
网页数据抓取软件
网页数据抓取软件(网页抓包嗅探器v1.0调用基于GoogleChromium的ChromiumEmbedded(CEF)框架特点抓取数据全面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-19 19:26
Web数据包嗅探器是个人制作的资源搜索和下载工具。通过web数据包嗅探器,用户可以下载网站的内容,而且使用非常简单。只需将您要下载的网站的链接复制到软件中,软件就会列出当前网站中可以下载的所有内容,用户只需复制软件中列出的链接即可下载
Web数据包嗅探器是个人制作的资源搜索和下载工具。通过web数据包嗅探器,用户可以下载网站的内容,而且使用非常简单。只需将要下载的网站链接复制到软件中,软件会列出当前网站中可以下载的所有内容,用户只需复制软件中列出的链接即可下载,非常方便
软件特性
网络包嗅探器v1.0调用基于Google chrome的chrome嵌入式框架(CEF)框架
特点:数据采集全面无遗漏,支持视频格式文件采集(如宝藏主画面视频)等
使用方法
1、首先设置捕获文件的格式并用“|”分隔
2、输入要爬网的URL,点击【打开】,爬网后的数据将显示在过滤结果中
3、点击对过滤结果进行排序排序,便于判断文件类型(一般大文件主要是视频)
4、如果常规结果无法捕获您想要的视频,请单击其他结果并将其从大到小排序。一般来说,前几个是
5、确定文件URL,将其复制到浏览器进行下载,或使用下载工具进行下载 查看全部
网页数据抓取软件(网页抓包嗅探器v1.0调用基于GoogleChromium的ChromiumEmbedded(CEF)框架特点抓取数据全面)
Web数据包嗅探器是个人制作的资源搜索和下载工具。通过web数据包嗅探器,用户可以下载网站的内容,而且使用非常简单。只需将您要下载的网站的链接复制到软件中,软件就会列出当前网站中可以下载的所有内容,用户只需复制软件中列出的链接即可下载
Web数据包嗅探器是个人制作的资源搜索和下载工具。通过web数据包嗅探器,用户可以下载网站的内容,而且使用非常简单。只需将要下载的网站链接复制到软件中,软件会列出当前网站中可以下载的所有内容,用户只需复制软件中列出的链接即可下载,非常方便
软件特性
网络包嗅探器v1.0调用基于Google chrome的chrome嵌入式框架(CEF)框架
特点:数据采集全面无遗漏,支持视频格式文件采集(如宝藏主画面视频)等
使用方法
1、首先设置捕获文件的格式并用“|”分隔
2、输入要爬网的URL,点击【打开】,爬网后的数据将显示在过滤结果中
3、点击对过滤结果进行排序排序,便于判断文件类型(一般大文件主要是视频)
4、如果常规结果无法捕获您想要的视频,请单击其他结果并将其从大到小排序。一般来说,前几个是
5、确定文件URL,将其复制到浏览器进行下载,或使用下载工具进行下载
网页数据抓取软件(网络爬虫或机器人解析网页的示例程序解析库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-19 16:22
)
1什么是网络爬虫
网络爬虫是指网站提取数据的技术,它可以将非结构化数据转换为结构化数据
网络爬虫的目的是从网络中提取数据网站. 提取的数据可以存储在本地文件中并保存在系统中,或者以表的形式存储在数据库中。网络爬虫使用HTTP或Web浏览器直接访问万维网(WWW)。网络爬虫或机器人抓取网页的过程是一个自动过程
捕获网页的过程分为获取网页和提取数据。网络爬虫能够获取网页,是网络爬虫的必要组成部分。获取网页后,需要提取网页数据。我们可以搜索、解析并将提取的数据保存到表中,然后重新排列格式
2数据提取
在本节中,我们将研究数据提取。我们可以使用Python漂亮的汤库进行数据提取。您还需要使用python库的requests模块
运行以下命令来安装请求和库
$ pip3 install requests
$ pip3 install beautifulsoup4
2.1Requests仓库
使用请求库以易于理解的格式在Python脚本中使用HTTP。这里,使用Python中的请求库获取web页面。请求库收录不同类型的请求。这里使用get请求。Get请求用于从web服务器获取信息。使用get请求获取指定网页的HTML内容。每个请求对应一个状态代码,该代码从服务器返回。这些状态代码为我们提供了有关相应请求的执行结果的相关信息。这里有一些状态代码
2.2BeautifulSoup仓库
Beauty soup也是一个python库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包
要在脚本中使用请求和模块,必须使用import语句导入它们。现在让我们看一个解析网页的示例程序。这里我们将解析一个来自百度的新闻网页网站. 创建一个名为parse_uWeb_uuPage.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
print(parse_obj)
运行脚本程序,如下所示。
student@ubuntu:~/work$ python3 parse_web_page.py
Output:
var IMDbTimer={starttime: new
Date().getTime(),pt:'java'};
if (typeof uet == 'function') {
uet("bb", "LoadTitle", {wb: 1});
}
(function(t){ (t.events = t.events || {})["csm_head_pre_title"] =
new Date().getTime(); })(IMDbTimer);
Top News - IMDb
(function(t){ (t.events = t.events || {})["csm_head_post_title"] =
new Date().getTime(); })(IMDbTimer);
if (typeof uet == 'function') {
uet("be", "LoadTitle", {wb: 1});
}
if (typeof uex == 'function') {
uex("ld", "LoadTitle", {wb: 1});
}
if (typeof uet == 'function') {
uet("bb", "LoadIcons", {wb: 1});
}
上面的示例程序抓取一个网页并用BeautifulSoup解析它。首先,导入请求和beautifulsoup模块,然后使用get请求访问URL并将结果分配给page_uResult变量,然后创建一个beautiful soup对象parse_Obj,该对象将返回requests_Result.content的结果页面作为参数,然后使用html.parser解析页面
现在我们将从类和标记中提取数据。转到web浏览器,右键单击要提取的内容,然后向下查找“检查”选项。单击它以获取类名。在程序中指定类名并运行脚本。创建一个名为extract_uufrom_u类的脚本。Py并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
print(top_news)
运行脚本程序,如下所示
student@ubuntu:~/work$ python3 extract_from_class.py
Output :
Issa Rae and Laura Dern are teaming up to star in a limited
series called "The Dolls" currently in development at HBO.
Inspired by true events, the
series recounts the aftermath of Christmas Eve riots in two small Arkansastowns in 1983, riots which erupted over Cabbage Patch Dolls. The seriesexplores class, race, privilege and what it takes to be a "goodmother."
Rae will serve as a writer and executive producer on the
series in addition to starring, with Dern also executive producing. Laura Kittrell and Amy Aniobi will also serve as writers and coexecutive
producers. Jayme Lemons of Dern’s
Jaywalker Pictures and Deniese Davis of Issa Rae Productions will also executive
produce.
Both Rae and Dern currently star in HBO shows, with Dern
appearing in the acclaimed drama "Big Little
Lies" and Rae starring in and having created the hit comedy "Insecure." Dern also recently starred in the
film "The Tale,
上面的示例程序首先导入请求和beautulsoup模块,然后创建一个请求对象并为其分配一个URL,然后创建一个beautulsoup对象parse_uuj。该对象将requests_uuresult.content的结果页作为参数返回,然后使用html.parser解析该页。最后,使用beautifulsoup的find()方法从新闻文章中获取信息
现在让我们看一个从特定标记中提取数据的示例程序。此示例程序将从标记中提取数据。创建一个名为extract_ufrom_u标记.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com/news')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
top_news_a_content = top_news.find_all('a')
print(top_news_a_content)
运行脚本程序,如下所示
student@ubuntu:~/work$ python3 extract_from_tag.py
Output:[Issa Rae, Laura
Dern, HBO, Laura Kittrell, Amy
Aniobi, Jayme Lemons, Jaywalker Pictures, Deniese Davis, Issa Rae Productions, Big Little Lies, Insecure, The
Tale]
上面的示例程序从标记中提取数据。这里使用的是新闻文章中的\uAll()方法\uuuuu从内容类中提取所有标记数据
3从维基百科网站获取信息@
在本节中,我们将学习一个示例程序网站从维基百科获取舞蹈类别列表。这里我们将列出所有印度古典舞蹈。创建一个名为extract\from_uwikipedia.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://en.wikipedia.org/wiki/ ... %2339;)
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
h_obj = parse_obj.find(class_='hlist noprint')
h_obj_a_content = h_obj.find_all('a')
print(h_obj)
print(h_obj_a_content)
运行脚本程序,如下所示
student@ubuntu:~/work$python3摘录自wikipedia.py
结果如下
Portal topics
Activities
Culture
Geography
Health
History
Mathematics
Nature
People
In the preceding example, we extracted the content from Wikipedia. In this
example also, we extracted the content from class as well as tag.
.... 查看全部
网页数据抓取软件(网络爬虫或机器人解析网页的示例程序解析库
)
1什么是网络爬虫
网络爬虫是指网站提取数据的技术,它可以将非结构化数据转换为结构化数据
网络爬虫的目的是从网络中提取数据网站. 提取的数据可以存储在本地文件中并保存在系统中,或者以表的形式存储在数据库中。网络爬虫使用HTTP或Web浏览器直接访问万维网(WWW)。网络爬虫或机器人抓取网页的过程是一个自动过程
捕获网页的过程分为获取网页和提取数据。网络爬虫能够获取网页,是网络爬虫的必要组成部分。获取网页后,需要提取网页数据。我们可以搜索、解析并将提取的数据保存到表中,然后重新排列格式
2数据提取
在本节中,我们将研究数据提取。我们可以使用Python漂亮的汤库进行数据提取。您还需要使用python库的requests模块
运行以下命令来安装请求和库
$ pip3 install requests
$ pip3 install beautifulsoup4
2.1Requests仓库
使用请求库以易于理解的格式在Python脚本中使用HTTP。这里,使用Python中的请求库获取web页面。请求库收录不同类型的请求。这里使用get请求。Get请求用于从web服务器获取信息。使用get请求获取指定网页的HTML内容。每个请求对应一个状态代码,该代码从服务器返回。这些状态代码为我们提供了有关相应请求的执行结果的相关信息。这里有一些状态代码
2.2BeautifulSoup仓库
Beauty soup也是一个python库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包
要在脚本中使用请求和模块,必须使用import语句导入它们。现在让我们看一个解析网页的示例程序。这里我们将解析一个来自百度的新闻网页网站. 创建一个名为parse_uWeb_uuPage.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
print(parse_obj)
运行脚本程序,如下所示。
student@ubuntu:~/work$ python3 parse_web_page.py
Output:
var IMDbTimer={starttime: new
Date().getTime(),pt:'java'};
if (typeof uet == 'function') {
uet("bb", "LoadTitle", {wb: 1});
}
(function(t){ (t.events = t.events || {})["csm_head_pre_title"] =
new Date().getTime(); })(IMDbTimer);
Top News - IMDb
(function(t){ (t.events = t.events || {})["csm_head_post_title"] =
new Date().getTime(); })(IMDbTimer);
if (typeof uet == 'function') {
uet("be", "LoadTitle", {wb: 1});
}
if (typeof uex == 'function') {
uex("ld", "LoadTitle", {wb: 1});
}
if (typeof uet == 'function') {
uet("bb", "LoadIcons", {wb: 1});
}
上面的示例程序抓取一个网页并用BeautifulSoup解析它。首先,导入请求和beautifulsoup模块,然后使用get请求访问URL并将结果分配给page_uResult变量,然后创建一个beautiful soup对象parse_Obj,该对象将返回requests_Result.content的结果页面作为参数,然后使用html.parser解析页面
现在我们将从类和标记中提取数据。转到web浏览器,右键单击要提取的内容,然后向下查找“检查”选项。单击它以获取类名。在程序中指定类名并运行脚本。创建一个名为extract_uufrom_u类的脚本。Py并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
print(top_news)
运行脚本程序,如下所示
student@ubuntu:~/work$ python3 extract_from_class.py
Output :
Issa Rae and Laura Dern are teaming up to star in a limited
series called "The Dolls" currently in development at HBO.
Inspired by true events, the
series recounts the aftermath of Christmas Eve riots in two small Arkansastowns in 1983, riots which erupted over Cabbage Patch Dolls. The seriesexplores class, race, privilege and what it takes to be a "goodmother."
Rae will serve as a writer and executive producer on the
series in addition to starring, with Dern also executive producing. Laura Kittrell and Amy Aniobi will also serve as writers and coexecutive
producers. Jayme Lemons of Dern’s
Jaywalker Pictures and Deniese Davis of Issa Rae Productions will also executive
produce.
Both Rae and Dern currently star in HBO shows, with Dern
appearing in the acclaimed drama "Big Little
Lies" and Rae starring in and having created the hit comedy "Insecure." Dern also recently starred in the
film "The Tale,
上面的示例程序首先导入请求和beautulsoup模块,然后创建一个请求对象并为其分配一个URL,然后创建一个beautulsoup对象parse_uuj。该对象将requests_uuresult.content的结果页作为参数返回,然后使用html.parser解析该页。最后,使用beautifulsoup的find()方法从新闻文章中获取信息
现在让我们看一个从特定标记中提取数据的示例程序。此示例程序将从标记中提取数据。创建一个名为extract_ufrom_u标记.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com/news')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
top_news_a_content = top_news.find_all('a')
print(top_news_a_content)
运行脚本程序,如下所示
student@ubuntu:~/work$ python3 extract_from_tag.py
Output:[Issa Rae, Laura
Dern, HBO, Laura Kittrell, Amy
Aniobi, Jayme Lemons, Jaywalker Pictures, Deniese Davis, Issa Rae Productions, Big Little Lies, Insecure, The
Tale]
上面的示例程序从标记中提取数据。这里使用的是新闻文章中的\uAll()方法\uuuuu从内容类中提取所有标记数据
3从维基百科网站获取信息@
在本节中,我们将学习一个示例程序网站从维基百科获取舞蹈类别列表。这里我们将列出所有印度古典舞蹈。创建一个名为extract\from_uwikipedia.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://en.wikipedia.org/wiki/ ... %2339;)
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
h_obj = parse_obj.find(class_='hlist noprint')
h_obj_a_content = h_obj.find_all('a')
print(h_obj)
print(h_obj_a_content)
运行脚本程序,如下所示
student@ubuntu:~/work$python3摘录自wikipedia.py
结果如下
Portal topics
Activities
Culture
Geography
Health
History
Mathematics
Nature
People
In the preceding example, we extracted the content from Wikipedia. In this
example also, we extracted the content from class as well as tag.
....
网页数据抓取软件(网络爬虫21世纪数据的价值所在!(附详细流程) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-19 16:17
)
简介:随着大数据技术、分布式存储和分布式计算的发展,数据的价值不断挖掘,特别是对于大量的网络数据,抓取网站数据内容,分析数据背后隐藏的价值。人工智能背后是对海量数据支持的需求,这是21世纪数据的价值所在
1、网络爬虫的基本流程:
1.1、initiate request:客户端通过HTTP库向目标站点发起请求,并等待服务器响应
1.2、get response content:服务器响应的内容就是页面的内容。类型包括HTML、JSON、二进制等
1.3、解析内容:可以通过正则表达式和网页解析库解析HTML。JSON可以直接转换为JSON对象解析。二进制数据,可进一步存储或处理
1.4、保存数据:结构化存储,可以保存为文本、保存到数据库或以特定格式保存为文件
2、Reques答复:
@k331、Request:
1)request-methods:主要有两种类型:get和post,以及head、put、delete、options等2)request-URL:URL是统一的资源定位器,网页、图片、视频等可用URL是唯一确定的
3)request header:收录请求时的头信息,如用户代理、主机、cookie等
4)request body:请求期间携带的附加数据,例如表单提交时的表单数据
@k332、Response:
1)响应状态:响应状态。例如,200表示成功,301表示跳转,404表示找不到页面,502表示服务器错误
2)response header:如内容类型、内容长度、服务器信息、设置cookie等
3)response body:最重要的部分,包括请求的资源内容,如HTML、图片和视频、二进制数据等
3、crawler可以捕获的数据:
3.1、网页文本:HTML文档、JSON格式文本等
3.2、图片:获取二进制文件并以图片格式保存
3.3、Video:它也是一个二进制文件,可以以视频格式保存
3.4、其他:只要可以请求数据,就可以获得信息
4、分辨率方法:
4.1、直接处理:适用于简单网页
@k562、Json解析:适合网页的是JSON字符串
4.3、正则表达式:适用于HTML解析
4.4、库解析:漂亮的汤库、pyquery库、XPath库等
5、请求的结果与浏览器看到的结果不同:
5.1、原因:浏览器的渲染效果。JavaScript和后台交互数据
5.2、如何解决JavaScript呈现问题:分析Ajax请求(JSON字符串)。Selenium/webdriver解决方案(可以安装PIP)。Splash解决方案(您可以在GitHub中搜索安装)。PyV8、Ghost.py
6、如何保存数据:
6.1、text:纯文本、JSON、XML等
6.2、关系数据库:如mysql、Oracle、SQL server等以结构化表的结构化形式存储
6.3、非关系数据库:如mongodb、redis和其他键值数据库
6.4、二进制文件:如图片、视频、音频等直接以特定格式保存
查看全部
网页数据抓取软件(网络爬虫21世纪数据的价值所在!(附详细流程)
)
简介:随着大数据技术、分布式存储和分布式计算的发展,数据的价值不断挖掘,特别是对于大量的网络数据,抓取网站数据内容,分析数据背后隐藏的价值。人工智能背后是对海量数据支持的需求,这是21世纪数据的价值所在

1、网络爬虫的基本流程:
1.1、initiate request:客户端通过HTTP库向目标站点发起请求,并等待服务器响应
1.2、get response content:服务器响应的内容就是页面的内容。类型包括HTML、JSON、二进制等
1.3、解析内容:可以通过正则表达式和网页解析库解析HTML。JSON可以直接转换为JSON对象解析。二进制数据,可进一步存储或处理
1.4、保存数据:结构化存储,可以保存为文本、保存到数据库或以特定格式保存为文件
2、Reques答复:
@k331、Request:
1)request-methods:主要有两种类型:get和post,以及head、put、delete、options等2)request-URL:URL是统一的资源定位器,网页、图片、视频等可用URL是唯一确定的
3)request header:收录请求时的头信息,如用户代理、主机、cookie等
4)request body:请求期间携带的附加数据,例如表单提交时的表单数据
@k332、Response:
1)响应状态:响应状态。例如,200表示成功,301表示跳转,404表示找不到页面,502表示服务器错误
2)response header:如内容类型、内容长度、服务器信息、设置cookie等
3)response body:最重要的部分,包括请求的资源内容,如HTML、图片和视频、二进制数据等

3、crawler可以捕获的数据:
3.1、网页文本:HTML文档、JSON格式文本等
3.2、图片:获取二进制文件并以图片格式保存
3.3、Video:它也是一个二进制文件,可以以视频格式保存
3.4、其他:只要可以请求数据,就可以获得信息

4、分辨率方法:
4.1、直接处理:适用于简单网页
@k562、Json解析:适合网页的是JSON字符串
4.3、正则表达式:适用于HTML解析
4.4、库解析:漂亮的汤库、pyquery库、XPath库等

5、请求的结果与浏览器看到的结果不同:
5.1、原因:浏览器的渲染效果。JavaScript和后台交互数据
5.2、如何解决JavaScript呈现问题:分析Ajax请求(JSON字符串)。Selenium/webdriver解决方案(可以安装PIP)。Splash解决方案(您可以在GitHub中搜索安装)。PyV8、Ghost.py
6、如何保存数据:
6.1、text:纯文本、JSON、XML等
6.2、关系数据库:如mysql、Oracle、SQL server等以结构化表的结构化形式存储
6.3、非关系数据库:如mongodb、redis和其他键值数据库
6.4、二进制文件:如图片、视频、音频等直接以特定格式保存

