
文章采集调用
读书笔记:写文章如何搜集素材?
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-10-18 11:04
来源:/ note / 691157510 /
高质量副本实际上是信息的组合。信息组合的背后是结构能力,但是结构能力可能无法很好地编写副本。好的副本的基础是信息。
对于文案写作,如何采集和使用此信息决定文案写作的质量。信息是否全面,有用以及是否给用户留下了深刻的印象,决定了用户是否转发,关注和购买。
采集信息不仅是在Internet上采集与该主题相关的所有内容,还只是一条信息。采集信息可以检验个人的系统思维能力。
创建轮廓
如何具有这种系统的思维能力?在“足够的阅读”一书中,作者提到了做阅读笔记的两个要点:“分析信息时询问原因和后果”和“在整理信息时清除适用的界限”。这两点收录主题写作的基本大纲,也适合于采集写作材料。它们可以用作采集信息的出色模板。具体来说,要采集的问题如下:
1.为什么这对我很重要?作者(根据以前的经验)如何得出此信息? (前)
2.作者对原因做了什么假设?这些假设如何得到验证或消除?还有其他可能性吗? (因为)
3.如果您遵循这些信息会怎样?对我有什么好处? (之后)
4.这样做的后果是什么?没有变化,问题有多严重? (水果)
5.有反对意见吗?是否有不支持这种观点的实际例子? (合适)
6.对此有什么要求?在什么情况下不起作用? (使用)
7.过去是否有类似信息?其他领域/行业/作者如何看待类似问题? (侧面)
8.无论是相反还是相似的信息,与该信息的真正区别是什么?交汇处在哪里? (边界)
识别和过滤信息
采集以上材料时,可以结合使用网络搜索关键词和主题阅读。但是,在Internet上通过关键词搜索的网页通常收录许多无效信息。您是否仍在逐页查看网页信息以从中获取分散的知识,然后将其组合在一起?我们如何停止这种低效的信息采集方法?
正确的方法是找到两到三篇有关相关主题的深入文章,并参考不同专家的观点,以快速掌握问题的实质。那么,如何从复杂信息中找到专家的深度文章?搜索方法:首先搜索该领域的专家,然后使用“专家+主题”的关键词搜索。
信息的存储和管理
曹林在《当前评论写作十讲》一书中提到了采集评论材料的方法。我认为这种方法对于所有书写材料管理都是通用的。
这是什么方法?首先,您的计算机和手机中应该有一个“有组织的”文件夹。此文件夹收录您可以随时从Internet提取的有趣信息和数据。
我自己的方法是在Evernote中创建一个“待组织”的笔记本,然后只需下载插件,连接浏览器,微信和Evernote即可轻松剪切信息。
在那之后,您需要花一些时间来整理这些信息。创建标签并将其分类到不同的文件夹中。
问题还是,如何创建一个文件夹?许多人的计算机混乱不堪。创建后许多文件夹将重叠,因此当您以后需要调用它们时很难检索数据。
我认为更方便的方法是使用“主题”作为分类标准。同时,根据日本作家奥野信之的方法,每个摘录必须标有“日期+来源+主题细目+原创链接”。
通过这种方式,所有这些材料都被放置在Evernote中,只要编写了“主题细目” 关键词,那么当您需要调用信息时,您只需要直接在Evernote中进行搜索,您就可以可以轻松地搜索主题。以下所有信息减少了在重叠文件夹中搜索信息的难度。
以上是材料采集和管理的方法。只要采集以上信息,就可以对信息进行分类。通过使用一些常见的文案写作技巧来区分背景信息和评估信息,您可以结合起来撰写高质量的文案写作。至于文案写作的方法,我将在其他文章中进行系统地解释。 查看全部
写文章如何采集资料?
来源:/ note / 691157510 /
高质量副本实际上是信息的组合。信息组合的背后是结构能力,但是结构能力可能无法很好地编写副本。好的副本的基础是信息。
对于文案写作,如何采集和使用此信息决定文案写作的质量。信息是否全面,有用以及是否给用户留下了深刻的印象,决定了用户是否转发,关注和购买。
采集信息不仅是在Internet上采集与该主题相关的所有内容,还只是一条信息。采集信息可以检验个人的系统思维能力。
创建轮廓
如何具有这种系统的思维能力?在“足够的阅读”一书中,作者提到了做阅读笔记的两个要点:“分析信息时询问原因和后果”和“在整理信息时清除适用的界限”。这两点收录主题写作的基本大纲,也适合于采集写作材料。它们可以用作采集信息的出色模板。具体来说,要采集的问题如下:
1.为什么这对我很重要?作者(根据以前的经验)如何得出此信息? (前)
2.作者对原因做了什么假设?这些假设如何得到验证或消除?还有其他可能性吗? (因为)
3.如果您遵循这些信息会怎样?对我有什么好处? (之后)
4.这样做的后果是什么?没有变化,问题有多严重? (水果)
5.有反对意见吗?是否有不支持这种观点的实际例子? (合适)
6.对此有什么要求?在什么情况下不起作用? (使用)
7.过去是否有类似信息?其他领域/行业/作者如何看待类似问题? (侧面)
8.无论是相反还是相似的信息,与该信息的真正区别是什么?交汇处在哪里? (边界)
识别和过滤信息
采集以上材料时,可以结合使用网络搜索关键词和主题阅读。但是,在Internet上通过关键词搜索的网页通常收录许多无效信息。您是否仍在逐页查看网页信息以从中获取分散的知识,然后将其组合在一起?我们如何停止这种低效的信息采集方法?
正确的方法是找到两到三篇有关相关主题的深入文章,并参考不同专家的观点,以快速掌握问题的实质。那么,如何从复杂信息中找到专家的深度文章?搜索方法:首先搜索该领域的专家,然后使用“专家+主题”的关键词搜索。
信息的存储和管理
曹林在《当前评论写作十讲》一书中提到了采集评论材料的方法。我认为这种方法对于所有书写材料管理都是通用的。
这是什么方法?首先,您的计算机和手机中应该有一个“有组织的”文件夹。此文件夹收录您可以随时从Internet提取的有趣信息和数据。
我自己的方法是在Evernote中创建一个“待组织”的笔记本,然后只需下载插件,连接浏览器,微信和Evernote即可轻松剪切信息。
在那之后,您需要花一些时间来整理这些信息。创建标签并将其分类到不同的文件夹中。
问题还是,如何创建一个文件夹?许多人的计算机混乱不堪。创建后许多文件夹将重叠,因此当您以后需要调用它们时很难检索数据。
我认为更方便的方法是使用“主题”作为分类标准。同时,根据日本作家奥野信之的方法,每个摘录必须标有“日期+来源+主题细目+原创链接”。
通过这种方式,所有这些材料都被放置在Evernote中,只要编写了“主题细目” 关键词,那么当您需要调用信息时,您只需要直接在Evernote中进行搜索,您就可以可以轻松地搜索主题。以下所有信息减少了在重叠文件夹中搜索信息的难度。
以上是材料采集和管理的方法。只要采集以上信息,就可以对信息进行分类。通过使用一些常见的文案写作技巧来区分背景信息和评估信息,您可以结合起来撰写高质量的文案写作。至于文案写作的方法,我将在其他文章中进行系统地解释。
优采云采集器pbootcms文章 (PbootDemoSkycaiji)插件怎么设
采集交流 • 优采云 发表了文章 • 0 个评论 • 444 次浏览 • 2020-08-30 03:35
pbootcms文章 (PbootDemoSkycaiji)插件直接在优采云采集器云平台,下载就可以使用了,插件是由没皮的小菠萝开发。插件默认是只有新闻栏目可以发布,产品案例那些是过滤了的须要自己自动更改一下。
下载好了插件我们可以在网站根目录上面优采云采集器安装里找到路径为:网站根目录采集器安装目录plugineleasecmsPbootDemoSkycaiji.php
打开这个文件开头这段代码的意思是手动读取我们的数据库信息,无论是mysql或是sqlite数据库都是一样的,自动去抓取链接。
这里就是对应着我们网站发布的信息,比如作者,文章内容,产品分类,略缩图等等,这里都可以按照我们的网站需求来添加更多参数。
这里的信息是对应了我们的网站数据库上面的数组,如果这儿没有的数组可以直接步入数据库对照着添加进来就可以了,有一点须要注意的是这儿的数据库数组要和上面的参数哪里对应上去,比如我们的参数上面添加了略缩图,那我们的这儿就一定要找到这个数组填写上我们在参数里降低的名称。
这里默认是过滤了其他目录,只取了我们数据库上面的新闻列表的信息,如果我们要发布产品或是案例的话这个就不能使用了,我们须要做的就是把
// $catsDb=$this->db()->table('__CONTENT_SORT__')->where("contenttpl='news.html'")->limit(100)->select();//文章分类 注释掉或是删除都可以。
添加$catsDb=$this->db()->table('__CONTENT_SORT__')->limit(100)->select();//文章分类就可以了默认是匹配所有网站的目录。以上就是pbootcms文章 (PbootDemoSkycaiji)插件的详尽介绍了,基本上看了以上的说明没有啥问题了。如何您还有不明白的可以咨询我们。 查看全部
优采云采集器pbootcms文章 (PbootDemoSkycaiji)插件怎么设
pbootcms文章 (PbootDemoSkycaiji)插件直接在优采云采集器云平台,下载就可以使用了,插件是由没皮的小菠萝开发。插件默认是只有新闻栏目可以发布,产品案例那些是过滤了的须要自己自动更改一下。

下载好了插件我们可以在网站根目录上面优采云采集器安装里找到路径为:网站根目录采集器安装目录plugineleasecmsPbootDemoSkycaiji.php

打开这个文件开头这段代码的意思是手动读取我们的数据库信息,无论是mysql或是sqlite数据库都是一样的,自动去抓取链接。

这里就是对应着我们网站发布的信息,比如作者,文章内容,产品分类,略缩图等等,这里都可以按照我们的网站需求来添加更多参数。

这里的信息是对应了我们的网站数据库上面的数组,如果这儿没有的数组可以直接步入数据库对照着添加进来就可以了,有一点须要注意的是这儿的数据库数组要和上面的参数哪里对应上去,比如我们的参数上面添加了略缩图,那我们的这儿就一定要找到这个数组填写上我们在参数里降低的名称。

这里默认是过滤了其他目录,只取了我们数据库上面的新闻列表的信息,如果我们要发布产品或是案例的话这个就不能使用了,我们须要做的就是把
// $catsDb=$this->db()->table('__CONTENT_SORT__')->where("contenttpl='news.html'")->limit(100)->select();//文章分类 注释掉或是删除都可以。
添加$catsDb=$this->db()->table('__CONTENT_SORT__')->limit(100)->select();//文章分类就可以了默认是匹配所有网站的目录。以上就是pbootcms文章 (PbootDemoSkycaiji)插件的详尽介绍了,基本上看了以上的说明没有啥问题了。如何您还有不明白的可以咨询我们。
文章采集调用 发布设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 492 次浏览 • 2020-08-28 19:06
发布设置
点击任务顶部进度条的“发布设置”,选择发布形式
本地cms程序
可手动检查出服务器中的CMS程序,实现优采云采集器和cms无缝对接
简单绑定对应的数据,不用登入即可入库,你还可以自行开发cms插件,理论上可实现任何CMS的任意入库操作
数据库
直接将数据入库,配置好数据库参数点击“数据表”
绑定数据表的主键和采集器的数组,多张表关联自增id,选择“自定义内容”输入“auto_id@表名”即可
存储为文件
支持Excel表格(xlsx或xls格式)、txt文本,隐藏采集字段可设置不写入文件的数组
生成api接口
可直接调用采集到的数据
调用插口
只要有相应cms的入库插口,就可以将数据远程发布到网站中,不必将采集器和网站放在同一服务器
当数据发送至远程插口并入库后须要返回响应状态,这样采集器能够正确记录数据的状态并拿来进行排重处理
你只须要在插口代码最后或则数据入库后插入代码
exit(json_encode(数组));//数组必须是键值对形式,这样在响应状态中就可以直接绑定接口中返回的数组键名
自定义插件
适用于任何网站程序,按要求创建插件文件并编撰代码即可 查看全部
文章采集调用 发布设置
发布设置
点击任务顶部进度条的“发布设置”,选择发布形式
本地cms程序
可手动检查出服务器中的CMS程序,实现优采云采集器和cms无缝对接

简单绑定对应的数据,不用登入即可入库,你还可以自行开发cms插件,理论上可实现任何CMS的任意入库操作

数据库
直接将数据入库,配置好数据库参数点击“数据表”

绑定数据表的主键和采集器的数组,多张表关联自增id,选择“自定义内容”输入“auto_id@表名”即可

存储为文件
支持Excel表格(xlsx或xls格式)、txt文本,隐藏采集字段可设置不写入文件的数组

生成api接口
可直接调用采集到的数据

调用插口
只要有相应cms的入库插口,就可以将数据远程发布到网站中,不必将采集器和网站放在同一服务器

当数据发送至远程插口并入库后须要返回响应状态,这样采集器能够正确记录数据的状态并拿来进行排重处理
你只须要在插口代码最后或则数据入库后插入代码
exit(json_encode(数组));//数组必须是键值对形式,这样在响应状态中就可以直接绑定接口中返回的数组键名
自定义插件
适用于任何网站程序,按要求创建插件文件并编撰代码即可
聚荣网手动发布信息工具【图文并茂】
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-08-28 01:54
聚荣网手动发布信息工具【图文并茂】z4pa
聚荣网手动发布信息工具【图文并茂】
大家好这儿是羚羊手动发布信息软件介绍:
羚羊信息技术有限公司主要业务范畴为各种B2B平台软件的 设计开发与应用、以及各种B2B平台综合业务的代办,目前拥有较强实力的设计团队、技术团队、销售和售后团队;凭 借多年的实战经验,在业界赢的了良好的口碑和信誉。
使用方式:插件包括一个和一个文件,运行时还需将好友或群拉到桌面,具体操作如下:,首先将和拷入大智慧根目录中,,用记事本等文本编辑工具打开,照原先的格式按须要修改或增减其中内容:,[内容],指须要发出的文字信息。 ,每天调用插件发送信息前,要将须要向其发送信息的好友和群全部拉到桌面产生独立打开的聊天窗口备用,大智慧手动发陌陌插件截图:热门推荐指南针全赢博弈股票软件版|股票期货财通证券单独下单程序版|股票证券太洋证券同花顺独立委托客户端安装版|股票证券华福证券股票期权专业交易系统正式版|股票。
一、定时发送功能
软件发布信息间隔时间没有规律,随意调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜下午发布信息的同学,发布完自动关机)。
二、保存配置功能
如果你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载原先的设置,省时、省事。
软件是否手动读写贴子内容到页面的回帖发帖框上面以及是否手动递交有验证码的,可勾选自动输入选项,并自行输入,也可开启手动打码台来手动辨识验证码。帖子是否发布成功,具体要看递交时贴子页面显示的信息,软件发送次数仅供参考。*说明:一般情况下,网站都有贴子发布时间间隔、数量的限制,以及一些敏感词的过滤。因此可适当延长随机发布间隔时间,同时采用软文和跟帖的方法,并通过批量切换目标。有些网站还会记录浏览器信息,以此判定是否人工还是机器发贴。这时可勾选启用内置浏览器选项,之后软件将通过调用系统浏览器来达到高度模拟人工发布的目的。另外,在一些旧的操作系统中,软件外置浏览器未能发贴,这时也可启用内置浏览器,注意需确保浏览器状态正常且为系统默认浏览器。
民生银行郭庆谈商业银行金融科技赋能的探求与实践【快译】年已过去一半,是时侯为您介绍我在去年发觉的个开源软件()程序了。其中一些程序可能并不新颖,因为它们不是在年首次发布的,但是对我来说它们太新颖,而且我认为它们太有帮助。这就是为何我想简略地回顾一下,但愿您也认为它们很有用。编辑器毫无疑问,这是我的选择。也许是因为我除了是系统管理员,还是开发人员。我发觉由开发的这款文本编辑器时,被惊艳了。很容易通过额外程序包来轻松扩充,这些程序包提供了面向诸多语言的代码手动完成功能、功能和外置的浏览器预览。被称为是您所有数据的安全之家,起初它只是的其中一位初期合作者所创建的单独项目。虽然在创始人与社区之间引了。 专为优化而开发,本类软件推荐刷工具(刷网站点击量)绿色版绿色版英文整合版流量版位安装包完整版网站抓取精灵正式版飞达鲁长尾词查询工具英文绿色版版本地服务器(迷你)绿色版网页截图扩充()工具条全新版爱站关键词采集工具无限制版域名批量查询()英文绿色版优采云采集器版连接数更改工具红色。
三、自动设置产品图片功能
图片有3种选择方法:
1、同步采集网站图片。 如果您在网站后台上传了图片,点击“采集相册”,可以手动采集图片到本地。
2、您的网站后台获取网址地址,取您想要发的产品的图片。
3、手动批量导出本地计算机上的图片。
四、强大的内容编辑器
软件外置文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本可在软件内部随时可视化编辑,就像在网站后台操作一样。
五、自动合成标题功能
无法想到好多标题?软件外置批量合成标题功能,自动批量合成成千上万个不重复的标题。根据您的须要,配置标题模板即可生成。
标题可以任意组合,常用格式是{字符1}{字符2}{字符3},通过各类自定义组合,可以形成千变万化的不同标题。
六、自动插入伪原创功能:图片以下的文字属于随机介绍。
1、按句号选择
2、按段落选择
可以在内容中的任何地方插入您的伪原创文章,句子中的文章放得越多越好,没有限制,软件在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不重复,搜索引擎也比较喜欢。
七、百度查询收录功能 查看全部
聚荣网手动发布信息工具【图文并茂】
聚荣网手动发布信息工具【图文并茂】z4pa
聚荣网手动发布信息工具【图文并茂】
大家好这儿是羚羊手动发布信息软件介绍:
羚羊信息技术有限公司主要业务范畴为各种B2B平台软件的 设计开发与应用、以及各种B2B平台综合业务的代办,目前拥有较强实力的设计团队、技术团队、销售和售后团队;凭 借多年的实战经验,在业界赢的了良好的口碑和信誉。

使用方式:插件包括一个和一个文件,运行时还需将好友或群拉到桌面,具体操作如下:,首先将和拷入大智慧根目录中,,用记事本等文本编辑工具打开,照原先的格式按须要修改或增减其中内容:,[内容],指须要发出的文字信息。 ,每天调用插件发送信息前,要将须要向其发送信息的好友和群全部拉到桌面产生独立打开的聊天窗口备用,大智慧手动发陌陌插件截图:热门推荐指南针全赢博弈股票软件版|股票期货财通证券单独下单程序版|股票证券太洋证券同花顺独立委托客户端安装版|股票证券华福证券股票期权专业交易系统正式版|股票。
一、定时发送功能
软件发布信息间隔时间没有规律,随意调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜下午发布信息的同学,发布完自动关机)。
二、保存配置功能
如果你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载原先的设置,省时、省事。

软件是否手动读写贴子内容到页面的回帖发帖框上面以及是否手动递交有验证码的,可勾选自动输入选项,并自行输入,也可开启手动打码台来手动辨识验证码。帖子是否发布成功,具体要看递交时贴子页面显示的信息,软件发送次数仅供参考。*说明:一般情况下,网站都有贴子发布时间间隔、数量的限制,以及一些敏感词的过滤。因此可适当延长随机发布间隔时间,同时采用软文和跟帖的方法,并通过批量切换目标。有些网站还会记录浏览器信息,以此判定是否人工还是机器发贴。这时可勾选启用内置浏览器选项,之后软件将通过调用系统浏览器来达到高度模拟人工发布的目的。另外,在一些旧的操作系统中,软件外置浏览器未能发贴,这时也可启用内置浏览器,注意需确保浏览器状态正常且为系统默认浏览器。
民生银行郭庆谈商业银行金融科技赋能的探求与实践【快译】年已过去一半,是时侯为您介绍我在去年发觉的个开源软件()程序了。其中一些程序可能并不新颖,因为它们不是在年首次发布的,但是对我来说它们太新颖,而且我认为它们太有帮助。这就是为何我想简略地回顾一下,但愿您也认为它们很有用。编辑器毫无疑问,这是我的选择。也许是因为我除了是系统管理员,还是开发人员。我发觉由开发的这款文本编辑器时,被惊艳了。很容易通过额外程序包来轻松扩充,这些程序包提供了面向诸多语言的代码手动完成功能、功能和外置的浏览器预览。被称为是您所有数据的安全之家,起初它只是的其中一位初期合作者所创建的单独项目。虽然在创始人与社区之间引了。 专为优化而开发,本类软件推荐刷工具(刷网站点击量)绿色版绿色版英文整合版流量版位安装包完整版网站抓取精灵正式版飞达鲁长尾词查询工具英文绿色版版本地服务器(迷你)绿色版网页截图扩充()工具条全新版爱站关键词采集工具无限制版域名批量查询()英文绿色版优采云采集器版连接数更改工具红色。
三、自动设置产品图片功能
图片有3种选择方法:
1、同步采集网站图片。 如果您在网站后台上传了图片,点击“采集相册”,可以手动采集图片到本地。
2、您的网站后台获取网址地址,取您想要发的产品的图片。
3、手动批量导出本地计算机上的图片。

四、强大的内容编辑器
软件外置文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本可在软件内部随时可视化编辑,就像在网站后台操作一样。
五、自动合成标题功能
无法想到好多标题?软件外置批量合成标题功能,自动批量合成成千上万个不重复的标题。根据您的须要,配置标题模板即可生成。
标题可以任意组合,常用格式是{字符1}{字符2}{字符3},通过各类自定义组合,可以形成千变万化的不同标题。
六、自动插入伪原创功能:图片以下的文字属于随机介绍。
1、按句号选择
2、按段落选择
可以在内容中的任何地方插入您的伪原创文章,句子中的文章放得越多越好,没有限制,软件在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不重复,搜索引擎也比较喜欢。

七、百度查询收录功能
织梦dedecms和mymps蚂蚁分类信息系统安装在同一目录下及调用解决方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-27 23:36
一直使用蚂蚁分类信息做了个地方信息网站,但是蚂蚁在新闻文章发布上功能有些小缺憾,比如目录单一,采集不便捷等不利于seo的问题,于是就想着能不能把蚂蚁分类和织梦安装在同一个目录下边实现互补融合,下面分享下解决过程和思路。
首先,需要解决两个系统有些目录名子重复的问题,我的思路是把织梦的data目录移出去,一是解决重复,而是对织梦的安全也比较好,然后就是include目录,我还是把织梦的include更名解决。测试后没有问题,两个系统能在一个域名下独立运行。
接下来,就须要解决调用的问题了,可以选择在织梦首页调用mymps的分类信息,也可以选择在mymps的首页调用织梦的文章,这两个问题都可以实现,最后我选择的前者,感觉这样更完美一些,毕竟只是用织梦系统填补下mymps的seo问题。
1.根目录index.php中引入常用变量
//引入织梦常量
require_once(DEDEINC.'/common.func.php');
require_once (dirname(__FILE__)."/deinc/common.inc.php");
require_once(DEDEINC.'/arc.listview.class.php');
2./include/global.inc.php
加入
define('DEDEINC', MYMPS_ROOT . '/deinc');
define('DEDEROOT', str_replace("\\", '/', substr(DEDEINC,0,-6) ) );
define('DEDEDATA', MYMPS_ROOT.'/../data');
define('DEDETEMPLATE', MYMPS_ROOT.'/templets');
3.原生php句子调用织梦文章列表
在index.php中添加
//调用织梦文章列表
$arr = '';
$article = array();
$query = "SELECT arc.* , tp.reid , tp.typename , tp.typedir , ch.addtable FROM `dede_archives` arc ".
"LEFT JOIN dede_arctype tp on tp.id=arc.typeid ".
"LEFT JOIN dede_channeltype as ch on arc.channel = ch.id WHERE arc.typeid='413' ORDER BY pubdate DESC LIMIT 0 , 10";
$arctitle = array();
$dsql->SetQuery($query);
$dsql->Execute();
while ($rowarc = $dsql->GetArray()) {
$arctitle[] = $rowarc;
$arr['id'] = $rowarc['id'];
$arr['title']= $rowarc['title'];
$arr['url'] = GetOneArchive($rowarc['id']);
$article[$rowarc['id']] = $arr;
}
//调用织梦文章列表 结束
然后在mymps的模板中调用织梦数据就行了
{$mymps[title]}</a>
织梦二次开发QQ群
本站客服QQ号:3149518909(点击一侧QQ号交流),群号(383578617)
如果您有任何织梦问题,请把问题发到群里,阁主将为您写解决教程!
转载请标明:织梦模板 织梦dedecms和mymps蚂蚁分类信息系统安装在同一目录下及调用解决方式 查看全部
织梦dedecms和mymps蚂蚁分类信息系统安装在同一目录下及调用解决方式
一直使用蚂蚁分类信息做了个地方信息网站,但是蚂蚁在新闻文章发布上功能有些小缺憾,比如目录单一,采集不便捷等不利于seo的问题,于是就想着能不能把蚂蚁分类和织梦安装在同一个目录下边实现互补融合,下面分享下解决过程和思路。
首先,需要解决两个系统有些目录名子重复的问题,我的思路是把织梦的data目录移出去,一是解决重复,而是对织梦的安全也比较好,然后就是include目录,我还是把织梦的include更名解决。测试后没有问题,两个系统能在一个域名下独立运行。
接下来,就须要解决调用的问题了,可以选择在织梦首页调用mymps的分类信息,也可以选择在mymps的首页调用织梦的文章,这两个问题都可以实现,最后我选择的前者,感觉这样更完美一些,毕竟只是用织梦系统填补下mymps的seo问题。

1.根目录index.php中引入常用变量
//引入织梦常量
require_once(DEDEINC.'/common.func.php');
require_once (dirname(__FILE__)."/deinc/common.inc.php");
require_once(DEDEINC.'/arc.listview.class.php');
2./include/global.inc.php
加入
define('DEDEINC', MYMPS_ROOT . '/deinc');
define('DEDEROOT', str_replace("\\", '/', substr(DEDEINC,0,-6) ) );
define('DEDEDATA', MYMPS_ROOT.'/../data');
define('DEDETEMPLATE', MYMPS_ROOT.'/templets');
3.原生php句子调用织梦文章列表
在index.php中添加
//调用织梦文章列表
$arr = '';
$article = array();
$query = "SELECT arc.* , tp.reid , tp.typename , tp.typedir , ch.addtable FROM `dede_archives` arc ".
"LEFT JOIN dede_arctype tp on tp.id=arc.typeid ".
"LEFT JOIN dede_channeltype as ch on arc.channel = ch.id WHERE arc.typeid='413' ORDER BY pubdate DESC LIMIT 0 , 10";
$arctitle = array();
$dsql->SetQuery($query);
$dsql->Execute();
while ($rowarc = $dsql->GetArray()) {
$arctitle[] = $rowarc;
$arr['id'] = $rowarc['id'];
$arr['title']= $rowarc['title'];
$arr['url'] = GetOneArchive($rowarc['id']);
$article[$rowarc['id']] = $arr;
}
//调用织梦文章列表 结束
然后在mymps的模板中调用织梦数据就行了
{$mymps[title]}</a>
织梦二次开发QQ群
本站客服QQ号:3149518909(点击一侧QQ号交流),群号(383578617)

