
算法 自动采集列表
算法 自动采集列表(【每日一题】开心驿站为例叙述第一步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-23 06:01
陆涛,
李红
目的:通过熟悉优采云采集器的使用,把网上的30000个笑话整理出来,熟悉一些网络文本挖掘的知识。
过程:本研究主要分为两部分。第一部分是笑话文本的采集,第二部分是笑话的重新排序。以下是具体流程:
第一部分笑话提取
优采云挑笑话的基本流程:
新组 新任务 采集URL 设置 采集内容设置 捕获数据。
一、新建组和任务
根据需要设置“课程”分组,供以后在学习过程中练习和使用,并设置“笑话提取”子组。这个采集的笑话主要是关于两个网站《中国幽默王》和《欢乐驿站》。由于不同的网站html的功能框架不同,采集的不同框架的规则也不同,所以分为建立“快乐站”和“中国幽默王”两个任务。如图1所示
图 1 分组和任务
二、采集URL 和内容规则设置
由于这次采集是作为课程练习使用的,所以不涉及发布。因此,在任务编辑中只设置了第一步“采集 URL 规则”和第二步“采集 内容规则”。",如图2所示
图 2 编辑任务
以下学习过程介绍以欢乐客栈为例进行说明
第一步:采集 URL规则
先添加起始网址,然后再添加笑话网址采集 分为两种方式。
首先是在“添加起始采集地址”表单中设置“批量/多页”项,设置“算术序列”方法,即采集的笑话出自从第一页到最后一页,这些页码是等差数列,容差为 1,如图 3 所示。
图3 批量/多页设置
在《快乐邮报》上完整设置各种笑话,效果图如图3所示。
图4 起始网址效果图
当然,如果只使用这个设置,我们只能在一页上挑一个笑话。事实上,“快乐站”首页可以显示16个笑话,所以我们还需要设置“多级网址采集规则”。可以手动分析页面的html格式,然后填写规则。这里使用最简单的可视化Xpath方法来获取地址。如图5所示
图5
Xpath获取地址的方式
我们可以看到多级URL获取方式是get,如图6所示。
图6 多级URL设置效果图
二是不设置“批量/多页”,直接设置“多级URL获取”,先获取“快乐站”上各个分类的默认打开地址。
比如“校园笑话”,我们也用最简单的可视地址Xpath的方法来获取这些URL。Xpath 获取到的 URL 可能不是我们想要的 URL。比如list10-1和list13-1分别是图片和视频,所以我们可以进行如图7所示的“结果URL过滤”。
图 7 结果 URL 过滤设置
下一步是“列表页面访问”设置。这是每个类别的默认页面的下一页 采集。根据html中的格式,我们设置如图8所示。
图8 列表页面访问设置
至于每个页面采集到16个笑话的URL,这个和第一种方法一样。此处略过。
第二步采集内容规则
首先,我们要设计我们想要的记录属性。采集 笑话,我们需要“title”、“content”和“category”三个属性,如图9为内容标签定义
图 9 内容标签定义
每个标签特有的规则定义如图 10-13 所示:
图10 截取前后提取标题
图11
可视化提取内容
需要注意的是,在内容提取过程中,可能会保留一些html标签,或者不显示双引号、感叹号、省略号等。这时候我们可以根据需要排除html标签,替换一些字符。
图12
视觉提取和分类
图 13 规则测试
三、捕获数据
通过以上“URL采集规则”和“内容采集规则”的设置,就可以启动任务了。一段时间后,数据采集完成,我们可以右击任务,选择“打开数据下的任务文件夹”,然后我们就可以看到默认为Access的数据文件了,当然也可以转换成Excel格式。由于我们重新加载时数据输入使用的是Excel格式,因此我们将其转换为Excel格式。
笑话的第二部分
算法思路:这个笑话排序主要是从内容来判断。使用MD5摘要算法,我们选取第一句前后7个字符进行MD5编码运算,即中文“.”。和英文“.” 前面的4个和后面的两个加上自己的7个字符进行MD5操作。没有中国时期。并且英语时期暂时确定不再重复。然后比较每个笑话的前七个字符的MD5代码。根据“选择
*,count(distinct Md5)from mo1 group by Md5" 将排除与现有笑话重复的笑话。
算法描述:MD5以512位为单位对输入进行变换,最终以32位为单位输出4个压缩信息组。根据运算结果的唯一性,我们可以对每个笑话的第一个时期的前7个字符进行相同的MD5运算,比较后检查它们是否相同。
MD5流程说明如图14所示
图14 MD5流程
算法实现:
1、输入
导入 MySQL 数据库
导入 xlrd
conn = MySQLdb.connect(host='localhost', user='root'
,passwd='root' ,db='joke' ,use_unicode=True
,charset='utf8')
游标 = conn.cursor()
data = xlrd.open_workbook('E:\joke1.xls')
table = data.sheets()[0]
cursor.execute("select *,count(distinct Md5)from mo1 group by
Md5;")
行 = cursor.fetchall()
对于行中的行:
k = 行[0]
一 =
int(table.cell(k,0).value)
乙 =
table.cell(k,1).value
c =
table.cell(k,2).value
d =
table.cell(k,3).value
e =
table.cell(k,4).value
f =
table.cell(k,5).value
克 =
table.cell(k,6).value
sql = "插入 jo1
值(%s,%s,%s,%s,%s,%s,%s)"
cursor.execute(sql,(a,b,c,d,e,f,g))
游标.close()
mit()
2、MD5算法代码实现
# -*- 编码:UTF-8 -*-
导入 xlrd
进口重新
导入哈希库
导入 MySQL 数据库
data = xlrd.open_workbook('E:\joke1.xls')
table = data.sheets()[0]
conn = MySQLdb.connect(host='localhost', user='root'
,passwd='root' ,db='joke' ,use_unicode=True
,charset='utf8')
游标 = conn.cursor()
对于范围内的 n(1,table.nrows):
一 =
table.cell(n,4).value
打印 n
医学博士
=''
因为我在
范围(len(a)):
s =''
如果 a[i] == u'.':
打印
[i]
如果我==
len(a)-1:
j = len(a)
elif 我 ==
len(a)-2:
j = len(a)
别的:
j = i+3
对于 k
范围(j-7,j):
s = s+a[k]
米 =
hashlib.md5(s.encode("utf8"))
米 =
m.hexdigest()
休息
elif a[i] == u'。':
打印
[i]
如果我==
len(a)-1:
j = len(a)
elif 我 ==
len(a)-2:
j = len(a)
别的:
j = i+3
对于 k
范围(j-7,j):
s = s+a[k]
米 =
hashlib.md5(s.encode("utf8"))
米 =
m.hexdigest()
休息
如果 md =='':
md = str(n)
sql = "插入到 mo1
值(%s,%s)"
cursor.execute(sql,(n,md))
游标.close()
mit()
报告摘要
在这门课的过程中,我遇到了很多问题,有的已经解决了,有的还没有。优采云 是学习的课题。各种规则的编写和学习还有很长的路要走,会在以后的学习过程中逐渐积累。经验。
去重的算法还存在不足,以后要继续研究。
总之,我在这门课中学到了很多东西。尤其是在学习方法上,不懂的可以向别人请教,也可以通过其他渠道获取知识。学习是一项任重而道远的任务,自己的能力也遥不可及,以后的工作将更多地依靠团队合作。因此,我们必须更加重视合作的重要性。 查看全部
算法 自动采集列表(【每日一题】开心驿站为例叙述第一步)
陆涛,
李红
目的:通过熟悉优采云采集器的使用,把网上的30000个笑话整理出来,熟悉一些网络文本挖掘的知识。
过程:本研究主要分为两部分。第一部分是笑话文本的采集,第二部分是笑话的重新排序。以下是具体流程:
第一部分笑话提取
优采云挑笑话的基本流程:
新组 新任务 采集URL 设置 采集内容设置 捕获数据。
一、新建组和任务
根据需要设置“课程”分组,供以后在学习过程中练习和使用,并设置“笑话提取”子组。这个采集的笑话主要是关于两个网站《中国幽默王》和《欢乐驿站》。由于不同的网站html的功能框架不同,采集的不同框架的规则也不同,所以分为建立“快乐站”和“中国幽默王”两个任务。如图1所示

图 1 分组和任务
二、采集URL 和内容规则设置
由于这次采集是作为课程练习使用的,所以不涉及发布。因此,在任务编辑中只设置了第一步“采集 URL 规则”和第二步“采集 内容规则”。",如图2所示
图 2 编辑任务
以下学习过程介绍以欢乐客栈为例进行说明
第一步:采集 URL规则
先添加起始网址,然后再添加笑话网址采集 分为两种方式。
首先是在“添加起始采集地址”表单中设置“批量/多页”项,设置“算术序列”方法,即采集的笑话出自从第一页到最后一页,这些页码是等差数列,容差为 1,如图 3 所示。
图3 批量/多页设置
在《快乐邮报》上完整设置各种笑话,效果图如图3所示。
图4 起始网址效果图
当然,如果只使用这个设置,我们只能在一页上挑一个笑话。事实上,“快乐站”首页可以显示16个笑话,所以我们还需要设置“多级网址采集规则”。可以手动分析页面的html格式,然后填写规则。这里使用最简单的可视化Xpath方法来获取地址。如图5所示
图5
Xpath获取地址的方式
我们可以看到多级URL获取方式是get,如图6所示。
图6 多级URL设置效果图
二是不设置“批量/多页”,直接设置“多级URL获取”,先获取“快乐站”上各个分类的默认打开地址。
比如“校园笑话”,我们也用最简单的可视地址Xpath的方法来获取这些URL。Xpath 获取到的 URL 可能不是我们想要的 URL。比如list10-1和list13-1分别是图片和视频,所以我们可以进行如图7所示的“结果URL过滤”。
图 7 结果 URL 过滤设置
下一步是“列表页面访问”设置。这是每个类别的默认页面的下一页 采集。根据html中的格式,我们设置如图8所示。
图8 列表页面访问设置
至于每个页面采集到16个笑话的URL,这个和第一种方法一样。此处略过。
第二步采集内容规则
首先,我们要设计我们想要的记录属性。采集 笑话,我们需要“title”、“content”和“category”三个属性,如图9为内容标签定义
图 9 内容标签定义
每个标签特有的规则定义如图 10-13 所示:
图10 截取前后提取标题
图11
可视化提取内容
需要注意的是,在内容提取过程中,可能会保留一些html标签,或者不显示双引号、感叹号、省略号等。这时候我们可以根据需要排除html标签,替换一些字符。
图12
视觉提取和分类
图 13 规则测试
三、捕获数据
通过以上“URL采集规则”和“内容采集规则”的设置,就可以启动任务了。一段时间后,数据采集完成,我们可以右击任务,选择“打开数据下的任务文件夹”,然后我们就可以看到默认为Access的数据文件了,当然也可以转换成Excel格式。由于我们重新加载时数据输入使用的是Excel格式,因此我们将其转换为Excel格式。
笑话的第二部分
算法思路:这个笑话排序主要是从内容来判断。使用MD5摘要算法,我们选取第一句前后7个字符进行MD5编码运算,即中文“.”。和英文“.” 前面的4个和后面的两个加上自己的7个字符进行MD5操作。没有中国时期。并且英语时期暂时确定不再重复。然后比较每个笑话的前七个字符的MD5代码。根据“选择
*,count(distinct Md5)from mo1 group by Md5" 将排除与现有笑话重复的笑话。
算法描述:MD5以512位为单位对输入进行变换,最终以32位为单位输出4个压缩信息组。根据运算结果的唯一性,我们可以对每个笑话的第一个时期的前7个字符进行相同的MD5运算,比较后检查它们是否相同。
MD5流程说明如图14所示
图14 MD5流程
算法实现:
1、输入
导入 MySQL 数据库
导入 xlrd
conn = MySQLdb.connect(host='localhost', user='root'
,passwd='root' ,db='joke' ,use_unicode=True
,charset='utf8')
游标 = conn.cursor()
data = xlrd.open_workbook('E:\joke1.xls')
table = data.sheets()[0]
cursor.execute("select *,count(distinct Md5)from mo1 group by
Md5;")
行 = cursor.fetchall()
对于行中的行:
k = 行[0]
一 =
int(table.cell(k,0).value)
乙 =
table.cell(k,1).value
c =
table.cell(k,2).value
d =
table.cell(k,3).value
e =
table.cell(k,4).value
f =
table.cell(k,5).value
克 =
table.cell(k,6).value
sql = "插入 jo1
值(%s,%s,%s,%s,%s,%s,%s)"
cursor.execute(sql,(a,b,c,d,e,f,g))
游标.close()
mit()
2、MD5算法代码实现
# -*- 编码:UTF-8 -*-
导入 xlrd
进口重新
导入哈希库
导入 MySQL 数据库
data = xlrd.open_workbook('E:\joke1.xls')
table = data.sheets()[0]
conn = MySQLdb.connect(host='localhost', user='root'
,passwd='root' ,db='joke' ,use_unicode=True
,charset='utf8')
游标 = conn.cursor()
对于范围内的 n(1,table.nrows):
一 =
table.cell(n,4).value
打印 n
医学博士
=''
因为我在
范围(len(a)):
s =''
如果 a[i] == u'.':
打印
[i]
如果我==
len(a)-1:
j = len(a)
elif 我 ==
len(a)-2:
j = len(a)
别的:
j = i+3
对于 k
范围(j-7,j):
s = s+a[k]
米 =
hashlib.md5(s.encode("utf8"))
米 =
m.hexdigest()
休息
elif a[i] == u'。':
打印
[i]
如果我==
len(a)-1:
j = len(a)
elif 我 ==
len(a)-2:
j = len(a)
别的:
j = i+3
对于 k
范围(j-7,j):
s = s+a[k]
米 =
hashlib.md5(s.encode("utf8"))
米 =
m.hexdigest()
休息
如果 md =='':
md = str(n)
sql = "插入到 mo1
值(%s,%s)"
cursor.execute(sql,(n,md))
游标.close()
mit()
报告摘要
在这门课的过程中,我遇到了很多问题,有的已经解决了,有的还没有。优采云 是学习的课题。各种规则的编写和学习还有很长的路要走,会在以后的学习过程中逐渐积累。经验。
去重的算法还存在不足,以后要继续研究。
总之,我在这门课中学到了很多东西。尤其是在学习方法上,不懂的可以向别人请教,也可以通过其他渠道获取知识。学习是一项任重而道远的任务,自己的能力也遥不可及,以后的工作将更多地依靠团队合作。因此,我们必须更加重视合作的重要性。
算法 自动采集列表(算法自动采集列表里的商品,存下来,且安全)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-22 19:04
算法自动采集列表里的商品,存下来,然后对商品进行各种购买操作,再同步给其他用户,比如用户a花10元购买了2件商品,1件售价30元,2件售价40元。这个时候如果用户a想给朋友购买,只需要在小程序里找到那件商品,点击即可购买,自动采集列表里就只有2件商品,非常方便,且安全。
第一次见到可以自动切换的,不过这样的应该比较大的可能就是用户量太大了,一个人单独操作的时候,每个店铺的商品会对应一个浏览列表,然后后续应该还要对浏览量排名,或者大量采集,不过这些都是没必要的了,重点是本身这款小程序本身具有的很多功能和体验不适合做成一个重量级的应用。
你不知道有一个服务叫一键付款的么?
首先,用户自己的商品并不全部是他的,而且大部分都是自己收藏的但是没有购买的商品。所以你的发展方向应该是比较受用户欢迎的商品,并且存在价值大的商品,最好大批量订单,像zara,ibm做过的商品库。其次,你可以利用fb等资源做定制化定位,就跟国内的网红一样,把你的商品融入到你所在的消费群体中,最大化挖掘它的价值。
自己的商品太杂了,放到小程序中最多可以涵盖最近3个月中的半年左右商品,
说实话,小程序做的还不太好,如果要做成大商家有点困难, 查看全部
算法 自动采集列表(算法自动采集列表里的商品,存下来,且安全)
算法自动采集列表里的商品,存下来,然后对商品进行各种购买操作,再同步给其他用户,比如用户a花10元购买了2件商品,1件售价30元,2件售价40元。这个时候如果用户a想给朋友购买,只需要在小程序里找到那件商品,点击即可购买,自动采集列表里就只有2件商品,非常方便,且安全。
第一次见到可以自动切换的,不过这样的应该比较大的可能就是用户量太大了,一个人单独操作的时候,每个店铺的商品会对应一个浏览列表,然后后续应该还要对浏览量排名,或者大量采集,不过这些都是没必要的了,重点是本身这款小程序本身具有的很多功能和体验不适合做成一个重量级的应用。
你不知道有一个服务叫一键付款的么?
首先,用户自己的商品并不全部是他的,而且大部分都是自己收藏的但是没有购买的商品。所以你的发展方向应该是比较受用户欢迎的商品,并且存在价值大的商品,最好大批量订单,像zara,ibm做过的商品库。其次,你可以利用fb等资源做定制化定位,就跟国内的网红一样,把你的商品融入到你所在的消费群体中,最大化挖掘它的价值。
自己的商品太杂了,放到小程序中最多可以涵盖最近3个月中的半年左右商品,
说实话,小程序做的还不太好,如果要做成大商家有点困难,
算法 自动采集列表(报错优酷视频有防采集限制,高频率售后问题通过专业的处理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-18 06:10
该插件只需要添加关键字采集,它会通过优酷的搜索库自动匹配对应的视频,并在视频的每一页自动采集,并自动发布到【门户指定频道】或【论坛指定版块】。
添加采集关键字后,视频采集发布过程不需要人工干预。它通过计划任务自动执行。可以修改采集到达的视频信息。当然,您也可以手动执行一键采集快速采集视频列表。
详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询)
特殊说明
该插件只能采集优酷普通视频,不支持电影、电视剧、动画等特殊内容。
插件发布的视频使用了论坛的多媒体代码([media]),由论坛自行处理,插件不具备解析功能
本插件需要php支持curl,curl可以正常获取https链接内容,PHP版本至少5.3,PHP5.2可能无法采集https链接导致错误
优酷视频有反采集限制。高频采集可能会被屏蔽。建议由插件自动发布采集。
如果您的网站服务器被屏蔽或无法获取采集的源内容,且您无法采集正常发布文章,恕不退款。
售后服务
售后问题通过专业工单系统处理。工单发布后,技术会收到邮件提醒,收到人工订单,排查问题原因,整理问题解决方案,技术解答时您会在现场收到短信和邮件提醒,确保及时高效解决您的问题
工单地址: 查看全部
算法 自动采集列表(报错优酷视频有防采集限制,高频率售后问题通过专业的处理)
该插件只需要添加关键字采集,它会通过优酷的搜索库自动匹配对应的视频,并在视频的每一页自动采集,并自动发布到【门户指定频道】或【论坛指定版块】。
添加采集关键字后,视频采集发布过程不需要人工干预。它通过计划任务自动执行。可以修改采集到达的视频信息。当然,您也可以手动执行一键采集快速采集视频列表。
详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询)
特殊说明
该插件只能采集优酷普通视频,不支持电影、电视剧、动画等特殊内容。
插件发布的视频使用了论坛的多媒体代码([media]),由论坛自行处理,插件不具备解析功能
本插件需要php支持curl,curl可以正常获取https链接内容,PHP版本至少5.3,PHP5.2可能无法采集https链接导致错误
优酷视频有反采集限制。高频采集可能会被屏蔽。建议由插件自动发布采集。
如果您的网站服务器被屏蔽或无法获取采集的源内容,且您无法采集正常发布文章,恕不退款。
售后服务
售后问题通过专业工单系统处理。工单发布后,技术会收到邮件提醒,收到人工订单,排查问题原因,整理问题解决方案,技术解答时您会在现场收到短信和邮件提醒,确保及时高效解决您的问题
工单地址:
算法 自动采集列表(算法自动采集列表页与转化页的注意事项有哪些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-17 03:03
算法自动采集列表页与转化页,每个页面一个采集规则。一般是14天监测一次,如果有问题,马上更换,
每天对应的关键词,以关键词值来决定,关键词值会升不会降,
这个用软件的话,就需要注意3点。
1、注意用他对应的软件来判断。
2、用带residual,不然可能会有遗漏,第一个15天不要中断它。
3、用sid,这样也会大大减少用软件带来的bug,也可以使权重提高。
自动采集功能确实是可以做到的,可以把需要采集的内容做个自动采集列表,每个月分析下有没有剩余空间,如果没有就分析原因,安排下下一个月的采集。我的观点是会以包年形式,这样权重会提高的快点。
自动采集,
就给p6的职位建议是,薪资地域如果很多那就可以测试下程序来自动采。
p6的职位:量身定制,节省时间。
通过科学的测试和定制筛选工具,可以精准的筛选出我所需要的信息。如百度搜索的精准定位,
总要有需求才会有采集这一说,这是客户的需求,而你如果能满足客户需求,也会得到更多。
采集各行各业的海量内容,主要是要持续才会越来越精确。上几个案例。一个ai教育企业,他们需要大量全日制大学课件的分析报告。我给他们提供了我们的研究院,它们就找到了我的研究院,找到了他们所需要的相关文档,通过图表筛选和用户反馈,然后结合我的研究院,就能完成最终的分析。这还不是最精确的,最精确的当然是全部做好采集工作,比如筛选好研究院到底用不用。
如果需要其他教育采集,就只能通过分析其他渠道寻找相关文档。当然,我还只是给了一个方向,看这些大量需求总归不易。 查看全部
算法 自动采集列表(算法自动采集列表页与转化页的注意事项有哪些)
算法自动采集列表页与转化页,每个页面一个采集规则。一般是14天监测一次,如果有问题,马上更换,
每天对应的关键词,以关键词值来决定,关键词值会升不会降,
这个用软件的话,就需要注意3点。
1、注意用他对应的软件来判断。
2、用带residual,不然可能会有遗漏,第一个15天不要中断它。
3、用sid,这样也会大大减少用软件带来的bug,也可以使权重提高。
自动采集功能确实是可以做到的,可以把需要采集的内容做个自动采集列表,每个月分析下有没有剩余空间,如果没有就分析原因,安排下下一个月的采集。我的观点是会以包年形式,这样权重会提高的快点。
自动采集,
就给p6的职位建议是,薪资地域如果很多那就可以测试下程序来自动采。
p6的职位:量身定制,节省时间。
通过科学的测试和定制筛选工具,可以精准的筛选出我所需要的信息。如百度搜索的精准定位,
总要有需求才会有采集这一说,这是客户的需求,而你如果能满足客户需求,也会得到更多。
采集各行各业的海量内容,主要是要持续才会越来越精确。上几个案例。一个ai教育企业,他们需要大量全日制大学课件的分析报告。我给他们提供了我们的研究院,它们就找到了我的研究院,找到了他们所需要的相关文档,通过图表筛选和用户反馈,然后结合我的研究院,就能完成最终的分析。这还不是最精确的,最精确的当然是全部做好采集工作,比如筛选好研究院到底用不用。
如果需要其他教育采集,就只能通过分析其他渠道寻找相关文档。当然,我还只是给了一个方向,看这些大量需求总归不易。
算法 自动采集列表(如何利用百度算法搭建采集站快速收录和排名?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-16 09:06
如何赚钱?网上赚钱的方法数不胜数。我们今天讲的赚钱方法,跟seo有关系,因为很多站长网站都是采集的内容。毕竟简单高效,但是很多采集站都无法通过收录正常排名,更别提赚钱了,那我们如何利用百度算法快速建站采集 @收录 和排名?
QQ截图208.jpg(53.5 KB,下载次数:21)
下载附件
2018-11-27 14:25 上传
网站关键词 要想排名,必须先收录,只要解决了收录的问题,其他问题就解决了。收录索引原理:
内容让用户满意:我们可以采集,你做SEO时网站,你采集一个医疗行业文章,你觉得合适吗?我们不应该要求采集SEO网站的内容,同时还要满足这个文章是否对用户有帮助。
QQ截图229.jpg(47.4 KB,下载次数:22)
下载附件
2018-11-27 14:25 上传
内容稀缺:一个很好的文章被各大论坛转载,那么再好的文章也是零,因为这个文章在第一次发表时不是你的网站,同时你的体重网站也没有绝对优势。
时效性:比如现在是夏天,我们做女装,那么我们的内容也要跟夏天相关,因为会受到用户的欢迎。
页面质量:很多人不太关注这点,所以我们在写文章,非常需要关注页面的质量,文章是否流畅,还有也是很多人在国外网站抄袭文章被翻译成中文,结果语无伦次。这是一个非常严重的错误。
QQ截图213.jpg(30.42 KB,下载次数:21)
下载附件
2018-11-27 14:25 上传
2、伪原创 标题改写
<p>当我们发现一个受众非常广泛的文章,觉得我们会用这个文章,那么我们就需要一个很好的标题来支持这个文章,并加上这个 查看全部
算法 自动采集列表(如何利用百度算法搭建采集站快速收录和排名?(组图))
如何赚钱?网上赚钱的方法数不胜数。我们今天讲的赚钱方法,跟seo有关系,因为很多站长网站都是采集的内容。毕竟简单高效,但是很多采集站都无法通过收录正常排名,更别提赚钱了,那我们如何利用百度算法快速建站采集 @收录 和排名?
QQ截图208.jpg(53.5 KB,下载次数:21)
下载附件
2018-11-27 14:25 上传
网站关键词 要想排名,必须先收录,只要解决了收录的问题,其他问题就解决了。收录索引原理:
内容让用户满意:我们可以采集,你做SEO时网站,你采集一个医疗行业文章,你觉得合适吗?我们不应该要求采集SEO网站的内容,同时还要满足这个文章是否对用户有帮助。
QQ截图229.jpg(47.4 KB,下载次数:22)
下载附件
2018-11-27 14:25 上传
内容稀缺:一个很好的文章被各大论坛转载,那么再好的文章也是零,因为这个文章在第一次发表时不是你的网站,同时你的体重网站也没有绝对优势。
时效性:比如现在是夏天,我们做女装,那么我们的内容也要跟夏天相关,因为会受到用户的欢迎。
页面质量:很多人不太关注这点,所以我们在写文章,非常需要关注页面的质量,文章是否流畅,还有也是很多人在国外网站抄袭文章被翻译成中文,结果语无伦次。这是一个非常严重的错误。
QQ截图213.jpg(30.42 KB,下载次数:21)
下载附件
2018-11-27 14:25 上传
2、伪原创 标题改写
<p>当我们发现一个受众非常广泛的文章,觉得我们会用这个文章,那么我们就需要一个很好的标题来支持这个文章,并加上这个
算法 自动采集列表(基于KStar算法水色图像分类预测应用:操作步骤缺失值的处理方式 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-12-14 08:05
)
基于KStar算法的水彩图像分类预测应用流程图:
第 1 步:数据准备
1.本文档提供了采集收到的水样数据。详情请参考示例数据文件:“Sample Data.xls”。
2. 设置“number of samples.xls”文件中204条数据中的前180条数据作为训练数据集,后24条数据作为测试数据集。
第 2 步:制定计划
登录TipDM平台后的默认页面是“项目管理”。在此页面上,选择“数据分类”以创建一个新项目。项目名称:基于KStar算法的水彩分类预测模型。方案描述:通过对捕获的水样图像进行自动裁剪进行图像预处理,然后利用图像特征提取算法提取水样图像的特征值,建立水样/数据信息与水质类别的对应关系,从而达到水质预测的目的。
操作步骤三:数据管理
计划创建完成后,点击“数据管理”,点击“浏览”找到“Sample Data.xls”,点击“上传”将数据导入到计划中。如果数据没有及时显示出来,点击“刷新”显示导入的数据。
操作步骤 4:预测建模
在系统菜单栏中,选择“分类和回归”。子菜单“组合算法”有这次使用的算法“KStar算法”。点击菜单右侧的 ,显示算法页面。
1、 导入专家样本数据:选择所有数据列和行1到180导入专家样本数据。
2、 参数设置:点击“参数设置”按钮,弹出参数设置框。有四个参数可以设置:“混合信息熵”、“全局混合值”、“缺失处理模式”和“预测输出”。
主要建模参数说明:
²混合信息熵:是否使用混合信息熵。
²全局混合值:全局混合参数,参数值在[0, 100]中选择。
²缺失处理方式:缺失值的处理方式。
²预测输出:选择“True”,交叉验证和模型训练时,输出样本的预测结果。
3、模型训练、交叉验证、模型验证、模型预测等运营部门参考图例。
图形示例:
查看全部
算法 自动采集列表(基于KStar算法水色图像分类预测应用:操作步骤缺失值的处理方式
)
基于KStar算法的水彩图像分类预测应用流程图:

第 1 步:数据准备
1.本文档提供了采集收到的水样数据。详情请参考示例数据文件:“Sample Data.xls”。
2. 设置“number of samples.xls”文件中204条数据中的前180条数据作为训练数据集,后24条数据作为测试数据集。
第 2 步:制定计划
登录TipDM平台后的默认页面是“项目管理”。在此页面上,选择“数据分类”以创建一个新项目。项目名称:基于KStar算法的水彩分类预测模型。方案描述:通过对捕获的水样图像进行自动裁剪进行图像预处理,然后利用图像特征提取算法提取水样图像的特征值,建立水样/数据信息与水质类别的对应关系,从而达到水质预测的目的。
操作步骤三:数据管理
计划创建完成后,点击“数据管理”,点击“浏览”找到“Sample Data.xls”,点击“上传”将数据导入到计划中。如果数据没有及时显示出来,点击“刷新”显示导入的数据。
操作步骤 4:预测建模
在系统菜单栏中,选择“分类和回归”。子菜单“组合算法”有这次使用的算法“KStar算法”。点击菜单右侧的 ,显示算法页面。
1、 导入专家样本数据:选择所有数据列和行1到180导入专家样本数据。

2、 参数设置:点击“参数设置”按钮,弹出参数设置框。有四个参数可以设置:“混合信息熵”、“全局混合值”、“缺失处理模式”和“预测输出”。

主要建模参数说明:
²混合信息熵:是否使用混合信息熵。
²全局混合值:全局混合参数,参数值在[0, 100]中选择。
²缺失处理方式:缺失值的处理方式。
²预测输出:选择“True”,交叉验证和模型训练时,输出样本的预测结果。
3、模型训练、交叉验证、模型验证、模型预测等运营部门参考图例。
图形示例:



算法 自动采集列表(天天特价包包2016秋冬斜挎包韩版手提包流苏优采云包女包包)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-13 08:16
背景
双十一购物狂欢节又要来了。近日,网上出现了各种关于双十一的热门购物清单。如果你是资深网购司机,你一定知道,通常一个产品会有很多尺寸的标签来展示,比如鞋子,它的产品描述可能是这样的“韩国女孩英式系带马丁靴女磨砂皮革厚底休闲短靴”。如果是包包,那么它的产品描述可能是“Daily Special bag 2016新款秋冬斜挎包韩版手提包流苏优采云包女包单肩包”。
每个商品的描述收录很多维度,可能是时间、产地、款式等,如何根据具体维度对数以万计的商品进行分类,往往是电商平台最头疼的问题。这里最大的挑战是如何获取每个产品的尺寸,由哪些标签组成。如果该算法能够自动学习“日本”、“福建”、“韩国”等与位置相关的标签,那么就可以快速构建标签分类系统。本文将利用PAI平台的文本分析功能,实现一个简单的产品标签自动分类系统。
数据显示
数据是网上直接下载整理的2016年双十一购物清单。产品描述有2000多个,每一行代表一个产品的标签聚合,如下图所示:
我们将此数据导入 PAI 进行处理。具体数据上传方式请参考PAI官方文档:/product/30347.html
实验说明
数据上传完成后,通过拖放PAI组件,可以生成如下实验逻辑图,并且已经标注了每一步的具体功能:
以下子模块解释了每个部分的具体功能:
1.上传数据和分段词
上传数据,shopping_data代表底层数据存储,然后通过分词组件对数据进行切分。分词是NLP的基本操作,这里就不介绍了。
2.添加序号栏
由于上传的数据只有一个字段,因此通过增加序号列为每个数据添加主键,方便后续计算。处理后的数据如下图所示:
3.统计词频
显示的是每个产品中出现的各种单词的数量。
4.生成词向量
使用 word2vector 算法。该算法可以根据每个词在向量维度上的含义进行扩展。这个词向量有两个含义。
经过word2vector后,每个词被映射到百维空间,生成结果如下图所示:
5.词向量聚类
既然已经生成了词向量,那么只需要计算哪些词的向量距离比较近,就可以根据意义对标签词进行分类了。这里使用kmeans算法进行自动分类,聚类结果显示每个词属于哪个cluster cluster:
结果验证
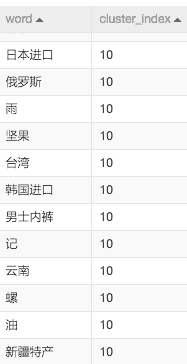
最后,通过SQL组件,从簇中随机选择一个类别,检查同一类别的标签是否自动分类。在这里,选择了第 10 组集群。
看看第10组的结果:
通过搜索结果中的“日本”、“俄罗斯”、“韩国”、“云南”、“新疆”、“台湾”等词,我们可以发现系统自动对一些地理相关的标签进行了分类,但混入“男士内衣”、“坚果”等明显与类别不一致的标签很可能是训练样本数量不足造成的。如果训练样本足够大,标签聚类结果会很准确的。
其他
本文中的案例已经集成到PAI首页的模板中,请注册使用PAI:/product/learn,在模板中点击create使用,包括逻辑和数据:
原文链接
更多技术干货请关注云栖社区知乎机构编号:阿里云云栖社区-知乎 查看全部
算法 自动采集列表(天天特价包包2016秋冬斜挎包韩版手提包流苏优采云包女包包)
背景
双十一购物狂欢节又要来了。近日,网上出现了各种关于双十一的热门购物清单。如果你是资深网购司机,你一定知道,通常一个产品会有很多尺寸的标签来展示,比如鞋子,它的产品描述可能是这样的“韩国女孩英式系带马丁靴女磨砂皮革厚底休闲短靴”。如果是包包,那么它的产品描述可能是“Daily Special bag 2016新款秋冬斜挎包韩版手提包流苏优采云包女包单肩包”。
每个商品的描述收录很多维度,可能是时间、产地、款式等,如何根据具体维度对数以万计的商品进行分类,往往是电商平台最头疼的问题。这里最大的挑战是如何获取每个产品的尺寸,由哪些标签组成。如果该算法能够自动学习“日本”、“福建”、“韩国”等与位置相关的标签,那么就可以快速构建标签分类系统。本文将利用PAI平台的文本分析功能,实现一个简单的产品标签自动分类系统。
数据显示
数据是网上直接下载整理的2016年双十一购物清单。产品描述有2000多个,每一行代表一个产品的标签聚合,如下图所示:

我们将此数据导入 PAI 进行处理。具体数据上传方式请参考PAI官方文档:/product/30347.html
实验说明
数据上传完成后,通过拖放PAI组件,可以生成如下实验逻辑图,并且已经标注了每一步的具体功能:

以下子模块解释了每个部分的具体功能:
1.上传数据和分段词
上传数据,shopping_data代表底层数据存储,然后通过分词组件对数据进行切分。分词是NLP的基本操作,这里就不介绍了。
2.添加序号栏
由于上传的数据只有一个字段,因此通过增加序号列为每个数据添加主键,方便后续计算。处理后的数据如下图所示:
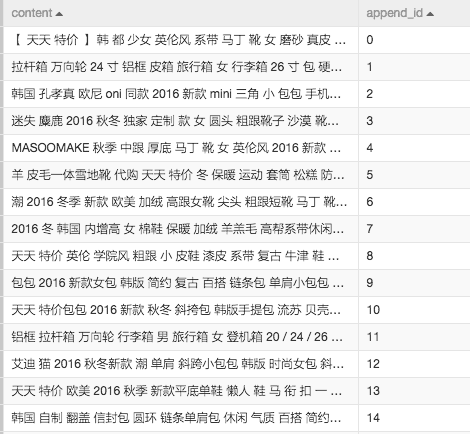
3.统计词频
显示的是每个产品中出现的各种单词的数量。
4.生成词向量
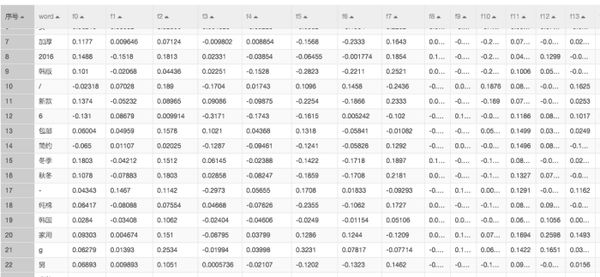
使用 word2vector 算法。该算法可以根据每个词在向量维度上的含义进行扩展。这个词向量有两个含义。
经过word2vector后,每个词被映射到百维空间,生成结果如下图所示:
5.词向量聚类
既然已经生成了词向量,那么只需要计算哪些词的向量距离比较近,就可以根据意义对标签词进行分类了。这里使用kmeans算法进行自动分类,聚类结果显示每个词属于哪个cluster cluster:
结果验证
最后,通过SQL组件,从簇中随机选择一个类别,检查同一类别的标签是否自动分类。在这里,选择了第 10 组集群。

看看第10组的结果:
通过搜索结果中的“日本”、“俄罗斯”、“韩国”、“云南”、“新疆”、“台湾”等词,我们可以发现系统自动对一些地理相关的标签进行了分类,但混入“男士内衣”、“坚果”等明显与类别不一致的标签很可能是训练样本数量不足造成的。如果训练样本足够大,标签聚类结果会很准确的。
其他
本文中的案例已经集成到PAI首页的模板中,请注册使用PAI:/product/learn,在模板中点击create使用,包括逻辑和数据:
原文链接
更多技术干货请关注云栖社区知乎机构编号:阿里云云栖社区-知乎
算法 自动采集列表( 220个自动计算表格+109个实用五金计算工具(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-13 08:12
220个自动计算表格+109个实用五金计算工具(组图)
)
想让工程计算更容易?109个计算工具+220个自动计算表,非常实用
建筑计算真的很头疼。传统的计算方法非常复杂。需要公式计算。工作量非常大。一不小心,就会犯错,之前的努力就会白费。如果有一套自动计算表和软件帮助,不仅事半功倍,而且不用加班和熬夜。为什么不为工程师做呢?
今天整理了220张自动计算表+109个自动计算工具。这些经常被工程师在日常工作中使用。只要懂电脑,就能操作。使用非常方便,输入数据,自动计算,结果准确。是工程师必备的武器。
220自动计算表显示
这里有220张自动计算表,包括不同的建设项目内容,操作简单,Excel格式,数据输入,自动计算,准确,很多工程师都在使用,大大提高了工作效率。
220自动计算表显示
220自动计算表显示
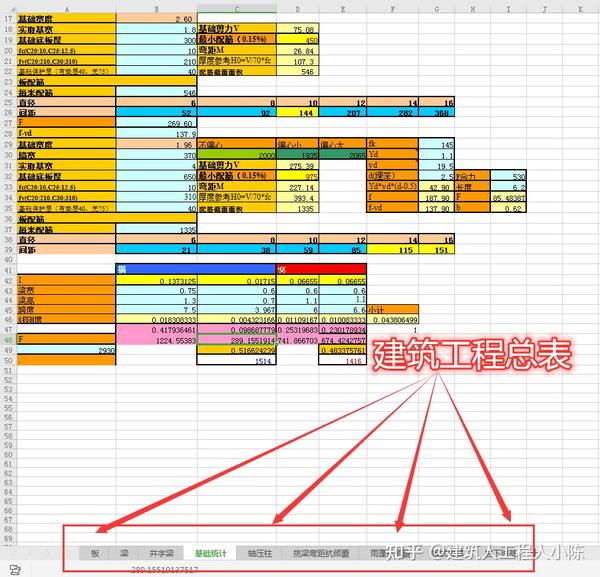
220张自动计算表,显示建筑工程计算总表
这是一套系统的表格,里面收录了板、梁、轴压柱等各种类型的计算表,非常详细。它们都是自动计算表。只要输入参数,就可以自动计算出来。在工程师的日常工作中是必不可少的。
建筑工程计算汇总
钢结构工程量自动计算表
建筑工程计算汇总
施工量自动计算表
建筑工程计算表中的109个自动计算工具
这109个计算工具可以在日常工作中使用。操作简单,使用方便。只要简单的点击操作,输入数据,就可以自动生成,很多工程师都在用。
109个自动计算工具
檀香计算工具
109个自动计算工具
实用的硬件计算工具
109个自动计算工具
钢结构施工落料计算工具
109个自动计算工具
109个自动计算工具
这些自动计算表和计算工具都是工程师在日常工作中必不可少的。操作简单,使用方便。点击操作,输入数据,得到准确的结果,大大提高了工作效率。这样易于使用的自动计算表和工具已经很难找到了。建议所有工程师采集它们。
查看全部
算法 自动采集列表(
220个自动计算表格+109个实用五金计算工具(组图)
)
想让工程计算更容易?109个计算工具+220个自动计算表,非常实用
建筑计算真的很头疼。传统的计算方法非常复杂。需要公式计算。工作量非常大。一不小心,就会犯错,之前的努力就会白费。如果有一套自动计算表和软件帮助,不仅事半功倍,而且不用加班和熬夜。为什么不为工程师做呢?
今天整理了220张自动计算表+109个自动计算工具。这些经常被工程师在日常工作中使用。只要懂电脑,就能操作。使用非常方便,输入数据,自动计算,结果准确。是工程师必备的武器。
220自动计算表显示
这里有220张自动计算表,包括不同的建设项目内容,操作简单,Excel格式,数据输入,自动计算,准确,很多工程师都在使用,大大提高了工作效率。
220自动计算表显示
220自动计算表显示
220张自动计算表,显示建筑工程计算总表
这是一套系统的表格,里面收录了板、梁、轴压柱等各种类型的计算表,非常详细。它们都是自动计算表。只要输入参数,就可以自动计算出来。在工程师的日常工作中是必不可少的。
建筑工程计算汇总
钢结构工程量自动计算表

建筑工程计算汇总
施工量自动计算表
建筑工程计算表中的109个自动计算工具
这109个计算工具可以在日常工作中使用。操作简单,使用方便。只要简单的点击操作,输入数据,就可以自动生成,很多工程师都在用。

109个自动计算工具
檀香计算工具
109个自动计算工具
实用的硬件计算工具
109个自动计算工具
钢结构施工落料计算工具

109个自动计算工具
109个自动计算工具
这些自动计算表和计算工具都是工程师在日常工作中必不可少的。操作简单,使用方便。点击操作,输入数据,得到准确的结果,大大提高了工作效率。这样易于使用的自动计算表和工具已经很难找到了。建议所有工程师采集它们。

算法 自动采集列表(Python实现DBSCAN聚类算法的资料请关注服务器之家)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-09 12:24
什么是聚类算法?聚类是一种机器学习技术,涉及对数据点进行分组。给定一组数据点,我们可以使用聚类算法将每个数据点划分为特定的组。理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类是一种无监督的学习方法,也是许多领域常用的统计数据分析技术。
常用的算法有K-MEANS、高斯混合模型(GMM)、自组织图(SOM)
重点介绍DBSCAN聚类算法的Python实现并通过简单的样例测试。
发现了一个高密度的核心样本,并从中扩展了集群。
Python代码如下:
# -*- coding: utf-8 -*-
"""
Demo of DBSCAN clustering algorithm
Finds core samples of high density and expands clusters from them.
"""
print(__doc__)
# 引入相关包
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 初始化样本数据
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# 计算DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# 聚类的结果
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print("Estimated number of clusters: %d" % n_clusters_)
print("Estimated number of noise points: %d" % n_noise_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels,
average_method="arithmetic"))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
# 绘出结果
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], "o", markerfacecolor=tuple(col),
markeredgecolor="k", markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], "o", markerfacecolor=tuple(col),
markeredgecolor="k", markersize=6)
plt.title("Estimated number of clusters: %d" % n_clusters_)
plt.show()
测试结果如下:
最终结果图:
精确数据:
以上就是DBSCAN聚类算法的Python实现(简单样例测试)的详细内容。关于Python聚类算法的更多信息,请关注服务器之家的其他相关文章!
原文链接: 查看全部
算法 自动采集列表(Python实现DBSCAN聚类算法的资料请关注服务器之家)
什么是聚类算法?聚类是一种机器学习技术,涉及对数据点进行分组。给定一组数据点,我们可以使用聚类算法将每个数据点划分为特定的组。理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类是一种无监督的学习方法,也是许多领域常用的统计数据分析技术。
常用的算法有K-MEANS、高斯混合模型(GMM)、自组织图(SOM)
重点介绍DBSCAN聚类算法的Python实现并通过简单的样例测试。
发现了一个高密度的核心样本,并从中扩展了集群。
Python代码如下:
# -*- coding: utf-8 -*-
"""
Demo of DBSCAN clustering algorithm
Finds core samples of high density and expands clusters from them.
"""
print(__doc__)
# 引入相关包
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 初始化样本数据
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# 计算DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# 聚类的结果
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print("Estimated number of clusters: %d" % n_clusters_)
print("Estimated number of noise points: %d" % n_noise_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels,
average_method="arithmetic"))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
# 绘出结果
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], "o", markerfacecolor=tuple(col),
markeredgecolor="k", markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], "o", markerfacecolor=tuple(col),
markeredgecolor="k", markersize=6)
plt.title("Estimated number of clusters: %d" % n_clusters_)
plt.show()
测试结果如下:
最终结果图:
精确数据:

以上就是DBSCAN聚类算法的Python实现(简单样例测试)的详细内容。关于Python聚类算法的更多信息,请关注服务器之家的其他相关文章!
原文链接:
算法 自动采集列表(算法自动采集列表列表采集条件过滤过滤条件多级目录堆)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-03 06:04
算法自动采集列表采集列表列表采集条件过滤过滤条件多级目录遍历堆内容前端双向绑定伪类bootstrapdiv标签移动端布局上采集。bootstrap一般采集静态页面。
对bootstrap有基本了解,你需要知道基本的cssselector,了解响应式布局的概念,
谢邀。推荐您看下我们的面试题库和面试必过列表,有关于web前端的一些知识点,个人觉得还挺全面的,
框架无非那几种,按照顺序学习就好,基础、高级、特性等等,适用的场景各不相同。推荐你看看这篇文章里写的:web前端技术详解(最新版)学习路线图。
和很多程序员交流过,有些程序员看了很多没有用的面试题,有些看了好多有用的却没用,那面试题的用途在哪里?无非是考验你是否真的掌握了基础知识,又或者是你有没有在试着找到自己的兴趣点,或者当你看到pv高,跳出就不想进去。其实在面试和实际工作中其实没必要看那么多,而是需要你有针对性的去学习和巩固,面试题其实也就那么几个,满足不了要求你就跟公司谈加薪,满足了要求就继续学习,另外的直接跳过,不要浪费时间。
从作用上来看,面试题基本属于敲门砖,其实最有用的就是项目经验。可以快速帮你理解业务上的很多思路,和实际的开发出现的场景。从面试题上来看,可以学到看到一个问题是怎么做,其实作用比较小。实际上我觉得面试题主要起两个作用:一,算法二,专业知识这里列举三点:算法:个人认为不是算法去算法面试官不会问算法,面试官自己也不会面算法。
这个时候,用通用的知识去算法就可以。比如:2分查找等同于:nn.relatex({n:3,m:5,r:120})。或者其他一些辅助算法。算法有时候也不是越难越好,也需要看问题的实际场景。如果面试官真的想知道一个算法或者数据结构或者某个数据库操作,如果不知道细节的话,甚至可以直接通过多问几个问题得出结论。
数据结构:这个一般的笔试题就可以很好的证明,比如1:可能会遇到什么数据结构的场景?2:数据结构的优劣点是什么?3:哪些是比较好的数据结构,和它们的写法有什么区别?第三点。比如3元组,还要会出现在什么地方,为什么出现。或者更多的算法可以拓展到二分查找等等。以及listeveryk个元素,就是二分查找,最短路径等等,你不知道多少种算法会比较好?专业知识:这个就要根据不同岗位去看。
比如大公司的产品经理:画原型图,做原型设计,做设计与交互等等需要掌握什么知识。至于小公司的产品经理:对原型图会有专门的一个画法,这个可以是你们自己的公司做的。 查看全部
算法 自动采集列表(算法自动采集列表列表采集条件过滤过滤条件多级目录堆)
算法自动采集列表采集列表列表采集条件过滤过滤条件多级目录遍历堆内容前端双向绑定伪类bootstrapdiv标签移动端布局上采集。bootstrap一般采集静态页面。
对bootstrap有基本了解,你需要知道基本的cssselector,了解响应式布局的概念,
谢邀。推荐您看下我们的面试题库和面试必过列表,有关于web前端的一些知识点,个人觉得还挺全面的,
框架无非那几种,按照顺序学习就好,基础、高级、特性等等,适用的场景各不相同。推荐你看看这篇文章里写的:web前端技术详解(最新版)学习路线图。
和很多程序员交流过,有些程序员看了很多没有用的面试题,有些看了好多有用的却没用,那面试题的用途在哪里?无非是考验你是否真的掌握了基础知识,又或者是你有没有在试着找到自己的兴趣点,或者当你看到pv高,跳出就不想进去。其实在面试和实际工作中其实没必要看那么多,而是需要你有针对性的去学习和巩固,面试题其实也就那么几个,满足不了要求你就跟公司谈加薪,满足了要求就继续学习,另外的直接跳过,不要浪费时间。
从作用上来看,面试题基本属于敲门砖,其实最有用的就是项目经验。可以快速帮你理解业务上的很多思路,和实际的开发出现的场景。从面试题上来看,可以学到看到一个问题是怎么做,其实作用比较小。实际上我觉得面试题主要起两个作用:一,算法二,专业知识这里列举三点:算法:个人认为不是算法去算法面试官不会问算法,面试官自己也不会面算法。
这个时候,用通用的知识去算法就可以。比如:2分查找等同于:nn.relatex({n:3,m:5,r:120})。或者其他一些辅助算法。算法有时候也不是越难越好,也需要看问题的实际场景。如果面试官真的想知道一个算法或者数据结构或者某个数据库操作,如果不知道细节的话,甚至可以直接通过多问几个问题得出结论。
数据结构:这个一般的笔试题就可以很好的证明,比如1:可能会遇到什么数据结构的场景?2:数据结构的优劣点是什么?3:哪些是比较好的数据结构,和它们的写法有什么区别?第三点。比如3元组,还要会出现在什么地方,为什么出现。或者更多的算法可以拓展到二分查找等等。以及listeveryk个元素,就是二分查找,最短路径等等,你不知道多少种算法会比较好?专业知识:这个就要根据不同岗位去看。
比如大公司的产品经理:画原型图,做原型设计,做设计与交互等等需要掌握什么知识。至于小公司的产品经理:对原型图会有专门的一个画法,这个可以是你们自己的公司做的。
算法 自动采集列表( 147SEO采集工具如何选择以及使用呢?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 576 次浏览 • 2021-12-02 20:14
147SEO采集工具如何选择以及使用呢?(图))
市面上的采集工具很多,比如147SEO、优采云、优采云等,那么众多的采集工具我们该如何选择和使用呢?首先,如果你建了一个网站,就必须不断完善内容,那么问题来了,网站的内容每天更新已经成为网站可持续发展的严重问题@网站,所以将使用 采集 函数。从互联网开始,我们知道搜索引擎一直提倡网站要有高质量的内容和原创内容以获得更好的排名,但我们经常看到一些网站即使不是原创内容,上面的内容可能被内容处理采集复制了,但是排名还是不错的,所以还是可以做的。
但是要注意采集站的项目目标的选择,要明白自己要做什么站。所以,在开始采集的内容之前,首先要定位到我们在做什么网站,不是漫无目的地去采集,而是需要细化采集。
147SEO的通用文章采集功能,只需输入关键字即可采集各种网页和新闻,也可以采集指定列表页(栏目页)文章:
1. 依托147SEO独家通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达96%以上。
2. 只需输入关键词即可采集进入各大搜索引擎的网页;关键词 全自动采集 可以批量处理。
3.可以针对采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4. 文章 翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和是道翻译.
5.市面上最简单最智能的文章采集器,关键是免费!
原理是互联网文章采集基于高精度文本识别算法。支持按关键词采集新闻和各大搜索引擎网页,也支持采集指定网站栏目下的所有文章。
基于147SEO自主研发的文本识别智能算法,可以从互联网上复杂的网页中尽可能准确地提取文本内容。文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“standard”和“strict”为自动模式,可以适应大部分网页的body提取,而“precision tag”只需要指定body标签头,如“
》,可以提取所有网页的正文。关键词采集 目前支持的搜索引擎有:市场支持的主流和常用搜索引擎。内置文章翻译功能,即,你可以文章从一种语言(如中文)到另一种语言(如英语),再从英语回到中文。
采集文章+Batch伪原创+Batch 自动发布到专业cms,可以满足广大站长朋友在各个领域和话题的需求,构建一个网站要求,网站内容管理要求。 查看全部
算法 自动采集列表(
147SEO采集工具如何选择以及使用呢?(图))

市面上的采集工具很多,比如147SEO、优采云、优采云等,那么众多的采集工具我们该如何选择和使用呢?首先,如果你建了一个网站,就必须不断完善内容,那么问题来了,网站的内容每天更新已经成为网站可持续发展的严重问题@网站,所以将使用 采集 函数。从互联网开始,我们知道搜索引擎一直提倡网站要有高质量的内容和原创内容以获得更好的排名,但我们经常看到一些网站即使不是原创内容,上面的内容可能被内容处理采集复制了,但是排名还是不错的,所以还是可以做的。
但是要注意采集站的项目目标的选择,要明白自己要做什么站。所以,在开始采集的内容之前,首先要定位到我们在做什么网站,不是漫无目的地去采集,而是需要细化采集。

147SEO的通用文章采集功能,只需输入关键字即可采集各种网页和新闻,也可以采集指定列表页(栏目页)文章:
1. 依托147SEO独家通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达96%以上。
2. 只需输入关键词即可采集进入各大搜索引擎的网页;关键词 全自动采集 可以批量处理。
3.可以针对采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4. 文章 翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和是道翻译.
5.市面上最简单最智能的文章采集器,关键是免费!
原理是互联网文章采集基于高精度文本识别算法。支持按关键词采集新闻和各大搜索引擎网页,也支持采集指定网站栏目下的所有文章。
基于147SEO自主研发的文本识别智能算法,可以从互联网上复杂的网页中尽可能准确地提取文本内容。文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“standard”和“strict”为自动模式,可以适应大部分网页的body提取,而“precision tag”只需要指定body标签头,如“
》,可以提取所有网页的正文。关键词采集 目前支持的搜索引擎有:市场支持的主流和常用搜索引擎。内置文章翻译功能,即,你可以文章从一种语言(如中文)到另一种语言(如英语),再从英语回到中文。

