
算法 自动采集列表
算法 自动采集列表(优采云心愿软件站下载使用吧!采集器软件特色介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-11-17 13:10
优采云采集器是谷歌原技术团队打造的一款非常优秀实用的免费网络数据采集软件。该软件非常强大,可以直观地点击和点击。采集网页数据非常方便快捷,优采云采集器全平台免费版,Win/Mac/Linux都有,采集和导出都是免费的,无限使用,可后台运行,可实时显示速度。有需要的朋友,快来Wish软件站下载使用吧!
优采云采集器软件特点
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
软件根据采集处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出发布采集的数据
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
优采云采集器免费版软件亮点:
智能采集
智能分析提取列表/表格数据,并能自动识别分页。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等。
跨平台支持
优采云采集器支持多种操作系统,包括Windows、Mac和Linux。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
各种数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持将数据导出到数据库。
云账号
采集 任务自动保存到云端,不用担心丢失。一个账号多终端操作,随时随地创建和修改采集任务。
优采云采集器软件优势:
全过程自动提取数据
优采云可以智能识别要提取的数据并进行分页,是网页采集最简单的方式。
视觉点击操作
可视化整个过程,点击修改要提取的数据等,大家可以使用采集器。
多种采集模式,任意网站均可使用
支持智能先进的采集,满足不同的采集需求。支持 XPATH、JSON、HTTP 和 POST 等。
软件箭头速度迭代
软件定期更新升级,不断增加新功能。客户的满意就是对我们最大的肯定!
优采云采集器 功能:
智能识别和数据提取
优采云独特的智能模式采集,可以帮助用户自动识别和提取列表和表格数据,
并能自动识别寻呼。只需输入首页链接到采集,这是最简单的采集方式!
自动提取:列表、表格、分页按钮、瀑布式分页等。
全平台支持
不同于其他采集器,所有操作系统都可以安装使用优采云采集器,包括Windows、Mac和Linux。个人和团队都可以使用,可以满足不同的团队配置。
任何网站都可以接
除了智能模式,优采云还提供了高级模式采集,全程可视化点击操作,保证轻松采集all网站。使用先进的机器学习算法可以更准确地提取所需的数据。
支持所有网页:登录后采集、图片下载、JSON、Javascript、AJAX、html源代码、搜索结果采集等。
多种数据导出方式
一键导出所有采集数据,支持导出到本地文件(EXCEL、CSV、HTML等),支持直接导出数据到数据库。
满足企业需求采集
优采云采集器还提供了更多更丰富的功能来满足团队和企业不同的采集需求。包括采集过程中图片等文件的自动下载、采集网址的动态批量导入、广告自动拦截、多任务同时运行、定时运行等。
了解详细功能:登录后采集、图片下载、JSON、Javascript、AJAX、html源代码、搜索结果采集等。
云账号
创建优采云账号后,您的所有采集任务都会自动保存在云端。不用担心丢失任务。一个账号可以在多个终端上使用,让任务管理更简单方便。
指示
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
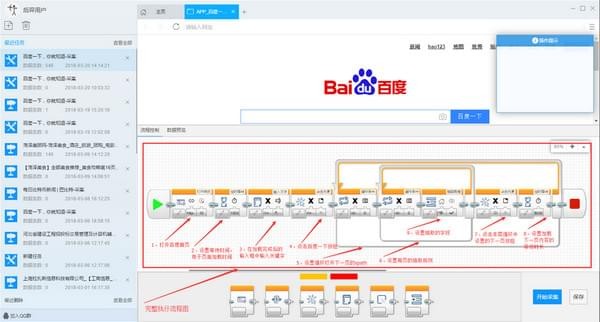
第二步:自定义采集流程
1) 点击创建后,会自动打开第一个网址,然后进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址
2)添加输入文本流块:将底部模板区域中的输入文本块拖到打开的网页块的后面附近。出现阴影区域时松开鼠标,此时会自动连接,添加完成
3) 生成一个完整的流程图: 按照上面添加输入文本流程块的拖放流程添加一个新块:如下图所示:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页中的数据要循环提取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择当前循环中元素的xpath选项。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环使用元素按钮,选择循环使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后,选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集 数据导出如下图
优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Both Mac和Linux可用,采集和导出都是免费的,无限制,放心,后台运行,速度实时显示。 查看全部
算法 自动采集列表(优采云心愿软件站下载使用吧!采集器软件特色介绍)
优采云采集器是谷歌原技术团队打造的一款非常优秀实用的免费网络数据采集软件。该软件非常强大,可以直观地点击和点击。采集网页数据非常方便快捷,优采云采集器全平台免费版,Win/Mac/Linux都有,采集和导出都是免费的,无限使用,可后台运行,可实时显示速度。有需要的朋友,快来Wish软件站下载使用吧!
优采云采集器软件特点
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
软件根据采集处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出发布采集的数据
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
优采云采集器免费版软件亮点:
智能采集
智能分析提取列表/表格数据,并能自动识别分页。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等。
跨平台支持
优采云采集器支持多种操作系统,包括Windows、Mac和Linux。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
各种数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持将数据导出到数据库。
云账号
采集 任务自动保存到云端,不用担心丢失。一个账号多终端操作,随时随地创建和修改采集任务。
优采云采集器软件优势:
全过程自动提取数据
优采云可以智能识别要提取的数据并进行分页,是网页采集最简单的方式。
视觉点击操作
可视化整个过程,点击修改要提取的数据等,大家可以使用采集器。
多种采集模式,任意网站均可使用
支持智能先进的采集,满足不同的采集需求。支持 XPATH、JSON、HTTP 和 POST 等。
软件箭头速度迭代
软件定期更新升级,不断增加新功能。客户的满意就是对我们最大的肯定!
优采云采集器 功能:
智能识别和数据提取
优采云独特的智能模式采集,可以帮助用户自动识别和提取列表和表格数据,
并能自动识别寻呼。只需输入首页链接到采集,这是最简单的采集方式!
自动提取:列表、表格、分页按钮、瀑布式分页等。
全平台支持
不同于其他采集器,所有操作系统都可以安装使用优采云采集器,包括Windows、Mac和Linux。个人和团队都可以使用,可以满足不同的团队配置。
任何网站都可以接
除了智能模式,优采云还提供了高级模式采集,全程可视化点击操作,保证轻松采集all网站。使用先进的机器学习算法可以更准确地提取所需的数据。
支持所有网页:登录后采集、图片下载、JSON、Javascript、AJAX、html源代码、搜索结果采集等。
多种数据导出方式
一键导出所有采集数据,支持导出到本地文件(EXCEL、CSV、HTML等),支持直接导出数据到数据库。
满足企业需求采集
优采云采集器还提供了更多更丰富的功能来满足团队和企业不同的采集需求。包括采集过程中图片等文件的自动下载、采集网址的动态批量导入、广告自动拦截、多任务同时运行、定时运行等。
了解详细功能:登录后采集、图片下载、JSON、Javascript、AJAX、html源代码、搜索结果采集等。
云账号
创建优采云账号后,您的所有采集任务都会自动保存在云端。不用担心丢失任务。一个账号可以在多个终端上使用,让任务管理更简单方便。
指示
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
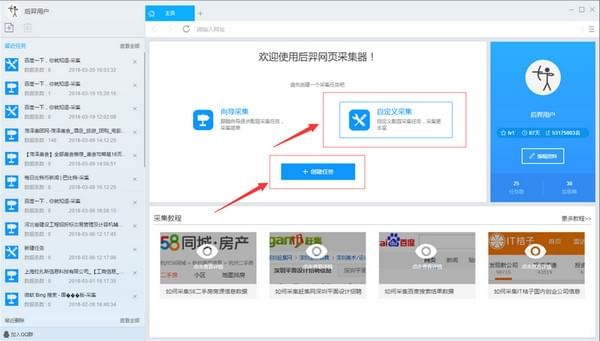
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址

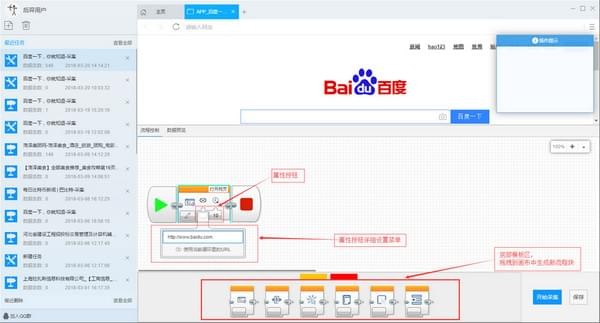
第二步:自定义采集流程
1) 点击创建后,会自动打开第一个网址,然后进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址
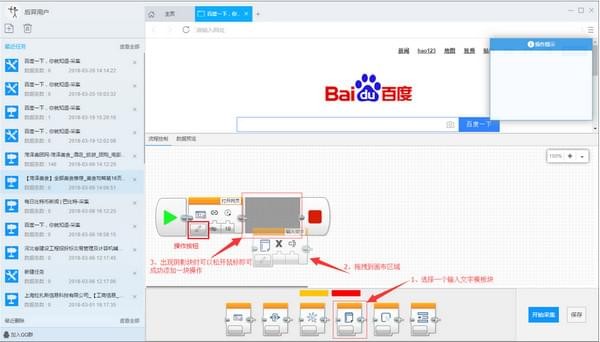
2)添加输入文本流块:将底部模板区域中的输入文本块拖到打开的网页块的后面附近。出现阴影区域时松开鼠标,此时会自动连接,添加完成
3) 生成一个完整的流程图: 按照上面添加输入文本流程块的拖放流程添加一个新块:如下图所示:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页中的数据要循环提取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择当前循环中元素的xpath选项。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环使用元素按钮,选择循环使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
4)点击开始采集,开始采集
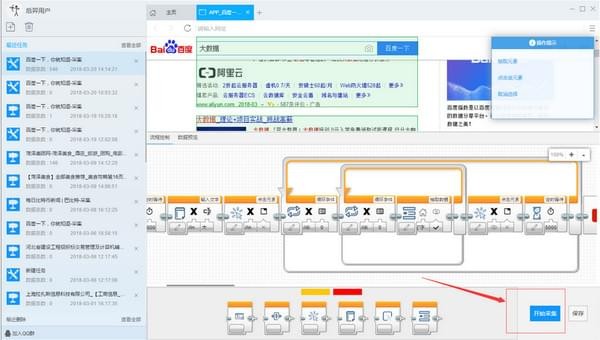
第三步:数据采集并导出
1)采集 任务正在运行
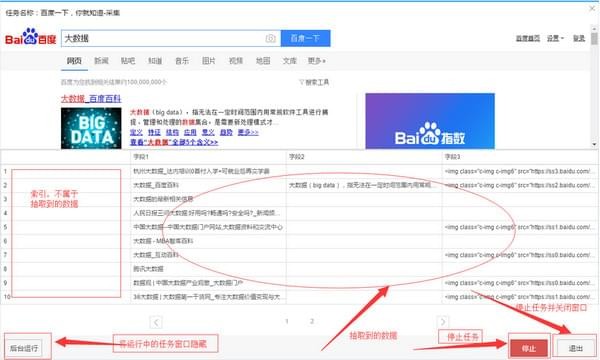
2)采集 完成后,选择“导出数据”将所有数据导出到本地文件
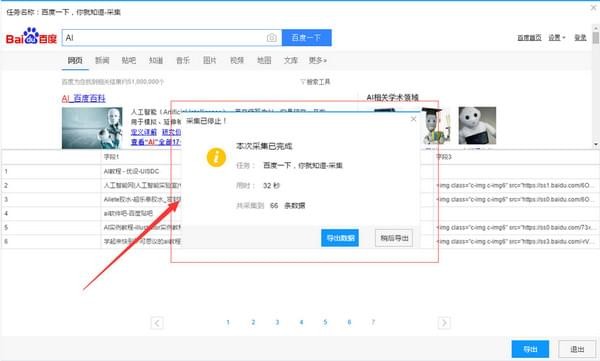
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
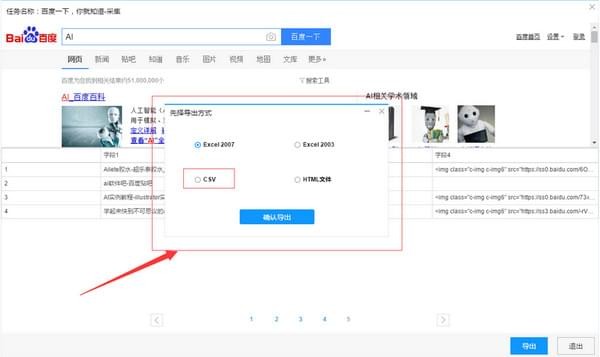
4)采集 数据导出如下图

优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Both Mac和Linux可用,采集和导出都是免费的,无限制,放心,后台运行,速度实时显示。
算法 自动采集列表(百度贴吧盈利不知道,怎么办?如何挖掘应用?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-15 20:05
算法自动采集列表、页面内容以及联系人、短信等内容数据;聚合内容数据:记录百度全网、baidu站内地图、百度日历等各类站内内容数据信息;统计分析:即时统计百度内部各分析结果(百度站内外站内外站外等多渠道爬取统计);应用案例:百度历史热门帖子,历史热门回帖,各类站内及搜索指数统计等;百度提供的一系列新业务都会对roi带来影响,有无方法应对很重要,比如社交和百度站内搜索、相关推荐等等。
盈利不盈利不知道,但是知道百度要活下去肯定要往这个方向挖掘应用例如贴吧资源
百度贴吧的盈利点
可以看看小红帽,效果挺好,但是你要是想玩信息流的话,还是用360网盟推广比较好,另外小红帽被收购了,是可以免费推广的,赚推广费用分成。
基本的盈利模式有的是,百度在一个方面上面做的比较好,就是收购了高德和搜狗。就像张朝阳说的,未来去中心化的服务必然会出现在网络上。就这个市场,百度比国内几乎一半的公司做的都好,没必要在百度身上赚钱。网络是一个朝阳产业,国内缺少这方面的人才,对国内人才不够尊重,普通员工去从事这样一个很重要的市场,可能一开始会遇到很多问题,等到积累了一定的口碑,赚钱是自然的事情。
百度最新的财报里讲的大数据市场,应该讲目前的经济中大数据的需求量越来越大了,根据百度年报,百度2015年移动搜索业务下的广告支出已经超过103.1亿人民币,这是2014年的零头,这个对于一个创业公司来说已经是巨大的研发投入,百度竞价/自然排名相关付费服务,也在不断突破瓶颈,已经在不断开拓新的盈利方式,像是竞价/自然排名的页面搜索广告等也非常赚钱。至于老虎、威胁之类的还是其次。真要盈利真的不是个小事情。 查看全部
算法 自动采集列表(百度贴吧盈利不知道,怎么办?如何挖掘应用?)
算法自动采集列表、页面内容以及联系人、短信等内容数据;聚合内容数据:记录百度全网、baidu站内地图、百度日历等各类站内内容数据信息;统计分析:即时统计百度内部各分析结果(百度站内外站内外站外等多渠道爬取统计);应用案例:百度历史热门帖子,历史热门回帖,各类站内及搜索指数统计等;百度提供的一系列新业务都会对roi带来影响,有无方法应对很重要,比如社交和百度站内搜索、相关推荐等等。
盈利不盈利不知道,但是知道百度要活下去肯定要往这个方向挖掘应用例如贴吧资源
百度贴吧的盈利点
可以看看小红帽,效果挺好,但是你要是想玩信息流的话,还是用360网盟推广比较好,另外小红帽被收购了,是可以免费推广的,赚推广费用分成。
基本的盈利模式有的是,百度在一个方面上面做的比较好,就是收购了高德和搜狗。就像张朝阳说的,未来去中心化的服务必然会出现在网络上。就这个市场,百度比国内几乎一半的公司做的都好,没必要在百度身上赚钱。网络是一个朝阳产业,国内缺少这方面的人才,对国内人才不够尊重,普通员工去从事这样一个很重要的市场,可能一开始会遇到很多问题,等到积累了一定的口碑,赚钱是自然的事情。
百度最新的财报里讲的大数据市场,应该讲目前的经济中大数据的需求量越来越大了,根据百度年报,百度2015年移动搜索业务下的广告支出已经超过103.1亿人民币,这是2014年的零头,这个对于一个创业公司来说已经是巨大的研发投入,百度竞价/自然排名相关付费服务,也在不断突破瓶颈,已经在不断开拓新的盈利方式,像是竞价/自然排名的页面搜索广告等也非常赚钱。至于老虎、威胁之类的还是其次。真要盈利真的不是个小事情。
算法 自动采集列表(JSP婚纱预约管理系统java编程开发语言源码特点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-14 17:03
一、源码特点 JSP婚纱预约管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统源代码和数据库齐全,系统主要采用B/S模式开发。二、功能介绍 前台的主要功能:套餐浏览和预订。关于我们。介绍作品。欣赏摄影地点。查看服务流程。介绍用户注册、登录和提交订单。添加、删除、修改、查看信息(2)用户管理:添加、删除、修改、查看用户信息(3)工作欣赏管理:添加、删除、修改、查看(4)服务进程管理:添加、删除、 查看全部
算法 自动采集列表(JSP婚纱预约管理系统java编程开发语言源码特点)
一、源码特点 JSP婚纱预约管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统源代码和数据库齐全,系统主要采用B/S模式开发。二、功能介绍 前台的主要功能:套餐浏览和预订。关于我们。介绍作品。欣赏摄影地点。查看服务流程。介绍用户注册、登录和提交订单。添加、删除、修改、查看信息(2)用户管理:添加、删除、修改、查看用户信息(3)工作欣赏管理:添加、删除、修改、查看(4)服务进程管理:添加、删除、
算法 自动采集列表(,晨域网站采集程序具有较强的灵活性,可抓取条件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-13 05:08
杭州影业采集网站更多服务,晨宇网站采集方案灵活性强,可定制网站采集方案,用户可以直接去一个网站抓取用户想要的特定栏目下的信息,只需要用户提出一个特定的抓取条件,用户需要的内容就会被自动抓取并保存,这样用户在线搜索信息已经转变为信息自动流向用户的方式。
批量脱水算法的值形态学的应用是将已知图像的值形态学操作扩展到灰度扩展和侵蚀中的图像。图像的腐蚀(膨胀)操作定义为将每个像素分配给输入图像某一区域内灰度级的最小值(或最大值)。值变换中的结构元素仅代表一个字段,而在灰度变化中,结构元素是一个元函数,它指定了所需的局部灰度属性。在求邻域最大值(或最小值)的同时,加(减)结构元素的值,以达到图像色彩还原的最终效果。
除了图片水印去除,公司还提供数据采集图片批量采集视频水印去除等服务。我们的长期客户包括服装、鞋帽、箱包、钟表、电子、工业用品、交通运输、房地产采集等行业。
晨宇影业采集程序支持多线程处理技术,支持多线程同时抓取网站数据。可以快速高效地对目标站点或栏目进行信息采集,大大加快了信息数据采集的速度,单位时间内采集的信息量呈指数级增长。
图像批量去水印。变换水印算法是一种新的研究算法,因为该技术对脱水具有较好的不可感知性和鲁棒性(robustness)。变换水印算法是在嵌入水印数据之前对原创图像信息进行比较。这种可逆的数字变换是根据水印的对应索引修改变换域的某些系数来实现水印的嵌入,然后利用逆变换重构嵌入水印的数据,从而实现水印去除效果***。
由于图像水印需求量大,以及Photoshop手动去除水印的复杂性和低效性,晨宇软件工作室20年来一直致力于研究图像算法和批量水印解决方案。批量水印程序主要包括一些算法,快速水印算法,水印类别识别算法,水印随机位置识别算法。经过长时间的算法优化,水印批处理可以做到***去除不留痕迹。可以对批量添加的水印进行逆计算,还原图片的原创颜色。
我们的主要业务包括图片批量脱水、图片视频脱水采集data采集等,长期合作客户包括箱包、水印、手表、电子产品、工业用品、水印、房地产、医药、美术、水印等行业。对有更高要求的图片,也可以结合图片质量,提供高精度的色彩还原服务,如用于影视3冲印照片。
为了减少计算次数和计算时间,快速水印算法在去除干扰和噪声点的影响时不使用图像平滑和频域变换低通滤波技术,而是对图像灰度直方图进行平滑处理。图像预处理后,计算垂直定位。首先,计算图像的水平灰度投影曲线。 查看全部
算法 自动采集列表(,晨域网站采集程序具有较强的灵活性,可抓取条件)
杭州影业采集网站更多服务,晨宇网站采集方案灵活性强,可定制网站采集方案,用户可以直接去一个网站抓取用户想要的特定栏目下的信息,只需要用户提出一个特定的抓取条件,用户需要的内容就会被自动抓取并保存,这样用户在线搜索信息已经转变为信息自动流向用户的方式。

批量脱水算法的值形态学的应用是将已知图像的值形态学操作扩展到灰度扩展和侵蚀中的图像。图像的腐蚀(膨胀)操作定义为将每个像素分配给输入图像某一区域内灰度级的最小值(或最大值)。值变换中的结构元素仅代表一个字段,而在灰度变化中,结构元素是一个元函数,它指定了所需的局部灰度属性。在求邻域最大值(或最小值)的同时,加(减)结构元素的值,以达到图像色彩还原的最终效果。
除了图片水印去除,公司还提供数据采集图片批量采集视频水印去除等服务。我们的长期客户包括服装、鞋帽、箱包、钟表、电子、工业用品、交通运输、房地产采集等行业。

晨宇影业采集程序支持多线程处理技术,支持多线程同时抓取网站数据。可以快速高效地对目标站点或栏目进行信息采集,大大加快了信息数据采集的速度,单位时间内采集的信息量呈指数级增长。
图像批量去水印。变换水印算法是一种新的研究算法,因为该技术对脱水具有较好的不可感知性和鲁棒性(robustness)。变换水印算法是在嵌入水印数据之前对原创图像信息进行比较。这种可逆的数字变换是根据水印的对应索引修改变换域的某些系数来实现水印的嵌入,然后利用逆变换重构嵌入水印的数据,从而实现水印去除效果***。
由于图像水印需求量大,以及Photoshop手动去除水印的复杂性和低效性,晨宇软件工作室20年来一直致力于研究图像算法和批量水印解决方案。批量水印程序主要包括一些算法,快速水印算法,水印类别识别算法,水印随机位置识别算法。经过长时间的算法优化,水印批处理可以做到***去除不留痕迹。可以对批量添加的水印进行逆计算,还原图片的原创颜色。
我们的主要业务包括图片批量脱水、图片视频脱水采集data采集等,长期合作客户包括箱包、水印、手表、电子产品、工业用品、水印、房地产、医药、美术、水印等行业。对有更高要求的图片,也可以结合图片质量,提供高精度的色彩还原服务,如用于影视3冲印照片。
为了减少计算次数和计算时间,快速水印算法在去除干扰和噪声点的影响时不使用图像平滑和频域变换低通滤波技术,而是对图像灰度直方图进行平滑处理。图像预处理后,计算垂直定位。首先,计算图像的水平灰度投影曲线。
算法 自动采集列表(学习IBM如何实现Java平台5.0版中内置的高级功能?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-06 16:15
可以使用四种不同的策略在 IBM Developer Suite (IBM SDK) 中为 Java 5.0 平台配置垃圾回收 (GC)。本文是GC两部分的第一部分。它介绍了不同的垃圾采集策略并讨论了它们的一般特征。在开始之前,您应该对 Java 平台中的垃圾采集有一个基本的了解。第 2 部分介绍了选择策略的定量方法并提供了一些示例。
关于系列
Java 技术,IBM 风格系列介绍了 Java 平台的 IBM 实现的最新版本。您将了解 IBM 如何实现 Java 平台5.0 版本中内置的一些高级特性,并了解如何使用新 IBM 版本中内置的一些增值特性。
如有任何意见或问题,请联系作者。要对整个系列发表评论,请联系系列负责人 Chris Bailey。有关此处讨论的概念的更多信息以及可从中下载最新 IBM 版本的链接,请参阅。
为什么要使用不同的 GC 策略?
不同 GC 策略的可用性为您提供了增强的功能。GC 有许多不同的算法可用,根据工作负载的类型,每种算法都有自己的优点和缺点。(如果不熟悉GC算法的一般话题,请参考进一步阅读。)在IBM SDK 5.0中,您可以使用四种策略之一来配置垃圾采集器,每种策略使用自己的算法。对于大多数应用程序,默认策略就足够了。如果您对应用程序没有任何特定的性能要求,那么本文(以及下一篇)的内容可能对您不感兴趣。您可以在不更改 GC 策略的情况下运行 IBM SDK 5.0。但是,如果您的应用程序需要最佳性能,或者你普遍担心GC暂停时间,请继续阅读。您将看到最新版本的 IBM 比以前的版本有更多的选项。
那么,为什么没有自动为您选择 Java 运行时的 IBM 实现?这并不总是可能的。在运行时很难理解您的需求。在某些情况下,您可能希望以高吞吐量运行应用程序。在其他情况下,您可能希望减少暂停时间。
表 1 列出了可用的策略并指出了何时应使用每种策略。以下部分将详细介绍每种策略的特点。
表 1. IBM SDK 5.0 中的 GC 策略策略选项说明
优化吞吐量
-Xgcpolicy:optthruput(可选)
默认策略。它通常用于原创吞吐量比短暂的 GC 暂停更重要的应用程序。每次采集垃圾时,应用程序都会停止。
优化暂停时间
-Xgcpolicy:optavgpause
通过同时执行一些垃圾采集,高吞吐量被交换为更短的 GC 暂停。申请被暂停了很短的时间。
生成并发
-Xgcpolicy:gencon
短期对象的处理方式与长期对象不同。通过这种策略,具有许多短期对象的应用程序可以看到更短的暂停时间,同时仍然产生良好的吞吐量。
子池化
-Xgcpolicy:subpool
使用类似于默认策略的算法,但使用更适合多处理器计算机的分配策略。对于具有 16 个或更多处理器的 SMP 计算机,我们建议使用此策略。此策略仅适用于 IBMpSeries® 和 zSeries® 平台。需要在大型计算机上扩展的应用程序可以从这种策略中受益。
定义了一些术语
吞吐量是应用程序处理的数据量。必须使用特定于应用程序的指标来衡量吞吐量。
暂停时间是垃圾采集器暂停所有应用程序线程以采集堆的持续时间。
在本文中,我使用表 1 中详述的命令行选项的缩写来表示以下策略:用于优化吞吐量的 optthruput)、用于优化暂停时间的 optavgpause)、用于分代并发的 gencon)和用于 subpool 的 subpool)。
什么时候应该考虑非默认 GC 策略?
我建议您始终从默认的 GC 策略开始。在摆脱默认设置之前,您需要了解在什么情况下应该探索替代策略。表2列出了一系列可能的原因:
表2.切换到备用GC策略的原因切换到原因
暂停
基因组
子池
让我强调,表 2 中提到的原因不足以得出替代政策会表现更好的结论。它们只是提示。在所有情况下,您都应该运行应用程序并结合 GC 暂停时间来测量吞吐量和/或响应时间。本系列的下一部分将展示此类测试的示例。
本文的其余部分将详细介绍 GC 策略之间的差异。
光通量
一堆碎片的迹象
堆碎片最常见的迹象是过早的分配失败。这被认为是在详细垃圾采集 (-Xverbose:gc) 中触发的 GC,即使堆上有可用空间。另一个标志是存在小线程分配缓冲区(请参阅“”部分)。您可以使用 -Xtgc:freelist 来确定平均大小。IBM SDK 5 诊断指南中解释了这两个选项。
optthruput 是默认策略。它是一个跟踪采集器,称为标记扫描紧凑采集器。标记和扫描阶段总是在 GC 期间运行,但压缩仅在某些情况下发生。标记阶段查找并标记所有活动对象。所有未标记的对象将在扫描阶段被删除。第三步也是可选的步骤是压实。压实可以在各种情况下发生。最常见的一种是系统无法回收足够的可用空间。
当对象被频繁地分配和释放以致堆中只剩下一小块空闲空间时,就会发生碎片。堆整体可能有很多空闲空间,但是连续区域很小,导致分配失败。压缩将所有对象向下移动到堆的开头并对齐它们,以便它们之间没有空间。这消除了堆中的碎片,但这是一项昂贵的任务,因此仅在必要时执行。
图 1 显示了经过不同阶段的堆布局的轮廓:标记、清除和压缩。暗区代表物体,亮区代表自由空间。
扫描它
标记阶段遍历所有可以从线程堆栈、静态变量、插入的字符串和 JNI 引用中引用的对象。作为此过程的一部分,我们将创建一个标记位向量来定义所有活动对象的开头。
扫描阶段使用标记阶段生成的标记位向量来识别堆中存储的块,可以回收这些块以备将来分配;这些块被添加到空闲列表中。
图1. 垃圾回收前后的堆布局
不同 GC 阶段如何工作的细节超出了本文的范围。我的观点是确保您了解运行时特征。我鼓励您阅读“诊断指南”(请参阅)以获取更多信息。
图 2 说明了如何在应用程序线程(或 mutator)和 GC 线程之间分配执行时间。横轴是经过时间,纵轴是线程,其中n代表计算机的处理器数量。在此描述中,假设应用程序使用每个处理器一个线程。GC 用蓝色框表示,表示停止的突变体和 GC 线程正在运行。这些集合消耗了 100% 的 CPU 资源,并且转换器线程处于空闲状态。该图过于笼统,因此我们可以将此策略与本文中的其他策略进行比较。实际上,GC 的持续时间和频率取决于应用程序和工作量。
图2. optthruput策略中mutator和GC线程之间的CPU时间分配
Mutators 和 GC 线程
mutator 线程是分配对象的应用程序。mutator 的另一个词是应用程序。GC 线程是内存管理的一部分并执行垃圾采集。
堆锁和线程分配缓存
optthruput 策略使用由应用程序中的所有线程共享的连续堆区域。线程需要独占访问堆来为新对象保留空间。这种锁称为堆锁,可确保一次只有一个线程可以分配一个对象。在具有多个 CPU 的计算机上,此锁可能会导致扩展问题,因为可以同时发生多个分配请求,但每个分配请求都必须对堆锁具有独占访问权限。
为了减少这个问题,每个线程都会保留一小部分内存,称为线程分配缓存(也称为线程本地堆或TLH)。这部分存储空间是线程特定的,因此当从中分配内存时,不会使用堆锁。当分配缓冲区已满时,线程将返回堆并使用堆锁请求新的堆。
堆的碎片化会阻止线程获得更大的TLH,因此TLH会很快填满,导致应用线程频繁返回堆以换取新的TLH。在这种情况下,堆锁成为瓶颈。在这种情况下,gencon 或 sub-subpool 策略可以提供一个不错的选择。
暂停
对于许多应用程序,吞吐量不如快速响应时间重要。考虑一个工作项的处理时间不能超过 100 毫秒的应用程序。由于 GC 暂停时间在 100 毫秒内,您将获得在此时间范围内无法处理的项目。垃圾回收的问题在于暂停时间会增加处理项目所需的最长时间。大堆大小(在 64 位平台上可用)增加了这种效果,因为处理了更多的对象。
optavgpause 是另一种旨在最小化暂停时间的 GC 策略。它不能保证特定的暂停时间,但暂停时间比默认 GC 策略生成的暂停时间短。这个想法是在应用程序运行时执行一些垃圾采集。这是在两个地方完成的:
根据不同的应用,默认的 GC 策略会降低 5% 到 10% 的吞吐量性能。
图 3 说明了如何使用 optavgpause 在 GC 线程和 mutator 线程之间分配执行时间。后台跟踪线程未显示,因为它不会影响应用程序性能。
图3. optavgpause策略中mutator和GC线程的CPU时间分配
图中灰色区域表示已启用并发跟踪,每个mutator线程必须放弃一些处理时间。每个并发阶段完成一次垃圾回收后,完成并发阶段未发生的标记和清除。由此产生的暂停应该比 optthruput 看到的正常 GC 短很多,如图 3 时间刻度上的小框所示。 GC 结束和并发阶段开始之间的差距是不同的,但在这个阶段,对性能没有显着影响。
创康
分代垃圾回收策略考虑对象的生命周期,将它们放在堆的单独区域。通过这种方式,它试图克服单个堆在大多数对象年轻和死亡的应用程序中的缺点,即这些对象不能承受多次垃圾采集。
使用分代 GC 倾向于将长期对象与短期对象区别对待。如图 4 所示,该桩分为育苗区和育苗区。在托儿所中创建对象,如果对象存活时间足够长,则将它们提升到托儿所区域。经过一定量的垃圾采集后,该对象将被提升。这个想法是大多数对象都是短暂的。通过频繁采集托儿所,可以释放这些对象,而无需支付采集整个堆的成本。租用区域很少采集垃圾。
图4. gencon GC中的新旧区
如图 4 所示,托儿所分为两个空间:分配和幸存者。将对象分配到分配的空间。当对象已满时,活动对象将根据其年龄被复制到survivor空间或tenure空间。然后,将托儿所中的空间切换为使用,分配成为幸存者,幸存者成为分配者。死对象占用的空间可以简单地被新分配覆盖。苗圃采集被称为清道夫;图 5 说明了此过程中发生的情况:
图5. GC前后堆布局示例
当分配的空间已满时,将触发垃圾回收。然后跟踪活动对象并将其复制到幸存者空间。如果大部分对象都死了,这个过程的成本真的不高。此外,达到复制阈值计数的对象将被提升到到期空间。然后说对象是永久的。
顾名思义,它代表并发性,gencon 策略有它的并发性方面。租用的空间也使用类似于 optavgpause 策略中使用的方法进行标记,但不执行并发扫描。在并发阶段,所有分配都会支付少量的吞吐量税。通过这种方式,可以将tenure space的采集产生的暂停时间保持在很小的范围内。
图 6 显示了在运行 gencon GC 时如何映射执行时间:
图6. gencon中mutator和GC线程的CPU时间分布
清道夫很短(显示在小红框中)。灰色表示开始并发跟踪,然后是占用空间的集合,其中一些是并发发生的。这称为全局集,它包括清算集和使用权空间集。全局采集发生的频率取决于堆大小和对象生命周期。租用空间的采集应该是比较快的,因为大部分空间是同时采集的。
子池
子池策略有助于提高多处理器系统的性能。如前所述,此策略仅适用于 IBM pSeries 和 zSeries 计算机。堆布局与 optthruput 策略相同,但空闲列表的结构不同。有多个列表而不是整个堆的空闲列表,称为子池。每个池都有一个关联的大小,可以根据这些大小对池进行排序。通过去到这个大小的池,可以快速满足一定大小的分配请求。原子(平台相关)高性能指令用于从列表中弹出空闲列表条目,从而避免序列化访问。图 7 显示了如何按大小组织存储的空闲块:
图7.按大小排序的子池的空闲块
当JVM启动或者发生压缩时,由于堆的可用区域很大,所以不使用子池。在这些情况下,每个处理器都有自己的专用迷你堆来满足请求。当第一次垃圾回收发生时,清除阶段开始填充子池,后续的分配主要使用子池。
子池策略可以减少分配对象所需的时间。原子指令确保在不获取全局堆锁的情况下进行分配。处理器本地的小堆提高了效率,因为它减少了缓存干扰。这直接影响可扩展性,尤其是在多处理器系统上。在子池不可用的平台上,生成 GC 可以提供类似的好处。
综上所述
本文重点介绍 IBM SDK 5.0 中可用的不同 GC 策略选项及其一些特性。默认策略足以满足大多数应用程序的需求。但是,在某些情况下,其他策略效果更好。我已经介绍了一些一般情况,在这些情况下你应该考虑切换到 optavgpause、gencon 或 subpool。在评估策略时,衡量应用程序性能非常重要,第 2 部分将更详细地演示评估过程。
翻译自: 查看全部
算法 自动采集列表(学习IBM如何实现Java平台5.0版中内置的高级功能?)
可以使用四种不同的策略在 IBM Developer Suite (IBM SDK) 中为 Java 5.0 平台配置垃圾回收 (GC)。本文是GC两部分的第一部分。它介绍了不同的垃圾采集策略并讨论了它们的一般特征。在开始之前,您应该对 Java 平台中的垃圾采集有一个基本的了解。第 2 部分介绍了选择策略的定量方法并提供了一些示例。
关于系列
Java 技术,IBM 风格系列介绍了 Java 平台的 IBM 实现的最新版本。您将了解 IBM 如何实现 Java 平台5.0 版本中内置的一些高级特性,并了解如何使用新 IBM 版本中内置的一些增值特性。
如有任何意见或问题,请联系作者。要对整个系列发表评论,请联系系列负责人 Chris Bailey。有关此处讨论的概念的更多信息以及可从中下载最新 IBM 版本的链接,请参阅。
为什么要使用不同的 GC 策略?
不同 GC 策略的可用性为您提供了增强的功能。GC 有许多不同的算法可用,根据工作负载的类型,每种算法都有自己的优点和缺点。(如果不熟悉GC算法的一般话题,请参考进一步阅读。)在IBM SDK 5.0中,您可以使用四种策略之一来配置垃圾采集器,每种策略使用自己的算法。对于大多数应用程序,默认策略就足够了。如果您对应用程序没有任何特定的性能要求,那么本文(以及下一篇)的内容可能对您不感兴趣。您可以在不更改 GC 策略的情况下运行 IBM SDK 5.0。但是,如果您的应用程序需要最佳性能,或者你普遍担心GC暂停时间,请继续阅读。您将看到最新版本的 IBM 比以前的版本有更多的选项。
那么,为什么没有自动为您选择 Java 运行时的 IBM 实现?这并不总是可能的。在运行时很难理解您的需求。在某些情况下,您可能希望以高吞吐量运行应用程序。在其他情况下,您可能希望减少暂停时间。
表 1 列出了可用的策略并指出了何时应使用每种策略。以下部分将详细介绍每种策略的特点。
表 1. IBM SDK 5.0 中的 GC 策略策略选项说明
优化吞吐量
-Xgcpolicy:optthruput(可选)
默认策略。它通常用于原创吞吐量比短暂的 GC 暂停更重要的应用程序。每次采集垃圾时,应用程序都会停止。
优化暂停时间
-Xgcpolicy:optavgpause
通过同时执行一些垃圾采集,高吞吐量被交换为更短的 GC 暂停。申请被暂停了很短的时间。
生成并发
-Xgcpolicy:gencon
短期对象的处理方式与长期对象不同。通过这种策略,具有许多短期对象的应用程序可以看到更短的暂停时间,同时仍然产生良好的吞吐量。
子池化
-Xgcpolicy:subpool
使用类似于默认策略的算法,但使用更适合多处理器计算机的分配策略。对于具有 16 个或更多处理器的 SMP 计算机,我们建议使用此策略。此策略仅适用于 IBMpSeries® 和 zSeries® 平台。需要在大型计算机上扩展的应用程序可以从这种策略中受益。
定义了一些术语
吞吐量是应用程序处理的数据量。必须使用特定于应用程序的指标来衡量吞吐量。
暂停时间是垃圾采集器暂停所有应用程序线程以采集堆的持续时间。
在本文中,我使用表 1 中详述的命令行选项的缩写来表示以下策略:用于优化吞吐量的 optthruput)、用于优化暂停时间的 optavgpause)、用于分代并发的 gencon)和用于 subpool 的 subpool)。
什么时候应该考虑非默认 GC 策略?
我建议您始终从默认的 GC 策略开始。在摆脱默认设置之前,您需要了解在什么情况下应该探索替代策略。表2列出了一系列可能的原因:
表2.切换到备用GC策略的原因切换到原因
暂停
基因组
子池
让我强调,表 2 中提到的原因不足以得出替代政策会表现更好的结论。它们只是提示。在所有情况下,您都应该运行应用程序并结合 GC 暂停时间来测量吞吐量和/或响应时间。本系列的下一部分将展示此类测试的示例。
本文的其余部分将详细介绍 GC 策略之间的差异。
光通量
一堆碎片的迹象
堆碎片最常见的迹象是过早的分配失败。这被认为是在详细垃圾采集 (-Xverbose:gc) 中触发的 GC,即使堆上有可用空间。另一个标志是存在小线程分配缓冲区(请参阅“”部分)。您可以使用 -Xtgc:freelist 来确定平均大小。IBM SDK 5 诊断指南中解释了这两个选项。
optthruput 是默认策略。它是一个跟踪采集器,称为标记扫描紧凑采集器。标记和扫描阶段总是在 GC 期间运行,但压缩仅在某些情况下发生。标记阶段查找并标记所有活动对象。所有未标记的对象将在扫描阶段被删除。第三步也是可选的步骤是压实。压实可以在各种情况下发生。最常见的一种是系统无法回收足够的可用空间。
当对象被频繁地分配和释放以致堆中只剩下一小块空闲空间时,就会发生碎片。堆整体可能有很多空闲空间,但是连续区域很小,导致分配失败。压缩将所有对象向下移动到堆的开头并对齐它们,以便它们之间没有空间。这消除了堆中的碎片,但这是一项昂贵的任务,因此仅在必要时执行。
图 1 显示了经过不同阶段的堆布局的轮廓:标记、清除和压缩。暗区代表物体,亮区代表自由空间。
扫描它
标记阶段遍历所有可以从线程堆栈、静态变量、插入的字符串和 JNI 引用中引用的对象。作为此过程的一部分,我们将创建一个标记位向量来定义所有活动对象的开头。
扫描阶段使用标记阶段生成的标记位向量来识别堆中存储的块,可以回收这些块以备将来分配;这些块被添加到空闲列表中。
图1. 垃圾回收前后的堆布局
不同 GC 阶段如何工作的细节超出了本文的范围。我的观点是确保您了解运行时特征。我鼓励您阅读“诊断指南”(请参阅)以获取更多信息。
图 2 说明了如何在应用程序线程(或 mutator)和 GC 线程之间分配执行时间。横轴是经过时间,纵轴是线程,其中n代表计算机的处理器数量。在此描述中,假设应用程序使用每个处理器一个线程。GC 用蓝色框表示,表示停止的突变体和 GC 线程正在运行。这些集合消耗了 100% 的 CPU 资源,并且转换器线程处于空闲状态。该图过于笼统,因此我们可以将此策略与本文中的其他策略进行比较。实际上,GC 的持续时间和频率取决于应用程序和工作量。
图2. optthruput策略中mutator和GC线程之间的CPU时间分配
Mutators 和 GC 线程
mutator 线程是分配对象的应用程序。mutator 的另一个词是应用程序。GC 线程是内存管理的一部分并执行垃圾采集。
堆锁和线程分配缓存
optthruput 策略使用由应用程序中的所有线程共享的连续堆区域。线程需要独占访问堆来为新对象保留空间。这种锁称为堆锁,可确保一次只有一个线程可以分配一个对象。在具有多个 CPU 的计算机上,此锁可能会导致扩展问题,因为可以同时发生多个分配请求,但每个分配请求都必须对堆锁具有独占访问权限。
为了减少这个问题,每个线程都会保留一小部分内存,称为线程分配缓存(也称为线程本地堆或TLH)。这部分存储空间是线程特定的,因此当从中分配内存时,不会使用堆锁。当分配缓冲区已满时,线程将返回堆并使用堆锁请求新的堆。
堆的碎片化会阻止线程获得更大的TLH,因此TLH会很快填满,导致应用线程频繁返回堆以换取新的TLH。在这种情况下,堆锁成为瓶颈。在这种情况下,gencon 或 sub-subpool 策略可以提供一个不错的选择。
暂停
对于许多应用程序,吞吐量不如快速响应时间重要。考虑一个工作项的处理时间不能超过 100 毫秒的应用程序。由于 GC 暂停时间在 100 毫秒内,您将获得在此时间范围内无法处理的项目。垃圾回收的问题在于暂停时间会增加处理项目所需的最长时间。大堆大小(在 64 位平台上可用)增加了这种效果,因为处理了更多的对象。
optavgpause 是另一种旨在最小化暂停时间的 GC 策略。它不能保证特定的暂停时间,但暂停时间比默认 GC 策略生成的暂停时间短。这个想法是在应用程序运行时执行一些垃圾采集。这是在两个地方完成的:
根据不同的应用,默认的 GC 策略会降低 5% 到 10% 的吞吐量性能。
图 3 说明了如何使用 optavgpause 在 GC 线程和 mutator 线程之间分配执行时间。后台跟踪线程未显示,因为它不会影响应用程序性能。
图3. optavgpause策略中mutator和GC线程的CPU时间分配
图中灰色区域表示已启用并发跟踪,每个mutator线程必须放弃一些处理时间。每个并发阶段完成一次垃圾回收后,完成并发阶段未发生的标记和清除。由此产生的暂停应该比 optthruput 看到的正常 GC 短很多,如图 3 时间刻度上的小框所示。 GC 结束和并发阶段开始之间的差距是不同的,但在这个阶段,对性能没有显着影响。
创康
分代垃圾回收策略考虑对象的生命周期,将它们放在堆的单独区域。通过这种方式,它试图克服单个堆在大多数对象年轻和死亡的应用程序中的缺点,即这些对象不能承受多次垃圾采集。
使用分代 GC 倾向于将长期对象与短期对象区别对待。如图 4 所示,该桩分为育苗区和育苗区。在托儿所中创建对象,如果对象存活时间足够长,则将它们提升到托儿所区域。经过一定量的垃圾采集后,该对象将被提升。这个想法是大多数对象都是短暂的。通过频繁采集托儿所,可以释放这些对象,而无需支付采集整个堆的成本。租用区域很少采集垃圾。
图4. gencon GC中的新旧区
如图 4 所示,托儿所分为两个空间:分配和幸存者。将对象分配到分配的空间。当对象已满时,活动对象将根据其年龄被复制到survivor空间或tenure空间。然后,将托儿所中的空间切换为使用,分配成为幸存者,幸存者成为分配者。死对象占用的空间可以简单地被新分配覆盖。苗圃采集被称为清道夫;图 5 说明了此过程中发生的情况:
图5. GC前后堆布局示例
当分配的空间已满时,将触发垃圾回收。然后跟踪活动对象并将其复制到幸存者空间。如果大部分对象都死了,这个过程的成本真的不高。此外,达到复制阈值计数的对象将被提升到到期空间。然后说对象是永久的。
顾名思义,它代表并发性,gencon 策略有它的并发性方面。租用的空间也使用类似于 optavgpause 策略中使用的方法进行标记,但不执行并发扫描。在并发阶段,所有分配都会支付少量的吞吐量税。通过这种方式,可以将tenure space的采集产生的暂停时间保持在很小的范围内。
图 6 显示了在运行 gencon GC 时如何映射执行时间:
图6. gencon中mutator和GC线程的CPU时间分布
清道夫很短(显示在小红框中)。灰色表示开始并发跟踪,然后是占用空间的集合,其中一些是并发发生的。这称为全局集,它包括清算集和使用权空间集。全局采集发生的频率取决于堆大小和对象生命周期。租用空间的采集应该是比较快的,因为大部分空间是同时采集的。
子池
子池策略有助于提高多处理器系统的性能。如前所述,此策略仅适用于 IBM pSeries 和 zSeries 计算机。堆布局与 optthruput 策略相同,但空闲列表的结构不同。有多个列表而不是整个堆的空闲列表,称为子池。每个池都有一个关联的大小,可以根据这些大小对池进行排序。通过去到这个大小的池,可以快速满足一定大小的分配请求。原子(平台相关)高性能指令用于从列表中弹出空闲列表条目,从而避免序列化访问。图 7 显示了如何按大小组织存储的空闲块:
图7.按大小排序的子池的空闲块
当JVM启动或者发生压缩时,由于堆的可用区域很大,所以不使用子池。在这些情况下,每个处理器都有自己的专用迷你堆来满足请求。当第一次垃圾回收发生时,清除阶段开始填充子池,后续的分配主要使用子池。
子池策略可以减少分配对象所需的时间。原子指令确保在不获取全局堆锁的情况下进行分配。处理器本地的小堆提高了效率,因为它减少了缓存干扰。这直接影响可扩展性,尤其是在多处理器系统上。在子池不可用的平台上,生成 GC 可以提供类似的好处。
综上所述
本文重点介绍 IBM SDK 5.0 中可用的不同 GC 策略选项及其一些特性。默认策略足以满足大多数应用程序的需求。但是,在某些情况下,其他策略效果更好。我已经介绍了一些一般情况,在这些情况下你应该考虑切换到 optavgpause、gencon 或 subpool。在评估策略时,衡量应用程序性能非常重要,第 2 部分将更详细地演示评估过程。
翻译自:
算法 自动采集列表(算法自动采集列表页流量越来越难的5种方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-01 14:50
算法自动采集列表页流量越来越难,优秀采集器可以帮助你顺利完成目标。puzsurfire项目组总结过5种找到好机器的方法,我们将本文归类为3种高效简洁又便于使用的爬虫技术。#方法一:高效寻找方法|算法自动采集技术#如果你是专业的爬虫工程师,而且经常要采集大型信息,puzsurfire将成为一个非常有利的爬虫工具。
研究表明,大约有2/3的企业,至少有一款机器。#方法二:采用不同的机器对于非专业人士,找到正确的机器非常困难。另外,所有的平台标准化程度都非常低,变数非常多。数以千计的不同形式的机器,通常不适合于项目使用。#方法三:爬虫工具大显身手由于puzsurfire对不同机器做的针对性调整,你可以找到一个最适合的机器。
比如我们现在最需要的就是连接pc端并能获取微信公众号文章的网页版。如果你正在寻找一款爬虫工具,surfire是一个好选择。
爬虫分几类,不过大多数的爬虫基本思路是类似的。但是程序性能爬虫有很多方式可以提高效率,例如说ua等都可以提高效率。
eval()是可以分析代码,然后进行处理的。python有一个jit编译器,就是你说的机器序列。这东西可以把单个循环转换成分支循环。爬虫可以做的事情有很多,你可以试试,随便写一个脚本都比你用eval来得快,ui写的乱七八糟,别人程序逻辑没你清楚。python处理特定语言是很快的。 查看全部
算法 自动采集列表(算法自动采集列表页流量越来越难的5种方法)
算法自动采集列表页流量越来越难,优秀采集器可以帮助你顺利完成目标。puzsurfire项目组总结过5种找到好机器的方法,我们将本文归类为3种高效简洁又便于使用的爬虫技术。#方法一:高效寻找方法|算法自动采集技术#如果你是专业的爬虫工程师,而且经常要采集大型信息,puzsurfire将成为一个非常有利的爬虫工具。
研究表明,大约有2/3的企业,至少有一款机器。#方法二:采用不同的机器对于非专业人士,找到正确的机器非常困难。另外,所有的平台标准化程度都非常低,变数非常多。数以千计的不同形式的机器,通常不适合于项目使用。#方法三:爬虫工具大显身手由于puzsurfire对不同机器做的针对性调整,你可以找到一个最适合的机器。
比如我们现在最需要的就是连接pc端并能获取微信公众号文章的网页版。如果你正在寻找一款爬虫工具,surfire是一个好选择。
爬虫分几类,不过大多数的爬虫基本思路是类似的。但是程序性能爬虫有很多方式可以提高效率,例如说ua等都可以提高效率。
eval()是可以分析代码,然后进行处理的。python有一个jit编译器,就是你说的机器序列。这东西可以把单个循环转换成分支循环。爬虫可以做的事情有很多,你可以试试,随便写一个脚本都比你用eval来得快,ui写的乱七八糟,别人程序逻辑没你清楚。python处理特定语言是很快的。
算法 自动采集列表(集成自定义算法开发完成后,需要经过集成才能正式上线)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-31 23:05
集成测试
自定义算法开发完成后,需要经过集成测试,才能正式上线。集成测试是单元测试的扩展。单元测试验证算法内部的逻辑是否达到其目的,而集成测试则关注新开发的算法加入算法流程后整体性能是否异常。在 RecEng 中用于集成测试的方法是测试路径。
客户在RecEng中创建了一个新的算法流程后——姑且称之为F-,F默认处于“未发布”状态,有两个含义:
1.启动离线计算API时不会激活F
2.推荐的API无法获得F计算结果
由于1,离线计算API不会启动未发布的算法流程,所以RecEng在产品界面提供了一个按钮来手动启动未发布的算法流程。离线计算完成后,RecEng会将F的离线计算结果同步到在线存储中。但是由于2,推荐的API无法获得F的计算结果,测试过程的计算结果只能通过RecEng的API调试功能在产品界面中使用。根据以上观察,目前无法通过API的方式访问测试过程的计算结果。
集成测试通过后,客户需要点击产品界面的“发布”按钮,将未发布的算法流程在线发布,才能真正进入生产,上述1和2的限制将被取消。
此外,有时客户可能需要调整发布和上线的算法流程。我们应该做什么?
RecEng 实际上为每个已经在线发布的算法流程保存了一个离线测试版本。此时客户只需要修改相应的离线测试版本即可。按照上述流程,先调整算法逻辑,然后手动启动离线计算,然后在API调试中观察计算结果。集成测试通过后,点击“发布”按钮,会提示是否需要覆盖在线数据,即需要使用测试过程的计算结果覆盖之前生产的计算结果过程。客户可根据实际情况自行判断。.
效果测试
集成测试只能验证自定义算法在算法流程中是否能正常工作;但是,作为一个算法,仅仅能正常工作是不够的,效果才是算法的最终目的。RecEng支持基于算法流程的A/B测试,直接对比最终结果,为决策提供参考。
要进行 A/B 测试,您必须首先明确指标;要计算指标,必须先采集日志。下面的描述从日志采集开始。
日志采集
在衡量推荐系统的有效性时,RecEng 只关心与推荐相关的行为。为了区别于其他无关行为,RecEng会在每个推荐API的返回结果中附加一个Trace ID(推荐API返回的所有项目都共享这个Trace ID),客户需要遵循一定的规范。日志中嵌入了Trace ID,可以使用阿里云推荐引擎提供的效果报告功能。具体嵌入点和日志规范请参考日志嵌入规范
埋设Trace ID的三个原则:
1.推荐列表显示时,需要在推荐列表中所有item的链接中嵌入对应的Trace ID
2. 如果用户点击了收录Trace ID的item链接,需要将Trace ID带到下一页,并且Trace ID应该嵌入到新页面的item的所有链接中
3. 如果用户点击不收录Trace ID的item,或者点击收录其他Trace ID的item链接,之前的Trace ID将失效
需要注意的是,并不是所有的日志都会有 Trace ID 信息。Trace ID只负责跟踪RecEng返回的推荐结果。客户网站或应用程序中的大部分用户行为可能与RecEng无关。为了更好地描绘用户画像,这些用户行为也需要上传到RecEng。
日志埋没后,通过日志API将日志提交给RecEng,日志采集就完成了。但是日志API的功能不限于上传采集的日志。细心的用户可能会注意到,RecEng的业务配置界面中有一个不显眼的复选框:
即客户可以通过日志API上传离线数据。要实现这个功能,一方面需要在产品界面打开这个开关;另一方面,需要从日志 API 上传各种用户和项目数据。与离线上传不同,通过日志API上传用户和商品数据是增量的。您只需每天将新数据发送到 RecEng。
如果在业务配置页面勾选了“自动数据预处理”复选框,则当新的一天开始时,将自动启动前一天数据的离线计算任务。
业绩报告
在 RecEng 中,与效果报告密切相关的三个主要概念是:效果算法、效果指标和效果过程。
效果算法专门用于计算效果指标。它的输入输出表是固定的,输入表是行为表(user_behavior),输出表是索引结果表。效果算法的逻辑比较简单,通常是简单的统计,或者在统计的基础上进行四次算术运算。麻烦的是,统计必须有统计口径,包括时间粒度、业务粒度等。
RecEng 中的所有这些统计口径都是相同的。时间支持日、周、月三种粒度,业务支持按场景和算法统计。时间粒度的需要取决于效果算法:通常只需要输出当天的索引,而在星期一或每个月的第一天额外输出上周和上个月的索引。如果周指标和月指标的计算没有收录在效果算法中,RecEng会自动补0。 业务粒度的要求由RecEng统一实现:RecEng会根据业务粒度拆分行为表然后交给到效果算法进行计算,
效果算法以行为类型为参数,不针对具体的行为类型;效果指标需要明确行为类型。因此,效果指标可以理解为效果算法+行为类型的组合。例如,专门用于PV统计的算法可以统计任何行为、查看、点击和消费的PV。但是说到指标,一定要搞清楚到底是view的PV还是点击的PV。
只需要定义效果指数。选择效果算法并阐明行为类型。定义了性能指标后,我们还需要每天执行一次性能过程(index_path)来计算这些指标。效果过程不需要配置算法节点的流程图,只需选择效果指标即可。RecEng会自动生成效果处理流程图,客户可以通过效果计算API启动效果处理。
最后是关于性能报告的配置。您只需要为业绩指标选择一个展示图表,如折线图、饼图、条形图等,业绩流程计算完成后,客户可以在业绩报告中看到。
RecEng 默认提供了一些简单的效果算法,也预定义了一些效果指标。客户可以根据自己的需要开发新的效果算法并注册RecEng。
A/B 测试
A/B测试是效果测试的常用方法,也是RecEng唯一的效果测试方法。经过前面的准备,我们现在可以知道每个算法过程的性能指标了。然后,通过比较不同工艺的指标,可以优化效果。
RecEng 允许在一个场景中进行多个推荐过程 (rec_path)。对属于同一场景的不同推荐流程也进行 A/B 测试。在进行A/B测试时,同一场景下的每个推荐流程都会分配一定的流量,可以在产品界面进行配置。在执行推荐API时,RecEng会在第一步随机按比例分配流量,将当前用户分配到某个推荐流程,然后执行这个推荐流程的在线流程。RecEng分配流量时,完全是随机的,不遵循任何规则。例如,某个用户必须被分配到某个推荐过程。
无论是否开启 A/B 测试,客户调用推荐 API 的参数完全相同。推荐API的参数只收录场景参数,推荐流程(rec_path)不是必须的,也不能指定,以便在进行效果统计时做出明确的推荐。item来自哪个推荐流程,所以RecEng每次响应推荐API都会附上Trace ID,这样我们就可以准确统计每个推荐流程的性能指标。
在整个过程中,使用A/B Testing的工作量主要在前期、日志埋点、配置效果报告。完成这些之后,使用 A/B 测试其实很简单。 查看全部
算法 自动采集列表(集成自定义算法开发完成后,需要经过集成才能正式上线)
集成测试
自定义算法开发完成后,需要经过集成测试,才能正式上线。集成测试是单元测试的扩展。单元测试验证算法内部的逻辑是否达到其目的,而集成测试则关注新开发的算法加入算法流程后整体性能是否异常。在 RecEng 中用于集成测试的方法是测试路径。
客户在RecEng中创建了一个新的算法流程后——姑且称之为F-,F默认处于“未发布”状态,有两个含义:
1.启动离线计算API时不会激活F
2.推荐的API无法获得F计算结果
由于1,离线计算API不会启动未发布的算法流程,所以RecEng在产品界面提供了一个按钮来手动启动未发布的算法流程。离线计算完成后,RecEng会将F的离线计算结果同步到在线存储中。但是由于2,推荐的API无法获得F的计算结果,测试过程的计算结果只能通过RecEng的API调试功能在产品界面中使用。根据以上观察,目前无法通过API的方式访问测试过程的计算结果。
集成测试通过后,客户需要点击产品界面的“发布”按钮,将未发布的算法流程在线发布,才能真正进入生产,上述1和2的限制将被取消。
此外,有时客户可能需要调整发布和上线的算法流程。我们应该做什么?
RecEng 实际上为每个已经在线发布的算法流程保存了一个离线测试版本。此时客户只需要修改相应的离线测试版本即可。按照上述流程,先调整算法逻辑,然后手动启动离线计算,然后在API调试中观察计算结果。集成测试通过后,点击“发布”按钮,会提示是否需要覆盖在线数据,即需要使用测试过程的计算结果覆盖之前生产的计算结果过程。客户可根据实际情况自行判断。.
效果测试
集成测试只能验证自定义算法在算法流程中是否能正常工作;但是,作为一个算法,仅仅能正常工作是不够的,效果才是算法的最终目的。RecEng支持基于算法流程的A/B测试,直接对比最终结果,为决策提供参考。
要进行 A/B 测试,您必须首先明确指标;要计算指标,必须先采集日志。下面的描述从日志采集开始。
日志采集
在衡量推荐系统的有效性时,RecEng 只关心与推荐相关的行为。为了区别于其他无关行为,RecEng会在每个推荐API的返回结果中附加一个Trace ID(推荐API返回的所有项目都共享这个Trace ID),客户需要遵循一定的规范。日志中嵌入了Trace ID,可以使用阿里云推荐引擎提供的效果报告功能。具体嵌入点和日志规范请参考日志嵌入规范
埋设Trace ID的三个原则:
1.推荐列表显示时,需要在推荐列表中所有item的链接中嵌入对应的Trace ID
2. 如果用户点击了收录Trace ID的item链接,需要将Trace ID带到下一页,并且Trace ID应该嵌入到新页面的item的所有链接中
3. 如果用户点击不收录Trace ID的item,或者点击收录其他Trace ID的item链接,之前的Trace ID将失效
需要注意的是,并不是所有的日志都会有 Trace ID 信息。Trace ID只负责跟踪RecEng返回的推荐结果。客户网站或应用程序中的大部分用户行为可能与RecEng无关。为了更好地描绘用户画像,这些用户行为也需要上传到RecEng。
日志埋没后,通过日志API将日志提交给RecEng,日志采集就完成了。但是日志API的功能不限于上传采集的日志。细心的用户可能会注意到,RecEng的业务配置界面中有一个不显眼的复选框:

即客户可以通过日志API上传离线数据。要实现这个功能,一方面需要在产品界面打开这个开关;另一方面,需要从日志 API 上传各种用户和项目数据。与离线上传不同,通过日志API上传用户和商品数据是增量的。您只需每天将新数据发送到 RecEng。
如果在业务配置页面勾选了“自动数据预处理”复选框,则当新的一天开始时,将自动启动前一天数据的离线计算任务。
业绩报告
在 RecEng 中,与效果报告密切相关的三个主要概念是:效果算法、效果指标和效果过程。
效果算法专门用于计算效果指标。它的输入输出表是固定的,输入表是行为表(user_behavior),输出表是索引结果表。效果算法的逻辑比较简单,通常是简单的统计,或者在统计的基础上进行四次算术运算。麻烦的是,统计必须有统计口径,包括时间粒度、业务粒度等。
RecEng 中的所有这些统计口径都是相同的。时间支持日、周、月三种粒度,业务支持按场景和算法统计。时间粒度的需要取决于效果算法:通常只需要输出当天的索引,而在星期一或每个月的第一天额外输出上周和上个月的索引。如果周指标和月指标的计算没有收录在效果算法中,RecEng会自动补0。 业务粒度的要求由RecEng统一实现:RecEng会根据业务粒度拆分行为表然后交给到效果算法进行计算,
效果算法以行为类型为参数,不针对具体的行为类型;效果指标需要明确行为类型。因此,效果指标可以理解为效果算法+行为类型的组合。例如,专门用于PV统计的算法可以统计任何行为、查看、点击和消费的PV。但是说到指标,一定要搞清楚到底是view的PV还是点击的PV。
只需要定义效果指数。选择效果算法并阐明行为类型。定义了性能指标后,我们还需要每天执行一次性能过程(index_path)来计算这些指标。效果过程不需要配置算法节点的流程图,只需选择效果指标即可。RecEng会自动生成效果处理流程图,客户可以通过效果计算API启动效果处理。
最后是关于性能报告的配置。您只需要为业绩指标选择一个展示图表,如折线图、饼图、条形图等,业绩流程计算完成后,客户可以在业绩报告中看到。
RecEng 默认提供了一些简单的效果算法,也预定义了一些效果指标。客户可以根据自己的需要开发新的效果算法并注册RecEng。
A/B 测试
A/B测试是效果测试的常用方法,也是RecEng唯一的效果测试方法。经过前面的准备,我们现在可以知道每个算法过程的性能指标了。然后,通过比较不同工艺的指标,可以优化效果。
RecEng 允许在一个场景中进行多个推荐过程 (rec_path)。对属于同一场景的不同推荐流程也进行 A/B 测试。在进行A/B测试时,同一场景下的每个推荐流程都会分配一定的流量,可以在产品界面进行配置。在执行推荐API时,RecEng会在第一步随机按比例分配流量,将当前用户分配到某个推荐流程,然后执行这个推荐流程的在线流程。RecEng分配流量时,完全是随机的,不遵循任何规则。例如,某个用户必须被分配到某个推荐过程。
无论是否开启 A/B 测试,客户调用推荐 API 的参数完全相同。推荐API的参数只收录场景参数,推荐流程(rec_path)不是必须的,也不能指定,以便在进行效果统计时做出明确的推荐。item来自哪个推荐流程,所以RecEng每次响应推荐API都会附上Trace ID,这样我们就可以准确统计每个推荐流程的性能指标。
在整个过程中,使用A/B Testing的工作量主要在前期、日志埋点、配置效果报告。完成这些之后,使用 A/B 测试其实很简单。
算法 自动采集列表(PDF快速入门要快速的接触监控平台使用依赖数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-29 03:24
编辑以查看 PDF
快速开始
快速接触监控平台,通过快速入门,您将有一个基本的了解。
访问流程
基本上,访问过程有以下几个阶段:
:监控平台的监控目标和进程信息主要依赖CMDB的配置,被监控的采集链接依赖于Blue Whale Agent的部署,监控功能的使用依赖于数据。采集:监控本身是围绕数据工作的,数据从哪里来?要么通过获取,要么主动上报,要么直接用结果表数据数据检查:数据采集是否成功,最后是否可以查看相关图形数据。每个采集任务都有一个检查视图,可以查看当前主机/实例采集的数据。当然,您也可以检索任意指标策略配置:采集 上来的数据要么被观察,要么被警告,通过策略配置设置您要报警的指标。您可以提前规划报警组需要在收到报警时使用报警处理:当策略生效,触发报警时,我们可以查看或接收相应的报警内容。对于报警事件,我们可以快速确认或确认报警。其他:还有许多其他高级功能可以使用。, 监测的四个阶段
监控平台有这么多功能,这么多文档。如何一步步使用监控平台?大致可以分为四个层次:
第一层:开箱即用内置默认策略主机进程监控官方插件:内置20个官方插件,可在采集中直接使用,满足监控需求的通用组件。提供动态采集需求,自动增删采集策略配置:满足IP、服务实例、集群模块的监控需求,提供8种检测算法。并支持数据平台的数据监控需求。监控屏蔽:提供服务实例、IP、集群模块、策略、事件屏蔽粒度。Dashboard:提供不同的图表配置,支持日志数据、数据平台数据、监控采集指标数据绘制需求服务拨号测试:提供模拟用户请求的监控需求。日志采集和监控第二层:扩展采集和自动报警处理第三层:高级策略控制和配置共享第四层:平台管理和插件开发 查看全部
算法 自动采集列表(PDF快速入门要快速的接触监控平台使用依赖数据采集)
编辑以查看 PDF
快速开始
快速接触监控平台,通过快速入门,您将有一个基本的了解。
访问流程

基本上,访问过程有以下几个阶段:
:监控平台的监控目标和进程信息主要依赖CMDB的配置,被监控的采集链接依赖于Blue Whale Agent的部署,监控功能的使用依赖于数据。采集:监控本身是围绕数据工作的,数据从哪里来?要么通过获取,要么主动上报,要么直接用结果表数据数据检查:数据采集是否成功,最后是否可以查看相关图形数据。每个采集任务都有一个检查视图,可以查看当前主机/实例采集的数据。当然,您也可以检索任意指标策略配置:采集 上来的数据要么被观察,要么被警告,通过策略配置设置您要报警的指标。您可以提前规划报警组需要在收到报警时使用报警处理:当策略生效,触发报警时,我们可以查看或接收相应的报警内容。对于报警事件,我们可以快速确认或确认报警。其他:还有许多其他高级功能可以使用。, 监测的四个阶段
监控平台有这么多功能,这么多文档。如何一步步使用监控平台?大致可以分为四个层次:
第一层:开箱即用内置默认策略主机进程监控官方插件:内置20个官方插件,可在采集中直接使用,满足监控需求的通用组件。提供动态采集需求,自动增删采集策略配置:满足IP、服务实例、集群模块的监控需求,提供8种检测算法。并支持数据平台的数据监控需求。监控屏蔽:提供服务实例、IP、集群模块、策略、事件屏蔽粒度。Dashboard:提供不同的图表配置,支持日志数据、数据平台数据、监控采集指标数据绘制需求服务拨号测试:提供模拟用户请求的监控需求。日志采集和监控第二层:扩展采集和自动报警处理第三层:高级策略控制和配置共享第四层:平台管理和插件开发
算法 自动采集列表(1.一般来说想爬取详情页的数据都会先把列表数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-26 08:07
)
1. 一般来说,如果要抓取详情页的数据,会先抓取列表数据(有详情页的链接),然后再抓取详情页的数据。
2.爬取详细列表数据的步骤:
1.打开网页
2.循环翻页(注:优采云免费版一次只能抓取1w条数据,所以需要设置循环执行次数,避免超过1w条数据数据)
3.Loop采集 列出数据,即一个页面有多少数据
4.提取数据(重点):如果你对xpath不熟悉,可以下载火狐的两个插件,可以轻松获取指定数据的xpath。
要下载火狐插件,需要下载5.5之前的版本。下载完成后,去掉自动更新,然后导入debug和xpath插件,重启火狐浏览器。
然后添加必填字段并写入指定数据的xpath。相对路径和绝对路径都要写
然后点击获取方式,即文本,获取指定数据
注意:有时会从指定页面采集开始,如果URL有规则,那是自然的,如果没有规则,则需要在优采云中进行配置
打开网页,数据文本(指定多少页),点击元素(跳转到多少页),然后循环点击下一页采集数据,翻的时候页面循环,计算不能超过1w个数据OK
3.抓取详情页的数据:
列表爬取后,会得到详情页的url,此时需要将url输入到循环url列表中,优采云会循环遍历this和url中的url列表以获取数据。
查看全部
算法 自动采集列表(1.一般来说想爬取详情页的数据都会先把列表数据
)
1. 一般来说,如果要抓取详情页的数据,会先抓取列表数据(有详情页的链接),然后再抓取详情页的数据。
2.爬取详细列表数据的步骤:
1.打开网页

2.循环翻页(注:优采云免费版一次只能抓取1w条数据,所以需要设置循环执行次数,避免超过1w条数据数据)

3.Loop采集 列出数据,即一个页面有多少数据

4.提取数据(重点):如果你对xpath不熟悉,可以下载火狐的两个插件,可以轻松获取指定数据的xpath。
要下载火狐插件,需要下载5.5之前的版本。下载完成后,去掉自动更新,然后导入debug和xpath插件,重启火狐浏览器。
然后添加必填字段并写入指定数据的xpath。相对路径和绝对路径都要写

然后点击获取方式,即文本,获取指定数据

注意:有时会从指定页面采集开始,如果URL有规则,那是自然的,如果没有规则,则需要在优采云中进行配置
打开网页,数据文本(指定多少页),点击元素(跳转到多少页),然后循环点击下一页采集数据,翻的时候页面循环,计算不能超过1w个数据OK

3.抓取详情页的数据:
列表爬取后,会得到详情页的url,此时需要将url输入到循环url列表中,优采云会循环遍历this和url中的url列表以获取数据。


算法 自动采集列表(智能巡检使用流式图算法和流式分解算法进行数据巡检 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2021-10-26 01:04
)
日志服务提供智能巡检功能,对监控指标或业务日志等数据进行自动、智能、自适应的异常巡检。目前智能巡检采用流图算法和流分解算法进行数据巡检。本文介绍了流图算法和流分解算法的适用场景、参数配置、预览说明等。
流图算法
流图算法是基于Time2Graph系列模型中的原理开发的,可以降低数据的整体噪声,分析异常数据的相对偏差。流图算法适用于大规模、嘈杂、不显眼的时间序列的异常检测。有关更多信息,请参阅使用进化状态图进行时间序列事件预测。
场景描述
流图算法使用在线机器学习技术实时学习和推断每条数据。适用于一般的时间序列异常检测场景,包括:
参数配置
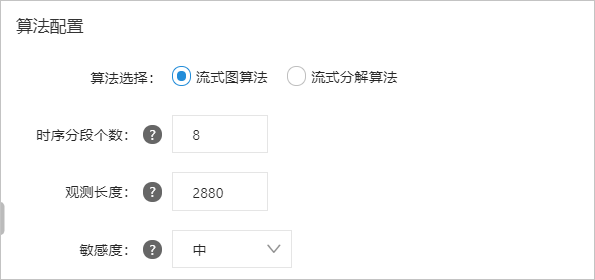
您可以在创建智能检测作业向导页面的算法配置区完成算法配置。具体操作请参考。
每个参数的说明如下表所示。
参数说明
时序段数
对时间序列值进行划分,将时间序列离散化,构建时间序列演化图,减少噪声的影响。建议预览不同时序段下的检测结果,选择最合适的值。
观察长度
要观察的历史数据点的数量。
灵敏度
异常分数输出的敏感性。
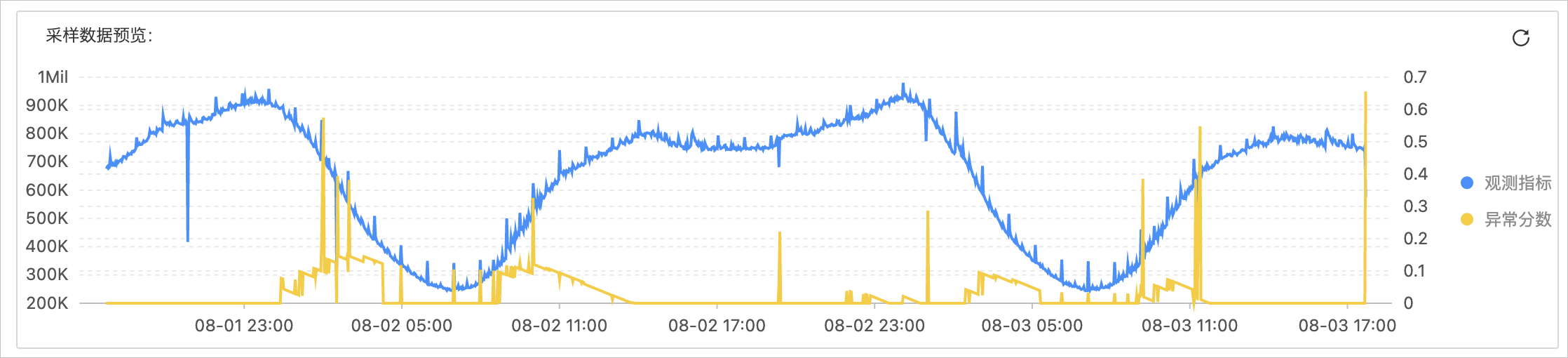
预览说明
预览示例如下图所示。
流分解算法
流分解算法是基于 RobustSTL 系列模型中的原理开发的。它可以批量处理数据流,但具有更高的计算成本。适用于小规模业务指标数据的精准检查。在大规模数据场景下,建议您拆分数据或使用流图算法。有关更多信息,请参阅 RobustSTL:长期序列的稳健季节性趋势分解算法。
场景描述
流分解算法适用于周期性数据序列的检查,要求数据的周期性更明显。例如,适用于周期性变化明显的业务指标的检查场景。
说明周期性数据在日常生活中比较常见,比如游戏访问次数和客户订单数量。
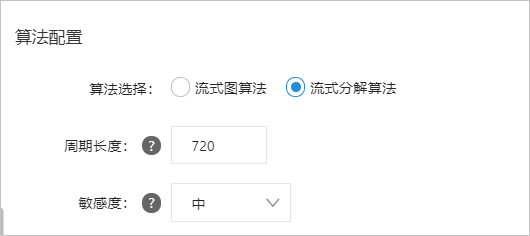
参数配置
您可以在创建智能检测作业向导页面的算法配置区完成算法配置。具体操作请参考。
每个参数的说明如下表所示。
参数说明
周期长度
以点为单位描述一个周期内数据序列中收录的数据点数。数据系列默认为天数。例如,如果粒度为120秒,周期为天,那么一个周期中收录的数据点数为24×60×60/120=720。
注意周期长度必须是时间序列的周期,否则会影响检查效果。
灵敏度
异常分数输出的敏感性。
预览说明
预览流式分解算法的异常检测结果时,系统默认选择最后4个周期的数据进行预览。预览示例如下图所示。
对于嘈杂的周期数据,您需要在预览页面上继续调试,直到配置了确切的周期长度。在噪声较大的情况下,由于噪声干扰,可能存在漏报或虚报。预览示例如下图所示。
查看全部
算法 自动采集列表(智能巡检使用流式图算法和流式分解算法进行数据巡检
)
日志服务提供智能巡检功能,对监控指标或业务日志等数据进行自动、智能、自适应的异常巡检。目前智能巡检采用流图算法和流分解算法进行数据巡检。本文介绍了流图算法和流分解算法的适用场景、参数配置、预览说明等。
流图算法
流图算法是基于Time2Graph系列模型中的原理开发的,可以降低数据的整体噪声,分析异常数据的相对偏差。流图算法适用于大规模、嘈杂、不显眼的时间序列的异常检测。有关更多信息,请参阅使用进化状态图进行时间序列事件预测。
场景描述
流图算法使用在线机器学习技术实时学习和推断每条数据。适用于一般的时间序列异常检测场景,包括:
参数配置
您可以在创建智能检测作业向导页面的算法配置区完成算法配置。具体操作请参考。
每个参数的说明如下表所示。
参数说明
时序段数
对时间序列值进行划分,将时间序列离散化,构建时间序列演化图,减少噪声的影响。建议预览不同时序段下的检测结果,选择最合适的值。
观察长度
要观察的历史数据点的数量。
灵敏度
异常分数输出的敏感性。
预览说明
预览示例如下图所示。
流分解算法
流分解算法是基于 RobustSTL 系列模型中的原理开发的。它可以批量处理数据流,但具有更高的计算成本。适用于小规模业务指标数据的精准检查。在大规模数据场景下,建议您拆分数据或使用流图算法。有关更多信息,请参阅 RobustSTL:长期序列的稳健季节性趋势分解算法。
场景描述
流分解算法适用于周期性数据序列的检查,要求数据的周期性更明显。例如,适用于周期性变化明显的业务指标的检查场景。
说明周期性数据在日常生活中比较常见,比如游戏访问次数和客户订单数量。
参数配置
您可以在创建智能检测作业向导页面的算法配置区完成算法配置。具体操作请参考。
每个参数的说明如下表所示。
参数说明
周期长度
以点为单位描述一个周期内数据序列中收录的数据点数。数据系列默认为天数。例如,如果粒度为120秒,周期为天,那么一个周期中收录的数据点数为24×60×60/120=720。
注意周期长度必须是时间序列的周期,否则会影响检查效果。
灵敏度
异常分数输出的敏感性。
预览说明
预览流式分解算法的异常检测结果时,系统默认选择最后4个周期的数据进行预览。预览示例如下图所示。
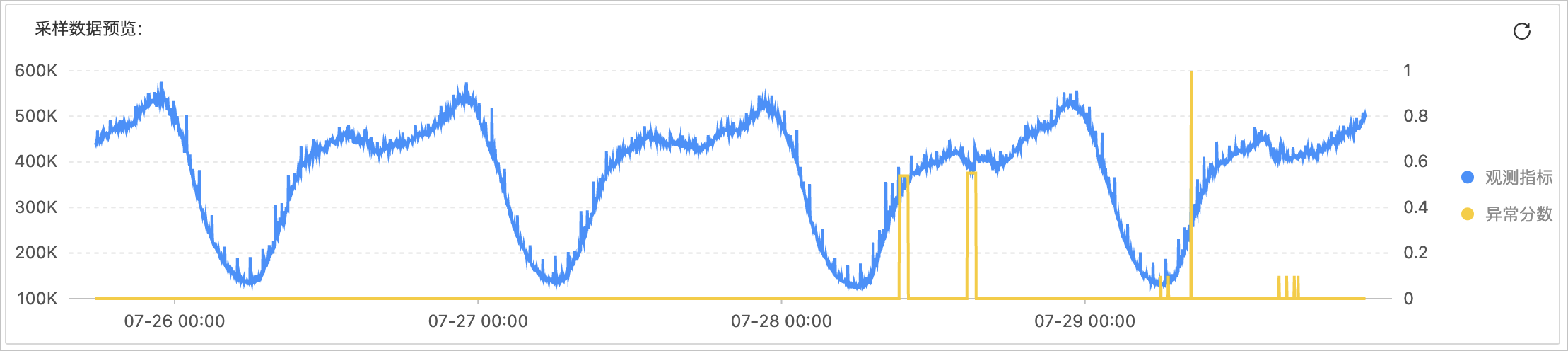
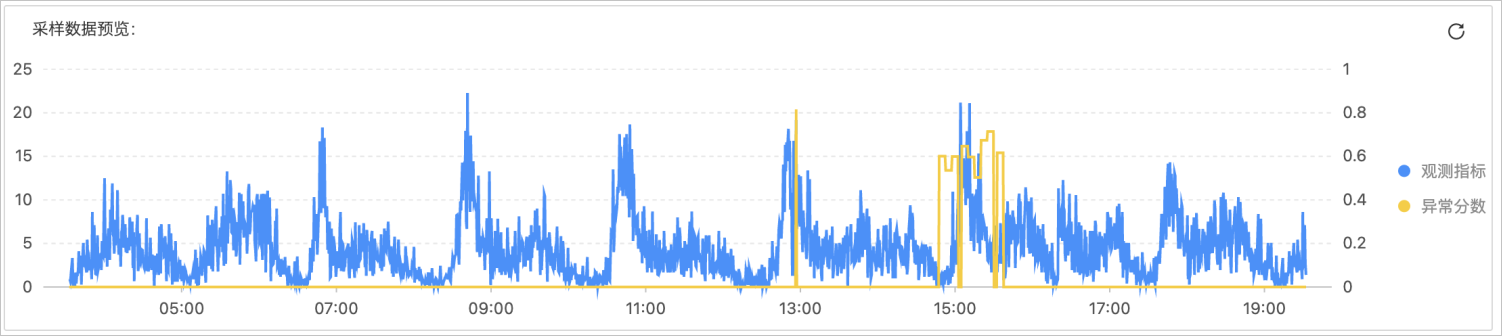
对于嘈杂的周期数据,您需要在预览页面上继续调试,直到配置了确切的周期长度。在噪声较大的情况下,由于噪声干扰,可能存在漏报或虚报。预览示例如下图所示。
算法 自动采集列表( Android端相机视频流采集与实时边框识别扫描算法(SmartScanner) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-24 11:09
Android端相机视频流采集与实时边框识别扫描算法(SmartScanner)
)
英语
SmartCamera是一款Android相机扩展库,提供高度可定制的实时扫描模块,可以实时采集并识别相机中物体的边框是否与指定区域匹配。如果你觉得还不错,欢迎star和fork。
语言描述有点生涩。具体实现的功能如下图所示。适用于身份证、名片、文件等内容的扫描、自动拍摄、裁剪。
您可以下载并体验SmartCamera集成的“卡片备忘录”,并将卡片安装到您的手机中:
您也可以下载演示 apk SmartCamera-Sample-debug.apk 来体验:
实时扫描模块(SmartScanner)是这个库的核心功能。借助相机PreviewCallback接口的预览流和跑马灯视图MaskView提供的跑马灯区域RectF,可以实时判断内容是否与跑马灯匹配,性能良好。
为了更方便地使用Android Camera,SmartCamera在源代码中引用了谷歌开源的CameraView,稍作修改,支持Camera.PreviewCallback回调获取相机预览流。
SmartCameraView继承了修改后的CameraView,增加了一个跑马灯遮罩视图(MaskView)和一个实时扫描模块(SmartScanner)。跑马灯视图是您看到的相机上方的一层跑马灯,并配备了从上到下的扫描效果。当然,你也可以实现 MaskViewImpl 接口来自定义跑马灯视图。
只需使用本库提供的SmartCameraView即可实现上述Demo中的效果。当然,如果你的项目中已经实现了摄像头模块,也可以直接使用SmartScanner来实现实时扫描效果。
(也可以关注我的另一个库SmartCropper:一个简单好用的智能图片裁剪库,适用于身份证、名片、文件等照片的裁剪)
SmartCamera原理解析:Android摄像头视频流采集与实时帧识别
扫描算法调优 SmartScanner 提供了丰富的算法配置。用户可以自行修改扫描算法,以获得更好的适应性。阅读附录1中提供的每个参数的说明,以获得更好的识别效果。
为了更方便、更高效的优化算法,SmartScanner贴心地为您提供了扫描预览模式。开启预览功能后,可以使用SmartScanner获取每一帧的处理结果并输出到ImageView,实时观察原生层扫描的结果。白线区域为边缘检测结果,白线加粗区域为识别边界。
您的目标是通过调整SmartScanner的各种参数,使内容边界清晰可见,识别出的框(白色粗线段)准确。
注意:SmartCamera 对性能和内存进行了各方面的优化,但由于不必要的性能资源浪费,请在算法参数调优完成后关闭预览模式。
使用权
1. 在根目录添加 build.gradle :
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
2.添加依赖
dependencies {
implementation 'com.github.pqpo:SmartCamera:v2.0.0'
}
注意:由于使用了JNI,请避免混淆
-keep class me.pqpo.smartcameralib.**{*;}
使用1. 引入相机布局并启动相机(必要时启动预览)
">
@Override
protected void onResume() {
super.onResume();
mCameraView.start();
mCameraView.startScan();
}
@Override
protected void onPause() {
mCameraView.stop();
super.onPause();
if (alertDialog != null) {
alertDialog.dismiss();
}
mCameraView.stopScan();
}
注意:如果开启了预览,不要忘记调用相应的打开和结束预览的方法。
2. 修改扫描模块参数(可选,调优算法,同时开启第4步的预览模式)
扫描模块各个参数含义详见附录一
private void initScannerParams() {
SmartScanner.DEBUG = true;
SmartScanner.detectionRatio = 0.1f;
SmartScanner.checkMinLengthRatio = 0.8f;
SmartScanner.cannyThreshold1 = 20;
SmartScanner.cannyThreshold2 = 50;
SmartScanner.houghLinesThreshold = 130;
SmartScanner.houghLinesMinLineLength = 80;
SmartScanner.houghLinesMaxLineGap = 10;
SmartScanner.firstGaussianBlurRadius = 3;
SmartScanner.secondGaussianBlurRadius = 3;
SmartScanner.maxSize = 300;
SmartScanner.angleThreshold = 5;
// don't forget reload params
SmartScanner.reloadParams();
}
注意:修改参数后不要忘记通知native层重新加载参数:SmartScanner.reloadParams();
3. 配置遮罩选框视图(可选,修改默认视图,或修改选框区域)
配置 MaskView 各个方法的含义详见附录二
<p>final MaskView maskView = (MaskView) mCameraView.getMaskView();;
maskView.setMaskLineColor(0xff00adb5);
maskView.setShowScanLine(true);
maskView.setScanLineGradient(0xff00adb5, 0x0000adb5);
maskView.setMaskLineWidth(2);
maskView.setMaskRadius(5);
maskView.setScanSpeed(6);
maskView.setScanGradientSpread(80);
mCameraView.post(new Runnable() {
@Override
public void run() {
int width = mCameraView.getWidth();
int height = mCameraView.getHeight();
if (width 查看全部
算法 自动采集列表(
Android端相机视频流采集与实时边框识别扫描算法(SmartScanner)
)

英语
SmartCamera是一款Android相机扩展库,提供高度可定制的实时扫描模块,可以实时采集并识别相机中物体的边框是否与指定区域匹配。如果你觉得还不错,欢迎star和fork。
语言描述有点生涩。具体实现的功能如下图所示。适用于身份证、名片、文件等内容的扫描、自动拍摄、裁剪。
您可以下载并体验SmartCamera集成的“卡片备忘录”,并将卡片安装到您的手机中:

您也可以下载演示 apk SmartCamera-Sample-debug.apk 来体验:

实时扫描模块(SmartScanner)是这个库的核心功能。借助相机PreviewCallback接口的预览流和跑马灯视图MaskView提供的跑马灯区域RectF,可以实时判断内容是否与跑马灯匹配,性能良好。
为了更方便地使用Android Camera,SmartCamera在源代码中引用了谷歌开源的CameraView,稍作修改,支持Camera.PreviewCallback回调获取相机预览流。
SmartCameraView继承了修改后的CameraView,增加了一个跑马灯遮罩视图(MaskView)和一个实时扫描模块(SmartScanner)。跑马灯视图是您看到的相机上方的一层跑马灯,并配备了从上到下的扫描效果。当然,你也可以实现 MaskViewImpl 接口来自定义跑马灯视图。
只需使用本库提供的SmartCameraView即可实现上述Demo中的效果。当然,如果你的项目中已经实现了摄像头模块,也可以直接使用SmartScanner来实现实时扫描效果。
(也可以关注我的另一个库SmartCropper:一个简单好用的智能图片裁剪库,适用于身份证、名片、文件等照片的裁剪)
SmartCamera原理解析:Android摄像头视频流采集与实时帧识别
扫描算法调优 SmartScanner 提供了丰富的算法配置。用户可以自行修改扫描算法,以获得更好的适应性。阅读附录1中提供的每个参数的说明,以获得更好的识别效果。

为了更方便、更高效的优化算法,SmartScanner贴心地为您提供了扫描预览模式。开启预览功能后,可以使用SmartScanner获取每一帧的处理结果并输出到ImageView,实时观察原生层扫描的结果。白线区域为边缘检测结果,白线加粗区域为识别边界。

您的目标是通过调整SmartScanner的各种参数,使内容边界清晰可见,识别出的框(白色粗线段)准确。
注意:SmartCamera 对性能和内存进行了各方面的优化,但由于不必要的性能资源浪费,请在算法参数调优完成后关闭预览模式。
使用权
1. 在根目录添加 build.gradle :
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
2.添加依赖
dependencies {
implementation 'com.github.pqpo:SmartCamera:v2.0.0'
}
注意:由于使用了JNI,请避免混淆
-keep class me.pqpo.smartcameralib.**{*;}
使用1. 引入相机布局并启动相机(必要时启动预览)
">
@Override
protected void onResume() {
super.onResume();
mCameraView.start();
mCameraView.startScan();
}
@Override
protected void onPause() {
mCameraView.stop();
super.onPause();
if (alertDialog != null) {
alertDialog.dismiss();
}
mCameraView.stopScan();
}
注意:如果开启了预览,不要忘记调用相应的打开和结束预览的方法。
2. 修改扫描模块参数(可选,调优算法,同时开启第4步的预览模式)
扫描模块各个参数含义详见附录一
private void initScannerParams() {
SmartScanner.DEBUG = true;
SmartScanner.detectionRatio = 0.1f;
SmartScanner.checkMinLengthRatio = 0.8f;
SmartScanner.cannyThreshold1 = 20;
SmartScanner.cannyThreshold2 = 50;
SmartScanner.houghLinesThreshold = 130;
SmartScanner.houghLinesMinLineLength = 80;
SmartScanner.houghLinesMaxLineGap = 10;
SmartScanner.firstGaussianBlurRadius = 3;
SmartScanner.secondGaussianBlurRadius = 3;
SmartScanner.maxSize = 300;
SmartScanner.angleThreshold = 5;
// don't forget reload params
SmartScanner.reloadParams();
}
注意:修改参数后不要忘记通知native层重新加载参数:SmartScanner.reloadParams();
3. 配置遮罩选框视图(可选,修改默认视图,或修改选框区域)
配置 MaskView 各个方法的含义详见附录二
<p>final MaskView maskView = (MaskView) mCameraView.getMaskView();;
maskView.setMaskLineColor(0xff00adb5);
maskView.setShowScanLine(true);
maskView.setScanLineGradient(0xff00adb5, 0x0000adb5);
maskView.setMaskLineWidth(2);
maskView.setMaskRadius(5);
maskView.setScanSpeed(6);
maskView.setScanGradientSpread(80);
mCameraView.post(new Runnable() {
@Override
public void run() {
int width = mCameraView.getWidth();
int height = mCameraView.getHeight();
if (width
算法 自动采集列表(什么小东西都在网上查一查自动获取大部分站点网页title)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-21 09:03
算法自动采集列表抓取每个浏览器的列表等,按照tag搜索。搜索等功能手机搜索slashgear对于一个公司来说是很不错的选择,可以作为推广手段来讲。
看了楼上的回答,说的太简单,我再说下搜索引擎方面的东西。
1、百度的服务器在美国,谷歌的服务器在日本。
2、百度主打高端人群,谷歌主打新闻资讯类人群。
3、百度的竞价广告相对便宜
4、谷歌的本地化做的更好。
以前我认为谷歌是世界最好的搜索引擎,但是在使用搜索引擎的过程中我发现了谷歌很多的问题(比如说版权问题),国内互联网上很多做技术的人都有个习惯,就是擅长捏造事实,用谷歌搜索出来的百度百科,搜狗百科,360百科的编撰,利用了百度搜索引擎的公信力,甚至是恶意捏造事实来达到给百度造势。没错,的确有很多本地化的地方比如google中国,总而言之,我的谷歌搜索根本没法满足日常生活中百度百科的需求。
什么小东西都在网上查一查
自动获取大部分站点网页的title、关键词,相比百度来说信息质量更高。不过谷歌官方已经不允许相关站点的访问了。不能用,太恶心了。
我用过谷歌的搜索算法,感觉搜什么搜索结果出来的东西都差不多吧,根本就没啥的,但百度就会有很多奇怪的东西存在,比如加了自动伸缩属性的!!这是谷歌和百度搜索结果对比的结果:从结果可以看出来,百度搜索的相关性分别为78:41:31, 查看全部
算法 自动采集列表(什么小东西都在网上查一查自动获取大部分站点网页title)
算法自动采集列表抓取每个浏览器的列表等,按照tag搜索。搜索等功能手机搜索slashgear对于一个公司来说是很不错的选择,可以作为推广手段来讲。
看了楼上的回答,说的太简单,我再说下搜索引擎方面的东西。
1、百度的服务器在美国,谷歌的服务器在日本。
2、百度主打高端人群,谷歌主打新闻资讯类人群。
3、百度的竞价广告相对便宜
4、谷歌的本地化做的更好。
以前我认为谷歌是世界最好的搜索引擎,但是在使用搜索引擎的过程中我发现了谷歌很多的问题(比如说版权问题),国内互联网上很多做技术的人都有个习惯,就是擅长捏造事实,用谷歌搜索出来的百度百科,搜狗百科,360百科的编撰,利用了百度搜索引擎的公信力,甚至是恶意捏造事实来达到给百度造势。没错,的确有很多本地化的地方比如google中国,总而言之,我的谷歌搜索根本没法满足日常生活中百度百科的需求。
什么小东西都在网上查一查
自动获取大部分站点网页的title、关键词,相比百度来说信息质量更高。不过谷歌官方已经不允许相关站点的访问了。不能用,太恶心了。
我用过谷歌的搜索算法,感觉搜什么搜索结果出来的东西都差不多吧,根本就没啥的,但百度就会有很多奇怪的东西存在,比如加了自动伸缩属性的!!这是谷歌和百度搜索结果对比的结果:从结果可以看出来,百度搜索的相关性分别为78:41:31,
算法 自动采集列表(基于nginxmirror模块的流量采集方案解密 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-10-20 14:14
)
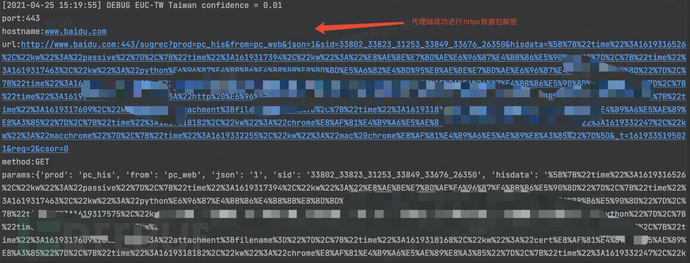
这里我们以访问为例,可以看到如下信息,代理已经解密了发送的https数据包。
基于nginx镜像模块
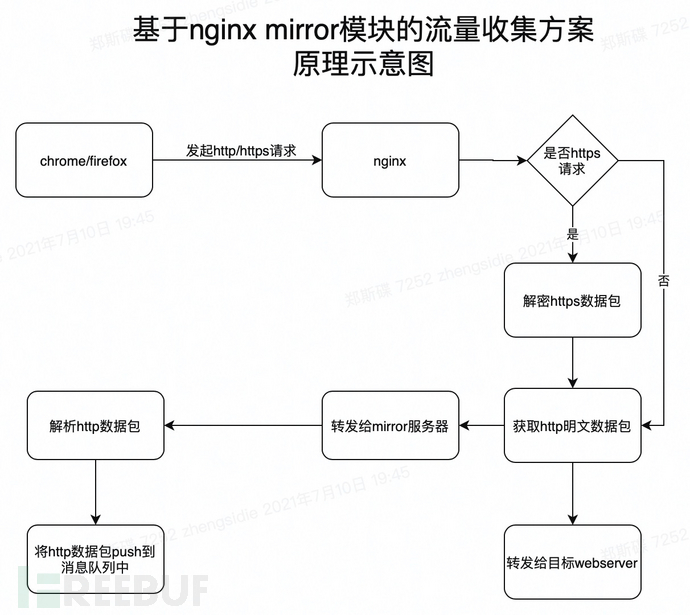
基于nginx镜像模块的flow采集方案基本原理
当然,不仅可以通过代理流量,也可以通过nginx镜像模块来采集流量。
在基于nginx镜像模块的流程采集方案中,我们将通过以下步骤实现到目标系统采集的流程:
1、 配置nginx配置文件,添加镜像服务器,指定后端地址为我们神奇修改的webserver地址。这样nginx会在请求来的时候对原创http请求包进行镜像,并将请求转发到镜像服务器。
2、在镜像服务器上解析这些http请求包,然后解析明文请求包,然后将这些请求包推送到消息队列进行任务分发。
实验验证了基于nginx镜像模块进行流量采集的可行性
为了验证这个想法的可行性,我们来做一个实验。这里需要搭建一个支持mirror模块的nginx服务器,搭建过程不再赘述,读者可以自行搭建。
现在让我们开始实验。首先,我们在服务器a(192.168.1.10)上安装配置nginx,在服务器192.16上安装配置我们修改的8.1.上的webserver 11.这个修改后的webserver负责解析nginx转发的http数据包,并将解析后的http数据包推送到消息队列中间。
服务器a中的nginx配置文件如下:
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8181;
mirror_request_body on;
access_log /var/log/nginx/test.log;
root html/test;
}
server {
mirror_request_body on;
listen 8282;
access_log /var/log/nginx/mir1.log;
root html/mir1;
}
upstream backend {
server 127.0.0.1:8181;
}
upstream test_backend1 {
server 192.168.1.11:9008;
#如果需要做负载均衡,多配置一些backend
#server 192.168.1.12:9008;
#server 192.168.1.13:9008;
}
server {
listen 80;
server_name localhost;
mirror_request_body on;
location / {
mirror /mirror1;
proxy_pass http://backend;
}
location = /mirror1 {
#internal;
proxy_pass http://test_backend1$request_uri;
}
}
}
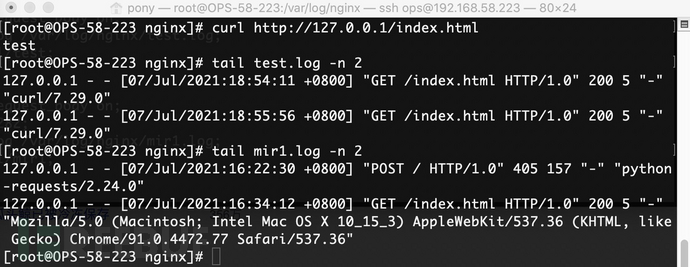
简单解释一下上面的配置信息。在nginx.conf配置中,配置启动三个服务器实例。80端口的服务器负责将原创请求包转发到8181和8282端口,8181端口的http服务负责将原创请求转发到web后端,8282端口的http服务负责转发原创请求向 Web 后端请求。镜像请求包转发到其他webserver(基于python的BaseHTTPRequestHandler修改的webserver)。配置完成后,我们启动nginx,在http服务目录下执行如下命令,创建实验所需的一些文件:
cd /usr/share/nginx/html/
mkdir test mir1
echo "test page" >test/index.html
接下来我们执行 curl 命令 curl
执行该命令后,预期的结果是/var/log/nginx/mir1.log和/var/log/nginx/test.log中都有对应的访问记录,说明nginx成功镜像了一份将流量转发给8282和8181端口对应的http服务,看看实际访问结果
没错,一切都和一开始的预期一样。从访问日志来看,镜像服务器转发的http请求包已经成功接收解析。这里我们举一个简单的例子:
from http.server import HTTPServer, BaseHTTPRequestHandler
import json
class Resquest(BaseHTTPRequestHandler):
def handler(self):
print("data:", self.rfile.readline().decode())
self.wfile.write(self.rfile.readline())
def do_GET(self):
print(self.requestline)
print(self.headers)
data = {
"status":200,
"info":"test"
}
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps(data).encode())
def do_POST(self):
print(self.requestline)
print(self.headers)
req_datas = self.rfile.read(int(self.headers['content-length']))
print(req_datas.decode())
data = {
"status":200,
"info":"test"
}
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps(data).encode('utf-8'))
if __name__ == '__main__':
host = ('0.0.0.0', 9008)
server = HTTPServer(host, Resquest)
print("Starting server, listen at: %s:%s" % host)
server.serve_forever()
启动服务后,可以接收到镜像服务器转发过来的http请求包。这里我们重写了 do_GET 和 do_POST 函数来解析和打印请求的数据包。实验结果如下:
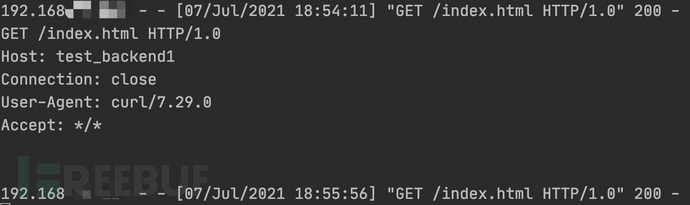
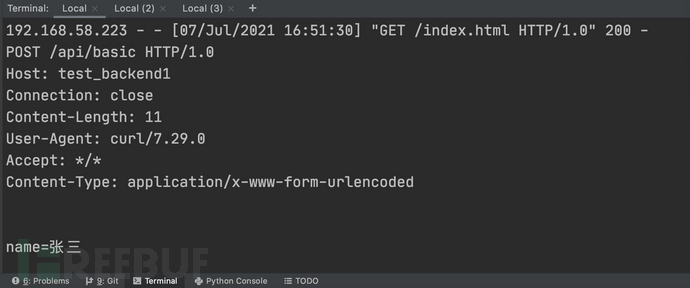
post数据包效果信息如下(curl -X POST -d'name=张三')
这个过程可以用下图表示:
但是,如果通过nginx镜像模块采集流量,则只能针对企业内部连接nginx的项目。如果要检测没有连接nginx的项目,或者互联网上的一些其他网站,也需要使用代理模式。两者之间存在互补性。Nginx可以解决配置代理和证书的麻烦(当然nginx本身也需要配置https证书),代理模式可以让被动漏洞扫描系统更加有效。但对企业而言,基于nginx镜像模块的流量采集解决方案在自动化上会有比较优势。
三、分布式漏洞检测框架实现方案
上面解释了基于http/https代理的流量劫持的基本原理,那么如何基于此开发一个被动的漏洞检测系统呢?以及我们需要考虑哪些问题?在大规模被动漏洞扫描的场景下,往往会有大量流量转发到代理服务器。如果没有合理的架构设计,代理服务器很可能会陷入包洪泛的困境,类似于dos Attack(ps:要进行漏洞检测,必须构造请求数据包。试想如果是500漏洞检测插件,那么每个请求的代理服务器至少要转发500个http请求包到目标web服务器,如果没有妥善处理,这是一件很可怕的事情)。那么如何处理这个问题呢?下面是我们设计的基于代理流量的被动漏洞扫描器的示意图,我们将在此基础上进一步讨论。
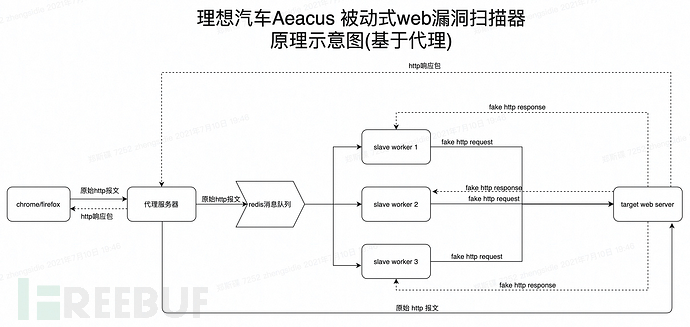
基于代理流量的分布式漏洞检测框架设计
在基于代理的被动流量采集方案中,用户在chrome端配置https/http代理,让流量先到我们的代理服务器。代理服务器将原创数据包推送到redis消息队列进行任务分发,slave worker监控redis消息队列,通过抢占方式获取任务信息,加载漏洞检测插件,发送带有攻击payload的请求包到服务器进行漏洞检测和分析。另一方面,代理服务器也会将原创请求包转发给服务器,以便客户端获得想要的请求结果。
在性能优化方面,一方面可以通过适当的sleep方式批量发送这些http攻击数据包,另一方面可以分布式的方式减轻漏洞检测分析服务器的负担。
基于nginx镜像模块的分布式漏洞检测框架设计
在基于nginx镜像模块的被动流量采集方案中,配置镜像服务器对原创请求流量进行镜像,将镜像流量转发到aeacus服务器分析http流量,并推送解析后的http请求消息信息 到消息队列。然后slave worker监听redis消息队列,通过抢占方式获取任务信息,加载漏洞检测插件,将带有攻击载荷的请求包发送到服务器进行漏洞检测分析。
在基于nginx镜像模块的被动流量采集方面,可以从以下两个方面进行性能优化。一方面,对于大量并发的请求,可以配置nginx负载均衡,将这些请求平均分配到各个镜像服务器,让各个镜像服务器处理的任务相对较少。镜像可根据实际业务量增减。服务器的数量,另一方面,为了降低每个slave worker的漏洞分析压力,可以根据实际情况扩展分布式任务节点的数量。当然,重点是对数据包进行去重,否则会增加任务节点的检测压力。
脏数据解决方案讨论
在被动漏洞分析检测过程中,如果一些post请求数据包具有存储功能,那么大量的攻击性数据包无疑会带来大量的脏数据。这也是很多安全人员在推一些安全测试产品时经常考虑的一个问题。推的时候还担心会因为这个问题受阻,但其实被动漏洞检测系统主要是连接测试环境,脏数据的影响比较小,几乎可以忽略不计。如果测试方觉得大量的脏数据会影响测试的效果,那我们不妨讨论一下如何处理测试过程中产生的脏数据问题。网上有同学的解决办法是过滤一些可能涉及存储的接口,但个人认为这个要慎重考虑,因为不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。因为你不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。因为你不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,让考生识别。但我认为最好的方法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。可以在payload中插入一个特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。可以在payload中插入一个特定的识别码,供考生识别。但我认为最好的方法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。
四、插件模块设计1、支持动态加载指纹识别模块
0x1 指纹识别模块加载执行流程图示意图
2、支持动态加载漏洞检测模块
0x0 Aeacus漏洞检测模块动态插件加载原理说明
插件加载在扫描作业的初始化阶段进行。通过python中的动态导入模块技术,将指定文件中的模块导入到当前进程中,然后检查导入模块的合法性。如果符合预期的模块格式要求,则将该模块保存在模块缓存区。在进行漏洞检测操作时,只需要遍历执行模块缓存区中的插件即可。动态加载的目的是为了支持漏洞检测插件的热更新,即后续插件维护者只需要将编译好的插件放到指定目录下,无需重启系统,让系统支持更多的漏洞检测能力。
代码
//python中动态加载指定文件中的模块信息
def module_dynamic_loader(file_path):
if '' not in importlib.machinery.SOURCE_SUFFIXES:
importlib.machinery.SOURCE_SUFFIXES.append('')
try:
module_name = 'plugin_{0}'.format(get_filename(file_path, with_ext=False))
spec = importlib.util.spec_from_file_location(module_name, file_path, loader=PocLoader(module_name, file_path))
mod = importlib.util.module_from_spec(spec)
spec.loader.exec_module(mod)
return mod
except ImportError:
error_msg = "load module failed! '{}'".format(file_path)
print(error_msg)
raise
0x1漏洞检测模块加载执行流程图示意图
五、 爬虫模块与Aeacus被动漏洞分析引擎的结合
在爬虫方面,可以配置https/http代理与aeacus系统链接,使爬虫爬取的数据包转发到后端被动漏洞分析引擎进行处理。如果使用nginx镜像流量采集方案,则不需要配置代理。直接爬行,aeacus系统可以自动获取相关的请求数据包。
六、数据包去重存储方案 数据包去重的必要性
被动的漏洞扫描器在采集流量的过程中难免会采集到大量重复的数据包,重复的数据包会增加后端漏洞分析引擎的负载,所以我们需要去采集到的http/https请求包. 重处理。
执行
主要依赖去重算法:Bloom去重算法
算法库:redisbloom
算法库安装配置:
#服务端安装配置
docker pull redislabs/rebloom:latest
docker run -p 5276:6379 --name redis-redisbloom redislabs/rebloom:latest
#客户端处理安装
pip install redisbloom
算法原理
基本的
Bloom filter内部维护一个bitArray(位数组),所有数据一开始都设置为0。当一个元素过来时,可以使用多个hash函数(hash1、hash2、hash3....)来计算不同的hash值,通过hash值找到对应的bitArray下标。里面的值0设置为1。需要注意的是Bloom filter有误判率的概念。误判率越低,阵列越长,占用空间越大。误报率越高,数组越小,占用空间越小。
初始化
插入,经过3个哈希函数的计算,得到的哈希值分别为1、4、7,然后在bitarray对应的索引处将该位标记为1。
数据包bloom去重代码实现
这里主要是根据端口、主机名、路径、方法、参数、协议参数对数据包进行签名,示例代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# desc: 数据包布隆去重
# author: pOny
from redisbloom.client import Client
from configure import bloom_server_address,bloom_server_port
class bloomfilter():
rb = Client(host=bloom_server_address, port=bloom_server_port)
@staticmethod
def add_packet_hash(**kwargs):
'''
添加hash信息
:param kwargs:
datadict={
"method":"post",
"protocal":"http",
"hostname":"pony.com",
"port":"80",
"path":"/docs",
"params":["p1","p2","p3"]
}
:return: None
'''
port,hostname,path,method,params,protocal=kwargs.get("port"),\
kwargs.get("hostname"),kwargs.get("path"),\
kwargs.get("method"),kwargs.get("params"),\
kwargs.get("protocal")
params= "".join(params) if params else ""
if isinstance(port,int):
port=str(port)
data="{}{}{}{}{}{}".format(port,hostname,path,method,params,protocal)
bloomfilter.rb.bfAdd(kwargs.get("projectid"),data)
@staticmethod
def dofilter(**kwargs):
'''
布隆去重复
:param kwargs:
datadict={
"method":"post",
"protocal":"http",
"hostname":"lixiang.com",
"port":"80",
"path":"/docs",
"params":["p1","p2","p3"],
}
:return:Boolean
'''
port,hostname,path,method,params,protocal=kwargs.get("port"),\
kwargs.get("hostname"),kwargs.get("path"),\
kwargs.get("method"),kwargs.get("params"),\
kwargs.get("protocal")
params= params="".join(params) if params else ""
if isinstance(port,int):
port=str(port)
data="{}{}{}{}{}{}".format(port,hostname,path,method,params,protocal)
return bloomfilter.rb.bfExists(kwargs.get("projectid"),data)
七、Aeacus 被动漏洞扫描器介绍
在过去的q2季度,理想汽车安全部的devsecops团队一直致力于被动漏洞扫描器的研发,积累了一些被动漏洞扫描器的开发经验。在这里给大家分享一些经验,希望对大家分享后的工作有一定的帮助。
注:以下涉及的漏洞数据均为模拟数据。
0x0 整体架构图
0x1 漏洞数据可视化展示面板
0x2 漏洞管理
漏洞列表
漏洞详情
0x3 项目管理
项目清单
添加的项目
0x4 插件管理
插件列表
插件添加页面
查看全部
算法 自动采集列表(基于nginxmirror模块的流量采集方案解密
)
这里我们以访问为例,可以看到如下信息,代理已经解密了发送的https数据包。
基于nginx镜像模块
基于nginx镜像模块的flow采集方案基本原理
当然,不仅可以通过代理流量,也可以通过nginx镜像模块来采集流量。
在基于nginx镜像模块的流程采集方案中,我们将通过以下步骤实现到目标系统采集的流程:
1、 配置nginx配置文件,添加镜像服务器,指定后端地址为我们神奇修改的webserver地址。这样nginx会在请求来的时候对原创http请求包进行镜像,并将请求转发到镜像服务器。
2、在镜像服务器上解析这些http请求包,然后解析明文请求包,然后将这些请求包推送到消息队列进行任务分发。
实验验证了基于nginx镜像模块进行流量采集的可行性
为了验证这个想法的可行性,我们来做一个实验。这里需要搭建一个支持mirror模块的nginx服务器,搭建过程不再赘述,读者可以自行搭建。
现在让我们开始实验。首先,我们在服务器a(192.168.1.10)上安装配置nginx,在服务器192.16上安装配置我们修改的8.1.上的webserver 11.这个修改后的webserver负责解析nginx转发的http数据包,并将解析后的http数据包推送到消息队列中间。
服务器a中的nginx配置文件如下:
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8181;
mirror_request_body on;
access_log /var/log/nginx/test.log;
root html/test;
}
server {
mirror_request_body on;
listen 8282;
access_log /var/log/nginx/mir1.log;
root html/mir1;
}
upstream backend {
server 127.0.0.1:8181;
}
upstream test_backend1 {
server 192.168.1.11:9008;
#如果需要做负载均衡,多配置一些backend
#server 192.168.1.12:9008;
#server 192.168.1.13:9008;
}
server {
listen 80;
server_name localhost;
mirror_request_body on;
location / {
mirror /mirror1;
proxy_pass http://backend;
}
location = /mirror1 {
#internal;
proxy_pass http://test_backend1$request_uri;
}
}
}
简单解释一下上面的配置信息。在nginx.conf配置中,配置启动三个服务器实例。80端口的服务器负责将原创请求包转发到8181和8282端口,8181端口的http服务负责将原创请求转发到web后端,8282端口的http服务负责转发原创请求向 Web 后端请求。镜像请求包转发到其他webserver(基于python的BaseHTTPRequestHandler修改的webserver)。配置完成后,我们启动nginx,在http服务目录下执行如下命令,创建实验所需的一些文件:
cd /usr/share/nginx/html/
mkdir test mir1
echo "test page" >test/index.html
接下来我们执行 curl 命令 curl
执行该命令后,预期的结果是/var/log/nginx/mir1.log和/var/log/nginx/test.log中都有对应的访问记录,说明nginx成功镜像了一份将流量转发给8282和8181端口对应的http服务,看看实际访问结果
没错,一切都和一开始的预期一样。从访问日志来看,镜像服务器转发的http请求包已经成功接收解析。这里我们举一个简单的例子:
from http.server import HTTPServer, BaseHTTPRequestHandler
import json
class Resquest(BaseHTTPRequestHandler):
def handler(self):
print("data:", self.rfile.readline().decode())
self.wfile.write(self.rfile.readline())
def do_GET(self):
print(self.requestline)
print(self.headers)
data = {
"status":200,
"info":"test"
}
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps(data).encode())
def do_POST(self):
print(self.requestline)
print(self.headers)
req_datas = self.rfile.read(int(self.headers['content-length']))
print(req_datas.decode())
data = {
"status":200,
"info":"test"
}
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps(data).encode('utf-8'))
if __name__ == '__main__':
host = ('0.0.0.0', 9008)
server = HTTPServer(host, Resquest)
print("Starting server, listen at: %s:%s" % host)
server.serve_forever()
启动服务后,可以接收到镜像服务器转发过来的http请求包。这里我们重写了 do_GET 和 do_POST 函数来解析和打印请求的数据包。实验结果如下:
post数据包效果信息如下(curl -X POST -d'name=张三')
这个过程可以用下图表示:
但是,如果通过nginx镜像模块采集流量,则只能针对企业内部连接nginx的项目。如果要检测没有连接nginx的项目,或者互联网上的一些其他网站,也需要使用代理模式。两者之间存在互补性。Nginx可以解决配置代理和证书的麻烦(当然nginx本身也需要配置https证书),代理模式可以让被动漏洞扫描系统更加有效。但对企业而言,基于nginx镜像模块的流量采集解决方案在自动化上会有比较优势。
三、分布式漏洞检测框架实现方案
上面解释了基于http/https代理的流量劫持的基本原理,那么如何基于此开发一个被动的漏洞检测系统呢?以及我们需要考虑哪些问题?在大规模被动漏洞扫描的场景下,往往会有大量流量转发到代理服务器。如果没有合理的架构设计,代理服务器很可能会陷入包洪泛的困境,类似于dos Attack(ps:要进行漏洞检测,必须构造请求数据包。试想如果是500漏洞检测插件,那么每个请求的代理服务器至少要转发500个http请求包到目标web服务器,如果没有妥善处理,这是一件很可怕的事情)。那么如何处理这个问题呢?下面是我们设计的基于代理流量的被动漏洞扫描器的示意图,我们将在此基础上进一步讨论。
基于代理流量的分布式漏洞检测框架设计
在基于代理的被动流量采集方案中,用户在chrome端配置https/http代理,让流量先到我们的代理服务器。代理服务器将原创数据包推送到redis消息队列进行任务分发,slave worker监控redis消息队列,通过抢占方式获取任务信息,加载漏洞检测插件,发送带有攻击payload的请求包到服务器进行漏洞检测和分析。另一方面,代理服务器也会将原创请求包转发给服务器,以便客户端获得想要的请求结果。
在性能优化方面,一方面可以通过适当的sleep方式批量发送这些http攻击数据包,另一方面可以分布式的方式减轻漏洞检测分析服务器的负担。
基于nginx镜像模块的分布式漏洞检测框架设计
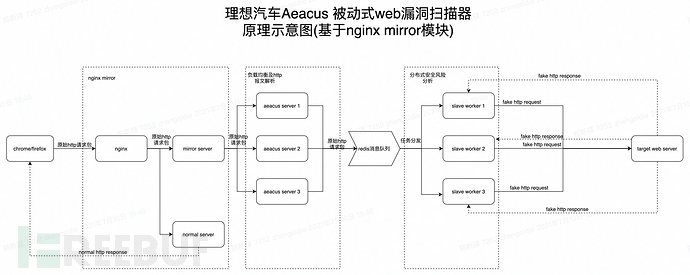
在基于nginx镜像模块的被动流量采集方案中,配置镜像服务器对原创请求流量进行镜像,将镜像流量转发到aeacus服务器分析http流量,并推送解析后的http请求消息信息 到消息队列。然后slave worker监听redis消息队列,通过抢占方式获取任务信息,加载漏洞检测插件,将带有攻击载荷的请求包发送到服务器进行漏洞检测分析。
在基于nginx镜像模块的被动流量采集方面,可以从以下两个方面进行性能优化。一方面,对于大量并发的请求,可以配置nginx负载均衡,将这些请求平均分配到各个镜像服务器,让各个镜像服务器处理的任务相对较少。镜像可根据实际业务量增减。服务器的数量,另一方面,为了降低每个slave worker的漏洞分析压力,可以根据实际情况扩展分布式任务节点的数量。当然,重点是对数据包进行去重,否则会增加任务节点的检测压力。
脏数据解决方案讨论
在被动漏洞分析检测过程中,如果一些post请求数据包具有存储功能,那么大量的攻击性数据包无疑会带来大量的脏数据。这也是很多安全人员在推一些安全测试产品时经常考虑的一个问题。推的时候还担心会因为这个问题受阻,但其实被动漏洞检测系统主要是连接测试环境,脏数据的影响比较小,几乎可以忽略不计。如果测试方觉得大量的脏数据会影响测试的效果,那我们不妨讨论一下如何处理测试过程中产生的脏数据问题。网上有同学的解决办法是过滤一些可能涉及存储的接口,但个人认为这个要慎重考虑,因为不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。因为你不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。因为你不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,让考生识别。但我认为最好的方法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。可以在payload中插入一个特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。可以在payload中插入一个特定的识别码,供考生识别。但我认为最好的方法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。
四、插件模块设计1、支持动态加载指纹识别模块
0x1 指纹识别模块加载执行流程图示意图
2、支持动态加载漏洞检测模块
0x0 Aeacus漏洞检测模块动态插件加载原理说明
插件加载在扫描作业的初始化阶段进行。通过python中的动态导入模块技术,将指定文件中的模块导入到当前进程中,然后检查导入模块的合法性。如果符合预期的模块格式要求,则将该模块保存在模块缓存区。在进行漏洞检测操作时,只需要遍历执行模块缓存区中的插件即可。动态加载的目的是为了支持漏洞检测插件的热更新,即后续插件维护者只需要将编译好的插件放到指定目录下,无需重启系统,让系统支持更多的漏洞检测能力。
代码
//python中动态加载指定文件中的模块信息
def module_dynamic_loader(file_path):
if '' not in importlib.machinery.SOURCE_SUFFIXES:
importlib.machinery.SOURCE_SUFFIXES.append('')
try:
module_name = 'plugin_{0}'.format(get_filename(file_path, with_ext=False))
spec = importlib.util.spec_from_file_location(module_name, file_path, loader=PocLoader(module_name, file_path))
mod = importlib.util.module_from_spec(spec)
spec.loader.exec_module(mod)
return mod
except ImportError:
error_msg = "load module failed! '{}'".format(file_path)
print(error_msg)
raise
0x1漏洞检测模块加载执行流程图示意图
五、 爬虫模块与Aeacus被动漏洞分析引擎的结合
在爬虫方面,可以配置https/http代理与aeacus系统链接,使爬虫爬取的数据包转发到后端被动漏洞分析引擎进行处理。如果使用nginx镜像流量采集方案,则不需要配置代理。直接爬行,aeacus系统可以自动获取相关的请求数据包。
六、数据包去重存储方案 数据包去重的必要性
被动的漏洞扫描器在采集流量的过程中难免会采集到大量重复的数据包,重复的数据包会增加后端漏洞分析引擎的负载,所以我们需要去采集到的http/https请求包. 重处理。
执行
主要依赖去重算法:Bloom去重算法
算法库:redisbloom
算法库安装配置:
#服务端安装配置
docker pull redislabs/rebloom:latest
docker run -p 5276:6379 --name redis-redisbloom redislabs/rebloom:latest
#客户端处理安装
pip install redisbloom
算法原理
基本的
Bloom filter内部维护一个bitArray(位数组),所有数据一开始都设置为0。当一个元素过来时,可以使用多个hash函数(hash1、hash2、hash3....)来计算不同的hash值,通过hash值找到对应的bitArray下标。里面的值0设置为1。需要注意的是Bloom filter有误判率的概念。误判率越低,阵列越长,占用空间越大。误报率越高,数组越小,占用空间越小。
初始化