网页数据抓取软件(网页搜索关键词并将相关信息返回上传文件操作通过input标签实现的上传功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-19 16:15
Selenium获取网页数据,搜索网页关键词并返回相关信息
from selenium import webdriver#导入驱动模块
import time#导入时间模块
# 实例化一个浏览器
driver = webdriver.Firefox()
# 隐式等待
driver.implicitly_wait(10)
# 浏览器最大化
driver.maximize_window()
# 打开指定的网页(URL就是指网址)
driver.get("http://www.baidu.com")
driver.find_element_by_css_selector('#kw').send_keys('蔡徐坤')
#使用CSS筛选器按照ID元素定位到搜索输入框
driver.find_element_by_css_selector('#su').click()
#使用CSS筛选器定位到元素百度一下按钮
a = driver.find_elements_by_css_selector('.c-container>h3')
#按照属性值进行筛选,父类和子类关系用>,使用elements获取到的结果是一个非文本列表
for i in a:
print(i.text)
driver.quit()
时间模块:年月日格式化输出
import time
getTime = time.strftime('%Y-%m-%d %H:%M:%S')
print(getTime)
上载文件操作
通过输入标签实现的上传功能可以看作是一个输入框,即通过send_ukeys()指定上传文件的本地文件路径
使用以下代码创建file.html文件:
upload_file
upload_file
通过浏览器打开file.html文件。该功能如下图所示
from selenium import webdriver
import os
driver = webdriver.Firefox()
file_path = 'file:///' + os.path.abspath('file.html')
driver.get(file_path)
# 定位上传按钮,添加本地文件
driver.find_element_by_name("file").send_keys('D:\\upload_file.txt')
driver.quit()
上传文件的具体应用请参见邮箱126中的邮件发送操作 查看全部
网页数据抓取软件(网页搜索关键词并将相关信息返回上传文件操作通过input标签实现的上传功能)
Selenium获取网页数据,搜索网页关键词并返回相关信息
from selenium import webdriver#导入驱动模块
import time#导入时间模块
# 实例化一个浏览器
driver = webdriver.Firefox()
# 隐式等待
driver.implicitly_wait(10)
# 浏览器最大化
driver.maximize_window()
# 打开指定的网页(URL就是指网址)
driver.get("http://www.baidu.com";)
driver.find_element_by_css_selector('#kw').send_keys('蔡徐坤')
#使用CSS筛选器按照ID元素定位到搜索输入框
driver.find_element_by_css_selector('#su').click()
#使用CSS筛选器定位到元素百度一下按钮
a = driver.find_elements_by_css_selector('.c-container>h3')
#按照属性值进行筛选,父类和子类关系用>,使用elements获取到的结果是一个非文本列表
for i in a:
print(i.text)
driver.quit()
时间模块:年月日格式化输出
import time
getTime = time.strftime('%Y-%m-%d %H:%M:%S')
print(getTime)
上载文件操作
通过输入标签实现的上传功能可以看作是一个输入框,即通过send_ukeys()指定上传文件的本地文件路径
使用以下代码创建file.html文件:
upload_file
upload_file
通过浏览器打开file.html文件。该功能如下图所示
from selenium import webdriver
import os
driver = webdriver.Firefox()
file_path = 'file:///' + os.path.abspath('file.html')
driver.get(file_path)
# 定位上传按钮,添加本地文件
driver.find_element_by_name("file").send_keys('D:\\upload_file.txt')
driver.quit()
上传文件的具体应用请参见邮箱126中的邮件发送操作
网页数据抓取软件(MicrosoftPowerQueryforExcel窗口中的有用数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-17 09:16
连接到power Bi桌面中的数据源
安装Microsoft power Bi desktop后,您可以连接到不断扩展的数据世界。Microsoft power query for Excel窗口中提供了所有类型的数据源。下图显示了如何通过选择功能区上的“主页”选项卡,然后选择“获取数据”来获取数据>;“更多”以连接到数据
假设你即将退休,你想住在一个阳光充足、犯罪率低、医疗服务好的地方。以下web资源提供了有关这些主题和其他主题的有用数据:
最佳退休地点排名
选择获取数据>;“Web”并粘贴地址:
选择“确定”后,power Bi desktop的查询功能将开始运行。该查询访问web资源,并在Navigator窗口中显示它在web页面上找到的信息。在这个例子中,它找到了一个表格(“最适合退休和最不适合退休的州/省/市/自治区/市的排名”)。我们对这张桌子很感兴趣,所以我们在列表中选择了它。“导航器”窗口显示预览
现在,我们可以通过在加载表之前选择窗口底部的“convert data”来编辑查询。或者,您可以直接加载表
选择“转换数据”时,power query editor将启动并显示表的代表性视图。将显示“查询设置”窗格(如果没有,请选择功能区上的“视图”选项卡,然后选择“显示”>;查询设置)
这是它的外观
在power Bi desktop中,您可以连接到多个数据源并将它们组合起来以执行各种有趣的操作 查看全部
网页数据抓取软件(MicrosoftPowerQueryforExcel窗口中的有用数据(图))
连接到power Bi桌面中的数据源
安装Microsoft power Bi desktop后,您可以连接到不断扩展的数据世界。Microsoft power query for Excel窗口中提供了所有类型的数据源。下图显示了如何通过选择功能区上的“主页”选项卡,然后选择“获取数据”来获取数据>;“更多”以连接到数据
假设你即将退休,你想住在一个阳光充足、犯罪率低、医疗服务好的地方。以下web资源提供了有关这些主题和其他主题的有用数据:
最佳退休地点排名
选择获取数据>;“Web”并粘贴地址:
选择“确定”后,power Bi desktop的查询功能将开始运行。该查询访问web资源,并在Navigator窗口中显示它在web页面上找到的信息。在这个例子中,它找到了一个表格(“最适合退休和最不适合退休的州/省/市/自治区/市的排名”)。我们对这张桌子很感兴趣,所以我们在列表中选择了它。“导航器”窗口显示预览
现在,我们可以通过在加载表之前选择窗口底部的“convert data”来编辑查询。或者,您可以直接加载表
选择“转换数据”时,power query editor将启动并显示表的代表性视图。将显示“查询设置”窗格(如果没有,请选择功能区上的“视图”选项卡,然后选择“显示”>;查询设置)
这是它的外观
在power Bi desktop中,您可以连接到多个数据源并将它们组合起来以执行各种有趣的操作
网页数据抓取软件(旋风软件园下载优采云采集器软件功能便捷定时功能(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-16 23:12
中国有句老话说,在学习过程中我们必须养成良好的复习习惯,优采云采集器这是一个帮助站长复习的好工具。它可以准确地帮你找到你的流量词,让你随时可以抓住粉丝的心。你在等什么,现在来惠而风软件园下载吧
正式介绍
优采云采集器对于任何需要从网络上获取信息的孩子来说都是一个必要的人工制品。这是一个可以让你的信息变得非常简单的工具@k11优采云改变了传统的网络数据思维方式,让用户越来越容易在互联网上获取数据
优采云采集器软件功能
方便的定时功能
只需点击几步设置,即可实现采集任务的定时控制。无论是单个采集的定时设置,还是一天或每周每月预设采集的定时设置,您都可以同时自由设置多个任务,根据需要重新组织所选时间,灵活分配自己的采集任务
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、删除空格、添加前缀或后缀、日期和时间格式化、HTML转码等功能,采集进程是全自动的,无需人工干预即可获得所需的格式数据
多级采集
许多主流新闻和电子商务网站,包括一级商品列表页面、二级商品详情页面和三级评论详情页面;无论网站有多少级别,优采云都无法限制采集数据的级别以满足各种业务采集的需要
API接口
通过优采云API,您可以轻松获取优采云任务信息和采集数据,灵活调度任务,如远程控制任务启动和停止,高效实现数据采集和归档。基于强大的API系统,还可以无缝连接公司内部各种管理平台,实现各项业务的自动化
定制采集
根据不同用户的采集需求,优采云可以提供一种自定义的自动生成爬虫的模式,并可以批量准确识别各种网页元素。它还具有翻页、下拉、AJAX、页面滚动、条件判断等功能。它支持不同网页结构的复杂网站采集并满足各种采集应用程序场景
支持网站post-login采集
优采云有一个内置的采集登录模块。登录后只需配置目标网站的账号和密码,即可使用采集模块访问数据;同时优采云它也有采集Cookie自定义函数。首次登录后,您可以自动记住cookies,避免多次输入密码的繁琐,并支持更多的网站或采集
优采云采集器独特亮点
云采集,关机正常
配置采集任务后,您可以关闭。任务可以在云中执行。大量企业云24*7不间断运行。您不必担心IP阻塞、网络中断和即时采集大量数据
任何人都可以使用它
你还在学习网页源代码和数据包捕获工具吗?现在不需要了。如果你可以上网,你可以使用采集、所见即所得界面和可视过程。你不需要了解技术。单击鼠标,您可以在2分钟内快速开始
任何网站都可以是采集
它不仅使用简单,而且功能强大:单击、登录、翻页,甚至识别验证代码。当网页出错或多组模板完全不同时,您也可以根据不同的情况进行不同的处理
免费使用
它是免费的,免费版本没有功能限制。您可以立即试用,然后立即下载并安装
更新日志
解决任务列表刷新后重新设置过滤条件的问题
解决在自定义配置中修改任务名称时,页签中任务保存ID不正确的问题
解决了在自定义配置中修改任务名称有时无效的问题
解决在设置字段以获取属性值时流程图区域将被隐藏的问题-在用户定义的配置中选择属性值
解决首次进入自定义配置时,向导提示后台出现用户调查界面的问题 查看全部
网页数据抓取软件(旋风软件园下载优采云采集器软件功能便捷定时功能(组图))
中国有句老话说,在学习过程中我们必须养成良好的复习习惯,优采云采集器这是一个帮助站长复习的好工具。它可以准确地帮你找到你的流量词,让你随时可以抓住粉丝的心。你在等什么,现在来惠而风软件园下载吧
正式介绍
优采云采集器对于任何需要从网络上获取信息的孩子来说都是一个必要的人工制品。这是一个可以让你的信息变得非常简单的工具@k11优采云改变了传统的网络数据思维方式,让用户越来越容易在互联网上获取数据
优采云采集器软件功能
方便的定时功能
只需点击几步设置,即可实现采集任务的定时控制。无论是单个采集的定时设置,还是一天或每周每月预设采集的定时设置,您都可以同时自由设置多个任务,根据需要重新组织所选时间,灵活分配自己的采集任务
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、删除空格、添加前缀或后缀、日期和时间格式化、HTML转码等功能,采集进程是全自动的,无需人工干预即可获得所需的格式数据
多级采集
许多主流新闻和电子商务网站,包括一级商品列表页面、二级商品详情页面和三级评论详情页面;无论网站有多少级别,优采云都无法限制采集数据的级别以满足各种业务采集的需要
API接口
通过优采云API,您可以轻松获取优采云任务信息和采集数据,灵活调度任务,如远程控制任务启动和停止,高效实现数据采集和归档。基于强大的API系统,还可以无缝连接公司内部各种管理平台,实现各项业务的自动化
定制采集
根据不同用户的采集需求,优采云可以提供一种自定义的自动生成爬虫的模式,并可以批量准确识别各种网页元素。它还具有翻页、下拉、AJAX、页面滚动、条件判断等功能。它支持不同网页结构的复杂网站采集并满足各种采集应用程序场景
支持网站post-login采集
优采云有一个内置的采集登录模块。登录后只需配置目标网站的账号和密码,即可使用采集模块访问数据;同时优采云它也有采集Cookie自定义函数。首次登录后,您可以自动记住cookies,避免多次输入密码的繁琐,并支持更多的网站或采集

优采云采集器独特亮点
云采集,关机正常
配置采集任务后,您可以关闭。任务可以在云中执行。大量企业云24*7不间断运行。您不必担心IP阻塞、网络中断和即时采集大量数据
任何人都可以使用它
你还在学习网页源代码和数据包捕获工具吗?现在不需要了。如果你可以上网,你可以使用采集、所见即所得界面和可视过程。你不需要了解技术。单击鼠标,您可以在2分钟内快速开始
任何网站都可以是采集
它不仅使用简单,而且功能强大:单击、登录、翻页,甚至识别验证代码。当网页出错或多组模板完全不同时,您也可以根据不同的情况进行不同的处理
免费使用
它是免费的,免费版本没有功能限制。您可以立即试用,然后立即下载并安装
更新日志
解决任务列表刷新后重新设置过滤条件的问题
解决在自定义配置中修改任务名称时,页签中任务保存ID不正确的问题
解决了在自定义配置中修改任务名称有时无效的问题
解决在设置字段以获取属性值时流程图区域将被隐藏的问题-在用户定义的配置中选择属性值
解决首次进入自定义配置时,向导提示后台出现用户调查界面的问题
网页数据抓取软件(2016年着手大数据不妨重点考虑以下几点:重点覆盖,定能有所)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-16 05:07
中国IDC圈1月15日报道:回顾2015年,整体大数据市场发展迅速,政府的支持前所未有。将大数据正式纳入国家政策也为社会各部门提供了许多机会和便利。放眼国际市场,大数据应用的规模不断扩大,几乎所有人都关注“数据”背后的巨大价值。未来5-10年将是中国推进大数据发展的关键节点。迫切需要构建高效的大数据应用机制和产业链。随着2016年的到来,大数据行业将迎来新一轮的竞争和挑战
根据对2015年大数据产业发展的分析,2016年启动大数据时,宜重点关注以下几点:
1、visual data capture:大数据的普及是工业应用的前提。所谓普及就是捕捉技术的普及。作为互联网这一最大的数据载体,网页数据捕获技术的普及可以通过网页捕获工具的普及来实现。著名网络爬虫优采云采集器V9它极大地发挥了它的便利性。通过设置简单的规则,软件可以自动采集数据。无论是定义操作过程还是查看采集结果,都可以通过优采云采集器V9一个用于过程可视化的软件工具比以前编写复杂程序采集更方便,前者可以带来高效便捷,和平民主化是不言而喻的
2、key areas大数据覆盖范围:大数据应用范围广泛,各行各业都在尝试启动深层金矿开采。然而,近年来,大数据的真正影响是在城市建设、金融和互联网企业、电子商务和医疗卫生等领域。据CCF大数据专家组预测,2016年城市、互联网交易、企业三部分数据将取得突破性进展,这些数据将通过上述网页捕获工具优采云捕获采集器V9可以轻松实现城市舆情监控,竞争产品数据信息捕获、企业信用数据收录等。如果我们能够确定趋势,看看先例,关注覆盖范围,我们将从中受益
3、大数据整合:大数据将导致多学科整合。不仅计算机领域的科学家,数学、生物、心理学等领域的科学家也将参与大数据的前沿研究,但他们中的许多人可能不精通IT技术,因此获取数据的效率非常低。为了促进数据交换和交换,改善大数据资源的共享,网页捕获工具优采云采集器V9在提高易用性的基础上,充分实现了整个网络的通用性,99%的网页中几乎所有可以看到的网页内容都可以轻松获取。如果用户注意采用标准化的存储格式和方式,届时信息融合也将非常方便
备受瞩目的大数据行业渴望展示其雄心壮志。大数据应用不再只是高喊口号。预计到2016年,中国大数据市场规模将达到238亿美元。激活中国大数据资产价值、开启新产业、新生态的目标,还需要社会各界的共同努力 查看全部
网页数据抓取软件(2016年着手大数据不妨重点考虑以下几点:重点覆盖,定能有所)
中国IDC圈1月15日报道:回顾2015年,整体大数据市场发展迅速,政府的支持前所未有。将大数据正式纳入国家政策也为社会各部门提供了许多机会和便利。放眼国际市场,大数据应用的规模不断扩大,几乎所有人都关注“数据”背后的巨大价值。未来5-10年将是中国推进大数据发展的关键节点。迫切需要构建高效的大数据应用机制和产业链。随着2016年的到来,大数据行业将迎来新一轮的竞争和挑战
根据对2015年大数据产业发展的分析,2016年启动大数据时,宜重点关注以下几点:
1、visual data capture:大数据的普及是工业应用的前提。所谓普及就是捕捉技术的普及。作为互联网这一最大的数据载体,网页数据捕获技术的普及可以通过网页捕获工具的普及来实现。著名网络爬虫优采云采集器V9它极大地发挥了它的便利性。通过设置简单的规则,软件可以自动采集数据。无论是定义操作过程还是查看采集结果,都可以通过优采云采集器V9一个用于过程可视化的软件工具比以前编写复杂程序采集更方便,前者可以带来高效便捷,和平民主化是不言而喻的
2、key areas大数据覆盖范围:大数据应用范围广泛,各行各业都在尝试启动深层金矿开采。然而,近年来,大数据的真正影响是在城市建设、金融和互联网企业、电子商务和医疗卫生等领域。据CCF大数据专家组预测,2016年城市、互联网交易、企业三部分数据将取得突破性进展,这些数据将通过上述网页捕获工具优采云捕获采集器V9可以轻松实现城市舆情监控,竞争产品数据信息捕获、企业信用数据收录等。如果我们能够确定趋势,看看先例,关注覆盖范围,我们将从中受益
3、大数据整合:大数据将导致多学科整合。不仅计算机领域的科学家,数学、生物、心理学等领域的科学家也将参与大数据的前沿研究,但他们中的许多人可能不精通IT技术,因此获取数据的效率非常低。为了促进数据交换和交换,改善大数据资源的共享,网页捕获工具优采云采集器V9在提高易用性的基础上,充分实现了整个网络的通用性,99%的网页中几乎所有可以看到的网页内容都可以轻松获取。如果用户注意采用标准化的存储格式和方式,届时信息融合也将非常方便
备受瞩目的大数据行业渴望展示其雄心壮志。大数据应用不再只是高喊口号。预计到2016年,中国大数据市场规模将达到238亿美元。激活中国大数据资产价值、开启新产业、新生态的目标,还需要社会各界的共同努力
网页数据抓取软件(以京东为例,演示数据抓取工具的使用方法: )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-16 05:05
)
以京东为例,演示如何使用数据捕获工具:
单击uibot编辑器工具栏上的[data capture]按钮打开数据捕获工具:
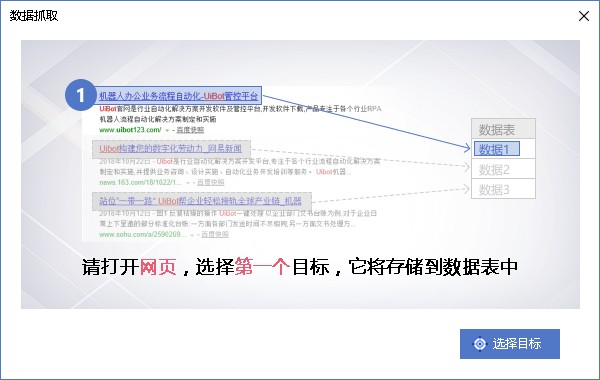
数据捕获工具需要首先选择一个目标,然后单击选择目标按钮:
此目标是采集的数据字段。如果需要采集商品名称,请首先选择商品名称:
如果要采集商品价格,首先选择商品价格元素、采集其他字段等,如评估数量:
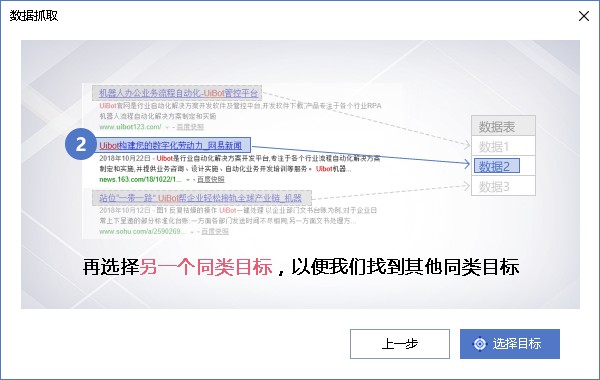
点击选择目标后,进入第二步,然后选择同类目标。Uibot将自动分析目标之间的关系,并进一步推断页面中的所有相关元素:
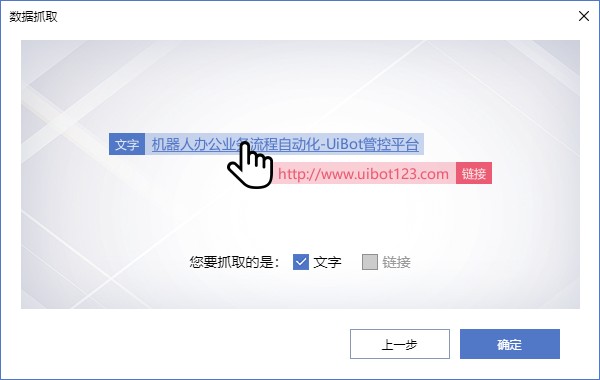
目标选择完成后,如果两个目标类型一致且存在关联关系,则进入本页面,可以选择采集内容是文本还是链接;我这里的采集数据是商品价格,所以只能选择文本。单击“确定”进入下一步:
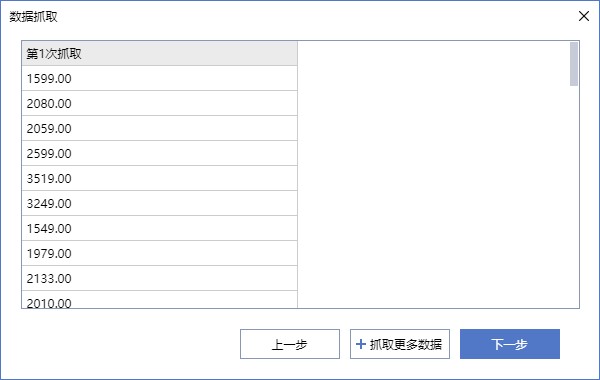
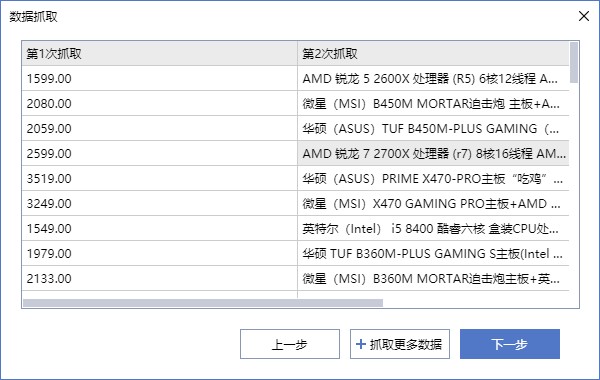
成功捕获数据后,将显示捕获的数据列。单击捕获更多数据按钮并重复前面的步骤。您可以添加多个数据捕获列,例如产品名称、评估和其他数据。您可以单击打开的数据或捕获链接:
数据捕获完成后,点击下一步按钮进入捕获页面翻页,可以一次捕获多页数据:
单击捕获翻页按钮并选择数据页面上的[下一页]按钮,以在数据捕获期间自动翻页以捕获数据:
翻页和爬网完成后,批量爬网数据的组件将自动添加到编辑器中:
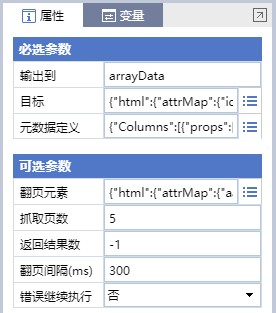
组件属性设置的屏幕截图如上图所示。目标是要捕获的数据来自哪个元素。元数据定义是要捕获的数据特征和相应的字段名设置。翻页元素对应于翻页按钮的元素选择特征。您可以在此处设置要提取的页数。默认设置为5,即取5页数据后退出:
查看全部
网页数据抓取软件(以京东为例,演示数据抓取工具的使用方法:
)
以京东为例,演示如何使用数据捕获工具:
单击uibot编辑器工具栏上的[data capture]按钮打开数据捕获工具:
数据捕获工具需要首先选择一个目标,然后单击选择目标按钮:
此目标是采集的数据字段。如果需要采集商品名称,请首先选择商品名称:
如果要采集商品价格,首先选择商品价格元素、采集其他字段等,如评估数量:

点击选择目标后,进入第二步,然后选择同类目标。Uibot将自动分析目标之间的关系,并进一步推断页面中的所有相关元素:
目标选择完成后,如果两个目标类型一致且存在关联关系,则进入本页面,可以选择采集内容是文本还是链接;我这里的采集数据是商品价格,所以只能选择文本。单击“确定”进入下一步:
成功捕获数据后,将显示捕获的数据列。单击捕获更多数据按钮并重复前面的步骤。您可以添加多个数据捕获列,例如产品名称、评估和其他数据。您可以单击打开的数据或捕获链接:
数据捕获完成后,点击下一步按钮进入捕获页面翻页,可以一次捕获多页数据:
单击捕获翻页按钮并选择数据页面上的[下一页]按钮,以在数据捕获期间自动翻页以捕获数据:
翻页和爬网完成后,批量爬网数据的组件将自动添加到编辑器中:

组件属性设置的屏幕截图如上图所示。目标是要捕获的数据来自哪个元素。元数据定义是要捕获的数据特征和相应的字段名设置。翻页元素对应于翻页按钮的元素选择特征。您可以在此处设置要提取的页数。默认设置为5,即取5页数据后退出:
网页数据抓取软件(初识webscraper开发人员安装方式(图):请输入图片描述本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-13 13:12
Web Scraper 是一款面向普通用户(无需专业 IT 技术)的免费爬虫工具,通过鼠标和简单的配置,您可以轻松获取您想要的数据。例如知乎答案列表、微博热点、微博评论、电商网站产品信息、博客文章list等
安装过程
在线安装方法
在线安装需要 FQ 网络和 Chrome App Store 访问权限
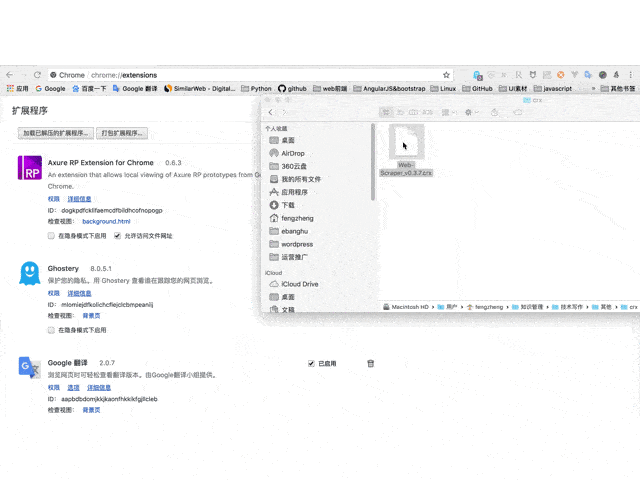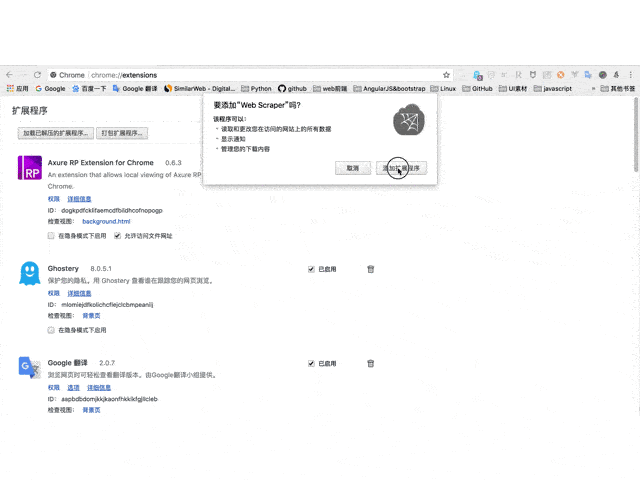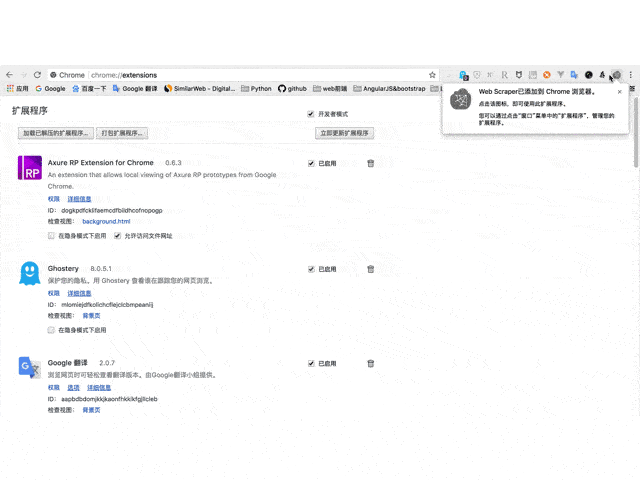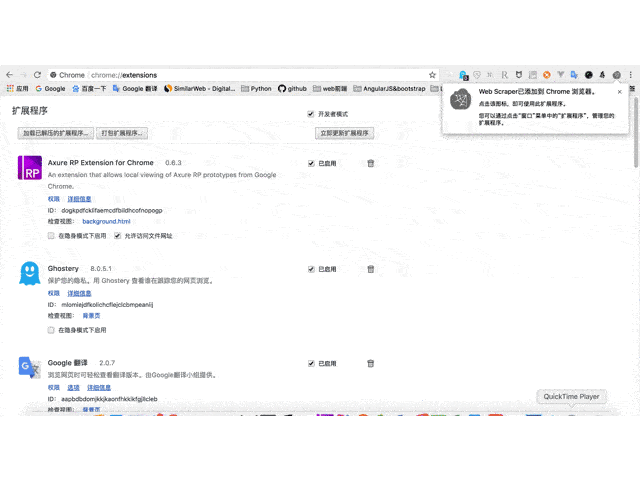
1、 在线访问 Web Scraper 插件并点击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的框中点击“添加扩展”
请输入图片描述
3、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
请输入图片描述
本地安装方式
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,将下载的扩展Web-Scraper_v0.3.7.crx拖到这个页面,点击“添加到扩展”以完成安装。如图:
请输入图片描述
2、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
${{2}}$
请输入图片描述
第一次接触网络爬虫
打开网页爬虫
开发者可以路过看看后面
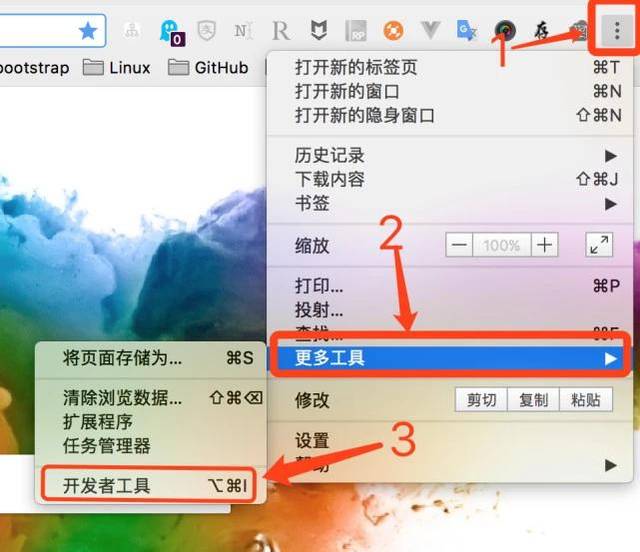
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具
请输入图片描述
打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。
请输入图片说明
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
请输入图片说明
原理及功能说明
数据爬取的思路大致可以概括如下:
1、通过一个或多个入口地址获取初始数据。比如文章列表页面,或者有一定规则的页面,比如带分页的列表页面;
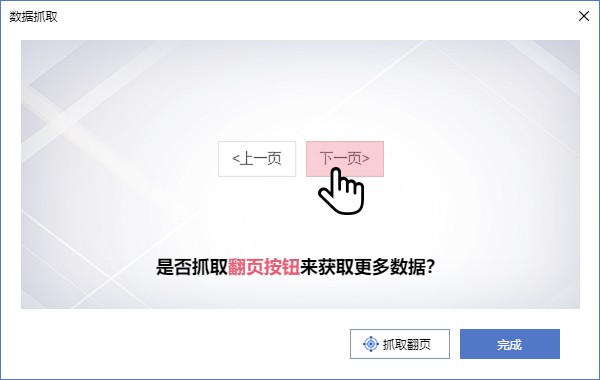
2、根据入口页面的一些信息,比如链接点,进入下一页获取必要的信息;
3、根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper标签,看到分为三部分:
请输入图片描述
新建站点地图:首先了解站点地图,字面意思是网站Map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你想得到一个问题在知乎上回答,创建一个站点地图,并将这个问题的地址设置为站点地图的起始地址,然后点击“创建站点地图”来创建站点地图。
请输入图片说明
站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。
请输入图片描述
站点地图:进入某个站点地图,可以进行一系列的操作,如下图:
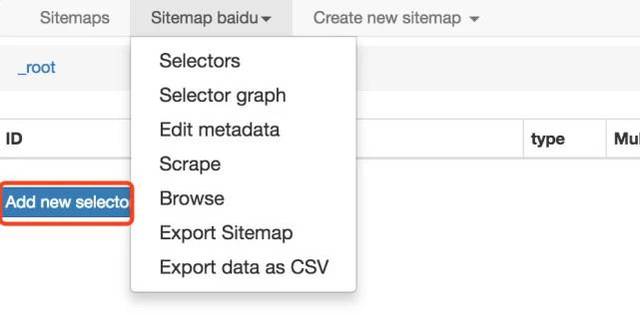
请输入图片描述
在红框中添加新的选择器是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
我需要解释一下。一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题,也可以对应整个区域。该区域可能收录标题、副标题和作者信息、内容等。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,根节点是什么,几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取。
Export data as CSV:以CSV格式导出捕获的数据。
至此,有一个简单的了解就足够了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践
简单试水hao123
从简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
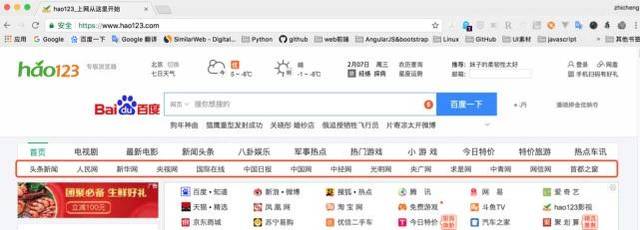
需求背景:见下hao123页面红框部分。我们的要求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然实际需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们已经打开了hao123页面,在这个页面底部打开了开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;
请输入图片描述
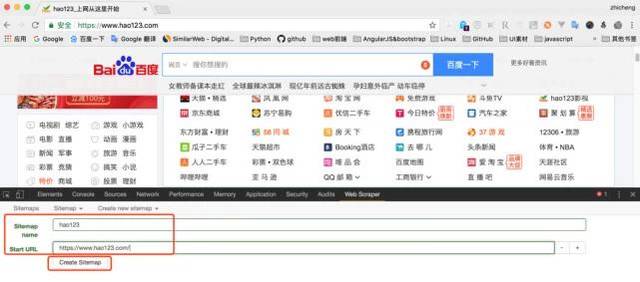
3、后输入sitemap名称和start url,名称只是为了我们标记,所以命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;
请输入图片描述
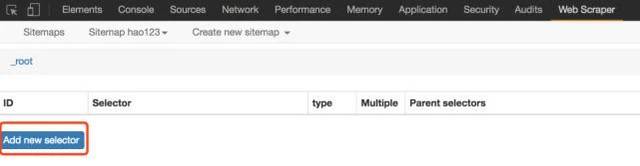
4、Web Scraper 自动定位到这个站点地图后,接下来我们添加一个选择器,点击“添加新的选择器”;
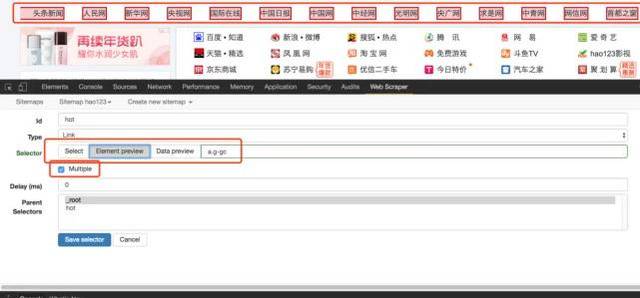
请输入图片描述
5、 首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;
请输入图片描述
6、然后点击select,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选中的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中之后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后别忘了勾选Multiple,即采集多条数据;
请输入图片描述
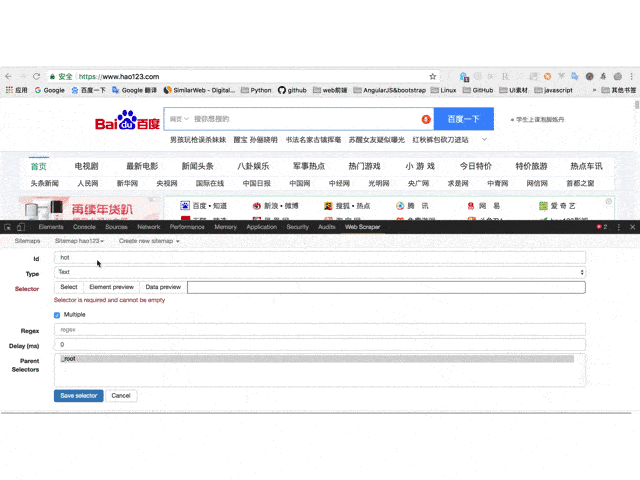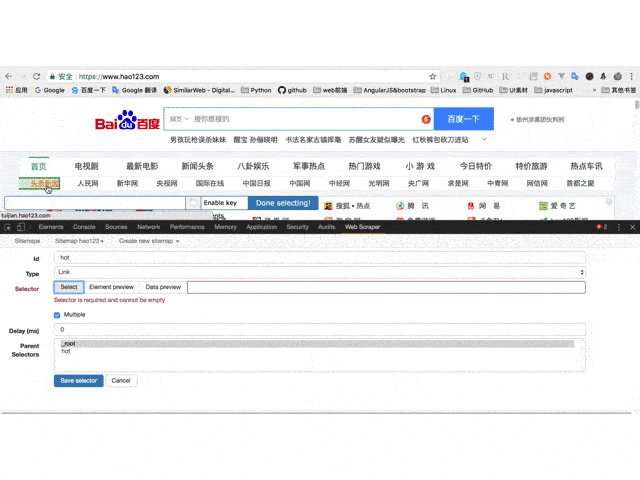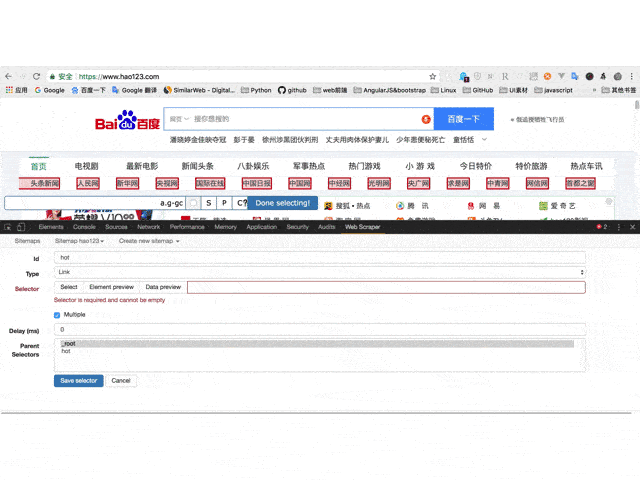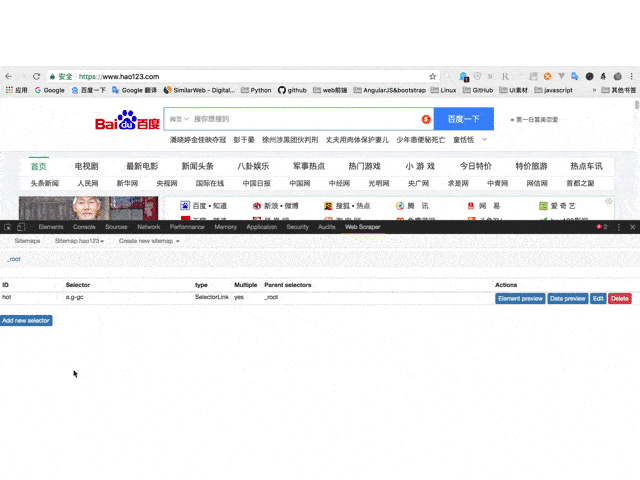
7、 最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。后面的文本框里面的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标直接手写xpath;
完整的操作流程如下:
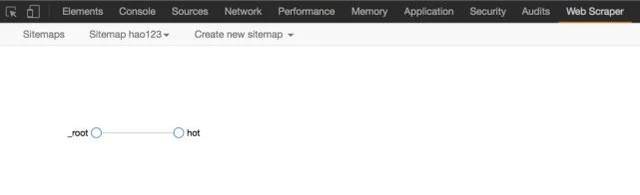
请输入图片描述
8、完成上一步后,就可以实际导出了。别着急,看看其他操作。 Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建一个sitemap会自动有一个_root节点,可以看到它的子选择器,也就是我们创建的Hot selector;
请输入图片描述
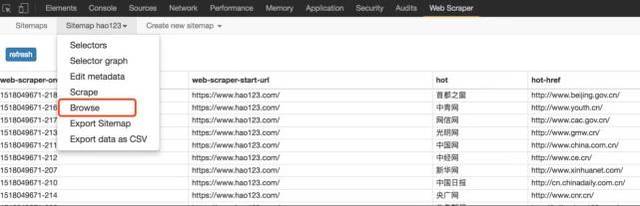
9、Scrape,开始抓取数据。
在10、Sitemap hao123下浏览,可以直接通过浏览器查看爬取的最终结果,需要重新;
请输入图片描述
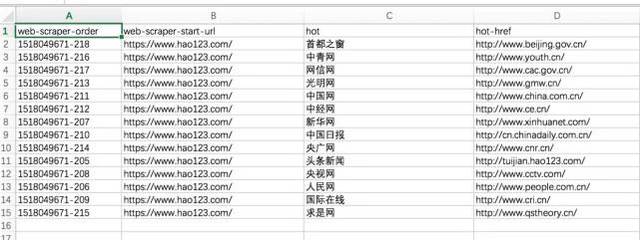
11、最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;
请输入图片描述
怎么样,现在试试
软件定制| 网站construction |获得更多干货 查看全部
网页数据抓取软件(初识webscraper开发人员安装方式(图):请输入图片描述本地)
Web Scraper 是一款面向普通用户(无需专业 IT 技术)的免费爬虫工具,通过鼠标和简单的配置,您可以轻松获取您想要的数据。例如知乎答案列表、微博热点、微博评论、电商网站产品信息、博客文章list等
安装过程
在线安装方法
在线安装需要 FQ 网络和 Chrome App Store 访问权限
1、 在线访问 Web Scraper 插件并点击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的框中点击“添加扩展”

请输入图片描述
3、 安装完成后,顶部工具栏会显示 Web Scraper 图标。

请输入图片描述
本地安装方式
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,将下载的扩展Web-Scraper_v0.3.7.crx拖到这个页面,点击“添加到扩展”以完成安装。如图:
请输入图片描述
2、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
${{2}}$
请输入图片描述
第一次接触网络爬虫
打开网页爬虫
开发者可以路过看看后面
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具
请输入图片描述
打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。
请输入图片说明
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。

请输入图片说明
原理及功能说明
数据爬取的思路大致可以概括如下:
1、通过一个或多个入口地址获取初始数据。比如文章列表页面,或者有一定规则的页面,比如带分页的列表页面;
2、根据入口页面的一些信息,比如链接点,进入下一页获取必要的信息;
3、根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper标签,看到分为三部分:
请输入图片描述
新建站点地图:首先了解站点地图,字面意思是网站Map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你想得到一个问题在知乎上回答,创建一个站点地图,并将这个问题的地址设置为站点地图的起始地址,然后点击“创建站点地图”来创建站点地图。
请输入图片说明
站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。
请输入图片描述
站点地图:进入某个站点地图,可以进行一系列的操作,如下图:
请输入图片描述
在红框中添加新的选择器是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
我需要解释一下。一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题,也可以对应整个区域。该区域可能收录标题、副标题和作者信息、内容等。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,根节点是什么,几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取。
Export data as CSV:以CSV格式导出捕获的数据。
至此,有一个简单的了解就足够了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践
简单试水hao123
从简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
需求背景:见下hao123页面红框部分。我们的要求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然实际需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们已经打开了hao123页面,在这个页面底部打开了开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;

请输入图片描述
3、后输入sitemap名称和start url,名称只是为了我们标记,所以命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;
请输入图片描述
4、Web Scraper 自动定位到这个站点地图后,接下来我们添加一个选择器,点击“添加新的选择器”;
请输入图片描述
5、 首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;

请输入图片描述
6、然后点击select,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选中的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中之后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后别忘了勾选Multiple,即采集多条数据;
请输入图片描述
7、 最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。后面的文本框里面的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标直接手写xpath;
完整的操作流程如下:
请输入图片描述
8、完成上一步后,就可以实际导出了。别着急,看看其他操作。 Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建一个sitemap会自动有一个_root节点,可以看到它的子选择器,也就是我们创建的Hot selector;
请输入图片描述
9、Scrape,开始抓取数据。
在10、Sitemap hao123下浏览,可以直接通过浏览器查看爬取的最终结果,需要重新;
请输入图片描述
11、最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;
请输入图片描述
怎么样,现在试试
软件定制| 网站construction |获得更多干货
网页数据抓取软件(网页数据来源之一函数(一)_星光_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-13 13:10
随着互联网的飞速发展,网络数据日益成为数据分析过程中最重要的数据来源之一。
或许正是基于这样的考虑。从 2013 版本开始,Excel 增加了一个名为 Web 的新函数类别。使用其下的功能,您可以通过网页链接从Web服务器获取数据,例如股票信息和天气查询。 、有道翻译等
给我一点栗子。
输入以下公式将A2单元格的值从英文翻译成中文或从中文翻译成英文。
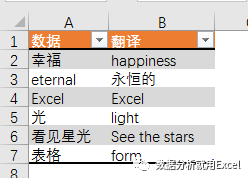
=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"//translation")
公式看起来很长。这主要是因为 URL 长度太长。其实公式的结构很简单。
主要由三部分组成。
第 1 部分构建 URL。
";i="&A2&"&doctype=xml"
这是有道在线翻译的网页地址,包括关键参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml,只有xml返回是因为 FILTERXML 函数可以获取 XML 结构化内容中的信息。
第 2 部分读取 URL。
WEBSERVICE 通过指定的网址从网络服务器获取数据(需要电脑连接互联网)。
在这个例子中,B2 公式
=WEBSERVICE(";i="&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第 3 部分获取目标数据。
此处使用了 FILTERXML 函数。 FILTERXML 函数的语法是:
FILTERXML(xml,xpath)
有两个参数,xml参数是有效的xml格式文本,xpath参数是xml中要查询的目标数据的标准路径。
通过第二部分得到的xml文件的内容,我们可以直接看到幸福翻译结果幸福在翻译路径下(粉红色部分),所以第二个参数设置为“//translation ”。
好的,这就是星光今天和大家分享的内容。有兴趣的朋友可以尝试使用网页功能从百度天气中获取自己家乡城市的天气信息~ 查看全部
网页数据抓取软件(网页数据来源之一函数(一)_星光_光明网(组图))
随着互联网的飞速发展,网络数据日益成为数据分析过程中最重要的数据来源之一。
或许正是基于这样的考虑。从 2013 版本开始,Excel 增加了一个名为 Web 的新函数类别。使用其下的功能,您可以通过网页链接从Web服务器获取数据,例如股票信息和天气查询。 、有道翻译等
给我一点栗子。
输入以下公式将A2单元格的值从英文翻译成中文或从中文翻译成英文。
=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"//translation")
公式看起来很长。这主要是因为 URL 长度太长。其实公式的结构很简单。
主要由三部分组成。
第 1 部分构建 URL。
";i="&A2&"&doctype=xml"
这是有道在线翻译的网页地址,包括关键参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml,只有xml返回是因为 FILTERXML 函数可以获取 XML 结构化内容中的信息。
第 2 部分读取 URL。
WEBSERVICE 通过指定的网址从网络服务器获取数据(需要电脑连接互联网)。
在这个例子中,B2 公式
=WEBSERVICE(";i="&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第 3 部分获取目标数据。
此处使用了 FILTERXML 函数。 FILTERXML 函数的语法是:
FILTERXML(xml,xpath)
有两个参数,xml参数是有效的xml格式文本,xpath参数是xml中要查询的目标数据的标准路径。
通过第二部分得到的xml文件的内容,我们可以直接看到幸福翻译结果幸福在翻译路径下(粉红色部分),所以第二个参数设置为“//translation ”。
好的,这就是星光今天和大家分享的内容。有兴趣的朋友可以尝试使用网页功能从百度天气中获取自己家乡城市的天气信息~
网页数据抓取软件(P.S.@AJAX数据库实例讲解(有时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-13 13:10
故事的缘由
我以前有个小网站,在上面发表了几篇关于使用SAS抓取网络数据的短文,然后在人大论坛上挂了一个链接。后来因为懒惰,这个网站被挂了,人们纷纷询问。更新此博客后播放
添加了一个简单易懂的,其他翻译已由@statnet收录发布,文章会在最后链接。
适用性
这种情况下的以下理论可以通过相同的方式访问。
附言@AJAX 数据库实例|| @AJAX 数据库实例说明
文字前戏
有时我们经常需要保存和备份某些在线数据,例如银行利率、股票报价,或者来自统计局、各种金融机构的数据,或者其他类型的网站。有时这些网站 会提供历史数据,有些则不会。但是我们可以使用SAS每天运行程序,获取累积的历史数据,供以后分析。下面以获取首页上海银行同业拆借利率为例进行说明。
以下是我们想要的首页数据
当我们打开这个网页并输入网页的源代码时,我们会惊讶地发现。什么情况下,首页看到的数据在源码中是查不到的。是否可以使用其他技术?来看看源码代表什么
网页布局。
按照网页布局,最新的Shibor数据的源代码应该放在大量文字后,他放一句话。
这是html的内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入首页。 OK,那我们就打开这个页面
查看源代码,发现这个网页中存在数据,那么我们就开始用SAS抓取它。
高潮
首先引入Filename,并用它添加infile语句将网页作为文件导入SAS数据集。 BaseSAS 中的 FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。该语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入到 SAS 数据集中。我们知道网页数据是一种标记语言,它遵循一定的规范,包括所有的属性设置。所以我们用 dlm=">" 来分隔,导入到一个变量中。因为数据太乱,无法区分导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们用dlm=">"来分隔,所以我们知道采集到的观测值只需要用
分隔 查看全部
网页数据抓取软件(P.S.@AJAX数据库实例讲解(有时))
故事的缘由
我以前有个小网站,在上面发表了几篇关于使用SAS抓取网络数据的短文,然后在人大论坛上挂了一个链接。后来因为懒惰,这个网站被挂了,人们纷纷询问。更新此博客后播放
添加了一个简单易懂的,其他翻译已由@statnet收录发布,文章会在最后链接。
适用性
这种情况下的以下理论可以通过相同的方式访问。
附言@AJAX 数据库实例|| @AJAX 数据库实例说明
文字前戏
有时我们经常需要保存和备份某些在线数据,例如银行利率、股票报价,或者来自统计局、各种金融机构的数据,或者其他类型的网站。有时这些网站 会提供历史数据,有些则不会。但是我们可以使用SAS每天运行程序,获取累积的历史数据,供以后分析。下面以获取首页上海银行同业拆借利率为例进行说明。
以下是我们想要的首页数据