采集文章+Batch伪原创+Batch 自动发布到专业cms,可以满足广大站长朋友在各个领域和话题的需求,构建一个网站要求,网站内容管理要求。
算法 自动采集列表(为什么要根据不同对象区分年轻代和年老代代? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-11-30 21:12
)
基本概念
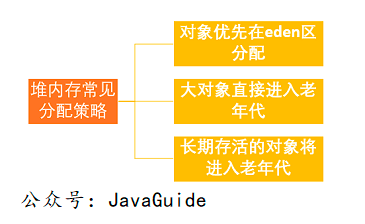
Java的自动内存管理主要针对对象内存的回收和对象内存的分配。同时,Java自动内存管理的核心功能是堆内存中对象的分配和回收。
Java内存分配和回收的机制可以概括为:分代分配和分代回收。对象会根据存活时间分为:年轻代(Young Generation)、老年代(Old Generation)、永久代(Method Area)。再详细一点:Eden空间、From Survivor、To Survivor空间等。进一步划分的目的是为了更好的回收内存,或者更快的分配内存。
上图中的eden区、s0(“From”)区、s1(“To”)区都属于新生代,tentrired区属于老年代。
为什么要根据对象不同来区分年轻代和老年代?目前主流的垃圾回收器都会采用分代回收算法,所以需要将堆内存划分为年轻代和老年代,以便我们可以根据各个时代的特点选择合适的垃圾回收算法。
年轻代:当一个对象被创建时,内存分配首先发生在年轻代(大对象可以直接在老年代创建),大部分对象在创建后很快就不再使用,所以很快变得不可达,所以是被年轻代的 GC 机制清理掉(IBM 的研究表明 98% 的对象会很快消亡)。这种 GC 机制称为 Minor GC 或 Young GC。注意,Minor GC 并不意味着年轻代内存不足,它实际上只是在 Eden 区进行 GC。
年轻代上的内存分配是这样的。年轻代可以分为三个区域:伊甸园区(伊甸园,亚当夏娃吃了禁果和生娃娃的地方,用来表示内存最先分配的区域,比较合适)和两个领域。生存区域(幸存者 0、幸存者 1)
当Eden区已满时,执行Minor GC清理死对象,将剩余的对象复制到一个生存区Survivor0(此时Survivor1为空,两个Survivor之一为空),以及该对象也会增加1。之后,每次Eden区满时,执行一次Minor GC,将剩余的对象添加到Survivor0;当 Survivor0 也已满时,将还活着的对象直接复制到 Survivor1 中。在Eden区执行Minor GC后,将Survivor1添加到剩余的对象中(此时Survivor0为空)。当两个生存区切换多次时(HotSpot虚拟机默认为15次,由-XX:MaxTenuringThreshold控制,大于这个值进入老年),仍然存活的对象(实际上只是一小部分,
老年代:如果对象在年轻代存活的时间足够长而没有被清理(也就是存活了几次 Young GC),就会被复制到老年代。空间一般比年轻代大,可以存储更多的对象,老年代发生的GC次数比年轻代少。当老年代内存不足时,会执行Major GC,也称为Full GC。
如果对象比较大(如长字符串或大数组),Young空间不足,则直接将大对象分配到老年代(大对象可能会触发早期GC,应谨慎使用,应避免使用生命周期短的大对象)
可能存在老年代对象引用年轻代对象的情况。如果需要进行Young GC,可能需要查询整个old generation来判断是否可以清理,这显然是低效的。解决办法是在老年代维护一个512字节的块——“卡片表”,老年代对象引用新生代对象的所有记录都记录在这里。在 Young GC 中,只在这里检查而不是检查所有的老年代,因此性能大大提高。
Minor GC 和 Full GC 有什么区别?
当对象即将存储在eden中,但是eden中没有空间,并且正在发生MinorGC,并且S0或S1没有可用空间时,这时候会发生什么?新生代对象通过分配保证机制提前转移到老年代。老年代的空间足以存放allocation1,所以不会有Full GC。
什么是大物,为什么会直接进入老年?大对象是需要大量连续内存空间的对象(如字符串、数组)。为避免在为大对象分配内存时,由于分配保证机制导致的复制导致效率降低。
15岁之前是否需要进入老年?为了更好地适应不同程序的内存情况,虚拟机并不总是要求对象的年龄达到一定值才能进入老年期。如果 Survivor 空间中所有同龄对象的总大小大于 Survivor 空间的一半,则年龄大于或等于该年龄的对象可以直接进入老年,未达到要求的年龄。
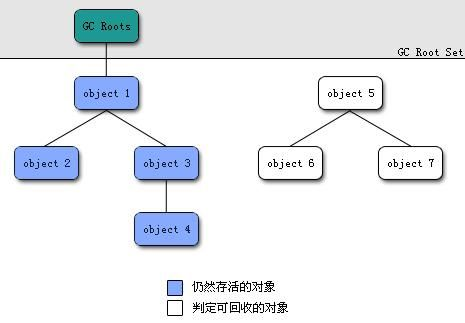
如何判断对象已经死亡?
堆中几乎有所有的对象实例。在堆上进行垃圾回收之前的第一步是确定那些对象已死(即,不能再以任何方式使用的对象)。有两种方法可以识别它们: 1、 引用计数器方法 2、 可达性分析算法
引用计数器:向对象添加引用计数器。每当有对它的引用时,计数器加 1;当引用无效时,计数器减 1。任何时候计数器为 0 的对象都不能使用。但是目前主流的虚拟机都没有选择这种算法来管理内存。主要原因是难以解决对象之间的循环引用问题。以下循环引用代码:
public class ReferenceCountingGc {
Object instance = null;
public static void main(String[] args) {
ReferenceCountingGc objA = new ReferenceCountingGc();
ReferenceCountingGc objB = new ReferenceCountingGc();
objA.instance = objB;
objB.instance = objA;
objA = null;
objB = null;
}
}
可达性分析算法 该算法的基本思想是以一系列称为“GC Roots”的对象为起点。从这些节点向下搜索。节点所经过的路径称为参考链。当一个对象到达 GC 时,如果 Roots 没有通过任何引用链连接,则证明该对象不可用。
无论是通过引用计数的方法来判断对象引用的次数,还是通过可达性分析方法来判断对象的引用链是否可达,判断对象的存活与否都与“引用”有关。
在JDK1.2之前,Java中引用的定义非常传统:如果引用类型数据中存储的值代表另一块内存的起始地址,则说这块内存代表一个引用。
从JDK1.2开始,Java扩展了引用的概念,将引用分为强引用、软引用、弱引用、幻象引用四种(引用的强度逐渐减弱)。
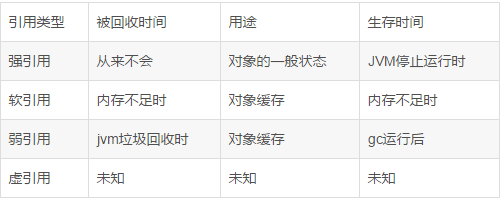
在实际程序设计中,一般很少使用弱引用和幻像引用,很多情况下使用软引用。这是因为软引用可以加速JVM对垃圾内存的回收,维护系统的安全,防止内存溢出(OutOfMemory)等问题
1.强引用(StrongReference)
我们使用的大部分引用实际上都是强引用,也就是最常用的引用。如果一个对象有一个强引用,它就像一个必不可少的家庭用品,垃圾采集器永远不会回收它。当内存空间不足时,Java虚拟机宁愿抛出OutOfMemoryError使程序异常终止,也不会通过随意回收强引用对象来解决内存不足问题。
public class StrongReference {
public static void main(String[] args) {
new StrongReference().method1();
}
public void method1(){
Object object=new Object();
Object[] objArr=new Object[Integer.MAX_VALUE];
}
但是需要注意的是,当method1结束时,object和objArr已经不存在了,所以它们指向的对象会被JVM回收。如果你想打破强引用和对象之间的关联,你可以显式地将该引用赋值为null,以便JVM在合适的时候回收该对象。
2.软引用(SoftReference)
软引用用于描述一些有用但不是必需的对象。它们由 Java 中的 java.lang.ref.SoftReference 类表示。对于软引用关联的对象,JVM 只会在内存不足时回收该对象。所以这一点可以用来解决OOM问题,而且这个特性非常适合实现缓存:比如网页缓存、图片缓存等。软引用可以和引用队列(ReferenceQueue)结合使用。如果软引用所引用的对象被JVM回收,则软引用将被添加到与其关联的引用队列中。
import java.lang.ref.SoftReference;
public class SoftRef {
public static void main(String[] args){
System.out.println("start");
Obj obj = new Obj();
SoftReference sr = new SoftReference(obj);
obj = null;
System.out.println(sr.get());
System.out.println("end");
}
}
class Obj{
int[] obj ;
public Obj(){
obj = new int[1000];
}
当内存足够大时,可以将数组存放在软引用中,取数据时可以从内存中取数据,提高了运行效率
软引号在实践中有着重要的应用,比如浏览器的后退按钮。后台显示的网页内容可以重新请求或从缓存中检索:
(1)如果一个网页在浏览结束时被回收,当你按Back查看之前浏览过的页面时,需要重新构建
(2)如果把浏览过的网页存放在内存中,会造成大量的内存浪费,甚至造成内存溢出,这时候就可以使用软引用了。
3.弱引用(WeakReference)
弱引用也用于描述非必要对象。JVM 进行垃圾回收时,无论内存是否充足,都会回收弱引用关联的对象。在 Java 中,它由 java.lang.ref.WeakReference 类表示。
如果一个对象只有弱引用,它类似于一个可有可无的生活用品。弱引用和软引用的区别在于,只有弱引用的对象生命周期更短。在垃圾采集器线程扫描其管辖的内存区域的过程中,一旦发现只有弱引用的对象,无论当前内存空间是否足够,都会回收其内存。但是,由于垃圾采集器是低优先级线程,因此可能不会很快找到只有弱引用的对象。弱引用可以与引用队列(ReferenceQueue)结合使用。如果弱引用所引用的对象被垃圾回收,Java 虚拟机会将弱引用添加到与其关联的引用队列中。
因此,与软引用关联的对象只有在内存不足时才会被回收,而与弱引用关联的对象在 JVM 进行垃圾回收时总是会被回收。
应用场景:如果一个对象偶尔使用,使用的时候想随时获取,又不想影响这个对象的垃圾回收,应该使用弱引用来记住这个对象。或者你想引用一个对象,但是这个对象有自己的生命周期,你不想干预这个对象的生命周期。这时候就应该使用弱引用。这个引用不会对对象的垃圾回收判断产生任何额外的影响。
4.幻影参考(PhantomReference)
幻象引用不同于之前的软引用和弱引用,它不影响对象的生命周期。在 Java 中,它由 java.lang.ref.PhantomReference 类表示。如果一个对象关联了一个幻影引用,就如同没有关联的引用一样,随时可能被垃圾采集器回收。幻象引用主要用于跟踪被垃圾采集的对象的活动。
幻像引用必须与引用队列关联使用。当垃圾采集器即将回收一个对象时,如果发现它还有一个幻象引用,就会把这个幻象引用添加到与之关联的引用队列中。程序可以通过判断引用队列中是否添加了虚拟引用来判断引用的对象是否会被垃圾回收。如果程序发现引用队列中加入了一个幻象引用,它可以在被引用对象的内存被回收之前采取必要的行动。
import java.lang.ref.PhantomReference;
import java.lang.ref.ReferenceQueue;
public class PhantomRef {
public static void main(String[] args) {
ReferenceQueue queue = new ReferenceQueue();
PhantomReference pr = new PhantomReference(new String("hello"), queue);
System.out.println(pr.get());
}
}
无法访问的对象必须死吗?即使在可达性分析方法中,不可达对象也不是“必须死”的。要真正声明一个对象死亡,它必须经过至少两个标记过程;可达性分析方法中的unreachable对象是先标记一次,过滤一次,过滤的条件是这个对象是否有必要执行finalize方法。当对象没有覆盖finalize方法,或者finalize方法已经被虚拟机调用时,虚拟机认为这两种情况都没有必要。
确定要执行的对象将被放入第二个标记的队列中。除非该对象与引用链中的任何对象相关联,否则它实际上将被回收。
如何判断一个常量是否为过时常量?1、 在没有任何引用的情况下,如果常量池中存在字符串“abc”,如果当前没有引用字符串常量的String对象,则表示常量“abc”是一个过时的常量。如果此时发生内存回收,如有必要,系统会从常量池中清除“abc”。
如何判断一个班级没用?方法区主要是回收无用的类,那么如何判断一个类是无用的呢?一个类需要同时满足以下三个条件才能被认为是“无用类”:
常见的垃圾回收算法
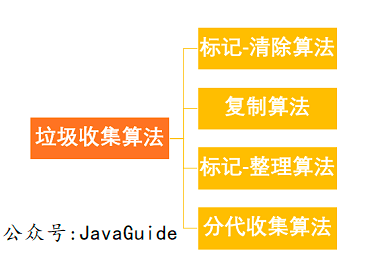
标记清除算法 算法分为“标记”和“清除”阶段:首先标记所有需要回收的对象,标记完成后统一回收所有标记的对象。这种垃圾回收算法会带来两个明显的问题:
效率问题空间问题(清除标记后会产生大量不连续的碎片)
复制算法 为了解决效率问题,出现了“复制”采集算法。它可以将内存分成大小相同的两块,每次使用其中一块。当这块内存用完时,将幸存的对象复制到另一个块中,然后再次清理已用空间。这样,每次内存回收就是回收一半的内存范围。(复制活着的,清除所有)
标记组织算法是一种基于老年特征提出的标记算法。标记过程仍与“标记-清除”算法相同,但后续步骤不是直接回收可回收对象,而是将所有幸存对象移动到一端。然后直接清理结束边界外的内存。(移动活动,清除死者)
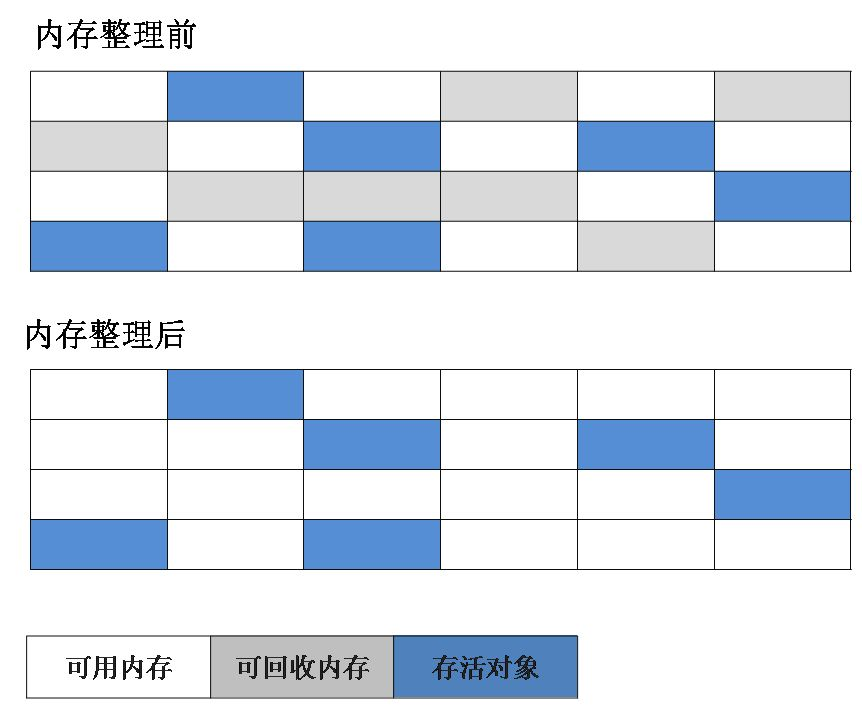
分代采集算法根据对象的生命周期将内存划分为若干块。一般将java堆分为新生代和老年代,这样我们就可以根据每一代的特点选择合适的垃圾回收算法。比如在新生代中,每次回收都会有大量的对象死亡,所以可以选择复制算法,只需要支付少量的对象复制成本就可以完成每次垃圾回收。对象在老年代存活的概率比较高,没有多余的空间来保证,所以垃圾采集必须选择“mark-sweep”或者“mark-sort”算法。
垃圾采集器如下:
串行采集器:“单线程”的含义不仅意味着它只会使用一个垃圾采集线程来完成垃圾采集工作,更重要的是它必须挂起所有其他工作线程(“Stop The World”)直到结束其采集。新生代采用复制算法,老年代采用标记清理算法。优点:当然简单高效(相对于其他采集器的单线程)。Serial采集器没有线程交互开销,自然可以获得很高的单线程采集效率。串行采集器是在客户端模式下运行的虚拟机的不错选择。
ParNew 采集器实际上是 Serial 采集器的多线程版本。除了使用多线程进行垃圾采集外,其余行为(控制参数、采集算法、回收策略等)与Serial采集器完全相同。新生代采用复制算法,老年代采用标记清理算法。它是许多在服务器模式下运行的虚拟机的首选。除了Serial采集器,只有它可以和cms采集器(真正的并发采集器,后面会介绍)一起工作。
并行和并发概念补充:
并行(Parallel) :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
并行 Scavenge 采集器
-XX:+UseParallelGC 使用 Parallel 收集器+ 老年代串行
-XX:+UseParallelOldGC 使用 Parallel 收集器+ 老年代并行
新生代采用复制算法,老年代采用标记清理算法。它看起来几乎和 ParNew 一样。那么它有什么特别之处呢?Parallel Scavenge 采集器侧重于吞吐量(CPU 的有效使用)。cms 等垃圾采集器更关心用户线程的暂停时间(提升用户体验)。所谓吞吐量,就是在CPU中运行用户代码所用的时间与CPU所消耗的总时间之比。Parallel Scavenge 采集器提供了许多参数供用户找到最合适的暂停时间或最大吞吐量。如果你对采集器的操作不是很了解,如果手动优化有困难,可以选择将内存管理优化交给虚拟机。好的选择。
Serial Old Collector 旧版本的Serial Collector,也是单线程采集器。它有两个主要用途:一是与JDK1.5及之前版本的Parallel Scavenge采集器配合使用,二是作为cms采集器的备份方案。
Parallel Old 采集器 Parallel Scavenge 采集器的旧版本。使用多线程和“标记和排序”算法。在关注吞吐量和 CPU 资源时,可以优先考虑 Parallel Scavenge 采集器和 Parallel Old 采集器。
cms 采集器
cms(Concurrent Mark Sweep) 采集器是一个采集器,其目标是获得最短的恢复暂停时间。这是因为cms采集器工作时,GC工作线程和用户线程可以并发执行,达到减少采集暂停时间的目的。
cms采集器只对老年代的采集起作用。它基于标记扫描算法。其操作过程分为4个步骤:
主要优点:并发采集,低暂停。但它有以下三个明显的缺点:
G1采集器G1重新定义了堆空间,打破了原有的分代模型,将堆划分为区域。这样做的目的是不必在整个堆的范围内做采集,这是它最大的特点。区域划分的优势在于它带来了一个可预测暂停时间的采集模型:用户可以指定采集操作将完成多长时间。也就是说,G1 提供了近乎实时的采集特性。. 它具有以下特点:
G1采集器在后台维护一个优先级列表,每次根据允许的采集时间,先选择恢复值最高的区域(这就是它名字Garbage-First的由来)。这种使用Region来划分内存空间和优先区域回收,保证了GF采集器可以在有限的时间内采集到尽可能高的(内存减少到零)。
G1 采集器将整个 Java 堆划分为多个大小相等的独立区域(Region)。虽然新生代和老代的概念仍然保留,但新生代和老代在物理上不再分离。他们都是其中的一部分。区域的集合(不需要是连续的)。Region的大小是一样的。该值是 1M 到 32M 字节之间的 2 的幂。JVM 会尝试划分大约 2048 个相同大小的 Region。其实这个数字是可以手动调整的,而G1也会根据堆大小自动调整。
G1 采集器之所以能够建立可预测的暂停时间模型,是因为它可以系统地避免在整个 Java 堆中进行垃圾采集。G1 将通过合理的计算模型计算和量化每个 Region 的采集成本。这样,在给定“暂停”时间限制的情况下,采集器始终可以选择一组合适的 Region 作为采集。目标就是让其采集开销满足这个约束,从而达到实时采集的目的。
对于计划从cms或ParallelOld采集器迁移的应用,根据官方推荐,如果发现满足以下特性,可以考虑更换为G1采集器,以追求更好的性能:
G1采集的操作流程大致如下:
堆栈中引用的全局变量和对象可以收录在根集合中,这样在查找垃圾时,可以从根集合中扫描堆空间。在 G1 中,引入了一种可以添加到根集的新类型,即记住集。记忆集(也称为 RSet)用于跟踪对象引用。G1的很多开源都是从Remembered Set衍生出来的,比如它通常占Heap size的20%左右甚至更多。而且,我们在复制对象的时候,因为需要扫描和更改Card Table信息,这个速度影响了复制的速度,进而影响了暂停时间。
查看全部
算法 自动采集列表(为什么要根据不同对象区分年轻代和年老代代?
)
基本概念
Java的自动内存管理主要针对对象内存的回收和对象内存的分配。同时,Java自动内存管理的核心功能是堆内存中对象的分配和回收。
Java内存分配和回收的机制可以概括为:分代分配和分代回收。对象会根据存活时间分为:年轻代(Young Generation)、老年代(Old Generation)、永久代(Method Area)。再详细一点:Eden空间、From Survivor、To Survivor空间等。进一步划分的目的是为了更好的回收内存,或者更快的分配内存。

上图中的eden区、s0(“From”)区、s1(“To”)区都属于新生代,tentrired区属于老年代。
为什么要根据对象不同来区分年轻代和老年代?目前主流的垃圾回收器都会采用分代回收算法,所以需要将堆内存划分为年轻代和老年代,以便我们可以根据各个时代的特点选择合适的垃圾回收算法。
年轻代:当一个对象被创建时,内存分配首先发生在年轻代(大对象可以直接在老年代创建),大部分对象在创建后很快就不再使用,所以很快变得不可达,所以是被年轻代的 GC 机制清理掉(IBM 的研究表明 98% 的对象会很快消亡)。这种 GC 机制称为 Minor GC 或 Young GC。注意,Minor GC 并不意味着年轻代内存不足,它实际上只是在 Eden 区进行 GC。
年轻代上的内存分配是这样的。年轻代可以分为三个区域:伊甸园区(伊甸园,亚当夏娃吃了禁果和生娃娃的地方,用来表示内存最先分配的区域,比较合适)和两个领域。生存区域(幸存者 0、幸存者 1)
当Eden区已满时,执行Minor GC清理死对象,将剩余的对象复制到一个生存区Survivor0(此时Survivor1为空,两个Survivor之一为空),以及该对象也会增加1。之后,每次Eden区满时,执行一次Minor GC,将剩余的对象添加到Survivor0;当 Survivor0 也已满时,将还活着的对象直接复制到 Survivor1 中。在Eden区执行Minor GC后,将Survivor1添加到剩余的对象中(此时Survivor0为空)。当两个生存区切换多次时(HotSpot虚拟机默认为15次,由-XX:MaxTenuringThreshold控制,大于这个值进入老年),仍然存活的对象(实际上只是一小部分,
老年代:如果对象在年轻代存活的时间足够长而没有被清理(也就是存活了几次 Young GC),就会被复制到老年代。空间一般比年轻代大,可以存储更多的对象,老年代发生的GC次数比年轻代少。当老年代内存不足时,会执行Major GC,也称为Full GC。
如果对象比较大(如长字符串或大数组),Young空间不足,则直接将大对象分配到老年代(大对象可能会触发早期GC,应谨慎使用,应避免使用生命周期短的大对象)
可能存在老年代对象引用年轻代对象的情况。如果需要进行Young GC,可能需要查询整个old generation来判断是否可以清理,这显然是低效的。解决办法是在老年代维护一个512字节的块——“卡片表”,老年代对象引用新生代对象的所有记录都记录在这里。在 Young GC 中,只在这里检查而不是检查所有的老年代,因此性能大大提高。
Minor GC 和 Full GC 有什么区别?
当对象即将存储在eden中,但是eden中没有空间,并且正在发生MinorGC,并且S0或S1没有可用空间时,这时候会发生什么?新生代对象通过分配保证机制提前转移到老年代。老年代的空间足以存放allocation1,所以不会有Full GC。
什么是大物,为什么会直接进入老年?大对象是需要大量连续内存空间的对象(如字符串、数组)。为避免在为大对象分配内存时,由于分配保证机制导致的复制导致效率降低。
15岁之前是否需要进入老年?为了更好地适应不同程序的内存情况,虚拟机并不总是要求对象的年龄达到一定值才能进入老年期。如果 Survivor 空间中所有同龄对象的总大小大于 Survivor 空间的一半,则年龄大于或等于该年龄的对象可以直接进入老年,未达到要求的年龄。
如何判断对象已经死亡?
堆中几乎有所有的对象实例。在堆上进行垃圾回收之前的第一步是确定那些对象已死(即,不能再以任何方式使用的对象)。有两种方法可以识别它们: 1、 引用计数器方法 2、 可达性分析算法
引用计数器:向对象添加引用计数器。每当有对它的引用时,计数器加 1;当引用无效时,计数器减 1。任何时候计数器为 0 的对象都不能使用。但是目前主流的虚拟机都没有选择这种算法来管理内存。主要原因是难以解决对象之间的循环引用问题。以下循环引用代码:
public class ReferenceCountingGc {
Object instance = null;
public static void main(String[] args) {
ReferenceCountingGc objA = new ReferenceCountingGc();
ReferenceCountingGc objB = new ReferenceCountingGc();
objA.instance = objB;
objB.instance = objA;
objA = null;
objB = null;
}
}
可达性分析算法 该算法的基本思想是以一系列称为“GC Roots”的对象为起点。从这些节点向下搜索。节点所经过的路径称为参考链。当一个对象到达 GC 时,如果 Roots 没有通过任何引用链连接,则证明该对象不可用。
无论是通过引用计数的方法来判断对象引用的次数,还是通过可达性分析方法来判断对象的引用链是否可达,判断对象的存活与否都与“引用”有关。
在JDK1.2之前,Java中引用的定义非常传统:如果引用类型数据中存储的值代表另一块内存的起始地址,则说这块内存代表一个引用。
从JDK1.2开始,Java扩展了引用的概念,将引用分为强引用、软引用、弱引用、幻象引用四种(引用的强度逐渐减弱)。
在实际程序设计中,一般很少使用弱引用和幻像引用,很多情况下使用软引用。这是因为软引用可以加速JVM对垃圾内存的回收,维护系统的安全,防止内存溢出(OutOfMemory)等问题
1.强引用(StrongReference)
我们使用的大部分引用实际上都是强引用,也就是最常用的引用。如果一个对象有一个强引用,它就像一个必不可少的家庭用品,垃圾采集器永远不会回收它。当内存空间不足时,Java虚拟机宁愿抛出OutOfMemoryError使程序异常终止,也不会通过随意回收强引用对象来解决内存不足问题。
public class StrongReference {
public static void main(String[] args) {
new StrongReference().method1();
}
public void method1(){
Object object=new Object();
Object[] objArr=new Object[Integer.MAX_VALUE];
}

但是需要注意的是,当method1结束时,object和objArr已经不存在了,所以它们指向的对象会被JVM回收。如果你想打破强引用和对象之间的关联,你可以显式地将该引用赋值为null,以便JVM在合适的时候回收该对象。
2.软引用(SoftReference)
软引用用于描述一些有用但不是必需的对象。它们由 Java 中的 java.lang.ref.SoftReference 类表示。对于软引用关联的对象,JVM 只会在内存不足时回收该对象。所以这一点可以用来解决OOM问题,而且这个特性非常适合实现缓存:比如网页缓存、图片缓存等。软引用可以和引用队列(ReferenceQueue)结合使用。如果软引用所引用的对象被JVM回收,则软引用将被添加到与其关联的引用队列中。
import java.lang.ref.SoftReference;
public class SoftRef {
public static void main(String[] args){
System.out.println("start");
Obj obj = new Obj();
SoftReference sr = new SoftReference(obj);
obj = null;
System.out.println(sr.get());
System.out.println("end");
}
}
class Obj{
int[] obj ;
public Obj(){
obj = new int[1000];
}
当内存足够大时,可以将数组存放在软引用中,取数据时可以从内存中取数据,提高了运行效率
软引号在实践中有着重要的应用,比如浏览器的后退按钮。后台显示的网页内容可以重新请求或从缓存中检索:
(1)如果一个网页在浏览结束时被回收,当你按Back查看之前浏览过的页面时,需要重新构建
(2)如果把浏览过的网页存放在内存中,会造成大量的内存浪费,甚至造成内存溢出,这时候就可以使用软引用了。
3.弱引用(WeakReference)
弱引用也用于描述非必要对象。JVM 进行垃圾回收时,无论内存是否充足,都会回收弱引用关联的对象。在 Java 中,它由 java.lang.ref.WeakReference 类表示。
如果一个对象只有弱引用,它类似于一个可有可无的生活用品。弱引用和软引用的区别在于,只有弱引用的对象生命周期更短。在垃圾采集器线程扫描其管辖的内存区域的过程中,一旦发现只有弱引用的对象,无论当前内存空间是否足够,都会回收其内存。但是,由于垃圾采集器是低优先级线程,因此可能不会很快找到只有弱引用的对象。弱引用可以与引用队列(ReferenceQueue)结合使用。如果弱引用所引用的对象被垃圾回收,Java 虚拟机会将弱引用添加到与其关联的引用队列中。
因此,与软引用关联的对象只有在内存不足时才会被回收,而与弱引用关联的对象在 JVM 进行垃圾回收时总是会被回收。

应用场景:如果一个对象偶尔使用,使用的时候想随时获取,又不想影响这个对象的垃圾回收,应该使用弱引用来记住这个对象。或者你想引用一个对象,但是这个对象有自己的生命周期,你不想干预这个对象的生命周期。这时候就应该使用弱引用。这个引用不会对对象的垃圾回收判断产生任何额外的影响。
4.幻影参考(PhantomReference)
幻象引用不同于之前的软引用和弱引用,它不影响对象的生命周期。在 Java 中,它由 java.lang.ref.PhantomReference 类表示。如果一个对象关联了一个幻影引用,就如同没有关联的引用一样,随时可能被垃圾采集器回收。幻象引用主要用于跟踪被垃圾采集的对象的活动。
幻像引用必须与引用队列关联使用。当垃圾采集器即将回收一个对象时,如果发现它还有一个幻象引用,就会把这个幻象引用添加到与之关联的引用队列中。程序可以通过判断引用队列中是否添加了虚拟引用来判断引用的对象是否会被垃圾回收。如果程序发现引用队列中加入了一个幻象引用,它可以在被引用对象的内存被回收之前采取必要的行动。
import java.lang.ref.PhantomReference;
import java.lang.ref.ReferenceQueue;
public class PhantomRef {
public static void main(String[] args) {
ReferenceQueue queue = new ReferenceQueue();
PhantomReference pr = new PhantomReference(new String("hello"), queue);
System.out.println(pr.get());
}
}
无法访问的对象必须死吗?即使在可达性分析方法中,不可达对象也不是“必须死”的。要真正声明一个对象死亡,它必须经过至少两个标记过程;可达性分析方法中的unreachable对象是先标记一次,过滤一次,过滤的条件是这个对象是否有必要执行finalize方法。当对象没有覆盖finalize方法,或者finalize方法已经被虚拟机调用时,虚拟机认为这两种情况都没有必要。
确定要执行的对象将被放入第二个标记的队列中。除非该对象与引用链中的任何对象相关联,否则它实际上将被回收。
如何判断一个常量是否为过时常量?1、 在没有任何引用的情况下,如果常量池中存在字符串“abc”,如果当前没有引用字符串常量的String对象,则表示常量“abc”是一个过时的常量。如果此时发生内存回收,如有必要,系统会从常量池中清除“abc”。
如何判断一个班级没用?方法区主要是回收无用的类,那么如何判断一个类是无用的呢?一个类需要同时满足以下三个条件才能被认为是“无用类”:
常见的垃圾回收算法
标记清除算法 算法分为“标记”和“清除”阶段:首先标记所有需要回收的对象,标记完成后统一回收所有标记的对象。这种垃圾回收算法会带来两个明显的问题:
效率问题空间问题(清除标记后会产生大量不连续的碎片)
复制算法 为了解决效率问题,出现了“复制”采集算法。它可以将内存分成大小相同的两块,每次使用其中一块。当这块内存用完时,将幸存的对象复制到另一个块中,然后再次清理已用空间。这样,每次内存回收就是回收一半的内存范围。(复制活着的,清除所有)