如果您有任何织梦问题,请把问题发到群里,阁主将为您写解决教程!
转载请标明:织梦模板 织梦dedecms和mymps蚂蚁分类信息系统安装在同一目录下及调用解决方式
如何使用代理IP进行数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-27 22:15
什么是代理?什么情况下会用到代理IP?如何使用代理IP进行数据采集?针对这种问题,小编为你们一一作答。
代理服务器的功能就是代理用户去获取网路信息,之后再把相应的信息反馈给顾客。用一个比较靠谱的比喻来说代理服务器相当于一个中介的环节。它是网路信息的中转站。通过代理IP访问目标网站,可以隐藏用户的真实IP地址。
例如要想要抓取一个内容有100万条的网站,但是她们设置了IP限制,每个小时只有1000条可以抓,如果你使用同一个IP,并且保持不变,那么想要抓取所有的信息,你要耗费40天的时间。但是假如你更换不同的IP地址,就可以提升数据采集的效率。
其他想切换IP或则隐藏自身IP地址的场景也会用到代理IP,比如说电商,游戏,注册等等。
代理IP分味开放代理和私密代理,开放代理是全网扫描来的,稳定性较差,爬虫是肯定不适宜做的。自己没事玩儿还好。如果是做爬虫的话,用私密,稳定性是十分可靠的。
私密代理IP网上有很多提供商,稳定性参差不齐,这里说一下ip代理精灵,我们公司有个项目是抓取亚马逊数据来进行剖析销量、评论等,用PHP进行抓取,抓取亚马逊要非常注意header头,否则输出的数据就是空了。还有一种方式,可以用PHP通过shell_exec来调用curl命令来进行抓取。 查看全部
如何使用代理IP进行数据采集
什么是代理?什么情况下会用到代理IP?如何使用代理IP进行数据采集?针对这种问题,小编为你们一一作答。
代理服务器的功能就是代理用户去获取网路信息,之后再把相应的信息反馈给顾客。用一个比较靠谱的比喻来说代理服务器相当于一个中介的环节。它是网路信息的中转站。通过代理IP访问目标网站,可以隐藏用户的真实IP地址。
例如要想要抓取一个内容有100万条的网站,但是她们设置了IP限制,每个小时只有1000条可以抓,如果你使用同一个IP,并且保持不变,那么想要抓取所有的信息,你要耗费40天的时间。但是假如你更换不同的IP地址,就可以提升数据采集的效率。
其他想切换IP或则隐藏自身IP地址的场景也会用到代理IP,比如说电商,游戏,注册等等。
代理IP分味开放代理和私密代理,开放代理是全网扫描来的,稳定性较差,爬虫是肯定不适宜做的。自己没事玩儿还好。如果是做爬虫的话,用私密,稳定性是十分可靠的。
私密代理IP网上有很多提供商,稳定性参差不齐,这里说一下ip代理精灵,我们公司有个项目是抓取亚马逊数据来进行剖析销量、评论等,用PHP进行抓取,抓取亚马逊要非常注意header头,否则输出的数据就是空了。还有一种方式,可以用PHP通过shell_exec来调用curl命令来进行抓取。
乐思实时采集开发包 -- 用于
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-27 04:51
乐思实时信息采集开发包
乐思实时信息采集开发包是为开发人员提供的用于网路信息采集的自动化对象。它通过COM对象提供了一组用于网路信息抽取的核心技巧。开发人员可以在任何一个支持Windows COM调用的语言(如VB, VC, Delphi,ASP, ASP.NET,PowerBuilder)中调用该组件,在无需关心HTTP请求与数据处理细节的情况下完成网路数据抽取与集成,从而轻松开发出适宜自己需求的网路信息抽取与集成的应用程序与网站。
它可以做哪些?
元搜索引擎:通过在后台调用各大搜索引擎,将各大搜索引擎的返回结果整合处理后,实时返回给查询用户。
行业搜索整合门户:通过将用户的查询关键词递交到多个行业网站查询,并将各个结果页面中的关键返回内容(去掉与查询无关的脚注,页尾,栏目,广告,动画)整合在一个页面中返回给用户。
网站整合:将各个下属单位的网站上的关键内容抽取下来后整合在一个页面显示,如省政府网站与下属市政府网站。
新闻文章抓取:你可以开发自己的新闻文章抓取程序,将来源于各大网站的新闻或文章标题,作者,来源,内容等保存到数据库中。
实时信息抓取:你可以在你的应用程序中集成来源于网上的实时信息:股票行情,博彩欧赔,天气预报,热点新闻等等。
RSS信息抓取:抽取来源于多个网站的RSS XML文件中的文章标题与内容,集成显示在你的网站或者应用程序中。
竞争情报监视:将各个竞争对手网站上的最新新闻,招聘信息,人事变动抽取后集成在一个窗口中显示,将自己与竞争对手的名称以及相关产品的关键字通过Google或则百度搜索,将搜索结果整合在一个窗口中显示或保存到数据库中。 查看全部
乐思实时采集开发包 -- 用于
乐思实时信息采集开发包
乐思实时信息采集开发包是为开发人员提供的用于网路信息采集的自动化对象。它通过COM对象提供了一组用于网路信息抽取的核心技巧。开发人员可以在任何一个支持Windows COM调用的语言(如VB, VC, Delphi,ASP, ASP.NET,PowerBuilder)中调用该组件,在无需关心HTTP请求与数据处理细节的情况下完成网路数据抽取与集成,从而轻松开发出适宜自己需求的网路信息抽取与集成的应用程序与网站。
它可以做哪些?
元搜索引擎:通过在后台调用各大搜索引擎,将各大搜索引擎的返回结果整合处理后,实时返回给查询用户。
行业搜索整合门户:通过将用户的查询关键词递交到多个行业网站查询,并将各个结果页面中的关键返回内容(去掉与查询无关的脚注,页尾,栏目,广告,动画)整合在一个页面中返回给用户。
网站整合:将各个下属单位的网站上的关键内容抽取下来后整合在一个页面显示,如省政府网站与下属市政府网站。
新闻文章抓取:你可以开发自己的新闻文章抓取程序,将来源于各大网站的新闻或文章标题,作者,来源,内容等保存到数据库中。
实时信息抓取:你可以在你的应用程序中集成来源于网上的实时信息:股票行情,博彩欧赔,天气预报,热点新闻等等。
RSS信息抓取:抽取来源于多个网站的RSS XML文件中的文章标题与内容,集成显示在你的网站或者应用程序中。
竞争情报监视:将各个竞争对手网站上的最新新闻,招聘信息,人事变动抽取后集成在一个窗口中显示,将自己与竞争对手的名称以及相关产品的关键字通过Google或则百度搜索,将搜索结果整合在一个窗口中显示或保存到数据库中。
源码剖析 Sentinel 实时数据采集实现原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2020-08-27 01:03
本篇将重点关注 Sentienl 实时数据搜集,即 Sentienl 具体是怎样搜集调用信息,以此来判定是否须要触发限流或熔断。
本节目录
Sentienl 实时数据搜集的入口类为 StatisticSlot。
我们先简单来看一下 StatisticSlot 该类的注释,来看一下该类的整体定位。
StatisticSlot,专用于实时统计的 slot。在步入一个资源时,在执行 Sentienl 的处理链条中会步入到该 slot 中,需要完成如下估算任务:
接下来用源码剖析的手段来详尽剖析 StatisticSlot 的实现原理。
1、源码剖析 StatisticSlot 1.1 StatisticSlot entry 详解
StatisticSlot#entry
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,boolean prioritized, Object... args) throws Throwable {
try {
// Do some checking.
fireEntry(context, resourceWrapper, node, count, prioritized, args); // @1
// Request passed, add thread count and pass count.
node.increaseThreadNum(); // @2
node.addPassRequest(count);
if (context.getCurEntry().getOriginNode() != null) { // @3
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) { // @4
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest(count);
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) { // @5
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (PriorityWaitException ex) { // @6
node.increaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (BlockException e) { // @7
// Blocked, set block exception to current entry.
context.getCurEntry().setError(e);
// Add block count.
node.increaseBlockQps(count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseBlockQps(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseBlockQps(count);
}
// Handle block event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onBlocked(e, context, resourceWrapper, node, count, args);
}
throw e;
} catch (Throwable e) { // @8
// Unexpected error, set error to current entry.
context.getCurEntry().setError(e);
// This should not happen.
node.increaseExceptionQps(count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseExceptionQps(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
Constants.ENTRY_NODE.increaseExceptionQps(count);
}
throw e;
}
}
代码@1:首先调用 fireEntry,先调用 Sentinel Slot Chain 中其他的处理器,执行完其他处理器的逻辑,例如 FlowSlot、DegradeSlot,因为 StatisticSlot 的职责是搜集统计信息。
代码@2:如果后续处理器成功执行,则将正在执行线程数统计指标加一,并将通过的恳求数目指标降低对应的值。下文会对 Sentinel Node 体系进行详尽的介绍,在 Sentinel 中使用 Node 来表示调用链中的某一个节点,每个节点关联一个资源,资源的实时统计信息就存贮在 Node 中,故该部份也是调用 DefaultNode 的相关技巧来改变线程数等,将在下文会向详尽介绍。
代码@3:如果上下文环境中保存了调用的源头(调用方)的节点信息不为空,则更新该节点的统计数据:线程数与通过数目。
代码@4:如果资源的步入类型为 EntryType.IN,表示入站流量,更新入站全局统计数据(集群范围 ClusterNode)。
代码@5:执行注册的步入Handler,可以通过 StatisticSlotCallbackRegistry 的 addEntryCallback 注册相关监听器。
代码@6:如果捕获到 PriorityWaitException ,则觉得是等待过一定时间,但最终还是算通过,只需降低线程的个数,但无需降低节点通过的数目,具体缘由我们在详尽剖析限流部份时会重点讨论,也会再度探讨 PriorityWaitException 的含意。
代码@7:如果捕获到 BlockException,则主要降低阻塞的数目。
代码@8:如果是系统异常,则降低异常数目。
我想里面的代码应当不难理解,但涉及到统计指标数据的变化,都是调用 DefaultNode node 相关的方式,从这儿也可以看出,Node 将是实时统计数据的直接持有者,那毋容置疑接下来将重点来学习 Node,为了知识体系的完备性,我们先来看一下 StatisticSlot 的 exit 方法。
1.2 StatisticSlot exit 详解
StatisticSlot#exit
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
DefaultNode node = (DefaultNode)context.getCurNode();
if (context.getCurEntry().getError() == null) { // @1
// Calculate response time (max RT is TIME_DROP_VALVE).
long rt = TimeUtil.currentTimeMillis() - context.getCurEntry().getCreateTime();
if (rt > Constants.TIME_DROP_VALVE) {
rt = Constants.TIME_DROP_VALVE;
}
// Record response time and success count.
node.addRtAndSuccess(rt, count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().addRtAndSuccess(rt, count);
}
node.decreaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().decreaseThreadNum();
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
Constants.ENTRY_NODE.addRtAndSuccess(rt, count);
Constants.ENTRY_NODE.decreaseThreadNum();
}
} else {
// Error may happen.
}
// Handle exit event with registered exit callback handlers.
Collection exitCallbacks = StatisticSlotCallbackRegistry.getExitCallbacks();
for (ProcessorSlotExitCallback handler : exitCallbacks) { // @2
handler.onExit(context, resourceWrapper, count, args);
}
fireExit(context, resourceWrapper, count); // @3
}
代码@1:成功执行,则重点关注响应时间,其实现亮点如下:
计算本次响应时间,将本次响应时间搜集到 Node 中。
将当前活跃线程数减一。
代码@2:执行退出时的 callback。可以通过 StatisticSlotCallbackRegistry 的 addExitCallback 方法添加退出回调函数。
代码@3:传播 exit 事件。
接下来我们将重点介绍 DefaultNode,即 Sentinel 的 Node 体系,持有资源的实时调用信息。
2、Sentienl Node 体系
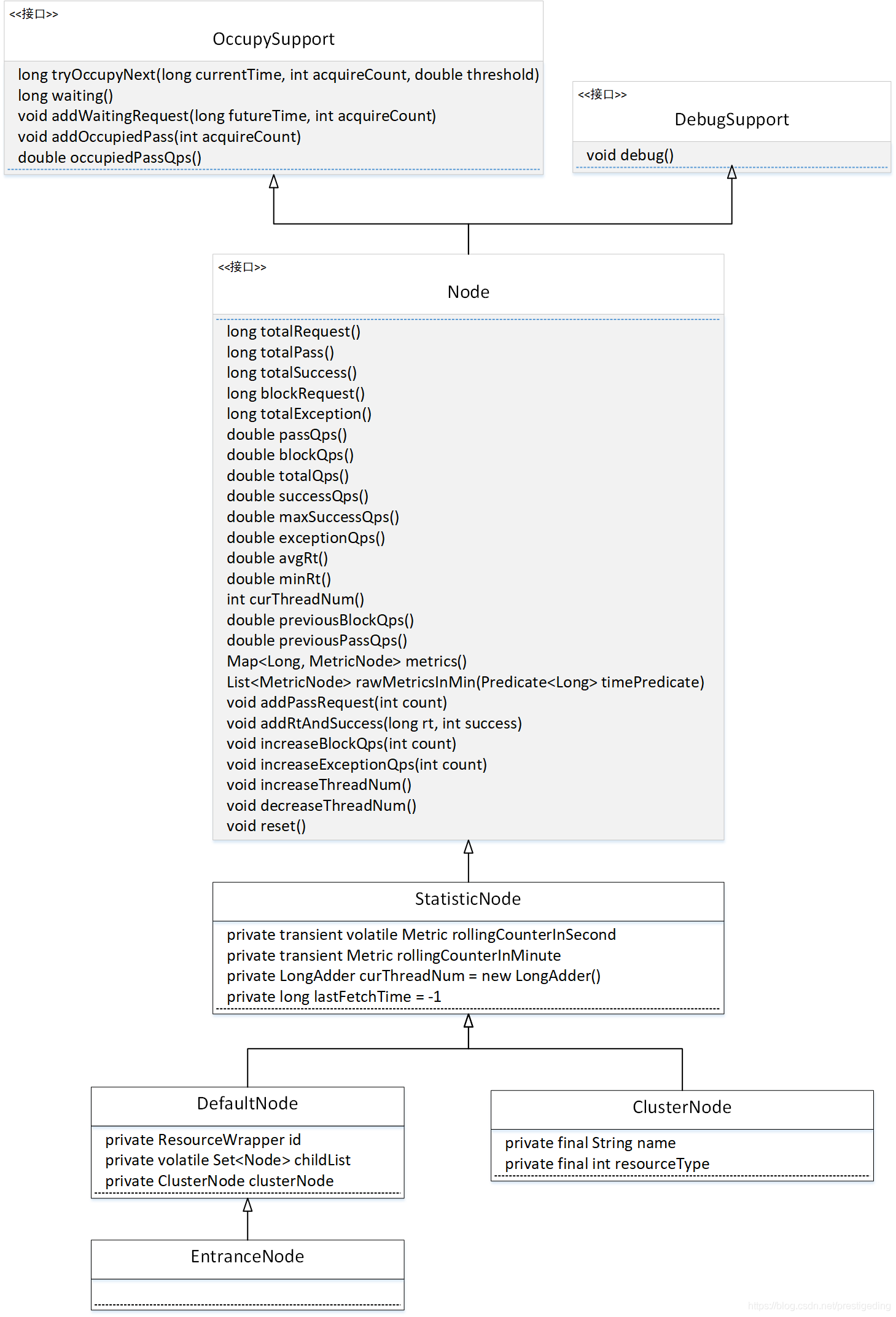
2.1 Node 类体系图
我们先简单介绍一下上述核心类的作用与核心插口或核心属性的含意。
long waiting()
获取当前已申请的未来的令牌的个数。 void addWaitingRequest(long futureTime, int acquireCount)
申请未来时间窗口中的令牌。 void addOccupiedPass(int acquireCount)
增加申请未来令牌通过的个数。 double occupiedPassQps()
当前占据未来令牌的QPS。 Node
持有实时统计信息的节点。定义了搜集统计信息与获取统计信息的插口,上面方式依据技巧名称即可获知其涵义,故这儿就不一一列举了。 StatisticNode
实现统计信息的默认实现类。 DefaultNode
用于在特定上下文环境中保存某一个资源的实时统计信息。 ClusterNode
实现基于集群限流模式的节点,将在集群限流模式部份详尽介绍。 EntranceNode
用来表示调用链入口的节点信息。
本文将详尽介绍 DefaultNode 与 StatisticNode,重点论述调用树与实时统计信息。DefaultNode 是 StatisticNode 的泛型,我们先从 StatisticNode 开始 Node 体系的探究。
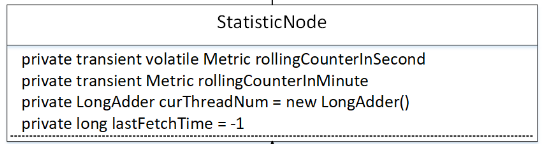
2、StatisticNode 详解 2.1 核心类图
我们对其核心属性进行一一详解:
关于 ArrayMetric 滑动窗口设计与实现原理,请参考笔者的另一篇博文:Alibaba Seninel 滑动窗口实现原理(文末附原理图)
接下来我们选购几个具有代表性的方式进行探究。
2.2 addPassRequest
public void addPassRequest(int count) {
rollingCounterInSecond.addPass(count);
rollingCounterInMinute.addPass(count);
}
增加通过恳求数目。即将实时调用信息向滑动窗口中进行统计。addPassRequest 即报告成功的通过数目。就是分别调用 秒级、分钟即对应的滑动窗口中添加数目,然后限流规则、熔断规则将基于滑动窗口中的值进行估算。
2.3 totalRequest
public long totalRequest() {
return rollingCounterInMinute.pass() + rollingCounterInMinute.block();
}
获取当前时间戳的总恳求数,获取分钟级时间窗口中的统计信息。
2.4 successQps
public double successQps() {
return rollingCounterInSecond.success() / rollingCounterInSecond.getWindowIntervalInSec();
}
成功TPS,用秒级统计滑动窗口中统计的个数 除以 窗口的间隔得出其 tps,即抽样个数越大,其统计越精确。
温馨提示:上面的方式在学习了上文的滑动窗口设计原理后将变得十分简单,大家在学习的过程中,可以总结出一个规律,什么时候时侯使用秒级滑动窗口,什么时候使用分钟级滑动窗口。
2.5 metrics
由于 Sentienl 基于滑动窗口来实时搜集统计信息,并储存在显存中,并随着时间的推移,旧的滑动窗口将失效,故须要提供一个方式,及时将所有的统计信息进行汇总输出,供监控客户端定时拉取,转储都其他客户端,例如数据库,方便监控数据的可视化,这也一般是中间件用于监控指标的监控与采集的通用设计方式。
public Map metrics() {
long currentTime = TimeUtil.currentTimeMillis();
currentTime = currentTime - currentTime % 1000; // @1
Map metrics = new ConcurrentHashMap();
List nodesOfEverySecond = rollingCounterInMinute.details(); // @2
long newLastFetchTime = lastFetchTime;
// Iterate metrics of all resources, filter valid metrics (not-empty and up-to-date).
for (MetricNode node : nodesOfEverySecond) {
if (isNodeInTime(node, currentTime) && isValidMetricNode(node)) { // @3
metrics.put(node.getTimestamp(), node);
newLastFetchTime = Math.max(newLastFetchTime, node.getTimestamp());
}
}
lastFetchTime = newLastFetchTime;
return metrics;
}
代码@1:获取当前时间对应的滑动窗口的开始时间,可以对比上文估算滑动窗口的算法。
代码@2:获取一分钟内的所有滑动窗口中的统计数据,使用 MetricNode 表示。
代码@3:遍历所有节点,刷选出不是当前滑动窗口外的所有数据。这里的重点是方式:isNodeInTime。
<p>private boolean isNodeInTime(MetricNode node, long currentTime) {
return node.getTimestamp() > lastFetchTime && node.getTimestamp() 查看全部
源码剖析 Sentinel 实时数据采集实现原理
本篇将重点关注 Sentienl 实时数据搜集,即 Sentienl 具体是怎样搜集调用信息,以此来判定是否须要触发限流或熔断。
本节目录
Sentienl 实时数据搜集的入口类为 StatisticSlot。
我们先简单来看一下 StatisticSlot 该类的注释,来看一下该类的整体定位。
StatisticSlot,专用于实时统计的 slot。在步入一个资源时,在执行 Sentienl 的处理链条中会步入到该 slot 中,需要完成如下估算任务:
接下来用源码剖析的手段来详尽剖析 StatisticSlot 的实现原理。
1、源码剖析 StatisticSlot 1.1 StatisticSlot entry 详解
StatisticSlot#entry
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,boolean prioritized, Object... args) throws Throwable {
try {
// Do some checking.
fireEntry(context, resourceWrapper, node, count, prioritized, args); // @1
// Request passed, add thread count and pass count.
node.increaseThreadNum(); // @2
node.addPassRequest(count);
if (context.getCurEntry().getOriginNode() != null) { // @3
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) { // @4
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest(count);
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) { // @5
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (PriorityWaitException ex) { // @6
node.increaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (BlockException e) { // @7
// Blocked, set block exception to current entry.
context.getCurEntry().setError(e);
// Add block count.
node.increaseBlockQps(count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseBlockQps(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseBlockQps(count);
}
// Handle block event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onBlocked(e, context, resourceWrapper, node, count, args);
}
throw e;
} catch (Throwable e) { // @8
// Unexpected error, set error to current entry.
context.getCurEntry().setError(e);
// This should not happen.
node.increaseExceptionQps(count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseExceptionQps(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
Constants.ENTRY_NODE.increaseExceptionQps(count);
}
throw e;
}
}
代码@1:首先调用 fireEntry,先调用 Sentinel Slot Chain 中其他的处理器,执行完其他处理器的逻辑,例如 FlowSlot、DegradeSlot,因为 StatisticSlot 的职责是搜集统计信息。
代码@2:如果后续处理器成功执行,则将正在执行线程数统计指标加一,并将通过的恳求数目指标降低对应的值。下文会对 Sentinel Node 体系进行详尽的介绍,在 Sentinel 中使用 Node 来表示调用链中的某一个节点,每个节点关联一个资源,资源的实时统计信息就存贮在 Node 中,故该部份也是调用 DefaultNode 的相关技巧来改变线程数等,将在下文会向详尽介绍。
代码@3:如果上下文环境中保存了调用的源头(调用方)的节点信息不为空,则更新该节点的统计数据:线程数与通过数目。
代码@4:如果资源的步入类型为 EntryType.IN,表示入站流量,更新入站全局统计数据(集群范围 ClusterNode)。
代码@5:执行注册的步入Handler,可以通过 StatisticSlotCallbackRegistry 的 addEntryCallback 注册相关监听器。
代码@6:如果捕获到 PriorityWaitException ,则觉得是等待过一定时间,但最终还是算通过,只需降低线程的个数,但无需降低节点通过的数目,具体缘由我们在详尽剖析限流部份时会重点讨论,也会再度探讨 PriorityWaitException 的含意。
代码@7:如果捕获到 BlockException,则主要降低阻塞的数目。
代码@8:如果是系统异常,则降低异常数目。
我想里面的代码应当不难理解,但涉及到统计指标数据的变化,都是调用 DefaultNode node 相关的方式,从这儿也可以看出,Node 将是实时统计数据的直接持有者,那毋容置疑接下来将重点来学习 Node,为了知识体系的完备性,我们先来看一下 StatisticSlot 的 exit 方法。
1.2 StatisticSlot exit 详解
StatisticSlot#exit
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
DefaultNode node = (DefaultNode)context.getCurNode();
if (context.getCurEntry().getError() == null) { // @1
// Calculate response time (max RT is TIME_DROP_VALVE).
long rt = TimeUtil.currentTimeMillis() - context.getCurEntry().getCreateTime();
if (rt > Constants.TIME_DROP_VALVE) {
rt = Constants.TIME_DROP_VALVE;
}
// Record response time and success count.
node.addRtAndSuccess(rt, count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().addRtAndSuccess(rt, count);
}
node.decreaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().decreaseThreadNum();
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
Constants.ENTRY_NODE.addRtAndSuccess(rt, count);
Constants.ENTRY_NODE.decreaseThreadNum();
}
} else {
// Error may happen.
}
// Handle exit event with registered exit callback handlers.
Collection exitCallbacks = StatisticSlotCallbackRegistry.getExitCallbacks();
for (ProcessorSlotExitCallback handler : exitCallbacks) { // @2
handler.onExit(context, resourceWrapper, count, args);
}
fireExit(context, resourceWrapper, count); // @3
}
代码@1:成功执行,则重点关注响应时间,其实现亮点如下:
计算本次响应时间,将本次响应时间搜集到 Node 中。
将当前活跃线程数减一。
代码@2:执行退出时的 callback。可以通过 StatisticSlotCallbackRegistry 的 addExitCallback 方法添加退出回调函数。
代码@3:传播 exit 事件。
接下来我们将重点介绍 DefaultNode,即 Sentinel 的 Node 体系,持有资源的实时调用信息。
2、Sentienl Node 体系
2.1 Node 类体系图
我们先简单介绍一下上述核心类的作用与核心插口或核心属性的含意。
long waiting()
获取当前已申请的未来的令牌的个数。 void addWaitingRequest(long futureTime, int acquireCount)
申请未来时间窗口中的令牌。 void addOccupiedPass(int acquireCount)
增加申请未来令牌通过的个数。 double occupiedPassQps()
当前占据未来令牌的QPS。 Node
持有实时统计信息的节点。定义了搜集统计信息与获取统计信息的插口,上面方式依据技巧名称即可获知其涵义,故这儿就不一一列举了。 StatisticNode
实现统计信息的默认实现类。 DefaultNode
用于在特定上下文环境中保存某一个资源的实时统计信息。 ClusterNode
实现基于集群限流模式的节点,将在集群限流模式部份详尽介绍。 EntranceNode
用来表示调用链入口的节点信息。
本文将详尽介绍 DefaultNode 与 StatisticNode,重点论述调用树与实时统计信息。DefaultNode 是 StatisticNode 的泛型,我们先从 StatisticNode 开始 Node 体系的探究。
2、StatisticNode 详解 2.1 核心类图
我们对其核心属性进行一一详解:
关于 ArrayMetric 滑动窗口设计与实现原理,请参考笔者的另一篇博文:Alibaba Seninel 滑动窗口实现原理(文末附原理图)
接下来我们选购几个具有代表性的方式进行探究。
2.2 addPassRequest
public void addPassRequest(int count) {
rollingCounterInSecond.addPass(count);
rollingCounterInMinute.addPass(count);
}
增加通过恳求数目。即将实时调用信息向滑动窗口中进行统计。addPassRequest 即报告成功的通过数目。就是分别调用 秒级、分钟即对应的滑动窗口中添加数目,然后限流规则、熔断规则将基于滑动窗口中的值进行估算。
2.3 totalRequest
public long totalRequest() {
return rollingCounterInMinute.pass() + rollingCounterInMinute.block();
}
获取当前时间戳的总恳求数,获取分钟级时间窗口中的统计信息。
2.4 successQps
public double successQps() {
return rollingCounterInSecond.success() / rollingCounterInSecond.getWindowIntervalInSec();
}
成功TPS,用秒级统计滑动窗口中统计的个数 除以 窗口的间隔得出其 tps,即抽样个数越大,其统计越精确。
温馨提示:上面的方式在学习了上文的滑动窗口设计原理后将变得十分简单,大家在学习的过程中,可以总结出一个规律,什么时候时侯使用秒级滑动窗口,什么时候使用分钟级滑动窗口。
2.5 metrics
由于 Sentienl 基于滑动窗口来实时搜集统计信息,并储存在显存中,并随着时间的推移,旧的滑动窗口将失效,故须要提供一个方式,及时将所有的统计信息进行汇总输出,供监控客户端定时拉取,转储都其他客户端,例如数据库,方便监控数据的可视化,这也一般是中间件用于监控指标的监控与采集的通用设计方式。
public Map metrics() {
long currentTime = TimeUtil.currentTimeMillis();
currentTime = currentTime - currentTime % 1000; // @1
Map metrics = new ConcurrentHashMap();
List nodesOfEverySecond = rollingCounterInMinute.details(); // @2
long newLastFetchTime = lastFetchTime;
// Iterate metrics of all resources, filter valid metrics (not-empty and up-to-date).
for (MetricNode node : nodesOfEverySecond) {
if (isNodeInTime(node, currentTime) && isValidMetricNode(node)) { // @3
metrics.put(node.getTimestamp(), node);
newLastFetchTime = Math.max(newLastFetchTime, node.getTimestamp());
}
}
lastFetchTime = newLastFetchTime;
return metrics;
}
代码@1:获取当前时间对应的滑动窗口的开始时间,可以对比上文估算滑动窗口的算法。
代码@2:获取一分钟内的所有滑动窗口中的统计数据,使用 MetricNode 表示。
代码@3:遍历所有节点,刷选出不是当前滑动窗口外的所有数据。这里的重点是方式:isNodeInTime。
<p>private boolean isNodeInTime(MetricNode node, long currentTime) {
return node.getTimestamp() > lastFetchTime && node.getTimestamp()
文章采集调用 xposed商店市场
采集交流 • 优采云 发表了文章 • 0 个评论 • 401 次浏览 • 2020-08-26 13:22
3.2 采集方式
3.2.1 目前情况
目前陌陌采集主要有以下三种形式:
(一)通过微信PC版采集,在电脑正常登陆微信PC版后,通过模拟鼠标键盘操作的方式来进行采集。该方式硬件投入较大。
(二)通过微信网页版采集,直接调用程序扫码登录微信网页版,登录后,微信关注的微信公众号,有新的信息推送到微信时,程序会自动获取推送信息。该方式下微信连接容易中断,无法保证采集的稳定性。
(三)直接通过VirtualXposed监控微信。这种方式是程序直接装在手机上,自动拦截推送的信息。通过分析拦截的数据包,解析出有用的数据。该方式成本相对较低,且稳定性较好。
经过各方面比对,最终选定第三种形式,也就是直接通过VirtualXposed监控陌陌APP发出和接收的所有恳求数据包,对其进行解析,分析出符合要求的文章链接。
3.2.2 备用方案
由于使用VirtualXposed拦截陌陌推送信息的方法,会对陌陌客户端进行篡
改,腾讯有可能升级技术,导致VirtualXposed插件未能再使用。或者,腾讯能通过技术确切的检查手机是否安装了VirtualXposed插件,从而大量封号,导致采集无法稳定进行。目前了解到的可行的备用方案有以下几种形式:
(一)使用3.2.1中的第二种方式。该种方式需要微信号在2017年10月份以前注册,否则无法登陆网页版;
(二)使用AnyProxy抓包的方式。该种方式对技术要求较高,目前尚未进行详细的测试。
3.3 采集流程
微信采集整体流程如下图3-1所示:
图 3-1
其中主要分为三部份:
1) 公众号的收集与添加;
2) 文章URL获取与解析;
3) 正文分布式采集;
3.3.1 公众号搜集与添加
公众号搜集可以通过以下步骤进行处理:
1) 遍历ES中八友历史数据,解析文章正文中存在的公众号信息,并保存数据;
2) 根据项目关键词,通过搜狗微信公众号搜索,进行搜索解析并保存入库;
3) 特殊需求的公众号由各个项目自行提供;
微信公众号添加详见4.3节。
3.3.2 文章URL获取与解析
微信文章URL处理流程如下图3-2所示:
图 3-2
3.3.3 正文采集
文章正文处理流程如下图3-3所示:
图 3-3
3.4 数据储存
微信采集过程中的数据储存主要分为三块,一是微信号和公众号的储存;二是公众号文章列表的储存;三是文章正文信息的储存。各个模块的储存详见下列介绍。
3.4.1 微信号储存
3.4.2 公众号储存
3.4.3 文章URL储存
在每位陌陌关注的公众号推送文章后,通过手机中安装的VirtualXposed插件,获取接收到的数据包,然后把数据包+手机号,一同发送到Redis插口,接口对数据包进行解析,把文章URL数据储存到Redis集群中。
根据八友陌陌插口每日的数据量剖析,微信全量采集时须要处理的比较活跃的公众号在40~50万个,每天文章量在80~120万左右。为了易于管理,计划在Redis集群中,每天生成一个hash类型的缓存表,表名格式为:WeChat_yyyyMMdd,其中数据格式为key=URL,value=当前添加时间。如下图3-4所示
图 3-4
3.4.4 采集历史记录储存
微信文章通过分布式形式进行,每个采集脚本恳求Redis插口服务,获取一定量的文章URL,然后采集正文,推送到kafka中。同时,请求过的URL信息,Redis插口会把信息从WeChat_yyyyMMdd缓存中删掉,并保存到采集历史缓存中。hash类型的缓存表表名格式为:WeChat_History_yyyyMMdd,如下图3-2所示。其中key=URL,value=请求时的当前系统时间。如下图3-5所示
图 3-5
3.5 采集监控
整个采集流程中须要监控的节点主要为:XPosed插件;Redis插口服务接收和解析、入库;正文采集(源码获取、解析,kafka推送)。具体处理如下:
3.5.1 XPosed监控
主要分为两部份,一是XPosed插件自身的监控,防止长时间运行造成关机等;二是XPosed数据包发送。
XPosed插件:自身缺陷机长时间运行,导致的关机等现象,目前仍未找到好的处理方法,只能通过重启插件或手机;
XPosed数据包:数据包异常主要彰显在调用Redis集群插口服务时,需要在插口服务异常的情况下,把获取到的数据推送到数据库或讲到文件里,当插口服务正常时重新发送。
3.5.2 Redis插口服务监控
主要监控XPosed数据包解析和保存另两个步骤,在出现异常时把数据讲到本地文件,待正常时重新进行二次处理。
3.5.3 正文采集监控
正文采集监控点主要包括:已采集URL记录、正文源码下载、正文解析,以及信息推送kafka等四部份。
① 已采集URL记录在历史信息表中,保留一个月,用于对采集异常的追溯;
② 正文源码下载:记录请求状态码;
③ 正文解析:记录解析状态;0:成功;1:失败;
④ 信息推送:推送异常数据保存在本地文件,待服务正常时进行二次推送。如果一条信息推送三次均未成功,则表示推送失败,同时删除内容。
同时,需要监控服务器IP被封的情况;
3.5.4 新增公众号监控
目前有些网站有公众号的搜索功能,前期可以使用项目相关的关键词在这种网站上进行搜索,获取部份新注册的公众号。搜索平台如下表3-1:
搜狗微信公众号搜索 %E9%93%B6%E8%A1%8C&ie=utf8&s_from=input&sug=y&sug_type=
推信网微信公众号推荐 %e9%87%91%e8%9e%8d&t=weixin&p=16
聚陌陌
4 采集运维管理
微信公众号数据的采集运维工作,主要彰显在微信号的注册、养号、解封等工作上,至于陌陌文章的采集,基于现有的服务器,使用分布式可以较容易的进行处理。在微信号前期注册和养号期间,计划分配到数据管理中心各人员,作为一个KPI加分指标。由各人员在屋内或则上下班路上,进行微信号注册、养号(发朋友圈、点赞、聊天)等。
4.1 微信注册
由于微信号的监管逐渐加大,新注册的微信号被封的机率较大,所以微信号在注册时须要找寻一定的规则,具体注意事项如下:
① 注册请用官微,不要用那些多开软件注册
② 使用4G网络,千万不要用wifi,不要开GPS。同一个Wifi或GPS多个微信号注册,相当容易被封号的。
③ 每个手机必须提前存3-5个手机号进去,注册成功的时候,可以直接加上微信好友
④ 选择不同位置注册,可使用不同出行方式(公交、地铁、步行),每次注册的距离大于1.5km,每次注册间隔时间大于10分钟,最好分开时间段注册,尽量一批号不要是同一天,最好是分散到 3-5 天注册完成。
⑤ 注册时如果5分钟之内收不到验证码,先暂停该号码注册,不要频繁发送验证码
⑥ 随意关注几个公众号(搜索微信安全中心、京东、爱奇艺搞笑等公众账号)
⑦ 注册后一定先自己任意使用微信,之后注册其他号完成后也要使用一下之前注册的微信
⑧ 注册之后不能将手机关闭
⑨ 新微信号注册,密码不要一样。建议采用:相同字符+手机号的形式,也比较容易记。
⑩ 个人资料的地区一定不要填写,因为一点开就开始获取位置了,这个记录宁可不让微信知道。个人资料不要一次性全部填完,每天填一点,分批填写,可以增加活跃的权重。
⑪ 设置头像,注意,头像图片必须每张都不一样,如果一定需要设置同样的头像,请通过制图软件修改图片的大小,亮度等,另存成不同的图片,这样对于微信系统来说,可以绕过一定的检测。
⑫ 名字最好多个号都不一样 。
注意事项:
现在有专门卖微信号,买回去之后就可以使用,不过为了安全起见,还是建议登陆一周,期间发一些朋友圈,或加一些陌陌,每天随意聊几句,这样可以减少异常机率
4.3 公众号添加 查看全部
文章采集调用 xposed商店市场
3.2 采集方式
3.2.1 目前情况
目前陌陌采集主要有以下三种形式:
(一)通过微信PC版采集,在电脑正常登陆微信PC版后,通过模拟鼠标键盘操作的方式来进行采集。该方式硬件投入较大。
(二)通过微信网页版采集,直接调用程序扫码登录微信网页版,登录后,微信关注的微信公众号,有新的信息推送到微信时,程序会自动获取推送信息。该方式下微信连接容易中断,无法保证采集的稳定性。
(三)直接通过VirtualXposed监控微信。这种方式是程序直接装在手机上,自动拦截推送的信息。通过分析拦截的数据包,解析出有用的数据。该方式成本相对较低,且稳定性较好。
经过各方面比对,最终选定第三种形式,也就是直接通过VirtualXposed监控陌陌APP发出和接收的所有恳求数据包,对其进行解析,分析出符合要求的文章链接。
3.2.2 备用方案
由于使用VirtualXposed拦截陌陌推送信息的方法,会对陌陌客户端进行篡
改,腾讯有可能升级技术,导致VirtualXposed插件未能再使用。或者,腾讯能通过技术确切的检查手机是否安装了VirtualXposed插件,从而大量封号,导致采集无法稳定进行。目前了解到的可行的备用方案有以下几种形式:
(一)使用3.2.1中的第二种方式。该种方式需要微信号在2017年10月份以前注册,否则无法登陆网页版;
(二)使用AnyProxy抓包的方式。该种方式对技术要求较高,目前尚未进行详细的测试。
3.3 采集流程
微信采集整体流程如下图3-1所示:
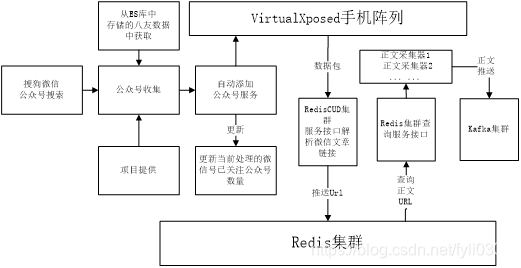
图 3-1
其中主要分为三部份:
1) 公众号的收集与添加;
2) 文章URL获取与解析;
3) 正文分布式采集;
3.3.1 公众号搜集与添加
公众号搜集可以通过以下步骤进行处理:
1) 遍历ES中八友历史数据,解析文章正文中存在的公众号信息,并保存数据;
2) 根据项目关键词,通过搜狗微信公众号搜索,进行搜索解析并保存入库;
3) 特殊需求的公众号由各个项目自行提供;
微信公众号添加详见4.3节。
3.3.2 文章URL获取与解析
微信文章URL处理流程如下图3-2所示:
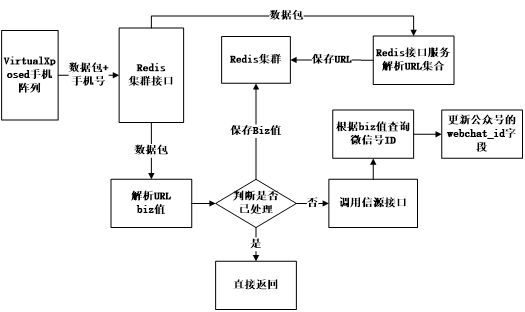
图 3-2
3.3.3 正文采集
文章正文处理流程如下图3-3所示:
图 3-3
3.4 数据储存
微信采集过程中的数据储存主要分为三块,一是微信号和公众号的储存;二是公众号文章列表的储存;三是文章正文信息的储存。各个模块的储存详见下列介绍。
3.4.1 微信号储存
3.4.2 公众号储存
3.4.3 文章URL储存
在每位陌陌关注的公众号推送文章后,通过手机中安装的VirtualXposed插件,获取接收到的数据包,然后把数据包+手机号,一同发送到Redis插口,接口对数据包进行解析,把文章URL数据储存到Redis集群中。
根据八友陌陌插口每日的数据量剖析,微信全量采集时须要处理的比较活跃的公众号在40~50万个,每天文章量在80~120万左右。为了易于管理,计划在Redis集群中,每天生成一个hash类型的缓存表,表名格式为:WeChat_yyyyMMdd,其中数据格式为key=URL,value=当前添加时间。如下图3-4所示
图 3-4
3.4.4 采集历史记录储存
微信文章通过分布式形式进行,每个采集脚本恳求Redis插口服务,获取一定量的文章URL,然后采集正文,推送到kafka中。同时,请求过的URL信息,Redis插口会把信息从WeChat_yyyyMMdd缓存中删掉,并保存到采集历史缓存中。hash类型的缓存表表名格式为:WeChat_History_yyyyMMdd,如下图3-2所示。其中key=URL,value=请求时的当前系统时间。如下图3-5所示
图 3-5
3.5 采集监控
整个采集流程中须要监控的节点主要为:XPosed插件;Redis插口服务接收和解析、入库;正文采集(源码获取、解析,kafka推送)。具体处理如下:
3.5.1 XPosed监控
主要分为两部份,一是XPosed插件自身的监控,防止长时间运行造成关机等;二是XPosed数据包发送。
XPosed插件:自身缺陷机长时间运行,导致的关机等现象,目前仍未找到好的处理方法,只能通过重启插件或手机;
XPosed数据包:数据包异常主要彰显在调用Redis集群插口服务时,需要在插口服务异常的情况下,把获取到的数据推送到数据库或讲到文件里,当插口服务正常时重新发送。
3.5.2 Redis插口服务监控
主要监控XPosed数据包解析和保存另两个步骤,在出现异常时把数据讲到本地文件,待正常时重新进行二次处理。
3.5.3 正文采集监控
正文采集监控点主要包括:已采集URL记录、正文源码下载、正文解析,以及信息推送kafka等四部份。
① 已采集URL记录在历史信息表中,保留一个月,用于对采集异常的追溯;
② 正文源码下载:记录请求状态码;
③ 正文解析:记录解析状态;0:成功;1:失败;
④ 信息推送:推送异常数据保存在本地文件,待服务正常时进行二次推送。如果一条信息推送三次均未成功,则表示推送失败,同时删除内容。
同时,需要监控服务器IP被封的情况;
3.5.4 新增公众号监控
目前有些网站有公众号的搜索功能,前期可以使用项目相关的关键词在这种网站上进行搜索,获取部份新注册的公众号。搜索平台如下表3-1:
搜狗微信公众号搜索 %E9%93%B6%E8%A1%8C&ie=utf8&s_from=input&sug=y&sug_type=
推信网微信公众号推荐 %e9%87%91%e8%9e%8d&t=weixin&p=16
聚陌陌
4 采集运维管理
微信公众号数据的采集运维工作,主要彰显在微信号的注册、养号、解封等工作上,至于陌陌文章的采集,基于现有的服务器,使用分布式可以较容易的进行处理。在微信号前期注册和养号期间,计划分配到数据管理中心各人员,作为一个KPI加分指标。由各人员在屋内或则上下班路上,进行微信号注册、养号(发朋友圈、点赞、聊天)等。
4.1 微信注册
由于微信号的监管逐渐加大,新注册的微信号被封的机率较大,所以微信号在注册时须要找寻一定的规则,具体注意事项如下:
① 注册请用官微,不要用那些多开软件注册
② 使用4G网络,千万不要用wifi,不要开GPS。同一个Wifi或GPS多个微信号注册,相当容易被封号的。
③ 每个手机必须提前存3-5个手机号进去,注册成功的时候,可以直接加上微信好友
④ 选择不同位置注册,可使用不同出行方式(公交、地铁、步行),每次注册的距离大于1.5km,每次注册间隔时间大于10分钟,最好分开时间段注册,尽量一批号不要是同一天,最好是分散到 3-5 天注册完成。
⑤ 注册时如果5分钟之内收不到验证码,先暂停该号码注册,不要频繁发送验证码
⑥ 随意关注几个公众号(搜索微信安全中心、京东、爱奇艺搞笑等公众账号)
⑦ 注册后一定先自己任意使用微信,之后注册其他号完成后也要使用一下之前注册的微信
⑧ 注册之后不能将手机关闭
⑨ 新微信号注册,密码不要一样。建议采用:相同字符+手机号的形式,也比较容易记。
⑩ 个人资料的地区一定不要填写,因为一点开就开始获取位置了,这个记录宁可不让微信知道。个人资料不要一次性全部填完,每天填一点,分批填写,可以增加活跃的权重。
⑪ 设置头像,注意,头像图片必须每张都不一样,如果一定需要设置同样的头像,请通过制图软件修改图片的大小,亮度等,另存成不同的图片,这样对于微信系统来说,可以绕过一定的检测。
⑫ 名字最好多个号都不一样 。
注意事项:
现在有专门卖微信号,买回去之后就可以使用,不过为了安全起见,还是建议登陆一周,期间发一些朋友圈,或加一些陌陌,每天随意聊几句,这样可以减少异常机率
4.3 公众号添加
采集站怎么操作?会不会被K?
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-08-26 03:39
我身边有很多同学,大多数是seo新人和网路编辑,他们都觉得网站文章采集不但不会被收录,而且都会被k,至于排行愈发是不可能了,这是大部分人对于采集文章的想法,而对于原创内容,大部分编辑是这样觉得的,觉得原创了,百度等搜索引擎都会马上收录,就会有索引,就会给排行,但是事实上很多人来问我说,我网站的内容都是原创的为何百度不收录啊。关于这种问题,其实我想跟你们说得是:虽然百度鼓励你们给自己的站点更新原创内容,但是不代表原创内容百度还会收录,百度都会给你挺好的排行,对于百度而言,其实它更注重的是内容的作用,内容是否能解答用户的需求,是否有用,有趣,有共鸣或则差异化和权威性(特别是医疗站点)。
可能说得有点绕,有得同学有点晕,下面我跟你们解释下,如果同样权重的网站,那么内容更新快,内容更新稳定,内容更新量多,网站是比较垂直的,内容对知识点解答得愈发全面的,那这个站点的内容收录量,索引量和排行就会比较好。而一些比较敏感的行业,比如医疗类,百度对这种站点的处理一般会比较敏感,所以通常新站会比较难获得好的排行,大部分排行是权重比较高,网站年龄比较长的站点。
其实一个网站哪怕是所有的文章都是采集的,但是有进行差异化处理,相关内容调用推荐,只有站点不是没有优化的站点,一般还会有不错的收录和排行,这是我通过实践的,用了两个站点进行采集,一个站点是纯采集,内容不做任何更改;一个站点会进行差异化处理,结果有进行差异化处理的站点不只索引量高,排名也好,而没进行差异化处理的网站,虽然索引量也不错,但是排行就寥寥无几了。
采集站怎么操作
关于采集站内容的处理,其实无非就几点:分类、分词、标签、去重、更新稳定和规律、最后便是对内容是否被蜘蛛爬取过,是否有收录和索引进行针对性处理,等内容量和收录量足够多了,内容知识点比较建立了,接下来就是seo频道(聚合页面、百科页面)的处理,让网站爆发大量内链和大量页面,以及差异化和全面性的内容,获得更多的流量。具体操作请关注韩神叨叨公众号:byhanshin
微信公众号韩神叨叨(byhanshin)原创文章,转载请标明出处,谢谢。献给跟我一样为了梦想在异地他乡奋斗的你 查看全部
采集站怎么操作?会不会被K?
我身边有很多同学,大多数是seo新人和网路编辑,他们都觉得网站文章采集不但不会被收录,而且都会被k,至于排行愈发是不可能了,这是大部分人对于采集文章的想法,而对于原创内容,大部分编辑是这样觉得的,觉得原创了,百度等搜索引擎都会马上收录,就会有索引,就会给排行,但是事实上很多人来问我说,我网站的内容都是原创的为何百度不收录啊。关于这种问题,其实我想跟你们说得是:虽然百度鼓励你们给自己的站点更新原创内容,但是不代表原创内容百度还会收录,百度都会给你挺好的排行,对于百度而言,其实它更注重的是内容的作用,内容是否能解答用户的需求,是否有用,有趣,有共鸣或则差异化和权威性(特别是医疗站点)。
可能说得有点绕,有得同学有点晕,下面我跟你们解释下,如果同样权重的网站,那么内容更新快,内容更新稳定,内容更新量多,网站是比较垂直的,内容对知识点解答得愈发全面的,那这个站点的内容收录量,索引量和排行就会比较好。而一些比较敏感的行业,比如医疗类,百度对这种站点的处理一般会比较敏感,所以通常新站会比较难获得好的排行,大部分排行是权重比较高,网站年龄比较长的站点。
其实一个网站哪怕是所有的文章都是采集的,但是有进行差异化处理,相关内容调用推荐,只有站点不是没有优化的站点,一般还会有不错的收录和排行,这是我通过实践的,用了两个站点进行采集,一个站点是纯采集,内容不做任何更改;一个站点会进行差异化处理,结果有进行差异化处理的站点不只索引量高,排名也好,而没进行差异化处理的网站,虽然索引量也不错,但是排行就寥寥无几了。
采集站怎么操作
关于采集站内容的处理,其实无非就几点:分类、分词、标签、去重、更新稳定和规律、最后便是对内容是否被蜘蛛爬取过,是否有收录和索引进行针对性处理,等内容量和收录量足够多了,内容知识点比较建立了,接下来就是seo频道(聚合页面、百科页面)的处理,让网站爆发大量内链和大量页面,以及差异化和全面性的内容,获得更多的流量。具体操作请关注韩神叨叨公众号:byhanshin
微信公众号韩神叨叨(byhanshin)原创文章,转载请标明出处,谢谢。献给跟我一样为了梦想在异地他乡奋斗的你
Ajax——ajax调用数据总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2020-08-26 00:56
在做人事系统添加批量更改的功能中,需要将前台中的数据传给后台,后台并执行一系列的操作。通过查询和学习了解到可以通过ajax将值传入到后台,并在后台对数据进行操作。
说的简单点,就是ajax调用后台的技巧。通过学习和实践,学习了几种ajax调用数据的几种方式,现在总结一下:
1. Ajax调用无参的后台方式的数据
Jquery前台代码:
//ajax调用无参数后台方式$(function () {$("#btnok").click(function () {$.ajax({type:"post",//ajax的形式为post(get方法对传送数据宽度有限制)url: "demo.aspx/Hello",//demo.aspx为目标文件,Hello为目标文件中的方式contentType: "application/json",//传值形式success: function (data) {//成功回传值后触发的方式alert(data.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用的无参数方式[WebMethod]public static string Hello(){return "Hello Ajax!";}运行结果:
2. Ajax调用有参后台方式中的数据
Jquery前台代码:
//ajax调用有参数后台方式$(function () {$("#btnName").click(function () {var strname = $("#txtName").val(); //strname获得文本框中输入的值$.ajax({type: "post", //ajax的形式为post(get方法对传送数据宽度有限制)contentType: "application/json",//传值形式url: "demo.aspx/getName", //demo.aspx为目标文件,getName为目标文件中的方式data: "{strName:'" + strname + "'}", //strName为后台方式的参数,采集软件,strname为文本框中输入的值contentType: "application/json",//传值形式success: function (result) {//成功回传值后触发的方式alert(result.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用的带参数的方式[WebMethod]public static string getName(string strName){return "欢迎"+strName;}
运行结果:
3. Ajax调用后台方式返回链表的数据
Jquery前台代码:
//ajax调用后台方式返回链表$(function () {$("#btnReArr").click(function () {$.ajax({type: "post", //ajax的形式为post(get方法对传送数据宽度有限制)contentType: "application/json",//传值形式url: "demo.aspx/GetArray", //demo.aspx为目标文件,GetArray为目标文件中的方式contentType: "application/json",//传值形式success: function (result) {//成功回传值后触发的方式alert(result.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用返回链表的方式[WebMethod]public static List GetArray(){List li = new List();for (int i = 0; i
运行结果:
4. Ajax调用xml中的数据
Jquery前台代码:
//ajax调用xml中的数据$(function () {$("#btnMaXML").click(function () {$.ajax({dataType: 'xml', //ajax的形式为post(get方法对传送数据宽度有限制)url: "demoXML.xml", //直接写xml的名子success: function (xml) {//成功回传值后触发的方式//查找xml元素$(xml).find("data>item").each(function () {var $dm = $(this);var $id = $dm.find("id"); //获取出id数组的值var $class = $dm.find("class");//获取出class数组的值alert($id.text()+","+$class.text());})}})})});
前台表单控件:
xml代码:
1英语2物理
运行结果:
相关报导:
Photo Credit: stillframe 对开发者来说,要使使用者下载 app 相当不容易,但当使用者下载以后,打开 app 的第一时间会是哪些画面迎接使用者呢?一个接着一个的步骤指引?还是注册登录画面?上述二者可能就会丧失使用者继续操作的意愿与对产品的兴趣。事实上 更多
亲爱的网友,我这儿有套课程想和你们分享,如果对这个课程有兴趣的,可以加我的QQ2059055336和我联系。 课程背景 本课程是院长使用WPF、ADO.NET、MVVM技术来实现太平人寿保险有限公司保险顾客管理系统,是学习WPF开发中的一门主打课程之一。 WPF是一个框架, 更多 查看全部
Ajax——ajax调用数据总结
在做人事系统添加批量更改的功能中,需要将前台中的数据传给后台,后台并执行一系列的操作。通过查询和学习了解到可以通过ajax将值传入到后台,并在后台对数据进行操作。
说的简单点,就是ajax调用后台的技巧。通过学习和实践,学习了几种ajax调用数据的几种方式,现在总结一下:
1. Ajax调用无参的后台方式的数据
Jquery前台代码:
//ajax调用无参数后台方式$(function () {$("#btnok").click(function () {$.ajax({type:"post",//ajax的形式为post(get方法对传送数据宽度有限制)url: "demo.aspx/Hello",//demo.aspx为目标文件,Hello为目标文件中的方式contentType: "application/json",//传值形式success: function (data) {//成功回传值后触发的方式alert(data.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用的无参数方式[WebMethod]public static string Hello(){return "Hello Ajax!";}运行结果:

2. Ajax调用有参后台方式中的数据
Jquery前台代码:
//ajax调用有参数后台方式$(function () {$("#btnName").click(function () {var strname = $("#txtName").val(); //strname获得文本框中输入的值$.ajax({type: "post", //ajax的形式为post(get方法对传送数据宽度有限制)contentType: "application/json",//传值形式url: "demo.aspx/getName", //demo.aspx为目标文件,getName为目标文件中的方式data: "{strName:'" + strname + "'}", //strName为后台方式的参数,采集软件,strname为文本框中输入的值contentType: "application/json",//传值形式success: function (result) {//成功回传值后触发的方式alert(result.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用的带参数的方式[WebMethod]public static string getName(string strName){return "欢迎"+strName;}
运行结果:

3. Ajax调用后台方式返回链表的数据
Jquery前台代码:
//ajax调用后台方式返回链表$(function () {$("#btnReArr").click(function () {$.ajax({type: "post", //ajax的形式为post(get方法对传送数据宽度有限制)contentType: "application/json",//传值形式url: "demo.aspx/GetArray", //demo.aspx为目标文件,GetArray为目标文件中的方式contentType: "application/json",//传值形式success: function (result) {//成功回传值后触发的方式alert(result.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用返回链表的方式[WebMethod]public static List GetArray(){List li = new List();for (int i = 0; i
运行结果:

4. Ajax调用xml中的数据
Jquery前台代码:
//ajax调用xml中的数据$(function () {$("#btnMaXML").click(function () {$.ajax({dataType: 'xml', //ajax的形式为post(get方法对传送数据宽度有限制)url: "demoXML.xml", //直接写xml的名子success: function (xml) {//成功回传值后触发的方式//查找xml元素$(xml).find("data>item").each(function () {var $dm = $(this);var $id = $dm.find("id"); //获取出id数组的值var $class = $dm.find("class");//获取出class数组的值alert($id.text()+","+$class.text());})}})})});
前台表单控件:
xml代码:
1英语2物理
运行结果:

相关报导:
Photo Credit: stillframe 对开发者来说,要使使用者下载 app 相当不容易,但当使用者下载以后,打开 app 的第一时间会是哪些画面迎接使用者呢?一个接着一个的步骤指引?还是注册登录画面?上述二者可能就会丧失使用者继续操作的意愿与对产品的兴趣。事实上 更多
亲爱的网友,我这儿有套课程想和你们分享,如果对这个课程有兴趣的,可以加我的QQ2059055336和我联系。 课程背景 本课程是院长使用WPF、ADO.NET、MVVM技术来实现太平人寿保险有限公司保险顾客管理系统,是学习WPF开发中的一门主打课程之一。 WPF是一个框架, 更多
如何大批量地获取新闻数据(比如把头条陌陌文章都给采集下来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 801 次浏览 • 2020-08-25 22:00
很多企业与事业单位都须要采集新闻资讯、政务公告等数据,用以发展自己的业务。业务不同,具体的采集需求也不尽相同。举几个简单的事例:
做融媒体的,他须要县市许多小道消息源第一时间汇总,以做更全面客观的报导。
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
我们服务过好多顾客,通过优采云大批量地获取数据新闻,从而做为她们自身业务的数据源或数据源的有力补充。这几年我们也帮助一些用户完成这块数据的获取,今天就来跟你们分享一下。这件事情有哪些难点,然后我们又是如何做的。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。
新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。
我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。 查看全部
如何大批量地获取新闻数据(比如把头条陌陌文章都给采集下来)
很多企业与事业单位都须要采集新闻资讯、政务公告等数据,用以发展自己的业务。业务不同,具体的采集需求也不尽相同。举几个简单的事例:
做融媒体的,他须要县市许多小道消息源第一时间汇总,以做更全面客观的报导。
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
我们服务过好多顾客,通过优采云大批量地获取数据新闻,从而做为她们自身业务的数据源或数据源的有力补充。这几年我们也帮助一些用户完成这块数据的获取,今天就来跟你们分享一下。这件事情有哪些难点,然后我们又是如何做的。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。

