
文章采集调用
DEDECMS采集仅下载图片(jpg)不下载视频(swf)的更改办法
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-08-10 00:30
DEDECMS采集仅下载图片(jpg)不下载视频(swf)的更改办法
今天尝试为织梦dedecms 站长基地采集文章的时侯,在视频这一块遇见了不少麻烦,发现在织梦dedecms的采集模块当中,仅有一个“下载数组里的多媒体资源”的勾选项。
也就是说,只要勾选这一项,它都会默认将多媒体资源全部手动上传至FTP本地上,图片一般是没有问题的,但对于视频,并不适宜上传至服务器,而且好多第三方视频网站的调用代码是不容许在其中添加其它代码的,这就要求我们必须限制视频格式的多媒体手动上传,看到官方好多同学碰到类似问题,官方也没有给与答复,于是经过自己不断研究总算找到解决办法,现分享给诸位,希望能对诸位有所帮助。
找到控制多媒体上传的文件(include/dede采集.class.php)找到以下代码:
if($v=='embed' && !preg_match("#\.(swf)\?(.*)$#i", $k)&& !preg_match("#\.(swf)$#i", $k))
修改为
if($v!='img' && !preg_match("#\.(jpg|gif|png)\?(.*)$#i", $k)&& !preg_match("#\.(jpg|gif|png)$#i", $k))
然后继续查找:
else if(preg_match("#\.(swf)\?(.*)$#i", $v) || preg_match("#\.(swf)$#i", $v))
{
$m = "embed";
}
将这句注释掉或则直接删掉掉。
最新标签 查看全部
简介: 今天尝试为织梦dedecms 站长基地采集文章的时侯,在视频这一块遇见了不少麻烦,发现在织梦dedecms的采集模块当中,仅有一个下载数组里的多媒体资源的勾选项。 也就是说,只要勾选这一项,它都会默认将多媒体资源全部手动上传至FTP本地上,图片一般是没有问题文章来源菜鸟建站网
DEDECMS采集仅下载图片(jpg)不下载视频(swf)的更改办法
今天尝试为织梦dedecms 站长基地采集文章的时侯,在视频这一块遇见了不少麻烦,发现在织梦dedecms的采集模块当中,仅有一个“下载数组里的多媒体资源”的勾选项。

也就是说,只要勾选这一项,它都会默认将多媒体资源全部手动上传至FTP本地上,图片一般是没有问题的,但对于视频,并不适宜上传至服务器,而且好多第三方视频网站的调用代码是不容许在其中添加其它代码的,这就要求我们必须限制视频格式的多媒体手动上传,看到官方好多同学碰到类似问题,官方也没有给与答复,于是经过自己不断研究总算找到解决办法,现分享给诸位,希望能对诸位有所帮助。
找到控制多媒体上传的文件(include/dede采集.class.php)找到以下代码:
if($v=='embed' && !preg_match("#\.(swf)\?(.*)$#i", $k)&& !preg_match("#\.(swf)$#i", $k))
修改为
if($v!='img' && !preg_match("#\.(jpg|gif|png)\?(.*)$#i", $k)&& !preg_match("#\.(jpg|gif|png)$#i", $k))
然后继续查找:
else if(preg_match("#\.(swf)\?(.*)$#i", $v) || preg_match("#\.(swf)$#i", $v))
{
$m = "embed";
}
将这句注释掉或则直接删掉掉。
最新标签
Fiddler 网页采集抓包神器__手机app抓包
采集交流 • 优采云 发表了文章 • 0 个评论 • 615 次浏览 • 2020-08-09 16:25
基于weiphp做了一个掌上头条插件,也是用的网页采集技术;和一个创业团队一起在做一个中考志愿补报系统,所有的数据也是从别的地方抓取。
总而言之,网页抓取与网页采集技术是一项十分实用的技能,他能使我们高效快速的获取我们开发产品所须要的一些基本数据。
网页抓取与网页采集过程中难免须要用到抓包技术,所谓抓包,就是我们在访问一个目标网站的时侯,需要剖析我们递交给浏览器的一些http请求以及递交给浏览器的一些数据,在晓得恳求是怎样发起的以及post了什么数据以后,我们能够针对目标网页写出相应的采集程序。特别是在模拟登录一些须要用户进行登入验证的网站时,抓包剖析就显得很重要。
一些浏览器自带抓包剖析工具或则有其可扩充的抓包插件,像火狐浏览器有firebug插件,IE浏览器有HttpWatch。每个抓包工具都有其独到的功能,这里就不一一介绍了,今天给你们介绍一个好用的抓包工具Fiddler。
手机APP抓包
现在我们来结合一个具体的事例来讲一下怎么抓包剖析手机APP的恳求数据,并达到自己的需求。我这儿给你们讲一个LOL盒子的抓包实例。
我们晓得,LOL盒子没有网页版,或者说网页版的功能并不象手机APP一样数据整合的这么齐全。如果我们要做一个陌陌版的LOL盒子,让用户在微信端回复一些关键词才能查看一些基本信息,比如用户在陌陌中回复“英雄”就能查看LOL全部的英雄信息,包括出装、符文之类的。那么我们想在陌陌端实现这种功能,肯定须要数据库的支持,如果我们的数据从LOL官网抓取的话,免不了要写好多匹配规则,所以一个简单高效的方式是直接抓取LOL盒子早已整合了的数据。那么题外话开始,我们开始抓LOL盒子集成的全部英雄的数据。
1、首先在手机下载LOL盒子,并步入首页(请忽视我这个战五渣的战斗力指数)
2、打开Fiddler并点Remove all把抓包信息全部消除
3、在LOL盒子中点击英雄步入查看英雄页面
4、可以看见查看英雄页面有免费、我的英雄、全部三个选项
5、这时候我们可以看见Fiddler早已抓到我们须要的数据插口了
6、我们在其中一个数据插口里面点击右键,复制url地址并在浏览器中打开
7、就能看见我们须要的周免英雄的数据插口了,是json格式的
到此为止,抓包剖析的整个流程你们一目了然了,得到了json插口以后,我们能够用curl技术把数据采集下来,并把json格式的数据转换成链表或则其他格式,然后就可以存到我们自己的数据库中了,当用户在陌陌中回复关键词时,我们就从数据库中取出相应的数据并回复给用户就行了。 查看全部
用curl技术开发了一个陌陌文章聚合类产品,把抓取到的数据转换成json格式,并在android端调用json数据插口加以显示;
基于weiphp做了一个掌上头条插件,也是用的网页采集技术;和一个创业团队一起在做一个中考志愿补报系统,所有的数据也是从别的地方抓取。
总而言之,网页抓取与网页采集技术是一项十分实用的技能,他能使我们高效快速的获取我们开发产品所须要的一些基本数据。
网页抓取与网页采集过程中难免须要用到抓包技术,所谓抓包,就是我们在访问一个目标网站的时侯,需要剖析我们递交给浏览器的一些http请求以及递交给浏览器的一些数据,在晓得恳求是怎样发起的以及post了什么数据以后,我们能够针对目标网页写出相应的采集程序。特别是在模拟登录一些须要用户进行登入验证的网站时,抓包剖析就显得很重要。
一些浏览器自带抓包剖析工具或则有其可扩充的抓包插件,像火狐浏览器有firebug插件,IE浏览器有HttpWatch。每个抓包工具都有其独到的功能,这里就不一一介绍了,今天给你们介绍一个好用的抓包工具Fiddler。
手机APP抓包
现在我们来结合一个具体的事例来讲一下怎么抓包剖析手机APP的恳求数据,并达到自己的需求。我这儿给你们讲一个LOL盒子的抓包实例。
我们晓得,LOL盒子没有网页版,或者说网页版的功能并不象手机APP一样数据整合的这么齐全。如果我们要做一个陌陌版的LOL盒子,让用户在微信端回复一些关键词才能查看一些基本信息,比如用户在陌陌中回复“英雄”就能查看LOL全部的英雄信息,包括出装、符文之类的。那么我们想在陌陌端实现这种功能,肯定须要数据库的支持,如果我们的数据从LOL官网抓取的话,免不了要写好多匹配规则,所以一个简单高效的方式是直接抓取LOL盒子早已整合了的数据。那么题外话开始,我们开始抓LOL盒子集成的全部英雄的数据。
1、首先在手机下载LOL盒子,并步入首页(请忽视我这个战五渣的战斗力指数)

2、打开Fiddler并点Remove all把抓包信息全部消除

3、在LOL盒子中点击英雄步入查看英雄页面
4、可以看见查看英雄页面有免费、我的英雄、全部三个选项

5、这时候我们可以看见Fiddler早已抓到我们须要的数据插口了

6、我们在其中一个数据插口里面点击右键,复制url地址并在浏览器中打开
7、就能看见我们须要的周免英雄的数据插口了,是json格式的
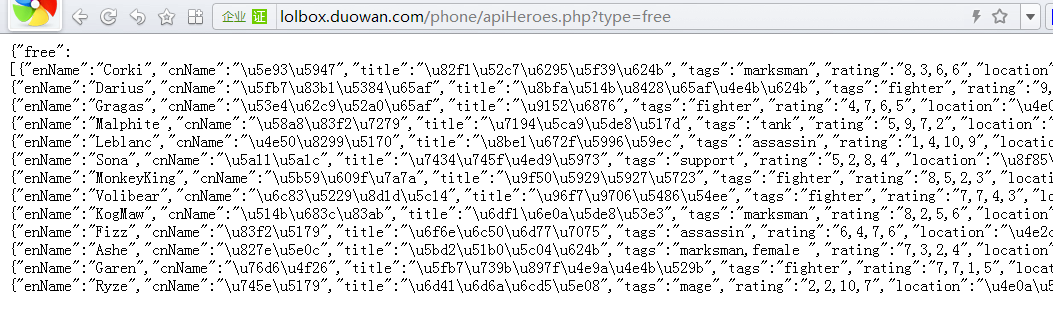
到此为止,抓包剖析的整个流程你们一目了然了,得到了json插口以后,我们能够用curl技术把数据采集下来,并把json格式的数据转换成链表或则其他格式,然后就可以存到我们自己的数据库中了,当用户在陌陌中回复关键词时,我们就从数据库中取出相应的数据并回复给用户就行了。
DEDE采集分页文章时相对路径问题解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-08-09 15:08
问题描述:
当采集目标文章中列表或则分页信息是绝对路径时,DEDE可以正确采集。
当采集目标文章中列表或则分页信息是相对路径,但是以 '/'开头(如 /2012/0328/1943.html)DEDE也可以正确采集。
当采集目标文章中列表或则分页信息是相对路径,但不是以 '/'开头(如 2012/0328/1943.html)DEDE就不能正确采集了。
解决方案:
问题的症结出在 dedehtml2.class.php 中的 FillUrl 函数上,大概在394行左右:
if( strlen($surl) < 7 )<br /> {<br /> $okurl = $this->BaseUrlPath.'/'.$surl;<br /> }<br /> else if( strtolower(substr($surl,0,7))=='http://' )<br /> {<br /> $okurl = preg_replace('/^http:\/\//i', '', $surl);<br /> }<br /> else<br /> {<br /> //$okurl = $this->BaseUrlPath.'/'.$surl; <br /> $okurl = $this->HomeUrl.'/'.$surl; <br /> }
被注释掉的(红色)代码是原创的,增加下边一行(绿色)代码问题就解决了。
DedeCms下载:
织梦CMS(DedeCMS) v5.7 SP1 GBK build20150618下载
界面预览 查看全部
使用DedeCMS在采集文章的时侯,发现DEDE采集文章相对路径文章时的一个bug,上网查询了一个晚上总算找到类似问题的解决办法,最后把这个问题的症结找到而且解决了。
问题描述:
当采集目标文章中列表或则分页信息是绝对路径时,DEDE可以正确采集。
当采集目标文章中列表或则分页信息是相对路径,但是以 '/'开头(如 /2012/0328/1943.html)DEDE也可以正确采集。
当采集目标文章中列表或则分页信息是相对路径,但不是以 '/'开头(如 2012/0328/1943.html)DEDE就不能正确采集了。
解决方案:
问题的症结出在 dedehtml2.class.php 中的 FillUrl 函数上,大概在394行左右:
if( strlen($surl) < 7 )<br /> {<br /> $okurl = $this->BaseUrlPath.'/'.$surl;<br /> }<br /> else if( strtolower(substr($surl,0,7))=='http://' )<br /> {<br /> $okurl = preg_replace('/^http:\/\//i', '', $surl);<br /> }<br /> else<br /> {<br /> //$okurl = $this->BaseUrlPath.'/'.$surl; <br /> $okurl = $this->HomeUrl.'/'.$surl; <br /> }
被注释掉的(红色)代码是原创的,增加下边一行(绿色)代码问题就解决了。
DedeCms下载:
织梦CMS(DedeCMS) v5.7 SP1 GBK build20150618下载


界面预览
非盈利机构ABUSE搜集约10万个恶意网站可供免费调用
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2020-08-09 13:48
这些恶意网站均为安全研究人员发觉后自动递交的,在初审通过后便会添加到恶意网站数据库里可免费调用。
数据库早已将各个恶意网站按不同类型进行标记,例如当前是否在线、恶意内容类型、潜在的恐吓信息等等。
安全软件开发商以及浏览器开发商等都可以免费调用这份数据库帮助用户拦截这些可能存在恐吓的恶意网站。
国内某345的部份地址也会警告:
需注意的是这份数据库不分辨恶意网站还是正常网站被入侵弄成恶意网站的,只有仍然存在恐吓都会被警告。
数据库每隔五分钟都会更新确保就能更及时的拦截恶意网站, 这也是 ABUSE 建立这个恶意网站列表的诱因。
该非盈利机构表示当前好多恶意网站存活数月才被拦截,对于用户来说这个拦截时效实在很慢不能保护用户。
蓝点网测试发觉这种恶意网站类型涵括多种,例如蓝点网检索还发觉有针对国外企业功击的垂钓 DOC 文档。
这类文档通过短信或则其他形式传播,当用户打开并放行Word 安全保护时就可能会执行恶意代码感染用户。
最后任何人都可以向这份恶意网站数据库添加恶意网站,只须要使用脸书帐号登入该网站后即可进行递交等。 查看全部
非盈利机构 ABUSE 最新公布的博客显示目前由全球各地安全研究人员递交的恶意网站列表早已超过10万个。
这些恶意网站均为安全研究人员发觉后自动递交的,在初审通过后便会添加到恶意网站数据库里可免费调用。
数据库早已将各个恶意网站按不同类型进行标记,例如当前是否在线、恶意内容类型、潜在的恐吓信息等等。
安全软件开发商以及浏览器开发商等都可以免费调用这份数据库帮助用户拦截这些可能存在恐吓的恶意网站。
国内某345的部份地址也会警告:
需注意的是这份数据库不分辨恶意网站还是正常网站被入侵弄成恶意网站的,只有仍然存在恐吓都会被警告。
数据库每隔五分钟都会更新确保就能更及时的拦截恶意网站, 这也是 ABUSE 建立这个恶意网站列表的诱因。
该非盈利机构表示当前好多恶意网站存活数月才被拦截,对于用户来说这个拦截时效实在很慢不能保护用户。
蓝点网测试发觉这种恶意网站类型涵括多种,例如蓝点网检索还发觉有针对国外企业功击的垂钓 DOC 文档。
这类文档通过短信或则其他形式传播,当用户打开并放行Word 安全保护时就可能会执行恶意代码感染用户。
最后任何人都可以向这份恶意网站数据库添加恶意网站,只须要使用脸书帐号登入该网站后即可进行递交等。
织梦调用指定列和分页下的文章列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-09 01:49
该站点的技术团队在织梦CMS,帝国模仿站点和二次开发方面拥有7年的经验. 拥有一支稳定的设计团队和技术团队,以确保您的售后技术服务. 仿制台最低为200元,欢迎咨询客服.
业务范围:
开源CMS(帝国,梦织)模仿站点,成品自适应模板,网站克隆,网站定制,修订,二次开发,获取,新功能开发!
仿站强度:
200元企业模仿站(标准企业站),最快3个小时下达订单,准确率达到99%.
—————————————————————————————————————————————— ——————————
说明: Dream Weaving的默认分页(列表)是在当前列下的页面,但是在许多情况下,如果我们划分,则需要在某些列下开发列表页面,例如医疗行业的典型案例该列合并为下一个疾病案例(如下图所示),因此导航中的典型案例需要调用很多指定的列列表和页面;
在这里,我们谈论最简单的方法. 除了当前列下的分页外,“织梦”还具有多个列下的列表页;
1. 使用模板找到该列->“更改”->“常规”选项->“列交叉”->“手动指定交叉列的ID(用逗号分隔)
2,只需使用默认列表调用,这很简单
{dede: list pagesize =“ 10” orderby ='pubdate'}
[field: title /]
{/ dede: list}
{dede: pagelist listitem =“ info,index,end,pre,next,pageno” listsize =“ 1” /} 查看全部
—————————————————————————————————————————————— ——————————
该站点的技术团队在织梦CMS,帝国模仿站点和二次开发方面拥有7年的经验. 拥有一支稳定的设计团队和技术团队,以确保您的售后技术服务. 仿制台最低为200元,欢迎咨询客服.
业务范围:
开源CMS(帝国,梦织)模仿站点,成品自适应模板,网站克隆,网站定制,修订,二次开发,获取,新功能开发!
仿站强度:
200元企业模仿站(标准企业站),最快3个小时下达订单,准确率达到99%.
—————————————————————————————————————————————— ——————————
说明: Dream Weaving的默认分页(列表)是在当前列下的页面,但是在许多情况下,如果我们划分,则需要在某些列下开发列表页面,例如医疗行业的典型案例该列合并为下一个疾病案例(如下图所示),因此导航中的典型案例需要调用很多指定的列列表和页面;

在这里,我们谈论最简单的方法. 除了当前列下的分页外,“织梦”还具有多个列下的列表页;
1. 使用模板找到该列->“更改”->“常规”选项->“列交叉”->“手动指定交叉列的ID(用逗号分隔)

