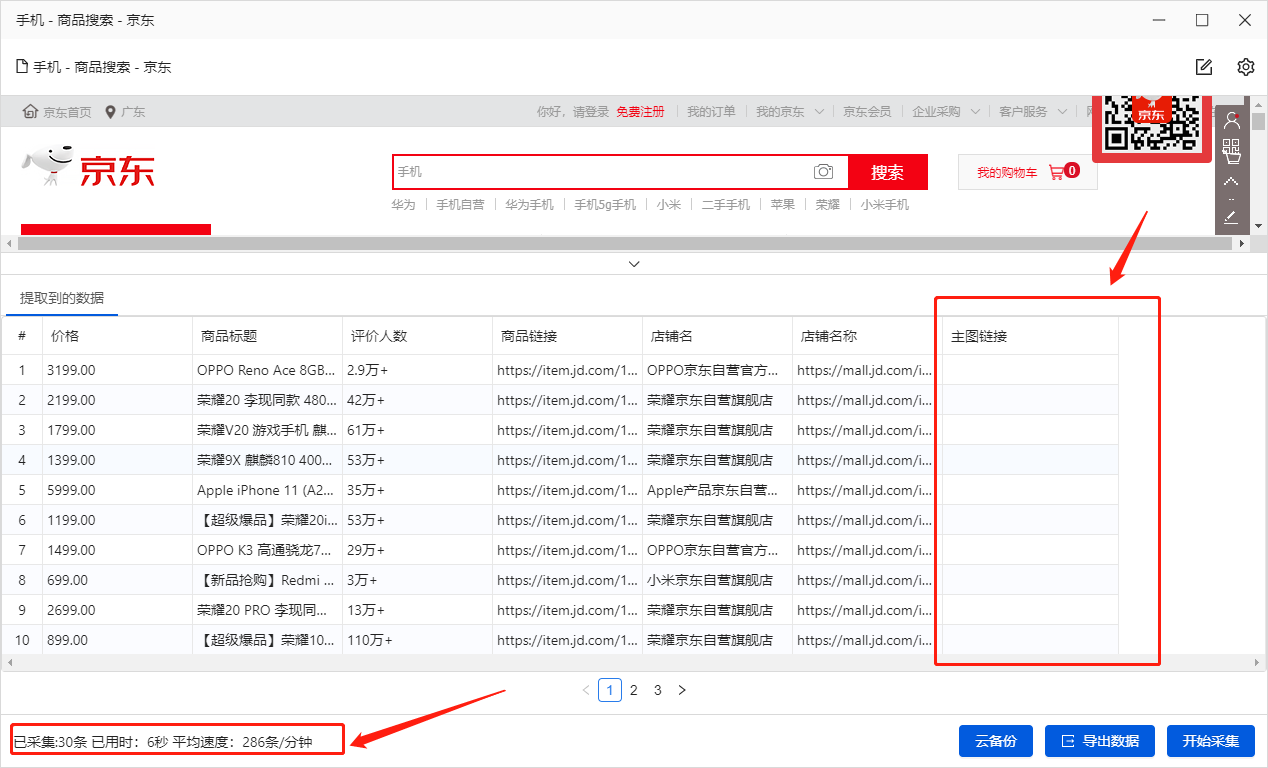
返回流程,手动执行采集流程。我们发现当主图显示在当前屏幕上时(循环中的item1、2、3),它的链接可以通过采集到达。当主图像未显示在当前屏幕上时(循环后面的项目),其链接 采集 不可用。
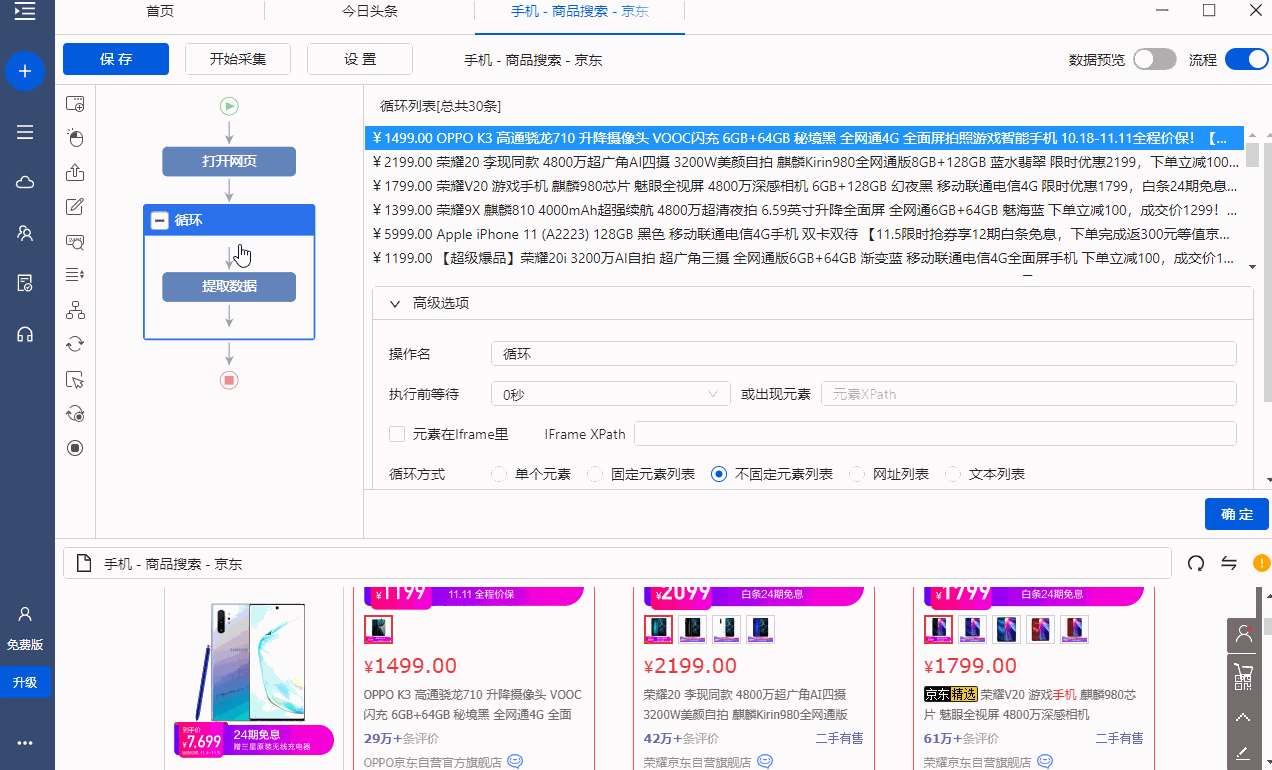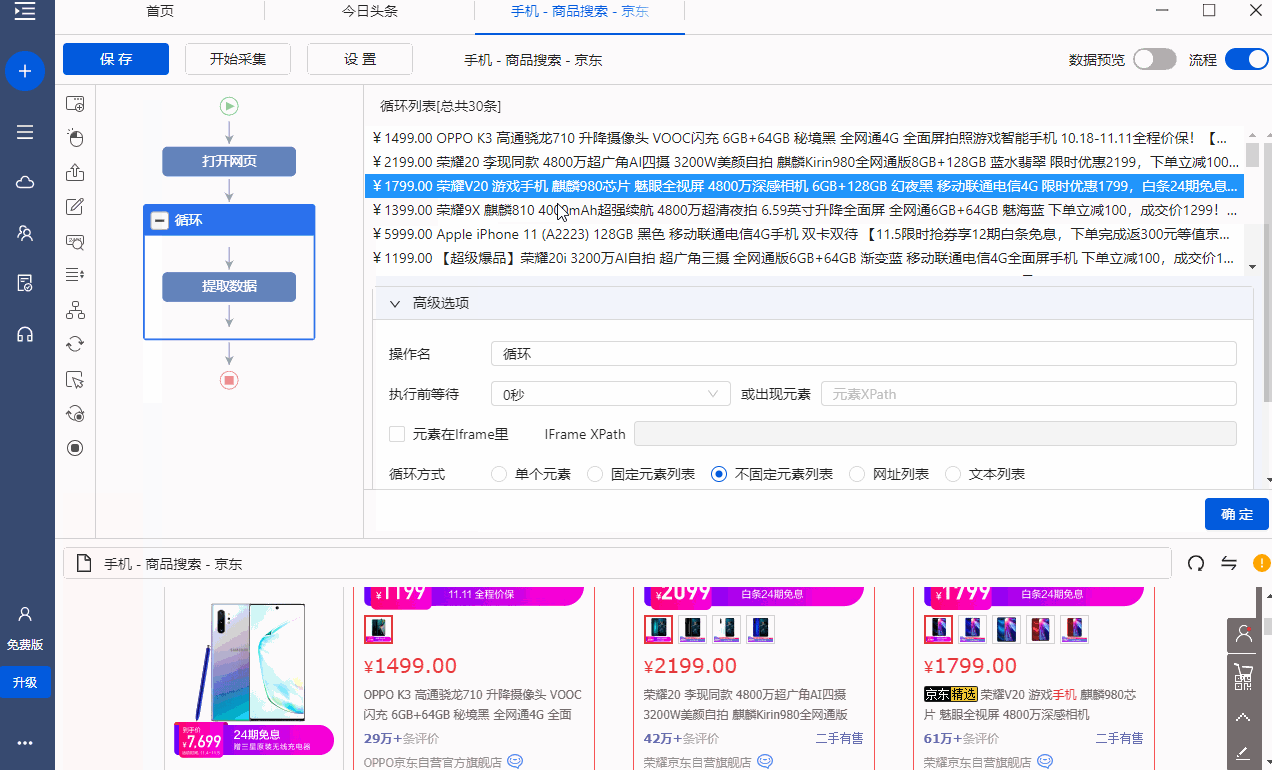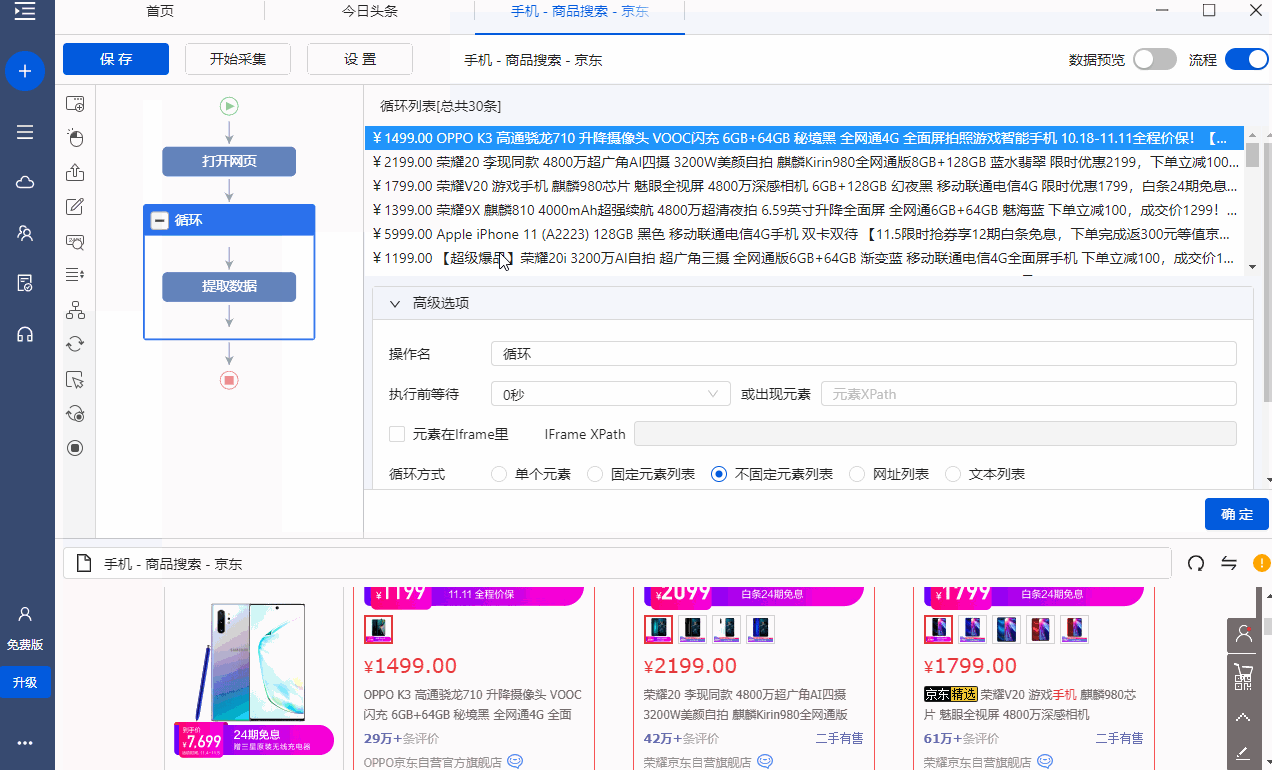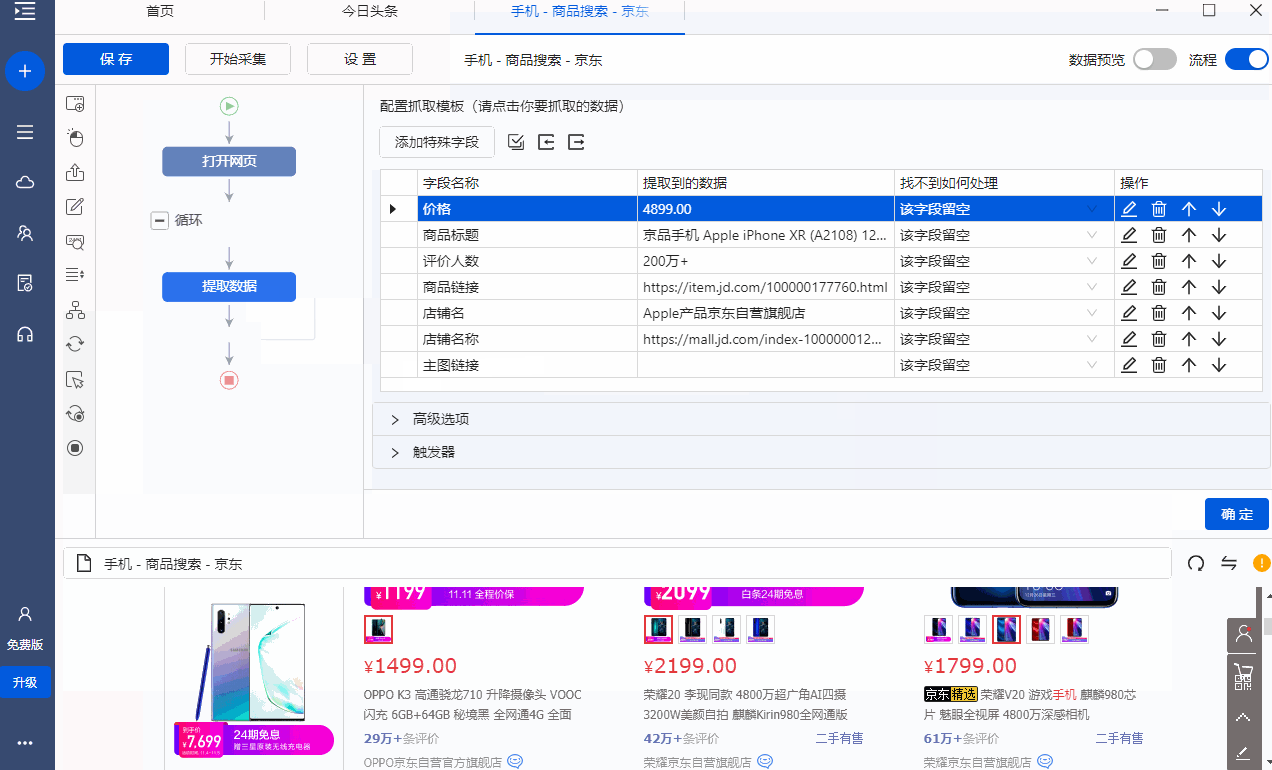
我们还需要在 优采云 中进行相同的设置。选择【打开网页】的步骤,打开【高级选项】,勾选【页面加载后向下滚动】,设置【滚动次数】10次,【每次间隔】2秒,【滚动模式】为【向下滚动】一屏]。
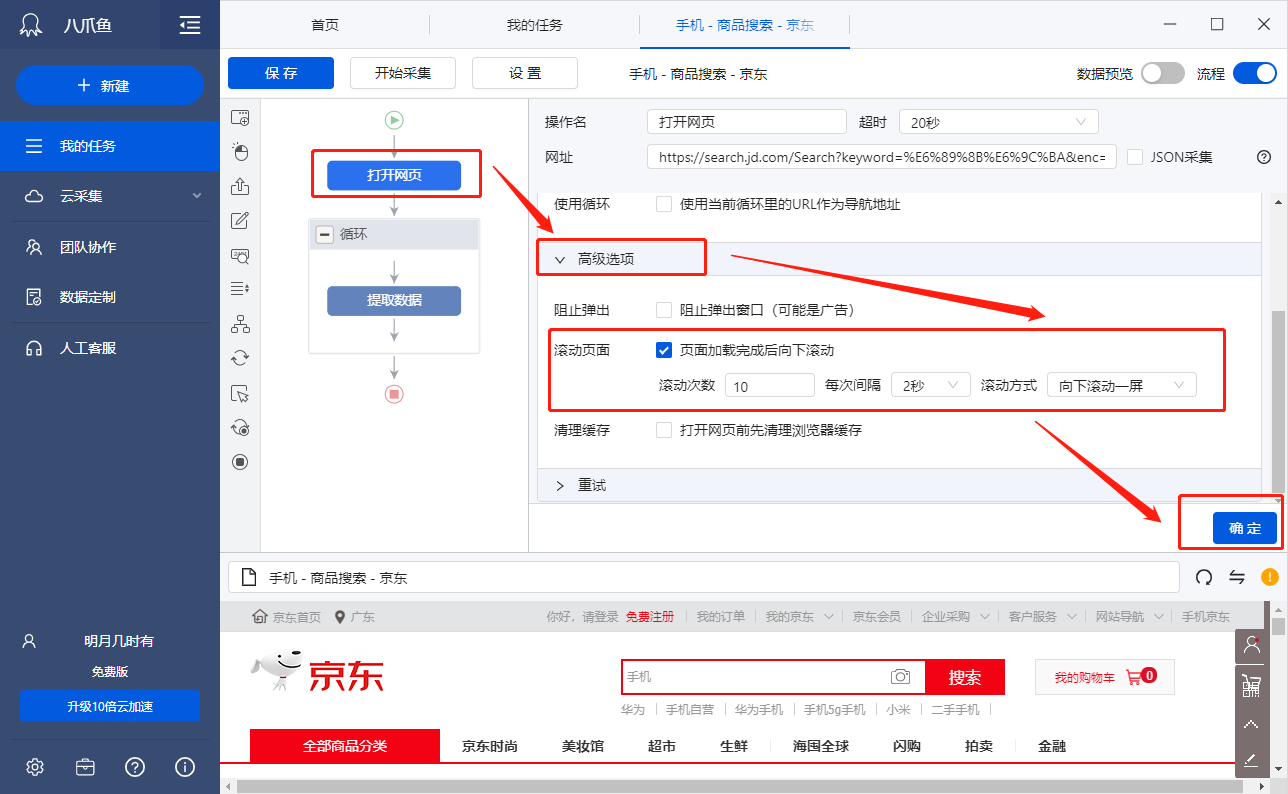
重新开始采集看看。优采云【向下滚动一屏】自动执行了10次。60个产品列表的主图在当前屏幕上显示2秒,主图链接也正常采集down。
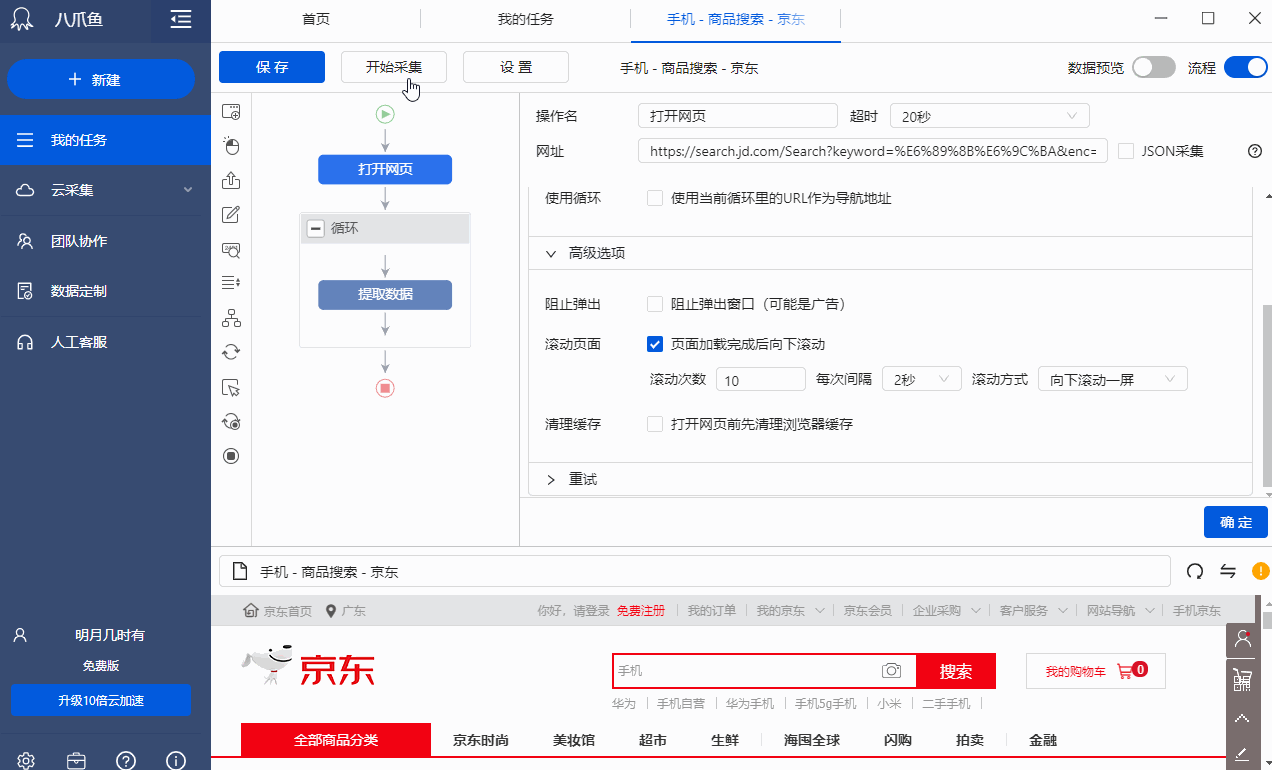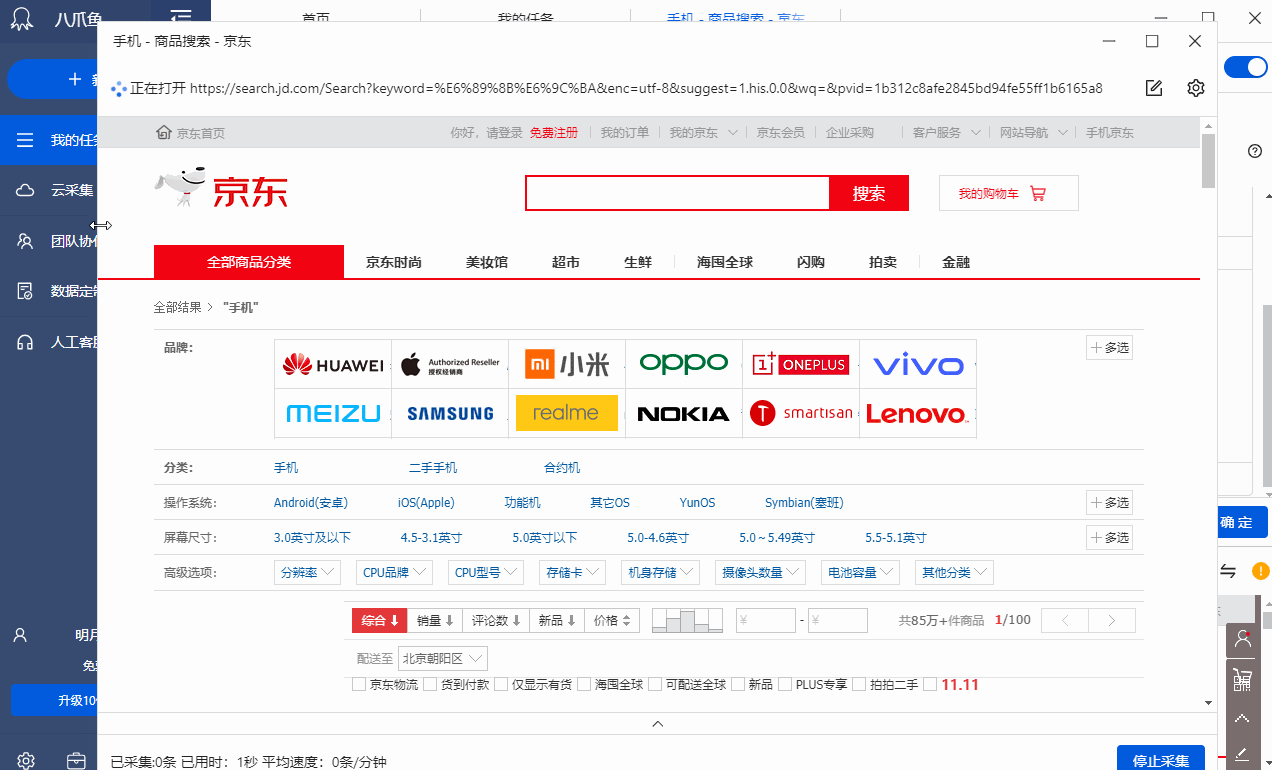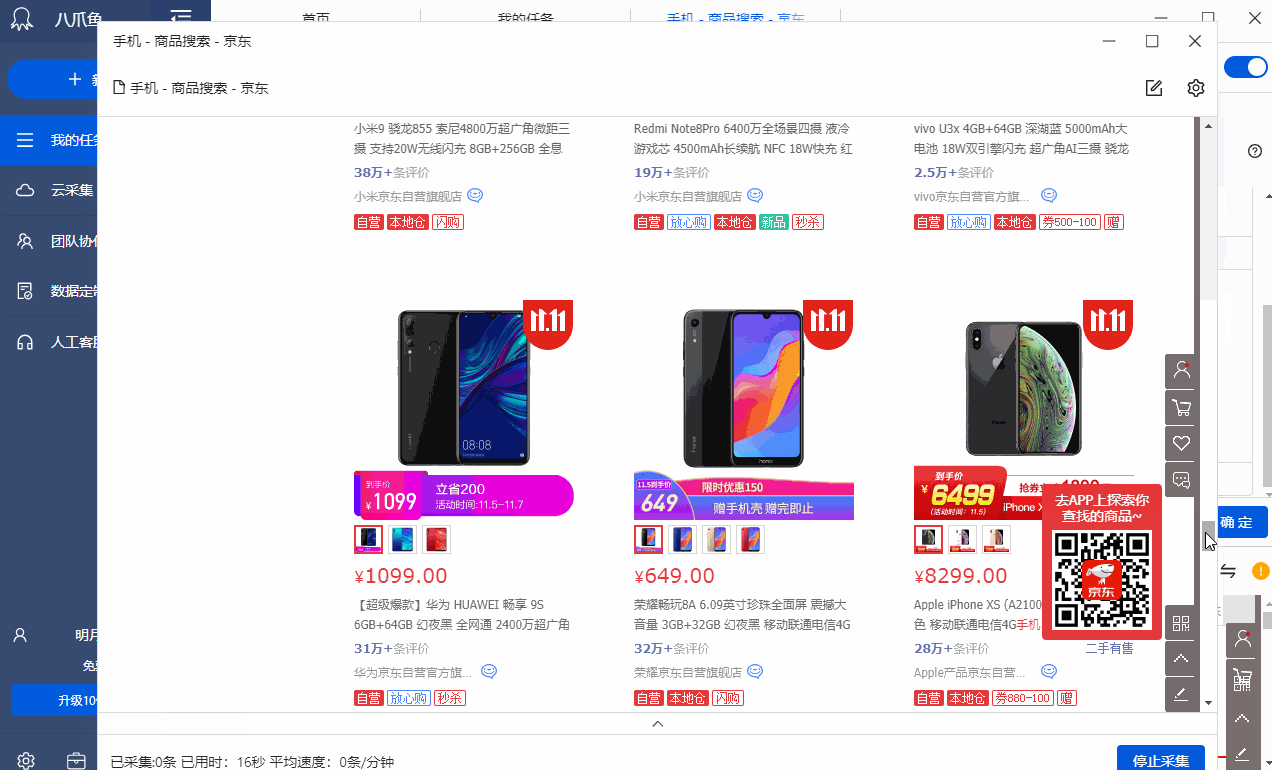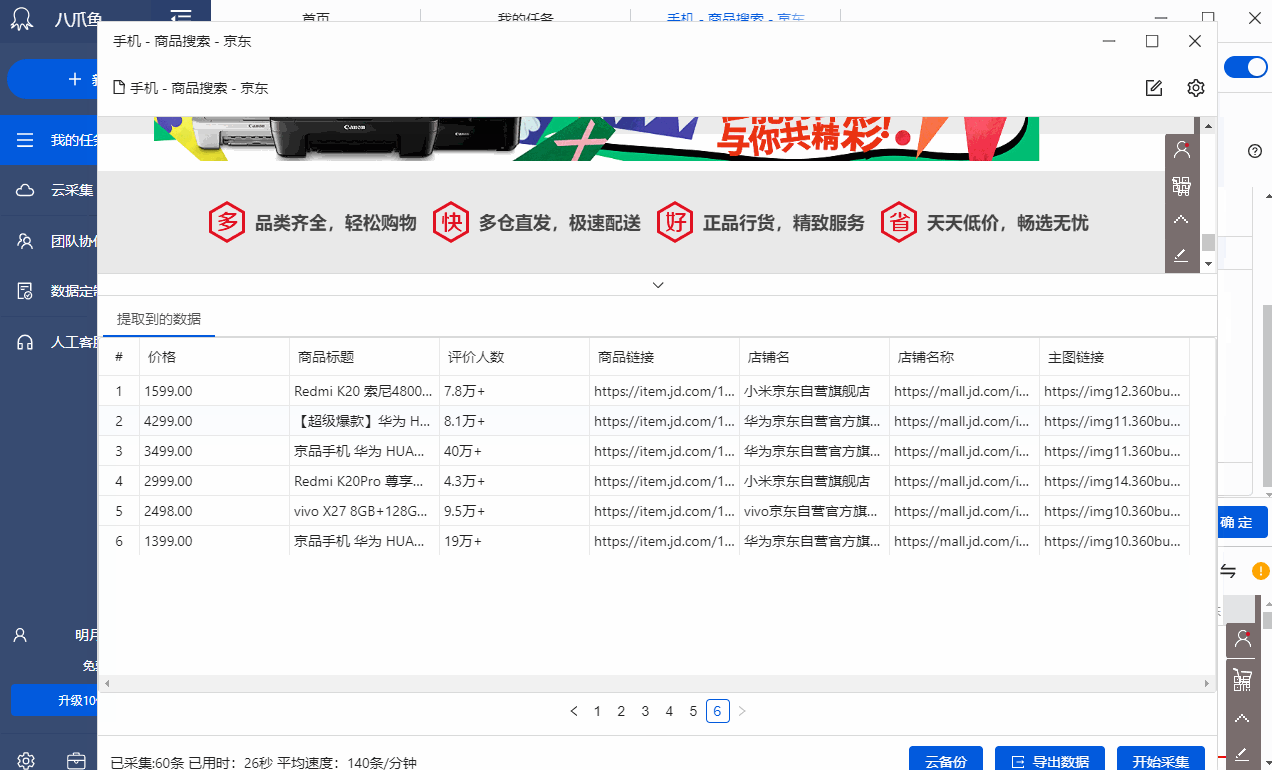
特别说明:
一种。如果某个字段或某些数据项没有采集到达,您可以手动执行规则进行检查。很有可能需要设置【向下滚动一屏】。
湾 本例中设置滚动次数为10次,可以在当前屏幕上显示所有列表。在采集的实际过程中,根据网页的情况设置采集的数量。
C。[向下滚动一屏]的一屏与运行采集任务时的窗口显示区域有关。如下图,左边的滚动画面>右边的滚动画面。
网页新闻抓取(【每日一题】如何爬取实际的新闻页面的具体内容观察)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-07 23:25
前言
前面的文章()主要是抓取首页的新闻列表而不是具体的新闻内容。本文将具体分析如何抓取实际新闻页面的具体内容
观察图中的新闻列表,你会发现一共有三种新闻。点进去可以发现三个新闻的页面类型不同。这里只选择性抓取类似于第一条新闻的类型,其他两种抓取方式类似,大家可以自己实践一下--_--
页面分析
一条新闻的内容无外乎三种:视频、图片、文字。以下是收录所有三个内容供分析的页面,链接如下:
打开控制台,视频一般会放在文章的顶部,id为tupian_div的div标签中(这里有坑,后面会讲...),文字会放在类left_zw的div标签在p标签中,图片会混在p标签中
视频部分的抓取
根据上一篇文章使用xpath解析html,视频主要在div下的source标签,尝试爬取地址
显然是孤独的爬上去的。. .
基本上可以判断视频是通过js动态加载的。如何处理这种情况会在下面的博客中讨论,因为内容还是比较大的。
这里的解决方法:div下面的第三个script标签里面有一个视频地址,有点推测。
提取视频地址的具体代码:
videos = news_demo.xpath('//div[@id="tupian_div"]//script')
videos_script = str(videos[2].xpath('text()'))
videos_address = videos_script[videos_script.find('source') + 11:videos_script.find('type=video/mp4') - 1]
这是针对有视频的新闻,所以需要判断新闻中是否有视频。
具体内容和图片抓取
ps = news_demo.xpath('//div[@class="left_zw"]/*')
for p in ps:
if len(p.xpath('img')) > 0:
print(p.xpath('img/@src')[0])
else:
if not p.xpath('text()'):
continue
for text in p.xpath('text()'):
print(text)
应该没有太多代码来解释。xpath的语法在上一篇博客中。
完整代码
def get_real_news(href):
# 采用get方法获取响应
resp = requests.get(href)
# 为防止获取的网页乱码,对响应内容进行重新编码,编码格式可能是utf-8或gbk
html_content = resp.content.decode('utf-8', 'replace')
news_demo = html.etree.HTML(html_content)
# 视频链接爬取
videos = news_demo.xpath('//div[@id="tupian_div"]//script')
if len(videos) == 3: # 判断是否有视频
videos_script = str(videos[2].xpath('text()'))
videos_address = videos_script[videos_script.find('source') + 11:videos_script.find('type=video/mp4') - 1]
print(videos_address)
# 正文内容获取
ps = news_demo.xpath('//div[@class="left_zw"]/*')
for p in ps:
if len(p.xpath('img')) > 0: # 判断p标签中是否嵌入图片
print(p.xpath('img/@src')[0])
else:
if not p.xpath('text()'):
continue
for text in p.xpath('text()'):
print(text)
完成
总结
这只是一个抓取新闻页面的例子。或许可以抓取部分同类型新闻页面,但无法保证每条新闻的内容都能被正确抓取。你还是需要足够的材料来试水,慢慢调试,提高复用性。
我这里只抓取了正文内容。你可以尝试自己解析,也可以尝试爬取其他类型的新闻。您还可以尝试在获取内容时添加标签,例如强标签中的文本。, 那么如果要渲染网页上的内容,可以使用strong标签。 查看全部
网页新闻抓取(【每日一题】如何爬取实际的新闻页面的具体内容观察)
前言
前面的文章()主要是抓取首页的新闻列表而不是具体的新闻内容。本文将具体分析如何抓取实际新闻页面的具体内容

观察图中的新闻列表,你会发现一共有三种新闻。点进去可以发现三个新闻的页面类型不同。这里只选择性抓取类似于第一条新闻的类型,其他两种抓取方式类似,大家可以自己实践一下--_--
页面分析
一条新闻的内容无外乎三种:视频、图片、文字。以下是收录所有三个内容供分析的页面,链接如下:

打开控制台,视频一般会放在文章的顶部,id为tupian_div的div标签中(这里有坑,后面会讲...),文字会放在类left_zw的div标签在p标签中,图片会混在p标签中
视频部分的抓取
根据上一篇文章使用xpath解析html,视频主要在div下的source标签,尝试爬取地址

显然是孤独的爬上去的。. .
基本上可以判断视频是通过js动态加载的。如何处理这种情况会在下面的博客中讨论,因为内容还是比较大的。
这里的解决方法:div下面的第三个script标签里面有一个视频地址,有点推测。

提取视频地址的具体代码:
videos = news_demo.xpath('//div[@id="tupian_div"]//script')
videos_script = str(videos[2].xpath('text()'))
videos_address = videos_script[videos_script.find('source') + 11:videos_script.find('type=video/mp4') - 1]
这是针对有视频的新闻,所以需要判断新闻中是否有视频。
具体内容和图片抓取
ps = news_demo.xpath('//div[@class="left_zw"]/*')
for p in ps:
if len(p.xpath('img')) > 0:
print(p.xpath('img/@src')[0])
else:
if not p.xpath('text()'):
continue
for text in p.xpath('text()'):
print(text)
应该没有太多代码来解释。xpath的语法在上一篇博客中。
完整代码
def get_real_news(href):
# 采用get方法获取响应
resp = requests.get(href)
# 为防止获取的网页乱码,对响应内容进行重新编码,编码格式可能是utf-8或gbk
html_content = resp.content.decode('utf-8', 'replace')
news_demo = html.etree.HTML(html_content)
# 视频链接爬取
videos = news_demo.xpath('//div[@id="tupian_div"]//script')
if len(videos) == 3: # 判断是否有视频
videos_script = str(videos[2].xpath('text()'))
videos_address = videos_script[videos_script.find('source') + 11:videos_script.find('type=video/mp4') - 1]
print(videos_address)
# 正文内容获取
ps = news_demo.xpath('//div[@class="left_zw"]/*')
for p in ps:
if len(p.xpath('img')) > 0: # 判断p标签中是否嵌入图片
print(p.xpath('img/@src')[0])
else:
if not p.xpath('text()'):
continue
for text in p.xpath('text()'):
print(text)
完成

总结
这只是一个抓取新闻页面的例子。或许可以抓取部分同类型新闻页面,但无法保证每条新闻的内容都能被正确抓取。你还是需要足够的材料来试水,慢慢调试,提高复用性。
我这里只抓取了正文内容。你可以尝试自己解析,也可以尝试爬取其他类型的新闻。您还可以尝试在获取内容时添加标签,例如强标签中的文本。, 那么如果要渲染网页上的内容,可以使用strong标签。
网页新闻抓取(Java程序中本发明文档构造一个FileWriter文件对象的说明图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-07 20:35
带有等标志的Html新闻网页可以准确抓取新闻列表的标题内容、链接地址和发布时间,对抓取结果进行分类,并保存在本地txt中。为实现上述目的,本发明采用如下技术方案: (1)创建存储对象:在本地服务器创建一个txt空文档,在Java程序中为该txt文档构造一个FileWriter文件对象,并设置content Encoding格式,避免文档存储过程中出现乱码现象,实现文档的可写性;(2)分析对象:使用Jsoup解析器解析新闻列表页面URL的Html ,并创建一个Document对象,获取解析后的文本Content;进一步分析Document对象,@3)提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,细化对象中各个元素节点的数据标识,区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。@3)提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,细化对象中各个元素节点的数据标识,区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。