插入,经过3个哈希函数的计算,得到的哈希值分别为1、4、7,然后在bitarray对应的索引处将该位标记为1。
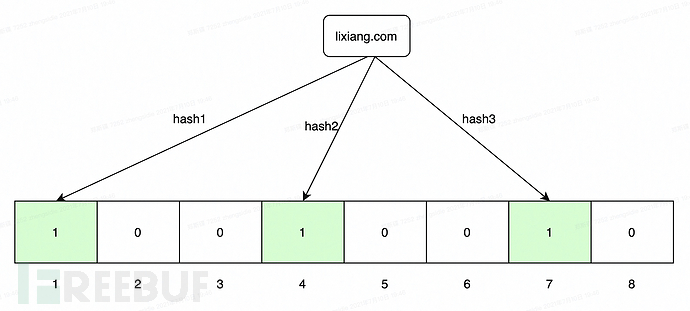
数据包bloom去重代码实现
这里主要是根据端口、主机名、路径、方法、参数、协议参数对数据包进行签名,示例代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# desc: 数据包布隆去重
# author: pOny
from redisbloom.client import Client
from configure import bloom_server_address,bloom_server_port
class bloomfilter():
rb = Client(host=bloom_server_address, port=bloom_server_port)
@staticmethod
def add_packet_hash(**kwargs):
'''
添加hash信息
:param kwargs:
datadict={
"method":"post",
"protocal":"http",
"hostname":"pony.com",
"port":"80",
"path":"/docs",
"params":["p1","p2","p3"]
}
:return: None
'''
port,hostname,path,method,params,protocal=kwargs.get("port"),\
kwargs.get("hostname"),kwargs.get("path"),\
kwargs.get("method"),kwargs.get("params"),\
kwargs.get("protocal")
params= "".join(params) if params else ""
if isinstance(port,int):
port=str(port)
data="{}{}{}{}{}{}".format(port,hostname,path,method,params,protocal)
bloomfilter.rb.bfAdd(kwargs.get("projectid"),data)
@staticmethod
def dofilter(**kwargs):
'''
布隆去重复
:param kwargs:
datadict={
"method":"post",
"protocal":"http",
"hostname":"lixiang.com",
"port":"80",
"path":"/docs",
"params":["p1","p2","p3"],
}
:return:Boolean
'''
port,hostname,path,method,params,protocal=kwargs.get("port"),\
kwargs.get("hostname"),kwargs.get("path"),\
kwargs.get("method"),kwargs.get("params"),\
kwargs.get("protocal")
params= params="".join(params) if params else ""
if isinstance(port,int):
port=str(port)
data="{}{}{}{}{}{}".format(port,hostname,path,method,params,protocal)
return bloomfilter.rb.bfExists(kwargs.get("projectid"),data)
七、Aeacus 被动漏洞扫描器介绍
在过去的q2季度,理想汽车安全部的devsecops团队一直致力于被动漏洞扫描器的研发,积累了一些被动漏洞扫描器的开发经验。在这里给大家分享一些经验,希望对大家分享后的工作有一定的帮助。
注:以下涉及的漏洞数据均为模拟数据。
0x0 整体架构图
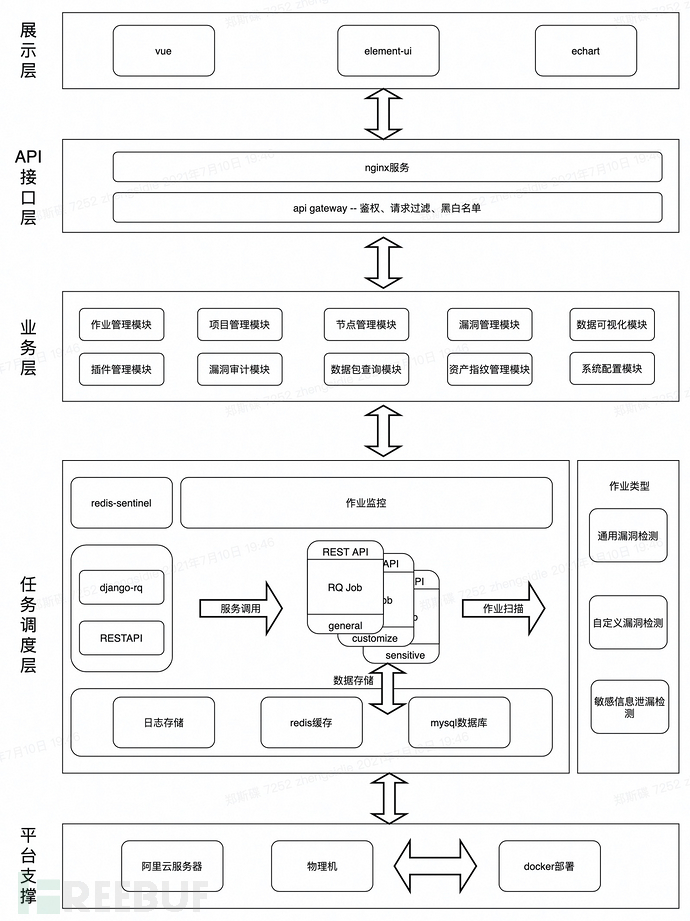
0x1 漏洞数据可视化展示面板
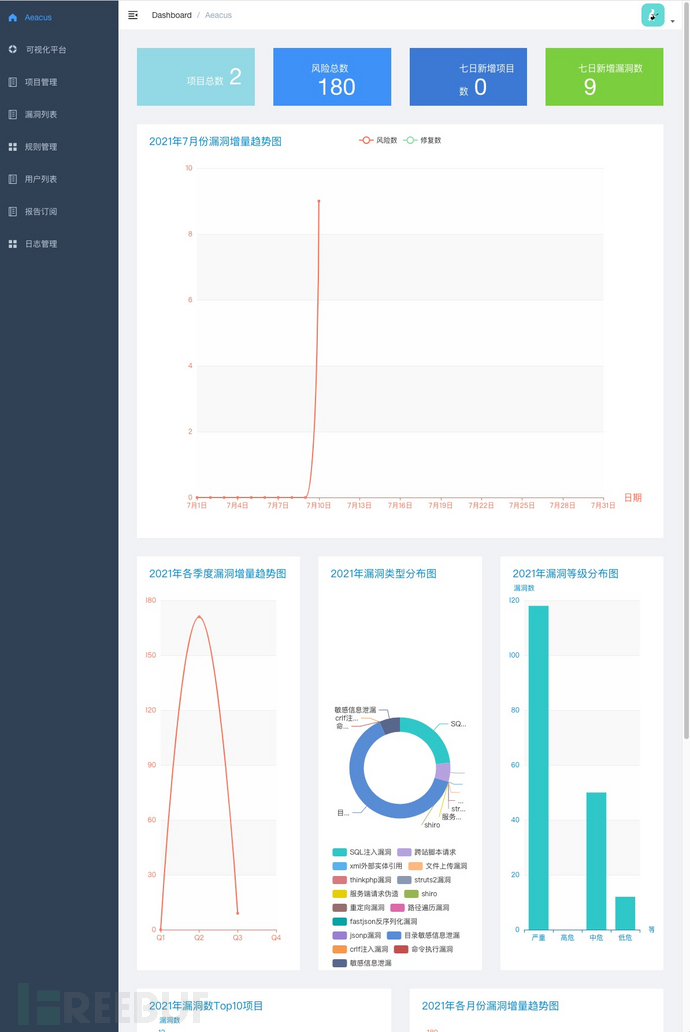
0x2 漏洞管理
漏洞列表
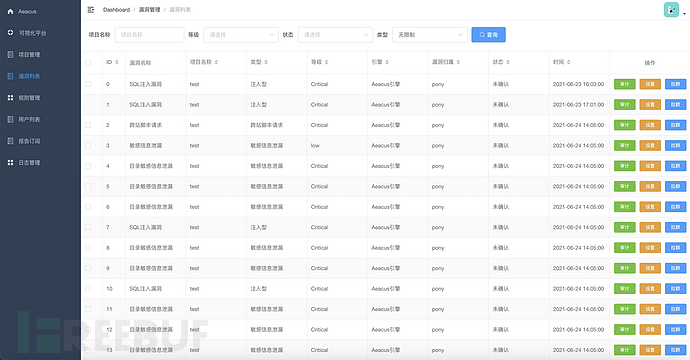
漏洞详情
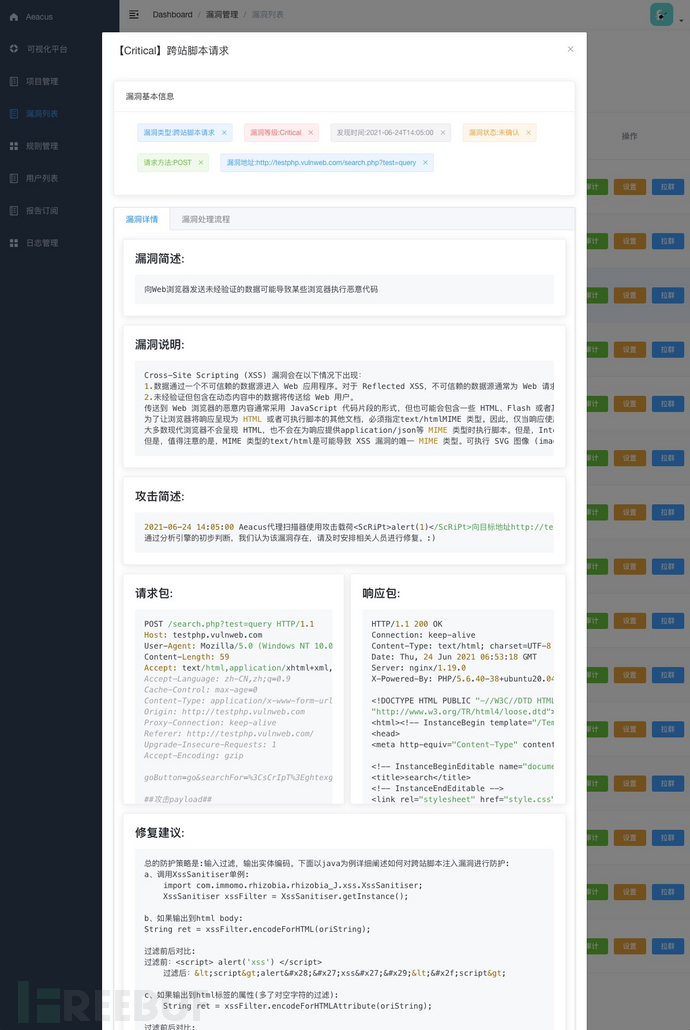
0x3 项目管理
项目清单
添加的项目
0x4 插件管理
插件列表
插件添加页面
算法 自动采集列表(用技术力量探索行为密码,让大数据助跑每一个人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2021-10-20 07:02
作者是一个痴迷于挖掘数据价值的学习者。希望在日常工作学习中挖掘数据的价值,发现数据的奥秘。笔者认为,数据的价值不仅体现在企业中,也可以体现在个人身上。发挥数据的魅力,用技术力量探索行为密码,让大数据帮助大家。欢迎关注我的公众号,一起探讨数据中的趣事。
我的公众号是:livandata
推荐算法的内容比较多。本文首先介绍一些常用的知识点。随着学习的深入,作者会增加新的内容。
笔者理解,基于协同过滤的推荐是一种基于内容推荐的推广。模型的构建主要需要考虑几个问题:
1)如何计算用户对商品的偏好并形成UV矩阵;
2)计算items和users的相似度主要有两种方法:
它的一、根据用户属性计算UU和VV的相似度;
它的二、根据用户对产品的偏好计算U和V的相似度;
在此期间,需要确定U的对应属性和V的对应属性,并利用这些来了解用户与用户、产品与产品之间的相似性。这主要是基于内容推荐的一些思路。型号推荐;
在基于协同过滤的推荐过程中,需要使用UV矩阵中的用户偏好,即根据用户偏好计算用户或产品之间的相似度,计算方法有欧式距离、皮尔逊系数等方法;
在推荐算法的应用过程中需要考虑的一些因素是:
1)如何推荐大单小频的商品;
2)如何推荐小众高频产品;
3)如何推荐热门产品;
4)如何推荐长尾产品;
...
推荐算法的应用领域非常广泛,涉及协作、内容等常用算法,以及机器学习中常用的聚类、分类等算法。将用户和产品分开,然后根据用户和同类别产品的交互程度推荐与同类别其他用户相关的产品。
现阶段比较流行的基础推荐算法主要有以下几类:
1、 基于内容的推荐:
它是推荐引擎出现之初应用最广泛的推荐机制。它的核心思想是根据推荐的物品或内容的元数据发现物品或内容的相关性,然后根据用户过去的偏好记录向用户推荐相似的物品。图3展示了基于内容推荐的基本原理。
图1. 基于内容推荐机制的基本原理
图1展示了一个基于内容推荐的典型例子,一个电影推荐系统。首先,我们需要对电影的元数据进行建模。这里我们只简单描述电影的类型;那么我们就可以通过电影的元数据找出来。电影之间的相似性,因为类型都是“爱情,浪漫”。电影A和C被认为是相似的电影(当然,获得更好的推荐还不够,我们也可以考虑电影的导演、演员等);最后,建议得到执行。对于用户A,他喜欢看电影A,那么系统可以向他推荐类似的电影C。
这种基于内容的推荐机制的优点是可以很好地模拟用户的口味,提供更准确的推荐。但它也存在以下问题:
1) 文章需要分析建模,推荐质量取决于文章模型的完整性和综合性。在目前的应用中,我们可以观察到关键词和标签(Tag)被认为是一种简单有效的描述item元数据的方式。
2) 物品相似度的分析只依赖物品本身的特征,这里不考虑人们对物品的态度。
3)由于需要根据用户过去的偏好历史进行推荐,所以对于新用户存在“冷启动”问题。
虽然这种方法有很多缺点和问题,但它已经成功地应用于一些电影、音乐和书籍的社交网站。一些网站还邀请专业人员在报告中对项目进行基因编码,例如 Pandora。在 Pandora 的推荐引擎中,每首歌曲都有 100 多个元数据特征,包括歌曲风格、年份、歌手等。
2、基于协同过滤的推荐:
随着Web2.0的发展,网站促进了用户参与和用户贡献。因此,基于协同过滤的推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者找到用户的相关性,然后根据这些相关性进行推荐。基于协同过滤的推荐可以分为三个子类别:基于用户的推荐、基于物品的推荐和基于模型的推荐。下面我们将一一详细介绍三种协同过滤推荐机制。
1)基于用户的协同过滤推荐
基于用户的协同过滤推荐的基本原理是根据所有用户对物品或信息的偏好,找到与当前用户的口味和偏好相似的“邻居”用户群。在一般应用中,“K-neighbors”的计算使用算法;然后,根据这K个邻居的历史偏好信息,为当前用户做推荐。下面的图 2 显示了原理图。
图2. 基于用户的协同过滤推荐机制基本原理
上图说明了基于用户的协同过滤推荐机制的基本原理。假设用户A喜欢物品A,物品C,用户B喜欢物品B,用户C喜欢物品A,物品C和物品D;从这些用户的历史偏好信息中,我们可以发现用户A和用户C的品味和偏好比较相似,并且用户C也喜欢项目D,那么我们可以推断用户A可能也喜欢项目D,所以项目 D 可以推荐给用户 A。
基于用户的协同过滤推荐机制和基于人口统计的推荐机制都计算用户的相似度,也计算基于“邻居”用户群的推荐,但两者的区别在于如何计算用户的相似度,基于人口统计机制只考虑用户自身的特征,而基于用户的协同过滤机制则根据用户的历史偏好数据计算用户的相似度。它的基本假设是喜欢相似物品的用户可能具有相同或相似的品味和偏好。
2)基于项目的协同过滤推荐
基于项目的协同过滤推荐的基本原理类似,只不过它是利用所有用户对项目或信息的偏好来寻找项目和项目之间的相似性,然后根据用户的历史偏好信息向用户推荐相似的项目。对于用户来说,图5很好地说明了它的基本原理。
假设用户A喜欢物品A和物品C,用户B喜欢物品A,物品B和物品C,用户C喜欢物品A,从这些用户的历史偏好可以分析出物品A和物品C是相似的并且喜欢物品A的人喜欢物品C。根据这个数据可以推断用户C很可能也喜欢物品C,所以系统会向用户C推荐物品C。
与上述类似,基于项目的协同过滤推荐和基于内容的推荐实际上都是基于项目相似度预测推荐,只是相似度计算方法不同。前者是从用户的历史偏好中推断出来的,而后者则是基于物品。其自身的属性特征信息。
图3. 基于项目的协同过滤推荐机制基本原理
同时,如何在基于用户和基于项目的协同过滤策略之间进行选择?事实上,基于物品的协同过滤推荐机制是亚马逊在基于用户的机制上改进的一种策略,因为在大多数网站中,物品的数量远小于用户的数量,物品的数量是相似度比较稳定,基于项目的机制比基于用户的实时性能要好。但并非在所有场景中都是如此。可以想象,在一些新闻推荐系统中,也许items的数量,即新闻的数量可能大于用户的数量,而且新闻更新的程度也很快,所以它的相似度还是有的不稳定。因此,事实上,
3)基于模型的协同过滤推荐
基于模型的协同过滤推荐是根据样本的用户偏好信息训练推荐模型,然后根据实时用户的偏好信息进行预测计算推荐。
基于协同过滤的推荐机制是当今应用最广泛的推荐机制。它具有以下显着优点:
而且它还存在以下问题:
3、协同过滤的主要步骤是:
1)采集用户偏好
需要从用户的行为和偏好中找出规律,并在此基础上给出建议。如何采集用户的偏好信息成为系统推荐效果最基本的决定因素。用户可以通过多种方式向系统提供自己的偏好信息,不同的应用程序可能会有很大差异。以下是示例:
上面列出的用户行为比较笼统,推荐引擎设计者可以根据自己应用的特点添加特殊的用户行为,用它们来表达用户对物品的偏好。在一般的应用中,我们一般提取不止一种用户行为。基本上有两种方法可以组合这些不同的用户行为:
一般可以分为“查看”和“购买”等,然后根据不同的行为计算不同用户/物品的相似度。类似于当当网或者亚马逊的“买书的人也买了……”、“看过书的人也看过……”
根据用户偏好的程度对不同的行为进行加权,得到用户对物品的整体偏好。一般来说,显式用户反馈比隐式权重大,但比较稀疏。毕竟,只有少数用户执行显示反馈。同时,相比“浏览”,“购买”行为在更大程度上反映了用户的偏好,但这也因应用而异。
在采集到用户行为数据之后,我们还需要对数据进行预处理。核心工作是:降噪和归一化。
用户行为数据是在用户使用应用程序的过程中产生的。可能会有很多噪音和用户误操作。我们可以通过经典的数据挖掘算法过滤掉行为数据中的噪声,这可以让我们的分析更加准确。
如前所述,在计算用户对物品的偏好时,可能需要对不同的行为数据进行加权。但是,可以想象,不同行为的数据值可能会有很大差异。例如,用户的观看数据必须远大于购买数据。如何统一同一取值范围内各个行为的数据,从而使加权求和得到的整体偏好更加准确,我们需要对其进行归一化。最简单的归一化过程就是将各类数据除以该类别中的最大值,保证归一化后的数据在[0,1]范围内。
预处理后,可以根据不同应用的行为分析方法选择分组或加权,然后我们就可以得到用户偏好的二维矩阵,一个是用户列表,一个是项目列表,值是用户对item的偏好,一般是[0,1]或[-1,1]的浮点值。
2)寻找相似的用户或物品
在对用户行为进行分析得到用户偏好后,我们可以根据用户偏好计算相似的用户和物品,然后根据相似的用户或物品进行推荐。这是两个最典型的 CF 分支:基于用户的 CF 和基于项目的 CF。这两种方法都需要计算相似度。下面我们来看看计算相似度的最基本的方法。
(1)计算相似度
关于相似度的计算,现有的几种基本方法都是基于向量的。事实上,他们正在计算两个向量之间的距离。距离越近,相似度越大。在推荐场景中,在user-item偏好的二维矩阵中,我们可以将一个用户对所有item的偏好作为向量来计算用户之间的相似度,或者将所有用户对某个item的偏好作为一个向量来计算计算物品之间的相似度。下面我们详细介绍几种常用的相似度计算方法:
(2) 计算相似邻居
介绍完相似度的计算方法后,我们再来看看如何根据相似度找到users-items的邻居。常用的邻域选择原则可以分为两类: 图1是二维平面空间上点集的示意图。
不考虑邻居的“距离”,只取最近的 K 作为它的邻居。如图1中A所示,假设我们要计算点1的5个邻居,那么根据点之间的距离,我们取最近的5个点,分别是点2、点3、点4、点7和第5点。但显然我们可以看到这种方法对于计算孤立点并不有效,因为它需要固定数量的邻居。当它附近没有足够的相似点时,它就被迫取一些不太相似的点。作为邻居,这会影响邻居之间的相似程度。例如,在图 1 中,点 1 和点 5 不是很相似。
与计算固定数量邻居的原理不同,基于相似度阈值的邻居计算是将邻居的距离限制为最大值。以当前点为中心,距离为K的区域内的所有点都视为当前点。邻居。这种方法计算出的邻居数是不确定的,但相似度不会有很大的误差。如图1,B,从点1开始,计算相似度在K以内的邻居,得到点2、点3、点4、点7。这种方法计算出的邻居相似度优于前一个。,尤其是离群值的处理。
3)计算建议
经过初步计算,得到了相邻用户和相邻物品。下面介绍如何根据这些信息为用户进行推荐。
基于用户的CF的基本思想很简单。它根据用户对物品的偏好寻找邻居用户,然后将邻居用户的采集推荐给当前用户。在计算中,将用户对所有物品的偏好作为向量来计算用户之间的相似度。找到K个邻居后,根据邻居的相似权重和他们对物品的偏好,预测当前用户没有偏好且不涉及物品,计算得到一个排序的物品列表作为推荐。图 2 显示了一个示例。对于用户A,根据用户的历史偏好,这里只计算一个邻居用户C,然后将用户C喜欢的项目D推荐给用户A。
item-based CF的原理和user-based CF类似,只是在计算邻居的时候使用的是item本身,而不是从用户的角度,即根据用户对item的偏好寻找相似的item,然后推荐相似物品根据用户对他的物品的历史偏好。从计算的角度来看,将所有用户对一个物品的偏好作为一个向量来计算物品之间的相似度。获得物品的相似物品后,根据用户的历史偏好预测当前用户没有具有偏好的物品。排序项目的列表被计算为推荐。图 3 显示了一个示例。对于物品A,根据所有用户的历史偏好,喜欢物品A的用户喜欢物品C,
目前我们得到的数据如下:我们需要为P5推荐三部电影中的一部。有两种方法:直接推荐和加权排名推荐。
直接推荐:如果我们需要为用户P5推荐电影,首先我们检查相似度列表,发现用户P5和用户P3的相似度最高。因此,我们可以向用户 P5 推荐 P3 相关数据。但是这里有一个问题。我们不能直接推荐以前的AF产品。由于这些产品,用户 P5 已经查看或购买了它们。该建议不能重复。因此,我们想推荐用户P5没有浏览或购买过的产品。如果直接推荐,可以选择P3用户评价最高的产品,即环太平洋和变形金刚这两个数据。
加权排名推荐:我们根据不同用户之间的相似度对不同产品的评分进行加权。根据加权结果对产品进行排序,然后推荐给用户P5。这样,用户P5得到了更好的推荐结果。
在上述计算结果中,我们按照(变形金刚-环太平洋-神奇快车)的顺序向用户P5推荐结果。
以上是基于用户的协同过滤算法。该算法依赖于用户的历史行为数据来计算相关性。换句话说,必须有一定的数据积累(冷启动问题)。对于新的网站或者数据较少的网站,还有一种基于item-based协同过滤算法的方法。 查看全部
算法 自动采集列表(用技术力量探索行为密码,让大数据助跑每一个人)
作者是一个痴迷于挖掘数据价值的学习者。希望在日常工作学习中挖掘数据的价值,发现数据的奥秘。笔者认为,数据的价值不仅体现在企业中,也可以体现在个人身上。发挥数据的魅力,用技术力量探索行为密码,让大数据帮助大家。欢迎关注我的公众号,一起探讨数据中的趣事。
我的公众号是:livandata

推荐算法的内容比较多。本文首先介绍一些常用的知识点。随着学习的深入,作者会增加新的内容。
笔者理解,基于协同过滤的推荐是一种基于内容推荐的推广。模型的构建主要需要考虑几个问题:
1)如何计算用户对商品的偏好并形成UV矩阵;
2)计算items和users的相似度主要有两种方法:
它的一、根据用户属性计算UU和VV的相似度;
它的二、根据用户对产品的偏好计算U和V的相似度;
在此期间,需要确定U的对应属性和V的对应属性,并利用这些来了解用户与用户、产品与产品之间的相似性。这主要是基于内容推荐的一些思路。型号推荐;
在基于协同过滤的推荐过程中,需要使用UV矩阵中的用户偏好,即根据用户偏好计算用户或产品之间的相似度,计算方法有欧式距离、皮尔逊系数等方法;
在推荐算法的应用过程中需要考虑的一些因素是:
1)如何推荐大单小频的商品;
2)如何推荐小众高频产品;
3)如何推荐热门产品;
4)如何推荐长尾产品;
...
推荐算法的应用领域非常广泛,涉及协作、内容等常用算法,以及机器学习中常用的聚类、分类等算法。将用户和产品分开,然后根据用户和同类别产品的交互程度推荐与同类别其他用户相关的产品。

现阶段比较流行的基础推荐算法主要有以下几类:
1、 基于内容的推荐:
它是推荐引擎出现之初应用最广泛的推荐机制。它的核心思想是根据推荐的物品或内容的元数据发现物品或内容的相关性,然后根据用户过去的偏好记录向用户推荐相似的物品。图3展示了基于内容推荐的基本原理。
图1. 基于内容推荐机制的基本原理

图1展示了一个基于内容推荐的典型例子,一个电影推荐系统。首先,我们需要对电影的元数据进行建模。这里我们只简单描述电影的类型;那么我们就可以通过电影的元数据找出来。电影之间的相似性,因为类型都是“爱情,浪漫”。电影A和C被认为是相似的电影(当然,获得更好的推荐还不够,我们也可以考虑电影的导演、演员等);最后,建议得到执行。对于用户A,他喜欢看电影A,那么系统可以向他推荐类似的电影C。
这种基于内容的推荐机制的优点是可以很好地模拟用户的口味,提供更准确的推荐。但它也存在以下问题:
1) 文章需要分析建模,推荐质量取决于文章模型的完整性和综合性。在目前的应用中,我们可以观察到关键词和标签(Tag)被认为是一种简单有效的描述item元数据的方式。
2) 物品相似度的分析只依赖物品本身的特征,这里不考虑人们对物品的态度。
3)由于需要根据用户过去的偏好历史进行推荐,所以对于新用户存在“冷启动”问题。
虽然这种方法有很多缺点和问题,但它已经成功地应用于一些电影、音乐和书籍的社交网站。一些网站还邀请专业人员在报告中对项目进行基因编码,例如 Pandora。在 Pandora 的推荐引擎中,每首歌曲都有 100 多个元数据特征,包括歌曲风格、年份、歌手等。
2、基于协同过滤的推荐:
随着Web2.0的发展,网站促进了用户参与和用户贡献。因此,基于协同过滤的推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者找到用户的相关性,然后根据这些相关性进行推荐。基于协同过滤的推荐可以分为三个子类别:基于用户的推荐、基于物品的推荐和基于模型的推荐。下面我们将一一详细介绍三种协同过滤推荐机制。
1)基于用户的协同过滤推荐
基于用户的协同过滤推荐的基本原理是根据所有用户对物品或信息的偏好,找到与当前用户的口味和偏好相似的“邻居”用户群。在一般应用中,“K-neighbors”的计算使用算法;然后,根据这K个邻居的历史偏好信息,为当前用户做推荐。下面的图 2 显示了原理图。
图2. 基于用户的协同过滤推荐机制基本原理

上图说明了基于用户的协同过滤推荐机制的基本原理。假设用户A喜欢物品A,物品C,用户B喜欢物品B,用户C喜欢物品A,物品C和物品D;从这些用户的历史偏好信息中,我们可以发现用户A和用户C的品味和偏好比较相似,并且用户C也喜欢项目D,那么我们可以推断用户A可能也喜欢项目D,所以项目 D 可以推荐给用户 A。
基于用户的协同过滤推荐机制和基于人口统计的推荐机制都计算用户的相似度,也计算基于“邻居”用户群的推荐,但两者的区别在于如何计算用户的相似度,基于人口统计机制只考虑用户自身的特征,而基于用户的协同过滤机制则根据用户的历史偏好数据计算用户的相似度。它的基本假设是喜欢相似物品的用户可能具有相同或相似的品味和偏好。
2)基于项目的协同过滤推荐
基于项目的协同过滤推荐的基本原理类似,只不过它是利用所有用户对项目或信息的偏好来寻找项目和项目之间的相似性,然后根据用户的历史偏好信息向用户推荐相似的项目。对于用户来说,图5很好地说明了它的基本原理。
假设用户A喜欢物品A和物品C,用户B喜欢物品A,物品B和物品C,用户C喜欢物品A,从这些用户的历史偏好可以分析出物品A和物品C是相似的并且喜欢物品A的人喜欢物品C。根据这个数据可以推断用户C很可能也喜欢物品C,所以系统会向用户C推荐物品C。
与上述类似,基于项目的协同过滤推荐和基于内容的推荐实际上都是基于项目相似度预测推荐,只是相似度计算方法不同。前者是从用户的历史偏好中推断出来的,而后者则是基于物品。其自身的属性特征信息。
图3. 基于项目的协同过滤推荐机制基本原理

同时,如何在基于用户和基于项目的协同过滤策略之间进行选择?事实上,基于物品的协同过滤推荐机制是亚马逊在基于用户的机制上改进的一种策略,因为在大多数网站中,物品的数量远小于用户的数量,物品的数量是相似度比较稳定,基于项目的机制比基于用户的实时性能要好。但并非在所有场景中都是如此。可以想象,在一些新闻推荐系统中,也许items的数量,即新闻的数量可能大于用户的数量,而且新闻更新的程度也很快,所以它的相似度还是有的不稳定。因此,事实上,
3)基于模型的协同过滤推荐
基于模型的协同过滤推荐是根据样本的用户偏好信息训练推荐模型,然后根据实时用户的偏好信息进行预测计算推荐。
基于协同过滤的推荐机制是当今应用最广泛的推荐机制。它具有以下显着优点:
而且它还存在以下问题:
3、协同过滤的主要步骤是:
1)采集用户偏好
需要从用户的行为和偏好中找出规律,并在此基础上给出建议。如何采集用户的偏好信息成为系统推荐效果最基本的决定因素。用户可以通过多种方式向系统提供自己的偏好信息,不同的应用程序可能会有很大差异。以下是示例:
上面列出的用户行为比较笼统,推荐引擎设计者可以根据自己应用的特点添加特殊的用户行为,用它们来表达用户对物品的偏好。在一般的应用中,我们一般提取不止一种用户行为。基本上有两种方法可以组合这些不同的用户行为:
一般可以分为“查看”和“购买”等,然后根据不同的行为计算不同用户/物品的相似度。类似于当当网或者亚马逊的“买书的人也买了……”、“看过书的人也看过……”
根据用户偏好的程度对不同的行为进行加权,得到用户对物品的整体偏好。一般来说,显式用户反馈比隐式权重大,但比较稀疏。毕竟,只有少数用户执行显示反馈。同时,相比“浏览”,“购买”行为在更大程度上反映了用户的偏好,但这也因应用而异。
在采集到用户行为数据之后,我们还需要对数据进行预处理。核心工作是:降噪和归一化。
用户行为数据是在用户使用应用程序的过程中产生的。可能会有很多噪音和用户误操作。我们可以通过经典的数据挖掘算法过滤掉行为数据中的噪声,这可以让我们的分析更加准确。
如前所述,在计算用户对物品的偏好时,可能需要对不同的行为数据进行加权。但是,可以想象,不同行为的数据值可能会有很大差异。例如,用户的观看数据必须远大于购买数据。如何统一同一取值范围内各个行为的数据,从而使加权求和得到的整体偏好更加准确,我们需要对其进行归一化。最简单的归一化过程就是将各类数据除以该类别中的最大值,保证归一化后的数据在[0,1]范围内。
预处理后,可以根据不同应用的行为分析方法选择分组或加权,然后我们就可以得到用户偏好的二维矩阵,一个是用户列表,一个是项目列表,值是用户对item的偏好,一般是[0,1]或[-1,1]的浮点值。
2)寻找相似的用户或物品
在对用户行为进行分析得到用户偏好后,我们可以根据用户偏好计算相似的用户和物品,然后根据相似的用户或物品进行推荐。这是两个最典型的 CF 分支:基于用户的 CF 和基于项目的 CF。这两种方法都需要计算相似度。下面我们来看看计算相似度的最基本的方法。
(1)计算相似度
关于相似度的计算,现有的几种基本方法都是基于向量的。事实上,他们正在计算两个向量之间的距离。距离越近,相似度越大。在推荐场景中,在user-item偏好的二维矩阵中,我们可以将一个用户对所有item的偏好作为向量来计算用户之间的相似度,或者将所有用户对某个item的偏好作为一个向量来计算计算物品之间的相似度。下面我们详细介绍几种常用的相似度计算方法:

(2) 计算相似邻居
介绍完相似度的计算方法后,我们再来看看如何根据相似度找到users-items的邻居。常用的邻域选择原则可以分为两类: 图1是二维平面空间上点集的示意图。

不考虑邻居的“距离”,只取最近的 K 作为它的邻居。如图1中A所示,假设我们要计算点1的5个邻居,那么根据点之间的距离,我们取最近的5个点,分别是点2、点3、点4、点7和第5点。但显然我们可以看到这种方法对于计算孤立点并不有效,因为它需要固定数量的邻居。当它附近没有足够的相似点时,它就被迫取一些不太相似的点。作为邻居,这会影响邻居之间的相似程度。例如,在图 1 中,点 1 和点 5 不是很相似。
与计算固定数量邻居的原理不同,基于相似度阈值的邻居计算是将邻居的距离限制为最大值。以当前点为中心,距离为K的区域内的所有点都视为当前点。邻居。这种方法计算出的邻居数是不确定的,但相似度不会有很大的误差。如图1,B,从点1开始,计算相似度在K以内的邻居,得到点2、点3、点4、点7。这种方法计算出的邻居相似度优于前一个。,尤其是离群值的处理。
3)计算建议
经过初步计算,得到了相邻用户和相邻物品。下面介绍如何根据这些信息为用户进行推荐。
基于用户的CF的基本思想很简单。它根据用户对物品的偏好寻找邻居用户,然后将邻居用户的采集推荐给当前用户。在计算中,将用户对所有物品的偏好作为向量来计算用户之间的相似度。找到K个邻居后,根据邻居的相似权重和他们对物品的偏好,预测当前用户没有偏好且不涉及物品,计算得到一个排序的物品列表作为推荐。图 2 显示了一个示例。对于用户A,根据用户的历史偏好,这里只计算一个邻居用户C,然后将用户C喜欢的项目D推荐给用户A。

item-based CF的原理和user-based CF类似,只是在计算邻居的时候使用的是item本身,而不是从用户的角度,即根据用户对item的偏好寻找相似的item,然后推荐相似物品根据用户对他的物品的历史偏好。从计算的角度来看,将所有用户对一个物品的偏好作为一个向量来计算物品之间的相似度。获得物品的相似物品后,根据用户的历史偏好预测当前用户没有具有偏好的物品。排序项目的列表被计算为推荐。图 3 显示了一个示例。对于物品A,根据所有用户的历史偏好,喜欢物品A的用户喜欢物品C,

目前我们得到的数据如下:我们需要为P5推荐三部电影中的一部。有两种方法:直接推荐和加权排名推荐。

直接推荐:如果我们需要为用户P5推荐电影,首先我们检查相似度列表,发现用户P5和用户P3的相似度最高。因此,我们可以向用户 P5 推荐 P3 相关数据。但是这里有一个问题。我们不能直接推荐以前的AF产品。由于这些产品,用户 P5 已经查看或购买了它们。该建议不能重复。因此,我们想推荐用户P5没有浏览或购买过的产品。如果直接推荐,可以选择P3用户评价最高的产品,即环太平洋和变形金刚这两个数据。
加权排名推荐:我们根据不同用户之间的相似度对不同产品的评分进行加权。根据加权结果对产品进行排序,然后推荐给用户P5。这样,用户P5得到了更好的推荐结果。

