
网页新闻抓取
网页新闻抓取(PythonGPU资源利用-pythonPython脚本在某些深度学习模型上运行推理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-06 05:12
给定一个新闻 文章 网页(来自任何主要新闻来源,例如 Times 或 Bloomberg),我想确定该页面上的主要 文章 内容并排除其他杂项元素,例如广告、菜单、侧边栏,用户评论。
有没有什么通用的方法可以用在大多数重大新闻网站上?
有没有好的数据挖掘工具或库?(最好是基于python的)
参考计划
不能保证这是可能的,但您可能使用的一种策略是尝试查找收录最可见文本的元素。
Python GPU资源利用-python
我有一个 Python 脚本来对某些深度学习模型运行推理。有什么办法可以查到GPU资源的利用率?例如,使用着色器、float16 乘法器等。我似乎无法在互联网上找到关于这些 GPU 资源的太多文档。谢谢!作为参考,您可以尝试在像 Renderdoc 这样的 GPU 分析器中运行 pyxthon 应用程序。它会分析你的跑步情况。您将能够获得有关已用资源、已用缓冲区、不同渲染状态的信息...
Python:图像处理可以产生皱纹纸效果-python
可能很难描述我的问题。我正在 Python 中寻找一种算法来在带有特定文本的白色图像上创建皱纹纸效果。我的第一次尝试是将一些真正的皱纹纸图像(具有透明度)添加到带有文本的图像中。看起来不错,但副作用是文字并没有真正起皱。所以我正在寻找更好的解决方案,有什么想法吗?谢谢参考。除了使用透明度,假设您有两张相同大小的图像,一张在皱纹纸上亮,一张在白色背景上暗...
Python uuid4,如何限制唯一字符的长度-python
在 Python 中,我使用 uuid4() 方法来创建唯一的字符集。但是我找不到将其限制为 10 或 8 个字符的方法。解决办法是什么?uuid4()ffc69c1b-9d87-4c19-8dac-c09ca857e3fc 谢谢。参考解决方案尝试:x = uuid4() str(x)[:8] 输出:"ffc69c1b" 有没有办法...
Python sqlite3 数据库被锁定-python
我在 Windows 上使用 Python 3 和 sqlite3。我正在开发一个使用数据库来存储联系人的小应用程序。我注意到如果应用程序被强行关闭(通过错误或通过任务管理器),您将收到一个 sqlite3 错误(sqlite3.OperationalError: database is locked)。我认为这是因为我在关闭应用程序之前没有正确关闭数据库连接。我试过:连接...
Python:如何停止多线程 numpy?-Python
我知道这似乎是一个荒谬的问题,但我必须在与部门其他人共享的计算服务器上定期运行作业,当我开始 10 个作业时,我真的希望它只占用 10 个内核而不是更多;我不在乎每次运行内核是否需要更长的时间:我只是不希望它侵入其他人的领土,这将要求我放弃工作等等。我只想拥有 10 个内核,仅此而已。更具体地说,我在 Redh 中使用 Python 2.7.3 和 numpy 1.6.1 ... 查看全部
网页新闻抓取(PythonGPU资源利用-pythonPython脚本在某些深度学习模型上运行推理)
给定一个新闻 文章 网页(来自任何主要新闻来源,例如 Times 或 Bloomberg),我想确定该页面上的主要 文章 内容并排除其他杂项元素,例如广告、菜单、侧边栏,用户评论。
有没有什么通用的方法可以用在大多数重大新闻网站上?
有没有好的数据挖掘工具或库?(最好是基于python的)
参考计划
不能保证这是可能的,但您可能使用的一种策略是尝试查找收录最可见文本的元素。
Python GPU资源利用-python
我有一个 Python 脚本来对某些深度学习模型运行推理。有什么办法可以查到GPU资源的利用率?例如,使用着色器、float16 乘法器等。我似乎无法在互联网上找到关于这些 GPU 资源的太多文档。谢谢!作为参考,您可以尝试在像 Renderdoc 这样的 GPU 分析器中运行 pyxthon 应用程序。它会分析你的跑步情况。您将能够获得有关已用资源、已用缓冲区、不同渲染状态的信息...
Python:图像处理可以产生皱纹纸效果-python
可能很难描述我的问题。我正在 Python 中寻找一种算法来在带有特定文本的白色图像上创建皱纹纸效果。我的第一次尝试是将一些真正的皱纹纸图像(具有透明度)添加到带有文本的图像中。看起来不错,但副作用是文字并没有真正起皱。所以我正在寻找更好的解决方案,有什么想法吗?谢谢参考。除了使用透明度,假设您有两张相同大小的图像,一张在皱纹纸上亮,一张在白色背景上暗...
Python uuid4,如何限制唯一字符的长度-python
在 Python 中,我使用 uuid4() 方法来创建唯一的字符集。但是我找不到将其限制为 10 或 8 个字符的方法。解决办法是什么?uuid4()ffc69c1b-9d87-4c19-8dac-c09ca857e3fc 谢谢。参考解决方案尝试:x = uuid4() str(x)[:8] 输出:"ffc69c1b" 有没有办法...
Python sqlite3 数据库被锁定-python
我在 Windows 上使用 Python 3 和 sqlite3。我正在开发一个使用数据库来存储联系人的小应用程序。我注意到如果应用程序被强行关闭(通过错误或通过任务管理器),您将收到一个 sqlite3 错误(sqlite3.OperationalError: database is locked)。我认为这是因为我在关闭应用程序之前没有正确关闭数据库连接。我试过:连接...
Python:如何停止多线程 numpy?-Python
我知道这似乎是一个荒谬的问题,但我必须在与部门其他人共享的计算服务器上定期运行作业,当我开始 10 个作业时,我真的希望它只占用 10 个内核而不是更多;我不在乎每次运行内核是否需要更长的时间:我只是不希望它侵入其他人的领土,这将要求我放弃工作等等。我只想拥有 10 个内核,仅此而已。更具体地说,我在 Redh 中使用 Python 2.7.3 和 numpy 1.6.1 ...
网页新闻抓取(【web实战篇】批量挂黑页新闻源网站被植入 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-04 19:26
)
慧智知教堂:【网络实战篇】网站被植入Webshell
慧智识故事:【网络实战】门罗币恶意挖矿
慧智知堂:【网络实战篇】批量黑页
新闻来源网站一般权重较高,收录速度快,可以被搜索引擎优先排序收录。黑灰产品推广引流必看,容易被攻击。被黑后,不良信息的主要内容主要是彩票马克六等赌博内容。新闻源网站程序,无论是自研还是开源程序,都容易被黑,开源程序更容易被黑。
症状:
某新闻源网站首页广告链接被劫持到菠菜网站
广告主题一共三个,链接形式如下:
/zhuanti/yyysc/index.shtml
/zhuanti/wwwsc/index.shtml
/zhuanti/zzzsc/index.shtml
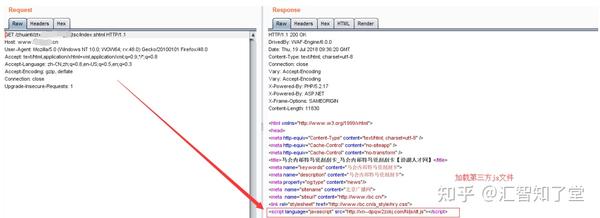
单击这三个链接将跳转到 Gaming网站。简单地捕获和分析过程:
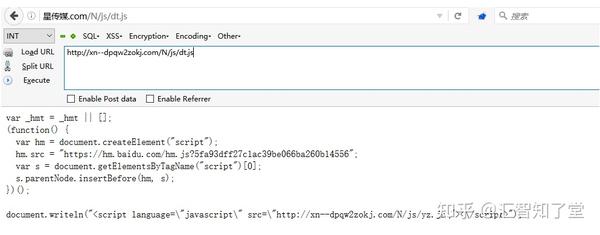
可以发现此时这个返回页面已经被劫持了,并且已经加载了第三方js文件/N/js/dt.js,进一步访问该文件:
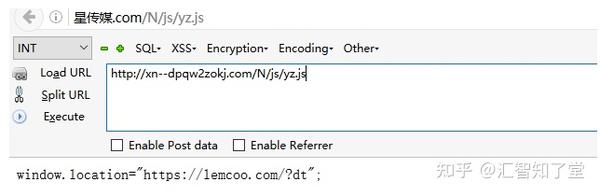
dt.js 进一步加载另一个 js,访问 /N/js/yz.js
我们发现链接跳转到了/?dt,进一步访问这个链接,网站是赌博链接的导航网站,访问后会随机跳转到第三方赌博< @网站。
问题处理:
找到url对应的文件位置。即使文件被删除,链接仍然可以访问。可以发现三个链接都是以“sc”为后缀的。
检查Nginx配置文件,发现Nginx配置文件VirtualHost.conf被篡改。带有“sc”后缀的特殊链接通过反向代理匹配并被劫持。网站是游戏链接导航网站。
删除恶意代理后,恢复特殊链接访问。
今天就分享到这里,下期分享《第五篇:移动终端劫持》,记得关注+点赞哦~
查看全部
网页新闻抓取(【web实战篇】批量挂黑页新闻源网站被植入
)
慧智知教堂:【网络实战篇】网站被植入Webshell
慧智识故事:【网络实战】门罗币恶意挖矿
慧智知堂:【网络实战篇】批量黑页
新闻来源网站一般权重较高,收录速度快,可以被搜索引擎优先排序收录。黑灰产品推广引流必看,容易被攻击。被黑后,不良信息的主要内容主要是彩票马克六等赌博内容。新闻源网站程序,无论是自研还是开源程序,都容易被黑,开源程序更容易被黑。
症状:
某新闻源网站首页广告链接被劫持到菠菜网站

广告主题一共三个,链接形式如下:
/zhuanti/yyysc/index.shtml
/zhuanti/wwwsc/index.shtml
/zhuanti/zzzsc/index.shtml
单击这三个链接将跳转到 Gaming网站。简单地捕获和分析过程:
可以发现此时这个返回页面已经被劫持了,并且已经加载了第三方js文件/N/js/dt.js,进一步访问该文件:
dt.js 进一步加载另一个 js,访问 /N/js/yz.js
我们发现链接跳转到了/?dt,进一步访问这个链接,网站是赌博链接的导航网站,访问后会随机跳转到第三方赌博< @网站。

问题处理:
找到url对应的文件位置。即使文件被删除,链接仍然可以访问。可以发现三个链接都是以“sc”为后缀的。
检查Nginx配置文件,发现Nginx配置文件VirtualHost.conf被篡改。带有“sc”后缀的特殊链接通过反向代理匹配并被劫持。网站是游戏链接导航网站。

删除恶意代理后,恢复特殊链接访问。
今天就分享到这里,下期分享《第五篇:移动终端劫持》,记得关注+点赞哦~

网页新闻抓取( 【每日一题】新浪新闻为例(二):反爬机制 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 437 次浏览 • 2021-10-04 19:24
【每日一题】新浪新闻为例(二):反爬机制
)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
现在各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
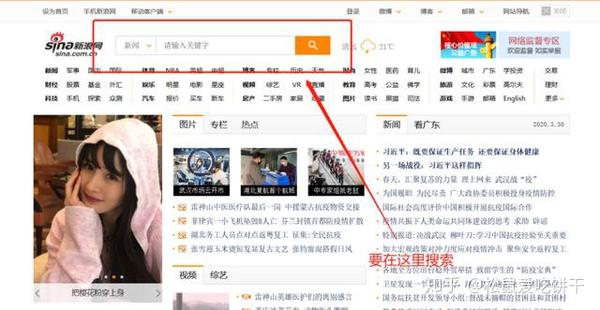
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
所以回到网站看看哪里出了问题
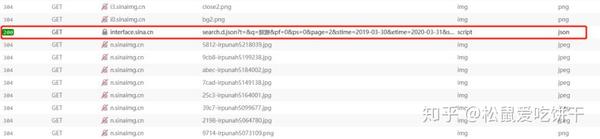
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
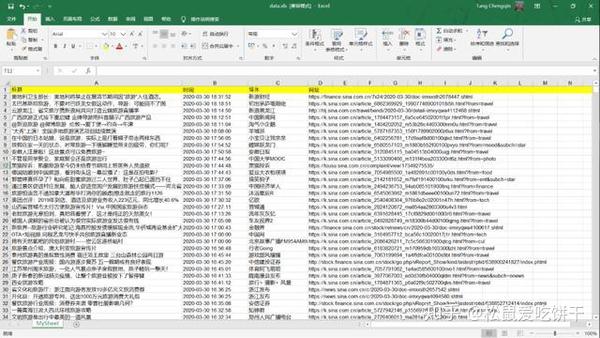
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果
查看全部
网页新闻抓取(
【每日一题】新浪新闻为例(二):反爬机制
)

前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
现在各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。

网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:

恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:

所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。

完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果
网页新闻抓取(新闻爬虫及爬取结果查询网站的搭建(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-01 02:25
新闻爬虫构建及爬取结果查询网站(一)
实验要求 核心要求
1、选择3-5条代表性新闻网站(如新浪新闻、网易新闻等,或垂直领域的权威网站,如经济领域的雪球财经、东方)财富等,或体育领域的腾讯体育、虎扑体育等)建立爬虫分析网站的不同新闻页面,爬取代码、标题、作者、时间、关键词 、摘要、结构化信息如内容和来源存储在数据库中。
2、建立网站,提供对爬取内容的子项全文搜索,并给出搜索到的关键词的时间流行度分析。
技能要求
1、 必须使用Node.JS来实现网络爬虫
2、必须使用Node.JS实现查询。网站后端,HTML+JS实现前端(尽量不要使用任何前后端框架)
爬行动物准备
一共选择了三个新闻网站进行抓取,分别是中国财经网、雪球网、东方财富网,抓取结果存储在postgresql中。
在本次实验中,基于 Node.js 的 Cheerio 和 Request 实现了一个爬虫。下面将详细介绍基础环境搭配、各个爬虫的实现、功能实现过程等。
Node.js 安装和配置
Node.js 官网:
安装非常简单,只要跟着一点点就行了。
vscode
Visual Studio Code(以下简称 vscode)是一个轻量级且功能强大的跨平台开源代码编辑器(IDE),支持 Windows、OS X 和 Linux。内置JavaScript、TypeScript和Node.js支持,拥有丰富的插件生态,可以安装插件支持C++、C#、Python、PHP等多种语言。
在这个实验中,我使用了 vscode 来调试 node.js。
可以参考官网:
要求
Request 也是一个 Node.js 模块库,可以轻松完成 http 请求。
安装
npm install request 的基本用法:
本次实验中,新闻页面主要通过请求获取。主要使用其默认的 GET 方法。
var request = require('request');
request('url', function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body) // 请求成功的处理逻辑
}
});
Cheerio 解析 HTML 简介(加载)
首先需要手动加载html文档,使用方法如下,其他更多加载方法可以参考官方文档
var cheerio = require('cheerio'),
$ = cheerio.load('...');
选择器
Cheerio 选择器几乎与 jQuery 相同。选择器是文档遍历和操作的起点。与在 jQuery 中一样,它是选择元素节点的最重要方法,但在 jQuery 中,选择器建立在 CSS 选择器标准库之上。
在本实验中,主要使用以下选择器方法。
选择页面上的所有超链接。首先获取页面中的所有标签,然后遍历获取其href属性的值,具体部分代码如下:
try {
seedurl_news = $('a');
} catch (e) { console.log('url列表所处的html块识别出错:' + e) };
seedurl_news.each(function(){
try {
var href = "";
href = $(this).attr('href'); //获取href属性
}catch(e) {
console.log('get the seed url err' + e);
}
}
根据指定的类属性名称进行选择。注意类名有空格时,改成.,示例代码如下:
$('.source.data-source')
如果要选择某个标签下它的子标签的内容,但是它的子标签没有唯一的类名或者id对应,可以使用.children(selector)来选择它的子节点,eq()就是选择几个子节点,从0开始。示例代码如下:
$('.article-meta').children().eq(1).text();
数据库存储 查看全部
网页新闻抓取(新闻爬虫及爬取结果查询网站的搭建(一))
新闻爬虫构建及爬取结果查询网站(一)
实验要求 核心要求
1、选择3-5条代表性新闻网站(如新浪新闻、网易新闻等,或垂直领域的权威网站,如经济领域的雪球财经、东方)财富等,或体育领域的腾讯体育、虎扑体育等)建立爬虫分析网站的不同新闻页面,爬取代码、标题、作者、时间、关键词 、摘要、结构化信息如内容和来源存储在数据库中。
2、建立网站,提供对爬取内容的子项全文搜索,并给出搜索到的关键词的时间流行度分析。
技能要求
1、 必须使用Node.JS来实现网络爬虫
2、必须使用Node.JS实现查询。网站后端,HTML+JS实现前端(尽量不要使用任何前后端框架)
爬行动物准备
一共选择了三个新闻网站进行抓取,分别是中国财经网、雪球网、东方财富网,抓取结果存储在postgresql中。
在本次实验中,基于 Node.js 的 Cheerio 和 Request 实现了一个爬虫。下面将详细介绍基础环境搭配、各个爬虫的实现、功能实现过程等。
Node.js 安装和配置
Node.js 官网:
安装非常简单,只要跟着一点点就行了。
vscode
Visual Studio Code(以下简称 vscode)是一个轻量级且功能强大的跨平台开源代码编辑器(IDE),支持 Windows、OS X 和 Linux。内置JavaScript、TypeScript和Node.js支持,拥有丰富的插件生态,可以安装插件支持C++、C#、Python、PHP等多种语言。
在这个实验中,我使用了 vscode 来调试 node.js。
可以参考官网:
要求
Request 也是一个 Node.js 模块库,可以轻松完成 http 请求。
安装
npm install request 的基本用法:
本次实验中,新闻页面主要通过请求获取。主要使用其默认的 GET 方法。
var request = require('request');
request('url', function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body) // 请求成功的处理逻辑
}
});
Cheerio 解析 HTML 简介(加载)
首先需要手动加载html文档,使用方法如下,其他更多加载方法可以参考官方文档
var cheerio = require('cheerio'),
$ = cheerio.load('...');
选择器
Cheerio 选择器几乎与 jQuery 相同。选择器是文档遍历和操作的起点。与在 jQuery 中一样,它是选择元素节点的最重要方法,但在 jQuery 中,选择器建立在 CSS 选择器标准库之上。
在本实验中,主要使用以下选择器方法。
选择页面上的所有超链接。首先获取页面中的所有标签,然后遍历获取其href属性的值,具体部分代码如下:
try {
seedurl_news = $('a');
} catch (e) { console.log('url列表所处的html块识别出错:' + e) };
seedurl_news.each(function(){
try {
var href = "";
href = $(this).attr('href'); //获取href属性
}catch(e) {
console.log('get the seed url err' + e);
}
}
根据指定的类属性名称进行选择。注意类名有空格时,改成.,示例代码如下:
$('.source.data-source')
如果要选择某个标签下它的子标签的内容,但是它的子标签没有唯一的类名或者id对应,可以使用.children(selector)来选择它的子节点,eq()就是选择几个子节点,从0开始。示例代码如下:
$('.article-meta').children().eq(1).text();
数据库存储
网页新闻抓取(如何用Python新闻利用BeautifulSoup分析HTML的应用?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-01 02:24
每天坐地铁上班,地铁信号差。但是我想一边坐地铁一边看新闻,所以写了下面这个新闻爬虫。没打算做一个漂亮的应用,所以只完成了原型,可以满足我最基本的需求。这个想法很简单:
寻找新闻来源;使用Python抓取新闻;使用 BeautifulSoup 分析 HTML 并提取内容;将其转换为易于阅读的格式并通过电子邮件发送。
下面详细介绍各个部分的实现。
新闻来源:Reddit
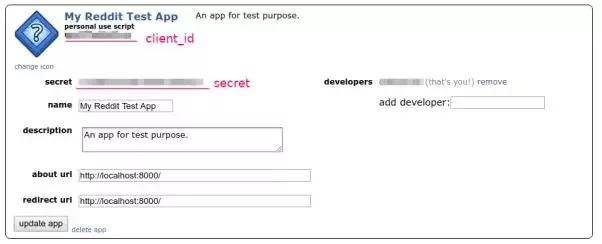
我们可以通过 Reddit 提交新闻链接并投票,所以 Reddit 是一个很好的新闻来源。但接下来的问题是:我们如何才能每天获得最热门的新闻?在考虑爬取之前,首先要考虑目标网站是否提供了API。因为使用 API 是完全合法的,更重要的是它可以提供机器可读的数据,所以不需要分析 HTML。幸运的是,Reddit 提供了一个 API。我们可以从 API 列表中找到所需的函数:/top。此函数可以返回 Reddit 或指定 subreddit 上最流行的新闻。下一个问题是:如何使用这个API?仔细阅读Reddit文档后,我发现了最有效的用法。第 1 步:在 Reddit 上创建一个应用程序。登录后,进入“偏好设置→应用程序”页面,有一个名为“的按钮”
创建应用后,可以在应用信息中找到App ID和Secret。
接下来的问题是如何使用App ID和Secret。由于我们只需要获取指定SubReddit上最热门的新闻,而无需访问任何与用户相关的信息,因此理论上我们不需要提供用户名或密码等个人信息。Reddit 提供了“Application Only OAuth”(#application-only-oauth)的形式。通过这种方式,应用程序可以匿名访问公共信息。运行以下命令:
$ curl -X POST -H 'User-Agent: myawesomeapp/1.0' -d grant_type=client_credentials --user 'OUR_CLIENT_ID:OUR_CLIENT_SECRET' https://www.reddit.com/api/v1/access_token
此命令将返回访问令牌:
{"access_token": "ABCDEFabcdef0123456789", "token_type": "bearer", "expires_in": 3600, "scope": "*"}
伟大的!获得访问令牌后,您就可以大展身手了。最后,如果不想自己写API访问代码,可以使用Python客户端:先做个测试,从/r/Python获取5条最流行的消息:
>>> import praw >>> import pprint >>> reddit = praw.Reddit(client_id='OUR_CLIENT_ID', ... client_secret='OUR_SECRET', ... grant_type='client_credentials', ... user_agent='mytestscript/1.0') >>> subs = reddit.subreddit('Python').top(limit=5) >>> pprint.pprint([(s.score, s.title) for s in subs]) [(6555, 'Automate the boring stuff with python - tinder'), (4548, 'MS is considering official Python integration with Excel, and is asking for ' 'input'), (4102, 'Python Cheet Sheet for begineers'), (3285, 'We started late, but we managed to leave Python footprint on r/place!'), (2899, "Python Section at Foyle's, London")]
它成功了!
抓取新闻页面
接下来的任务是抓取新闻页面,其实很简单。通过上一步,我们可以得到Submission对象,其URL属性就是新闻的地址。我们还可以通过 domain 属性过滤掉属于 Reddit 的 URL:
subs = [sub for sub in subs if not sub.domain.startswith('self.')]
我们只需要抓取 URL,这可以通过 Requests 轻松完成:
for sub in subs: res = requests.get(sub.url) if (res.status_code == 200 and 'content-type' in res.headers and res.headers.get('content-type').startswith('text/html')): html = res.text
这里我们跳过了内容类型不是 text/html 的新闻地址,因为 Reddit 用户可能会提交直接指向图片的链接,而我们不需要这个。
提取新闻内容
下一步是从 HTML 中提取内容。我们的目标是提取新闻的标题和正文,可以忽略其他不需要阅读的内容,例如页眉、页脚、侧边栏等。这项工作很难,没有通用的解决方案。虽然 BeautifulSoup 可以帮助我们提取文本内容,但它会一起提取第一页页脚。幸运的是,我发现网站的当前结构比以前好很多。没有表格布局,没有总和
, 整个 文章 页面清楚地使用和
标题和每个段落都有标记。而大多数 网站 会将标题和正文放在同一个容器元素中,例如,像这样:
Site Navigation Page Title <p>Paragraph 1
Paragraph 2 Sidebar Copyright... </p>
本例中的顶级
它是标题和正文的容器。因此,您可以使用以下算法来查找文本:
虽然这个算法很初级,没有考虑任何语义信息,但它是完全可行的。毕竟当算法失败时,只需要忽略文章,少读一个文章。没什么大不了的……当然你可以通过解析来实现,或者#main、.sidebar等语义元素。实现更准确的算法。使用此算法,您可以轻松编写解析代码:
soup = BeautifulSoup(text, 'html.parser') # find the article title h1 = soup.body.find('h1') # find the common parent for and all <p>s. root = h1 while root.name != 'body' and len(root.find_all('p')) done, title = "SMS Spoofing with Python for Good and Evil" ...
抓取的新闻文件:
最后要做的就是把这个脚本放到服务器上,设置cronjob每天运行一次,然后把生成的文件发送到我的邮箱。我没有花太多时间去关注细节,所以其实这个脚本还有很多需要改进的地方。如果有兴趣,可以继续添加更多功能,比如提取图片。
【编辑推荐】
为什么程序员和开发者应该在 2020 年学习 Python 魔术操作:教你使用 Python 识别恶意软件以及为什么你的 Python 代码应该是扁平和稀疏的。使用 Python 构建您自己的 Markdown 编辑器。Python炫操作(02):七种合并字典的方法 查看全部
网页新闻抓取(如何用Python新闻利用BeautifulSoup分析HTML的应用?(组图))
每天坐地铁上班,地铁信号差。但是我想一边坐地铁一边看新闻,所以写了下面这个新闻爬虫。没打算做一个漂亮的应用,所以只完成了原型,可以满足我最基本的需求。这个想法很简单:
寻找新闻来源;使用Python抓取新闻;使用 BeautifulSoup 分析 HTML 并提取内容;将其转换为易于阅读的格式并通过电子邮件发送。
下面详细介绍各个部分的实现。
新闻来源:Reddit
我们可以通过 Reddit 提交新闻链接并投票,所以 Reddit 是一个很好的新闻来源。但接下来的问题是:我们如何才能每天获得最热门的新闻?在考虑爬取之前,首先要考虑目标网站是否提供了API。因为使用 API 是完全合法的,更重要的是它可以提供机器可读的数据,所以不需要分析 HTML。幸运的是,Reddit 提供了一个 API。我们可以从 API 列表中找到所需的函数:/top。此函数可以返回 Reddit 或指定 subreddit 上最流行的新闻。下一个问题是:如何使用这个API?仔细阅读Reddit文档后,我发现了最有效的用法。第 1 步:在 Reddit 上创建一个应用程序。登录后,进入“偏好设置→应用程序”页面,有一个名为“的按钮”

创建应用后,可以在应用信息中找到App ID和Secret。
接下来的问题是如何使用App ID和Secret。由于我们只需要获取指定SubReddit上最热门的新闻,而无需访问任何与用户相关的信息,因此理论上我们不需要提供用户名或密码等个人信息。Reddit 提供了“Application Only OAuth”(#application-only-oauth)的形式。通过这种方式,应用程序可以匿名访问公共信息。运行以下命令:
$ curl -X POST -H 'User-Agent: myawesomeapp/1.0' -d grant_type=client_credentials --user 'OUR_CLIENT_ID:OUR_CLIENT_SECRET' https://www.reddit.com/api/v1/access_token
此命令将返回访问令牌:
{"access_token": "ABCDEFabcdef0123456789", "token_type": "bearer", "expires_in": 3600, "scope": "*"}
伟大的!获得访问令牌后,您就可以大展身手了。最后,如果不想自己写API访问代码,可以使用Python客户端:先做个测试,从/r/Python获取5条最流行的消息:
>>> import praw >>> import pprint >>> reddit = praw.Reddit(client_id='OUR_CLIENT_ID', ... client_secret='OUR_SECRET', ... grant_type='client_credentials', ... user_agent='mytestscript/1.0') >>> subs = reddit.subreddit('Python').top(limit=5) >>> pprint.pprint([(s.score, s.title) for s in subs]) [(6555, 'Automate the boring stuff with python - tinder'), (4548, 'MS is considering official Python integration with Excel, and is asking for ' 'input'), (4102, 'Python Cheet Sheet for begineers'), (3285, 'We started late, but we managed to leave Python footprint on r/place!'), (2899, "Python Section at Foyle's, London")]
它成功了!
抓取新闻页面
接下来的任务是抓取新闻页面,其实很简单。通过上一步,我们可以得到Submission对象,其URL属性就是新闻的地址。我们还可以通过 domain 属性过滤掉属于 Reddit 的 URL:
subs = [sub for sub in subs if not sub.domain.startswith('self.')]
我们只需要抓取 URL,这可以通过 Requests 轻松完成:
for sub in subs: res = requests.get(sub.url) if (res.status_code == 200 and 'content-type' in res.headers and res.headers.get('content-type').startswith('text/html')): html = res.text
这里我们跳过了内容类型不是 text/html 的新闻地址,因为 Reddit 用户可能会提交直接指向图片的链接,而我们不需要这个。
提取新闻内容
下一步是从 HTML 中提取内容。我们的目标是提取新闻的标题和正文,可以忽略其他不需要阅读的内容,例如页眉、页脚、侧边栏等。这项工作很难,没有通用的解决方案。虽然 BeautifulSoup 可以帮助我们提取文本内容,但它会一起提取第一页页脚。幸运的是,我发现网站的当前结构比以前好很多。没有表格布局,没有总和
, 整个 文章 页面清楚地使用和
标题和每个段落都有标记。而大多数 网站 会将标题和正文放在同一个容器元素中,例如,像这样:
Site Navigation Page Title <p>Paragraph 1
Paragraph 2 Sidebar Copyright... </p>
本例中的顶级
它是标题和正文的容器。因此,您可以使用以下算法来查找文本:
虽然这个算法很初级,没有考虑任何语义信息,但它是完全可行的。毕竟当算法失败时,只需要忽略文章,少读一个文章。没什么大不了的……当然你可以通过解析来实现,或者#main、.sidebar等语义元素。实现更准确的算法。使用此算法,您可以轻松编写解析代码:
soup = BeautifulSoup(text, 'html.parser') # find the article title h1 = soup.body.find('h1') # find the common parent for and all <p>s. root = h1 while root.name != 'body' and len(root.find_all('p')) done, title = "SMS Spoofing with Python for Good and Evil" ...
抓取的新闻文件:
最后要做的就是把这个脚本放到服务器上,设置cronjob每天运行一次,然后把生成的文件发送到我的邮箱。我没有花太多时间去关注细节,所以其实这个脚本还有很多需要改进的地方。如果有兴趣,可以继续添加更多功能,比如提取图片。
【编辑推荐】
为什么程序员和开发者应该在 2020 年学习 Python 魔术操作:教你使用 Python 识别恶意软件以及为什么你的 Python 代码应该是扁平和稀疏的。使用 Python 构建您自己的 Markdown 编辑器。Python炫操作(02):七种合并字典的方法
网页新闻抓取(阿里巴巴的网页源代码提取新闻信息的基本方法(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2021-10-01 02:23
)
百度新闻信息抓取
内容
前言
通过对百度新闻标题、链接、日期和来源的爬取,了解使用python语言爬取少量数据的基本方法。
获取在百度新闻中搜索“阿里巴巴”的网页源代码
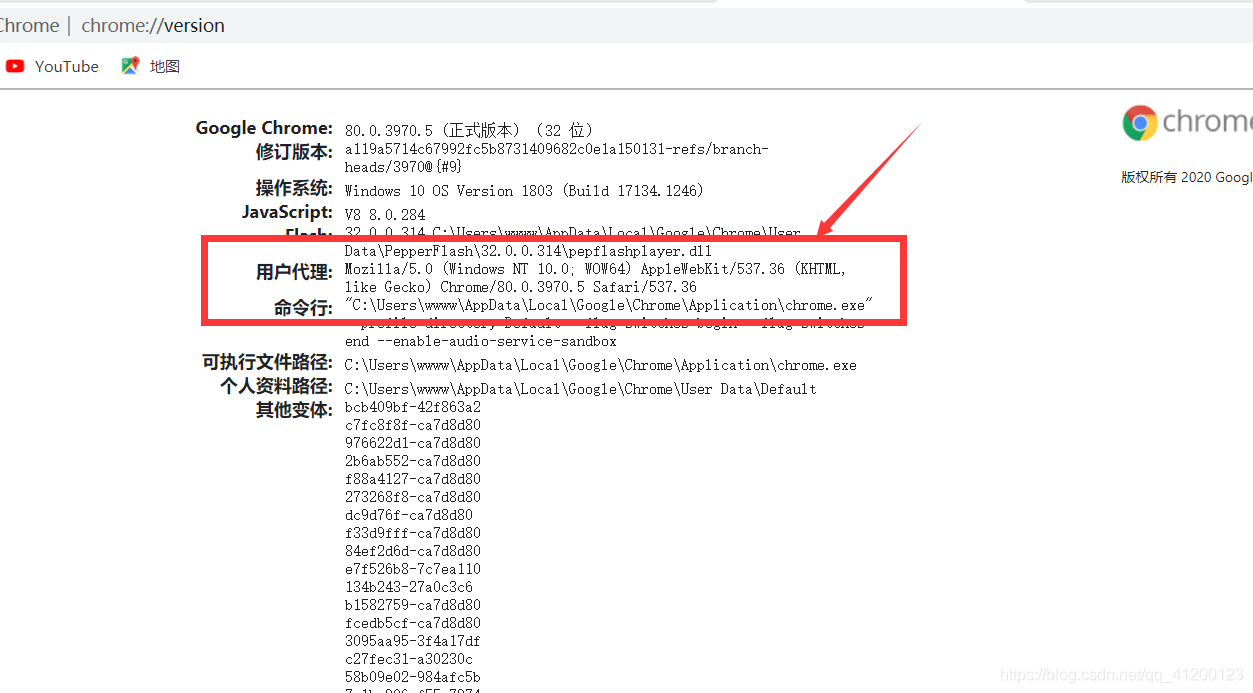
为了获取请求头,我们可以在谷歌浏览器的地址栏中输入 about:version 来获取请求头。
除了请求头,我们还需要构造url。
在网页上输入阿里巴巴,然后在地址栏中找到url,通过简化url得到这样一个url---->阿里巴巴。
有了请求头,我们就可以写基本的爬虫代码了,呵呵。
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
print(res)
部分结果如下:
// 回馈
设置超时(功能(){
var s = document.createElement("脚本");
s.charset="utf-8";
s.src="";
document.body.appendChild(s);
},0);
编写正则表达式提取新闻信息
有了源码,我们必须分析源码,才能提取出下面新闻的来源和日期。
我发现新闻的标题、链接、日期都在“p class="c-author"下面,所以我知道怎么提取了。
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
info = re.findall(p_info, res, re.S)
print(info)
</p>
代码结果收录\n、\t、
同样的,我们用同样的方法,通过正则表达式获取特定的标题和链接。
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_href = '.*?(.*?)'
title = re.findall(p_title, res, re.S)
print("链接是:", '\n', href)
print("标题是:", '\n', title)
结果:
数据清洗和打印
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
info = re.findall(p_info, res, re.S)
# 新闻来源和日期清洗
for i in range(len(info)):
info[i].split(' ')
info[i] = re.sub('', '', info[i])
p_href = '.*?(.*?)'
title = re.findall(p_title, res, re.S)
# 新闻标题清洗----strip()->除去不需要的空格和换行符、.*?->代替文本之间的所有内容,清洗掉
for i in range(len(title)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
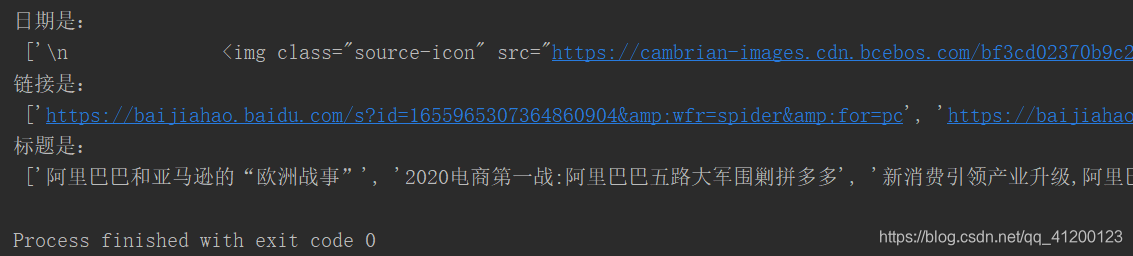
print("日期是:", '\n', info)
print("链接是:", '\n', href)
print("标题是:", '\n', title)
</p>
结果(缺陷:日期未清洗):
实战完整代码
先介绍爬取新闻标题、日期、链接的完整代码:
# 1.批量爬取一家公司的多页信息
def baidu(page):
import requests
import re
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
num = (page - 1) * 10
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴&Ppn=' + str(num)
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
p_href = '.*?(.*?)'
info = re.findall(p_info, res, re.S)
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
source = [] # 先创建两个空列表来储存等会分割后的来源和日期
date = []
for i in range(len(info)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
info[i] = re.sub('', '', info[i])
source.append(info[i].split(' ')[0])
date.append(info[i].split(' ')[1])
source[i] = source[i].strip()
date[i] = date[i].strip()
print(str(i + 1) + '.' + title[i] + '(' + date[i] + '-' + source[i] + ')')
print(href[i])
for i in range(10): # i是从0开始的序号,所以下面要写成i+1
baidu(i+1)
print('第' + str(i+1) + '页爬取成功')
</p>
结果:
然后介绍爬取多个公司新闻的标题、日期、链接的代码:
import requests
import re
def baidu(company):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... 39%3B + company
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
p_href = '.*?(.*?)'
info = re.findall(p_info, res, re.S)
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
source = [] # 先创建两个空列表来储存等会分割后的来源和日期
date = []
for i in range(len(info)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
info[i] = re.sub('', '', info[i])
source.append(info[i].split(' ')[0])
date.append(info[i].split(' ')[1])
source[i] = source[i].strip()
date[i] = date[i].strip()
print(str(i + 1) + '.' + title[i] + '(' + date[i] + '-' + source[i] + ')')
print(href[i])
while True: # 24小时不间断爬取
companys = ['华能信托', '阿里巴巴', '万科集团', '百度', '腾讯', '京东']
for i in companys:
try:
baidu(i)
print(i + '百度新闻爬取成功')
except:
print(i + '百度新闻爬取失败')
</p>
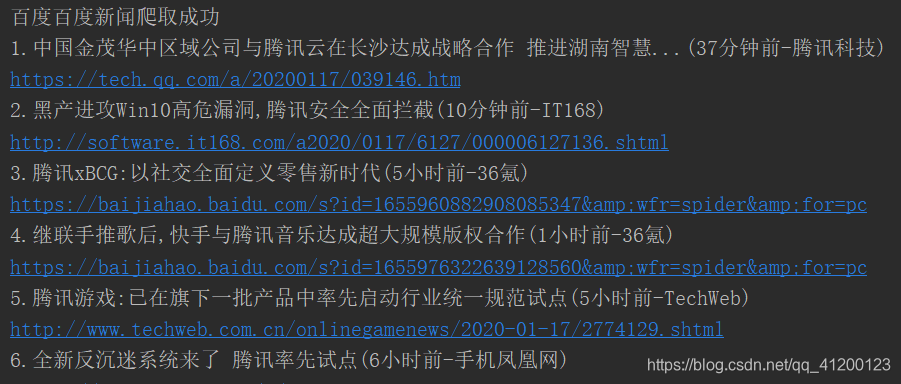
部分结果如下图所示:
查看全部
网页新闻抓取(阿里巴巴的网页源代码提取新闻信息的基本方法(图)
)
百度新闻信息抓取
内容
前言
通过对百度新闻标题、链接、日期和来源的爬取,了解使用python语言爬取少量数据的基本方法。
获取在百度新闻中搜索“阿里巴巴”的网页源代码
为了获取请求头,我们可以在谷歌浏览器的地址栏中输入 about:version 来获取请求头。
除了请求头,我们还需要构造url。
在网页上输入阿里巴巴,然后在地址栏中找到url,通过简化url得到这样一个url---->阿里巴巴。
有了请求头,我们就可以写基本的爬虫代码了,呵呵。
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
print(res)
部分结果如下:
// 回馈
设置超时(功能(){
var s = document.createElement("脚本");
s.charset="utf-8";
s.src="";
document.body.appendChild(s);
},0);
编写正则表达式提取新闻信息
有了源码,我们必须分析源码,才能提取出下面新闻的来源和日期。