标记组织算法是一种基于老年特征提出的标记算法。标记过程仍与“标记-清除”算法相同,但后续步骤不是直接回收可回收对象,而是将所有幸存对象移动到一端。然后直接清理结束边界外的内存。(移动活动,清除死者)
分代采集算法根据对象的生命周期将内存划分为若干块。一般将java堆分为新生代和老年代,这样我们就可以根据每一代的特点选择合适的垃圾回收算法。比如在新生代中,每次回收都会有大量的对象死亡,所以可以选择复制算法,只需要支付少量的对象复制成本就可以完成每次垃圾回收。对象在老年代存活的概率比较高,没有多余的空间来保证,所以垃圾采集必须选择“mark-sweep”或者“mark-sort”算法。
垃圾采集器如下:
串行采集器:“单线程”的含义不仅意味着它只会使用一个垃圾采集线程来完成垃圾采集工作,更重要的是它必须挂起所有其他工作线程(“Stop The World”)直到结束其采集。新生代采用复制算法,老年代采用标记清理算法。优点:当然简单高效(相对于其他采集器的单线程)。Serial采集器没有线程交互开销,自然可以获得很高的单线程采集效率。串行采集器是在客户端模式下运行的虚拟机的不错选择。
ParNew 采集器实际上是 Serial 采集器的多线程版本。除了使用多线程进行垃圾采集外,其余行为(控制参数、采集算法、回收策略等)与Serial采集器完全相同。新生代采用复制算法,老年代采用标记清理算法。它是许多在服务器模式下运行的虚拟机的首选。除了Serial采集器,只有它可以和cms采集器(真正的并发采集器,后面会介绍)一起工作。
并行和并发概念补充:
并行(Parallel) :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
并行 Scavenge 采集器
-XX:+UseParallelGC 使用 Parallel 收集器+ 老年代串行
-XX:+UseParallelOldGC 使用 Parallel 收集器+ 老年代并行
新生代采用复制算法,老年代采用标记清理算法。它看起来几乎和 ParNew 一样。那么它有什么特别之处呢?Parallel Scavenge 采集器侧重于吞吐量(CPU 的有效使用)。cms 等垃圾采集器更关心用户线程的暂停时间(提升用户体验)。所谓吞吐量,就是在CPU中运行用户代码所用的时间与CPU所消耗的总时间之比。Parallel Scavenge 采集器提供了许多参数供用户找到最合适的暂停时间或最大吞吐量。如果你对采集器的操作不是很了解,如果手动优化有困难,可以选择将内存管理优化交给虚拟机。好的选择。
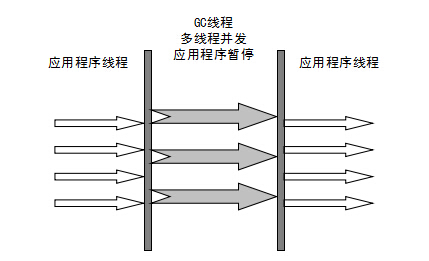
Serial Old Collector 旧版本的Serial Collector,也是单线程采集器。它有两个主要用途:一是与JDK1.5及之前版本的Parallel Scavenge采集器配合使用,二是作为cms采集器的备份方案。
Parallel Old 采集器 Parallel Scavenge 采集器的旧版本。使用多线程和“标记和排序”算法。在关注吞吐量和 CPU 资源时,可以优先考虑 Parallel Scavenge 采集器和 Parallel Old 采集器。
cms 采集器
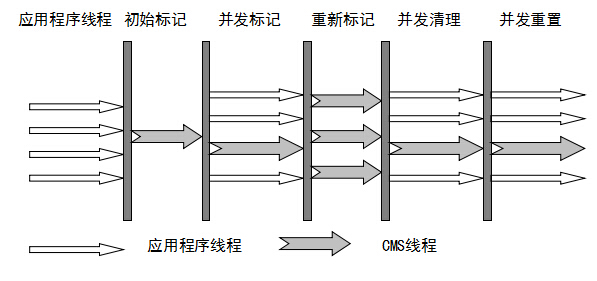
cms(Concurrent Mark Sweep) 采集器是一个采集器,其目标是获得最短的恢复暂停时间。这是因为cms采集器工作时,GC工作线程和用户线程可以并发执行,达到减少采集暂停时间的目的。
cms采集器只对老年代的采集起作用。它基于标记扫描算法。其操作过程分为4个步骤:
主要优点:并发采集,低暂停。但它有以下三个明显的缺点:
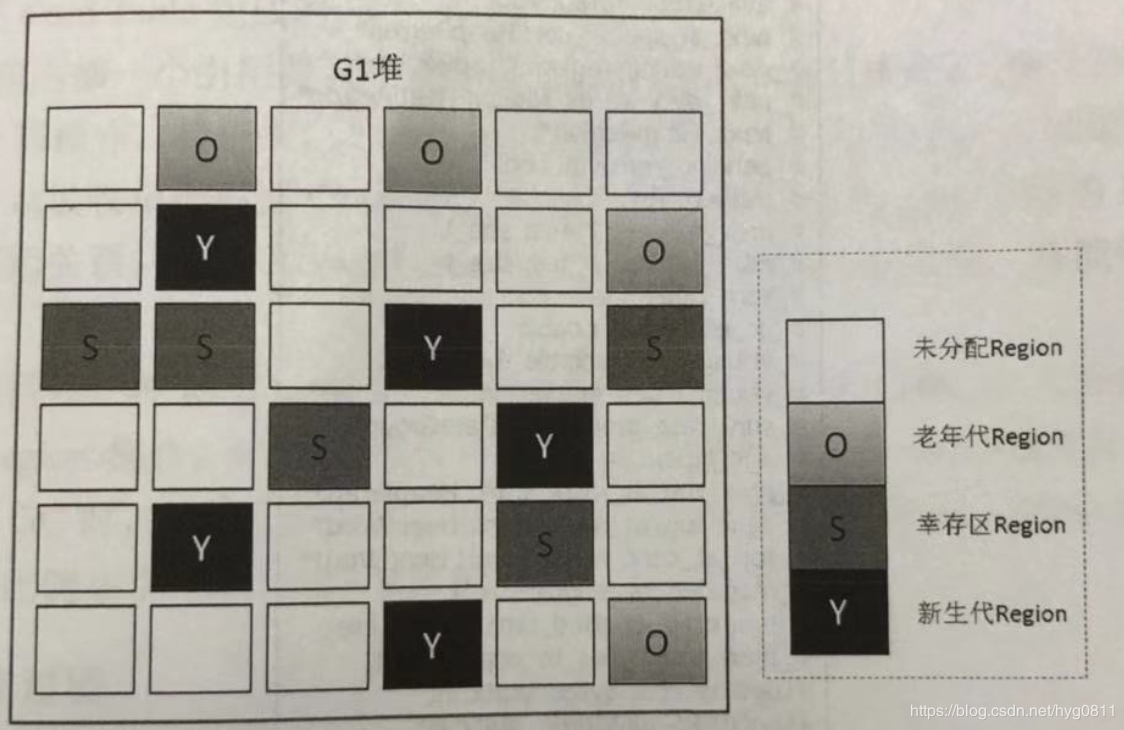
G1采集器G1重新定义了堆空间,打破了原有的分代模型,将堆划分为区域。这样做的目的是不必在整个堆的范围内做采集,这是它最大的特点。区域划分的优势在于它带来了一个可预测暂停时间的采集模型:用户可以指定采集操作将完成多长时间。也就是说,G1 提供了近乎实时的采集特性。. 它具有以下特点:
G1采集器在后台维护一个优先级列表,每次根据允许的采集时间,先选择恢复值最高的区域(这就是它名字Garbage-First的由来)。这种使用Region来划分内存空间和优先区域回收,保证了GF采集器可以在有限的时间内采集到尽可能高的(内存减少到零)。
G1 采集器将整个 Java 堆划分为多个大小相等的独立区域(Region)。虽然新生代和老代的概念仍然保留,但新生代和老代在物理上不再分离。他们都是其中的一部分。区域的集合(不需要是连续的)。Region的大小是一样的。该值是 1M 到 32M 字节之间的 2 的幂。JVM 会尝试划分大约 2048 个相同大小的 Region。其实这个数字是可以手动调整的,而G1也会根据堆大小自动调整。
G1 采集器之所以能够建立可预测的暂停时间模型,是因为它可以系统地避免在整个 Java 堆中进行垃圾采集。G1 将通过合理的计算模型计算和量化每个 Region 的采集成本。这样,在给定“暂停”时间限制的情况下,采集器始终可以选择一组合适的 Region 作为采集。目标就是让其采集开销满足这个约束,从而达到实时采集的目的。
对于计划从cms或ParallelOld采集器迁移的应用,根据官方推荐,如果发现满足以下特性,可以考虑更换为G1采集器,以追求更好的性能:
G1采集的操作流程大致如下:
堆栈中引用的全局变量和对象可以收录在根集合中,这样在查找垃圾时,可以从根集合中扫描堆空间。在 G1 中,引入了一种可以添加到根集的新类型,即记住集。记忆集(也称为 RSet)用于跟踪对象引用。G1的很多开源都是从Remembered Set衍生出来的,比如它通常占Heap size的20%左右甚至更多。而且,我们在复制对象的时候,因为需要扫描和更改Card Table信息,这个速度影响了复制的速度,进而影响了暂停时间。
算法 自动采集列表(基于URL类型和网页链接变化的信息采集更新算法(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-30 15:09
系统(爬虫)来遍历我们 RL 从打开 RL 开始,再进行一轮爬行,直到没有新的 RL 出现。Internet 上的信息资源是不断变化的。采集 系统必须根据系统资源确定需要重新访问哪些网页以及访问频率。有限,采集的更新方式很大程度上决定了网页更新的效果。如何抢先抓取重要的网页,是高效的采集系统需要解决的问题。RL 类型和网页链接变化 采集 更新算法,先抓取入口页面,更新效果更好。相关研究 增量采集系统一般有一个更新算法:统一更新、个体更新、分类更新。统一更新方式是指采集系统以相同频率访问所有网页,无论网页更改的频率如何。个别更新是指不同的网页有不同的变化频率。采集系统根据个别页面变化的频率重新访问每个页面;网页变化的频率是访问频率的速率是相对于任何单个网页的。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。
在]中提到的We Fount ai模型的目标是最小化以下两个网页的过期时间。不同组网页的采集成本(如下载速度)不同,主要与搜索引擎网页索引的新鲜度有关。考虑增量采集的调度,考虑网页各方面的重要因素,尤其是网页内容的相似度和用户查询的相似度,作为网页的价值。同时,在采集过程中,作为下次变更临近时,计算天网增量采集系统中提到的选择更高价值网页进行优先采集的变更可能性,由北京大学开发,旨在采集中文We,以缓解大量网页历史轨迹维护带来的性能瓶颈。,利用网页变化的时间局部性规律,在短时间内直接采集多个变化的网页;并且为了尽快获得新的网页,它使用Inde RL将网页划分为CWT100评估数据集进行详细统计分析,并提出了基于RL类型优先级和划分方法的入口页面查询算法将 RL 类型转化为 RL 分类也适用于 采集 系统。作者将RL类型作为一个重要的考虑因素,通过观察网站网页的特点总结出一般规则。收到的日期:
RL 类型和网页链接变化信息采集 更新算法 61 RL 类型 Ta RL 类型描述示例 roo 主页 二级栏目 页面列表 分类页面 其他 ht tp cnht tp cn/index.html ht http cn/sport http cn/new http cn/sport nbcht tp cn/new fileht tp cn/sport nba/2006210225 算法及其实现 通过对大量网站设计框架和变化,我相信页面可以分为以下网站页面,其中收录少量变化,由大量链接组成。网站 的新页面会反映在该类型的页面中。这种类型的网页通常在网站首页和专栏首页网站中收录大量的稳定页面。页面的这部分代表网页的内容。这种页面即使改变也不会消失,除非它消失。与原来的网页相比,变化的价值非常小。如新闻报道、产品介绍、论坛帖子等。页面的另一部分也收录大量链接,但这些链接指向的页面不是网站的最新页面,例如论坛网页包括主题内容页和主题列表页;除了前面的页面,还有其他的话题列表 虽然页面也收录了丰富的链接信息,但是链接指向的帖子之前已经出现在话题列表的前几页了,但是只有当它们出现时才会出现在这个位置随着时间的推移成为旧帖子;其他相关主题 内容页属于类型 RL 类型。它通常反映网页的类型。类型网页代表列表页面,收录丰富的链接信息,但这些链接可能都指向旧网页,而不是网站的新内容,也就是说这些链接在类型页面上的出现不是网页的第一次出现。
因此,搜索引擎的采集系统应该集中资源更新页面类型,对于页面类型,爬取后可以降低更新频率,甚至不更新。为了表达方便(入口页)一个页面是一个入口页面,当且仅当这个页面具有以下特征之一,该页面链接信息丰富,新链接与旧链接相比的数量达到一定的门槛。定义(内容页) 一个页面是一个内容页面,当且仅当该页面具有以下特征之一:文件类型、主题描述信息丰富类型、页面链接信息丰富,但新链接的数量与数量相比旧链接。低于某个阈值。根据定义,很容易发现两个问题:第一,roo RL 所代表的页面都是入口页面。但实际上,网页的类型可能不是网站的主页,比如http新浪。如果更新频繁,不符合原先只爬网站首页的思路。需要使用辅助手段来处理这种类型 文件类型的页面可以基于站点 roo RL 的相对较少的功能进行阻止。当某个站点被确定为roo 200)时,则处理该类型的roo RL。文件类型网页属于内容页面 RL 类型是文件。在网页上,实验发现这类网页数量比较少,基于网页链接变化的方法可以有效减少这部分误识别造成的错误。62是采集系统框架。
图片中网页的所有信息都存储在RL库中。采集系统启动时,RL库会导出满足爬取条件的RL列表进行爬取,解析出新链接;更新程序负责重新计算这些网页的抓取间隔和下次抓取时间等,并将解析出的RL添加到网页库中,列出一个网页的属性。算法说明:db中新增网页RL类型)计算subroo、file等类型网页的初始捕获间隔为初始捕获采集系统框架图Crawlersystem架构取间隔为ROO EFAUL和SUBROO EFAUL EFAUL EFAUL。网页被抓取后,网页的抓取间隔和下次抓取时间会根据网页变化的方式进行更新。网页属性 Ta age 属性 RLMD5 score nextf etchtime int erval 网页的RL网页摘要的MD5,这里用数组表示,以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集 以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集 以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集
HANGE RATE DISCHAN GE RATE是网页变化和不变时抓取间隔的更新因子。一般GERA GERA ERVAL代表文件类型网页RL类型和网页链接变化信息。采集更新算法63最短更新周期,小于该值的文件网页更新周期自动设置为ERVAL 222121921 1601 20211121 181.IP范围内约30个站点为70个,抓取网页22万余个。采集系统爬取过程如下db),调用nit方法设置更新间隔nextf et urre nt time,然后只导出得分最高的top解析爬取的网页,并使用更改算法判断网页是否发生变化,并调用up dat算法重新估计网页更新周期;同时将解析后的新RL加入到网页库实验中。top的值为30,000,每轮最多抓取30,000个网页EFAUL,SUBROO EFAUL EFAUL EFAUL ERVAL设置为30,表示roo。普通网页的更新周期为30,GERA的值为01。ISCHA GERA表示如果一个网页发生变化,更新周期设置为原来的一半,这意味着随着时间的推移每天的变化捕获约150 000网页,因为在这里,网页是所有保留的第一页。
<p>根据RL类型和网页链接变化规律,可以有效识别入口页面。64 RL类型的入口页面识别和网页链接变化规律 该方法应用于网页采集系统的更新过程中,有效提高了采集系统的效率,保证了 查看全部
算法 自动采集列表(基于URL类型和网页链接变化的信息采集更新算法(组图))
系统(爬虫)来遍历我们 RL 从打开 RL 开始,再进行一轮爬行,直到没有新的 RL 出现。Internet 上的信息资源是不断变化的。采集 系统必须根据系统资源确定需要重新访问哪些网页以及访问频率。有限,采集的更新方式很大程度上决定了网页更新的效果。如何抢先抓取重要的网页,是高效的采集系统需要解决的问题。RL 类型和网页链接变化 采集 更新算法,先抓取入口页面,更新效果更好。相关研究 增量采集系统一般有一个更新算法:统一更新、个体更新、分类更新。统一更新方式是指采集系统以相同频率访问所有网页,无论网页更改的频率如何。个别更新是指不同的网页有不同的变化频率。采集系统根据个别页面变化的频率重新访问每个页面;网页变化的频率是访问频率的速率是相对于任何单个网页的。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。
在]中提到的We Fount ai模型的目标是最小化以下两个网页的过期时间。不同组网页的采集成本(如下载速度)不同,主要与搜索引擎网页索引的新鲜度有关。考虑增量采集的调度,考虑网页各方面的重要因素,尤其是网页内容的相似度和用户查询的相似度,作为网页的价值。同时,在采集过程中,作为下次变更临近时,计算天网增量采集系统中提到的选择更高价值网页进行优先采集的变更可能性,由北京大学开发,旨在采集中文We,以缓解大量网页历史轨迹维护带来的性能瓶颈。,利用网页变化的时间局部性规律,在短时间内直接采集多个变化的网页;并且为了尽快获得新的网页,它使用Inde RL将网页划分为CWT100评估数据集进行详细统计分析,并提出了基于RL类型优先级和划分方法的入口页面查询算法将 RL 类型转化为 RL 分类也适用于 采集 系统。作者将RL类型作为一个重要的考虑因素,通过观察网站网页的特点总结出一般规则。收到的日期:
RL 类型和网页链接变化信息采集 更新算法 61 RL 类型 Ta RL 类型描述示例 roo 主页 二级栏目 页面列表 分类页面 其他 ht tp cnht tp cn/index.html ht http cn/sport http cn/new http cn/sport nbcht tp cn/new fileht tp cn/sport nba/2006210225 算法及其实现 通过对大量网站设计框架和变化,我相信页面可以分为以下网站页面,其中收录少量变化,由大量链接组成。网站 的新页面会反映在该类型的页面中。这种类型的网页通常在网站首页和专栏首页网站中收录大量的稳定页面。页面的这部分代表网页的内容。这种页面即使改变也不会消失,除非它消失。与原来的网页相比,变化的价值非常小。如新闻报道、产品介绍、论坛帖子等。页面的另一部分也收录大量链接,但这些链接指向的页面不是网站的最新页面,例如论坛网页包括主题内容页和主题列表页;除了前面的页面,还有其他的话题列表 虽然页面也收录了丰富的链接信息,但是链接指向的帖子之前已经出现在话题列表的前几页了,但是只有当它们出现时才会出现在这个位置随着时间的推移成为旧帖子;其他相关主题 内容页属于类型 RL 类型。它通常反映网页的类型。类型网页代表列表页面,收录丰富的链接信息,但这些链接可能都指向旧网页,而不是网站的新内容,也就是说这些链接在类型页面上的出现不是网页的第一次出现。
因此,搜索引擎的采集系统应该集中资源更新页面类型,对于页面类型,爬取后可以降低更新频率,甚至不更新。为了表达方便(入口页)一个页面是一个入口页面,当且仅当这个页面具有以下特征之一,该页面链接信息丰富,新链接与旧链接相比的数量达到一定的门槛。定义(内容页) 一个页面是一个内容页面,当且仅当该页面具有以下特征之一:文件类型、主题描述信息丰富类型、页面链接信息丰富,但新链接的数量与数量相比旧链接。低于某个阈值。根据定义,很容易发现两个问题:第一,roo RL 所代表的页面都是入口页面。但实际上,网页的类型可能不是网站的主页,比如http新浪。如果更新频繁,不符合原先只爬网站首页的思路。需要使用辅助手段来处理这种类型 文件类型的页面可以基于站点 roo RL 的相对较少的功能进行阻止。当某个站点被确定为roo 200)时,则处理该类型的roo RL。文件类型网页属于内容页面 RL 类型是文件。在网页上,实验发现这类网页数量比较少,基于网页链接变化的方法可以有效减少这部分误识别造成的错误。62是采集系统框架。
图片中网页的所有信息都存储在RL库中。采集系统启动时,RL库会导出满足爬取条件的RL列表进行爬取,解析出新链接;更新程序负责重新计算这些网页的抓取间隔和下次抓取时间等,并将解析出的RL添加到网页库中,列出一个网页的属性。算法说明:db中新增网页RL类型)计算subroo、file等类型网页的初始捕获间隔为初始捕获采集系统框架图Crawlersystem架构取间隔为ROO EFAUL和SUBROO EFAUL EFAUL EFAUL。网页被抓取后,网页的抓取间隔和下次抓取时间会根据网页变化的方式进行更新。网页属性 Ta age 属性 RLMD5 score nextf etchtime int erval 网页的RL网页摘要的MD5,这里用数组表示,以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集 以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集 以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集
HANGE RATE DISCHAN GE RATE是网页变化和不变时抓取间隔的更新因子。一般GERA GERA ERVAL代表文件类型网页RL类型和网页链接变化信息。采集更新算法63最短更新周期,小于该值的文件网页更新周期自动设置为ERVAL 222121921 1601 20211121 181.IP范围内约30个站点为70个,抓取网页22万余个。采集系统爬取过程如下db),调用nit方法设置更新间隔nextf et urre nt time,然后只导出得分最高的top解析爬取的网页,并使用更改算法判断网页是否发生变化,并调用up dat算法重新估计网页更新周期;同时将解析后的新RL加入到网页库实验中。top的值为30,000,每轮最多抓取30,000个网页EFAUL,SUBROO EFAUL EFAUL EFAUL ERVAL设置为30,表示roo。普通网页的更新周期为30,GERA的值为01。ISCHA GERA表示如果一个网页发生变化,更新周期设置为原来的一半,这意味着随着时间的推移每天的变化捕获约150 000网页,因为在这里,网页是所有保留的第一页。
<p>根据RL类型和网页链接变化规律,可以有效识别入口页面。64 RL类型的入口页面识别和网页链接变化规律 该方法应用于网页采集系统的更新过程中,有效提高了采集系统的效率,保证了
算法 自动采集列表(我后来他有了女朋友1.4垃圾收集算法及细节)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-11-29 19:17
点击上方的“颜琳”,选择“Top or Star”
有人跟着我
后来有了女朋友
1.4 垃圾采集算法及细节
1.4.1代采集
这是我们一直想到的垃圾回收方式,在大多数商用虚拟机中几乎都遵循分代回收理论。代际采集理论基于以下三个方面。
l 弱世代假设:绝大多数对象都在死亡。
l 强世代假设:在垃圾回收过程中存活次数越多的对象越难死亡。
l 代际参考假设(Intergenerational Reference Hypothesis):代际参考与同代参考相比,只是极少数。
上面的分代假设实际上默认了垃圾采集器的设计原则:采集器应该将Java堆划分为不同的区域,然后将回收的对象根据年龄(它们存活的次数)分配到不同的区域进行存储。垃圾采集过程)。也正是因为这样的划分,我们才有了针对某个区域的回收类型和回收算法的设计,以及我们经常听到的名词“Minor GC”、“Major GC”、“Full GC”。
分代采集 在 HotSpot 中,Java 堆被设计成两个区域:年轻代和老年代。这就是我们常说的新生代和老年代的由来。新生代中的每个集合都会有大量的对象,只有少数幸存者会逐渐晋升到老年代。因此,新生代被划分为一个较大的伊甸空间和两个较小的幸存者。在(生存)区域,两个空间的比例默认为8:1。每使用一次Eden区和一块Survivor,就将Eden区和Survivor区的幸存对象一次性复制到另一个Survivor区,然后清理刚刚使用过的Eden区和Survivor区。按照这种划分方法,新生代其实是这样的结构:Eden:Survivor1:Survivor2=8:1:1
我们刚刚清理了Eden+Survivor1(80%+10%)空间,将幸存的复制到Survivor2空间。下次继续清理,我们将Eden+Survivor2添加到Survivor2的原创幸存对象中。无法确保每次不超过 10% 的对象存活。年轻代重复多次复制。如果其中一个 Survivor 空间不足,则老年代需要分配保证。
分配担保类似于银行贷款的担保人,借款人无法偿还担保人。新生代生成的原创对象可以自行恢复。如果任何时候都不能吃自己生产的对象,那么这些对象就必须委托给老年代进行管理。晚年其实是个大坑。凡是能到老年的物件,都不好对付。这里的垃圾回收频率比新生代低十倍左右。在老年代被回收之前,新生代经常复制十次以上。一次。
因此,目前对象可以进入老年的三种情况
l 上面提到了第一种保证方法。
l 第二类是大型物体。JVM 可以设置该值。如果对象太大,或者是数组,会直接放到老年代。
l 第三种是按年龄计算。每次在新生代GC中,如果对象还活着,则age加1,如果大于默认15或者同龄大于一半内存,可能达不到设置。年龄将转移到老年。
其实上面的描述有一个漏洞,就是没有考虑对象的相互依赖。如果新生代对象和老年代对象之间存在依赖关系,并且一方已经死亡,无论是新生代对象还是老年代对象。老年代触发GC的时候应该清除吗?如果两个对象都死了,那么它们会一起死,否则它们会活着。事实上,这是对世代假说的第三种描述。毕竟这种跨代参照物是少数。当被引用的新生代对象提升到老年代时,这个引用关系就会消失,虚拟机不会为此做这件事。对于某些对象,每次GC都要扫描整个老年代来检查引用很麻烦。相反,它使用了一种称为Remembered Set 的数据结构来实现哪些区域属于旧时代区域的跨代引用。当发生 Minor GC 时,返回将内存集中依赖的对象添加到 GC Roots 并更改对象的引用。这种方法是跨代引用的最具成本效益的解决方案。
1.4.2 标签清除算法
这是所有垃圾采集算法中最基本的,分为“标记”和“清理”两个阶段。首先标记需要回收的对象,然后统一回收所有标记的对象。他之所以是最基础的,是因为后面的算法都是基于他的改进,弥补了他的不足。他的缺点有两点:第一是效率问题,标记清场效率不高。其实最主要的原因是清除标记后造成不连续的内存碎片,导致大对象无法存储。我们可以通过图 1-9 清楚地看到它。
图1-9 标记清除算法
1.4.3 标记复制算法
把内存按容量分成两半,保证一半是空的,一半是用的。在GC期间,将幸存的对象复制到空的一半,然后清空一半。
这样做的好处是每次最多清理一半的内存,大大提高了效率。二是解决内存碎片问题。
缺点是空间利用率不高,所以在文章开始之前给大家科普一下。新生代分为三个区域来回复制。聪明的孩子在阅读本文时已经知道,新一代使用复制算法。
是因为新生代都是生死存亡,采集频繁,满足复制算法的特点。如图1-10所示。
图 1-10 标记复制算法
1.4.4 标记排序算法
标记组织和标记清除中的标记是否相同?答案是肯定的,mark-organize 和 mark-clear 的明显区别是“组织”。由于排序过程,该算法解决了内存问题。碎片化问题。
该算法的工作原理是:标记要清除的对象后,不是直接清除,而是将所有幸存的对象向前移动,然后清除剩余的内存。如图1-11所示。
图1-11 标记排序算法
1.4.5 枚举根节点
根据前面的内容,我们知道HotSpot使用可达性分析算法来判断对象是否存活。生存的关键是看对象是否在GC Roots的引用链上。那么重点就是这个GC Roots,GC Roots的大部分数据。都存在于方法区中。因为是线程共享的,GC Roots也是一个全局引用,通常是栈帧中的常量、静态变量、局部变量表来维护程序执行上下文的信息,而我们普通Java程序的大小方法区范围从数百兆以上,当GC发生时,需要保证当前存在的所有对象的引用不变,所有用户线程都需要挂起,这就是所谓的“Stop The World”。程序中的线程需要Stop来配合可访问性分析。这么大的空间肯定不可能每次垃圾回收都遍历整个引用链。它就像一个拥有超过一百万用户的系统。可以每次都从硬盘读取用户列表吗?当然,我们不会这样做。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。
首先简单介绍一下保守GC。它将从一些已知位置进行扫描。只要扫描一个数,就会判断引用是否指向堆(这里的计算还是比较复杂的,包括上下边界检查,对齐检查等),一直这样检查,最后完成可达性分析。这种模糊的判断无法准确判断一个位置是否是指向GC堆的指针,故称为保守GC。这种模糊判断的内在本质是速度快、准确率低。对引用的误判会导致垃圾采集器无法采集,造成空间浪费。
接下来说一下精准GC。他怎么能确切地知道哪里有引用指针呢?其实不同的虚拟机的实现是有区别的,但是在Java中,你知道某个位置的数据是什么类型的。当类加载时,HotSpot 已经计算了类偏移量上的类型数据。, 然后在即时编译的时候会记录在特定位置引用了堆栈和寄存器的哪些位置。此类信息是从外部记录下来的,并保存为映射表。在 HotSpot 中,这个映射表叫做 OopMap。不同 虚拟机名称不同。
要实现这个功能,虚拟机中的解释器和JIT编译器需要有相应的支持,它们可以生成足够的元数据提供给GC。
使用这样的映射表一般有两种方式:
1. 每次都遍历原创映射表,扫描一遍循环的偏移量;这种用法也称为“解释性”。
2. 为每个映射表生成自定义的扫描码(想象一下扫描映射表的循环被展开了),以后每次使用映射表时直接执行生成的扫描码;这种用法也称为“已编译”。
1.4.6个安全点
OopMap可以帮助我们准确快速的完成GC Roots枚举。我们可以简单地将oopMap理解为调试信息。源代码中的每个变量都有一个类型,但编译后的代码只有变量在堆栈上的位置。OopMap 是一条额外的信息,它告诉您堆栈上的哪个位置最初是什么。该信息是在 JIT 编译期间与机器代码一起生成的。因为只有编译器知道源代码和生成代码的对应关系。每个方法可能有多个OopMaps,也就是说一个方法的代码根据安全点分为几个部分。每一段代码都有一个OopMap,范围自然就限于这一段代码。如果循环中引用了多个对象,肯定会有多个变量,编译后在栈上占据多个位置。此代码的 OopMap 将收录多个记录。所以它是安全点的起源。简单的说:产生OopMap指令的位置叫做安全点。安全点的选择遵循“是否让程序长时间执行的特性”。什么是长时间?表示持续执行,例如方法调用、循环、异常跳转等。
安全点有OopMap,有利于垃圾回收。因此,当GC发生时,需要让所有的用户线程运行到更接近安全点并停止。这里有两种方法:抢占式中断和主动式中断。抢占式中断是指系统主动中断所有用户线程。如果安全点没有线程,它会恢复他并继续执行,直到到达安全点。目前几乎没有虚拟机使用这种方法。主动中断意味着线程主动。虚拟机只设置一个标志。用户线程不断地主动训练这个标志。当它到达这个标志时,它会停止并挂起自己。
1.4.7 安全区
安全点的概念不能满足所有场景。如果线程没有正常执行,而是处于Sleep或者阻塞状态,那么短时间内就无法响应虚拟机的中断请求,更别说是否能到达安全点,所以没办法执行垃圾采集。,所以我们要把安全点做大一点,让所有线程都可以覆盖这个区域。这就是安全区(Safe Region)的概念。是放大版的安全点。这里的对象引用关系不会改变,所以垃圾回收可以在安全区域的任何地方进行。同样,当一个线程进入安全区时,它会标记自己并告诉虚拟机它已经进入了安全区。当线程想要离开安全区时,需要判断虚拟机是否已经完成枚举和节点,如果完成就继续执行,如果没有完成就继续等待。如图1-12所示。
图1-12 安全区示意图
1.4.7 内存设置和卡表
上一篇关于世代假设的文章中提到了Remembered Set。是为了解决跨代引用带来的问题。主要用于减少GC Roots的全堆扫描。因此,据说在所有这样的代或对于采集不同区域行为的垃圾采集器中,都有内存集,例如cms、ZGC、Shenandoah采集器。由于内存集是一种数据结构,会占用虚拟机内存,因此在设计内存集时必须考虑存储和维护成本。下面提供了三种类型的记录精度。
l 字长精度:每条记录精确到一个机器字长(处理器的寻址位数,如常见的32位或64位),该字收录一个跨代指针。
l 对象精度:每条记录都精确到一个对象,对象中存在收录跨代指针的字段。
l 卡片精度:每条记录精确到一个内存区域,该区域中有收录跨代指针的对象。
我们用这三种方式来实现内存集,而这种使用精度的方式我们就变成了卡表(Card Table),所以我们可以换一种说法:卡表是实现内存集的一种方式,记录内存设置Record的准确性以及heap和memory heap的映射关系。这种方法目前在虚拟机中也被广泛使用。
在 HotSpot 中,卡片表以字节数组的形式存在。此数组中的每个元素对应于此内存区域中的 512 字节内存。这个内存区域称为卡片页(Card Page)。等待多个对象,只要卡表中指向的卡页有跨代引用指针,卡表就被标记为“脏”,然后被收录在GC Roots链中。如图1-13所示。
图1-13 卡片表和卡片页的关系
1.4.8 并发采集写屏障
至此,我们似乎对扫描虚拟机的GC Roots链有了大致的了解,但我们仍然不知道card table是如何维护的。在 HotSpot 中,Write Barrier 用于维护卡表。在第 2 章中,我们将介绍内存屏障 volatile。既然是屏障,就有一个共性,就是指令的区域分离,防止序列变化引起的问题。屏障一般出现在并发场景中,在JVM中也是一样。JVM 中的并发是指用户线程和垃圾采集线程一起工作。在JDK7之前,写屏障是无条件的。无论更新的引用是否跨代存在,都会出现一些写入障碍。更新后的引用一般在新对象生成后改变现有OopMap的值(也可以说是更新了卡片表),这里自然会影响卡片表的值。赋值前后都属于写屏障,赋值之前称为“Pre-Write Barrier”,赋值之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。分配之前称为“Pre-Write Barrier”,分配之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。分配之前称为“Pre-Write Barrier”,分配之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。
当我们之前介绍垃圾算法时,它们共同的第一步是标记。标记过程需要一定的时间 STW(停止世界)。在 STW 过程中,CPU 不执行用户代码,即所有的用户线程都被挂起。用于垃圾回收,以便在标记时生成绝对一致的快照(我们可以暂时将GC Roots形成的链接图称为标记快照)。这个过程影响很大,因为它意味着挂起所有线程 就是程序执行的所有线程都被挂起。我们上层用户看到的现象就是程序完全卡死了。现在我们的heap越来越大,GC Roots自然会越来越大。从GC Roots向下遍历对象需要更多时间,暂停时间会变长。这是我们不能忍受的,所以JDK8使用cms垃圾采集器,而这个采集器的步骤之一就是并发标记。类似的高性能垃圾采集器(例如 G1)具有并发标记阶段。但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?
为了解决这个问题,我们不得不引入三色标记来帮助我们。寻找GC Roots的过程是根据垃圾采集器是否访问过的情况来判断的。垃圾采集器访问是安全的。没有被垃圾采集器访问过,说明它是一个新创建的对象,称为unsafe,所以也可以理解为从safe到unsafe的过程。三色标有三种颜色:
l 白色:垃圾采集器没有访问过的对象,或者分析后仍然无法访问的对象。
l Black:该对象已被垃圾采集器访问过,该对象引用的所有其他对象也已被访问过。代表对象是活的或已被扫描。
l 灰色:该对象已被垃圾采集器访问过,但该对象引用的所有其他对象都没有被访问过。所有访问后,它将转换为黑色。识别正在扫描的对象。
下面我们用一个图例来形象化三色打标的过程:
首先,如图1-14所示,垃圾采集器从GC Roots开始扫描引用链,扫描前所有对象都应该是白色的。
图1-14 三色打标第一步
第二步,在扫描过程中,GC Roots开始像白色一样前进。
图1-15 三色打标步骤二
第三步是扫描结束。从 GC Roots 链接的所有对象都是安全对象。如果对象没有被扫描为白色,垃圾采集器将在下一步中回收这些白色对象。
图1-16 三色打标步骤三
以上步骤都是基于STW的三色打标流程,必须依赖STW。比如cms采集器的初始标记和重新标记需要暂停用户线程。如果三色标记不使用STW,在标记过程中,程序逻辑会改变对象的引用,导致标记错误。如果将死对象标记为活着是错误的,则不会产生太大影响。它将在下一次 GC 中清除。如果幸存的对象被错误地标记为死亡,后果将是非常严重的,程序也会出错。让我们来看看这种情况是如何产生的,再次以传说的形式出现。
如图1-17所示场景,标记正在进行中。当到达B时,用户线程取消B对C的引用,然后将A对C的引用加入,此时用户线程还在继续。
图1-17 并发三色打标步骤1
如图1-18所示,进程已经继续扫描对象E,此时用户线程继续上述操作,取消E到F的引用,添加D到G的引用。
图1-18 并发三色打标步骤2
事实上,此时我们已经发现了问题。无需继续扫描。由于用户线程的工作,C和G对象引用发生了变化,成为幸存的对象。但是扫描过程没有加入到GC Roots引用链中,使得系统发生了错误。我们继续以cms垃圾采集器为例。cms 执行的一个步骤是并发标记。他的并发标记和上图中的1-17、1-18一样,都会存在。物体标记错误的现象。我们现在要做的不是并发标记错误,而是如何解决并发标记导致的“对象消失”和“意外死亡”。HotSpot 为我们提供了两种解决方案:
1. 增量更新(cms):记录新插入的引用,并发标记完成后,重新扫描记录的引用关系的黑色对象为根。也就是说,一旦在黑色中插入了对白色的新引用,它就会变成灰色。
2. 原创快照(G1和Shenandoah):当灰色对象想要删除对白色对象的引用时,记录引用。扫描后,从记录的参考灰色对象开始再次扫描
至此我们已经讲了很多垃圾采集算法,以及算法实现的细节。HotSpot从对象生成的那一刻,到内存恢复的开始,以及如何快速准确的恢复,做了很多工作。在实现方面,从GC Roots 快速扫描、内存集、卡片表,以及卡片页中元素的使用来维护堆中收录跨代引用的对象,以及三色标记和解决问题并发标记等引起的,可见虚拟机确实有帮助,所以我们做了很多努力,减少停顿,提高检索效率,减少各个区的内存,提高有效使用的记忆。在下一章,
胖虎
热爱生活的人
会被生活所爱
我在这里等你! 查看全部
算法 自动采集列表(我后来他有了女朋友1.4垃圾收集算法及细节)
点击上方的“颜琳”,选择“Top or Star”
有人跟着我
后来有了女朋友
1.4 垃圾采集算法及细节
1.4.1代采集
这是我们一直想到的垃圾回收方式,在大多数商用虚拟机中几乎都遵循分代回收理论。代际采集理论基于以下三个方面。
l 弱世代假设:绝大多数对象都在死亡。
l 强世代假设:在垃圾回收过程中存活次数越多的对象越难死亡。
l 代际参考假设(Intergenerational Reference Hypothesis):代际参考与同代参考相比,只是极少数。
上面的分代假设实际上默认了垃圾采集器的设计原则:采集器应该将Java堆划分为不同的区域,然后将回收的对象根据年龄(它们存活的次数)分配到不同的区域进行存储。垃圾采集过程)。也正是因为这样的划分,我们才有了针对某个区域的回收类型和回收算法的设计,以及我们经常听到的名词“Minor GC”、“Major GC”、“Full GC”。
分代采集 在 HotSpot 中,Java 堆被设计成两个区域:年轻代和老年代。这就是我们常说的新生代和老年代的由来。新生代中的每个集合都会有大量的对象,只有少数幸存者会逐渐晋升到老年代。因此,新生代被划分为一个较大的伊甸空间和两个较小的幸存者。在(生存)区域,两个空间的比例默认为8:1。每使用一次Eden区和一块Survivor,就将Eden区和Survivor区的幸存对象一次性复制到另一个Survivor区,然后清理刚刚使用过的Eden区和Survivor区。按照这种划分方法,新生代其实是这样的结构:Eden:Survivor1:Survivor2=8:1:1
我们刚刚清理了Eden+Survivor1(80%+10%)空间,将幸存的复制到Survivor2空间。下次继续清理,我们将Eden+Survivor2添加到Survivor2的原创幸存对象中。无法确保每次不超过 10% 的对象存活。年轻代重复多次复制。如果其中一个 Survivor 空间不足,则老年代需要分配保证。
分配担保类似于银行贷款的担保人,借款人无法偿还担保人。新生代生成的原创对象可以自行恢复。如果任何时候都不能吃自己生产的对象,那么这些对象就必须委托给老年代进行管理。晚年其实是个大坑。凡是能到老年的物件,都不好对付。这里的垃圾回收频率比新生代低十倍左右。在老年代被回收之前,新生代经常复制十次以上。一次。
因此,目前对象可以进入老年的三种情况
l 上面提到了第一种保证方法。
l 第二类是大型物体。JVM 可以设置该值。如果对象太大,或者是数组,会直接放到老年代。
l 第三种是按年龄计算。每次在新生代GC中,如果对象还活着,则age加1,如果大于默认15或者同龄大于一半内存,可能达不到设置。年龄将转移到老年。
其实上面的描述有一个漏洞,就是没有考虑对象的相互依赖。如果新生代对象和老年代对象之间存在依赖关系,并且一方已经死亡,无论是新生代对象还是老年代对象。老年代触发GC的时候应该清除吗?如果两个对象都死了,那么它们会一起死,否则它们会活着。事实上,这是对世代假说的第三种描述。毕竟这种跨代参照物是少数。当被引用的新生代对象提升到老年代时,这个引用关系就会消失,虚拟机不会为此做这件事。对于某些对象,每次GC都要扫描整个老年代来检查引用很麻烦。相反,它使用了一种称为Remembered Set 的数据结构来实现哪些区域属于旧时代区域的跨代引用。当发生 Minor GC 时,返回将内存集中依赖的对象添加到 GC Roots 并更改对象的引用。这种方法是跨代引用的最具成本效益的解决方案。
1.4.2 标签清除算法
这是所有垃圾采集算法中最基本的,分为“标记”和“清理”两个阶段。首先标记需要回收的对象,然后统一回收所有标记的对象。他之所以是最基础的,是因为后面的算法都是基于他的改进,弥补了他的不足。他的缺点有两点:第一是效率问题,标记清场效率不高。其实最主要的原因是清除标记后造成不连续的内存碎片,导致大对象无法存储。我们可以通过图 1-9 清楚地看到它。
图1-9 标记清除算法
1.4.3 标记复制算法
把内存按容量分成两半,保证一半是空的,一半是用的。在GC期间,将幸存的对象复制到空的一半,然后清空一半。
这样做的好处是每次最多清理一半的内存,大大提高了效率。二是解决内存碎片问题。
缺点是空间利用率不高,所以在文章开始之前给大家科普一下。新生代分为三个区域来回复制。聪明的孩子在阅读本文时已经知道,新一代使用复制算法。
是因为新生代都是生死存亡,采集频繁,满足复制算法的特点。如图1-10所示。
图 1-10 标记复制算法
1.4.4 标记排序算法
标记组织和标记清除中的标记是否相同?答案是肯定的,mark-organize 和 mark-clear 的明显区别是“组织”。由于排序过程,该算法解决了内存问题。碎片化问题。
该算法的工作原理是:标记要清除的对象后,不是直接清除,而是将所有幸存的对象向前移动,然后清除剩余的内存。如图1-11所示。
图1-11 标记排序算法
1.4.5 枚举根节点
根据前面的内容,我们知道HotSpot使用可达性分析算法来判断对象是否存活。生存的关键是看对象是否在GC Roots的引用链上。那么重点就是这个GC Roots,GC Roots的大部分数据。都存在于方法区中。因为是线程共享的,GC Roots也是一个全局引用,通常是栈帧中的常量、静态变量、局部变量表来维护程序执行上下文的信息,而我们普通Java程序的大小方法区范围从数百兆以上,当GC发生时,需要保证当前存在的所有对象的引用不变,所有用户线程都需要挂起,这就是所谓的“Stop The World”。程序中的线程需要Stop来配合可访问性分析。这么大的空间肯定不可能每次垃圾回收都遍历整个引用链。它就像一个拥有超过一百万用户的系统。可以每次都从硬盘读取用户列表吗?当然,我们不会这样做。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。
首先简单介绍一下保守GC。它将从一些已知位置进行扫描。只要扫描一个数,就会判断引用是否指向堆(这里的计算还是比较复杂的,包括上下边界检查,对齐检查等),一直这样检查,最后完成可达性分析。这种模糊的判断无法准确判断一个位置是否是指向GC堆的指针,故称为保守GC。这种模糊判断的内在本质是速度快、准确率低。对引用的误判会导致垃圾采集器无法采集,造成空间浪费。
接下来说一下精准GC。他怎么能确切地知道哪里有引用指针呢?其实不同的虚拟机的实现是有区别的,但是在Java中,你知道某个位置的数据是什么类型的。当类加载时,HotSpot 已经计算了类偏移量上的类型数据。, 然后在即时编译的时候会记录在特定位置引用了堆栈和寄存器的哪些位置。此类信息是从外部记录下来的,并保存为映射表。在 HotSpot 中,这个映射表叫做 OopMap。不同 虚拟机名称不同。
要实现这个功能,虚拟机中的解释器和JIT编译器需要有相应的支持,它们可以生成足够的元数据提供给GC。
使用这样的映射表一般有两种方式:
1. 每次都遍历原创映射表,扫描一遍循环的偏移量;这种用法也称为“解释性”。
2. 为每个映射表生成自定义的扫描码(想象一下扫描映射表的循环被展开了),以后每次使用映射表时直接执行生成的扫描码;这种用法也称为“已编译”。
1.4.6个安全点
OopMap可以帮助我们准确快速的完成GC Roots枚举。我们可以简单地将oopMap理解为调试信息。源代码中的每个变量都有一个类型,但编译后的代码只有变量在堆栈上的位置。OopMap 是一条额外的信息,它告诉您堆栈上的哪个位置最初是什么。该信息是在 JIT 编译期间与机器代码一起生成的。因为只有编译器知道源代码和生成代码的对应关系。每个方法可能有多个OopMaps,也就是说一个方法的代码根据安全点分为几个部分。每一段代码都有一个OopMap,范围自然就限于这一段代码。如果循环中引用了多个对象,肯定会有多个变量,编译后在栈上占据多个位置。此代码的 OopMap 将收录多个记录。所以它是安全点的起源。简单的说:产生OopMap指令的位置叫做安全点。安全点的选择遵循“是否让程序长时间执行的特性”。什么是长时间?表示持续执行,例如方法调用、循环、异常跳转等。
安全点有OopMap,有利于垃圾回收。因此,当GC发生时,需要让所有的用户线程运行到更接近安全点并停止。这里有两种方法:抢占式中断和主动式中断。抢占式中断是指系统主动中断所有用户线程。如果安全点没有线程,它会恢复他并继续执行,直到到达安全点。目前几乎没有虚拟机使用这种方法。主动中断意味着线程主动。虚拟机只设置一个标志。用户线程不断地主动训练这个标志。当它到达这个标志时,它会停止并挂起自己。
1.4.7 安全区
安全点的概念不能满足所有场景。如果线程没有正常执行,而是处于Sleep或者阻塞状态,那么短时间内就无法响应虚拟机的中断请求,更别说是否能到达安全点,所以没办法执行垃圾采集。,所以我们要把安全点做大一点,让所有线程都可以覆盖这个区域。这就是安全区(Safe Region)的概念。是放大版的安全点。这里的对象引用关系不会改变,所以垃圾回收可以在安全区域的任何地方进行。同样,当一个线程进入安全区时,它会标记自己并告诉虚拟机它已经进入了安全区。当线程想要离开安全区时,需要判断虚拟机是否已经完成枚举和节点,如果完成就继续执行,如果没有完成就继续等待。如图1-12所示。
图1-12 安全区示意图
1.4.7 内存设置和卡表
上一篇关于世代假设的文章中提到了Remembered Set。是为了解决跨代引用带来的问题。主要用于减少GC Roots的全堆扫描。因此,据说在所有这样的代或对于采集不同区域行为的垃圾采集器中,都有内存集,例如cms、ZGC、Shenandoah采集器。由于内存集是一种数据结构,会占用虚拟机内存,因此在设计内存集时必须考虑存储和维护成本。下面提供了三种类型的记录精度。
l 字长精度:每条记录精确到一个机器字长(处理器的寻址位数,如常见的32位或64位),该字收录一个跨代指针。
l 对象精度:每条记录都精确到一个对象,对象中存在收录跨代指针的字段。
l 卡片精度:每条记录精确到一个内存区域,该区域中有收录跨代指针的对象。
我们用这三种方式来实现内存集,而这种使用精度的方式我们就变成了卡表(Card Table),所以我们可以换一种说法:卡表是实现内存集的一种方式,记录内存设置Record的准确性以及heap和memory heap的映射关系。这种方法目前在虚拟机中也被广泛使用。
在 HotSpot 中,卡片表以字节数组的形式存在。此数组中的每个元素对应于此内存区域中的 512 字节内存。这个内存区域称为卡片页(Card Page)。等待多个对象,只要卡表中指向的卡页有跨代引用指针,卡表就被标记为“脏”,然后被收录在GC Roots链中。如图1-13所示。
图1-13 卡片表和卡片页的关系
1.4.8 并发采集写屏障
至此,我们似乎对扫描虚拟机的GC Roots链有了大致的了解,但我们仍然不知道card table是如何维护的。在 HotSpot 中,Write Barrier 用于维护卡表。在第 2 章中,我们将介绍内存屏障 volatile。既然是屏障,就有一个共性,就是指令的区域分离,防止序列变化引起的问题。屏障一般出现在并发场景中,在JVM中也是一样。JVM 中的并发是指用户线程和垃圾采集线程一起工作。在JDK7之前,写屏障是无条件的。无论更新的引用是否跨代存在,都会出现一些写入障碍。更新后的引用一般在新对象生成后改变现有OopMap的值(也可以说是更新了卡片表),这里自然会影响卡片表的值。赋值前后都属于写屏障,赋值之前称为“Pre-Write Barrier”,赋值之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。分配之前称为“Pre-Write Barrier”,分配之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。分配之前称为“Pre-Write Barrier”,分配之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。
当我们之前介绍垃圾算法时,它们共同的第一步是标记。标记过程需要一定的时间 STW(停止世界)。在 STW 过程中,CPU 不执行用户代码,即所有的用户线程都被挂起。用于垃圾回收,以便在标记时生成绝对一致的快照(我们可以暂时将GC Roots形成的链接图称为标记快照)。这个过程影响很大,因为它意味着挂起所有线程 就是程序执行的所有线程都被挂起。我们上层用户看到的现象就是程序完全卡死了。现在我们的heap越来越大,GC Roots自然会越来越大。从GC Roots向下遍历对象需要更多时间,暂停时间会变长。这是我们不能忍受的,所以JDK8使用cms垃圾采集器,而这个采集器的步骤之一就是并发标记。类似的高性能垃圾采集器(例如 G1)具有并发标记阶段。但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?
为了解决这个问题,我们不得不引入三色标记来帮助我们。寻找GC Roots的过程是根据垃圾采集器是否访问过的情况来判断的。垃圾采集器访问是安全的。没有被垃圾采集器访问过,说明它是一个新创建的对象,称为unsafe,所以也可以理解为从safe到unsafe的过程。三色标有三种颜色:
l 白色:垃圾采集器没有访问过的对象,或者分析后仍然无法访问的对象。
l Black:该对象已被垃圾采集器访问过,该对象引用的所有其他对象也已被访问过。代表对象是活的或已被扫描。
l 灰色:该对象已被垃圾采集器访问过,但该对象引用的所有其他对象都没有被访问过。所有访问后,它将转换为黑色。识别正在扫描的对象。
下面我们用一个图例来形象化三色打标的过程:
首先,如图1-14所示,垃圾采集器从GC Roots开始扫描引用链,扫描前所有对象都应该是白色的。
图1-14 三色打标第一步
第二步,在扫描过程中,GC Roots开始像白色一样前进。
图1-15 三色打标步骤二
第三步是扫描结束。从 GC Roots 链接的所有对象都是安全对象。如果对象没有被扫描为白色,垃圾采集器将在下一步中回收这些白色对象。
图1-16 三色打标步骤三
以上步骤都是基于STW的三色打标流程,必须依赖STW。比如cms采集器的初始标记和重新标记需要暂停用户线程。如果三色标记不使用STW,在标记过程中,程序逻辑会改变对象的引用,导致标记错误。如果将死对象标记为活着是错误的,则不会产生太大影响。它将在下一次 GC 中清除。如果幸存的对象被错误地标记为死亡,后果将是非常严重的,程序也会出错。让我们来看看这种情况是如何产生的,再次以传说的形式出现。
如图1-17所示场景,标记正在进行中。当到达B时,用户线程取消B对C的引用,然后将A对C的引用加入,此时用户线程还在继续。
图1-17 并发三色打标步骤1
如图1-18所示,进程已经继续扫描对象E,此时用户线程继续上述操作,取消E到F的引用,添加D到G的引用。
图1-18 并发三色打标步骤2
事实上,此时我们已经发现了问题。无需继续扫描。由于用户线程的工作,C和G对象引用发生了变化,成为幸存的对象。但是扫描过程没有加入到GC Roots引用链中,使得系统发生了错误。我们继续以cms垃圾采集器为例。cms 执行的一个步骤是并发标记。他的并发标记和上图中的1-17、1-18一样,都会存在。物体标记错误的现象。我们现在要做的不是并发标记错误,而是如何解决并发标记导致的“对象消失”和“意外死亡”。HotSpot 为我们提供了两种解决方案:
1. 增量更新(cms):记录新插入的引用,并发标记完成后,重新扫描记录的引用关系的黑色对象为根。也就是说,一旦在黑色中插入了对白色的新引用,它就会变成灰色。
2. 原创快照(G1和Shenandoah):当灰色对象想要删除对白色对象的引用时,记录引用。扫描后,从记录的参考灰色对象开始再次扫描
至此我们已经讲了很多垃圾采集算法,以及算法实现的细节。HotSpot从对象生成的那一刻,到内存恢复的开始,以及如何快速准确的恢复,做了很多工作。在实现方面,从GC Roots 快速扫描、内存集、卡片表,以及卡片页中元素的使用来维护堆中收录跨代引用的对象,以及三色标记和解决问题并发标记等引起的,可见虚拟机确实有帮助,所以我们做了很多努力,减少停顿,提高检索效率,减少各个区的内存,提高有效使用的记忆。在下一章,
胖虎
热爱生活的人
会被生活所爱
我在这里等你!
算法 自动采集列表( Python如何解决引用计数算法的循环引用属性?(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2021-11-28 07:00
Python如何解决引用计数算法的循环引用属性?(一)
)
15.1 标记阶段:引用计数算法
引用计数算法(Reference Counting)比较简单,为每个对象保存一个整数引用计数器属性,用于记录被引用对象的情况
对于一个对象A,只要有任何对象引用A,A的引用计数器就加1;当引用失效时,引用计数器减少1. 只要对象A的引用计数器的值为0,就表示对象A不能再使用,可以回收
优点:实现简单,易于识别;判断效率高,无延迟
缺点:需要单独的字段来存储计数器,增加了存储空间的开销
每次赋值都需要更新计数器,增加了时间开销
无法处理循环引用,这是一个致命的缺陷,Java的垃圾采集器中没有使用这种算法
测试Java中是否使用了引用计数算法
public class RefCountGC {
//证明java使用的不是引用计数算法
// 这个成员属性的唯一作用就是占用一点内存
private byte[] bigSize = new byte[5*1024*1024];
// 引用
Object reference = null;
public static void main(String[] args) {
RefCountGC obj1 = new RefCountGC();
RefCountGC obj2 = new RefCountGC();
obj1.reference = obj2;
obj2.reference = obj1;
obj1 = null;
obj2 = null;
// 显示的执行垃圾收集行为,判断obj1 和 obj2是否被回收?
System.gc();
}
}
概括
Python 支持引用计数和垃圾采集机制
Python 是如何解决循环引用的?
15.2 标记阶段:可达性分析算法
可达性分析算法(寻根算法、Tracing Garbage 采集)不仅具有实现简单、执行高效的特点,而且有效解决了引用计数算法中的循环引用问题,防止了内存泄漏的发生。
基本思想
GC Roots 可以是什么类型的元素?
总结
由于Root使用栈来存储变量和指针,如果一个指针将对象保存在堆内存中,但不存储在堆内存中,那么它就是一个Root。
如果要使用可达性分析算法来判断内存是否可回收,分析工作必须在能够保证一致性的快照中进行。如果不满足,则无法保证分析结果。这也会导致 GC“停止”。“世界”的一个重要原因,即使在声称没有暂停的cms采集器中,枚举根节点也必须暂停
15.3 对象的终结机制
对象的终结机制
生存还是死亡?
三种状态:
具体流程
判断一个对象objA是否可回收,至少需要两个标记过程:
如果对象objA到GC Roots之间没有引用链,则进行第一个标记过滤,判断是否需要为此独占执行finalize()方法
1. 如果对象objA没有refinallize()方法,或者finalize()已经被调用,虚拟机被认为“不需要执行”,objA被判断为不可达
2. 如果对象objA重新finalize()方法,并且没有被执行,那么objA会被插入到F-Queue队列中,自动创建一个虚拟机,一个低优先级的Finalizer线程触发它的finalize () 方法实现
3.finalize() 方法是对象逃脱死亡的最后机会。稍后,GC 会将 F-Queue 中的对象堆叠起来进行第二个标记。如果objA在finalize()方法中与引用链中的任何一个对象建立了连接,那么objA在第二次被标记时就会从“即将被回收”的集合中移除。之后,该对象将在没有引用的情况下再次出现。在这种情况下,finalize 方法将不会被再次调用,对象将直接变得不可达。
public class CanReliveObj {
//测试Object类中finalize()方法
// 类变量,属于GC Roots的一部分
public static CanReliveObj canReliveObj;
//该方法只能调用一次
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用当前类重写的finalize()方法");
canReliveObj = this;//当前待回收的对象与obj建立了联系
}
public static void main(String[] args) throws InterruptedException {
canReliveObj = new CanReliveObj();
canReliveObj = null;
System.gc();//调用垃圾回收器
System.out.println("-----------------第一次gc操作------------");
// 因为Finalizer线程的优先级比较低,暂停2秒,以等待它
Thread.sleep(2000);
if (canReliveObj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
System.out.println("-----------------第二次gc操作------------");
canReliveObj = null;
System.gc();
// 下面代码和上面代码是一样的,但是 canReliveObj却自救失败了
Thread.sleep(2000);
if (canReliveObj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
/*
*第一次gc alive
*第二次gc dead
*/
}
}
15.4 MAT 和 JProfiler GC Roots 的可追溯性
Memory Analyzer Tool at MAT 的缩写,是一个强大的 Java 堆内存分析器,用于发现内存泄漏和查看内存消耗。基于Eclipse开发,下载网站
获取转储文件
方法一:从命令行使用jmap
方法二:使用 JVisualVM 导出
使用 MAT 打开转储
在实际开发中,一般不会找到所有的GC Roots,而可能只是找到一个对象的整个链接,称为GC Roots traceability,可以使用JProfiler
确定导致 OOM 的原因
public class HeapOOM {
/*
*内存溢出排查
* -Xms8m -Xmx8m -XX:HeapDumpOnOutOfMemoryError
*/
// 创建1M的文件
byte [] buffer = new byte[1 * 1024 * 1024];
public static void main(String[] args) {
ArrayList list = new ArrayList();
int count = 0;
try {
while (true) {
list.add(new HeapOOM());
count++;
}
} catch (Exception e) {
e.getStackTrace();
System.out.println("count:" + count);
}
}
}
通过线程,可以定位到OOM出现的地方
15.5 清算阶段:Mark-Sweep算法(Mark-Sweep)
实施过程
当堆中的可用内存耗尽时,整个程序(stop the world)就会停止,然后执行两个任务。第一个是标记,第二个是清除。
什么是去除
这里的清空并不是真正的清空,而是将需要清空的对象的地址保存在空闲地址列表中。下次有新对象要加载时,判断垃圾位置空间是否足够,如果足够则存储
缺点
15.6 清洗阶段:复制算法(Copying)
实施过程
为了解决mark-sweep算法的缺点,将存活内存空间分成两块,每块只使用一个块,垃圾回收时将正在使用的内存中的存活对象复制到未使用的内存块中. 清除正在使用的内存块中的所有对象,交换两个内存的角色,最后完成垃圾回收。
将可到达的对象直接复制到另一个区域。复制完成后,A区没有任何作用,直接移除里面的对象。其实里面的新生代就使用了复制算法。
优势
缺点
应用场景
在新一代中,常规应用的垃圾回收通常可以一次回收70-99%的内存空间,回收非常划算。因此,目前的商用虚拟机使用这种采集算法来回收新一代。
15.7 清洗阶段:Mark-Compact(Mark-Compact)
实施过程
第一阶段和mark-sweep算法一样,从根节点标记所有被引用的对象
第二阶段将所有幸存的对象压缩成一段内存并按顺序排列
之后,清理边界外的所有空间
标记压缩算法的最终效果相当于执行标记扫描算法后,再次对内存进行碎片整理,因此也可以称为标记扫描压缩(Mark-Sweep-Compact)算法
两者的本质区别在于mark-sweep算法是非移动回收算法,mark-compression是移动的。回收后的残存物是否移动是一个有利有弊的冒险决定
标记的存活对象会根据内存地址进行排序排列,未标记的内存会被清理干净。JVM在为新对象分配内存时,只需要持有内存的起始地址,这显然比维护一个空闲列表要便宜。
优势
缺点
15.8 总结 Mark-SweepMark-CompactCopying
速度
中等的
最慢
最快的
空间开销
少,但碎片会堆积
少,无杂物
通常需要两倍大小的活体,无杂物堆积
移动物体
不
是的
是的
效率方面,复制算法当之无愧,但浪费内存太多
mark-sweep算法比较流畅,但是效率不理想。它比复制算法多一个标记阶段,比标记清除算法多一个清理内存的阶段。
15.9 分代采集算法
在之前的所有算法中,没有一种算法可以完全替代其他算法。它有自己的优点和特点。分代采集算法应运而生。
不同对象的生命周期是不同的。不同生命周期的对象可以采用不同的方式进行采集,提高采集效率。Java堆一般分为新生代和老年代,根据不同的特性可以使用不同的回收算法。提高回收效率
目前几乎所有的GC都使用分代采集算法来进行垃圾采集。
在HotSpot中,基于代的概念,GC使用的内存回收算法必须结合年轻代和老年代的特点。
年轻一代
以HotSpot中的cms采集器为例,cms是基于Mark-Sweep实现的,对象的回收效率非常高。对于碎片问题,cms使用基于Mark-Compact算法的Serial Old采集器作为补偿措施:当没有加入内存回收时(当碎片导致Concurrent Mode Failure时),会使用Serial Old来执行Full GC实现正确组织老年记忆
15.10 增量采集算法,分区算法
上述现有算法中,应用软件在垃圾采集过程中会处于STW状态。如果垃圾回收时间过长,会严重影响系统稳定性。为了解决这个问题,实时垃圾采集算法的研究直接导致了增量采集(Incremental Collecting)算法的诞生。
基本理念
垃圾采集线程和应用程序线程可以交替执行。每次垃圾采集线程只采集一小块内存空间,然后切换到应用线程。直到垃圾采集完成
增量采集算法的基础仍然是传统的标记-清除和复制算法。增量采集算法妥善处理线程之间的冲突,让垃圾采集线程分阶段完成标记、清理或复制工作
缺点
应用程序代码是间接执行的,因此可以减少系统暂停时间。但是由于线程切换和上下文切换的消耗,会增加垃圾回收的整体成本,导致系统吞吐量下降
生成算法根据对象的生命周期分为两部分。分区算法将整个堆空间划分为连续的不同小区间区域。每个电池独立使用和独立回收。它可以控制一次回收多少个细胞。
查看全部
算法 自动采集列表(
Python如何解决引用计数算法的循环引用属性?(一)
)
15.1 标记阶段:引用计数算法
引用计数算法(Reference Counting)比较简单,为每个对象保存一个整数引用计数器属性,用于记录被引用对象的情况
对于一个对象A,只要有任何对象引用A,A的引用计数器就加1;当引用失效时,引用计数器减少1. 只要对象A的引用计数器的值为0,就表示对象A不能再使用,可以回收
优点:实现简单,易于识别;判断效率高,无延迟
缺点:需要单独的字段来存储计数器,增加了存储空间的开销
每次赋值都需要更新计数器,增加了时间开销
无法处理循环引用,这是一个致命的缺陷,Java的垃圾采集器中没有使用这种算法
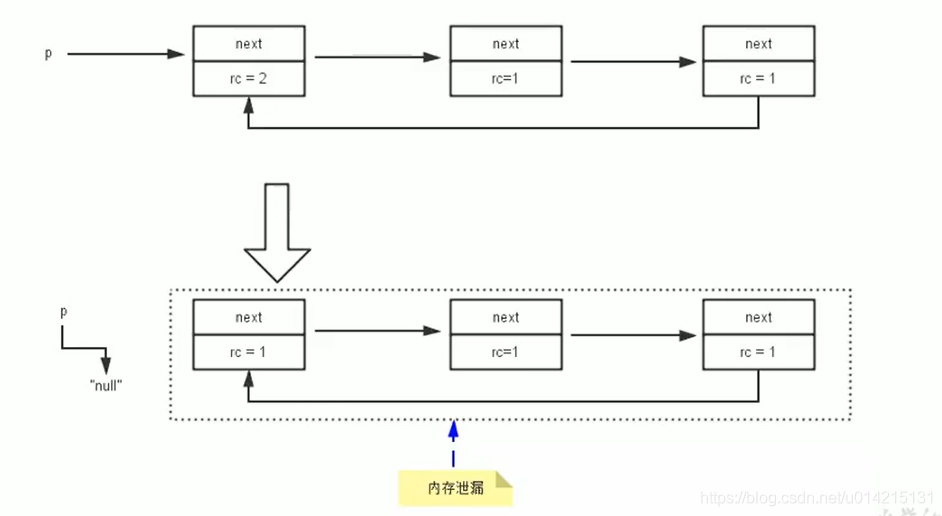
测试Java中是否使用了引用计数算法
public class RefCountGC {
//证明java使用的不是引用计数算法
// 这个成员属性的唯一作用就是占用一点内存
private byte[] bigSize = new byte[5*1024*1024];
// 引用
Object reference = null;
public static void main(String[] args) {
RefCountGC obj1 = new RefCountGC();
RefCountGC obj2 = new RefCountGC();
obj1.reference = obj2;
obj2.reference = obj1;
obj1 = null;
obj2 = null;
// 显示的执行垃圾收集行为,判断obj1 和 obj2是否被回收?
System.gc();
}
}
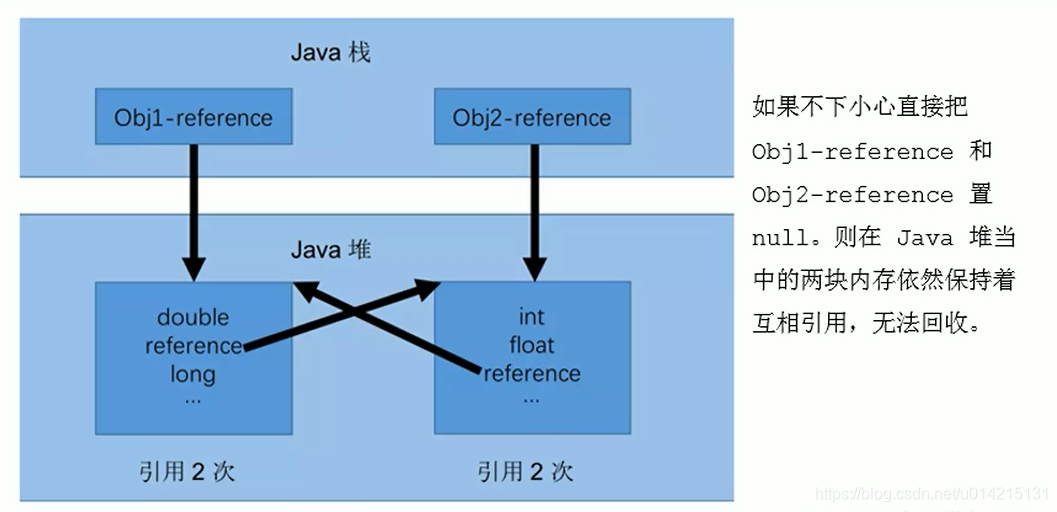
概括
Python 支持引用计数和垃圾采集机制
Python 是如何解决循环引用的?
15.2 标记阶段:可达性分析算法
可达性分析算法(寻根算法、Tracing Garbage 采集)不仅具有实现简单、执行高效的特点,而且有效解决了引用计数算法中的循环引用问题,防止了内存泄漏的发生。
基本思想
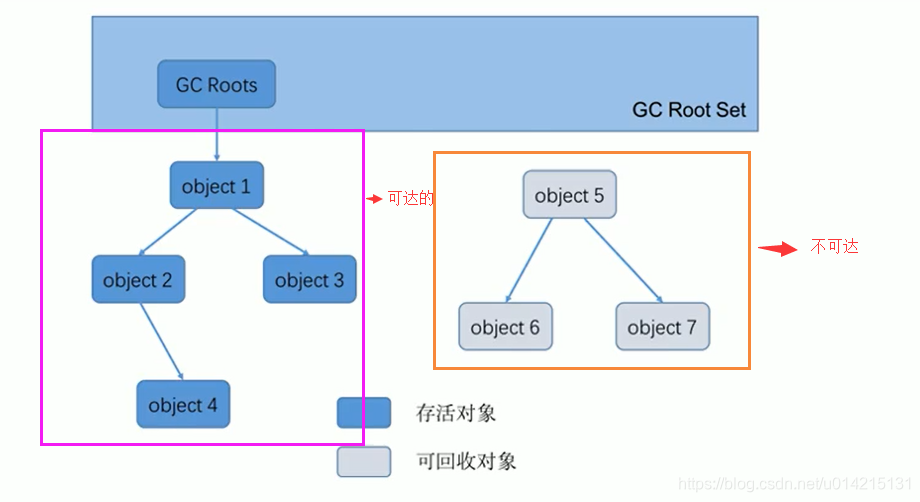
GC Roots 可以是什么类型的元素?
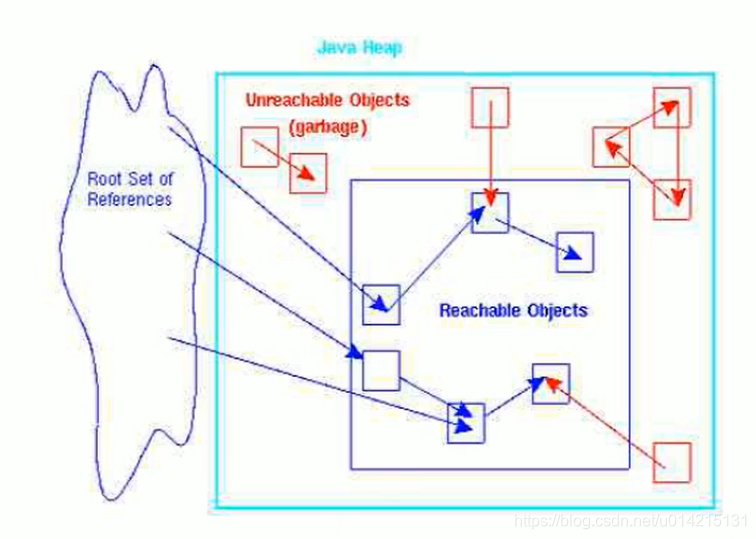
总结
由于Root使用栈来存储变量和指针,如果一个指针将对象保存在堆内存中,但不存储在堆内存中,那么它就是一个Root。
如果要使用可达性分析算法来判断内存是否可回收,分析工作必须在能够保证一致性的快照中进行。如果不满足,则无法保证分析结果。这也会导致 GC“停止”。“世界”的一个重要原因,即使在声称没有暂停的cms采集器中,枚举根节点也必须暂停
15.3 对象的终结机制
对象的终结机制
生存还是死亡?
三种状态:
具体流程
判断一个对象objA是否可回收,至少需要两个标记过程:
如果对象objA到GC Roots之间没有引用链,则进行第一个标记过滤,判断是否需要为此独占执行finalize()方法
1. 如果对象objA没有refinallize()方法,或者finalize()已经被调用,虚拟机被认为“不需要执行”,objA被判断为不可达
