【干货】一个小项目的运用及解析日志日志
优采云 发布时间: 2021-08-27 19:14【干货】一个小项目的运用及解析日志日志
不知不觉中,我已经上课三个星期了,还写了几个小项目。这里有一个有趣的爬虫项目:搜狗输入法词库爬虫,和你聊聊公司这里是如何写项目指南
本次抓取的内容为:搜狗所有词库
地址:/dict/cate/index/167
这次有点复杂,需要一些前置知识:
项目文件整理:
PS:这里的代码是我自己重构的,
应该使用内部框架捕获公司中的代码。所以我不能分享它
告诉我:我们公司还在用Python2.7,编码问题要死我了! !
我猜是因为2.7的print可以省一对括号,这样就永远不会升级了~
看项目结构:
├── configs.py # 数据库的配置文件
├── jiebao.py # 搜狗的词库是加密的,用来解密词库用的
├── spider
│ ├── log_SougouDownloader.log.20171118 # 词库下载日志
│ ├── log_SougouSpider.log.20171118 # 抓取日志
│ └── spider.py # 爬虫文件
├── store_new
│ ├── __init__.py
│ └── stroe.py # 数据库操作的封装
└── utils
└── tools.py # 日志模块
整体画面比较清晰
我将源文件放在 GitHub 中:
/Ehco1996/Python-crawler/tree/master/搜狗
爬虫逻辑和数据库表设计
看门户的网页结构:
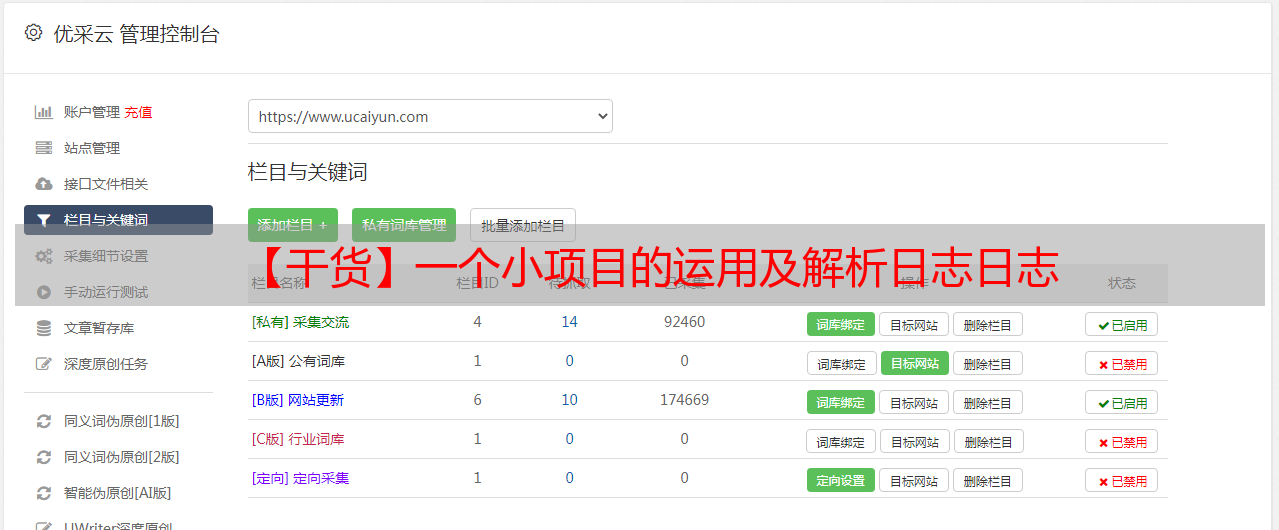
我们需要解决:
由于数据量大
大约有 10,000 个同义词库文件可供下载
大约有1亿关键词需要解决
无法将所有逻辑耦合在一起
这里我创建了三个数据库表:
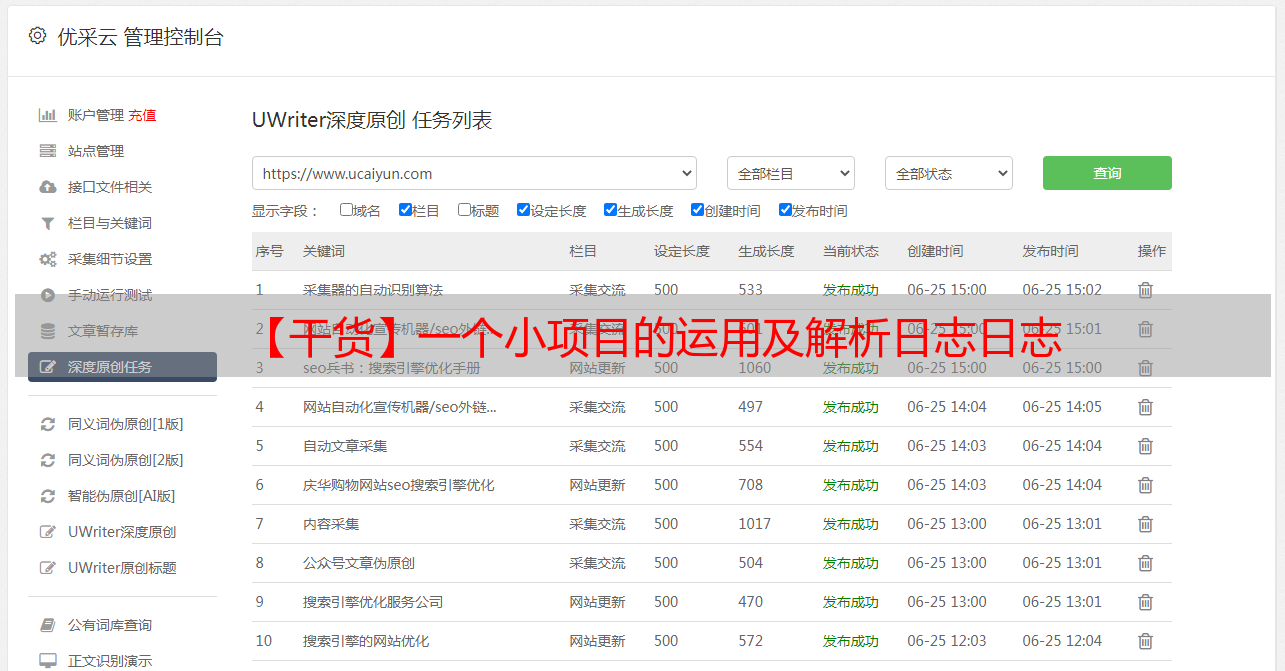
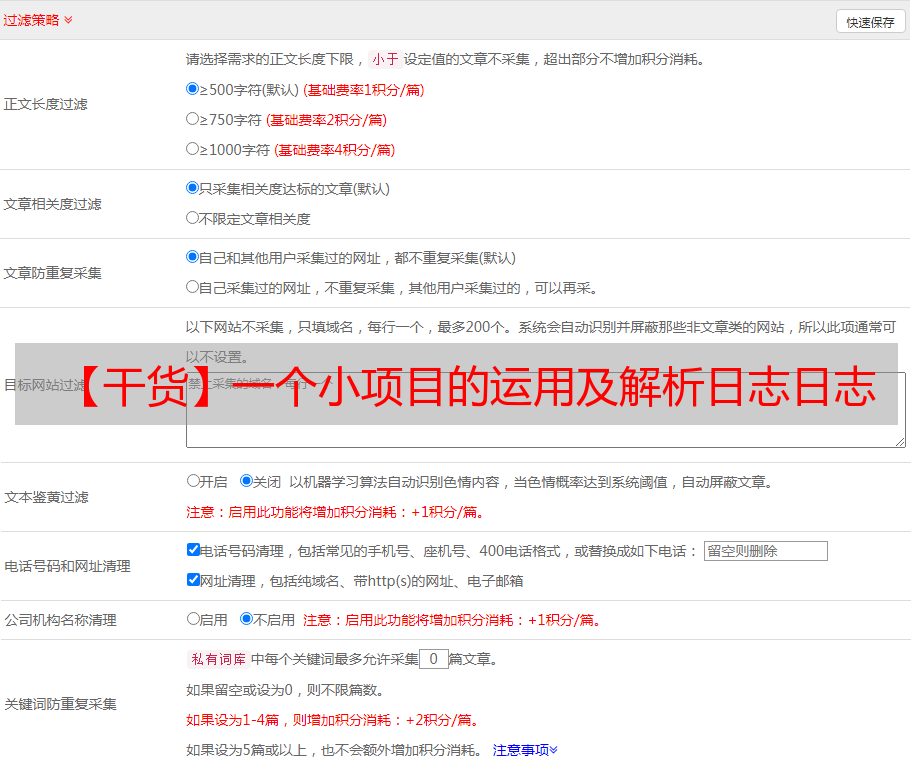
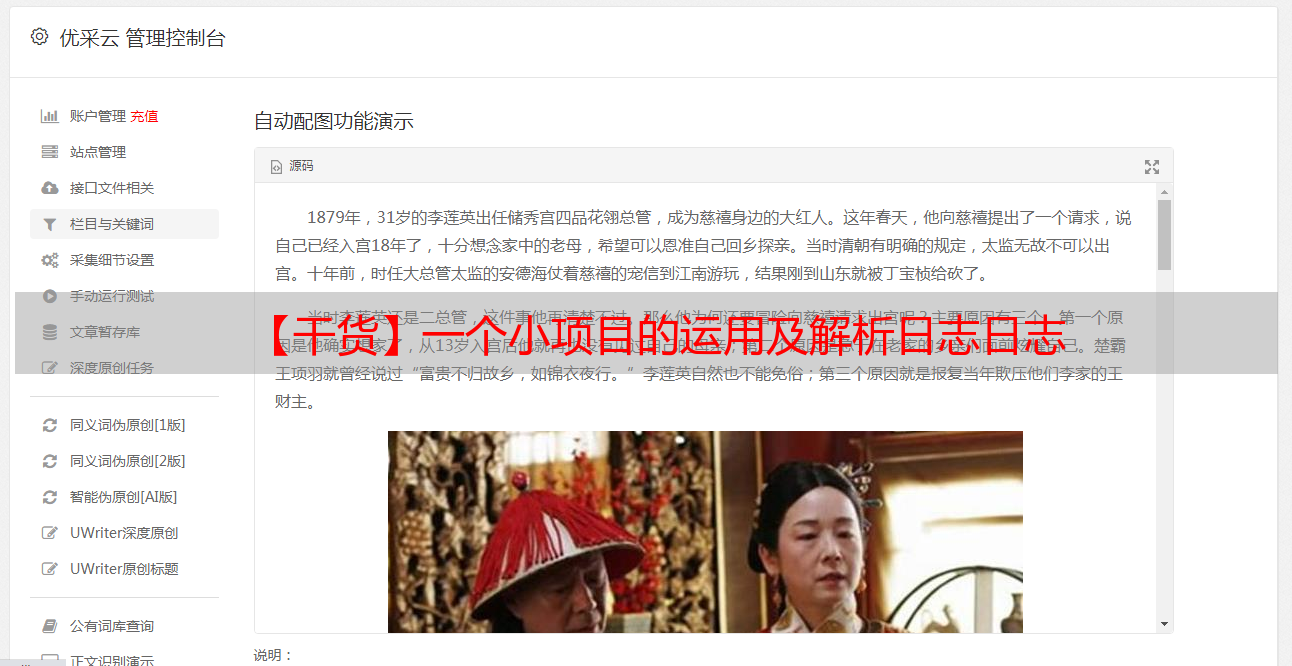
所以总体逻辑是这样的:
代码部分
一、二级cate页面分析
def cate_ext(self, html, type1):
'''
解析列表页的所有分类名
Args:
html 文本
type1 一级目录名
'''
res = []
soup = BeautifulSoup(html, 'lxml')
cate_list = soup.find('div', {'id': 'dict_cate_show'})