2,只需使用默认列表调用,这很简单
{dede: list pagesize =“ 10” orderby ='pubdate'}
[field: title /]
{/ dede: list}
{dede: pagelist listitem =“ info,index,end,pre,next,pageno” listsize =“ 1” /}
LabVIEW调用数据采集卡DLL函数
采集交流 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2020-08-08 01:06
与传统的编程语言不同,LabVIEW使用一种功能强大的图形语言编程语言为测试工程师而非专业程序员服务. 编程非常方便. 人机交互界面直观友好. 它具有强大的数据可视化分析和仪器控制功能. 使用LabVIEW开发环境,用户可以创建32位编译器,从而为常规数据采集,测试和测量任务提供更快的运行速度. LabVIEW是真正的编译器. 用户可以创建独立的可执行文件,这些文件可以独立于开发环境运行. 对于大多数编程任务,LabVIEW通常生成高效的代码. 1 LabVIEW是调用外部程序代码的方法之一. 动态链接库机制1.1动态链接库机制概述LabVIEW是一个功能强大的虚拟仪器开发环境,已与GPIB VXI RS-232 RS-485插值数据采集完全集成在一起. LabVIEW还具有一个内置库,可通过共享ActiveX的DLL和其他方式实现与外部程序代码或软件系统的连接,从而提供大量的连接机制. LabVIEW提供了四种调用外部程序代码的方法. 动态链接库DLL机制是从LabVIEW调用标准共享库和用户定义的库函数的通用方法. 具体实现是使用LabVIEW函数模板的Advanced子模板中的Call Library Function节点.
呼叫库功能节点收录大量数据类型和呼叫规范. 使用它可以调用大多数标准共享库和用户定义的库,包括Windows9X / XP / 2000 / NT下的动态链接库. 动态链接库Macintosh UNIX共享库功能下的“代码片段共享库功能”下的代码片段当用户需要调用的代码已经存在,或者用户熟悉以下代码段UNIX中共享库的创建过程时: 在Windows动态链接库中,调用库函数节点非常有用. 此时,它也是最合适的方法,因为图书馆使用的是收据日期. 2004-04-21基金项目湖北省教育厅重点项目2003A006作者简介襄樊学院物理系副教授,湖北鄂州. 15.调用LabVIEW到数据采集卡DLL功能16适用于多种开发环境的格式标准,因此用户几乎可以使用任何开发环境来创建LabVIEW可以调用的库. 1.2动态链接库机制的实现步骤在Windows 9X下,使用LabVIEW 6.1(Windows95 / 98 / NT)中的动态链接库机制来调用DLL. DLL返回计算机的名称.
1)创建一个调用库函数节点,创建一个新的LabVIEW程序主机名. 将vi保存到新创建的目录d: \ temp. 图1库函数调用前面板框图. 该程序如图2所示的库函数调用框图. 通过在功能模板的“高级”子模板中选择“调用库功能”功能模块,可以选择“调用库功能”节点. 生产的. 该LabVIEW程序通过调用库函数节点来调用DLL. 该DLL将返回计算机的名称,并将返回的结果存储在字符串指示器“计算机名称”中,然后将字符串常量LabVIEW MachineName连接起来以显示字符串指示器“ Message”. 2)配置调用库功能节点在程序框图程序窗口中双击“调用库功能”节点. 在弹出对话框中,配置调用库功能节点,然后在LibraryName Path项目中输入d: \ temp \ hostname. dll表示此节点链接的DLL文件的名称,它是C源代码的主机名. c编译并键入FunctionName项目MachineName,以在链接到该节点的DLL文件中指示函数的名称. 参数返回类型是选择Void的类型. 添加的另一个参数是arg1的类型. 字符串格式为选择“字符串句柄3”. )编辑C源文件以编辑C源文件的主机名.
c保存到目录d: \ temp includeextcode. h收录LabVIEW函数的#include #include #include BOOL WINAPI DllMain(HANDLE hDLL,DWORD dwReason,LPVOID lpReserved)返回TRUE;函数获取计算机名__declspec(dllexport)无效MachineName(void * LVHandle)charcomputerName [MAX_COMPUTERNAME_LENGTH + 1]; intENGTH compNameLength;襄樊学院学报第二十五期2004 Getcomputer name GetComputerName(computerName,&compNameLength); SizeLabVIEW句柄正确大小DSSetHandleSize(LVHandle,compNameLength stringsize LabVIEWhandle **(int32 **)LVHandle LabVIEWhandle sprintf((*(char **)LVHandle)+4,“%s”,computerName);该程序首先调用Windows API函数GetComputerName获取机器名,然后调用LabVIEW函数DSSetHandleSize设置LabVIEW句柄的大小,最后,将机器名的32位整数机器名字符串依次写入到句柄中.
4)编译C源代码. 将C源代码更改为d: \ temp \主机名. c编译为DLL文件d: \ temp \ hostname. dll可以使用VC ++ 6.0 Windows95 / 98/2000 / NT来完成此编译. 5)运行VI以运行LabVIEW程序的主机名. vi的结果如下. 图3前面板运行结果. 2结束语本文重点介绍和实现一种将LabVIEW与外部代码,动态链接库机制连接的高级技术,并给出一个应用示例. 由于LabVIEW中引入了C语言的强大功能,因此LabVIEW的整体性能得到了改善. 该方法已在LabVIEW 6.1 Windows95 / 98 / NT和Visual Windows9X / XP / 2000 / NT环境中实现. 实践证明,该方法高效,易于实现. 这是增强LabVIEW与其他Windows应用程序之间数据共享能力的好方法. 参考文献: National Instruments Corporation LabVIEW用户手册1998. National Instruments Corporation 1998编程参考手册.
LabVIEW数据采集调用DLL函数刘传清(襄樊大学物理系,襄樊441053)摘要介绍了虚拟仪器的开发环境LabVIEW分析了先进技术动态链接库(DLL),该方法通常可从LabVIEW调用外部代码. 事实证明,有效的做法是提高LabVIEW与Windows其他应用程序共享数据的能力. 关键词: 虚拟仪器; LabVIEW;动态链接库 查看全部
《襄樊大学学报》. ,2004年第25届襄樊大学学报25号5号LabVIEW调用数据采集卡的DLL函数,湖北襄樊襄樊学院物理系441053摘要首先介绍虚拟仪器的特性及其开发环境LabVIEW6,并实现连接LabVIEW的先进技术之一与外部代码. 动态链接库DLL机制. 实践证明,该机制高效且易于实现,是增强LabVIEW与其他Windows应用程序之间数据共享能力的好方法. 关键字虚拟仪器LabVIEW动态链接库DLL中文库分类号TN311.11文档标记代码A文章编号1 05-0015-03 0引言LabVIEW的出现是基于National Instruments的一种基于G语言的开发环境. 虚拟仪器所谓的连接到行业的虚拟仪器就是在通用计算机平台上根据自己的需求定义和设计仪器的测试功能. 本质是将传统仪器硬件与最新的计算机软件技术充分结合,以实现和扩展具有模块化软件的传统仪器. 功能. 与虚拟仪器相比,系统仪器在智能,处理能力,性能价格比和可操作性方面具有明显的技术优势. LabVIEW实验室虚拟仪器工程工作台目前是世界上使用最广泛的虚拟仪器开发环境之一. 它主要用于仪器控制,数据采集,数据分析,数据显示等,并且适用于Windows9X / XP / 2000 /许多不同的操作系统平台,例如NT Macintosh UNIX.
与传统的编程语言不同,LabVIEW使用一种功能强大的图形语言编程语言为测试工程师而非专业程序员服务. 编程非常方便. 人机交互界面直观友好. 它具有强大的数据可视化分析和仪器控制功能. 使用LabVIEW开发环境,用户可以创建32位编译器,从而为常规数据采集,测试和测量任务提供更快的运行速度. LabVIEW是真正的编译器. 用户可以创建独立的可执行文件,这些文件可以独立于开发环境运行. 对于大多数编程任务,LabVIEW通常生成高效的代码. 1 LabVIEW是调用外部程序代码的方法之一. 动态链接库机制1.1动态链接库机制概述LabVIEW是一个功能强大的虚拟仪器开发环境,已与GPIB VXI RS-232 RS-485插值数据采集完全集成在一起. LabVIEW还具有一个内置库,可通过共享ActiveX的DLL和其他方式实现与外部程序代码或软件系统的连接,从而提供大量的连接机制. LabVIEW提供了四种调用外部程序代码的方法. 动态链接库DLL机制是从LabVIEW调用标准共享库和用户定义的库函数的通用方法. 具体实现是使用LabVIEW函数模板的Advanced子模板中的Call Library Function节点.
呼叫库功能节点收录大量数据类型和呼叫规范. 使用它可以调用大多数标准共享库和用户定义的库,包括Windows9X / XP / 2000 / NT下的动态链接库. 动态链接库Macintosh UNIX共享库功能下的“代码片段共享库功能”下的代码片段当用户需要调用的代码已经存在,或者用户熟悉以下代码段UNIX中共享库的创建过程时: 在Windows动态链接库中,调用库函数节点非常有用. 此时,它也是最合适的方法,因为图书馆使用的是收据日期. 2004-04-21基金项目湖北省教育厅重点项目2003A006作者简介襄樊学院物理系副教授,湖北鄂州. 15.调用LabVIEW到数据采集卡DLL功能16适用于多种开发环境的格式标准,因此用户几乎可以使用任何开发环境来创建LabVIEW可以调用的库. 1.2动态链接库机制的实现步骤在Windows 9X下,使用LabVIEW 6.1(Windows95 / 98 / NT)中的动态链接库机制来调用DLL. DLL返回计算机的名称.
1)创建一个调用库函数节点,创建一个新的LabVIEW程序主机名. 将vi保存到新创建的目录d: \ temp. 图1库函数调用前面板框图. 该程序如图2所示的库函数调用框图. 通过在功能模板的“高级”子模板中选择“调用库功能”功能模块,可以选择“调用库功能”节点. 生产的. 该LabVIEW程序通过调用库函数节点来调用DLL. 该DLL将返回计算机的名称,并将返回的结果存储在字符串指示器“计算机名称”中,然后将字符串常量LabVIEW MachineName连接起来以显示字符串指示器“ Message”. 2)配置调用库功能节点在程序框图程序窗口中双击“调用库功能”节点. 在弹出对话框中,配置调用库功能节点,然后在LibraryName Path项目中输入d: \ temp \ hostname. dll表示此节点链接的DLL文件的名称,它是C源代码的主机名. c编译并键入FunctionName项目MachineName,以在链接到该节点的DLL文件中指示函数的名称. 参数返回类型是选择Void的类型. 添加的另一个参数是arg1的类型. 字符串格式为选择“字符串句柄3”. )编辑C源文件以编辑C源文件的主机名.
c保存到目录d: \ temp includeextcode. h收录LabVIEW函数的#include #include #include BOOL WINAPI DllMain(HANDLE hDLL,DWORD dwReason,LPVOID lpReserved)返回TRUE;函数获取计算机名__declspec(dllexport)无效MachineName(void * LVHandle)charcomputerName [MAX_COMPUTERNAME_LENGTH + 1]; intENGTH compNameLength;襄樊学院学报第二十五期2004 Getcomputer name GetComputerName(computerName,&compNameLength); SizeLabVIEW句柄正确大小DSSetHandleSize(LVHandle,compNameLength stringsize LabVIEWhandle **(int32 **)LVHandle LabVIEWhandle sprintf((*(char **)LVHandle)+4,“%s”,computerName);该程序首先调用Windows API函数GetComputerName获取机器名,然后调用LabVIEW函数DSSetHandleSize设置LabVIEW句柄的大小,最后,将机器名的32位整数机器名字符串依次写入到句柄中.
4)编译C源代码. 将C源代码更改为d: \ temp \主机名. c编译为DLL文件d: \ temp \ hostname. dll可以使用VC ++ 6.0 Windows95 / 98/2000 / NT来完成此编译. 5)运行VI以运行LabVIEW程序的主机名. vi的结果如下. 图3前面板运行结果. 2结束语本文重点介绍和实现一种将LabVIEW与外部代码,动态链接库机制连接的高级技术,并给出一个应用示例. 由于LabVIEW中引入了C语言的强大功能,因此LabVIEW的整体性能得到了改善. 该方法已在LabVIEW 6.1 Windows95 / 98 / NT和Visual Windows9X / XP / 2000 / NT环境中实现. 实践证明,该方法高效,易于实现. 这是增强LabVIEW与其他Windows应用程序之间数据共享能力的好方法. 参考文献: National Instruments Corporation LabVIEW用户手册1998. National Instruments Corporation 1998编程参考手册.
LabVIEW数据采集调用DLL函数刘传清(襄樊大学物理系,襄樊441053)摘要介绍了虚拟仪器的开发环境LabVIEW分析了先进技术动态链接库(DLL),该方法通常可从LabVIEW调用外部代码. 事实证明,有效的做法是提高LabVIEW与Windows其他应用程序共享数据的能力. 关键词: 虚拟仪器; LabVIEW;动态链接库
[织梦cms站]主页/列表页调用文章描述字数限制
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-07 20:09
接下来,我们将介绍一种或两种方法来修改首页/列表页面上文章描述的字符数限制:
1. 使用infolen可以限制所调用的文章描述中的单词数,如以下标记所示:
{dede: arclist row =“ 1” infolen ='170'}
[field: info /]...
{/ dede: arclist}
上面的infolen ='170'表示调用170字节的文章描述,170字节= 85个汉字.
2. 使用[field: description function ='cn_substr(@ me,170)'/]代替[field: info /]标签,具体步骤如下:
170表示受字数限制的字节数,170字节= 85个汉字,请根据要显示的字符数进行更改.
Dedecms编织梦的官方默认最大字节数是255. 有时它可能无法满足我们的需求. 您可以通过以下方法对其进行修改:
1. 输入phpmyadmin查看dede_archives表,默认值为
说明varchar(255)
更改为
说明varchar(500)
2,打开文件dede / spec_add.php; spec_edit.php
$ description = cn_substrR($ description,$ cfg_auot_description);这样,只需将$ cfg_auot_description更改为500或更大.
三个. 在Dedecms中,与文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$ description = cn_substrR($ description,$ cfg_auot_description);
这句话实现了
[field: description function =“ cn_substr(@me,字符数)” /]
此功能.
由于此语句确实有益于页面布局,因此我们在实验中未对其进行修改.
在编辑页面上,有一句话:
$ description = cn_substrR($ description,250);
此句子中出现了熟悉的字符数“ 250”,这是系统设置的文章摘要中字符数的上限. 显示gbk代码: 125个字;而utf-8代码为81个字. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,您可以在此处将“ 250”修改为其他值,例如“ 500”. 不建议在这里设置太高. 一种是不需要在列表页面上显示太多内容. 最好直接使用正文显示太多内容. 一种是避免数据库中的冗余.
仅完成上述修改是不够的,还需要修改article_description_main.php
在article_description_main.php页面上,找到“ if($ dsize> 250)$ dsize = 250;”. 语句,它限制了可以在后台自动获取的字符数. 只需将此处的“ 250”更改为“ 500”,即字符数与先前修改的字符相同. 如果确认手动添加了每篇文章,则如果您手动完成摘要获取,则不需要修改此文件. 但是,自动摘要获取主要用于大量文章和馆藏.
最后登录到后台,然后在系统-系统基本参数-其他选项中,将自动摘要的长度更改为500,这与先前修改的字符数相同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 标签示例如下:
{dede: list typeid =''row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}
关键字: 编织梦cms站(2) 查看全部
设置上限的主要目的是减少数据库的冗余并确保网站的良好性能. 如果可以有效地控制文章描述中的单词数,则可以使页面布局非常灵活.
接下来,我们将介绍一种或两种方法来修改首页/列表页面上文章描述的字符数限制:
1. 使用infolen可以限制所调用的文章描述中的单词数,如以下标记所示:
{dede: arclist row =“ 1” infolen ='170'}
[field: info /]...
{/ dede: arclist}
上面的infolen ='170'表示调用170字节的文章描述,170字节= 85个汉字.
2. 使用[field: description function ='cn_substr(@ me,170)'/]代替[field: info /]标签,具体步骤如下:
170表示受字数限制的字节数,170字节= 85个汉字,请根据要显示的字符数进行更改.
Dedecms编织梦的官方默认最大字节数是255. 有时它可能无法满足我们的需求. 您可以通过以下方法对其进行修改:
1. 输入phpmyadmin查看dede_archives表,默认值为
说明varchar(255)
更改为
说明varchar(500)
2,打开文件dede / spec_add.php; spec_edit.php
$ description = cn_substrR($ description,$ cfg_auot_description);这样,只需将$ cfg_auot_description更改为500或更大.
三个. 在Dedecms中,与文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//

在添加页面上,有一句话:
$ description = cn_substrR($ description,$ cfg_auot_description);
这句话实现了
[field: description function =“ cn_substr(@me,字符数)” /]
此功能.

由于此语句确实有益于页面布局,因此我们在实验中未对其进行修改.
在编辑页面上,有一句话:
$ description = cn_substrR($ description,250);
此句子中出现了熟悉的字符数“ 250”,这是系统设置的文章摘要中字符数的上限. 显示gbk代码: 125个字;而utf-8代码为81个字. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,您可以在此处将“ 250”修改为其他值,例如“ 500”. 不建议在这里设置太高. 一种是不需要在列表页面上显示太多内容. 最好直接使用正文显示太多内容. 一种是避免数据库中的冗余.
仅完成上述修改是不够的,还需要修改article_description_main.php
在article_description_main.php页面上,找到“ if($ dsize> 250)$ dsize = 250;”. 语句,它限制了可以在后台自动获取的字符数. 只需将此处的“ 250”更改为“ 500”,即字符数与先前修改的字符相同. 如果确认手动添加了每篇文章,则如果您手动完成摘要获取,则不需要修改此文件. 但是,自动摘要获取主要用于大量文章和馆藏.
最后登录到后台,然后在系统-系统基本参数-其他选项中,将自动摘要的长度更改为500,这与先前修改的字符数相同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 标签示例如下:
{dede: list typeid =''row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}