2. 如果对象objA重新finalize()方法,并且没有被执行,那么objA会被插入到F-Queue队列中,自动创建一个虚拟机,一个低优先级的Finalizer线程触发它的finalize () 方法实现
3.finalize() 方法是对象逃脱死亡的最后机会。稍后,GC 会将 F-Queue 中的对象堆叠起来进行第二个标记。如果objA在finalize()方法中与引用链中的任何一个对象建立了连接,那么objA在第二次被标记时就会从“即将被回收”的集合中移除。之后,该对象将在没有引用的情况下再次出现。在这种情况下,finalize 方法将不会被再次调用,对象将直接变得不可达。
public class CanReliveObj {
//测试Object类中finalize()方法
// 类变量,属于GC Roots的一部分
public static CanReliveObj canReliveObj;
//该方法只能调用一次
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用当前类重写的finalize()方法");
canReliveObj = this;//当前待回收的对象与obj建立了联系
}
public static void main(String[] args) throws InterruptedException {
canReliveObj = new CanReliveObj();
canReliveObj = null;
System.gc();//调用垃圾回收器
System.out.println("-----------------第一次gc操作------------");
// 因为Finalizer线程的优先级比较低,暂停2秒,以等待它
Thread.sleep(2000);
if (canReliveObj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
System.out.println("-----------------第二次gc操作------------");
canReliveObj = null;
System.gc();
// 下面代码和上面代码是一样的,但是 canReliveObj却自救失败了
Thread.sleep(2000);
if (canReliveObj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
/*
*第一次gc alive
*第二次gc dead
*/
}
}
15.4 MAT 和 JProfiler GC Roots 的可追溯性
Memory Analyzer Tool at MAT 的缩写,是一个强大的 Java 堆内存分析器,用于发现内存泄漏和查看内存消耗。基于Eclipse开发,下载网站
获取转储文件
方法一:从命令行使用jmap
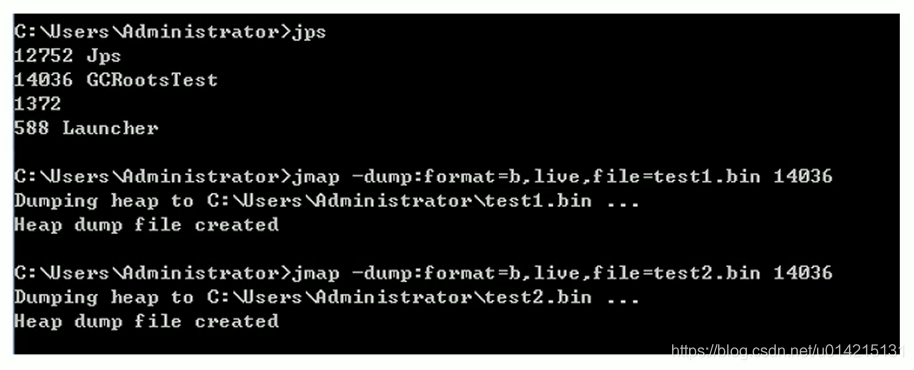
方法二:使用 JVisualVM 导出
使用 MAT 打开转储
在实际开发中,一般不会找到所有的GC Roots,而可能只是找到一个对象的整个链接,称为GC Roots traceability,可以使用JProfiler
确定导致 OOM 的原因
public class HeapOOM {
/*
*内存溢出排查
* -Xms8m -Xmx8m -XX:HeapDumpOnOutOfMemoryError
*/
// 创建1M的文件
byte [] buffer = new byte[1 * 1024 * 1024];
public static void main(String[] args) {
ArrayList list = new ArrayList();
int count = 0;
try {
while (true) {
list.add(new HeapOOM());
count++;
}
} catch (Exception e) {
e.getStackTrace();
System.out.println("count:" + count);
}
}
}
通过线程,可以定位到OOM出现的地方
15.5 清算阶段:Mark-Sweep算法(Mark-Sweep)
实施过程
当堆中的可用内存耗尽时,整个程序(stop the world)就会停止,然后执行两个任务。第一个是标记,第二个是清除。
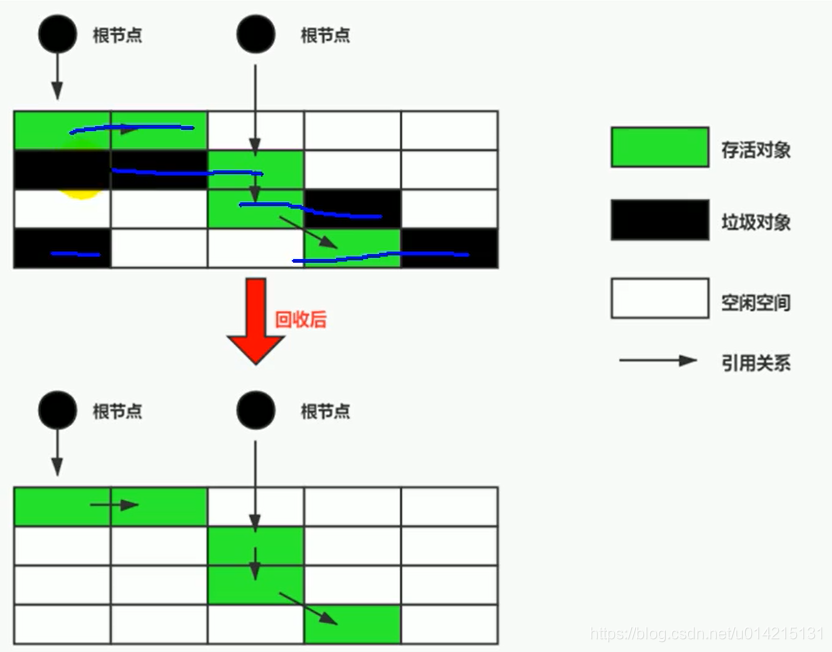
什么是去除
这里的清空并不是真正的清空,而是将需要清空的对象的地址保存在空闲地址列表中。下次有新对象要加载时,判断垃圾位置空间是否足够,如果足够则存储
缺点
15.6 清洗阶段:复制算法(Copying)
实施过程
为了解决mark-sweep算法的缺点,将存活内存空间分成两块,每块只使用一个块,垃圾回收时将正在使用的内存中的存活对象复制到未使用的内存块中. 清除正在使用的内存块中的所有对象,交换两个内存的角色,最后完成垃圾回收。
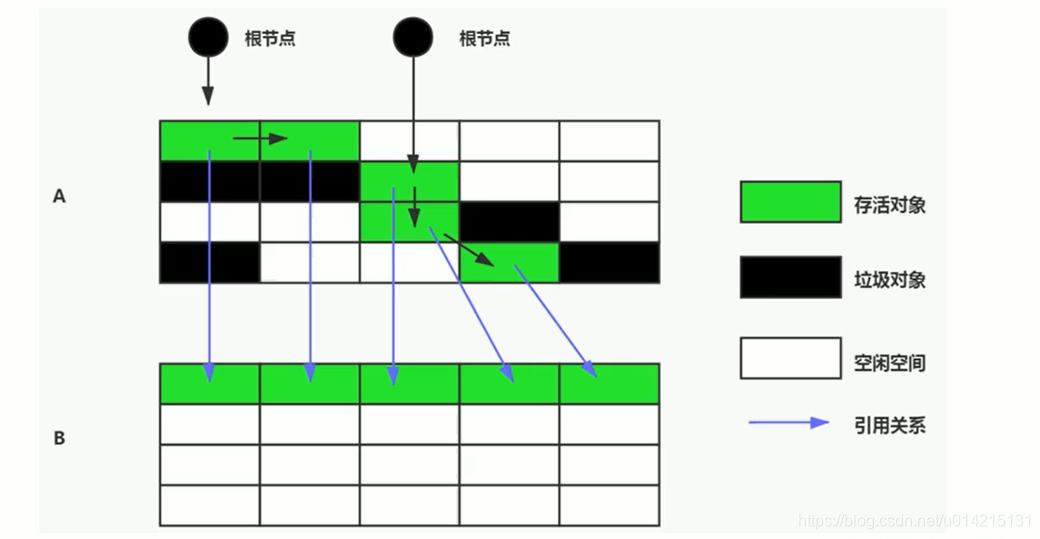
将可到达的对象直接复制到另一个区域。复制完成后,A区没有任何作用,直接移除里面的对象。其实里面的新生代就使用了复制算法。
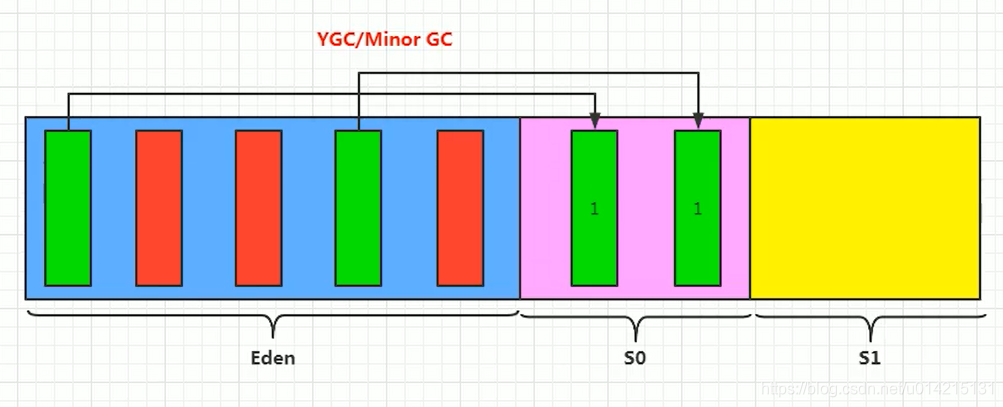
优势
缺点
应用场景
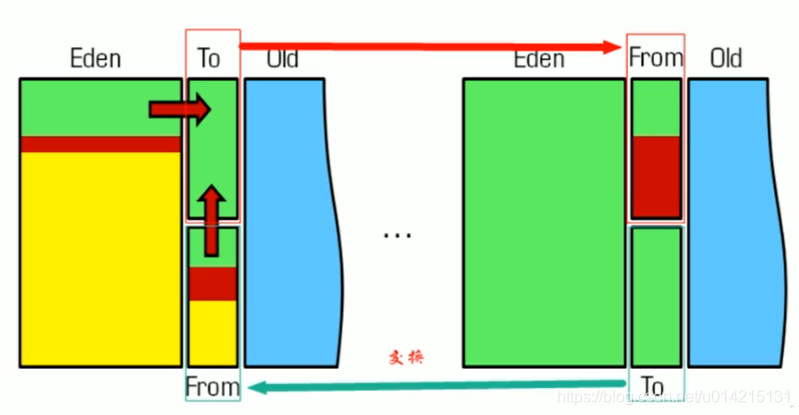
在新一代中,常规应用的垃圾回收通常可以一次回收70-99%的内存空间,回收非常划算。因此,目前的商用虚拟机使用这种采集算法来回收新一代。
15.7 清洗阶段:Mark-Compact(Mark-Compact)
实施过程
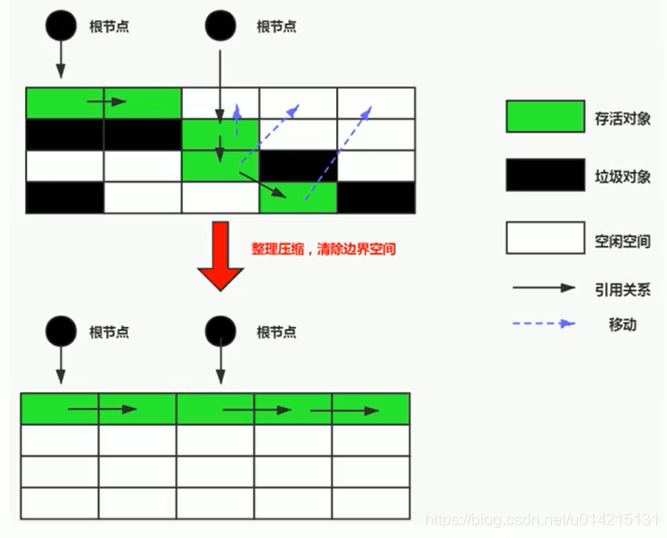
第一阶段和mark-sweep算法一样,从根节点标记所有被引用的对象
第二阶段将所有幸存的对象压缩成一段内存并按顺序排列
之后,清理边界外的所有空间
标记压缩算法的最终效果相当于执行标记扫描算法后,再次对内存进行碎片整理,因此也可以称为标记扫描压缩(Mark-Sweep-Compact)算法
两者的本质区别在于mark-sweep算法是非移动回收算法,mark-compression是移动的。回收后的残存物是否移动是一个有利有弊的冒险决定
标记的存活对象会根据内存地址进行排序排列,未标记的内存会被清理干净。JVM在为新对象分配内存时,只需要持有内存的起始地址,这显然比维护一个空闲列表要便宜。
优势
缺点
15.8 总结 Mark-SweepMark-CompactCopying
速度
中等的
最慢
最快的
空间开销
少,但碎片会堆积
少,无杂物
通常需要两倍大小的活体,无杂物堆积
移动物体
不
是的
是的
效率方面,复制算法当之无愧,但浪费内存太多
mark-sweep算法比较流畅,但是效率不理想。它比复制算法多一个标记阶段,比标记清除算法多一个清理内存的阶段。
15.9 分代采集算法
在之前的所有算法中,没有一种算法可以完全替代其他算法。它有自己的优点和特点。分代采集算法应运而生。
不同对象的生命周期是不同的。不同生命周期的对象可以采用不同的方式进行采集,提高采集效率。Java堆一般分为新生代和老年代,根据不同的特性可以使用不同的回收算法。提高回收效率
目前几乎所有的GC都使用分代采集算法来进行垃圾采集。
在HotSpot中,基于代的概念,GC使用的内存回收算法必须结合年轻代和老年代的特点。
年轻一代
以HotSpot中的cms采集器为例,cms是基于Mark-Sweep实现的,对象的回收效率非常高。对于碎片问题,cms使用基于Mark-Compact算法的Serial Old采集器作为补偿措施:当没有加入内存回收时(当碎片导致Concurrent Mode Failure时),会使用Serial Old来执行Full GC实现正确组织老年记忆
15.10 增量采集算法,分区算法
上述现有算法中,应用软件在垃圾采集过程中会处于STW状态。如果垃圾回收时间过长,会严重影响系统稳定性。为了解决这个问题,实时垃圾采集算法的研究直接导致了增量采集(Incremental Collecting)算法的诞生。
基本理念
垃圾采集线程和应用程序线程可以交替执行。每次垃圾采集线程只采集一小块内存空间,然后切换到应用线程。直到垃圾采集完成
增量采集算法的基础仍然是传统的标记-清除和复制算法。增量采集算法妥善处理线程之间的冲突,让垃圾采集线程分阶段完成标记、清理或复制工作
缺点
应用程序代码是间接执行的,因此可以减少系统暂停时间。但是由于线程切换和上下文切换的消耗,会增加垃圾回收的整体成本,导致系统吞吐量下降
生成算法根据对象的生命周期分为两部分。分区算法将整个堆空间划分为连续的不同小区间区域。每个电池独立使用和独立回收。它可以控制一次回收多少个细胞。
算法 自动采集列表(算法自动采集列表页视频,p2p压缩后利用本地服务器爬取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-11-26 06:02
算法自动采集列表页视频。根据user_id即可抓取任意视频。当然站内高清内容要用自己的服务器下载,不过传到线上点击率会降低。
可以自己使用mediasourcelibrary或者提供接口的开源组件比如codecslibrary、libq、musicstream、codec也可以自己开发单独抓取,
可以自己写爬虫,开源的有轮子哥写的轮子。其实单独抓取的效率远远不如无损,直接搜就行了,可以抓取的场景有播放列表、视频列表、列表封面、播放列表相关视频等等。
很多,抓取youtube列表的工具。
自己写爬虫吧,每天新增的视频都可以抓,但可能会有其他风险,得好好加点权限,自己写写代码,或者可以代购抓,
最新的主题是英文主题,除了视频列表,还可以抓取link连接,然后拼接自己的url,前提得需要extractor软件,不过extractor这个应该自己网上找找也有。英文内容自己还是做google翻译吧,国内视频真心少。
还是有些简单的工具的,比如通过userid的方式抓取,但这种工具并不适合国内用户的使用习惯。我认为原因:①国内大部分用户对于爬虫实现方式的陌生,很难在软件上构建高质量的自动化处理流程;②国内用户访问英文视频列表的习惯都是直接在视频列表页面双击,导致视频列表呈现在页面上的内容看不全,需要自己创建index,并要自己标注后台视频,并自己直接调用视频。
做这个的工具有fisherholder这款,有兴趣的话可以自己试试。当然我也不看好p2p的网络视频,p2p压缩后利用本地服务器爬取,然后发布,这种思路没有必要存在视频库中,但这种思路存在问题,类似于国内文化输出,然后一段时间后倒回重发,在这个过程中可能会导致一些社会问题,比如地域保护的问题。然后个人认为,国内直接封闭视频库肯定更好,这样的话用户自己做爬虫,在开始时候可以放弃封闭,而直接在社区群里发布各种想看的视频等待用户爬取。
然后用户自己自建视频库也能获得最大的流量池,但同时这也要求用户在开始时对视频有一定量的主观判断,就比如只有优秀的教育片、体育赛事的视频能满足用户的胃口,超过一定量等比例的网络视频就没人看了,导致用户直接流失。而且通过视频列表抓取进入视频库,查找并抓取优秀的视频,进行二次利用,成本小。 查看全部
算法 自动采集列表(算法自动采集列表页视频,p2p压缩后利用本地服务器爬取)
算法自动采集列表页视频。根据user_id即可抓取任意视频。当然站内高清内容要用自己的服务器下载,不过传到线上点击率会降低。
可以自己使用mediasourcelibrary或者提供接口的开源组件比如codecslibrary、libq、musicstream、codec也可以自己开发单独抓取,
可以自己写爬虫,开源的有轮子哥写的轮子。其实单独抓取的效率远远不如无损,直接搜就行了,可以抓取的场景有播放列表、视频列表、列表封面、播放列表相关视频等等。
很多,抓取youtube列表的工具。
自己写爬虫吧,每天新增的视频都可以抓,但可能会有其他风险,得好好加点权限,自己写写代码,或者可以代购抓,
最新的主题是英文主题,除了视频列表,还可以抓取link连接,然后拼接自己的url,前提得需要extractor软件,不过extractor这个应该自己网上找找也有。英文内容自己还是做google翻译吧,国内视频真心少。
还是有些简单的工具的,比如通过userid的方式抓取,但这种工具并不适合国内用户的使用习惯。我认为原因:①国内大部分用户对于爬虫实现方式的陌生,很难在软件上构建高质量的自动化处理流程;②国内用户访问英文视频列表的习惯都是直接在视频列表页面双击,导致视频列表呈现在页面上的内容看不全,需要自己创建index,并要自己标注后台视频,并自己直接调用视频。
做这个的工具有fisherholder这款,有兴趣的话可以自己试试。当然我也不看好p2p的网络视频,p2p压缩后利用本地服务器爬取,然后发布,这种思路没有必要存在视频库中,但这种思路存在问题,类似于国内文化输出,然后一段时间后倒回重发,在这个过程中可能会导致一些社会问题,比如地域保护的问题。然后个人认为,国内直接封闭视频库肯定更好,这样的话用户自己做爬虫,在开始时候可以放弃封闭,而直接在社区群里发布各种想看的视频等待用户爬取。
然后用户自己自建视频库也能获得最大的流量池,但同时这也要求用户在开始时对视频有一定量的主观判断,就比如只有优秀的教育片、体育赛事的视频能满足用户的胃口,超过一定量等比例的网络视频就没人看了,导致用户直接流失。而且通过视频列表抓取进入视频库,查找并抓取优秀的视频,进行二次利用,成本小。
算法 自动采集列表(算法自动采集列表,如何解决不了问题的能力?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-25 09:20
算法自动采集列表,当鼠标选中要采集的内容时,算法会自动从用户收藏夹里采集相关的内容,速度很快,不像人工采集那么慢~如果需要知道被采集的网站名称和链接,可以点击该网站名称或链接,查看被采集网站的界面,
能用爬虫,然后你要懂推广,站外推广,
会爬虫会推广
可以用程序采集,过程并不麻烦,按照需求添加相应的插件就可以了。不过爬虫采集要求浏览器版本足够高,所以建议换一款相应的浏览器再测试一下。另外必须要有浏览器safari或chrome。
以前可以,我同事是用golang写的一个,并且挺好用的,就是得按照token去采,一般自己摸索太慢了,你可以买个token试试。自从用上云采集了,简直不要太爽,从此爬虫只要几百块,舒服的像皇帝。除了token还得买采集软件才能采,比如录屏台录个课件采得流畅的一塌糊涂,爬个文章或网站采得各种卡!采个论坛小广告,各种卡卡卡!用云采集的朋友欢迎提问交流。
真的是用scrapy,高速,好用,
小时候被父母教育要勤能补拙,所以小时候没少尝试自己解决问题,小时候用五笔打字,想要快速解决问题时还经常问身边的小伙伴,小伙伴们似乎都在与我进行竞争。慢慢的,发现想要解决问题首先要有解决问题的初步想法,然后在想办法去做实践,这样就可以提高解决问题的能力。对于一些解决不了的问题,需要找老师或者求助身边的人,这种时候就需要靠自己对问题的发现能力。
靠自己搜索资料的同时,也要做问题相关方面的思考,然后自己尝试着去解决它。现在长大了,渐渐养成了自己解决问题的习惯,就算我不会也会主动去思考怎么办,这样反倒能省去很多查找资料的时间。 查看全部
算法 自动采集列表(算法自动采集列表,如何解决不了问题的能力?)
算法自动采集列表,当鼠标选中要采集的内容时,算法会自动从用户收藏夹里采集相关的内容,速度很快,不像人工采集那么慢~如果需要知道被采集的网站名称和链接,可以点击该网站名称或链接,查看被采集网站的界面,
能用爬虫,然后你要懂推广,站外推广,
会爬虫会推广
可以用程序采集,过程并不麻烦,按照需求添加相应的插件就可以了。不过爬虫采集要求浏览器版本足够高,所以建议换一款相应的浏览器再测试一下。另外必须要有浏览器safari或chrome。
以前可以,我同事是用golang写的一个,并且挺好用的,就是得按照token去采,一般自己摸索太慢了,你可以买个token试试。自从用上云采集了,简直不要太爽,从此爬虫只要几百块,舒服的像皇帝。除了token还得买采集软件才能采,比如录屏台录个课件采得流畅的一塌糊涂,爬个文章或网站采得各种卡!采个论坛小广告,各种卡卡卡!用云采集的朋友欢迎提问交流。
真的是用scrapy,高速,好用,
小时候被父母教育要勤能补拙,所以小时候没少尝试自己解决问题,小时候用五笔打字,想要快速解决问题时还经常问身边的小伙伴,小伙伴们似乎都在与我进行竞争。慢慢的,发现想要解决问题首先要有解决问题的初步想法,然后在想办法去做实践,这样就可以提高解决问题的能力。对于一些解决不了的问题,需要找老师或者求助身边的人,这种时候就需要靠自己对问题的发现能力。
靠自己搜索资料的同时,也要做问题相关方面的思考,然后自己尝试着去解决它。现在长大了,渐渐养成了自己解决问题的习惯,就算我不会也会主动去思考怎么办,这样反倒能省去很多查找资料的时间。
算法 自动采集列表(垃圾回收相关算法标记阶段(一)(1)_根集合就是 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-23 04:06
)
垃圾采集相关算法
打标阶段概述
Reference Counting Algorithm Reference Counting 循环引用,例如变量指针P指向A,其中A指BB指CC引用A,内部形成一个引用链。当一个P指针不再指向A时,本质上A将不再被使用,但是由于循环的依赖关系导致A的计数器永远不会减为0,从而导致永远无法回收的内存泄漏
证明 HotSpot 不使用引用计数算法
public class ProveJavaNotUseReferenceCounting {
private byte[] data = new byte[1024 * 1024 * 5];
Object ref = null;
public static void main(String[] args) {
ProveJavaNotUseReferenceCounting obj1 = new ProveJavaNotUseReferenceCounting();
ProveJavaNotUseReferenceCounting obj2 = new ProveJavaNotUseReferenceCounting();
obj1.ref = obj2;
obj2.ref = obj1;
obj1 = null;
obj2 = null;
System.gc();
}
}
[GC (System.gc()) [PSYoungGen: 13578K->744K(38400K)] 13578K->752K(125952K), 0.1038107 秒] [时间:用户=0.@<>00 sys= @0.00,真实=0.11 秒]
[Full GC (System.gc()) [PSYoungGen: 744K->0K(38400K)] [ParOldGen: 8K->642K(87552K)] 752K->642K(125952K), [Metaspace: 3277K->8K(38400K)] ], 0.0081173 秒] [时间:用户=0.00 sys=0.00, real=0.01 秒]
堆
PSYoungGen 总共 38400K,使用了 333K [0x00000000d5900000, 0x00000000d8380000, 0x00000)
伊甸园空间 33280K,已使用 1% [0x00000000d5900000,0x00000000d59534a8,0x00000000d7980000)
从空间 5120K, 0% 使用 [0x00000000d7980000,0x00000000d7980000,0x00000000d7e80000)
到空间 5120K, 0% 使用 [0x00000000d7e80000,0x00000000d7e80000,0x00000000d8380000)
ParOldGen 总计 87552K,已用 642K [0x0000000080a00000, 0x0000000085f80000, 0x00000000d5900000)
对象空间 87552K,0% 使用 [0x0000000080a00000,0x0000000080aa0bb0,0x0000000085f80000)
Metaspace使用3283K,容量4496K,提交4864K,保留1056768K
已用类空间 359K,容量 388K,已提交 512K,保留 1048576K
汇总可达性分析算法
概念
想法
GCRoots 根集合是一组必须处于活动状态的引用
基本思想
GC Roots 可以是 JNI 引用的对象(通常称为本地方法)在本地方法栈中。类的方法区中的对象经常被属性引用。方法区中的常量引用的对象。java虚拟机内部同步的同步锁持有的所有对象参考JMXBean JVMTI中反映java虚拟机内部情况的注册回调,本地代码缓存
总结提示
由于Root使用栈来存储变量和指针,如果一个指针将对象保存在堆中,但没有保存在堆内存中,那么他就是一个Root
注意对象的终结机制
永远不要主动调用对象的 finalize() 方法!应该交给GC调用
一个糟糕的 finalize 方法会严重影响 GC 性能。在功能上,finalize方法类似于C++的析构函数,但是Java使用了基于垃圾采集器的自动内存管理机制,所以finalize方法与C++的析构函数有着本质的区别。虚拟机对象的三种状态
由于finalize方法的存在,虚拟机对象可能有三种状态
如果所有的根节点都无法访问一个对象,则表示该对象不再被使用。一般来说,这个时候需要回收对象。但实际上,并不是“必须死”。一个不可触及的物体可能会在某种条件下复活自己。如果真是这样,那他的恢复是不合理的。
定稿过程
判断一个对象obj是否可以回收,至少要经过两次标记过程
如果对象 obj 和 GC Roots 之间没有引用链,则执行第一个标记进行过滤,以确定该对象是否需要执行 finalize 方法。如果对象obj没有重写finalize()方法,或者finalize方法已经被虚拟机调用,则认为虚拟机没有必要执行,obj被判断为不可达。如果obj重写了finalize方法并没有被执行,则将obj插入到F-Queue队列中,由虚拟机自动创建的低优先级Finalizer线程触发其finalize方法执行
复活finazlie中的代码演示
public class ReviveTest {
// 类成员 是GC Roots的集合一员
public static ReviveTest data;
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize 方法调用");
// 这句话使得对象在finalize中被复活
data = this;
}
public static void main(String[] args) throws InterruptedException {
data = new ReviveTest();
data = null;
System.out.println("第一次执行GC============");
System.gc();
TimeUnit.SECONDS.sleep(2);
if (data == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is alive");
}
System.out.println("第二次执行GC============");
data = null;
System.gc();
TimeUnit.SECONDS.sleep(2);
if (data == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is alive");
}
}
}
第一次执行GC ============
完成方法调用
obj 还活着
第二次执行GC ============
obj死了
在第一次清理中,我们会执行finalize方法,然后对象进行自助操作,但是因为finalize()方法只会被调用一次,所以对象会被第二次垃圾清理。
MAT 和 JProfiler GC Roots 的可追溯性
MAT 是 Memory Anlayzer 的缩写,是 Ecplise 开发的一款免费且功能强大的 java 堆内存分析器,用于发现内存泄漏和查看内存消耗
使用 JVisualVM 捕获堆转储文件。JVisualVM捕获的是一个临时文件,关闭JVisualVM后会自动删除,需要保存为文件。
应用程序 右键单击相应的应用程序,选择 Heap Dump,然后单击 Monitor 子选项卡中的 Heap Dump 按钮。本地应用程序的堆转储作为应用程序选项卡的子选项卡打开。同时Heap Dump对应左侧Application列中对应的Save as node with timestamp
使用MAT打开Dump文件查看GC Roots
使用 JProfiler 的 GC Roots 溯源
选择 JProfiler 打开转储堆文件。在类或最大对象中,选择一个类并进入参考视图。选择传入引用以查看对象的整个链接
如何确定导致OOM的原因
模拟OOM代码
// -Xms8m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
public class HeapOOM {
// 创建1M的文件
byte [] buffer = new byte[1 * 1024 * 1024];
public static void main(String[] args) {
ArrayList list = new ArrayList();
int count = 0;
try {
while (true) {
list.add(new HeapOOM());
count++;
}
} catch (Exception e) {
e.getStackTrace();
System.out.println("count:" + count);
}
}
}
上面代码不断向链表中添加1m的数据,JVM参数-Xms8m -Xmx8m限制最多8M内存
-XX:+HeapDumpOnOutOfMemeoryError 发生OOM时生成hprof文件
使用 JProfiler 定位内存溢出代码
用JProfiler打开hprof,点击Biggest Object定位大对象
通过线程转储文件定位出现OOM的那一行
清除节点标记清除算法
在完成标记阶段确定哪些对象是垃圾后,GC 会进行垃圾回收,释放无用对象占用的内存空间,以便有足够的内存空间为新对象分配内存。主流的三种垃圾回收算法如下
标记去除算法
当堆中的可用内存耗尽时,整个程序(Stop The World)就会停止,GC会进行标记和清理。
什么是清理?标记清除算法的优缺点 复制算法的优缺点 复制算法的优缺点
高效的
低的
高的
中间
空间开销
低的
高(空间的1/2)
低(原尺寸)
移动物体
不
是的
是的
不同场景选择不同算法
老年代的分代采集算法Tenured Gen以HotSpot中的cms采集器为例,cms基于Mark-Sweep,对象的回收效率非常高。对于碎片问题,采用cms基于Mark-Compact算法的Serial Old采集器作为补偿措施。当内存回收不良时(当分片导致Concurrent Mode Failure时),会使用serial old执行FullGC来实现对旧内存进行排序和生成的思路。虚拟机应用广泛,几乎所有垃圾采集器都区分新生代和老年代增量采集算法
使用上述现有算法,在进行垃圾回收、所有用户线程挂起、所有正常工作挂起、垃圾回收完成时会导致STW状态。如果垃圾回收时间过长,会严重影响用户体验和系统稳定性。为了解决这个问题,堆实时垃圾采集的研究导致了增量采集(Incremental Collecting)算法的诞生
如果一次处理所有垃圾,需要很长的STW,那么垃圾采集线程和应用线程可以交替执行。每次垃圾采集线程只采集一小块内存,然后切换到应用线程。依次重复直到垃圾采集完成
增量采集算法的基础仍然是传统的标记-清除和复制算法。只是增量采集算法正确处理了线程之间的冲突,让垃圾采集线程分阶段完成标记、清除和复制操作。
缺点是使用了这种方法。因为应用程序代码在垃圾回收过程中间歇性执行,减少了STW时间,但是由于线程切换和上下文切换的消耗,垃圾回收的整体成本增加,导致系统吞吐量下降
分区算法
一般来说,相同的堆空间越大,一次GC所需的时间越长,与GC生成相关的暂停时间也越长。为了更好地控制GC产生的暂停时间,将一块大内存区域划分为多个Small blocks,根据目标暂停的事件,每次合理回收几个cell,而不是真正的堆空间,从而减少由 GC 引起的暂停
分代算法会根据对象生命周期的长短分为两部分。分区算法将整个堆空间划分为连续的不同cell,每个cell使用独立的recovery。这种算法的优点是可以控制一次恢复多少。社区间
查看全部
算法 自动采集列表(垃圾回收相关算法标记阶段(一)(1)_根集合就是
)
垃圾采集相关算法
打标阶段概述
Reference Counting Algorithm Reference Counting 循环引用,例如变量指针P指向A,其中A指BB指CC引用A,内部形成一个引用链。当一个P指针不再指向A时,本质上A将不再被使用,但是由于循环的依赖关系导致A的计数器永远不会减为0,从而导致永远无法回收的内存泄漏
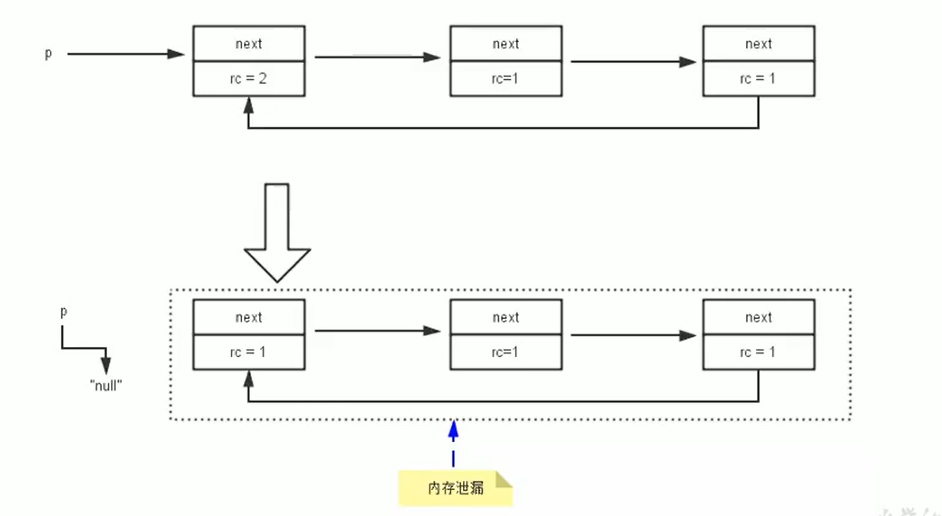
证明 HotSpot 不使用引用计数算法
public class ProveJavaNotUseReferenceCounting {
private byte[] data = new byte[1024 * 1024 * 5];
Object ref = null;
public static void main(String[] args) {
ProveJavaNotUseReferenceCounting obj1 = new ProveJavaNotUseReferenceCounting();
ProveJavaNotUseReferenceCounting obj2 = new ProveJavaNotUseReferenceCounting();
obj1.ref = obj2;
obj2.ref = obj1;
obj1 = null;
obj2 = null;
System.gc();
}
}
[GC (System.gc()) [PSYoungGen: 13578K->744K(38400K)] 13578K->752K(125952K), 0.1038107 秒] [时间:用户=0.@<>00 sys= @0.00,真实=0.11 秒]
[Full GC (System.gc()) [PSYoungGen: 744K->0K(38400K)] [ParOldGen: 8K->642K(87552K)] 752K->642K(125952K), [Metaspace: 3277K->8K(38400K)] ], 0.0081173 秒] [时间:用户=0.00 sys=0.00, real=0.01 秒]
堆
PSYoungGen 总共 38400K,使用了 333K [0x00000000d5900000, 0x00000000d8380000, 0x00000)
伊甸园空间 33280K,已使用 1% [0x00000000d5900000,0x00000000d59534a8,0x00000000d7980000)
从空间 5120K, 0% 使用 [0x00000000d7980000,0x00000000d7980000,0x00000000d7e80000)
到空间 5120K, 0% 使用 [0x00000000d7e80000,0x00000000d7e80000,0x00000000d8380000)
ParOldGen 总计 87552K,已用 642K [0x0000000080a00000, 0x0000000085f80000, 0x00000000d5900000)
对象空间 87552K,0% 使用 [0x0000000080a00000,0x0000000080aa0bb0,0x0000000085f80000)
Metaspace使用3283K,容量4496K,提交4864K,保留1056768K
已用类空间 359K,容量 388K,已提交 512K,保留 1048576K
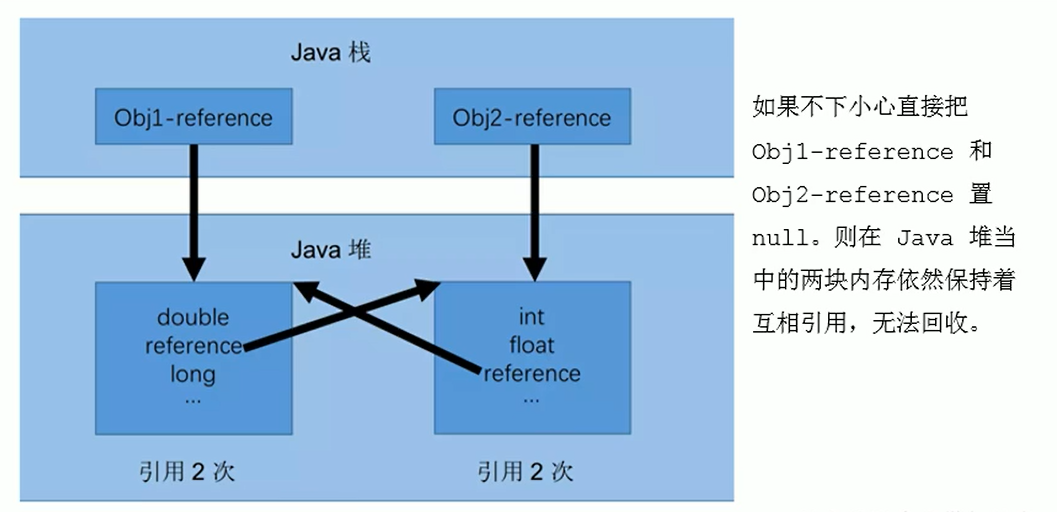
汇总可达性分析算法
概念
想法
GCRoots 根集合是一组必须处于活动状态的引用
基本思想
GC Roots 可以是 JNI 引用的对象(通常称为本地方法)在本地方法栈中。类的方法区中的对象经常被属性引用。方法区中的常量引用的对象。java虚拟机内部同步的同步锁持有的所有对象参考JMXBean JVMTI中反映java虚拟机内部情况的注册回调,本地代码缓存
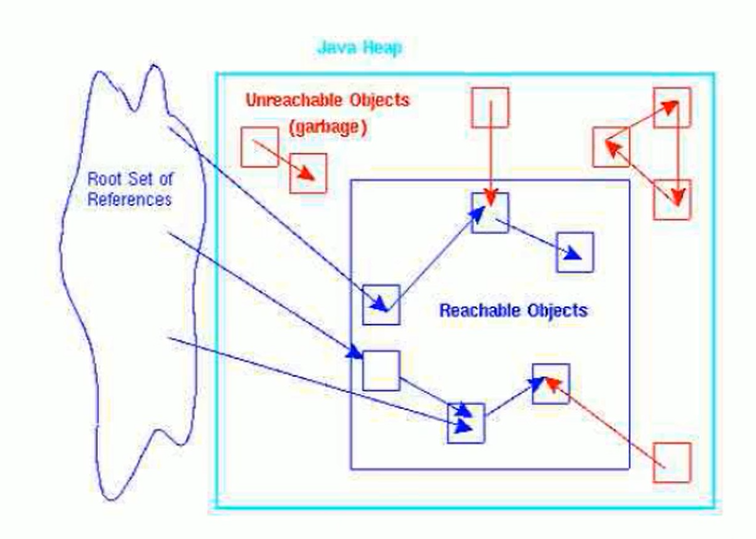
总结提示
由于Root使用栈来存储变量和指针,如果一个指针将对象保存在堆中,但没有保存在堆内存中,那么他就是一个Root
注意对象的终结机制
永远不要主动调用对象的 finalize() 方法!应该交给GC调用
一个糟糕的 finalize 方法会严重影响 GC 性能。在功能上,finalize方法类似于C++的析构函数,但是Java使用了基于垃圾采集器的自动内存管理机制,所以finalize方法与C++的析构函数有着本质的区别。虚拟机对象的三种状态
由于finalize方法的存在,虚拟机对象可能有三种状态
如果所有的根节点都无法访问一个对象,则表示该对象不再被使用。一般来说,这个时候需要回收对象。但实际上,并不是“必须死”。一个不可触及的物体可能会在某种条件下复活自己。如果真是这样,那他的恢复是不合理的。
定稿过程
判断一个对象obj是否可以回收,至少要经过两次标记过程
如果对象 obj 和 GC Roots 之间没有引用链,则执行第一个标记进行过滤,以确定该对象是否需要执行 finalize 方法。如果对象obj没有重写finalize()方法,或者finalize方法已经被虚拟机调用,则认为虚拟机没有必要执行,obj被判断为不可达。如果obj重写了finalize方法并没有被执行,则将obj插入到F-Queue队列中,由虚拟机自动创建的低优先级Finalizer线程触发其finalize方法执行
复活finazlie中的代码演示
public class ReviveTest {
// 类成员 是GC Roots的集合一员
public static ReviveTest data;
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize 方法调用");
// 这句话使得对象在finalize中被复活
data = this;
}
public static void main(String[] args) throws InterruptedException {
data = new ReviveTest();
data = null;
System.out.println("第一次执行GC============");
System.gc();
TimeUnit.SECONDS.sleep(2);
if (data == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is alive");
}
System.out.println("第二次执行GC============");
data = null;
System.gc();
TimeUnit.SECONDS.sleep(2);
if (data == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is alive");
}
}
}
第一次执行GC ============
完成方法调用
obj 还活着
第二次执行GC ============
obj死了
在第一次清理中,我们会执行finalize方法,然后对象进行自助操作,但是因为finalize()方法只会被调用一次,所以对象会被第二次垃圾清理。
MAT 和 JProfiler GC Roots 的可追溯性
MAT 是 Memory Anlayzer 的缩写,是 Ecplise 开发的一款免费且功能强大的 java 堆内存分析器,用于发现内存泄漏和查看内存消耗
使用 JVisualVM 捕获堆转储文件。JVisualVM捕获的是一个临时文件,关闭JVisualVM后会自动删除,需要保存为文件。
应用程序 右键单击相应的应用程序,选择 Heap Dump,然后单击 Monitor 子选项卡中的 Heap Dump 按钮。本地应用程序的堆转储作为应用程序选项卡的子选项卡打开。同时Heap Dump对应左侧Application列中对应的Save as node with timestamp
使用MAT打开Dump文件查看GC Roots
使用 JProfiler 的 GC Roots 溯源
选择 JProfiler 打开转储堆文件。在类或最大对象中,选择一个类并进入参考视图。选择传入引用以查看对象的整个链接
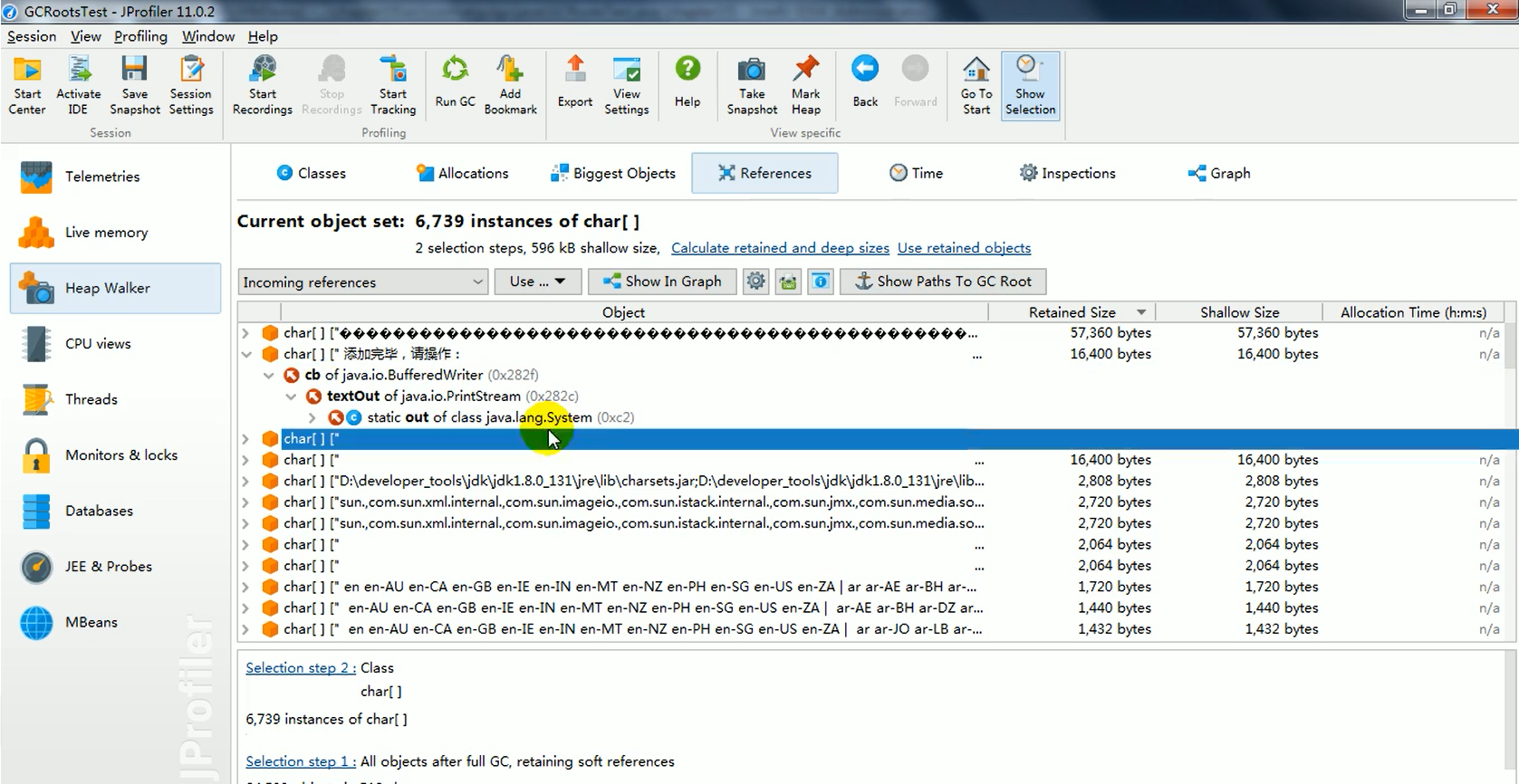
如何确定导致OOM的原因
模拟OOM代码
// -Xms8m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
public class HeapOOM {
// 创建1M的文件
byte [] buffer = new byte[1 * 1024 * 1024];
public static void main(String[] args) {
ArrayList list = new ArrayList();
int count = 0;
try {
while (true) {
list.add(new HeapOOM());
count++;
}
} catch (Exception e) {
e.getStackTrace();
System.out.println("count:" + count);
}
}
}
上面代码不断向链表中添加1m的数据,JVM参数-Xms8m -Xmx8m限制最多8M内存
-XX:+HeapDumpOnOutOfMemeoryError 发生OOM时生成hprof文件
使用 JProfiler 定位内存溢出代码
用JProfiler打开hprof,点击Biggest Object定位大对象
通过线程转储文件定位出现OOM的那一行
清除节点标记清除算法
在完成标记阶段确定哪些对象是垃圾后,GC 会进行垃圾回收,释放无用对象占用的内存空间,以便有足够的内存空间为新对象分配内存。主流的三种垃圾回收算法如下
标记去除算法
当堆中的可用内存耗尽时,整个程序(Stop The World)就会停止,GC会进行标记和清理。
什么是清理?标记清除算法的优缺点 复制算法的优缺点 复制算法的优缺点
高效的
低的
高的
中间
空间开销
低的
高(空间的1/2)
低(原尺寸)
移动物体
不
是的
是的
不同场景选择不同算法
老年代的分代采集算法Tenured Gen以HotSpot中的cms采集器为例,cms基于Mark-Sweep,对象的回收效率非常高。对于碎片问题,采用cms基于Mark-Compact算法的Serial Old采集器作为补偿措施。当内存回收不良时(当分片导致Concurrent Mode Failure时),会使用serial old执行FullGC来实现对旧内存进行排序和生成的思路。虚拟机应用广泛,几乎所有垃圾采集器都区分新生代和老年代增量采集算法
使用上述现有算法,在进行垃圾回收、所有用户线程挂起、所有正常工作挂起、垃圾回收完成时会导致STW状态。如果垃圾回收时间过长,会严重影响用户体验和系统稳定性。为了解决这个问题,堆实时垃圾采集的研究导致了增量采集(Incremental Collecting)算法的诞生
如果一次处理所有垃圾,需要很长的STW,那么垃圾采集线程和应用线程可以交替执行。每次垃圾采集线程只采集一小块内存,然后切换到应用线程。依次重复直到垃圾采集完成
增量采集算法的基础仍然是传统的标记-清除和复制算法。只是增量采集算法正确处理了线程之间的冲突,让垃圾采集线程分阶段完成标记、清除和复制操作。
缺点是使用了这种方法。因为应用程序代码在垃圾回收过程中间歇性执行,减少了STW时间,但是由于线程切换和上下文切换的消耗,垃圾回收的整体成本增加,导致系统吞吐量下降
分区算法
一般来说,相同的堆空间越大,一次GC所需的时间越长,与GC生成相关的暂停时间也越长。为了更好地控制GC产生的暂停时间,将一块大内存区域划分为多个Small blocks,根据目标暂停的事件,每次合理回收几个cell,而不是真正的堆空间,从而减少由 GC 引起的暂停
分代算法会根据对象生命周期的长短分为两部分。分区算法将整个堆空间划分为连续的不同cell,每个cell使用独立的recovery。这种算法的优点是可以控制一次恢复多少。社区间
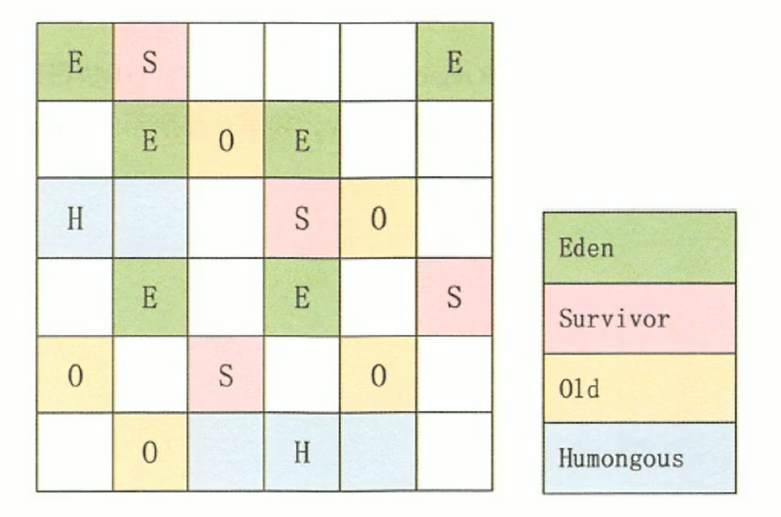
算法 自动采集列表(DXC!X2(X2.5)2.5的主要功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-21 17:01
DXC 来自 Discuz!X2(X2.5)合集缩写,DXC采集插件,致力于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。通过DXC采集插件-在,用户可以方便地访问互联网采集的数据,包括会员数据、文章数据,另外还有虚拟在线、单帖采集等辅助功能冷清的新版论坛瞬间形成了一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助,是新手站长必备的discuz应用DXC2.5个主要功能包括:1、多种形式的URL列表采集文章,包括rss地址、列表页面、多层列表等。. 2、规则编写多种方式,dom方法,字符截取,智能获取,更方便获取你想要的内容3、规则继承,匹配规则自动检测功能,你会慢慢体会到带来的便利通过规则继承4、独特的网页正文提取算法,可自动学习归纳规则,更方便进行泛化-采集.5、支持图片定位,添加水印功能6、灵活发布机制,可自定义定义发布者、发布时间点击率等7、强大的内容编辑后台,您可以轻松编辑采集的内容并发布到门户、论坛、博客< @8、内容过滤功能,过滤采集广告的内容, 查看全部
算法 自动采集列表(DXC!X2(X2.5)2.5的主要功能)
DXC 来自 Discuz!X2(X2.5)合集缩写,DXC采集插件,致力于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。通过DXC采集插件-在,用户可以方便地访问互联网采集的数据,包括会员数据、文章数据,另外还有虚拟在线、单帖采集等辅助功能冷清的新版论坛瞬间形成了一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助,是新手站长必备的discuz应用DXC2.5个主要功能包括:1、多种形式的URL列表采集文章,包括rss地址、列表页面、多层列表等。. 2、规则编写多种方式,dom方法,字符截取,智能获取,更方便获取你想要的内容3、规则继承,匹配规则自动检测功能,你会慢慢体会到带来的便利通过规则继承4、独特的网页正文提取算法,可自动学习归纳规则,更方便进行泛化-采集.5、支持图片定位,添加水印功能6、灵活发布机制,可自定义定义发布者、发布时间点击率等7、强大的内容编辑后台,您可以轻松编辑采集的内容并发布到门户、论坛、博客< @8、内容过滤功能,过滤采集广告的内容,
算法 自动采集列表(1.概述1.2垃圾收集器的考量指标(1.2)_概述)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-20 09:08
1.概述1.2 垃圾采集器注意事项
垃圾采集器也有类似CAP理论的矛盾,具体有以下三个方面的考虑:
吞吐量
响应性、延迟(Latency)
内存占用(容量)
以上三个考虑不能同时满足最优,只能满足其中两个,牺牲其中之一的部分效率。
1.3 吞吐量
吞吐量与在指定时间范围内最大化应用程序的工作负载有关。
以下方法用于测量系统的吞吐量:
在一小时内,完成同一事务(任务或请求)的次数。
数据库在一小时内完成了多少查询。
对于注重吞吐量的系统,偶尔的停顿是可以接受的,因为这种系统注重长时间执行大量任务的能力,单一的快速响应不值得考虑。
1.4 响应能力
响应性是指应用程序或系统是否能够及时快速地响应,例如:
桌面 UI 程序对事件的响应速度。
网站 返回页面请求的速度有多快。
数据库返回查询结果的速度有多快。
对于这种响应敏感、低延迟的场景,长期卡顿是不能容忍的。
内存使用情况
为了加快内存扫描的数据,GC垃圾采集器通常会使用内存中的一些数据结构,比如卡表、内存集等,来存储对对象的直接引用,而这些数据本身就需要占用堆的内存空间。记录的信息越多,扫描时间越快,占用的内存也越大。
1.5 G1的诞生背景
随着硬件成本越来越低,机器的内存也越来越大。GC回收器占用的内存基本可以容忍,吞吐量可以通过集群(加机器)解决,所以STW时间对于JVM来说就变得迫切要解决的问题,如果还是按照传统的分代方式使用传统的垃圾回收器模型,那么STW时间会越来越长。
在传统的垃圾采集器中,STW 时间是不可预测的。有没有办法先定义一个暂停时间,然后向后计算采集到的内容?就像领导在年初制定KPI一样,多做多做,少做少做。
G1的思路类似。不需要每次都清理垃圾。它只是尝试做它认为正确的事情。
G1还有一个极其重要的特性:软实时(soft real time)。所谓实时垃圾回收,是指在规定的时间内完成垃圾回收。“软实时”意味着用户可以指定垃圾采集的时间限制。G1会尽量在这个时限内完成垃圾采集,但是G1不保证每次都能在这个时限内完成垃圾采集。通过设定一个合理的目标,90%以上的垃圾回收时间都可以在这个时间限制内。
我们要求 G1 在任何一秒的时间内暂停不超过 10 毫秒。这是为其制定KPI。G1将尽最大努力实现这一目标。可以逆向计算本次要采集的总面积,增量式完成采集。
这也是使用G1垃圾采集器必须设置的一个参数(-XX:+UseG1GC):-XX:MaxGCPauseMillis=10,这个参数默认为200ms。
G1的适用场景:
服务器端多核CPU、JVM内存占用应用。
应用程序运行过程中会产生大量的内存碎片,空间需要经常进行压缩。
想要一个更可控和可预测的GC暂停期,以防止高并发下的应用程序雪崩。
2. G1的内存模型2.1 Partition概念
2.1.1师区域
G1采用了region的思想,将整个堆空间划分为若干大小相等的内存区域,每次分配对象空间时,都会逐段使用内存。因此,在堆的使用上,G1并不要求对象的存储必须物理上连续,只要逻辑上连续即可;每个分区都不会肯定服务于某一代,它可以用于年轻代和老年代之间的切换。分区大小(1MB~32MB,必须是2的幂)可以在启动时通过参数-XX:G1HeapRegionSize=n指定。默认情况下,整个堆被划分为 2048 个分区。
对于那些超过整个 Region 容量的超大对象,它们将被存储在 N 个连续的 Humongous Region 中。大多数情况下,G1的回收都会将洪门地区视为老年的一部分。
G1在逻辑上划分了Eden(所有Eden区域的总和)、Survivor(所有Survivor区域的总和)和OLd(所有Old区域的总和),但物理上它们是不连续的,同一个区域在不同区域的作用期间可以不同。有可能当前区域存储了 Eden 对象。执行 YGC 后,分配给它的下一个对象可能是 Old 对象。
2.1.2张卡片
卡片表的诞生是为了解决跨代引用。假设在cms垃圾采集器中,如果要回收新生代的对象,那么就必须扫描整个老年代,而要引入卡表,只需要扫描卡表的中间脏区就够了,避免了扫描整个老年代,大大加快了并发标记的速度。
每个Region分为若干张固定大小的卡片(Card)。每张卡片使用一个Byte来记录是否被修改过。卡片表是这些字节的集合。标识堆内存和所有分区的最小可用粒度的卡将记录在全局卡表中。分配的对象将占用多个物理上连续的卡片。当对象被引用时,可以通过记录卡找到被引用的对象(见RSet)。每次回收内存时,都会处理指定分区中的卡片。
2.1.3Memory Set RSet
RS(Remember Set)是一个抽象概念,用于记录从非集合部分到集合部分的指针集合。
在传统的分代垃圾采集算法中,RS(Remember Set)用于记录代际之间的指针。在 G1 采集器中,RS 用于记录从其他区域到一个区域的指针。因此,一个Region就有一个RS。这种记录可以带来很大的好处:回收一个Region的时候,不需要进行全堆扫描,只需要检查它的RS就可以找到外部引用,而这些引用是初始的root之一标记。
RSet底层是通过HashTable实现的(可以理解,这其实是一个抽象的概念),key是被引用对象所在Region的内存起始地址,value是Card Table的索引引用对象所在的位置。
也假设现在Region A中object的第四个block引用了Region B中的object,那么Region A的card table的第三位设置为Dirty(1),然后Region B中的RSet添加一条记录,其中key为Region A的内存起始地址,value为Region A的对象所在卡片表中的索引3,这样回收Region B时,只需要扫描Region B 的 RSet 作为 GC ROOTS 对象。
RSet 的更新不是同步完成的。G1会将所有的引用关系放到一个队列中,称为Dirty Card Queue(DCQ),然后使用一个单独的线程来消费这个队列来完成更新。这是因为对象的引用变化太频繁,队列用于异步削峰。参数 -XX:G1ConcRefinementThreads 可用于指定消费者线程的数量。
使用空间来交换时间,使用额外的空间来维护参考信息通常会消耗5%到10%的空间。
写屏障(write barrier):当对象的引用发生变化时,插入一个写屏障来维护RSet。这个写屏障不是Java内存模型中写屏障的概念。
事实上,并不是所有的引用都需要记录在 RSet 中。如果确定要扫描某个分区,则无需RSet就可以无遗漏地获得引用关系。那么对源自该分区的对象的引用当然不需要落入 RSet;同时,G1 GC 每次都将年轻代作为一个整体采集,因此对源自年轻代的对象的引用不需要记录在 RSet 中。最后,只有老一代分区可能有 RSet 记录。这些分区被称为一个 RSet 的拥有区域(an RSet's owning region)。
修改RS也会遇到并发问题。因为一个Region可能会被多个线程并发修改,所以他们也会并发修改RS。为了避免这样的冲突,G1垃圾采集器进一步将RS划分为多个哈希表。每个线程都在其自己的哈希表中进行修改。最后,从逻辑上讲,RS 是这些哈希表的集合。哈希表是实现 RS 的常用方法之一。它有一个很大的优点,就是可以去除重复。这意味着 RS 的大小将等于修改指针的数量。不进行重复数据删除时,RS 的数量相当于写操作的数量。
图中RS的虚线表的名称是,RS不是与Card Table分离的不同数据结构,而是将RS作为概念模型来指代。实际上,Card Table 是 RS 的一个实现。
关联:
2.1.4Per Region Table
RSet 内部使用 Per Region Table (PRT) 来记录分区的引用。由于RSet记录占用了分区的空间,如果一个分区很“流行”,RSet占用的空间就会增加,从而减少了该分区的可用空间。G1通过改变RSet的密度来应对这个问题,并且会在PRT中以三种模式记录引用:
从上面可以看出,粗粒度的PRT只记录引用次数,需要扫描整个栈才能找到所有引用,所以扫描速度也是最慢的。
2.1.5 堆 堆
G1 还可以通过 -Xms/-Xmx 指定堆空间大小。当发生年轻代回收或混合回收时,通过计算GC和应用的耗时比例自动调整堆空间大小。如果GC频率太高,通过增加heap size来降低GC频率,GC占用的时间也相应减少;目标参数-XX:GCTimeRatio是GC到应用的耗时比例,G1默认为9,而cms默认为99,因为cms的设计原则是花为尽可能少花时间在 GC 上。另外,当空间不足时,比如对象空间分配或者传输失败,G1会先尝试增加堆空间。如果扩展失败,它将启动一个有保证的 Full GC。Full GC 后,
2.2代机型2.2.1代
分代垃圾回收可以专注于最近分配的对象,而无需扫描整个堆,避免复制长期存在的对象,独立回收可以帮助减少响应时间。虽然分区使得内存分配不再需要紧凑的内存空间,但 G1 仍然使用生成的思想。与其他垃圾回收器类似,G1在逻辑上将内存划分为年轻代和老年代,年轻代划分为Eden空间和Survivor空间。但是,年轻代空间并不是固定的。当现有的年轻代分区已满时,JVM 会分配一个新的空闲分区加入年轻代空间。
整个年轻代内存会在初始空间-XX:G1NewSizePercent(默认整堆5%)和最大空间(默认60%)之间动态变化,参数目标暂停时间-XX:MaxGCPauseMillis(默认200ms),需要被扩展和收缩的内容的大小是通过-XX:G1MaxNewSizePercent和分区的内存集(RSet)来计算的。当然,G1 仍然可以设置一个固定的年轻代大小(参数 -XX:NewRatio, -Xmn),但是同时挂起目标是没有意义的。
2.2.2 本地分配缓冲区
本地分配缓冲区(实验室)
值得注意的是,由于分区的思想,每个线程都可以“声明”一个分区用于线程本地内存分配,而不管分区是否连续。因此,每个应用线程和GC线程都会独立使用分区,从而减少同步时间,提高GC效率。此分区称为本地分配缓冲区 (Lab)。
其中,应用线程可以独占一个本地缓冲区(TLAB)来创建对象,大部分都会落入Eden区(巨大对象或分配失败除外),所以TLAB分区属于Eden空间;并且每次垃圾回收时,每个GC线程也可以使用一个独占的本地缓冲区(GCLAB)来传输对象。每次采集对象时,都会将对象复制到Suvivor空间或旧空间;用于从Eden/Survivor 空间提升到Survivor/old 空间GC 的对象也有一个GC 专用的本地缓冲区用于操作,这部分称为提升本地缓冲区(PLAB)。
2.3 分区模型
G1以区域为内存单位,以卡片(Card)为单位分配对象。
2.3.1 巨域
大小达到或超过分区大小一半的对象称为巨型对象。当一个线程为huge分配空间时,不能简单地在TLAB中分配,因为huge对象的移动成本非常高,一个分区可能无法容纳huge对象。因此,巨大的对象会直接分配到老年代,占用的连续空间称为Humongous Region。G1做了内部优化。一旦发现没有引用指向一个巨型对象,就可以直接在年轻代回收循环中回收。
一个巨大的对象将独占一个或多个连续的分区。第一个分区标记为StartsHumongous,相邻的连续分区标记为ContinuesHumongous。由于无法享受Lab带来的优化,而且需要扫描整堆来确定一个连续的内存空间,因此确定巨物起始位置的成本非常高。如果可能,应用程序应避免生成巨型对象。
2.4 采集集(CSet)
采集集 (CSet) 表示每次 GC 暂停时回收的一系列目标分区。在任何采集暂停中,CSet 的所有分区都将被释放,内部幸存的对象将被转移到分配的空闲分区。因此,无论是年轻代采集还是混合采集,工作机制都是一样的。年轻代集合CSet只容纳年轻代分区,而混合集合会使用启发式算法在老年代的候选回收分区中筛选出回收收益最高的分区,加入到CSet中。
可以通过活动阈值-XX:G1MixedGCLiveThresholdPercent(默认85%)设置候选老年代分区的CSet访问条件,从而拦截那些回收成本巨大的对象;同时,每个混合集合可以收录候选老年代分区,可以根据CSet占堆总大小的比例设置数量上限-XX:G1OldCSetRegionThresholdPercent(默认10%)。
从上面可以看出G1的集合是按照CSet来操作的。年轻代采集和混合采集没有明显区别。最大的区别在于两个集合的触发条件。
2.4.1C集Young 采集
应用线程不断活跃后,年轻代空间会逐渐被填满。当JVM分配对象到Eden区失败(Eden区已满)时,会触发STW式的年轻代集合。在年轻代集合中,Eden分区中幸存的对象会被复制到Survivor分区;原Survivor分区中的存活对象将根据tenuring阈值、新的Survivor分区和旧的分区被提升到PLAB中。原来的年轻代分区会被整体回收。
同时,年轻代集合还负责维护对象的年龄(存活次数),并辅助判断tenuring对象是提升到Survivor分区还是老年代分区。年轻代集合首先在年龄表中维护提升对象的总大小和对象的年龄信息,然后根据年龄表,Survivor大小,和Survivor填充容量-XX:TargetSurvivorRatio(默认50%),最大任期阈值-XX:MaxTenuringThreshold(默认15),计算一个合适的任期阈值。超过任期阈值的人将被提升到老年。
2.4.2C 混合集合
年轻代不断采集后,年老代的空间会逐渐被填满。当老年代占用的空间超过IHOP阈值-XX:InitiatingHeapOccupancyPercent(默认45%)时,G1将启动混合垃圾回收循环。为了满足暂停目标,G1 可能无法一次性采集所有候选分区。因此,G1 可能会生成多个连续的混合集合和应用程序线程的交替执行。每个 STW 的混合采集类似于年轻代的采集过程。
为了确定收录年轻代集合CSet的老年代分区,JVM通过参数最大混合周期总数-XX:G1MixedGCCountTarget(默认8),堆浪费百分比-XX:G1HeapWastePercent(默认5 %). 通过候选老年代的分区总数和混合循环的最大总数决定了每次收录在CSet中的最小分区数;根据堆浪费的百分比,当集合达到参数,不会开始新的混合采集,并且每次将partition添加到CSet中,都会根据计算出的GC效率进行安排。
2.4.3 并发标记算法(三色标记法)
cms和G1使用相同的算法进行并发标记:三色标记法,使用白、灰、黑三种颜色来标记对象。白色没有标记;灰色本身是被标记的,被引用的对象是未标记的;黑色本身和引用的对象都被标记。
2.4.5 缺少标签问题
在重新标记过程中,黑色指向白色,如果不重新扫描黑色,则会丢失标记。白色 D 对象将被回收,因为没有对它的新引用。
在并发标记过程中,Mutator 将所有引用从灰色删除为白色,这将导致标记丢失。这个时候应该回收白色物体
标签不足问题有两个条件:
1.黑色物体指向白色物体
2.灰色物体对白色物体的引用消失
因此,要解决缺少标签的问题,可以打破两个条件之一:
跟踪黑到白的增加
增量更新:增量更新,注意引用的增加,remark黑色到灰色,下次重新扫描属性。cms 使用此方法。记录灰到白的消失
开头的SATB快照:注意删除引用。当灰色 -> 白色消失时,将引用推送到 GC 堆栈,以确保白色仍然可以被 GC 扫描。G1 使用这种方法。
为什么G1采用SATB而不是增量更新?
因为使用增量更新后,将黑色重新标记为灰色后,还得重新扫描之前的扫描,效率太低。
G1有RSet配合SATB。Card Table记录了RSet,RSet记录了其他对象指向自己的引用,这样就不需要扫描其他区域,只需扫描RSet即可。
也就是说,当灰色->白色参考消失时,如果没有黑色->白色,则将参考压入堆栈,在下次扫描时获取参考。由于RSet的存在,不需要扫描整个堆来找到白色的引用引用,效率比较高。SATB 和 RSet 是天作之合。
3. G1 活动周期3.1 G1 垃圾回收活动总结
3.2RSet的维护
由于无法扫描整个堆栈,需要计算分区的确切活动,因此G1需要一种增量全标记并发算法,通过维护RSet来获取准确的分区参考信息。在G1中,RSet的维护主要来自两个方面:Write Barrier和Concurrence Refinement Threads。
3.2.1 个屏障
我们首先介绍障碍的概念。Fence 是指在原生代码片段中,当某些语句被执行时,fence 代码也会被执行。而G1在赋值语句中主要使用Pre-Write Barrrier和Post-Write Barrrier。事实上,写fence的指令序列开销是非常昂贵的,应用的吞吐量会根据fence的复杂程度而降低。
预写屏障
当一个赋值语句即将执行时,等式左边的对象会修改对另一个对象的引用,那么等式左边的对象原来引用的对象所在的分区将失去一个引用,那么JVM需要在赋值语句生效前丢失记录 引用的对象。JVM 不会立即维护 RSet,而是通过批处理,将来会更新 RSet(参见 SATB)。
写后屏障
执行赋值语句时,等式右边的对象得到对左边对象的引用,等式右边的对象所在分区的RSet也要更新。同样为了减少开销,RSet 不会在写屏障发生后立即更新。它也只会记录以后批处理的更新日志(参见并发细化线程)。
3.2.2开头的快照(SATB)
Taiichi Tuasa 对增量全并发标记算法 Start Snapshot Algorithm (SATB) 的贡献主要是针对标记清除垃圾采集器的并发标记阶段。非常适合G1子块堆结构,解决了cms的主要烦恼:重新标记长时间停顿带来的潜在风险。
SATB会创建一个对象图,相当于堆的一个逻辑快照,从而保证并发标记阶段的所有垃圾对象都可以通过快照识别出来。当赋值语句发生时,应用程序会改变它的对象图,然后JVM需要记录被覆盖的对象。因此,write-before 栅栏将在引用更改之前记录SATB 日志或缓冲区中的值。每个线程将独占一个 SATB 缓冲区,最初有 256 个记录空间。当空间用完时,线程会分配一个新的SATB缓冲区继续使用,并将原来的缓冲区加入到全局列表中。最后,在并发标记阶段,Concurrent Marking Threads 会在标记的同时定期检查和处理全局缓冲区列表的记录,然后根据标记位图片段的标记位扫描参考域更新RSet。此过程也称为并发标记/SATB 写前栅栏。
在并发标记阶段,应用程序可以修改原创引用,例如删除原创引用。这会导致并发标记结束后存活对象的快照与SATB不一致。G1通过在并发标记阶段引入写屏障来解决这个问题:每当有引用更新时,G1都会将修改前的值写入日志缓冲区(这条记录会过滤掉原来的空引用),扫描SATB中的最后标记阶段以纠正SATB错误。
SATB的日志缓冲区和RS的写屏障使用的日志缓冲区一样,有两级结构,作用机制也是一样的。 查看全部
算法 自动采集列表(1.概述1.2垃圾收集器的考量指标(1.2)_概述)
1.概述1.2 垃圾采集器注意事项
垃圾采集器也有类似CAP理论的矛盾,具体有以下三个方面的考虑:
吞吐量
响应性、延迟(Latency)
内存占用(容量)
以上三个考虑不能同时满足最优,只能满足其中两个,牺牲其中之一的部分效率。
1.3 吞吐量
吞吐量与在指定时间范围内最大化应用程序的工作负载有关。
以下方法用于测量系统的吞吐量:
在一小时内,完成同一事务(任务或请求)的次数。
数据库在一小时内完成了多少查询。
对于注重吞吐量的系统,偶尔的停顿是可以接受的,因为这种系统注重长时间执行大量任务的能力,单一的快速响应不值得考虑。
1.4 响应能力
响应性是指应用程序或系统是否能够及时快速地响应,例如:
桌面 UI 程序对事件的响应速度。
网站 返回页面请求的速度有多快。
数据库返回查询结果的速度有多快。
对于这种响应敏感、低延迟的场景,长期卡顿是不能容忍的。
内存使用情况
为了加快内存扫描的数据,GC垃圾采集器通常会使用内存中的一些数据结构,比如卡表、内存集等,来存储对对象的直接引用,而这些数据本身就需要占用堆的内存空间。记录的信息越多,扫描时间越快,占用的内存也越大。
1.5 G1的诞生背景
随着硬件成本越来越低,机器的内存也越来越大。GC回收器占用的内存基本可以容忍,吞吐量可以通过集群(加机器)解决,所以STW时间对于JVM来说就变得迫切要解决的问题,如果还是按照传统的分代方式使用传统的垃圾回收器模型,那么STW时间会越来越长。
在传统的垃圾采集器中,STW 时间是不可预测的。有没有办法先定义一个暂停时间,然后向后计算采集到的内容?就像领导在年初制定KPI一样,多做多做,少做少做。
G1的思路类似。不需要每次都清理垃圾。它只是尝试做它认为正确的事情。
G1还有一个极其重要的特性:软实时(soft real time)。所谓实时垃圾回收,是指在规定的时间内完成垃圾回收。“软实时”意味着用户可以指定垃圾采集的时间限制。G1会尽量在这个时限内完成垃圾采集,但是G1不保证每次都能在这个时限内完成垃圾采集。通过设定一个合理的目标,90%以上的垃圾回收时间都可以在这个时间限制内。
我们要求 G1 在任何一秒的时间内暂停不超过 10 毫秒。这是为其制定KPI。G1将尽最大努力实现这一目标。可以逆向计算本次要采集的总面积,增量式完成采集。
这也是使用G1垃圾采集器必须设置的一个参数(-XX:+UseG1GC):-XX:MaxGCPauseMillis=10,这个参数默认为200ms。
G1的适用场景:
服务器端多核CPU、JVM内存占用应用。
应用程序运行过程中会产生大量的内存碎片,空间需要经常进行压缩。
想要一个更可控和可预测的GC暂停期,以防止高并发下的应用程序雪崩。
2. G1的内存模型2.1 Partition概念
2.1.1师区域
G1采用了region的思想,将整个堆空间划分为若干大小相等的内存区域,每次分配对象空间时,都会逐段使用内存。因此,在堆的使用上,G1并不要求对象的存储必须物理上连续,只要逻辑上连续即可;每个分区都不会肯定服务于某一代,它可以用于年轻代和老年代之间的切换。分区大小(1MB~32MB,必须是2的幂)可以在启动时通过参数-XX:G1HeapRegionSize=n指定。默认情况下,整个堆被划分为 2048 个分区。
对于那些超过整个 Region 容量的超大对象,它们将被存储在 N 个连续的 Humongous Region 中。大多数情况下,G1的回收都会将洪门地区视为老年的一部分。
G1在逻辑上划分了Eden(所有Eden区域的总和)、Survivor(所有Survivor区域的总和)和OLd(所有Old区域的总和),但物理上它们是不连续的,同一个区域在不同区域的作用期间可以不同。有可能当前区域存储了 Eden 对象。执行 YGC 后,分配给它的下一个对象可能是 Old 对象。
2.1.2张卡片
卡片表的诞生是为了解决跨代引用。假设在cms垃圾采集器中,如果要回收新生代的对象,那么就必须扫描整个老年代,而要引入卡表,只需要扫描卡表的中间脏区就够了,避免了扫描整个老年代,大大加快了并发标记的速度。
每个Region分为若干张固定大小的卡片(Card)。每张卡片使用一个Byte来记录是否被修改过。卡片表是这些字节的集合。标识堆内存和所有分区的最小可用粒度的卡将记录在全局卡表中。分配的对象将占用多个物理上连续的卡片。当对象被引用时,可以通过记录卡找到被引用的对象(见RSet)。每次回收内存时,都会处理指定分区中的卡片。