以@网站的通知公告为例。如图2所示,一种基于Jsoup的网络新闻列表抓取和保存方法包括以下步骤: 步骤1:在本地或服务器上创建一个空的news.txt文件。用Java为txt文档构造一个FileWriter对象,将其编码格式设置为“UTF-8”,避免出现乱码;第二步:输入通知公告的新闻列表页面的url,使用Jsoup.connect("url")。get()方法解析页面的Html,得到一个Document对象dom,其中Documentdom=Jsoup.connect("url").get(); 第三步:使用select选择器方法提取Document对象并返回Elements集合,或者使用getElementsByClass/Tag提取指定的样式和标签内容,同时返回Elements对象es;选择方法是 Elements=dom.select("table"); getElementsByClass/Tag 方法是指 Elements=dom.getElementsByTag("table"); 第四步:定义多个字符串title、linkHref、datetime,获取Element对象中的标题、链接地址和发布时间;第五步:根据continuous es tr中是否有多个,td进行判断。
如果存在,则使用for循环方法通过Stringtitle/datetime=es.get(i).select("td").get(j).text()获取标题内容或发布时间,并通过StringlinkHref=es .get( i).getElementsByTag("a").attr("abs: href") 获取链接地址;其中i代表行数tr,j代表列数td;第六步:同步骤(4),如果不存在,直接根据Stringtitle/datetime=es.getElementsByTag("").text()获取标题或时间,通过StringlinkHref=es获取链接。 getElementsByTag("a").attr("href"); 第七步:将获取的title、linkHref、datetime按照一定的顺序和格式进行封装,封装的结果使用fwrite.write()不断写入txt ; 第八步:程序运行后,使用flush清除缓存并关闭文件,实现抓取并保存该页面新闻列表的过程。当前页面 1 1 2 3 当前页面 1 1 2 3 查看全部
网页新闻抓取(Java程序中本发明文档构造一个FileWriter文件对象的说明图)
带有等标志的Html新闻网页可以准确抓取新闻列表的标题内容、链接地址和发布时间,对抓取结果进行分类,并保存在本地txt中。为实现上述目的,本发明采用如下技术方案: (1)创建存储对象:在本地服务器创建一个txt空文档,在Java程序中为该txt文档构造一个FileWriter文件对象,并设置content Encoding格式,避免文档存储过程中出现乱码现象,实现文档的可写性;(2)分析对象:使用Jsoup解析器解析新闻列表页面URL的Html ,并创建一个Document对象,获取解析后的文本Content;进一步分析Document对象,@3)提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,细化对象中各个元素节点的数据标识,区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。@3)提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,细化对象中各个元素节点的数据标识,区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。
以@网站的通知公告为例。如图2所示,一种基于Jsoup的网络新闻列表抓取和保存方法包括以下步骤: 步骤1:在本地或服务器上创建一个空的news.txt文件。用Java为txt文档构造一个FileWriter对象,将其编码格式设置为“UTF-8”,避免出现乱码;第二步:输入通知公告的新闻列表页面的url,使用Jsoup.connect("url")。get()方法解析页面的Html,得到一个Document对象dom,其中Documentdom=Jsoup.connect("url").get(); 第三步:使用select选择器方法提取Document对象并返回Elements集合,或者使用getElementsByClass/Tag提取指定的样式和标签内容,同时返回Elements对象es;选择方法是 Elements=dom.select("table"); getElementsByClass/Tag 方法是指 Elements=dom.getElementsByTag("table"); 第四步:定义多个字符串title、linkHref、datetime,获取Element对象中的标题、链接地址和发布时间;第五步:根据continuous es tr中是否有多个,td进行判断。
如果存在,则使用for循环方法通过Stringtitle/datetime=es.get(i).select("td").get(j).text()获取标题内容或发布时间,并通过StringlinkHref=es .get( i).getElementsByTag("a").attr("abs: href") 获取链接地址;其中i代表行数tr,j代表列数td;第六步:同步骤(4),如果不存在,直接根据Stringtitle/datetime=es.getElementsByTag("").text()获取标题或时间,通过StringlinkHref=es获取链接。 getElementsByTag("a").attr("href"); 第七步:将获取的title、linkHref、datetime按照一定的顺序和格式进行封装,封装的结果使用fwrite.write()不断写入txt ; 第八步:程序运行后,使用flush清除缓存并关闭文件,实现抓取并保存该页面新闻列表的过程。当前页面 1 1 2 3 当前页面 1 1 2 3
网页新闻抓取(本篇博客在爬取新闻网站信息2的基础上进行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-07 20:28
本博客基于爬取新闻网站信息2.
主要内容如下:
1.定义获取页面20个链接的函数
2.构造多个分页链接
3.获取多个分页链接的新闻内容
4.使用pandas整理爬取的数据
5.保存数据到csv文件
6.Scrapy 安装
1.定义获取页面20个链接的函数
#定义获取一页20条链接内容的函数
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text)
#获取一个页面所有链接(20个左右)
for ent in jd['result']['data']:
#getNewsDetail为获取一个链接内容详情
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
#测试
url = 'https://feed.sina.com.cn/api/r ... 39%3B
parseListLinks(url)
2.构造多个分页链接
#构造多个分页链接
pageurl = "https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8"
for i in range(1,10):
newsurl = pageurl.format(i)
print(newsurl)
3.获取多个分页链接的新闻内容
#抓取多个分页链接新闻内容
import requests
url = 'https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8'
news_total = []
for i in range(1,3):
newsurl = url.format(i)
newsary = parseListLinks(url)
news_total.extend(newsary)
#测试打印抓取的两个页面
print(news_total)
4.使用pandas整理爬取的数据
pandas是一个python数据分析包(Python Data Analysis Library),这里我们使用pandas的DataFrame函数将爬取中提取的数据组织成二维表数据结构。
安装pandas套件:进入cmd命令行输入如下命令安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
#用pandas整理爬取出的资料
import pandas
df = pandas.DataFrame(news_total)
#查看后5行数据
df.tail()
5.保存数据到csv文件
使用 to_csv 函数将数据存储在 csv 文件中。 “ruiyigongfang.csv”是我们导出的文件名。存放在jupyter notebook启动根目录下,一般在C:\Users\Administrator目录下。
查看ruiyigongfang.csv文件的内容
到此,用python3爬取新闻网站信息的项目已经完成。
总结:
爬虫的主要过程分为三个阶段:
下载数据:使用requests包,通过requests.get('url')方法获取网页信息
提取数据:使用BeautifulSoup4套件通过soup.select('xxx');解析关系的内容;
保存数据:通过pandas套件将数据组织成二维数据结构,然后通过to_csv()函数将数据以csv格式保存在本地。
----------------------------------------------- ---------------------------------------------
接下来会有第二个python爬虫项目,等待下次博客更新!
这里先介绍一下简单而强大的爬虫框架Scrapy的安装,为后面的项目做准备。
Scrapy 安装
环境:windows系统,python3
步骤:
1.安装轮子:
py -3 -m pip install wheel
2.安装lxml:
py -3 -m pip install lxml
3.安装扭曲:
下载扭曲:~gohlke/pythonlibs/#twisted
注意:下载的版本必须与安装的python版本和电脑的位数一致。对于python3.7,选择cp37,其他版本以此类推。例如:
安装扭曲:
pip install xxx/xxx/Twistedxxx
注:xxx/xxx/Twistedxxx为下载的twisted文件的绝对路径。比如下载的文件放在D:\目录下,文件名是Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
命令应该是 pip install D:\Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
4.安装 Scrapy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
5.安装 win32py
下载:注意下载与python版本和电脑相同位数的文件
安装:双击pywin32-224.win-amd64-py3.7.exe文件安装
6.验证
scrapy -h
说明:
安装Scrapy依赖于wheel、lxml和Twisted模块
运行 Scrapy 依赖于 win32py
完成!享受吧! 查看全部
网页新闻抓取(本篇博客在爬取新闻网站信息2的基础上进行)
本博客基于爬取新闻网站信息2.
