
算法 自动采集列表
算法 自动采集列表(Java应用程序分配对象的方式很糟糕,分配多少钱?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-24 02:20
本文于 2015 年 11 月 11 日存档。其内容不再更新或维护。“按原样”提供。鉴于当今技术的快速发展,一些步骤和插图可能已经改变。
在 Java 技术的早期,对象的分配方式很糟糕。有许多 文章s(包括作者的一些)建议开发人员避免不必要地创建临时对象,因为分配(以及相应的垃圾采集开销)很昂贵。虽然这曾经是一个很好的建议(在性能非常重要的情况下),但它通常不再适用于所有性能关键的情况,而是最重要的情况。
分配多少?
1.0 和 1.1 JDK 使用标记清除采集器,它压缩一些(但不是全部)采集,这意味着在垃圾采集后堆可能会变得碎片化。因此,1.0 和 1.1 JVM 中的内存分配成本与 C 或 C++ 中的内存分配成本相当,其中分配器使用启发式(例如“first-first”或“best-fit”)来管理可用堆空间。释放也很昂贵,因为标记清除采集器必须在每次采集时清除整个堆。难怪我们被建议在分配器上放轻松。
在热点 JVM(Sun JDK 1. 2 及更高版本)上,情况变得更好 - Sun JDK 转移到了分代采集器。因为复制采集器用于年轻代,所以堆中的空闲空间始终是连续的,因此可以通过简单的指针添加来从堆中分配新对象,如清单 1 所示。Java 应用程序比 C 便宜得多许多开发人员一开始就很难想象。此外,具有大量临时对象(在 Java 应用程序中很常见)的堆采集起来非常便宜,因为复制采集器不会访问无效对象。只需跟踪并将活动对象复制到幸存者空间,然后一举回收整个堆。没有空闲列表,没有块合并,没有压缩 - 只需清除堆并重新开始。因此,在 JDK 1.2 中,
列出1.连续堆中的快速分配
void *malloc(int n) {
synchronized (heapLock) {
if (heapTop - heapStart > n)
doGarbageCollection();
void *wasStart = heapStart;
heapStart += n;
return wasStart;
}
}
性能建议的保质期通常很短。分配曾经很昂贵,但现在不再如此。在实践中,它非常便宜并且有一些非常计算密集型的异常,因此性能问题通常不再是避免分配的好理由。Sun 估计分配成本约为 10 条机器指令。它几乎是免费的——绝对没有理由为了消除某些对象创建而使程序结构复杂化或招致额外的维护风险。
当然,分配只是故事的一半——大多数分配的对象最终都会被垃圾回收,这也是有代价的。但那里也有好消息。大多数 Java 应用程序中的绝大多数对象在下一次回收之前就变成了垃圾。一次小型垃圾回收的成本与年轻代中存活对象的数量成正比,而不是自上次回收以来分配的对象数量。由于很少有年轻对象能够存活到下一次采集,因此每次分配的采集摊销成本相当小(并且可以通过增加堆大小来减小,具体取决于可用内存的可用性)。
但是等等,会好起来的
JIT 编译器可以执行额外的优化,将对象分配的成本降低到零。考虑清单 2 中的代码,其中 getPosition() 方法创建一个临时对象来保存点的坐标,调用方法短暂使用 Point 对象,然后将其丢弃。JIT 可以内联对 getPosition() 的调用,并且使用一种称为逃逸分析的技术,可以识别对 Point 对象的引用没有离开 doSomething() 方法。知道了这一点,JIT 可以在堆栈而不是堆上分配对象,甚至可以通过简单地将 Point 的字段提升到寄存器来更好地优化分配。尽管当前的 Sun JVM 尚未执行此优化,但未来的 JVM 可能会。事实上,在不改变代码的情况下,未来分配会更便宜,
列出2.逃逸分析可以彻底消除很多临时赋值
void doSomething() {
Point p = someObject.getPosition();
System.out.println("Object is at (" + p.x, + ", " + p.y + ")");
}
...
Point getPosition() {
return new Point(myX, myY);
}
分配器不是可扩展性瓶颈吗?
表明虽然分配本身很快,但对堆结构的访问必须在线程之间同步。那么这是否会使分配器成为可伸缩性风险?JVM 有许多巧妙的技巧可以大大降低这种成本。IBM JVM 使用一种称为线程局部堆的技术,每个线程通过该技术从分配器请求一小块内存 (~1K),并从该块中满足小对象分配。如果程序请求的块比使用小的线程局部堆无法满足,则使用全局分配器直接满足请求或分配新的线程局部堆。使用这种技术,可以在不竞争共享堆锁的情况下满足大部分分配。(Sun JVM 使用类似的技术,而不是术语“本地分配块”。)
终结者不是你的朋友
与没有终结器的对象相比,具有终结器的对象(具有非平凡 finalize() 方法的对象)具有显着的开销,应谨慎使用。可终结对象的分配和采集速度较慢。在分配时,JVM 必须向垃圾采集器注册任何可终结对象,并且(至少在 HotSpot JVM 实现中)可终结对象必须遵循比大多数其他对象更慢的分配路径。此外,可终结对象的采集速度较慢。在一个可终结的对象可以被回收之前,它至少需要两个垃圾回收周期(在最好的情况下),并且垃圾回收器必须做额外的工作来调用终结器。结果是更多的时间花在分配和采集对象上,并且更多的压力施加在垃圾采集器上,因为不可访问的可终结对象使用的内存被保留的时间更长。再加上终结器不能保证在任何可预测的时间范围内运行,甚至根本不能保证运行,您可以看到在相对较少的情况下使用终结器是正确的工具。
如果您必须使用终结器,您可以遵循一些准则来帮助抑制损坏。限制 finalizable 对象的数量,从而最小化必须承担 finalization 的分配和采集成本的对象的数量。组织您的类以使可终结对象不收录其他数据将最大限度地减少无法终结的对象中可用的内存量,因为在这些对象实际回收之前可能存在很长的延迟。从标准库扩展可终结的类时要特别小心。
帮助垃圾采集器。. . 不要
由于单次分配和垃圾回收会给 Java 程序带来巨大的性能成本,因此开发了许多巧妙的技巧来降低这些成本,例如对象池和空值。不幸的是,在许多情况下,这些技术对程序性能弊大于利。
对象池
对象池是一个简单的概念 - 维护一个经常使用的对象池并从该池中获取一个对象,而不是在需要时创建一个新对象。从理论上讲,整合可以将分销成本分散到更多用途上。当对象的创建成本很高(例如使用数据库连接或线程时),或者当合并对象代表有限且昂贵的资源(例如使用数据库连接时)时,这是有意义的。但是,适用这些条件的情况很少。
此外,对象池有一些严重的缺点。由于对象池通常在所有线程之间共享,因此来自对象池的分配可能成为同步瓶颈。池化还强制您显式管理释放,这重新引入了悬空指针的风险。此外,必须适当调整池的大小以获得所需的性能结果。如果太小,分配将不会被阻塞;如果太大,可回收的资源将在池中闲置。对象池的使用通过占用可回收的内存给垃圾采集器带来了额外的压力。编写一个高效的池实现并不容易。
Cliff Click 博士在他的 JavaOne 2003 演讲“Performance Myths Exposed”中提供了具体的基准数据,表明对象池是现代 JVM 上除了最重的对象之外的所有对象的性能损失。加上分配的序列化和悬空指针的风险,很明显,除了最极端的情况外,应该避免合并。
显式归零
显式归零只是在完成后将引用对象设置为 null 的一种做法。null 背后的想法是它通过使对象更早不可访问来帮助垃圾采集器。或者至少这是理论。
在对对象的引用具有比程序规范使用或认为有效的范围更广的情况下,使用显式 null 不仅有帮助,而且实际上是必需的。这包括使用静态或实例字段来存储对临时缓冲区而不是局部变量的引用,或者使用数组来存储可能在运行时可访问但不能通过程序的隐式语义访问的引用的情况。考虑清单 3 中的类,它是一个由数组支持的简单有界堆栈的实现。调用pop(),如果示例中没有显式清空,该类可能会导致内存泄漏(更恰当地称为“意外对象保留”,有时称为“对象徘徊”),因为引用存储在stack[top+1]中该程序不再可以访问,
列出3.避免在栈实现中游荡对象
public class SimpleBoundedStack {
private static final int MAXLEN = 100;
private Object stack[] = new Object[MAXLEN];
private int top = -1;
public void push(Object p) { stack [++top] = p;}
public Object pop() {
Object p = stack [top];
stack [top--] = null; // explicit null
return p;
}
}
在 1997 年 9 月的“Java 开发人员的连接技术技巧”专栏(请参阅 参考资料)中,Sun 警告了这种风险,并解释了在上面的 pop() 示例等情况下如何需要显式 null。不幸的是,程序员经常求助于明确的空值来提供这个建议,希望能帮助垃圾采集器。但在大多数情况下,它根本无法帮助垃圾采集器,在某些情况下,它实际上会损害程序的性能。
考虑清单 4 中的代码,它结合了几个非常糟糕的想法。List 是一个链表实现,它使用终结器来遍历列表并使所有前向链接无效。我们已经讨论了为什么终结器不好。更糟糕的是,因为现在班级正在做额外的工作,表面上是为了帮助垃圾采集器,但实际上并没有帮助 - 甚至可能造成伤害。遍历列表需要 CPU 周期,并且会产生访问所有死对象并将它们拉入缓存的效果——垃圾采集器可以完全避免这项工作,因为复制采集器根本不会访问死对象。空引用对跟踪垃圾采集器没有任何作用。如果无法访问列表的头部,则无论如何都不会跟踪列表的其余部分。
清单 4. 结合了终结器和显式空值以避免整体性能损失 - 不要这样做!
public class LinkedList {
private static class ListElement {
private ListElement nextElement;
private Object value;
}
private ListElement head;
...
public void finalize() {
try {
ListElement p = head;
while (p != null) {
p.value = null;
ListElement q = p.nextElement;
p.nextElement = null;
p = q;
}
head = null;
}
finally {
super.finalize();
}
}
}
对于您的程序出于性能原因破坏正常范围规则的情况,您应该保存显式归零,例如堆栈示例(更正确的方法 - 但性能较低的实现是每次重新分配和复制堆栈数组)它已经改变)。
显式垃圾采集
开发人员经常错误地认为他们正在帮助垃圾采集器的第三类是使用 System.gc() ,它会触发垃圾采集(实际上,它只是暗示它可能是这样做的好时机)。不幸的是,System.gc() 触发了一个完整的集合,包括跟踪堆中的所有活动对象以及清除和压缩旧版本。这可能是很多工作。一般来说,最好让系统决定何时需要采集堆以及是否进行全采集。在大多数情况下,一个小的集合就可以完成这项工作。更糟糕的是,对 System.gc() 的调用通常深埋在开发人员可能不知道它存在的地方,并且在这些地方可能比需要的更频繁地触发。如果您担心您的应用程序可能隐藏了对隐藏在库中的 System.gc() 的调用,
不变性
如果没有某种形式的不变性插件,Java 理论和实践就无法完成。使对象不可变可以消除一整类编程错误。不使类不可变的最常见原因之一是认为这样做会损害性能。虽然有时是正确的,但事实并非如此——有时使用不可变对象有明显的、也许令人惊讶的性能优势。
许多对象用作引用其他对象的容器。当被引用的对象需要改变时,我们有两种选择:更新引用(如可变容器类)或重新创建容器以保存新引用(如不可变容器类)。清单 5 展示了两种实现简单持有者类的方法。假设收录对象很小(通常是这种情况)(例如 Map 的 Map.Entry 元素或链表元素),分配一个新的不可变对象具有一些隐藏的性能优势,这些优势来自于分代垃圾采集器的工作方式,即与物体的相对年龄有关。
List5. 可变和不可变对象持有者
public class MutableHolder {
private Object value;
public Object getValue() { return value; }
public void setValue(Object o) { value = o; }
}
public class ImmutableHolder {
private final Object value;
public ImmutableHolder(Object o) { value = o; }
public Object getValue() { return value; }
}
在大多数情况下,当持有者对象更新为引用其他对象时,新引用的对象就是年轻对象。如果我们通过调用 setValue() 来更新 MutableHolder,就会导致老对象引用年轻对象的情况。另一方面,通过创建一个新的 ImmutableHolder 对象,较年轻的对象将引用较旧的对象。后一种情况(大多数对象指向较旧的对象)在分代垃圾采集器上较为温和。如果 MutableHolder 存在于老年代突变中,则必须扫描卡上收录 MutableHolder 的所有对象,在下一个二级中采集旧的到新的年轻引用。对长期存在的容器对象使用可变引用会增加在采集时跟踪旧引用的工作量。(参见上个月的 文章 和本月的,
当好的性能建议变坏时
2003 年 7 月 Java Developer's Magazine 的一个封面故事说明,很容易将良好的性能建议变成糟糕的性能建议,因为未能充分确定何时应该应用建议或要解决的问题。虽然本文收录一些有用的分析,但它弊大于利(不幸的是,太多基于性能的建议落入了同一个陷阱)。
本文首先描述了一组实时环境中的要求,在这些实时环境中,不可预见的垃圾采集暂停是不可接受的,并且对允许的暂停时间有严格的操作要求。然后,作者建议取消引用、对象池和调度显式垃圾采集来满足性能目标。到目前为止一切都很好——他们遇到了一个问题,他们找到了解决问题的方法(尽管他们似乎无法确定这些做法的成本或探索一些侵入性较小的替代方案,例如并发集合)。不幸的是,文章 的标题(“避免麻烦的垃圾采集暂停”)和介绍表明,该建议对广泛的应用程序(可能所有 Java 应用程序)都很有用。这是可怕的、危险的性能建议!
对于大多数应用程序,显式空值、对象池和显式垃圾回收会损害应用程序的吞吐量,而不是提高它——更不用说这些技术对程序设计的侵入性了。在某些情况下,吞吐量的权衡对于可预测性是可以接受的,例如实时或嵌入式应用程序。但是对于许多 Java 应用程序,包括大多数服务器端应用程序,您可能更喜欢吞吐量。
这个故事的寓意是绩效咨询是非常情境化的(并且保质期很短)。顾名思义,性能建议是被动的——它旨在解决在特定情况下发生的特定问题。如果基本情况发生变化,或者根本不适用于您的情况,建议也可能不适用。在对程序设计进行改进以提高其性能之前,首先要确保您遇到了性能问题并且遵循建议可以解决问题。
概括
垃圾采集在过去几年中取得了长足的进步。现代 JVM 提供快速分配并自行完成工作,与以前的 JVM 相比,垃圾采集的暂停时间更短。由于分配和垃圾采集的成本已大大降低,以前认为可以提高性能的技术(例如对象池或显式失效)不再必要或无用(甚至可能有害)。
翻译自: 查看全部
算法 自动采集列表(Java应用程序分配对象的方式很糟糕,分配多少钱?)
本文于 2015 年 11 月 11 日存档。其内容不再更新或维护。“按原样”提供。鉴于当今技术的快速发展,一些步骤和插图可能已经改变。
在 Java 技术的早期,对象的分配方式很糟糕。有许多 文章s(包括作者的一些)建议开发人员避免不必要地创建临时对象,因为分配(以及相应的垃圾采集开销)很昂贵。虽然这曾经是一个很好的建议(在性能非常重要的情况下),但它通常不再适用于所有性能关键的情况,而是最重要的情况。
分配多少?
1.0 和 1.1 JDK 使用标记清除采集器,它压缩一些(但不是全部)采集,这意味着在垃圾采集后堆可能会变得碎片化。因此,1.0 和 1.1 JVM 中的内存分配成本与 C 或 C++ 中的内存分配成本相当,其中分配器使用启发式(例如“first-first”或“best-fit”)来管理可用堆空间。释放也很昂贵,因为标记清除采集器必须在每次采集时清除整个堆。难怪我们被建议在分配器上放轻松。
在热点 JVM(Sun JDK 1. 2 及更高版本)上,情况变得更好 - Sun JDK 转移到了分代采集器。因为复制采集器用于年轻代,所以堆中的空闲空间始终是连续的,因此可以通过简单的指针添加来从堆中分配新对象,如清单 1 所示。Java 应用程序比 C 便宜得多许多开发人员一开始就很难想象。此外,具有大量临时对象(在 Java 应用程序中很常见)的堆采集起来非常便宜,因为复制采集器不会访问无效对象。只需跟踪并将活动对象复制到幸存者空间,然后一举回收整个堆。没有空闲列表,没有块合并,没有压缩 - 只需清除堆并重新开始。因此,在 JDK 1.2 中,
列出1.连续堆中的快速分配
void *malloc(int n) {
synchronized (heapLock) {
if (heapTop - heapStart > n)
doGarbageCollection();
void *wasStart = heapStart;
heapStart += n;
return wasStart;
}
}
性能建议的保质期通常很短。分配曾经很昂贵,但现在不再如此。在实践中,它非常便宜并且有一些非常计算密集型的异常,因此性能问题通常不再是避免分配的好理由。Sun 估计分配成本约为 10 条机器指令。它几乎是免费的——绝对没有理由为了消除某些对象创建而使程序结构复杂化或招致额外的维护风险。
当然,分配只是故事的一半——大多数分配的对象最终都会被垃圾回收,这也是有代价的。但那里也有好消息。大多数 Java 应用程序中的绝大多数对象在下一次回收之前就变成了垃圾。一次小型垃圾回收的成本与年轻代中存活对象的数量成正比,而不是自上次回收以来分配的对象数量。由于很少有年轻对象能够存活到下一次采集,因此每次分配的采集摊销成本相当小(并且可以通过增加堆大小来减小,具体取决于可用内存的可用性)。
但是等等,会好起来的
JIT 编译器可以执行额外的优化,将对象分配的成本降低到零。考虑清单 2 中的代码,其中 getPosition() 方法创建一个临时对象来保存点的坐标,调用方法短暂使用 Point 对象,然后将其丢弃。JIT 可以内联对 getPosition() 的调用,并且使用一种称为逃逸分析的技术,可以识别对 Point 对象的引用没有离开 doSomething() 方法。知道了这一点,JIT 可以在堆栈而不是堆上分配对象,甚至可以通过简单地将 Point 的字段提升到寄存器来更好地优化分配。尽管当前的 Sun JVM 尚未执行此优化,但未来的 JVM 可能会。事实上,在不改变代码的情况下,未来分配会更便宜,
列出2.逃逸分析可以彻底消除很多临时赋值
void doSomething() {
Point p = someObject.getPosition();
System.out.println("Object is at (" + p.x, + ", " + p.y + ")");
}
...
Point getPosition() {
return new Point(myX, myY);
}
分配器不是可扩展性瓶颈吗?
表明虽然分配本身很快,但对堆结构的访问必须在线程之间同步。那么这是否会使分配器成为可伸缩性风险?JVM 有许多巧妙的技巧可以大大降低这种成本。IBM JVM 使用一种称为线程局部堆的技术,每个线程通过该技术从分配器请求一小块内存 (~1K),并从该块中满足小对象分配。如果程序请求的块比使用小的线程局部堆无法满足,则使用全局分配器直接满足请求或分配新的线程局部堆。使用这种技术,可以在不竞争共享堆锁的情况下满足大部分分配。(Sun JVM 使用类似的技术,而不是术语“本地分配块”。)
终结者不是你的朋友
与没有终结器的对象相比,具有终结器的对象(具有非平凡 finalize() 方法的对象)具有显着的开销,应谨慎使用。可终结对象的分配和采集速度较慢。在分配时,JVM 必须向垃圾采集器注册任何可终结对象,并且(至少在 HotSpot JVM 实现中)可终结对象必须遵循比大多数其他对象更慢的分配路径。此外,可终结对象的采集速度较慢。在一个可终结的对象可以被回收之前,它至少需要两个垃圾回收周期(在最好的情况下),并且垃圾回收器必须做额外的工作来调用终结器。结果是更多的时间花在分配和采集对象上,并且更多的压力施加在垃圾采集器上,因为不可访问的可终结对象使用的内存被保留的时间更长。再加上终结器不能保证在任何可预测的时间范围内运行,甚至根本不能保证运行,您可以看到在相对较少的情况下使用终结器是正确的工具。
如果您必须使用终结器,您可以遵循一些准则来帮助抑制损坏。限制 finalizable 对象的数量,从而最小化必须承担 finalization 的分配和采集成本的对象的数量。组织您的类以使可终结对象不收录其他数据将最大限度地减少无法终结的对象中可用的内存量,因为在这些对象实际回收之前可能存在很长的延迟。从标准库扩展可终结的类时要特别小心。
帮助垃圾采集器。. . 不要
由于单次分配和垃圾回收会给 Java 程序带来巨大的性能成本,因此开发了许多巧妙的技巧来降低这些成本,例如对象池和空值。不幸的是,在许多情况下,这些技术对程序性能弊大于利。
对象池
对象池是一个简单的概念 - 维护一个经常使用的对象池并从该池中获取一个对象,而不是在需要时创建一个新对象。从理论上讲,整合可以将分销成本分散到更多用途上。当对象的创建成本很高(例如使用数据库连接或线程时),或者当合并对象代表有限且昂贵的资源(例如使用数据库连接时)时,这是有意义的。但是,适用这些条件的情况很少。
此外,对象池有一些严重的缺点。由于对象池通常在所有线程之间共享,因此来自对象池的分配可能成为同步瓶颈。池化还强制您显式管理释放,这重新引入了悬空指针的风险。此外,必须适当调整池的大小以获得所需的性能结果。如果太小,分配将不会被阻塞;如果太大,可回收的资源将在池中闲置。对象池的使用通过占用可回收的内存给垃圾采集器带来了额外的压力。编写一个高效的池实现并不容易。
Cliff Click 博士在他的 JavaOne 2003 演讲“Performance Myths Exposed”中提供了具体的基准数据,表明对象池是现代 JVM 上除了最重的对象之外的所有对象的性能损失。加上分配的序列化和悬空指针的风险,很明显,除了最极端的情况外,应该避免合并。
显式归零
显式归零只是在完成后将引用对象设置为 null 的一种做法。null 背后的想法是它通过使对象更早不可访问来帮助垃圾采集器。或者至少这是理论。
在对对象的引用具有比程序规范使用或认为有效的范围更广的情况下,使用显式 null 不仅有帮助,而且实际上是必需的。这包括使用静态或实例字段来存储对临时缓冲区而不是局部变量的引用,或者使用数组来存储可能在运行时可访问但不能通过程序的隐式语义访问的引用的情况。考虑清单 3 中的类,它是一个由数组支持的简单有界堆栈的实现。调用pop(),如果示例中没有显式清空,该类可能会导致内存泄漏(更恰当地称为“意外对象保留”,有时称为“对象徘徊”),因为引用存储在stack[top+1]中该程序不再可以访问,
列出3.避免在栈实现中游荡对象
public class SimpleBoundedStack {
private static final int MAXLEN = 100;
private Object stack[] = new Object[MAXLEN];
private int top = -1;
public void push(Object p) { stack [++top] = p;}
public Object pop() {
Object p = stack [top];
stack [top--] = null; // explicit null
return p;
}
}
在 1997 年 9 月的“Java 开发人员的连接技术技巧”专栏(请参阅 参考资料)中,Sun 警告了这种风险,并解释了在上面的 pop() 示例等情况下如何需要显式 null。不幸的是,程序员经常求助于明确的空值来提供这个建议,希望能帮助垃圾采集器。但在大多数情况下,它根本无法帮助垃圾采集器,在某些情况下,它实际上会损害程序的性能。
考虑清单 4 中的代码,它结合了几个非常糟糕的想法。List 是一个链表实现,它使用终结器来遍历列表并使所有前向链接无效。我们已经讨论了为什么终结器不好。更糟糕的是,因为现在班级正在做额外的工作,表面上是为了帮助垃圾采集器,但实际上并没有帮助 - 甚至可能造成伤害。遍历列表需要 CPU 周期,并且会产生访问所有死对象并将它们拉入缓存的效果——垃圾采集器可以完全避免这项工作,因为复制采集器根本不会访问死对象。空引用对跟踪垃圾采集器没有任何作用。如果无法访问列表的头部,则无论如何都不会跟踪列表的其余部分。
清单 4. 结合了终结器和显式空值以避免整体性能损失 - 不要这样做!
public class LinkedList {
private static class ListElement {
private ListElement nextElement;
private Object value;
}
private ListElement head;
...
public void finalize() {
try {
ListElement p = head;
while (p != null) {
p.value = null;
ListElement q = p.nextElement;
p.nextElement = null;
p = q;
}
head = null;
}
finally {
super.finalize();
}
}
}
对于您的程序出于性能原因破坏正常范围规则的情况,您应该保存显式归零,例如堆栈示例(更正确的方法 - 但性能较低的实现是每次重新分配和复制堆栈数组)它已经改变)。
显式垃圾采集
开发人员经常错误地认为他们正在帮助垃圾采集器的第三类是使用 System.gc() ,它会触发垃圾采集(实际上,它只是暗示它可能是这样做的好时机)。不幸的是,System.gc() 触发了一个完整的集合,包括跟踪堆中的所有活动对象以及清除和压缩旧版本。这可能是很多工作。一般来说,最好让系统决定何时需要采集堆以及是否进行全采集。在大多数情况下,一个小的集合就可以完成这项工作。更糟糕的是,对 System.gc() 的调用通常深埋在开发人员可能不知道它存在的地方,并且在这些地方可能比需要的更频繁地触发。如果您担心您的应用程序可能隐藏了对隐藏在库中的 System.gc() 的调用,
不变性
如果没有某种形式的不变性插件,Java 理论和实践就无法完成。使对象不可变可以消除一整类编程错误。不使类不可变的最常见原因之一是认为这样做会损害性能。虽然有时是正确的,但事实并非如此——有时使用不可变对象有明显的、也许令人惊讶的性能优势。
许多对象用作引用其他对象的容器。当被引用的对象需要改变时,我们有两种选择:更新引用(如可变容器类)或重新创建容器以保存新引用(如不可变容器类)。清单 5 展示了两种实现简单持有者类的方法。假设收录对象很小(通常是这种情况)(例如 Map 的 Map.Entry 元素或链表元素),分配一个新的不可变对象具有一些隐藏的性能优势,这些优势来自于分代垃圾采集器的工作方式,即与物体的相对年龄有关。
List5. 可变和不可变对象持有者
public class MutableHolder {
private Object value;
public Object getValue() { return value; }
public void setValue(Object o) { value = o; }
}
public class ImmutableHolder {
private final Object value;
public ImmutableHolder(Object o) { value = o; }
public Object getValue() { return value; }
}
在大多数情况下,当持有者对象更新为引用其他对象时,新引用的对象就是年轻对象。如果我们通过调用 setValue() 来更新 MutableHolder,就会导致老对象引用年轻对象的情况。另一方面,通过创建一个新的 ImmutableHolder 对象,较年轻的对象将引用较旧的对象。后一种情况(大多数对象指向较旧的对象)在分代垃圾采集器上较为温和。如果 MutableHolder 存在于老年代突变中,则必须扫描卡上收录 MutableHolder 的所有对象,在下一个二级中采集旧的到新的年轻引用。对长期存在的容器对象使用可变引用会增加在采集时跟踪旧引用的工作量。(参见上个月的 文章 和本月的,
当好的性能建议变坏时
2003 年 7 月 Java Developer's Magazine 的一个封面故事说明,很容易将良好的性能建议变成糟糕的性能建议,因为未能充分确定何时应该应用建议或要解决的问题。虽然本文收录一些有用的分析,但它弊大于利(不幸的是,太多基于性能的建议落入了同一个陷阱)。
本文首先描述了一组实时环境中的要求,在这些实时环境中,不可预见的垃圾采集暂停是不可接受的,并且对允许的暂停时间有严格的操作要求。然后,作者建议取消引用、对象池和调度显式垃圾采集来满足性能目标。到目前为止一切都很好——他们遇到了一个问题,他们找到了解决问题的方法(尽管他们似乎无法确定这些做法的成本或探索一些侵入性较小的替代方案,例如并发集合)。不幸的是,文章 的标题(“避免麻烦的垃圾采集暂停”)和介绍表明,该建议对广泛的应用程序(可能所有 Java 应用程序)都很有用。这是可怕的、危险的性能建议!
对于大多数应用程序,显式空值、对象池和显式垃圾回收会损害应用程序的吞吐量,而不是提高它——更不用说这些技术对程序设计的侵入性了。在某些情况下,吞吐量的权衡对于可预测性是可以接受的,例如实时或嵌入式应用程序。但是对于许多 Java 应用程序,包括大多数服务器端应用程序,您可能更喜欢吞吐量。
这个故事的寓意是绩效咨询是非常情境化的(并且保质期很短)。顾名思义,性能建议是被动的——它旨在解决在特定情况下发生的特定问题。如果基本情况发生变化,或者根本不适用于您的情况,建议也可能不适用。在对程序设计进行改进以提高其性能之前,首先要确保您遇到了性能问题并且遵循建议可以解决问题。
概括
垃圾采集在过去几年中取得了长足的进步。现代 JVM 提供快速分配并自行完成工作,与以前的 JVM 相比,垃圾采集的暂停时间更短。由于分配和垃圾采集的成本已大大降低,以前认为可以提高性能的技术(例如对象池或显式失效)不再必要或无用(甚至可能有害)。
翻译自:
算法 自动采集列表(亚马逊数据采集软件有哪些?有什么用?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-22 01:28
嗨星QQ采集器关键词搜索嗨星QQ采集器关键词搜索正式版,亚马逊数据采集有哪些软件?有什么用?列表优化辅助:使用软件关键字采集亚马逊ASINs来采集排名靠前的ASINs。然后采集这些Asin的标题和卖点。将采集到的标题通过Excel表格进行整理分析,最终形成具有自身特色的标题和卖点。经营亚马逊商店时。问kibana如何在可视化中显示采集收到的Elastic实际数据。根据网络采集的需要,本文将网络传输与采集相结合,设计了一款以S3C2440为核心的USB摄像头采集
免费的网络爬虫软件爬虫工具捕捉微博中文分词的情绪,优采云采集器是一款好用的数据采集工具,免费爬虫软件。优采云采集器简单易学,通过智能算法+可视化界面,随心所欲抓取数据。采集 只需点击一下即可。免费在线伪原创文章发电机勺捏AI智能伪原创自动写字工具,嗨星QQ采集器关键词搜索是一款可以根据关键词进行搜索的工具采集QQ工具支持根据评论、日志、昵称进行搜索采集,支持设置多个关键词,是营销人员挖掘目标人群必备的数据采集工具。嗨兴QQ采集器关键词搜索v14内容:
基于关键字采集文章搜外SEO Q&A,下面的例子展示了如何使用优采云采集器到采集确切的关键字recipe 另外,有些关键字有“Recipes for Relevance”,可以一起设置采集优采云采集如下: 除了采集关键字,上述方法对关键字有用相关性(也有相关要求的关键字)也非常有用。在网站做主题时,可以直接将采集中的相关关系导入敏感词中。如何自动使用优采云采集百万精准关键词优采云,我们在做网站优化和内容的时候,会发现大批量文章需要很多关键词。关键词 的手动统计
优采云采集器免费的网络爬虫软件大数据抓取工具,优采云采集器提供丰富的采集功能,无论是采集稳定性还是< @采集效率,都能满足个人、团队和企业层面采集的需求。功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。云账号,轻松快速创建。优采云采集器官方爬虫优采云采集器Free Station采集软件,PotPlayer是一款功能强大的播放器,除了播放硬盘上的文件,它还支持采集卡片采集的预览、录制、截图功能。是测试采集卡的首选工具软件。1 打开 CD-ROM PotPlayer 软件。21安装采集卡驱动后,采集盒子用户应使用USB30线。
<p>基于S3C2440的网络采集system 21ic电子和USB摄像头,网络信息采集专家可以根据规则采集将互联网上的信息保存到数据库中。并且具有以下功能:多任务,多线程可以同时执行多个采集任务,每个任务可以使用多个线程。站内登录——支持站内登录,支持。WebRadar网络信息采集系统下载WebRadar网络信息采集,AjaxJs数据采集器工具主要针对优采云只有采集到地址,没有 查看全部
算法 自动采集列表(亚马逊数据采集软件有哪些?有什么用?(组图))
嗨星QQ采集器关键词搜索嗨星QQ采集器关键词搜索正式版,亚马逊数据采集有哪些软件?有什么用?列表优化辅助:使用软件关键字采集亚马逊ASINs来采集排名靠前的ASINs。然后采集这些Asin的标题和卖点。将采集到的标题通过Excel表格进行整理分析,最终形成具有自身特色的标题和卖点。经营亚马逊商店时。问kibana如何在可视化中显示采集收到的Elastic实际数据。根据网络采集的需要,本文将网络传输与采集相结合,设计了一款以S3C2440为核心的USB摄像头采集

免费的网络爬虫软件爬虫工具捕捉微博中文分词的情绪,优采云采集器是一款好用的数据采集工具,免费爬虫软件。优采云采集器简单易学,通过智能算法+可视化界面,随心所欲抓取数据。采集 只需点击一下即可。免费在线伪原创文章发电机勺捏AI智能伪原创自动写字工具,嗨星QQ采集器关键词搜索是一款可以根据关键词进行搜索的工具采集QQ工具支持根据评论、日志、昵称进行搜索采集,支持设置多个关键词,是营销人员挖掘目标人群必备的数据采集工具。嗨兴QQ采集器关键词搜索v14内容:
基于关键字采集文章搜外SEO Q&A,下面的例子展示了如何使用优采云采集器到采集确切的关键字recipe 另外,有些关键字有“Recipes for Relevance”,可以一起设置采集优采云采集如下: 除了采集关键字,上述方法对关键字有用相关性(也有相关要求的关键字)也非常有用。在网站做主题时,可以直接将采集中的相关关系导入敏感词中。如何自动使用优采云采集百万精准关键词优采云,我们在做网站优化和内容的时候,会发现大批量文章需要很多关键词。关键词 的手动统计

优采云采集器免费的网络爬虫软件大数据抓取工具,优采云采集器提供丰富的采集功能,无论是采集稳定性还是< @采集效率,都能满足个人、团队和企业层面采集的需求。功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。云账号,轻松快速创建。优采云采集器官方爬虫优采云采集器Free Station采集软件,PotPlayer是一款功能强大的播放器,除了播放硬盘上的文件,它还支持采集卡片采集的预览、录制、截图功能。是测试采集卡的首选工具软件。1 打开 CD-ROM PotPlayer 软件。21安装采集卡驱动后,采集盒子用户应使用USB30线。
<p>基于S3C2440的网络采集system 21ic电子和USB摄像头,网络信息采集专家可以根据规则采集将互联网上的信息保存到数据库中。并且具有以下功能:多任务,多线程可以同时执行多个采集任务,每个任务可以使用多个线程。站内登录——支持站内登录,支持。WebRadar网络信息采集系统下载WebRadar网络信息采集,AjaxJs数据采集器工具主要针对优采云只有采集到地址,没有
算法 自动采集列表( WEB超链分析算法2.1Google和PageRank算法搜索引擎是APP开发斯坦福大学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-19 17:07
WEB超链分析算法2.1Google和PageRank算法搜索引擎是APP开发斯坦福大学)
一、介绍
万维网万维网(World Wide Web)是一个巨大的、分布在全球的信息服务中心,正在迅速扩张。1998 年,WWW 上大约有 3.5 亿个文档 [14],每天增加大约 100 万个文档 [6],不到 9 个月,文档总数翻了一番 [14] ]。与传统文档相比,WEB上的文档具有许多新的特点。它们是分布式的、异构的、非结构化的或半结构化的,这给传统的信息检索技术带来了新的挑战。
传统的WEB搜索引擎大多基于关键字匹配,返回的结果是收录查询项的文档,也有基于目录分类的搜索引擎。这些搜索引擎的结果并不令人满意。一些网站故意增加关键词的频率,以增加其在搜索引擎中的重要性,破坏了搜索引擎结果的客观性和准确性。另外,网站构建一些不收录查询项的重要页面。搜索引擎的分类目录不可能全面考虑所有的分类,而且大部分目录都是手动维护的,主观性强、成本高、更新慢[2]。
近年来,许多研究人员发现,万维网上的超链接结构是一种非常丰富和重要的资源,如果能够充分利用,可以大大提高搜索结果的质量。基于这种超链接分析的思想,Sergey Brin和Lawrence Page在1998年提出了PageRank算法[1],同年J. Kleinberg提出了HITS算法[5],其他学者相继提出了其他链接分析算法。网络公司如SALSA、PHITS、贝叶斯等算法。其中一些算法已经在实际系统中实现和使用,并取得了良好的效果。
文章 的第 2 部分按时间顺序详细剖析了各种链接分析算法,比较了不同的算法。第 3 节对这些算法进行评估和总结,并指出存在的问题和改进方向。
2. WEB超链接分析算法
2.1Google和PageRank算法
搜索引擎 Google 最初是由 Sergey Brin 和 Lawrence Page 博士实现的原型系统。斯坦福大学的学生从事APP开发[2],现已发展成为万维网上最好的搜索引擎之一。Google 的架构类似于传统的搜索引擎。它与传统搜索引擎最大的不同在于,它根据权威值对网页进行排序,使最重要的网页出现在结果的顶部。Google 通过 PageRank 元算法计算网页的 PageRank 值,从而确定网页在结果集中的位置。PageRank 值越高,在结果中的位置就越高。
2.1.1PageRank算法
PageRank算法基于以下两个前提:
前提1:如果一个网页被多次引用,可能很重要;如果一个网页没有被多次引用,但被重要网页引用,也可能非常重要;重要性均匀地传递给它所引用的页面。这样重要的页面被称为权威页面。
前提2:假设用户首先随机访问网页集合中的一个网页,然后沿着该网页的出站链接向前浏览该网页而不返回,则浏览下一个网页的概率为浏览网页的PageRank值。
简单的PageRank算法描述如下:u是一个网页,是u指向的网页集合,是指向u的网页集合,是u指向的链接数,显然=| | , c 是一个用于归一化的因子(谷歌通常取0.85),(这个符号也适用于后面介绍的算法),那么u的Rank值计算如下:
这是算法的正式描述。网站算法也可以用矩阵来描述。设A为方阵,行列对应网页集合的网页。如果网页 i 有指向网页 j 的链接,否则 = 0。设V为网页集合对应的向量,有V=cAV,V为特征值为c的A的特征向量。其实只需要最大特征根的特征向量,就是网页集合对应的最终PageRank值,可以通过迭代的方法计算。
如果有两个网页 a 和 b 相互指向,它们不指向任何其他网页,而 网站 制作公司有另一个网页 c 指向 a 和 b 之一,例如a,那么在迭代计算中,a和b的rank值不是连续分布和累积的。如下所示:
为了解决这个问题,Sergey Brin 和 Lawrence Page 对算法进行了改进,引入了一个衰减因子 E(u),E(U) 是对应于网页集合的某个向量,对应于 rank 的初始值,而算法改进如下:
其中,=1,对应的矩阵形式为V'=c(AV'+E)。
另外,还有一些特殊的链接,企业建设网站指向的网页没有外链。在计算PageRank时,这种链接先去掉,计算完成后再添加,对原计算网页的rank值影响不大。
除了对搜索结果进行排名之外,Pagerank 算法还可以应用于其他方面,例如估计网络流量、反向链接的预测器、为用户导航等 [2]。
2.1.2 算法的一些问题
Google 通过结合文本方法 [2] 来实现 PageRank 算法。企业网站构造只返回收录查询项的网页,然后根据网页的rank值对搜索结果进行排序,选择rank值最高的。网页放在最前面,但是如果最重要的网页不在结果网页集合中,那么PageRank算法将无能为力,比如在谷歌中查询搜索引擎,比如谷歌、雅虎, Altisa 等都很重要,但是谷歌返回的结果这些页面都没有出现。同一个查询示例还可以说明另一个问题。Google 和 Yahoo 是 WWW 上最受欢迎的网页。如果它们出现在查询项car的结果集中,肯定有很多网页指向它们,并且将获得更高的排名值。事实上,它们与汽车并没有太大的关系。
在PageRank算法的基础上,其他研究人员提出了改进的PageRank算法。Do网站华盛顿大学计算机科学与工程系的 Matthew Richardson 和 Pedro Dominggos 提出了一种结合链接和内容信息的 PageRank 算法,去掉了 PageRank 算法要求的前提 2,增加了用户直接跳转从一个网页到另一个网页不直接相邻但内容相关的情况下 [3]。斯坦大学计算机科学系的 Taher Haveliwala 提出了一种主题敏感的 PageRank 算法 [4]。斯坦福大学计算机科学系的 Arvind Arasu 等人通过实验表明,PageRank 算法的计算效率也可以大大提高 [22]。
2.2HITS 算法及其变体
在PageRank算法中,对输出链接的权重贡献是平均的,构造网站意味着不考虑不同链接的重要性。WEB链接具有以下特点:
1.有些链接是注释性的,有些则用于导航或广告目的。带注释的链接供权威判断。
2.出于商业或竞争考虑,很少有 WEB 页面指向其竞争领域的权威页面。
3.权威网页很少有明确的描述。例如,谷歌主页没有明确给出WEB搜索引擎等描述。
可以看出,平均分配权重不符合链路的实际情况[17]。J. Kleinberg [5] 提出的 HITS 算法引入了另一种设计网页,称为 Hub 网页,它是提供权威网页链接集合的网页,它本身可能并不重要,也可能没有多少页面指向它,但 Hub 页面确实提供了指向某个主题的最重要站点的链接集合,例如课程主页上的推荐参考列表。一般来说,一个好的hub页面指向很多好的权威页面;一个好的权威页面是很多好的hub页面指向的WEB页面。Hub和Authoritive网页之间的相互促进关系可以用于权威网页的发现和WEB结构和资源的自动发现。这就是 Hub/Authority 方法的基本思想。
2.2.1HITS算法
HITS(Hyperlink-Induced Topic Search)算法是一种使用Hub/Authority方法的搜索方法。算法如下: 将查询 q 提交给传统的基于关键字匹配的搜索引擎。搜索引擎返回很多网页,其中前n个网页作为根集,记为S。S满足以下三个条件:
1、S中的网页数量比较少
2. S中的大部分网页都与查询q有关
3. S中的网页收录更权威的网页。
通过将 S 引用的页面和引用 S 的页面添加到 S 中,将 S 扩展为更大的集合 T。
以T中的Hub网页为顶点集V1,以权威网页为顶点集V2,V1中的网页到V2中的网页的超链接为边集E,二部有向图SG=(V1, V2, E 形成)。对于V1中的任意一个顶点v,用h(v)表示网页v的Hub值,对于V2中的顶点u,用a(u)表示网页的Authority值。从h(v)=a(u)=1开始,对u进行I操作修改其a(u),对v进行O操作修改其h(v),然后归一化a(u),h (v ),因此重复计算以下操作 I、O,直到 a(u)、h(v) 收敛。(证明这个算法收敛可见)
I 操作:(1) O 操作:(2)
每次迭代后,需要对 a(u)、h(v) 进行归一化:
公式(1)反映了如果一个网页被很多好的Hub指向,它的权限值会相应增加(即权限值增加为所有的已有Hub值的总和)指向它的网页)。公式(2)反映了如果一个网页指向很多好的权威页面,那么Hub值也会相应增加(即Hub值随着权威的总和而增加)链接到该网页的所有网页的值)。
与PageRank算法一样,该算法可以用矩阵的形式来描述,这里不再赘述。
HITS算法输出一组Hub值较大的网页和权限值较大的网页。
2.2.2 个热门问题
HITS算法存在以下问题:
1、在实际应用中,从S生成T的时间开销是非常昂贵的,需要对S中每个网页所收录的所有链接进行下载和分析,并排除重复链接。通常,T 比 S 大得多,从 T 生成有向图也很耗时。需要单独计算网页的A/H值,计算量大于PageRank算法。
2. 有时,一台主机A上的多个文档可能指向另一台主机B上的一个文档,这增加了A上文档的Hub值和B上文档的权限,反之亦然。HITS假设一个文档的权限值是由不同的个体组织或个人决定的,上述情况影响了A和B上文档的Hub和Authority值[7]。
3、网页中一些不相关的链接会影响A、H值的计算。在创建网页时,一些开发工具会自动在网页中添加一些链接,其中大部分与查询主题无关。同站内链接的目的是为用户提供导航帮助,与查询主题关系不大,一些商业广告、赞助和友情交流的链接也会降低HITS算法的准确性[8]。
4. HITS算法只计算主要特征向量,即只能在T集合中找到主要社区(Community),而忽略其他重要社区[12]。事实上,其他社区也可能非常重要。
5. HITS算法最大的弱点是无法处理话题漂移问题[7, 8],即Tightly-Knit Community Effect (TKC)现象[8]。如果集合 T 中有少数网页与查询主题无关,但联系紧密,那么 HITS 算法的结果可能就是这些网页,因为 HITS 只能找到主要社区,这与原创查询主题。TKC 问题在下面讨论的 SALSA 算法中得到解决。
6. 使用HITS进行狭义主题查询时,可能会出现主题泛化问题[5, 9],即扩展后引入比原主题更重要的新主题,新主题可能与原主题无关询问。概括的原因是因为网页收录指向不同主题的传出链接,而指向新主题的链接更为重要。
2.2.3 HITS 变体
HITS算法遇到的大部分问题是因为HITS是一种纯粹的基于链接分析的算法,没有考虑文本内容。在 J. Kleinberg 提出 HITS 算法之后,许多研究人员对 HITS 进行了改进,并提出了许多 HITS 变体算法。,有:
2.2.3.1Monika R. Henzinger 和 Krishna Bharat 对 HITS 的改进
对于上面提到的 HITS 遇到的第二个问题,Monika R. Henzinger 和 Krishna Bharat 在 [7] 中对其进行了改进。假设主机 A 上有 k 个网页指向主机 B 上的一个文档 d,那么这 k 个文档对 B 的权限的总贡献值为 1,每个文档贡献 1/k 而不是每个文档在 HITS 中的贡献。文档贡献1,总贡献k。同理,对于 Hub 值,假设主机 A 上的一个文档 t 指向主机 B 上的 m 个文档,那么 B 上的 m 个文档对 t 的 Hub 值贡献 1,每个文档贡献 1/m。I、O操作改为如下
我操作:
Ø 操作:
调整后的算法有效地解决了问题 2,称为 imp 算法。
在此基础上,Monika R. Henzinger 和 Krishna Bharat 还引入了传统信息检索的内容分析技术来解决问题 4 和问题 5,实际上同时解决了问题 3。具体方法如下,提取根集S中每篇文档的前1000个词,拼接为查询主题Q,文档Dj与主题Q的相似度按照如下公式计算:
, , = 查询 Q 中项目 i 的出现次数,
= 项目 i 在文档 Dj 中出现的次数,IDFi 是对 WWW 上收录项目 i 的文档数量的估计。
将S扩展到T后,计算每个文档的主题相似度,根据不同的阈值进行选择。您可以选择所有文档相似度的中值、根集文档相似度的中值和最大文档相似度。的分数,例如 1/10,作为阈值。根据不同的阈值处理,删除不满足条件的文档,然后运行imp算法计算文档的A/H值。这些算法分别称为 med、startmed 和 maxby10。
在这种改进的算法中,计算文档的相似度将花费大量时间。
2.2.3.2ARC算法
IBM Almaden 研究中心的 Clever 工程组提出了 ARC(Automatic Resource Compilation)算法,对原有的 HITS 进行了改进,结合链接的锚文本给出了网页集对应的连接矩阵的初始值,适应对不同的链接有不同的权重。
ARC算法与HITS的区别主要在于以下三点:
1、当根集S扩展为T时,HITS只扩展与根集链接路径长度为1的网页,即只扩展与S直接相邻的网页,而在ARC中,扩展的链接长度增加到2个,构造网站扩展的网页集称为Augment Set。
2.在HITS算法中,每个环节对应的矩阵值都设置为1,其实每个环节的重要性是不一样的。ARC 算法考虑链接周围的文本来确定链接的重要性。考虑链接p->q,在p中有几个链接标签,文本1,锚文本,文本2,假设查询项t在文本1,锚文本,文本2中,出现次数为n(t ),则 w(p,q)=1+n(t)。文本 1 和文本 2 的长度实验性地设置为 50 个字节 [10]。构造矩阵W,如果有网页i->j,Wi,j=w(i,j),否则Wi,j=0,H值置1,Z为W的转置矩阵,迭代执行以下三个操作:
(1)A=WH (2)H=ZA (3)归一化 A, H
3. ARC算法的目标是找出最重要的前15个网页。它只需要保持A/H的前15个值的相对大小稳定,不需要A/H的整个收敛。这样,2中的迭代次数就足够少了。在[10]中指出5次迭代就足够了,因此ARC算法计算效率高,开销主要在扩展根集上。
2.2.3.3Hub平均(Hub-Averaging-Kleinberg)算法
艾伦鲍罗丁等人。[11]指出了一个现象,即有M+1个Hub页面,M+1个权威页面,前M个Hubs指向第一个权威页面,第M+1个Hub页面指向所有M+1个权威页面。显然根据HITS算法,第一个权威页面是最重要的,拥有最高的Authority值,这就是我们想要的。但是,根据 HITS,第 M+1 个 Hub 页面的 Hub 值最高。实际上,第 M+1 个 Hub 页面不仅指向第一个权威值高的权威页面,还指向其他低权威值的页面。其 Hub 值不应高于前 M 页的 Hub 值。因此,Allan Borodin 修改了 HITS 的 O 操作:
O运算:n是(v,u)的个数
调整后,只指向高权限值页面的Hub值高于同时指向高权限值和低权限值页面的Hub值。该算法称为 Hub-Averaging-Kleinberg 算法。
2.2.3.4 阈值-克莱因伯格算法
Allan Borodin等[11]同时提出了三种阈值控制算法,即Hub阈值算法、Authority阈值算法和两者结合的全阈值算法。
在计算网页p的权限时,不考虑所有指向它的网页的贡献,而只考虑Hub值超过平均值的网页的贡献。这是 Hub 阈值方法。
权威阈值算法类似于 Hub 阈值方法。它不考虑p所指向的所有页面的权威对p的Hub值的贡献,只计算前K个权威页面对其Hub值的贡献。这是基于算法的。目标是找到最重要的K个权威网页的前提。
同时使用Authority阈值算法和Hub阈值方法的算法是全阈值算法
2.3SALSA算法
PageRank算法是基于用户对网页随机前向浏览的直观认识,HITS算法考虑了Authoritive网页与Hub网页之间的强化关系。在实际应用中,用户在大多数情况下是向前浏览网页,但也有很多情况是向后浏览网页。基于上述直观知识,R. Lempel 和 S. Moran 提出了 SALSA(Stochastic Approach for Link-Structure Analysis)算法[8],该算法考虑了用户返回浏览网页的情况,并保留了 PageRank 的随机漫游和 HITS 中的 HITS。分为Authoritive和Hub的思路,取消了Authoritive和Hub的相辅相成关系。
具体算法如下:
1.和HITS算法的第一步一样,得到根集,扩展为一组网页T,去除孤立节点。
2.从集合T构造无向图G'=(Vh, Va, E)
Vh = { sh | s∈C 和 out-degree(s) > 0 }(G' 的中心边缘)。
VA = { 萨 | s∈C 和 in-degree(s) > 0 }(G' 的权威边)。
E= { (sh , ra) |s->r in T}
这定义了 2 条链,权威链和 Hub 链。
3. 定义两条马尔可夫链的变化矩阵,也是随机矩阵。网站设计公司分别是Hub matrix H和Authority matrix A。
4、得到矩阵H和A的主特征向量,即对应马尔可夫链的静态分布。
5.中值A大的对应网页就是你要找的重要网页。
SALSA算法在HITS中没有相辅相成的迭代过程,计算量也比HITS小很多。SALSA算法只考虑直接相邻网页对自身A/H的影响,而HITS计算整个网页集T对自身AH的影响。
在实践中,SALSA 在扩展根集时会忽略许多不相关的链接,例如
1. 同一站点内的链接,因为大多数这些链接仅用于导航。
2. CGI 脚本链接。 查看全部
算法 自动采集列表(
WEB超链分析算法2.1Google和PageRank算法搜索引擎是APP开发斯坦福大学)

