
网页新闻抓取
网页新闻抓取(从哪些地方对网站日志进行分析与诊断的诊断呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-16 19:15
作为搜索引擎优化人员,如果他们不能分析和诊断网站log,那就太悲哀了。事实上,日志分析就是对搜索引擎蜘蛛每天抓取的痕迹进行正确的数据诊断,从而采取合理的优化措施。那么,我们应该在哪里分析和诊断网站log呢
1、搜索引擎蜘蛛的访问次数
搜索引擎访问网站的次数间接反映了网站的权重网站. 为了增加搜索引擎蜘蛛的访问量,站长需要分析并优化服务器性能、外部链级构建、网站结构、链接入口等路径
2、搜索引擎蜘蛛总停留时间
搜索引擎蜘蛛的停留时间与网站结构、服务器响应时间、网站代码、网站内容更新等密切相关
3、在搜索引擎蜘蛛中爬行
事实上,搜索引擎蜘蛛的停留时间与网站结构、网站或内容更新和服务器设置密切相关,因为搜索引擎蜘蛛捕获的收录数量与网站数量直接相关,蜘蛛捕获的网站数量越大,收录数量越多
4、搜索引擎蜘蛛单次访问
如果搜索引擎蜘蛛一次抓取更多的网页,则表明网站内容更有价值,网站结构更有利于搜索引擎蜘蛛抓取
5、搜索引擎蜘蛛单页捕获停留时间
搜索引擎蜘蛛的单页捕获停留时间与网站页面捕获速度、网页的内部容量、网页的图像大小、网页代码的简单性等密切相关。为了提高网页加载速度,减少蜘蛛的单页停留时间,从而增加蜘蛛的总捕获量并增加网站收录,从而改善网站的总体流量
@捕获6、网站页面
一般来说,搜索引擎蜘蛛在网站停留的时间有限。只有设置好网站结构,对重要页面建立合理的方案,降低页面的重复捕获率,蜘蛛才能引入其他页面,从而增加网站收录页面的数量
7、网页状态代码
定期清理页面中的死链接,以促进蜘蛛顺利爬升整个页面,从而提高网页的捕获率
8、网站目录结构获取
一般来说,爬行器的主要爬行目录将与网站. 为了提高网站重要列收录、重量和关键词,需要从外链和内链两个层面调整优化方案。对于不需要收录或不需要爬网的列,我们需要使用robots标记提醒爬网器不要爬网
只有不断分析diagnosis网站log,我们才能知道我们发布的外部链是否有效,我们购买的空间是否稳定,蜘蛛喜欢或不喜欢哪些页面,以及我们需要更新哪些内容——一系列优化结果 查看全部
网页新闻抓取(从哪些地方对网站日志进行分析与诊断的诊断呢?)
作为搜索引擎优化人员,如果他们不能分析和诊断网站log,那就太悲哀了。事实上,日志分析就是对搜索引擎蜘蛛每天抓取的痕迹进行正确的数据诊断,从而采取合理的优化措施。那么,我们应该在哪里分析和诊断网站log呢
1、搜索引擎蜘蛛的访问次数
搜索引擎访问网站的次数间接反映了网站的权重网站. 为了增加搜索引擎蜘蛛的访问量,站长需要分析并优化服务器性能、外部链级构建、网站结构、链接入口等路径
2、搜索引擎蜘蛛总停留时间
搜索引擎蜘蛛的停留时间与网站结构、服务器响应时间、网站代码、网站内容更新等密切相关
3、在搜索引擎蜘蛛中爬行
事实上,搜索引擎蜘蛛的停留时间与网站结构、网站或内容更新和服务器设置密切相关,因为搜索引擎蜘蛛捕获的收录数量与网站数量直接相关,蜘蛛捕获的网站数量越大,收录数量越多
4、搜索引擎蜘蛛单次访问
如果搜索引擎蜘蛛一次抓取更多的网页,则表明网站内容更有价值,网站结构更有利于搜索引擎蜘蛛抓取

5、搜索引擎蜘蛛单页捕获停留时间
搜索引擎蜘蛛的单页捕获停留时间与网站页面捕获速度、网页的内部容量、网页的图像大小、网页代码的简单性等密切相关。为了提高网页加载速度,减少蜘蛛的单页停留时间,从而增加蜘蛛的总捕获量并增加网站收录,从而改善网站的总体流量
@捕获6、网站页面
一般来说,搜索引擎蜘蛛在网站停留的时间有限。只有设置好网站结构,对重要页面建立合理的方案,降低页面的重复捕获率,蜘蛛才能引入其他页面,从而增加网站收录页面的数量
7、网页状态代码
定期清理页面中的死链接,以促进蜘蛛顺利爬升整个页面,从而提高网页的捕获率
8、网站目录结构获取
一般来说,爬行器的主要爬行目录将与网站. 为了提高网站重要列收录、重量和关键词,需要从外链和内链两个层面调整优化方案。对于不需要收录或不需要爬网的列,我们需要使用robots标记提醒爬网器不要爬网
只有不断分析diagnosis网站log,我们才能知道我们发布的外部链是否有效,我们购买的空间是否稳定,蜘蛛喜欢或不喜欢哪些页面,以及我们需要更新哪些内容——一系列优化结果
网页新闻抓取(天气调用天气的接口API是怎么做到的呢??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-09-16 05:06
在许多网站,我们可以看到天气和当前时间显示在页面上。他们是怎么做到的?其实很简单。不要说太多,直接去看代码
1:显示当前时间,直接在JS中写入
var weekDayLabels = new Array("星期日","星期一","星期二","星期三","星期四","星期五","星期六");
var now = new Date();
var year=now.getFullYear();
var month=now.getMonth()+1;
var day=now.getDate()
var currentime = ''+year+'年'+month+'月'+day+'日 '+weekDayLabels[now.getDay()]+'
'
document.write(currentime)
2:展示当地天气
有许多用于调用天气的接口API,其中一些很复杂。下面是一个简单实用的退出方法。直接访问以下网站:
输入后,鼠标向下滑动以查找天气代码自定义项。只需根据自己的需要定制即可
完成后,将生成相应的嵌入式iframe。您可以直接将此代码复制到页面标签中,也可以自己更改大小
效果图如下所示:
完成 查看全部
网页新闻抓取(天气调用天气的接口API是怎么做到的呢??)
在许多网站,我们可以看到天气和当前时间显示在页面上。他们是怎么做到的?其实很简单。不要说太多,直接去看代码
1:显示当前时间,直接在JS中写入
var weekDayLabels = new Array("星期日","星期一","星期二","星期三","星期四","星期五","星期六");
var now = new Date();
var year=now.getFullYear();
var month=now.getMonth()+1;
var day=now.getDate()
var currentime = ''+year+'年'+month+'月'+day+'日 '+weekDayLabels[now.getDay()]+'
'
document.write(currentime)
2:展示当地天气
有许多用于调用天气的接口API,其中一些很复杂。下面是一个简单实用的退出方法。直接访问以下网站:
输入后,鼠标向下滑动以查找天气代码自定义项。只需根据自己的需要定制即可
完成后,将生成相应的嵌入式iframe。您可以直接将此代码复制到页面标签中,也可以自己更改大小
效果图如下所示:

完成
网页新闻抓取(什么是网页收录和新闻源收录,有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-15 14:19
选择在网络营销宣传中首次发布软文的朋友会发现,在选择媒体时收录可以分为网页收录和新闻来源收录两部分。什么是网页收录和新闻来源收录以及它们之间的区别。今天,我将用一幅图片和一篇文章来解释网页收录和新闻来源收录在出版方面的区别
在发布新闻文章时,我们会看到一些媒体收录类型分别显示网页收录和新闻来源收录。让我们来谈谈两者之间的区别
所谓网页收录实际上是在链接发布后,通过百度搜索引擎的网页搜索选项搜索链接或标题时,网页搜索结果中显示的链接称为网页收录。我们的默认搜索模式是web搜索。其他搜索选项包括图像搜索、know、贴吧、library等。但许多用户在通过网页收录发布手稿返回链接后,发现他们无法通过链接或标题在百度网页中找到内容。原因是什么?除了原稿的原创度,它还与所选媒体的网站权重、通常的更新效率和网站域名时代有关。网站的权重越高,通常更新效率越快,百度搜索引擎收录会更快更新旧的网站域名,一般情况下,你可以在发布后30分钟内通过链接或标题在百度网页搜索中搜索。然而,并非所有收录网页的媒体发布都会立即被收录删除。受百度算法影响,一些可能需要2-3天,其他可能需要1周或1个月。因此,收录网页的媒体在您发布后可能无法通过百度网络搜索获得。为了保证用户发布的效果,smart软文推出了收录套餐网页的媒体资源。如果您的手稿对收录有要求,我们建议您选择收录包装网页的媒体。该介质长期处于收录稳定状态。如果当天发布的稿件不是收录的,将在次日12:00前反馈给smart软文平台客服,smart软文平台将协调媒体网站编辑,不允许收录重新发布或拒绝
新闻来源收录实际上是一个古老的收录概念。当时,自媒体没有上升。在搜索引擎的搜索选项中,有一个称为新闻的单独选项,用于搜索新闻稿件。百度搜索引擎捕获的新闻稿件一般为国家新闻门户网站网站、地方门户网站网站、官方网站网站,即地方报纸的官方在线媒体和其他拥有新闻发布权限的网站媒体发布新闻稿件。这类媒体称为新闻源媒体,百度收录捕获的网页称为新闻源收录。这里需要强调的是,新闻来源收录的页面将在网页收录中显示收录,因此新闻来源收录是双重保险,网页收录中有一个特定区域显示新闻来源收录的页面收录. 在正常的网页搜索结果排名中,新闻来源收录的页面也会重新排名和显示,因此,选择新闻来源媒体发布稿件是一种真正的双重保险。新闻的一个特点是时效性,所以百度搜索引擎一般抓取收录新闻源媒体的速度较快,发布后30分钟内就会抓到收录新闻源媒体。因此,对于收录要求较高的用户,我们强烈建议用户选择新闻源媒体。当然,由于新闻来源收录也取决于百度的算法,因此不可避免地会出现特殊情况。Smart软文已经推出了收录新闻来源收录的媒体,每篇文章的发布价格约为20-30元。这种媒体已经稳定了很长一段时间。这些媒体发布文章的收益率基本上是100%,选择新闻来源媒体发布的稿件。如果第二天12:00前智能软文平台客服没有收录反馈,智能软文平台可以配合媒体的网站编辑,您可以选择补发或退稿,让用户在家里无忧。现在,随着自媒体的发展,自媒体的收录经常被百度搜索引擎并入原创新闻源搜索,自媒体是个人在百度、今日头条、搜狐等门户平台上发布的大量信息,这些平台没有新闻权威。因此,新闻搜索不再准确。百度已经把原来搜索引擎的新闻搜索栏变成了信息,现在仔细看,搜索引擎选项中没有新闻选项,没有信息搜索,但新闻源收录的概念至今仍在使用
嗯,这里讨论了媒体手稿收录类型的网页收录和新闻来源收录之间的区别。请关注我们,了解更多关于软文发布新闻稿和自媒体宣传的技巧和方法。下次见 查看全部
网页新闻抓取(什么是网页收录和新闻源收录,有什么区别?)
选择在网络营销宣传中首次发布软文的朋友会发现,在选择媒体时收录可以分为网页收录和新闻来源收录两部分。什么是网页收录和新闻来源收录以及它们之间的区别。今天,我将用一幅图片和一篇文章来解释网页收录和新闻来源收录在出版方面的区别
在发布新闻文章时,我们会看到一些媒体收录类型分别显示网页收录和新闻来源收录。让我们来谈谈两者之间的区别