当我们打开这个网页并输入网页的源代码时,我们会惊讶地发现。什么情况下,首页看到的数据在源码中是查不到的。是否可以使用其他技术?来看看源码代表什么
网页布局。
按照网页布局,最新的Shibor数据的源代码应该放在大量文字后,他放一句话。
这是html的内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入首页。 OK,那我们就打开这个页面
查看源代码,发现这个网页中存在数据,那么我们就开始用SAS抓取它。
高潮
首先引入Filename,并用它添加infile语句将网页作为文件导入SAS数据集。 BaseSAS 中的 FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。该语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入到 SAS 数据集中。我们知道网页数据是一种标记语言,它遵循一定的规范,包括所有的属性设置。所以我们用 dlm=">" 来分隔,导入到一个变量中。因为数据太乱,无法区分导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们用dlm=">"来分隔,所以我们知道采集到的观测值只需要用
分隔
网页数据抓取软件(没过第一篇的基本语法及简单的爬虫技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-11 00:12
这是很久以前反弹的文章。我很幸运今天能够弥补。也是因为最近才开始想明白一些事情。如果你还没有通过第一篇文章,你可以点击下面的链接来看看。本文假设大家已经掌握了python的基本语法和简单的爬虫技术。
这次我们来讲解一个豆瓣爬虫,包括验证码验证和登录后简单的数据爬取。
好的,废话不多说,给我看代码
首先我们需要了解一个背景知识,登录网站,其实就是向服务器提交一些数据,包括:用户名密码,验证码,以及其他你看不到的数据。这部分你看不到的数据随着网站而变化,但是基本套路都会收录一个类似id的数据,而且每次提交的值都不一样,提交是前端无法执行的看看吧。
第一步,我们在chrome上查看登录页面,观察前面提到的一些值需要提交。
这里有一个小技巧。如果不使用fidler或charles等抓包工具直接登录,是看不到需要提交的数据的。因此,笔者估计是输入了错误的验证码进行验证。通过查看元素的登录,可以看到需要提交的数据。
如上图,可以找到其他隐藏提交信息,其中:captcha-solution为验证码,captcha-id为隐藏id值。
第二步是找到隐藏的id和验证码提交。
解决验证码提交问题。主流方法有两种。一种是手动输入,适合低复杂度、低并发的新手爬虫。这就是我们介绍的;另一种是利用ocr图像识别技术,以一定的准确率训练数据。判断,这种方法比较重,不适合初学者。有兴趣的小朋友可以自行尝试。
手动输入,首先我们要看到验证码,然后输入。采用的方法是将验证码图片下载到本地,使用时到对应路径打开图片输入,然后提交登录表单。
通过观察可以发现验证码图片是存放在这个路径下的,所以解析页面找到这个路径后,就可以下载图片了。
获取隐藏id比较简单。在源码下找到对应的id,然后动态赋值给提交表单。
#coding=utf-8
#输入中文没有上面一行会报错,注意
导入请求
从 lxml 导入 html
导入操作系统
重新导入
导入 urllib.request
login_url =""
s = requests.session()
r = s.get(login_url)
tree = html.fromstring(r.text)
el = tree.xpath('//input[@name="captcha-id"]')[0]
captcha_id = el.attrib['value']
#获取隐藏id
el2 = tree.xpath('//img[@id="captcha_image"]')[0]
captcha_image_url = el2.attrib['src']
imgPath = r'E:\img'
res=urllib.request.urlopen(captcha_image_url)
filename=os.path.join(imgPath,"1"+'.jpg')
with open(filename,'wb') as f:
f.write(res.read())
#保存验证码图片
captcha_solution= input('请输入验证码:')
第三步是提交表单。
形式与第一步观察到的值一致。
运行结果如下:
好的,到这里爬虫就完成了。对于下一篇的内容,其实很多人已经发现api数据获取是一种更加方便和稳定的方式。通过页面爬取的方法,页面的结构会发生变化,其次需要和对方进行反爬虫。该机制是明智而勇敢的。取而代之的是,API 的使用方式是一种便捷、高速、高雅的方式。 查看全部
网页数据抓取软件(没过第一篇的基本语法及简单的爬虫技术)
这是很久以前反弹的文章。我很幸运今天能够弥补。也是因为最近才开始想明白一些事情。如果你还没有通过第一篇文章,你可以点击下面的链接来看看。本文假设大家已经掌握了python的基本语法和简单的爬虫技术。
这次我们来讲解一个豆瓣爬虫,包括验证码验证和登录后简单的数据爬取。
好的,废话不多说,给我看代码
首先我们需要了解一个背景知识,登录网站,其实就是向服务器提交一些数据,包括:用户名密码,验证码,以及其他你看不到的数据。这部分你看不到的数据随着网站而变化,但是基本套路都会收录一个类似id的数据,而且每次提交的值都不一样,提交是前端无法执行的看看吧。
第一步,我们在chrome上查看登录页面,观察前面提到的一些值需要提交。
这里有一个小技巧。如果不使用fidler或charles等抓包工具直接登录,是看不到需要提交的数据的。因此,笔者估计是输入了错误的验证码进行验证。通过查看元素的登录,可以看到需要提交的数据。
如上图,可以找到其他隐藏提交信息,其中:captcha-solution为验证码,captcha-id为隐藏id值。
第二步是找到隐藏的id和验证码提交。
解决验证码提交问题。主流方法有两种。一种是手动输入,适合低复杂度、低并发的新手爬虫。这就是我们介绍的;另一种是利用ocr图像识别技术,以一定的准确率训练数据。判断,这种方法比较重,不适合初学者。有兴趣的小朋友可以自行尝试。
手动输入,首先我们要看到验证码,然后输入。采用的方法是将验证码图片下载到本地,使用时到对应路径打开图片输入,然后提交登录表单。
通过观察可以发现验证码图片是存放在这个路径下的,所以解析页面找到这个路径后,就可以下载图片了。
获取隐藏id比较简单。在源码下找到对应的id,然后动态赋值给提交表单。
#coding=utf-8
#输入中文没有上面一行会报错,注意
导入请求
从 lxml 导入 html
导入操作系统
重新导入
导入 urllib.request
login_url =""
s = requests.session()
r = s.get(login_url)
tree = html.fromstring(r.text)
el = tree.xpath('//input[@name="captcha-id"]')[0]
captcha_id = el.attrib['value']
#获取隐藏id
el2 = tree.xpath('//img[@id="captcha_image"]')[0]
captcha_image_url = el2.attrib['src']
imgPath = r'E:\img'
res=urllib.request.urlopen(captcha_image_url)
filename=os.path.join(imgPath,"1"+'.jpg')
with open(filename,'wb') as f:
f.write(res.read())
#保存验证码图片
captcha_solution= input('请输入验证码:')
第三步是提交表单。
形式与第一步观察到的值一致。
运行结果如下:
好的,到这里爬虫就完成了。对于下一篇的内容,其实很多人已经发现api数据获取是一种更加方便和稳定的方式。通过页面爬取的方法,页面的结构会发生变化,其次需要和对方进行反爬虫。该机制是明智而勇敢的。取而代之的是,API 的使用方式是一种便捷、高速、高雅的方式。
网页数据抓取软件(【url规范】百度支持抓取的url长度不超过1024)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-10 10:03
[网址规范]
百度支持抓取的网址长度不超过1024。如果您的链接长度过长,请在保证正常访问的同时适当简化,确保链接可以被百度和收录抓取正常。
[重定向错误]
重定向是指百度蜘蛛访问链接时发生的重定向。如果重定向后的链接过长或者连续重定向次数超过5次,就会出现重定向错误,爬取失败。
[服务器连接错误]
这种情况意味着百度无法访问您的网站,原因是服务器响应缓慢或您的网站屏蔽了百度蜘蛛。这将导致百度无法收录 或更新您的网站 内容。您可能会看到以下特定错误:连接超时、连接失败、连接被拒绝、无响应、响应截断、连接重置、标头截断、超时。
如何处理服务器连接错误?
减少动态页面请求的过多页面加载。如果网站为多个URL提供相同的内容,则视为动态提供内容(例如提供的内容相同)。动态网页的响应时间可能很长,这会导致超时问题。或者,服务器可能会回到过载状态,请求百度蜘蛛减慢爬取网站的速度。一般情况下,建议尽量使用短参数,谨慎使用。
确保您的网站 托管服务器没有停机、过载或配置错误。如果连接问题、超时问题或响应问题仍然存在,请联系您的网站hosting 服务提供商,并考虑增强您的网站 处理流量的能力。
检查网站是否不小心屏蔽了百度蜘蛛的IP。您可能由于系统级问题(例如 DNS 配置问题、未正确配置防火墙或 DoS 保护系统、内容管理系统配置问题)而阻止百度访问。防御系统是保证托管服务正常运行的关键因素之一,这些系统通常配置为自动防止过多的服务器请求。由于百度蜘蛛通常比普通用户发出更多的请求,这些防御系统可能会被触发,导致它们阻止百度蜘蛛访问和抓取您的网站。解决这类问题,需要确定网站基础设施的哪一部分阻塞了百度蜘蛛,然后取消阻塞。如果您无权控制防火墙,则需要联系您的托管服务提供商解决此问题。
[机器人禁令问题]
在爬虫诊断工具中,如果返回爬虫失败结论是robots被禁止,请确认是否在URL上设置robots防止百度蜘蛛抓取网站的部分内容,如果不使用robots文件屏蔽百度,请点击旁边的错误链接,百度会立即更新您网站的robots信息;如果您的操作不当导致被封禁,请及时修改robots文件,以免造成您的网站在百度收录量和流量下降。 查看全部
网页数据抓取软件(【url规范】百度支持抓取的url长度不超过1024)
[网址规范]
百度支持抓取的网址长度不超过1024。如果您的链接长度过长,请在保证正常访问的同时适当简化,确保链接可以被百度和收录抓取正常。
[重定向错误]
重定向是指百度蜘蛛访问链接时发生的重定向。如果重定向后的链接过长或者连续重定向次数超过5次,就会出现重定向错误,爬取失败。
[服务器连接错误]
这种情况意味着百度无法访问您的网站,原因是服务器响应缓慢或您的网站屏蔽了百度蜘蛛。这将导致百度无法收录 或更新您的网站 内容。您可能会看到以下特定错误:连接超时、连接失败、连接被拒绝、无响应、响应截断、连接重置、标头截断、超时。
如何处理服务器连接错误?
减少动态页面请求的过多页面加载。如果网站为多个URL提供相同的内容,则视为动态提供内容(例如提供的内容相同)。动态网页的响应时间可能很长,这会导致超时问题。或者,服务器可能会回到过载状态,请求百度蜘蛛减慢爬取网站的速度。一般情况下,建议尽量使用短参数,谨慎使用。
确保您的网站 托管服务器没有停机、过载或配置错误。如果连接问题、超时问题或响应问题仍然存在,请联系您的网站hosting 服务提供商,并考虑增强您的网站 处理流量的能力。
检查网站是否不小心屏蔽了百度蜘蛛的IP。您可能由于系统级问题(例如 DNS 配置问题、未正确配置防火墙或 DoS 保护系统、内容管理系统配置问题)而阻止百度访问。防御系统是保证托管服务正常运行的关键因素之一,这些系统通常配置为自动防止过多的服务器请求。由于百度蜘蛛通常比普通用户发出更多的请求,这些防御系统可能会被触发,导致它们阻止百度蜘蛛访问和抓取您的网站。解决这类问题,需要确定网站基础设施的哪一部分阻塞了百度蜘蛛,然后取消阻塞。如果您无权控制防火墙,则需要联系您的托管服务提供商解决此问题。
[机器人禁令问题]
在爬虫诊断工具中,如果返回爬虫失败结论是robots被禁止,请确认是否在URL上设置robots防止百度蜘蛛抓取网站的部分内容,如果不使用robots文件屏蔽百度,请点击旁边的错误链接,百度会立即更新您网站的robots信息;如果您的操作不当导致被封禁,请及时修改robots文件,以免造成您的网站在百度收录量和流量下降。
网页数据抓取软件(闲人日记:如何获取交叉熵函数的开发者工具?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-09-09 03:11
)
懒人日记
时间:2021 年 3 月 9 日
这上来明明是闲置的,还没更新!怎么说呢,不想做,总能找到很多理由。毕竟,“不想做”就是“不想做”。废话少说,进入正题。
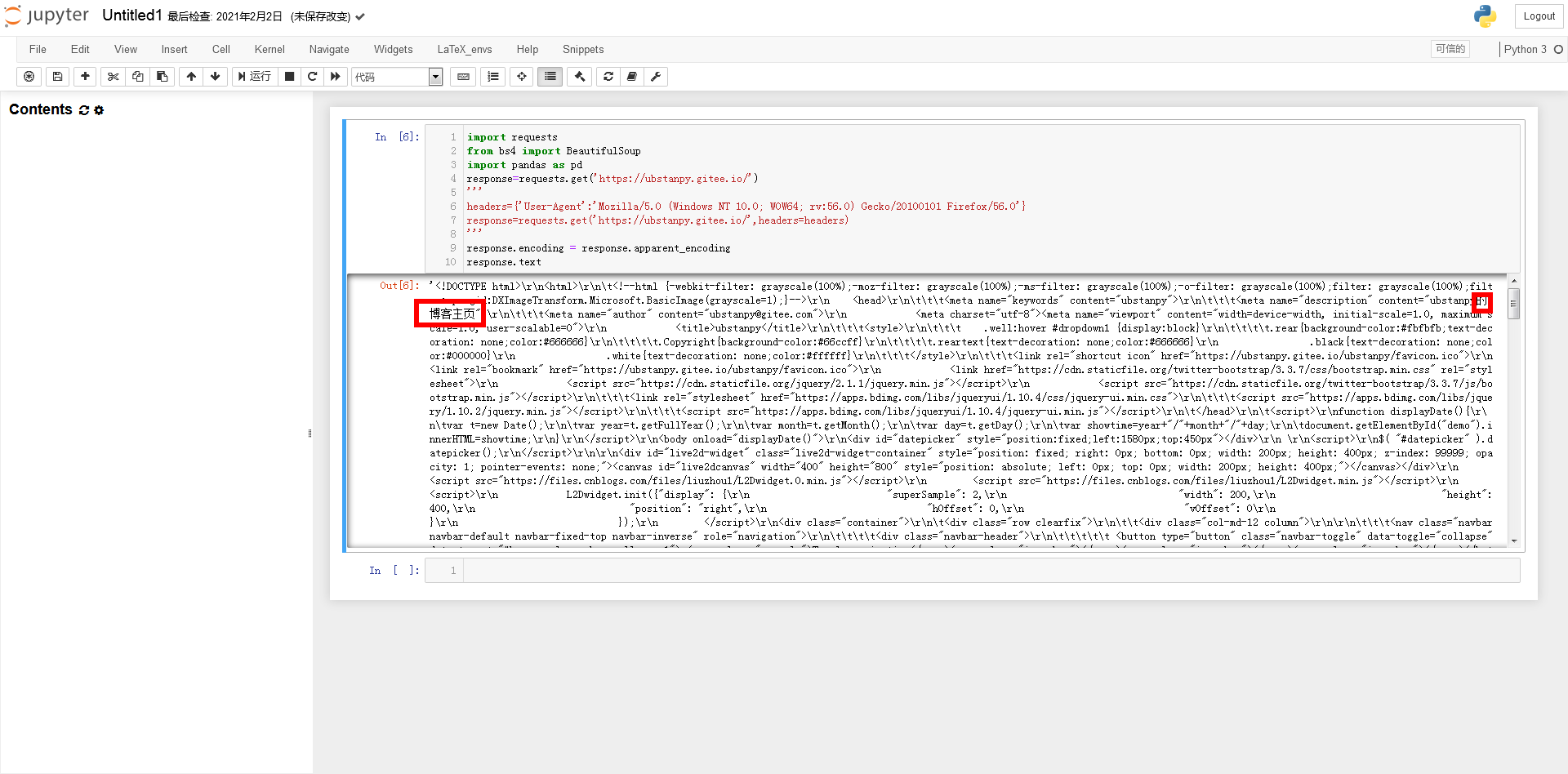
打开网站主页进行实验。可以看到网页上有一个非常明显的表格。这个表是文章看到别人写交叉熵函数时移动的数据。接下来我们将尝试使用Python获取如下数据,并使用不同色块的类属性作为行索引。
只看一条数据。
接下来F12打开浏览器的开发者工具。我们先来看看网页的源代码。这可以帮助我们分析事后如何处理数据。但是在开始之前,笔者首先要说的是,编写爬虫没有固定的、具体的方法,必须“具体情况具体分析”!很多时候我们面对的需求是不同的,有些网站不能使用下面的方法获取数据(获取的方法会有很大的不同),这些都需要很多具体的经验,以及具体的处理问题。经验的经验。 . .
点击元素选择工具,点击目标元素,查看器跳转到目标元素的代码。见图一。
示意图一
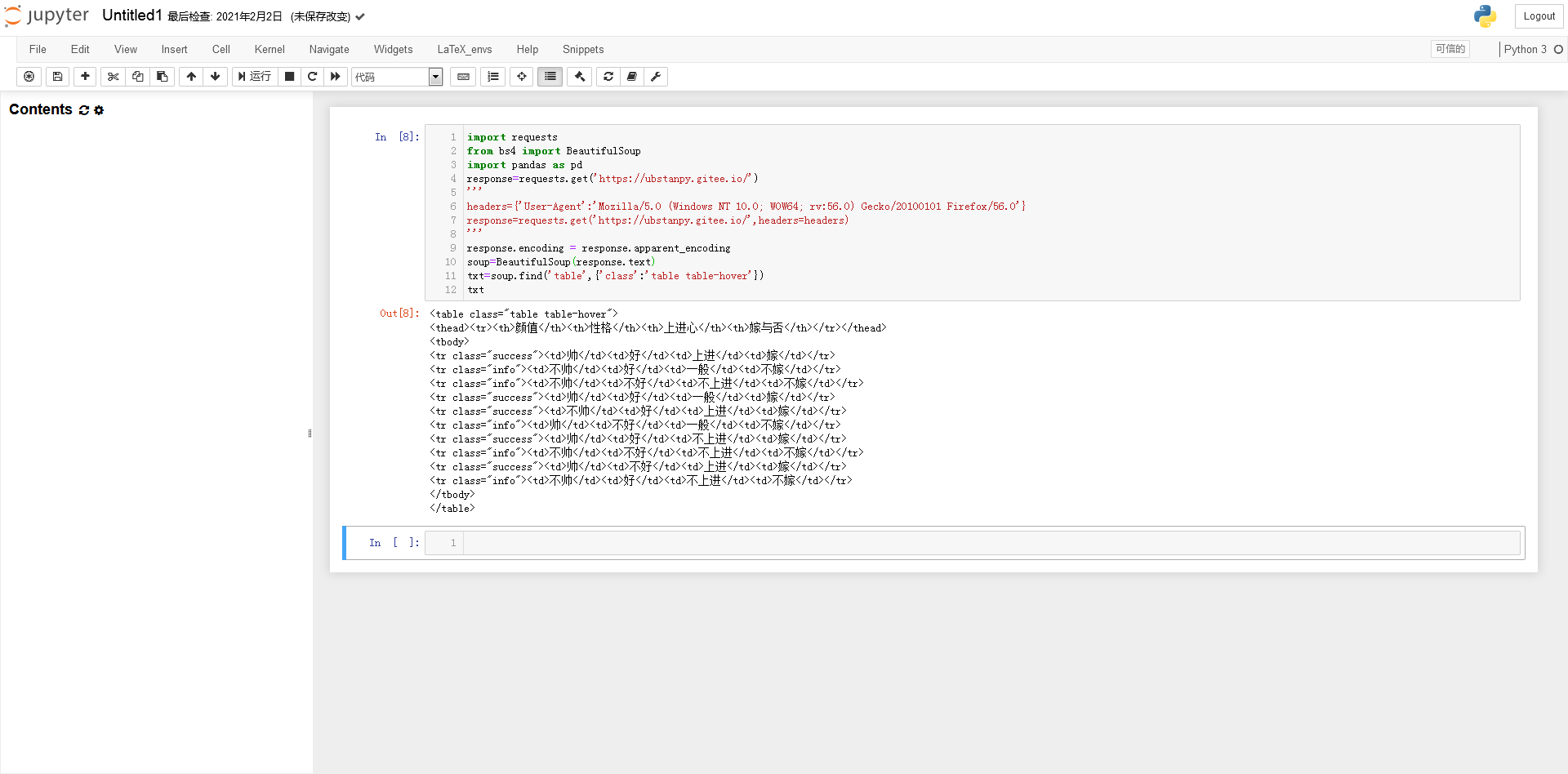
我们来看看元素之间的“父子关系”!左边的“代”比较大,其中,在图2这个...里面是我们要获取数据的目标表的源代码,我们发现只有这个表出现了在整个网页中。 class=table table-hover 参数类的属性值,这将是脚本找到这个 table 对象的重要依据。
示意图二
为了演示方便,只列出了tbody的6个tr。
好的,我们接下来开始工作。首先,我们要先安装一些爬虫相关的库或模块。如果没有安装,可以在cmd中输入命令安装:pip install requests beautifulsoup4 pandas(requests和beautifulsoup4、pandas也安装了)。安装成功后,我们进入下一步。打开 Jupyther Notebook,这是数据科学中常用的 Python 集成开发环境。如果使用Python的IDLE工具,最好一行一行的输入命令,否则容易报错。
分别导入请求和beautifulsoup4、pandas:
对于网络请求,部分网站必须带头发送,否则无法获取。
输入response.text,你会发现所有的汉字都变成了乱码。这时候就需要转换编码了。查看输出编码:
响应文本
一般我们只需要将编码转换为utf-8即可解决中文乱码:
或输入以下代码:
处理编码问题后
可以看出还是比较乱的,和真正的源码不太一样。 “\r”表示当前位置返回到开头,“\n”表示换行,“\t”表示跳到下一个制表符位置。因此,创建一个 bs4.BeautifulSoup 类型的对象:
将文本转换为源代码
BeautifulSoup 模块使响应文本更加规则。
找到变量soup中第一个属性类为“table table-hover”且标签为table的代码块:
...代码块
获取tbody中所有tr标签的代码块:
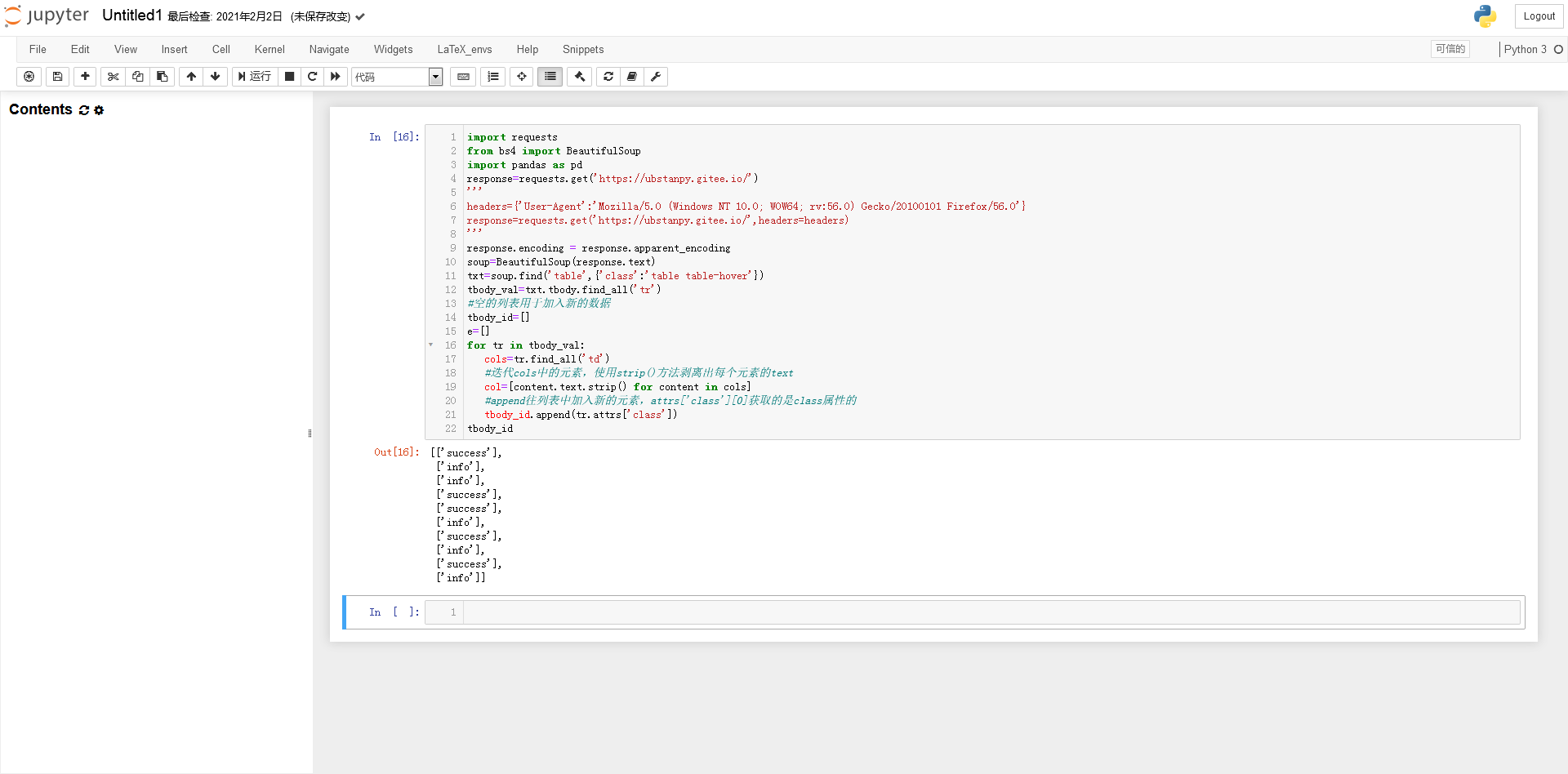
全部在 tbody...
代码块列表
处理成需求数据的结构(警告!下面有很多图帮你解读代码):
列
列
因为 attrs['class'] 返回一个列表
提取list对象中的字符串(否则tbody_id不能作为索引)
主题数据
将列表数据转换为pandas DataFrame类型数据
数据表
请根据自己的需要设计。这几乎是结束了。如果要将数据表导出为Excel表格,只需要使用pandas的to_excel()函数即可。
背后的故事
18年,作者和数学建模的小伙伴遇到一个课题,需要采集大量足球彩票网站数据进行数据分析。那时我们用的是matlab,对互联网技术或编程了解不多。水平也有待提高。所以我用了最慢的方法,一页一页地采集页面。可以说是慢到让人吐血。那是我第一次通宵工作。如果你现在看,你有更多的选择。
后记
作者在百度经验中遇到很多墙,文章一直发不上来,一直被告知踩到了“雷区”进行修改。几个小时后,更改无法通过,这令人费解。最后不得不放弃。之前微信公众号上发的内容没人看,虽然只是比较基础的内容,自然会和别人的代码有很多相似之处。但无论如何,我在我的网站上爬取数据,而网站只用于各种实验。
今天突然发现b站的专栏增加了一些作者和其他朋友之前一直在说的功能,有点惊喜!我爱小破站(poyin)。
查看全部
网页数据抓取软件(闲人日记:如何获取交叉熵函数的开发者工具?(上)
)
懒人日记
时间:2021 年 3 月 9 日
这上来明明是闲置的,还没更新!怎么说呢,不想做,总能找到很多理由。毕竟,“不想做”就是“不想做”。废话少说,进入正题。

