网页新闻抓取(爬虫课题中的需求如下的分析与分析方法(上) )
优采云 发布时间: 2021-10-11 15:28网页新闻抓取(爬虫课题中的需求如下的分析与分析方法(上)
)
昨晚,我的朋友向我求助。他的一个主题需要爬取《人民日报》中的文章,方便后续的分词、词性标注、词频统计等一系列数据统计和分析。于是他找到了我。
对爬虫的一般要求如下。简单的看了一下这个网站还有他想爬的东西。难度不大,但涉及的知识相当全面。正好用来练手,所以就答应了。.
在写爬虫之前,回顾一下爬虫的思路。
首先你要清楚自己要爬取什么内容。需求明确了,就可以有目标了;那么,你必须分析目标网站,包括URL结构、HTML页面、网络请求和返回结果等,目的是找到我们网站中的爬取目标在哪里,怎么才能我们得到它,然后指定爬取策略;接下来是编码环节,利用编码发起网络请求,解析网页内容,提取目标数据,并进行数据存储;最后,对代码进行测试,对程序进行改进,比如增加一些输入输出交互使程序使用更方便,增加异常捕获和处理部分,使程序更加健壮。
一、明确需求
他的需求其实很简单,就是人民日报每天有一份报纸,每份报纸有几页,每一页有几个文章。他希望将这些文章全部抓取并按照一定的规则存储在本地(具体要求如下图所示)。
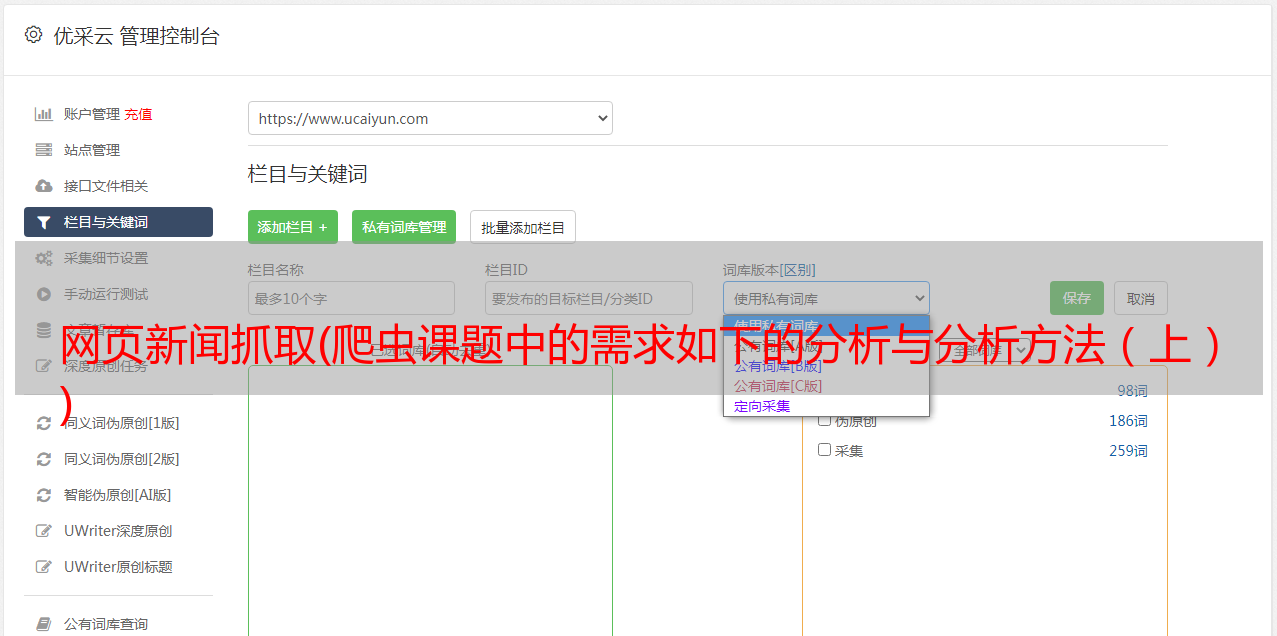
二、分析目标网站
1. URL 组成结构
人民日报网站的网址结构比较直观。基本上重要的参数,比如日期、页码、文章号等,都反映在URL中,组成的规则也很简单,像这样
布局目录:
文章内容:
在页面目录的链接中,“/2019-05/06/”表示日期,后面的“_01”表示这是第一页的链接。