lis = cate_list.find_all('a')
for li in lis:
type2 = li.text.replace('"', '')
url = 'http://pinyin.sogou.com' + li['href'] + '/default/{}'
res.append({
'url': url,
'type1': type1,
'type2': type2,
})
return res
这里我通过解析一级分类的入口页面得到所有二级分类的地址
词库文件下载地址解析:
def list_ext(self, html, type1, type2):
'''
解析搜狗词库的列表页面
args:
html: 文本
type1 一级目录名
type2 二级目录名
retrun list
每一条数据都为字典类型
'''
res = []
try:
soup = BeautifulSoup(html, 'lxml')
# 偶数部分
divs = soup.find_all("div", class_='dict_detail_block')
for data in divs:
name = data.find('div', class_='detail_title').a.text
url = data.find('div', class_='dict_dl_btn').a['href']
res.append({'filename': type1 + '_' + type2 + '_' + name,
'type1': type1,
'type2': type2,
'url': url,
})
# 奇数部分
divs_odd = soup.find_all("div", class_='dict_detail_block odd')
for data in divs_odd:
name = data.find('div', class_='detail_title').a.text
url = data.find('div', class_='dict_dl_btn').a['href']
res.append({'filename': type1 + '_' + type2 + '_' + name,
'type1': type1,
'type2': type2,
'url': url,
})
except:
print('解析失败')
return - 1
return res
爬虫入口:
def start(self):
'''
解析搜狗词库的下载地址和分类名称
'''
# 从数据库读取二级分类的入口地址
cate_list = self.store.find_all('sougou_cate')
for cate in cate_list:
type1 = cate['type1']
type2 = cate['type2']
for i in range(1, int(cate['page']) + 1):
print('正在解析{}的第{}页'.format(type1 + type2, i))
url = cate['url'].format(i)
html = get_html_text(url)
if html != -1:
res = self.list_ext(html, type1, type2)
self.log.info('正在解析页面 {}'.format(url))
for data in res:
self.store.save_one_data('sougou_detail', data)
self.log.info('正在存储数据{}'.format(data['filename']))
time.sleep(3)
这里我从cate表中读取记录发送请求,解析出下载地址
数据库操作的包可以直接看我的store_new/store.py文件
你也可以阅读我上周写的文章:/p/30911268
词库文件下载逻辑:
def start(self):
# 从数据库检索记录
res = self.store.find_all('sougou_detail')
self.log.warn('一共有{}条词库等待下载'.format(len(res)))
for data in res:
content = self.get_html_content(data['url'])
filename = self.strip_wd(data['filename'])
# 如果下载失败,我们等三秒再重试
if content == -1:
time.sleep(3)
self.log.info('{}下载失败 正在重试'.format(filename))
content = self.get_html_content(data[1])
self.download_file(content, filename)
self.log.info('正在下载文件{}'.format(filename))
time.sleep(1)
这部分没什么难的,主要是文件读写操作