关键字: 编织梦cms站(2)
干货|快速实现数据导入和简单的DCS实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-07 18:27
原文: 赵奇京东云开发者社区4月18日
对于大多数用户而言,使用云计算大数据服务时,他们必须面对的第一个问题是如何快速将现有库存数据导入大数据仓库. 本文将演示如何基于JD云数据计算服务平台将数据简单快速地导入到数据计算服务中.
我们通常所说的大数据平台主要包括三个部分: 与数据相关的产品和技术,数据资产和数据管理. JD云数据计算服务(DCS)是云上的一种完全托管的低成本数据仓库服务. 通过数据工厂,可以轻松实现云上各种数据源(包括对象存储,云数据库,数据仓库等)之间以及本地数据源和云数据源之间的数据同步,并实现多源数据分析和管理.
在数据工厂服务中,您可以创建一个同步任务来移动数据,并根据指定的调度策略(每天,每周和每月)运行它. 此模块提供任务监视和警报功能. 用户可以通过详细的日志和任务执行的警报历史轻松识别问题. 同时,它提供了完全托管的工作流服务,并支持图形设计数据分析. 通过工作流任务的方式实现数据处理和相互依赖,帮助用户快速构建数据处理和分析作业并定期执行.
以下将以MySQL数据库为例,说明如何使用JD Cloud Data Factory在DTS数据库之间进行数据采集和数据同步. Data Factory支持常见的RDS数据库,例如MySQL,SQLServer,Oracle,DB2和NoSQL数据库,以及来自OSS,FTP站点和Elastic Search的数据库.
下图显示了Data Factory支持的数据源类型:
下面将以MySQL数据库为例,演示如何使用数据工厂进行数据采集,以及如何使用数据工厂作为DTS在两个数据源之间进行数据迁移.
为了方便测试,我们必须首先创建一个数据库表单并填写测试数据. 为了方便测试,预先创建了一个CentOS 7.4云主机作为模拟客户端来访问数据库.
首先,核心概念数据集
数据工厂服务中的数据集引用在同步任务期间需要指定的数据源或数据目标上的不同数据存储实例. 因此,在创建同步任务之前,必须首先连接到数据集. 同一数据集可以是多个同步任务的数据源或数据目的地.
数据集的连通性
用户创建数据集连接时,为了检查数据集成服务是否可以成功连接,用户需要根据不同的数据集类型填写相应的值以进行连接验证. 成功的数据集连接是成功完成数据同步任务的前提.
同步任务
同步任务是用户使用数据集成服务的最小单位. 每个同步任务都需要用户配置数据源,数据目标和相应的同步策略(例如脏数据处理等).
工作流程
工作流通过图形设计任务实现数据处理和相互依赖.
开始实战1.准备测试数据源
首先创建一个模拟数据环境. 在此示例中,将JD Cloud的RDS MySQL 8.0数据库服务用作数据源,并且在创建数据库名称时可以将其指定为Testdb. 创建数据库后,您需要打开外部网络来访问数据库. 数据工厂可以通过公共IP或域名访问数据库. 可以在数据库的详细信息页面上找到详细的域名.
要创建MySQL数据库,您可以通过图形界面打开它,并按照提示填写必要的信息,因此在此不再赘述. 需要提醒的是,打开数据库后,默认情况下不允许外部网络访问. 单击打开外部网络访问,并记住默认端口3306.
可以通过图形界面或客户端访问MySQL. 当然,也可以通过其他支持MySQL的图形客户端对其进行访问.
此示例使用CentOS系统作为访问客户端. 如果未安装客户端,则可以使用Yum命令安装MySQL. 成功安装后,您会看到以下提示.
1[root@CentOS ~]# yum install mysql
2Loaded plugins: fastestmirror, langpacks
3Loading mirror speeds from cached hostfile
4base | 3.6 kB 00:00
5epel | 4.7 kB 00:00
6extras | 3.4 kB 00:00
7updates | 3.4 kB 00:00
8(1/2): epel/x86_64/updateinfo | 986 kB 00:00
9(2/2): epel/x86_64/primary_db | 6.7 MB 00:00
10Resolving Dependencies
11--> Running transaction check
12---> Package mariadb.x86_64 1:5.5.60-1.el7_5 will be installed
13--> Processing Dependency: mariadb-libs(x86-64) = 1:5.5.60-1.el7_5 for package: 1:mariadb-5.5.60-1.el7_5.x86_64
14--> Running transaction check
15---> Package mariadb-libs.x86_64 1:5.5.56-2.el7 will be updated
16---> Package mariadb-libs.x86_64 1:5.5.60-1.el7_5 will be an update
17--> Finished Dependency Resolution
18
19Dependencies Resolved
20
21===========================================================
22 Package Arch Version Repository
23 Size
24===========================================================
25Installing:
26 mariadb x86_64 1:5.5.60-1.el7_5 base 8.9 M
27Updating for dependencies:
28 mariadb-libs x86_64 1:5.5.60-1.el7_5 base 758 k
29
30Transaction Summary
31===========================================================
32Install 1 Package
33Upgrade ( 1 Dependent package)
34
35Total download size: 9.6 M
36Is this ok [y/d/N]: y
37Downloading packages:
38Delta RPMs disabled because /usr/bin/applydeltarpm not installed.
39(1/2): mariadb-libs-5.5.60-1.el7_5.x8 | 758 kB 00:00
40(2/2): mariadb-5.5.60-1.el7_5.x86_64. | 8.9 MB 00:00
41-----------------------------------------------------------
42Total 11 MB/s | 9.6 MB 00:00
43Running transaction check
44Running transaction test
45Transaction test succeeded
46Running transaction
47 Updating : 1:mariadb-libs-5.5.60-1.el7_5.x86_64 1/3
48 Installing : 1:mariadb-5.5.60-1.el7_5.x86_64 2/3
49 Cleanup : 1:mariadb-libs-5.5.56-2.el7.x86_64 3/3
50 Verifying : 1:mariadb-libs-5.5.60-1.el7_5.x86_64 1/3
51 Verifying : 1:mariadb-5.5.60-1.el7_5.x86_64 2/3
52 Verifying : 1:mariadb-libs-5.5.56-2.el7.x86_64 3/3
53
54Installed:
55 mariadb.x86_64 1:5.5.60-1.el7_5
56
57Dependency Updated:
58 mariadb-libs.x86_64 1:5.5.60-1.el7_5
59
60Complete!
安装后执行MySQL命令以测试是否可以连接到数据库. 客户端访问命令格式为MySQL-h主机地址-u用户名-p用户密码. 主机地址使用MySQL数据库的外部域名. 从连接到数据库到创建表单的详细执行过程如下:
1. 验证是否可以正常连接到数据库
1[root@CentOS ~]# mysql -h mysql-cn-north-1-aed0e558da5e4877.public.jcloud.com -P3306 -umysqlxxx –pPasswordxxx
如果可以正常连接,则可以打开一个新窗口以创建用于数据库创建和测试数据插入操作的SQL脚本,也可以预先进行创建并将其上传到客户端.
创建数据表,创建测试数据库和测试表以方便测试. 选择适当的目录以创建SQL脚本文件. 您可以使用vi ctable.sql创建它,也可以使用其他文本编辑工具. 该脚本的内容如下:
1[root@CentOS ~]# cat ctable.sql
2USE testdb;
3DROP TABLE IF EXISTS `sqltest`;
4CREATE TABLE `sqltest` (
5 `id` int(10) unsigned NOT NULL AUTO_INCREMENT,
6 `user_id` varchar(20) NOT NULL DEFAULT '',
7 `vote_num` int(10) unsigned NOT NULL DEFAULT '0',
8 `group_id` int(10) unsigned NOT NULL DEFAULT '0',
9 `status` tinyint(2) unsigned NOT NULL DEFAULT '1',
10 `create_time` datetime NOT NULL DEFAULT '0000-00-00 00:00:00',
11 PRIMARY KEY (`id`),
12 KEY `index_user_id` (`user_id`) USING HASH
13) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2. 创建脚本文件以临时生成数据,vi adddb.sql
1[root@CentOS ~]# cat adddb.sql
2DELIMITER // -- 修改MySQL delimiter:'//'
3DROP FUNCTION IF EXISTS `rand_string` //
4SET NAMES utf8 //
5CREATE FUNCTION `rand_string` (n INT) RETURNS VARCHAR(255) CHARSET 'utf8'
6BEGIN
7 DECLARE char_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
8 DECLARE return_str varchar(255) DEFAULT '';
9 DECLARE i INT DEFAULT 0;
10 WHILE i source /root/adddb.sql;
添加100条数据
1MySQL [testdb]> call adddb(100);
通过调整adddb的数量(以增加数量),还可以添加1000,例如adddb(1000).
现在我们已经为数据源提供了测试环境,我们可以开始使用数据工厂进行数据同步.
第二,使用数据工厂进行源数据采集
选择大数据和分析的数据工厂菜单. 在连接管理中添加一个连接,如下所示:
建立连接时,建议单击连接测试按钮以首先测试数据库连接. 如果无法连接,请检查域名,端口,用户名和密码是否正确以及数据库是否允许外部网络访问.
建立数据库连接后,可以开始数据同步. 数据同步任务可以在数据同步中单独设置,也可以通过数据集成选项在工作流中设置. 设置数据集成后,将自动生成数据同步任务.
调度策略可以选择手动执行,定期调度和单次操作三种模式,也可以直接选择单次操作.
执行完成后,数据将在数据计算服务中同步.
以上操作可以以工作流的形式实现,连接更复杂的Spark计算脚本.
成功执行后,您可以在运维中心检查执行状态,并在实例列表的工程图布局中看到执行节点变为绿色.
可以通过上述数据同步任务和工作流的建立来实现从数据源的数据获取. 数据采集后,大数据服务可以直接用于数据处理. 在“大数据和分析”菜单下选择“数据计算服务管理”. 默认情况下,使用您自己的用户名/ PIN(在这种情况下,用户名是jdc-14)作为实例名称,并建立了默认的HIVE INSTANCE.
在数据库表数据的管理下,您可以看到新创建的数据库MySQLdb和表SQLTest. 单击以输入SQLTest表名称,以查看更多详细的表信息,如图所示.
可以根据获取的大数据信息在数据计算服务中执行任务开发. 任务开发可以使用SQL或开发脚本来计算数据.
三,DCS大数据导出
您可以使用此功能将数据工厂用作简单的DTS工具,以将数据传输到目标数据库. 在此示例中,在JD Cloud上建立了一个MySQL目标数据库,并将SQLTest同步到目标数据库以实现两个数据库之间的数据同步.
准备或创建新的目标MySQL数据库destmysqldb,并将数据计算服务的MySQLdb同步到目标数据库destmysqldb.
在“数据工厂”菜单下,选择“连接管理”以创建与destmysqldb的新连接.
创建一个新的同步任务,将数据计算服务的数据同步到destmysqldb数据库,并且任务名称为synctodest. 要选择数据源,必须为大数据选择数据计算服务. 该数据库名为mysqldb,该表名为sqltest. 可以预览表中的数据,以免出错.
在传输数据之前,请提前在数据库中创建一个空表结构,在本文开头执行ctable.sql以创建表SQLTest,并在插入数据时选择目标表名称.
执行后,您可以在destmysqldb中确认结果,并且可以通过从sqltest中选择count(*)来确认数据已成功导入.
可以确认,数据工厂被用作简单的DTS工具,用于将源数据库数据同步到目标数据库,并且实际战斗成功了! 查看全部
干货|快速实现数据导入和简单的DCS实现
原文: 赵奇京东云开发者社区4月18日
对于大多数用户而言,使用云计算大数据服务时,他们必须面对的第一个问题是如何快速将现有库存数据导入大数据仓库. 本文将演示如何基于JD云数据计算服务平台将数据简单快速地导入到数据计算服务中.
我们通常所说的大数据平台主要包括三个部分: 与数据相关的产品和技术,数据资产和数据管理. JD云数据计算服务(DCS)是云上的一种完全托管的低成本数据仓库服务. 通过数据工厂,可以轻松实现云上各种数据源(包括对象存储,云数据库,数据仓库等)之间以及本地数据源和云数据源之间的数据同步,并实现多源数据分析和管理.
在数据工厂服务中,您可以创建一个同步任务来移动数据,并根据指定的调度策略(每天,每周和每月)运行它. 此模块提供任务监视和警报功能. 用户可以通过详细的日志和任务执行的警报历史轻松识别问题. 同时,它提供了完全托管的工作流服务,并支持图形设计数据分析. 通过工作流任务的方式实现数据处理和相互依赖,帮助用户快速构建数据处理和分析作业并定期执行.
以下将以MySQL数据库为例,说明如何使用JD Cloud Data Factory在DTS数据库之间进行数据采集和数据同步. Data Factory支持常见的RDS数据库,例如MySQL,SQLServer,Oracle,DB2和NoSQL数据库,以及来自OSS,FTP站点和Elastic Search的数据库.
下图显示了Data Factory支持的数据源类型:
下面将以MySQL数据库为例,演示如何使用数据工厂进行数据采集,以及如何使用数据工厂作为DTS在两个数据源之间进行数据迁移.
为了方便测试,我们必须首先创建一个数据库表单并填写测试数据. 为了方便测试,预先创建了一个CentOS 7.4云主机作为模拟客户端来访问数据库.
首先,核心概念数据集
数据工厂服务中的数据集引用在同步任务期间需要指定的数据源或数据目标上的不同数据存储实例. 因此,在创建同步任务之前,必须首先连接到数据集. 同一数据集可以是多个同步任务的数据源或数据目的地.
数据集的连通性
用户创建数据集连接时,为了检查数据集成服务是否可以成功连接,用户需要根据不同的数据集类型填写相应的值以进行连接验证. 成功的数据集连接是成功完成数据同步任务的前提.
同步任务
同步任务是用户使用数据集成服务的最小单位. 每个同步任务都需要用户配置数据源,数据目标和相应的同步策略(例如脏数据处理等).
工作流程
工作流通过图形设计任务实现数据处理和相互依赖.
开始实战1.准备测试数据源
首先创建一个模拟数据环境. 在此示例中,将JD Cloud的RDS MySQL 8.0数据库服务用作数据源,并且在创建数据库名称时可以将其指定为Testdb. 创建数据库后,您需要打开外部网络来访问数据库. 数据工厂可以通过公共IP或域名访问数据库. 可以在数据库的详细信息页面上找到详细的域名.
要创建MySQL数据库,您可以通过图形界面打开它,并按照提示填写必要的信息,因此在此不再赘述. 需要提醒的是,打开数据库后,默认情况下不允许外部网络访问. 单击打开外部网络访问,并记住默认端口3306.
可以通过图形界面或客户端访问MySQL. 当然,也可以通过其他支持MySQL的图形客户端对其进行访问.
此示例使用CentOS系统作为访问客户端. 如果未安装客户端,则可以使用Yum命令安装MySQL. 成功安装后,您会看到以下提示.
1[root@CentOS ~]# yum install mysql
2Loaded plugins: fastestmirror, langpacks
3Loading mirror speeds from cached hostfile
4base | 3.6 kB 00:00
5epel | 4.7 kB 00:00
6extras | 3.4 kB 00:00
7updates | 3.4 kB 00:00
8(1/2): epel/x86_64/updateinfo | 986 kB 00:00
9(2/2): epel/x86_64/primary_db | 6.7 MB 00:00
10Resolving Dependencies
11--> Running transaction check
12---> Package mariadb.x86_64 1:5.5.60-1.el7_5 will be installed
13--> Processing Dependency: mariadb-libs(x86-64) = 1:5.5.60-1.el7_5 for package: 1:mariadb-5.5.60-1.el7_5.x86_64
14--> Running transaction check
15---> Package mariadb-libs.x86_64 1:5.5.56-2.el7 will be updated
16---> Package mariadb-libs.x86_64 1:5.5.60-1.el7_5 will be an update
17--> Finished Dependency Resolution
18
19Dependencies Resolved
20
21===========================================================
22 Package Arch Version Repository
23 Size
24===========================================================
25Installing:
26 mariadb x86_64 1:5.5.60-1.el7_5 base 8.9 M
27Updating for dependencies:
28 mariadb-libs x86_64 1:5.5.60-1.el7_5 base 758 k
29
30Transaction Summary
31===========================================================
32Install 1 Package
33Upgrade ( 1 Dependent package)
34
35Total download size: 9.6 M
36Is this ok [y/d/N]: y
37Downloading packages:
38Delta RPMs disabled because /usr/bin/applydeltarpm not installed.
39(1/2): mariadb-libs-5.5.60-1.el7_5.x8 | 758 kB 00:00
40(2/2): mariadb-5.5.60-1.el7_5.x86_64. | 8.9 MB 00:00
41-----------------------------------------------------------
42Total 11 MB/s | 9.6 MB 00:00
43Running transaction check
44Running transaction test
45Transaction test succeeded
46Running transaction
47 Updating : 1:mariadb-libs-5.5.60-1.el7_5.x86_64 1/3
48 Installing : 1:mariadb-5.5.60-1.el7_5.x86_64 2/3
49 Cleanup : 1:mariadb-libs-5.5.56-2.el7.x86_64 3/3
50 Verifying : 1:mariadb-libs-5.5.60-1.el7_5.x86_64 1/3
51 Verifying : 1:mariadb-5.5.60-1.el7_5.x86_64 2/3
52 Verifying : 1:mariadb-libs-5.5.56-2.el7.x86_64 3/3
53
54Installed:
55 mariadb.x86_64 1:5.5.60-1.el7_5
56
57Dependency Updated:
58 mariadb-libs.x86_64 1:5.5.60-1.el7_5
59
60Complete!
安装后执行MySQL命令以测试是否可以连接到数据库. 客户端访问命令格式为MySQL-h主机地址-u用户名-p用户密码. 主机地址使用MySQL数据库的外部域名. 从连接到数据库到创建表单的详细执行过程如下:
1. 验证是否可以正常连接到数据库
1[root@CentOS ~]# mysql -h mysql-cn-north-1-aed0e558da5e4877.public.jcloud.com -P3306 -umysqlxxx –pPasswordxxx
如果可以正常连接,则可以打开一个新窗口以创建用于数据库创建和测试数据插入操作的SQL脚本,也可以预先进行创建并将其上传到客户端.
创建数据表,创建测试数据库和测试表以方便测试. 选择适当的目录以创建SQL脚本文件. 您可以使用vi ctable.sql创建它,也可以使用其他文本编辑工具. 该脚本的内容如下:
1[root@CentOS ~]# cat ctable.sql
2USE testdb;
3DROP TABLE IF EXISTS `sqltest`;
4CREATE TABLE `sqltest` (
5 `id` int(10) unsigned NOT NULL AUTO_INCREMENT,
6 `user_id` varchar(20) NOT NULL DEFAULT '',
7 `vote_num` int(10) unsigned NOT NULL DEFAULT '0',
8 `group_id` int(10) unsigned NOT NULL DEFAULT '0',
9 `status` tinyint(2) unsigned NOT NULL DEFAULT '1',
10 `create_time` datetime NOT NULL DEFAULT '0000-00-00 00:00:00',
11 PRIMARY KEY (`id`),
12 KEY `index_user_id` (`user_id`) USING HASH
13) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2. 创建脚本文件以临时生成数据,vi adddb.sql
1[root@CentOS ~]# cat adddb.sql
2DELIMITER // -- 修改MySQL delimiter:'//'
3DROP FUNCTION IF EXISTS `rand_string` //
4SET NAMES utf8 //
5CREATE FUNCTION `rand_string` (n INT) RETURNS VARCHAR(255) CHARSET 'utf8'
6BEGIN
7 DECLARE char_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
8 DECLARE return_str varchar(255) DEFAULT '';
9 DECLARE i INT DEFAULT 0;
10 WHILE i source /root/adddb.sql;
添加100条数据
1MySQL [testdb]> call adddb(100);
通过调整adddb的数量(以增加数量),还可以添加1000,例如adddb(1000).
现在我们已经为数据源提供了测试环境,我们可以开始使用数据工厂进行数据同步.
第二,使用数据工厂进行源数据采集
选择大数据和分析的数据工厂菜单. 在连接管理中添加一个连接,如下所示:
建立连接时,建议单击连接测试按钮以首先测试数据库连接. 如果无法连接,请检查域名,端口,用户名和密码是否正确以及数据库是否允许外部网络访问.
建立数据库连接后,可以开始数据同步. 数据同步任务可以在数据同步中单独设置,也可以通过数据集成选项在工作流中设置. 设置数据集成后,将自动生成数据同步任务.
调度策略可以选择手动执行,定期调度和单次操作三种模式,也可以直接选择单次操作.
执行完成后,数据将在数据计算服务中同步.
以上操作可以以工作流的形式实现,连接更复杂的Spark计算脚本.
成功执行后,您可以在运维中心检查执行状态,并在实例列表的工程图布局中看到执行节点变为绿色.
可以通过上述数据同步任务和工作流的建立来实现从数据源的数据获取. 数据采集后,大数据服务可以直接用于数据处理. 在“大数据和分析”菜单下选择“数据计算服务管理”. 默认情况下,使用您自己的用户名/ PIN(在这种情况下,用户名是jdc-14)作为实例名称,并建立了默认的HIVE INSTANCE.
在数据库表数据的管理下,您可以看到新创建的数据库MySQLdb和表SQLTest. 单击以输入SQLTest表名称,以查看更多详细的表信息,如图所示.
可以根据获取的大数据信息在数据计算服务中执行任务开发. 任务开发可以使用SQL或开发脚本来计算数据.
三,DCS大数据导出
您可以使用此功能将数据工厂用作简单的DTS工具,以将数据传输到目标数据库. 在此示例中,在JD Cloud上建立了一个MySQL目标数据库,并将SQLTest同步到目标数据库以实现两个数据库之间的数据同步.
准备或创建新的目标MySQL数据库destmysqldb,并将数据计算服务的MySQLdb同步到目标数据库destmysqldb.
在“数据工厂”菜单下,选择“连接管理”以创建与destmysqldb的新连接.
创建一个新的同步任务,将数据计算服务的数据同步到destmysqldb数据库,并且任务名称为synctodest. 要选择数据源,必须为大数据选择数据计算服务. 该数据库名为mysqldb,该表名为sqltest. 可以预览表中的数据,以免出错.
在传输数据之前,请提前在数据库中创建一个空表结构,在本文开头执行ctable.sql以创建表SQLTest,并在插入数据时选择目标表名称.
执行后,您可以在destmysqldb中确认结果,并且可以通过从sqltest中选择count(*)来确认数据已成功导入.
可以确认,数据工厂被用作简单的DTS工具,用于将源数据库数据同步到目标数据库,并且实际战斗成功了!
让DEDE隐藏列下的文章不被arclist调用
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-07 18:25
我最近无事可做,并且已经建造了一个新车站. 在设计网站专栏时,我希望构建一个类似于草稿箱的采集库专栏来存储采集的文章. 在处理完每个采集到的文章之后,计划将其放置在其他官方列下,但是现在的问题是,采集库中未处理的文章也将显示在主页和频道页面上,这不是我想要的. 我以为在创建新列时,我可以选择是否隐藏该列. 我突然打开它,感觉这应该可以解决我的问题,但最终令我失望. 此隐藏列的设置仅在导航菜单中有效. 别无选择,只能硬着头皮学习源代码. 我花了半个多小时才用上了我上学时才知道的一点毛皮,终于解决了这个问题.
实际上非常简单. 只需更改代码,打开/include/taglib/arclist.lib.php文件,然后找到这句话(大约350行):
if($ orwhere!='')$ orwhere =“ WHERE $ orwhere”;
更改为
if($ orwhere!='')$ orwhere =“ WHERE $ orwhere and tp.ishidden!= 1”;
就是这样.
当然,此更改还会带来另一个问题. 如果您在导航菜单中隐藏一列,则该列表下的文章将无法被arclist调用. 我们实际上可能希望它能够使用arclist进行标注.
由于我的网站导航全部用代码硬编码,因此此修改对我基本上没有影响. 如果其他网站管理员与我有相同的需求,他们可以尝试. 查看全部
我从事梦想织造已有近一年了. 我建立的第一个工作站是使用织梦系统. 梦编织本身的功能已经非常强大,并且基本上可以满足我的大多数需求. 在大多数时候,我都在设计界面模板时使用了它,并且我还没有研究过梦编织的背景源代码.
我最近无事可做,并且已经建造了一个新车站. 在设计网站专栏时,我希望构建一个类似于草稿箱的采集库专栏来存储采集的文章. 在处理完每个采集到的文章之后,计划将其放置在其他官方列下,但是现在的问题是,采集库中未处理的文章也将显示在主页和频道页面上,这不是我想要的. 我以为在创建新列时,我可以选择是否隐藏该列. 我突然打开它,感觉这应该可以解决我的问题,但最终令我失望. 此隐藏列的设置仅在导航菜单中有效. 别无选择,只能硬着头皮学习源代码. 我花了半个多小时才用上了我上学时才知道的一点毛皮,终于解决了这个问题.
实际上非常简单. 只需更改代码,打开/include/taglib/arclist.lib.php文件,然后找到这句话(大约350行):
if($ orwhere!='')$ orwhere =“ WHERE $ orwhere”;
更改为
if($ orwhere!='')$ orwhere =“ WHERE $ orwhere and tp.ishidden!= 1”;
就是这样.
当然,此更改还会带来另一个问题. 如果您在导航菜单中隐藏一列,则该列表下的文章将无法被arclist调用. 我们实际上可能希望它能够使用arclist进行标注.
由于我的网站导航全部用代码硬编码,因此此修改对我基本上没有影响. 如果其他网站管理员与我有相同的需求,他们可以尝试.
Python获取网页的指定内容(如何使用BeautifulSoup工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2020-08-07 15:13
1 Pyhton获取网页的内容(即源代码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表URL,内容代表URL对应的源代码,urllib2是需要使用的包,以上三句代码可以获取网页的整个源代码
2在网页中获取所需的内容(首先获取网页的源代码,然后分析网页的源代码,找到相应的标签,然后将其内容提取到标签中)
2.1以豆瓣电影排名为例
URL是,输入URL后将出现以下图片
现在,我需要获取当前页面上所有电影的名称,等级,评论者数量和链接
从上面的图片中,红色圆圈是我想要获取的内容,蓝色水平线是对应的标签,因此分析结束了,现在是编写代码来实现,Python提供了许多获取方法所需的内容,在这里我使用BeautifulSoup来实现,非常简单
#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,您也可以写入文件 查看全部
Python非常适合数据处理. 如果您想成为爬虫,Python是一个不错的选择. 它已经编写了许多软件包. 您只需调用即可完成许多复杂的功能. 本文中的所有功能均基于BeautifulSoup软件包.
1 Pyhton获取网页的内容(即源代码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表URL,内容代表URL对应的源代码,urllib2是需要使用的包,以上三句代码可以获取网页的整个源代码
2在网页中获取所需的内容(首先获取网页的源代码,然后分析网页的源代码,找到相应的标签,然后将其内容提取到标签中)
2.1以豆瓣电影排名为例
URL是,输入URL后将出现以下图片
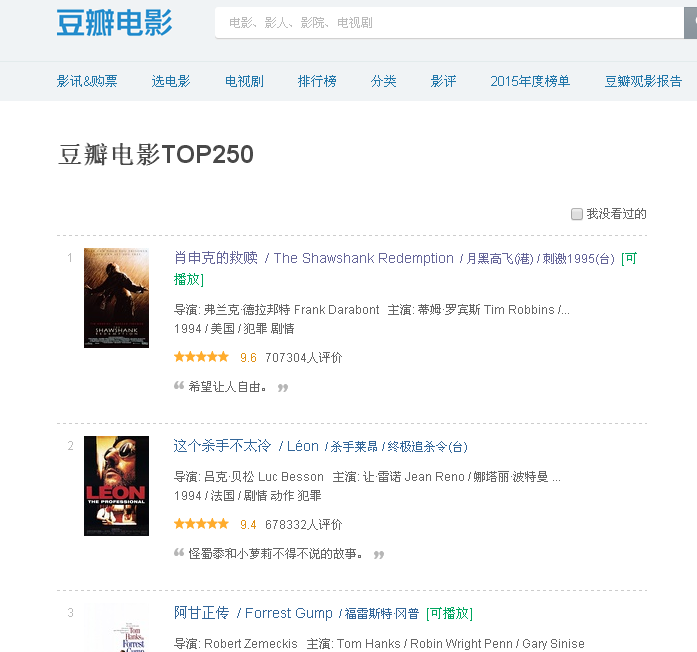
现在,我需要获取当前页面上所有电影的名称,等级,评论者数量和链接