文章的内容链接中,“/2019-05/06/”表示日期,后面的“_20190506_5_01”表示这是5月6日该报第一版第五章, 2019文章
值得注意的是,如果日期的“月”、“日”和“页码”数小于10,则必须在日期前加上“0”,而文章@的文章编号> 没有必要。
知道了这一点之后,我们就可以按照这个规则构造一个链接到任何一天的报纸页面,以及一个链接到任何文章文章。
例如,2018 年 6 月 5 日第 4 版目录的链接是:
2018 年 6 月 1 日第 2 版第 3 部分的链接:文章:
点击访问,发现确实如此。至此,网站的URL组成结构分析完毕。
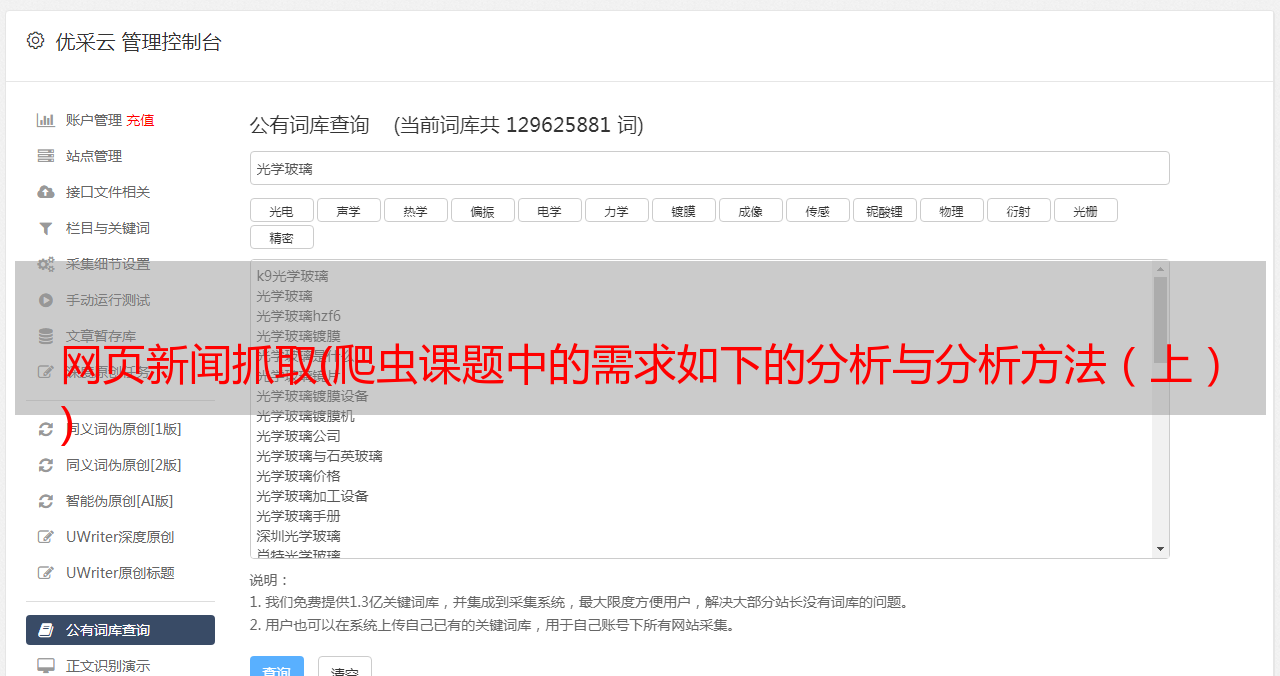
2. 分析网页的HTML结构
在URL分析中,我们也发现网站的页面跳转是通过改变URL来完成的,不涉及Ajax等动态加载方式。也就是说,它的所有数据都是从头开始加载的,我们只需要从html中提取相应的数据即可。
PS:如果使用Ajax的话,网站开头显示的数据是不完整的,只有在触发某些操作时,比如浏览到页面底部,或者点击查看更多按钮等,稍后,它将向服务器发送请求以获取剩余数据。如果是这种情况,我们的爬取策略不是从 HTML 中查找,而是直接向服务器发送请求,然后解析服务器返回的 json 文件。具体方法请参考《Python Web爬虫实战:爬取主题下知乎 18934响应数据》。
好的,让我们回到正题,让我们分析一下我们的目标网站。按F12调出开发者工具(点击图中1处的小箭头,再点击网页中的内容,可以在html源代码中快速找到对应的位置)。