新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。

我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。
一种文章采集的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2020-08-25 21:18
专利名称:一种文章采集的方式
技术领域:
本发明涉及一种针对各式各样的网站文章进行手动采集的技巧。
背景技术:
文章采集是按照用户定义的关键词字,从各式各样的网站上检索出相关的数据, 并对数据进行合理的截取、分类、去重和过滤,然后以文件或数据库的形式保存出来。文章采集应用的关键在于怎样从众多的网站获取所须要的确切内容到预期的中 心资源库中,然后进行快速的借助。文章采集的核心技术是模式定义和模式匹配。模式属 于人工智能的术语,是对前人积累的经验的具象和升华。简单地说,就是从不断重复出现的 事件中发觉和具象出的规律,是解决问题的经验的总结。只要是一再重复出现的事物,就可 能存在某种模式。文章采集的模式大多不是程序手动发觉的,目前几乎所有的文章采集产 品都须要通过人工来定义。但模式本身是个很复杂、很具象的内容,所以所有的开发者精力 都花在如何使模式定义更简单、更准确上,这也是文章采集技术竞争力的评判标准。目前大 多采用正则表达式定义和文档结构定义。传统的文章采集存在几个方面的问题1、采集的是每篇文章,需要手工进行页面 处理能够被借助;2、不能分栏目采集;3、只支持单一站点的采集;4、采集的文章不能手动 套用自己网站的格式进行发布,需要进行手工处理。
发明内容
本发明的目的在于提供一种文章采集的方式,支持网站群的多站点采集,可针对 文章进行分段采集和分栏目采集,采集的文章能手动套用自己网站的格式进行发布,不需 要进行手工处理。一种文章采集的方式,具体包括如下步骤先选取采集来源,采用正则表达式制订 采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点的栏目 进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集; 根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用 文章合并模板进行发布。所述的采用正则表达式制订采集规则,是指输入须要采集的静态页面地址,确定 地址中到第N个“/”为须要被采集的静态文件内容的地址,并将其手动转换成正则表达式 规则。所述的关键信息处理方法,指确定须要采集内容的文章标题或则关键信息的字符 串位置。本发明采用正则表达式定义的形式,根据用户自定义的任务配置,批量而精确地 抽取目标网路媒体栏目中的新闻或文章,转化为结构化的记录(标题,作者,内容,采集时 间,来源,分类,相关图片等),保存在本地数据库中,用于内部使用或内网发布,快速实现外 部信息的获取,对各种网站新闻的采集具有较快的速率和较高的准确率。本发明可在手动、手动两种模式下运行,自动由系统定期到指定的站点更新最新的信息,手动提供了及时触 发的机制;支持不同的信息采集使用不同的模式。本发明对传统的文章采集技术进行改进,真正满足了用户的应用需求1、可以针 对文章进行分段采集,只获取所须要的内容;2、每个栏目都可以订制相应的采集任务,文章 采集后手动储存在对应栏目下;3、采用多线程技术,支持网站群的多站点采集;4、结合模 板弓I擎技术,文章采集后可以手动套用网站模板进行手动发布。
图1为本发明的逻辑流程图。
图2为本发明施行例中采集内容的字符串位置示意图。以下结合附图和具体施行例对本发明作进一步阐述。
具体施行例形式如图1所示,本发明一种文章采集的方式,具体包括如下先选取采集来源,采用正则表达式制订采集规则,使用关键信息处理方法确定采 集内容的范围,将采集的内容和目标站点的栏目进行绑定。所述的采用正则表达式制订采集规则指输入须要采集的静态页面地址,该路径 指向待采集页面的某个栏目中的其中一篇文章,确定第N个“/”开始下的内容,自动转换成 正则表达式规则,符合表达式规则的静态文件内容将被采集。所述的关键信息处理方法指确定须要采集内容的文章标题或则关键信息的字符 串位置(如图2举例所示)。由于每位网站内容展示位置不一样,在配置采集时需先找到所 要采集内容的字符串位置,才能准确地采集到数据。所述的将采集的内容和目标站点的栏目进行绑定就是用户在采集配置中,用户 需选择所属栏目,或在创建栏目时,用户可选择指定的文章模板,开始采集时,通过栏目找 到指定的文章模板,在发布时合并生成静态页面。开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集; 根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用 文章合并模板进行发布。所述的文章合并模板指将动态的文章数据通过调用模板引擎生成静态的HTML 页面。以上所述,仅是本发明较佳施行例而已,并非对本发明的技术范围作任何限制,故 凡是根据本发明的技术实质对以上施行例所作的任何细微更改、等同变化与修饰,均仍属 于本发明技术方案的范围内。
权利要求
1.一种文章采集的方式,其特点在于包括如下步骤先选取采集来源,采用正则抒发 式制订采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点 的栏目进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站 点采集;根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发 布,则调用文章合并模板进行发布。
2.根据权力要求1所述的一种文章采集的方式,其特点在于所述的采用正则表达式 制定采集规则,是指输入须要采集的静态页面地址,确定地址中到第N个“/”为须要被采集 的静态文件内容的地址,并将其手动转换成正则表达式规则。
3.根据权力要求1所述的一种文章采集的方式,其特点在于所述的关键信息处理方 式,指确定须要采集内容的文章标题或则关键信息的字符串位置。
全文摘要
一种文章采集的方式,先选取采集来源,采用正则表达式制订采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点的栏目进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集;根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用文章合并模板进行发布;本发明按照用户自定义的任务配置,批量而精确地抽取目标网路媒体栏目中的新闻或文章,转化为结构化的记录保存或用于内部使用或内网发布,能快速实现外部信息的获取,对各种网站新闻的采集具有较快的速率和较高的准确率。
文档编号G06F17/30GK102096705SQ20101061842
公开日2011年6月15日 申请日期2010年12月31日 优先权日2010年12月31日
发明者曾文语, 林雅珊 申请人:南威软件股份有限公司 查看全部
一种文章采集的方式
专利名称:一种文章采集的方式
技术领域:
本发明涉及一种针对各式各样的网站文章进行手动采集的技巧。
背景技术:
文章采集是按照用户定义的关键词字,从各式各样的网站上检索出相关的数据, 并对数据进行合理的截取、分类、去重和过滤,然后以文件或数据库的形式保存出来。文章采集应用的关键在于怎样从众多的网站获取所须要的确切内容到预期的中 心资源库中,然后进行快速的借助。文章采集的核心技术是模式定义和模式匹配。模式属 于人工智能的术语,是对前人积累的经验的具象和升华。简单地说,就是从不断重复出现的 事件中发觉和具象出的规律,是解决问题的经验的总结。只要是一再重复出现的事物,就可 能存在某种模式。文章采集的模式大多不是程序手动发觉的,目前几乎所有的文章采集产 品都须要通过人工来定义。但模式本身是个很复杂、很具象的内容,所以所有的开发者精力 都花在如何使模式定义更简单、更准确上,这也是文章采集技术竞争力的评判标准。目前大 多采用正则表达式定义和文档结构定义。传统的文章采集存在几个方面的问题1、采集的是每篇文章,需要手工进行页面 处理能够被借助;2、不能分栏目采集;3、只支持单一站点的采集;4、采集的文章不能手动 套用自己网站的格式进行发布,需要进行手工处理。
发明内容
本发明的目的在于提供一种文章采集的方式,支持网站群的多站点采集,可针对 文章进行分段采集和分栏目采集,采集的文章能手动套用自己网站的格式进行发布,不需 要进行手工处理。一种文章采集的方式,具体包括如下步骤先选取采集来源,采用正则表达式制订 采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点的栏目 进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集; 根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用 文章合并模板进行发布。所述的采用正则表达式制订采集规则,是指输入须要采集的静态页面地址,确定 地址中到第N个“/”为须要被采集的静态文件内容的地址,并将其手动转换成正则表达式 规则。所述的关键信息处理方法,指确定须要采集内容的文章标题或则关键信息的字符 串位置。本发明采用正则表达式定义的形式,根据用户自定义的任务配置,批量而精确地 抽取目标网路媒体栏目中的新闻或文章,转化为结构化的记录(标题,作者,内容,采集时 间,来源,分类,相关图片等),保存在本地数据库中,用于内部使用或内网发布,快速实现外 部信息的获取,对各种网站新闻的采集具有较快的速率和较高的准确率。本发明可在手动、手动两种模式下运行,自动由系统定期到指定的站点更新最新的信息,手动提供了及时触 发的机制;支持不同的信息采集使用不同的模式。本发明对传统的文章采集技术进行改进,真正满足了用户的应用需求1、可以针 对文章进行分段采集,只获取所须要的内容;2、每个栏目都可以订制相应的采集任务,文章 采集后手动储存在对应栏目下;3、采用多线程技术,支持网站群的多站点采集;4、结合模 板弓I擎技术,文章采集后可以手动套用网站模板进行手动发布。
图1为本发明的逻辑流程图。
图2为本发明施行例中采集内容的字符串位置示意图。以下结合附图和具体施行例对本发明作进一步阐述。
具体施行例形式如图1所示,本发明一种文章采集的方式,具体包括如下先选取采集来源,采用正则表达式制订采集规则,使用关键信息处理方法确定采 集内容的范围,将采集的内容和目标站点的栏目进行绑定。所述的采用正则表达式制订采集规则指输入须要采集的静态页面地址,该路径 指向待采集页面的某个栏目中的其中一篇文章,确定第N个“/”开始下的内容,自动转换成 正则表达式规则,符合表达式规则的静态文件内容将被采集。所述的关键信息处理方法指确定须要采集内容的文章标题或则关键信息的字符 串位置(如图2举例所示)。由于每位网站内容展示位置不一样,在配置采集时需先找到所 要采集内容的字符串位置,才能准确地采集到数据。所述的将采集的内容和目标站点的栏目进行绑定就是用户在采集配置中,用户 需选择所属栏目,或在创建栏目时,用户可选择指定的文章模板,开始采集时,通过栏目找 到指定的文章模板,在发布时合并生成静态页面。开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集; 根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用 文章合并模板进行发布。所述的文章合并模板指将动态的文章数据通过调用模板引擎生成静态的HTML 页面。以上所述,仅是本发明较佳施行例而已,并非对本发明的技术范围作任何限制,故 凡是根据本发明的技术实质对以上施行例所作的任何细微更改、等同变化与修饰,均仍属 于本发明技术方案的范围内。
权利要求
1.一种文章采集的方式,其特点在于包括如下步骤先选取采集来源,采用正则抒发 式制订采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点 的栏目进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站 点采集;根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发 布,则调用文章合并模板进行发布。
2.根据权力要求1所述的一种文章采集的方式,其特点在于所述的采用正则表达式 制定采集规则,是指输入须要采集的静态页面地址,确定地址中到第N个“/”为须要被采集 的静态文件内容的地址,并将其手动转换成正则表达式规则。
3.根据权力要求1所述的一种文章采集的方式,其特点在于所述的关键信息处理方 式,指确定须要采集内容的文章标题或则关键信息的字符串位置。
全文摘要
一种文章采集的方式,先选取采集来源,采用正则表达式制订采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点的栏目进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集;根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用文章合并模板进行发布;本发明按照用户自定义的任务配置,批量而精确地抽取目标网路媒体栏目中的新闻或文章,转化为结构化的记录保存或用于内部使用或内网发布,能快速实现外部信息的获取,对各种网站新闻的采集具有较快的速率和较高的准确率。
文档编号G06F17/30GK102096705SQ20101061842
公开日2011年6月15日 申请日期2010年12月31日 优先权日2010年12月31日
发明者曾文语, 林雅珊 申请人:南威软件股份有限公司
LabVIEW对数据采集卡DLL函数的调用
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-08-25 09:29
襄樊学院学报Sept。,2004 第25 XiangfanUniversity Vol。25 No。5 LabVIEW对数据采集卡DLL 函数的调用 摘要:首先介绍虚拟仪器及其开发环境LabVIEW6的特性,分析并实现了将LabVIEW与外部代码进行联接的中级技术之一—动态链接库(DLL)机制.实践表明,此机制高效、易行,是提高 LabVIEW与其它Windows应用程序之间的数据共享能力的一条挺好的途径. 关键词:虚拟仪器;LabVIEW;动态链接库;DLL 中图分类号:TN311。11文献标志码:A文章编号:1009-2854(2004)05-0015-03 0序言 美国国家仪器NI 公司的基于G 语言的开发环境LabVIEW的出现,使得虚拟仪器的思想为工业界所接 所谓虚拟仪器,就是在通用计算机平台上,用户按照自己的需求定义和设计仪器的测试功能,其实质是将传统仪器硬件和最新计算机软件技术充分结合上去,以模块化软件实现并扩充传统仪器的功能。 统仪器相比,虚拟仪器在智能化程度、处理能力、性能价格比、可操作性等方面均具有显著的技术优势。LabVIEW(Laboratory Virtual Instrument Engineering Workbench实验室虚拟仪器工程平台)是目前国 际上首推应用最广的虚拟仪器开发环境之一,主要应用于仪器控制、数据采集、数据剖析、数据显示等领 域,并适用于Windows 9X/XP/2000/ NT、Macintosh、UNIX 等多种不同的操作系统平台。
与传统程序语言 不同,LabVIEW采用强悍的图形化语言(G 语言)编程,面向测试工程师而非专业程序员,编程十分便捷, 人机交互界面直观友好,具有强悍的数据可视化剖析和仪器控制能力等特性。 使用LabVIEW开发环境,用户可以创建32 位的编译程序,从而为常规的数据采集、测试、测量等任 务提供了更快的运行速率。 LabVIEW是真正的编译器,用户可以创建独立的可执行文件,能够脱离开发环 境而单独运行。 对于大多编程任务,LabVIEW一般能形成高效的代码。 1LabVIEW调用外部程序代码的途径之一——动态链接库机制 1.1动态链接库机制概述 LabVIEW是一个功能强悍的虚拟仪器开发环境,它完整地集成了与GPIB、VXI、RS-232、RS-485 内插式数据采集卡等硬件的通信。LabVIEW还具有外置程序库,提供了大量的联接机制,通过DLLs、共享 库、ActiveX 等途径实现与外部程序代码或软件系统的联接。 LabVIEW提供了4 种调用外部程序代码的途径,其中动态链接库(Dynamic Link LibraryDLL)机制 是从LabVIEW调用标准共享库和用户自定义库函数的通用方式。
具体实现时,是使用LabVIEW功能模板 中“Advanced”子模板里的“调用库函数(Call Library Function)”结点。 “调用库函数结点”包括大量的数据类型和调用规范,使用它可调用大多数标准共享库和用户自定义 库中的函数,包括:Windows9X/XP/2000/NT 下的动态链接库(Dynamic Link Library)、Macintosh 下的代码段(Code Fragment)、UNIX 下的共享库函数(Shared Library Function)等。 当用户须要调用的代码已然存在,或者用户比较熟悉 Windows 中动态链接库、Macintosh 中代码段、 UNIX 中共享库的创建过程时,“调用库函数结点”非常有用,此时使用它也最为合适恰当,因为库使用了 收稿日期:2004-04-21 基金项目:湖北省教育厅重点项目(2003A006) 作者简介:刘传清(1964- )男,湖北钟祥人,襄樊学院物理学系副教授。 15 刘传清:LabVIEW对数据采集卡DLL函数的调用 16 对几个开发环境都适用的格式标准,故用户可以使用几乎任何开发环境去创建LabVIEW才能调用的库。
1.2动态链接库机制实现步骤 在Windows 9X 下,利用LabVIEW 6。1 Windows95/98/NT)中的“动态链接库机制”调用一个DLL, 此DLL 返回机器的名称。 1)建立“调用库函数结点” 新建LabVIEW程序“hostname。vi”,存至新建目录“d:\temp”下,其前面板如下: 图1库函数调用前面板视口图程序如下: 图2库函数调用程序框图其中,“Call Library Function”结点是通过选择功能模板中“Advanced”子模板里的 “Call Library Function”功能模块而形成的。 此LabVIEW程序通过“调用库函数结点”调用一个DLL,此DLL 将返回机器的名称,返回结果存至 字符串指示量“Machine Name”中,而后将字符串常量“LabVIEW ”与“MachineName”相 拼接,拼接之结果在字符串指示量“Message”中显示。 2)配置“调用库函数结点” 双击框图程序窗口的“Call Library Function”结点,在弹出的对话框中对此“调用库函数结点”进行配 其中:在“Library Name Path”一项中键入“d:\temp\hostname。
dll”(即,指明此结点所链接的DLL文件名, 源代码“hostname。c”编译而至);在“Function Name”一项中键入“MachineName”(即,指明与此结点相链接的DLL 文件中的函数的 名称); 参数“return type”的类型选择“Void”;所降低的另一个参数“arg1”的类型选择“String”、字符串 格式选择“String Handle”; 3)编辑C 源文件 编辑C 源文件“hostname。c”(存至目录“d:\temp”下),其内容如下: includeextcode。h which contains LabVIEWfunctions #include #include #include BOOL WINAPI DllMain (HANDLE hDLL, DWORD dwReason, LPVOID lpReserved) returnTRUE; functionsgets computername __declspec(dllexport) void MachineName(void *LVHandle) charcomputerName[MAX_COMPUTERNAME_LENGTH+1]; int compNameLength MAX_COMPUTERNAME_LENGTH+1;第25 襄樊学院学报2004 Getcomputer name GetComputerName(computerName,&compNameLength); SizeLabVIEW handle correctsize DSSetHandleSize(LVHandle,compNameLength stringsize LabVIEWhandle **(int32**)LVHandle LabVIEWhandle sprintf((*(char**)LVHandle)+4,"%s",computerName); 此程序首先了调用Windows的API 函数“GetComputerName”获取机器名;然后调用LabVIEW的函 数“DSSetHandleSize”来设置 LabVIEW 句柄之大小;最后将机器名宽度(32 位整型)、机器名(字符串 型)依次写入句柄中。
4)编译C 源代码 源代码“d:\temp\hostname。c”编译成一个DLL 文件“d:\temp\hostname。dll”。 可使用VC++ 6。0 Windows95/98/2000/NT),完成此编译工作。 5)运行VI 运行LabVIEW程序“hostname。vi”,结果如下: 图3前面板运行结果 2结束语 本文注重阐明并实现了将LabVIEW与外部代码进行联接的中级技术之一动态链接库机制,并给出了 应用实例。 由于在LabVIEW中引入了C 语言的强悍功能,从而提升了LabVIEW的整体性能。 本方式已在LabVIEW 6。1 Windows95/98/NT 及Visual Windows9X/XP/2000/NT 环境下 实现。 实践证明,此方式高效、易行,是提高 LabVIEW 与其它Windows 应用程序之间的数据共享能力的 一条挺好的途径。 参考文献: LabVIEWUser Manual,National Instruments Corporation,1998。 ProgrammingReference Manual,National Instruments Corporation,1998。
LabVIEW Data Acquisition Invoke DLLFunctions LIU Chuan-qing (Department Physics,Xiangfan University, Xiangfan 441053, China) Abstract paperintroduces virtual instrument itsdevelopment environmentLabVIEW, analyzes advancedtechnology-Dynamic Link Library(DLL) ,which generalmethods callingexternal code from LabVIEW。 hasbeen proved goodone enhanceLabVIEW’ sharingdata otherapplications Windows。Key words:Virtual instrument; LabVIEW; Dynamic Link Library 查看全部
LabVIEW对数据采集卡DLL函数的调用
襄樊学院学报Sept。,2004 第25 XiangfanUniversity Vol。25 No。5 LabVIEW对数据采集卡DLL 函数的调用 摘要:首先介绍虚拟仪器及其开发环境LabVIEW6的特性,分析并实现了将LabVIEW与外部代码进行联接的中级技术之一—动态链接库(DLL)机制.实践表明,此机制高效、易行,是提高 LabVIEW与其它Windows应用程序之间的数据共享能力的一条挺好的途径. 关键词:虚拟仪器;LabVIEW;动态链接库;DLL 中图分类号:TN311。11文献标志码:A文章编号:1009-2854(2004)05-0015-03 0序言 美国国家仪器NI 公司的基于G 语言的开发环境LabVIEW的出现,使得虚拟仪器的思想为工业界所接 所谓虚拟仪器,就是在通用计算机平台上,用户按照自己的需求定义和设计仪器的测试功能,其实质是将传统仪器硬件和最新计算机软件技术充分结合上去,以模块化软件实现并扩充传统仪器的功能。 统仪器相比,虚拟仪器在智能化程度、处理能力、性能价格比、可操作性等方面均具有显著的技术优势。LabVIEW(Laboratory Virtual Instrument Engineering Workbench实验室虚拟仪器工程平台)是目前国 际上首推应用最广的虚拟仪器开发环境之一,主要应用于仪器控制、数据采集、数据剖析、数据显示等领 域,并适用于Windows 9X/XP/2000/ NT、Macintosh、UNIX 等多种不同的操作系统平台。
与传统程序语言 不同,LabVIEW采用强悍的图形化语言(G 语言)编程,面向测试工程师而非专业程序员,编程十分便捷, 人机交互界面直观友好,具有强悍的数据可视化剖析和仪器控制能力等特性。 使用LabVIEW开发环境,用户可以创建32 位的编译程序,从而为常规的数据采集、测试、测量等任 务提供了更快的运行速率。 LabVIEW是真正的编译器,用户可以创建独立的可执行文件,能够脱离开发环 境而单独运行。 对于大多编程任务,LabVIEW一般能形成高效的代码。 1LabVIEW调用外部程序代码的途径之一——动态链接库机制 1.1动态链接库机制概述 LabVIEW是一个功能强悍的虚拟仪器开发环境,它完整地集成了与GPIB、VXI、RS-232、RS-485 内插式数据采集卡等硬件的通信。LabVIEW还具有外置程序库,提供了大量的联接机制,通过DLLs、共享 库、ActiveX 等途径实现与外部程序代码或软件系统的联接。 LabVIEW提供了4 种调用外部程序代码的途径,其中动态链接库(Dynamic Link LibraryDLL)机制 是从LabVIEW调用标准共享库和用户自定义库函数的通用方式。
具体实现时,是使用LabVIEW功能模板 中“Advanced”子模板里的“调用库函数(Call Library Function)”结点。 “调用库函数结点”包括大量的数据类型和调用规范,使用它可调用大多数标准共享库和用户自定义 库中的函数,包括:Windows9X/XP/2000/NT 下的动态链接库(Dynamic Link Library)、Macintosh 下的代码段(Code Fragment)、UNIX 下的共享库函数(Shared Library Function)等。 当用户须要调用的代码已然存在,或者用户比较熟悉 Windows 中动态链接库、Macintosh 中代码段、 UNIX 中共享库的创建过程时,“调用库函数结点”非常有用,此时使用它也最为合适恰当,因为库使用了 收稿日期:2004-04-21 基金项目:湖北省教育厅重点项目(2003A006) 作者简介:刘传清(1964- )男,湖北钟祥人,襄樊学院物理学系副教授。 15 刘传清:LabVIEW对数据采集卡DLL函数的调用 16 对几个开发环境都适用的格式标准,故用户可以使用几乎任何开发环境去创建LabVIEW才能调用的库。
1.2动态链接库机制实现步骤 在Windows 9X 下,利用LabVIEW 6。1 Windows95/98/NT)中的“动态链接库机制”调用一个DLL, 此DLL 返回机器的名称。 1)建立“调用库函数结点” 新建LabVIEW程序“hostname。vi”,存至新建目录“d:\temp”下,其前面板如下: 图1库函数调用前面板视口图程序如下: 图2库函数调用程序框图其中,“Call Library Function”结点是通过选择功能模板中“Advanced”子模板里的 “Call Library Function”功能模块而形成的。 此LabVIEW程序通过“调用库函数结点”调用一个DLL,此DLL 将返回机器的名称,返回结果存至 字符串指示量“Machine Name”中,而后将字符串常量“LabVIEW ”与“MachineName”相 拼接,拼接之结果在字符串指示量“Message”中显示。 2)配置“调用库函数结点” 双击框图程序窗口的“Call Library Function”结点,在弹出的对话框中对此“调用库函数结点”进行配 其中:在“Library Name Path”一项中键入“d:\temp\hostname。
dll”(即,指明此结点所链接的DLL文件名, 源代码“hostname。c”编译而至);在“Function Name”一项中键入“MachineName”(即,指明与此结点相链接的DLL 文件中的函数的 名称); 参数“return type”的类型选择“Void”;所降低的另一个参数“arg1”的类型选择“String”、字符串 格式选择“String Handle”; 3)编辑C 源文件 编辑C 源文件“hostname。c”(存至目录“d:\temp”下),其内容如下: includeextcode。h which contains LabVIEWfunctions #include #include #include BOOL WINAPI DllMain (HANDLE hDLL, DWORD dwReason, LPVOID lpReserved) returnTRUE; functionsgets computername __declspec(dllexport) void MachineName(void *LVHandle) charcomputerName[MAX_COMPUTERNAME_LENGTH+1]; int compNameLength MAX_COMPUTERNAME_LENGTH+1;第25 襄樊学院学报2004 Getcomputer name GetComputerName(computerName,&compNameLength); SizeLabVIEW handle correctsize DSSetHandleSize(LVHandle,compNameLength stringsize LabVIEWhandle **(int32**)LVHandle LabVIEWhandle sprintf((*(char**)LVHandle)+4,"%s",computerName); 此程序首先了调用Windows的API 函数“GetComputerName”获取机器名;然后调用LabVIEW的函 数“DSSetHandleSize”来设置 LabVIEW 句柄之大小;最后将机器名宽度(32 位整型)、机器名(字符串 型)依次写入句柄中。
4)编译C 源代码 源代码“d:\temp\hostname。c”编译成一个DLL 文件“d:\temp\hostname。dll”。 可使用VC++ 6。0 Windows95/98/2000/NT),完成此编译工作。 5)运行VI 运行LabVIEW程序“hostname。vi”,结果如下: 图3前面板运行结果 2结束语 本文注重阐明并实现了将LabVIEW与外部代码进行联接的中级技术之一动态链接库机制,并给出了 应用实例。 由于在LabVIEW中引入了C 语言的强悍功能,从而提升了LabVIEW的整体性能。 本方式已在LabVIEW 6。1 Windows95/98/NT 及Visual Windows9X/XP/2000/NT 环境下 实现。 实践证明,此方式高效、易行,是提高 LabVIEW 与其它Windows 应用程序之间的数据共享能力的 一条挺好的途径。 参考文献: LabVIEWUser Manual,National Instruments Corporation,1998。 ProgrammingReference Manual,National Instruments Corporation,1998。
LabVIEW Data Acquisition Invoke DLLFunctions LIU Chuan-qing (Department Physics,Xiangfan University, Xiangfan 441053, China) Abstract paperintroduces virtual instrument itsdevelopment environmentLabVIEW, analyzes advancedtechnology-Dynamic Link Library(DLL) ,which generalmethods callingexternal code from LabVIEW。 hasbeen proved goodone enhanceLabVIEW’ sharingdata otherapplications Windows。Key words:Virtual instrument; LabVIEW; Dynamic Link Library
【采集】如何提升网站访问速率的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-24 22:01
3. 如果友情链接一定要出现在首页,请将链接所在的整个Table放在页面的最下方,因为页面是由上到下逐行显示的,将其放在页面的最下方,不会延后其他内容的显示。
4. 友情链接的LOGO图片先下载后再传到自己的网页空间,这样,速度由自己的网站空间决定而不受友情网站的影响。
-----------------------------------------------------------------------------------------------------------
转载本文请知名出处:Just Do IT ()
一个大型的网站,比如个人网站,可以使用最简单的html静态页面就实现了,配合一些图片达到美化疗效,所有的页面均储存在一个目录下,这样的网站对系统构架、性能的要求都很简单,随着互联网业务的不断丰富,网站相关的技术经过这些年的发展,已经细分到太细的方方面面,尤其对于小型网站来说,所采用的技术更是涉及面十分广,从硬件到软件、编程语言、数据库、WebServer、防火墙等各个领域都有了很高的要求,已经不是原先简单的html静态网站所能比拟的。
大型网站,比如门户网站。在面对大量用户访问、高并发恳求方面,基本的解决方案集中在这样几个环节:使用高性能的服务器、高性能的数据库、高效率的编程语言、还有高性能的Web容器。但是不仅这几个方面,还无法根本解决小型网站面临的高负载和高并发问题。
上面提供的几个解决思路在一定程度上也意味着更大的投入,并且这样的解决思路具备困局,没有挺好的扩展性,下面我从低成本、高性能和高扩张性的角度来说说我的一些经验。
1、HTML静态化
其实你们都晓得,效率最高、消耗最小的就是纯静态化的html页面,所以我们尽可能让我们的网站上的页面采用静态页面来实现,这个最简单的方式虽然也是最有效的方式。但是对于大量内容而且频繁更新的网站,我们难以全部自动去逐个实现,于是出现了我们常见的信息发布系统CMS,像我们常访问的各个门户站点的新闻频道,甚至她们的其他频道,都是通过信息发布系统来管理和实现的,信息发布系统可以实现最简单的信息录入手动生成静态页面,还能具备频道管理、权限管理、自动抓取等功能,对于一个小型网站来说,拥有一套高效、可管理的CMS是必不可少的。
除了门户和信息发布类型的网站,对于交互性要求很高的社区类型网站来说,尽可能的静态化也是提升性能的必要手段,将社区内的贴子、文章进行实时的静态化,有更新的时侯再重新静态化也是大量使用的策略,像Mop的大杂烩就是使用了这样的策略,网易社区等也是这么。
同时,html静态化也是个别缓存策略使用的手段,对于系统中频繁使用数据库查询并且内容更新太小的应用,可以考虑使用html静态化来实现,比如峰会中峰会的公用设置信息,这些信息目前的主流峰会都可以进行后台管理而且储存再数据库中,这些信息虽然大量被前台程序调用,但是更新频度太小,可以考虑将这部份内容进行后台更新的时侯进行静态化,这样避开了大量的数据库访问恳求。
2、图片服务器分离
大家晓得,对于Web服务器来说,不管是Apache、IIS还是其他容器,图片是最消耗资源的,于是我们有必要将图片与页面进行分离,这是基本上小型网站都会采用的策略,他们都有独立的图片服务器,甚至好多台图片服务器。这样的构架可以减少提供页面访问恳求的服务器系统压力,并且可以保证系统不会由于图片问题而崩溃,在应用服务器和图片服务器上,可以进行不同的配置优化,比如apache在配置ContentType的时侯可以尽量少支持,尽可能少的LoadModule,保证更高的系统消耗和执行效率。
3、数据库集群和库表散列
大型网站都有复杂的应用,这些应用必须使用数据库,那么在面对大量访问的时侯,数据库的困局很快能够凸显下来,这时一台数据库将很快未能满足应用,于是我们须要使用数据库集群或则库表散列。
在数据库集群方面,很多数据库都有自己的解决方案,Oracle、Sybase等都有挺好的方案,常用的MySQL提供的Master/Slave也是类似的方案,您使用了什么样的DB,就参考相应的解决方案来施行即可。
上面提及的数据库集群因为在构架、成本、扩张性方面就会遭到所采用DB类型的限制,于是我们须要从应用程序的角度来考虑改善系统构架,库表散列是常用而且最有效的解决方案。我们在应用程序中安装业务和应用或则功能模块将数据库进行分离,不同的模块对应不同的数据库或则表,再根据一定的策略对某个页面或则功能进行更小的数据库散列,比如用户表,按照用户ID进行表散列,这样才能够低成本的提高系统的性能但是有挺好的扩展性。sohu的峰会就是采用了这样的构架,将峰会的用户、设置、帖子等信息进行数据库分离,然后对贴子、用户根据蓝筹股和ID进行散列数据库和表,最终可以在配置文件中进行简单的配置便能使系统随时降低一台低成本的数据库进来补充系统性能。
4、缓存
缓存一词搞技术的都接触过,很多地方用到缓存。网站架构和网站开发中的缓存也是十分重要。这里先述说最基本的两种缓存。高级和分布式的缓存在前面述说。
架构方面的缓存,对Apache比较熟悉的人都能晓得Apache提供了自己的缓存模块,也可以使用外加的Squid模块进行缓存,这两种方法均可以有效的增强Apache的访问响应能力。
网站程序开发方面的缓存,Linux上提供的Memory Cache是常用的缓存插口,可以在web开发中使用,比如用Java开发的时侯就可以调用MemoryCache对一些数据进行缓存和通信共享,一些小型社区使用了这样的构架。另外,在使用web语言开发的时侯,各种语言基本都有自己的缓存模块和技巧,PHP有Pear的Cache模块,Java就更多了,.net不是太熟悉,相信也肯定有。
5、镜像
镜像是小型网站常采用的增强性能和数据安全性的方法,镜像的技术可以解决不同网路接入商和地域带来的用户访问速率差别,比如ChinaNet和EduNet之间的差别就使得了好多网站在教育网内搭建镜像站点,数据进行定时更新或则实时更新。在镜像的细节技术方面,这里不探讨很深,有很多专业的现成的解决构架和产品可选。也有廉价的通过软件实现的思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是小型网站解决高负荷访问和大量并发恳求采用的终极解决办法。
负载均衡技术发展了多年,有很多专业的服务提供商和产品可以选择,我个人接触过一些解决方式,其中有两个构架可以给你们做参考。
硬件四层交换
第四层交换使用第三层和第四层信息包的报头信息,根据应用区间辨识业务流,将整个区间段的业务流分配到合适的应用服务器进行处理。第四层交换功能如同是虚IP,指向化学服务器。它传输的业务服从的合同多种多样,有HTTP、FTP、NFS、Telnet或其他合同。这些业务在数学服务器基础上,需要复杂的载量平衡算法。在IP世界,业务类型由终端TCP或UDP端口地址来决定,在第四层交换中的应用区间则由源端和终端IP地址、TCP和UDP端口共同决定。
在硬件四层交换产品领域,有一些著名的产品可以选择,比如Alteon、F5等,这些产品太高昂,但是物有所值,能够提供特别优秀的性能和太灵活的管理能力。Yahoo中国曾经接近2000台服务器使用了三四台Alteon就搞定了。
软件四层交换
大家晓得了硬件四层交换机的原理后,基于OSI模型来实现的软件四层交换也就应运而生,这样的解决方案实现的原理一致,不过性能稍差。但是满足一定量的压力还是游刃有余的,有人说软件实现方法虽然更灵活,处理能力完全看你配置的熟悉能力。
软件四层交换我们可以使用Linux上常用的LVS来解决,LVS就是Linux Virtual Server,他提供了基于心跳线heartbeat的实时灾难应对解决方案,提高系统的鲁棒性,同时可供了灵活的虚拟VIP配置和管理功能,可以同时满足多种应用需求,这对于分布式的系统来说必不可少。
一个典型的使用负载均衡的策略就是,在软件或则硬件四层交换的基础上搭建squid集群,这种思路在好多小型网站包括搜索引擎上被采用,这样的构架低成本、高性能还有太强的扩张性,随时往构架上面增减节点都十分容易。这样的构架我打算空了专门详尽整理一下和你们剖析。
对于小型网站来说,前面提及的每位方式可能就会被同时使用到,我这儿介绍得比较晦涩,具体实现过程中好多细节还须要你们渐渐熟悉和感受,有时一个太小的squid参数或则apache参数设置,对于系统性能的影响都会很大,希望你们一起讨论,达到抛砖引玉之效。
----------------------------------------------------------------------------------------------------------
常规方式:
1.用ACDSEE将图片压缩
2.分页,将一个页面弄成多个
3.不要将所有的图、flash等在同一个表格中,因为IE会将一个表格中所有内容都下载完后才显示下来,你可以放到多个表格中,下载一个都会显示一个。
4.换个服务器快的空间 查看全部
【采集】如何提升网站访问速率的文章
3. 如果友情链接一定要出现在首页,请将链接所在的整个Table放在页面的最下方,因为页面是由上到下逐行显示的,将其放在页面的最下方,不会延后其他内容的显示。
4. 友情链接的LOGO图片先下载后再传到自己的网页空间,这样,速度由自己的网站空间决定而不受友情网站的影响。
-----------------------------------------------------------------------------------------------------------
转载本文请知名出处:Just Do IT ()
一个大型的网站,比如个人网站,可以使用最简单的html静态页面就实现了,配合一些图片达到美化疗效,所有的页面均储存在一个目录下,这样的网站对系统构架、性能的要求都很简单,随着互联网业务的不断丰富,网站相关的技术经过这些年的发展,已经细分到太细的方方面面,尤其对于小型网站来说,所采用的技术更是涉及面十分广,从硬件到软件、编程语言、数据库、WebServer、防火墙等各个领域都有了很高的要求,已经不是原先简单的html静态网站所能比拟的。
大型网站,比如门户网站。在面对大量用户访问、高并发恳求方面,基本的解决方案集中在这样几个环节:使用高性能的服务器、高性能的数据库、高效率的编程语言、还有高性能的Web容器。但是不仅这几个方面,还无法根本解决小型网站面临的高负载和高并发问题。
上面提供的几个解决思路在一定程度上也意味着更大的投入,并且这样的解决思路具备困局,没有挺好的扩展性,下面我从低成本、高性能和高扩张性的角度来说说我的一些经验。
1、HTML静态化
其实你们都晓得,效率最高、消耗最小的就是纯静态化的html页面,所以我们尽可能让我们的网站上的页面采用静态页面来实现,这个最简单的方式虽然也是最有效的方式。但是对于大量内容而且频繁更新的网站,我们难以全部自动去逐个实现,于是出现了我们常见的信息发布系统CMS,像我们常访问的各个门户站点的新闻频道,甚至她们的其他频道,都是通过信息发布系统来管理和实现的,信息发布系统可以实现最简单的信息录入手动生成静态页面,还能具备频道管理、权限管理、自动抓取等功能,对于一个小型网站来说,拥有一套高效、可管理的CMS是必不可少的。
除了门户和信息发布类型的网站,对于交互性要求很高的社区类型网站来说,尽可能的静态化也是提升性能的必要手段,将社区内的贴子、文章进行实时的静态化,有更新的时侯再重新静态化也是大量使用的策略,像Mop的大杂烩就是使用了这样的策略,网易社区等也是这么。
同时,html静态化也是个别缓存策略使用的手段,对于系统中频繁使用数据库查询并且内容更新太小的应用,可以考虑使用html静态化来实现,比如峰会中峰会的公用设置信息,这些信息目前的主流峰会都可以进行后台管理而且储存再数据库中,这些信息虽然大量被前台程序调用,但是更新频度太小,可以考虑将这部份内容进行后台更新的时侯进行静态化,这样避开了大量的数据库访问恳求。
2、图片服务器分离
大家晓得,对于Web服务器来说,不管是Apache、IIS还是其他容器,图片是最消耗资源的,于是我们有必要将图片与页面进行分离,这是基本上小型网站都会采用的策略,他们都有独立的图片服务器,甚至好多台图片服务器。这样的构架可以减少提供页面访问恳求的服务器系统压力,并且可以保证系统不会由于图片问题而崩溃,在应用服务器和图片服务器上,可以进行不同的配置优化,比如apache在配置ContentType的时侯可以尽量少支持,尽可能少的LoadModule,保证更高的系统消耗和执行效率。
3、数据库集群和库表散列
大型网站都有复杂的应用,这些应用必须使用数据库,那么在面对大量访问的时侯,数据库的困局很快能够凸显下来,这时一台数据库将很快未能满足应用,于是我们须要使用数据库集群或则库表散列。
在数据库集群方面,很多数据库都有自己的解决方案,Oracle、Sybase等都有挺好的方案,常用的MySQL提供的Master/Slave也是类似的方案,您使用了什么样的DB,就参考相应的解决方案来施行即可。
上面提及的数据库集群因为在构架、成本、扩张性方面就会遭到所采用DB类型的限制,于是我们须要从应用程序的角度来考虑改善系统构架,库表散列是常用而且最有效的解决方案。我们在应用程序中安装业务和应用或则功能模块将数据库进行分离,不同的模块对应不同的数据库或则表,再根据一定的策略对某个页面或则功能进行更小的数据库散列,比如用户表,按照用户ID进行表散列,这样才能够低成本的提高系统的性能但是有挺好的扩展性。sohu的峰会就是采用了这样的构架,将峰会的用户、设置、帖子等信息进行数据库分离,然后对贴子、用户根据蓝筹股和ID进行散列数据库和表,最终可以在配置文件中进行简单的配置便能使系统随时降低一台低成本的数据库进来补充系统性能。
4、缓存
缓存一词搞技术的都接触过,很多地方用到缓存。网站架构和网站开发中的缓存也是十分重要。这里先述说最基本的两种缓存。高级和分布式的缓存在前面述说。
架构方面的缓存,对Apache比较熟悉的人都能晓得Apache提供了自己的缓存模块,也可以使用外加的Squid模块进行缓存,这两种方法均可以有效的增强Apache的访问响应能力。
网站程序开发方面的缓存,Linux上提供的Memory Cache是常用的缓存插口,可以在web开发中使用,比如用Java开发的时侯就可以调用MemoryCache对一些数据进行缓存和通信共享,一些小型社区使用了这样的构架。另外,在使用web语言开发的时侯,各种语言基本都有自己的缓存模块和技巧,PHP有Pear的Cache模块,Java就更多了,.net不是太熟悉,相信也肯定有。
5、镜像
镜像是小型网站常采用的增强性能和数据安全性的方法,镜像的技术可以解决不同网路接入商和地域带来的用户访问速率差别,比如ChinaNet和EduNet之间的差别就使得了好多网站在教育网内搭建镜像站点,数据进行定时更新或则实时更新。在镜像的细节技术方面,这里不探讨很深,有很多专业的现成的解决构架和产品可选。也有廉价的通过软件实现的思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是小型网站解决高负荷访问和大量并发恳求采用的终极解决办法。
负载均衡技术发展了多年,有很多专业的服务提供商和产品可以选择,我个人接触过一些解决方式,其中有两个构架可以给你们做参考。
硬件四层交换
第四层交换使用第三层和第四层信息包的报头信息,根据应用区间辨识业务流,将整个区间段的业务流分配到合适的应用服务器进行处理。第四层交换功能如同是虚IP,指向化学服务器。它传输的业务服从的合同多种多样,有HTTP、FTP、NFS、Telnet或其他合同。这些业务在数学服务器基础上,需要复杂的载量平衡算法。在IP世界,业务类型由终端TCP或UDP端口地址来决定,在第四层交换中的应用区间则由源端和终端IP地址、TCP和UDP端口共同决定。
在硬件四层交换产品领域,有一些著名的产品可以选择,比如Alteon、F5等,这些产品太高昂,但是物有所值,能够提供特别优秀的性能和太灵活的管理能力。Yahoo中国曾经接近2000台服务器使用了三四台Alteon就搞定了。
软件四层交换
大家晓得了硬件四层交换机的原理后,基于OSI模型来实现的软件四层交换也就应运而生,这样的解决方案实现的原理一致,不过性能稍差。但是满足一定量的压力还是游刃有余的,有人说软件实现方法虽然更灵活,处理能力完全看你配置的熟悉能力。
软件四层交换我们可以使用Linux上常用的LVS来解决,LVS就是Linux Virtual Server,他提供了基于心跳线heartbeat的实时灾难应对解决方案,提高系统的鲁棒性,同时可供了灵活的虚拟VIP配置和管理功能,可以同时满足多种应用需求,这对于分布式的系统来说必不可少。
一个典型的使用负载均衡的策略就是,在软件或则硬件四层交换的基础上搭建squid集群,这种思路在好多小型网站包括搜索引擎上被采用,这样的构架低成本、高性能还有太强的扩张性,随时往构架上面增减节点都十分容易。这样的构架我打算空了专门详尽整理一下和你们剖析。
对于小型网站来说,前面提及的每位方式可能就会被同时使用到,我这儿介绍得比较晦涩,具体实现过程中好多细节还须要你们渐渐熟悉和感受,有时一个太小的squid参数或则apache参数设置,对于系统性能的影响都会很大,希望你们一起讨论,达到抛砖引玉之效。
----------------------------------------------------------------------------------------------------------
常规方式:
1.用ACDSEE将图片压缩
2.分页,将一个页面弄成多个
3.不要将所有的图、flash等在同一个表格中,因为IE会将一个表格中所有内容都下载完后才显示下来,你可以放到多个表格中,下载一个都会显示一个。
4.换个服务器快的空间
如果公众号写文章也须要加入【参考文献】……
采集交流 • 优采云 发表了文章 • 0 个评论 • 458 次浏览 • 2020-08-24 17:45
而这两个数据,也是全部可以得到。
文章引用行为的获取
我们打开一篇“引用了”其他文章的公众号文章,F12检测文章的源代码可以看见,文章是以超链接的方式出现的:
文章源代码
所以在采集文章时,如果在源代码中采集到
文本
的数组,则可以觉得此处有“引用”行为。
引用来源剖析
找到了文章的引用行为,我们须要对被引用的文章进行剖析,分析的核心在就于这篇文章的链接,也就是刚刚herf旁边的那一串。
幸运的是,微信在链接里保存了我们须要的所有数据。
以昨天那篇文章的链接为例:
#wechat_redirect
我们把链接分为三部份:
/s?
__biz=MzU1MTAwNzY4Mg==&mid=2247483897&idx=1&sn=893614b6d6fd28d04b0f51e7c857c876&chksm=fb96a554cce12c4266018f581467f009021b89f5df0d546b1d08f4a08055ce17916f2ae74745&scene=21#wechat_redirect
了解链接组成的同学们应当晓得,前两部份是链接的主题,每个文章的链接都是一样的。关键信息在于“?”后面的部份。
在链接里,“?”后面的部份是链接的传参,顾名思义,就是向服务器传递的参数,是对链接的解释(或者叫备注)。
观察链接里的参数,有五个:
__biz
mid
idx
sn
chksm
我们这儿只用到前两个参数:
__biz可以觉得是微信公众平台对外公布的公众账号的惟一
idmid是图文消息id
通过__biz参数可以获得公众号的ID数据,是惟一辨识的,目前技术上可以转化成帐号的;
通过mid参数,我们则可以定位到文章的ID,也是惟一辨识的。
到此,对于文章引用行为技术层面的问题都早已解决。
“被引量”的使用
和学术领域相同,一篇文章被引用一次,则代表该文章影响力+1,被引量越多,文章影响力就越高。
对于公众号而言,可以使用帐号所有文章的被引量估算帐号的“影响因子”,可以使用SCI的估算方式,也可以使用GoogleScholar的H-index的估算方式。
和学术领域相同,文章也存在”自引“和”负引用“的问题。
自引在学术领域是一个不怎样受待见的事情,因为“被引量”这个指标早已作为一种评价标准,引用自己的文章给自己+1这些行为不是很好看。
负引用这件事在学术领域还不这么严重,一篇论文的推论不管对错,学术层面的价值是存在的。但是在媒体行业就不同了,毕竟媒体好多时侯传递的是价值观。比如某篇文章观点狭隘,被全网喷,我们只能说那篇文章影响力高,但是价值就没多少了。
这里我们就不深入讨论了。
最后说点啥
目前的内容行业,充斥着营销号、流量号,一群自媒体人聚在一起不是讨论什么样的文章有价值、什么样的内容有深度,而是讨论明天的利润怎样、多少阅读量才会开通流量主。
我们每晚仅有的几分钟阅读时间里,有一半浪费在这些“耸人听闻”但毫无营养的标题党上,反而这些报导事实、传递价值的深度内容或由于文字很长、或由于标题不够吸睛,被吞没在这爆燃的信息海洋中。
是时侯该有人站出来做点哪些了,比如给内容行业加入一个早已谋害学术圈的“影响因子”。
本文首发自我的个人公众号喜新(ID:noyanjiu),请随意转载,不用告诉我。 查看全部
如果公众号写文章也须要加入【参考文献】……
而这两个数据,也是全部可以得到。
文章引用行为的获取
我们打开一篇“引用了”其他文章的公众号文章,F12检测文章的源代码可以看见,文章是以超链接的方式出现的:
文章源代码
所以在采集文章时,如果在源代码中采集到
文本
的数组,则可以觉得此处有“引用”行为。
引用来源剖析
找到了文章的引用行为,我们须要对被引用的文章进行剖析,分析的核心在就于这篇文章的链接,也就是刚刚herf旁边的那一串。
幸运的是,微信在链接里保存了我们须要的所有数据。
以昨天那篇文章的链接为例:
#wechat_redirect
我们把链接分为三部份:
/s?
__biz=MzU1MTAwNzY4Mg==&mid=2247483897&idx=1&sn=893614b6d6fd28d04b0f51e7c857c876&chksm=fb96a554cce12c4266018f581467f009021b89f5df0d546b1d08f4a08055ce17916f2ae74745&scene=21#wechat_redirect
了解链接组成的同学们应当晓得,前两部份是链接的主题,每个文章的链接都是一样的。关键信息在于“?”后面的部份。
在链接里,“?”后面的部份是链接的传参,顾名思义,就是向服务器传递的参数,是对链接的解释(或者叫备注)。
观察链接里的参数,有五个:
__biz
mid
idx
sn
chksm
我们这儿只用到前两个参数:
__biz可以觉得是微信公众平台对外公布的公众账号的惟一
idmid是图文消息id
通过__biz参数可以获得公众号的ID数据,是惟一辨识的,目前技术上可以转化成帐号的;
通过mid参数,我们则可以定位到文章的ID,也是惟一辨识的。
到此,对于文章引用行为技术层面的问题都早已解决。
“被引量”的使用
和学术领域相同,一篇文章被引用一次,则代表该文章影响力+1,被引量越多,文章影响力就越高。
对于公众号而言,可以使用帐号所有文章的被引量估算帐号的“影响因子”,可以使用SCI的估算方式,也可以使用GoogleScholar的H-index的估算方式。
和学术领域相同,文章也存在”自引“和”负引用“的问题。
自引在学术领域是一个不怎样受待见的事情,因为“被引量”这个指标早已作为一种评价标准,引用自己的文章给自己+1这些行为不是很好看。
负引用这件事在学术领域还不这么严重,一篇论文的推论不管对错,学术层面的价值是存在的。但是在媒体行业就不同了,毕竟媒体好多时侯传递的是价值观。比如某篇文章观点狭隘,被全网喷,我们只能说那篇文章影响力高,但是价值就没多少了。
这里我们就不深入讨论了。
最后说点啥
目前的内容行业,充斥着营销号、流量号,一群自媒体人聚在一起不是讨论什么样的文章有价值、什么样的内容有深度,而是讨论明天的利润怎样、多少阅读量才会开通流量主。
我们每晚仅有的几分钟阅读时间里,有一半浪费在这些“耸人听闻”但毫无营养的标题党上,反而这些报导事实、传递价值的深度内容或由于文字很长、或由于标题不够吸睛,被吞没在这爆燃的信息海洋中。
是时侯该有人站出来做点哪些了,比如给内容行业加入一个早已谋害学术圈的“影响因子”。
本文首发自我的个人公众号喜新(ID:noyanjiu),请随意转载,不用告诉我。
网页抓取利器hawk使用心得
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2020-08-24 17:43
(1)抓取目的
现在网站有大量数据,但网站本身并不提供api接口,如果要批量获得这种页面数据,必须通过网页抓取方法实现。
比如某房产网站的二手房数据,在页面上太整齐的展示,因此可以通过剖析网页的html源码,找到单价、单价、位置、户型等数据,并最终实现批量抓取。
(2)抓取原理
1)首先要获取网页的html源码,这个并不难,在浏览器里右击菜单里选择“查看网页源代码”就能看见html源码,页面上能看到的文字基本在都在html源码里。
2)得到html源码后,就须要定位到各个数据的位置,比如“总价”,如下图所示:
可以见到“560”在html里能找到。
同时可以得到“总价”这个数组的xpath:
/html/body/div[4]/div[1]/ul/li[8]/div[1]/div[6]/div[1]/span
我们可以把html看成是一个标签树,xpath就是在标签树的找寻路径。
依此可以得到“单价”、“户型”等数组的xpath,也就可以获取1条发布信息的数据。
3)得到1条信息的数据后,一个页面一般会显示二三十条信息,可以发觉这种信息的格式都是一致的,如下图所示:
因此可以发觉这种信息都在
/html/body/div[4]/div[1]/ul/
路径下
第1条就是/html/body/div[4]/div[1]/ul/li[1]
第2条就是/html/body/div[4]/div[1]/ul/li[2]
……
基于此,通过基础path+数组相对path就可以得到每位数组的绝对path,然后可以编程实现单个页面的抓取功能了。
4)得到单个页面的数据后,就可以实现多页面抓取,假如网站有100页数据,通过观察网站地址url可以发觉,一般第二页就是 “xxx/page2”,第一百页就是“xxx/page100”,因此这个也是挺有规律的,修改下url就可以实现多页面抓取了。
(3)hawk抓取
由于网页抓取这么常见,可以在网上搜到大量的抓取软件,并不一定须要自己再开发一个抓取软件(写一个抓取软件不难,写一个通用性强且好用的难),hawk就是一个相当好用的抓取软件。
hawk的介绍页面:
关于hawk的详尽介绍,可以看其主页,这里说一下个人使用心得:
1)hawk收录”网页采集器”和”数据清洗”两个模块,网页采集用于定位各个数组的xpath,数据清洗用于抓取数据,并对各个数组做一定的处理,以及导入数据。
2)网页采集器模块挺好用,输入url得到网页html源码后,在“搜索字符”里输入比较典型的搜索文本,比如“农光南路双朝北两居室”后,hawk会在html里搜索这个字符串,获取xpath。
“添加数组”后,再点击“手气不错”会手动搜索出每条信息里收录的所有数组值,这个功能真的太强悍,有点人工智能的疗效了,网页采集工作一次完成。
3)数据清洗模块也挺好用,个人用了其中4个模块
1 生成区间数2 合并多列 3 从爬虫转换4 写入数据表
具体操作可观看主页提供的视频教程,其中第三步“从爬虫转换”要设置网页采集器的名称(视频少了这个步骤),最后导入到Excel表,得到想要的数据。
hawk这个软件功能太全,而且界面操作便捷,支持好多的数据模块,推荐使用。 查看全部
网页抓取利器hawk使用心得
(1)抓取目的
现在网站有大量数据,但网站本身并不提供api接口,如果要批量获得这种页面数据,必须通过网页抓取方法实现。
比如某房产网站的二手房数据,在页面上太整齐的展示,因此可以通过剖析网页的html源码,找到单价、单价、位置、户型等数据,并最终实现批量抓取。
(2)抓取原理
1)首先要获取网页的html源码,这个并不难,在浏览器里右击菜单里选择“查看网页源代码”就能看见html源码,页面上能看到的文字基本在都在html源码里。
2)得到html源码后,就须要定位到各个数据的位置,比如“总价”,如下图所示:
可以见到“560”在html里能找到。
同时可以得到“总价”这个数组的xpath:
/html/body/div[4]/div[1]/ul/li[8]/div[1]/div[6]/div[1]/span
我们可以把html看成是一个标签树,xpath就是在标签树的找寻路径。
依此可以得到“单价”、“户型”等数组的xpath,也就可以获取1条发布信息的数据。
3)得到1条信息的数据后,一个页面一般会显示二三十条信息,可以发觉这种信息的格式都是一致的,如下图所示:

因此可以发觉这种信息都在
/html/body/div[4]/div[1]/ul/
路径下
第1条就是/html/body/div[4]/div[1]/ul/li[1]
第2条就是/html/body/div[4]/div[1]/ul/li[2]
……
基于此,通过基础path+数组相对path就可以得到每位数组的绝对path,然后可以编程实现单个页面的抓取功能了。
4)得到单个页面的数据后,就可以实现多页面抓取,假如网站有100页数据,通过观察网站地址url可以发觉,一般第二页就是 “xxx/page2”,第一百页就是“xxx/page100”,因此这个也是挺有规律的,修改下url就可以实现多页面抓取了。
(3)hawk抓取
由于网页抓取这么常见,可以在网上搜到大量的抓取软件,并不一定须要自己再开发一个抓取软件(写一个抓取软件不难,写一个通用性强且好用的难),hawk就是一个相当好用的抓取软件。
hawk的介绍页面:
关于hawk的详尽介绍,可以看其主页,这里说一下个人使用心得:
1)hawk收录”网页采集器”和”数据清洗”两个模块,网页采集用于定位各个数组的xpath,数据清洗用于抓取数据,并对各个数组做一定的处理,以及导入数据。
2)网页采集器模块挺好用,输入url得到网页html源码后,在“搜索字符”里输入比较典型的搜索文本,比如“农光南路双朝北两居室”后,hawk会在html里搜索这个字符串,获取xpath。
“添加数组”后,再点击“手气不错”会手动搜索出每条信息里收录的所有数组值,这个功能真的太强悍,有点人工智能的疗效了,网页采集工作一次完成。
3)数据清洗模块也挺好用,个人用了其中4个模块
1 生成区间数2 合并多列 3 从爬虫转换4 写入数据表
具体操作可观看主页提供的视频教程,其中第三步“从爬虫转换”要设置网页采集器的名称(视频少了这个步骤),最后导入到Excel表,得到想要的数据。
hawk这个软件功能太全,而且界面操作便捷,支持好多的数据模块,推荐使用。
DEDECMS后台更新文章模板时提示未能解析文档的完
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-23 07:21
织梦dedecms建企业站特别快,因为这款程序可以套模板建站。可是假如对这款程序不熟悉建站过程中还会碰到好多使人疑惑的问题。因为模板可能和程序的编码格式不同或则使用的模板和程序不兼容就会出问题。一位站长同学之前用的是无忧的共享空间,后面因为须要给网站做优化和排行,再三考虑后联系小编帮忙升级为独立IP空间。小编帮忙升级后就又开始帮忙做迁移了。一切数据都迁移过去后当登录网站的后台去一键更新网站的时侯出问题了,提示模板文件不存在如下图:
小编特意把模板文件上传覆盖的如何会提示模板文件不存在呢?小编再度的上传了一下模板覆盖登录后台还是这个报错。小编通过剖析研究后找到了问题的诱因。由于织梦dedecms系统文章模板的模板必须是以.htm结尾的,而模板文件名的后缀是.html.原来是这儿出了问题。知道了问题的诱因再去找解决方式就容易多了。下面编把整理的方式来分享下吧。
第一步:连接FTP工具。按照路径找到include/arc.archives.class.php文件。使用中级编辑器打开,(小编介绍使用Editplus)。
第二步:打开后,使用快捷键 Ctrl+h 找到htm$全部替换为html$ 如下图:
第三步:把修改后的文件上传到对应的目录下,再登录织梦的后台去更新下系统缓存再一键更新网站就可以解决了。
以上方式就是小编整理下来的解决方式了,特此分享给更多的站长朋友们。如果有疑问欢迎联系小编QQ:340555009.感谢对无忧小编的支持。 查看全部
DEDECMS后台更新文章模板时提示未能解析文档的完
织梦dedecms建企业站特别快,因为这款程序可以套模板建站。可是假如对这款程序不熟悉建站过程中还会碰到好多使人疑惑的问题。因为模板可能和程序的编码格式不同或则使用的模板和程序不兼容就会出问题。一位站长同学之前用的是无忧的共享空间,后面因为须要给网站做优化和排行,再三考虑后联系小编帮忙升级为独立IP空间。小编帮忙升级后就又开始帮忙做迁移了。一切数据都迁移过去后当登录网站的后台去一键更新网站的时侯出问题了,提示模板文件不存在如下图:

小编特意把模板文件上传覆盖的如何会提示模板文件不存在呢?小编再度的上传了一下模板覆盖登录后台还是这个报错。小编通过剖析研究后找到了问题的诱因。由于织梦dedecms系统文章模板的模板必须是以.htm结尾的,而模板文件名的后缀是.html.原来是这儿出了问题。知道了问题的诱因再去找解决方式就容易多了。下面编把整理的方式来分享下吧。
第一步:连接FTP工具。按照路径找到include/arc.archives.class.php文件。使用中级编辑器打开,(小编介绍使用Editplus)。
第二步:打开后,使用快捷键 Ctrl+h 找到htm$全部替换为html$ 如下图:

第三步:把修改后的文件上传到对应的目录下,再登录织梦的后台去更新下系统缓存再一键更新网站就可以解决了。
以上方式就是小编整理下来的解决方式了,特此分享给更多的站长朋友们。如果有疑问欢迎联系小编QQ:340555009.感谢对无忧小编的支持。
爬取nyist-6000张证件照进行微软小冰逼格剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2020-08-22 11:44
Python爬取nyist-6000张证件照进行逼格剖析***## 前言本文章同步至我的网站:
前几天中学要求更新档案资料库的相片,所以要求每位人去照证件照,大多数人是在中学上面的一个拍照的地方照的,为了容易让同学们领到合照,他们会每晚把每位人的证件照上传到一个网站,于是我就用爬虫爬取了6000+照片,结合微软小冰的人脸辨识中的逼格剖析功能对每张相片进行打分,然后进行一次简单的逼格剖析,下面简单说一说我的过程,结论在最后
工具打算:
采集照片的网址:
微软小冰的逼格剖析网址:
微软的图片服务器网址:
一、爬取并保存图片
首先,我们打开要采集照片的地址:,会见到这样:
然后引入相关的库:
import re
import requests
from bs4 import BeautifulSoup
import lxml
import os
我们打开这种链接发觉:
因为日期的不同,所以网页地址显得只是前面的数字,所以我们只须要找到我们要爬取的第一个页面的标号和最后一个页面的标号,然后对每一个页面分别爬取就好了。
随便打开一个页面,会发觉图片是这样的:
我们解析一下网页源代码会发觉是这样的:
这些图片都无一例外的藏在img标签上面的,所以我们只须要把这种上面的内容提取下来就可以得到每一张图片的地址了。
提取的方式有很多种,比如用BeautifulSoup,但是这儿因为这个标签并不需要解析成文档树,可以直接写一个正则表达式提取下来,所以我们可以如此写:
/upfile/201709/\d+\.JPG
只须要简单的匹配一下多位数字就可以了,这样我们可以写出具体代码:
这样由于正则匹配的缘故,会返回一个收录所有图片地址的列表,那么如今我们要做的就是借助这个列表,进行保存:
这个也很简单,我们遍历一下这个列表,然后构造每一个图片链接,这里也须要用正则表达式来匹配一下文件名,用requests恳求一下把二进制的东西保存成.jpg文件就好了
现在我们的代码已然实现了对每位页面的图片进行保存,剩下的就是调用这两个函数了,我们只须要遍历一下要爬的网页的id,然后等着爬取完成就好了,爬虫爬完后会得到一个文件夹,里面就是你爬好的相片,就像这样:
到了现今,第一步就做完了,已经拥有这几千张护照照了
二、调用微软小冰人脸辨识中的测逼格功能
首先,我们打开微软小冰的辨识页面:
显示这样:
这时我们点"上传图片",然后进行抓包
我们发觉有两个post恳求,分别是把当前图片传到微软服务器,还有一个是进行逼格测试,进行逼格测试的时侯其中的一个参数要传入当前这个图片在微软服务器的地址,所以我们要分两步来做:
把图片上传至微软服务器,并且得到返回的图片地址运用得到的图片地址,进行颜值颜值测试
通过抓包可以发觉两个post地址,一个是递交图片的地址,另一个是获得逼格分数的地址:
upload_url = 'http://kan.msxiaobing.com/Api/Image/UploadBase64'
comp_url = 'https://kan.msxiaobing.com/Api/ImageAnalyze/Process'
我们先说第一个,通过查看抓到的包,我们会发觉每一张图片在传入服务器之前会先经过base64编码方法对图片进行编码,然后会post到谷歌的服务器,然后返回地址,那么我们就应当先对一张图片进行base64加密,然后我们会发觉返回结果是这样的:
{'Host': 'https://mediaplatform.msxiaobing.com', 'Url': '/image/fetchimage?key=JMGsDUAgbwOliRBabKjOIkANmt-Cu2pqpAsmCZyiMDJ6wxaO8iaLjrucUw'}
这是一段json信息,我们须要的是url上面的值,所以我们就用requests中外置的json解析器对它进行解析,所以,代码可以如此写:
def get_img_url(file_name):
with open(file_name,'rb') as f:
img_base64=base64.b64encode(f.read())
r=requests.post(upload_url,data=img_base64)
url='https://mediaplatform.msxiaobing.com' + r.json()['Url']
return url
我们通过把二进制信息进行编码,然后传入微软服务器,获得了这一张图片在服务器中的地址,然后在通过构造,得到完整的地址
那么我们如今进行第二步,把信息发到微软服务器,然后得到地址,我们看一下抓的包:
Remote Address:42.159.132.179:443
Request URL:https://kan.msxiaobing.com/Api ... 71450
Request Method:POST
Status Code:200 OK
Response Headers
view source
Cache-Control:no-cache
Content-Encoding:gzip
Content-Type:application/json; charset=utf-8
Date:Thu, 07 Sep 2017 17:18:28 GMT
Expires:-1
Pragma:no-cache
Server:Microsoft-IIS/8.0
Transfer-Encoding:chunked
Vary:Accept-Encoding
X-Powered-By:ASP.NET
Request Headers
view source
Accept:*/*
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.8
Connection:keep-alive
Content-Length:194
Content-Type:application/x-www-form-urlencoded; charset=UTF-8
Cookie:_ga=GA1.2.1597838376.1504599720; ai_user=sp1jt|2017-09-05T10:53:04.090Z; ARRAffinity=d48a0dd61144e14e99ea10eca4fef5d81bf07933a2831679353d2761cf0db5aa; cpid=YE5cTN4wQk4hTFdMf7FVTzM0bjPlNN1MJrFATNhI10hNAA; salt=761703E5A961C3EC8AD465F2A70F639F; ai_session=pWq6U|1504804573893.97|1504804670104.895
Host:kan.msxiaobing.com
Origin:https://kan.msxiaobing.com
Referer:https://kan.msxiaobing.com/Ima ... 2e702
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36
x-ms-request-id:4KL3u
x-ms-request-root-id:idMkH
X-Requested-With:XMLHttpRequest
Query String Parameters
view source
view URL encoded
service:yanzhi
tid:a14a6fd556cf45c181cb116f06471450
Form Data
view source
view URL encoded
MsgId:1504804707562
CreateTime:1504804707
Content[imageUrl]:https://mediaplatform.msxiaobi ... mOmXA
我们要构造data上面的信息,也就是要构造MsgId,CreateTime,Content[imageUrl]这三个信息,首先我们观察MsgId,发现它实质上就是当前的时间戳加了一个3位数的随机数,而第二个CreateTime虽然就是当前的时间戳,第三个Content[imageUrl]那当然就是我们刚才得到的图片地址了,我们就把这种参数给发起来
然后把这种恳求发起来之后,会发觉它的返回结果是none,那么这是为什么呢,这是因为谷歌添加了cookies和refer验证,所以我们要把这两个东西置于headers上面一起给传过去,然后都会发觉它返回一段json:
{‘msgId’: ‘4d39f92788774d65bd0261d6f4754865’, ‘timestamp’: 73, ‘receiverId’: None, ‘content’: {‘text’: ‘有潜力的姑娘!6.6分!性格肯定超好,男神最喜欢这些男孩纸咯,羡慕!’, ‘imageUrl’: ‘’, ‘metadata’: {‘AnswerFeed’: ‘FaceBeautyRanking’, ‘w’: ‘vvXoifT_gNLyhvXNhsPhjMz_pt_kbkdXisHliuToh-_uhcXkgePArM3_sN_kiuzeiuTlhvv-hMDGj_3vrPX5vsXDh_b6gv_khMr6hsjxjtvXrPHKt9XtiPfCg938jtPI’, ‘aid’: ‘303DB2A95867544E3E5EE047977CECF4’}}}
我们依照惯例,对它进行解析,我们提取下来['content']['text']里面的内容就行了,所以这一段的代码:
def get_score(img_url):
sys_time = int(time.time())
payload = {'service': 'yanzhi',
'tid': '7531216b61b14d208496ee52bca9a9a8'}
form = {
'MsgId': str(sys_time) + '733',
'CreateTime': sys_time,
'Content[imageUrl]': img_url,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
'Cookie': '_ga=GA1.2.1597838376.1504599720; _gid=GA1.2.1466467655.1504599720; ai_user=sp1jt|2017-09-05T10:53:04.090Z; cpid=YDLcMF5LPDFfSlQyfUkvMs9IbjQZMiQ2XTJHMVswUTFPAA; salt=EAA803807C2E9ECD7D786D3FA9516786; ARRAffinity=3dc0ec2b3434a920266e7d4652ca9f67c3f662b5a675f83cf7467278ef043663; ai_session=sQna0|1504664570638.64|1504664570638'+str(random.randint(11, 999)),
'Referer': 'https://kan.msxiaobing.com/ImageGame/Portal?task=yanzhi&feid=d89e6ce730dab7a2410c6dad803b5986'
}
r = requests.post(comp_url, params=payload, data=form, headers=headers)
print(r.json())
text = r.json()['content']['text']
return text
这样的话,我们就可以获得小冰对这个相片的评价,那么对于后期处理,我们只要用正则表达式把其中的关于逼格分数的地方提取下来就好了,那么这时候就须要保存刚才获得的评价分数,所以我们采用的方法就是对文件重命名,就是把文件名改成:分数+原来的文件名的方式,代码如下:
为了便捷我们对于程序的调试,所以用一个txt文件随时把程序的log信息传进去,就像这样:
至此,打分环节也完成了,下面进行下一项
三、把分数用图表的形式勾画下来
这一步须要用到matplotlib库中的pyplot,用它可以勾画出好多种不同的图,先引入库:
import matplotlib.pyplot as plt
import os
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
由于微软小冰的API调用次数的限制,我只成功的对2118张图片进行了逼格的打分,很容易的得到了每位分数段区间的数目:
<p>def get_score():
score_num=[]
for i in range(6):
score_num.append(0)
list=os.listdir()
for name in list:
if len(name)==24:
score=float(name[:3])
if score>=3 and score=4 and score=5 and score=6 and score=7 and score=8 and score 查看全部
爬取nyist-6000张证件照进行微软小冰逼格剖析
Python爬取nyist-6000张证件照进行逼格剖析***## 前言本文章同步至我的网站:
前几天中学要求更新档案资料库的相片,所以要求每位人去照证件照,大多数人是在中学上面的一个拍照的地方照的,为了容易让同学们领到合照,他们会每晚把每位人的证件照上传到一个网站,于是我就用爬虫爬取了6000+照片,结合微软小冰的人脸辨识中的逼格剖析功能对每张相片进行打分,然后进行一次简单的逼格剖析,下面简单说一说我的过程,结论在最后
工具打算:
采集照片的网址:
微软小冰的逼格剖析网址:
微软的图片服务器网址:
一、爬取并保存图片
首先,我们打开要采集照片的地址:,会见到这样:

然后引入相关的库:
import re
import requests
from bs4 import BeautifulSoup
import lxml
import os
我们打开这种链接发觉:
因为日期的不同,所以网页地址显得只是前面的数字,所以我们只须要找到我们要爬取的第一个页面的标号和最后一个页面的标号,然后对每一个页面分别爬取就好了。
随便打开一个页面,会发觉图片是这样的:

我们解析一下网页源代码会发觉是这样的:
这些图片都无一例外的藏在img标签上面的,所以我们只须要把这种上面的内容提取下来就可以得到每一张图片的地址了。
提取的方式有很多种,比如用BeautifulSoup,但是这儿因为这个标签并不需要解析成文档树,可以直接写一个正则表达式提取下来,所以我们可以如此写:
/upfile/201709/\d+\.JPG
只须要简单的匹配一下多位数字就可以了,这样我们可以写出具体代码:
这样由于正则匹配的缘故,会返回一个收录所有图片地址的列表,那么如今我们要做的就是借助这个列表,进行保存:
这个也很简单,我们遍历一下这个列表,然后构造每一个图片链接,这里也须要用正则表达式来匹配一下文件名,用requests恳求一下把二进制的东西保存成.jpg文件就好了
现在我们的代码已然实现了对每位页面的图片进行保存,剩下的就是调用这两个函数了,我们只须要遍历一下要爬的网页的id,然后等着爬取完成就好了,爬虫爬完后会得到一个文件夹,里面就是你爬好的相片,就像这样:

到了现今,第一步就做完了,已经拥有这几千张护照照了
二、调用微软小冰人脸辨识中的测逼格功能
首先,我们打开微软小冰的辨识页面:
显示这样:
这时我们点"上传图片",然后进行抓包
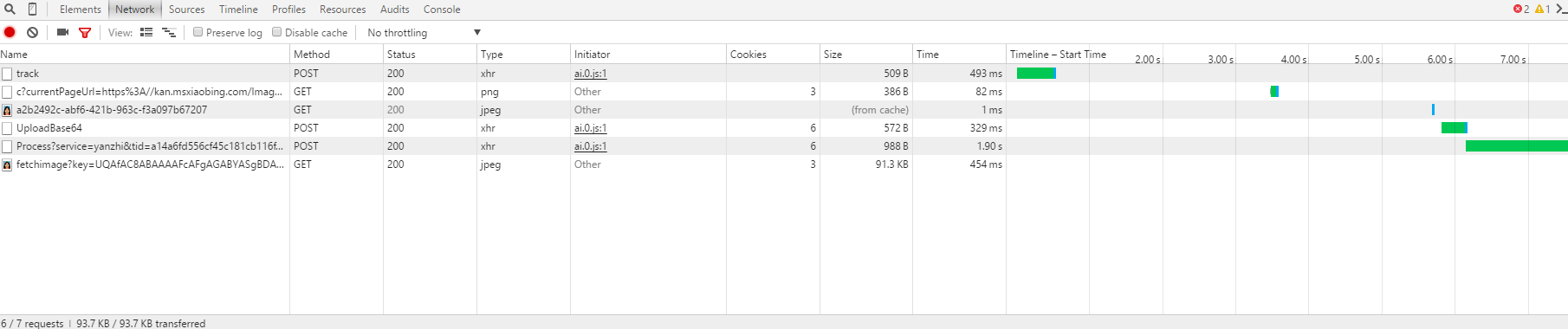
我们发觉有两个post恳求,分别是把当前图片传到微软服务器,还有一个是进行逼格测试,进行逼格测试的时侯其中的一个参数要传入当前这个图片在微软服务器的地址,所以我们要分两步来做:
把图片上传至微软服务器,并且得到返回的图片地址运用得到的图片地址,进行颜值颜值测试
通过抓包可以发觉两个post地址,一个是递交图片的地址,另一个是获得逼格分数的地址:
upload_url = 'http://kan.msxiaobing.com/Api/Image/UploadBase64'
comp_url = 'https://kan.msxiaobing.com/Api/ImageAnalyze/Process'
我们先说第一个,通过查看抓到的包,我们会发觉每一张图片在传入服务器之前会先经过base64编码方法对图片进行编码,然后会post到谷歌的服务器,然后返回地址,那么我们就应当先对一张图片进行base64加密,然后我们会发觉返回结果是这样的:
{'Host': 'https://mediaplatform.msxiaobing.com', 'Url': '/image/fetchimage?key=JMGsDUAgbwOliRBabKjOIkANmt-Cu2pqpAsmCZyiMDJ6wxaO8iaLjrucUw'}
这是一段json信息,我们须要的是url上面的值,所以我们就用requests中外置的json解析器对它进行解析,所以,代码可以如此写:
def get_img_url(file_name):
with open(file_name,'rb') as f:
img_base64=base64.b64encode(f.read())
r=requests.post(upload_url,data=img_base64)
url='https://mediaplatform.msxiaobing.com' + r.json()['Url']
return url
我们通过把二进制信息进行编码,然后传入微软服务器,获得了这一张图片在服务器中的地址,然后在通过构造,得到完整的地址
那么我们如今进行第二步,把信息发到微软服务器,然后得到地址,我们看一下抓的包:
Remote Address:42.159.132.179:443
Request URL:https://kan.msxiaobing.com/Api ... 71450
Request Method:POST
Status Code:200 OK
Response Headers
view source
Cache-Control:no-cache
Content-Encoding:gzip
Content-Type:application/json; charset=utf-8
Date:Thu, 07 Sep 2017 17:18:28 GMT
Expires:-1
Pragma:no-cache
Server:Microsoft-IIS/8.0
Transfer-Encoding:chunked
Vary:Accept-Encoding
X-Powered-By:ASP.NET
Request Headers
view source
Accept:*/*
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.8
Connection:keep-alive
Content-Length:194
Content-Type:application/x-www-form-urlencoded; charset=UTF-8
Cookie:_ga=GA1.2.1597838376.1504599720; ai_user=sp1jt|2017-09-05T10:53:04.090Z; ARRAffinity=d48a0dd61144e14e99ea10eca4fef5d81bf07933a2831679353d2761cf0db5aa; cpid=YE5cTN4wQk4hTFdMf7FVTzM0bjPlNN1MJrFATNhI10hNAA; salt=761703E5A961C3EC8AD465F2A70F639F; ai_session=pWq6U|1504804573893.97|1504804670104.895
Host:kan.msxiaobing.com
Origin:https://kan.msxiaobing.com
Referer:https://kan.msxiaobing.com/Ima ... 2e702
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36
x-ms-request-id:4KL3u
x-ms-request-root-id:idMkH
X-Requested-With:XMLHttpRequest
Query String Parameters
view source
view URL encoded
service:yanzhi
tid:a14a6fd556cf45c181cb116f06471450
Form Data
view source
view URL encoded
MsgId:1504804707562
CreateTime:1504804707
Content[imageUrl]:https://mediaplatform.msxiaobi ... mOmXA
我们要构造data上面的信息,也就是要构造MsgId,CreateTime,Content[imageUrl]这三个信息,首先我们观察MsgId,发现它实质上就是当前的时间戳加了一个3位数的随机数,而第二个CreateTime虽然就是当前的时间戳,第三个Content[imageUrl]那当然就是我们刚才得到的图片地址了,我们就把这种参数给发起来
然后把这种恳求发起来之后,会发觉它的返回结果是none,那么这是为什么呢,这是因为谷歌添加了cookies和refer验证,所以我们要把这两个东西置于headers上面一起给传过去,然后都会发觉它返回一段json:
{‘msgId’: ‘4d39f92788774d65bd0261d6f4754865’, ‘timestamp’: 73, ‘receiverId’: None, ‘content’: {‘text’: ‘有潜力的姑娘!6.6分!性格肯定超好,男神最喜欢这些男孩纸咯,羡慕!’, ‘imageUrl’: ‘’, ‘metadata’: {‘AnswerFeed’: ‘FaceBeautyRanking’, ‘w’: ‘vvXoifT_gNLyhvXNhsPhjMz_pt_kbkdXisHliuToh-_uhcXkgePArM3_sN_kiuzeiuTlhvv-hMDGj_3vrPX5vsXDh_b6gv_khMr6hsjxjtvXrPHKt9XtiPfCg938jtPI’, ‘aid’: ‘303DB2A95867544E3E5EE047977CECF4’}}}
我们依照惯例,对它进行解析,我们提取下来['content']['text']里面的内容就行了,所以这一段的代码:
def get_score(img_url):
sys_time = int(time.time())
payload = {'service': 'yanzhi',
'tid': '7531216b61b14d208496ee52bca9a9a8'}
form = {
'MsgId': str(sys_time) + '733',
'CreateTime': sys_time,
'Content[imageUrl]': img_url,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
'Cookie': '_ga=GA1.2.1597838376.1504599720; _gid=GA1.2.1466467655.1504599720; ai_user=sp1jt|2017-09-05T10:53:04.090Z; cpid=YDLcMF5LPDFfSlQyfUkvMs9IbjQZMiQ2XTJHMVswUTFPAA; salt=EAA803807C2E9ECD7D786D3FA9516786; ARRAffinity=3dc0ec2b3434a920266e7d4652ca9f67c3f662b5a675f83cf7467278ef043663; ai_session=sQna0|1504664570638.64|1504664570638'+str(random.randint(11, 999)),
'Referer': 'https://kan.msxiaobing.com/ImageGame/Portal?task=yanzhi&feid=d89e6ce730dab7a2410c6dad803b5986'
}
r = requests.post(comp_url, params=payload, data=form, headers=headers)
print(r.json())
text = r.json()['content']['text']
return text
这样的话,我们就可以获得小冰对这个相片的评价,那么对于后期处理,我们只要用正则表达式把其中的关于逼格分数的地方提取下来就好了,那么这时候就须要保存刚才获得的评价分数,所以我们采用的方法就是对文件重命名,就是把文件名改成:分数+原来的文件名的方式,代码如下:
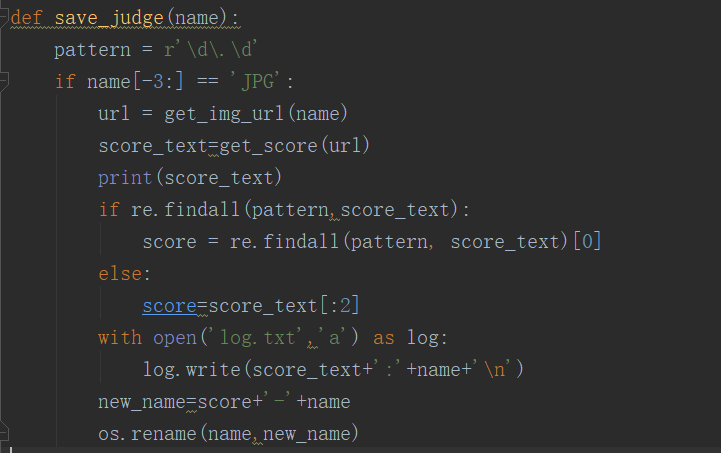
为了便捷我们对于程序的调试,所以用一个txt文件随时把程序的log信息传进去,就像这样:
至此,打分环节也完成了,下面进行下一项
三、把分数用图表的形式勾画下来
这一步须要用到matplotlib库中的pyplot,用它可以勾画出好多种不同的图,先引入库:
import matplotlib.pyplot as plt
import os
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
由于微软小冰的API调用次数的限制,我只成功的对2118张图片进行了逼格的打分,很容易的得到了每位分数段区间的数目:
<p>def get_score():
score_num=[]
for i in range(6):
score_num.append(0)
list=os.listdir()
for name in list:
if len(name)==24:
score=float(name[:3])
if score>=3 and score=4 and score=5 and score=6 and score=7 and score=8 and score
详解Java中的pinpoint1.8.5安装及使用手册
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2020-08-21 15:01
详解Java中的pinpoint1.8.5安装及使用手册
更新时间:2019年10月13日 09:15:53 转载作者:luozhiyun
pinpoint是开源在github上的一款APM监控工具,它是用Java编撰的,用于大规模分布式系统监控。这篇文章主要介绍了pinpoint1.8.5安装及使用手册,非常不错,具有一定的参考借鉴价值,需要的同学可以参考下
pinpoint1.8.5安装及使用手册
简介
pinpoint是开源在github上的一款APM监控工具,它是用Java编撰的,用于大规模分布式系统监控。它对性能的影响最小(只降低约3%资源利用率),安装agent是无侵入式的。
各大APM工具,几乎都是按照google这篇精典的Dapper论文而至,一定要读一读。这里是它的源文地址:,感谢那位朋友的翻译:
pinpoint提供了一些功能:
服务映射:通过可视化其组件怎么互连来了解任何分布式系统的关联关系。单击节点可显示有关组件的详尽信息,例如其当前状态和事务计数。
实时的活跃线程数
请求/响应散点图
调用栈
查看有关应用程序的其他详尽信息,例如CPU使用率,内存/垃圾搜集,TPS和JVM参数
整个pinpoint构架分为3部份:pinpoint-collector、pinpoint-agent、pinpoint-webUI。
pinpoint-agent:用来搜集单个应用的信息,并将搜集好的应用信息发送到pinpoint-collector中
pinpoint-collector:用来处理pinpoint-agent发送过来的信息,并将信息搜集好以后储存到HBase中
pinpoint-webUI:查找出HBase中的数据并展示
所以我这儿须要打算两台机器:
10.200.201.xxx:用于安装pinpoint-collector、pinpoint-webUI、HBase
10.200.201.yyy:用于安装pinpoint-agent,负责搜集应用的信息
环境安装
安装jdk
我这儿用的是rpm包直接安装的:rpm -ivh jdk-8u171-linux-x64.rpm
安装好后配置一下JAVA_HOME:
使用vim配置一下环境变量:
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_45
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
然后加载一些profile文件:
source /etc/profile
安装HBase
这里有个对照图:
由前面我们可以看见HBase我们须要安装1.2.x版本的
下载地址:
我这儿下载的是1.2.12版本的。
将Hbse放在指定目录
cd /app/install
tar -zxvf hbase-1.2.12-bin.tar.gz
修改配置信息
修改hbase-env.sh
vim /app/install/hbase-1.2.12/conf/hbase-env.sh
#加入JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_45
修改hbase-site.xml
vim /app/install/hbase-1.2.12/conf/hbase-site.xml
hbase.rootdir
file:///app/data/hbase
hbase.zookeeper.property.dataDir
/app/data/zookeeper
hbase.zookeeper.property.clientPort
2181
Property from ZooKeeper'sconfig zoo.cfg. The port at which the clients will connect.
hbase.cluster.distributed
false
启动HBase
cd /app/install/hbase-1.2.12/bin
./start-hbase.sh
# 查看Hbase是否启动成功,如果启动成功的会看到"HMaster"的进程
[root@localhost bin]# jps
12075 Jps
11784 HMaster
初始化pinpoint库
下载脚本:
#进入到hbase的bin目录中
cd /app/install/hbase-1.2.12/bin
#执行脚本
./bin/hbase shell /app/install/pinpoint/hbase/scripts/hbase-create.hbase
# 执行完了以后,进入Hbase
./hbase shell
#进入后可以看到Hbase的版本,还有一些相关的信息
2019-10-12 16:18:28,074 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version 1.2.12, r91d5ec4c4dcd10ceec984c6e663ea82acf353995, Sat Apr 6 15:27:28 CDT 2019
# 输入"status 'detailed'"可以查看刚才初始化的表,是否存在
hbase(main):002:0> status 'detailed'
也可以登入web,来查看HBase的数据是否初始化成功
:16010/master-status
安装pinpoint-collector
制作一个tomcat容器,端口号为8081
#将pinpoint-collector的war包丢到Tomcat的webapps目录下
cp pinpoint-collector-1.8.5.war ../apache-tomcat-8081/webapps/
#将war包名字改一下
mv pinpoint-web-1.8.5.war pp-collector.war
#启动tomcat
./bin/startup.sh
# 查看日志,是否成功启动
tail -f ../logs/catalina.out
#如果hbase安装在别的机器下需要修改一下配置
cd /app/install/apache-tomcat-8081
vim webapps/pp-collector/WEB-INF/classes/hbase.properties
#修改hbase的ip和hbase所对应的端口号
hbase.client.host=10.200.201.xxx
hbase.client.port=2181
安装pinpoint-web
解压一个tomcat容器,端口号为8080
#将pinpoint-web放到tomcat的webapps容器中
cp pinpoint-web-1.8.5.war ../apache-tomcat-8080/webapps/
#修改一下war包名
mv pinpoint-web-1.8.5.war pp-web.war
#启动tomcat
./bin/startup.sh
# 查看日志,是否成功启动
tail -f ../logs/catalina.out
#如果hbase安装在别的机器下需要修改一下配置
cd /app/install/apache-tomcat-8080
vim webapps/pp-web/WEB-INF/classes/hbase.properties
#修改hbase的ip和hbase所对应的端口号
hbase.client.host=10.200.201.xxx
hbase.client.port=2181
然后可以在浏览器中::8080/pp-web/
部署pinpoint-agent采集监控数据
传入pinpoint-agent包
首先将pinpoint-agent-1.8.5.tar.gz传入到服务器10.200.201.yyy的/app/install/pinpoint-agent/中
然后执行tar -zxvf pinpoint-agent-1.8.5.tar.gz解压
配置pp-agent采集器
cd /app/install/pinpoint-agent
vim pinpoint.config
# 主要修改IP,只需要指定到安装pp-col的IP就行了,安装pp-col启动后,自动就开启了9994,9995,9996的端口了。这里就不需要操心了,如果有端口需求,要去pp-col的配置文件("pp-collector/webapps/ROOT/WEB-INF/classes/pinpoint-collector.properties")中,修改这些端口
profiler.collector.ip=10.200.201.xxx
如果监控的是tomcat
# 修改测试项目下的tomcat启动文件"catalina.sh",修改这个只要是为了监控测试环境的Tomcat,增加探针
vi catalina.sh
# 第一行是pp-agent的jar包位置
# 第二行是agent的ID,这个ID是唯一的,我是用pp + 今天的日期命名的,只要与其他的项目的ID不重复就好了
# 第三行是采集项目的名字,这个名字可以随便取,只要各个项目不重复就好了
CATALINA_OPTS="$CATALINA_OPTS -javaagent:$AGENT_PATH/pinpoint-bootstrap-$VERSION.jar"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.agentId=$AGENT_ID"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.applicationName=$APPLICATION_NAME"
# 配置好了。就可以开始监控了,我们启动测试用的Tomcat的服务器
cd /data/pp-test/bin/
./startup.sh
# 查看启动日志,确实Tomcat启动
tail -f ../logs/catalina.out
springboot包部署
如果是jar包布署,直接在启动命令加启动参数:
nohup java -javaagent:/app/install/pinpoint-agent/pinpoint-bootstrap-1.8.5.jar -Dpinpoint.agentId=$AGENT_ID -Dpinpoint.applicationName=$APPLICATION_NAME
功能设置
设置监控
如果根据前面的方式安装完了以后在进行监控设置的或则用户设置的时侯会报错的:
所以须要配置一下mysql:
首先须要跑两个sql脚本:
然后步入到pinpoint-web的war所在的tomcat的容器中,修改配置文件:WEB-INF/classes/jdbc.properties
并设值mysql的帐号密码
jdbc.url=jdbc:mysql://localhost:13306/pinpoint?characterEncoding=UTF-8
jdbc.username=admin
jdbc.password=admin
我们可以在application上面给不同的应用设置不同的提醒规则,具体的提醒规则如下:
SLOW COUNT:发送到应用程序的慢速恳求数超过配置的阀值时触发
SLOW RATE
发送到应用程序的慢速恳求的比率(%)超过配置的阀值时触发
ERROR COUNT
发送到应用程序的失败恳求数超过配置的阀值时触发。
ERROR RATE
发送到应用程序的失败恳求的比率(%)超过配置的阀值时触发。
TOTAL COUNT
发送到应用程序的所有恳求数超过配置的阀值时触发。
SLOW COUNT TO CALLEE
当应用程序发送的慢速恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
例如),127.0.0.1:8080
SLOW RATE TO CALLEE
当应用程序发送的慢速恳求的比率(%)超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
ERROR COUNT TO CALLEE
当应用程序发送的失败恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
ERROR RATE TO CALLEE
当应用程序发送的失败恳求的比率(%)超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
TOTAL COUNT TO CALLEE
当应用程序发送的所有恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
HEAP USAGE RATE
当应用程序的堆使用率(%)超过配置的阀值时触发。
JVM CPU USAGE RATE
当应用程序的CPU使用率(%)超过配置的阀值时触发。
SYSTEM CPU USAGE RATE
当应用程序的CPU使用率(%)超过配置的阀值时发送警报。
DATASOURCE CONNECTION USAGE RATE
当应用程序的数据源联接使用率(%)超过配置的阀值时触发。
FILE DESCRIPTOR COUNT
当打开的文件描述符的数目超过配置的阀值时,发送警报。
然后须要在webapps/pp-web/WEB-INF/classes/batch.properties上面配置一下邮件服务器的信息:
pinpoint.url= #pinpoint-web server url
alarm.mail.server.url= #smtp server address
alarm.mail.server.port= #smtp server port
alarm.mail.server.username= #username for smtp server authentication
alarm.mail.server.password= #password for smtp server authentication
alarm.mail.sender.address= #sender's email address
#例如
pinpoint.url=http://pinpoint.com
alarm.mail.server.url=stmp.server.com
alarm.mail.server.port=583
alarm.mail.server.username=pinpoint
alarm.mail.server.password=pinpoint
alarm.mail.sender.address=pinpoint_operator@pinpoint.com
总结
以上所述是小编给你们介绍的pinpoint1.8.5安装及使用手册,希望对你们有所帮助! 查看全部
详解Java中的pinpoint1.8.5安装及使用手册
详解Java中的pinpoint1.8.5安装及使用手册
更新时间:2019年10月13日 09:15:53 转载作者:luozhiyun
pinpoint是开源在github上的一款APM监控工具,它是用Java编撰的,用于大规模分布式系统监控。这篇文章主要介绍了pinpoint1.8.5安装及使用手册,非常不错,具有一定的参考借鉴价值,需要的同学可以参考下
pinpoint1.8.5安装及使用手册
简介
pinpoint是开源在github上的一款APM监控工具,它是用Java编撰的,用于大规模分布式系统监控。它对性能的影响最小(只降低约3%资源利用率),安装agent是无侵入式的。
各大APM工具,几乎都是按照google这篇精典的Dapper论文而至,一定要读一读。这里是它的源文地址:,感谢那位朋友的翻译:
pinpoint提供了一些功能:
服务映射:通过可视化其组件怎么互连来了解任何分布式系统的关联关系。单击节点可显示有关组件的详尽信息,例如其当前状态和事务计数。
实时的活跃线程数
请求/响应散点图
调用栈
查看有关应用程序的其他详尽信息,例如CPU使用率,内存/垃圾搜集,TPS和JVM参数

整个pinpoint构架分为3部份:pinpoint-collector、pinpoint-agent、pinpoint-webUI。
pinpoint-agent:用来搜集单个应用的信息,并将搜集好的应用信息发送到pinpoint-collector中
pinpoint-collector:用来处理pinpoint-agent发送过来的信息,并将信息搜集好以后储存到HBase中
pinpoint-webUI:查找出HBase中的数据并展示
所以我这儿须要打算两台机器:
10.200.201.xxx:用于安装pinpoint-collector、pinpoint-webUI、HBase
10.200.201.yyy:用于安装pinpoint-agent,负责搜集应用的信息
环境安装
安装jdk
我这儿用的是rpm包直接安装的:rpm -ivh jdk-8u171-linux-x64.rpm
安装好后配置一下JAVA_HOME:
使用vim配置一下环境变量:
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_45
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
然后加载一些profile文件:
source /etc/profile
安装HBase
这里有个对照图:

由前面我们可以看见HBase我们须要安装1.2.x版本的
下载地址:
我这儿下载的是1.2.12版本的。
将Hbse放在指定目录
cd /app/install
tar -zxvf hbase-1.2.12-bin.tar.gz
修改配置信息
修改hbase-env.sh
vim /app/install/hbase-1.2.12/conf/hbase-env.sh
#加入JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_45
修改hbase-site.xml
vim /app/install/hbase-1.2.12/conf/hbase-site.xml
hbase.rootdir
file:///app/data/hbase
hbase.zookeeper.property.dataDir
/app/data/zookeeper
hbase.zookeeper.property.clientPort
2181
Property from ZooKeeper'sconfig zoo.cfg. The port at which the clients will connect.
hbase.cluster.distributed
false
启动HBase
cd /app/install/hbase-1.2.12/bin
./start-hbase.sh
# 查看Hbase是否启动成功,如果启动成功的会看到"HMaster"的进程
[root@localhost bin]# jps
12075 Jps
11784 HMaster
初始化pinpoint库
下载脚本:
#进入到hbase的bin目录中
cd /app/install/hbase-1.2.12/bin
#执行脚本
./bin/hbase shell /app/install/pinpoint/hbase/scripts/hbase-create.hbase
# 执行完了以后,进入Hbase
./hbase shell
#进入后可以看到Hbase的版本,还有一些相关的信息
2019-10-12 16:18:28,074 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version 1.2.12, r91d5ec4c4dcd10ceec984c6e663ea82acf353995, Sat Apr 6 15:27:28 CDT 2019
# 输入"status 'detailed'"可以查看刚才初始化的表,是否存在
hbase(main):002:0> status 'detailed'
也可以登入web,来查看HBase的数据是否初始化成功
:16010/master-status

安装pinpoint-collector
制作一个tomcat容器,端口号为8081
#将pinpoint-collector的war包丢到Tomcat的webapps目录下
cp pinpoint-collector-1.8.5.war ../apache-tomcat-8081/webapps/
#将war包名字改一下
mv pinpoint-web-1.8.5.war pp-collector.war
#启动tomcat
./bin/startup.sh
# 查看日志,是否成功启动
tail -f ../logs/catalina.out
#如果hbase安装在别的机器下需要修改一下配置
cd /app/install/apache-tomcat-8081
vim webapps/pp-collector/WEB-INF/classes/hbase.properties
#修改hbase的ip和hbase所对应的端口号
hbase.client.host=10.200.201.xxx
hbase.client.port=2181
安装pinpoint-web
解压一个tomcat容器,端口号为8080
#将pinpoint-web放到tomcat的webapps容器中
cp pinpoint-web-1.8.5.war ../apache-tomcat-8080/webapps/
#修改一下war包名
mv pinpoint-web-1.8.5.war pp-web.war
#启动tomcat
./bin/startup.sh
# 查看日志,是否成功启动
tail -f ../logs/catalina.out
#如果hbase安装在别的机器下需要修改一下配置
cd /app/install/apache-tomcat-8080
vim webapps/pp-web/WEB-INF/classes/hbase.properties
#修改hbase的ip和hbase所对应的端口号
hbase.client.host=10.200.201.xxx
hbase.client.port=2181
然后可以在浏览器中::8080/pp-web/

部署pinpoint-agent采集监控数据
传入pinpoint-agent包
首先将pinpoint-agent-1.8.5.tar.gz传入到服务器10.200.201.yyy的/app/install/pinpoint-agent/中
然后执行tar -zxvf pinpoint-agent-1.8.5.tar.gz解压
配置pp-agent采集器
cd /app/install/pinpoint-agent
vim pinpoint.config
# 主要修改IP,只需要指定到安装pp-col的IP就行了,安装pp-col启动后,自动就开启了9994,9995,9996的端口了。这里就不需要操心了,如果有端口需求,要去pp-col的配置文件("pp-collector/webapps/ROOT/WEB-INF/classes/pinpoint-collector.properties")中,修改这些端口
profiler.collector.ip=10.200.201.xxx
如果监控的是tomcat
# 修改测试项目下的tomcat启动文件"catalina.sh",修改这个只要是为了监控测试环境的Tomcat,增加探针
vi catalina.sh
# 第一行是pp-agent的jar包位置
# 第二行是agent的ID,这个ID是唯一的,我是用pp + 今天的日期命名的,只要与其他的项目的ID不重复就好了
# 第三行是采集项目的名字,这个名字可以随便取,只要各个项目不重复就好了
CATALINA_OPTS="$CATALINA_OPTS -javaagent:$AGENT_PATH/pinpoint-bootstrap-$VERSION.jar"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.agentId=$AGENT_ID"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.applicationName=$APPLICATION_NAME"
# 配置好了。就可以开始监控了,我们启动测试用的Tomcat的服务器
cd /data/pp-test/bin/
./startup.sh
# 查看启动日志,确实Tomcat启动
tail -f ../logs/catalina.out
springboot包部署
如果是jar包布署,直接在启动命令加启动参数:
nohup java -javaagent:/app/install/pinpoint-agent/pinpoint-bootstrap-1.8.5.jar -Dpinpoint.agentId=$AGENT_ID -Dpinpoint.applicationName=$APPLICATION_NAME
功能设置
设置监控
如果根据前面的方式安装完了以后在进行监控设置的或则用户设置的时侯会报错的:

所以须要配置一下mysql:
首先须要跑两个sql脚本:
然后步入到pinpoint-web的war所在的tomcat的容器中,修改配置文件:WEB-INF/classes/jdbc.properties
并设值mysql的帐号密码
jdbc.url=jdbc:mysql://localhost:13306/pinpoint?characterEncoding=UTF-8
jdbc.username=admin
jdbc.password=admin
我们可以在application上面给不同的应用设置不同的提醒规则,具体的提醒规则如下:

SLOW COUNT:发送到应用程序的慢速恳求数超过配置的阀值时触发
SLOW RATE
发送到应用程序的慢速恳求的比率(%)超过配置的阀值时触发
ERROR COUNT
发送到应用程序的失败恳求数超过配置的阀值时触发。
ERROR RATE
发送到应用程序的失败恳求的比率(%)超过配置的阀值时触发。
TOTAL COUNT
发送到应用程序的所有恳求数超过配置的阀值时触发。
SLOW COUNT TO CALLEE
当应用程序发送的慢速恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
例如),127.0.0.1:8080
SLOW RATE TO CALLEE
当应用程序发送的慢速恳求的比率(%)超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
ERROR COUNT TO CALLEE
当应用程序发送的失败恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
ERROR RATE TO CALLEE
当应用程序发送的失败恳求的比率(%)超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
TOTAL COUNT TO CALLEE
当应用程序发送的所有恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
HEAP USAGE RATE
当应用程序的堆使用率(%)超过配置的阀值时触发。
JVM CPU USAGE RATE
当应用程序的CPU使用率(%)超过配置的阀值时触发。
SYSTEM CPU USAGE RATE
当应用程序的CPU使用率(%)超过配置的阀值时发送警报。
DATASOURCE CONNECTION USAGE RATE
当应用程序的数据源联接使用率(%)超过配置的阀值时触发。
FILE DESCRIPTOR COUNT
当打开的文件描述符的数目超过配置的阀值时,发送警报。
然后须要在webapps/pp-web/WEB-INF/classes/batch.properties上面配置一下邮件服务器的信息:
pinpoint.url= #pinpoint-web server url
alarm.mail.server.url= #smtp server address
alarm.mail.server.port= #smtp server port
alarm.mail.server.username= #username for smtp server authentication
alarm.mail.server.password= #password for smtp server authentication
alarm.mail.sender.address= #sender's email address
#例如
pinpoint.url=http://pinpoint.com
alarm.mail.server.url=stmp.server.com
alarm.mail.server.port=583
alarm.mail.server.username=pinpoint
alarm.mail.server.password=pinpoint
alarm.mail.sender.address=pinpoint_operator@pinpoint.com
总结
以上所述是小编给你们介绍的pinpoint1.8.5安装及使用手册,希望对你们有所帮助!
读书笔记:写文章如何搜集素材?
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-10-18 11:04
来源:/ note / 691157510 /
高质量副本实际上是信息的组合。信息组合的背后是结构能力,但是结构能力可能无法很好地编写副本。好的副本的基础是信息。
对于文案写作,如何采集和使用此信息决定文案写作的质量。信息是否全面,有用以及是否给用户留下了深刻的印象,决定了用户是否转发,关注和购买。
采集信息不仅是在Internet上采集与该主题相关的所有内容,还只是一条信息。采集信息可以检验个人的系统思维能力。
创建轮廓
如何具有这种系统的思维能力?在“足够的阅读”一书中,作者提到了做阅读笔记的两个要点:“分析信息时询问原因和后果”和“在整理信息时清除适用的界限”。这两点收录主题写作的基本大纲,也适合于采集写作材料。它们可以用作采集信息的出色模板。具体来说,要采集的问题如下:
1.为什么这对我很重要?作者(根据以前的经验)如何得出此信息? (前)
2.作者对原因做了什么假设?这些假设如何得到验证或消除?还有其他可能性吗? (因为)
3.如果您遵循这些信息会怎样?对我有什么好处? (之后)
4.这样做的后果是什么?没有变化,问题有多严重? (水果)
5.有反对意见吗?是否有不支持这种观点的实际例子? (合适)
6.对此有什么要求?在什么情况下不起作用? (使用)
7.过去是否有类似信息?其他领域/行业/作者如何看待类似问题? (侧面)
8.无论是相反还是相似的信息,与该信息的真正区别是什么?交汇处在哪里? (边界)
识别和过滤信息
采集以上材料时,可以结合使用网络搜索关键词和主题阅读。但是,在Internet上通过关键词搜索的网页通常收录许多无效信息。您是否仍在逐页查看网页信息以从中获取分散的知识,然后将其组合在一起?我们如何停止这种低效的信息采集方法?
正确的方法是找到两到三篇有关相关主题的深入文章,并参考不同专家的观点,以快速掌握问题的实质。那么,如何从复杂信息中找到专家的深度文章?搜索方法:首先搜索该领域的专家,然后使用“专家+主题”的关键词搜索。
信息的存储和管理
曹林在《当前评论写作十讲》一书中提到了采集评论材料的方法。我认为这种方法对于所有书写材料管理都是通用的。
这是什么方法?首先,您的计算机和手机中应该有一个“有组织的”文件夹。此文件夹收录您可以随时从Internet提取的有趣信息和数据。
我自己的方法是在Evernote中创建一个“待组织”的笔记本,然后只需下载插件,连接浏览器,微信和Evernote即可轻松剪切信息。
在那之后,您需要花一些时间来整理这些信息。创建标签并将其分类到不同的文件夹中。
问题还是,如何创建一个文件夹?许多人的计算机混乱不堪。创建后许多文件夹将重叠,因此当您以后需要调用它们时很难检索数据。
我认为更方便的方法是使用“主题”作为分类标准。同时,根据日本作家奥野信之的方法,每个摘录必须标有“日期+来源+主题细目+原创链接”。
通过这种方式,所有这些材料都被放置在Evernote中,只要编写了“主题细目” 关键词,那么当您需要调用信息时,您只需要直接在Evernote中进行搜索,您就可以可以轻松地搜索主题。以下所有信息减少了在重叠文件夹中搜索信息的难度。
以上是材料采集和管理的方法。只要采集以上信息,就可以对信息进行分类。通过使用一些常见的文案写作技巧来区分背景信息和评估信息,您可以结合起来撰写高质量的文案写作。至于文案写作的方法,我将在其他文章中进行系统地解释。 查看全部
写文章如何采集资料?
来源:/ note / 691157510 /
高质量副本实际上是信息的组合。信息组合的背后是结构能力,但是结构能力可能无法很好地编写副本。好的副本的基础是信息。
对于文案写作,如何采集和使用此信息决定文案写作的质量。信息是否全面,有用以及是否给用户留下了深刻的印象,决定了用户是否转发,关注和购买。
采集信息不仅是在Internet上采集与该主题相关的所有内容,还只是一条信息。采集信息可以检验个人的系统思维能力。
创建轮廓
如何具有这种系统的思维能力?在“足够的阅读”一书中,作者提到了做阅读笔记的两个要点:“分析信息时询问原因和后果”和“在整理信息时清除适用的界限”。这两点收录主题写作的基本大纲,也适合于采集写作材料。它们可以用作采集信息的出色模板。具体来说,要采集的问题如下:
1.为什么这对我很重要?作者(根据以前的经验)如何得出此信息? (前)
2.作者对原因做了什么假设?这些假设如何得到验证或消除?还有其他可能性吗? (因为)
3.如果您遵循这些信息会怎样?对我有什么好处? (之后)
4.这样做的后果是什么?没有变化,问题有多严重? (水果)
5.有反对意见吗?是否有不支持这种观点的实际例子? (合适)
6.对此有什么要求?在什么情况下不起作用? (使用)
7.过去是否有类似信息?其他领域/行业/作者如何看待类似问题? (侧面)
8.无论是相反还是相似的信息,与该信息的真正区别是什么?交汇处在哪里? (边界)
识别和过滤信息
采集以上材料时,可以结合使用网络搜索关键词和主题阅读。但是,在Internet上通过关键词搜索的网页通常收录许多无效信息。您是否仍在逐页查看网页信息以从中获取分散的知识,然后将其组合在一起?我们如何停止这种低效的信息采集方法?
正确的方法是找到两到三篇有关相关主题的深入文章,并参考不同专家的观点,以快速掌握问题的实质。那么,如何从复杂信息中找到专家的深度文章?搜索方法:首先搜索该领域的专家,然后使用“专家+主题”的关键词搜索。
信息的存储和管理
曹林在《当前评论写作十讲》一书中提到了采集评论材料的方法。我认为这种方法对于所有书写材料管理都是通用的。
这是什么方法?首先,您的计算机和手机中应该有一个“有组织的”文件夹。此文件夹收录您可以随时从Internet提取的有趣信息和数据。
我自己的方法是在Evernote中创建一个“待组织”的笔记本,然后只需下载插件,连接浏览器,微信和Evernote即可轻松剪切信息。
在那之后,您需要花一些时间来整理这些信息。创建标签并将其分类到不同的文件夹中。
问题还是,如何创建一个文件夹?许多人的计算机混乱不堪。创建后许多文件夹将重叠,因此当您以后需要调用它们时很难检索数据。
我认为更方便的方法是使用“主题”作为分类标准。同时,根据日本作家奥野信之的方法,每个摘录必须标有“日期+来源+主题细目+原创链接”。
通过这种方式,所有这些材料都被放置在Evernote中,只要编写了“主题细目” 关键词,那么当您需要调用信息时,您只需要直接在Evernote中进行搜索,您就可以可以轻松地搜索主题。以下所有信息减少了在重叠文件夹中搜索信息的难度。
以上是材料采集和管理的方法。只要采集以上信息,就可以对信息进行分类。通过使用一些常见的文案写作技巧来区分背景信息和评估信息,您可以结合起来撰写高质量的文案写作。至于文案写作的方法,我将在其他文章中进行系统地解释。
优采云采集器pbootcms文章 (PbootDemoSkycaiji)插件怎么设
采集交流 • 优采云 发表了文章 • 0 个评论 • 444 次浏览 • 2020-08-30 03:35
pbootcms文章 (PbootDemoSkycaiji)插件直接在优采云采集器云平台,下载就可以使用了,插件是由没皮的小菠萝开发。插件默认是只有新闻栏目可以发布,产品案例那些是过滤了的须要自己自动更改一下。
下载好了插件我们可以在网站根目录上面优采云采集器安装里找到路径为:网站根目录采集器安装目录plugineleasecmsPbootDemoSkycaiji.php
打开这个文件开头这段代码的意思是手动读取我们的数据库信息,无论是mysql或是sqlite数据库都是一样的,自动去抓取链接。
这里就是对应着我们网站发布的信息,比如作者,文章内容,产品分类,略缩图等等,这里都可以按照我们的网站需求来添加更多参数。
这里的信息是对应了我们的网站数据库上面的数组,如果这儿没有的数组可以直接步入数据库对照着添加进来就可以了,有一点须要注意的是这儿的数据库数组要和上面的参数哪里对应上去,比如我们的参数上面添加了略缩图,那我们的这儿就一定要找到这个数组填写上我们在参数里降低的名称。
这里默认是过滤了其他目录,只取了我们数据库上面的新闻列表的信息,如果我们要发布产品或是案例的话这个就不能使用了,我们须要做的就是把
// $catsDb=$this->db()->table('__CONTENT_SORT__')->where("contenttpl='news.html'")->limit(100)->select();//文章分类 注释掉或是删除都可以。
添加$catsDb=$this->db()->table('__CONTENT_SORT__')->limit(100)->select();//文章分类就可以了默认是匹配所有网站的目录。以上就是pbootcms文章 (PbootDemoSkycaiji)插件的详尽介绍了,基本上看了以上的说明没有啥问题了。如何您还有不明白的可以咨询我们。 查看全部
优采云采集器pbootcms文章 (PbootDemoSkycaiji)插件怎么设
pbootcms文章 (PbootDemoSkycaiji)插件直接在优采云采集器云平台,下载就可以使用了,插件是由没皮的小菠萝开发。插件默认是只有新闻栏目可以发布,产品案例那些是过滤了的须要自己自动更改一下。
下载好了插件我们可以在网站根目录上面优采云采集器安装里找到路径为:网站根目录采集器安装目录plugineleasecmsPbootDemoSkycaiji.php
打开这个文件开头这段代码的意思是手动读取我们的数据库信息,无论是mysql或是sqlite数据库都是一样的,自动去抓取链接。
这里就是对应着我们网站发布的信息,比如作者,文章内容,产品分类,略缩图等等,这里都可以按照我们的网站需求来添加更多参数。
这里的信息是对应了我们的网站数据库上面的数组,如果这儿没有的数组可以直接步入数据库对照着添加进来就可以了,有一点须要注意的是这儿的数据库数组要和上面的参数哪里对应上去,比如我们的参数上面添加了略缩图,那我们的这儿就一定要找到这个数组填写上我们在参数里降低的名称。
这里默认是过滤了其他目录,只取了我们数据库上面的新闻列表的信息,如果我们要发布产品或是案例的话这个就不能使用了,我们须要做的就是把
// $catsDb=$this->db()->table('__CONTENT_SORT__')->where("contenttpl='news.html'")->limit(100)->select();//文章分类 注释掉或是删除都可以。
添加$catsDb=$this->db()->table('__CONTENT_SORT__')->limit(100)->select();//文章分类就可以了默认是匹配所有网站的目录。以上就是pbootcms文章 (PbootDemoSkycaiji)插件的详尽介绍了,基本上看了以上的说明没有啥问题了。如何您还有不明白的可以咨询我们。
文章采集调用 发布设置
采集交流 • 优采云 发表了文章 • 0 个评论 • 492 次浏览 • 2020-08-28 19:06
发布设置
点击任务顶部进度条的“发布设置”,选择发布形式
本地cms程序
可手动检查出服务器中的CMS程序,实现优采云采集器和cms无缝对接
简单绑定对应的数据,不用登入即可入库,你还可以自行开发cms插件,理论上可实现任何CMS的任意入库操作
数据库
直接将数据入库,配置好数据库参数点击“数据表”
绑定数据表的主键和采集器的数组,多张表关联自增id,选择“自定义内容”输入“auto_id@表名”即可
存储为文件
支持Excel表格(xlsx或xls格式)、txt文本,隐藏采集字段可设置不写入文件的数组
生成api接口
可直接调用采集到的数据
调用插口
只要有相应cms的入库插口,就可以将数据远程发布到网站中,不必将采集器和网站放在同一服务器
当数据发送至远程插口并入库后须要返回响应状态,这样采集器能够正确记录数据的状态并拿来进行排重处理
你只须要在插口代码最后或则数据入库后插入代码
exit(json_encode(数组));//数组必须是键值对形式,这样在响应状态中就可以直接绑定接口中返回的数组键名
自定义插件
适用于任何网站程序,按要求创建插件文件并编撰代码即可 查看全部
文章采集调用 发布设置
发布设置
点击任务顶部进度条的“发布设置”,选择发布形式
本地cms程序
可手动检查出服务器中的CMS程序,实现优采云采集器和cms无缝对接
简单绑定对应的数据,不用登入即可入库,你还可以自行开发cms插件,理论上可实现任何CMS的任意入库操作
数据库
直接将数据入库,配置好数据库参数点击“数据表”
绑定数据表的主键和采集器的数组,多张表关联自增id,选择“自定义内容”输入“auto_id@表名”即可
存储为文件
支持Excel表格(xlsx或xls格式)、txt文本,隐藏采集字段可设置不写入文件的数组
生成api接口
可直接调用采集到的数据
调用插口
只要有相应cms的入库插口,就可以将数据远程发布到网站中,不必将采集器和网站放在同一服务器
当数据发送至远程插口并入库后须要返回响应状态,这样采集器能够正确记录数据的状态并拿来进行排重处理
你只须要在插口代码最后或则数据入库后插入代码
exit(json_encode(数组));//数组必须是键值对形式,这样在响应状态中就可以直接绑定接口中返回的数组键名
自定义插件
适用于任何网站程序,按要求创建插件文件并编撰代码即可
聚荣网手动发布信息工具【图文并茂】
采集交流 • 优采云 发表了文章 • 0 个评论 • 223 次浏览 • 2020-08-28 01:54
聚荣网手动发布信息工具【图文并茂】z4pa
聚荣网手动发布信息工具【图文并茂】
大家好这儿是羚羊手动发布信息软件介绍:
羚羊信息技术有限公司主要业务范畴为各种B2B平台软件的 设计开发与应用、以及各种B2B平台综合业务的代办,目前拥有较强实力的设计团队、技术团队、销售和售后团队;凭 借多年的实战经验,在业界赢的了良好的口碑和信誉。
使用方式:插件包括一个和一个文件,运行时还需将好友或群拉到桌面,具体操作如下:,首先将和拷入大智慧根目录中,,用记事本等文本编辑工具打开,照原先的格式按须要修改或增减其中内容:,[内容],指须要发出的文字信息。 ,每天调用插件发送信息前,要将须要向其发送信息的好友和群全部拉到桌面产生独立打开的聊天窗口备用,大智慧手动发陌陌插件截图:热门推荐指南针全赢博弈股票软件版|股票期货财通证券单独下单程序版|股票证券太洋证券同花顺独立委托客户端安装版|股票证券华福证券股票期权专业交易系统正式版|股票。
一、定时发送功能
软件发布信息间隔时间没有规律,随意调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜下午发布信息的同学,发布完自动关机)。
二、保存配置功能
如果你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载原先的设置,省时、省事。
软件是否手动读写贴子内容到页面的回帖发帖框上面以及是否手动递交有验证码的,可勾选自动输入选项,并自行输入,也可开启手动打码台来手动辨识验证码。帖子是否发布成功,具体要看递交时贴子页面显示的信息,软件发送次数仅供参考。*说明:一般情况下,网站都有贴子发布时间间隔、数量的限制,以及一些敏感词的过滤。因此可适当延长随机发布间隔时间,同时采用软文和跟帖的方法,并通过批量切换目标。有些网站还会记录浏览器信息,以此判定是否人工还是机器发贴。这时可勾选启用内置浏览器选项,之后软件将通过调用系统浏览器来达到高度模拟人工发布的目的。另外,在一些旧的操作系统中,软件外置浏览器未能发贴,这时也可启用内置浏览器,注意需确保浏览器状态正常且为系统默认浏览器。
民生银行郭庆谈商业银行金融科技赋能的探求与实践【快译】年已过去一半,是时侯为您介绍我在去年发觉的个开源软件()程序了。其中一些程序可能并不新颖,因为它们不是在年首次发布的,但是对我来说它们太新颖,而且我认为它们太有帮助。这就是为何我想简略地回顾一下,但愿您也认为它们很有用。编辑器毫无疑问,这是我的选择。也许是因为我除了是系统管理员,还是开发人员。我发觉由开发的这款文本编辑器时,被惊艳了。很容易通过额外程序包来轻松扩充,这些程序包提供了面向诸多语言的代码手动完成功能、功能和外置的浏览器预览。被称为是您所有数据的安全之家,起初它只是的其中一位初期合作者所创建的单独项目。虽然在创始人与社区之间引了。 专为优化而开发,本类软件推荐刷工具(刷网站点击量)绿色版绿色版英文整合版流量版位安装包完整版网站抓取精灵正式版飞达鲁长尾词查询工具英文绿色版版本地服务器(迷你)绿色版网页截图扩充()工具条全新版爱站关键词采集工具无限制版域名批量查询()英文绿色版优采云采集器版连接数更改工具红色。
三、自动设置产品图片功能
图片有3种选择方法:
1、同步采集网站图片。 如果您在网站后台上传了图片,点击“采集相册”,可以手动采集图片到本地。
2、您的网站后台获取网址地址,取您想要发的产品的图片。
3、手动批量导出本地计算机上的图片。
四、强大的内容编辑器
软件外置文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本可在软件内部随时可视化编辑,就像在网站后台操作一样。
五、自动合成标题功能
无法想到好多标题?软件外置批量合成标题功能,自动批量合成成千上万个不重复的标题。根据您的须要,配置标题模板即可生成。
标题可以任意组合,常用格式是{字符1}{字符2}{字符3},通过各类自定义组合,可以形成千变万化的不同标题。
六、自动插入伪原创功能:图片以下的文字属于随机介绍。
1、按句号选择
2、按段落选择
可以在内容中的任何地方插入您的伪原创文章,句子中的文章放得越多越好,没有限制,软件在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不重复,搜索引擎也比较喜欢。
七、百度查询收录功能 查看全部
聚荣网手动发布信息工具【图文并茂】
聚荣网手动发布信息工具【图文并茂】z4pa
聚荣网手动发布信息工具【图文并茂】
大家好这儿是羚羊手动发布信息软件介绍:
羚羊信息技术有限公司主要业务范畴为各种B2B平台软件的 设计开发与应用、以及各种B2B平台综合业务的代办,目前拥有较强实力的设计团队、技术团队、销售和售后团队;凭 借多年的实战经验,在业界赢的了良好的口碑和信誉。
使用方式:插件包括一个和一个文件,运行时还需将好友或群拉到桌面,具体操作如下:,首先将和拷入大智慧根目录中,,用记事本等文本编辑工具打开,照原先的格式按须要修改或增减其中内容:,[内容],指须要发出的文字信息。 ,每天调用插件发送信息前,要将须要向其发送信息的好友和群全部拉到桌面产生独立打开的聊天窗口备用,大智慧手动发陌陌插件截图:热门推荐指南针全赢博弈股票软件版|股票期货财通证券单独下单程序版|股票证券太洋证券同花顺独立委托客户端安装版|股票证券华福证券股票期权专业交易系统正式版|股票。
一、定时发送功能
软件发布信息间隔时间没有规律,随意调控间隔时间,做到每两条信息之间的间隔没有规律,定时关机功能(一般适宜下午发布信息的同学,发布完自动关机)。
二、保存配置功能
如果你有多个产品须要分别发布,可以分别保存产品功能的配置,只需配置一次,保存配置后,以后导出配置即可加载原先的设置,省时、省事。
软件是否手动读写贴子内容到页面的回帖发帖框上面以及是否手动递交有验证码的,可勾选自动输入选项,并自行输入,也可开启手动打码台来手动辨识验证码。帖子是否发布成功,具体要看递交时贴子页面显示的信息,软件发送次数仅供参考。*说明:一般情况下,网站都有贴子发布时间间隔、数量的限制,以及一些敏感词的过滤。因此可适当延长随机发布间隔时间,同时采用软文和跟帖的方法,并通过批量切换目标。有些网站还会记录浏览器信息,以此判定是否人工还是机器发贴。这时可勾选启用内置浏览器选项,之后软件将通过调用系统浏览器来达到高度模拟人工发布的目的。另外,在一些旧的操作系统中,软件外置浏览器未能发贴,这时也可启用内置浏览器,注意需确保浏览器状态正常且为系统默认浏览器。
民生银行郭庆谈商业银行金融科技赋能的探求与实践【快译】年已过去一半,是时侯为您介绍我在去年发觉的个开源软件()程序了。其中一些程序可能并不新颖,因为它们不是在年首次发布的,但是对我来说它们太新颖,而且我认为它们太有帮助。这就是为何我想简略地回顾一下,但愿您也认为它们很有用。编辑器毫无疑问,这是我的选择。也许是因为我除了是系统管理员,还是开发人员。我发觉由开发的这款文本编辑器时,被惊艳了。很容易通过额外程序包来轻松扩充,这些程序包提供了面向诸多语言的代码手动完成功能、功能和外置的浏览器预览。被称为是您所有数据的安全之家,起初它只是的其中一位初期合作者所创建的单独项目。虽然在创始人与社区之间引了。 专为优化而开发,本类软件推荐刷工具(刷网站点击量)绿色版绿色版英文整合版流量版位安装包完整版网站抓取精灵正式版飞达鲁长尾词查询工具英文绿色版版本地服务器(迷你)绿色版网页截图扩充()工具条全新版爱站关键词采集工具无限制版域名批量查询()英文绿色版优采云采集器版连接数更改工具红色。
三、自动设置产品图片功能
图片有3种选择方法:
1、同步采集网站图片。 如果您在网站后台上传了图片,点击“采集相册”,可以手动采集图片到本地。
2、您的网站后台获取网址地址,取您想要发的产品的图片。
3、手动批量导出本地计算机上的图片。
四、强大的内容编辑器
软件外置文本编辑器,自动辨识网站内容递交格式是纯文本,还是html文本。html文本可在软件内部随时可视化编辑,就像在网站后台操作一样。
五、自动合成标题功能
无法想到好多标题?软件外置批量合成标题功能,自动批量合成成千上万个不重复的标题。根据您的须要,配置标题模板即可生成。
标题可以任意组合,常用格式是{字符1}{字符2}{字符3},通过各类自定义组合,可以形成千变万化的不同标题。
六、自动插入伪原创功能:图片以下的文字属于随机介绍。
1、按句号选择
2、按段落选择
可以在内容中的任何地方插入您的伪原创文章,句子中的文章放得越多越好,没有限制,软件在发布每条信息时,会手动随机按您的要求调用,每次发下来的文章都不重复,搜索引擎也比较喜欢。
七、百度查询收录功能
织梦dedecms和mymps蚂蚁分类信息系统安装在同一目录下及调用解决方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2020-08-27 23:36
一直使用蚂蚁分类信息做了个地方信息网站,但是蚂蚁在新闻文章发布上功能有些小缺憾,比如目录单一,采集不便捷等不利于seo的问题,于是就想着能不能把蚂蚁分类和织梦安装在同一个目录下边实现互补融合,下面分享下解决过程和思路。
首先,需要解决两个系统有些目录名子重复的问题,我的思路是把织梦的data目录移出去,一是解决重复,而是对织梦的安全也比较好,然后就是include目录,我还是把织梦的include更名解决。测试后没有问题,两个系统能在一个域名下独立运行。
接下来,就须要解决调用的问题了,可以选择在织梦首页调用mymps的分类信息,也可以选择在mymps的首页调用织梦的文章,这两个问题都可以实现,最后我选择的前者,感觉这样更完美一些,毕竟只是用织梦系统填补下mymps的seo问题。
1.根目录index.php中引入常用变量
//引入织梦常量
require_once(DEDEINC.'/common.func.php');
require_once (dirname(__FILE__)."/deinc/common.inc.php");
require_once(DEDEINC.'/arc.listview.class.php');
2./include/global.inc.php
加入
define('DEDEINC', MYMPS_ROOT . '/deinc');
define('DEDEROOT', str_replace("\\", '/', substr(DEDEINC,0,-6) ) );
define('DEDEDATA', MYMPS_ROOT.'/../data');
define('DEDETEMPLATE', MYMPS_ROOT.'/templets');
3.原生php句子调用织梦文章列表
在index.php中添加
//调用织梦文章列表
$arr = '';
$article = array();
$query = "SELECT arc.* , tp.reid , tp.typename , tp.typedir , ch.addtable FROM `dede_archives` arc ".
"LEFT JOIN dede_arctype tp on tp.id=arc.typeid ".
"LEFT JOIN dede_channeltype as ch on arc.channel = ch.id WHERE arc.typeid='413' ORDER BY pubdate DESC LIMIT 0 , 10";
$arctitle = array();
$dsql->SetQuery($query);
$dsql->Execute();
while ($rowarc = $dsql->GetArray()) {
$arctitle[] = $rowarc;
$arr['id'] = $rowarc['id'];
$arr['title']= $rowarc['title'];
$arr['url'] = GetOneArchive($rowarc['id']);
$article[$rowarc['id']] = $arr;
}
//调用织梦文章列表 结束
然后在mymps的模板中调用织梦数据就行了
{$mymps[title]}</a>
织梦二次开发QQ群
本站客服QQ号:3149518909(点击一侧QQ号交流),群号(383578617)
如果您有任何织梦问题,请把问题发到群里,阁主将为您写解决教程!
转载请标明:织梦模板 织梦dedecms和mymps蚂蚁分类信息系统安装在同一目录下及调用解决方式 查看全部
织梦dedecms和mymps蚂蚁分类信息系统安装在同一目录下及调用解决方式
一直使用蚂蚁分类信息做了个地方信息网站,但是蚂蚁在新闻文章发布上功能有些小缺憾,比如目录单一,采集不便捷等不利于seo的问题,于是就想着能不能把蚂蚁分类和织梦安装在同一个目录下边实现互补融合,下面分享下解决过程和思路。
首先,需要解决两个系统有些目录名子重复的问题,我的思路是把织梦的data目录移出去,一是解决重复,而是对织梦的安全也比较好,然后就是include目录,我还是把织梦的include更名解决。测试后没有问题,两个系统能在一个域名下独立运行。
接下来,就须要解决调用的问题了,可以选择在织梦首页调用mymps的分类信息,也可以选择在mymps的首页调用织梦的文章,这两个问题都可以实现,最后我选择的前者,感觉这样更完美一些,毕竟只是用织梦系统填补下mymps的seo问题。
1.根目录index.php中引入常用变量
//引入织梦常量
require_once(DEDEINC.'/common.func.php');
require_once (dirname(__FILE__)."/deinc/common.inc.php");
require_once(DEDEINC.'/arc.listview.class.php');
2./include/global.inc.php
加入
define('DEDEINC', MYMPS_ROOT . '/deinc');
define('DEDEROOT', str_replace("\\", '/', substr(DEDEINC,0,-6) ) );
define('DEDEDATA', MYMPS_ROOT.'/../data');
define('DEDETEMPLATE', MYMPS_ROOT.'/templets');
3.原生php句子调用织梦文章列表
在index.php中添加
//调用织梦文章列表
$arr = '';
$article = array();
$query = "SELECT arc.* , tp.reid , tp.typename , tp.typedir , ch.addtable FROM `dede_archives` arc ".
"LEFT JOIN dede_arctype tp on tp.id=arc.typeid ".
"LEFT JOIN dede_channeltype as ch on arc.channel = ch.id WHERE arc.typeid='413' ORDER BY pubdate DESC LIMIT 0 , 10";
$arctitle = array();
$dsql->SetQuery($query);
$dsql->Execute();
while ($rowarc = $dsql->GetArray()) {
$arctitle[] = $rowarc;
$arr['id'] = $rowarc['id'];
$arr['title']= $rowarc['title'];
$arr['url'] = GetOneArchive($rowarc['id']);
$article[$rowarc['id']] = $arr;
}
//调用织梦文章列表 结束
然后在mymps的模板中调用织梦数据就行了
{$mymps[title]}</a>
织梦二次开发QQ群
本站客服QQ号:3149518909(点击一侧QQ号交流),群号(383578617)
如果您有任何织梦问题,请把问题发到群里,阁主将为您写解决教程!
转载请标明:织梦模板 织梦dedecms和mymps蚂蚁分类信息系统安装在同一目录下及调用解决方式
如何使用代理IP进行数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-27 22:15
什么是代理?什么情况下会用到代理IP?如何使用代理IP进行数据采集?针对这种问题,小编为你们一一作答。
代理服务器的功能就是代理用户去获取网路信息,之后再把相应的信息反馈给顾客。用一个比较靠谱的比喻来说代理服务器相当于一个中介的环节。它是网路信息的中转站。通过代理IP访问目标网站,可以隐藏用户的真实IP地址。
例如要想要抓取一个内容有100万条的网站,但是她们设置了IP限制,每个小时只有1000条可以抓,如果你使用同一个IP,并且保持不变,那么想要抓取所有的信息,你要耗费40天的时间。但是假如你更换不同的IP地址,就可以提升数据采集的效率。
其他想切换IP或则隐藏自身IP地址的场景也会用到代理IP,比如说电商,游戏,注册等等。
代理IP分味开放代理和私密代理,开放代理是全网扫描来的,稳定性较差,爬虫是肯定不适宜做的。自己没事玩儿还好。如果是做爬虫的话,用私密,稳定性是十分可靠的。
私密代理IP网上有很多提供商,稳定性参差不齐,这里说一下ip代理精灵,我们公司有个项目是抓取亚马逊数据来进行剖析销量、评论等,用PHP进行抓取,抓取亚马逊要非常注意header头,否则输出的数据就是空了。还有一种方式,可以用PHP通过shell_exec来调用curl命令来进行抓取。 查看全部
如何使用代理IP进行数据采集
什么是代理?什么情况下会用到代理IP?如何使用代理IP进行数据采集?针对这种问题,小编为你们一一作答。
代理服务器的功能就是代理用户去获取网路信息,之后再把相应的信息反馈给顾客。用一个比较靠谱的比喻来说代理服务器相当于一个中介的环节。它是网路信息的中转站。通过代理IP访问目标网站,可以隐藏用户的真实IP地址。
例如要想要抓取一个内容有100万条的网站,但是她们设置了IP限制,每个小时只有1000条可以抓,如果你使用同一个IP,并且保持不变,那么想要抓取所有的信息,你要耗费40天的时间。但是假如你更换不同的IP地址,就可以提升数据采集的效率。
其他想切换IP或则隐藏自身IP地址的场景也会用到代理IP,比如说电商,游戏,注册等等。
代理IP分味开放代理和私密代理,开放代理是全网扫描来的,稳定性较差,爬虫是肯定不适宜做的。自己没事玩儿还好。如果是做爬虫的话,用私密,稳定性是十分可靠的。
私密代理IP网上有很多提供商,稳定性参差不齐,这里说一下ip代理精灵,我们公司有个项目是抓取亚马逊数据来进行剖析销量、评论等,用PHP进行抓取,抓取亚马逊要非常注意header头,否则输出的数据就是空了。还有一种方式,可以用PHP通过shell_exec来调用curl命令来进行抓取。
乐思实时采集开发包 -- 用于
采集交流 • 优采云 发表了文章 • 0 个评论 • 300 次浏览 • 2020-08-27 04:51
乐思实时信息采集开发包
乐思实时信息采集开发包是为开发人员提供的用于网路信息采集的自动化对象。它通过COM对象提供了一组用于网路信息抽取的核心技巧。开发人员可以在任何一个支持Windows COM调用的语言(如VB, VC, Delphi,ASP, ASP.NET,PowerBuilder)中调用该组件,在无需关心HTTP请求与数据处理细节的情况下完成网路数据抽取与集成,从而轻松开发出适宜自己需求的网路信息抽取与集成的应用程序与网站。
它可以做哪些?
元搜索引擎:通过在后台调用各大搜索引擎,将各大搜索引擎的返回结果整合处理后,实时返回给查询用户。
行业搜索整合门户:通过将用户的查询关键词递交到多个行业网站查询,并将各个结果页面中的关键返回内容(去掉与查询无关的脚注,页尾,栏目,广告,动画)整合在一个页面中返回给用户。
网站整合:将各个下属单位的网站上的关键内容抽取下来后整合在一个页面显示,如省政府网站与下属市政府网站。
新闻文章抓取:你可以开发自己的新闻文章抓取程序,将来源于各大网站的新闻或文章标题,作者,来源,内容等保存到数据库中。
实时信息抓取:你可以在你的应用程序中集成来源于网上的实时信息:股票行情,博彩欧赔,天气预报,热点新闻等等。
RSS信息抓取:抽取来源于多个网站的RSS XML文件中的文章标题与内容,集成显示在你的网站或者应用程序中。
竞争情报监视:将各个竞争对手网站上的最新新闻,招聘信息,人事变动抽取后集成在一个窗口中显示,将自己与竞争对手的名称以及相关产品的关键字通过Google或则百度搜索,将搜索结果整合在一个窗口中显示或保存到数据库中。 查看全部
乐思实时采集开发包 -- 用于
乐思实时信息采集开发包
乐思实时信息采集开发包是为开发人员提供的用于网路信息采集的自动化对象。它通过COM对象提供了一组用于网路信息抽取的核心技巧。开发人员可以在任何一个支持Windows COM调用的语言(如VB, VC, Delphi,ASP, ASP.NET,PowerBuilder)中调用该组件,在无需关心HTTP请求与数据处理细节的情况下完成网路数据抽取与集成,从而轻松开发出适宜自己需求的网路信息抽取与集成的应用程序与网站。
它可以做哪些?
元搜索引擎:通过在后台调用各大搜索引擎,将各大搜索引擎的返回结果整合处理后,实时返回给查询用户。
行业搜索整合门户:通过将用户的查询关键词递交到多个行业网站查询,并将各个结果页面中的关键返回内容(去掉与查询无关的脚注,页尾,栏目,广告,动画)整合在一个页面中返回给用户。
网站整合:将各个下属单位的网站上的关键内容抽取下来后整合在一个页面显示,如省政府网站与下属市政府网站。
新闻文章抓取:你可以开发自己的新闻文章抓取程序,将来源于各大网站的新闻或文章标题,作者,来源,内容等保存到数据库中。
实时信息抓取:你可以在你的应用程序中集成来源于网上的实时信息:股票行情,博彩欧赔,天气预报,热点新闻等等。
RSS信息抓取:抽取来源于多个网站的RSS XML文件中的文章标题与内容,集成显示在你的网站或者应用程序中。
竞争情报监视:将各个竞争对手网站上的最新新闻,招聘信息,人事变动抽取后集成在一个窗口中显示,将自己与竞争对手的名称以及相关产品的关键字通过Google或则百度搜索,将搜索结果整合在一个窗口中显示或保存到数据库中。
源码剖析 Sentinel 实时数据采集实现原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2020-08-27 01:03
本篇将重点关注 Sentienl 实时数据搜集,即 Sentienl 具体是怎样搜集调用信息,以此来判定是否须要触发限流或熔断。
本节目录
Sentienl 实时数据搜集的入口类为 StatisticSlot。
我们先简单来看一下 StatisticSlot 该类的注释,来看一下该类的整体定位。
StatisticSlot,专用于实时统计的 slot。在步入一个资源时,在执行 Sentienl 的处理链条中会步入到该 slot 中,需要完成如下估算任务:
接下来用源码剖析的手段来详尽剖析 StatisticSlot 的实现原理。
1、源码剖析 StatisticSlot 1.1 StatisticSlot entry 详解
StatisticSlot#entry
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,boolean prioritized, Object... args) throws Throwable {
try {
// Do some checking.
fireEntry(context, resourceWrapper, node, count, prioritized, args); // @1
// Request passed, add thread count and pass count.
node.increaseThreadNum(); // @2
node.addPassRequest(count);
if (context.getCurEntry().getOriginNode() != null) { // @3
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) { // @4
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest(count);
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) { // @5
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (PriorityWaitException ex) { // @6
node.increaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (BlockException e) { // @7
// Blocked, set block exception to current entry.
context.getCurEntry().setError(e);
// Add block count.
node.increaseBlockQps(count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseBlockQps(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseBlockQps(count);
}
// Handle block event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onBlocked(e, context, resourceWrapper, node, count, args);
}
throw e;
} catch (Throwable e) { // @8
// Unexpected error, set error to current entry.
context.getCurEntry().setError(e);
// This should not happen.
node.increaseExceptionQps(count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseExceptionQps(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
Constants.ENTRY_NODE.increaseExceptionQps(count);
}
throw e;
}
}
代码@1:首先调用 fireEntry,先调用 Sentinel Slot Chain 中其他的处理器,执行完其他处理器的逻辑,例如 FlowSlot、DegradeSlot,因为 StatisticSlot 的职责是搜集统计信息。
代码@2:如果后续处理器成功执行,则将正在执行线程数统计指标加一,并将通过的恳求数目指标降低对应的值。下文会对 Sentinel Node 体系进行详尽的介绍,在 Sentinel 中使用 Node 来表示调用链中的某一个节点,每个节点关联一个资源,资源的实时统计信息就存贮在 Node 中,故该部份也是调用 DefaultNode 的相关技巧来改变线程数等,将在下文会向详尽介绍。
代码@3:如果上下文环境中保存了调用的源头(调用方)的节点信息不为空,则更新该节点的统计数据:线程数与通过数目。
代码@4:如果资源的步入类型为 EntryType.IN,表示入站流量,更新入站全局统计数据(集群范围 ClusterNode)。
代码@5:执行注册的步入Handler,可以通过 StatisticSlotCallbackRegistry 的 addEntryCallback 注册相关监听器。
代码@6:如果捕获到 PriorityWaitException ,则觉得是等待过一定时间,但最终还是算通过,只需降低线程的个数,但无需降低节点通过的数目,具体缘由我们在详尽剖析限流部份时会重点讨论,也会再度探讨 PriorityWaitException 的含意。
代码@7:如果捕获到 BlockException,则主要降低阻塞的数目。
代码@8:如果是系统异常,则降低异常数目。
我想里面的代码应当不难理解,但涉及到统计指标数据的变化,都是调用 DefaultNode node 相关的方式,从这儿也可以看出,Node 将是实时统计数据的直接持有者,那毋容置疑接下来将重点来学习 Node,为了知识体系的完备性,我们先来看一下 StatisticSlot 的 exit 方法。
1.2 StatisticSlot exit 详解
StatisticSlot#exit
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
DefaultNode node = (DefaultNode)context.getCurNode();
if (context.getCurEntry().getError() == null) { // @1
// Calculate response time (max RT is TIME_DROP_VALVE).
long rt = TimeUtil.currentTimeMillis() - context.getCurEntry().getCreateTime();
if (rt > Constants.TIME_DROP_VALVE) {
rt = Constants.TIME_DROP_VALVE;
}
// Record response time and success count.
node.addRtAndSuccess(rt, count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().addRtAndSuccess(rt, count);
}
node.decreaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().decreaseThreadNum();
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
Constants.ENTRY_NODE.addRtAndSuccess(rt, count);
Constants.ENTRY_NODE.decreaseThreadNum();
}
} else {
// Error may happen.
}
// Handle exit event with registered exit callback handlers.
Collection exitCallbacks = StatisticSlotCallbackRegistry.getExitCallbacks();
for (ProcessorSlotExitCallback handler : exitCallbacks) { // @2
handler.onExit(context, resourceWrapper, count, args);
}
fireExit(context, resourceWrapper, count); // @3
}
代码@1:成功执行,则重点关注响应时间,其实现亮点如下:
计算本次响应时间,将本次响应时间搜集到 Node 中。
将当前活跃线程数减一。
代码@2:执行退出时的 callback。可以通过 StatisticSlotCallbackRegistry 的 addExitCallback 方法添加退出回调函数。
代码@3:传播 exit 事件。
接下来我们将重点介绍 DefaultNode,即 Sentinel 的 Node 体系,持有资源的实时调用信息。
2、Sentienl Node 体系
2.1 Node 类体系图
我们先简单介绍一下上述核心类的作用与核心插口或核心属性的含意。
long waiting()
获取当前已申请的未来的令牌的个数。 void addWaitingRequest(long futureTime, int acquireCount)
申请未来时间窗口中的令牌。 void addOccupiedPass(int acquireCount)
增加申请未来令牌通过的个数。 double occupiedPassQps()
当前占据未来令牌的QPS。 Node
持有实时统计信息的节点。定义了搜集统计信息与获取统计信息的插口,上面方式依据技巧名称即可获知其涵义,故这儿就不一一列举了。 StatisticNode
实现统计信息的默认实现类。 DefaultNode
用于在特定上下文环境中保存某一个资源的实时统计信息。 ClusterNode
实现基于集群限流模式的节点,将在集群限流模式部份详尽介绍。 EntranceNode
用来表示调用链入口的节点信息。
本文将详尽介绍 DefaultNode 与 StatisticNode,重点论述调用树与实时统计信息。DefaultNode 是 StatisticNode 的泛型,我们先从 StatisticNode 开始 Node 体系的探究。
2、StatisticNode 详解 2.1 核心类图
我们对其核心属性进行一一详解:
关于 ArrayMetric 滑动窗口设计与实现原理,请参考笔者的另一篇博文:Alibaba Seninel 滑动窗口实现原理(文末附原理图)
接下来我们选购几个具有代表性的方式进行探究。
2.2 addPassRequest
public void addPassRequest(int count) {
rollingCounterInSecond.addPass(count);
rollingCounterInMinute.addPass(count);
}
增加通过恳求数目。即将实时调用信息向滑动窗口中进行统计。addPassRequest 即报告成功的通过数目。就是分别调用 秒级、分钟即对应的滑动窗口中添加数目,然后限流规则、熔断规则将基于滑动窗口中的值进行估算。
2.3 totalRequest
public long totalRequest() {
return rollingCounterInMinute.pass() + rollingCounterInMinute.block();
}
获取当前时间戳的总恳求数,获取分钟级时间窗口中的统计信息。
2.4 successQps
public double successQps() {
return rollingCounterInSecond.success() / rollingCounterInSecond.getWindowIntervalInSec();
}
成功TPS,用秒级统计滑动窗口中统计的个数 除以 窗口的间隔得出其 tps,即抽样个数越大,其统计越精确。
温馨提示:上面的方式在学习了上文的滑动窗口设计原理后将变得十分简单,大家在学习的过程中,可以总结出一个规律,什么时候时侯使用秒级滑动窗口,什么时候使用分钟级滑动窗口。
2.5 metrics
由于 Sentienl 基于滑动窗口来实时搜集统计信息,并储存在显存中,并随着时间的推移,旧的滑动窗口将失效,故须要提供一个方式,及时将所有的统计信息进行汇总输出,供监控客户端定时拉取,转储都其他客户端,例如数据库,方便监控数据的可视化,这也一般是中间件用于监控指标的监控与采集的通用设计方式。
public Map metrics() {
long currentTime = TimeUtil.currentTimeMillis();
currentTime = currentTime - currentTime % 1000; // @1
Map metrics = new ConcurrentHashMap();
List nodesOfEverySecond = rollingCounterInMinute.details(); // @2
long newLastFetchTime = lastFetchTime;
// Iterate metrics of all resources, filter valid metrics (not-empty and up-to-date).
for (MetricNode node : nodesOfEverySecond) {
if (isNodeInTime(node, currentTime) && isValidMetricNode(node)) { // @3
metrics.put(node.getTimestamp(), node);
newLastFetchTime = Math.max(newLastFetchTime, node.getTimestamp());
}
}
lastFetchTime = newLastFetchTime;
return metrics;
}
代码@1:获取当前时间对应的滑动窗口的开始时间,可以对比上文估算滑动窗口的算法。
代码@2:获取一分钟内的所有滑动窗口中的统计数据,使用 MetricNode 表示。
代码@3:遍历所有节点,刷选出不是当前滑动窗口外的所有数据。这里的重点是方式:isNodeInTime。
<p>private boolean isNodeInTime(MetricNode node, long currentTime) {
return node.getTimestamp() > lastFetchTime && node.getTimestamp() 查看全部
源码剖析 Sentinel 实时数据采集实现原理
本篇将重点关注 Sentienl 实时数据搜集,即 Sentienl 具体是怎样搜集调用信息,以此来判定是否须要触发限流或熔断。
本节目录
Sentienl 实时数据搜集的入口类为 StatisticSlot。
我们先简单来看一下 StatisticSlot 该类的注释,来看一下该类的整体定位。
StatisticSlot,专用于实时统计的 slot。在步入一个资源时,在执行 Sentienl 的处理链条中会步入到该 slot 中,需要完成如下估算任务:
接下来用源码剖析的手段来详尽剖析 StatisticSlot 的实现原理。
1、源码剖析 StatisticSlot 1.1 StatisticSlot entry 详解
StatisticSlot#entry
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,boolean prioritized, Object... args) throws Throwable {
try {
// Do some checking.
fireEntry(context, resourceWrapper, node, count, prioritized, args); // @1
// Request passed, add thread count and pass count.
node.increaseThreadNum(); // @2
node.addPassRequest(count);
if (context.getCurEntry().getOriginNode() != null) { // @3
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) { // @4
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest(count);
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) { // @5