打开网站主页进行实验。可以看到网页上有一个非常明显的表格。这个表是文章看到别人写交叉熵函数时移动的数据。接下来我们将尝试使用Python获取如下数据,并使用不同色块的类属性作为行索引。
只看一条数据。
接下来F12打开浏览器的开发者工具。我们先来看看网页的源代码。这可以帮助我们分析事后如何处理数据。但是在开始之前,笔者首先要说的是,编写爬虫没有固定的、具体的方法,必须“具体情况具体分析”!很多时候我们面对的需求是不同的,有些网站不能使用下面的方法获取数据(获取的方法会有很大的不同),这些都需要很多具体的经验,以及具体的处理问题。经验的经验。 . .
点击元素选择工具,点击目标元素,查看器跳转到目标元素的代码。见图一。
示意图一
我们来看看元素之间的“父子关系”!左边的“代”比较大,其中,在图2这个...里面是我们要获取数据的目标表的源代码,我们发现只有这个表出现了在整个网页中。 class=table table-hover 参数类的属性值,这将是脚本找到这个 table 对象的重要依据。
示意图二
为了演示方便,只列出了tbody的6个tr。
好的,我们接下来开始工作。首先,我们要先安装一些爬虫相关的库或模块。如果没有安装,可以在cmd中输入命令安装:pip install requests beautifulsoup4 pandas(requests和beautifulsoup4、pandas也安装了)。安装成功后,我们进入下一步。打开 Jupyther Notebook,这是数据科学中常用的 Python 集成开发环境。如果使用Python的IDLE工具,最好一行一行的输入命令,否则容易报错。
分别导入请求和beautifulsoup4、pandas:
对于网络请求,部分网站必须带头发送,否则无法获取。
输入response.text,你会发现所有的汉字都变成了乱码。这时候就需要转换编码了。查看输出编码:

响应文本
一般我们只需要将编码转换为utf-8即可解决中文乱码:
或输入以下代码:
处理编码问题后
可以看出还是比较乱的,和真正的源码不太一样。 “\r”表示当前位置返回到开头,“\n”表示换行,“\t”表示跳到下一个制表符位置。因此,创建一个 bs4.BeautifulSoup 类型的对象:

将文本转换为源代码
BeautifulSoup 模块使响应文本更加规则。
找到变量soup中第一个属性类为“table table-hover”且标签为table的代码块:
...代码块
获取tbody中所有tr标签的代码块:

全部在 tbody...
代码块列表
处理成需求数据的结构(警告!下面有很多图帮你解读代码):

列

列
因为 attrs['class'] 返回一个列表
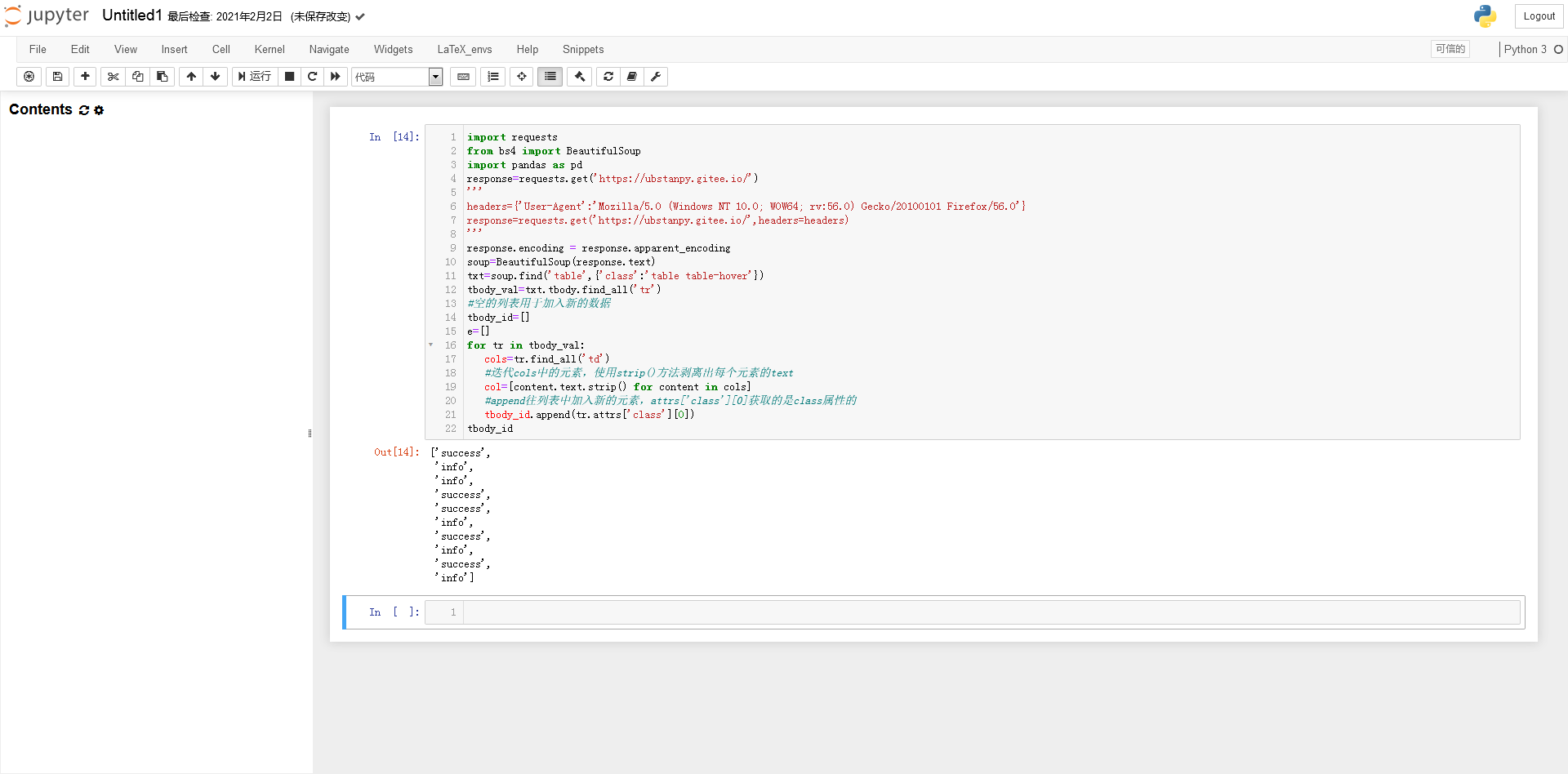
提取list对象中的字符串(否则tbody_id不能作为索引)
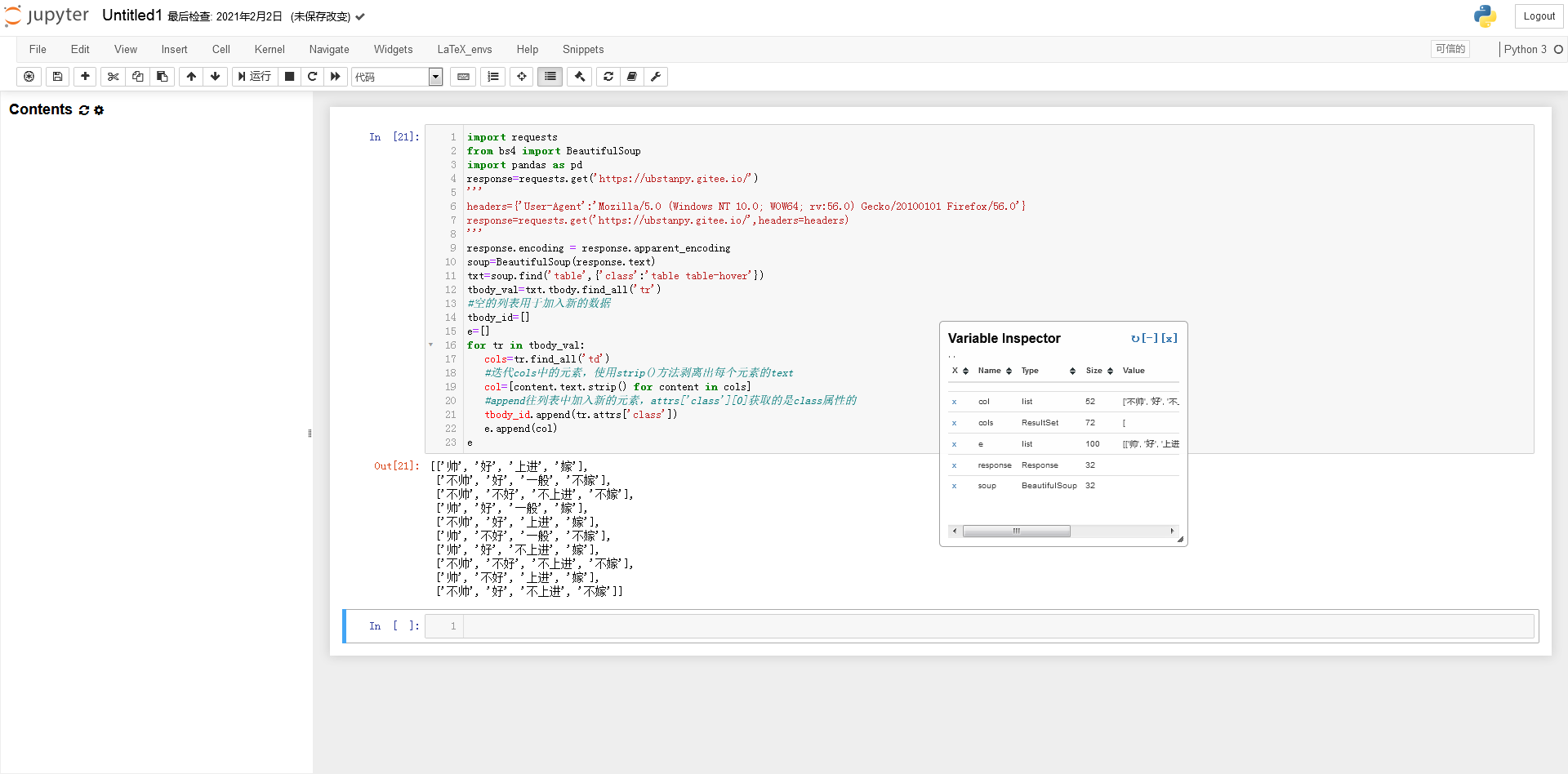
主题数据
将列表数据转换为pandas DataFrame类型数据
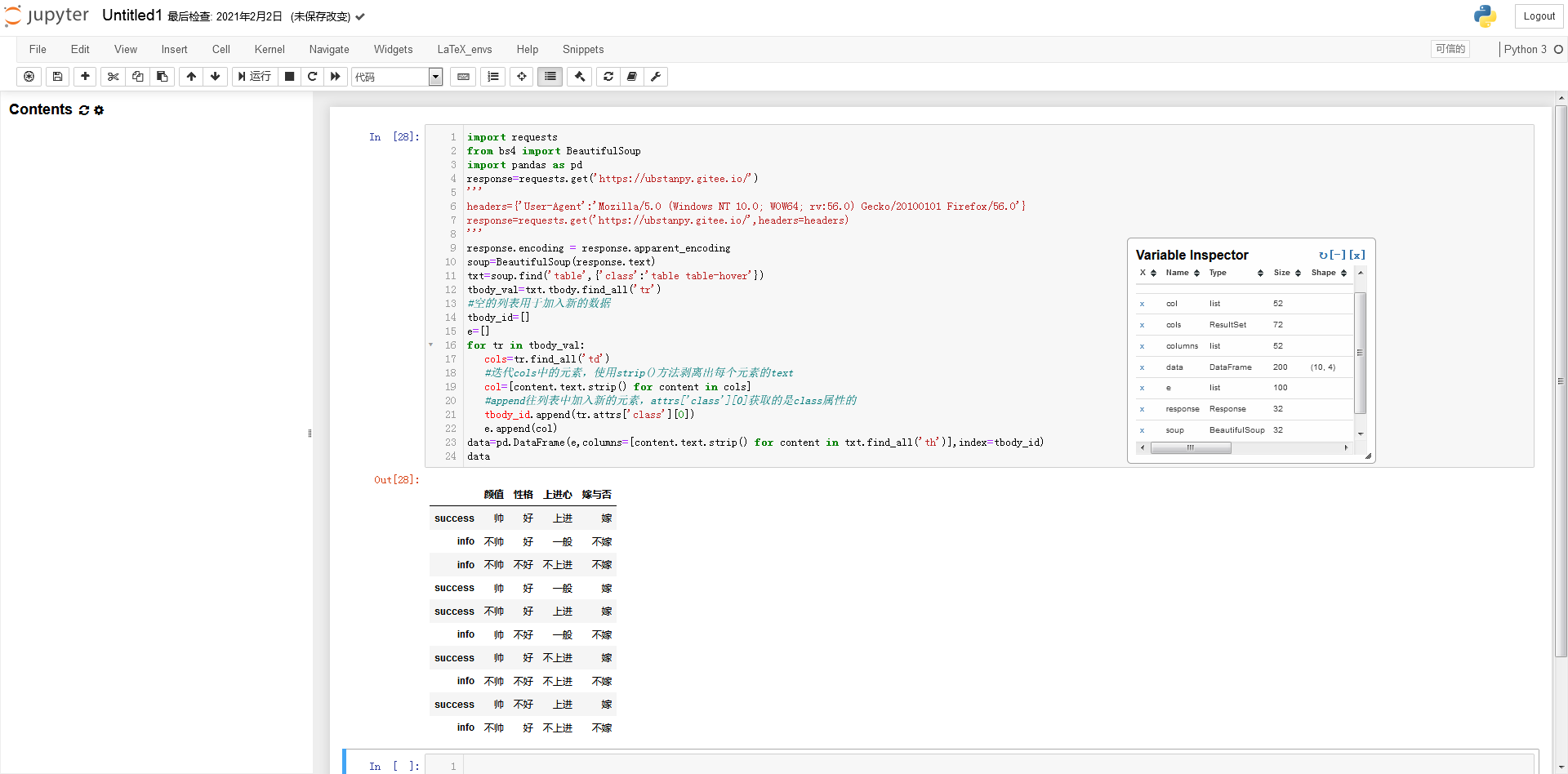
数据表
请根据自己的需要设计。这几乎是结束了。如果要将数据表导出为Excel表格,只需要使用pandas的to_excel()函数即可。
背后的故事
18年,作者和数学建模的小伙伴遇到一个课题,需要采集大量足球彩票网站数据进行数据分析。那时我们用的是matlab,对互联网技术或编程了解不多。水平也有待提高。所以我用了最慢的方法,一页一页地采集页面。可以说是慢到让人吐血。那是我第一次通宵工作。如果你现在看,你有更多的选择。
后记
作者在百度经验中遇到很多墙,文章一直发不上来,一直被告知踩到了“雷区”进行修改。几个小时后,更改无法通过,这令人费解。最后不得不放弃。之前微信公众号上发的内容没人看,虽然只是比较基础的内容,自然会和别人的代码有很多相似之处。但无论如何,我在我的网站上爬取数据,而网站只用于各种实验。
今天突然发现b站的专栏增加了一些作者和其他朋友之前一直在说的功能,有点惊喜!我爱小破站(poyin)。