主要内容如下:
1.定义获取页面20个链接的函数
2.构造多个分页链接
3.获取多个分页链接的新闻内容
4.使用pandas整理爬取的数据
5.保存数据到csv文件
6.Scrapy 安装
1.定义获取页面20个链接的函数
#定义获取一页20条链接内容的函数
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text)
#获取一个页面所有链接(20个左右)
for ent in jd['result']['data']:
#getNewsDetail为获取一个链接内容详情
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
#测试
url = 'https://feed.sina.com.cn/api/r ... 39%3B
parseListLinks(url)
2.构造多个分页链接
#构造多个分页链接
pageurl = "https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8"
for i in range(1,10):
newsurl = pageurl.format(i)
print(newsurl)
3.获取多个分页链接的新闻内容
#抓取多个分页链接新闻内容
import requests
url = 'https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8'
news_total = []
for i in range(1,3):
newsurl = url.format(i)
newsary = parseListLinks(url)
news_total.extend(newsary)
#测试打印抓取的两个页面
print(news_total)
4.使用pandas整理爬取的数据
pandas是一个python数据分析包(Python Data Analysis Library),这里我们使用pandas的DataFrame函数将爬取中提取的数据组织成二维表数据结构。
安装pandas套件:进入cmd命令行输入如下命令安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
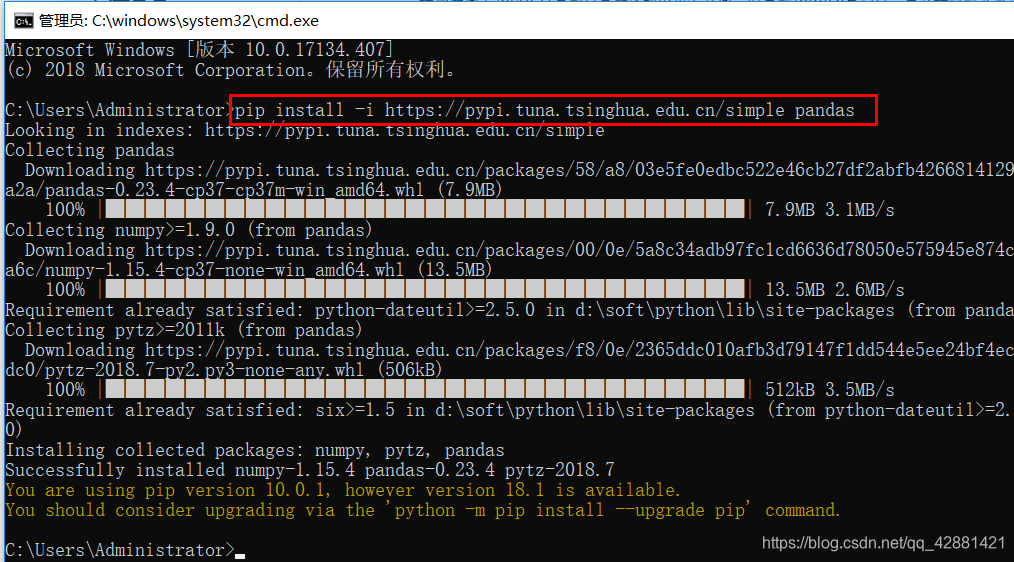
#用pandas整理爬取出的资料
import pandas
df = pandas.DataFrame(news_total)
#查看后5行数据
df.tail()
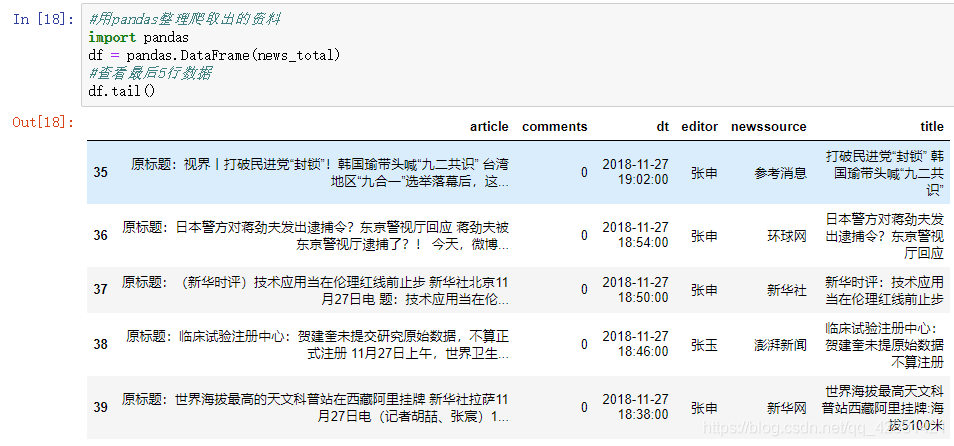
5.保存数据到csv文件
使用 to_csv 函数将数据存储在 csv 文件中。 “ruiyigongfang.csv”是我们导出的文件名。存放在jupyter notebook启动根目录下,一般在C:\Users\Administrator目录下。

查看ruiyigongfang.csv文件的内容
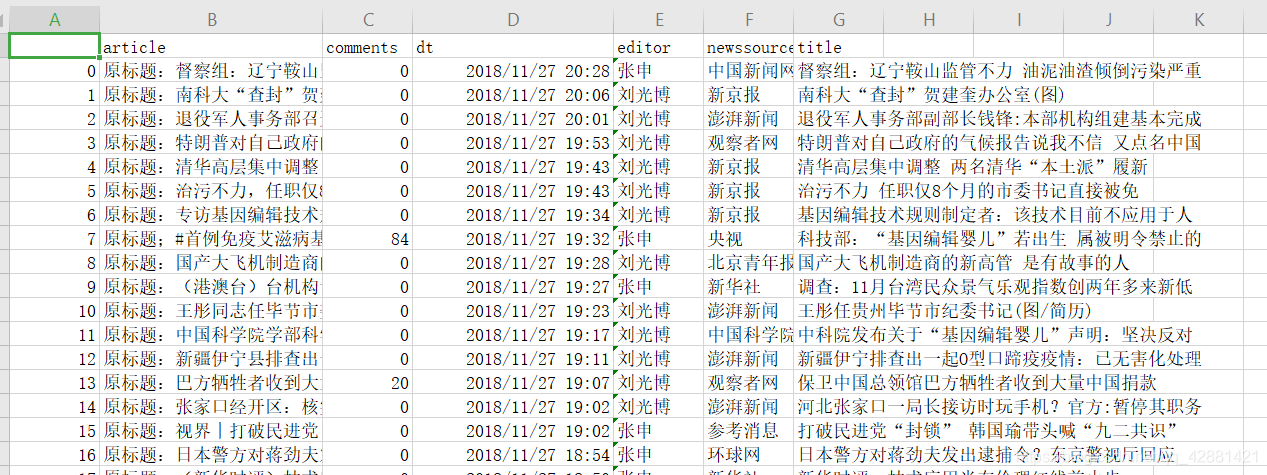
到此,用python3爬取新闻网站信息的项目已经完成。
总结:
爬虫的主要过程分为三个阶段:

下载数据:使用requests包,通过requests.get('url')方法获取网页信息
提取数据:使用BeautifulSoup4套件通过soup.select('xxx');解析关系的内容;
保存数据:通过pandas套件将数据组织成二维数据结构,然后通过to_csv()函数将数据以csv格式保存在本地。
----------------------------------------------- ---------------------------------------------
接下来会有第二个python爬虫项目,等待下次博客更新!
这里先介绍一下简单而强大的爬虫框架Scrapy的安装,为后面的项目做准备。
Scrapy 安装
环境:windows系统,python3
步骤:
1.安装轮子:
py -3 -m pip install wheel
2.安装lxml:
py -3 -m pip install lxml
3.安装扭曲:
下载扭曲:~gohlke/pythonlibs/#twisted
注意:下载的版本必须与安装的python版本和电脑的位数一致。对于python3.7,选择cp37,其他版本以此类推。例如:
安装扭曲:
pip install xxx/xxx/Twistedxxx
注:xxx/xxx/Twistedxxx为下载的twisted文件的绝对路径。比如下载的文件放在D:\目录下,文件名是Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
命令应该是 pip install D:\Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
4.安装 Scrapy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
5.安装 win32py
下载:注意下载与python版本和电脑相同位数的文件
安装:双击pywin32-224.win-amd64-py3.7.exe文件安装
6.验证
scrapy -h
说明:
安装Scrapy依赖于wheel、lxml和Twisted模块
运行 Scrapy 依赖于 win32py
完成!享受吧!
网页新闻抓取(搜索引擎问题是如何更快地网站网站,可采取哪些措施来提高速度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-06 20:23
搜索引擎包括抓取工具、索引和算法。其中,爬虫工具跟随链接。对于 网站 建立的链接,爬虫将页面的 HTML 版本保存在索引数据库中。每次爬虫绕过网站并找到新版本时,都会更新索引。
爬虫爬取溯源与爬取网站有关。网站 可能会阻止抓取工具。有几种方法可以防止爬虫在 网站 上爬行。如果网站上的网页被屏蔽,爬虫会被拒绝,相应的页面也不会出现在搜索结果中。如果robot文件阻塞了爬虫,爬取之前网站工具会查看网页的HTTP头。HTTP 标头收录状态代码。如果状态码显示该网页不存在,则不会抓取网站。在HTTP headers模块中,会告知所有相关信息。如果特定网页上的元标记阻止搜索引擎将该网页编入索引,则该网页将被抓取但不会添加到索引中。
虽然可爬性只是一个技术基础,但是如何更快地爬取网站,以及可以采取哪些措施来提高爬取速度,是经常被各类站长问到的一个问题。在抓取网站时,搜索引擎有两种可能。如果他们没有找到足够多的网站 链接,那么这并不重要,网站 响应太慢,或者遇到太多错误。当没有足够多的高质量入站链接时,内容不会很快被抓取。如果想让爬虫进行更多的爬虫操作,就需要做一些链接建设。
网站生产解决了爬虫爬行响应慢的问题,如动态页面JS代码量大、服务器不稳定、收录404页面、网站生产线修改模板等问题到内容页面中的某些文件夹它没有被删除,但链接显示了一个 404 页面。首先解决自己网站的所有问题。
那么最重要的就是提交给爬虫了。最好将代码自动推送到页面上的布局中。详细到每个内容页面,提交会自动触发,从而增加爬虫的爬取频率。最后是核心,也是高质量的外链,尽量在自己网站主题相关的网站上做外链,保持一定的垂直度。目前很多网站都设置了外链nofollow的标签,选择在外链上发布。对于论坛或博客,或者在推广软文时,首先检查外链标签是否设置为nofollow,以确保可以引入爬虫链接。 查看全部
网页新闻抓取(搜索引擎问题是如何更快地网站网站,可采取哪些措施来提高速度)
搜索引擎包括抓取工具、索引和算法。其中,爬虫工具跟随链接。对于 网站 建立的链接,爬虫将页面的 HTML 版本保存在索引数据库中。每次爬虫绕过网站并找到新版本时,都会更新索引。

爬虫爬取溯源与爬取网站有关。网站 可能会阻止抓取工具。有几种方法可以防止爬虫在 网站 上爬行。如果网站上的网页被屏蔽,爬虫会被拒绝,相应的页面也不会出现在搜索结果中。如果robot文件阻塞了爬虫,爬取之前网站工具会查看网页的HTTP头。HTTP 标头收录状态代码。如果状态码显示该网页不存在,则不会抓取网站。在HTTP headers模块中,会告知所有相关信息。如果特定网页上的元标记阻止搜索引擎将该网页编入索引,则该网页将被抓取但不会添加到索引中。
虽然可爬性只是一个技术基础,但是如何更快地爬取网站,以及可以采取哪些措施来提高爬取速度,是经常被各类站长问到的一个问题。在抓取网站时,搜索引擎有两种可能。如果他们没有找到足够多的网站 链接,那么这并不重要,网站 响应太慢,或者遇到太多错误。当没有足够多的高质量入站链接时,内容不会很快被抓取。如果想让爬虫进行更多的爬虫操作,就需要做一些链接建设。
网站生产解决了爬虫爬行响应慢的问题,如动态页面JS代码量大、服务器不稳定、收录404页面、网站生产线修改模板等问题到内容页面中的某些文件夹它没有被删除,但链接显示了一个 404 页面。首先解决自己网站的所有问题。
那么最重要的就是提交给爬虫了。最好将代码自动推送到页面上的布局中。详细到每个内容页面,提交会自动触发,从而增加爬虫的爬取频率。最后是核心,也是高质量的外链,尽量在自己网站主题相关的网站上做外链,保持一定的垂直度。目前很多网站都设置了外链nofollow的标签,选择在外链上发布。对于论坛或博客,或者在推广软文时,首先检查外链标签是否设置为nofollow,以确保可以引入爬虫链接。
网页新闻抓取( Python学习交流群:爬取前的准备:jsonJavascript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-10-17 19:13
Python学习交流群:爬取前的准备:jsonJavascript)
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
【前言】
Python学习交流群:834179111,群里有很多学习资料。欢迎大家前来交流学习。
爬行前的准备:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
json
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
Javascript 对象
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
使用请求获取网页信息
使用 BeautifulSoup 将网页信息转换为可操作的块
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
可以通过beautifulSoup中的select方法获取对应的元素,获取的元素为列表形式,可以用for循环一一解析出来
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取到html标签值后,可以使用['href']获取'href'属性的值,如
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻编号:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
re正则表达式的使用:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
使用 for 循环获取多页新闻
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻发布时间:
获取的信息可能收录不需要的成分,即可以获取其他我们不想要的元素,例如发布者。里面的元素可以用contents拆分成list形式,用contents[0]获取对应的元素
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
时间字符串转换
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻文章:
检查其类别后,根据上述选择获取新闻内容。获取的内容为列表形式。您可以使用 for 循环删除标签并将内容添加到您创建的列表中(例如 article = [])
*** 其中,可以使用''.join(article)将文章列表中的每一项用换行符''分隔开;**
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
上面获取单个消息的代码可以在一行中完成:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取评论数:(获取评论数后会发现评论是以js的形式发送给浏览器的,所以必须先将获取到的内容转换成json格式才能读取python字典):
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
完整代码(以新浪新闻为例):
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
存储的excel文件如下:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
问题:在jupyter notebook中导入pandas时可能会出现导入错误
解决方法:不要使用命令行打开jupyter notebook,直接找软件打开或者在Anocanda Navigator中打开即可 查看全部
网页新闻抓取(
Python学习交流群:爬取前的准备:jsonJavascript)
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
【前言】
Python学习交流群:834179111,群里有很多学习资料。欢迎大家前来交流学习。
爬行前的准备:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
json
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
Javascript 对象
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
使用请求获取网页信息
使用 BeautifulSoup 将网页信息转换为可操作的块
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
可以通过beautifulSoup中的select方法获取对应的元素,获取的元素为列表形式,可以用for循环一一解析出来
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取到html标签值后,可以使用['href']获取'href'属性的值,如
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻编号:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
re正则表达式的使用:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
使用 for 循环获取多页新闻
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻发布时间:
获取的信息可能收录不需要的成分,即可以获取其他我们不想要的元素,例如发布者。里面的元素可以用contents拆分成list形式,用contents[0]获取对应的元素
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
时间字符串转换
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取新闻文章:
检查其类别后,根据上述选择获取新闻内容。获取的内容为列表形式。您可以使用 for 循环删除标签并将内容添加到您创建的列表中(例如 article = [])
*** 其中,可以使用''.join(article)将文章列表中的每一项用换行符''分隔开;**
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
上面获取单个消息的代码可以在一行中完成:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
获取评论数:(获取评论数后会发现评论是以js的形式发送给浏览器的,所以必须先将获取到的内容转换成json格式才能读取python字典):
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
完整代码(以新浪新闻为例):
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
存储的excel文件如下:
今天给大家分享一些新浪新闻的数据,用Python在网上爬取
问题:在jupyter notebook中导入pandas时可能会出现导入错误
解决方法:不要使用命令行打开jupyter notebook,直接找软件打开或者在Anocanda Navigator中打开即可
网页新闻抓取(网站title就是所谓的网站标题,百度上将其其称为)
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-15 04:08
#seo#网站title 就是所谓的网站title。百度称之为“网页标题是网页的高级概括”。它有多大用处?先来看看你有没有遇到过这样的情况。有些网站的 关键词 排名比你低,但他们的访问者比你多。网站建设周期时间差不多,但在网页易用性方面明显优于对方,但无论排名如何,都没有那么高。问题的根源不是你的网站内容不如人,可能是你的页面标题做的不好。这些排名靠前的网站都有一个共同点,就是网站的标题写得很好,相比之下,垃圾网站的标题写得往往很差!
那么如果我们按照较高的排名写标题网站?一开始对网站的优化也不是没有这么幼稚的想法,后来发现每个站点的权重不一样,所以titte上写的方法难免会不一样。那么学习别人的网站title就没有意义了。
特殊关键词的使用
比如标题中使用了“官网”这个词,如果放在一些普通的网站上,那么这些网站很可能会因为两个字而被降级。官网上的两个字是需要做官网认证,不是随便加的。如果大家都这样写,谁知道哪个网站才是真正的官网呢?
使用高权重关键词
关键词 用于酒店预订和旅游度假,这样写一个较低的权重网站怎么办?结果可能是这个网站没有可以排名的关键词。这是为什么?总之,你没有足够的重量来支撑你设置的关键词。就像“定一个小目标,赚他一亿”这句话的权威。王健林说的,显然比嘴上说的更有说服力。这也是标题的艺术。
现在,让我们回到正题,网站的标题应该怎么写?下面的网络优化问题为大家介绍几个重点,希望对各位朋友有所帮助:
标题长度
很多人在准备网站title时的想法通常是这样的:把你做的所有关键词都放在title上。不要想一想:搜索引擎能接受你的网站上这么多的关键词标题吗?每个站点都有权对配额进行加权。设置的关键字越多,单个关键词的权重越低,最终可能导致网站的所有关键词都上不来。
品牌词和流量词的选择
许多 网站 都是这种情况。网站标题搜搜搜,都是写的产品关键词或者流量关键词,从头到尾都没有网站名字。为了得到更多的关键词,放弃自己的品牌词,这样真的好吗?同样的产品,一个是名牌产品,一个是无品牌产品。相信不用我多说,大家都知道如何选择。其实搜索引擎蜘蛛也在思考。
疑问词的选择
很多网站在发布文章时,往往采取“XXX哪家公司强?”这样的做法。真的有用吗?在这里我想说的网络优化的事情是:这句话是可以的,但是搜索引擎识别这一套,就看你自己的实力了。如果将标题设置为“哪个挖掘机技术强?”,即使你的名字和别人很相似,第一个出来的可能是蓝翔。这个网站有发言权吗?这确实是一个值得思考的问题,否则,也许搜索引擎蜘蛛会不喜欢它。
网站title 就像我们微信里的描述,让陌生人一句话就能理解我们。网站title 就是用这句话让搜索引擎理解这个网站。如果第一印象好,搜索引擎愿意联系这个网站,自然会提升网站的排名和流量。所以,不要在这个问题上敷衍了事,说不定你会因此多得到几百w的订单。 查看全部
网页新闻抓取(网站title就是所谓的网站标题,百度上将其其称为)
#seo#网站title 就是所谓的网站title。百度称之为“网页标题是网页的高级概括”。它有多大用处?先来看看你有没有遇到过这样的情况。有些网站的 关键词 排名比你低,但他们的访问者比你多。网站建设周期时间差不多,但在网页易用性方面明显优于对方,但无论排名如何,都没有那么高。问题的根源不是你的网站内容不如人,可能是你的页面标题做的不好。这些排名靠前的网站都有一个共同点,就是网站的标题写得很好,相比之下,垃圾网站的标题写得往往很差!
那么如果我们按照较高的排名写标题网站?一开始对网站的优化也不是没有这么幼稚的想法,后来发现每个站点的权重不一样,所以titte上写的方法难免会不一样。那么学习别人的网站title就没有意义了。
特殊关键词的使用
比如标题中使用了“官网”这个词,如果放在一些普通的网站上,那么这些网站很可能会因为两个字而被降级。官网上的两个字是需要做官网认证,不是随便加的。如果大家都这样写,谁知道哪个网站才是真正的官网呢?