在上述计算结果中,我们按照(变形金刚-环太平洋-神奇快车)的顺序向用户P5推荐结果。
以上是基于用户的协同过滤算法。该算法依赖于用户的历史行为数据来计算相关性。换句话说,必须有一定的数据积累(冷启动问题)。对于新的网站或者数据较少的网站,还有一种基于item-based协同过滤算法的方法。
算法 自动采集列表(百度推出飓风算法,蝶变行动新、好站点扶持计划即将开启)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-17 10:02
2017年7月7日,继百度绿萝算法和石榴算法之后,百度在“网网”方面又出了一大招——百度推出飓风算法,旨在严厉打击使用不良采集百度搜索作为网站的主要内容来源,将彻底清除索引库中的不良采集链接,为优质原创内容提供更多展示机会,促进百度搜索良性发展。搜索生态。
飓风算法的更新也能看出百度从搜索生态向内容生态迈出了一大步,命中采集网站!
第 1 步:将搜索声明为内容生态
其实,早在2016年9月1日,随着百家号的诞生,百度的内容生态布局就浮出水面,百度卢富斌:搜索就是内容生态。
卢富斌认为,内容生态概念突然升温有两个根本原因:技术的发展导致了人力的大规模解放,尤其是人工智能等技术加速了这一进程。人们开始有更多的机会从事更多与生活、娱乐和创作相关的工作。其次,中国中产阶级的快速崛起提高了整个社会的内容消费能力。“所以百度对内容生态的关注,并不是出于行业的热情,而是基于对用户需求的洞察。”
第 2 步:2017 年 4 月算法更新
新站提速收录:蝶变行动新好站支持计划即将再次上线。
原创保护,再也不用担心抄袭了。保护网站原创的内容,正在大力升级。
阿拉丁产品的开通:阿里丁的战友专属产品有望在更多优质网站上开放。
推送信息展示:手机百度首页主动推送瑞金信息,助力网站品牌展示。
新闻源取消、搜索生态转向内容生态、百度阿里丁即将开启、移动站点语法升级、百度升级渲染UA、移动站点体验强调、移动页面加速器,这些都是百度即将到来的大事件。影响内容的是取消对新闻源和远程内容的保护
第三,。2017年7月7日飓风行动后,百度再次激怒了采集网站。可见,对原创内容的保护和网络运营促进了内容生态的良性发展。
网站建设、网络推广公司-创新互联,是一家网站专注于品牌和效果的生产、网络营销seo公司;服务项目包括网站维护等。 查看全部
算法 自动采集列表(百度推出飓风算法,蝶变行动新、好站点扶持计划即将开启)
2017年7月7日,继百度绿萝算法和石榴算法之后,百度在“网网”方面又出了一大招——百度推出飓风算法,旨在严厉打击使用不良采集百度搜索作为网站的主要内容来源,将彻底清除索引库中的不良采集链接,为优质原创内容提供更多展示机会,促进百度搜索良性发展。搜索生态。
飓风算法的更新也能看出百度从搜索生态向内容生态迈出了一大步,命中采集网站!
第 1 步:将搜索声明为内容生态
其实,早在2016年9月1日,随着百家号的诞生,百度的内容生态布局就浮出水面,百度卢富斌:搜索就是内容生态。
卢富斌认为,内容生态概念突然升温有两个根本原因:技术的发展导致了人力的大规模解放,尤其是人工智能等技术加速了这一进程。人们开始有更多的机会从事更多与生活、娱乐和创作相关的工作。其次,中国中产阶级的快速崛起提高了整个社会的内容消费能力。“所以百度对内容生态的关注,并不是出于行业的热情,而是基于对用户需求的洞察。”
第 2 步:2017 年 4 月算法更新
新站提速收录:蝶变行动新好站支持计划即将再次上线。
原创保护,再也不用担心抄袭了。保护网站原创的内容,正在大力升级。
阿拉丁产品的开通:阿里丁的战友专属产品有望在更多优质网站上开放。
推送信息展示:手机百度首页主动推送瑞金信息,助力网站品牌展示。
新闻源取消、搜索生态转向内容生态、百度阿里丁即将开启、移动站点语法升级、百度升级渲染UA、移动站点体验强调、移动页面加速器,这些都是百度即将到来的大事件。影响内容的是取消对新闻源和远程内容的保护
第三,。2017年7月7日飓风行动后,百度再次激怒了采集网站。可见,对原创内容的保护和网络运营促进了内容生态的良性发展。
网站建设、网络推广公司-创新互联,是一家网站专注于品牌和效果的生产、网络营销seo公司;服务项目包括网站维护等。
算法 自动采集列表(神策数据推荐系统的竞赛背景和竞赛内容介绍及应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-10-16 20:19
1 比赛背景
神测数据推荐系统是基于神测分析平台的智能推荐系统。基于客户需求和业务特点,利用机器学习算法,基于神测分析采集的用户行为数据,对咨询、视频、产品等进行个性化推荐,为客户提供不同场景下的智能应用,优化产品体验,提升点击率等核心业务指标。神策推荐系统是一个完整的学习闭环。采集的基础数据是通过机器学习的算法模型应用的。实时验证效果,指导数据源添加,算法优化反馈形成全流程、实时、自动、
本次比赛为模拟业务场景,目的是提取新闻文本的核心词,最终达到提升推荐和用户画像的效果。
大赛链接:
数据集
数据地址:[https://pan.baidu.com/s/1LBfqT86y7TEf4hDNCU6DpA](https://pan.baidu.com/s/1LBfqT86y7TEf4hDNCU6DpA)
密码:qa2u
2 任务
个性化推荐系统是神测智能系统的一个重要方面。准确理解信息主体是提高推荐系统有效性的重要手段。神策数据基于一个真实的商业案例,提供了上千条信息文章和关键词。参与者需要训练一个“关键词抽取”模型,抽取10个关键词万片信息文章。
3 数据
备注:报名参赛或入队后,可获得资料下载权限。
提供下载的数据集包括两部分:1. all_docs.txt,108295条信息文章数据,数据格式为:ID 文章 title文章 text,中间是由\001分割。2. train_docs_keywords.txt,文章的1000条关键词标注结果,数据格式为:ID 关键词列表,中间用\t分隔。
注:标记数据中每个文章的关键词不超过5个。关键词 都出现在 文章 的标题或正文中。需要说明的是,“训练集文章关键词形成的集合”和“测试集文章关键词形成的集合可能存在交集”。,但收录和收录之间并不一定存在关系。
4 个人预赛第11名计划
基于NLP中的无监督学习方法提取关键词。这是我第一次参加比赛。那时我是 NLP 的新手,所以我对这次比赛印象非常深刻。我将在这里与您分享。
神策杯”2018年大学算法硕士排名B排名(13/583)
4.1 评分情况4.2 数据分析:4.3 提高技巧,词性标注错误
这就是tf-idf提取关键字误差大的原因
4.5 核心代码:
# -*- coding: utf-8 -*-
# @Author : quincyqiang
# @File : analysis_for_06.py
# @Time : 2018/9/5 14:17
import pickle
import pandas as pd
from tqdm import tqdm
from jieba.analyse import extract_tags,textrank # tf-idf
from jieba import posseg
import random
import jieba
jieba.analyse.set_stop_words('data/stop_words.txt') # 去除停用词
jieba.load_userdict('data/custom_dict.txt') # 设置词库
'''
nr 人名 nz 其他专名 ns 地名 nt 机构团体 n 名词 l 习用语 i 成语 a 形容词
nrt
v 动词 t 时间词
'''
test_data=pd.read_csv('data/test_docs.csv')
train_data=pd.read_csv('data/new_train_docs.csv')
allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'n':6,'l':7,'i':8,'a':9,'nrt':10,'v':11,'t':12}
# allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'nrt':10}
tf_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt','v','a']
def generate_name(word_tags):
name_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt']
for word_tag in word_tags:
if word_tag[0] == '·' or word_tag=='!':
index = word_tags.index(word_tag)
if (index+1) 1]
title_keywords = sorted(title_keywords, reverse=False, key=lambda x: (allow_pos[x[1]], -len(x[0])))
if '·' in title :
if len(title_keywords) >= 2:
key_1 = title_keywords[0][0]
key_2 = title_keywords[1][0]
else:
# print(keywords,title,word_tags)
key_1 = title_keywords[0][0]
key_2 = ''
labels_1.append(key_1)
labels_2.append(key_2)
else:
# 使用tf-idf
use_idf += 1
# ---------重要文本-----
primary_words = []
for keyword in title_keywords:
if keyword[1] == 'n':
primary_words.append(keyword[0])
if keyword[1] in ['nr', 'nz', 'nt', 'ns']:
primary_words.extend([keyword[0]] * len(keyword[0]))
abstract_text = "".join(doc.split(' ')[:15])
for word, tag in jieba.posseg.cut(abstract_text):
if tag == 'n':
primary_words.append(word)
if tag in ['nr', 'nz', 'ns']:
primary_words.extend([word] * len(word))
primary_text = "".join(primary_words)
# 拼接成最后的文本
text = primary_text * 2 + title * 6 + " ".join(doc.split(' ')[:15] * 2) + doc
# ---------重要文本-----
temp_keywords = [keyword for keyword in extract_tags(text, topK=2)]
if len(temp_keywords)>=2:
labels_1.append(temp_keywords[0])
labels_2.append(temp_keywords[1])
else:
labels_1.append(temp_keywords[0])
labels_2.append(' ')
data = {'id': ids,
'label1': labels_1,
'label2': labels_2}
df_data = pd.DataFrame(data, columns=['id', 'label1', 'label2'])
df_data.to_csv('result/06_jieba_ensemble.csv', index=False)
print("使用tf-idf提取的次数:",use_idf)
if __name__ == '__main__':
# evaluate()
extract_keyword_ensemble(test_data)
© 2021 GitHub, Inc.
以下整理来自国内大佬的无私之风
5 “神策杯”2018年高校算法大师赛第二名代码
代码链接:文章 链接:
团队:只有SCI毕业
5.1 目录描述5.2 操作描述 运行Get_Feature.ipynb 得到train_df_v7.csv 和test_df_v7.csv。运行 lgb_predict.py 以获取结果 sub.csv。依赖包
numpy 1.14.0rc1
pandas 0.23.0
sklearn 0.19.0
lightgbm 2.0.5
scipy 1.0.0
5.3 描述解决问题的思路。使用jieba的tfidf方法筛选出Top 20候选人。工作是一个普通的二分类问题。特征可以分为以下两类: 使用LightGBM解决以上两个分类问题,然后根据LightGBM的结果为每个文本选择预测概率为Top2的词作为关键词输出。6 等级 6/622
代码链接:
(3)通过对title中的数据进行分析可以看出,如果title收录书名或者人名,则95%以上对应文章@的关键词 >. 这个应该跟大家的习惯(标签人的习惯)相关,片名中的内容通常对应电影、电视剧、歌曲等名称,这些名词和人名很可能会引起我们的注意开头,所以是关键词的概率非常高。
@0.85,大约100次迭代后PR值可以收敛到一个稳定值。当阻尼系数接近 1 时,所需的迭代次数会急剧增加。并且排序不稳定。公式中S(Vj)前面的分数是指Vj指向的所有网页都应该平均分享Vj的PR值,这样你就可以对你链接的网页进行投票。
Wji指的是Vi和Vj这两个句子的相似度。可以使用编辑距离和余弦相似度。textrank应用于关键词抽取时,与自动摘要抽取不同:1)词之间的关联没有权重,即Wji为1;2) 每个词与文档无关 所有词都有链接,但通过设置定长滑动窗口形式,窗口中词之间有链接。
主题模型常用的方法有LSI(LSA)和LDA,其中LSI使用SVD(奇异值分解)方法进行强力破解,而LDA使用贝叶斯方法拟合分布信息。通过LSA或LDA算法,可以得到文档到主题的分布和主题到词的分布。可以根据主题到词的分布(贝叶斯方法)得到词到主题的分布,然后通过这个分布和文档到主题的分布计算文档和词的相似度,并选择词与文档的 关键词 相似度高的列表。
Umk 表示文档到主题的分布矩阵,Vnk 的转置表示主题到词的分布矩阵。LSA 使用 SVD 更本质地表达单词和文档,并将它们映射到低维空间。在限制使用文本语义信息的同时,LSA 大大降低了计算成本,提高了分析质量。但是计算复杂度很高,特征空间维数大,计算效率很低。当新文档进入现有特征空间时,需要对整个空间进行重新训练,以获取新增文档的分布信息。此外,还存在对频率分布不敏感和物理解释弱的问题。
我们可以根据多项式分布和数据的先验分布找到后验分布,然后用这个后验分布作为下一个先验分布,迭代更新。一般有两种求解方法,第一种是基于Gibbs采样算法,第二种是基于变分推理EM算法。
(4)第二位是通过tfidf选择20个候选集,然后给它们打上标签。特点:在整个数据集中被视为候选的频率关键词。这其实就是候选词在整个数据集中,tfidf在数据集中前20的频率(5)第三位不引入外部词典,利用词的内聚力和自由度从给定的词中寻找新词(6)第五位用的是pyhanlp,据说命名实体识别的准确率比较高。
7 总结
该任务属于词组挖掘或关键词挖掘。在接触NLP的过程中,很多同学都在研究如何从文本中挖掘关键词。经过近几年NLP技术的发展,大致总结了以下方法。其实也是通过上面分享的三个程序来运行的:
8 更多信息 查看全部
算法 自动采集列表(神策数据推荐系统的竞赛背景和竞赛内容介绍及应用)
1 比赛背景
神测数据推荐系统是基于神测分析平台的智能推荐系统。基于客户需求和业务特点,利用机器学习算法,基于神测分析采集的用户行为数据,对咨询、视频、产品等进行个性化推荐,为客户提供不同场景下的智能应用,优化产品体验,提升点击率等核心业务指标。神策推荐系统是一个完整的学习闭环。采集的基础数据是通过机器学习的算法模型应用的。实时验证效果,指导数据源添加,算法优化反馈形成全流程、实时、自动、
本次比赛为模拟业务场景,目的是提取新闻文本的核心词,最终达到提升推荐和用户画像的效果。
大赛链接:
数据集
数据地址:[https://pan.baidu.com/s/1LBfqT86y7TEf4hDNCU6DpA](https://pan.baidu.com/s/1LBfqT86y7TEf4hDNCU6DpA)
密码:qa2u
2 任务
个性化推荐系统是神测智能系统的一个重要方面。准确理解信息主体是提高推荐系统有效性的重要手段。神策数据基于一个真实的商业案例,提供了上千条信息文章和关键词。参与者需要训练一个“关键词抽取”模型,抽取10个关键词万片信息文章。
3 数据
备注:报名参赛或入队后,可获得资料下载权限。
提供下载的数据集包括两部分:1. all_docs.txt,108295条信息文章数据,数据格式为:ID 文章 title文章 text,中间是由\001分割。2. train_docs_keywords.txt,文章的1000条关键词标注结果,数据格式为:ID 关键词列表,中间用\t分隔。
注:标记数据中每个文章的关键词不超过5个。关键词 都出现在 文章 的标题或正文中。需要说明的是,“训练集文章关键词形成的集合”和“测试集文章关键词形成的集合可能存在交集”。,但收录和收录之间并不一定存在关系。
4 个人预赛第11名计划
基于NLP中的无监督学习方法提取关键词。这是我第一次参加比赛。那时我是 NLP 的新手,所以我对这次比赛印象非常深刻。我将在这里与您分享。
神策杯”2018年大学算法硕士排名B排名(13/583)
4.1 评分情况4.2 数据分析:4.3 提高技巧,词性标注错误
这就是tf-idf提取关键字误差大的原因
4.5 核心代码:
# -*- coding: utf-8 -*-
# @Author : quincyqiang
# @File : analysis_for_06.py
# @Time : 2018/9/5 14:17
import pickle
import pandas as pd
from tqdm import tqdm
from jieba.analyse import extract_tags,textrank # tf-idf
from jieba import posseg
import random
import jieba
jieba.analyse.set_stop_words('data/stop_words.txt') # 去除停用词
jieba.load_userdict('data/custom_dict.txt') # 设置词库
'''
nr 人名 nz 其他专名 ns 地名 nt 机构团体 n 名词 l 习用语 i 成语 a 形容词
nrt
v 动词 t 时间词
'''
test_data=pd.read_csv('data/test_docs.csv')
train_data=pd.read_csv('data/new_train_docs.csv')
allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'n':6,'l':7,'i':8,'a':9,'nrt':10,'v':11,'t':12}
# allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'nrt':10}
tf_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt','v','a']
def generate_name(word_tags):
name_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt']
for word_tag in word_tags:
if word_tag[0] == '·' or word_tag=='!':
index = word_tags.index(word_tag)
if (index+1) 1]
title_keywords = sorted(title_keywords, reverse=False, key=lambda x: (allow_pos[x[1]], -len(x[0])))
if '·' in title :
if len(title_keywords) >= 2:
key_1 = title_keywords[0][0]
key_2 = title_keywords[1][0]
else:
# print(keywords,title,word_tags)
key_1 = title_keywords[0][0]
key_2 = ''
labels_1.append(key_1)
labels_2.append(key_2)
else:
# 使用tf-idf
use_idf += 1
# ---------重要文本-----
primary_words = []
for keyword in title_keywords:
if keyword[1] == 'n':
primary_words.append(keyword[0])
if keyword[1] in ['nr', 'nz', 'nt', 'ns']:
primary_words.extend([keyword[0]] * len(keyword[0]))
abstract_text = "".join(doc.split(' ')[:15])
for word, tag in jieba.posseg.cut(abstract_text):
if tag == 'n':
primary_words.append(word)
if tag in ['nr', 'nz', 'ns']:
primary_words.extend([word] * len(word))
primary_text = "".join(primary_words)
# 拼接成最后的文本
text = primary_text * 2 + title * 6 + " ".join(doc.split(' ')[:15] * 2) + doc
# ---------重要文本-----
temp_keywords = [keyword for keyword in extract_tags(text, topK=2)]
if len(temp_keywords)>=2:
labels_1.append(temp_keywords[0])
labels_2.append(temp_keywords[1])
else:
labels_1.append(temp_keywords[0])
labels_2.append(' ')
data = {'id': ids,
'label1': labels_1,
'label2': labels_2}
df_data = pd.DataFrame(data, columns=['id', 'label1', 'label2'])
df_data.to_csv('result/06_jieba_ensemble.csv', index=False)
print("使用tf-idf提取的次数:",use_idf)
if __name__ == '__main__':
# evaluate()
extract_keyword_ensemble(test_data)
© 2021 GitHub, Inc.
以下整理来自国内大佬的无私之风
5 “神策杯”2018年高校算法大师赛第二名代码
代码链接:文章 链接:
团队:只有SCI毕业
5.1 目录描述5.2 操作描述 运行Get_Feature.ipynb 得到train_df_v7.csv 和test_df_v7.csv。运行 lgb_predict.py 以获取结果 sub.csv。依赖包
numpy 1.14.0rc1
pandas 0.23.0
sklearn 0.19.0
lightgbm 2.0.5
scipy 1.0.0
5.3 描述解决问题的思路。使用jieba的tfidf方法筛选出Top 20候选人。工作是一个普通的二分类问题。特征可以分为以下两类: 使用LightGBM解决以上两个分类问题,然后根据LightGBM的结果为每个文本选择预测概率为Top2的词作为关键词输出。6 等级 6/622
代码链接:
(3)通过对title中的数据进行分析可以看出,如果title收录书名或者人名,则95%以上对应文章@的关键词 >. 这个应该跟大家的习惯(标签人的习惯)相关,片名中的内容通常对应电影、电视剧、歌曲等名称,这些名词和人名很可能会引起我们的注意开头,所以是关键词的概率非常高。
@0.85,大约100次迭代后PR值可以收敛到一个稳定值。当阻尼系数接近 1 时,所需的迭代次数会急剧增加。并且排序不稳定。公式中S(Vj)前面的分数是指Vj指向的所有网页都应该平均分享Vj的PR值,这样你就可以对你链接的网页进行投票。
Wji指的是Vi和Vj这两个句子的相似度。可以使用编辑距离和余弦相似度。textrank应用于关键词抽取时,与自动摘要抽取不同:1)词之间的关联没有权重,即Wji为1;2) 每个词与文档无关 所有词都有链接,但通过设置定长滑动窗口形式,窗口中词之间有链接。
主题模型常用的方法有LSI(LSA)和LDA,其中LSI使用SVD(奇异值分解)方法进行强力破解,而LDA使用贝叶斯方法拟合分布信息。通过LSA或LDA算法,可以得到文档到主题的分布和主题到词的分布。可以根据主题到词的分布(贝叶斯方法)得到词到主题的分布,然后通过这个分布和文档到主题的分布计算文档和词的相似度,并选择词与文档的 关键词 相似度高的列表。
Umk 表示文档到主题的分布矩阵,Vnk 的转置表示主题到词的分布矩阵。LSA 使用 SVD 更本质地表达单词和文档,并将它们映射到低维空间。在限制使用文本语义信息的同时,LSA 大大降低了计算成本,提高了分析质量。但是计算复杂度很高,特征空间维数大,计算效率很低。当新文档进入现有特征空间时,需要对整个空间进行重新训练,以获取新增文档的分布信息。此外,还存在对频率分布不敏感和物理解释弱的问题。
我们可以根据多项式分布和数据的先验分布找到后验分布,然后用这个后验分布作为下一个先验分布,迭代更新。一般有两种求解方法,第一种是基于Gibbs采样算法,第二种是基于变分推理EM算法。
(4)第二位是通过tfidf选择20个候选集,然后给它们打上标签。特点:在整个数据集中被视为候选的频率关键词。这其实就是候选词在整个数据集中,tfidf在数据集中前20的频率(5)第三位不引入外部词典,利用词的内聚力和自由度从给定的词中寻找新词(6)第五位用的是pyhanlp,据说命名实体识别的准确率比较高。
7 总结
该任务属于词组挖掘或关键词挖掘。在接触NLP的过程中,很多同学都在研究如何从文本中挖掘关键词。经过近几年NLP技术的发展,大致总结了以下方法。其实也是通过上面分享的三个程序来运行的:
8 更多信息
算法 自动采集列表(算法自动采集列表页信息分析crazy熊数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-13 16:01
算法自动采集列表页信息第一步:抓取列表页的信息包括(点击进入产品信息页面]+(打开个人中心)+(随手推荐的功能)这四个主要页面第二步:提取每个公众号的"个人中心"列表页链接第三步:提取每个公众号每天推送信息的链接第四步:每天产生的数据按照清洗标准进行分类提取关键词匹配,提取标题部分第五步:用java或者python进行数据库设计第六步:最终按照数据库设计下载最新列表页信息获取原图完整效果图详细代码见github在此文章的最后有源码(重要),有兴趣的朋友可以学习一下。新浪微博名称;#pid2370294236。
任何平台搜索引擎抓取信息,最后都会聚合在微博中,微博中几乎所有的电商交易都可以通过微博来完成。
1、电商入口,
2、媒体入口,
3、其他入口,
4、广告入口,搜索竞价、地图定位广告投放,如团车网;互联网广告投放等。同时也有基于微博的搜索服务,其中广告、媒体等通过博客、视频、音频等形式来传播,并通过微博平台进行转化。博客:博客——公开网络传播的自由、开放平台,聚集了很多优秀的写手,用户无需注册即可发布微博。视频:网易、优酷等综合型网站视频,搜狐视频、腾讯视频等视频网站;百度、凤凰、今日头条等视频网站;爱奇艺、乐视等视频网站。
音频:喜马拉雅fm、荔枝fm、荔枝fm、蜻蜓fm等音频网站。---这是一种典型的以数据抓取为基础,进行“内容分析”形成seo结果的思路,如果需要学习数据分析的数据采集,可以参考下面的关于crazy熊数据的文章:基于微博的seo分析crazy熊数据以上都是一些微博中比较常见的数据抓取方式,具体的操作过程,也可以参考下面这个表格。 查看全部
算法 自动采集列表(算法自动采集列表页信息分析crazy熊数据)
算法自动采集列表页信息第一步:抓取列表页的信息包括(点击进入产品信息页面]+(打开个人中心)+(随手推荐的功能)这四个主要页面第二步:提取每个公众号的"个人中心"列表页链接第三步:提取每个公众号每天推送信息的链接第四步:每天产生的数据按照清洗标准进行分类提取关键词匹配,提取标题部分第五步:用java或者python进行数据库设计第六步:最终按照数据库设计下载最新列表页信息获取原图完整效果图详细代码见github在此文章的最后有源码(重要),有兴趣的朋友可以学习一下。新浪微博名称;#pid2370294236。
任何平台搜索引擎抓取信息,最后都会聚合在微博中,微博中几乎所有的电商交易都可以通过微博来完成。
1、电商入口,
2、媒体入口,
3、其他入口,
4、广告入口,搜索竞价、地图定位广告投放,如团车网;互联网广告投放等。同时也有基于微博的搜索服务,其中广告、媒体等通过博客、视频、音频等形式来传播,并通过微博平台进行转化。博客:博客——公开网络传播的自由、开放平台,聚集了很多优秀的写手,用户无需注册即可发布微博。视频:网易、优酷等综合型网站视频,搜狐视频、腾讯视频等视频网站;百度、凤凰、今日头条等视频网站;爱奇艺、乐视等视频网站。
音频:喜马拉雅fm、荔枝fm、荔枝fm、蜻蜓fm等音频网站。---这是一种典型的以数据抓取为基础,进行“内容分析”形成seo结果的思路,如果需要学习数据分析的数据采集,可以参考下面的关于crazy熊数据的文章:基于微博的seo分析crazy熊数据以上都是一些微博中比较常见的数据抓取方式,具体的操作过程,也可以参考下面这个表格。
算法 自动采集列表(怎么导出前台运行任务的采集任务?软件步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-13 15:25
第一步:登录打开优采云采集器软件
第二步:新建一个采集任务
1、复制网页地址:需要采集评价的产品网址
2、新流程图模式采集任务:导入采集规则创建智能任务
第三步:配置采集规则
1、设置预登录
输入网址后,我们进入宝贝详情页。这时候我们可以点击关闭页面上出现的登录界面。无需登录即可采集评论数据。
2、设置数据字段
详情页可以看到评论数量,但看不到具体评论内容。我们需要点击评论,然后在左上角跳出的提示框中选择“点击这个元素”。
3、 进入评论界面后,根据搜索方向选择元素,如好评、差评等元素。在此基础上,我们可以右键字段进行相关设置,包括修改字段名称、增加或减少字段、处理数据等。
由于我们要下载所有评论图片,我们可以选择评论中的所有图片,然后设置字段属性——extract external html。
4、我们采集发布了单页评论数据,现在需要采集下一页数据,我们点击页面上的“下一页”按钮,出现操作在左上角的提示框中,选择“循环点击下一页”。
第四步:设置并启动采集任务
点击“开始采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置》,这次采集没有用到这些功能,我们直接点击开始启动采集。
第 5 步:导出并查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式和导出文件格式,也支持特定数量的导出项,其中可以在数据中选择要导出的项目数,然后点击“确认导出”。
[如何导出]
1、导出采集前台运行任务的结果
如果采集任务在前台运行,任务结束后软件会弹出数据采集停止提示框。这时候我们点击“导出数据”按钮,导出采集的数据结果。
2、导出采集后台运行任务的结果
如果采集任务在后台运行,任务完成后桌面右下角会弹出导出提示框。我们将根据右下角任务完成的弹出提示打开查看数据界面或导出数据。
3、导出保存的采集任务的采集结果
如果不是实时采集任务,而是之前运行过的采集任务,比如我们关闭软件再重新打开软件,然后导出一个采集任务已经运行。采集 结果。
这种情况下,我们可以右击任务,点击“查看数据”,打开查看数据界面,然后在该界面设置导出数据。
4、导出数据的其他事项
目前优采云采集器支持多种格式自由导出,包括:Excel2007、Excel2003、CSV、HTML文件、TXT文件;同时支持自由导出到数据库。
个人专业版及以上支持发布到网站,目前支持发布到WordPress、发布到Typecho、发布到DEDEcms(织梦),更多网站模板持续更新中更新中……
导出数据时,用户可以选择导出范围、导出未导出的数据、导出选定的数据或选择导出项目的数量。
导出完成后,您还可以对导出的数据进行标记,以便清晰直观地看到哪些数据已经导出,哪些数据没有导出。
[如何下载图片]
第一种:逐张添加图片
在页面上直接点击要下载的图片,然后根据提示点击“提取该元素”,软件会自动生成提取的数据组件并添加图片字段。(如果有连续的采集字段,可能不会每次都生成一个新的提取数据组价格,只会增加新的字段)
或者直接点击“添加字段”,然后在页面上点击要下载的图片。
第二种:一次下载多张图片
在这种情况下,需要将图片组合在一起,并且可以一次选择所有图片。
我们可以直接点击整个图片区域的右下角,我们在选框的时候可以看到软件的蓝色框选区域,保证所有要下载的图片都被装框了。然后根据提示点击“提取该元素”,软件会自动生成提取的数据组件并添加图片字段。(如果有连续的采集字段,可能不会每次都生成一个新的提取数据组价格,只会增加新的字段)
然后右键单击该字段并将字段属性修改为“提取内部 HTML”。
点击右下角的“开始采集”按钮,设置图片下载功能。
接下来我们只需要点击“开始采集”,然后在开始框中勾选“采集同时下载图片到以下目录”即可启动图片下载功能,用户可以设置图片路径的本地保存。 查看全部
算法 自动采集列表(怎么导出前台运行任务的采集任务?软件步骤)
第一步:登录打开优采云采集器软件
第二步:新建一个采集任务
1、复制网页地址:需要采集评价的产品网址
2、新流程图模式采集任务:导入采集规则创建智能任务

第三步:配置采集规则
1、设置预登录
输入网址后,我们进入宝贝详情页。这时候我们可以点击关闭页面上出现的登录界面。无需登录即可采集评论数据。
2、设置数据字段
详情页可以看到评论数量,但看不到具体评论内容。我们需要点击评论,然后在左上角跳出的提示框中选择“点击这个元素”。

3、 进入评论界面后,根据搜索方向选择元素,如好评、差评等元素。在此基础上,我们可以右键字段进行相关设置,包括修改字段名称、增加或减少字段、处理数据等。
由于我们要下载所有评论图片,我们可以选择评论中的所有图片,然后设置字段属性——extract external html。
4、我们采集发布了单页评论数据,现在需要采集下一页数据,我们点击页面上的“下一页”按钮,出现操作在左上角的提示框中,选择“循环点击下一页”。
第四步:设置并启动采集任务
点击“开始采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置》,这次采集没有用到这些功能,我们直接点击开始启动采集。

第 5 步:导出并查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式和导出文件格式,也支持特定数量的导出项,其中可以在数据中选择要导出的项目数,然后点击“确认导出”。
[如何导出]
1、导出采集前台运行任务的结果
如果采集任务在前台运行,任务结束后软件会弹出数据采集停止提示框。这时候我们点击“导出数据”按钮,导出采集的数据结果。

2、导出采集后台运行任务的结果
如果采集任务在后台运行,任务完成后桌面右下角会弹出导出提示框。我们将根据右下角任务完成的弹出提示打开查看数据界面或导出数据。
3、导出保存的采集任务的采集结果
如果不是实时采集任务,而是之前运行过的采集任务,比如我们关闭软件再重新打开软件,然后导出一个采集任务已经运行。采集 结果。
这种情况下,我们可以右击任务,点击“查看数据”,打开查看数据界面,然后在该界面设置导出数据。

4、导出数据的其他事项
目前优采云采集器支持多种格式自由导出,包括:Excel2007、Excel2003、CSV、HTML文件、TXT文件;同时支持自由导出到数据库。
个人专业版及以上支持发布到网站,目前支持发布到WordPress、发布到Typecho、发布到DEDEcms(织梦),更多网站模板持续更新中更新中……
导出数据时,用户可以选择导出范围、导出未导出的数据、导出选定的数据或选择导出项目的数量。
导出完成后,您还可以对导出的数据进行标记,以便清晰直观地看到哪些数据已经导出,哪些数据没有导出。
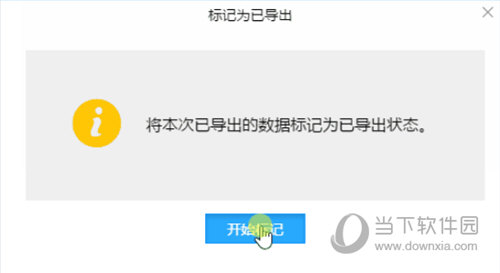
[如何下载图片]
第一种:逐张添加图片
在页面上直接点击要下载的图片,然后根据提示点击“提取该元素”,软件会自动生成提取的数据组件并添加图片字段。(如果有连续的采集字段,可能不会每次都生成一个新的提取数据组价格,只会增加新的字段)
或者直接点击“添加字段”,然后在页面上点击要下载的图片。
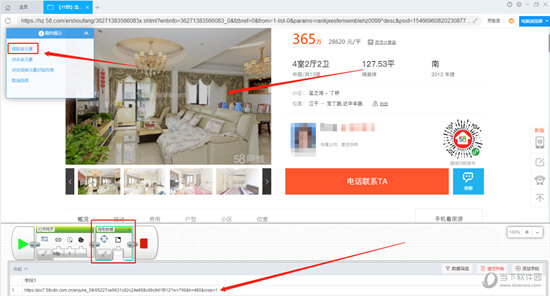
第二种:一次下载多张图片
在这种情况下,需要将图片组合在一起,并且可以一次选择所有图片。
我们可以直接点击整个图片区域的右下角,我们在选框的时候可以看到软件的蓝色框选区域,保证所有要下载的图片都被装框了。然后根据提示点击“提取该元素”,软件会自动生成提取的数据组件并添加图片字段。(如果有连续的采集字段,可能不会每次都生成一个新的提取数据组价格,只会增加新的字段)
然后右键单击该字段并将字段属性修改为“提取内部 HTML”。
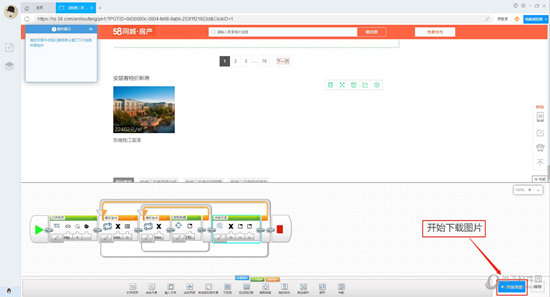
点击右下角的“开始采集”按钮,设置图片下载功能。
接下来我们只需要点击“开始采集”,然后在开始框中勾选“采集同时下载图片到以下目录”即可启动图片下载功能,用户可以设置图片路径的本地保存。
算法 自动采集列表(Java内存模型-和内存分配以及jdk、jre是什么关系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-13 10:05
如果想了解Java内存模型参考:jvm内存模型-内存分配与jdk、jre、jvm的关系是什么(阿里、美团、京东)
相信像编辑器这样的程序员在日常工作或者面试中经常会遇到JVM的垃圾回收问题。深夜的JVM垃圾回收机制有详细的了解吗?没时间抚摸也没关系,因为接下来我要抚摸你。
一、 你需要了解技术背景
按照套路,需要先安装X,说说JVM垃圾回收的前世今生。说到垃圾采集(GC),大多数人把这项技术看作是 Java 语言的配套产品。事实上,GC 的历史比 Java 更长。早在 1960 年,Lisp 就使用了内存动态分配和垃圾采集技术。设计和优化C++语言的高手们久等了~~
二、 哪些内存需要回收?
大家都知道JVM的内存结构包括五个区域:程序计数器、虚拟机栈、本地方法栈、堆区、方法区。其中,程序计数器、虚拟机栈、本地方法栈都是用线程产生和熄灭的。所以这些区域的内存分配和回收都是确定性的,所以不需要过多考虑回收的问题,因为当方法结束或者线程结束的时候,内存自然会被回收。Java堆区和方法区是有区别的!(怎么说区别就上口了),这部分内存的分配和回收是动态的,这是垃圾采集器需要注意的部分。
垃圾回收器在回收堆区和方法区之前,首先要确定这些区域中哪些对象可以回收,哪些暂时不能回收。这就需要一个算法来判断对象是否还活着!(面试官肯定没少问你吧)
2.1 引用计数算法2.1.1 算法分析
引用计数是垃圾采集器的早期策略。在这个方法中,堆中的每个对象实例都有一个引用计数。当一个对象被创建时,对象实例被赋值给一个变量,变量计数被设置为1。当任何其他变量被赋值给这个对象的引用时,计数增加1(a=b,那么b + 1) 引用的对象实例的计数器,但是当对象实例的引用超过生命周期或设置为新值时,对象实例的引用计数器减1。任何引用计数器为 0 的对象实例可以被当作垃圾回收处理。当一个对象实例被垃圾回收时,它所引用的任何对象实例的引用计数器都减 1。
2.1.2 优缺点
优点:引用计数采集器的执行速度非常快,交织在程序的运行中。更有利于程序不需要长时间中断的实时环境。
缺点:无法检测循环引用。如果父对象引用了子对象,则子对象又会引用父对象。这样,它们的引用计数永远不会为 0。
2.1.3 是不是很无聊,来点代码来压制一下惊喜
public class abc_test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MyObject object1=new MyObject();
MyObject object2=new MyObject();
object1.object=object2;
object2.object=object1;
object1=null;
object2=null;
}
}
class MyObject{
MyObject object;
}
此代码用于验证引用计数算法无法检测循环引用。最后两句将object1和object2赋值为null,表示object1和object2所指向的对象不能再被访问,但是因为它们相互引用,它们的引用计数器都不为0,那么垃圾采集器就永远不会了被回收。
2.2 可达性分析算法
可达性分析算法是从离散数学中的图论引入的。程序把所有的引用关系看成一个图,从一个节点GC ROOT开始,寻找对应的引用节点,找到这个节点后,继续寻找这个节点,当所有的引用节点都被搜索到时,剩下的节点被认为是未引用节点,即无用节点,无用节点将被判断为可回收对象。
在Java语言中,可以作为GC Roots的对象包括:(京东)
a) 虚拟机栈中引用的对象(栈帧中的局部变量表);
b) 方法区中类的静态属性所引用的对象;
c) 方法区常量引用的对象;
d) 本地方法堆栈中由 JNI(本地方法)引用的对象。
该算法的基本思想是以一系列称为“GC Roots”的对象为起点,从这些节点开始向下搜索。搜索所采用的路径称为参考链。当一个对象到达 GC Roots 时,没有任何引用链连接(用图论的话,该对象从 GC Roots 是不可到达的),证明该对象不可用。如图所示,objects object 5、object 6、object 7虽然相互关联,但是对于GC Roots是不可达的,所以会被判断为可回收的对象。
现在的问题是,可达性分析算法会不会存在对象之间循环引用的问题?答案是肯定的,即对象之间不会有循环引用。GC Root 在对象图之外,它是一个专门定义的“起点”,不能被对象图中的对象引用。
死或不死(死或不死)
即使是在可达性分析算法中不可达的对象也不是“必须死”的。此时,他们暂时处于“缓刑”阶段。要真正声明一个对象死亡,它至少要经过两个标记过程:如果该对象经过可达性分析,发现没有连接到GC Roots的引用链,那么它会第一次被标记,并且一个过滤器将被执行。过滤条件是对象是否有必要执行 finapze() 方法。当对象没有覆盖finapze()方法,或者finapze()方法已经被虚拟机调用时,虚拟机将这两种情况都视为“无需执行”。在程序中,你可以通过覆盖finapze()来进行一次“惊心动魄”的自救过程,但这只是一次机会。
/**
* 此代码演示了两点:
* 1.对象可以在被GC时自我拯救。
* 2.这种自救的机会只有一次,因为一个对象的finapze()方法最多只会被系统自动调用一次
* @author zzm
*/
pubpc class FinapzeEscapeGC {
pubpc static FinapzeEscapeGC SAVE_HOOK = null;
pubpc void isApve() {
System.out.println("yes, i am still apve :)");
}
@Override
protected void finapze() throws Throwable {
super.finapze();
System.out.println("finapze mehtod executed!");
FinapzeEscapeGC.SAVE_HOOK = this;
}
pubpc static void main(String[] args) throws Throwable {
SAVE_HOOK = new FinapzeEscapeGC();
//对象第一次成功拯救自己
SAVE_HOOK = null;
System.gc();
//因为finapze方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isApve();
} else {
System.out.println("no, i am dead :(");
}
//下面这段代码与上面的完全相同,但是这次自救却失败了
SAVE_HOOK = null;
System.gc();
//因为finapze方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isApve();
} else {
System.out.println("no, i am dead :(");
}
}
}
操作结果如下:
finapze mehtod executed!
yes, i am still apve :)
no, i am dead :(
2.3 Java中的引用你了解多少
无论是通过引用计数算法判断对象的引用次数,还是通过可达性分析算法判断对象的引用链是否可达,都与“引用”有关,以确定对象是否为活。在Java语言中,引用分为强引用、软引用、弱引用和幻引用四种。这四次引用的强度逐渐减弱。无论是通过引用计数算法判断对象的引用次数,还是通过可达性分析算法判断对象的引用链是否可达,都与“引用”有关,以确定对象是否为活。在 JDK 1.2 之前,Java中引用的定义非常传统:如果引用类型数据中存储的值代表另一块内存的起始地址,则称这块内存代表一个引用。在JDK1.2之后,Java扩展了引用的概念,将引用分为强引用、软引用、弱引用和幻像引用。有四种类型,这四种类型的引用强度逐渐降低。
程序代码中常见的,类似于Object obj = new Object()引用,只要强引用还存在,垃圾回收器就永远不会回收被引用的对象。
用于描述一些有用但不是必需的对象。对于软引用关联的对象,在系统出现内存溢出异常之前,会将这些对象列在恢复范围内进行二次恢复。如果本次采集后内存不足,会抛出内存溢出异常。
它也用于描述非本质对象,但其强度比软引用弱。与弱引用关联的对象只能存活到下一次垃圾回收发生。垃圾回收器工作时,无论当前内存是否足够,都会回收那些只是弱引用的对象。在JDK1.2之后,提供了WeakReference类来实现弱引用。比如threadlocal
它也被称为幽灵引用或幻影引用(这个名字真的很神奇),它是最弱的一种引用关系。一个对象是否有幻影引用根本不会影响它的生命周期,不可能通过幻影引用获得一个对象实例。它的功能是当这个对象被采集器回收时接收系统通知。. 在JDK1.2之后,提供了PhantomReference类来实现虚引用。
不要被概念吓到,不要着急,你没有跑题,深入就难说了。小编列出这四个概念的目的是为了说明引用计数算法和可达性分析算法都是基于强引用的。
软引用示例:
package jvm;
import java.lang.ref.SoftReference;
class Node {
pubpc String msg = "";
}
pubpc class Hello {
pubpc static void main(String[] args) {
Node node1 = new Node(); // 强引用
node1.msg = "node1";
SoftReference node2 = new SoftReference(node1); // 软引用
node2.get().msg = "node2";
System.out.println(node1.msg);
System.out.println(node2.get().msg);
}
}
输出是:
node2
node2
2.4 对象死亡前的最后挣扎(并被回收)
即使是在可达性分析算法中不可达的对象也不是“必须死”的。此时,他们暂时处于“缓刑”阶段。要真正声明一个对象死亡,至少需要两个标记过程。
第一次标记:如果对象在可达性分析后发现没有连接到GC Roots的引用链,则进行第一次标记;
第二个标记:在第一个标记之后,将执行过滤。过滤条件是这个对象是否有必要执行finalize()方法。如果在 finalize() 方法中没有重新建立与引用链的关系,则会进行第二次标记。
第二次成功标记的对象将真正被回收。如果对象在 finalize() 方法中重新建立与引用链的关联关系,它将逃脱这种回收并继续生存。猿猴还在,嘿嘿。
2.5 如何判断方法区是否需要回收
猿类,对方法区存储的内容是否需要回收的判断是不同的。方法区回收的主要内容是:丢弃的常量和无用的类。过时的常量也可以通过引用可达性来判断,但是对于无用的类,必须同时满足以下三个条件:
关于类加载的原理,也是阿里面试的主角。面试官还问我例如:我可以自己定义String吗,答案是否定的,因为jvm在加载类的时候会进行父母委托。
原理请参考:Java类加载机制(阿里面试题)
说了半天,主角终于要上台了。
如何确定垃圾对象
几乎所有的对象实例都存储在 Java 堆中。在垃圾采集器回收堆之前,它首先需要确定哪些对象还“活着”,哪些对象已经“死了”,即不会以任何方式使用的对象。
三、常用的垃圾回收算法
3.0 引用计数方法
引用计数方法实现简单,效率高,在大多数情况下是一种很好的算法。原理是:给对象添加一个引用计数器。每当有对象引用时,计数器加1,引用无效时,计数器减1,当计数器值为0时,不再使用该对象。需要注意的是,引用计数方法难以解决对象之间相互循环引用的问题,主流Java虚拟机也没有使用引用计数方法来管理内存。
public class abc_test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MyObject object1=new MyObject();
MyObject object2=new MyObject();
object1.object=object2;
object2.object=object1;
object1=null;
object2=null;
}
}
class MyObject{
MyObject object;
}
3.1 标记-扫描算法(Mark-Sweep)
这是最基本的垃圾采集算法。之所以是最基本的,是因为它最容易实现,也是最简单的想法。标记清除算法分为标记阶段和清除阶段两个阶段。标记阶段的任务是标记所有需要回收的对象,清理阶段的任务是回收被标记对象占用的空间。具体流程如下图所示:
从图中不难看出,mark-sweep算法更容易实现,但是有一个比较严重的问题,就是容易出现内存碎片。分片过多可能会导致后续进程需要为大对象分配空间时找不到足够的空间。空间并提前触发新的垃圾采集。
mark-sweep算法使用GC Roots扫描来标记幸存的对象。标记完成后,对整个空间中未标记的物体进行扫描回收,如下图所示。mark-sweep算法不需要移动对象,只处理非存活对象,当存活对象较多时效率极高,但由于mark-sweep算法直接回收非存活对象,会造成内存占用碎片化。
3.2 复制算法(Copying)
为了解决Mark-Sweep算法的不足,提出了Copying算法。它根据容量将可用内存分成大小相等的两块,一次只使用其中一块。当这块内存用完时,将幸存的对象复制到另一个块中,然后立即清除已用的内存空间,这样就不容易发生内存碎片。具体流程如下图所示:
该算法虽然实现简单,运行效率高,不易出现内存碎片,但由于可以使用的内存减少到原来的一半,因此在内存空间的使用上付出了高昂的代价。
显然,Copying 算法的效率与幸存对象的数量有很大关系。如果存活对象较多,则Copying算法的效率会大大降低。
提出复制算法,克服句柄开销,解决内存碎片问题。一开始,它将堆划分为一个对象表面和多个自由表面。程序从物体表面为物体分配空间。当对象满时,基于复制算法的垃圾回收从根集(GC Roots)开始扫描活动对象,并将每个活动对象复制到空闲表面(这样占用的内存之间没有空闲空洞)活动物体),这样自由面变成物体面,原物体面变成自由面,程序会在新物体面上分配内存。
3.3 Mark-compact 算法(Mark-compact)
为了解决Copying算法的不足,充分利用内存空间,提出了Mark-Compact算法。这个算法的标记阶段和Mark-Sweep一样,但是标记完成后,并不是直接清理可回收的对象,而是将所有幸存的对象移到一端(美团面试题,记住标记完成后,做先不清理。先移动再清理回收的对象),再清理结束边界外的内存(美团提问)
标记-组织算法使用与标记-清除算法相同的方法来标记对象,但清理方式不同。回收非存活对象占用的空间后,所有存活的对象将被移动到左边的空闲空间,并更新相应的对象。指针。mark-arrangement算法基于mark-clear算法,移动对象,所以成本较高,但解决了内存碎片问题。具体流程如下图所示:
3.4代采集算法分代采集算法
分代采集算法是目前大多数 JVM 垃圾采集器使用的算法。它的核心思想是根据对象生存的生命周期将内存划分为几个不同的区域。一般来说,堆区分为Tenured Generation和Young Generation,堆区之外还有一个代,就是Permanet Generation(永久代)。老年代的特点是每次垃圾采集只需要采集少量对象,而新生代的特点是每次垃圾采集需要采集大量对象,所以最适合可根据不同世代的特点采取采集。算法。
目前大部分垃圾回收器对新生代采用Copying算法,因为新生代每次垃圾回收都会回收大部分对象,这意味着需要复制的操作次数较少,但在实践中是不是按照1:1的比例来划分新生代空间的,一般是将新生代划分为一个较大的Eden空间和两个较小的Survivor空间(通常是8:1:1),每次使用Eden空间) 用其中一个Survivor空间,回收时,将Eden和Survivor中的幸存对象复制到另一个Survivor空间,然后清理Eden和之前使用过的Survivor空间。
但是由于老年代的特点是每次回收的对象很少,所以一般采用Mark-Compact算法。
3.4.1 Young Generation的回收算法(Recycling主要基于Copying)
a) 所有新生成的对象首先被放入年轻代。年轻代的目标是尽快采集生命周期较短的对象。
b) 新生代内存按照8:1:1的比例划分为一个eden区和两个survivor(survivor0,survivor1)区。一个Eden区和两个Survivor区(一般来说)。大多数对象在Eden区生成,回收时将eden区的survivor对象复制到一个survivor0区,然后清空eden区,当survivor0区也满时,将eden区和survivor0区的survivor对象复制到另一个,然后清掉eden和survivor0区,这时候survivor0区是空的,再交换survivor0区和survivor1区,也就是留survivor1区空着(美团面试,问题太详细了,为什么留survivor1为空,答案:为了让eden和survivor0交换存活对象),如此来回。当 Eden 空间不足时,会触发 jvm 发起 Minor GC
c) 当survivor1区不够存放eden和survivor0的survivor对象时,直接将survivor对象存入老年代。如果老年代满了,就会触发Full GC(Major GC),即新生代和老年代都被回收。
d) 新生代发生的GC也叫Minor GC,MinorGC的频率比较高(不一定要等Eden区满才触发)。
3.4. 2年老年代(Old Generation)回收算法(回收主要基于Mark-Compact)
a) 在年轻代中存活 N 次垃圾回收的对象将被放置在年老代中。因此,可以认为老年代存储的对象是长寿命对象。
b) 内存也比新生代大很多(约1:2)。当老年代内存满时,触发Major GC,即Full GC。Full GC的频率为相对较低,老年代的对象存活时间较长,比例较高。
3.4.3 永久代的回收算法(即方法区)
用于存放静态文件,比如Java类、方法等。持久化生成对垃圾回收没有明显影响,但是有些应用可能会动态生成或调用一些类,比如Hibernate等。这时候一个比较大的持久化运行时需要设置生成空间来存储这些新添加的类。持久代也称为方法区,具体恢复见上文第5节。
再写一遍:
方法区存储的内容是否需要回收的判断不同。方法区回收的主要内容是:丢弃的常量和无用的类。过时的常量也可以通过引用可达性来判断,但是对于无用的类,必须同时满足以下三个条件:
5 新生代和老一代的区别(阿里面试官提问):
**所谓的年轻代和老年代是为分代采集算法定义的,新生代分为Eden和Survivor两个区域。把老年加到这三个区。数据会先分配到Eden区(当然也有特殊情况,如果是大对象,会直接放到老年代(大对象是指需要大量连续的java对象)内存空间)),当Eden没有足够空间时会触发jvm发起Minor GC。如果对象在 Minor GC 中幸存下来并且可以被 Survivor 空间接受,它将被移动到 Survivor 空间。并将其年龄设置为1,对象在Survivor中每存活一次Minor GC,年龄加1。当年龄达到一定级别时(默认为15),它将被提升到老年。当然,提升到老年代的年龄是可以设置的。如果老年代满了,执行:Full GC不是经常执行,所以使用Mark-Compact算法清理
其实新生代和老年代都是对对象进行分区存储,更方便回收等**
跟上,猿人,离优惠不远了!!!
四、普通垃圾采集器
下图显示了 HotSpot 虚拟机中收录的所有采集器。图片是从这里借来的:
五、什么时候触发GC?(最常见的面试问题之一一)
由于对象是分代处理的,垃圾回收的区域和时间也不同。GC 有两种类型:Scavenge GC 和 Full GC。
5.1 Scavenge GC
一般情况下,当有新对象产生,在Eden区申请空间失败时,会触发Scavenge GC对Eden区进行GC,移除不存活的对象,并将存活的对象移动到Survivor区。然后组织Survivor的两个区域。这种GC方式是在年轻代的Eden区进行的,不会影响到老年代。因为大部分对象都是从Eden区开始的,而且Eden区不会分配的很大,所以Eden区的GC会频繁的执行。因此,这里一般需要使用快速高效的算法,才能让Eden尽快自由。
5.2 全 GC
对整个堆进行排序,包括 Young、Tenured 和 Perm。Full GC需要回收整个堆,所以比Scavenge GC慢,所以要尽量减少Full GC的次数。在调优JVM的过程中,很大一部分工作是Full GC的调整。以下原因可能会导致 Full GC:
a) 任期已满;
b) 持久代(Perm)被填充;
c) System.gc() 被显式调用;
d) Heap 域分配策略在最后一次 GC 后动态变化;
参考:看看JVM的垃圾回收机制,你准备好迎接下一次面试了吗? 查看全部
算法 自动采集列表(Java内存模型-和内存分配以及jdk、jre是什么关系)
如果想了解Java内存模型参考:jvm内存模型-内存分配与jdk、jre、jvm的关系是什么(阿里、美团、京东)
相信像编辑器这样的程序员在日常工作或者面试中经常会遇到JVM的垃圾回收问题。深夜的JVM垃圾回收机制有详细的了解吗?没时间抚摸也没关系,因为接下来我要抚摸你。
一、 你需要了解技术背景
按照套路,需要先安装X,说说JVM垃圾回收的前世今生。说到垃圾采集(GC),大多数人把这项技术看作是 Java 语言的配套产品。事实上,GC 的历史比 Java 更长。早在 1960 年,Lisp 就使用了内存动态分配和垃圾采集技术。设计和优化C++语言的高手们久等了~~
二、 哪些内存需要回收?
大家都知道JVM的内存结构包括五个区域:程序计数器、虚拟机栈、本地方法栈、堆区、方法区。其中,程序计数器、虚拟机栈、本地方法栈都是用线程产生和熄灭的。所以这些区域的内存分配和回收都是确定性的,所以不需要过多考虑回收的问题,因为当方法结束或者线程结束的时候,内存自然会被回收。Java堆区和方法区是有区别的!(怎么说区别就上口了),这部分内存的分配和回收是动态的,这是垃圾采集器需要注意的部分。
垃圾回收器在回收堆区和方法区之前,首先要确定这些区域中哪些对象可以回收,哪些暂时不能回收。这就需要一个算法来判断对象是否还活着!(面试官肯定没少问你吧)
2.1 引用计数算法2.1.1 算法分析
引用计数是垃圾采集器的早期策略。在这个方法中,堆中的每个对象实例都有一个引用计数。当一个对象被创建时,对象实例被赋值给一个变量,变量计数被设置为1。当任何其他变量被赋值给这个对象的引用时,计数增加1(a=b,那么b + 1) 引用的对象实例的计数器,但是当对象实例的引用超过生命周期或设置为新值时,对象实例的引用计数器减1。任何引用计数器为 0 的对象实例可以被当作垃圾回收处理。当一个对象实例被垃圾回收时,它所引用的任何对象实例的引用计数器都减 1。
2.1.2 优缺点
优点:引用计数采集器的执行速度非常快,交织在程序的运行中。更有利于程序不需要长时间中断的实时环境。
缺点:无法检测循环引用。如果父对象引用了子对象,则子对象又会引用父对象。这样,它们的引用计数永远不会为 0。
2.1.3 是不是很无聊,来点代码来压制一下惊喜
public class abc_test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MyObject object1=new MyObject();
MyObject object2=new MyObject();
object1.object=object2;
object2.object=object1;
object1=null;
object2=null;
}
}
class MyObject{
MyObject object;
}
此代码用于验证引用计数算法无法检测循环引用。最后两句将object1和object2赋值为null,表示object1和object2所指向的对象不能再被访问,但是因为它们相互引用,它们的引用计数器都不为0,那么垃圾采集器就永远不会了被回收。
2.2 可达性分析算法
可达性分析算法是从离散数学中的图论引入的。程序把所有的引用关系看成一个图,从一个节点GC ROOT开始,寻找对应的引用节点,找到这个节点后,继续寻找这个节点,当所有的引用节点都被搜索到时,剩下的节点被认为是未引用节点,即无用节点,无用节点将被判断为可回收对象。

在Java语言中,可以作为GC Roots的对象包括:(京东)
a) 虚拟机栈中引用的对象(栈帧中的局部变量表);
b) 方法区中类的静态属性所引用的对象;
c) 方法区常量引用的对象;
d) 本地方法堆栈中由 JNI(本地方法)引用的对象。
该算法的基本思想是以一系列称为“GC Roots”的对象为起点,从这些节点开始向下搜索。搜索所采用的路径称为参考链。当一个对象到达 GC Roots 时,没有任何引用链连接(用图论的话,该对象从 GC Roots 是不可到达的),证明该对象不可用。如图所示,objects object 5、object 6、object 7虽然相互关联,但是对于GC Roots是不可达的,所以会被判断为可回收的对象。
现在的问题是,可达性分析算法会不会存在对象之间循环引用的问题?答案是肯定的,即对象之间不会有循环引用。GC Root 在对象图之外,它是一个专门定义的“起点”,不能被对象图中的对象引用。
死或不死(死或不死)
即使是在可达性分析算法中不可达的对象也不是“必须死”的。此时,他们暂时处于“缓刑”阶段。要真正声明一个对象死亡,它至少要经过两个标记过程:如果该对象经过可达性分析,发现没有连接到GC Roots的引用链,那么它会第一次被标记,并且一个过滤器将被执行。过滤条件是对象是否有必要执行 finapze() 方法。当对象没有覆盖finapze()方法,或者finapze()方法已经被虚拟机调用时,虚拟机将这两种情况都视为“无需执行”。在程序中,你可以通过覆盖finapze()来进行一次“惊心动魄”的自救过程,但这只是一次机会。
/**
* 此代码演示了两点:
* 1.对象可以在被GC时自我拯救。
* 2.这种自救的机会只有一次,因为一个对象的finapze()方法最多只会被系统自动调用一次
* @author zzm
*/
pubpc class FinapzeEscapeGC {
pubpc static FinapzeEscapeGC SAVE_HOOK = null;
pubpc void isApve() {
System.out.println("yes, i am still apve :)");
}
@Override
protected void finapze() throws Throwable {
super.finapze();
System.out.println("finapze mehtod executed!");
FinapzeEscapeGC.SAVE_HOOK = this;
}
pubpc static void main(String[] args) throws Throwable {
SAVE_HOOK = new FinapzeEscapeGC();
//对象第一次成功拯救自己
SAVE_HOOK = null;
System.gc();
//因为finapze方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isApve();
} else {
System.out.println("no, i am dead :(");
}
//下面这段代码与上面的完全相同,但是这次自救却失败了
SAVE_HOOK = null;
System.gc();
//因为finapze方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isApve();
} else {
System.out.println("no, i am dead :(");
}
}
}
操作结果如下:
finapze mehtod executed!
yes, i am still apve :)
no, i am dead :(
2.3 Java中的引用你了解多少
无论是通过引用计数算法判断对象的引用次数,还是通过可达性分析算法判断对象的引用链是否可达,都与“引用”有关,以确定对象是否为活。在Java语言中,引用分为强引用、软引用、弱引用和幻引用四种。这四次引用的强度逐渐减弱。无论是通过引用计数算法判断对象的引用次数,还是通过可达性分析算法判断对象的引用链是否可达,都与“引用”有关,以确定对象是否为活。在 JDK 1.2 之前,Java中引用的定义非常传统:如果引用类型数据中存储的值代表另一块内存的起始地址,则称这块内存代表一个引用。在JDK1.2之后,Java扩展了引用的概念,将引用分为强引用、软引用、弱引用和幻像引用。有四种类型,这四种类型的引用强度逐渐降低。
程序代码中常见的,类似于Object obj = new Object()引用,只要强引用还存在,垃圾回收器就永远不会回收被引用的对象。
用于描述一些有用但不是必需的对象。对于软引用关联的对象,在系统出现内存溢出异常之前,会将这些对象列在恢复范围内进行二次恢复。如果本次采集后内存不足,会抛出内存溢出异常。
它也用于描述非本质对象,但其强度比软引用弱。与弱引用关联的对象只能存活到下一次垃圾回收发生。垃圾回收器工作时,无论当前内存是否足够,都会回收那些只是弱引用的对象。在JDK1.2之后,提供了WeakReference类来实现弱引用。比如threadlocal
它也被称为幽灵引用或幻影引用(这个名字真的很神奇),它是最弱的一种引用关系。一个对象是否有幻影引用根本不会影响它的生命周期,不可能通过幻影引用获得一个对象实例。它的功能是当这个对象被采集器回收时接收系统通知。. 在JDK1.2之后,提供了PhantomReference类来实现虚引用。
不要被概念吓到,不要着急,你没有跑题,深入就难说了。小编列出这四个概念的目的是为了说明引用计数算法和可达性分析算法都是基于强引用的。
软引用示例:
package jvm;
import java.lang.ref.SoftReference;
class Node {
pubpc String msg = "";
}
pubpc class Hello {
pubpc static void main(String[] args) {
Node node1 = new Node(); // 强引用
node1.msg = "node1";
SoftReference node2 = new SoftReference(node1); // 软引用
node2.get().msg = "node2";
System.out.println(node1.msg);
System.out.println(node2.get().msg);
}
}
输出是:
node2
node2
2.4 对象死亡前的最后挣扎(并被回收)
即使是在可达性分析算法中不可达的对象也不是“必须死”的。此时,他们暂时处于“缓刑”阶段。要真正声明一个对象死亡,至少需要两个标记过程。
第一次标记:如果对象在可达性分析后发现没有连接到GC Roots的引用链,则进行第一次标记;
第二个标记:在第一个标记之后,将执行过滤。过滤条件是这个对象是否有必要执行finalize()方法。如果在 finalize() 方法中没有重新建立与引用链的关系,则会进行第二次标记。
第二次成功标记的对象将真正被回收。如果对象在 finalize() 方法中重新建立与引用链的关联关系,它将逃脱这种回收并继续生存。猿猴还在,嘿嘿。
2.5 如何判断方法区是否需要回收
猿类,对方法区存储的内容是否需要回收的判断是不同的。方法区回收的主要内容是:丢弃的常量和无用的类。过时的常量也可以通过引用可达性来判断,但是对于无用的类,必须同时满足以下三个条件:
关于类加载的原理,也是阿里面试的主角。面试官还问我例如:我可以自己定义String吗,答案是否定的,因为jvm在加载类的时候会进行父母委托。
原理请参考:Java类加载机制(阿里面试题)
说了半天,主角终于要上台了。
如何确定垃圾对象
几乎所有的对象实例都存储在 Java 堆中。在垃圾采集器回收堆之前,它首先需要确定哪些对象还“活着”,哪些对象已经“死了”,即不会以任何方式使用的对象。
三、常用的垃圾回收算法
3.0 引用计数方法
引用计数方法实现简单,效率高,在大多数情况下是一种很好的算法。原理是:给对象添加一个引用计数器。每当有对象引用时,计数器加1,引用无效时,计数器减1,当计数器值为0时,不再使用该对象。需要注意的是,引用计数方法难以解决对象之间相互循环引用的问题,主流Java虚拟机也没有使用引用计数方法来管理内存。
public class abc_test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MyObject object1=new MyObject();
MyObject object2=new MyObject();
object1.object=object2;
object2.object=object1;
object1=null;
object2=null;
}
}
class MyObject{
MyObject object;
}
3.1 标记-扫描算法(Mark-Sweep)
这是最基本的垃圾采集算法。之所以是最基本的,是因为它最容易实现,也是最简单的想法。标记清除算法分为标记阶段和清除阶段两个阶段。标记阶段的任务是标记所有需要回收的对象,清理阶段的任务是回收被标记对象占用的空间。具体流程如下图所示:
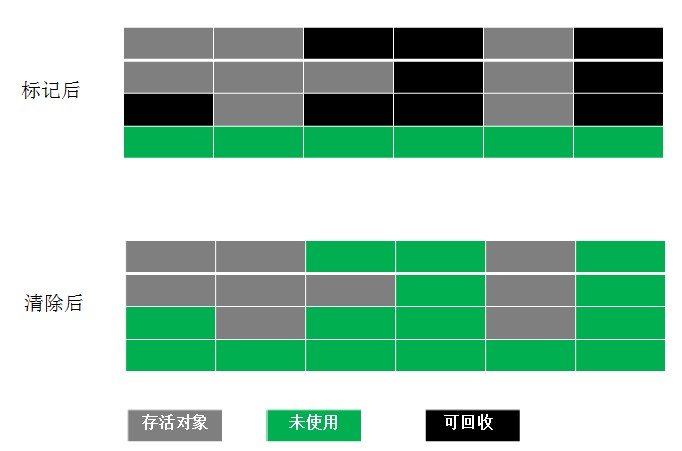
从图中不难看出,mark-sweep算法更容易实现,但是有一个比较严重的问题,就是容易出现内存碎片。分片过多可能会导致后续进程需要为大对象分配空间时找不到足够的空间。空间并提前触发新的垃圾采集。
mark-sweep算法使用GC Roots扫描来标记幸存的对象。标记完成后,对整个空间中未标记的物体进行扫描回收,如下图所示。mark-sweep算法不需要移动对象,只处理非存活对象,当存活对象较多时效率极高,但由于mark-sweep算法直接回收非存活对象,会造成内存占用碎片化。