我发现新闻的标题、链接、日期都在“p class="c-author"下面,所以我知道怎么提取了。
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
info = re.findall(p_info, res, re.S)
print(info)
</p>
代码结果收录\n、\t、

同样的,我们用同样的方法,通过正则表达式获取特定的标题和链接。
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_href = '.*?(.*?)'
title = re.findall(p_title, res, re.S)
print("链接是:", '\n', href)
print("标题是:", '\n', title)
结果:

数据清洗和打印
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
info = re.findall(p_info, res, re.S)
# 新闻来源和日期清洗
for i in range(len(info)):
info[i].split(' ')
info[i] = re.sub('', '', info[i])
p_href = '.*?(.*?)'
title = re.findall(p_title, res, re.S)
# 新闻标题清洗----strip()->除去不需要的空格和换行符、.*?->代替文本之间的所有内容,清洗掉
for i in range(len(title)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
print("日期是:", '\n', info)
print("链接是:", '\n', href)
print("标题是:", '\n', title)
</p>
结果(缺陷:日期未清洗):
实战完整代码
先介绍爬取新闻标题、日期、链接的完整代码:
# 1.批量爬取一家公司的多页信息
def baidu(page):
import requests
import re
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
num = (page - 1) * 10
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴&Ppn=' + str(num)
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
p_href = '.*?(.*?)'
info = re.findall(p_info, res, re.S)
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
source = [] # 先创建两个空列表来储存等会分割后的来源和日期
date = []
for i in range(len(info)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
info[i] = re.sub('', '', info[i])
source.append(info[i].split(' ')[0])
date.append(info[i].split(' ')[1])
source[i] = source[i].strip()
date[i] = date[i].strip()
print(str(i + 1) + '.' + title[i] + '(' + date[i] + '-' + source[i] + ')')
print(href[i])
for i in range(10): # i是从0开始的序号,所以下面要写成i+1
baidu(i+1)
print('第' + str(i+1) + '页爬取成功')
</p>
结果:

然后介绍爬取多个公司新闻的标题、日期、链接的代码:
import requests
import re
def baidu(company):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... 39%3B + company
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
p_href = '.*?(.*?)'
info = re.findall(p_info, res, re.S)
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
source = [] # 先创建两个空列表来储存等会分割后的来源和日期
date = []
for i in range(len(info)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
info[i] = re.sub('', '', info[i])
source.append(info[i].split(' ')[0])
date.append(info[i].split(' ')[1])
source[i] = source[i].strip()
date[i] = date[i].strip()
print(str(i + 1) + '.' + title[i] + '(' + date[i] + '-' + source[i] + ')')
print(href[i])
while True: # 24小时不间断爬取
companys = ['华能信托', '阿里巴巴', '万科集团', '百度', '腾讯', '京东']
for i in companys:
try:
baidu(i)
print(i + '百度新闻爬取成功')
except:
print(i + '百度新闻爬取失败')
</p>
部分结果如下图所示:
网页新闻抓取(【】此文级别的爬虫,老司机们就不用看了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-30 05:15
本文是一个入门级的爬虫程序,所以老驱动程序不必阅读它
这主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间和新闻文本
首先,我们打开163网站,并随意选择一个类别。我在这里选择的类别是国内新闻。然后右键单击以查看源代码,并发现在源代码页的中间没有新闻列表。这表明此网页是异步的。即通过API接口获取的数据
确认后,您可以使用F12打开谷歌浏览器的控制台并单击网络。我们不断往下拉,发现右边出现了诸如“…Special/00804kva/cm_guonei_03.JS?”之类的地址。单击response并找到我们正在寻找的API接口
可以看出,这些接口的地址都有一定的规则:“cm_guonei_03.JS”,“cm_guonei_04.JS”,所以很明显:
上面的连接是我们这次要请求的地址
接下来,只需要两个Python库:
请求
json
美丽之群
请求库用于发出网络请求。换句话说,它模拟浏览器来获取资源
由于我们的采集API接口是JSON格式的,因此我们需要使用JSON库来解析它。Beauty soup用于解析HTML文档,它可以轻松帮助我们获取指定Div的内容
让我们开始编写爬虫程序:
第一步是导入上述三个包:
导入json
导入请求
从bs4导入BeautifulSoup
接下来,我们定义一种方法来获取指定页码中的数据:
def获取页面(第页):
url_uTemp='{}.js'
return_uuList=[]
对于范围内的i(第页):
url=url_uuu临时格式(i)
response=requests.get(url)
如果response.status uucode!=200:
继续
Content=response.text#获取响应正文
_Content=formatcontent(Content)#格式化JSON字符串
result=json.loads(_content)
return_uuList.append(结果)
返回列表
这样,获得与每个页码对应的内容列表:
之后,通过分析数据,我们可以看到下图中圈出的是要捕获的标题、发布时间和新闻内容页面
现在您已经获得了内容页面的URL,开始抓取新闻正文
在抓取文本之前,首先分析文本的HTML页面,找到文本在HTML文档中的位置、作者和来源
我们可以看到文章源在文档中的位置是id=“ne\u article\u source”的a标记
作者的位置是class=“EP editor”的span标记
正文位置是class=“post\u text”的div标签
以下是采访三项内容的代码采集:
def获取内容(url):
来源=“”
作者=“”
正文=“”
resp=requests.get(url)
如果响应状态uucode==200:
body=resp.text
bs4=美联(车身)
source=bs4.find('a',id='ne\u article\u source')。get\utext()
author=bs4.查找('span',class='ep-editor')。获取文本()
body=bs4.find('div',class='post_text')。get_utext()
返回源、作者、正文
到目前为止,我们想要捕获的所有数据都是采集
然后,当然,下一步是保存它们。为了方便我直接以文本的形式保存它们。以下是最终结果:
格式为JSON字符串“title”:['date'、'URL'、'source'、'author'、'body']
应该注意的是,当前的实现方法是完全同步和线性的。问题是采集将非常缓慢。主要延迟在网络IO中,下次可以升级为异步IO。异步采集。有兴趣的朋友可以关注下一个文章 查看全部
网页新闻抓取(【】此文级别的爬虫,老司机们就不用看了)
本文是一个入门级的爬虫程序,所以老驱动程序不必阅读它
这主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间和新闻文本
首先,我们打开163网站,并随意选择一个类别。我在这里选择的类别是国内新闻。然后右键单击以查看源代码,并发现在源代码页的中间没有新闻列表。这表明此网页是异步的。即通过API接口获取的数据
确认后,您可以使用F12打开谷歌浏览器的控制台并单击网络。我们不断往下拉,发现右边出现了诸如“…Special/00804kva/cm_guonei_03.JS?”之类的地址。单击response并找到我们正在寻找的API接口

可以看出,这些接口的地址都有一定的规则:“cm_guonei_03.JS”,“cm_guonei_04.JS”,所以很明显:
上面的连接是我们这次要请求的地址
接下来,只需要两个Python库:
请求
json
美丽之群
请求库用于发出网络请求。换句话说,它模拟浏览器来获取资源
由于我们的采集API接口是JSON格式的,因此我们需要使用JSON库来解析它。Beauty soup用于解析HTML文档,它可以轻松帮助我们获取指定Div的内容
让我们开始编写爬虫程序:
第一步是导入上述三个包:
导入json
导入请求
从bs4导入BeautifulSoup
接下来,我们定义一种方法来获取指定页码中的数据:
def获取页面(第页):
url_uTemp='{}.js'
return_uuList=[]
对于范围内的i(第页):
url=url_uuu临时格式(i)
response=requests.get(url)
如果response.status uucode!=200:
继续
Content=response.text#获取响应正文
_Content=formatcontent(Content)#格式化JSON字符串
result=json.loads(_content)
return_uuList.append(结果)
返回列表
这样,获得与每个页码对应的内容列表:

之后,通过分析数据,我们可以看到下图中圈出的是要捕获的标题、发布时间和新闻内容页面

现在您已经获得了内容页面的URL,开始抓取新闻正文
在抓取文本之前,首先分析文本的HTML页面,找到文本在HTML文档中的位置、作者和来源
我们可以看到文章源在文档中的位置是id=“ne\u article\u source”的a标记
作者的位置是class=“EP editor”的span标记
正文位置是class=“post\u text”的div标签
以下是采访三项内容的代码采集:
def获取内容(url):
来源=“”
作者=“”
正文=“”
resp=requests.get(url)
如果响应状态uucode==200:
body=resp.text
bs4=美联(车身)
source=bs4.find('a',id='ne\u article\u source')。get\utext()
author=bs4.查找('span',class='ep-editor')。获取文本()
body=bs4.find('div',class='post_text')。get_utext()
返回源、作者、正文
到目前为止,我们想要捕获的所有数据都是采集
然后,当然,下一步是保存它们。为了方便我直接以文本的形式保存它们。以下是最终结果:

格式为JSON字符串“title”:['date'、'URL'、'source'、'author'、'body']
应该注意的是,当前的实现方法是完全同步和线性的。问题是采集将非常缓慢。主要延迟在网络IO中,下次可以升级为异步IO。异步采集。有兴趣的朋友可以关注下一个文章
网页新闻抓取(SEO过度的页面提取方法,准确率挺高,依赖又少)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-09-29 10:26
项目中需要采集相关行业新闻,寻找基于文本和符号密度的网页正文提取方法。准确率相当高,依赖性小。特别推荐。
该方法是论文《Method of Web Page Body Extraction based on Text and Symbol Density》的实现。有兴趣的可以去看看原论文
本文中描述的算法看起来简洁、清晰且合乎逻辑。还有一个更有用的标准:
1
2
3
4
5
Ti - LTi
SbDi = --------------
Sbi + 1
SbDi: 符号密度
Sbi:符号数量
如果节点中文本的符号出现的频率更高,符号密度SbDi的值会更小,但文档说它会更大。如何解决?
因为它在这里考虑的是一个“逻辑”文本。它不是专门为欺骗该程序而构建的文本。在普通的文章中,文章越长,标点符号就会被读取,这是很自然的。而且你可能会认为,在某个栏目中直接写上数百个标点符号的新闻,没有汉字。这种情况当然可以欺骗程序,但属于“故意构建”的坏情况。
在正常的文章中,标点符号越多,正文中的文本就越多。分子和分母同时增加。显然,文本会比标点符号增长得更快,所以这个比例会增加。
根据GNE作者kingname的测试,使用该算法对今日头条、网易新闻、有民星空、观察家网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,几乎可以达到100%的准确率。个人使用经验,只要合理添加noise_node_list,也可以得到文本(部分SEO过度的页面除外)。
实施过程
算法实现
目前有python和nodeJS两种实现,依赖很少
python版本还提供了一个非常有用的noise_node_list参数,可以根据实际页面排除不相关的内容。
功能限制
因为它只提取新闻网页,如果你想提取其他类型的内容,它可能不起作用,但你可以尝试添加更多过滤XPath。
在线版
这里是网络版讲解使用过程
需要输入两件事:
由于没有提供爬虫功能,可以通过Chrome开发者工具的Copy OuterHTML获取页面的HTML代码和Copy XPath来获取排除的元素。
使用 Copy OuterHTML 复制整个网页的 HTML 代码。
如果提取的内容不是您想要的,您可以选择提取的元素,单击复制 XPath,然后将其粘贴到过滤器 XPath 中。它可以是多个 XPath,以逗号分隔。
输入效果
提取新闻信息
效果如下:
网络版测试 网络版提取的图片可能有防盗链功能,无法显示。
参考 查看全部
网页新闻抓取(SEO过度的页面提取方法,准确率挺高,依赖又少)
项目中需要采集相关行业新闻,寻找基于文本和符号密度的网页正文提取方法。准确率相当高,依赖性小。特别推荐。

该方法是论文《Method of Web Page Body Extraction based on Text and Symbol Density》的实现。有兴趣的可以去看看原论文
本文中描述的算法看起来简洁、清晰且合乎逻辑。还有一个更有用的标准:
1
2
3
4
5
Ti - LTi
SbDi = --------------
Sbi + 1
SbDi: 符号密度
Sbi:符号数量
如果节点中文本的符号出现的频率更高,符号密度SbDi的值会更小,但文档说它会更大。如何解决?
因为它在这里考虑的是一个“逻辑”文本。它不是专门为欺骗该程序而构建的文本。在普通的文章中,文章越长,标点符号就会被读取,这是很自然的。而且你可能会认为,在某个栏目中直接写上数百个标点符号的新闻,没有汉字。这种情况当然可以欺骗程序,但属于“故意构建”的坏情况。
在正常的文章中,标点符号越多,正文中的文本就越多。分子和分母同时增加。显然,文本会比标点符号增长得更快,所以这个比例会增加。
根据GNE作者kingname的测试,使用该算法对今日头条、网易新闻、有民星空、观察家网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,几乎可以达到100%的准确率。个人使用经验,只要合理添加noise_node_list,也可以得到文本(部分SEO过度的页面除外)。
实施过程
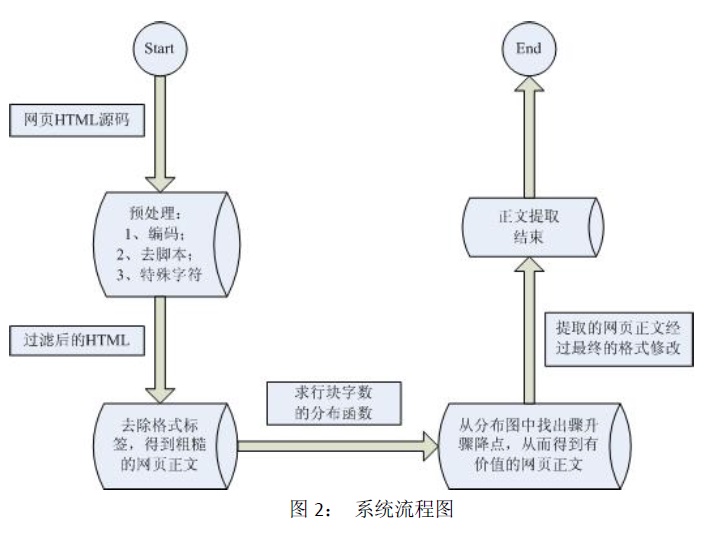
算法实现
目前有python和nodeJS两种实现,依赖很少
python版本还提供了一个非常有用的noise_node_list参数,可以根据实际页面排除不相关的内容。
功能限制
因为它只提取新闻网页,如果你想提取其他类型的内容,它可能不起作用,但你可以尝试添加更多过滤XPath。
在线版
这里是网络版讲解使用过程
需要输入两件事:
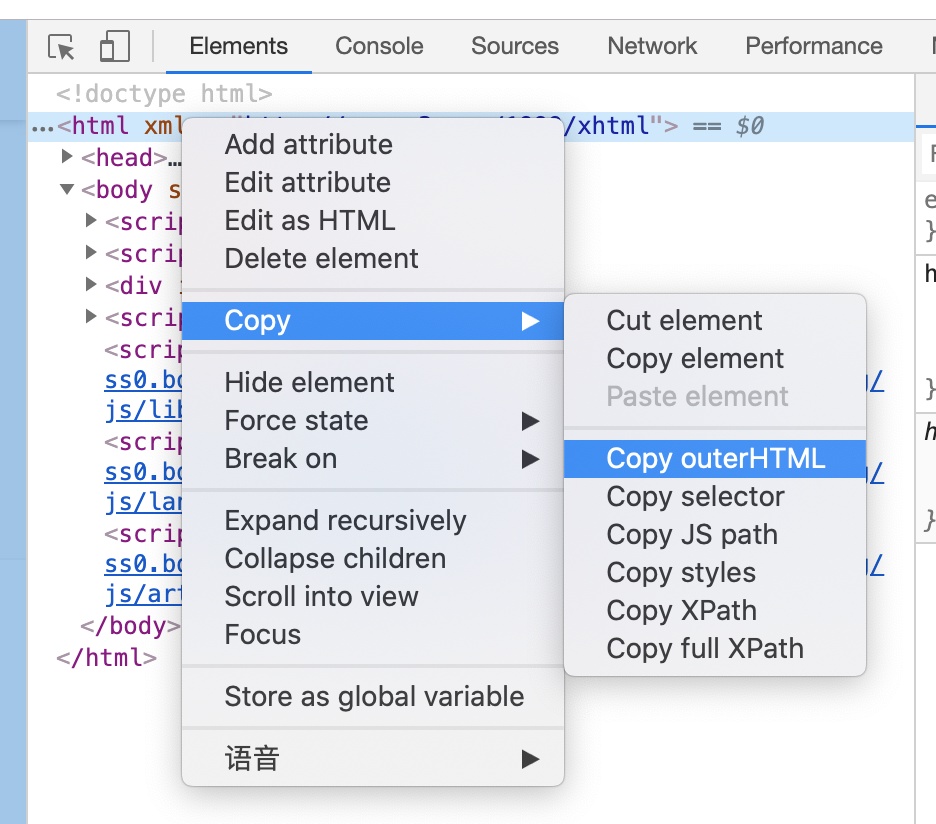
由于没有提供爬虫功能,可以通过Chrome开发者工具的Copy OuterHTML获取页面的HTML代码和Copy XPath来获取排除的元素。
使用 Copy OuterHTML 复制整个网页的 HTML 代码。
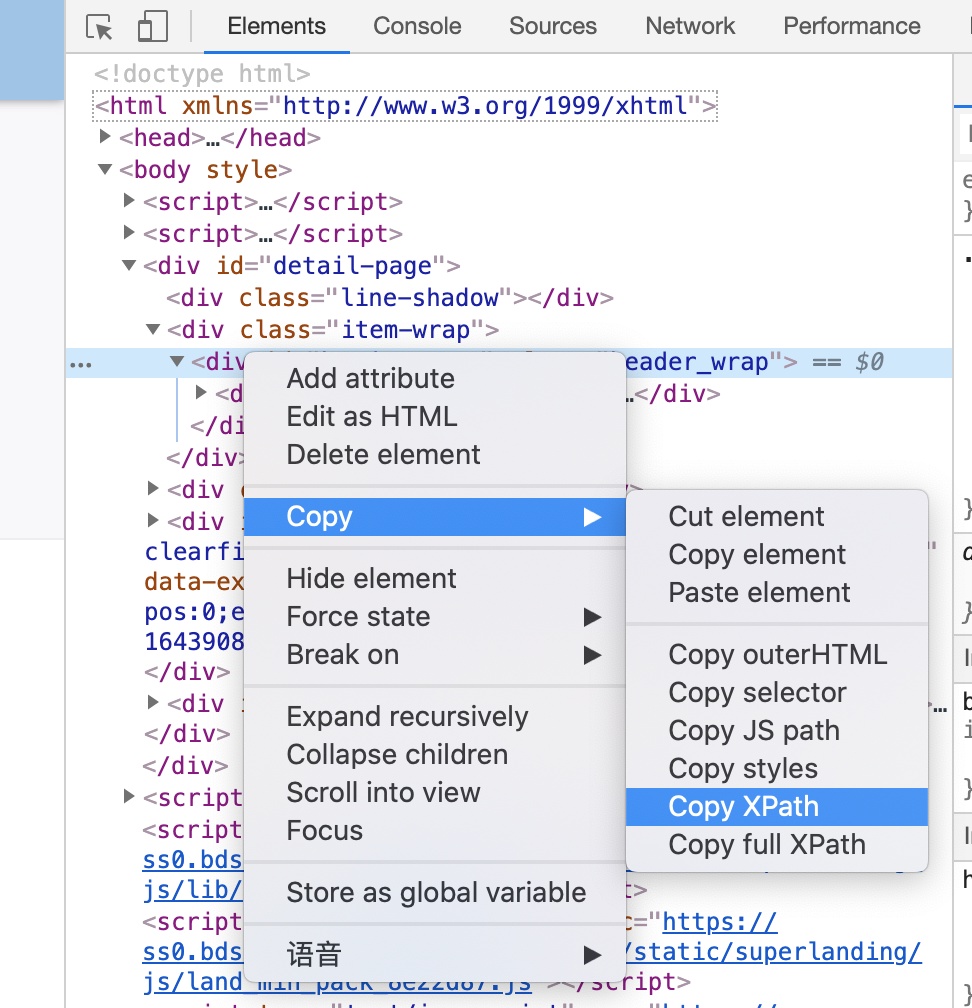
如果提取的内容不是您想要的,您可以选择提取的元素,单击复制 XPath,然后将其粘贴到过滤器 XPath 中。它可以是多个 XPath,以逗号分隔。
输入效果
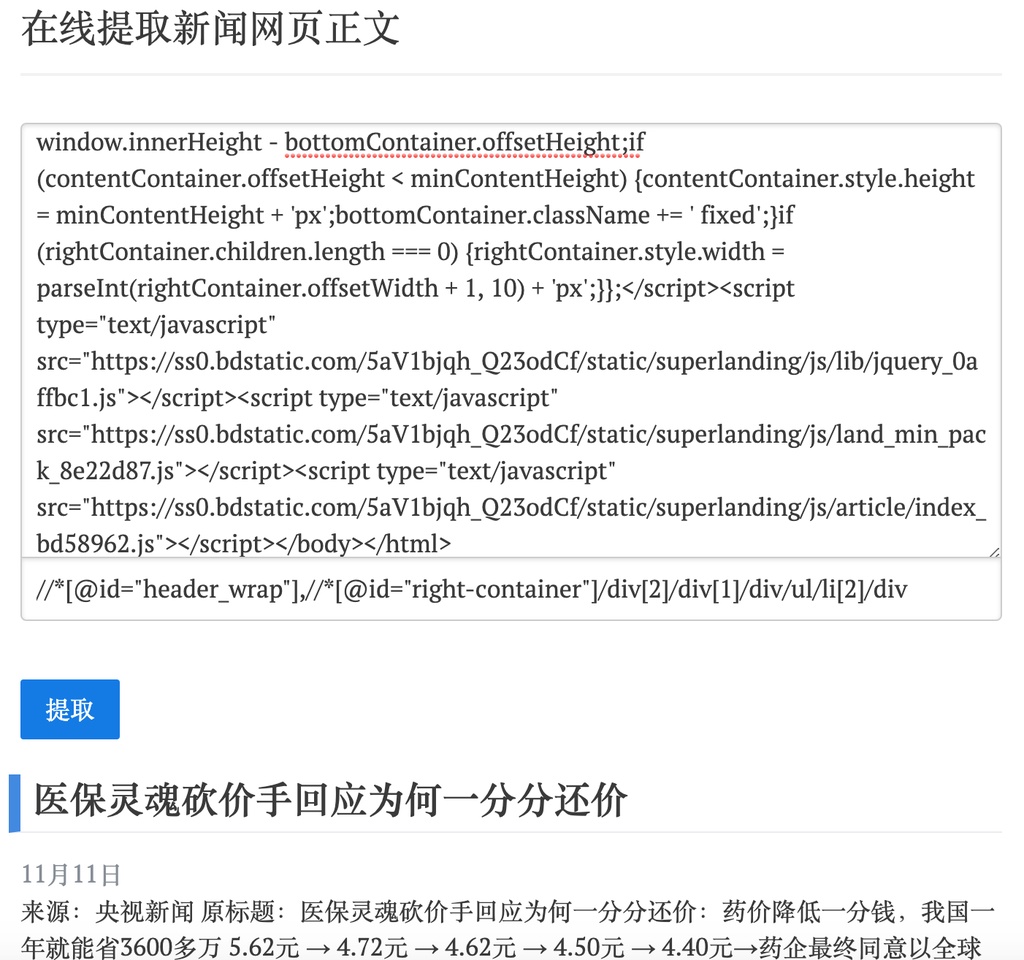
提取新闻信息
效果如下:

网络版测试 网络版提取的图片可能有防盗链功能,无法显示。
参考
网页新闻抓取(NodeJs.js使用NodeJs做网络爬虫RSS抓取新闻(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2021-09-27 21:14
Node.js是一个基于chrome JavaScript运行时的平台,用于轻松构建快速且易于扩展的网络应用程序。借助事件驱动和非阻塞I/O模型,Node.js变得轻量级和高效。它非常适合跨分布式设备运行的数据密集型实时应用程序·
有许多网站提供RSS服务,如百度、网易、新浪、husniff等。有许多基于Java、C++和PHP的RSS爬行网站。今天,让我们来谈谈nodejs抓取RSS信息
使用nodejs作为网络爬虫来捕获RSS新闻。每个站点都有不同的编码格式,如GBK、UTF-8、iso8859-1等,因此需要对其进行编码。对于中国人来说,UTF-8是最酷的。抓取多个站点,然后将它们保存到数据库中。充分利用JavaScript异步编程的特点,爬网速度超快
这个项目是为新闻Android客户端实现的。将来,我还会上传新闻客户端的源代码
此项目的源代码位于GitHub中:
环境要求:
Nodejs(必选),我的版本是0.10.24
Mongodb(可选)或其他数据库,如mysql
编程工具:webstrom
步骤1:创建一个新的nodejs项目。我通常创建一个express web项目。步骤2:在package.json文件中添加依赖项
"dependencies": {
"express": "3.4.8",
"ejs": "*",
"feedparser":"0.16.6",
"request":"2.33.0",
"iconv":"2.0.7",
"mongoose":"3.8.7",
"mongodb":"*"
}
执行以下代码将相关文件导入模块中的项目节点:
npm install -d
步骤3:
完成基本准备后,就可以开始编写代码了。RSS捕获主要依赖于feedparser库。GitHub地址:
首先配置要捕获的站点信息
创建一个rssitejson文件
{
"channel":[
{
"from":"baidu",
"name":"civilnews",
"work":false, //false 则不抓取
"title":"百度国内最新新闻",
"link":"http://news.baidu.com/n%3Fcmd% ... ot%3B,
"typeId":1
},{
"from":"netEase",
"name":"rss_gn",
"title":"网易最新新闻",
"link":"http://news.163.com/special/00 ... ot%3B,
"typeId":2
}
]
}
我想抓住这两个网站。通道的值是一个对象数组。如果您需要多个站点,只需直接添加它们
介绍相关软件包
var request = require('request')
, FeedParser = require('feedparser')
, rssSite = require('../config/rssSite.json')
, Iconv = require('iconv').Iconv;
您需要遍历新配置的通道以找到所需的URL地址
var channels = rssSite.channel;
channels.forEach(function(e,i){
if(e.work != false){
console.log("begin:"+ e.title);
fetch(e.link,e.typeId);
}
});
工作为false的站点不会被爬网。就是黑名单。TypeID标识新闻属于哪一列、社会、金融或其他
关键是fetch函数,它是捕获和分析的地方。在我解释之前,我会发布代码
function fetch(feed,typeId) {
var posts;
// Define our streams
var req = request(feed, {timeout: 10000, pool: false});
req.setMaxListeners(50);
// Some feeds do not response without user-agent and accept headers.
req.setHeader('user-agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36')
.setHeader('accept', 'text/html,application/xhtml+xml');
var feedparser = new FeedParser();
// Define our handlers
req.on('error', done);
req.on('response', function(res) {
var stream = this
, iconv
, charset;
posts = new Array();
if (res.statusCode != 200) return this.emit('error', new Error('Bad status code'));
charset = getParams(res.headers['content-type'] || '').charset;
if (!iconv && charset && !/utf-*8/i.test(charset)) {
try {
iconv = new Iconv(charset, 'utf-8');
iconv.on('error', done);
stream = this.pipe(iconv);
} catch(err) {
this.emit('error', err);
}
}
stream.pipe(feedparser);
});
feedparser.on('error', done);
feedparser.on('end', function(err){
// postService.savePost(posts); //存到数据库
});
feedparser.on('readable', function() {
var post;
while (post = this.read()) {
posts.push(transToPost(post));//保存到对象数组
}
});
function transToPost(post){
var mPost = new Post({
title : post.title,
link : post.link,
description : post.description,
pubDate : post.pubDate,
source : post.source,
author : post.author,
typeId : typeId
});
return mPost;
}
}
1、关键功能:请求(URL,[选项]);这是一个可以发送HTTP请求的函数。地址:
var req = request(feed, {timeout: 10000, pool: false});
Req需要侦听多个状态响应和错误。发送请求后,将收到响应。收到响应后,将拼接接收到的数据。在拼接之前,需要进行编码转换。非utf8代码转换为UTF8.,此处使用库iconv。地址:
res.headers['content-type'].charset;
通过这种方式,您可以获得所获取站点的编码格式
拼接前需要进行代码转换。当然,这里使用了一种巧妙的方法,管道
然后把它转换成我无法操作的对象。此时,需要启动feedparser
var feedparser = new FeedParser();
Feedparse还侦听多个状态:可读、结束、错误
readable的回调方法将一次读取一条记录。每次读取一条记录时,我都会将其保存到数组对象中
读取所有数据后,调用end的回调函数。此时,站点捕获已完成。或多个站点
步骤4:保存到数据库
所有数据都存储在POST的数组对象中。你无论如何都可以寄。保存到mongodb只需几行代码。这里使用猫鼬图书馆
当然,mongodb库也是必要的。猫鼬与BaseDao相似。操作mongodb数据库非常方便
首先建立模式:
var mongoose = require('mongoose');
var PostSchema = new mongoose.Schema({
title:String,
link :String,
description :String,
pubDate :String,
source :String,
author :String,
typeId : Number
});
module.exports = PostSchema;
重新建立模型:
var mongoose = require('mongoose');
var PostSchema = require('../schemas/PostSchema');
var Post = mongoose.model('Post',PostSchema);
module.exports = Post;
好的,您可以将其保存到数据库中。mongodb似乎无法批量插入。我在这里骑自行车。如果标题不存在,请插入它,否则将出现重复新闻
<p>var Post = require('../model/Post');
function savePost(posts){
for(var i = 0 ;i 查看全部
网页新闻抓取(NodeJs.js使用NodeJs做网络爬虫RSS抓取新闻(组图))
Node.js是一个基于chrome JavaScript运行时的平台,用于轻松构建快速且易于扩展的网络应用程序。借助事件驱动和非阻塞I/O模型,Node.js变得轻量级和高效。它非常适合跨分布式设备运行的数据密集型实时应用程序·
有许多网站提供RSS服务,如百度、网易、新浪、husniff等。有许多基于Java、C++和PHP的RSS爬行网站。今天,让我们来谈谈nodejs抓取RSS信息
使用nodejs作为网络爬虫来捕获RSS新闻。每个站点都有不同的编码格式,如GBK、UTF-8、iso8859-1等,因此需要对其进行编码。对于中国人来说,UTF-8是最酷的。抓取多个站点,然后将它们保存到数据库中。充分利用JavaScript异步编程的特点,爬网速度超快
这个项目是为新闻Android客户端实现的。将来,我还会上传新闻客户端的源代码
此项目的源代码位于GitHub中:
环境要求:
Nodejs(必选),我的版本是0.10.24
Mongodb(可选)或其他数据库,如mysql
编程工具:webstrom
步骤1:创建一个新的nodejs项目。我通常创建一个express web项目。步骤2:在package.json文件中添加依赖项
"dependencies": {
"express": "3.4.8",
"ejs": "*",
"feedparser":"0.16.6",
"request":"2.33.0",
"iconv":"2.0.7",
"mongoose":"3.8.7",
"mongodb":"*"
}
执行以下代码将相关文件导入模块中的项目节点:
npm install -d
步骤3:
完成基本准备后,就可以开始编写代码了。RSS捕获主要依赖于feedparser库。GitHub地址:
首先配置要捕获的站点信息
创建一个rssitejson文件
{
"channel":[
{
"from":"baidu",
"name":"civilnews",
"work":false, //false 则不抓取
"title":"百度国内最新新闻",
"link":"http://news.baidu.com/n%3Fcmd% ... ot%3B,
"typeId":1
},{
"from":"netEase",
"name":"rss_gn",
"title":"网易最新新闻",
"link":"http://news.163.com/special/00 ... ot%3B,
"typeId":2
}
]
}
我想抓住这两个网站。通道的值是一个对象数组。如果您需要多个站点,只需直接添加它们
介绍相关软件包
var request = require('request')
, FeedParser = require('feedparser')
, rssSite = require('../config/rssSite.json')
, Iconv = require('iconv').Iconv;
您需要遍历新配置的通道以找到所需的URL地址
var channels = rssSite.channel;
channels.forEach(function(e,i){
if(e.work != false){
console.log("begin:"+ e.title);
fetch(e.link,e.typeId);
}
});
工作为false的站点不会被爬网。就是黑名单。TypeID标识新闻属于哪一列、社会、金融或其他
关键是fetch函数,它是捕获和分析的地方。在我解释之前,我会发布代码
function fetch(feed,typeId) {
var posts;
// Define our streams
var req = request(feed, {timeout: 10000, pool: false});
req.setMaxListeners(50);
// Some feeds do not response without user-agent and accept headers.
req.setHeader('user-agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36')
.setHeader('accept', 'text/html,application/xhtml+xml');
var feedparser = new FeedParser();
// Define our handlers
req.on('error', done);
req.on('response', function(res) {
var stream = this
, iconv
, charset;
posts = new Array();
if (res.statusCode != 200) return this.emit('error', new Error('Bad status code'));
charset = getParams(res.headers['content-type'] || '').charset;
if (!iconv && charset && !/utf-*8/i.test(charset)) {
try {
iconv = new Iconv(charset, 'utf-8');
iconv.on('error', done);
stream = this.pipe(iconv);
} catch(err) {
this.emit('error', err);
}
}
stream.pipe(feedparser);
});
feedparser.on('error', done);
feedparser.on('end', function(err){
// postService.savePost(posts); //存到数据库
});
feedparser.on('readable', function() {
var post;
while (post = this.read()) {
posts.push(transToPost(post));//保存到对象数组
}
});
function transToPost(post){
var mPost = new Post({
title : post.title,
link : post.link,
description : post.description,
pubDate : post.pubDate,
source : post.source,
author : post.author,
typeId : typeId
});
return mPost;
}
}
1、关键功能:请求(URL,[选项]);这是一个可以发送HTTP请求的函数。地址:
var req = request(feed, {timeout: 10000, pool: false});
Req需要侦听多个状态响应和错误。发送请求后,将收到响应。收到响应后,将拼接接收到的数据。在拼接之前,需要进行编码转换。非utf8代码转换为UTF8.,此处使用库iconv。地址:
res.headers['content-type'].charset;
通过这种方式,您可以获得所获取站点的编码格式
拼接前需要进行代码转换。当然,这里使用了一种巧妙的方法,管道
然后把它转换成我无法操作的对象。此时,需要启动feedparser
var feedparser = new FeedParser();
Feedparse还侦听多个状态:可读、结束、错误
readable的回调方法将一次读取一条记录。每次读取一条记录时,我都会将其保存到数组对象中
读取所有数据后,调用end的回调函数。此时,站点捕获已完成。或多个站点
步骤4:保存到数据库
所有数据都存储在POST的数组对象中。你无论如何都可以寄。保存到mongodb只需几行代码。这里使用猫鼬图书馆
当然,mongodb库也是必要的。猫鼬与BaseDao相似。操作mongodb数据库非常方便
首先建立模式:
var mongoose = require('mongoose');
var PostSchema = new mongoose.Schema({
title:String,
link :String,
description :String,
pubDate :String,
source :String,
author :String,
typeId : Number
});
module.exports = PostSchema;
重新建立模型:
var mongoose = require('mongoose');
var PostSchema = require('../schemas/PostSchema');
var Post = mongoose.model('Post',PostSchema);
module.exports = Post;
好的,您可以将其保存到数据库中。mongodb似乎无法批量插入。我在这里骑自行车。如果标题不存在,请插入它,否则将出现重复新闻
<p>var Post = require('../model/Post');
function savePost(posts){
for(var i = 0 ;i
网页新闻抓取(常见搜索引擎蜘蛛名称如下:屏蔽百度蜘蛛的抓取方式研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-27 21:12
在做网站操作,尤其是网站排名优化的时候,我们一直在思考如何引导搜索引擎蜘蛛抓取网页,收录。然而,在很多情况下,一些网站不想被搜索引擎光顾,因为他们真正对的用户群体与目标地区不同。这个时候我们如何解决这个问题?今天就跟作者小丹一起学习吧!
当我们看到需要阻止抓取时,大多数 SEOer 会想到 robots.txt 文件。因为在我们的认知中,机器人文件可以通过杜杰的搜索引擎有效地抓取某些页面。但是你要知道,这个方法虽然很好,但更多时候小丹认为它更适合网站未完成,以避免死链或调查期的存在。
如果我们只是想屏蔽某个搜索引擎的爬取,就不用负担篇幅了,用一点简单的代码就可以了。比如我们要屏蔽百度蜘蛛的爬取
就是这样。当然,这只是阻止百度抓取的一种方式。如果您想要任何搜索引擎,只需将百度蜘蛛替换为改变搜索引擎的蜘蛛即可。
常见的搜索引擎蜘蛛名称如下:
1、baiduspider 百度综合索引蜘蛛
2、Googlebot 谷歌蜘蛛
3、Googlebot-Image 是专门用来抓取图片的蜘蛛
4、Mediapartners-谷歌广告网络代码蜘蛛
5、Yahoo Slurp Yahoo Spider
6、雅虎!Slup 中国雅虎中国蜘蛛
7、Yahoo!-AdCrawler 雅虎广告蜘蛛
8、YodaoBot 网易蜘蛛
9、Sosospider 腾讯SOSO综合蜘蛛
10、搜狗蜘蛛
11、MSNBot Live 集成蜘蛛
但是,如果要屏蔽所有搜索引擎,则必须使用robot 文件:
说到这里,很多朋友应该明白,代码中禁止创建网页快照的命令是noarchive。因此,如果我们对搜索引擎有限制,我们可以将代码添加到网页中,直接根据我们的禁止快照;反之,无需添加任何代码,即可保证各大搜索引擎都能正常访问网站并创建快照。 查看全部
网页新闻抓取(常见搜索引擎蜘蛛名称如下:屏蔽百度蜘蛛的抓取方式研究)
在做网站操作,尤其是网站排名优化的时候,我们一直在思考如何引导搜索引擎蜘蛛抓取网页,收录。然而,在很多情况下,一些网站不想被搜索引擎光顾,因为他们真正对的用户群体与目标地区不同。这个时候我们如何解决这个问题?今天就跟作者小丹一起学习吧!
当我们看到需要阻止抓取时,大多数 SEOer 会想到 robots.txt 文件。因为在我们的认知中,机器人文件可以通过杜杰的搜索引擎有效地抓取某些页面。但是你要知道,这个方法虽然很好,但更多时候小丹认为它更适合网站未完成,以避免死链或调查期的存在。
如果我们只是想屏蔽某个搜索引擎的爬取,就不用负担篇幅了,用一点简单的代码就可以了。比如我们要屏蔽百度蜘蛛的爬取
就是这样。当然,这只是阻止百度抓取的一种方式。如果您想要任何搜索引擎,只需将百度蜘蛛替换为改变搜索引擎的蜘蛛即可。
常见的搜索引擎蜘蛛名称如下:
1、baiduspider 百度综合索引蜘蛛
2、Googlebot 谷歌蜘蛛
3、Googlebot-Image 是专门用来抓取图片的蜘蛛
4、Mediapartners-谷歌广告网络代码蜘蛛
5、Yahoo Slurp Yahoo Spider
6、雅虎!Slup 中国雅虎中国蜘蛛
7、Yahoo!-AdCrawler 雅虎广告蜘蛛
8、YodaoBot 网易蜘蛛
9、Sosospider 腾讯SOSO综合蜘蛛
10、搜狗蜘蛛
11、MSNBot Live 集成蜘蛛
但是,如果要屏蔽所有搜索引擎,则必须使用robot 文件:
说到这里,很多朋友应该明白,代码中禁止创建网页快照的命令是noarchive。因此,如果我们对搜索引擎有限制,我们可以将代码添加到网页中,直接根据我们的禁止快照;反之,无需添加任何代码,即可保证各大搜索引擎都能正常访问网站并创建快照。
网页新闻抓取(上绝大部分网页正文(包含图片等富媒体)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-27 21:10
## 获取新闻网页正文内容![]()> 该接口可以实时获取网页文章/新闻全文内容,支持网上大部分网页文字(包括图片等富媒体)。由于网页结构错综复杂,变化频繁,不保证所有网站永美##界面费用([点击购买]())>最低0.005元/次##接口调用([调用指令]())###请求地址```GET```###请求参数| 姓名| 类型| 必填| 说明|| --- | --- | --- | --- | | 应用代码| 字符串| 是|用户授权码,参考【API调用】() || 网址 | 字符串 | 是| 如果网页 URL 地址收录特殊字符,值应该是urlencode编码的|###返回`data`参数| 姓名| 类型| 说明|| --- | --- | --- || 标题 | 字符串 | 标题|| 内容 | 文字 | 网页内容|| 图片 | 字符串 | 网页第一张图片 || 时间 | 日期 | 网页时间|## SDK 调用```$client = new Client("YourAppCode");$result = $client->websiteHtmltext()->withUrl('#039;)->request();dump( $result );```JSON返回示例:~~~{code: 0,message: "success",data: [{"title": "新闻标题","content": "新闻内容html","图片" : "第一张图片的地址","ctime": 查看全部
网页新闻抓取(上绝大部分网页正文(包含图片等富媒体)())
## 获取新闻网页正文内容![]()> 该接口可以实时获取网页文章/新闻全文内容,支持网上大部分网页文字(包括图片等富媒体)。由于网页结构错综复杂,变化频繁,不保证所有网站永美##界面费用([点击购买]())>最低0.005元/次##接口调用([调用指令]())###请求地址```GET```###请求参数| 姓名| 类型| 必填| 说明|| --- | --- | --- | --- | | 应用代码| 字符串| 是|用户授权码,参考【API调用】() || 网址 | 字符串 | 是| 如果网页 URL 地址收录特殊字符,值应该是urlencode编码的|###返回`data`参数| 姓名| 类型| 说明|| --- | --- | --- || 标题 | 字符串 | 标题|| 内容 | 文字 | 网页内容|| 图片 | 字符串 | 网页第一张图片 || 时间 | 日期 | 网页时间|## SDK 调用```$client = new Client("YourAppCode");$result = $client->websiteHtmltext()->withUrl('#039;)->request();dump( $result );```JSON返回示例:~~~{code: 0,message: "success",data: [{"title": "新闻标题","content": "新闻内容html","图片" : "第一张图片的地址","ctime":
网页新闻抓取(基于存储架构如图所示存储架构图第三章新闻实时抓取系统(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-09-27 21:08
第三章新闻实时抓取系统——使用高效的二进制数据存储,包括图片、视频等大对象。片段的自动处理支持云计算的可扩展性。支持查询优化。支持多种语言。可以通过网络访问。与传统的关系型数据库相比,适合海量数据的存储。当数据量剧增时,只需在集群中增加服务器即可解决容量问题,免去扩容带来的分库分表的大工作量。自然支持文档类型数据的存储,没有模式限制。使用方法比关系数据库更灵活。基于如图所示的存储架构,存储架构图第三章新闻实时抓取系统第四节爬虫模块爬虫引擎和下载器是直接复用爬虫框架的功能模块,而调度器、蜘蛛和处理管道是基于新闻爬虫的功能模块。 - 开发和定制。本节重点介绍调度程序、蜘蛛程序和处理管道。蜘蛛的功能与框架中定义的蜘蛛模块基本相同。负责解析下载的网页,提取需要进一步爬取的超链接。它是爬虫模块中爬行队列的唯一提供者。整个爬虫模块的难点之一——爬取策略是在spider中实现的。蜘蛛是基于蜘蛛模块在继承自《第三章新闻实时抓取系统》的框架中实现的代码的主类。上面的规则就是一条数据的格式。键值为“...” 一条规则是正则表达式规则,用于判断匹配是否为提取链接后的新闻页面。
该规则告诉程序提取优采云节点中所有节点的属性,其属性值为标签,即超链接。蜘蛛不仅可以通过正则表达式提取和识别新闻链接,还可以利用新闻链接中收录的日期信息来判断该新闻是否为当天的新闻,并将识别出的新闻传递给调度器,让调度器决定放置相应的优先级。新闻页面抓取队列。调度器调度器是爬虫模块的核心组件。它维护着整个爬虫系统的运行。调度器算法的性能决定了整个系统的爬取效率。上一章提到的新闻爬虫应该关注的两个核心问题。更新策略是使用调度程序实现的。调度器访问其中维护的三个队列,决定下一个要爬取的链接,以及更新队列和权重判断。调度器确定下一个要爬取的链接的算法如下: 输入导航页面优先级队列 高优先级新闻页面爬取队列 低优先级新闻页面爬取队列 输出下一个要爬取的请求 第三章 新闻 调度算法实时抓取系统首先判断导航页面优先级队列中的第一个是否为抓取时间。如果是,设置下一次爬取时间,然后返回。如果未到爬取时间,则爬取优先级优先。如果新闻抓取队列为空,然后选择新闻爬取队列中优先级低的数据。数据处理管道当新闻页面被下载器下载并被蜘蛛分析时,解析的页面和一些新闻位置信息将传递给引擎,并将数据转发到数据处理管道。
论文实现的数据处理流水线的主要功能是将下载的页面内容和解析后的相关链接信息存入其中。它收录三个模块。这三个模块分别是网页编码识别与编码转换、链接信息存储、转换。代码后的页面存储。该图显示了数据处理管道的结构。第三章新闻实时抓取系统图新闻爬虫数据处理流水线图第三章新闻实时抓取系统第五节系统运行数据本文设计和实现的爬虫系统已应用于实际生产过程中,以了解实时监控系统运行状态,在后台实现监控系统。为了展示系统的爬虫性能,论文选取系统运行一整天的统计数据进行分析处理。系统运行环境爬虫模块部署在两台服务器上。这两天服务器的所有软硬件配置都是一样的。服务器配置信息如下所示。操作系统选择部署在两台服务器上。两台服务器的配置与爬虫模块部署的服务器相同。除了硬盘配置不同,硬盘是一样的。在两台服务器上部署的方法在服务器配置上也是一样的。运行数据随机选取系统运行的某一天的数据时间。爬虫模块配置新闻站点初始化的导航页数。
这一小时的页面爬取统计如表所示。表中的数据是根据抓取页面时响应的状态。在这一小时内发出了下载网页的请求。一个页面的成功爬取百分比会高于普通爬虫。因为论文实现了定向抓取,抓取了最新的链接作为主要的无效链接。第三章实时新闻抓取抓取系统占比较小,抓取比例较高。表格爬取状态统计状态码状态含义爬取成功次数百分比未找到页面重定向禁止访问未授权服务器错误其他总页面成功下载本次收录多次重复下载导航页面,新闻页面和非新闻页面。它们的比率显示在下面所示的饼图中。可以看到,系统需要的新闻页面只占了总爬取页面的一部分。抓取到的非新闻页面与新闻页面格式相同,但一般为图片或视频页面。该系统尚未得到日本人的认可。当然一些非新闻是导航页面,没有放在初始化集合中。稍后将处理这些导航页面并将其添加到集合中。各类型页面占比如图,朱叶豪,《新闻嘉瑞如树皮新乡页面》
通过对系统运行过程中的数据进行分析,可以发现这种分布式抓取系统的高效率可以应用到实际生产过程中。新闻爬虫不同于传统的网络爬虫,它有特定的爬取要求。与全网网络爬虫相比,新闻爬虫具有实时性、爬行目标明确、数据提取领域清晰等特点。海量的互联网数据要求新闻爬虫具有良好的算法和系统架构。论文中实现的新闻爬虫有两个核心算法,即爬取策略和更新策略。这两种策略决定了爬虫的效率。爬取策略明确定义了新闻爬虫要爬取的页面类型和区分方法,而更新策略必须保证系统能够最有效地抓取最新消息。核心算法策略还必须有优秀的系统架构来支撑,才能实现高效的新闻爬虫。本文实现的分布式实时新闻爬虫系统由数据模块、爬虫模块和系统配置模块三大部分组成。其中data模块用于保存爬虫运行时需要的数据以及最终爬取的页面数据。包括调度器的实现,主要负责与爬虫模块交互,存储各种爬取队列,主要存储下载的新闻页面。爬虫模块包括蜘蛛、调度器和数据处理管道。蜘蛛负责解析页面调度器,负责爬取队列的运行控制,而数据处理管道则处理下载的数据。爬虫模块可以部署在多台服务器上。这些多个模块作为数据交换的枢纽,构成了整个分布式实时新闻爬取系统。
通过对实时新闻抓取系统运行时间数据的统计分析,系统的抓取效率更高。这是因为爬虫系统良好的爬虫策略过滤掉了大部分非新闻页面,更新策略保证了可以及时爬取。到新消息。第四章新闻数据处理 第四章新闻数据处理 当新闻页面下载到本地并转码后存储在系统中时,需要对这些页面进行一系列的处理,以确保能够获得完整的新闻信息。一般情况下,新闻页面会收录大量的噪音数据。新闻显示系统不需要此信息。系统需要有一种有效的方法从噪声数据中区分新闻的各种属性并完整地提取出来。由于各个新闻站点的数据格式不同,提取的新闻信息还需要经过一系列的处理,使其符合系统要求的格式。论文针对新闻爬虫爬取后的数据处理问题设计了一套较为完善的处理流水线。本章将重点介绍新闻显示系统如何清理和处理下载的新闻页面。第一节新闻数据抽取新闻数据抽取是新闻爬虫在抓取新闻页面后首先要做的工作,也是整个处理系统中最关键的模块。处理系统的所有模块都是基于新闻数据提取的结果。做提取工作尤为重要。本节将介绍一些传统的网页文本数据提取方法,以及系统根据新闻数据的特点实现的提取方法。新闻数据提取的特点对于信息检索系统来说,网页正文数据的提取是爬虫爬取网页后进行数据处理的关键步骤。
为了消除噪声数据的干扰,提供更准确的检索结果,信息检索系统倾向于关注文本数据的提取工作。一般网页中的噪声数据包括页面样式布局信息、广告信息、网站导航信息、前端脚本等。图片新闻页面的噪音区域显示了新浪新闻页面中收录的噪音数据。图中所有的红框都是不需要的区域。顶部红框区域为导航信息右侧区域和新闻正文中的红框区域。这是一个广告,文字下方是一些其他链接。必须充分识别和清理这些信息。对于新闻展示系统来说,新闻数据的提取也是一项非常重要的任务。 查看全部
网页新闻抓取(基于存储架构如图所示存储架构图第三章新闻实时抓取系统(组图))
第三章新闻实时抓取系统——使用高效的二进制数据存储,包括图片、视频等大对象。片段的自动处理支持云计算的可扩展性。支持查询优化。支持多种语言。可以通过网络访问。与传统的关系型数据库相比,适合海量数据的存储。当数据量剧增时,只需在集群中增加服务器即可解决容量问题,免去扩容带来的分库分表的大工作量。自然支持文档类型数据的存储,没有模式限制。使用方法比关系数据库更灵活。基于如图所示的存储架构,存储架构图第三章新闻实时抓取系统第四节爬虫模块爬虫引擎和下载器是直接复用爬虫框架的功能模块,而调度器、蜘蛛和处理管道是基于新闻爬虫的功能模块。 - 开发和定制。本节重点介绍调度程序、蜘蛛程序和处理管道。蜘蛛的功能与框架中定义的蜘蛛模块基本相同。负责解析下载的网页,提取需要进一步爬取的超链接。它是爬虫模块中爬行队列的唯一提供者。整个爬虫模块的难点之一——爬取策略是在spider中实现的。蜘蛛是基于蜘蛛模块在继承自《第三章新闻实时抓取系统》的框架中实现的代码的主类。上面的规则就是一条数据的格式。键值为“...” 一条规则是正则表达式规则,用于判断匹配是否为提取链接后的新闻页面。
该规则告诉程序提取优采云节点中所有节点的属性,其属性值为标签,即超链接。蜘蛛不仅可以通过正则表达式提取和识别新闻链接,还可以利用新闻链接中收录的日期信息来判断该新闻是否为当天的新闻,并将识别出的新闻传递给调度器,让调度器决定放置相应的优先级。新闻页面抓取队列。调度器调度器是爬虫模块的核心组件。它维护着整个爬虫系统的运行。调度器算法的性能决定了整个系统的爬取效率。上一章提到的新闻爬虫应该关注的两个核心问题。更新策略是使用调度程序实现的。调度器访问其中维护的三个队列,决定下一个要爬取的链接,以及更新队列和权重判断。调度器确定下一个要爬取的链接的算法如下: 输入导航页面优先级队列 高优先级新闻页面爬取队列 低优先级新闻页面爬取队列 输出下一个要爬取的请求 第三章 新闻 调度算法实时抓取系统首先判断导航页面优先级队列中的第一个是否为抓取时间。如果是,设置下一次爬取时间,然后返回。如果未到爬取时间,则爬取优先级优先。如果新闻抓取队列为空,然后选择新闻爬取队列中优先级低的数据。数据处理管道当新闻页面被下载器下载并被蜘蛛分析时,解析的页面和一些新闻位置信息将传递给引擎,并将数据转发到数据处理管道。
论文实现的数据处理流水线的主要功能是将下载的页面内容和解析后的相关链接信息存入其中。它收录三个模块。这三个模块分别是网页编码识别与编码转换、链接信息存储、转换。代码后的页面存储。该图显示了数据处理管道的结构。第三章新闻实时抓取系统图新闻爬虫数据处理流水线图第三章新闻实时抓取系统第五节系统运行数据本文设计和实现的爬虫系统已应用于实际生产过程中,以了解实时监控系统运行状态,在后台实现监控系统。为了展示系统的爬虫性能,论文选取系统运行一整天的统计数据进行分析处理。系统运行环境爬虫模块部署在两台服务器上。这两天服务器的所有软硬件配置都是一样的。服务器配置信息如下所示。操作系统选择部署在两台服务器上。两台服务器的配置与爬虫模块部署的服务器相同。除了硬盘配置不同,硬盘是一样的。在两台服务器上部署的方法在服务器配置上也是一样的。运行数据随机选取系统运行的某一天的数据时间。爬虫模块配置新闻站点初始化的导航页数。
这一小时的页面爬取统计如表所示。表中的数据是根据抓取页面时响应的状态。在这一小时内发出了下载网页的请求。一个页面的成功爬取百分比会高于普通爬虫。因为论文实现了定向抓取,抓取了最新的链接作为主要的无效链接。第三章实时新闻抓取抓取系统占比较小,抓取比例较高。表格爬取状态统计状态码状态含义爬取成功次数百分比未找到页面重定向禁止访问未授权服务器错误其他总页面成功下载本次收录多次重复下载导航页面,新闻页面和非新闻页面。它们的比率显示在下面所示的饼图中。可以看到,系统需要的新闻页面只占了总爬取页面的一部分。抓取到的非新闻页面与新闻页面格式相同,但一般为图片或视频页面。该系统尚未得到日本人的认可。当然一些非新闻是导航页面,没有放在初始化集合中。稍后将处理这些导航页面并将其添加到集合中。各类型页面占比如图,朱叶豪,《新闻嘉瑞如树皮新乡页面》
通过对系统运行过程中的数据进行分析,可以发现这种分布式抓取系统的高效率可以应用到实际生产过程中。新闻爬虫不同于传统的网络爬虫,它有特定的爬取要求。与全网网络爬虫相比,新闻爬虫具有实时性、爬行目标明确、数据提取领域清晰等特点。海量的互联网数据要求新闻爬虫具有良好的算法和系统架构。论文中实现的新闻爬虫有两个核心算法,即爬取策略和更新策略。这两种策略决定了爬虫的效率。爬取策略明确定义了新闻爬虫要爬取的页面类型和区分方法,而更新策略必须保证系统能够最有效地抓取最新消息。核心算法策略还必须有优秀的系统架构来支撑,才能实现高效的新闻爬虫。本文实现的分布式实时新闻爬虫系统由数据模块、爬虫模块和系统配置模块三大部分组成。其中data模块用于保存爬虫运行时需要的数据以及最终爬取的页面数据。包括调度器的实现,主要负责与爬虫模块交互,存储各种爬取队列,主要存储下载的新闻页面。爬虫模块包括蜘蛛、调度器和数据处理管道。蜘蛛负责解析页面调度器,负责爬取队列的运行控制,而数据处理管道则处理下载的数据。爬虫模块可以部署在多台服务器上。这些多个模块作为数据交换的枢纽,构成了整个分布式实时新闻爬取系统。
通过对实时新闻抓取系统运行时间数据的统计分析,系统的抓取效率更高。这是因为爬虫系统良好的爬虫策略过滤掉了大部分非新闻页面,更新策略保证了可以及时爬取。到新消息。第四章新闻数据处理 第四章新闻数据处理 当新闻页面下载到本地并转码后存储在系统中时,需要对这些页面进行一系列的处理,以确保能够获得完整的新闻信息。一般情况下,新闻页面会收录大量的噪音数据。新闻显示系统不需要此信息。系统需要有一种有效的方法从噪声数据中区分新闻的各种属性并完整地提取出来。由于各个新闻站点的数据格式不同,提取的新闻信息还需要经过一系列的处理,使其符合系统要求的格式。论文针对新闻爬虫爬取后的数据处理问题设计了一套较为完善的处理流水线。本章将重点介绍新闻显示系统如何清理和处理下载的新闻页面。第一节新闻数据抽取新闻数据抽取是新闻爬虫在抓取新闻页面后首先要做的工作,也是整个处理系统中最关键的模块。处理系统的所有模块都是基于新闻数据提取的结果。做提取工作尤为重要。本节将介绍一些传统的网页文本数据提取方法,以及系统根据新闻数据的特点实现的提取方法。新闻数据提取的特点对于信息检索系统来说,网页正文数据的提取是爬虫爬取网页后进行数据处理的关键步骤。
为了消除噪声数据的干扰,提供更准确的检索结果,信息检索系统倾向于关注文本数据的提取工作。一般网页中的噪声数据包括页面样式布局信息、广告信息、网站导航信息、前端脚本等。图片新闻页面的噪音区域显示了新浪新闻页面中收录的噪音数据。图中所有的红框都是不需要的区域。顶部红框区域为导航信息右侧区域和新闻正文中的红框区域。这是一个广告,文字下方是一些其他链接。必须充分识别和清理这些信息。对于新闻展示系统来说,新闻数据的提取也是一项非常重要的任务。
网页新闻抓取(网站相当于一个图结构的解决方法和解决办法(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-26 04:37
)
哪里
标签。
3.编写程序,调试运行。
这里使用了 Python 的 urllib 和 Beautifulsoup 包。
我使用python3。3和2在语法上有一些差异,但大体逻辑是一样的。
urllib负责url的处理,主要是request、parse、error这些模块。负责向url发送请求,获取页面信息,处理错误。
Beautifulsoup 负责解析页面。获取到的页面是一个html树状结构,通过findAll()、select()、get()、get_text()等函数可以很方便的获取到我们想要的内容。
4.最后,如果要获取整个portal网站的数据,需要一些递归。整个网站相当于一个图结构,dfs(深度优先遍历)是更好的方法。
关于爬虫程序的编写,一些烦人的点:
(1)不同页面的url不一样。门户越大网站,分类越多,总会出现一些没见过也没有考虑过的情况。有时在判断程序不全面,会报错;同样,一些新闻文本页面的页面标签和布局不一样,很难用一种提取方法提取,对于上述问题,我们需要在程序中写更多的情况来处理if错误,防止爬行时报错并终止;
(2) 编码问题,这是我遇到的最难的问题,尤其是爬行的时候,想抓取新闻保存在txt中,可能有些页面有很特殊的字符,无法编解码,经常会导致程序意外终止 解决办法:对于极少数难以处理的网站,在源头过滤掉,在取数据的时候,往往不会关心一两页数据。
还有人告诉我python爬虫的特点是:简单,暴力,和python语言风格一样。
#coding: utf-8
import codecs
from urllib import request, parse
from bs4 import BeautifulSoup
import re
import time
from urllib.error import HTTPError, URLError
import sys
###新闻类定义
class News(object):
def __init__(self):
self.url = None #该新闻对应的url
self.topic = None #新闻标题
self.date = None #新闻发布日期
self.content = None #新闻的正文内容
self.author = None #新闻作者
###如果url符合解析要求,则对该页面进行信息提取
def getNews(url):
#获取页面所有元素
html = request.urlopen(url).read().decode('utf-8', 'ignore')
#解析
soup = BeautifulSoup(html, 'html.parser')
#获取信息
if not(soup.find('div', {'id':'artical'})): return
news = News() #建立新闻对象
page = soup.find('div', {'id':'artical'})
if not(page.find('h1', {'id':'artical_topic'})): return
topic = page.find('h1', {'id':'artical_topic'}).get_text() #新闻标题
news.topic = topic
if not(page.find('div', {'id': 'main_content'})): return
main_content = page.find('div', {'id': 'main_content'}) #新闻正文内容
content = ''
for p in main_content.select('p'):
content = content + p.get_text()
news.content = content
news.url = url #新闻页面对应的url
f.write(news.topic+'\t'+news.content+'\n')
##dfs算法遍历全站###
def dfs(url):
global count
print(url)
pattern1 = 'http://news\.ifeng\.com\/[a-z0-9_\/\.]*$' #可以继续访问的url规则
pattern2 = 'http://news\.ifeng\.com\/a\/[0-9]{8}\/[0-9]{8}\_0\.shtml$' #解析新闻信息的url规则
#该url访问过,则直接返回
if url in visited: return
print(url)
#把该url添加进visited()
visited.add(url)
# print(visited)
try:
#该url没有访问过的话,则继续解析操作
html = request.urlopen(url).read().decode('utf-8', 'ignore')
# print(html)
soup = BeautifulSoup(html, 'html.parser')
if re.match(pattern2, url):
getNews(url)
# count += 1
####提取该页面其中所有的url####
links = soup.findAll('a', href=re.compile(pattern1))
for link in links:
print(link['href'])
if link['href'] not in visited:
dfs(link['href'])
# count += 1
except URLError as e:
print(e)
return
except HTTPError as e:
print(e)
return
# print(count)
# if count > 3: return
visited = set() ##存储访问过的url
f = open('ifeng/news.txt', 'a+', encoding='utf-8')
dfs('http://news.ifeng.com/') 查看全部
网页新闻抓取(网站相当于一个图结构的解决方法和解决办法(一)
)
哪里
标签。
3.编写程序,调试运行。
这里使用了 Python 的 urllib 和 Beautifulsoup 包。
我使用python3。3和2在语法上有一些差异,但大体逻辑是一样的。
urllib负责url的处理,主要是request、parse、error这些模块。负责向url发送请求,获取页面信息,处理错误。
Beautifulsoup 负责解析页面。获取到的页面是一个html树状结构,通过findAll()、select()、get()、get_text()等函数可以很方便的获取到我们想要的内容。
4.最后,如果要获取整个portal网站的数据,需要一些递归。整个网站相当于一个图结构,dfs(深度优先遍历)是更好的方法。
关于爬虫程序的编写,一些烦人的点:
(1)不同页面的url不一样。门户越大网站,分类越多,总会出现一些没见过也没有考虑过的情况。有时在判断程序不全面,会报错;同样,一些新闻文本页面的页面标签和布局不一样,很难用一种提取方法提取,对于上述问题,我们需要在程序中写更多的情况来处理if错误,防止爬行时报错并终止;
(2) 编码问题,这是我遇到的最难的问题,尤其是爬行的时候,想抓取新闻保存在txt中,可能有些页面有很特殊的字符,无法编解码,经常会导致程序意外终止 解决办法:对于极少数难以处理的网站,在源头过滤掉,在取数据的时候,往往不会关心一两页数据。
还有人告诉我python爬虫的特点是:简单,暴力,和python语言风格一样。
#coding: utf-8
import codecs
from urllib import request, parse
from bs4 import BeautifulSoup
import re
import time
from urllib.error import HTTPError, URLError
import sys
###新闻类定义
class News(object):
def __init__(self):
self.url = None #该新闻对应的url
self.topic = None #新闻标题
self.date = None #新闻发布日期
self.content = None #新闻的正文内容
self.author = None #新闻作者
###如果url符合解析要求,则对该页面进行信息提取
def getNews(url):
#获取页面所有元素
html = request.urlopen(url).read().decode('utf-8', 'ignore')
#解析
soup = BeautifulSoup(html, 'html.parser')
#获取信息
if not(soup.find('div', {'id':'artical'})): return
news = News() #建立新闻对象
page = soup.find('div', {'id':'artical'})
if not(page.find('h1', {'id':'artical_topic'})): return
topic = page.find('h1', {'id':'artical_topic'}).get_text() #新闻标题
news.topic = topic
if not(page.find('div', {'id': 'main_content'})): return
main_content = page.find('div', {'id': 'main_content'}) #新闻正文内容
content = ''
for p in main_content.select('p'):
content = content + p.get_text()
news.content = content
news.url = url #新闻页面对应的url
f.write(news.topic+'\t'+news.content+'\n')
##dfs算法遍历全站###
def dfs(url):
global count
print(url)
pattern1 = 'http://news\.ifeng\.com\/[a-z0-9_\/\.]*$' #可以继续访问的url规则
pattern2 = 'http://news\.ifeng\.com\/a\/[0-9]{8}\/[0-9]{8}\_0\.shtml$' #解析新闻信息的url规则
#该url访问过,则直接返回
if url in visited: return
print(url)
#把该url添加进visited()
visited.add(url)
# print(visited)
try:
#该url没有访问过的话,则继续解析操作
html = request.urlopen(url).read().decode('utf-8', 'ignore')
# print(html)
soup = BeautifulSoup(html, 'html.parser')
if re.match(pattern2, url):
getNews(url)
# count += 1
####提取该页面其中所有的url####
links = soup.findAll('a', href=re.compile(pattern1))
for link in links:
print(link['href'])
if link['href'] not in visited:
dfs(link['href'])
# count += 1
except URLError as e:
print(e)
return
except HTTPError as e:
print(e)
return
# print(count)
# if count > 3: return
visited = set() ##存储访问过的url
f = open('ifeng/news.txt', 'a+', encoding='utf-8')
dfs('http://news.ifeng.com/')
网页新闻抓取(基于文本及符号密度的网页正文提取方法(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2021-09-22 08:09
)
项目来源
开发这个项目,我发现了来自自动化算法的纸张,以提取Hownet中的新闻网站文本 - “基于文本密度和符号文本提取方法”)
本文描述的算法看起来简单明了,逻辑。但是,由于纸质讨论了算法的原理,没有特定的语言,因此我根据纸张使用提取器的Python实现。并使用今天的头条新闻,网易新闻,无家可归的天空,观察者,凤凰,腾讯新闻,Readhub,新浪新闻做了一个测试,发现提取物非常好,几乎能够实现100%的准确性。
项目状态
本文中描述的文本,基于提取,我添加了标题,文章发布了作者自动检测和功能提取。
目前这个项目是一个非常非常早期的演示,发布它希望尽快让每个人的反馈,以实现更好的目标开发。
命名为提取器,而不是爬行动物,以避免不必要的风险,因此,该项目的输入是HTML,输出为字典。请使用适当的方法获取自己的目标网站 HTML。
项目现在没有,无法在将来提供网站 html函数的主动性。
如何使用在线体验
如果您想体验GNE提取的影响,那么您可以访问。在正常情况下,您只需要将其粘贴到多行文本框的顶部页面中,然后提取按钮。通过更多其他参数,允许更精确地提取。编写特定参数的操作,请参阅
环境
如果要体验GNE功能,请按照以下步骤操作:
安装gne
# 以下两种方案任选一种即可
# 使用 pip 安装
pip install --upgrade gne
# 使用 pipenv 安装
pipenv install gne
使用gne提取文本
&gt; &gt;来自GNE Import GeneralNewsextractor&Gt; &gt; &gt; html ='''呈现页面html代码''''&gt; &gt; &gt; Extractor = GeneralNewsextractor()&gt; &gt; &gt;结果= Extractor .Extract(HTML,HOTE_NODE_LIST = ['// div [@ class =“注释列表”list“”)&gt; &gt; &gt;打印(结果){“title”:“xxxx”,“publish_time”:“2019 -09-10 11:12:13”,“作者”:“yyy”,“内容”:“zzzz”,“图像”: [“/xxx.jpg”,“/yyy.png”]}“&gt;
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
>>> print(result)
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz", "images": ["/xxx.jpg", "/yyy.png"]}
有关详细说明,请参阅文档GNE
提取列表页面(beta)
&gt ;; &gt
来自GNE Import ListPapeExtractor&gt; &gt; &gt; html ='''呈现页面html代码''''&gt; &gt; &gt; list_extractor = listpageExtractor()&gt; &gt; &gt;结果= list_extractor .Extract(html,feature ='任何元素xpath的列表“)&gt;&gt;&gt;打印(结果)”
>>> from gne import ListPageExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> list_extractor = ListPageExtractor()
>>> result = list_extractor.extract(html,
feature='列表中任意元素的 XPath")
>>> print(result)
开发环境
如果您需要参加该项目的开发,请按照以下步骤操作。
如果要读取源代码,现在请直接按键盘上的句点键(即,留下问号),您可以获得更好的阅读体验。
本项目使用第三方库的Python Pipenv管理。如果你不知道pipenv是什么,请把我指向跳。
后
已安装pipenv,按以下步骤运行代码:
git clone https://github.com/kingname/Ge ... r.git
cd GeneralNewsExtractor
pipenv install
pipenv shell
python3 example.py
特殊说明
example.py项目代码提供了项目使用的基本示例。
元素选项卡在标签中位于,右侧,选择复制 - 复制offichtml,如图所示
图。
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
对于大多数新闻页面,上面的措辞将能够解决问题。
但是,将有一些新闻页面评论下面,可能有长啰嗦的评论,它们看起来比真正的新闻更像是文本的正文,所以Extractor.extract()方法有一个默认参数kide_node_list,对于网页提前预处理以查看整个区域被删除。
keate_mode_list值是一个列表,一个列表,其中每个元素是xpath,对应于您提前需要的目标标签删除,可能会导致干扰。
例如,与以下注释XPath对应的查看器Web区域为// div [@ class =“注释列表”。因此,当提取观察者网络时,为了防止干扰评论,可以添加此参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
gne将基于此XPath,自动查找其他数据线内的列表。
运行射击网易新闻
今天的头条新闻
新浪新闻
p> phoenix
查看全部
网页新闻抓取(基于文本及符号密度的网页正文提取方法(图)
)
项目来源
开发这个项目,我发现了来自自动化算法的纸张,以提取Hownet中的新闻网站文本 - “基于文本密度和符号文本提取方法”)
本文描述的算法看起来简单明了,逻辑。但是,由于纸质讨论了算法的原理,没有特定的语言,因此我根据纸张使用提取器的Python实现。并使用今天的头条新闻,网易新闻,无家可归的天空,观察者,凤凰,腾讯新闻,Readhub,新浪新闻做了一个测试,发现提取物非常好,几乎能够实现100%的准确性。
项目状态
本文中描述的文本,基于提取,我添加了标题,文章发布了作者自动检测和功能提取。
目前这个项目是一个非常非常早期的演示,发布它希望尽快让每个人的反馈,以实现更好的目标开发。
命名为提取器,而不是爬行动物,以避免不必要的风险,因此,该项目的输入是HTML,输出为字典。请使用适当的方法获取自己的目标网站 HTML。
项目现在没有,无法在将来提供网站 html函数的主动性。
如何使用在线体验
如果您想体验GNE提取的影响,那么您可以访问。在正常情况下,您只需要将其粘贴到多行文本框的顶部页面中,然后提取按钮。通过更多其他参数,允许更精确地提取。编写特定参数的操作,请参阅
环境
如果要体验GNE功能,请按照以下步骤操作:
安装gne
# 以下两种方案任选一种即可
# 使用 pip 安装
pip install --upgrade gne
# 使用 pipenv 安装
pipenv install gne
使用gne提取文本
&gt; &gt;来自GNE Import GeneralNewsextractor&Gt; &gt; &gt; html ='''呈现页面html代码''''&gt; &gt; &gt; Extractor = GeneralNewsextractor()&gt; &gt; &gt;结果= Extractor .Extract(HTML,HOTE_NODE_LIST = ['// div [@ class =“注释列表”list“”)&gt; &gt; &gt;打印(结果){“title”:“xxxx”,“publish_time”:“2019 -09-10 11:12:13”,“作者”:“yyy”,“内容”:“zzzz”,“图像”: [“/xxx.jpg”,“/yyy.png”]}“&gt;
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
>>> print(result)
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz", "images": ["/xxx.jpg", "/yyy.png"]}
有关详细说明,请参阅文档GNE
提取列表页面(beta)
&gt ;; &gt
来自GNE Import ListPapeExtractor&gt; &gt; &gt; html ='''呈现页面html代码''''&gt; &gt; &gt; list_extractor = listpageExtractor()&gt; &gt; &gt;结果= list_extractor .Extract(html,feature ='任何元素xpath的列表“)&gt;&gt;&gt;打印(结果)”
>>> from gne import ListPageExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> list_extractor = ListPageExtractor()
>>> result = list_extractor.extract(html,
feature='列表中任意元素的 XPath")
>>> print(result)
开发环境
如果您需要参加该项目的开发,请按照以下步骤操作。
如果要读取源代码,现在请直接按键盘上的句点键(即,留下问号),您可以获得更好的阅读体验。
本项目使用第三方库的Python Pipenv管理。如果你不知道pipenv是什么,请把我指向跳。
后
已安装pipenv,按以下步骤运行代码:
git clone https://github.com/kingname/Ge ... r.git
cd GeneralNewsExtractor
pipenv install
pipenv shell
python3 example.py
特殊说明
example.py项目代码提供了项目使用的基本示例。