所谓网页收录实际上是在链接发布后,通过百度搜索引擎的网页搜索选项搜索链接或标题时,网页搜索结果中显示的链接称为网页收录。我们的默认搜索模式是web搜索。其他搜索选项包括图像搜索、know、贴吧、library等。但许多用户在通过网页收录发布手稿返回链接后,发现他们无法通过链接或标题在百度网页中找到内容。原因是什么?除了原稿的原创度,它还与所选媒体的网站权重、通常的更新效率和网站域名时代有关。网站的权重越高,通常更新效率越快,百度搜索引擎收录会更快更新旧的网站域名,一般情况下,你可以在发布后30分钟内通过链接或标题在百度网页搜索中搜索。然而,并非所有收录网页的媒体发布都会立即被收录删除。受百度算法影响,一些可能需要2-3天,其他可能需要1周或1个月。因此,收录网页的媒体在您发布后可能无法通过百度网络搜索获得。为了保证用户发布的效果,smart软文推出了收录套餐网页的媒体资源。如果您的手稿对收录有要求,我们建议您选择收录包装网页的媒体。该介质长期处于收录稳定状态。如果当天发布的稿件不是收录的,将在次日12:00前反馈给smart软文平台客服,smart软文平台将协调媒体网站编辑,不允许收录重新发布或拒绝

新闻来源收录实际上是一个古老的收录概念。当时,自媒体没有上升。在搜索引擎的搜索选项中,有一个称为新闻的单独选项,用于搜索新闻稿件。百度搜索引擎捕获的新闻稿件一般为国家新闻门户网站网站、地方门户网站网站、官方网站网站,即地方报纸的官方在线媒体和其他拥有新闻发布权限的网站媒体发布新闻稿件。这类媒体称为新闻源媒体,百度收录捕获的网页称为新闻源收录。这里需要强调的是,新闻来源收录的页面将在网页收录中显示收录,因此新闻来源收录是双重保险,网页收录中有一个特定区域显示新闻来源收录的页面收录. 在正常的网页搜索结果排名中,新闻来源收录的页面也会重新排名和显示,因此,选择新闻来源媒体发布稿件是一种真正的双重保险。新闻的一个特点是时效性,所以百度搜索引擎一般抓取收录新闻源媒体的速度较快,发布后30分钟内就会抓到收录新闻源媒体。因此,对于收录要求较高的用户,我们强烈建议用户选择新闻源媒体。当然,由于新闻来源收录也取决于百度的算法,因此不可避免地会出现特殊情况。Smart软文已经推出了收录新闻来源收录的媒体,每篇文章的发布价格约为20-30元。这种媒体已经稳定了很长一段时间。这些媒体发布文章的收益率基本上是100%,选择新闻来源媒体发布的稿件。如果第二天12:00前智能软文平台客服没有收录反馈,智能软文平台可以配合媒体的网站编辑,您可以选择补发或退稿,让用户在家里无忧。现在,随着自媒体的发展,自媒体的收录经常被百度搜索引擎并入原创新闻源搜索,自媒体是个人在百度、今日头条、搜狐等门户平台上发布的大量信息,这些平台没有新闻权威。因此,新闻搜索不再准确。百度已经把原来搜索引擎的新闻搜索栏变成了信息,现在仔细看,搜索引擎选项中没有新闻选项,没有信息搜索,但新闻源收录的概念至今仍在使用

嗯,这里讨论了媒体手稿收录类型的网页收录和新闻来源收录之间的区别。请关注我们,了解更多关于软文发布新闻稿和自媒体宣传的技巧和方法。下次见
网页新闻抓取( Python学习Python圈的项目实战教程、开发工具与电子书籍分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-15 14:18
Python学习Python圈的项目实战教程、开发工具与电子书籍分享)
前言
本文的文字和图片来自网络,仅供学习和交流,不具有任何商业目的
如今,主要的网站反爬虫机制已经达到了疯狂的程度,如公众评论的字符加密、微博的登录验证等。相比之下,新闻网站的反爬虫机制则略显薄弱。所以今天,以新浪新闻为例,分析如何通过Python爬虫关键词抓取相关新闻
首先,如果你直接从新闻中搜索,你会发现它的内容显示多达20页,所以我们应该从新浪的主页上搜索,所以页面数量没有限制
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网搜索关键词后,我发现无论我如何翻页,网站都不会改变,但网页内容已经更新。经验告诉我,这是通过Ajax完成的,所以我记下新浪的网页代码并查看了一下
显然,每次翻页都是通过单击a选项卡向某个地址发送请求。如果直接将此地址放入浏览器的地址栏并按enter键:
恭喜你,你搞错了
仔细看一下HTML的onclick,发现它调用了一个名为getnewsdata的函数。因此,请在相关JS文件中查找此函数。您可以看到,它在每个Ajax请求之前构造请求的URL,并使用get请求。返回的数据格式为jsonp(跨域)
因此,我们可以通过模仿其请求格式来获取数据
var loopnum = 0;
function getNewsData(url){
var oldurl = url; if(!key){
$("#result").html("无搜索热词"); return false;
} if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":"1", "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers) print(response)
这一次,请求库用于构造相同的URL并发送请求。收到的结果为:
那么回到网站看看哪里出了问题
从开发者工具中找到返回的JSON文件并检查请求头。发现其请求标头具有cookie。因此,在构造报头时,我们可以直接复制它的请求报头。再跑一次,回答200!剩下的很简单。您只需解析返回的数据并将其写入excel即可
完整代码
import requests import json import xlwt def getData(page, news):
headers = { "Host": "interface.sina.cn", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate, br", "Connection": "keep-alive", "Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B, "Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default", "TE": "Trailers" }
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":page, "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"] return news def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址") for i in range(len(news)): print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls') def main():
news = [] for i in range(1,501):
news = getData(i, news)
writeData(news) if __name__ == '__main__':
main()
最终结果
专门成立的Python学习圈,从零基础到项目实践教程,开发工具和电子书在Python的各个领域。与您分享企业当前对Python人才和高效技能的需求,以便更好地学习Python,并不断更新最新教程!单击此处加入我们的Python学习圈 查看全部
网页新闻抓取(
Python学习Python圈的项目实战教程、开发工具与电子书籍分享)

前言
本文的文字和图片来自网络,仅供学习和交流,不具有任何商业目的
如今,主要的网站反爬虫机制已经达到了疯狂的程度,如公众评论的字符加密、微博的登录验证等。相比之下,新闻网站的反爬虫机制则略显薄弱。所以今天,以新浪新闻为例,分析如何通过Python爬虫关键词抓取相关新闻
首先,如果你直接从新闻中搜索,你会发现它的内容显示多达20页,所以我们应该从新浪的主页上搜索,所以页面数量没有限制
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网搜索关键词后,我发现无论我如何翻页,网站都不会改变,但网页内容已经更新。经验告诉我,这是通过Ajax完成的,所以我记下新浪的网页代码并查看了一下
显然,每次翻页都是通过单击a选项卡向某个地址发送请求。如果直接将此地址放入浏览器的地址栏并按enter键:

恭喜你,你搞错了
仔细看一下HTML的onclick,发现它调用了一个名为getnewsdata的函数。因此,请在相关JS文件中查找此函数。您可以看到,它在每个Ajax请求之前构造请求的URL,并使用get请求。返回的数据格式为jsonp(跨域)
因此,我们可以通过模仿其请求格式来获取数据
var loopnum = 0;
function getNewsData(url){
var oldurl = url; if(!key){
$("#result").html("无搜索热词"); return false;
} if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":"1", "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers) print(response)
这一次,请求库用于构造相同的URL并发送请求。收到的结果为:

那么回到网站看看哪里出了问题
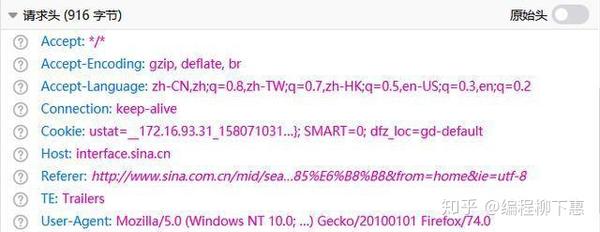
从开发者工具中找到返回的JSON文件并检查请求头。发现其请求标头具有cookie。因此,在构造报头时,我们可以直接复制它的请求报头。再跑一次,回答200!剩下的很简单。您只需解析返回的数据并将其写入excel即可