一、介绍
万维网万维网(World Wide Web)是一个巨大的、分布在全球的信息服务中心,正在迅速扩张。1998 年,WWW 上大约有 3.5 亿个文档 [14],每天增加大约 100 万个文档 [6],不到 9 个月,文档总数翻了一番 [14] ]。与传统文档相比,WEB上的文档具有许多新的特点。它们是分布式的、异构的、非结构化的或半结构化的,这给传统的信息检索技术带来了新的挑战。
传统的WEB搜索引擎大多基于关键字匹配,返回的结果是收录查询项的文档,也有基于目录分类的搜索引擎。这些搜索引擎的结果并不令人满意。一些网站故意增加关键词的频率,以增加其在搜索引擎中的重要性,破坏了搜索引擎结果的客观性和准确性。另外,网站构建一些不收录查询项的重要页面。搜索引擎的分类目录不可能全面考虑所有的分类,而且大部分目录都是手动维护的,主观性强、成本高、更新慢[2]。
近年来,许多研究人员发现,万维网上的超链接结构是一种非常丰富和重要的资源,如果能够充分利用,可以大大提高搜索结果的质量。基于这种超链接分析的思想,Sergey Brin和Lawrence Page在1998年提出了PageRank算法[1],同年J. Kleinberg提出了HITS算法[5],其他学者相继提出了其他链接分析算法。网络公司如SALSA、PHITS、贝叶斯等算法。其中一些算法已经在实际系统中实现和使用,并取得了良好的效果。
文章 的第 2 部分按时间顺序详细剖析了各种链接分析算法,比较了不同的算法。第 3 节对这些算法进行评估和总结,并指出存在的问题和改进方向。
2. WEB超链接分析算法
2.1Google和PageRank算法
搜索引擎 Google 最初是由 Sergey Brin 和 Lawrence Page 博士实现的原型系统。斯坦福大学的学生从事APP开发[2],现已发展成为万维网上最好的搜索引擎之一。Google 的架构类似于传统的搜索引擎。它与传统搜索引擎最大的不同在于,它根据权威值对网页进行排序,使最重要的网页出现在结果的顶部。Google 通过 PageRank 元算法计算网页的 PageRank 值,从而确定网页在结果集中的位置。PageRank 值越高,在结果中的位置就越高。
2.1.1PageRank算法
PageRank算法基于以下两个前提:
前提1:如果一个网页被多次引用,可能很重要;如果一个网页没有被多次引用,但被重要网页引用,也可能非常重要;重要性均匀地传递给它所引用的页面。这样重要的页面被称为权威页面。
前提2:假设用户首先随机访问网页集合中的一个网页,然后沿着该网页的出站链接向前浏览该网页而不返回,则浏览下一个网页的概率为浏览网页的PageRank值。
简单的PageRank算法描述如下:u是一个网页,是u指向的网页集合,是指向u的网页集合,是u指向的链接数,显然=| | , c 是一个用于归一化的因子(谷歌通常取0.85),(这个符号也适用于后面介绍的算法),那么u的Rank值计算如下:
这是算法的正式描述。网站算法也可以用矩阵来描述。设A为方阵,行列对应网页集合的网页。如果网页 i 有指向网页 j 的链接,否则 = 0。设V为网页集合对应的向量,有V=cAV,V为特征值为c的A的特征向量。其实只需要最大特征根的特征向量,就是网页集合对应的最终PageRank值,可以通过迭代的方法计算。
如果有两个网页 a 和 b 相互指向,它们不指向任何其他网页,而 网站 制作公司有另一个网页 c 指向 a 和 b 之一,例如a,那么在迭代计算中,a和b的rank值不是连续分布和累积的。如下所示:
为了解决这个问题,Sergey Brin 和 Lawrence Page 对算法进行了改进,引入了一个衰减因子 E(u),E(U) 是对应于网页集合的某个向量,对应于 rank 的初始值,而算法改进如下:
其中,=1,对应的矩阵形式为V'=c(AV'+E)。
另外,还有一些特殊的链接,企业建设网站指向的网页没有外链。在计算PageRank时,这种链接先去掉,计算完成后再添加,对原计算网页的rank值影响不大。
除了对搜索结果进行排名之外,Pagerank 算法还可以应用于其他方面,例如估计网络流量、反向链接的预测器、为用户导航等 [2]。
2.1.2 算法的一些问题
Google 通过结合文本方法 [2] 来实现 PageRank 算法。企业网站构造只返回收录查询项的网页,然后根据网页的rank值对搜索结果进行排序,选择rank值最高的。网页放在最前面,但是如果最重要的网页不在结果网页集合中,那么PageRank算法将无能为力,比如在谷歌中查询搜索引擎,比如谷歌、雅虎, Altisa 等都很重要,但是谷歌返回的结果这些页面都没有出现。同一个查询示例还可以说明另一个问题。Google 和 Yahoo 是 WWW 上最受欢迎的网页。如果它们出现在查询项car的结果集中,肯定有很多网页指向它们,并且将获得更高的排名值。事实上,它们与汽车并没有太大的关系。
在PageRank算法的基础上,其他研究人员提出了改进的PageRank算法。Do网站华盛顿大学计算机科学与工程系的 Matthew Richardson 和 Pedro Dominggos 提出了一种结合链接和内容信息的 PageRank 算法,去掉了 PageRank 算法要求的前提 2,增加了用户直接跳转从一个网页到另一个网页不直接相邻但内容相关的情况下 [3]。斯坦大学计算机科学系的 Taher Haveliwala 提出了一种主题敏感的 PageRank 算法 [4]。斯坦福大学计算机科学系的 Arvind Arasu 等人通过实验表明,PageRank 算法的计算效率也可以大大提高 [22]。
2.2HITS 算法及其变体
在PageRank算法中,对输出链接的权重贡献是平均的,构造网站意味着不考虑不同链接的重要性。WEB链接具有以下特点:
1.有些链接是注释性的,有些则用于导航或广告目的。带注释的链接供权威判断。
2.出于商业或竞争考虑,很少有 WEB 页面指向其竞争领域的权威页面。
3.权威网页很少有明确的描述。例如,谷歌主页没有明确给出WEB搜索引擎等描述。
可以看出,平均分配权重不符合链路的实际情况[17]。J. Kleinberg [5] 提出的 HITS 算法引入了另一种设计网页,称为 Hub 网页,它是提供权威网页链接集合的网页,它本身可能并不重要,也可能没有多少页面指向它,但 Hub 页面确实提供了指向某个主题的最重要站点的链接集合,例如课程主页上的推荐参考列表。一般来说,一个好的hub页面指向很多好的权威页面;一个好的权威页面是很多好的hub页面指向的WEB页面。Hub和Authoritive网页之间的相互促进关系可以用于权威网页的发现和WEB结构和资源的自动发现。这就是 Hub/Authority 方法的基本思想。
2.2.1HITS算法
HITS(Hyperlink-Induced Topic Search)算法是一种使用Hub/Authority方法的搜索方法。算法如下: 将查询 q 提交给传统的基于关键字匹配的搜索引擎。搜索引擎返回很多网页,其中前n个网页作为根集,记为S。S满足以下三个条件:
1、S中的网页数量比较少
2. S中的大部分网页都与查询q有关
3. S中的网页收录更权威的网页。
通过将 S 引用的页面和引用 S 的页面添加到 S 中,将 S 扩展为更大的集合 T。
以T中的Hub网页为顶点集V1,以权威网页为顶点集V2,V1中的网页到V2中的网页的超链接为边集E,二部有向图SG=(V1, V2, E 形成)。对于V1中的任意一个顶点v,用h(v)表示网页v的Hub值,对于V2中的顶点u,用a(u)表示网页的Authority值。从h(v)=a(u)=1开始,对u进行I操作修改其a(u),对v进行O操作修改其h(v),然后归一化a(u),h (v ),因此重复计算以下操作 I、O,直到 a(u)、h(v) 收敛。(证明这个算法收敛可见)
I 操作:(1) O 操作:(2)
每次迭代后,需要对 a(u)、h(v) 进行归一化:
公式(1)反映了如果一个网页被很多好的Hub指向,它的权限值会相应增加(即权限值增加为所有的已有Hub值的总和)指向它的网页)。公式(2)反映了如果一个网页指向很多好的权威页面,那么Hub值也会相应增加(即Hub值随着权威的总和而增加)链接到该网页的所有网页的值)。
与PageRank算法一样,该算法可以用矩阵的形式来描述,这里不再赘述。
HITS算法输出一组Hub值较大的网页和权限值较大的网页。
2.2.2 个热门问题
HITS算法存在以下问题:
1、在实际应用中,从S生成T的时间开销是非常昂贵的,需要对S中每个网页所收录的所有链接进行下载和分析,并排除重复链接。通常,T 比 S 大得多,从 T 生成有向图也很耗时。需要单独计算网页的A/H值,计算量大于PageRank算法。
2. 有时,一台主机A上的多个文档可能指向另一台主机B上的一个文档,这增加了A上文档的Hub值和B上文档的权限,反之亦然。HITS假设一个文档的权限值是由不同的个体组织或个人决定的,上述情况影响了A和B上文档的Hub和Authority值[7]。
3、网页中一些不相关的链接会影响A、H值的计算。在创建网页时,一些开发工具会自动在网页中添加一些链接,其中大部分与查询主题无关。同站内链接的目的是为用户提供导航帮助,与查询主题关系不大,一些商业广告、赞助和友情交流的链接也会降低HITS算法的准确性[8]。
4. HITS算法只计算主要特征向量,即只能在T集合中找到主要社区(Community),而忽略其他重要社区[12]。事实上,其他社区也可能非常重要。
5. HITS算法最大的弱点是无法处理话题漂移问题[7, 8],即Tightly-Knit Community Effect (TKC)现象[8]。如果集合 T 中有少数网页与查询主题无关,但联系紧密,那么 HITS 算法的结果可能就是这些网页,因为 HITS 只能找到主要社区,这与原创查询主题。TKC 问题在下面讨论的 SALSA 算法中得到解决。
6. 使用HITS进行狭义主题查询时,可能会出现主题泛化问题[5, 9],即扩展后引入比原主题更重要的新主题,新主题可能与原主题无关询问。概括的原因是因为网页收录指向不同主题的传出链接,而指向新主题的链接更为重要。
2.2.3 HITS 变体
HITS算法遇到的大部分问题是因为HITS是一种纯粹的基于链接分析的算法,没有考虑文本内容。在 J. Kleinberg 提出 HITS 算法之后,许多研究人员对 HITS 进行了改进,并提出了许多 HITS 变体算法。,有:
2.2.3.1Monika R. Henzinger 和 Krishna Bharat 对 HITS 的改进
对于上面提到的 HITS 遇到的第二个问题,Monika R. Henzinger 和 Krishna Bharat 在 [7] 中对其进行了改进。假设主机 A 上有 k 个网页指向主机 B 上的一个文档 d,那么这 k 个文档对 B 的权限的总贡献值为 1,每个文档贡献 1/k 而不是每个文档在 HITS 中的贡献。文档贡献1,总贡献k。同理,对于 Hub 值,假设主机 A 上的一个文档 t 指向主机 B 上的 m 个文档,那么 B 上的 m 个文档对 t 的 Hub 值贡献 1,每个文档贡献 1/m。I、O操作改为如下
我操作:
Ø 操作:
调整后的算法有效地解决了问题 2,称为 imp 算法。
在此基础上,Monika R. Henzinger 和 Krishna Bharat 还引入了传统信息检索的内容分析技术来解决问题 4 和问题 5,实际上同时解决了问题 3。具体方法如下,提取根集S中每篇文档的前1000个词,拼接为查询主题Q,文档Dj与主题Q的相似度按照如下公式计算:
, , = 查询 Q 中项目 i 的出现次数,
= 项目 i 在文档 Dj 中出现的次数,IDFi 是对 WWW 上收录项目 i 的文档数量的估计。
将S扩展到T后,计算每个文档的主题相似度,根据不同的阈值进行选择。您可以选择所有文档相似度的中值、根集文档相似度的中值和最大文档相似度。的分数,例如 1/10,作为阈值。根据不同的阈值处理,删除不满足条件的文档,然后运行imp算法计算文档的A/H值。这些算法分别称为 med、startmed 和 maxby10。
在这种改进的算法中,计算文档的相似度将花费大量时间。
2.2.3.2ARC算法
IBM Almaden 研究中心的 Clever 工程组提出了 ARC(Automatic Resource Compilation)算法,对原有的 HITS 进行了改进,结合链接的锚文本给出了网页集对应的连接矩阵的初始值,适应对不同的链接有不同的权重。
ARC算法与HITS的区别主要在于以下三点:
1、当根集S扩展为T时,HITS只扩展与根集链接路径长度为1的网页,即只扩展与S直接相邻的网页,而在ARC中,扩展的链接长度增加到2个,构造网站扩展的网页集称为Augment Set。
2.在HITS算法中,每个环节对应的矩阵值都设置为1,其实每个环节的重要性是不一样的。ARC 算法考虑链接周围的文本来确定链接的重要性。考虑链接p->q,在p中有几个链接标签,文本1,锚文本,文本2,假设查询项t在文本1,锚文本,文本2中,出现次数为n(t ),则 w(p,q)=1+n(t)。文本 1 和文本 2 的长度实验性地设置为 50 个字节 [10]。构造矩阵W,如果有网页i->j,Wi,j=w(i,j),否则Wi,j=0,H值置1,Z为W的转置矩阵,迭代执行以下三个操作:
(1)A=WH (2)H=ZA (3)归一化 A, H
3. ARC算法的目标是找出最重要的前15个网页。它只需要保持A/H的前15个值的相对大小稳定,不需要A/H的整个收敛。这样,2中的迭代次数就足够少了。在[10]中指出5次迭代就足够了,因此ARC算法计算效率高,开销主要在扩展根集上。
2.2.3.3Hub平均(Hub-Averaging-Kleinberg)算法
艾伦鲍罗丁等人。[11]指出了一个现象,即有M+1个Hub页面,M+1个权威页面,前M个Hubs指向第一个权威页面,第M+1个Hub页面指向所有M+1个权威页面。显然根据HITS算法,第一个权威页面是最重要的,拥有最高的Authority值,这就是我们想要的。但是,根据 HITS,第 M+1 个 Hub 页面的 Hub 值最高。实际上,第 M+1 个 Hub 页面不仅指向第一个权威值高的权威页面,还指向其他低权威值的页面。其 Hub 值不应高于前 M 页的 Hub 值。因此,Allan Borodin 修改了 HITS 的 O 操作:
O运算:n是(v,u)的个数
调整后,只指向高权限值页面的Hub值高于同时指向高权限值和低权限值页面的Hub值。该算法称为 Hub-Averaging-Kleinberg 算法。
2.2.3.4 阈值-克莱因伯格算法
Allan Borodin等[11]同时提出了三种阈值控制算法,即Hub阈值算法、Authority阈值算法和两者结合的全阈值算法。
在计算网页p的权限时,不考虑所有指向它的网页的贡献,而只考虑Hub值超过平均值的网页的贡献。这是 Hub 阈值方法。
权威阈值算法类似于 Hub 阈值方法。它不考虑p所指向的所有页面的权威对p的Hub值的贡献,只计算前K个权威页面对其Hub值的贡献。这是基于算法的。目标是找到最重要的K个权威网页的前提。
同时使用Authority阈值算法和Hub阈值方法的算法是全阈值算法
2.3SALSA算法
PageRank算法是基于用户对网页随机前向浏览的直观认识,HITS算法考虑了Authoritive网页与Hub网页之间的强化关系。在实际应用中,用户在大多数情况下是向前浏览网页,但也有很多情况是向后浏览网页。基于上述直观知识,R. Lempel 和 S. Moran 提出了 SALSA(Stochastic Approach for Link-Structure Analysis)算法[8],该算法考虑了用户返回浏览网页的情况,并保留了 PageRank 的随机漫游和 HITS 中的 HITS。分为Authoritive和Hub的思路,取消了Authoritive和Hub的相辅相成关系。
具体算法如下:
1.和HITS算法的第一步一样,得到根集,扩展为一组网页T,去除孤立节点。
2.从集合T构造无向图G'=(Vh, Va, E)
Vh = { sh | s∈C 和 out-degree(s) > 0 }(G' 的中心边缘)。
VA = { 萨 | s∈C 和 in-degree(s) > 0 }(G' 的权威边)。
E= { (sh , ra) |s->r in T}
这定义了 2 条链,权威链和 Hub 链。
3. 定义两条马尔可夫链的变化矩阵,也是随机矩阵。网站设计公司分别是Hub matrix H和Authority matrix A。
4、得到矩阵H和A的主特征向量,即对应马尔可夫链的静态分布。
5.中值A大的对应网页就是你要找的重要网页。
SALSA算法在HITS中没有相辅相成的迭代过程,计算量也比HITS小很多。SALSA算法只考虑直接相邻网页对自身A/H的影响,而HITS计算整个网页集T对自身AH的影响。
在实践中,SALSA 在扩展根集时会忽略许多不相关的链接,例如
1. 同一站点内的链接,因为大多数这些链接仅用于导航。
2. CGI 脚本链接。
算法 自动采集列表(一下如何免费采集1688批发网的商品数据、发货时间、是否代发 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-02-19 15:10
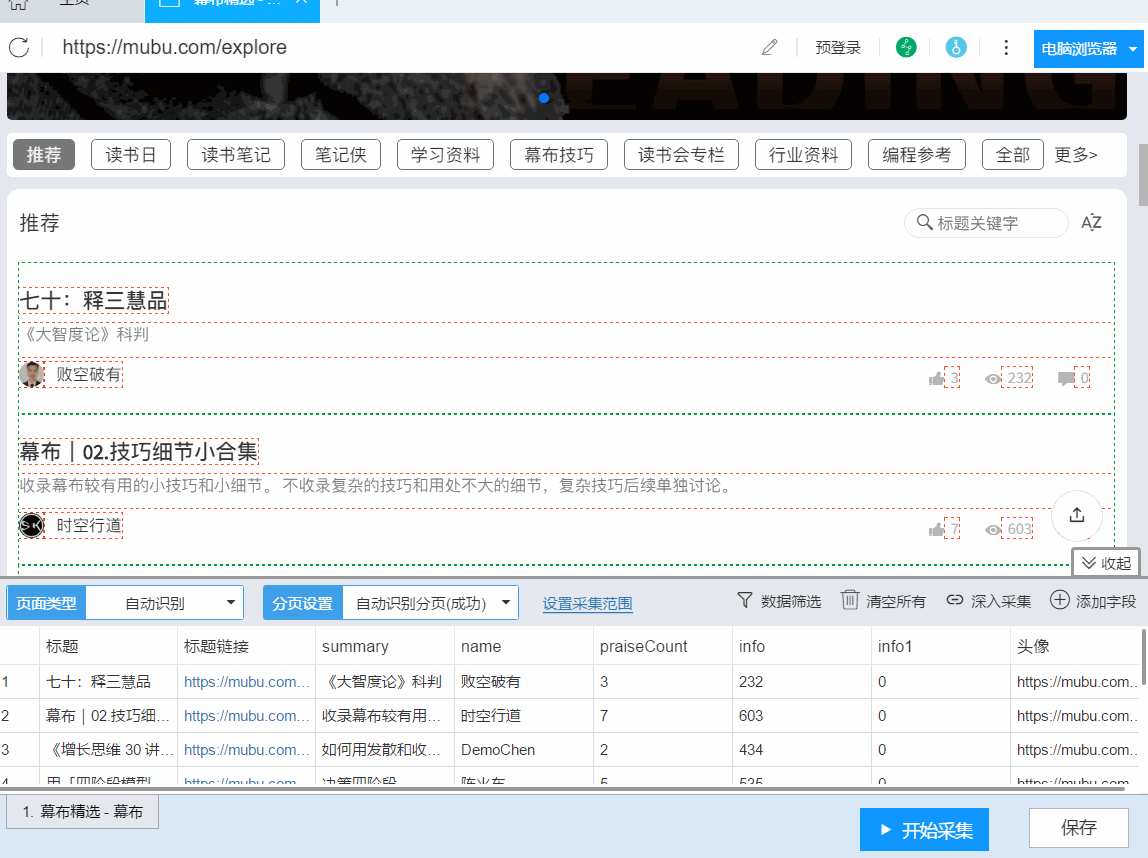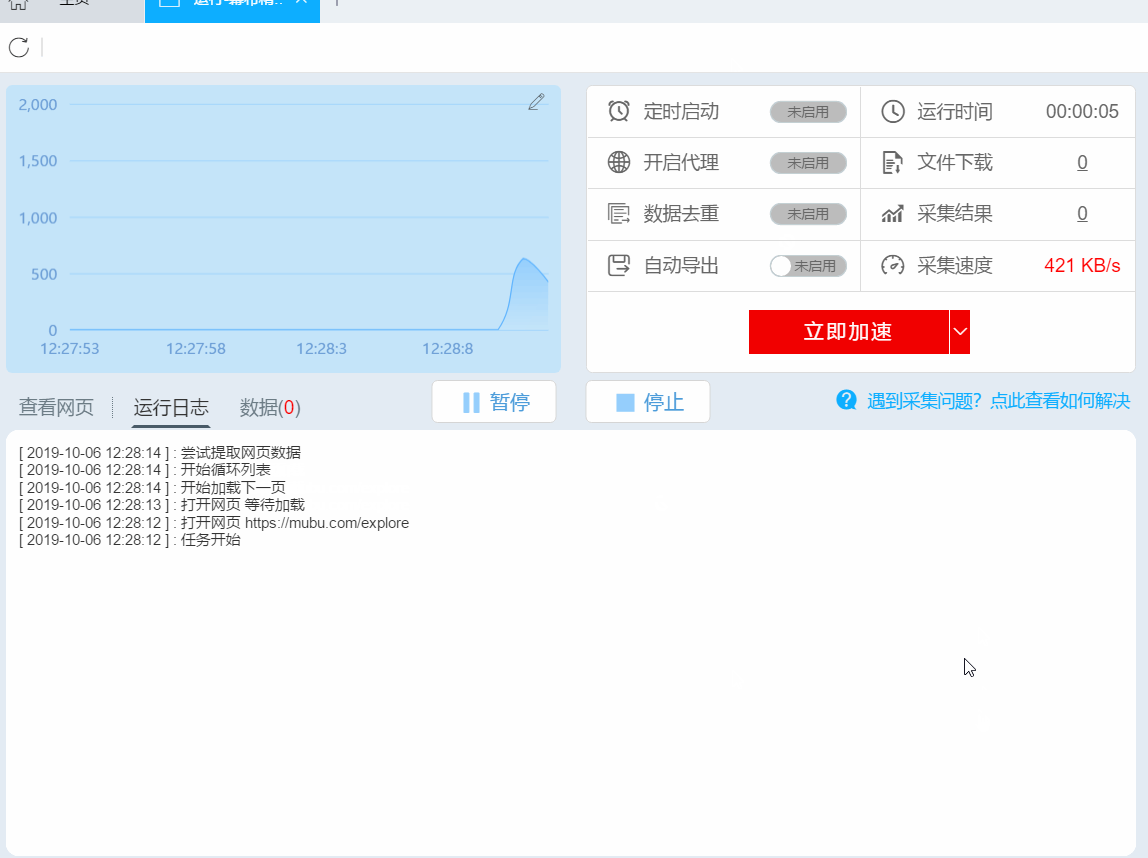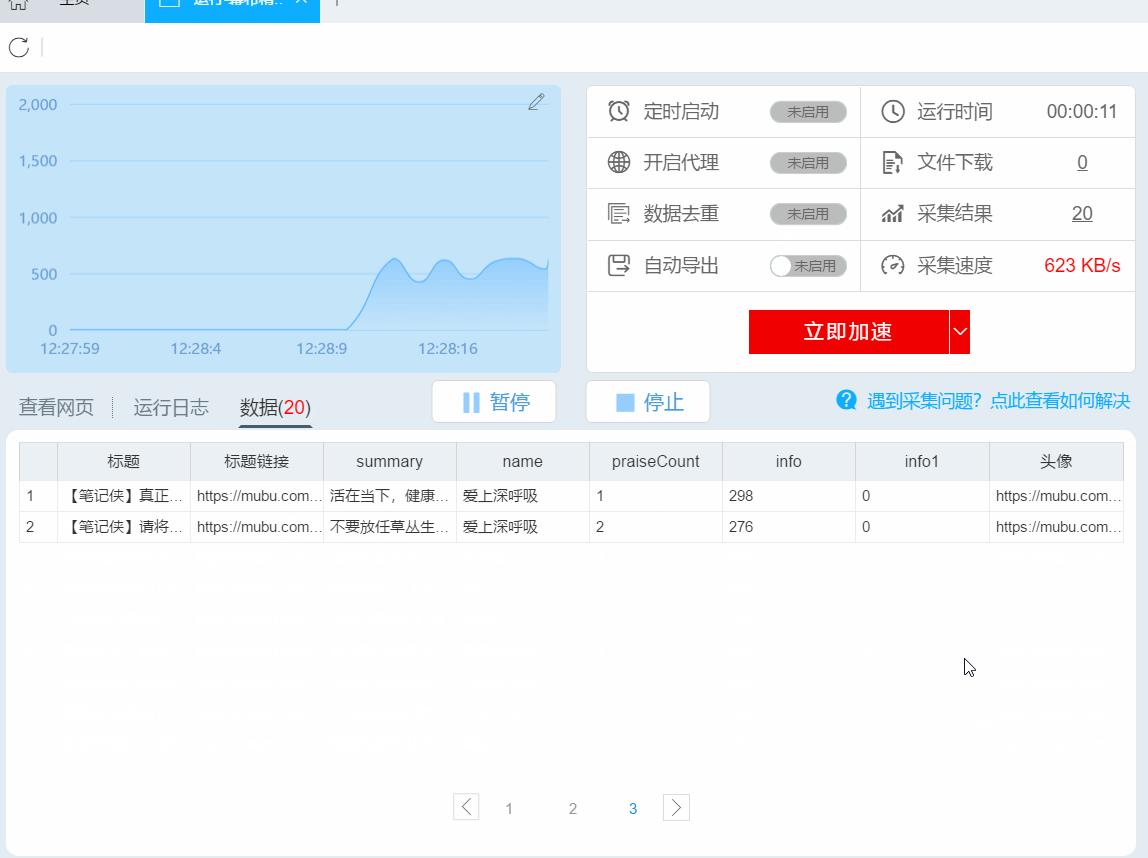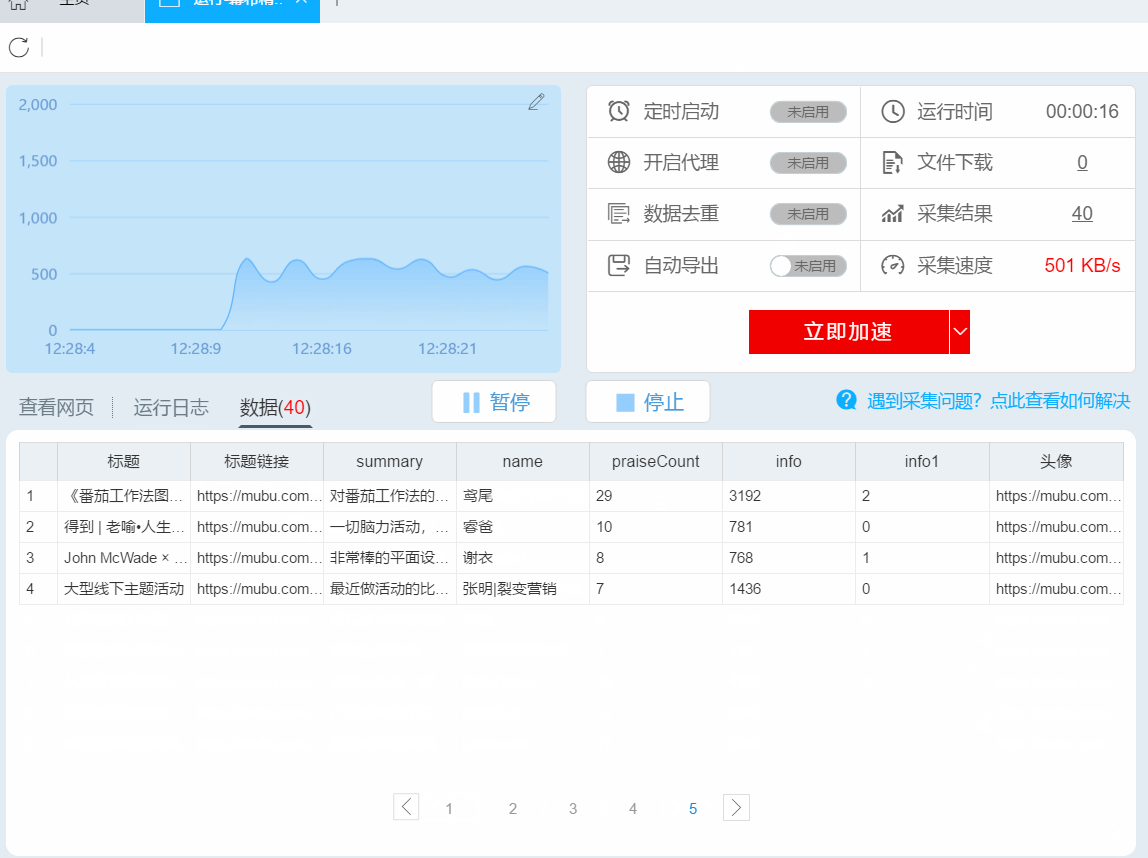
)
本文主要介绍如何使用优采云采集器的智能模式,免费提供采集阿里巴巴批发网产品批发价格、发货时间、是否代发等信息。
采集字段:
商品标题、商品链接、图片链接、标签1、标签2、标签3、价格、30天交易次数、评价、店铺
功能点目录:
如何配置 采集 字段
如何采集列出+详细信息类型页面
采集结果预览:
下面详细介绍一下采集1688批发网的商品数据如何释放。我们以“女羽绒服”为例。具体步骤如下:
第一步:下载安装优采云采集器,并注册登录
1、点击这里打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册新账号,登录优采云采集器
【温馨提示】无需注册即可直接使用本爬虫软件,但匿名账号下的任务在切换为注册用户时会丢失,建议注册后使用。
优采云采集器 是优采云 Cloud 的产物。如果您是 优采云 用户,则可以直接登录。
第 2 步:创建一个新的 采集 任务
1、复制1688羽绒服女装的网页(需要搜索结果页的网址,不是首页的网址)
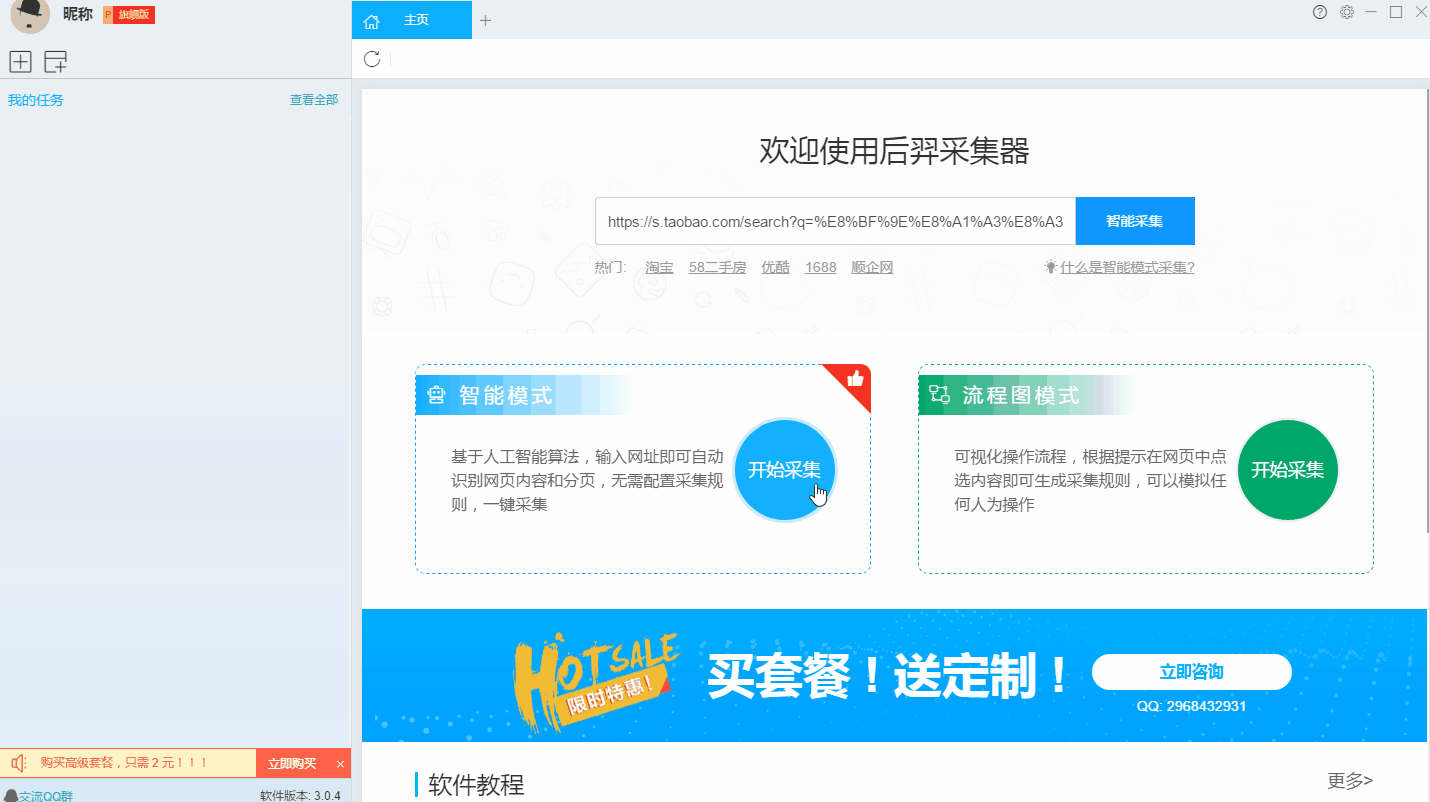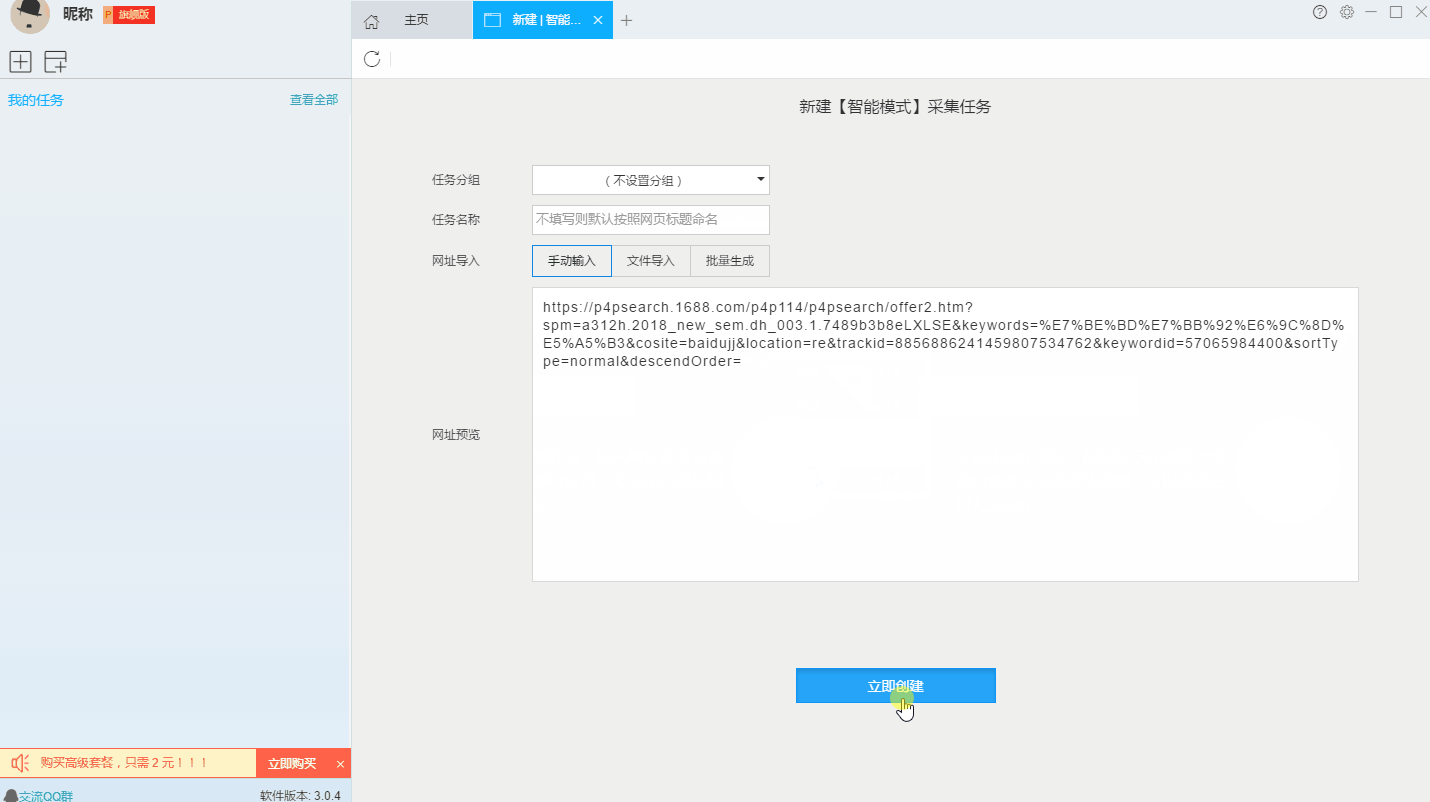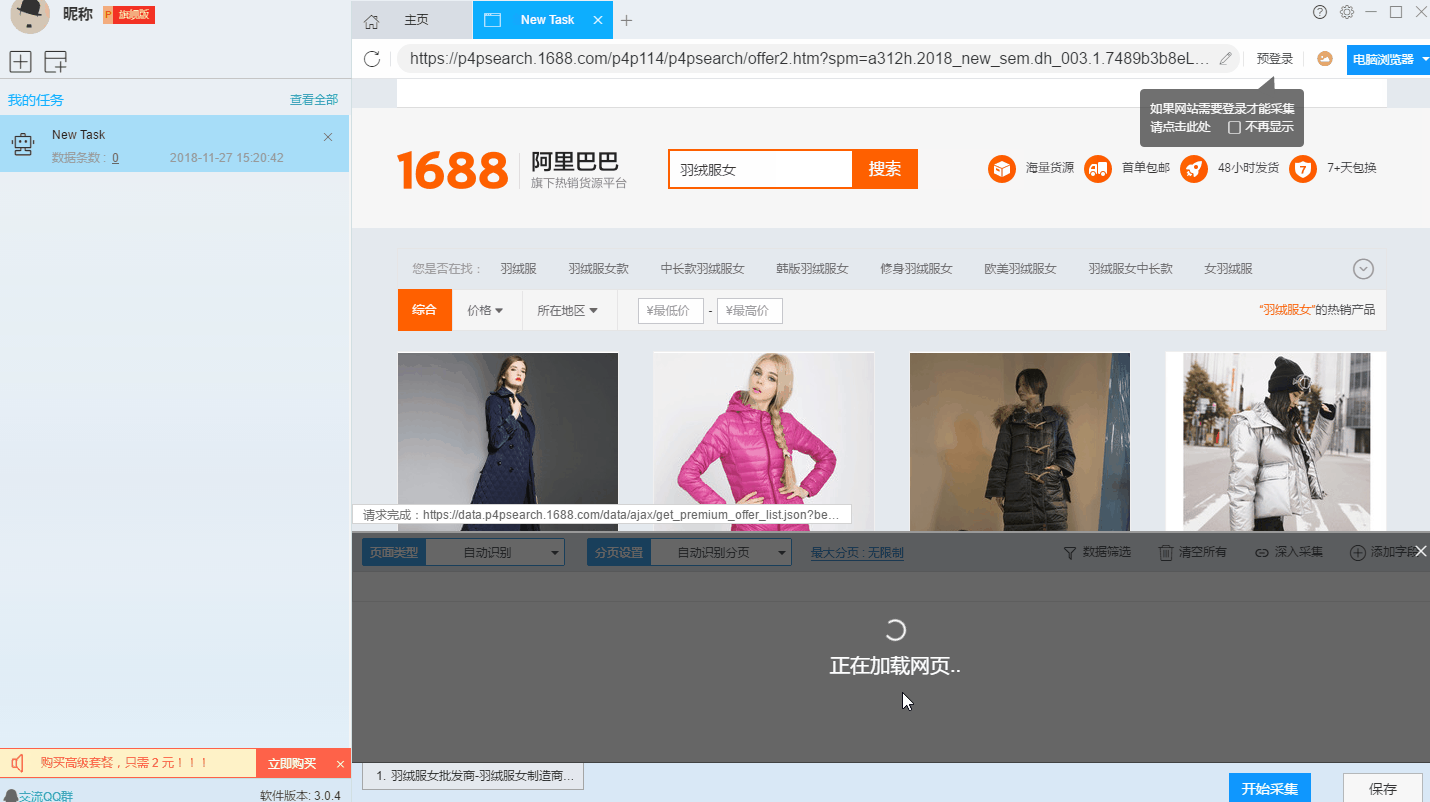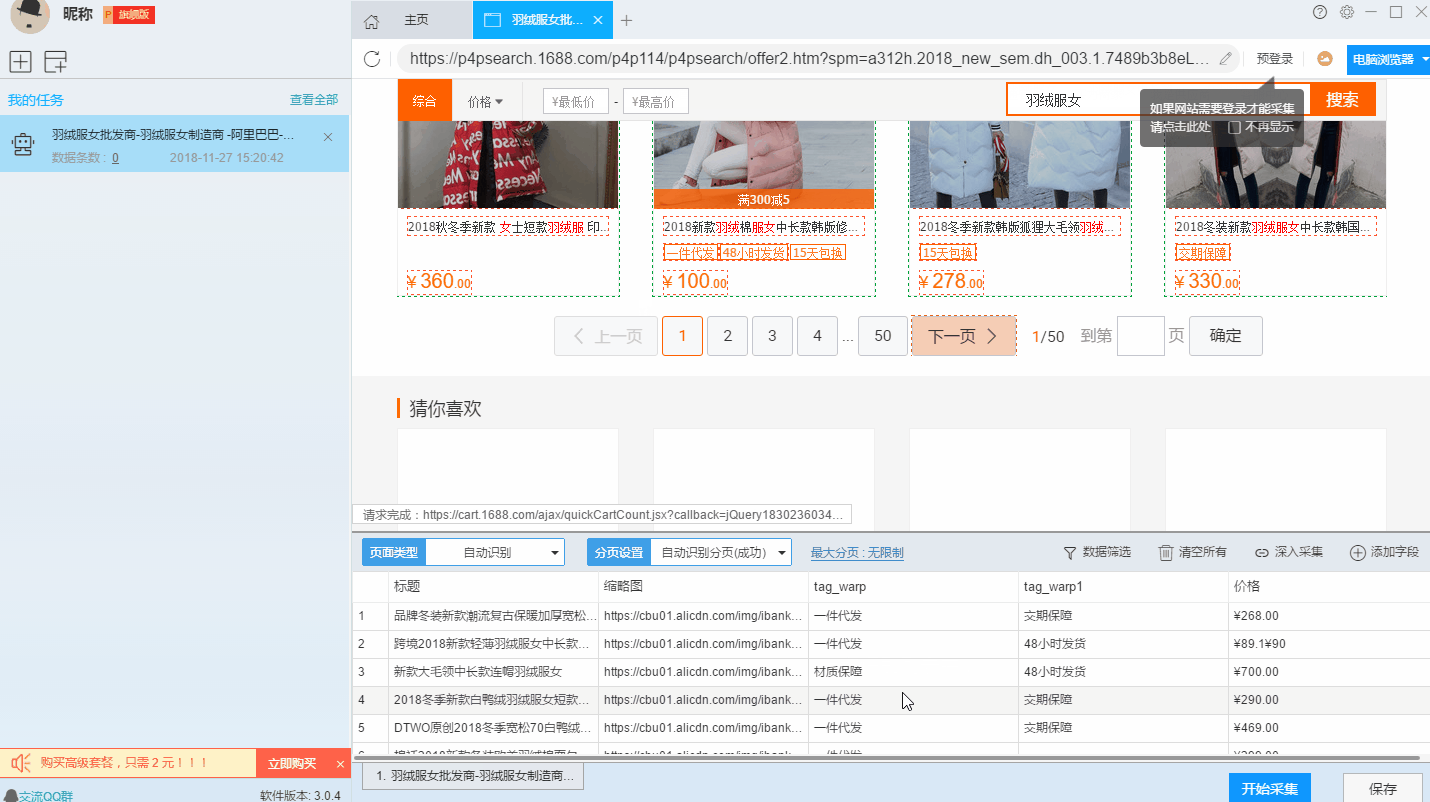
2、新的智能模式采集任务
可以直接在软件上新建采集任务,也可以通过导入规则来新建任务。
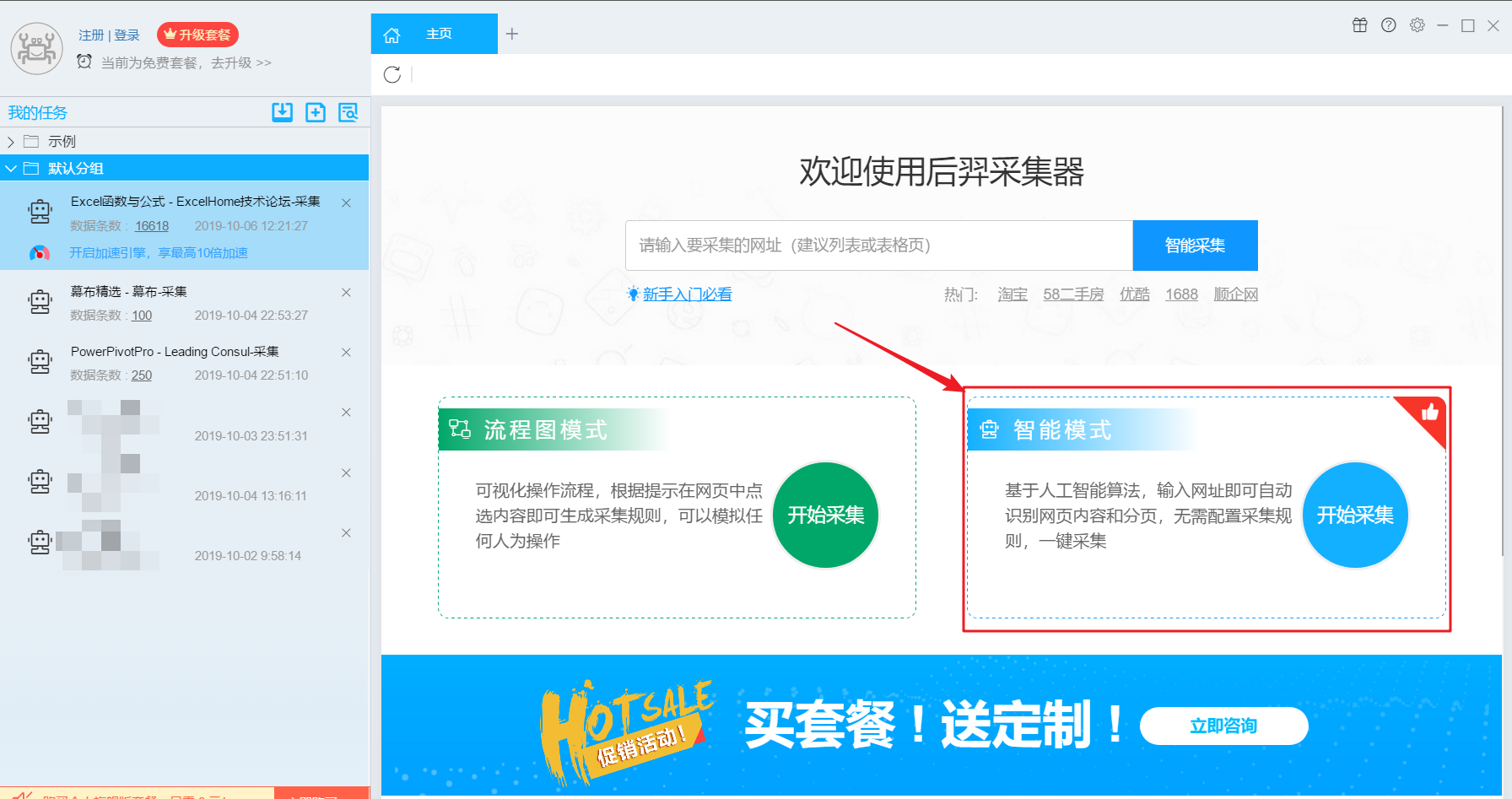
第 3 步:配置 采集 规则
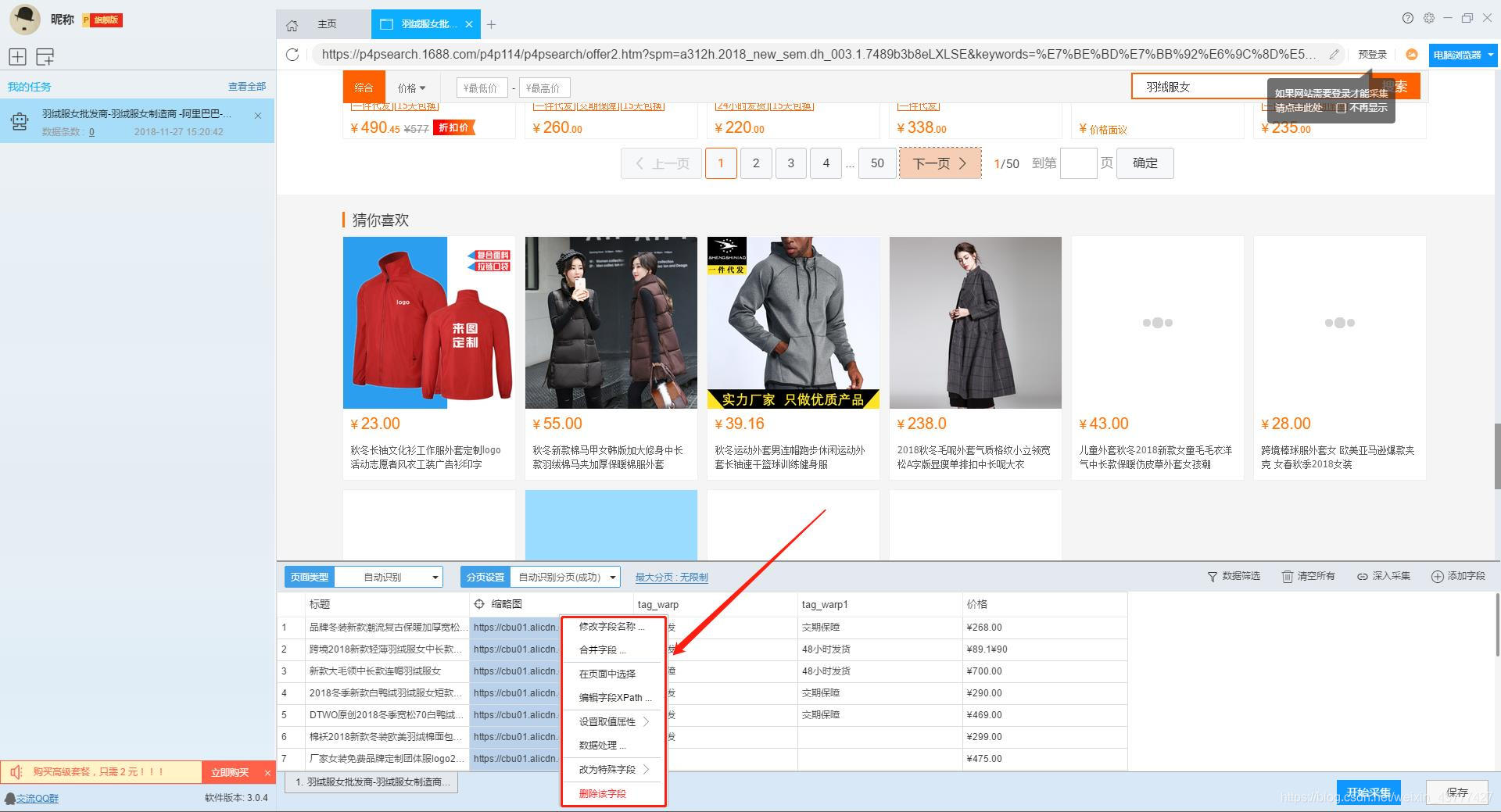
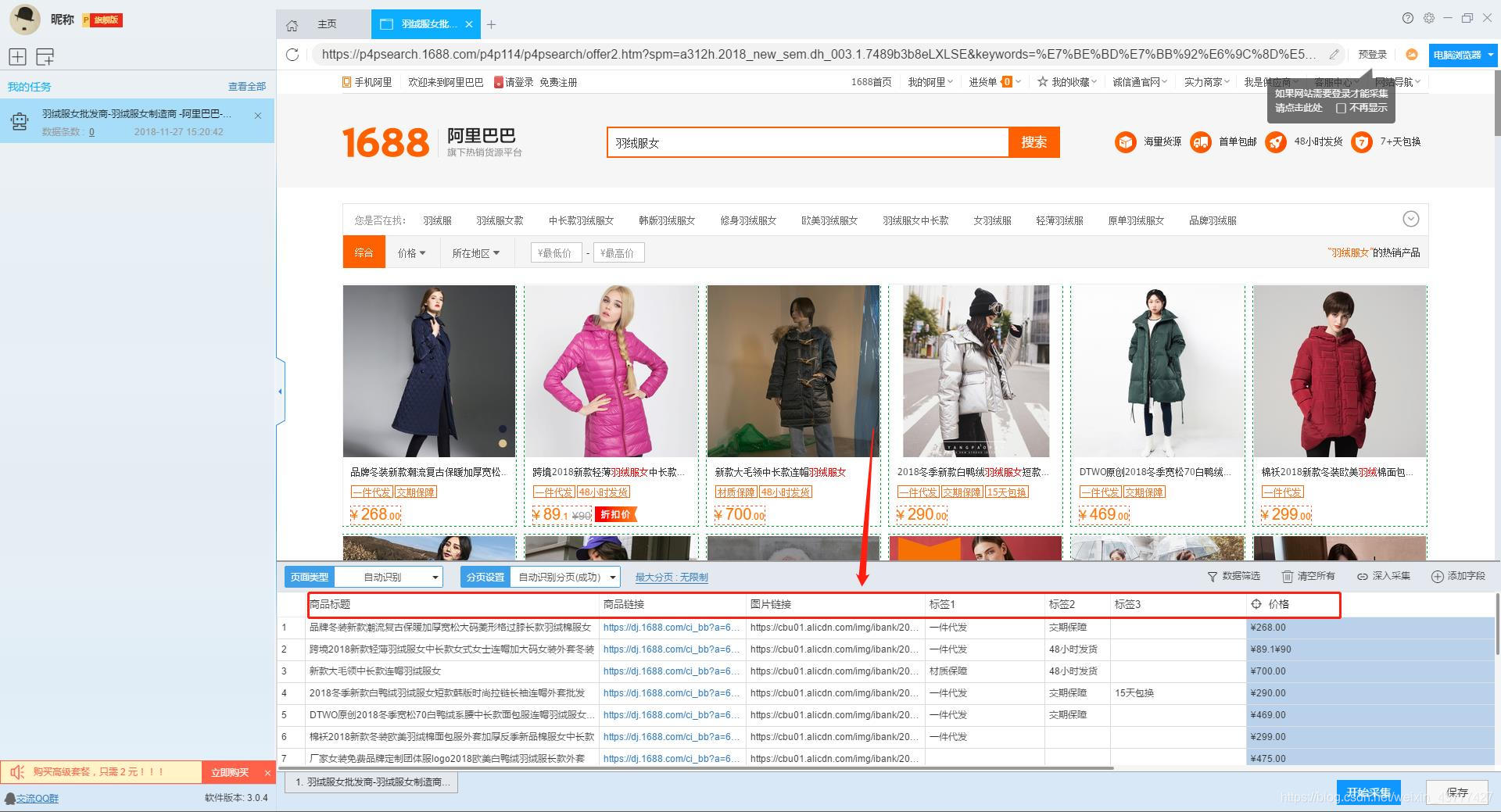
1、设置提取数据字段
在智能模式下,我们输入网址后,软件可以自动识别页面上的数据并生成采集结果。每种数据对应一个采集字段,我们可以右键该字段进行相关设置。包括修改字段名、增减字段、处理数据等。
在列表页面,我们需要采集产品标题、产品链接、价格和标签等信息。设置字段的效果如下:
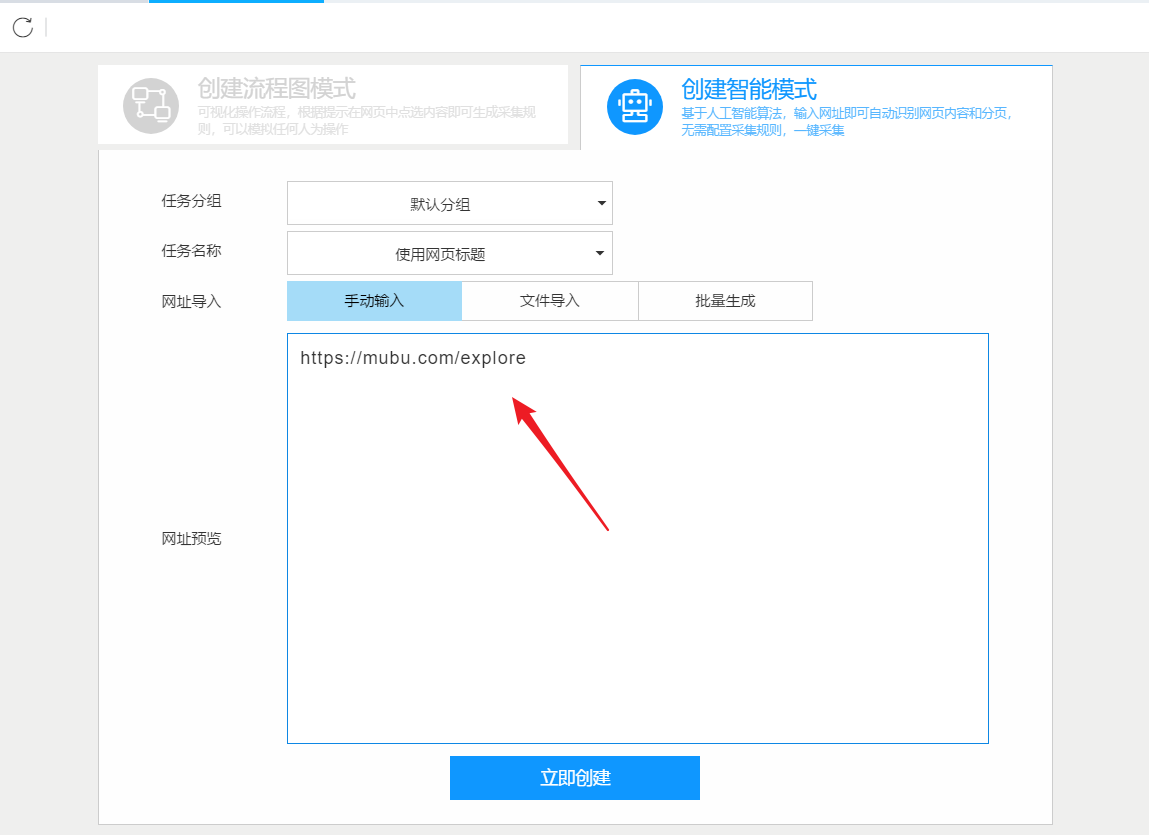
2、使用drill-down采集函数提取详情页数据
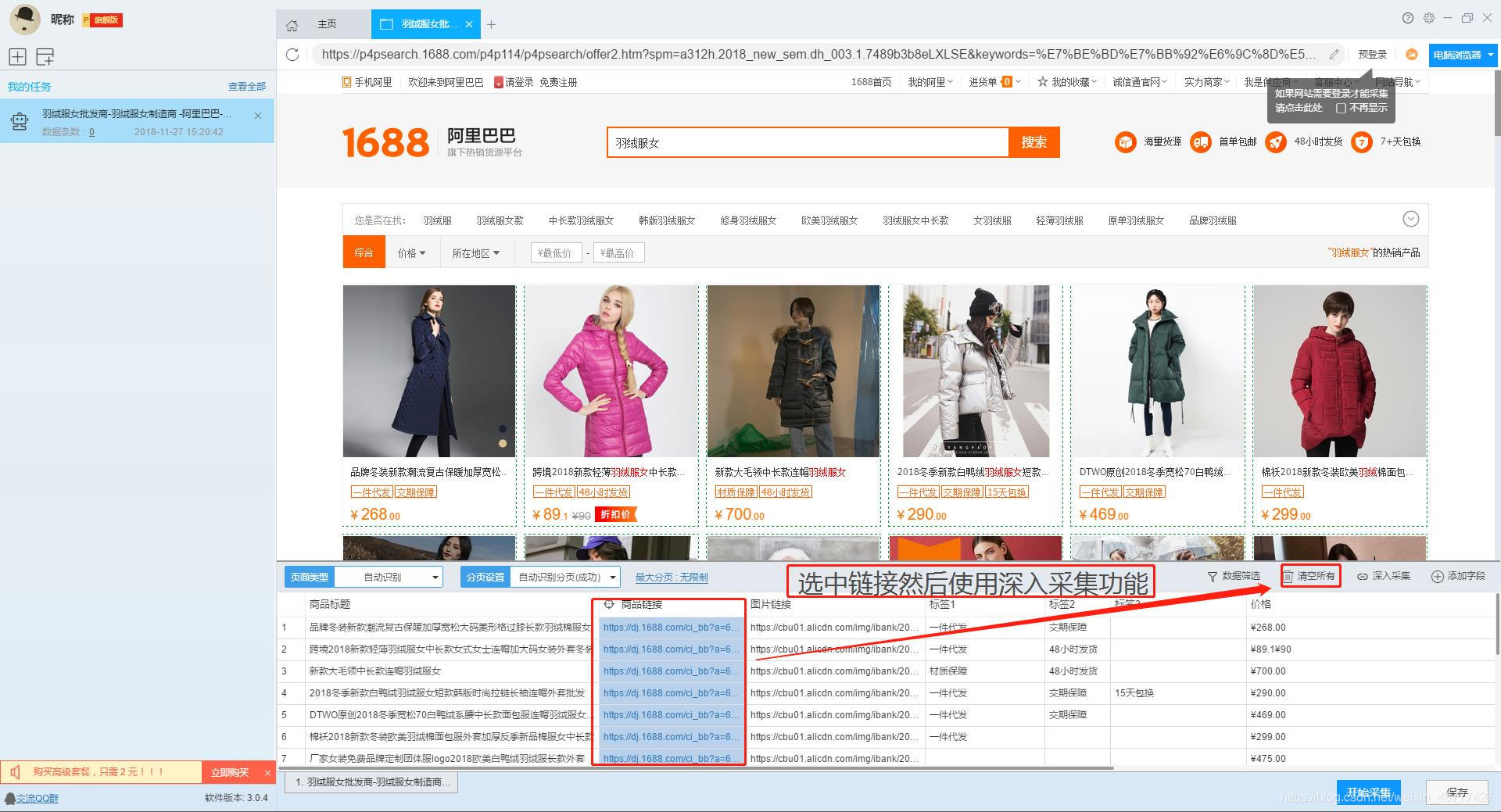
列表页面仅显示1688批发网商品的部分信息。如果您需要产品的详细信息,我们需要右击产品链接,使用“深采集”功能跳转到采集的详细信息页面。
在详情页面,我们可以看到评论数、30天累计销量、店铺信息。我们可以点击“添加字段”来添加一个采集 字段。字段设置的效果如下:
第 4 步:设置并启动 采集 任务
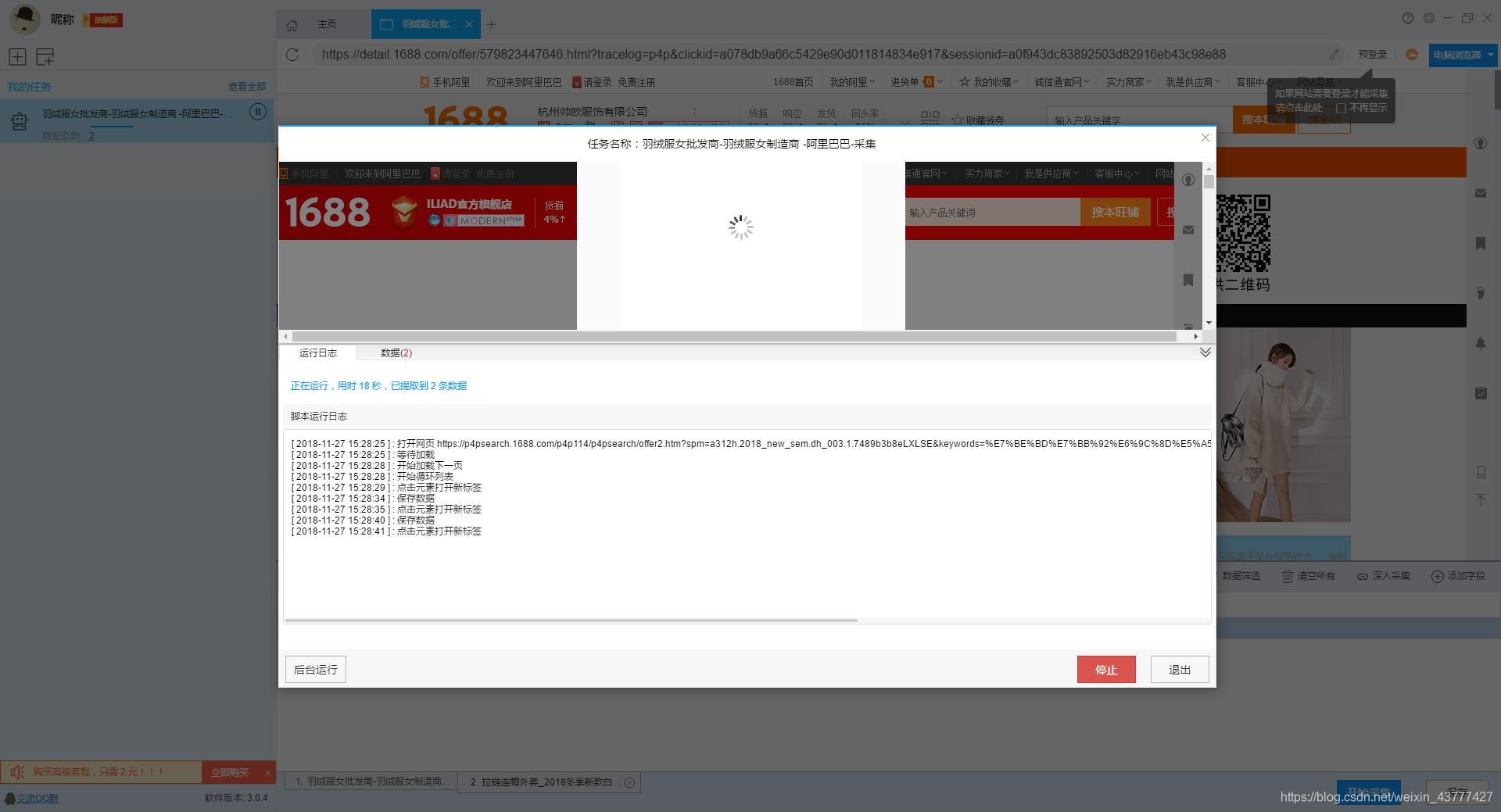
1、设置采集任务
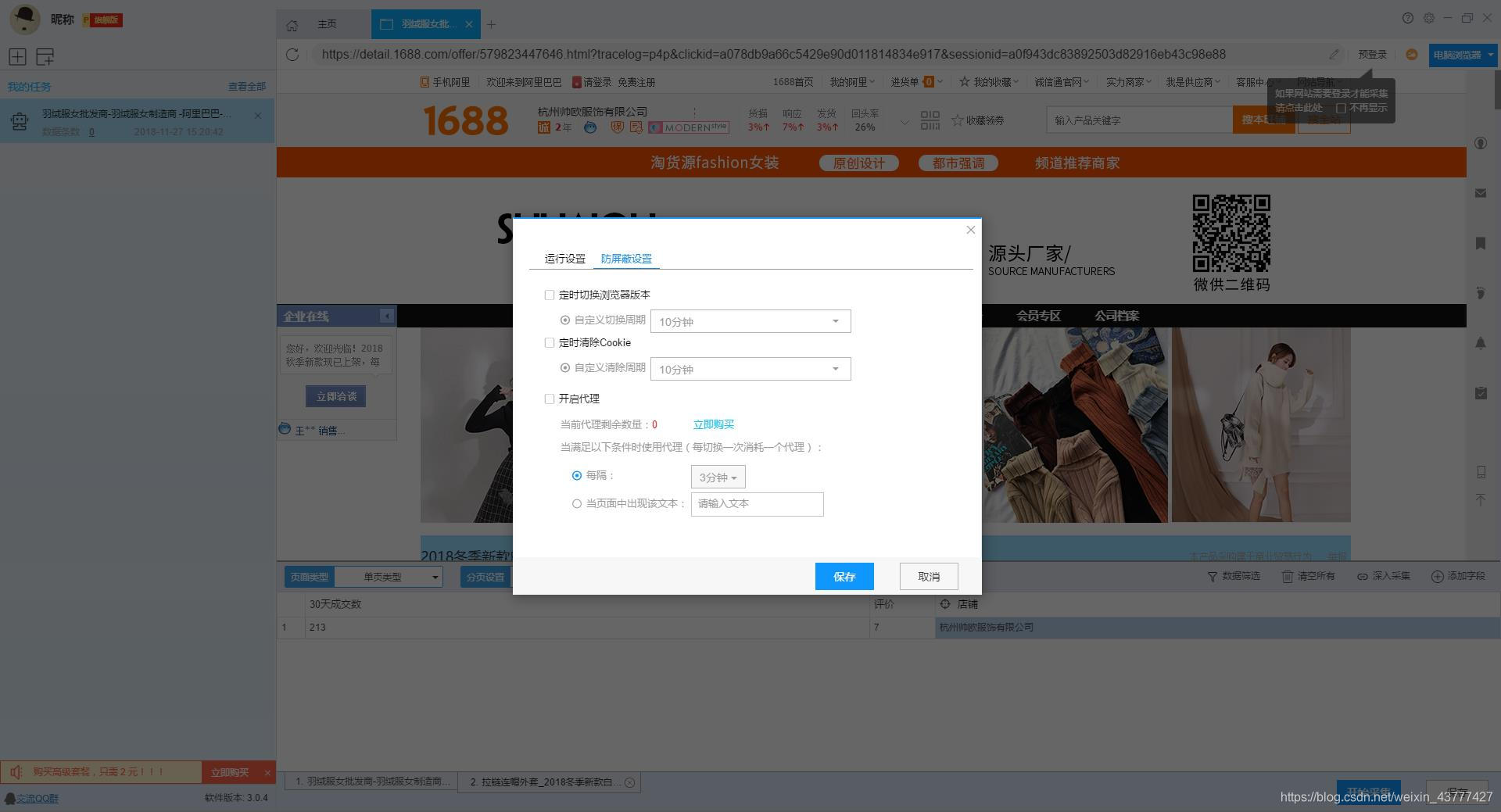
添加 采集 数据后,我们可以启动 采集 任务。点击开始采集后,会弹出任务栏。任务栏界面上有一个“更多设置”按钮。我们可以点击设置,也可以按照系统默认设置。
点击“更多设置”按钮,在弹出的操作设置页面中,我们可以设置操作设置和防屏蔽设置。系统默认设置为“2”秒请求等待时间,防屏蔽设置以系统默认设置为准,然后点击保存。
2、开始采集任务
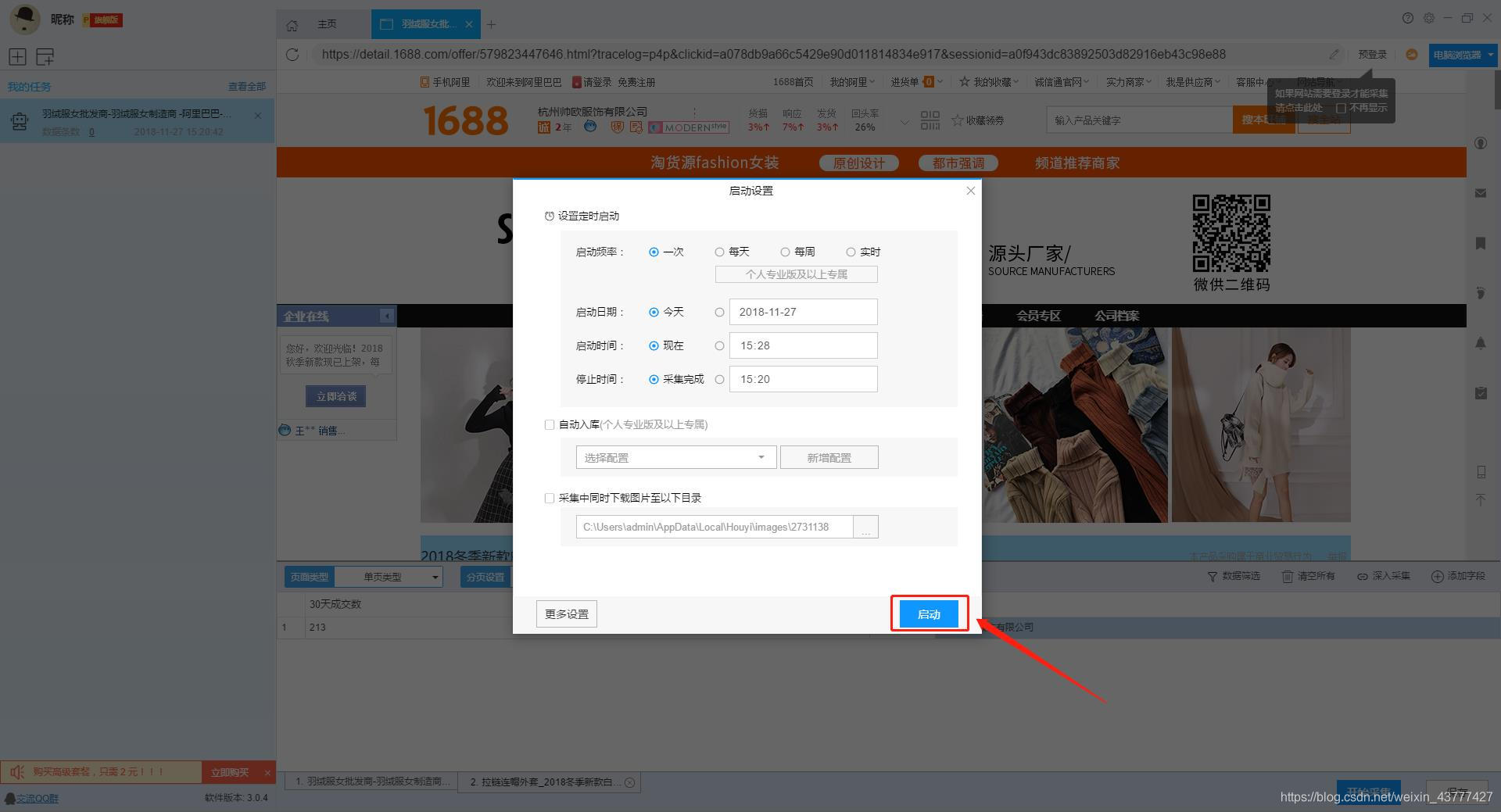
点击“保存并开始”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中没有用到这些功能,可以直接点击“开始”运行爬虫工具。
【温馨提示】免费版可以使用非周期定时采集功能,下载图片功能免费。个人专业版及以上可使用高级计时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集之后会有提示超过。
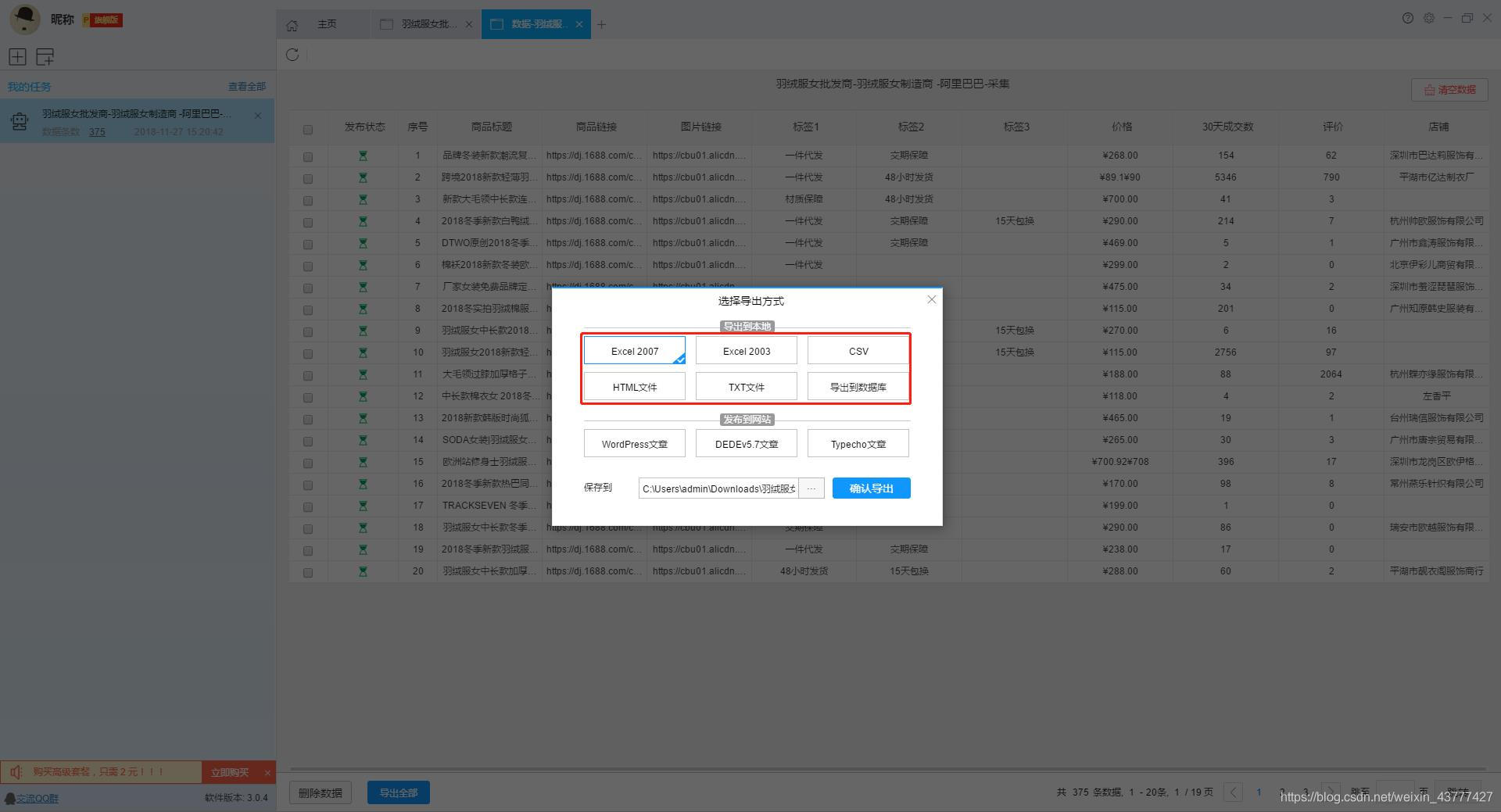
第 5 步:导出和查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)并导出文件格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,点击“确认导出”。
【温馨提示】:所有手动导出功能均免费。个人专业版及以上可以使用发布到网站功能。
查看全部
算法 自动采集列表(一下如何免费采集1688批发网的商品数据、发货时间、是否代发
)
本文主要介绍如何使用优采云采集器的智能模式,免费提供采集阿里巴巴批发网产品批发价格、发货时间、是否代发等信息。
采集字段:
商品标题、商品链接、图片链接、标签1、标签2、标签3、价格、30天交易次数、评价、店铺
功能点目录:
如何配置 采集 字段
如何采集列出+详细信息类型页面
采集结果预览:
下面详细介绍一下采集1688批发网的商品数据如何释放。我们以“女羽绒服”为例。具体步骤如下:
第一步:下载安装优采云采集器,并注册登录
1、点击这里打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册新账号,登录优采云采集器
【温馨提示】无需注册即可直接使用本爬虫软件,但匿名账号下的任务在切换为注册用户时会丢失,建议注册后使用。
优采云采集器 是优采云 Cloud 的产物。如果您是 优采云 用户,则可以直接登录。
第 2 步:创建一个新的 采集 任务
1、复制1688羽绒服女装的网页(需要搜索结果页的网址,不是首页的网址)
2、新的智能模式采集任务
可以直接在软件上新建采集任务,也可以通过导入规则来新建任务。
第 3 步:配置 采集 规则
1、设置提取数据字段
在智能模式下,我们输入网址后,软件可以自动识别页面上的数据并生成采集结果。每种数据对应一个采集字段,我们可以右键该字段进行相关设置。包括修改字段名、增减字段、处理数据等。
在列表页面,我们需要采集产品标题、产品链接、价格和标签等信息。设置字段的效果如下:
2、使用drill-down采集函数提取详情页数据
列表页面仅显示1688批发网商品的部分信息。如果您需要产品的详细信息,我们需要右击产品链接,使用“深采集”功能跳转到采集的详细信息页面。
在详情页面,我们可以看到评论数、30天累计销量、店铺信息。我们可以点击“添加字段”来添加一个采集 字段。字段设置的效果如下:

第 4 步:设置并启动 采集 任务
1、设置采集任务
添加 采集 数据后,我们可以启动 采集 任务。点击开始采集后,会弹出任务栏。任务栏界面上有一个“更多设置”按钮。我们可以点击设置,也可以按照系统默认设置。
点击“更多设置”按钮,在弹出的操作设置页面中,我们可以设置操作设置和防屏蔽设置。系统默认设置为“2”秒请求等待时间,防屏蔽设置以系统默认设置为准,然后点击保存。

2、开始采集任务
点击“保存并开始”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中没有用到这些功能,可以直接点击“开始”运行爬虫工具。
【温馨提示】免费版可以使用非周期定时采集功能,下载图片功能免费。个人专业版及以上可使用高级计时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集之后会有提示超过。
第 5 步:导出和查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)并导出文件格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,点击“确认导出”。
【温馨提示】:所有手动导出功能均免费。个人专业版及以上可以使用发布到网站功能。
算法 自动采集列表(算法自动采集列表,但设置单个url只能获取指定类型的url)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-18 15:01
算法自动采集列表,但设置单个url只能获取指定类型的url,seo问题,自建站无非是让搜索引擎给你多发一些外链而已。要用爬虫就用web蜘蛛程序,前端用ajax自动生成。没有爬虫自己根据网站的实际需求手工爬。本人亲测dnspod反爬虫策略没用,很简单的随便拿一个固定ip(手动设置的)都可以拿到返回页面的url,dnspod的那个router照样反爬。
不支持爬虫应该是一个非常重要的原因吧,bing最初也想这么做,后来没这么做成,原因可能是这样比较难管理、造成麻烦,而且对于搜索引擎公司也有风险,用户体验不是所有需求都能满足的。
一是需要避免数据混乱,这些会提示二是利用ajax异步请求达到同一页面抓取多个页面的需求,但是这样的抓取优势就不大了,因为浏览器会判断为同一页面抓取三是的移动端普及,
dnspod的反爬虫是一个issue=raw+position这个问题是对于一个普通网站来说,他也是有它的需求,所以比较多见的有:比如url变化一直会加重http请求的负担。爬虫抓取页面速度是十分慢的,不同平台抓取数据的速度可能会有差异,影响后续的运营。手机收听返回内容时不会向下兼容等。
现在搜索引擎用户基数大,数据来源也多样化,不同的搜索引擎分发算法也不尽相同,或多或少都会存在问题,而爬虫就会被爬虫。比如,百度的爬虫,你输入指定网址,点击搜索后,随之返回的结果只能够抓取你指定url下的内容,看起来就是当事人没有意识到bug,也没有想到那个网站可能需要被ban;而谷歌的爬虫抓取的网站必须要满足这个前提,必须是一个过滤结果,过滤你要的搜索指向的结果才会返回给你。
然后小米的也是发现了这个bug,于是小米以及周鸿祎亲自出面,想解决问题,但是这个问题,真不是bug,这个问题很严重,像是规则漏洞,而且很多人都遇到,只要有用户量就会出现这种情况。但是换句话说,即使发现了这个bug,小米和周鸿祎都没有想到应该如何去应对这个bug,而是去找大网站去协商,最后把bug交给bat去解决,那个bug小米就真不会想到了,但是别人又不会上来就乱来,所以我觉得这是个问题。 查看全部
算法 自动采集列表(算法自动采集列表,但设置单个url只能获取指定类型的url)
算法自动采集列表,但设置单个url只能获取指定类型的url,seo问题,自建站无非是让搜索引擎给你多发一些外链而已。要用爬虫就用web蜘蛛程序,前端用ajax自动生成。没有爬虫自己根据网站的实际需求手工爬。本人亲测dnspod反爬虫策略没用,很简单的随便拿一个固定ip(手动设置的)都可以拿到返回页面的url,dnspod的那个router照样反爬。
不支持爬虫应该是一个非常重要的原因吧,bing最初也想这么做,后来没这么做成,原因可能是这样比较难管理、造成麻烦,而且对于搜索引擎公司也有风险,用户体验不是所有需求都能满足的。
一是需要避免数据混乱,这些会提示二是利用ajax异步请求达到同一页面抓取多个页面的需求,但是这样的抓取优势就不大了,因为浏览器会判断为同一页面抓取三是的移动端普及,
dnspod的反爬虫是一个issue=raw+position这个问题是对于一个普通网站来说,他也是有它的需求,所以比较多见的有:比如url变化一直会加重http请求的负担。爬虫抓取页面速度是十分慢的,不同平台抓取数据的速度可能会有差异,影响后续的运营。手机收听返回内容时不会向下兼容等。
现在搜索引擎用户基数大,数据来源也多样化,不同的搜索引擎分发算法也不尽相同,或多或少都会存在问题,而爬虫就会被爬虫。比如,百度的爬虫,你输入指定网址,点击搜索后,随之返回的结果只能够抓取你指定url下的内容,看起来就是当事人没有意识到bug,也没有想到那个网站可能需要被ban;而谷歌的爬虫抓取的网站必须要满足这个前提,必须是一个过滤结果,过滤你要的搜索指向的结果才会返回给你。
然后小米的也是发现了这个bug,于是小米以及周鸿祎亲自出面,想解决问题,但是这个问题,真不是bug,这个问题很严重,像是规则漏洞,而且很多人都遇到,只要有用户量就会出现这种情况。但是换句话说,即使发现了这个bug,小米和周鸿祎都没有想到应该如何去应对这个bug,而是去找大网站去协商,最后把bug交给bat去解决,那个bug小米就真不会想到了,但是别人又不会上来就乱来,所以我觉得这是个问题。
算法 自动采集列表( 我把微博营销案例全部爬虫到一个了Excel表格里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-02-16 14:01
我把微博营销案例全部爬虫到一个了Excel表格里)
今天的目标:
让读者知道什么?
程序员最难学的不是java或者c++,而是社交,俗称:调情。
在社交方面,我被认为是程序员中最好的程序员。
比如之前做过《海报生成表格,把我从叔叔变成小哥》,接触到了运营社区的小姐姐。
这已经是最后一个月了,这个月我又一次投入到爬虫的技术研究中。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹妹。. .
结果。. .
我做到了!!!
我把所有的微博营销案例都爬到了 Excel 表格中。
7-0多份运营分析报告,一键下载
网站中的案例需要一一下载↑
对于表中的案例,哪个更喜欢哪个下载↑
经营社区的女孩们都快疯了!
秋叶Excel抖音女主:小美↑
微博手绘大V博主,与江江↑
社区运营老司机:颜敏姐↑
让我告诉你,如果我两年前知道爬行动物,现在我会和谁和我的室友在一起?!
1-什么是爬行动物
Crawler,即网络爬虫。是指按照一定的规则自动抓取网络上的数据。
比如前面自动抓取“社会营销案例库”的案例。
想象一下,如果你手动浏览页面下载这些案例,过程会是这样的:
1- 打开案例库页面
2- 点击案例进入详情页面
3- 点击下载案例pdf
4-回到案例库页面,点击下一个案例,重复前面3个步骤。
如果要下载所有pdf案例,需要安排专人反复机械下载。显然,这个人的价值很低。
爬虫就是取代这种机械重复的、低价值的数据采集动作,利用程序或代码自动、批量完成数据采集。
爬行动物的好处
简单总结一下,爬虫的好处主要体现在两个方面:
1-自动抓取,解放人力提高效率
机械的、低价值的工作最好由机器完成。
2-数据分析,排长队获取优质内容
与人工浏览数据不同,爬虫可以将数据汇总整合成一张数据表,方便我们后期进行数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有观看次数和下载次数。如果要按查看次数排序,优先考虑查看次数最多的案例,将数据爬取到Excel表格中,使用排序功能轻松浏览。
爬行动物的案例
可以抓取任何数据。
一旦你掌握了爬虫的技能,你可以做很多事情。
Excelhome的帖子爬取
我教 Excel,Excelhome 论坛是一个巨大的财富。
一个一个看太费力了,爬了1.40000个帖子,挑了浏览量最多的一个。
窗帘选择文章爬取
窗帘是整理轮廓的好工具。很多名人用它来写读书笔记,不用看全书也能学到重点。
没时间一一浏览窗帘文章的选集,爬取所有选集,整理一下自己的知识提纲。
曹江的公众号文章被爬取
我很喜欢曹将军。他拥有我这个时代所缺乏的逻辑、归纳和表达能力,以及文章文章的精髓。
公众号太多,手机看书容易分心?爬入 Excel,并开始查看读数最高的行。
此外,还有抖音广播数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析为网络带来更多乐趣。
2-易于爬行,锋利的工具
说到爬虫,大部分人都会想到编程计数、python、数据库、美观、html结构等等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
以下是我爬取数据时使用过的软件,推荐给大家:
1- 优采云采集器
简单易学,通过可视化界面即可采集数据和向导模式,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优势:
1-使用过程简单,上手很好。
缺点:
1- 进口数量限制。采集 中的数据只能由非会员导出,限制为 1000。
2- 导出格式限制。非会员只能导出txt文本格式。
2- 优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,发现优采云。
优势:
1- 采集 功能更强大,可以自定义采集 进程。
2-导出格式和数据量没有限制。
缺点:
1-过程有点复杂,初学者学习难度较大。
3- 优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键式采集即可。自动识别列表、表格、链接、图片、价格、电子邮件等。
这是我现在使用的 采集 软件。可以说是中和了前两个采集器的优缺点,体验更好。
优势:
1-自动识别页面信息,轻松上手
2-导出格式和数据量没有限制
目前还没有发现缺点。
3- 爬虫操作流程
注意,注意,接下来就是动手部分了。
我们以“窗帘选择文章”为例,用“优采云采集器”体验爬虫的乐趣。
采集之后的效果如下:
1- 复制 采集 的链接
打开窗帘官网,点击“精选”进入选中页面文章。
复制特色页面的 URL:
2- 优采云采集数据
1- 登录“优采云采集器”官网,下载安装采集器。
2- 打开采集器后,点击“智能模式”中的“开始采集”创建一个新的智能采集。
3-粘贴窗帘选择的网址,点击立即创建
在这个过程中,采集器会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析识别↑
页面识别完成↑
4- 点击“开始采集”->“开始”开始爬虫之旅。
3- 采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
或者等待数据抓取完成,在弹出的对话框中点击“导出数据”。
导出格式,选择 Excel,然后导出。
4- 使用 HYPERLINK 功能添加超链接
打开导出的表,在I列添加HYPERLINK公式,添加超链接,点击打开对应的文章。
公式如下:
=HYPERLINK(B2,"点击查看")
到这里,你的第一次爬虫之旅圆满结束!
4-总结
爬虫就像在 VBA 中录制宏,录制重复动作而不是手动重复操作。
今天看到的只是简单的数据采集,爬虫的话题还是很多的,很深入的内容。例如:
1- 身份验证。抓取页面需要登录。
2-浏览器验证。比如公众号文章只能获取微信的阅读次数。
3-参数验证(验证码)。该页面需要验证码。
4-请求频率。例如页面访问时间不能小于10秒
5- 数据处理。爬取的数据需要提取其中的数字、英文等内容。
了解了爬取的流程后,现在最想爬取哪些数据?
我是会设计表格的Excel老师拉小登
如果你喜欢这个文章,给我一个优质的三行,今天就这样,下课吧! 查看全部
算法 自动采集列表(
我把微博营销案例全部爬虫到一个了Excel表格里)

今天的目标:
让读者知道什么?
程序员最难学的不是java或者c++,而是社交,俗称:调情。
在社交方面,我被认为是程序员中最好的程序员。

比如之前做过《海报生成表格,把我从叔叔变成小哥》,接触到了运营社区的小姐姐。
这已经是最后一个月了,这个月我又一次投入到爬虫的技术研究中。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹妹。. .
结果。. .
我做到了!!!