使用高权重关键词
关键词 用于酒店预订和旅游度假,这样写一个较低的权重网站怎么办?结果可能是这个网站没有可以排名的关键词。这是为什么?总之,你没有足够的重量来支撑你设置的关键词。就像“定一个小目标,赚他一亿”这句话的权威。王健林说的,显然比嘴上说的更有说服力。这也是标题的艺术。
现在,让我们回到正题,网站的标题应该怎么写?下面的网络优化问题为大家介绍几个重点,希望对各位朋友有所帮助:
标题长度
很多人在准备网站title时的想法通常是这样的:把你做的所有关键词都放在title上。不要想一想:搜索引擎能接受你的网站上这么多的关键词标题吗?每个站点都有权对配额进行加权。设置的关键字越多,单个关键词的权重越低,最终可能导致网站的所有关键词都上不来。
品牌词和流量词的选择
许多 网站 都是这种情况。网站标题搜搜搜,都是写的产品关键词或者流量关键词,从头到尾都没有网站名字。为了得到更多的关键词,放弃自己的品牌词,这样真的好吗?同样的产品,一个是名牌产品,一个是无品牌产品。相信不用我多说,大家都知道如何选择。其实搜索引擎蜘蛛也在思考。
疑问词的选择
很多网站在发布文章时,往往采取“XXX哪家公司强?”这样的做法。真的有用吗?在这里我想说的网络优化的事情是:这句话是可以的,但是搜索引擎识别这一套,就看你自己的实力了。如果将标题设置为“哪个挖掘机技术强?”,即使你的名字和别人很相似,第一个出来的可能是蓝翔。这个网站有发言权吗?这确实是一个值得思考的问题,否则,也许搜索引擎蜘蛛会不喜欢它。
网站title 就像我们微信里的描述,让陌生人一句话就能理解我们。网站title 就是用这句话让搜索引擎理解这个网站。如果第一印象好,搜索引擎愿意联系这个网站,自然会提升网站的排名和流量。所以,不要在这个问题上敷衍了事,说不定你会因此多得到几百w的订单。
网页新闻抓取( 爬取一个新闻网站为分析思路很简单(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-15 04:02
爬取一个新闻网站为分析思路很简单(图))
Python爬取新闻网站并破解反爬取
一开始我觉得爬一个新闻网站很容易,因为一般的新闻网站比较容易爬。
但是,当我开始分析和编写代码时,运行它之后,我发现它并没有那么简单。
需要爬取的消息网站是
分析
这个想法很简单:
分析网站-->找出每个页面的URL规则-->分析每个页面收录的新闻链接-->回收批量下载
看起来是不是很简单?现在我开始分析每个URL的页数
我分开开的
链接到第一页
链接到第二页
链接到第三页
可以通过观察发现
page=后面的数字是页码,然后我把页码改成其他数字打开用原来的页面跳转到其他页面看同样的内容,所以现在找到每个页面的URL模式,然后然后通过for循环。你可以继续爬
for i in range(1,3):
url="http://www.shxz.gov.cn/sites/C ... 2Bstr(i)+"&ctgId=fe188544-e1fe-4230-b754-40e8d70ae432&leftBarId=08f6f7e1-badb-49fd-8da9-009f8dcc14a0"
然后分析每个页面的URL,右击查看,然后直接复制一个新闻标题,在页面源码上按Ctr+F就可以找到第一条新闻的标题。下面有一段代码。我点进去发现直接跳到了第一个新闻界面,然后我试着查了一下这样的网址有多少,发现有17个,但是每页不重复的新闻是12个,剩下的5个旁边是推荐内容。
ViewCon2_pg.ashx?ctgId=fe188544-e1fe-4230-b754-40e8d70ae432&infId=7f2c956f-75b0-4a59-808b-fa72b3307db0&leftBarId=08f40df8df9da-f40df9dad
跳转后的网址是
只需要找出每个页面的12个ViewCon2_pg.ash······这个代码,然后在前面加上每个新闻的URL,所以我只需要过滤掉每个页面的12段代码
观察源码,选择正则表达式过滤
<p>pat=' 查看全部
网页新闻抓取(
爬取一个新闻网站为分析思路很简单(图))
Python爬取新闻网站并破解反爬取
一开始我觉得爬一个新闻网站很容易,因为一般的新闻网站比较容易爬。
但是,当我开始分析和编写代码时,运行它之后,我发现它并没有那么简单。
需要爬取的消息网站是
分析
这个想法很简单:
分析网站-->找出每个页面的URL规则-->分析每个页面收录的新闻链接-->回收批量下载
看起来是不是很简单?现在我开始分析每个URL的页数
我分开开的
链接到第一页
链接到第二页
链接到第三页
可以通过观察发现
page=后面的数字是页码,然后我把页码改成其他数字打开用原来的页面跳转到其他页面看同样的内容,所以现在找到每个页面的URL模式,然后然后通过for循环。你可以继续爬
for i in range(1,3):
url="http://www.shxz.gov.cn/sites/C ... 2Bstr(i)+"&ctgId=fe188544-e1fe-4230-b754-40e8d70ae432&leftBarId=08f6f7e1-badb-49fd-8da9-009f8dcc14a0"
然后分析每个页面的URL,右击查看,然后直接复制一个新闻标题,在页面源码上按Ctr+F就可以找到第一条新闻的标题。下面有一段代码。我点进去发现直接跳到了第一个新闻界面,然后我试着查了一下这样的网址有多少,发现有17个,但是每页不重复的新闻是12个,剩下的5个旁边是推荐内容。
ViewCon2_pg.ashx?ctgId=fe188544-e1fe-4230-b754-40e8d70ae432&infId=7f2c956f-75b0-4a59-808b-fa72b3307db0&leftBarId=08f40df8df9da-f40df9dad
跳转后的网址是
只需要找出每个页面的12个ViewCon2_pg.ash······这个代码,然后在前面加上每个新闻的URL,所以我只需要过滤掉每个页面的12段代码
观察源码,选择正则表达式过滤
<p>pat='
网页新闻抓取(2016.10.12河北邮币卡电子盘交易所每日一练)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-14 04:25
以这个文章为例,
抓取文章的内容时,不要抓取【今日直播】的模块内容
抓取文章的内容代码:
from pyquery import PyQuery as pq
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
}
url = 'https://finance.sina.com.cn/mo ... 39%3B
res = requests.get(url,headers=headers)
response = pq(bytes(res.text, res.encoding).decode('utf-8', 'ignore')) # 转码
content_1 = response("#artibody p").text() # 获取内容
print(content_1)
【注意】由于爬取时文章的内容是乱码,需要转码。转码请参考网页抓取时的文字乱码解决方法。
此时获取的内容收录【今日直播】
解析网页获取【今日直播】标签
利用代码
response("#artibody blockquote").remove()
删除【今日直播】标签模块
response("#artibody blockquote").remove()
content_2 = response("#artibody p").text()
print(content_2)
此时获取的内容中没有【今日直播】 查看全部
网页新闻抓取(2016.10.12河北邮币卡电子盘交易所每日一练)
以这个文章为例,
抓取文章的内容时,不要抓取【今日直播】的模块内容
抓取文章的内容代码:
from pyquery import PyQuery as pq
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
}
url = 'https://finance.sina.com.cn/mo ... 39%3B
res = requests.get(url,headers=headers)
response = pq(bytes(res.text, res.encoding).decode('utf-8', 'ignore')) # 转码
content_1 = response("#artibody p").text() # 获取内容
print(content_1)
【注意】由于爬取时文章的内容是乱码,需要转码。转码请参考网页抓取时的文字乱码解决方法。
此时获取的内容收录【今日直播】
解析网页获取【今日直播】标签
利用代码
response("#artibody blockquote").remove()
删除【今日直播】标签模块
response("#artibody blockquote").remove()
content_2 = response("#artibody p").text()
print(content_2)
此时获取的内容中没有【今日直播】
网页新闻抓取(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-13 16:19
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是由于论文只讲了算法原理,并没有具体的语言实现,所以我根据论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻对结果进行了测试,发现提取效果非常好,几乎100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面信息抽取。如果目标网站不是新闻页面,也不是今日头条中的相册类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者是空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
验证消息:GNE 查看全部
网页新闻抓取(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是由于论文只讲了算法原理,并没有具体的语言实现,所以我根据论文用Python实现了这个提取器。我们还使用了今日头条、网易新闻、友民之星、观察家、凤凰网、腾讯新闻、ReadHub、新浪新闻对结果进行了测试,发现提取效果非常好,几乎100%的准确率。
项目状态
在论文中描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用合适的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
如何使用
项目代码中的GeneralNewsCrawler.py 提供了本项目的基本使用示例。
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
from GeneralNewsCrawler import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
对于大多数新闻页面,上述书写方法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
已知问题 目前此项仅适用于新闻页面信息抽取。如果目标网站不是新闻页面,也不是今日头条中的相册类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者是空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
验证消息:GNE
网页新闻抓取( 如何通过Python爬虫按关键词抓取相关的新闻(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-13 08:36
如何通过Python爬虫按关键词抓取相关的新闻(二)
)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果
查看全部
网页新闻抓取(
如何通过Python爬虫按关键词抓取相关的新闻(二)
)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果
网页新闻抓取(主权项:1.基于Ajax的新闻网页动态数据的抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-13 08:33
主权项:
1.基于Ajax的新闻网页动态数据抓取方法,其特点是以下步骤: 步骤(101):建立新闻网页抓取内容数据库,设置新闻网页抓取的编码内容库的方法;获取待爬取新闻页面的新闻列表页面的URL地址; 步骤(102):访问待爬取的新闻页面的新闻列表页面的URL地址,判断通过浏览器开发者工具新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具查找Ajax请求的数据源;如果没有,结束;步骤(103):确定数据源和Ajax请求的数据源) 步骤(101)是编码方式一致,如果不一致,则对数据源进行编码转换,然后转到步骤(104) ; 如果一致,直接进入步骤(104)@)>; 步骤(104): 解析数据格式:将数据源的格式解析成obj新闻列表页面后台语言处理的ect格式或数组格式;步骤(105):更改步骤(104)将解析后的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进入步骤(106)@) >; 否则,将数据作为字符串处理;完成后转步骤(106)@>; Step(106)@>:遍历数据对象或数组类型的输出列表;Step(107):使用网络爬虫采集 Step(106)@>得到Output list;Step(108):将采集的数据存入数据库。
展开 查看全部
网页新闻抓取(主权项:1.基于Ajax的新闻网页动态数据的抓取方法)
主权项:
1.基于Ajax的新闻网页动态数据抓取方法,其特点是以下步骤: 步骤(101):建立新闻网页抓取内容数据库,设置新闻网页抓取的编码内容库的方法;获取待爬取新闻页面的新闻列表页面的URL地址; 步骤(102):访问待爬取的新闻页面的新闻列表页面的URL地址,判断通过浏览器开发者工具新闻列表页面是否通过Ajax动态加载数据;如果是,通过浏览器开发者工具查找Ajax请求的数据源;如果没有,结束;步骤(103):确定数据源和Ajax请求的数据源) 步骤(101)是编码方式一致,如果不一致,则对数据源进行编码转换,然后转到步骤(104) ; 如果一致,直接进入步骤(104)@)>; 步骤(104): 解析数据格式:将数据源的格式解析成obj新闻列表页面后台语言处理的ect格式或数组格式;步骤(105):更改步骤(104)将解析后的数据封装成对象或数组类型;判断是否封装成功,如果成功则直接进入步骤(106)@) >; 否则,将数据作为字符串处理;完成后转步骤(106)@>; Step(106)@>:遍历数据对象或数组类型的输出列表;Step(107):使用网络爬虫采集 Step(106)@>得到Output list;Step(108):将采集的数据存入数据库。
展开
网页新闻抓取(Python开发简单爬虫,开始要爬取的澎湃新闻网页url )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-13 08:28
)
前言
因为学校的大数据课程需要获取数据,我们设置了爬虫实验。之前没怎么接触过爬虫,所以在网上找了个视频。这里推荐牧奇网的爬虫视频:Python开发一个简单的爬虫。短小精悍,实用。
开始
需要爬取的澎湃新闻网页的url为:按照基本爬虫写,需要:
图片
这里的写法比较简单,只选择了一条评论超过1k的新闻进行爬取。使用的主要库是 urllib.request(网络下载器)和 beautifulsoup(网络解析器)。因为澎湃新闻评论是通过下拉浏览器侧边栏自动刷新的,使用了自动工具,最后将数据写入txt文件,使用了python写文件的一些知识,所以这个主要流程爬虫是:
(刚开始爬,发现一条评论无法爬取……自闭……打开网页仔细查看后,发现评论信息被下拉刷新了。不知有没有是任何可以模拟网页自动下拉刷新的工具。我在网上搜索了资料,发现selenium是一个可以用ChromeDriver控制谷歌浏览器的自动化工具。)
还有一个坑。之前用beautifulsoup的时候,不知道可以递归调用find()和find_all()函数。我为如何找到子标签的问题苦苦挣扎了很长时间。这样看来,beautifulsoup还是蛮好用的。
我们来谈谈解析数据的问题。要分析网页的数据,您需要了解网页的内容。您只需要在要查看的网页内容上右击,查看元素,就可以看到该网页的内容(例如在这里查看昵称的网页结构):
图片
图片
结尾有坑。写入文件时,最好将字符集指定为utf-8,否则会出现乱码。
完整代码如下:
#-*-coding:utf-8-*-
# 解析html的
from bs4 import BeautifulSoup
# 模仿浏览器的
from selenium import webdriver
# 模仿键盘,操作下拉框的
from selenium.webdriver.common.keys import Keys
# 网页解析器BeautifulSoup
from bs4 import BeautifulSoup
import urllib.request
# 正则表达式
import re
# 找到的一则评论大于1k的有关校园暴力的url
# https://www.thepaper.cn/newsDetail_forward_3564808
url = "https://www.thepaper.cn/newsDe ... ot%3B
# 打开文件(指定编码,否则会出现乱码的情况)
with open('./my_data','wt',encoding='utf-8') as f:
# 爬取评论节点(评论如果不下拉刷新的话爬取不到,页面是下拉刷新的,需要使用自动化工具)
# 打开浏览器
driver = webdriver.Chrome(executable_path="D:\\chromedriver.exe")
# 打开你的访问地址
driver.get(url)
# 将页面最大化
driver.maximize_window()
# 循环下拉
# js="var q=document.documentElement.scrollTop=10000"为js脚本,页面下拉
js="var q=document.documentElement.scrollTop=250000"
for i in range(10000):
driver.execute_script(js)
driver.implicitly_wait(3)
# 创建beautifulsoup对象
html = BeautifulSoup(driver.page_source)
# 新闻标题:太原师范学院回应“女生自述遭室友的校园暴力”:正认真核查
title = html.find('h1',class_="news_title").get_text()
print("标题: {}".format(title), file=f)
# 新闻链接就是url
print("链接: {}".format(url), file=f)
# 获取评论数
comment_num_block = html.find('h2',id="comm_span")
comment = re.search(r'\d+[k]*', comment_num_block.get_text()).group()
print("评论数: {}".format(comment), file=f)
# 获取新闻发表时间
publish_time_block = html.find('div',class_="news_about")
# 匹配日期正则表达式
time = re.search(r'\d{4}-\d{1,2}-\d{1,2}', publish_time_block.get_text()).group()
print("时间: {}".format(time), file=f)
print("", file=f)
# 爬取评论节点
# 评论的节点为
comment_nodes = html.find_all('div', class_="comment_que")
count = 1
# print("开始打印评论:")
for node in comment_nodes:
# 获取昵称
nickname = node.find('div', class_="aqwright").find('h3').find('a').get_text().strip()
print("Nickname:{}".format(nickname), file=f)
# 获取评论主体内容
content = node.find('div', class_="aqwright").find('div', class_="ansright_cont").get_text().strip()
print("Content:{}".format(content), file=f)
count = count + 1
if (count < 1000):
# 在每一条评论间打印空行
print("",file=f)
print(count)
else:
break 查看全部
网页新闻抓取(Python开发简单爬虫,开始要爬取的澎湃新闻网页url
)
前言
因为学校的大数据课程需要获取数据,我们设置了爬虫实验。之前没怎么接触过爬虫,所以在网上找了个视频。这里推荐牧奇网的爬虫视频:Python开发一个简单的爬虫。短小精悍,实用。
开始
需要爬取的澎湃新闻网页的url为:按照基本爬虫写,需要:
图片
这里的写法比较简单,只选择了一条评论超过1k的新闻进行爬取。使用的主要库是 urllib.request(网络下载器)和 beautifulsoup(网络解析器)。因为澎湃新闻评论是通过下拉浏览器侧边栏自动刷新的,使用了自动工具,最后将数据写入txt文件,使用了python写文件的一些知识,所以这个主要流程爬虫是:
(刚开始爬,发现一条评论无法爬取……自闭……打开网页仔细查看后,发现评论信息被下拉刷新了。不知有没有是任何可以模拟网页自动下拉刷新的工具。我在网上搜索了资料,发现selenium是一个可以用ChromeDriver控制谷歌浏览器的自动化工具。)
还有一个坑。之前用beautifulsoup的时候,不知道可以递归调用find()和find_all()函数。我为如何找到子标签的问题苦苦挣扎了很长时间。这样看来,beautifulsoup还是蛮好用的。
我们来谈谈解析数据的问题。要分析网页的数据,您需要了解网页的内容。您只需要在要查看的网页内容上右击,查看元素,就可以看到该网页的内容(例如在这里查看昵称的网页结构):
图片
图片
结尾有坑。写入文件时,最好将字符集指定为utf-8,否则会出现乱码。
完整代码如下:
#-*-coding:utf-8-*-
# 解析html的
from bs4 import BeautifulSoup
# 模仿浏览器的
from selenium import webdriver
# 模仿键盘,操作下拉框的
from selenium.webdriver.common.keys import Keys
# 网页解析器BeautifulSoup
from bs4 import BeautifulSoup
import urllib.request
# 正则表达式
import re
# 找到的一则评论大于1k的有关校园暴力的url
# https://www.thepaper.cn/newsDetail_forward_3564808
url = "https://www.thepaper.cn/newsDe ... ot%3B
# 打开文件(指定编码,否则会出现乱码的情况)
with open('./my_data','wt',encoding='utf-8') as f:
# 爬取评论节点(评论如果不下拉刷新的话爬取不到,页面是下拉刷新的,需要使用自动化工具)
# 打开浏览器
driver = webdriver.Chrome(executable_path="D:\\chromedriver.exe")
# 打开你的访问地址
driver.get(url)
# 将页面最大化
driver.maximize_window()
# 循环下拉
# js="var q=document.documentElement.scrollTop=10000"为js脚本,页面下拉
js="var q=document.documentElement.scrollTop=250000"
for i in range(10000):
driver.execute_script(js)
driver.implicitly_wait(3)
# 创建beautifulsoup对象
html = BeautifulSoup(driver.page_source)
# 新闻标题:太原师范学院回应“女生自述遭室友的校园暴力”:正认真核查
title = html.find('h1',class_="news_title").get_text()
print("标题: {}".format(title), file=f)
# 新闻链接就是url
print("链接: {}".format(url), file=f)
# 获取评论数
comment_num_block = html.find('h2',id="comm_span")
comment = re.search(r'\d+[k]*', comment_num_block.get_text()).group()
print("评论数: {}".format(comment), file=f)
# 获取新闻发表时间
publish_time_block = html.find('div',class_="news_about")
# 匹配日期正则表达式
time = re.search(r'\d{4}-\d{1,2}-\d{1,2}', publish_time_block.get_text()).group()
print("时间: {}".format(time), file=f)
print("", file=f)
# 爬取评论节点
# 评论的节点为
comment_nodes = html.find_all('div', class_="comment_que")
count = 1
# print("开始打印评论:")
for node in comment_nodes:
# 获取昵称
nickname = node.find('div', class_="aqwright").find('h3').find('a').get_text().strip()
print("Nickname:{}".format(nickname), file=f)
# 获取评论主体内容
content = node.find('div', class_="aqwright").find('div', class_="ansright_cont").get_text().strip()
print("Content:{}".format(content), file=f)
count = count + 1
if (count < 1000):
# 在每一条评论间打印空行
print("",file=f)
print(count)
else:
break
网页新闻抓取(公司简介大渡河公司重构url流域已完成流域规划报告(咨询稿) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-13 08:23
)
一、公司简介
大渡河公司于2000年11月在成都高新区注册成立,主要任务是开发以公嘴和通街子为母电站,滚动开发大渡河流域水电站,是我国最大的水电开发、建设和国家能源集团的运营管理。综合性大型流域水电开发公司。
公司目前主要负责大渡河流域开发和西藏巴龙藏布河流域开发建设。拥有西藏大渡河干流和支流、巴隆藏布河流域水能资源约3000万千瓦。大渡河流域规划建设梯级电站28座,总装机容量约2340万千瓦。公司负责开发干流17座梯级电站,涉及四川省三州两市(甘孜州、阿坝州、凉山州、雅安市、乐山市)的12个县。总装机容量约1757万千瓦。, 准备构建稳步推进的可持续发展格局。巴龙藏布江流域已完成流域规划报告(征求意见稿),初步规划“一库九层”规划,规划装机容量1142万千瓦。截至目前,公司总资产910.68亿元,四川装机容量约占四川水电总装机容量的四分之一。
二、需求分析
分析网站新闻标题、作者、日期等统计数据,分析网站在线新闻有以上共性,即哪些类型的新闻更容易上传,也可以分析公司较高的稿件作者越多,稿件越多,一定程度上可以体现作者的水平。
三、具体实现
1、利用python爬虫技术获取公司新闻相关信息网站
第一步爬取url:重构url放入多线程队列
url = 'http://www.spddr.com/spddr/index.jsp?id=360'
base_url = 'http://www.spddr.com/spddr/'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
第二步解析url:在多线程队列中获取重构后的url,并进行解析,最后将解析后的信息放入线程队列
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
第三步,下载保存信息:将解析后的信息从队列中取出,执行下载保存操作
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
四、整个代码如下
from lxml import etree
import requests
import csv
import random
from headers_list import headers_list
import threading
from queue import Queue
headers = {
'User-Agent':random.choice(headers_list),
'Cookie': 'JSESSIONID=91AFDB0A74FDB3DE1011B2E59CF99993; JSESSIONID=DD7458D1055A53D464AE8DF68400DE1F',
'Referer': '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
}
#定义一个Producter类,类名通常是大写开头的单词,它继承的是threading.Thread
class Producter(threading.Thread):
# 用init方法绑定属性,比如定义一个人的类,那你可以再定义人的属性,比如有手、有脚
def __init__(self,page_queue,writer_queue,*args,**kwargs):
super(Producter,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
def run(self):
while True:
try:
url = '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
base_url = '[http://www.spddr.com/spddr/](http://www.spddr.com/spddr/)'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
except:
print("解析网页出错")
#定义一个Consumer类,类名通常是大写开头的单词,它继承的是threading.Thread
class Consumer(threading.Thread):
def __init__(self,page_queue,writer_queue,glock,writer,*args,**kwargs):
super(Consumer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
self.glock = glock
self.writer = writer
def run(self):
while True:
try:
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
except:
print("提取信息出错!")
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
if __name__ == '__main__':
# 创建FIFO队列
page_queue = Queue(1000)
writer_queue = Queue(1000)
# 创建线程锁
glock = threading.Lock()
#csv表头信息
head = ['title', 'author', 'department', 'time']
#打开csv文件
fp = open('daduhe.csv', 'a', newline='', errors='ignore', encoding='utf-8')
#用字典方式写入表头信息
writer = csv.DictWriter(fp, head)
writer.writeheader()
for i in range(1,207):
data = {
'nowPage': i,
'totalpage': 206,
'id': 360,
'pages': i,
}
page_queue.put(data)
for x in range(10):
t = Producter(page_queue,writer_queue)#根据Producter类创建一个实例t的线程
t.start()#开启线程
for x in range(10):
t = Consumer(page_queue,writer_queue,glock,writer)#根据Producter类创建一个实例t的线程
t.start() 查看全部
网页新闻抓取(公司简介大渡河公司重构url流域已完成流域规划报告(咨询稿)
)
一、公司简介
大渡河公司于2000年11月在成都高新区注册成立,主要任务是开发以公嘴和通街子为母电站,滚动开发大渡河流域水电站,是我国最大的水电开发、建设和国家能源集团的运营管理。综合性大型流域水电开发公司。
公司目前主要负责大渡河流域开发和西藏巴龙藏布河流域开发建设。拥有西藏大渡河干流和支流、巴隆藏布河流域水能资源约3000万千瓦。大渡河流域规划建设梯级电站28座,总装机容量约2340万千瓦。公司负责开发干流17座梯级电站,涉及四川省三州两市(甘孜州、阿坝州、凉山州、雅安市、乐山市)的12个县。总装机容量约1757万千瓦。, 准备构建稳步推进的可持续发展格局。巴龙藏布江流域已完成流域规划报告(征求意见稿),初步规划“一库九层”规划,规划装机容量1142万千瓦。截至目前,公司总资产910.68亿元,四川装机容量约占四川水电总装机容量的四分之一。
二、需求分析
分析网站新闻标题、作者、日期等统计数据,分析网站在线新闻有以上共性,即哪些类型的新闻更容易上传,也可以分析公司较高的稿件作者越多,稿件越多,一定程度上可以体现作者的水平。
三、具体实现
1、利用python爬虫技术获取公司新闻相关信息网站
第一步爬取url:重构url放入多线程队列
url = 'http://www.spddr.com/spddr/index.jsp?id=360'
base_url = 'http://www.spddr.com/spddr/'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
第二步解析url:在多线程队列中获取重构后的url,并进行解析,最后将解析后的信息放入线程队列
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
第三步,下载保存信息:将解析后的信息从队列中取出,执行下载保存操作
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
四、整个代码如下
from lxml import etree
import requests
import csv
import random
from headers_list import headers_list
import threading
from queue import Queue
headers = {
'User-Agent':random.choice(headers_list),
'Cookie': 'JSESSIONID=91AFDB0A74FDB3DE1011B2E59CF99993; JSESSIONID=DD7458D1055A53D464AE8DF68400DE1F',
'Referer': '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
}
#定义一个Producter类,类名通常是大写开头的单词,它继承的是threading.Thread
class Producter(threading.Thread):
# 用init方法绑定属性,比如定义一个人的类,那你可以再定义人的属性,比如有手、有脚
def __init__(self,page_queue,writer_queue,*args,**kwargs):
super(Producter,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
def run(self):
while True:
try:
url = '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
base_url = '[http://www.spddr.com/spddr/](http://www.spddr.com/spddr/)'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
except:
print("解析网页出错")
#定义一个Consumer类,类名通常是大写开头的单词,它继承的是threading.Thread
class Consumer(threading.Thread):
def __init__(self,page_queue,writer_queue,glock,writer,*args,**kwargs):
super(Consumer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
self.glock = glock
self.writer = writer
def run(self):
while True:
try:
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
except:
print("提取信息出错!")