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (PriorityWaitException ex) { // @6
node.increaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
}
// Handle pass event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (BlockException e) { // @7
// Blocked, set block exception to current entry.
context.getCurEntry().setError(e);
// Add block count.
node.increaseBlockQps(count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseBlockQps(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseBlockQps(count);
}
// Handle block event with registered entry callback handlers.
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onBlocked(e, context, resourceWrapper, node, count, args);
}
throw e;
} catch (Throwable e) { // @8
// Unexpected error, set error to current entry.
context.getCurEntry().setError(e);
// This should not happen.
node.increaseExceptionQps(count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseExceptionQps(count);
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
Constants.ENTRY_NODE.increaseExceptionQps(count);
}
throw e;
}
}
代码@1:首先调用 fireEntry,先调用 Sentinel Slot Chain 中其他的处理器,执行完其他处理器的逻辑,例如 FlowSlot、DegradeSlot,因为 StatisticSlot 的职责是搜集统计信息。
代码@2:如果后续处理器成功执行,则将正在执行线程数统计指标加一,并将通过的恳求数目指标降低对应的值。下文会对 Sentinel Node 体系进行详尽的介绍,在 Sentinel 中使用 Node 来表示调用链中的某一个节点,每个节点关联一个资源,资源的实时统计信息就存贮在 Node 中,故该部份也是调用 DefaultNode 的相关技巧来改变线程数等,将在下文会向详尽介绍。
代码@3:如果上下文环境中保存了调用的源头(调用方)的节点信息不为空,则更新该节点的统计数据:线程数与通过数目。
代码@4:如果资源的步入类型为 EntryType.IN,表示入站流量,更新入站全局统计数据(集群范围 ClusterNode)。
代码@5:执行注册的步入Handler,可以通过 StatisticSlotCallbackRegistry 的 addEntryCallback 注册相关监听器。
代码@6:如果捕获到 PriorityWaitException ,则觉得是等待过一定时间,但最终还是算通过,只需降低线程的个数,但无需降低节点通过的数目,具体缘由我们在详尽剖析限流部份时会重点讨论,也会再度探讨 PriorityWaitException 的含意。
代码@7:如果捕获到 BlockException,则主要降低阻塞的数目。
代码@8:如果是系统异常,则降低异常数目。
我想里面的代码应当不难理解,但涉及到统计指标数据的变化,都是调用 DefaultNode node 相关的方式,从这儿也可以看出,Node 将是实时统计数据的直接持有者,那毋容置疑接下来将重点来学习 Node,为了知识体系的完备性,我们先来看一下 StatisticSlot 的 exit 方法。
1.2 StatisticSlot exit 详解
StatisticSlot#exit
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
DefaultNode node = (DefaultNode)context.getCurNode();
if (context.getCurEntry().getError() == null) { // @1
// Calculate response time (max RT is TIME_DROP_VALVE).
long rt = TimeUtil.currentTimeMillis() - context.getCurEntry().getCreateTime();
if (rt > Constants.TIME_DROP_VALVE) {
rt = Constants.TIME_DROP_VALVE;
}
// Record response time and success count.
node.addRtAndSuccess(rt, count);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().addRtAndSuccess(rt, count);
}
node.decreaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().decreaseThreadNum();
}
if (resourceWrapper.getEntryType() == EntryType.IN) {
Constants.ENTRY_NODE.addRtAndSuccess(rt, count);
Constants.ENTRY_NODE.decreaseThreadNum();
}
} else {
// Error may happen.
}
// Handle exit event with registered exit callback handlers.
Collection exitCallbacks = StatisticSlotCallbackRegistry.getExitCallbacks();
for (ProcessorSlotExitCallback handler : exitCallbacks) { // @2
handler.onExit(context, resourceWrapper, count, args);
}
fireExit(context, resourceWrapper, count); // @3
}
代码@1:成功执行,则重点关注响应时间,其实现亮点如下:
计算本次响应时间,将本次响应时间搜集到 Node 中。
将当前活跃线程数减一。
代码@2:执行退出时的 callback。可以通过 StatisticSlotCallbackRegistry 的 addExitCallback 方法添加退出回调函数。
代码@3:传播 exit 事件。
接下来我们将重点介绍 DefaultNode,即 Sentinel 的 Node 体系,持有资源的实时调用信息。
2、Sentienl Node 体系
2.1 Node 类体系图
我们先简单介绍一下上述核心类的作用与核心插口或核心属性的含意。
long waiting()
获取当前已申请的未来的令牌的个数。 void addWaitingRequest(long futureTime, int acquireCount)
申请未来时间窗口中的令牌。 void addOccupiedPass(int acquireCount)
增加申请未来令牌通过的个数。 double occupiedPassQps()
当前占据未来令牌的QPS。 Node
持有实时统计信息的节点。定义了搜集统计信息与获取统计信息的插口,上面方式依据技巧名称即可获知其涵义,故这儿就不一一列举了。 StatisticNode
实现统计信息的默认实现类。 DefaultNode
用于在特定上下文环境中保存某一个资源的实时统计信息。 ClusterNode
实现基于集群限流模式的节点,将在集群限流模式部份详尽介绍。 EntranceNode
用来表示调用链入口的节点信息。
本文将详尽介绍 DefaultNode 与 StatisticNode,重点论述调用树与实时统计信息。DefaultNode 是 StatisticNode 的泛型,我们先从 StatisticNode 开始 Node 体系的探究。
2、StatisticNode 详解 2.1 核心类图
我们对其核心属性进行一一详解:
关于 ArrayMetric 滑动窗口设计与实现原理,请参考笔者的另一篇博文:Alibaba Seninel 滑动窗口实现原理(文末附原理图)
接下来我们选购几个具有代表性的方式进行探究。
2.2 addPassRequest
public void addPassRequest(int count) {
rollingCounterInSecond.addPass(count);
rollingCounterInMinute.addPass(count);
}
增加通过恳求数目。即将实时调用信息向滑动窗口中进行统计。addPassRequest 即报告成功的通过数目。就是分别调用 秒级、分钟即对应的滑动窗口中添加数目,然后限流规则、熔断规则将基于滑动窗口中的值进行估算。
2.3 totalRequest
public long totalRequest() {
return rollingCounterInMinute.pass() + rollingCounterInMinute.block();
}
获取当前时间戳的总恳求数,获取分钟级时间窗口中的统计信息。
2.4 successQps
public double successQps() {
return rollingCounterInSecond.success() / rollingCounterInSecond.getWindowIntervalInSec();
}
成功TPS,用秒级统计滑动窗口中统计的个数 除以 窗口的间隔得出其 tps,即抽样个数越大,其统计越精确。
温馨提示:上面的方式在学习了上文的滑动窗口设计原理后将变得十分简单,大家在学习的过程中,可以总结出一个规律,什么时候时侯使用秒级滑动窗口,什么时候使用分钟级滑动窗口。
2.5 metrics
由于 Sentienl 基于滑动窗口来实时搜集统计信息,并储存在显存中,并随着时间的推移,旧的滑动窗口将失效,故须要提供一个方式,及时将所有的统计信息进行汇总输出,供监控客户端定时拉取,转储都其他客户端,例如数据库,方便监控数据的可视化,这也一般是中间件用于监控指标的监控与采集的通用设计方式。
public Map metrics() {
long currentTime = TimeUtil.currentTimeMillis();
currentTime = currentTime - currentTime % 1000; // @1
Map metrics = new ConcurrentHashMap();
List nodesOfEverySecond = rollingCounterInMinute.details(); // @2
long newLastFetchTime = lastFetchTime;
// Iterate metrics of all resources, filter valid metrics (not-empty and up-to-date).
for (MetricNode node : nodesOfEverySecond) {
if (isNodeInTime(node, currentTime) && isValidMetricNode(node)) { // @3
metrics.put(node.getTimestamp(), node);
newLastFetchTime = Math.max(newLastFetchTime, node.getTimestamp());
}
}
lastFetchTime = newLastFetchTime;
return metrics;
}
代码@1:获取当前时间对应的滑动窗口的开始时间,可以对比上文估算滑动窗口的算法。
代码@2:获取一分钟内的所有滑动窗口中的统计数据,使用 MetricNode 表示。
代码@3:遍历所有节点,刷选出不是当前滑动窗口外的所有数据。这里的重点是方式:isNodeInTime。
<p>private boolean isNodeInTime(MetricNode node, long currentTime) {
return node.getTimestamp() > lastFetchTime && node.getTimestamp()
文章采集调用 xposed商店市场
采集交流 • 优采云 发表了文章 • 0 个评论 • 401 次浏览 • 2020-08-26 13:22
3.2 采集方式
3.2.1 目前情况
目前陌陌采集主要有以下三种形式:
(一)通过微信PC版采集,在电脑正常登陆微信PC版后,通过模拟鼠标键盘操作的方式来进行采集。该方式硬件投入较大。
(二)通过微信网页版采集,直接调用程序扫码登录微信网页版,登录后,微信关注的微信公众号,有新的信息推送到微信时,程序会自动获取推送信息。该方式下微信连接容易中断,无法保证采集的稳定性。
(三)直接通过VirtualXposed监控微信。这种方式是程序直接装在手机上,自动拦截推送的信息。通过分析拦截的数据包,解析出有用的数据。该方式成本相对较低,且稳定性较好。
经过各方面比对,最终选定第三种形式,也就是直接通过VirtualXposed监控陌陌APP发出和接收的所有恳求数据包,对其进行解析,分析出符合要求的文章链接。
3.2.2 备用方案
由于使用VirtualXposed拦截陌陌推送信息的方法,会对陌陌客户端进行篡
改,腾讯有可能升级技术,导致VirtualXposed插件未能再使用。或者,腾讯能通过技术确切的检查手机是否安装了VirtualXposed插件,从而大量封号,导致采集无法稳定进行。目前了解到的可行的备用方案有以下几种形式:
(一)使用3.2.1中的第二种方式。该种方式需要微信号在2017年10月份以前注册,否则无法登陆网页版;
(二)使用AnyProxy抓包的方式。该种方式对技术要求较高,目前尚未进行详细的测试。
3.3 采集流程
微信采集整体流程如下图3-1所示:
图 3-1
其中主要分为三部份:
1) 公众号的收集与添加;
2) 文章URL获取与解析;
3) 正文分布式采集;
3.3.1 公众号搜集与添加
公众号搜集可以通过以下步骤进行处理:
1) 遍历ES中八友历史数据,解析文章正文中存在的公众号信息,并保存数据;
2) 根据项目关键词,通过搜狗微信公众号搜索,进行搜索解析并保存入库;
3) 特殊需求的公众号由各个项目自行提供;
微信公众号添加详见4.3节。
3.3.2 文章URL获取与解析
微信文章URL处理流程如下图3-2所示:
图 3-2
3.3.3 正文采集
文章正文处理流程如下图3-3所示:
图 3-3
3.4 数据储存
微信采集过程中的数据储存主要分为三块,一是微信号和公众号的储存;二是公众号文章列表的储存;三是文章正文信息的储存。各个模块的储存详见下列介绍。
3.4.1 微信号储存
3.4.2 公众号储存
3.4.3 文章URL储存
在每位陌陌关注的公众号推送文章后,通过手机中安装的VirtualXposed插件,获取接收到的数据包,然后把数据包+手机号,一同发送到Redis插口,接口对数据包进行解析,把文章URL数据储存到Redis集群中。
根据八友陌陌插口每日的数据量剖析,微信全量采集时须要处理的比较活跃的公众号在40~50万个,每天文章量在80~120万左右。为了易于管理,计划在Redis集群中,每天生成一个hash类型的缓存表,表名格式为:WeChat_yyyyMMdd,其中数据格式为key=URL,value=当前添加时间。如下图3-4所示
图 3-4
3.4.4 采集历史记录储存
微信文章通过分布式形式进行,每个采集脚本恳求Redis插口服务,获取一定量的文章URL,然后采集正文,推送到kafka中。同时,请求过的URL信息,Redis插口会把信息从WeChat_yyyyMMdd缓存中删掉,并保存到采集历史缓存中。hash类型的缓存表表名格式为:WeChat_History_yyyyMMdd,如下图3-2所示。其中key=URL,value=请求时的当前系统时间。如下图3-5所示
图 3-5
3.5 采集监控
整个采集流程中须要监控的节点主要为:XPosed插件;Redis插口服务接收和解析、入库;正文采集(源码获取、解析,kafka推送)。具体处理如下:
3.5.1 XPosed监控
主要分为两部份,一是XPosed插件自身的监控,防止长时间运行造成关机等;二是XPosed数据包发送。
XPosed插件:自身缺陷机长时间运行,导致的关机等现象,目前仍未找到好的处理方法,只能通过重启插件或手机;
XPosed数据包:数据包异常主要彰显在调用Redis集群插口服务时,需要在插口服务异常的情况下,把获取到的数据推送到数据库或讲到文件里,当插口服务正常时重新发送。
3.5.2 Redis插口服务监控
主要监控XPosed数据包解析和保存另两个步骤,在出现异常时把数据讲到本地文件,待正常时重新进行二次处理。
3.5.3 正文采集监控
正文采集监控点主要包括:已采集URL记录、正文源码下载、正文解析,以及信息推送kafka等四部份。
① 已采集URL记录在历史信息表中,保留一个月,用于对采集异常的追溯;
② 正文源码下载:记录请求状态码;
③ 正文解析:记录解析状态;0:成功;1:失败;
④ 信息推送:推送异常数据保存在本地文件,待服务正常时进行二次推送。如果一条信息推送三次均未成功,则表示推送失败,同时删除内容。
同时,需要监控服务器IP被封的情况;
3.5.4 新增公众号监控
目前有些网站有公众号的搜索功能,前期可以使用项目相关的关键词在这种网站上进行搜索,获取部份新注册的公众号。搜索平台如下表3-1:
搜狗微信公众号搜索 %E9%93%B6%E8%A1%8C&ie=utf8&s_from=input&sug=y&sug_type=
推信网微信公众号推荐 %e9%87%91%e8%9e%8d&t=weixin&p=16
聚陌陌
4 采集运维管理
微信公众号数据的采集运维工作,主要彰显在微信号的注册、养号、解封等工作上,至于陌陌文章的采集,基于现有的服务器,使用分布式可以较容易的进行处理。在微信号前期注册和养号期间,计划分配到数据管理中心各人员,作为一个KPI加分指标。由各人员在屋内或则上下班路上,进行微信号注册、养号(发朋友圈、点赞、聊天)等。
4.1 微信注册
由于微信号的监管逐渐加大,新注册的微信号被封的机率较大,所以微信号在注册时须要找寻一定的规则,具体注意事项如下:
① 注册请用官微,不要用那些多开软件注册
② 使用4G网络,千万不要用wifi,不要开GPS。同一个Wifi或GPS多个微信号注册,相当容易被封号的。
③ 每个手机必须提前存3-5个手机号进去,注册成功的时候,可以直接加上微信好友
④ 选择不同位置注册,可使用不同出行方式(公交、地铁、步行),每次注册的距离大于1.5km,每次注册间隔时间大于10分钟,最好分开时间段注册,尽量一批号不要是同一天,最好是分散到 3-5 天注册完成。
⑤ 注册时如果5分钟之内收不到验证码,先暂停该号码注册,不要频繁发送验证码
⑥ 随意关注几个公众号(搜索微信安全中心、京东、爱奇艺搞笑等公众账号)
⑦ 注册后一定先自己任意使用微信,之后注册其他号完成后也要使用一下之前注册的微信
⑧ 注册之后不能将手机关闭
⑨ 新微信号注册,密码不要一样。建议采用:相同字符+手机号的形式,也比较容易记。
⑩ 个人资料的地区一定不要填写,因为一点开就开始获取位置了,这个记录宁可不让微信知道。个人资料不要一次性全部填完,每天填一点,分批填写,可以增加活跃的权重。
⑪ 设置头像,注意,头像图片必须每张都不一样,如果一定需要设置同样的头像,请通过制图软件修改图片的大小,亮度等,另存成不同的图片,这样对于微信系统来说,可以绕过一定的检测。
⑫ 名字最好多个号都不一样 。
注意事项:
现在有专门卖微信号,买回去之后就可以使用,不过为了安全起见,还是建议登陆一周,期间发一些朋友圈,或加一些陌陌,每天随意聊几句,这样可以减少异常机率
4.3 公众号添加 查看全部
文章采集调用 xposed商店市场
3.2 采集方式
3.2.1 目前情况
目前陌陌采集主要有以下三种形式:
(一)通过微信PC版采集,在电脑正常登陆微信PC版后,通过模拟鼠标键盘操作的方式来进行采集。该方式硬件投入较大。
(二)通过微信网页版采集,直接调用程序扫码登录微信网页版,登录后,微信关注的微信公众号,有新的信息推送到微信时,程序会自动获取推送信息。该方式下微信连接容易中断,无法保证采集的稳定性。
(三)直接通过VirtualXposed监控微信。这种方式是程序直接装在手机上,自动拦截推送的信息。通过分析拦截的数据包,解析出有用的数据。该方式成本相对较低,且稳定性较好。
经过各方面比对,最终选定第三种形式,也就是直接通过VirtualXposed监控陌陌APP发出和接收的所有恳求数据包,对其进行解析,分析出符合要求的文章链接。
3.2.2 备用方案
由于使用VirtualXposed拦截陌陌推送信息的方法,会对陌陌客户端进行篡
改,腾讯有可能升级技术,导致VirtualXposed插件未能再使用。或者,腾讯能通过技术确切的检查手机是否安装了VirtualXposed插件,从而大量封号,导致采集无法稳定进行。目前了解到的可行的备用方案有以下几种形式:
(一)使用3.2.1中的第二种方式。该种方式需要微信号在2017年10月份以前注册,否则无法登陆网页版;
(二)使用AnyProxy抓包的方式。该种方式对技术要求较高,目前尚未进行详细的测试。
3.3 采集流程
微信采集整体流程如下图3-1所示:
图 3-1
其中主要分为三部份:
1) 公众号的收集与添加;
2) 文章URL获取与解析;
3) 正文分布式采集;
3.3.1 公众号搜集与添加
公众号搜集可以通过以下步骤进行处理:
1) 遍历ES中八友历史数据,解析文章正文中存在的公众号信息,并保存数据;
2) 根据项目关键词,通过搜狗微信公众号搜索,进行搜索解析并保存入库;
3) 特殊需求的公众号由各个项目自行提供;
微信公众号添加详见4.3节。
3.3.2 文章URL获取与解析
微信文章URL处理流程如下图3-2所示:
图 3-2
3.3.3 正文采集
文章正文处理流程如下图3-3所示:
图 3-3
3.4 数据储存
微信采集过程中的数据储存主要分为三块,一是微信号和公众号的储存;二是公众号文章列表的储存;三是文章正文信息的储存。各个模块的储存详见下列介绍。
3.4.1 微信号储存
3.4.2 公众号储存
3.4.3 文章URL储存
在每位陌陌关注的公众号推送文章后,通过手机中安装的VirtualXposed插件,获取接收到的数据包,然后把数据包+手机号,一同发送到Redis插口,接口对数据包进行解析,把文章URL数据储存到Redis集群中。
根据八友陌陌插口每日的数据量剖析,微信全量采集时须要处理的比较活跃的公众号在40~50万个,每天文章量在80~120万左右。为了易于管理,计划在Redis集群中,每天生成一个hash类型的缓存表,表名格式为:WeChat_yyyyMMdd,其中数据格式为key=URL,value=当前添加时间。如下图3-4所示
图 3-4
3.4.4 采集历史记录储存
微信文章通过分布式形式进行,每个采集脚本恳求Redis插口服务,获取一定量的文章URL,然后采集正文,推送到kafka中。同时,请求过的URL信息,Redis插口会把信息从WeChat_yyyyMMdd缓存中删掉,并保存到采集历史缓存中。hash类型的缓存表表名格式为:WeChat_History_yyyyMMdd,如下图3-2所示。其中key=URL,value=请求时的当前系统时间。如下图3-5所示
图 3-5
3.5 采集监控
整个采集流程中须要监控的节点主要为:XPosed插件;Redis插口服务接收和解析、入库;正文采集(源码获取、解析,kafka推送)。具体处理如下:
3.5.1 XPosed监控
主要分为两部份,一是XPosed插件自身的监控,防止长时间运行造成关机等;二是XPosed数据包发送。
XPosed插件:自身缺陷机长时间运行,导致的关机等现象,目前仍未找到好的处理方法,只能通过重启插件或手机;
XPosed数据包:数据包异常主要彰显在调用Redis集群插口服务时,需要在插口服务异常的情况下,把获取到的数据推送到数据库或讲到文件里,当插口服务正常时重新发送。
3.5.2 Redis插口服务监控
主要监控XPosed数据包解析和保存另两个步骤,在出现异常时把数据讲到本地文件,待正常时重新进行二次处理。
3.5.3 正文采集监控
正文采集监控点主要包括:已采集URL记录、正文源码下载、正文解析,以及信息推送kafka等四部份。
① 已采集URL记录在历史信息表中,保留一个月,用于对采集异常的追溯;
② 正文源码下载:记录请求状态码;
③ 正文解析:记录解析状态;0:成功;1:失败;
④ 信息推送:推送异常数据保存在本地文件,待服务正常时进行二次推送。如果一条信息推送三次均未成功,则表示推送失败,同时删除内容。
同时,需要监控服务器IP被封的情况;
3.5.4 新增公众号监控
目前有些网站有公众号的搜索功能,前期可以使用项目相关的关键词在这种网站上进行搜索,获取部份新注册的公众号。搜索平台如下表3-1:
搜狗微信公众号搜索 %E9%93%B6%E8%A1%8C&ie=utf8&s_from=input&sug=y&sug_type=
推信网微信公众号推荐 %e9%87%91%e8%9e%8d&t=weixin&p=16
聚陌陌
4 采集运维管理
微信公众号数据的采集运维工作,主要彰显在微信号的注册、养号、解封等工作上,至于陌陌文章的采集,基于现有的服务器,使用分布式可以较容易的进行处理。在微信号前期注册和养号期间,计划分配到数据管理中心各人员,作为一个KPI加分指标。由各人员在屋内或则上下班路上,进行微信号注册、养号(发朋友圈、点赞、聊天)等。
4.1 微信注册
由于微信号的监管逐渐加大,新注册的微信号被封的机率较大,所以微信号在注册时须要找寻一定的规则,具体注意事项如下:
① 注册请用官微,不要用那些多开软件注册
② 使用4G网络,千万不要用wifi,不要开GPS。同一个Wifi或GPS多个微信号注册,相当容易被封号的。
③ 每个手机必须提前存3-5个手机号进去,注册成功的时候,可以直接加上微信好友
④ 选择不同位置注册,可使用不同出行方式(公交、地铁、步行),每次注册的距离大于1.5km,每次注册间隔时间大于10分钟,最好分开时间段注册,尽量一批号不要是同一天,最好是分散到 3-5 天注册完成。
⑤ 注册时如果5分钟之内收不到验证码,先暂停该号码注册,不要频繁发送验证码
⑥ 随意关注几个公众号(搜索微信安全中心、京东、爱奇艺搞笑等公众账号)
⑦ 注册后一定先自己任意使用微信,之后注册其他号完成后也要使用一下之前注册的微信
⑧ 注册之后不能将手机关闭
⑨ 新微信号注册,密码不要一样。建议采用:相同字符+手机号的形式,也比较容易记。
⑩ 个人资料的地区一定不要填写,因为一点开就开始获取位置了,这个记录宁可不让微信知道。个人资料不要一次性全部填完,每天填一点,分批填写,可以增加活跃的权重。
⑪ 设置头像,注意,头像图片必须每张都不一样,如果一定需要设置同样的头像,请通过制图软件修改图片的大小,亮度等,另存成不同的图片,这样对于微信系统来说,可以绕过一定的检测。
⑫ 名字最好多个号都不一样 。
注意事项:
现在有专门卖微信号,买回去之后就可以使用,不过为了安全起见,还是建议登陆一周,期间发一些朋友圈,或加一些陌陌,每天随意聊几句,这样可以减少异常机率
4.3 公众号添加
采集站怎么操作?会不会被K?
采集交流 • 优采云 发表了文章 • 0 个评论 • 344 次浏览 • 2020-08-26 03:39
我身边有很多同学,大多数是seo新人和网路编辑,他们都觉得网站文章采集不但不会被收录,而且都会被k,至于排行愈发是不可能了,这是大部分人对于采集文章的想法,而对于原创内容,大部分编辑是这样觉得的,觉得原创了,百度等搜索引擎都会马上收录,就会有索引,就会给排行,但是事实上很多人来问我说,我网站的内容都是原创的为何百度不收录啊。关于这种问题,其实我想跟你们说得是:虽然百度鼓励你们给自己的站点更新原创内容,但是不代表原创内容百度还会收录,百度都会给你挺好的排行,对于百度而言,其实它更注重的是内容的作用,内容是否能解答用户的需求,是否有用,有趣,有共鸣或则差异化和权威性(特别是医疗站点)。
可能说得有点绕,有得同学有点晕,下面我跟你们解释下,如果同样权重的网站,那么内容更新快,内容更新稳定,内容更新量多,网站是比较垂直的,内容对知识点解答得愈发全面的,那这个站点的内容收录量,索引量和排行就会比较好。而一些比较敏感的行业,比如医疗类,百度对这种站点的处理一般会比较敏感,所以通常新站会比较难获得好的排行,大部分排行是权重比较高,网站年龄比较长的站点。
其实一个网站哪怕是所有的文章都是采集的,但是有进行差异化处理,相关内容调用推荐,只有站点不是没有优化的站点,一般还会有不错的收录和排行,这是我通过实践的,用了两个站点进行采集,一个站点是纯采集,内容不做任何更改;一个站点会进行差异化处理,结果有进行差异化处理的站点不只索引量高,排名也好,而没进行差异化处理的网站,虽然索引量也不错,但是排行就寥寥无几了。
采集站怎么操作
关于采集站内容的处理,其实无非就几点:分类、分词、标签、去重、更新稳定和规律、最后便是对内容是否被蜘蛛爬取过,是否有收录和索引进行针对性处理,等内容量和收录量足够多了,内容知识点比较建立了,接下来就是seo频道(聚合页面、百科页面)的处理,让网站爆发大量内链和大量页面,以及差异化和全面性的内容,获得更多的流量。具体操作请关注韩神叨叨公众号:byhanshin
微信公众号韩神叨叨(byhanshin)原创文章,转载请标明出处,谢谢。献给跟我一样为了梦想在异地他乡奋斗的你 查看全部
采集站怎么操作?会不会被K?
我身边有很多同学,大多数是seo新人和网路编辑,他们都觉得网站文章采集不但不会被收录,而且都会被k,至于排行愈发是不可能了,这是大部分人对于采集文章的想法,而对于原创内容,大部分编辑是这样觉得的,觉得原创了,百度等搜索引擎都会马上收录,就会有索引,就会给排行,但是事实上很多人来问我说,我网站的内容都是原创的为何百度不收录啊。关于这种问题,其实我想跟你们说得是:虽然百度鼓励你们给自己的站点更新原创内容,但是不代表原创内容百度还会收录,百度都会给你挺好的排行,对于百度而言,其实它更注重的是内容的作用,内容是否能解答用户的需求,是否有用,有趣,有共鸣或则差异化和权威性(特别是医疗站点)。
可能说得有点绕,有得同学有点晕,下面我跟你们解释下,如果同样权重的网站,那么内容更新快,内容更新稳定,内容更新量多,网站是比较垂直的,内容对知识点解答得愈发全面的,那这个站点的内容收录量,索引量和排行就会比较好。而一些比较敏感的行业,比如医疗类,百度对这种站点的处理一般会比较敏感,所以通常新站会比较难获得好的排行,大部分排行是权重比较高,网站年龄比较长的站点。
其实一个网站哪怕是所有的文章都是采集的,但是有进行差异化处理,相关内容调用推荐,只有站点不是没有优化的站点,一般还会有不错的收录和排行,这是我通过实践的,用了两个站点进行采集,一个站点是纯采集,内容不做任何更改;一个站点会进行差异化处理,结果有进行差异化处理的站点不只索引量高,排名也好,而没进行差异化处理的网站,虽然索引量也不错,但是排行就寥寥无几了。
采集站怎么操作
关于采集站内容的处理,其实无非就几点:分类、分词、标签、去重、更新稳定和规律、最后便是对内容是否被蜘蛛爬取过,是否有收录和索引进行针对性处理,等内容量和收录量足够多了,内容知识点比较建立了,接下来就是seo频道(聚合页面、百科页面)的处理,让网站爆发大量内链和大量页面,以及差异化和全面性的内容,获得更多的流量。具体操作请关注韩神叨叨公众号:byhanshin
微信公众号韩神叨叨(byhanshin)原创文章,转载请标明出处,谢谢。献给跟我一样为了梦想在异地他乡奋斗的你
Ajax——ajax调用数据总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2020-08-26 00:56
在做人事系统添加批量更改的功能中,需要将前台中的数据传给后台,后台并执行一系列的操作。通过查询和学习了解到可以通过ajax将值传入到后台,并在后台对数据进行操作。
说的简单点,就是ajax调用后台的技巧。通过学习和实践,学习了几种ajax调用数据的几种方式,现在总结一下:
1. Ajax调用无参的后台方式的数据
Jquery前台代码:
//ajax调用无参数后台方式$(function () {$("#btnok").click(function () {$.ajax({type:"post",//ajax的形式为post(get方法对传送数据宽度有限制)url: "demo.aspx/Hello",//demo.aspx为目标文件,Hello为目标文件中的方式contentType: "application/json",//传值形式success: function (data) {//成功回传值后触发的方式alert(data.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用的无参数方式[WebMethod]public static string Hello(){return "Hello Ajax!";}运行结果:
2. Ajax调用有参后台方式中的数据
Jquery前台代码:
//ajax调用有参数后台方式$(function () {$("#btnName").click(function () {var strname = $("#txtName").val(); //strname获得文本框中输入的值$.ajax({type: "post", //ajax的形式为post(get方法对传送数据宽度有限制)contentType: "application/json",//传值形式url: "demo.aspx/getName", //demo.aspx为目标文件,getName为目标文件中的方式data: "{strName:'" + strname + "'}", //strName为后台方式的参数,采集软件,strname为文本框中输入的值contentType: "application/json",//传值形式success: function (result) {//成功回传值后触发的方式alert(result.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用的带参数的方式[WebMethod]public static string getName(string strName){return "欢迎"+strName;}
运行结果:
3. Ajax调用后台方式返回链表的数据
Jquery前台代码:
//ajax调用后台方式返回链表$(function () {$("#btnReArr").click(function () {$.ajax({type: "post", //ajax的形式为post(get方法对传送数据宽度有限制)contentType: "application/json",//传值形式url: "demo.aspx/GetArray", //demo.aspx为目标文件,GetArray为目标文件中的方式contentType: "application/json",//传值形式success: function (result) {//成功回传值后触发的方式alert(result.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用返回链表的方式[WebMethod]public static List GetArray(){List li = new List();for (int i = 0; i
运行结果:
4. Ajax调用xml中的数据
Jquery前台代码:
//ajax调用xml中的数据$(function () {$("#btnMaXML").click(function () {$.ajax({dataType: 'xml', //ajax的形式为post(get方法对传送数据宽度有限制)url: "demoXML.xml", //直接写xml的名子success: function (xml) {//成功回传值后触发的方式//查找xml元素$(xml).find("data>item").each(function () {var $dm = $(this);var $id = $dm.find("id"); //获取出id数组的值var $class = $dm.find("class");//获取出class数组的值alert($id.text()+","+$class.text());})}})})});
前台表单控件:
xml代码:
1英语2物理
运行结果:
相关报导:
Photo Credit: stillframe 对开发者来说,要使使用者下载 app 相当不容易,但当使用者下载以后,打开 app 的第一时间会是哪些画面迎接使用者呢?一个接着一个的步骤指引?还是注册登录画面?上述二者可能就会丧失使用者继续操作的意愿与对产品的兴趣。事实上 更多
亲爱的网友,我这儿有套课程想和你们分享,如果对这个课程有兴趣的,可以加我的QQ2059055336和我联系。 课程背景 本课程是院长使用WPF、ADO.NET、MVVM技术来实现太平人寿保险有限公司保险顾客管理系统,是学习WPF开发中的一门主打课程之一。 WPF是一个框架, 更多 查看全部
Ajax——ajax调用数据总结
在做人事系统添加批量更改的功能中,需要将前台中的数据传给后台,后台并执行一系列的操作。通过查询和学习了解到可以通过ajax将值传入到后台,并在后台对数据进行操作。
说的简单点,就是ajax调用后台的技巧。通过学习和实践,学习了几种ajax调用数据的几种方式,现在总结一下:
1. Ajax调用无参的后台方式的数据
Jquery前台代码:
//ajax调用无参数后台方式$(function () {$("#btnok").click(function () {$.ajax({type:"post",//ajax的形式为post(get方法对传送数据宽度有限制)url: "demo.aspx/Hello",//demo.aspx为目标文件,Hello为目标文件中的方式contentType: "application/json",//传值形式success: function (data) {//成功回传值后触发的方式alert(data.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用的无参数方式[WebMethod]public static string Hello(){return "Hello Ajax!";}运行结果:
2. Ajax调用有参后台方式中的数据
Jquery前台代码:
//ajax调用有参数后台方式$(function () {$("#btnName").click(function () {var strname = $("#txtName").val(); //strname获得文本框中输入的值$.ajax({type: "post", //ajax的形式为post(get方法对传送数据宽度有限制)contentType: "application/json",//传值形式url: "demo.aspx/getName", //demo.aspx为目标文件,getName为目标文件中的方式data: "{strName:'" + strname + "'}", //strName为后台方式的参数,采集软件,strname为文本框中输入的值contentType: "application/json",//传值形式success: function (result) {//成功回传值后触发的方式alert(result.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用的带参数的方式[WebMethod]public static string getName(string strName){return "欢迎"+strName;}
运行结果:
3. Ajax调用后台方式返回链表的数据
Jquery前台代码:
//ajax调用后台方式返回链表$(function () {$("#btnReArr").click(function () {$.ajax({type: "post", //ajax的形式为post(get方法对传送数据宽度有限制)contentType: "application/json",//传值形式url: "demo.aspx/GetArray", //demo.aspx为目标文件,GetArray为目标文件中的方式contentType: "application/json",//传值形式success: function (result) {//成功回传值后触发的方式alert(result.d);//后台返回的参数}})})});
前台表单控件:
后台代码:
//ajax调用返回链表的方式[WebMethod]public static List GetArray(){List li = new List();for (int i = 0; i
运行结果:
4. Ajax调用xml中的数据
Jquery前台代码:
//ajax调用xml中的数据$(function () {$("#btnMaXML").click(function () {$.ajax({dataType: 'xml', //ajax的形式为post(get方法对传送数据宽度有限制)url: "demoXML.xml", //直接写xml的名子success: function (xml) {//成功回传值后触发的方式//查找xml元素$(xml).find("data>item").each(function () {var $dm = $(this);var $id = $dm.find("id"); //获取出id数组的值var $class = $dm.find("class");//获取出class数组的值alert($id.text()+","+$class.text());})}})})});
前台表单控件:
xml代码:
1英语2物理
运行结果:
相关报导:
Photo Credit: stillframe 对开发者来说,要使使用者下载 app 相当不容易,但当使用者下载以后,打开 app 的第一时间会是哪些画面迎接使用者呢?一个接着一个的步骤指引?还是注册登录画面?上述二者可能就会丧失使用者继续操作的意愿与对产品的兴趣。事实上 更多
亲爱的网友,我这儿有套课程想和你们分享,如果对这个课程有兴趣的,可以加我的QQ2059055336和我联系。 课程背景 本课程是院长使用WPF、ADO.NET、MVVM技术来实现太平人寿保险有限公司保险顾客管理系统,是学习WPF开发中的一门主打课程之一。 WPF是一个框架, 更多
如何大批量地获取新闻数据(比如把头条陌陌文章都给采集下来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 801 次浏览 • 2020-08-25 22:00
很多企业与事业单位都须要采集新闻资讯、政务公告等数据,用以发展自己的业务。业务不同,具体的采集需求也不尽相同。举几个简单的事例:
做融媒体的,他须要县市许多小道消息源第一时间汇总,以做更全面客观的报导。
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
我们服务过好多顾客,通过优采云大批量地获取数据新闻,从而做为她们自身业务的数据源或数据源的有力补充。这几年我们也帮助一些用户完成这块数据的获取,今天就来跟你们分享一下。这件事情有哪些难点,然后我们又是如何做的。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。
新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。
我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。 查看全部
如何大批量地获取新闻数据(比如把头条陌陌文章都给采集下来)
很多企业与事业单位都须要采集新闻资讯、政务公告等数据,用以发展自己的业务。业务不同,具体的采集需求也不尽相同。举几个简单的事例:
做融媒体的,他须要县市许多小道消息源第一时间汇总,以做更全面客观的报导。
做舆情监测的,需要将特定风波相关的全部新闻资讯全部采集下来,以预测风波发展态势、及时进行疏导与评估疏导疗效。
做内容分发的,需要将各个新闻资讯平台更新的数据实时采集下来,再通过个性化推荐系统将其分发给感兴趣的人。
做垂直内容聚合的,需要采集互联网上某特定领域、特定分类下的新闻资讯数据,再发布到自己的平台上。
做新政风向标研究的,需要海量第一时间搜集各地区各部门政务公告,包括类似证监会银监会等信息聚合。
这些采集需求都具有数据源诸多、数据体量大、实时性强的特性,统称为企业级新闻与政务公告资讯采集。
我们服务过好多顾客,通过优采云大批量地获取数据新闻,从而做为她们自身业务的数据源或数据源的有力补充。这几年我们也帮助一些用户完成这块数据的获取,今天就来跟你们分享一下。这件事情有哪些难点,然后我们又是如何做的。
一、3大难点
第一,数据源诸多,采集的目标网站成百上千。
新闻与政务公告数据源诸多,媒体门户网站(人民网/新华网/央视网等)、自媒体平台(今日头条/百家号/一点资讯等)、垂直新闻媒体网站(汽车之家/东方财富等)、各地各政务系统网站等百花齐放。客户的采集目标网站可能成百上千。我们做过最多一个顾客是超过3000个网站的采集。
如果针对每位网站去写爬虫脚本,需投入好多的技术资源、时间精力和服务器硬件成本,各种流程出来两三个月可能都未能上线。如要设计一套通用的爬虫系统,这个通用算法难度是十分大的(参考百度的搜索引擎爬虫),基本舍弃这个看法。
第二,新闻资讯时效性强,需实时采集。
我们都晓得新闻资讯时效性强,需要各个目标网站的数据一更新就立刻将其采集下来。要做到这点,需要2个能力:一个是定时采集,一个是高并发采集。
定时采集就是说定时手动地启动采集,它还得有一套合理的定时策略,不能一刀切。因为每位网站的更新频度是不一样的,如果一刀切定时过长(比如全部都每隔2小时启动一次),更新快的网站就会漏采数据;如果一刀切定时过短(比如全部都每隔1分钟启动1次),更新慢的网站数次启动都不会有新增数据,造成服务器资源浪费。
高并发就是说要多条线同时采集,才能在极短时间内完成多个网站更新数据的采集。比如50个网站同时更新数据,1台笔记本采和10台笔记本同时采,其他条件不变的情况下,肯定是10台同时采更快完成。
第三,采集结果需实时导入到企业数据库或内部系统。
新闻资讯数据时效性强,通常是即采即用的,要求提供高负载高吞吐的API接口,以实现采集结果秒级同步到企业的数据库或内部系统中。
二、优采云解决方案
以上采集难点,我们都帮助顾客一一解决了。一方面是因为优采云拥有行业领先的数据采集能力,一方面是因为顾客成功团队的服务意识和服务水平真的太棒。
一种文章采集的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2020-08-25 21:18
专利名称:一种文章采集的方式
技术领域:
本发明涉及一种针对各式各样的网站文章进行手动采集的技巧。
背景技术:
文章采集是按照用户定义的关键词字,从各式各样的网站上检索出相关的数据, 并对数据进行合理的截取、分类、去重和过滤,然后以文件或数据库的形式保存出来。文章采集应用的关键在于怎样从众多的网站获取所须要的确切内容到预期的中 心资源库中,然后进行快速的借助。文章采集的核心技术是模式定义和模式匹配。模式属 于人工智能的术语,是对前人积累的经验的具象和升华。简单地说,就是从不断重复出现的 事件中发觉和具象出的规律,是解决问题的经验的总结。只要是一再重复出现的事物,就可 能存在某种模式。文章采集的模式大多不是程序手动发觉的,目前几乎所有的文章采集产 品都须要通过人工来定义。但模式本身是个很复杂、很具象的内容,所以所有的开发者精力 都花在如何使模式定义更简单、更准确上,这也是文章采集技术竞争力的评判标准。目前大 多采用正则表达式定义和文档结构定义。传统的文章采集存在几个方面的问题1、采集的是每篇文章,需要手工进行页面 处理能够被借助;2、不能分栏目采集;3、只支持单一站点的采集;4、采集的文章不能手动 套用自己网站的格式进行发布,需要进行手工处理。
发明内容
本发明的目的在于提供一种文章采集的方式,支持网站群的多站点采集,可针对 文章进行分段采集和分栏目采集,采集的文章能手动套用自己网站的格式进行发布,不需 要进行手工处理。一种文章采集的方式,具体包括如下步骤先选取采集来源,采用正则表达式制订 采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点的栏目 进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集; 根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用 文章合并模板进行发布。所述的采用正则表达式制订采集规则,是指输入须要采集的静态页面地址,确定 地址中到第N个“/”为须要被采集的静态文件内容的地址,并将其手动转换成正则表达式 规则。所述的关键信息处理方法,指确定须要采集内容的文章标题或则关键信息的字符 串位置。本发明采用正则表达式定义的形式,根据用户自定义的任务配置,批量而精确地 抽取目标网路媒体栏目中的新闻或文章,转化为结构化的记录(标题,作者,内容,采集时 间,来源,分类,相关图片等),保存在本地数据库中,用于内部使用或内网发布,快速实现外 部信息的获取,对各种网站新闻的采集具有较快的速率和较高的准确率。本发明可在手动、手动两种模式下运行,自动由系统定期到指定的站点更新最新的信息,手动提供了及时触 发的机制;支持不同的信息采集使用不同的模式。本发明对传统的文章采集技术进行改进,真正满足了用户的应用需求1、可以针 对文章进行分段采集,只获取所须要的内容;2、每个栏目都可以订制相应的采集任务,文章 采集后手动储存在对应栏目下;3、采用多线程技术,支持网站群的多站点采集;4、结合模 板弓I擎技术,文章采集后可以手动套用网站模板进行手动发布。
图1为本发明的逻辑流程图。
图2为本发明施行例中采集内容的字符串位置示意图。以下结合附图和具体施行例对本发明作进一步阐述。
具体施行例形式如图1所示,本发明一种文章采集的方式,具体包括如下先选取采集来源,采用正则表达式制订采集规则,使用关键信息处理方法确定采 集内容的范围,将采集的内容和目标站点的栏目进行绑定。所述的采用正则表达式制订采集规则指输入须要采集的静态页面地址,该路径 指向待采集页面的某个栏目中的其中一篇文章,确定第N个“/”开始下的内容,自动转换成 正则表达式规则,符合表达式规则的静态文件内容将被采集。所述的关键信息处理方法指确定须要采集内容的文章标题或则关键信息的字符 串位置(如图2举例所示)。由于每位网站内容展示位置不一样,在配置采集时需先找到所 要采集内容的字符串位置,才能准确地采集到数据。所述的将采集的内容和目标站点的栏目进行绑定就是用户在采集配置中,用户 需选择所属栏目,或在创建栏目时,用户可选择指定的文章模板,开始采集时,通过栏目找 到指定的文章模板,在发布时合并生成静态页面。开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集; 根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用 文章合并模板进行发布。所述的文章合并模板指将动态的文章数据通过调用模板引擎生成静态的HTML 页面。以上所述,仅是本发明较佳施行例而已,并非对本发明的技术范围作任何限制,故 凡是根据本发明的技术实质对以上施行例所作的任何细微更改、等同变化与修饰,均仍属 于本发明技术方案的范围内。
权利要求
1.一种文章采集的方式,其特点在于包括如下步骤先选取采集来源,采用正则抒发 式制订采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点 的栏目进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站 点采集;根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发 布,则调用文章合并模板进行发布。
2.根据权力要求1所述的一种文章采集的方式,其特点在于所述的采用正则表达式 制定采集规则,是指输入须要采集的静态页面地址,确定地址中到第N个“/”为须要被采集 的静态文件内容的地址,并将其手动转换成正则表达式规则。
3.根据权力要求1所述的一种文章采集的方式,其特点在于所述的关键信息处理方 式,指确定须要采集内容的文章标题或则关键信息的字符串位置。
全文摘要
一种文章采集的方式,先选取采集来源,采用正则表达式制订采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点的栏目进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集;根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用文章合并模板进行发布;本发明按照用户自定义的任务配置,批量而精确地抽取目标网路媒体栏目中的新闻或文章,转化为结构化的记录保存或用于内部使用或内网发布,能快速实现外部信息的获取,对各种网站新闻的采集具有较快的速率和较高的准确率。
文档编号G06F17/30GK102096705SQ20101061842
公开日2011年6月15日 申请日期2010年12月31日 优先权日2010年12月31日
发明者曾文语, 林雅珊 申请人:南威软件股份有限公司 查看全部
一种文章采集的方式
专利名称:一种文章采集的方式
技术领域:
本发明涉及一种针对各式各样的网站文章进行手动采集的技巧。
背景技术:
文章采集是按照用户定义的关键词字,从各式各样的网站上检索出相关的数据, 并对数据进行合理的截取、分类、去重和过滤,然后以文件或数据库的形式保存出来。文章采集应用的关键在于怎样从众多的网站获取所须要的确切内容到预期的中 心资源库中,然后进行快速的借助。文章采集的核心技术是模式定义和模式匹配。模式属 于人工智能的术语,是对前人积累的经验的具象和升华。简单地说,就是从不断重复出现的 事件中发觉和具象出的规律,是解决问题的经验的总结。只要是一再重复出现的事物,就可 能存在某种模式。文章采集的模式大多不是程序手动发觉的,目前几乎所有的文章采集产 品都须要通过人工来定义。但模式本身是个很复杂、很具象的内容,所以所有的开发者精力 都花在如何使模式定义更简单、更准确上,这也是文章采集技术竞争力的评判标准。目前大 多采用正则表达式定义和文档结构定义。传统的文章采集存在几个方面的问题1、采集的是每篇文章,需要手工进行页面 处理能够被借助;2、不能分栏目采集;3、只支持单一站点的采集;4、采集的文章不能手动 套用自己网站的格式进行发布,需要进行手工处理。
发明内容