网页数据抓取软件(网页抓包嗅探器v1.0调用基于GoogleChromium的ChromiumEmbedded(CEF)框架特点抓取数据全面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-19 19:26
Web数据包嗅探器是个人制作的资源搜索和下载工具。通过web数据包嗅探器,用户可以下载网站的内容,而且使用非常简单。只需将您要下载的网站的链接复制到软件中,软件就会列出当前网站中可以下载的所有内容,用户只需复制软件中列出的链接即可下载
Web数据包嗅探器是个人制作的资源搜索和下载工具。通过web数据包嗅探器,用户可以下载网站的内容,而且使用非常简单。只需将要下载的网站链接复制到软件中,软件会列出当前网站中可以下载的所有内容,用户只需复制软件中列出的链接即可下载,非常方便
软件特性
网络包嗅探器v1.0调用基于Google chrome的chrome嵌入式框架(CEF)框架
特点:数据采集全面无遗漏,支持视频格式文件采集(如宝藏主画面视频)等
使用方法
1、首先设置捕获文件的格式并用“|”分隔
2、输入要爬网的URL,点击【打开】,爬网后的数据将显示在过滤结果中
3、点击对过滤结果进行排序排序,便于判断文件类型(一般大文件主要是视频)
4、如果常规结果无法捕获您想要的视频,请单击其他结果并将其从大到小排序。一般来说,前几个是
5、确定文件URL,将其复制到浏览器进行下载,或使用下载工具进行下载 查看全部
网页数据抓取软件(网页抓包嗅探器v1.0调用基于GoogleChromium的ChromiumEmbedded(CEF)框架特点抓取数据全面)
Web数据包嗅探器是个人制作的资源搜索和下载工具。通过web数据包嗅探器,用户可以下载网站的内容,而且使用非常简单。只需将您要下载的网站的链接复制到软件中,软件就会列出当前网站中可以下载的所有内容,用户只需复制软件中列出的链接即可下载
Web数据包嗅探器是个人制作的资源搜索和下载工具。通过web数据包嗅探器,用户可以下载网站的内容,而且使用非常简单。只需将要下载的网站链接复制到软件中,软件会列出当前网站中可以下载的所有内容,用户只需复制软件中列出的链接即可下载,非常方便
软件特性
网络包嗅探器v1.0调用基于Google chrome的chrome嵌入式框架(CEF)框架
特点:数据采集全面无遗漏,支持视频格式文件采集(如宝藏主画面视频)等
使用方法
1、首先设置捕获文件的格式并用“|”分隔
2、输入要爬网的URL,点击【打开】,爬网后的数据将显示在过滤结果中
3、点击对过滤结果进行排序排序,便于判断文件类型(一般大文件主要是视频)
4、如果常规结果无法捕获您想要的视频,请单击其他结果并将其从大到小排序。一般来说,前几个是
5、确定文件URL,将其复制到浏览器进行下载,或使用下载工具进行下载
网页数据抓取软件(网络爬虫或机器人解析网页的示例程序解析库 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-19 16:22
)
1什么是网络爬虫
网络爬虫是指网站提取数据的技术,它可以将非结构化数据转换为结构化数据
网络爬虫的目的是从网络中提取数据网站. 提取的数据可以存储在本地文件中并保存在系统中,或者以表的形式存储在数据库中。网络爬虫使用HTTP或Web浏览器直接访问万维网(WWW)。网络爬虫或机器人抓取网页的过程是一个自动过程
捕获网页的过程分为获取网页和提取数据。网络爬虫能够获取网页,是网络爬虫的必要组成部分。获取网页后,需要提取网页数据。我们可以搜索、解析并将提取的数据保存到表中,然后重新排列格式
2数据提取
在本节中,我们将研究数据提取。我们可以使用Python漂亮的汤库进行数据提取。您还需要使用python库的requests模块
运行以下命令来安装请求和库
$ pip3 install requests
$ pip3 install beautifulsoup4
2.1Requests仓库
使用请求库以易于理解的格式在Python脚本中使用HTTP。这里,使用Python中的请求库获取web页面。请求库收录不同类型的请求。这里使用get请求。Get请求用于从web服务器获取信息。使用get请求获取指定网页的HTML内容。每个请求对应一个状态代码,该代码从服务器返回。这些状态代码为我们提供了有关相应请求的执行结果的相关信息。这里有一些状态代码
2.2BeautifulSoup仓库
Beauty soup也是一个python库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包
要在脚本中使用请求和模块,必须使用import语句导入它们。现在让我们看一个解析网页的示例程序。这里我们将解析一个来自百度的新闻网页网站. 创建一个名为parse_uWeb_uuPage.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
print(parse_obj)
运行脚本程序,如下所示。
student@ubuntu:~/work$ python3 parse_web_page.py
Output:
var IMDbTimer={starttime: new
Date().getTime(),pt:'java'};
if (typeof uet == 'function') {
uet("bb", "LoadTitle", {wb: 1});
}
(function(t){ (t.events = t.events || {})["csm_head_pre_title"] =
new Date().getTime(); })(IMDbTimer);
Top News - IMDb
(function(t){ (t.events = t.events || {})["csm_head_post_title"] =
new Date().getTime(); })(IMDbTimer);
if (typeof uet == 'function') {
uet("be", "LoadTitle", {wb: 1});
}
if (typeof uex == 'function') {
uex("ld", "LoadTitle", {wb: 1});
}
if (typeof uet == 'function') {
uet("bb", "LoadIcons", {wb: 1});
}
上面的示例程序抓取一个网页并用BeautifulSoup解析它。首先,导入请求和beautifulsoup模块,然后使用get请求访问URL并将结果分配给page_uResult变量,然后创建一个beautiful soup对象parse_Obj,该对象将返回requests_Result.content的结果页面作为参数,然后使用html.parser解析页面
现在我们将从类和标记中提取数据。转到web浏览器,右键单击要提取的内容,然后向下查找“检查”选项。单击它以获取类名。在程序中指定类名并运行脚本。创建一个名为extract_uufrom_u类的脚本。Py并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
print(top_news)
运行脚本程序,如下所示
student@ubuntu:~/work$ python3 extract_from_class.py
Output :
Issa Rae and Laura Dern are teaming up to star in a limited
series called "The Dolls" currently in development at HBO.
Inspired by true events, the
series recounts the aftermath of Christmas Eve riots in two small Arkansastowns in 1983, riots which erupted over Cabbage Patch Dolls. The seriesexplores class, race, privilege and what it takes to be a "goodmother."
Rae will serve as a writer and executive producer on the
series in addition to starring, with Dern also executive producing. Laura Kittrell and Amy Aniobi will also serve as writers and coexecutive
producers. Jayme Lemons of Dern’s
Jaywalker Pictures and Deniese Davis of Issa Rae Productions will also executive
produce.
Both Rae and Dern currently star in HBO shows, with Dern
appearing in the acclaimed drama "Big Little
Lies" and Rae starring in and having created the hit comedy "Insecure." Dern also recently starred in the
film "The Tale,
上面的示例程序首先导入请求和beautulsoup模块,然后创建一个请求对象并为其分配一个URL,然后创建一个beautulsoup对象parse_uuj。该对象将requests_uuresult.content的结果页作为参数返回,然后使用html.parser解析该页。最后,使用beautifulsoup的find()方法从新闻文章中获取信息
现在让我们看一个从特定标记中提取数据的示例程序。此示例程序将从标记中提取数据。创建一个名为extract_ufrom_u标记.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com/news')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
top_news_a_content = top_news.find_all('a')
print(top_news_a_content)
运行脚本程序,如下所示
student@ubuntu:~/work$ python3 extract_from_tag.py
Output:[Issa Rae, Laura
Dern, HBO, Laura Kittrell, Amy
Aniobi, Jayme Lemons, Jaywalker Pictures, Deniese Davis, Issa Rae Productions, Big Little Lies, Insecure, The
Tale]
上面的示例程序从标记中提取数据。这里使用的是新闻文章中的\uAll()方法\uuuuu从内容类中提取所有标记数据
3从维基百科网站获取信息@
在本节中,我们将学习一个示例程序网站从维基百科获取舞蹈类别列表。这里我们将列出所有印度古典舞蹈。创建一个名为extract\from_uwikipedia.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://en.wikipedia.org/wiki/ ... %2339;)
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
h_obj = parse_obj.find(class_='hlist noprint')
h_obj_a_content = h_obj.find_all('a')
print(h_obj)
print(h_obj_a_content)
运行脚本程序,如下所示
student@ubuntu:~/work$python3摘录自wikipedia.py
结果如下
Portal topics
Activities
Culture
Geography
Health
History
Mathematics
Nature
People
In the preceding example, we extracted the content from Wikipedia. In this
example also, we extracted the content from class as well as tag.
.... 查看全部
网页数据抓取软件(网络爬虫或机器人解析网页的示例程序解析库
)
1什么是网络爬虫
网络爬虫是指网站提取数据的技术,它可以将非结构化数据转换为结构化数据
网络爬虫的目的是从网络中提取数据网站. 提取的数据可以存储在本地文件中并保存在系统中,或者以表的形式存储在数据库中。网络爬虫使用HTTP或Web浏览器直接访问万维网(WWW)。网络爬虫或机器人抓取网页的过程是一个自动过程
捕获网页的过程分为获取网页和提取数据。网络爬虫能够获取网页,是网络爬虫的必要组成部分。获取网页后,需要提取网页数据。我们可以搜索、解析并将提取的数据保存到表中,然后重新排列格式
2数据提取
在本节中,我们将研究数据提取。我们可以使用Python漂亮的汤库进行数据提取。您还需要使用python库的requests模块
运行以下命令来安装请求和库
$ pip3 install requests
$ pip3 install beautifulsoup4
2.1Requests仓库
使用请求库以易于理解的格式在Python脚本中使用HTTP。这里,使用Python中的请求库获取web页面。请求库收录不同类型的请求。这里使用get请求。Get请求用于从web服务器获取信息。使用get请求获取指定网页的HTML内容。每个请求对应一个状态代码,该代码从服务器返回。这些状态代码为我们提供了有关相应请求的执行结果的相关信息。这里有一些状态代码
2.2BeautifulSoup仓库
Beauty soup也是一个python库,收录简单的搜索、导航和修改方法。它只是一个从网页中提取所需数据的工具包
要在脚本中使用请求和模块,必须使用import语句导入它们。现在让我们看一个解析网页的示例程序。这里我们将解析一个来自百度的新闻网页网站. 创建一个名为parse_uWeb_uuPage.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
print(parse_obj)
运行脚本程序,如下所示。
student@ubuntu:~/work$ python3 parse_web_page.py
Output:
var IMDbTimer={starttime: new
Date().getTime(),pt:'java'};
if (typeof uet == 'function') {
uet("bb", "LoadTitle", {wb: 1});
}
(function(t){ (t.events = t.events || {})["csm_head_pre_title"] =
new Date().getTime(); })(IMDbTimer);
Top News - IMDb
(function(t){ (t.events = t.events || {})["csm_head_post_title"] =
new Date().getTime(); })(IMDbTimer);
if (typeof uet == 'function') {
uet("be", "LoadTitle", {wb: 1});
}
if (typeof uex == 'function') {
uex("ld", "LoadTitle", {wb: 1});
}
if (typeof uet == 'function') {
uet("bb", "LoadIcons", {wb: 1});
}
上面的示例程序抓取一个网页并用BeautifulSoup解析它。首先,导入请求和beautifulsoup模块,然后使用get请求访问URL并将结果分配给page_uResult变量,然后创建一个beautiful soup对象parse_Obj,该对象将返回requests_Result.content的结果页面作为参数,然后使用html.parser解析页面
现在我们将从类和标记中提取数据。转到web浏览器,右键单击要提取的内容,然后向下查找“检查”选项。单击它以获取类名。在程序中指定类名并运行脚本。创建一个名为extract_uufrom_u类的脚本。Py并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
print(top_news)
运行脚本程序,如下所示
student@ubuntu:~/work$ python3 extract_from_class.py
Output :
Issa Rae and Laura Dern are teaming up to star in a limited
series called "The Dolls" currently in development at HBO.
Inspired by true events, the
series recounts the aftermath of Christmas Eve riots in two small Arkansastowns in 1983, riots which erupted over Cabbage Patch Dolls. The seriesexplores class, race, privilege and what it takes to be a "goodmother."
Rae will serve as a writer and executive producer on the
series in addition to starring, with Dern also executive producing. Laura Kittrell and Amy Aniobi will also serve as writers and coexecutive
producers. Jayme Lemons of Dern’s
Jaywalker Pictures and Deniese Davis of Issa Rae Productions will also executive
produce.
Both Rae and Dern currently star in HBO shows, with Dern
appearing in the acclaimed drama "Big Little
Lies" and Rae starring in and having created the hit comedy "Insecure." Dern also recently starred in the
film "The Tale,
上面的示例程序首先导入请求和beautulsoup模块,然后创建一个请求对象并为其分配一个URL,然后创建一个beautulsoup对象parse_uuj。该对象将requests_uuresult.content的结果页作为参数返回,然后使用html.parser解析该页。最后,使用beautifulsoup的find()方法从新闻文章中获取信息
现在让我们看一个从特定标记中提取数据的示例程序。此示例程序将从标记中提取数据。创建一个名为extract_ufrom_u标记.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://www.news.baidu.com/news')
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
top_news = parse_obj.find(class_='news-article__content')
top_news_a_content = top_news.find_all('a')
print(top_news_a_content)
运行脚本程序,如下所示
student@ubuntu:~/work$ python3 extract_from_tag.py
Output:[Issa Rae, Laura
Dern, HBO, Laura Kittrell, Amy
Aniobi, Jayme Lemons, Jaywalker Pictures, Deniese Davis, Issa Rae Productions, Big Little Lies, Insecure, The
Tale]
上面的示例程序从标记中提取数据。这里使用的是新闻文章中的\uAll()方法\uuuuu从内容类中提取所有标记数据
3从维基百科网站获取信息@
在本节中,我们将学习一个示例程序网站从维基百科获取舞蹈类别列表。这里我们将列出所有印度古典舞蹈。创建一个名为extract\from_uwikipedia.py的脚本,并在其中编写以下代码
import requests
from bs4 import BeautifulSoup
page_result = requests.get('https://en.wikipedia.org/wiki/ ... %2339;)
parse_obj = BeautifulSoup(page_result.content, 'html.parser')
h_obj = parse_obj.find(class_='hlist noprint')
h_obj_a_content = h_obj.find_all('a')
print(h_obj)
print(h_obj_a_content)
运行脚本程序,如下所示
student@ubuntu:~/work$python3摘录自wikipedia.py
结果如下
Portal topics
Activities
Culture
Geography
Health
History
Mathematics
Nature
People
In the preceding example, we extracted the content from Wikipedia. In this
example also, we extracted the content from class as well as tag.
....
网页数据抓取软件(网络爬虫21世纪数据的价值所在!(附详细流程) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-19 16:17
)
简介:随着大数据技术、分布式存储和分布式计算的发展,数据的价值不断挖掘,特别是对于大量的网络数据,抓取网站数据内容,分析数据背后隐藏的价值。人工智能背后是对海量数据支持的需求,这是21世纪数据的价值所在
1、网络爬虫的基本流程:
1.1、initiate request:客户端通过HTTP库向目标站点发起请求,并等待服务器响应
1.2、get response content:服务器响应的内容就是页面的内容。类型包括HTML、JSON、二进制等
1.3、解析内容:可以通过正则表达式和网页解析库解析HTML。JSON可以直接转换为JSON对象解析。二进制数据,可进一步存储或处理
1.4、保存数据:结构化存储,可以保存为文本、保存到数据库或以特定格式保存为文件
2、Reques答复:
@k331、Request:
1)request-methods:主要有两种类型:get和post,以及head、put、delete、options等2)request-URL:URL是统一的资源定位器,网页、图片、视频等可用URL是唯一确定的
3)request header:收录请求时的头信息,如用户代理、主机、cookie等
4)request body:请求期间携带的附加数据,例如表单提交时的表单数据
@k332、Response:
1)响应状态:响应状态。例如,200表示成功,301表示跳转,404表示找不到页面,502表示服务器错误
2)response header:如内容类型、内容长度、服务器信息、设置cookie等
3)response body:最重要的部分,包括请求的资源内容,如HTML、图片和视频、二进制数据等
3、crawler可以捕获的数据:
3.1、网页文本:HTML文档、JSON格式文本等
3.2、图片:获取二进制文件并以图片格式保存
3.3、Video:它也是一个二进制文件,可以以视频格式保存
3.4、其他:只要可以请求数据,就可以获得信息
4、分辨率方法:
4.1、直接处理:适用于简单网页
@k562、Json解析:适合网页的是JSON字符串
4.3、正则表达式:适用于HTML解析
4.4、库解析:漂亮的汤库、pyquery库、XPath库等
5、请求的结果与浏览器看到的结果不同:
5.1、原因:浏览器的渲染效果。JavaScript和后台交互数据
5.2、如何解决JavaScript呈现问题:分析Ajax请求(JSON字符串)。Selenium/webdriver解决方案(可以安装PIP)。Splash解决方案(您可以在GitHub中搜索安装)。PyV8、Ghost.py
6、如何保存数据:
6.1、text:纯文本、JSON、XML等
6.2、关系数据库:如mysql、Oracle、SQL server等以结构化表的结构化形式存储
6.3、非关系数据库:如mongodb、redis和其他键值数据库
6.4、二进制文件:如图片、视频、音频等直接以特定格式保存
查看全部
网页数据抓取软件(网络爬虫21世纪数据的价值所在!(附详细流程)
)
简介:随着大数据技术、分布式存储和分布式计算的发展,数据的价值不断挖掘,特别是对于大量的网络数据,抓取网站数据内容,分析数据背后隐藏的价值。人工智能背后是对海量数据支持的需求,这是21世纪数据的价值所在
1、网络爬虫的基本流程:
1.1、initiate request:客户端通过HTTP库向目标站点发起请求,并等待服务器响应
1.2、get response content:服务器响应的内容就是页面的内容。类型包括HTML、JSON、二进制等
1.3、解析内容:可以通过正则表达式和网页解析库解析HTML。JSON可以直接转换为JSON对象解析。二进制数据,可进一步存储或处理
1.4、保存数据:结构化存储,可以保存为文本、保存到数据库或以特定格式保存为文件
2、Reques答复:
@k331、Request:
1)request-methods:主要有两种类型:get和post,以及head、put、delete、options等2)request-URL:URL是统一的资源定位器,网页、图片、视频等可用URL是唯一确定的
3)request header:收录请求时的头信息,如用户代理、主机、cookie等
4)request body:请求期间携带的附加数据,例如表单提交时的表单数据
@k332、Response:
1)响应状态:响应状态。例如,200表示成功,301表示跳转,404表示找不到页面,502表示服务器错误
2)response header:如内容类型、内容长度、服务器信息、设置cookie等
3)response body:最重要的部分,包括请求的资源内容,如HTML、图片和视频、二进制数据等
3、crawler可以捕获的数据:
3.1、网页文本:HTML文档、JSON格式文本等
3.2、图片:获取二进制文件并以图片格式保存
3.3、Video:它也是一个二进制文件,可以以视频格式保存
3.4、其他:只要可以请求数据,就可以获得信息
4、分辨率方法:
4.1、直接处理:适用于简单网页
@k562、Json解析:适合网页的是JSON字符串
4.3、正则表达式:适用于HTML解析
4.4、库解析:漂亮的汤库、pyquery库、XPath库等
5、请求的结果与浏览器看到的结果不同:
5.1、原因:浏览器的渲染效果。JavaScript和后台交互数据
5.2、如何解决JavaScript呈现问题:分析Ajax请求(JSON字符串)。Selenium/webdriver解决方案(可以安装PIP)。Splash解决方案(您可以在GitHub中搜索安装)。PyV8、Ghost.py
6、如何保存数据:
6.1、text:纯文本、JSON、XML等
6.2、关系数据库:如mysql、Oracle、SQL server等以结构化表的结构化形式存储
6.3、非关系数据库:如mongodb、redis和其他键值数据库
6.4、二进制文件:如图片、视频、音频等直接以特定格式保存
网页数据抓取软件(网页搜索关键词并将相关信息返回上传文件操作通过input标签实现的上传功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-19 16:15
Selenium获取网页数据,搜索网页关键词并返回相关信息
from selenium import webdriver#导入驱动模块
import time#导入时间模块
# 实例化一个浏览器
driver = webdriver.Firefox()
# 隐式等待
driver.implicitly_wait(10)
# 浏览器最大化
driver.maximize_window()
# 打开指定的网页(URL就是指网址)
driver.get("http://www.baidu.com")
driver.find_element_by_css_selector('#kw').send_keys('蔡徐坤')
#使用CSS筛选器按照ID元素定位到搜索输入框
driver.find_element_by_css_selector('#su').click()
#使用CSS筛选器定位到元素百度一下按钮
a = driver.find_elements_by_css_selector('.c-container>h3')
#按照属性值进行筛选,父类和子类关系用>,使用elements获取到的结果是一个非文本列表
for i in a:
print(i.text)
driver.quit()
时间模块:年月日格式化输出
import time
getTime = time.strftime('%Y-%m-%d %H:%M:%S')
print(getTime)
上载文件操作
通过输入标签实现的上传功能可以看作是一个输入框,即通过send_ukeys()指定上传文件的本地文件路径
使用以下代码创建file.html文件:
upload_file
upload_file
通过浏览器打开file.html文件。该功能如下图所示
from selenium import webdriver
import os
driver = webdriver.Firefox()
file_path = 'file:///' + os.path.abspath('file.html')
driver.get(file_path)
# 定位上传按钮,添加本地文件
driver.find_element_by_name("file").send_keys('D:\\upload_file.txt')
driver.quit()