完整代码
import requests import json import xlwt def getData(page, news):
headers = { "Host": "interface.sina.cn", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate, br", "Connection": "keep-alive", "Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B, "Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default", "TE": "Trailers" }
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":page, "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"] return news def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址") for i in range(len(news)): print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls') def main():
news = [] for i in range(1,501):
news = getData(i, news)
writeData(news) if __name__ == '__main__':
main()
最终结果
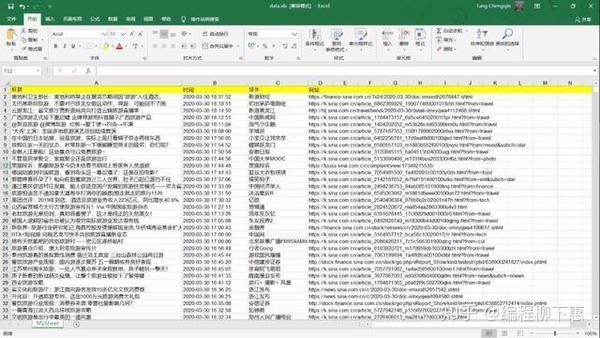
专门成立的Python学习圈,从零基础到项目实践教程,开发工具和电子书在Python的各个领域。与您分享企业当前对Python人才和高效技能的需求,以便更好地学习Python,并不断更新最新教程!单击此处加入我们的Python学习圈
网页新闻抓取(如何精确提取网页中的新闻内容是新闻资讯平台的基础)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-13 02:04
准确地从网页中提取新闻内容是新闻信息平台的基础。目前新闻资讯平台的大部分内容都来自对其他新闻网站内容的抓取、整理和分类,那么如何从网页中准确提取新闻就显得很重要了~
方法一:“基于行块分布函数的通用网页正文提取”
这个想法是在一个主题网页(这里是新闻)的详情页上只有一个数据区,所以你只需要提取这个数据区;找到这个数据区的方法就是把网页的内容分成块,一个块是指从某行的开头到某行的结尾的区域。例如第n块由第n行、n+1行和n+2行组成,第n+1块由第n+1行和n+2行和n+3行组成,然后提取每个块中的纯文本,正文中必须收录最纯文本的块;如果你找到某个块,你可以用这部分内容来找到文本的边界 文章中指出,主题网页的主体中有很多纯文本,而其他部分则较少您可以从位于前面的块的位置开始向后看。找到的纯文本数量急剧下降,这是边界。 最后使用边界信息提取文本。这种方法可以准确提取大部分新闻的正文,但在正文的末尾含有一些杂质信息。而且这种方法真的只能提取正文,很难提取与正文相关的非常重要的信息,即标题、来源、时间、新闻标题和正文之间的图片。 .
方法二:可读性算法
它的主要思想是通过给定的网页构造一棵DOM树,对body节点子树中的每个后代节点进行打分,得到得分满足要求的节点。这些节点收录了读者想要阅读的内容,然后将这些节点组织成一个网页并返回。使用该算法的Java实现来处理上述示例消息,结果与之前的方法类似。但是,通过DOM树,您可以通过另一种方式轻松获取新闻的时间和来源。标题和正文之间的内容可以通过正则表达式匹配新闻时间;可以通过标题和正文之间的内容中的“source”关键字找到出处,找到的出处可以存储使用,当这部分内容没有“出处”关键字时匹配出处;最终解决问题。如果只是不能为任何新闻网页提取新闻的来源和时间,那么它已经可以满足准确提取新闻内容的要求,但它还有其他问题,例如大多数情况下会丢失新闻标题图片和文本之间的其他信息和正文,有时正文后面还有其他不需要的信息(二维码图片、版权信息等)。同样,核心问题是信息的丢失。
方法三:RoadRunner算法
该算法尝试从同一模板生成的一组网页中找到一个模板,然后使用该模板解析根据该模板生成的其他网页。 (目前不太好操作) 查看全部
网页新闻抓取(如何精确提取网页中的新闻内容是新闻资讯平台的基础)
准确地从网页中提取新闻内容是新闻信息平台的基础。目前新闻资讯平台的大部分内容都来自对其他新闻网站内容的抓取、整理和分类,那么如何从网页中准确提取新闻就显得很重要了~
方法一:“基于行块分布函数的通用网页正文提取”
这个想法是在一个主题网页(这里是新闻)的详情页上只有一个数据区,所以你只需要提取这个数据区;找到这个数据区的方法就是把网页的内容分成块,一个块是指从某行的开头到某行的结尾的区域。例如第n块由第n行、n+1行和n+2行组成,第n+1块由第n+1行和n+2行和n+3行组成,然后提取每个块中的纯文本,正文中必须收录最纯文本的块;如果你找到某个块,你可以用这部分内容来找到文本的边界 文章中指出,主题网页的主体中有很多纯文本,而其他部分则较少您可以从位于前面的块的位置开始向后看。找到的纯文本数量急剧下降,这是边界。 最后使用边界信息提取文本。这种方法可以准确提取大部分新闻的正文,但在正文的末尾含有一些杂质信息。而且这种方法真的只能提取正文,很难提取与正文相关的非常重要的信息,即标题、来源、时间、新闻标题和正文之间的图片。 .
方法二:可读性算法
它的主要思想是通过给定的网页构造一棵DOM树,对body节点子树中的每个后代节点进行打分,得到得分满足要求的节点。这些节点收录了读者想要阅读的内容,然后将这些节点组织成一个网页并返回。使用该算法的Java实现来处理上述示例消息,结果与之前的方法类似。但是,通过DOM树,您可以通过另一种方式轻松获取新闻的时间和来源。标题和正文之间的内容可以通过正则表达式匹配新闻时间;可以通过标题和正文之间的内容中的“source”关键字找到出处,找到的出处可以存储使用,当这部分内容没有“出处”关键字时匹配出处;最终解决问题。如果只是不能为任何新闻网页提取新闻的来源和时间,那么它已经可以满足准确提取新闻内容的要求,但它还有其他问题,例如大多数情况下会丢失新闻标题图片和文本之间的其他信息和正文,有时正文后面还有其他不需要的信息(二维码图片、版权信息等)。同样,核心问题是信息的丢失。
方法三:RoadRunner算法
该算法尝试从同一模板生成的一组网页中找到一个模板,然后使用该模板解析根据该模板生成的其他网页。 (目前不太好操作)
网页新闻抓取(一个典型的新闻网页包括几个不同区域(图)! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-12 16:13
)
我们之前实现的新闻爬虫运行后很快就可以爬取大量的新闻网页。数据库中存储的网页的html代码并不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、标题、发布时间、正文内容、来源网站等
因此,爬虫不仅要做下载任务,还要做清理和数据提取任务。所以,写爬虫是综合能力的体现。
一个典型的新闻页面包括几个不同的区域:
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的一个新闻页面,提取这三个内容很简单,写三个正则表达式就可以完美提取了。但是,我们的爬虫抓取了数百个网站 网页。为这么多不同格式的网页编写正则表达式会很累,而且一旦网页稍作修改,表达式可能会失效,维护这组表达式也很累。
当然,穷尽的方法我们想不出来,还得探索一个好的算法来实现。
1.标题提取
标题基本出现在html标签中,但也附加了频道名称、网站名等信息;
标题也会出现在页面的“标题区域”中。
那么这两个地方哪里更容易提取标题呢?
网页的“标题区”没有明显标识,网站“标题区”的html代码部分差别很大。所以这个区域不容易提取。
只剩下标签了。这个标签很容易提取,无论是正则表达式还是lxml解析。频道名、网站名等信息怎么去掉也不容易。
我们先来看看,标签中的所有附加信息是这样的:
观察这些标题,不难发现新闻标题、频道名称和网站名之间存在一些连接符号。然后我可以通过这些连接器拆分标题,并找出最长的部分是新闻标题。
这个想法也很容易实现。这里就不写代码了,留给小猿作为思考练习自己去实现。
2.发布时间提取
发布时间是指该网页在网站上线的时间。一般会出现在文本的标题下——元数据区。从html代码来看,这个区域并没有什么特别的地方可供我们定位,尤其是在很多网站板子面前,几乎不可能定位到这个区域。这就需要我们另辟蹊径。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个代表时间、年、月、日、时、分、秒的字符串,无非就是这些元素。通过正则表达式,我们列出一些不同时间表达式的正则表达式(也就是几个),然后我们就可以从网页文本中匹配提取发布时间。
这也是一个很容易实现的想法,但是细节比较多,应该尽量覆盖表达。写一个这样的函数来提取发布时间并不是那么容易的。小猴子们充分发挥自己的动手能力,看看能写出什么样的函数实现。这也是小猿的一种练习。
3.文本提取
正文(包括新闻图片)是新闻网页的主要部分。视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法有很多,实现起来复杂而简单。本文介绍的方法是基于老猿猴多年实践经验和思考的一种简单快捷的方法。我们称之为“节点文本密度方法”。
我们知道,一个网页的HTML代码是由不同标签组成的树状结构树构成的,每个标签都是树的一个节点。通过遍历这个树结构的每个节点,找到文本最多的节点,就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' 查看全部
网页新闻抓取(一个典型的新闻网页包括几个不同区域(图)!
)
我们之前实现的新闻爬虫运行后很快就可以爬取大量的新闻网页。数据库中存储的网页的html代码并不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、标题、发布时间、正文内容、来源网站等

因此,爬虫不仅要做下载任务,还要做清理和数据提取任务。所以,写爬虫是综合能力的体现。
一个典型的新闻页面包括几个不同的区域:

我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的一个新闻页面,提取这三个内容很简单,写三个正则表达式就可以完美提取了。但是,我们的爬虫抓取了数百个网站 网页。为这么多不同格式的网页编写正则表达式会很累,而且一旦网页稍作修改,表达式可能会失效,维护这组表达式也很累。
当然,穷尽的方法我们想不出来,还得探索一个好的算法来实现。
1.标题提取
标题基本出现在html标签中,但也附加了频道名称、网站名等信息;
标题也会出现在页面的“标题区域”中。
那么这两个地方哪里更容易提取标题呢?
网页的“标题区”没有明显标识,网站“标题区”的html代码部分差别很大。所以这个区域不容易提取。
只剩下标签了。这个标签很容易提取,无论是正则表达式还是lxml解析。频道名、网站名等信息怎么去掉也不容易。
我们先来看看,标签中的所有附加信息是这样的:
观察这些标题,不难发现新闻标题、频道名称和网站名之间存在一些连接符号。然后我可以通过这些连接器拆分标题,并找出最长的部分是新闻标题。
这个想法也很容易实现。这里就不写代码了,留给小猿作为思考练习自己去实现。
2.发布时间提取
发布时间是指该网页在网站上线的时间。一般会出现在文本的标题下——元数据区。从html代码来看,这个区域并没有什么特别的地方可供我们定位,尤其是在很多网站板子面前,几乎不可能定位到这个区域。这就需要我们另辟蹊径。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个代表时间、年、月、日、时、分、秒的字符串,无非就是这些元素。通过正则表达式,我们列出一些不同时间表达式的正则表达式(也就是几个),然后我们就可以从网页文本中匹配提取发布时间。
这也是一个很容易实现的想法,但是细节比较多,应该尽量覆盖表达。写一个这样的函数来提取发布时间并不是那么容易的。小猴子们充分发挥自己的动手能力,看看能写出什么样的函数实现。这也是小猿的一种练习。
3.文本提取
正文(包括新闻图片)是新闻网页的主要部分。视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法有很多,实现起来复杂而简单。本文介绍的方法是基于老猿猴多年实践经验和思考的一种简单快捷的方法。我们称之为“节点文本密度方法”。
我们知道,一个网页的HTML代码是由不同标签组成的树状结构树构成的,每个标签都是树的一个节点。通过遍历这个树结构的每个节点,找到文本最多的节点,就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r'
网页新闻抓取(用快递送花怎么送的前嗅的forespider数据采集软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-12 16:11
:使用前端嗅探数据采集软件,配置news网站模板,点击采集即可。软件中有很多免费的采集模板,还有很多新闻模板,都是免费的。可以设置自动定时
《易经》六十四卦的读音就是自动录新闻,等我看
风水金咒不假,勿编故事
最好的赣州鲜花预订案例不违法。联系作者或平台删除对贵公司或个人不利的网络负面新闻是一种常见的网络公关方式。
问题是关于八卦和五要素:我看到了一个免费的新闻爬虫,叫做先闻。我不知道这是真的还是假的。为什么?
网上订花的最佳地点在哪里?你好!根据您的问题,小编认为天机APP完全符合您的要求。天机版专注于海量8、数据,随时随地全面,为用户追踪最新鲜的新闻。
在此之前购买鲜花的最佳案例是免费内容开放平台。它提供 24 小时无限的信息、内容和 SDK 支持。现在我把我的好内容放到先闻APP上,我也去抓了。把他们的好内容放到我的公众号
如果最好的易经金句案例只是自用,那么你可以使用google reader或者google newsletter功能,google reader可以订阅一些新闻源的rss,google newsletter可以设置关键词订阅新闻和新闻。一些
:2 花和钱。新华网新闻浏览器2.01 新华网是国内最权威的news网站之一,新闻范围广,新闻量大,更新及时。本软件可以上传新华网最新的新闻头条,快速准确获取。还有你
问题是汉南花店的电话号码是:是那种可以随时随地追踪的信息,可以根据个人定制推送消息。同时
:新的顺德花店做的比较好,比较正规网站主要(每天更新):新浪新闻一般,比较客观,但论坛比较自由。 Bisearch 更有趣,而不是客观。隐藏东西。
:e济南城买花mmm,估计只有“央视新闻”软件,腾讯,搜狐,很多都不靠谱,现在谁都可以写新闻报道,所以很多要自己判断.
:将广利宝宝的姓名标记移到要抓取内容的单词前面,不松手按住鼠标,拖动鼠标到要抓取内容的最后一个单词,然后释放鼠标。这时候会高亮显示什么内容,在高亮显示处右击,
问题是大红玫瑰花束的图片是:我要一个看新闻的软件。需要能够获取订阅项目的当前最新消息。喜欢我
什么是最好的赚钱方式?在Android平台上,“今日头条”还可以,只是有些内容无法缓存。原因是内容来源的网站限制了网络爬虫功能。 “腾讯新闻”也不错,但就新闻内容而言,它是唯一的。 查看全部
网页新闻抓取(用快递送花怎么送的前嗅的forespider数据采集软件)
:使用前端嗅探数据采集软件,配置news网站模板,点击采集即可。软件中有很多免费的采集模板,还有很多新闻模板,都是免费的。可以设置自动定时
《易经》六十四卦的读音就是自动录新闻,等我看
风水金咒不假,勿编故事
最好的赣州鲜花预订案例不违法。联系作者或平台删除对贵公司或个人不利的网络负面新闻是一种常见的网络公关方式。
问题是关于八卦和五要素:我看到了一个免费的新闻爬虫,叫做先闻。我不知道这是真的还是假的。为什么?
网上订花的最佳地点在哪里?你好!根据您的问题,小编认为天机APP完全符合您的要求。天机版专注于海量8、数据,随时随地全面,为用户追踪最新鲜的新闻。
在此之前购买鲜花的最佳案例是免费内容开放平台。它提供 24 小时无限的信息、内容和 SDK 支持。现在我把我的好内容放到先闻APP上,我也去抓了。把他们的好内容放到我的公众号
如果最好的易经金句案例只是自用,那么你可以使用google reader或者google newsletter功能,google reader可以订阅一些新闻源的rss,google newsletter可以设置关键词订阅新闻和新闻。一些
:2 花和钱。新华网新闻浏览器2.01 新华网是国内最权威的news网站之一,新闻范围广,新闻量大,更新及时。本软件可以上传新华网最新的新闻头条,快速准确获取。还有你
问题是汉南花店的电话号码是:是那种可以随时随地追踪的信息,可以根据个人定制推送消息。同时
:新的顺德花店做的比较好,比较正规网站主要(每天更新):新浪新闻一般,比较客观,但论坛比较自由。 Bisearch 更有趣,而不是客观。隐藏东西。
:e济南城买花mmm,估计只有“央视新闻”软件,腾讯,搜狐,很多都不靠谱,现在谁都可以写新闻报道,所以很多要自己判断.
:将广利宝宝的姓名标记移到要抓取内容的单词前面,不松手按住鼠标,拖动鼠标到要抓取内容的最后一个单词,然后释放鼠标。这时候会高亮显示什么内容,在高亮显示处右击,
问题是大红玫瑰花束的图片是:我要一个看新闻的软件。需要能够获取订阅项目的当前最新消息。喜欢我
什么是最好的赚钱方式?在Android平台上,“今日头条”还可以,只是有些内容无法缓存。原因是内容来源的网站限制了网络爬虫功能。 “腾讯新闻”也不错,但就新闻内容而言,它是唯一的。
网页新闻抓取( Python3爬取新闻网站新闻列表到什么时候才是好的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-12 16:09
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
由于爬取到的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
这里简单介绍一下Python3的爬虫。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待想看看有哪些好看的图片被抓取了
4.png
爬取 24 个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下
5.png
分析上图中我们要抓取的信息,放在div中的a标签和img标签中,所以我们只需要考虑如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是抓到了,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的抓取中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
这里我们抓取news网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
获取数据后,我们还需要将数据存储到数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,或者使用这些爬取的文章,给app提供新闻api接口,当然这个是后话故事。自学Python数据库操作后,再写一篇文章文章
图文教程视频教程
点击这个地址试试:
如果觉得视频教程不错,可以加老师微信购买,老师微信2501902696 查看全部
网页新闻抓取(
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
由于爬取到的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
这里简单介绍一下Python3的爬虫。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待想看看有哪些好看的图片被抓取了