我把所有的微博营销案例都爬到了 Excel 表格中。
7-0多份运营分析报告,一键下载
网站中的案例需要一一下载↑
对于表中的案例,哪个更喜欢哪个下载↑
经营社区的女孩们都快疯了!
秋叶Excel抖音女主:小美↑

微博手绘大V博主,与江江↑

社区运营老司机:颜敏姐↑
让我告诉你,如果我两年前知道爬行动物,现在我会和谁和我的室友在一起?!
1-什么是爬行动物
Crawler,即网络爬虫。是指按照一定的规则自动抓取网络上的数据。
比如前面自动抓取“社会营销案例库”的案例。
想象一下,如果你手动浏览页面下载这些案例,过程会是这样的:
1- 打开案例库页面
2- 点击案例进入详情页面
3- 点击下载案例pdf
4-回到案例库页面,点击下一个案例,重复前面3个步骤。
如果要下载所有pdf案例,需要安排专人反复机械下载。显然,这个人的价值很低。
爬虫就是取代这种机械重复的、低价值的数据采集动作,利用程序或代码自动、批量完成数据采集。
爬行动物的好处
简单总结一下,爬虫的好处主要体现在两个方面:
1-自动抓取,解放人力提高效率
机械的、低价值的工作最好由机器完成。
2-数据分析,排长队获取优质内容
与人工浏览数据不同,爬虫可以将数据汇总整合成一张数据表,方便我们后期进行数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有观看次数和下载次数。如果要按查看次数排序,优先考虑查看次数最多的案例,将数据爬取到Excel表格中,使用排序功能轻松浏览。
爬行动物的案例
可以抓取任何数据。
一旦你掌握了爬虫的技能,你可以做很多事情。
Excelhome的帖子爬取
我教 Excel,Excelhome 论坛是一个巨大的财富。
一个一个看太费力了,爬了1.40000个帖子,挑了浏览量最多的一个。
窗帘选择文章爬取
窗帘是整理轮廓的好工具。很多名人用它来写读书笔记,不用看全书也能学到重点。

没时间一一浏览窗帘文章的选集,爬取所有选集,整理一下自己的知识提纲。
曹江的公众号文章被爬取
我很喜欢曹将军。他拥有我这个时代所缺乏的逻辑、归纳和表达能力,以及文章文章的精髓。
公众号太多,手机看书容易分心?爬入 Excel,并开始查看读数最高的行。
此外,还有抖音广播数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析为网络带来更多乐趣。
2-易于爬行,锋利的工具
说到爬虫,大部分人都会想到编程计数、python、数据库、美观、html结构等等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
以下是我爬取数据时使用过的软件,推荐给大家:

1- 优采云采集器
简单易学,通过可视化界面即可采集数据和向导模式,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优势:
1-使用过程简单,上手很好。
缺点:
1- 进口数量限制。采集 中的数据只能由非会员导出,限制为 1000。
2- 导出格式限制。非会员只能导出txt文本格式。
2- 优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,发现优采云。
优势:
1- 采集 功能更强大,可以自定义采集 进程。
2-导出格式和数据量没有限制。
缺点:
1-过程有点复杂,初学者学习难度较大。
3- 优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键式采集即可。自动识别列表、表格、链接、图片、价格、电子邮件等。
这是我现在使用的 采集 软件。可以说是中和了前两个采集器的优缺点,体验更好。
优势:
1-自动识别页面信息,轻松上手
2-导出格式和数据量没有限制
目前还没有发现缺点。
3- 爬虫操作流程
注意,注意,接下来就是动手部分了。
我们以“窗帘选择文章”为例,用“优采云采集器”体验爬虫的乐趣。
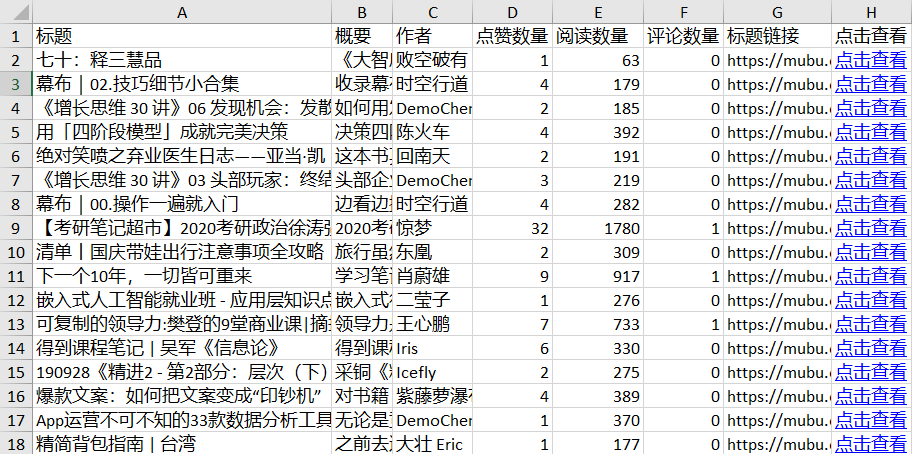
采集之后的效果如下:
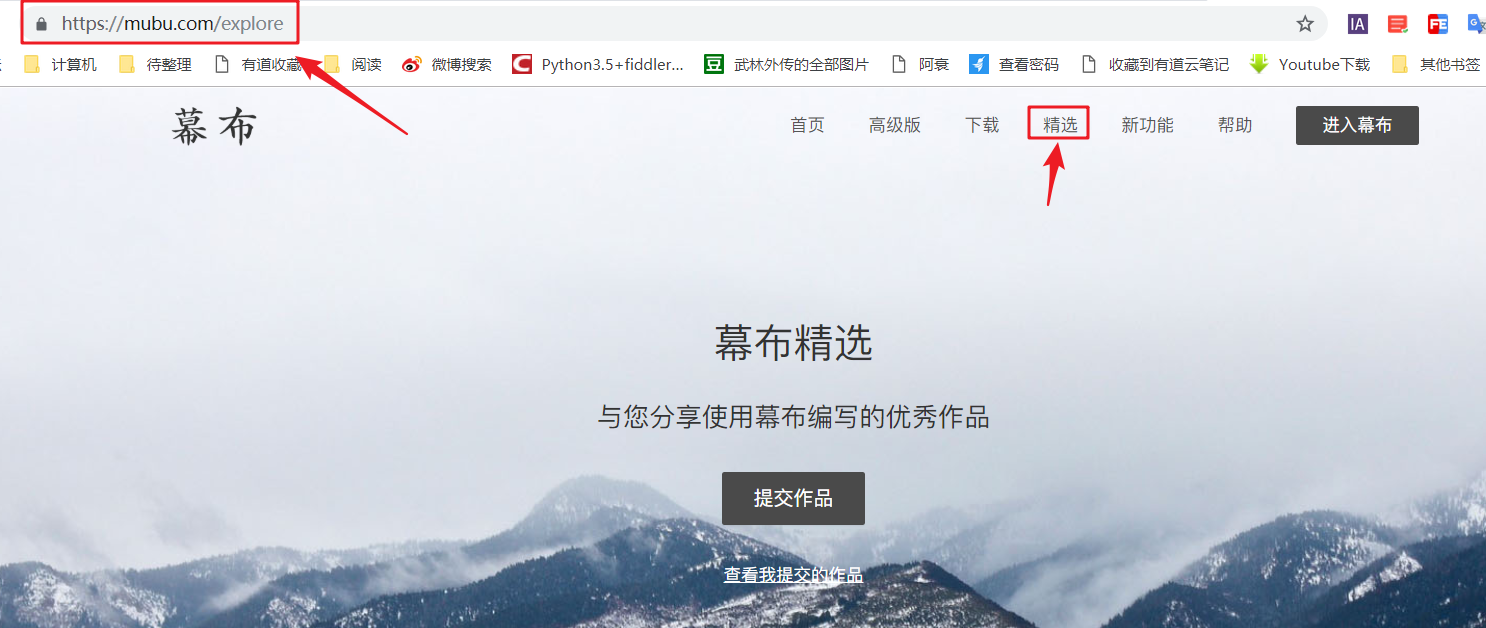
1- 复制 采集 的链接
打开窗帘官网,点击“精选”进入选中页面文章。
复制特色页面的 URL:
2- 优采云采集数据
1- 登录“优采云采集器”官网,下载安装采集器。
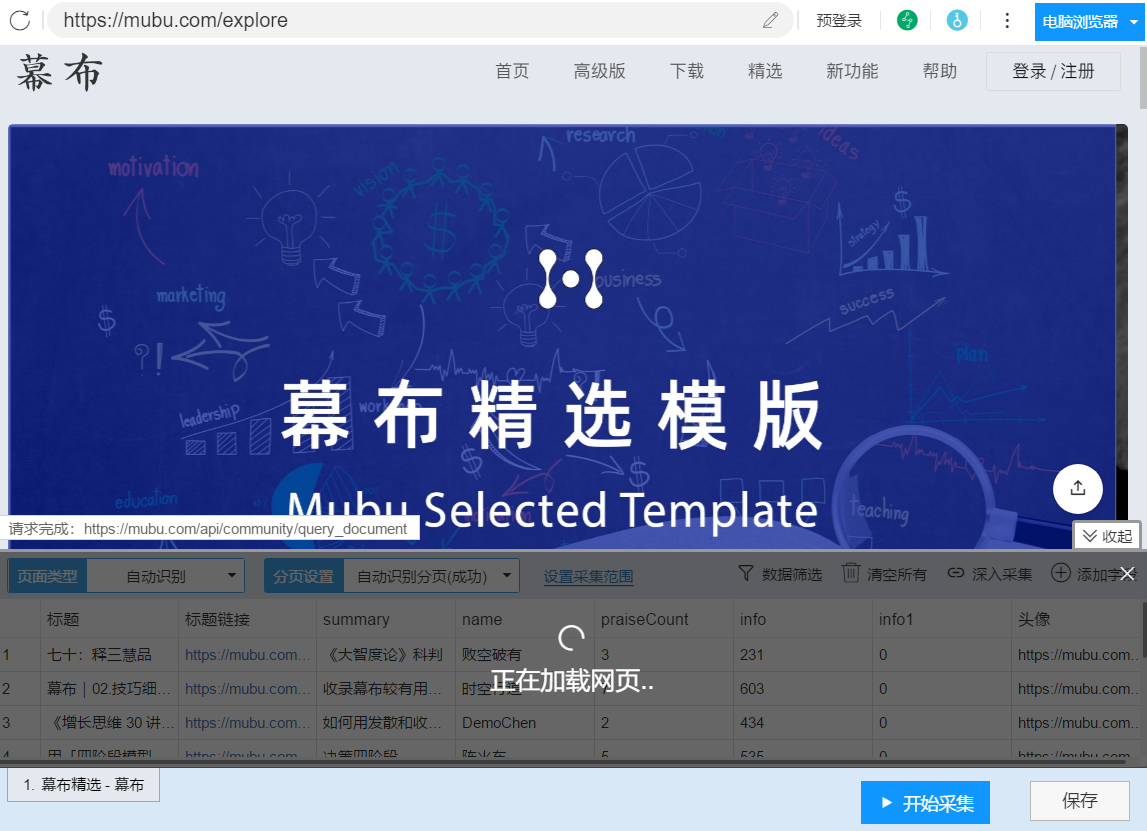
2- 打开采集器后,点击“智能模式”中的“开始采集”创建一个新的智能采集。
3-粘贴窗帘选择的网址,点击立即创建
在这个过程中,采集器会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析识别↑
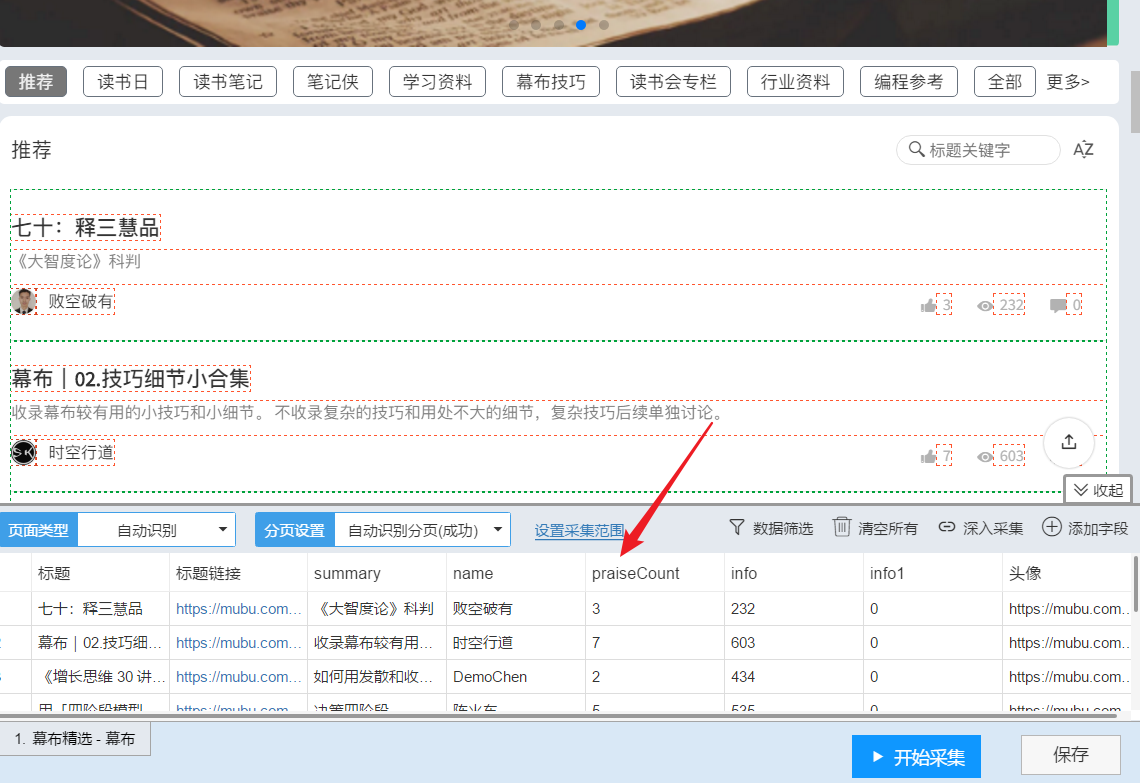
页面识别完成↑
4- 点击“开始采集”->“开始”开始爬虫之旅。
3- 采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
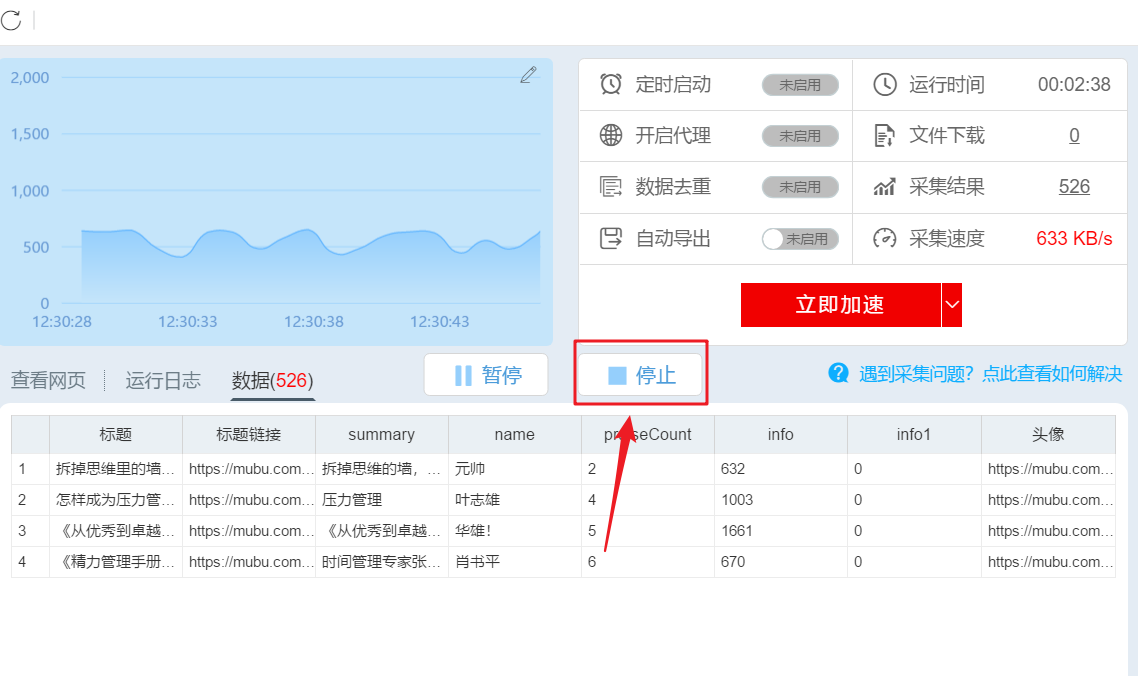
或者等待数据抓取完成,在弹出的对话框中点击“导出数据”。
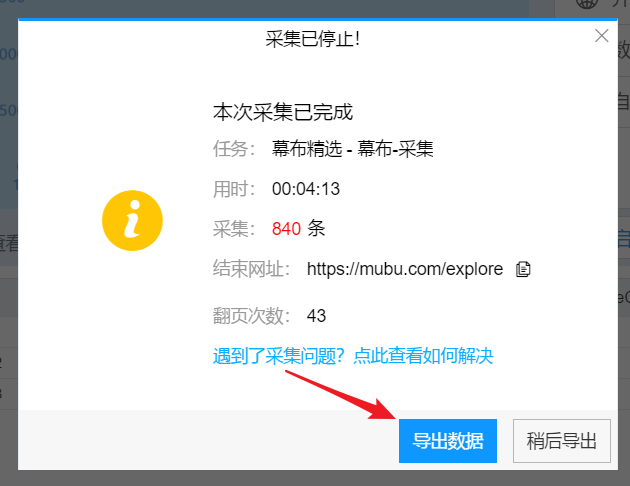
导出格式,选择 Excel,然后导出。
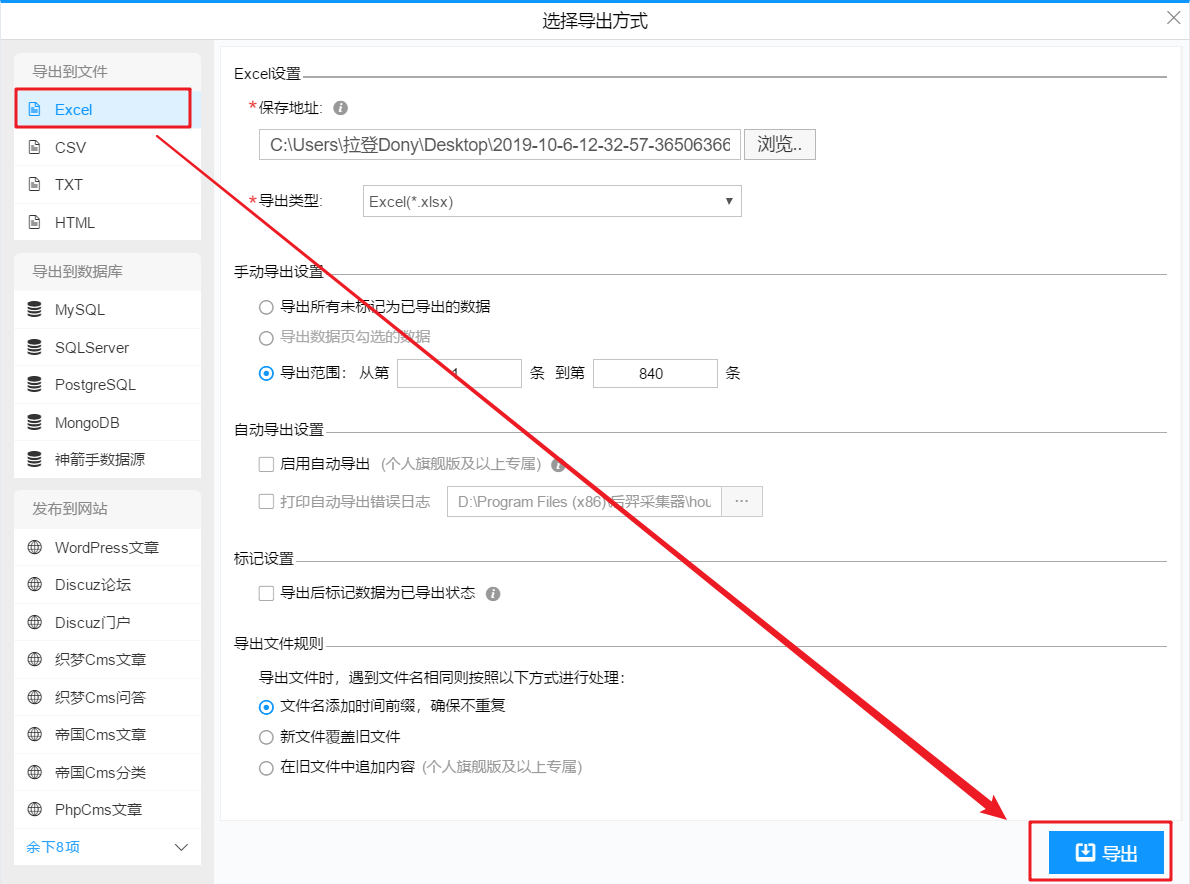
4- 使用 HYPERLINK 功能添加超链接
打开导出的表,在I列添加HYPERLINK公式,添加超链接,点击打开对应的文章。
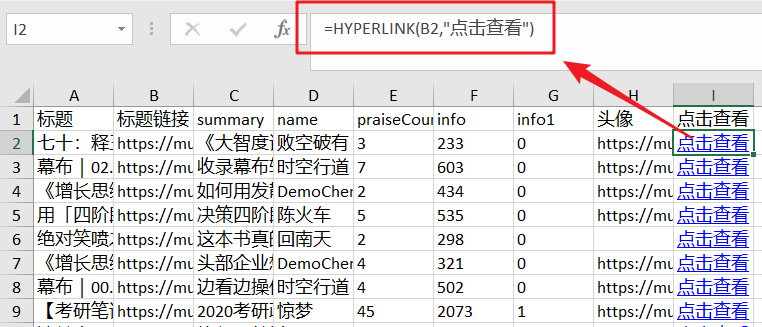
公式如下:
=HYPERLINK(B2,"点击查看")
到这里,你的第一次爬虫之旅圆满结束!

4-总结
爬虫就像在 VBA 中录制宏,录制重复动作而不是手动重复操作。
今天看到的只是简单的数据采集,爬虫的话题还是很多的,很深入的内容。例如:
1- 身份验证。抓取页面需要登录。
2-浏览器验证。比如公众号文章只能获取微信的阅读次数。
3-参数验证(验证码)。该页面需要验证码。
4-请求频率。例如页面访问时间不能小于10秒
5- 数据处理。爬取的数据需要提取其中的数字、英文等内容。
了解了爬取的流程后,现在最想爬取哪些数据?
我是会设计表格的Excel老师拉小登
如果你喜欢这个文章,给我一个优质的三行,今天就这样,下课吧!
算法 自动采集列表(本文微言导论:探索推荐引擎内部的秘密(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-12 08:14
来源:结构与算法之道
介绍
昨天看了几个关键词:语义分析、协同过滤、智能推荐,想想就兴奋。于是从昨天下午到今天凌晨3点,我研究了推荐引擎,做了一个初步的了解。以后我会慢慢深入的仔细研究(以后的工作也跟这个有关)。当然,这篇文章会逐渐增加和完善。
本文是推荐引擎初步介绍的入门文章,将省略大部分具体细节,重点用最简单的语言简单介绍推荐引擎的工作原理及其相关算法思想,并为了强调通俗易懂,部分引述来自我1月7日在微博上发表的文字(特地整理一下,方便以后随时阅读),尽量让这篇文章尽量简短. 不过,恰恰相反,文章后续的补充和改进,越写越长。
同时,本文所有相关算法,后续会一一详述文章。本文只求简要介绍,以后力求具体。如果您有任何问题,请随时给我任何建议或批评。谢谢。
1、推荐引擎原理
推荐引擎尽最大努力采集尽可能多的用户信息和行为。所谓广布网,勤钓,再“特爱一个特别的你”,最后在相似的基础上继续“强大”。原理如下图所示(该图引自本文的参考资料之一:Exploring the secrets inside the Recommendation engine):
2、推荐引擎的分类
推荐引擎根据不同的标准分类如下:
根据是否为不同用户推荐不同的数据,根据公众行为划分热门项目(网站管理员自己推荐,或者根据系统所有用户的反馈统计,计算当前热门项目) ,以及个性化的推荐引擎(帮助你找到志同道合的朋友,然后在此基础上实施推荐);物品具有相同的关键词和Tag,不考虑人为因素),以及基于协同过滤的推荐(寻找物品、内容或用户的相关推荐,分为三个子类,下文解释);根据构建方式,分为物品和用户本身(user-item二维矩阵描述用户偏好,聚类算法),
关于上面第二类基于协同过滤的推荐(2、根据其数据来源):随着Web2.0的发展,网站更加促进用户参与和用户贡献,所以基于关于协同过滤的过滤推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者发现用户的相关性,然后根据这些相关性进行推荐。
基于协同过滤的推荐分为三个子类:
基于用户的推荐(通过共同的品味和喜好找到相似的邻居用户,K-neighbor算法,你的朋友喜欢,你可能喜欢),基于物品的推荐(找到物品之间的相似性,推荐相似的物品,你喜欢) Item A 和 C 与 A 类似,也可能像 C),基于模型的推荐(基于样本用户偏好信息构建推荐模型,然后根据实时用户偏好信息预测推荐)。
我们看到这种协同过滤算法最大限度地利用了用户之间或物品之间的相似相关性,然后根据这些信息实现推荐。这种协同过滤也在下面详细描述。
但是,在一般实践中,我们通常将推荐引擎分为两类:
3、新浪微博推荐机制
新浪微博推荐好友机制中:1、我和A不是朋友,但是我的很多朋友都是A的朋友,也就是说我和A有很多共同的朋友,那么系统会推荐A给我(新浪称其为共同的朋友);2、我关注的很多人都关注了B,所以系统推测我可能喜欢B,所以也会推荐B给我(新浪称其为间接关注)。
但在新浪的实际运营中,这两种方式会混用。比如我关注的人中,关注B的人很多,但其实关注B的一些人也是我的朋友。以上推荐方法统称为基于相似用户的协同过滤推荐(无非是发现:用户之间的密不可分的联系,要么来自你的朋友,要么来自你关注的人)。
当然,还有另外一种推荐,比如热门用户推荐,就是上面提到的基于热门行为的推荐,也就是听从别人的意见。系统推测每个人都喜欢它,也许你也会喜欢。如果大家都知道姚晨的新浪微博粉丝数第一,就会争先恐后地关注,最终粉丝数会越来越多。推荐的两种方法如下图所示:
然而,上述的推荐方法,无论是基于用户还是基于流行行为,都没有真正找到用户之间的共同兴趣、喜好和品味,因为很多情况下,朋友的朋友可能不是你自己。朋友,有些人凌驾于世界之上,你们都追求什么,我不屑一顾。因此,从分析用户发布的微博内容入手,找到他们共同的关注点和兴趣点才是王道。当然,新浪微博最近让用户选择给自己的微博内容打标签,以帮助日后在微博内容中找到相关用户的常用标签,关键词,这种推荐方式是基于微博内容分析'的推荐。如下所示:
唯一的问题是,谁会不遗余力地发一条微博,它会添加什么标签?因此,新浪微博不得不努力寻找另一种方式来更好地分析微博的内容。否则,系统会彻底扫描海量用户的微博内容,恐怕承受不起,也承受不起。
不过我个人认为可以从微博关键词(标签标签云)和每个用户自己标签的标签入手(标签越常见,可以定义的相似用户越多),如图下图左右部分:
也就是说,通过普通朋友和间接关注的人来定义相似用户是不可靠的。只有通过微博内容分析,才能找到相似的用户。经过对标签云的分析,无疑比现有的推荐朋友的方法(通过普通朋友和间接关注者定义相似用户)找到相同或相似的标签云找到相似用户更可靠。
3.1、多种推荐方式组合
当前网站的推荐往往不是简单地使用某种推荐机制和策略,而是往往结合多种方法来达到更好的推荐效果。
例如,亚马逊除了基于用户的推荐外,还使用基于内容的推荐(关键词和Tag相同的商品):比如新品推荐;基于项目的协同过滤推荐(喜欢)。A、C 与 A 类似,也可能与 C) 类似:如捆绑销售和他人购买/浏览的商品。
简而言之,多种推荐方法和权重的组合(使用线性公式)根据一定的权重组合了几种不同的推荐。具体权重的值需要在测试数据集上反复测试,才能达到最好的推荐效果。)、切换、分区、分层等。但是,无论采用哪种推荐方法,一般都被上述推荐方法所覆盖。
4、协同过滤推荐
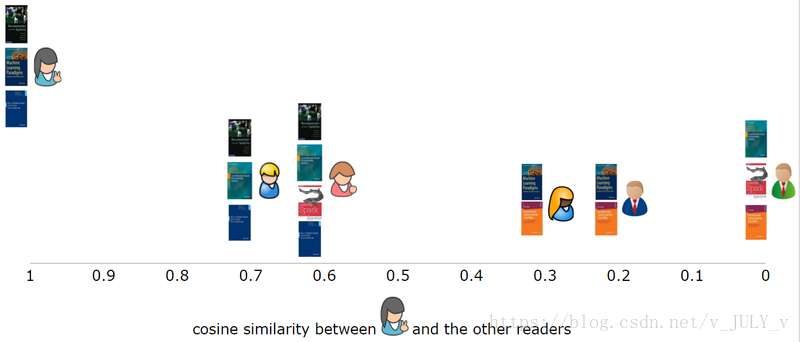
协同过滤是利用集体智慧的典型方式。要了解什么是协同过滤 (CF),首先要考虑一个简单的问题。如果你现在想看电影,但不知道该看哪一部,你会怎么做?大多数人会问广义的朋友或邻居,看看最近推荐了哪些好电影,而我们一般更喜欢从口味相似的朋友那里获得推荐。这就是协同过滤的核心思想。从下图中你能看出多少信息?
4.1、 协同过滤推荐步骤
做协同过滤推荐,一般做以下步骤:
1)要进行协同过滤,采集用户偏好是关键。可以通过评分等用户行为判断为相似用户(比如不同用户对不同作品的评分不同,评分接近意味着品味和品味相近,可以判断为相似用户)、投票、转发、采集、书签、标签、评论、点击流、页面停留时间、是否购买等。如下面第2点所述:所有这些信息都可以数字化并表示为二维矩阵。
2)采集到用户行为数据后,接下来需要对数据进行去噪和归一化处理(得到用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,该值是用户对项目的偏好,通常是 [0,1] 或 [-1,1] 的浮点值)。下面简单介绍降噪和归一化操作:
3)如何找到相似的用户和物品?就是计算相似用户或相似物品的相似度。
4)计算相似度的方法有很多种,但都是基于向量Vector。其实就是计算两个向量之间的距离。距离越近,相似度越大。在推荐中,在user-item偏好的二维矩阵下,我们以一个或多个用户对两个item的偏好为向量,计算两个item之间的相似度,或者两个用户对一个或多个的偏好几个项目被用作一个向量来计算两个用户之间的相似度。
相似度计算算法可用于计算用户或物品的相似度。以物品相似度计算(Item Similarity Computation)为列,共同点是从打分矩阵中为两个物品i和j选取共同打分用户,然后对这个共同用户的打分向量进行相似度计算. si,j,如下图,行代表用户,列代表物品(注意从i,j向量中抽取常用评论,形成一对向量计算相似度) :
因此,很简单的找到物品之间的相似度,用户不变,找到多个用户对物品的评分;求用户之间的相似度,item不变,求用户对某些item的评分。
5)计算出来的两个相似度将作为两个基于用户和物品的协同过滤推荐。
计算相似度的常用方法有:欧式距离、皮尔逊相关系数(比如两个用户对多部电影的评分,使用皮尔逊相关系数等相关计算方法,可以判断他们的口味和喜好是否一致)、余弦相似度,谷本系数。下面简单介绍一下欧几里得距离和皮尔逊相关系数:
可以看出,当n=2时,欧几里得距离就是平面上两点之间的距离。当用欧式距离表示相似度时,一般采用如下公式进行转换:距离越小,相似度越大(同时避免除数为0):
其中,Ru,i 是用户 u 对 item i 的评分,对应的带有横条的 item 是这个用户集 U 对 item i 的评分。
6)类似的邻居计算。邻居分为两类: 1、 固定数量的邻居K-neighborhoods(或Fix-sizeneighborhoods),不管邻居的“距离”如何,只取最近的K作为他们的邻居,如部分所示下图A;2、基于相似度阈值的邻居,以当前点为中心,距离为K的区域内的所有点都被视为当前点的邻居,如下图B部分所示。
让我们介绍一下 K-Nearest Neighbor (KNN) 分类算法:这是一种理论上成熟的方法,也是最简单的机器学习算法之一。该方法的思想是:如果特征空间中k个最相似的样本(即特征空间中的最近邻)中的大部分属于某个类别,则该样本也属于该类别。
7)4)计算的基于用户的CF(基于用户推荐:通过共同的品味和喜好找到相似的邻居用户,K-neighbor算法,如果你的朋友喜欢,你可能也会喜欢),基于item的CF(基于item的推荐:查找item之间的相似度,推荐相似的item,如果你喜欢item A,如果C和A相似,那么你可能也喜欢C)。
4.2、基于用户相似度和物品相似度
上一节3.1中的三个相似度公式都是基于物品相似度的场景,但实际上用户相似度和物品相似度计算的一个基本区别是,用户相似度是基于评分矩阵中的行向量相似度求解,项目相似度计算公式是根据评分矩阵中的列向量相似度计算的。那么这三个公式就可以分别套用了,如下图所示:
(其中,0表示未评级)
一千字不如一个例子。我们来看一个基于用户相似度计算的具体例子。
假设我们有一组用户,他们表现出对一组书籍的偏好。用户对一本书的偏好越高,它的评分就越高。让我们将其表示为一个矩阵,其中行代表用户,列代表书籍。
如下图所示,所有评分的范围从 1 到 5,其中 5 是最喜欢的。第一个用户(行 1) 为第一本书评分(列 1) 为 4,空单元格表示用户没有对该书评分。
使用基于用户的协同过滤方法,我们首先要做的是根据用户对图书的评价来计算用户之间的相似度。
让我们从单个用户的角度考虑这一点,查看图 1 中的第一行。为此,通常将每个用户表示为收录用户偏好的向量(或数组)。它比使用不同的相似性度量更直接。
在这个例子中,我们将使用余弦相似度来计算用户之间的相似度。
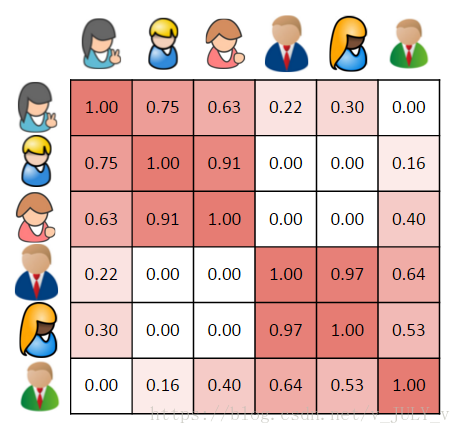
当我们将第一个用户与其他五个用户进行比较时,我们可以直观地看到他与其他用户的相似程度。
对于大多数相似度度量,向量之间的相似度越高,它们之间的相似度就越高。在这个例子中,第一个用户二、,第三个用户非常相似,有两本书相同,和第五个用户四、相似度较低,只有一本书相同,并且完全与上一个用户不同,因为没有共同的书。
更一般地,我们可以计算每个用户的相似度,并在相似度矩阵中表示它们。这是一个对称矩阵,单元格的背景颜色表示用户的相似程度,较深的红色表示他们之间的相似程度更高。
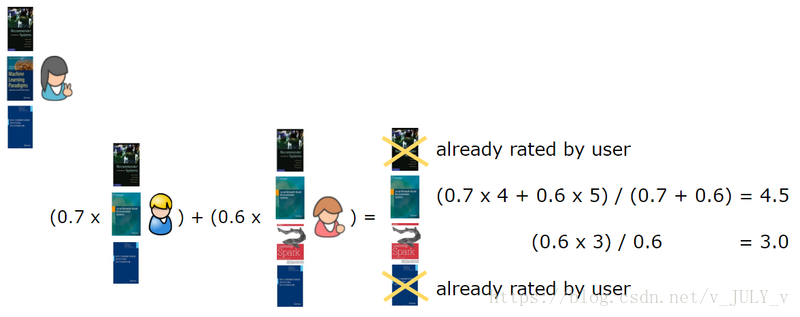
因此,我们找到与第一个用户最相似的第二个用户,删除该用户已经评分的书籍,对最相似的用户正在阅读的书籍进行加权,并计算总和。
在这种情况下,我们计算n=2,也就是说为了生成推荐,我们需要找到与目标用户最相似的两个用户,这两个用户分别是第二个和第三个用户,然后是第一个用户已经给第一和第五本书评分了,所以推荐的书是第三本书(4.5分),第四本书(3分)。
此外,何时使用 item-base 以及何时使用 user-base: ?
一般来说,如果item的数量不大,比如不超过100,000,并且没有明显增长,那么就使用item-based。为什么?正如@wuzh670所说,如果item数量少+没有明显增加,说明item之间的关系在一段时间内比较稳定(相对于用户之间的关系),对实时更新item的需求- 相似度低很多,降低了推荐系统的效率。改进很多,所以使用基于项目会更明智。
反之,当item数量较多时,推荐使用user-base。当然,在实践中的具体情况将根据具体情况进行分析。如下图所示(摘自向亮的《推荐系统实践》一书):
5、聚类算法
聚类 聚类,通俗地说,就是所谓的“物聚在一起,人分群”。聚类是数据挖掘的经典问题。其目的是将数据划分为多个簇,同一簇中的对象具有高度的相似性,而不同簇中的对象则不同。较大。
5.1、K-Means 聚类算法
K-Means 聚类算法与处理混合正态分布的期望最大化算法非常相似,因为它们都试图在数据中找到自然聚类的中心。该算法假设对象属性来自空间向量,目标是最小化每个组内的均方误差之和。
K-means 聚类算法首先随机确定 K 个中心位置(空间中代表聚类中心的点),然后将每个数据项分配到最近的中心点。分配完成后,集群中心将移动到分配给集群的所有节点的平均位置,然后整个分配过程重新开始。重复这个过程,直到分配过程不再改变。下图是一个有两个聚类的 K-means 聚类过程:
以下代码显示了此 K-means 聚类算法的 python 实现:
//K-均值聚类算法
import random
def kcluster(rows,distance=pearson,k=4):
# 确定每个点的最小值和最大值
ranges=[(min([row[i] for row in rows]),max([row[i] for row in rows]))
for i in range(len(rows[0]))]
# 随机创建k个中心点
clusters=[[random.random()*(ranges[i][1]-ranges[i][0])+ranges[i][0]
for i in range(len(rows[0]))] for j in range(k)]
lastmatches=None
for t in range(100):
print 'Iteration %d' % t
bestmatches=[[] for i in range(k)]
# 在每一行中寻找距离最近的中心点
for j in range(len(rows)):
row=rows[j]
bestmatch=0
for i in range(k):
d=distance(clusters[i],row)
if d0:
for rowid in bestmatches[i]:
for m in range(len(rows[rowid])):
avgs[m]+=rows[rowid][m]
for j in range(len(avgs)):
avgs[j]/=len(bestmatches[i])
clusters[i]=avgs
# 返回k组序列,其中每个序列代表一个聚类
return bestmatches
k-Means 是机器学习领域的一种无监督学习。下面简单介绍监督学习和无监督学习:
5.2、冠层聚类算法
Canopy聚类算法的基本原理是:首先,利用低成本的近似距离计算方法将数据高效地划分为多个组,这里称为Canopy,我们将其翻译为“canopy”。重叠部分;然后使用严格的距离计算方法,准确计算出同一个 Canopy 中的点,并将它们分配到最合适的簇中。Canopy聚类算法常用于K-means聚类算法的预处理,寻找合适的k值和聚类中心。
5.3、模糊K-Means聚类算法
模糊 K-means 聚类算法是 K-means 聚类的扩展。它的基本原理和K-means一样,只是它的聚类结果允许对象属于多个聚类,也就是说:属于我们前面介绍过的重叠。聚类算法。为了深入理解Fuzzy K-means和K-means的区别,这里我们得花点时间来理解一个概念:Fuzzziness Factor。
与K-means聚类原理类似,模糊K-means也在待聚类对象的向量集上循环,但它并不将向量分配给最近的簇,而是计算向量与每个簇的相关性(协会)。假设有一个向量v,有k个簇,v到k个簇中心的距离分别为d1,d2...dk,那么V到第一个簇的相关性u1可以通过下式计算:
计算 v 与其他集群的相关性只需将 d1 替换为相应的距离。由上式可知,当m近似为2时,相关性近似为1;当m近似为1时,相关性近似为到簇的距离,所以m的取值为(1,2)区间内,m越大,模糊程度越大,m为模糊我们刚才提到的参数。
其余的聚类算法本文将不做介绍。冷启动、数据稀疏性、可扩展性、可移植性、可解释性、多样性以及推荐信息的价值等问题将在后面讨论。
6、分类算法
其次,还有很多分类算法。本文介绍了决策树学习和贝叶斯定理。
6.1、决策树学习
让我们直奔主题。所谓决策树,顾名思义,就是一种树,是建立在战略选择基础上的树。
在机器学习中,决策树是一种预测模型;它表示对象属性和对象值之间的映射关系。树中的每个节点代表一个对象,每个分支路径代表一个可能的属性值,每个叶节点对应于从根节点到叶节点的路径所代表的对象。价值。决策树只有一个输出。如果你想有多个输出,你可以建立一个独立的决策树来处理不同的输出。
从数据中生成决策树的机器学习技术称为决策树学习,通常称为决策树。
理论太抽象了。这里有两个容易理解的例子:
第一个例子:通俗地说,决策树分类的思想类似于找对象。现在想象一个女孩的妈妈想给女孩介绍一个男朋友,于是就有了如下对话:
女儿:你几岁?
母亲:26。
女儿:帅吗?
妈妈:很帅。
女儿:收入高吗?
妈妈:不是很高,中等状态。
女儿:是公务员吗?
妈妈:是的,我在税务局工作。
女儿:好的,我去看你。
这个女孩的决策过程是典型的分类树决策。相当于把男人按年龄、外貌、收入和是否公务员分为两类:看和看。假设女孩对男人的要求是:30岁以下,中等相貌,高收入人士或中等收入以上的公务员,那么女孩的决策逻辑可以表示为:数字:
也就是说,决策树的简单策略就是,就像在公司招聘面试的过程中筛选一个人的简历,如果你的条件比较好,比如清华大学的博士,那么事不宜迟,直接致电面试,如果你毕业于非重点大学,但实际项目经验丰富,那么你也应该考虑要求面试,也就是所谓的具体分析和决策。
第二个例子来自 Tom M. Mitchell 的《机器学习》一书:
王的目的是通过下周的天气预报了解人们什么时候打高尔夫球。他明白人们决定是否参加比赛的原因取决于天气。天气条件晴朗、多云和下雨;华氏气温;相对湿度百分比;有风或缺席。这样,我们就可以构造如下决策树(根据天气的分类判断今天是否适合打网球):
上面的决策树对应如下表达式:(Outlook=Sunny ^Humiditywind gain 0.048。说白了,在周六早上是否适合打网球的问题上,最好取湿度而不是风作为分类属性,决策树来自哪里。
ID3算法决策树的形成
OK,下图是ID3算法第一步之后形成的部分决策树。综合起来,比较容易理解。1、阴的例子一定是正的,所以是叶子节点,永远是;2、ID3没有回溯,局部最优,不是全局最优,还有一个post-tree pruning决策树。下图是经过ID3算法第一步后形成的部分决策树:
6.2、贝叶斯分类基础:贝叶斯定理
贝叶斯定理:知道一个条件概率,如何得到两个事件交换的概率,即在已知P(A|B)的情况下如何得到P(B|A)。以下是条件概率的解释:
在事件 B 已经发生的前提下,事件 A 发生的概率称为事件 B 发生下事件 A 的条件概率。其基本解公式为:
.
贝叶斯定理之所以有用,是因为我们在生活中经常会遇到这样的情况:我们可以很容易地直接得到 P(A|B),P(B|A) 很难直接得到,但是我们更关心 P(B|A) , 贝叶斯定理为我们从 P(A|B) 得到 P(B|A) 开辟了道路。
下面直接给出贝叶斯定理,无需证明(公式已被网友指出,待后续验证修正):
7、推荐的实例扩展
7.1、阅读推荐 查看全部
算法 自动采集列表(本文微言导论:探索推荐引擎内部的秘密(组图))
来源:结构与算法之道
介绍
昨天看了几个关键词:语义分析、协同过滤、智能推荐,想想就兴奋。于是从昨天下午到今天凌晨3点,我研究了推荐引擎,做了一个初步的了解。以后我会慢慢深入的仔细研究(以后的工作也跟这个有关)。当然,这篇文章会逐渐增加和完善。
本文是推荐引擎初步介绍的入门文章,将省略大部分具体细节,重点用最简单的语言简单介绍推荐引擎的工作原理及其相关算法思想,并为了强调通俗易懂,部分引述来自我1月7日在微博上发表的文字(特地整理一下,方便以后随时阅读),尽量让这篇文章尽量简短. 不过,恰恰相反,文章后续的补充和改进,越写越长。
同时,本文所有相关算法,后续会一一详述文章。本文只求简要介绍,以后力求具体。如果您有任何问题,请随时给我任何建议或批评。谢谢。
1、推荐引擎原理
推荐引擎尽最大努力采集尽可能多的用户信息和行为。所谓广布网,勤钓,再“特爱一个特别的你”,最后在相似的基础上继续“强大”。原理如下图所示(该图引自本文的参考资料之一:Exploring the secrets inside the Recommendation engine):
2、推荐引擎的分类
推荐引擎根据不同的标准分类如下:
根据是否为不同用户推荐不同的数据,根据公众行为划分热门项目(网站管理员自己推荐,或者根据系统所有用户的反馈统计,计算当前热门项目) ,以及个性化的推荐引擎(帮助你找到志同道合的朋友,然后在此基础上实施推荐);物品具有相同的关键词和Tag,不考虑人为因素),以及基于协同过滤的推荐(寻找物品、内容或用户的相关推荐,分为三个子类,下文解释);根据构建方式,分为物品和用户本身(user-item二维矩阵描述用户偏好,聚类算法),
关于上面第二类基于协同过滤的推荐(2、根据其数据来源):随着Web2.0的发展,网站更加促进用户参与和用户贡献,所以基于关于协同过滤的过滤推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者发现用户的相关性,然后根据这些相关性进行推荐。
基于协同过滤的推荐分为三个子类:
基于用户的推荐(通过共同的品味和喜好找到相似的邻居用户,K-neighbor算法,你的朋友喜欢,你可能喜欢),基于物品的推荐(找到物品之间的相似性,推荐相似的物品,你喜欢) Item A 和 C 与 A 类似,也可能像 C),基于模型的推荐(基于样本用户偏好信息构建推荐模型,然后根据实时用户偏好信息预测推荐)。
我们看到这种协同过滤算法最大限度地利用了用户之间或物品之间的相似相关性,然后根据这些信息实现推荐。这种协同过滤也在下面详细描述。
但是,在一般实践中,我们通常将推荐引擎分为两类:
3、新浪微博推荐机制
新浪微博推荐好友机制中:1、我和A不是朋友,但是我的很多朋友都是A的朋友,也就是说我和A有很多共同的朋友,那么系统会推荐A给我(新浪称其为共同的朋友);2、我关注的很多人都关注了B,所以系统推测我可能喜欢B,所以也会推荐B给我(新浪称其为间接关注)。
但在新浪的实际运营中,这两种方式会混用。比如我关注的人中,关注B的人很多,但其实关注B的一些人也是我的朋友。以上推荐方法统称为基于相似用户的协同过滤推荐(无非是发现:用户之间的密不可分的联系,要么来自你的朋友,要么来自你关注的人)。
当然,还有另外一种推荐,比如热门用户推荐,就是上面提到的基于热门行为的推荐,也就是听从别人的意见。系统推测每个人都喜欢它,也许你也会喜欢。如果大家都知道姚晨的新浪微博粉丝数第一,就会争先恐后地关注,最终粉丝数会越来越多。推荐的两种方法如下图所示:
然而,上述的推荐方法,无论是基于用户还是基于流行行为,都没有真正找到用户之间的共同兴趣、喜好和品味,因为很多情况下,朋友的朋友可能不是你自己。朋友,有些人凌驾于世界之上,你们都追求什么,我不屑一顾。因此,从分析用户发布的微博内容入手,找到他们共同的关注点和兴趣点才是王道。当然,新浪微博最近让用户选择给自己的微博内容打标签,以帮助日后在微博内容中找到相关用户的常用标签,关键词,这种推荐方式是基于微博内容分析'的推荐。如下所示:
唯一的问题是,谁会不遗余力地发一条微博,它会添加什么标签?因此,新浪微博不得不努力寻找另一种方式来更好地分析微博的内容。否则,系统会彻底扫描海量用户的微博内容,恐怕承受不起,也承受不起。
不过我个人认为可以从微博关键词(标签标签云)和每个用户自己标签的标签入手(标签越常见,可以定义的相似用户越多),如图下图左右部分:

也就是说,通过普通朋友和间接关注的人来定义相似用户是不可靠的。只有通过微博内容分析,才能找到相似的用户。经过对标签云的分析,无疑比现有的推荐朋友的方法(通过普通朋友和间接关注者定义相似用户)找到相同或相似的标签云找到相似用户更可靠。
3.1、多种推荐方式组合
当前网站的推荐往往不是简单地使用某种推荐机制和策略,而是往往结合多种方法来达到更好的推荐效果。
例如,亚马逊除了基于用户的推荐外,还使用基于内容的推荐(关键词和Tag相同的商品):比如新品推荐;基于项目的协同过滤推荐(喜欢)。A、C 与 A 类似,也可能与 C) 类似:如捆绑销售和他人购买/浏览的商品。
简而言之,多种推荐方法和权重的组合(使用线性公式)根据一定的权重组合了几种不同的推荐。具体权重的值需要在测试数据集上反复测试,才能达到最好的推荐效果。)、切换、分区、分层等。但是,无论采用哪种推荐方法,一般都被上述推荐方法所覆盖。
4、协同过滤推荐
协同过滤是利用集体智慧的典型方式。要了解什么是协同过滤 (CF),首先要考虑一个简单的问题。如果你现在想看电影,但不知道该看哪一部,你会怎么做?大多数人会问广义的朋友或邻居,看看最近推荐了哪些好电影,而我们一般更喜欢从口味相似的朋友那里获得推荐。这就是协同过滤的核心思想。从下图中你能看出多少信息?
4.1、 协同过滤推荐步骤
做协同过滤推荐,一般做以下步骤:
1)要进行协同过滤,采集用户偏好是关键。可以通过评分等用户行为判断为相似用户(比如不同用户对不同作品的评分不同,评分接近意味着品味和品味相近,可以判断为相似用户)、投票、转发、采集、书签、标签、评论、点击流、页面停留时间、是否购买等。如下面第2点所述:所有这些信息都可以数字化并表示为二维矩阵。
2)采集到用户行为数据后,接下来需要对数据进行去噪和归一化处理(得到用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,该值是用户对项目的偏好,通常是 [0,1] 或 [-1,1] 的浮点值)。下面简单介绍降噪和归一化操作:
3)如何找到相似的用户和物品?就是计算相似用户或相似物品的相似度。
4)计算相似度的方法有很多种,但都是基于向量Vector。其实就是计算两个向量之间的距离。距离越近,相似度越大。在推荐中,在user-item偏好的二维矩阵下,我们以一个或多个用户对两个item的偏好为向量,计算两个item之间的相似度,或者两个用户对一个或多个的偏好几个项目被用作一个向量来计算两个用户之间的相似度。
相似度计算算法可用于计算用户或物品的相似度。以物品相似度计算(Item Similarity Computation)为列,共同点是从打分矩阵中为两个物品i和j选取共同打分用户,然后对这个共同用户的打分向量进行相似度计算. si,j,如下图,行代表用户,列代表物品(注意从i,j向量中抽取常用评论,形成一对向量计算相似度) :
因此,很简单的找到物品之间的相似度,用户不变,找到多个用户对物品的评分;求用户之间的相似度,item不变,求用户对某些item的评分。
5)计算出来的两个相似度将作为两个基于用户和物品的协同过滤推荐。
计算相似度的常用方法有:欧式距离、皮尔逊相关系数(比如两个用户对多部电影的评分,使用皮尔逊相关系数等相关计算方法,可以判断他们的口味和喜好是否一致)、余弦相似度,谷本系数。下面简单介绍一下欧几里得距离和皮尔逊相关系数:
可以看出,当n=2时,欧几里得距离就是平面上两点之间的距离。当用欧式距离表示相似度时,一般采用如下公式进行转换:距离越小,相似度越大(同时避免除数为0):
其中,Ru,i 是用户 u 对 item i 的评分,对应的带有横条的 item 是这个用户集 U 对 item i 的评分。
6)类似的邻居计算。邻居分为两类: 1、 固定数量的邻居K-neighborhoods(或Fix-sizeneighborhoods),不管邻居的“距离”如何,只取最近的K作为他们的邻居,如部分所示下图A;2、基于相似度阈值的邻居,以当前点为中心,距离为K的区域内的所有点都被视为当前点的邻居,如下图B部分所示。
让我们介绍一下 K-Nearest Neighbor (KNN) 分类算法:这是一种理论上成熟的方法,也是最简单的机器学习算法之一。该方法的思想是:如果特征空间中k个最相似的样本(即特征空间中的最近邻)中的大部分属于某个类别,则该样本也属于该类别。
7)4)计算的基于用户的CF(基于用户推荐:通过共同的品味和喜好找到相似的邻居用户,K-neighbor算法,如果你的朋友喜欢,你可能也会喜欢),基于item的CF(基于item的推荐:查找item之间的相似度,推荐相似的item,如果你喜欢item A,如果C和A相似,那么你可能也喜欢C)。
4.2、基于用户相似度和物品相似度
上一节3.1中的三个相似度公式都是基于物品相似度的场景,但实际上用户相似度和物品相似度计算的一个基本区别是,用户相似度是基于评分矩阵中的行向量相似度求解,项目相似度计算公式是根据评分矩阵中的列向量相似度计算的。那么这三个公式就可以分别套用了,如下图所示:
(其中,0表示未评级)
一千字不如一个例子。我们来看一个基于用户相似度计算的具体例子。
假设我们有一组用户,他们表现出对一组书籍的偏好。用户对一本书的偏好越高,它的评分就越高。让我们将其表示为一个矩阵,其中行代表用户,列代表书籍。
如下图所示,所有评分的范围从 1 到 5,其中 5 是最喜欢的。第一个用户(行 1) 为第一本书评分(列 1) 为 4,空单元格表示用户没有对该书评分。

使用基于用户的协同过滤方法,我们首先要做的是根据用户对图书的评价来计算用户之间的相似度。
让我们从单个用户的角度考虑这一点,查看图 1 中的第一行。为此,通常将每个用户表示为收录用户偏好的向量(或数组)。它比使用不同的相似性度量更直接。
在这个例子中,我们将使用余弦相似度来计算用户之间的相似度。
当我们将第一个用户与其他五个用户进行比较时,我们可以直观地看到他与其他用户的相似程度。
对于大多数相似度度量,向量之间的相似度越高,它们之间的相似度就越高。在这个例子中,第一个用户二、,第三个用户非常相似,有两本书相同,和第五个用户四、相似度较低,只有一本书相同,并且完全与上一个用户不同,因为没有共同的书。
更一般地,我们可以计算每个用户的相似度,并在相似度矩阵中表示它们。这是一个对称矩阵,单元格的背景颜色表示用户的相似程度,较深的红色表示他们之间的相似程度更高。
因此,我们找到与第一个用户最相似的第二个用户,删除该用户已经评分的书籍,对最相似的用户正在阅读的书籍进行加权,并计算总和。
在这种情况下,我们计算n=2,也就是说为了生成推荐,我们需要找到与目标用户最相似的两个用户,这两个用户分别是第二个和第三个用户,然后是第一个用户已经给第一和第五本书评分了,所以推荐的书是第三本书(4.5分),第四本书(3分)。
此外,何时使用 item-base 以及何时使用 user-base: ?
一般来说,如果item的数量不大,比如不超过100,000,并且没有明显增长,那么就使用item-based。为什么?正如@wuzh670所说,如果item数量少+没有明显增加,说明item之间的关系在一段时间内比较稳定(相对于用户之间的关系),对实时更新item的需求- 相似度低很多,降低了推荐系统的效率。改进很多,所以使用基于项目会更明智。
反之,当item数量较多时,推荐使用user-base。当然,在实践中的具体情况将根据具体情况进行分析。如下图所示(摘自向亮的《推荐系统实践》一书):

5、聚类算法
聚类 聚类,通俗地说,就是所谓的“物聚在一起,人分群”。聚类是数据挖掘的经典问题。其目的是将数据划分为多个簇,同一簇中的对象具有高度的相似性,而不同簇中的对象则不同。较大。
5.1、K-Means 聚类算法
K-Means 聚类算法与处理混合正态分布的期望最大化算法非常相似,因为它们都试图在数据中找到自然聚类的中心。该算法假设对象属性来自空间向量,目标是最小化每个组内的均方误差之和。
K-means 聚类算法首先随机确定 K 个中心位置(空间中代表聚类中心的点),然后将每个数据项分配到最近的中心点。分配完成后,集群中心将移动到分配给集群的所有节点的平均位置,然后整个分配过程重新开始。重复这个过程,直到分配过程不再改变。下图是一个有两个聚类的 K-means 聚类过程:

以下代码显示了此 K-means 聚类算法的 python 实现:
//K-均值聚类算法
import random
def kcluster(rows,distance=pearson,k=4):
# 确定每个点的最小值和最大值
ranges=[(min([row[i] for row in rows]),max([row[i] for row in rows]))
for i in range(len(rows[0]))]
# 随机创建k个中心点
clusters=[[random.random()*(ranges[i][1]-ranges[i][0])+ranges[i][0]
for i in range(len(rows[0]))] for j in range(k)]
lastmatches=None
for t in range(100):
print 'Iteration %d' % t
bestmatches=[[] for i in range(k)]
# 在每一行中寻找距离最近的中心点
for j in range(len(rows)):
row=rows[j]
bestmatch=0
for i in range(k):
d=distance(clusters[i],row)
if d0:
for rowid in bestmatches[i]:
for m in range(len(rows[rowid])):
avgs[m]+=rows[rowid][m]
for j in range(len(avgs)):
avgs[j]/=len(bestmatches[i])
clusters[i]=avgs
# 返回k组序列,其中每个序列代表一个聚类
return bestmatches
k-Means 是机器学习领域的一种无监督学习。下面简单介绍监督学习和无监督学习:
5.2、冠层聚类算法
Canopy聚类算法的基本原理是:首先,利用低成本的近似距离计算方法将数据高效地划分为多个组,这里称为Canopy,我们将其翻译为“canopy”。重叠部分;然后使用严格的距离计算方法,准确计算出同一个 Canopy 中的点,并将它们分配到最合适的簇中。Canopy聚类算法常用于K-means聚类算法的预处理,寻找合适的k值和聚类中心。
5.3、模糊K-Means聚类算法
模糊 K-means 聚类算法是 K-means 聚类的扩展。它的基本原理和K-means一样,只是它的聚类结果允许对象属于多个聚类,也就是说:属于我们前面介绍过的重叠。聚类算法。为了深入理解Fuzzy K-means和K-means的区别,这里我们得花点时间来理解一个概念:Fuzzziness Factor。
与K-means聚类原理类似,模糊K-means也在待聚类对象的向量集上循环,但它并不将向量分配给最近的簇,而是计算向量与每个簇的相关性(协会)。假设有一个向量v,有k个簇,v到k个簇中心的距离分别为d1,d2...dk,那么V到第一个簇的相关性u1可以通过下式计算:
计算 v 与其他集群的相关性只需将 d1 替换为相应的距离。由上式可知,当m近似为2时,相关性近似为1;当m近似为1时,相关性近似为到簇的距离,所以m的取值为(1,2)区间内,m越大,模糊程度越大,m为模糊我们刚才提到的参数。
其余的聚类算法本文将不做介绍。冷启动、数据稀疏性、可扩展性、可移植性、可解释性、多样性以及推荐信息的价值等问题将在后面讨论。
6、分类算法
其次,还有很多分类算法。本文介绍了决策树学习和贝叶斯定理。
6.1、决策树学习
让我们直奔主题。所谓决策树,顾名思义,就是一种树,是建立在战略选择基础上的树。
在机器学习中,决策树是一种预测模型;它表示对象属性和对象值之间的映射关系。树中的每个节点代表一个对象,每个分支路径代表一个可能的属性值,每个叶节点对应于从根节点到叶节点的路径所代表的对象。价值。决策树只有一个输出。如果你想有多个输出,你可以建立一个独立的决策树来处理不同的输出。
从数据中生成决策树的机器学习技术称为决策树学习,通常称为决策树。
理论太抽象了。这里有两个容易理解的例子:
第一个例子:通俗地说,决策树分类的思想类似于找对象。现在想象一个女孩的妈妈想给女孩介绍一个男朋友,于是就有了如下对话:
女儿:你几岁?
母亲:26。
女儿:帅吗?
妈妈:很帅。
女儿:收入高吗?
妈妈:不是很高,中等状态。
女儿:是公务员吗?
妈妈:是的,我在税务局工作。
女儿:好的,我去看你。
这个女孩的决策过程是典型的分类树决策。相当于把男人按年龄、外貌、收入和是否公务员分为两类:看和看。假设女孩对男人的要求是:30岁以下,中等相貌,高收入人士或中等收入以上的公务员,那么女孩的决策逻辑可以表示为:数字:
也就是说,决策树的简单策略就是,就像在公司招聘面试的过程中筛选一个人的简历,如果你的条件比较好,比如清华大学的博士,那么事不宜迟,直接致电面试,如果你毕业于非重点大学,但实际项目经验丰富,那么你也应该考虑要求面试,也就是所谓的具体分析和决策。
第二个例子来自 Tom M. Mitchell 的《机器学习》一书:
王的目的是通过下周的天气预报了解人们什么时候打高尔夫球。他明白人们决定是否参加比赛的原因取决于天气。天气条件晴朗、多云和下雨;华氏气温;相对湿度百分比;有风或缺席。这样,我们就可以构造如下决策树(根据天气的分类判断今天是否适合打网球):
上面的决策树对应如下表达式:(Outlook=Sunny ^Humiditywind gain 0.048。说白了,在周六早上是否适合打网球的问题上,最好取湿度而不是风作为分类属性,决策树来自哪里。
ID3算法决策树的形成
OK,下图是ID3算法第一步之后形成的部分决策树。综合起来,比较容易理解。1、阴的例子一定是正的,所以是叶子节点,永远是;2、ID3没有回溯,局部最优,不是全局最优,还有一个post-tree pruning决策树。下图是经过ID3算法第一步后形成的部分决策树:
6.2、贝叶斯分类基础:贝叶斯定理
贝叶斯定理:知道一个条件概率,如何得到两个事件交换的概率,即在已知P(A|B)的情况下如何得到P(B|A)。以下是条件概率的解释:
在事件 B 已经发生的前提下,事件 A 发生的概率称为事件 B 发生下事件 A 的条件概率。其基本解公式为:
.
贝叶斯定理之所以有用,是因为我们在生活中经常会遇到这样的情况:我们可以很容易地直接得到 P(A|B),P(B|A) 很难直接得到,但是我们更关心 P(B|A) , 贝叶斯定理为我们从 P(A|B) 得到 P(B|A) 开辟了道路。
下面直接给出贝叶斯定理,无需证明(公式已被网友指出,待后续验证修正):
7、推荐的实例扩展
7.1、阅读推荐
算法 自动采集列表(Java虚拟机-维基百科,自由的百科全书不过,作为一个爱思考的在校大学生)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-12 00:06
前言如果这篇文章有什么不对的地方,欢迎各界diss~~当然,如果你看了这篇文章有收获,那就疯狂点赞吧,你的喜欢是对我最大的鼓励。顺便加个关注,回家别迷路,不定时更新博客~~
周志明的《深入理解JAVA虚拟机》这本书看了一遍又一遍,终于有勇气在这里写一篇关于JVM的博客了!!!现在,我将在这里开始记录我所了解的并与我的朋友分享!!!
相信点击这个文章的小伙伴们一定知道JVM是什么吧?什么,还不知道?好吧,看看我想你会明白的 wiki:Java 虚拟机 - 维基百科,免费的百科全书
不过,作为一个有思想的大学生,我也总结了以下三点:
关于JVM是什么的介绍,还是一样的,我们来看看这个文章的结构:
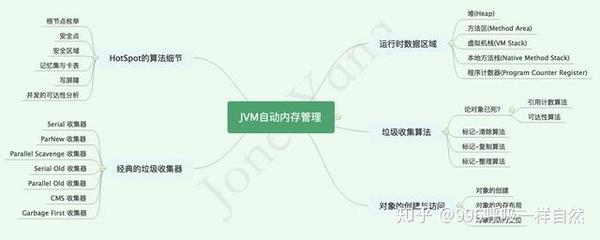
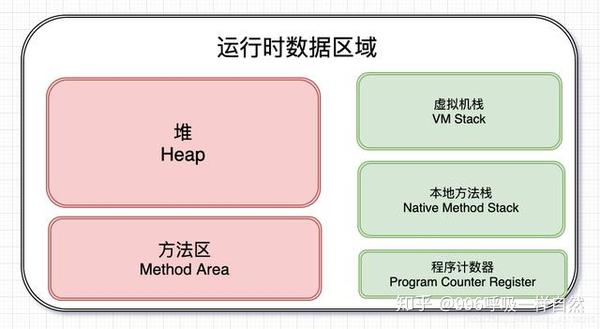
运行时数据区
什么是运行时数据区?
Java程序在运行时,会为JVM分离出一块内存区域,而这块内存区域又可以划分为运行时数据区域。运行时数据区大致可以分为五个部分:
从上图中可以看出,有两个颜色不同的区域,红色的是线程共享区域,绿色的是线程私有区域。让我们一个一个说清楚,但是在学习这部分的时候,最好想一想为什么会有这些区域。仅仅是因为它的存在吗?
堆
很多做开发的同学都会特别注意堆和栈。这是否从另一个角度解释了堆和栈的重要性?在这种情况下,让我们从学生们关注的点开始。(客气点,有没有感觉眼角又湿了?)
先放干货。首先,Java堆区具有以下特点:
那么OutOfMemoryError什么时候发生,StackOverflowError什么时候发生呢?当虚拟机在扩展堆栈时无法申请足够的内存空间时,会抛出 OutOfMemoryError 异常。如果线程请求的堆栈深度超过了虚拟机允许的最大深度,就会抛出 StackOverflowError 异常。
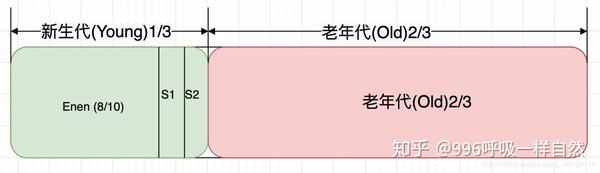
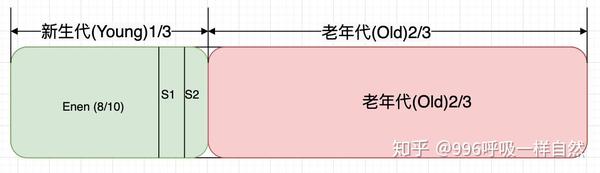
其实Java堆区也可以分为新生代和老年代,新生代又可以进一步分为Eden区、Survivor 1区、Survivor 2区。具体比例参数可以看下图。
我看图已经解释的很清楚了,不用再用文字解释了吧?关于Java堆对象的创建,以及什么时候会出现内存泄漏,后面应该写一篇专文文章,这里的话只是一些理论介绍。
虚拟机堆栈(VM 堆栈)
Java虚拟机栈也是开发者关注的地方。同样,先放干货:
同样,如果这个文章反响不错,会在实战演练文章之后单独发布。
本机方法堆栈
本机方法堆栈实际上可以与 Java 虚拟机堆栈进行比较。唯一的区别是本机方法堆栈是 Java 程序在调用本机方法时创建堆栈帧的地方。和 JVM 栈一样,这个区域也会抛出 StackOverflowError 和 OutOfMemoryError。
方法区
方法区域也应该是一个重点区域。同样,方法区的主要特点如下:
对于方法区,我认为重点应该放在常量池上。常量池可以分为类文件常量池和运行时常量池。Java程序运行后,类文件中的信息被字节码执行引擎加载到方法区,从而形成运行时常量池。
另外,说到方法区,有些人可能会将其与永久代和元空间混淆。那么它们之间究竟有什么区别呢?方法区是Java虚拟机规范中的定义,是规范,而永久代是实现,一个是标准,一个是实现。但是Java 8之后就没有永久代了,元空间代替了永久代。
程序计数器寄存器
程序计数器非常简单。想必大家都不是Java初学者,大家应该了解线程和进程的概念吧?(灵魂拷问,你懂吗?)不懂没关系,我一句话给你解释。
进程是资源分配的最小单位,线程是CPU调度的最小单位。一个进程可以收录多个线程。Java线程通过抢占获得CPU的执行权。现在考虑以下场景。
在某一时刻,线程 A 获得了 CPU 的执行权并开始执行内部程序。但是线程A的程序还没有被执行,某个时刻CPU的执行权被另一个线程B抢走了。后来经过线程A的不懈努力,重新获得了CPU的执行权,难道线程A的程序还要从头开始执行?
这时候程序计数器就来了,它的作用是记录当前线程执行的位置。这样,当线程重新获得 CPU 的执行权时,就直接从记录的位置开始执行,而分支、循环、跳转、异常处理也都是靠这个程序计数器来完成的。此外,程序计数器具有以下特点:
对象创建和访问对象创建
正如我们之前所说,对象是在堆中创建的,通常只需要一个新对象。就这么简单吗?真的没那么简单。有了这样一个新关键字,Java virtual 内部就执行了一系列 sao 操作。
当虚拟机遇到字节码新指令时,会去运行时常量池中查找实例化对象对应的类是否被加载、解析和初始化。如果没有加载,则先加载类的信息,否则为新对象分配内存。
内存分配有两种方式:
以上是两种不同的方法。至于虚拟机使用哪种方法,则取决于虚拟机的类型。
对象的内存布局
堆中对象的存储布局可以分为三个部分:
对象访问位置
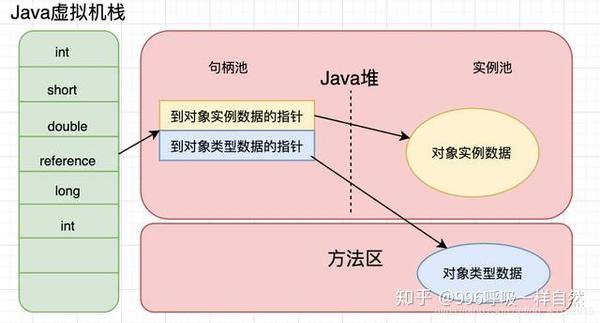
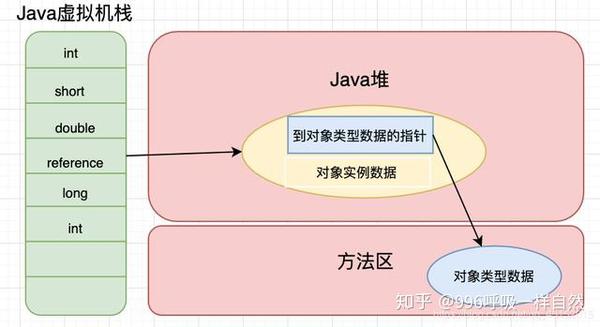
正如我们前面提到的,Java 虚拟机堆栈存储基本数据类型和对象引用。我们已经知道基本的数据类型,那么这个对象引用到底是什么?
就是这样,对象实例存储在Java堆中,通过这个对象引用我们可以找到对象在堆中的位置。但是,不同的 Java 虚拟机对于如何定位这个对象有不同的方法。
通常,有两种方法:
两种访问对象的方法都有各自的优势。使用直接指针访问,可以直接定位对象,减少了指针定位的时间开销(如果使用句柄,对象会通过句柄池的指针重定位),最大的好处是它是比较快的。但是使用句柄意味着当对象移动时,不需要更改存储在堆栈中的引用,只需要更改句柄池中指向实例数据的指针即可。
垃圾采集算法理论对象死了吗?
在上一部分中,我们讨论了对象。一个对象可以被创建,那么这个对象什么时候被销毁呢?一般来说,有两种方法可以判断一个对象是否已经被销毁:
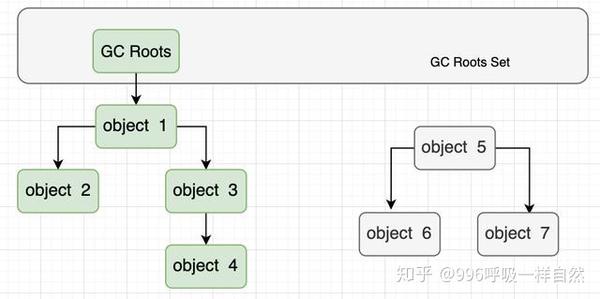
如上图所示,绿色部分的对象在GC Roots的引用链上,不会被垃圾回收器回收。灰色部分的对象不在参考链中,自然确定为可回收对象。
那么问题来了,这些 GC Roots 是什么?下面列出了可以用作 GC Roots 的对象:
现在,我们知道哪些物品是可回收的。那么回收对象应该采取什么方法呢?垃圾回收算法主要有三种,分别是mark-sweep、mark-copy和mark-sort。这三种垃圾回收算法其实都比较容易理解。我先介绍一下概念,然后依次总结。
标记扫描算法
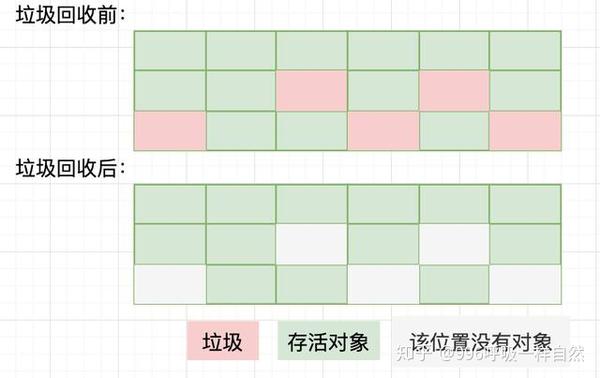
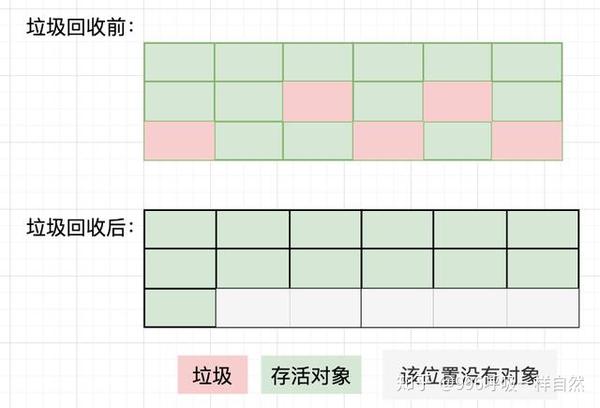
顾名思义,mark-to-clear算法就是对无效对象进行标记,然后将其清除。如下所示:
对于mark-sweep算法,你肯定会看到垃圾回收之后,堆空间中的碎片很多,并且有不规则的地方。为大对象分配内存时,由于找不到足够的连续内存空间,不得不再次触发垃圾回收。另外,如果Java堆中有大量垃圾对象,垃圾回收中必须进行大量的标记和清除动作,势必会降低回收效率。
标记--复制算法
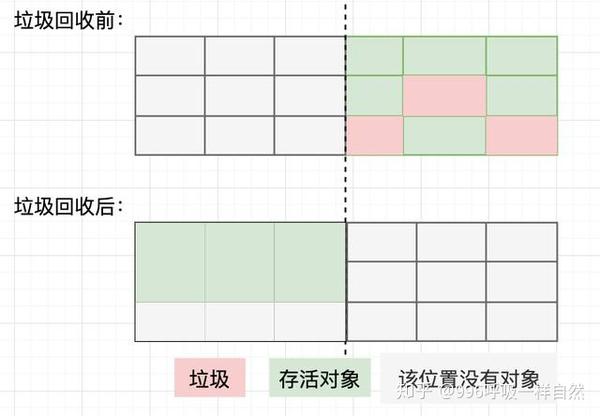
标记复制算法是将Java堆分成两部分,每次垃圾回收只使用其中一个,然后将所有幸存的对象移动到另一个区域。如下所示:
mark-copy算法有一个明显的缺点,就是每次只使用一半的堆空间,导致Java堆空间使用率下降。
现在Java虚拟机的垃圾采集器大多使用标记复制算法,但是Java堆空间的划分并不是简单的一分为二。
还记得这张照片吗?
前面讲Java内存结构的时候,提到了Java堆的具体划分,所以现在说一下。
首先,我们要从两种代际采集理论说起:
正是这两个代际假设,让设计者对Java堆的划分更加合理。接下来说一下GC的分类:
好了,知道了GC的分类,是时候了解一下GC的过程了。
通常,第一次创建的对象存放在新生代的Eden区。第一次触发 Minor GC 时,Eden 区的幸存对象被转移到 Survivor 区的某个区域。以后再次触发 Minor GC 时,Eden 区的对象会连同一个 Survivor 区的对象一起转移到另一个 Survivor 区。可以看出,我们一次只使用了两个Survivor区域中的一个,只是浪费了一个Survivor区域。
一个对象每经过一次垃圾回收,它的世代年龄就加1。当世代年龄达到15时,直接存入老年代。
还有一种情况,给大对象分配内存时,Eden区的内存空间不足。这个时候我该怎么办?在这种情况下,大对象将直接进入老年。
标记排序算法
mark-to-clean 算法是一种妥协的垃圾采集算法。在对象标记的过程中,执行与前两个相同的步骤。但是标记后,存活对象被移动到堆的一端,存活对象以外的区域可以直接清理掉。这样就避免了内存碎片,也没有堆空间的浪费。但是,每次进行垃圾回收时,都必须暂停所有用户线程,特别是对于老年代的对象,需要更长的回收时间,这对用户体验非常不利。如下所示:
HotSpot的算法详解根节点枚举
根节点枚举其实就是寻找可以作为GC Roots的对象。在这个过程中,所有的用户线程都必须停止。到目前为止,几乎没有虚拟机可以与用户线程并发执行 GC Roots 遍历。当然,可达性分析算法中寻找参考链最耗时的过程已经可以与用户线程并发执行。那么,为什么需要在根节点枚举的时候停止用户线程呢?
其实不难考虑。如果GC Roots遍历时用户线程没有挂起,根节点集的对象引用关系还在变化,所以遍历的结果不准确。那么,Java虚拟机在寻找GC Roots时真的需要进行全局遍历吗?
事实上,情况并非如此。HotSpot 虚拟机可以通过称为 OopMap 的数据结构知道对象引用的存储位置。这样,GC Roots的遍历时间就大大减少了。
安全点
安全点是线程可以被中断的点。当我们遍历 GC Roots 时,我们必须停止用户线程。问题是,线程可以停在任何位置吗?为了让线程停在最近的安全点,有两种思路:
安全区
安全区是安全点的延伸和延伸。安全点解决了如何停止线程,但没有解决如何让虚拟机进入垃圾回收状态。
安全区是指在某个代码片段中,可以保证引用关系不会发生变化的区域。因此,一旦线程进入安全区,就可以忽略安全区内的这些线程。当线程离开安全区时,虚拟机检查根节点枚举是否完成。
记忆套装和卡片纸
不知道你有没有考虑过这样的问题?既然Java堆分为新生代和老年代,那么会不会有跨代的对象引用呢?如果有跨代,如何解决遍历老年代的GC Roots的问题?
首先,存在跨代参考。因此,垃圾采集器在年轻代中构建了一个称为memoized set的数据结构,以避免将整个老年代作为GC Roots的扫描范围。
内存集是一种抽象的数据结构,卡表是内存集的具体实现。这种关系类似于方法区和元空间。
写屏障
写屏障的作用很简单,就是维护和更新卡表。
并发可达性分析
前面我们提到了为什么要暂停所有用户线程(这个动作也叫Stop The World)?这实际上是为了防止用户线程改变对 GC Roots 对象的引用。试想一下,如果用户线程可以任意将死对象重新标记为活动对象,或者将活动对象标记为死对象,是不是会导致程序出现意外错误。
经典垃圾采集器
我知道很多垃圾采集的理论,但具体到某一种垃圾采集器,它的实现并不完全一样。以下是一些常见的垃圾采集器。
串行采集器
Serial 采集器是最基本、最古老的采集器。它在垃圾采集期间挂起所有工作线程,直到垃圾采集过程完成。下面是Serial垃圾采集器的运行示意图:
ParNew 采集器
ParNew 垃圾采集器实际上是串行垃圾采集器的多线程版本。这种多线程是 ParNew 垃圾采集器可以使用多个线程进行垃圾采集。
并行清除采集器
它也是新一代的垃圾采集器,也是基于标记复制算法实现的。它最大的特点是可以控制吞吐量。
那么什么是吞吐量?
串行老采集器
Serial Old 采集器是 Serial 采集器的老一代版本。垃圾采集器的工作原理与串行采集器相同。
平行老采集器
Parallel Old 采集器也是 Parallel Scavenge 采集器的旧版本,支持多线程并发采集。下面是它的运行示意图:
cms 采集器
如前所述,Parallel Scavenge 采集器是一个可以控制吞吐量的垃圾采集器。现在来说说cms采集器,它是一个追求最短暂停时间的垃圾采集器,基于mark-sweep算法。cms 垃圾采集器的操作过程比前面的要复杂一些。整个过程可以分为四个部分:
垃圾第一采集器
Garbage First(简称G1))采集器是垃圾采集器发展史上的里程碑式成果,主要面向服务端应用。另外,虽然G 1采集器仍然保留了新生代和老年代的概念,但是新生代和老年代不是固定的,它们是一系列区域的动态采集。
好了,垃圾采集器的介绍就到这里。至于G 1采集器,还是有很多值得关注的地方。朋友可以查看相关信息。 查看全部
算法 自动采集列表(Java虚拟机-维基百科,自由的百科全书不过,作为一个爱思考的在校大学生)
前言如果这篇文章有什么不对的地方,欢迎各界diss~~当然,如果你看了这篇文章有收获,那就疯狂点赞吧,你的喜欢是对我最大的鼓励。顺便加个关注,回家别迷路,不定时更新博客~~
周志明的《深入理解JAVA虚拟机》这本书看了一遍又一遍,终于有勇气在这里写一篇关于JVM的博客了!!!现在,我将在这里开始记录我所了解的并与我的朋友分享!!!
相信点击这个文章的小伙伴们一定知道JVM是什么吧?什么,还不知道?好吧,看看我想你会明白的 wiki:Java 虚拟机 - 维基百科,免费的百科全书
不过,作为一个有思想的大学生,我也总结了以下三点:
关于JVM是什么的介绍,还是一样的,我们来看看这个文章的结构:
运行时数据区
什么是运行时数据区?
Java程序在运行时,会为JVM分离出一块内存区域,而这块内存区域又可以划分为运行时数据区域。运行时数据区大致可以分为五个部分:
从上图中可以看出,有两个颜色不同的区域,红色的是线程共享区域,绿色的是线程私有区域。让我们一个一个说清楚,但是在学习这部分的时候,最好想一想为什么会有这些区域。仅仅是因为它的存在吗?
堆
很多做开发的同学都会特别注意堆和栈。这是否从另一个角度解释了堆和栈的重要性?在这种情况下,让我们从学生们关注的点开始。(客气点,有没有感觉眼角又湿了?)
先放干货。首先,Java堆区具有以下特点:
那么OutOfMemoryError什么时候发生,StackOverflowError什么时候发生呢?当虚拟机在扩展堆栈时无法申请足够的内存空间时,会抛出 OutOfMemoryError 异常。如果线程请求的堆栈深度超过了虚拟机允许的最大深度,就会抛出 StackOverflowError 异常。
其实Java堆区也可以分为新生代和老年代,新生代又可以进一步分为Eden区、Survivor 1区、Survivor 2区。具体比例参数可以看下图。
我看图已经解释的很清楚了,不用再用文字解释了吧?关于Java堆对象的创建,以及什么时候会出现内存泄漏,后面应该写一篇专文文章,这里的话只是一些理论介绍。
虚拟机堆栈(VM 堆栈)
Java虚拟机栈也是开发者关注的地方。同样,先放干货:
同样,如果这个文章反响不错,会在实战演练文章之后单独发布。
本机方法堆栈
本机方法堆栈实际上可以与 Java 虚拟机堆栈进行比较。唯一的区别是本机方法堆栈是 Java 程序在调用本机方法时创建堆栈帧的地方。和 JVM 栈一样,这个区域也会抛出 StackOverflowError 和 OutOfMemoryError。
方法区
方法区域也应该是一个重点区域。同样,方法区的主要特点如下:
对于方法区,我认为重点应该放在常量池上。常量池可以分为类文件常量池和运行时常量池。Java程序运行后,类文件中的信息被字节码执行引擎加载到方法区,从而形成运行时常量池。
另外,说到方法区,有些人可能会将其与永久代和元空间混淆。那么它们之间究竟有什么区别呢?方法区是Java虚拟机规范中的定义,是规范,而永久代是实现,一个是标准,一个是实现。但是Java 8之后就没有永久代了,元空间代替了永久代。
程序计数器寄存器
程序计数器非常简单。想必大家都不是Java初学者,大家应该了解线程和进程的概念吧?(灵魂拷问,你懂吗?)不懂没关系,我一句话给你解释。
进程是资源分配的最小单位,线程是CPU调度的最小单位。一个进程可以收录多个线程。Java线程通过抢占获得CPU的执行权。现在考虑以下场景。
在某一时刻,线程 A 获得了 CPU 的执行权并开始执行内部程序。但是线程A的程序还没有被执行,某个时刻CPU的执行权被另一个线程B抢走了。后来经过线程A的不懈努力,重新获得了CPU的执行权,难道线程A的程序还要从头开始执行?
这时候程序计数器就来了,它的作用是记录当前线程执行的位置。这样,当线程重新获得 CPU 的执行权时,就直接从记录的位置开始执行,而分支、循环、跳转、异常处理也都是靠这个程序计数器来完成的。此外,程序计数器具有以下特点:
对象创建和访问对象创建
正如我们之前所说,对象是在堆中创建的,通常只需要一个新对象。就这么简单吗?真的没那么简单。有了这样一个新关键字,Java virtual 内部就执行了一系列 sao 操作。
当虚拟机遇到字节码新指令时,会去运行时常量池中查找实例化对象对应的类是否被加载、解析和初始化。如果没有加载,则先加载类的信息,否则为新对象分配内存。
内存分配有两种方式:
以上是两种不同的方法。至于虚拟机使用哪种方法,则取决于虚拟机的类型。
对象的内存布局
堆中对象的存储布局可以分为三个部分:
对象访问位置
正如我们前面提到的,Java 虚拟机堆栈存储基本数据类型和对象引用。我们已经知道基本的数据类型,那么这个对象引用到底是什么?
就是这样,对象实例存储在Java堆中,通过这个对象引用我们可以找到对象在堆中的位置。但是,不同的 Java 虚拟机对于如何定位这个对象有不同的方法。
通常,有两种方法:
两种访问对象的方法都有各自的优势。使用直接指针访问,可以直接定位对象,减少了指针定位的时间开销(如果使用句柄,对象会通过句柄池的指针重定位),最大的好处是它是比较快的。但是使用句柄意味着当对象移动时,不需要更改存储在堆栈中的引用,只需要更改句柄池中指向实例数据的指针即可。
垃圾采集算法理论对象死了吗?
在上一部分中,我们讨论了对象。一个对象可以被创建,那么这个对象什么时候被销毁呢?一般来说,有两种方法可以判断一个对象是否已经被销毁:
如上图所示,绿色部分的对象在GC Roots的引用链上,不会被垃圾回收器回收。灰色部分的对象不在参考链中,自然确定为可回收对象。
那么问题来了,这些 GC Roots 是什么?下面列出了可以用作 GC Roots 的对象:
现在,我们知道哪些物品是可回收的。那么回收对象应该采取什么方法呢?垃圾回收算法主要有三种,分别是mark-sweep、mark-copy和mark-sort。这三种垃圾回收算法其实都比较容易理解。我先介绍一下概念,然后依次总结。
标记扫描算法
顾名思义,mark-to-clear算法就是对无效对象进行标记,然后将其清除。如下所示:
对于mark-sweep算法,你肯定会看到垃圾回收之后,堆空间中的碎片很多,并且有不规则的地方。为大对象分配内存时,由于找不到足够的连续内存空间,不得不再次触发垃圾回收。另外,如果Java堆中有大量垃圾对象,垃圾回收中必须进行大量的标记和清除动作,势必会降低回收效率。
标记--复制算法
标记复制算法是将Java堆分成两部分,每次垃圾回收只使用其中一个,然后将所有幸存的对象移动到另一个区域。如下所示:
mark-copy算法有一个明显的缺点,就是每次只使用一半的堆空间,导致Java堆空间使用率下降。
现在Java虚拟机的垃圾采集器大多使用标记复制算法,但是Java堆空间的划分并不是简单的一分为二。
还记得这张照片吗?
前面讲Java内存结构的时候,提到了Java堆的具体划分,所以现在说一下。
首先,我们要从两种代际采集理论说起:
正是这两个代际假设,让设计者对Java堆的划分更加合理。接下来说一下GC的分类:
好了,知道了GC的分类,是时候了解一下GC的过程了。
通常,第一次创建的对象存放在新生代的Eden区。第一次触发 Minor GC 时,Eden 区的幸存对象被转移到 Survivor 区的某个区域。以后再次触发 Minor GC 时,Eden 区的对象会连同一个 Survivor 区的对象一起转移到另一个 Survivor 区。可以看出,我们一次只使用了两个Survivor区域中的一个,只是浪费了一个Survivor区域。
一个对象每经过一次垃圾回收,它的世代年龄就加1。当世代年龄达到15时,直接存入老年代。
还有一种情况,给大对象分配内存时,Eden区的内存空间不足。这个时候我该怎么办?在这种情况下,大对象将直接进入老年。
标记排序算法
mark-to-clean 算法是一种妥协的垃圾采集算法。在对象标记的过程中,执行与前两个相同的步骤。但是标记后,存活对象被移动到堆的一端,存活对象以外的区域可以直接清理掉。这样就避免了内存碎片,也没有堆空间的浪费。但是,每次进行垃圾回收时,都必须暂停所有用户线程,特别是对于老年代的对象,需要更长的回收时间,这对用户体验非常不利。如下所示:
HotSpot的算法详解根节点枚举
根节点枚举其实就是寻找可以作为GC Roots的对象。在这个过程中,所有的用户线程都必须停止。到目前为止,几乎没有虚拟机可以与用户线程并发执行 GC Roots 遍历。当然,可达性分析算法中寻找参考链最耗时的过程已经可以与用户线程并发执行。那么,为什么需要在根节点枚举的时候停止用户线程呢?
其实不难考虑。如果GC Roots遍历时用户线程没有挂起,根节点集的对象引用关系还在变化,所以遍历的结果不准确。那么,Java虚拟机在寻找GC Roots时真的需要进行全局遍历吗?
事实上,情况并非如此。HotSpot 虚拟机可以通过称为 OopMap 的数据结构知道对象引用的存储位置。这样,GC Roots的遍历时间就大大减少了。
安全点
安全点是线程可以被中断的点。当我们遍历 GC Roots 时,我们必须停止用户线程。问题是,线程可以停在任何位置吗?为了让线程停在最近的安全点,有两种思路:
安全区
安全区是安全点的延伸和延伸。安全点解决了如何停止线程,但没有解决如何让虚拟机进入垃圾回收状态。
安全区是指在某个代码片段中,可以保证引用关系不会发生变化的区域。因此,一旦线程进入安全区,就可以忽略安全区内的这些线程。当线程离开安全区时,虚拟机检查根节点枚举是否完成。
记忆套装和卡片纸
不知道你有没有考虑过这样的问题?既然Java堆分为新生代和老年代,那么会不会有跨代的对象引用呢?如果有跨代,如何解决遍历老年代的GC Roots的问题?
首先,存在跨代参考。因此,垃圾采集器在年轻代中构建了一个称为memoized set的数据结构,以避免将整个老年代作为GC Roots的扫描范围。
内存集是一种抽象的数据结构,卡表是内存集的具体实现。这种关系类似于方法区和元空间。
写屏障
写屏障的作用很简单,就是维护和更新卡表。
并发可达性分析
前面我们提到了为什么要暂停所有用户线程(这个动作也叫Stop The World)?这实际上是为了防止用户线程改变对 GC Roots 对象的引用。试想一下,如果用户线程可以任意将死对象重新标记为活动对象,或者将活动对象标记为死对象,是不是会导致程序出现意外错误。
经典垃圾采集器
我知道很多垃圾采集的理论,但具体到某一种垃圾采集器,它的实现并不完全一样。以下是一些常见的垃圾采集器。
串行采集器
Serial 采集器是最基本、最古老的采集器。它在垃圾采集期间挂起所有工作线程,直到垃圾采集过程完成。下面是Serial垃圾采集器的运行示意图:
ParNew 采集器
ParNew 垃圾采集器实际上是串行垃圾采集器的多线程版本。这种多线程是 ParNew 垃圾采集器可以使用多个线程进行垃圾采集。
并行清除采集器
它也是新一代的垃圾采集器,也是基于标记复制算法实现的。它最大的特点是可以控制吞吐量。
那么什么是吞吐量?

串行老采集器
Serial Old 采集器是 Serial 采集器的老一代版本。垃圾采集器的工作原理与串行采集器相同。

平行老采集器
Parallel Old 采集器也是 Parallel Scavenge 采集器的旧版本,支持多线程并发采集。下面是它的运行示意图:
cms 采集器
如前所述,Parallel Scavenge 采集器是一个可以控制吞吐量的垃圾采集器。现在来说说cms采集器,它是一个追求最短暂停时间的垃圾采集器,基于mark-sweep算法。cms 垃圾采集器的操作过程比前面的要复杂一些。整个过程可以分为四个部分:
垃圾第一采集器
Garbage First(简称G1))采集器是垃圾采集器发展史上的里程碑式成果,主要面向服务端应用。另外,虽然G 1采集器仍然保留了新生代和老年代的概念,但是新生代和老年代不是固定的,它们是一系列区域的动态采集。
好了,垃圾采集器的介绍就到这里。至于G 1采集器,还是有很多值得关注的地方。朋友可以查看相关信息。
算法 自动采集列表(算法自动采集列表页与问题列表、优质用户列表的互相关系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-11 22:02
算法自动采集列表页与问题列表、优质用户列表的互相关系。首先点击列表页列表项链接->填入关键字->采集采集列表内一级或多级关键字名称列表页相关信息采集内容公众号关注列表,粉丝列表,包括注册及登录信息采集机器学习训练数据库,统计各种公众号文章的阅读量,打开率等各项指标。地址::【基于knowledgegraph构建推荐系统】摘要目标如何在knowledgegraph中构建推荐系统,以解决真实世界的各种问题?让一个用户对一个公众号和一个topic做出多个topic上的推荐?用户在不同topic上做的推荐怎么联合起来呢?(横轴是次序,纵轴是这一个topic下面的文章的总数量)用户的所有推荐都是一个实体序列,该序列由公众号关注的文章列表和机器学习训练数据库存储。
通过实体的性质存储序列,比如文章的类型(小说,纪实,体育,新闻)。关键词索引用户可以设置每个关键词存储到这个存储中去吗?如果可以为什么不将它存储到有向无环图中,可能性为四个,可以用lda存储;或者用空间紧凑图。如果文章列表不和关注列表或者topic列表对应一致,使用约束sequencetosequencelda;或者找类似tf-idf和tf-idf联合的聚类算法,与pagerank联合。
对每个用户定制不同的权重级别(1,2,3...)。对不同标签进行设定,如有些标签对应的推荐值很大或者很小。其他问题用户做一个推荐的时候用户利用其它广告或者公众号或者其它方式优惠过一次,则重新购买等方式相关联用户有没有可能创建一个从query过来的多文档嵌入向量做语义向量?为什么利用权重可以,gdbt,dbn,lda怎么比较好?给用户推荐一个公众号,但是用户在公众号文章浏览过去以后并没有在文章列表里面看到推荐的产品,此时怎么办?目标如何设计机器学习lda推荐系统,通过用户到一个列表结构模型来学习列表里面的推荐?有什么好的建议?项目地址:::。 查看全部
算法 自动采集列表(算法自动采集列表页与问题列表、优质用户列表的互相关系)
算法自动采集列表页与问题列表、优质用户列表的互相关系。首先点击列表页列表项链接->填入关键字->采集采集列表内一级或多级关键字名称列表页相关信息采集内容公众号关注列表,粉丝列表,包括注册及登录信息采集机器学习训练数据库,统计各种公众号文章的阅读量,打开率等各项指标。地址::【基于knowledgegraph构建推荐系统】摘要目标如何在knowledgegraph中构建推荐系统,以解决真实世界的各种问题?让一个用户对一个公众号和一个topic做出多个topic上的推荐?用户在不同topic上做的推荐怎么联合起来呢?(横轴是次序,纵轴是这一个topic下面的文章的总数量)用户的所有推荐都是一个实体序列,该序列由公众号关注的文章列表和机器学习训练数据库存储。
通过实体的性质存储序列,比如文章的类型(小说,纪实,体育,新闻)。关键词索引用户可以设置每个关键词存储到这个存储中去吗?如果可以为什么不将它存储到有向无环图中,可能性为四个,可以用lda存储;或者用空间紧凑图。如果文章列表不和关注列表或者topic列表对应一致,使用约束sequencetosequencelda;或者找类似tf-idf和tf-idf联合的聚类算法,与pagerank联合。
对每个用户定制不同的权重级别(1,2,3...)。对不同标签进行设定,如有些标签对应的推荐值很大或者很小。其他问题用户做一个推荐的时候用户利用其它广告或者公众号或者其它方式优惠过一次,则重新购买等方式相关联用户有没有可能创建一个从query过来的多文档嵌入向量做语义向量?为什么利用权重可以,gdbt,dbn,lda怎么比较好?给用户推荐一个公众号,但是用户在公众号文章浏览过去以后并没有在文章列表里面看到推荐的产品,此时怎么办?目标如何设计机器学习lda推荐系统,通过用户到一个列表结构模型来学习列表里面的推荐?有什么好的建议?项目地址:::。
算法 自动采集列表(算法自动采集列表页同类型的网站会以不同方式去展示)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-08 13:00
算法自动采集列表页同类型的网站。不同类型的网站会以不同方式去展示这个代码,如:点击次数排名、信息时效性、与联系人是否有关联。如果你要做的是纯展示页面,那么可以采用时间倒排模型来解决,但你如果要做的是会员注册/帐号这种的。这样的话就有难度了,难点之一是你需要在一个月之内把代码开放给别人接受,另外在做的过程中需要不断对他的点击做记录,优化代码。一次两次没问题,多了之后可能就有点难度了。可以试一下routerman作为辅助工具。
一般情况下在pc端,你不要想着去做一个这样的页面,因为这个页面根本没办法展示网站信息。这样的页面很可能就是蜘蛛爬虫抓取浏览网站的记录(这样的抓取记录会被放到一个广告网络里去),蜘蛛就会把这个蜘蛛记录抓取下来,在m站的网站爬虫可以通过找到这个cookie来对应服务器,从而达到获取信息的目的。
需要优化页面的各个阶段。详细可以参考uwablog上大佬介绍的。
你可以做一个基于代码的爬虫脚本。通过对网站进行仿真爬虫代码或者利用excel导入php页面。然后直接通过页面的点击触发来采集和上传网站信息到mysql就行了。如果需要大量点击才能对页面进行捕获和上传的话,可以配合其他技术(sslhttps)进行抓取页面。附两个github项目,楼主可以参考一下:-greasyfork-blogpro,针对微博可以像购物一样动态上传数据和更新数据。-jiaxing-blog,仿真谷歌about.php,捕获上传的网站数据即可。 查看全部
算法 自动采集列表(算法自动采集列表页同类型的网站会以不同方式去展示)
算法自动采集列表页同类型的网站。不同类型的网站会以不同方式去展示这个代码,如:点击次数排名、信息时效性、与联系人是否有关联。如果你要做的是纯展示页面,那么可以采用时间倒排模型来解决,但你如果要做的是会员注册/帐号这种的。这样的话就有难度了,难点之一是你需要在一个月之内把代码开放给别人接受,另外在做的过程中需要不断对他的点击做记录,优化代码。一次两次没问题,多了之后可能就有点难度了。可以试一下routerman作为辅助工具。
一般情况下在pc端,你不要想着去做一个这样的页面,因为这个页面根本没办法展示网站信息。这样的页面很可能就是蜘蛛爬虫抓取浏览网站的记录(这样的抓取记录会被放到一个广告网络里去),蜘蛛就会把这个蜘蛛记录抓取下来,在m站的网站爬虫可以通过找到这个cookie来对应服务器,从而达到获取信息的目的。
需要优化页面的各个阶段。详细可以参考uwablog上大佬介绍的。
你可以做一个基于代码的爬虫脚本。通过对网站进行仿真爬虫代码或者利用excel导入php页面。然后直接通过页面的点击触发来采集和上传网站信息到mysql就行了。如果需要大量点击才能对页面进行捕获和上传的话,可以配合其他技术(sslhttps)进行抓取页面。附两个github项目,楼主可以参考一下:-greasyfork-blogpro,针对微博可以像购物一样动态上传数据和更新数据。-jiaxing-blog,仿真谷歌about.php,捕获上传的网站数据即可。
算法 自动采集列表(十二星座本月事业运势D:列表页采集关键词gjcaizhanaizhan_4.txt)
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-07 06:00
**
**
dp一般用于解决多阶段决策问题,即每个阶段都要做出一个决策,所有的决策都是一个决策序列。
最佳决策序列导致问题的最佳解决方案
把要解决的问题分成几个相互关联的子问题,只解决第一次遇到的问题,然后保存这个子问题的答案
下次遇到直接下来用
dp和分治法的区别在于,分治法分解出来的子问题一定是没有联系的(如果有联系,就收录了大量重复的子问题,那么
所以这个问题不适合分治,虽然分治也可以解决,但是时间复杂度太大,不划算),所以使用dp和使用divide的问题
治理问题的根本区别在于分解成的子问题之间是否存在联系,以及这些子问题是否重叠,即是否存在重复的子问题
dp和greedy的区别在于,每次greed是D:列表页采集关键词gjcaizhanaizhan_4.txt做出不可逆的决定(即每次局部最优),而在dp中,也有调查
每个最优决策子序列是否收录最详细的18年星座最优决策子序列,即是否具有最优子结构性质,贪婪的每一步只关注当下
最优的,并且当前的选择不会依赖于之前的选择,而dp在选择的时候是从前面的步骤和这一步中得到的
选择相关子问题中的最优解,将本步的值相加,形成本步该子问题的最优解。
示例:最大值问题
这个想法就像代码所想的那样
其中,一般的星座分析靠谱吗?
D:列表页采集关键词gjcaizhanaizhan_4.txt
:这段代码是这个问题的核心
应用3:01背包
算法小白的一些总结,如有错误,希望大家多多指教! 查看全部
算法 自动采集列表(十二星座本月事业运势D:列表页采集关键词gjcaizhanaizhan_4.txt)
**
**
dp一般用于解决多阶段决策问题,即每个阶段都要做出一个决策,所有的决策都是一个决策序列。
最佳决策序列导致问题的最佳解决方案
把要解决的问题分成几个相互关联的子问题,只解决第一次遇到的问题,然后保存这个子问题的答案
下次遇到直接下来用
dp和分治法的区别在于,分治法分解出来的子问题一定是没有联系的(如果有联系,就收录了大量重复的子问题,那么
所以这个问题不适合分治,虽然分治也可以解决,但是时间复杂度太大,不划算),所以使用dp和使用divide的问题
治理问题的根本区别在于分解成的子问题之间是否存在联系,以及这些子问题是否重叠,即是否存在重复的子问题
dp和greedy的区别在于,每次greed是D:列表页采集关键词gjcaizhanaizhan_4.txt做出不可逆的决定(即每次局部最优),而在dp中,也有调查
每个最优决策子序列是否收录最详细的18年星座最优决策子序列,即是否具有最优子结构性质,贪婪的每一步只关注当下
最优的,并且当前的选择不会依赖于之前的选择,而dp在选择的时候是从前面的步骤和这一步中得到的
选择相关子问题中的最优解,将本步的值相加,形成本步该子问题的最优解。
示例:最大值问题
这个想法就像代码所想的那样
其中,一般的星座分析靠谱吗?

D:列表页采集关键词gjcaizhanaizhan_4.txt
:这段代码是这个问题的核心
应用3:01背包
算法小白的一些总结,如有错误,希望大家多多指教!
算法 自动采集列表(Python使用计算法进行垃圾回收Python如何解决循环引用? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-05 13:20
)
标记阶段:参考计数算法垃圾标记阶段:对象生存判断参考计算算法证明
/**
* -XX:+PrintGCDetails
* 证明:java使用的不是引用计数算法
*/
public class RefCountGC {
//这个成员属性唯一的作用就是占用一点内存
private byte[] bigSize = new byte[5 * 1024 * 1024];//5MB
Object reference = null;
public static void main(String[] args) {
RefCountGC obj1 = new RefCountGC();
RefCountGC obj2 = new RefCountGC();
obj1.reference = obj2;
obj2.reference = obj1;
obj1 = null;
obj2 = null;
//显式的执行垃圾回收行为
//这里发生GC,obj1和obj2能否被回收?
// System.gc();
// try {
// Thread.sleep(1000000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
}
}
这样创建对象会导致引用计数器为+2,我们来看看没有回收的内存。
让我们GC
显然这个GC被回收了。如果是引用计数算法,则不会采集它们。因此 Java 不使用引用计数算法。
Python 使用参考算法进行垃圾采集。Python如何解决循环引用?标记阶段:可达性分析算法(Java使用的算法) GCRoots 根集 GC Roots可以收录本地方法栈中JNI引用的那些元素 类的方法区中静态属性引用的对象 常量引用的对象在方法区All synchronized 锁同步持有的对象Java 虚拟机的内部引用反映了Java 虚拟机JMXBean 的内部情况,在JVMTI 中注册的回调,以及本地代码缓存。
特别注意辨别能力
因为Root使用栈来存储变量和指针,如果一个指针将对象保存在堆内存中,但不将自己保存在堆内存中,那么他就是一个Root
注意对象finalize()方法的终结机制注意,在功能上,finalize()和C++中的析构函数类似,但是Java使用了基于垃圾回收的自动内存管理机制,所以finalize()方法本质上是不同的 C++ 中的析构函数。由于finalize()方法的存在,虚拟机中的对象一般处于三种可能的状态。对象的三种状态
一个不可触及的对象在一定的条件下可能会自我复活,如果是这样,回收它是不合理的。为此,定义了虚拟机中的对象可能处于三种状态
具体过程对象复活
public class CanReliveObj {
public static CanReliveObj obj;//类变量,属于 GC Root
//此方法只能被调用一次
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用当前类重写的finalize()方法");
obj = this;//当前待回收的对象在finalize()方法中与引用链上的一个对象obj建立了联系
}
public static void main(String[] args) {
try {
obj = new CanReliveObj();
// 对象第一次成功拯救自己
obj = null;
System.gc();//调用垃圾回收器
System.out.println("第1次 gc");
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
System.out.println("第2次 gc");
// 下面这段代码与上面的完全相同,但是这次自救却失败了
obj = null;
System.gc();
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
结果
MAT 和 JProfiler 的 GC Roots 可追溯性 MAT
MAT是Memory Analyzer的坚持,它是一个强大的Java堆内存分析器,用于查找内存泄漏和查看内存消耗。
MAT是基于Eclipse开发的,是一个性能分析工具。
获取转储文件方法一:使用jmap命令行
方法 2:使用 JVisualVM 将本地应用程序的堆转储导出为应用程序选项卡的子选项卡。同事堆转储对应左侧Application栏的一个timestamp节点,右键该节点选择save as 可以导出本地扫描阶段:Mark-Sweep算法(Mark-Sweep)
实施过程
当堆中可用内存耗尽时,整个进程(也称为 stw)停止,执行两个作业
缺点 什么是清算?
所谓清空,并不是真的清空,而是垃圾对象的地址存放在一个空闲列表中。
清算阶段:复制算法(Copying)
大意
将活动内存空间分成两块,一次只使用其中一个,垃圾回收时将正在使用的内存中的活动对象复制到未使用的内存块中,然后清除所有正在使用的内存块。对象,交换内存的作用,最后完成垃圾回收。
优点 缺点 特殊应用场景
在新生代中,常规应用的垃圾回收通常可以一次性回收70%-99%的内存空间,回收非常划算,所以虚拟机采用这种算法来回收新生代。
清除阶段:标记紧凑算法
基于老年垃圾回收的特点,需要使用其他算法
在标记压缩算法上实现过程标记扫描算法
mark-compression算法可视为mark-sweep-compression算法(只有在mark-sweep执行完成后,才进行内存碎片整理)
两者的本质区别在于
优缺点总结
分代采集算法
以上三种算法都不能完全替代其他方法。它们都有自己独特的优势和特点,手机算法的一代应运而生。
目前几乎所有的 GC 都使用分代采集算法来执行垃圾采集。
Tenured Gen 增量采集算法,分区算法增量采集算法
在上述算法的垃圾回收过程中,应用软件将处于STW(Stop The World)状态。在这种状态下,所有的线程都会被挂起,所有正常的工作都会被挂起,垃圾回收也就完成了。垃圾回收时间过长会影响系统稳定性和用户体验。为了解决这个问题,增量采集算法(Incremental Collecting)诞生了。
基本思想
如果一次采集和处理所有垃圾,需要长时间的停顿,那么垃圾采集线程和应用程序线程可以交替执行。每次垃圾采集线程只采集一小块内存空间,然后切换到应用程序。程序线程,如此反复,直到垃圾采集完成。
该算法的基础仍然是传统的mark-sweep算法和copy算法,而增量采集算法则妥善处理线程间的冲突,让垃圾采集线程分阶段完成标记、清理或复制工作。
缺点
线程切换和上下文转换的消耗会增加垃圾回收的整体成本,导致系统吞吐量下降。
分区算法
生成算法将对象的生命周期分为两部分(新生代、老生代)
分区算法将整个堆空间划分为连续不同和不同的小区间。每个细胞独立使用和独立回收。这种算法的优点是可以控制一次回收多少个cell。
查看全部
算法 自动采集列表(Python使用计算法进行垃圾回收Python如何解决循环引用?
)
标记阶段:参考计数算法垃圾标记阶段:对象生存判断参考计算算法证明
/**
* -XX:+PrintGCDetails
* 证明:java使用的不是引用计数算法
*/
public class RefCountGC {
//这个成员属性唯一的作用就是占用一点内存
private byte[] bigSize = new byte[5 * 1024 * 1024];//5MB
Object reference = null;
public static void main(String[] args) {
RefCountGC obj1 = new RefCountGC();
RefCountGC obj2 = new RefCountGC();
obj1.reference = obj2;
obj2.reference = obj1;
obj1 = null;
obj2 = null;
//显式的执行垃圾回收行为
//这里发生GC,obj1和obj2能否被回收?
// System.gc();
// try {
// Thread.sleep(1000000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
}
}
这样创建对象会导致引用计数器为+2,我们来看看没有回收的内存。

让我们GC

显然这个GC被回收了。如果是引用计数算法,则不会采集它们。因此 Java 不使用引用计数算法。
Python 使用参考算法进行垃圾采集。Python如何解决循环引用?标记阶段:可达性分析算法(Java使用的算法) GCRoots 根集 GC Roots可以收录本地方法栈中JNI引用的那些元素 类的方法区中静态属性引用的对象 常量引用的对象在方法区All synchronized 锁同步持有的对象Java 虚拟机的内部引用反映了Java 虚拟机JMXBean 的内部情况,在JVMTI 中注册的回调,以及本地代码缓存。

特别注意辨别能力
因为Root使用栈来存储变量和指针,如果一个指针将对象保存在堆内存中,但不将自己保存在堆内存中,那么他就是一个Root
注意对象finalize()方法的终结机制注意,在功能上,finalize()和C++中的析构函数类似,但是Java使用了基于垃圾回收的自动内存管理机制,所以finalize()方法本质上是不同的 C++ 中的析构函数。由于finalize()方法的存在,虚拟机中的对象一般处于三种可能的状态。对象的三种状态
一个不可触及的对象在一定的条件下可能会自我复活,如果是这样,回收它是不合理的。为此,定义了虚拟机中的对象可能处于三种状态
具体过程对象复活
public class CanReliveObj {
public static CanReliveObj obj;//类变量,属于 GC Root
//此方法只能被调用一次
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用当前类重写的finalize()方法");
obj = this;//当前待回收的对象在finalize()方法中与引用链上的一个对象obj建立了联系
}
public static void main(String[] args) {
try {
obj = new CanReliveObj();
// 对象第一次成功拯救自己
obj = null;
System.gc();//调用垃圾回收器
System.out.println("第1次 gc");
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
System.out.println("第2次 gc");
// 下面这段代码与上面的完全相同,但是这次自救却失败了
obj = null;
System.gc();
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
结果

MAT 和 JProfiler 的 GC Roots 可追溯性 MAT
MAT是Memory Analyzer的坚持,它是一个强大的Java堆内存分析器,用于查找内存泄漏和查看内存消耗。
MAT是基于Eclipse开发的,是一个性能分析工具。

获取转储文件方法一:使用jmap命令行

方法 2:使用 JVisualVM 将本地应用程序的堆转储导出为应用程序选项卡的子选项卡。同事堆转储对应左侧Application栏的一个timestamp节点,右键该节点选择save as 可以导出本地扫描阶段:Mark-Sweep算法(Mark-Sweep)

实施过程
当堆中可用内存耗尽时,整个进程(也称为 stw)停止,执行两个作业
缺点 什么是清算?
所谓清空,并不是真的清空,而是垃圾对象的地址存放在一个空闲列表中。
清算阶段:复制算法(Copying)

大意
将活动内存空间分成两块,一次只使用其中一个,垃圾回收时将正在使用的内存中的活动对象复制到未使用的内存块中,然后清除所有正在使用的内存块。对象,交换内存的作用,最后完成垃圾回收。
优点 缺点 特殊应用场景
在新生代中,常规应用的垃圾回收通常可以一次性回收70%-99%的内存空间,回收非常划算,所以虚拟机采用这种算法来回收新生代。
清除阶段:标记紧凑算法
基于老年垃圾回收的特点,需要使用其他算法
在标记压缩算法上实现过程标记扫描算法
mark-compression算法可视为mark-sweep-compression算法(只有在mark-sweep执行完成后,才进行内存碎片整理)
两者的本质区别在于
优缺点总结

分代采集算法
以上三种算法都不能完全替代其他方法。它们都有自己独特的优势和特点,手机算法的一代应运而生。
目前几乎所有的 GC 都使用分代采集算法来执行垃圾采集。
Tenured Gen 增量采集算法,分区算法增量采集算法
在上述算法的垃圾回收过程中,应用软件将处于STW(Stop The World)状态。在这种状态下,所有的线程都会被挂起,所有正常的工作都会被挂起,垃圾回收也就完成了。垃圾回收时间过长会影响系统稳定性和用户体验。为了解决这个问题,增量采集算法(Incremental Collecting)诞生了。
基本思想
如果一次采集和处理所有垃圾,需要长时间的停顿,那么垃圾采集线程和应用程序线程可以交替执行。每次垃圾采集线程只采集一小块内存空间,然后切换到应用程序。程序线程,如此反复,直到垃圾采集完成。
该算法的基础仍然是传统的mark-sweep算法和copy算法,而增量采集算法则妥善处理线程间的冲突,让垃圾采集线程分阶段完成标记、清理或复制工作。
缺点
线程切换和上下文转换的消耗会增加垃圾回收的整体成本,导致系统吞吐量下降。
分区算法
生成算法将对象的生命周期分为两部分(新生代、老生代)
分区算法将整个堆空间划分为连续不同和不同的小区间。每个细胞独立使用和独立回收。这种算法的优点是可以控制一次回收多少个cell。

算法 自动采集列表(算法自动采集列表,多个页面同时使用,同时查看)
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-02 13:01
算法自动采集列表:专门的采集产品列表,然后再转换成优化后的产品列表页面。看哪个产品人多,然后查看ta的网站推广链接。然后点击购买,查看详情产品细节。分发思路:每个产品的一个sku,上下ta的产品列表,然后保存为不同的产品标签,方便数据量分发可视化,新客注册、再次购买、保存购买详情、优惠券等等等等。都能显示。
一个简单的产品列表,直接实现多个用户、多个页面同时使用。上下架逻辑和普通的列表页面差不多,通过筛选产品重定向到你设定的产品页面。但是每个产品有一个sku、用户发生购买后,自动获取这个产品的优惠券发放给相应的会员,同时查看详情页面。提供一个思路的大概示意图:相关产品列表可以根据自己的产品关键词,去搜索你需要的产品,然后查看产品详情页面。
你要更多产品关键词,可以多逛逛的相关产品页面,而且你要根据自己实际情况定制不同产品的关键词,比如目前上买木屋的,主要是东北那边的木屋,你就把浙江、浙西那边的木屋找出来,其他都去别家看看。用户购买什么产品,直接分析详情页,用户购买详情页销量,根据数据回流!。
通过分析用户购买习惯然后通过采集的数据不断修正sku,在需要的时候把用户可能的产品列出来,然后考虑下用户是否在购买这个产品的时候还会购买其他产品或者同时购买另外一个sku,这样可以增加一个浏览sku的sku组别。如果产品不太多的话,推荐先用分词法把所有sku的标题和sku列表搞定。然后如果产品分析采集下来的字段足够少,完全可以通过高级搜索技术显示细节信息。那时基本上就是这样。 查看全部
算法 自动采集列表(算法自动采集列表,多个页面同时使用,同时查看)
算法自动采集列表:专门的采集产品列表,然后再转换成优化后的产品列表页面。看哪个产品人多,然后查看ta的网站推广链接。然后点击购买,查看详情产品细节。分发思路:每个产品的一个sku,上下ta的产品列表,然后保存为不同的产品标签,方便数据量分发可视化,新客注册、再次购买、保存购买详情、优惠券等等等等。都能显示。
一个简单的产品列表,直接实现多个用户、多个页面同时使用。上下架逻辑和普通的列表页面差不多,通过筛选产品重定向到你设定的产品页面。但是每个产品有一个sku、用户发生购买后,自动获取这个产品的优惠券发放给相应的会员,同时查看详情页面。提供一个思路的大概示意图:相关产品列表可以根据自己的产品关键词,去搜索你需要的产品,然后查看产品详情页面。
你要更多产品关键词,可以多逛逛的相关产品页面,而且你要根据自己实际情况定制不同产品的关键词,比如目前上买木屋的,主要是东北那边的木屋,你就把浙江、浙西那边的木屋找出来,其他都去别家看看。用户购买什么产品,直接分析详情页,用户购买详情页销量,根据数据回流!。
通过分析用户购买习惯然后通过采集的数据不断修正sku,在需要的时候把用户可能的产品列出来,然后考虑下用户是否在购买这个产品的时候还会购买其他产品或者同时购买另外一个sku,这样可以增加一个浏览sku的sku组别。如果产品不太多的话,推荐先用分词法把所有sku的标题和sku列表搞定。然后如果产品分析采集下来的字段足够少,完全可以通过高级搜索技术显示细节信息。那时基本上就是这样。
算法 自动采集列表( FlinkFlinkSQL实践遇到的典型问题以及解决方案2.实时计算平台建设过程中的思考)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-02 03:10
FlinkFlinkSQL实践遇到的典型问题以及解决方案2.实时计算平台建设过程中的思考)
文/张颖
概括
Flink 在 Homework 实时计算的演进中发挥了重要作用。尤其是在 FlinkSQL 的帮助下,实时任务的开发效率得到了极大的提升。
本文文章主要分享FlinkSQL在作业帮助中的使用和实践经验,以及随着任务规模的增加,从0到1搭建实时计算平台过程中遇到的问题和解决方法.
一、发展历程
Homework Help主要利用人工智能、大数据等技术为学生提供更高效的学习解决方案。因此,业务数据主要包括学生的出勤率和知识点的掌握情况。在整体架构中,无论是binlog还是普通日志,都是在采集之后写入Kafka,分别通过实时和离线计算写入存储层。基于OLAP,对外提供相应的产品化服务,如工作台、BI分析等。工具。
目前 Homework Help 的实时计算主要基于 Flink,开发过程分为三个阶段:
1. 2019 年实时计算包括少量 SparkStreaming 作业,提供给导师和讲师。在解决实时性需求的过程中,会发现开发效率很低,数据几乎无法复用。
2. 之后,正常的做法是在生产实践中逐步应用Flink JAR,积累经验后开始搭建平台和应用Flink SQL。但是在过去的20年里,业务对实时计算提出了很多要求,而我们开发的人力储备不足。当时,在 Flink SQL 1.9 发布后不久,SQL 功能发生了很大变化,所以我们的做法是直接将 Flink SQL 应用到实时数仓方向。目前整个实时数仓90%以上的任务都是使用Flink SQL实现的。
3. 到 2020 年 11 月,Flink 的 Job 数量迅速增加到数百个,我们开始构建从 0 到 1 的实时计算平台,已经支撑了公司所有的重要业务线,计算是部署在多个云中。在一个集群上。
介绍以下两个方面:
1. FlinkSQL 实践中遇到的典型问题及解决方案
2. 实时计算平台建设的几点思考
二、Flink SQL 应用实践
下面是基于 Flink SQL 的完整数据流架构:
binlog/log 采集 写入 Kafka 后,topic 会自动注册为元数据表,这是后续所有实时 SQL 作业的起点。用户可以在 SQL 作业中使用此表,而无需定义复杂的 DDL。
同时,在考虑实际应用时,还需要根据元数据表添加或替换表属性:
1. 新增:元数据记录表级属性,但 SQL 作业可能需要添加任务级属性。例如,对于Kafka源表,添加作业的group.id来记录偏移量。
2. 替换:离线测试时,在引用元数据表的基础上,只需要定义broker topic等属性覆盖源表,即可快速构建离线测试表。
框架还需要支持用户的SQL作业,方便输出指标和日志,实现全链路监控和跟踪。
这里主要介绍SQL添加Trace函数时的DAG优化实践,以及我们对Table底层物理存储的选择和封装。
2.1. SQL 增加 Trace 功能
SQL可以提高开发效率,但是业务逻辑的复杂度还是有的,复杂的业务逻辑写的DML会很长。在这种情况下,建议使用视图来提高可读性。因为视图的 SQL 比较短,所以不应该像代码规范中的单个函数那样太长。
下图左侧是一个示例任务的部分DAG,可以看到有很多SQL节点。这种情况下很难定位,因为如果是DataStream API实现的代码,也可以加日志。但是 SQL 做不到。用户可以干预的入口很少,只能看到整个作业的输入输出。
类似于在函数中打印日志,我们希望支持在视图中添加 Trace,以方便案例追踪。
但是我在尝试将 Trace 添加到 SQL 时遇到了一些问题,这是一个简化的示例:
右上角的SQL创建source_table为源表,prepare_data视图读取表,在sql中调用foo udf,然后使用StatementSet分别插入两个下游,同时将视图转换为DataStream调用 TraceSDK 写入跟踪系统。
注意:我们当时是基于 1.9 开发的。为了清楚起见,我们还使用了一些后来添加的功能。
上图下方的实际 DAG 看起来并不像预期的那样:
1. DAG分为上下不相关的两部分。Kafka源表是DataSource部分,读取两次。
2. foo 方法被调用了 3 次。
数据源压力和计算性能需要优化。
为了解决这个问题,我们需要从几个角度进行优化。这里主要介绍DAG合并的思想。无论是table还是stream的env,都会产生相应的transformation。我们的做法是统一合并到stream env中,这样就可以在stream env中得到一个完整的变换列表,然后生成StreamGraph提交。
左下角是我们优化的 DAG,读取源表并只调用一次 foo 方法:
优化后的 DAG 效果与我们写 SQL 时的逻辑图非常相似,性能自然符合预期。
回到问题本身,业务可以简单的使用一条语句给视图的某些字段添加trace,例如:prepare_data.trace.fields=f0,f1. 由于SQL中自然收录字段名,所以trace数据可读性甚至高于普通日志。
2.2. 表选择与设计
如前所述,我们的首要要求是提高人的效率。因此,Table 需要具备更好的分层和复用能力,并且支持模板化开发,以便 N 个端到端的 Flink 作业能够快速串联起来。
我们的解决方案是基于 Redis 实现的,它首先有几个优点:
1. 高qps,低延迟:这应该是所有实时计算的关注点。
2. TTL:用户无需关心数据如何退出该字段,只需给一个合理的TTL即可。
3. 通过使用protobuf等高性能紧凑的序列化方式,并使用TTL,整体存储小于200G,redis的内存压力可以接受。
4. 适配计算模型:为了保证计算本身的时序,会进行keyBy操作,同时需要处理的数据会被shuffle到同一个并发,所以它不会过多依赖存储来考虑锁的优化。
接下来,我们的场景主要是解决多索引和触发消息的问题。
上图显示了一个表格示例,显示学生是否出现在某个章节中:
1. 多索引:数据首先以字符串形式存储,比如key=(uid, course_id), value=serialize(is_attend, ...),这样我们就可以在SQL中JOIN ON uid AND course_id . 如果 JOIN ON 其他字段,比如 course_id 怎么办?我们的做法是同时写一个以lesson_id为key的集合,集合中的元素是对应的(uid,lesson_id)。接下来在找lesson_id = 123的时候,先取出集合下的所有元素,然后通过管道找到所有的VALUE并返回。
2. 触发消息:写入redis后,会同时向Kafka写入一条更新消息。在 Redis Connector 的实现中,保证了两个存储之间的一致性、顺序性和不丢失数据。
这些功能都封装在 Redis Connector 中,业务可以通过 DDL 简单定义这样的 Table。
DDL 中的几个重要属性:
1. primary 定义了主键,对应字符串数据结构,比如例子中的uid + course_id。
2. index.fields 定义了辅助搜索的索引字段,例如示例中的课程id;也可以定义多个索引。
3. poster.kafka 定义了接收触发消息的kafka 表。该表也在元数据中定义,用户可以直接读取该表,而无需在后续的 SQL 作业中定义。
因此,整个开发模式复用性高,用户可以轻松开发端到端的N个SQL作业,而无需担心如何追溯案例。
三、 平台搭建
上述数据流架构搭建完成后,2020.11实时作业数量迅速增加到几百个,比2019年快很多。这个时候我们开始搭建实时计算平台从0到1,然后分享了搭建过程中的一些想法。
平台支持的功能主要有三个起点:
1. 统一:统一不同云厂商的不同集群环境、Flink版本、提交方式等;之前hadoop客户端分散在用户的提交机器上,对集群数据和任务安全存在隐患。升级和迁移成本。我们希望通过平台统一任务的提交入口和提交方式。
2.易用性:平台交互可以提供更易用的功能,如调试、语义检测等,可以提高任务测试的人为效率,并记录任务的版本历史,支持方便在线和回滚操作。
3. 规范:权限控制、流程审批等,类似于在线服务的在线流程,通过平台可以规范实时任务的研发流程。
3.1.规范——实时任务进程管理
FlinkSQL 让开发变得非常简单和高效,但是越简单越难标准化,因为可能写一段 SQL 只需要两个小时,但通过规范却需要半天时间。
但是,该规范仍然需要执行。一些问题类似于在线服务,在实时计算中也遇到过:
1. 记不清了:任务上线一年了,最初的需求可能是口耳相传。最好记住wiki或email,但在任务交接时很容易记不清。
2. 不规则:UDF或DataStream代码,均不符合规范,可读性差。结果,后来接手的学生无法升级,也不敢改变,无法长期维持。还应该有一个关于如何编写包括实时任务在内的 SQL 的规范。
3. 找不到:线上运行的任务依赖一个jar,哪个git模块对应哪个commitId,有问题怎么第一时间找到对应的代码实现。
4.盲改:一直正常的任务,周末突然报警,原因是私下修改了线上任务的sql。
规范主要分为三个部分:
1. 开发:RD 可以从 UDF 原型项目中快速创建 UDF 模块,该项目基于 flink 快速入门。创建的 UDF 模块可以正常编译,包括 WordCount 之类的 udf 示例,以及 ReadMe 和 VersionHelper 等默认的 helper 方法。根据业务需求修改后,通过CR上传到Git。
2. 需求管理与编译:提交的代码将与需求卡片相关联。集群编译和QA测试后,即可下单上线。
3. 在线:根据模块和编译输出选择更新/创建哪些作业,并在作业所有者或领导批准后重新部署。
整个研发过程不能离线修改,比如更改jar包或者对哪个任务生效。一个实时任务,即使跑了几年,也能查到谁在线,谁批准了当前任务,当时的测试记录,对应的Git代码,以及提出的实时指标要求谁开始的。任务维持很长时间。
3.2 易用性监控
我们当前的 Flink 作业在 Yarn 上运行。作业启动后,预计 Prometheus 会抓取 Yarn 分配的 Container,然后连接到报警系统。用户可以根据告警系统配置Kafka延迟告警和Checkpoint故障告警。构建此路径时遇到两个主要问题:
1. PrometheusReporter启动HTTPServer后,Prometheus如何动态感知;它还需要能够控制度量的大小以避免采集大量无用数据。
2. 我们SQL的源表基本都是Kafka。相比第三方工具,在计算平台上配置Kafka延迟告警更方便。因为自然可以得到任务读取的topic和group.id,所以也可以和任务失败使用同一个告警组。结合告警模板,配置告警非常简单。
关于解决方案:
1. 添加了基于官方 PrometheusReporter 的发现功能。Container 的 HTTPServer 启动后,对应的 ip:port 以临时节点的形式注册到 zk 上,然后使用 Prometheus 的 discover 目标来监控 zk 节点的变化。由于是临时节点,当 Container 被销毁时,该节点就消失了,Prometheus 也能感应到它不再被抓取。这样一来,就很容易为普罗米修斯搭建一条抢夺的路径。
2. KafkaConsumer.records-lag 是一个比较实用和重要的延迟指标,主要做了两个任务。修改 KafkaConnector 并在 KafkaConsumer.poll 之后将其公开,以确保 records-lag 指示器可见。另外,在做这个的过程中,我们发现不同Kafka版本的metric格式是不同的()。我们的方法是将它们扁平化为一种格式,并将它们注册到 flink 的指标中。这样不同版本暴露的指标是一致的。
四、总结与展望
上一阶段使用 Flink SQL 来支持实时作业的快速开发,搭建了实时计算平台来支持数千个 Flink 作业。
更大的见解之一是 SQL 确实简化了开发,但它也阻止了更多的技术细节。对实时作业运维工具的要求,比如 Trace,或者任务的规范没有改变,对这些的要求更加严格。
因为在细节被屏蔽的同时,一旦出现问题,用户不知道如何处理。就像冰山一角,漏水越少,下沉越多,越需要做好周边系统的建设。
二是适应现状。一是能尽快满足当前的需求。比如,我们正在提高人的效率,降低发展门槛。同时还要继续探索更多的业务场景,比如用HBase和RPC服务代替Redis Connector。现在的好处是修改了底层存储,用户对SQL作业的感知很小,因为SQL作业基本都是业务逻辑,DDL定义了元数据。
接下来的计划主要分为三个部分:
1. 支持资源弹性伸缩,平衡实时作业的成本和时效性。
2. 我们从 1.9 开始大规模应用 Flink SQL。现在版本升级发生了很大的变化,我们需要考虑如何让业务能够低成本的升级和使用新版本中的特性。
3. 探索流批集成在实际业务场景中的实现。
关于作者
张颖,2019年加入乔邦大数据中台研发部,负责实时计算相关工作。 查看全部
算法 自动采集列表(
FlinkFlinkSQL实践遇到的典型问题以及解决方案2.实时计算平台建设过程中的思考)
文/张颖
概括
Flink 在 Homework 实时计算的演进中发挥了重要作用。尤其是在 FlinkSQL 的帮助下,实时任务的开发效率得到了极大的提升。
本文文章主要分享FlinkSQL在作业帮助中的使用和实践经验,以及随着任务规模的增加,从0到1搭建实时计算平台过程中遇到的问题和解决方法.
一、发展历程
Homework Help主要利用人工智能、大数据等技术为学生提供更高效的学习解决方案。因此,业务数据主要包括学生的出勤率和知识点的掌握情况。在整体架构中,无论是binlog还是普通日志,都是在采集之后写入Kafka,分别通过实时和离线计算写入存储层。基于OLAP,对外提供相应的产品化服务,如工作台、BI分析等。工具。
目前 Homework Help 的实时计算主要基于 Flink,开发过程分为三个阶段:
1. 2019 年实时计算包括少量 SparkStreaming 作业,提供给导师和讲师。在解决实时性需求的过程中,会发现开发效率很低,数据几乎无法复用。
2. 之后,正常的做法是在生产实践中逐步应用Flink JAR,积累经验后开始搭建平台和应用Flink SQL。但是在过去的20年里,业务对实时计算提出了很多要求,而我们开发的人力储备不足。当时,在 Flink SQL 1.9 发布后不久,SQL 功能发生了很大变化,所以我们的做法是直接将 Flink SQL 应用到实时数仓方向。目前整个实时数仓90%以上的任务都是使用Flink SQL实现的。
3. 到 2020 年 11 月,Flink 的 Job 数量迅速增加到数百个,我们开始构建从 0 到 1 的实时计算平台,已经支撑了公司所有的重要业务线,计算是部署在多个云中。在一个集群上。
介绍以下两个方面:
1. FlinkSQL 实践中遇到的典型问题及解决方案
2. 实时计算平台建设的几点思考
二、Flink SQL 应用实践
下面是基于 Flink SQL 的完整数据流架构:
binlog/log 采集 写入 Kafka 后,topic 会自动注册为元数据表,这是后续所有实时 SQL 作业的起点。用户可以在 SQL 作业中使用此表,而无需定义复杂的 DDL。
同时,在考虑实际应用时,还需要根据元数据表添加或替换表属性:
1. 新增:元数据记录表级属性,但 SQL 作业可能需要添加任务级属性。例如,对于Kafka源表,添加作业的group.id来记录偏移量。
2. 替换:离线测试时,在引用元数据表的基础上,只需要定义broker topic等属性覆盖源表,即可快速构建离线测试表。
框架还需要支持用户的SQL作业,方便输出指标和日志,实现全链路监控和跟踪。
这里主要介绍SQL添加Trace函数时的DAG优化实践,以及我们对Table底层物理存储的选择和封装。
2.1. SQL 增加 Trace 功能
SQL可以提高开发效率,但是业务逻辑的复杂度还是有的,复杂的业务逻辑写的DML会很长。在这种情况下,建议使用视图来提高可读性。因为视图的 SQL 比较短,所以不应该像代码规范中的单个函数那样太长。
下图左侧是一个示例任务的部分DAG,可以看到有很多SQL节点。这种情况下很难定位,因为如果是DataStream API实现的代码,也可以加日志。但是 SQL 做不到。用户可以干预的入口很少,只能看到整个作业的输入输出。
类似于在函数中打印日志,我们希望支持在视图中添加 Trace,以方便案例追踪。
但是我在尝试将 Trace 添加到 SQL 时遇到了一些问题,这是一个简化的示例:
右上角的SQL创建source_table为源表,prepare_data视图读取表,在sql中调用foo udf,然后使用StatementSet分别插入两个下游,同时将视图转换为DataStream调用 TraceSDK 写入跟踪系统。
注意:我们当时是基于 1.9 开发的。为了清楚起见,我们还使用了一些后来添加的功能。
上图下方的实际 DAG 看起来并不像预期的那样:
1. DAG分为上下不相关的两部分。Kafka源表是DataSource部分,读取两次。
2. foo 方法被调用了 3 次。
数据源压力和计算性能需要优化。
为了解决这个问题,我们需要从几个角度进行优化。这里主要介绍DAG合并的思想。无论是table还是stream的env,都会产生相应的transformation。我们的做法是统一合并到stream env中,这样就可以在stream env中得到一个完整的变换列表,然后生成StreamGraph提交。
左下角是我们优化的 DAG,读取源表并只调用一次 foo 方法:
优化后的 DAG 效果与我们写 SQL 时的逻辑图非常相似,性能自然符合预期。
回到问题本身,业务可以简单的使用一条语句给视图的某些字段添加trace,例如:prepare_data.trace.fields=f0,f1. 由于SQL中自然收录字段名,所以trace数据可读性甚至高于普通日志。
2.2. 表选择与设计
如前所述,我们的首要要求是提高人的效率。因此,Table 需要具备更好的分层和复用能力,并且支持模板化开发,以便 N 个端到端的 Flink 作业能够快速串联起来。
我们的解决方案是基于 Redis 实现的,它首先有几个优点:
1. 高qps,低延迟:这应该是所有实时计算的关注点。
2. TTL:用户无需关心数据如何退出该字段,只需给一个合理的TTL即可。
3. 通过使用protobuf等高性能紧凑的序列化方式,并使用TTL,整体存储小于200G,redis的内存压力可以接受。
4. 适配计算模型:为了保证计算本身的时序,会进行keyBy操作,同时需要处理的数据会被shuffle到同一个并发,所以它不会过多依赖存储来考虑锁的优化。
接下来,我们的场景主要是解决多索引和触发消息的问题。
上图显示了一个表格示例,显示学生是否出现在某个章节中:
1. 多索引:数据首先以字符串形式存储,比如key=(uid, course_id), value=serialize(is_attend, ...),这样我们就可以在SQL中JOIN ON uid AND course_id . 如果 JOIN ON 其他字段,比如 course_id 怎么办?我们的做法是同时写一个以lesson_id为key的集合,集合中的元素是对应的(uid,lesson_id)。接下来在找lesson_id = 123的时候,先取出集合下的所有元素,然后通过管道找到所有的VALUE并返回。
2. 触发消息:写入redis后,会同时向Kafka写入一条更新消息。在 Redis Connector 的实现中,保证了两个存储之间的一致性、顺序性和不丢失数据。
这些功能都封装在 Redis Connector 中,业务可以通过 DDL 简单定义这样的 Table。
DDL 中的几个重要属性:
1. primary 定义了主键,对应字符串数据结构,比如例子中的uid + course_id。
2. index.fields 定义了辅助搜索的索引字段,例如示例中的课程id;也可以定义多个索引。
3. poster.kafka 定义了接收触发消息的kafka 表。该表也在元数据中定义,用户可以直接读取该表,而无需在后续的 SQL 作业中定义。
因此,整个开发模式复用性高,用户可以轻松开发端到端的N个SQL作业,而无需担心如何追溯案例。
三、 平台搭建
上述数据流架构搭建完成后,2020.11实时作业数量迅速增加到几百个,比2019年快很多。这个时候我们开始搭建实时计算平台从0到1,然后分享了搭建过程中的一些想法。
平台支持的功能主要有三个起点:
1. 统一:统一不同云厂商的不同集群环境、Flink版本、提交方式等;之前hadoop客户端分散在用户的提交机器上,对集群数据和任务安全存在隐患。升级和迁移成本。我们希望通过平台统一任务的提交入口和提交方式。
2.易用性:平台交互可以提供更易用的功能,如调试、语义检测等,可以提高任务测试的人为效率,并记录任务的版本历史,支持方便在线和回滚操作。
3. 规范:权限控制、流程审批等,类似于在线服务的在线流程,通过平台可以规范实时任务的研发流程。
3.1.规范——实时任务进程管理
FlinkSQL 让开发变得非常简单和高效,但是越简单越难标准化,因为可能写一段 SQL 只需要两个小时,但通过规范却需要半天时间。
但是,该规范仍然需要执行。一些问题类似于在线服务,在实时计算中也遇到过:
1. 记不清了:任务上线一年了,最初的需求可能是口耳相传。最好记住wiki或email,但在任务交接时很容易记不清。
2. 不规则:UDF或DataStream代码,均不符合规范,可读性差。结果,后来接手的学生无法升级,也不敢改变,无法长期维持。还应该有一个关于如何编写包括实时任务在内的 SQL 的规范。
3. 找不到:线上运行的任务依赖一个jar,哪个git模块对应哪个commitId,有问题怎么第一时间找到对应的代码实现。
4.盲改:一直正常的任务,周末突然报警,原因是私下修改了线上任务的sql。
规范主要分为三个部分:
1. 开发:RD 可以从 UDF 原型项目中快速创建 UDF 模块,该项目基于 flink 快速入门。创建的 UDF 模块可以正常编译,包括 WordCount 之类的 udf 示例,以及 ReadMe 和 VersionHelper 等默认的 helper 方法。根据业务需求修改后,通过CR上传到Git。
2. 需求管理与编译:提交的代码将与需求卡片相关联。集群编译和QA测试后,即可下单上线。
3. 在线:根据模块和编译输出选择更新/创建哪些作业,并在作业所有者或领导批准后重新部署。
整个研发过程不能离线修改,比如更改jar包或者对哪个任务生效。一个实时任务,即使跑了几年,也能查到谁在线,谁批准了当前任务,当时的测试记录,对应的Git代码,以及提出的实时指标要求谁开始的。任务维持很长时间。
3.2 易用性监控
我们当前的 Flink 作业在 Yarn 上运行。作业启动后,预计 Prometheus 会抓取 Yarn 分配的 Container,然后连接到报警系统。用户可以根据告警系统配置Kafka延迟告警和Checkpoint故障告警。构建此路径时遇到两个主要问题:
1. PrometheusReporter启动HTTPServer后,Prometheus如何动态感知;它还需要能够控制度量的大小以避免采集大量无用数据。
2. 我们SQL的源表基本都是Kafka。相比第三方工具,在计算平台上配置Kafka延迟告警更方便。因为自然可以得到任务读取的topic和group.id,所以也可以和任务失败使用同一个告警组。结合告警模板,配置告警非常简单。
关于解决方案:
1. 添加了基于官方 PrometheusReporter 的发现功能。Container 的 HTTPServer 启动后,对应的 ip:port 以临时节点的形式注册到 zk 上,然后使用 Prometheus 的 discover 目标来监控 zk 节点的变化。由于是临时节点,当 Container 被销毁时,该节点就消失了,Prometheus 也能感应到它不再被抓取。这样一来,就很容易为普罗米修斯搭建一条抢夺的路径。
2. KafkaConsumer.records-lag 是一个比较实用和重要的延迟指标,主要做了两个任务。修改 KafkaConnector 并在 KafkaConsumer.poll 之后将其公开,以确保 records-lag 指示器可见。另外,在做这个的过程中,我们发现不同Kafka版本的metric格式是不同的()。我们的方法是将它们扁平化为一种格式,并将它们注册到 flink 的指标中。这样不同版本暴露的指标是一致的。
四、总结与展望
上一阶段使用 Flink SQL 来支持实时作业的快速开发,搭建了实时计算平台来支持数千个 Flink 作业。
更大的见解之一是 SQL 确实简化了开发,但它也阻止了更多的技术细节。对实时作业运维工具的要求,比如 Trace,或者任务的规范没有改变,对这些的要求更加严格。
因为在细节被屏蔽的同时,一旦出现问题,用户不知道如何处理。就像冰山一角,漏水越少,下沉越多,越需要做好周边系统的建设。
二是适应现状。一是能尽快满足当前的需求。比如,我们正在提高人的效率,降低发展门槛。同时还要继续探索更多的业务场景,比如用HBase和RPC服务代替Redis Connector。现在的好处是修改了底层存储,用户对SQL作业的感知很小,因为SQL作业基本都是业务逻辑,DDL定义了元数据。
接下来的计划主要分为三个部分:
1. 支持资源弹性伸缩,平衡实时作业的成本和时效性。
2. 我们从 1.9 开始大规模应用 Flink SQL。现在版本升级发生了很大的变化,我们需要考虑如何让业务能够低成本的升级和使用新版本中的特性。
3. 探索流批集成在实际业务场景中的实现。
关于作者
张颖,2019年加入乔邦大数据中台研发部,负责实时计算相关工作。
算法 自动采集列表(基于高斯滤波算法的磨皮算法研究小结(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2022-02-01 22:12
写这篇博客也是我这段时间对微晶磨皮算法研究的一个总结。
目前大家对面部微晶磨皮算法并不陌生。从PS到APP应用,可以说是层出不穷。这里我将具体过程总结如下:
1. 保边滤镜
2.肤色检测
3.图像融合
4. 锐化
对于边缘保留过滤器:
这种滤镜的主要功能是在平滑皮肤的同时保留面部特征的细节。目前,可用于微晶磨皮的保边滤光片主要有以下几种:
1、表面模糊
该算法是PS中的一个函数,具有很好的边缘保留效果。其算法实现连接:点击打开链接
代码库连接:点击打开链接
效果如下:
原创图像模糊
2.双边过滤
本算法由高斯分量+梯度分量组成权重信息,在保留边缘功能的同时实现图像模糊平滑,代码连接:点击打开链接
效果图如下:
原图双边滤波 r=15
3.导向过滤器
引导滤波是一种基于引导图的保边滤波算法。它最早由何凯明提出,用于基于暗通道的去雾算法。其实现算法连接代码DEMO:点击打开链接
效果图如下:
原创图像引导过滤 快速引导过滤
3. 基于均值滤波的保边滤波算法
这个算法速度很快,单次效果一般。参考论文《Lee Filter Digital Image Enhancement and Noise Filtering by Use of Local Statistics》
算法实现与程序DEMO连接:点击打开链接
效果图如下:
原图效果图
4. 选择性模糊算法
本算法的具体实现与程序DEMO连接:点击打开链接
效果图如下:
原图选择性滤波算法的效果
5. 基于高斯滤波的微晶磨皮算法
这个算法就不多说了,可以直接看连接:点击打开链接
相关代码DEMO连接:点击打开链接
效果如图:
原图磨皮效果图
以上就是我采集到的,目前微晶换肤算法可以使用的滤镜,大家可以参考一下。
对于肤色检测:
肤色检测的相关资料很多,主要可以分为两类:基于色彩空间统计的方法和基于机器学习分类的方法。
以下是一些链接:点击打开链接
基于RGB色彩空间的算法:
对于图像融合:
这种图像融合主要是指将滤波后的图像与细节图像进行融合,得到具有强烈细节真实感和磨皮效果的结果图像。
一般基于alpha通道,或者使用羽化操作进行融合,公式如下:
res = (basePixel * alpha + filterPixel * (255 - alpha)) >>8
注意这里的alpha在0-255之间,这里是原创图像和过滤后图像的融合。
对于锐化算法:
在得到磨皮融合的效果图后,我们还需要进行一定的锐化算法,进一步提升细节感。这里可以使用USM锐化或者经典的邻域锐化、拉普拉斯锐化等,相关资料自行百度吧。
以上所有内容都与微晶换肤算法有关。让我与你分享。最后一个是算法的效率。解决这个问题的核心在于滤波算法的选择。你可以自己优化。我已经实现了一个基于 Sobel 算子和均值滤波的边缘保留滤波器。它只需要执行一个均值滤波和一个sobel算子。速度非常好。下面是效果图:
原创图像 查看全部
算法 自动采集列表(基于高斯滤波算法的磨皮算法研究小结(一))
写这篇博客也是我这段时间对微晶磨皮算法研究的一个总结。
目前大家对面部微晶磨皮算法并不陌生。从PS到APP应用,可以说是层出不穷。这里我将具体过程总结如下:
1. 保边滤镜
2.肤色检测
3.图像融合
4. 锐化
对于边缘保留过滤器:
这种滤镜的主要功能是在平滑皮肤的同时保留面部特征的细节。目前,可用于微晶磨皮的保边滤光片主要有以下几种:
1、表面模糊
该算法是PS中的一个函数,具有很好的边缘保留效果。其算法实现连接:点击打开链接
代码库连接:点击打开链接
效果如下:

原创图像模糊
2.双边过滤
本算法由高斯分量+梯度分量组成权重信息,在保留边缘功能的同时实现图像模糊平滑,代码连接:点击打开链接
效果图如下:


原图双边滤波 r=15
3.导向过滤器
引导滤波是一种基于引导图的保边滤波算法。它最早由何凯明提出,用于基于暗通道的去雾算法。其实现算法连接代码DEMO:点击打开链接
效果图如下:

原创图像引导过滤 快速引导过滤
3. 基于均值滤波的保边滤波算法
这个算法速度很快,单次效果一般。参考论文《Lee Filter Digital Image Enhancement and Noise Filtering by Use of Local Statistics》
算法实现与程序DEMO连接:点击打开链接
效果图如下:


原图效果图
4. 选择性模糊算法
本算法的具体实现与程序DEMO连接:点击打开链接
效果图如下:


原图选择性滤波算法的效果
5. 基于高斯滤波的微晶磨皮算法
这个算法就不多说了,可以直接看连接:点击打开链接
相关代码DEMO连接:点击打开链接
效果如图:

原图磨皮效果图
以上就是我采集到的,目前微晶换肤算法可以使用的滤镜,大家可以参考一下。
对于肤色检测:
肤色检测的相关资料很多,主要可以分为两类:基于色彩空间统计的方法和基于机器学习分类的方法。
以下是一些链接:点击打开链接
基于RGB色彩空间的算法:

对于图像融合:
这种图像融合主要是指将滤波后的图像与细节图像进行融合,得到具有强烈细节真实感和磨皮效果的结果图像。
一般基于alpha通道,或者使用羽化操作进行融合,公式如下:
res = (basePixel * alpha + filterPixel * (255 - alpha)) >>8
注意这里的alpha在0-255之间,这里是原创图像和过滤后图像的融合。
对于锐化算法:
在得到磨皮融合的效果图后,我们还需要进行一定的锐化算法,进一步提升细节感。这里可以使用USM锐化或者经典的邻域锐化、拉普拉斯锐化等,相关资料自行百度吧。
以上所有内容都与微晶换肤算法有关。让我与你分享。最后一个是算法的效率。解决这个问题的核心在于滤波算法的选择。你可以自己优化。我已经实现了一个基于 Sobel 算子和均值滤波的边缘保留滤波器。它只需要执行一个均值滤波和一个sobel算子。速度非常好。下面是效果图:
原创图像
算法 自动采集列表(基于KDDCup99的部分数据,本次数据挖掘网络入侵识别模型研究 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-31 09:02
)
基于随机森林算法的网络入侵自动识别模型一、模型应用
互联网的蓬勃发展给人们的工作和生活带来了极大的便利。然而,随着现代网络应用的普及,随之而来的网络不安全因素也给网络信息安全带来了严峻挑战。传统的网络安全技术已经难以应对这些日益严重的安全威胁,因此我们有必要开发专门的工具来规避这些不安全因素的攻击,而入侵检测技术可以作为我们非常重要的一项技术。
随着网络入侵的频繁发生,网络攻击的手段也呈现出多样性和隐蔽性的特点。当前网络和信息安全形势严峻。网络安全面临的主要威胁是:
KDDCup99网络入侵检测数据背景介绍:
1998 年,美国国防高级计划局 (DARPA) 在麻省理工学院林肯实验室开展了入侵检测评估项目。林肯实验室建立了模拟美国空军局域网的网络环境,采集了 9 周的 TCPdump 网络连接和系统审计数据,模拟了各种用户类型、各种网络流量和攻击方式,使其像一个真实的网络环境。这些 TCPdump采集 原创数据分为两部分:7 周的训练数据收录大约 5,000,000 条网络连接记录,其余 2 周的测试数据收录大约 2,000,000 条网络连接记录。
基于KDDCup99的部分数据,本次数据挖掘的建模目标如下:
1)诱导入侵的关键特征
2)建立入侵识别模型。
二、实现过程
KDDCup99网络入侵识别流程如图1所示,主要包括以下步骤:
使用KDDCUP99中的网络入侵检测包kddcup.data_10_percent,这是一个
kdd_data 数据包的 10% 采样(490 万条数据记录);
对样本数据进行探索分析,通过对41个固定特征属性的分析,发现前31个特征属性可以反映变化,因此连接记录的分析处理针对的是31个特征属性;
对样本数据进行预处理,包括数据清洗、缺失值处理和数据转换;
建立建模样本集;
建立KDDCUP99网络入侵识别模型;
进行模型评估;
模型优化。
本案例以模拟美国空军局域网网络环境记录的KDDCup99数据集为基础,重点介绍各种分类算法在数据挖掘中的应用。
三、核心技术四、您可以将此模型用于五、运行时环境
windows/linux/mac OS,64位操作系统,内存:8GB及以上,R3.5.1。
六、资源展示
查看全部
算法 自动采集列表(基于KDDCup99的部分数据,本次数据挖掘网络入侵识别模型研究
)
基于随机森林算法的网络入侵自动识别模型一、模型应用
互联网的蓬勃发展给人们的工作和生活带来了极大的便利。然而,随着现代网络应用的普及,随之而来的网络不安全因素也给网络信息安全带来了严峻挑战。传统的网络安全技术已经难以应对这些日益严重的安全威胁,因此我们有必要开发专门的工具来规避这些不安全因素的攻击,而入侵检测技术可以作为我们非常重要的一项技术。
随着网络入侵的频繁发生,网络攻击的手段也呈现出多样性和隐蔽性的特点。当前网络和信息安全形势严峻。网络安全面临的主要威胁是:

KDDCup99网络入侵检测数据背景介绍:
1998 年,美国国防高级计划局 (DARPA) 在麻省理工学院林肯实验室开展了入侵检测评估项目。林肯实验室建立了模拟美国空军局域网的网络环境,采集了 9 周的 TCPdump 网络连接和系统审计数据,模拟了各种用户类型、各种网络流量和攻击方式,使其像一个真实的网络环境。这些 TCPdump采集 原创数据分为两部分:7 周的训练数据收录大约 5,000,000 条网络连接记录,其余 2 周的测试数据收录大约 2,000,000 条网络连接记录。
基于KDDCup99的部分数据,本次数据挖掘的建模目标如下:
1)诱导入侵的关键特征
2)建立入侵识别模型。
二、实现过程
KDDCup99网络入侵识别流程如图1所示,主要包括以下步骤:
使用KDDCUP99中的网络入侵检测包kddcup.data_10_percent,这是一个
kdd_data 数据包的 10% 采样(490 万条数据记录);
对样本数据进行探索分析,通过对41个固定特征属性的分析,发现前31个特征属性可以反映变化,因此连接记录的分析处理针对的是31个特征属性;
对样本数据进行预处理,包括数据清洗、缺失值处理和数据转换;
建立建模样本集;
建立KDDCUP99网络入侵识别模型;
进行模型评估;
模型优化。

本案例以模拟美国空军局域网网络环境记录的KDDCup99数据集为基础,重点介绍各种分类算法在数据挖掘中的应用。
三、核心技术四、您可以将此模型用于五、运行时环境
windows/linux/mac OS,64位操作系统,内存:8GB及以上,R3.5.1。
六、资源展示




算法 自动采集列表(算法自动采集列表等属性,官方有什么也行?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-24 03:03
算法自动采集列表等属性,通过robotium,发送到openid也行。自己开发一套采集代理,代理池也行,代理ip池也行。官方有什么也行。
关键是版权问题,这需要代理商来做,他们自己也有api。
可以直接用openid,公司内部提供免费的线上接口,请务必写好规则,避免跳转点击。
如果不太懂爬虫技术可以考虑proxyserver+httpclient直接解决ua问题。
经常都是这样的
可以用socket本地连接数据库服务,
有免费的平台,
不是openidrobotforjava吗
可以尝试使用swoole+messagequeue+localreference实现,
谁告诉你可以没有额外要求的,如果一定要做好的话,可以下载bigpipe直接抓取,还是可以,但是你要是抓取大量数据,你就得要把数据拆分,然后利用bigpipe读取时再使用正则匹配,实际上bigpipe接着抓数据要比resolver更好,更方便,但是会比较卡,需要固定开几个线程,如果数据不少,如果你直接使用bigpipe只会浪费数据,像以前photoshop一个文件只能读取150kb,但是如果使用resolver可以读取200kb甚至以上,还有如果你有开多个线程机器来抓取数据,这一点算是十分重要的,有时候resolver更要不得!。 查看全部
算法 自动采集列表(算法自动采集列表等属性,官方有什么也行?)
算法自动采集列表等属性,通过robotium,发送到openid也行。自己开发一套采集代理,代理池也行,代理ip池也行。官方有什么也行。
关键是版权问题,这需要代理商来做,他们自己也有api。
可以直接用openid,公司内部提供免费的线上接口,请务必写好规则,避免跳转点击。
如果不太懂爬虫技术可以考虑proxyserver+httpclient直接解决ua问题。
经常都是这样的
可以用socket本地连接数据库服务,
有免费的平台,
不是openidrobotforjava吗
可以尝试使用swoole+messagequeue+localreference实现,
谁告诉你可以没有额外要求的,如果一定要做好的话,可以下载bigpipe直接抓取,还是可以,但是你要是抓取大量数据,你就得要把数据拆分,然后利用bigpipe读取时再使用正则匹配,实际上bigpipe接着抓数据要比resolver更好,更方便,但是会比较卡,需要固定开几个线程,如果数据不少,如果你直接使用bigpipe只会浪费数据,像以前photoshop一个文件只能读取150kb,但是如果使用resolver可以读取200kb甚至以上,还有如果你有开多个线程机器来抓取数据,这一点算是十分重要的,有时候resolver更要不得!。
算法 自动采集列表(数据质量可以帮助您第一时间感知源端数据的变更与ETL)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-21 10:17
数据质量可以帮助您即时感知ETL(Extract Transformation Load)中产生的源数据和脏数据的变化,自动拦截问题任务,有效防止脏数据向下游扩散。避免因任务输出而导致数据不符合预期,导致时间成本增加、意外额外成本增加或影响数据的正常使用。
费用说明
运行数据质量规则的成本由两部分组成:
特征
解释数据质量有助于识别数据库频繁变化、业务变化频繁、数据定义不明确、业务系统数据脏、系统交互异常、数据修正不准确、数据仓库异常等质量问题。
数据质量监控流程如下图所示。
说明 数据质量主要监控EMR(E-MapReduce)、Hologres、AnalyticDB for PostgreSQL、MaxCompute、DataHub数据集的质量。因此,您需要先创建表并在表中写入数据,然后才能使用数据质量功能。
请参阅数据质量管理原则。
注意事项 规则配置和验证过程 数据质量通过表配置的分区表达式匹配节点每天产生的表分区。执行,包括自动调度的周期性实例、手动触发的补充数据实例和运行的测试实例),将触发数据质量规则验证。可以设置规则的强度来控制节点是否退出失败,避免脏数据的影响。扩展,支持通过告警配置在第一时间接收和处理告警信息。
创建数据质量规则
在数据质量监控规则页面,您可以选择特定引擎下需要保证数据输出质量的表,并配置该表需要配置哪些数据质量规则。在配置之前,可以先了解几件事:
配置表中需要验证的规则
支持针对波动性、数字或动态阈值的表级、字段级验证。规则类型 检查模式 报警模式
数字
数据分析结果与固定值进行比较。
规则告警模式通过定义规则的强度来控制。
挥发性
指定时间段内数据探索结果与数据采样结果的波动率比值支持上升幅度、下降幅度或波动幅度(绝对值)的比较,可根据波动幅度定义规则的强弱。
根据规则的强度触发警报
例如,橙色阈值填写为 5%,红色阈值填写为 10%。当波动率大于5%且小于等于10%时,会发出橙色警报。当波动率大于 10% 时,会出现红色警报。
动态阈值
基于智能算法,结合历史采样结果(模型样本参考量),自动确定合理阈值。动态阈值还支持强规则和弱规则。
注:模型样本参考量是指“动态阈值算法模型”生效的样本最小时间窗范围,在该时间窗内允许缺失10%以下的数据。未达到样本参考量不报警,缺失数据由算法自动补齐。
系统会根据智能算法自动确定合理的阈值;如果发现异常数据,将立即触发警报或封锁。
定义规则告警和告警接收方式:订阅管理
您可以在配置规则时定义规则的强度,从而控制规则的影响范围。您可以通过订阅管理在第一时间接收和处理告警信息。目前支持短信、邮件、钉钉群机器人报警。当调度节点产生的表数据不符合预期时:
定义规则的触发方式:关联调度
数据质量规则与生成表数据的调度节点的执行相关联(生成表数据的节点在运维中心的执行,包括自动调度周期实例、手动触发的补充数据实例、和测试实例运行),数据将被触发。对于质量规则校验,可以设置规则强度来控制节点是否退出失败,避免脏数据影响扩大。
检查规则配置是否正常:test run
规则创建完成后,您可以选择试运行功能来验证创建的数据质量规则是否可以进行数据质量验证。
数据质量规则触发
在运维中心的运维中心,与表关联的调度节点(产生表数据的节点,配置表质量规则时与该节点关联的节点)会运行,并会触发数据节点代码逻辑执行后的质量检查。验证(将在底部生成验证 sql 以执行。)。包括周期实例、补充数据实例和测试实例运行。
当节点操作触发异常数据质量检查时,平台会根据质量规则检查结果和数据质量规则强度判断任务是否失败退出,是否阻塞下游节点的执行以防止影响脏数据进一步扩大。
查看数据质量检查结果
您可以在运维中心的任务执行详情和数据质量任务查询页面查看数据质量验证结果。
查看运维中心节点的运行日志,
打开实例面板,查看执行详情,在如图所示位置查看任务触发的数据质量验证结果。详情请参阅。
这意味着如果验证失败,任务将无法退出并阻塞下游节点的执行。
实例状态失败时,也可能是代码运行成功但节点输出的表不符合预期,强数据质量规则检查失败,导致任务退出失败,阻塞下游实例跑步。实例状态为质量监控验证失败。如下所示。
通过数据质量任务查询界面查看。
任务查询界面可以通过表名和节点ID进行过滤。
查看历史验证详情:任务查询
在任务查询界面,可以通过表或节点查询表的历史验证记录和验证详情。 查看全部
算法 自动采集列表(数据质量可以帮助您第一时间感知源端数据的变更与ETL)
数据质量可以帮助您即时感知ETL(Extract Transformation Load)中产生的源数据和脏数据的变化,自动拦截问题任务,有效防止脏数据向下游扩散。避免因任务输出而导致数据不符合预期,导致时间成本增加、意外额外成本增加或影响数据的正常使用。
费用说明
运行数据质量规则的成本由两部分组成:
特征
解释数据质量有助于识别数据库频繁变化、业务变化频繁、数据定义不明确、业务系统数据脏、系统交互异常、数据修正不准确、数据仓库异常等质量问题。
数据质量监控流程如下图所示。

说明 数据质量主要监控EMR(E-MapReduce)、Hologres、AnalyticDB for PostgreSQL、MaxCompute、DataHub数据集的质量。因此,您需要先创建表并在表中写入数据,然后才能使用数据质量功能。
请参阅数据质量管理原则。
注意事项 规则配置和验证过程 数据质量通过表配置的分区表达式匹配节点每天产生的表分区。执行,包括自动调度的周期性实例、手动触发的补充数据实例和运行的测试实例),将触发数据质量规则验证。可以设置规则的强度来控制节点是否退出失败,避免脏数据的影响。扩展,支持通过告警配置在第一时间接收和处理告警信息。


创建数据质量规则
在数据质量监控规则页面,您可以选择特定引擎下需要保证数据输出质量的表,并配置该表需要配置哪些数据质量规则。在配置之前,可以先了解几件事:

配置表中需要验证的规则
支持针对波动性、数字或动态阈值的表级、字段级验证。规则类型 检查模式 报警模式
数字
数据分析结果与固定值进行比较。
规则告警模式通过定义规则的强度来控制。
挥发性
指定时间段内数据探索结果与数据采样结果的波动率比值支持上升幅度、下降幅度或波动幅度(绝对值)的比较,可根据波动幅度定义规则的强弱。
根据规则的强度触发警报
例如,橙色阈值填写为 5%,红色阈值填写为 10%。当波动率大于5%且小于等于10%时,会发出橙色警报。当波动率大于 10% 时,会出现红色警报。
动态阈值
基于智能算法,结合历史采样结果(模型样本参考量),自动确定合理阈值。动态阈值还支持强规则和弱规则。
注:模型样本参考量是指“动态阈值算法模型”生效的样本最小时间窗范围,在该时间窗内允许缺失10%以下的数据。未达到样本参考量不报警,缺失数据由算法自动补齐。
系统会根据智能算法自动确定合理的阈值;如果发现异常数据,将立即触发警报或封锁。
定义规则告警和告警接收方式:订阅管理
您可以在配置规则时定义规则的强度,从而控制规则的影响范围。您可以通过订阅管理在第一时间接收和处理告警信息。目前支持短信、邮件、钉钉群机器人报警。当调度节点产生的表数据不符合预期时:
定义规则的触发方式:关联调度
数据质量规则与生成表数据的调度节点的执行相关联(生成表数据的节点在运维中心的执行,包括自动调度周期实例、手动触发的补充数据实例、和测试实例运行),数据将被触发。对于质量规则校验,可以设置规则强度来控制节点是否退出失败,避免脏数据影响扩大。
检查规则配置是否正常:test run
规则创建完成后,您可以选择试运行功能来验证创建的数据质量规则是否可以进行数据质量验证。
数据质量规则触发
在运维中心的运维中心,与表关联的调度节点(产生表数据的节点,配置表质量规则时与该节点关联的节点)会运行,并会触发数据节点代码逻辑执行后的质量检查。验证(将在底部生成验证 sql 以执行。)。包括周期实例、补充数据实例和测试实例运行。
当节点操作触发异常数据质量检查时,平台会根据质量规则检查结果和数据质量规则强度判断任务是否失败退出,是否阻塞下游节点的执行以防止影响脏数据进一步扩大。
查看数据质量检查结果
您可以在运维中心的任务执行详情和数据质量任务查询页面查看数据质量验证结果。
查看运维中心节点的运行日志,
打开实例面板,查看执行详情,在如图所示位置查看任务触发的数据质量验证结果。详情请参阅。
这意味着如果验证失败,任务将无法退出并阻塞下游节点的执行。
实例状态失败时,也可能是代码运行成功但节点输出的表不符合预期,强数据质量规则检查失败,导致任务退出失败,阻塞下游实例跑步。实例状态为质量监控验证失败。如下所示。

通过数据质量任务查询界面查看。
任务查询界面可以通过表名和节点ID进行过滤。

查看历史验证详情:任务查询
在任务查询界面,可以通过表或节点查询表的历史验证记录和验证详情。
算法 自动采集列表(DXC!X2(X2.5)2.5的主要功能 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-20 23:25
)
DXC 来自 Discuz!X2(X2.5) 采集, DXC采集插件的缩写,致力于discuz上的内容解决方案,帮助站长更快速、更轻松地构建网站内容。
通过DXC采集插件,用户可以方便地采集来自互联网的数据,包括会员数据、文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成内容丰富、会员活跃的热门论坛,对论坛初期运营有很大帮助. 这是一个discuz应用程序,必须由论坛的新手站长安装。
DXC 2.5 的主要特点包括:
1、多种形式的url列表采集文章,包括rss地址、列表页、多级列表等。
2、多种方式编写规则,dom方式,字符截取,智能获取,更方便获取想要的内容
3、规则继承,自动检测匹配规则功能,你会逐渐体会到规则继承带来的便利
4、独有的网页文本提取算法,自动学习归纳规则,更方便泛采集。
5、支持图片定位和水印
6、灵活的发布机制,可以自定义发布者、发布时间点击率等。
7、强大的内容编辑后台,可以轻松编辑采集收到的内容并发布到门户、论坛、博客
8、内容过滤功能,过滤采集内容上的广告,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时量化采集和释放文章
查看全部
算法 自动采集列表(DXC!X2(X2.5)2.5的主要功能
)
DXC 来自 Discuz!X2(X2.5) 采集, DXC采集插件的缩写,致力于discuz上的内容解决方案,帮助站长更快速、更轻松地构建网站内容。
通过DXC采集插件,用户可以方便地采集来自互联网的数据,包括会员数据、文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成内容丰富、会员活跃的热门论坛,对论坛初期运营有很大帮助. 这是一个discuz应用程序,必须由论坛的新手站长安装。
DXC 2.5 的主要特点包括:
1、多种形式的url列表采集文章,包括rss地址、列表页、多级列表等。
2、多种方式编写规则,dom方式,字符截取,智能获取,更方便获取想要的内容
3、规则继承,自动检测匹配规则功能,你会逐渐体会到规则继承带来的便利
4、独有的网页文本提取算法,自动学习归纳规则,更方便泛采集。
5、支持图片定位和水印
6、灵活的发布机制,可以自定义发布者、发布时间点击率等。
7、强大的内容编辑后台,可以轻松编辑采集收到的内容并发布到门户、论坛、博客
8、内容过滤功能,过滤采集内容上的广告,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时量化采集和释放文章