2.1.3Memory Set RSet
RS(Remember Set)是一个抽象概念,用于记录从非集合部分到集合部分的指针集合。
在传统的分代垃圾采集算法中,RS(Remember Set)用于记录代际之间的指针。在 G1 采集器中,RS 用于记录从其他区域到一个区域的指针。因此,一个Region就有一个RS。这种记录可以带来很大的好处:回收一个Region的时候,不需要进行全堆扫描,只需要检查它的RS就可以找到外部引用,而这些引用是初始的root之一标记。
RSet底层是通过HashTable实现的(可以理解,这其实是一个抽象的概念),key是被引用对象所在Region的内存起始地址,value是Card Table的索引引用对象所在的位置。
也假设现在Region A中object的第四个block引用了Region B中的object,那么Region A的card table的第三位设置为Dirty(1),然后Region B中的RSet添加一条记录,其中key为Region A的内存起始地址,value为Region A的对象所在卡片表中的索引3,这样回收Region B时,只需要扫描Region B 的 RSet 作为 GC ROOTS 对象。
RSet 的更新不是同步完成的。G1会将所有的引用关系放到一个队列中,称为Dirty Card Queue(DCQ),然后使用一个单独的线程来消费这个队列来完成更新。这是因为对象的引用变化太频繁,队列用于异步削峰。参数 -XX:G1ConcRefinementThreads 可用于指定消费者线程的数量。
使用空间来交换时间,使用额外的空间来维护参考信息通常会消耗5%到10%的空间。
写屏障(write barrier):当对象的引用发生变化时,插入一个写屏障来维护RSet。这个写屏障不是Java内存模型中写屏障的概念。
事实上,并不是所有的引用都需要记录在 RSet 中。如果确定要扫描某个分区,则无需RSet就可以无遗漏地获得引用关系。那么对源自该分区的对象的引用当然不需要落入 RSet;同时,G1 GC 每次都将年轻代作为一个整体采集,因此对源自年轻代的对象的引用不需要记录在 RSet 中。最后,只有老一代分区可能有 RSet 记录。这些分区被称为一个 RSet 的拥有区域(an RSet's owning region)。
修改RS也会遇到并发问题。因为一个Region可能会被多个线程并发修改,所以他们也会并发修改RS。为了避免这样的冲突,G1垃圾采集器进一步将RS划分为多个哈希表。每个线程都在其自己的哈希表中进行修改。最后,从逻辑上讲,RS 是这些哈希表的集合。哈希表是实现 RS 的常用方法之一。它有一个很大的优点,就是可以去除重复。这意味着 RS 的大小将等于修改指针的数量。不进行重复数据删除时,RS 的数量相当于写操作的数量。
图中RS的虚线表的名称是,RS不是与Card Table分离的不同数据结构,而是将RS作为概念模型来指代。实际上,Card Table 是 RS 的一个实现。
关联:
2.1.4Per Region Table
RSet 内部使用 Per Region Table (PRT) 来记录分区的引用。由于RSet记录占用了分区的空间,如果一个分区很“流行”,RSet占用的空间就会增加,从而减少了该分区的可用空间。G1通过改变RSet的密度来应对这个问题,并且会在PRT中以三种模式记录引用:
从上面可以看出,粗粒度的PRT只记录引用次数,需要扫描整个栈才能找到所有引用,所以扫描速度也是最慢的。
2.1.5 堆 堆
G1 还可以通过 -Xms/-Xmx 指定堆空间大小。当发生年轻代回收或混合回收时,通过计算GC和应用的耗时比例自动调整堆空间大小。如果GC频率太高,通过增加heap size来降低GC频率,GC占用的时间也相应减少;目标参数-XX:GCTimeRatio是GC到应用的耗时比例,G1默认为9,而cms默认为99,因为cms的设计原则是花为尽可能少花时间在 GC 上。另外,当空间不足时,比如对象空间分配或者传输失败,G1会先尝试增加堆空间。如果扩展失败,它将启动一个有保证的 Full GC。Full GC 后,
2.2代机型2.2.1代
分代垃圾回收可以专注于最近分配的对象,而无需扫描整个堆,避免复制长期存在的对象,独立回收可以帮助减少响应时间。虽然分区使得内存分配不再需要紧凑的内存空间,但 G1 仍然使用生成的思想。与其他垃圾回收器类似,G1在逻辑上将内存划分为年轻代和老年代,年轻代划分为Eden空间和Survivor空间。但是,年轻代空间并不是固定的。当现有的年轻代分区已满时,JVM 会分配一个新的空闲分区加入年轻代空间。
整个年轻代内存会在初始空间-XX:G1NewSizePercent(默认整堆5%)和最大空间(默认60%)之间动态变化,参数目标暂停时间-XX:MaxGCPauseMillis(默认200ms),需要被扩展和收缩的内容的大小是通过-XX:G1MaxNewSizePercent和分区的内存集(RSet)来计算的。当然,G1 仍然可以设置一个固定的年轻代大小(参数 -XX:NewRatio, -Xmn),但是同时挂起目标是没有意义的。
2.2.2 本地分配缓冲区
本地分配缓冲区(实验室)
值得注意的是,由于分区的思想,每个线程都可以“声明”一个分区用于线程本地内存分配,而不管分区是否连续。因此,每个应用线程和GC线程都会独立使用分区,从而减少同步时间,提高GC效率。此分区称为本地分配缓冲区 (Lab)。
其中,应用线程可以独占一个本地缓冲区(TLAB)来创建对象,大部分都会落入Eden区(巨大对象或分配失败除外),所以TLAB分区属于Eden空间;并且每次垃圾回收时,每个GC线程也可以使用一个独占的本地缓冲区(GCLAB)来传输对象。每次采集对象时,都会将对象复制到Suvivor空间或旧空间;用于从Eden/Survivor 空间提升到Survivor/old 空间GC 的对象也有一个GC 专用的本地缓冲区用于操作,这部分称为提升本地缓冲区(PLAB)。
2.3 分区模型
G1以区域为内存单位,以卡片(Card)为单位分配对象。
2.3.1 巨域
大小达到或超过分区大小一半的对象称为巨型对象。当一个线程为huge分配空间时,不能简单地在TLAB中分配,因为huge对象的移动成本非常高,一个分区可能无法容纳huge对象。因此,巨大的对象会直接分配到老年代,占用的连续空间称为Humongous Region。G1做了内部优化。一旦发现没有引用指向一个巨型对象,就可以直接在年轻代回收循环中回收。
一个巨大的对象将独占一个或多个连续的分区。第一个分区标记为StartsHumongous,相邻的连续分区标记为ContinuesHumongous。由于无法享受Lab带来的优化,而且需要扫描整堆来确定一个连续的内存空间,因此确定巨物起始位置的成本非常高。如果可能,应用程序应避免生成巨型对象。
2.4 采集集(CSet)
采集集 (CSet) 表示每次 GC 暂停时回收的一系列目标分区。在任何采集暂停中,CSet 的所有分区都将被释放,内部幸存的对象将被转移到分配的空闲分区。因此,无论是年轻代采集还是混合采集,工作机制都是一样的。年轻代集合CSet只容纳年轻代分区,而混合集合会使用启发式算法在老年代的候选回收分区中筛选出回收收益最高的分区,加入到CSet中。
可以通过活动阈值-XX:G1MixedGCLiveThresholdPercent(默认85%)设置候选老年代分区的CSet访问条件,从而拦截那些回收成本巨大的对象;同时,每个混合集合可以收录候选老年代分区,可以根据CSet占堆总大小的比例设置数量上限-XX:G1OldCSetRegionThresholdPercent(默认10%)。
从上面可以看出G1的集合是按照CSet来操作的。年轻代采集和混合采集没有明显区别。最大的区别在于两个集合的触发条件。
2.4.1C集Young 采集
应用线程不断活跃后,年轻代空间会逐渐被填满。当JVM分配对象到Eden区失败(Eden区已满)时,会触发STW式的年轻代集合。在年轻代集合中,Eden分区中幸存的对象会被复制到Survivor分区;原Survivor分区中的存活对象将根据tenuring阈值、新的Survivor分区和旧的分区被提升到PLAB中。原来的年轻代分区会被整体回收。
同时,年轻代集合还负责维护对象的年龄(存活次数),并辅助判断tenuring对象是提升到Survivor分区还是老年代分区。年轻代集合首先在年龄表中维护提升对象的总大小和对象的年龄信息,然后根据年龄表,Survivor大小,和Survivor填充容量-XX:TargetSurvivorRatio(默认50%),最大任期阈值-XX:MaxTenuringThreshold(默认15),计算一个合适的任期阈值。超过任期阈值的人将被提升到老年。
2.4.2C 混合集合
年轻代不断采集后,年老代的空间会逐渐被填满。当老年代占用的空间超过IHOP阈值-XX:InitiatingHeapOccupancyPercent(默认45%)时,G1将启动混合垃圾回收循环。为了满足暂停目标,G1 可能无法一次性采集所有候选分区。因此,G1 可能会生成多个连续的混合集合和应用程序线程的交替执行。每个 STW 的混合采集类似于年轻代的采集过程。
为了确定收录年轻代集合CSet的老年代分区,JVM通过参数最大混合周期总数-XX:G1MixedGCCountTarget(默认8),堆浪费百分比-XX:G1HeapWastePercent(默认5 %). 通过候选老年代的分区总数和混合循环的最大总数决定了每次收录在CSet中的最小分区数;根据堆浪费的百分比,当集合达到参数,不会开始新的混合采集,并且每次将partition添加到CSet中,都会根据计算出的GC效率进行安排。
2.4.3 并发标记算法(三色标记法)
cms和G1使用相同的算法进行并发标记:三色标记法,使用白、灰、黑三种颜色来标记对象。白色没有标记;灰色本身是被标记的,被引用的对象是未标记的;黑色本身和引用的对象都被标记。
2.4.5 缺少标签问题
在重新标记过程中,黑色指向白色,如果不重新扫描黑色,则会丢失标记。白色 D 对象将被回收,因为没有对它的新引用。
在并发标记过程中,Mutator 将所有引用从灰色删除为白色,这将导致标记丢失。这个时候应该回收白色物体
标签不足问题有两个条件:
1.黑色物体指向白色物体
2.灰色物体对白色物体的引用消失
因此,要解决缺少标签的问题,可以打破两个条件之一:
跟踪黑到白的增加
增量更新:增量更新,注意引用的增加,remark黑色到灰色,下次重新扫描属性。cms 使用此方法。记录灰到白的消失
开头的SATB快照:注意删除引用。当灰色 -> 白色消失时,将引用推送到 GC 堆栈,以确保白色仍然可以被 GC 扫描。G1 使用这种方法。
为什么G1采用SATB而不是增量更新?
因为使用增量更新后,将黑色重新标记为灰色后,还得重新扫描之前的扫描,效率太低。
G1有RSet配合SATB。Card Table记录了RSet,RSet记录了其他对象指向自己的引用,这样就不需要扫描其他区域,只需扫描RSet即可。
也就是说,当灰色->白色参考消失时,如果没有黑色->白色,则将参考压入堆栈,在下次扫描时获取参考。由于RSet的存在,不需要扫描整个堆来找到白色的引用引用,效率比较高。SATB 和 RSet 是天作之合。
3. G1 活动周期3.1 G1 垃圾回收活动总结
3.2RSet的维护
由于无法扫描整个堆栈,需要计算分区的确切活动,因此G1需要一种增量全标记并发算法,通过维护RSet来获取准确的分区参考信息。在G1中,RSet的维护主要来自两个方面:Write Barrier和Concurrence Refinement Threads。
3.2.1 个屏障
我们首先介绍障碍的概念。Fence 是指在原生代码片段中,当某些语句被执行时,fence 代码也会被执行。而G1在赋值语句中主要使用Pre-Write Barrrier和Post-Write Barrrier。事实上,写fence的指令序列开销是非常昂贵的,应用的吞吐量会根据fence的复杂程度而降低。
预写屏障
当一个赋值语句即将执行时,等式左边的对象会修改对另一个对象的引用,那么等式左边的对象原来引用的对象所在的分区将失去一个引用,那么JVM需要在赋值语句生效前丢失记录 引用的对象。JVM 不会立即维护 RSet,而是通过批处理,将来会更新 RSet(参见 SATB)。
写后屏障
执行赋值语句时,等式右边的对象得到对左边对象的引用,等式右边的对象所在分区的RSet也要更新。同样为了减少开销,RSet 不会在写屏障发生后立即更新。它也只会记录以后批处理的更新日志(参见并发细化线程)。
3.2.2开头的快照(SATB)
Taiichi Tuasa 对增量全并发标记算法 Start Snapshot Algorithm (SATB) 的贡献主要是针对标记清除垃圾采集器的并发标记阶段。非常适合G1子块堆结构,解决了cms的主要烦恼:重新标记长时间停顿带来的潜在风险。
SATB会创建一个对象图,相当于堆的一个逻辑快照,从而保证并发标记阶段的所有垃圾对象都可以通过快照识别出来。当赋值语句发生时,应用程序会改变它的对象图,然后JVM需要记录被覆盖的对象。因此,write-before 栅栏将在引用更改之前记录SATB 日志或缓冲区中的值。每个线程将独占一个 SATB 缓冲区,最初有 256 个记录空间。当空间用完时,线程会分配一个新的SATB缓冲区继续使用,并将原来的缓冲区加入到全局列表中。最后,在并发标记阶段,Concurrent Marking Threads 会在标记的同时定期检查和处理全局缓冲区列表的记录,然后根据标记位图片段的标记位扫描参考域更新RSet。此过程也称为并发标记/SATB 写前栅栏。
在并发标记阶段,应用程序可以修改原创引用,例如删除原创引用。这会导致并发标记结束后存活对象的快照与SATB不一致。G1通过在并发标记阶段引入写屏障来解决这个问题:每当有引用更新时,G1都会将修改前的值写入日志缓冲区(这条记录会过滤掉原来的空引用),扫描SATB中的最后标记阶段以纠正SATB错误。
SATB的日志缓冲区和RS的写屏障使用的日志缓冲区一样,有两级结构,作用机制也是一样的。
算法 自动采集列表(【每日一题】开心驿站为例叙述第一步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-23 06:01
陆涛,
李红
目的:通过熟悉优采云采集器的使用,把网上的30000个笑话整理出来,熟悉一些网络文本挖掘的知识。
过程:本研究主要分为两部分。第一部分是笑话文本的采集,第二部分是笑话的重新排序。以下是具体流程:
第一部分笑话提取
优采云挑笑话的基本流程:
新组 新任务 采集URL 设置 采集内容设置 捕获数据。
一、新建组和任务
根据需要设置“课程”分组,供以后在学习过程中练习和使用,并设置“笑话提取”子组。这个采集的笑话主要是关于两个网站《中国幽默王》和《欢乐驿站》。由于不同的网站html的功能框架不同,采集的不同框架的规则也不同,所以分为建立“快乐站”和“中国幽默王”两个任务。如图1所示
图 1 分组和任务
二、采集URL 和内容规则设置
由于这次采集是作为课程练习使用的,所以不涉及发布。因此,在任务编辑中只设置了第一步“采集 URL 规则”和第二步“采集 内容规则”。",如图2所示
图 2 编辑任务
以下学习过程介绍以欢乐客栈为例进行说明
第一步:采集 URL规则
先添加起始网址,然后再添加笑话网址采集 分为两种方式。
首先是在“添加起始采集地址”表单中设置“批量/多页”项,设置“算术序列”方法,即采集的笑话出自从第一页到最后一页,这些页码是等差数列,容差为 1,如图 3 所示。
图3 批量/多页设置
在《快乐邮报》上完整设置各种笑话,效果图如图3所示。
图4 起始网址效果图
当然,如果只使用这个设置,我们只能在一页上挑一个笑话。事实上,“快乐站”首页可以显示16个笑话,所以我们还需要设置“多级网址采集规则”。可以手动分析页面的html格式,然后填写规则。这里使用最简单的可视化Xpath方法来获取地址。如图5所示
图5
Xpath获取地址的方式
我们可以看到多级URL获取方式是get,如图6所示。
图6 多级URL设置效果图
二是不设置“批量/多页”,直接设置“多级URL获取”,先获取“快乐站”上各个分类的默认打开地址。
比如“校园笑话”,我们也用最简单的可视地址Xpath的方法来获取这些URL。Xpath 获取到的 URL 可能不是我们想要的 URL。比如list10-1和list13-1分别是图片和视频,所以我们可以进行如图7所示的“结果URL过滤”。
图 7 结果 URL 过滤设置
下一步是“列表页面访问”设置。这是每个类别的默认页面的下一页 采集。根据html中的格式,我们设置如图8所示。
图8 列表页面访问设置
至于每个页面采集到16个笑话的URL,这个和第一种方法一样。此处略过。
第二步采集内容规则
首先,我们要设计我们想要的记录属性。采集 笑话,我们需要“title”、“content”和“category”三个属性,如图9为内容标签定义
图 9 内容标签定义
每个标签特有的规则定义如图 10-13 所示:
图10 截取前后提取标题
图11
可视化提取内容
需要注意的是,在内容提取过程中,可能会保留一些html标签,或者不显示双引号、感叹号、省略号等。这时候我们可以根据需要排除html标签,替换一些字符。
图12
视觉提取和分类
图 13 规则测试
三、捕获数据
通过以上“URL采集规则”和“内容采集规则”的设置,就可以启动任务了。一段时间后,数据采集完成,我们可以右击任务,选择“打开数据下的任务文件夹”,然后我们就可以看到默认为Access的数据文件了,当然也可以转换成Excel格式。由于我们重新加载时数据输入使用的是Excel格式,因此我们将其转换为Excel格式。
笑话的第二部分
算法思路:这个笑话排序主要是从内容来判断。使用MD5摘要算法,我们选取第一句前后7个字符进行MD5编码运算,即中文“.”。和英文“.” 前面的4个和后面的两个加上自己的7个字符进行MD5操作。没有中国时期。并且英语时期暂时确定不再重复。然后比较每个笑话的前七个字符的MD5代码。根据“选择
*,count(distinct Md5)from mo1 group by Md5" 将排除与现有笑话重复的笑话。
算法描述:MD5以512位为单位对输入进行变换,最终以32位为单位输出4个压缩信息组。根据运算结果的唯一性,我们可以对每个笑话的第一个时期的前7个字符进行相同的MD5运算,比较后检查它们是否相同。
MD5流程说明如图14所示
图14 MD5流程
算法实现:
1、输入
导入 MySQL 数据库
导入 xlrd
conn = MySQLdb.connect(host='localhost', user='root'
,passwd='root' ,db='joke' ,use_unicode=True
,charset='utf8')
游标 = conn.cursor()
data = xlrd.open_workbook('E:\joke1.xls')
table = data.sheets()[0]
cursor.execute("select *,count(distinct Md5)from mo1 group by
Md5;")
行 = cursor.fetchall()
对于行中的行:
k = 行[0]
一 =
int(table.cell(k,0).value)
乙 =
table.cell(k,1).value
c =
table.cell(k,2).value
d =
table.cell(k,3).value
e =
table.cell(k,4).value
f =
table.cell(k,5).value
克 =
table.cell(k,6).value
sql = "插入 jo1
值(%s,%s,%s,%s,%s,%s,%s)"
cursor.execute(sql,(a,b,c,d,e,f,g))
游标.close()
mit()
2、MD5算法代码实现
# -*- 编码:UTF-8 -*-
导入 xlrd
进口重新
导入哈希库
导入 MySQL 数据库
data = xlrd.open_workbook('E:\joke1.xls')
table = data.sheets()[0]
conn = MySQLdb.connect(host='localhost', user='root'
,passwd='root' ,db='joke' ,use_unicode=True
,charset='utf8')
游标 = conn.cursor()
对于范围内的 n(1,table.nrows):
一 =
table.cell(n,4).value
打印 n
医学博士
=''
因为我在
范围(len(a)):
s =''
如果 a[i] == u'.':
打印
[i]
如果我==
len(a)-1:
j = len(a)
elif 我 ==
len(a)-2:
j = len(a)
别的:
j = i+3
对于 k
范围(j-7,j):
s = s+a[k]
米 =
hashlib.md5(s.encode("utf8"))
米 =
m.hexdigest()
休息
elif a[i] == u'。':
打印
[i]
如果我==
len(a)-1:
j = len(a)
elif 我 ==
len(a)-2:
j = len(a)
别的:
j = i+3
对于 k
范围(j-7,j):
s = s+a[k]
米 =
hashlib.md5(s.encode("utf8"))
米 =
m.hexdigest()
休息
如果 md =='':
md = str(n)
sql = "插入到 mo1
值(%s,%s)"
cursor.execute(sql,(n,md))
游标.close()
mit()
报告摘要
在这门课的过程中,我遇到了很多问题,有的已经解决了,有的还没有。优采云 是学习的课题。各种规则的编写和学习还有很长的路要走,会在以后的学习过程中逐渐积累。经验。
去重的算法还存在不足,以后要继续研究。
总之,我在这门课中学到了很多东西。尤其是在学习方法上,不懂的可以向别人请教,也可以通过其他渠道获取知识。学习是一项任重而道远的任务,自己的能力也遥不可及,以后的工作将更多地依靠团队合作。因此,我们必须更加重视合作的重要性。 查看全部
算法 自动采集列表(【每日一题】开心驿站为例叙述第一步)
陆涛,
李红
目的:通过熟悉优采云采集器的使用,把网上的30000个笑话整理出来,熟悉一些网络文本挖掘的知识。
过程:本研究主要分为两部分。第一部分是笑话文本的采集,第二部分是笑话的重新排序。以下是具体流程:
第一部分笑话提取
优采云挑笑话的基本流程:
新组 新任务 采集URL 设置 采集内容设置 捕获数据。
一、新建组和任务
根据需要设置“课程”分组,供以后在学习过程中练习和使用,并设置“笑话提取”子组。这个采集的笑话主要是关于两个网站《中国幽默王》和《欢乐驿站》。由于不同的网站html的功能框架不同,采集的不同框架的规则也不同,所以分为建立“快乐站”和“中国幽默王”两个任务。如图1所示
图 1 分组和任务
二、采集URL 和内容规则设置
由于这次采集是作为课程练习使用的,所以不涉及发布。因此,在任务编辑中只设置了第一步“采集 URL 规则”和第二步“采集 内容规则”。",如图2所示
图 2 编辑任务
以下学习过程介绍以欢乐客栈为例进行说明
第一步:采集 URL规则
先添加起始网址,然后再添加笑话网址采集 分为两种方式。
首先是在“添加起始采集地址”表单中设置“批量/多页”项,设置“算术序列”方法,即采集的笑话出自从第一页到最后一页,这些页码是等差数列,容差为 1,如图 3 所示。
图3 批量/多页设置
在《快乐邮报》上完整设置各种笑话,效果图如图3所示。
图4 起始网址效果图
当然,如果只使用这个设置,我们只能在一页上挑一个笑话。事实上,“快乐站”首页可以显示16个笑话,所以我们还需要设置“多级网址采集规则”。可以手动分析页面的html格式,然后填写规则。这里使用最简单的可视化Xpath方法来获取地址。如图5所示
图5
Xpath获取地址的方式
我们可以看到多级URL获取方式是get,如图6所示。
图6 多级URL设置效果图
二是不设置“批量/多页”,直接设置“多级URL获取”,先获取“快乐站”上各个分类的默认打开地址。
比如“校园笑话”,我们也用最简单的可视地址Xpath的方法来获取这些URL。Xpath 获取到的 URL 可能不是我们想要的 URL。比如list10-1和list13-1分别是图片和视频,所以我们可以进行如图7所示的“结果URL过滤”。
图 7 结果 URL 过滤设置
下一步是“列表页面访问”设置。这是每个类别的默认页面的下一页 采集。根据html中的格式,我们设置如图8所示。
图8 列表页面访问设置
至于每个页面采集到16个笑话的URL,这个和第一种方法一样。此处略过。
第二步采集内容规则
首先,我们要设计我们想要的记录属性。采集 笑话,我们需要“title”、“content”和“category”三个属性,如图9为内容标签定义
图 9 内容标签定义
每个标签特有的规则定义如图 10-13 所示:
图10 截取前后提取标题
图11
可视化提取内容
需要注意的是,在内容提取过程中,可能会保留一些html标签,或者不显示双引号、感叹号、省略号等。这时候我们可以根据需要排除html标签,替换一些字符。
图12
视觉提取和分类
图 13 规则测试
三、捕获数据
通过以上“URL采集规则”和“内容采集规则”的设置,就可以启动任务了。一段时间后,数据采集完成,我们可以右击任务,选择“打开数据下的任务文件夹”,然后我们就可以看到默认为Access的数据文件了,当然也可以转换成Excel格式。由于我们重新加载时数据输入使用的是Excel格式,因此我们将其转换为Excel格式。
笑话的第二部分
算法思路:这个笑话排序主要是从内容来判断。使用MD5摘要算法,我们选取第一句前后7个字符进行MD5编码运算,即中文“.”。和英文“.” 前面的4个和后面的两个加上自己的7个字符进行MD5操作。没有中国时期。并且英语时期暂时确定不再重复。然后比较每个笑话的前七个字符的MD5代码。根据“选择
*,count(distinct Md5)from mo1 group by Md5" 将排除与现有笑话重复的笑话。
算法描述:MD5以512位为单位对输入进行变换,最终以32位为单位输出4个压缩信息组。根据运算结果的唯一性,我们可以对每个笑话的第一个时期的前7个字符进行相同的MD5运算,比较后检查它们是否相同。
MD5流程说明如图14所示
图14 MD5流程
算法实现:
1、输入
导入 MySQL 数据库
导入 xlrd
conn = MySQLdb.connect(host='localhost', user='root'
,passwd='root' ,db='joke' ,use_unicode=True
,charset='utf8')
游标 = conn.cursor()
data = xlrd.open_workbook('E:\joke1.xls')
table = data.sheets()[0]
cursor.execute("select *,count(distinct Md5)from mo1 group by
Md5;")
行 = cursor.fetchall()
对于行中的行:
k = 行[0]
一 =
int(table.cell(k,0).value)
乙 =
table.cell(k,1).value
c =
table.cell(k,2).value
d =
table.cell(k,3).value
e =
table.cell(k,4).value
f =
table.cell(k,5).value
克 =
table.cell(k,6).value
sql = "插入 jo1
值(%s,%s,%s,%s,%s,%s,%s)"
cursor.execute(sql,(a,b,c,d,e,f,g))
游标.close()
mit()
2、MD5算法代码实现
# -*- 编码:UTF-8 -*-
导入 xlrd
进口重新
导入哈希库
导入 MySQL 数据库
data = xlrd.open_workbook('E:\joke1.xls')
table = data.sheets()[0]
conn = MySQLdb.connect(host='localhost', user='root'
,passwd='root' ,db='joke' ,use_unicode=True
,charset='utf8')
游标 = conn.cursor()
对于范围内的 n(1,table.nrows):
一 =
table.cell(n,4).value
打印 n
医学博士
=''
因为我在
范围(len(a)):
s =''
如果 a[i] == u'.':
打印
[i]
如果我==
len(a)-1:
j = len(a)
elif 我 ==
len(a)-2:
j = len(a)
别的:
j = i+3
对于 k
范围(j-7,j):
s = s+a[k]
米 =
hashlib.md5(s.encode("utf8"))
米 =
m.hexdigest()
休息
elif a[i] == u'。':
打印
[i]
如果我==
len(a)-1:
j = len(a)
elif 我 ==
len(a)-2:
j = len(a)
别的:
j = i+3
对于 k
范围(j-7,j):
s = s+a[k]
米 =
hashlib.md5(s.encode("utf8"))
米 =
m.hexdigest()
休息
如果 md =='':
md = str(n)
sql = "插入到 mo1
值(%s,%s)"
cursor.execute(sql,(n,md))
游标.close()
mit()
报告摘要
在这门课的过程中,我遇到了很多问题,有的已经解决了,有的还没有。优采云 是学习的课题。各种规则的编写和学习还有很长的路要走,会在以后的学习过程中逐渐积累。经验。
去重的算法还存在不足,以后要继续研究。
总之,我在这门课中学到了很多东西。尤其是在学习方法上,不懂的可以向别人请教,也可以通过其他渠道获取知识。学习是一项任重而道远的任务,自己的能力也遥不可及,以后的工作将更多地依靠团队合作。因此,我们必须更加重视合作的重要性。
算法 自动采集列表(算法自动采集列表里的商品,存下来,且安全)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-22 19:04
算法自动采集列表里的商品,存下来,然后对商品进行各种购买操作,再同步给其他用户,比如用户a花10元购买了2件商品,1件售价30元,2件售价40元。这个时候如果用户a想给朋友购买,只需要在小程序里找到那件商品,点击即可购买,自动采集列表里就只有2件商品,非常方便,且安全。
第一次见到可以自动切换的,不过这样的应该比较大的可能就是用户量太大了,一个人单独操作的时候,每个店铺的商品会对应一个浏览列表,然后后续应该还要对浏览量排名,或者大量采集,不过这些都是没必要的了,重点是本身这款小程序本身具有的很多功能和体验不适合做成一个重量级的应用。
你不知道有一个服务叫一键付款的么?
首先,用户自己的商品并不全部是他的,而且大部分都是自己收藏的但是没有购买的商品。所以你的发展方向应该是比较受用户欢迎的商品,并且存在价值大的商品,最好大批量订单,像zara,ibm做过的商品库。其次,你可以利用fb等资源做定制化定位,就跟国内的网红一样,把你的商品融入到你所在的消费群体中,最大化挖掘它的价值。
自己的商品太杂了,放到小程序中最多可以涵盖最近3个月中的半年左右商品,
说实话,小程序做的还不太好,如果要做成大商家有点困难, 查看全部
算法 自动采集列表(算法自动采集列表里的商品,存下来,且安全)
算法自动采集列表里的商品,存下来,然后对商品进行各种购买操作,再同步给其他用户,比如用户a花10元购买了2件商品,1件售价30元,2件售价40元。这个时候如果用户a想给朋友购买,只需要在小程序里找到那件商品,点击即可购买,自动采集列表里就只有2件商品,非常方便,且安全。
第一次见到可以自动切换的,不过这样的应该比较大的可能就是用户量太大了,一个人单独操作的时候,每个店铺的商品会对应一个浏览列表,然后后续应该还要对浏览量排名,或者大量采集,不过这些都是没必要的了,重点是本身这款小程序本身具有的很多功能和体验不适合做成一个重量级的应用。
你不知道有一个服务叫一键付款的么?
首先,用户自己的商品并不全部是他的,而且大部分都是自己收藏的但是没有购买的商品。所以你的发展方向应该是比较受用户欢迎的商品,并且存在价值大的商品,最好大批量订单,像zara,ibm做过的商品库。其次,你可以利用fb等资源做定制化定位,就跟国内的网红一样,把你的商品融入到你所在的消费群体中,最大化挖掘它的价值。
自己的商品太杂了,放到小程序中最多可以涵盖最近3个月中的半年左右商品,
说实话,小程序做的还不太好,如果要做成大商家有点困难,
算法 自动采集列表(报错优酷视频有防采集限制,高频率售后问题通过专业的处理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-18 06:10
该插件只需要添加关键字采集,它会通过优酷的搜索库自动匹配对应的视频,并在视频的每一页自动采集,并自动发布到【门户指定频道】或【论坛指定版块】。
添加采集关键字后,视频采集发布过程不需要人工干预。它通过计划任务自动执行。可以修改采集到达的视频信息。当然,您也可以手动执行一键采集快速采集视频列表。
详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询)
特殊说明
该插件只能采集优酷普通视频,不支持电影、电视剧、动画等特殊内容。
插件发布的视频使用了论坛的多媒体代码([media]),由论坛自行处理,插件不具备解析功能
本插件需要php支持curl,curl可以正常获取https链接内容,PHP版本至少5.3,PHP5.2可能无法采集https链接导致错误
优酷视频有反采集限制。高频采集可能会被屏蔽。建议由插件自动发布采集。
如果您的网站服务器被屏蔽或无法获取采集的源内容,且您无法采集正常发布文章,恕不退款。
售后服务
售后问题通过专业工单系统处理。工单发布后,技术会收到邮件提醒,收到人工订单,排查问题原因,整理问题解决方案,技术解答时您会在现场收到短信和邮件提醒,确保及时高效解决您的问题
工单地址: 查看全部
算法 自动采集列表(报错优酷视频有防采集限制,高频率售后问题通过专业的处理)
该插件只需要添加关键字采集,它会通过优酷的搜索库自动匹配对应的视频,并在视频的每一页自动采集,并自动发布到【门户指定频道】或【论坛指定版块】。
添加采集关键字后,视频采集发布过程不需要人工干预。它通过计划任务自动执行。可以修改采集到达的视频信息。当然,您也可以手动执行一键采集快速采集视频列表。
详情请通过应用截图、更新日志等方式了解,或添加售前QQ(15326940)咨询)
特殊说明
该插件只能采集优酷普通视频,不支持电影、电视剧、动画等特殊内容。
插件发布的视频使用了论坛的多媒体代码([media]),由论坛自行处理,插件不具备解析功能
本插件需要php支持curl,curl可以正常获取https链接内容,PHP版本至少5.3,PHP5.2可能无法采集https链接导致错误
优酷视频有反采集限制。高频采集可能会被屏蔽。建议由插件自动发布采集。
如果您的网站服务器被屏蔽或无法获取采集的源内容,且您无法采集正常发布文章,恕不退款。
售后服务
售后问题通过专业工单系统处理。工单发布后,技术会收到邮件提醒,收到人工订单,排查问题原因,整理问题解决方案,技术解答时您会在现场收到短信和邮件提醒,确保及时高效解决您的问题
工单地址:
算法 自动采集列表(算法自动采集列表页与转化页的注意事项有哪些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-17 03:03
算法自动采集列表页与转化页,每个页面一个采集规则。一般是14天监测一次,如果有问题,马上更换,
每天对应的关键词,以关键词值来决定,关键词值会升不会降,
这个用软件的话,就需要注意3点。
1、注意用他对应的软件来判断。
2、用带residual,不然可能会有遗漏,第一个15天不要中断它。
3、用sid,这样也会大大减少用软件带来的bug,也可以使权重提高。
自动采集功能确实是可以做到的,可以把需要采集的内容做个自动采集列表,每个月分析下有没有剩余空间,如果没有就分析原因,安排下下一个月的采集。我的观点是会以包年形式,这样权重会提高的快点。
自动采集,
就给p6的职位建议是,薪资地域如果很多那就可以测试下程序来自动采。
p6的职位:量身定制,节省时间。
通过科学的测试和定制筛选工具,可以精准的筛选出我所需要的信息。如百度搜索的精准定位,
总要有需求才会有采集这一说,这是客户的需求,而你如果能满足客户需求,也会得到更多。
采集各行各业的海量内容,主要是要持续才会越来越精确。上几个案例。一个ai教育企业,他们需要大量全日制大学课件的分析报告。我给他们提供了我们的研究院,它们就找到了我的研究院,找到了他们所需要的相关文档,通过图表筛选和用户反馈,然后结合我的研究院,就能完成最终的分析。这还不是最精确的,最精确的当然是全部做好采集工作,比如筛选好研究院到底用不用。
如果需要其他教育采集,就只能通过分析其他渠道寻找相关文档。当然,我还只是给了一个方向,看这些大量需求总归不易。 查看全部
算法 自动采集列表(算法自动采集列表页与转化页的注意事项有哪些)
算法自动采集列表页与转化页,每个页面一个采集规则。一般是14天监测一次,如果有问题,马上更换,
每天对应的关键词,以关键词值来决定,关键词值会升不会降,
这个用软件的话,就需要注意3点。
1、注意用他对应的软件来判断。
2、用带residual,不然可能会有遗漏,第一个15天不要中断它。
3、用sid,这样也会大大减少用软件带来的bug,也可以使权重提高。
自动采集功能确实是可以做到的,可以把需要采集的内容做个自动采集列表,每个月分析下有没有剩余空间,如果没有就分析原因,安排下下一个月的采集。我的观点是会以包年形式,这样权重会提高的快点。
自动采集,
就给p6的职位建议是,薪资地域如果很多那就可以测试下程序来自动采。
p6的职位:量身定制,节省时间。
通过科学的测试和定制筛选工具,可以精准的筛选出我所需要的信息。如百度搜索的精准定位,
总要有需求才会有采集这一说,这是客户的需求,而你如果能满足客户需求,也会得到更多。
采集各行各业的海量内容,主要是要持续才会越来越精确。上几个案例。一个ai教育企业,他们需要大量全日制大学课件的分析报告。我给他们提供了我们的研究院,它们就找到了我的研究院,找到了他们所需要的相关文档,通过图表筛选和用户反馈,然后结合我的研究院,就能完成最终的分析。这还不是最精确的,最精确的当然是全部做好采集工作,比如筛选好研究院到底用不用。
如果需要其他教育采集,就只能通过分析其他渠道寻找相关文档。当然,我还只是给了一个方向,看这些大量需求总归不易。
算法 自动采集列表(如何利用百度算法搭建采集站快速收录和排名?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-16 09:06
如何赚钱?网上赚钱的方法数不胜数。我们今天讲的赚钱方法,跟seo有关系,因为很多站长网站都是采集的内容。毕竟简单高效,但是很多采集站都无法通过收录正常排名,更别提赚钱了,那我们如何利用百度算法快速建站采集 @收录 和排名?
QQ截图208.jpg(53.5 KB,下载次数:21)
下载附件
2018-11-27 14:25 上传
网站关键词 要想排名,必须先收录,只要解决了收录的问题,其他问题就解决了。收录索引原理:
内容让用户满意:我们可以采集,你做SEO时网站,你采集一个医疗行业文章,你觉得合适吗?我们不应该要求采集SEO网站的内容,同时还要满足这个文章是否对用户有帮助。
QQ截图229.jpg(47.4 KB,下载次数:22)
下载附件
2018-11-27 14:25 上传
内容稀缺:一个很好的文章被各大论坛转载,那么再好的文章也是零,因为这个文章在第一次发表时不是你的网站,同时你的体重网站也没有绝对优势。
时效性:比如现在是夏天,我们做女装,那么我们的内容也要跟夏天相关,因为会受到用户的欢迎。
页面质量:很多人不太关注这点,所以我们在写文章,非常需要关注页面的质量,文章是否流畅,还有也是很多人在国外网站抄袭文章被翻译成中文,结果语无伦次。这是一个非常严重的错误。
QQ截图213.jpg(30.42 KB,下载次数:21)
下载附件
2018-11-27 14:25 上传
2、伪原创 标题改写
<p>当我们发现一个受众非常广泛的文章,觉得我们会用这个文章,那么我们就需要一个很好的标题来支持这个文章,并加上这个 查看全部
算法 自动采集列表(如何利用百度算法搭建采集站快速收录和排名?(组图))
如何赚钱?网上赚钱的方法数不胜数。我们今天讲的赚钱方法,跟seo有关系,因为很多站长网站都是采集的内容。毕竟简单高效,但是很多采集站都无法通过收录正常排名,更别提赚钱了,那我们如何利用百度算法快速建站采集 @收录 和排名?
QQ截图208.jpg(53.5 KB,下载次数:21)
下载附件
2018-11-27 14:25 上传
网站关键词 要想排名,必须先收录,只要解决了收录的问题,其他问题就解决了。收录索引原理:
内容让用户满意:我们可以采集,你做SEO时网站,你采集一个医疗行业文章,你觉得合适吗?我们不应该要求采集SEO网站的内容,同时还要满足这个文章是否对用户有帮助。
QQ截图229.jpg(47.4 KB,下载次数:22)
下载附件
2018-11-27 14:25 上传
内容稀缺:一个很好的文章被各大论坛转载,那么再好的文章也是零,因为这个文章在第一次发表时不是你的网站,同时你的体重网站也没有绝对优势。
时效性:比如现在是夏天,我们做女装,那么我们的内容也要跟夏天相关,因为会受到用户的欢迎。
页面质量:很多人不太关注这点,所以我们在写文章,非常需要关注页面的质量,文章是否流畅,还有也是很多人在国外网站抄袭文章被翻译成中文,结果语无伦次。这是一个非常严重的错误。
QQ截图213.jpg(30.42 KB,下载次数:21)
下载附件
2018-11-27 14:25 上传
2、伪原创 标题改写
<p>当我们发现一个受众非常广泛的文章,觉得我们会用这个文章,那么我们就需要一个很好的标题来支持这个文章,并加上这个
算法 自动采集列表(基于KStar算法水色图像分类预测应用:操作步骤缺失值的处理方式 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-12-14 08:05
)
基于KStar算法的水彩图像分类预测应用流程图:
第 1 步:数据准备
1.本文档提供了采集收到的水样数据。详情请参考示例数据文件:“Sample Data.xls”。
2. 设置“number of samples.xls”文件中204条数据中的前180条数据作为训练数据集,后24条数据作为测试数据集。
第 2 步:制定计划
登录TipDM平台后的默认页面是“项目管理”。在此页面上,选择“数据分类”以创建一个新项目。项目名称:基于KStar算法的水彩分类预测模型。方案描述:通过对捕获的水样图像进行自动裁剪进行图像预处理,然后利用图像特征提取算法提取水样图像的特征值,建立水样/数据信息与水质类别的对应关系,从而达到水质预测的目的。
操作步骤三:数据管理
计划创建完成后,点击“数据管理”,点击“浏览”找到“Sample Data.xls”,点击“上传”将数据导入到计划中。如果数据没有及时显示出来,点击“刷新”显示导入的数据。
操作步骤 4:预测建模
在系统菜单栏中,选择“分类和回归”。子菜单“组合算法”有这次使用的算法“KStar算法”。点击菜单右侧的 ,显示算法页面。
1、 导入专家样本数据:选择所有数据列和行1到180导入专家样本数据。
2、 参数设置:点击“参数设置”按钮,弹出参数设置框。有四个参数可以设置:“混合信息熵”、“全局混合值”、“缺失处理模式”和“预测输出”。
主要建模参数说明:
²混合信息熵:是否使用混合信息熵。
²全局混合值:全局混合参数,参数值在[0, 100]中选择。
²缺失处理方式:缺失值的处理方式。
²预测输出:选择“True”,交叉验证和模型训练时,输出样本的预测结果。
3、模型训练、交叉验证、模型验证、模型预测等运营部门参考图例。
图形示例:
查看全部
算法 自动采集列表(基于KStar算法水色图像分类预测应用:操作步骤缺失值的处理方式
)
基于KStar算法的水彩图像分类预测应用流程图:
第 1 步:数据准备
1.本文档提供了采集收到的水样数据。详情请参考示例数据文件:“Sample Data.xls”。
2. 设置“number of samples.xls”文件中204条数据中的前180条数据作为训练数据集,后24条数据作为测试数据集。
第 2 步:制定计划
登录TipDM平台后的默认页面是“项目管理”。在此页面上,选择“数据分类”以创建一个新项目。项目名称:基于KStar算法的水彩分类预测模型。方案描述:通过对捕获的水样图像进行自动裁剪进行图像预处理,然后利用图像特征提取算法提取水样图像的特征值,建立水样/数据信息与水质类别的对应关系,从而达到水质预测的目的。
操作步骤三:数据管理
计划创建完成后,点击“数据管理”,点击“浏览”找到“Sample Data.xls”,点击“上传”将数据导入到计划中。如果数据没有及时显示出来,点击“刷新”显示导入的数据。
操作步骤 4:预测建模
在系统菜单栏中,选择“分类和回归”。子菜单“组合算法”有这次使用的算法“KStar算法”。点击菜单右侧的 ,显示算法页面。
1、 导入专家样本数据:选择所有数据列和行1到180导入专家样本数据。
2、 参数设置:点击“参数设置”按钮,弹出参数设置框。有四个参数可以设置:“混合信息熵”、“全局混合值”、“缺失处理模式”和“预测输出”。
主要建模参数说明:
²混合信息熵:是否使用混合信息熵。
²全局混合值:全局混合参数,参数值在[0, 100]中选择。
²缺失处理方式:缺失值的处理方式。
²预测输出:选择“True”,交叉验证和模型训练时,输出样本的预测结果。
3、模型训练、交叉验证、模型验证、模型预测等运营部门参考图例。
图形示例:
算法 自动采集列表(天天特价包包2016秋冬斜挎包韩版手提包流苏优采云包女包包)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-13 08:16
背景
双十一购物狂欢节又要来了。近日,网上出现了各种关于双十一的热门购物清单。如果你是资深网购司机,你一定知道,通常一个产品会有很多尺寸的标签来展示,比如鞋子,它的产品描述可能是这样的“韩国女孩英式系带马丁靴女磨砂皮革厚底休闲短靴”。如果是包包,那么它的产品描述可能是“Daily Special bag 2016新款秋冬斜挎包韩版手提包流苏优采云包女包单肩包”。
每个商品的描述收录很多维度,可能是时间、产地、款式等,如何根据具体维度对数以万计的商品进行分类,往往是电商平台最头疼的问题。这里最大的挑战是如何获取每个产品的尺寸,由哪些标签组成。如果该算法能够自动学习“日本”、“福建”、“韩国”等与位置相关的标签,那么就可以快速构建标签分类系统。本文将利用PAI平台的文本分析功能,实现一个简单的产品标签自动分类系统。
数据显示
数据是网上直接下载整理的2016年双十一购物清单。产品描述有2000多个,每一行代表一个产品的标签聚合,如下图所示:
我们将此数据导入 PAI 进行处理。具体数据上传方式请参考PAI官方文档:/product/30347.html
实验说明
数据上传完成后,通过拖放PAI组件,可以生成如下实验逻辑图,并且已经标注了每一步的具体功能:
以下子模块解释了每个部分的具体功能:
1.上传数据和分段词
上传数据,shopping_data代表底层数据存储,然后通过分词组件对数据进行切分。分词是NLP的基本操作,这里就不介绍了。
2.添加序号栏
由于上传的数据只有一个字段,因此通过增加序号列为每个数据添加主键,方便后续计算。处理后的数据如下图所示:
3.统计词频
显示的是每个产品中出现的各种单词的数量。
4.生成词向量
使用 word2vector 算法。该算法可以根据每个词在向量维度上的含义进行扩展。这个词向量有两个含义。
经过word2vector后,每个词被映射到百维空间,生成结果如下图所示:
5.词向量聚类
既然已经生成了词向量,那么只需要计算哪些词的向量距离比较近,就可以根据意义对标签词进行分类了。这里使用kmeans算法进行自动分类,聚类结果显示每个词属于哪个cluster cluster:
结果验证
最后,通过SQL组件,从簇中随机选择一个类别,检查同一类别的标签是否自动分类。在这里,选择了第 10 组集群。
看看第10组的结果:
通过搜索结果中的“日本”、“俄罗斯”、“韩国”、“云南”、“新疆”、“台湾”等词,我们可以发现系统自动对一些地理相关的标签进行了分类,但混入“男士内衣”、“坚果”等明显与类别不一致的标签很可能是训练样本数量不足造成的。如果训练样本足够大,标签聚类结果会很准确的。
其他
本文中的案例已经集成到PAI首页的模板中,请注册使用PAI:/product/learn,在模板中点击create使用,包括逻辑和数据:
原文链接
更多技术干货请关注云栖社区知乎机构编号:阿里云云栖社区-知乎 查看全部
算法 自动采集列表(天天特价包包2016秋冬斜挎包韩版手提包流苏优采云包女包包)
背景
双十一购物狂欢节又要来了。近日,网上出现了各种关于双十一的热门购物清单。如果你是资深网购司机,你一定知道,通常一个产品会有很多尺寸的标签来展示,比如鞋子,它的产品描述可能是这样的“韩国女孩英式系带马丁靴女磨砂皮革厚底休闲短靴”。如果是包包,那么它的产品描述可能是“Daily Special bag 2016新款秋冬斜挎包韩版手提包流苏优采云包女包单肩包”。
每个商品的描述收录很多维度,可能是时间、产地、款式等,如何根据具体维度对数以万计的商品进行分类,往往是电商平台最头疼的问题。这里最大的挑战是如何获取每个产品的尺寸,由哪些标签组成。如果该算法能够自动学习“日本”、“福建”、“韩国”等与位置相关的标签,那么就可以快速构建标签分类系统。本文将利用PAI平台的文本分析功能,实现一个简单的产品标签自动分类系统。
数据显示
数据是网上直接下载整理的2016年双十一购物清单。产品描述有2000多个,每一行代表一个产品的标签聚合,如下图所示:
我们将此数据导入 PAI 进行处理。具体数据上传方式请参考PAI官方文档:/product/30347.html
实验说明
数据上传完成后,通过拖放PAI组件,可以生成如下实验逻辑图,并且已经标注了每一步的具体功能:
以下子模块解释了每个部分的具体功能:
1.上传数据和分段词
上传数据,shopping_data代表底层数据存储,然后通过分词组件对数据进行切分。分词是NLP的基本操作,这里就不介绍了。
2.添加序号栏
由于上传的数据只有一个字段,因此通过增加序号列为每个数据添加主键,方便后续计算。处理后的数据如下图所示:
3.统计词频
显示的是每个产品中出现的各种单词的数量。
4.生成词向量
使用 word2vector 算法。该算法可以根据每个词在向量维度上的含义进行扩展。这个词向量有两个含义。
经过word2vector后,每个词被映射到百维空间,生成结果如下图所示:
5.词向量聚类
既然已经生成了词向量,那么只需要计算哪些词的向量距离比较近,就可以根据意义对标签词进行分类了。这里使用kmeans算法进行自动分类,聚类结果显示每个词属于哪个cluster cluster:
结果验证
最后,通过SQL组件,从簇中随机选择一个类别,检查同一类别的标签是否自动分类。在这里,选择了第 10 组集群。
看看第10组的结果:
通过搜索结果中的“日本”、“俄罗斯”、“韩国”、“云南”、“新疆”、“台湾”等词,我们可以发现系统自动对一些地理相关的标签进行了分类,但混入“男士内衣”、“坚果”等明显与类别不一致的标签很可能是训练样本数量不足造成的。如果训练样本足够大,标签聚类结果会很准确的。
其他
本文中的案例已经集成到PAI首页的模板中,请注册使用PAI:/product/learn,在模板中点击create使用,包括逻辑和数据:
原文链接
更多技术干货请关注云栖社区知乎机构编号:阿里云云栖社区-知乎
算法 自动采集列表( 220个自动计算表格+109个实用五金计算工具(组图) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-13 08:12
220个自动计算表格+109个实用五金计算工具(组图)
)
想让工程计算更容易?109个计算工具+220个自动计算表,非常实用
建筑计算真的很头疼。传统的计算方法非常复杂。需要公式计算。工作量非常大。一不小心,就会犯错,之前的努力就会白费。如果有一套自动计算表和软件帮助,不仅事半功倍,而且不用加班和熬夜。为什么不为工程师做呢?
今天整理了220张自动计算表+109个自动计算工具。这些经常被工程师在日常工作中使用。只要懂电脑,就能操作。使用非常方便,输入数据,自动计算,结果准确。是工程师必备的武器。
220自动计算表显示
这里有220张自动计算表,包括不同的建设项目内容,操作简单,Excel格式,数据输入,自动计算,准确,很多工程师都在使用,大大提高了工作效率。
220自动计算表显示
220自动计算表显示
220张自动计算表,显示建筑工程计算总表
这是一套系统的表格,里面收录了板、梁、轴压柱等各种类型的计算表,非常详细。它们都是自动计算表。只要输入参数,就可以自动计算出来。在工程师的日常工作中是必不可少的。
建筑工程计算汇总
钢结构工程量自动计算表
建筑工程计算汇总
施工量自动计算表
建筑工程计算表中的109个自动计算工具
这109个计算工具可以在日常工作中使用。操作简单,使用方便。只要简单的点击操作,输入数据,就可以自动生成,很多工程师都在用。
109个自动计算工具
檀香计算工具
109个自动计算工具
实用的硬件计算工具
109个自动计算工具
钢结构施工落料计算工具
109个自动计算工具
109个自动计算工具
这些自动计算表和计算工具都是工程师在日常工作中必不可少的。操作简单,使用方便。点击操作,输入数据,得到准确的结果,大大提高了工作效率。这样易于使用的自动计算表和工具已经很难找到了。建议所有工程师采集它们。
查看全部
算法 自动采集列表(
220个自动计算表格+109个实用五金计算工具(组图)
)
想让工程计算更容易?109个计算工具+220个自动计算表,非常实用
建筑计算真的很头疼。传统的计算方法非常复杂。需要公式计算。工作量非常大。一不小心,就会犯错,之前的努力就会白费。如果有一套自动计算表和软件帮助,不仅事半功倍,而且不用加班和熬夜。为什么不为工程师做呢?
今天整理了220张自动计算表+109个自动计算工具。这些经常被工程师在日常工作中使用。只要懂电脑,就能操作。使用非常方便,输入数据,自动计算,结果准确。是工程师必备的武器。
220自动计算表显示
这里有220张自动计算表,包括不同的建设项目内容,操作简单,Excel格式,数据输入,自动计算,准确,很多工程师都在使用,大大提高了工作效率。
220自动计算表显示
220自动计算表显示
220张自动计算表,显示建筑工程计算总表
这是一套系统的表格,里面收录了板、梁、轴压柱等各种类型的计算表,非常详细。它们都是自动计算表。只要输入参数,就可以自动计算出来。在工程师的日常工作中是必不可少的。
建筑工程计算汇总
钢结构工程量自动计算表
建筑工程计算汇总
施工量自动计算表
建筑工程计算表中的109个自动计算工具
这109个计算工具可以在日常工作中使用。操作简单,使用方便。只要简单的点击操作,输入数据,就可以自动生成,很多工程师都在用。
109个自动计算工具
檀香计算工具
109个自动计算工具
实用的硬件计算工具
109个自动计算工具
钢结构施工落料计算工具
109个自动计算工具
109个自动计算工具
这些自动计算表和计算工具都是工程师在日常工作中必不可少的。操作简单,使用方便。点击操作,输入数据,得到准确的结果,大大提高了工作效率。这样易于使用的自动计算表和工具已经很难找到了。建议所有工程师采集它们。
算法 自动采集列表(Python实现DBSCAN聚类算法的资料请关注服务器之家)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-09 12:24
什么是聚类算法?聚类是一种机器学习技术,涉及对数据点进行分组。给定一组数据点,我们可以使用聚类算法将每个数据点划分为特定的组。理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类是一种无监督的学习方法,也是许多领域常用的统计数据分析技术。
常用的算法有K-MEANS、高斯混合模型(GMM)、自组织图(SOM)
重点介绍DBSCAN聚类算法的Python实现并通过简单的样例测试。
发现了一个高密度的核心样本,并从中扩展了集群。
Python代码如下:
# -*- coding: utf-8 -*-
"""
Demo of DBSCAN clustering algorithm
Finds core samples of high density and expands clusters from them.
"""
print(__doc__)
# 引入相关包
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 初始化样本数据
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# 计算DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# 聚类的结果
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print("Estimated number of clusters: %d" % n_clusters_)
print("Estimated number of noise points: %d" % n_noise_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels,
average_method="arithmetic"))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
# 绘出结果
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], "o", markerfacecolor=tuple(col),
markeredgecolor="k", markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], "o", markerfacecolor=tuple(col),
markeredgecolor="k", markersize=6)
plt.title("Estimated number of clusters: %d" % n_clusters_)
plt.show()
测试结果如下:
最终结果图:
精确数据:
以上就是DBSCAN聚类算法的Python实现(简单样例测试)的详细内容。关于Python聚类算法的更多信息,请关注服务器之家的其他相关文章!
原文链接: 查看全部
算法 自动采集列表(Python实现DBSCAN聚类算法的资料请关注服务器之家)
什么是聚类算法?聚类是一种机器学习技术,涉及对数据点进行分组。给定一组数据点,我们可以使用聚类算法将每个数据点划分为特定的组。理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类是一种无监督的学习方法,也是许多领域常用的统计数据分析技术。
常用的算法有K-MEANS、高斯混合模型(GMM)、自组织图(SOM)
重点介绍DBSCAN聚类算法的Python实现并通过简单的样例测试。
发现了一个高密度的核心样本,并从中扩展了集群。
Python代码如下:
# -*- coding: utf-8 -*-
"""
Demo of DBSCAN clustering algorithm
Finds core samples of high density and expands clusters from them.
"""
print(__doc__)
# 引入相关包
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
# 初始化样本数据
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
X = StandardScaler().fit_transform(X)
# 计算DBSCAN
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
# 聚类的结果
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
n_noise_ = list(labels).count(-1)
print("Estimated number of clusters: %d" % n_clusters_)
print("Estimated number of noise points: %d" % n_noise_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels,
average_method="arithmetic"))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
# 绘出结果
unique_labels = set(labels)
colors = [plt.cm.Spectral(each)
for each in np.linspace(0, 1, len(unique_labels))]
for k, col in zip(unique_labels, colors):
if k == -1:
col = [0, 0, 0, 1]
class_member_mask = (labels == k)
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], "o", markerfacecolor=tuple(col),
markeredgecolor="k", markersize=14)
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], "o", markerfacecolor=tuple(col),
markeredgecolor="k", markersize=6)
plt.title("Estimated number of clusters: %d" % n_clusters_)
plt.show()
测试结果如下:
最终结果图:
精确数据:
以上就是DBSCAN聚类算法的Python实现(简单样例测试)的详细内容。关于Python聚类算法的更多信息,请关注服务器之家的其他相关文章!
原文链接:
算法 自动采集列表(算法自动采集列表列表采集条件过滤过滤条件多级目录堆)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-03 06:04
算法自动采集列表采集列表列表采集条件过滤过滤条件多级目录遍历堆内容前端双向绑定伪类bootstrapdiv标签移动端布局上采集。bootstrap一般采集静态页面。
对bootstrap有基本了解,你需要知道基本的cssselector,了解响应式布局的概念,
谢邀。推荐您看下我们的面试题库和面试必过列表,有关于web前端的一些知识点,个人觉得还挺全面的,
框架无非那几种,按照顺序学习就好,基础、高级、特性等等,适用的场景各不相同。推荐你看看这篇文章里写的:web前端技术详解(最新版)学习路线图。
和很多程序员交流过,有些程序员看了很多没有用的面试题,有些看了好多有用的却没用,那面试题的用途在哪里?无非是考验你是否真的掌握了基础知识,又或者是你有没有在试着找到自己的兴趣点,或者当你看到pv高,跳出就不想进去。其实在面试和实际工作中其实没必要看那么多,而是需要你有针对性的去学习和巩固,面试题其实也就那么几个,满足不了要求你就跟公司谈加薪,满足了要求就继续学习,另外的直接跳过,不要浪费时间。
从作用上来看,面试题基本属于敲门砖,其实最有用的就是项目经验。可以快速帮你理解业务上的很多思路,和实际的开发出现的场景。从面试题上来看,可以学到看到一个问题是怎么做,其实作用比较小。实际上我觉得面试题主要起两个作用:一,算法二,专业知识这里列举三点:算法:个人认为不是算法去算法面试官不会问算法,面试官自己也不会面算法。
这个时候,用通用的知识去算法就可以。比如:2分查找等同于:nn.relatex({n:3,m:5,r:120})。或者其他一些辅助算法。算法有时候也不是越难越好,也需要看问题的实际场景。如果面试官真的想知道一个算法或者数据结构或者某个数据库操作,如果不知道细节的话,甚至可以直接通过多问几个问题得出结论。
数据结构:这个一般的笔试题就可以很好的证明,比如1:可能会遇到什么数据结构的场景?2:数据结构的优劣点是什么?3:哪些是比较好的数据结构,和它们的写法有什么区别?第三点。比如3元组,还要会出现在什么地方,为什么出现。或者更多的算法可以拓展到二分查找等等。以及listeveryk个元素,就是二分查找,最短路径等等,你不知道多少种算法会比较好?专业知识:这个就要根据不同岗位去看。
比如大公司的产品经理:画原型图,做原型设计,做设计与交互等等需要掌握什么知识。至于小公司的产品经理:对原型图会有专门的一个画法,这个可以是你们自己的公司做的。 查看全部
算法 自动采集列表(算法自动采集列表列表采集条件过滤过滤条件多级目录堆)
算法自动采集列表采集列表列表采集条件过滤过滤条件多级目录遍历堆内容前端双向绑定伪类bootstrapdiv标签移动端布局上采集。bootstrap一般采集静态页面。
对bootstrap有基本了解,你需要知道基本的cssselector,了解响应式布局的概念,
谢邀。推荐您看下我们的面试题库和面试必过列表,有关于web前端的一些知识点,个人觉得还挺全面的,
框架无非那几种,按照顺序学习就好,基础、高级、特性等等,适用的场景各不相同。推荐你看看这篇文章里写的:web前端技术详解(最新版)学习路线图。
和很多程序员交流过,有些程序员看了很多没有用的面试题,有些看了好多有用的却没用,那面试题的用途在哪里?无非是考验你是否真的掌握了基础知识,又或者是你有没有在试着找到自己的兴趣点,或者当你看到pv高,跳出就不想进去。其实在面试和实际工作中其实没必要看那么多,而是需要你有针对性的去学习和巩固,面试题其实也就那么几个,满足不了要求你就跟公司谈加薪,满足了要求就继续学习,另外的直接跳过,不要浪费时间。
从作用上来看,面试题基本属于敲门砖,其实最有用的就是项目经验。可以快速帮你理解业务上的很多思路,和实际的开发出现的场景。从面试题上来看,可以学到看到一个问题是怎么做,其实作用比较小。实际上我觉得面试题主要起两个作用:一,算法二,专业知识这里列举三点:算法:个人认为不是算法去算法面试官不会问算法,面试官自己也不会面算法。
这个时候,用通用的知识去算法就可以。比如:2分查找等同于:nn.relatex({n:3,m:5,r:120})。或者其他一些辅助算法。算法有时候也不是越难越好,也需要看问题的实际场景。如果面试官真的想知道一个算法或者数据结构或者某个数据库操作,如果不知道细节的话,甚至可以直接通过多问几个问题得出结论。
数据结构:这个一般的笔试题就可以很好的证明,比如1:可能会遇到什么数据结构的场景?2:数据结构的优劣点是什么?3:哪些是比较好的数据结构,和它们的写法有什么区别?第三点。比如3元组,还要会出现在什么地方,为什么出现。或者更多的算法可以拓展到二分查找等等。以及listeveryk个元素,就是二分查找,最短路径等等,你不知道多少种算法会比较好?专业知识:这个就要根据不同岗位去看。
比如大公司的产品经理:画原型图,做原型设计,做设计与交互等等需要掌握什么知识。至于小公司的产品经理:对原型图会有专门的一个画法,这个可以是你们自己的公司做的。
算法 自动采集列表( 147SEO采集工具如何选择以及使用呢?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 576 次浏览 • 2021-12-02 20:14
147SEO采集工具如何选择以及使用呢?(图))
市面上的采集工具很多,比如147SEO、优采云、优采云等,那么众多的采集工具我们该如何选择和使用呢?首先,如果你建了一个网站,就必须不断完善内容,那么问题来了,网站的内容每天更新已经成为网站可持续发展的严重问题@网站,所以将使用 采集 函数。从互联网开始,我们知道搜索引擎一直提倡网站要有高质量的内容和原创内容以获得更好的排名,但我们经常看到一些网站即使不是原创内容,上面的内容可能被内容处理采集复制了,但是排名还是不错的,所以还是可以做的。
但是要注意采集站的项目目标的选择,要明白自己要做什么站。所以,在开始采集的内容之前,首先要定位到我们在做什么网站,不是漫无目的地去采集,而是需要细化采集。
147SEO的通用文章采集功能,只需输入关键字即可采集各种网页和新闻,也可以采集指定列表页(栏目页)文章:
1. 依托147SEO独家通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达96%以上。
2. 只需输入关键词即可采集进入各大搜索引擎的网页;关键词 全自动采集 可以批量处理。
3.可以针对采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4. 文章 翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和是道翻译.
5.市面上最简单最智能的文章采集器,关键是免费!
原理是互联网文章采集基于高精度文本识别算法。支持按关键词采集新闻和各大搜索引擎网页,也支持采集指定网站栏目下的所有文章。
基于147SEO自主研发的文本识别智能算法,可以从互联网上复杂的网页中尽可能准确地提取文本内容。文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“standard”和“strict”为自动模式,可以适应大部分网页的body提取,而“precision tag”只需要指定body标签头,如“
》,可以提取所有网页的正文。关键词采集 目前支持的搜索引擎有:市场支持的主流和常用搜索引擎。内置文章翻译功能,即,你可以文章从一种语言(如中文)到另一种语言(如英语),再从英语回到中文。
采集文章+Batch伪原创+Batch 自动发布到专业cms,可以满足广大站长朋友在各个领域和话题的需求,构建一个网站要求,网站内容管理要求。 查看全部
算法 自动采集列表(
147SEO采集工具如何选择以及使用呢?(图))
市面上的采集工具很多,比如147SEO、优采云、优采云等,那么众多的采集工具我们该如何选择和使用呢?首先,如果你建了一个网站,就必须不断完善内容,那么问题来了,网站的内容每天更新已经成为网站可持续发展的严重问题@网站,所以将使用 采集 函数。从互联网开始,我们知道搜索引擎一直提倡网站要有高质量的内容和原创内容以获得更好的排名,但我们经常看到一些网站即使不是原创内容,上面的内容可能被内容处理采集复制了,但是排名还是不错的,所以还是可以做的。
但是要注意采集站的项目目标的选择,要明白自己要做什么站。所以,在开始采集的内容之前,首先要定位到我们在做什么网站,不是漫无目的地去采集,而是需要细化采集。
147SEO的通用文章采集功能,只需输入关键字即可采集各种网页和新闻,也可以采集指定列表页(栏目页)文章:
1. 依托147SEO独家通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达96%以上。
2. 只需输入关键词即可采集进入各大搜索引擎的网页;关键词 全自动采集 可以批量处理。
3.可以针对采集指定网站列列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4. 文章 翻译功能,可以把采集好文章翻译成英文再翻译回中文,实现翻译伪原创,支持谷歌和是道翻译.
5.市面上最简单最智能的文章采集器,关键是免费!
原理是互联网文章采集基于高精度文本识别算法。支持按关键词采集新闻和各大搜索引擎网页,也支持采集指定网站栏目下的所有文章。
基于147SEO自主研发的文本识别智能算法,可以从互联网上复杂的网页中尽可能准确地提取文本内容。文本识别有 3 种算法,“标准”、“严格”和“精确标签”。其中“standard”和“strict”为自动模式,可以适应大部分网页的body提取,而“precision tag”只需要指定body标签头,如“
》,可以提取所有网页的正文。关键词采集 目前支持的搜索引擎有:市场支持的主流和常用搜索引擎。内置文章翻译功能,即,你可以文章从一种语言(如中文)到另一种语言(如英语),再从英语回到中文。
采集文章+Batch伪原创+Batch 自动发布到专业cms,可以满足广大站长朋友在各个领域和话题的需求,构建一个网站要求,网站内容管理要求。
算法 自动采集列表(为什么要根据不同对象区分年轻代和年老代代? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-11-30 21:12
)
基本概念
Java的自动内存管理主要针对对象内存的回收和对象内存的分配。同时,Java自动内存管理的核心功能是堆内存中对象的分配和回收。
Java内存分配和回收的机制可以概括为:分代分配和分代回收。对象会根据存活时间分为:年轻代(Young Generation)、老年代(Old Generation)、永久代(Method Area)。再详细一点:Eden空间、From Survivor、To Survivor空间等。进一步划分的目的是为了更好的回收内存,或者更快的分配内存。
上图中的eden区、s0(“From”)区、s1(“To”)区都属于新生代,tentrired区属于老年代。
为什么要根据对象不同来区分年轻代和老年代?目前主流的垃圾回收器都会采用分代回收算法,所以需要将堆内存划分为年轻代和老年代,以便我们可以根据各个时代的特点选择合适的垃圾回收算法。
年轻代:当一个对象被创建时,内存分配首先发生在年轻代(大对象可以直接在老年代创建),大部分对象在创建后很快就不再使用,所以很快变得不可达,所以是被年轻代的 GC 机制清理掉(IBM 的研究表明 98% 的对象会很快消亡)。这种 GC 机制称为 Minor GC 或 Young GC。注意,Minor GC 并不意味着年轻代内存不足,它实际上只是在 Eden 区进行 GC。
年轻代上的内存分配是这样的。年轻代可以分为三个区域:伊甸园区(伊甸园,亚当夏娃吃了禁果和生娃娃的地方,用来表示内存最先分配的区域,比较合适)和两个领域。生存区域(幸存者 0、幸存者 1)
当Eden区已满时,执行Minor GC清理死对象,将剩余的对象复制到一个生存区Survivor0(此时Survivor1为空,两个Survivor之一为空),以及该对象也会增加1。之后,每次Eden区满时,执行一次Minor GC,将剩余的对象添加到Survivor0;当 Survivor0 也已满时,将还活着的对象直接复制到 Survivor1 中。在Eden区执行Minor GC后,将Survivor1添加到剩余的对象中(此时Survivor0为空)。当两个生存区切换多次时(HotSpot虚拟机默认为15次,由-XX:MaxTenuringThreshold控制,大于这个值进入老年),仍然存活的对象(实际上只是一小部分,
老年代:如果对象在年轻代存活的时间足够长而没有被清理(也就是存活了几次 Young GC),就会被复制到老年代。空间一般比年轻代大,可以存储更多的对象,老年代发生的GC次数比年轻代少。当老年代内存不足时,会执行Major GC,也称为Full GC。
如果对象比较大(如长字符串或大数组),Young空间不足,则直接将大对象分配到老年代(大对象可能会触发早期GC,应谨慎使用,应避免使用生命周期短的大对象)
可能存在老年代对象引用年轻代对象的情况。如果需要进行Young GC,可能需要查询整个old generation来判断是否可以清理,这显然是低效的。解决办法是在老年代维护一个512字节的块——“卡片表”,老年代对象引用新生代对象的所有记录都记录在这里。在 Young GC 中,只在这里检查而不是检查所有的老年代,因此性能大大提高。
Minor GC 和 Full GC 有什么区别?
当对象即将存储在eden中,但是eden中没有空间,并且正在发生MinorGC,并且S0或S1没有可用空间时,这时候会发生什么?新生代对象通过分配保证机制提前转移到老年代。老年代的空间足以存放allocation1,所以不会有Full GC。
什么是大物,为什么会直接进入老年?大对象是需要大量连续内存空间的对象(如字符串、数组)。为避免在为大对象分配内存时,由于分配保证机制导致的复制导致效率降低。
15岁之前是否需要进入老年?为了更好地适应不同程序的内存情况,虚拟机并不总是要求对象的年龄达到一定值才能进入老年期。如果 Survivor 空间中所有同龄对象的总大小大于 Survivor 空间的一半,则年龄大于或等于该年龄的对象可以直接进入老年,未达到要求的年龄。
如何判断对象已经死亡?
堆中几乎有所有的对象实例。在堆上进行垃圾回收之前的第一步是确定那些对象已死(即,不能再以任何方式使用的对象)。有两种方法可以识别它们: 1、 引用计数器方法 2、 可达性分析算法
引用计数器:向对象添加引用计数器。每当有对它的引用时,计数器加 1;当引用无效时,计数器减 1。任何时候计数器为 0 的对象都不能使用。但是目前主流的虚拟机都没有选择这种算法来管理内存。主要原因是难以解决对象之间的循环引用问题。以下循环引用代码:
public class ReferenceCountingGc {
Object instance = null;
public static void main(String[] args) {
ReferenceCountingGc objA = new ReferenceCountingGc();
ReferenceCountingGc objB = new ReferenceCountingGc();
objA.instance = objB;
objB.instance = objA;
objA = null;
objB = null;
}
}
可达性分析算法 该算法的基本思想是以一系列称为“GC Roots”的对象为起点。从这些节点向下搜索。节点所经过的路径称为参考链。当一个对象到达 GC 时,如果 Roots 没有通过任何引用链连接,则证明该对象不可用。
无论是通过引用计数的方法来判断对象引用的次数,还是通过可达性分析方法来判断对象的引用链是否可达,判断对象的存活与否都与“引用”有关。
在JDK1.2之前,Java中引用的定义非常传统:如果引用类型数据中存储的值代表另一块内存的起始地址,则说这块内存代表一个引用。
从JDK1.2开始,Java扩展了引用的概念,将引用分为强引用、软引用、弱引用、幻象引用四种(引用的强度逐渐减弱)。
在实际程序设计中,一般很少使用弱引用和幻像引用,很多情况下使用软引用。这是因为软引用可以加速JVM对垃圾内存的回收,维护系统的安全,防止内存溢出(OutOfMemory)等问题
1.强引用(StrongReference)
我们使用的大部分引用实际上都是强引用,也就是最常用的引用。如果一个对象有一个强引用,它就像一个必不可少的家庭用品,垃圾采集器永远不会回收它。当内存空间不足时,Java虚拟机宁愿抛出OutOfMemoryError使程序异常终止,也不会通过随意回收强引用对象来解决内存不足问题。
public class StrongReference {
public static void main(String[] args) {
new StrongReference().method1();
}
public void method1(){
Object object=new Object();
Object[] objArr=new Object[Integer.MAX_VALUE];
}
但是需要注意的是,当method1结束时,object和objArr已经不存在了,所以它们指向的对象会被JVM回收。如果你想打破强引用和对象之间的关联,你可以显式地将该引用赋值为null,以便JVM在合适的时候回收该对象。
2.软引用(SoftReference)
软引用用于描述一些有用但不是必需的对象。它们由 Java 中的 java.lang.ref.SoftReference 类表示。对于软引用关联的对象,JVM 只会在内存不足时回收该对象。所以这一点可以用来解决OOM问题,而且这个特性非常适合实现缓存:比如网页缓存、图片缓存等。软引用可以和引用队列(ReferenceQueue)结合使用。如果软引用所引用的对象被JVM回收,则软引用将被添加到与其关联的引用队列中。
import java.lang.ref.SoftReference;
public class SoftRef {
public static void main(String[] args){
System.out.println("start");
Obj obj = new Obj();
SoftReference sr = new SoftReference(obj);
obj = null;
System.out.println(sr.get());
System.out.println("end");
}
}
class Obj{
int[] obj ;
public Obj(){
obj = new int[1000];
}
当内存足够大时,可以将数组存放在软引用中,取数据时可以从内存中取数据,提高了运行效率
软引号在实践中有着重要的应用,比如浏览器的后退按钮。后台显示的网页内容可以重新请求或从缓存中检索:
(1)如果一个网页在浏览结束时被回收,当你按Back查看之前浏览过的页面时,需要重新构建
(2)如果把浏览过的网页存放在内存中,会造成大量的内存浪费,甚至造成内存溢出,这时候就可以使用软引用了。
3.弱引用(WeakReference)
弱引用也用于描述非必要对象。JVM 进行垃圾回收时,无论内存是否充足,都会回收弱引用关联的对象。在 Java 中,它由 java.lang.ref.WeakReference 类表示。
如果一个对象只有弱引用,它类似于一个可有可无的生活用品。弱引用和软引用的区别在于,只有弱引用的对象生命周期更短。在垃圾采集器线程扫描其管辖的内存区域的过程中,一旦发现只有弱引用的对象,无论当前内存空间是否足够,都会回收其内存。但是,由于垃圾采集器是低优先级线程,因此可能不会很快找到只有弱引用的对象。弱引用可以与引用队列(ReferenceQueue)结合使用。如果弱引用所引用的对象被垃圾回收,Java 虚拟机会将弱引用添加到与其关联的引用队列中。
因此,与软引用关联的对象只有在内存不足时才会被回收,而与弱引用关联的对象在 JVM 进行垃圾回收时总是会被回收。
应用场景:如果一个对象偶尔使用,使用的时候想随时获取,又不想影响这个对象的垃圾回收,应该使用弱引用来记住这个对象。或者你想引用一个对象,但是这个对象有自己的生命周期,你不想干预这个对象的生命周期。这时候就应该使用弱引用。这个引用不会对对象的垃圾回收判断产生任何额外的影响。
4.幻影参考(PhantomReference)
幻象引用不同于之前的软引用和弱引用,它不影响对象的生命周期。在 Java 中,它由 java.lang.ref.PhantomReference 类表示。如果一个对象关联了一个幻影引用,就如同没有关联的引用一样,随时可能被垃圾采集器回收。幻象引用主要用于跟踪被垃圾采集的对象的活动。
幻像引用必须与引用队列关联使用。当垃圾采集器即将回收一个对象时,如果发现它还有一个幻象引用,就会把这个幻象引用添加到与之关联的引用队列中。程序可以通过判断引用队列中是否添加了虚拟引用来判断引用的对象是否会被垃圾回收。如果程序发现引用队列中加入了一个幻象引用,它可以在被引用对象的内存被回收之前采取必要的行动。
import java.lang.ref.PhantomReference;
import java.lang.ref.ReferenceQueue;
public class PhantomRef {
public static void main(String[] args) {
ReferenceQueue queue = new ReferenceQueue();
PhantomReference pr = new PhantomReference(new String("hello"), queue);
System.out.println(pr.get());
}
}
无法访问的对象必须死吗?即使在可达性分析方法中,不可达对象也不是“必须死”的。要真正声明一个对象死亡,它必须经过至少两个标记过程;可达性分析方法中的unreachable对象是先标记一次,过滤一次,过滤的条件是这个对象是否有必要执行finalize方法。当对象没有覆盖finalize方法,或者finalize方法已经被虚拟机调用时,虚拟机认为这两种情况都没有必要。
确定要执行的对象将被放入第二个标记的队列中。除非该对象与引用链中的任何对象相关联,否则它实际上将被回收。
如何判断一个常量是否为过时常量?1、 在没有任何引用的情况下,如果常量池中存在字符串“abc”,如果当前没有引用字符串常量的String对象,则表示常量“abc”是一个过时的常量。如果此时发生内存回收,如有必要,系统会从常量池中清除“abc”。
如何判断一个班级没用?方法区主要是回收无用的类,那么如何判断一个类是无用的呢?一个类需要同时满足以下三个条件才能被认为是“无用类”:
常见的垃圾回收算法
标记清除算法 算法分为“标记”和“清除”阶段:首先标记所有需要回收的对象,标记完成后统一回收所有标记的对象。这种垃圾回收算法会带来两个明显的问题:
效率问题空间问题(清除标记后会产生大量不连续的碎片)
复制算法 为了解决效率问题,出现了“复制”采集算法。它可以将内存分成大小相同的两块,每次使用其中一块。当这块内存用完时,将幸存的对象复制到另一个块中,然后再次清理已用空间。这样,每次内存回收就是回收一半的内存范围。(复制活着的,清除所有)
标记组织算法是一种基于老年特征提出的标记算法。标记过程仍与“标记-清除”算法相同,但后续步骤不是直接回收可回收对象,而是将所有幸存对象移动到一端。然后直接清理结束边界外的内存。(移动活动,清除死者)
分代采集算法根据对象的生命周期将内存划分为若干块。一般将java堆分为新生代和老年代,这样我们就可以根据每一代的特点选择合适的垃圾回收算法。比如在新生代中,每次回收都会有大量的对象死亡,所以可以选择复制算法,只需要支付少量的对象复制成本就可以完成每次垃圾回收。对象在老年代存活的概率比较高,没有多余的空间来保证,所以垃圾采集必须选择“mark-sweep”或者“mark-sort”算法。
垃圾采集器如下:
串行采集器:“单线程”的含义不仅意味着它只会使用一个垃圾采集线程来完成垃圾采集工作,更重要的是它必须挂起所有其他工作线程(“Stop The World”)直到结束其采集。新生代采用复制算法,老年代采用标记清理算法。优点:当然简单高效(相对于其他采集器的单线程)。Serial采集器没有线程交互开销,自然可以获得很高的单线程采集效率。串行采集器是在客户端模式下运行的虚拟机的不错选择。
ParNew 采集器实际上是 Serial 采集器的多线程版本。除了使用多线程进行垃圾采集外,其余行为(控制参数、采集算法、回收策略等)与Serial采集器完全相同。新生代采用复制算法,老年代采用标记清理算法。它是许多在服务器模式下运行的虚拟机的首选。除了Serial采集器,只有它可以和cms采集器(真正的并发采集器,后面会介绍)一起工作。
并行和并发概念补充:
并行(Parallel) :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
并行 Scavenge 采集器
-XX:+UseParallelGC 使用 Parallel 收集器+ 老年代串行
-XX:+UseParallelOldGC 使用 Parallel 收集器+ 老年代并行
新生代采用复制算法,老年代采用标记清理算法。它看起来几乎和 ParNew 一样。那么它有什么特别之处呢?Parallel Scavenge 采集器侧重于吞吐量(CPU 的有效使用)。cms 等垃圾采集器更关心用户线程的暂停时间(提升用户体验)。所谓吞吐量,就是在CPU中运行用户代码所用的时间与CPU所消耗的总时间之比。Parallel Scavenge 采集器提供了许多参数供用户找到最合适的暂停时间或最大吞吐量。如果你对采集器的操作不是很了解,如果手动优化有困难,可以选择将内存管理优化交给虚拟机。好的选择。
Serial Old Collector 旧版本的Serial Collector,也是单线程采集器。它有两个主要用途:一是与JDK1.5及之前版本的Parallel Scavenge采集器配合使用,二是作为cms采集器的备份方案。
Parallel Old 采集器 Parallel Scavenge 采集器的旧版本。使用多线程和“标记和排序”算法。在关注吞吐量和 CPU 资源时,可以优先考虑 Parallel Scavenge 采集器和 Parallel Old 采集器。
cms 采集器
cms(Concurrent Mark Sweep) 采集器是一个采集器,其目标是获得最短的恢复暂停时间。这是因为cms采集器工作时,GC工作线程和用户线程可以并发执行,达到减少采集暂停时间的目的。
cms采集器只对老年代的采集起作用。它基于标记扫描算法。其操作过程分为4个步骤:
主要优点:并发采集,低暂停。但它有以下三个明显的缺点:
G1采集器G1重新定义了堆空间,打破了原有的分代模型,将堆划分为区域。这样做的目的是不必在整个堆的范围内做采集,这是它最大的特点。区域划分的优势在于它带来了一个可预测暂停时间的采集模型:用户可以指定采集操作将完成多长时间。也就是说,G1 提供了近乎实时的采集特性。. 它具有以下特点:
G1采集器在后台维护一个优先级列表,每次根据允许的采集时间,先选择恢复值最高的区域(这就是它名字Garbage-First的由来)。这种使用Region来划分内存空间和优先区域回收,保证了GF采集器可以在有限的时间内采集到尽可能高的(内存减少到零)。
G1 采集器将整个 Java 堆划分为多个大小相等的独立区域(Region)。虽然新生代和老代的概念仍然保留,但新生代和老代在物理上不再分离。他们都是其中的一部分。区域的集合(不需要是连续的)。Region的大小是一样的。该值是 1M 到 32M 字节之间的 2 的幂。JVM 会尝试划分大约 2048 个相同大小的 Region。其实这个数字是可以手动调整的,而G1也会根据堆大小自动调整。
G1 采集器之所以能够建立可预测的暂停时间模型,是因为它可以系统地避免在整个 Java 堆中进行垃圾采集。G1 将通过合理的计算模型计算和量化每个 Region 的采集成本。这样,在给定“暂停”时间限制的情况下,采集器始终可以选择一组合适的 Region 作为采集。目标就是让其采集开销满足这个约束,从而达到实时采集的目的。
对于计划从cms或ParallelOld采集器迁移的应用,根据官方推荐,如果发现满足以下特性,可以考虑更换为G1采集器,以追求更好的性能:
G1采集的操作流程大致如下:
堆栈中引用的全局变量和对象可以收录在根集合中,这样在查找垃圾时,可以从根集合中扫描堆空间。在 G1 中,引入了一种可以添加到根集的新类型,即记住集。记忆集(也称为 RSet)用于跟踪对象引用。G1的很多开源都是从Remembered Set衍生出来的,比如它通常占Heap size的20%左右甚至更多。而且,我们在复制对象的时候,因为需要扫描和更改Card Table信息,这个速度影响了复制的速度,进而影响了暂停时间。
查看全部
算法 自动采集列表(为什么要根据不同对象区分年轻代和年老代代?
)
基本概念
Java的自动内存管理主要针对对象内存的回收和对象内存的分配。同时,Java自动内存管理的核心功能是堆内存中对象的分配和回收。
Java内存分配和回收的机制可以概括为:分代分配和分代回收。对象会根据存活时间分为:年轻代(Young Generation)、老年代(Old Generation)、永久代(Method Area)。再详细一点:Eden空间、From Survivor、To Survivor空间等。进一步划分的目的是为了更好的回收内存,或者更快的分配内存。
上图中的eden区、s0(“From”)区、s1(“To”)区都属于新生代,tentrired区属于老年代。
为什么要根据对象不同来区分年轻代和老年代?目前主流的垃圾回收器都会采用分代回收算法,所以需要将堆内存划分为年轻代和老年代,以便我们可以根据各个时代的特点选择合适的垃圾回收算法。
年轻代:当一个对象被创建时,内存分配首先发生在年轻代(大对象可以直接在老年代创建),大部分对象在创建后很快就不再使用,所以很快变得不可达,所以是被年轻代的 GC 机制清理掉(IBM 的研究表明 98% 的对象会很快消亡)。这种 GC 机制称为 Minor GC 或 Young GC。注意,Minor GC 并不意味着年轻代内存不足,它实际上只是在 Eden 区进行 GC。
年轻代上的内存分配是这样的。年轻代可以分为三个区域:伊甸园区(伊甸园,亚当夏娃吃了禁果和生娃娃的地方,用来表示内存最先分配的区域,比较合适)和两个领域。生存区域(幸存者 0、幸存者 1)
当Eden区已满时,执行Minor GC清理死对象,将剩余的对象复制到一个生存区Survivor0(此时Survivor1为空,两个Survivor之一为空),以及该对象也会增加1。之后,每次Eden区满时,执行一次Minor GC,将剩余的对象添加到Survivor0;当 Survivor0 也已满时,将还活着的对象直接复制到 Survivor1 中。在Eden区执行Minor GC后,将Survivor1添加到剩余的对象中(此时Survivor0为空)。当两个生存区切换多次时(HotSpot虚拟机默认为15次,由-XX:MaxTenuringThreshold控制,大于这个值进入老年),仍然存活的对象(实际上只是一小部分,
老年代:如果对象在年轻代存活的时间足够长而没有被清理(也就是存活了几次 Young GC),就会被复制到老年代。空间一般比年轻代大,可以存储更多的对象,老年代发生的GC次数比年轻代少。当老年代内存不足时,会执行Major GC,也称为Full GC。
如果对象比较大(如长字符串或大数组),Young空间不足,则直接将大对象分配到老年代(大对象可能会触发早期GC,应谨慎使用,应避免使用生命周期短的大对象)
可能存在老年代对象引用年轻代对象的情况。如果需要进行Young GC,可能需要查询整个old generation来判断是否可以清理,这显然是低效的。解决办法是在老年代维护一个512字节的块——“卡片表”,老年代对象引用新生代对象的所有记录都记录在这里。在 Young GC 中,只在这里检查而不是检查所有的老年代,因此性能大大提高。
Minor GC 和 Full GC 有什么区别?
当对象即将存储在eden中,但是eden中没有空间,并且正在发生MinorGC,并且S0或S1没有可用空间时,这时候会发生什么?新生代对象通过分配保证机制提前转移到老年代。老年代的空间足以存放allocation1,所以不会有Full GC。
什么是大物,为什么会直接进入老年?大对象是需要大量连续内存空间的对象(如字符串、数组)。为避免在为大对象分配内存时,由于分配保证机制导致的复制导致效率降低。
15岁之前是否需要进入老年?为了更好地适应不同程序的内存情况,虚拟机并不总是要求对象的年龄达到一定值才能进入老年期。如果 Survivor 空间中所有同龄对象的总大小大于 Survivor 空间的一半,则年龄大于或等于该年龄的对象可以直接进入老年,未达到要求的年龄。
如何判断对象已经死亡?
堆中几乎有所有的对象实例。在堆上进行垃圾回收之前的第一步是确定那些对象已死(即,不能再以任何方式使用的对象)。有两种方法可以识别它们: 1、 引用计数器方法 2、 可达性分析算法
引用计数器:向对象添加引用计数器。每当有对它的引用时,计数器加 1;当引用无效时,计数器减 1。任何时候计数器为 0 的对象都不能使用。但是目前主流的虚拟机都没有选择这种算法来管理内存。主要原因是难以解决对象之间的循环引用问题。以下循环引用代码:
public class ReferenceCountingGc {
Object instance = null;
public static void main(String[] args) {
ReferenceCountingGc objA = new ReferenceCountingGc();
ReferenceCountingGc objB = new ReferenceCountingGc();
objA.instance = objB;
objB.instance = objA;
objA = null;
objB = null;
}
}
可达性分析算法 该算法的基本思想是以一系列称为“GC Roots”的对象为起点。从这些节点向下搜索。节点所经过的路径称为参考链。当一个对象到达 GC 时,如果 Roots 没有通过任何引用链连接,则证明该对象不可用。
无论是通过引用计数的方法来判断对象引用的次数,还是通过可达性分析方法来判断对象的引用链是否可达,判断对象的存活与否都与“引用”有关。
在JDK1.2之前,Java中引用的定义非常传统:如果引用类型数据中存储的值代表另一块内存的起始地址,则说这块内存代表一个引用。
从JDK1.2开始,Java扩展了引用的概念,将引用分为强引用、软引用、弱引用、幻象引用四种(引用的强度逐渐减弱)。
在实际程序设计中,一般很少使用弱引用和幻像引用,很多情况下使用软引用。这是因为软引用可以加速JVM对垃圾内存的回收,维护系统的安全,防止内存溢出(OutOfMemory)等问题
1.强引用(StrongReference)
我们使用的大部分引用实际上都是强引用,也就是最常用的引用。如果一个对象有一个强引用,它就像一个必不可少的家庭用品,垃圾采集器永远不会回收它。当内存空间不足时,Java虚拟机宁愿抛出OutOfMemoryError使程序异常终止,也不会通过随意回收强引用对象来解决内存不足问题。
public class StrongReference {
public static void main(String[] args) {
new StrongReference().method1();
}
public void method1(){
Object object=new Object();
Object[] objArr=new Object[Integer.MAX_VALUE];
}
但是需要注意的是,当method1结束时,object和objArr已经不存在了,所以它们指向的对象会被JVM回收。如果你想打破强引用和对象之间的关联,你可以显式地将该引用赋值为null,以便JVM在合适的时候回收该对象。
2.软引用(SoftReference)
软引用用于描述一些有用但不是必需的对象。它们由 Java 中的 java.lang.ref.SoftReference 类表示。对于软引用关联的对象,JVM 只会在内存不足时回收该对象。所以这一点可以用来解决OOM问题,而且这个特性非常适合实现缓存:比如网页缓存、图片缓存等。软引用可以和引用队列(ReferenceQueue)结合使用。如果软引用所引用的对象被JVM回收,则软引用将被添加到与其关联的引用队列中。
import java.lang.ref.SoftReference;
public class SoftRef {
public static void main(String[] args){
System.out.println("start");
Obj obj = new Obj();
SoftReference sr = new SoftReference(obj);
obj = null;
System.out.println(sr.get());
System.out.println("end");
}
}
class Obj{
int[] obj ;
public Obj(){
obj = new int[1000];
}
当内存足够大时,可以将数组存放在软引用中,取数据时可以从内存中取数据,提高了运行效率
软引号在实践中有着重要的应用,比如浏览器的后退按钮。后台显示的网页内容可以重新请求或从缓存中检索:
(1)如果一个网页在浏览结束时被回收,当你按Back查看之前浏览过的页面时,需要重新构建
(2)如果把浏览过的网页存放在内存中,会造成大量的内存浪费,甚至造成内存溢出,这时候就可以使用软引用了。
3.弱引用(WeakReference)
弱引用也用于描述非必要对象。JVM 进行垃圾回收时,无论内存是否充足,都会回收弱引用关联的对象。在 Java 中,它由 java.lang.ref.WeakReference 类表示。
如果一个对象只有弱引用,它类似于一个可有可无的生活用品。弱引用和软引用的区别在于,只有弱引用的对象生命周期更短。在垃圾采集器线程扫描其管辖的内存区域的过程中,一旦发现只有弱引用的对象,无论当前内存空间是否足够,都会回收其内存。但是,由于垃圾采集器是低优先级线程,因此可能不会很快找到只有弱引用的对象。弱引用可以与引用队列(ReferenceQueue)结合使用。如果弱引用所引用的对象被垃圾回收,Java 虚拟机会将弱引用添加到与其关联的引用队列中。
因此,与软引用关联的对象只有在内存不足时才会被回收,而与弱引用关联的对象在 JVM 进行垃圾回收时总是会被回收。
应用场景:如果一个对象偶尔使用,使用的时候想随时获取,又不想影响这个对象的垃圾回收,应该使用弱引用来记住这个对象。或者你想引用一个对象,但是这个对象有自己的生命周期,你不想干预这个对象的生命周期。这时候就应该使用弱引用。这个引用不会对对象的垃圾回收判断产生任何额外的影响。
4.幻影参考(PhantomReference)
幻象引用不同于之前的软引用和弱引用,它不影响对象的生命周期。在 Java 中,它由 java.lang.ref.PhantomReference 类表示。如果一个对象关联了一个幻影引用,就如同没有关联的引用一样,随时可能被垃圾采集器回收。幻象引用主要用于跟踪被垃圾采集的对象的活动。
幻像引用必须与引用队列关联使用。当垃圾采集器即将回收一个对象时,如果发现它还有一个幻象引用,就会把这个幻象引用添加到与之关联的引用队列中。程序可以通过判断引用队列中是否添加了虚拟引用来判断引用的对象是否会被垃圾回收。如果程序发现引用队列中加入了一个幻象引用,它可以在被引用对象的内存被回收之前采取必要的行动。
import java.lang.ref.PhantomReference;
import java.lang.ref.ReferenceQueue;
public class PhantomRef {
public static void main(String[] args) {
ReferenceQueue queue = new ReferenceQueue();
PhantomReference pr = new PhantomReference(new String("hello"), queue);
System.out.println(pr.get());
}
}
无法访问的对象必须死吗?即使在可达性分析方法中,不可达对象也不是“必须死”的。要真正声明一个对象死亡,它必须经过至少两个标记过程;可达性分析方法中的unreachable对象是先标记一次,过滤一次,过滤的条件是这个对象是否有必要执行finalize方法。当对象没有覆盖finalize方法,或者finalize方法已经被虚拟机调用时,虚拟机认为这两种情况都没有必要。
确定要执行的对象将被放入第二个标记的队列中。除非该对象与引用链中的任何对象相关联,否则它实际上将被回收。
如何判断一个常量是否为过时常量?1、 在没有任何引用的情况下,如果常量池中存在字符串“abc”,如果当前没有引用字符串常量的String对象,则表示常量“abc”是一个过时的常量。如果此时发生内存回收,如有必要,系统会从常量池中清除“abc”。
如何判断一个班级没用?方法区主要是回收无用的类,那么如何判断一个类是无用的呢?一个类需要同时满足以下三个条件才能被认为是“无用类”:
常见的垃圾回收算法
标记清除算法 算法分为“标记”和“清除”阶段:首先标记所有需要回收的对象,标记完成后统一回收所有标记的对象。这种垃圾回收算法会带来两个明显的问题:
效率问题空间问题(清除标记后会产生大量不连续的碎片)
复制算法 为了解决效率问题,出现了“复制”采集算法。它可以将内存分成大小相同的两块,每次使用其中一块。当这块内存用完时,将幸存的对象复制到另一个块中,然后再次清理已用空间。这样,每次内存回收就是回收一半的内存范围。(复制活着的,清除所有)
标记组织算法是一种基于老年特征提出的标记算法。标记过程仍与“标记-清除”算法相同,但后续步骤不是直接回收可回收对象,而是将所有幸存对象移动到一端。然后直接清理结束边界外的内存。(移动活动,清除死者)
分代采集算法根据对象的生命周期将内存划分为若干块。一般将java堆分为新生代和老年代,这样我们就可以根据每一代的特点选择合适的垃圾回收算法。比如在新生代中,每次回收都会有大量的对象死亡,所以可以选择复制算法,只需要支付少量的对象复制成本就可以完成每次垃圾回收。对象在老年代存活的概率比较高,没有多余的空间来保证,所以垃圾采集必须选择“mark-sweep”或者“mark-sort”算法。
垃圾采集器如下:
串行采集器:“单线程”的含义不仅意味着它只会使用一个垃圾采集线程来完成垃圾采集工作,更重要的是它必须挂起所有其他工作线程(“Stop The World”)直到结束其采集。新生代采用复制算法,老年代采用标记清理算法。优点:当然简单高效(相对于其他采集器的单线程)。Serial采集器没有线程交互开销,自然可以获得很高的单线程采集效率。串行采集器是在客户端模式下运行的虚拟机的不错选择。
ParNew 采集器实际上是 Serial 采集器的多线程版本。除了使用多线程进行垃圾采集外,其余行为(控制参数、采集算法、回收策略等)与Serial采集器完全相同。新生代采用复制算法,老年代采用标记清理算法。它是许多在服务器模式下运行的虚拟机的首选。除了Serial采集器,只有它可以和cms采集器(真正的并发采集器,后面会介绍)一起工作。
并行和并发概念补充:
并行(Parallel) :指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行,可能会交替执行),用户程序在继续运行,而垃圾收集器运行在另一个 CPU 上。
并行 Scavenge 采集器
-XX:+UseParallelGC 使用 Parallel 收集器+ 老年代串行
-XX:+UseParallelOldGC 使用 Parallel 收集器+ 老年代并行
新生代采用复制算法,老年代采用标记清理算法。它看起来几乎和 ParNew 一样。那么它有什么特别之处呢?Parallel Scavenge 采集器侧重于吞吐量(CPU 的有效使用)。cms 等垃圾采集器更关心用户线程的暂停时间(提升用户体验)。所谓吞吐量,就是在CPU中运行用户代码所用的时间与CPU所消耗的总时间之比。Parallel Scavenge 采集器提供了许多参数供用户找到最合适的暂停时间或最大吞吐量。如果你对采集器的操作不是很了解,如果手动优化有困难,可以选择将内存管理优化交给虚拟机。好的选择。
Serial Old Collector 旧版本的Serial Collector,也是单线程采集器。它有两个主要用途:一是与JDK1.5及之前版本的Parallel Scavenge采集器配合使用,二是作为cms采集器的备份方案。
Parallel Old 采集器 Parallel Scavenge 采集器的旧版本。使用多线程和“标记和排序”算法。在关注吞吐量和 CPU 资源时,可以优先考虑 Parallel Scavenge 采集器和 Parallel Old 采集器。
cms 采集器
cms(Concurrent Mark Sweep) 采集器是一个采集器,其目标是获得最短的恢复暂停时间。这是因为cms采集器工作时,GC工作线程和用户线程可以并发执行,达到减少采集暂停时间的目的。
cms采集器只对老年代的采集起作用。它基于标记扫描算法。其操作过程分为4个步骤:
主要优点:并发采集,低暂停。但它有以下三个明显的缺点:
G1采集器G1重新定义了堆空间,打破了原有的分代模型,将堆划分为区域。这样做的目的是不必在整个堆的范围内做采集,这是它最大的特点。区域划分的优势在于它带来了一个可预测暂停时间的采集模型:用户可以指定采集操作将完成多长时间。也就是说,G1 提供了近乎实时的采集特性。. 它具有以下特点:
G1采集器在后台维护一个优先级列表,每次根据允许的采集时间,先选择恢复值最高的区域(这就是它名字Garbage-First的由来)。这种使用Region来划分内存空间和优先区域回收,保证了GF采集器可以在有限的时间内采集到尽可能高的(内存减少到零)。
G1 采集器将整个 Java 堆划分为多个大小相等的独立区域(Region)。虽然新生代和老代的概念仍然保留,但新生代和老代在物理上不再分离。他们都是其中的一部分。区域的集合(不需要是连续的)。Region的大小是一样的。该值是 1M 到 32M 字节之间的 2 的幂。JVM 会尝试划分大约 2048 个相同大小的 Region。其实这个数字是可以手动调整的,而G1也会根据堆大小自动调整。
G1 采集器之所以能够建立可预测的暂停时间模型,是因为它可以系统地避免在整个 Java 堆中进行垃圾采集。G1 将通过合理的计算模型计算和量化每个 Region 的采集成本。这样,在给定“暂停”时间限制的情况下,采集器始终可以选择一组合适的 Region 作为采集。目标就是让其采集开销满足这个约束,从而达到实时采集的目的。
对于计划从cms或ParallelOld采集器迁移的应用,根据官方推荐,如果发现满足以下特性,可以考虑更换为G1采集器,以追求更好的性能:
G1采集的操作流程大致如下:
堆栈中引用的全局变量和对象可以收录在根集合中,这样在查找垃圾时,可以从根集合中扫描堆空间。在 G1 中,引入了一种可以添加到根集的新类型,即记住集。记忆集(也称为 RSet)用于跟踪对象引用。G1的很多开源都是从Remembered Set衍生出来的,比如它通常占Heap size的20%左右甚至更多。而且,我们在复制对象的时候,因为需要扫描和更改Card Table信息,这个速度影响了复制的速度,进而影响了暂停时间。
算法 自动采集列表(基于URL类型和网页链接变化的信息采集更新算法(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-30 15:09
系统(爬虫)来遍历我们 RL 从打开 RL 开始,再进行一轮爬行,直到没有新的 RL 出现。Internet 上的信息资源是不断变化的。采集 系统必须根据系统资源确定需要重新访问哪些网页以及访问频率。有限,采集的更新方式很大程度上决定了网页更新的效果。如何抢先抓取重要的网页,是高效的采集系统需要解决的问题。RL 类型和网页链接变化 采集 更新算法,先抓取入口页面,更新效果更好。相关研究 增量采集系统一般有一个更新算法:统一更新、个体更新、分类更新。统一更新方式是指采集系统以相同频率访问所有网页,无论网页更改的频率如何。个别更新是指不同的网页有不同的变化频率。采集系统根据个别页面变化的频率重新访问每个页面;网页变化的频率是访问频率的速率是相对于任何单个网页的。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。
在]中提到的We Fount ai模型的目标是最小化以下两个网页的过期时间。不同组网页的采集成本(如下载速度)不同,主要与搜索引擎网页索引的新鲜度有关。考虑增量采集的调度,考虑网页各方面的重要因素,尤其是网页内容的相似度和用户查询的相似度,作为网页的价值。同时,在采集过程中,作为下次变更临近时,计算天网增量采集系统中提到的选择更高价值网页进行优先采集的变更可能性,由北京大学开发,旨在采集中文We,以缓解大量网页历史轨迹维护带来的性能瓶颈。,利用网页变化的时间局部性规律,在短时间内直接采集多个变化的网页;并且为了尽快获得新的网页,它使用Inde RL将网页划分为CWT100评估数据集进行详细统计分析,并提出了基于RL类型优先级和划分方法的入口页面查询算法将 RL 类型转化为 RL 分类也适用于 采集 系统。作者将RL类型作为一个重要的考虑因素,通过观察网站网页的特点总结出一般规则。收到的日期:
RL 类型和网页链接变化信息采集 更新算法 61 RL 类型 Ta RL 类型描述示例 roo 主页 二级栏目 页面列表 分类页面 其他 ht tp cnht tp cn/index.html ht http cn/sport http cn/new http cn/sport nbcht tp cn/new fileht tp cn/sport nba/2006210225 算法及其实现 通过对大量网站设计框架和变化,我相信页面可以分为以下网站页面,其中收录少量变化,由大量链接组成。网站 的新页面会反映在该类型的页面中。这种类型的网页通常在网站首页和专栏首页网站中收录大量的稳定页面。页面的这部分代表网页的内容。这种页面即使改变也不会消失,除非它消失。与原来的网页相比,变化的价值非常小。如新闻报道、产品介绍、论坛帖子等。页面的另一部分也收录大量链接,但这些链接指向的页面不是网站的最新页面,例如论坛网页包括主题内容页和主题列表页;除了前面的页面,还有其他的话题列表 虽然页面也收录了丰富的链接信息,但是链接指向的帖子之前已经出现在话题列表的前几页了,但是只有当它们出现时才会出现在这个位置随着时间的推移成为旧帖子;其他相关主题 内容页属于类型 RL 类型。它通常反映网页的类型。类型网页代表列表页面,收录丰富的链接信息,但这些链接可能都指向旧网页,而不是网站的新内容,也就是说这些链接在类型页面上的出现不是网页的第一次出现。
因此,搜索引擎的采集系统应该集中资源更新页面类型,对于页面类型,爬取后可以降低更新频率,甚至不更新。为了表达方便(入口页)一个页面是一个入口页面,当且仅当这个页面具有以下特征之一,该页面链接信息丰富,新链接与旧链接相比的数量达到一定的门槛。定义(内容页) 一个页面是一个内容页面,当且仅当该页面具有以下特征之一:文件类型、主题描述信息丰富类型、页面链接信息丰富,但新链接的数量与数量相比旧链接。低于某个阈值。根据定义,很容易发现两个问题:第一,roo RL 所代表的页面都是入口页面。但实际上,网页的类型可能不是网站的主页,比如http新浪。如果更新频繁,不符合原先只爬网站首页的思路。需要使用辅助手段来处理这种类型 文件类型的页面可以基于站点 roo RL 的相对较少的功能进行阻止。当某个站点被确定为roo 200)时,则处理该类型的roo RL。文件类型网页属于内容页面 RL 类型是文件。在网页上,实验发现这类网页数量比较少,基于网页链接变化的方法可以有效减少这部分误识别造成的错误。62是采集系统框架。
图片中网页的所有信息都存储在RL库中。采集系统启动时,RL库会导出满足爬取条件的RL列表进行爬取,解析出新链接;更新程序负责重新计算这些网页的抓取间隔和下次抓取时间等,并将解析出的RL添加到网页库中,列出一个网页的属性。算法说明:db中新增网页RL类型)计算subroo、file等类型网页的初始捕获间隔为初始捕获采集系统框架图Crawlersystem架构取间隔为ROO EFAUL和SUBROO EFAUL EFAUL EFAUL。网页被抓取后,网页的抓取间隔和下次抓取时间会根据网页变化的方式进行更新。网页属性 Ta age 属性 RLMD5 score nextf etchtime int erval 网页的RL网页摘要的MD5,这里用数组表示,以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集 以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集 以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集
HANGE RATE DISCHAN GE RATE是网页变化和不变时抓取间隔的更新因子。一般GERA GERA ERVAL代表文件类型网页RL类型和网页链接变化信息。采集更新算法63最短更新周期,小于该值的文件网页更新周期自动设置为ERVAL 222121921 1601 20211121 181.IP范围内约30个站点为70个,抓取网页22万余个。采集系统爬取过程如下db),调用nit方法设置更新间隔nextf et urre nt time,然后只导出得分最高的top解析爬取的网页,并使用更改算法判断网页是否发生变化,并调用up dat算法重新估计网页更新周期;同时将解析后的新RL加入到网页库实验中。top的值为30,000,每轮最多抓取30,000个网页EFAUL,SUBROO EFAUL EFAUL EFAUL ERVAL设置为30,表示roo。普通网页的更新周期为30,GERA的值为01。ISCHA GERA表示如果一个网页发生变化,更新周期设置为原来的一半,这意味着随着时间的推移每天的变化捕获约150 000网页,因为在这里,网页是所有保留的第一页。
<p>根据RL类型和网页链接变化规律,可以有效识别入口页面。64 RL类型的入口页面识别和网页链接变化规律 该方法应用于网页采集系统的更新过程中,有效提高了采集系统的效率,保证了 查看全部
算法 自动采集列表(基于URL类型和网页链接变化的信息采集更新算法(组图))
系统(爬虫)来遍历我们 RL 从打开 RL 开始,再进行一轮爬行,直到没有新的 RL 出现。Internet 上的信息资源是不断变化的。采集 系统必须根据系统资源确定需要重新访问哪些网页以及访问频率。有限,采集的更新方式很大程度上决定了网页更新的效果。如何抢先抓取重要的网页,是高效的采集系统需要解决的问题。RL 类型和网页链接变化 采集 更新算法,先抓取入口页面,更新效果更好。相关研究 增量采集系统一般有一个更新算法:统一更新、个体更新、分类更新。统一更新方式是指采集系统以相同频率访问所有网页,无论网页更改的频率如何。个别更新是指不同的网页有不同的变化频率。采集系统根据个别页面变化的频率重新访问每个页面;网页变化的频率是访问频率的速率是相对于任何单个网页的。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。更新是对网页进行分类。不同类型的网页采用不同的更新周期] 介绍了增量采集系统的典型架构和更新算法。
在]中提到的We Fount ai模型的目标是最小化以下两个网页的过期时间。不同组网页的采集成本(如下载速度)不同,主要与搜索引擎网页索引的新鲜度有关。考虑增量采集的调度,考虑网页各方面的重要因素,尤其是网页内容的相似度和用户查询的相似度,作为网页的价值。同时,在采集过程中,作为下次变更临近时,计算天网增量采集系统中提到的选择更高价值网页进行优先采集的变更可能性,由北京大学开发,旨在采集中文We,以缓解大量网页历史轨迹维护带来的性能瓶颈。,利用网页变化的时间局部性规律,在短时间内直接采集多个变化的网页;并且为了尽快获得新的网页,它使用Inde RL将网页划分为CWT100评估数据集进行详细统计分析,并提出了基于RL类型优先级和划分方法的入口页面查询算法将 RL 类型转化为 RL 分类也适用于 采集 系统。作者将RL类型作为一个重要的考虑因素,通过观察网站网页的特点总结出一般规则。收到的日期:
RL 类型和网页链接变化信息采集 更新算法 61 RL 类型 Ta RL 类型描述示例 roo 主页 二级栏目 页面列表 分类页面 其他 ht tp cnht tp cn/index.html ht http cn/sport http cn/new http cn/sport nbcht tp cn/new fileht tp cn/sport nba/2006210225 算法及其实现 通过对大量网站设计框架和变化,我相信页面可以分为以下网站页面,其中收录少量变化,由大量链接组成。网站 的新页面会反映在该类型的页面中。这种类型的网页通常在网站首页和专栏首页网站中收录大量的稳定页面。页面的这部分代表网页的内容。这种页面即使改变也不会消失,除非它消失。与原来的网页相比,变化的价值非常小。如新闻报道、产品介绍、论坛帖子等。页面的另一部分也收录大量链接,但这些链接指向的页面不是网站的最新页面,例如论坛网页包括主题内容页和主题列表页;除了前面的页面,还有其他的话题列表 虽然页面也收录了丰富的链接信息,但是链接指向的帖子之前已经出现在话题列表的前几页了,但是只有当它们出现时才会出现在这个位置随着时间的推移成为旧帖子;其他相关主题 内容页属于类型 RL 类型。它通常反映网页的类型。类型网页代表列表页面,收录丰富的链接信息,但这些链接可能都指向旧网页,而不是网站的新内容,也就是说这些链接在类型页面上的出现不是网页的第一次出现。
因此,搜索引擎的采集系统应该集中资源更新页面类型,对于页面类型,爬取后可以降低更新频率,甚至不更新。为了表达方便(入口页)一个页面是一个入口页面,当且仅当这个页面具有以下特征之一,该页面链接信息丰富,新链接与旧链接相比的数量达到一定的门槛。定义(内容页) 一个页面是一个内容页面,当且仅当该页面具有以下特征之一:文件类型、主题描述信息丰富类型、页面链接信息丰富,但新链接的数量与数量相比旧链接。低于某个阈值。根据定义,很容易发现两个问题:第一,roo RL 所代表的页面都是入口页面。但实际上,网页的类型可能不是网站的主页,比如http新浪。如果更新频繁,不符合原先只爬网站首页的思路。需要使用辅助手段来处理这种类型 文件类型的页面可以基于站点 roo RL 的相对较少的功能进行阻止。当某个站点被确定为roo 200)时,则处理该类型的roo RL。文件类型网页属于内容页面 RL 类型是文件。在网页上,实验发现这类网页数量比较少,基于网页链接变化的方法可以有效减少这部分误识别造成的错误。62是采集系统框架。
图片中网页的所有信息都存储在RL库中。采集系统启动时,RL库会导出满足爬取条件的RL列表进行爬取,解析出新链接;更新程序负责重新计算这些网页的抓取间隔和下次抓取时间等,并将解析出的RL添加到网页库中,列出一个网页的属性。算法说明:db中新增网页RL类型)计算subroo、file等类型网页的初始捕获间隔为初始捕获采集系统框架图Crawlersystem架构取间隔为ROO EFAUL和SUBROO EFAUL EFAUL EFAUL。网页被抓取后,网页的抓取间隔和下次抓取时间会根据网页变化的方式进行更新。网页属性 Ta age 属性 RLMD5 score nextf etchtime int erval 网页的RL网页摘要的MD5,这里用数组表示,以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集 以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集 以便能够识别相同和相似网页的重要性。; 如果nextf etchtime 系统。当前时间,执行爬取间隔;网页更新后,nextf et chtime nextfet chtime etchint erval utlink 被链接出网页;按链接出url排序,方便对比采集
HANGE RATE DISCHAN GE RATE是网页变化和不变时抓取间隔的更新因子。一般GERA GERA ERVAL代表文件类型网页RL类型和网页链接变化信息。采集更新算法63最短更新周期,小于该值的文件网页更新周期自动设置为ERVAL 222121921 1601 20211121 181.IP范围内约30个站点为70个,抓取网页22万余个。采集系统爬取过程如下db),调用nit方法设置更新间隔nextf et urre nt time,然后只导出得分最高的top解析爬取的网页,并使用更改算法判断网页是否发生变化,并调用up dat算法重新估计网页更新周期;同时将解析后的新RL加入到网页库实验中。top的值为30,000,每轮最多抓取30,000个网页EFAUL,SUBROO EFAUL EFAUL EFAUL ERVAL设置为30,表示roo。普通网页的更新周期为30,GERA的值为01。ISCHA GERA表示如果一个网页发生变化,更新周期设置为原来的一半,这意味着随着时间的推移每天的变化捕获约150 000网页,因为在这里,网页是所有保留的第一页。
<p>根据RL类型和网页链接变化规律,可以有效识别入口页面。64 RL类型的入口页面识别和网页链接变化规律 该方法应用于网页采集系统的更新过程中,有效提高了采集系统的效率,保证了
算法 自动采集列表(我后来他有了女朋友1.4垃圾收集算法及细节)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-11-29 19:17
点击上方的“颜琳”,选择“Top or Star”
有人跟着我
后来有了女朋友
1.4 垃圾采集算法及细节
1.4.1代采集
这是我们一直想到的垃圾回收方式,在大多数商用虚拟机中几乎都遵循分代回收理论。代际采集理论基于以下三个方面。
l 弱世代假设:绝大多数对象都在死亡。
l 强世代假设:在垃圾回收过程中存活次数越多的对象越难死亡。
l 代际参考假设(Intergenerational Reference Hypothesis):代际参考与同代参考相比,只是极少数。
上面的分代假设实际上默认了垃圾采集器的设计原则:采集器应该将Java堆划分为不同的区域,然后将回收的对象根据年龄(它们存活的次数)分配到不同的区域进行存储。垃圾采集过程)。也正是因为这样的划分,我们才有了针对某个区域的回收类型和回收算法的设计,以及我们经常听到的名词“Minor GC”、“Major GC”、“Full GC”。