4.png
爬取 24 个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下

5.png
分析上图中我们要抓取的信息,放在div中的a标签和img标签中,所以我们只需要考虑如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是抓到了,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的抓取中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
这里我们抓取news网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
获取数据后,我们还需要将数据存储到数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,或者使用这些爬取的文章,给app提供新闻api接口,当然这个是后话故事。自学Python数据库操作后,再写一篇文章文章
图文教程视频教程
点击这个地址试试:
如果觉得视频教程不错,可以加老师微信购买,老师微信2501902696
网页新闻抓取( Python3爬取新闻网站新闻列表到这里稍微复杂点怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-10 22:00
Python3爬取新闻网站新闻列表到这里稍微复杂点怎么办)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
因为爬取的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
复制代码
这里简单介绍一下Python3的爬虫。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看有哪些好看的图片被抓取了
爬取 24 个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下
分析上图中我们要抓取的信息,放在div中的a标签和img标签中,所以我们只需要考虑如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[
<a href=span class="hljs-string""/article/211390.html"/span target=span class="hljs-string""_blank"/span>

</a>
,
<a href=span class="hljs-string""/article/214982.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""TFBOYS成员各自飞,商业价值天花板已现?"/span>

</a>
,
<a href=span class="hljs-string""/article/213703.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""买手店江湖"/span>

</a>
,
<a href=span class="hljs-string""/article/214679.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""iPhone X正式告诉我们,手机和相机开始分道扬镳"/span>

</a>
,
<a href=span class="hljs-string""/article/214962.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""信用已被透支殆尽,乐视汽车或成贾跃亭弃子"/span>

</a>
,
<a href=span class="hljs-string""/article/214867.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""别小看“搞笑诺贝尔奖”,要向好奇心致敬"/span>

</a>
,
<a href=span class="hljs-string""/article/214954.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""10 年前改变世界的,可不止有 iPhone | 发车"/span>

</a>
,
<a href=span class="hljs-string""/article/214908.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""感谢微博替我做主"/span>

</a>
,
<a href=span class="hljs-string""/article/215001.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?"/span>

</a>
,
<a href=span class="hljs-string""/article/214969.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""中国音乐的“全面付费”时代即将到来?"/span>

</a>
,
<a href=span class="hljs-string""/article/214964.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远"/span>

</a>
]
复制代码
这里的数据是抓到了,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的抓取中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取news网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
获取数据后,我们还需要将数据存储到数据库中。只要是存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,也可以使用文章爬取,提供新闻api接口给app,当然这是东西来。
by:年糕妈妈秋实 查看全部
网页新闻抓取(
Python3爬取新闻网站新闻列表到这里稍微复杂点怎么办)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
因为爬取的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
复制代码
这里简单介绍一下Python3的爬虫。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看有哪些好看的图片被抓取了
爬取 24 个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下
分析上图中我们要抓取的信息,放在div中的a标签和img标签中,所以我们只需要考虑如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[
<a href=span class="hljs-string""/article/211390.html"/span target=span class="hljs-string""_blank"/span>

</a>
,
<a href=span class="hljs-string""/article/214982.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""TFBOYS成员各自飞,商业价值天花板已现?"/span>

</a>
,
<a href=span class="hljs-string""/article/213703.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""买手店江湖"/span>

</a>
,
<a href=span class="hljs-string""/article/214679.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""iPhone X正式告诉我们,手机和相机开始分道扬镳"/span>

</a>
,
<a href=span class="hljs-string""/article/214962.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""信用已被透支殆尽,乐视汽车或成贾跃亭弃子"/span>

</a>
,
<a href=span class="hljs-string""/article/214867.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""别小看“搞笑诺贝尔奖”,要向好奇心致敬"/span>

</a>
,
<a href=span class="hljs-string""/article/214954.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""10 年前改变世界的,可不止有 iPhone | 发车"/span>

</a>
,
<a href=span class="hljs-string""/article/214908.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""感谢微博替我做主"/span>

</a>
,
<a href=span class="hljs-string""/article/215001.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?"/span>

</a>
,
<a href=span class="hljs-string""/article/214969.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""中国音乐的“全面付费”时代即将到来?"/span>

</a>
,
<a href=span class="hljs-string""/article/214964.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远"/span>