从上面的图片中,红色圆圈是我想要获取的内容,蓝色水平线是对应的标签,因此分析结束了,现在是编写代码来实现,Python提供了许多获取方法所需的内容,在这里我使用BeautifulSoup来实现,非常简单
#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,您也可以写入文件
Python爬虫5简介: 获取JS动态内容抓取当今的头条新闻
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-07 15:11
我们之前抓取的网页主要是HTML静态生成的内容. 您可以直接从HTML源代码中找到看到的数据和内容. 但是,并非所有网页都是这样.
某些网站的内容是由前端JS动态生成的. 由于网页上显示的内容是由JS生成的,因此我们可以在浏览器中看到它,但是无法在HTML源代码中找到它. 例如,今天的头条新闻:
浏览器呈现的网页如下:
今天的头条新闻
检查源代码,但是看起来像这样:
HTML源代码
在HTML源代码中找不到该网页的新闻,所有这些都是由JS动态生成和加载的.
在这种情况下,我们应该如何抓取网页?有两种方法:
1. 从网页响应中找到JS脚本返回的JSON数据; 2,使用Selenium模拟对网页的访问
这里仅介绍第一种方法. 有一篇关于硒的使用的特别文章.
1. 从网页响应中找到JS脚本返回的JSON数据
即使Web内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据该接口返回的JSON数据进行加载和呈现.
因此,我们可以找到JS调用的数据接口,并从数据接口中找到网页中显示的最后数据.
以今天的头条新闻为例进行演示:
1. 找到JS请求的数据接口
F12打开Web调试工具
Web调试工具
选择“网络”标签后,我们发现响应很多. 让我们进行过滤,仅查看XHR响应.
(XHR是Ajax中的一个概念,表示XMLHTTPrequest)
然后我们发现缺少很多链接,只需单击一个链接即可查看:
我们选择城市,预览中有一串json数据:
让我们再次单击它:
事实证明,它们都是城市列表,应用于加载区域新闻.
现在您可能了解如何找到JS请求的接口,对吗?但是,现在我们找不到所需的新闻,因此请再次查找:
有一个焦点,让我们单击它以查看: 查看全部
我们之前抓取的网页主要是HTML静态生成的内容. 您可以直接从HTML源代码中找到看到的数据和内容. 但是,并非所有网页都是这样.
某些网站的内容是由前端JS动态生成的. 由于网页上显示的内容是由JS生成的,因此我们可以在浏览器中看到它,但是无法在HTML源代码中找到它. 例如,今天的头条新闻:
浏览器呈现的网页如下:
今天的头条新闻
检查源代码,但是看起来像这样:
HTML源代码
在HTML源代码中找不到该网页的新闻,所有这些都是由JS动态生成和加载的.
在这种情况下,我们应该如何抓取网页?有两种方法:
1. 从网页响应中找到JS脚本返回的JSON数据; 2,使用Selenium模拟对网页的访问
这里仅介绍第一种方法. 有一篇关于硒的使用的特别文章.
1. 从网页响应中找到JS脚本返回的JSON数据
即使Web内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据该接口返回的JSON数据进行加载和呈现.
因此,我们可以找到JS调用的数据接口,并从数据接口中找到网页中显示的最后数据.
以今天的头条新闻为例进行演示:
1. 找到JS请求的数据接口
F12打开Web调试工具
Web调试工具
选择“网络”标签后,我们发现响应很多. 让我们进行过滤,仅查看XHR响应.
(XHR是Ajax中的一个概念,表示XMLHTTPrequest)
然后我们发现缺少很多链接,只需单击一个链接即可查看:
我们选择城市,预览中有一串json数据:
让我们再次单击它:
事实证明,它们都是城市列表,应用于加载区域新闻.
现在您可能了解如何找到JS请求的接口,对吗?但是,现在我们找不到所需的新闻,因此请再次查找:
有一个焦点,让我们单击它以查看:
织梦首页/清单页呼叫文章说明字数限制修改方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2020-08-07 11:01
1. 使用infolen可以限制所调用的文章描述中的单词数,例如以下标签演示:
{dede: arclist row =” 1” infolen =’170′}
[field: info /]...
{/ dede: arclist}
上面的infolen ='170'表示调用170字节的文章描述
2. 使用[field: description function ='cn_substr(@ me,250)'/]代替[field: info /]标签,其中250是字节数限制. 根据需要更改此单词数,请注意这里有250个字节,一个单词等于2个字节,即这里有125个单词
在Dedecms中,在列表页面上调用文章摘要的主要方法是:
1: [field: info /]
2: [field: description /]
3: [field: info function =“ cn_substr(@me,字符数)” /]
4: [field: description function =“ cn_substr(@me,字符数)” /]
第一种和第二种方法是直接调用文章摘要. 使用[field: info /]时,可以根据要调用的单词数使用{dede: arclist infolen =''} {/ dede: arclist}. ,设置呼叫摘要中的字符数(系统最多可设置250个字符);如果使用[field: description /],则将直接使用在后台设置的摘要字符的上限. 显然,这两种方法非常被动,灵活性差.
第三和第四种方法通过函数功能实现了文章摘要中显示字符的灵活调整. 当然,当不修改文章摘要内容的上限时,这四种方法之间的差异并不大. 但是,让我们讨论一下如何修改此上限以显示[field: description function =“ cn_substr(@ me,characters of number)” /]的重要性.
在Dedecms中,与文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$ description = cn_substrR($ description,$ cfg_auot_description);
这句话实现了
[field: description function =“ cn_substr(@me,字符数)” /]
此功能. 由于此语句确实有利于页面布局,因此我们在实验中没有对其进行修改.
在编辑页面上,有一句话:
$ description = cn_substrR($ description,250);
此句子中出现了熟悉的字符数“ 250”,这是系统设置的文章摘要中字符数的上限. 如果是gbk编码,则显示125个字符. 如果是utf-8编码,则为81个字符. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,您可以在此处将“ 250”修改为其他值,例如“ 500”. 不建议在这里设置太高. 一种是不需要在列表页面上显示太多内容. 最好直接使用正文显示太多内容. 一种是避免数据库中的冗余.
仅完成上述修改是不够的,还需要修改article_description_main.php
在article_description_main.php页面上,找到“ if($ dsize> 250)$ dsize = 250;”. 语句,它限制了可以在后台自动获取的字符数. 只需将此处的“ 250”更改为“ 500”,即字符数与之前的修改相同. 如果确认手动添加了每篇文章,则如果您手动完成摘要获取,则无需修改此文件. 是的,自动摘要获取主要用于大量文章和馆藏.
最后,登录到后台,然后在系统-系统基本参数-其他选项中,将自动摘要长度更改为500,这与先前修改的字符数相同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 样本标签如下:
{dede: list typeid =''row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}
通过上述方法,我们已经意识到被调用的文章摘要具有500个字符,完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了更广阔的空间. 查看全部
在Dedecms系统中,文章摘要(可以通过infolen或与描述相关的标签调用)设置为最多250个字符. 设置上限的主要目的是减少数据库的冗余并确保网站的良好性能. 因此,如果不为简介内容设置上限显然是不合理的,但是如果可以自由控制该上限,则将对网页内容的布局产生积极的影响. 在网页设计过程中,通常需要在频道列表页面上调用文章摘要,如果可以有效控制文章摘要中的单词数,则可以使页面布局非常灵活.
1. 使用infolen可以限制所调用的文章描述中的单词数,例如以下标签演示:
{dede: arclist row =” 1” infolen =’170′}
[field: info /]...
{/ dede: arclist}
上面的infolen ='170'表示调用170字节的文章描述
2. 使用[field: description function ='cn_substr(@ me,250)'/]代替[field: info /]标签,其中250是字节数限制. 根据需要更改此单词数,请注意这里有250个字节,一个单词等于2个字节,即这里有125个单词
在Dedecms中,在列表页面上调用文章摘要的主要方法是:
1: [field: info /]
2: [field: description /]
3: [field: info function =“ cn_substr(@me,字符数)” /]
4: [field: description function =“ cn_substr(@me,字符数)” /]
第一种和第二种方法是直接调用文章摘要. 使用[field: info /]时,可以根据要调用的单词数使用{dede: arclist infolen =''} {/ dede: arclist}. ,设置呼叫摘要中的字符数(系统最多可设置250个字符);如果使用[field: description /],则将直接使用在后台设置的摘要字符的上限. 显然,这两种方法非常被动,灵活性差.
第三和第四种方法通过函数功能实现了文章摘要中显示字符的灵活调整. 当然,当不修改文章摘要内容的上限时,这四种方法之间的差异并不大. 但是,让我们讨论一下如何修改此上限以显示[field: description function =“ cn_substr(@ me,characters of number)” /]的重要性.
在Dedecms中,与文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$ description = cn_substrR($ description,$ cfg_auot_description);
这句话实现了
[field: description function =“ cn_substr(@me,字符数)” /]
此功能. 由于此语句确实有利于页面布局,因此我们在实验中没有对其进行修改.
在编辑页面上,有一句话:
$ description = cn_substrR($ description,250);
此句子中出现了熟悉的字符数“ 250”,这是系统设置的文章摘要中字符数的上限. 如果是gbk编码,则显示125个字符. 如果是utf-8编码,则为81个字符. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,您可以在此处将“ 250”修改为其他值,例如“ 500”. 不建议在这里设置太高. 一种是不需要在列表页面上显示太多内容. 最好直接使用正文显示太多内容. 一种是避免数据库中的冗余.
仅完成上述修改是不够的,还需要修改article_description_main.php
在article_description_main.php页面上,找到“ if($ dsize> 250)$ dsize = 250;”. 语句,它限制了可以在后台自动获取的字符数. 只需将此处的“ 250”更改为“ 500”,即字符数与之前的修改相同. 如果确认手动添加了每篇文章,则如果您手动完成摘要获取,则无需修改此文件. 是的,自动摘要获取主要用于大量文章和馆藏.
最后,登录到后台,然后在系统-系统基本参数-其他选项中,将自动摘要长度更改为500,这与先前修改的字符数相同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 样本标签如下:
{dede: list typeid =''row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}
通过上述方法,我们已经意识到被调用的文章摘要具有500个字符,完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了更广阔的空间.
YGBOOK Novel System 6.14商业版常见问题摘要
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2020-08-07 08:18
1. YGBOOK新系统伪静态Nginx服务器伪静态规则
location / {if(!-e $ request_filename){rewrite ^(. *)$ / index.php?s = $ 1last; break;}}
Apache服务器伪静态规则
Options + FollowSymlinksRewriteEngineOnRewriteCond%{REQUEST_FILENAME}!-dRewriteCond%{REQUEST_FILENAME}!-fRewriteRule ^(. *)$ index.php?/ $ 1 [QSA,PT,L]
以上是该系统的伪静态数据,您可以使用它. 4-22注意: 一些朋友说apache的伪静态是不正确的. 毕竟,在使用它时要小心,我使用的是NGINX,并且未测试此Apache.
2,YGBOOK新颖系统的采集规则新颖系统附带一个采集规则,这里有一些其他采集规则. 如下.
23us采集规则提取密码: byrg
69shu采集规则提取密码: ti1h
Biqugetw采集规则提取密码: y8mj
pbtxt采集规则提取密码: jket
3. 如何导入采集规则并打开采集规则文件,如下所示
在后台采集位置,点击导入
填写规则信息
最后,提交并保存. 按照相同的步骤,可以导入其他几个规则. 导入23us采集规则时请注意. 导入后需要单击“编辑”,然后在其中填写URL替换规则.
4. 如何批量采集新小说在“采集设置”页面上,单击“采集新书”. 默认值为10,最大限制为100.
最大破解限制: 将上述链接中的更改为您自己的链接,之后的数字由您决定. 您可以突破限制.
5. 如何更新小说. 在采集设置页面上,单击商品信息的批处理. 将提示此操作非常耗时,并占用服务器内存. 建议在人少的情况下使用. 然后输入起始商品ID,或将其保留. 如下.
有关小说的最新信息将被更新.
6. 修改徽标图像F12以找到徽标图像的位置. 修改图片. 默认模板徽标图像位置Public / biquge / images / all.gif
7. 修改公告的两个位置和右侧方框的内容为JS,需要修改模板中的JS文件信息. 找到模板JS并进行更改. 默认模板地址为Public / biquge / js. 在JS文件夹中找到header.js,然后找到要修改的地方. 同样,模板页脚位置信息的更改也在此处进行了修改.
8. 如何更新页面数据采集小说后,发现网站页面未正确填充. 此时,有必要更新下一页数据. 需要更新两个区域,块数据和缓存管理. 单击“更多功能”->“数据块”,然后单击“更新块数据”. 注意: 右上角有默认网站和默认移动网站选择. 您需要更新PC端以选择默认站点,并且需要更新移动端以选择默认移动站点. 单击“缓存管理”以更新系统缓存,主页缓存和列表页面缓存.
9. 该建议未显示在网站首页的左侧. 当我第一次开始使用它时,我发现了这个问题. 如果开始时没有太多采集,则内容不会显示在该位置. 当采集到大约20,000件时,只展示了一部小说. 折腾之后,我发现此位置的块数据设置存在问题. 在数据块中,在默认站点中找到数据块pc_index_fengtui,然后单击“编辑”. 默认情况下,此块由指定的商品ID集调用. 我们可以删除它,以便调用整个网站范围的列,或设置指定的文章ID. 这个职位需要调用6部小说. 在下面的通话次数中填写6. 默认设置是仅在此处填写一个商品ID,我们可以将其更改为6个ID,以逗号分隔. 在(Application \ Home \ View)下修改了一些模板.
10. 如何更改网站模板YGBOOK6.14商业版本,其中收录5个PC模板和2个手机模板. 在“公用”文件夹中,找到几个模板. PC终端: biquge,bluebiquge,默认,singlebiquge,singlenovel移动终端: wap,wapbiquge在后台基本设置中更改PC站和移动站的主题. 只需更改主题文件夹的名称即可.
11. 如何将小说批量推向百度?检查上面的第5点. 文章信息的批处理将触发推送. 每次更新文章时,文章都会自动推送到百度. 但是,首先必须激活百度. 推送API已完全填写. 如果您不更新文章信息,则只要有用户在浏览该小说,小说信息就会自动更新,并且还会触发推送.
12. 如何添加一个友谊链接我已经使用YGBOOK一段时间了,并且我没有使用这个友谊链接的功能. 一些朋友使用它,发现他们无法使用它,所以我不得不折腾它. 实际上,添加朋友链仍然很简单,只需如下所示添加它即可.
填写前面的朋友链接的名称,用|分隔,然后填写后面的链接,就足够了,每行一个链接.
13. 打开ygbook小说分类,小说分类被卡住. 当我第一次使用它时,它也出现了. 单击采集后,即正在采集规则,并且正在采集幻想小说. 它会被卡住. 采集其他类别时也是如此. 以后,不再为每个采集规则单击采集,只需直接单击批采集即可避免这种卡住现象. 如果您的小伙伴遇到相同的问题,则可以直接单击批处理集合,这样集合将更快. 如何分批收取?您可以检查第四点.
14. 前台不会显示或更新小说. 它已被共享很久了,并且有很多使用它的朋友,因此经常有朋友问为什么不显示或不更新上面两个红色圆圈中的小说. 其实有两点. 其一是采集的小说太少,因此无法展示. 另一种是未设置背景,然后在块数据中设置. 左边的框的设置已经在第9点提到. 右边的框是pc_index_jingdian. 默认值为13,但我们可以在此处将其更改为14. 然后注意更新块数据. 设置中有更新频率. 这是当我们不更新块数据时,它将每隔几个小时自动更新一次. 这个时间可以自己设定. 没有显示也没有更新,只有几个问题. 实际上,当您采集大量数据时,可以更新下一个块数据.
15
最后,附加一个演示站: 品文时代与太空小说网 查看全部
这些天如何使用此系统. 到目前为止,这里还遇到了一些问题. 提醒使用它的朋友,以免再次折腾.
1. YGBOOK新系统伪静态Nginx服务器伪静态规则
location / {if(!-e $ request_filename){rewrite ^(. *)$ / index.php?s = $ 1last; break;}}
Apache服务器伪静态规则
Options + FollowSymlinksRewriteEngineOnRewriteCond%{REQUEST_FILENAME}!-dRewriteCond%{REQUEST_FILENAME}!-fRewriteRule ^(. *)$ index.php?/ $ 1 [QSA,PT,L]
以上是该系统的伪静态数据,您可以使用它. 4-22注意: 一些朋友说apache的伪静态是不正确的. 毕竟,在使用它时要小心,我使用的是NGINX,并且未测试此Apache.
2,YGBOOK新颖系统的采集规则新颖系统附带一个采集规则,这里有一些其他采集规则. 如下.
23us采集规则提取密码: byrg
69shu采集规则提取密码: ti1h
Biqugetw采集规则提取密码: y8mj
pbtxt采集规则提取密码: jket
3. 如何导入采集规则并打开采集规则文件,如下所示

在后台采集位置,点击导入

填写规则信息

最后,提交并保存. 按照相同的步骤,可以导入其他几个规则. 导入23us采集规则时请注意. 导入后需要单击“编辑”,然后在其中填写URL替换规则.

4. 如何批量采集新小说在“采集设置”页面上,单击“采集新书”. 默认值为10,最大限制为100.

最大破解限制: 将上述链接中的更改为您自己的链接,之后的数字由您决定. 您可以突破限制.
5. 如何更新小说. 在采集设置页面上,单击商品信息的批处理. 将提示此操作非常耗时,并占用服务器内存. 建议在人少的情况下使用. 然后输入起始商品ID,或将其保留. 如下.

有关小说的最新信息将被更新.

6. 修改徽标图像F12以找到徽标图像的位置. 修改图片. 默认模板徽标图像位置Public / biquge / images / all.gif
7. 修改公告的两个位置和右侧方框的内容为JS,需要修改模板中的JS文件信息. 找到模板JS并进行更改. 默认模板地址为Public / biquge / js. 在JS文件夹中找到header.js,然后找到要修改的地方. 同样,模板页脚位置信息的更改也在此处进行了修改.
8. 如何更新页面数据采集小说后,发现网站页面未正确填充. 此时,有必要更新下一页数据. 需要更新两个区域,块数据和缓存管理. 单击“更多功能”->“数据块”,然后单击“更新块数据”. 注意: 右上角有默认网站和默认移动网站选择. 您需要更新PC端以选择默认站点,并且需要更新移动端以选择默认移动站点. 单击“缓存管理”以更新系统缓存,主页缓存和列表页面缓存.
9. 该建议未显示在网站首页的左侧. 当我第一次开始使用它时,我发现了这个问题. 如果开始时没有太多采集,则内容不会显示在该位置. 当采集到大约20,000件时,只展示了一部小说. 折腾之后,我发现此位置的块数据设置存在问题. 在数据块中,在默认站点中找到数据块pc_index_fengtui,然后单击“编辑”. 默认情况下,此块由指定的商品ID集调用. 我们可以删除它,以便调用整个网站范围的列,或设置指定的文章ID. 这个职位需要调用6部小说. 在下面的通话次数中填写6. 默认设置是仅在此处填写一个商品ID,我们可以将其更改为6个ID,以逗号分隔. 在(Application \ Home \ View)下修改了一些模板.
10. 如何更改网站模板YGBOOK6.14商业版本,其中收录5个PC模板和2个手机模板. 在“公用”文件夹中,找到几个模板. PC终端: biquge,bluebiquge,默认,singlebiquge,singlenovel移动终端: wap,wapbiquge在后台基本设置中更改PC站和移动站的主题. 只需更改主题文件夹的名称即可.
11. 如何将小说批量推向百度?检查上面的第5点. 文章信息的批处理将触发推送. 每次更新文章时,文章都会自动推送到百度. 但是,首先必须激活百度. 推送API已完全填写. 如果您不更新文章信息,则只要有用户在浏览该小说,小说信息就会自动更新,并且还会触发推送.
12. 如何添加一个友谊链接我已经使用YGBOOK一段时间了,并且我没有使用这个友谊链接的功能. 一些朋友使用它,发现他们无法使用它,所以我不得不折腾它. 实际上,添加朋友链仍然很简单,只需如下所示添加它即可.