元素选项卡在标签中位于,右侧,选择复制 - 复制offichtml,如图所示
图。

from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
对于大多数新闻页面,上面的措辞将能够解决问题。
但是,将有一些新闻页面评论下面,可能有长啰嗦的评论,它们看起来比真正的新闻更像是文本的正文,所以Extractor.extract()方法有一个默认参数kide_node_list,对于网页提前预处理以查看整个区域被删除。
keate_mode_list值是一个列表,一个列表,其中每个元素是xpath,对应于您提前需要的目标标签删除,可能会导致干扰。
例如,与以下注释XPath对应的查看器Web区域为// div [@ class =“注释列表”。因此,当提取观察者网络时,为了防止干扰评论,可以添加此参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])

gne将基于此XPath,自动查找其他数据线内的列表。
运行射击网易新闻

今天的头条新闻

新浪新闻

p> phoenix

网页新闻抓取(我找到的3种实现方法,但基于dom节点的评分制筛选算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-21 02:16
请看看官方拍摄。 。 。
我一直对网页的内容非常感兴趣,我三年前做了一个“新闻读者”,我喜欢当时观看这个消息,想法是如果没有广告时观看新闻,一个安静有多好,然后我开发了一个浏览器书签小插件,使用JS提取页面,然后通过层封面显示在页面上,它只能被规律地思考,这也是大多数爬行者爬行者。
当时,网上,新浪,QQ和等各种主要门户都实现了这个功能。这是最傻瓜式方法,但益处是高精度。 DIDTTRESS是,一旦目标网页修改源代码,您可能需要重新出现。
我找到了越来越多的页面,我要观看,这种方式不再适合我的需求。但最近因为我已经开发了,我需要一个集合助手,所以我开始寻找解决方案。
我主要发现三种解决方案:
1)评评评制制算算制算算算制
有一个被称为可读,地址的外国浏览器书签插件:当时,这是非常钦佩的,并且精度高。
2)基于文本密度分析(DOM-Indumenty)
这种方法的想法也很好,适用性更好,我试图使用js来实现,但能够做出有限匹配的能力太高,放弃了。
3)基于图像识别
alpha狗使用的方法非常接近,通过图像识别,只要机器人可以完成,有大量的情况,但没有看到文本识别特定实现(或没有找到案例)。
上面是我找到的三种实现方法。
但基于我只是一个Web开发人员,只有理解JS,其他语言技能非常有限。所以我尝试了基于DOM的筛选,并且可读性相对复杂。我还能获得更有效的解决方案吗?
我发现了一个法律,文本部分一般来说,P标签的数量非常多,多于其他部分,因为大多数网页的内容被所需的编辑器释放,这些编辑器生成语义节点。
所以,我将使用此规则并开发一个小插件,效果也不错。当然,它仍然是非常原创的,需要改善。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码非常简单,但我已经过超过80%的网页(主要是文章页面)可以成功。基于此,我开发了Jspapa 采集 Assistant:
如果您有更好的解决方案,您可以讨论它。
如果需要重新打印本文,请联系作者,请指定源 查看全部
网页新闻抓取(我找到的3种实现方法,但基于dom节点的评分制筛选算法)
请看看官方拍摄。 。 。
我一直对网页的内容非常感兴趣,我三年前做了一个“新闻读者”,我喜欢当时观看这个消息,想法是如果没有广告时观看新闻,一个安静有多好,然后我开发了一个浏览器书签小插件,使用JS提取页面,然后通过层封面显示在页面上,它只能被规律地思考,这也是大多数爬行者爬行者。
当时,网上,新浪,QQ和等各种主要门户都实现了这个功能。这是最傻瓜式方法,但益处是高精度。 DIDTTRESS是,一旦目标网页修改源代码,您可能需要重新出现。
我找到了越来越多的页面,我要观看,这种方式不再适合我的需求。但最近因为我已经开发了,我需要一个集合助手,所以我开始寻找解决方案。
我主要发现三种解决方案:
1)评评评制制算算制算算算制
有一个被称为可读,地址的外国浏览器书签插件:当时,这是非常钦佩的,并且精度高。
2)基于文本密度分析(DOM-Indumenty)
这种方法的想法也很好,适用性更好,我试图使用js来实现,但能够做出有限匹配的能力太高,放弃了。
3)基于图像识别
alpha狗使用的方法非常接近,通过图像识别,只要机器人可以完成,有大量的情况,但没有看到文本识别特定实现(或没有找到案例)。
上面是我找到的三种实现方法。
但基于我只是一个Web开发人员,只有理解JS,其他语言技能非常有限。所以我尝试了基于DOM的筛选,并且可读性相对复杂。我还能获得更有效的解决方案吗?
我发现了一个法律,文本部分一般来说,P标签的数量非常多,多于其他部分,因为大多数网页的内容被所需的编辑器释放,这些编辑器生成语义节点。
所以,我将使用此规则并开发一个小插件,效果也不错。当然,它仍然是非常原创的,需要改善。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码非常简单,但我已经过超过80%的网页(主要是文章页面)可以成功。基于此,我开发了Jspapa 采集 Assistant:
如果您有更好的解决方案,您可以讨论它。
如果需要重新打印本文,请联系作者,请指定源
网页新闻抓取(通过网页抓取工具优采云采集器创造一个大数据智媒体)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-09-21 02:13
当前媒体电流,在焦点事件的主题或可持续主题,形成媒体主题,有很多手动操作,如信息采集,及时更新等,但高效的Web Raw工具将创建一个大数据智能介质。
通过网页优采云采集器可以自动采集与公众对应的焦点事件。例如,一个连续的多日事件,您必须在每个重要节点时间中抓取数据,然后在优采云采集器中设置更新时间和频率。例如,我们要注意金融市场,您可以随时更新和自动化到动态媒体列。
和关注于焦点的某个方面的重点也可以根据网状抓取工具进行分类和智能分级。我们甚至可以使用Web捕获该工具以维护智能媒体站。用户想要锁定几个或多个信息输出页面,并在Web Grab工具中提供信息输出页面优采云采集器,配置网站捕获和内容的详细规则,获取一系列放电,筛选,清洁处理,最后选择自动和定时,以便自动和定时选择。 @指定列。
未来媒体不可避免地是媒体的大数据,核心元素是数据的大小,并且我们必须使用数据有效地学习并播放数据的值。基于媒体稿件数据的高科技媒体产品,允许人们更快,准确地学习,帮助人们更好地发现信息的价值和本质。
一些专家提出,如果没有对大数据的支持,事实上,许多新闻都是不幸的。在传统媒体中难以具有智能分析,警告或决定,因此大数据智能是一种不可避免的趋势。
但是,网络创建的目前网络大数据并不完全取代人类大脑,因为人类的大脑是自我理解,而且需要人工智能继续探索,将大量无聊内容融合要提取其化身信息,可能有一天可以取代人类大脑来实现更复杂的原创,智能媒体将更加个性化,定制和高效。 查看全部
网页新闻抓取(通过网页抓取工具优采云采集器创造一个大数据智媒体)
当前媒体电流,在焦点事件的主题或可持续主题,形成媒体主题,有很多手动操作,如信息采集,及时更新等,但高效的Web Raw工具将创建一个大数据智能介质。

通过网页优采云采集器可以自动采集与公众对应的焦点事件。例如,一个连续的多日事件,您必须在每个重要节点时间中抓取数据,然后在优采云采集器中设置更新时间和频率。例如,我们要注意金融市场,您可以随时更新和自动化到动态媒体列。
和关注于焦点的某个方面的重点也可以根据网状抓取工具进行分类和智能分级。我们甚至可以使用Web捕获该工具以维护智能媒体站。用户想要锁定几个或多个信息输出页面,并在Web Grab工具中提供信息输出页面优采云采集器,配置网站捕获和内容的详细规则,获取一系列放电,筛选,清洁处理,最后选择自动和定时,以便自动和定时选择。 @指定列。
未来媒体不可避免地是媒体的大数据,核心元素是数据的大小,并且我们必须使用数据有效地学习并播放数据的值。基于媒体稿件数据的高科技媒体产品,允许人们更快,准确地学习,帮助人们更好地发现信息的价值和本质。
一些专家提出,如果没有对大数据的支持,事实上,许多新闻都是不幸的。在传统媒体中难以具有智能分析,警告或决定,因此大数据智能是一种不可避免的趋势。
但是,网络创建的目前网络大数据并不完全取代人类大脑,因为人类的大脑是自我理解,而且需要人工智能继续探索,将大量无聊内容融合要提取其化身信息,可能有一天可以取代人类大脑来实现更复杂的原创,智能媒体将更加个性化,定制和高效。
网页新闻抓取( 手机端OPPO手机自带“智慧识物”功能(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 608 次浏览 • 2021-09-20 20:45
手机端OPPO手机自带“智慧识物”功能(组图))
网页无法复制(教你一个技巧,轻松提取文本,并通过网络自由复制)
我相信你在生活中会遇到这样的问题:当我们需要复制网页文档中的一段文本时,网页却无法被复制。最后,我们只能逐字打字,这既费时又费力
但这次别担心。小编为您采集整理了四个软件工具,可以帮助您更轻松方便地提取网页文本。来看看
一、计算机终端
1、QQ截图提取文本
使用电脑QQ截图功能提取和复制文本。打开QQ,按住键盘上的[Ctrl]+[ALT]+[a]屏幕截图,然后单击下面选项栏中的小字符识别图标以执行字符识别和提取
2、Word文件提取文本
除了QQ截图,我们还可以尝试使用word文档来提取web文档。创建新文档并打开WPS主页,单击文件-打开,将复制的web文档地址粘贴到文件名,然后单击打开
接下来,word将自动打开网页。我们需要选择将其作为word文档打开,然后才能复制它
3、fast-PDF转换器
fast PDF Converter支持PDF与各种格式文档(如word、PPT和excel)之间的相互转换,以及PDF合并、压缩和图片字符识别(OCR)功能。如果我们需要复制web文档,我们还可以使用此软件复制文本
打开软件,选择[feature conversion]-[image to text(OCR)],在软件中打开网页截图,点击[start conversion],然后打开word文档,瞬间复制文本
二、移动终端
Oppo手机具有“智能物体识别”功能
除了电脑软件工具外,oppo手机还拥有自己的“智能物体识别”功能,它还可以识别和提取无法复制的文字。打开[intelligent object recognition]功能,拍摄要识别的文本,点击[recognition text on this page]
事实上,很多手机都有字符识别功能。你可以去看看你的手机是否有这个工具
以上四种方法都是小编练习过的。软件比较通用,操作相对简单。你知道有什么工具可以从web文档中提取文本吗?欢迎来到下面的评论区进行分享和讨论
版权声明:本文转载是为了传播更多信息。如果源标签有误或侵犯了您的合法权益,请您持所有权证书与我们联系,我们将及时更正并删除。感谢您的支持和理解 查看全部
网页新闻抓取(
手机端OPPO手机自带“智慧识物”功能(组图))
网页无法复制(教你一个技巧,轻松提取文本,并通过网络自由复制)
我相信你在生活中会遇到这样的问题:当我们需要复制网页文档中的一段文本时,网页却无法被复制。最后,我们只能逐字打字,这既费时又费力

但这次别担心。小编为您采集整理了四个软件工具,可以帮助您更轻松方便地提取网页文本。来看看
一、计算机终端
1、QQ截图提取文本
使用电脑QQ截图功能提取和复制文本。打开QQ,按住键盘上的[Ctrl]+[ALT]+[a]屏幕截图,然后单击下面选项栏中的小字符识别图标以执行字符识别和提取

2、Word文件提取文本
除了QQ截图,我们还可以尝试使用word文档来提取web文档。创建新文档并打开WPS主页,单击文件-打开,将复制的web文档地址粘贴到文件名,然后单击打开
接下来,word将自动打开网页。我们需要选择将其作为word文档打开,然后才能复制它

3、fast-PDF转换器
fast PDF Converter支持PDF与各种格式文档(如word、PPT和excel)之间的相互转换,以及PDF合并、压缩和图片字符识别(OCR)功能。如果我们需要复制web文档,我们还可以使用此软件复制文本
打开软件,选择[feature conversion]-[image to text(OCR)],在软件中打开网页截图,点击[start conversion],然后打开word文档,瞬间复制文本

二、移动终端
Oppo手机具有“智能物体识别”功能
除了电脑软件工具外,oppo手机还拥有自己的“智能物体识别”功能,它还可以识别和提取无法复制的文字。打开[intelligent object recognition]功能,拍摄要识别的文本,点击[recognition text on this page]
事实上,很多手机都有字符识别功能。你可以去看看你的手机是否有这个工具

以上四种方法都是小编练习过的。软件比较通用,操作相对简单。你知道有什么工具可以从web文档中提取文本吗?欢迎来到下面的评论区进行分享和讨论
版权声明:本文转载是为了传播更多信息。如果源标签有误或侵犯了您的合法权益,请您持所有权证书与我们联系,我们将及时更正并删除。感谢您的支持和理解
网页新闻抓取(爬取网易新闻,实战出真知,打开网易)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-17 02:10
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
在学习了python的基本语法之后,我对爬虫产生了极大的兴趣。我不怎么胡说八道。今天,我要爬网易新闻,从实战中学习
当你打开网易新闻,你会发现新闻分为几个部分:
这一次,我们选择国内板块攀登文章
1.ready
下载地址
理解网页
网页色彩丰富、美丽,就像一幅水彩画。要抓取数据,首先需要知道需要抓取的数据是如何呈现的,就像学习画图一样。在你开始之前,你需要知道画的是什么,铅笔还是水彩笔。。。可能有各种类型,但Web信息只有两种表示方法:
Html是一种用来描述网页的语言
JSON是一种轻量级数据交换格式
抓取网页信息实际上是向网页发出请求,服务器会将数据反馈给您
2.get动态加载源代码
导入所需的模块和库:
1 from bs4 import BeautifulSoup
2 import time
3 import def_text_save as dts
4 import def_get_data as dgd
5 from selenium import webdriver
6 from selenium.webdriver.common.keys import Keys
7 from selenium.webdriver.common.action_chains import ActionChains #引入ActionChains鼠标操作类
要获取网页信息,我们需要发送请求。请求可以帮助我们很好地做到这一点。然而,仔细观察发现,网易新闻是动态加载的,请求返回即时信息,而随后在网页中加载的数据不会返回。Selenium可以帮助我们获得更多数据,我们理解Selenium是一种自动化测试工具。Selenium测试直接在浏览器中运行,就像真实用户一样
我使用的浏览器是Firefox
1 browser = webdriver.Firefox()#根据浏览器切换
2 browser.maximize_window()#最大化窗口
3 browser.get('http://news.163.com/domestic/')
这样,我们就可以驱动浏览器自动登录到网易新闻页面
当然,我们的目标是爬下国内板块,同时观察网页。当网页继续向下刷时,将加载新新闻。在底部,我们甚至需要单击按钮刷新:
此时,selenium可以展示其优势:鼠标和键盘操作的自动化和模拟:
1 diver.execute_script("window.scrollBy(0,5000)")
2 #使网页向下拉,括号内为每次下拉数值
右键单击网页中的“加载更多”按钮,然后单击“查看元素”以查看
通过这个类,我们可以找到按钮。当我们遇到按钮时,单击事件可以帮助我们自动单击按钮以完成页面刷新
1 # 爬取板块动态加载部分源代码
2
3 info1=[]
4 info_links=[] #存储文章内容链接
5 try:
6 while True :
7 if browser.page_source.find("load_more_btn") != -1 :
8 browser.find_element_by_class_name("load_more_btn").click()
9 browser.execute_script("window.scrollBy(0,5000)")
10 time.sleep(1)
11 except:
12 url = browser.page_source#返回加载完全的网页源码
13 browser.close()#关闭浏览器
获取有用的信息
简而言之,BeautifulSoup是一个Python库。它的主要功能是从网页中获取数据,这可以减轻新手的负担。通过beautiful soup解析网页源代码并添加附加函数,我们可以轻松获得所需的信息,例如获取文章标题、标签和文本内容超链接
同样,在文章标题区域中单击鼠标右键可查看元素:
观察网页结构,发现文章是每个div标签class=“news\u title”下的标题和超链接。汤。Find_all()函数可以帮助我们找到所需的所有信息,并且可以一次性提取此级别结构下的内容。最后,通过字典逐一取出标签信息
1 info_total=[]
2 def get_data(url):
3 soup=BeautifulSoup(url,"html.parser")
4 titles=soup.find_all('div','news_title')
5 labels=soup.find('div','ns_area second2016_main clearfix').find_all('div','keywords')
6 for title, label in zip(titles,labels ):
7 data = {
8 '文章标题': title.get_text().split(),
9 '文章标签':label.get_text().split() ,
10 'link':title.find("a").get('href')
11 }
12 info_total.append(data)
13 return info_total
4.get新闻内容
从那时起,新闻链接被取出并存储在列表中。我们现在需要做的是使用链接获取新闻主题内容。新闻主题内容页是静态加载的,可以轻松处理请求:
1 def get_content(url):
2 info_text = []
3 info=[]
4 adata=requests.get(url)
5 soup=BeautifulSoup(adata.text,'html.parser')
6 try :
7 articles = soup.find("div", 'post_header').find('div', 'post_content_main').find('div', 'post_text').find_all('p')
8 except :
9 articles = soup.find("div", 'post_content post_area clearfix').find('div', 'post_body').find('div', 'post_text').find_all(
10 'p')
11 for a in articles:
12 a=a.get_text()
13 a= ' '.join(a.split())
14 info_text.append(a)
15 return (info_text)
之所以使用try-except,是因为在不同的情况下,网易新闻文章在某个时间段前后,文本信息的位置标签是不同的
最后,遍历整个列表并取出所有文本内容:
1 for i in info1 :
2 info_links.append(i.get('link'))
3 x=0 #控制访问文章目录
4 info_content={}# 存储文章内容
5 for i in info_links:
6 try :
7 info_content['文章内容']=dgd.get_content(i)
8 except:
9 continue
10 s=str(info1[x]["文章标题"]).replace('[','').replace(']','').replace("'",'').replace(',','').replace('《','').replace('》','').replace('/','').replace(',',' ')
11 s= ''.join(s.split())
12 file = '/home/lsgo18/PycharmProjects/网易新闻'+'/'+s
13 print(s)
14 dts.text_save(file,info_content['文章内容'],info1[x]['文章标签'])
15 x = x + 1
将数据存储到本地TXT文件
Python提供了一个文件处理函数open()。第一个参数是文件路径,第二个参数是文件处理模式,“W”模式是只写模式(如果没有文件,将创建该文件,如果有,将清空该文件)
1 def text_save(filename, data,lable): #filename为写入CSV文件的路径
2 file = open(filename,'w')
3 file.write(str(lable).replace('[','').replace(']','')+'\n')
4 for i in range(len(data)):
5 s =str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
6 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符
7 file.write(s)
8 file.close()
9 print("保存文件成功")
已成功编写一个简单的爬虫程序:
到目前为止,网易新闻的抓取方法已经被引入。我希望它对你有用 查看全部
网页新闻抓取(爬取网易新闻,实战出真知,打开网易)
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
在学习了python的基本语法之后,我对爬虫产生了极大的兴趣。我不怎么胡说八道。今天,我要爬网易新闻,从实战中学习
当你打开网易新闻,你会发现新闻分为几个部分:
这一次,我们选择国内板块攀登文章
1.ready
下载地址
理解网页
网页色彩丰富、美丽,就像一幅水彩画。要抓取数据,首先需要知道需要抓取的数据是如何呈现的,就像学习画图一样。在你开始之前,你需要知道画的是什么,铅笔还是水彩笔。。。可能有各种类型,但Web信息只有两种表示方法:
Html是一种用来描述网页的语言
JSON是一种轻量级数据交换格式
抓取网页信息实际上是向网页发出请求,服务器会将数据反馈给您
2.get动态加载源代码
导入所需的模块和库:
1 from bs4 import BeautifulSoup
2 import time
3 import def_text_save as dts
4 import def_get_data as dgd
5 from selenium import webdriver
6 from selenium.webdriver.common.keys import Keys
7 from selenium.webdriver.common.action_chains import ActionChains #引入ActionChains鼠标操作类
要获取网页信息,我们需要发送请求。请求可以帮助我们很好地做到这一点。然而,仔细观察发现,网易新闻是动态加载的,请求返回即时信息,而随后在网页中加载的数据不会返回。Selenium可以帮助我们获得更多数据,我们理解Selenium是一种自动化测试工具。Selenium测试直接在浏览器中运行,就像真实用户一样
我使用的浏览器是Firefox
1 browser = webdriver.Firefox()#根据浏览器切换
2 browser.maximize_window()#最大化窗口
3 browser.get('http://news.163.com/domestic/')
这样,我们就可以驱动浏览器自动登录到网易新闻页面
当然,我们的目标是爬下国内板块,同时观察网页。当网页继续向下刷时,将加载新新闻。在底部,我们甚至需要单击按钮刷新:
此时,selenium可以展示其优势:鼠标和键盘操作的自动化和模拟:
1 diver.execute_script("window.scrollBy(0,5000)")
2 #使网页向下拉,括号内为每次下拉数值
右键单击网页中的“加载更多”按钮,然后单击“查看元素”以查看

通过这个类,我们可以找到按钮。当我们遇到按钮时,单击事件可以帮助我们自动单击按钮以完成页面刷新
1 # 爬取板块动态加载部分源代码
2
3 info1=[]
4 info_links=[] #存储文章内容链接
5 try:
6 while True :
7 if browser.page_source.find("load_more_btn") != -1 :
8 browser.find_element_by_class_name("load_more_btn").click()
9 browser.execute_script("window.scrollBy(0,5000)")
10 time.sleep(1)
11 except:
12 url = browser.page_source#返回加载完全的网页源码
13 browser.close()#关闭浏览器
获取有用的信息
简而言之,BeautifulSoup是一个Python库。它的主要功能是从网页中获取数据,这可以减轻新手的负担。通过beautiful soup解析网页源代码并添加附加函数,我们可以轻松获得所需的信息,例如获取文章标题、标签和文本内容超链接

同样,在文章标题区域中单击鼠标右键可查看元素:
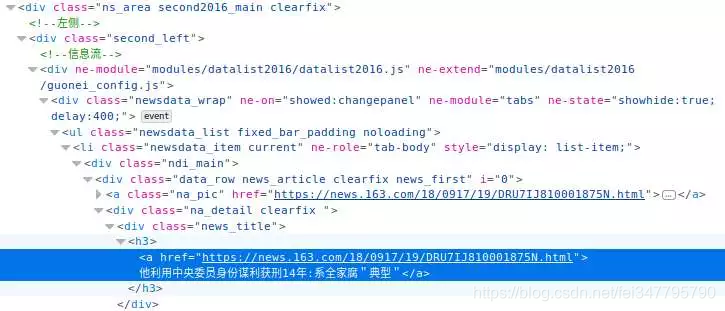
观察网页结构,发现文章是每个div标签class=“news\u title”下的标题和超链接。汤。Find_all()函数可以帮助我们找到所需的所有信息,并且可以一次性提取此级别结构下的内容。最后,通过字典逐一取出标签信息
1 info_total=[]
2 def get_data(url):
3 soup=BeautifulSoup(url,"html.parser")
4 titles=soup.find_all('div','news_title')
5 labels=soup.find('div','ns_area second2016_main clearfix').find_all('div','keywords')
6 for title, label in zip(titles,labels ):
7 data = {
8 '文章标题': title.get_text().split(),
9 '文章标签':label.get_text().split() ,
10 'link':title.find("a").get('href')
11 }
12 info_total.append(data)
13 return info_total
4.get新闻内容
从那时起,新闻链接被取出并存储在列表中。我们现在需要做的是使用链接获取新闻主题内容。新闻主题内容页是静态加载的,可以轻松处理请求:
1 def get_content(url):
2 info_text = []
3 info=[]
4 adata=requests.get(url)
5 soup=BeautifulSoup(adata.text,'html.parser')
6 try :
7 articles = soup.find("div", 'post_header').find('div', 'post_content_main').find('div', 'post_text').find_all('p')
8 except :
9 articles = soup.find("div", 'post_content post_area clearfix').find('div', 'post_body').find('div', 'post_text').find_all(
10 'p')
11 for a in articles:
12 a=a.get_text()
13 a= ' '.join(a.split())
14 info_text.append(a)
15 return (info_text)
之所以使用try-except,是因为在不同的情况下,网易新闻文章在某个时间段前后,文本信息的位置标签是不同的
最后,遍历整个列表并取出所有文本内容:
1 for i in info1 :
2 info_links.append(i.get('link'))
3 x=0 #控制访问文章目录
4 info_content={}# 存储文章内容
5 for i in info_links:
6 try :
7 info_content['文章内容']=dgd.get_content(i)
8 except:
9 continue
10 s=str(info1[x]["文章标题"]).replace('[','').replace(']','').replace("'",'').replace(',','').replace('《','').replace('》','').replace('/','').replace(',',' ')
11 s= ''.join(s.split())
12 file = '/home/lsgo18/PycharmProjects/网易新闻'+'/'+s
13 print(s)
14 dts.text_save(file,info_content['文章内容'],info1[x]['文章标签'])
15 x = x + 1
将数据存储到本地TXT文件
Python提供了一个文件处理函数open()。第一个参数是文件路径,第二个参数是文件处理模式,“W”模式是只写模式(如果没有文件,将创建该文件,如果有,将清空该文件)
1 def text_save(filename, data,lable): #filename为写入CSV文件的路径
2 file = open(filename,'w')
3 file.write(str(lable).replace('[','').replace(']','')+'\n')
4 for i in range(len(data)):
5 s =str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
6 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符
7 file.write(s)
8 file.close()
9 print("保存文件成功")
已成功编写一个简单的爬虫程序:
到目前为止,网易新闻的抓取方法已经被引入。我希望它对你有用
网页新闻抓取( Python3爬取新闻网站新闻列表到什么时候才是好的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-17 02:09
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
因为捕获的HTML文档相对较长,所以这里发布了一个简单的部分供您查看
..........后面省略一大堆
这是对Python3爬虫的简单介绍。这很简单吗?我建议你再敲几下
3、 Python3将抓取网页中的图片并将其保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待地想看看他们爬上了多美的画面
爬上去很容易就能得到24个女孩的照片。这不是很简单吗
4、 Python3爬行新闻网站news列表
这里有点复杂。让我们向您解释一下分布情况
分析我们想要在上图中捕获的信息,然后将其放入div中的a标记和img标记中,因此我们想要考虑的是如何获取这些信息
这里我们将使用导入的Beauty soup4库,以及这里的关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
以上代码获取的alllist就是我们想要获取的新闻列表。捕获的信息如下所示
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是被捕获的,但是太混乱了,还有很多我们不想要的东西。让我们通过遍历来优化我们的有效信息
这里添加了异常处理。主要原因是有些新闻可能没有标题、URL或图片。如果未完成异常处理,我们可能会中断爬网
###过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
在这里,我们抓取新闻网站新闻信息,就这样完成了。完整的代码发布在下面
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
当获得数据时,我们还需要将数据保存到数据库中。只要数据库中有数据,我们就可以进行以下数据分析和处理。我们还可以使用这些爬网的文章为应用程序提供新闻API接口。当然,这些都是以后的事了。在我自学了如何操作python数据库之后,我将编写一个文章@
视频说明:
过去回顾
Python 001~ Python开发工具pycharm(Mac和Windows)的安装和破解简介
开始使用Python 002~创建您的第一个Python项目
Python 012介绍~ Python 3零基础~将爬行数据保存到数据库中,用数据库去重复函数
Python 010~Python 3操作数据库简介借助pycharm快速连接和操作MySQL数据库
Python 020入门~抓取前程无忧的位置信息并存储在MySQL数据库中 查看全部
网页新闻抓取(
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
因为捕获的HTML文档相对较长,所以这里发布了一个简单的部分供您查看
..........后面省略一大堆
这是对Python3爬虫的简单介绍。这很简单吗?我建议你再敲几下
3、 Python3将抓取网页中的图片并将其保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待地想看看他们爬上了多美的画面
爬上去很容易就能得到24个女孩的照片。这不是很简单吗
4、 Python3爬行新闻网站news列表
这里有点复杂。让我们向您解释一下分布情况