上传文件的具体应用请参见邮箱126中的邮件发送操作 查看全部
网页数据抓取软件(网页搜索关键词并将相关信息返回上传文件操作通过input标签实现的上传功能)
Selenium获取网页数据,搜索网页关键词并返回相关信息
from selenium import webdriver#导入驱动模块
import time#导入时间模块
# 实例化一个浏览器
driver = webdriver.Firefox()
# 隐式等待
driver.implicitly_wait(10)
# 浏览器最大化
driver.maximize_window()
# 打开指定的网页(URL就是指网址)
driver.get("http://www.baidu.com";)
driver.find_element_by_css_selector('#kw').send_keys('蔡徐坤')
#使用CSS筛选器按照ID元素定位到搜索输入框
driver.find_element_by_css_selector('#su').click()
#使用CSS筛选器定位到元素百度一下按钮
a = driver.find_elements_by_css_selector('.c-container>h3')
#按照属性值进行筛选,父类和子类关系用>,使用elements获取到的结果是一个非文本列表
for i in a:
print(i.text)
driver.quit()
时间模块:年月日格式化输出
import time
getTime = time.strftime('%Y-%m-%d %H:%M:%S')
print(getTime)
上载文件操作
通过输入标签实现的上传功能可以看作是一个输入框,即通过send_ukeys()指定上传文件的本地文件路径
使用以下代码创建file.html文件:
upload_file
upload_file
通过浏览器打开file.html文件。该功能如下图所示
from selenium import webdriver
import os
driver = webdriver.Firefox()
file_path = 'file:///' + os.path.abspath('file.html')
driver.get(file_path)
# 定位上传按钮,添加本地文件
driver.find_element_by_name("file").send_keys('D:\\upload_file.txt')
driver.quit()
上传文件的具体应用请参见邮箱126中的邮件发送操作
网页数据抓取软件(MicrosoftPowerQueryforExcel窗口中的有用数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-09-17 09:16
连接到power Bi桌面中的数据源
安装Microsoft power Bi desktop后,您可以连接到不断扩展的数据世界。Microsoft power query for Excel窗口中提供了所有类型的数据源。下图显示了如何通过选择功能区上的“主页”选项卡,然后选择“获取数据”来获取数据>;“更多”以连接到数据
假设你即将退休,你想住在一个阳光充足、犯罪率低、医疗服务好的地方。以下web资源提供了有关这些主题和其他主题的有用数据:
最佳退休地点排名
选择获取数据>;“Web”并粘贴地址:
选择“确定”后,power Bi desktop的查询功能将开始运行。该查询访问web资源,并在Navigator窗口中显示它在web页面上找到的信息。在这个例子中,它找到了一个表格(“最适合退休和最不适合退休的州/省/市/自治区/市的排名”)。我们对这张桌子很感兴趣,所以我们在列表中选择了它。“导航器”窗口显示预览
现在,我们可以通过在加载表之前选择窗口底部的“convert data”来编辑查询。或者,您可以直接加载表
选择“转换数据”时,power query editor将启动并显示表的代表性视图。将显示“查询设置”窗格(如果没有,请选择功能区上的“视图”选项卡,然后选择“显示”>;查询设置)
这是它的外观
在power Bi desktop中,您可以连接到多个数据源并将它们组合起来以执行各种有趣的操作 查看全部
网页数据抓取软件(MicrosoftPowerQueryforExcel窗口中的有用数据(图))
连接到power Bi桌面中的数据源
安装Microsoft power Bi desktop后,您可以连接到不断扩展的数据世界。Microsoft power query for Excel窗口中提供了所有类型的数据源。下图显示了如何通过选择功能区上的“主页”选项卡,然后选择“获取数据”来获取数据>;“更多”以连接到数据
假设你即将退休,你想住在一个阳光充足、犯罪率低、医疗服务好的地方。以下web资源提供了有关这些主题和其他主题的有用数据:
最佳退休地点排名
选择获取数据>;“Web”并粘贴地址:
选择“确定”后,power Bi desktop的查询功能将开始运行。该查询访问web资源,并在Navigator窗口中显示它在web页面上找到的信息。在这个例子中,它找到了一个表格(“最适合退休和最不适合退休的州/省/市/自治区/市的排名”)。我们对这张桌子很感兴趣,所以我们在列表中选择了它。“导航器”窗口显示预览
现在,我们可以通过在加载表之前选择窗口底部的“convert data”来编辑查询。或者,您可以直接加载表
选择“转换数据”时,power query editor将启动并显示表的代表性视图。将显示“查询设置”窗格(如果没有,请选择功能区上的“视图”选项卡,然后选择“显示”>;查询设置)
这是它的外观
在power Bi desktop中,您可以连接到多个数据源并将它们组合起来以执行各种有趣的操作
网页数据抓取软件(旋风软件园下载优采云采集器软件功能便捷定时功能(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-16 23:12
中国有句老话说,在学习过程中我们必须养成良好的复习习惯,优采云采集器这是一个帮助站长复习的好工具。它可以准确地帮你找到你的流量词,让你随时可以抓住粉丝的心。你在等什么,现在来惠而风软件园下载吧
正式介绍
优采云采集器对于任何需要从网络上获取信息的孩子来说都是一个必要的人工制品。这是一个可以让你的信息变得非常简单的工具@k11优采云改变了传统的网络数据思维方式,让用户越来越容易在互联网上获取数据
优采云采集器软件功能
方便的定时功能
只需点击几步设置,即可实现采集任务的定时控制。无论是单个采集的定时设置,还是一天或每周每月预设采集的定时设置,您都可以同时自由设置多个任务,根据需要重新组织所选时间,灵活分配自己的采集任务
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、删除空格、添加前缀或后缀、日期和时间格式化、HTML转码等功能,采集进程是全自动的,无需人工干预即可获得所需的格式数据
多级采集
许多主流新闻和电子商务网站,包括一级商品列表页面、二级商品详情页面和三级评论详情页面;无论网站有多少级别,优采云都无法限制采集数据的级别以满足各种业务采集的需要
API接口
通过优采云API,您可以轻松获取优采云任务信息和采集数据,灵活调度任务,如远程控制任务启动和停止,高效实现数据采集和归档。基于强大的API系统,还可以无缝连接公司内部各种管理平台,实现各项业务的自动化
定制采集
根据不同用户的采集需求,优采云可以提供一种自定义的自动生成爬虫的模式,并可以批量准确识别各种网页元素。它还具有翻页、下拉、AJAX、页面滚动、条件判断等功能。它支持不同网页结构的复杂网站采集并满足各种采集应用程序场景
支持网站post-login采集
优采云有一个内置的采集登录模块。登录后只需配置目标网站的账号和密码,即可使用采集模块访问数据;同时优采云它也有采集Cookie自定义函数。首次登录后,您可以自动记住cookies,避免多次输入密码的繁琐,并支持更多的网站或采集
优采云采集器独特亮点
云采集,关机正常
配置采集任务后,您可以关闭。任务可以在云中执行。大量企业云24*7不间断运行。您不必担心IP阻塞、网络中断和即时采集大量数据
任何人都可以使用它
你还在学习网页源代码和数据包捕获工具吗?现在不需要了。如果你可以上网,你可以使用采集、所见即所得界面和可视过程。你不需要了解技术。单击鼠标,您可以在2分钟内快速开始
任何网站都可以是采集
它不仅使用简单,而且功能强大:单击、登录、翻页,甚至识别验证代码。当网页出错或多组模板完全不同时,您也可以根据不同的情况进行不同的处理
免费使用
它是免费的,免费版本没有功能限制。您可以立即试用,然后立即下载并安装
更新日志
解决任务列表刷新后重新设置过滤条件的问题
解决在自定义配置中修改任务名称时,页签中任务保存ID不正确的问题
解决了在自定义配置中修改任务名称有时无效的问题
解决在设置字段以获取属性值时流程图区域将被隐藏的问题-在用户定义的配置中选择属性值
解决首次进入自定义配置时,向导提示后台出现用户调查界面的问题 查看全部
网页数据抓取软件(旋风软件园下载优采云采集器软件功能便捷定时功能(组图))
中国有句老话说,在学习过程中我们必须养成良好的复习习惯,优采云采集器这是一个帮助站长复习的好工具。它可以准确地帮你找到你的流量词,让你随时可以抓住粉丝的心。你在等什么,现在来惠而风软件园下载吧
正式介绍
优采云采集器对于任何需要从网络上获取信息的孩子来说都是一个必要的人工制品。这是一个可以让你的信息变得非常简单的工具@k11优采云改变了传统的网络数据思维方式,让用户越来越容易在互联网上获取数据
优采云采集器软件功能
方便的定时功能
只需点击几步设置,即可实现采集任务的定时控制。无论是单个采集的定时设置,还是一天或每周每月预设采集的定时设置,您都可以同时自由设置多个任务,根据需要重新组织所选时间,灵活分配自己的采集任务
自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、删除空格、添加前缀或后缀、日期和时间格式化、HTML转码等功能,采集进程是全自动的,无需人工干预即可获得所需的格式数据
多级采集
许多主流新闻和电子商务网站,包括一级商品列表页面、二级商品详情页面和三级评论详情页面;无论网站有多少级别,优采云都无法限制采集数据的级别以满足各种业务采集的需要
API接口
通过优采云API,您可以轻松获取优采云任务信息和采集数据,灵活调度任务,如远程控制任务启动和停止,高效实现数据采集和归档。基于强大的API系统,还可以无缝连接公司内部各种管理平台,实现各项业务的自动化
定制采集
根据不同用户的采集需求,优采云可以提供一种自定义的自动生成爬虫的模式,并可以批量准确识别各种网页元素。它还具有翻页、下拉、AJAX、页面滚动、条件判断等功能。它支持不同网页结构的复杂网站采集并满足各种采集应用程序场景
支持网站post-login采集
优采云有一个内置的采集登录模块。登录后只需配置目标网站的账号和密码,即可使用采集模块访问数据;同时优采云它也有采集Cookie自定义函数。首次登录后,您可以自动记住cookies,避免多次输入密码的繁琐,并支持更多的网站或采集
优采云采集器独特亮点
云采集,关机正常
配置采集任务后,您可以关闭。任务可以在云中执行。大量企业云24*7不间断运行。您不必担心IP阻塞、网络中断和即时采集大量数据
任何人都可以使用它
你还在学习网页源代码和数据包捕获工具吗?现在不需要了。如果你可以上网,你可以使用采集、所见即所得界面和可视过程。你不需要了解技术。单击鼠标,您可以在2分钟内快速开始
任何网站都可以是采集
它不仅使用简单,而且功能强大:单击、登录、翻页,甚至识别验证代码。当网页出错或多组模板完全不同时,您也可以根据不同的情况进行不同的处理
免费使用
它是免费的,免费版本没有功能限制。您可以立即试用,然后立即下载并安装
更新日志
解决任务列表刷新后重新设置过滤条件的问题
解决在自定义配置中修改任务名称时,页签中任务保存ID不正确的问题
解决了在自定义配置中修改任务名称有时无效的问题
解决在设置字段以获取属性值时流程图区域将被隐藏的问题-在用户定义的配置中选择属性值
解决首次进入自定义配置时,向导提示后台出现用户调查界面的问题
网页数据抓取软件(2016年着手大数据不妨重点考虑以下几点:重点覆盖,定能有所)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-16 05:07
中国IDC圈1月15日报道:回顾2015年,整体大数据市场发展迅速,政府的支持前所未有。将大数据正式纳入国家政策也为社会各部门提供了许多机会和便利。放眼国际市场,大数据应用的规模不断扩大,几乎所有人都关注“数据”背后的巨大价值。未来5-10年将是中国推进大数据发展的关键节点。迫切需要构建高效的大数据应用机制和产业链。随着2016年的到来,大数据行业将迎来新一轮的竞争和挑战
根据对2015年大数据产业发展的分析,2016年启动大数据时,宜重点关注以下几点:
1、visual data capture:大数据的普及是工业应用的前提。所谓普及就是捕捉技术的普及。作为互联网这一最大的数据载体,网页数据捕获技术的普及可以通过网页捕获工具的普及来实现。著名网络爬虫优采云采集器V9它极大地发挥了它的便利性。通过设置简单的规则,软件可以自动采集数据。无论是定义操作过程还是查看采集结果,都可以通过优采云采集器V9一个用于过程可视化的软件工具比以前编写复杂程序采集更方便,前者可以带来高效便捷,和平民主化是不言而喻的
2、key areas大数据覆盖范围:大数据应用范围广泛,各行各业都在尝试启动深层金矿开采。然而,近年来,大数据的真正影响是在城市建设、金融和互联网企业、电子商务和医疗卫生等领域。据CCF大数据专家组预测,2016年城市、互联网交易、企业三部分数据将取得突破性进展,这些数据将通过上述网页捕获工具优采云捕获采集器V9可以轻松实现城市舆情监控,竞争产品数据信息捕获、企业信用数据收录等。如果我们能够确定趋势,看看先例,关注覆盖范围,我们将从中受益
3、大数据整合:大数据将导致多学科整合。不仅计算机领域的科学家,数学、生物、心理学等领域的科学家也将参与大数据的前沿研究,但他们中的许多人可能不精通IT技术,因此获取数据的效率非常低。为了促进数据交换和交换,改善大数据资源的共享,网页捕获工具优采云采集器V9在提高易用性的基础上,充分实现了整个网络的通用性,99%的网页中几乎所有可以看到的网页内容都可以轻松获取。如果用户注意采用标准化的存储格式和方式,届时信息融合也将非常方便
备受瞩目的大数据行业渴望展示其雄心壮志。大数据应用不再只是高喊口号。预计到2016年,中国大数据市场规模将达到238亿美元。激活中国大数据资产价值、开启新产业、新生态的目标,还需要社会各界的共同努力 查看全部
网页数据抓取软件(2016年着手大数据不妨重点考虑以下几点:重点覆盖,定能有所)
中国IDC圈1月15日报道:回顾2015年,整体大数据市场发展迅速,政府的支持前所未有。将大数据正式纳入国家政策也为社会各部门提供了许多机会和便利。放眼国际市场,大数据应用的规模不断扩大,几乎所有人都关注“数据”背后的巨大价值。未来5-10年将是中国推进大数据发展的关键节点。迫切需要构建高效的大数据应用机制和产业链。随着2016年的到来,大数据行业将迎来新一轮的竞争和挑战
根据对2015年大数据产业发展的分析,2016年启动大数据时,宜重点关注以下几点:
1、visual data capture:大数据的普及是工业应用的前提。所谓普及就是捕捉技术的普及。作为互联网这一最大的数据载体,网页数据捕获技术的普及可以通过网页捕获工具的普及来实现。著名网络爬虫优采云采集器V9它极大地发挥了它的便利性。通过设置简单的规则,软件可以自动采集数据。无论是定义操作过程还是查看采集结果,都可以通过优采云采集器V9一个用于过程可视化的软件工具比以前编写复杂程序采集更方便,前者可以带来高效便捷,和平民主化是不言而喻的
2、key areas大数据覆盖范围:大数据应用范围广泛,各行各业都在尝试启动深层金矿开采。然而,近年来,大数据的真正影响是在城市建设、金融和互联网企业、电子商务和医疗卫生等领域。据CCF大数据专家组预测,2016年城市、互联网交易、企业三部分数据将取得突破性进展,这些数据将通过上述网页捕获工具优采云捕获采集器V9可以轻松实现城市舆情监控,竞争产品数据信息捕获、企业信用数据收录等。如果我们能够确定趋势,看看先例,关注覆盖范围,我们将从中受益
3、大数据整合:大数据将导致多学科整合。不仅计算机领域的科学家,数学、生物、心理学等领域的科学家也将参与大数据的前沿研究,但他们中的许多人可能不精通IT技术,因此获取数据的效率非常低。为了促进数据交换和交换,改善大数据资源的共享,网页捕获工具优采云采集器V9在提高易用性的基础上,充分实现了整个网络的通用性,99%的网页中几乎所有可以看到的网页内容都可以轻松获取。如果用户注意采用标准化的存储格式和方式,届时信息融合也将非常方便
备受瞩目的大数据行业渴望展示其雄心壮志。大数据应用不再只是高喊口号。预计到2016年,中国大数据市场规模将达到238亿美元。激活中国大数据资产价值、开启新产业、新生态的目标,还需要社会各界的共同努力
网页数据抓取软件(以京东为例,演示数据抓取工具的使用方法: )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-16 05:05
)
以京东为例,演示如何使用数据捕获工具:
单击uibot编辑器工具栏上的[data capture]按钮打开数据捕获工具:
数据捕获工具需要首先选择一个目标,然后单击选择目标按钮:
此目标是采集的数据字段。如果需要采集商品名称,请首先选择商品名称:
如果要采集商品价格,首先选择商品价格元素、采集其他字段等,如评估数量:
点击选择目标后,进入第二步,然后选择同类目标。Uibot将自动分析目标之间的关系,并进一步推断页面中的所有相关元素:
目标选择完成后,如果两个目标类型一致且存在关联关系,则进入本页面,可以选择采集内容是文本还是链接;我这里的采集数据是商品价格,所以只能选择文本。单击“确定”进入下一步:
成功捕获数据后,将显示捕获的数据列。单击捕获更多数据按钮并重复前面的步骤。您可以添加多个数据捕获列,例如产品名称、评估和其他数据。您可以单击打开的数据或捕获链接:
数据捕获完成后,点击下一步按钮进入捕获页面翻页,可以一次捕获多页数据:
单击捕获翻页按钮并选择数据页面上的[下一页]按钮,以在数据捕获期间自动翻页以捕获数据:
翻页和爬网完成后,批量爬网数据的组件将自动添加到编辑器中:
组件属性设置的屏幕截图如上图所示。目标是要捕获的数据来自哪个元素。元数据定义是要捕获的数据特征和相应的字段名设置。翻页元素对应于翻页按钮的元素选择特征。您可以在此处设置要提取的页数。默认设置为5,即取5页数据后退出:
查看全部
网页数据抓取软件(以京东为例,演示数据抓取工具的使用方法:
)
以京东为例,演示如何使用数据捕获工具:
单击uibot编辑器工具栏上的[data capture]按钮打开数据捕获工具:
数据捕获工具需要首先选择一个目标,然后单击选择目标按钮:
此目标是采集的数据字段。如果需要采集商品名称,请首先选择商品名称:
如果要采集商品价格,首先选择商品价格元素、采集其他字段等,如评估数量:
点击选择目标后,进入第二步,然后选择同类目标。Uibot将自动分析目标之间的关系,并进一步推断页面中的所有相关元素:
目标选择完成后,如果两个目标类型一致且存在关联关系,则进入本页面,可以选择采集内容是文本还是链接;我这里的采集数据是商品价格,所以只能选择文本。单击“确定”进入下一步:
成功捕获数据后,将显示捕获的数据列。单击捕获更多数据按钮并重复前面的步骤。您可以添加多个数据捕获列,例如产品名称、评估和其他数据。您可以单击打开的数据或捕获链接:
数据捕获完成后,点击下一步按钮进入捕获页面翻页,可以一次捕获多页数据:
单击捕获翻页按钮并选择数据页面上的[下一页]按钮,以在数据捕获期间自动翻页以捕获数据:
翻页和爬网完成后,批量爬网数据的组件将自动添加到编辑器中:
组件属性设置的屏幕截图如上图所示。目标是要捕获的数据来自哪个元素。元数据定义是要捕获的数据特征和相应的字段名设置。翻页元素对应于翻页按钮的元素选择特征。您可以在此处设置要提取的页数。默认设置为5,即取5页数据后退出:
网页数据抓取软件(初识webscraper开发人员安装方式(图):请输入图片描述本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-09-13 13:12
Web Scraper 是一款面向普通用户(无需专业 IT 技术)的免费爬虫工具,通过鼠标和简单的配置,您可以轻松获取您想要的数据。例如知乎答案列表、微博热点、微博评论、电商网站产品信息、博客文章list等
安装过程
在线安装方法
在线安装需要 FQ 网络和 Chrome App Store 访问权限
1、 在线访问 Web Scraper 插件并点击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的框中点击“添加扩展”
请输入图片描述
3、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
请输入图片描述
本地安装方式
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,将下载的扩展Web-Scraper_v0.3.7.crx拖到这个页面,点击“添加到扩展”以完成安装。如图:
请输入图片描述
2、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
${{2}}$
请输入图片描述
第一次接触网络爬虫
打开网页爬虫
开发者可以路过看看后面
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具
请输入图片描述
打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。
请输入图片说明
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
请输入图片说明
原理及功能说明
数据爬取的思路大致可以概括如下:
1、通过一个或多个入口地址获取初始数据。比如文章列表页面,或者有一定规则的页面,比如带分页的列表页面;
2、根据入口页面的一些信息,比如链接点,进入下一页获取必要的信息;
3、根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper标签,看到分为三部分:
请输入图片描述
新建站点地图:首先了解站点地图,字面意思是网站Map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你想得到一个问题在知乎上回答,创建一个站点地图,并将这个问题的地址设置为站点地图的起始地址,然后点击“创建站点地图”来创建站点地图。
请输入图片说明
站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。
请输入图片描述
站点地图:进入某个站点地图,可以进行一系列的操作,如下图:
请输入图片描述
在红框中添加新的选择器是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
我需要解释一下。一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题,也可以对应整个区域。该区域可能收录标题、副标题和作者信息、内容等。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,根节点是什么,几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取。
Export data as CSV:以CSV格式导出捕获的数据。
至此,有一个简单的了解就足够了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践
简单试水hao123
从简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
需求背景:见下hao123页面红框部分。我们的要求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然实际需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们已经打开了hao123页面,在这个页面底部打开了开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;
请输入图片描述
3、后输入sitemap名称和start url,名称只是为了我们标记,所以命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;
请输入图片描述
4、Web Scraper 自动定位到这个站点地图后,接下来我们添加一个选择器,点击“添加新的选择器”;
请输入图片描述
5、 首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;
请输入图片描述
6、然后点击select,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选中的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中之后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后别忘了勾选Multiple,即采集多条数据;
请输入图片描述
7、 最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。后面的文本框里面的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标直接手写xpath;
完整的操作流程如下:
请输入图片描述
8、完成上一步后,就可以实际导出了。别着急,看看其他操作。 Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建一个sitemap会自动有一个_root节点,可以看到它的子选择器,也就是我们创建的Hot selector;
请输入图片描述
9、Scrape,开始抓取数据。
在10、Sitemap hao123下浏览,可以直接通过浏览器查看爬取的最终结果,需要重新;
请输入图片描述
11、最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;
请输入图片描述
怎么样,现在试试
软件定制| 网站construction |获得更多干货 查看全部
网页数据抓取软件(初识webscraper开发人员安装方式(图):请输入图片描述本地)
Web Scraper 是一款面向普通用户(无需专业 IT 技术)的免费爬虫工具,通过鼠标和简单的配置,您可以轻松获取您想要的数据。例如知乎答案列表、微博热点、微博评论、电商网站产品信息、博客文章list等
安装过程
在线安装方法
在线安装需要 FQ 网络和 Chrome App Store 访问权限
1、 在线访问 Web Scraper 插件并点击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的框中点击“添加扩展”
请输入图片描述
3、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
请输入图片描述
本地安装方式
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,将下载的扩展Web-Scraper_v0.3.7.crx拖到这个页面,点击“添加到扩展”以完成安装。如图:
请输入图片描述
2、 安装完成后,顶部工具栏会显示 Web Scraper 图标。
${{2}}$
请输入图片描述
第一次接触网络爬虫
打开网页爬虫
开发者可以路过看看后面
windows系统下可以使用快捷键F12,部分笔记本机型需要按Fn+F12;
Mac系统下可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置—>更多工具—>开发者工具
请输入图片描述
打开后的效果如下,绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,是我们后面要操作的部分。
请输入图片说明
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
请输入图片说明
原理及功能说明
数据爬取的思路大致可以概括如下:
1、通过一个或多个入口地址获取初始数据。比如文章列表页面,或者有一定规则的页面,比如带分页的列表页面;
2、根据入口页面的一些信息,比如链接点,进入下一页获取必要的信息;
3、根据上一层的链接继续下一层,获取必要的信息(这一步可以无限循环);
原理大致相同。接下来,让我们正式认识一下Web Scraper工具。来吧,打开开发者工具,点击Web Scraper标签,看到分为三部分:
请输入图片描述
新建站点地图:首先了解站点地图,字面意思是网站Map,这里可以理解为入口地址,可以理解为对应一个网站,对应一个需求,假设你想得到一个问题在知乎上回答,创建一个站点地图,并将这个问题的地址设置为站点地图的起始地址,然后点击“创建站点地图”来创建站点地图。
请输入图片说明
站点地图:站点地图的集合。所有创建的站点地图都会显示在这里,可以在此处输入站点地图进行修改、数据抓取等操作。
请输入图片描述
站点地图:进入某个站点地图,可以进行一系列的操作,如下图:
请输入图片描述
在红框中添加新的选择器是必不可少的一步。什么是选择器,字面意思是:选择器,一个选择器对应网页的一部分,也就是收录我们要采集的数据的部分。
我需要解释一下。一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题,也可以对应整个区域。该区域可能收录标题、副标题和作者信息、内容等。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑结构图,根节点是什么,几个选择器,选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
Scrape:开始数据抓取。
Export data as CSV:以CSV格式导出捕获的数据。
至此,有一个简单的了解就足够了。真知灼见,具体操作案例令人信服。下面举几个例子来说明具体的用法。
案例实践
简单试水hao123
从简单到深入,我们以一个简单的例子作为入口,作为对Web Scraper服务的进一步了解
需求背景:见下hao123页面红框部分。我们的要求是统计这部分区域的所有网站名称和链接地址,最后在Excel中生成。因为这部分内容已经足够简单了,当然实际需求可能比这更复杂,而且人工统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们已经打开了hao123页面,在这个页面底部打开了开发者工具,并找到了Web Scraper标签栏;