这样我们就可以知道布局目录存放在一个id=“pageList”的div标签下,而在一个class=“right_title1”或“right_title2”的div标签中,每个div代表一个布局,链接布局在 id = "pageLink" 的标签中。
用同样的方法,我们可以知道文章目录存放在id=“titleList”的div标签下的ul标签中。每个li标签代表一块文章,而文章链接在li标签下的a标签中。
进入文章内容页面后,我们可以知道文章标题是存放在h1、h2、h3标签中的(有的文章标题只用到了h1标签,有的< @文章H2 或 h3 标签可能用于字幕),正文部分存储在 id = "ozoom" 的 div 标签下的 p 标签中。
至此,目标网站的HTML页面分析完成。
3. 制定爬取策略
通过分析目标网站的URL组成结构和HTML结构,我们完成了爬虫的初步研究工作。接下来,我们需要根据网站的特点制定相应的爬取策略,然后评估每种方法的性能优劣和难易程度,最后选择最优方案进行编码实现。
策略一:第一遍,先爬取页面目录,保存每个页面的链接;第二遍,依次访问各个页面的链接,并保存页面的文章链接;第三次,依次访问每个文章链接,将文章的标题和正文保存在本地。
策略二:既然我们已经知道文章链接是如何构建的,那么我们或许可以跳过目录的爬取,直接循环构建文章链接来爬取文章的内容文章。
经过一些比较和简单的编码测试,我决定使用策略一来完成这个爬虫。
主要原因是策略二的逻辑虽然比较简单方便,但有两个问题需要解决。1.每天的报纸页数都不一样,每一页的文章页数也不同。正在构建 URL。如何保证文章不重复或省略?2. 在某些特殊情况下,文章 的编号是不连续的。如何解决这个问题呢?