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
if __name__ == '__main__':
# 创建FIFO队列
page_queue = Queue(1000)
writer_queue = Queue(1000)
# 创建线程锁
glock = threading.Lock()
#csv表头信息
head = ['title', 'author', 'department', 'time']
#打开csv文件
fp = open('daduhe.csv', 'a', newline='', errors='ignore', encoding='utf-8')
#用字典方式写入表头信息
writer = csv.DictWriter(fp, head)
writer.writeheader()
for i in range(1,207):
data = {
'nowPage': i,
'totalpage': 206,
'id': 360,
'pages': i,
}
page_queue.put(data)
for x in range(10):
t = Producter(page_queue,writer_queue)#根据Producter类创建一个实例t的线程
t.start()#开启线程
for x in range(10):
t = Consumer(page_queue,writer_queue,glock,writer)#根据Producter类创建一个实例t的线程
t.start()
网页新闻抓取(田朴珺否认与王石婚姻危机,怒怼网友:吃饱了撑的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-10-12 06:14
据说,大老王的妻子田朴君否认与王石有婚姻危机,被网友气愤:受够了。
王石
之后,大老王成了热搜名人。
再次成为网红
不少网友表示,怎么能这么说话呢?反正你也是个“贵族”……
今天,我们不讨论这个。我们专门讲解如何使用Python在海量新浪新闻中获取我们想认识的人的消息。我们以大老王的消息为例。本文只讨论技术问题。如果您有兴趣批量获取新浪新闻内容,建议您继续往下阅读。如果你通过这篇文章,你可以得到一个很好的工具。
获取新闻
情况总结
对于这个话题,我尝试了N种方法。如果只抓取新闻,比如首页展示的新闻,新浪没有实施反爬措施,或者反爬措施比较容易破解。但是,如果使用搜索功能,仍然很难抓取搜索到的内容......
今天,我们将教你如何降低这个难度。
简单的方法
刚开始的时候,我的想法是这样的。我先进入新闻搜索页面,然后搜索“王石”,出现了以下内容。
搜索王士后界面
可以看到,内容一共7页,有点小。第一页只有4条新闻,之后每页有20条新闻。(抱歉,我发现了一个bug,截至发帖时,文章的总数并不是我看到的132个,实际上只有116个,我们自己验证一下)
想法
分析网址信息
网址信息
我在使用requests库时,第一页信息正常,但是第二页无法获取。其实页面是由js代码控制的。每次点击页码都会出现相应的内容。如果使用修改后的 URL 传递参数,一般不会从第二页获取内容。
因此,分析网站地址的信息和内容应该是解决此类问题的重中之重。
那该怎么办呢?
我们知道,对于这种js加载页面问题,有两种方式:一种是使用Python中的相关模块来执行js代码,网上有很多教程,感兴趣的朋友可以参考学习;另一种是使用selenium或者PhantomJS等自动化模块模拟一个人打开一个网页,然后获取该网页的源代码(此时获取的代码就是执行js后的代码),然后分析内容。
怎么做?
想法
今天,我们重点用第二种方法来梳理一下新浪新闻中关于王石的新闻。我们的想法是直接打开这个搜索页面,首先获取第一页的内容,从中提取出我们需要的信息;那么你每次使用selenium点击下一页的内容时,都会得到下一页的源码,提取你需要的信息。最后,我们每个页面需要的信息通过一个列表返回。
准备环境
Python3.7 安装 selenium、requests、bs4 库
具体实施步骤
【获取单页内容】
准备开始
一、设置UA代理
header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome /63.0.3239.132 Safari/537.36'}
这里的UA代理是爬虫的基础。UA代理池可以自己搭建,这里不再赘述。
然后获取单页的内容。由于搜索URL的URL是经过编码的,这里应该设置一个URL处理函数
def parse_key(key):
返回 parse.quote(key, encoding='gb2312')
然后使用这个函数来获取单个页面的内容。
def get_text(key='王石'):
req = requests.get(url.format(parse_key(key)), headers=header).text
返回请求
这里没有异常处理,貌似不需要了,可以自己添加。
【使用selenium自动化处理】
自动化处理
定义一个函数,使用webdriver打开URL并返回webdriver对象,方便我们后续的操作
def in_url(url):
wb = webdriver.Ie()
wb.get(url)
返回 wb
然后,当我们点击一个页码时,就会显示每个页面的新闻内容并获取源代码。
def click_element(wb, el_no, total_no):
如果 el_no == 1:
e = wb.find_element_by_xpath('//*[@id="_function_code_page"]/a[1]')
e.click()
elif 1
e = wb.find_element_by_xpath('//*[@id="_function_code_page"]/a[{}]'.format(
el_no + 2))
e.click()
返回 wb.page_source
以上两步是重点。通过分析,我们知道每次点击“Next Page”,xpath变化范围为页码+2(因为网页中增加了“Previous Page”和“Next Page”选项),当el_no为1时,我们实际点击获取第二页的内容。以上内容不难理解。
【使用BeautifulSoup库获取有效信息】
汤不错,可以煮吗
下面是我们定义的获取信息的函数。它可以从单个页面的内容中搜索所有“h2”标签内容(包括新闻标题、作者、发布日期、新闻链接等),我们会从标签中一一获取关键内容出来。
def find_info_bs4(html):
r_lst = []
汤 = BeautifulSoup(html,'html.parser')
对于soup.find_all('h2') 中的项目:
tmp_dict = {}
tmp_dict['title'] = item.find('a').text
打印(tmp_dict['title'])
tmp_dict['author'] = item.find('span').text.split('')[0]
打印(tmp_dict['作者'])
tmp_dict['time'] = "".join(item.find('span').text.split('')[1:])
打印(tmp_dict['时间'])
tmp_dict['url'] = item.find('a').get('href')
打印(tmp_dict['url'])
r_lst.append(tmp_dict)
返回 r_lst
【整合流程】
资源整合
# 使用selenium输入网址
wb = in_url(url.format(parse_key('王石')))
# 最后结果
结果_lst = []
print('第一页')
# 首先将第一页新闻过滤器添加到result_lst
result_lst.extend(find_info_bs4(wb.page_source))
打印('{}'.format(len(find_info_bs4(wb.page_source))))
# 获取总页数,有多少分页元素就有多少页
n = len(wb.find_elements_by_xpath('//*[@id="_function_code_page"]/a'))
# 遍历每一页
对于范围内的 i (1, n):
print('第{}页'.format(i + 1))
# 点击获取源代码
html = click_element(wb, i, n)
# 提取有效信息并将字典添加到result_lst
result_lst.extend(find_info_bs4(html))
打印('添加记录{)项目'。格式(len(find_info_bs4(html))))
# 打印最终消息的数量
打印(len(result_lst))
执行结果显示
最后得到如下内容
程序运行结果显示
好了,今天就到此为止。这个怎么样?是不是很酷?有兴趣的小朋友可以试一试。如果修改关键字,则可以检索其他新闻内容。实际上,您可以更改 result_lst 来设置数据类型。当然,你也可以将这些函数封装成一个类来使用。你可以做更多的扩展,这取决于你。
欢迎大家关注我,更多有趣的内容稍后发布。 查看全部
网页新闻抓取(田朴珺否认与王石婚姻危机,怒怼网友:吃饱了撑的)
据说,大老王的妻子田朴君否认与王石有婚姻危机,被网友气愤:受够了。
王石
之后,大老王成了热搜名人。
再次成为网红
不少网友表示,怎么能这么说话呢?反正你也是个“贵族”……
今天,我们不讨论这个。我们专门讲解如何使用Python在海量新浪新闻中获取我们想认识的人的消息。我们以大老王的消息为例。本文只讨论技术问题。如果您有兴趣批量获取新浪新闻内容,建议您继续往下阅读。如果你通过这篇文章,你可以得到一个很好的工具。
获取新闻
情况总结
对于这个话题,我尝试了N种方法。如果只抓取新闻,比如首页展示的新闻,新浪没有实施反爬措施,或者反爬措施比较容易破解。但是,如果使用搜索功能,仍然很难抓取搜索到的内容......
今天,我们将教你如何降低这个难度。
简单的方法
刚开始的时候,我的想法是这样的。我先进入新闻搜索页面,然后搜索“王石”,出现了以下内容。
搜索王士后界面
可以看到,内容一共7页,有点小。第一页只有4条新闻,之后每页有20条新闻。(抱歉,我发现了一个bug,截至发帖时,文章的总数并不是我看到的132个,实际上只有116个,我们自己验证一下)
想法
分析网址信息
网址信息
我在使用requests库时,第一页信息正常,但是第二页无法获取。其实页面是由js代码控制的。每次点击页码都会出现相应的内容。如果使用修改后的 URL 传递参数,一般不会从第二页获取内容。
因此,分析网站地址的信息和内容应该是解决此类问题的重中之重。
那该怎么办呢?
我们知道,对于这种js加载页面问题,有两种方式:一种是使用Python中的相关模块来执行js代码,网上有很多教程,感兴趣的朋友可以参考学习;另一种是使用selenium或者PhantomJS等自动化模块模拟一个人打开一个网页,然后获取该网页的源代码(此时获取的代码就是执行js后的代码),然后分析内容。
怎么做?
想法
今天,我们重点用第二种方法来梳理一下新浪新闻中关于王石的新闻。我们的想法是直接打开这个搜索页面,首先获取第一页的内容,从中提取出我们需要的信息;那么你每次使用selenium点击下一页的内容时,都会得到下一页的源码,提取你需要的信息。最后,我们每个页面需要的信息通过一个列表返回。
准备环境
Python3.7 安装 selenium、requests、bs4 库
具体实施步骤
【获取单页内容】
准备开始
一、设置UA代理
header = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome /63.0.3239.132 Safari/537.36'}
这里的UA代理是爬虫的基础。UA代理池可以自己搭建,这里不再赘述。
然后获取单页的内容。由于搜索URL的URL是经过编码的,这里应该设置一个URL处理函数
def parse_key(key):
返回 parse.quote(key, encoding='gb2312')
然后使用这个函数来获取单个页面的内容。
def get_text(key='王石'):
req = requests.get(url.format(parse_key(key)), headers=header).text
返回请求
这里没有异常处理,貌似不需要了,可以自己添加。
【使用selenium自动化处理】
自动化处理
定义一个函数,使用webdriver打开URL并返回webdriver对象,方便我们后续的操作
def in_url(url):
wb = webdriver.Ie()
wb.get(url)
返回 wb
然后,当我们点击一个页码时,就会显示每个页面的新闻内容并获取源代码。
def click_element(wb, el_no, total_no):
如果 el_no == 1:
e = wb.find_element_by_xpath('//*[@id="_function_code_page"]/a[1]')
e.click()
elif 1
e = wb.find_element_by_xpath('//*[@id="_function_code_page"]/a[{}]'.format(
el_no + 2))
e.click()
返回 wb.page_source
以上两步是重点。通过分析,我们知道每次点击“Next Page”,xpath变化范围为页码+2(因为网页中增加了“Previous Page”和“Next Page”选项),当el_no为1时,我们实际点击获取第二页的内容。以上内容不难理解。
【使用BeautifulSoup库获取有效信息】
汤不错,可以煮吗
下面是我们定义的获取信息的函数。它可以从单个页面的内容中搜索所有“h2”标签内容(包括新闻标题、作者、发布日期、新闻链接等),我们会从标签中一一获取关键内容出来。
def find_info_bs4(html):
r_lst = []
汤 = BeautifulSoup(html,'html.parser')
对于soup.find_all('h2') 中的项目:
tmp_dict = {}
tmp_dict['title'] = item.find('a').text
打印(tmp_dict['title'])
tmp_dict['author'] = item.find('span').text.split('')[0]
打印(tmp_dict['作者'])
tmp_dict['time'] = "".join(item.find('span').text.split('')[1:])
打印(tmp_dict['时间'])
tmp_dict['url'] = item.find('a').get('href')
打印(tmp_dict['url'])
r_lst.append(tmp_dict)
返回 r_lst
【整合流程】
资源整合
# 使用selenium输入网址
wb = in_url(url.format(parse_key('王石')))
# 最后结果
结果_lst = []
print('第一页')
# 首先将第一页新闻过滤器添加到result_lst
result_lst.extend(find_info_bs4(wb.page_source))
打印('{}'.format(len(find_info_bs4(wb.page_source))))
# 获取总页数,有多少分页元素就有多少页
n = len(wb.find_elements_by_xpath('//*[@id="_function_code_page"]/a'))
# 遍历每一页
对于范围内的 i (1, n):
print('第{}页'.format(i + 1))
# 点击获取源代码
html = click_element(wb, i, n)
# 提取有效信息并将字典添加到result_lst
result_lst.extend(find_info_bs4(html))
打印('添加记录{)项目'。格式(len(find_info_bs4(html))))
# 打印最终消息的数量
打印(len(result_lst))
执行结果显示
最后得到如下内容
程序运行结果显示
好了,今天就到此为止。这个怎么样?是不是很酷?有兴趣的小朋友可以试一试。如果修改关键字,则可以检索其他新闻内容。实际上,您可以更改 result_lst 来设置数据类型。当然,你也可以将这些函数封装成一个类来使用。你可以做更多的扩展,这取决于你。
欢迎大家关注我,更多有趣的内容稍后发布。
网页新闻抓取(爬虫课题中的需求如下的分析与分析方法(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-11 15:28
)
昨晚,我的朋友向我求助。他的一个主题需要爬取《人民日报》中的文章,方便后续的分词、词性标注、词频统计等一系列数据统计和分析。于是他找到了我。
对爬虫的一般要求如下。简单的看了一下这个网站还有他想爬的东西。难度不大,但涉及的知识相当全面。正好用来练手,所以就答应了。.
在写爬虫之前,回顾一下爬虫的思路。
首先你要清楚自己要爬取什么内容。需求明确了,就可以有目标了;那么,你必须分析目标网站,包括URL结构、HTML页面、网络请求和返回结果等,目的是找到我们网站中的爬取目标在哪里,怎么才能我们得到它,然后指定爬取策略;接下来是编码环节,利用编码发起网络请求,解析网页内容,提取目标数据,并进行数据存储;最后,对代码进行测试,对程序进行改进,比如增加一些输入输出交互使程序使用更方便,增加异常捕获和处理部分,使程序更加健壮。
一、明确需求
他的需求其实很简单,就是人民日报每天有一份报纸,每份报纸有几页,每一页有几个文章。他希望将这些文章全部抓取并按照一定的规则存储在本地(具体要求如下图所示)。
二、分析目标网站
1. URL 组成结构
人民日报网站的网址结构比较直观。基本上重要的参数,比如日期、页码、文章号等,都反映在URL中,组成的规则也很简单,像这样
布局目录:
文章内容:
在页面目录的链接中,“/2019-05/06/”表示日期,后面的“_01”表示这是第一页的链接。
文章的内容链接中,“/2019-05/06/”表示日期,后面的“_20190506_5_01”表示这是5月6日该报第一版第五章, 2019文章
值得注意的是,如果日期的“月”、“日”和“页码”数小于10,则必须在日期前加上“0”,而文章@的文章编号> 没有必要。
知道了这一点之后,我们就可以按照这个规则构造一个链接到任何一天的报纸页面,以及一个链接到任何文章文章。
例如,2018 年 6 月 5 日第 4 版目录的链接是:
2018 年 6 月 1 日第 2 版第 3 部分的链接:文章:
点击访问,发现确实如此。至此,网站的URL组成结构分析完毕。
2. 分析网页的HTML结构
在URL分析中,我们也发现网站的页面跳转是通过改变URL来完成的,不涉及Ajax等动态加载方式。也就是说,它的所有数据都是从头开始加载的,我们只需要从html中提取相应的数据即可。
PS:如果使用Ajax的话,网站开头显示的数据是不完整的,只有在触发某些操作时,比如浏览到页面底部,或者点击查看更多按钮等,稍后,它将向服务器发送请求以获取剩余数据。如果是这种情况,我们的爬取策略不是从 HTML 中查找,而是直接向服务器发送请求,然后解析服务器返回的 json 文件。具体方法请参考《Python Web爬虫实战:爬取主题下知乎 18934响应数据》。
好的,让我们回到正题,让我们分析一下我们的目标网站。按F12调出开发者工具(点击图中1处的小箭头,再点击网页中的内容,可以在html源代码中快速找到对应的位置)。
这样我们就可以知道布局目录存放在一个id=“pageList”的div标签下,而在一个class=“right_title1”或“right_title2”的div标签中,每个div代表一个布局,链接布局在 id = "pageLink" 的标签中。
用同样的方法,我们可以知道文章目录存放在id=“titleList”的div标签下的ul标签中。每个li标签代表一块文章,而文章链接在li标签下的a标签中。
进入文章内容页面后,我们可以知道文章标题是存放在h1、h2、h3标签中的(有的文章标题只用到了h1标签,有的< @文章H2 或 h3 标签可能用于字幕),正文部分存储在 id = "ozoom" 的 div 标签下的 p 标签中。
至此,目标网站的HTML页面分析完成。
3. 制定爬取策略
通过分析目标网站的URL组成结构和HTML结构,我们完成了爬虫的初步研究工作。接下来,我们需要根据网站的特点制定相应的爬取策略,然后评估每种方法的性能优劣和难易程度,最后选择最优方案进行编码实现。
策略一:第一遍,先爬取页面目录,保存每个页面的链接;第二遍,依次访问各个页面的链接,并保存页面的文章链接;第三次,依次访问每个文章链接,将文章的标题和正文保存在本地。
策略二:既然我们已经知道文章链接是如何构建的,那么我们或许可以跳过目录的爬取,直接循环构建文章链接来爬取文章的内容文章。
经过一些比较和简单的编码测试,我决定使用策略一来完成这个爬虫。
主要原因是策略二的逻辑虽然比较简单方便,但有两个问题需要解决。1.每天的报纸页数都不一样,每一页的文章页数也不同。正在构建 URL。如何保证文章不重复或省略?2. 在某些特殊情况下,文章 的编号是不连续的。如何解决这个问题呢?
所以,综合考虑,我认为策略一可能更稳定,更安全(如果你想到解决策略二问题的方法,你可以尝试一下,或者如果你想到其他策略,请留言和我们将一起讨论)。
三、编码链接
接下来是实际的编码环节,不多说,直接开始。
首先导入本项目中用到的库:
import requests
import bs4
import os
import datetime
import time
其中,requests库主要用于发起网络请求,接收服务器返回的数据;bs4库主要用于解析html内容,是一个非常简单易用的库;os 库主要用于将数据输出存储在本地文件中。
def fetchUrl(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
fetchUrl函数用于发起网络请求,可以访问目标url,获取目标网页的html内容并返回。
事实上,异常捕获应该在这里完成(为了简单起见,我把它省略了,伸出我的舌头)。由于网络情况比较复杂,可能会因为各种原因导致访问失败。r.raise_for_status() 代码实际上是在判断访问是否成功。如果访问失败,返回的状态码不是200,执行到这里。会直接抛出相应的异常。
def getPageList(year, month, day):
'''
功能:获取当天报纸的各版面的链接列表
参数:年,月,日
'''
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/nbs.D110000renmrb_01.htm'
html = fetchUrl(url)
bsobj = bs4.BeautifulSoup(html,'html.parser')
pageList = bsobj.find('div', attrs = {'id': 'pageList'}).ul.find_all('div', attrs = {'class': 'right_title-name'})
linkList = []
for page in pageList:
link = page.a["href"]
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link
linkList.append(url)
return linkList
getPageList函数用于抓取当天报纸各版面的链接,保存为数组,返回。
def getTitleList(year, month, day, pageUrl):
'''
功能:获取报纸某一版面的文章链接列表
参数:年,月,日,该版面的链接
'''
html = fetchUrl(pageUrl)
bsobj = bs4.BeautifulSoup(html,'html.parser')
titleList = bsobj.find('div', attrs = {'id': 'titleList'}).ul.find_all('li')
linkList = []
for title in titleList:
tempList = title.find_all('a')
for temp in tempList:
link = temp["href"]
if 'nw.D110000renmrb' in link:
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link
linkList.append(url)
return linkList
getPageList函数用于抓取当日报纸某个页面中文章的所有链接,保存为数组,返回。
def getContent(html):
'''
功能:解析 HTML 网页,获取新闻的文章内容
参数:html 网页内容
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
# 获取文章 标题
title = bsobj.h3.text + '\n' + bsobj.h1.text + '\n' + bsobj.h2.text + '\n'
#print(title)
# 获取文章 内容
pList = bsobj.find('div', attrs = {'id': 'ozoom'}).find_all('p')
content = ''
for p in pList:
content += p.text + '\n'
#print(content)
# 返回结果 标题+内容
resp = title + content
return resp
getContent函数用于访问文章的内容页面,抓取文章的title和body,返回。
def saveFile(content, path, filename):
'''
功能:将文章内容 content 保存到本地文件中
参数:要保存的内容,路径,文件名
'''
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
# 保存文件
with open(path + filename, 'w', encoding='utf-8') as f:
f.write(content)
saveFile函数用于将文章的内容保存到指定的本地文件夹。
def download_rmrb(year, month, day, destdir):
'''
功能:爬取《人民日报》网站 某年 某月 某日 的新闻内容,并保存在 指定目录下
参数:年,月,日,文件保存的根目录
'''
pageList = getPageList(year, month, day)
for page in pageList:
titleList = getTitleList(year, month, day, page)
for url in titleList:
# 获取新闻文章内容
html = fetchUrl(url)
content = getContent(html)
# 生成保存的文件路径及文件名
temp = url.split('_')[2].split('.')[0].split('-')
pageNo = temp[1]
titleNo = temp[0] if int(temp[0]) >= 10 else '0' + temp[0]
path = destdir + '/' + year + month + day + '/'
fileName = year + month + day + '-' + pageNo + '-' + titleNo + '.txt'
# 保存文件
saveFile(content, path, fileName)
download_rmrb 函数是需求中需要的主要函数。根据年、月、日参数,可以将当天报纸文章的所有内容按规则下载并保存到指定路径destdir。
if __name__ == '__main__':
'''
主函数:程序入口
'''
year = "2019"
month = "05"
day = "06"
destdir = "D:/data"
download_rmrb(year, month, day, destdir)
print("爬取完成:" + year + month + day)
至此,程序的主要功能已经完成。
四、改进程序
通过上一章的编码,我们已经实现了通过调用download_rmrb函数,可以下载特定日期的所有文章内容。但同时我们也可以发现,在程序入口的main函数中,日期是硬编码在代码中的,也就是说,如果我们要爬取其他日期的报纸,就必须修改源代码。
很不方便,是不是,我们改进一下,日期是用户以交互方式输入的。
if __name__ == '__main__':
'''
主函数:程序入口
'''
# 爬取指定日期的新闻
newsDate = input('请输入要爬取的日期(格式如 20190502 ):')
year = newsDate[0:4]
month = newsDate[4:6]
day = newsDate[6:8]
download_rmrb(year, month, day, 'D:/data')
print("爬取完成:" + year + month + day)
不是更方便吗?但问题又来了。如果我想一次攀登一个月或一年怎么办?不用我手动输入几十次或几百次吗?因此,我们可以改进程序。用户输入实际日期和结束日期,程序爬取期间的所有日期都是文章。
实际运行测试,假设我们要抓取2019年4月的所有报纸内容,那么我们开始日期输入20190401,结束日期输入20190501,回车运行。
等待一段时间后,程序已经运行完成。我们去文件夹看看我们爬取了什么。
爬取的内容整齐地排列在文件夹中,真的很舒服。随便打开一个文件看看,没问题。
到这里这个爬虫就全部完成了。
写在后面的字
这次好久没有写新的爬虫文章了。一是因为我快毕业了,忙着做毕业设计;另一种是写教程文章,真的很辛苦。,需要整理思路和语言,重新整理代码,要求各种截图,让零基础或者刚入门的人都能看懂,写出来。第三,我找不到一个有趣的动机,因为爬虫总是为了使用而写的,你不能为了炫耀你的技能而写爬虫。那是没有意义的。
一开始就写了一个爬虫来记录自己的成长过程。如果我在学习过程中的这些记录能同时帮助到更多后来者,那就更好了。
2019 年 7 月 10 日更新
有读者在评论中反映,不能使用输入起止日期的方式来抓取一段时间内的新闻,运行时会报如下错误。
我查了一下,确实是我的疏忽。
这是因为计算日期的函数在datetime库中,在写博客整理代码的过程中,忽略了引用这个库,导致程序运行出错。
解决方法是在程序中添加两行代码:
import datetime
import time
我对博客的代码做了改动,请放心食用。
感谢weixin_42435870,宋心悦悦的朋友指出了问题,非常感谢!!