填写前面的朋友链接的名称,用|分隔,然后填写后面的链接,就足够了,每行一个链接.
13. 打开ygbook小说分类,小说分类被卡住. 当我第一次使用它时,它也出现了. 单击采集后,即正在采集规则,并且正在采集幻想小说. 它会被卡住. 采集其他类别时也是如此. 以后,不再为每个采集规则单击采集,只需直接单击批采集即可避免这种卡住现象. 如果您的小伙伴遇到相同的问题,则可以直接单击批处理集合,这样集合将更快. 如何分批收取?您可以检查第四点.
14. 前台不会显示或更新小说. 它已被共享很久了,并且有很多使用它的朋友,因此经常有朋友问为什么不显示或不更新上面两个红色圆圈中的小说. 其实有两点. 其一是采集的小说太少,因此无法展示. 另一种是未设置背景,然后在块数据中设置. 左边的框的设置已经在第9点提到. 右边的框是pc_index_jingdian. 默认值为13,但我们可以在此处将其更改为14. 然后注意更新块数据. 设置中有更新频率. 这是当我们不更新块数据时,它将每隔几个小时自动更新一次. 这个时间可以自己设定. 没有显示也没有更新,只有几个问题. 实际上,当您采集大量数据时,可以更新下一个块数据.
15
最后,附加一个演示站: 品文时代与太空小说网
Dream weaving dedecms系统修改了文章描述中调用字数的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-08-07 06:21
让我们首先讨论如何修改此上限,以便我们可以显示方法的要点[field: description function =“ cn_substr(@me,character number)”/].
与Dedecms系统中的文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一个句子: $ description = cn_substrR($ description,$ cfg_auot_description);这句话实现了[field: description function =“ cn_substr(@me,字符数)” /]此功能. 由于此语句对页面布局确实有利,因此我们尝试不做任何更改.
在编辑页面上,有一个句子: $ description = cn_substrR($ description,250);该句子的字符数为250,这是系统设置的文章摘要字符数的上限. 如果是gbk编码,则显示125个字符. 如果是utf-8编码,则为81个字符. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,只需将250更改为另一个值,例如500. 建议不要在此处设置太高. 一种是不需要在列表页面上显示太多的内容(显示太多的内容不如间接使用主体好),另一种是避免数据库中的冗余.
仅完成上述修改是不够的,您需要修改article_description_main.php
在article_description_main.php页面上,我发现if($ dsize> 250)$ dsize = 250;语句,它限制了可以从后台检索的字符数. 只需将此处的250更改为500,织梦台就与之前修改的字符数有所不同. (如果确认已手动添加每篇文章,则无需修改此文件即可手动完成摘要获取. 次要摘要获取仍适用于大量文章和馆藏准备. )
首先,登录到后台,然后在系统-系统基本参数-其他选项中,将驱动摘要的长度更改为500,这意味着它与先前修改的字符数不同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 标签示例如下:
{dede: list typeid =” row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}
通过上述方法,我们已经意识到被调用的文本摘要为500个字符,这完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了更多空间.
让我们谈谈如何在常规的Dedecms文章或列表页面上调用文章摘要方法.
1: [field: info /]
2: [field: description /]
3: [field: info function =“ cn_substr(@me,字符数)” /]
4: [field: description function =“ cn_substr(@me,字符数)” /]
第一种和第二种方法是间接调用文章摘要. 就被调用的单词数而言,使用[field: info /]时,可以在{dede: arclist infolen =''} {/ dede: arclist}中,在通话摘要中设置字符数(向上系统设置的250个字符);如果使用[field: description /],则间接使用在后台设置的摘要字符的上限(背景也有上限250个字符). 显然,这两种方法都是非常被动和灵活的.
第三和第四种方法通过函数功能实现了文章摘要中显示字符的灵活调整. 当然,如果没有正确修改文章摘要的上限,则这四种方法之间的差异并不大. 查看全部
dedecms系统文章调用描述的字符数和数字最多为250个字节,并且文章摘要(可通过infolen或与描述相关的标签调用)的字符数限制为250个字符. 设置上限的第二个目的是减少数据库的冗余. 我保证网络的出色性能. 因此,不对引言的内容设置上限显然是不合理的,但是如果可以自由控制该上限,则仿冒网站的仿冒网站将对Web内容的布局产生积极影响. 在网页设计过程中,.NET源代码. 通常需要从渠道列表页面到文章摘要调用dedecms. 如果不能有效地控制文章摘要中的单词数,则页面布局可以非常灵活.
让我们首先讨论如何修改此上限,以便我们可以显示方法的要点[field: description function =“ cn_substr(@me,character number)”/].
与Dedecms系统中的文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一个句子: $ description = cn_substrR($ description,$ cfg_auot_description);这句话实现了[field: description function =“ cn_substr(@me,字符数)” /]此功能. 由于此语句对页面布局确实有利,因此我们尝试不做任何更改.
在编辑页面上,有一个句子: $ description = cn_substrR($ description,250);该句子的字符数为250,这是系统设置的文章摘要字符数的上限. 如果是gbk编码,则显示125个字符. 如果是utf-8编码,则为81个字符. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,只需将250更改为另一个值,例如500. 建议不要在此处设置太高. 一种是不需要在列表页面上显示太多的内容(显示太多的内容不如间接使用主体好),另一种是避免数据库中的冗余.
仅完成上述修改是不够的,您需要修改article_description_main.php
在article_description_main.php页面上,我发现if($ dsize> 250)$ dsize = 250;语句,它限制了可以从后台检索的字符数. 只需将此处的250更改为500,织梦台就与之前修改的字符数有所不同. (如果确认已手动添加每篇文章,则无需修改此文件即可手动完成摘要获取. 次要摘要获取仍适用于大量文章和馆藏准备. )
首先,登录到后台,然后在系统-系统基本参数-其他选项中,将驱动摘要的长度更改为500,这意味着它与先前修改的字符数不同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 标签示例如下:
{dede: list typeid =” row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}
通过上述方法,我们已经意识到被调用的文本摘要为500个字符,这完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了更多空间.
让我们谈谈如何在常规的Dedecms文章或列表页面上调用文章摘要方法.
1: [field: info /]
2: [field: description /]
3: [field: info function =“ cn_substr(@me,字符数)” /]
4: [field: description function =“ cn_substr(@me,字符数)” /]
第一种和第二种方法是间接调用文章摘要. 就被调用的单词数而言,使用[field: info /]时,可以在{dede: arclist infolen =''} {/ dede: arclist}中,在通话摘要中设置字符数(向上系统设置的250个字符);如果使用[field: description /],则间接使用在后台设置的摘要字符的上限(背景也有上限250个字符). 显然,这两种方法都是非常被动和灵活的.
第三和第四种方法通过函数功能实现了文章摘要中显示字符的灵活调整. 当然,如果没有正确修改文章摘要的上限,则这四种方法之间的差异并不大.
杨浩原创文章生成器
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-07 05:05
工作原理:
构建文章[template],然后在[template]中引用[element].
可以自由创建无限个[Elements],每个[element]可以放置任何内容,然后设置元素内容的分隔符. 随机调用时,元素的内容由分隔符分开,例如分隔符是换行符. 调用[Element]时,它是一行一行的随机
The
分隔符是其他字符的组合,因此您可以随机调用一个段落,一个段落甚至整个文章!调用整个文章时,您无需将文章的内容放在[Element]中,您可以直接放置文件路径,并且在调用时文章的内容将自动被调用! !
调用数千篇文章时,此功能非常有效!
支持非重复随机呼叫: 例如,5个号码1-5,5个呼叫,这5个号码必须出现一次,但是出现的顺序是随机的. 那么6-10个呼叫是新的非重复随机呼叫,11-15个呼叫是相同的,依此类推.
简单地说: 元素负责随机调用的数据,然后在模板中引用该元素,自由匹配,以便可以生成文章! !
从模板的内容中提取生成时的文件名. 它会逐行解释,直到合法文件名(即可以保存的文件名)为止. 当整个文章被解释并且没有合适的文件名时,文件名就会重复. 这时,如果设置了“当文件名重复时不生成”,则生成将被忽略,否则文件名会自动按数字前进,并且将保存文章,直到不再重复文件名!因此,建议将标题元素放在模板的第一行和第二行中. 建议将元素的分隔符设置为换行符,即逐行随机调用,而文章正文可以自由设置并插入元素调用中
Yang Hao原创文章生成器v9.4更新:
修改: “分隔符”已更改为“分隔符”,以使其更易于理解. 换行符是一种将元素内容分成多个块的符号.
新功能: 元素块的多个引号,并支持设置随机时间
新功能: 自然随机调用方法,即允许自然重复调用
新功能: 文章标题的数量随机
解决了百度标题采集器和百度描述采集器无法处理数据的问题.
修复了在智能第一针之间切换时的一些详细问题. 查看全部
Yang Hao原创文章生成器是一个真正强大的原创文章生成器!只要构建模板并组织元素,就可以生成任何所需的文章!尤其是网站管理员,需要花费一些时间来获取数据,并且一旦生成就可以一劳永逸. 将来将不会缺少文章! ! !它能做什么?它可以转换成千上万的文章,句子或短语,并将其转换为完全原创的文章! !
工作原理:
构建文章[template],然后在[template]中引用[element].
可以自由创建无限个[Elements],每个[element]可以放置任何内容,然后设置元素内容的分隔符. 随机调用时,元素的内容由分隔符分开,例如分隔符是换行符. 调用[Element]时,它是一行一行的随机
The
分隔符是其他字符的组合,因此您可以随机调用一个段落,一个段落甚至整个文章!调用整个文章时,您无需将文章的内容放在[Element]中,您可以直接放置文件路径,并且在调用时文章的内容将自动被调用! !
调用数千篇文章时,此功能非常有效!
支持非重复随机呼叫: 例如,5个号码1-5,5个呼叫,这5个号码必须出现一次,但是出现的顺序是随机的. 那么6-10个呼叫是新的非重复随机呼叫,11-15个呼叫是相同的,依此类推.
简单地说: 元素负责随机调用的数据,然后在模板中引用该元素,自由匹配,以便可以生成文章! !
从模板的内容中提取生成时的文件名. 它会逐行解释,直到合法文件名(即可以保存的文件名)为止. 当整个文章被解释并且没有合适的文件名时,文件名就会重复. 这时,如果设置了“当文件名重复时不生成”,则生成将被忽略,否则文件名会自动按数字前进,并且将保存文章,直到不再重复文件名!因此,建议将标题元素放在模板的第一行和第二行中. 建议将元素的分隔符设置为换行符,即逐行随机调用,而文章正文可以自由设置并插入元素调用中
Yang Hao原创文章生成器v9.4更新:
修改: “分隔符”已更改为“分隔符”,以使其更易于理解. 换行符是一种将元素内容分成多个块的符号.
新功能: 元素块的多个引号,并支持设置随机时间
新功能: 自然随机调用方法,即允许自然重复调用
新功能: 文章标题的数量随机
解决了百度标题采集器和百度描述采集器无法处理数据的问题.
修复了在智能第一针之间切换时的一些详细问题.
呼叫链系列之一,Zipkin体系结构介绍,Springboot集合(springmvc
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-07 03:19
Zipkin分布式跟踪系统;它可以帮助采集时间数据并解决微服务架构下的延迟问题;它管理这些数据的采集和搜索; Zipkin的设计基于Google的Google Dapper论文.
每个应用程序向Zipkin报告计时数据,Zipkin UI呈现一个依赖关系图以显示通过每个应用程序传递了多少跟踪请求. 如果您想解决延迟问题,则可以对所有跟踪请求进行过滤或排序,并查看每个跟踪请求占总跟踪时间的百分比.
2. 为什么要使用Zipkin
随着业务变得越来越复杂,系统也经历了各种分裂,特别是随着微服务架构和容器技术的兴起,一个看似简单的应用程序可能在后台支持数十甚至数百个服务. 前端请求可能需要多个服务调用才能在最后完成;当请求变慢或不可用时,我们不知道是由哪个后端服务引起的,因此我们需要解决如何快速定位服务失败点的问题,Zipkin分布式跟踪系统可以解决此类问题.
3,Zipkin下载并启动
官员提供了三种启动方式,这是第二种启动方式;
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
访问localhost: 9411
详细参考:
第二个Zipkin架构
跟踪器(Tracer)位于您的应用程序中,它记录发生的操作的时间和元数据,并提供相应的类库,该类库对用户的使用是透明的. 采集的跟踪数据称为Span;
已检测应用程序中将数据发送到Zipkin的组件称为Reporter. 记者通过几种传输方式之一将跟踪数据发送到Zipkin采集器,
然后存储(存储)跟踪数据,并通过API查询存储以向UI提供数据.
体系结构图如下:
1,跟踪
Zipkin使用跟踪结构来跟踪请求. 一个请求可能在后台由几个服务处理. 每个服务的处理都是一个跨度,并且跨度之间存在依赖性. 跟踪是树形结构中的一组Span;
2,跨度
<p>每个服务的处理和跟踪都是一个Span,可以将其理解为基本工作单元,包括一些描述性信息: id,parentId,名称,时间戳,持续时间,注释等,例如: 查看全部
1. 什么是Zipkin
Zipkin分布式跟踪系统;它可以帮助采集时间数据并解决微服务架构下的延迟问题;它管理这些数据的采集和搜索; Zipkin的设计基于Google的Google Dapper论文.
每个应用程序向Zipkin报告计时数据,Zipkin UI呈现一个依赖关系图以显示通过每个应用程序传递了多少跟踪请求. 如果您想解决延迟问题,则可以对所有跟踪请求进行过滤或排序,并查看每个跟踪请求占总跟踪时间的百分比.
2. 为什么要使用Zipkin
随着业务变得越来越复杂,系统也经历了各种分裂,特别是随着微服务架构和容器技术的兴起,一个看似简单的应用程序可能在后台支持数十甚至数百个服务. 前端请求可能需要多个服务调用才能在最后完成;当请求变慢或不可用时,我们不知道是由哪个后端服务引起的,因此我们需要解决如何快速定位服务失败点的问题,Zipkin分布式跟踪系统可以解决此类问题.
3,Zipkin下载并启动
官员提供了三种启动方式,这是第二种启动方式;
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
访问localhost: 9411
详细参考:
第二个Zipkin架构
跟踪器(Tracer)位于您的应用程序中,它记录发生的操作的时间和元数据,并提供相应的类库,该类库对用户的使用是透明的. 采集的跟踪数据称为Span;
已检测应用程序中将数据发送到Zipkin的组件称为Reporter. 记者通过几种传输方式之一将跟踪数据发送到Zipkin采集器,
然后存储(存储)跟踪数据,并通过API查询存储以向UI提供数据.
体系结构图如下:

1,跟踪
Zipkin使用跟踪结构来跟踪请求. 一个请求可能在后台由几个服务处理. 每个服务的处理都是一个跨度,并且跨度之间存在依赖性. 跟踪是树形结构中的一组Span;
2,跨度
<p>每个服务的处理和跟踪都是一个Span,可以将其理解为基本工作单元,包括一些描述性信息: id,parentId,名称,时间戳,持续时间,注释等,例如:
织梦DEDECMS文章页面呼叫文章浏览时间优化了呼叫代码标签
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-07 03:18
在使用Dream Weaving建立网站时,在文章页面的信息页面上,调用文章查看次数的正式标签为: {dede: field.click/}该标签调用静态观看次数,也就是说,我们生成文章当时随机生成的视图数量,无论文章页面如何刷新,都不会增加视图数量,并且用户体验非常差. Internet上存在一种解决方案,即将呼叫标签更改为: 这样,可以动态调用,刷新和增加文章视图的数量,但在使用后发现了问题. 每次将页面加载到此位置时,它都会冻结,因为这是一个js调用,每次对服务器发出请求时,此处的标签都会被及时加载,并且肯定会卡在这里. 经过研究,给出了最佳解决方案. 具体想法是: 我们可以首先自定义一个数字(可以定义为0). 第一次加载网页时,它会加载我们预先确定的数字,然后通过最后加载的网页JS调用实际的点击次数. 具体步骤是: 1.使用span标签在点击计数的位置定义0次点击计数. 2.修改Dede核心功能,然后在plus / count.php中找到echo“ document.write('”. $ row ['click'] ..“'); rn”;. 关于第25行,将其替换为echo'document.getElementById(“ countnum”). innerHTML ='. $ row ['click']; 3.在页面底部添加js代码,在页面底部添加js,可以完美解决加载视图数时卡住的问题. 用户体验非常好. 到目前为止,文章页面会动态调用文章浏览量.
WordPress将最新文章称为五种方法,包括排除粘性文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-06 20:22
在不使用插件的情况下调用最新文章是我们在进行wordpress转换和开发时经常遇到的功能. 我们已经在Internet上采集了几种常用方法. 当页面同时收录最新文章和热门文章时,我们应考虑将最新文章排除在列表之外.
一种,最简单的方法wp_get_archvies
可以使用非常简单的单行模板标签wp_get_archvies来实现对最新WordPress文章的调用
(显示10条最新更新的文章)
或
type = postbypost: 按最新帖子排序
限制: 将文章数限制为最新的20条
format = custom: 用于自定义此文章列表的显示样式(也可以省略fromat = custom,文章标题默认显示在UL列表中. )
二,query_posts()函数
最新的帖子列表也可以通过WP的query_posts()函数调用. 尽管代码会更多,但是您可以更好地控制Loop的显示. 例如,您可以设置是否显示摘要. 您也可以查看官方说明以了解具体用法.
调用最新文章: (只需将以下代码直接放在您要显示的位置即可)
最新文章
阅读6篇文章,并排除类别ID为111的文章
三,推荐WP_Query函数
四个. 推荐get_results()函数
5. 从最新文章中排除热门文章
最新文章
六. 摘要
1,使用get_results()函数最快
2. 建议使用WP_Query()函数,该函数非常灵活且控制良好. 这也是官方网站推荐的功能
摘要
以上是WordPress调用Script House为您采集的最新文章. 五种方法包括排除顶部文章的所有内容. 希望本文可以帮助您解决WordPress调用最新文章的问题. 五个方法包括排除上一篇文章遇到的程序开发. 问题.
如果您认为Scripthome网站的内容还不错,欢迎向程序员朋友推荐Scripthome网站. 查看全部
本文由Script House采集并组织,主要介绍了WordPress调用最新文章的五种方法,包括排除热门文章. Script House的编辑认为这是相当不错的. 现在,我将与您分享并提供参考.
在不使用插件的情况下调用最新文章是我们在进行wordpress转换和开发时经常遇到的功能. 我们已经在Internet上采集了几种常用方法. 当页面同时收录最新文章和热门文章时,我们应考虑将最新文章排除在列表之外.
一种,最简单的方法wp_get_archvies
可以使用非常简单的单行模板标签wp_get_archvies来实现对最新WordPress文章的调用
(显示10条最新更新的文章)
或
type = postbypost: 按最新帖子排序
限制: 将文章数限制为最新的20条
format = custom: 用于自定义此文章列表的显示样式(也可以省略fromat = custom,文章标题默认显示在UL列表中. )
二,query_posts()函数
最新的帖子列表也可以通过WP的query_posts()函数调用. 尽管代码会更多,但是您可以更好地控制Loop的显示. 例如,您可以设置是否显示摘要. 您也可以查看官方说明以了解具体用法.
调用最新文章: (只需将以下代码直接放在您要显示的位置即可)
最新文章
阅读6篇文章,并排除类别ID为111的文章
三,推荐WP_Query函数
四个. 推荐get_results()函数
5. 从最新文章中排除热门文章
最新文章
六. 摘要
1,使用get_results()函数最快
2. 建议使用WP_Query()函数,该函数非常灵活且控制良好. 这也是官方网站推荐的功能
摘要
以上是WordPress调用Script House为您采集的最新文章. 五种方法包括排除顶部文章的所有内容. 希望本文可以帮助您解决WordPress调用最新文章的问题. 五个方法包括排除上一篇文章遇到的程序开发. 问题.
如果您认为Scripthome网站的内容还不错,欢迎向程序员朋友推荐Scripthome网站.
Empire CMS内容页面调用当前文章的作者信息,并调用除当前文章以外的成员相关文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2020-08-06 18:15
1. 通话会员信息:
将以下代码添加到内容页面模板中.
$ userr = sys_ShowMemberInfo(0,'');
会员头像:
成员:
会员ID:
注册时间:
会员积分: 积分
发布新闻: 文章
成员组:
作者文章列表: e / space / list.php?userid =&mid = 1“>文章列表
第二,调用用户发布的其他文章的信息(成员投稿的文章):
1,php调用
调用当前成员提交的文章(5篇文章):
---------------------
$ sql = $ empire-> query(“从{$ dbtbpre} ecms_news中选择*,其中userid ='$ navinfor [userid]'和classid ='$ navinfor [classid]'和id $ navinfor [id]和ismember = 1按新闻时间升序限制5“)排序;
while($ r = $ empire-> fetch($ sql))
if($ navinfor [ismember] == 1)
{
$ titleurl = sys_ReturnBqTitleLink($ r); //链接
“ target =” _ blank“ title =”“>
}
其他
{
暂时没有其他文章
}
2,智能标记调用
----------------------
[e: loop = {“从[!db.pre!] ecms_news中选择*,其中userid ='$ navinfor [userid]'和classid ='$ navinfor [classid]'和id $ navinfor [id]和ismember = 1按新闻时间降序限制10“,0,24,0}]
if($ navinfor [ismember] == 1)
{
“ title =”“>
}
其他
{
暂时没有其他文章
}
[/ e: loop]
或
[e: loop = {'selfinfo',10,0,0,“ userid ='$ navinfor [userid]'and classid ='$ navinfor [classid]'and id $ navinfor [id] and ismember = 1 “}]
if($ navinfor [ismember] == 1)
{
“ title =”“>
}
其他
{
暂时没有其他文章
}
[/ e: loop]
=============================================通话用户对其他文章发表的评论============================================ ==========
注意: id $ navinfor [id]或and id!= $ navinfor [id]表示: 不等于当前文章ID
①,classid ='$ navinfor [classid]'的意思是: 仅调用当前列中的文章(如果删除该列,则将调用整个模型中其他列中成员发布的文章)
②,classid也可以指定显示列的id格式,例如: classid = 34或(2,3)中的classid)
③,classid也可以排除当前列. 格式如下: classid $ navinfor [classid]即: 在其他列中调用当前发布者发布的信息
“目前没有其他文章”可以删除
注意: 以上内容(调用用户发布的其他文章信息)可以调用“成员”和“访客”的文章,但背景“网站管理员”发布的文章除外. 查看全部
内容页面调用当前文章的作者信息,并调用当前文章以外的成员相关文章
1. 通话会员信息:
将以下代码添加到内容页面模板中.
$ userr = sys_ShowMemberInfo(0,'');
会员头像:

成员:
会员ID:
注册时间:
会员积分: 积分
发布新闻: 文章
成员组:
作者文章列表: e / space / list.php?userid =&mid = 1“>文章列表
第二,调用用户发布的其他文章的信息(成员投稿的文章):
1,php调用
调用当前成员提交的文章(5篇文章):
---------------------
$ sql = $ empire-> query(“从{$ dbtbpre} ecms_news中选择*,其中userid ='$ navinfor [userid]'和classid ='$ navinfor [classid]'和id $ navinfor [id]和ismember = 1按新闻时间升序限制5“)排序;
while($ r = $ empire-> fetch($ sql))
if($ navinfor [ismember] == 1)
{
$ titleurl = sys_ReturnBqTitleLink($ r); //链接
“ target =” _ blank“ title =”“>
}
其他
{
暂时没有其他文章
}
2,智能标记调用
----------------------
[e: loop = {“从[!db.pre!] ecms_news中选择*,其中userid ='$ navinfor [userid]'和classid ='$ navinfor [classid]'和id $ navinfor [id]和ismember = 1按新闻时间降序限制10“,0,24,0}]
if($ navinfor [ismember] == 1)
{
“ title =”“>
}
其他
{
暂时没有其他文章
}
[/ e: loop]
或
[e: loop = {'selfinfo',10,0,0,“ userid ='$ navinfor [userid]'and classid ='$ navinfor [classid]'and id $ navinfor [id] and ismember = 1 “}]
if($ navinfor [ismember] == 1)
{
“ title =”“>
}
其他
{
暂时没有其他文章
}
[/ e: loop]
=============================================通话用户对其他文章发表的评论============================================ ==========
注意: id $ navinfor [id]或and id!= $ navinfor [id]表示: 不等于当前文章ID
①,classid ='$ navinfor [classid]'的意思是: 仅调用当前列中的文章(如果删除该列,则将调用整个模型中其他列中成员发布的文章)
②,classid也可以指定显示列的id格式,例如: classid = 34或(2,3)中的classid)
③,classid也可以排除当前列. 格式如下: classid $ navinfor [classid]即: 在其他列中调用当前发布者发布的信息
“目前没有其他文章”可以删除
注意: 以上内容(调用用户发布的其他文章信息)可以调用“成员”和“访客”的文章,但背景“网站管理员”发布的文章除外.
织梦调用相关文章时,likearticle不能排除当前文章的解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2020-08-06 18:14
/ ************************************************** ****************************************************** **** /
if($ keyword!='')
{
if(!empty($ typeid)){
$ typeid =“ AND arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
其中arc.arcrank> -1AND($ keyword)$ typeid $ orderquery limit 0,$ row“;
}
其他
{
if(!empty($ typeid)){
$ typeid =“ arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
WHERE arc.arcrank> -1AND $ typeid $ orderquery limit 0,$ row“;
}
/ ************************************************** *************************************************** / <//p
p从上面的代码中,我们可以看到dedecms试图在程序开始时对文章进行过滤以排除该文章(AND arc.id'$ aid'“),但失败了. 如何成功排除这很简单. 我们可以在此代码中再次将其排除: AND($ keyword)$ typeid. 必须添加这两个代码. 修改完成后,以下是以下内容(请注意区别)之间的绿色粗体代码):/p
p/ ************************************************** ****************************************************** **** //p
pif($ keyword!='')/p
p{/p
pif(!empty($ typeid)){/p
p$ typeid =“ AND arc.typeid IN($ typeid)AND arc.id'$ aid'”;/p
p}/p
p$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,/p
ptp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath/p
pFROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id/p
p其中arc.arcrank> -1AND($ keyword)$ typeidAND arc.id'$ aid'$ orderquery limit 0,$ row“;
}
其他
{
if(!empty($ typeid)){
$ typeid =“ arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
WHERE arc.arcrank> -1AND $ typeidAND arc.id'$ aid'$ orderquery limit 0,$ row“;
}
<p>/ ************************************************** *************************************************** / 查看全部
通常,当我们发布文章时,为了增加用户的停留时间,我们将在文章末尾或适当位置调用与该文章相关的文章,以再次赢得用户的点击. 在dedecms(V5版本.7)中,在调用类似文章时,实际的调用代码为{dede: likearticle}. 该代码的原理是通过识别文章的标题,类别,关键字等来提出建议,以判断相似性. 后台调用代码如下/include/taglib/likearticle.lib.php,打开文件并找到以下代码:
/ ************************************************** ****************************************************** **** /
if($ keyword!='')
{
if(!empty($ typeid)){
$ typeid =“ AND arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
其中arc.arcrank> -1AND($ keyword)$ typeid $ orderquery limit 0,$ row“;
}
其他
{
if(!empty($ typeid)){
$ typeid =“ arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
WHERE arc.arcrank> -1AND $ typeid $ orderquery limit 0,$ row“;
}
/ ************************************************** *************************************************** / <//p
p从上面的代码中,我们可以看到dedecms试图在程序开始时对文章进行过滤以排除该文章(AND arc.id'$ aid'“),但失败了. 如何成功排除这很简单. 我们可以在此代码中再次将其排除: AND($ keyword)$ typeid. 必须添加这两个代码. 修改完成后,以下是以下内容(请注意区别)之间的绿色粗体代码):/p
p/ ************************************************** ****************************************************** **** //p
pif($ keyword!='')/p
p{/p
pif(!empty($ typeid)){/p
p$ typeid =“ AND arc.typeid IN($ typeid)AND arc.id'$ aid'”;/p
p}/p
p$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,/p
ptp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath/p
pFROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id/p
p其中arc.arcrank> -1AND($ keyword)$ typeidAND arc.id'$ aid'$ orderquery limit 0,$ row“;
}
其他
{
if(!empty($ typeid)){
$ typeid =“ arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
WHERE arc.arcrank> -1AND $ typeidAND arc.id'$ aid'$ orderquery limit 0,$ row“;
}
<p>/ ************************************************** *************************************************** /
DEDECMS采集仅下载图片(jpg)不下载视频(swf)的更改办法
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-08-10 00:30
DEDECMS采集仅下载图片(jpg)不下载视频(swf)的更改办法
今天尝试为织梦dedecms 站长基地采集文章的时侯,在视频这一块遇见了不少麻烦,发现在织梦dedecms的采集模块当中,仅有一个“下载数组里的多媒体资源”的勾选项。
也就是说,只要勾选这一项,它都会默认将多媒体资源全部手动上传至FTP本地上,图片一般是没有问题的,但对于视频,并不适宜上传至服务器,而且好多第三方视频网站的调用代码是不容许在其中添加其它代码的,这就要求我们必须限制视频格式的多媒体手动上传,看到官方好多同学碰到类似问题,官方也没有给与答复,于是经过自己不断研究总算找到解决办法,现分享给诸位,希望能对诸位有所帮助。
找到控制多媒体上传的文件(include/dede采集.class.php)找到以下代码:
if($v=='embed' && !preg_match("#\.(swf)\?(.*)$#i", $k)&& !preg_match("#\.(swf)$#i", $k))
修改为
if($v!='img' && !preg_match("#\.(jpg|gif|png)\?(.*)$#i", $k)&& !preg_match("#\.(jpg|gif|png)$#i", $k))
然后继续查找:
else if(preg_match("#\.(swf)\?(.*)$#i", $v) || preg_match("#\.(swf)$#i", $v))
{
$m = "embed";
}
将这句注释掉或则直接删掉掉。
最新标签 查看全部
简介: 今天尝试为织梦dedecms 站长基地采集文章的时侯,在视频这一块遇见了不少麻烦,发现在织梦dedecms的采集模块当中,仅有一个下载数组里的多媒体资源的勾选项。 也就是说,只要勾选这一项,它都会默认将多媒体资源全部手动上传至FTP本地上,图片一般是没有问题文章来源菜鸟建站网
DEDECMS采集仅下载图片(jpg)不下载视频(swf)的更改办法
今天尝试为织梦dedecms 站长基地采集文章的时侯,在视频这一块遇见了不少麻烦,发现在织梦dedecms的采集模块当中,仅有一个“下载数组里的多媒体资源”的勾选项。
也就是说,只要勾选这一项,它都会默认将多媒体资源全部手动上传至FTP本地上,图片一般是没有问题的,但对于视频,并不适宜上传至服务器,而且好多第三方视频网站的调用代码是不容许在其中添加其它代码的,这就要求我们必须限制视频格式的多媒体手动上传,看到官方好多同学碰到类似问题,官方也没有给与答复,于是经过自己不断研究总算找到解决办法,现分享给诸位,希望能对诸位有所帮助。
找到控制多媒体上传的文件(include/dede采集.class.php)找到以下代码:
if($v=='embed' && !preg_match("#\.(swf)\?(.*)$#i", $k)&& !preg_match("#\.(swf)$#i", $k))
修改为
if($v!='img' && !preg_match("#\.(jpg|gif|png)\?(.*)$#i", $k)&& !preg_match("#\.(jpg|gif|png)$#i", $k))
然后继续查找:
else if(preg_match("#\.(swf)\?(.*)$#i", $v) || preg_match("#\.(swf)$#i", $v))
{
$m = "embed";
}
将这句注释掉或则直接删掉掉。
最新标签
Fiddler 网页采集抓包神器__手机app抓包
采集交流 • 优采云 发表了文章 • 0 个评论 • 615 次浏览 • 2020-08-09 16:25
基于weiphp做了一个掌上头条插件,也是用的网页采集技术;和一个创业团队一起在做一个中考志愿补报系统,所有的数据也是从别的地方抓取。
总而言之,网页抓取与网页采集技术是一项十分实用的技能,他能使我们高效快速的获取我们开发产品所须要的一些基本数据。
网页抓取与网页采集过程中难免须要用到抓包技术,所谓抓包,就是我们在访问一个目标网站的时侯,需要剖析我们递交给浏览器的一些http请求以及递交给浏览器的一些数据,在晓得恳求是怎样发起的以及post了什么数据以后,我们能够针对目标网页写出相应的采集程序。特别是在模拟登录一些须要用户进行登入验证的网站时,抓包剖析就显得很重要。
一些浏览器自带抓包剖析工具或则有其可扩充的抓包插件,像火狐浏览器有firebug插件,IE浏览器有HttpWatch。每个抓包工具都有其独到的功能,这里就不一一介绍了,今天给你们介绍一个好用的抓包工具Fiddler。
手机APP抓包
现在我们来结合一个具体的事例来讲一下怎么抓包剖析手机APP的恳求数据,并达到自己的需求。我这儿给你们讲一个LOL盒子的抓包实例。
我们晓得,LOL盒子没有网页版,或者说网页版的功能并不象手机APP一样数据整合的这么齐全。如果我们要做一个陌陌版的LOL盒子,让用户在微信端回复一些关键词才能查看一些基本信息,比如用户在陌陌中回复“英雄”就能查看LOL全部的英雄信息,包括出装、符文之类的。那么我们想在陌陌端实现这种功能,肯定须要数据库的支持,如果我们的数据从LOL官网抓取的话,免不了要写好多匹配规则,所以一个简单高效的方式是直接抓取LOL盒子早已整合了的数据。那么题外话开始,我们开始抓LOL盒子集成的全部英雄的数据。
1、首先在手机下载LOL盒子,并步入首页(请忽视我这个战五渣的战斗力指数)
2、打开Fiddler并点Remove all把抓包信息全部消除
3、在LOL盒子中点击英雄步入查看英雄页面
4、可以看见查看英雄页面有免费、我的英雄、全部三个选项
5、这时候我们可以看见Fiddler早已抓到我们须要的数据插口了
6、我们在其中一个数据插口里面点击右键,复制url地址并在浏览器中打开
7、就能看见我们须要的周免英雄的数据插口了,是json格式的
到此为止,抓包剖析的整个流程你们一目了然了,得到了json插口以后,我们能够用curl技术把数据采集下来,并把json格式的数据转换成链表或则其他格式,然后就可以存到我们自己的数据库中了,当用户在陌陌中回复关键词时,我们就从数据库中取出相应的数据并回复给用户就行了。 查看全部
用curl技术开发了一个陌陌文章聚合类产品,把抓取到的数据转换成json格式,并在android端调用json数据插口加以显示;
基于weiphp做了一个掌上头条插件,也是用的网页采集技术;和一个创业团队一起在做一个中考志愿补报系统,所有的数据也是从别的地方抓取。
总而言之,网页抓取与网页采集技术是一项十分实用的技能,他能使我们高效快速的获取我们开发产品所须要的一些基本数据。
网页抓取与网页采集过程中难免须要用到抓包技术,所谓抓包,就是我们在访问一个目标网站的时侯,需要剖析我们递交给浏览器的一些http请求以及递交给浏览器的一些数据,在晓得恳求是怎样发起的以及post了什么数据以后,我们能够针对目标网页写出相应的采集程序。特别是在模拟登录一些须要用户进行登入验证的网站时,抓包剖析就显得很重要。
一些浏览器自带抓包剖析工具或则有其可扩充的抓包插件,像火狐浏览器有firebug插件,IE浏览器有HttpWatch。每个抓包工具都有其独到的功能,这里就不一一介绍了,今天给你们介绍一个好用的抓包工具Fiddler。
手机APP抓包
现在我们来结合一个具体的事例来讲一下怎么抓包剖析手机APP的恳求数据,并达到自己的需求。我这儿给你们讲一个LOL盒子的抓包实例。
我们晓得,LOL盒子没有网页版,或者说网页版的功能并不象手机APP一样数据整合的这么齐全。如果我们要做一个陌陌版的LOL盒子,让用户在微信端回复一些关键词才能查看一些基本信息,比如用户在陌陌中回复“英雄”就能查看LOL全部的英雄信息,包括出装、符文之类的。那么我们想在陌陌端实现这种功能,肯定须要数据库的支持,如果我们的数据从LOL官网抓取的话,免不了要写好多匹配规则,所以一个简单高效的方式是直接抓取LOL盒子早已整合了的数据。那么题外话开始,我们开始抓LOL盒子集成的全部英雄的数据。
1、首先在手机下载LOL盒子,并步入首页(请忽视我这个战五渣的战斗力指数)
2、打开Fiddler并点Remove all把抓包信息全部消除
3、在LOL盒子中点击英雄步入查看英雄页面
4、可以看见查看英雄页面有免费、我的英雄、全部三个选项
5、这时候我们可以看见Fiddler早已抓到我们须要的数据插口了
6、我们在其中一个数据插口里面点击右键,复制url地址并在浏览器中打开
7、就能看见我们须要的周免英雄的数据插口了,是json格式的
到此为止,抓包剖析的整个流程你们一目了然了,得到了json插口以后,我们能够用curl技术把数据采集下来,并把json格式的数据转换成链表或则其他格式,然后就可以存到我们自己的数据库中了,当用户在陌陌中回复关键词时,我们就从数据库中取出相应的数据并回复给用户就行了。
DEDE采集分页文章时相对路径问题解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 271 次浏览 • 2020-08-09 15:08
问题描述:
当采集目标文章中列表或则分页信息是绝对路径时,DEDE可以正确采集。
当采集目标文章中列表或则分页信息是相对路径,但是以 '/'开头(如 /2012/0328/1943.html)DEDE也可以正确采集。
当采集目标文章中列表或则分页信息是相对路径,但不是以 '/'开头(如 2012/0328/1943.html)DEDE就不能正确采集了。
解决方案:
问题的症结出在 dedehtml2.class.php 中的 FillUrl 函数上,大概在394行左右:
if( strlen($surl) < 7 )<br /> {<br /> $okurl = $this->BaseUrlPath.'/'.$surl;<br /> }<br /> else if( strtolower(substr($surl,0,7))=='http://' )<br /> {<br /> $okurl = preg_replace('/^http:\/\//i', '', $surl);<br /> }<br /> else<br /> {<br /> //$okurl = $this->BaseUrlPath.'/'.$surl; <br /> $okurl = $this->HomeUrl.'/'.$surl; <br /> }
被注释掉的(红色)代码是原创的,增加下边一行(绿色)代码问题就解决了。
DedeCms下载:
织梦CMS(DedeCMS) v5.7 SP1 GBK build20150618下载
界面预览 查看全部
使用DedeCMS在采集文章的时侯,发现DEDE采集文章相对路径文章时的一个bug,上网查询了一个晚上总算找到类似问题的解决办法,最后把这个问题的症结找到而且解决了。
问题描述:
当采集目标文章中列表或则分页信息是绝对路径时,DEDE可以正确采集。
当采集目标文章中列表或则分页信息是相对路径,但是以 '/'开头(如 /2012/0328/1943.html)DEDE也可以正确采集。
当采集目标文章中列表或则分页信息是相对路径,但不是以 '/'开头(如 2012/0328/1943.html)DEDE就不能正确采集了。
解决方案:
问题的症结出在 dedehtml2.class.php 中的 FillUrl 函数上,大概在394行左右:
if( strlen($surl) < 7 )<br /> {<br /> $okurl = $this->BaseUrlPath.'/'.$surl;<br /> }<br /> else if( strtolower(substr($surl,0,7))=='http://' )<br /> {<br /> $okurl = preg_replace('/^http:\/\//i', '', $surl);<br /> }<br /> else<br /> {<br /> //$okurl = $this->BaseUrlPath.'/'.$surl; <br /> $okurl = $this->HomeUrl.'/'.$surl; <br /> }
被注释掉的(红色)代码是原创的,增加下边一行(绿色)代码问题就解决了。
DedeCms下载:
织梦CMS(DedeCMS) v5.7 SP1 GBK build20150618下载
界面预览
非盈利机构ABUSE搜集约10万个恶意网站可供免费调用
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2020-08-09 13:48
这些恶意网站均为安全研究人员发觉后自动递交的,在初审通过后便会添加到恶意网站数据库里可免费调用。
数据库早已将各个恶意网站按不同类型进行标记,例如当前是否在线、恶意内容类型、潜在的恐吓信息等等。
安全软件开发商以及浏览器开发商等都可以免费调用这份数据库帮助用户拦截这些可能存在恐吓的恶意网站。
国内某345的部份地址也会警告:
需注意的是这份数据库不分辨恶意网站还是正常网站被入侵弄成恶意网站的,只有仍然存在恐吓都会被警告。
数据库每隔五分钟都会更新确保就能更及时的拦截恶意网站, 这也是 ABUSE 建立这个恶意网站列表的诱因。
该非盈利机构表示当前好多恶意网站存活数月才被拦截,对于用户来说这个拦截时效实在很慢不能保护用户。
蓝点网测试发觉这种恶意网站类型涵括多种,例如蓝点网检索还发觉有针对国外企业功击的垂钓 DOC 文档。
这类文档通过短信或则其他形式传播,当用户打开并放行Word 安全保护时就可能会执行恶意代码感染用户。
最后任何人都可以向这份恶意网站数据库添加恶意网站,只须要使用脸书帐号登入该网站后即可进行递交等。 查看全部
非盈利机构 ABUSE 最新公布的博客显示目前由全球各地安全研究人员递交的恶意网站列表早已超过10万个。
这些恶意网站均为安全研究人员发觉后自动递交的,在初审通过后便会添加到恶意网站数据库里可免费调用。
数据库早已将各个恶意网站按不同类型进行标记,例如当前是否在线、恶意内容类型、潜在的恐吓信息等等。
安全软件开发商以及浏览器开发商等都可以免费调用这份数据库帮助用户拦截这些可能存在恐吓的恶意网站。
国内某345的部份地址也会警告:
需注意的是这份数据库不分辨恶意网站还是正常网站被入侵弄成恶意网站的,只有仍然存在恐吓都会被警告。
数据库每隔五分钟都会更新确保就能更及时的拦截恶意网站, 这也是 ABUSE 建立这个恶意网站列表的诱因。
该非盈利机构表示当前好多恶意网站存活数月才被拦截,对于用户来说这个拦截时效实在很慢不能保护用户。
蓝点网测试发觉这种恶意网站类型涵括多种,例如蓝点网检索还发觉有针对国外企业功击的垂钓 DOC 文档。
这类文档通过短信或则其他形式传播,当用户打开并放行Word 安全保护时就可能会执行恶意代码感染用户。
最后任何人都可以向这份恶意网站数据库添加恶意网站,只须要使用脸书帐号登入该网站后即可进行递交等。
织梦调用指定列和分页下的文章列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2020-08-09 01:49
该站点的技术团队在织梦CMS,帝国模仿站点和二次开发方面拥有7年的经验. 拥有一支稳定的设计团队和技术团队,以确保您的售后技术服务. 仿制台最低为200元,欢迎咨询客服.
业务范围:
开源CMS(帝国,梦织)模仿站点,成品自适应模板,网站克隆,网站定制,修订,二次开发,获取,新功能开发!
仿站强度:
200元企业模仿站(标准企业站),最快3个小时下达订单,准确率达到99%.
—————————————————————————————————————————————— ——————————