算法 自动采集列表(importrequestsbs4bs4frombs42.1数据采集的步骤(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-20 15:08
1 资料采集概览
要开始一个数据分析项目,您需要做的第一件事就是获取原创数据。获取原创数据的方法有很多。例如:
获取数据集文件
使用爬虫采集数据
直接访问excel、csv等数据文件
其他方法...
在本次福布斯系列数据分析项目实战中,在数据采集方面,主要数据来源于对数据采集的爬虫使用,同时也辅助其他数据进行对比。
本文主要介绍使用爬虫获取数据采集的思路和步骤。
采集福布斯全球上市公司2000强榜单涵盖2007年至2017年,跨越10余年。
这个采集网站的目标是多个网页,但是多个网页的分布结构不同。虽然思路和步骤大同小异,但需要单独写,分别采集。
2 数据采集 步骤
data采集大致分为几个步骤:
下载目标主页内容
采集 主页上的数据
采集 链接到主页上的其他分发页面 网站
下载和采集各个分发页面数据
保存 采集 数据
涉及的 python 库包括 requests、BeautifulSoup 和 csv。下面以采集某年的数据为例,描述数据采集的步骤。
导入请求
从 bs4 导入 BeautifulSoup
导入 csv
2.1 数据下载模块
主要基于requests,代码如下:
定义下载(网址):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, 像 Gecko ) Chrome/59.0.3071.115 Safari/537.36'}
响应 = requests.get(url,headers=headers)
# 打印(response.status_code)
返回响应.文本
该模块将用于主网页的数据下载和各子页面的数据下载。是一个比较常见的模块。
2.2 采集 主页上的数据
主网页的页面结构主要分为两部分,一是收录其他页面数据的网页链接,二是主网页上的公司数据列表,以表格的形式显示在网页上。
这些数据可以用 BeautifulSoup 解析。代码模块如下:
def get_content_first_page(html, year):
'''
获取排名 1-100 的公司列表,包括标题
'''
汤 = BeautifulSoup(html, 'lxml')
身体 = 汤. 身体
body_content = body.find('div', {'id': 'bodyContent'})
表格 = body_content.find_all('table', {'class': 'XXXXtable'})
# 一共有3张桌子,最后一张就是我们想要的
trs = 表[-1].find_all('tr')
# 获取头文件名
# trs[1],这和其他年份不同
row_title = [item.text.strip() for item in trs[1].find_all('th')]
row_title.insert(0, '年份')
rank_list = []
rank_list.append(row_title)
对于 i, tr in enumerate(trs):
如果 i == 0 或 i == 1:
继续
tds = tr.find_all('td')
# 获取公司排名和名单
row = [ item.text.strip() for item in tds]
row.insert(0, 年)
rank_list.append(行)
返回排名列表
def get_page_urls(html):
'''
获取排名 101-2000 的公司的网页链接
'''
汤 = BeautifulSoup(html, 'lxml')
身体 = 汤. 身体
body_content = body.find('div', {'id': 'bodyContent'})
label_div = body_content.find('div', {'align':'center'})
label_a = label_div.find('p').find('b').find_all('a')
page_urls = ['basic_url' + item.get('href') for item in label_a]
返回 page_urls
2.3 每个分发页面上的数据采集
步骤也是网页下载和表格数据爬取。代码内容与主网页类似,但在细节上存在一些差异,这里不再赘述。
2.4 数据存储
采集 的数据最终保存为 csv 文件。模块代码如下:
def save_data_to_csv_file(数据,文件名):
'''
将数据保存到 csv 文件
'''
使用 open(file_name, 'a', errors='ignore', newline='') 作为 f:
f_csv = csv.writer(f)
f_csv.writerows(数据)
2.5 个数据采集主函数
def get_forbes_global_year_2007(year=2007):
网址 = '网址'
html = 下载(网址)
# 打印(html)
data_first_page = get_content_first_page(html, 年份)
# 打印(data_first_page)
save_data_to_csv_file(data_first_page, 'forbes_'+str(year)+'.csv')
page_urls = get_page_urls(html)
# 打印(page_urls)
对于 page_urls 中的 url:
html = 下载(网址)
data_other_page = get_content_other_page(html, year)
# 打印(data_other_page)
print('保存数据...', url)
save_data_to_csv_file(data_other_page, 'forbes_'+str(year)+'.csv')
如果 __name__ == '__main__':
# 获取 2009 年福布斯全球 2000 强的数据
get_forbes_global_year_2007()
3 总结
本文只介绍data采集的思路和各个模块,不提供目标网页的链接。一方面由于原创网页的数据信息比较杂乱,需要在采集的时候编写多个采集程序,另一方面,由于我们的重点是后续的数据分析部分,我们希望不要专注于数据爬取。
在后续分析过程中,我们会检查数据结构、数据完整性及相关信息,请继续关注。
结尾。 查看全部
算法 自动采集列表(importrequestsbs4bs4frombs42.1数据采集的步骤(组图))
1 资料采集概览
要开始一个数据分析项目,您需要做的第一件事就是获取原创数据。获取原创数据的方法有很多。例如:
获取数据集文件
使用爬虫采集数据
直接访问excel、csv等数据文件
其他方法...
在本次福布斯系列数据分析项目实战中,在数据采集方面,主要数据来源于对数据采集的爬虫使用,同时也辅助其他数据进行对比。
本文主要介绍使用爬虫获取数据采集的思路和步骤。
采集福布斯全球上市公司2000强榜单涵盖2007年至2017年,跨越10余年。
这个采集网站的目标是多个网页,但是多个网页的分布结构不同。虽然思路和步骤大同小异,但需要单独写,分别采集。
2 数据采集 步骤
data采集大致分为几个步骤:
下载目标主页内容
采集 主页上的数据
采集 链接到主页上的其他分发页面 网站
下载和采集各个分发页面数据
保存 采集 数据
涉及的 python 库包括 requests、BeautifulSoup 和 csv。下面以采集某年的数据为例,描述数据采集的步骤。
导入请求
从 bs4 导入 BeautifulSoup
导入 csv
2.1 数据下载模块
主要基于requests,代码如下:
定义下载(网址):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, 像 Gecko ) Chrome/59.0.3071.115 Safari/537.36'}
响应 = requests.get(url,headers=headers)
# 打印(response.status_code)
返回响应.文本
该模块将用于主网页的数据下载和各子页面的数据下载。是一个比较常见的模块。
2.2 采集 主页上的数据
主网页的页面结构主要分为两部分,一是收录其他页面数据的网页链接,二是主网页上的公司数据列表,以表格的形式显示在网页上。
这些数据可以用 BeautifulSoup 解析。代码模块如下:
def get_content_first_page(html, year):
'''
获取排名 1-100 的公司列表,包括标题
'''
汤 = BeautifulSoup(html, 'lxml')
身体 = 汤. 身体
body_content = body.find('div', {'id': 'bodyContent'})
表格 = body_content.find_all('table', {'class': 'XXXXtable'})
# 一共有3张桌子,最后一张就是我们想要的
trs = 表[-1].find_all('tr')
# 获取头文件名
# trs[1],这和其他年份不同
row_title = [item.text.strip() for item in trs[1].find_all('th')]
row_title.insert(0, '年份')
rank_list = []
rank_list.append(row_title)
对于 i, tr in enumerate(trs):
如果 i == 0 或 i == 1:
继续
tds = tr.find_all('td')
# 获取公司排名和名单
row = [ item.text.strip() for item in tds]
row.insert(0, 年)
rank_list.append(行)
返回排名列表
def get_page_urls(html):
'''
获取排名 101-2000 的公司的网页链接
'''
汤 = BeautifulSoup(html, 'lxml')
身体 = 汤. 身体
body_content = body.find('div', {'id': 'bodyContent'})
label_div = body_content.find('div', {'align':'center'})
label_a = label_div.find('p').find('b').find_all('a')
page_urls = ['basic_url' + item.get('href') for item in label_a]
返回 page_urls
2.3 每个分发页面上的数据采集
步骤也是网页下载和表格数据爬取。代码内容与主网页类似,但在细节上存在一些差异,这里不再赘述。
2.4 数据存储
采集 的数据最终保存为 csv 文件。模块代码如下:
def save_data_to_csv_file(数据,文件名):
'''
将数据保存到 csv 文件
'''
使用 open(file_name, 'a', errors='ignore', newline='') 作为 f:
f_csv = csv.writer(f)
f_csv.writerows(数据)
2.5 个数据采集主函数
def get_forbes_global_year_2007(year=2007):
网址 = '网址'
html = 下载(网址)
# 打印(html)
data_first_page = get_content_first_page(html, 年份)
# 打印(data_first_page)
save_data_to_csv_file(data_first_page, 'forbes_'+str(year)+'.csv')
page_urls = get_page_urls(html)
# 打印(page_urls)
对于 page_urls 中的 url:
html = 下载(网址)
data_other_page = get_content_other_page(html, year)
# 打印(data_other_page)
print('保存数据...', url)
save_data_to_csv_file(data_other_page, 'forbes_'+str(year)+'.csv')
如果 __name__ == '__main__':
# 获取 2009 年福布斯全球 2000 强的数据
get_forbes_global_year_2007()
3 总结
本文只介绍data采集的思路和各个模块,不提供目标网页的链接。一方面由于原创网页的数据信息比较杂乱,需要在采集的时候编写多个采集程序,另一方面,由于我们的重点是后续的数据分析部分,我们希望不要专注于数据爬取。
在后续分析过程中,我们会检查数据结构、数据完整性及相关信息,请继续关注。
结尾。
算法 自动采集列表(Java应用程序分配对象的方式很糟糕,分配多少钱?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-02-24 02:20
本文于 2015 年 11 月 11 日存档。其内容不再更新或维护。“按原样”提供。鉴于当今技术的快速发展,一些步骤和插图可能已经改变。
在 Java 技术的早期,对象的分配方式很糟糕。有许多 文章s(包括作者的一些)建议开发人员避免不必要地创建临时对象,因为分配(以及相应的垃圾采集开销)很昂贵。虽然这曾经是一个很好的建议(在性能非常重要的情况下),但它通常不再适用于所有性能关键的情况,而是最重要的情况。
分配多少?
1.0 和 1.1 JDK 使用标记清除采集器,它压缩一些(但不是全部)采集,这意味着在垃圾采集后堆可能会变得碎片化。因此,1.0 和 1.1 JVM 中的内存分配成本与 C 或 C++ 中的内存分配成本相当,其中分配器使用启发式(例如“first-first”或“best-fit”)来管理可用堆空间。释放也很昂贵,因为标记清除采集器必须在每次采集时清除整个堆。难怪我们被建议在分配器上放轻松。
在热点 JVM(Sun JDK 1. 2 及更高版本)上,情况变得更好 - Sun JDK 转移到了分代采集器。因为复制采集器用于年轻代,所以堆中的空闲空间始终是连续的,因此可以通过简单的指针添加来从堆中分配新对象,如清单 1 所示。Java 应用程序比 C 便宜得多许多开发人员一开始就很难想象。此外,具有大量临时对象(在 Java 应用程序中很常见)的堆采集起来非常便宜,因为复制采集器不会访问无效对象。只需跟踪并将活动对象复制到幸存者空间,然后一举回收整个堆。没有空闲列表,没有块合并,没有压缩 - 只需清除堆并重新开始。因此,在 JDK 1.2 中,
列出1.连续堆中的快速分配
void *malloc(int n) {
synchronized (heapLock) {
if (heapTop - heapStart > n)
doGarbageCollection();
void *wasStart = heapStart;
heapStart += n;
return wasStart;
}
}
性能建议的保质期通常很短。分配曾经很昂贵,但现在不再如此。在实践中,它非常便宜并且有一些非常计算密集型的异常,因此性能问题通常不再是避免分配的好理由。Sun 估计分配成本约为 10 条机器指令。它几乎是免费的——绝对没有理由为了消除某些对象创建而使程序结构复杂化或招致额外的维护风险。
当然,分配只是故事的一半——大多数分配的对象最终都会被垃圾回收,这也是有代价的。但那里也有好消息。大多数 Java 应用程序中的绝大多数对象在下一次回收之前就变成了垃圾。一次小型垃圾回收的成本与年轻代中存活对象的数量成正比,而不是自上次回收以来分配的对象数量。由于很少有年轻对象能够存活到下一次采集,因此每次分配的采集摊销成本相当小(并且可以通过增加堆大小来减小,具体取决于可用内存的可用性)。
但是等等,会好起来的
JIT 编译器可以执行额外的优化,将对象分配的成本降低到零。考虑清单 2 中的代码,其中 getPosition() 方法创建一个临时对象来保存点的坐标,调用方法短暂使用 Point 对象,然后将其丢弃。JIT 可以内联对 getPosition() 的调用,并且使用一种称为逃逸分析的技术,可以识别对 Point 对象的引用没有离开 doSomething() 方法。知道了这一点,JIT 可以在堆栈而不是堆上分配对象,甚至可以通过简单地将 Point 的字段提升到寄存器来更好地优化分配。尽管当前的 Sun JVM 尚未执行此优化,但未来的 JVM 可能会。事实上,在不改变代码的情况下,未来分配会更便宜,
列出2.逃逸分析可以彻底消除很多临时赋值
void doSomething() {
Point p = someObject.getPosition();
System.out.println("Object is at (" + p.x, + ", " + p.y + ")");
}
...
Point getPosition() {
return new Point(myX, myY);
}
分配器不是可扩展性瓶颈吗?
表明虽然分配本身很快,但对堆结构的访问必须在线程之间同步。那么这是否会使分配器成为可伸缩性风险?JVM 有许多巧妙的技巧可以大大降低这种成本。IBM JVM 使用一种称为线程局部堆的技术,每个线程通过该技术从分配器请求一小块内存 (~1K),并从该块中满足小对象分配。如果程序请求的块比使用小的线程局部堆无法满足,则使用全局分配器直接满足请求或分配新的线程局部堆。使用这种技术,可以在不竞争共享堆锁的情况下满足大部分分配。(Sun JVM 使用类似的技术,而不是术语“本地分配块”。)
终结者不是你的朋友
与没有终结器的对象相比,具有终结器的对象(具有非平凡 finalize() 方法的对象)具有显着的开销,应谨慎使用。可终结对象的分配和采集速度较慢。在分配时,JVM 必须向垃圾采集器注册任何可终结对象,并且(至少在 HotSpot JVM 实现中)可终结对象必须遵循比大多数其他对象更慢的分配路径。此外,可终结对象的采集速度较慢。在一个可终结的对象可以被回收之前,它至少需要两个垃圾回收周期(在最好的情况下),并且垃圾回收器必须做额外的工作来调用终结器。结果是更多的时间花在分配和采集对象上,并且更多的压力施加在垃圾采集器上,因为不可访问的可终结对象使用的内存被保留的时间更长。再加上终结器不能保证在任何可预测的时间范围内运行,甚至根本不能保证运行,您可以看到在相对较少的情况下使用终结器是正确的工具。
如果您必须使用终结器,您可以遵循一些准则来帮助抑制损坏。限制 finalizable 对象的数量,从而最小化必须承担 finalization 的分配和采集成本的对象的数量。组织您的类以使可终结对象不收录其他数据将最大限度地减少无法终结的对象中可用的内存量,因为在这些对象实际回收之前可能存在很长的延迟。从标准库扩展可终结的类时要特别小心。
帮助垃圾采集器。. . 不要
由于单次分配和垃圾回收会给 Java 程序带来巨大的性能成本,因此开发了许多巧妙的技巧来降低这些成本,例如对象池和空值。不幸的是,在许多情况下,这些技术对程序性能弊大于利。
对象池
对象池是一个简单的概念 - 维护一个经常使用的对象池并从该池中获取一个对象,而不是在需要时创建一个新对象。从理论上讲,整合可以将分销成本分散到更多用途上。当对象的创建成本很高(例如使用数据库连接或线程时),或者当合并对象代表有限且昂贵的资源(例如使用数据库连接时)时,这是有意义的。但是,适用这些条件的情况很少。
此外,对象池有一些严重的缺点。由于对象池通常在所有线程之间共享,因此来自对象池的分配可能成为同步瓶颈。池化还强制您显式管理释放,这重新引入了悬空指针的风险。此外,必须适当调整池的大小以获得所需的性能结果。如果太小,分配将不会被阻塞;如果太大,可回收的资源将在池中闲置。对象池的使用通过占用可回收的内存给垃圾采集器带来了额外的压力。编写一个高效的池实现并不容易。
Cliff Click 博士在他的 JavaOne 2003 演讲“Performance Myths Exposed”中提供了具体的基准数据,表明对象池是现代 JVM 上除了最重的对象之外的所有对象的性能损失。加上分配的序列化和悬空指针的风险,很明显,除了最极端的情况外,应该避免合并。
显式归零
显式归零只是在完成后将引用对象设置为 null 的一种做法。null 背后的想法是它通过使对象更早不可访问来帮助垃圾采集器。或者至少这是理论。
在对对象的引用具有比程序规范使用或认为有效的范围更广的情况下,使用显式 null 不仅有帮助,而且实际上是必需的。这包括使用静态或实例字段来存储对临时缓冲区而不是局部变量的引用,或者使用数组来存储可能在运行时可访问但不能通过程序的隐式语义访问的引用的情况。考虑清单 3 中的类,它是一个由数组支持的简单有界堆栈的实现。调用pop(),如果示例中没有显式清空,该类可能会导致内存泄漏(更恰当地称为“意外对象保留”,有时称为“对象徘徊”),因为引用存储在stack[top+1]中该程序不再可以访问,
列出3.避免在栈实现中游荡对象
public class SimpleBoundedStack {
private static final int MAXLEN = 100;
private Object stack[] = new Object[MAXLEN];
private int top = -1;
public void push(Object p) { stack [++top] = p;}
public Object pop() {
Object p = stack [top];
stack [top--] = null; // explicit null
return p;
}
}
在 1997 年 9 月的“Java 开发人员的连接技术技巧”专栏(请参阅 参考资料)中,Sun 警告了这种风险,并解释了在上面的 pop() 示例等情况下如何需要显式 null。不幸的是,程序员经常求助于明确的空值来提供这个建议,希望能帮助垃圾采集器。但在大多数情况下,它根本无法帮助垃圾采集器,在某些情况下,它实际上会损害程序的性能。
考虑清单 4 中的代码,它结合了几个非常糟糕的想法。List 是一个链表实现,它使用终结器来遍历列表并使所有前向链接无效。我们已经讨论了为什么终结器不好。更糟糕的是,因为现在班级正在做额外的工作,表面上是为了帮助垃圾采集器,但实际上并没有帮助 - 甚至可能造成伤害。遍历列表需要 CPU 周期,并且会产生访问所有死对象并将它们拉入缓存的效果——垃圾采集器可以完全避免这项工作,因为复制采集器根本不会访问死对象。空引用对跟踪垃圾采集器没有任何作用。如果无法访问列表的头部,则无论如何都不会跟踪列表的其余部分。
清单 4. 结合了终结器和显式空值以避免整体性能损失 - 不要这样做!
public class LinkedList {
private static class ListElement {
private ListElement nextElement;
private Object value;
}
private ListElement head;
...
public void finalize() {
try {
ListElement p = head;
while (p != null) {
p.value = null;
ListElement q = p.nextElement;
p.nextElement = null;
p = q;
}
head = null;
}
finally {
super.finalize();
}
}
}
对于您的程序出于性能原因破坏正常范围规则的情况,您应该保存显式归零,例如堆栈示例(更正确的方法 - 但性能较低的实现是每次重新分配和复制堆栈数组)它已经改变)。
显式垃圾采集
开发人员经常错误地认为他们正在帮助垃圾采集器的第三类是使用 System.gc() ,它会触发垃圾采集(实际上,它只是暗示它可能是这样做的好时机)。不幸的是,System.gc() 触发了一个完整的集合,包括跟踪堆中的所有活动对象以及清除和压缩旧版本。这可能是很多工作。一般来说,最好让系统决定何时需要采集堆以及是否进行全采集。在大多数情况下,一个小的集合就可以完成这项工作。更糟糕的是,对 System.gc() 的调用通常深埋在开发人员可能不知道它存在的地方,并且在这些地方可能比需要的更频繁地触发。如果您担心您的应用程序可能隐藏了对隐藏在库中的 System.gc() 的调用,
不变性
如果没有某种形式的不变性插件,Java 理论和实践就无法完成。使对象不可变可以消除一整类编程错误。不使类不可变的最常见原因之一是认为这样做会损害性能。虽然有时是正确的,但事实并非如此——有时使用不可变对象有明显的、也许令人惊讶的性能优势。
许多对象用作引用其他对象的容器。当被引用的对象需要改变时,我们有两种选择:更新引用(如可变容器类)或重新创建容器以保存新引用(如不可变容器类)。清单 5 展示了两种实现简单持有者类的方法。假设收录对象很小(通常是这种情况)(例如 Map 的 Map.Entry 元素或链表元素),分配一个新的不可变对象具有一些隐藏的性能优势,这些优势来自于分代垃圾采集器的工作方式,即与物体的相对年龄有关。
List5. 可变和不可变对象持有者
public class MutableHolder {
private Object value;
public Object getValue() { return value; }
public void setValue(Object o) { value = o; }
}
public class ImmutableHolder {
private final Object value;
public ImmutableHolder(Object o) { value = o; }
public Object getValue() { return value; }
}
在大多数情况下,当持有者对象更新为引用其他对象时,新引用的对象就是年轻对象。如果我们通过调用 setValue() 来更新 MutableHolder,就会导致老对象引用年轻对象的情况。另一方面,通过创建一个新的 ImmutableHolder 对象,较年轻的对象将引用较旧的对象。后一种情况(大多数对象指向较旧的对象)在分代垃圾采集器上较为温和。如果 MutableHolder 存在于老年代突变中,则必须扫描卡上收录 MutableHolder 的所有对象,在下一个二级中采集旧的到新的年轻引用。对长期存在的容器对象使用可变引用会增加在采集时跟踪旧引用的工作量。(参见上个月的 文章 和本月的,
当好的性能建议变坏时
2003 年 7 月 Java Developer's Magazine 的一个封面故事说明,很容易将良好的性能建议变成糟糕的性能建议,因为未能充分确定何时应该应用建议或要解决的问题。虽然本文收录一些有用的分析,但它弊大于利(不幸的是,太多基于性能的建议落入了同一个陷阱)。
本文首先描述了一组实时环境中的要求,在这些实时环境中,不可预见的垃圾采集暂停是不可接受的,并且对允许的暂停时间有严格的操作要求。然后,作者建议取消引用、对象池和调度显式垃圾采集来满足性能目标。到目前为止一切都很好——他们遇到了一个问题,他们找到了解决问题的方法(尽管他们似乎无法确定这些做法的成本或探索一些侵入性较小的替代方案,例如并发集合)。不幸的是,文章 的标题(“避免麻烦的垃圾采集暂停”)和介绍表明,该建议对广泛的应用程序(可能所有 Java 应用程序)都很有用。这是可怕的、危险的性能建议!
对于大多数应用程序,显式空值、对象池和显式垃圾回收会损害应用程序的吞吐量,而不是提高它——更不用说这些技术对程序设计的侵入性了。在某些情况下,吞吐量的权衡对于可预测性是可以接受的,例如实时或嵌入式应用程序。但是对于许多 Java 应用程序,包括大多数服务器端应用程序,您可能更喜欢吞吐量。
这个故事的寓意是绩效咨询是非常情境化的(并且保质期很短)。顾名思义,性能建议是被动的——它旨在解决在特定情况下发生的特定问题。如果基本情况发生变化,或者根本不适用于您的情况,建议也可能不适用。在对程序设计进行改进以提高其性能之前,首先要确保您遇到了性能问题并且遵循建议可以解决问题。
概括
垃圾采集在过去几年中取得了长足的进步。现代 JVM 提供快速分配并自行完成工作,与以前的 JVM 相比,垃圾采集的暂停时间更短。由于分配和垃圾采集的成本已大大降低,以前认为可以提高性能的技术(例如对象池或显式失效)不再必要或无用(甚至可能有害)。
翻译自: 查看全部
算法 自动采集列表(Java应用程序分配对象的方式很糟糕,分配多少钱?)
本文于 2015 年 11 月 11 日存档。其内容不再更新或维护。“按原样”提供。鉴于当今技术的快速发展,一些步骤和插图可能已经改变。
在 Java 技术的早期,对象的分配方式很糟糕。有许多 文章s(包括作者的一些)建议开发人员避免不必要地创建临时对象,因为分配(以及相应的垃圾采集开销)很昂贵。虽然这曾经是一个很好的建议(在性能非常重要的情况下),但它通常不再适用于所有性能关键的情况,而是最重要的情况。
分配多少?
1.0 和 1.1 JDK 使用标记清除采集器,它压缩一些(但不是全部)采集,这意味着在垃圾采集后堆可能会变得碎片化。因此,1.0 和 1.1 JVM 中的内存分配成本与 C 或 C++ 中的内存分配成本相当,其中分配器使用启发式(例如“first-first”或“best-fit”)来管理可用堆空间。释放也很昂贵,因为标记清除采集器必须在每次采集时清除整个堆。难怪我们被建议在分配器上放轻松。
在热点 JVM(Sun JDK 1. 2 及更高版本)上,情况变得更好 - Sun JDK 转移到了分代采集器。因为复制采集器用于年轻代,所以堆中的空闲空间始终是连续的,因此可以通过简单的指针添加来从堆中分配新对象,如清单 1 所示。Java 应用程序比 C 便宜得多许多开发人员一开始就很难想象。此外,具有大量临时对象(在 Java 应用程序中很常见)的堆采集起来非常便宜,因为复制采集器不会访问无效对象。只需跟踪并将活动对象复制到幸存者空间,然后一举回收整个堆。没有空闲列表,没有块合并,没有压缩 - 只需清除堆并重新开始。因此,在 JDK 1.2 中,
列出1.连续堆中的快速分配
void *malloc(int n) {
synchronized (heapLock) {
if (heapTop - heapStart > n)
doGarbageCollection();
void *wasStart = heapStart;
heapStart += n;
return wasStart;
}
}
性能建议的保质期通常很短。分配曾经很昂贵,但现在不再如此。在实践中,它非常便宜并且有一些非常计算密集型的异常,因此性能问题通常不再是避免分配的好理由。Sun 估计分配成本约为 10 条机器指令。它几乎是免费的——绝对没有理由为了消除某些对象创建而使程序结构复杂化或招致额外的维护风险。
当然,分配只是故事的一半——大多数分配的对象最终都会被垃圾回收,这也是有代价的。但那里也有好消息。大多数 Java 应用程序中的绝大多数对象在下一次回收之前就变成了垃圾。一次小型垃圾回收的成本与年轻代中存活对象的数量成正比,而不是自上次回收以来分配的对象数量。由于很少有年轻对象能够存活到下一次采集,因此每次分配的采集摊销成本相当小(并且可以通过增加堆大小来减小,具体取决于可用内存的可用性)。
但是等等,会好起来的
JIT 编译器可以执行额外的优化,将对象分配的成本降低到零。考虑清单 2 中的代码,其中 getPosition() 方法创建一个临时对象来保存点的坐标,调用方法短暂使用 Point 对象,然后将其丢弃。JIT 可以内联对 getPosition() 的调用,并且使用一种称为逃逸分析的技术,可以识别对 Point 对象的引用没有离开 doSomething() 方法。知道了这一点,JIT 可以在堆栈而不是堆上分配对象,甚至可以通过简单地将 Point 的字段提升到寄存器来更好地优化分配。尽管当前的 Sun JVM 尚未执行此优化,但未来的 JVM 可能会。事实上,在不改变代码的情况下,未来分配会更便宜,
列出2.逃逸分析可以彻底消除很多临时赋值
void doSomething() {
Point p = someObject.getPosition();
System.out.println("Object is at (" + p.x, + ", " + p.y + ")");
}
...
Point getPosition() {
return new Point(myX, myY);
}
分配器不是可扩展性瓶颈吗?
表明虽然分配本身很快,但对堆结构的访问必须在线程之间同步。那么这是否会使分配器成为可伸缩性风险?JVM 有许多巧妙的技巧可以大大降低这种成本。IBM JVM 使用一种称为线程局部堆的技术,每个线程通过该技术从分配器请求一小块内存 (~1K),并从该块中满足小对象分配。如果程序请求的块比使用小的线程局部堆无法满足,则使用全局分配器直接满足请求或分配新的线程局部堆。使用这种技术,可以在不竞争共享堆锁的情况下满足大部分分配。(Sun JVM 使用类似的技术,而不是术语“本地分配块”。)
终结者不是你的朋友
与没有终结器的对象相比,具有终结器的对象(具有非平凡 finalize() 方法的对象)具有显着的开销,应谨慎使用。可终结对象的分配和采集速度较慢。在分配时,JVM 必须向垃圾采集器注册任何可终结对象,并且(至少在 HotSpot JVM 实现中)可终结对象必须遵循比大多数其他对象更慢的分配路径。此外,可终结对象的采集速度较慢。在一个可终结的对象可以被回收之前,它至少需要两个垃圾回收周期(在最好的情况下),并且垃圾回收器必须做额外的工作来调用终结器。结果是更多的时间花在分配和采集对象上,并且更多的压力施加在垃圾采集器上,因为不可访问的可终结对象使用的内存被保留的时间更长。再加上终结器不能保证在任何可预测的时间范围内运行,甚至根本不能保证运行,您可以看到在相对较少的情况下使用终结器是正确的工具。
如果您必须使用终结器,您可以遵循一些准则来帮助抑制损坏。限制 finalizable 对象的数量,从而最小化必须承担 finalization 的分配和采集成本的对象的数量。组织您的类以使可终结对象不收录其他数据将最大限度地减少无法终结的对象中可用的内存量,因为在这些对象实际回收之前可能存在很长的延迟。从标准库扩展可终结的类时要特别小心。
帮助垃圾采集器。. . 不要
由于单次分配和垃圾回收会给 Java 程序带来巨大的性能成本,因此开发了许多巧妙的技巧来降低这些成本,例如对象池和空值。不幸的是,在许多情况下,这些技术对程序性能弊大于利。
对象池
对象池是一个简单的概念 - 维护一个经常使用的对象池并从该池中获取一个对象,而不是在需要时创建一个新对象。从理论上讲,整合可以将分销成本分散到更多用途上。当对象的创建成本很高(例如使用数据库连接或线程时),或者当合并对象代表有限且昂贵的资源(例如使用数据库连接时)时,这是有意义的。但是,适用这些条件的情况很少。
此外,对象池有一些严重的缺点。由于对象池通常在所有线程之间共享,因此来自对象池的分配可能成为同步瓶颈。池化还强制您显式管理释放,这重新引入了悬空指针的风险。此外,必须适当调整池的大小以获得所需的性能结果。如果太小,分配将不会被阻塞;如果太大,可回收的资源将在池中闲置。对象池的使用通过占用可回收的内存给垃圾采集器带来了额外的压力。编写一个高效的池实现并不容易。
Cliff Click 博士在他的 JavaOne 2003 演讲“Performance Myths Exposed”中提供了具体的基准数据,表明对象池是现代 JVM 上除了最重的对象之外的所有对象的性能损失。加上分配的序列化和悬空指针的风险,很明显,除了最极端的情况外,应该避免合并。
显式归零
显式归零只是在完成后将引用对象设置为 null 的一种做法。null 背后的想法是它通过使对象更早不可访问来帮助垃圾采集器。或者至少这是理论。
在对对象的引用具有比程序规范使用或认为有效的范围更广的情况下,使用显式 null 不仅有帮助,而且实际上是必需的。这包括使用静态或实例字段来存储对临时缓冲区而不是局部变量的引用,或者使用数组来存储可能在运行时可访问但不能通过程序的隐式语义访问的引用的情况。考虑清单 3 中的类,它是一个由数组支持的简单有界堆栈的实现。调用pop(),如果示例中没有显式清空,该类可能会导致内存泄漏(更恰当地称为“意外对象保留”,有时称为“对象徘徊”),因为引用存储在stack[top+1]中该程序不再可以访问,
列出3.避免在栈实现中游荡对象
public class SimpleBoundedStack {
private static final int MAXLEN = 100;
private Object stack[] = new Object[MAXLEN];
private int top = -1;
public void push(Object p) { stack [++top] = p;}
public Object pop() {
Object p = stack [top];
stack [top--] = null; // explicit null
return p;
}
}
在 1997 年 9 月的“Java 开发人员的连接技术技巧”专栏(请参阅 参考资料)中,Sun 警告了这种风险,并解释了在上面的 pop() 示例等情况下如何需要显式 null。不幸的是,程序员经常求助于明确的空值来提供这个建议,希望能帮助垃圾采集器。但在大多数情况下,它根本无法帮助垃圾采集器,在某些情况下,它实际上会损害程序的性能。
考虑清单 4 中的代码,它结合了几个非常糟糕的想法。List 是一个链表实现,它使用终结器来遍历列表并使所有前向链接无效。我们已经讨论了为什么终结器不好。更糟糕的是,因为现在班级正在做额外的工作,表面上是为了帮助垃圾采集器,但实际上并没有帮助 - 甚至可能造成伤害。遍历列表需要 CPU 周期,并且会产生访问所有死对象并将它们拉入缓存的效果——垃圾采集器可以完全避免这项工作,因为复制采集器根本不会访问死对象。空引用对跟踪垃圾采集器没有任何作用。如果无法访问列表的头部,则无论如何都不会跟踪列表的其余部分。
清单 4. 结合了终结器和显式空值以避免整体性能损失 - 不要这样做!
public class LinkedList {
private static class ListElement {
private ListElement nextElement;
private Object value;
}
private ListElement head;
...
public void finalize() {
try {
ListElement p = head;
while (p != null) {
p.value = null;
ListElement q = p.nextElement;
p.nextElement = null;
p = q;
}
head = null;
}
finally {
super.finalize();
}
}
}
对于您的程序出于性能原因破坏正常范围规则的情况,您应该保存显式归零,例如堆栈示例(更正确的方法 - 但性能较低的实现是每次重新分配和复制堆栈数组)它已经改变)。
显式垃圾采集
开发人员经常错误地认为他们正在帮助垃圾采集器的第三类是使用 System.gc() ,它会触发垃圾采集(实际上,它只是暗示它可能是这样做的好时机)。不幸的是,System.gc() 触发了一个完整的集合,包括跟踪堆中的所有活动对象以及清除和压缩旧版本。这可能是很多工作。一般来说,最好让系统决定何时需要采集堆以及是否进行全采集。在大多数情况下,一个小的集合就可以完成这项工作。更糟糕的是,对 System.gc() 的调用通常深埋在开发人员可能不知道它存在的地方,并且在这些地方可能比需要的更频繁地触发。如果您担心您的应用程序可能隐藏了对隐藏在库中的 System.gc() 的调用,
不变性
如果没有某种形式的不变性插件,Java 理论和实践就无法完成。使对象不可变可以消除一整类编程错误。不使类不可变的最常见原因之一是认为这样做会损害性能。虽然有时是正确的,但事实并非如此——有时使用不可变对象有明显的、也许令人惊讶的性能优势。
许多对象用作引用其他对象的容器。当被引用的对象需要改变时,我们有两种选择:更新引用(如可变容器类)或重新创建容器以保存新引用(如不可变容器类)。清单 5 展示了两种实现简单持有者类的方法。假设收录对象很小(通常是这种情况)(例如 Map 的 Map.Entry 元素或链表元素),分配一个新的不可变对象具有一些隐藏的性能优势,这些优势来自于分代垃圾采集器的工作方式,即与物体的相对年龄有关。
List5. 可变和不可变对象持有者
public class MutableHolder {
private Object value;
public Object getValue() { return value; }
public void setValue(Object o) { value = o; }
}
public class ImmutableHolder {
private final Object value;
public ImmutableHolder(Object o) { value = o; }
public Object getValue() { return value; }
}
在大多数情况下,当持有者对象更新为引用其他对象时,新引用的对象就是年轻对象。如果我们通过调用 setValue() 来更新 MutableHolder,就会导致老对象引用年轻对象的情况。另一方面,通过创建一个新的 ImmutableHolder 对象,较年轻的对象将引用较旧的对象。后一种情况(大多数对象指向较旧的对象)在分代垃圾采集器上较为温和。如果 MutableHolder 存在于老年代突变中,则必须扫描卡上收录 MutableHolder 的所有对象,在下一个二级中采集旧的到新的年轻引用。对长期存在的容器对象使用可变引用会增加在采集时跟踪旧引用的工作量。(参见上个月的 文章 和本月的,
当好的性能建议变坏时
2003 年 7 月 Java Developer's Magazine 的一个封面故事说明,很容易将良好的性能建议变成糟糕的性能建议,因为未能充分确定何时应该应用建议或要解决的问题。虽然本文收录一些有用的分析,但它弊大于利(不幸的是,太多基于性能的建议落入了同一个陷阱)。
本文首先描述了一组实时环境中的要求,在这些实时环境中,不可预见的垃圾采集暂停是不可接受的,并且对允许的暂停时间有严格的操作要求。然后,作者建议取消引用、对象池和调度显式垃圾采集来满足性能目标。到目前为止一切都很好——他们遇到了一个问题,他们找到了解决问题的方法(尽管他们似乎无法确定这些做法的成本或探索一些侵入性较小的替代方案,例如并发集合)。不幸的是,文章 的标题(“避免麻烦的垃圾采集暂停”)和介绍表明,该建议对广泛的应用程序(可能所有 Java 应用程序)都很有用。这是可怕的、危险的性能建议!
对于大多数应用程序,显式空值、对象池和显式垃圾回收会损害应用程序的吞吐量,而不是提高它——更不用说这些技术对程序设计的侵入性了。在某些情况下,吞吐量的权衡对于可预测性是可以接受的,例如实时或嵌入式应用程序。但是对于许多 Java 应用程序,包括大多数服务器端应用程序,您可能更喜欢吞吐量。
这个故事的寓意是绩效咨询是非常情境化的(并且保质期很短)。顾名思义,性能建议是被动的——它旨在解决在特定情况下发生的特定问题。如果基本情况发生变化,或者根本不适用于您的情况,建议也可能不适用。在对程序设计进行改进以提高其性能之前,首先要确保您遇到了性能问题并且遵循建议可以解决问题。
概括
垃圾采集在过去几年中取得了长足的进步。现代 JVM 提供快速分配并自行完成工作,与以前的 JVM 相比,垃圾采集的暂停时间更短。由于分配和垃圾采集的成本已大大降低,以前认为可以提高性能的技术(例如对象池或显式失效)不再必要或无用(甚至可能有害)。
翻译自:
算法 自动采集列表(亚马逊数据采集软件有哪些?有什么用?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-22 01:28
嗨星QQ采集器关键词搜索嗨星QQ采集器关键词搜索正式版,亚马逊数据采集有哪些软件?有什么用?列表优化辅助:使用软件关键字采集亚马逊ASINs来采集排名靠前的ASINs。然后采集这些Asin的标题和卖点。将采集到的标题通过Excel表格进行整理分析,最终形成具有自身特色的标题和卖点。经营亚马逊商店时。问kibana如何在可视化中显示采集收到的Elastic实际数据。根据网络采集的需要,本文将网络传输与采集相结合,设计了一款以S3C2440为核心的USB摄像头采集
免费的网络爬虫软件爬虫工具捕捉微博中文分词的情绪,优采云采集器是一款好用的数据采集工具,免费爬虫软件。优采云采集器简单易学,通过智能算法+可视化界面,随心所欲抓取数据。采集 只需点击一下即可。免费在线伪原创文章发电机勺捏AI智能伪原创自动写字工具,嗨星QQ采集器关键词搜索是一款可以根据关键词进行搜索的工具采集QQ工具支持根据评论、日志、昵称进行搜索采集,支持设置多个关键词,是营销人员挖掘目标人群必备的数据采集工具。嗨兴QQ采集器关键词搜索v14内容:
基于关键字采集文章搜外SEO Q&A,下面的例子展示了如何使用优采云采集器到采集确切的关键字recipe 另外,有些关键字有“Recipes for Relevance”,可以一起设置采集优采云采集如下: 除了采集关键字,上述方法对关键字有用相关性(也有相关要求的关键字)也非常有用。在网站做主题时,可以直接将采集中的相关关系导入敏感词中。如何自动使用优采云采集百万精准关键词优采云,我们在做网站优化和内容的时候,会发现大批量文章需要很多关键词。关键词 的手动统计
优采云采集器免费的网络爬虫软件大数据抓取工具,优采云采集器提供丰富的采集功能,无论是采集稳定性还是< @采集效率,都能满足个人、团队和企业层面采集的需求。功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。云账号,轻松快速创建。优采云采集器官方爬虫优采云采集器Free Station采集软件,PotPlayer是一款功能强大的播放器,除了播放硬盘上的文件,它还支持采集卡片采集的预览、录制、截图功能。是测试采集卡的首选工具软件。1 打开 CD-ROM PotPlayer 软件。21安装采集卡驱动后,采集盒子用户应使用USB30线。
<p>基于S3C2440的网络采集system 21ic电子和USB摄像头,网络信息采集专家可以根据规则采集将互联网上的信息保存到数据库中。并且具有以下功能:多任务,多线程可以同时执行多个采集任务,每个任务可以使用多个线程。站内登录——支持站内登录,支持。WebRadar网络信息采集系统下载WebRadar网络信息采集,AjaxJs数据采集器工具主要针对优采云只有采集到地址,没有 查看全部
算法 自动采集列表(亚马逊数据采集软件有哪些?有什么用?(组图))
嗨星QQ采集器关键词搜索嗨星QQ采集器关键词搜索正式版,亚马逊数据采集有哪些软件?有什么用?列表优化辅助:使用软件关键字采集亚马逊ASINs来采集排名靠前的ASINs。然后采集这些Asin的标题和卖点。将采集到的标题通过Excel表格进行整理分析,最终形成具有自身特色的标题和卖点。经营亚马逊商店时。问kibana如何在可视化中显示采集收到的Elastic实际数据。根据网络采集的需要,本文将网络传输与采集相结合,设计了一款以S3C2440为核心的USB摄像头采集
免费的网络爬虫软件爬虫工具捕捉微博中文分词的情绪,优采云采集器是一款好用的数据采集工具,免费爬虫软件。优采云采集器简单易学,通过智能算法+可视化界面,随心所欲抓取数据。采集 只需点击一下即可。免费在线伪原创文章发电机勺捏AI智能伪原创自动写字工具,嗨星QQ采集器关键词搜索是一款可以根据关键词进行搜索的工具采集QQ工具支持根据评论、日志、昵称进行搜索采集,支持设置多个关键词,是营销人员挖掘目标人群必备的数据采集工具。嗨兴QQ采集器关键词搜索v14内容:
基于关键字采集文章搜外SEO Q&A,下面的例子展示了如何使用优采云采集器到采集确切的关键字recipe 另外,有些关键字有“Recipes for Relevance”,可以一起设置采集优采云采集如下: 除了采集关键字,上述方法对关键字有用相关性(也有相关要求的关键字)也非常有用。在网站做主题时,可以直接将采集中的相关关系导入敏感词中。如何自动使用优采云采集百万精准关键词优采云,我们在做网站优化和内容的时候,会发现大批量文章需要很多关键词。关键词 的手动统计
优采云采集器免费的网络爬虫软件大数据抓取工具,优采云采集器提供丰富的采集功能,无论是采集稳定性还是< @采集效率,都能满足个人、团队和企业层面采集的需求。功能丰富:定时采集、自动导出、文件下载、加速引擎、分组启动导出、Webhook、RESTful API、智能识别SKU和大图等。云账号,轻松快速创建。优采云采集器官方爬虫优采云采集器Free Station采集软件,PotPlayer是一款功能强大的播放器,除了播放硬盘上的文件,它还支持采集卡片采集的预览、录制、截图功能。是测试采集卡的首选工具软件。1 打开 CD-ROM PotPlayer 软件。21安装采集卡驱动后,采集盒子用户应使用USB30线。
<p>基于S3C2440的网络采集system 21ic电子和USB摄像头,网络信息采集专家可以根据规则采集将互联网上的信息保存到数据库中。并且具有以下功能:多任务,多线程可以同时执行多个采集任务,每个任务可以使用多个线程。站内登录——支持站内登录,支持。WebRadar网络信息采集系统下载WebRadar网络信息采集,AjaxJs数据采集器工具主要针对优采云只有采集到地址,没有
算法 自动采集列表( WEB超链分析算法2.1Google和PageRank算法搜索引擎是APP开发斯坦福大学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-19 17:07
WEB超链分析算法2.1Google和PageRank算法搜索引擎是APP开发斯坦福大学)
一、介绍
万维网万维网(World Wide Web)是一个巨大的、分布在全球的信息服务中心,正在迅速扩张。1998 年,WWW 上大约有 3.5 亿个文档 [14],每天增加大约 100 万个文档 [6],不到 9 个月,文档总数翻了一番 [14] ]。与传统文档相比,WEB上的文档具有许多新的特点。它们是分布式的、异构的、非结构化的或半结构化的,这给传统的信息检索技术带来了新的挑战。
传统的WEB搜索引擎大多基于关键字匹配,返回的结果是收录查询项的文档,也有基于目录分类的搜索引擎。这些搜索引擎的结果并不令人满意。一些网站故意增加关键词的频率,以增加其在搜索引擎中的重要性,破坏了搜索引擎结果的客观性和准确性。另外,网站构建一些不收录查询项的重要页面。搜索引擎的分类目录不可能全面考虑所有的分类,而且大部分目录都是手动维护的,主观性强、成本高、更新慢[2]。
近年来,许多研究人员发现,万维网上的超链接结构是一种非常丰富和重要的资源,如果能够充分利用,可以大大提高搜索结果的质量。基于这种超链接分析的思想,Sergey Brin和Lawrence Page在1998年提出了PageRank算法[1],同年J. Kleinberg提出了HITS算法[5],其他学者相继提出了其他链接分析算法。网络公司如SALSA、PHITS、贝叶斯等算法。其中一些算法已经在实际系统中实现和使用,并取得了良好的效果。
文章 的第 2 部分按时间顺序详细剖析了各种链接分析算法,比较了不同的算法。第 3 节对这些算法进行评估和总结,并指出存在的问题和改进方向。
2. WEB超链接分析算法
2.1Google和PageRank算法
搜索引擎 Google 最初是由 Sergey Brin 和 Lawrence Page 博士实现的原型系统。斯坦福大学的学生从事APP开发[2],现已发展成为万维网上最好的搜索引擎之一。Google 的架构类似于传统的搜索引擎。它与传统搜索引擎最大的不同在于,它根据权威值对网页进行排序,使最重要的网页出现在结果的顶部。Google 通过 PageRank 元算法计算网页的 PageRank 值,从而确定网页在结果集中的位置。PageRank 值越高,在结果中的位置就越高。
2.1.1PageRank算法
PageRank算法基于以下两个前提:
前提1:如果一个网页被多次引用,可能很重要;如果一个网页没有被多次引用,但被重要网页引用,也可能非常重要;重要性均匀地传递给它所引用的页面。这样重要的页面被称为权威页面。
前提2:假设用户首先随机访问网页集合中的一个网页,然后沿着该网页的出站链接向前浏览该网页而不返回,则浏览下一个网页的概率为浏览网页的PageRank值。
简单的PageRank算法描述如下:u是一个网页,是u指向的网页集合,是指向u的网页集合,是u指向的链接数,显然=| | , c 是一个用于归一化的因子(谷歌通常取0.85),(这个符号也适用于后面介绍的算法),那么u的Rank值计算如下:
这是算法的正式描述。网站算法也可以用矩阵来描述。设A为方阵,行列对应网页集合的网页。如果网页 i 有指向网页 j 的链接,否则 = 0。设V为网页集合对应的向量,有V=cAV,V为特征值为c的A的特征向量。其实只需要最大特征根的特征向量,就是网页集合对应的最终PageRank值,可以通过迭代的方法计算。
如果有两个网页 a 和 b 相互指向,它们不指向任何其他网页,而 网站 制作公司有另一个网页 c 指向 a 和 b 之一,例如a,那么在迭代计算中,a和b的rank值不是连续分布和累积的。如下所示:
为了解决这个问题,Sergey Brin 和 Lawrence Page 对算法进行了改进,引入了一个衰减因子 E(u),E(U) 是对应于网页集合的某个向量,对应于 rank 的初始值,而算法改进如下:
其中,=1,对应的矩阵形式为V'=c(AV'+E)。
另外,还有一些特殊的链接,企业建设网站指向的网页没有外链。在计算PageRank时,这种链接先去掉,计算完成后再添加,对原计算网页的rank值影响不大。
除了对搜索结果进行排名之外,Pagerank 算法还可以应用于其他方面,例如估计网络流量、反向链接的预测器、为用户导航等 [2]。
2.1.2 算法的一些问题
Google 通过结合文本方法 [2] 来实现 PageRank 算法。企业网站构造只返回收录查询项的网页,然后根据网页的rank值对搜索结果进行排序,选择rank值最高的。网页放在最前面,但是如果最重要的网页不在结果网页集合中,那么PageRank算法将无能为力,比如在谷歌中查询搜索引擎,比如谷歌、雅虎, Altisa 等都很重要,但是谷歌返回的结果这些页面都没有出现。同一个查询示例还可以说明另一个问题。Google 和 Yahoo 是 WWW 上最受欢迎的网页。如果它们出现在查询项car的结果集中,肯定有很多网页指向它们,并且将获得更高的排名值。事实上,它们与汽车并没有太大的关系。
在PageRank算法的基础上,其他研究人员提出了改进的PageRank算法。Do网站华盛顿大学计算机科学与工程系的 Matthew Richardson 和 Pedro Dominggos 提出了一种结合链接和内容信息的 PageRank 算法,去掉了 PageRank 算法要求的前提 2,增加了用户直接跳转从一个网页到另一个网页不直接相邻但内容相关的情况下 [3]。斯坦大学计算机科学系的 Taher Haveliwala 提出了一种主题敏感的 PageRank 算法 [4]。斯坦福大学计算机科学系的 Arvind Arasu 等人通过实验表明,PageRank 算法的计算效率也可以大大提高 [22]。
2.2HITS 算法及其变体
在PageRank算法中,对输出链接的权重贡献是平均的,构造网站意味着不考虑不同链接的重要性。WEB链接具有以下特点:
1.有些链接是注释性的,有些则用于导航或广告目的。带注释的链接供权威判断。
2.出于商业或竞争考虑,很少有 WEB 页面指向其竞争领域的权威页面。
3.权威网页很少有明确的描述。例如,谷歌主页没有明确给出WEB搜索引擎等描述。
可以看出,平均分配权重不符合链路的实际情况[17]。J. Kleinberg [5] 提出的 HITS 算法引入了另一种设计网页,称为 Hub 网页,它是提供权威网页链接集合的网页,它本身可能并不重要,也可能没有多少页面指向它,但 Hub 页面确实提供了指向某个主题的最重要站点的链接集合,例如课程主页上的推荐参考列表。一般来说,一个好的hub页面指向很多好的权威页面;一个好的权威页面是很多好的hub页面指向的WEB页面。Hub和Authoritive网页之间的相互促进关系可以用于权威网页的发现和WEB结构和资源的自动发现。这就是 Hub/Authority 方法的基本思想。
2.2.1HITS算法
HITS(Hyperlink-Induced Topic Search)算法是一种使用Hub/Authority方法的搜索方法。算法如下: 将查询 q 提交给传统的基于关键字匹配的搜索引擎。搜索引擎返回很多网页,其中前n个网页作为根集,记为S。S满足以下三个条件:
1、S中的网页数量比较少
2. S中的大部分网页都与查询q有关
3. S中的网页收录更权威的网页。
通过将 S 引用的页面和引用 S 的页面添加到 S 中,将 S 扩展为更大的集合 T。
以T中的Hub网页为顶点集V1,以权威网页为顶点集V2,V1中的网页到V2中的网页的超链接为边集E,二部有向图SG=(V1, V2, E 形成)。对于V1中的任意一个顶点v,用h(v)表示网页v的Hub值,对于V2中的顶点u,用a(u)表示网页的Authority值。从h(v)=a(u)=1开始,对u进行I操作修改其a(u),对v进行O操作修改其h(v),然后归一化a(u),h (v ),因此重复计算以下操作 I、O,直到 a(u)、h(v) 收敛。(证明这个算法收敛可见)
I 操作:(1) O 操作:(2)
每次迭代后,需要对 a(u)、h(v) 进行归一化:
公式(1)反映了如果一个网页被很多好的Hub指向,它的权限值会相应增加(即权限值增加为所有的已有Hub值的总和)指向它的网页)。公式(2)反映了如果一个网页指向很多好的权威页面,那么Hub值也会相应增加(即Hub值随着权威的总和而增加)链接到该网页的所有网页的值)。
与PageRank算法一样,该算法可以用矩阵的形式来描述,这里不再赘述。
HITS算法输出一组Hub值较大的网页和权限值较大的网页。
2.2.2 个热门问题
HITS算法存在以下问题:
1、在实际应用中,从S生成T的时间开销是非常昂贵的,需要对S中每个网页所收录的所有链接进行下载和分析,并排除重复链接。通常,T 比 S 大得多,从 T 生成有向图也很耗时。需要单独计算网页的A/H值,计算量大于PageRank算法。
2. 有时,一台主机A上的多个文档可能指向另一台主机B上的一个文档,这增加了A上文档的Hub值和B上文档的权限,反之亦然。HITS假设一个文档的权限值是由不同的个体组织或个人决定的,上述情况影响了A和B上文档的Hub和Authority值[7]。
3、网页中一些不相关的链接会影响A、H值的计算。在创建网页时,一些开发工具会自动在网页中添加一些链接,其中大部分与查询主题无关。同站内链接的目的是为用户提供导航帮助,与查询主题关系不大,一些商业广告、赞助和友情交流的链接也会降低HITS算法的准确性[8]。
4. HITS算法只计算主要特征向量,即只能在T集合中找到主要社区(Community),而忽略其他重要社区[12]。事实上,其他社区也可能非常重要。
5. HITS算法最大的弱点是无法处理话题漂移问题[7, 8],即Tightly-Knit Community Effect (TKC)现象[8]。如果集合 T 中有少数网页与查询主题无关,但联系紧密,那么 HITS 算法的结果可能就是这些网页,因为 HITS 只能找到主要社区,这与原创查询主题。TKC 问题在下面讨论的 SALSA 算法中得到解决。
6. 使用HITS进行狭义主题查询时,可能会出现主题泛化问题[5, 9],即扩展后引入比原主题更重要的新主题,新主题可能与原主题无关询问。概括的原因是因为网页收录指向不同主题的传出链接,而指向新主题的链接更为重要。
2.2.3 HITS 变体
HITS算法遇到的大部分问题是因为HITS是一种纯粹的基于链接分析的算法,没有考虑文本内容。在 J. Kleinberg 提出 HITS 算法之后,许多研究人员对 HITS 进行了改进,并提出了许多 HITS 变体算法。,有:
2.2.3.1Monika R. Henzinger 和 Krishna Bharat 对 HITS 的改进
对于上面提到的 HITS 遇到的第二个问题,Monika R. Henzinger 和 Krishna Bharat 在 [7] 中对其进行了改进。假设主机 A 上有 k 个网页指向主机 B 上的一个文档 d,那么这 k 个文档对 B 的权限的总贡献值为 1,每个文档贡献 1/k 而不是每个文档在 HITS 中的贡献。文档贡献1,总贡献k。同理,对于 Hub 值,假设主机 A 上的一个文档 t 指向主机 B 上的 m 个文档,那么 B 上的 m 个文档对 t 的 Hub 值贡献 1,每个文档贡献 1/m。I、O操作改为如下
我操作:
Ø 操作:
调整后的算法有效地解决了问题 2,称为 imp 算法。
在此基础上,Monika R. Henzinger 和 Krishna Bharat 还引入了传统信息检索的内容分析技术来解决问题 4 和问题 5,实际上同时解决了问题 3。具体方法如下,提取根集S中每篇文档的前1000个词,拼接为查询主题Q,文档Dj与主题Q的相似度按照如下公式计算:
, , = 查询 Q 中项目 i 的出现次数,
= 项目 i 在文档 Dj 中出现的次数,IDFi 是对 WWW 上收录项目 i 的文档数量的估计。
将S扩展到T后,计算每个文档的主题相似度,根据不同的阈值进行选择。您可以选择所有文档相似度的中值、根集文档相似度的中值和最大文档相似度。的分数,例如 1/10,作为阈值。根据不同的阈值处理,删除不满足条件的文档,然后运行imp算法计算文档的A/H值。这些算法分别称为 med、startmed 和 maxby10。
在这种改进的算法中,计算文档的相似度将花费大量时间。
2.2.3.2ARC算法
IBM Almaden 研究中心的 Clever 工程组提出了 ARC(Automatic Resource Compilation)算法,对原有的 HITS 进行了改进,结合链接的锚文本给出了网页集对应的连接矩阵的初始值,适应对不同的链接有不同的权重。
ARC算法与HITS的区别主要在于以下三点:
1、当根集S扩展为T时,HITS只扩展与根集链接路径长度为1的网页,即只扩展与S直接相邻的网页,而在ARC中,扩展的链接长度增加到2个,构造网站扩展的网页集称为Augment Set。
2.在HITS算法中,每个环节对应的矩阵值都设置为1,其实每个环节的重要性是不一样的。ARC 算法考虑链接周围的文本来确定链接的重要性。考虑链接p->q,在p中有几个链接标签,文本1,锚文本,文本2,假设查询项t在文本1,锚文本,文本2中,出现次数为n(t ),则 w(p,q)=1+n(t)。文本 1 和文本 2 的长度实验性地设置为 50 个字节 [10]。构造矩阵W,如果有网页i->j,Wi,j=w(i,j),否则Wi,j=0,H值置1,Z为W的转置矩阵,迭代执行以下三个操作:
(1)A=WH (2)H=ZA (3)归一化 A, H
3. ARC算法的目标是找出最重要的前15个网页。它只需要保持A/H的前15个值的相对大小稳定,不需要A/H的整个收敛。这样,2中的迭代次数就足够少了。在[10]中指出5次迭代就足够了,因此ARC算法计算效率高,开销主要在扩展根集上。
2.2.3.3Hub平均(Hub-Averaging-Kleinberg)算法
艾伦鲍罗丁等人。[11]指出了一个现象,即有M+1个Hub页面,M+1个权威页面,前M个Hubs指向第一个权威页面,第M+1个Hub页面指向所有M+1个权威页面。显然根据HITS算法,第一个权威页面是最重要的,拥有最高的Authority值,这就是我们想要的。但是,根据 HITS,第 M+1 个 Hub 页面的 Hub 值最高。实际上,第 M+1 个 Hub 页面不仅指向第一个权威值高的权威页面,还指向其他低权威值的页面。其 Hub 值不应高于前 M 页的 Hub 值。因此,Allan Borodin 修改了 HITS 的 O 操作:
O运算:n是(v,u)的个数
调整后,只指向高权限值页面的Hub值高于同时指向高权限值和低权限值页面的Hub值。该算法称为 Hub-Averaging-Kleinberg 算法。
2.2.3.4 阈值-克莱因伯格算法
Allan Borodin等[11]同时提出了三种阈值控制算法,即Hub阈值算法、Authority阈值算法和两者结合的全阈值算法。
在计算网页p的权限时,不考虑所有指向它的网页的贡献,而只考虑Hub值超过平均值的网页的贡献。这是 Hub 阈值方法。
权威阈值算法类似于 Hub 阈值方法。它不考虑p所指向的所有页面的权威对p的Hub值的贡献,只计算前K个权威页面对其Hub值的贡献。这是基于算法的。目标是找到最重要的K个权威网页的前提。
同时使用Authority阈值算法和Hub阈值方法的算法是全阈值算法
2.3SALSA算法
PageRank算法是基于用户对网页随机前向浏览的直观认识,HITS算法考虑了Authoritive网页与Hub网页之间的强化关系。在实际应用中,用户在大多数情况下是向前浏览网页,但也有很多情况是向后浏览网页。基于上述直观知识,R. Lempel 和 S. Moran 提出了 SALSA(Stochastic Approach for Link-Structure Analysis)算法[8],该算法考虑了用户返回浏览网页的情况,并保留了 PageRank 的随机漫游和 HITS 中的 HITS。分为Authoritive和Hub的思路,取消了Authoritive和Hub的相辅相成关系。
具体算法如下:
1.和HITS算法的第一步一样,得到根集,扩展为一组网页T,去除孤立节点。
2.从集合T构造无向图G'=(Vh, Va, E)
Vh = { sh | s∈C 和 out-degree(s) > 0 }(G' 的中心边缘)。
VA = { 萨 | s∈C 和 in-degree(s) > 0 }(G' 的权威边)。
E= { (sh , ra) |s->r in T}
这定义了 2 条链,权威链和 Hub 链。
3. 定义两条马尔可夫链的变化矩阵,也是随机矩阵。网站设计公司分别是Hub matrix H和Authority matrix A。
4、得到矩阵H和A的主特征向量,即对应马尔可夫链的静态分布。
5.中值A大的对应网页就是你要找的重要网页。
SALSA算法在HITS中没有相辅相成的迭代过程,计算量也比HITS小很多。SALSA算法只考虑直接相邻网页对自身A/H的影响,而HITS计算整个网页集T对自身AH的影响。
在实践中,SALSA 在扩展根集时会忽略许多不相关的链接,例如
1. 同一站点内的链接,因为大多数这些链接仅用于导航。
2. CGI 脚本链接。 查看全部
算法 自动采集列表(
WEB超链分析算法2.1Google和PageRank算法搜索引擎是APP开发斯坦福大学)
一、介绍
万维网万维网(World Wide Web)是一个巨大的、分布在全球的信息服务中心,正在迅速扩张。1998 年,WWW 上大约有 3.5 亿个文档 [14],每天增加大约 100 万个文档 [6],不到 9 个月,文档总数翻了一番 [14] ]。与传统文档相比,WEB上的文档具有许多新的特点。它们是分布式的、异构的、非结构化的或半结构化的,这给传统的信息检索技术带来了新的挑战。
传统的WEB搜索引擎大多基于关键字匹配,返回的结果是收录查询项的文档,也有基于目录分类的搜索引擎。这些搜索引擎的结果并不令人满意。一些网站故意增加关键词的频率,以增加其在搜索引擎中的重要性,破坏了搜索引擎结果的客观性和准确性。另外,网站构建一些不收录查询项的重要页面。搜索引擎的分类目录不可能全面考虑所有的分类,而且大部分目录都是手动维护的,主观性强、成本高、更新慢[2]。
近年来,许多研究人员发现,万维网上的超链接结构是一种非常丰富和重要的资源,如果能够充分利用,可以大大提高搜索结果的质量。基于这种超链接分析的思想,Sergey Brin和Lawrence Page在1998年提出了PageRank算法[1],同年J. Kleinberg提出了HITS算法[5],其他学者相继提出了其他链接分析算法。网络公司如SALSA、PHITS、贝叶斯等算法。其中一些算法已经在实际系统中实现和使用,并取得了良好的效果。
文章 的第 2 部分按时间顺序详细剖析了各种链接分析算法,比较了不同的算法。第 3 节对这些算法进行评估和总结,并指出存在的问题和改进方向。
2. WEB超链接分析算法
2.1Google和PageRank算法
搜索引擎 Google 最初是由 Sergey Brin 和 Lawrence Page 博士实现的原型系统。斯坦福大学的学生从事APP开发[2],现已发展成为万维网上最好的搜索引擎之一。Google 的架构类似于传统的搜索引擎。它与传统搜索引擎最大的不同在于,它根据权威值对网页进行排序,使最重要的网页出现在结果的顶部。Google 通过 PageRank 元算法计算网页的 PageRank 值,从而确定网页在结果集中的位置。PageRank 值越高,在结果中的位置就越高。
2.1.1PageRank算法
PageRank算法基于以下两个前提:
前提1:如果一个网页被多次引用,可能很重要;如果一个网页没有被多次引用,但被重要网页引用,也可能非常重要;重要性均匀地传递给它所引用的页面。这样重要的页面被称为权威页面。
前提2:假设用户首先随机访问网页集合中的一个网页,然后沿着该网页的出站链接向前浏览该网页而不返回,则浏览下一个网页的概率为浏览网页的PageRank值。
简单的PageRank算法描述如下:u是一个网页,是u指向的网页集合,是指向u的网页集合,是u指向的链接数,显然=| | , c 是一个用于归一化的因子(谷歌通常取0.85),(这个符号也适用于后面介绍的算法),那么u的Rank值计算如下:
这是算法的正式描述。网站算法也可以用矩阵来描述。设A为方阵,行列对应网页集合的网页。如果网页 i 有指向网页 j 的链接,否则 = 0。设V为网页集合对应的向量,有V=cAV,V为特征值为c的A的特征向量。其实只需要最大特征根的特征向量,就是网页集合对应的最终PageRank值,可以通过迭代的方法计算。
如果有两个网页 a 和 b 相互指向,它们不指向任何其他网页,而 网站 制作公司有另一个网页 c 指向 a 和 b 之一,例如a,那么在迭代计算中,a和b的rank值不是连续分布和累积的。如下所示:
为了解决这个问题,Sergey Brin 和 Lawrence Page 对算法进行了改进,引入了一个衰减因子 E(u),E(U) 是对应于网页集合的某个向量,对应于 rank 的初始值,而算法改进如下:
其中,=1,对应的矩阵形式为V'=c(AV'+E)。
另外,还有一些特殊的链接,企业建设网站指向的网页没有外链。在计算PageRank时,这种链接先去掉,计算完成后再添加,对原计算网页的rank值影响不大。
除了对搜索结果进行排名之外,Pagerank 算法还可以应用于其他方面,例如估计网络流量、反向链接的预测器、为用户导航等 [2]。
2.1.2 算法的一些问题
Google 通过结合文本方法 [2] 来实现 PageRank 算法。企业网站构造只返回收录查询项的网页,然后根据网页的rank值对搜索结果进行排序,选择rank值最高的。网页放在最前面,但是如果最重要的网页不在结果网页集合中,那么PageRank算法将无能为力,比如在谷歌中查询搜索引擎,比如谷歌、雅虎, Altisa 等都很重要,但是谷歌返回的结果这些页面都没有出现。同一个查询示例还可以说明另一个问题。Google 和 Yahoo 是 WWW 上最受欢迎的网页。如果它们出现在查询项car的结果集中,肯定有很多网页指向它们,并且将获得更高的排名值。事实上,它们与汽车并没有太大的关系。
在PageRank算法的基础上,其他研究人员提出了改进的PageRank算法。Do网站华盛顿大学计算机科学与工程系的 Matthew Richardson 和 Pedro Dominggos 提出了一种结合链接和内容信息的 PageRank 算法,去掉了 PageRank 算法要求的前提 2,增加了用户直接跳转从一个网页到另一个网页不直接相邻但内容相关的情况下 [3]。斯坦大学计算机科学系的 Taher Haveliwala 提出了一种主题敏感的 PageRank 算法 [4]。斯坦福大学计算机科学系的 Arvind Arasu 等人通过实验表明,PageRank 算法的计算效率也可以大大提高 [22]。
2.2HITS 算法及其变体
在PageRank算法中,对输出链接的权重贡献是平均的,构造网站意味着不考虑不同链接的重要性。WEB链接具有以下特点:
1.有些链接是注释性的,有些则用于导航或广告目的。带注释的链接供权威判断。
2.出于商业或竞争考虑,很少有 WEB 页面指向其竞争领域的权威页面。
3.权威网页很少有明确的描述。例如,谷歌主页没有明确给出WEB搜索引擎等描述。
可以看出,平均分配权重不符合链路的实际情况[17]。J. Kleinberg [5] 提出的 HITS 算法引入了另一种设计网页,称为 Hub 网页,它是提供权威网页链接集合的网页,它本身可能并不重要,也可能没有多少页面指向它,但 Hub 页面确实提供了指向某个主题的最重要站点的链接集合,例如课程主页上的推荐参考列表。一般来说,一个好的hub页面指向很多好的权威页面;一个好的权威页面是很多好的hub页面指向的WEB页面。Hub和Authoritive网页之间的相互促进关系可以用于权威网页的发现和WEB结构和资源的自动发现。这就是 Hub/Authority 方法的基本思想。
2.2.1HITS算法
HITS(Hyperlink-Induced Topic Search)算法是一种使用Hub/Authority方法的搜索方法。算法如下: 将查询 q 提交给传统的基于关键字匹配的搜索引擎。搜索引擎返回很多网页,其中前n个网页作为根集,记为S。S满足以下三个条件:
1、S中的网页数量比较少
2. S中的大部分网页都与查询q有关
3. S中的网页收录更权威的网页。
通过将 S 引用的页面和引用 S 的页面添加到 S 中,将 S 扩展为更大的集合 T。
以T中的Hub网页为顶点集V1,以权威网页为顶点集V2,V1中的网页到V2中的网页的超链接为边集E,二部有向图SG=(V1, V2, E 形成)。对于V1中的任意一个顶点v,用h(v)表示网页v的Hub值,对于V2中的顶点u,用a(u)表示网页的Authority值。从h(v)=a(u)=1开始,对u进行I操作修改其a(u),对v进行O操作修改其h(v),然后归一化a(u),h (v ),因此重复计算以下操作 I、O,直到 a(u)、h(v) 收敛。(证明这个算法收敛可见)
I 操作:(1) O 操作:(2)
每次迭代后,需要对 a(u)、h(v) 进行归一化:
公式(1)反映了如果一个网页被很多好的Hub指向,它的权限值会相应增加(即权限值增加为所有的已有Hub值的总和)指向它的网页)。公式(2)反映了如果一个网页指向很多好的权威页面,那么Hub值也会相应增加(即Hub值随着权威的总和而增加)链接到该网页的所有网页的值)。
与PageRank算法一样,该算法可以用矩阵的形式来描述,这里不再赘述。
HITS算法输出一组Hub值较大的网页和权限值较大的网页。
2.2.2 个热门问题
HITS算法存在以下问题:
1、在实际应用中,从S生成T的时间开销是非常昂贵的,需要对S中每个网页所收录的所有链接进行下载和分析,并排除重复链接。通常,T 比 S 大得多,从 T 生成有向图也很耗时。需要单独计算网页的A/H值,计算量大于PageRank算法。
2. 有时,一台主机A上的多个文档可能指向另一台主机B上的一个文档,这增加了A上文档的Hub值和B上文档的权限,反之亦然。HITS假设一个文档的权限值是由不同的个体组织或个人决定的,上述情况影响了A和B上文档的Hub和Authority值[7]。
3、网页中一些不相关的链接会影响A、H值的计算。在创建网页时,一些开发工具会自动在网页中添加一些链接,其中大部分与查询主题无关。同站内链接的目的是为用户提供导航帮助,与查询主题关系不大,一些商业广告、赞助和友情交流的链接也会降低HITS算法的准确性[8]。
4. HITS算法只计算主要特征向量,即只能在T集合中找到主要社区(Community),而忽略其他重要社区[12]。事实上,其他社区也可能非常重要。
5. HITS算法最大的弱点是无法处理话题漂移问题[7, 8],即Tightly-Knit Community Effect (TKC)现象[8]。如果集合 T 中有少数网页与查询主题无关,但联系紧密,那么 HITS 算法的结果可能就是这些网页,因为 HITS 只能找到主要社区,这与原创查询主题。TKC 问题在下面讨论的 SALSA 算法中得到解决。
6. 使用HITS进行狭义主题查询时,可能会出现主题泛化问题[5, 9],即扩展后引入比原主题更重要的新主题,新主题可能与原主题无关询问。概括的原因是因为网页收录指向不同主题的传出链接,而指向新主题的链接更为重要。
2.2.3 HITS 变体
HITS算法遇到的大部分问题是因为HITS是一种纯粹的基于链接分析的算法,没有考虑文本内容。在 J. Kleinberg 提出 HITS 算法之后,许多研究人员对 HITS 进行了改进,并提出了许多 HITS 变体算法。,有:
2.2.3.1Monika R. Henzinger 和 Krishna Bharat 对 HITS 的改进
对于上面提到的 HITS 遇到的第二个问题,Monika R. Henzinger 和 Krishna Bharat 在 [7] 中对其进行了改进。假设主机 A 上有 k 个网页指向主机 B 上的一个文档 d,那么这 k 个文档对 B 的权限的总贡献值为 1,每个文档贡献 1/k 而不是每个文档在 HITS 中的贡献。文档贡献1,总贡献k。同理,对于 Hub 值,假设主机 A 上的一个文档 t 指向主机 B 上的 m 个文档,那么 B 上的 m 个文档对 t 的 Hub 值贡献 1,每个文档贡献 1/m。I、O操作改为如下
我操作:
Ø 操作:
调整后的算法有效地解决了问题 2,称为 imp 算法。
在此基础上,Monika R. Henzinger 和 Krishna Bharat 还引入了传统信息检索的内容分析技术来解决问题 4 和问题 5,实际上同时解决了问题 3。具体方法如下,提取根集S中每篇文档的前1000个词,拼接为查询主题Q,文档Dj与主题Q的相似度按照如下公式计算:
, , = 查询 Q 中项目 i 的出现次数,
= 项目 i 在文档 Dj 中出现的次数,IDFi 是对 WWW 上收录项目 i 的文档数量的估计。
将S扩展到T后,计算每个文档的主题相似度,根据不同的阈值进行选择。您可以选择所有文档相似度的中值、根集文档相似度的中值和最大文档相似度。的分数,例如 1/10,作为阈值。根据不同的阈值处理,删除不满足条件的文档,然后运行imp算法计算文档的A/H值。这些算法分别称为 med、startmed 和 maxby10。
在这种改进的算法中,计算文档的相似度将花费大量时间。
2.2.3.2ARC算法
IBM Almaden 研究中心的 Clever 工程组提出了 ARC(Automatic Resource Compilation)算法,对原有的 HITS 进行了改进,结合链接的锚文本给出了网页集对应的连接矩阵的初始值,适应对不同的链接有不同的权重。
ARC算法与HITS的区别主要在于以下三点:
1、当根集S扩展为T时,HITS只扩展与根集链接路径长度为1的网页,即只扩展与S直接相邻的网页,而在ARC中,扩展的链接长度增加到2个,构造网站扩展的网页集称为Augment Set。
2.在HITS算法中,每个环节对应的矩阵值都设置为1,其实每个环节的重要性是不一样的。ARC 算法考虑链接周围的文本来确定链接的重要性。考虑链接p->q,在p中有几个链接标签,文本1,锚文本,文本2,假设查询项t在文本1,锚文本,文本2中,出现次数为n(t ),则 w(p,q)=1+n(t)。文本 1 和文本 2 的长度实验性地设置为 50 个字节 [10]。构造矩阵W,如果有网页i->j,Wi,j=w(i,j),否则Wi,j=0,H值置1,Z为W的转置矩阵,迭代执行以下三个操作:
(1)A=WH (2)H=ZA (3)归一化 A, H
3. ARC算法的目标是找出最重要的前15个网页。它只需要保持A/H的前15个值的相对大小稳定,不需要A/H的整个收敛。这样,2中的迭代次数就足够少了。在[10]中指出5次迭代就足够了,因此ARC算法计算效率高,开销主要在扩展根集上。
2.2.3.3Hub平均(Hub-Averaging-Kleinberg)算法
艾伦鲍罗丁等人。[11]指出了一个现象,即有M+1个Hub页面,M+1个权威页面,前M个Hubs指向第一个权威页面,第M+1个Hub页面指向所有M+1个权威页面。显然根据HITS算法,第一个权威页面是最重要的,拥有最高的Authority值,这就是我们想要的。但是,根据 HITS,第 M+1 个 Hub 页面的 Hub 值最高。实际上,第 M+1 个 Hub 页面不仅指向第一个权威值高的权威页面,还指向其他低权威值的页面。其 Hub 值不应高于前 M 页的 Hub 值。因此,Allan Borodin 修改了 HITS 的 O 操作:
O运算:n是(v,u)的个数
调整后,只指向高权限值页面的Hub值高于同时指向高权限值和低权限值页面的Hub值。该算法称为 Hub-Averaging-Kleinberg 算法。
2.2.3.4 阈值-克莱因伯格算法
Allan Borodin等[11]同时提出了三种阈值控制算法,即Hub阈值算法、Authority阈值算法和两者结合的全阈值算法。
在计算网页p的权限时,不考虑所有指向它的网页的贡献,而只考虑Hub值超过平均值的网页的贡献。这是 Hub 阈值方法。
权威阈值算法类似于 Hub 阈值方法。它不考虑p所指向的所有页面的权威对p的Hub值的贡献,只计算前K个权威页面对其Hub值的贡献。这是基于算法的。目标是找到最重要的K个权威网页的前提。
同时使用Authority阈值算法和Hub阈值方法的算法是全阈值算法
2.3SALSA算法
PageRank算法是基于用户对网页随机前向浏览的直观认识,HITS算法考虑了Authoritive网页与Hub网页之间的强化关系。在实际应用中,用户在大多数情况下是向前浏览网页,但也有很多情况是向后浏览网页。基于上述直观知识,R. Lempel 和 S. Moran 提出了 SALSA(Stochastic Approach for Link-Structure Analysis)算法[8],该算法考虑了用户返回浏览网页的情况,并保留了 PageRank 的随机漫游和 HITS 中的 HITS。分为Authoritive和Hub的思路,取消了Authoritive和Hub的相辅相成关系。
具体算法如下:
1.和HITS算法的第一步一样,得到根集,扩展为一组网页T,去除孤立节点。
2.从集合T构造无向图G'=(Vh, Va, E)
Vh = { sh | s∈C 和 out-degree(s) > 0 }(G' 的中心边缘)。
VA = { 萨 | s∈C 和 in-degree(s) > 0 }(G' 的权威边)。
E= { (sh , ra) |s->r in T}
这定义了 2 条链,权威链和 Hub 链。
3. 定义两条马尔可夫链的变化矩阵,也是随机矩阵。网站设计公司分别是Hub matrix H和Authority matrix A。
4、得到矩阵H和A的主特征向量,即对应马尔可夫链的静态分布。
5.中值A大的对应网页就是你要找的重要网页。
SALSA算法在HITS中没有相辅相成的迭代过程,计算量也比HITS小很多。SALSA算法只考虑直接相邻网页对自身A/H的影响,而HITS计算整个网页集T对自身AH的影响。
在实践中,SALSA 在扩展根集时会忽略许多不相关的链接,例如
1. 同一站点内的链接,因为大多数这些链接仅用于导航。
2. CGI 脚本链接。
算法 自动采集列表(一下如何免费采集1688批发网的商品数据、发货时间、是否代发 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2022-02-19 15:10
)
本文主要介绍如何使用优采云采集器的智能模式,免费提供采集阿里巴巴批发网产品批发价格、发货时间、是否代发等信息。
采集字段:
商品标题、商品链接、图片链接、标签1、标签2、标签3、价格、30天交易次数、评价、店铺
功能点目录:
如何配置 采集 字段
如何采集列出+详细信息类型页面
采集结果预览:
下面详细介绍一下采集1688批发网的商品数据如何释放。我们以“女羽绒服”为例。具体步骤如下:
第一步:下载安装优采云采集器,并注册登录
1、点击这里打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册新账号,登录优采云采集器
【温馨提示】无需注册即可直接使用本爬虫软件,但匿名账号下的任务在切换为注册用户时会丢失,建议注册后使用。
优采云采集器 是优采云 Cloud 的产物。如果您是 优采云 用户,则可以直接登录。
第 2 步:创建一个新的 采集 任务
1、复制1688羽绒服女装的网页(需要搜索结果页的网址,不是首页的网址)
2、新的智能模式采集任务
可以直接在软件上新建采集任务,也可以通过导入规则来新建任务。
第 3 步:配置 采集 规则
1、设置提取数据字段
在智能模式下,我们输入网址后,软件可以自动识别页面上的数据并生成采集结果。每种数据对应一个采集字段,我们可以右键该字段进行相关设置。包括修改字段名、增减字段、处理数据等。
在列表页面,我们需要采集产品标题、产品链接、价格和标签等信息。设置字段的效果如下:
2、使用drill-down采集函数提取详情页数据
列表页面仅显示1688批发网商品的部分信息。如果您需要产品的详细信息,我们需要右击产品链接,使用“深采集”功能跳转到采集的详细信息页面。
在详情页面,我们可以看到评论数、30天累计销量、店铺信息。我们可以点击“添加字段”来添加一个采集 字段。字段设置的效果如下:
第 4 步:设置并启动 采集 任务
1、设置采集任务
添加 采集 数据后,我们可以启动 采集 任务。点击开始采集后,会弹出任务栏。任务栏界面上有一个“更多设置”按钮。我们可以点击设置,也可以按照系统默认设置。
点击“更多设置”按钮,在弹出的操作设置页面中,我们可以设置操作设置和防屏蔽设置。系统默认设置为“2”秒请求等待时间,防屏蔽设置以系统默认设置为准,然后点击保存。
2、开始采集任务
点击“保存并开始”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中没有用到这些功能,可以直接点击“开始”运行爬虫工具。
【温馨提示】免费版可以使用非周期定时采集功能,下载图片功能免费。个人专业版及以上可使用高级计时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集之后会有提示超过。