所以,综合考虑,我认为策略一可能更稳定,更安全(如果你想到解决策略二问题的方法,你可以尝试一下,或者如果你想到其他策略,请留言和我们将一起讨论)。
三、编码链接
接下来是实际的编码环节,不多说,直接开始。
首先导入本项目中用到的库:
import requests
import bs4
import os
import datetime
import time
其中,requests库主要用于发起网络请求,接收服务器返回的数据;bs4库主要用于解析html内容,是一个非常简单易用的库;os 库主要用于将数据输出存储在本地文件中。
def fetchUrl(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url,headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
fetchUrl函数用于发起网络请求,可以访问目标url,获取目标网页的html内容并返回。
事实上,异常捕获应该在这里完成(为了简单起见,我把它省略了,伸出我的舌头)。由于网络情况比较复杂,可能会因为各种原因导致访问失败。r.raise_for_status() 代码实际上是在判断访问是否成功。如果访问失败,返回的状态码不是200,执行到这里。会直接抛出相应的异常。
def getPageList(year, month, day):
'''
功能:获取当天报纸的各版面的链接列表
参数:年,月,日
'''
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/nbs.D110000renmrb_01.htm'
html = fetchUrl(url)
bsobj = bs4.BeautifulSoup(html,'html.parser')
pageList = bsobj.find('div', attrs = {'id': 'pageList'}).ul.find_all('div', attrs = {'class': 'right_title-name'})
linkList = []
for page in pageList:
link = page.a["href"]
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link
linkList.append(url)
return linkList
getPageList函数用于抓取当天报纸各版面的链接,保存为数组,返回。
def getTitleList(year, month, day, pageUrl):
'''
功能:获取报纸某一版面的文章链接列表
参数:年,月,日,该版面的链接
'''
html = fetchUrl(pageUrl)
bsobj = bs4.BeautifulSoup(html,'html.parser')
titleList = bsobj.find('div', attrs = {'id': 'titleList'}).ul.find_all('li')
linkList = []
for title in titleList:
tempList = title.find_all('a')
for temp in tempList:
link = temp["href"]
if 'nw.D110000renmrb' in link:
url = 'http://paper.people.com.cn/rmrb/html/' + year + '-' + month + '/' + day + '/' + link
linkList.append(url)
return linkList
getPageList函数用于抓取当日报纸某个页面中文章的所有链接,保存为数组,返回。
def getContent(html):
'''
功能:解析 HTML 网页,获取新闻的文章内容
参数:html 网页内容
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
# 获取文章 标题
title = bsobj.h3.text + '\n' + bsobj.h1.text + '\n' + bsobj.h2.text + '\n'
#print(title)
# 获取文章 内容
pList = bsobj.find('div', attrs = {'id': 'ozoom'}).find_all('p')
content = ''
for p in pList:
content += p.text + '\n'
#print(content)
# 返回结果 标题+内容
resp = title + content
return resp
getContent函数用于访问文章的内容页面,抓取文章的title和body,返回。
def saveFile(content, path, filename):
'''
功能:将文章内容 content 保存到本地文件中
参数:要保存的内容,路径,文件名
'''
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
# 保存文件
with open(path + filename, 'w', encoding='utf-8') as f:
f.write(content)
saveFile函数用于将文章的内容保存到指定的本地文件夹。
def download_rmrb(year, month, day, destdir):
'''
功能:爬取《人民日报》网站 某年 某月 某日 的新闻内容,并保存在 指定目录下
参数:年,月,日,文件保存的根目录
'''
pageList = getPageList(year, month, day)
for page in pageList:
titleList = getTitleList(year, month, day, page)
for url in titleList:
# 获取新闻文章内容
html = fetchUrl(url)
content = getContent(html)