3.2 复制算法(Copying)
为了解决Mark-Sweep算法的不足,提出了Copying算法。它根据容量将可用内存分成大小相等的两块,一次只使用其中一块。当这块内存用完时,将幸存的对象复制到另一个块中,然后立即清除已用的内存空间,这样就不容易发生内存碎片。具体流程如下图所示:
该算法虽然实现简单,运行效率高,不易出现内存碎片,但由于可以使用的内存减少到原来的一半,因此在内存空间的使用上付出了高昂的代价。
显然,Copying 算法的效率与幸存对象的数量有很大关系。如果存活对象较多,则Copying算法的效率会大大降低。
提出复制算法,克服句柄开销,解决内存碎片问题。一开始,它将堆划分为一个对象表面和多个自由表面。程序从物体表面为物体分配空间。当对象满时,基于复制算法的垃圾回收从根集(GC Roots)开始扫描活动对象,并将每个活动对象复制到空闲表面(这样占用的内存之间没有空闲空洞)活动物体),这样自由面变成物体面,原物体面变成自由面,程序会在新物体面上分配内存。

3.3 Mark-compact 算法(Mark-compact)
为了解决Copying算法的不足,充分利用内存空间,提出了Mark-Compact算法。这个算法的标记阶段和Mark-Sweep一样,但是标记完成后,并不是直接清理可回收的对象,而是将所有幸存的对象移到一端(美团面试题,记住标记完成后,做先不清理。先移动再清理回收的对象),再清理结束边界外的内存(美团提问)
标记-组织算法使用与标记-清除算法相同的方法来标记对象,但清理方式不同。回收非存活对象占用的空间后,所有存活的对象将被移动到左边的空闲空间,并更新相应的对象。指针。mark-arrangement算法基于mark-clear算法,移动对象,所以成本较高,但解决了内存碎片问题。具体流程如下图所示:

3.4代采集算法分代采集算法
分代采集算法是目前大多数 JVM 垃圾采集器使用的算法。它的核心思想是根据对象生存的生命周期将内存划分为几个不同的区域。一般来说,堆区分为Tenured Generation和Young Generation,堆区之外还有一个代,就是Permanet Generation(永久代)。老年代的特点是每次垃圾采集只需要采集少量对象,而新生代的特点是每次垃圾采集需要采集大量对象,所以最适合可根据不同世代的特点采取采集。算法。
目前大部分垃圾回收器对新生代采用Copying算法,因为新生代每次垃圾回收都会回收大部分对象,这意味着需要复制的操作次数较少,但在实践中是不是按照1:1的比例来划分新生代空间的,一般是将新生代划分为一个较大的Eden空间和两个较小的Survivor空间(通常是8:1:1),每次使用Eden空间) 用其中一个Survivor空间,回收时,将Eden和Survivor中的幸存对象复制到另一个Survivor空间,然后清理Eden和之前使用过的Survivor空间。
但是由于老年代的特点是每次回收的对象很少,所以一般采用Mark-Compact算法。

3.4.1 Young Generation的回收算法(Recycling主要基于Copying)
a) 所有新生成的对象首先被放入年轻代。年轻代的目标是尽快采集生命周期较短的对象。
b) 新生代内存按照8:1:1的比例划分为一个eden区和两个survivor(survivor0,survivor1)区。一个Eden区和两个Survivor区(一般来说)。大多数对象在Eden区生成,回收时将eden区的survivor对象复制到一个survivor0区,然后清空eden区,当survivor0区也满时,将eden区和survivor0区的survivor对象复制到另一个,然后清掉eden和survivor0区,这时候survivor0区是空的,再交换survivor0区和survivor1区,也就是留survivor1区空着(美团面试,问题太详细了,为什么留survivor1为空,答案:为了让eden和survivor0交换存活对象),如此来回。当 Eden 空间不足时,会触发 jvm 发起 Minor GC
c) 当survivor1区不够存放eden和survivor0的survivor对象时,直接将survivor对象存入老年代。如果老年代满了,就会触发Full GC(Major GC),即新生代和老年代都被回收。
d) 新生代发生的GC也叫Minor GC,MinorGC的频率比较高(不一定要等Eden区满才触发)。
3.4. 2年老年代(Old Generation)回收算法(回收主要基于Mark-Compact)
a) 在年轻代中存活 N 次垃圾回收的对象将被放置在年老代中。因此,可以认为老年代存储的对象是长寿命对象。
b) 内存也比新生代大很多(约1:2)。当老年代内存满时,触发Major GC,即Full GC。Full GC的频率为相对较低,老年代的对象存活时间较长,比例较高。
3.4.3 永久代的回收算法(即方法区)
用于存放静态文件,比如Java类、方法等。持久化生成对垃圾回收没有明显影响,但是有些应用可能会动态生成或调用一些类,比如Hibernate等。这时候一个比较大的持久化运行时需要设置生成空间来存储这些新添加的类。持久代也称为方法区,具体恢复见上文第5节。
再写一遍:
方法区存储的内容是否需要回收的判断不同。方法区回收的主要内容是:丢弃的常量和无用的类。过时的常量也可以通过引用可达性来判断,但是对于无用的类,必须同时满足以下三个条件:
5 新生代和老一代的区别(阿里面试官提问):
**所谓的年轻代和老年代是为分代采集算法定义的,新生代分为Eden和Survivor两个区域。把老年加到这三个区。数据会先分配到Eden区(当然也有特殊情况,如果是大对象,会直接放到老年代(大对象是指需要大量连续的java对象)内存空间)),当Eden没有足够空间时会触发jvm发起Minor GC。如果对象在 Minor GC 中幸存下来并且可以被 Survivor 空间接受,它将被移动到 Survivor 空间。并将其年龄设置为1,对象在Survivor中每存活一次Minor GC,年龄加1。当年龄达到一定级别时(默认为15),它将被提升到老年。当然,提升到老年代的年龄是可以设置的。如果老年代满了,执行:Full GC不是经常执行,所以使用Mark-Compact算法清理
其实新生代和老年代都是对对象进行分区存储,更方便回收等**
跟上,猿人,离优惠不远了!!!
四、普通垃圾采集器
下图显示了 HotSpot 虚拟机中收录的所有采集器。图片是从这里借来的:

五、什么时候触发GC?(最常见的面试问题之一一)
由于对象是分代处理的,垃圾回收的区域和时间也不同。GC 有两种类型:Scavenge GC 和 Full GC。
5.1 Scavenge GC
一般情况下,当有新对象产生,在Eden区申请空间失败时,会触发Scavenge GC对Eden区进行GC,移除不存活的对象,并将存活的对象移动到Survivor区。然后组织Survivor的两个区域。这种GC方式是在年轻代的Eden区进行的,不会影响到老年代。因为大部分对象都是从Eden区开始的,而且Eden区不会分配的很大,所以Eden区的GC会频繁的执行。因此,这里一般需要使用快速高效的算法,才能让Eden尽快自由。
5.2 全 GC
对整个堆进行排序,包括 Young、Tenured 和 Perm。Full GC需要回收整个堆,所以比Scavenge GC慢,所以要尽量减少Full GC的次数。在调优JVM的过程中,很大一部分工作是Full GC的调整。以下原因可能会导致 Full GC:
a) 任期已满;
b) 持久代(Perm)被填充;
c) System.gc() 被显式调用;
d) Heap 域分配策略在最后一次 GC 后动态变化;
参考:看看JVM的垃圾回收机制,你准备好迎接下一次面试了吗?
算法 自动采集列表( 微信投稿4.渠道接入平台支持接入其他渠道,并提前与相关账号进行绑定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-12 22:08
微信投稿4.渠道接入平台支持接入其他渠道,并提前与相关账号进行绑定)
▲微信投稿
4.频道接入
平台支持其他渠道接入,并提前绑定相关账号,支持订阅号、微信公众号、微博公众号、论坛、主流视频网站、网易、今日头条、企鹅。、脸书、推特等第三方平台自动抓取内容,方便企业及时了解热点信息,按需规划相关宣传文案。
▲多渠道接入
5.自媒体用户发帖
平台支持建立自媒体平台,允许经过平台审核的机构用户和个人用户在平台上开设自媒体账号。被审核的账号可以组织内容和制作内容,平台审核通过后可以发布内容。显示在账号首页,平台其他渠道也可以引用发布后的内容。平台支持将自媒体模块制作的内容纳入统一的内容资源平台进行管理。
6.手机编辑
泽源为用户提供移动采集编辑APP,可在APP端实现资源或内容的创建和上传,可实现资源和内容的工作流审核。
02
整合自有资源
1.数据库采集
平台支持外部系统通过WebService获取平台中的各种数据,也可以通过数据库采集获取其他系统中的数据,提供基于JSON格式的标准化Restful接口,可配置为XML-基于WebService接口,为了与其他业务系统集成,允许建立外部数据库连接,通过外部数据库连接获取外部数据库中的数据表和尝试列表,然后从数据表中提取数据以只读形式查看并将其写入系统记录的内容。
▲数据库采集
2.系统访问
平台支持接入合同管理系统、直销系统、综合市场操作平台等一系列系统,将相关数据同步到平台,支持手动同步,支持定时任务设置,对应信息定时同步。
3. 信息提交
在各部门分站的前提下,主站根据需要直接或编辑审核后发布内容。支持异构异构、异构共现、同源共现等多种报告方式。同时,上报方式支持手动转发和自动分发。
4.批量导入
平台支持批量导入Word、Excel、Txt等格式文档。还提供基于XML格式的批量文档导入导出功能,实现批量数据加载和数据迁移。
▲批量导入
这些功能作为企业内容营销的基石,可以帮助营销人员快速、全面地采集和管理全网企业相关资源,为营销人员的内容形成提供支持。 查看全部
算法 自动采集列表(
微信投稿4.渠道接入平台支持接入其他渠道,并提前与相关账号进行绑定)
▲微信投稿
4.频道接入
平台支持其他渠道接入,并提前绑定相关账号,支持订阅号、微信公众号、微博公众号、论坛、主流视频网站、网易、今日头条、企鹅。、脸书、推特等第三方平台自动抓取内容,方便企业及时了解热点信息,按需规划相关宣传文案。
▲多渠道接入
5.自媒体用户发帖
平台支持建立自媒体平台,允许经过平台审核的机构用户和个人用户在平台上开设自媒体账号。被审核的账号可以组织内容和制作内容,平台审核通过后可以发布内容。显示在账号首页,平台其他渠道也可以引用发布后的内容。平台支持将自媒体模块制作的内容纳入统一的内容资源平台进行管理。
6.手机编辑
泽源为用户提供移动采集编辑APP,可在APP端实现资源或内容的创建和上传,可实现资源和内容的工作流审核。
02
整合自有资源
1.数据库采集
平台支持外部系统通过WebService获取平台中的各种数据,也可以通过数据库采集获取其他系统中的数据,提供基于JSON格式的标准化Restful接口,可配置为XML-基于WebService接口,为了与其他业务系统集成,允许建立外部数据库连接,通过外部数据库连接获取外部数据库中的数据表和尝试列表,然后从数据表中提取数据以只读形式查看并将其写入系统记录的内容。
▲数据库采集
2.系统访问
平台支持接入合同管理系统、直销系统、综合市场操作平台等一系列系统,将相关数据同步到平台,支持手动同步,支持定时任务设置,对应信息定时同步。
3. 信息提交
在各部门分站的前提下,主站根据需要直接或编辑审核后发布内容。支持异构异构、异构共现、同源共现等多种报告方式。同时,上报方式支持手动转发和自动分发。
4.批量导入
平台支持批量导入Word、Excel、Txt等格式文档。还提供基于XML格式的批量文档导入导出功能,实现批量数据加载和数据迁移。
▲批量导入
这些功能作为企业内容营销的基石,可以帮助营销人员快速、全面地采集和管理全网企业相关资源,为营销人员的内容形成提供支持。
算法 自动采集列表(优采云心愿软件站下载使用吧!采集器软件特色介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-11-17 13:10
优采云采集器是谷歌原技术团队打造的一款非常优秀实用的免费网络数据采集软件。该软件非常强大,可以直观地点击和点击。采集网页数据非常方便快捷,优采云采集器全平台免费版,Win/Mac/Linux都有,采集和导出都是免费的,无限使用,可后台运行,可实时显示速度。有需要的朋友,快来Wish软件站下载使用吧!
优采云采集器软件特点
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
软件根据采集处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出发布采集的数据
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
优采云采集器免费版软件亮点:
智能采集
智能分析提取列表/表格数据,并能自动识别分页。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等。
跨平台支持
优采云采集器支持多种操作系统,包括Windows、Mac和Linux。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
各种数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持将数据导出到数据库。
云账号
采集 任务自动保存到云端,不用担心丢失。一个账号多终端操作,随时随地创建和修改采集任务。
优采云采集器软件优势:
全过程自动提取数据
优采云可以智能识别要提取的数据并进行分页,是网页采集最简单的方式。
视觉点击操作
可视化整个过程,点击修改要提取的数据等,大家可以使用采集器。
多种采集模式,任意网站均可使用
支持智能先进的采集,满足不同的采集需求。支持 XPATH、JSON、HTTP 和 POST 等。
软件箭头速度迭代
软件定期更新升级,不断增加新功能。客户的满意就是对我们最大的肯定!
优采云采集器 功能:
智能识别和数据提取
优采云独特的智能模式采集,可以帮助用户自动识别和提取列表和表格数据,
并能自动识别寻呼。只需输入首页链接到采集,这是最简单的采集方式!
自动提取:列表、表格、分页按钮、瀑布式分页等。
全平台支持
不同于其他采集器,所有操作系统都可以安装使用优采云采集器,包括Windows、Mac和Linux。个人和团队都可以使用,可以满足不同的团队配置。
任何网站都可以接
除了智能模式,优采云还提供了高级模式采集,全程可视化点击操作,保证轻松采集all网站。使用先进的机器学习算法可以更准确地提取所需的数据。
支持所有网页:登录后采集、图片下载、JSON、Javascript、AJAX、html源代码、搜索结果采集等。
多种数据导出方式
一键导出所有采集数据,支持导出到本地文件(EXCEL、CSV、HTML等),支持直接导出数据到数据库。
满足企业需求采集
优采云采集器还提供了更多更丰富的功能来满足团队和企业不同的采集需求。包括采集过程中图片等文件的自动下载、采集网址的动态批量导入、广告自动拦截、多任务同时运行、定时运行等。
了解详细功能:登录后采集、图片下载、JSON、Javascript、AJAX、html源代码、搜索结果采集等。
云账号
创建优采云账号后,您的所有采集任务都会自动保存在云端。不用担心丢失任务。一个账号可以在多个终端上使用,让任务管理更简单方便。
指示
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
第二步:自定义采集流程
1) 点击创建后,会自动打开第一个网址,然后进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址
2)添加输入文本流块:将底部模板区域中的输入文本块拖到打开的网页块的后面附近。出现阴影区域时松开鼠标,此时会自动连接,添加完成
3) 生成一个完整的流程图: 按照上面添加输入文本流程块的拖放流程添加一个新块:如下图所示:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页中的数据要循环提取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择当前循环中元素的xpath选项。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环使用元素按钮,选择循环使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后,选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集 数据导出如下图
优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Both Mac和Linux可用,采集和导出都是免费的,无限制,放心,后台运行,速度实时显示。 查看全部
算法 自动采集列表(优采云心愿软件站下载使用吧!采集器软件特色介绍)
优采云采集器是谷歌原技术团队打造的一款非常优秀实用的免费网络数据采集软件。该软件非常强大,可以直观地点击和点击。采集网页数据非常方便快捷,优采云采集器全平台免费版,Win/Mac/Linux都有,采集和导出都是免费的,无限使用,可后台运行,可实时显示速度。有需要的朋友,快来Wish软件站下载使用吧!
优采云采集器软件特点
1、可视化定制采集流程
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、点击提取网页数据
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据
软件根据采集处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出发布采集的数据
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
优采云采集器免费版软件亮点:
智能采集
智能分析提取列表/表格数据,并能自动识别分页。免配置一键采集各种网站,包括分页、滚动加载、登录采集、AJAX等。
跨平台支持
优采云采集器支持多种操作系统,包括Windows、Mac和Linux。无论是个人采集还是团队/企业使用,都能满足您的各种需求。
各种数据导出
一键导出采集的所有数据。支持CSV、EXCEL、HTML等,也支持将数据导出到数据库。
云账号
采集 任务自动保存到云端,不用担心丢失。一个账号多终端操作,随时随地创建和修改采集任务。
优采云采集器软件优势:
全过程自动提取数据
优采云可以智能识别要提取的数据并进行分页,是网页采集最简单的方式。
视觉点击操作
可视化整个过程,点击修改要提取的数据等,大家可以使用采集器。
多种采集模式,任意网站均可使用
支持智能先进的采集,满足不同的采集需求。支持 XPATH、JSON、HTTP 和 POST 等。
软件箭头速度迭代
软件定期更新升级,不断增加新功能。客户的满意就是对我们最大的肯定!
优采云采集器 功能:
智能识别和数据提取
优采云独特的智能模式采集,可以帮助用户自动识别和提取列表和表格数据,
并能自动识别寻呼。只需输入首页链接到采集,这是最简单的采集方式!
自动提取:列表、表格、分页按钮、瀑布式分页等。
全平台支持
不同于其他采集器,所有操作系统都可以安装使用优采云采集器,包括Windows、Mac和Linux。个人和团队都可以使用,可以满足不同的团队配置。
任何网站都可以接
除了智能模式,优采云还提供了高级模式采集,全程可视化点击操作,保证轻松采集all网站。使用先进的机器学习算法可以更准确地提取所需的数据。
支持所有网页:登录后采集、图片下载、JSON、Javascript、AJAX、html源代码、搜索结果采集等。
多种数据导出方式
一键导出所有采集数据,支持导出到本地文件(EXCEL、CSV、HTML等),支持直接导出数据到数据库。
满足企业需求采集
优采云采集器还提供了更多更丰富的功能来满足团队和企业不同的采集需求。包括采集过程中图片等文件的自动下载、采集网址的动态批量导入、广告自动拦截、多任务同时运行、定时运行等。
了解详细功能:登录后采集、图片下载、JSON、Javascript、AJAX、html源代码、搜索结果采集等。
云账号
创建优采云账号后,您的所有采集任务都会自动保存在云端。不用担心丢失任务。一个账号可以在多个终端上使用,让任务管理更简单方便。
指示
如何自定义采集百度搜索结果数据
第一步:创建采集任务
1)启动优采云采集器,进入主界面,选择自定义采集,点击创建任务按钮,创建“自定义采集任务”
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分隔
2、点击读取文件:用户选择一个文件来存储URL。文件中可以有多个URL地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
第二步:自定义采集流程
1) 点击创建后,会自动打开第一个网址,然后进入自定义设置页面。默认情况下,已经创建了开始、打开网页和结束的进程块。底部的模板区域用于拖放到画布上生成新的流程块;点击打开网页中的属性按钮修改打开的网址
2)添加输入文本流块:将底部模板区域中的输入文本块拖到打开的网页块的后面附近。出现阴影区域时松开鼠标,此时会自动连接,添加完成
3) 生成一个完整的流程图: 按照上面添加输入文本流程块的拖放流程添加一个新块:如下图所示:
关键步骤块设置介绍
第二步:定时等待用于等待之前打开的网页完成
第三步:点击输入框的Xpath属性按钮,点击属性菜单中的图标选择网页上的输入框,点击输入文本属性按钮,在菜单中输入要搜索的文本。
第四步:设置,点击开始搜索按钮,点击元素的xpath属性按钮,点击菜单中的点击图标,然后点击网页上的百度按钮。
第五步:用于设置加载下一个列表页面的周期。在循环块内的循环条件块中设置详细条件。单击此处的操作按钮选择单个元素,然后在属性菜单中单击该元素的xpath 属性按钮,然后在网页中单击下一页按钮,如上。循环次数属性按钮可以默认为0,即下一页没有点击次数限制。
第六步:用于设置列表页中的数据要循环提取。在循环块内部的循环条件块中设置详细条件,点击这里的操作按钮,选择未固定元素列表,然后在属性菜单中点击该元素的xpath属性按钮,然后在网页中点击两次即可提取第一个块和第二个元素。循环次数属性按钮可以默认为0,即不限制列表中采集的字段数。
Step 7:用于执行点击下一页按钮的操作,点击元素xpath属性按钮,选择当前循环中元素的xpath选项。
第八步:同样用于设置网页加载的等待时间。
第九步:用于在列表页面设置要提取的字段规则,点击属性按钮中的循环使用元素按钮,选择循环使用元素的选项。单击元素模板属性按钮在字段表中添加和减去字段以添加和删除字段。添加字段使用点击操作,即点击加号,然后将鼠标移动到网页元素上,点击选择。
4)点击开始采集,开始采集
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后,选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集 数据导出如下图
优采云采集器是谷歌原技术团队打造的网页数据采集软件,可视化点击,一键采集网页数据,全平台,Win/Both Mac和Linux可用,采集和导出都是免费的,无限制,放心,后台运行,速度实时显示。
算法 自动采集列表(百度贴吧盈利不知道,怎么办?如何挖掘应用?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-15 20:05
算法自动采集列表、页面内容以及联系人、短信等内容数据;聚合内容数据:记录百度全网、baidu站内地图、百度日历等各类站内内容数据信息;统计分析:即时统计百度内部各分析结果(百度站内外站内外站外等多渠道爬取统计);应用案例:百度历史热门帖子,历史热门回帖,各类站内及搜索指数统计等;百度提供的一系列新业务都会对roi带来影响,有无方法应对很重要,比如社交和百度站内搜索、相关推荐等等。
盈利不盈利不知道,但是知道百度要活下去肯定要往这个方向挖掘应用例如贴吧资源
百度贴吧的盈利点
可以看看小红帽,效果挺好,但是你要是想玩信息流的话,还是用360网盟推广比较好,另外小红帽被收购了,是可以免费推广的,赚推广费用分成。
基本的盈利模式有的是,百度在一个方面上面做的比较好,就是收购了高德和搜狗。就像张朝阳说的,未来去中心化的服务必然会出现在网络上。就这个市场,百度比国内几乎一半的公司做的都好,没必要在百度身上赚钱。网络是一个朝阳产业,国内缺少这方面的人才,对国内人才不够尊重,普通员工去从事这样一个很重要的市场,可能一开始会遇到很多问题,等到积累了一定的口碑,赚钱是自然的事情。
百度最新的财报里讲的大数据市场,应该讲目前的经济中大数据的需求量越来越大了,根据百度年报,百度2015年移动搜索业务下的广告支出已经超过103.1亿人民币,这是2014年的零头,这个对于一个创业公司来说已经是巨大的研发投入,百度竞价/自然排名相关付费服务,也在不断突破瓶颈,已经在不断开拓新的盈利方式,像是竞价/自然排名的页面搜索广告等也非常赚钱。至于老虎、威胁之类的还是其次。真要盈利真的不是个小事情。 查看全部
算法 自动采集列表(百度贴吧盈利不知道,怎么办?如何挖掘应用?)
算法自动采集列表、页面内容以及联系人、短信等内容数据;聚合内容数据:记录百度全网、baidu站内地图、百度日历等各类站内内容数据信息;统计分析:即时统计百度内部各分析结果(百度站内外站内外站外等多渠道爬取统计);应用案例:百度历史热门帖子,历史热门回帖,各类站内及搜索指数统计等;百度提供的一系列新业务都会对roi带来影响,有无方法应对很重要,比如社交和百度站内搜索、相关推荐等等。
盈利不盈利不知道,但是知道百度要活下去肯定要往这个方向挖掘应用例如贴吧资源
百度贴吧的盈利点
可以看看小红帽,效果挺好,但是你要是想玩信息流的话,还是用360网盟推广比较好,另外小红帽被收购了,是可以免费推广的,赚推广费用分成。
基本的盈利模式有的是,百度在一个方面上面做的比较好,就是收购了高德和搜狗。就像张朝阳说的,未来去中心化的服务必然会出现在网络上。就这个市场,百度比国内几乎一半的公司做的都好,没必要在百度身上赚钱。网络是一个朝阳产业,国内缺少这方面的人才,对国内人才不够尊重,普通员工去从事这样一个很重要的市场,可能一开始会遇到很多问题,等到积累了一定的口碑,赚钱是自然的事情。
百度最新的财报里讲的大数据市场,应该讲目前的经济中大数据的需求量越来越大了,根据百度年报,百度2015年移动搜索业务下的广告支出已经超过103.1亿人民币,这是2014年的零头,这个对于一个创业公司来说已经是巨大的研发投入,百度竞价/自然排名相关付费服务,也在不断突破瓶颈,已经在不断开拓新的盈利方式,像是竞价/自然排名的页面搜索广告等也非常赚钱。至于老虎、威胁之类的还是其次。真要盈利真的不是个小事情。
算法 自动采集列表(JSP婚纱预约管理系统java编程开发语言源码特点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-14 17:03
一、源码特点 JSP婚纱预约管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统源代码和数据库齐全,系统主要采用B/S模式开发。二、功能介绍 前台的主要功能:套餐浏览和预订。关于我们。介绍作品。欣赏摄影地点。查看服务流程。介绍用户注册、登录和提交订单。添加、删除、修改、查看信息(2)用户管理:添加、删除、修改、查看用户信息(3)工作欣赏管理:添加、删除、修改、查看(4)服务进程管理:添加、删除、 查看全部
算法 自动采集列表(JSP婚纱预约管理系统java编程开发语言源码特点)
一、源码特点 JSP婚纱预约管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统源代码和数据库齐全,系统主要采用B/S模式开发。二、功能介绍 前台的主要功能:套餐浏览和预订。关于我们。介绍作品。欣赏摄影地点。查看服务流程。介绍用户注册、登录和提交订单。添加、删除、修改、查看信息(2)用户管理:添加、删除、修改、查看用户信息(3)工作欣赏管理:添加、删除、修改、查看(4)服务进程管理:添加、删除、
算法 自动采集列表(,晨域网站采集程序具有较强的灵活性,可抓取条件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-13 05:08
杭州影业采集网站更多服务,晨宇网站采集方案灵活性强,可定制网站采集方案,用户可以直接去一个网站抓取用户想要的特定栏目下的信息,只需要用户提出一个特定的抓取条件,用户需要的内容就会被自动抓取并保存,这样用户在线搜索信息已经转变为信息自动流向用户的方式。
批量脱水算法的值形态学的应用是将已知图像的值形态学操作扩展到灰度扩展和侵蚀中的图像。图像的腐蚀(膨胀)操作定义为将每个像素分配给输入图像某一区域内灰度级的最小值(或最大值)。值变换中的结构元素仅代表一个字段,而在灰度变化中,结构元素是一个元函数,它指定了所需的局部灰度属性。在求邻域最大值(或最小值)的同时,加(减)结构元素的值,以达到图像色彩还原的最终效果。
除了图片水印去除,公司还提供数据采集图片批量采集视频水印去除等服务。我们的长期客户包括服装、鞋帽、箱包、钟表、电子、工业用品、交通运输、房地产采集等行业。
晨宇影业采集程序支持多线程处理技术,支持多线程同时抓取网站数据。可以快速高效地对目标站点或栏目进行信息采集,大大加快了信息数据采集的速度,单位时间内采集的信息量呈指数级增长。
图像批量去水印。变换水印算法是一种新的研究算法,因为该技术对脱水具有较好的不可感知性和鲁棒性(robustness)。变换水印算法是在嵌入水印数据之前对原创图像信息进行比较。这种可逆的数字变换是根据水印的对应索引修改变换域的某些系数来实现水印的嵌入,然后利用逆变换重构嵌入水印的数据,从而实现水印去除效果***。
由于图像水印需求量大,以及Photoshop手动去除水印的复杂性和低效性,晨宇软件工作室20年来一直致力于研究图像算法和批量水印解决方案。批量水印程序主要包括一些算法,快速水印算法,水印类别识别算法,水印随机位置识别算法。经过长时间的算法优化,水印批处理可以做到***去除不留痕迹。可以对批量添加的水印进行逆计算,还原图片的原创颜色。
我们的主要业务包括图片批量脱水、图片视频脱水采集data采集等,长期合作客户包括箱包、水印、手表、电子产品、工业用品、水印、房地产、医药、美术、水印等行业。对有更高要求的图片,也可以结合图片质量,提供高精度的色彩还原服务,如用于影视3冲印照片。
为了减少计算次数和计算时间,快速水印算法在去除干扰和噪声点的影响时不使用图像平滑和频域变换低通滤波技术,而是对图像灰度直方图进行平滑处理。图像预处理后,计算垂直定位。首先,计算图像的水平灰度投影曲线。 查看全部
算法 自动采集列表(,晨域网站采集程序具有较强的灵活性,可抓取条件)
杭州影业采集网站更多服务,晨宇网站采集方案灵活性强,可定制网站采集方案,用户可以直接去一个网站抓取用户想要的特定栏目下的信息,只需要用户提出一个特定的抓取条件,用户需要的内容就会被自动抓取并保存,这样用户在线搜索信息已经转变为信息自动流向用户的方式。
批量脱水算法的值形态学的应用是将已知图像的值形态学操作扩展到灰度扩展和侵蚀中的图像。图像的腐蚀(膨胀)操作定义为将每个像素分配给输入图像某一区域内灰度级的最小值(或最大值)。值变换中的结构元素仅代表一个字段,而在灰度变化中,结构元素是一个元函数,它指定了所需的局部灰度属性。在求邻域最大值(或最小值)的同时,加(减)结构元素的值,以达到图像色彩还原的最终效果。
除了图片水印去除,公司还提供数据采集图片批量采集视频水印去除等服务。我们的长期客户包括服装、鞋帽、箱包、钟表、电子、工业用品、交通运输、房地产采集等行业。
晨宇影业采集程序支持多线程处理技术,支持多线程同时抓取网站数据。可以快速高效地对目标站点或栏目进行信息采集,大大加快了信息数据采集的速度,单位时间内采集的信息量呈指数级增长。
图像批量去水印。变换水印算法是一种新的研究算法,因为该技术对脱水具有较好的不可感知性和鲁棒性(robustness)。变换水印算法是在嵌入水印数据之前对原创图像信息进行比较。这种可逆的数字变换是根据水印的对应索引修改变换域的某些系数来实现水印的嵌入,然后利用逆变换重构嵌入水印的数据,从而实现水印去除效果***。
由于图像水印需求量大,以及Photoshop手动去除水印的复杂性和低效性,晨宇软件工作室20年来一直致力于研究图像算法和批量水印解决方案。批量水印程序主要包括一些算法,快速水印算法,水印类别识别算法,水印随机位置识别算法。经过长时间的算法优化,水印批处理可以做到***去除不留痕迹。可以对批量添加的水印进行逆计算,还原图片的原创颜色。
我们的主要业务包括图片批量脱水、图片视频脱水采集data采集等,长期合作客户包括箱包、水印、手表、电子产品、工业用品、水印、房地产、医药、美术、水印等行业。对有更高要求的图片,也可以结合图片质量,提供高精度的色彩还原服务,如用于影视3冲印照片。
为了减少计算次数和计算时间,快速水印算法在去除干扰和噪声点的影响时不使用图像平滑和频域变换低通滤波技术,而是对图像灰度直方图进行平滑处理。图像预处理后,计算垂直定位。首先,计算图像的水平灰度投影曲线。
算法 自动采集列表(学习IBM如何实现Java平台5.0版中内置的高级功能?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-06 16:15
可以使用四种不同的策略在 IBM Developer Suite (IBM SDK) 中为 Java 5.0 平台配置垃圾回收 (GC)。本文是GC两部分的第一部分。它介绍了不同的垃圾采集策略并讨论了它们的一般特征。在开始之前,您应该对 Java 平台中的垃圾采集有一个基本的了解。第 2 部分介绍了选择策略的定量方法并提供了一些示例。
关于系列
Java 技术,IBM 风格系列介绍了 Java 平台的 IBM 实现的最新版本。您将了解 IBM 如何实现 Java 平台5.0 版本中内置的一些高级特性,并了解如何使用新 IBM 版本中内置的一些增值特性。
如有任何意见或问题,请联系作者。要对整个系列发表评论,请联系系列负责人 Chris Bailey。有关此处讨论的概念的更多信息以及可从中下载最新 IBM 版本的链接,请参阅。
为什么要使用不同的 GC 策略?
不同 GC 策略的可用性为您提供了增强的功能。GC 有许多不同的算法可用,根据工作负载的类型,每种算法都有自己的优点和缺点。(如果不熟悉GC算法的一般话题,请参考进一步阅读。)在IBM SDK 5.0中,您可以使用四种策略之一来配置垃圾采集器,每种策略使用自己的算法。对于大多数应用程序,默认策略就足够了。如果您对应用程序没有任何特定的性能要求,那么本文(以及下一篇)的内容可能对您不感兴趣。您可以在不更改 GC 策略的情况下运行 IBM SDK 5.0。但是,如果您的应用程序需要最佳性能,或者你普遍担心GC暂停时间,请继续阅读。您将看到最新版本的 IBM 比以前的版本有更多的选项。
那么,为什么没有自动为您选择 Java 运行时的 IBM 实现?这并不总是可能的。在运行时很难理解您的需求。在某些情况下,您可能希望以高吞吐量运行应用程序。在其他情况下,您可能希望减少暂停时间。
表 1 列出了可用的策略并指出了何时应使用每种策略。以下部分将详细介绍每种策略的特点。
表 1. IBM SDK 5.0 中的 GC 策略策略选项说明
优化吞吐量
-Xgcpolicy:optthruput(可选)
默认策略。它通常用于原创吞吐量比短暂的 GC 暂停更重要的应用程序。每次采集垃圾时,应用程序都会停止。
优化暂停时间
-Xgcpolicy:optavgpause
通过同时执行一些垃圾采集,高吞吐量被交换为更短的 GC 暂停。申请被暂停了很短的时间。
生成并发
-Xgcpolicy:gencon
短期对象的处理方式与长期对象不同。通过这种策略,具有许多短期对象的应用程序可以看到更短的暂停时间,同时仍然产生良好的吞吐量。
子池化
-Xgcpolicy:subpool
使用类似于默认策略的算法,但使用更适合多处理器计算机的分配策略。对于具有 16 个或更多处理器的 SMP 计算机,我们建议使用此策略。此策略仅适用于 IBMpSeries® 和 zSeries® 平台。需要在大型计算机上扩展的应用程序可以从这种策略中受益。
定义了一些术语
吞吐量是应用程序处理的数据量。必须使用特定于应用程序的指标来衡量吞吐量。
暂停时间是垃圾采集器暂停所有应用程序线程以采集堆的持续时间。
在本文中,我使用表 1 中详述的命令行选项的缩写来表示以下策略:用于优化吞吐量的 optthruput)、用于优化暂停时间的 optavgpause)、用于分代并发的 gencon)和用于 subpool 的 subpool)。
什么时候应该考虑非默认 GC 策略?
我建议您始终从默认的 GC 策略开始。在摆脱默认设置之前,您需要了解在什么情况下应该探索替代策略。表2列出了一系列可能的原因:
表2.切换到备用GC策略的原因切换到原因
暂停
基因组
子池
让我强调,表 2 中提到的原因不足以得出替代政策会表现更好的结论。它们只是提示。在所有情况下,您都应该运行应用程序并结合 GC 暂停时间来测量吞吐量和/或响应时间。本系列的下一部分将展示此类测试的示例。
本文的其余部分将详细介绍 GC 策略之间的差异。
光通量
一堆碎片的迹象
堆碎片最常见的迹象是过早的分配失败。这被认为是在详细垃圾采集 (-Xverbose:gc) 中触发的 GC,即使堆上有可用空间。另一个标志是存在小线程分配缓冲区(请参阅“”部分)。您可以使用 -Xtgc:freelist 来确定平均大小。IBM SDK 5 诊断指南中解释了这两个选项。
optthruput 是默认策略。它是一个跟踪采集器,称为标记扫描紧凑采集器。标记和扫描阶段总是在 GC 期间运行,但压缩仅在某些情况下发生。标记阶段查找并标记所有活动对象。所有未标记的对象将在扫描阶段被删除。第三步也是可选的步骤是压实。压实可以在各种情况下发生。最常见的一种是系统无法回收足够的可用空间。
当对象被频繁地分配和释放以致堆中只剩下一小块空闲空间时,就会发生碎片。堆整体可能有很多空闲空间,但是连续区域很小,导致分配失败。压缩将所有对象向下移动到堆的开头并对齐它们,以便它们之间没有空间。这消除了堆中的碎片,但这是一项昂贵的任务,因此仅在必要时执行。
图 1 显示了经过不同阶段的堆布局的轮廓:标记、清除和压缩。暗区代表物体,亮区代表自由空间。
扫描它
标记阶段遍历所有可以从线程堆栈、静态变量、插入的字符串和 JNI 引用中引用的对象。作为此过程的一部分,我们将创建一个标记位向量来定义所有活动对象的开头。
扫描阶段使用标记阶段生成的标记位向量来识别堆中存储的块,可以回收这些块以备将来分配;这些块被添加到空闲列表中。
图1. 垃圾回收前后的堆布局
不同 GC 阶段如何工作的细节超出了本文的范围。我的观点是确保您了解运行时特征。我鼓励您阅读“诊断指南”(请参阅)以获取更多信息。
图 2 说明了如何在应用程序线程(或 mutator)和 GC 线程之间分配执行时间。横轴是经过时间,纵轴是线程,其中n代表计算机的处理器数量。在此描述中,假设应用程序使用每个处理器一个线程。GC 用蓝色框表示,表示停止的突变体和 GC 线程正在运行。这些集合消耗了 100% 的 CPU 资源,并且转换器线程处于空闲状态。该图过于笼统,因此我们可以将此策略与本文中的其他策略进行比较。实际上,GC 的持续时间和频率取决于应用程序和工作量。
图2. optthruput策略中mutator和GC线程之间的CPU时间分配
Mutators 和 GC 线程
mutator 线程是分配对象的应用程序。mutator 的另一个词是应用程序。GC 线程是内存管理的一部分并执行垃圾采集。
堆锁和线程分配缓存
optthruput 策略使用由应用程序中的所有线程共享的连续堆区域。线程需要独占访问堆来为新对象保留空间。这种锁称为堆锁,可确保一次只有一个线程可以分配一个对象。在具有多个 CPU 的计算机上,此锁可能会导致扩展问题,因为可以同时发生多个分配请求,但每个分配请求都必须对堆锁具有独占访问权限。
为了减少这个问题,每个线程都会保留一小部分内存,称为线程分配缓存(也称为线程本地堆或TLH)。这部分存储空间是线程特定的,因此当从中分配内存时,不会使用堆锁。当分配缓冲区已满时,线程将返回堆并使用堆锁请求新的堆。
堆的碎片化会阻止线程获得更大的TLH,因此TLH会很快填满,导致应用线程频繁返回堆以换取新的TLH。在这种情况下,堆锁成为瓶颈。在这种情况下,gencon 或 sub-subpool 策略可以提供一个不错的选择。
暂停
对于许多应用程序,吞吐量不如快速响应时间重要。考虑一个工作项的处理时间不能超过 100 毫秒的应用程序。由于 GC 暂停时间在 100 毫秒内,您将获得在此时间范围内无法处理的项目。垃圾回收的问题在于暂停时间会增加处理项目所需的最长时间。大堆大小(在 64 位平台上可用)增加了这种效果,因为处理了更多的对象。
optavgpause 是另一种旨在最小化暂停时间的 GC 策略。它不能保证特定的暂停时间,但暂停时间比默认 GC 策略生成的暂停时间短。这个想法是在应用程序运行时执行一些垃圾采集。这是在两个地方完成的:
根据不同的应用,默认的 GC 策略会降低 5% 到 10% 的吞吐量性能。
图 3 说明了如何使用 optavgpause 在 GC 线程和 mutator 线程之间分配执行时间。后台跟踪线程未显示,因为它不会影响应用程序性能。
图3. optavgpause策略中mutator和GC线程的CPU时间分配
图中灰色区域表示已启用并发跟踪,每个mutator线程必须放弃一些处理时间。每个并发阶段完成一次垃圾回收后,完成并发阶段未发生的标记和清除。由此产生的暂停应该比 optthruput 看到的正常 GC 短很多,如图 3 时间刻度上的小框所示。 GC 结束和并发阶段开始之间的差距是不同的,但在这个阶段,对性能没有显着影响。
创康
分代垃圾回收策略考虑对象的生命周期,将它们放在堆的单独区域。通过这种方式,它试图克服单个堆在大多数对象年轻和死亡的应用程序中的缺点,即这些对象不能承受多次垃圾采集。
使用分代 GC 倾向于将长期对象与短期对象区别对待。如图 4 所示,该桩分为育苗区和育苗区。在托儿所中创建对象,如果对象存活时间足够长,则将它们提升到托儿所区域。经过一定量的垃圾采集后,该对象将被提升。这个想法是大多数对象都是短暂的。通过频繁采集托儿所,可以释放这些对象,而无需支付采集整个堆的成本。租用区域很少采集垃圾。
图4. gencon GC中的新旧区
如图 4 所示,托儿所分为两个空间:分配和幸存者。将对象分配到分配的空间。当对象已满时,活动对象将根据其年龄被复制到survivor空间或tenure空间。然后,将托儿所中的空间切换为使用,分配成为幸存者,幸存者成为分配者。死对象占用的空间可以简单地被新分配覆盖。苗圃采集被称为清道夫;图 5 说明了此过程中发生的情况:
图5. GC前后堆布局示例
当分配的空间已满时,将触发垃圾回收。然后跟踪活动对象并将其复制到幸存者空间。如果大部分对象都死了,这个过程的成本真的不高。此外,达到复制阈值计数的对象将被提升到到期空间。然后说对象是永久的。
顾名思义,它代表并发性,gencon 策略有它的并发性方面。租用的空间也使用类似于 optavgpause 策略中使用的方法进行标记,但不执行并发扫描。在并发阶段,所有分配都会支付少量的吞吐量税。通过这种方式,可以将tenure space的采集产生的暂停时间保持在很小的范围内。
图 6 显示了在运行 gencon GC 时如何映射执行时间:
图6. gencon中mutator和GC线程的CPU时间分布
清道夫很短(显示在小红框中)。灰色表示开始并发跟踪,然后是占用空间的集合,其中一些是并发发生的。这称为全局集,它包括清算集和使用权空间集。全局采集发生的频率取决于堆大小和对象生命周期。租用空间的采集应该是比较快的,因为大部分空间是同时采集的。
子池
子池策略有助于提高多处理器系统的性能。如前所述,此策略仅适用于 IBM pSeries 和 zSeries 计算机。堆布局与 optthruput 策略相同,但空闲列表的结构不同。有多个列表而不是整个堆的空闲列表,称为子池。每个池都有一个关联的大小,可以根据这些大小对池进行排序。通过去到这个大小的池,可以快速满足一定大小的分配请求。原子(平台相关)高性能指令用于从列表中弹出空闲列表条目,从而避免序列化访问。图 7 显示了如何按大小组织存储的空闲块:
图7.按大小排序的子池的空闲块
当JVM启动或者发生压缩时,由于堆的可用区域很大,所以不使用子池。在这些情况下,每个处理器都有自己的专用迷你堆来满足请求。当第一次垃圾回收发生时,清除阶段开始填充子池,后续的分配主要使用子池。
子池策略可以减少分配对象所需的时间。原子指令确保在不获取全局堆锁的情况下进行分配。处理器本地的小堆提高了效率,因为它减少了缓存干扰。这直接影响可扩展性,尤其是在多处理器系统上。在子池不可用的平台上,生成 GC 可以提供类似的好处。
综上所述
本文重点介绍 IBM SDK 5.0 中可用的不同 GC 策略选项及其一些特性。默认策略足以满足大多数应用程序的需求。但是,在某些情况下,其他策略效果更好。我已经介绍了一些一般情况,在这些情况下你应该考虑切换到 optavgpause、gencon 或 subpool。在评估策略时,衡量应用程序性能非常重要,第 2 部分将更详细地演示评估过程。
翻译自: 查看全部
算法 自动采集列表(学习IBM如何实现Java平台5.0版中内置的高级功能?)
可以使用四种不同的策略在 IBM Developer Suite (IBM SDK) 中为 Java 5.0 平台配置垃圾回收 (GC)。本文是GC两部分的第一部分。它介绍了不同的垃圾采集策略并讨论了它们的一般特征。在开始之前,您应该对 Java 平台中的垃圾采集有一个基本的了解。第 2 部分介绍了选择策略的定量方法并提供了一些示例。
关于系列
Java 技术,IBM 风格系列介绍了 Java 平台的 IBM 实现的最新版本。您将了解 IBM 如何实现 Java 平台5.0 版本中内置的一些高级特性,并了解如何使用新 IBM 版本中内置的一些增值特性。
如有任何意见或问题,请联系作者。要对整个系列发表评论,请联系系列负责人 Chris Bailey。有关此处讨论的概念的更多信息以及可从中下载最新 IBM 版本的链接,请参阅。
为什么要使用不同的 GC 策略?
不同 GC 策略的可用性为您提供了增强的功能。GC 有许多不同的算法可用,根据工作负载的类型,每种算法都有自己的优点和缺点。(如果不熟悉GC算法的一般话题,请参考进一步阅读。)在IBM SDK 5.0中,您可以使用四种策略之一来配置垃圾采集器,每种策略使用自己的算法。对于大多数应用程序,默认策略就足够了。如果您对应用程序没有任何特定的性能要求,那么本文(以及下一篇)的内容可能对您不感兴趣。您可以在不更改 GC 策略的情况下运行 IBM SDK 5.0。但是,如果您的应用程序需要最佳性能,或者你普遍担心GC暂停时间,请继续阅读。您将看到最新版本的 IBM 比以前的版本有更多的选项。
那么,为什么没有自动为您选择 Java 运行时的 IBM 实现?这并不总是可能的。在运行时很难理解您的需求。在某些情况下,您可能希望以高吞吐量运行应用程序。在其他情况下,您可能希望减少暂停时间。
表 1 列出了可用的策略并指出了何时应使用每种策略。以下部分将详细介绍每种策略的特点。
表 1. IBM SDK 5.0 中的 GC 策略策略选项说明
优化吞吐量
-Xgcpolicy:optthruput(可选)
默认策略。它通常用于原创吞吐量比短暂的 GC 暂停更重要的应用程序。每次采集垃圾时,应用程序都会停止。
优化暂停时间
-Xgcpolicy:optavgpause
通过同时执行一些垃圾采集,高吞吐量被交换为更短的 GC 暂停。申请被暂停了很短的时间。
生成并发
-Xgcpolicy:gencon
短期对象的处理方式与长期对象不同。通过这种策略,具有许多短期对象的应用程序可以看到更短的暂停时间,同时仍然产生良好的吞吐量。
子池化
-Xgcpolicy:subpool
使用类似于默认策略的算法,但使用更适合多处理器计算机的分配策略。对于具有 16 个或更多处理器的 SMP 计算机,我们建议使用此策略。此策略仅适用于 IBMpSeries® 和 zSeries® 平台。需要在大型计算机上扩展的应用程序可以从这种策略中受益。
定义了一些术语
吞吐量是应用程序处理的数据量。必须使用特定于应用程序的指标来衡量吞吐量。
暂停时间是垃圾采集器暂停所有应用程序线程以采集堆的持续时间。
在本文中,我使用表 1 中详述的命令行选项的缩写来表示以下策略:用于优化吞吐量的 optthruput)、用于优化暂停时间的 optavgpause)、用于分代并发的 gencon)和用于 subpool 的 subpool)。
什么时候应该考虑非默认 GC 策略?
我建议您始终从默认的 GC 策略开始。在摆脱默认设置之前,您需要了解在什么情况下应该探索替代策略。表2列出了一系列可能的原因:
表2.切换到备用GC策略的原因切换到原因
暂停
基因组
子池
让我强调,表 2 中提到的原因不足以得出替代政策会表现更好的结论。它们只是提示。在所有情况下,您都应该运行应用程序并结合 GC 暂停时间来测量吞吐量和/或响应时间。本系列的下一部分将展示此类测试的示例。
本文的其余部分将详细介绍 GC 策略之间的差异。
光通量
一堆碎片的迹象
堆碎片最常见的迹象是过早的分配失败。这被认为是在详细垃圾采集 (-Xverbose:gc) 中触发的 GC,即使堆上有可用空间。另一个标志是存在小线程分配缓冲区(请参阅“”部分)。您可以使用 -Xtgc:freelist 来确定平均大小。IBM SDK 5 诊断指南中解释了这两个选项。
optthruput 是默认策略。它是一个跟踪采集器,称为标记扫描紧凑采集器。标记和扫描阶段总是在 GC 期间运行,但压缩仅在某些情况下发生。标记阶段查找并标记所有活动对象。所有未标记的对象将在扫描阶段被删除。第三步也是可选的步骤是压实。压实可以在各种情况下发生。最常见的一种是系统无法回收足够的可用空间。
当对象被频繁地分配和释放以致堆中只剩下一小块空闲空间时,就会发生碎片。堆整体可能有很多空闲空间,但是连续区域很小,导致分配失败。压缩将所有对象向下移动到堆的开头并对齐它们,以便它们之间没有空间。这消除了堆中的碎片,但这是一项昂贵的任务,因此仅在必要时执行。
图 1 显示了经过不同阶段的堆布局的轮廓:标记、清除和压缩。暗区代表物体,亮区代表自由空间。
扫描它
标记阶段遍历所有可以从线程堆栈、静态变量、插入的字符串和 JNI 引用中引用的对象。作为此过程的一部分,我们将创建一个标记位向量来定义所有活动对象的开头。
扫描阶段使用标记阶段生成的标记位向量来识别堆中存储的块,可以回收这些块以备将来分配;这些块被添加到空闲列表中。
图1. 垃圾回收前后的堆布局
不同 GC 阶段如何工作的细节超出了本文的范围。我的观点是确保您了解运行时特征。我鼓励您阅读“诊断指南”(请参阅)以获取更多信息。
图 2 说明了如何在应用程序线程(或 mutator)和 GC 线程之间分配执行时间。横轴是经过时间,纵轴是线程,其中n代表计算机的处理器数量。在此描述中,假设应用程序使用每个处理器一个线程。GC 用蓝色框表示,表示停止的突变体和 GC 线程正在运行。这些集合消耗了 100% 的 CPU 资源,并且转换器线程处于空闲状态。该图过于笼统,因此我们可以将此策略与本文中的其他策略进行比较。实际上,GC 的持续时间和频率取决于应用程序和工作量。
图2. optthruput策略中mutator和GC线程之间的CPU时间分配
Mutators 和 GC 线程
mutator 线程是分配对象的应用程序。mutator 的另一个词是应用程序。GC 线程是内存管理的一部分并执行垃圾采集。
堆锁和线程分配缓存
optthruput 策略使用由应用程序中的所有线程共享的连续堆区域。线程需要独占访问堆来为新对象保留空间。这种锁称为堆锁,可确保一次只有一个线程可以分配一个对象。在具有多个 CPU 的计算机上,此锁可能会导致扩展问题,因为可以同时发生多个分配请求,但每个分配请求都必须对堆锁具有独占访问权限。
为了减少这个问题,每个线程都会保留一小部分内存,称为线程分配缓存(也称为线程本地堆或TLH)。这部分存储空间是线程特定的,因此当从中分配内存时,不会使用堆锁。当分配缓冲区已满时,线程将返回堆并使用堆锁请求新的堆。
堆的碎片化会阻止线程获得更大的TLH,因此TLH会很快填满,导致应用线程频繁返回堆以换取新的TLH。在这种情况下,堆锁成为瓶颈。在这种情况下,gencon 或 sub-subpool 策略可以提供一个不错的选择。
暂停
对于许多应用程序,吞吐量不如快速响应时间重要。考虑一个工作项的处理时间不能超过 100 毫秒的应用程序。由于 GC 暂停时间在 100 毫秒内,您将获得在此时间范围内无法处理的项目。垃圾回收的问题在于暂停时间会增加处理项目所需的最长时间。大堆大小(在 64 位平台上可用)增加了这种效果,因为处理了更多的对象。
optavgpause 是另一种旨在最小化暂停时间的 GC 策略。它不能保证特定的暂停时间,但暂停时间比默认 GC 策略生成的暂停时间短。这个想法是在应用程序运行时执行一些垃圾采集。这是在两个地方完成的:
根据不同的应用,默认的 GC 策略会降低 5% 到 10% 的吞吐量性能。
图 3 说明了如何使用 optavgpause 在 GC 线程和 mutator 线程之间分配执行时间。后台跟踪线程未显示,因为它不会影响应用程序性能。
图3. optavgpause策略中mutator和GC线程的CPU时间分配
图中灰色区域表示已启用并发跟踪,每个mutator线程必须放弃一些处理时间。每个并发阶段完成一次垃圾回收后,完成并发阶段未发生的标记和清除。由此产生的暂停应该比 optthruput 看到的正常 GC 短很多,如图 3 时间刻度上的小框所示。 GC 结束和并发阶段开始之间的差距是不同的,但在这个阶段,对性能没有显着影响。
创康
分代垃圾回收策略考虑对象的生命周期,将它们放在堆的单独区域。通过这种方式,它试图克服单个堆在大多数对象年轻和死亡的应用程序中的缺点,即这些对象不能承受多次垃圾采集。
使用分代 GC 倾向于将长期对象与短期对象区别对待。如图 4 所示,该桩分为育苗区和育苗区。在托儿所中创建对象,如果对象存活时间足够长,则将它们提升到托儿所区域。经过一定量的垃圾采集后,该对象将被提升。这个想法是大多数对象都是短暂的。通过频繁采集托儿所,可以释放这些对象,而无需支付采集整个堆的成本。租用区域很少采集垃圾。
图4. gencon GC中的新旧区
如图 4 所示,托儿所分为两个空间:分配和幸存者。将对象分配到分配的空间。当对象已满时,活动对象将根据其年龄被复制到survivor空间或tenure空间。然后,将托儿所中的空间切换为使用,分配成为幸存者,幸存者成为分配者。死对象占用的空间可以简单地被新分配覆盖。苗圃采集被称为清道夫;图 5 说明了此过程中发生的情况:
图5. GC前后堆布局示例
当分配的空间已满时,将触发垃圾回收。然后跟踪活动对象并将其复制到幸存者空间。如果大部分对象都死了,这个过程的成本真的不高。此外,达到复制阈值计数的对象将被提升到到期空间。然后说对象是永久的。
顾名思义,它代表并发性,gencon 策略有它的并发性方面。租用的空间也使用类似于 optavgpause 策略中使用的方法进行标记,但不执行并发扫描。在并发阶段,所有分配都会支付少量的吞吐量税。通过这种方式,可以将tenure space的采集产生的暂停时间保持在很小的范围内。
图 6 显示了在运行 gencon GC 时如何映射执行时间:
图6. gencon中mutator和GC线程的CPU时间分布
清道夫很短(显示在小红框中)。灰色表示开始并发跟踪,然后是占用空间的集合,其中一些是并发发生的。这称为全局集,它包括清算集和使用权空间集。全局采集发生的频率取决于堆大小和对象生命周期。租用空间的采集应该是比较快的,因为大部分空间是同时采集的。
子池
子池策略有助于提高多处理器系统的性能。如前所述,此策略仅适用于 IBM pSeries 和 zSeries 计算机。堆布局与 optthruput 策略相同,但空闲列表的结构不同。有多个列表而不是整个堆的空闲列表,称为子池。每个池都有一个关联的大小,可以根据这些大小对池进行排序。通过去到这个大小的池,可以快速满足一定大小的分配请求。原子(平台相关)高性能指令用于从列表中弹出空闲列表条目,从而避免序列化访问。图 7 显示了如何按大小组织存储的空闲块:
图7.按大小排序的子池的空闲块
当JVM启动或者发生压缩时,由于堆的可用区域很大,所以不使用子池。在这些情况下,每个处理器都有自己的专用迷你堆来满足请求。当第一次垃圾回收发生时,清除阶段开始填充子池,后续的分配主要使用子池。
子池策略可以减少分配对象所需的时间。原子指令确保在不获取全局堆锁的情况下进行分配。处理器本地的小堆提高了效率,因为它减少了缓存干扰。这直接影响可扩展性,尤其是在多处理器系统上。在子池不可用的平台上,生成 GC 可以提供类似的好处。
综上所述
本文重点介绍 IBM SDK 5.0 中可用的不同 GC 策略选项及其一些特性。默认策略足以满足大多数应用程序的需求。但是,在某些情况下,其他策略效果更好。我已经介绍了一些一般情况,在这些情况下你应该考虑切换到 optavgpause、gencon 或 subpool。在评估策略时,衡量应用程序性能非常重要,第 2 部分将更详细地演示评估过程。
翻译自:
算法 自动采集列表(算法自动采集列表页流量越来越难的5种方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-01 14:50
算法自动采集列表页流量越来越难,优秀采集器可以帮助你顺利完成目标。puzsurfire项目组总结过5种找到好机器的方法,我们将本文归类为3种高效简洁又便于使用的爬虫技术。#方法一:高效寻找方法|算法自动采集技术#如果你是专业的爬虫工程师,而且经常要采集大型信息,puzsurfire将成为一个非常有利的爬虫工具。
研究表明,大约有2/3的企业,至少有一款机器。#方法二:采用不同的机器对于非专业人士,找到正确的机器非常困难。另外,所有的平台标准化程度都非常低,变数非常多。数以千计的不同形式的机器,通常不适合于项目使用。#方法三:爬虫工具大显身手由于puzsurfire对不同机器做的针对性调整,你可以找到一个最适合的机器。
比如我们现在最需要的就是连接pc端并能获取微信公众号文章的网页版。如果你正在寻找一款爬虫工具,surfire是一个好选择。
爬虫分几类,不过大多数的爬虫基本思路是类似的。但是程序性能爬虫有很多方式可以提高效率,例如说ua等都可以提高效率。
eval()是可以分析代码,然后进行处理的。python有一个jit编译器,就是你说的机器序列。这东西可以把单个循环转换成分支循环。爬虫可以做的事情有很多,你可以试试,随便写一个脚本都比你用eval来得快,ui写的乱七八糟,别人程序逻辑没你清楚。python处理特定语言是很快的。 查看全部
算法 自动采集列表(算法自动采集列表页流量越来越难的5种方法)
算法自动采集列表页流量越来越难,优秀采集器可以帮助你顺利完成目标。puzsurfire项目组总结过5种找到好机器的方法,我们将本文归类为3种高效简洁又便于使用的爬虫技术。#方法一:高效寻找方法|算法自动采集技术#如果你是专业的爬虫工程师,而且经常要采集大型信息,puzsurfire将成为一个非常有利的爬虫工具。
研究表明,大约有2/3的企业,至少有一款机器。#方法二:采用不同的机器对于非专业人士,找到正确的机器非常困难。另外,所有的平台标准化程度都非常低,变数非常多。数以千计的不同形式的机器,通常不适合于项目使用。#方法三:爬虫工具大显身手由于puzsurfire对不同机器做的针对性调整,你可以找到一个最适合的机器。
比如我们现在最需要的就是连接pc端并能获取微信公众号文章的网页版。如果你正在寻找一款爬虫工具,surfire是一个好选择。
爬虫分几类,不过大多数的爬虫基本思路是类似的。但是程序性能爬虫有很多方式可以提高效率,例如说ua等都可以提高效率。
eval()是可以分析代码,然后进行处理的。python有一个jit编译器,就是你说的机器序列。这东西可以把单个循环转换成分支循环。爬虫可以做的事情有很多,你可以试试,随便写一个脚本都比你用eval来得快,ui写的乱七八糟,别人程序逻辑没你清楚。python处理特定语言是很快的。
算法 自动采集列表(集成自定义算法开发完成后,需要经过集成才能正式上线)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-31 23:05
集成测试
自定义算法开发完成后,需要经过集成测试,才能正式上线。集成测试是单元测试的扩展。单元测试验证算法内部的逻辑是否达到其目的,而集成测试则关注新开发的算法加入算法流程后整体性能是否异常。在 RecEng 中用于集成测试的方法是测试路径。
客户在RecEng中创建了一个新的算法流程后——姑且称之为F-,F默认处于“未发布”状态,有两个含义:
1.启动离线计算API时不会激活F
2.推荐的API无法获得F计算结果
由于1,离线计算API不会启动未发布的算法流程,所以RecEng在产品界面提供了一个按钮来手动启动未发布的算法流程。离线计算完成后,RecEng会将F的离线计算结果同步到在线存储中。但是由于2,推荐的API无法获得F的计算结果,测试过程的计算结果只能通过RecEng的API调试功能在产品界面中使用。根据以上观察,目前无法通过API的方式访问测试过程的计算结果。
集成测试通过后,客户需要点击产品界面的“发布”按钮,将未发布的算法流程在线发布,才能真正进入生产,上述1和2的限制将被取消。
此外,有时客户可能需要调整发布和上线的算法流程。我们应该做什么?
RecEng 实际上为每个已经在线发布的算法流程保存了一个离线测试版本。此时客户只需要修改相应的离线测试版本即可。按照上述流程,先调整算法逻辑,然后手动启动离线计算,然后在API调试中观察计算结果。集成测试通过后,点击“发布”按钮,会提示是否需要覆盖在线数据,即需要使用测试过程的计算结果覆盖之前生产的计算结果过程。客户可根据实际情况自行判断。.
效果测试
集成测试只能验证自定义算法在算法流程中是否能正常工作;但是,作为一个算法,仅仅能正常工作是不够的,效果才是算法的最终目的。RecEng支持基于算法流程的A/B测试,直接对比最终结果,为决策提供参考。
要进行 A/B 测试,您必须首先明确指标;要计算指标,必须先采集日志。下面的描述从日志采集开始。
日志采集
在衡量推荐系统的有效性时,RecEng 只关心与推荐相关的行为。为了区别于其他无关行为,RecEng会在每个推荐API的返回结果中附加一个Trace ID(推荐API返回的所有项目都共享这个Trace ID),客户需要遵循一定的规范。日志中嵌入了Trace ID,可以使用阿里云推荐引擎提供的效果报告功能。具体嵌入点和日志规范请参考日志嵌入规范
埋设Trace ID的三个原则:
1.推荐列表显示时,需要在推荐列表中所有item的链接中嵌入对应的Trace ID
2. 如果用户点击了收录Trace ID的item链接,需要将Trace ID带到下一页,并且Trace ID应该嵌入到新页面的item的所有链接中
3. 如果用户点击不收录Trace ID的item,或者点击收录其他Trace ID的item链接,之前的Trace ID将失效
需要注意的是,并不是所有的日志都会有 Trace ID 信息。Trace ID只负责跟踪RecEng返回的推荐结果。客户网站或应用程序中的大部分用户行为可能与RecEng无关。为了更好地描绘用户画像,这些用户行为也需要上传到RecEng。
日志埋没后,通过日志API将日志提交给RecEng,日志采集就完成了。但是日志API的功能不限于上传采集的日志。细心的用户可能会注意到,RecEng的业务配置界面中有一个不显眼的复选框:
即客户可以通过日志API上传离线数据。要实现这个功能,一方面需要在产品界面打开这个开关;另一方面,需要从日志 API 上传各种用户和项目数据。与离线上传不同,通过日志API上传用户和商品数据是增量的。您只需每天将新数据发送到 RecEng。
如果在业务配置页面勾选了“自动数据预处理”复选框,则当新的一天开始时,将自动启动前一天数据的离线计算任务。
业绩报告
在 RecEng 中,与效果报告密切相关的三个主要概念是:效果算法、效果指标和效果过程。
效果算法专门用于计算效果指标。它的输入输出表是固定的,输入表是行为表(user_behavior),输出表是索引结果表。效果算法的逻辑比较简单,通常是简单的统计,或者在统计的基础上进行四次算术运算。麻烦的是,统计必须有统计口径,包括时间粒度、业务粒度等。
RecEng 中的所有这些统计口径都是相同的。时间支持日、周、月三种粒度,业务支持按场景和算法统计。时间粒度的需要取决于效果算法:通常只需要输出当天的索引,而在星期一或每个月的第一天额外输出上周和上个月的索引。如果周指标和月指标的计算没有收录在效果算法中,RecEng会自动补0。 业务粒度的要求由RecEng统一实现:RecEng会根据业务粒度拆分行为表然后交给到效果算法进行计算,
效果算法以行为类型为参数,不针对具体的行为类型;效果指标需要明确行为类型。因此,效果指标可以理解为效果算法+行为类型的组合。例如,专门用于PV统计的算法可以统计任何行为、查看、点击和消费的PV。但是说到指标,一定要搞清楚到底是view的PV还是点击的PV。
只需要定义效果指数。选择效果算法并阐明行为类型。定义了性能指标后,我们还需要每天执行一次性能过程(index_path)来计算这些指标。效果过程不需要配置算法节点的流程图,只需选择效果指标即可。RecEng会自动生成效果处理流程图,客户可以通过效果计算API启动效果处理。
最后是关于性能报告的配置。您只需要为业绩指标选择一个展示图表,如折线图、饼图、条形图等,业绩流程计算完成后,客户可以在业绩报告中看到。
RecEng 默认提供了一些简单的效果算法,也预定义了一些效果指标。客户可以根据自己的需要开发新的效果算法并注册RecEng。
A/B 测试
A/B测试是效果测试的常用方法,也是RecEng唯一的效果测试方法。经过前面的准备,我们现在可以知道每个算法过程的性能指标了。然后,通过比较不同工艺的指标,可以优化效果。
RecEng 允许在一个场景中进行多个推荐过程 (rec_path)。对属于同一场景的不同推荐流程也进行 A/B 测试。在进行A/B测试时,同一场景下的每个推荐流程都会分配一定的流量,可以在产品界面进行配置。在执行推荐API时,RecEng会在第一步随机按比例分配流量,将当前用户分配到某个推荐流程,然后执行这个推荐流程的在线流程。RecEng分配流量时,完全是随机的,不遵循任何规则。例如,某个用户必须被分配到某个推荐过程。
无论是否开启 A/B 测试,客户调用推荐 API 的参数完全相同。推荐API的参数只收录场景参数,推荐流程(rec_path)不是必须的,也不能指定,以便在进行效果统计时做出明确的推荐。item来自哪个推荐流程,所以RecEng每次响应推荐API都会附上Trace ID,这样我们就可以准确统计每个推荐流程的性能指标。
在整个过程中,使用A/B Testing的工作量主要在前期、日志埋点、配置效果报告。完成这些之后,使用 A/B 测试其实很简单。 查看全部
算法 自动采集列表(集成自定义算法开发完成后,需要经过集成才能正式上线)
集成测试
自定义算法开发完成后,需要经过集成测试,才能正式上线。集成测试是单元测试的扩展。单元测试验证算法内部的逻辑是否达到其目的,而集成测试则关注新开发的算法加入算法流程后整体性能是否异常。在 RecEng 中用于集成测试的方法是测试路径。
客户在RecEng中创建了一个新的算法流程后——姑且称之为F-,F默认处于“未发布”状态,有两个含义:
1.启动离线计算API时不会激活F
2.推荐的API无法获得F计算结果
由于1,离线计算API不会启动未发布的算法流程,所以RecEng在产品界面提供了一个按钮来手动启动未发布的算法流程。离线计算完成后,RecEng会将F的离线计算结果同步到在线存储中。但是由于2,推荐的API无法获得F的计算结果,测试过程的计算结果只能通过RecEng的API调试功能在产品界面中使用。根据以上观察,目前无法通过API的方式访问测试过程的计算结果。
集成测试通过后,客户需要点击产品界面的“发布”按钮,将未发布的算法流程在线发布,才能真正进入生产,上述1和2的限制将被取消。
此外,有时客户可能需要调整发布和上线的算法流程。我们应该做什么?
RecEng 实际上为每个已经在线发布的算法流程保存了一个离线测试版本。此时客户只需要修改相应的离线测试版本即可。按照上述流程,先调整算法逻辑,然后手动启动离线计算,然后在API调试中观察计算结果。集成测试通过后,点击“发布”按钮,会提示是否需要覆盖在线数据,即需要使用测试过程的计算结果覆盖之前生产的计算结果过程。客户可根据实际情况自行判断。.
效果测试
集成测试只能验证自定义算法在算法流程中是否能正常工作;但是,作为一个算法,仅仅能正常工作是不够的,效果才是算法的最终目的。RecEng支持基于算法流程的A/B测试,直接对比最终结果,为决策提供参考。
要进行 A/B 测试,您必须首先明确指标;要计算指标,必须先采集日志。下面的描述从日志采集开始。
日志采集
在衡量推荐系统的有效性时,RecEng 只关心与推荐相关的行为。为了区别于其他无关行为,RecEng会在每个推荐API的返回结果中附加一个Trace ID(推荐API返回的所有项目都共享这个Trace ID),客户需要遵循一定的规范。日志中嵌入了Trace ID,可以使用阿里云推荐引擎提供的效果报告功能。具体嵌入点和日志规范请参考日志嵌入规范
埋设Trace ID的三个原则:
1.推荐列表显示时,需要在推荐列表中所有item的链接中嵌入对应的Trace ID
2. 如果用户点击了收录Trace ID的item链接,需要将Trace ID带到下一页,并且Trace ID应该嵌入到新页面的item的所有链接中
3. 如果用户点击不收录Trace ID的item,或者点击收录其他Trace ID的item链接,之前的Trace ID将失效
需要注意的是,并不是所有的日志都会有 Trace ID 信息。Trace ID只负责跟踪RecEng返回的推荐结果。客户网站或应用程序中的大部分用户行为可能与RecEng无关。为了更好地描绘用户画像,这些用户行为也需要上传到RecEng。
日志埋没后,通过日志API将日志提交给RecEng,日志采集就完成了。但是日志API的功能不限于上传采集的日志。细心的用户可能会注意到,RecEng的业务配置界面中有一个不显眼的复选框:
即客户可以通过日志API上传离线数据。要实现这个功能,一方面需要在产品界面打开这个开关;另一方面,需要从日志 API 上传各种用户和项目数据。与离线上传不同,通过日志API上传用户和商品数据是增量的。您只需每天将新数据发送到 RecEng。
如果在业务配置页面勾选了“自动数据预处理”复选框,则当新的一天开始时,将自动启动前一天数据的离线计算任务。
业绩报告
在 RecEng 中,与效果报告密切相关的三个主要概念是:效果算法、效果指标和效果过程。
效果算法专门用于计算效果指标。它的输入输出表是固定的,输入表是行为表(user_behavior),输出表是索引结果表。效果算法的逻辑比较简单,通常是简单的统计,或者在统计的基础上进行四次算术运算。麻烦的是,统计必须有统计口径,包括时间粒度、业务粒度等。
RecEng 中的所有这些统计口径都是相同的。时间支持日、周、月三种粒度,业务支持按场景和算法统计。时间粒度的需要取决于效果算法:通常只需要输出当天的索引,而在星期一或每个月的第一天额外输出上周和上个月的索引。如果周指标和月指标的计算没有收录在效果算法中,RecEng会自动补0。 业务粒度的要求由RecEng统一实现:RecEng会根据业务粒度拆分行为表然后交给到效果算法进行计算,
效果算法以行为类型为参数,不针对具体的行为类型;效果指标需要明确行为类型。因此,效果指标可以理解为效果算法+行为类型的组合。例如,专门用于PV统计的算法可以统计任何行为、查看、点击和消费的PV。但是说到指标,一定要搞清楚到底是view的PV还是点击的PV。
只需要定义效果指数。选择效果算法并阐明行为类型。定义了性能指标后,我们还需要每天执行一次性能过程(index_path)来计算这些指标。效果过程不需要配置算法节点的流程图,只需选择效果指标即可。RecEng会自动生成效果处理流程图,客户可以通过效果计算API启动效果处理。
最后是关于性能报告的配置。您只需要为业绩指标选择一个展示图表,如折线图、饼图、条形图等,业绩流程计算完成后,客户可以在业绩报告中看到。
RecEng 默认提供了一些简单的效果算法,也预定义了一些效果指标。客户可以根据自己的需要开发新的效果算法并注册RecEng。
A/B 测试
A/B测试是效果测试的常用方法,也是RecEng唯一的效果测试方法。经过前面的准备,我们现在可以知道每个算法过程的性能指标了。然后,通过比较不同工艺的指标,可以优化效果。
RecEng 允许在一个场景中进行多个推荐过程 (rec_path)。对属于同一场景的不同推荐流程也进行 A/B 测试。在进行A/B测试时,同一场景下的每个推荐流程都会分配一定的流量,可以在产品界面进行配置。在执行推荐API时,RecEng会在第一步随机按比例分配流量,将当前用户分配到某个推荐流程,然后执行这个推荐流程的在线流程。RecEng分配流量时,完全是随机的,不遵循任何规则。例如,某个用户必须被分配到某个推荐过程。
无论是否开启 A/B 测试,客户调用推荐 API 的参数完全相同。推荐API的参数只收录场景参数,推荐流程(rec_path)不是必须的,也不能指定,以便在进行效果统计时做出明确的推荐。item来自哪个推荐流程,所以RecEng每次响应推荐API都会附上Trace ID,这样我们就可以准确统计每个推荐流程的性能指标。
在整个过程中,使用A/B Testing的工作量主要在前期、日志埋点、配置效果报告。完成这些之后,使用 A/B 测试其实很简单。
算法 自动采集列表(PDF快速入门要快速的接触监控平台使用依赖数据采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-10-29 03:24
编辑以查看 PDF
快速开始
快速接触监控平台,通过快速入门,您将有一个基本的了解。
访问流程
基本上,访问过程有以下几个阶段:
:监控平台的监控目标和进程信息主要依赖CMDB的配置,被监控的采集链接依赖于Blue Whale Agent的部署,监控功能的使用依赖于数据。采集:监控本身是围绕数据工作的,数据从哪里来?要么通过获取,要么主动上报,要么直接用结果表数据数据检查:数据采集是否成功,最后是否可以查看相关图形数据。每个采集任务都有一个检查视图,可以查看当前主机/实例采集的数据。当然,您也可以检索任意指标策略配置:采集 上来的数据要么被观察,要么被警告,通过策略配置设置您要报警的指标。您可以提前规划报警组需要在收到报警时使用报警处理:当策略生效,触发报警时,我们可以查看或接收相应的报警内容。对于报警事件,我们可以快速确认或确认报警。其他:还有许多其他高级功能可以使用。, 监测的四个阶段
监控平台有这么多功能,这么多文档。如何一步步使用监控平台?大致可以分为四个层次:
第一层:开箱即用内置默认策略主机进程监控官方插件:内置20个官方插件,可在采集中直接使用,满足监控需求的通用组件。提供动态采集需求,自动增删采集策略配置:满足IP、服务实例、集群模块的监控需求,提供8种检测算法。并支持数据平台的数据监控需求。监控屏蔽:提供服务实例、IP、集群模块、策略、事件屏蔽粒度。Dashboard:提供不同的图表配置,支持日志数据、数据平台数据、监控采集指标数据绘制需求服务拨号测试:提供模拟用户请求的监控需求。日志采集和监控第二层:扩展采集和自动报警处理第三层:高级策略控制和配置共享第四层:平台管理和插件开发 查看全部
算法 自动采集列表(PDF快速入门要快速的接触监控平台使用依赖数据采集)
编辑以查看 PDF
快速开始
快速接触监控平台,通过快速入门,您将有一个基本的了解。
访问流程
基本上,访问过程有以下几个阶段:
:监控平台的监控目标和进程信息主要依赖CMDB的配置,被监控的采集链接依赖于Blue Whale Agent的部署,监控功能的使用依赖于数据。采集:监控本身是围绕数据工作的,数据从哪里来?要么通过获取,要么主动上报,要么直接用结果表数据数据检查:数据采集是否成功,最后是否可以查看相关图形数据。每个采集任务都有一个检查视图,可以查看当前主机/实例采集的数据。当然,您也可以检索任意指标策略配置:采集 上来的数据要么被观察,要么被警告,通过策略配置设置您要报警的指标。您可以提前规划报警组需要在收到报警时使用报警处理:当策略生效,触发报警时,我们可以查看或接收相应的报警内容。对于报警事件,我们可以快速确认或确认报警。其他:还有许多其他高级功能可以使用。, 监测的四个阶段
监控平台有这么多功能,这么多文档。如何一步步使用监控平台?大致可以分为四个层次:
第一层:开箱即用内置默认策略主机进程监控官方插件:内置20个官方插件,可在采集中直接使用,满足监控需求的通用组件。提供动态采集需求,自动增删采集策略配置:满足IP、服务实例、集群模块的监控需求,提供8种检测算法。并支持数据平台的数据监控需求。监控屏蔽:提供服务实例、IP、集群模块、策略、事件屏蔽粒度。Dashboard:提供不同的图表配置,支持日志数据、数据平台数据、监控采集指标数据绘制需求服务拨号测试:提供模拟用户请求的监控需求。日志采集和监控第二层:扩展采集和自动报警处理第三层:高级策略控制和配置共享第四层:平台管理和插件开发
算法 自动采集列表(1.一般来说想爬取详情页的数据都会先把列表数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-26 08:07
)
1. 一般来说,如果要抓取详情页的数据,会先抓取列表数据(有详情页的链接),然后再抓取详情页的数据。
2.爬取详细列表数据的步骤:
1.打开网页
2.循环翻页(注:优采云免费版一次只能抓取1w条数据,所以需要设置循环执行次数,避免超过1w条数据数据)
3.Loop采集 列出数据,即一个页面有多少数据
4.提取数据(重点):如果你对xpath不熟悉,可以下载火狐的两个插件,可以轻松获取指定数据的xpath。
要下载火狐插件,需要下载5.5之前的版本。下载完成后,去掉自动更新,然后导入debug和xpath插件,重启火狐浏览器。
然后添加必填字段并写入指定数据的xpath。相对路径和绝对路径都要写
然后点击获取方式,即文本,获取指定数据
注意:有时会从指定页面采集开始,如果URL有规则,那是自然的,如果没有规则,则需要在优采云中进行配置
打开网页,数据文本(指定多少页),点击元素(跳转到多少页),然后循环点击下一页采集数据,翻的时候页面循环,计算不能超过1w个数据OK
3.抓取详情页的数据:
列表爬取后,会得到详情页的url,此时需要将url输入到循环url列表中,优采云会循环遍历this和url中的url列表以获取数据。
查看全部
算法 自动采集列表(1.一般来说想爬取详情页的数据都会先把列表数据
)
1. 一般来说,如果要抓取详情页的数据,会先抓取列表数据(有详情页的链接),然后再抓取详情页的数据。
2.爬取详细列表数据的步骤:
1.打开网页
2.循环翻页(注:优采云免费版一次只能抓取1w条数据,所以需要设置循环执行次数,避免超过1w条数据数据)
3.Loop采集 列出数据,即一个页面有多少数据
4.提取数据(重点):如果你对xpath不熟悉,可以下载火狐的两个插件,可以轻松获取指定数据的xpath。
要下载火狐插件,需要下载5.5之前的版本。下载完成后,去掉自动更新,然后导入debug和xpath插件,重启火狐浏览器。
然后添加必填字段并写入指定数据的xpath。相对路径和绝对路径都要写
然后点击获取方式,即文本,获取指定数据
注意:有时会从指定页面采集开始,如果URL有规则,那是自然的,如果没有规则,则需要在优采云中进行配置
打开网页,数据文本(指定多少页),点击元素(跳转到多少页),然后循环点击下一页采集数据,翻的时候页面循环,计算不能超过1w个数据OK
3.抓取详情页的数据:
列表爬取后,会得到详情页的url,此时需要将url输入到循环url列表中,优采云会循环遍历this和url中的url列表以获取数据。
算法 自动采集列表(智能巡检使用流式图算法和流式分解算法进行数据巡检 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2021-10-26 01:04
)
日志服务提供智能巡检功能,对监控指标或业务日志等数据进行自动、智能、自适应的异常巡检。目前智能巡检采用流图算法和流分解算法进行数据巡检。本文介绍了流图算法和流分解算法的适用场景、参数配置、预览说明等。
流图算法
流图算法是基于Time2Graph系列模型中的原理开发的,可以降低数据的整体噪声,分析异常数据的相对偏差。流图算法适用于大规模、嘈杂、不显眼的时间序列的异常检测。有关更多信息,请参阅使用进化状态图进行时间序列事件预测。
场景描述
流图算法使用在线机器学习技术实时学习和推断每条数据。适用于一般的时间序列异常检测场景,包括:
参数配置
您可以在创建智能检测作业向导页面的算法配置区完成算法配置。具体操作请参考。
每个参数的说明如下表所示。
参数说明
时序段数
对时间序列值进行划分,将时间序列离散化,构建时间序列演化图,减少噪声的影响。建议预览不同时序段下的检测结果,选择最合适的值。
观察长度
要观察的历史数据点的数量。
灵敏度
异常分数输出的敏感性。
预览说明
预览示例如下图所示。
流分解算法
流分解算法是基于 RobustSTL 系列模型中的原理开发的。它可以批量处理数据流,但具有更高的计算成本。适用于小规模业务指标数据的精准检查。在大规模数据场景下,建议您拆分数据或使用流图算法。有关更多信息,请参阅 RobustSTL:长期序列的稳健季节性趋势分解算法。
场景描述
流分解算法适用于周期性数据序列的检查,要求数据的周期性更明显。例如,适用于周期性变化明显的业务指标的检查场景。
说明周期性数据在日常生活中比较常见,比如游戏访问次数和客户订单数量。
参数配置
您可以在创建智能检测作业向导页面的算法配置区完成算法配置。具体操作请参考。
每个参数的说明如下表所示。
参数说明
周期长度
以点为单位描述一个周期内数据序列中收录的数据点数。数据系列默认为天数。例如,如果粒度为120秒,周期为天,那么一个周期中收录的数据点数为24×60×60/120=720。
注意周期长度必须是时间序列的周期,否则会影响检查效果。
灵敏度
异常分数输出的敏感性。
预览说明
预览流式分解算法的异常检测结果时,系统默认选择最后4个周期的数据进行预览。预览示例如下图所示。
对于嘈杂的周期数据,您需要在预览页面上继续调试,直到配置了确切的周期长度。在噪声较大的情况下,由于噪声干扰,可能存在漏报或虚报。预览示例如下图所示。
查看全部
算法 自动采集列表(智能巡检使用流式图算法和流式分解算法进行数据巡检
)
日志服务提供智能巡检功能,对监控指标或业务日志等数据进行自动、智能、自适应的异常巡检。目前智能巡检采用流图算法和流分解算法进行数据巡检。本文介绍了流图算法和流分解算法的适用场景、参数配置、预览说明等。
流图算法
流图算法是基于Time2Graph系列模型中的原理开发的,可以降低数据的整体噪声,分析异常数据的相对偏差。流图算法适用于大规模、嘈杂、不显眼的时间序列的异常检测。有关更多信息,请参阅使用进化状态图进行时间序列事件预测。
场景描述
流图算法使用在线机器学习技术实时学习和推断每条数据。适用于一般的时间序列异常检测场景,包括:
参数配置
您可以在创建智能检测作业向导页面的算法配置区完成算法配置。具体操作请参考。
每个参数的说明如下表所示。
参数说明
时序段数
对时间序列值进行划分,将时间序列离散化,构建时间序列演化图,减少噪声的影响。建议预览不同时序段下的检测结果,选择最合适的值。
观察长度
要观察的历史数据点的数量。
灵敏度
异常分数输出的敏感性。
预览说明
预览示例如下图所示。
流分解算法
流分解算法是基于 RobustSTL 系列模型中的原理开发的。它可以批量处理数据流,但具有更高的计算成本。适用于小规模业务指标数据的精准检查。在大规模数据场景下,建议您拆分数据或使用流图算法。有关更多信息,请参阅 RobustSTL:长期序列的稳健季节性趋势分解算法。
场景描述
流分解算法适用于周期性数据序列的检查,要求数据的周期性更明显。例如,适用于周期性变化明显的业务指标的检查场景。
说明周期性数据在日常生活中比较常见,比如游戏访问次数和客户订单数量。
参数配置
您可以在创建智能检测作业向导页面的算法配置区完成算法配置。具体操作请参考。
每个参数的说明如下表所示。
参数说明
周期长度
以点为单位描述一个周期内数据序列中收录的数据点数。数据系列默认为天数。例如,如果粒度为120秒,周期为天,那么一个周期中收录的数据点数为24×60×60/120=720。
注意周期长度必须是时间序列的周期,否则会影响检查效果。
灵敏度
异常分数输出的敏感性。
预览说明
预览流式分解算法的异常检测结果时,系统默认选择最后4个周期的数据进行预览。预览示例如下图所示。
对于嘈杂的周期数据,您需要在预览页面上继续调试,直到配置了确切的周期长度。在噪声较大的情况下,由于噪声干扰,可能存在漏报或虚报。预览示例如下图所示。
算法 自动采集列表( Android端相机视频流采集与实时边框识别扫描算法(SmartScanner) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-24 11:09
Android端相机视频流采集与实时边框识别扫描算法(SmartScanner)
)
英语
SmartCamera是一款Android相机扩展库,提供高度可定制的实时扫描模块,可以实时采集并识别相机中物体的边框是否与指定区域匹配。如果你觉得还不错,欢迎star和fork。
语言描述有点生涩。具体实现的功能如下图所示。适用于身份证、名片、文件等内容的扫描、自动拍摄、裁剪。
您可以下载并体验SmartCamera集成的“卡片备忘录”,并将卡片安装到您的手机中:
您也可以下载演示 apk SmartCamera-Sample-debug.apk 来体验:
实时扫描模块(SmartScanner)是这个库的核心功能。借助相机PreviewCallback接口的预览流和跑马灯视图MaskView提供的跑马灯区域RectF,可以实时判断内容是否与跑马灯匹配,性能良好。