第 5 步:导出和查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)并导出文件格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,点击“确认导出”。
【温馨提示】:所有手动导出功能均免费。个人专业版及以上可以使用发布到网站功能。
查看全部
算法 自动采集列表(一下如何免费采集1688批发网的商品数据、发货时间、是否代发
)
本文主要介绍如何使用优采云采集器的智能模式,免费提供采集阿里巴巴批发网产品批发价格、发货时间、是否代发等信息。
采集字段:
商品标题、商品链接、图片链接、标签1、标签2、标签3、价格、30天交易次数、评价、店铺
功能点目录:
如何配置 采集 字段
如何采集列出+详细信息类型页面
采集结果预览:
下面详细介绍一下采集1688批发网的商品数据如何释放。我们以“女羽绒服”为例。具体步骤如下:
第一步:下载安装优采云采集器,并注册登录
1、点击这里打开优采云采集器官网,下载安装爬虫软件工具——优采云采集器软件
2、点击注册登录,注册新账号,登录优采云采集器
【温馨提示】无需注册即可直接使用本爬虫软件,但匿名账号下的任务在切换为注册用户时会丢失,建议注册后使用。
优采云采集器 是优采云 Cloud 的产物。如果您是 优采云 用户,则可以直接登录。
第 2 步:创建一个新的 采集 任务
1、复制1688羽绒服女装的网页(需要搜索结果页的网址,不是首页的网址)
2、新的智能模式采集任务
可以直接在软件上新建采集任务,也可以通过导入规则来新建任务。
第 3 步:配置 采集 规则
1、设置提取数据字段
在智能模式下,我们输入网址后,软件可以自动识别页面上的数据并生成采集结果。每种数据对应一个采集字段,我们可以右键该字段进行相关设置。包括修改字段名、增减字段、处理数据等。
在列表页面,我们需要采集产品标题、产品链接、价格和标签等信息。设置字段的效果如下:
2、使用drill-down采集函数提取详情页数据
列表页面仅显示1688批发网商品的部分信息。如果您需要产品的详细信息,我们需要右击产品链接,使用“深采集”功能跳转到采集的详细信息页面。
在详情页面,我们可以看到评论数、30天累计销量、店铺信息。我们可以点击“添加字段”来添加一个采集 字段。字段设置的效果如下:
第 4 步:设置并启动 采集 任务
1、设置采集任务
添加 采集 数据后,我们可以启动 采集 任务。点击开始采集后,会弹出任务栏。任务栏界面上有一个“更多设置”按钮。我们可以点击设置,也可以按照系统默认设置。
点击“更多设置”按钮,在弹出的操作设置页面中,我们可以设置操作设置和防屏蔽设置。系统默认设置为“2”秒请求等待时间,防屏蔽设置以系统默认设置为准,然后点击保存。
2、开始采集任务
点击“保存并开始”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中没有用到这些功能,可以直接点击“开始”运行爬虫工具。
【温馨提示】免费版可以使用非周期定时采集功能,下载图片功能免费。个人专业版及以上可使用高级计时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集之后会有提示超过。
第 5 步:导出和查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)并导出文件格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,点击“确认导出”。
【温馨提示】:所有手动导出功能均免费。个人专业版及以上可以使用发布到网站功能。
算法 自动采集列表(算法自动采集列表,但设置单个url只能获取指定类型的url)
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-18 15:01
算法自动采集列表,但设置单个url只能获取指定类型的url,seo问题,自建站无非是让搜索引擎给你多发一些外链而已。要用爬虫就用web蜘蛛程序,前端用ajax自动生成。没有爬虫自己根据网站的实际需求手工爬。本人亲测dnspod反爬虫策略没用,很简单的随便拿一个固定ip(手动设置的)都可以拿到返回页面的url,dnspod的那个router照样反爬。
不支持爬虫应该是一个非常重要的原因吧,bing最初也想这么做,后来没这么做成,原因可能是这样比较难管理、造成麻烦,而且对于搜索引擎公司也有风险,用户体验不是所有需求都能满足的。
一是需要避免数据混乱,这些会提示二是利用ajax异步请求达到同一页面抓取多个页面的需求,但是这样的抓取优势就不大了,因为浏览器会判断为同一页面抓取三是的移动端普及,
dnspod的反爬虫是一个issue=raw+position这个问题是对于一个普通网站来说,他也是有它的需求,所以比较多见的有:比如url变化一直会加重http请求的负担。爬虫抓取页面速度是十分慢的,不同平台抓取数据的速度可能会有差异,影响后续的运营。手机收听返回内容时不会向下兼容等。
现在搜索引擎用户基数大,数据来源也多样化,不同的搜索引擎分发算法也不尽相同,或多或少都会存在问题,而爬虫就会被爬虫。比如,百度的爬虫,你输入指定网址,点击搜索后,随之返回的结果只能够抓取你指定url下的内容,看起来就是当事人没有意识到bug,也没有想到那个网站可能需要被ban;而谷歌的爬虫抓取的网站必须要满足这个前提,必须是一个过滤结果,过滤你要的搜索指向的结果才会返回给你。
然后小米的也是发现了这个bug,于是小米以及周鸿祎亲自出面,想解决问题,但是这个问题,真不是bug,这个问题很严重,像是规则漏洞,而且很多人都遇到,只要有用户量就会出现这种情况。但是换句话说,即使发现了这个bug,小米和周鸿祎都没有想到应该如何去应对这个bug,而是去找大网站去协商,最后把bug交给bat去解决,那个bug小米就真不会想到了,但是别人又不会上来就乱来,所以我觉得这是个问题。 查看全部
算法 自动采集列表(算法自动采集列表,但设置单个url只能获取指定类型的url)
算法自动采集列表,但设置单个url只能获取指定类型的url,seo问题,自建站无非是让搜索引擎给你多发一些外链而已。要用爬虫就用web蜘蛛程序,前端用ajax自动生成。没有爬虫自己根据网站的实际需求手工爬。本人亲测dnspod反爬虫策略没用,很简单的随便拿一个固定ip(手动设置的)都可以拿到返回页面的url,dnspod的那个router照样反爬。
不支持爬虫应该是一个非常重要的原因吧,bing最初也想这么做,后来没这么做成,原因可能是这样比较难管理、造成麻烦,而且对于搜索引擎公司也有风险,用户体验不是所有需求都能满足的。
一是需要避免数据混乱,这些会提示二是利用ajax异步请求达到同一页面抓取多个页面的需求,但是这样的抓取优势就不大了,因为浏览器会判断为同一页面抓取三是的移动端普及,
dnspod的反爬虫是一个issue=raw+position这个问题是对于一个普通网站来说,他也是有它的需求,所以比较多见的有:比如url变化一直会加重http请求的负担。爬虫抓取页面速度是十分慢的,不同平台抓取数据的速度可能会有差异,影响后续的运营。手机收听返回内容时不会向下兼容等。
现在搜索引擎用户基数大,数据来源也多样化,不同的搜索引擎分发算法也不尽相同,或多或少都会存在问题,而爬虫就会被爬虫。比如,百度的爬虫,你输入指定网址,点击搜索后,随之返回的结果只能够抓取你指定url下的内容,看起来就是当事人没有意识到bug,也没有想到那个网站可能需要被ban;而谷歌的爬虫抓取的网站必须要满足这个前提,必须是一个过滤结果,过滤你要的搜索指向的结果才会返回给你。
然后小米的也是发现了这个bug,于是小米以及周鸿祎亲自出面,想解决问题,但是这个问题,真不是bug,这个问题很严重,像是规则漏洞,而且很多人都遇到,只要有用户量就会出现这种情况。但是换句话说,即使发现了这个bug,小米和周鸿祎都没有想到应该如何去应对这个bug,而是去找大网站去协商,最后把bug交给bat去解决,那个bug小米就真不会想到了,但是别人又不会上来就乱来,所以我觉得这是个问题。
算法 自动采集列表( 我把微博营销案例全部爬虫到一个了Excel表格里)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-02-16 14:01
我把微博营销案例全部爬虫到一个了Excel表格里)
今天的目标:
让读者知道什么?
程序员最难学的不是java或者c++,而是社交,俗称:调情。
在社交方面,我被认为是程序员中最好的程序员。
比如之前做过《海报生成表格,把我从叔叔变成小哥》,接触到了运营社区的小姐姐。
这已经是最后一个月了,这个月我又一次投入到爬虫的技术研究中。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹妹。. .
结果。. .
我做到了!!!
我把所有的微博营销案例都爬到了 Excel 表格中。
7-0多份运营分析报告,一键下载
网站中的案例需要一一下载↑
对于表中的案例,哪个更喜欢哪个下载↑
经营社区的女孩们都快疯了!
秋叶Excel抖音女主:小美↑
微博手绘大V博主,与江江↑
社区运营老司机:颜敏姐↑
让我告诉你,如果我两年前知道爬行动物,现在我会和谁和我的室友在一起?!
1-什么是爬行动物
Crawler,即网络爬虫。是指按照一定的规则自动抓取网络上的数据。
比如前面自动抓取“社会营销案例库”的案例。
想象一下,如果你手动浏览页面下载这些案例,过程会是这样的:
1- 打开案例库页面
2- 点击案例进入详情页面
3- 点击下载案例pdf
4-回到案例库页面,点击下一个案例,重复前面3个步骤。
如果要下载所有pdf案例,需要安排专人反复机械下载。显然,这个人的价值很低。
爬虫就是取代这种机械重复的、低价值的数据采集动作,利用程序或代码自动、批量完成数据采集。
爬行动物的好处
简单总结一下,爬虫的好处主要体现在两个方面:
1-自动抓取,解放人力提高效率
机械的、低价值的工作最好由机器完成。
2-数据分析,排长队获取优质内容
与人工浏览数据不同,爬虫可以将数据汇总整合成一张数据表,方便我们后期进行数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有观看次数和下载次数。如果要按查看次数排序,优先考虑查看次数最多的案例,将数据爬取到Excel表格中,使用排序功能轻松浏览。
爬行动物的案例
可以抓取任何数据。
一旦你掌握了爬虫的技能,你可以做很多事情。
Excelhome的帖子爬取
我教 Excel,Excelhome 论坛是一个巨大的财富。
一个一个看太费力了,爬了1.40000个帖子,挑了浏览量最多的一个。
窗帘选择文章爬取
窗帘是整理轮廓的好工具。很多名人用它来写读书笔记,不用看全书也能学到重点。
没时间一一浏览窗帘文章的选集,爬取所有选集,整理一下自己的知识提纲。
曹江的公众号文章被爬取
我很喜欢曹将军。他拥有我这个时代所缺乏的逻辑、归纳和表达能力,以及文章文章的精髓。
公众号太多,手机看书容易分心?爬入 Excel,并开始查看读数最高的行。
此外,还有抖音广播数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析为网络带来更多乐趣。
2-易于爬行,锋利的工具
说到爬虫,大部分人都会想到编程计数、python、数据库、美观、html结构等等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
以下是我爬取数据时使用过的软件,推荐给大家:
1- 优采云采集器
简单易学,通过可视化界面即可采集数据和向导模式,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优势:
1-使用过程简单,上手很好。
缺点:
1- 进口数量限制。采集 中的数据只能由非会员导出,限制为 1000。
2- 导出格式限制。非会员只能导出txt文本格式。
2- 优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,发现优采云。
优势:
1- 采集 功能更强大,可以自定义采集 进程。
2-导出格式和数据量没有限制。
缺点:
1-过程有点复杂,初学者学习难度较大。
3- 优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键式采集即可。自动识别列表、表格、链接、图片、价格、电子邮件等。
这是我现在使用的 采集 软件。可以说是中和了前两个采集器的优缺点,体验更好。
优势:
1-自动识别页面信息,轻松上手
2-导出格式和数据量没有限制
目前还没有发现缺点。
3- 爬虫操作流程
注意,注意,接下来就是动手部分了。
我们以“窗帘选择文章”为例,用“优采云采集器”体验爬虫的乐趣。
采集之后的效果如下:
1- 复制 采集 的链接
打开窗帘官网,点击“精选”进入选中页面文章。
复制特色页面的 URL:
2- 优采云采集数据
1- 登录“优采云采集器”官网,下载安装采集器。
2- 打开采集器后,点击“智能模式”中的“开始采集”创建一个新的智能采集。
3-粘贴窗帘选择的网址,点击立即创建
在这个过程中,采集器会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析识别↑
页面识别完成↑
4- 点击“开始采集”->“开始”开始爬虫之旅。
3- 采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
或者等待数据抓取完成,在弹出的对话框中点击“导出数据”。
导出格式,选择 Excel,然后导出。
4- 使用 HYPERLINK 功能添加超链接
打开导出的表,在I列添加HYPERLINK公式,添加超链接,点击打开对应的文章。
公式如下:
=HYPERLINK(B2,"点击查看")
到这里,你的第一次爬虫之旅圆满结束!
4-总结
爬虫就像在 VBA 中录制宏,录制重复动作而不是手动重复操作。
今天看到的只是简单的数据采集,爬虫的话题还是很多的,很深入的内容。例如:
1- 身份验证。抓取页面需要登录。
2-浏览器验证。比如公众号文章只能获取微信的阅读次数。
3-参数验证(验证码)。该页面需要验证码。
4-请求频率。例如页面访问时间不能小于10秒
5- 数据处理。爬取的数据需要提取其中的数字、英文等内容。
了解了爬取的流程后,现在最想爬取哪些数据?
我是会设计表格的Excel老师拉小登
如果你喜欢这个文章,给我一个优质的三行,今天就这样,下课吧! 查看全部
算法 自动采集列表(
我把微博营销案例全部爬虫到一个了Excel表格里)
今天的目标:
让读者知道什么?
程序员最难学的不是java或者c++,而是社交,俗称:调情。
在社交方面,我被认为是程序员中最好的程序员。
比如之前做过《海报生成表格,把我从叔叔变成小哥》,接触到了运营社区的小姐姐。
这已经是最后一个月了,这个月我又一次投入到爬虫的技术研究中。
技术满足的反面是孤独和空虚。
于是,我决定再次用爬虫来逗妹妹。. .
结果。. .
我做到了!!!
我把所有的微博营销案例都爬到了 Excel 表格中。
7-0多份运营分析报告,一键下载
网站中的案例需要一一下载↑
对于表中的案例,哪个更喜欢哪个下载↑
经营社区的女孩们都快疯了!
秋叶Excel抖音女主:小美↑
微博手绘大V博主,与江江↑
社区运营老司机:颜敏姐↑
让我告诉你,如果我两年前知道爬行动物,现在我会和谁和我的室友在一起?!
1-什么是爬行动物
Crawler,即网络爬虫。是指按照一定的规则自动抓取网络上的数据。
比如前面自动抓取“社会营销案例库”的案例。
想象一下,如果你手动浏览页面下载这些案例,过程会是这样的:
1- 打开案例库页面
2- 点击案例进入详情页面
3- 点击下载案例pdf
4-回到案例库页面,点击下一个案例,重复前面3个步骤。
如果要下载所有pdf案例,需要安排专人反复机械下载。显然,这个人的价值很低。
爬虫就是取代这种机械重复的、低价值的数据采集动作,利用程序或代码自动、批量完成数据采集。
爬行动物的好处
简单总结一下,爬虫的好处主要体现在两个方面:
1-自动抓取,解放人力提高效率
机械的、低价值的工作最好由机器完成。
2-数据分析,排长队获取优质内容
与人工浏览数据不同,爬虫可以将数据汇总整合成一张数据表,方便我们后期进行数据统计和数据分析。
例如,在“社交营销案例库”中,每个案例都有观看次数和下载次数。如果要按查看次数排序,优先考虑查看次数最多的案例,将数据爬取到Excel表格中,使用排序功能轻松浏览。
爬行动物的案例
可以抓取任何数据。
一旦你掌握了爬虫的技能,你可以做很多事情。
Excelhome的帖子爬取
我教 Excel,Excelhome 论坛是一个巨大的财富。
一个一个看太费力了,爬了1.40000个帖子,挑了浏览量最多的一个。
窗帘选择文章爬取
窗帘是整理轮廓的好工具。很多名人用它来写读书笔记,不用看全书也能学到重点。
没时间一一浏览窗帘文章的选集,爬取所有选集,整理一下自己的知识提纲。
曹江的公众号文章被爬取
我很喜欢曹将军。他拥有我这个时代所缺乏的逻辑、归纳和表达能力,以及文章文章的精髓。
公众号太多,手机看书容易分心?爬入 Excel,并开始查看读数最高的行。
此外,还有抖音广播数据、公众号阅读、评论数据、B站弹幕数据、网易云评论数据。
爬虫+数据分析为网络带来更多乐趣。
2-易于爬行,锋利的工具
说到爬虫,大部分人都会想到编程计数、python、数据库、美观、html结构等等,让人望而生畏。
其实基础爬虫很简单,借助一些采集软件,一键即可轻松完成。
常用爬虫软件
以下是我爬取数据时使用过的软件,推荐给大家:
1- 优采云采集器
简单易学,通过可视化界面即可采集数据和向导模式,鼠标点击,用户无需任何技术基础,输入网址,一键提取数据。
这是我接触的第一个爬虫软件,
优势:
1-使用过程简单,上手很好。
缺点:
1- 进口数量限制。采集 中的数据只能由非会员导出,限制为 1000。
2- 导出格式限制。非会员只能导出txt文本格式。
2- 优采云
无需学习爬虫编程技术,简单三步即可轻松抓取网页数据,支持多种格式一键导出,快速导入数据库
在优采云不能满足我的需求后,我开始尝试更专业的采集软件,发现优采云。
优势:
1- 采集 功能更强大,可以自定义采集 进程。
2-导出格式和数据量没有限制。
缺点:
1-过程有点复杂,初学者学习难度较大。
3- 优采云采集器(推荐)
智能识别数据,小白神器
基于人工智能算法,只需输入网址即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键式采集即可。自动识别列表、表格、链接、图片、价格、电子邮件等。
这是我现在使用的 采集 软件。可以说是中和了前两个采集器的优缺点,体验更好。
优势:
1-自动识别页面信息,轻松上手
2-导出格式和数据量没有限制
目前还没有发现缺点。
3- 爬虫操作流程
注意,注意,接下来就是动手部分了。
我们以“窗帘选择文章”为例,用“优采云采集器”体验爬虫的乐趣。
采集之后的效果如下:
1- 复制 采集 的链接
打开窗帘官网,点击“精选”进入选中页面文章。
复制特色页面的 URL:
2- 优采云采集数据
1- 登录“优采云采集器”官网,下载安装采集器。
2- 打开采集器后,点击“智能模式”中的“开始采集”创建一个新的智能采集。
3-粘贴窗帘选择的网址,点击立即创建
在这个过程中,采集器会自动识别页面上的列表和数据内容。整个过程由AI算法自动完成,等待识别完成。
页面分析识别↑
页面识别完成↑
4- 点击“开始采集”->“开始”开始爬虫之旅。
3- 采集数据导出
在数据爬取过程中,您可以点击“停止”结束数据爬取。
或者等待数据抓取完成,在弹出的对话框中点击“导出数据”。
导出格式,选择 Excel,然后导出。
4- 使用 HYPERLINK 功能添加超链接
打开导出的表,在I列添加HYPERLINK公式,添加超链接,点击打开对应的文章。
公式如下:
=HYPERLINK(B2,"点击查看")
到这里,你的第一次爬虫之旅圆满结束!
4-总结
爬虫就像在 VBA 中录制宏,录制重复动作而不是手动重复操作。
今天看到的只是简单的数据采集,爬虫的话题还是很多的,很深入的内容。例如:
1- 身份验证。抓取页面需要登录。
2-浏览器验证。比如公众号文章只能获取微信的阅读次数。
3-参数验证(验证码)。该页面需要验证码。
4-请求频率。例如页面访问时间不能小于10秒
5- 数据处理。爬取的数据需要提取其中的数字、英文等内容。
了解了爬取的流程后,现在最想爬取哪些数据?
我是会设计表格的Excel老师拉小登
如果你喜欢这个文章,给我一个优质的三行,今天就这样,下课吧!
算法 自动采集列表(本文微言导论:探索推荐引擎内部的秘密(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-12 08:14
来源:结构与算法之道
介绍
昨天看了几个关键词:语义分析、协同过滤、智能推荐,想想就兴奋。于是从昨天下午到今天凌晨3点,我研究了推荐引擎,做了一个初步的了解。以后我会慢慢深入的仔细研究(以后的工作也跟这个有关)。当然,这篇文章会逐渐增加和完善。
本文是推荐引擎初步介绍的入门文章,将省略大部分具体细节,重点用最简单的语言简单介绍推荐引擎的工作原理及其相关算法思想,并为了强调通俗易懂,部分引述来自我1月7日在微博上发表的文字(特地整理一下,方便以后随时阅读),尽量让这篇文章尽量简短. 不过,恰恰相反,文章后续的补充和改进,越写越长。
同时,本文所有相关算法,后续会一一详述文章。本文只求简要介绍,以后力求具体。如果您有任何问题,请随时给我任何建议或批评。谢谢。
1、推荐引擎原理
推荐引擎尽最大努力采集尽可能多的用户信息和行为。所谓广布网,勤钓,再“特爱一个特别的你”,最后在相似的基础上继续“强大”。原理如下图所示(该图引自本文的参考资料之一:Exploring the secrets inside the Recommendation engine):
2、推荐引擎的分类
推荐引擎根据不同的标准分类如下:
根据是否为不同用户推荐不同的数据,根据公众行为划分热门项目(网站管理员自己推荐,或者根据系统所有用户的反馈统计,计算当前热门项目) ,以及个性化的推荐引擎(帮助你找到志同道合的朋友,然后在此基础上实施推荐);物品具有相同的关键词和Tag,不考虑人为因素),以及基于协同过滤的推荐(寻找物品、内容或用户的相关推荐,分为三个子类,下文解释);根据构建方式,分为物品和用户本身(user-item二维矩阵描述用户偏好,聚类算法),
关于上面第二类基于协同过滤的推荐(2、根据其数据来源):随着Web2.0的发展,网站更加促进用户参与和用户贡献,所以基于关于协同过滤的过滤推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者发现用户的相关性,然后根据这些相关性进行推荐。
基于协同过滤的推荐分为三个子类:
基于用户的推荐(通过共同的品味和喜好找到相似的邻居用户,K-neighbor算法,你的朋友喜欢,你可能喜欢),基于物品的推荐(找到物品之间的相似性,推荐相似的物品,你喜欢) Item A 和 C 与 A 类似,也可能像 C),基于模型的推荐(基于样本用户偏好信息构建推荐模型,然后根据实时用户偏好信息预测推荐)。
我们看到这种协同过滤算法最大限度地利用了用户之间或物品之间的相似相关性,然后根据这些信息实现推荐。这种协同过滤也在下面详细描述。
但是,在一般实践中,我们通常将推荐引擎分为两类:
3、新浪微博推荐机制
新浪微博推荐好友机制中:1、我和A不是朋友,但是我的很多朋友都是A的朋友,也就是说我和A有很多共同的朋友,那么系统会推荐A给我(新浪称其为共同的朋友);2、我关注的很多人都关注了B,所以系统推测我可能喜欢B,所以也会推荐B给我(新浪称其为间接关注)。
但在新浪的实际运营中,这两种方式会混用。比如我关注的人中,关注B的人很多,但其实关注B的一些人也是我的朋友。以上推荐方法统称为基于相似用户的协同过滤推荐(无非是发现:用户之间的密不可分的联系,要么来自你的朋友,要么来自你关注的人)。
当然,还有另外一种推荐,比如热门用户推荐,就是上面提到的基于热门行为的推荐,也就是听从别人的意见。系统推测每个人都喜欢它,也许你也会喜欢。如果大家都知道姚晨的新浪微博粉丝数第一,就会争先恐后地关注,最终粉丝数会越来越多。推荐的两种方法如下图所示:
然而,上述的推荐方法,无论是基于用户还是基于流行行为,都没有真正找到用户之间的共同兴趣、喜好和品味,因为很多情况下,朋友的朋友可能不是你自己。朋友,有些人凌驾于世界之上,你们都追求什么,我不屑一顾。因此,从分析用户发布的微博内容入手,找到他们共同的关注点和兴趣点才是王道。当然,新浪微博最近让用户选择给自己的微博内容打标签,以帮助日后在微博内容中找到相关用户的常用标签,关键词,这种推荐方式是基于微博内容分析'的推荐。如下所示:
唯一的问题是,谁会不遗余力地发一条微博,它会添加什么标签?因此,新浪微博不得不努力寻找另一种方式来更好地分析微博的内容。否则,系统会彻底扫描海量用户的微博内容,恐怕承受不起,也承受不起。
不过我个人认为可以从微博关键词(标签标签云)和每个用户自己标签的标签入手(标签越常见,可以定义的相似用户越多),如图下图左右部分:
也就是说,通过普通朋友和间接关注的人来定义相似用户是不可靠的。只有通过微博内容分析,才能找到相似的用户。经过对标签云的分析,无疑比现有的推荐朋友的方法(通过普通朋友和间接关注者定义相似用户)找到相同或相似的标签云找到相似用户更可靠。
3.1、多种推荐方式组合
当前网站的推荐往往不是简单地使用某种推荐机制和策略,而是往往结合多种方法来达到更好的推荐效果。
例如,亚马逊除了基于用户的推荐外,还使用基于内容的推荐(关键词和Tag相同的商品):比如新品推荐;基于项目的协同过滤推荐(喜欢)。A、C 与 A 类似,也可能与 C) 类似:如捆绑销售和他人购买/浏览的商品。
简而言之,多种推荐方法和权重的组合(使用线性公式)根据一定的权重组合了几种不同的推荐。具体权重的值需要在测试数据集上反复测试,才能达到最好的推荐效果。)、切换、分区、分层等。但是,无论采用哪种推荐方法,一般都被上述推荐方法所覆盖。
4、协同过滤推荐
协同过滤是利用集体智慧的典型方式。要了解什么是协同过滤 (CF),首先要考虑一个简单的问题。如果你现在想看电影,但不知道该看哪一部,你会怎么做?大多数人会问广义的朋友或邻居,看看最近推荐了哪些好电影,而我们一般更喜欢从口味相似的朋友那里获得推荐。这就是协同过滤的核心思想。从下图中你能看出多少信息?
4.1、 协同过滤推荐步骤
做协同过滤推荐,一般做以下步骤:
1)要进行协同过滤,采集用户偏好是关键。可以通过评分等用户行为判断为相似用户(比如不同用户对不同作品的评分不同,评分接近意味着品味和品味相近,可以判断为相似用户)、投票、转发、采集、书签、标签、评论、点击流、页面停留时间、是否购买等。如下面第2点所述:所有这些信息都可以数字化并表示为二维矩阵。
2)采集到用户行为数据后,接下来需要对数据进行去噪和归一化处理(得到用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,该值是用户对项目的偏好,通常是 [0,1] 或 [-1,1] 的浮点值)。下面简单介绍降噪和归一化操作:
3)如何找到相似的用户和物品?就是计算相似用户或相似物品的相似度。
4)计算相似度的方法有很多种,但都是基于向量Vector。其实就是计算两个向量之间的距离。距离越近,相似度越大。在推荐中,在user-item偏好的二维矩阵下,我们以一个或多个用户对两个item的偏好为向量,计算两个item之间的相似度,或者两个用户对一个或多个的偏好几个项目被用作一个向量来计算两个用户之间的相似度。
相似度计算算法可用于计算用户或物品的相似度。以物品相似度计算(Item Similarity Computation)为列,共同点是从打分矩阵中为两个物品i和j选取共同打分用户,然后对这个共同用户的打分向量进行相似度计算. si,j,如下图,行代表用户,列代表物品(注意从i,j向量中抽取常用评论,形成一对向量计算相似度) :
因此,很简单的找到物品之间的相似度,用户不变,找到多个用户对物品的评分;求用户之间的相似度,item不变,求用户对某些item的评分。
5)计算出来的两个相似度将作为两个基于用户和物品的协同过滤推荐。
计算相似度的常用方法有:欧式距离、皮尔逊相关系数(比如两个用户对多部电影的评分,使用皮尔逊相关系数等相关计算方法,可以判断他们的口味和喜好是否一致)、余弦相似度,谷本系数。下面简单介绍一下欧几里得距离和皮尔逊相关系数:
可以看出,当n=2时,欧几里得距离就是平面上两点之间的距离。当用欧式距离表示相似度时,一般采用如下公式进行转换:距离越小,相似度越大(同时避免除数为0):
其中,Ru,i 是用户 u 对 item i 的评分,对应的带有横条的 item 是这个用户集 U 对 item i 的评分。
6)类似的邻居计算。邻居分为两类: 1、 固定数量的邻居K-neighborhoods(或Fix-sizeneighborhoods),不管邻居的“距离”如何,只取最近的K作为他们的邻居,如部分所示下图A;2、基于相似度阈值的邻居,以当前点为中心,距离为K的区域内的所有点都被视为当前点的邻居,如下图B部分所示。
让我们介绍一下 K-Nearest Neighbor (KNN) 分类算法:这是一种理论上成熟的方法,也是最简单的机器学习算法之一。该方法的思想是:如果特征空间中k个最相似的样本(即特征空间中的最近邻)中的大部分属于某个类别,则该样本也属于该类别。
7)4)计算的基于用户的CF(基于用户推荐:通过共同的品味和喜好找到相似的邻居用户,K-neighbor算法,如果你的朋友喜欢,你可能也会喜欢),基于item的CF(基于item的推荐:查找item之间的相似度,推荐相似的item,如果你喜欢item A,如果C和A相似,那么你可能也喜欢C)。
4.2、基于用户相似度和物品相似度
上一节3.1中的三个相似度公式都是基于物品相似度的场景,但实际上用户相似度和物品相似度计算的一个基本区别是,用户相似度是基于评分矩阵中的行向量相似度求解,项目相似度计算公式是根据评分矩阵中的列向量相似度计算的。那么这三个公式就可以分别套用了,如下图所示:
(其中,0表示未评级)
一千字不如一个例子。我们来看一个基于用户相似度计算的具体例子。
假设我们有一组用户,他们表现出对一组书籍的偏好。用户对一本书的偏好越高,它的评分就越高。让我们将其表示为一个矩阵,其中行代表用户,列代表书籍。
如下图所示,所有评分的范围从 1 到 5,其中 5 是最喜欢的。第一个用户(行 1) 为第一本书评分(列 1) 为 4,空单元格表示用户没有对该书评分。
使用基于用户的协同过滤方法,我们首先要做的是根据用户对图书的评价来计算用户之间的相似度。
让我们从单个用户的角度考虑这一点,查看图 1 中的第一行。为此,通常将每个用户表示为收录用户偏好的向量(或数组)。它比使用不同的相似性度量更直接。
在这个例子中,我们将使用余弦相似度来计算用户之间的相似度。
当我们将第一个用户与其他五个用户进行比较时,我们可以直观地看到他与其他用户的相似程度。
对于大多数相似度度量,向量之间的相似度越高,它们之间的相似度就越高。在这个例子中,第一个用户二、,第三个用户非常相似,有两本书相同,和第五个用户四、相似度较低,只有一本书相同,并且完全与上一个用户不同,因为没有共同的书。
更一般地,我们可以计算每个用户的相似度,并在相似度矩阵中表示它们。这是一个对称矩阵,单元格的背景颜色表示用户的相似程度,较深的红色表示他们之间的相似程度更高。
因此,我们找到与第一个用户最相似的第二个用户,删除该用户已经评分的书籍,对最相似的用户正在阅读的书籍进行加权,并计算总和。
在这种情况下,我们计算n=2,也就是说为了生成推荐,我们需要找到与目标用户最相似的两个用户,这两个用户分别是第二个和第三个用户,然后是第一个用户已经给第一和第五本书评分了,所以推荐的书是第三本书(4.5分),第四本书(3分)。
此外,何时使用 item-base 以及何时使用 user-base: ?
一般来说,如果item的数量不大,比如不超过100,000,并且没有明显增长,那么就使用item-based。为什么?正如@wuzh670所说,如果item数量少+没有明显增加,说明item之间的关系在一段时间内比较稳定(相对于用户之间的关系),对实时更新item的需求- 相似度低很多,降低了推荐系统的效率。改进很多,所以使用基于项目会更明智。
反之,当item数量较多时,推荐使用user-base。当然,在实践中的具体情况将根据具体情况进行分析。如下图所示(摘自向亮的《推荐系统实践》一书):
5、聚类算法
聚类 聚类,通俗地说,就是所谓的“物聚在一起,人分群”。聚类是数据挖掘的经典问题。其目的是将数据划分为多个簇,同一簇中的对象具有高度的相似性,而不同簇中的对象则不同。较大。
5.1、K-Means 聚类算法
K-Means 聚类算法与处理混合正态分布的期望最大化算法非常相似,因为它们都试图在数据中找到自然聚类的中心。该算法假设对象属性来自空间向量,目标是最小化每个组内的均方误差之和。
K-means 聚类算法首先随机确定 K 个中心位置(空间中代表聚类中心的点),然后将每个数据项分配到最近的中心点。分配完成后,集群中心将移动到分配给集群的所有节点的平均位置,然后整个分配过程重新开始。重复这个过程,直到分配过程不再改变。下图是一个有两个聚类的 K-means 聚类过程:
以下代码显示了此 K-means 聚类算法的 python 实现:
//K-均值聚类算法
import random
def kcluster(rows,distance=pearson,k=4):
# 确定每个点的最小值和最大值
ranges=[(min([row[i] for row in rows]),max([row[i] for row in rows]))
for i in range(len(rows[0]))]
# 随机创建k个中心点
clusters=[[random.random()*(ranges[i][1]-ranges[i][0])+ranges[i][0]
for i in range(len(rows[0]))] for j in range(k)]
lastmatches=None
for t in range(100):
print 'Iteration %d' % t
bestmatches=[[] for i in range(k)]
# 在每一行中寻找距离最近的中心点
for j in range(len(rows)):
row=rows[j]
bestmatch=0
for i in range(k):
d=distance(clusters[i],row)
if d0:
for rowid in bestmatches[i]:
for m in range(len(rows[rowid])):
avgs[m]+=rows[rowid][m]
for j in range(len(avgs)):
avgs[j]/=len(bestmatches[i])
clusters[i]=avgs
# 返回k组序列,其中每个序列代表一个聚类
return bestmatches
k-Means 是机器学习领域的一种无监督学习。下面简单介绍监督学习和无监督学习:
5.2、冠层聚类算法
Canopy聚类算法的基本原理是:首先,利用低成本的近似距离计算方法将数据高效地划分为多个组,这里称为Canopy,我们将其翻译为“canopy”。重叠部分;然后使用严格的距离计算方法,准确计算出同一个 Canopy 中的点,并将它们分配到最合适的簇中。Canopy聚类算法常用于K-means聚类算法的预处理,寻找合适的k值和聚类中心。
5.3、模糊K-Means聚类算法
模糊 K-means 聚类算法是 K-means 聚类的扩展。它的基本原理和K-means一样,只是它的聚类结果允许对象属于多个聚类,也就是说:属于我们前面介绍过的重叠。聚类算法。为了深入理解Fuzzy K-means和K-means的区别,这里我们得花点时间来理解一个概念:Fuzzziness Factor。
与K-means聚类原理类似,模糊K-means也在待聚类对象的向量集上循环,但它并不将向量分配给最近的簇,而是计算向量与每个簇的相关性(协会)。假设有一个向量v,有k个簇,v到k个簇中心的距离分别为d1,d2...dk,那么V到第一个簇的相关性u1可以通过下式计算:
计算 v 与其他集群的相关性只需将 d1 替换为相应的距离。由上式可知,当m近似为2时,相关性近似为1;当m近似为1时,相关性近似为到簇的距离,所以m的取值为(1,2)区间内,m越大,模糊程度越大,m为模糊我们刚才提到的参数。
其余的聚类算法本文将不做介绍。冷启动、数据稀疏性、可扩展性、可移植性、可解释性、多样性以及推荐信息的价值等问题将在后面讨论。
6、分类算法
其次,还有很多分类算法。本文介绍了决策树学习和贝叶斯定理。
6.1、决策树学习
让我们直奔主题。所谓决策树,顾名思义,就是一种树,是建立在战略选择基础上的树。
在机器学习中,决策树是一种预测模型;它表示对象属性和对象值之间的映射关系。树中的每个节点代表一个对象,每个分支路径代表一个可能的属性值,每个叶节点对应于从根节点到叶节点的路径所代表的对象。价值。决策树只有一个输出。如果你想有多个输出,你可以建立一个独立的决策树来处理不同的输出。
从数据中生成决策树的机器学习技术称为决策树学习,通常称为决策树。
理论太抽象了。这里有两个容易理解的例子:
第一个例子:通俗地说,决策树分类的思想类似于找对象。现在想象一个女孩的妈妈想给女孩介绍一个男朋友,于是就有了如下对话:
女儿:你几岁?
母亲:26。
女儿:帅吗?
妈妈:很帅。
女儿:收入高吗?
妈妈:不是很高,中等状态。
女儿:是公务员吗?
妈妈:是的,我在税务局工作。
女儿:好的,我去看你。
这个女孩的决策过程是典型的分类树决策。相当于把男人按年龄、外貌、收入和是否公务员分为两类:看和看。假设女孩对男人的要求是:30岁以下,中等相貌,高收入人士或中等收入以上的公务员,那么女孩的决策逻辑可以表示为:数字:
也就是说,决策树的简单策略就是,就像在公司招聘面试的过程中筛选一个人的简历,如果你的条件比较好,比如清华大学的博士,那么事不宜迟,直接致电面试,如果你毕业于非重点大学,但实际项目经验丰富,那么你也应该考虑要求面试,也就是所谓的具体分析和决策。
第二个例子来自 Tom M. Mitchell 的《机器学习》一书:
王的目的是通过下周的天气预报了解人们什么时候打高尔夫球。他明白人们决定是否参加比赛的原因取决于天气。天气条件晴朗、多云和下雨;华氏气温;相对湿度百分比;有风或缺席。这样,我们就可以构造如下决策树(根据天气的分类判断今天是否适合打网球):
上面的决策树对应如下表达式:(Outlook=Sunny ^Humiditywind gain 0.048。说白了,在周六早上是否适合打网球的问题上,最好取湿度而不是风作为分类属性,决策树来自哪里。
ID3算法决策树的形成
OK,下图是ID3算法第一步之后形成的部分决策树。综合起来,比较容易理解。1、阴的例子一定是正的,所以是叶子节点,永远是;2、ID3没有回溯,局部最优,不是全局最优,还有一个post-tree pruning决策树。下图是经过ID3算法第一步后形成的部分决策树:
6.2、贝叶斯分类基础:贝叶斯定理
贝叶斯定理:知道一个条件概率,如何得到两个事件交换的概率,即在已知P(A|B)的情况下如何得到P(B|A)。以下是条件概率的解释:
在事件 B 已经发生的前提下,事件 A 发生的概率称为事件 B 发生下事件 A 的条件概率。其基本解公式为:
.
贝叶斯定理之所以有用,是因为我们在生活中经常会遇到这样的情况:我们可以很容易地直接得到 P(A|B),P(B|A) 很难直接得到,但是我们更关心 P(B|A) , 贝叶斯定理为我们从 P(A|B) 得到 P(B|A) 开辟了道路。
下面直接给出贝叶斯定理,无需证明(公式已被网友指出,待后续验证修正):
7、推荐的实例扩展
7.1、阅读推荐 查看全部
算法 自动采集列表(本文微言导论:探索推荐引擎内部的秘密(组图))
来源:结构与算法之道
介绍
昨天看了几个关键词:语义分析、协同过滤、智能推荐,想想就兴奋。于是从昨天下午到今天凌晨3点,我研究了推荐引擎,做了一个初步的了解。以后我会慢慢深入的仔细研究(以后的工作也跟这个有关)。当然,这篇文章会逐渐增加和完善。
本文是推荐引擎初步介绍的入门文章,将省略大部分具体细节,重点用最简单的语言简单介绍推荐引擎的工作原理及其相关算法思想,并为了强调通俗易懂,部分引述来自我1月7日在微博上发表的文字(特地整理一下,方便以后随时阅读),尽量让这篇文章尽量简短. 不过,恰恰相反,文章后续的补充和改进,越写越长。
同时,本文所有相关算法,后续会一一详述文章。本文只求简要介绍,以后力求具体。如果您有任何问题,请随时给我任何建议或批评。谢谢。
1、推荐引擎原理
推荐引擎尽最大努力采集尽可能多的用户信息和行为。所谓广布网,勤钓,再“特爱一个特别的你”,最后在相似的基础上继续“强大”。原理如下图所示(该图引自本文的参考资料之一:Exploring the secrets inside the Recommendation engine):
2、推荐引擎的分类
推荐引擎根据不同的标准分类如下:
根据是否为不同用户推荐不同的数据,根据公众行为划分热门项目(网站管理员自己推荐,或者根据系统所有用户的反馈统计,计算当前热门项目) ,以及个性化的推荐引擎(帮助你找到志同道合的朋友,然后在此基础上实施推荐);物品具有相同的关键词和Tag,不考虑人为因素),以及基于协同过滤的推荐(寻找物品、内容或用户的相关推荐,分为三个子类,下文解释);根据构建方式,分为物品和用户本身(user-item二维矩阵描述用户偏好,聚类算法),
关于上面第二类基于协同过滤的推荐(2、根据其数据来源):随着Web2.0的发展,网站更加促进用户参与和用户贡献,所以基于关于协同过滤的过滤推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者发现用户的相关性,然后根据这些相关性进行推荐。
基于协同过滤的推荐分为三个子类:
基于用户的推荐(通过共同的品味和喜好找到相似的邻居用户,K-neighbor算法,你的朋友喜欢,你可能喜欢),基于物品的推荐(找到物品之间的相似性,推荐相似的物品,你喜欢) Item A 和 C 与 A 类似,也可能像 C),基于模型的推荐(基于样本用户偏好信息构建推荐模型,然后根据实时用户偏好信息预测推荐)。
我们看到这种协同过滤算法最大限度地利用了用户之间或物品之间的相似相关性,然后根据这些信息实现推荐。这种协同过滤也在下面详细描述。
但是,在一般实践中,我们通常将推荐引擎分为两类:
3、新浪微博推荐机制
新浪微博推荐好友机制中:1、我和A不是朋友,但是我的很多朋友都是A的朋友,也就是说我和A有很多共同的朋友,那么系统会推荐A给我(新浪称其为共同的朋友);2、我关注的很多人都关注了B,所以系统推测我可能喜欢B,所以也会推荐B给我(新浪称其为间接关注)。
但在新浪的实际运营中,这两种方式会混用。比如我关注的人中,关注B的人很多,但其实关注B的一些人也是我的朋友。以上推荐方法统称为基于相似用户的协同过滤推荐(无非是发现:用户之间的密不可分的联系,要么来自你的朋友,要么来自你关注的人)。
当然,还有另外一种推荐,比如热门用户推荐,就是上面提到的基于热门行为的推荐,也就是听从别人的意见。系统推测每个人都喜欢它,也许你也会喜欢。如果大家都知道姚晨的新浪微博粉丝数第一,就会争先恐后地关注,最终粉丝数会越来越多。推荐的两种方法如下图所示:
然而,上述的推荐方法,无论是基于用户还是基于流行行为,都没有真正找到用户之间的共同兴趣、喜好和品味,因为很多情况下,朋友的朋友可能不是你自己。朋友,有些人凌驾于世界之上,你们都追求什么,我不屑一顾。因此,从分析用户发布的微博内容入手,找到他们共同的关注点和兴趣点才是王道。当然,新浪微博最近让用户选择给自己的微博内容打标签,以帮助日后在微博内容中找到相关用户的常用标签,关键词,这种推荐方式是基于微博内容分析'的推荐。如下所示:
唯一的问题是,谁会不遗余力地发一条微博,它会添加什么标签?因此,新浪微博不得不努力寻找另一种方式来更好地分析微博的内容。否则,系统会彻底扫描海量用户的微博内容,恐怕承受不起,也承受不起。
不过我个人认为可以从微博关键词(标签标签云)和每个用户自己标签的标签入手(标签越常见,可以定义的相似用户越多),如图下图左右部分:
也就是说,通过普通朋友和间接关注的人来定义相似用户是不可靠的。只有通过微博内容分析,才能找到相似的用户。经过对标签云的分析,无疑比现有的推荐朋友的方法(通过普通朋友和间接关注者定义相似用户)找到相同或相似的标签云找到相似用户更可靠。
3.1、多种推荐方式组合
当前网站的推荐往往不是简单地使用某种推荐机制和策略,而是往往结合多种方法来达到更好的推荐效果。
例如,亚马逊除了基于用户的推荐外,还使用基于内容的推荐(关键词和Tag相同的商品):比如新品推荐;基于项目的协同过滤推荐(喜欢)。A、C 与 A 类似,也可能与 C) 类似:如捆绑销售和他人购买/浏览的商品。
简而言之,多种推荐方法和权重的组合(使用线性公式)根据一定的权重组合了几种不同的推荐。具体权重的值需要在测试数据集上反复测试,才能达到最好的推荐效果。)、切换、分区、分层等。但是,无论采用哪种推荐方法,一般都被上述推荐方法所覆盖。
4、协同过滤推荐
协同过滤是利用集体智慧的典型方式。要了解什么是协同过滤 (CF),首先要考虑一个简单的问题。如果你现在想看电影,但不知道该看哪一部,你会怎么做?大多数人会问广义的朋友或邻居,看看最近推荐了哪些好电影,而我们一般更喜欢从口味相似的朋友那里获得推荐。这就是协同过滤的核心思想。从下图中你能看出多少信息?
4.1、 协同过滤推荐步骤
做协同过滤推荐,一般做以下步骤:
1)要进行协同过滤,采集用户偏好是关键。可以通过评分等用户行为判断为相似用户(比如不同用户对不同作品的评分不同,评分接近意味着品味和品味相近,可以判断为相似用户)、投票、转发、采集、书签、标签、评论、点击流、页面停留时间、是否购买等。如下面第2点所述:所有这些信息都可以数字化并表示为二维矩阵。
2)采集到用户行为数据后,接下来需要对数据进行去噪和归一化处理(得到用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,该值是用户对项目的偏好,通常是 [0,1] 或 [-1,1] 的浮点值)。下面简单介绍降噪和归一化操作:
3)如何找到相似的用户和物品?就是计算相似用户或相似物品的相似度。
4)计算相似度的方法有很多种,但都是基于向量Vector。其实就是计算两个向量之间的距离。距离越近,相似度越大。在推荐中,在user-item偏好的二维矩阵下,我们以一个或多个用户对两个item的偏好为向量,计算两个item之间的相似度,或者两个用户对一个或多个的偏好几个项目被用作一个向量来计算两个用户之间的相似度。
相似度计算算法可用于计算用户或物品的相似度。以物品相似度计算(Item Similarity Computation)为列,共同点是从打分矩阵中为两个物品i和j选取共同打分用户,然后对这个共同用户的打分向量进行相似度计算. si,j,如下图,行代表用户,列代表物品(注意从i,j向量中抽取常用评论,形成一对向量计算相似度) :
因此,很简单的找到物品之间的相似度,用户不变,找到多个用户对物品的评分;求用户之间的相似度,item不变,求用户对某些item的评分。
5)计算出来的两个相似度将作为两个基于用户和物品的协同过滤推荐。
计算相似度的常用方法有:欧式距离、皮尔逊相关系数(比如两个用户对多部电影的评分,使用皮尔逊相关系数等相关计算方法,可以判断他们的口味和喜好是否一致)、余弦相似度,谷本系数。下面简单介绍一下欧几里得距离和皮尔逊相关系数:
可以看出,当n=2时,欧几里得距离就是平面上两点之间的距离。当用欧式距离表示相似度时,一般采用如下公式进行转换:距离越小,相似度越大(同时避免除数为0):
其中,Ru,i 是用户 u 对 item i 的评分,对应的带有横条的 item 是这个用户集 U 对 item i 的评分。
6)类似的邻居计算。邻居分为两类: 1、 固定数量的邻居K-neighborhoods(或Fix-sizeneighborhoods),不管邻居的“距离”如何,只取最近的K作为他们的邻居,如部分所示下图A;2、基于相似度阈值的邻居,以当前点为中心,距离为K的区域内的所有点都被视为当前点的邻居,如下图B部分所示。
让我们介绍一下 K-Nearest Neighbor (KNN) 分类算法:这是一种理论上成熟的方法,也是最简单的机器学习算法之一。该方法的思想是:如果特征空间中k个最相似的样本(即特征空间中的最近邻)中的大部分属于某个类别,则该样本也属于该类别。
7)4)计算的基于用户的CF(基于用户推荐:通过共同的品味和喜好找到相似的邻居用户,K-neighbor算法,如果你的朋友喜欢,你可能也会喜欢),基于item的CF(基于item的推荐:查找item之间的相似度,推荐相似的item,如果你喜欢item A,如果C和A相似,那么你可能也喜欢C)。
4.2、基于用户相似度和物品相似度
上一节3.1中的三个相似度公式都是基于物品相似度的场景,但实际上用户相似度和物品相似度计算的一个基本区别是,用户相似度是基于评分矩阵中的行向量相似度求解,项目相似度计算公式是根据评分矩阵中的列向量相似度计算的。那么这三个公式就可以分别套用了,如下图所示:
(其中,0表示未评级)
一千字不如一个例子。我们来看一个基于用户相似度计算的具体例子。
假设我们有一组用户,他们表现出对一组书籍的偏好。用户对一本书的偏好越高,它的评分就越高。让我们将其表示为一个矩阵,其中行代表用户,列代表书籍。
如下图所示,所有评分的范围从 1 到 5,其中 5 是最喜欢的。第一个用户(行 1) 为第一本书评分(列 1) 为 4,空单元格表示用户没有对该书评分。
使用基于用户的协同过滤方法,我们首先要做的是根据用户对图书的评价来计算用户之间的相似度。
让我们从单个用户的角度考虑这一点,查看图 1 中的第一行。为此,通常将每个用户表示为收录用户偏好的向量(或数组)。它比使用不同的相似性度量更直接。
在这个例子中,我们将使用余弦相似度来计算用户之间的相似度。
当我们将第一个用户与其他五个用户进行比较时,我们可以直观地看到他与其他用户的相似程度。
对于大多数相似度度量,向量之间的相似度越高,它们之间的相似度就越高。在这个例子中,第一个用户二、,第三个用户非常相似,有两本书相同,和第五个用户四、相似度较低,只有一本书相同,并且完全与上一个用户不同,因为没有共同的书。
更一般地,我们可以计算每个用户的相似度,并在相似度矩阵中表示它们。这是一个对称矩阵,单元格的背景颜色表示用户的相似程度,较深的红色表示他们之间的相似程度更高。
因此,我们找到与第一个用户最相似的第二个用户,删除该用户已经评分的书籍,对最相似的用户正在阅读的书籍进行加权,并计算总和。
在这种情况下,我们计算n=2,也就是说为了生成推荐,我们需要找到与目标用户最相似的两个用户,这两个用户分别是第二个和第三个用户,然后是第一个用户已经给第一和第五本书评分了,所以推荐的书是第三本书(4.5分),第四本书(3分)。
此外,何时使用 item-base 以及何时使用 user-base: ?
一般来说,如果item的数量不大,比如不超过100,000,并且没有明显增长,那么就使用item-based。为什么?正如@wuzh670所说,如果item数量少+没有明显增加,说明item之间的关系在一段时间内比较稳定(相对于用户之间的关系),对实时更新item的需求- 相似度低很多,降低了推荐系统的效率。改进很多,所以使用基于项目会更明智。
反之,当item数量较多时,推荐使用user-base。当然,在实践中的具体情况将根据具体情况进行分析。如下图所示(摘自向亮的《推荐系统实践》一书):
5、聚类算法
聚类 聚类,通俗地说,就是所谓的“物聚在一起,人分群”。聚类是数据挖掘的经典问题。其目的是将数据划分为多个簇,同一簇中的对象具有高度的相似性,而不同簇中的对象则不同。较大。
5.1、K-Means 聚类算法
K-Means 聚类算法与处理混合正态分布的期望最大化算法非常相似,因为它们都试图在数据中找到自然聚类的中心。该算法假设对象属性来自空间向量,目标是最小化每个组内的均方误差之和。
K-means 聚类算法首先随机确定 K 个中心位置(空间中代表聚类中心的点),然后将每个数据项分配到最近的中心点。分配完成后,集群中心将移动到分配给集群的所有节点的平均位置,然后整个分配过程重新开始。重复这个过程,直到分配过程不再改变。下图是一个有两个聚类的 K-means 聚类过程:
以下代码显示了此 K-means 聚类算法的 python 实现:
//K-均值聚类算法
import random
def kcluster(rows,distance=pearson,k=4):
# 确定每个点的最小值和最大值
ranges=[(min([row[i] for row in rows]),max([row[i] for row in rows]))
for i in range(len(rows[0]))]
# 随机创建k个中心点
clusters=[[random.random()*(ranges[i][1]-ranges[i][0])+ranges[i][0]
for i in range(len(rows[0]))] for j in range(k)]
lastmatches=None
for t in range(100):
print 'Iteration %d' % t
bestmatches=[[] for i in range(k)]
# 在每一行中寻找距离最近的中心点
for j in range(len(rows)):
row=rows[j]
bestmatch=0
for i in range(k):
d=distance(clusters[i],row)
if d0:
for rowid in bestmatches[i]:
for m in range(len(rows[rowid])):
avgs[m]+=rows[rowid][m]
for j in range(len(avgs)):
avgs[j]/=len(bestmatches[i])
clusters[i]=avgs
# 返回k组序列,其中每个序列代表一个聚类
return bestmatches
k-Means 是机器学习领域的一种无监督学习。下面简单介绍监督学习和无监督学习:
5.2、冠层聚类算法
Canopy聚类算法的基本原理是:首先,利用低成本的近似距离计算方法将数据高效地划分为多个组,这里称为Canopy,我们将其翻译为“canopy”。重叠部分;然后使用严格的距离计算方法,准确计算出同一个 Canopy 中的点,并将它们分配到最合适的簇中。Canopy聚类算法常用于K-means聚类算法的预处理,寻找合适的k值和聚类中心。
5.3、模糊K-Means聚类算法
模糊 K-means 聚类算法是 K-means 聚类的扩展。它的基本原理和K-means一样,只是它的聚类结果允许对象属于多个聚类,也就是说:属于我们前面介绍过的重叠。聚类算法。为了深入理解Fuzzy K-means和K-means的区别,这里我们得花点时间来理解一个概念:Fuzzziness Factor。
与K-means聚类原理类似,模糊K-means也在待聚类对象的向量集上循环,但它并不将向量分配给最近的簇,而是计算向量与每个簇的相关性(协会)。假设有一个向量v,有k个簇,v到k个簇中心的距离分别为d1,d2...dk,那么V到第一个簇的相关性u1可以通过下式计算:
计算 v 与其他集群的相关性只需将 d1 替换为相应的距离。由上式可知,当m近似为2时,相关性近似为1;当m近似为1时,相关性近似为到簇的距离,所以m的取值为(1,2)区间内,m越大,模糊程度越大,m为模糊我们刚才提到的参数。
其余的聚类算法本文将不做介绍。冷启动、数据稀疏性、可扩展性、可移植性、可解释性、多样性以及推荐信息的价值等问题将在后面讨论。
6、分类算法
其次,还有很多分类算法。本文介绍了决策树学习和贝叶斯定理。
6.1、决策树学习
让我们直奔主题。所谓决策树,顾名思义,就是一种树,是建立在战略选择基础上的树。
在机器学习中,决策树是一种预测模型;它表示对象属性和对象值之间的映射关系。树中的每个节点代表一个对象,每个分支路径代表一个可能的属性值,每个叶节点对应于从根节点到叶节点的路径所代表的对象。价值。决策树只有一个输出。如果你想有多个输出,你可以建立一个独立的决策树来处理不同的输出。
从数据中生成决策树的机器学习技术称为决策树学习,通常称为决策树。
理论太抽象了。这里有两个容易理解的例子:
第一个例子:通俗地说,决策树分类的思想类似于找对象。现在想象一个女孩的妈妈想给女孩介绍一个男朋友,于是就有了如下对话:
女儿:你几岁?
母亲:26。
女儿:帅吗?
妈妈:很帅。
女儿:收入高吗?
妈妈:不是很高,中等状态。
女儿:是公务员吗?
妈妈:是的,我在税务局工作。
女儿:好的,我去看你。
这个女孩的决策过程是典型的分类树决策。相当于把男人按年龄、外貌、收入和是否公务员分为两类:看和看。假设女孩对男人的要求是:30岁以下,中等相貌,高收入人士或中等收入以上的公务员,那么女孩的决策逻辑可以表示为:数字:
也就是说,决策树的简单策略就是,就像在公司招聘面试的过程中筛选一个人的简历,如果你的条件比较好,比如清华大学的博士,那么事不宜迟,直接致电面试,如果你毕业于非重点大学,但实际项目经验丰富,那么你也应该考虑要求面试,也就是所谓的具体分析和决策。
第二个例子来自 Tom M. Mitchell 的《机器学习》一书:
王的目的是通过下周的天气预报了解人们什么时候打高尔夫球。他明白人们决定是否参加比赛的原因取决于天气。天气条件晴朗、多云和下雨;华氏气温;相对湿度百分比;有风或缺席。这样,我们就可以构造如下决策树(根据天气的分类判断今天是否适合打网球):
上面的决策树对应如下表达式:(Outlook=Sunny ^Humiditywind gain 0.048。说白了,在周六早上是否适合打网球的问题上,最好取湿度而不是风作为分类属性,决策树来自哪里。
ID3算法决策树的形成
OK,下图是ID3算法第一步之后形成的部分决策树。综合起来,比较容易理解。1、阴的例子一定是正的,所以是叶子节点,永远是;2、ID3没有回溯,局部最优,不是全局最优,还有一个post-tree pruning决策树。下图是经过ID3算法第一步后形成的部分决策树:
6.2、贝叶斯分类基础:贝叶斯定理
贝叶斯定理:知道一个条件概率,如何得到两个事件交换的概率,即在已知P(A|B)的情况下如何得到P(B|A)。以下是条件概率的解释:
在事件 B 已经发生的前提下,事件 A 发生的概率称为事件 B 发生下事件 A 的条件概率。其基本解公式为:
.
贝叶斯定理之所以有用,是因为我们在生活中经常会遇到这样的情况:我们可以很容易地直接得到 P(A|B),P(B|A) 很难直接得到,但是我们更关心 P(B|A) , 贝叶斯定理为我们从 P(A|B) 得到 P(B|A) 开辟了道路。
下面直接给出贝叶斯定理,无需证明(公式已被网友指出,待后续验证修正):
7、推荐的实例扩展
7.1、阅读推荐
算法 自动采集列表(Java虚拟机-维基百科,自由的百科全书不过,作为一个爱思考的在校大学生)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-12 00:06
前言如果这篇文章有什么不对的地方,欢迎各界diss~~当然,如果你看了这篇文章有收获,那就疯狂点赞吧,你的喜欢是对我最大的鼓励。顺便加个关注,回家别迷路,不定时更新博客~~
周志明的《深入理解JAVA虚拟机》这本书看了一遍又一遍,终于有勇气在这里写一篇关于JVM的博客了!!!现在,我将在这里开始记录我所了解的并与我的朋友分享!!!
相信点击这个文章的小伙伴们一定知道JVM是什么吧?什么,还不知道?好吧,看看我想你会明白的 wiki:Java 虚拟机 - 维基百科,免费的百科全书
不过,作为一个有思想的大学生,我也总结了以下三点:
关于JVM是什么的介绍,还是一样的,我们来看看这个文章的结构:
运行时数据区
什么是运行时数据区?
Java程序在运行时,会为JVM分离出一块内存区域,而这块内存区域又可以划分为运行时数据区域。运行时数据区大致可以分为五个部分:
从上图中可以看出,有两个颜色不同的区域,红色的是线程共享区域,绿色的是线程私有区域。让我们一个一个说清楚,但是在学习这部分的时候,最好想一想为什么会有这些区域。仅仅是因为它的存在吗?
堆
很多做开发的同学都会特别注意堆和栈。这是否从另一个角度解释了堆和栈的重要性?在这种情况下,让我们从学生们关注的点开始。(客气点,有没有感觉眼角又湿了?)
先放干货。首先,Java堆区具有以下特点:
那么OutOfMemoryError什么时候发生,StackOverflowError什么时候发生呢?当虚拟机在扩展堆栈时无法申请足够的内存空间时,会抛出 OutOfMemoryError 异常。如果线程请求的堆栈深度超过了虚拟机允许的最大深度,就会抛出 StackOverflowError 异常。
其实Java堆区也可以分为新生代和老年代,新生代又可以进一步分为Eden区、Survivor 1区、Survivor 2区。具体比例参数可以看下图。
我看图已经解释的很清楚了,不用再用文字解释了吧?关于Java堆对象的创建,以及什么时候会出现内存泄漏,后面应该写一篇专文文章,这里的话只是一些理论介绍。
虚拟机堆栈(VM 堆栈)
Java虚拟机栈也是开发者关注的地方。同样,先放干货:
同样,如果这个文章反响不错,会在实战演练文章之后单独发布。
本机方法堆栈
本机方法堆栈实际上可以与 Java 虚拟机堆栈进行比较。唯一的区别是本机方法堆栈是 Java 程序在调用本机方法时创建堆栈帧的地方。和 JVM 栈一样,这个区域也会抛出 StackOverflowError 和 OutOfMemoryError。
方法区
方法区域也应该是一个重点区域。同样,方法区的主要特点如下:
对于方法区,我认为重点应该放在常量池上。常量池可以分为类文件常量池和运行时常量池。Java程序运行后,类文件中的信息被字节码执行引擎加载到方法区,从而形成运行时常量池。
另外,说到方法区,有些人可能会将其与永久代和元空间混淆。那么它们之间究竟有什么区别呢?方法区是Java虚拟机规范中的定义,是规范,而永久代是实现,一个是标准,一个是实现。但是Java 8之后就没有永久代了,元空间代替了永久代。
程序计数器寄存器
程序计数器非常简单。想必大家都不是Java初学者,大家应该了解线程和进程的概念吧?(灵魂拷问,你懂吗?)不懂没关系,我一句话给你解释。
进程是资源分配的最小单位,线程是CPU调度的最小单位。一个进程可以收录多个线程。Java线程通过抢占获得CPU的执行权。现在考虑以下场景。
在某一时刻,线程 A 获得了 CPU 的执行权并开始执行内部程序。但是线程A的程序还没有被执行,某个时刻CPU的执行权被另一个线程B抢走了。后来经过线程A的不懈努力,重新获得了CPU的执行权,难道线程A的程序还要从头开始执行?
这时候程序计数器就来了,它的作用是记录当前线程执行的位置。这样,当线程重新获得 CPU 的执行权时,就直接从记录的位置开始执行,而分支、循环、跳转、异常处理也都是靠这个程序计数器来完成的。此外,程序计数器具有以下特点:
对象创建和访问对象创建
正如我们之前所说,对象是在堆中创建的,通常只需要一个新对象。就这么简单吗?真的没那么简单。有了这样一个新关键字,Java virtual 内部就执行了一系列 sao 操作。
当虚拟机遇到字节码新指令时,会去运行时常量池中查找实例化对象对应的类是否被加载、解析和初始化。如果没有加载,则先加载类的信息,否则为新对象分配内存。
内存分配有两种方式:
以上是两种不同的方法。至于虚拟机使用哪种方法,则取决于虚拟机的类型。
对象的内存布局
堆中对象的存储布局可以分为三个部分:
对象访问位置
正如我们前面提到的,Java 虚拟机堆栈存储基本数据类型和对象引用。我们已经知道基本的数据类型,那么这个对象引用到底是什么?
就是这样,对象实例存储在Java堆中,通过这个对象引用我们可以找到对象在堆中的位置。但是,不同的 Java 虚拟机对于如何定位这个对象有不同的方法。
通常,有两种方法:
两种访问对象的方法都有各自的优势。使用直接指针访问,可以直接定位对象,减少了指针定位的时间开销(如果使用句柄,对象会通过句柄池的指针重定位),最大的好处是它是比较快的。但是使用句柄意味着当对象移动时,不需要更改存储在堆栈中的引用,只需要更改句柄池中指向实例数据的指针即可。
垃圾采集算法理论对象死了吗?
在上一部分中,我们讨论了对象。一个对象可以被创建,那么这个对象什么时候被销毁呢?一般来说,有两种方法可以判断一个对象是否已经被销毁:
如上图所示,绿色部分的对象在GC Roots的引用链上,不会被垃圾回收器回收。灰色部分的对象不在参考链中,自然确定为可回收对象。
那么问题来了,这些 GC Roots 是什么?下面列出了可以用作 GC Roots 的对象:
现在,我们知道哪些物品是可回收的。那么回收对象应该采取什么方法呢?垃圾回收算法主要有三种,分别是mark-sweep、mark-copy和mark-sort。这三种垃圾回收算法其实都比较容易理解。我先介绍一下概念,然后依次总结。
标记扫描算法
顾名思义,mark-to-clear算法就是对无效对象进行标记,然后将其清除。如下所示:
对于mark-sweep算法,你肯定会看到垃圾回收之后,堆空间中的碎片很多,并且有不规则的地方。为大对象分配内存时,由于找不到足够的连续内存空间,不得不再次触发垃圾回收。另外,如果Java堆中有大量垃圾对象,垃圾回收中必须进行大量的标记和清除动作,势必会降低回收效率。
标记--复制算法
标记复制算法是将Java堆分成两部分,每次垃圾回收只使用其中一个,然后将所有幸存的对象移动到另一个区域。如下所示:
mark-copy算法有一个明显的缺点,就是每次只使用一半的堆空间,导致Java堆空间使用率下降。
现在Java虚拟机的垃圾采集器大多使用标记复制算法,但是Java堆空间的划分并不是简单的一分为二。
还记得这张照片吗?
前面讲Java内存结构的时候,提到了Java堆的具体划分,所以现在说一下。
首先,我们要从两种代际采集理论说起:
正是这两个代际假设,让设计者对Java堆的划分更加合理。接下来说一下GC的分类:
好了,知道了GC的分类,是时候了解一下GC的过程了。
通常,第一次创建的对象存放在新生代的Eden区。第一次触发 Minor GC 时,Eden 区的幸存对象被转移到 Survivor 区的某个区域。以后再次触发 Minor GC 时,Eden 区的对象会连同一个 Survivor 区的对象一起转移到另一个 Survivor 区。可以看出,我们一次只使用了两个Survivor区域中的一个,只是浪费了一个Survivor区域。
一个对象每经过一次垃圾回收,它的世代年龄就加1。当世代年龄达到15时,直接存入老年代。
还有一种情况,给大对象分配内存时,Eden区的内存空间不足。这个时候我该怎么办?在这种情况下,大对象将直接进入老年。
标记排序算法
mark-to-clean 算法是一种妥协的垃圾采集算法。在对象标记的过程中,执行与前两个相同的步骤。但是标记后,存活对象被移动到堆的一端,存活对象以外的区域可以直接清理掉。这样就避免了内存碎片,也没有堆空间的浪费。但是,每次进行垃圾回收时,都必须暂停所有用户线程,特别是对于老年代的对象,需要更长的回收时间,这对用户体验非常不利。如下所示:
HotSpot的算法详解根节点枚举
根节点枚举其实就是寻找可以作为GC Roots的对象。在这个过程中,所有的用户线程都必须停止。到目前为止,几乎没有虚拟机可以与用户线程并发执行 GC Roots 遍历。当然,可达性分析算法中寻找参考链最耗时的过程已经可以与用户线程并发执行。那么,为什么需要在根节点枚举的时候停止用户线程呢?
其实不难考虑。如果GC Roots遍历时用户线程没有挂起,根节点集的对象引用关系还在变化,所以遍历的结果不准确。那么,Java虚拟机在寻找GC Roots时真的需要进行全局遍历吗?
事实上,情况并非如此。HotSpot 虚拟机可以通过称为 OopMap 的数据结构知道对象引用的存储位置。这样,GC Roots的遍历时间就大大减少了。
安全点
安全点是线程可以被中断的点。当我们遍历 GC Roots 时,我们必须停止用户线程。问题是,线程可以停在任何位置吗?为了让线程停在最近的安全点,有两种思路:
安全区
安全区是安全点的延伸和延伸。安全点解决了如何停止线程,但没有解决如何让虚拟机进入垃圾回收状态。
安全区是指在某个代码片段中,可以保证引用关系不会发生变化的区域。因此,一旦线程进入安全区,就可以忽略安全区内的这些线程。当线程离开安全区时,虚拟机检查根节点枚举是否完成。
记忆套装和卡片纸
不知道你有没有考虑过这样的问题?既然Java堆分为新生代和老年代,那么会不会有跨代的对象引用呢?如果有跨代,如何解决遍历老年代的GC Roots的问题?
首先,存在跨代参考。因此,垃圾采集器在年轻代中构建了一个称为memoized set的数据结构,以避免将整个老年代作为GC Roots的扫描范围。
内存集是一种抽象的数据结构,卡表是内存集的具体实现。这种关系类似于方法区和元空间。
写屏障
写屏障的作用很简单,就是维护和更新卡表。
并发可达性分析
前面我们提到了为什么要暂停所有用户线程(这个动作也叫Stop The World)?这实际上是为了防止用户线程改变对 GC Roots 对象的引用。试想一下,如果用户线程可以任意将死对象重新标记为活动对象,或者将活动对象标记为死对象,是不是会导致程序出现意外错误。
经典垃圾采集器
我知道很多垃圾采集的理论,但具体到某一种垃圾采集器,它的实现并不完全一样。以下是一些常见的垃圾采集器。
串行采集器
Serial 采集器是最基本、最古老的采集器。它在垃圾采集期间挂起所有工作线程,直到垃圾采集过程完成。下面是Serial垃圾采集器的运行示意图:
ParNew 采集器
ParNew 垃圾采集器实际上是串行垃圾采集器的多线程版本。这种多线程是 ParNew 垃圾采集器可以使用多个线程进行垃圾采集。
并行清除采集器
它也是新一代的垃圾采集器,也是基于标记复制算法实现的。它最大的特点是可以控制吞吐量。
那么什么是吞吐量?
串行老采集器
Serial Old 采集器是 Serial 采集器的老一代版本。垃圾采集器的工作原理与串行采集器相同。
平行老采集器
Parallel Old 采集器也是 Parallel Scavenge 采集器的旧版本,支持多线程并发采集。下面是它的运行示意图:
cms 采集器
如前所述,Parallel Scavenge 采集器是一个可以控制吞吐量的垃圾采集器。现在来说说cms采集器,它是一个追求最短暂停时间的垃圾采集器,基于mark-sweep算法。cms 垃圾采集器的操作过程比前面的要复杂一些。整个过程可以分为四个部分:
垃圾第一采集器
Garbage First(简称G1))采集器是垃圾采集器发展史上的里程碑式成果,主要面向服务端应用。另外,虽然G 1采集器仍然保留了新生代和老年代的概念,但是新生代和老年代不是固定的,它们是一系列区域的动态采集。
好了,垃圾采集器的介绍就到这里。至于G 1采集器,还是有很多值得关注的地方。朋友可以查看相关信息。 查看全部
算法 自动采集列表(Java虚拟机-维基百科,自由的百科全书不过,作为一个爱思考的在校大学生)
前言如果这篇文章有什么不对的地方,欢迎各界diss~~当然,如果你看了这篇文章有收获,那就疯狂点赞吧,你的喜欢是对我最大的鼓励。顺便加个关注,回家别迷路,不定时更新博客~~
周志明的《深入理解JAVA虚拟机》这本书看了一遍又一遍,终于有勇气在这里写一篇关于JVM的博客了!!!现在,我将在这里开始记录我所了解的并与我的朋友分享!!!
相信点击这个文章的小伙伴们一定知道JVM是什么吧?什么,还不知道?好吧,看看我想你会明白的 wiki:Java 虚拟机 - 维基百科,免费的百科全书
不过,作为一个有思想的大学生,我也总结了以下三点:
关于JVM是什么的介绍,还是一样的,我们来看看这个文章的结构:
运行时数据区
什么是运行时数据区?
Java程序在运行时,会为JVM分离出一块内存区域,而这块内存区域又可以划分为运行时数据区域。运行时数据区大致可以分为五个部分:
从上图中可以看出,有两个颜色不同的区域,红色的是线程共享区域,绿色的是线程私有区域。让我们一个一个说清楚,但是在学习这部分的时候,最好想一想为什么会有这些区域。仅仅是因为它的存在吗?
堆
很多做开发的同学都会特别注意堆和栈。这是否从另一个角度解释了堆和栈的重要性?在这种情况下,让我们从学生们关注的点开始。(客气点,有没有感觉眼角又湿了?)
先放干货。首先,Java堆区具有以下特点:
那么OutOfMemoryError什么时候发生,StackOverflowError什么时候发生呢?当虚拟机在扩展堆栈时无法申请足够的内存空间时,会抛出 OutOfMemoryError 异常。如果线程请求的堆栈深度超过了虚拟机允许的最大深度,就会抛出 StackOverflowError 异常。
其实Java堆区也可以分为新生代和老年代,新生代又可以进一步分为Eden区、Survivor 1区、Survivor 2区。具体比例参数可以看下图。
我看图已经解释的很清楚了,不用再用文字解释了吧?关于Java堆对象的创建,以及什么时候会出现内存泄漏,后面应该写一篇专文文章,这里的话只是一些理论介绍。
虚拟机堆栈(VM 堆栈)
Java虚拟机栈也是开发者关注的地方。同样,先放干货:
同样,如果这个文章反响不错,会在实战演练文章之后单独发布。
本机方法堆栈
本机方法堆栈实际上可以与 Java 虚拟机堆栈进行比较。唯一的区别是本机方法堆栈是 Java 程序在调用本机方法时创建堆栈帧的地方。和 JVM 栈一样,这个区域也会抛出 StackOverflowError 和 OutOfMemoryError。
方法区
方法区域也应该是一个重点区域。同样,方法区的主要特点如下:
对于方法区,我认为重点应该放在常量池上。常量池可以分为类文件常量池和运行时常量池。Java程序运行后,类文件中的信息被字节码执行引擎加载到方法区,从而形成运行时常量池。
另外,说到方法区,有些人可能会将其与永久代和元空间混淆。那么它们之间究竟有什么区别呢?方法区是Java虚拟机规范中的定义,是规范,而永久代是实现,一个是标准,一个是实现。但是Java 8之后就没有永久代了,元空间代替了永久代。
程序计数器寄存器
程序计数器非常简单。想必大家都不是Java初学者,大家应该了解线程和进程的概念吧?(灵魂拷问,你懂吗?)不懂没关系,我一句话给你解释。
进程是资源分配的最小单位,线程是CPU调度的最小单位。一个进程可以收录多个线程。Java线程通过抢占获得CPU的执行权。现在考虑以下场景。
在某一时刻,线程 A 获得了 CPU 的执行权并开始执行内部程序。但是线程A的程序还没有被执行,某个时刻CPU的执行权被另一个线程B抢走了。后来经过线程A的不懈努力,重新获得了CPU的执行权,难道线程A的程序还要从头开始执行?
这时候程序计数器就来了,它的作用是记录当前线程执行的位置。这样,当线程重新获得 CPU 的执行权时,就直接从记录的位置开始执行,而分支、循环、跳转、异常处理也都是靠这个程序计数器来完成的。此外,程序计数器具有以下特点:
对象创建和访问对象创建
正如我们之前所说,对象是在堆中创建的,通常只需要一个新对象。就这么简单吗?真的没那么简单。有了这样一个新关键字,Java virtual 内部就执行了一系列 sao 操作。
当虚拟机遇到字节码新指令时,会去运行时常量池中查找实例化对象对应的类是否被加载、解析和初始化。如果没有加载,则先加载类的信息,否则为新对象分配内存。
内存分配有两种方式:
以上是两种不同的方法。至于虚拟机使用哪种方法,则取决于虚拟机的类型。
对象的内存布局
堆中对象的存储布局可以分为三个部分:
对象访问位置
正如我们前面提到的,Java 虚拟机堆栈存储基本数据类型和对象引用。我们已经知道基本的数据类型,那么这个对象引用到底是什么?
就是这样,对象实例存储在Java堆中,通过这个对象引用我们可以找到对象在堆中的位置。但是,不同的 Java 虚拟机对于如何定位这个对象有不同的方法。
通常,有两种方法:
两种访问对象的方法都有各自的优势。使用直接指针访问,可以直接定位对象,减少了指针定位的时间开销(如果使用句柄,对象会通过句柄池的指针重定位),最大的好处是它是比较快的。但是使用句柄意味着当对象移动时,不需要更改存储在堆栈中的引用,只需要更改句柄池中指向实例数据的指针即可。
垃圾采集算法理论对象死了吗?
在上一部分中,我们讨论了对象。一个对象可以被创建,那么这个对象什么时候被销毁呢?一般来说,有两种方法可以判断一个对象是否已经被销毁:
如上图所示,绿色部分的对象在GC Roots的引用链上,不会被垃圾回收器回收。灰色部分的对象不在参考链中,自然确定为可回收对象。
那么问题来了,这些 GC Roots 是什么?下面列出了可以用作 GC Roots 的对象:
现在,我们知道哪些物品是可回收的。那么回收对象应该采取什么方法呢?垃圾回收算法主要有三种,分别是mark-sweep、mark-copy和mark-sort。这三种垃圾回收算法其实都比较容易理解。我先介绍一下概念,然后依次总结。
标记扫描算法
顾名思义,mark-to-clear算法就是对无效对象进行标记,然后将其清除。如下所示:
对于mark-sweep算法,你肯定会看到垃圾回收之后,堆空间中的碎片很多,并且有不规则的地方。为大对象分配内存时,由于找不到足够的连续内存空间,不得不再次触发垃圾回收。另外,如果Java堆中有大量垃圾对象,垃圾回收中必须进行大量的标记和清除动作,势必会降低回收效率。
标记--复制算法
标记复制算法是将Java堆分成两部分,每次垃圾回收只使用其中一个,然后将所有幸存的对象移动到另一个区域。如下所示:
mark-copy算法有一个明显的缺点,就是每次只使用一半的堆空间,导致Java堆空间使用率下降。
现在Java虚拟机的垃圾采集器大多使用标记复制算法,但是Java堆空间的划分并不是简单的一分为二。
还记得这张照片吗?
前面讲Java内存结构的时候,提到了Java堆的具体划分,所以现在说一下。
首先,我们要从两种代际采集理论说起:
正是这两个代际假设,让设计者对Java堆的划分更加合理。接下来说一下GC的分类:
好了,知道了GC的分类,是时候了解一下GC的过程了。
通常,第一次创建的对象存放在新生代的Eden区。第一次触发 Minor GC 时,Eden 区的幸存对象被转移到 Survivor 区的某个区域。以后再次触发 Minor GC 时,Eden 区的对象会连同一个 Survivor 区的对象一起转移到另一个 Survivor 区。可以看出,我们一次只使用了两个Survivor区域中的一个,只是浪费了一个Survivor区域。
一个对象每经过一次垃圾回收,它的世代年龄就加1。当世代年龄达到15时,直接存入老年代。
还有一种情况,给大对象分配内存时,Eden区的内存空间不足。这个时候我该怎么办?在这种情况下,大对象将直接进入老年。
标记排序算法
mark-to-clean 算法是一种妥协的垃圾采集算法。在对象标记的过程中,执行与前两个相同的步骤。但是标记后,存活对象被移动到堆的一端,存活对象以外的区域可以直接清理掉。这样就避免了内存碎片,也没有堆空间的浪费。但是,每次进行垃圾回收时,都必须暂停所有用户线程,特别是对于老年代的对象,需要更长的回收时间,这对用户体验非常不利。如下所示:
HotSpot的算法详解根节点枚举
根节点枚举其实就是寻找可以作为GC Roots的对象。在这个过程中,所有的用户线程都必须停止。到目前为止,几乎没有虚拟机可以与用户线程并发执行 GC Roots 遍历。当然,可达性分析算法中寻找参考链最耗时的过程已经可以与用户线程并发执行。那么,为什么需要在根节点枚举的时候停止用户线程呢?
其实不难考虑。如果GC Roots遍历时用户线程没有挂起,根节点集的对象引用关系还在变化,所以遍历的结果不准确。那么,Java虚拟机在寻找GC Roots时真的需要进行全局遍历吗?
事实上,情况并非如此。HotSpot 虚拟机可以通过称为 OopMap 的数据结构知道对象引用的存储位置。这样,GC Roots的遍历时间就大大减少了。
安全点
安全点是线程可以被中断的点。当我们遍历 GC Roots 时,我们必须停止用户线程。问题是,线程可以停在任何位置吗?为了让线程停在最近的安全点,有两种思路:
安全区
安全区是安全点的延伸和延伸。安全点解决了如何停止线程,但没有解决如何让虚拟机进入垃圾回收状态。
安全区是指在某个代码片段中,可以保证引用关系不会发生变化的区域。因此,一旦线程进入安全区,就可以忽略安全区内的这些线程。当线程离开安全区时,虚拟机检查根节点枚举是否完成。
记忆套装和卡片纸
不知道你有没有考虑过这样的问题?既然Java堆分为新生代和老年代,那么会不会有跨代的对象引用呢?如果有跨代,如何解决遍历老年代的GC Roots的问题?
首先,存在跨代参考。因此,垃圾采集器在年轻代中构建了一个称为memoized set的数据结构,以避免将整个老年代作为GC Roots的扫描范围。
内存集是一种抽象的数据结构,卡表是内存集的具体实现。这种关系类似于方法区和元空间。
写屏障
写屏障的作用很简单,就是维护和更新卡表。
并发可达性分析
前面我们提到了为什么要暂停所有用户线程(这个动作也叫Stop The World)?这实际上是为了防止用户线程改变对 GC Roots 对象的引用。试想一下,如果用户线程可以任意将死对象重新标记为活动对象,或者将活动对象标记为死对象,是不是会导致程序出现意外错误。
经典垃圾采集器
我知道很多垃圾采集的理论,但具体到某一种垃圾采集器,它的实现并不完全一样。以下是一些常见的垃圾采集器。
串行采集器
Serial 采集器是最基本、最古老的采集器。它在垃圾采集期间挂起所有工作线程,直到垃圾采集过程完成。下面是Serial垃圾采集器的运行示意图:
ParNew 采集器
ParNew 垃圾采集器实际上是串行垃圾采集器的多线程版本。这种多线程是 ParNew 垃圾采集器可以使用多个线程进行垃圾采集。
并行清除采集器
它也是新一代的垃圾采集器,也是基于标记复制算法实现的。它最大的特点是可以控制吞吐量。
那么什么是吞吐量?
串行老采集器
Serial Old 采集器是 Serial 采集器的老一代版本。垃圾采集器的工作原理与串行采集器相同。
平行老采集器
Parallel Old 采集器也是 Parallel Scavenge 采集器的旧版本,支持多线程并发采集。下面是它的运行示意图:
cms 采集器
如前所述,Parallel Scavenge 采集器是一个可以控制吞吐量的垃圾采集器。现在来说说cms采集器,它是一个追求最短暂停时间的垃圾采集器,基于mark-sweep算法。cms 垃圾采集器的操作过程比前面的要复杂一些。整个过程可以分为四个部分:
垃圾第一采集器
Garbage First(简称G1))采集器是垃圾采集器发展史上的里程碑式成果,主要面向服务端应用。另外,虽然G 1采集器仍然保留了新生代和老年代的概念,但是新生代和老年代不是固定的,它们是一系列区域的动态采集。
好了,垃圾采集器的介绍就到这里。至于G 1采集器,还是有很多值得关注的地方。朋友可以查看相关信息。
算法 自动采集列表(算法自动采集列表页与问题列表、优质用户列表的互相关系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-02-11 22:02
算法自动采集列表页与问题列表、优质用户列表的互相关系。首先点击列表页列表项链接->填入关键字->采集采集列表内一级或多级关键字名称列表页相关信息采集内容公众号关注列表,粉丝列表,包括注册及登录信息采集机器学习训练数据库,统计各种公众号文章的阅读量,打开率等各项指标。地址::【基于knowledgegraph构建推荐系统】摘要目标如何在knowledgegraph中构建推荐系统,以解决真实世界的各种问题?让一个用户对一个公众号和一个topic做出多个topic上的推荐?用户在不同topic上做的推荐怎么联合起来呢?(横轴是次序,纵轴是这一个topic下面的文章的总数量)用户的所有推荐都是一个实体序列,该序列由公众号关注的文章列表和机器学习训练数据库存储。
通过实体的性质存储序列,比如文章的类型(小说,纪实,体育,新闻)。关键词索引用户可以设置每个关键词存储到这个存储中去吗?如果可以为什么不将它存储到有向无环图中,可能性为四个,可以用lda存储;或者用空间紧凑图。如果文章列表不和关注列表或者topic列表对应一致,使用约束sequencetosequencelda;或者找类似tf-idf和tf-idf联合的聚类算法,与pagerank联合。
对每个用户定制不同的权重级别(1,2,3...)。对不同标签进行设定,如有些标签对应的推荐值很大或者很小。其他问题用户做一个推荐的时候用户利用其它广告或者公众号或者其它方式优惠过一次,则重新购买等方式相关联用户有没有可能创建一个从query过来的多文档嵌入向量做语义向量?为什么利用权重可以,gdbt,dbn,lda怎么比较好?给用户推荐一个公众号,但是用户在公众号文章浏览过去以后并没有在文章列表里面看到推荐的产品,此时怎么办?目标如何设计机器学习lda推荐系统,通过用户到一个列表结构模型来学习列表里面的推荐?有什么好的建议?项目地址:::。 查看全部
算法 自动采集列表(算法自动采集列表页与问题列表、优质用户列表的互相关系)
算法自动采集列表页与问题列表、优质用户列表的互相关系。首先点击列表页列表项链接->填入关键字->采集采集列表内一级或多级关键字名称列表页相关信息采集内容公众号关注列表,粉丝列表,包括注册及登录信息采集机器学习训练数据库,统计各种公众号文章的阅读量,打开率等各项指标。地址::【基于knowledgegraph构建推荐系统】摘要目标如何在knowledgegraph中构建推荐系统,以解决真实世界的各种问题?让一个用户对一个公众号和一个topic做出多个topic上的推荐?用户在不同topic上做的推荐怎么联合起来呢?(横轴是次序,纵轴是这一个topic下面的文章的总数量)用户的所有推荐都是一个实体序列,该序列由公众号关注的文章列表和机器学习训练数据库存储。
通过实体的性质存储序列,比如文章的类型(小说,纪实,体育,新闻)。关键词索引用户可以设置每个关键词存储到这个存储中去吗?如果可以为什么不将它存储到有向无环图中,可能性为四个,可以用lda存储;或者用空间紧凑图。如果文章列表不和关注列表或者topic列表对应一致,使用约束sequencetosequencelda;或者找类似tf-idf和tf-idf联合的聚类算法,与pagerank联合。
对每个用户定制不同的权重级别(1,2,3...)。对不同标签进行设定,如有些标签对应的推荐值很大或者很小。其他问题用户做一个推荐的时候用户利用其它广告或者公众号或者其它方式优惠过一次,则重新购买等方式相关联用户有没有可能创建一个从query过来的多文档嵌入向量做语义向量?为什么利用权重可以,gdbt,dbn,lda怎么比较好?给用户推荐一个公众号,但是用户在公众号文章浏览过去以后并没有在文章列表里面看到推荐的产品,此时怎么办?目标如何设计机器学习lda推荐系统,通过用户到一个列表结构模型来学习列表里面的推荐?有什么好的建议?项目地址:::。
算法 自动采集列表(算法自动采集列表页同类型的网站会以不同方式去展示)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-08 13:00