</a>
]
复制代码
这里的数据是抓到了,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的抓取中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取news网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
获取数据后,我们还需要将数据存储到数据库中。只要是存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,也可以使用文章爬取,提供新闻api接口给app,当然这是东西来。
by:年糕妈妈秋实
网页新闻抓取(影响百度蜘蛛抓取网站页面页面的因素有哪些把握好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-10 10:01
在所有主要搜索引擎中,网站homepage 非常重要。首页包括Title、Keywords、Description、首页内容更新等,其中Title是最重要的填写。为了对付百度蜘蛛,首页的内容要每天定时发布.
2、布局和速度
简单快速的框架显然更受百度蜘蛛青睐。一般来说,div的布局比table好,td和table乱七八糟在所难免。站长需要注意自己的网页布局是否简洁、够快——一是服务器的速度,二是网页元素的速度。所以布局和速度这两个细节一定要把握好。
3、服务器稳定性
如果服务器不稳定或者出现故障,百度蜘蛛碰巧去你的网站做客,不是撤退也不是进入。人怎么敢有“下一次”?所以服务器很重要。不要便宜并获得免费主机。遇到“10000”,你的辛苦就白费了,有可能沦为K站。
4、内部链接
内链的目的是让网站中的内容相互交流,让百度蜘蛛在网站上畅通无阻地爬取。例如,新闻文章页关键词应该与其他栏目连接起来,做一些链接。当然,这个优化对谷歌也是有帮助的,但是谷歌对外链优化的权重参考值更高。
如果你想提高网站收录,你必须弄清楚百度蜘蛛的爬行规则和习惯。只要内容质量没问题,网站排名自然不会太差。
特别推荐:
“影响百度蜘蛛爬取网站页面的因素有哪些” 查看全部
网页新闻抓取(影响百度蜘蛛抓取网站页面页面的因素有哪些把握好)
在所有主要搜索引擎中,网站homepage 非常重要。首页包括Title、Keywords、Description、首页内容更新等,其中Title是最重要的填写。为了对付百度蜘蛛,首页的内容要每天定时发布.
2、布局和速度
简单快速的框架显然更受百度蜘蛛青睐。一般来说,div的布局比table好,td和table乱七八糟在所难免。站长需要注意自己的网页布局是否简洁、够快——一是服务器的速度,二是网页元素的速度。所以布局和速度这两个细节一定要把握好。
3、服务器稳定性
如果服务器不稳定或者出现故障,百度蜘蛛碰巧去你的网站做客,不是撤退也不是进入。人怎么敢有“下一次”?所以服务器很重要。不要便宜并获得免费主机。遇到“10000”,你的辛苦就白费了,有可能沦为K站。
4、内部链接
内链的目的是让网站中的内容相互交流,让百度蜘蛛在网站上畅通无阻地爬取。例如,新闻文章页关键词应该与其他栏目连接起来,做一些链接。当然,这个优化对谷歌也是有帮助的,但是谷歌对外链优化的权重参考值更高。
如果你想提高网站收录,你必须弄清楚百度蜘蛛的爬行规则和习惯。只要内容质量没问题,网站排名自然不会太差。
特别推荐:
“影响百度蜘蛛爬取网站页面的因素有哪些”
网页新闻抓取(从哪些地方对网站日志进行分析与诊断的诊断呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-16 19:15
作为搜索引擎优化人员,如果他们不能分析和诊断网站log,那就太悲哀了。事实上,日志分析就是对搜索引擎蜘蛛每天抓取的痕迹进行正确的数据诊断,从而采取合理的优化措施。那么,我们应该在哪里分析和诊断网站log呢
1、搜索引擎蜘蛛的访问次数
搜索引擎访问网站的次数间接反映了网站的权重网站. 为了增加搜索引擎蜘蛛的访问量,站长需要分析并优化服务器性能、外部链级构建、网站结构、链接入口等路径
2、搜索引擎蜘蛛总停留时间
搜索引擎蜘蛛的停留时间与网站结构、服务器响应时间、网站代码、网站内容更新等密切相关
3、在搜索引擎蜘蛛中爬行
事实上,搜索引擎蜘蛛的停留时间与网站结构、网站或内容更新和服务器设置密切相关,因为搜索引擎蜘蛛捕获的收录数量与网站数量直接相关,蜘蛛捕获的网站数量越大,收录数量越多
4、搜索引擎蜘蛛单次访问
如果搜索引擎蜘蛛一次抓取更多的网页,则表明网站内容更有价值,网站结构更有利于搜索引擎蜘蛛抓取
5、搜索引擎蜘蛛单页捕获停留时间
搜索引擎蜘蛛的单页捕获停留时间与网站页面捕获速度、网页的内部容量、网页的图像大小、网页代码的简单性等密切相关。为了提高网页加载速度,减少蜘蛛的单页停留时间,从而增加蜘蛛的总捕获量并增加网站收录,从而改善网站的总体流量
@捕获6、网站页面
一般来说,搜索引擎蜘蛛在网站停留的时间有限。只有设置好网站结构,对重要页面建立合理的方案,降低页面的重复捕获率,蜘蛛才能引入其他页面,从而增加网站收录页面的数量
7、网页状态代码
定期清理页面中的死链接,以促进蜘蛛顺利爬升整个页面,从而提高网页的捕获率
8、网站目录结构获取
一般来说,爬行器的主要爬行目录将与网站. 为了提高网站重要列收录、重量和关键词,需要从外链和内链两个层面调整优化方案。对于不需要收录或不需要爬网的列,我们需要使用robots标记提醒爬网器不要爬网
只有不断分析diagnosis网站log,我们才能知道我们发布的外部链是否有效,我们购买的空间是否稳定,蜘蛛喜欢或不喜欢哪些页面,以及我们需要更新哪些内容——一系列优化结果 查看全部
网页新闻抓取(从哪些地方对网站日志进行分析与诊断的诊断呢?)
作为搜索引擎优化人员,如果他们不能分析和诊断网站log,那就太悲哀了。事实上,日志分析就是对搜索引擎蜘蛛每天抓取的痕迹进行正确的数据诊断,从而采取合理的优化措施。那么,我们应该在哪里分析和诊断网站log呢
1、搜索引擎蜘蛛的访问次数
搜索引擎访问网站的次数间接反映了网站的权重网站. 为了增加搜索引擎蜘蛛的访问量,站长需要分析并优化服务器性能、外部链级构建、网站结构、链接入口等路径
2、搜索引擎蜘蛛总停留时间
搜索引擎蜘蛛的停留时间与网站结构、服务器响应时间、网站代码、网站内容更新等密切相关
3、在搜索引擎蜘蛛中爬行
事实上,搜索引擎蜘蛛的停留时间与网站结构、网站或内容更新和服务器设置密切相关,因为搜索引擎蜘蛛捕获的收录数量与网站数量直接相关,蜘蛛捕获的网站数量越大,收录数量越多
4、搜索引擎蜘蛛单次访问
如果搜索引擎蜘蛛一次抓取更多的网页,则表明网站内容更有价值,网站结构更有利于搜索引擎蜘蛛抓取
5、搜索引擎蜘蛛单页捕获停留时间
搜索引擎蜘蛛的单页捕获停留时间与网站页面捕获速度、网页的内部容量、网页的图像大小、网页代码的简单性等密切相关。为了提高网页加载速度,减少蜘蛛的单页停留时间,从而增加蜘蛛的总捕获量并增加网站收录,从而改善网站的总体流量
@捕获6、网站页面
一般来说,搜索引擎蜘蛛在网站停留的时间有限。只有设置好网站结构,对重要页面建立合理的方案,降低页面的重复捕获率,蜘蛛才能引入其他页面,从而增加网站收录页面的数量
7、网页状态代码
定期清理页面中的死链接,以促进蜘蛛顺利爬升整个页面,从而提高网页的捕获率
8、网站目录结构获取
一般来说,爬行器的主要爬行目录将与网站. 为了提高网站重要列收录、重量和关键词,需要从外链和内链两个层面调整优化方案。对于不需要收录或不需要爬网的列,我们需要使用robots标记提醒爬网器不要爬网
只有不断分析diagnosis网站log,我们才能知道我们发布的外部链是否有效,我们购买的空间是否稳定,蜘蛛喜欢或不喜欢哪些页面,以及我们需要更新哪些内容——一系列优化结果
网页新闻抓取(天气调用天气的接口API是怎么做到的呢??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-09-16 05:06
在许多网站,我们可以看到天气和当前时间显示在页面上。他们是怎么做到的?其实很简单。不要说太多,直接去看代码
1:显示当前时间,直接在JS中写入
var weekDayLabels = new Array("星期日","星期一","星期二","星期三","星期四","星期五","星期六");
var now = new Date();
var year=now.getFullYear();
var month=now.getMonth()+1;
var day=now.getDate()
var currentime = ''+year+'年'+month+'月'+day+'日 '+weekDayLabels[now.getDay()]+'
'
document.write(currentime)
2:展示当地天气
有许多用于调用天气的接口API,其中一些很复杂。下面是一个简单实用的退出方法。直接访问以下网站:
输入后,鼠标向下滑动以查找天气代码自定义项。只需根据自己的需要定制即可
完成后,将生成相应的嵌入式iframe。您可以直接将此代码复制到页面标签中,也可以自己更改大小
效果图如下所示:
完成 查看全部
网页新闻抓取(天气调用天气的接口API是怎么做到的呢??)
在许多网站,我们可以看到天气和当前时间显示在页面上。他们是怎么做到的?其实很简单。不要说太多,直接去看代码
1:显示当前时间,直接在JS中写入
var weekDayLabels = new Array("星期日","星期一","星期二","星期三","星期四","星期五","星期六");
var now = new Date();
var year=now.getFullYear();
var month=now.getMonth()+1;
var day=now.getDate()
var currentime = ''+year+'年'+month+'月'+day+'日 '+weekDayLabels[now.getDay()]+'
'
document.write(currentime)
2:展示当地天气
有许多用于调用天气的接口API,其中一些很复杂。下面是一个简单实用的退出方法。直接访问以下网站:
输入后,鼠标向下滑动以查找天气代码自定义项。只需根据自己的需要定制即可
完成后,将生成相应的嵌入式iframe。您可以直接将此代码复制到页面标签中,也可以自己更改大小
效果图如下所示:
完成
网页新闻抓取(什么是网页收录和新闻源收录,有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-15 14:19
选择在网络营销宣传中首次发布软文的朋友会发现,在选择媒体时收录可以分为网页收录和新闻来源收录两部分。什么是网页收录和新闻来源收录以及它们之间的区别。今天,我将用一幅图片和一篇文章来解释网页收录和新闻来源收录在出版方面的区别
在发布新闻文章时,我们会看到一些媒体收录类型分别显示网页收录和新闻来源收录。让我们来谈谈两者之间的区别
所谓网页收录实际上是在链接发布后,通过百度搜索引擎的网页搜索选项搜索链接或标题时,网页搜索结果中显示的链接称为网页收录。我们的默认搜索模式是web搜索。其他搜索选项包括图像搜索、know、贴吧、library等。但许多用户在通过网页收录发布手稿返回链接后,发现他们无法通过链接或标题在百度网页中找到内容。原因是什么?除了原稿的原创度,它还与所选媒体的网站权重、通常的更新效率和网站域名时代有关。网站的权重越高,通常更新效率越快,百度搜索引擎收录会更快更新旧的网站域名,一般情况下,你可以在发布后30分钟内通过链接或标题在百度网页搜索中搜索。然而,并非所有收录网页的媒体发布都会立即被收录删除。受百度算法影响,一些可能需要2-3天,其他可能需要1周或1个月。因此,收录网页的媒体在您发布后可能无法通过百度网络搜索获得。为了保证用户发布的效果,smart软文推出了收录套餐网页的媒体资源。如果您的手稿对收录有要求,我们建议您选择收录包装网页的媒体。该介质长期处于收录稳定状态。如果当天发布的稿件不是收录的,将在次日12:00前反馈给smart软文平台客服,smart软文平台将协调媒体网站编辑,不允许收录重新发布或拒绝
新闻来源收录实际上是一个古老的收录概念。当时,自媒体没有上升。在搜索引擎的搜索选项中,有一个称为新闻的单独选项,用于搜索新闻稿件。百度搜索引擎捕获的新闻稿件一般为国家新闻门户网站网站、地方门户网站网站、官方网站网站,即地方报纸的官方在线媒体和其他拥有新闻发布权限的网站媒体发布新闻稿件。这类媒体称为新闻源媒体,百度收录捕获的网页称为新闻源收录。这里需要强调的是,新闻来源收录的页面将在网页收录中显示收录,因此新闻来源收录是双重保险,网页收录中有一个特定区域显示新闻来源收录的页面收录. 在正常的网页搜索结果排名中,新闻来源收录的页面也会重新排名和显示,因此,选择新闻来源媒体发布稿件是一种真正的双重保险。新闻的一个特点是时效性,所以百度搜索引擎一般抓取收录新闻源媒体的速度较快,发布后30分钟内就会抓到收录新闻源媒体。因此,对于收录要求较高的用户,我们强烈建议用户选择新闻源媒体。当然,由于新闻来源收录也取决于百度的算法,因此不可避免地会出现特殊情况。Smart软文已经推出了收录新闻来源收录的媒体,每篇文章的发布价格约为20-30元。这种媒体已经稳定了很长一段时间。这些媒体发布文章的收益率基本上是100%,选择新闻来源媒体发布的稿件。如果第二天12:00前智能软文平台客服没有收录反馈,智能软文平台可以配合媒体的网站编辑,您可以选择补发或退稿,让用户在家里无忧。现在,随着自媒体的发展,自媒体的收录经常被百度搜索引擎并入原创新闻源搜索,自媒体是个人在百度、今日头条、搜狐等门户平台上发布的大量信息,这些平台没有新闻权威。因此,新闻搜索不再准确。百度已经把原来搜索引擎的新闻搜索栏变成了信息,现在仔细看,搜索引擎选项中没有新闻选项,没有信息搜索,但新闻源收录的概念至今仍在使用
嗯,这里讨论了媒体手稿收录类型的网页收录和新闻来源收录之间的区别。请关注我们,了解更多关于软文发布新闻稿和自媒体宣传的技巧和方法。下次见 查看全部
网页新闻抓取(什么是网页收录和新闻源收录,有什么区别?)
选择在网络营销宣传中首次发布软文的朋友会发现,在选择媒体时收录可以分为网页收录和新闻来源收录两部分。什么是网页收录和新闻来源收录以及它们之间的区别。今天,我将用一幅图片和一篇文章来解释网页收录和新闻来源收录在出版方面的区别
在发布新闻文章时,我们会看到一些媒体收录类型分别显示网页收录和新闻来源收录。让我们来谈谈两者之间的区别
所谓网页收录实际上是在链接发布后,通过百度搜索引擎的网页搜索选项搜索链接或标题时,网页搜索结果中显示的链接称为网页收录。我们的默认搜索模式是web搜索。其他搜索选项包括图像搜索、know、贴吧、library等。但许多用户在通过网页收录发布手稿返回链接后,发现他们无法通过链接或标题在百度网页中找到内容。原因是什么?除了原稿的原创度,它还与所选媒体的网站权重、通常的更新效率和网站域名时代有关。网站的权重越高,通常更新效率越快,百度搜索引擎收录会更快更新旧的网站域名,一般情况下,你可以在发布后30分钟内通过链接或标题在百度网页搜索中搜索。然而,并非所有收录网页的媒体发布都会立即被收录删除。受百度算法影响,一些可能需要2-3天,其他可能需要1周或1个月。因此,收录网页的媒体在您发布后可能无法通过百度网络搜索获得。为了保证用户发布的效果,smart软文推出了收录套餐网页的媒体资源。如果您的手稿对收录有要求,我们建议您选择收录包装网页的媒体。该介质长期处于收录稳定状态。如果当天发布的稿件不是收录的,将在次日12:00前反馈给smart软文平台客服,smart软文平台将协调媒体网站编辑,不允许收录重新发布或拒绝