分析词库文件逻辑:
def start():
# 使用多线程解析
threads = list()
# 读文件存入queue的线程
threads.append(
Thread(target=ext_to_queue))
# 存数据库的线程
for i in range(10):
threads.append(
Thread(target=save_to_db))
for thread in threads:
thread.start()
好了,所有步骤都完成了
说说其中的一些“坑”吧。
Logging 日志模块的使用
因为爬取下载次数比较多,
没有日志是绝对不可能的,
毕竟我们不能总是在电脑前看程序输出!
其实我们写的程序基本上都是在服务器上运行的。
我总是通过查看程序的日志文件来判断运行状态。
在前面的代码中,可以看到我登录了很多地方
让我们看看日志文件是什么样的:
蜘蛛日志
下载器日志
运行状态一目了然?
如果你想知道如何实现它,你可以看到文件utils/tools.py
其实就是使用Python自带的日志模块
多线程的使用
共下载 9000 多个同义词库文件
字典关键词平均有2w个词条
那么总共需要存储1.80亿条数据
假设一秒可以存储10条数据
需要存储这么多数据:5000 多个小时
想想就很可怕。真的要这么久,黄花菜会冷的。
这里需要使用多线程来操作,
因为涉及文件读写
我们必须使用队列来帮助我们满足需求
逻辑是这样的:
首先打开一个主线程来读取/解析本地词库文件:
接下来打开10~50个线程(取决于数据库的最大连接数)来操作队列:
由于篇幅原因,我只放出从队列中取数据的代码片段
如果你想要整个逻辑,你可以阅读jiebao.py
def save_to_db():
'''
从数据队列里拿一条数据
并存入数据库
'''
store = DbToMysql(configs.TEST_DB)
while True:
try:
st = time.time()
data = res_queue.get_nowait()
t = int(time.time() - st)
if t > 5:
print("res_queue", t)
save_data(data, store)
except:
print("queue is empty wait for a while")
time.sleep(2)
使用多线程后,速度快了几十倍。
经测试:1秒可存储500条记录
最后看一下关键词在数据库中解析出来的:
运行一段时间后,已经有4000万条数据了。