为了更方便地使用Android Camera,SmartCamera在源代码中引用了谷歌开源的CameraView,稍作修改,支持Camera.PreviewCallback回调获取相机预览流。
SmartCameraView继承了修改后的CameraView,增加了一个跑马灯遮罩视图(MaskView)和一个实时扫描模块(SmartScanner)。跑马灯视图是您看到的相机上方的一层跑马灯,并配备了从上到下的扫描效果。当然,你也可以实现 MaskViewImpl 接口来自定义跑马灯视图。
只需使用本库提供的SmartCameraView即可实现上述Demo中的效果。当然,如果你的项目中已经实现了摄像头模块,也可以直接使用SmartScanner来实现实时扫描效果。
(也可以关注我的另一个库SmartCropper:一个简单好用的智能图片裁剪库,适用于身份证、名片、文件等照片的裁剪)
SmartCamera原理解析:Android摄像头视频流采集与实时帧识别
扫描算法调优 SmartScanner 提供了丰富的算法配置。用户可以自行修改扫描算法,以获得更好的适应性。阅读附录1中提供的每个参数的说明,以获得更好的识别效果。
为了更方便、更高效的优化算法,SmartScanner贴心地为您提供了扫描预览模式。开启预览功能后,可以使用SmartScanner获取每一帧的处理结果并输出到ImageView,实时观察原生层扫描的结果。白线区域为边缘检测结果,白线加粗区域为识别边界。
您的目标是通过调整SmartScanner的各种参数,使内容边界清晰可见,识别出的框(白色粗线段)准确。
注意:SmartCamera 对性能和内存进行了各方面的优化,但由于不必要的性能资源浪费,请在算法参数调优完成后关闭预览模式。
使用权
1. 在根目录添加 build.gradle :
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
2.添加依赖
dependencies {
implementation 'com.github.pqpo:SmartCamera:v2.0.0'
}
注意:由于使用了JNI,请避免混淆
-keep class me.pqpo.smartcameralib.**{*;}
使用1. 引入相机布局并启动相机(必要时启动预览)
">
@Override
protected void onResume() {
super.onResume();
mCameraView.start();
mCameraView.startScan();
}
@Override
protected void onPause() {
mCameraView.stop();
super.onPause();
if (alertDialog != null) {
alertDialog.dismiss();
}
mCameraView.stopScan();
}
注意:如果开启了预览,不要忘记调用相应的打开和结束预览的方法。
2. 修改扫描模块参数(可选,调优算法,同时开启第4步的预览模式)
扫描模块各个参数含义详见附录一
private void initScannerParams() {
SmartScanner.DEBUG = true;
SmartScanner.detectionRatio = 0.1f;
SmartScanner.checkMinLengthRatio = 0.8f;
SmartScanner.cannyThreshold1 = 20;
SmartScanner.cannyThreshold2 = 50;
SmartScanner.houghLinesThreshold = 130;
SmartScanner.houghLinesMinLineLength = 80;
SmartScanner.houghLinesMaxLineGap = 10;
SmartScanner.firstGaussianBlurRadius = 3;
SmartScanner.secondGaussianBlurRadius = 3;
SmartScanner.maxSize = 300;
SmartScanner.angleThreshold = 5;
// don't forget reload params
SmartScanner.reloadParams();
}
注意:修改参数后不要忘记通知native层重新加载参数:SmartScanner.reloadParams();
3. 配置遮罩选框视图(可选,修改默认视图,或修改选框区域)
配置 MaskView 各个方法的含义详见附录二
<p>final MaskView maskView = (MaskView) mCameraView.getMaskView();;
maskView.setMaskLineColor(0xff00adb5);
maskView.setShowScanLine(true);
maskView.setScanLineGradient(0xff00adb5, 0x0000adb5);
maskView.setMaskLineWidth(2);
maskView.setMaskRadius(5);
maskView.setScanSpeed(6);
maskView.setScanGradientSpread(80);
mCameraView.post(new Runnable() {
@Override
public void run() {
int width = mCameraView.getWidth();
int height = mCameraView.getHeight();
if (width 查看全部
算法 自动采集列表(
Android端相机视频流采集与实时边框识别扫描算法(SmartScanner)
)
英语
SmartCamera是一款Android相机扩展库,提供高度可定制的实时扫描模块,可以实时采集并识别相机中物体的边框是否与指定区域匹配。如果你觉得还不错,欢迎star和fork。
语言描述有点生涩。具体实现的功能如下图所示。适用于身份证、名片、文件等内容的扫描、自动拍摄、裁剪。
您可以下载并体验SmartCamera集成的“卡片备忘录”,并将卡片安装到您的手机中:
您也可以下载演示 apk SmartCamera-Sample-debug.apk 来体验:
实时扫描模块(SmartScanner)是这个库的核心功能。借助相机PreviewCallback接口的预览流和跑马灯视图MaskView提供的跑马灯区域RectF,可以实时判断内容是否与跑马灯匹配,性能良好。
为了更方便地使用Android Camera,SmartCamera在源代码中引用了谷歌开源的CameraView,稍作修改,支持Camera.PreviewCallback回调获取相机预览流。
SmartCameraView继承了修改后的CameraView,增加了一个跑马灯遮罩视图(MaskView)和一个实时扫描模块(SmartScanner)。跑马灯视图是您看到的相机上方的一层跑马灯,并配备了从上到下的扫描效果。当然,你也可以实现 MaskViewImpl 接口来自定义跑马灯视图。
只需使用本库提供的SmartCameraView即可实现上述Demo中的效果。当然,如果你的项目中已经实现了摄像头模块,也可以直接使用SmartScanner来实现实时扫描效果。
(也可以关注我的另一个库SmartCropper:一个简单好用的智能图片裁剪库,适用于身份证、名片、文件等照片的裁剪)
SmartCamera原理解析:Android摄像头视频流采集与实时帧识别
扫描算法调优 SmartScanner 提供了丰富的算法配置。用户可以自行修改扫描算法,以获得更好的适应性。阅读附录1中提供的每个参数的说明,以获得更好的识别效果。
为了更方便、更高效的优化算法,SmartScanner贴心地为您提供了扫描预览模式。开启预览功能后,可以使用SmartScanner获取每一帧的处理结果并输出到ImageView,实时观察原生层扫描的结果。白线区域为边缘检测结果,白线加粗区域为识别边界。
您的目标是通过调整SmartScanner的各种参数,使内容边界清晰可见,识别出的框(白色粗线段)准确。
注意:SmartCamera 对性能和内存进行了各方面的优化,但由于不必要的性能资源浪费,请在算法参数调优完成后关闭预览模式。
使用权
1. 在根目录添加 build.gradle :
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
2.添加依赖
dependencies {
implementation 'com.github.pqpo:SmartCamera:v2.0.0'
}
注意:由于使用了JNI,请避免混淆
-keep class me.pqpo.smartcameralib.**{*;}
使用1. 引入相机布局并启动相机(必要时启动预览)
">
@Override
protected void onResume() {
super.onResume();
mCameraView.start();
mCameraView.startScan();
}
@Override
protected void onPause() {
mCameraView.stop();
super.onPause();
if (alertDialog != null) {
alertDialog.dismiss();
}
mCameraView.stopScan();
}
注意:如果开启了预览,不要忘记调用相应的打开和结束预览的方法。
2. 修改扫描模块参数(可选,调优算法,同时开启第4步的预览模式)
扫描模块各个参数含义详见附录一
private void initScannerParams() {
SmartScanner.DEBUG = true;
SmartScanner.detectionRatio = 0.1f;
SmartScanner.checkMinLengthRatio = 0.8f;
SmartScanner.cannyThreshold1 = 20;
SmartScanner.cannyThreshold2 = 50;
SmartScanner.houghLinesThreshold = 130;
SmartScanner.houghLinesMinLineLength = 80;
SmartScanner.houghLinesMaxLineGap = 10;
SmartScanner.firstGaussianBlurRadius = 3;
SmartScanner.secondGaussianBlurRadius = 3;
SmartScanner.maxSize = 300;
SmartScanner.angleThreshold = 5;
// don't forget reload params
SmartScanner.reloadParams();
}
注意:修改参数后不要忘记通知native层重新加载参数:SmartScanner.reloadParams();
3. 配置遮罩选框视图(可选,修改默认视图,或修改选框区域)
配置 MaskView 各个方法的含义详见附录二
<p>final MaskView maskView = (MaskView) mCameraView.getMaskView();;
maskView.setMaskLineColor(0xff00adb5);
maskView.setShowScanLine(true);
maskView.setScanLineGradient(0xff00adb5, 0x0000adb5);
maskView.setMaskLineWidth(2);
maskView.setMaskRadius(5);
maskView.setScanSpeed(6);
maskView.setScanGradientSpread(80);
mCameraView.post(new Runnable() {
@Override
public void run() {
int width = mCameraView.getWidth();
int height = mCameraView.getHeight();
if (width
算法 自动采集列表(什么小东西都在网上查一查自动获取大部分站点网页title)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-21 09:03
算法自动采集列表抓取每个浏览器的列表等,按照tag搜索。搜索等功能手机搜索slashgear对于一个公司来说是很不错的选择,可以作为推广手段来讲。
看了楼上的回答,说的太简单,我再说下搜索引擎方面的东西。
1、百度的服务器在美国,谷歌的服务器在日本。
2、百度主打高端人群,谷歌主打新闻资讯类人群。
3、百度的竞价广告相对便宜
4、谷歌的本地化做的更好。
以前我认为谷歌是世界最好的搜索引擎,但是在使用搜索引擎的过程中我发现了谷歌很多的问题(比如说版权问题),国内互联网上很多做技术的人都有个习惯,就是擅长捏造事实,用谷歌搜索出来的百度百科,搜狗百科,360百科的编撰,利用了百度搜索引擎的公信力,甚至是恶意捏造事实来达到给百度造势。没错,的确有很多本地化的地方比如google中国,总而言之,我的谷歌搜索根本没法满足日常生活中百度百科的需求。
什么小东西都在网上查一查
自动获取大部分站点网页的title、关键词,相比百度来说信息质量更高。不过谷歌官方已经不允许相关站点的访问了。不能用,太恶心了。
我用过谷歌的搜索算法,感觉搜什么搜索结果出来的东西都差不多吧,根本就没啥的,但百度就会有很多奇怪的东西存在,比如加了自动伸缩属性的!!这是谷歌和百度搜索结果对比的结果:从结果可以看出来,百度搜索的相关性分别为78:41:31, 查看全部
算法 自动采集列表(什么小东西都在网上查一查自动获取大部分站点网页title)
算法自动采集列表抓取每个浏览器的列表等,按照tag搜索。搜索等功能手机搜索slashgear对于一个公司来说是很不错的选择,可以作为推广手段来讲。
看了楼上的回答,说的太简单,我再说下搜索引擎方面的东西。
1、百度的服务器在美国,谷歌的服务器在日本。
2、百度主打高端人群,谷歌主打新闻资讯类人群。
3、百度的竞价广告相对便宜
4、谷歌的本地化做的更好。
以前我认为谷歌是世界最好的搜索引擎,但是在使用搜索引擎的过程中我发现了谷歌很多的问题(比如说版权问题),国内互联网上很多做技术的人都有个习惯,就是擅长捏造事实,用谷歌搜索出来的百度百科,搜狗百科,360百科的编撰,利用了百度搜索引擎的公信力,甚至是恶意捏造事实来达到给百度造势。没错,的确有很多本地化的地方比如google中国,总而言之,我的谷歌搜索根本没法满足日常生活中百度百科的需求。
什么小东西都在网上查一查
自动获取大部分站点网页的title、关键词,相比百度来说信息质量更高。不过谷歌官方已经不允许相关站点的访问了。不能用,太恶心了。
我用过谷歌的搜索算法,感觉搜什么搜索结果出来的东西都差不多吧,根本就没啥的,但百度就会有很多奇怪的东西存在,比如加了自动伸缩属性的!!这是谷歌和百度搜索结果对比的结果:从结果可以看出来,百度搜索的相关性分别为78:41:31,
算法 自动采集列表(基于nginxmirror模块的流量采集方案解密 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-10-20 14:14
)
这里我们以访问为例,可以看到如下信息,代理已经解密了发送的https数据包。
基于nginx镜像模块
基于nginx镜像模块的flow采集方案基本原理
当然,不仅可以通过代理流量,也可以通过nginx镜像模块来采集流量。
在基于nginx镜像模块的流程采集方案中,我们将通过以下步骤实现到目标系统采集的流程:
1、 配置nginx配置文件,添加镜像服务器,指定后端地址为我们神奇修改的webserver地址。这样nginx会在请求来的时候对原创http请求包进行镜像,并将请求转发到镜像服务器。
2、在镜像服务器上解析这些http请求包,然后解析明文请求包,然后将这些请求包推送到消息队列进行任务分发。
实验验证了基于nginx镜像模块进行流量采集的可行性
为了验证这个想法的可行性,我们来做一个实验。这里需要搭建一个支持mirror模块的nginx服务器,搭建过程不再赘述,读者可以自行搭建。
现在让我们开始实验。首先,我们在服务器a(192.168.1.10)上安装配置nginx,在服务器192.16上安装配置我们修改的8.1.上的webserver 11.这个修改后的webserver负责解析nginx转发的http数据包,并将解析后的http数据包推送到消息队列中间。
服务器a中的nginx配置文件如下:
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8181;
mirror_request_body on;
access_log /var/log/nginx/test.log;
root html/test;
}
server {
mirror_request_body on;
listen 8282;
access_log /var/log/nginx/mir1.log;
root html/mir1;
}
upstream backend {
server 127.0.0.1:8181;
}
upstream test_backend1 {
server 192.168.1.11:9008;
#如果需要做负载均衡,多配置一些backend
#server 192.168.1.12:9008;
#server 192.168.1.13:9008;
}
server {
listen 80;
server_name localhost;
mirror_request_body on;
location / {
mirror /mirror1;
proxy_pass http://backend;
}
location = /mirror1 {
#internal;
proxy_pass http://test_backend1$request_uri;
}
}
}
简单解释一下上面的配置信息。在nginx.conf配置中,配置启动三个服务器实例。80端口的服务器负责将原创请求包转发到8181和8282端口,8181端口的http服务负责将原创请求转发到web后端,8282端口的http服务负责转发原创请求向 Web 后端请求。镜像请求包转发到其他webserver(基于python的BaseHTTPRequestHandler修改的webserver)。配置完成后,我们启动nginx,在http服务目录下执行如下命令,创建实验所需的一些文件:
cd /usr/share/nginx/html/
mkdir test mir1
echo "test page" >test/index.html
接下来我们执行 curl 命令 curl
执行该命令后,预期的结果是/var/log/nginx/mir1.log和/var/log/nginx/test.log中都有对应的访问记录,说明nginx成功镜像了一份将流量转发给8282和8181端口对应的http服务,看看实际访问结果
没错,一切都和一开始的预期一样。从访问日志来看,镜像服务器转发的http请求包已经成功接收解析。这里我们举一个简单的例子:
from http.server import HTTPServer, BaseHTTPRequestHandler
import json
class Resquest(BaseHTTPRequestHandler):
def handler(self):
print("data:", self.rfile.readline().decode())
self.wfile.write(self.rfile.readline())
def do_GET(self):
print(self.requestline)
print(self.headers)
data = {
"status":200,
"info":"test"
}
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps(data).encode())
def do_POST(self):
print(self.requestline)
print(self.headers)
req_datas = self.rfile.read(int(self.headers['content-length']))
print(req_datas.decode())
data = {
"status":200,
"info":"test"
}
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps(data).encode('utf-8'))
if __name__ == '__main__':
host = ('0.0.0.0', 9008)
server = HTTPServer(host, Resquest)
print("Starting server, listen at: %s:%s" % host)
server.serve_forever()
启动服务后,可以接收到镜像服务器转发过来的http请求包。这里我们重写了 do_GET 和 do_POST 函数来解析和打印请求的数据包。实验结果如下:
post数据包效果信息如下(curl -X POST -d'name=张三')
这个过程可以用下图表示:
但是,如果通过nginx镜像模块采集流量,则只能针对企业内部连接nginx的项目。如果要检测没有连接nginx的项目,或者互联网上的一些其他网站,也需要使用代理模式。两者之间存在互补性。Nginx可以解决配置代理和证书的麻烦(当然nginx本身也需要配置https证书),代理模式可以让被动漏洞扫描系统更加有效。但对企业而言,基于nginx镜像模块的流量采集解决方案在自动化上会有比较优势。
三、分布式漏洞检测框架实现方案
上面解释了基于http/https代理的流量劫持的基本原理,那么如何基于此开发一个被动的漏洞检测系统呢?以及我们需要考虑哪些问题?在大规模被动漏洞扫描的场景下,往往会有大量流量转发到代理服务器。如果没有合理的架构设计,代理服务器很可能会陷入包洪泛的困境,类似于dos Attack(ps:要进行漏洞检测,必须构造请求数据包。试想如果是500漏洞检测插件,那么每个请求的代理服务器至少要转发500个http请求包到目标web服务器,如果没有妥善处理,这是一件很可怕的事情)。那么如何处理这个问题呢?下面是我们设计的基于代理流量的被动漏洞扫描器的示意图,我们将在此基础上进一步讨论。
基于代理流量的分布式漏洞检测框架设计
在基于代理的被动流量采集方案中,用户在chrome端配置https/http代理,让流量先到我们的代理服务器。代理服务器将原创数据包推送到redis消息队列进行任务分发,slave worker监控redis消息队列,通过抢占方式获取任务信息,加载漏洞检测插件,发送带有攻击payload的请求包到服务器进行漏洞检测和分析。另一方面,代理服务器也会将原创请求包转发给服务器,以便客户端获得想要的请求结果。
在性能优化方面,一方面可以通过适当的sleep方式批量发送这些http攻击数据包,另一方面可以分布式的方式减轻漏洞检测分析服务器的负担。
基于nginx镜像模块的分布式漏洞检测框架设计
在基于nginx镜像模块的被动流量采集方案中,配置镜像服务器对原创请求流量进行镜像,将镜像流量转发到aeacus服务器分析http流量,并推送解析后的http请求消息信息 到消息队列。然后slave worker监听redis消息队列,通过抢占方式获取任务信息,加载漏洞检测插件,将带有攻击载荷的请求包发送到服务器进行漏洞检测分析。
在基于nginx镜像模块的被动流量采集方面,可以从以下两个方面进行性能优化。一方面,对于大量并发的请求,可以配置nginx负载均衡,将这些请求平均分配到各个镜像服务器,让各个镜像服务器处理的任务相对较少。镜像可根据实际业务量增减。服务器的数量,另一方面,为了降低每个slave worker的漏洞分析压力,可以根据实际情况扩展分布式任务节点的数量。当然,重点是对数据包进行去重,否则会增加任务节点的检测压力。
脏数据解决方案讨论
在被动漏洞分析检测过程中,如果一些post请求数据包具有存储功能,那么大量的攻击性数据包无疑会带来大量的脏数据。这也是很多安全人员在推一些安全测试产品时经常考虑的一个问题。推的时候还担心会因为这个问题受阻,但其实被动漏洞检测系统主要是连接测试环境,脏数据的影响比较小,几乎可以忽略不计。如果测试方觉得大量的脏数据会影响测试的效果,那我们不妨讨论一下如何处理测试过程中产生的脏数据问题。网上有同学的解决办法是过滤一些可能涉及存储的接口,但个人认为这个要慎重考虑,因为不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。因为你不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。因为你不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,让考生识别。但我认为最好的方法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。可以在payload中插入一个特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。可以在payload中插入一个特定的识别码,供考生识别。但我认为最好的方法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。
四、插件模块设计1、支持动态加载指纹识别模块
0x1 指纹识别模块加载执行流程图示意图
2、支持动态加载漏洞检测模块
0x0 Aeacus漏洞检测模块动态插件加载原理说明
插件加载在扫描作业的初始化阶段进行。通过python中的动态导入模块技术,将指定文件中的模块导入到当前进程中,然后检查导入模块的合法性。如果符合预期的模块格式要求,则将该模块保存在模块缓存区。在进行漏洞检测操作时,只需要遍历执行模块缓存区中的插件即可。动态加载的目的是为了支持漏洞检测插件的热更新,即后续插件维护者只需要将编译好的插件放到指定目录下,无需重启系统,让系统支持更多的漏洞检测能力。
代码
//python中动态加载指定文件中的模块信息
def module_dynamic_loader(file_path):
if '' not in importlib.machinery.SOURCE_SUFFIXES:
importlib.machinery.SOURCE_SUFFIXES.append('')
try:
module_name = 'plugin_{0}'.format(get_filename(file_path, with_ext=False))
spec = importlib.util.spec_from_file_location(module_name, file_path, loader=PocLoader(module_name, file_path))
mod = importlib.util.module_from_spec(spec)
spec.loader.exec_module(mod)
return mod
except ImportError:
error_msg = "load module failed! '{}'".format(file_path)
print(error_msg)
raise
0x1漏洞检测模块加载执行流程图示意图
五、 爬虫模块与Aeacus被动漏洞分析引擎的结合
在爬虫方面,可以配置https/http代理与aeacus系统链接,使爬虫爬取的数据包转发到后端被动漏洞分析引擎进行处理。如果使用nginx镜像流量采集方案,则不需要配置代理。直接爬行,aeacus系统可以自动获取相关的请求数据包。
六、数据包去重存储方案 数据包去重的必要性
被动的漏洞扫描器在采集流量的过程中难免会采集到大量重复的数据包,重复的数据包会增加后端漏洞分析引擎的负载,所以我们需要去采集到的http/https请求包. 重处理。
执行
主要依赖去重算法:Bloom去重算法
算法库:redisbloom
算法库安装配置:
#服务端安装配置
docker pull redislabs/rebloom:latest
docker run -p 5276:6379 --name redis-redisbloom redislabs/rebloom:latest
#客户端处理安装
pip install redisbloom
算法原理
基本的
Bloom filter内部维护一个bitArray(位数组),所有数据一开始都设置为0。当一个元素过来时,可以使用多个hash函数(hash1、hash2、hash3....)来计算不同的hash值,通过hash值找到对应的bitArray下标。里面的值0设置为1。需要注意的是Bloom filter有误判率的概念。误判率越低,阵列越长,占用空间越大。误报率越高,数组越小,占用空间越小。
初始化
插入,经过3个哈希函数的计算,得到的哈希值分别为1、4、7,然后在bitarray对应的索引处将该位标记为1。
数据包bloom去重代码实现
这里主要是根据端口、主机名、路径、方法、参数、协议参数对数据包进行签名,示例代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# desc: 数据包布隆去重
# author: pOny
from redisbloom.client import Client
from configure import bloom_server_address,bloom_server_port
class bloomfilter():
rb = Client(host=bloom_server_address, port=bloom_server_port)
@staticmethod
def add_packet_hash(**kwargs):
'''
添加hash信息
:param kwargs:
datadict={
"method":"post",
"protocal":"http",
"hostname":"pony.com",
"port":"80",
"path":"/docs",
"params":["p1","p2","p3"]
}
:return: None
'''
port,hostname,path,method,params,protocal=kwargs.get("port"),\
kwargs.get("hostname"),kwargs.get("path"),\
kwargs.get("method"),kwargs.get("params"),\
kwargs.get("protocal")
params= "".join(params) if params else ""
if isinstance(port,int):
port=str(port)
data="{}{}{}{}{}{}".format(port,hostname,path,method,params,protocal)
bloomfilter.rb.bfAdd(kwargs.get("projectid"),data)
@staticmethod
def dofilter(**kwargs):
'''
布隆去重复
:param kwargs:
datadict={
"method":"post",
"protocal":"http",
"hostname":"lixiang.com",
"port":"80",
"path":"/docs",
"params":["p1","p2","p3"],
}
:return:Boolean
'''
port,hostname,path,method,params,protocal=kwargs.get("port"),\
kwargs.get("hostname"),kwargs.get("path"),\
kwargs.get("method"),kwargs.get("params"),\
kwargs.get("protocal")
params= params="".join(params) if params else ""
if isinstance(port,int):
port=str(port)
data="{}{}{}{}{}{}".format(port,hostname,path,method,params,protocal)
return bloomfilter.rb.bfExists(kwargs.get("projectid"),data)
七、Aeacus 被动漏洞扫描器介绍
在过去的q2季度,理想汽车安全部的devsecops团队一直致力于被动漏洞扫描器的研发,积累了一些被动漏洞扫描器的开发经验。在这里给大家分享一些经验,希望对大家分享后的工作有一定的帮助。
注:以下涉及的漏洞数据均为模拟数据。
0x0 整体架构图
0x1 漏洞数据可视化展示面板
0x2 漏洞管理
漏洞列表
漏洞详情
0x3 项目管理
项目清单
添加的项目
0x4 插件管理
插件列表
插件添加页面
查看全部
算法 自动采集列表(基于nginxmirror模块的流量采集方案解密
)
这里我们以访问为例,可以看到如下信息,代理已经解密了发送的https数据包。
基于nginx镜像模块
基于nginx镜像模块的flow采集方案基本原理
当然,不仅可以通过代理流量,也可以通过nginx镜像模块来采集流量。
在基于nginx镜像模块的流程采集方案中,我们将通过以下步骤实现到目标系统采集的流程:
1、 配置nginx配置文件,添加镜像服务器,指定后端地址为我们神奇修改的webserver地址。这样nginx会在请求来的时候对原创http请求包进行镜像,并将请求转发到镜像服务器。
2、在镜像服务器上解析这些http请求包,然后解析明文请求包,然后将这些请求包推送到消息队列进行任务分发。
实验验证了基于nginx镜像模块进行流量采集的可行性
为了验证这个想法的可行性,我们来做一个实验。这里需要搭建一个支持mirror模块的nginx服务器,搭建过程不再赘述,读者可以自行搭建。
现在让我们开始实验。首先,我们在服务器a(192.168.1.10)上安装配置nginx,在服务器192.16上安装配置我们修改的8.1.上的webserver 11.这个修改后的webserver负责解析nginx转发的http数据包,并将解析后的http数据包推送到消息队列中间。
服务器a中的nginx配置文件如下:
worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8181;
mirror_request_body on;
access_log /var/log/nginx/test.log;
root html/test;
}
server {
mirror_request_body on;
listen 8282;
access_log /var/log/nginx/mir1.log;
root html/mir1;
}
upstream backend {
server 127.0.0.1:8181;
}
upstream test_backend1 {
server 192.168.1.11:9008;
#如果需要做负载均衡,多配置一些backend
#server 192.168.1.12:9008;
#server 192.168.1.13:9008;
}
server {
listen 80;
server_name localhost;
mirror_request_body on;
location / {
mirror /mirror1;
proxy_pass http://backend;
}
location = /mirror1 {
#internal;
proxy_pass http://test_backend1$request_uri;
}
}
}
简单解释一下上面的配置信息。在nginx.conf配置中,配置启动三个服务器实例。80端口的服务器负责将原创请求包转发到8181和8282端口,8181端口的http服务负责将原创请求转发到web后端,8282端口的http服务负责转发原创请求向 Web 后端请求。镜像请求包转发到其他webserver(基于python的BaseHTTPRequestHandler修改的webserver)。配置完成后,我们启动nginx,在http服务目录下执行如下命令,创建实验所需的一些文件:
cd /usr/share/nginx/html/
mkdir test mir1
echo "test page" >test/index.html
接下来我们执行 curl 命令 curl
执行该命令后,预期的结果是/var/log/nginx/mir1.log和/var/log/nginx/test.log中都有对应的访问记录,说明nginx成功镜像了一份将流量转发给8282和8181端口对应的http服务,看看实际访问结果
没错,一切都和一开始的预期一样。从访问日志来看,镜像服务器转发的http请求包已经成功接收解析。这里我们举一个简单的例子:
from http.server import HTTPServer, BaseHTTPRequestHandler
import json
class Resquest(BaseHTTPRequestHandler):
def handler(self):
print("data:", self.rfile.readline().decode())
self.wfile.write(self.rfile.readline())
def do_GET(self):
print(self.requestline)
print(self.headers)
data = {
"status":200,
"info":"test"
}
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps(data).encode())
def do_POST(self):
print(self.requestline)
print(self.headers)
req_datas = self.rfile.read(int(self.headers['content-length']))
print(req_datas.decode())
data = {
"status":200,
"info":"test"
}
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(json.dumps(data).encode('utf-8'))
if __name__ == '__main__':
host = ('0.0.0.0', 9008)
server = HTTPServer(host, Resquest)
print("Starting server, listen at: %s:%s" % host)
server.serve_forever()
启动服务后,可以接收到镜像服务器转发过来的http请求包。这里我们重写了 do_GET 和 do_POST 函数来解析和打印请求的数据包。实验结果如下:
post数据包效果信息如下(curl -X POST -d'name=张三')
这个过程可以用下图表示:
但是,如果通过nginx镜像模块采集流量,则只能针对企业内部连接nginx的项目。如果要检测没有连接nginx的项目,或者互联网上的一些其他网站,也需要使用代理模式。两者之间存在互补性。Nginx可以解决配置代理和证书的麻烦(当然nginx本身也需要配置https证书),代理模式可以让被动漏洞扫描系统更加有效。但对企业而言,基于nginx镜像模块的流量采集解决方案在自动化上会有比较优势。
三、分布式漏洞检测框架实现方案
上面解释了基于http/https代理的流量劫持的基本原理,那么如何基于此开发一个被动的漏洞检测系统呢?以及我们需要考虑哪些问题?在大规模被动漏洞扫描的场景下,往往会有大量流量转发到代理服务器。如果没有合理的架构设计,代理服务器很可能会陷入包洪泛的困境,类似于dos Attack(ps:要进行漏洞检测,必须构造请求数据包。试想如果是500漏洞检测插件,那么每个请求的代理服务器至少要转发500个http请求包到目标web服务器,如果没有妥善处理,这是一件很可怕的事情)。那么如何处理这个问题呢?下面是我们设计的基于代理流量的被动漏洞扫描器的示意图,我们将在此基础上进一步讨论。
基于代理流量的分布式漏洞检测框架设计
在基于代理的被动流量采集方案中,用户在chrome端配置https/http代理,让流量先到我们的代理服务器。代理服务器将原创数据包推送到redis消息队列进行任务分发,slave worker监控redis消息队列,通过抢占方式获取任务信息,加载漏洞检测插件,发送带有攻击payload的请求包到服务器进行漏洞检测和分析。另一方面,代理服务器也会将原创请求包转发给服务器,以便客户端获得想要的请求结果。
在性能优化方面,一方面可以通过适当的sleep方式批量发送这些http攻击数据包,另一方面可以分布式的方式减轻漏洞检测分析服务器的负担。
基于nginx镜像模块的分布式漏洞检测框架设计
在基于nginx镜像模块的被动流量采集方案中,配置镜像服务器对原创请求流量进行镜像,将镜像流量转发到aeacus服务器分析http流量,并推送解析后的http请求消息信息 到消息队列。然后slave worker监听redis消息队列,通过抢占方式获取任务信息,加载漏洞检测插件,将带有攻击载荷的请求包发送到服务器进行漏洞检测分析。
在基于nginx镜像模块的被动流量采集方面,可以从以下两个方面进行性能优化。一方面,对于大量并发的请求,可以配置nginx负载均衡,将这些请求平均分配到各个镜像服务器,让各个镜像服务器处理的任务相对较少。镜像可根据实际业务量增减。服务器的数量,另一方面,为了降低每个slave worker的漏洞分析压力,可以根据实际情况扩展分布式任务节点的数量。当然,重点是对数据包进行去重,否则会增加任务节点的检测压力。
脏数据解决方案讨论
在被动漏洞分析检测过程中,如果一些post请求数据包具有存储功能,那么大量的攻击性数据包无疑会带来大量的脏数据。这也是很多安全人员在推一些安全测试产品时经常考虑的一个问题。推的时候还担心会因为这个问题受阻,但其实被动漏洞检测系统主要是连接测试环境,脏数据的影响比较小,几乎可以忽略不计。如果测试方觉得大量的脏数据会影响测试的效果,那我们不妨讨论一下如何处理测试过程中产生的脏数据问题。网上有同学的解决办法是过滤一些可能涉及存储的接口,但个人认为这个要慎重考虑,因为不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。因为你不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。因为你不能保证这些接口没有漏洞,容易造成漏报。并且如果不想让脏数据误导考生,可以在payload中插入特定的识别码,让考生识别。但我认为最好的方法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。可以在payload中插入一个特定的识别码,供考生识别。但我认为最好的办法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。可以在payload中插入一个特定的识别码,供考生识别。但我认为最好的方法是在测试环节之后安排安全测试。在测试链路中,只采集流量,不进行安全测试分析。测试同学确认功能测试没问题后,再发送到测试服务器。安全检查和分析的相应检查说明。
四、插件模块设计1、支持动态加载指纹识别模块
0x1 指纹识别模块加载执行流程图示意图
2、支持动态加载漏洞检测模块
0x0 Aeacus漏洞检测模块动态插件加载原理说明
插件加载在扫描作业的初始化阶段进行。通过python中的动态导入模块技术,将指定文件中的模块导入到当前进程中,然后检查导入模块的合法性。如果符合预期的模块格式要求,则将该模块保存在模块缓存区。在进行漏洞检测操作时,只需要遍历执行模块缓存区中的插件即可。动态加载的目的是为了支持漏洞检测插件的热更新,即后续插件维护者只需要将编译好的插件放到指定目录下,无需重启系统,让系统支持更多的漏洞检测能力。
代码
//python中动态加载指定文件中的模块信息
def module_dynamic_loader(file_path):
if '' not in importlib.machinery.SOURCE_SUFFIXES:
importlib.machinery.SOURCE_SUFFIXES.append('')
try:
module_name = 'plugin_{0}'.format(get_filename(file_path, with_ext=False))
spec = importlib.util.spec_from_file_location(module_name, file_path, loader=PocLoader(module_name, file_path))
mod = importlib.util.module_from_spec(spec)
spec.loader.exec_module(mod)
return mod
except ImportError:
error_msg = "load module failed! '{}'".format(file_path)
print(error_msg)
raise
0x1漏洞检测模块加载执行流程图示意图
五、 爬虫模块与Aeacus被动漏洞分析引擎的结合
在爬虫方面,可以配置https/http代理与aeacus系统链接,使爬虫爬取的数据包转发到后端被动漏洞分析引擎进行处理。如果使用nginx镜像流量采集方案,则不需要配置代理。直接爬行,aeacus系统可以自动获取相关的请求数据包。
六、数据包去重存储方案 数据包去重的必要性
被动的漏洞扫描器在采集流量的过程中难免会采集到大量重复的数据包,重复的数据包会增加后端漏洞分析引擎的负载,所以我们需要去采集到的http/https请求包. 重处理。
执行
主要依赖去重算法:Bloom去重算法
算法库:redisbloom
算法库安装配置:
#服务端安装配置
docker pull redislabs/rebloom:latest
docker run -p 5276:6379 --name redis-redisbloom redislabs/rebloom:latest
#客户端处理安装
pip install redisbloom
算法原理
基本的
Bloom filter内部维护一个bitArray(位数组),所有数据一开始都设置为0。当一个元素过来时,可以使用多个hash函数(hash1、hash2、hash3....)来计算不同的hash值,通过hash值找到对应的bitArray下标。里面的值0设置为1。需要注意的是Bloom filter有误判率的概念。误判率越低,阵列越长,占用空间越大。误报率越高,数组越小,占用空间越小。
初始化
插入,经过3个哈希函数的计算,得到的哈希值分别为1、4、7,然后在bitarray对应的索引处将该位标记为1。
数据包bloom去重代码实现
这里主要是根据端口、主机名、路径、方法、参数、协议参数对数据包进行签名,示例代码如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# desc: 数据包布隆去重
# author: pOny
from redisbloom.client import Client
from configure import bloom_server_address,bloom_server_port
class bloomfilter():
rb = Client(host=bloom_server_address, port=bloom_server_port)
@staticmethod
def add_packet_hash(**kwargs):
'''
添加hash信息
:param kwargs:
datadict={
"method":"post",
"protocal":"http",
"hostname":"pony.com",
"port":"80",
"path":"/docs",
"params":["p1","p2","p3"]
}
:return: None
'''
port,hostname,path,method,params,protocal=kwargs.get("port"),\
kwargs.get("hostname"),kwargs.get("path"),\
kwargs.get("method"),kwargs.get("params"),\
kwargs.get("protocal")
params= "".join(params) if params else ""
if isinstance(port,int):
port=str(port)
data="{}{}{}{}{}{}".format(port,hostname,path,method,params,protocal)
bloomfilter.rb.bfAdd(kwargs.get("projectid"),data)
@staticmethod
def dofilter(**kwargs):
'''
布隆去重复
:param kwargs:
datadict={
"method":"post",
"protocal":"http",
"hostname":"lixiang.com",
"port":"80",
"path":"/docs",
"params":["p1","p2","p3"],
}
:return:Boolean
'''
port,hostname,path,method,params,protocal=kwargs.get("port"),\
kwargs.get("hostname"),kwargs.get("path"),\
kwargs.get("method"),kwargs.get("params"),\
kwargs.get("protocal")
params= params="".join(params) if params else ""
if isinstance(port,int):
port=str(port)
data="{}{}{}{}{}{}".format(port,hostname,path,method,params,protocal)
return bloomfilter.rb.bfExists(kwargs.get("projectid"),data)
七、Aeacus 被动漏洞扫描器介绍
在过去的q2季度,理想汽车安全部的devsecops团队一直致力于被动漏洞扫描器的研发,积累了一些被动漏洞扫描器的开发经验。在这里给大家分享一些经验,希望对大家分享后的工作有一定的帮助。
注:以下涉及的漏洞数据均为模拟数据。
0x0 整体架构图
0x1 漏洞数据可视化展示面板
0x2 漏洞管理
漏洞列表
漏洞详情
0x3 项目管理
项目清单
添加的项目
0x4 插件管理
插件列表
插件添加页面
算法 自动采集列表(用技术力量探索行为密码,让大数据助跑每一个人)
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2021-10-20 07:02
作者是一个痴迷于挖掘数据价值的学习者。希望在日常工作学习中挖掘数据的价值,发现数据的奥秘。笔者认为,数据的价值不仅体现在企业中,也可以体现在个人身上。发挥数据的魅力,用技术力量探索行为密码,让大数据帮助大家。欢迎关注我的公众号,一起探讨数据中的趣事。
我的公众号是:livandata
推荐算法的内容比较多。本文首先介绍一些常用的知识点。随着学习的深入,作者会增加新的内容。
笔者理解,基于协同过滤的推荐是一种基于内容推荐的推广。模型的构建主要需要考虑几个问题:
1)如何计算用户对商品的偏好并形成UV矩阵;
2)计算items和users的相似度主要有两种方法:
它的一、根据用户属性计算UU和VV的相似度;
它的二、根据用户对产品的偏好计算U和V的相似度;
在此期间,需要确定U的对应属性和V的对应属性,并利用这些来了解用户与用户、产品与产品之间的相似性。这主要是基于内容推荐的一些思路。型号推荐;
在基于协同过滤的推荐过程中,需要使用UV矩阵中的用户偏好,即根据用户偏好计算用户或产品之间的相似度,计算方法有欧式距离、皮尔逊系数等方法;
在推荐算法的应用过程中需要考虑的一些因素是:
1)如何推荐大单小频的商品;
2)如何推荐小众高频产品;
3)如何推荐热门产品;
4)如何推荐长尾产品;
...
推荐算法的应用领域非常广泛,涉及协作、内容等常用算法,以及机器学习中常用的聚类、分类等算法。将用户和产品分开,然后根据用户和同类别产品的交互程度推荐与同类别其他用户相关的产品。
现阶段比较流行的基础推荐算法主要有以下几类:
1、 基于内容的推荐:
它是推荐引擎出现之初应用最广泛的推荐机制。它的核心思想是根据推荐的物品或内容的元数据发现物品或内容的相关性,然后根据用户过去的偏好记录向用户推荐相似的物品。图3展示了基于内容推荐的基本原理。
图1. 基于内容推荐机制的基本原理
图1展示了一个基于内容推荐的典型例子,一个电影推荐系统。首先,我们需要对电影的元数据进行建模。这里我们只简单描述电影的类型;那么我们就可以通过电影的元数据找出来。电影之间的相似性,因为类型都是“爱情,浪漫”。电影A和C被认为是相似的电影(当然,获得更好的推荐还不够,我们也可以考虑电影的导演、演员等);最后,建议得到执行。对于用户A,他喜欢看电影A,那么系统可以向他推荐类似的电影C。
这种基于内容的推荐机制的优点是可以很好地模拟用户的口味,提供更准确的推荐。但它也存在以下问题:
1) 文章需要分析建模,推荐质量取决于文章模型的完整性和综合性。在目前的应用中,我们可以观察到关键词和标签(Tag)被认为是一种简单有效的描述item元数据的方式。
2) 物品相似度的分析只依赖物品本身的特征,这里不考虑人们对物品的态度。
3)由于需要根据用户过去的偏好历史进行推荐,所以对于新用户存在“冷启动”问题。
虽然这种方法有很多缺点和问题,但它已经成功地应用于一些电影、音乐和书籍的社交网站。一些网站还邀请专业人员在报告中对项目进行基因编码,例如 Pandora。在 Pandora 的推荐引擎中,每首歌曲都有 100 多个元数据特征,包括歌曲风格、年份、歌手等。
2、基于协同过滤的推荐:
随着Web2.0的发展,网站促进了用户参与和用户贡献。因此,基于协同过滤的推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者找到用户的相关性,然后根据这些相关性进行推荐。基于协同过滤的推荐可以分为三个子类别:基于用户的推荐、基于物品的推荐和基于模型的推荐。下面我们将一一详细介绍三种协同过滤推荐机制。
1)基于用户的协同过滤推荐
基于用户的协同过滤推荐的基本原理是根据所有用户对物品或信息的偏好,找到与当前用户的口味和偏好相似的“邻居”用户群。在一般应用中,“K-neighbors”的计算使用算法;然后,根据这K个邻居的历史偏好信息,为当前用户做推荐。下面的图 2 显示了原理图。
图2. 基于用户的协同过滤推荐机制基本原理
上图说明了基于用户的协同过滤推荐机制的基本原理。假设用户A喜欢物品A,物品C,用户B喜欢物品B,用户C喜欢物品A,物品C和物品D;从这些用户的历史偏好信息中,我们可以发现用户A和用户C的品味和偏好比较相似,并且用户C也喜欢项目D,那么我们可以推断用户A可能也喜欢项目D,所以项目 D 可以推荐给用户 A。
基于用户的协同过滤推荐机制和基于人口统计的推荐机制都计算用户的相似度,也计算基于“邻居”用户群的推荐,但两者的区别在于如何计算用户的相似度,基于人口统计机制只考虑用户自身的特征,而基于用户的协同过滤机制则根据用户的历史偏好数据计算用户的相似度。它的基本假设是喜欢相似物品的用户可能具有相同或相似的品味和偏好。
2)基于项目的协同过滤推荐
基于项目的协同过滤推荐的基本原理类似,只不过它是利用所有用户对项目或信息的偏好来寻找项目和项目之间的相似性,然后根据用户的历史偏好信息向用户推荐相似的项目。对于用户来说,图5很好地说明了它的基本原理。
假设用户A喜欢物品A和物品C,用户B喜欢物品A,物品B和物品C,用户C喜欢物品A,从这些用户的历史偏好可以分析出物品A和物品C是相似的并且喜欢物品A的人喜欢物品C。根据这个数据可以推断用户C很可能也喜欢物品C,所以系统会向用户C推荐物品C。
与上述类似,基于项目的协同过滤推荐和基于内容的推荐实际上都是基于项目相似度预测推荐,只是相似度计算方法不同。前者是从用户的历史偏好中推断出来的,而后者则是基于物品。其自身的属性特征信息。
图3. 基于项目的协同过滤推荐机制基本原理
同时,如何在基于用户和基于项目的协同过滤策略之间进行选择?事实上,基于物品的协同过滤推荐机制是亚马逊在基于用户的机制上改进的一种策略,因为在大多数网站中,物品的数量远小于用户的数量,物品的数量是相似度比较稳定,基于项目的机制比基于用户的实时性能要好。但并非在所有场景中都是如此。可以想象,在一些新闻推荐系统中,也许items的数量,即新闻的数量可能大于用户的数量,而且新闻更新的程度也很快,所以它的相似度还是有的不稳定。因此,事实上,
3)基于模型的协同过滤推荐
基于模型的协同过滤推荐是根据样本的用户偏好信息训练推荐模型,然后根据实时用户的偏好信息进行预测计算推荐。
基于协同过滤的推荐机制是当今应用最广泛的推荐机制。它具有以下显着优点:
而且它还存在以下问题:
3、协同过滤的主要步骤是:
1)采集用户偏好
需要从用户的行为和偏好中找出规律,并在此基础上给出建议。如何采集用户的偏好信息成为系统推荐效果最基本的决定因素。用户可以通过多种方式向系统提供自己的偏好信息,不同的应用程序可能会有很大差异。以下是示例:
上面列出的用户行为比较笼统,推荐引擎设计者可以根据自己应用的特点添加特殊的用户行为,用它们来表达用户对物品的偏好。在一般的应用中,我们一般提取不止一种用户行为。基本上有两种方法可以组合这些不同的用户行为:
一般可以分为“查看”和“购买”等,然后根据不同的行为计算不同用户/物品的相似度。类似于当当网或者亚马逊的“买书的人也买了……”、“看过书的人也看过……”
根据用户偏好的程度对不同的行为进行加权,得到用户对物品的整体偏好。一般来说,显式用户反馈比隐式权重大,但比较稀疏。毕竟,只有少数用户执行显示反馈。同时,相比“浏览”,“购买”行为在更大程度上反映了用户的偏好,但这也因应用而异。
在采集到用户行为数据之后,我们还需要对数据进行预处理。核心工作是:降噪和归一化。
用户行为数据是在用户使用应用程序的过程中产生的。可能会有很多噪音和用户误操作。我们可以通过经典的数据挖掘算法过滤掉行为数据中的噪声,这可以让我们的分析更加准确。
如前所述,在计算用户对物品的偏好时,可能需要对不同的行为数据进行加权。但是,可以想象,不同行为的数据值可能会有很大差异。例如,用户的观看数据必须远大于购买数据。如何统一同一取值范围内各个行为的数据,从而使加权求和得到的整体偏好更加准确,我们需要对其进行归一化。最简单的归一化过程就是将各类数据除以该类别中的最大值,保证归一化后的数据在[0,1]范围内。
预处理后,可以根据不同应用的行为分析方法选择分组或加权,然后我们就可以得到用户偏好的二维矩阵,一个是用户列表,一个是项目列表,值是用户对item的偏好,一般是[0,1]或[-1,1]的浮点值。
2)寻找相似的用户或物品
在对用户行为进行分析得到用户偏好后,我们可以根据用户偏好计算相似的用户和物品,然后根据相似的用户或物品进行推荐。这是两个最典型的 CF 分支:基于用户的 CF 和基于项目的 CF。这两种方法都需要计算相似度。下面我们来看看计算相似度的最基本的方法。
(1)计算相似度
关于相似度的计算,现有的几种基本方法都是基于向量的。事实上,他们正在计算两个向量之间的距离。距离越近,相似度越大。在推荐场景中,在user-item偏好的二维矩阵中,我们可以将一个用户对所有item的偏好作为向量来计算用户之间的相似度,或者将所有用户对某个item的偏好作为一个向量来计算计算物品之间的相似度。下面我们详细介绍几种常用的相似度计算方法:
(2) 计算相似邻居
介绍完相似度的计算方法后,我们再来看看如何根据相似度找到users-items的邻居。常用的邻域选择原则可以分为两类: 图1是二维平面空间上点集的示意图。
不考虑邻居的“距离”,只取最近的 K 作为它的邻居。如图1中A所示,假设我们要计算点1的5个邻居,那么根据点之间的距离,我们取最近的5个点,分别是点2、点3、点4、点7和第5点。但显然我们可以看到这种方法对于计算孤立点并不有效,因为它需要固定数量的邻居。当它附近没有足够的相似点时,它就被迫取一些不太相似的点。作为邻居,这会影响邻居之间的相似程度。例如,在图 1 中,点 1 和点 5 不是很相似。
与计算固定数量邻居的原理不同,基于相似度阈值的邻居计算是将邻居的距离限制为最大值。以当前点为中心,距离为K的区域内的所有点都视为当前点。邻居。这种方法计算出的邻居数是不确定的,但相似度不会有很大的误差。如图1,B,从点1开始,计算相似度在K以内的邻居,得到点2、点3、点4、点7。这种方法计算出的邻居相似度优于前一个。,尤其是离群值的处理。
3)计算建议
经过初步计算,得到了相邻用户和相邻物品。下面介绍如何根据这些信息为用户进行推荐。
基于用户的CF的基本思想很简单。它根据用户对物品的偏好寻找邻居用户,然后将邻居用户的采集推荐给当前用户。在计算中,将用户对所有物品的偏好作为向量来计算用户之间的相似度。找到K个邻居后,根据邻居的相似权重和他们对物品的偏好,预测当前用户没有偏好且不涉及物品,计算得到一个排序的物品列表作为推荐。图 2 显示了一个示例。对于用户A,根据用户的历史偏好,这里只计算一个邻居用户C,然后将用户C喜欢的项目D推荐给用户A。
item-based CF的原理和user-based CF类似,只是在计算邻居的时候使用的是item本身,而不是从用户的角度,即根据用户对item的偏好寻找相似的item,然后推荐相似物品根据用户对他的物品的历史偏好。从计算的角度来看,将所有用户对一个物品的偏好作为一个向量来计算物品之间的相似度。获得物品的相似物品后,根据用户的历史偏好预测当前用户没有具有偏好的物品。排序项目的列表被计算为推荐。图 3 显示了一个示例。对于物品A,根据所有用户的历史偏好,喜欢物品A的用户喜欢物品C,
目前我们得到的数据如下:我们需要为P5推荐三部电影中的一部。有两种方法:直接推荐和加权排名推荐。
直接推荐:如果我们需要为用户P5推荐电影,首先我们检查相似度列表,发现用户P5和用户P3的相似度最高。因此,我们可以向用户 P5 推荐 P3 相关数据。但是这里有一个问题。我们不能直接推荐以前的AF产品。由于这些产品,用户 P5 已经查看或购买了它们。该建议不能重复。因此,我们想推荐用户P5没有浏览或购买过的产品。如果直接推荐,可以选择P3用户评价最高的产品,即环太平洋和变形金刚这两个数据。
加权排名推荐:我们根据不同用户之间的相似度对不同产品的评分进行加权。根据加权结果对产品进行排序,然后推荐给用户P5。这样,用户P5得到了更好的推荐结果。
在上述计算结果中,我们按照(变形金刚-环太平洋-神奇快车)的顺序向用户P5推荐结果。
以上是基于用户的协同过滤算法。该算法依赖于用户的历史行为数据来计算相关性。换句话说,必须有一定的数据积累(冷启动问题)。对于新的网站或者数据较少的网站,还有一种基于item-based协同过滤算法的方法。 查看全部
算法 自动采集列表(用技术力量探索行为密码,让大数据助跑每一个人)
作者是一个痴迷于挖掘数据价值的学习者。希望在日常工作学习中挖掘数据的价值,发现数据的奥秘。笔者认为,数据的价值不仅体现在企业中,也可以体现在个人身上。发挥数据的魅力,用技术力量探索行为密码,让大数据帮助大家。欢迎关注我的公众号,一起探讨数据中的趣事。
我的公众号是:livandata
推荐算法的内容比较多。本文首先介绍一些常用的知识点。随着学习的深入,作者会增加新的内容。
笔者理解,基于协同过滤的推荐是一种基于内容推荐的推广。模型的构建主要需要考虑几个问题:
1)如何计算用户对商品的偏好并形成UV矩阵;
2)计算items和users的相似度主要有两种方法:
它的一、根据用户属性计算UU和VV的相似度;
它的二、根据用户对产品的偏好计算U和V的相似度;
在此期间,需要确定U的对应属性和V的对应属性,并利用这些来了解用户与用户、产品与产品之间的相似性。这主要是基于内容推荐的一些思路。型号推荐;
在基于协同过滤的推荐过程中,需要使用UV矩阵中的用户偏好,即根据用户偏好计算用户或产品之间的相似度,计算方法有欧式距离、皮尔逊系数等方法;
在推荐算法的应用过程中需要考虑的一些因素是:
1)如何推荐大单小频的商品;
2)如何推荐小众高频产品;
3)如何推荐热门产品;
4)如何推荐长尾产品;
...
推荐算法的应用领域非常广泛,涉及协作、内容等常用算法,以及机器学习中常用的聚类、分类等算法。将用户和产品分开,然后根据用户和同类别产品的交互程度推荐与同类别其他用户相关的产品。
现阶段比较流行的基础推荐算法主要有以下几类:
1、 基于内容的推荐:
它是推荐引擎出现之初应用最广泛的推荐机制。它的核心思想是根据推荐的物品或内容的元数据发现物品或内容的相关性,然后根据用户过去的偏好记录向用户推荐相似的物品。图3展示了基于内容推荐的基本原理。
图1. 基于内容推荐机制的基本原理
图1展示了一个基于内容推荐的典型例子,一个电影推荐系统。首先,我们需要对电影的元数据进行建模。这里我们只简单描述电影的类型;那么我们就可以通过电影的元数据找出来。电影之间的相似性,因为类型都是“爱情,浪漫”。电影A和C被认为是相似的电影(当然,获得更好的推荐还不够,我们也可以考虑电影的导演、演员等);最后,建议得到执行。对于用户A,他喜欢看电影A,那么系统可以向他推荐类似的电影C。
这种基于内容的推荐机制的优点是可以很好地模拟用户的口味,提供更准确的推荐。但它也存在以下问题:
1) 文章需要分析建模,推荐质量取决于文章模型的完整性和综合性。在目前的应用中,我们可以观察到关键词和标签(Tag)被认为是一种简单有效的描述item元数据的方式。
2) 物品相似度的分析只依赖物品本身的特征,这里不考虑人们对物品的态度。
3)由于需要根据用户过去的偏好历史进行推荐,所以对于新用户存在“冷启动”问题。
虽然这种方法有很多缺点和问题,但它已经成功地应用于一些电影、音乐和书籍的社交网站。一些网站还邀请专业人员在报告中对项目进行基因编码,例如 Pandora。在 Pandora 的推荐引擎中,每首歌曲都有 100 多个元数据特征,包括歌曲风格、年份、歌手等。
2、基于协同过滤的推荐:
随着Web2.0的发展,网站促进了用户参与和用户贡献。因此,基于协同过滤的推荐机制应运而生。它的原理很简单,就是根据用户对物品或信息的偏好,找到物品或内容本身的相关性,或者找到用户的相关性,然后根据这些相关性进行推荐。基于协同过滤的推荐可以分为三个子类别:基于用户的推荐、基于物品的推荐和基于模型的推荐。下面我们将一一详细介绍三种协同过滤推荐机制。
1)基于用户的协同过滤推荐
基于用户的协同过滤推荐的基本原理是根据所有用户对物品或信息的偏好,找到与当前用户的口味和偏好相似的“邻居”用户群。在一般应用中,“K-neighbors”的计算使用算法;然后,根据这K个邻居的历史偏好信息,为当前用户做推荐。下面的图 2 显示了原理图。
图2. 基于用户的协同过滤推荐机制基本原理
上图说明了基于用户的协同过滤推荐机制的基本原理。假设用户A喜欢物品A,物品C,用户B喜欢物品B,用户C喜欢物品A,物品C和物品D;从这些用户的历史偏好信息中,我们可以发现用户A和用户C的品味和偏好比较相似,并且用户C也喜欢项目D,那么我们可以推断用户A可能也喜欢项目D,所以项目 D 可以推荐给用户 A。
基于用户的协同过滤推荐机制和基于人口统计的推荐机制都计算用户的相似度,也计算基于“邻居”用户群的推荐,但两者的区别在于如何计算用户的相似度,基于人口统计机制只考虑用户自身的特征,而基于用户的协同过滤机制则根据用户的历史偏好数据计算用户的相似度。它的基本假设是喜欢相似物品的用户可能具有相同或相似的品味和偏好。
2)基于项目的协同过滤推荐
基于项目的协同过滤推荐的基本原理类似,只不过它是利用所有用户对项目或信息的偏好来寻找项目和项目之间的相似性,然后根据用户的历史偏好信息向用户推荐相似的项目。对于用户来说,图5很好地说明了它的基本原理。
假设用户A喜欢物品A和物品C,用户B喜欢物品A,物品B和物品C,用户C喜欢物品A,从这些用户的历史偏好可以分析出物品A和物品C是相似的并且喜欢物品A的人喜欢物品C。根据这个数据可以推断用户C很可能也喜欢物品C,所以系统会向用户C推荐物品C。
与上述类似,基于项目的协同过滤推荐和基于内容的推荐实际上都是基于项目相似度预测推荐,只是相似度计算方法不同。前者是从用户的历史偏好中推断出来的,而后者则是基于物品。其自身的属性特征信息。
图3. 基于项目的协同过滤推荐机制基本原理
同时,如何在基于用户和基于项目的协同过滤策略之间进行选择?事实上,基于物品的协同过滤推荐机制是亚马逊在基于用户的机制上改进的一种策略,因为在大多数网站中,物品的数量远小于用户的数量,物品的数量是相似度比较稳定,基于项目的机制比基于用户的实时性能要好。但并非在所有场景中都是如此。可以想象,在一些新闻推荐系统中,也许items的数量,即新闻的数量可能大于用户的数量,而且新闻更新的程度也很快,所以它的相似度还是有的不稳定。因此,事实上,
3)基于模型的协同过滤推荐
基于模型的协同过滤推荐是根据样本的用户偏好信息训练推荐模型,然后根据实时用户的偏好信息进行预测计算推荐。
基于协同过滤的推荐机制是当今应用最广泛的推荐机制。它具有以下显着优点:
而且它还存在以下问题:
3、协同过滤的主要步骤是:
1)采集用户偏好
需要从用户的行为和偏好中找出规律,并在此基础上给出建议。如何采集用户的偏好信息成为系统推荐效果最基本的决定因素。用户可以通过多种方式向系统提供自己的偏好信息,不同的应用程序可能会有很大差异。以下是示例:
上面列出的用户行为比较笼统,推荐引擎设计者可以根据自己应用的特点添加特殊的用户行为,用它们来表达用户对物品的偏好。在一般的应用中,我们一般提取不止一种用户行为。基本上有两种方法可以组合这些不同的用户行为:
一般可以分为“查看”和“购买”等,然后根据不同的行为计算不同用户/物品的相似度。类似于当当网或者亚马逊的“买书的人也买了……”、“看过书的人也看过……”
根据用户偏好的程度对不同的行为进行加权,得到用户对物品的整体偏好。一般来说,显式用户反馈比隐式权重大,但比较稀疏。毕竟,只有少数用户执行显示反馈。同时,相比“浏览”,“购买”行为在更大程度上反映了用户的偏好,但这也因应用而异。
在采集到用户行为数据之后,我们还需要对数据进行预处理。核心工作是:降噪和归一化。
用户行为数据是在用户使用应用程序的过程中产生的。可能会有很多噪音和用户误操作。我们可以通过经典的数据挖掘算法过滤掉行为数据中的噪声,这可以让我们的分析更加准确。
如前所述,在计算用户对物品的偏好时,可能需要对不同的行为数据进行加权。但是,可以想象,不同行为的数据值可能会有很大差异。例如,用户的观看数据必须远大于购买数据。如何统一同一取值范围内各个行为的数据,从而使加权求和得到的整体偏好更加准确,我们需要对其进行归一化。最简单的归一化过程就是将各类数据除以该类别中的最大值,保证归一化后的数据在[0,1]范围内。
预处理后,可以根据不同应用的行为分析方法选择分组或加权,然后我们就可以得到用户偏好的二维矩阵,一个是用户列表,一个是项目列表,值是用户对item的偏好,一般是[0,1]或[-1,1]的浮点值。
2)寻找相似的用户或物品
在对用户行为进行分析得到用户偏好后,我们可以根据用户偏好计算相似的用户和物品,然后根据相似的用户或物品进行推荐。这是两个最典型的 CF 分支:基于用户的 CF 和基于项目的 CF。这两种方法都需要计算相似度。下面我们来看看计算相似度的最基本的方法。
(1)计算相似度
关于相似度的计算,现有的几种基本方法都是基于向量的。事实上,他们正在计算两个向量之间的距离。距离越近,相似度越大。在推荐场景中,在user-item偏好的二维矩阵中,我们可以将一个用户对所有item的偏好作为向量来计算用户之间的相似度,或者将所有用户对某个item的偏好作为一个向量来计算计算物品之间的相似度。下面我们详细介绍几种常用的相似度计算方法:
(2) 计算相似邻居
介绍完相似度的计算方法后,我们再来看看如何根据相似度找到users-items的邻居。常用的邻域选择原则可以分为两类: 图1是二维平面空间上点集的示意图。
不考虑邻居的“距离”,只取最近的 K 作为它的邻居。如图1中A所示,假设我们要计算点1的5个邻居,那么根据点之间的距离,我们取最近的5个点,分别是点2、点3、点4、点7和第5点。但显然我们可以看到这种方法对于计算孤立点并不有效,因为它需要固定数量的邻居。当它附近没有足够的相似点时,它就被迫取一些不太相似的点。作为邻居,这会影响邻居之间的相似程度。例如,在图 1 中,点 1 和点 5 不是很相似。
与计算固定数量邻居的原理不同,基于相似度阈值的邻居计算是将邻居的距离限制为最大值。以当前点为中心,距离为K的区域内的所有点都视为当前点。邻居。这种方法计算出的邻居数是不确定的,但相似度不会有很大的误差。如图1,B,从点1开始,计算相似度在K以内的邻居,得到点2、点3、点4、点7。这种方法计算出的邻居相似度优于前一个。,尤其是离群值的处理。
3)计算建议
经过初步计算,得到了相邻用户和相邻物品。下面介绍如何根据这些信息为用户进行推荐。
基于用户的CF的基本思想很简单。它根据用户对物品的偏好寻找邻居用户,然后将邻居用户的采集推荐给当前用户。在计算中,将用户对所有物品的偏好作为向量来计算用户之间的相似度。找到K个邻居后,根据邻居的相似权重和他们对物品的偏好,预测当前用户没有偏好且不涉及物品,计算得到一个排序的物品列表作为推荐。图 2 显示了一个示例。对于用户A,根据用户的历史偏好,这里只计算一个邻居用户C,然后将用户C喜欢的项目D推荐给用户A。
item-based CF的原理和user-based CF类似,只是在计算邻居的时候使用的是item本身,而不是从用户的角度,即根据用户对item的偏好寻找相似的item,然后推荐相似物品根据用户对他的物品的历史偏好。从计算的角度来看,将所有用户对一个物品的偏好作为一个向量来计算物品之间的相似度。获得物品的相似物品后,根据用户的历史偏好预测当前用户没有具有偏好的物品。排序项目的列表被计算为推荐。图 3 显示了一个示例。对于物品A,根据所有用户的历史偏好,喜欢物品A的用户喜欢物品C,
目前我们得到的数据如下:我们需要为P5推荐三部电影中的一部。有两种方法:直接推荐和加权排名推荐。
直接推荐:如果我们需要为用户P5推荐电影,首先我们检查相似度列表,发现用户P5和用户P3的相似度最高。因此,我们可以向用户 P5 推荐 P3 相关数据。但是这里有一个问题。我们不能直接推荐以前的AF产品。由于这些产品,用户 P5 已经查看或购买了它们。该建议不能重复。因此,我们想推荐用户P5没有浏览或购买过的产品。如果直接推荐,可以选择P3用户评价最高的产品,即环太平洋和变形金刚这两个数据。
加权排名推荐:我们根据不同用户之间的相似度对不同产品的评分进行加权。根据加权结果对产品进行排序,然后推荐给用户P5。这样,用户P5得到了更好的推荐结果。
在上述计算结果中,我们按照(变形金刚-环太平洋-神奇快车)的顺序向用户P5推荐结果。
以上是基于用户的协同过滤算法。该算法依赖于用户的历史行为数据来计算相关性。换句话说,必须有一定的数据积累(冷启动问题)。对于新的网站或者数据较少的网站,还有一种基于item-based协同过滤算法的方法。
算法 自动采集列表(百度推出飓风算法,蝶变行动新、好站点扶持计划即将开启)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-10-17 10:02
2017年7月7日,继百度绿萝算法和石榴算法之后,百度在“网网”方面又出了一大招——百度推出飓风算法,旨在严厉打击使用不良采集百度搜索作为网站的主要内容来源,将彻底清除索引库中的不良采集链接,为优质原创内容提供更多展示机会,促进百度搜索良性发展。搜索生态。
飓风算法的更新也能看出百度从搜索生态向内容生态迈出了一大步,命中采集网站!
第 1 步:将搜索声明为内容生态
其实,早在2016年9月1日,随着百家号的诞生,百度的内容生态布局就浮出水面,百度卢富斌:搜索就是内容生态。
卢富斌认为,内容生态概念突然升温有两个根本原因:技术的发展导致了人力的大规模解放,尤其是人工智能等技术加速了这一进程。人们开始有更多的机会从事更多与生活、娱乐和创作相关的工作。其次,中国中产阶级的快速崛起提高了整个社会的内容消费能力。“所以百度对内容生态的关注,并不是出于行业的热情,而是基于对用户需求的洞察。”
第 2 步:2017 年 4 月算法更新
新站提速收录:蝶变行动新好站支持计划即将再次上线。
原创保护,再也不用担心抄袭了。保护网站原创的内容,正在大力升级。
阿拉丁产品的开通:阿里丁的战友专属产品有望在更多优质网站上开放。
推送信息展示:手机百度首页主动推送瑞金信息,助力网站品牌展示。
新闻源取消、搜索生态转向内容生态、百度阿里丁即将开启、移动站点语法升级、百度升级渲染UA、移动站点体验强调、移动页面加速器,这些都是百度即将到来的大事件。影响内容的是取消对新闻源和远程内容的保护
第三,。2017年7月7日飓风行动后,百度再次激怒了采集网站。可见,对原创内容的保护和网络运营促进了内容生态的良性发展。
网站建设、网络推广公司-创新互联,是一家网站专注于品牌和效果的生产、网络营销seo公司;服务项目包括网站维护等。 查看全部
算法 自动采集列表(百度推出飓风算法,蝶变行动新、好站点扶持计划即将开启)
2017年7月7日,继百度绿萝算法和石榴算法之后,百度在“网网”方面又出了一大招——百度推出飓风算法,旨在严厉打击使用不良采集百度搜索作为网站的主要内容来源,将彻底清除索引库中的不良采集链接,为优质原创内容提供更多展示机会,促进百度搜索良性发展。搜索生态。
飓风算法的更新也能看出百度从搜索生态向内容生态迈出了一大步,命中采集网站!
第 1 步:将搜索声明为内容生态
其实,早在2016年9月1日,随着百家号的诞生,百度的内容生态布局就浮出水面,百度卢富斌:搜索就是内容生态。
卢富斌认为,内容生态概念突然升温有两个根本原因:技术的发展导致了人力的大规模解放,尤其是人工智能等技术加速了这一进程。人们开始有更多的机会从事更多与生活、娱乐和创作相关的工作。其次,中国中产阶级的快速崛起提高了整个社会的内容消费能力。“所以百度对内容生态的关注,并不是出于行业的热情,而是基于对用户需求的洞察。”
第 2 步:2017 年 4 月算法更新
新站提速收录:蝶变行动新好站支持计划即将再次上线。
原创保护,再也不用担心抄袭了。保护网站原创的内容,正在大力升级。
阿拉丁产品的开通:阿里丁的战友专属产品有望在更多优质网站上开放。
推送信息展示:手机百度首页主动推送瑞金信息,助力网站品牌展示。
新闻源取消、搜索生态转向内容生态、百度阿里丁即将开启、移动站点语法升级、百度升级渲染UA、移动站点体验强调、移动页面加速器,这些都是百度即将到来的大事件。影响内容的是取消对新闻源和远程内容的保护
第三,。2017年7月7日飓风行动后,百度再次激怒了采集网站。可见,对原创内容的保护和网络运营促进了内容生态的良性发展。
网站建设、网络推广公司-创新互联,是一家网站专注于品牌和效果的生产、网络营销seo公司;服务项目包括网站维护等。
算法 自动采集列表(神策数据推荐系统的竞赛背景和竞赛内容介绍及应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-10-16 20:19
1 比赛背景
神测数据推荐系统是基于神测分析平台的智能推荐系统。基于客户需求和业务特点,利用机器学习算法,基于神测分析采集的用户行为数据,对咨询、视频、产品等进行个性化推荐,为客户提供不同场景下的智能应用,优化产品体验,提升点击率等核心业务指标。神策推荐系统是一个完整的学习闭环。采集的基础数据是通过机器学习的算法模型应用的。实时验证效果,指导数据源添加,算法优化反馈形成全流程、实时、自动、