2020 年 7 月 26 日更新
通过读者朋友的反馈,我发现《人民日报》的网站近日进行了改版,7月1日的新闻版面采用了新的版式。这也导致无法使用原创代码抓取2020年7月1日之后的新闻。
所以这里有一个更新以兼容 网站 的新格式。
1. 在getPageList函数中,替换原来的
pageList = bsobj.find('div', attrs = {'id': 'pageList'}).ul.find_all('div', attrs = {'class': 'right_title-name'})
改成:
temp = bsobj.find('div', attrs = {'id': 'pageList'})
if temp:
pageList = temp.ul.find_all('div', attrs = {'class': 'right_title-name'})
else:
pageList = bsobj.find('div', attrs = {'class': 'swiper-container'}).find_all('div', attrs = {'class': 'swiper-slide'})
2. 在getTitleList函数中,替换原来的
titleList = bsobj.find('div', attrs = {'id': 'titleList'}).ul.find_all('li')
改成:
temp = bsobj.find('div', attrs = {'id': 'titleList'})
if temp:
titleList = temp.ul.find_all('li')
else:
titleList = bsobj.find('ul', attrs = {'class': 'news-list'}).find_all('li')
简单解释一下上面的变化,
1. 在原来的网站中,对布局列表和文章列表的标签进行了调整,所以我们需要使用新的标签和新的属性来获取它们。
2. 为了兼容,我们先获取之前版本的标签。如果有,就说明是改版前的接口。如果不可用,说明是改版后的接口。您需要使用新的标签属性来获取它。
如果文章有什么不明白的地方,或者解释有误,欢迎在评论区批评指正,或扫描下方二维码加我微信。让我们一起学习交流,共同进步。
查看全部
网页新闻抓取(爬虫课题中的需求如下的分析与分析方法(上)
)
昨晚,我的朋友向我求助。他的一个主题需要爬取《人民日报》中的文章,方便后续的分词、词性标注、词频统计等一系列数据统计和分析。于是他找到了我。
对爬虫的一般要求如下。简单的看了一下这个网站还有他想爬的东西。难度不大,但涉及的知识相当全面。正好用来练手,所以就答应了。.
在写爬虫之前,回顾一下爬虫的思路。
首先你要清楚自己要爬取什么内容。需求明确了,就可以有目标了;那么,你必须分析目标网站,包括URL结构、HTML页面、网络请求和返回结果等,目的是找到我们网站中的爬取目标在哪里,怎么才能我们得到它,然后指定爬取策略;接下来是编码环节,利用编码发起网络请求,解析网页内容,提取目标数据,并进行数据存储;最后,对代码进行测试,对程序进行改进,比如增加一些输入输出交互使程序使用更方便,增加异常捕获和处理部分,使程序更加健壮。
一、明确需求
他的需求其实很简单,就是人民日报每天有一份报纸,每份报纸有几页,每一页有几个文章。他希望将这些文章全部抓取并按照一定的规则存储在本地(具体要求如下图所示)。
二、分析目标网站
1. URL 组成结构
人民日报网站的网址结构比较直观。基本上重要的参数,比如日期、页码、文章号等,都反映在URL中,组成的规则也很简单,像这样
布局目录:
文章内容:
在页面目录的链接中,“/2019-05/06/”表示日期,后面的“_01”表示这是第一页的链接。
文章的内容链接中,“/2019-05/06/”表示日期,后面的“_20190506_5_01”表示这是5月6日该报第一版第五章, 2019文章
值得注意的是,如果日期的“月”、“日”和“页码”数小于10,则必须在日期前加上“0”,而文章@的文章编号> 没有必要。
知道了这一点之后,我们就可以按照这个规则构造一个链接到任何一天的报纸页面,以及一个链接到任何文章文章。
例如,2018 年 6 月 5 日第 4 版目录的链接是:
2018 年 6 月 1 日第 2 版第 3 部分的链接:文章:
点击访问,发现确实如此。至此,网站的URL组成结构分析完毕。
2. 分析网页的HTML结构
在URL分析中,我们也发现网站的页面跳转是通过改变URL来完成的,不涉及Ajax等动态加载方式。也就是说,它的所有数据都是从头开始加载的,我们只需要从html中提取相应的数据即可。
PS:如果使用Ajax的话,网站开头显示的数据是不完整的,只有在触发某些操作时,比如浏览到页面底部,或者点击查看更多按钮等,稍后,它将向服务器发送请求以获取剩余数据。如果是这种情况,我们的爬取策略不是从 HTML 中查找,而是直接向服务器发送请求,然后解析服务器返回的 json 文件。具体方法请参考《Python Web爬虫实战:爬取主题下知乎 18934响应数据》。
好的,让我们回到正题,让我们分析一下我们的目标网站。按F12调出开发者工具(点击图中1处的小箭头,再点击网页中的内容,可以在html源代码中快速找到对应的位置)。
这样我们就可以知道布局目录存放在一个id=“pageList”的div标签下,而在一个class=“right_title1”或“right_title2”的div标签中,每个div代表一个布局,链接布局在 id = "pageLink" 的标签中。
用同样的方法,我们可以知道文章目录存放在id=“titleList”的div标签下的ul标签中。每个li标签代表一块文章,而文章链接在li标签下的a标签中。
进入文章内容页面后,我们可以知道文章标题是存放在h1、h2、h3标签中的(有的文章标题只用到了h1标签,有的< @文章H2 或 h3 标签可能用于字幕),正文部分存储在 id = "ozoom" 的 div 标签下的 p 标签中。
至此,目标网站的HTML页面分析完成。
3. 制定爬取策略
通过分析目标网站的URL组成结构和HTML结构,我们完成了爬虫的初步研究工作。接下来,我们需要根据网站的特点制定相应的爬取策略,然后评估每种方法的性能优劣和难易程度,最后选择最优方案进行编码实现。
策略一:第一遍,先爬取页面目录,保存每个页面的链接;第二遍,依次访问各个页面的链接,并保存页面的文章链接;第三次,依次访问每个文章链接,将文章的标题和正文保存在本地。
策略二:既然我们已经知道文章链接是如何构建的,那么我们或许可以跳过目录的爬取,直接循环构建文章链接来爬取文章的内容文章。
经过一些比较和简单的编码测试,我决定使用策略一来完成这个爬虫。
主要原因是策略二的逻辑虽然比较简单方便,但有两个问题需要解决。1.每天的报纸页数都不一样,每一页的文章页数也不同。正在构建 URL。如何保证文章不重复或省略?2. 在某些特殊情况下,文章 的编号是不连续的。如何解决这个问题呢?
所以,综合考虑,我认为策略一可能更稳定,更安全(如果你想到解决策略二问题的方法,你可以尝试一下,或者如果你想到其他策略,请留言和我们将一起讨论)。
三、编码链接
接下来是实际的编码环节,不多说,直接开始。
首先导入本项目中用到的库:
import requests
import bs4
import os
import datetime
import time
其中,requests库主要用于发起网络请求,接收服务器返回的数据;bs4库主要用于解析html内容,是一个非常简单易用的库;os 库主要用于将数据输出存储在本地文件中。
def fetchUrl(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
fetchUrl函数用于发起网络请求,可以访问目标url,获取目标网页的html内容并返回。
事实上,异常捕获应该在这里完成(为了简单起见,我把它省略了,伸出我的舌头)。由于网络情况比较复杂,可能会因为各种原因导致访问失败。r.raise_for_status() 代码实际上是在判断访问是否成功。如果访问失败,返回的状态码不是200,执行到这里。会直接抛出相应的异常。
def getPageList(year, month, day):
'''
功能:获取当天报纸的各版面的链接列表
参数:年,月,日
'''
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/nbs.D110000renmrb_01.htm'
html = fetchUrl(url)
bsobj = bs4.BeautifulSoup(html,'html.parser')
pageList = bsobj.find('div', attrs = {'id': 'pageList'}).ul.find_all('div', attrs = {'class': 'right_title-name'})
linkList = []
for page in pageList:
link = page.a["href"]
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link
linkList.append(url)
return linkList
getPageList函数用于抓取当天报纸各版面的链接,保存为数组,返回。
def getTitleList(year, month, day, pageUrl):
'''
功能:获取报纸某一版面的文章链接列表
参数:年,月,日,该版面的链接
'''
html = fetchUrl(pageUrl)
bsobj = bs4.BeautifulSoup(html,'html.parser')
titleList = bsobj.find('div', attrs = {'id': 'titleList'}).ul.find_all('li')
linkList = []
for title in titleList:
tempList = title.find_all('a')
for temp in tempList:
link = temp["href"]
if 'nw.D110000renmrb' in link:
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link
linkList.append(url)
return linkList
getPageList函数用于抓取当日报纸某个页面中文章的所有链接,保存为数组,返回。
def getContent(html):
'''
功能:解析 HTML 网页,获取新闻的文章内容
参数:html 网页内容
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
# 获取文章 标题
title = bsobj.h3.text + '\n' + bsobj.h1.text + '\n' + bsobj.h2.text + '\n'
#print(title)
# 获取文章 内容
pList = bsobj.find('div', attrs = {'id': 'ozoom'}).find_all('p')
content = ''
for p in pList:
content += p.text + '\n'
#print(content)
# 返回结果 标题+内容
resp = title + content
return resp
getContent函数用于访问文章的内容页面,抓取文章的title和body,返回。
def saveFile(content, path, filename):
'''
功能:将文章内容 content 保存到本地文件中
参数:要保存的内容,路径,文件名
'''
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
# 保存文件
with open(path + filename, 'w', encoding='utf-8') as f:
f.write(content)
saveFile函数用于将文章的内容保存到指定的本地文件夹。
def download_rmrb(year, month, day, destdir):
'''
功能:爬取《人民日报》网站 某年 某月 某日 的新闻内容,并保存在 指定目录下
参数:年,月,日,文件保存的根目录
'''
pageList = getPageList(year, month, day)
for page in pageList:
titleList = getTitleList(year, month, day, page)
for url in titleList:
# 获取新闻文章内容
html = fetchUrl(url)
content = getContent(html)
# 生成保存的文件路径及文件名
temp = url.split('_')[2].split('.')[0].split('-')
pageNo = temp[1]
titleNo = temp[0] if int(temp[0]) >= 10 else '0' + temp[0]
path = destdir + '/' + year + month + day + '/'
fileName = year + month + day + '-' + pageNo + '-' + titleNo + '.txt'
# 保存文件
saveFile(content, path, fileName)
download_rmrb 函数是需求中需要的主要函数。根据年、月、日参数,可以将当天报纸文章的所有内容按规则下载并保存到指定路径destdir。
if __name__ == '__main__':
'''
主函数:程序入口
'''
year = "2019"
month = "05"
day = "06"
destdir = "D:/data"
download_rmrb(year, month, day, destdir)
print("爬取完成:" + year + month + day)
至此,程序的主要功能已经完成。
四、改进程序
通过上一章的编码,我们已经实现了通过调用download_rmrb函数,可以下载特定日期的所有文章内容。但同时我们也可以发现,在程序入口的main函数中,日期是硬编码在代码中的,也就是说,如果我们要爬取其他日期的报纸,就必须修改源代码。
很不方便,是不是,我们改进一下,日期是用户以交互方式输入的。
if __name__ == '__main__':
'''
主函数:程序入口
'''
# 爬取指定日期的新闻
newsDate = input('请输入要爬取的日期(格式如 20190502 ):')
year = newsDate[0:4]
month = newsDate[4:6]
day = newsDate[6:8]
download_rmrb(year, month, day, 'D:/data')
print("爬取完成:" + year + month + day)
不是更方便吗?但问题又来了。如果我想一次攀登一个月或一年怎么办?不用我手动输入几十次或几百次吗?因此,我们可以改进程序。用户输入实际日期和结束日期,程序爬取期间的所有日期都是文章。
实际运行测试,假设我们要抓取2019年4月的所有报纸内容,那么我们开始日期输入20190401,结束日期输入20190501,回车运行。
等待一段时间后,程序已经运行完成。我们去文件夹看看我们爬取了什么。
爬取的内容整齐地排列在文件夹中,真的很舒服。随便打开一个文件看看,没问题。
到这里这个爬虫就全部完成了。
写在后面的字
这次好久没有写新的爬虫文章了。一是因为我快毕业了,忙着做毕业设计;另一种是写教程文章,真的很辛苦。,需要整理思路和语言,重新整理代码,要求各种截图,让零基础或者刚入门的人都能看懂,写出来。第三,我找不到一个有趣的动机,因为爬虫总是为了使用而写的,你不能为了炫耀你的技能而写爬虫。那是没有意义的。
一开始就写了一个爬虫来记录自己的成长过程。如果我在学习过程中的这些记录能同时帮助到更多后来者,那就更好了。
2019 年 7 月 10 日更新
有读者在评论中反映,不能使用输入起止日期的方式来抓取一段时间内的新闻,运行时会报如下错误。
我查了一下,确实是我的疏忽。
这是因为计算日期的函数在datetime库中,在写博客整理代码的过程中,忽略了引用这个库,导致程序运行出错。
解决方法是在程序中添加两行代码:
import datetime
import time
我对博客的代码做了改动,请放心食用。
感谢weixin_42435870,宋心悦悦的朋友指出了问题,非常感谢!!
2020 年 7 月 26 日更新
通过读者朋友的反馈,我发现《人民日报》的网站近日进行了改版,7月1日的新闻版面采用了新的版式。这也导致无法使用原创代码抓取2020年7月1日之后的新闻。
所以这里有一个更新以兼容 网站 的新格式。
1. 在getPageList函数中,替换原来的
pageList = bsobj.find('div', attrs = {'id': 'pageList'}).ul.find_all('div', attrs = {'class': 'right_title-name'})
改成:
temp = bsobj.find('div', attrs = {'id': 'pageList'})
if temp:
pageList = temp.ul.find_all('div', attrs = {'class': 'right_title-name'})
else:
pageList = bsobj.find('div', attrs = {'class': 'swiper-container'}).find_all('div', attrs = {'class': 'swiper-slide'})
2. 在getTitleList函数中,替换原来的
titleList = bsobj.find('div', attrs = {'id': 'titleList'}).ul.find_all('li')
改成:
temp = bsobj.find('div', attrs = {'id': 'titleList'})
if temp:
titleList = temp.ul.find_all('li')
else:
titleList = bsobj.find('ul', attrs = {'class': 'news-list'}).find_all('li')
简单解释一下上面的变化,
1. 在原来的网站中,对布局列表和文章列表的标签进行了调整,所以我们需要使用新的标签和新的属性来获取它们。
2. 为了兼容,我们先获取之前版本的标签。如果有,就说明是改版前的接口。如果不可用,说明是改版后的接口。您需要使用新的标签属性来获取它。
如果文章有什么不明白的地方,或者解释有误,欢迎在评论区批评指正,或扫描下方二维码加我微信。让我们一起学习交流,共同进步。
网页新闻抓取(就是一条中去一条 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-11 15:16
)
第一次写小爬虫,python确实很强大,大概二十行代码抓取内容存成txt文本
直接编码
#coding = 'utf-8'
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = 'utf-8'
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select('.news-item')
#抓取需要的内容并且放入文件中
#抓取的内容有时间,内容文本,以及内容的链接
fname = "F:/asdf666.txt"
try:
f = open(fname, 'w')
for element in elements:
if len(element.select('h2')) > 0:
f.write(element.select('.time')[0].text)
f.write(element.select('h2')[0].text)
f.write(element.select('a')[0]['href'])
f.write('\n\n')
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为这是第一个小爬虫,功能很简单也很单一,就是直接抓取新闻页面上的部分新闻。
然后抓取新闻的时间和超链接
然后按照新闻的顺序整合,放到一个文本文件中存储
截图效果图,效果很简单,一一记录,时间,新闻内容,新闻链接(因为是今天写的,所以是今天的新闻)
查看全部
网页新闻抓取(就是一条中去一条
)
第一次写小爬虫,python确实很强大,大概二十行代码抓取内容存成txt文本
直接编码
#coding = 'utf-8'
import requests
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
#抓取web页面
url = "http://news.sina.com.cn/china/"
res = requests.get(url)
res.encoding = 'utf-8'
#放进soup里面进行网页内容剖析
soup = BeautifulSoup(res.text, "html.parser")
elements = soup.select('.news-item')
#抓取需要的内容并且放入文件中
#抓取的内容有时间,内容文本,以及内容的链接
fname = "F:/asdf666.txt"
try:
f = open(fname, 'w')
for element in elements:
if len(element.select('h2')) > 0:
f.write(element.select('.time')[0].text)
f.write(element.select('h2')[0].text)
f.write(element.select('a')[0]['href'])
f.write('\n\n')
f.close()
except Exception, e:
print e
else:
pass
finally:
pass
因为这是第一个小爬虫,功能很简单也很单一,就是直接抓取新闻页面上的部分新闻。
然后抓取新闻的时间和超链接
然后按照新闻的顺序整合,放到一个文本文件中存储
截图效果图,效果很简单,一一记录,时间,新闻内容,新闻链接(因为是今天写的,所以是今天的新闻)
网页新闻抓取( 简单的来说,对于爬取网页的内容来说的一些介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-10-11 15:14
简单的来说,对于爬取网页的内容来说的一些介绍)
简单来说,对于爬取网页的内容:http在爬取过程中不需要输入账号密码,而https则需要输入账号和密码,以及密码带来的一系列问题帐户。因此,抓取https相对复杂。
二、选的框架scarpy 2.1 介绍scrapy
这里
有Scarpy的简单框架介绍
2.1.1 Scrapy结构2.1.2数据流
数据流向由执行引擎控制,如图中各个步骤所示。
* Step1:scrapy引擎首先获取初始URL(Requests)。
* Step2:然后交给Scheduler调度Requests,请求下一个URL。
* Step3:调度器将下一个请求返回给scrapy引擎
* Step4:scrapy引擎通过Downloader Middlewares向下载器Downloader(process_request())发送请求。
* Step5:Downloader Middlewares 完成网页下载后,会生成响应并通过 Downloader Middlewares 将其发送回scrapy 引擎(process_response())。
* Step6:scrapy引擎收到Response后,会通过Spider Middlewares发送给Spider做进一步处理。
* Step7:Spider 处理完响应后,会将抓取的项目和新请求(链接在下一页)返回给抓取引擎。
* Step8:crapy引擎将处理后的item发送到Item Pipelines,然后将Requests发送回Scheduler,请求下一个可能的URL进行爬取。
* Step9:从step1开始重复上面的操作,直到Scheduler中没有多余的URL可以请求
提示:解释第 7 步
Spider 分析的结果有两种:
* 一个是需要进一步爬取的链接,比如“下一页”的链接,会被发回给Scheduler;
* 另一个是需要保存的数据。它们被发送到 Item Pipeline 进行后期处理(详细分析、过滤、存储等)。
2.1.3 爬取过程第三部分,半年爬取中新网各种新闻
我的环境是Python3.6+Scrapy,Windows,IDE:PyCharm
3.1 创建一个scrapy项目**
在命令行输入scrapy startproject qqnews
会出现以下文件
3.1.1 在qqnew.py中编写我们的主要爬虫代码**
首先我们需要导入对应的文件
from scrapy.spiders import Spider
from qqnews.items import QqnewsItem
spider 会自动从 start_urls 抓取网页,可以收录多个 URL。
并且会默认调用parse函数,parse在蜘蛛抓取网页后会默认调用callback。
提示:因为我们要抓取半年的新闻数据,所以先通过start_urls获取半年每个月的网址,可以观察网址的规则。比如后面两天的网址,很容易看到规则。
我们可以通过拼接字符串来抓取每天的网址
* 每天:
* 每个月:
代码最后一句写的是scrapy.Request(url_month, callback=self.parse_month)
* url_month: 解析拼接后接下来要爬取的每一天的网址
* callback=self.parse_month:这句话的意思是,对于每一天的url,都会调用一个自定义的parse_month来解析每一天的网页内容
class QQNewsSpider(Spider):
name = 'qqnews'
start_urls=[#'http://www.chinanews.com/society.shtml',
#'http://www.chinanews.com/mil/news.shtml',
'http://finance.chinanews.com/it/gd.shtml',
]
def parse(self,response):
#找到所有连接的入口,一条一条的新闻做解析 //*[@id="news"] //*[@id="news"]/div[2]/div[1]/div[1]/em/a
for month in range(1,8):
for day in range(1,31):
if month is 2 and day>28 :
continue
elif month is 7 and day>6:
continue
else:
if day in range(1,10):
url_month='http://www.chinanews.com/scrol ... 2Bstr(month)+'0'+str(day)+'/news.shtml'
else:
url_month='http://www.chinanews.com/scrol ... 2Bstr(month)+str(day)+'/news.shtml'
yield scrapy.Request(url_month,callback=self.parse_month)
我们已经从前面的代码中得到了每天的新闻对应的链接地址,接下来我们要抓取对应页面的新闻标题和新闻内容。
是自定义def parse_month(self, response)处理的内容。
配合chrome浏览器右键“查看”,找到每天对应的新闻标题
Scrapy 提供了一种方便的方式来解析网页数据,文章 中使用 Xpath 进行分析。
提示:
* //ul/li 表示选择ul标签下的所有li标签
* a/@href 表示选择一个标签的所有 href 属性
* a/text() 表示选择标签文本
* div[@id="content_right"] 表示选择所有id属性为content_right的div标签
def parse_month(self,response):
#print(response.body)
#到了没一个月的页面下,提取每一天的url
urls=response.xpath('//div[@id="content_right"]/div[@class="content_list"]/ul/li/div[@class="dd_bt"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url,callback=self.parse_news)
找到新闻标题对应的新闻内容网址后,我们就可以抓取每日新闻标题和对应的新闻内容了。
然后通过self.parse_news,
在其中存储标题和内容。这是我们先导入的item=QqnewsItem()
def parse_news(self,response):
item=QqnewsItem()
item['title']=response.xpath('//div[@class="con_left"]/div[@id="cont_1_1_2"]/h1/text()').extract()
item['text']='\n'.join(response.xpath('//div[@class="left_zw"]/p/text()').extract())
yield item
在 items.py 中添加一些类
class QqnewsItem(scrapy.Item):
# define the fields for your item here like:
text=scrapy.Field()#新闻的内容
title=scrapy.Field()#新闻的标题
最后,如果要将抓取到的内容保存到文件中,可以新建一个begin.py,直接执行下面这句话。
在 begin.py
from scrapy import cmdline
cmdline.execute("scrapy crawl qqnews -o IT.csv".split())
然后我们就可以根据fastText将抓取到的数据处理成fastText格式,然后直接训练。
参考文章: 查看全部
网页新闻抓取(
简单的来说,对于爬取网页的内容来说的一些介绍)
简单来说,对于爬取网页的内容:http在爬取过程中不需要输入账号密码,而https则需要输入账号和密码,以及密码带来的一系列问题帐户。因此,抓取https相对复杂。
二、选的框架scarpy 2.1 介绍scrapy
这里
有Scarpy的简单框架介绍
2.1.1 Scrapy结构2.1.2数据流
数据流向由执行引擎控制,如图中各个步骤所示。
* Step1:scrapy引擎首先获取初始URL(Requests)。
* Step2:然后交给Scheduler调度Requests,请求下一个URL。
* Step3:调度器将下一个请求返回给scrapy引擎
* Step4:scrapy引擎通过Downloader Middlewares向下载器Downloader(process_request())发送请求。
* Step5:Downloader Middlewares 完成网页下载后,会生成响应并通过 Downloader Middlewares 将其发送回scrapy 引擎(process_response())。
* Step6:scrapy引擎收到Response后,会通过Spider Middlewares发送给Spider做进一步处理。
* Step7:Spider 处理完响应后,会将抓取的项目和新请求(链接在下一页)返回给抓取引擎。