说明: Dream Weaving的默认分页(列表)是在当前列下的页面,但是在许多情况下,如果我们划分,则需要在某些列下开发列表页面,例如医疗行业的典型案例该列合并为下一个疾病案例(如下图所示),因此导航中的典型案例需要调用很多指定的列列表和页面;
在这里,我们谈论最简单的方法. 除了当前列下的分页外,“织梦”还具有多个列下的列表页;
1. 使用模板找到该列->“更改”->“常规”选项->“列交叉”->“手动指定交叉列的ID(用逗号分隔)
2,只需使用默认列表调用,这很简单
{dede: list pagesize =“ 10” orderby ='pubdate'}
[field: title /]
{/ dede: list}
{dede: pagelist listitem =“ info,index,end,pre,next,pageno” listsize =“ 1” /} 查看全部
—————————————————————————————————————————————— ——————————
该站点的技术团队在织梦CMS,帝国模仿站点和二次开发方面拥有7年的经验. 拥有一支稳定的设计团队和技术团队,以确保您的售后技术服务. 仿制台最低为200元,欢迎咨询客服.
业务范围:
开源CMS(帝国,梦织)模仿站点,成品自适应模板,网站克隆,网站定制,修订,二次开发,获取,新功能开发!
仿站强度:
200元企业模仿站(标准企业站),最快3个小时下达订单,准确率达到99%.
—————————————————————————————————————————————— ——————————
说明: Dream Weaving的默认分页(列表)是在当前列下的页面,但是在许多情况下,如果我们划分,则需要在某些列下开发列表页面,例如医疗行业的典型案例该列合并为下一个疾病案例(如下图所示),因此导航中的典型案例需要调用很多指定的列列表和页面;
在这里,我们谈论最简单的方法. 除了当前列下的分页外,“织梦”还具有多个列下的列表页;
1. 使用模板找到该列->“更改”->“常规”选项->“列交叉”->“手动指定交叉列的ID(用逗号分隔)
2,只需使用默认列表调用,这很简单
{dede: list pagesize =“ 10” orderby ='pubdate'}
[field: title /]
{/ dede: list}
{dede: pagelist listitem =“ info,index,end,pre,next,pageno” listsize =“ 1” /}
LabVIEW调用数据采集卡DLL函数
采集交流 • 优采云 发表了文章 • 0 个评论 • 368 次浏览 • 2020-08-08 01:06
与传统的编程语言不同,LabVIEW使用一种功能强大的图形语言编程语言为测试工程师而非专业程序员服务. 编程非常方便. 人机交互界面直观友好. 它具有强大的数据可视化分析和仪器控制功能. 使用LabVIEW开发环境,用户可以创建32位编译器,从而为常规数据采集,测试和测量任务提供更快的运行速度. LabVIEW是真正的编译器. 用户可以创建独立的可执行文件,这些文件可以独立于开发环境运行. 对于大多数编程任务,LabVIEW通常生成高效的代码. 1 LabVIEW是调用外部程序代码的方法之一. 动态链接库机制1.1动态链接库机制概述LabVIEW是一个功能强大的虚拟仪器开发环境,已与GPIB VXI RS-232 RS-485插值数据采集完全集成在一起. LabVIEW还具有一个内置库,可通过共享ActiveX的DLL和其他方式实现与外部程序代码或软件系统的连接,从而提供大量的连接机制. LabVIEW提供了四种调用外部程序代码的方法. 动态链接库DLL机制是从LabVIEW调用标准共享库和用户定义的库函数的通用方法. 具体实现是使用LabVIEW函数模板的Advanced子模板中的Call Library Function节点.
呼叫库功能节点收录大量数据类型和呼叫规范. 使用它可以调用大多数标准共享库和用户定义的库,包括Windows9X / XP / 2000 / NT下的动态链接库. 动态链接库Macintosh UNIX共享库功能下的“代码片段共享库功能”下的代码片段当用户需要调用的代码已经存在,或者用户熟悉以下代码段UNIX中共享库的创建过程时: 在Windows动态链接库中,调用库函数节点非常有用. 此时,它也是最合适的方法,因为图书馆使用的是收据日期. 2004-04-21基金项目湖北省教育厅重点项目2003A006作者简介襄樊学院物理系副教授,湖北鄂州. 15.调用LabVIEW到数据采集卡DLL功能16适用于多种开发环境的格式标准,因此用户几乎可以使用任何开发环境来创建LabVIEW可以调用的库. 1.2动态链接库机制的实现步骤在Windows 9X下,使用LabVIEW 6.1(Windows95 / 98 / NT)中的动态链接库机制来调用DLL. DLL返回计算机的名称.
1)创建一个调用库函数节点,创建一个新的LabVIEW程序主机名. 将vi保存到新创建的目录d: \ temp. 图1库函数调用前面板框图. 该程序如图2所示的库函数调用框图. 通过在功能模板的“高级”子模板中选择“调用库功能”功能模块,可以选择“调用库功能”节点. 生产的. 该LabVIEW程序通过调用库函数节点来调用DLL. 该DLL将返回计算机的名称,并将返回的结果存储在字符串指示器“计算机名称”中,然后将字符串常量LabVIEW MachineName连接起来以显示字符串指示器“ Message”. 2)配置调用库功能节点在程序框图程序窗口中双击“调用库功能”节点. 在弹出对话框中,配置调用库功能节点,然后在LibraryName Path项目中输入d: \ temp \ hostname. dll表示此节点链接的DLL文件的名称,它是C源代码的主机名. c编译并键入FunctionName项目MachineName,以在链接到该节点的DLL文件中指示函数的名称. 参数返回类型是选择Void的类型. 添加的另一个参数是arg1的类型. 字符串格式为选择“字符串句柄3”. )编辑C源文件以编辑C源文件的主机名.
c保存到目录d: \ temp includeextcode. h收录LabVIEW函数的#include #include #include BOOL WINAPI DllMain(HANDLE hDLL,DWORD dwReason,LPVOID lpReserved)返回TRUE;函数获取计算机名__declspec(dllexport)无效MachineName(void * LVHandle)charcomputerName [MAX_COMPUTERNAME_LENGTH + 1]; intENGTH compNameLength;襄樊学院学报第二十五期2004 Getcomputer name GetComputerName(computerName,&compNameLength); SizeLabVIEW句柄正确大小DSSetHandleSize(LVHandle,compNameLength stringsize LabVIEWhandle **(int32 **)LVHandle LabVIEWhandle sprintf((*(char **)LVHandle)+4,“%s”,computerName);该程序首先调用Windows API函数GetComputerName获取机器名,然后调用LabVIEW函数DSSetHandleSize设置LabVIEW句柄的大小,最后,将机器名的32位整数机器名字符串依次写入到句柄中.
4)编译C源代码. 将C源代码更改为d: \ temp \主机名. c编译为DLL文件d: \ temp \ hostname. dll可以使用VC ++ 6.0 Windows95 / 98/2000 / NT来完成此编译. 5)运行VI以运行LabVIEW程序的主机名. vi的结果如下. 图3前面板运行结果. 2结束语本文重点介绍和实现一种将LabVIEW与外部代码,动态链接库机制连接的高级技术,并给出一个应用示例. 由于LabVIEW中引入了C语言的强大功能,因此LabVIEW的整体性能得到了改善. 该方法已在LabVIEW 6.1 Windows95 / 98 / NT和Visual Windows9X / XP / 2000 / NT环境中实现. 实践证明,该方法高效,易于实现. 这是增强LabVIEW与其他Windows应用程序之间数据共享能力的好方法. 参考文献: National Instruments Corporation LabVIEW用户手册1998. National Instruments Corporation 1998编程参考手册.
LabVIEW数据采集调用DLL函数刘传清(襄樊大学物理系,襄樊441053)摘要介绍了虚拟仪器的开发环境LabVIEW分析了先进技术动态链接库(DLL),该方法通常可从LabVIEW调用外部代码. 事实证明,有效的做法是提高LabVIEW与Windows其他应用程序共享数据的能力. 关键词: 虚拟仪器; LabVIEW;动态链接库 查看全部
《襄樊大学学报》. ,2004年第25届襄樊大学学报25号5号LabVIEW调用数据采集卡的DLL函数,湖北襄樊襄樊学院物理系441053摘要首先介绍虚拟仪器的特性及其开发环境LabVIEW6,并实现连接LabVIEW的先进技术之一与外部代码. 动态链接库DLL机制. 实践证明,该机制高效且易于实现,是增强LabVIEW与其他Windows应用程序之间数据共享能力的好方法. 关键字虚拟仪器LabVIEW动态链接库DLL中文库分类号TN311.11文档标记代码A文章编号1 05-0015-03 0引言LabVIEW的出现是基于National Instruments的一种基于G语言的开发环境. 虚拟仪器所谓的连接到行业的虚拟仪器就是在通用计算机平台上根据自己的需求定义和设计仪器的测试功能. 本质是将传统仪器硬件与最新的计算机软件技术充分结合,以实现和扩展具有模块化软件的传统仪器. 功能. 与虚拟仪器相比,系统仪器在智能,处理能力,性能价格比和可操作性方面具有明显的技术优势. LabVIEW实验室虚拟仪器工程工作台目前是世界上使用最广泛的虚拟仪器开发环境之一. 它主要用于仪器控制,数据采集,数据分析,数据显示等,并且适用于Windows9X / XP / 2000 /许多不同的操作系统平台,例如NT Macintosh UNIX.
与传统的编程语言不同,LabVIEW使用一种功能强大的图形语言编程语言为测试工程师而非专业程序员服务. 编程非常方便. 人机交互界面直观友好. 它具有强大的数据可视化分析和仪器控制功能. 使用LabVIEW开发环境,用户可以创建32位编译器,从而为常规数据采集,测试和测量任务提供更快的运行速度. LabVIEW是真正的编译器. 用户可以创建独立的可执行文件,这些文件可以独立于开发环境运行. 对于大多数编程任务,LabVIEW通常生成高效的代码. 1 LabVIEW是调用外部程序代码的方法之一. 动态链接库机制1.1动态链接库机制概述LabVIEW是一个功能强大的虚拟仪器开发环境,已与GPIB VXI RS-232 RS-485插值数据采集完全集成在一起. LabVIEW还具有一个内置库,可通过共享ActiveX的DLL和其他方式实现与外部程序代码或软件系统的连接,从而提供大量的连接机制. LabVIEW提供了四种调用外部程序代码的方法. 动态链接库DLL机制是从LabVIEW调用标准共享库和用户定义的库函数的通用方法. 具体实现是使用LabVIEW函数模板的Advanced子模板中的Call Library Function节点.
呼叫库功能节点收录大量数据类型和呼叫规范. 使用它可以调用大多数标准共享库和用户定义的库,包括Windows9X / XP / 2000 / NT下的动态链接库. 动态链接库Macintosh UNIX共享库功能下的“代码片段共享库功能”下的代码片段当用户需要调用的代码已经存在,或者用户熟悉以下代码段UNIX中共享库的创建过程时: 在Windows动态链接库中,调用库函数节点非常有用. 此时,它也是最合适的方法,因为图书馆使用的是收据日期. 2004-04-21基金项目湖北省教育厅重点项目2003A006作者简介襄樊学院物理系副教授,湖北鄂州. 15.调用LabVIEW到数据采集卡DLL功能16适用于多种开发环境的格式标准,因此用户几乎可以使用任何开发环境来创建LabVIEW可以调用的库. 1.2动态链接库机制的实现步骤在Windows 9X下,使用LabVIEW 6.1(Windows95 / 98 / NT)中的动态链接库机制来调用DLL. DLL返回计算机的名称.
1)创建一个调用库函数节点,创建一个新的LabVIEW程序主机名. 将vi保存到新创建的目录d: \ temp. 图1库函数调用前面板框图. 该程序如图2所示的库函数调用框图. 通过在功能模板的“高级”子模板中选择“调用库功能”功能模块,可以选择“调用库功能”节点. 生产的. 该LabVIEW程序通过调用库函数节点来调用DLL. 该DLL将返回计算机的名称,并将返回的结果存储在字符串指示器“计算机名称”中,然后将字符串常量LabVIEW MachineName连接起来以显示字符串指示器“ Message”. 2)配置调用库功能节点在程序框图程序窗口中双击“调用库功能”节点. 在弹出对话框中,配置调用库功能节点,然后在LibraryName Path项目中输入d: \ temp \ hostname. dll表示此节点链接的DLL文件的名称,它是C源代码的主机名. c编译并键入FunctionName项目MachineName,以在链接到该节点的DLL文件中指示函数的名称. 参数返回类型是选择Void的类型. 添加的另一个参数是arg1的类型. 字符串格式为选择“字符串句柄3”. )编辑C源文件以编辑C源文件的主机名.
c保存到目录d: \ temp includeextcode. h收录LabVIEW函数的#include #include #include BOOL WINAPI DllMain(HANDLE hDLL,DWORD dwReason,LPVOID lpReserved)返回TRUE;函数获取计算机名__declspec(dllexport)无效MachineName(void * LVHandle)charcomputerName [MAX_COMPUTERNAME_LENGTH + 1]; intENGTH compNameLength;襄樊学院学报第二十五期2004 Getcomputer name GetComputerName(computerName,&compNameLength); SizeLabVIEW句柄正确大小DSSetHandleSize(LVHandle,compNameLength stringsize LabVIEWhandle **(int32 **)LVHandle LabVIEWhandle sprintf((*(char **)LVHandle)+4,“%s”,computerName);该程序首先调用Windows API函数GetComputerName获取机器名,然后调用LabVIEW函数DSSetHandleSize设置LabVIEW句柄的大小,最后,将机器名的32位整数机器名字符串依次写入到句柄中.
4)编译C源代码. 将C源代码更改为d: \ temp \主机名. c编译为DLL文件d: \ temp \ hostname. dll可以使用VC ++ 6.0 Windows95 / 98/2000 / NT来完成此编译. 5)运行VI以运行LabVIEW程序的主机名. vi的结果如下. 图3前面板运行结果. 2结束语本文重点介绍和实现一种将LabVIEW与外部代码,动态链接库机制连接的高级技术,并给出一个应用示例. 由于LabVIEW中引入了C语言的强大功能,因此LabVIEW的整体性能得到了改善. 该方法已在LabVIEW 6.1 Windows95 / 98 / NT和Visual Windows9X / XP / 2000 / NT环境中实现. 实践证明,该方法高效,易于实现. 这是增强LabVIEW与其他Windows应用程序之间数据共享能力的好方法. 参考文献: National Instruments Corporation LabVIEW用户手册1998. National Instruments Corporation 1998编程参考手册.
LabVIEW数据采集调用DLL函数刘传清(襄樊大学物理系,襄樊441053)摘要介绍了虚拟仪器的开发环境LabVIEW分析了先进技术动态链接库(DLL),该方法通常可从LabVIEW调用外部代码. 事实证明,有效的做法是提高LabVIEW与Windows其他应用程序共享数据的能力. 关键词: 虚拟仪器; LabVIEW;动态链接库
[织梦cms站]主页/列表页调用文章描述字数限制
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-07 20:09
接下来,我们将介绍一种或两种方法来修改首页/列表页面上文章描述的字符数限制:
1. 使用infolen可以限制所调用的文章描述中的单词数,如以下标记所示:
{dede: arclist row =“ 1” infolen ='170'}
[field: info /]...
{/ dede: arclist}
上面的infolen ='170'表示调用170字节的文章描述,170字节= 85个汉字.
2. 使用[field: description function ='cn_substr(@ me,170)'/]代替[field: info /]标签,具体步骤如下:
170表示受字数限制的字节数,170字节= 85个汉字,请根据要显示的字符数进行更改.
Dedecms编织梦的官方默认最大字节数是255. 有时它可能无法满足我们的需求. 您可以通过以下方法对其进行修改:
1. 输入phpmyadmin查看dede_archives表,默认值为
说明varchar(255)
更改为
说明varchar(500)
2,打开文件dede / spec_add.php; spec_edit.php
$ description = cn_substrR($ description,$ cfg_auot_description);这样,只需将$ cfg_auot_description更改为500或更大.
三个. 在Dedecms中,与文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$ description = cn_substrR($ description,$ cfg_auot_description);
这句话实现了
[field: description function =“ cn_substr(@me,字符数)” /]
此功能.
由于此语句确实有益于页面布局,因此我们在实验中未对其进行修改.
在编辑页面上,有一句话:
$ description = cn_substrR($ description,250);
此句子中出现了熟悉的字符数“ 250”,这是系统设置的文章摘要中字符数的上限. 显示gbk代码: 125个字;而utf-8代码为81个字. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,您可以在此处将“ 250”修改为其他值,例如“ 500”. 不建议在这里设置太高. 一种是不需要在列表页面上显示太多内容. 最好直接使用正文显示太多内容. 一种是避免数据库中的冗余.
仅完成上述修改是不够的,还需要修改article_description_main.php
在article_description_main.php页面上,找到“ if($ dsize> 250)$ dsize = 250;”. 语句,它限制了可以在后台自动获取的字符数. 只需将此处的“ 250”更改为“ 500”,即字符数与先前修改的字符相同. 如果确认手动添加了每篇文章,则如果您手动完成摘要获取,则不需要修改此文件. 但是,自动摘要获取主要用于大量文章和馆藏.
最后登录到后台,然后在系统-系统基本参数-其他选项中,将自动摘要的长度更改为500,这与先前修改的字符数相同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 标签示例如下:
{dede: list typeid =''row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}
关键字: 编织梦cms站(2) 查看全部
设置上限的主要目的是减少数据库的冗余并确保网站的良好性能. 如果可以有效地控制文章描述中的单词数,则可以使页面布局非常灵活.
接下来,我们将介绍一种或两种方法来修改首页/列表页面上文章描述的字符数限制:
1. 使用infolen可以限制所调用的文章描述中的单词数,如以下标记所示:
{dede: arclist row =“ 1” infolen ='170'}
[field: info /]...
{/ dede: arclist}
上面的infolen ='170'表示调用170字节的文章描述,170字节= 85个汉字.
2. 使用[field: description function ='cn_substr(@ me,170)'/]代替[field: info /]标签,具体步骤如下:
170表示受字数限制的字节数,170字节= 85个汉字,请根据要显示的字符数进行更改.
Dedecms编织梦的官方默认最大字节数是255. 有时它可能无法满足我们的需求. 您可以通过以下方法对其进行修改:
1. 输入phpmyadmin查看dede_archives表,默认值为
说明varchar(255)
更改为
说明varchar(500)
2,打开文件dede / spec_add.php; spec_edit.php
$ description = cn_substrR($ description,$ cfg_auot_description);这样,只需将$ cfg_auot_description更改为500或更大.
三个. 在Dedecms中,与文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$ description = cn_substrR($ description,$ cfg_auot_description);
这句话实现了
[field: description function =“ cn_substr(@me,字符数)” /]
此功能.
由于此语句确实有益于页面布局,因此我们在实验中未对其进行修改.
在编辑页面上,有一句话:
$ description = cn_substrR($ description,250);
此句子中出现了熟悉的字符数“ 250”,这是系统设置的文章摘要中字符数的上限. 显示gbk代码: 125个字;而utf-8代码为81个字. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,您可以在此处将“ 250”修改为其他值,例如“ 500”. 不建议在这里设置太高. 一种是不需要在列表页面上显示太多内容. 最好直接使用正文显示太多内容. 一种是避免数据库中的冗余.
仅完成上述修改是不够的,还需要修改article_description_main.php
在article_description_main.php页面上,找到“ if($ dsize> 250)$ dsize = 250;”. 语句,它限制了可以在后台自动获取的字符数. 只需将此处的“ 250”更改为“ 500”,即字符数与先前修改的字符相同. 如果确认手动添加了每篇文章,则如果您手动完成摘要获取,则不需要修改此文件. 但是,自动摘要获取主要用于大量文章和馆藏.
最后登录到后台,然后在系统-系统基本参数-其他选项中,将自动摘要的长度更改为500,这与先前修改的字符数相同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 标签示例如下:
{dede: list typeid =''row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}
关键字: 编织梦cms站(2)
干货|快速实现数据导入和简单的DCS实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-07 18:27
原文: 赵奇京东云开发者社区4月18日
对于大多数用户而言,使用云计算大数据服务时,他们必须面对的第一个问题是如何快速将现有库存数据导入大数据仓库. 本文将演示如何基于JD云数据计算服务平台将数据简单快速地导入到数据计算服务中.
我们通常所说的大数据平台主要包括三个部分: 与数据相关的产品和技术,数据资产和数据管理. JD云数据计算服务(DCS)是云上的一种完全托管的低成本数据仓库服务. 通过数据工厂,可以轻松实现云上各种数据源(包括对象存储,云数据库,数据仓库等)之间以及本地数据源和云数据源之间的数据同步,并实现多源数据分析和管理.
在数据工厂服务中,您可以创建一个同步任务来移动数据,并根据指定的调度策略(每天,每周和每月)运行它. 此模块提供任务监视和警报功能. 用户可以通过详细的日志和任务执行的警报历史轻松识别问题. 同时,它提供了完全托管的工作流服务,并支持图形设计数据分析. 通过工作流任务的方式实现数据处理和相互依赖,帮助用户快速构建数据处理和分析作业并定期执行.
以下将以MySQL数据库为例,说明如何使用JD Cloud Data Factory在DTS数据库之间进行数据采集和数据同步. Data Factory支持常见的RDS数据库,例如MySQL,SQLServer,Oracle,DB2和NoSQL数据库,以及来自OSS,FTP站点和Elastic Search的数据库.
下图显示了Data Factory支持的数据源类型:
下面将以MySQL数据库为例,演示如何使用数据工厂进行数据采集,以及如何使用数据工厂作为DTS在两个数据源之间进行数据迁移.
为了方便测试,我们必须首先创建一个数据库表单并填写测试数据. 为了方便测试,预先创建了一个CentOS 7.4云主机作为模拟客户端来访问数据库.
首先,核心概念数据集
数据工厂服务中的数据集引用在同步任务期间需要指定的数据源或数据目标上的不同数据存储实例. 因此,在创建同步任务之前,必须首先连接到数据集. 同一数据集可以是多个同步任务的数据源或数据目的地.
数据集的连通性
用户创建数据集连接时,为了检查数据集成服务是否可以成功连接,用户需要根据不同的数据集类型填写相应的值以进行连接验证. 成功的数据集连接是成功完成数据同步任务的前提.