分析我们想要在上图中捕获的信息,然后将其放入div中的a标记和img标记中,因此我们想要考虑的是如何获取这些信息
这里我们将使用导入的Beauty soup4库,以及这里的关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
以上代码获取的alllist就是我们想要获取的新闻列表。捕获的信息如下所示
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是被捕获的,但是太混乱了,还有很多我们不想要的东西。让我们通过遍历来优化我们的有效信息
这里添加了异常处理。主要原因是有些新闻可能没有标题、URL或图片。如果未完成异常处理,我们可能会中断爬网
###过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
在这里,我们抓取新闻网站新闻信息,就这样完成了。完整的代码发布在下面
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
当获得数据时,我们还需要将数据保存到数据库中。只要数据库中有数据,我们就可以进行以下数据分析和处理。我们还可以使用这些爬网的文章为应用程序提供新闻API接口。当然,这些都是以后的事了。在我自学了如何操作python数据库之后,我将编写一个文章@
视频说明:
过去回顾
Python 001~ Python开发工具pycharm(Mac和Windows)的安装和破解简介
开始使用Python 002~创建您的第一个Python项目
Python 012介绍~ Python 3零基础~将爬行数据保存到数据库中,用数据库去重复函数
Python 010~Python 3操作数据库简介借助pycharm快速连接和操作MySQL数据库
Python 020入门~抓取前程无忧的位置信息并存储在MySQL数据库中
网页新闻抓取(公司简介大渡河公司重构url流域已完成流域规划报告(咨询稿) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-17 02:07
)
一、公司简介
大渡河公司于2000年11月在成都高新区注册成立。其主要任务是在大渡河流域开发水电站,以龚嘴和铜街子为母电站。是国家能源集团旗下最大的集水电开发、建设、运营和管理于一体的大流域水电开发公司
目前,公司主要负责大渡河流域开发和西藏巴龙藏布盆地开发的前期准备工作。西藏大渡河干流及支流、巴龙藏布盆地水电资源约3000万千瓦。大渡河流域规划建设梯级水电站28座,总装机容量约2340万千瓦。该公司负责开发干流17座梯级水电站,涉及四川省三地两市(甘孜州、阿坝州、凉山州、雅安市、乐山市)12个县,总装机容量约1757万千瓦,形成生产、在建、准备稳步推进的可持续发展格局。巴龙藏布盆地已完成流域规划报告(咨询稿),初步规划“一库九级”方案,规划装机容量1142万千瓦。截至目前,公司总资产为910.68亿元,在四川投产安装,约占四川水电统一调度总装机容量的四分之一
二、需求分析
分析并统计网站新闻标题、作者、日期等信息,分析网站在线新闻的共性,即哪些类型的主题新闻更容易发布。此外,还可以对公司发表文章较多的作者进行分析,在一定程度上反映作者的水平
三、具体实施
1、使用Python爬虫技术获取公司网站新闻的相关信息
第一步是抓取URL:重建URL并将其放入多线程队列
url = 'http://www.spddr.com/spddr/index.jsp?id=360'
base_url = 'http://www.spddr.com/spddr/'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
第二步是解析URL:在多线程队列中获取重构后的URL并进行解析,最后将解析后的信息放入线程队列
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
步骤3:下载并保存信息:将解析后的信息从队列中取出,并执行下载和保存操作
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
四、所有代码如下所示
from lxml import etree
import requests
import csv
import random
from headers_list import headers_list
import threading
from queue import Queue
headers = {
'User-Agent':random.choice(headers_list),
'Cookie': 'JSESSIONID=91AFDB0A74FDB3DE1011B2E59CF99993; JSESSIONID=DD7458D1055A53D464AE8DF68400DE1F',
'Referer': '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
}
#定义一个Producter类,类名通常是大写开头的单词,它继承的是threading.Thread
class Producter(threading.Thread):
# 用init方法绑定属性,比如定义一个人的类,那你可以再定义人的属性,比如有手、有脚
def __init__(self,page_queue,writer_queue,*args,**kwargs):
super(Producter,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
def run(self):
while True:
try:
url = '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
base_url = '[http://www.spddr.com/spddr/](http://www.spddr.com/spddr/)'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
except:
print("解析网页出错")
#定义一个Consumer类,类名通常是大写开头的单词,它继承的是threading.Thread
class Consumer(threading.Thread):
def __init__(self,page_queue,writer_queue,glock,writer,*args,**kwargs):
super(Consumer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
self.glock = glock
self.writer = writer
def run(self):
while True:
try:
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
except:
print("提取信息出错!")
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
if __name__ == '__main__':
# 创建FIFO队列
page_queue = Queue(1000)
writer_queue = Queue(1000)
# 创建线程锁
glock = threading.Lock()
#csv表头信息
head = ['title', 'author', 'department', 'time']
#打开csv文件
fp = open('daduhe.csv', 'a', newline='', errors='ignore', encoding='utf-8')
#用字典方式写入表头信息
writer = csv.DictWriter(fp, head)
writer.writeheader()
for i in range(1,207):
data = {
'nowPage': i,
'totalpage': 206,
'id': 360,
'pages': i,
}
page_queue.put(data)
for x in range(10):
t = Producter(page_queue,writer_queue)#根据Producter类创建一个实例t的线程
t.start()#开启线程
for x in range(10):
t = Consumer(page_queue,writer_queue,glock,writer)#根据Producter类创建一个实例t的线程
t.start() 查看全部
网页新闻抓取(公司简介大渡河公司重构url流域已完成流域规划报告(咨询稿)
)
一、公司简介
大渡河公司于2000年11月在成都高新区注册成立。其主要任务是在大渡河流域开发水电站,以龚嘴和铜街子为母电站。是国家能源集团旗下最大的集水电开发、建设、运营和管理于一体的大流域水电开发公司
目前,公司主要负责大渡河流域开发和西藏巴龙藏布盆地开发的前期准备工作。西藏大渡河干流及支流、巴龙藏布盆地水电资源约3000万千瓦。大渡河流域规划建设梯级水电站28座,总装机容量约2340万千瓦。该公司负责开发干流17座梯级水电站,涉及四川省三地两市(甘孜州、阿坝州、凉山州、雅安市、乐山市)12个县,总装机容量约1757万千瓦,形成生产、在建、准备稳步推进的可持续发展格局。巴龙藏布盆地已完成流域规划报告(咨询稿),初步规划“一库九级”方案,规划装机容量1142万千瓦。截至目前,公司总资产为910.68亿元,在四川投产安装,约占四川水电统一调度总装机容量的四分之一
二、需求分析
分析并统计网站新闻标题、作者、日期等信息,分析网站在线新闻的共性,即哪些类型的主题新闻更容易发布。此外,还可以对公司发表文章较多的作者进行分析,在一定程度上反映作者的水平
三、具体实施
1、使用Python爬虫技术获取公司网站新闻的相关信息
第一步是抓取URL:重建URL并将其放入多线程队列
url = 'http://www.spddr.com/spddr/index.jsp?id=360'
base_url = 'http://www.spddr.com/spddr/'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
第二步是解析URL:在多线程队列中获取重构后的URL并进行解析,最后将解析后的信息放入线程队列
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
步骤3:下载并保存信息:将解析后的信息从队列中取出,并执行下载和保存操作
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
四、所有代码如下所示
from lxml import etree
import requests
import csv
import random
from headers_list import headers_list
import threading
from queue import Queue
headers = {
'User-Agent':random.choice(headers_list),
'Cookie': 'JSESSIONID=91AFDB0A74FDB3DE1011B2E59CF99993; JSESSIONID=DD7458D1055A53D464AE8DF68400DE1F',
'Referer': '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
}
#定义一个Producter类,类名通常是大写开头的单词,它继承的是threading.Thread
class Producter(threading.Thread):
# 用init方法绑定属性,比如定义一个人的类,那你可以再定义人的属性,比如有手、有脚
def __init__(self,page_queue,writer_queue,*args,**kwargs):
super(Producter,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
def run(self):
while True:
try:
url = '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
base_url = '[http://www.spddr.com/spddr/](http://www.spddr.com/spddr/)'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
except:
print("解析网页出错")
#定义一个Consumer类,类名通常是大写开头的单词,它继承的是threading.Thread
class Consumer(threading.Thread):
def __init__(self,page_queue,writer_queue,glock,writer,*args,**kwargs):
super(Consumer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
self.glock = glock
self.writer = writer
def run(self):
while True:
try:
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
except:
print("提取信息出错!")
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
if __name__ == '__main__':
# 创建FIFO队列
page_queue = Queue(1000)
writer_queue = Queue(1000)
# 创建线程锁
glock = threading.Lock()
#csv表头信息
head = ['title', 'author', 'department', 'time']
#打开csv文件
fp = open('daduhe.csv', 'a', newline='', errors='ignore', encoding='utf-8')
#用字典方式写入表头信息
writer = csv.DictWriter(fp, head)
writer.writeheader()
for i in range(1,207):
data = {
'nowPage': i,
'totalpage': 206,
'id': 360,
'pages': i,
}
page_queue.put(data)
for x in range(10):
t = Producter(page_queue,writer_queue)#根据Producter类创建一个实例t的线程
t.start()#开启线程
for x in range(10):
t = Consumer(page_queue,writer_queue,glock,writer)#根据Producter类创建一个实例t的线程
t.start()
网页新闻抓取(PythonGPU资源利用-pythonPython脚本在某些深度学习模型上运行推理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-06 05:12
给定一个新闻 文章 网页(来自任何主要新闻来源,例如 Times 或 Bloomberg),我想确定该页面上的主要 文章 内容并排除其他杂项元素,例如广告、菜单、侧边栏,用户评论。
有没有什么通用的方法可以用在大多数重大新闻网站上?
有没有好的数据挖掘工具或库?(最好是基于python的)
参考计划
不能保证这是可能的,但您可能使用的一种策略是尝试查找收录最可见文本的元素。
Python GPU资源利用-python
我有一个 Python 脚本来对某些深度学习模型运行推理。有什么办法可以查到GPU资源的利用率?例如,使用着色器、float16 乘法器等。我似乎无法在互联网上找到关于这些 GPU 资源的太多文档。谢谢!作为参考,您可以尝试在像 Renderdoc 这样的 GPU 分析器中运行 pyxthon 应用程序。它会分析你的跑步情况。您将能够获得有关已用资源、已用缓冲区、不同渲染状态的信息...
Python:图像处理可以产生皱纹纸效果-python
可能很难描述我的问题。我正在 Python 中寻找一种算法来在带有特定文本的白色图像上创建皱纹纸效果。我的第一次尝试是将一些真正的皱纹纸图像(具有透明度)添加到带有文本的图像中。看起来不错,但副作用是文字并没有真正起皱。所以我正在寻找更好的解决方案,有什么想法吗?谢谢参考。除了使用透明度,假设您有两张相同大小的图像,一张在皱纹纸上亮,一张在白色背景上暗...
Python uuid4,如何限制唯一字符的长度-python
在 Python 中,我使用 uuid4() 方法来创建唯一的字符集。但是我找不到将其限制为 10 或 8 个字符的方法。解决办法是什么?uuid4()ffc69c1b-9d87-4c19-8dac-c09ca857e3fc 谢谢。参考解决方案尝试:x = uuid4() str(x)[:8] 输出:"ffc69c1b" 有没有办法...
Python sqlite3 数据库被锁定-python
我在 Windows 上使用 Python 3 和 sqlite3。我正在开发一个使用数据库来存储联系人的小应用程序。我注意到如果应用程序被强行关闭(通过错误或通过任务管理器),您将收到一个 sqlite3 错误(sqlite3.OperationalError: database is locked)。我认为这是因为我在关闭应用程序之前没有正确关闭数据库连接。我试过:连接...
Python:如何停止多线程 numpy?-Python
我知道这似乎是一个荒谬的问题,但我必须在与部门其他人共享的计算服务器上定期运行作业,当我开始 10 个作业时,我真的希望它只占用 10 个内核而不是更多;我不在乎每次运行内核是否需要更长的时间:我只是不希望它侵入其他人的领土,这将要求我放弃工作等等。我只想拥有 10 个内核,仅此而已。更具体地说,我在 Redh 中使用 Python 2.7.3 和 numpy 1.6.1 ... 查看全部
网页新闻抓取(PythonGPU资源利用-pythonPython脚本在某些深度学习模型上运行推理)
给定一个新闻 文章 网页(来自任何主要新闻来源,例如 Times 或 Bloomberg),我想确定该页面上的主要 文章 内容并排除其他杂项元素,例如广告、菜单、侧边栏,用户评论。
有没有什么通用的方法可以用在大多数重大新闻网站上?
有没有好的数据挖掘工具或库?(最好是基于python的)
参考计划
不能保证这是可能的,但您可能使用的一种策略是尝试查找收录最可见文本的元素。
Python GPU资源利用-python
我有一个 Python 脚本来对某些深度学习模型运行推理。有什么办法可以查到GPU资源的利用率?例如,使用着色器、float16 乘法器等。我似乎无法在互联网上找到关于这些 GPU 资源的太多文档。谢谢!作为参考,您可以尝试在像 Renderdoc 这样的 GPU 分析器中运行 pyxthon 应用程序。它会分析你的跑步情况。您将能够获得有关已用资源、已用缓冲区、不同渲染状态的信息...
Python:图像处理可以产生皱纹纸效果-python
可能很难描述我的问题。我正在 Python 中寻找一种算法来在带有特定文本的白色图像上创建皱纹纸效果。我的第一次尝试是将一些真正的皱纹纸图像(具有透明度)添加到带有文本的图像中。看起来不错,但副作用是文字并没有真正起皱。所以我正在寻找更好的解决方案,有什么想法吗?谢谢参考。除了使用透明度,假设您有两张相同大小的图像,一张在皱纹纸上亮,一张在白色背景上暗...
Python uuid4,如何限制唯一字符的长度-python
在 Python 中,我使用 uuid4() 方法来创建唯一的字符集。但是我找不到将其限制为 10 或 8 个字符的方法。解决办法是什么?uuid4()ffc69c1b-9d87-4c19-8dac-c09ca857e3fc 谢谢。参考解决方案尝试:x = uuid4() str(x)[:8] 输出:"ffc69c1b" 有没有办法...
Python sqlite3 数据库被锁定-python
我在 Windows 上使用 Python 3 和 sqlite3。我正在开发一个使用数据库来存储联系人的小应用程序。我注意到如果应用程序被强行关闭(通过错误或通过任务管理器),您将收到一个 sqlite3 错误(sqlite3.OperationalError: database is locked)。我认为这是因为我在关闭应用程序之前没有正确关闭数据库连接。我试过:连接...
Python:如何停止多线程 numpy?-Python
我知道这似乎是一个荒谬的问题,但我必须在与部门其他人共享的计算服务器上定期运行作业,当我开始 10 个作业时,我真的希望它只占用 10 个内核而不是更多;我不在乎每次运行内核是否需要更长的时间:我只是不希望它侵入其他人的领土,这将要求我放弃工作等等。我只想拥有 10 个内核,仅此而已。更具体地说,我在 Redh 中使用 Python 2.7.3 和 numpy 1.6.1 ...
网页新闻抓取(【web实战篇】批量挂黑页新闻源网站被植入 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-04 19:26
)
慧智知教堂:【网络实战篇】网站被植入Webshell
慧智识故事:【网络实战】门罗币恶意挖矿
慧智知堂:【网络实战篇】批量黑页
新闻来源网站一般权重较高,收录速度快,可以被搜索引擎优先排序收录。黑灰产品推广引流必看,容易被攻击。被黑后,不良信息的主要内容主要是彩票马克六等赌博内容。新闻源网站程序,无论是自研还是开源程序,都容易被黑,开源程序更容易被黑。
症状:
某新闻源网站首页广告链接被劫持到菠菜网站
广告主题一共三个,链接形式如下:
/zhuanti/yyysc/index.shtml
/zhuanti/wwwsc/index.shtml
/zhuanti/zzzsc/index.shtml
单击这三个链接将跳转到 Gaming网站。简单地捕获和分析过程:
可以发现此时这个返回页面已经被劫持了,并且已经加载了第三方js文件/N/js/dt.js,进一步访问该文件:
dt.js 进一步加载另一个 js,访问 /N/js/yz.js
我们发现链接跳转到了/?dt,进一步访问这个链接,网站是赌博链接的导航网站,访问后会随机跳转到第三方赌博< @网站。
问题处理:
找到url对应的文件位置。即使文件被删除,链接仍然可以访问。可以发现三个链接都是以“sc”为后缀的。
检查Nginx配置文件,发现Nginx配置文件VirtualHost.conf被篡改。带有“sc”后缀的特殊链接通过反向代理匹配并被劫持。网站是游戏链接导航网站。
删除恶意代理后,恢复特殊链接访问。
今天就分享到这里,下期分享《第五篇:移动终端劫持》,记得关注+点赞哦~
查看全部
网页新闻抓取(【web实战篇】批量挂黑页新闻源网站被植入
)
慧智知教堂:【网络实战篇】网站被植入Webshell
慧智识故事:【网络实战】门罗币恶意挖矿
慧智知堂:【网络实战篇】批量黑页
新闻来源网站一般权重较高,收录速度快,可以被搜索引擎优先排序收录。黑灰产品推广引流必看,容易被攻击。被黑后,不良信息的主要内容主要是彩票马克六等赌博内容。新闻源网站程序,无论是自研还是开源程序,都容易被黑,开源程序更容易被黑。
症状:
某新闻源网站首页广告链接被劫持到菠菜网站
广告主题一共三个,链接形式如下:
/zhuanti/yyysc/index.shtml
/zhuanti/wwwsc/index.shtml
/zhuanti/zzzsc/index.shtml
单击这三个链接将跳转到 Gaming网站。简单地捕获和分析过程:
可以发现此时这个返回页面已经被劫持了,并且已经加载了第三方js文件/N/js/dt.js,进一步访问该文件:
dt.js 进一步加载另一个 js,访问 /N/js/yz.js
我们发现链接跳转到了/?dt,进一步访问这个链接,网站是赌博链接的导航网站,访问后会随机跳转到第三方赌博< @网站。
问题处理:
找到url对应的文件位置。即使文件被删除,链接仍然可以访问。可以发现三个链接都是以“sc”为后缀的。
检查Nginx配置文件,发现Nginx配置文件VirtualHost.conf被篡改。带有“sc”后缀的特殊链接通过反向代理匹配并被劫持。网站是游戏链接导航网站。
删除恶意代理后,恢复特殊链接访问。
今天就分享到这里,下期分享《第五篇:移动终端劫持》,记得关注+点赞哦~
网页新闻抓取( 【每日一题】新浪新闻为例(二):反爬机制 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 437 次浏览 • 2021-10-04 19:24
【每日一题】新浪新闻为例(二):反爬机制
)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
现在各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果
查看全部
网页新闻抓取(
【每日一题】新浪新闻为例(二):反爬机制
)
前言
本文文字及图片均来自网络,仅供学习交流之用。它们没有任何商业用途。版权属于原作者。如果您有任何问题,请联系我们进行处理。
现在各大网站的反爬机制可以说是疯狂了,比如大众点评的字符加密、微博登录验证等。相比之下,新闻网站的反爬机制稍微弱一些。所以今天我就以新浪新闻为例,分析一下如何使用Python爬虫按关键词抓取相关新闻。
首先,如果直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们要从新浪首页搜索,这样就没有页数限制了。
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网并进行关键字搜索后,我发现页面的URL无论如何都不会改变,但页面内容已经更新。经验告诉我,这是通过ajax完成的,所以我把新浪网页的代码拿下来看了看。看。
显然,每次翻页时,都会通过单击 a 标签向地址发送请求。如果你直接把这个地址放到浏览器的地址栏中,按回车:
恭喜,我遇到了错误
仔细查看html的onclick,发现它调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它在每次ajax请求之前都构造了请求的url,并且使用了getRequest,返回数据格式为jsonp(跨域)。
所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;
function getNewsData(url){
var oldurl = url;
if(!key){
$("#result").html("无搜索热词");
return false;
}
if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":"1",
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
print(response)
这次我使用了requests库,构造了相同的url,并发送了请求。收到的结果是一个冷的403 Forbidden:
所以回到网站看看哪里出了问题
在开发者工具中找到返回的json文件,查看请求头,发现它的请求头中收录一个cookie,所以我们在构造头时直接复制它的请求头即可。再次运行,response200!剩下的就简单了,解析返回的数据,写入Excel即可。
完整代码
import requests
import json
import xlwt
def getData(page, news):
headers = {
"Host": "interface.sina.cn",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,
"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default",
"TE": "Trailers"
}
params = {
"t":"",
"q":"旅游",
"pf":"0",
"ps":"0",
"page":page,
"stime":"2019-03-30",
"etime":"2020-03-31",
"sort":"rel",
"highlight":"1",
"num":"10",
"ie":"utf-8"
}
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"]
return news
def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址")
for i in range(len(news)):
print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls')
def main():
news = []
for i in range(1,501):
news = getData(i, news)
writeData(news)
if __name__ == '__main__':
main()
最后结果
网页新闻抓取(新闻爬虫及爬取结果查询网站的搭建(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-01 02:25
新闻爬虫构建及爬取结果查询网站(一)
实验要求 核心要求
1、选择3-5条代表性新闻网站(如新浪新闻、网易新闻等,或垂直领域的权威网站,如经济领域的雪球财经、东方)财富等,或体育领域的腾讯体育、虎扑体育等)建立爬虫分析网站的不同新闻页面,爬取代码、标题、作者、时间、关键词 、摘要、结构化信息如内容和来源存储在数据库中。
2、建立网站,提供对爬取内容的子项全文搜索,并给出搜索到的关键词的时间流行度分析。
技能要求
1、 必须使用Node.JS来实现网络爬虫
2、必须使用Node.JS实现查询。网站后端,HTML+JS实现前端(尽量不要使用任何前后端框架)
爬行动物准备
一共选择了三个新闻网站进行抓取,分别是中国财经网、雪球网、东方财富网,抓取结果存储在postgresql中。
在本次实验中,基于 Node.js 的 Cheerio 和 Request 实现了一个爬虫。下面将详细介绍基础环境搭配、各个爬虫的实现、功能实现过程等。
Node.js 安装和配置
Node.js 官网:
安装非常简单,只要跟着一点点就行了。
vscode
Visual Studio Code(以下简称 vscode)是一个轻量级且功能强大的跨平台开源代码编辑器(IDE),支持 Windows、OS X 和 Linux。内置JavaScript、TypeScript和Node.js支持,拥有丰富的插件生态,可以安装插件支持C++、C#、Python、PHP等多种语言。
在这个实验中,我使用了 vscode 来调试 node.js。
可以参考官网:
要求
Request 也是一个 Node.js 模块库,可以轻松完成 http 请求。
安装
npm install request 的基本用法:
本次实验中,新闻页面主要通过请求获取。主要使用其默认的 GET 方法。
var request = require('request');
request('url', function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body) // 请求成功的处理逻辑
}
});
Cheerio 解析 HTML 简介(加载)
首先需要手动加载html文档,使用方法如下,其他更多加载方法可以参考官方文档
var cheerio = require('cheerio'),
$ = cheerio.load('...');
选择器
Cheerio 选择器几乎与 jQuery 相同。选择器是文档遍历和操作的起点。与在 jQuery 中一样,它是选择元素节点的最重要方法,但在 jQuery 中,选择器建立在 CSS 选择器标准库之上。
在本实验中,主要使用以下选择器方法。
选择页面上的所有超链接。首先获取页面中的所有标签,然后遍历获取其href属性的值,具体部分代码如下:
try {
seedurl_news = $('a');
} catch (e) { console.log('url列表所处的html块识别出错:' + e) };
seedurl_news.each(function(){
try {
var href = "";
href = $(this).attr('href'); //获取href属性
}catch(e) {
console.log('get the seed url err' + e);
}
}
根据指定的类属性名称进行选择。注意类名有空格时,改成.,示例代码如下:
$('.source.data-source')
如果要选择某个标签下它的子标签的内容,但是它的子标签没有唯一的类名或者id对应,可以使用.children(selector)来选择它的子节点,eq()就是选择几个子节点,从0开始。示例代码如下:
$('.article-meta').children().eq(1).text();
数据库存储 查看全部
网页新闻抓取(新闻爬虫及爬取结果查询网站的搭建(一))
新闻爬虫构建及爬取结果查询网站(一)
实验要求 核心要求
1、选择3-5条代表性新闻网站(如新浪新闻、网易新闻等,或垂直领域的权威网站,如经济领域的雪球财经、东方)财富等,或体育领域的腾讯体育、虎扑体育等)建立爬虫分析网站的不同新闻页面,爬取代码、标题、作者、时间、关键词 、摘要、结构化信息如内容和来源存储在数据库中。
2、建立网站,提供对爬取内容的子项全文搜索,并给出搜索到的关键词的时间流行度分析。
技能要求
1、 必须使用Node.JS来实现网络爬虫
2、必须使用Node.JS实现查询。网站后端,HTML+JS实现前端(尽量不要使用任何前后端框架)
爬行动物准备
一共选择了三个新闻网站进行抓取,分别是中国财经网、雪球网、东方财富网,抓取结果存储在postgresql中。
在本次实验中,基于 Node.js 的 Cheerio 和 Request 实现了一个爬虫。下面将详细介绍基础环境搭配、各个爬虫的实现、功能实现过程等。
Node.js 安装和配置
Node.js 官网:
安装非常简单,只要跟着一点点就行了。
vscode
Visual Studio Code(以下简称 vscode)是一个轻量级且功能强大的跨平台开源代码编辑器(IDE),支持 Windows、OS X 和 Linux。内置JavaScript、TypeScript和Node.js支持,拥有丰富的插件生态,可以安装插件支持C++、C#、Python、PHP等多种语言。
在这个实验中,我使用了 vscode 来调试 node.js。
可以参考官网:
要求
Request 也是一个 Node.js 模块库,可以轻松完成 http 请求。
安装
npm install request 的基本用法:
本次实验中,新闻页面主要通过请求获取。主要使用其默认的 GET 方法。
var request = require('request');
request('url', function (error, response, body) {
if (!error && response.statusCode == 200) {
console.log(body) // 请求成功的处理逻辑
}
});
Cheerio 解析 HTML 简介(加载)
首先需要手动加载html文档,使用方法如下,其他更多加载方法可以参考官方文档
var cheerio = require('cheerio'),
$ = cheerio.load('...');
选择器
Cheerio 选择器几乎与 jQuery 相同。选择器是文档遍历和操作的起点。与在 jQuery 中一样,它是选择元素节点的最重要方法,但在 jQuery 中,选择器建立在 CSS 选择器标准库之上。
在本实验中,主要使用以下选择器方法。
选择页面上的所有超链接。首先获取页面中的所有标签,然后遍历获取其href属性的值,具体部分代码如下:
try {
seedurl_news = $('a');
} catch (e) { console.log('url列表所处的html块识别出错:' + e) };
seedurl_news.each(function(){
try {
var href = "";
href = $(this).attr('href'); //获取href属性
}catch(e) {
console.log('get the seed url err' + e);
}
}
根据指定的类属性名称进行选择。注意类名有空格时,改成.,示例代码如下:
$('.source.data-source')
如果要选择某个标签下它的子标签的内容,但是它的子标签没有唯一的类名或者id对应,可以使用.children(selector)来选择它的子节点,eq()就是选择几个子节点,从0开始。示例代码如下:
$('.article-meta').children().eq(1).text();
数据库存储
网页新闻抓取(如何用Python新闻利用BeautifulSoup分析HTML的应用?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-01 02:24
每天坐地铁上班,地铁信号差。但是我想一边坐地铁一边看新闻,所以写了下面这个新闻爬虫。没打算做一个漂亮的应用,所以只完成了原型,可以满足我最基本的需求。这个想法很简单:
寻找新闻来源;使用Python抓取新闻;使用 BeautifulSoup 分析 HTML 并提取内容;将其转换为易于阅读的格式并通过电子邮件发送。
下面详细介绍各个部分的实现。
新闻来源:Reddit
我们可以通过 Reddit 提交新闻链接并投票,所以 Reddit 是一个很好的新闻来源。但接下来的问题是:我们如何才能每天获得最热门的新闻?在考虑爬取之前,首先要考虑目标网站是否提供了API。因为使用 API 是完全合法的,更重要的是它可以提供机器可读的数据,所以不需要分析 HTML。幸运的是,Reddit 提供了一个 API。我们可以从 API 列表中找到所需的函数:/top。此函数可以返回 Reddit 或指定 subreddit 上最流行的新闻。下一个问题是:如何使用这个API?仔细阅读Reddit文档后,我发现了最有效的用法。第 1 步:在 Reddit 上创建一个应用程序。登录后,进入“偏好设置→应用程序”页面,有一个名为“的按钮”
创建应用后,可以在应用信息中找到App ID和Secret。
接下来的问题是如何使用App ID和Secret。由于我们只需要获取指定SubReddit上最热门的新闻,而无需访问任何与用户相关的信息,因此理论上我们不需要提供用户名或密码等个人信息。Reddit 提供了“Application Only OAuth”(#application-only-oauth)的形式。通过这种方式,应用程序可以匿名访问公共信息。运行以下命令:
$ curl -X POST -H 'User-Agent: myawesomeapp/1.0' -d grant_type=client_credentials --user 'OUR_CLIENT_ID:OUR_CLIENT_SECRET' https://www.reddit.com/api/v1/access_token
此命令将返回访问令牌:
{"access_token": "ABCDEFabcdef0123456789", "token_type": "bearer", "expires_in": 3600, "scope": "*"}
伟大的!获得访问令牌后,您就可以大展身手了。最后,如果不想自己写API访问代码,可以使用Python客户端:先做个测试,从/r/Python获取5条最流行的消息:
>>> import praw >>> import pprint >>> reddit = praw.Reddit(client_id='OUR_CLIENT_ID', ... client_secret='OUR_SECRET', ... grant_type='client_credentials', ... user_agent='mytestscript/1.0') >>> subs = reddit.subreddit('Python').top(limit=5) >>> pprint.pprint([(s.score, s.title) for s in subs]) [(6555, 'Automate the boring stuff with python - tinder'), (4548, 'MS is considering official Python integration with Excel, and is asking for ' 'input'), (4102, 'Python Cheet Sheet for begineers'), (3285, 'We started late, but we managed to leave Python footprint on r/place!'), (2899, "Python Section at Foyle's, London")]
它成功了!
抓取新闻页面
接下来的任务是抓取新闻页面,其实很简单。通过上一步,我们可以得到Submission对象,其URL属性就是新闻的地址。我们还可以通过 domain 属性过滤掉属于 Reddit 的 URL:
subs = [sub for sub in subs if not sub.domain.startswith('self.')]
我们只需要抓取 URL,这可以通过 Requests 轻松完成:
for sub in subs: res = requests.get(sub.url) if (res.status_code == 200 and 'content-type' in res.headers and res.headers.get('content-type').startswith('text/html')): html = res.text
这里我们跳过了内容类型不是 text/html 的新闻地址,因为 Reddit 用户可能会提交直接指向图片的链接,而我们不需要这个。
提取新闻内容
下一步是从 HTML 中提取内容。我们的目标是提取新闻的标题和正文,可以忽略其他不需要阅读的内容,例如页眉、页脚、侧边栏等。这项工作很难,没有通用的解决方案。虽然 BeautifulSoup 可以帮助我们提取文本内容,但它会一起提取第一页页脚。幸运的是,我发现网站的当前结构比以前好很多。没有表格布局,没有总和
, 整个 文章 页面清楚地使用和
标题和每个段落都有标记。而大多数 网站 会将标题和正文放在同一个容器元素中,例如,像这样:
Site Navigation Page Title <p>Paragraph 1
Paragraph 2 Sidebar Copyright... </p>
本例中的顶级
它是标题和正文的容器。因此,您可以使用以下算法来查找文本:
虽然这个算法很初级,没有考虑任何语义信息,但它是完全可行的。毕竟当算法失败时,只需要忽略文章,少读一个文章。没什么大不了的……当然你可以通过解析来实现,或者#main、.sidebar等语义元素。实现更准确的算法。使用此算法,您可以轻松编写解析代码:
soup = BeautifulSoup(text, 'html.parser') # find the article title h1 = soup.body.find('h1') # find the common parent for and all <p>s. root = h1 while root.name != 'body' and len(root.find_all('p')) done, title = "SMS Spoofing with Python for Good and Evil" ...
抓取的新闻文件:
最后要做的就是把这个脚本放到服务器上,设置cronjob每天运行一次,然后把生成的文件发送到我的邮箱。我没有花太多时间去关注细节,所以其实这个脚本还有很多需要改进的地方。如果有兴趣,可以继续添加更多功能,比如提取图片。
【编辑推荐】
为什么程序员和开发者应该在 2020 年学习 Python 魔术操作:教你使用 Python 识别恶意软件以及为什么你的 Python 代码应该是扁平和稀疏的。使用 Python 构建您自己的 Markdown 编辑器。Python炫操作(02):七种合并字典的方法 查看全部
网页新闻抓取(如何用Python新闻利用BeautifulSoup分析HTML的应用?(组图))
每天坐地铁上班,地铁信号差。但是我想一边坐地铁一边看新闻,所以写了下面这个新闻爬虫。没打算做一个漂亮的应用,所以只完成了原型,可以满足我最基本的需求。这个想法很简单:
寻找新闻来源;使用Python抓取新闻;使用 BeautifulSoup 分析 HTML 并提取内容;将其转换为易于阅读的格式并通过电子邮件发送。
下面详细介绍各个部分的实现。
新闻来源:Reddit
我们可以通过 Reddit 提交新闻链接并投票,所以 Reddit 是一个很好的新闻来源。但接下来的问题是:我们如何才能每天获得最热门的新闻?在考虑爬取之前,首先要考虑目标网站是否提供了API。因为使用 API 是完全合法的,更重要的是它可以提供机器可读的数据,所以不需要分析 HTML。幸运的是,Reddit 提供了一个 API。我们可以从 API 列表中找到所需的函数:/top。此函数可以返回 Reddit 或指定 subreddit 上最流行的新闻。下一个问题是:如何使用这个API?仔细阅读Reddit文档后,我发现了最有效的用法。第 1 步:在 Reddit 上创建一个应用程序。登录后,进入“偏好设置→应用程序”页面,有一个名为“的按钮”
创建应用后,可以在应用信息中找到App ID和Secret。
接下来的问题是如何使用App ID和Secret。由于我们只需要获取指定SubReddit上最热门的新闻,而无需访问任何与用户相关的信息,因此理论上我们不需要提供用户名或密码等个人信息。Reddit 提供了“Application Only OAuth”(#application-only-oauth)的形式。通过这种方式,应用程序可以匿名访问公共信息。运行以下命令:
$ curl -X POST -H 'User-Agent: myawesomeapp/1.0' -d grant_type=client_credentials --user 'OUR_CLIENT_ID:OUR_CLIENT_SECRET' https://www.reddit.com/api/v1/access_token
此命令将返回访问令牌:
{"access_token": "ABCDEFabcdef0123456789", "token_type": "bearer", "expires_in": 3600, "scope": "*"}
伟大的!获得访问令牌后,您就可以大展身手了。最后,如果不想自己写API访问代码,可以使用Python客户端:先做个测试,从/r/Python获取5条最流行的消息:
>>> import praw >>> import pprint >>> reddit = praw.Reddit(client_id='OUR_CLIENT_ID', ... client_secret='OUR_SECRET', ... grant_type='client_credentials', ... user_agent='mytestscript/1.0') >>> subs = reddit.subreddit('Python').top(limit=5) >>> pprint.pprint([(s.score, s.title) for s in subs]) [(6555, 'Automate the boring stuff with python - tinder'), (4548, 'MS is considering official Python integration with Excel, and is asking for ' 'input'), (4102, 'Python Cheet Sheet for begineers'), (3285, 'We started late, but we managed to leave Python footprint on r/place!'), (2899, "Python Section at Foyle's, London")]