算法自动采集列表页同类型的网站。不同类型的网站会以不同方式去展示这个代码,如:点击次数排名、信息时效性、与联系人是否有关联。如果你要做的是纯展示页面,那么可以采用时间倒排模型来解决,但你如果要做的是会员注册/帐号这种的。这样的话就有难度了,难点之一是你需要在一个月之内把代码开放给别人接受,另外在做的过程中需要不断对他的点击做记录,优化代码。一次两次没问题,多了之后可能就有点难度了。可以试一下routerman作为辅助工具。
一般情况下在pc端,你不要想着去做一个这样的页面,因为这个页面根本没办法展示网站信息。这样的页面很可能就是蜘蛛爬虫抓取浏览网站的记录(这样的抓取记录会被放到一个广告网络里去),蜘蛛就会把这个蜘蛛记录抓取下来,在m站的网站爬虫可以通过找到这个cookie来对应服务器,从而达到获取信息的目的。
需要优化页面的各个阶段。详细可以参考uwablog上大佬介绍的。
你可以做一个基于代码的爬虫脚本。通过对网站进行仿真爬虫代码或者利用excel导入php页面。然后直接通过页面的点击触发来采集和上传网站信息到mysql就行了。如果需要大量点击才能对页面进行捕获和上传的话,可以配合其他技术(sslhttps)进行抓取页面。附两个github项目,楼主可以参考一下:-greasyfork-blogpro,针对微博可以像购物一样动态上传数据和更新数据。-jiaxing-blog,仿真谷歌about.php,捕获上传的网站数据即可。 查看全部
算法 自动采集列表(算法自动采集列表页同类型的网站会以不同方式去展示)
算法自动采集列表页同类型的网站。不同类型的网站会以不同方式去展示这个代码,如:点击次数排名、信息时效性、与联系人是否有关联。如果你要做的是纯展示页面,那么可以采用时间倒排模型来解决,但你如果要做的是会员注册/帐号这种的。这样的话就有难度了,难点之一是你需要在一个月之内把代码开放给别人接受,另外在做的过程中需要不断对他的点击做记录,优化代码。一次两次没问题,多了之后可能就有点难度了。可以试一下routerman作为辅助工具。
一般情况下在pc端,你不要想着去做一个这样的页面,因为这个页面根本没办法展示网站信息。这样的页面很可能就是蜘蛛爬虫抓取浏览网站的记录(这样的抓取记录会被放到一个广告网络里去),蜘蛛就会把这个蜘蛛记录抓取下来,在m站的网站爬虫可以通过找到这个cookie来对应服务器,从而达到获取信息的目的。
需要优化页面的各个阶段。详细可以参考uwablog上大佬介绍的。
你可以做一个基于代码的爬虫脚本。通过对网站进行仿真爬虫代码或者利用excel导入php页面。然后直接通过页面的点击触发来采集和上传网站信息到mysql就行了。如果需要大量点击才能对页面进行捕获和上传的话,可以配合其他技术(sslhttps)进行抓取页面。附两个github项目,楼主可以参考一下:-greasyfork-blogpro,针对微博可以像购物一样动态上传数据和更新数据。-jiaxing-blog,仿真谷歌about.php,捕获上传的网站数据即可。
算法 自动采集列表(十二星座本月事业运势D:列表页采集关键词gjcaizhanaizhan_4.txt)
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-07 06:00
**
**
dp一般用于解决多阶段决策问题,即每个阶段都要做出一个决策,所有的决策都是一个决策序列。
最佳决策序列导致问题的最佳解决方案
把要解决的问题分成几个相互关联的子问题,只解决第一次遇到的问题,然后保存这个子问题的答案
下次遇到直接下来用
dp和分治法的区别在于,分治法分解出来的子问题一定是没有联系的(如果有联系,就收录了大量重复的子问题,那么
所以这个问题不适合分治,虽然分治也可以解决,但是时间复杂度太大,不划算),所以使用dp和使用divide的问题
治理问题的根本区别在于分解成的子问题之间是否存在联系,以及这些子问题是否重叠,即是否存在重复的子问题
dp和greedy的区别在于,每次greed是D:列表页采集关键词gjcaizhanaizhan_4.txt做出不可逆的决定(即每次局部最优),而在dp中,也有调查
每个最优决策子序列是否收录最详细的18年星座最优决策子序列,即是否具有最优子结构性质,贪婪的每一步只关注当下
最优的,并且当前的选择不会依赖于之前的选择,而dp在选择的时候是从前面的步骤和这一步中得到的
选择相关子问题中的最优解,将本步的值相加,形成本步该子问题的最优解。
示例:最大值问题
这个想法就像代码所想的那样
其中,一般的星座分析靠谱吗?
D:列表页采集关键词gjcaizhanaizhan_4.txt
:这段代码是这个问题的核心
应用3:01背包
算法小白的一些总结,如有错误,希望大家多多指教! 查看全部
算法 自动采集列表(十二星座本月事业运势D:列表页采集关键词gjcaizhanaizhan_4.txt)
**
**
dp一般用于解决多阶段决策问题,即每个阶段都要做出一个决策,所有的决策都是一个决策序列。
最佳决策序列导致问题的最佳解决方案
把要解决的问题分成几个相互关联的子问题,只解决第一次遇到的问题,然后保存这个子问题的答案
下次遇到直接下来用
dp和分治法的区别在于,分治法分解出来的子问题一定是没有联系的(如果有联系,就收录了大量重复的子问题,那么
所以这个问题不适合分治,虽然分治也可以解决,但是时间复杂度太大,不划算),所以使用dp和使用divide的问题
治理问题的根本区别在于分解成的子问题之间是否存在联系,以及这些子问题是否重叠,即是否存在重复的子问题
dp和greedy的区别在于,每次greed是D:列表页采集关键词gjcaizhanaizhan_4.txt做出不可逆的决定(即每次局部最优),而在dp中,也有调查
每个最优决策子序列是否收录最详细的18年星座最优决策子序列,即是否具有最优子结构性质,贪婪的每一步只关注当下
最优的,并且当前的选择不会依赖于之前的选择,而dp在选择的时候是从前面的步骤和这一步中得到的
选择相关子问题中的最优解,将本步的值相加,形成本步该子问题的最优解。
示例:最大值问题
这个想法就像代码所想的那样
其中,一般的星座分析靠谱吗?
D:列表页采集关键词gjcaizhanaizhan_4.txt
:这段代码是这个问题的核心
应用3:01背包
算法小白的一些总结,如有错误,希望大家多多指教!
算法 自动采集列表(Python使用计算法进行垃圾回收Python如何解决循环引用? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-05 13:20
)
标记阶段:参考计数算法垃圾标记阶段:对象生存判断参考计算算法证明
/**
* -XX:+PrintGCDetails
* 证明:java使用的不是引用计数算法
*/
public class RefCountGC {
//这个成员属性唯一的作用就是占用一点内存
private byte[] bigSize = new byte[5 * 1024 * 1024];//5MB
Object reference = null;
public static void main(String[] args) {
RefCountGC obj1 = new RefCountGC();
RefCountGC obj2 = new RefCountGC();
obj1.reference = obj2;
obj2.reference = obj1;
obj1 = null;
obj2 = null;
//显式的执行垃圾回收行为
//这里发生GC,obj1和obj2能否被回收?
// System.gc();
// try {
// Thread.sleep(1000000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
}
}
这样创建对象会导致引用计数器为+2,我们来看看没有回收的内存。
让我们GC
显然这个GC被回收了。如果是引用计数算法,则不会采集它们。因此 Java 不使用引用计数算法。
Python 使用参考算法进行垃圾采集。Python如何解决循环引用?标记阶段:可达性分析算法(Java使用的算法) GCRoots 根集 GC Roots可以收录本地方法栈中JNI引用的那些元素 类的方法区中静态属性引用的对象 常量引用的对象在方法区All synchronized 锁同步持有的对象Java 虚拟机的内部引用反映了Java 虚拟机JMXBean 的内部情况,在JVMTI 中注册的回调,以及本地代码缓存。
特别注意辨别能力
因为Root使用栈来存储变量和指针,如果一个指针将对象保存在堆内存中,但不将自己保存在堆内存中,那么他就是一个Root
注意对象finalize()方法的终结机制注意,在功能上,finalize()和C++中的析构函数类似,但是Java使用了基于垃圾回收的自动内存管理机制,所以finalize()方法本质上是不同的 C++ 中的析构函数。由于finalize()方法的存在,虚拟机中的对象一般处于三种可能的状态。对象的三种状态
一个不可触及的对象在一定的条件下可能会自我复活,如果是这样,回收它是不合理的。为此,定义了虚拟机中的对象可能处于三种状态
具体过程对象复活
public class CanReliveObj {
public static CanReliveObj obj;//类变量,属于 GC Root
//此方法只能被调用一次
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用当前类重写的finalize()方法");
obj = this;//当前待回收的对象在finalize()方法中与引用链上的一个对象obj建立了联系
}
public static void main(String[] args) {
try {
obj = new CanReliveObj();
// 对象第一次成功拯救自己
obj = null;
System.gc();//调用垃圾回收器
System.out.println("第1次 gc");
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
System.out.println("第2次 gc");
// 下面这段代码与上面的完全相同,但是这次自救却失败了
obj = null;
System.gc();
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
结果
MAT 和 JProfiler 的 GC Roots 可追溯性 MAT
MAT是Memory Analyzer的坚持,它是一个强大的Java堆内存分析器,用于查找内存泄漏和查看内存消耗。
MAT是基于Eclipse开发的,是一个性能分析工具。
获取转储文件方法一:使用jmap命令行
方法 2:使用 JVisualVM 将本地应用程序的堆转储导出为应用程序选项卡的子选项卡。同事堆转储对应左侧Application栏的一个timestamp节点,右键该节点选择save as 可以导出本地扫描阶段:Mark-Sweep算法(Mark-Sweep)
实施过程
当堆中可用内存耗尽时,整个进程(也称为 stw)停止,执行两个作业
缺点 什么是清算?
所谓清空,并不是真的清空,而是垃圾对象的地址存放在一个空闲列表中。
清算阶段:复制算法(Copying)
大意
将活动内存空间分成两块,一次只使用其中一个,垃圾回收时将正在使用的内存中的活动对象复制到未使用的内存块中,然后清除所有正在使用的内存块。对象,交换内存的作用,最后完成垃圾回收。
优点 缺点 特殊应用场景
在新生代中,常规应用的垃圾回收通常可以一次性回收70%-99%的内存空间,回收非常划算,所以虚拟机采用这种算法来回收新生代。
清除阶段:标记紧凑算法
基于老年垃圾回收的特点,需要使用其他算法
在标记压缩算法上实现过程标记扫描算法
mark-compression算法可视为mark-sweep-compression算法(只有在mark-sweep执行完成后,才进行内存碎片整理)
两者的本质区别在于
优缺点总结
分代采集算法
以上三种算法都不能完全替代其他方法。它们都有自己独特的优势和特点,手机算法的一代应运而生。
目前几乎所有的 GC 都使用分代采集算法来执行垃圾采集。
Tenured Gen 增量采集算法,分区算法增量采集算法
在上述算法的垃圾回收过程中,应用软件将处于STW(Stop The World)状态。在这种状态下,所有的线程都会被挂起,所有正常的工作都会被挂起,垃圾回收也就完成了。垃圾回收时间过长会影响系统稳定性和用户体验。为了解决这个问题,增量采集算法(Incremental Collecting)诞生了。
基本思想
如果一次采集和处理所有垃圾,需要长时间的停顿,那么垃圾采集线程和应用程序线程可以交替执行。每次垃圾采集线程只采集一小块内存空间,然后切换到应用程序。程序线程,如此反复,直到垃圾采集完成。
该算法的基础仍然是传统的mark-sweep算法和copy算法,而增量采集算法则妥善处理线程间的冲突,让垃圾采集线程分阶段完成标记、清理或复制工作。
缺点
线程切换和上下文转换的消耗会增加垃圾回收的整体成本,导致系统吞吐量下降。
分区算法
生成算法将对象的生命周期分为两部分(新生代、老生代)
分区算法将整个堆空间划分为连续不同和不同的小区间。每个细胞独立使用和独立回收。这种算法的优点是可以控制一次回收多少个cell。
查看全部
算法 自动采集列表(Python使用计算法进行垃圾回收Python如何解决循环引用?
)
标记阶段:参考计数算法垃圾标记阶段:对象生存判断参考计算算法证明
/**
* -XX:+PrintGCDetails
* 证明:java使用的不是引用计数算法
*/
public class RefCountGC {
//这个成员属性唯一的作用就是占用一点内存
private byte[] bigSize = new byte[5 * 1024 * 1024];//5MB
Object reference = null;
public static void main(String[] args) {
RefCountGC obj1 = new RefCountGC();
RefCountGC obj2 = new RefCountGC();
obj1.reference = obj2;
obj2.reference = obj1;
obj1 = null;
obj2 = null;
//显式的执行垃圾回收行为
//这里发生GC,obj1和obj2能否被回收?
// System.gc();
// try {
// Thread.sleep(1000000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
}
}
这样创建对象会导致引用计数器为+2,我们来看看没有回收的内存。
让我们GC
显然这个GC被回收了。如果是引用计数算法,则不会采集它们。因此 Java 不使用引用计数算法。
Python 使用参考算法进行垃圾采集。Python如何解决循环引用?标记阶段:可达性分析算法(Java使用的算法) GCRoots 根集 GC Roots可以收录本地方法栈中JNI引用的那些元素 类的方法区中静态属性引用的对象 常量引用的对象在方法区All synchronized 锁同步持有的对象Java 虚拟机的内部引用反映了Java 虚拟机JMXBean 的内部情况,在JVMTI 中注册的回调,以及本地代码缓存。
特别注意辨别能力
因为Root使用栈来存储变量和指针,如果一个指针将对象保存在堆内存中,但不将自己保存在堆内存中,那么他就是一个Root
注意对象finalize()方法的终结机制注意,在功能上,finalize()和C++中的析构函数类似,但是Java使用了基于垃圾回收的自动内存管理机制,所以finalize()方法本质上是不同的 C++ 中的析构函数。由于finalize()方法的存在,虚拟机中的对象一般处于三种可能的状态。对象的三种状态
一个不可触及的对象在一定的条件下可能会自我复活,如果是这样,回收它是不合理的。为此,定义了虚拟机中的对象可能处于三种状态
具体过程对象复活
public class CanReliveObj {
public static CanReliveObj obj;//类变量,属于 GC Root
//此方法只能被调用一次
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用当前类重写的finalize()方法");
obj = this;//当前待回收的对象在finalize()方法中与引用链上的一个对象obj建立了联系
}
public static void main(String[] args) {
try {
obj = new CanReliveObj();
// 对象第一次成功拯救自己
obj = null;
System.gc();//调用垃圾回收器
System.out.println("第1次 gc");
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
System.out.println("第2次 gc");
// 下面这段代码与上面的完全相同,但是这次自救却失败了
obj = null;
System.gc();
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
结果
MAT 和 JProfiler 的 GC Roots 可追溯性 MAT
MAT是Memory Analyzer的坚持,它是一个强大的Java堆内存分析器,用于查找内存泄漏和查看内存消耗。
MAT是基于Eclipse开发的,是一个性能分析工具。
获取转储文件方法一:使用jmap命令行
方法 2:使用 JVisualVM 将本地应用程序的堆转储导出为应用程序选项卡的子选项卡。同事堆转储对应左侧Application栏的一个timestamp节点,右键该节点选择save as 可以导出本地扫描阶段:Mark-Sweep算法(Mark-Sweep)
实施过程
当堆中可用内存耗尽时,整个进程(也称为 stw)停止,执行两个作业
缺点 什么是清算?
所谓清空,并不是真的清空,而是垃圾对象的地址存放在一个空闲列表中。
清算阶段:复制算法(Copying)
大意
将活动内存空间分成两块,一次只使用其中一个,垃圾回收时将正在使用的内存中的活动对象复制到未使用的内存块中,然后清除所有正在使用的内存块。对象,交换内存的作用,最后完成垃圾回收。
优点 缺点 特殊应用场景
在新生代中,常规应用的垃圾回收通常可以一次性回收70%-99%的内存空间,回收非常划算,所以虚拟机采用这种算法来回收新生代。
清除阶段:标记紧凑算法
基于老年垃圾回收的特点,需要使用其他算法
在标记压缩算法上实现过程标记扫描算法
mark-compression算法可视为mark-sweep-compression算法(只有在mark-sweep执行完成后,才进行内存碎片整理)
两者的本质区别在于
优缺点总结
分代采集算法
以上三种算法都不能完全替代其他方法。它们都有自己独特的优势和特点,手机算法的一代应运而生。
目前几乎所有的 GC 都使用分代采集算法来执行垃圾采集。
Tenured Gen 增量采集算法,分区算法增量采集算法
在上述算法的垃圾回收过程中,应用软件将处于STW(Stop The World)状态。在这种状态下,所有的线程都会被挂起,所有正常的工作都会被挂起,垃圾回收也就完成了。垃圾回收时间过长会影响系统稳定性和用户体验。为了解决这个问题,增量采集算法(Incremental Collecting)诞生了。
基本思想
如果一次采集和处理所有垃圾,需要长时间的停顿,那么垃圾采集线程和应用程序线程可以交替执行。每次垃圾采集线程只采集一小块内存空间,然后切换到应用程序。程序线程,如此反复,直到垃圾采集完成。
该算法的基础仍然是传统的mark-sweep算法和copy算法,而增量采集算法则妥善处理线程间的冲突,让垃圾采集线程分阶段完成标记、清理或复制工作。
缺点
线程切换和上下文转换的消耗会增加垃圾回收的整体成本,导致系统吞吐量下降。
分区算法
生成算法将对象的生命周期分为两部分(新生代、老生代)
分区算法将整个堆空间划分为连续不同和不同的小区间。每个细胞独立使用和独立回收。这种算法的优点是可以控制一次回收多少个cell。
算法 自动采集列表(算法自动采集列表,多个页面同时使用,同时查看)
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-02-02 13:01
算法自动采集列表:专门的采集产品列表,然后再转换成优化后的产品列表页面。看哪个产品人多,然后查看ta的网站推广链接。然后点击购买,查看详情产品细节。分发思路:每个产品的一个sku,上下ta的产品列表,然后保存为不同的产品标签,方便数据量分发可视化,新客注册、再次购买、保存购买详情、优惠券等等等等。都能显示。
一个简单的产品列表,直接实现多个用户、多个页面同时使用。上下架逻辑和普通的列表页面差不多,通过筛选产品重定向到你设定的产品页面。但是每个产品有一个sku、用户发生购买后,自动获取这个产品的优惠券发放给相应的会员,同时查看详情页面。提供一个思路的大概示意图:相关产品列表可以根据自己的产品关键词,去搜索你需要的产品,然后查看产品详情页面。
你要更多产品关键词,可以多逛逛的相关产品页面,而且你要根据自己实际情况定制不同产品的关键词,比如目前上买木屋的,主要是东北那边的木屋,你就把浙江、浙西那边的木屋找出来,其他都去别家看看。用户购买什么产品,直接分析详情页,用户购买详情页销量,根据数据回流!。
通过分析用户购买习惯然后通过采集的数据不断修正sku,在需要的时候把用户可能的产品列出来,然后考虑下用户是否在购买这个产品的时候还会购买其他产品或者同时购买另外一个sku,这样可以增加一个浏览sku的sku组别。如果产品不太多的话,推荐先用分词法把所有sku的标题和sku列表搞定。然后如果产品分析采集下来的字段足够少,完全可以通过高级搜索技术显示细节信息。那时基本上就是这样。 查看全部
算法 自动采集列表(算法自动采集列表,多个页面同时使用,同时查看)
算法自动采集列表:专门的采集产品列表,然后再转换成优化后的产品列表页面。看哪个产品人多,然后查看ta的网站推广链接。然后点击购买,查看详情产品细节。分发思路:每个产品的一个sku,上下ta的产品列表,然后保存为不同的产品标签,方便数据量分发可视化,新客注册、再次购买、保存购买详情、优惠券等等等等。都能显示。
一个简单的产品列表,直接实现多个用户、多个页面同时使用。上下架逻辑和普通的列表页面差不多,通过筛选产品重定向到你设定的产品页面。但是每个产品有一个sku、用户发生购买后,自动获取这个产品的优惠券发放给相应的会员,同时查看详情页面。提供一个思路的大概示意图:相关产品列表可以根据自己的产品关键词,去搜索你需要的产品,然后查看产品详情页面。
你要更多产品关键词,可以多逛逛的相关产品页面,而且你要根据自己实际情况定制不同产品的关键词,比如目前上买木屋的,主要是东北那边的木屋,你就把浙江、浙西那边的木屋找出来,其他都去别家看看。用户购买什么产品,直接分析详情页,用户购买详情页销量,根据数据回流!。
通过分析用户购买习惯然后通过采集的数据不断修正sku,在需要的时候把用户可能的产品列出来,然后考虑下用户是否在购买这个产品的时候还会购买其他产品或者同时购买另外一个sku,这样可以增加一个浏览sku的sku组别。如果产品不太多的话,推荐先用分词法把所有sku的标题和sku列表搞定。然后如果产品分析采集下来的字段足够少,完全可以通过高级搜索技术显示细节信息。那时基本上就是这样。
算法 自动采集列表( FlinkFlinkSQL实践遇到的典型问题以及解决方案2.实时计算平台建设过程中的思考)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-02 03:10
FlinkFlinkSQL实践遇到的典型问题以及解决方案2.实时计算平台建设过程中的思考)
文/张颖
概括
Flink 在 Homework 实时计算的演进中发挥了重要作用。尤其是在 FlinkSQL 的帮助下,实时任务的开发效率得到了极大的提升。
本文文章主要分享FlinkSQL在作业帮助中的使用和实践经验,以及随着任务规模的增加,从0到1搭建实时计算平台过程中遇到的问题和解决方法.
一、发展历程
Homework Help主要利用人工智能、大数据等技术为学生提供更高效的学习解决方案。因此,业务数据主要包括学生的出勤率和知识点的掌握情况。在整体架构中,无论是binlog还是普通日志,都是在采集之后写入Kafka,分别通过实时和离线计算写入存储层。基于OLAP,对外提供相应的产品化服务,如工作台、BI分析等。工具。
目前 Homework Help 的实时计算主要基于 Flink,开发过程分为三个阶段:
1. 2019 年实时计算包括少量 SparkStreaming 作业,提供给导师和讲师。在解决实时性需求的过程中,会发现开发效率很低,数据几乎无法复用。
2. 之后,正常的做法是在生产实践中逐步应用Flink JAR,积累经验后开始搭建平台和应用Flink SQL。但是在过去的20年里,业务对实时计算提出了很多要求,而我们开发的人力储备不足。当时,在 Flink SQL 1.9 发布后不久,SQL 功能发生了很大变化,所以我们的做法是直接将 Flink SQL 应用到实时数仓方向。目前整个实时数仓90%以上的任务都是使用Flink SQL实现的。
3. 到 2020 年 11 月,Flink 的 Job 数量迅速增加到数百个,我们开始构建从 0 到 1 的实时计算平台,已经支撑了公司所有的重要业务线,计算是部署在多个云中。在一个集群上。
介绍以下两个方面:
1. FlinkSQL 实践中遇到的典型问题及解决方案
2. 实时计算平台建设的几点思考
二、Flink SQL 应用实践
下面是基于 Flink SQL 的完整数据流架构:
binlog/log 采集 写入 Kafka 后,topic 会自动注册为元数据表,这是后续所有实时 SQL 作业的起点。用户可以在 SQL 作业中使用此表,而无需定义复杂的 DDL。
同时,在考虑实际应用时,还需要根据元数据表添加或替换表属性:
1. 新增:元数据记录表级属性,但 SQL 作业可能需要添加任务级属性。例如,对于Kafka源表,添加作业的group.id来记录偏移量。
2. 替换:离线测试时,在引用元数据表的基础上,只需要定义broker topic等属性覆盖源表,即可快速构建离线测试表。
框架还需要支持用户的SQL作业,方便输出指标和日志,实现全链路监控和跟踪。
这里主要介绍SQL添加Trace函数时的DAG优化实践,以及我们对Table底层物理存储的选择和封装。
2.1. SQL 增加 Trace 功能
SQL可以提高开发效率,但是业务逻辑的复杂度还是有的,复杂的业务逻辑写的DML会很长。在这种情况下,建议使用视图来提高可读性。因为视图的 SQL 比较短,所以不应该像代码规范中的单个函数那样太长。
下图左侧是一个示例任务的部分DAG,可以看到有很多SQL节点。这种情况下很难定位,因为如果是DataStream API实现的代码,也可以加日志。但是 SQL 做不到。用户可以干预的入口很少,只能看到整个作业的输入输出。
类似于在函数中打印日志,我们希望支持在视图中添加 Trace,以方便案例追踪。
但是我在尝试将 Trace 添加到 SQL 时遇到了一些问题,这是一个简化的示例:
右上角的SQL创建source_table为源表,prepare_data视图读取表,在sql中调用foo udf,然后使用StatementSet分别插入两个下游,同时将视图转换为DataStream调用 TraceSDK 写入跟踪系统。
注意:我们当时是基于 1.9 开发的。为了清楚起见,我们还使用了一些后来添加的功能。
上图下方的实际 DAG 看起来并不像预期的那样:
1. DAG分为上下不相关的两部分。Kafka源表是DataSource部分,读取两次。
2. foo 方法被调用了 3 次。
数据源压力和计算性能需要优化。
为了解决这个问题,我们需要从几个角度进行优化。这里主要介绍DAG合并的思想。无论是table还是stream的env,都会产生相应的transformation。我们的做法是统一合并到stream env中,这样就可以在stream env中得到一个完整的变换列表,然后生成StreamGraph提交。
左下角是我们优化的 DAG,读取源表并只调用一次 foo 方法:
优化后的 DAG 效果与我们写 SQL 时的逻辑图非常相似,性能自然符合预期。
回到问题本身,业务可以简单的使用一条语句给视图的某些字段添加trace,例如:prepare_data.trace.fields=f0,f1. 由于SQL中自然收录字段名,所以trace数据可读性甚至高于普通日志。
2.2. 表选择与设计
如前所述,我们的首要要求是提高人的效率。因此,Table 需要具备更好的分层和复用能力,并且支持模板化开发,以便 N 个端到端的 Flink 作业能够快速串联起来。
我们的解决方案是基于 Redis 实现的,它首先有几个优点:
1. 高qps,低延迟:这应该是所有实时计算的关注点。
2. TTL:用户无需关心数据如何退出该字段,只需给一个合理的TTL即可。
3. 通过使用protobuf等高性能紧凑的序列化方式,并使用TTL,整体存储小于200G,redis的内存压力可以接受。
4. 适配计算模型:为了保证计算本身的时序,会进行keyBy操作,同时需要处理的数据会被shuffle到同一个并发,所以它不会过多依赖存储来考虑锁的优化。
接下来,我们的场景主要是解决多索引和触发消息的问题。
上图显示了一个表格示例,显示学生是否出现在某个章节中:
1. 多索引:数据首先以字符串形式存储,比如key=(uid, course_id), value=serialize(is_attend, ...),这样我们就可以在SQL中JOIN ON uid AND course_id . 如果 JOIN ON 其他字段,比如 course_id 怎么办?我们的做法是同时写一个以lesson_id为key的集合,集合中的元素是对应的(uid,lesson_id)。接下来在找lesson_id = 123的时候,先取出集合下的所有元素,然后通过管道找到所有的VALUE并返回。
2. 触发消息:写入redis后,会同时向Kafka写入一条更新消息。在 Redis Connector 的实现中,保证了两个存储之间的一致性、顺序性和不丢失数据。
这些功能都封装在 Redis Connector 中,业务可以通过 DDL 简单定义这样的 Table。
DDL 中的几个重要属性:
1. primary 定义了主键,对应字符串数据结构,比如例子中的uid + course_id。
2. index.fields 定义了辅助搜索的索引字段,例如示例中的课程id;也可以定义多个索引。
3. poster.kafka 定义了接收触发消息的kafka 表。该表也在元数据中定义,用户可以直接读取该表,而无需在后续的 SQL 作业中定义。
因此,整个开发模式复用性高,用户可以轻松开发端到端的N个SQL作业,而无需担心如何追溯案例。
三、 平台搭建
上述数据流架构搭建完成后,2020.11实时作业数量迅速增加到几百个,比2019年快很多。这个时候我们开始搭建实时计算平台从0到1,然后分享了搭建过程中的一些想法。
平台支持的功能主要有三个起点:
1. 统一:统一不同云厂商的不同集群环境、Flink版本、提交方式等;之前hadoop客户端分散在用户的提交机器上,对集群数据和任务安全存在隐患。升级和迁移成本。我们希望通过平台统一任务的提交入口和提交方式。
2.易用性:平台交互可以提供更易用的功能,如调试、语义检测等,可以提高任务测试的人为效率,并记录任务的版本历史,支持方便在线和回滚操作。
3. 规范:权限控制、流程审批等,类似于在线服务的在线流程,通过平台可以规范实时任务的研发流程。
3.1.规范——实时任务进程管理
FlinkSQL 让开发变得非常简单和高效,但是越简单越难标准化,因为可能写一段 SQL 只需要两个小时,但通过规范却需要半天时间。
但是,该规范仍然需要执行。一些问题类似于在线服务,在实时计算中也遇到过:
1. 记不清了:任务上线一年了,最初的需求可能是口耳相传。最好记住wiki或email,但在任务交接时很容易记不清。
2. 不规则:UDF或DataStream代码,均不符合规范,可读性差。结果,后来接手的学生无法升级,也不敢改变,无法长期维持。还应该有一个关于如何编写包括实时任务在内的 SQL 的规范。
3. 找不到:线上运行的任务依赖一个jar,哪个git模块对应哪个commitId,有问题怎么第一时间找到对应的代码实现。
4.盲改:一直正常的任务,周末突然报警,原因是私下修改了线上任务的sql。
规范主要分为三个部分:
1. 开发:RD 可以从 UDF 原型项目中快速创建 UDF 模块,该项目基于 flink 快速入门。创建的 UDF 模块可以正常编译,包括 WordCount 之类的 udf 示例,以及 ReadMe 和 VersionHelper 等默认的 helper 方法。根据业务需求修改后,通过CR上传到Git。
2. 需求管理与编译:提交的代码将与需求卡片相关联。集群编译和QA测试后,即可下单上线。
3. 在线:根据模块和编译输出选择更新/创建哪些作业,并在作业所有者或领导批准后重新部署。
整个研发过程不能离线修改,比如更改jar包或者对哪个任务生效。一个实时任务,即使跑了几年,也能查到谁在线,谁批准了当前任务,当时的测试记录,对应的Git代码,以及提出的实时指标要求谁开始的。任务维持很长时间。
3.2 易用性监控
我们当前的 Flink 作业在 Yarn 上运行。作业启动后,预计 Prometheus 会抓取 Yarn 分配的 Container,然后连接到报警系统。用户可以根据告警系统配置Kafka延迟告警和Checkpoint故障告警。构建此路径时遇到两个主要问题:
1. PrometheusReporter启动HTTPServer后,Prometheus如何动态感知;它还需要能够控制度量的大小以避免采集大量无用数据。
2. 我们SQL的源表基本都是Kafka。相比第三方工具,在计算平台上配置Kafka延迟告警更方便。因为自然可以得到任务读取的topic和group.id,所以也可以和任务失败使用同一个告警组。结合告警模板,配置告警非常简单。
关于解决方案:
1. 添加了基于官方 PrometheusReporter 的发现功能。Container 的 HTTPServer 启动后,对应的 ip:port 以临时节点的形式注册到 zk 上,然后使用 Prometheus 的 discover 目标来监控 zk 节点的变化。由于是临时节点,当 Container 被销毁时,该节点就消失了,Prometheus 也能感应到它不再被抓取。这样一来,就很容易为普罗米修斯搭建一条抢夺的路径。
2. KafkaConsumer.records-lag 是一个比较实用和重要的延迟指标,主要做了两个任务。修改 KafkaConnector 并在 KafkaConsumer.poll 之后将其公开,以确保 records-lag 指示器可见。另外,在做这个的过程中,我们发现不同Kafka版本的metric格式是不同的()。我们的方法是将它们扁平化为一种格式,并将它们注册到 flink 的指标中。这样不同版本暴露的指标是一致的。
四、总结与展望
上一阶段使用 Flink SQL 来支持实时作业的快速开发,搭建了实时计算平台来支持数千个 Flink 作业。
更大的见解之一是 SQL 确实简化了开发,但它也阻止了更多的技术细节。对实时作业运维工具的要求,比如 Trace,或者任务的规范没有改变,对这些的要求更加严格。
因为在细节被屏蔽的同时,一旦出现问题,用户不知道如何处理。就像冰山一角,漏水越少,下沉越多,越需要做好周边系统的建设。
二是适应现状。一是能尽快满足当前的需求。比如,我们正在提高人的效率,降低发展门槛。同时还要继续探索更多的业务场景,比如用HBase和RPC服务代替Redis Connector。现在的好处是修改了底层存储,用户对SQL作业的感知很小,因为SQL作业基本都是业务逻辑,DDL定义了元数据。
接下来的计划主要分为三个部分:
1. 支持资源弹性伸缩,平衡实时作业的成本和时效性。
2. 我们从 1.9 开始大规模应用 Flink SQL。现在版本升级发生了很大的变化,我们需要考虑如何让业务能够低成本的升级和使用新版本中的特性。
3. 探索流批集成在实际业务场景中的实现。
关于作者
张颖,2019年加入乔邦大数据中台研发部,负责实时计算相关工作。 查看全部
算法 自动采集列表(
FlinkFlinkSQL实践遇到的典型问题以及解决方案2.实时计算平台建设过程中的思考)
文/张颖
概括
Flink 在 Homework 实时计算的演进中发挥了重要作用。尤其是在 FlinkSQL 的帮助下,实时任务的开发效率得到了极大的提升。
本文文章主要分享FlinkSQL在作业帮助中的使用和实践经验,以及随着任务规模的增加,从0到1搭建实时计算平台过程中遇到的问题和解决方法.
一、发展历程
Homework Help主要利用人工智能、大数据等技术为学生提供更高效的学习解决方案。因此,业务数据主要包括学生的出勤率和知识点的掌握情况。在整体架构中,无论是binlog还是普通日志,都是在采集之后写入Kafka,分别通过实时和离线计算写入存储层。基于OLAP,对外提供相应的产品化服务,如工作台、BI分析等。工具。
目前 Homework Help 的实时计算主要基于 Flink,开发过程分为三个阶段:
1. 2019 年实时计算包括少量 SparkStreaming 作业,提供给导师和讲师。在解决实时性需求的过程中,会发现开发效率很低,数据几乎无法复用。
2. 之后,正常的做法是在生产实践中逐步应用Flink JAR,积累经验后开始搭建平台和应用Flink SQL。但是在过去的20年里,业务对实时计算提出了很多要求,而我们开发的人力储备不足。当时,在 Flink SQL 1.9 发布后不久,SQL 功能发生了很大变化,所以我们的做法是直接将 Flink SQL 应用到实时数仓方向。目前整个实时数仓90%以上的任务都是使用Flink SQL实现的。
3. 到 2020 年 11 月,Flink 的 Job 数量迅速增加到数百个,我们开始构建从 0 到 1 的实时计算平台,已经支撑了公司所有的重要业务线,计算是部署在多个云中。在一个集群上。
介绍以下两个方面:
1. FlinkSQL 实践中遇到的典型问题及解决方案
2. 实时计算平台建设的几点思考
二、Flink SQL 应用实践
下面是基于 Flink SQL 的完整数据流架构:
binlog/log 采集 写入 Kafka 后,topic 会自动注册为元数据表,这是后续所有实时 SQL 作业的起点。用户可以在 SQL 作业中使用此表,而无需定义复杂的 DDL。
同时,在考虑实际应用时,还需要根据元数据表添加或替换表属性:
1. 新增:元数据记录表级属性,但 SQL 作业可能需要添加任务级属性。例如,对于Kafka源表,添加作业的group.id来记录偏移量。
2. 替换:离线测试时,在引用元数据表的基础上,只需要定义broker topic等属性覆盖源表,即可快速构建离线测试表。
框架还需要支持用户的SQL作业,方便输出指标和日志,实现全链路监控和跟踪。
这里主要介绍SQL添加Trace函数时的DAG优化实践,以及我们对Table底层物理存储的选择和封装。
2.1. SQL 增加 Trace 功能
SQL可以提高开发效率,但是业务逻辑的复杂度还是有的,复杂的业务逻辑写的DML会很长。在这种情况下,建议使用视图来提高可读性。因为视图的 SQL 比较短,所以不应该像代码规范中的单个函数那样太长。
下图左侧是一个示例任务的部分DAG,可以看到有很多SQL节点。这种情况下很难定位,因为如果是DataStream API实现的代码,也可以加日志。但是 SQL 做不到。用户可以干预的入口很少,只能看到整个作业的输入输出。
类似于在函数中打印日志,我们希望支持在视图中添加 Trace,以方便案例追踪。
但是我在尝试将 Trace 添加到 SQL 时遇到了一些问题,这是一个简化的示例:
右上角的SQL创建source_table为源表,prepare_data视图读取表,在sql中调用foo udf,然后使用StatementSet分别插入两个下游,同时将视图转换为DataStream调用 TraceSDK 写入跟踪系统。
注意:我们当时是基于 1.9 开发的。为了清楚起见,我们还使用了一些后来添加的功能。
上图下方的实际 DAG 看起来并不像预期的那样:
1. DAG分为上下不相关的两部分。Kafka源表是DataSource部分,读取两次。
2. foo 方法被调用了 3 次。
数据源压力和计算性能需要优化。
为了解决这个问题,我们需要从几个角度进行优化。这里主要介绍DAG合并的思想。无论是table还是stream的env,都会产生相应的transformation。我们的做法是统一合并到stream env中,这样就可以在stream env中得到一个完整的变换列表,然后生成StreamGraph提交。
左下角是我们优化的 DAG,读取源表并只调用一次 foo 方法:
优化后的 DAG 效果与我们写 SQL 时的逻辑图非常相似,性能自然符合预期。
回到问题本身,业务可以简单的使用一条语句给视图的某些字段添加trace,例如:prepare_data.trace.fields=f0,f1. 由于SQL中自然收录字段名,所以trace数据可读性甚至高于普通日志。
2.2. 表选择与设计
如前所述,我们的首要要求是提高人的效率。因此,Table 需要具备更好的分层和复用能力,并且支持模板化开发,以便 N 个端到端的 Flink 作业能够快速串联起来。
我们的解决方案是基于 Redis 实现的,它首先有几个优点:
1. 高qps,低延迟:这应该是所有实时计算的关注点。
2. TTL:用户无需关心数据如何退出该字段,只需给一个合理的TTL即可。
3. 通过使用protobuf等高性能紧凑的序列化方式,并使用TTL,整体存储小于200G,redis的内存压力可以接受。
4. 适配计算模型:为了保证计算本身的时序,会进行keyBy操作,同时需要处理的数据会被shuffle到同一个并发,所以它不会过多依赖存储来考虑锁的优化。
接下来,我们的场景主要是解决多索引和触发消息的问题。
上图显示了一个表格示例,显示学生是否出现在某个章节中:
1. 多索引:数据首先以字符串形式存储,比如key=(uid, course_id), value=serialize(is_attend, ...),这样我们就可以在SQL中JOIN ON uid AND course_id . 如果 JOIN ON 其他字段,比如 course_id 怎么办?我们的做法是同时写一个以lesson_id为key的集合,集合中的元素是对应的(uid,lesson_id)。接下来在找lesson_id = 123的时候,先取出集合下的所有元素,然后通过管道找到所有的VALUE并返回。
2. 触发消息:写入redis后,会同时向Kafka写入一条更新消息。在 Redis Connector 的实现中,保证了两个存储之间的一致性、顺序性和不丢失数据。
这些功能都封装在 Redis Connector 中,业务可以通过 DDL 简单定义这样的 Table。
DDL 中的几个重要属性:
1. primary 定义了主键,对应字符串数据结构,比如例子中的uid + course_id。
2. index.fields 定义了辅助搜索的索引字段,例如示例中的课程id;也可以定义多个索引。
3. poster.kafka 定义了接收触发消息的kafka 表。该表也在元数据中定义,用户可以直接读取该表,而无需在后续的 SQL 作业中定义。
因此,整个开发模式复用性高,用户可以轻松开发端到端的N个SQL作业,而无需担心如何追溯案例。
三、 平台搭建
上述数据流架构搭建完成后,2020.11实时作业数量迅速增加到几百个,比2019年快很多。这个时候我们开始搭建实时计算平台从0到1,然后分享了搭建过程中的一些想法。
平台支持的功能主要有三个起点:
1. 统一:统一不同云厂商的不同集群环境、Flink版本、提交方式等;之前hadoop客户端分散在用户的提交机器上,对集群数据和任务安全存在隐患。升级和迁移成本。我们希望通过平台统一任务的提交入口和提交方式。
2.易用性:平台交互可以提供更易用的功能,如调试、语义检测等,可以提高任务测试的人为效率,并记录任务的版本历史,支持方便在线和回滚操作。
3. 规范:权限控制、流程审批等,类似于在线服务的在线流程,通过平台可以规范实时任务的研发流程。
3.1.规范——实时任务进程管理
FlinkSQL 让开发变得非常简单和高效,但是越简单越难标准化,因为可能写一段 SQL 只需要两个小时,但通过规范却需要半天时间。
但是,该规范仍然需要执行。一些问题类似于在线服务,在实时计算中也遇到过:
1. 记不清了:任务上线一年了,最初的需求可能是口耳相传。最好记住wiki或email,但在任务交接时很容易记不清。
2. 不规则:UDF或DataStream代码,均不符合规范,可读性差。结果,后来接手的学生无法升级,也不敢改变,无法长期维持。还应该有一个关于如何编写包括实时任务在内的 SQL 的规范。
3. 找不到:线上运行的任务依赖一个jar,哪个git模块对应哪个commitId,有问题怎么第一时间找到对应的代码实现。
4.盲改:一直正常的任务,周末突然报警,原因是私下修改了线上任务的sql。
规范主要分为三个部分:
1. 开发:RD 可以从 UDF 原型项目中快速创建 UDF 模块,该项目基于 flink 快速入门。创建的 UDF 模块可以正常编译,包括 WordCount 之类的 udf 示例,以及 ReadMe 和 VersionHelper 等默认的 helper 方法。根据业务需求修改后,通过CR上传到Git。
2. 需求管理与编译:提交的代码将与需求卡片相关联。集群编译和QA测试后,即可下单上线。
3. 在线:根据模块和编译输出选择更新/创建哪些作业,并在作业所有者或领导批准后重新部署。
整个研发过程不能离线修改,比如更改jar包或者对哪个任务生效。一个实时任务,即使跑了几年,也能查到谁在线,谁批准了当前任务,当时的测试记录,对应的Git代码,以及提出的实时指标要求谁开始的。任务维持很长时间。
3.2 易用性监控
我们当前的 Flink 作业在 Yarn 上运行。作业启动后,预计 Prometheus 会抓取 Yarn 分配的 Container,然后连接到报警系统。用户可以根据告警系统配置Kafka延迟告警和Checkpoint故障告警。构建此路径时遇到两个主要问题:
1. PrometheusReporter启动HTTPServer后,Prometheus如何动态感知;它还需要能够控制度量的大小以避免采集大量无用数据。
2. 我们SQL的源表基本都是Kafka。相比第三方工具,在计算平台上配置Kafka延迟告警更方便。因为自然可以得到任务读取的topic和group.id,所以也可以和任务失败使用同一个告警组。结合告警模板,配置告警非常简单。
关于解决方案:
1. 添加了基于官方 PrometheusReporter 的发现功能。Container 的 HTTPServer 启动后,对应的 ip:port 以临时节点的形式注册到 zk 上,然后使用 Prometheus 的 discover 目标来监控 zk 节点的变化。由于是临时节点,当 Container 被销毁时,该节点就消失了,Prometheus 也能感应到它不再被抓取。这样一来,就很容易为普罗米修斯搭建一条抢夺的路径。
2. KafkaConsumer.records-lag 是一个比较实用和重要的延迟指标,主要做了两个任务。修改 KafkaConnector 并在 KafkaConsumer.poll 之后将其公开,以确保 records-lag 指示器可见。另外,在做这个的过程中,我们发现不同Kafka版本的metric格式是不同的()。我们的方法是将它们扁平化为一种格式,并将它们注册到 flink 的指标中。这样不同版本暴露的指标是一致的。
四、总结与展望
上一阶段使用 Flink SQL 来支持实时作业的快速开发,搭建了实时计算平台来支持数千个 Flink 作业。
更大的见解之一是 SQL 确实简化了开发,但它也阻止了更多的技术细节。对实时作业运维工具的要求,比如 Trace,或者任务的规范没有改变,对这些的要求更加严格。
因为在细节被屏蔽的同时,一旦出现问题,用户不知道如何处理。就像冰山一角,漏水越少,下沉越多,越需要做好周边系统的建设。
二是适应现状。一是能尽快满足当前的需求。比如,我们正在提高人的效率,降低发展门槛。同时还要继续探索更多的业务场景,比如用HBase和RPC服务代替Redis Connector。现在的好处是修改了底层存储,用户对SQL作业的感知很小,因为SQL作业基本都是业务逻辑,DDL定义了元数据。
接下来的计划主要分为三个部分:
1. 支持资源弹性伸缩,平衡实时作业的成本和时效性。
2. 我们从 1.9 开始大规模应用 Flink SQL。现在版本升级发生了很大的变化,我们需要考虑如何让业务能够低成本的升级和使用新版本中的特性。
3. 探索流批集成在实际业务场景中的实现。
关于作者
张颖,2019年加入乔邦大数据中台研发部,负责实时计算相关工作。
算法 自动采集列表(基于高斯滤波算法的磨皮算法研究小结(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2022-02-01 22:12
写这篇博客也是我这段时间对微晶磨皮算法研究的一个总结。
目前大家对面部微晶磨皮算法并不陌生。从PS到APP应用,可以说是层出不穷。这里我将具体过程总结如下:
1. 保边滤镜
2.肤色检测
3.图像融合
4. 锐化
对于边缘保留过滤器:
这种滤镜的主要功能是在平滑皮肤的同时保留面部特征的细节。目前,可用于微晶磨皮的保边滤光片主要有以下几种:
1、表面模糊
该算法是PS中的一个函数,具有很好的边缘保留效果。其算法实现连接:点击打开链接
代码库连接:点击打开链接
效果如下:
原创图像模糊
2.双边过滤
本算法由高斯分量+梯度分量组成权重信息,在保留边缘功能的同时实现图像模糊平滑,代码连接:点击打开链接
效果图如下:
原图双边滤波 r=15
3.导向过滤器
引导滤波是一种基于引导图的保边滤波算法。它最早由何凯明提出,用于基于暗通道的去雾算法。其实现算法连接代码DEMO:点击打开链接
效果图如下:
原创图像引导过滤 快速引导过滤
3. 基于均值滤波的保边滤波算法
这个算法速度很快,单次效果一般。参考论文《Lee Filter Digital Image Enhancement and Noise Filtering by Use of Local Statistics》
算法实现与程序DEMO连接:点击打开链接
效果图如下:
原图效果图
4. 选择性模糊算法
本算法的具体实现与程序DEMO连接:点击打开链接
效果图如下:
原图选择性滤波算法的效果
5. 基于高斯滤波的微晶磨皮算法
这个算法就不多说了,可以直接看连接:点击打开链接
相关代码DEMO连接:点击打开链接
效果如图:
原图磨皮效果图
以上就是我采集到的,目前微晶换肤算法可以使用的滤镜,大家可以参考一下。
对于肤色检测:
肤色检测的相关资料很多,主要可以分为两类:基于色彩空间统计的方法和基于机器学习分类的方法。
以下是一些链接:点击打开链接
基于RGB色彩空间的算法:
对于图像融合:
这种图像融合主要是指将滤波后的图像与细节图像进行融合,得到具有强烈细节真实感和磨皮效果的结果图像。
一般基于alpha通道,或者使用羽化操作进行融合,公式如下:
res = (basePixel * alpha + filterPixel * (255 - alpha)) >>8
注意这里的alpha在0-255之间,这里是原创图像和过滤后图像的融合。
对于锐化算法:
在得到磨皮融合的效果图后,我们还需要进行一定的锐化算法,进一步提升细节感。这里可以使用USM锐化或者经典的邻域锐化、拉普拉斯锐化等,相关资料自行百度吧。
以上所有内容都与微晶换肤算法有关。让我与你分享。最后一个是算法的效率。解决这个问题的核心在于滤波算法的选择。你可以自己优化。我已经实现了一个基于 Sobel 算子和均值滤波的边缘保留滤波器。它只需要执行一个均值滤波和一个sobel算子。速度非常好。下面是效果图:
原创图像 查看全部
算法 自动采集列表(基于高斯滤波算法的磨皮算法研究小结(一))
写这篇博客也是我这段时间对微晶磨皮算法研究的一个总结。
目前大家对面部微晶磨皮算法并不陌生。从PS到APP应用,可以说是层出不穷。这里我将具体过程总结如下:
1. 保边滤镜
2.肤色检测
3.图像融合
4. 锐化
对于边缘保留过滤器:
这种滤镜的主要功能是在平滑皮肤的同时保留面部特征的细节。目前,可用于微晶磨皮的保边滤光片主要有以下几种:
1、表面模糊
该算法是PS中的一个函数,具有很好的边缘保留效果。其算法实现连接:点击打开链接
代码库连接:点击打开链接
效果如下:
原创图像模糊
2.双边过滤
本算法由高斯分量+梯度分量组成权重信息,在保留边缘功能的同时实现图像模糊平滑,代码连接:点击打开链接
效果图如下:
原图双边滤波 r=15
3.导向过滤器
引导滤波是一种基于引导图的保边滤波算法。它最早由何凯明提出,用于基于暗通道的去雾算法。其实现算法连接代码DEMO:点击打开链接
效果图如下:
原创图像引导过滤 快速引导过滤
3. 基于均值滤波的保边滤波算法
这个算法速度很快,单次效果一般。参考论文《Lee Filter Digital Image Enhancement and Noise Filtering by Use of Local Statistics》
算法实现与程序DEMO连接:点击打开链接
效果图如下:
原图效果图
4. 选择性模糊算法
本算法的具体实现与程序DEMO连接:点击打开链接
效果图如下:
原图选择性滤波算法的效果
5. 基于高斯滤波的微晶磨皮算法
这个算法就不多说了,可以直接看连接:点击打开链接
相关代码DEMO连接:点击打开链接
效果如图:
原图磨皮效果图
以上就是我采集到的,目前微晶换肤算法可以使用的滤镜,大家可以参考一下。
对于肤色检测:
肤色检测的相关资料很多,主要可以分为两类:基于色彩空间统计的方法和基于机器学习分类的方法。
以下是一些链接:点击打开链接
基于RGB色彩空间的算法:
对于图像融合:
这种图像融合主要是指将滤波后的图像与细节图像进行融合,得到具有强烈细节真实感和磨皮效果的结果图像。
一般基于alpha通道,或者使用羽化操作进行融合,公式如下:
res = (basePixel * alpha + filterPixel * (255 - alpha)) >>8
注意这里的alpha在0-255之间,这里是原创图像和过滤后图像的融合。
对于锐化算法:
在得到磨皮融合的效果图后,我们还需要进行一定的锐化算法,进一步提升细节感。这里可以使用USM锐化或者经典的邻域锐化、拉普拉斯锐化等,相关资料自行百度吧。
以上所有内容都与微晶换肤算法有关。让我与你分享。最后一个是算法的效率。解决这个问题的核心在于滤波算法的选择。你可以自己优化。我已经实现了一个基于 Sobel 算子和均值滤波的边缘保留滤波器。它只需要执行一个均值滤波和一个sobel算子。速度非常好。下面是效果图:
原创图像
算法 自动采集列表(基于KDDCup99的部分数据,本次数据挖掘网络入侵识别模型研究 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-01-31 09:02
)
基于随机森林算法的网络入侵自动识别模型一、模型应用
互联网的蓬勃发展给人们的工作和生活带来了极大的便利。然而,随着现代网络应用的普及,随之而来的网络不安全因素也给网络信息安全带来了严峻挑战。传统的网络安全技术已经难以应对这些日益严重的安全威胁,因此我们有必要开发专门的工具来规避这些不安全因素的攻击,而入侵检测技术可以作为我们非常重要的一项技术。
随着网络入侵的频繁发生,网络攻击的手段也呈现出多样性和隐蔽性的特点。当前网络和信息安全形势严峻。网络安全面临的主要威胁是:
KDDCup99网络入侵检测数据背景介绍:
1998 年,美国国防高级计划局 (DARPA) 在麻省理工学院林肯实验室开展了入侵检测评估项目。林肯实验室建立了模拟美国空军局域网的网络环境,采集了 9 周的 TCPdump 网络连接和系统审计数据,模拟了各种用户类型、各种网络流量和攻击方式,使其像一个真实的网络环境。这些 TCPdump采集 原创数据分为两部分:7 周的训练数据收录大约 5,000,000 条网络连接记录,其余 2 周的测试数据收录大约 2,000,000 条网络连接记录。
基于KDDCup99的部分数据,本次数据挖掘的建模目标如下:
1)诱导入侵的关键特征
2)建立入侵识别模型。
二、实现过程
KDDCup99网络入侵识别流程如图1所示,主要包括以下步骤:
使用KDDCUP99中的网络入侵检测包kddcup.data_10_percent,这是一个
kdd_data 数据包的 10% 采样(490 万条数据记录);
对样本数据进行探索分析,通过对41个固定特征属性的分析,发现前31个特征属性可以反映变化,因此连接记录的分析处理针对的是31个特征属性;
对样本数据进行预处理,包括数据清洗、缺失值处理和数据转换;
建立建模样本集;
建立KDDCUP99网络入侵识别模型;
进行模型评估;
模型优化。
本案例以模拟美国空军局域网网络环境记录的KDDCup99数据集为基础,重点介绍各种分类算法在数据挖掘中的应用。
三、核心技术四、您可以将此模型用于五、运行时环境
windows/linux/mac OS,64位操作系统,内存:8GB及以上,R3.5.1。
六、资源展示
查看全部
算法 自动采集列表(基于KDDCup99的部分数据,本次数据挖掘网络入侵识别模型研究
)
基于随机森林算法的网络入侵自动识别模型一、模型应用
互联网的蓬勃发展给人们的工作和生活带来了极大的便利。然而,随着现代网络应用的普及,随之而来的网络不安全因素也给网络信息安全带来了严峻挑战。传统的网络安全技术已经难以应对这些日益严重的安全威胁,因此我们有必要开发专门的工具来规避这些不安全因素的攻击,而入侵检测技术可以作为我们非常重要的一项技术。
随着网络入侵的频繁发生,网络攻击的手段也呈现出多样性和隐蔽性的特点。当前网络和信息安全形势严峻。网络安全面临的主要威胁是:
KDDCup99网络入侵检测数据背景介绍:
1998 年,美国国防高级计划局 (DARPA) 在麻省理工学院林肯实验室开展了入侵检测评估项目。林肯实验室建立了模拟美国空军局域网的网络环境,采集了 9 周的 TCPdump 网络连接和系统审计数据,模拟了各种用户类型、各种网络流量和攻击方式,使其像一个真实的网络环境。这些 TCPdump采集 原创数据分为两部分:7 周的训练数据收录大约 5,000,000 条网络连接记录,其余 2 周的测试数据收录大约 2,000,000 条网络连接记录。
基于KDDCup99的部分数据,本次数据挖掘的建模目标如下:
1)诱导入侵的关键特征
2)建立入侵识别模型。
二、实现过程
KDDCup99网络入侵识别流程如图1所示,主要包括以下步骤:
使用KDDCUP99中的网络入侵检测包kddcup.data_10_percent,这是一个
kdd_data 数据包的 10% 采样(490 万条数据记录);
对样本数据进行探索分析,通过对41个固定特征属性的分析,发现前31个特征属性可以反映变化,因此连接记录的分析处理针对的是31个特征属性;
对样本数据进行预处理,包括数据清洗、缺失值处理和数据转换;
建立建模样本集;
建立KDDCUP99网络入侵识别模型;
进行模型评估;
模型优化。
本案例以模拟美国空军局域网网络环境记录的KDDCup99数据集为基础,重点介绍各种分类算法在数据挖掘中的应用。
三、核心技术四、您可以将此模型用于五、运行时环境
windows/linux/mac OS,64位操作系统,内存:8GB及以上,R3.5.1。
六、资源展示
算法 自动采集列表(算法自动采集列表等属性,官方有什么也行?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-24 03:03
算法自动采集列表等属性,通过robotium,发送到openid也行。自己开发一套采集代理,代理池也行,代理ip池也行。官方有什么也行。
关键是版权问题,这需要代理商来做,他们自己也有api。
可以直接用openid,公司内部提供免费的线上接口,请务必写好规则,避免跳转点击。
如果不太懂爬虫技术可以考虑proxyserver+httpclient直接解决ua问题。
经常都是这样的
可以用socket本地连接数据库服务,
有免费的平台,
不是openidrobotforjava吗
可以尝试使用swoole+messagequeue+localreference实现,
谁告诉你可以没有额外要求的,如果一定要做好的话,可以下载bigpipe直接抓取,还是可以,但是你要是抓取大量数据,你就得要把数据拆分,然后利用bigpipe读取时再使用正则匹配,实际上bigpipe接着抓数据要比resolver更好,更方便,但是会比较卡,需要固定开几个线程,如果数据不少,如果你直接使用bigpipe只会浪费数据,像以前photoshop一个文件只能读取150kb,但是如果使用resolver可以读取200kb甚至以上,还有如果你有开多个线程机器来抓取数据,这一点算是十分重要的,有时候resolver更要不得!。 查看全部
算法 自动采集列表(算法自动采集列表等属性,官方有什么也行?)
算法自动采集列表等属性,通过robotium,发送到openid也行。自己开发一套采集代理,代理池也行,代理ip池也行。官方有什么也行。
关键是版权问题,这需要代理商来做,他们自己也有api。
可以直接用openid,公司内部提供免费的线上接口,请务必写好规则,避免跳转点击。
如果不太懂爬虫技术可以考虑proxyserver+httpclient直接解决ua问题。
经常都是这样的
可以用socket本地连接数据库服务,
有免费的平台,
不是openidrobotforjava吗
可以尝试使用swoole+messagequeue+localreference实现,
谁告诉你可以没有额外要求的,如果一定要做好的话,可以下载bigpipe直接抓取,还是可以,但是你要是抓取大量数据,你就得要把数据拆分,然后利用bigpipe读取时再使用正则匹配,实际上bigpipe接着抓数据要比resolver更好,更方便,但是会比较卡,需要固定开几个线程,如果数据不少,如果你直接使用bigpipe只会浪费数据,像以前photoshop一个文件只能读取150kb,但是如果使用resolver可以读取200kb甚至以上,还有如果你有开多个线程机器来抓取数据,这一点算是十分重要的,有时候resolver更要不得!。
算法 自动采集列表(数据质量可以帮助您第一时间感知源端数据的变更与ETL)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-21 10:17
数据质量可以帮助您即时感知ETL(Extract Transformation Load)中产生的源数据和脏数据的变化,自动拦截问题任务,有效防止脏数据向下游扩散。避免因任务输出而导致数据不符合预期,导致时间成本增加、意外额外成本增加或影响数据的正常使用。
费用说明
运行数据质量规则的成本由两部分组成:
特征
解释数据质量有助于识别数据库频繁变化、业务变化频繁、数据定义不明确、业务系统数据脏、系统交互异常、数据修正不准确、数据仓库异常等质量问题。
数据质量监控流程如下图所示。
说明 数据质量主要监控EMR(E-MapReduce)、Hologres、AnalyticDB for PostgreSQL、MaxCompute、DataHub数据集的质量。因此,您需要先创建表并在表中写入数据,然后才能使用数据质量功能。
请参阅数据质量管理原则。
注意事项 规则配置和验证过程 数据质量通过表配置的分区表达式匹配节点每天产生的表分区。执行,包括自动调度的周期性实例、手动触发的补充数据实例和运行的测试实例),将触发数据质量规则验证。可以设置规则的强度来控制节点是否退出失败,避免脏数据的影响。扩展,支持通过告警配置在第一时间接收和处理告警信息。
创建数据质量规则
在数据质量监控规则页面,您可以选择特定引擎下需要保证数据输出质量的表,并配置该表需要配置哪些数据质量规则。在配置之前,可以先了解几件事:
配置表中需要验证的规则
支持针对波动性、数字或动态阈值的表级、字段级验证。规则类型 检查模式 报警模式
数字
数据分析结果与固定值进行比较。
规则告警模式通过定义规则的强度来控制。
挥发性
指定时间段内数据探索结果与数据采样结果的波动率比值支持上升幅度、下降幅度或波动幅度(绝对值)的比较,可根据波动幅度定义规则的强弱。
根据规则的强度触发警报
例如,橙色阈值填写为 5%,红色阈值填写为 10%。当波动率大于5%且小于等于10%时,会发出橙色警报。当波动率大于 10% 时,会出现红色警报。
动态阈值
基于智能算法,结合历史采样结果(模型样本参考量),自动确定合理阈值。动态阈值还支持强规则和弱规则。
注:模型样本参考量是指“动态阈值算法模型”生效的样本最小时间窗范围,在该时间窗内允许缺失10%以下的数据。未达到样本参考量不报警,缺失数据由算法自动补齐。
系统会根据智能算法自动确定合理的阈值;如果发现异常数据,将立即触发警报或封锁。
定义规则告警和告警接收方式:订阅管理
您可以在配置规则时定义规则的强度,从而控制规则的影响范围。您可以通过订阅管理在第一时间接收和处理告警信息。目前支持短信、邮件、钉钉群机器人报警。当调度节点产生的表数据不符合预期时:
定义规则的触发方式:关联调度
数据质量规则与生成表数据的调度节点的执行相关联(生成表数据的节点在运维中心的执行,包括自动调度周期实例、手动触发的补充数据实例、和测试实例运行),数据将被触发。对于质量规则校验,可以设置规则强度来控制节点是否退出失败,避免脏数据影响扩大。
检查规则配置是否正常:test run
规则创建完成后,您可以选择试运行功能来验证创建的数据质量规则是否可以进行数据质量验证。
数据质量规则触发
在运维中心的运维中心,与表关联的调度节点(产生表数据的节点,配置表质量规则时与该节点关联的节点)会运行,并会触发数据节点代码逻辑执行后的质量检查。验证(将在底部生成验证 sql 以执行。)。包括周期实例、补充数据实例和测试实例运行。
当节点操作触发异常数据质量检查时,平台会根据质量规则检查结果和数据质量规则强度判断任务是否失败退出,是否阻塞下游节点的执行以防止影响脏数据进一步扩大。
查看数据质量检查结果
您可以在运维中心的任务执行详情和数据质量任务查询页面查看数据质量验证结果。
查看运维中心节点的运行日志,
打开实例面板,查看执行详情,在如图所示位置查看任务触发的数据质量验证结果。详情请参阅。
这意味着如果验证失败,任务将无法退出并阻塞下游节点的执行。
实例状态失败时,也可能是代码运行成功但节点输出的表不符合预期,强数据质量规则检查失败,导致任务退出失败,阻塞下游实例跑步。实例状态为质量监控验证失败。如下所示。
通过数据质量任务查询界面查看。
任务查询界面可以通过表名和节点ID进行过滤。
查看历史验证详情:任务查询
在任务查询界面,可以通过表或节点查询表的历史验证记录和验证详情。 查看全部
算法 自动采集列表(数据质量可以帮助您第一时间感知源端数据的变更与ETL)
数据质量可以帮助您即时感知ETL(Extract Transformation Load)中产生的源数据和脏数据的变化,自动拦截问题任务,有效防止脏数据向下游扩散。避免因任务输出而导致数据不符合预期,导致时间成本增加、意外额外成本增加或影响数据的正常使用。
费用说明
运行数据质量规则的成本由两部分组成:
特征
解释数据质量有助于识别数据库频繁变化、业务变化频繁、数据定义不明确、业务系统数据脏、系统交互异常、数据修正不准确、数据仓库异常等质量问题。
数据质量监控流程如下图所示。
说明 数据质量主要监控EMR(E-MapReduce)、Hologres、AnalyticDB for PostgreSQL、MaxCompute、DataHub数据集的质量。因此,您需要先创建表并在表中写入数据,然后才能使用数据质量功能。
请参阅数据质量管理原则。
注意事项 规则配置和验证过程 数据质量通过表配置的分区表达式匹配节点每天产生的表分区。执行,包括自动调度的周期性实例、手动触发的补充数据实例和运行的测试实例),将触发数据质量规则验证。可以设置规则的强度来控制节点是否退出失败,避免脏数据的影响。扩展,支持通过告警配置在第一时间接收和处理告警信息。
创建数据质量规则
在数据质量监控规则页面,您可以选择特定引擎下需要保证数据输出质量的表,并配置该表需要配置哪些数据质量规则。在配置之前,可以先了解几件事:
配置表中需要验证的规则
支持针对波动性、数字或动态阈值的表级、字段级验证。规则类型 检查模式 报警模式
数字
数据分析结果与固定值进行比较。
规则告警模式通过定义规则的强度来控制。
挥发性
指定时间段内数据探索结果与数据采样结果的波动率比值支持上升幅度、下降幅度或波动幅度(绝对值)的比较,可根据波动幅度定义规则的强弱。
根据规则的强度触发警报
例如,橙色阈值填写为 5%,红色阈值填写为 10%。当波动率大于5%且小于等于10%时,会发出橙色警报。当波动率大于 10% 时,会出现红色警报。
动态阈值
基于智能算法,结合历史采样结果(模型样本参考量),自动确定合理阈值。动态阈值还支持强规则和弱规则。
注:模型样本参考量是指“动态阈值算法模型”生效的样本最小时间窗范围,在该时间窗内允许缺失10%以下的数据。未达到样本参考量不报警,缺失数据由算法自动补齐。
系统会根据智能算法自动确定合理的阈值;如果发现异常数据,将立即触发警报或封锁。
定义规则告警和告警接收方式:订阅管理
您可以在配置规则时定义规则的强度,从而控制规则的影响范围。您可以通过订阅管理在第一时间接收和处理告警信息。目前支持短信、邮件、钉钉群机器人报警。当调度节点产生的表数据不符合预期时:
定义规则的触发方式:关联调度
数据质量规则与生成表数据的调度节点的执行相关联(生成表数据的节点在运维中心的执行,包括自动调度周期实例、手动触发的补充数据实例、和测试实例运行),数据将被触发。对于质量规则校验,可以设置规则强度来控制节点是否退出失败,避免脏数据影响扩大。
检查规则配置是否正常:test run
规则创建完成后,您可以选择试运行功能来验证创建的数据质量规则是否可以进行数据质量验证。
数据质量规则触发
在运维中心的运维中心,与表关联的调度节点(产生表数据的节点,配置表质量规则时与该节点关联的节点)会运行,并会触发数据节点代码逻辑执行后的质量检查。验证(将在底部生成验证 sql 以执行。)。包括周期实例、补充数据实例和测试实例运行。
当节点操作触发异常数据质量检查时,平台会根据质量规则检查结果和数据质量规则强度判断任务是否失败退出,是否阻塞下游节点的执行以防止影响脏数据进一步扩大。
查看数据质量检查结果
您可以在运维中心的任务执行详情和数据质量任务查询页面查看数据质量验证结果。
查看运维中心节点的运行日志,
打开实例面板,查看执行详情,在如图所示位置查看任务触发的数据质量验证结果。详情请参阅。
这意味着如果验证失败,任务将无法退出并阻塞下游节点的执行。
实例状态失败时,也可能是代码运行成功但节点输出的表不符合预期,强数据质量规则检查失败,导致任务退出失败,阻塞下游实例跑步。实例状态为质量监控验证失败。如下所示。
通过数据质量任务查询界面查看。
任务查询界面可以通过表名和节点ID进行过滤。
查看历史验证详情:任务查询
在任务查询界面,可以通过表或节点查询表的历史验证记录和验证详情。
算法 自动采集列表(DXC!X2(X2.5)2.5的主要功能 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-01-20 23:25
)
DXC 来自 Discuz!X2(X2.5) 采集, DXC采集插件的缩写,致力于discuz上的内容解决方案,帮助站长更快速、更轻松地构建网站内容。
通过DXC采集插件,用户可以方便地采集来自互联网的数据,包括会员数据、文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成内容丰富、会员活跃的热门论坛,对论坛初期运营有很大帮助. 这是一个discuz应用程序,必须由论坛的新手站长安装。
DXC 2.5 的主要特点包括:
1、多种形式的url列表采集文章,包括rss地址、列表页、多级列表等。
2、多种方式编写规则,dom方式,字符截取,智能获取,更方便获取想要的内容
3、规则继承,自动检测匹配规则功能,你会逐渐体会到规则继承带来的便利
4、独有的网页文本提取算法,自动学习归纳规则,更方便泛采集。
5、支持图片定位和水印
6、灵活的发布机制,可以自定义发布者、发布时间点击率等。
7、强大的内容编辑后台,可以轻松编辑采集收到的内容并发布到门户、论坛、博客
8、内容过滤功能,过滤采集内容上的广告,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时量化采集和释放文章
查看全部
算法 自动采集列表(DXC!X2(X2.5)2.5的主要功能
)
DXC 来自 Discuz!X2(X2.5) 采集, DXC采集插件的缩写,致力于discuz上的内容解决方案,帮助站长更快速、更轻松地构建网站内容。
通过DXC采集插件,用户可以方便地采集来自互联网的数据,包括会员数据、文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成内容丰富、会员活跃的热门论坛,对论坛初期运营有很大帮助. 这是一个discuz应用程序,必须由论坛的新手站长安装。
DXC 2.5 的主要特点包括:
1、多种形式的url列表采集文章,包括rss地址、列表页、多级列表等。
2、多种方式编写规则,dom方式,字符截取,智能获取,更方便获取想要的内容
3、规则继承,自动检测匹配规则功能,你会逐渐体会到规则继承带来的便利
4、独有的网页文本提取算法,自动学习归纳规则,更方便泛采集。
5、支持图片定位和水印
6、灵活的发布机制,可以自定义发布者、发布时间点击率等。
7、强大的内容编辑后台,可以轻松编辑采集收到的内容并发布到门户、论坛、博客
8、内容过滤功能,过滤采集内容上的广告,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时量化采集和释放文章
算法 自动采集列表(importrequestsbs4bs4frombs42.1数据采集的步骤(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-20 15:08
1 资料采集概览
要开始一个数据分析项目,您需要做的第一件事就是获取原创数据。获取原创数据的方法有很多。例如:
获取数据集文件
使用爬虫采集数据
直接访问excel、csv等数据文件
其他方法...
在本次福布斯系列数据分析项目实战中,在数据采集方面,主要数据来源于对数据采集的爬虫使用,同时也辅助其他数据进行对比。
本文主要介绍使用爬虫获取数据采集的思路和步骤。
采集福布斯全球上市公司2000强榜单涵盖2007年至2017年,跨越10余年。
这个采集网站的目标是多个网页,但是多个网页的分布结构不同。虽然思路和步骤大同小异,但需要单独写,分别采集。
2 数据采集 步骤
data采集大致分为几个步骤:
下载目标主页内容
采集 主页上的数据
采集 链接到主页上的其他分发页面 网站
下载和采集各个分发页面数据
保存 采集 数据
涉及的 python 库包括 requests、BeautifulSoup 和 csv。下面以采集某年的数据为例,描述数据采集的步骤。
导入请求
从 bs4 导入 BeautifulSoup
导入 csv
2.1 数据下载模块
主要基于requests,代码如下:
定义下载(网址):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, 像 Gecko ) Chrome/59.0.3071.115 Safari/537.36'}
响应 = requests.get(url,headers=headers)
# 打印(response.status_code)
返回响应.文本
该模块将用于主网页的数据下载和各子页面的数据下载。是一个比较常见的模块。
2.2 采集 主页上的数据
主网页的页面结构主要分为两部分,一是收录其他页面数据的网页链接,二是主网页上的公司数据列表,以表格的形式显示在网页上。
这些数据可以用 BeautifulSoup 解析。代码模块如下:
def get_content_first_page(html, year):
'''
获取排名 1-100 的公司列表,包括标题
'''
汤 = BeautifulSoup(html, 'lxml')
身体 = 汤. 身体
body_content = body.find('div', {'id': 'bodyContent'})
表格 = body_content.find_all('table', {'class': 'XXXXtable'})
# 一共有3张桌子,最后一张就是我们想要的
trs = 表[-1].find_all('tr')
# 获取头文件名
# trs[1],这和其他年份不同
row_title = [item.text.strip() for item in trs[1].find_all('th')]
row_title.insert(0, '年份')
rank_list = []
rank_list.append(row_title)
对于 i, tr in enumerate(trs):
如果 i == 0 或 i == 1:
继续
tds = tr.find_all('td')
# 获取公司排名和名单
row = [ item.text.strip() for item in tds]
row.insert(0, 年)
rank_list.append(行)
返回排名列表
def get_page_urls(html):
'''
获取排名 101-2000 的公司的网页链接
'''
汤 = BeautifulSoup(html, 'lxml')
身体 = 汤. 身体
body_content = body.find('div', {'id': 'bodyContent'})
label_div = body_content.find('div', {'align':'center'})
label_a = label_div.find('p').find('b').find_all('a')
page_urls = ['basic_url' + item.get('href') for item in label_a]
返回 page_urls
2.3 每个分发页面上的数据采集
步骤也是网页下载和表格数据爬取。代码内容与主网页类似,但在细节上存在一些差异,这里不再赘述。
2.4 数据存储
采集 的数据最终保存为 csv 文件。模块代码如下:
def save_data_to_csv_file(数据,文件名):
'''
将数据保存到 csv 文件
'''
使用 open(file_name, 'a', errors='ignore', newline='') 作为 f:
f_csv = csv.writer(f)
f_csv.writerows(数据)
2.5 个数据采集主函数
def get_forbes_global_year_2007(year=2007):
网址 = '网址'
html = 下载(网址)
# 打印(html)
data_first_page = get_content_first_page(html, 年份)
# 打印(data_first_page)
save_data_to_csv_file(data_first_page, 'forbes_'+str(year)+'.csv')
page_urls = get_page_urls(html)
# 打印(page_urls)
对于 page_urls 中的 url:
html = 下载(网址)
data_other_page = get_content_other_page(html, year)
# 打印(data_other_page)
print('保存数据...', url)
save_data_to_csv_file(data_other_page, 'forbes_'+str(year)+'.csv')
如果 __name__ == '__main__':
# 获取 2009 年福布斯全球 2000 强的数据
get_forbes_global_year_2007()
3 总结
本文只介绍data采集的思路和各个模块,不提供目标网页的链接。一方面由于原创网页的数据信息比较杂乱,需要在采集的时候编写多个采集程序,另一方面,由于我们的重点是后续的数据分析部分,我们希望不要专注于数据爬取。
在后续分析过程中,我们会检查数据结构、数据完整性及相关信息,请继续关注。
结尾。 查看全部
算法 自动采集列表(importrequestsbs4bs4frombs42.1数据采集的步骤(组图))
1 资料采集概览
要开始一个数据分析项目,您需要做的第一件事就是获取原创数据。获取原创数据的方法有很多。例如:
获取数据集文件
使用爬虫采集数据
直接访问excel、csv等数据文件
其他方法...
在本次福布斯系列数据分析项目实战中,在数据采集方面,主要数据来源于对数据采集的爬虫使用,同时也辅助其他数据进行对比。
本文主要介绍使用爬虫获取数据采集的思路和步骤。
采集福布斯全球上市公司2000强榜单涵盖2007年至2017年,跨越10余年。
这个采集网站的目标是多个网页,但是多个网页的分布结构不同。虽然思路和步骤大同小异,但需要单独写,分别采集。
2 数据采集 步骤
data采集大致分为几个步骤:
下载目标主页内容
采集 主页上的数据
采集 链接到主页上的其他分发页面 网站
下载和采集各个分发页面数据
保存 采集 数据
涉及的 python 库包括 requests、BeautifulSoup 和 csv。下面以采集某年的数据为例,描述数据采集的步骤。
导入请求
从 bs4 导入 BeautifulSoup
导入 csv
2.1 数据下载模块
主要基于requests,代码如下:
定义下载(网址):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, 像 Gecko ) Chrome/59.0.3071.115 Safari/537.36'}
响应 = requests.get(url,headers=headers)
# 打印(response.status_code)
返回响应.文本
该模块将用于主网页的数据下载和各子页面的数据下载。是一个比较常见的模块。
2.2 采集 主页上的数据
主网页的页面结构主要分为两部分,一是收录其他页面数据的网页链接,二是主网页上的公司数据列表,以表格的形式显示在网页上。
这些数据可以用 BeautifulSoup 解析。代码模块如下:
def get_content_first_page(html, year):
'''
获取排名 1-100 的公司列表,包括标题
'''
汤 = BeautifulSoup(html, 'lxml')
身体 = 汤. 身体
body_content = body.find('div', {'id': 'bodyContent'})
表格 = body_content.find_all('table', {'class': 'XXXXtable'})
# 一共有3张桌子,最后一张就是我们想要的
trs = 表[-1].find_all('tr')
# 获取头文件名
# trs[1],这和其他年份不同
row_title = [item.text.strip() for item in trs[1].find_all('th')]
row_title.insert(0, '年份')
rank_list = []
rank_list.append(row_title)
对于 i, tr in enumerate(trs):
如果 i == 0 或 i == 1:
继续
tds = tr.find_all('td')
# 获取公司排名和名单
row = [ item.text.strip() for item in tds]
row.insert(0, 年)
rank_list.append(行)
返回排名列表
def get_page_urls(html):
'''
获取排名 101-2000 的公司的网页链接
'''
汤 = BeautifulSoup(html, 'lxml')
身体 = 汤. 身体
body_content = body.find('div', {'id': 'bodyContent'})
label_div = body_content.find('div', {'align':'center'})
label_a = label_div.find('p').find('b').find_all('a')
page_urls = ['basic_url' + item.get('href') for item in label_a]
返回 page_urls
2.3 每个分发页面上的数据采集
步骤也是网页下载和表格数据爬取。代码内容与主网页类似,但在细节上存在一些差异,这里不再赘述。
2.4 数据存储
采集 的数据最终保存为 csv 文件。模块代码如下:
def save_data_to_csv_file(数据,文件名):
'''
将数据保存到 csv 文件
'''
使用 open(file_name, 'a', errors='ignore', newline='') 作为 f:
f_csv = csv.writer(f)
f_csv.writerows(数据)
2.5 个数据采集主函数
def get_forbes_global_year_2007(year=2007):
网址 = '网址'
html = 下载(网址)
# 打印(html)
data_first_page = get_content_first_page(html, 年份)
# 打印(data_first_page)
save_data_to_csv_file(data_first_page, 'forbes_'+str(year)+'.csv')
page_urls = get_page_urls(html)
# 打印(page_urls)
对于 page_urls 中的 url:
html = 下载(网址)
data_other_page = get_content_other_page(html, year)
# 打印(data_other_page)
print('保存数据...', url)
save_data_to_csv_file(data_other_page, 'forbes_'+str(year)+'.csv')
如果 __name__ == '__main__':
# 获取 2009 年福布斯全球 2000 强的数据
get_forbes_global_year_2007()
3 总结
本文只介绍data采集的思路和各个模块,不提供目标网页的链接。一方面由于原创网页的数据信息比较杂乱,需要在采集的时候编写多个采集程序,另一方面,由于我们的重点是后续的数据分析部分,我们希望不要专注于数据爬取。
在后续分析过程中,我们会检查数据结构、数据完整性及相关信息,请继续关注。
结尾。