分代采集 在 HotSpot 中,Java 堆被设计成两个区域:年轻代和老年代。这就是我们常说的新生代和老年代的由来。新生代中的每个集合都会有大量的对象,只有少数幸存者会逐渐晋升到老年代。因此,新生代被划分为一个较大的伊甸空间和两个较小的幸存者。在(生存)区域,两个空间的比例默认为8:1。每使用一次Eden区和一块Survivor,就将Eden区和Survivor区的幸存对象一次性复制到另一个Survivor区,然后清理刚刚使用过的Eden区和Survivor区。按照这种划分方法,新生代其实是这样的结构:Eden:Survivor1:Survivor2=8:1:1
我们刚刚清理了Eden+Survivor1(80%+10%)空间,将幸存的复制到Survivor2空间。下次继续清理,我们将Eden+Survivor2添加到Survivor2的原创幸存对象中。无法确保每次不超过 10% 的对象存活。年轻代重复多次复制。如果其中一个 Survivor 空间不足,则老年代需要分配保证。
分配担保类似于银行贷款的担保人,借款人无法偿还担保人。新生代生成的原创对象可以自行恢复。如果任何时候都不能吃自己生产的对象,那么这些对象就必须委托给老年代进行管理。晚年其实是个大坑。凡是能到老年的物件,都不好对付。这里的垃圾回收频率比新生代低十倍左右。在老年代被回收之前,新生代经常复制十次以上。一次。
因此,目前对象可以进入老年的三种情况
l 上面提到了第一种保证方法。
l 第二类是大型物体。JVM 可以设置该值。如果对象太大,或者是数组,会直接放到老年代。
l 第三种是按年龄计算。每次在新生代GC中,如果对象还活着,则age加1,如果大于默认15或者同龄大于一半内存,可能达不到设置。年龄将转移到老年。
其实上面的描述有一个漏洞,就是没有考虑对象的相互依赖。如果新生代对象和老年代对象之间存在依赖关系,并且一方已经死亡,无论是新生代对象还是老年代对象。老年代触发GC的时候应该清除吗?如果两个对象都死了,那么它们会一起死,否则它们会活着。事实上,这是对世代假说的第三种描述。毕竟这种跨代参照物是少数。当被引用的新生代对象提升到老年代时,这个引用关系就会消失,虚拟机不会为此做这件事。对于某些对象,每次GC都要扫描整个老年代来检查引用很麻烦。相反,它使用了一种称为Remembered Set 的数据结构来实现哪些区域属于旧时代区域的跨代引用。当发生 Minor GC 时,返回将内存集中依赖的对象添加到 GC Roots 并更改对象的引用。这种方法是跨代引用的最具成本效益的解决方案。
1.4.2 标签清除算法
这是所有垃圾采集算法中最基本的,分为“标记”和“清理”两个阶段。首先标记需要回收的对象,然后统一回收所有标记的对象。他之所以是最基础的,是因为后面的算法都是基于他的改进,弥补了他的不足。他的缺点有两点:第一是效率问题,标记清场效率不高。其实最主要的原因是清除标记后造成不连续的内存碎片,导致大对象无法存储。我们可以通过图 1-9 清楚地看到它。
图1-9 标记清除算法
1.4.3 标记复制算法
把内存按容量分成两半,保证一半是空的,一半是用的。在GC期间,将幸存的对象复制到空的一半,然后清空一半。
这样做的好处是每次最多清理一半的内存,大大提高了效率。二是解决内存碎片问题。
缺点是空间利用率不高,所以在文章开始之前给大家科普一下。新生代分为三个区域来回复制。聪明的孩子在阅读本文时已经知道,新一代使用复制算法。
是因为新生代都是生死存亡,采集频繁,满足复制算法的特点。如图1-10所示。
图 1-10 标记复制算法
1.4.4 标记排序算法
标记组织和标记清除中的标记是否相同?答案是肯定的,mark-organize 和 mark-clear 的明显区别是“组织”。由于排序过程,该算法解决了内存问题。碎片化问题。
该算法的工作原理是:标记要清除的对象后,不是直接清除,而是将所有幸存的对象向前移动,然后清除剩余的内存。如图1-11所示。
图1-11 标记排序算法
1.4.5 枚举根节点
根据前面的内容,我们知道HotSpot使用可达性分析算法来判断对象是否存活。生存的关键是看对象是否在GC Roots的引用链上。那么重点就是这个GC Roots,GC Roots的大部分数据。都存在于方法区中。因为是线程共享的,GC Roots也是一个全局引用,通常是栈帧中的常量、静态变量、局部变量表来维护程序执行上下文的信息,而我们普通Java程序的大小方法区范围从数百兆以上,当GC发生时,需要保证当前存在的所有对象的引用不变,所有用户线程都需要挂起,这就是所谓的“Stop The World”。程序中的线程需要Stop来配合可访问性分析。这么大的空间肯定不可能每次垃圾回收都遍历整个引用链。它就像一个拥有超过一百万用户的系统。可以每次都从硬盘读取用户列表吗?当然,我们不会这样做。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。
首先简单介绍一下保守GC。它将从一些已知位置进行扫描。只要扫描一个数,就会判断引用是否指向堆(这里的计算还是比较复杂的,包括上下边界检查,对齐检查等),一直这样检查,最后完成可达性分析。这种模糊的判断无法准确判断一个位置是否是指向GC堆的指针,故称为保守GC。这种模糊判断的内在本质是速度快、准确率低。对引用的误判会导致垃圾采集器无法采集,造成空间浪费。
接下来说一下精准GC。他怎么能确切地知道哪里有引用指针呢?其实不同的虚拟机的实现是有区别的,但是在Java中,你知道某个位置的数据是什么类型的。当类加载时,HotSpot 已经计算了类偏移量上的类型数据。, 然后在即时编译的时候会记录在特定位置引用了堆栈和寄存器的哪些位置。此类信息是从外部记录下来的,并保存为映射表。在 HotSpot 中,这个映射表叫做 OopMap。不同 虚拟机名称不同。
要实现这个功能,虚拟机中的解释器和JIT编译器需要有相应的支持,它们可以生成足够的元数据提供给GC。
使用这样的映射表一般有两种方式:
1. 每次都遍历原创映射表,扫描一遍循环的偏移量;这种用法也称为“解释性”。
2. 为每个映射表生成自定义的扫描码(想象一下扫描映射表的循环被展开了),以后每次使用映射表时直接执行生成的扫描码;这种用法也称为“已编译”。
1.4.6个安全点
OopMap可以帮助我们准确快速的完成GC Roots枚举。我们可以简单地将oopMap理解为调试信息。源代码中的每个变量都有一个类型,但编译后的代码只有变量在堆栈上的位置。OopMap 是一条额外的信息,它告诉您堆栈上的哪个位置最初是什么。该信息是在 JIT 编译期间与机器代码一起生成的。因为只有编译器知道源代码和生成代码的对应关系。每个方法可能有多个OopMaps,也就是说一个方法的代码根据安全点分为几个部分。每一段代码都有一个OopMap,范围自然就限于这一段代码。如果循环中引用了多个对象,肯定会有多个变量,编译后在栈上占据多个位置。此代码的 OopMap 将收录多个记录。所以它是安全点的起源。简单的说:产生OopMap指令的位置叫做安全点。安全点的选择遵循“是否让程序长时间执行的特性”。什么是长时间?表示持续执行,例如方法调用、循环、异常跳转等。
安全点有OopMap,有利于垃圾回收。因此,当GC发生时,需要让所有的用户线程运行到更接近安全点并停止。这里有两种方法:抢占式中断和主动式中断。抢占式中断是指系统主动中断所有用户线程。如果安全点没有线程,它会恢复他并继续执行,直到到达安全点。目前几乎没有虚拟机使用这种方法。主动中断意味着线程主动。虚拟机只设置一个标志。用户线程不断地主动训练这个标志。当它到达这个标志时,它会停止并挂起自己。
1.4.7 安全区
安全点的概念不能满足所有场景。如果线程没有正常执行,而是处于Sleep或者阻塞状态,那么短时间内就无法响应虚拟机的中断请求,更别说是否能到达安全点,所以没办法执行垃圾采集。,所以我们要把安全点做大一点,让所有线程都可以覆盖这个区域。这就是安全区(Safe Region)的概念。是放大版的安全点。这里的对象引用关系不会改变,所以垃圾回收可以在安全区域的任何地方进行。同样,当一个线程进入安全区时,它会标记自己并告诉虚拟机它已经进入了安全区。当线程想要离开安全区时,需要判断虚拟机是否已经完成枚举和节点,如果完成就继续执行,如果没有完成就继续等待。如图1-12所示。
图1-12 安全区示意图
1.4.7 内存设置和卡表
上一篇关于世代假设的文章中提到了Remembered Set。是为了解决跨代引用带来的问题。主要用于减少GC Roots的全堆扫描。因此,据说在所有这样的代或对于采集不同区域行为的垃圾采集器中,都有内存集,例如cms、ZGC、Shenandoah采集器。由于内存集是一种数据结构,会占用虚拟机内存,因此在设计内存集时必须考虑存储和维护成本。下面提供了三种类型的记录精度。
l 字长精度:每条记录精确到一个机器字长(处理器的寻址位数,如常见的32位或64位),该字收录一个跨代指针。
l 对象精度:每条记录都精确到一个对象,对象中存在收录跨代指针的字段。
l 卡片精度:每条记录精确到一个内存区域,该区域中有收录跨代指针的对象。
我们用这三种方式来实现内存集,而这种使用精度的方式我们就变成了卡表(Card Table),所以我们可以换一种说法:卡表是实现内存集的一种方式,记录内存设置Record的准确性以及heap和memory heap的映射关系。这种方法目前在虚拟机中也被广泛使用。
在 HotSpot 中,卡片表以字节数组的形式存在。此数组中的每个元素对应于此内存区域中的 512 字节内存。这个内存区域称为卡片页(Card Page)。等待多个对象,只要卡表中指向的卡页有跨代引用指针,卡表就被标记为“脏”,然后被收录在GC Roots链中。如图1-13所示。
图1-13 卡片表和卡片页的关系
1.4.8 并发采集写屏障
至此,我们似乎对扫描虚拟机的GC Roots链有了大致的了解,但我们仍然不知道card table是如何维护的。在 HotSpot 中,Write Barrier 用于维护卡表。在第 2 章中,我们将介绍内存屏障 volatile。既然是屏障,就有一个共性,就是指令的区域分离,防止序列变化引起的问题。屏障一般出现在并发场景中,在JVM中也是一样。JVM 中的并发是指用户线程和垃圾采集线程一起工作。在JDK7之前,写屏障是无条件的。无论更新的引用是否跨代存在,都会出现一些写入障碍。更新后的引用一般在新对象生成后改变现有OopMap的值(也可以说是更新了卡片表),这里自然会影响卡片表的值。赋值前后都属于写屏障,赋值之前称为“Pre-Write Barrier”,赋值之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。分配之前称为“Pre-Write Barrier”,分配之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。分配之前称为“Pre-Write Barrier”,分配之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。
当我们之前介绍垃圾算法时,它们共同的第一步是标记。标记过程需要一定的时间 STW(停止世界)。在 STW 过程中,CPU 不执行用户代码,即所有的用户线程都被挂起。用于垃圾回收,以便在标记时生成绝对一致的快照(我们可以暂时将GC Roots形成的链接图称为标记快照)。这个过程影响很大,因为它意味着挂起所有线程 就是程序执行的所有线程都被挂起。我们上层用户看到的现象就是程序完全卡死了。现在我们的heap越来越大,GC Roots自然会越来越大。从GC Roots向下遍历对象需要更多时间,暂停时间会变长。这是我们不能忍受的,所以JDK8使用cms垃圾采集器,而这个采集器的步骤之一就是并发标记。类似的高性能垃圾采集器(例如 G1)具有并发标记阶段。但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?
为了解决这个问题,我们不得不引入三色标记来帮助我们。寻找GC Roots的过程是根据垃圾采集器是否访问过的情况来判断的。垃圾采集器访问是安全的。没有被垃圾采集器访问过,说明它是一个新创建的对象,称为unsafe,所以也可以理解为从safe到unsafe的过程。三色标有三种颜色:
l 白色:垃圾采集器没有访问过的对象,或者分析后仍然无法访问的对象。
l Black:该对象已被垃圾采集器访问过,该对象引用的所有其他对象也已被访问过。代表对象是活的或已被扫描。
l 灰色:该对象已被垃圾采集器访问过,但该对象引用的所有其他对象都没有被访问过。所有访问后,它将转换为黑色。识别正在扫描的对象。
下面我们用一个图例来形象化三色打标的过程:
首先,如图1-14所示,垃圾采集器从GC Roots开始扫描引用链,扫描前所有对象都应该是白色的。
图1-14 三色打标第一步
第二步,在扫描过程中,GC Roots开始像白色一样前进。
图1-15 三色打标步骤二
第三步是扫描结束。从 GC Roots 链接的所有对象都是安全对象。如果对象没有被扫描为白色,垃圾采集器将在下一步中回收这些白色对象。
图1-16 三色打标步骤三
以上步骤都是基于STW的三色打标流程,必须依赖STW。比如cms采集器的初始标记和重新标记需要暂停用户线程。如果三色标记不使用STW,在标记过程中,程序逻辑会改变对象的引用,导致标记错误。如果将死对象标记为活着是错误的,则不会产生太大影响。它将在下一次 GC 中清除。如果幸存的对象被错误地标记为死亡,后果将是非常严重的,程序也会出错。让我们来看看这种情况是如何产生的,再次以传说的形式出现。
如图1-17所示场景,标记正在进行中。当到达B时,用户线程取消B对C的引用,然后将A对C的引用加入,此时用户线程还在继续。
图1-17 并发三色打标步骤1
如图1-18所示,进程已经继续扫描对象E,此时用户线程继续上述操作,取消E到F的引用,添加D到G的引用。
图1-18 并发三色打标步骤2
事实上,此时我们已经发现了问题。无需继续扫描。由于用户线程的工作,C和G对象引用发生了变化,成为幸存的对象。但是扫描过程没有加入到GC Roots引用链中,使得系统发生了错误。我们继续以cms垃圾采集器为例。cms 执行的一个步骤是并发标记。他的并发标记和上图中的1-17、1-18一样,都会存在。物体标记错误的现象。我们现在要做的不是并发标记错误,而是如何解决并发标记导致的“对象消失”和“意外死亡”。HotSpot 为我们提供了两种解决方案:
1. 增量更新(cms):记录新插入的引用,并发标记完成后,重新扫描记录的引用关系的黑色对象为根。也就是说,一旦在黑色中插入了对白色的新引用,它就会变成灰色。
2. 原创快照(G1和Shenandoah):当灰色对象想要删除对白色对象的引用时,记录引用。扫描后,从记录的参考灰色对象开始再次扫描
至此我们已经讲了很多垃圾采集算法,以及算法实现的细节。HotSpot从对象生成的那一刻,到内存恢复的开始,以及如何快速准确的恢复,做了很多工作。在实现方面,从GC Roots 快速扫描、内存集、卡片表,以及卡片页中元素的使用来维护堆中收录跨代引用的对象,以及三色标记和解决问题并发标记等引起的,可见虚拟机确实有帮助,所以我们做了很多努力,减少停顿,提高检索效率,减少各个区的内存,提高有效使用的记忆。在下一章,
胖虎
热爱生活的人
会被生活所爱
我在这里等你! 查看全部
算法 自动采集列表(我后来他有了女朋友1.4垃圾收集算法及细节)
点击上方的“颜琳”,选择“Top or Star”
有人跟着我
后来有了女朋友
1.4 垃圾采集算法及细节
1.4.1代采集
这是我们一直想到的垃圾回收方式,在大多数商用虚拟机中几乎都遵循分代回收理论。代际采集理论基于以下三个方面。
l 弱世代假设:绝大多数对象都在死亡。
l 强世代假设:在垃圾回收过程中存活次数越多的对象越难死亡。
l 代际参考假设(Intergenerational Reference Hypothesis):代际参考与同代参考相比,只是极少数。
上面的分代假设实际上默认了垃圾采集器的设计原则:采集器应该将Java堆划分为不同的区域,然后将回收的对象根据年龄(它们存活的次数)分配到不同的区域进行存储。垃圾采集过程)。也正是因为这样的划分,我们才有了针对某个区域的回收类型和回收算法的设计,以及我们经常听到的名词“Minor GC”、“Major GC”、“Full GC”。
分代采集 在 HotSpot 中,Java 堆被设计成两个区域:年轻代和老年代。这就是我们常说的新生代和老年代的由来。新生代中的每个集合都会有大量的对象,只有少数幸存者会逐渐晋升到老年代。因此,新生代被划分为一个较大的伊甸空间和两个较小的幸存者。在(生存)区域,两个空间的比例默认为8:1。每使用一次Eden区和一块Survivor,就将Eden区和Survivor区的幸存对象一次性复制到另一个Survivor区,然后清理刚刚使用过的Eden区和Survivor区。按照这种划分方法,新生代其实是这样的结构:Eden:Survivor1:Survivor2=8:1:1
我们刚刚清理了Eden+Survivor1(80%+10%)空间,将幸存的复制到Survivor2空间。下次继续清理,我们将Eden+Survivor2添加到Survivor2的原创幸存对象中。无法确保每次不超过 10% 的对象存活。年轻代重复多次复制。如果其中一个 Survivor 空间不足,则老年代需要分配保证。
分配担保类似于银行贷款的担保人,借款人无法偿还担保人。新生代生成的原创对象可以自行恢复。如果任何时候都不能吃自己生产的对象,那么这些对象就必须委托给老年代进行管理。晚年其实是个大坑。凡是能到老年的物件,都不好对付。这里的垃圾回收频率比新生代低十倍左右。在老年代被回收之前,新生代经常复制十次以上。一次。
因此,目前对象可以进入老年的三种情况
l 上面提到了第一种保证方法。
l 第二类是大型物体。JVM 可以设置该值。如果对象太大,或者是数组,会直接放到老年代。
l 第三种是按年龄计算。每次在新生代GC中,如果对象还活着,则age加1,如果大于默认15或者同龄大于一半内存,可能达不到设置。年龄将转移到老年。
其实上面的描述有一个漏洞,就是没有考虑对象的相互依赖。如果新生代对象和老年代对象之间存在依赖关系,并且一方已经死亡,无论是新生代对象还是老年代对象。老年代触发GC的时候应该清除吗?如果两个对象都死了,那么它们会一起死,否则它们会活着。事实上,这是对世代假说的第三种描述。毕竟这种跨代参照物是少数。当被引用的新生代对象提升到老年代时,这个引用关系就会消失,虚拟机不会为此做这件事。对于某些对象,每次GC都要扫描整个老年代来检查引用很麻烦。相反,它使用了一种称为Remembered Set 的数据结构来实现哪些区域属于旧时代区域的跨代引用。当发生 Minor GC 时,返回将内存集中依赖的对象添加到 GC Roots 并更改对象的引用。这种方法是跨代引用的最具成本效益的解决方案。
1.4.2 标签清除算法
这是所有垃圾采集算法中最基本的,分为“标记”和“清理”两个阶段。首先标记需要回收的对象,然后统一回收所有标记的对象。他之所以是最基础的,是因为后面的算法都是基于他的改进,弥补了他的不足。他的缺点有两点:第一是效率问题,标记清场效率不高。其实最主要的原因是清除标记后造成不连续的内存碎片,导致大对象无法存储。我们可以通过图 1-9 清楚地看到它。
图1-9 标记清除算法
1.4.3 标记复制算法
把内存按容量分成两半,保证一半是空的,一半是用的。在GC期间,将幸存的对象复制到空的一半,然后清空一半。
这样做的好处是每次最多清理一半的内存,大大提高了效率。二是解决内存碎片问题。
缺点是空间利用率不高,所以在文章开始之前给大家科普一下。新生代分为三个区域来回复制。聪明的孩子在阅读本文时已经知道,新一代使用复制算法。
是因为新生代都是生死存亡,采集频繁,满足复制算法的特点。如图1-10所示。
图 1-10 标记复制算法
1.4.4 标记排序算法
标记组织和标记清除中的标记是否相同?答案是肯定的,mark-organize 和 mark-clear 的明显区别是“组织”。由于排序过程,该算法解决了内存问题。碎片化问题。
该算法的工作原理是:标记要清除的对象后,不是直接清除,而是将所有幸存的对象向前移动,然后清除剩余的内存。如图1-11所示。
图1-11 标记排序算法
1.4.5 枚举根节点
根据前面的内容,我们知道HotSpot使用可达性分析算法来判断对象是否存活。生存的关键是看对象是否在GC Roots的引用链上。那么重点就是这个GC Roots,GC Roots的大部分数据。都存在于方法区中。因为是线程共享的,GC Roots也是一个全局引用,通常是栈帧中的常量、静态变量、局部变量表来维护程序执行上下文的信息,而我们普通Java程序的大小方法区范围从数百兆以上,当GC发生时,需要保证当前存在的所有对象的引用不变,所有用户线程都需要挂起,这就是所谓的“Stop The World”。程序中的线程需要Stop来配合可访问性分析。这么大的空间肯定不可能每次垃圾回收都遍历整个引用链。它就像一个拥有超过一百万用户的系统。可以每次都从硬盘读取用户列表吗?当然,我们不会这样做。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。为了解决这个问题,首先使用了conservative GC和后来的accurate GC。Accurate GC会引用一个OopMap,用于保存类型的映射表,HotSpot中使用了accurate GC。
首先简单介绍一下保守GC。它将从一些已知位置进行扫描。只要扫描一个数,就会判断引用是否指向堆(这里的计算还是比较复杂的,包括上下边界检查,对齐检查等),一直这样检查,最后完成可达性分析。这种模糊的判断无法准确判断一个位置是否是指向GC堆的指针,故称为保守GC。这种模糊判断的内在本质是速度快、准确率低。对引用的误判会导致垃圾采集器无法采集,造成空间浪费。
接下来说一下精准GC。他怎么能确切地知道哪里有引用指针呢?其实不同的虚拟机的实现是有区别的,但是在Java中,你知道某个位置的数据是什么类型的。当类加载时,HotSpot 已经计算了类偏移量上的类型数据。, 然后在即时编译的时候会记录在特定位置引用了堆栈和寄存器的哪些位置。此类信息是从外部记录下来的,并保存为映射表。在 HotSpot 中,这个映射表叫做 OopMap。不同 虚拟机名称不同。
要实现这个功能,虚拟机中的解释器和JIT编译器需要有相应的支持,它们可以生成足够的元数据提供给GC。
使用这样的映射表一般有两种方式:
1. 每次都遍历原创映射表,扫描一遍循环的偏移量;这种用法也称为“解释性”。
2. 为每个映射表生成自定义的扫描码(想象一下扫描映射表的循环被展开了),以后每次使用映射表时直接执行生成的扫描码;这种用法也称为“已编译”。
1.4.6个安全点
OopMap可以帮助我们准确快速的完成GC Roots枚举。我们可以简单地将oopMap理解为调试信息。源代码中的每个变量都有一个类型,但编译后的代码只有变量在堆栈上的位置。OopMap 是一条额外的信息,它告诉您堆栈上的哪个位置最初是什么。该信息是在 JIT 编译期间与机器代码一起生成的。因为只有编译器知道源代码和生成代码的对应关系。每个方法可能有多个OopMaps,也就是说一个方法的代码根据安全点分为几个部分。每一段代码都有一个OopMap,范围自然就限于这一段代码。如果循环中引用了多个对象,肯定会有多个变量,编译后在栈上占据多个位置。此代码的 OopMap 将收录多个记录。所以它是安全点的起源。简单的说:产生OopMap指令的位置叫做安全点。安全点的选择遵循“是否让程序长时间执行的特性”。什么是长时间?表示持续执行,例如方法调用、循环、异常跳转等。
安全点有OopMap,有利于垃圾回收。因此,当GC发生时,需要让所有的用户线程运行到更接近安全点并停止。这里有两种方法:抢占式中断和主动式中断。抢占式中断是指系统主动中断所有用户线程。如果安全点没有线程,它会恢复他并继续执行,直到到达安全点。目前几乎没有虚拟机使用这种方法。主动中断意味着线程主动。虚拟机只设置一个标志。用户线程不断地主动训练这个标志。当它到达这个标志时,它会停止并挂起自己。
1.4.7 安全区
安全点的概念不能满足所有场景。如果线程没有正常执行,而是处于Sleep或者阻塞状态,那么短时间内就无法响应虚拟机的中断请求,更别说是否能到达安全点,所以没办法执行垃圾采集。,所以我们要把安全点做大一点,让所有线程都可以覆盖这个区域。这就是安全区(Safe Region)的概念。是放大版的安全点。这里的对象引用关系不会改变,所以垃圾回收可以在安全区域的任何地方进行。同样,当一个线程进入安全区时,它会标记自己并告诉虚拟机它已经进入了安全区。当线程想要离开安全区时,需要判断虚拟机是否已经完成枚举和节点,如果完成就继续执行,如果没有完成就继续等待。如图1-12所示。
图1-12 安全区示意图
1.4.7 内存设置和卡表
上一篇关于世代假设的文章中提到了Remembered Set。是为了解决跨代引用带来的问题。主要用于减少GC Roots的全堆扫描。因此,据说在所有这样的代或对于采集不同区域行为的垃圾采集器中,都有内存集,例如cms、ZGC、Shenandoah采集器。由于内存集是一种数据结构,会占用虚拟机内存,因此在设计内存集时必须考虑存储和维护成本。下面提供了三种类型的记录精度。
l 字长精度:每条记录精确到一个机器字长(处理器的寻址位数,如常见的32位或64位),该字收录一个跨代指针。
l 对象精度:每条记录都精确到一个对象,对象中存在收录跨代指针的字段。
l 卡片精度:每条记录精确到一个内存区域,该区域中有收录跨代指针的对象。
我们用这三种方式来实现内存集,而这种使用精度的方式我们就变成了卡表(Card Table),所以我们可以换一种说法:卡表是实现内存集的一种方式,记录内存设置Record的准确性以及heap和memory heap的映射关系。这种方法目前在虚拟机中也被广泛使用。
在 HotSpot 中,卡片表以字节数组的形式存在。此数组中的每个元素对应于此内存区域中的 512 字节内存。这个内存区域称为卡片页(Card Page)。等待多个对象,只要卡表中指向的卡页有跨代引用指针,卡表就被标记为“脏”,然后被收录在GC Roots链中。如图1-13所示。
图1-13 卡片表和卡片页的关系
1.4.8 并发采集写屏障
至此,我们似乎对扫描虚拟机的GC Roots链有了大致的了解,但我们仍然不知道card table是如何维护的。在 HotSpot 中,Write Barrier 用于维护卡表。在第 2 章中,我们将介绍内存屏障 volatile。既然是屏障,就有一个共性,就是指令的区域分离,防止序列变化引起的问题。屏障一般出现在并发场景中,在JVM中也是一样。JVM 中的并发是指用户线程和垃圾采集线程一起工作。在JDK7之前,写屏障是无条件的。无论更新的引用是否跨代存在,都会出现一些写入障碍。更新后的引用一般在新对象生成后改变现有OopMap的值(也可以说是更新了卡片表),这里自然会影响卡片表的值。赋值前后都属于写屏障,赋值之前称为“Pre-Write Barrier”,赋值之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。分配之前称为“Pre-Write Barrier”,分配之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。分配之前称为“Pre-Write Barrier”,分配之后称为“Post-Write Barrier”。我个人认为这个方法比较懒,所以HotSpot在JDK7之后加了-XX:+UseCondCardMark来设置卡表更新判断。虽然写屏障使开销更小,但在并发期间会发生错误共享。
当我们之前介绍垃圾算法时,它们共同的第一步是标记。标记过程需要一定的时间 STW(停止世界)。在 STW 过程中,CPU 不执行用户代码,即所有的用户线程都被挂起。用于垃圾回收,以便在标记时生成绝对一致的快照(我们可以暂时将GC Roots形成的链接图称为标记快照)。这个过程影响很大,因为它意味着挂起所有线程 就是程序执行的所有线程都被挂起。我们上层用户看到的现象就是程序完全卡死了。现在我们的heap越来越大,GC Roots自然会越来越大。从GC Roots向下遍历对象需要更多时间,暂停时间会变长。这是我们不能忍受的,所以JDK8使用cms垃圾采集器,而这个采集器的步骤之一就是并发标记。类似的高性能垃圾采集器(例如 G1)具有并发标记阶段。但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?但是我们是否也可以在并发标记期间生成一个绝对一致的快照?如果不能保证,就会导致错误地将死对象标记为死对象,将活对象错误地标记为死对象。这就像你的宠物在屋子里走来走去,你正在整理他掉下来的头发。如果两者同时进行,能保证新落下的头发也能采集起来吗?
为了解决这个问题,我们不得不引入三色标记来帮助我们。寻找GC Roots的过程是根据垃圾采集器是否访问过的情况来判断的。垃圾采集器访问是安全的。没有被垃圾采集器访问过,说明它是一个新创建的对象,称为unsafe,所以也可以理解为从safe到unsafe的过程。三色标有三种颜色:
l 白色:垃圾采集器没有访问过的对象,或者分析后仍然无法访问的对象。
l Black:该对象已被垃圾采集器访问过,该对象引用的所有其他对象也已被访问过。代表对象是活的或已被扫描。
l 灰色:该对象已被垃圾采集器访问过,但该对象引用的所有其他对象都没有被访问过。所有访问后,它将转换为黑色。识别正在扫描的对象。
下面我们用一个图例来形象化三色打标的过程:
首先,如图1-14所示,垃圾采集器从GC Roots开始扫描引用链,扫描前所有对象都应该是白色的。
图1-14 三色打标第一步
第二步,在扫描过程中,GC Roots开始像白色一样前进。
图1-15 三色打标步骤二
第三步是扫描结束。从 GC Roots 链接的所有对象都是安全对象。如果对象没有被扫描为白色,垃圾采集器将在下一步中回收这些白色对象。
图1-16 三色打标步骤三
以上步骤都是基于STW的三色打标流程,必须依赖STW。比如cms采集器的初始标记和重新标记需要暂停用户线程。如果三色标记不使用STW,在标记过程中,程序逻辑会改变对象的引用,导致标记错误。如果将死对象标记为活着是错误的,则不会产生太大影响。它将在下一次 GC 中清除。如果幸存的对象被错误地标记为死亡,后果将是非常严重的,程序也会出错。让我们来看看这种情况是如何产生的,再次以传说的形式出现。
如图1-17所示场景,标记正在进行中。当到达B时,用户线程取消B对C的引用,然后将A对C的引用加入,此时用户线程还在继续。
图1-17 并发三色打标步骤1
如图1-18所示,进程已经继续扫描对象E,此时用户线程继续上述操作,取消E到F的引用,添加D到G的引用。
图1-18 并发三色打标步骤2
事实上,此时我们已经发现了问题。无需继续扫描。由于用户线程的工作,C和G对象引用发生了变化,成为幸存的对象。但是扫描过程没有加入到GC Roots引用链中,使得系统发生了错误。我们继续以cms垃圾采集器为例。cms 执行的一个步骤是并发标记。他的并发标记和上图中的1-17、1-18一样,都会存在。物体标记错误的现象。我们现在要做的不是并发标记错误,而是如何解决并发标记导致的“对象消失”和“意外死亡”。HotSpot 为我们提供了两种解决方案:
1. 增量更新(cms):记录新插入的引用,并发标记完成后,重新扫描记录的引用关系的黑色对象为根。也就是说,一旦在黑色中插入了对白色的新引用,它就会变成灰色。
2. 原创快照(G1和Shenandoah):当灰色对象想要删除对白色对象的引用时,记录引用。扫描后,从记录的参考灰色对象开始再次扫描
至此我们已经讲了很多垃圾采集算法,以及算法实现的细节。HotSpot从对象生成的那一刻,到内存恢复的开始,以及如何快速准确的恢复,做了很多工作。在实现方面,从GC Roots 快速扫描、内存集、卡片表,以及卡片页中元素的使用来维护堆中收录跨代引用的对象,以及三色标记和解决问题并发标记等引起的,可见虚拟机确实有帮助,所以我们做了很多努力,减少停顿,提高检索效率,减少各个区的内存,提高有效使用的记忆。在下一章,
胖虎
热爱生活的人
会被生活所爱
我在这里等你!
算法 自动采集列表( Python如何解决引用计数算法的循环引用属性?(一) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2021-11-28 07:00
Python如何解决引用计数算法的循环引用属性?(一)
)
15.1 标记阶段:引用计数算法
引用计数算法(Reference Counting)比较简单,为每个对象保存一个整数引用计数器属性,用于记录被引用对象的情况
对于一个对象A,只要有任何对象引用A,A的引用计数器就加1;当引用失效时,引用计数器减少1. 只要对象A的引用计数器的值为0,就表示对象A不能再使用,可以回收
优点:实现简单,易于识别;判断效率高,无延迟
缺点:需要单独的字段来存储计数器,增加了存储空间的开销
每次赋值都需要更新计数器,增加了时间开销
无法处理循环引用,这是一个致命的缺陷,Java的垃圾采集器中没有使用这种算法
测试Java中是否使用了引用计数算法
public class RefCountGC {
//证明java使用的不是引用计数算法
// 这个成员属性的唯一作用就是占用一点内存
private byte[] bigSize = new byte[5*1024*1024];
// 引用
Object reference = null;
public static void main(String[] args) {
RefCountGC obj1 = new RefCountGC();
RefCountGC obj2 = new RefCountGC();
obj1.reference = obj2;
obj2.reference = obj1;
obj1 = null;
obj2 = null;
// 显示的执行垃圾收集行为,判断obj1 和 obj2是否被回收?
System.gc();
}
}
概括
Python 支持引用计数和垃圾采集机制
Python 是如何解决循环引用的?
15.2 标记阶段:可达性分析算法
可达性分析算法(寻根算法、Tracing Garbage 采集)不仅具有实现简单、执行高效的特点,而且有效解决了引用计数算法中的循环引用问题,防止了内存泄漏的发生。
基本思想
GC Roots 可以是什么类型的元素?
总结
由于Root使用栈来存储变量和指针,如果一个指针将对象保存在堆内存中,但不存储在堆内存中,那么它就是一个Root。
如果要使用可达性分析算法来判断内存是否可回收,分析工作必须在能够保证一致性的快照中进行。如果不满足,则无法保证分析结果。这也会导致 GC“停止”。“世界”的一个重要原因,即使在声称没有暂停的cms采集器中,枚举根节点也必须暂停
15.3 对象的终结机制
对象的终结机制
生存还是死亡?
三种状态:
具体流程
判断一个对象objA是否可回收,至少需要两个标记过程:
如果对象objA到GC Roots之间没有引用链,则进行第一个标记过滤,判断是否需要为此独占执行finalize()方法
1. 如果对象objA没有refinallize()方法,或者finalize()已经被调用,虚拟机被认为“不需要执行”,objA被判断为不可达
2. 如果对象objA重新finalize()方法,并且没有被执行,那么objA会被插入到F-Queue队列中,自动创建一个虚拟机,一个低优先级的Finalizer线程触发它的finalize () 方法实现
3.finalize() 方法是对象逃脱死亡的最后机会。稍后,GC 会将 F-Queue 中的对象堆叠起来进行第二个标记。如果objA在finalize()方法中与引用链中的任何一个对象建立了连接,那么objA在第二次被标记时就会从“即将被回收”的集合中移除。之后,该对象将在没有引用的情况下再次出现。在这种情况下,finalize 方法将不会被再次调用,对象将直接变得不可达。
public class CanReliveObj {
//测试Object类中finalize()方法
// 类变量,属于GC Roots的一部分
public static CanReliveObj canReliveObj;
//该方法只能调用一次
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用当前类重写的finalize()方法");
canReliveObj = this;//当前待回收的对象与obj建立了联系
}
public static void main(String[] args) throws InterruptedException {
canReliveObj = new CanReliveObj();
canReliveObj = null;
System.gc();//调用垃圾回收器
System.out.println("-----------------第一次gc操作------------");
// 因为Finalizer线程的优先级比较低,暂停2秒,以等待它
Thread.sleep(2000);
if (canReliveObj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
System.out.println("-----------------第二次gc操作------------");
canReliveObj = null;
System.gc();
// 下面代码和上面代码是一样的,但是 canReliveObj却自救失败了
Thread.sleep(2000);
if (canReliveObj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
/*
*第一次gc alive
*第二次gc dead
*/
}
}
15.4 MAT 和 JProfiler GC Roots 的可追溯性
Memory Analyzer Tool at MAT 的缩写,是一个强大的 Java 堆内存分析器,用于发现内存泄漏和查看内存消耗。基于Eclipse开发,下载网站
获取转储文件
方法一:从命令行使用jmap
方法二:使用 JVisualVM 导出
使用 MAT 打开转储
在实际开发中,一般不会找到所有的GC Roots,而可能只是找到一个对象的整个链接,称为GC Roots traceability,可以使用JProfiler
确定导致 OOM 的原因
public class HeapOOM {
/*
*内存溢出排查
* -Xms8m -Xmx8m -XX:HeapDumpOnOutOfMemoryError
*/
// 创建1M的文件
byte [] buffer = new byte[1 * 1024 * 1024];
public static void main(String[] args) {
ArrayList list = new ArrayList();
int count = 0;
try {
while (true) {
list.add(new HeapOOM());
count++;
}
} catch (Exception e) {
e.getStackTrace();
System.out.println("count:" + count);
}
}
}
通过线程,可以定位到OOM出现的地方
15.5 清算阶段:Mark-Sweep算法(Mark-Sweep)
实施过程
当堆中的可用内存耗尽时,整个程序(stop the world)就会停止,然后执行两个任务。第一个是标记,第二个是清除。
什么是去除
这里的清空并不是真正的清空,而是将需要清空的对象的地址保存在空闲地址列表中。下次有新对象要加载时,判断垃圾位置空间是否足够,如果足够则存储
缺点
15.6 清洗阶段:复制算法(Copying)
实施过程
为了解决mark-sweep算法的缺点,将存活内存空间分成两块,每块只使用一个块,垃圾回收时将正在使用的内存中的存活对象复制到未使用的内存块中. 清除正在使用的内存块中的所有对象,交换两个内存的角色,最后完成垃圾回收。
将可到达的对象直接复制到另一个区域。复制完成后,A区没有任何作用,直接移除里面的对象。其实里面的新生代就使用了复制算法。
优势
缺点
应用场景
在新一代中,常规应用的垃圾回收通常可以一次回收70-99%的内存空间,回收非常划算。因此,目前的商用虚拟机使用这种采集算法来回收新一代。
15.7 清洗阶段:Mark-Compact(Mark-Compact)
实施过程
第一阶段和mark-sweep算法一样,从根节点标记所有被引用的对象
第二阶段将所有幸存的对象压缩成一段内存并按顺序排列
之后,清理边界外的所有空间
标记压缩算法的最终效果相当于执行标记扫描算法后,再次对内存进行碎片整理,因此也可以称为标记扫描压缩(Mark-Sweep-Compact)算法
两者的本质区别在于mark-sweep算法是非移动回收算法,mark-compression是移动的。回收后的残存物是否移动是一个有利有弊的冒险决定
标记的存活对象会根据内存地址进行排序排列,未标记的内存会被清理干净。JVM在为新对象分配内存时,只需要持有内存的起始地址,这显然比维护一个空闲列表要便宜。
优势
缺点
15.8 总结 Mark-SweepMark-CompactCopying
速度
中等的
最慢
最快的
空间开销
少,但碎片会堆积
少,无杂物
通常需要两倍大小的活体,无杂物堆积
移动物体
不
是的
是的
效率方面,复制算法当之无愧,但浪费内存太多
mark-sweep算法比较流畅,但是效率不理想。它比复制算法多一个标记阶段,比标记清除算法多一个清理内存的阶段。
15.9 分代采集算法
在之前的所有算法中,没有一种算法可以完全替代其他算法。它有自己的优点和特点。分代采集算法应运而生。
不同对象的生命周期是不同的。不同生命周期的对象可以采用不同的方式进行采集,提高采集效率。Java堆一般分为新生代和老年代,根据不同的特性可以使用不同的回收算法。提高回收效率
目前几乎所有的GC都使用分代采集算法来进行垃圾采集。
在HotSpot中,基于代的概念,GC使用的内存回收算法必须结合年轻代和老年代的特点。
年轻一代
以HotSpot中的cms采集器为例,cms是基于Mark-Sweep实现的,对象的回收效率非常高。对于碎片问题,cms使用基于Mark-Compact算法的Serial Old采集器作为补偿措施:当没有加入内存回收时(当碎片导致Concurrent Mode Failure时),会使用Serial Old来执行Full GC实现正确组织老年记忆
15.10 增量采集算法,分区算法
上述现有算法中,应用软件在垃圾采集过程中会处于STW状态。如果垃圾回收时间过长,会严重影响系统稳定性。为了解决这个问题,实时垃圾采集算法的研究直接导致了增量采集(Incremental Collecting)算法的诞生。
基本理念
垃圾采集线程和应用程序线程可以交替执行。每次垃圾采集线程只采集一小块内存空间,然后切换到应用线程。直到垃圾采集完成
增量采集算法的基础仍然是传统的标记-清除和复制算法。增量采集算法妥善处理线程之间的冲突,让垃圾采集线程分阶段完成标记、清理或复制工作
缺点
应用程序代码是间接执行的,因此可以减少系统暂停时间。但是由于线程切换和上下文切换的消耗,会增加垃圾回收的整体成本,导致系统吞吐量下降
生成算法根据对象的生命周期分为两部分。分区算法将整个堆空间划分为连续的不同小区间区域。每个电池独立使用和独立回收。它可以控制一次回收多少个细胞。
查看全部
算法 自动采集列表(
Python如何解决引用计数算法的循环引用属性?(一)
)
15.1 标记阶段:引用计数算法
引用计数算法(Reference Counting)比较简单,为每个对象保存一个整数引用计数器属性,用于记录被引用对象的情况
对于一个对象A,只要有任何对象引用A,A的引用计数器就加1;当引用失效时,引用计数器减少1. 只要对象A的引用计数器的值为0,就表示对象A不能再使用,可以回收
优点:实现简单,易于识别;判断效率高,无延迟
缺点:需要单独的字段来存储计数器,增加了存储空间的开销
每次赋值都需要更新计数器,增加了时间开销
无法处理循环引用,这是一个致命的缺陷,Java的垃圾采集器中没有使用这种算法
测试Java中是否使用了引用计数算法
public class RefCountGC {
//证明java使用的不是引用计数算法
// 这个成员属性的唯一作用就是占用一点内存
private byte[] bigSize = new byte[5*1024*1024];
// 引用
Object reference = null;
public static void main(String[] args) {
RefCountGC obj1 = new RefCountGC();
RefCountGC obj2 = new RefCountGC();
obj1.reference = obj2;
obj2.reference = obj1;
obj1 = null;
obj2 = null;
// 显示的执行垃圾收集行为,判断obj1 和 obj2是否被回收?
System.gc();
}
}
概括
Python 支持引用计数和垃圾采集机制
Python 是如何解决循环引用的?
15.2 标记阶段:可达性分析算法
可达性分析算法(寻根算法、Tracing Garbage 采集)不仅具有实现简单、执行高效的特点,而且有效解决了引用计数算法中的循环引用问题,防止了内存泄漏的发生。
基本思想
GC Roots 可以是什么类型的元素?
总结
由于Root使用栈来存储变量和指针,如果一个指针将对象保存在堆内存中,但不存储在堆内存中,那么它就是一个Root。
如果要使用可达性分析算法来判断内存是否可回收,分析工作必须在能够保证一致性的快照中进行。如果不满足,则无法保证分析结果。这也会导致 GC“停止”。“世界”的一个重要原因,即使在声称没有暂停的cms采集器中,枚举根节点也必须暂停
15.3 对象的终结机制
对象的终结机制
生存还是死亡?
三种状态:
具体流程
判断一个对象objA是否可回收,至少需要两个标记过程:
如果对象objA到GC Roots之间没有引用链,则进行第一个标记过滤,判断是否需要为此独占执行finalize()方法
1. 如果对象objA没有refinallize()方法,或者finalize()已经被调用,虚拟机被认为“不需要执行”,objA被判断为不可达
2. 如果对象objA重新finalize()方法,并且没有被执行,那么objA会被插入到F-Queue队列中,自动创建一个虚拟机,一个低优先级的Finalizer线程触发它的finalize () 方法实现
3.finalize() 方法是对象逃脱死亡的最后机会。稍后,GC 会将 F-Queue 中的对象堆叠起来进行第二个标记。如果objA在finalize()方法中与引用链中的任何一个对象建立了连接,那么objA在第二次被标记时就会从“即将被回收”的集合中移除。之后,该对象将在没有引用的情况下再次出现。在这种情况下,finalize 方法将不会被再次调用,对象将直接变得不可达。
public class CanReliveObj {
//测试Object类中finalize()方法
// 类变量,属于GC Roots的一部分
public static CanReliveObj canReliveObj;
//该方法只能调用一次
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用当前类重写的finalize()方法");
canReliveObj = this;//当前待回收的对象与obj建立了联系
}
public static void main(String[] args) throws InterruptedException {
canReliveObj = new CanReliveObj();
canReliveObj = null;
System.gc();//调用垃圾回收器
System.out.println("-----------------第一次gc操作------------");
// 因为Finalizer线程的优先级比较低,暂停2秒,以等待它
Thread.sleep(2000);
if (canReliveObj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
System.out.println("-----------------第二次gc操作------------");
canReliveObj = null;
System.gc();
// 下面代码和上面代码是一样的,但是 canReliveObj却自救失败了
Thread.sleep(2000);
if (canReliveObj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
/*
*第一次gc alive
*第二次gc dead
*/
}
}
15.4 MAT 和 JProfiler GC Roots 的可追溯性
Memory Analyzer Tool at MAT 的缩写,是一个强大的 Java 堆内存分析器,用于发现内存泄漏和查看内存消耗。基于Eclipse开发,下载网站
获取转储文件
方法一:从命令行使用jmap
方法二:使用 JVisualVM 导出
使用 MAT 打开转储
在实际开发中,一般不会找到所有的GC Roots,而可能只是找到一个对象的整个链接,称为GC Roots traceability,可以使用JProfiler
确定导致 OOM 的原因
public class HeapOOM {
/*
*内存溢出排查
* -Xms8m -Xmx8m -XX:HeapDumpOnOutOfMemoryError
*/
// 创建1M的文件
byte [] buffer = new byte[1 * 1024 * 1024];
public static void main(String[] args) {
ArrayList list = new ArrayList();
int count = 0;
try {
while (true) {
list.add(new HeapOOM());
count++;
}
} catch (Exception e) {
e.getStackTrace();
System.out.println("count:" + count);
}
}
}
通过线程,可以定位到OOM出现的地方
15.5 清算阶段:Mark-Sweep算法(Mark-Sweep)
实施过程
当堆中的可用内存耗尽时,整个程序(stop the world)就会停止,然后执行两个任务。第一个是标记,第二个是清除。
什么是去除
这里的清空并不是真正的清空,而是将需要清空的对象的地址保存在空闲地址列表中。下次有新对象要加载时,判断垃圾位置空间是否足够,如果足够则存储
缺点
15.6 清洗阶段:复制算法(Copying)
实施过程
为了解决mark-sweep算法的缺点,将存活内存空间分成两块,每块只使用一个块,垃圾回收时将正在使用的内存中的存活对象复制到未使用的内存块中. 清除正在使用的内存块中的所有对象,交换两个内存的角色,最后完成垃圾回收。
将可到达的对象直接复制到另一个区域。复制完成后,A区没有任何作用,直接移除里面的对象。其实里面的新生代就使用了复制算法。
优势
缺点
应用场景
在新一代中,常规应用的垃圾回收通常可以一次回收70-99%的内存空间,回收非常划算。因此,目前的商用虚拟机使用这种采集算法来回收新一代。
15.7 清洗阶段:Mark-Compact(Mark-Compact)
实施过程
第一阶段和mark-sweep算法一样,从根节点标记所有被引用的对象
第二阶段将所有幸存的对象压缩成一段内存并按顺序排列
之后,清理边界外的所有空间
标记压缩算法的最终效果相当于执行标记扫描算法后,再次对内存进行碎片整理,因此也可以称为标记扫描压缩(Mark-Sweep-Compact)算法
两者的本质区别在于mark-sweep算法是非移动回收算法,mark-compression是移动的。回收后的残存物是否移动是一个有利有弊的冒险决定
标记的存活对象会根据内存地址进行排序排列,未标记的内存会被清理干净。JVM在为新对象分配内存时,只需要持有内存的起始地址,这显然比维护一个空闲列表要便宜。
优势
缺点
15.8 总结 Mark-SweepMark-CompactCopying
速度
中等的
最慢
最快的
空间开销
少,但碎片会堆积
少,无杂物
通常需要两倍大小的活体,无杂物堆积
移动物体
不
是的
是的
效率方面,复制算法当之无愧,但浪费内存太多
mark-sweep算法比较流畅,但是效率不理想。它比复制算法多一个标记阶段,比标记清除算法多一个清理内存的阶段。
15.9 分代采集算法
在之前的所有算法中,没有一种算法可以完全替代其他算法。它有自己的优点和特点。分代采集算法应运而生。
不同对象的生命周期是不同的。不同生命周期的对象可以采用不同的方式进行采集,提高采集效率。Java堆一般分为新生代和老年代,根据不同的特性可以使用不同的回收算法。提高回收效率
目前几乎所有的GC都使用分代采集算法来进行垃圾采集。
在HotSpot中,基于代的概念,GC使用的内存回收算法必须结合年轻代和老年代的特点。
年轻一代
以HotSpot中的cms采集器为例,cms是基于Mark-Sweep实现的,对象的回收效率非常高。对于碎片问题,cms使用基于Mark-Compact算法的Serial Old采集器作为补偿措施:当没有加入内存回收时(当碎片导致Concurrent Mode Failure时),会使用Serial Old来执行Full GC实现正确组织老年记忆
15.10 增量采集算法,分区算法
上述现有算法中,应用软件在垃圾采集过程中会处于STW状态。如果垃圾回收时间过长,会严重影响系统稳定性。为了解决这个问题,实时垃圾采集算法的研究直接导致了增量采集(Incremental Collecting)算法的诞生。
基本理念
垃圾采集线程和应用程序线程可以交替执行。每次垃圾采集线程只采集一小块内存空间,然后切换到应用线程。直到垃圾采集完成
增量采集算法的基础仍然是传统的标记-清除和复制算法。增量采集算法妥善处理线程之间的冲突,让垃圾采集线程分阶段完成标记、清理或复制工作
缺点
应用程序代码是间接执行的,因此可以减少系统暂停时间。但是由于线程切换和上下文切换的消耗,会增加垃圾回收的整体成本,导致系统吞吐量下降
生成算法根据对象的生命周期分为两部分。分区算法将整个堆空间划分为连续的不同小区间区域。每个电池独立使用和独立回收。它可以控制一次回收多少个细胞。
算法 自动采集列表(算法自动采集列表页视频,p2p压缩后利用本地服务器爬取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-11-26 06:02
算法自动采集列表页视频。根据user_id即可抓取任意视频。当然站内高清内容要用自己的服务器下载,不过传到线上点击率会降低。
可以自己使用mediasourcelibrary或者提供接口的开源组件比如codecslibrary、libq、musicstream、codec也可以自己开发单独抓取,
可以自己写爬虫,开源的有轮子哥写的轮子。其实单独抓取的效率远远不如无损,直接搜就行了,可以抓取的场景有播放列表、视频列表、列表封面、播放列表相关视频等等。
很多,抓取youtube列表的工具。
自己写爬虫吧,每天新增的视频都可以抓,但可能会有其他风险,得好好加点权限,自己写写代码,或者可以代购抓,
最新的主题是英文主题,除了视频列表,还可以抓取link连接,然后拼接自己的url,前提得需要extractor软件,不过extractor这个应该自己网上找找也有。英文内容自己还是做google翻译吧,国内视频真心少。
还是有些简单的工具的,比如通过userid的方式抓取,但这种工具并不适合国内用户的使用习惯。我认为原因:①国内大部分用户对于爬虫实现方式的陌生,很难在软件上构建高质量的自动化处理流程;②国内用户访问英文视频列表的习惯都是直接在视频列表页面双击,导致视频列表呈现在页面上的内容看不全,需要自己创建index,并要自己标注后台视频,并自己直接调用视频。
做这个的工具有fisherholder这款,有兴趣的话可以自己试试。当然我也不看好p2p的网络视频,p2p压缩后利用本地服务器爬取,然后发布,这种思路没有必要存在视频库中,但这种思路存在问题,类似于国内文化输出,然后一段时间后倒回重发,在这个过程中可能会导致一些社会问题,比如地域保护的问题。然后个人认为,国内直接封闭视频库肯定更好,这样的话用户自己做爬虫,在开始时候可以放弃封闭,而直接在社区群里发布各种想看的视频等待用户爬取。
然后用户自己自建视频库也能获得最大的流量池,但同时这也要求用户在开始时对视频有一定量的主观判断,就比如只有优秀的教育片、体育赛事的视频能满足用户的胃口,超过一定量等比例的网络视频就没人看了,导致用户直接流失。而且通过视频列表抓取进入视频库,查找并抓取优秀的视频,进行二次利用,成本小。 查看全部
算法 自动采集列表(算法自动采集列表页视频,p2p压缩后利用本地服务器爬取)
算法自动采集列表页视频。根据user_id即可抓取任意视频。当然站内高清内容要用自己的服务器下载,不过传到线上点击率会降低。
可以自己使用mediasourcelibrary或者提供接口的开源组件比如codecslibrary、libq、musicstream、codec也可以自己开发单独抓取,
可以自己写爬虫,开源的有轮子哥写的轮子。其实单独抓取的效率远远不如无损,直接搜就行了,可以抓取的场景有播放列表、视频列表、列表封面、播放列表相关视频等等。
很多,抓取youtube列表的工具。
自己写爬虫吧,每天新增的视频都可以抓,但可能会有其他风险,得好好加点权限,自己写写代码,或者可以代购抓,
最新的主题是英文主题,除了视频列表,还可以抓取link连接,然后拼接自己的url,前提得需要extractor软件,不过extractor这个应该自己网上找找也有。英文内容自己还是做google翻译吧,国内视频真心少。
还是有些简单的工具的,比如通过userid的方式抓取,但这种工具并不适合国内用户的使用习惯。我认为原因:①国内大部分用户对于爬虫实现方式的陌生,很难在软件上构建高质量的自动化处理流程;②国内用户访问英文视频列表的习惯都是直接在视频列表页面双击,导致视频列表呈现在页面上的内容看不全,需要自己创建index,并要自己标注后台视频,并自己直接调用视频。
做这个的工具有fisherholder这款,有兴趣的话可以自己试试。当然我也不看好p2p的网络视频,p2p压缩后利用本地服务器爬取,然后发布,这种思路没有必要存在视频库中,但这种思路存在问题,类似于国内文化输出,然后一段时间后倒回重发,在这个过程中可能会导致一些社会问题,比如地域保护的问题。然后个人认为,国内直接封闭视频库肯定更好,这样的话用户自己做爬虫,在开始时候可以放弃封闭,而直接在社区群里发布各种想看的视频等待用户爬取。
然后用户自己自建视频库也能获得最大的流量池,但同时这也要求用户在开始时对视频有一定量的主观判断,就比如只有优秀的教育片、体育赛事的视频能满足用户的胃口,超过一定量等比例的网络视频就没人看了,导致用户直接流失。而且通过视频列表抓取进入视频库,查找并抓取优秀的视频,进行二次利用,成本小。
算法 自动采集列表(算法自动采集列表,如何解决不了问题的能力?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-25 09:20
算法自动采集列表,当鼠标选中要采集的内容时,算法会自动从用户收藏夹里采集相关的内容,速度很快,不像人工采集那么慢~如果需要知道被采集的网站名称和链接,可以点击该网站名称或链接,查看被采集网站的界面,
能用爬虫,然后你要懂推广,站外推广,
会爬虫会推广
可以用程序采集,过程并不麻烦,按照需求添加相应的插件就可以了。不过爬虫采集要求浏览器版本足够高,所以建议换一款相应的浏览器再测试一下。另外必须要有浏览器safari或chrome。
以前可以,我同事是用golang写的一个,并且挺好用的,就是得按照token去采,一般自己摸索太慢了,你可以买个token试试。自从用上云采集了,简直不要太爽,从此爬虫只要几百块,舒服的像皇帝。除了token还得买采集软件才能采,比如录屏台录个课件采得流畅的一塌糊涂,爬个文章或网站采得各种卡!采个论坛小广告,各种卡卡卡!用云采集的朋友欢迎提问交流。
真的是用scrapy,高速,好用,
小时候被父母教育要勤能补拙,所以小时候没少尝试自己解决问题,小时候用五笔打字,想要快速解决问题时还经常问身边的小伙伴,小伙伴们似乎都在与我进行竞争。慢慢的,发现想要解决问题首先要有解决问题的初步想法,然后在想办法去做实践,这样就可以提高解决问题的能力。对于一些解决不了的问题,需要找老师或者求助身边的人,这种时候就需要靠自己对问题的发现能力。
靠自己搜索资料的同时,也要做问题相关方面的思考,然后自己尝试着去解决它。现在长大了,渐渐养成了自己解决问题的习惯,就算我不会也会主动去思考怎么办,这样反倒能省去很多查找资料的时间。 查看全部
算法 自动采集列表(算法自动采集列表,如何解决不了问题的能力?)
算法自动采集列表,当鼠标选中要采集的内容时,算法会自动从用户收藏夹里采集相关的内容,速度很快,不像人工采集那么慢~如果需要知道被采集的网站名称和链接,可以点击该网站名称或链接,查看被采集网站的界面,
能用爬虫,然后你要懂推广,站外推广,
会爬虫会推广
可以用程序采集,过程并不麻烦,按照需求添加相应的插件就可以了。不过爬虫采集要求浏览器版本足够高,所以建议换一款相应的浏览器再测试一下。另外必须要有浏览器safari或chrome。
以前可以,我同事是用golang写的一个,并且挺好用的,就是得按照token去采,一般自己摸索太慢了,你可以买个token试试。自从用上云采集了,简直不要太爽,从此爬虫只要几百块,舒服的像皇帝。除了token还得买采集软件才能采,比如录屏台录个课件采得流畅的一塌糊涂,爬个文章或网站采得各种卡!采个论坛小广告,各种卡卡卡!用云采集的朋友欢迎提问交流。
真的是用scrapy,高速,好用,
小时候被父母教育要勤能补拙,所以小时候没少尝试自己解决问题,小时候用五笔打字,想要快速解决问题时还经常问身边的小伙伴,小伙伴们似乎都在与我进行竞争。慢慢的,发现想要解决问题首先要有解决问题的初步想法,然后在想办法去做实践,这样就可以提高解决问题的能力。对于一些解决不了的问题,需要找老师或者求助身边的人,这种时候就需要靠自己对问题的发现能力。
靠自己搜索资料的同时,也要做问题相关方面的思考,然后自己尝试着去解决它。现在长大了,渐渐养成了自己解决问题的习惯,就算我不会也会主动去思考怎么办,这样反倒能省去很多查找资料的时间。
算法 自动采集列表(垃圾回收相关算法标记阶段(一)(1)_根集合就是 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-23 04:06
)
垃圾采集相关算法
打标阶段概述
Reference Counting Algorithm Reference Counting 循环引用,例如变量指针P指向A,其中A指BB指CC引用A,内部形成一个引用链。当一个P指针不再指向A时,本质上A将不再被使用,但是由于循环的依赖关系导致A的计数器永远不会减为0,从而导致永远无法回收的内存泄漏