新闻来源收录实际上是一个古老的收录概念。当时,自媒体没有上升。在搜索引擎的搜索选项中,有一个称为新闻的单独选项,用于搜索新闻稿件。百度搜索引擎捕获的新闻稿件一般为国家新闻门户网站网站、地方门户网站网站、官方网站网站,即地方报纸的官方在线媒体和其他拥有新闻发布权限的网站媒体发布新闻稿件。这类媒体称为新闻源媒体,百度收录捕获的网页称为新闻源收录。这里需要强调的是,新闻来源收录的页面将在网页收录中显示收录,因此新闻来源收录是双重保险,网页收录中有一个特定区域显示新闻来源收录的页面收录. 在正常的网页搜索结果排名中,新闻来源收录的页面也会重新排名和显示,因此,选择新闻来源媒体发布稿件是一种真正的双重保险。新闻的一个特点是时效性,所以百度搜索引擎一般抓取收录新闻源媒体的速度较快,发布后30分钟内就会抓到收录新闻源媒体。因此,对于收录要求较高的用户,我们强烈建议用户选择新闻源媒体。当然,由于新闻来源收录也取决于百度的算法,因此不可避免地会出现特殊情况。Smart软文已经推出了收录新闻来源收录的媒体,每篇文章的发布价格约为20-30元。这种媒体已经稳定了很长一段时间。这些媒体发布文章的收益率基本上是100%,选择新闻来源媒体发布的稿件。如果第二天12:00前智能软文平台客服没有收录反馈,智能软文平台可以配合媒体的网站编辑,您可以选择补发或退稿,让用户在家里无忧。现在,随着自媒体的发展,自媒体的收录经常被百度搜索引擎并入原创新闻源搜索,自媒体是个人在百度、今日头条、搜狐等门户平台上发布的大量信息,这些平台没有新闻权威。因此,新闻搜索不再准确。百度已经把原来搜索引擎的新闻搜索栏变成了信息,现在仔细看,搜索引擎选项中没有新闻选项,没有信息搜索,但新闻源收录的概念至今仍在使用
嗯,这里讨论了媒体手稿收录类型的网页收录和新闻来源收录之间的区别。请关注我们,了解更多关于软文发布新闻稿和自媒体宣传的技巧和方法。下次见
网页新闻抓取( Python学习Python圈的项目实战教程、开发工具与电子书籍分享)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-15 14:18
Python学习Python圈的项目实战教程、开发工具与电子书籍分享)
前言
本文的文字和图片来自网络,仅供学习和交流,不具有任何商业目的
如今,主要的网站反爬虫机制已经达到了疯狂的程度,如公众评论的字符加密、微博的登录验证等。相比之下,新闻网站的反爬虫机制则略显薄弱。所以今天,以新浪新闻为例,分析如何通过Python爬虫关键词抓取相关新闻
首先,如果你直接从新闻中搜索,你会发现它的内容显示多达20页,所以我们应该从新浪的主页上搜索,所以页面数量没有限制
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网搜索关键词后,我发现无论我如何翻页,网站都不会改变,但网页内容已经更新。经验告诉我,这是通过Ajax完成的,所以我记下新浪的网页代码并查看了一下
显然,每次翻页都是通过单击a选项卡向某个地址发送请求。如果直接将此地址放入浏览器的地址栏并按enter键:
恭喜你,你搞错了
仔细看一下HTML的onclick,发现它调用了一个名为getnewsdata的函数。因此,请在相关JS文件中查找此函数。您可以看到,它在每个Ajax请求之前构造请求的URL,并使用get请求。返回的数据格式为jsonp(跨域)
因此,我们可以通过模仿其请求格式来获取数据
var loopnum = 0;
function getNewsData(url){
var oldurl = url; if(!key){
$("#result").html("无搜索热词"); return false;
} if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":"1", "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers) print(response)
这一次,请求库用于构造相同的URL并发送请求。收到的结果为:
那么回到网站看看哪里出了问题
从开发者工具中找到返回的JSON文件并检查请求头。发现其请求标头具有cookie。因此,在构造报头时,我们可以直接复制它的请求报头。再跑一次,回答200!剩下的很简单。您只需解析返回的数据并将其写入excel即可
完整代码
import requests import json import xlwt def getData(page, news):
headers = { "Host": "interface.sina.cn", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate, br", "Connection": "keep-alive", "Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B, "Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default", "TE": "Trailers" }
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":page, "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"] return news def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址") for i in range(len(news)): print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls') def main():
news = [] for i in range(1,501):
news = getData(i, news)
writeData(news) if __name__ == '__main__':
main()
最终结果
专门成立的Python学习圈,从零基础到项目实践教程,开发工具和电子书在Python的各个领域。与您分享企业当前对Python人才和高效技能的需求,以便更好地学习Python,并不断更新最新教程!单击此处加入我们的Python学习圈 查看全部
网页新闻抓取(
Python学习Python圈的项目实战教程、开发工具与电子书籍分享)
前言
本文的文字和图片来自网络,仅供学习和交流,不具有任何商业目的
如今,主要的网站反爬虫机制已经达到了疯狂的程度,如公众评论的字符加密、微博的登录验证等。相比之下,新闻网站的反爬虫机制则略显薄弱。所以今天,以新浪新闻为例,分析如何通过Python爬虫关键词抓取相关新闻
首先,如果你直接从新闻中搜索,你会发现它的内容显示多达20页,所以我们应该从新浪的主页上搜索,所以页面数量没有限制
网页结构分析
1
2
3
4
5
6
7
8
9
10
下一页
进入新浪网搜索关键词后,我发现无论我如何翻页,网站都不会改变,但网页内容已经更新。经验告诉我,这是通过Ajax完成的,所以我记下新浪的网页代码并查看了一下
显然,每次翻页都是通过单击a选项卡向某个地址发送请求。如果直接将此地址放入浏览器的地址栏并按enter键:
恭喜你,你搞错了
仔细看一下HTML的onclick,发现它调用了一个名为getnewsdata的函数。因此,请在相关JS文件中查找此函数。您可以看到,它在每个Ajax请求之前构造请求的URL,并使用get请求。返回的数据格式为jsonp(跨域)
因此,我们可以通过模仿其请求格式来获取数据
var loopnum = 0;
function getNewsData(url){
var oldurl = url; if(!key){
$("#result").html("无搜索热词"); return false;
} if(!url){
url = 'https://interface.sina.cn/home ... onent(key);
}
var stime = getStartDay();
var etime = getEndDay();
url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';
$.ajax({
type: 'GET',
dataType: 'jsonp',
cache : false,
url:url,
success: //回调函数太长了就不写了
})
发送请求
import requests
headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",
}
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":"1", "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers) print(response)
这一次,请求库用于构造相同的URL并发送请求。收到的结果为:
那么回到网站看看哪里出了问题
从开发者工具中找到返回的JSON文件并检查请求头。发现其请求标头具有cookie。因此,在构造报头时,我们可以直接复制它的请求报头。再跑一次,回答200!剩下的很简单。您只需解析返回的数据并将其写入excel即可
完整代码
import requests import json import xlwt def getData(page, news):
headers = { "Host": "interface.sina.cn", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0", "Accept": "*/*", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate, br", "Connection": "keep-alive", "Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B, "Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default", "TE": "Trailers" }
params = { "t":"", "q":"旅游", "pf":"0", "ps":"0", "page":page, "stime":"2019-03-30", "etime":"2020-03-31", "sort":"rel", "highlight":"1", "num":"10", "ie":"utf-8" }
response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)
dic = json.loads(response.text)
news += dic["result"]["list"] return news def writeData(news):
workbook = xlwt.Workbook(encoding = 'utf-8')
worksheet = workbook.add_sheet('MySheet')
worksheet.write(0, 0, "标题")
worksheet.write(0, 1, "时间")
worksheet.write(0, 2, "媒体")
worksheet.write(0, 3, "网址") for i in range(len(news)): print(news[i])
worksheet.write(i+1, 0, news[i]["origin_title"])
worksheet.write(i+1, 1, news[i]["datetime"])
worksheet.write(i+1, 2, news[i]["media"])
worksheet.write(i+1, 3, news[i]["url"])
workbook.save('data.xls') def main():
news = [] for i in range(1,501):
news = getData(i, news)
writeData(news) if __name__ == '__main__':
main()
最终结果
专门成立的Python学习圈,从零基础到项目实践教程,开发工具和电子书在Python的各个领域。与您分享企业当前对Python人才和高效技能的需求,以便更好地学习Python,并不断更新最新教程!单击此处加入我们的Python学习圈
网页新闻抓取(如何精确提取网页中的新闻内容是新闻资讯平台的基础)
网站优化 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-09-13 02:04
准确地从网页中提取新闻内容是新闻信息平台的基础。目前新闻资讯平台的大部分内容都来自对其他新闻网站内容的抓取、整理和分类,那么如何从网页中准确提取新闻就显得很重要了~
方法一:“基于行块分布函数的通用网页正文提取”
这个想法是在一个主题网页(这里是新闻)的详情页上只有一个数据区,所以你只需要提取这个数据区;找到这个数据区的方法就是把网页的内容分成块,一个块是指从某行的开头到某行的结尾的区域。例如第n块由第n行、n+1行和n+2行组成,第n+1块由第n+1行和n+2行和n+3行组成,然后提取每个块中的纯文本,正文中必须收录最纯文本的块;如果你找到某个块,你可以用这部分内容来找到文本的边界 文章中指出,主题网页的主体中有很多纯文本,而其他部分则较少您可以从位于前面的块的位置开始向后看。找到的纯文本数量急剧下降,这是边界。 最后使用边界信息提取文本。这种方法可以准确提取大部分新闻的正文,但在正文的末尾含有一些杂质信息。而且这种方法真的只能提取正文,很难提取与正文相关的非常重要的信息,即标题、来源、时间、新闻标题和正文之间的图片。 .
方法二:可读性算法
它的主要思想是通过给定的网页构造一棵DOM树,对body节点子树中的每个后代节点进行打分,得到得分满足要求的节点。这些节点收录了读者想要阅读的内容,然后将这些节点组织成一个网页并返回。使用该算法的Java实现来处理上述示例消息,结果与之前的方法类似。但是,通过DOM树,您可以通过另一种方式轻松获取新闻的时间和来源。标题和正文之间的内容可以通过正则表达式匹配新闻时间;可以通过标题和正文之间的内容中的“source”关键字找到出处,找到的出处可以存储使用,当这部分内容没有“出处”关键字时匹配出处;最终解决问题。如果只是不能为任何新闻网页提取新闻的来源和时间,那么它已经可以满足准确提取新闻内容的要求,但它还有其他问题,例如大多数情况下会丢失新闻标题图片和文本之间的其他信息和正文,有时正文后面还有其他不需要的信息(二维码图片、版权信息等)。同样,核心问题是信息的丢失。
方法三:RoadRunner算法
该算法尝试从同一模板生成的一组网页中找到一个模板,然后使用该模板解析根据该模板生成的其他网页。 (目前不太好操作) 查看全部
网页新闻抓取(如何精确提取网页中的新闻内容是新闻资讯平台的基础)
准确地从网页中提取新闻内容是新闻信息平台的基础。目前新闻资讯平台的大部分内容都来自对其他新闻网站内容的抓取、整理和分类,那么如何从网页中准确提取新闻就显得很重要了~
方法一:“基于行块分布函数的通用网页正文提取”
这个想法是在一个主题网页(这里是新闻)的详情页上只有一个数据区,所以你只需要提取这个数据区;找到这个数据区的方法就是把网页的内容分成块,一个块是指从某行的开头到某行的结尾的区域。例如第n块由第n行、n+1行和n+2行组成,第n+1块由第n+1行和n+2行和n+3行组成,然后提取每个块中的纯文本,正文中必须收录最纯文本的块;如果你找到某个块,你可以用这部分内容来找到文本的边界 文章中指出,主题网页的主体中有很多纯文本,而其他部分则较少您可以从位于前面的块的位置开始向后看。找到的纯文本数量急剧下降,这是边界。 最后使用边界信息提取文本。这种方法可以准确提取大部分新闻的正文,但在正文的末尾含有一些杂质信息。而且这种方法真的只能提取正文,很难提取与正文相关的非常重要的信息,即标题、来源、时间、新闻标题和正文之间的图片。 .