* Step8:crapy引擎将处理后的item发送到Item Pipelines,然后将Requests发送回Scheduler,请求下一个可能的URL进行爬取。
* Step9:从step1开始重复上面的操作,直到Scheduler中没有多余的URL可以请求
提示:解释第 7 步
Spider 分析的结果有两种:
* 一个是需要进一步爬取的链接,比如“下一页”的链接,会被发回给Scheduler;
* 另一个是需要保存的数据。它们被发送到 Item Pipeline 进行后期处理(详细分析、过滤、存储等)。
2.1.3 爬取过程第三部分,半年爬取中新网各种新闻
我的环境是Python3.6+Scrapy,Windows,IDE:PyCharm
3.1 创建一个scrapy项目**
在命令行输入scrapy startproject qqnews
会出现以下文件
3.1.1 在qqnew.py中编写我们的主要爬虫代码**
首先我们需要导入对应的文件
from scrapy.spiders import Spider
from qqnews.items import QqnewsItem
spider 会自动从 start_urls 抓取网页,可以收录多个 URL。
并且会默认调用parse函数,parse在蜘蛛抓取网页后会默认调用callback。
提示:因为我们要抓取半年的新闻数据,所以先通过start_urls获取半年每个月的网址,可以观察网址的规则。比如后面两天的网址,很容易看到规则。
我们可以通过拼接字符串来抓取每天的网址
* 每天:
* 每个月:
代码最后一句写的是scrapy.Request(url_month, callback=self.parse_month)
* url_month: 解析拼接后接下来要爬取的每一天的网址
* callback=self.parse_month:这句话的意思是,对于每一天的url,都会调用一个自定义的parse_month来解析每一天的网页内容
class QQNewsSpider(Spider):
name = 'qqnews'
start_urls=[#'http://www.chinanews.com/society.shtml',
#'http://www.chinanews.com/mil/news.shtml',
'http://finance.chinanews.com/it/gd.shtml',
]
def parse(self,response):
#找到所有连接的入口,一条一条的新闻做解析 //*[@id="news"] //*[@id="news"]/div[2]/div[1]/div[1]/em/a
for month in range(1,8):
for day in range(1,31):
if month is 2 and day>28 :
continue
elif month is 7 and day>6:
continue
else:
if day in range(1,10):
url_month='http://www.chinanews.com/scrol ... 2Bstr(month)+'0'+str(day)+'/news.shtml'
else:
url_month='http://www.chinanews.com/scrol ... 2Bstr(month)+str(day)+'/news.shtml'
yield scrapy.Request(url_month,callback=self.parse_month)
我们已经从前面的代码中得到了每天的新闻对应的链接地址,接下来我们要抓取对应页面的新闻标题和新闻内容。
是自定义def parse_month(self, response)处理的内容。
配合chrome浏览器右键“查看”,找到每天对应的新闻标题
Scrapy 提供了一种方便的方式来解析网页数据,文章 中使用 Xpath 进行分析。
提示:
* //ul/li 表示选择ul标签下的所有li标签
* a/@href 表示选择一个标签的所有 href 属性
* a/text() 表示选择标签文本
* div[@id="content_right"] 表示选择所有id属性为content_right的div标签
def parse_month(self,response):
#print(response.body)
#到了没一个月的页面下,提取每一天的url
urls=response.xpath('//div[@id="content_right"]/div[@class="content_list"]/ul/li/div[@class="dd_bt"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url,callback=self.parse_news)
找到新闻标题对应的新闻内容网址后,我们就可以抓取每日新闻标题和对应的新闻内容了。
然后通过self.parse_news,
在其中存储标题和内容。这是我们先导入的item=QqnewsItem()
def parse_news(self,response):
item=QqnewsItem()
item['title']=response.xpath('//div[@class="con_left"]/div[@id="cont_1_1_2"]/h1/text()').extract()
item['text']='\n'.join(response.xpath('//div[@class="left_zw"]/p/text()').extract())
yield item
在 items.py 中添加一些类
class QqnewsItem(scrapy.Item):
# define the fields for your item here like:
text=scrapy.Field()#新闻的内容
title=scrapy.Field()#新闻的标题
最后,如果要将抓取到的内容保存到文件中,可以新建一个begin.py,直接执行下面这句话。
在 begin.py
from scrapy import cmdline
cmdline.execute("scrapy crawl qqnews -o IT.csv".split())
然后我们就可以根据fastText将抓取到的数据处理成fastText格式,然后直接训练。
参考文章:
网页新闻抓取(1.图片优化有时候,由于网络太慢导致图片加载失败、或者浏览器禁止显示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-10 19:02
1.图片优化
有时因为网络太慢,图片加载失败,或者浏览器禁止显示图片,以及网站被病毒感染,这些情况都可能导致图片无法正常显示。这时候就需要设置图片的alt属性了。图片未显示出现的文字说明。搜索引擎蜘蛛可以根据替代文字读取图片的内容。图片的alt属性是图片优化中最重要的内容。图片在搜索引擎中的排名主要是根据alt优化的程度。设计alt时,要求每张图片都设置alt,尽量写关键词(但不要堆积关键词,否则搜索引擎会被视为作弊)。此外,图片也有标题属性。图片的title属性是鼠标在图片上移动时出现的图片说明。优化图片时,建议同时设置alt和title。
2.关键词优化
关键词优化是指对网站中关键词的选词和排版优化,达到优化网站排名的效果。相关关键词在搜索引擎排名中占据有利位置。出现在正文前50-100字的关键词权重比较高。通常建议第一段文字的第一句出现关键词,中间的文字,两三遍关键词,关键词在最后就足以达到优化的目的。在关键词的布局中,有一个概念“关键词密度”,即关键词出现的次数除以总词数,用百分比表示。关键词 频率越高,密度越大。一般来说,关键词 密度应该在 2% 到 8% 之间。
3. 精简代码
就搜索引擎的工作原理而言,搜索引擎工作的第一步是提取文本,即精简html代码。可以说html风格的代码对关键词来说是噪声,所以为了提高信号噪声比,必须对代码进行简化。常见的可以精简代码的地方如下:(1)页面的样式应该用CSS来设计。不要在html代码中再次定义CSS中定义的样式效果。(2)插入外部文件:将CSS和JavaScript分别做成一个文件,放在html代码之外,在html代码中添加一段insert代码即可。(3)删除注释:注释是解释代码,是的留给开发者,用户不需要理解。(4) 减少表的使用:使用 div 而不是表格。总之,页面中不应该有多余的代码。简化的代码有助于将*有意义的内容放在*之前,更容易被搜索引擎蜘蛛抓取,从而提高网站的排名。
4.标题优化
网页优化最重要的内容就是标题优化。Title 表示页面的标题。一般建议将标题放在标签之后,以便搜索引擎快速抓取标题。标题优化要注意以下问题:(1)唯一且不重复。每个页面必须有自己唯一的标题。如果同一网站中不同页面的标题相同,则标题优化会丢失 用户体验很差,用户无法从标题中一眼看出页面的具体内容;(2)字数限制。根据百度和谷歌字数要求,尽量不要标题超过30个字,超出部分,搜索引擎会自动剪掉,搜索引擎会减重,不会对排名产生任何影响;(3)不要堆砌关键词。一页*3到4多关键词就够了,不要太多,如:鼠标|鼠标批发|鼠标零售|鼠标批发和零售|鼠标网,这样的页面可以直接写成鼠标批发零售|页面的相关性有利于用户体验,用户可以一目了然地看到页面的大致内容。
5.元标签优化
元标签用于设计网页的属性。Meta标签优化主要包括描述标签和关键词(keyWords)标签。描述标签用于描述页面的主题。它描述了页面与什么相关以及它的用途。
在设计描述标签时,要注意以下几点:
(1)准确概括页面内容。设计描述时,需要提炼*页面的主要内容,准确描述页面内容,才能吸引用户点击。不要:描述标签内容与页面内容无关;
(2)为每个页面设置唯一的描述标签。这样的设计可以提高内部页面的相关性,在一定程度上可以引导用户和搜索引擎打开其他内部页面。另外,不要设置重复描述内容,keyWords标签用于设计页面的主题关键词。
设计keyWords标签时要注意:
(1)说明关键词是否出现在网页上。
(2)每个网页的关键词应该是不同的。
(3)关键词在每个网页上出现的次数不能超过5次,一般3到5次为宜。 查看全部
网页新闻抓取(1.图片优化有时候,由于网络太慢导致图片加载失败、或者浏览器禁止显示)
1.图片优化
有时因为网络太慢,图片加载失败,或者浏览器禁止显示图片,以及网站被病毒感染,这些情况都可能导致图片无法正常显示。这时候就需要设置图片的alt属性了。图片未显示出现的文字说明。搜索引擎蜘蛛可以根据替代文字读取图片的内容。图片的alt属性是图片优化中最重要的内容。图片在搜索引擎中的排名主要是根据alt优化的程度。设计alt时,要求每张图片都设置alt,尽量写关键词(但不要堆积关键词,否则搜索引擎会被视为作弊)。此外,图片也有标题属性。图片的title属性是鼠标在图片上移动时出现的图片说明。优化图片时,建议同时设置alt和title。
2.关键词优化
关键词优化是指对网站中关键词的选词和排版优化,达到优化网站排名的效果。相关关键词在搜索引擎排名中占据有利位置。出现在正文前50-100字的关键词权重比较高。通常建议第一段文字的第一句出现关键词,中间的文字,两三遍关键词,关键词在最后就足以达到优化的目的。在关键词的布局中,有一个概念“关键词密度”,即关键词出现的次数除以总词数,用百分比表示。关键词 频率越高,密度越大。一般来说,关键词 密度应该在 2% 到 8% 之间。
3. 精简代码
就搜索引擎的工作原理而言,搜索引擎工作的第一步是提取文本,即精简html代码。可以说html风格的代码对关键词来说是噪声,所以为了提高信号噪声比,必须对代码进行简化。常见的可以精简代码的地方如下:(1)页面的样式应该用CSS来设计。不要在html代码中再次定义CSS中定义的样式效果。(2)插入外部文件:将CSS和JavaScript分别做成一个文件,放在html代码之外,在html代码中添加一段insert代码即可。(3)删除注释:注释是解释代码,是的留给开发者,用户不需要理解。(4) 减少表的使用:使用 div 而不是表格。总之,页面中不应该有多余的代码。简化的代码有助于将*有意义的内容放在*之前,更容易被搜索引擎蜘蛛抓取,从而提高网站的排名。
4.标题优化
网页优化最重要的内容就是标题优化。Title 表示页面的标题。一般建议将标题放在标签之后,以便搜索引擎快速抓取标题。标题优化要注意以下问题:(1)唯一且不重复。每个页面必须有自己唯一的标题。如果同一网站中不同页面的标题相同,则标题优化会丢失 用户体验很差,用户无法从标题中一眼看出页面的具体内容;(2)字数限制。根据百度和谷歌字数要求,尽量不要标题超过30个字,超出部分,搜索引擎会自动剪掉,搜索引擎会减重,不会对排名产生任何影响;(3)不要堆砌关键词。一页*3到4多关键词就够了,不要太多,如:鼠标|鼠标批发|鼠标零售|鼠标批发和零售|鼠标网,这样的页面可以直接写成鼠标批发零售|页面的相关性有利于用户体验,用户可以一目了然地看到页面的大致内容。
5.元标签优化
元标签用于设计网页的属性。Meta标签优化主要包括描述标签和关键词(keyWords)标签。描述标签用于描述页面的主题。它描述了页面与什么相关以及它的用途。
在设计描述标签时,要注意以下几点:
(1)准确概括页面内容。设计描述时,需要提炼*页面的主要内容,准确描述页面内容,才能吸引用户点击。不要:描述标签内容与页面内容无关;
(2)为每个页面设置唯一的描述标签。这样的设计可以提高内部页面的相关性,在一定程度上可以引导用户和搜索引擎打开其他内部页面。另外,不要设置重复描述内容,keyWords标签用于设计页面的主题关键词。
设计keyWords标签时要注意:
(1)说明关键词是否出现在网页上。
(2)每个网页的关键词应该是不同的。
(3)关键词在每个网页上出现的次数不能超过5次,一般3到5次为宜。
网页新闻抓取( 【每日一题】新浪新闻为例(二):反爬机制 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-10-10 19:01
【每日一题】新浪新闻为例(二):反爬机制
)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=2')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第2页/spanspan style="color: #800000;""/span>2</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=3')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第3页/spanspan style="color: #800000;""/span>3</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=4')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第4页/spanspan style="color: #800000;""/span>4</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=5')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第5页/spanspan style="color: #800000;""/span>5</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=6')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第6页/spanspan style="color: #800000;""/span>6</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=7')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第7页/spanspan style="color: #800000;""/span>7</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=8')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第8页/spanspan style="color: #800000;""/span>8</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=9')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第9页/spanspan style="color: #800000;""/span>9</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=10')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第10页/spanspan style="color: #800000;""/span>10</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=2');/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"下一页/spanspan style="color: #800000;""/span>下一页</a>
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/homepage/search.d.json?q='+encodeURIComponent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果
查看全部
网页新闻抓取(
【每日一题】新浪新闻为例(二):反爬机制
)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
如今各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=2')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第2页/spanspan style="color: #800000;""/span>2</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=3')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第3页/spanspan style="color: #800000;""/span>3</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=4')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第4页/spanspan style="color: #800000;""/span>4</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=5')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第5页/spanspan style="color: #800000;""/span>5</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=6')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第6页/spanspan style="color: #800000;""/span>6</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=7')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第7页/spanspan style="color: #800000;""/span>7</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=8')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第8页/spanspan style="color: #800000;""/span>8</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=9')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第9页/spanspan style="color: #800000;""/span>9</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=10')/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"第10页/spanspan style="color: #800000;""/span>10</a>
<a href=https://www.cnblogs.com/hhh188764/p/span style="color: #800000;""/spanspan style="color: #800000;"javascript:;/spanspan style="color: #800000;""/span onclick=span style="color: #800000;""/spanspan style="color: #800000;"getNewsData('https://interface.sina.cn/homepage/search.d.json?t=&q=%E6%97%85%E6%B8%B8&pf=0&ps=0&page=2');/spanspan style="color: #800000;""/span title=span style="color: #800000;""/spanspan style="color: #800000;"下一页/spanspan style="color: #800000;""/span>下一页</a>
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/homepage/search.d.json?q='+encodeURIComponent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果
网页新闻抓取(优采云中如何判断网页是否需要设置页面滚动的设置 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-09 13:14
)
网站有很多,页面中的数据需要向下滚动才能加载出来。相应的,还需要在优采云中设置【页面滚动】。
如何判断一个网页是否需要设置为【页面滚动】?【页面滚动】如何设置滚动方式、滚动次数、每次间隔?
本教程将讲解【页面滚动】的设置方法和常见应用场景。
一、【直接滚动到底部】
如果直接将滚动条拖到底部,出现类似【Loading】的字样,很快又出现新数据,滚动条变短反弹,需要设置【直接滚动到底部】,【Scrolling】次]根据网页根据自身情况和采集要求设置。[每个间隔]时间需要比数据加载时间稍长,这与网络速度等因素有关。
常见应用场景一:没有翻页按钮,需要不断向下滚动才能加载新数据。常见的网页有:今日头条首页、百度图片搜索、新浪微博首页。
以今日头条首页为例。, 我们需要采集 新闻列表数据。首先按照之前列出数据采集的方法配置采集的任务。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
观察网页,发现这个网页没有翻页按钮。将滚动条直接拉到底部,出现“Loading”字样。新数据很快就会出现,滚动条会变短并反弹回来。
这也可以在 优采云 中验证。网页默认打开,【循环列表】中有6条新闻。滚动到底部一次,加载新数据,【循环列表】中的新闻增加到24条。再次滚动到底部,[循环列表]中的新闻增加到34条。
因此,我们需要在优采云中设置【页面滚动】。选择【打开网页】的步骤,打开【高级选项】,勾选【页面加载后向下滚动】,设置【滚动次数】5次,【每次间隔时间】2秒,【滚动方式】为【滚动】到末】部】。然后点击【确定】保存。
启动采集,看看采集的结果。优采云自动执行【直接滚动到底部】5次,然后采集5次后滚动数据。
特别说明:
一种。此网页无限向下滚动加载数据,优采云 无法采集 一次获取所有数据。上面的例子设置滚动5次,在实际采集过程中可以按需,建议不要超过x次。
湾 这类网页常用于数据实时性较高的新闻网站,可以设置定时启动优采云,少量次采集最新数据。
C。有时候网页速度很快,像【加载中】这样的提示不明显。【是否有新数据】和【观察滚动条的反弹次数】是比较有用的判断标准。
二、【向下滚动一屏】
其他数据需要在当前屏幕上显示一段时间才能完全加载,然后被采集接收。需要设置【向下滚动一屏】,【滚动次数】根据网页本身和采集要求设置,【每次间隔】时间需要略大于数据加载时间,这与网速等因素。
常见应用场景一:数据需要在当前屏幕上显示一段时间才能完全加载,然后才可以采集。
以京东商品列表为例。%E6%89%8B%E6%9C%BA&enc=utf-8&suggest=1.his.0.0&wq=&pvid=1b312c8afe2845bd94fe55ff1b6165a8,我们想要一份所有产品的清单。首先按照之前列出数据采集的方法配置采集的任务。下面是一个配置好的任务,需要特别注意【主图片链接】字段。
启动采集,看看采集的结果。我们发现【主图链接】字段没有采集到达。
返回流程,手动执行采集流程。我们发现当主图显示在当前屏幕上时(循环中的item1、2、3),它的链接可以通过采集到达。当主图像未显示在当前屏幕上时(循环后面的项目),其链接 采集 不可用。
我们还需要在 优采云 中进行相同的设置。选择【打开网页】的步骤,打开【高级选项】,勾选【页面加载后向下滚动】,设置【滚动次数】10次,【每次间隔】2秒,【滚动模式】为【向下滚动】一屏]。
重新开始采集看看。优采云【向下滚动一屏】自动执行了10次。60个产品列表的主图在当前屏幕上显示2秒,主图链接也正常采集down。
特别说明:
一种。如果某个字段或某些数据项没有采集到达,您可以手动执行规则进行检查。很有可能需要设置【向下滚动一屏】。
湾 本例中设置滚动次数为10次,可以在当前屏幕上显示所有列表。在采集的实际过程中,根据网页的情况设置采集的数量。
C。[向下滚动一屏]的一屏与运行采集任务时的窗口显示区域有关。如下图,左边的滚动画面>右边的滚动画面。
查看全部
网页新闻抓取(优采云中如何判断网页是否需要设置页面滚动的设置
)
网站有很多,页面中的数据需要向下滚动才能加载出来。相应的,还需要在优采云中设置【页面滚动】。
如何判断一个网页是否需要设置为【页面滚动】?【页面滚动】如何设置滚动方式、滚动次数、每次间隔?
本教程将讲解【页面滚动】的设置方法和常见应用场景。
一、【直接滚动到底部】
如果直接将滚动条拖到底部,出现类似【Loading】的字样,很快又出现新数据,滚动条变短反弹,需要设置【直接滚动到底部】,【Scrolling】次]根据网页根据自身情况和采集要求设置。[每个间隔]时间需要比数据加载时间稍长,这与网络速度等因素有关。
常见应用场景一:没有翻页按钮,需要不断向下滚动才能加载新数据。常见的网页有:今日头条首页、百度图片搜索、新浪微博首页。
以今日头条首页为例。, 我们需要采集 新闻列表数据。首先按照之前列出数据采集的方法配置采集的任务。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
观察网页,发现这个网页没有翻页按钮。将滚动条直接拉到底部,出现“Loading”字样。新数据很快就会出现,滚动条会变短并反弹回来。
这也可以在 优采云 中验证。网页默认打开,【循环列表】中有6条新闻。滚动到底部一次,加载新数据,【循环列表】中的新闻增加到24条。再次滚动到底部,[循环列表]中的新闻增加到34条。
因此,我们需要在优采云中设置【页面滚动】。选择【打开网页】的步骤,打开【高级选项】,勾选【页面加载后向下滚动】,设置【滚动次数】5次,【每次间隔时间】2秒,【滚动方式】为【滚动】到末】部】。然后点击【确定】保存。
启动采集,看看采集的结果。优采云自动执行【直接滚动到底部】5次,然后采集5次后滚动数据。
特别说明:
一种。此网页无限向下滚动加载数据,优采云 无法采集 一次获取所有数据。上面的例子设置滚动5次,在实际采集过程中可以按需,建议不要超过x次。
湾 这类网页常用于数据实时性较高的新闻网站,可以设置定时启动优采云,少量次采集最新数据。
C。有时候网页速度很快,像【加载中】这样的提示不明显。【是否有新数据】和【观察滚动条的反弹次数】是比较有用的判断标准。
二、【向下滚动一屏】
其他数据需要在当前屏幕上显示一段时间才能完全加载,然后被采集接收。需要设置【向下滚动一屏】,【滚动次数】根据网页本身和采集要求设置,【每次间隔】时间需要略大于数据加载时间,这与网速等因素。
常见应用场景一:数据需要在当前屏幕上显示一段时间才能完全加载,然后才可以采集。
以京东商品列表为例。%E6%89%8B%E6%9C%BA&enc=utf-8&suggest=1.his.0.0&wq=&pvid=1b312c8afe2845bd94fe55ff1b6165a8,我们想要一份所有产品的清单。首先按照之前列出数据采集的方法配置采集的任务。下面是一个配置好的任务,需要特别注意【主图片链接】字段。
启动采集,看看采集的结果。我们发现【主图链接】字段没有采集到达。
返回流程,手动执行采集流程。我们发现当主图显示在当前屏幕上时(循环中的item1、2、3),它的链接可以通过采集到达。当主图像未显示在当前屏幕上时(循环后面的项目),其链接 采集 不可用。
我们还需要在 优采云 中进行相同的设置。选择【打开网页】的步骤,打开【高级选项】,勾选【页面加载后向下滚动】,设置【滚动次数】10次,【每次间隔】2秒,【滚动模式】为【向下滚动】一屏]。
重新开始采集看看。优采云【向下滚动一屏】自动执行了10次。60个产品列表的主图在当前屏幕上显示2秒,主图链接也正常采集down。
特别说明:
一种。如果某个字段或某些数据项没有采集到达,您可以手动执行规则进行检查。很有可能需要设置【向下滚动一屏】。
湾 本例中设置滚动次数为10次,可以在当前屏幕上显示所有列表。在采集的实际过程中,根据网页的情况设置采集的数量。
C。[向下滚动一屏]的一屏与运行采集任务时的窗口显示区域有关。如下图,左边的滚动画面>右边的滚动画面。
网页新闻抓取(【每日一题】如何爬取实际的新闻页面的具体内容观察)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-07 23:25
前言
前面的文章()主要是抓取首页的新闻列表而不是具体的新闻内容。本文将具体分析如何抓取实际新闻页面的具体内容
观察图中的新闻列表,你会发现一共有三种新闻。点进去可以发现三个新闻的页面类型不同。这里只选择性抓取类似于第一条新闻的类型,其他两种抓取方式类似,大家可以自己实践一下--_--
页面分析
一条新闻的内容无外乎三种:视频、图片、文字。以下是收录所有三个内容供分析的页面,链接如下:
打开控制台,视频一般会放在文章的顶部,id为tupian_div的div标签中(这里有坑,后面会讲...),文字会放在类left_zw的div标签在p标签中,图片会混在p标签中
视频部分的抓取
根据上一篇文章使用xpath解析html,视频主要在div下的source标签,尝试爬取地址
显然是孤独的爬上去的。. .