证明 HotSpot 不使用引用计数算法
public class ProveJavaNotUseReferenceCounting {
private byte[] data = new byte[1024 * 1024 * 5];
Object ref = null;
public static void main(String[] args) {
ProveJavaNotUseReferenceCounting obj1 = new ProveJavaNotUseReferenceCounting();
ProveJavaNotUseReferenceCounting obj2 = new ProveJavaNotUseReferenceCounting();
obj1.ref = obj2;
obj2.ref = obj1;
obj1 = null;
obj2 = null;
System.gc();
}
}
[GC (System.gc()) [PSYoungGen: 13578K->744K(38400K)] 13578K->752K(125952K), 0.1038107 秒] [时间:用户=0.@<>00 sys= @0.00,真实=0.11 秒]
[Full GC (System.gc()) [PSYoungGen: 744K->0K(38400K)] [ParOldGen: 8K->642K(87552K)] 752K->642K(125952K), [Metaspace: 3277K->8K(38400K)] ], 0.0081173 秒] [时间:用户=0.00 sys=0.00, real=0.01 秒]
堆
PSYoungGen 总共 38400K,使用了 333K [0x00000000d5900000, 0x00000000d8380000, 0x00000)
伊甸园空间 33280K,已使用 1% [0x00000000d5900000,0x00000000d59534a8,0x00000000d7980000)
从空间 5120K, 0% 使用 [0x00000000d7980000,0x00000000d7980000,0x00000000d7e80000)
到空间 5120K, 0% 使用 [0x00000000d7e80000,0x00000000d7e80000,0x00000000d8380000)
ParOldGen 总计 87552K,已用 642K [0x0000000080a00000, 0x0000000085f80000, 0x00000000d5900000)
对象空间 87552K,0% 使用 [0x0000000080a00000,0x0000000080aa0bb0,0x0000000085f80000)
Metaspace使用3283K,容量4496K,提交4864K,保留1056768K
已用类空间 359K,容量 388K,已提交 512K,保留 1048576K
汇总可达性分析算法
概念
想法
GCRoots 根集合是一组必须处于活动状态的引用
基本思想
GC Roots 可以是 JNI 引用的对象(通常称为本地方法)在本地方法栈中。类的方法区中的对象经常被属性引用。方法区中的常量引用的对象。java虚拟机内部同步的同步锁持有的所有对象参考JMXBean JVMTI中反映java虚拟机内部情况的注册回调,本地代码缓存
总结提示
由于Root使用栈来存储变量和指针,如果一个指针将对象保存在堆中,但没有保存在堆内存中,那么他就是一个Root
注意对象的终结机制
永远不要主动调用对象的 finalize() 方法!应该交给GC调用
一个糟糕的 finalize 方法会严重影响 GC 性能。在功能上,finalize方法类似于C++的析构函数,但是Java使用了基于垃圾采集器的自动内存管理机制,所以finalize方法与C++的析构函数有着本质的区别。虚拟机对象的三种状态
由于finalize方法的存在,虚拟机对象可能有三种状态
如果所有的根节点都无法访问一个对象,则表示该对象不再被使用。一般来说,这个时候需要回收对象。但实际上,并不是“必须死”。一个不可触及的物体可能会在某种条件下复活自己。如果真是这样,那他的恢复是不合理的。
定稿过程
判断一个对象obj是否可以回收,至少要经过两次标记过程
如果对象 obj 和 GC Roots 之间没有引用链,则执行第一个标记进行过滤,以确定该对象是否需要执行 finalize 方法。如果对象obj没有重写finalize()方法,或者finalize方法已经被虚拟机调用,则认为虚拟机没有必要执行,obj被判断为不可达。如果obj重写了finalize方法并没有被执行,则将obj插入到F-Queue队列中,由虚拟机自动创建的低优先级Finalizer线程触发其finalize方法执行
复活finazlie中的代码演示
public class ReviveTest {
// 类成员 是GC Roots的集合一员
public static ReviveTest data;
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize 方法调用");
// 这句话使得对象在finalize中被复活
data = this;
}
public static void main(String[] args) throws InterruptedException {
data = new ReviveTest();
data = null;
System.out.println("第一次执行GC============");
System.gc();
TimeUnit.SECONDS.sleep(2);
if (data == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is alive");
}
System.out.println("第二次执行GC============");
data = null;
System.gc();
TimeUnit.SECONDS.sleep(2);
if (data == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is alive");
}
}
}
第一次执行GC ============
完成方法调用
obj 还活着
第二次执行GC ============
obj死了
在第一次清理中,我们会执行finalize方法,然后对象进行自助操作,但是因为finalize()方法只会被调用一次,所以对象会被第二次垃圾清理。
MAT 和 JProfiler GC Roots 的可追溯性
MAT 是 Memory Anlayzer 的缩写,是 Ecplise 开发的一款免费且功能强大的 java 堆内存分析器,用于发现内存泄漏和查看内存消耗
使用 JVisualVM 捕获堆转储文件。JVisualVM捕获的是一个临时文件,关闭JVisualVM后会自动删除,需要保存为文件。
应用程序 右键单击相应的应用程序,选择 Heap Dump,然后单击 Monitor 子选项卡中的 Heap Dump 按钮。本地应用程序的堆转储作为应用程序选项卡的子选项卡打开。同时Heap Dump对应左侧Application列中对应的Save as node with timestamp
使用MAT打开Dump文件查看GC Roots
使用 JProfiler 的 GC Roots 溯源
选择 JProfiler 打开转储堆文件。在类或最大对象中,选择一个类并进入参考视图。选择传入引用以查看对象的整个链接
如何确定导致OOM的原因
模拟OOM代码
// -Xms8m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
public class HeapOOM {
// 创建1M的文件
byte [] buffer = new byte[1 * 1024 * 1024];
public static void main(String[] args) {
ArrayList list = new ArrayList();
int count = 0;
try {
while (true) {
list.add(new HeapOOM());
count++;
}
} catch (Exception e) {
e.getStackTrace();
System.out.println("count:" + count);
}
}
}
上面代码不断向链表中添加1m的数据,JVM参数-Xms8m -Xmx8m限制最多8M内存
-XX:+HeapDumpOnOutOfMemeoryError 发生OOM时生成hprof文件
使用 JProfiler 定位内存溢出代码
用JProfiler打开hprof,点击Biggest Object定位大对象
通过线程转储文件定位出现OOM的那一行
清除节点标记清除算法
在完成标记阶段确定哪些对象是垃圾后,GC 会进行垃圾回收,释放无用对象占用的内存空间,以便有足够的内存空间为新对象分配内存。主流的三种垃圾回收算法如下
标记去除算法
当堆中的可用内存耗尽时,整个程序(Stop The World)就会停止,GC会进行标记和清理。
什么是清理?标记清除算法的优缺点 复制算法的优缺点 复制算法的优缺点
高效的
低的
高的
中间
空间开销
低的
高(空间的1/2)
低(原尺寸)
移动物体
不
是的
是的
不同场景选择不同算法
老年代的分代采集算法Tenured Gen以HotSpot中的cms采集器为例,cms基于Mark-Sweep,对象的回收效率非常高。对于碎片问题,采用cms基于Mark-Compact算法的Serial Old采集器作为补偿措施。当内存回收不良时(当分片导致Concurrent Mode Failure时),会使用serial old执行FullGC来实现对旧内存进行排序和生成的思路。虚拟机应用广泛,几乎所有垃圾采集器都区分新生代和老年代增量采集算法
使用上述现有算法,在进行垃圾回收、所有用户线程挂起、所有正常工作挂起、垃圾回收完成时会导致STW状态。如果垃圾回收时间过长,会严重影响用户体验和系统稳定性。为了解决这个问题,堆实时垃圾采集的研究导致了增量采集(Incremental Collecting)算法的诞生
如果一次处理所有垃圾,需要很长的STW,那么垃圾采集线程和应用线程可以交替执行。每次垃圾采集线程只采集一小块内存,然后切换到应用线程。依次重复直到垃圾采集完成
增量采集算法的基础仍然是传统的标记-清除和复制算法。只是增量采集算法正确处理了线程之间的冲突,让垃圾采集线程分阶段完成标记、清除和复制操作。
缺点是使用了这种方法。因为应用程序代码在垃圾回收过程中间歇性执行,减少了STW时间,但是由于线程切换和上下文切换的消耗,垃圾回收的整体成本增加,导致系统吞吐量下降
分区算法
一般来说,相同的堆空间越大,一次GC所需的时间越长,与GC生成相关的暂停时间也越长。为了更好地控制GC产生的暂停时间,将一块大内存区域划分为多个Small blocks,根据目标暂停的事件,每次合理回收几个cell,而不是真正的堆空间,从而减少由 GC 引起的暂停
分代算法会根据对象生命周期的长短分为两部分。分区算法将整个堆空间划分为连续的不同cell,每个cell使用独立的recovery。这种算法的优点是可以控制一次恢复多少。社区间
查看全部
算法 自动采集列表(垃圾回收相关算法标记阶段(一)(1)_根集合就是
)
垃圾采集相关算法
打标阶段概述
Reference Counting Algorithm Reference Counting 循环引用,例如变量指针P指向A,其中A指BB指CC引用A,内部形成一个引用链。当一个P指针不再指向A时,本质上A将不再被使用,但是由于循环的依赖关系导致A的计数器永远不会减为0,从而导致永远无法回收的内存泄漏
证明 HotSpot 不使用引用计数算法
public class ProveJavaNotUseReferenceCounting {
private byte[] data = new byte[1024 * 1024 * 5];
Object ref = null;
public static void main(String[] args) {
ProveJavaNotUseReferenceCounting obj1 = new ProveJavaNotUseReferenceCounting();
ProveJavaNotUseReferenceCounting obj2 = new ProveJavaNotUseReferenceCounting();
obj1.ref = obj2;
obj2.ref = obj1;
obj1 = null;
obj2 = null;
System.gc();
}
}
[GC (System.gc()) [PSYoungGen: 13578K->744K(38400K)] 13578K->752K(125952K), 0.1038107 秒] [时间:用户=0.@<>00 sys= @0.00,真实=0.11 秒]
[Full GC (System.gc()) [PSYoungGen: 744K->0K(38400K)] [ParOldGen: 8K->642K(87552K)] 752K->642K(125952K), [Metaspace: 3277K->8K(38400K)] ], 0.0081173 秒] [时间:用户=0.00 sys=0.00, real=0.01 秒]
堆
PSYoungGen 总共 38400K,使用了 333K [0x00000000d5900000, 0x00000000d8380000, 0x00000)
伊甸园空间 33280K,已使用 1% [0x00000000d5900000,0x00000000d59534a8,0x00000000d7980000)
从空间 5120K, 0% 使用 [0x00000000d7980000,0x00000000d7980000,0x00000000d7e80000)
到空间 5120K, 0% 使用 [0x00000000d7e80000,0x00000000d7e80000,0x00000000d8380000)
ParOldGen 总计 87552K,已用 642K [0x0000000080a00000, 0x0000000085f80000, 0x00000000d5900000)
对象空间 87552K,0% 使用 [0x0000000080a00000,0x0000000080aa0bb0,0x0000000085f80000)
Metaspace使用3283K,容量4496K,提交4864K,保留1056768K
已用类空间 359K,容量 388K,已提交 512K,保留 1048576K
汇总可达性分析算法
概念
想法
GCRoots 根集合是一组必须处于活动状态的引用
基本思想
GC Roots 可以是 JNI 引用的对象(通常称为本地方法)在本地方法栈中。类的方法区中的对象经常被属性引用。方法区中的常量引用的对象。java虚拟机内部同步的同步锁持有的所有对象参考JMXBean JVMTI中反映java虚拟机内部情况的注册回调,本地代码缓存
总结提示
由于Root使用栈来存储变量和指针,如果一个指针将对象保存在堆中,但没有保存在堆内存中,那么他就是一个Root
注意对象的终结机制
永远不要主动调用对象的 finalize() 方法!应该交给GC调用
一个糟糕的 finalize 方法会严重影响 GC 性能。在功能上,finalize方法类似于C++的析构函数,但是Java使用了基于垃圾采集器的自动内存管理机制,所以finalize方法与C++的析构函数有着本质的区别。虚拟机对象的三种状态
由于finalize方法的存在,虚拟机对象可能有三种状态
如果所有的根节点都无法访问一个对象,则表示该对象不再被使用。一般来说,这个时候需要回收对象。但实际上,并不是“必须死”。一个不可触及的物体可能会在某种条件下复活自己。如果真是这样,那他的恢复是不合理的。
定稿过程
判断一个对象obj是否可以回收,至少要经过两次标记过程
如果对象 obj 和 GC Roots 之间没有引用链,则执行第一个标记进行过滤,以确定该对象是否需要执行 finalize 方法。如果对象obj没有重写finalize()方法,或者finalize方法已经被虚拟机调用,则认为虚拟机没有必要执行,obj被判断为不可达。如果obj重写了finalize方法并没有被执行,则将obj插入到F-Queue队列中,由虚拟机自动创建的低优先级Finalizer线程触发其finalize方法执行
复活finazlie中的代码演示
public class ReviveTest {
// 类成员 是GC Roots的集合一员
public static ReviveTest data;
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize 方法调用");
// 这句话使得对象在finalize中被复活
data = this;
}
public static void main(String[] args) throws InterruptedException {
data = new ReviveTest();
data = null;
System.out.println("第一次执行GC============");
System.gc();
TimeUnit.SECONDS.sleep(2);
if (data == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is alive");
}
System.out.println("第二次执行GC============");
data = null;
System.gc();
TimeUnit.SECONDS.sleep(2);
if (data == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is alive");
}
}
}
第一次执行GC ============
完成方法调用
obj 还活着
第二次执行GC ============
obj死了
在第一次清理中,我们会执行finalize方法,然后对象进行自助操作,但是因为finalize()方法只会被调用一次,所以对象会被第二次垃圾清理。
MAT 和 JProfiler GC Roots 的可追溯性
MAT 是 Memory Anlayzer 的缩写,是 Ecplise 开发的一款免费且功能强大的 java 堆内存分析器,用于发现内存泄漏和查看内存消耗
使用 JVisualVM 捕获堆转储文件。JVisualVM捕获的是一个临时文件,关闭JVisualVM后会自动删除,需要保存为文件。
应用程序 右键单击相应的应用程序,选择 Heap Dump,然后单击 Monitor 子选项卡中的 Heap Dump 按钮。本地应用程序的堆转储作为应用程序选项卡的子选项卡打开。同时Heap Dump对应左侧Application列中对应的Save as node with timestamp
使用MAT打开Dump文件查看GC Roots
使用 JProfiler 的 GC Roots 溯源
选择 JProfiler 打开转储堆文件。在类或最大对象中,选择一个类并进入参考视图。选择传入引用以查看对象的整个链接
如何确定导致OOM的原因
模拟OOM代码
// -Xms8m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
public class HeapOOM {
// 创建1M的文件
byte [] buffer = new byte[1 * 1024 * 1024];
public static void main(String[] args) {
ArrayList list = new ArrayList();
int count = 0;
try {
while (true) {
list.add(new HeapOOM());
count++;
}
} catch (Exception e) {
e.getStackTrace();
System.out.println("count:" + count);
}
}
}
上面代码不断向链表中添加1m的数据,JVM参数-Xms8m -Xmx8m限制最多8M内存
-XX:+HeapDumpOnOutOfMemeoryError 发生OOM时生成hprof文件
使用 JProfiler 定位内存溢出代码
用JProfiler打开hprof,点击Biggest Object定位大对象
通过线程转储文件定位出现OOM的那一行
清除节点标记清除算法
在完成标记阶段确定哪些对象是垃圾后,GC 会进行垃圾回收,释放无用对象占用的内存空间,以便有足够的内存空间为新对象分配内存。主流的三种垃圾回收算法如下
标记去除算法
当堆中的可用内存耗尽时,整个程序(Stop The World)就会停止,GC会进行标记和清理。
什么是清理?标记清除算法的优缺点 复制算法的优缺点 复制算法的优缺点
高效的
低的
高的
中间
空间开销
低的
高(空间的1/2)
低(原尺寸)
移动物体
不
是的
是的
不同场景选择不同算法
老年代的分代采集算法Tenured Gen以HotSpot中的cms采集器为例,cms基于Mark-Sweep,对象的回收效率非常高。对于碎片问题,采用cms基于Mark-Compact算法的Serial Old采集器作为补偿措施。当内存回收不良时(当分片导致Concurrent Mode Failure时),会使用serial old执行FullGC来实现对旧内存进行排序和生成的思路。虚拟机应用广泛,几乎所有垃圾采集器都区分新生代和老年代增量采集算法
使用上述现有算法,在进行垃圾回收、所有用户线程挂起、所有正常工作挂起、垃圾回收完成时会导致STW状态。如果垃圾回收时间过长,会严重影响用户体验和系统稳定性。为了解决这个问题,堆实时垃圾采集的研究导致了增量采集(Incremental Collecting)算法的诞生
如果一次处理所有垃圾,需要很长的STW,那么垃圾采集线程和应用线程可以交替执行。每次垃圾采集线程只采集一小块内存,然后切换到应用线程。依次重复直到垃圾采集完成
增量采集算法的基础仍然是传统的标记-清除和复制算法。只是增量采集算法正确处理了线程之间的冲突,让垃圾采集线程分阶段完成标记、清除和复制操作。
缺点是使用了这种方法。因为应用程序代码在垃圾回收过程中间歇性执行,减少了STW时间,但是由于线程切换和上下文切换的消耗,垃圾回收的整体成本增加,导致系统吞吐量下降
分区算法
一般来说,相同的堆空间越大,一次GC所需的时间越长,与GC生成相关的暂停时间也越长。为了更好地控制GC产生的暂停时间,将一块大内存区域划分为多个Small blocks,根据目标暂停的事件,每次合理回收几个cell,而不是真正的堆空间,从而减少由 GC 引起的暂停
分代算法会根据对象生命周期的长短分为两部分。分区算法将整个堆空间划分为连续的不同cell,每个cell使用独立的recovery。这种算法的优点是可以控制一次恢复多少。社区间
算法 自动采集列表(DXC!X2(X2.5)2.5的主要功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-21 17:01
DXC 来自 Discuz!X2(X2.5)合集缩写,DXC采集插件,致力于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。通过DXC采集插件-在,用户可以方便地访问互联网采集的数据,包括会员数据、文章数据,另外还有虚拟在线、单帖采集等辅助功能冷清的新版论坛瞬间形成了一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助,是新手站长必备的discuz应用DXC2.5个主要功能包括:1、多种形式的URL列表采集文章,包括rss地址、列表页面、多层列表等。. 2、规则编写多种方式,dom方法,字符截取,智能获取,更方便获取你想要的内容3、规则继承,匹配规则自动检测功能,你会慢慢体会到带来的便利通过规则继承4、独特的网页正文提取算法,可自动学习归纳规则,更方便进行泛化-采集.5、支持图片定位,添加水印功能6、灵活发布机制,可自定义定义发布者、发布时间点击率等7、强大的内容编辑后台,您可以轻松编辑采集的内容并发布到门户、论坛、博客< @8、内容过滤功能,过滤采集广告的内容, 查看全部
算法 自动采集列表(DXC!X2(X2.5)2.5的主要功能)
DXC 来自 Discuz!X2(X2.5)合集缩写,DXC采集插件,致力于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。通过DXC采集插件-在,用户可以方便地访问互联网采集的数据,包括会员数据、文章数据,另外还有虚拟在线、单帖采集等辅助功能冷清的新版论坛瞬间形成了一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助,是新手站长必备的discuz应用DXC2.5个主要功能包括:1、多种形式的URL列表采集文章,包括rss地址、列表页面、多层列表等。. 2、规则编写多种方式,dom方法,字符截取,智能获取,更方便获取你想要的内容3、规则继承,匹配规则自动检测功能,你会慢慢体会到带来的便利通过规则继承4、独特的网页正文提取算法,可自动学习归纳规则,更方便进行泛化-采集.5、支持图片定位,添加水印功能6、灵活发布机制,可自定义定义发布者、发布时间点击率等7、强大的内容编辑后台,您可以轻松编辑采集的内容并发布到门户、论坛、博客< @8、内容过滤功能,过滤采集广告的内容,
算法 自动采集列表(1.概述1.2垃圾收集器的考量指标(1.2)_概述)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-20 09:08
1.概述1.2 垃圾采集器注意事项
垃圾采集器也有类似CAP理论的矛盾,具体有以下三个方面的考虑:
吞吐量
响应性、延迟(Latency)
内存占用(容量)
以上三个考虑不能同时满足最优,只能满足其中两个,牺牲其中之一的部分效率。
1.3 吞吐量
吞吐量与在指定时间范围内最大化应用程序的工作负载有关。
以下方法用于测量系统的吞吐量:
在一小时内,完成同一事务(任务或请求)的次数。
数据库在一小时内完成了多少查询。
对于注重吞吐量的系统,偶尔的停顿是可以接受的,因为这种系统注重长时间执行大量任务的能力,单一的快速响应不值得考虑。
1.4 响应能力
响应性是指应用程序或系统是否能够及时快速地响应,例如:
桌面 UI 程序对事件的响应速度。
网站 返回页面请求的速度有多快。
数据库返回查询结果的速度有多快。
对于这种响应敏感、低延迟的场景,长期卡顿是不能容忍的。
内存使用情况
为了加快内存扫描的数据,GC垃圾采集器通常会使用内存中的一些数据结构,比如卡表、内存集等,来存储对对象的直接引用,而这些数据本身就需要占用堆的内存空间。记录的信息越多,扫描时间越快,占用的内存也越大。
1.5 G1的诞生背景
随着硬件成本越来越低,机器的内存也越来越大。GC回收器占用的内存基本可以容忍,吞吐量可以通过集群(加机器)解决,所以STW时间对于JVM来说就变得迫切要解决的问题,如果还是按照传统的分代方式使用传统的垃圾回收器模型,那么STW时间会越来越长。
在传统的垃圾采集器中,STW 时间是不可预测的。有没有办法先定义一个暂停时间,然后向后计算采集到的内容?就像领导在年初制定KPI一样,多做多做,少做少做。
G1的思路类似。不需要每次都清理垃圾。它只是尝试做它认为正确的事情。
G1还有一个极其重要的特性:软实时(soft real time)。所谓实时垃圾回收,是指在规定的时间内完成垃圾回收。“软实时”意味着用户可以指定垃圾采集的时间限制。G1会尽量在这个时限内完成垃圾采集,但是G1不保证每次都能在这个时限内完成垃圾采集。通过设定一个合理的目标,90%以上的垃圾回收时间都可以在这个时间限制内。
我们要求 G1 在任何一秒的时间内暂停不超过 10 毫秒。这是为其制定KPI。G1将尽最大努力实现这一目标。可以逆向计算本次要采集的总面积,增量式完成采集。
这也是使用G1垃圾采集器必须设置的一个参数(-XX:+UseG1GC):-XX:MaxGCPauseMillis=10,这个参数默认为200ms。
G1的适用场景:
服务器端多核CPU、JVM内存占用应用。
应用程序运行过程中会产生大量的内存碎片,空间需要经常进行压缩。
想要一个更可控和可预测的GC暂停期,以防止高并发下的应用程序雪崩。
2. G1的内存模型2.1 Partition概念
2.1.1师区域
G1采用了region的思想,将整个堆空间划分为若干大小相等的内存区域,每次分配对象空间时,都会逐段使用内存。因此,在堆的使用上,G1并不要求对象的存储必须物理上连续,只要逻辑上连续即可;每个分区都不会肯定服务于某一代,它可以用于年轻代和老年代之间的切换。分区大小(1MB~32MB,必须是2的幂)可以在启动时通过参数-XX:G1HeapRegionSize=n指定。默认情况下,整个堆被划分为 2048 个分区。
对于那些超过整个 Region 容量的超大对象,它们将被存储在 N 个连续的 Humongous Region 中。大多数情况下,G1的回收都会将洪门地区视为老年的一部分。
G1在逻辑上划分了Eden(所有Eden区域的总和)、Survivor(所有Survivor区域的总和)和OLd(所有Old区域的总和),但物理上它们是不连续的,同一个区域在不同区域的作用期间可以不同。有可能当前区域存储了 Eden 对象。执行 YGC 后,分配给它的下一个对象可能是 Old 对象。
2.1.2张卡片
卡片表的诞生是为了解决跨代引用。假设在cms垃圾采集器中,如果要回收新生代的对象,那么就必须扫描整个老年代,而要引入卡表,只需要扫描卡表的中间脏区就够了,避免了扫描整个老年代,大大加快了并发标记的速度。
每个Region分为若干张固定大小的卡片(Card)。每张卡片使用一个Byte来记录是否被修改过。卡片表是这些字节的集合。标识堆内存和所有分区的最小可用粒度的卡将记录在全局卡表中。分配的对象将占用多个物理上连续的卡片。当对象被引用时,可以通过记录卡找到被引用的对象(见RSet)。每次回收内存时,都会处理指定分区中的卡片。
2.1.3Memory Set RSet
RS(Remember Set)是一个抽象概念,用于记录从非集合部分到集合部分的指针集合。
在传统的分代垃圾采集算法中,RS(Remember Set)用于记录代际之间的指针。在 G1 采集器中,RS 用于记录从其他区域到一个区域的指针。因此,一个Region就有一个RS。这种记录可以带来很大的好处:回收一个Region的时候,不需要进行全堆扫描,只需要检查它的RS就可以找到外部引用,而这些引用是初始的root之一标记。
RSet底层是通过HashTable实现的(可以理解,这其实是一个抽象的概念),key是被引用对象所在Region的内存起始地址,value是Card Table的索引引用对象所在的位置。
也假设现在Region A中object的第四个block引用了Region B中的object,那么Region A的card table的第三位设置为Dirty(1),然后Region B中的RSet添加一条记录,其中key为Region A的内存起始地址,value为Region A的对象所在卡片表中的索引3,这样回收Region B时,只需要扫描Region B 的 RSet 作为 GC ROOTS 对象。
RSet 的更新不是同步完成的。G1会将所有的引用关系放到一个队列中,称为Dirty Card Queue(DCQ),然后使用一个单独的线程来消费这个队列来完成更新。这是因为对象的引用变化太频繁,队列用于异步削峰。参数 -XX:G1ConcRefinementThreads 可用于指定消费者线程的数量。
使用空间来交换时间,使用额外的空间来维护参考信息通常会消耗5%到10%的空间。
写屏障(write barrier):当对象的引用发生变化时,插入一个写屏障来维护RSet。这个写屏障不是Java内存模型中写屏障的概念。
事实上,并不是所有的引用都需要记录在 RSet 中。如果确定要扫描某个分区,则无需RSet就可以无遗漏地获得引用关系。那么对源自该分区的对象的引用当然不需要落入 RSet;同时,G1 GC 每次都将年轻代作为一个整体采集,因此对源自年轻代的对象的引用不需要记录在 RSet 中。最后,只有老一代分区可能有 RSet 记录。这些分区被称为一个 RSet 的拥有区域(an RSet's owning region)。
修改RS也会遇到并发问题。因为一个Region可能会被多个线程并发修改,所以他们也会并发修改RS。为了避免这样的冲突,G1垃圾采集器进一步将RS划分为多个哈希表。每个线程都在其自己的哈希表中进行修改。最后,从逻辑上讲,RS 是这些哈希表的集合。哈希表是实现 RS 的常用方法之一。它有一个很大的优点,就是可以去除重复。这意味着 RS 的大小将等于修改指针的数量。不进行重复数据删除时,RS 的数量相当于写操作的数量。
图中RS的虚线表的名称是,RS不是与Card Table分离的不同数据结构,而是将RS作为概念模型来指代。实际上,Card Table 是 RS 的一个实现。
关联:
2.1.4Per Region Table
RSet 内部使用 Per Region Table (PRT) 来记录分区的引用。由于RSet记录占用了分区的空间,如果一个分区很“流行”,RSet占用的空间就会增加,从而减少了该分区的可用空间。G1通过改变RSet的密度来应对这个问题,并且会在PRT中以三种模式记录引用:
从上面可以看出,粗粒度的PRT只记录引用次数,需要扫描整个栈才能找到所有引用,所以扫描速度也是最慢的。
2.1.5 堆 堆
G1 还可以通过 -Xms/-Xmx 指定堆空间大小。当发生年轻代回收或混合回收时,通过计算GC和应用的耗时比例自动调整堆空间大小。如果GC频率太高,通过增加heap size来降低GC频率,GC占用的时间也相应减少;目标参数-XX:GCTimeRatio是GC到应用的耗时比例,G1默认为9,而cms默认为99,因为cms的设计原则是花为尽可能少花时间在 GC 上。另外,当空间不足时,比如对象空间分配或者传输失败,G1会先尝试增加堆空间。如果扩展失败,它将启动一个有保证的 Full GC。Full GC 后,
2.2代机型2.2.1代
分代垃圾回收可以专注于最近分配的对象,而无需扫描整个堆,避免复制长期存在的对象,独立回收可以帮助减少响应时间。虽然分区使得内存分配不再需要紧凑的内存空间,但 G1 仍然使用生成的思想。与其他垃圾回收器类似,G1在逻辑上将内存划分为年轻代和老年代,年轻代划分为Eden空间和Survivor空间。但是,年轻代空间并不是固定的。当现有的年轻代分区已满时,JVM 会分配一个新的空闲分区加入年轻代空间。
整个年轻代内存会在初始空间-XX:G1NewSizePercent(默认整堆5%)和最大空间(默认60%)之间动态变化,参数目标暂停时间-XX:MaxGCPauseMillis(默认200ms),需要被扩展和收缩的内容的大小是通过-XX:G1MaxNewSizePercent和分区的内存集(RSet)来计算的。当然,G1 仍然可以设置一个固定的年轻代大小(参数 -XX:NewRatio, -Xmn),但是同时挂起目标是没有意义的。
2.2.2 本地分配缓冲区
本地分配缓冲区(实验室)
值得注意的是,由于分区的思想,每个线程都可以“声明”一个分区用于线程本地内存分配,而不管分区是否连续。因此,每个应用线程和GC线程都会独立使用分区,从而减少同步时间,提高GC效率。此分区称为本地分配缓冲区 (Lab)。
其中,应用线程可以独占一个本地缓冲区(TLAB)来创建对象,大部分都会落入Eden区(巨大对象或分配失败除外),所以TLAB分区属于Eden空间;并且每次垃圾回收时,每个GC线程也可以使用一个独占的本地缓冲区(GCLAB)来传输对象。每次采集对象时,都会将对象复制到Suvivor空间或旧空间;用于从Eden/Survivor 空间提升到Survivor/old 空间GC 的对象也有一个GC 专用的本地缓冲区用于操作,这部分称为提升本地缓冲区(PLAB)。
2.3 分区模型
G1以区域为内存单位,以卡片(Card)为单位分配对象。
2.3.1 巨域
大小达到或超过分区大小一半的对象称为巨型对象。当一个线程为huge分配空间时,不能简单地在TLAB中分配,因为huge对象的移动成本非常高,一个分区可能无法容纳huge对象。因此,巨大的对象会直接分配到老年代,占用的连续空间称为Humongous Region。G1做了内部优化。一旦发现没有引用指向一个巨型对象,就可以直接在年轻代回收循环中回收。
一个巨大的对象将独占一个或多个连续的分区。第一个分区标记为StartsHumongous,相邻的连续分区标记为ContinuesHumongous。由于无法享受Lab带来的优化,而且需要扫描整堆来确定一个连续的内存空间,因此确定巨物起始位置的成本非常高。如果可能,应用程序应避免生成巨型对象。
2.4 采集集(CSet)
采集集 (CSet) 表示每次 GC 暂停时回收的一系列目标分区。在任何采集暂停中,CSet 的所有分区都将被释放,内部幸存的对象将被转移到分配的空闲分区。因此,无论是年轻代采集还是混合采集,工作机制都是一样的。年轻代集合CSet只容纳年轻代分区,而混合集合会使用启发式算法在老年代的候选回收分区中筛选出回收收益最高的分区,加入到CSet中。
可以通过活动阈值-XX:G1MixedGCLiveThresholdPercent(默认85%)设置候选老年代分区的CSet访问条件,从而拦截那些回收成本巨大的对象;同时,每个混合集合可以收录候选老年代分区,可以根据CSet占堆总大小的比例设置数量上限-XX:G1OldCSetRegionThresholdPercent(默认10%)。
从上面可以看出G1的集合是按照CSet来操作的。年轻代采集和混合采集没有明显区别。最大的区别在于两个集合的触发条件。
2.4.1C集Young 采集
应用线程不断活跃后,年轻代空间会逐渐被填满。当JVM分配对象到Eden区失败(Eden区已满)时,会触发STW式的年轻代集合。在年轻代集合中,Eden分区中幸存的对象会被复制到Survivor分区;原Survivor分区中的存活对象将根据tenuring阈值、新的Survivor分区和旧的分区被提升到PLAB中。原来的年轻代分区会被整体回收。
同时,年轻代集合还负责维护对象的年龄(存活次数),并辅助判断tenuring对象是提升到Survivor分区还是老年代分区。年轻代集合首先在年龄表中维护提升对象的总大小和对象的年龄信息,然后根据年龄表,Survivor大小,和Survivor填充容量-XX:TargetSurvivorRatio(默认50%),最大任期阈值-XX:MaxTenuringThreshold(默认15),计算一个合适的任期阈值。超过任期阈值的人将被提升到老年。
2.4.2C 混合集合
年轻代不断采集后,年老代的空间会逐渐被填满。当老年代占用的空间超过IHOP阈值-XX:InitiatingHeapOccupancyPercent(默认45%)时,G1将启动混合垃圾回收循环。为了满足暂停目标,G1 可能无法一次性采集所有候选分区。因此,G1 可能会生成多个连续的混合集合和应用程序线程的交替执行。每个 STW 的混合采集类似于年轻代的采集过程。
为了确定收录年轻代集合CSet的老年代分区,JVM通过参数最大混合周期总数-XX:G1MixedGCCountTarget(默认8),堆浪费百分比-XX:G1HeapWastePercent(默认5 %). 通过候选老年代的分区总数和混合循环的最大总数决定了每次收录在CSet中的最小分区数;根据堆浪费的百分比,当集合达到参数,不会开始新的混合采集,并且每次将partition添加到CSet中,都会根据计算出的GC效率进行安排。
2.4.3 并发标记算法(三色标记法)
cms和G1使用相同的算法进行并发标记:三色标记法,使用白、灰、黑三种颜色来标记对象。白色没有标记;灰色本身是被标记的,被引用的对象是未标记的;黑色本身和引用的对象都被标记。
2.4.5 缺少标签问题
在重新标记过程中,黑色指向白色,如果不重新扫描黑色,则会丢失标记。白色 D 对象将被回收,因为没有对它的新引用。
在并发标记过程中,Mutator 将所有引用从灰色删除为白色,这将导致标记丢失。这个时候应该回收白色物体
标签不足问题有两个条件:
1.黑色物体指向白色物体
2.灰色物体对白色物体的引用消失
因此,要解决缺少标签的问题,可以打破两个条件之一:
跟踪黑到白的增加
增量更新:增量更新,注意引用的增加,remark黑色到灰色,下次重新扫描属性。cms 使用此方法。记录灰到白的消失
开头的SATB快照:注意删除引用。当灰色 -> 白色消失时,将引用推送到 GC 堆栈,以确保白色仍然可以被 GC 扫描。G1 使用这种方法。
为什么G1采用SATB而不是增量更新?
因为使用增量更新后,将黑色重新标记为灰色后,还得重新扫描之前的扫描,效率太低。
G1有RSet配合SATB。Card Table记录了RSet,RSet记录了其他对象指向自己的引用,这样就不需要扫描其他区域,只需扫描RSet即可。
也就是说,当灰色->白色参考消失时,如果没有黑色->白色,则将参考压入堆栈,在下次扫描时获取参考。由于RSet的存在,不需要扫描整个堆来找到白色的引用引用,效率比较高。SATB 和 RSet 是天作之合。
3. G1 活动周期3.1 G1 垃圾回收活动总结
3.2RSet的维护
由于无法扫描整个堆栈,需要计算分区的确切活动,因此G1需要一种增量全标记并发算法,通过维护RSet来获取准确的分区参考信息。在G1中,RSet的维护主要来自两个方面:Write Barrier和Concurrence Refinement Threads。
3.2.1 个屏障
我们首先介绍障碍的概念。Fence 是指在原生代码片段中,当某些语句被执行时,fence 代码也会被执行。而G1在赋值语句中主要使用Pre-Write Barrrier和Post-Write Barrrier。事实上,写fence的指令序列开销是非常昂贵的,应用的吞吐量会根据fence的复杂程度而降低。
预写屏障
当一个赋值语句即将执行时,等式左边的对象会修改对另一个对象的引用,那么等式左边的对象原来引用的对象所在的分区将失去一个引用,那么JVM需要在赋值语句生效前丢失记录 引用的对象。JVM 不会立即维护 RSet,而是通过批处理,将来会更新 RSet(参见 SATB)。
写后屏障
执行赋值语句时,等式右边的对象得到对左边对象的引用,等式右边的对象所在分区的RSet也要更新。同样为了减少开销,RSet 不会在写屏障发生后立即更新。它也只会记录以后批处理的更新日志(参见并发细化线程)。
3.2.2开头的快照(SATB)
Taiichi Tuasa 对增量全并发标记算法 Start Snapshot Algorithm (SATB) 的贡献主要是针对标记清除垃圾采集器的并发标记阶段。非常适合G1子块堆结构,解决了cms的主要烦恼:重新标记长时间停顿带来的潜在风险。
SATB会创建一个对象图,相当于堆的一个逻辑快照,从而保证并发标记阶段的所有垃圾对象都可以通过快照识别出来。当赋值语句发生时,应用程序会改变它的对象图,然后JVM需要记录被覆盖的对象。因此,write-before 栅栏将在引用更改之前记录SATB 日志或缓冲区中的值。每个线程将独占一个 SATB 缓冲区,最初有 256 个记录空间。当空间用完时,线程会分配一个新的SATB缓冲区继续使用,并将原来的缓冲区加入到全局列表中。最后,在并发标记阶段,Concurrent Marking Threads 会在标记的同时定期检查和处理全局缓冲区列表的记录,然后根据标记位图片段的标记位扫描参考域更新RSet。此过程也称为并发标记/SATB 写前栅栏。
在并发标记阶段,应用程序可以修改原创引用,例如删除原创引用。这会导致并发标记结束后存活对象的快照与SATB不一致。G1通过在并发标记阶段引入写屏障来解决这个问题:每当有引用更新时,G1都会将修改前的值写入日志缓冲区(这条记录会过滤掉原来的空引用),扫描SATB中的最后标记阶段以纠正SATB错误。
SATB的日志缓冲区和RS的写屏障使用的日志缓冲区一样,有两级结构,作用机制也是一样的。 查看全部
算法 自动采集列表(1.概述1.2垃圾收集器的考量指标(1.2)_概述)
1.概述1.2 垃圾采集器注意事项
垃圾采集器也有类似CAP理论的矛盾,具体有以下三个方面的考虑:
吞吐量
响应性、延迟(Latency)
内存占用(容量)
以上三个考虑不能同时满足最优,只能满足其中两个,牺牲其中之一的部分效率。
1.3 吞吐量
吞吐量与在指定时间范围内最大化应用程序的工作负载有关。
以下方法用于测量系统的吞吐量:
在一小时内,完成同一事务(任务或请求)的次数。
数据库在一小时内完成了多少查询。
对于注重吞吐量的系统,偶尔的停顿是可以接受的,因为这种系统注重长时间执行大量任务的能力,单一的快速响应不值得考虑。
1.4 响应能力
响应性是指应用程序或系统是否能够及时快速地响应,例如:
桌面 UI 程序对事件的响应速度。
网站 返回页面请求的速度有多快。
数据库返回查询结果的速度有多快。
对于这种响应敏感、低延迟的场景,长期卡顿是不能容忍的。
内存使用情况
为了加快内存扫描的数据,GC垃圾采集器通常会使用内存中的一些数据结构,比如卡表、内存集等,来存储对对象的直接引用,而这些数据本身就需要占用堆的内存空间。记录的信息越多,扫描时间越快,占用的内存也越大。
1.5 G1的诞生背景
随着硬件成本越来越低,机器的内存也越来越大。GC回收器占用的内存基本可以容忍,吞吐量可以通过集群(加机器)解决,所以STW时间对于JVM来说就变得迫切要解决的问题,如果还是按照传统的分代方式使用传统的垃圾回收器模型,那么STW时间会越来越长。
在传统的垃圾采集器中,STW 时间是不可预测的。有没有办法先定义一个暂停时间,然后向后计算采集到的内容?就像领导在年初制定KPI一样,多做多做,少做少做。
G1的思路类似。不需要每次都清理垃圾。它只是尝试做它认为正确的事情。
G1还有一个极其重要的特性:软实时(soft real time)。所谓实时垃圾回收,是指在规定的时间内完成垃圾回收。“软实时”意味着用户可以指定垃圾采集的时间限制。G1会尽量在这个时限内完成垃圾采集,但是G1不保证每次都能在这个时限内完成垃圾采集。通过设定一个合理的目标,90%以上的垃圾回收时间都可以在这个时间限制内。
我们要求 G1 在任何一秒的时间内暂停不超过 10 毫秒。这是为其制定KPI。G1将尽最大努力实现这一目标。可以逆向计算本次要采集的总面积,增量式完成采集。
这也是使用G1垃圾采集器必须设置的一个参数(-XX:+UseG1GC):-XX:MaxGCPauseMillis=10,这个参数默认为200ms。
G1的适用场景:
服务器端多核CPU、JVM内存占用应用。
应用程序运行过程中会产生大量的内存碎片,空间需要经常进行压缩。
想要一个更可控和可预测的GC暂停期,以防止高并发下的应用程序雪崩。
2. G1的内存模型2.1 Partition概念
2.1.1师区域
G1采用了region的思想,将整个堆空间划分为若干大小相等的内存区域,每次分配对象空间时,都会逐段使用内存。因此,在堆的使用上,G1并不要求对象的存储必须物理上连续,只要逻辑上连续即可;每个分区都不会肯定服务于某一代,它可以用于年轻代和老年代之间的切换。分区大小(1MB~32MB,必须是2的幂)可以在启动时通过参数-XX:G1HeapRegionSize=n指定。默认情况下,整个堆被划分为 2048 个分区。
对于那些超过整个 Region 容量的超大对象,它们将被存储在 N 个连续的 Humongous Region 中。大多数情况下,G1的回收都会将洪门地区视为老年的一部分。
G1在逻辑上划分了Eden(所有Eden区域的总和)、Survivor(所有Survivor区域的总和)和OLd(所有Old区域的总和),但物理上它们是不连续的,同一个区域在不同区域的作用期间可以不同。有可能当前区域存储了 Eden 对象。执行 YGC 后,分配给它的下一个对象可能是 Old 对象。
2.1.2张卡片
卡片表的诞生是为了解决跨代引用。假设在cms垃圾采集器中,如果要回收新生代的对象,那么就必须扫描整个老年代,而要引入卡表,只需要扫描卡表的中间脏区就够了,避免了扫描整个老年代,大大加快了并发标记的速度。
每个Region分为若干张固定大小的卡片(Card)。每张卡片使用一个Byte来记录是否被修改过。卡片表是这些字节的集合。标识堆内存和所有分区的最小可用粒度的卡将记录在全局卡表中。分配的对象将占用多个物理上连续的卡片。当对象被引用时,可以通过记录卡找到被引用的对象(见RSet)。每次回收内存时,都会处理指定分区中的卡片。
2.1.3Memory Set RSet
RS(Remember Set)是一个抽象概念,用于记录从非集合部分到集合部分的指针集合。
在传统的分代垃圾采集算法中,RS(Remember Set)用于记录代际之间的指针。在 G1 采集器中,RS 用于记录从其他区域到一个区域的指针。因此,一个Region就有一个RS。这种记录可以带来很大的好处:回收一个Region的时候,不需要进行全堆扫描,只需要检查它的RS就可以找到外部引用,而这些引用是初始的root之一标记。
RSet底层是通过HashTable实现的(可以理解,这其实是一个抽象的概念),key是被引用对象所在Region的内存起始地址,value是Card Table的索引引用对象所在的位置。
也假设现在Region A中object的第四个block引用了Region B中的object,那么Region A的card table的第三位设置为Dirty(1),然后Region B中的RSet添加一条记录,其中key为Region A的内存起始地址,value为Region A的对象所在卡片表中的索引3,这样回收Region B时,只需要扫描Region B 的 RSet 作为 GC ROOTS 对象。
RSet 的更新不是同步完成的。G1会将所有的引用关系放到一个队列中,称为Dirty Card Queue(DCQ),然后使用一个单独的线程来消费这个队列来完成更新。这是因为对象的引用变化太频繁,队列用于异步削峰。参数 -XX:G1ConcRefinementThreads 可用于指定消费者线程的数量。
使用空间来交换时间,使用额外的空间来维护参考信息通常会消耗5%到10%的空间。
写屏障(write barrier):当对象的引用发生变化时,插入一个写屏障来维护RSet。这个写屏障不是Java内存模型中写屏障的概念。
事实上,并不是所有的引用都需要记录在 RSet 中。如果确定要扫描某个分区,则无需RSet就可以无遗漏地获得引用关系。那么对源自该分区的对象的引用当然不需要落入 RSet;同时,G1 GC 每次都将年轻代作为一个整体采集,因此对源自年轻代的对象的引用不需要记录在 RSet 中。最后,只有老一代分区可能有 RSet 记录。这些分区被称为一个 RSet 的拥有区域(an RSet's owning region)。
修改RS也会遇到并发问题。因为一个Region可能会被多个线程并发修改,所以他们也会并发修改RS。为了避免这样的冲突,G1垃圾采集器进一步将RS划分为多个哈希表。每个线程都在其自己的哈希表中进行修改。最后,从逻辑上讲,RS 是这些哈希表的集合。哈希表是实现 RS 的常用方法之一。它有一个很大的优点,就是可以去除重复。这意味着 RS 的大小将等于修改指针的数量。不进行重复数据删除时,RS 的数量相当于写操作的数量。
图中RS的虚线表的名称是,RS不是与Card Table分离的不同数据结构,而是将RS作为概念模型来指代。实际上,Card Table 是 RS 的一个实现。
关联:
2.1.4Per Region Table
RSet 内部使用 Per Region Table (PRT) 来记录分区的引用。由于RSet记录占用了分区的空间,如果一个分区很“流行”,RSet占用的空间就会增加,从而减少了该分区的可用空间。G1通过改变RSet的密度来应对这个问题,并且会在PRT中以三种模式记录引用:
从上面可以看出,粗粒度的PRT只记录引用次数,需要扫描整个栈才能找到所有引用,所以扫描速度也是最慢的。
2.1.5 堆 堆
G1 还可以通过 -Xms/-Xmx 指定堆空间大小。当发生年轻代回收或混合回收时,通过计算GC和应用的耗时比例自动调整堆空间大小。如果GC频率太高,通过增加heap size来降低GC频率,GC占用的时间也相应减少;目标参数-XX:GCTimeRatio是GC到应用的耗时比例,G1默认为9,而cms默认为99,因为cms的设计原则是花为尽可能少花时间在 GC 上。另外,当空间不足时,比如对象空间分配或者传输失败,G1会先尝试增加堆空间。如果扩展失败,它将启动一个有保证的 Full GC。Full GC 后,
2.2代机型2.2.1代
分代垃圾回收可以专注于最近分配的对象,而无需扫描整个堆,避免复制长期存在的对象,独立回收可以帮助减少响应时间。虽然分区使得内存分配不再需要紧凑的内存空间,但 G1 仍然使用生成的思想。与其他垃圾回收器类似,G1在逻辑上将内存划分为年轻代和老年代,年轻代划分为Eden空间和Survivor空间。但是,年轻代空间并不是固定的。当现有的年轻代分区已满时,JVM 会分配一个新的空闲分区加入年轻代空间。
整个年轻代内存会在初始空间-XX:G1NewSizePercent(默认整堆5%)和最大空间(默认60%)之间动态变化,参数目标暂停时间-XX:MaxGCPauseMillis(默认200ms),需要被扩展和收缩的内容的大小是通过-XX:G1MaxNewSizePercent和分区的内存集(RSet)来计算的。当然,G1 仍然可以设置一个固定的年轻代大小(参数 -XX:NewRatio, -Xmn),但是同时挂起目标是没有意义的。
2.2.2 本地分配缓冲区
本地分配缓冲区(实验室)
值得注意的是,由于分区的思想,每个线程都可以“声明”一个分区用于线程本地内存分配,而不管分区是否连续。因此,每个应用线程和GC线程都会独立使用分区,从而减少同步时间,提高GC效率。此分区称为本地分配缓冲区 (Lab)。
其中,应用线程可以独占一个本地缓冲区(TLAB)来创建对象,大部分都会落入Eden区(巨大对象或分配失败除外),所以TLAB分区属于Eden空间;并且每次垃圾回收时,每个GC线程也可以使用一个独占的本地缓冲区(GCLAB)来传输对象。每次采集对象时,都会将对象复制到Suvivor空间或旧空间;用于从Eden/Survivor 空间提升到Survivor/old 空间GC 的对象也有一个GC 专用的本地缓冲区用于操作,这部分称为提升本地缓冲区(PLAB)。
2.3 分区模型
G1以区域为内存单位,以卡片(Card)为单位分配对象。
2.3.1 巨域
大小达到或超过分区大小一半的对象称为巨型对象。当一个线程为huge分配空间时,不能简单地在TLAB中分配,因为huge对象的移动成本非常高,一个分区可能无法容纳huge对象。因此,巨大的对象会直接分配到老年代,占用的连续空间称为Humongous Region。G1做了内部优化。一旦发现没有引用指向一个巨型对象,就可以直接在年轻代回收循环中回收。
一个巨大的对象将独占一个或多个连续的分区。第一个分区标记为StartsHumongous,相邻的连续分区标记为ContinuesHumongous。由于无法享受Lab带来的优化,而且需要扫描整堆来确定一个连续的内存空间,因此确定巨物起始位置的成本非常高。如果可能,应用程序应避免生成巨型对象。
2.4 采集集(CSet)
采集集 (CSet) 表示每次 GC 暂停时回收的一系列目标分区。在任何采集暂停中,CSet 的所有分区都将被释放,内部幸存的对象将被转移到分配的空闲分区。因此,无论是年轻代采集还是混合采集,工作机制都是一样的。年轻代集合CSet只容纳年轻代分区,而混合集合会使用启发式算法在老年代的候选回收分区中筛选出回收收益最高的分区,加入到CSet中。
可以通过活动阈值-XX:G1MixedGCLiveThresholdPercent(默认85%)设置候选老年代分区的CSet访问条件,从而拦截那些回收成本巨大的对象;同时,每个混合集合可以收录候选老年代分区,可以根据CSet占堆总大小的比例设置数量上限-XX:G1OldCSetRegionThresholdPercent(默认10%)。
从上面可以看出G1的集合是按照CSet来操作的。年轻代采集和混合采集没有明显区别。最大的区别在于两个集合的触发条件。
2.4.1C集Young 采集
应用线程不断活跃后,年轻代空间会逐渐被填满。当JVM分配对象到Eden区失败(Eden区已满)时,会触发STW式的年轻代集合。在年轻代集合中,Eden分区中幸存的对象会被复制到Survivor分区;原Survivor分区中的存活对象将根据tenuring阈值、新的Survivor分区和旧的分区被提升到PLAB中。原来的年轻代分区会被整体回收。
同时,年轻代集合还负责维护对象的年龄(存活次数),并辅助判断tenuring对象是提升到Survivor分区还是老年代分区。年轻代集合首先在年龄表中维护提升对象的总大小和对象的年龄信息,然后根据年龄表,Survivor大小,和Survivor填充容量-XX:TargetSurvivorRatio(默认50%),最大任期阈值-XX:MaxTenuringThreshold(默认15),计算一个合适的任期阈值。超过任期阈值的人将被提升到老年。
2.4.2C 混合集合
年轻代不断采集后,年老代的空间会逐渐被填满。当老年代占用的空间超过IHOP阈值-XX:InitiatingHeapOccupancyPercent(默认45%)时,G1将启动混合垃圾回收循环。为了满足暂停目标,G1 可能无法一次性采集所有候选分区。因此,G1 可能会生成多个连续的混合集合和应用程序线程的交替执行。每个 STW 的混合采集类似于年轻代的采集过程。
为了确定收录年轻代集合CSet的老年代分区,JVM通过参数最大混合周期总数-XX:G1MixedGCCountTarget(默认8),堆浪费百分比-XX:G1HeapWastePercent(默认5 %). 通过候选老年代的分区总数和混合循环的最大总数决定了每次收录在CSet中的最小分区数;根据堆浪费的百分比,当集合达到参数,不会开始新的混合采集,并且每次将partition添加到CSet中,都会根据计算出的GC效率进行安排。
2.4.3 并发标记算法(三色标记法)
cms和G1使用相同的算法进行并发标记:三色标记法,使用白、灰、黑三种颜色来标记对象。白色没有标记;灰色本身是被标记的,被引用的对象是未标记的;黑色本身和引用的对象都被标记。
2.4.5 缺少标签问题
在重新标记过程中,黑色指向白色,如果不重新扫描黑色,则会丢失标记。白色 D 对象将被回收,因为没有对它的新引用。
在并发标记过程中,Mutator 将所有引用从灰色删除为白色,这将导致标记丢失。这个时候应该回收白色物体
标签不足问题有两个条件:
1.黑色物体指向白色物体
2.灰色物体对白色物体的引用消失
因此,要解决缺少标签的问题,可以打破两个条件之一:
跟踪黑到白的增加
增量更新:增量更新,注意引用的增加,remark黑色到灰色,下次重新扫描属性。cms 使用此方法。记录灰到白的消失
开头的SATB快照:注意删除引用。当灰色 -> 白色消失时,将引用推送到 GC 堆栈,以确保白色仍然可以被 GC 扫描。G1 使用这种方法。
为什么G1采用SATB而不是增量更新?
因为使用增量更新后,将黑色重新标记为灰色后,还得重新扫描之前的扫描,效率太低。
G1有RSet配合SATB。Card Table记录了RSet,RSet记录了其他对象指向自己的引用,这样就不需要扫描其他区域,只需扫描RSet即可。
也就是说,当灰色->白色参考消失时,如果没有黑色->白色,则将参考压入堆栈,在下次扫描时获取参考。由于RSet的存在,不需要扫描整个堆来找到白色的引用引用,效率比较高。SATB 和 RSet 是天作之合。
3. G1 活动周期3.1 G1 垃圾回收活动总结
3.2RSet的维护
由于无法扫描整个堆栈,需要计算分区的确切活动,因此G1需要一种增量全标记并发算法,通过维护RSet来获取准确的分区参考信息。在G1中,RSet的维护主要来自两个方面:Write Barrier和Concurrence Refinement Threads。
3.2.1 个屏障
我们首先介绍障碍的概念。Fence 是指在原生代码片段中,当某些语句被执行时,fence 代码也会被执行。而G1在赋值语句中主要使用Pre-Write Barrrier和Post-Write Barrrier。事实上,写fence的指令序列开销是非常昂贵的,应用的吞吐量会根据fence的复杂程度而降低。
预写屏障
当一个赋值语句即将执行时,等式左边的对象会修改对另一个对象的引用,那么等式左边的对象原来引用的对象所在的分区将失去一个引用,那么JVM需要在赋值语句生效前丢失记录 引用的对象。JVM 不会立即维护 RSet,而是通过批处理,将来会更新 RSet(参见 SATB)。
写后屏障
执行赋值语句时,等式右边的对象得到对左边对象的引用,等式右边的对象所在分区的RSet也要更新。同样为了减少开销,RSet 不会在写屏障发生后立即更新。它也只会记录以后批处理的更新日志(参见并发细化线程)。
3.2.2开头的快照(SATB)
Taiichi Tuasa 对增量全并发标记算法 Start Snapshot Algorithm (SATB) 的贡献主要是针对标记清除垃圾采集器的并发标记阶段。非常适合G1子块堆结构,解决了cms的主要烦恼:重新标记长时间停顿带来的潜在风险。
SATB会创建一个对象图,相当于堆的一个逻辑快照,从而保证并发标记阶段的所有垃圾对象都可以通过快照识别出来。当赋值语句发生时,应用程序会改变它的对象图,然后JVM需要记录被覆盖的对象。因此,write-before 栅栏将在引用更改之前记录SATB 日志或缓冲区中的值。每个线程将独占一个 SATB 缓冲区,最初有 256 个记录空间。当空间用完时,线程会分配一个新的SATB缓冲区继续使用,并将原来的缓冲区加入到全局列表中。最后,在并发标记阶段,Concurrent Marking Threads 会在标记的同时定期检查和处理全局缓冲区列表的记录,然后根据标记位图片段的标记位扫描参考域更新RSet。此过程也称为并发标记/SATB 写前栅栏。
在并发标记阶段,应用程序可以修改原创引用,例如删除原创引用。这会导致并发标记结束后存活对象的快照与SATB不一致。G1通过在并发标记阶段引入写屏障来解决这个问题:每当有引用更新时,G1都会将修改前的值写入日志缓冲区(这条记录会过滤掉原来的空引用),扫描SATB中的最后标记阶段以纠正SATB错误。
SATB的日志缓冲区和RS的写屏障使用的日志缓冲区一样,有两级结构,作用机制也是一样的。