# 生成保存的文件路径及文件名
temp = url.split('_')[2].split('.')[0].split('-')
pageNo = temp[1]
titleNo = temp[0] if int(temp[0]) >= 10 else '0' + temp[0]
path = destdir + '/' + year + month + day + '/'
fileName = year + month + day + '-' + pageNo + '-' + titleNo + '.txt'
# 保存文件
saveFile(content, path, fileName)
download_rmrb 函数是需求中需要的主要函数。根据年、月、日参数,可以将当天报纸文章的所有内容按规则下载并保存到指定路径destdir。
if __name__ == '__main__':
'''
主函数:程序入口
'''
year = "2019"
month = "05"
day = "06"
destdir = "D:/data"
download_rmrb(year, month, day, destdir)
print("爬取完成:" + year + month + day)
至此,程序的主要功能已经完成。
四、改进程序
通过上一章的编码,我们已经实现了通过调用download_rmrb函数,可以下载特定日期的所有文章内容。但同时我们也可以发现,在程序入口的main函数中,日期是硬编码在代码中的,也就是说,如果我们要爬取其他日期的报纸,就必须修改源代码。
很不方便,是不是,我们改进一下,日期是用户以交互方式输入的。
if __name__ == '__main__':
'''
主函数:程序入口
'''
# 爬取指定日期的新闻
newsDate = input('请输入要爬取的日期(格式如 20190502 ):')
year = newsDate[0:4]
month = newsDate[4:6]
day = newsDate[6:8]
download_rmrb(year, month, day, 'D:/data')
print("爬取完成:" + year + month + day)
不是更方便吗?但问题又来了。如果我想一次攀登一个月或一年怎么办?不用我手动输入几十次或几百次吗?因此,我们可以改进程序。用户输入实际日期和结束日期,程序爬取期间的所有日期都是文章。
实际运行测试,假设我们要抓取2019年4月的所有报纸内容,那么我们开始日期输入20190401,结束日期输入20190501,回车运行。
等待一段时间后,程序已经运行完成。我们去文件夹看看我们爬取了什么。
爬取的内容整齐地排列在文件夹中,真的很舒服。随便打开一个文件看看,没问题。
到这里这个爬虫就全部完成了。
写在后面的字
这次好久没有写新的爬虫文章了。一是因为我快毕业了,忙着做毕业设计;另一种是写教程文章,真的很辛苦。,需要整理思路和语言,重新整理代码,要求各种截图,让零基础或者刚入门的人都能看懂,写出来。第三,我找不到一个有趣的动机,因为爬虫总是为了使用而写的,你不能为了炫耀你的技能而写爬虫。那是没有意义的。
一开始就写了一个爬虫来记录自己的成长过程。如果我在学习过程中的这些记录能同时帮助到更多后来者,那就更好了。
2019 年 7 月 10 日更新
有读者在评论中反映,不能使用输入起止日期的方式来抓取一段时间内的新闻,运行时会报如下错误。
我查了一下,确实是我的疏忽。
这是因为计算日期的函数在datetime库中,在写博客整理代码的过程中,忽略了引用这个库,导致程序运行出错。
解决方法是在程序中添加两行代码:
import datetime
import time
我对博客的代码做了改动,请放心食用。
感谢weixin_42435870,宋心悦悦的朋友指出了问题,非常感谢!!
2020 年 7 月 26 日更新
通过读者朋友的反馈,我发现《人民日报》的网站近日进行了改版,7月1日的新闻版面采用了新的版式。这也导致无法使用原创代码抓取2020年7月1日之后的新闻。
所以这里有一个更新以兼容 网站 的新格式。
1. 在getPageList函数中,替换原来的
pageList = bsobj.find('div', attrs = {'id': 'pageList'}).ul.find_all('div', attrs = {'class': 'right_title-name'})
改成:
temp = bsobj.find('div', attrs = {'id': 'pageList'})
if temp:
pageList = temp.ul.find_all('div', attrs = {'class': 'right_title-name'})
else:
pageList = bsobj.find('div', attrs = {'class': 'swiper-container'}).find_all('div', attrs = {'class': 'swiper-slide'})
2. 在getTitleList函数中,替换原来的
titleList = bsobj.find('div', attrs = {'id': 'titleList'}).ul.find_all('li')
改成:
temp = bsobj.find('div', attrs = {'id': 'titleList'})
if temp:
titleList = temp.ul.find_all('li')
else:
titleList = bsobj.find('ul', attrs = {'class': 'news-list'}).find_all('li')
简单解释一下上面的变化,
1. 在原来的网站中,对布局列表和文章列表的标签进行了调整,所以我们需要使用新的标签和新的属性来获取它们。
2. 为了兼容,我们先获取之前版本的标签。如果有,就说明是改版前的接口。如果不可用,说明是改版后的接口。您需要使用新的标签属性来获取它。
如果文章有什么不明白的地方,或者解释有误,欢迎在评论区批评指正,或扫描下方二维码加我微信。让我们一起学习交流,共同进步。