方法二:可读性算法
它的主要思想是通过给定的网页构造一棵DOM树,对body节点子树中的每个后代节点进行打分,得到得分满足要求的节点。这些节点收录了读者想要阅读的内容,然后将这些节点组织成一个网页并返回。使用该算法的Java实现来处理上述示例消息,结果与之前的方法类似。但是,通过DOM树,您可以通过另一种方式轻松获取新闻的时间和来源。标题和正文之间的内容可以通过正则表达式匹配新闻时间;可以通过标题和正文之间的内容中的“source”关键字找到出处,找到的出处可以存储使用,当这部分内容没有“出处”关键字时匹配出处;最终解决问题。如果只是不能为任何新闻网页提取新闻的来源和时间,那么它已经可以满足准确提取新闻内容的要求,但它还有其他问题,例如大多数情况下会丢失新闻标题图片和文本之间的其他信息和正文,有时正文后面还有其他不需要的信息(二维码图片、版权信息等)。同样,核心问题是信息的丢失。
方法三:RoadRunner算法
该算法尝试从同一模板生成的一组网页中找到一个模板,然后使用该模板解析根据该模板生成的其他网页。 (目前不太好操作)
网页新闻抓取(一个典型的新闻网页包括几个不同区域(图)! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-12 16:13
)
我们之前实现的新闻爬虫运行后很快就可以爬取大量的新闻网页。数据库中存储的网页的html代码并不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、标题、发布时间、正文内容、来源网站等
因此,爬虫不仅要做下载任务,还要做清理和数据提取任务。所以,写爬虫是综合能力的体现。
一个典型的新闻页面包括几个不同的区域:
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的一个新闻页面,提取这三个内容很简单,写三个正则表达式就可以完美提取了。但是,我们的爬虫抓取了数百个网站 网页。为这么多不同格式的网页编写正则表达式会很累,而且一旦网页稍作修改,表达式可能会失效,维护这组表达式也很累。
当然,穷尽的方法我们想不出来,还得探索一个好的算法来实现。
1.标题提取
标题基本出现在html标签中,但也附加了频道名称、网站名等信息;
标题也会出现在页面的“标题区域”中。
那么这两个地方哪里更容易提取标题呢?
网页的“标题区”没有明显标识,网站“标题区”的html代码部分差别很大。所以这个区域不容易提取。
只剩下标签了。这个标签很容易提取,无论是正则表达式还是lxml解析。频道名、网站名等信息怎么去掉也不容易。
我们先来看看,标签中的所有附加信息是这样的:
观察这些标题,不难发现新闻标题、频道名称和网站名之间存在一些连接符号。然后我可以通过这些连接器拆分标题,并找出最长的部分是新闻标题。
这个想法也很容易实现。这里就不写代码了,留给小猿作为思考练习自己去实现。
2.发布时间提取
发布时间是指该网页在网站上线的时间。一般会出现在文本的标题下——元数据区。从html代码来看,这个区域并没有什么特别的地方可供我们定位,尤其是在很多网站板子面前,几乎不可能定位到这个区域。这就需要我们另辟蹊径。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个代表时间、年、月、日、时、分、秒的字符串,无非就是这些元素。通过正则表达式,我们列出一些不同时间表达式的正则表达式(也就是几个),然后我们就可以从网页文本中匹配提取发布时间。
这也是一个很容易实现的想法,但是细节比较多,应该尽量覆盖表达。写一个这样的函数来提取发布时间并不是那么容易的。小猴子们充分发挥自己的动手能力,看看能写出什么样的函数实现。这也是小猿的一种练习。
3.文本提取
正文(包括新闻图片)是新闻网页的主要部分。视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法有很多,实现起来复杂而简单。本文介绍的方法是基于老猿猴多年实践经验和思考的一种简单快捷的方法。我们称之为“节点文本密度方法”。
我们知道,一个网页的HTML代码是由不同标签组成的树状结构树构成的,每个标签都是树的一个节点。通过遍历这个树结构的每个节点,找到文本最多的节点,就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' 查看全部
网页新闻抓取(一个典型的新闻网页包括几个不同区域(图)!
)
我们之前实现的新闻爬虫运行后很快就可以爬取大量的新闻网页。数据库中存储的网页的html代码并不是我们想要的最终结果。最终结果应该是结构化数据,至少包括url、标题、发布时间、正文内容、来源网站等
因此,爬虫不仅要做下载任务,还要做清理和数据提取任务。所以,写爬虫是综合能力的体现。
一个典型的新闻页面包括几个不同的区域:
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们爬取的html中提取出来的。如果只是网站的一个新闻页面,提取这三个内容很简单,写三个正则表达式就可以完美提取了。但是,我们的爬虫抓取了数百个网站 网页。为这么多不同格式的网页编写正则表达式会很累,而且一旦网页稍作修改,表达式可能会失效,维护这组表达式也很累。
当然,穷尽的方法我们想不出来,还得探索一个好的算法来实现。
1.标题提取
标题基本出现在html标签中,但也附加了频道名称、网站名等信息;
标题也会出现在页面的“标题区域”中。
那么这两个地方哪里更容易提取标题呢?
网页的“标题区”没有明显标识,网站“标题区”的html代码部分差别很大。所以这个区域不容易提取。
只剩下标签了。这个标签很容易提取,无论是正则表达式还是lxml解析。频道名、网站名等信息怎么去掉也不容易。
我们先来看看,标签中的所有附加信息是这样的:
观察这些标题,不难发现新闻标题、频道名称和网站名之间存在一些连接符号。然后我可以通过这些连接器拆分标题,并找出最长的部分是新闻标题。
这个想法也很容易实现。这里就不写代码了,留给小猿作为思考练习自己去实现。
2.发布时间提取
发布时间是指该网页在网站上线的时间。一般会出现在文本的标题下——元数据区。从html代码来看,这个区域并没有什么特别的地方可供我们定位,尤其是在很多网站板子面前,几乎不可能定位到这个区域。这就需要我们另辟蹊径。
和标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个代表时间、年、月、日、时、分、秒的字符串,无非就是这些元素。通过正则表达式,我们列出一些不同时间表达式的正则表达式(也就是几个),然后我们就可以从网页文本中匹配提取发布时间。
这也是一个很容易实现的想法,但是细节比较多,应该尽量覆盖表达。写一个这样的函数来提取发布时间并不是那么容易的。小猴子们充分发挥自己的动手能力,看看能写出什么样的函数实现。这也是小猿的一种练习。
3.文本提取
正文(包括新闻图片)是新闻网页的主要部分。视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法有很多,实现起来复杂而简单。本文介绍的方法是基于老猿猴多年实践经验和思考的一种简单快捷的方法。我们称之为“节点文本密度方法”。
我们知道,一个网页的HTML代码是由不同标签组成的树状结构树构成的,每个标签都是树的一个节点。通过遍历这个树结构的每个节点,找到文本最多的节点,就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
<p>#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r'
网页新闻抓取(用快递送花怎么送的前嗅的forespider数据采集软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-12 16:11
:使用前端嗅探数据采集软件,配置news网站模板,点击采集即可。软件中有很多免费的采集模板,还有很多新闻模板,都是免费的。可以设置自动定时
《易经》六十四卦的读音就是自动录新闻,等我看
风水金咒不假,勿编故事
最好的赣州鲜花预订案例不违法。联系作者或平台删除对贵公司或个人不利的网络负面新闻是一种常见的网络公关方式。
问题是关于八卦和五要素:我看到了一个免费的新闻爬虫,叫做先闻。我不知道这是真的还是假的。为什么?
网上订花的最佳地点在哪里?你好!根据您的问题,小编认为天机APP完全符合您的要求。天机版专注于海量8、数据,随时随地全面,为用户追踪最新鲜的新闻。
在此之前购买鲜花的最佳案例是免费内容开放平台。它提供 24 小时无限的信息、内容和 SDK 支持。现在我把我的好内容放到先闻APP上,我也去抓了。把他们的好内容放到我的公众号
如果最好的易经金句案例只是自用,那么你可以使用google reader或者google newsletter功能,google reader可以订阅一些新闻源的rss,google newsletter可以设置关键词订阅新闻和新闻。一些
:2 花和钱。新华网新闻浏览器2.01 新华网是国内最权威的news网站之一,新闻范围广,新闻量大,更新及时。本软件可以上传新华网最新的新闻头条,快速准确获取。还有你
问题是汉南花店的电话号码是:是那种可以随时随地追踪的信息,可以根据个人定制推送消息。同时
:新的顺德花店做的比较好,比较正规网站主要(每天更新):新浪新闻一般,比较客观,但论坛比较自由。 Bisearch 更有趣,而不是客观。隐藏东西。
:e济南城买花mmm,估计只有“央视新闻”软件,腾讯,搜狐,很多都不靠谱,现在谁都可以写新闻报道,所以很多要自己判断.
:将广利宝宝的姓名标记移到要抓取内容的单词前面,不松手按住鼠标,拖动鼠标到要抓取内容的最后一个单词,然后释放鼠标。这时候会高亮显示什么内容,在高亮显示处右击,
问题是大红玫瑰花束的图片是:我要一个看新闻的软件。需要能够获取订阅项目的当前最新消息。喜欢我
什么是最好的赚钱方式?在Android平台上,“今日头条”还可以,只是有些内容无法缓存。原因是内容来源的网站限制了网络爬虫功能。 “腾讯新闻”也不错,但就新闻内容而言,它是唯一的。 查看全部
网页新闻抓取(用快递送花怎么送的前嗅的forespider数据采集软件)
:使用前端嗅探数据采集软件,配置news网站模板,点击采集即可。软件中有很多免费的采集模板,还有很多新闻模板,都是免费的。可以设置自动定时
《易经》六十四卦的读音就是自动录新闻,等我看
风水金咒不假,勿编故事
最好的赣州鲜花预订案例不违法。联系作者或平台删除对贵公司或个人不利的网络负面新闻是一种常见的网络公关方式。
问题是关于八卦和五要素:我看到了一个免费的新闻爬虫,叫做先闻。我不知道这是真的还是假的。为什么?
网上订花的最佳地点在哪里?你好!根据您的问题,小编认为天机APP完全符合您的要求。天机版专注于海量8、数据,随时随地全面,为用户追踪最新鲜的新闻。
在此之前购买鲜花的最佳案例是免费内容开放平台。它提供 24 小时无限的信息、内容和 SDK 支持。现在我把我的好内容放到先闻APP上,我也去抓了。把他们的好内容放到我的公众号
如果最好的易经金句案例只是自用,那么你可以使用google reader或者google newsletter功能,google reader可以订阅一些新闻源的rss,google newsletter可以设置关键词订阅新闻和新闻。一些
:2 花和钱。新华网新闻浏览器2.01 新华网是国内最权威的news网站之一,新闻范围广,新闻量大,更新及时。本软件可以上传新华网最新的新闻头条,快速准确获取。还有你
问题是汉南花店的电话号码是:是那种可以随时随地追踪的信息,可以根据个人定制推送消息。同时
:新的顺德花店做的比较好,比较正规网站主要(每天更新):新浪新闻一般,比较客观,但论坛比较自由。 Bisearch 更有趣,而不是客观。隐藏东西。
:e济南城买花mmm,估计只有“央视新闻”软件,腾讯,搜狐,很多都不靠谱,现在谁都可以写新闻报道,所以很多要自己判断.
:将广利宝宝的姓名标记移到要抓取内容的单词前面,不松手按住鼠标,拖动鼠标到要抓取内容的最后一个单词,然后释放鼠标。这时候会高亮显示什么内容,在高亮显示处右击,
问题是大红玫瑰花束的图片是:我要一个看新闻的软件。需要能够获取订阅项目的当前最新消息。喜欢我
什么是最好的赚钱方式?在Android平台上,“今日头条”还可以,只是有些内容无法缓存。原因是内容来源的网站限制了网络爬虫功能。 “腾讯新闻”也不错,但就新闻内容而言,它是唯一的。
网页新闻抓取( Python3爬取新闻网站新闻列表到什么时候才是好的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-12 16:09
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
由于爬取到的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
这里简单介绍一下Python3的爬虫。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待想看看有哪些好看的图片被抓取了
4.png
爬取 24 个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下
5.png
分析上图中我们要抓取的信息,放在div中的a标签和img标签中,所以我们只需要考虑如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是抓到了,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的抓取中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
这里我们抓取news网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
获取数据后,我们还需要将数据存储到数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,或者使用这些爬取的文章,给app提供新闻api接口,当然这个是后话故事。自学Python数据库操作后,再写一篇文章文章
图文教程视频教程
点击这个地址试试:
如果觉得视频教程不错,可以加老师微信购买,老师微信2501902696 查看全部
网页新闻抓取(
Python3爬取新闻网站新闻列表到什么时候才是好的)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
由于爬取到的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
这里简单介绍一下Python3的爬虫。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
迫不及待想看看有哪些好看的图片被抓取了
4.png
爬取 24 个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下
5.png
分析上图中我们要抓取的信息,放在div中的a标签和img标签中,所以我们只需要考虑如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[