它成功了!
抓取新闻页面
接下来的任务是抓取新闻页面,其实很简单。通过上一步,我们可以得到Submission对象,其URL属性就是新闻的地址。我们还可以通过 domain 属性过滤掉属于 Reddit 的 URL:
subs = [sub for sub in subs if not sub.domain.startswith('self.')]
我们只需要抓取 URL,这可以通过 Requests 轻松完成:
for sub in subs: res = requests.get(sub.url) if (res.status_code == 200 and 'content-type' in res.headers and res.headers.get('content-type').startswith('text/html')): html = res.text
这里我们跳过了内容类型不是 text/html 的新闻地址,因为 Reddit 用户可能会提交直接指向图片的链接,而我们不需要这个。
提取新闻内容
下一步是从 HTML 中提取内容。我们的目标是提取新闻的标题和正文,可以忽略其他不需要阅读的内容,例如页眉、页脚、侧边栏等。这项工作很难,没有通用的解决方案。虽然 BeautifulSoup 可以帮助我们提取文本内容,但它会一起提取第一页页脚。幸运的是,我发现网站的当前结构比以前好很多。没有表格布局,没有总和
, 整个 文章 页面清楚地使用和
标题和每个段落都有标记。而大多数 网站 会将标题和正文放在同一个容器元素中,例如,像这样:
Site Navigation Page Title <p>Paragraph 1
Paragraph 2 Sidebar Copyright... </p>
本例中的顶级
它是标题和正文的容器。因此,您可以使用以下算法来查找文本:
虽然这个算法很初级,没有考虑任何语义信息,但它是完全可行的。毕竟当算法失败时,只需要忽略文章,少读一个文章。没什么大不了的……当然你可以通过解析来实现,或者#main、.sidebar等语义元素。实现更准确的算法。使用此算法,您可以轻松编写解析代码:
soup = BeautifulSoup(text, 'html.parser') # find the article title h1 = soup.body.find('h1') # find the common parent for and all <p>s. root = h1 while root.name != 'body' and len(root.find_all('p')) done, title = "SMS Spoofing with Python for Good and Evil" ...
抓取的新闻文件:
最后要做的就是把这个脚本放到服务器上,设置cronjob每天运行一次,然后把生成的文件发送到我的邮箱。我没有花太多时间去关注细节,所以其实这个脚本还有很多需要改进的地方。如果有兴趣,可以继续添加更多功能,比如提取图片。
【编辑推荐】
为什么程序员和开发者应该在 2020 年学习 Python 魔术操作:教你使用 Python 识别恶意软件以及为什么你的 Python 代码应该是扁平和稀疏的。使用 Python 构建您自己的 Markdown 编辑器。Python炫操作(02):七种合并字典的方法
网页新闻抓取(阿里巴巴的网页源代码提取新闻信息的基本方法(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 298 次浏览 • 2021-10-01 02:23
)
百度新闻信息抓取
内容
前言
通过对百度新闻标题、链接、日期和来源的爬取,了解使用python语言爬取少量数据的基本方法。
获取在百度新闻中搜索“阿里巴巴”的网页源代码
为了获取请求头,我们可以在谷歌浏览器的地址栏中输入 about:version 来获取请求头。
除了请求头,我们还需要构造url。
在网页上输入阿里巴巴,然后在地址栏中找到url,通过简化url得到这样一个url---->阿里巴巴。
有了请求头,我们就可以写基本的爬虫代码了,呵呵。
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
print(res)
部分结果如下:
// 回馈
设置超时(功能(){
var s = document.createElement("脚本");
s.charset="utf-8";
s.src="";
document.body.appendChild(s);
},0);
编写正则表达式提取新闻信息
有了源码,我们必须分析源码,才能提取出下面新闻的来源和日期。
我发现新闻的标题、链接、日期都在“p class="c-author"下面,所以我知道怎么提取了。
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
info = re.findall(p_info, res, re.S)
print(info)
</p>
代码结果收录\n、\t、
同样的,我们用同样的方法,通过正则表达式获取特定的标题和链接。
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_href = '.*?(.*?)'
title = re.findall(p_title, res, re.S)
print("链接是:", '\n', href)
print("标题是:", '\n', title)
结果:
数据清洗和打印
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
info = re.findall(p_info, res, re.S)
# 新闻来源和日期清洗
for i in range(len(info)):
info[i].split(' ')
info[i] = re.sub('', '', info[i])
p_href = '.*?(.*?)'
title = re.findall(p_title, res, re.S)
# 新闻标题清洗----strip()->除去不需要的空格和换行符、.*?->代替文本之间的所有内容,清洗掉
for i in range(len(title)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
print("日期是:", '\n', info)
print("链接是:", '\n', href)
print("标题是:", '\n', title)
</p>
结果(缺陷:日期未清洗):
实战完整代码
先介绍爬取新闻标题、日期、链接的完整代码:
# 1.批量爬取一家公司的多页信息
def baidu(page):
import requests
import re
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
num = (page - 1) * 10
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴&Ppn=' + str(num)
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
p_href = '.*?(.*?)'
info = re.findall(p_info, res, re.S)
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
source = [] # 先创建两个空列表来储存等会分割后的来源和日期
date = []
for i in range(len(info)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
info[i] = re.sub('', '', info[i])
source.append(info[i].split(' ')[0])
date.append(info[i].split(' ')[1])
source[i] = source[i].strip()
date[i] = date[i].strip()
print(str(i + 1) + '.' + title[i] + '(' + date[i] + '-' + source[i] + ')')
print(href[i])
for i in range(10): # i是从0开始的序号,所以下面要写成i+1
baidu(i+1)
print('第' + str(i+1) + '页爬取成功')
</p>
结果:
然后介绍爬取多个公司新闻的标题、日期、链接的代码:
import requests
import re
def baidu(company):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... 39%3B + company
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
p_href = '.*?(.*?)'
info = re.findall(p_info, res, re.S)
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
source = [] # 先创建两个空列表来储存等会分割后的来源和日期
date = []
for i in range(len(info)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
info[i] = re.sub('', '', info[i])
source.append(info[i].split(' ')[0])
date.append(info[i].split(' ')[1])
source[i] = source[i].strip()
date[i] = date[i].strip()
print(str(i + 1) + '.' + title[i] + '(' + date[i] + '-' + source[i] + ')')
print(href[i])
while True: # 24小时不间断爬取
companys = ['华能信托', '阿里巴巴', '万科集团', '百度', '腾讯', '京东']
for i in companys:
try:
baidu(i)
print(i + '百度新闻爬取成功')
except:
print(i + '百度新闻爬取失败')
</p>
部分结果如下图所示:
查看全部
网页新闻抓取(阿里巴巴的网页源代码提取新闻信息的基本方法(图)
)
百度新闻信息抓取
内容
前言
通过对百度新闻标题、链接、日期和来源的爬取,了解使用python语言爬取少量数据的基本方法。
获取在百度新闻中搜索“阿里巴巴”的网页源代码
为了获取请求头,我们可以在谷歌浏览器的地址栏中输入 about:version 来获取请求头。
除了请求头,我们还需要构造url。
在网页上输入阿里巴巴,然后在地址栏中找到url,通过简化url得到这样一个url---->阿里巴巴。
有了请求头,我们就可以写基本的爬虫代码了,呵呵。
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
print(res)
部分结果如下:
// 回馈
设置超时(功能(){
var s = document.createElement("脚本");
s.charset="utf-8";
s.src="";
document.body.appendChild(s);
},0);
编写正则表达式提取新闻信息
有了源码,我们必须分析源码,才能提取出下面新闻的来源和日期。
我发现新闻的标题、链接、日期都在“p class="c-author"下面,所以我知道怎么提取了。
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
info = re.findall(p_info, res, re.S)
print(info)
</p>
代码结果收录\n、\t、
同样的,我们用同样的方法,通过正则表达式获取特定的标题和链接。
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_href = '.*?(.*?)'
title = re.findall(p_title, res, re.S)
print("链接是:", '\n', href)
print("标题是:", '\n', title)
结果:
数据清洗和打印
import requests
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴'
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
info = re.findall(p_info, res, re.S)
# 新闻来源和日期清洗
for i in range(len(info)):
info[i].split(' ')
info[i] = re.sub('', '', info[i])
p_href = '.*?(.*?)'
title = re.findall(p_title, res, re.S)
# 新闻标题清洗----strip()->除去不需要的空格和换行符、.*?->代替文本之间的所有内容,清洗掉
for i in range(len(title)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
print("日期是:", '\n', info)
print("链接是:", '\n', href)
print("标题是:", '\n', title)
</p>
结果(缺陷:日期未清洗):
实战完整代码
先介绍爬取新闻标题、日期、链接的完整代码:
# 1.批量爬取一家公司的多页信息
def baidu(page):
import requests
import re
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
num = (page - 1) * 10
url = 'https://www.baidu.com/s%3Ftn%3 ... wd%3D阿里巴巴&Ppn=' + str(num)
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
p_href = '.*?(.*?)'
info = re.findall(p_info, res, re.S)
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
source = [] # 先创建两个空列表来储存等会分割后的来源和日期
date = []
for i in range(len(info)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
info[i] = re.sub('', '', info[i])
source.append(info[i].split(' ')[0])
date.append(info[i].split(' ')[1])
source[i] = source[i].strip()
date[i] = date[i].strip()
print(str(i + 1) + '.' + title[i] + '(' + date[i] + '-' + source[i] + ')')
print(href[i])
for i in range(10): # i是从0开始的序号,所以下面要写成i+1
baidu(i+1)
print('第' + str(i+1) + '页爬取成功')
</p>
结果:
然后介绍爬取多个公司新闻的标题、日期、链接的代码:
import requests
import re
def baidu(company):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
url = 'https://www.baidu.com/s%3Ftn%3 ... 39%3B + company
res = requests.get(url, headers=headers).text
p_info = '<p class="c-author">(.*?)'
p_href = '.*?(.*?)'
info = re.findall(p_info, res, re.S)
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
source = [] # 先创建两个空列表来储存等会分割后的来源和日期
date = []
for i in range(len(info)):
title[i] = title[i].strip()
title[i] = re.sub('', '', title[i])
info[i] = re.sub('', '', info[i])
source.append(info[i].split(' ')[0])
date.append(info[i].split(' ')[1])
source[i] = source[i].strip()
date[i] = date[i].strip()
print(str(i + 1) + '.' + title[i] + '(' + date[i] + '-' + source[i] + ')')
print(href[i])
while True: # 24小时不间断爬取
companys = ['华能信托', '阿里巴巴', '万科集团', '百度', '腾讯', '京东']
for i in companys:
try:
baidu(i)
print(i + '百度新闻爬取成功')
except:
print(i + '百度新闻爬取失败')
</p>
部分结果如下图所示:
网页新闻抓取(【】此文级别的爬虫,老司机们就不用看了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-30 05:15
本文是一个入门级的爬虫程序,所以老驱动程序不必阅读它
这主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间和新闻文本
首先,我们打开163网站,并随意选择一个类别。我在这里选择的类别是国内新闻。然后右键单击以查看源代码,并发现在源代码页的中间没有新闻列表。这表明此网页是异步的。即通过API接口获取的数据
确认后,您可以使用F12打开谷歌浏览器的控制台并单击网络。我们不断往下拉,发现右边出现了诸如“…Special/00804kva/cm_guonei_03.JS?”之类的地址。单击response并找到我们正在寻找的API接口
可以看出,这些接口的地址都有一定的规则:“cm_guonei_03.JS”,“cm_guonei_04.JS”,所以很明显:
上面的连接是我们这次要请求的地址
接下来,只需要两个Python库:
请求
json
美丽之群
请求库用于发出网络请求。换句话说,它模拟浏览器来获取资源
由于我们的采集API接口是JSON格式的,因此我们需要使用JSON库来解析它。Beauty soup用于解析HTML文档,它可以轻松帮助我们获取指定Div的内容
让我们开始编写爬虫程序:
第一步是导入上述三个包:
导入json
导入请求
从bs4导入BeautifulSoup
接下来,我们定义一种方法来获取指定页码中的数据:
def获取页面(第页):
url_uTemp='{}.js'
return_uuList=[]
对于范围内的i(第页):
url=url_uuu临时格式(i)
response=requests.get(url)
如果response.status uucode!=200:
继续
Content=response.text#获取响应正文
_Content=formatcontent(Content)#格式化JSON字符串
result=json.loads(_content)
return_uuList.append(结果)
返回列表
这样,获得与每个页码对应的内容列表:
之后,通过分析数据,我们可以看到下图中圈出的是要捕获的标题、发布时间和新闻内容页面
现在您已经获得了内容页面的URL,开始抓取新闻正文
在抓取文本之前,首先分析文本的HTML页面,找到文本在HTML文档中的位置、作者和来源
我们可以看到文章源在文档中的位置是id=“ne\u article\u source”的a标记
作者的位置是class=“EP editor”的span标记
正文位置是class=“post\u text”的div标签
以下是采访三项内容的代码采集:
def获取内容(url):
来源=“”
作者=“”
正文=“”
resp=requests.get(url)
如果响应状态uucode==200:
body=resp.text
bs4=美联(车身)
source=bs4.find('a',id='ne\u article\u source')。get\utext()
author=bs4.查找('span',class='ep-editor')。获取文本()
body=bs4.find('div',class='post_text')。get_utext()
返回源、作者、正文
到目前为止,我们想要捕获的所有数据都是采集
然后,当然,下一步是保存它们。为了方便我直接以文本的形式保存它们。以下是最终结果:
格式为JSON字符串“title”:['date'、'URL'、'source'、'author'、'body']
应该注意的是,当前的实现方法是完全同步和线性的。问题是采集将非常缓慢。主要延迟在网络IO中,下次可以升级为异步IO。异步采集。有兴趣的朋友可以关注下一个文章 查看全部
网页新闻抓取(【】此文级别的爬虫,老司机们就不用看了)
本文是一个入门级的爬虫程序,所以老驱动程序不必阅读它
这主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间和新闻文本
首先,我们打开163网站,并随意选择一个类别。我在这里选择的类别是国内新闻。然后右键单击以查看源代码,并发现在源代码页的中间没有新闻列表。这表明此网页是异步的。即通过API接口获取的数据
确认后,您可以使用F12打开谷歌浏览器的控制台并单击网络。我们不断往下拉,发现右边出现了诸如“…Special/00804kva/cm_guonei_03.JS?”之类的地址。单击response并找到我们正在寻找的API接口
可以看出,这些接口的地址都有一定的规则:“cm_guonei_03.JS”,“cm_guonei_04.JS”,所以很明显:
上面的连接是我们这次要请求的地址
接下来,只需要两个Python库:
请求
json
美丽之群
请求库用于发出网络请求。换句话说,它模拟浏览器来获取资源
由于我们的采集API接口是JSON格式的,因此我们需要使用JSON库来解析它。Beauty soup用于解析HTML文档,它可以轻松帮助我们获取指定Div的内容
让我们开始编写爬虫程序:
第一步是导入上述三个包:
导入json
导入请求
从bs4导入BeautifulSoup
接下来,我们定义一种方法来获取指定页码中的数据:
def获取页面(第页):
url_uTemp='{}.js'
return_uuList=[]
对于范围内的i(第页):
url=url_uuu临时格式(i)
response=requests.get(url)
如果response.status uucode!=200:
继续
Content=response.text#获取响应正文
_Content=formatcontent(Content)#格式化JSON字符串
result=json.loads(_content)
return_uuList.append(结果)
返回列表
这样,获得与每个页码对应的内容列表:
之后,通过分析数据,我们可以看到下图中圈出的是要捕获的标题、发布时间和新闻内容页面
现在您已经获得了内容页面的URL,开始抓取新闻正文
在抓取文本之前,首先分析文本的HTML页面,找到文本在HTML文档中的位置、作者和来源
我们可以看到文章源在文档中的位置是id=“ne\u article\u source”的a标记
作者的位置是class=“EP editor”的span标记
正文位置是class=“post\u text”的div标签
以下是采访三项内容的代码采集:
def获取内容(url):
来源=“”
作者=“”
正文=“”
resp=requests.get(url)
如果响应状态uucode==200:
body=resp.text
bs4=美联(车身)
source=bs4.find('a',id='ne\u article\u source')。get\utext()
author=bs4.查找('span',class='ep-editor')。获取文本()
body=bs4.find('div',class='post_text')。get_utext()
返回源、作者、正文
到目前为止,我们想要捕获的所有数据都是采集
然后,当然,下一步是保存它们。为了方便我直接以文本的形式保存它们。以下是最终结果:
格式为JSON字符串“title”:['date'、'URL'、'source'、'author'、'body']
应该注意的是,当前的实现方法是完全同步和线性的。问题是采集将非常缓慢。主要延迟在网络IO中,下次可以升级为异步IO。异步采集。有兴趣的朋友可以关注下一个文章
网页新闻抓取(SEO过度的页面提取方法,准确率挺高,依赖又少)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-09-29 10:26
项目中需要采集相关行业新闻,寻找基于文本和符号密度的网页正文提取方法。准确率相当高,依赖性小。特别推荐。
该方法是论文《Method of Web Page Body Extraction based on Text and Symbol Density》的实现。有兴趣的可以去看看原论文
本文中描述的算法看起来简洁、清晰且合乎逻辑。还有一个更有用的标准:
1
2
3
4
5
Ti - LTi
SbDi = --------------
Sbi + 1
SbDi: 符号密度
Sbi:符号数量
如果节点中文本的符号出现的频率更高,符号密度SbDi的值会更小,但文档说它会更大。如何解决?
因为它在这里考虑的是一个“逻辑”文本。它不是专门为欺骗该程序而构建的文本。在普通的文章中,文章越长,标点符号就会被读取,这是很自然的。而且你可能会认为,在某个栏目中直接写上数百个标点符号的新闻,没有汉字。这种情况当然可以欺骗程序,但属于“故意构建”的坏情况。
在正常的文章中,标点符号越多,正文中的文本就越多。分子和分母同时增加。显然,文本会比标点符号增长得更快,所以这个比例会增加。
根据GNE作者kingname的测试,使用该算法对今日头条、网易新闻、有民星空、观察家网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,几乎可以达到100%的准确率。个人使用经验,只要合理添加noise_node_list,也可以得到文本(部分SEO过度的页面除外)。
实施过程
算法实现
目前有python和nodeJS两种实现,依赖很少
python版本还提供了一个非常有用的noise_node_list参数,可以根据实际页面排除不相关的内容。
功能限制
因为它只提取新闻网页,如果你想提取其他类型的内容,它可能不起作用,但你可以尝试添加更多过滤XPath。
在线版
这里是网络版讲解使用过程
需要输入两件事:
由于没有提供爬虫功能,可以通过Chrome开发者工具的Copy OuterHTML获取页面的HTML代码和Copy XPath来获取排除的元素。
使用 Copy OuterHTML 复制整个网页的 HTML 代码。
如果提取的内容不是您想要的,您可以选择提取的元素,单击复制 XPath,然后将其粘贴到过滤器 XPath 中。它可以是多个 XPath,以逗号分隔。
输入效果
提取新闻信息
效果如下:
网络版测试 网络版提取的图片可能有防盗链功能,无法显示。
参考 查看全部
网页新闻抓取(SEO过度的页面提取方法,准确率挺高,依赖又少)
项目中需要采集相关行业新闻,寻找基于文本和符号密度的网页正文提取方法。准确率相当高,依赖性小。特别推荐。
该方法是论文《Method of Web Page Body Extraction based on Text and Symbol Density》的实现。有兴趣的可以去看看原论文
本文中描述的算法看起来简洁、清晰且合乎逻辑。还有一个更有用的标准:
1
2
3
4
5
Ti - LTi
SbDi = --------------
Sbi + 1
SbDi: 符号密度
Sbi:符号数量
如果节点中文本的符号出现的频率更高,符号密度SbDi的值会更小,但文档说它会更大。如何解决?
因为它在这里考虑的是一个“逻辑”文本。它不是专门为欺骗该程序而构建的文本。在普通的文章中,文章越长,标点符号就会被读取,这是很自然的。而且你可能会认为,在某个栏目中直接写上数百个标点符号的新闻,没有汉字。这种情况当然可以欺骗程序,但属于“故意构建”的坏情况。
在正常的文章中,标点符号越多,正文中的文本就越多。分子和分母同时增加。显然,文本会比标点符号增长得更快,所以这个比例会增加。
根据GNE作者kingname的测试,使用该算法对今日头条、网易新闻、有民星空、观察家网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,几乎可以达到100%的准确率。个人使用经验,只要合理添加noise_node_list,也可以得到文本(部分SEO过度的页面除外)。
实施过程
算法实现
目前有python和nodeJS两种实现,依赖很少
python版本还提供了一个非常有用的noise_node_list参数,可以根据实际页面排除不相关的内容。
功能限制
因为它只提取新闻网页,如果你想提取其他类型的内容,它可能不起作用,但你可以尝试添加更多过滤XPath。
在线版
这里是网络版讲解使用过程
需要输入两件事:
由于没有提供爬虫功能,可以通过Chrome开发者工具的Copy OuterHTML获取页面的HTML代码和Copy XPath来获取排除的元素。
使用 Copy OuterHTML 复制整个网页的 HTML 代码。
如果提取的内容不是您想要的,您可以选择提取的元素,单击复制 XPath,然后将其粘贴到过滤器 XPath 中。它可以是多个 XPath,以逗号分隔。
输入效果
提取新闻信息
效果如下:
网络版测试 网络版提取的图片可能有防盗链功能,无法显示。
参考
网页新闻抓取(NodeJs.js使用NodeJs做网络爬虫RSS抓取新闻(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2021-09-27 21:14
Node.js是一个基于chrome JavaScript运行时的平台,用于轻松构建快速且易于扩展的网络应用程序。借助事件驱动和非阻塞I/O模型,Node.js变得轻量级和高效。它非常适合跨分布式设备运行的数据密集型实时应用程序·
有许多网站提供RSS服务,如百度、网易、新浪、husniff等。有许多基于Java、C++和PHP的RSS爬行网站。今天,让我们来谈谈nodejs抓取RSS信息
使用nodejs作为网络爬虫来捕获RSS新闻。每个站点都有不同的编码格式,如GBK、UTF-8、iso8859-1等,因此需要对其进行编码。对于中国人来说,UTF-8是最酷的。抓取多个站点,然后将它们保存到数据库中。充分利用JavaScript异步编程的特点,爬网速度超快
这个项目是为新闻Android客户端实现的。将来,我还会上传新闻客户端的源代码
此项目的源代码位于GitHub中:
环境要求:
Nodejs(必选),我的版本是0.10.24
Mongodb(可选)或其他数据库,如mysql
编程工具:webstrom
步骤1:创建一个新的nodejs项目。我通常创建一个express web项目。步骤2:在package.json文件中添加依赖项
"dependencies": {
"express": "3.4.8",
"ejs": "*",
"feedparser":"0.16.6",
"request":"2.33.0",
"iconv":"2.0.7",
"mongoose":"3.8.7",
"mongodb":"*"
}
执行以下代码将相关文件导入模块中的项目节点:
npm install -d
步骤3:
完成基本准备后,就可以开始编写代码了。RSS捕获主要依赖于feedparser库。GitHub地址:
首先配置要捕获的站点信息
创建一个rssitejson文件
{
"channel":[
{
"from":"baidu",
"name":"civilnews",
"work":false, //false 则不抓取
"title":"百度国内最新新闻",
"link":"http://news.baidu.com/n%3Fcmd% ... ot%3B,
"typeId":1
},{
"from":"netEase",
"name":"rss_gn",
"title":"网易最新新闻",
"link":"http://news.163.com/special/00 ... ot%3B,
"typeId":2
}
]
}
我想抓住这两个网站。通道的值是一个对象数组。如果您需要多个站点,只需直接添加它们
介绍相关软件包
var request = require('request')
, FeedParser = require('feedparser')
, rssSite = require('../config/rssSite.json')
, Iconv = require('iconv').Iconv;
您需要遍历新配置的通道以找到所需的URL地址
var channels = rssSite.channel;
channels.forEach(function(e,i){
if(e.work != false){
console.log("begin:"+ e.title);
fetch(e.link,e.typeId);
}
});
工作为false的站点不会被爬网。就是黑名单。TypeID标识新闻属于哪一列、社会、金融或其他
关键是fetch函数,它是捕获和分析的地方。在我解释之前,我会发布代码
function fetch(feed,typeId) {
var posts;
// Define our streams
var req = request(feed, {timeout: 10000, pool: false});
req.setMaxListeners(50);
// Some feeds do not response without user-agent and accept headers.
req.setHeader('user-agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36')
.setHeader('accept', 'text/html,application/xhtml+xml');
var feedparser = new FeedParser();
// Define our handlers
req.on('error', done);
req.on('response', function(res) {
var stream = this
, iconv
, charset;
posts = new Array();
if (res.statusCode != 200) return this.emit('error', new Error('Bad status code'));
charset = getParams(res.headers['content-type'] || '').charset;
if (!iconv && charset && !/utf-*8/i.test(charset)) {
try {
iconv = new Iconv(charset, 'utf-8');
iconv.on('error', done);
stream = this.pipe(iconv);
} catch(err) {
this.emit('error', err);
}
}
stream.pipe(feedparser);
});
feedparser.on('error', done);
feedparser.on('end', function(err){
// postService.savePost(posts); //存到数据库
});
feedparser.on('readable', function() {
var post;
while (post = this.read()) {
posts.push(transToPost(post));//保存到对象数组
}
});
function transToPost(post){
var mPost = new Post({
title : post.title,
link : post.link,
description : post.description,
pubDate : post.pubDate,
source : post.source,
author : post.author,
typeId : typeId
});
return mPost;
}
}
1、关键功能:请求(URL,[选项]);这是一个可以发送HTTP请求的函数。地址:
var req = request(feed, {timeout: 10000, pool: false});
Req需要侦听多个状态响应和错误。发送请求后,将收到响应。收到响应后,将拼接接收到的数据。在拼接之前,需要进行编码转换。非utf8代码转换为UTF8.,此处使用库iconv。地址:
res.headers['content-type'].charset;
通过这种方式,您可以获得所获取站点的编码格式
拼接前需要进行代码转换。当然,这里使用了一种巧妙的方法,管道
然后把它转换成我无法操作的对象。此时,需要启动feedparser
var feedparser = new FeedParser();
Feedparse还侦听多个状态:可读、结束、错误
readable的回调方法将一次读取一条记录。每次读取一条记录时,我都会将其保存到数组对象中
读取所有数据后,调用end的回调函数。此时,站点捕获已完成。或多个站点
步骤4:保存到数据库
所有数据都存储在POST的数组对象中。你无论如何都可以寄。保存到mongodb只需几行代码。这里使用猫鼬图书馆
当然,mongodb库也是必要的。猫鼬与BaseDao相似。操作mongodb数据库非常方便
首先建立模式:
var mongoose = require('mongoose');
var PostSchema = new mongoose.Schema({
title:String,
link :String,
description :String,
pubDate :String,
source :String,
author :String,
typeId : Number
});
module.exports = PostSchema;
重新建立模型:
var mongoose = require('mongoose');
var PostSchema = require('../schemas/PostSchema');
var Post = mongoose.model('Post',PostSchema);
module.exports = Post;
好的,您可以将其保存到数据库中。mongodb似乎无法批量插入。我在这里骑自行车。如果标题不存在,请插入它,否则将出现重复新闻
<p>var Post = require('../model/Post');
function savePost(posts){
for(var i = 0 ;i 查看全部
网页新闻抓取(NodeJs.js使用NodeJs做网络爬虫RSS抓取新闻(组图))
Node.js是一个基于chrome JavaScript运行时的平台,用于轻松构建快速且易于扩展的网络应用程序。借助事件驱动和非阻塞I/O模型,Node.js变得轻量级和高效。它非常适合跨分布式设备运行的数据密集型实时应用程序·
有许多网站提供RSS服务,如百度、网易、新浪、husniff等。有许多基于Java、C++和PHP的RSS爬行网站。今天,让我们来谈谈nodejs抓取RSS信息
使用nodejs作为网络爬虫来捕获RSS新闻。每个站点都有不同的编码格式,如GBK、UTF-8、iso8859-1等,因此需要对其进行编码。对于中国人来说,UTF-8是最酷的。抓取多个站点,然后将它们保存到数据库中。充分利用JavaScript异步编程的特点,爬网速度超快
这个项目是为新闻Android客户端实现的。将来,我还会上传新闻客户端的源代码
此项目的源代码位于GitHub中:
环境要求:
Nodejs(必选),我的版本是0.10.24
Mongodb(可选)或其他数据库,如mysql
编程工具:webstrom
步骤1:创建一个新的nodejs项目。我通常创建一个express web项目。步骤2:在package.json文件中添加依赖项
"dependencies": {
"express": "3.4.8",
"ejs": "*",
"feedparser":"0.16.6",
"request":"2.33.0",
"iconv":"2.0.7",
"mongoose":"3.8.7",
"mongodb":"*"
}
执行以下代码将相关文件导入模块中的项目节点:
npm install -d
步骤3:
完成基本准备后,就可以开始编写代码了。RSS捕获主要依赖于feedparser库。GitHub地址:
首先配置要捕获的站点信息
创建一个rssitejson文件
{
"channel":[
{
"from":"baidu",
"name":"civilnews",
"work":false, //false 则不抓取
"title":"百度国内最新新闻",
"link":"http://news.baidu.com/n%3Fcmd% ... ot%3B,
"typeId":1
},{
"from":"netEase",
"name":"rss_gn",
"title":"网易最新新闻",
"link":"http://news.163.com/special/00 ... ot%3B,
"typeId":2
}
]
}
我想抓住这两个网站。通道的值是一个对象数组。如果您需要多个站点,只需直接添加它们
介绍相关软件包
var request = require('request')
, FeedParser = require('feedparser')
, rssSite = require('../config/rssSite.json')
, Iconv = require('iconv').Iconv;
您需要遍历新配置的通道以找到所需的URL地址
var channels = rssSite.channel;
channels.forEach(function(e,i){
if(e.work != false){
console.log("begin:"+ e.title);
fetch(e.link,e.typeId);
}
});
工作为false的站点不会被爬网。就是黑名单。TypeID标识新闻属于哪一列、社会、金融或其他
关键是fetch函数,它是捕获和分析的地方。在我解释之前,我会发布代码
function fetch(feed,typeId) {
var posts;
// Define our streams
var req = request(feed, {timeout: 10000, pool: false});
req.setMaxListeners(50);
// Some feeds do not response without user-agent and accept headers.
req.setHeader('user-agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36')
.setHeader('accept', 'text/html,application/xhtml+xml');
var feedparser = new FeedParser();
// Define our handlers
req.on('error', done);
req.on('response', function(res) {
var stream = this
, iconv
, charset;
posts = new Array();
if (res.statusCode != 200) return this.emit('error', new Error('Bad status code'));
charset = getParams(res.headers['content-type'] || '').charset;
if (!iconv && charset && !/utf-*8/i.test(charset)) {
try {
iconv = new Iconv(charset, 'utf-8');
iconv.on('error', done);
stream = this.pipe(iconv);
} catch(err) {
this.emit('error', err);
}
}
stream.pipe(feedparser);
});
feedparser.on('error', done);
feedparser.on('end', function(err){
// postService.savePost(posts); //存到数据库
});
feedparser.on('readable', function() {
var post;
while (post = this.read()) {
posts.push(transToPost(post));//保存到对象数组
}
});
function transToPost(post){
var mPost = new Post({
title : post.title,
link : post.link,
description : post.description,
pubDate : post.pubDate,
source : post.source,
author : post.author,
typeId : typeId
});
return mPost;
}
}
1、关键功能:请求(URL,[选项]);这是一个可以发送HTTP请求的函数。地址:
var req = request(feed, {timeout: 10000, pool: false});
Req需要侦听多个状态响应和错误。发送请求后,将收到响应。收到响应后,将拼接接收到的数据。在拼接之前,需要进行编码转换。非utf8代码转换为UTF8.,此处使用库iconv。地址:
res.headers['content-type'].charset;
通过这种方式,您可以获得所获取站点的编码格式
拼接前需要进行代码转换。当然,这里使用了一种巧妙的方法,管道
然后把它转换成我无法操作的对象。此时,需要启动feedparser
var feedparser = new FeedParser();
Feedparse还侦听多个状态:可读、结束、错误
readable的回调方法将一次读取一条记录。每次读取一条记录时,我都会将其保存到数组对象中
读取所有数据后,调用end的回调函数。此时,站点捕获已完成。或多个站点
步骤4:保存到数据库
所有数据都存储在POST的数组对象中。你无论如何都可以寄。保存到mongodb只需几行代码。这里使用猫鼬图书馆
当然,mongodb库也是必要的。猫鼬与BaseDao相似。操作mongodb数据库非常方便
首先建立模式:
var mongoose = require('mongoose');
var PostSchema = new mongoose.Schema({
title:String,
link :String,
description :String,
pubDate :String,
source :String,
author :String,
typeId : Number
});
module.exports = PostSchema;
重新建立模型:
var mongoose = require('mongoose');
var PostSchema = require('../schemas/PostSchema');
var Post = mongoose.model('Post',PostSchema);
module.exports = Post;
好的,您可以将其保存到数据库中。mongodb似乎无法批量插入。我在这里骑自行车。如果标题不存在,请插入它,否则将出现重复新闻
<p>var Post = require('../model/Post');
function savePost(posts){
for(var i = 0 ;i
网页新闻抓取(常见搜索引擎蜘蛛名称如下:屏蔽百度蜘蛛的抓取方式研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-27 21:12
在做网站操作,尤其是网站排名优化的时候,我们一直在思考如何引导搜索引擎蜘蛛抓取网页,收录。然而,在很多情况下,一些网站不想被搜索引擎光顾,因为他们真正对的用户群体与目标地区不同。这个时候我们如何解决这个问题?今天就跟作者小丹一起学习吧!
当我们看到需要阻止抓取时,大多数 SEOer 会想到 robots.txt 文件。因为在我们的认知中,机器人文件可以通过杜杰的搜索引擎有效地抓取某些页面。但是你要知道,这个方法虽然很好,但更多时候小丹认为它更适合网站未完成,以避免死链或调查期的存在。
如果我们只是想屏蔽某个搜索引擎的爬取,就不用负担篇幅了,用一点简单的代码就可以了。比如我们要屏蔽百度蜘蛛的爬取
就是这样。当然,这只是阻止百度抓取的一种方式。如果您想要任何搜索引擎,只需将百度蜘蛛替换为改变搜索引擎的蜘蛛即可。
常见的搜索引擎蜘蛛名称如下:
1、baiduspider 百度综合索引蜘蛛
2、Googlebot 谷歌蜘蛛
3、Googlebot-Image 是专门用来抓取图片的蜘蛛
4、Mediapartners-谷歌广告网络代码蜘蛛
5、Yahoo Slurp Yahoo Spider
6、雅虎!Slup 中国雅虎中国蜘蛛
7、Yahoo!-AdCrawler 雅虎广告蜘蛛
8、YodaoBot 网易蜘蛛
9、Sosospider 腾讯SOSO综合蜘蛛
10、搜狗蜘蛛
11、MSNBot Live 集成蜘蛛
但是,如果要屏蔽所有搜索引擎,则必须使用robot 文件:
说到这里,很多朋友应该明白,代码中禁止创建网页快照的命令是noarchive。因此,如果我们对搜索引擎有限制,我们可以将代码添加到网页中,直接根据我们的禁止快照;反之,无需添加任何代码,即可保证各大搜索引擎都能正常访问网站并创建快照。 查看全部
网页新闻抓取(常见搜索引擎蜘蛛名称如下:屏蔽百度蜘蛛的抓取方式研究)
在做网站操作,尤其是网站排名优化的时候,我们一直在思考如何引导搜索引擎蜘蛛抓取网页,收录。然而,在很多情况下,一些网站不想被搜索引擎光顾,因为他们真正对的用户群体与目标地区不同。这个时候我们如何解决这个问题?今天就跟作者小丹一起学习吧!
当我们看到需要阻止抓取时,大多数 SEOer 会想到 robots.txt 文件。因为在我们的认知中,机器人文件可以通过杜杰的搜索引擎有效地抓取某些页面。但是你要知道,这个方法虽然很好,但更多时候小丹认为它更适合网站未完成,以避免死链或调查期的存在。
如果我们只是想屏蔽某个搜索引擎的爬取,就不用负担篇幅了,用一点简单的代码就可以了。比如我们要屏蔽百度蜘蛛的爬取
就是这样。当然,这只是阻止百度抓取的一种方式。如果您想要任何搜索引擎,只需将百度蜘蛛替换为改变搜索引擎的蜘蛛即可。
常见的搜索引擎蜘蛛名称如下:
1、baiduspider 百度综合索引蜘蛛
2、Googlebot 谷歌蜘蛛
3、Googlebot-Image 是专门用来抓取图片的蜘蛛
4、Mediapartners-谷歌广告网络代码蜘蛛
5、Yahoo Slurp Yahoo Spider
6、雅虎!Slup 中国雅虎中国蜘蛛
7、Yahoo!-AdCrawler 雅虎广告蜘蛛
8、YodaoBot 网易蜘蛛
9、Sosospider 腾讯SOSO综合蜘蛛
10、搜狗蜘蛛
11、MSNBot Live 集成蜘蛛
但是,如果要屏蔽所有搜索引擎,则必须使用robot 文件:
说到这里,很多朋友应该明白,代码中禁止创建网页快照的命令是noarchive。因此,如果我们对搜索引擎有限制,我们可以将代码添加到网页中,直接根据我们的禁止快照;反之,无需添加任何代码,即可保证各大搜索引擎都能正常访问网站并创建快照。
网页新闻抓取(上绝大部分网页正文(包含图片等富媒体)())
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-09-27 21:10
## 获取新闻网页正文内容![]()> 该接口可以实时获取网页文章/新闻全文内容,支持网上大部分网页文字(包括图片等富媒体)。由于网页结构错综复杂,变化频繁,不保证所有网站永美##界面费用([点击购买]())>最低0.005元/次##接口调用([调用指令]())###请求地址```GET```###请求参数| 姓名| 类型| 必填| 说明|| --- | --- | --- | --- | | 应用代码| 字符串| 是|用户授权码,参考【API调用】() || 网址 | 字符串 | 是| 如果网页 URL 地址收录特殊字符,值应该是urlencode编码的|###返回`data`参数| 姓名| 类型| 说明|| --- | --- | --- || 标题 | 字符串 | 标题|| 内容 | 文字 | 网页内容|| 图片 | 字符串 | 网页第一张图片 || 时间 | 日期 | 网页时间|## SDK 调用```$client = new Client("YourAppCode");$result = $client->websiteHtmltext()->withUrl('#039;)->request();dump( $result );```JSON返回示例:~~~{code: 0,message: "success",data: [{"title": "新闻标题","content": "新闻内容html","图片" : "第一张图片的地址","ctime": 查看全部
网页新闻抓取(上绝大部分网页正文(包含图片等富媒体)())
## 获取新闻网页正文内容![]()> 该接口可以实时获取网页文章/新闻全文内容,支持网上大部分网页文字(包括图片等富媒体)。由于网页结构错综复杂,变化频繁,不保证所有网站永美##界面费用([点击购买]())>最低0.005元/次##接口调用([调用指令]())###请求地址```GET```###请求参数| 姓名| 类型| 必填| 说明|| --- | --- | --- | --- | | 应用代码| 字符串| 是|用户授权码,参考【API调用】() || 网址 | 字符串 | 是| 如果网页 URL 地址收录特殊字符,值应该是urlencode编码的|###返回`data`参数| 姓名| 类型| 说明|| --- | --- | --- || 标题 | 字符串 | 标题|| 内容 | 文字 | 网页内容|| 图片 | 字符串 | 网页第一张图片 || 时间 | 日期 | 网页时间|## SDK 调用```$client = new Client("YourAppCode");$result = $client->websiteHtmltext()->withUrl('#039;)->request();dump( $result );```JSON返回示例:~~~{code: 0,message: "success",data: [{"title": "新闻标题","content": "新闻内容html","图片" : "第一张图片的地址","ctime":
网页新闻抓取(基于存储架构如图所示存储架构图第三章新闻实时抓取系统(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-09-27 21:08
第三章新闻实时抓取系统——使用高效的二进制数据存储,包括图片、视频等大对象。片段的自动处理支持云计算的可扩展性。支持查询优化。支持多种语言。可以通过网络访问。与传统的关系型数据库相比,适合海量数据的存储。当数据量剧增时,只需在集群中增加服务器即可解决容量问题,免去扩容带来的分库分表的大工作量。自然支持文档类型数据的存储,没有模式限制。使用方法比关系数据库更灵活。基于如图所示的存储架构,存储架构图第三章新闻实时抓取系统第四节爬虫模块爬虫引擎和下载器是直接复用爬虫框架的功能模块,而调度器、蜘蛛和处理管道是基于新闻爬虫的功能模块。 - 开发和定制。本节重点介绍调度程序、蜘蛛程序和处理管道。蜘蛛的功能与框架中定义的蜘蛛模块基本相同。负责解析下载的网页,提取需要进一步爬取的超链接。它是爬虫模块中爬行队列的唯一提供者。整个爬虫模块的难点之一——爬取策略是在spider中实现的。蜘蛛是基于蜘蛛模块在继承自《第三章新闻实时抓取系统》的框架中实现的代码的主类。上面的规则就是一条数据的格式。键值为“...” 一条规则是正则表达式规则,用于判断匹配是否为提取链接后的新闻页面。
该规则告诉程序提取优采云节点中所有节点的属性,其属性值为标签,即超链接。蜘蛛不仅可以通过正则表达式提取和识别新闻链接,还可以利用新闻链接中收录的日期信息来判断该新闻是否为当天的新闻,并将识别出的新闻传递给调度器,让调度器决定放置相应的优先级。新闻页面抓取队列。调度器调度器是爬虫模块的核心组件。它维护着整个爬虫系统的运行。调度器算法的性能决定了整个系统的爬取效率。上一章提到的新闻爬虫应该关注的两个核心问题。更新策略是使用调度程序实现的。调度器访问其中维护的三个队列,决定下一个要爬取的链接,以及更新队列和权重判断。调度器确定下一个要爬取的链接的算法如下: 输入导航页面优先级队列 高优先级新闻页面爬取队列 低优先级新闻页面爬取队列 输出下一个要爬取的请求 第三章 新闻 调度算法实时抓取系统首先判断导航页面优先级队列中的第一个是否为抓取时间。如果是,设置下一次爬取时间,然后返回。如果未到爬取时间,则爬取优先级优先。如果新闻抓取队列为空,然后选择新闻爬取队列中优先级低的数据。数据处理管道当新闻页面被下载器下载并被蜘蛛分析时,解析的页面和一些新闻位置信息将传递给引擎,并将数据转发到数据处理管道。
论文实现的数据处理流水线的主要功能是将下载的页面内容和解析后的相关链接信息存入其中。它收录三个模块。这三个模块分别是网页编码识别与编码转换、链接信息存储、转换。代码后的页面存储。该图显示了数据处理管道的结构。第三章新闻实时抓取系统图新闻爬虫数据处理流水线图第三章新闻实时抓取系统第五节系统运行数据本文设计和实现的爬虫系统已应用于实际生产过程中,以了解实时监控系统运行状态,在后台实现监控系统。为了展示系统的爬虫性能,论文选取系统运行一整天的统计数据进行分析处理。系统运行环境爬虫模块部署在两台服务器上。这两天服务器的所有软硬件配置都是一样的。服务器配置信息如下所示。操作系统选择部署在两台服务器上。两台服务器的配置与爬虫模块部署的服务器相同。除了硬盘配置不同,硬盘是一样的。在两台服务器上部署的方法在服务器配置上也是一样的。运行数据随机选取系统运行的某一天的数据时间。爬虫模块配置新闻站点初始化的导航页数。
这一小时的页面爬取统计如表所示。表中的数据是根据抓取页面时响应的状态。在这一小时内发出了下载网页的请求。一个页面的成功爬取百分比会高于普通爬虫。因为论文实现了定向抓取,抓取了最新的链接作为主要的无效链接。第三章实时新闻抓取抓取系统占比较小,抓取比例较高。表格爬取状态统计状态码状态含义爬取成功次数百分比未找到页面重定向禁止访问未授权服务器错误其他总页面成功下载本次收录多次重复下载导航页面,新闻页面和非新闻页面。它们的比率显示在下面所示的饼图中。可以看到,系统需要的新闻页面只占了总爬取页面的一部分。抓取到的非新闻页面与新闻页面格式相同,但一般为图片或视频页面。该系统尚未得到日本人的认可。当然一些非新闻是导航页面,没有放在初始化集合中。稍后将处理这些导航页面并将其添加到集合中。各类型页面占比如图,朱叶豪,《新闻嘉瑞如树皮新乡页面》
通过对系统运行过程中的数据进行分析,可以发现这种分布式抓取系统的高效率可以应用到实际生产过程中。新闻爬虫不同于传统的网络爬虫,它有特定的爬取要求。与全网网络爬虫相比,新闻爬虫具有实时性、爬行目标明确、数据提取领域清晰等特点。海量的互联网数据要求新闻爬虫具有良好的算法和系统架构。论文中实现的新闻爬虫有两个核心算法,即爬取策略和更新策略。这两种策略决定了爬虫的效率。爬取策略明确定义了新闻爬虫要爬取的页面类型和区分方法,而更新策略必须保证系统能够最有效地抓取最新消息。核心算法策略还必须有优秀的系统架构来支撑,才能实现高效的新闻爬虫。本文实现的分布式实时新闻爬虫系统由数据模块、爬虫模块和系统配置模块三大部分组成。其中data模块用于保存爬虫运行时需要的数据以及最终爬取的页面数据。包括调度器的实现,主要负责与爬虫模块交互,存储各种爬取队列,主要存储下载的新闻页面。爬虫模块包括蜘蛛、调度器和数据处理管道。蜘蛛负责解析页面调度器,负责爬取队列的运行控制,而数据处理管道则处理下载的数据。爬虫模块可以部署在多台服务器上。这些多个模块作为数据交换的枢纽,构成了整个分布式实时新闻爬取系统。
通过对实时新闻抓取系统运行时间数据的统计分析,系统的抓取效率更高。这是因为爬虫系统良好的爬虫策略过滤掉了大部分非新闻页面,更新策略保证了可以及时爬取。到新消息。第四章新闻数据处理 第四章新闻数据处理 当新闻页面下载到本地并转码后存储在系统中时,需要对这些页面进行一系列的处理,以确保能够获得完整的新闻信息。一般情况下,新闻页面会收录大量的噪音数据。新闻显示系统不需要此信息。系统需要有一种有效的方法从噪声数据中区分新闻的各种属性并完整地提取出来。由于各个新闻站点的数据格式不同,提取的新闻信息还需要经过一系列的处理,使其符合系统要求的格式。论文针对新闻爬虫爬取后的数据处理问题设计了一套较为完善的处理流水线。本章将重点介绍新闻显示系统如何清理和处理下载的新闻页面。第一节新闻数据抽取新闻数据抽取是新闻爬虫在抓取新闻页面后首先要做的工作,也是整个处理系统中最关键的模块。处理系统的所有模块都是基于新闻数据提取的结果。做提取工作尤为重要。本节将介绍一些传统的网页文本数据提取方法,以及系统根据新闻数据的特点实现的提取方法。新闻数据提取的特点对于信息检索系统来说,网页正文数据的提取是爬虫爬取网页后进行数据处理的关键步骤。
为了消除噪声数据的干扰,提供更准确的检索结果,信息检索系统倾向于关注文本数据的提取工作。一般网页中的噪声数据包括页面样式布局信息、广告信息、网站导航信息、前端脚本等。图片新闻页面的噪音区域显示了新浪新闻页面中收录的噪音数据。图中所有的红框都是不需要的区域。顶部红框区域为导航信息右侧区域和新闻正文中的红框区域。这是一个广告,文字下方是一些其他链接。必须充分识别和清理这些信息。对于新闻展示系统来说,新闻数据的提取也是一项非常重要的任务。 查看全部
网页新闻抓取(基于存储架构如图所示存储架构图第三章新闻实时抓取系统(组图))
第三章新闻实时抓取系统——使用高效的二进制数据存储,包括图片、视频等大对象。片段的自动处理支持云计算的可扩展性。支持查询优化。支持多种语言。可以通过网络访问。与传统的关系型数据库相比,适合海量数据的存储。当数据量剧增时,只需在集群中增加服务器即可解决容量问题,免去扩容带来的分库分表的大工作量。自然支持文档类型数据的存储,没有模式限制。使用方法比关系数据库更灵活。基于如图所示的存储架构,存储架构图第三章新闻实时抓取系统第四节爬虫模块爬虫引擎和下载器是直接复用爬虫框架的功能模块,而调度器、蜘蛛和处理管道是基于新闻爬虫的功能模块。 - 开发和定制。本节重点介绍调度程序、蜘蛛程序和处理管道。蜘蛛的功能与框架中定义的蜘蛛模块基本相同。负责解析下载的网页,提取需要进一步爬取的超链接。它是爬虫模块中爬行队列的唯一提供者。整个爬虫模块的难点之一——爬取策略是在spider中实现的。蜘蛛是基于蜘蛛模块在继承自《第三章新闻实时抓取系统》的框架中实现的代码的主类。上面的规则就是一条数据的格式。键值为“...” 一条规则是正则表达式规则,用于判断匹配是否为提取链接后的新闻页面。
该规则告诉程序提取优采云节点中所有节点的属性,其属性值为标签,即超链接。蜘蛛不仅可以通过正则表达式提取和识别新闻链接,还可以利用新闻链接中收录的日期信息来判断该新闻是否为当天的新闻,并将识别出的新闻传递给调度器,让调度器决定放置相应的优先级。新闻页面抓取队列。调度器调度器是爬虫模块的核心组件。它维护着整个爬虫系统的运行。调度器算法的性能决定了整个系统的爬取效率。上一章提到的新闻爬虫应该关注的两个核心问题。更新策略是使用调度程序实现的。调度器访问其中维护的三个队列,决定下一个要爬取的链接,以及更新队列和权重判断。调度器确定下一个要爬取的链接的算法如下: 输入导航页面优先级队列 高优先级新闻页面爬取队列 低优先级新闻页面爬取队列 输出下一个要爬取的请求 第三章 新闻 调度算法实时抓取系统首先判断导航页面优先级队列中的第一个是否为抓取时间。如果是,设置下一次爬取时间,然后返回。如果未到爬取时间,则爬取优先级优先。如果新闻抓取队列为空,然后选择新闻爬取队列中优先级低的数据。数据处理管道当新闻页面被下载器下载并被蜘蛛分析时,解析的页面和一些新闻位置信息将传递给引擎,并将数据转发到数据处理管道。
论文实现的数据处理流水线的主要功能是将下载的页面内容和解析后的相关链接信息存入其中。它收录三个模块。这三个模块分别是网页编码识别与编码转换、链接信息存储、转换。代码后的页面存储。该图显示了数据处理管道的结构。第三章新闻实时抓取系统图新闻爬虫数据处理流水线图第三章新闻实时抓取系统第五节系统运行数据本文设计和实现的爬虫系统已应用于实际生产过程中,以了解实时监控系统运行状态,在后台实现监控系统。为了展示系统的爬虫性能,论文选取系统运行一整天的统计数据进行分析处理。系统运行环境爬虫模块部署在两台服务器上。这两天服务器的所有软硬件配置都是一样的。服务器配置信息如下所示。操作系统选择部署在两台服务器上。两台服务器的配置与爬虫模块部署的服务器相同。除了硬盘配置不同,硬盘是一样的。在两台服务器上部署的方法在服务器配置上也是一样的。运行数据随机选取系统运行的某一天的数据时间。爬虫模块配置新闻站点初始化的导航页数。
这一小时的页面爬取统计如表所示。表中的数据是根据抓取页面时响应的状态。在这一小时内发出了下载网页的请求。一个页面的成功爬取百分比会高于普通爬虫。因为论文实现了定向抓取,抓取了最新的链接作为主要的无效链接。第三章实时新闻抓取抓取系统占比较小,抓取比例较高。表格爬取状态统计状态码状态含义爬取成功次数百分比未找到页面重定向禁止访问未授权服务器错误其他总页面成功下载本次收录多次重复下载导航页面,新闻页面和非新闻页面。它们的比率显示在下面所示的饼图中。可以看到,系统需要的新闻页面只占了总爬取页面的一部分。抓取到的非新闻页面与新闻页面格式相同,但一般为图片或视频页面。该系统尚未得到日本人的认可。当然一些非新闻是导航页面,没有放在初始化集合中。稍后将处理这些导航页面并将其添加到集合中。各类型页面占比如图,朱叶豪,《新闻嘉瑞如树皮新乡页面》
通过对系统运行过程中的数据进行分析,可以发现这种分布式抓取系统的高效率可以应用到实际生产过程中。新闻爬虫不同于传统的网络爬虫,它有特定的爬取要求。与全网网络爬虫相比,新闻爬虫具有实时性、爬行目标明确、数据提取领域清晰等特点。海量的互联网数据要求新闻爬虫具有良好的算法和系统架构。论文中实现的新闻爬虫有两个核心算法,即爬取策略和更新策略。这两种策略决定了爬虫的效率。爬取策略明确定义了新闻爬虫要爬取的页面类型和区分方法,而更新策略必须保证系统能够最有效地抓取最新消息。核心算法策略还必须有优秀的系统架构来支撑,才能实现高效的新闻爬虫。本文实现的分布式实时新闻爬虫系统由数据模块、爬虫模块和系统配置模块三大部分组成。其中data模块用于保存爬虫运行时需要的数据以及最终爬取的页面数据。包括调度器的实现,主要负责与爬虫模块交互,存储各种爬取队列,主要存储下载的新闻页面。爬虫模块包括蜘蛛、调度器和数据处理管道。蜘蛛负责解析页面调度器,负责爬取队列的运行控制,而数据处理管道则处理下载的数据。爬虫模块可以部署在多台服务器上。这些多个模块作为数据交换的枢纽,构成了整个分布式实时新闻爬取系统。
通过对实时新闻抓取系统运行时间数据的统计分析,系统的抓取效率更高。这是因为爬虫系统良好的爬虫策略过滤掉了大部分非新闻页面,更新策略保证了可以及时爬取。到新消息。第四章新闻数据处理 第四章新闻数据处理 当新闻页面下载到本地并转码后存储在系统中时,需要对这些页面进行一系列的处理,以确保能够获得完整的新闻信息。一般情况下,新闻页面会收录大量的噪音数据。新闻显示系统不需要此信息。系统需要有一种有效的方法从噪声数据中区分新闻的各种属性并完整地提取出来。由于各个新闻站点的数据格式不同,提取的新闻信息还需要经过一系列的处理,使其符合系统要求的格式。论文针对新闻爬虫爬取后的数据处理问题设计了一套较为完善的处理流水线。本章将重点介绍新闻显示系统如何清理和处理下载的新闻页面。第一节新闻数据抽取新闻数据抽取是新闻爬虫在抓取新闻页面后首先要做的工作,也是整个处理系统中最关键的模块。处理系统的所有模块都是基于新闻数据提取的结果。做提取工作尤为重要。本节将介绍一些传统的网页文本数据提取方法,以及系统根据新闻数据的特点实现的提取方法。新闻数据提取的特点对于信息检索系统来说,网页正文数据的提取是爬虫爬取网页后进行数据处理的关键步骤。
为了消除噪声数据的干扰,提供更准确的检索结果,信息检索系统倾向于关注文本数据的提取工作。一般网页中的噪声数据包括页面样式布局信息、广告信息、网站导航信息、前端脚本等。图片新闻页面的噪音区域显示了新浪新闻页面中收录的噪音数据。图中所有的红框都是不需要的区域。顶部红框区域为导航信息右侧区域和新闻正文中的红框区域。这是一个广告,文字下方是一些其他链接。必须充分识别和清理这些信息。对于新闻展示系统来说,新闻数据的提取也是一项非常重要的任务。
网页新闻抓取(网站相当于一个图结构的解决方法和解决办法(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-26 04:37
)
哪里
标签。
3.编写程序,调试运行。
这里使用了 Python 的 urllib 和 Beautifulsoup 包。
我使用python3。3和2在语法上有一些差异,但大体逻辑是一样的。
urllib负责url的处理,主要是request、parse、error这些模块。负责向url发送请求,获取页面信息,处理错误。
Beautifulsoup 负责解析页面。获取到的页面是一个html树状结构,通过findAll()、select()、get()、get_text()等函数可以很方便的获取到我们想要的内容。
4.最后,如果要获取整个portal网站的数据,需要一些递归。整个网站相当于一个图结构,dfs(深度优先遍历)是更好的方法。
关于爬虫程序的编写,一些烦人的点:
(1)不同页面的url不一样。门户越大网站,分类越多,总会出现一些没见过也没有考虑过的情况。有时在判断程序不全面,会报错;同样,一些新闻文本页面的页面标签和布局不一样,很难用一种提取方法提取,对于上述问题,我们需要在程序中写更多的情况来处理if错误,防止爬行时报错并终止;
(2) 编码问题,这是我遇到的最难的问题,尤其是爬行的时候,想抓取新闻保存在txt中,可能有些页面有很特殊的字符,无法编解码,经常会导致程序意外终止 解决办法:对于极少数难以处理的网站,在源头过滤掉,在取数据的时候,往往不会关心一两页数据。
还有人告诉我python爬虫的特点是:简单,暴力,和python语言风格一样。
#coding: utf-8
import codecs
from urllib import request, parse
from bs4 import BeautifulSoup
import re
import time
from urllib.error import HTTPError, URLError
import sys
###新闻类定义
class News(object):
def __init__(self):
self.url = None #该新闻对应的url
self.topic = None #新闻标题
self.date = None #新闻发布日期
self.content = None #新闻的正文内容
self.author = None #新闻作者
###如果url符合解析要求,则对该页面进行信息提取
def getNews(url):
#获取页面所有元素
html = request.urlopen(url).read().decode('utf-8', 'ignore')
#解析
soup = BeautifulSoup(html, 'html.parser')
#获取信息
if not(soup.find('div', {'id':'artical'})): return
news = News() #建立新闻对象
page = soup.find('div', {'id':'artical'})
if not(page.find('h1', {'id':'artical_topic'})): return
topic = page.find('h1', {'id':'artical_topic'}).get_text() #新闻标题
news.topic = topic
if not(page.find('div', {'id': 'main_content'})): return
main_content = page.find('div', {'id': 'main_content'}) #新闻正文内容
content = ''
for p in main_content.select('p'):
content = content + p.get_text()
news.content = content
news.url = url #新闻页面对应的url
f.write(news.topic+'\t'+news.content+'\n')
##dfs算法遍历全站###
def dfs(url):
global count
print(url)
pattern1 = 'http://news\.ifeng\.com\/[a-z0-9_\/\.]*$' #可以继续访问的url规则
pattern2 = 'http://news\.ifeng\.com\/a\/[0-9]{8}\/[0-9]{8}\_0\.shtml$' #解析新闻信息的url规则
#该url访问过,则直接返回
if url in visited: return
print(url)
#把该url添加进visited()
visited.add(url)
# print(visited)
try:
#该url没有访问过的话,则继续解析操作
html = request.urlopen(url).read().decode('utf-8', 'ignore')
# print(html)
soup = BeautifulSoup(html, 'html.parser')
if re.match(pattern2, url):
getNews(url)
# count += 1
####提取该页面其中所有的url####
links = soup.findAll('a', href=re.compile(pattern1))
for link in links:
print(link['href'])
if link['href'] not in visited:
dfs(link['href'])
# count += 1
except URLError as e:
print(e)
return
except HTTPError as e:
print(e)
return
# print(count)
# if count > 3: return
visited = set() ##存储访问过的url
f = open('ifeng/news.txt', 'a+', encoding='utf-8')
dfs('http://news.ifeng.com/') 查看全部
网页新闻抓取(网站相当于一个图结构的解决方法和解决办法(一)
)
哪里
标签。
3.编写程序,调试运行。
这里使用了 Python 的 urllib 和 Beautifulsoup 包。
我使用python3。3和2在语法上有一些差异,但大体逻辑是一样的。
urllib负责url的处理,主要是request、parse、error这些模块。负责向url发送请求,获取页面信息,处理错误。
Beautifulsoup 负责解析页面。获取到的页面是一个html树状结构,通过findAll()、select()、get()、get_text()等函数可以很方便的获取到我们想要的内容。
4.最后,如果要获取整个portal网站的数据,需要一些递归。整个网站相当于一个图结构,dfs(深度优先遍历)是更好的方法。
关于爬虫程序的编写,一些烦人的点:
(1)不同页面的url不一样。门户越大网站,分类越多,总会出现一些没见过也没有考虑过的情况。有时在判断程序不全面,会报错;同样,一些新闻文本页面的页面标签和布局不一样,很难用一种提取方法提取,对于上述问题,我们需要在程序中写更多的情况来处理if错误,防止爬行时报错并终止;
(2) 编码问题,这是我遇到的最难的问题,尤其是爬行的时候,想抓取新闻保存在txt中,可能有些页面有很特殊的字符,无法编解码,经常会导致程序意外终止 解决办法:对于极少数难以处理的网站,在源头过滤掉,在取数据的时候,往往不会关心一两页数据。
还有人告诉我python爬虫的特点是:简单,暴力,和python语言风格一样。
#coding: utf-8
import codecs
from urllib import request, parse
from bs4 import BeautifulSoup
import re
import time
from urllib.error import HTTPError, URLError
import sys
###新闻类定义
class News(object):
def __init__(self):
self.url = None #该新闻对应的url
self.topic = None #新闻标题
self.date = None #新闻发布日期
self.content = None #新闻的正文内容
self.author = None #新闻作者
###如果url符合解析要求,则对该页面进行信息提取
def getNews(url):
#获取页面所有元素
html = request.urlopen(url).read().decode('utf-8', 'ignore')
#解析
soup = BeautifulSoup(html, 'html.parser')
#获取信息
if not(soup.find('div', {'id':'artical'})): return
news = News() #建立新闻对象
page = soup.find('div', {'id':'artical'})
if not(page.find('h1', {'id':'artical_topic'})): return
topic = page.find('h1', {'id':'artical_topic'}).get_text() #新闻标题
news.topic = topic
if not(page.find('div', {'id': 'main_content'})): return
main_content = page.find('div', {'id': 'main_content'}) #新闻正文内容
content = ''
for p in main_content.select('p'):
content = content + p.get_text()
news.content = content
news.url = url #新闻页面对应的url
f.write(news.topic+'\t'+news.content+'\n')
##dfs算法遍历全站###
def dfs(url):
global count
print(url)
pattern1 = 'http://news\.ifeng\.com\/[a-z0-9_\/\.]*$' #可以继续访问的url规则
pattern2 = 'http://news\.ifeng\.com\/a\/[0-9]{8}\/[0-9]{8}\_0\.shtml$' #解析新闻信息的url规则
#该url访问过,则直接返回
if url in visited: return
print(url)
#把该url添加进visited()
visited.add(url)
# print(visited)
try:
#该url没有访问过的话,则继续解析操作
html = request.urlopen(url).read().decode('utf-8', 'ignore')
# print(html)
soup = BeautifulSoup(html, 'html.parser')
if re.match(pattern2, url):
getNews(url)
# count += 1
####提取该页面其中所有的url####
links = soup.findAll('a', href=re.compile(pattern1))
for link in links:
print(link['href'])
if link['href'] not in visited:
dfs(link['href'])
# count += 1
except URLError as e:
print(e)
return
except HTTPError as e:
print(e)
return
# print(count)
# if count > 3: return
visited = set() ##存储访问过的url
f = open('ifeng/news.txt', 'a+', encoding='utf-8')
dfs('http://news.ifeng.com/')
网页新闻抓取(基于文本及符号密度的网页正文提取方法(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2021-09-22 08:09
)
项目来源
开发这个项目,我发现了来自自动化算法的纸张,以提取Hownet中的新闻网站文本 - “基于文本密度和符号文本提取方法”)
本文描述的算法看起来简单明了,逻辑。但是,由于纸质讨论了算法的原理,没有特定的语言,因此我根据纸张使用提取器的Python实现。并使用今天的头条新闻,网易新闻,无家可归的天空,观察者,凤凰,腾讯新闻,Readhub,新浪新闻做了一个测试,发现提取物非常好,几乎能够实现100%的准确性。
项目状态
本文中描述的文本,基于提取,我添加了标题,文章发布了作者自动检测和功能提取。
目前这个项目是一个非常非常早期的演示,发布它希望尽快让每个人的反馈,以实现更好的目标开发。
命名为提取器,而不是爬行动物,以避免不必要的风险,因此,该项目的输入是HTML,输出为字典。请使用适当的方法获取自己的目标网站 HTML。
项目现在没有,无法在将来提供网站 html函数的主动性。
如何使用在线体验
如果您想体验GNE提取的影响,那么您可以访问。在正常情况下,您只需要将其粘贴到多行文本框的顶部页面中,然后提取按钮。通过更多其他参数,允许更精确地提取。编写特定参数的操作,请参阅
环境
如果要体验GNE功能,请按照以下步骤操作:
安装gne
# 以下两种方案任选一种即可
# 使用 pip 安装
pip install --upgrade gne
# 使用 pipenv 安装
pipenv install gne
使用gne提取文本
&gt; &gt;来自GNE Import GeneralNewsextractor&Gt; &gt; &gt; html ='''呈现页面html代码''''&gt; &gt; &gt; Extractor = GeneralNewsextractor()&gt; &gt; &gt;结果= Extractor .Extract(HTML,HOTE_NODE_LIST = ['// div [@ class =“注释列表”list“”)&gt; &gt; &gt;打印(结果){“title”:“xxxx”,“publish_time”:“2019 -09-10 11:12:13”,“作者”:“yyy”,“内容”:“zzzz”,“图像”: [“/xxx.jpg”,“/yyy.png”]}“&gt;
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
>>> print(result)
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz", "images": ["/xxx.jpg", "/yyy.png"]}
有关详细说明,请参阅文档GNE
提取列表页面(beta)
&gt ;; &gt
来自GNE Import ListPapeExtractor&gt; &gt; &gt; html ='''呈现页面html代码''''&gt; &gt; &gt; list_extractor = listpageExtractor()&gt; &gt; &gt;结果= list_extractor .Extract(html,feature ='任何元素xpath的列表“)&gt;&gt;&gt;打印(结果)”
>>> from gne import ListPageExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> list_extractor = ListPageExtractor()
>>> result = list_extractor.extract(html,
feature='列表中任意元素的 XPath")
>>> print(result)
开发环境
如果您需要参加该项目的开发,请按照以下步骤操作。
如果要读取源代码,现在请直接按键盘上的句点键(即,留下问号),您可以获得更好的阅读体验。
本项目使用第三方库的Python Pipenv管理。如果你不知道pipenv是什么,请把我指向跳。
后
已安装pipenv,按以下步骤运行代码:
git clone https://github.com/kingname/Ge ... r.git
cd GeneralNewsExtractor
pipenv install
pipenv shell
python3 example.py
特殊说明
example.py项目代码提供了项目使用的基本示例。
元素选项卡在标签中位于,右侧,选择复制 - 复制offichtml,如图所示
图。
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
对于大多数新闻页面,上面的措辞将能够解决问题。
但是,将有一些新闻页面评论下面,可能有长啰嗦的评论,它们看起来比真正的新闻更像是文本的正文,所以Extractor.extract()方法有一个默认参数kide_node_list,对于网页提前预处理以查看整个区域被删除。
keate_mode_list值是一个列表,一个列表,其中每个元素是xpath,对应于您提前需要的目标标签删除,可能会导致干扰。
例如,与以下注释XPath对应的查看器Web区域为// div [@ class =“注释列表”。因此,当提取观察者网络时,为了防止干扰评论,可以添加此参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
gne将基于此XPath,自动查找其他数据线内的列表。
运行射击网易新闻
今天的头条新闻
新浪新闻
p> phoenix
查看全部
网页新闻抓取(基于文本及符号密度的网页正文提取方法(图)
)
项目来源
开发这个项目,我发现了来自自动化算法的纸张,以提取Hownet中的新闻网站文本 - “基于文本密度和符号文本提取方法”)
本文描述的算法看起来简单明了,逻辑。但是,由于纸质讨论了算法的原理,没有特定的语言,因此我根据纸张使用提取器的Python实现。并使用今天的头条新闻,网易新闻,无家可归的天空,观察者,凤凰,腾讯新闻,Readhub,新浪新闻做了一个测试,发现提取物非常好,几乎能够实现100%的准确性。
项目状态
本文中描述的文本,基于提取,我添加了标题,文章发布了作者自动检测和功能提取。
目前这个项目是一个非常非常早期的演示,发布它希望尽快让每个人的反馈,以实现更好的目标开发。
命名为提取器,而不是爬行动物,以避免不必要的风险,因此,该项目的输入是HTML,输出为字典。请使用适当的方法获取自己的目标网站 HTML。
项目现在没有,无法在将来提供网站 html函数的主动性。
如何使用在线体验
如果您想体验GNE提取的影响,那么您可以访问。在正常情况下,您只需要将其粘贴到多行文本框的顶部页面中,然后提取按钮。通过更多其他参数,允许更精确地提取。编写特定参数的操作,请参阅
环境
如果要体验GNE功能,请按照以下步骤操作:
安装gne
# 以下两种方案任选一种即可
# 使用 pip 安装
pip install --upgrade gne
# 使用 pipenv 安装
pipenv install gne
使用gne提取文本
&gt; &gt;来自GNE Import GeneralNewsextractor&Gt; &gt; &gt; html ='''呈现页面html代码''''&gt; &gt; &gt; Extractor = GeneralNewsextractor()&gt; &gt; &gt;结果= Extractor .Extract(HTML,HOTE_NODE_LIST = ['// div [@ class =“注释列表”list“”)&gt; &gt; &gt;打印(结果){“title”:“xxxx”,“publish_time”:“2019 -09-10 11:12:13”,“作者”:“yyy”,“内容”:“zzzz”,“图像”: [“/xxx.jpg”,“/yyy.png”]}“&gt;
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
>>> print(result)
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz", "images": ["/xxx.jpg", "/yyy.png"]}
有关详细说明,请参阅文档GNE
提取列表页面(beta)
&gt ;; &gt
来自GNE Import ListPapeExtractor&gt; &gt; &gt; html ='''呈现页面html代码''''&gt; &gt; &gt; list_extractor = listpageExtractor()&gt; &gt; &gt;结果= list_extractor .Extract(html,feature ='任何元素xpath的列表“)&gt;&gt;&gt;打印(结果)”
>>> from gne import ListPageExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> list_extractor = ListPageExtractor()
>>> result = list_extractor.extract(html,
feature='列表中任意元素的 XPath")
>>> print(result)
开发环境
如果您需要参加该项目的开发,请按照以下步骤操作。
如果要读取源代码,现在请直接按键盘上的句点键(即,留下问号),您可以获得更好的阅读体验。
本项目使用第三方库的Python Pipenv管理。如果你不知道pipenv是什么,请把我指向跳。
后
已安装pipenv,按以下步骤运行代码:
git clone https://github.com/kingname/Ge ... r.git
cd GeneralNewsExtractor
pipenv install
pipenv shell
python3 example.py
特殊说明
example.py项目代码提供了项目使用的基本示例。
元素选项卡在标签中位于,右侧,选择复制 - 复制offichtml,如图所示
图。
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
对于大多数新闻页面,上面的措辞将能够解决问题。
但是,将有一些新闻页面评论下面,可能有长啰嗦的评论,它们看起来比真正的新闻更像是文本的正文,所以Extractor.extract()方法有一个默认参数kide_node_list,对于网页提前预处理以查看整个区域被删除。
keate_mode_list值是一个列表,一个列表,其中每个元素是xpath,对应于您提前需要的目标标签删除,可能会导致干扰。
例如,与以下注释XPath对应的查看器Web区域为// div [@ class =“注释列表”。因此,当提取观察者网络时,为了防止干扰评论,可以添加此参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
gne将基于此XPath,自动查找其他数据线内的列表。
运行射击网易新闻
今天的头条新闻
新浪新闻
p> phoenix
网页新闻抓取(我找到的3种实现方法,但基于dom节点的评分制筛选算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-21 02:16
请看看官方拍摄。 。 。
我一直对网页的内容非常感兴趣,我三年前做了一个“新闻读者”,我喜欢当时观看这个消息,想法是如果没有广告时观看新闻,一个安静有多好,然后我开发了一个浏览器书签小插件,使用JS提取页面,然后通过层封面显示在页面上,它只能被规律地思考,这也是大多数爬行者爬行者。
当时,网上,新浪,QQ和等各种主要门户都实现了这个功能。这是最傻瓜式方法,但益处是高精度。 DIDTTRESS是,一旦目标网页修改源代码,您可能需要重新出现。
我找到了越来越多的页面,我要观看,这种方式不再适合我的需求。但最近因为我已经开发了,我需要一个集合助手,所以我开始寻找解决方案。
我主要发现三种解决方案:
1)评评评制制算算制算算算制
有一个被称为可读,地址的外国浏览器书签插件:当时,这是非常钦佩的,并且精度高。
2)基于文本密度分析(DOM-Indumenty)
这种方法的想法也很好,适用性更好,我试图使用js来实现,但能够做出有限匹配的能力太高,放弃了。
3)基于图像识别
alpha狗使用的方法非常接近,通过图像识别,只要机器人可以完成,有大量的情况,但没有看到文本识别特定实现(或没有找到案例)。
上面是我找到的三种实现方法。
但基于我只是一个Web开发人员,只有理解JS,其他语言技能非常有限。所以我尝试了基于DOM的筛选,并且可读性相对复杂。我还能获得更有效的解决方案吗?
我发现了一个法律,文本部分一般来说,P标签的数量非常多,多于其他部分,因为大多数网页的内容被所需的编辑器释放,这些编辑器生成语义节点。
所以,我将使用此规则并开发一个小插件,效果也不错。当然,它仍然是非常原创的,需要改善。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码非常简单,但我已经过超过80%的网页(主要是文章页面)可以成功。基于此,我开发了Jspapa 采集 Assistant:
如果您有更好的解决方案,您可以讨论它。
如果需要重新打印本文,请联系作者,请指定源 查看全部
网页新闻抓取(我找到的3种实现方法,但基于dom节点的评分制筛选算法)
请看看官方拍摄。 。 。
我一直对网页的内容非常感兴趣,我三年前做了一个“新闻读者”,我喜欢当时观看这个消息,想法是如果没有广告时观看新闻,一个安静有多好,然后我开发了一个浏览器书签小插件,使用JS提取页面,然后通过层封面显示在页面上,它只能被规律地思考,这也是大多数爬行者爬行者。
当时,网上,新浪,QQ和等各种主要门户都实现了这个功能。这是最傻瓜式方法,但益处是高精度。 DIDTTRESS是,一旦目标网页修改源代码,您可能需要重新出现。
我找到了越来越多的页面,我要观看,这种方式不再适合我的需求。但最近因为我已经开发了,我需要一个集合助手,所以我开始寻找解决方案。
我主要发现三种解决方案:
1)评评评制制算算制算算算制
有一个被称为可读,地址的外国浏览器书签插件:当时,这是非常钦佩的,并且精度高。
2)基于文本密度分析(DOM-Indumenty)
这种方法的想法也很好,适用性更好,我试图使用js来实现,但能够做出有限匹配的能力太高,放弃了。
3)基于图像识别
alpha狗使用的方法非常接近,通过图像识别,只要机器人可以完成,有大量的情况,但没有看到文本识别特定实现(或没有找到案例)。
上面是我找到的三种实现方法。
但基于我只是一个Web开发人员,只有理解JS,其他语言技能非常有限。所以我尝试了基于DOM的筛选,并且可读性相对复杂。我还能获得更有效的解决方案吗?