本次比赛为模拟业务场景,目的是提取新闻文本的核心词,最终达到提升推荐和用户画像的效果。
大赛链接:
数据集
数据地址:[https://pan.baidu.com/s/1LBfqT86y7TEf4hDNCU6DpA](https://pan.baidu.com/s/1LBfqT86y7TEf4hDNCU6DpA)
密码:qa2u
2 任务
个性化推荐系统是神测智能系统的一个重要方面。准确理解信息主体是提高推荐系统有效性的重要手段。神策数据基于一个真实的商业案例,提供了上千条信息文章和关键词。参与者需要训练一个“关键词抽取”模型,抽取10个关键词万片信息文章。
3 数据
备注:报名参赛或入队后,可获得资料下载权限。
提供下载的数据集包括两部分:1. all_docs.txt,108295条信息文章数据,数据格式为:ID 文章 title文章 text,中间是由\001分割。2. train_docs_keywords.txt,文章的1000条关键词标注结果,数据格式为:ID 关键词列表,中间用\t分隔。
注:标记数据中每个文章的关键词不超过5个。关键词 都出现在 文章 的标题或正文中。需要说明的是,“训练集文章关键词形成的集合”和“测试集文章关键词形成的集合可能存在交集”。,但收录和收录之间并不一定存在关系。
4 个人预赛第11名计划
基于NLP中的无监督学习方法提取关键词。这是我第一次参加比赛。那时我是 NLP 的新手,所以我对这次比赛印象非常深刻。我将在这里与您分享。
神策杯”2018年大学算法硕士排名B排名(13/583)
4.1 评分情况4.2 数据分析:4.3 提高技巧,词性标注错误
这就是tf-idf提取关键字误差大的原因
4.5 核心代码:
# -*- coding: utf-8 -*-
# @Author : quincyqiang
# @File : analysis_for_06.py
# @Time : 2018/9/5 14:17
import pickle
import pandas as pd
from tqdm import tqdm
from jieba.analyse import extract_tags,textrank # tf-idf
from jieba import posseg
import random
import jieba
jieba.analyse.set_stop_words('data/stop_words.txt') # 去除停用词
jieba.load_userdict('data/custom_dict.txt') # 设置词库
'''
nr 人名 nz 其他专名 ns 地名 nt 机构团体 n 名词 l 习用语 i 成语 a 形容词
nrt
v 动词 t 时间词
'''
test_data=pd.read_csv('data/test_docs.csv')
train_data=pd.read_csv('data/new_train_docs.csv')
allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'n':6,'l':7,'i':8,'a':9,'nrt':10,'v':11,'t':12}
# allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'nrt':10}
tf_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt','v','a']
def generate_name(word_tags):
name_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt']
for word_tag in word_tags:
if word_tag[0] == '·' or word_tag=='!':
index = word_tags.index(word_tag)
if (index+1) 1]
title_keywords = sorted(title_keywords, reverse=False, key=lambda x: (allow_pos[x[1]], -len(x[0])))
if '·' in title :
if len(title_keywords) >= 2:
key_1 = title_keywords[0][0]
key_2 = title_keywords[1][0]
else:
# print(keywords,title,word_tags)
key_1 = title_keywords[0][0]
key_2 = ''
labels_1.append(key_1)
labels_2.append(key_2)
else:
# 使用tf-idf
use_idf += 1
# ---------重要文本-----
primary_words = []
for keyword in title_keywords:
if keyword[1] == 'n':
primary_words.append(keyword[0])
if keyword[1] in ['nr', 'nz', 'nt', 'ns']:
primary_words.extend([keyword[0]] * len(keyword[0]))
abstract_text = "".join(doc.split(' ')[:15])
for word, tag in jieba.posseg.cut(abstract_text):
if tag == 'n':
primary_words.append(word)
if tag in ['nr', 'nz', 'ns']:
primary_words.extend([word] * len(word))
primary_text = "".join(primary_words)
# 拼接成最后的文本
text = primary_text * 2 + title * 6 + " ".join(doc.split(' ')[:15] * 2) + doc
# ---------重要文本-----
temp_keywords = [keyword for keyword in extract_tags(text, topK=2)]
if len(temp_keywords)>=2:
labels_1.append(temp_keywords[0])
labels_2.append(temp_keywords[1])
else:
labels_1.append(temp_keywords[0])
labels_2.append(' ')
data = {'id': ids,
'label1': labels_1,
'label2': labels_2}
df_data = pd.DataFrame(data, columns=['id', 'label1', 'label2'])
df_data.to_csv('result/06_jieba_ensemble.csv', index=False)
print("使用tf-idf提取的次数:",use_idf)
if __name__ == '__main__':
# evaluate()
extract_keyword_ensemble(test_data)
© 2021 GitHub, Inc.
以下整理来自国内大佬的无私之风
5 “神策杯”2018年高校算法大师赛第二名代码
代码链接:文章 链接:
团队:只有SCI毕业
5.1 目录描述5.2 操作描述 运行Get_Feature.ipynb 得到train_df_v7.csv 和test_df_v7.csv。运行 lgb_predict.py 以获取结果 sub.csv。依赖包
numpy 1.14.0rc1
pandas 0.23.0
sklearn 0.19.0
lightgbm 2.0.5
scipy 1.0.0
5.3 描述解决问题的思路。使用jieba的tfidf方法筛选出Top 20候选人。工作是一个普通的二分类问题。特征可以分为以下两类: 使用LightGBM解决以上两个分类问题,然后根据LightGBM的结果为每个文本选择预测概率为Top2的词作为关键词输出。6 等级 6/622
代码链接:
(3)通过对title中的数据进行分析可以看出,如果title收录书名或者人名,则95%以上对应文章@的关键词 >. 这个应该跟大家的习惯(标签人的习惯)相关,片名中的内容通常对应电影、电视剧、歌曲等名称,这些名词和人名很可能会引起我们的注意开头,所以是关键词的概率非常高。
@0.85,大约100次迭代后PR值可以收敛到一个稳定值。当阻尼系数接近 1 时,所需的迭代次数会急剧增加。并且排序不稳定。公式中S(Vj)前面的分数是指Vj指向的所有网页都应该平均分享Vj的PR值,这样你就可以对你链接的网页进行投票。
Wji指的是Vi和Vj这两个句子的相似度。可以使用编辑距离和余弦相似度。textrank应用于关键词抽取时,与自动摘要抽取不同:1)词之间的关联没有权重,即Wji为1;2) 每个词与文档无关 所有词都有链接,但通过设置定长滑动窗口形式,窗口中词之间有链接。
主题模型常用的方法有LSI(LSA)和LDA,其中LSI使用SVD(奇异值分解)方法进行强力破解,而LDA使用贝叶斯方法拟合分布信息。通过LSA或LDA算法,可以得到文档到主题的分布和主题到词的分布。可以根据主题到词的分布(贝叶斯方法)得到词到主题的分布,然后通过这个分布和文档到主题的分布计算文档和词的相似度,并选择词与文档的 关键词 相似度高的列表。
Umk 表示文档到主题的分布矩阵,Vnk 的转置表示主题到词的分布矩阵。LSA 使用 SVD 更本质地表达单词和文档,并将它们映射到低维空间。在限制使用文本语义信息的同时,LSA 大大降低了计算成本,提高了分析质量。但是计算复杂度很高,特征空间维数大,计算效率很低。当新文档进入现有特征空间时,需要对整个空间进行重新训练,以获取新增文档的分布信息。此外,还存在对频率分布不敏感和物理解释弱的问题。
我们可以根据多项式分布和数据的先验分布找到后验分布,然后用这个后验分布作为下一个先验分布,迭代更新。一般有两种求解方法,第一种是基于Gibbs采样算法,第二种是基于变分推理EM算法。
(4)第二位是通过tfidf选择20个候选集,然后给它们打上标签。特点:在整个数据集中被视为候选的频率关键词。这其实就是候选词在整个数据集中,tfidf在数据集中前20的频率(5)第三位不引入外部词典,利用词的内聚力和自由度从给定的词中寻找新词(6)第五位用的是pyhanlp,据说命名实体识别的准确率比较高。
7 总结
该任务属于词组挖掘或关键词挖掘。在接触NLP的过程中,很多同学都在研究如何从文本中挖掘关键词。经过近几年NLP技术的发展,大致总结了以下方法。其实也是通过上面分享的三个程序来运行的:
8 更多信息 查看全部
算法 自动采集列表(神策数据推荐系统的竞赛背景和竞赛内容介绍及应用)
1 比赛背景
神测数据推荐系统是基于神测分析平台的智能推荐系统。基于客户需求和业务特点,利用机器学习算法,基于神测分析采集的用户行为数据,对咨询、视频、产品等进行个性化推荐,为客户提供不同场景下的智能应用,优化产品体验,提升点击率等核心业务指标。神策推荐系统是一个完整的学习闭环。采集的基础数据是通过机器学习的算法模型应用的。实时验证效果,指导数据源添加,算法优化反馈形成全流程、实时、自动、
本次比赛为模拟业务场景,目的是提取新闻文本的核心词,最终达到提升推荐和用户画像的效果。
大赛链接:
数据集
数据地址:[https://pan.baidu.com/s/1LBfqT86y7TEf4hDNCU6DpA](https://pan.baidu.com/s/1LBfqT86y7TEf4hDNCU6DpA)
密码:qa2u
2 任务
个性化推荐系统是神测智能系统的一个重要方面。准确理解信息主体是提高推荐系统有效性的重要手段。神策数据基于一个真实的商业案例,提供了上千条信息文章和关键词。参与者需要训练一个“关键词抽取”模型,抽取10个关键词万片信息文章。
3 数据
备注:报名参赛或入队后,可获得资料下载权限。
提供下载的数据集包括两部分:1. all_docs.txt,108295条信息文章数据,数据格式为:ID 文章 title文章 text,中间是由\001分割。2. train_docs_keywords.txt,文章的1000条关键词标注结果,数据格式为:ID 关键词列表,中间用\t分隔。
注:标记数据中每个文章的关键词不超过5个。关键词 都出现在 文章 的标题或正文中。需要说明的是,“训练集文章关键词形成的集合”和“测试集文章关键词形成的集合可能存在交集”。,但收录和收录之间并不一定存在关系。
4 个人预赛第11名计划
基于NLP中的无监督学习方法提取关键词。这是我第一次参加比赛。那时我是 NLP 的新手,所以我对这次比赛印象非常深刻。我将在这里与您分享。
神策杯”2018年大学算法硕士排名B排名(13/583)
4.1 评分情况4.2 数据分析:4.3 提高技巧,词性标注错误
这就是tf-idf提取关键字误差大的原因
4.5 核心代码:
# -*- coding: utf-8 -*-
# @Author : quincyqiang
# @File : analysis_for_06.py
# @Time : 2018/9/5 14:17
import pickle
import pandas as pd
from tqdm import tqdm
from jieba.analyse import extract_tags,textrank # tf-idf
from jieba import posseg
import random
import jieba
jieba.analyse.set_stop_words('data/stop_words.txt') # 去除停用词
jieba.load_userdict('data/custom_dict.txt') # 设置词库
'''
nr 人名 nz 其他专名 ns 地名 nt 机构团体 n 名词 l 习用语 i 成语 a 形容词
nrt
v 动词 t 时间词
'''
test_data=pd.read_csv('data/test_docs.csv')
train_data=pd.read_csv('data/new_train_docs.csv')
allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'n':6,'l':7,'i':8,'a':9,'nrt':10,'v':11,'t':12}
# allow_pos={'nr':1,'nz':2,'ns':3,'nt':4,'eng':5,'nrt':10}
tf_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt','v','a']
def generate_name(word_tags):
name_pos = ['ns', 'n', 'vn', 'nr', 'nt', 'eng', 'nrt']
for word_tag in word_tags:
if word_tag[0] == '·' or word_tag=='!':
index = word_tags.index(word_tag)
if (index+1) 1]
title_keywords = sorted(title_keywords, reverse=False, key=lambda x: (allow_pos[x[1]], -len(x[0])))
if '·' in title :
if len(title_keywords) >= 2:
key_1 = title_keywords[0][0]
key_2 = title_keywords[1][0]
else:
# print(keywords,title,word_tags)
key_1 = title_keywords[0][0]
key_2 = ''
labels_1.append(key_1)
labels_2.append(key_2)
else:
# 使用tf-idf
use_idf += 1
# ---------重要文本-----
primary_words = []
for keyword in title_keywords:
if keyword[1] == 'n':
primary_words.append(keyword[0])
if keyword[1] in ['nr', 'nz', 'nt', 'ns']:
primary_words.extend([keyword[0]] * len(keyword[0]))
abstract_text = "".join(doc.split(' ')[:15])
for word, tag in jieba.posseg.cut(abstract_text):
if tag == 'n':
primary_words.append(word)
if tag in ['nr', 'nz', 'ns']:
primary_words.extend([word] * len(word))
primary_text = "".join(primary_words)
# 拼接成最后的文本
text = primary_text * 2 + title * 6 + " ".join(doc.split(' ')[:15] * 2) + doc
# ---------重要文本-----
temp_keywords = [keyword for keyword in extract_tags(text, topK=2)]
if len(temp_keywords)>=2:
labels_1.append(temp_keywords[0])
labels_2.append(temp_keywords[1])
else:
labels_1.append(temp_keywords[0])
labels_2.append(' ')
data = {'id': ids,
'label1': labels_1,
'label2': labels_2}
df_data = pd.DataFrame(data, columns=['id', 'label1', 'label2'])
df_data.to_csv('result/06_jieba_ensemble.csv', index=False)
print("使用tf-idf提取的次数:",use_idf)
if __name__ == '__main__':
# evaluate()
extract_keyword_ensemble(test_data)
© 2021 GitHub, Inc.
以下整理来自国内大佬的无私之风
5 “神策杯”2018年高校算法大师赛第二名代码
代码链接:文章 链接:
团队:只有SCI毕业
5.1 目录描述5.2 操作描述 运行Get_Feature.ipynb 得到train_df_v7.csv 和test_df_v7.csv。运行 lgb_predict.py 以获取结果 sub.csv。依赖包
numpy 1.14.0rc1
pandas 0.23.0
sklearn 0.19.0
lightgbm 2.0.5
scipy 1.0.0
5.3 描述解决问题的思路。使用jieba的tfidf方法筛选出Top 20候选人。工作是一个普通的二分类问题。特征可以分为以下两类: 使用LightGBM解决以上两个分类问题,然后根据LightGBM的结果为每个文本选择预测概率为Top2的词作为关键词输出。6 等级 6/622
代码链接:
(3)通过对title中的数据进行分析可以看出,如果title收录书名或者人名,则95%以上对应文章@的关键词 >. 这个应该跟大家的习惯(标签人的习惯)相关,片名中的内容通常对应电影、电视剧、歌曲等名称,这些名词和人名很可能会引起我们的注意开头,所以是关键词的概率非常高。
@0.85,大约100次迭代后PR值可以收敛到一个稳定值。当阻尼系数接近 1 时,所需的迭代次数会急剧增加。并且排序不稳定。公式中S(Vj)前面的分数是指Vj指向的所有网页都应该平均分享Vj的PR值,这样你就可以对你链接的网页进行投票。
Wji指的是Vi和Vj这两个句子的相似度。可以使用编辑距离和余弦相似度。textrank应用于关键词抽取时,与自动摘要抽取不同:1)词之间的关联没有权重,即Wji为1;2) 每个词与文档无关 所有词都有链接,但通过设置定长滑动窗口形式,窗口中词之间有链接。
主题模型常用的方法有LSI(LSA)和LDA,其中LSI使用SVD(奇异值分解)方法进行强力破解,而LDA使用贝叶斯方法拟合分布信息。通过LSA或LDA算法,可以得到文档到主题的分布和主题到词的分布。可以根据主题到词的分布(贝叶斯方法)得到词到主题的分布,然后通过这个分布和文档到主题的分布计算文档和词的相似度,并选择词与文档的 关键词 相似度高的列表。
Umk 表示文档到主题的分布矩阵,Vnk 的转置表示主题到词的分布矩阵。LSA 使用 SVD 更本质地表达单词和文档,并将它们映射到低维空间。在限制使用文本语义信息的同时,LSA 大大降低了计算成本,提高了分析质量。但是计算复杂度很高,特征空间维数大,计算效率很低。当新文档进入现有特征空间时,需要对整个空间进行重新训练,以获取新增文档的分布信息。此外,还存在对频率分布不敏感和物理解释弱的问题。
我们可以根据多项式分布和数据的先验分布找到后验分布,然后用这个后验分布作为下一个先验分布,迭代更新。一般有两种求解方法,第一种是基于Gibbs采样算法,第二种是基于变分推理EM算法。
(4)第二位是通过tfidf选择20个候选集,然后给它们打上标签。特点:在整个数据集中被视为候选的频率关键词。这其实就是候选词在整个数据集中,tfidf在数据集中前20的频率(5)第三位不引入外部词典,利用词的内聚力和自由度从给定的词中寻找新词(6)第五位用的是pyhanlp,据说命名实体识别的准确率比较高。
7 总结
该任务属于词组挖掘或关键词挖掘。在接触NLP的过程中,很多同学都在研究如何从文本中挖掘关键词。经过近几年NLP技术的发展,大致总结了以下方法。其实也是通过上面分享的三个程序来运行的:
8 更多信息
算法 自动采集列表(算法自动采集列表页信息分析crazy熊数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-10-13 16:01
算法自动采集列表页信息第一步:抓取列表页的信息包括(点击进入产品信息页面]+(打开个人中心)+(随手推荐的功能)这四个主要页面第二步:提取每个公众号的"个人中心"列表页链接第三步:提取每个公众号每天推送信息的链接第四步:每天产生的数据按照清洗标准进行分类提取关键词匹配,提取标题部分第五步:用java或者python进行数据库设计第六步:最终按照数据库设计下载最新列表页信息获取原图完整效果图详细代码见github在此文章的最后有源码(重要),有兴趣的朋友可以学习一下。新浪微博名称;#pid2370294236。
任何平台搜索引擎抓取信息,最后都会聚合在微博中,微博中几乎所有的电商交易都可以通过微博来完成。
1、电商入口,
2、媒体入口,
3、其他入口,
4、广告入口,搜索竞价、地图定位广告投放,如团车网;互联网广告投放等。同时也有基于微博的搜索服务,其中广告、媒体等通过博客、视频、音频等形式来传播,并通过微博平台进行转化。博客:博客——公开网络传播的自由、开放平台,聚集了很多优秀的写手,用户无需注册即可发布微博。视频:网易、优酷等综合型网站视频,搜狐视频、腾讯视频等视频网站;百度、凤凰、今日头条等视频网站;爱奇艺、乐视等视频网站。
音频:喜马拉雅fm、荔枝fm、荔枝fm、蜻蜓fm等音频网站。---这是一种典型的以数据抓取为基础,进行“内容分析”形成seo结果的思路,如果需要学习数据分析的数据采集,可以参考下面的关于crazy熊数据的文章:基于微博的seo分析crazy熊数据以上都是一些微博中比较常见的数据抓取方式,具体的操作过程,也可以参考下面这个表格。 查看全部
算法 自动采集列表(算法自动采集列表页信息分析crazy熊数据)
算法自动采集列表页信息第一步:抓取列表页的信息包括(点击进入产品信息页面]+(打开个人中心)+(随手推荐的功能)这四个主要页面第二步:提取每个公众号的"个人中心"列表页链接第三步:提取每个公众号每天推送信息的链接第四步:每天产生的数据按照清洗标准进行分类提取关键词匹配,提取标题部分第五步:用java或者python进行数据库设计第六步:最终按照数据库设计下载最新列表页信息获取原图完整效果图详细代码见github在此文章的最后有源码(重要),有兴趣的朋友可以学习一下。新浪微博名称;#pid2370294236。
任何平台搜索引擎抓取信息,最后都会聚合在微博中,微博中几乎所有的电商交易都可以通过微博来完成。
1、电商入口,
2、媒体入口,
3、其他入口,
4、广告入口,搜索竞价、地图定位广告投放,如团车网;互联网广告投放等。同时也有基于微博的搜索服务,其中广告、媒体等通过博客、视频、音频等形式来传播,并通过微博平台进行转化。博客:博客——公开网络传播的自由、开放平台,聚集了很多优秀的写手,用户无需注册即可发布微博。视频:网易、优酷等综合型网站视频,搜狐视频、腾讯视频等视频网站;百度、凤凰、今日头条等视频网站;爱奇艺、乐视等视频网站。
音频:喜马拉雅fm、荔枝fm、荔枝fm、蜻蜓fm等音频网站。---这是一种典型的以数据抓取为基础,进行“内容分析”形成seo结果的思路,如果需要学习数据分析的数据采集,可以参考下面的关于crazy熊数据的文章:基于微博的seo分析crazy熊数据以上都是一些微博中比较常见的数据抓取方式,具体的操作过程,也可以参考下面这个表格。
算法 自动采集列表(怎么导出前台运行任务的采集任务?软件步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-13 15:25
第一步:登录打开优采云采集器软件
第二步:新建一个采集任务
1、复制网页地址:需要采集评价的产品网址
2、新流程图模式采集任务:导入采集规则创建智能任务
第三步:配置采集规则
1、设置预登录
输入网址后,我们进入宝贝详情页。这时候我们可以点击关闭页面上出现的登录界面。无需登录即可采集评论数据。
2、设置数据字段
详情页可以看到评论数量,但看不到具体评论内容。我们需要点击评论,然后在左上角跳出的提示框中选择“点击这个元素”。
3、 进入评论界面后,根据搜索方向选择元素,如好评、差评等元素。在此基础上,我们可以右键字段进行相关设置,包括修改字段名称、增加或减少字段、处理数据等。
由于我们要下载所有评论图片,我们可以选择评论中的所有图片,然后设置字段属性——extract external html。
4、我们采集发布了单页评论数据,现在需要采集下一页数据,我们点击页面上的“下一页”按钮,出现操作在左上角的提示框中,选择“循环点击下一页”。
第四步:设置并启动采集任务
点击“开始采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置》,这次采集没有用到这些功能,我们直接点击开始启动采集。
第 5 步:导出并查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式和导出文件格式,也支持特定数量的导出项,其中可以在数据中选择要导出的项目数,然后点击“确认导出”。
[如何导出]
1、导出采集前台运行任务的结果
如果采集任务在前台运行,任务结束后软件会弹出数据采集停止提示框。这时候我们点击“导出数据”按钮,导出采集的数据结果。
2、导出采集后台运行任务的结果
如果采集任务在后台运行,任务完成后桌面右下角会弹出导出提示框。我们将根据右下角任务完成的弹出提示打开查看数据界面或导出数据。
3、导出保存的采集任务的采集结果
如果不是实时采集任务,而是之前运行过的采集任务,比如我们关闭软件再重新打开软件,然后导出一个采集任务已经运行。采集 结果。
这种情况下,我们可以右击任务,点击“查看数据”,打开查看数据界面,然后在该界面设置导出数据。
4、导出数据的其他事项
目前优采云采集器支持多种格式自由导出,包括:Excel2007、Excel2003、CSV、HTML文件、TXT文件;同时支持自由导出到数据库。
个人专业版及以上支持发布到网站,目前支持发布到WordPress、发布到Typecho、发布到DEDEcms(织梦),更多网站模板持续更新中更新中……
导出数据时,用户可以选择导出范围、导出未导出的数据、导出选定的数据或选择导出项目的数量。
导出完成后,您还可以对导出的数据进行标记,以便清晰直观地看到哪些数据已经导出,哪些数据没有导出。
[如何下载图片]
第一种:逐张添加图片
在页面上直接点击要下载的图片,然后根据提示点击“提取该元素”,软件会自动生成提取的数据组件并添加图片字段。(如果有连续的采集字段,可能不会每次都生成一个新的提取数据组价格,只会增加新的字段)
或者直接点击“添加字段”,然后在页面上点击要下载的图片。
第二种:一次下载多张图片
在这种情况下,需要将图片组合在一起,并且可以一次选择所有图片。
我们可以直接点击整个图片区域的右下角,我们在选框的时候可以看到软件的蓝色框选区域,保证所有要下载的图片都被装框了。然后根据提示点击“提取该元素”,软件会自动生成提取的数据组件并添加图片字段。(如果有连续的采集字段,可能不会每次都生成一个新的提取数据组价格,只会增加新的字段)
然后右键单击该字段并将字段属性修改为“提取内部 HTML”。
点击右下角的“开始采集”按钮,设置图片下载功能。
接下来我们只需要点击“开始采集”,然后在开始框中勾选“采集同时下载图片到以下目录”即可启动图片下载功能,用户可以设置图片路径的本地保存。 查看全部
算法 自动采集列表(怎么导出前台运行任务的采集任务?软件步骤)
第一步:登录打开优采云采集器软件
第二步:新建一个采集任务
1、复制网页地址:需要采集评价的产品网址
2、新流程图模式采集任务:导入采集规则创建智能任务
第三步:配置采集规则
1、设置预登录
输入网址后,我们进入宝贝详情页。这时候我们可以点击关闭页面上出现的登录界面。无需登录即可采集评论数据。
2、设置数据字段
详情页可以看到评论数量,但看不到具体评论内容。我们需要点击评论,然后在左上角跳出的提示框中选择“点击这个元素”。
3、 进入评论界面后,根据搜索方向选择元素,如好评、差评等元素。在此基础上,我们可以右键字段进行相关设置,包括修改字段名称、增加或减少字段、处理数据等。
由于我们要下载所有评论图片,我们可以选择评论中的所有图片,然后设置字段属性——extract external html。
4、我们采集发布了单页评论数据,现在需要采集下一页数据,我们点击页面上的“下一页”按钮,出现操作在左上角的提示框中,选择“循环点击下一页”。
第四步:设置并启动采集任务
点击“开始采集”按钮,在弹出的启动设置页面中进行一些高级设置,包括“定时启动、防阻塞、自动导出、文件下载、加速引擎、重复数据删除、开发者设置》,这次采集没有用到这些功能,我们直接点击开始启动采集。
第 5 步:导出并查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式和导出文件格式,也支持特定数量的导出项,其中可以在数据中选择要导出的项目数,然后点击“确认导出”。
[如何导出]
1、导出采集前台运行任务的结果
如果采集任务在前台运行,任务结束后软件会弹出数据采集停止提示框。这时候我们点击“导出数据”按钮,导出采集的数据结果。
2、导出采集后台运行任务的结果
如果采集任务在后台运行,任务完成后桌面右下角会弹出导出提示框。我们将根据右下角任务完成的弹出提示打开查看数据界面或导出数据。
3、导出保存的采集任务的采集结果
如果不是实时采集任务,而是之前运行过的采集任务,比如我们关闭软件再重新打开软件,然后导出一个采集任务已经运行。采集 结果。
这种情况下,我们可以右击任务,点击“查看数据”,打开查看数据界面,然后在该界面设置导出数据。
4、导出数据的其他事项
目前优采云采集器支持多种格式自由导出,包括:Excel2007、Excel2003、CSV、HTML文件、TXT文件;同时支持自由导出到数据库。
个人专业版及以上支持发布到网站,目前支持发布到WordPress、发布到Typecho、发布到DEDEcms(织梦),更多网站模板持续更新中更新中……
导出数据时,用户可以选择导出范围、导出未导出的数据、导出选定的数据或选择导出项目的数量。
导出完成后,您还可以对导出的数据进行标记,以便清晰直观地看到哪些数据已经导出,哪些数据没有导出。
[如何下载图片]
第一种:逐张添加图片
在页面上直接点击要下载的图片,然后根据提示点击“提取该元素”,软件会自动生成提取的数据组件并添加图片字段。(如果有连续的采集字段,可能不会每次都生成一个新的提取数据组价格,只会增加新的字段)
或者直接点击“添加字段”,然后在页面上点击要下载的图片。
第二种:一次下载多张图片
在这种情况下,需要将图片组合在一起,并且可以一次选择所有图片。
我们可以直接点击整个图片区域的右下角,我们在选框的时候可以看到软件的蓝色框选区域,保证所有要下载的图片都被装框了。然后根据提示点击“提取该元素”,软件会自动生成提取的数据组件并添加图片字段。(如果有连续的采集字段,可能不会每次都生成一个新的提取数据组价格,只会增加新的字段)
然后右键单击该字段并将字段属性修改为“提取内部 HTML”。
点击右下角的“开始采集”按钮,设置图片下载功能。
接下来我们只需要点击“开始采集”,然后在开始框中勾选“采集同时下载图片到以下目录”即可启动图片下载功能,用户可以设置图片路径的本地保存。
算法 自动采集列表(Java内存模型-和内存分配以及jdk、jre是什么关系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-10-13 10:05
如果想了解Java内存模型参考:jvm内存模型-内存分配与jdk、jre、jvm的关系是什么(阿里、美团、京东)
相信像编辑器这样的程序员在日常工作或者面试中经常会遇到JVM的垃圾回收问题。深夜的JVM垃圾回收机制有详细的了解吗?没时间抚摸也没关系,因为接下来我要抚摸你。
一、 你需要了解技术背景
按照套路,需要先安装X,说说JVM垃圾回收的前世今生。说到垃圾采集(GC),大多数人把这项技术看作是 Java 语言的配套产品。事实上,GC 的历史比 Java 更长。早在 1960 年,Lisp 就使用了内存动态分配和垃圾采集技术。设计和优化C++语言的高手们久等了~~
二、 哪些内存需要回收?
大家都知道JVM的内存结构包括五个区域:程序计数器、虚拟机栈、本地方法栈、堆区、方法区。其中,程序计数器、虚拟机栈、本地方法栈都是用线程产生和熄灭的。所以这些区域的内存分配和回收都是确定性的,所以不需要过多考虑回收的问题,因为当方法结束或者线程结束的时候,内存自然会被回收。Java堆区和方法区是有区别的!(怎么说区别就上口了),这部分内存的分配和回收是动态的,这是垃圾采集器需要注意的部分。
垃圾回收器在回收堆区和方法区之前,首先要确定这些区域中哪些对象可以回收,哪些暂时不能回收。这就需要一个算法来判断对象是否还活着!(面试官肯定没少问你吧)
2.1 引用计数算法2.1.1 算法分析
引用计数是垃圾采集器的早期策略。在这个方法中,堆中的每个对象实例都有一个引用计数。当一个对象被创建时,对象实例被赋值给一个变量,变量计数被设置为1。当任何其他变量被赋值给这个对象的引用时,计数增加1(a=b,那么b + 1) 引用的对象实例的计数器,但是当对象实例的引用超过生命周期或设置为新值时,对象实例的引用计数器减1。任何引用计数器为 0 的对象实例可以被当作垃圾回收处理。当一个对象实例被垃圾回收时,它所引用的任何对象实例的引用计数器都减 1。
2.1.2 优缺点
优点:引用计数采集器的执行速度非常快,交织在程序的运行中。更有利于程序不需要长时间中断的实时环境。
缺点:无法检测循环引用。如果父对象引用了子对象,则子对象又会引用父对象。这样,它们的引用计数永远不会为 0。
2.1.3 是不是很无聊,来点代码来压制一下惊喜
public class abc_test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MyObject object1=new MyObject();
MyObject object2=new MyObject();
object1.object=object2;
object2.object=object1;
object1=null;
object2=null;
}
}
class MyObject{
MyObject object;
}
此代码用于验证引用计数算法无法检测循环引用。最后两句将object1和object2赋值为null,表示object1和object2所指向的对象不能再被访问,但是因为它们相互引用,它们的引用计数器都不为0,那么垃圾采集器就永远不会了被回收。
2.2 可达性分析算法
可达性分析算法是从离散数学中的图论引入的。程序把所有的引用关系看成一个图,从一个节点GC ROOT开始,寻找对应的引用节点,找到这个节点后,继续寻找这个节点,当所有的引用节点都被搜索到时,剩下的节点被认为是未引用节点,即无用节点,无用节点将被判断为可回收对象。
在Java语言中,可以作为GC Roots的对象包括:(京东)
a) 虚拟机栈中引用的对象(栈帧中的局部变量表);
b) 方法区中类的静态属性所引用的对象;
c) 方法区常量引用的对象;
d) 本地方法堆栈中由 JNI(本地方法)引用的对象。
该算法的基本思想是以一系列称为“GC Roots”的对象为起点,从这些节点开始向下搜索。搜索所采用的路径称为参考链。当一个对象到达 GC Roots 时,没有任何引用链连接(用图论的话,该对象从 GC Roots 是不可到达的),证明该对象不可用。如图所示,objects object 5、object 6、object 7虽然相互关联,但是对于GC Roots是不可达的,所以会被判断为可回收的对象。
现在的问题是,可达性分析算法会不会存在对象之间循环引用的问题?答案是肯定的,即对象之间不会有循环引用。GC Root 在对象图之外,它是一个专门定义的“起点”,不能被对象图中的对象引用。
死或不死(死或不死)
即使是在可达性分析算法中不可达的对象也不是“必须死”的。此时,他们暂时处于“缓刑”阶段。要真正声明一个对象死亡,它至少要经过两个标记过程:如果该对象经过可达性分析,发现没有连接到GC Roots的引用链,那么它会第一次被标记,并且一个过滤器将被执行。过滤条件是对象是否有必要执行 finapze() 方法。当对象没有覆盖finapze()方法,或者finapze()方法已经被虚拟机调用时,虚拟机将这两种情况都视为“无需执行”。在程序中,你可以通过覆盖finapze()来进行一次“惊心动魄”的自救过程,但这只是一次机会。
/**
* 此代码演示了两点:
* 1.对象可以在被GC时自我拯救。
* 2.这种自救的机会只有一次,因为一个对象的finapze()方法最多只会被系统自动调用一次
* @author zzm
*/
pubpc class FinapzeEscapeGC {
pubpc static FinapzeEscapeGC SAVE_HOOK = null;
pubpc void isApve() {
System.out.println("yes, i am still apve :)");
}
@Override
protected void finapze() throws Throwable {
super.finapze();
System.out.println("finapze mehtod executed!");
FinapzeEscapeGC.SAVE_HOOK = this;
}
pubpc static void main(String[] args) throws Throwable {
SAVE_HOOK = new FinapzeEscapeGC();
//对象第一次成功拯救自己
SAVE_HOOK = null;
System.gc();
//因为finapze方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isApve();
} else {
System.out.println("no, i am dead :(");
}
//下面这段代码与上面的完全相同,但是这次自救却失败了
SAVE_HOOK = null;
System.gc();
//因为finapze方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isApve();
} else {
System.out.println("no, i am dead :(");
}
}
}
操作结果如下:
finapze mehtod executed!
yes, i am still apve :)
no, i am dead :(
2.3 Java中的引用你了解多少
无论是通过引用计数算法判断对象的引用次数,还是通过可达性分析算法判断对象的引用链是否可达,都与“引用”有关,以确定对象是否为活。在Java语言中,引用分为强引用、软引用、弱引用和幻引用四种。这四次引用的强度逐渐减弱。无论是通过引用计数算法判断对象的引用次数,还是通过可达性分析算法判断对象的引用链是否可达,都与“引用”有关,以确定对象是否为活。在 JDK 1.2 之前,Java中引用的定义非常传统:如果引用类型数据中存储的值代表另一块内存的起始地址,则称这块内存代表一个引用。在JDK1.2之后,Java扩展了引用的概念,将引用分为强引用、软引用、弱引用和幻像引用。有四种类型,这四种类型的引用强度逐渐降低。
程序代码中常见的,类似于Object obj = new Object()引用,只要强引用还存在,垃圾回收器就永远不会回收被引用的对象。
用于描述一些有用但不是必需的对象。对于软引用关联的对象,在系统出现内存溢出异常之前,会将这些对象列在恢复范围内进行二次恢复。如果本次采集后内存不足,会抛出内存溢出异常。
它也用于描述非本质对象,但其强度比软引用弱。与弱引用关联的对象只能存活到下一次垃圾回收发生。垃圾回收器工作时,无论当前内存是否足够,都会回收那些只是弱引用的对象。在JDK1.2之后,提供了WeakReference类来实现弱引用。比如threadlocal
它也被称为幽灵引用或幻影引用(这个名字真的很神奇),它是最弱的一种引用关系。一个对象是否有幻影引用根本不会影响它的生命周期,不可能通过幻影引用获得一个对象实例。它的功能是当这个对象被采集器回收时接收系统通知。. 在JDK1.2之后,提供了PhantomReference类来实现虚引用。
不要被概念吓到,不要着急,你没有跑题,深入就难说了。小编列出这四个概念的目的是为了说明引用计数算法和可达性分析算法都是基于强引用的。
软引用示例:
package jvm;
import java.lang.ref.SoftReference;
class Node {
pubpc String msg = "";
}
pubpc class Hello {
pubpc static void main(String[] args) {
Node node1 = new Node(); // 强引用
node1.msg = "node1";
SoftReference node2 = new SoftReference(node1); // 软引用
node2.get().msg = "node2";
System.out.println(node1.msg);
System.out.println(node2.get().msg);
}
}
输出是:
node2
node2
2.4 对象死亡前的最后挣扎(并被回收)
即使是在可达性分析算法中不可达的对象也不是“必须死”的。此时,他们暂时处于“缓刑”阶段。要真正声明一个对象死亡,至少需要两个标记过程。
第一次标记:如果对象在可达性分析后发现没有连接到GC Roots的引用链,则进行第一次标记;
第二个标记:在第一个标记之后,将执行过滤。过滤条件是这个对象是否有必要执行finalize()方法。如果在 finalize() 方法中没有重新建立与引用链的关系,则会进行第二次标记。
第二次成功标记的对象将真正被回收。如果对象在 finalize() 方法中重新建立与引用链的关联关系,它将逃脱这种回收并继续生存。猿猴还在,嘿嘿。
2.5 如何判断方法区是否需要回收
猿类,对方法区存储的内容是否需要回收的判断是不同的。方法区回收的主要内容是:丢弃的常量和无用的类。过时的常量也可以通过引用可达性来判断,但是对于无用的类,必须同时满足以下三个条件:
关于类加载的原理,也是阿里面试的主角。面试官还问我例如:我可以自己定义String吗,答案是否定的,因为jvm在加载类的时候会进行父母委托。
原理请参考:Java类加载机制(阿里面试题)
说了半天,主角终于要上台了。
如何确定垃圾对象
几乎所有的对象实例都存储在 Java 堆中。在垃圾采集器回收堆之前,它首先需要确定哪些对象还“活着”,哪些对象已经“死了”,即不会以任何方式使用的对象。
三、常用的垃圾回收算法
3.0 引用计数方法
引用计数方法实现简单,效率高,在大多数情况下是一种很好的算法。原理是:给对象添加一个引用计数器。每当有对象引用时,计数器加1,引用无效时,计数器减1,当计数器值为0时,不再使用该对象。需要注意的是,引用计数方法难以解决对象之间相互循环引用的问题,主流Java虚拟机也没有使用引用计数方法来管理内存。
public class abc_test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MyObject object1=new MyObject();
MyObject object2=new MyObject();
object1.object=object2;
object2.object=object1;
object1=null;
object2=null;
}
}
class MyObject{
MyObject object;
}
3.1 标记-扫描算法(Mark-Sweep)
这是最基本的垃圾采集算法。之所以是最基本的,是因为它最容易实现,也是最简单的想法。标记清除算法分为标记阶段和清除阶段两个阶段。标记阶段的任务是标记所有需要回收的对象,清理阶段的任务是回收被标记对象占用的空间。具体流程如下图所示:
从图中不难看出,mark-sweep算法更容易实现,但是有一个比较严重的问题,就是容易出现内存碎片。分片过多可能会导致后续进程需要为大对象分配空间时找不到足够的空间。空间并提前触发新的垃圾采集。
mark-sweep算法使用GC Roots扫描来标记幸存的对象。标记完成后,对整个空间中未标记的物体进行扫描回收,如下图所示。mark-sweep算法不需要移动对象,只处理非存活对象,当存活对象较多时效率极高,但由于mark-sweep算法直接回收非存活对象,会造成内存占用碎片化。
3.2 复制算法(Copying)
为了解决Mark-Sweep算法的不足,提出了Copying算法。它根据容量将可用内存分成大小相等的两块,一次只使用其中一块。当这块内存用完时,将幸存的对象复制到另一个块中,然后立即清除已用的内存空间,这样就不容易发生内存碎片。具体流程如下图所示:
该算法虽然实现简单,运行效率高,不易出现内存碎片,但由于可以使用的内存减少到原来的一半,因此在内存空间的使用上付出了高昂的代价。
显然,Copying 算法的效率与幸存对象的数量有很大关系。如果存活对象较多,则Copying算法的效率会大大降低。
提出复制算法,克服句柄开销,解决内存碎片问题。一开始,它将堆划分为一个对象表面和多个自由表面。程序从物体表面为物体分配空间。当对象满时,基于复制算法的垃圾回收从根集(GC Roots)开始扫描活动对象,并将每个活动对象复制到空闲表面(这样占用的内存之间没有空闲空洞)活动物体),这样自由面变成物体面,原物体面变成自由面,程序会在新物体面上分配内存。
3.3 Mark-compact 算法(Mark-compact)
为了解决Copying算法的不足,充分利用内存空间,提出了Mark-Compact算法。这个算法的标记阶段和Mark-Sweep一样,但是标记完成后,并不是直接清理可回收的对象,而是将所有幸存的对象移到一端(美团面试题,记住标记完成后,做先不清理。先移动再清理回收的对象),再清理结束边界外的内存(美团提问)
标记-组织算法使用与标记-清除算法相同的方法来标记对象,但清理方式不同。回收非存活对象占用的空间后,所有存活的对象将被移动到左边的空闲空间,并更新相应的对象。指针。mark-arrangement算法基于mark-clear算法,移动对象,所以成本较高,但解决了内存碎片问题。具体流程如下图所示:
3.4代采集算法分代采集算法
分代采集算法是目前大多数 JVM 垃圾采集器使用的算法。它的核心思想是根据对象生存的生命周期将内存划分为几个不同的区域。一般来说,堆区分为Tenured Generation和Young Generation,堆区之外还有一个代,就是Permanet Generation(永久代)。老年代的特点是每次垃圾采集只需要采集少量对象,而新生代的特点是每次垃圾采集需要采集大量对象,所以最适合可根据不同世代的特点采取采集。算法。
目前大部分垃圾回收器对新生代采用Copying算法,因为新生代每次垃圾回收都会回收大部分对象,这意味着需要复制的操作次数较少,但在实践中是不是按照1:1的比例来划分新生代空间的,一般是将新生代划分为一个较大的Eden空间和两个较小的Survivor空间(通常是8:1:1),每次使用Eden空间) 用其中一个Survivor空间,回收时,将Eden和Survivor中的幸存对象复制到另一个Survivor空间,然后清理Eden和之前使用过的Survivor空间。
但是由于老年代的特点是每次回收的对象很少,所以一般采用Mark-Compact算法。
3.4.1 Young Generation的回收算法(Recycling主要基于Copying)
a) 所有新生成的对象首先被放入年轻代。年轻代的目标是尽快采集生命周期较短的对象。
b) 新生代内存按照8:1:1的比例划分为一个eden区和两个survivor(survivor0,survivor1)区。一个Eden区和两个Survivor区(一般来说)。大多数对象在Eden区生成,回收时将eden区的survivor对象复制到一个survivor0区,然后清空eden区,当survivor0区也满时,将eden区和survivor0区的survivor对象复制到另一个,然后清掉eden和survivor0区,这时候survivor0区是空的,再交换survivor0区和survivor1区,也就是留survivor1区空着(美团面试,问题太详细了,为什么留survivor1为空,答案:为了让eden和survivor0交换存活对象),如此来回。当 Eden 空间不足时,会触发 jvm 发起 Minor GC
c) 当survivor1区不够存放eden和survivor0的survivor对象时,直接将survivor对象存入老年代。如果老年代满了,就会触发Full GC(Major GC),即新生代和老年代都被回收。
d) 新生代发生的GC也叫Minor GC,MinorGC的频率比较高(不一定要等Eden区满才触发)。
3.4. 2年老年代(Old Generation)回收算法(回收主要基于Mark-Compact)
a) 在年轻代中存活 N 次垃圾回收的对象将被放置在年老代中。因此,可以认为老年代存储的对象是长寿命对象。
b) 内存也比新生代大很多(约1:2)。当老年代内存满时,触发Major GC,即Full GC。Full GC的频率为相对较低,老年代的对象存活时间较长,比例较高。
3.4.3 永久代的回收算法(即方法区)
用于存放静态文件,比如Java类、方法等。持久化生成对垃圾回收没有明显影响,但是有些应用可能会动态生成或调用一些类,比如Hibernate等。这时候一个比较大的持久化运行时需要设置生成空间来存储这些新添加的类。持久代也称为方法区,具体恢复见上文第5节。
再写一遍:
方法区存储的内容是否需要回收的判断不同。方法区回收的主要内容是:丢弃的常量和无用的类。过时的常量也可以通过引用可达性来判断,但是对于无用的类,必须同时满足以下三个条件:
5 新生代和老一代的区别(阿里面试官提问):
**所谓的年轻代和老年代是为分代采集算法定义的,新生代分为Eden和Survivor两个区域。把老年加到这三个区。数据会先分配到Eden区(当然也有特殊情况,如果是大对象,会直接放到老年代(大对象是指需要大量连续的java对象)内存空间)),当Eden没有足够空间时会触发jvm发起Minor GC。如果对象在 Minor GC 中幸存下来并且可以被 Survivor 空间接受,它将被移动到 Survivor 空间。并将其年龄设置为1,对象在Survivor中每存活一次Minor GC,年龄加1。当年龄达到一定级别时(默认为15),它将被提升到老年。当然,提升到老年代的年龄是可以设置的。如果老年代满了,执行:Full GC不是经常执行,所以使用Mark-Compact算法清理
其实新生代和老年代都是对对象进行分区存储,更方便回收等**
跟上,猿人,离优惠不远了!!!
四、普通垃圾采集器
下图显示了 HotSpot 虚拟机中收录的所有采集器。图片是从这里借来的:
五、什么时候触发GC?(最常见的面试问题之一一)
由于对象是分代处理的,垃圾回收的区域和时间也不同。GC 有两种类型:Scavenge GC 和 Full GC。
5.1 Scavenge GC
一般情况下,当有新对象产生,在Eden区申请空间失败时,会触发Scavenge GC对Eden区进行GC,移除不存活的对象,并将存活的对象移动到Survivor区。然后组织Survivor的两个区域。这种GC方式是在年轻代的Eden区进行的,不会影响到老年代。因为大部分对象都是从Eden区开始的,而且Eden区不会分配的很大,所以Eden区的GC会频繁的执行。因此,这里一般需要使用快速高效的算法,才能让Eden尽快自由。
5.2 全 GC
对整个堆进行排序,包括 Young、Tenured 和 Perm。Full GC需要回收整个堆,所以比Scavenge GC慢,所以要尽量减少Full GC的次数。在调优JVM的过程中,很大一部分工作是Full GC的调整。以下原因可能会导致 Full GC:
a) 任期已满;
b) 持久代(Perm)被填充;
c) System.gc() 被显式调用;
d) Heap 域分配策略在最后一次 GC 后动态变化;
参考:看看JVM的垃圾回收机制,你准备好迎接下一次面试了吗? 查看全部
算法 自动采集列表(Java内存模型-和内存分配以及jdk、jre是什么关系)
如果想了解Java内存模型参考:jvm内存模型-内存分配与jdk、jre、jvm的关系是什么(阿里、美团、京东)
相信像编辑器这样的程序员在日常工作或者面试中经常会遇到JVM的垃圾回收问题。深夜的JVM垃圾回收机制有详细的了解吗?没时间抚摸也没关系,因为接下来我要抚摸你。
一、 你需要了解技术背景
按照套路,需要先安装X,说说JVM垃圾回收的前世今生。说到垃圾采集(GC),大多数人把这项技术看作是 Java 语言的配套产品。事实上,GC 的历史比 Java 更长。早在 1960 年,Lisp 就使用了内存动态分配和垃圾采集技术。设计和优化C++语言的高手们久等了~~
二、 哪些内存需要回收?
大家都知道JVM的内存结构包括五个区域:程序计数器、虚拟机栈、本地方法栈、堆区、方法区。其中,程序计数器、虚拟机栈、本地方法栈都是用线程产生和熄灭的。所以这些区域的内存分配和回收都是确定性的,所以不需要过多考虑回收的问题,因为当方法结束或者线程结束的时候,内存自然会被回收。Java堆区和方法区是有区别的!(怎么说区别就上口了),这部分内存的分配和回收是动态的,这是垃圾采集器需要注意的部分。
垃圾回收器在回收堆区和方法区之前,首先要确定这些区域中哪些对象可以回收,哪些暂时不能回收。这就需要一个算法来判断对象是否还活着!(面试官肯定没少问你吧)
2.1 引用计数算法2.1.1 算法分析
引用计数是垃圾采集器的早期策略。在这个方法中,堆中的每个对象实例都有一个引用计数。当一个对象被创建时,对象实例被赋值给一个变量,变量计数被设置为1。当任何其他变量被赋值给这个对象的引用时,计数增加1(a=b,那么b + 1) 引用的对象实例的计数器,但是当对象实例的引用超过生命周期或设置为新值时,对象实例的引用计数器减1。任何引用计数器为 0 的对象实例可以被当作垃圾回收处理。当一个对象实例被垃圾回收时,它所引用的任何对象实例的引用计数器都减 1。
2.1.2 优缺点
优点:引用计数采集器的执行速度非常快,交织在程序的运行中。更有利于程序不需要长时间中断的实时环境。
缺点:无法检测循环引用。如果父对象引用了子对象,则子对象又会引用父对象。这样,它们的引用计数永远不会为 0。
2.1.3 是不是很无聊,来点代码来压制一下惊喜
public class abc_test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MyObject object1=new MyObject();
MyObject object2=new MyObject();
object1.object=object2;
object2.object=object1;
object1=null;
object2=null;
}
}
class MyObject{
MyObject object;
}
此代码用于验证引用计数算法无法检测循环引用。最后两句将object1和object2赋值为null,表示object1和object2所指向的对象不能再被访问,但是因为它们相互引用,它们的引用计数器都不为0,那么垃圾采集器就永远不会了被回收。
2.2 可达性分析算法
可达性分析算法是从离散数学中的图论引入的。程序把所有的引用关系看成一个图,从一个节点GC ROOT开始,寻找对应的引用节点,找到这个节点后,继续寻找这个节点,当所有的引用节点都被搜索到时,剩下的节点被认为是未引用节点,即无用节点,无用节点将被判断为可回收对象。
在Java语言中,可以作为GC Roots的对象包括:(京东)
a) 虚拟机栈中引用的对象(栈帧中的局部变量表);
b) 方法区中类的静态属性所引用的对象;
c) 方法区常量引用的对象;
d) 本地方法堆栈中由 JNI(本地方法)引用的对象。
该算法的基本思想是以一系列称为“GC Roots”的对象为起点,从这些节点开始向下搜索。搜索所采用的路径称为参考链。当一个对象到达 GC Roots 时,没有任何引用链连接(用图论的话,该对象从 GC Roots 是不可到达的),证明该对象不可用。如图所示,objects object 5、object 6、object 7虽然相互关联,但是对于GC Roots是不可达的,所以会被判断为可回收的对象。
现在的问题是,可达性分析算法会不会存在对象之间循环引用的问题?答案是肯定的,即对象之间不会有循环引用。GC Root 在对象图之外,它是一个专门定义的“起点”,不能被对象图中的对象引用。
死或不死(死或不死)
即使是在可达性分析算法中不可达的对象也不是“必须死”的。此时,他们暂时处于“缓刑”阶段。要真正声明一个对象死亡,它至少要经过两个标记过程:如果该对象经过可达性分析,发现没有连接到GC Roots的引用链,那么它会第一次被标记,并且一个过滤器将被执行。过滤条件是对象是否有必要执行 finapze() 方法。当对象没有覆盖finapze()方法,或者finapze()方法已经被虚拟机调用时,虚拟机将这两种情况都视为“无需执行”。在程序中,你可以通过覆盖finapze()来进行一次“惊心动魄”的自救过程,但这只是一次机会。
/**
* 此代码演示了两点:
* 1.对象可以在被GC时自我拯救。
* 2.这种自救的机会只有一次,因为一个对象的finapze()方法最多只会被系统自动调用一次
* @author zzm
*/
pubpc class FinapzeEscapeGC {
pubpc static FinapzeEscapeGC SAVE_HOOK = null;
pubpc void isApve() {
System.out.println("yes, i am still apve :)");
}
@Override
protected void finapze() throws Throwable {
super.finapze();
System.out.println("finapze mehtod executed!");
FinapzeEscapeGC.SAVE_HOOK = this;
}
pubpc static void main(String[] args) throws Throwable {
SAVE_HOOK = new FinapzeEscapeGC();
//对象第一次成功拯救自己
SAVE_HOOK = null;
System.gc();
//因为finapze方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isApve();
} else {
System.out.println("no, i am dead :(");
}
//下面这段代码与上面的完全相同,但是这次自救却失败了
SAVE_HOOK = null;
System.gc();
//因为finapze方法优先级很低,所以暂停0.5秒以等待它
Thread.sleep(500);
if (SAVE_HOOK != null) {
SAVE_HOOK.isApve();
} else {
System.out.println("no, i am dead :(");
}
}
}
操作结果如下:
finapze mehtod executed!
yes, i am still apve :)
no, i am dead :(
2.3 Java中的引用你了解多少
无论是通过引用计数算法判断对象的引用次数,还是通过可达性分析算法判断对象的引用链是否可达,都与“引用”有关,以确定对象是否为活。在Java语言中,引用分为强引用、软引用、弱引用和幻引用四种。这四次引用的强度逐渐减弱。无论是通过引用计数算法判断对象的引用次数,还是通过可达性分析算法判断对象的引用链是否可达,都与“引用”有关,以确定对象是否为活。在 JDK 1.2 之前,Java中引用的定义非常传统:如果引用类型数据中存储的值代表另一块内存的起始地址,则称这块内存代表一个引用。在JDK1.2之后,Java扩展了引用的概念,将引用分为强引用、软引用、弱引用和幻像引用。有四种类型,这四种类型的引用强度逐渐降低。
程序代码中常见的,类似于Object obj = new Object()引用,只要强引用还存在,垃圾回收器就永远不会回收被引用的对象。
用于描述一些有用但不是必需的对象。对于软引用关联的对象,在系统出现内存溢出异常之前,会将这些对象列在恢复范围内进行二次恢复。如果本次采集后内存不足,会抛出内存溢出异常。
它也用于描述非本质对象,但其强度比软引用弱。与弱引用关联的对象只能存活到下一次垃圾回收发生。垃圾回收器工作时,无论当前内存是否足够,都会回收那些只是弱引用的对象。在JDK1.2之后,提供了WeakReference类来实现弱引用。比如threadlocal
它也被称为幽灵引用或幻影引用(这个名字真的很神奇),它是最弱的一种引用关系。一个对象是否有幻影引用根本不会影响它的生命周期,不可能通过幻影引用获得一个对象实例。它的功能是当这个对象被采集器回收时接收系统通知。. 在JDK1.2之后,提供了PhantomReference类来实现虚引用。
不要被概念吓到,不要着急,你没有跑题,深入就难说了。小编列出这四个概念的目的是为了说明引用计数算法和可达性分析算法都是基于强引用的。
软引用示例:
package jvm;
import java.lang.ref.SoftReference;
class Node {
pubpc String msg = "";
}
pubpc class Hello {
pubpc static void main(String[] args) {
Node node1 = new Node(); // 强引用
node1.msg = "node1";
SoftReference node2 = new SoftReference(node1); // 软引用
node2.get().msg = "node2";
System.out.println(node1.msg);
System.out.println(node2.get().msg);
}
}
输出是:
node2
node2
2.4 对象死亡前的最后挣扎(并被回收)
即使是在可达性分析算法中不可达的对象也不是“必须死”的。此时,他们暂时处于“缓刑”阶段。要真正声明一个对象死亡,至少需要两个标记过程。
第一次标记:如果对象在可达性分析后发现没有连接到GC Roots的引用链,则进行第一次标记;
第二个标记:在第一个标记之后,将执行过滤。过滤条件是这个对象是否有必要执行finalize()方法。如果在 finalize() 方法中没有重新建立与引用链的关系,则会进行第二次标记。
第二次成功标记的对象将真正被回收。如果对象在 finalize() 方法中重新建立与引用链的关联关系,它将逃脱这种回收并继续生存。猿猴还在,嘿嘿。
2.5 如何判断方法区是否需要回收
猿类,对方法区存储的内容是否需要回收的判断是不同的。方法区回收的主要内容是:丢弃的常量和无用的类。过时的常量也可以通过引用可达性来判断,但是对于无用的类,必须同时满足以下三个条件:
关于类加载的原理,也是阿里面试的主角。面试官还问我例如:我可以自己定义String吗,答案是否定的,因为jvm在加载类的时候会进行父母委托。
原理请参考:Java类加载机制(阿里面试题)
说了半天,主角终于要上台了。
如何确定垃圾对象
几乎所有的对象实例都存储在 Java 堆中。在垃圾采集器回收堆之前,它首先需要确定哪些对象还“活着”,哪些对象已经“死了”,即不会以任何方式使用的对象。
三、常用的垃圾回收算法
3.0 引用计数方法
引用计数方法实现简单,效率高,在大多数情况下是一种很好的算法。原理是:给对象添加一个引用计数器。每当有对象引用时,计数器加1,引用无效时,计数器减1,当计数器值为0时,不再使用该对象。需要注意的是,引用计数方法难以解决对象之间相互循环引用的问题,主流Java虚拟机也没有使用引用计数方法来管理内存。
public class abc_test {
public static void main(String[] args) {
// TODO Auto-generated method stub
MyObject object1=new MyObject();
MyObject object2=new MyObject();
object1.object=object2;
object2.object=object1;
object1=null;
object2=null;
}
}
class MyObject{
MyObject object;
}
3.1 标记-扫描算法(Mark-Sweep)
这是最基本的垃圾采集算法。之所以是最基本的,是因为它最容易实现,也是最简单的想法。标记清除算法分为标记阶段和清除阶段两个阶段。标记阶段的任务是标记所有需要回收的对象,清理阶段的任务是回收被标记对象占用的空间。具体流程如下图所示:
从图中不难看出,mark-sweep算法更容易实现,但是有一个比较严重的问题,就是容易出现内存碎片。分片过多可能会导致后续进程需要为大对象分配空间时找不到足够的空间。空间并提前触发新的垃圾采集。
mark-sweep算法使用GC Roots扫描来标记幸存的对象。标记完成后,对整个空间中未标记的物体进行扫描回收,如下图所示。mark-sweep算法不需要移动对象,只处理非存活对象,当存活对象较多时效率极高,但由于mark-sweep算法直接回收非存活对象,会造成内存占用碎片化。
3.2 复制算法(Copying)
为了解决Mark-Sweep算法的不足,提出了Copying算法。它根据容量将可用内存分成大小相等的两块,一次只使用其中一块。当这块内存用完时,将幸存的对象复制到另一个块中,然后立即清除已用的内存空间,这样就不容易发生内存碎片。具体流程如下图所示:
该算法虽然实现简单,运行效率高,不易出现内存碎片,但由于可以使用的内存减少到原来的一半,因此在内存空间的使用上付出了高昂的代价。
显然,Copying 算法的效率与幸存对象的数量有很大关系。如果存活对象较多,则Copying算法的效率会大大降低。
提出复制算法,克服句柄开销,解决内存碎片问题。一开始,它将堆划分为一个对象表面和多个自由表面。程序从物体表面为物体分配空间。当对象满时,基于复制算法的垃圾回收从根集(GC Roots)开始扫描活动对象,并将每个活动对象复制到空闲表面(这样占用的内存之间没有空闲空洞)活动物体),这样自由面变成物体面,原物体面变成自由面,程序会在新物体面上分配内存。
3.3 Mark-compact 算法(Mark-compact)
为了解决Copying算法的不足,充分利用内存空间,提出了Mark-Compact算法。这个算法的标记阶段和Mark-Sweep一样,但是标记完成后,并不是直接清理可回收的对象,而是将所有幸存的对象移到一端(美团面试题,记住标记完成后,做先不清理。先移动再清理回收的对象),再清理结束边界外的内存(美团提问)
标记-组织算法使用与标记-清除算法相同的方法来标记对象,但清理方式不同。回收非存活对象占用的空间后,所有存活的对象将被移动到左边的空闲空间,并更新相应的对象。指针。mark-arrangement算法基于mark-clear算法,移动对象,所以成本较高,但解决了内存碎片问题。具体流程如下图所示:
3.4代采集算法分代采集算法
分代采集算法是目前大多数 JVM 垃圾采集器使用的算法。它的核心思想是根据对象生存的生命周期将内存划分为几个不同的区域。一般来说,堆区分为Tenured Generation和Young Generation,堆区之外还有一个代,就是Permanet Generation(永久代)。老年代的特点是每次垃圾采集只需要采集少量对象,而新生代的特点是每次垃圾采集需要采集大量对象,所以最适合可根据不同世代的特点采取采集。算法。
目前大部分垃圾回收器对新生代采用Copying算法,因为新生代每次垃圾回收都会回收大部分对象,这意味着需要复制的操作次数较少,但在实践中是不是按照1:1的比例来划分新生代空间的,一般是将新生代划分为一个较大的Eden空间和两个较小的Survivor空间(通常是8:1:1),每次使用Eden空间) 用其中一个Survivor空间,回收时,将Eden和Survivor中的幸存对象复制到另一个Survivor空间,然后清理Eden和之前使用过的Survivor空间。
但是由于老年代的特点是每次回收的对象很少,所以一般采用Mark-Compact算法。
3.4.1 Young Generation的回收算法(Recycling主要基于Copying)
a) 所有新生成的对象首先被放入年轻代。年轻代的目标是尽快采集生命周期较短的对象。
b) 新生代内存按照8:1:1的比例划分为一个eden区和两个survivor(survivor0,survivor1)区。一个Eden区和两个Survivor区(一般来说)。大多数对象在Eden区生成,回收时将eden区的survivor对象复制到一个survivor0区,然后清空eden区,当survivor0区也满时,将eden区和survivor0区的survivor对象复制到另一个,然后清掉eden和survivor0区,这时候survivor0区是空的,再交换survivor0区和survivor1区,也就是留survivor1区空着(美团面试,问题太详细了,为什么留survivor1为空,答案:为了让eden和survivor0交换存活对象),如此来回。当 Eden 空间不足时,会触发 jvm 发起 Minor GC
c) 当survivor1区不够存放eden和survivor0的survivor对象时,直接将survivor对象存入老年代。如果老年代满了,就会触发Full GC(Major GC),即新生代和老年代都被回收。
d) 新生代发生的GC也叫Minor GC,MinorGC的频率比较高(不一定要等Eden区满才触发)。
3.4. 2年老年代(Old Generation)回收算法(回收主要基于Mark-Compact)
a) 在年轻代中存活 N 次垃圾回收的对象将被放置在年老代中。因此,可以认为老年代存储的对象是长寿命对象。
b) 内存也比新生代大很多(约1:2)。当老年代内存满时,触发Major GC,即Full GC。Full GC的频率为相对较低,老年代的对象存活时间较长,比例较高。
3.4.3 永久代的回收算法(即方法区)
用于存放静态文件,比如Java类、方法等。持久化生成对垃圾回收没有明显影响,但是有些应用可能会动态生成或调用一些类,比如Hibernate等。这时候一个比较大的持久化运行时需要设置生成空间来存储这些新添加的类。持久代也称为方法区,具体恢复见上文第5节。
再写一遍:
方法区存储的内容是否需要回收的判断不同。方法区回收的主要内容是:丢弃的常量和无用的类。过时的常量也可以通过引用可达性来判断,但是对于无用的类,必须同时满足以下三个条件:
5 新生代和老一代的区别(阿里面试官提问):
**所谓的年轻代和老年代是为分代采集算法定义的,新生代分为Eden和Survivor两个区域。把老年加到这三个区。数据会先分配到Eden区(当然也有特殊情况,如果是大对象,会直接放到老年代(大对象是指需要大量连续的java对象)内存空间)),当Eden没有足够空间时会触发jvm发起Minor GC。如果对象在 Minor GC 中幸存下来并且可以被 Survivor 空间接受,它将被移动到 Survivor 空间。并将其年龄设置为1,对象在Survivor中每存活一次Minor GC,年龄加1。当年龄达到一定级别时(默认为15),它将被提升到老年。当然,提升到老年代的年龄是可以设置的。如果老年代满了,执行:Full GC不是经常执行,所以使用Mark-Compact算法清理
其实新生代和老年代都是对对象进行分区存储,更方便回收等**
跟上,猿人,离优惠不远了!!!
四、普通垃圾采集器
下图显示了 HotSpot 虚拟机中收录的所有采集器。图片是从这里借来的:
五、什么时候触发GC?(最常见的面试问题之一一)
由于对象是分代处理的,垃圾回收的区域和时间也不同。GC 有两种类型:Scavenge GC 和 Full GC。
5.1 Scavenge GC
一般情况下,当有新对象产生,在Eden区申请空间失败时,会触发Scavenge GC对Eden区进行GC,移除不存活的对象,并将存活的对象移动到Survivor区。然后组织Survivor的两个区域。这种GC方式是在年轻代的Eden区进行的,不会影响到老年代。因为大部分对象都是从Eden区开始的,而且Eden区不会分配的很大,所以Eden区的GC会频繁的执行。因此,这里一般需要使用快速高效的算法,才能让Eden尽快自由。
5.2 全 GC
对整个堆进行排序,包括 Young、Tenured 和 Perm。Full GC需要回收整个堆,所以比Scavenge GC慢,所以要尽量减少Full GC的次数。在调优JVM的过程中,很大一部分工作是Full GC的调整。以下原因可能会导致 Full GC:
a) 任期已满;
b) 持久代(Perm)被填充;
c) System.gc() 被显式调用;
d) Heap 域分配策略在最后一次 GC 后动态变化;
参考:看看JVM的垃圾回收机制,你准备好迎接下一次面试了吗?
算法 自动采集列表( 微信投稿4.渠道接入平台支持接入其他渠道,并提前与相关账号进行绑定)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-10-12 22:08
微信投稿4.渠道接入平台支持接入其他渠道,并提前与相关账号进行绑定)
▲微信投稿
4.频道接入
平台支持其他渠道接入,并提前绑定相关账号,支持订阅号、微信公众号、微博公众号、论坛、主流视频网站、网易、今日头条、企鹅。、脸书、推特等第三方平台自动抓取内容,方便企业及时了解热点信息,按需规划相关宣传文案。
▲多渠道接入
5.自媒体用户发帖
平台支持建立自媒体平台,允许经过平台审核的机构用户和个人用户在平台上开设自媒体账号。被审核的账号可以组织内容和制作内容,平台审核通过后可以发布内容。显示在账号首页,平台其他渠道也可以引用发布后的内容。平台支持将自媒体模块制作的内容纳入统一的内容资源平台进行管理。
6.手机编辑
泽源为用户提供移动采集编辑APP,可在APP端实现资源或内容的创建和上传,可实现资源和内容的工作流审核。
02
整合自有资源
1.数据库采集
平台支持外部系统通过WebService获取平台中的各种数据,也可以通过数据库采集获取其他系统中的数据,提供基于JSON格式的标准化Restful接口,可配置为XML-基于WebService接口,为了与其他业务系统集成,允许建立外部数据库连接,通过外部数据库连接获取外部数据库中的数据表和尝试列表,然后从数据表中提取数据以只读形式查看并将其写入系统记录的内容。
▲数据库采集
2.系统访问
平台支持接入合同管理系统、直销系统、综合市场操作平台等一系列系统,将相关数据同步到平台,支持手动同步,支持定时任务设置,对应信息定时同步。
3. 信息提交
在各部门分站的前提下,主站根据需要直接或编辑审核后发布内容。支持异构异构、异构共现、同源共现等多种报告方式。同时,上报方式支持手动转发和自动分发。
4.批量导入
平台支持批量导入Word、Excel、Txt等格式文档。还提供基于XML格式的批量文档导入导出功能,实现批量数据加载和数据迁移。
▲批量导入
这些功能作为企业内容营销的基石,可以帮助营销人员快速、全面地采集和管理全网企业相关资源,为营销人员的内容形成提供支持。 查看全部
算法 自动采集列表(
微信投稿4.渠道接入平台支持接入其他渠道,并提前与相关账号进行绑定)
▲微信投稿
4.频道接入
平台支持其他渠道接入,并提前绑定相关账号,支持订阅号、微信公众号、微博公众号、论坛、主流视频网站、网易、今日头条、企鹅。、脸书、推特等第三方平台自动抓取内容,方便企业及时了解热点信息,按需规划相关宣传文案。
▲多渠道接入
5.自媒体用户发帖
平台支持建立自媒体平台,允许经过平台审核的机构用户和个人用户在平台上开设自媒体账号。被审核的账号可以组织内容和制作内容,平台审核通过后可以发布内容。显示在账号首页,平台其他渠道也可以引用发布后的内容。平台支持将自媒体模块制作的内容纳入统一的内容资源平台进行管理。
6.手机编辑
泽源为用户提供移动采集编辑APP,可在APP端实现资源或内容的创建和上传,可实现资源和内容的工作流审核。
02
整合自有资源
1.数据库采集
平台支持外部系统通过WebService获取平台中的各种数据,也可以通过数据库采集获取其他系统中的数据,提供基于JSON格式的标准化Restful接口,可配置为XML-基于WebService接口,为了与其他业务系统集成,允许建立外部数据库连接,通过外部数据库连接获取外部数据库中的数据表和尝试列表,然后从数据表中提取数据以只读形式查看并将其写入系统记录的内容。
▲数据库采集
2.系统访问
平台支持接入合同管理系统、直销系统、综合市场操作平台等一系列系统,将相关数据同步到平台,支持手动同步,支持定时任务设置,对应信息定时同步。
3. 信息提交
在各部门分站的前提下,主站根据需要直接或编辑审核后发布内容。支持异构异构、异构共现、同源共现等多种报告方式。同时,上报方式支持手动转发和自动分发。
4.批量导入
平台支持批量导入Word、Excel、Txt等格式文档。还提供基于XML格式的批量文档导入导出功能,实现批量数据加载和数据迁移。
▲批量导入
这些功能作为企业内容营销的基石,可以帮助营销人员快速、全面地采集和管理全网企业相关资源,为营销人员的内容形成提供支持。