,

,

,

,

,

,

,

,

,

,

]
这里的数据是抓到了,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的抓取中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
这里我们抓取news网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
获取数据后,我们还需要将数据存储到数据库中。只要存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,或者使用这些爬取的文章,给app提供新闻api接口,当然这个是后话故事。自学Python数据库操作后,再写一篇文章文章
图文教程视频教程
点击这个地址试试:
如果觉得视频教程不错,可以加老师微信购买,老师微信2501902696
网页新闻抓取( Python3爬取新闻网站新闻列表到这里稍微复杂点怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-10 22:00
Python3爬取新闻网站新闻列表到这里稍微复杂点怎么办)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
因为爬取的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
复制代码
这里简单介绍一下Python3的爬虫。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看有哪些好看的图片被抓取了
爬取 24 个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下
分析上图中我们要抓取的信息,放在div中的a标签和img标签中,所以我们只需要考虑如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[
<a href=span class="hljs-string""/article/211390.html"/span target=span class="hljs-string""_blank"/span>

</a>
,
<a href=span class="hljs-string""/article/214982.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""TFBOYS成员各自飞,商业价值天花板已现?"/span>

</a>
,
<a href=span class="hljs-string""/article/213703.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""买手店江湖"/span>

</a>
,
<a href=span class="hljs-string""/article/214679.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""iPhone X正式告诉我们,手机和相机开始分道扬镳"/span>

</a>
,
<a href=span class="hljs-string""/article/214962.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""信用已被透支殆尽,乐视汽车或成贾跃亭弃子"/span>

</a>
,
<a href=span class="hljs-string""/article/214867.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""别小看“搞笑诺贝尔奖”,要向好奇心致敬"/span>

</a>
,
<a href=span class="hljs-string""/article/214954.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""10 年前改变世界的,可不止有 iPhone | 发车"/span>

</a>
,
<a href=span class="hljs-string""/article/214908.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""感谢微博替我做主"/span>

</a>
,
<a href=span class="hljs-string""/article/215001.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?"/span>

</a>
,
<a href=span class="hljs-string""/article/214969.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""中国音乐的“全面付费”时代即将到来?"/span>

</a>
,
<a href=span class="hljs-string""/article/214964.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远"/span>

</a>
]
复制代码
这里的数据是抓到了,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的抓取中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取news网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
获取数据后,我们还需要将数据存储到数据库中。只要是存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,也可以使用文章爬取,提供新闻api接口给app,当然这是东西来。
by:年糕妈妈秋实 查看全部
网页新闻抓取(
Python3爬取新闻网站新闻列表到这里稍微复杂点怎么办)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
因为爬取的html文档比较长,这里发个简单的帖子给大家看看
..........后面省略一大堆
复制代码
这里简单介绍一下Python3的爬虫。是不是很简单?我建议你输入几次。
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看有哪些好看的图片被抓取了
爬取 24 个女孩的照片真是太容易了。是不是很简单。
四、Python3抓取新闻网站新闻列表
这里稍微复杂一点,给大家解释一下
分析上图中我们要抓取的信息,放在div中的a标签和img标签中,所以我们只需要考虑如何获取这些信息
这里要用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,抓到的如下
[
<a href=span class="hljs-string""/article/211390.html"/span target=span class="hljs-string""_blank"/span>

</a>
,
<a href=span class="hljs-string""/article/214982.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""TFBOYS成员各自飞,商业价值天花板已现?"/span>

</a>
,
<a href=span class="hljs-string""/article/213703.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""买手店江湖"/span>

</a>
,
<a href=span class="hljs-string""/article/214679.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""iPhone X正式告诉我们,手机和相机开始分道扬镳"/span>

</a>
,
<a href=span class="hljs-string""/article/214962.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""信用已被透支殆尽,乐视汽车或成贾跃亭弃子"/span>

</a>
,
<a href=span class="hljs-string""/article/214867.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""别小看“搞笑诺贝尔奖”,要向好奇心致敬"/span>

</a>
,
<a href=span class="hljs-string""/article/214954.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""10 年前改变世界的,可不止有 iPhone | 发车"/span>

</a>
,
<a href=span class="hljs-string""/article/214908.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""感谢微博替我做主"/span>

</a>
,
<a href=span class="hljs-string""/article/215001.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?"/span>

</a>
,
<a href=span class="hljs-string""/article/214969.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""中国音乐的“全面付费”时代即将到来?"/span>

</a>
,
<a href=span class="hljs-string""/article/214964.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远"/span>

</a>
]
复制代码
这里的数据是抓到了,但是太乱了,还有很多不是我们想要的,下面就是通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里添加异常处理,主要是因为有些新闻可能没有标题,没有网址或图片。如果不进行异常处理,可能会导致我们的抓取中断。
过滤后的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取news网站新闻信息就大功告成了,下面贴出完整代码
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
获取数据后,我们还需要将数据存储到数据库中。只要是存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,也可以使用文章爬取,提供新闻api接口给app,当然这是东西来。
by:年糕妈妈秋实
网页新闻抓取(影响百度蜘蛛抓取网站页面页面的因素有哪些把握好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-10 10:01
在所有主要搜索引擎中,网站homepage 非常重要。首页包括Title、Keywords、Description、首页内容更新等,其中Title是最重要的填写。为了对付百度蜘蛛,首页的内容要每天定时发布.
2、布局和速度
简单快速的框架显然更受百度蜘蛛青睐。一般来说,div的布局比table好,td和table乱七八糟在所难免。站长需要注意自己的网页布局是否简洁、够快——一是服务器的速度,二是网页元素的速度。所以布局和速度这两个细节一定要把握好。
3、服务器稳定性
如果服务器不稳定或者出现故障,百度蜘蛛碰巧去你的网站做客,不是撤退也不是进入。人怎么敢有“下一次”?所以服务器很重要。不要便宜并获得免费主机。遇到“10000”,你的辛苦就白费了,有可能沦为K站。
4、内部链接
内链的目的是让网站中的内容相互交流,让百度蜘蛛在网站上畅通无阻地爬取。例如,新闻文章页关键词应该与其他栏目连接起来,做一些链接。当然,这个优化对谷歌也是有帮助的,但是谷歌对外链优化的权重参考值更高。
如果你想提高网站收录,你必须弄清楚百度蜘蛛的爬行规则和习惯。只要内容质量没问题,网站排名自然不会太差。
特别推荐:
“影响百度蜘蛛爬取网站页面的因素有哪些” 查看全部
网页新闻抓取(影响百度蜘蛛抓取网站页面页面的因素有哪些把握好)
在所有主要搜索引擎中,网站homepage 非常重要。首页包括Title、Keywords、Description、首页内容更新等,其中Title是最重要的填写。为了对付百度蜘蛛,首页的内容要每天定时发布.
2、布局和速度
简单快速的框架显然更受百度蜘蛛青睐。一般来说,div的布局比table好,td和table乱七八糟在所难免。站长需要注意自己的网页布局是否简洁、够快——一是服务器的速度,二是网页元素的速度。所以布局和速度这两个细节一定要把握好。
3、服务器稳定性
如果服务器不稳定或者出现故障,百度蜘蛛碰巧去你的网站做客,不是撤退也不是进入。人怎么敢有“下一次”?所以服务器很重要。不要便宜并获得免费主机。遇到“10000”,你的辛苦就白费了,有可能沦为K站。
4、内部链接
内链的目的是让网站中的内容相互交流,让百度蜘蛛在网站上畅通无阻地爬取。例如,新闻文章页关键词应该与其他栏目连接起来,做一些链接。当然,这个优化对谷歌也是有帮助的,但是谷歌对外链优化的权重参考值更高。
如果你想提高网站收录,你必须弄清楚百度蜘蛛的爬行规则和习惯。只要内容质量没问题,网站排名自然不会太差。
特别推荐:
“影响百度蜘蛛爬取网站页面的因素有哪些”