基本上可以判断视频是通过js动态加载的。如何处理这种情况会在下面的博客中讨论,因为内容还是比较大的。
这里的解决方法:div下面的第三个script标签里面有一个视频地址,有点推测。
提取视频地址的具体代码:
videos = news_demo.xpath('//div[@id="tupian_div"]//script')
videos_script = str(videos[2].xpath('text()'))
videos_address = videos_script[videos_script.find('source') + 11:videos_script.find('type=video/mp4') - 1]
这是针对有视频的新闻,所以需要判断新闻中是否有视频。
具体内容和图片抓取
ps = news_demo.xpath('//div[@class="left_zw"]/*')
for p in ps:
if len(p.xpath('img')) > 0:
print(p.xpath('img/@src')[0])
else:
if not p.xpath('text()'):
continue
for text in p.xpath('text()'):
print(text)
应该没有太多代码来解释。xpath的语法在上一篇博客中。
完整代码
def get_real_news(href):
# 采用get方法获取响应
resp = requests.get(href)
# 为防止获取的网页乱码,对响应内容进行重新编码,编码格式可能是utf-8或gbk
html_content = resp.content.decode('utf-8', 'replace')
news_demo = html.etree.HTML(html_content)
# 视频链接爬取
videos = news_demo.xpath('//div[@id="tupian_div"]//script')
if len(videos) == 3: # 判断是否有视频
videos_script = str(videos[2].xpath('text()'))
videos_address = videos_script[videos_script.find('source') + 11:videos_script.find('type=video/mp4') - 1]
print(videos_address)
# 正文内容获取
ps = news_demo.xpath('//div[@class="left_zw"]/*')
for p in ps:
if len(p.xpath('img')) > 0: # 判断p标签中是否嵌入图片
print(p.xpath('img/@src')[0])
else:
if not p.xpath('text()'):
continue
for text in p.xpath('text()'):
print(text)
完成
总结
这只是一个抓取新闻页面的例子。或许可以抓取部分同类型新闻页面,但无法保证每条新闻的内容都能被正确抓取。你还是需要足够的材料来试水,慢慢调试,提高复用性。
我这里只抓取了正文内容。你可以尝试自己解析,也可以尝试爬取其他类型的新闻。您还可以尝试在获取内容时添加标签,例如强标签中的文本。, 那么如果要渲染网页上的内容,可以使用strong标签。 查看全部
网页新闻抓取(【每日一题】如何爬取实际的新闻页面的具体内容观察)
前言
前面的文章()主要是抓取首页的新闻列表而不是具体的新闻内容。本文将具体分析如何抓取实际新闻页面的具体内容
观察图中的新闻列表,你会发现一共有三种新闻。点进去可以发现三个新闻的页面类型不同。这里只选择性抓取类似于第一条新闻的类型,其他两种抓取方式类似,大家可以自己实践一下--_--
页面分析
一条新闻的内容无外乎三种:视频、图片、文字。以下是收录所有三个内容供分析的页面,链接如下:
打开控制台,视频一般会放在文章的顶部,id为tupian_div的div标签中(这里有坑,后面会讲...),文字会放在类left_zw的div标签在p标签中,图片会混在p标签中
视频部分的抓取
根据上一篇文章使用xpath解析html,视频主要在div下的source标签,尝试爬取地址
显然是孤独的爬上去的。. .
基本上可以判断视频是通过js动态加载的。如何处理这种情况会在下面的博客中讨论,因为内容还是比较大的。
这里的解决方法:div下面的第三个script标签里面有一个视频地址,有点推测。
提取视频地址的具体代码:
videos = news_demo.xpath('//div[@id="tupian_div"]//script')
videos_script = str(videos[2].xpath('text()'))
videos_address = videos_script[videos_script.find('source') + 11:videos_script.find('type=video/mp4') - 1]
这是针对有视频的新闻,所以需要判断新闻中是否有视频。
具体内容和图片抓取
ps = news_demo.xpath('//div[@class="left_zw"]/*')
for p in ps:
if len(p.xpath('img')) > 0:
print(p.xpath('img/@src')[0])
else:
if not p.xpath('text()'):
continue
for text in p.xpath('text()'):
print(text)
应该没有太多代码来解释。xpath的语法在上一篇博客中。
完整代码
def get_real_news(href):
# 采用get方法获取响应
resp = requests.get(href)
# 为防止获取的网页乱码,对响应内容进行重新编码,编码格式可能是utf-8或gbk
html_content = resp.content.decode('utf-8', 'replace')
news_demo = html.etree.HTML(html_content)
# 视频链接爬取
videos = news_demo.xpath('//div[@id="tupian_div"]//script')
if len(videos) == 3: # 判断是否有视频
videos_script = str(videos[2].xpath('text()'))
videos_address = videos_script[videos_script.find('source') + 11:videos_script.find('type=video/mp4') - 1]
print(videos_address)
# 正文内容获取
ps = news_demo.xpath('//div[@class="left_zw"]/*')
for p in ps:
if len(p.xpath('img')) > 0: # 判断p标签中是否嵌入图片
print(p.xpath('img/@src')[0])
else:
if not p.xpath('text()'):
continue
for text in p.xpath('text()'):
print(text)
完成
总结
这只是一个抓取新闻页面的例子。或许可以抓取部分同类型新闻页面,但无法保证每条新闻的内容都能被正确抓取。你还是需要足够的材料来试水,慢慢调试,提高复用性。
我这里只抓取了正文内容。你可以尝试自己解析,也可以尝试爬取其他类型的新闻。您还可以尝试在获取内容时添加标签,例如强标签中的文本。, 那么如果要渲染网页上的内容,可以使用strong标签。
网页新闻抓取(Java程序中本发明文档构造一个FileWriter文件对象的说明图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-07 20:35
带有等标志的Html新闻网页可以准确抓取新闻列表的标题内容、链接地址和发布时间,对抓取结果进行分类,并保存在本地txt中。为实现上述目的,本发明采用如下技术方案: (1)创建存储对象:在本地服务器创建一个txt空文档,在Java程序中为该txt文档构造一个FileWriter文件对象,并设置content Encoding格式,避免文档存储过程中出现乱码现象,实现文档的可写性;(2)分析对象:使用Jsoup解析器解析新闻列表页面URL的Html ,并创建一个Document对象,获取解析后的文本Content;进一步分析Document对象,@3)提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,细化对象中各个元素节点的数据标识,区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。@3)提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,细化对象中各个元素节点的数据标识,区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。
以@网站的通知公告为例。如图2所示,一种基于Jsoup的网络新闻列表抓取和保存方法包括以下步骤: 步骤1:在本地或服务器上创建一个空的news.txt文件。用Java为txt文档构造一个FileWriter对象,将其编码格式设置为“UTF-8”,避免出现乱码;第二步:输入通知公告的新闻列表页面的url,使用Jsoup.connect("url")。get()方法解析页面的Html,得到一个Document对象dom,其中Documentdom=Jsoup.connect("url").get(); 第三步:使用select选择器方法提取Document对象并返回Elements集合,或者使用getElementsByClass/Tag提取指定的样式和标签内容,同时返回Elements对象es;选择方法是 Elements=dom.select("table"); getElementsByClass/Tag 方法是指 Elements=dom.getElementsByTag("table"); 第四步:定义多个字符串title、linkHref、datetime,获取Element对象中的标题、链接地址和发布时间;第五步:根据continuous es tr中是否有多个,td进行判断。
如果存在,则使用for循环方法通过Stringtitle/datetime=es.get(i).select("td").get(j).text()获取标题内容或发布时间,并通过StringlinkHref=es .get( i).getElementsByTag("a").attr("abs: href") 获取链接地址;其中i代表行数tr,j代表列数td;第六步:同步骤(4),如果不存在,直接根据Stringtitle/datetime=es.getElementsByTag("").text()获取标题或时间,通过StringlinkHref=es获取链接。 getElementsByTag("a").attr("href"); 第七步:将获取的title、linkHref、datetime按照一定的顺序和格式进行封装,封装的结果使用fwrite.write()不断写入txt ; 第八步:程序运行后,使用flush清除缓存并关闭文件,实现抓取并保存该页面新闻列表的过程。当前页面 1 1 2 3 当前页面 1 1 2 3 查看全部
网页新闻抓取(Java程序中本发明文档构造一个FileWriter文件对象的说明图)
带有等标志的Html新闻网页可以准确抓取新闻列表的标题内容、链接地址和发布时间,对抓取结果进行分类,并保存在本地txt中。为实现上述目的,本发明采用如下技术方案: (1)创建存储对象:在本地服务器创建一个txt空文档,在Java程序中为该txt文档构造一个FileWriter文件对象,并设置content Encoding格式,避免文档存储过程中出现乱码现象,实现文档的可写性;(2)分析对象:使用Jsoup解析器解析新闻列表页面URL的Html ,并创建一个Document对象,获取解析后的文本Content;进一步分析Document对象,@3)提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,细化对象中各个元素节点的数据标识,区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。@3)提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,细化对象中各个元素节点的数据标识,区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。区分标题内容、链接地址和发布时间;并定义几个字符串来获取 Elements 对象中的标题内容、链接地址和发布时间。,实现新闻列表信息的提取。(4) 使用流文件写入将标题内容、链接地址和发布时间按一定顺序保存在txt中,并使用for循环导出所有列表信息,实现整个新闻列表页面的爬取。
以@网站的通知公告为例。如图2所示,一种基于Jsoup的网络新闻列表抓取和保存方法包括以下步骤: 步骤1:在本地或服务器上创建一个空的news.txt文件。用Java为txt文档构造一个FileWriter对象,将其编码格式设置为“UTF-8”,避免出现乱码;第二步:输入通知公告的新闻列表页面的url,使用Jsoup.connect("url")。get()方法解析页面的Html,得到一个Document对象dom,其中Documentdom=Jsoup.connect("url").get(); 第三步:使用select选择器方法提取Document对象并返回Elements集合,或者使用getElementsByClass/Tag提取指定的样式和标签内容,同时返回Elements对象es;选择方法是 Elements=dom.select("table"); getElementsByClass/Tag 方法是指 Elements=dom.getElementsByTag("table"); 第四步:定义多个字符串title、linkHref、datetime,获取Element对象中的标题、链接地址和发布时间;第五步:根据continuous es tr中是否有多个,td进行判断。
如果存在,则使用for循环方法通过Stringtitle/datetime=es.get(i).select("td").get(j).text()获取标题内容或发布时间,并通过StringlinkHref=es .get( i).getElementsByTag("a").attr("abs: href") 获取链接地址;其中i代表行数tr,j代表列数td;第六步:同步骤(4),如果不存在,直接根据Stringtitle/datetime=es.getElementsByTag("").text()获取标题或时间,通过StringlinkHref=es获取链接。 getElementsByTag("a").attr("href"); 第七步:将获取的title、linkHref、datetime按照一定的顺序和格式进行封装,封装的结果使用fwrite.write()不断写入txt ; 第八步:程序运行后,使用flush清除缓存并关闭文件,实现抓取并保存该页面新闻列表的过程。当前页面 1 1 2 3 当前页面 1 1 2 3
网页新闻抓取(本篇博客在爬取新闻网站信息2的基础上进行)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-07 20:28
本博客基于爬取新闻网站信息2.
主要内容如下:
1.定义获取页面20个链接的函数
2.构造多个分页链接
3.获取多个分页链接的新闻内容
4.使用pandas整理爬取的数据
5.保存数据到csv文件
6.Scrapy 安装
1.定义获取页面20个链接的函数
#定义获取一页20条链接内容的函数
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text)
#获取一个页面所有链接(20个左右)
for ent in jd['result']['data']:
#getNewsDetail为获取一个链接内容详情
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
#测试
url = 'https://feed.sina.com.cn/api/r ... 39%3B
parseListLinks(url)
2.构造多个分页链接
#构造多个分页链接
pageurl = "https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8"
for i in range(1,10):
newsurl = pageurl.format(i)
print(newsurl)
3.获取多个分页链接的新闻内容
#抓取多个分页链接新闻内容
import requests
url = 'https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8'
news_total = []
for i in range(1,3):
newsurl = url.format(i)
newsary = parseListLinks(url)
news_total.extend(newsary)
#测试打印抓取的两个页面
print(news_total)
4.使用pandas整理爬取的数据
pandas是一个python数据分析包(Python Data Analysis Library),这里我们使用pandas的DataFrame函数将爬取中提取的数据组织成二维表数据结构。
安装pandas套件:进入cmd命令行输入如下命令安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
#用pandas整理爬取出的资料
import pandas
df = pandas.DataFrame(news_total)
#查看后5行数据
df.tail()
5.保存数据到csv文件
使用 to_csv 函数将数据存储在 csv 文件中。 “ruiyigongfang.csv”是我们导出的文件名。存放在jupyter notebook启动根目录下,一般在C:\Users\Administrator目录下。
查看ruiyigongfang.csv文件的内容
到此,用python3爬取新闻网站信息的项目已经完成。
总结:
爬虫的主要过程分为三个阶段:
下载数据:使用requests包,通过requests.get('url')方法获取网页信息
提取数据:使用BeautifulSoup4套件通过soup.select('xxx');解析关系的内容;
保存数据:通过pandas套件将数据组织成二维数据结构,然后通过to_csv()函数将数据以csv格式保存在本地。
----------------------------------------------- ---------------------------------------------
接下来会有第二个python爬虫项目,等待下次博客更新!
这里先介绍一下简单而强大的爬虫框架Scrapy的安装,为后面的项目做准备。
Scrapy 安装
环境:windows系统,python3
步骤:
1.安装轮子:
py -3 -m pip install wheel
2.安装lxml:
py -3 -m pip install lxml
3.安装扭曲:
下载扭曲:~gohlke/pythonlibs/#twisted
注意:下载的版本必须与安装的python版本和电脑的位数一致。对于python3.7,选择cp37,其他版本以此类推。例如:
安装扭曲:
pip install xxx/xxx/Twistedxxx
注:xxx/xxx/Twistedxxx为下载的twisted文件的绝对路径。比如下载的文件放在D:\目录下,文件名是Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
命令应该是 pip install D:\Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
4.安装 Scrapy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
5.安装 win32py
下载:注意下载与python版本和电脑相同位数的文件
安装:双击pywin32-224.win-amd64-py3.7.exe文件安装
6.验证
scrapy -h
说明:
安装Scrapy依赖于wheel、lxml和Twisted模块
运行 Scrapy 依赖于 win32py
完成!享受吧! 查看全部
网页新闻抓取(本篇博客在爬取新闻网站信息2的基础上进行)
本博客基于爬取新闻网站信息2.
主要内容如下:
1.定义获取页面20个链接的函数
2.构造多个分页链接
3.获取多个分页链接的新闻内容
4.使用pandas整理爬取的数据
5.保存数据到csv文件
6.Scrapy 安装
1.定义获取页面20个链接的函数
#定义获取一页20条链接内容的函数
def parseListLinks(url):
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text)
#获取一个页面所有链接(20个左右)
for ent in jd['result']['data']:
#getNewsDetail为获取一个链接内容详情
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails
#测试
url = 'https://feed.sina.com.cn/api/r ... 39%3B
parseListLinks(url)
2.构造多个分页链接
#构造多个分页链接
pageurl = "https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8"
for i in range(1,10):
newsurl = pageurl.format(i)
print(newsurl)
3.获取多个分页链接的新闻内容
#抓取多个分页链接新闻内容
import requests
url = 'https://feed.sina.com.cn/api/r ... ge%3D{}&encode=utf-8'
news_total = []
for i in range(1,3):
newsurl = url.format(i)
newsary = parseListLinks(url)
news_total.extend(newsary)
#测试打印抓取的两个页面
print(news_total)
4.使用pandas整理爬取的数据
pandas是一个python数据分析包(Python Data Analysis Library),这里我们使用pandas的DataFrame函数将爬取中提取的数据组织成二维表数据结构。
安装pandas套件:进入cmd命令行输入如下命令安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
#用pandas整理爬取出的资料
import pandas
df = pandas.DataFrame(news_total)
#查看后5行数据
df.tail()
5.保存数据到csv文件
使用 to_csv 函数将数据存储在 csv 文件中。 “ruiyigongfang.csv”是我们导出的文件名。存放在jupyter notebook启动根目录下,一般在C:\Users\Administrator目录下。
查看ruiyigongfang.csv文件的内容
到此,用python3爬取新闻网站信息的项目已经完成。
总结:
爬虫的主要过程分为三个阶段:
下载数据:使用requests包,通过requests.get('url')方法获取网页信息
提取数据:使用BeautifulSoup4套件通过soup.select('xxx');解析关系的内容;
保存数据:通过pandas套件将数据组织成二维数据结构,然后通过to_csv()函数将数据以csv格式保存在本地。
----------------------------------------------- ---------------------------------------------
接下来会有第二个python爬虫项目,等待下次博客更新!
这里先介绍一下简单而强大的爬虫框架Scrapy的安装,为后面的项目做准备。
Scrapy 安装
环境:windows系统,python3
步骤:
1.安装轮子:
py -3 -m pip install wheel
2.安装lxml:
py -3 -m pip install lxml
3.安装扭曲:
下载扭曲:~gohlke/pythonlibs/#twisted
注意:下载的版本必须与安装的python版本和电脑的位数一致。对于python3.7,选择cp37,其他版本以此类推。例如:
安装扭曲:
pip install xxx/xxx/Twistedxxx
注:xxx/xxx/Twistedxxx为下载的twisted文件的绝对路径。比如下载的文件放在D:\目录下,文件名是Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
命令应该是 pip install D:\Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
4.安装 Scrapy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
5.安装 win32py
下载:注意下载与python版本和电脑相同位数的文件
安装:双击pywin32-224.win-amd64-py3.7.exe文件安装
6.验证
scrapy -h
说明:
安装Scrapy依赖于wheel、lxml和Twisted模块
运行 Scrapy 依赖于 win32py
完成!享受吧!
网页新闻抓取(搜索引擎问题是如何更快地网站网站,可采取哪些措施来提高速度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-06 20:23
搜索引擎包括抓取工具、索引和算法。其中,爬虫工具跟随链接。对于 网站 建立的链接,爬虫将页面的 HTML 版本保存在索引数据库中。每次爬虫绕过网站并找到新版本时,都会更新索引。
爬虫爬取溯源与爬取网站有关。网站 可能会阻止抓取工具。有几种方法可以防止爬虫在 网站 上爬行。如果网站上的网页被屏蔽,爬虫会被拒绝,相应的页面也不会出现在搜索结果中。如果robot文件阻塞了爬虫,爬取之前网站工具会查看网页的HTTP头。HTTP 标头收录状态代码。如果状态码显示该网页不存在,则不会抓取网站。在HTTP headers模块中,会告知所有相关信息。如果特定网页上的元标记阻止搜索引擎将该网页编入索引,则该网页将被抓取但不会添加到索引中。
虽然可爬性只是一个技术基础,但是如何更快地爬取网站,以及可以采取哪些措施来提高爬取速度,是经常被各类站长问到的一个问题。在抓取网站时,搜索引擎有两种可能。如果他们没有找到足够多的网站 链接,那么这并不重要,网站 响应太慢,或者遇到太多错误。当没有足够多的高质量入站链接时,内容不会很快被抓取。如果想让爬虫进行更多的爬虫操作,就需要做一些链接建设。
网站生产解决了爬虫爬行响应慢的问题,如动态页面JS代码量大、服务器不稳定、收录404页面、网站生产线修改模板等问题到内容页面中的某些文件夹它没有被删除,但链接显示了一个 404 页面。首先解决自己网站的所有问题。
那么最重要的就是提交给爬虫了。最好将代码自动推送到页面上的布局中。详细到每个内容页面,提交会自动触发,从而增加爬虫的爬取频率。最后是核心,也是高质量的外链,尽量在自己网站主题相关的网站上做外链,保持一定的垂直度。目前很多网站都设置了外链nofollow的标签,选择在外链上发布。对于论坛或博客,或者在推广软文时,首先检查外链标签是否设置为nofollow,以确保可以引入爬虫链接。 查看全部
网页新闻抓取(搜索引擎问题是如何更快地网站网站,可采取哪些措施来提高速度)
搜索引擎包括抓取工具、索引和算法。其中,爬虫工具跟随链接。对于 网站 建立的链接,爬虫将页面的 HTML 版本保存在索引数据库中。每次爬虫绕过网站并找到新版本时,都会更新索引。
爬虫爬取溯源与爬取网站有关。网站 可能会阻止抓取工具。有几种方法可以防止爬虫在 网站 上爬行。如果网站上的网页被屏蔽,爬虫会被拒绝,相应的页面也不会出现在搜索结果中。如果robot文件阻塞了爬虫,爬取之前网站工具会查看网页的HTTP头。HTTP 标头收录状态代码。如果状态码显示该网页不存在,则不会抓取网站。在HTTP headers模块中,会告知所有相关信息。如果特定网页上的元标记阻止搜索引擎将该网页编入索引,则该网页将被抓取但不会添加到索引中。
虽然可爬性只是一个技术基础,但是如何更快地爬取网站,以及可以采取哪些措施来提高爬取速度,是经常被各类站长问到的一个问题。在抓取网站时,搜索引擎有两种可能。如果他们没有找到足够多的网站 链接,那么这并不重要,网站 响应太慢,或者遇到太多错误。当没有足够多的高质量入站链接时,内容不会很快被抓取。如果想让爬虫进行更多的爬虫操作,就需要做一些链接建设。
网站生产解决了爬虫爬行响应慢的问题,如动态页面JS代码量大、服务器不稳定、收录404页面、网站生产线修改模板等问题到内容页面中的某些文件夹它没有被删除,但链接显示了一个 404 页面。首先解决自己网站的所有问题。
那么最重要的就是提交给爬虫了。最好将代码自动推送到页面上的布局中。详细到每个内容页面,提交会自动触发,从而增加爬虫的爬取频率。最后是核心,也是高质量的外链,尽量在自己网站主题相关的网站上做外链,保持一定的垂直度。目前很多网站都设置了外链nofollow的标签,选择在外链上发布。对于论坛或博客,或者在推广软文时,首先检查外链标签是否设置为nofollow,以确保可以引入爬虫链接。