本发明的目的在于提供一种文章采集的方式,支持网站群的多站点采集,可针对 文章进行分段采集和分栏目采集,采集的文章能手动套用自己网站的格式进行发布,不需 要进行手工处理。一种文章采集的方式,具体包括如下步骤先选取采集来源,采用正则表达式制订 采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点的栏目 进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集; 根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用 文章合并模板进行发布。所述的采用正则表达式制订采集规则,是指输入须要采集的静态页面地址,确定 地址中到第N个“/”为须要被采集的静态文件内容的地址,并将其手动转换成正则表达式 规则。所述的关键信息处理方法,指确定须要采集内容的文章标题或则关键信息的字符 串位置。本发明采用正则表达式定义的形式,根据用户自定义的任务配置,批量而精确地 抽取目标网路媒体栏目中的新闻或文章,转化为结构化的记录(标题,作者,内容,采集时 间,来源,分类,相关图片等),保存在本地数据库中,用于内部使用或内网发布,快速实现外 部信息的获取,对各种网站新闻的采集具有较快的速率和较高的准确率。本发明可在手动、手动两种模式下运行,自动由系统定期到指定的站点更新最新的信息,手动提供了及时触 发的机制;支持不同的信息采集使用不同的模式。本发明对传统的文章采集技术进行改进,真正满足了用户的应用需求1、可以针 对文章进行分段采集,只获取所须要的内容;2、每个栏目都可以订制相应的采集任务,文章 采集后手动储存在对应栏目下;3、采用多线程技术,支持网站群的多站点采集;4、结合模 板弓I擎技术,文章采集后可以手动套用网站模板进行手动发布。
图1为本发明的逻辑流程图。
图2为本发明施行例中采集内容的字符串位置示意图。以下结合附图和具体施行例对本发明作进一步阐述。
具体施行例形式如图1所示,本发明一种文章采集的方式,具体包括如下先选取采集来源,采用正则表达式制订采集规则,使用关键信息处理方法确定采 集内容的范围,将采集的内容和目标站点的栏目进行绑定。所述的采用正则表达式制订采集规则指输入须要采集的静态页面地址,该路径 指向待采集页面的某个栏目中的其中一篇文章,确定第N个“/”开始下的内容,自动转换成 正则表达式规则,符合表达式规则的静态文件内容将被采集。所述的关键信息处理方法指确定须要采集内容的文章标题或则关键信息的字符 串位置(如图2举例所示)。由于每位网站内容展示位置不一样,在配置采集时需先找到所 要采集内容的字符串位置,才能准确地采集到数据。所述的将采集的内容和目标站点的栏目进行绑定就是用户在采集配置中,用户 需选择所属栏目,或在创建栏目时,用户可选择指定的文章模板,开始采集时,通过栏目找 到指定的文章模板,在发布时合并生成静态页面。开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集; 根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用 文章合并模板进行发布。所述的文章合并模板指将动态的文章数据通过调用模板引擎生成静态的HTML 页面。以上所述,仅是本发明较佳施行例而已,并非对本发明的技术范围作任何限制,故 凡是根据本发明的技术实质对以上施行例所作的任何细微更改、等同变化与修饰,均仍属 于本发明技术方案的范围内。
权利要求
1.一种文章采集的方式,其特点在于包括如下步骤先选取采集来源,采用正则抒发 式制订采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点 的栏目进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站 点采集;根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发 布,则调用文章合并模板进行发布。
2.根据权力要求1所述的一种文章采集的方式,其特点在于所述的采用正则表达式 制定采集规则,是指输入须要采集的静态页面地址,确定地址中到第N个“/”为须要被采集 的静态文件内容的地址,并将其手动转换成正则表达式规则。
3.根据权力要求1所述的一种文章采集的方式,其特点在于所述的关键信息处理方 式,指确定须要采集内容的文章标题或则关键信息的字符串位置。
全文摘要
一种文章采集的方式,先选取采集来源,采用正则表达式制订采集规则,使用关键信息处理方法确定采集内容的范围,将采集的内容和目标站点的栏目进行绑定;开始采集文章时,先搜索采集来源,采用多线程技术,进行网站群的多站点采集;根据设定的采集规则,把采集到的内容储存在各自对应的栏目下;若须要手动发布,则调用文章合并模板进行发布;本发明按照用户自定义的任务配置,批量而精确地抽取目标网路媒体栏目中的新闻或文章,转化为结构化的记录保存或用于内部使用或内网发布,能快速实现外部信息的获取,对各种网站新闻的采集具有较快的速率和较高的准确率。
文档编号G06F17/30GK102096705SQ20101061842
公开日2011年6月15日 申请日期2010年12月31日 优先权日2010年12月31日
发明者曾文语, 林雅珊 申请人:南威软件股份有限公司
LabVIEW对数据采集卡DLL函数的调用
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-08-25 09:29
襄樊学院学报Sept。,2004 第25 XiangfanUniversity Vol。25 No。5 LabVIEW对数据采集卡DLL 函数的调用 摘要:首先介绍虚拟仪器及其开发环境LabVIEW6的特性,分析并实现了将LabVIEW与外部代码进行联接的中级技术之一—动态链接库(DLL)机制.实践表明,此机制高效、易行,是提高 LabVIEW与其它Windows应用程序之间的数据共享能力的一条挺好的途径. 关键词:虚拟仪器;LabVIEW;动态链接库;DLL 中图分类号:TN311。11文献标志码:A文章编号:1009-2854(2004)05-0015-03 0序言 美国国家仪器NI 公司的基于G 语言的开发环境LabVIEW的出现,使得虚拟仪器的思想为工业界所接 所谓虚拟仪器,就是在通用计算机平台上,用户按照自己的需求定义和设计仪器的测试功能,其实质是将传统仪器硬件和最新计算机软件技术充分结合上去,以模块化软件实现并扩充传统仪器的功能。 统仪器相比,虚拟仪器在智能化程度、处理能力、性能价格比、可操作性等方面均具有显著的技术优势。LabVIEW(Laboratory Virtual Instrument Engineering Workbench实验室虚拟仪器工程平台)是目前国 际上首推应用最广的虚拟仪器开发环境之一,主要应用于仪器控制、数据采集、数据剖析、数据显示等领 域,并适用于Windows 9X/XP/2000/ NT、Macintosh、UNIX 等多种不同的操作系统平台。
与传统程序语言 不同,LabVIEW采用强悍的图形化语言(G 语言)编程,面向测试工程师而非专业程序员,编程十分便捷, 人机交互界面直观友好,具有强悍的数据可视化剖析和仪器控制能力等特性。 使用LabVIEW开发环境,用户可以创建32 位的编译程序,从而为常规的数据采集、测试、测量等任 务提供了更快的运行速率。 LabVIEW是真正的编译器,用户可以创建独立的可执行文件,能够脱离开发环 境而单独运行。 对于大多编程任务,LabVIEW一般能形成高效的代码。 1LabVIEW调用外部程序代码的途径之一——动态链接库机制 1.1动态链接库机制概述 LabVIEW是一个功能强悍的虚拟仪器开发环境,它完整地集成了与GPIB、VXI、RS-232、RS-485 内插式数据采集卡等硬件的通信。LabVIEW还具有外置程序库,提供了大量的联接机制,通过DLLs、共享 库、ActiveX 等途径实现与外部程序代码或软件系统的联接。 LabVIEW提供了4 种调用外部程序代码的途径,其中动态链接库(Dynamic Link LibraryDLL)机制 是从LabVIEW调用标准共享库和用户自定义库函数的通用方式。
具体实现时,是使用LabVIEW功能模板 中“Advanced”子模板里的“调用库函数(Call Library Function)”结点。 “调用库函数结点”包括大量的数据类型和调用规范,使用它可调用大多数标准共享库和用户自定义 库中的函数,包括:Windows9X/XP/2000/NT 下的动态链接库(Dynamic Link Library)、Macintosh 下的代码段(Code Fragment)、UNIX 下的共享库函数(Shared Library Function)等。 当用户须要调用的代码已然存在,或者用户比较熟悉 Windows 中动态链接库、Macintosh 中代码段、 UNIX 中共享库的创建过程时,“调用库函数结点”非常有用,此时使用它也最为合适恰当,因为库使用了 收稿日期:2004-04-21 基金项目:湖北省教育厅重点项目(2003A006) 作者简介:刘传清(1964- )男,湖北钟祥人,襄樊学院物理学系副教授。 15 刘传清:LabVIEW对数据采集卡DLL函数的调用 16 对几个开发环境都适用的格式标准,故用户可以使用几乎任何开发环境去创建LabVIEW才能调用的库。
1.2动态链接库机制实现步骤 在Windows 9X 下,利用LabVIEW 6。1 Windows95/98/NT)中的“动态链接库机制”调用一个DLL, 此DLL 返回机器的名称。 1)建立“调用库函数结点” 新建LabVIEW程序“hostname。vi”,存至新建目录“d:\temp”下,其前面板如下: 图1库函数调用前面板视口图程序如下: 图2库函数调用程序框图其中,“Call Library Function”结点是通过选择功能模板中“Advanced”子模板里的 “Call Library Function”功能模块而形成的。 此LabVIEW程序通过“调用库函数结点”调用一个DLL,此DLL 将返回机器的名称,返回结果存至 字符串指示量“Machine Name”中,而后将字符串常量“LabVIEW ”与“MachineName”相 拼接,拼接之结果在字符串指示量“Message”中显示。 2)配置“调用库函数结点” 双击框图程序窗口的“Call Library Function”结点,在弹出的对话框中对此“调用库函数结点”进行配 其中:在“Library Name Path”一项中键入“d:\temp\hostname。
dll”(即,指明此结点所链接的DLL文件名, 源代码“hostname。c”编译而至);在“Function Name”一项中键入“MachineName”(即,指明与此结点相链接的DLL 文件中的函数的 名称); 参数“return type”的类型选择“Void”;所降低的另一个参数“arg1”的类型选择“String”、字符串 格式选择“String Handle”; 3)编辑C 源文件 编辑C 源文件“hostname。c”(存至目录“d:\temp”下),其内容如下: includeextcode。h which contains LabVIEWfunctions #include #include #include BOOL WINAPI DllMain (HANDLE hDLL, DWORD dwReason, LPVOID lpReserved) returnTRUE; functionsgets computername __declspec(dllexport) void MachineName(void *LVHandle) charcomputerName[MAX_COMPUTERNAME_LENGTH+1]; int compNameLength MAX_COMPUTERNAME_LENGTH+1;第25 襄樊学院学报2004 Getcomputer name GetComputerName(computerName,&compNameLength); SizeLabVIEW handle correctsize DSSetHandleSize(LVHandle,compNameLength stringsize LabVIEWhandle **(int32**)LVHandle LabVIEWhandle sprintf((*(char**)LVHandle)+4,"%s",computerName); 此程序首先了调用Windows的API 函数“GetComputerName”获取机器名;然后调用LabVIEW的函 数“DSSetHandleSize”来设置 LabVIEW 句柄之大小;最后将机器名宽度(32 位整型)、机器名(字符串 型)依次写入句柄中。
4)编译C 源代码 源代码“d:\temp\hostname。c”编译成一个DLL 文件“d:\temp\hostname。dll”。 可使用VC++ 6。0 Windows95/98/2000/NT),完成此编译工作。 5)运行VI 运行LabVIEW程序“hostname。vi”,结果如下: 图3前面板运行结果 2结束语 本文注重阐明并实现了将LabVIEW与外部代码进行联接的中级技术之一动态链接库机制,并给出了 应用实例。 由于在LabVIEW中引入了C 语言的强悍功能,从而提升了LabVIEW的整体性能。 本方式已在LabVIEW 6。1 Windows95/98/NT 及Visual Windows9X/XP/2000/NT 环境下 实现。 实践证明,此方式高效、易行,是提高 LabVIEW 与其它Windows 应用程序之间的数据共享能力的 一条挺好的途径。 参考文献: LabVIEWUser Manual,National Instruments Corporation,1998。 ProgrammingReference Manual,National Instruments Corporation,1998。
LabVIEW Data Acquisition Invoke DLLFunctions LIU Chuan-qing (Department Physics,Xiangfan University, Xiangfan 441053, China) Abstract paperintroduces virtual instrument itsdevelopment environmentLabVIEW, analyzes advancedtechnology-Dynamic Link Library(DLL) ,which generalmethods callingexternal code from LabVIEW。 hasbeen proved goodone enhanceLabVIEW’ sharingdata otherapplications Windows。Key words:Virtual instrument; LabVIEW; Dynamic Link Library 查看全部
LabVIEW对数据采集卡DLL函数的调用
襄樊学院学报Sept。,2004 第25 XiangfanUniversity Vol。25 No。5 LabVIEW对数据采集卡DLL 函数的调用 摘要:首先介绍虚拟仪器及其开发环境LabVIEW6的特性,分析并实现了将LabVIEW与外部代码进行联接的中级技术之一—动态链接库(DLL)机制.实践表明,此机制高效、易行,是提高 LabVIEW与其它Windows应用程序之间的数据共享能力的一条挺好的途径. 关键词:虚拟仪器;LabVIEW;动态链接库;DLL 中图分类号:TN311。11文献标志码:A文章编号:1009-2854(2004)05-0015-03 0序言 美国国家仪器NI 公司的基于G 语言的开发环境LabVIEW的出现,使得虚拟仪器的思想为工业界所接 所谓虚拟仪器,就是在通用计算机平台上,用户按照自己的需求定义和设计仪器的测试功能,其实质是将传统仪器硬件和最新计算机软件技术充分结合上去,以模块化软件实现并扩充传统仪器的功能。 统仪器相比,虚拟仪器在智能化程度、处理能力、性能价格比、可操作性等方面均具有显著的技术优势。LabVIEW(Laboratory Virtual Instrument Engineering Workbench实验室虚拟仪器工程平台)是目前国 际上首推应用最广的虚拟仪器开发环境之一,主要应用于仪器控制、数据采集、数据剖析、数据显示等领 域,并适用于Windows 9X/XP/2000/ NT、Macintosh、UNIX 等多种不同的操作系统平台。
与传统程序语言 不同,LabVIEW采用强悍的图形化语言(G 语言)编程,面向测试工程师而非专业程序员,编程十分便捷, 人机交互界面直观友好,具有强悍的数据可视化剖析和仪器控制能力等特性。 使用LabVIEW开发环境,用户可以创建32 位的编译程序,从而为常规的数据采集、测试、测量等任 务提供了更快的运行速率。 LabVIEW是真正的编译器,用户可以创建独立的可执行文件,能够脱离开发环 境而单独运行。 对于大多编程任务,LabVIEW一般能形成高效的代码。 1LabVIEW调用外部程序代码的途径之一——动态链接库机制 1.1动态链接库机制概述 LabVIEW是一个功能强悍的虚拟仪器开发环境,它完整地集成了与GPIB、VXI、RS-232、RS-485 内插式数据采集卡等硬件的通信。LabVIEW还具有外置程序库,提供了大量的联接机制,通过DLLs、共享 库、ActiveX 等途径实现与外部程序代码或软件系统的联接。 LabVIEW提供了4 种调用外部程序代码的途径,其中动态链接库(Dynamic Link LibraryDLL)机制 是从LabVIEW调用标准共享库和用户自定义库函数的通用方式。
具体实现时,是使用LabVIEW功能模板 中“Advanced”子模板里的“调用库函数(Call Library Function)”结点。 “调用库函数结点”包括大量的数据类型和调用规范,使用它可调用大多数标准共享库和用户自定义 库中的函数,包括:Windows9X/XP/2000/NT 下的动态链接库(Dynamic Link Library)、Macintosh 下的代码段(Code Fragment)、UNIX 下的共享库函数(Shared Library Function)等。 当用户须要调用的代码已然存在,或者用户比较熟悉 Windows 中动态链接库、Macintosh 中代码段、 UNIX 中共享库的创建过程时,“调用库函数结点”非常有用,此时使用它也最为合适恰当,因为库使用了 收稿日期:2004-04-21 基金项目:湖北省教育厅重点项目(2003A006) 作者简介:刘传清(1964- )男,湖北钟祥人,襄樊学院物理学系副教授。 15 刘传清:LabVIEW对数据采集卡DLL函数的调用 16 对几个开发环境都适用的格式标准,故用户可以使用几乎任何开发环境去创建LabVIEW才能调用的库。
1.2动态链接库机制实现步骤 在Windows 9X 下,利用LabVIEW 6。1 Windows95/98/NT)中的“动态链接库机制”调用一个DLL, 此DLL 返回机器的名称。 1)建立“调用库函数结点” 新建LabVIEW程序“hostname。vi”,存至新建目录“d:\temp”下,其前面板如下: 图1库函数调用前面板视口图程序如下: 图2库函数调用程序框图其中,“Call Library Function”结点是通过选择功能模板中“Advanced”子模板里的 “Call Library Function”功能模块而形成的。 此LabVIEW程序通过“调用库函数结点”调用一个DLL,此DLL 将返回机器的名称,返回结果存至 字符串指示量“Machine Name”中,而后将字符串常量“LabVIEW ”与“MachineName”相 拼接,拼接之结果在字符串指示量“Message”中显示。 2)配置“调用库函数结点” 双击框图程序窗口的“Call Library Function”结点,在弹出的对话框中对此“调用库函数结点”进行配 其中:在“Library Name Path”一项中键入“d:\temp\hostname。
dll”(即,指明此结点所链接的DLL文件名, 源代码“hostname。c”编译而至);在“Function Name”一项中键入“MachineName”(即,指明与此结点相链接的DLL 文件中的函数的 名称); 参数“return type”的类型选择“Void”;所降低的另一个参数“arg1”的类型选择“String”、字符串 格式选择“String Handle”; 3)编辑C 源文件 编辑C 源文件“hostname。c”(存至目录“d:\temp”下),其内容如下: includeextcode。h which contains LabVIEWfunctions #include #include #include BOOL WINAPI DllMain (HANDLE hDLL, DWORD dwReason, LPVOID lpReserved) returnTRUE; functionsgets computername __declspec(dllexport) void MachineName(void *LVHandle) charcomputerName[MAX_COMPUTERNAME_LENGTH+1]; int compNameLength MAX_COMPUTERNAME_LENGTH+1;第25 襄樊学院学报2004 Getcomputer name GetComputerName(computerName,&compNameLength); SizeLabVIEW handle correctsize DSSetHandleSize(LVHandle,compNameLength stringsize LabVIEWhandle **(int32**)LVHandle LabVIEWhandle sprintf((*(char**)LVHandle)+4,"%s",computerName); 此程序首先了调用Windows的API 函数“GetComputerName”获取机器名;然后调用LabVIEW的函 数“DSSetHandleSize”来设置 LabVIEW 句柄之大小;最后将机器名宽度(32 位整型)、机器名(字符串 型)依次写入句柄中。
4)编译C 源代码 源代码“d:\temp\hostname。c”编译成一个DLL 文件“d:\temp\hostname。dll”。 可使用VC++ 6。0 Windows95/98/2000/NT),完成此编译工作。 5)运行VI 运行LabVIEW程序“hostname。vi”,结果如下: 图3前面板运行结果 2结束语 本文注重阐明并实现了将LabVIEW与外部代码进行联接的中级技术之一动态链接库机制,并给出了 应用实例。 由于在LabVIEW中引入了C 语言的强悍功能,从而提升了LabVIEW的整体性能。 本方式已在LabVIEW 6。1 Windows95/98/NT 及Visual Windows9X/XP/2000/NT 环境下 实现。 实践证明,此方式高效、易行,是提高 LabVIEW 与其它Windows 应用程序之间的数据共享能力的 一条挺好的途径。 参考文献: LabVIEWUser Manual,National Instruments Corporation,1998。 ProgrammingReference Manual,National Instruments Corporation,1998。
LabVIEW Data Acquisition Invoke DLLFunctions LIU Chuan-qing (Department Physics,Xiangfan University, Xiangfan 441053, China) Abstract paperintroduces virtual instrument itsdevelopment environmentLabVIEW, analyzes advancedtechnology-Dynamic Link Library(DLL) ,which generalmethods callingexternal code from LabVIEW。 hasbeen proved goodone enhanceLabVIEW’ sharingdata otherapplications Windows。Key words:Virtual instrument; LabVIEW; Dynamic Link Library
【采集】如何提升网站访问速率的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-08-24 22:01
3. 如果友情链接一定要出现在首页,请将链接所在的整个Table放在页面的最下方,因为页面是由上到下逐行显示的,将其放在页面的最下方,不会延后其他内容的显示。
4. 友情链接的LOGO图片先下载后再传到自己的网页空间,这样,速度由自己的网站空间决定而不受友情网站的影响。
-----------------------------------------------------------------------------------------------------------
转载本文请知名出处:Just Do IT ()
一个大型的网站,比如个人网站,可以使用最简单的html静态页面就实现了,配合一些图片达到美化疗效,所有的页面均储存在一个目录下,这样的网站对系统构架、性能的要求都很简单,随着互联网业务的不断丰富,网站相关的技术经过这些年的发展,已经细分到太细的方方面面,尤其对于小型网站来说,所采用的技术更是涉及面十分广,从硬件到软件、编程语言、数据库、WebServer、防火墙等各个领域都有了很高的要求,已经不是原先简单的html静态网站所能比拟的。
大型网站,比如门户网站。在面对大量用户访问、高并发恳求方面,基本的解决方案集中在这样几个环节:使用高性能的服务器、高性能的数据库、高效率的编程语言、还有高性能的Web容器。但是不仅这几个方面,还无法根本解决小型网站面临的高负载和高并发问题。
上面提供的几个解决思路在一定程度上也意味着更大的投入,并且这样的解决思路具备困局,没有挺好的扩展性,下面我从低成本、高性能和高扩张性的角度来说说我的一些经验。
1、HTML静态化
其实你们都晓得,效率最高、消耗最小的就是纯静态化的html页面,所以我们尽可能让我们的网站上的页面采用静态页面来实现,这个最简单的方式虽然也是最有效的方式。但是对于大量内容而且频繁更新的网站,我们难以全部自动去逐个实现,于是出现了我们常见的信息发布系统CMS,像我们常访问的各个门户站点的新闻频道,甚至她们的其他频道,都是通过信息发布系统来管理和实现的,信息发布系统可以实现最简单的信息录入手动生成静态页面,还能具备频道管理、权限管理、自动抓取等功能,对于一个小型网站来说,拥有一套高效、可管理的CMS是必不可少的。
除了门户和信息发布类型的网站,对于交互性要求很高的社区类型网站来说,尽可能的静态化也是提升性能的必要手段,将社区内的贴子、文章进行实时的静态化,有更新的时侯再重新静态化也是大量使用的策略,像Mop的大杂烩就是使用了这样的策略,网易社区等也是这么。
同时,html静态化也是个别缓存策略使用的手段,对于系统中频繁使用数据库查询并且内容更新太小的应用,可以考虑使用html静态化来实现,比如峰会中峰会的公用设置信息,这些信息目前的主流峰会都可以进行后台管理而且储存再数据库中,这些信息虽然大量被前台程序调用,但是更新频度太小,可以考虑将这部份内容进行后台更新的时侯进行静态化,这样避开了大量的数据库访问恳求。
2、图片服务器分离
大家晓得,对于Web服务器来说,不管是Apache、IIS还是其他容器,图片是最消耗资源的,于是我们有必要将图片与页面进行分离,这是基本上小型网站都会采用的策略,他们都有独立的图片服务器,甚至好多台图片服务器。这样的构架可以减少提供页面访问恳求的服务器系统压力,并且可以保证系统不会由于图片问题而崩溃,在应用服务器和图片服务器上,可以进行不同的配置优化,比如apache在配置ContentType的时侯可以尽量少支持,尽可能少的LoadModule,保证更高的系统消耗和执行效率。
3、数据库集群和库表散列
大型网站都有复杂的应用,这些应用必须使用数据库,那么在面对大量访问的时侯,数据库的困局很快能够凸显下来,这时一台数据库将很快未能满足应用,于是我们须要使用数据库集群或则库表散列。
在数据库集群方面,很多数据库都有自己的解决方案,Oracle、Sybase等都有挺好的方案,常用的MySQL提供的Master/Slave也是类似的方案,您使用了什么样的DB,就参考相应的解决方案来施行即可。
上面提及的数据库集群因为在构架、成本、扩张性方面就会遭到所采用DB类型的限制,于是我们须要从应用程序的角度来考虑改善系统构架,库表散列是常用而且最有效的解决方案。我们在应用程序中安装业务和应用或则功能模块将数据库进行分离,不同的模块对应不同的数据库或则表,再根据一定的策略对某个页面或则功能进行更小的数据库散列,比如用户表,按照用户ID进行表散列,这样才能够低成本的提高系统的性能但是有挺好的扩展性。sohu的峰会就是采用了这样的构架,将峰会的用户、设置、帖子等信息进行数据库分离,然后对贴子、用户根据蓝筹股和ID进行散列数据库和表,最终可以在配置文件中进行简单的配置便能使系统随时降低一台低成本的数据库进来补充系统性能。
4、缓存
缓存一词搞技术的都接触过,很多地方用到缓存。网站架构和网站开发中的缓存也是十分重要。这里先述说最基本的两种缓存。高级和分布式的缓存在前面述说。
架构方面的缓存,对Apache比较熟悉的人都能晓得Apache提供了自己的缓存模块,也可以使用外加的Squid模块进行缓存,这两种方法均可以有效的增强Apache的访问响应能力。
网站程序开发方面的缓存,Linux上提供的Memory Cache是常用的缓存插口,可以在web开发中使用,比如用Java开发的时侯就可以调用MemoryCache对一些数据进行缓存和通信共享,一些小型社区使用了这样的构架。另外,在使用web语言开发的时侯,各种语言基本都有自己的缓存模块和技巧,PHP有Pear的Cache模块,Java就更多了,.net不是太熟悉,相信也肯定有。
5、镜像
镜像是小型网站常采用的增强性能和数据安全性的方法,镜像的技术可以解决不同网路接入商和地域带来的用户访问速率差别,比如ChinaNet和EduNet之间的差别就使得了好多网站在教育网内搭建镜像站点,数据进行定时更新或则实时更新。在镜像的细节技术方面,这里不探讨很深,有很多专业的现成的解决构架和产品可选。也有廉价的通过软件实现的思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是小型网站解决高负荷访问和大量并发恳求采用的终极解决办法。
负载均衡技术发展了多年,有很多专业的服务提供商和产品可以选择,我个人接触过一些解决方式,其中有两个构架可以给你们做参考。
硬件四层交换
第四层交换使用第三层和第四层信息包的报头信息,根据应用区间辨识业务流,将整个区间段的业务流分配到合适的应用服务器进行处理。第四层交换功能如同是虚IP,指向化学服务器。它传输的业务服从的合同多种多样,有HTTP、FTP、NFS、Telnet或其他合同。这些业务在数学服务器基础上,需要复杂的载量平衡算法。在IP世界,业务类型由终端TCP或UDP端口地址来决定,在第四层交换中的应用区间则由源端和终端IP地址、TCP和UDP端口共同决定。
在硬件四层交换产品领域,有一些著名的产品可以选择,比如Alteon、F5等,这些产品太高昂,但是物有所值,能够提供特别优秀的性能和太灵活的管理能力。Yahoo中国曾经接近2000台服务器使用了三四台Alteon就搞定了。
软件四层交换
大家晓得了硬件四层交换机的原理后,基于OSI模型来实现的软件四层交换也就应运而生,这样的解决方案实现的原理一致,不过性能稍差。但是满足一定量的压力还是游刃有余的,有人说软件实现方法虽然更灵活,处理能力完全看你配置的熟悉能力。
软件四层交换我们可以使用Linux上常用的LVS来解决,LVS就是Linux Virtual Server,他提供了基于心跳线heartbeat的实时灾难应对解决方案,提高系统的鲁棒性,同时可供了灵活的虚拟VIP配置和管理功能,可以同时满足多种应用需求,这对于分布式的系统来说必不可少。
一个典型的使用负载均衡的策略就是,在软件或则硬件四层交换的基础上搭建squid集群,这种思路在好多小型网站包括搜索引擎上被采用,这样的构架低成本、高性能还有太强的扩张性,随时往构架上面增减节点都十分容易。这样的构架我打算空了专门详尽整理一下和你们剖析。
对于小型网站来说,前面提及的每位方式可能就会被同时使用到,我这儿介绍得比较晦涩,具体实现过程中好多细节还须要你们渐渐熟悉和感受,有时一个太小的squid参数或则apache参数设置,对于系统性能的影响都会很大,希望你们一起讨论,达到抛砖引玉之效。
----------------------------------------------------------------------------------------------------------
常规方式:
1.用ACDSEE将图片压缩
2.分页,将一个页面弄成多个
3.不要将所有的图、flash等在同一个表格中,因为IE会将一个表格中所有内容都下载完后才显示下来,你可以放到多个表格中,下载一个都会显示一个。
4.换个服务器快的空间 查看全部
【采集】如何提升网站访问速率的文章
3. 如果友情链接一定要出现在首页,请将链接所在的整个Table放在页面的最下方,因为页面是由上到下逐行显示的,将其放在页面的最下方,不会延后其他内容的显示。
4. 友情链接的LOGO图片先下载后再传到自己的网页空间,这样,速度由自己的网站空间决定而不受友情网站的影响。
-----------------------------------------------------------------------------------------------------------
转载本文请知名出处:Just Do IT ()
一个大型的网站,比如个人网站,可以使用最简单的html静态页面就实现了,配合一些图片达到美化疗效,所有的页面均储存在一个目录下,这样的网站对系统构架、性能的要求都很简单,随着互联网业务的不断丰富,网站相关的技术经过这些年的发展,已经细分到太细的方方面面,尤其对于小型网站来说,所采用的技术更是涉及面十分广,从硬件到软件、编程语言、数据库、WebServer、防火墙等各个领域都有了很高的要求,已经不是原先简单的html静态网站所能比拟的。
大型网站,比如门户网站。在面对大量用户访问、高并发恳求方面,基本的解决方案集中在这样几个环节:使用高性能的服务器、高性能的数据库、高效率的编程语言、还有高性能的Web容器。但是不仅这几个方面,还无法根本解决小型网站面临的高负载和高并发问题。
上面提供的几个解决思路在一定程度上也意味着更大的投入,并且这样的解决思路具备困局,没有挺好的扩展性,下面我从低成本、高性能和高扩张性的角度来说说我的一些经验。
1、HTML静态化
其实你们都晓得,效率最高、消耗最小的就是纯静态化的html页面,所以我们尽可能让我们的网站上的页面采用静态页面来实现,这个最简单的方式虽然也是最有效的方式。但是对于大量内容而且频繁更新的网站,我们难以全部自动去逐个实现,于是出现了我们常见的信息发布系统CMS,像我们常访问的各个门户站点的新闻频道,甚至她们的其他频道,都是通过信息发布系统来管理和实现的,信息发布系统可以实现最简单的信息录入手动生成静态页面,还能具备频道管理、权限管理、自动抓取等功能,对于一个小型网站来说,拥有一套高效、可管理的CMS是必不可少的。
除了门户和信息发布类型的网站,对于交互性要求很高的社区类型网站来说,尽可能的静态化也是提升性能的必要手段,将社区内的贴子、文章进行实时的静态化,有更新的时侯再重新静态化也是大量使用的策略,像Mop的大杂烩就是使用了这样的策略,网易社区等也是这么。
同时,html静态化也是个别缓存策略使用的手段,对于系统中频繁使用数据库查询并且内容更新太小的应用,可以考虑使用html静态化来实现,比如峰会中峰会的公用设置信息,这些信息目前的主流峰会都可以进行后台管理而且储存再数据库中,这些信息虽然大量被前台程序调用,但是更新频度太小,可以考虑将这部份内容进行后台更新的时侯进行静态化,这样避开了大量的数据库访问恳求。
2、图片服务器分离
大家晓得,对于Web服务器来说,不管是Apache、IIS还是其他容器,图片是最消耗资源的,于是我们有必要将图片与页面进行分离,这是基本上小型网站都会采用的策略,他们都有独立的图片服务器,甚至好多台图片服务器。这样的构架可以减少提供页面访问恳求的服务器系统压力,并且可以保证系统不会由于图片问题而崩溃,在应用服务器和图片服务器上,可以进行不同的配置优化,比如apache在配置ContentType的时侯可以尽量少支持,尽可能少的LoadModule,保证更高的系统消耗和执行效率。
3、数据库集群和库表散列
大型网站都有复杂的应用,这些应用必须使用数据库,那么在面对大量访问的时侯,数据库的困局很快能够凸显下来,这时一台数据库将很快未能满足应用,于是我们须要使用数据库集群或则库表散列。
在数据库集群方面,很多数据库都有自己的解决方案,Oracle、Sybase等都有挺好的方案,常用的MySQL提供的Master/Slave也是类似的方案,您使用了什么样的DB,就参考相应的解决方案来施行即可。
上面提及的数据库集群因为在构架、成本、扩张性方面就会遭到所采用DB类型的限制,于是我们须要从应用程序的角度来考虑改善系统构架,库表散列是常用而且最有效的解决方案。我们在应用程序中安装业务和应用或则功能模块将数据库进行分离,不同的模块对应不同的数据库或则表,再根据一定的策略对某个页面或则功能进行更小的数据库散列,比如用户表,按照用户ID进行表散列,这样才能够低成本的提高系统的性能但是有挺好的扩展性。sohu的峰会就是采用了这样的构架,将峰会的用户、设置、帖子等信息进行数据库分离,然后对贴子、用户根据蓝筹股和ID进行散列数据库和表,最终可以在配置文件中进行简单的配置便能使系统随时降低一台低成本的数据库进来补充系统性能。
4、缓存
缓存一词搞技术的都接触过,很多地方用到缓存。网站架构和网站开发中的缓存也是十分重要。这里先述说最基本的两种缓存。高级和分布式的缓存在前面述说。
架构方面的缓存,对Apache比较熟悉的人都能晓得Apache提供了自己的缓存模块,也可以使用外加的Squid模块进行缓存,这两种方法均可以有效的增强Apache的访问响应能力。
网站程序开发方面的缓存,Linux上提供的Memory Cache是常用的缓存插口,可以在web开发中使用,比如用Java开发的时侯就可以调用MemoryCache对一些数据进行缓存和通信共享,一些小型社区使用了这样的构架。另外,在使用web语言开发的时侯,各种语言基本都有自己的缓存模块和技巧,PHP有Pear的Cache模块,Java就更多了,.net不是太熟悉,相信也肯定有。
5、镜像
镜像是小型网站常采用的增强性能和数据安全性的方法,镜像的技术可以解决不同网路接入商和地域带来的用户访问速率差别,比如ChinaNet和EduNet之间的差别就使得了好多网站在教育网内搭建镜像站点,数据进行定时更新或则实时更新。在镜像的细节技术方面,这里不探讨很深,有很多专业的现成的解决构架和产品可选。也有廉价的通过软件实现的思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是小型网站解决高负荷访问和大量并发恳求采用的终极解决办法。
负载均衡技术发展了多年,有很多专业的服务提供商和产品可以选择,我个人接触过一些解决方式,其中有两个构架可以给你们做参考。
硬件四层交换
第四层交换使用第三层和第四层信息包的报头信息,根据应用区间辨识业务流,将整个区间段的业务流分配到合适的应用服务器进行处理。第四层交换功能如同是虚IP,指向化学服务器。它传输的业务服从的合同多种多样,有HTTP、FTP、NFS、Telnet或其他合同。这些业务在数学服务器基础上,需要复杂的载量平衡算法。在IP世界,业务类型由终端TCP或UDP端口地址来决定,在第四层交换中的应用区间则由源端和终端IP地址、TCP和UDP端口共同决定。
在硬件四层交换产品领域,有一些著名的产品可以选择,比如Alteon、F5等,这些产品太高昂,但是物有所值,能够提供特别优秀的性能和太灵活的管理能力。Yahoo中国曾经接近2000台服务器使用了三四台Alteon就搞定了。
软件四层交换
大家晓得了硬件四层交换机的原理后,基于OSI模型来实现的软件四层交换也就应运而生,这样的解决方案实现的原理一致,不过性能稍差。但是满足一定量的压力还是游刃有余的,有人说软件实现方法虽然更灵活,处理能力完全看你配置的熟悉能力。
软件四层交换我们可以使用Linux上常用的LVS来解决,LVS就是Linux Virtual Server,他提供了基于心跳线heartbeat的实时灾难应对解决方案,提高系统的鲁棒性,同时可供了灵活的虚拟VIP配置和管理功能,可以同时满足多种应用需求,这对于分布式的系统来说必不可少。
一个典型的使用负载均衡的策略就是,在软件或则硬件四层交换的基础上搭建squid集群,这种思路在好多小型网站包括搜索引擎上被采用,这样的构架低成本、高性能还有太强的扩张性,随时往构架上面增减节点都十分容易。这样的构架我打算空了专门详尽整理一下和你们剖析。
对于小型网站来说,前面提及的每位方式可能就会被同时使用到,我这儿介绍得比较晦涩,具体实现过程中好多细节还须要你们渐渐熟悉和感受,有时一个太小的squid参数或则apache参数设置,对于系统性能的影响都会很大,希望你们一起讨论,达到抛砖引玉之效。
----------------------------------------------------------------------------------------------------------
常规方式:
1.用ACDSEE将图片压缩
2.分页,将一个页面弄成多个
3.不要将所有的图、flash等在同一个表格中,因为IE会将一个表格中所有内容都下载完后才显示下来,你可以放到多个表格中,下载一个都会显示一个。
4.换个服务器快的空间
如果公众号写文章也须要加入【参考文献】……
采集交流 • 优采云 发表了文章 • 0 个评论 • 458 次浏览 • 2020-08-24 17:45
而这两个数据,也是全部可以得到。
文章引用行为的获取
我们打开一篇“引用了”其他文章的公众号文章,F12检测文章的源代码可以看见,文章是以超链接的方式出现的:
文章源代码
所以在采集文章时,如果在源代码中采集到
文本
的数组,则可以觉得此处有“引用”行为。
引用来源剖析
找到了文章的引用行为,我们须要对被引用的文章进行剖析,分析的核心在就于这篇文章的链接,也就是刚刚herf旁边的那一串。
幸运的是,微信在链接里保存了我们须要的所有数据。
以昨天那篇文章的链接为例:
#wechat_redirect
我们把链接分为三部份:
/s?
__biz=MzU1MTAwNzY4Mg==&mid=2247483897&idx=1&sn=893614b6d6fd28d04b0f51e7c857c876&chksm=fb96a554cce12c4266018f581467f009021b89f5df0d546b1d08f4a08055ce17916f2ae74745&scene=21#wechat_redirect
了解链接组成的同学们应当晓得,前两部份是链接的主题,每个文章的链接都是一样的。关键信息在于“?”后面的部份。
在链接里,“?”后面的部份是链接的传参,顾名思义,就是向服务器传递的参数,是对链接的解释(或者叫备注)。
观察链接里的参数,有五个:
__biz
mid
idx
sn
chksm
我们这儿只用到前两个参数:
__biz可以觉得是微信公众平台对外公布的公众账号的惟一
idmid是图文消息id
通过__biz参数可以获得公众号的ID数据,是惟一辨识的,目前技术上可以转化成帐号的;
通过mid参数,我们则可以定位到文章的ID,也是惟一辨识的。
到此,对于文章引用行为技术层面的问题都早已解决。
“被引量”的使用
和学术领域相同,一篇文章被引用一次,则代表该文章影响力+1,被引量越多,文章影响力就越高。
对于公众号而言,可以使用帐号所有文章的被引量估算帐号的“影响因子”,可以使用SCI的估算方式,也可以使用GoogleScholar的H-index的估算方式。
和学术领域相同,文章也存在”自引“和”负引用“的问题。
自引在学术领域是一个不怎样受待见的事情,因为“被引量”这个指标早已作为一种评价标准,引用自己的文章给自己+1这些行为不是很好看。
负引用这件事在学术领域还不这么严重,一篇论文的推论不管对错,学术层面的价值是存在的。但是在媒体行业就不同了,毕竟媒体好多时侯传递的是价值观。比如某篇文章观点狭隘,被全网喷,我们只能说那篇文章影响力高,但是价值就没多少了。
这里我们就不深入讨论了。
最后说点啥
目前的内容行业,充斥着营销号、流量号,一群自媒体人聚在一起不是讨论什么样的文章有价值、什么样的内容有深度,而是讨论明天的利润怎样、多少阅读量才会开通流量主。
我们每晚仅有的几分钟阅读时间里,有一半浪费在这些“耸人听闻”但毫无营养的标题党上,反而这些报导事实、传递价值的深度内容或由于文字很长、或由于标题不够吸睛,被吞没在这爆燃的信息海洋中。
是时侯该有人站出来做点哪些了,比如给内容行业加入一个早已谋害学术圈的“影响因子”。
本文首发自我的个人公众号喜新(ID:noyanjiu),请随意转载,不用告诉我。 查看全部
如果公众号写文章也须要加入【参考文献】……
而这两个数据,也是全部可以得到。
文章引用行为的获取
我们打开一篇“引用了”其他文章的公众号文章,F12检测文章的源代码可以看见,文章是以超链接的方式出现的:
文章源代码
所以在采集文章时,如果在源代码中采集到
文本
的数组,则可以觉得此处有“引用”行为。
引用来源剖析
找到了文章的引用行为,我们须要对被引用的文章进行剖析,分析的核心在就于这篇文章的链接,也就是刚刚herf旁边的那一串。
幸运的是,微信在链接里保存了我们须要的所有数据。
以昨天那篇文章的链接为例:
#wechat_redirect
我们把链接分为三部份:
/s?
__biz=MzU1MTAwNzY4Mg==&mid=2247483897&idx=1&sn=893614b6d6fd28d04b0f51e7c857c876&chksm=fb96a554cce12c4266018f581467f009021b89f5df0d546b1d08f4a08055ce17916f2ae74745&scene=21#wechat_redirect
了解链接组成的同学们应当晓得,前两部份是链接的主题,每个文章的链接都是一样的。关键信息在于“?”后面的部份。
在链接里,“?”后面的部份是链接的传参,顾名思义,就是向服务器传递的参数,是对链接的解释(或者叫备注)。
观察链接里的参数,有五个:
__biz
mid
idx
sn
chksm
我们这儿只用到前两个参数:
__biz可以觉得是微信公众平台对外公布的公众账号的惟一
idmid是图文消息id
通过__biz参数可以获得公众号的ID数据,是惟一辨识的,目前技术上可以转化成帐号的;
通过mid参数,我们则可以定位到文章的ID,也是惟一辨识的。
到此,对于文章引用行为技术层面的问题都早已解决。
“被引量”的使用
和学术领域相同,一篇文章被引用一次,则代表该文章影响力+1,被引量越多,文章影响力就越高。
对于公众号而言,可以使用帐号所有文章的被引量估算帐号的“影响因子”,可以使用SCI的估算方式,也可以使用GoogleScholar的H-index的估算方式。
和学术领域相同,文章也存在”自引“和”负引用“的问题。
自引在学术领域是一个不怎样受待见的事情,因为“被引量”这个指标早已作为一种评价标准,引用自己的文章给自己+1这些行为不是很好看。
负引用这件事在学术领域还不这么严重,一篇论文的推论不管对错,学术层面的价值是存在的。但是在媒体行业就不同了,毕竟媒体好多时侯传递的是价值观。比如某篇文章观点狭隘,被全网喷,我们只能说那篇文章影响力高,但是价值就没多少了。
这里我们就不深入讨论了。
最后说点啥
目前的内容行业,充斥着营销号、流量号,一群自媒体人聚在一起不是讨论什么样的文章有价值、什么样的内容有深度,而是讨论明天的利润怎样、多少阅读量才会开通流量主。
我们每晚仅有的几分钟阅读时间里,有一半浪费在这些“耸人听闻”但毫无营养的标题党上,反而这些报导事实、传递价值的深度内容或由于文字很长、或由于标题不够吸睛,被吞没在这爆燃的信息海洋中。
是时侯该有人站出来做点哪些了,比如给内容行业加入一个早已谋害学术圈的“影响因子”。
本文首发自我的个人公众号喜新(ID:noyanjiu),请随意转载,不用告诉我。
网页抓取利器hawk使用心得
采集交流 • 优采云 发表了文章 • 0 个评论 • 224 次浏览 • 2020-08-24 17:43
(1)抓取目的
现在网站有大量数据,但网站本身并不提供api接口,如果要批量获得这种页面数据,必须通过网页抓取方法实现。
比如某房产网站的二手房数据,在页面上太整齐的展示,因此可以通过剖析网页的html源码,找到单价、单价、位置、户型等数据,并最终实现批量抓取。
(2)抓取原理
1)首先要获取网页的html源码,这个并不难,在浏览器里右击菜单里选择“查看网页源代码”就能看见html源码,页面上能看到的文字基本在都在html源码里。
2)得到html源码后,就须要定位到各个数据的位置,比如“总价”,如下图所示:
可以见到“560”在html里能找到。
同时可以得到“总价”这个数组的xpath:
/html/body/div[4]/div[1]/ul/li[8]/div[1]/div[6]/div[1]/span
我们可以把html看成是一个标签树,xpath就是在标签树的找寻路径。
依此可以得到“单价”、“户型”等数组的xpath,也就可以获取1条发布信息的数据。
3)得到1条信息的数据后,一个页面一般会显示二三十条信息,可以发觉这种信息的格式都是一致的,如下图所示:
因此可以发觉这种信息都在
/html/body/div[4]/div[1]/ul/
路径下
第1条就是/html/body/div[4]/div[1]/ul/li[1]
第2条就是/html/body/div[4]/div[1]/ul/li[2]
……
基于此,通过基础path+数组相对path就可以得到每位数组的绝对path,然后可以编程实现单个页面的抓取功能了。
4)得到单个页面的数据后,就可以实现多页面抓取,假如网站有100页数据,通过观察网站地址url可以发觉,一般第二页就是 “xxx/page2”,第一百页就是“xxx/page100”,因此这个也是挺有规律的,修改下url就可以实现多页面抓取了。
(3)hawk抓取
由于网页抓取这么常见,可以在网上搜到大量的抓取软件,并不一定须要自己再开发一个抓取软件(写一个抓取软件不难,写一个通用性强且好用的难),hawk就是一个相当好用的抓取软件。
hawk的介绍页面:
关于hawk的详尽介绍,可以看其主页,这里说一下个人使用心得:
1)hawk收录”网页采集器”和”数据清洗”两个模块,网页采集用于定位各个数组的xpath,数据清洗用于抓取数据,并对各个数组做一定的处理,以及导入数据。
2)网页采集器模块挺好用,输入url得到网页html源码后,在“搜索字符”里输入比较典型的搜索文本,比如“农光南路双朝北两居室”后,hawk会在html里搜索这个字符串,获取xpath。
“添加数组”后,再点击“手气不错”会手动搜索出每条信息里收录的所有数组值,这个功能真的太强悍,有点人工智能的疗效了,网页采集工作一次完成。
3)数据清洗模块也挺好用,个人用了其中4个模块
1 生成区间数2 合并多列 3 从爬虫转换4 写入数据表
具体操作可观看主页提供的视频教程,其中第三步“从爬虫转换”要设置网页采集器的名称(视频少了这个步骤),最后导入到Excel表,得到想要的数据。
hawk这个软件功能太全,而且界面操作便捷,支持好多的数据模块,推荐使用。 查看全部
网页抓取利器hawk使用心得
(1)抓取目的
现在网站有大量数据,但网站本身并不提供api接口,如果要批量获得这种页面数据,必须通过网页抓取方法实现。
比如某房产网站的二手房数据,在页面上太整齐的展示,因此可以通过剖析网页的html源码,找到单价、单价、位置、户型等数据,并最终实现批量抓取。
(2)抓取原理
1)首先要获取网页的html源码,这个并不难,在浏览器里右击菜单里选择“查看网页源代码”就能看见html源码,页面上能看到的文字基本在都在html源码里。
2)得到html源码后,就须要定位到各个数据的位置,比如“总价”,如下图所示:
可以见到“560”在html里能找到。
同时可以得到“总价”这个数组的xpath:
/html/body/div[4]/div[1]/ul/li[8]/div[1]/div[6]/div[1]/span
我们可以把html看成是一个标签树,xpath就是在标签树的找寻路径。
依此可以得到“单价”、“户型”等数组的xpath,也就可以获取1条发布信息的数据。
3)得到1条信息的数据后,一个页面一般会显示二三十条信息,可以发觉这种信息的格式都是一致的,如下图所示:
因此可以发觉这种信息都在
/html/body/div[4]/div[1]/ul/
路径下
第1条就是/html/body/div[4]/div[1]/ul/li[1]
第2条就是/html/body/div[4]/div[1]/ul/li[2]
……
基于此,通过基础path+数组相对path就可以得到每位数组的绝对path,然后可以编程实现单个页面的抓取功能了。
4)得到单个页面的数据后,就可以实现多页面抓取,假如网站有100页数据,通过观察网站地址url可以发觉,一般第二页就是 “xxx/page2”,第一百页就是“xxx/page100”,因此这个也是挺有规律的,修改下url就可以实现多页面抓取了。
(3)hawk抓取
由于网页抓取这么常见,可以在网上搜到大量的抓取软件,并不一定须要自己再开发一个抓取软件(写一个抓取软件不难,写一个通用性强且好用的难),hawk就是一个相当好用的抓取软件。
hawk的介绍页面:
关于hawk的详尽介绍,可以看其主页,这里说一下个人使用心得:
1)hawk收录”网页采集器”和”数据清洗”两个模块,网页采集用于定位各个数组的xpath,数据清洗用于抓取数据,并对各个数组做一定的处理,以及导入数据。
2)网页采集器模块挺好用,输入url得到网页html源码后,在“搜索字符”里输入比较典型的搜索文本,比如“农光南路双朝北两居室”后,hawk会在html里搜索这个字符串,获取xpath。
“添加数组”后,再点击“手气不错”会手动搜索出每条信息里收录的所有数组值,这个功能真的太强悍,有点人工智能的疗效了,网页采集工作一次完成。
3)数据清洗模块也挺好用,个人用了其中4个模块
1 生成区间数2 合并多列 3 从爬虫转换4 写入数据表
具体操作可观看主页提供的视频教程,其中第三步“从爬虫转换”要设置网页采集器的名称(视频少了这个步骤),最后导入到Excel表,得到想要的数据。
hawk这个软件功能太全,而且界面操作便捷,支持好多的数据模块,推荐使用。
DEDECMS后台更新文章模板时提示未能解析文档的完
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-23 07:21
织梦dedecms建企业站特别快,因为这款程序可以套模板建站。可是假如对这款程序不熟悉建站过程中还会碰到好多使人疑惑的问题。因为模板可能和程序的编码格式不同或则使用的模板和程序不兼容就会出问题。一位站长同学之前用的是无忧的共享空间,后面因为须要给网站做优化和排行,再三考虑后联系小编帮忙升级为独立IP空间。小编帮忙升级后就又开始帮忙做迁移了。一切数据都迁移过去后当登录网站的后台去一键更新网站的时侯出问题了,提示模板文件不存在如下图:
小编特意把模板文件上传覆盖的如何会提示模板文件不存在呢?小编再度的上传了一下模板覆盖登录后台还是这个报错。小编通过剖析研究后找到了问题的诱因。由于织梦dedecms系统文章模板的模板必须是以.htm结尾的,而模板文件名的后缀是.html.原来是这儿出了问题。知道了问题的诱因再去找解决方式就容易多了。下面编把整理的方式来分享下吧。
第一步:连接FTP工具。按照路径找到include/arc.archives.class.php文件。使用中级编辑器打开,(小编介绍使用Editplus)。
第二步:打开后,使用快捷键 Ctrl+h 找到htm$全部替换为html$ 如下图:
第三步:把修改后的文件上传到对应的目录下,再登录织梦的后台去更新下系统缓存再一键更新网站就可以解决了。
以上方式就是小编整理下来的解决方式了,特此分享给更多的站长朋友们。如果有疑问欢迎联系小编QQ:340555009.感谢对无忧小编的支持。 查看全部
DEDECMS后台更新文章模板时提示未能解析文档的完
织梦dedecms建企业站特别快,因为这款程序可以套模板建站。可是假如对这款程序不熟悉建站过程中还会碰到好多使人疑惑的问题。因为模板可能和程序的编码格式不同或则使用的模板和程序不兼容就会出问题。一位站长同学之前用的是无忧的共享空间,后面因为须要给网站做优化和排行,再三考虑后联系小编帮忙升级为独立IP空间。小编帮忙升级后就又开始帮忙做迁移了。一切数据都迁移过去后当登录网站的后台去一键更新网站的时侯出问题了,提示模板文件不存在如下图:
小编特意把模板文件上传覆盖的如何会提示模板文件不存在呢?小编再度的上传了一下模板覆盖登录后台还是这个报错。小编通过剖析研究后找到了问题的诱因。由于织梦dedecms系统文章模板的模板必须是以.htm结尾的,而模板文件名的后缀是.html.原来是这儿出了问题。知道了问题的诱因再去找解决方式就容易多了。下面编把整理的方式来分享下吧。
第一步:连接FTP工具。按照路径找到include/arc.archives.class.php文件。使用中级编辑器打开,(小编介绍使用Editplus)。
第二步:打开后,使用快捷键 Ctrl+h 找到htm$全部替换为html$ 如下图:
第三步:把修改后的文件上传到对应的目录下,再登录织梦的后台去更新下系统缓存再一键更新网站就可以解决了。
以上方式就是小编整理下来的解决方式了,特此分享给更多的站长朋友们。如果有疑问欢迎联系小编QQ:340555009.感谢对无忧小编的支持。
爬取nyist-6000张证件照进行微软小冰逼格剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2020-08-22 11:44
Python爬取nyist-6000张证件照进行逼格剖析***## 前言本文章同步至我的网站:
前几天中学要求更新档案资料库的相片,所以要求每位人去照证件照,大多数人是在中学上面的一个拍照的地方照的,为了容易让同学们领到合照,他们会每晚把每位人的证件照上传到一个网站,于是我就用爬虫爬取了6000+照片,结合微软小冰的人脸辨识中的逼格剖析功能对每张相片进行打分,然后进行一次简单的逼格剖析,下面简单说一说我的过程,结论在最后
工具打算:
采集照片的网址:
微软小冰的逼格剖析网址:
微软的图片服务器网址:
一、爬取并保存图片
首先,我们打开要采集照片的地址:,会见到这样:
然后引入相关的库:
import re
import requests
from bs4 import BeautifulSoup
import lxml
import os
我们打开这种链接发觉:
因为日期的不同,所以网页地址显得只是前面的数字,所以我们只须要找到我们要爬取的第一个页面的标号和最后一个页面的标号,然后对每一个页面分别爬取就好了。
随便打开一个页面,会发觉图片是这样的:
我们解析一下网页源代码会发觉是这样的:
这些图片都无一例外的藏在img标签上面的,所以我们只须要把这种上面的内容提取下来就可以得到每一张图片的地址了。
提取的方式有很多种,比如用BeautifulSoup,但是这儿因为这个标签并不需要解析成文档树,可以直接写一个正则表达式提取下来,所以我们可以如此写:
/upfile/201709/\d+\.JPG
只须要简单的匹配一下多位数字就可以了,这样我们可以写出具体代码:
这样由于正则匹配的缘故,会返回一个收录所有图片地址的列表,那么如今我们要做的就是借助这个列表,进行保存:
这个也很简单,我们遍历一下这个列表,然后构造每一个图片链接,这里也须要用正则表达式来匹配一下文件名,用requests恳求一下把二进制的东西保存成.jpg文件就好了
现在我们的代码已然实现了对每位页面的图片进行保存,剩下的就是调用这两个函数了,我们只须要遍历一下要爬的网页的id,然后等着爬取完成就好了,爬虫爬完后会得到一个文件夹,里面就是你爬好的相片,就像这样:
到了现今,第一步就做完了,已经拥有这几千张护照照了
二、调用微软小冰人脸辨识中的测逼格功能
首先,我们打开微软小冰的辨识页面:
显示这样:
这时我们点"上传图片",然后进行抓包
我们发觉有两个post恳求,分别是把当前图片传到微软服务器,还有一个是进行逼格测试,进行逼格测试的时侯其中的一个参数要传入当前这个图片在微软服务器的地址,所以我们要分两步来做:
把图片上传至微软服务器,并且得到返回的图片地址运用得到的图片地址,进行颜值颜值测试
通过抓包可以发觉两个post地址,一个是递交图片的地址,另一个是获得逼格分数的地址:
upload_url = 'http://kan.msxiaobing.com/Api/Image/UploadBase64'
comp_url = 'https://kan.msxiaobing.com/Api/ImageAnalyze/Process'
我们先说第一个,通过查看抓到的包,我们会发觉每一张图片在传入服务器之前会先经过base64编码方法对图片进行编码,然后会post到谷歌的服务器,然后返回地址,那么我们就应当先对一张图片进行base64加密,然后我们会发觉返回结果是这样的:
{'Host': 'https://mediaplatform.msxiaobing.com', 'Url': '/image/fetchimage?key=JMGsDUAgbwOliRBabKjOIkANmt-Cu2pqpAsmCZyiMDJ6wxaO8iaLjrucUw'}
这是一段json信息,我们须要的是url上面的值,所以我们就用requests中外置的json解析器对它进行解析,所以,代码可以如此写:
def get_img_url(file_name):
with open(file_name,'rb') as f:
img_base64=base64.b64encode(f.read())
r=requests.post(upload_url,data=img_base64)
url='https://mediaplatform.msxiaobing.com' + r.json()['Url']
return url
我们通过把二进制信息进行编码,然后传入微软服务器,获得了这一张图片在服务器中的地址,然后在通过构造,得到完整的地址
那么我们如今进行第二步,把信息发到微软服务器,然后得到地址,我们看一下抓的包:
Remote Address:42.159.132.179:443
Request URL:https://kan.msxiaobing.com/Api ... 71450
Request Method:POST
Status Code:200 OK
Response Headers
view source
Cache-Control:no-cache
Content-Encoding:gzip
Content-Type:application/json; charset=utf-8
Date:Thu, 07 Sep 2017 17:18:28 GMT
Expires:-1
Pragma:no-cache
Server:Microsoft-IIS/8.0
Transfer-Encoding:chunked
Vary:Accept-Encoding
X-Powered-By:ASP.NET
Request Headers
view source
Accept:*/*
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.8
Connection:keep-alive
Content-Length:194
Content-Type:application/x-www-form-urlencoded; charset=UTF-8
Cookie:_ga=GA1.2.1597838376.1504599720; ai_user=sp1jt|2017-09-05T10:53:04.090Z; ARRAffinity=d48a0dd61144e14e99ea10eca4fef5d81bf07933a2831679353d2761cf0db5aa; cpid=YE5cTN4wQk4hTFdMf7FVTzM0bjPlNN1MJrFATNhI10hNAA; salt=761703E5A961C3EC8AD465F2A70F639F; ai_session=pWq6U|1504804573893.97|1504804670104.895
Host:kan.msxiaobing.com
Origin:https://kan.msxiaobing.com
Referer:https://kan.msxiaobing.com/Ima ... 2e702
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36
x-ms-request-id:4KL3u
x-ms-request-root-id:idMkH
X-Requested-With:XMLHttpRequest
Query String Parameters
view source
view URL encoded
service:yanzhi
tid:a14a6fd556cf45c181cb116f06471450
Form Data
view source
view URL encoded
MsgId:1504804707562
CreateTime:1504804707
Content[imageUrl]:https://mediaplatform.msxiaobi ... mOmXA
我们要构造data上面的信息,也就是要构造MsgId,CreateTime,Content[imageUrl]这三个信息,首先我们观察MsgId,发现它实质上就是当前的时间戳加了一个3位数的随机数,而第二个CreateTime虽然就是当前的时间戳,第三个Content[imageUrl]那当然就是我们刚才得到的图片地址了,我们就把这种参数给发起来
然后把这种恳求发起来之后,会发觉它的返回结果是none,那么这是为什么呢,这是因为谷歌添加了cookies和refer验证,所以我们要把这两个东西置于headers上面一起给传过去,然后都会发觉它返回一段json:
{‘msgId’: ‘4d39f92788774d65bd0261d6f4754865’, ‘timestamp’: 73, ‘receiverId’: None, ‘content’: {‘text’: ‘有潜力的姑娘!6.6分!性格肯定超好,男神最喜欢这些男孩纸咯,羡慕!’, ‘imageUrl’: ‘’, ‘metadata’: {‘AnswerFeed’: ‘FaceBeautyRanking’, ‘w’: ‘vvXoifT_gNLyhvXNhsPhjMz_pt_kbkdXisHliuToh-_uhcXkgePArM3_sN_kiuzeiuTlhvv-hMDGj_3vrPX5vsXDh_b6gv_khMr6hsjxjtvXrPHKt9XtiPfCg938jtPI’, ‘aid’: ‘303DB2A95867544E3E5EE047977CECF4’}}}
我们依照惯例,对它进行解析,我们提取下来['content']['text']里面的内容就行了,所以这一段的代码:
def get_score(img_url):
sys_time = int(time.time())
payload = {'service': 'yanzhi',
'tid': '7531216b61b14d208496ee52bca9a9a8'}
form = {
'MsgId': str(sys_time) + '733',
'CreateTime': sys_time,
'Content[imageUrl]': img_url,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
'Cookie': '_ga=GA1.2.1597838376.1504599720; _gid=GA1.2.1466467655.1504599720; ai_user=sp1jt|2017-09-05T10:53:04.090Z; cpid=YDLcMF5LPDFfSlQyfUkvMs9IbjQZMiQ2XTJHMVswUTFPAA; salt=EAA803807C2E9ECD7D786D3FA9516786; ARRAffinity=3dc0ec2b3434a920266e7d4652ca9f67c3f662b5a675f83cf7467278ef043663; ai_session=sQna0|1504664570638.64|1504664570638'+str(random.randint(11, 999)),
'Referer': 'https://kan.msxiaobing.com/ImageGame/Portal?task=yanzhi&feid=d89e6ce730dab7a2410c6dad803b5986'
}
r = requests.post(comp_url, params=payload, data=form, headers=headers)
print(r.json())
text = r.json()['content']['text']
return text
这样的话,我们就可以获得小冰对这个相片的评价,那么对于后期处理,我们只要用正则表达式把其中的关于逼格分数的地方提取下来就好了,那么这时候就须要保存刚才获得的评价分数,所以我们采用的方法就是对文件重命名,就是把文件名改成:分数+原来的文件名的方式,代码如下:
为了便捷我们对于程序的调试,所以用一个txt文件随时把程序的log信息传进去,就像这样:
至此,打分环节也完成了,下面进行下一项
三、把分数用图表的形式勾画下来
这一步须要用到matplotlib库中的pyplot,用它可以勾画出好多种不同的图,先引入库:
import matplotlib.pyplot as plt
import os
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
由于微软小冰的API调用次数的限制,我只成功的对2118张图片进行了逼格的打分,很容易的得到了每位分数段区间的数目:
<p>def get_score():
score_num=[]
for i in range(6):
score_num.append(0)
list=os.listdir()
for name in list:
if len(name)==24:
score=float(name[:3])
if score>=3 and score=4 and score=5 and score=6 and score=7 and score=8 and score 查看全部
爬取nyist-6000张证件照进行微软小冰逼格剖析
Python爬取nyist-6000张证件照进行逼格剖析***## 前言本文章同步至我的网站:
前几天中学要求更新档案资料库的相片,所以要求每位人去照证件照,大多数人是在中学上面的一个拍照的地方照的,为了容易让同学们领到合照,他们会每晚把每位人的证件照上传到一个网站,于是我就用爬虫爬取了6000+照片,结合微软小冰的人脸辨识中的逼格剖析功能对每张相片进行打分,然后进行一次简单的逼格剖析,下面简单说一说我的过程,结论在最后
工具打算:
采集照片的网址:
微软小冰的逼格剖析网址:
微软的图片服务器网址:
一、爬取并保存图片
首先,我们打开要采集照片的地址:,会见到这样:
然后引入相关的库:
import re
import requests
from bs4 import BeautifulSoup
import lxml
import os
我们打开这种链接发觉:
因为日期的不同,所以网页地址显得只是前面的数字,所以我们只须要找到我们要爬取的第一个页面的标号和最后一个页面的标号,然后对每一个页面分别爬取就好了。
随便打开一个页面,会发觉图片是这样的:
我们解析一下网页源代码会发觉是这样的:
这些图片都无一例外的藏在img标签上面的,所以我们只须要把这种上面的内容提取下来就可以得到每一张图片的地址了。
提取的方式有很多种,比如用BeautifulSoup,但是这儿因为这个标签并不需要解析成文档树,可以直接写一个正则表达式提取下来,所以我们可以如此写:
/upfile/201709/\d+\.JPG
只须要简单的匹配一下多位数字就可以了,这样我们可以写出具体代码:
这样由于正则匹配的缘故,会返回一个收录所有图片地址的列表,那么如今我们要做的就是借助这个列表,进行保存:
这个也很简单,我们遍历一下这个列表,然后构造每一个图片链接,这里也须要用正则表达式来匹配一下文件名,用requests恳求一下把二进制的东西保存成.jpg文件就好了
现在我们的代码已然实现了对每位页面的图片进行保存,剩下的就是调用这两个函数了,我们只须要遍历一下要爬的网页的id,然后等着爬取完成就好了,爬虫爬完后会得到一个文件夹,里面就是你爬好的相片,就像这样:
到了现今,第一步就做完了,已经拥有这几千张护照照了
二、调用微软小冰人脸辨识中的测逼格功能
首先,我们打开微软小冰的辨识页面:
显示这样:
这时我们点"上传图片",然后进行抓包
我们发觉有两个post恳求,分别是把当前图片传到微软服务器,还有一个是进行逼格测试,进行逼格测试的时侯其中的一个参数要传入当前这个图片在微软服务器的地址,所以我们要分两步来做:
把图片上传至微软服务器,并且得到返回的图片地址运用得到的图片地址,进行颜值颜值测试
通过抓包可以发觉两个post地址,一个是递交图片的地址,另一个是获得逼格分数的地址:
upload_url = 'http://kan.msxiaobing.com/Api/Image/UploadBase64'
comp_url = 'https://kan.msxiaobing.com/Api/ImageAnalyze/Process'
我们先说第一个,通过查看抓到的包,我们会发觉每一张图片在传入服务器之前会先经过base64编码方法对图片进行编码,然后会post到谷歌的服务器,然后返回地址,那么我们就应当先对一张图片进行base64加密,然后我们会发觉返回结果是这样的:
{'Host': 'https://mediaplatform.msxiaobing.com', 'Url': '/image/fetchimage?key=JMGsDUAgbwOliRBabKjOIkANmt-Cu2pqpAsmCZyiMDJ6wxaO8iaLjrucUw'}
这是一段json信息,我们须要的是url上面的值,所以我们就用requests中外置的json解析器对它进行解析,所以,代码可以如此写:
def get_img_url(file_name):
with open(file_name,'rb') as f:
img_base64=base64.b64encode(f.read())
r=requests.post(upload_url,data=img_base64)
url='https://mediaplatform.msxiaobing.com' + r.json()['Url']
return url
我们通过把二进制信息进行编码,然后传入微软服务器,获得了这一张图片在服务器中的地址,然后在通过构造,得到完整的地址
那么我们如今进行第二步,把信息发到微软服务器,然后得到地址,我们看一下抓的包:
Remote Address:42.159.132.179:443
Request URL:https://kan.msxiaobing.com/Api ... 71450
Request Method:POST
Status Code:200 OK
Response Headers
view source
Cache-Control:no-cache
Content-Encoding:gzip
Content-Type:application/json; charset=utf-8
Date:Thu, 07 Sep 2017 17:18:28 GMT
Expires:-1
Pragma:no-cache
Server:Microsoft-IIS/8.0
Transfer-Encoding:chunked
Vary:Accept-Encoding
X-Powered-By:ASP.NET
Request Headers
view source
Accept:*/*
Accept-Encoding:gzip, deflate
Accept-Language:zh-CN,zh;q=0.8
Connection:keep-alive
Content-Length:194
Content-Type:application/x-www-form-urlencoded; charset=UTF-8
Cookie:_ga=GA1.2.1597838376.1504599720; ai_user=sp1jt|2017-09-05T10:53:04.090Z; ARRAffinity=d48a0dd61144e14e99ea10eca4fef5d81bf07933a2831679353d2761cf0db5aa; cpid=YE5cTN4wQk4hTFdMf7FVTzM0bjPlNN1MJrFATNhI10hNAA; salt=761703E5A961C3EC8AD465F2A70F639F; ai_session=pWq6U|1504804573893.97|1504804670104.895
Host:kan.msxiaobing.com
Origin:https://kan.msxiaobing.com
Referer:https://kan.msxiaobing.com/Ima ... 2e702
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36
x-ms-request-id:4KL3u
x-ms-request-root-id:idMkH
X-Requested-With:XMLHttpRequest
Query String Parameters
view source
view URL encoded
service:yanzhi
tid:a14a6fd556cf45c181cb116f06471450
Form Data
view source
view URL encoded
MsgId:1504804707562
CreateTime:1504804707
Content[imageUrl]:https://mediaplatform.msxiaobi ... mOmXA
我们要构造data上面的信息,也就是要构造MsgId,CreateTime,Content[imageUrl]这三个信息,首先我们观察MsgId,发现它实质上就是当前的时间戳加了一个3位数的随机数,而第二个CreateTime虽然就是当前的时间戳,第三个Content[imageUrl]那当然就是我们刚才得到的图片地址了,我们就把这种参数给发起来
然后把这种恳求发起来之后,会发觉它的返回结果是none,那么这是为什么呢,这是因为谷歌添加了cookies和refer验证,所以我们要把这两个东西置于headers上面一起给传过去,然后都会发觉它返回一段json:
{‘msgId’: ‘4d39f92788774d65bd0261d6f4754865’, ‘timestamp’: 73, ‘receiverId’: None, ‘content’: {‘text’: ‘有潜力的姑娘!6.6分!性格肯定超好,男神最喜欢这些男孩纸咯,羡慕!’, ‘imageUrl’: ‘’, ‘metadata’: {‘AnswerFeed’: ‘FaceBeautyRanking’, ‘w’: ‘vvXoifT_gNLyhvXNhsPhjMz_pt_kbkdXisHliuToh-_uhcXkgePArM3_sN_kiuzeiuTlhvv-hMDGj_3vrPX5vsXDh_b6gv_khMr6hsjxjtvXrPHKt9XtiPfCg938jtPI’, ‘aid’: ‘303DB2A95867544E3E5EE047977CECF4’}}}
我们依照惯例,对它进行解析,我们提取下来['content']['text']里面的内容就行了,所以这一段的代码:
def get_score(img_url):
sys_time = int(time.time())
payload = {'service': 'yanzhi',
'tid': '7531216b61b14d208496ee52bca9a9a8'}
form = {
'MsgId': str(sys_time) + '733',
'CreateTime': sys_time,
'Content[imageUrl]': img_url,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
'Cookie': '_ga=GA1.2.1597838376.1504599720; _gid=GA1.2.1466467655.1504599720; ai_user=sp1jt|2017-09-05T10:53:04.090Z; cpid=YDLcMF5LPDFfSlQyfUkvMs9IbjQZMiQ2XTJHMVswUTFPAA; salt=EAA803807C2E9ECD7D786D3FA9516786; ARRAffinity=3dc0ec2b3434a920266e7d4652ca9f67c3f662b5a675f83cf7467278ef043663; ai_session=sQna0|1504664570638.64|1504664570638'+str(random.randint(11, 999)),
'Referer': 'https://kan.msxiaobing.com/ImageGame/Portal?task=yanzhi&feid=d89e6ce730dab7a2410c6dad803b5986'
}
r = requests.post(comp_url, params=payload, data=form, headers=headers)
print(r.json())
text = r.json()['content']['text']
return text
这样的话,我们就可以获得小冰对这个相片的评价,那么对于后期处理,我们只要用正则表达式把其中的关于逼格分数的地方提取下来就好了,那么这时候就须要保存刚才获得的评价分数,所以我们采用的方法就是对文件重命名,就是把文件名改成:分数+原来的文件名的方式,代码如下:
为了便捷我们对于程序的调试,所以用一个txt文件随时把程序的log信息传进去,就像这样:
至此,打分环节也完成了,下面进行下一项
三、把分数用图表的形式勾画下来
这一步须要用到matplotlib库中的pyplot,用它可以勾画出好多种不同的图,先引入库:
import matplotlib.pyplot as plt
import os
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
由于微软小冰的API调用次数的限制,我只成功的对2118张图片进行了逼格的打分,很容易的得到了每位分数段区间的数目:
<p>def get_score():
score_num=[]
for i in range(6):
score_num.append(0)
list=os.listdir()
for name in list:
if len(name)==24:
score=float(name[:3])
if score>=3 and score=4 and score=5 and score=6 and score=7 and score=8 and score
详解Java中的pinpoint1.8.5安装及使用手册
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2020-08-21 15:01
详解Java中的pinpoint1.8.5安装及使用手册
更新时间:2019年10月13日 09:15:53 转载作者:luozhiyun
pinpoint是开源在github上的一款APM监控工具,它是用Java编撰的,用于大规模分布式系统监控。这篇文章主要介绍了pinpoint1.8.5安装及使用手册,非常不错,具有一定的参考借鉴价值,需要的同学可以参考下
pinpoint1.8.5安装及使用手册
简介
pinpoint是开源在github上的一款APM监控工具,它是用Java编撰的,用于大规模分布式系统监控。它对性能的影响最小(只降低约3%资源利用率),安装agent是无侵入式的。
各大APM工具,几乎都是按照google这篇精典的Dapper论文而至,一定要读一读。这里是它的源文地址:,感谢那位朋友的翻译:
pinpoint提供了一些功能:
服务映射:通过可视化其组件怎么互连来了解任何分布式系统的关联关系。单击节点可显示有关组件的详尽信息,例如其当前状态和事务计数。
实时的活跃线程数
请求/响应散点图
调用栈
查看有关应用程序的其他详尽信息,例如CPU使用率,内存/垃圾搜集,TPS和JVM参数
整个pinpoint构架分为3部份:pinpoint-collector、pinpoint-agent、pinpoint-webUI。
pinpoint-agent:用来搜集单个应用的信息,并将搜集好的应用信息发送到pinpoint-collector中
pinpoint-collector:用来处理pinpoint-agent发送过来的信息,并将信息搜集好以后储存到HBase中
pinpoint-webUI:查找出HBase中的数据并展示
所以我这儿须要打算两台机器:
10.200.201.xxx:用于安装pinpoint-collector、pinpoint-webUI、HBase
10.200.201.yyy:用于安装pinpoint-agent,负责搜集应用的信息
环境安装
安装jdk
我这儿用的是rpm包直接安装的:rpm -ivh jdk-8u171-linux-x64.rpm
安装好后配置一下JAVA_HOME:
使用vim配置一下环境变量:
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_45
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
然后加载一些profile文件:
source /etc/profile
安装HBase
这里有个对照图:
由前面我们可以看见HBase我们须要安装1.2.x版本的
下载地址:
我这儿下载的是1.2.12版本的。
将Hbse放在指定目录
cd /app/install
tar -zxvf hbase-1.2.12-bin.tar.gz
修改配置信息
修改hbase-env.sh
vim /app/install/hbase-1.2.12/conf/hbase-env.sh
#加入JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_45
修改hbase-site.xml
vim /app/install/hbase-1.2.12/conf/hbase-site.xml
hbase.rootdir
file:///app/data/hbase
hbase.zookeeper.property.dataDir
/app/data/zookeeper
hbase.zookeeper.property.clientPort
2181
Property from ZooKeeper'sconfig zoo.cfg. The port at which the clients will connect.
hbase.cluster.distributed
false
启动HBase
cd /app/install/hbase-1.2.12/bin
./start-hbase.sh
# 查看Hbase是否启动成功,如果启动成功的会看到"HMaster"的进程
[root@localhost bin]# jps
12075 Jps
11784 HMaster
初始化pinpoint库
下载脚本:
#进入到hbase的bin目录中
cd /app/install/hbase-1.2.12/bin
#执行脚本
./bin/hbase shell /app/install/pinpoint/hbase/scripts/hbase-create.hbase
# 执行完了以后,进入Hbase
./hbase shell
#进入后可以看到Hbase的版本,还有一些相关的信息
2019-10-12 16:18:28,074 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version 1.2.12, r91d5ec4c4dcd10ceec984c6e663ea82acf353995, Sat Apr 6 15:27:28 CDT 2019
# 输入"status 'detailed'"可以查看刚才初始化的表,是否存在
hbase(main):002:0> status 'detailed'
也可以登入web,来查看HBase的数据是否初始化成功
:16010/master-status
安装pinpoint-collector
制作一个tomcat容器,端口号为8081
#将pinpoint-collector的war包丢到Tomcat的webapps目录下
cp pinpoint-collector-1.8.5.war ../apache-tomcat-8081/webapps/
#将war包名字改一下
mv pinpoint-web-1.8.5.war pp-collector.war
#启动tomcat
./bin/startup.sh
# 查看日志,是否成功启动
tail -f ../logs/catalina.out
#如果hbase安装在别的机器下需要修改一下配置
cd /app/install/apache-tomcat-8081
vim webapps/pp-collector/WEB-INF/classes/hbase.properties
#修改hbase的ip和hbase所对应的端口号
hbase.client.host=10.200.201.xxx
hbase.client.port=2181
安装pinpoint-web
解压一个tomcat容器,端口号为8080
#将pinpoint-web放到tomcat的webapps容器中
cp pinpoint-web-1.8.5.war ../apache-tomcat-8080/webapps/
#修改一下war包名
mv pinpoint-web-1.8.5.war pp-web.war
#启动tomcat
./bin/startup.sh
# 查看日志,是否成功启动
tail -f ../logs/catalina.out
#如果hbase安装在别的机器下需要修改一下配置
cd /app/install/apache-tomcat-8080
vim webapps/pp-web/WEB-INF/classes/hbase.properties
#修改hbase的ip和hbase所对应的端口号
hbase.client.host=10.200.201.xxx
hbase.client.port=2181
然后可以在浏览器中::8080/pp-web/
部署pinpoint-agent采集监控数据
传入pinpoint-agent包
首先将pinpoint-agent-1.8.5.tar.gz传入到服务器10.200.201.yyy的/app/install/pinpoint-agent/中
然后执行tar -zxvf pinpoint-agent-1.8.5.tar.gz解压
配置pp-agent采集器
cd /app/install/pinpoint-agent
vim pinpoint.config
# 主要修改IP,只需要指定到安装pp-col的IP就行了,安装pp-col启动后,自动就开启了9994,9995,9996的端口了。这里就不需要操心了,如果有端口需求,要去pp-col的配置文件("pp-collector/webapps/ROOT/WEB-INF/classes/pinpoint-collector.properties")中,修改这些端口
profiler.collector.ip=10.200.201.xxx
如果监控的是tomcat
# 修改测试项目下的tomcat启动文件"catalina.sh",修改这个只要是为了监控测试环境的Tomcat,增加探针
vi catalina.sh
# 第一行是pp-agent的jar包位置
# 第二行是agent的ID,这个ID是唯一的,我是用pp + 今天的日期命名的,只要与其他的项目的ID不重复就好了
# 第三行是采集项目的名字,这个名字可以随便取,只要各个项目不重复就好了
CATALINA_OPTS="$CATALINA_OPTS -javaagent:$AGENT_PATH/pinpoint-bootstrap-$VERSION.jar"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.agentId=$AGENT_ID"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.applicationName=$APPLICATION_NAME"
# 配置好了。就可以开始监控了,我们启动测试用的Tomcat的服务器
cd /data/pp-test/bin/
./startup.sh
# 查看启动日志,确实Tomcat启动
tail -f ../logs/catalina.out
springboot包部署
如果是jar包布署,直接在启动命令加启动参数:
nohup java -javaagent:/app/install/pinpoint-agent/pinpoint-bootstrap-1.8.5.jar -Dpinpoint.agentId=$AGENT_ID -Dpinpoint.applicationName=$APPLICATION_NAME
功能设置
设置监控
如果根据前面的方式安装完了以后在进行监控设置的或则用户设置的时侯会报错的:
所以须要配置一下mysql:
首先须要跑两个sql脚本:
然后步入到pinpoint-web的war所在的tomcat的容器中,修改配置文件:WEB-INF/classes/jdbc.properties
并设值mysql的帐号密码
jdbc.url=jdbc:mysql://localhost:13306/pinpoint?characterEncoding=UTF-8
jdbc.username=admin
jdbc.password=admin
我们可以在application上面给不同的应用设置不同的提醒规则,具体的提醒规则如下:
SLOW COUNT:发送到应用程序的慢速恳求数超过配置的阀值时触发
SLOW RATE
发送到应用程序的慢速恳求的比率(%)超过配置的阀值时触发
ERROR COUNT
发送到应用程序的失败恳求数超过配置的阀值时触发。
ERROR RATE
发送到应用程序的失败恳求的比率(%)超过配置的阀值时触发。
TOTAL COUNT
发送到应用程序的所有恳求数超过配置的阀值时触发。
SLOW COUNT TO CALLEE
当应用程序发送的慢速恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
例如),127.0.0.1:8080
SLOW RATE TO CALLEE
当应用程序发送的慢速恳求的比率(%)超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
ERROR COUNT TO CALLEE
当应用程序发送的失败恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
ERROR RATE TO CALLEE
当应用程序发送的失败恳求的比率(%)超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
TOTAL COUNT TO CALLEE
当应用程序发送的所有恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
HEAP USAGE RATE
当应用程序的堆使用率(%)超过配置的阀值时触发。
JVM CPU USAGE RATE
当应用程序的CPU使用率(%)超过配置的阀值时触发。
SYSTEM CPU USAGE RATE
当应用程序的CPU使用率(%)超过配置的阀值时发送警报。
DATASOURCE CONNECTION USAGE RATE
当应用程序的数据源联接使用率(%)超过配置的阀值时触发。
FILE DESCRIPTOR COUNT
当打开的文件描述符的数目超过配置的阀值时,发送警报。
然后须要在webapps/pp-web/WEB-INF/classes/batch.properties上面配置一下邮件服务器的信息:
pinpoint.url= #pinpoint-web server url
alarm.mail.server.url= #smtp server address
alarm.mail.server.port= #smtp server port
alarm.mail.server.username= #username for smtp server authentication
alarm.mail.server.password= #password for smtp server authentication
alarm.mail.sender.address= #sender's email address
#例如
pinpoint.url=http://pinpoint.com
alarm.mail.server.url=stmp.server.com
alarm.mail.server.port=583
alarm.mail.server.username=pinpoint
alarm.mail.server.password=pinpoint
alarm.mail.sender.address=pinpoint_operator@pinpoint.com
总结
以上所述是小编给你们介绍的pinpoint1.8.5安装及使用手册,希望对你们有所帮助! 查看全部
详解Java中的pinpoint1.8.5安装及使用手册
详解Java中的pinpoint1.8.5安装及使用手册
更新时间:2019年10月13日 09:15:53 转载作者:luozhiyun
pinpoint是开源在github上的一款APM监控工具,它是用Java编撰的,用于大规模分布式系统监控。这篇文章主要介绍了pinpoint1.8.5安装及使用手册,非常不错,具有一定的参考借鉴价值,需要的同学可以参考下
pinpoint1.8.5安装及使用手册
简介
pinpoint是开源在github上的一款APM监控工具,它是用Java编撰的,用于大规模分布式系统监控。它对性能的影响最小(只降低约3%资源利用率),安装agent是无侵入式的。
各大APM工具,几乎都是按照google这篇精典的Dapper论文而至,一定要读一读。这里是它的源文地址:,感谢那位朋友的翻译:
pinpoint提供了一些功能:
服务映射:通过可视化其组件怎么互连来了解任何分布式系统的关联关系。单击节点可显示有关组件的详尽信息,例如其当前状态和事务计数。
实时的活跃线程数
请求/响应散点图
调用栈
查看有关应用程序的其他详尽信息,例如CPU使用率,内存/垃圾搜集,TPS和JVM参数
整个pinpoint构架分为3部份:pinpoint-collector、pinpoint-agent、pinpoint-webUI。
pinpoint-agent:用来搜集单个应用的信息,并将搜集好的应用信息发送到pinpoint-collector中
pinpoint-collector:用来处理pinpoint-agent发送过来的信息,并将信息搜集好以后储存到HBase中
pinpoint-webUI:查找出HBase中的数据并展示
所以我这儿须要打算两台机器:
10.200.201.xxx:用于安装pinpoint-collector、pinpoint-webUI、HBase
10.200.201.yyy:用于安装pinpoint-agent,负责搜集应用的信息
环境安装
安装jdk
我这儿用的是rpm包直接安装的:rpm -ivh jdk-8u171-linux-x64.rpm
安装好后配置一下JAVA_HOME:
使用vim配置一下环境变量:
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_45
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
然后加载一些profile文件:
source /etc/profile
安装HBase
这里有个对照图:
由前面我们可以看见HBase我们须要安装1.2.x版本的
下载地址:
我这儿下载的是1.2.12版本的。
将Hbse放在指定目录
cd /app/install
tar -zxvf hbase-1.2.12-bin.tar.gz
修改配置信息
修改hbase-env.sh
vim /app/install/hbase-1.2.12/conf/hbase-env.sh
#加入JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_45
修改hbase-site.xml
vim /app/install/hbase-1.2.12/conf/hbase-site.xml
hbase.rootdir
file:///app/data/hbase
hbase.zookeeper.property.dataDir
/app/data/zookeeper
hbase.zookeeper.property.clientPort
2181
Property from ZooKeeper'sconfig zoo.cfg. The port at which the clients will connect.
hbase.cluster.distributed
false
启动HBase
cd /app/install/hbase-1.2.12/bin
./start-hbase.sh
# 查看Hbase是否启动成功,如果启动成功的会看到"HMaster"的进程
[root@localhost bin]# jps
12075 Jps
11784 HMaster
初始化pinpoint库
下载脚本:
#进入到hbase的bin目录中
cd /app/install/hbase-1.2.12/bin
#执行脚本
./bin/hbase shell /app/install/pinpoint/hbase/scripts/hbase-create.hbase
# 执行完了以后,进入Hbase
./hbase shell
#进入后可以看到Hbase的版本,还有一些相关的信息
2019-10-12 16:18:28,074 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version 1.2.12, r91d5ec4c4dcd10ceec984c6e663ea82acf353995, Sat Apr 6 15:27:28 CDT 2019
# 输入"status 'detailed'"可以查看刚才初始化的表,是否存在
hbase(main):002:0> status 'detailed'
也可以登入web,来查看HBase的数据是否初始化成功
:16010/master-status
安装pinpoint-collector
制作一个tomcat容器,端口号为8081
#将pinpoint-collector的war包丢到Tomcat的webapps目录下
cp pinpoint-collector-1.8.5.war ../apache-tomcat-8081/webapps/
#将war包名字改一下
mv pinpoint-web-1.8.5.war pp-collector.war
#启动tomcat
./bin/startup.sh
# 查看日志,是否成功启动
tail -f ../logs/catalina.out
#如果hbase安装在别的机器下需要修改一下配置
cd /app/install/apache-tomcat-8081
vim webapps/pp-collector/WEB-INF/classes/hbase.properties
#修改hbase的ip和hbase所对应的端口号
hbase.client.host=10.200.201.xxx
hbase.client.port=2181
安装pinpoint-web
解压一个tomcat容器,端口号为8080
#将pinpoint-web放到tomcat的webapps容器中
cp pinpoint-web-1.8.5.war ../apache-tomcat-8080/webapps/
#修改一下war包名
mv pinpoint-web-1.8.5.war pp-web.war
#启动tomcat
./bin/startup.sh
# 查看日志,是否成功启动
tail -f ../logs/catalina.out
#如果hbase安装在别的机器下需要修改一下配置
cd /app/install/apache-tomcat-8080
vim webapps/pp-web/WEB-INF/classes/hbase.properties
#修改hbase的ip和hbase所对应的端口号
hbase.client.host=10.200.201.xxx
hbase.client.port=2181
然后可以在浏览器中::8080/pp-web/
部署pinpoint-agent采集监控数据
传入pinpoint-agent包
首先将pinpoint-agent-1.8.5.tar.gz传入到服务器10.200.201.yyy的/app/install/pinpoint-agent/中
然后执行tar -zxvf pinpoint-agent-1.8.5.tar.gz解压
配置pp-agent采集器
cd /app/install/pinpoint-agent
vim pinpoint.config
# 主要修改IP,只需要指定到安装pp-col的IP就行了,安装pp-col启动后,自动就开启了9994,9995,9996的端口了。这里就不需要操心了,如果有端口需求,要去pp-col的配置文件("pp-collector/webapps/ROOT/WEB-INF/classes/pinpoint-collector.properties")中,修改这些端口
profiler.collector.ip=10.200.201.xxx
如果监控的是tomcat
# 修改测试项目下的tomcat启动文件"catalina.sh",修改这个只要是为了监控测试环境的Tomcat,增加探针
vi catalina.sh
# 第一行是pp-agent的jar包位置
# 第二行是agent的ID,这个ID是唯一的,我是用pp + 今天的日期命名的,只要与其他的项目的ID不重复就好了
# 第三行是采集项目的名字,这个名字可以随便取,只要各个项目不重复就好了
CATALINA_OPTS="$CATALINA_OPTS -javaagent:$AGENT_PATH/pinpoint-bootstrap-$VERSION.jar"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.agentId=$AGENT_ID"
CATALINA_OPTS="$CATALINA_OPTS -Dpinpoint.applicationName=$APPLICATION_NAME"
# 配置好了。就可以开始监控了,我们启动测试用的Tomcat的服务器
cd /data/pp-test/bin/
./startup.sh
# 查看启动日志,确实Tomcat启动
tail -f ../logs/catalina.out
springboot包部署
如果是jar包布署,直接在启动命令加启动参数:
nohup java -javaagent:/app/install/pinpoint-agent/pinpoint-bootstrap-1.8.5.jar -Dpinpoint.agentId=$AGENT_ID -Dpinpoint.applicationName=$APPLICATION_NAME
功能设置
设置监控
如果根据前面的方式安装完了以后在进行监控设置的或则用户设置的时侯会报错的:
所以须要配置一下mysql:
首先须要跑两个sql脚本:
然后步入到pinpoint-web的war所在的tomcat的容器中,修改配置文件:WEB-INF/classes/jdbc.properties
并设值mysql的帐号密码
jdbc.url=jdbc:mysql://localhost:13306/pinpoint?characterEncoding=UTF-8
jdbc.username=admin
jdbc.password=admin
我们可以在application上面给不同的应用设置不同的提醒规则,具体的提醒规则如下:
SLOW COUNT:发送到应用程序的慢速恳求数超过配置的阀值时触发
SLOW RATE
发送到应用程序的慢速恳求的比率(%)超过配置的阀值时触发
ERROR COUNT
发送到应用程序的失败恳求数超过配置的阀值时触发。
ERROR RATE
发送到应用程序的失败恳求的比率(%)超过配置的阀值时触发。
TOTAL COUNT
发送到应用程序的所有恳求数超过配置的阀值时触发。
SLOW COUNT TO CALLEE
当应用程序发送的慢速恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
例如),127.0.0.1:8080
SLOW RATE TO CALLEE
当应用程序发送的慢速恳求的比率(%)超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
ERROR COUNT TO CALLEE
当应用程序发送的失败恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
ERROR RATE TO CALLEE
当应用程序发送的失败恳求的比率(%)超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
TOTAL COUNT TO CALLEE
当应用程序发送的所有恳求数超过配置的阀值时触发。 您必须在配置UI的“注释...”框中指定域或地址(IP,端口)
ex) , 127.0.0.1:8080
HEAP USAGE RATE
当应用程序的堆使用率(%)超过配置的阀值时触发。
JVM CPU USAGE RATE
当应用程序的CPU使用率(%)超过配置的阀值时触发。
SYSTEM CPU USAGE RATE
当应用程序的CPU使用率(%)超过配置的阀值时发送警报。
DATASOURCE CONNECTION USAGE RATE
当应用程序的数据源联接使用率(%)超过配置的阀值时触发。
FILE DESCRIPTOR COUNT
当打开的文件描述符的数目超过配置的阀值时,发送警报。
然后须要在webapps/pp-web/WEB-INF/classes/batch.properties上面配置一下邮件服务器的信息:
pinpoint.url= #pinpoint-web server url
alarm.mail.server.url= #smtp server address
alarm.mail.server.port= #smtp server port
alarm.mail.server.username= #username for smtp server authentication
alarm.mail.server.password= #password for smtp server authentication
alarm.mail.sender.address= #sender's email address
#例如
pinpoint.url=http://pinpoint.com
alarm.mail.server.url=stmp.server.com
alarm.mail.server.port=583
alarm.mail.server.username=pinpoint
alarm.mail.server.password=pinpoint
alarm.mail.sender.address=pinpoint_operator@pinpoint.com
总结
以上所述是小编给你们介绍的pinpoint1.8.5安装及使用手册,希望对你们有所帮助!