2、点击“创建站点地图”;
请输入图片描述
3、后输入sitemap名称和start url,名称只是为了我们标记,所以命名为hao123(注意不支持中文),start url为hao123的url,然后点击create sitemap;
请输入图片描述
4、Web Scraper 自动定位到这个站点地图后,接下来我们添加一个选择器,点击“添加新的选择器”;
请输入图片描述
5、 首先给这个选择器分配一个id,它只是一个容易识别的名字。我把它命名为热这里。因为要获取名称和链接,所以将类型设置为链接。这种类型是专门为网页链接准备的。选择Link type后,会自动提取name和link这两个属性;
请输入图片描述
6、然后点击select,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,表示这是我们当前选中的区域。我们将光标定位在需求中提到的那一栏的某个链接上,比如第一条头条新闻,点击这里,这部分会变成红色,表示已经被选中,我们的目的是选中有多个,所以选中之后这个,继续选择第二个,我们会发现这一行的链接都变红了,没错,这就是我们想要的效果。然后点击“完成选择!” (数据预览是被选中元素的标识符,可以手动修改。元素由类和元素名称决定,如:div.p_name a)。最后别忘了勾选Multiple,即采集多条数据;
请输入图片描述
7、 最后保存,保存选择器。单击元素预览可预览所选区域,单击数据预览可在浏览器中预览捕获的数据。后面的文本框里面的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标直接手写xpath;
完整的操作流程如下:
请输入图片描述
8、完成上一步后,就可以实际导出了。别着急,看看其他操作。 Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建一个sitemap会自动有一个_root节点,可以看到它的子选择器,也就是我们创建的Hot selector;
请输入图片描述
9、Scrape,开始抓取数据。
在10、Sitemap hao123下浏览,可以直接通过浏览器查看爬取的最终结果,需要重新;
请输入图片描述
11、最后使用Export data as CSV导出为CSV格式,其中hot列为标题,hot-href列为链接;
请输入图片描述
怎么样,现在试试
软件定制| 网站construction |获得更多干货
网页数据抓取软件(网页数据来源之一函数(一)_星光_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-09-13 13:10
随着互联网的飞速发展,网络数据日益成为数据分析过程中最重要的数据来源之一。
或许正是基于这样的考虑。从 2013 版本开始,Excel 增加了一个名为 Web 的新函数类别。使用其下的功能,您可以通过网页链接从Web服务器获取数据,例如股票信息和天气查询。 、有道翻译等
给我一点栗子。
输入以下公式将A2单元格的值从英文翻译成中文或从中文翻译成英文。
=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"//translation")
公式看起来很长。这主要是因为 URL 长度太长。其实公式的结构很简单。
主要由三部分组成。
第 1 部分构建 URL。
";i="&A2&"&doctype=xml"
这是有道在线翻译的网页地址,包括关键参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml,只有xml返回是因为 FILTERXML 函数可以获取 XML 结构化内容中的信息。
第 2 部分读取 URL。
WEBSERVICE 通过指定的网址从网络服务器获取数据(需要电脑连接互联网)。
在这个例子中,B2 公式
=WEBSERVICE(";i="&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第 3 部分获取目标数据。
此处使用了 FILTERXML 函数。 FILTERXML 函数的语法是:
FILTERXML(xml,xpath)
有两个参数,xml参数是有效的xml格式文本,xpath参数是xml中要查询的目标数据的标准路径。
通过第二部分得到的xml文件的内容,我们可以直接看到幸福翻译结果幸福在翻译路径下(粉红色部分),所以第二个参数设置为“//translation ”。
好的,这就是星光今天和大家分享的内容。有兴趣的朋友可以尝试使用网页功能从百度天气中获取自己家乡城市的天气信息~ 查看全部
网页数据抓取软件(网页数据来源之一函数(一)_星光_光明网(组图))
随着互联网的飞速发展,网络数据日益成为数据分析过程中最重要的数据来源之一。
或许正是基于这样的考虑。从 2013 版本开始,Excel 增加了一个名为 Web 的新函数类别。使用其下的功能,您可以通过网页链接从Web服务器获取数据,例如股票信息和天气查询。 、有道翻译等
给我一点栗子。
输入以下公式将A2单元格的值从英文翻译成中文或从中文翻译成英文。
=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"//translation")
公式看起来很长。这主要是因为 URL 长度太长。其实公式的结构很简单。
主要由三部分组成。
第 1 部分构建 URL。
";i="&A2&"&doctype=xml"
这是有道在线翻译的网页地址,包括关键参数部分,i="&A2是需要翻译的词汇,doctype=xml是返回文件的类型,是xml,只有xml返回是因为 FILTERXML 函数可以获取 XML 结构化内容中的信息。
第 2 部分读取 URL。
WEBSERVICE 通过指定的网址从网络服务器获取数据(需要电脑连接互联网)。
在这个例子中,B2 公式
=WEBSERVICE(";i="&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第 3 部分获取目标数据。
此处使用了 FILTERXML 函数。 FILTERXML 函数的语法是:
FILTERXML(xml,xpath)
有两个参数,xml参数是有效的xml格式文本,xpath参数是xml中要查询的目标数据的标准路径。
通过第二部分得到的xml文件的内容,我们可以直接看到幸福翻译结果幸福在翻译路径下(粉红色部分),所以第二个参数设置为“//translation ”。
好的,这就是星光今天和大家分享的内容。有兴趣的朋友可以尝试使用网页功能从百度天气中获取自己家乡城市的天气信息~
网页数据抓取软件(P.S.@AJAX数据库实例讲解(有时))
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-09-13 13:10
故事的缘由
我以前有个小网站,在上面发表了几篇关于使用SAS抓取网络数据的短文,然后在人大论坛上挂了一个链接。后来因为懒惰,这个网站被挂了,人们纷纷询问。更新此博客后播放
添加了一个简单易懂的,其他翻译已由@statnet收录发布,文章会在最后链接。
适用性
这种情况下的以下理论可以通过相同的方式访问。
附言@AJAX 数据库实例|| @AJAX 数据库实例说明
文字前戏
有时我们经常需要保存和备份某些在线数据,例如银行利率、股票报价,或者来自统计局、各种金融机构的数据,或者其他类型的网站。有时这些网站 会提供历史数据,有些则不会。但是我们可以使用SAS每天运行程序,获取累积的历史数据,供以后分析。下面以获取首页上海银行同业拆借利率为例进行说明。
以下是我们想要的首页数据
当我们打开这个网页并输入网页的源代码时,我们会惊讶地发现。什么情况下,首页看到的数据在源码中是查不到的。是否可以使用其他技术?来看看源码代表什么
网页布局。
按照网页布局,最新的Shibor数据的源代码应该放在大量文字后,他放一句话。
这是html的内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入首页。 OK,那我们就打开这个页面
查看源代码,发现这个网页中存在数据,那么我们就开始用SAS抓取它。
高潮
首先引入Filename,并用它添加infile语句将网页作为文件导入SAS数据集。 BaseSAS 中的 FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。该语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入到 SAS 数据集中。我们知道网页数据是一种标记语言,它遵循一定的规范,包括所有的属性设置。所以我们用 dlm=">" 来分隔,导入到一个变量中。因为数据太乱,无法区分导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们用dlm=">"来分隔,所以我们知道采集到的观测值只需要用
分隔 查看全部
网页数据抓取软件(P.S.@AJAX数据库实例讲解(有时))
故事的缘由
我以前有个小网站,在上面发表了几篇关于使用SAS抓取网络数据的短文,然后在人大论坛上挂了一个链接。后来因为懒惰,这个网站被挂了,人们纷纷询问。更新此博客后播放
添加了一个简单易懂的,其他翻译已由@statnet收录发布,文章会在最后链接。
适用性
这种情况下的以下理论可以通过相同的方式访问。
附言@AJAX 数据库实例|| @AJAX 数据库实例说明
文字前戏
有时我们经常需要保存和备份某些在线数据,例如银行利率、股票报价,或者来自统计局、各种金融机构的数据,或者其他类型的网站。有时这些网站 会提供历史数据,有些则不会。但是我们可以使用SAS每天运行程序,获取累积的历史数据,供以后分析。下面以获取首页上海银行同业拆借利率为例进行说明。
以下是我们想要的首页数据
当我们打开这个网页并输入网页的源代码时,我们会惊讶地发现。什么情况下,首页看到的数据在源码中是查不到的。是否可以使用其他技术?来看看源码代表什么
网页布局。
按照网页布局,最新的Shibor数据的源代码应该放在大量文字后,他放一句话。
这是html的内联框架结构,意思是他把数据放到另一个网页上,然后把这个网页嵌入首页。 OK,那我们就打开这个页面
查看源代码,发现这个网页中存在数据,那么我们就开始用SAS抓取它。
高潮
首先引入Filename,并用它添加infile语句将网页作为文件导入SAS数据集。 BaseSAS 中的 FILENAME 语句(URL 访问方法)使用户能够从网站访问源代码并将其读入数据集。该语句的语法是:
FILENAME fileref URL 'external-file';
将 Shibor 数据网页导入到 SAS 数据集中。我们知道网页数据是一种标记语言,它遵循一定的规范,包括所有的属性设置。所以我们用 dlm=">" 来分隔,导入到一个变量中。因为数据太乱,无法区分导入到不同的变量中。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;
DATA Zhaocl01;
FORMAT WEBPAGE $1000.;
INFILE SOURCE LRECL=32767 DELIMITER=">";
INPUT WEBPAGE $ @@;
RUN;
因为我们用dlm=">"来分隔,所以我们知道采集到的观测值只需要用
分隔
网页数据抓取软件(没过第一篇的基本语法及简单的爬虫技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-09-11 00:12
这是很久以前反弹的文章。我很幸运今天能够弥补。也是因为最近才开始想明白一些事情。如果你还没有通过第一篇文章,你可以点击下面的链接来看看。本文假设大家已经掌握了python的基本语法和简单的爬虫技术。
这次我们来讲解一个豆瓣爬虫,包括验证码验证和登录后简单的数据爬取。
好的,废话不多说,给我看代码
首先我们需要了解一个背景知识,登录网站,其实就是向服务器提交一些数据,包括:用户名密码,验证码,以及其他你看不到的数据。这部分你看不到的数据随着网站而变化,但是基本套路都会收录一个类似id的数据,而且每次提交的值都不一样,提交是前端无法执行的看看吧。
第一步,我们在chrome上查看登录页面,观察前面提到的一些值需要提交。
这里有一个小技巧。如果不使用fidler或charles等抓包工具直接登录,是看不到需要提交的数据的。因此,笔者估计是输入了错误的验证码进行验证。通过查看元素的登录,可以看到需要提交的数据。
如上图,可以找到其他隐藏提交信息,其中:captcha-solution为验证码,captcha-id为隐藏id值。
第二步是找到隐藏的id和验证码提交。
解决验证码提交问题。主流方法有两种。一种是手动输入,适合低复杂度、低并发的新手爬虫。这就是我们介绍的;另一种是利用ocr图像识别技术,以一定的准确率训练数据。判断,这种方法比较重,不适合初学者。有兴趣的小朋友可以自行尝试。
手动输入,首先我们要看到验证码,然后输入。采用的方法是将验证码图片下载到本地,使用时到对应路径打开图片输入,然后提交登录表单。
通过观察可以发现验证码图片是存放在这个路径下的,所以解析页面找到这个路径后,就可以下载图片了。
获取隐藏id比较简单。在源码下找到对应的id,然后动态赋值给提交表单。
#coding=utf-8
#输入中文没有上面一行会报错,注意
导入请求
从 lxml 导入 html
导入操作系统
重新导入
导入 urllib.request
login_url =""
s = requests.session()
r = s.get(login_url)
tree = html.fromstring(r.text)
el = tree.xpath('//input[@name="captcha-id"]')[0]
captcha_id = el.attrib['value']
#获取隐藏id
el2 = tree.xpath('//img[@id="captcha_image"]')[0]
captcha_image_url = el2.attrib['src']
imgPath = r'E:\img'
res=urllib.request.urlopen(captcha_image_url)
filename=os.path.join(imgPath,"1"+'.jpg')
with open(filename,'wb') as f:
f.write(res.read())
#保存验证码图片
captcha_solution= input('请输入验证码:')
第三步是提交表单。
形式与第一步观察到的值一致。
运行结果如下:
好的,到这里爬虫就完成了。对于下一篇的内容,其实很多人已经发现api数据获取是一种更加方便和稳定的方式。通过页面爬取的方法,页面的结构会发生变化,其次需要和对方进行反爬虫。该机制是明智而勇敢的。取而代之的是,API 的使用方式是一种便捷、高速、高雅的方式。 查看全部
网页数据抓取软件(没过第一篇的基本语法及简单的爬虫技术)
这是很久以前反弹的文章。我很幸运今天能够弥补。也是因为最近才开始想明白一些事情。如果你还没有通过第一篇文章,你可以点击下面的链接来看看。本文假设大家已经掌握了python的基本语法和简单的爬虫技术。
这次我们来讲解一个豆瓣爬虫,包括验证码验证和登录后简单的数据爬取。
好的,废话不多说,给我看代码
首先我们需要了解一个背景知识,登录网站,其实就是向服务器提交一些数据,包括:用户名密码,验证码,以及其他你看不到的数据。这部分你看不到的数据随着网站而变化,但是基本套路都会收录一个类似id的数据,而且每次提交的值都不一样,提交是前端无法执行的看看吧。
第一步,我们在chrome上查看登录页面,观察前面提到的一些值需要提交。
这里有一个小技巧。如果不使用fidler或charles等抓包工具直接登录,是看不到需要提交的数据的。因此,笔者估计是输入了错误的验证码进行验证。通过查看元素的登录,可以看到需要提交的数据。
如上图,可以找到其他隐藏提交信息,其中:captcha-solution为验证码,captcha-id为隐藏id值。
第二步是找到隐藏的id和验证码提交。
解决验证码提交问题。主流方法有两种。一种是手动输入,适合低复杂度、低并发的新手爬虫。这就是我们介绍的;另一种是利用ocr图像识别技术,以一定的准确率训练数据。判断,这种方法比较重,不适合初学者。有兴趣的小朋友可以自行尝试。
手动输入,首先我们要看到验证码,然后输入。采用的方法是将验证码图片下载到本地,使用时到对应路径打开图片输入,然后提交登录表单。
通过观察可以发现验证码图片是存放在这个路径下的,所以解析页面找到这个路径后,就可以下载图片了。
获取隐藏id比较简单。在源码下找到对应的id,然后动态赋值给提交表单。
#coding=utf-8
#输入中文没有上面一行会报错,注意
导入请求
从 lxml 导入 html
导入操作系统
重新导入
导入 urllib.request
login_url =""
s = requests.session()
r = s.get(login_url)
tree = html.fromstring(r.text)
el = tree.xpath('//input[@name="captcha-id"]')[0]
captcha_id = el.attrib['value']
#获取隐藏id
el2 = tree.xpath('//img[@id="captcha_image"]')[0]
captcha_image_url = el2.attrib['src']
imgPath = r'E:\img'
res=urllib.request.urlopen(captcha_image_url)
filename=os.path.join(imgPath,"1"+'.jpg')
with open(filename,'wb') as f:
f.write(res.read())
#保存验证码图片
captcha_solution= input('请输入验证码:')
第三步是提交表单。
形式与第一步观察到的值一致。
运行结果如下:
好的,到这里爬虫就完成了。对于下一篇的内容,其实很多人已经发现api数据获取是一种更加方便和稳定的方式。通过页面爬取的方法,页面的结构会发生变化,其次需要和对方进行反爬虫。该机制是明智而勇敢的。取而代之的是,API 的使用方式是一种便捷、高速、高雅的方式。
网页数据抓取软件(【url规范】百度支持抓取的url长度不超过1024)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-09-10 10:03
[网址规范]
百度支持抓取的网址长度不超过1024。如果您的链接长度过长,请在保证正常访问的同时适当简化,确保链接可以被百度和收录抓取正常。
[重定向错误]
重定向是指百度蜘蛛访问链接时发生的重定向。如果重定向后的链接过长或者连续重定向次数超过5次,就会出现重定向错误,爬取失败。
[服务器连接错误]
这种情况意味着百度无法访问您的网站,原因是服务器响应缓慢或您的网站屏蔽了百度蜘蛛。这将导致百度无法收录 或更新您的网站 内容。您可能会看到以下特定错误:连接超时、连接失败、连接被拒绝、无响应、响应截断、连接重置、标头截断、超时。
如何处理服务器连接错误?
减少动态页面请求的过多页面加载。如果网站为多个URL提供相同的内容,则视为动态提供内容(例如提供的内容相同)。动态网页的响应时间可能很长,这会导致超时问题。或者,服务器可能会回到过载状态,请求百度蜘蛛减慢爬取网站的速度。一般情况下,建议尽量使用短参数,谨慎使用。
确保您的网站 托管服务器没有停机、过载或配置错误。如果连接问题、超时问题或响应问题仍然存在,请联系您的网站hosting 服务提供商,并考虑增强您的网站 处理流量的能力。
检查网站是否不小心屏蔽了百度蜘蛛的IP。您可能由于系统级问题(例如 DNS 配置问题、未正确配置防火墙或 DoS 保护系统、内容管理系统配置问题)而阻止百度访问。防御系统是保证托管服务正常运行的关键因素之一,这些系统通常配置为自动防止过多的服务器请求。由于百度蜘蛛通常比普通用户发出更多的请求,这些防御系统可能会被触发,导致它们阻止百度蜘蛛访问和抓取您的网站。解决这类问题,需要确定网站基础设施的哪一部分阻塞了百度蜘蛛,然后取消阻塞。如果您无权控制防火墙,则需要联系您的托管服务提供商解决此问题。
[机器人禁令问题]
在爬虫诊断工具中,如果返回爬虫失败结论是robots被禁止,请确认是否在URL上设置robots防止百度蜘蛛抓取网站的部分内容,如果不使用robots文件屏蔽百度,请点击旁边的错误链接,百度会立即更新您网站的robots信息;如果您的操作不当导致被封禁,请及时修改robots文件,以免造成您的网站在百度收录量和流量下降。 查看全部
网页数据抓取软件(【url规范】百度支持抓取的url长度不超过1024)
[网址规范]
百度支持抓取的网址长度不超过1024。如果您的链接长度过长,请在保证正常访问的同时适当简化,确保链接可以被百度和收录抓取正常。
[重定向错误]
重定向是指百度蜘蛛访问链接时发生的重定向。如果重定向后的链接过长或者连续重定向次数超过5次,就会出现重定向错误,爬取失败。
[服务器连接错误]
这种情况意味着百度无法访问您的网站,原因是服务器响应缓慢或您的网站屏蔽了百度蜘蛛。这将导致百度无法收录 或更新您的网站 内容。您可能会看到以下特定错误:连接超时、连接失败、连接被拒绝、无响应、响应截断、连接重置、标头截断、超时。
如何处理服务器连接错误?
减少动态页面请求的过多页面加载。如果网站为多个URL提供相同的内容,则视为动态提供内容(例如提供的内容相同)。动态网页的响应时间可能很长,这会导致超时问题。或者,服务器可能会回到过载状态,请求百度蜘蛛减慢爬取网站的速度。一般情况下,建议尽量使用短参数,谨慎使用。
确保您的网站 托管服务器没有停机、过载或配置错误。如果连接问题、超时问题或响应问题仍然存在,请联系您的网站hosting 服务提供商,并考虑增强您的网站 处理流量的能力。
检查网站是否不小心屏蔽了百度蜘蛛的IP。您可能由于系统级问题(例如 DNS 配置问题、未正确配置防火墙或 DoS 保护系统、内容管理系统配置问题)而阻止百度访问。防御系统是保证托管服务正常运行的关键因素之一,这些系统通常配置为自动防止过多的服务器请求。由于百度蜘蛛通常比普通用户发出更多的请求,这些防御系统可能会被触发,导致它们阻止百度蜘蛛访问和抓取您的网站。解决这类问题,需要确定网站基础设施的哪一部分阻塞了百度蜘蛛,然后取消阻塞。如果您无权控制防火墙,则需要联系您的托管服务提供商解决此问题。
[机器人禁令问题]
在爬虫诊断工具中,如果返回爬虫失败结论是robots被禁止,请确认是否在URL上设置robots防止百度蜘蛛抓取网站的部分内容,如果不使用robots文件屏蔽百度,请点击旁边的错误链接,百度会立即更新您网站的robots信息;如果您的操作不当导致被封禁,请及时修改robots文件,以免造成您的网站在百度收录量和流量下降。
网页数据抓取软件(闲人日记:如何获取交叉熵函数的开发者工具?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 215 次浏览 • 2021-09-09 03:11
)
懒人日记
时间:2021 年 3 月 9 日
这上来明明是闲置的,还没更新!怎么说呢,不想做,总能找到很多理由。毕竟,“不想做”就是“不想做”。废话少说,进入正题。
打开网站主页进行实验。可以看到网页上有一个非常明显的表格。这个表是文章看到别人写交叉熵函数时移动的数据。接下来我们将尝试使用Python获取如下数据,并使用不同色块的类属性作为行索引。
只看一条数据。
接下来F12打开浏览器的开发者工具。我们先来看看网页的源代码。这可以帮助我们分析事后如何处理数据。但是在开始之前,笔者首先要说的是,编写爬虫没有固定的、具体的方法,必须“具体情况具体分析”!很多时候我们面对的需求是不同的,有些网站不能使用下面的方法获取数据(获取的方法会有很大的不同),这些都需要很多具体的经验,以及具体的处理问题。经验的经验。 . .
点击元素选择工具,点击目标元素,查看器跳转到目标元素的代码。见图一。
示意图一
我们来看看元素之间的“父子关系”!左边的“代”比较大,其中,在图2这个...里面是我们要获取数据的目标表的源代码,我们发现只有这个表出现了在整个网页中。 class=table table-hover 参数类的属性值,这将是脚本找到这个 table 对象的重要依据。
示意图二
为了演示方便,只列出了tbody的6个tr。
好的,我们接下来开始工作。首先,我们要先安装一些爬虫相关的库或模块。如果没有安装,可以在cmd中输入命令安装:pip install requests beautifulsoup4 pandas(requests和beautifulsoup4、pandas也安装了)。安装成功后,我们进入下一步。打开 Jupyther Notebook,这是数据科学中常用的 Python 集成开发环境。如果使用Python的IDLE工具,最好一行一行的输入命令,否则容易报错。
分别导入请求和beautifulsoup4、pandas:
对于网络请求,部分网站必须带头发送,否则无法获取。
输入response.text,你会发现所有的汉字都变成了乱码。这时候就需要转换编码了。查看输出编码:
响应文本
一般我们只需要将编码转换为utf-8即可解决中文乱码:
或输入以下代码:
处理编码问题后
可以看出还是比较乱的,和真正的源码不太一样。 “\r”表示当前位置返回到开头,“\n”表示换行,“\t”表示跳到下一个制表符位置。因此,创建一个 bs4.BeautifulSoup 类型的对象:
将文本转换为源代码
BeautifulSoup 模块使响应文本更加规则。
找到变量soup中第一个属性类为“table table-hover”且标签为table的代码块:
...代码块
获取tbody中所有tr标签的代码块:
全部在 tbody...
代码块列表
处理成需求数据的结构(警告!下面有很多图帮你解读代码):
列
列
因为 attrs['class'] 返回一个列表
提取list对象中的字符串(否则tbody_id不能作为索引)
主题数据
将列表数据转换为pandas DataFrame类型数据
数据表
请根据自己的需要设计。这几乎是结束了。如果要将数据表导出为Excel表格,只需要使用pandas的to_excel()函数即可。
背后的故事
18年,作者和数学建模的小伙伴遇到一个课题,需要采集大量足球彩票网站数据进行数据分析。那时我们用的是matlab,对互联网技术或编程了解不多。水平也有待提高。所以我用了最慢的方法,一页一页地采集页面。可以说是慢到让人吐血。那是我第一次通宵工作。如果你现在看,你有更多的选择。
后记
作者在百度经验中遇到很多墙,文章一直发不上来,一直被告知踩到了“雷区”进行修改。几个小时后,更改无法通过,这令人费解。最后不得不放弃。之前微信公众号上发的内容没人看,虽然只是比较基础的内容,自然会和别人的代码有很多相似之处。但无论如何,我在我的网站上爬取数据,而网站只用于各种实验。
今天突然发现b站的专栏增加了一些作者和其他朋友之前一直在说的功能,有点惊喜!我爱小破站(poyin)。
查看全部
网页数据抓取软件(闲人日记:如何获取交叉熵函数的开发者工具?(上)
)
懒人日记
时间:2021 年 3 月 9 日
这上来明明是闲置的,还没更新!怎么说呢,不想做,总能找到很多理由。毕竟,“不想做”就是“不想做”。废话少说,进入正题。
打开网站主页进行实验。可以看到网页上有一个非常明显的表格。这个表是文章看到别人写交叉熵函数时移动的数据。接下来我们将尝试使用Python获取如下数据,并使用不同色块的类属性作为行索引。
只看一条数据。
接下来F12打开浏览器的开发者工具。我们先来看看网页的源代码。这可以帮助我们分析事后如何处理数据。但是在开始之前,笔者首先要说的是,编写爬虫没有固定的、具体的方法,必须“具体情况具体分析”!很多时候我们面对的需求是不同的,有些网站不能使用下面的方法获取数据(获取的方法会有很大的不同),这些都需要很多具体的经验,以及具体的处理问题。经验的经验。 . .
点击元素选择工具,点击目标元素,查看器跳转到目标元素的代码。见图一。
示意图一
我们来看看元素之间的“父子关系”!左边的“代”比较大,其中,在图2这个...里面是我们要获取数据的目标表的源代码,我们发现只有这个表出现了在整个网页中。 class=table table-hover 参数类的属性值,这将是脚本找到这个 table 对象的重要依据。
示意图二
为了演示方便,只列出了tbody的6个tr。
好的,我们接下来开始工作。首先,我们要先安装一些爬虫相关的库或模块。如果没有安装,可以在cmd中输入命令安装:pip install requests beautifulsoup4 pandas(requests和beautifulsoup4、pandas也安装了)。安装成功后,我们进入下一步。打开 Jupyther Notebook,这是数据科学中常用的 Python 集成开发环境。如果使用Python的IDLE工具,最好一行一行的输入命令,否则容易报错。
分别导入请求和beautifulsoup4、pandas:
对于网络请求,部分网站必须带头发送,否则无法获取。
输入response.text,你会发现所有的汉字都变成了乱码。这时候就需要转换编码了。查看输出编码:
响应文本
一般我们只需要将编码转换为utf-8即可解决中文乱码:
或输入以下代码:
处理编码问题后
可以看出还是比较乱的,和真正的源码不太一样。 “\r”表示当前位置返回到开头,“\n”表示换行,“\t”表示跳到下一个制表符位置。因此,创建一个 bs4.BeautifulSoup 类型的对象:
将文本转换为源代码
BeautifulSoup 模块使响应文本更加规则。
找到变量soup中第一个属性类为“table table-hover”且标签为table的代码块:
...代码块
获取tbody中所有tr标签的代码块:
全部在 tbody...
代码块列表
处理成需求数据的结构(警告!下面有很多图帮你解读代码):
列
列
因为 attrs['class'] 返回一个列表
提取list对象中的字符串(否则tbody_id不能作为索引)
主题数据
将列表数据转换为pandas DataFrame类型数据
数据表
请根据自己的需要设计。这几乎是结束了。如果要将数据表导出为Excel表格,只需要使用pandas的to_excel()函数即可。
背后的故事
18年,作者和数学建模的小伙伴遇到一个课题,需要采集大量足球彩票网站数据进行数据分析。那时我们用的是matlab,对互联网技术或编程了解不多。水平也有待提高。所以我用了最慢的方法,一页一页地采集页面。可以说是慢到让人吐血。那是我第一次通宵工作。如果你现在看,你有更多的选择。
后记
作者在百度经验中遇到很多墙,文章一直发不上来,一直被告知踩到了“雷区”进行修改。几个小时后,更改无法通过,这令人费解。最后不得不放弃。之前微信公众号上发的内容没人看,虽然只是比较基础的内容,自然会和别人的代码有很多相似之处。但无论如何,我在我的网站上爬取数据,而网站只用于各种实验。
今天突然发现b站的专栏增加了一些作者和其他朋友之前一直在说的功能,有点惊喜!我爱小破站(poyin)。