我发现了一个法律,文本部分一般来说,P标签的数量非常多,多于其他部分,因为大多数网页的内容被所需的编辑器释放,这些编辑器生成语义节点。
所以,我将使用此规则并开发一个小插件,效果也不错。当然,它仍然是非常原创的,需要改善。
var pt = $doc.find("p").siblings().parent();
var l = pt.length - 1;
var e = l;
var arr = [];
while(l>=0){
arr[l] = $(pt[l]).find("p").length;
l--;
}
var temArr = arr.concat();
var newArr = arrSort(arr);
var c = temArr.indexOf(newArr[e]);
content = $(pt[c]).html();
代码非常简单,但我已经过超过80%的网页(主要是文章页面)可以成功。基于此,我开发了Jspapa 采集 Assistant:
如果您有更好的解决方案,您可以讨论它。
如果需要重新打印本文,请联系作者,请指定源
网页新闻抓取(通过网页抓取工具优采云采集器创造一个大数据智媒体)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-09-21 02:13
当前媒体电流,在焦点事件的主题或可持续主题,形成媒体主题,有很多手动操作,如信息采集,及时更新等,但高效的Web Raw工具将创建一个大数据智能介质。
通过网页优采云采集器可以自动采集与公众对应的焦点事件。例如,一个连续的多日事件,您必须在每个重要节点时间中抓取数据,然后在优采云采集器中设置更新时间和频率。例如,我们要注意金融市场,您可以随时更新和自动化到动态媒体列。
和关注于焦点的某个方面的重点也可以根据网状抓取工具进行分类和智能分级。我们甚至可以使用Web捕获该工具以维护智能媒体站。用户想要锁定几个或多个信息输出页面,并在Web Grab工具中提供信息输出页面优采云采集器,配置网站捕获和内容的详细规则,获取一系列放电,筛选,清洁处理,最后选择自动和定时,以便自动和定时选择。 @指定列。
未来媒体不可避免地是媒体的大数据,核心元素是数据的大小,并且我们必须使用数据有效地学习并播放数据的值。基于媒体稿件数据的高科技媒体产品,允许人们更快,准确地学习,帮助人们更好地发现信息的价值和本质。
一些专家提出,如果没有对大数据的支持,事实上,许多新闻都是不幸的。在传统媒体中难以具有智能分析,警告或决定,因此大数据智能是一种不可避免的趋势。
但是,网络创建的目前网络大数据并不完全取代人类大脑,因为人类的大脑是自我理解,而且需要人工智能继续探索,将大量无聊内容融合要提取其化身信息,可能有一天可以取代人类大脑来实现更复杂的原创,智能媒体将更加个性化,定制和高效。 查看全部
网页新闻抓取(通过网页抓取工具优采云采集器创造一个大数据智媒体)
当前媒体电流,在焦点事件的主题或可持续主题,形成媒体主题,有很多手动操作,如信息采集,及时更新等,但高效的Web Raw工具将创建一个大数据智能介质。
通过网页优采云采集器可以自动采集与公众对应的焦点事件。例如,一个连续的多日事件,您必须在每个重要节点时间中抓取数据,然后在优采云采集器中设置更新时间和频率。例如,我们要注意金融市场,您可以随时更新和自动化到动态媒体列。
和关注于焦点的某个方面的重点也可以根据网状抓取工具进行分类和智能分级。我们甚至可以使用Web捕获该工具以维护智能媒体站。用户想要锁定几个或多个信息输出页面,并在Web Grab工具中提供信息输出页面优采云采集器,配置网站捕获和内容的详细规则,获取一系列放电,筛选,清洁处理,最后选择自动和定时,以便自动和定时选择。 @指定列。
未来媒体不可避免地是媒体的大数据,核心元素是数据的大小,并且我们必须使用数据有效地学习并播放数据的值。基于媒体稿件数据的高科技媒体产品,允许人们更快,准确地学习,帮助人们更好地发现信息的价值和本质。
一些专家提出,如果没有对大数据的支持,事实上,许多新闻都是不幸的。在传统媒体中难以具有智能分析,警告或决定,因此大数据智能是一种不可避免的趋势。
但是,网络创建的目前网络大数据并不完全取代人类大脑,因为人类的大脑是自我理解,而且需要人工智能继续探索,将大量无聊内容融合要提取其化身信息,可能有一天可以取代人类大脑来实现更复杂的原创,智能媒体将更加个性化,定制和高效。
网页新闻抓取( 手机端OPPO手机自带“智慧识物”功能(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 608 次浏览 • 2021-09-20 20:45
手机端OPPO手机自带“智慧识物”功能(组图))
网页无法复制(教你一个技巧,轻松提取文本,并通过网络自由复制)
我相信你在生活中会遇到这样的问题:当我们需要复制网页文档中的一段文本时,网页却无法被复制。最后,我们只能逐字打字,这既费时又费力
但这次别担心。小编为您采集整理了四个软件工具,可以帮助您更轻松方便地提取网页文本。来看看
一、计算机终端
1、QQ截图提取文本
使用电脑QQ截图功能提取和复制文本。打开QQ,按住键盘上的[Ctrl]+[ALT]+[a]屏幕截图,然后单击下面选项栏中的小字符识别图标以执行字符识别和提取
2、Word文件提取文本
除了QQ截图,我们还可以尝试使用word文档来提取web文档。创建新文档并打开WPS主页,单击文件-打开,将复制的web文档地址粘贴到文件名,然后单击打开
接下来,word将自动打开网页。我们需要选择将其作为word文档打开,然后才能复制它
3、fast-PDF转换器
fast PDF Converter支持PDF与各种格式文档(如word、PPT和excel)之间的相互转换,以及PDF合并、压缩和图片字符识别(OCR)功能。如果我们需要复制web文档,我们还可以使用此软件复制文本
打开软件,选择[feature conversion]-[image to text(OCR)],在软件中打开网页截图,点击[start conversion],然后打开word文档,瞬间复制文本
二、移动终端
Oppo手机具有“智能物体识别”功能
除了电脑软件工具外,oppo手机还拥有自己的“智能物体识别”功能,它还可以识别和提取无法复制的文字。打开[intelligent object recognition]功能,拍摄要识别的文本,点击[recognition text on this page]
事实上,很多手机都有字符识别功能。你可以去看看你的手机是否有这个工具
以上四种方法都是小编练习过的。软件比较通用,操作相对简单。你知道有什么工具可以从web文档中提取文本吗?欢迎来到下面的评论区进行分享和讨论
版权声明:本文转载是为了传播更多信息。如果源标签有误或侵犯了您的合法权益,请您持所有权证书与我们联系,我们将及时更正并删除。感谢您的支持和理解 查看全部
网页新闻抓取(
手机端OPPO手机自带“智慧识物”功能(组图))
网页无法复制(教你一个技巧,轻松提取文本,并通过网络自由复制)
我相信你在生活中会遇到这样的问题:当我们需要复制网页文档中的一段文本时,网页却无法被复制。最后,我们只能逐字打字,这既费时又费力
但这次别担心。小编为您采集整理了四个软件工具,可以帮助您更轻松方便地提取网页文本。来看看
一、计算机终端
1、QQ截图提取文本
使用电脑QQ截图功能提取和复制文本。打开QQ,按住键盘上的[Ctrl]+[ALT]+[a]屏幕截图,然后单击下面选项栏中的小字符识别图标以执行字符识别和提取
2、Word文件提取文本
除了QQ截图,我们还可以尝试使用word文档来提取web文档。创建新文档并打开WPS主页,单击文件-打开,将复制的web文档地址粘贴到文件名,然后单击打开
接下来,word将自动打开网页。我们需要选择将其作为word文档打开,然后才能复制它
3、fast-PDF转换器
fast PDF Converter支持PDF与各种格式文档(如word、PPT和excel)之间的相互转换,以及PDF合并、压缩和图片字符识别(OCR)功能。如果我们需要复制web文档,我们还可以使用此软件复制文本
打开软件,选择[feature conversion]-[image to text(OCR)],在软件中打开网页截图,点击[start conversion],然后打开word文档,瞬间复制文本
二、移动终端
Oppo手机具有“智能物体识别”功能
除了电脑软件工具外,oppo手机还拥有自己的“智能物体识别”功能,它还可以识别和提取无法复制的文字。打开[intelligent object recognition]功能,拍摄要识别的文本,点击[recognition text on this page]
事实上,很多手机都有字符识别功能。你可以去看看你的手机是否有这个工具
以上四种方法都是小编练习过的。软件比较通用,操作相对简单。你知道有什么工具可以从web文档中提取文本吗?欢迎来到下面的评论区进行分享和讨论
版权声明:本文转载是为了传播更多信息。如果源标签有误或侵犯了您的合法权益,请您持所有权证书与我们联系,我们将及时更正并删除。感谢您的支持和理解
网页新闻抓取(爬取网易新闻,实战出真知,打开网易)
网站优化 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-09-17 02:10
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
在学习了python的基本语法之后,我对爬虫产生了极大的兴趣。我不怎么胡说八道。今天,我要爬网易新闻,从实战中学习
当你打开网易新闻,你会发现新闻分为几个部分:
这一次,我们选择国内板块攀登文章
1.ready
下载地址
理解网页
网页色彩丰富、美丽,就像一幅水彩画。要抓取数据,首先需要知道需要抓取的数据是如何呈现的,就像学习画图一样。在你开始之前,你需要知道画的是什么,铅笔还是水彩笔。。。可能有各种类型,但Web信息只有两种表示方法:
Html是一种用来描述网页的语言
JSON是一种轻量级数据交换格式
抓取网页信息实际上是向网页发出请求,服务器会将数据反馈给您
2.get动态加载源代码
导入所需的模块和库:
1 from bs4 import BeautifulSoup
2 import time
3 import def_text_save as dts
4 import def_get_data as dgd
5 from selenium import webdriver
6 from selenium.webdriver.common.keys import Keys
7 from selenium.webdriver.common.action_chains import ActionChains #引入ActionChains鼠标操作类
要获取网页信息,我们需要发送请求。请求可以帮助我们很好地做到这一点。然而,仔细观察发现,网易新闻是动态加载的,请求返回即时信息,而随后在网页中加载的数据不会返回。Selenium可以帮助我们获得更多数据,我们理解Selenium是一种自动化测试工具。Selenium测试直接在浏览器中运行,就像真实用户一样
我使用的浏览器是Firefox
1 browser = webdriver.Firefox()#根据浏览器切换
2 browser.maximize_window()#最大化窗口
3 browser.get('http://news.163.com/domestic/')
这样,我们就可以驱动浏览器自动登录到网易新闻页面
当然,我们的目标是爬下国内板块,同时观察网页。当网页继续向下刷时,将加载新新闻。在底部,我们甚至需要单击按钮刷新:
此时,selenium可以展示其优势:鼠标和键盘操作的自动化和模拟:
1 diver.execute_script("window.scrollBy(0,5000)")
2 #使网页向下拉,括号内为每次下拉数值
右键单击网页中的“加载更多”按钮,然后单击“查看元素”以查看
通过这个类,我们可以找到按钮。当我们遇到按钮时,单击事件可以帮助我们自动单击按钮以完成页面刷新
1 # 爬取板块动态加载部分源代码
2
3 info1=[]
4 info_links=[] #存储文章内容链接
5 try:
6 while True :
7 if browser.page_source.find("load_more_btn") != -1 :
8 browser.find_element_by_class_name("load_more_btn").click()
9 browser.execute_script("window.scrollBy(0,5000)")
10 time.sleep(1)
11 except:
12 url = browser.page_source#返回加载完全的网页源码
13 browser.close()#关闭浏览器
获取有用的信息
简而言之,BeautifulSoup是一个Python库。它的主要功能是从网页中获取数据,这可以减轻新手的负担。通过beautiful soup解析网页源代码并添加附加函数,我们可以轻松获得所需的信息,例如获取文章标题、标签和文本内容超链接
同样,在文章标题区域中单击鼠标右键可查看元素:
观察网页结构,发现文章是每个div标签class=“news\u title”下的标题和超链接。汤。Find_all()函数可以帮助我们找到所需的所有信息,并且可以一次性提取此级别结构下的内容。最后,通过字典逐一取出标签信息
1 info_total=[]
2 def get_data(url):
3 soup=BeautifulSoup(url,"html.parser")
4 titles=soup.find_all('div','news_title')
5 labels=soup.find('div','ns_area second2016_main clearfix').find_all('div','keywords')
6 for title, label in zip(titles,labels ):
7 data = {
8 '文章标题': title.get_text().split(),
9 '文章标签':label.get_text().split() ,
10 'link':title.find("a").get('href')
11 }
12 info_total.append(data)
13 return info_total
4.get新闻内容
从那时起,新闻链接被取出并存储在列表中。我们现在需要做的是使用链接获取新闻主题内容。新闻主题内容页是静态加载的,可以轻松处理请求:
1 def get_content(url):
2 info_text = []
3 info=[]
4 adata=requests.get(url)
5 soup=BeautifulSoup(adata.text,'html.parser')
6 try :
7 articles = soup.find("div", 'post_header').find('div', 'post_content_main').find('div', 'post_text').find_all('p')
8 except :
9 articles = soup.find("div", 'post_content post_area clearfix').find('div', 'post_body').find('div', 'post_text').find_all(
10 'p')
11 for a in articles:
12 a=a.get_text()
13 a= ' '.join(a.split())
14 info_text.append(a)
15 return (info_text)
之所以使用try-except,是因为在不同的情况下,网易新闻文章在某个时间段前后,文本信息的位置标签是不同的
最后,遍历整个列表并取出所有文本内容:
1 for i in info1 :
2 info_links.append(i.get('link'))
3 x=0 #控制访问文章目录
4 info_content={}# 存储文章内容
5 for i in info_links:
6 try :
7 info_content['文章内容']=dgd.get_content(i)
8 except:
9 continue
10 s=str(info1[x]["文章标题"]).replace('[','').replace(']','').replace("'",'').replace(',','').replace('《','').replace('》','').replace('/','').replace(',',' ')
11 s= ''.join(s.split())
12 file = '/home/lsgo18/PycharmProjects/网易新闻'+'/'+s
13 print(s)
14 dts.text_save(file,info_content['文章内容'],info1[x]['文章标签'])
15 x = x + 1
将数据存储到本地TXT文件
Python提供了一个文件处理函数open()。第一个参数是文件路径,第二个参数是文件处理模式,“W”模式是只写模式(如果没有文件,将创建该文件,如果有,将清空该文件)
1 def text_save(filename, data,lable): #filename为写入CSV文件的路径
2 file = open(filename,'w')
3 file.write(str(lable).replace('[','').replace(']','')+'\n')
4 for i in range(len(data)):
5 s =str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
6 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符
7 file.write(s)
8 file.close()
9 print("保存文件成功")
已成功编写一个简单的爬虫程序:
到目前为止,网易新闻的抓取方法已经被引入。我希望它对你有用 查看全部
网页新闻抓取(爬取网易新闻,实战出真知,打开网易)
PS:如果你需要Python学习材料,你可以点击下面的链接自己获取
在学习了python的基本语法之后,我对爬虫产生了极大的兴趣。我不怎么胡说八道。今天,我要爬网易新闻,从实战中学习
当你打开网易新闻,你会发现新闻分为几个部分:
这一次,我们选择国内板块攀登文章
1.ready
下载地址
理解网页
网页色彩丰富、美丽,就像一幅水彩画。要抓取数据,首先需要知道需要抓取的数据是如何呈现的,就像学习画图一样。在你开始之前,你需要知道画的是什么,铅笔还是水彩笔。。。可能有各种类型,但Web信息只有两种表示方法:
Html是一种用来描述网页的语言
JSON是一种轻量级数据交换格式
抓取网页信息实际上是向网页发出请求,服务器会将数据反馈给您
2.get动态加载源代码
导入所需的模块和库:
1 from bs4 import BeautifulSoup
2 import time
3 import def_text_save as dts
4 import def_get_data as dgd
5 from selenium import webdriver
6 from selenium.webdriver.common.keys import Keys
7 from selenium.webdriver.common.action_chains import ActionChains #引入ActionChains鼠标操作类
要获取网页信息,我们需要发送请求。请求可以帮助我们很好地做到这一点。然而,仔细观察发现,网易新闻是动态加载的,请求返回即时信息,而随后在网页中加载的数据不会返回。Selenium可以帮助我们获得更多数据,我们理解Selenium是一种自动化测试工具。Selenium测试直接在浏览器中运行,就像真实用户一样
我使用的浏览器是Firefox
1 browser = webdriver.Firefox()#根据浏览器切换
2 browser.maximize_window()#最大化窗口
3 browser.get('http://news.163.com/domestic/')
这样,我们就可以驱动浏览器自动登录到网易新闻页面
当然,我们的目标是爬下国内板块,同时观察网页。当网页继续向下刷时,将加载新新闻。在底部,我们甚至需要单击按钮刷新:
此时,selenium可以展示其优势:鼠标和键盘操作的自动化和模拟:
1 diver.execute_script("window.scrollBy(0,5000)")
2 #使网页向下拉,括号内为每次下拉数值
右键单击网页中的“加载更多”按钮,然后单击“查看元素”以查看
通过这个类,我们可以找到按钮。当我们遇到按钮时,单击事件可以帮助我们自动单击按钮以完成页面刷新
1 # 爬取板块动态加载部分源代码
2
3 info1=[]
4 info_links=[] #存储文章内容链接
5 try:
6 while True :
7 if browser.page_source.find("load_more_btn") != -1 :
8 browser.find_element_by_class_name("load_more_btn").click()
9 browser.execute_script("window.scrollBy(0,5000)")
10 time.sleep(1)
11 except:
12 url = browser.page_source#返回加载完全的网页源码
13 browser.close()#关闭浏览器
获取有用的信息
简而言之,BeautifulSoup是一个Python库。它的主要功能是从网页中获取数据,这可以减轻新手的负担。通过beautiful soup解析网页源代码并添加附加函数,我们可以轻松获得所需的信息,例如获取文章标题、标签和文本内容超链接
同样,在文章标题区域中单击鼠标右键可查看元素:
观察网页结构,发现文章是每个div标签class=“news\u title”下的标题和超链接。汤。Find_all()函数可以帮助我们找到所需的所有信息,并且可以一次性提取此级别结构下的内容。最后,通过字典逐一取出标签信息
1 info_total=[]
2 def get_data(url):
3 soup=BeautifulSoup(url,"html.parser")
4 titles=soup.find_all('div','news_title')
5 labels=soup.find('div','ns_area second2016_main clearfix').find_all('div','keywords')
6 for title, label in zip(titles,labels ):
7 data = {
8 '文章标题': title.get_text().split(),
9 '文章标签':label.get_text().split() ,
10 'link':title.find("a").get('href')
11 }
12 info_total.append(data)
13 return info_total
4.get新闻内容
从那时起,新闻链接被取出并存储在列表中。我们现在需要做的是使用链接获取新闻主题内容。新闻主题内容页是静态加载的,可以轻松处理请求:
1 def get_content(url):
2 info_text = []
3 info=[]
4 adata=requests.get(url)
5 soup=BeautifulSoup(adata.text,'html.parser')
6 try :
7 articles = soup.find("div", 'post_header').find('div', 'post_content_main').find('div', 'post_text').find_all('p')
8 except :
9 articles = soup.find("div", 'post_content post_area clearfix').find('div', 'post_body').find('div', 'post_text').find_all(
10 'p')
11 for a in articles:
12 a=a.get_text()
13 a= ' '.join(a.split())
14 info_text.append(a)
15 return (info_text)
之所以使用try-except,是因为在不同的情况下,网易新闻文章在某个时间段前后,文本信息的位置标签是不同的
最后,遍历整个列表并取出所有文本内容:
1 for i in info1 :
2 info_links.append(i.get('link'))
3 x=0 #控制访问文章目录
4 info_content={}# 存储文章内容
5 for i in info_links:
6 try :
7 info_content['文章内容']=dgd.get_content(i)
8 except:
9 continue
10 s=str(info1[x]["文章标题"]).replace('[','').replace(']','').replace("'",'').replace(',','').replace('《','').replace('》','').replace('/','').replace(',',' ')
11 s= ''.join(s.split())
12 file = '/home/lsgo18/PycharmProjects/网易新闻'+'/'+s
13 print(s)
14 dts.text_save(file,info_content['文章内容'],info1[x]['文章标签'])
15 x = x + 1
将数据存储到本地TXT文件
Python提供了一个文件处理函数open()。第一个参数是文件路径,第二个参数是文件处理模式,“W”模式是只写模式(如果没有文件,将创建该文件,如果有,将清空该文件)
1 def text_save(filename, data,lable): #filename为写入CSV文件的路径
2 file = open(filename,'w')
3 file.write(str(lable).replace('[','').replace(']','')+'\n')
4 for i in range(len(data)):
5 s =str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择
6 s = s.replace("'",'').replace(',','') +'\n' #去除单引号,逗号,每行末尾追加换行符
7 file.write(s)
8 file.close()
9 print("保存文件成功")
已成功编写一个简单的爬虫程序:
到目前为止,网易新闻的抓取方法已经被引入。我希望它对你有用
网页新闻抓取( Python3爬取新闻网站新闻列表到什么时候才是好的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-17 02:09
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
因为捕获的HTML文档相对较长,所以这里发布了一个简单的部分供您查看
..........后面省略一大堆
这是对Python3爬虫的简单介绍。这很简单吗?我建议你再敲几下
3、 Python3将抓取网页中的图片并将其保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待地想看看他们爬上了多美的画面
爬上去很容易就能得到24个女孩的照片。这不是很简单吗
4、 Python3爬行新闻网站news列表
这里有点复杂。让我们向您解释一下分布情况
分析我们想要在上图中捕获的信息,然后将其放入div中的a标记和img标记中,因此我们想要考虑的是如何获取这些信息
这里我们将使用导入的Beauty soup4库,以及这里的关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
以上代码获取的alllist就是我们想要获取的新闻列表。捕获的信息如下所示
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是被捕获的,但是太混乱了,还有很多我们不想要的东西。让我们通过遍历来优化我们的有效信息
这里添加了异常处理。主要原因是有些新闻可能没有标题、URL或图片。如果未完成异常处理,我们可能会中断爬网
###过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
在这里,我们抓取新闻网站新闻信息,就这样完成了。完整的代码发布在下面
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
当获得数据时,我们还需要将数据保存到数据库中。只要数据库中有数据,我们就可以进行以下数据分析和处理。我们还可以使用这些爬网的文章为应用程序提供新闻API接口。当然,这些都是以后的事了。在我自学了如何操作python数据库之后,我将编写一个文章@
视频说明:
过去回顾
Python 001~ Python开发工具pycharm(Mac和Windows)的安装和破解简介
开始使用Python 002~创建您的第一个Python项目
Python 012介绍~ Python 3零基础~将爬行数据保存到数据库中,用数据库去重复函数
Python 010~Python 3操作数据库简介借助pycharm快速连接和操作MySQL数据库
Python 020入门~抓取前程无忧的位置信息并存储在MySQL数据库中 查看全部
网页新闻抓取(
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
因为捕获的HTML文档相对较长,所以这里发布了一个简单的部分供您查看
..........后面省略一大堆
这是对Python3爬虫的简单介绍。这很简单吗?我建议你再敲几下
3、 Python3将抓取网页中的图片并将其保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待地想看看他们爬上了多美的画面
爬上去很容易就能得到24个女孩的照片。这不是很简单吗
4、 Python3爬行新闻网站news列表
这里有点复杂。让我们向您解释一下分布情况
分析我们想要在上图中捕获的信息,然后将其放入div中的a标记和img标记中,因此我们想要考虑的是如何获取这些信息
这里我们将使用导入的Beauty soup4库,以及这里的关键代码
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
以上代码获取的alllist就是我们想要获取的新闻列表。捕获的信息如下所示
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是被捕获的,但是太混乱了,还有很多我们不想要的东西。让我们通过遍历来优化我们的有效信息
这里添加了异常处理。主要原因是有些新闻可能没有标题、URL或图片。如果未完成异常处理,我们可能会中断爬网
###过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
在这里,我们抓取新闻网站新闻信息,就这样完成了。完整的代码发布在下面
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
当获得数据时,我们还需要将数据保存到数据库中。只要数据库中有数据,我们就可以进行以下数据分析和处理。我们还可以使用这些爬网的文章为应用程序提供新闻API接口。当然,这些都是以后的事了。在我自学了如何操作python数据库之后,我将编写一个文章@
视频说明:
过去回顾
Python 001~ Python开发工具pycharm(Mac和Windows)的安装和破解简介
开始使用Python 002~创建您的第一个Python项目
Python 012介绍~ Python 3零基础~将爬行数据保存到数据库中,用数据库去重复函数
Python 010~Python 3操作数据库简介借助pycharm快速连接和操作MySQL数据库
Python 020入门~抓取前程无忧的位置信息并存储在MySQL数据库中
网页新闻抓取(公司简介大渡河公司重构url流域已完成流域规划报告(咨询稿) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-17 02:07
)
一、公司简介
大渡河公司于2000年11月在成都高新区注册成立。其主要任务是在大渡河流域开发水电站,以龚嘴和铜街子为母电站。是国家能源集团旗下最大的集水电开发、建设、运营和管理于一体的大流域水电开发公司
目前,公司主要负责大渡河流域开发和西藏巴龙藏布盆地开发的前期准备工作。西藏大渡河干流及支流、巴龙藏布盆地水电资源约3000万千瓦。大渡河流域规划建设梯级水电站28座,总装机容量约2340万千瓦。该公司负责开发干流17座梯级水电站,涉及四川省三地两市(甘孜州、阿坝州、凉山州、雅安市、乐山市)12个县,总装机容量约1757万千瓦,形成生产、在建、准备稳步推进的可持续发展格局。巴龙藏布盆地已完成流域规划报告(咨询稿),初步规划“一库九级”方案,规划装机容量1142万千瓦。截至目前,公司总资产为910.68亿元,在四川投产安装,约占四川水电统一调度总装机容量的四分之一
二、需求分析
分析并统计网站新闻标题、作者、日期等信息,分析网站在线新闻的共性,即哪些类型的主题新闻更容易发布。此外,还可以对公司发表文章较多的作者进行分析,在一定程度上反映作者的水平
三、具体实施
1、使用Python爬虫技术获取公司网站新闻的相关信息
第一步是抓取URL:重建URL并将其放入多线程队列
url = 'http://www.spddr.com/spddr/index.jsp?id=360'
base_url = 'http://www.spddr.com/spddr/'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
第二步是解析URL:在多线程队列中获取重构后的URL并进行解析,最后将解析后的信息放入线程队列
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
步骤3:下载并保存信息:将解析后的信息从队列中取出,并执行下载和保存操作
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
四、所有代码如下所示
from lxml import etree
import requests
import csv
import random
from headers_list import headers_list
import threading
from queue import Queue
headers = {
'User-Agent':random.choice(headers_list),
'Cookie': 'JSESSIONID=91AFDB0A74FDB3DE1011B2E59CF99993; JSESSIONID=DD7458D1055A53D464AE8DF68400DE1F',
'Referer': '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
}
#定义一个Producter类,类名通常是大写开头的单词,它继承的是threading.Thread
class Producter(threading.Thread):
# 用init方法绑定属性,比如定义一个人的类,那你可以再定义人的属性,比如有手、有脚
def __init__(self,page_queue,writer_queue,*args,**kwargs):
super(Producter,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
def run(self):
while True:
try:
url = '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
base_url = '[http://www.spddr.com/spddr/](http://www.spddr.com/spddr/)'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
except:
print("解析网页出错")
#定义一个Consumer类,类名通常是大写开头的单词,它继承的是threading.Thread
class Consumer(threading.Thread):
def __init__(self,page_queue,writer_queue,glock,writer,*args,**kwargs):
super(Consumer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
self.glock = glock
self.writer = writer
def run(self):
while True:
try:
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
except:
print("提取信息出错!")
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
if __name__ == '__main__':
# 创建FIFO队列
page_queue = Queue(1000)
writer_queue = Queue(1000)
# 创建线程锁
glock = threading.Lock()
#csv表头信息
head = ['title', 'author', 'department', 'time']
#打开csv文件
fp = open('daduhe.csv', 'a', newline='', errors='ignore', encoding='utf-8')
#用字典方式写入表头信息
writer = csv.DictWriter(fp, head)
writer.writeheader()
for i in range(1,207):
data = {
'nowPage': i,
'totalpage': 206,
'id': 360,
'pages': i,
}
page_queue.put(data)
for x in range(10):
t = Producter(page_queue,writer_queue)#根据Producter类创建一个实例t的线程
t.start()#开启线程
for x in range(10):
t = Consumer(page_queue,writer_queue,glock,writer)#根据Producter类创建一个实例t的线程
t.start() 查看全部
网页新闻抓取(公司简介大渡河公司重构url流域已完成流域规划报告(咨询稿)
)
一、公司简介
大渡河公司于2000年11月在成都高新区注册成立。其主要任务是在大渡河流域开发水电站,以龚嘴和铜街子为母电站。是国家能源集团旗下最大的集水电开发、建设、运营和管理于一体的大流域水电开发公司
目前,公司主要负责大渡河流域开发和西藏巴龙藏布盆地开发的前期准备工作。西藏大渡河干流及支流、巴龙藏布盆地水电资源约3000万千瓦。大渡河流域规划建设梯级水电站28座,总装机容量约2340万千瓦。该公司负责开发干流17座梯级水电站,涉及四川省三地两市(甘孜州、阿坝州、凉山州、雅安市、乐山市)12个县,总装机容量约1757万千瓦,形成生产、在建、准备稳步推进的可持续发展格局。巴龙藏布盆地已完成流域规划报告(咨询稿),初步规划“一库九级”方案,规划装机容量1142万千瓦。截至目前,公司总资产为910.68亿元,在四川投产安装,约占四川水电统一调度总装机容量的四分之一
二、需求分析
分析并统计网站新闻标题、作者、日期等信息,分析网站在线新闻的共性,即哪些类型的主题新闻更容易发布。此外,还可以对公司发表文章较多的作者进行分析,在一定程度上反映作者的水平
三、具体实施
1、使用Python爬虫技术获取公司网站新闻的相关信息
第一步是抓取URL:重建URL并将其放入多线程队列
url = 'http://www.spddr.com/spddr/index.jsp?id=360'
base_url = 'http://www.spddr.com/spddr/'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
第二步是解析URL:在多线程队列中获取重构后的URL并进行解析,最后将解析后的信息放入线程队列
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
步骤3:下载并保存信息:将解析后的信息从队列中取出,并执行下载和保存操作
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
四、所有代码如下所示
from lxml import etree
import requests
import csv
import random
from headers_list import headers_list
import threading
from queue import Queue
headers = {
'User-Agent':random.choice(headers_list),
'Cookie': 'JSESSIONID=91AFDB0A74FDB3DE1011B2E59CF99993; JSESSIONID=DD7458D1055A53D464AE8DF68400DE1F',
'Referer': '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
}
#定义一个Producter类,类名通常是大写开头的单词,它继承的是threading.Thread
class Producter(threading.Thread):
# 用init方法绑定属性,比如定义一个人的类,那你可以再定义人的属性,比如有手、有脚
def __init__(self,page_queue,writer_queue,*args,**kwargs):
super(Producter,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
def run(self):
while True:
try:
url = '[http://www.spddr.com/spddr/index.jsp?id=360](http://www.spddr.com/spddr/index.jsp?id=360)'
base_url = '[http://www.spddr.com/spddr/](http://www.spddr.com/spddr/)'
#获取队列中的data数据
data = self.page_queue.get()
#经分析,网站是通过post方法进行请求
html = requests.post(url, headers=headers, data=data)
tree = etree.HTML(html.text)
#获取每条新闻的url链接
urls = tree.xpath('//div[@class="item"]//span/a/@href')
for u in urls:
# 将获取的每条新闻的url链接进行拼接,重构成新的新闻链接,并将其放入队列中
self.writer_queue.put(base_url + u)
print('*' * 30 + "正在获取第{}页地址".format(data['pages']) + '*' * 30)
#如果队列中的已经取完了,那么就跳出while循环
if self.page_queue.empty():
break
except:
print("解析网页出错")
#定义一个Consumer类,类名通常是大写开头的单词,它继承的是threading.Thread
class Consumer(threading.Thread):
def __init__(self,page_queue,writer_queue,glock,writer,*args,**kwargs):
super(Consumer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.writer_queue = writer_queue
self.glock = glock
self.writer = writer
def run(self):
while True:
try:
#若两个队列中的数据都已经获取完,那么意味着信息已经爬去完毕,于是跳出循环
if self.page_queue.empty() and self.writer_queue.empty():
break
#在队列中获取重构后的新闻链接
url = self.writer_queue.get()
#分析网页后得出具体的新闻页面时通过get方法
html = requests.get(url, headers=headers)
tree = etree.HTML(html.text)
#用xpath获取新闻标题
title = tree.xpath('//div[@class="newsContent"]//strong/font/text()')[0].strip()
#由于作者和日期是一起的,于是将信息全部获取
com = tree.xpath('//tr/td[@align="center"]/div/text()')[0]
#分析后作者和日期是用“:”分割,于是提取信息时也采用“:”分割提取
author = ":".join(com.split()).split(':')[1]
department = ":".join(com.split()).split(':')[3]
time = ":".join(com.split()).split(':')[-1]
#信息提取后重构为字典
infos = {
'title': title,
'author': author,
'department': department,
'time': time
}
print("正在获取信息标题为《{}》的文章".format(title))
#调用信息下载保存函数
self.write_infos(infos)
except:
print("提取信息出错!")
def write_infos(self,infos):
print(30 * '=' + "开始下载" + 30 * '=')
#由于是多线程逐条保存信息,为了避免数据出错,在保存的时候进行开锁操作
self.glock.acquire()
#逐条保存信息
self.writer.writerow(infos)
##由于是多线程逐条保存信息,为了避免数据出错,在保存完毕后进行锁操作
self.glock.release()
if __name__ == '__main__':
# 创建FIFO队列
page_queue = Queue(1000)
writer_queue = Queue(1000)
# 创建线程锁
glock = threading.Lock()
#csv表头信息
head = ['title', 'author', 'department', 'time']
#打开csv文件
fp = open('daduhe.csv', 'a', newline='', errors='ignore', encoding='utf-8')
#用字典方式写入表头信息
writer = csv.DictWriter(fp, head)
writer.writeheader()
for i in range(1,207):
data = {
'nowPage': i,
'totalpage': 206,
'id': 360,
'pages': i,
}
page_queue.put(data)
for x in range(10):
t = Producter(page_queue,writer_queue)#根据Producter类创建一个实例t的线程
t.start()#开启线程
for x in range(10):
t = Consumer(page_queue,writer_queue,glock,writer)#根据Producter类创建一个实例t的线程
t.start()