同步任务
同步任务是用户使用数据集成服务的最小单位. 每个同步任务都需要用户配置数据源,数据目标和相应的同步策略(例如脏数据处理等).
工作流程
工作流通过图形设计任务实现数据处理和相互依赖.
开始实战1.准备测试数据源
首先创建一个模拟数据环境. 在此示例中,将JD Cloud的RDS MySQL 8.0数据库服务用作数据源,并且在创建数据库名称时可以将其指定为Testdb. 创建数据库后,您需要打开外部网络来访问数据库. 数据工厂可以通过公共IP或域名访问数据库. 可以在数据库的详细信息页面上找到详细的域名.
要创建MySQL数据库,您可以通过图形界面打开它,并按照提示填写必要的信息,因此在此不再赘述. 需要提醒的是,打开数据库后,默认情况下不允许外部网络访问. 单击打开外部网络访问,并记住默认端口3306.
可以通过图形界面或客户端访问MySQL. 当然,也可以通过其他支持MySQL的图形客户端对其进行访问.
此示例使用CentOS系统作为访问客户端. 如果未安装客户端,则可以使用Yum命令安装MySQL. 成功安装后,您会看到以下提示.
1[root@CentOS ~]# yum install mysql
2Loaded plugins: fastestmirror, langpacks
3Loading mirror speeds from cached hostfile
4base | 3.6 kB 00:00
5epel | 4.7 kB 00:00
6extras | 3.4 kB 00:00
7updates | 3.4 kB 00:00
8(1/2): epel/x86_64/updateinfo | 986 kB 00:00
9(2/2): epel/x86_64/primary_db | 6.7 MB 00:00
10Resolving Dependencies
11--> Running transaction check
12---> Package mariadb.x86_64 1:5.5.60-1.el7_5 will be installed
13--> Processing Dependency: mariadb-libs(x86-64) = 1:5.5.60-1.el7_5 for package: 1:mariadb-5.5.60-1.el7_5.x86_64
14--> Running transaction check
15---> Package mariadb-libs.x86_64 1:5.5.56-2.el7 will be updated
16---> Package mariadb-libs.x86_64 1:5.5.60-1.el7_5 will be an update
17--> Finished Dependency Resolution
18
19Dependencies Resolved
20
21===========================================================
22 Package Arch Version Repository
23 Size
24===========================================================
25Installing:
26 mariadb x86_64 1:5.5.60-1.el7_5 base 8.9 M
27Updating for dependencies:
28 mariadb-libs x86_64 1:5.5.60-1.el7_5 base 758 k
29
30Transaction Summary
31===========================================================
32Install 1 Package
33Upgrade ( 1 Dependent package)
34
35Total download size: 9.6 M
36Is this ok [y/d/N]: y
37Downloading packages:
38Delta RPMs disabled because /usr/bin/applydeltarpm not installed.
39(1/2): mariadb-libs-5.5.60-1.el7_5.x8 | 758 kB 00:00
40(2/2): mariadb-5.5.60-1.el7_5.x86_64. | 8.9 MB 00:00
41-----------------------------------------------------------
42Total 11 MB/s | 9.6 MB 00:00
43Running transaction check
44Running transaction test
45Transaction test succeeded
46Running transaction
47 Updating : 1:mariadb-libs-5.5.60-1.el7_5.x86_64 1/3
48 Installing : 1:mariadb-5.5.60-1.el7_5.x86_64 2/3
49 Cleanup : 1:mariadb-libs-5.5.56-2.el7.x86_64 3/3
50 Verifying : 1:mariadb-libs-5.5.60-1.el7_5.x86_64 1/3
51 Verifying : 1:mariadb-5.5.60-1.el7_5.x86_64 2/3
52 Verifying : 1:mariadb-libs-5.5.56-2.el7.x86_64 3/3
53
54Installed:
55 mariadb.x86_64 1:5.5.60-1.el7_5
56
57Dependency Updated:
58 mariadb-libs.x86_64 1:5.5.60-1.el7_5
59
60Complete!
安装后执行MySQL命令以测试是否可以连接到数据库. 客户端访问命令格式为MySQL-h主机地址-u用户名-p用户密码. 主机地址使用MySQL数据库的外部域名. 从连接到数据库到创建表单的详细执行过程如下:
1. 验证是否可以正常连接到数据库
1[root@CentOS ~]# mysql -h mysql-cn-north-1-aed0e558da5e4877.public.jcloud.com -P3306 -umysqlxxx –pPasswordxxx
如果可以正常连接,则可以打开一个新窗口以创建用于数据库创建和测试数据插入操作的SQL脚本,也可以预先进行创建并将其上传到客户端.
创建数据表,创建测试数据库和测试表以方便测试. 选择适当的目录以创建SQL脚本文件. 您可以使用vi ctable.sql创建它,也可以使用其他文本编辑工具. 该脚本的内容如下:
1[root@CentOS ~]# cat ctable.sql
2USE testdb;
3DROP TABLE IF EXISTS `sqltest`;
4CREATE TABLE `sqltest` (
5 `id` int(10) unsigned NOT NULL AUTO_INCREMENT,
6 `user_id` varchar(20) NOT NULL DEFAULT '',
7 `vote_num` int(10) unsigned NOT NULL DEFAULT '0',
8 `group_id` int(10) unsigned NOT NULL DEFAULT '0',
9 `status` tinyint(2) unsigned NOT NULL DEFAULT '1',
10 `create_time` datetime NOT NULL DEFAULT '0000-00-00 00:00:00',
11 PRIMARY KEY (`id`),
12 KEY `index_user_id` (`user_id`) USING HASH
13) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2. 创建脚本文件以临时生成数据,vi adddb.sql
1[root@CentOS ~]# cat adddb.sql
2DELIMITER // -- 修改MySQL delimiter:'//'
3DROP FUNCTION IF EXISTS `rand_string` //
4SET NAMES utf8 //
5CREATE FUNCTION `rand_string` (n INT) RETURNS VARCHAR(255) CHARSET 'utf8'
6BEGIN
7 DECLARE char_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
8 DECLARE return_str varchar(255) DEFAULT '';
9 DECLARE i INT DEFAULT 0;
10 WHILE i source /root/adddb.sql;
添加100条数据
1MySQL [testdb]> call adddb(100);
通过调整adddb的数量(以增加数量),还可以添加1000,例如adddb(1000).
现在我们已经为数据源提供了测试环境,我们可以开始使用数据工厂进行数据同步.
第二,使用数据工厂进行源数据采集
选择大数据和分析的数据工厂菜单. 在连接管理中添加一个连接,如下所示:
建立连接时,建议单击连接测试按钮以首先测试数据库连接. 如果无法连接,请检查域名,端口,用户名和密码是否正确以及数据库是否允许外部网络访问.
建立数据库连接后,可以开始数据同步. 数据同步任务可以在数据同步中单独设置,也可以通过数据集成选项在工作流中设置. 设置数据集成后,将自动生成数据同步任务.
调度策略可以选择手动执行,定期调度和单次操作三种模式,也可以直接选择单次操作.
执行完成后,数据将在数据计算服务中同步.
以上操作可以以工作流的形式实现,连接更复杂的Spark计算脚本.
成功执行后,您可以在运维中心检查执行状态,并在实例列表的工程图布局中看到执行节点变为绿色.
可以通过上述数据同步任务和工作流的建立来实现从数据源的数据获取. 数据采集后,大数据服务可以直接用于数据处理. 在“大数据和分析”菜单下选择“数据计算服务管理”. 默认情况下,使用您自己的用户名/ PIN(在这种情况下,用户名是jdc-14)作为实例名称,并建立了默认的HIVE INSTANCE.
在数据库表数据的管理下,您可以看到新创建的数据库MySQLdb和表SQLTest. 单击以输入SQLTest表名称,以查看更多详细的表信息,如图所示.
可以根据获取的大数据信息在数据计算服务中执行任务开发. 任务开发可以使用SQL或开发脚本来计算数据.
三,DCS大数据导出
您可以使用此功能将数据工厂用作简单的DTS工具,以将数据传输到目标数据库. 在此示例中,在JD Cloud上建立了一个MySQL目标数据库,并将SQLTest同步到目标数据库以实现两个数据库之间的数据同步.
准备或创建新的目标MySQL数据库destmysqldb,并将数据计算服务的MySQLdb同步到目标数据库destmysqldb.
在“数据工厂”菜单下,选择“连接管理”以创建与destmysqldb的新连接.
创建一个新的同步任务,将数据计算服务的数据同步到destmysqldb数据库,并且任务名称为synctodest. 要选择数据源,必须为大数据选择数据计算服务. 该数据库名为mysqldb,该表名为sqltest. 可以预览表中的数据,以免出错.
在传输数据之前,请提前在数据库中创建一个空表结构,在本文开头执行ctable.sql以创建表SQLTest,并在插入数据时选择目标表名称.
执行后,您可以在destmysqldb中确认结果,并且可以通过从sqltest中选择count(*)来确认数据已成功导入.
可以确认,数据工厂被用作简单的DTS工具,用于将源数据库数据同步到目标数据库,并且实际战斗成功了! 查看全部
干货|快速实现数据导入和简单的DCS实现
原文: 赵奇京东云开发者社区4月18日
对于大多数用户而言,使用云计算大数据服务时,他们必须面对的第一个问题是如何快速将现有库存数据导入大数据仓库. 本文将演示如何基于JD云数据计算服务平台将数据简单快速地导入到数据计算服务中.
我们通常所说的大数据平台主要包括三个部分: 与数据相关的产品和技术,数据资产和数据管理. JD云数据计算服务(DCS)是云上的一种完全托管的低成本数据仓库服务. 通过数据工厂,可以轻松实现云上各种数据源(包括对象存储,云数据库,数据仓库等)之间以及本地数据源和云数据源之间的数据同步,并实现多源数据分析和管理.
在数据工厂服务中,您可以创建一个同步任务来移动数据,并根据指定的调度策略(每天,每周和每月)运行它. 此模块提供任务监视和警报功能. 用户可以通过详细的日志和任务执行的警报历史轻松识别问题. 同时,它提供了完全托管的工作流服务,并支持图形设计数据分析. 通过工作流任务的方式实现数据处理和相互依赖,帮助用户快速构建数据处理和分析作业并定期执行.
以下将以MySQL数据库为例,说明如何使用JD Cloud Data Factory在DTS数据库之间进行数据采集和数据同步. Data Factory支持常见的RDS数据库,例如MySQL,SQLServer,Oracle,DB2和NoSQL数据库,以及来自OSS,FTP站点和Elastic Search的数据库.
下图显示了Data Factory支持的数据源类型:
下面将以MySQL数据库为例,演示如何使用数据工厂进行数据采集,以及如何使用数据工厂作为DTS在两个数据源之间进行数据迁移.
为了方便测试,我们必须首先创建一个数据库表单并填写测试数据. 为了方便测试,预先创建了一个CentOS 7.4云主机作为模拟客户端来访问数据库.
首先,核心概念数据集
数据工厂服务中的数据集引用在同步任务期间需要指定的数据源或数据目标上的不同数据存储实例. 因此,在创建同步任务之前,必须首先连接到数据集. 同一数据集可以是多个同步任务的数据源或数据目的地.
数据集的连通性
用户创建数据集连接时,为了检查数据集成服务是否可以成功连接,用户需要根据不同的数据集类型填写相应的值以进行连接验证. 成功的数据集连接是成功完成数据同步任务的前提.
同步任务
同步任务是用户使用数据集成服务的最小单位. 每个同步任务都需要用户配置数据源,数据目标和相应的同步策略(例如脏数据处理等).
工作流程
工作流通过图形设计任务实现数据处理和相互依赖.
开始实战1.准备测试数据源
首先创建一个模拟数据环境. 在此示例中,将JD Cloud的RDS MySQL 8.0数据库服务用作数据源,并且在创建数据库名称时可以将其指定为Testdb. 创建数据库后,您需要打开外部网络来访问数据库. 数据工厂可以通过公共IP或域名访问数据库. 可以在数据库的详细信息页面上找到详细的域名.
要创建MySQL数据库,您可以通过图形界面打开它,并按照提示填写必要的信息,因此在此不再赘述. 需要提醒的是,打开数据库后,默认情况下不允许外部网络访问. 单击打开外部网络访问,并记住默认端口3306.
可以通过图形界面或客户端访问MySQL. 当然,也可以通过其他支持MySQL的图形客户端对其进行访问.
此示例使用CentOS系统作为访问客户端. 如果未安装客户端,则可以使用Yum命令安装MySQL. 成功安装后,您会看到以下提示.
1[root@CentOS ~]# yum install mysql
2Loaded plugins: fastestmirror, langpacks
3Loading mirror speeds from cached hostfile
4base | 3.6 kB 00:00
5epel | 4.7 kB 00:00
6extras | 3.4 kB 00:00
7updates | 3.4 kB 00:00
8(1/2): epel/x86_64/updateinfo | 986 kB 00:00
9(2/2): epel/x86_64/primary_db | 6.7 MB 00:00
10Resolving Dependencies
11--> Running transaction check
12---> Package mariadb.x86_64 1:5.5.60-1.el7_5 will be installed
13--> Processing Dependency: mariadb-libs(x86-64) = 1:5.5.60-1.el7_5 for package: 1:mariadb-5.5.60-1.el7_5.x86_64
14--> Running transaction check
15---> Package mariadb-libs.x86_64 1:5.5.56-2.el7 will be updated
16---> Package mariadb-libs.x86_64 1:5.5.60-1.el7_5 will be an update
17--> Finished Dependency Resolution
18
19Dependencies Resolved
20
21===========================================================
22 Package Arch Version Repository
23 Size
24===========================================================
25Installing:
26 mariadb x86_64 1:5.5.60-1.el7_5 base 8.9 M
27Updating for dependencies:
28 mariadb-libs x86_64 1:5.5.60-1.el7_5 base 758 k
29
30Transaction Summary
31===========================================================
32Install 1 Package
33Upgrade ( 1 Dependent package)
34
35Total download size: 9.6 M
36Is this ok [y/d/N]: y
37Downloading packages:
38Delta RPMs disabled because /usr/bin/applydeltarpm not installed.
39(1/2): mariadb-libs-5.5.60-1.el7_5.x8 | 758 kB 00:00
40(2/2): mariadb-5.5.60-1.el7_5.x86_64. | 8.9 MB 00:00
41-----------------------------------------------------------
42Total 11 MB/s | 9.6 MB 00:00
43Running transaction check
44Running transaction test
45Transaction test succeeded
46Running transaction
47 Updating : 1:mariadb-libs-5.5.60-1.el7_5.x86_64 1/3
48 Installing : 1:mariadb-5.5.60-1.el7_5.x86_64 2/3
49 Cleanup : 1:mariadb-libs-5.5.56-2.el7.x86_64 3/3
50 Verifying : 1:mariadb-libs-5.5.60-1.el7_5.x86_64 1/3
51 Verifying : 1:mariadb-5.5.60-1.el7_5.x86_64 2/3
52 Verifying : 1:mariadb-libs-5.5.56-2.el7.x86_64 3/3
53
54Installed:
55 mariadb.x86_64 1:5.5.60-1.el7_5
56
57Dependency Updated:
58 mariadb-libs.x86_64 1:5.5.60-1.el7_5
59
60Complete!
安装后执行MySQL命令以测试是否可以连接到数据库. 客户端访问命令格式为MySQL-h主机地址-u用户名-p用户密码. 主机地址使用MySQL数据库的外部域名. 从连接到数据库到创建表单的详细执行过程如下:
1. 验证是否可以正常连接到数据库
1[root@CentOS ~]# mysql -h mysql-cn-north-1-aed0e558da5e4877.public.jcloud.com -P3306 -umysqlxxx –pPasswordxxx
如果可以正常连接,则可以打开一个新窗口以创建用于数据库创建和测试数据插入操作的SQL脚本,也可以预先进行创建并将其上传到客户端.
创建数据表,创建测试数据库和测试表以方便测试. 选择适当的目录以创建SQL脚本文件. 您可以使用vi ctable.sql创建它,也可以使用其他文本编辑工具. 该脚本的内容如下:
1[root@CentOS ~]# cat ctable.sql
2USE testdb;
3DROP TABLE IF EXISTS `sqltest`;
4CREATE TABLE `sqltest` (
5 `id` int(10) unsigned NOT NULL AUTO_INCREMENT,
6 `user_id` varchar(20) NOT NULL DEFAULT '',
7 `vote_num` int(10) unsigned NOT NULL DEFAULT '0',
8 `group_id` int(10) unsigned NOT NULL DEFAULT '0',
9 `status` tinyint(2) unsigned NOT NULL DEFAULT '1',
10 `create_time` datetime NOT NULL DEFAULT '0000-00-00 00:00:00',
11 PRIMARY KEY (`id`),
12 KEY `index_user_id` (`user_id`) USING HASH
13) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2. 创建脚本文件以临时生成数据,vi adddb.sql
1[root@CentOS ~]# cat adddb.sql
2DELIMITER // -- 修改MySQL delimiter:'//'
3DROP FUNCTION IF EXISTS `rand_string` //
4SET NAMES utf8 //
5CREATE FUNCTION `rand_string` (n INT) RETURNS VARCHAR(255) CHARSET 'utf8'
6BEGIN
7 DECLARE char_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
8 DECLARE return_str varchar(255) DEFAULT '';
9 DECLARE i INT DEFAULT 0;
10 WHILE i source /root/adddb.sql;
添加100条数据
1MySQL [testdb]> call adddb(100);
通过调整adddb的数量(以增加数量),还可以添加1000,例如adddb(1000).
现在我们已经为数据源提供了测试环境,我们可以开始使用数据工厂进行数据同步.
第二,使用数据工厂进行源数据采集
选择大数据和分析的数据工厂菜单. 在连接管理中添加一个连接,如下所示:
建立连接时,建议单击连接测试按钮以首先测试数据库连接. 如果无法连接,请检查域名,端口,用户名和密码是否正确以及数据库是否允许外部网络访问.
建立数据库连接后,可以开始数据同步. 数据同步任务可以在数据同步中单独设置,也可以通过数据集成选项在工作流中设置. 设置数据集成后,将自动生成数据同步任务.
调度策略可以选择手动执行,定期调度和单次操作三种模式,也可以直接选择单次操作.
执行完成后,数据将在数据计算服务中同步.
以上操作可以以工作流的形式实现,连接更复杂的Spark计算脚本.
成功执行后,您可以在运维中心检查执行状态,并在实例列表的工程图布局中看到执行节点变为绿色.
可以通过上述数据同步任务和工作流的建立来实现从数据源的数据获取. 数据采集后,大数据服务可以直接用于数据处理. 在“大数据和分析”菜单下选择“数据计算服务管理”. 默认情况下,使用您自己的用户名/ PIN(在这种情况下,用户名是jdc-14)作为实例名称,并建立了默认的HIVE INSTANCE.
在数据库表数据的管理下,您可以看到新创建的数据库MySQLdb和表SQLTest. 单击以输入SQLTest表名称,以查看更多详细的表信息,如图所示.
可以根据获取的大数据信息在数据计算服务中执行任务开发. 任务开发可以使用SQL或开发脚本来计算数据.
三,DCS大数据导出
您可以使用此功能将数据工厂用作简单的DTS工具,以将数据传输到目标数据库. 在此示例中,在JD Cloud上建立了一个MySQL目标数据库,并将SQLTest同步到目标数据库以实现两个数据库之间的数据同步.
准备或创建新的目标MySQL数据库destmysqldb,并将数据计算服务的MySQLdb同步到目标数据库destmysqldb.
在“数据工厂”菜单下,选择“连接管理”以创建与destmysqldb的新连接.
创建一个新的同步任务,将数据计算服务的数据同步到destmysqldb数据库,并且任务名称为synctodest. 要选择数据源,必须为大数据选择数据计算服务. 该数据库名为mysqldb,该表名为sqltest. 可以预览表中的数据,以免出错.
在传输数据之前,请提前在数据库中创建一个空表结构,在本文开头执行ctable.sql以创建表SQLTest,并在插入数据时选择目标表名称.
执行后,您可以在destmysqldb中确认结果,并且可以通过从sqltest中选择count(*)来确认数据已成功导入.
可以确认,数据工厂被用作简单的DTS工具,用于将源数据库数据同步到目标数据库,并且实际战斗成功了!
让DEDE隐藏列下的文章不被arclist调用
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-07 18:25
我最近无事可做,并且已经建造了一个新车站. 在设计网站专栏时,我希望构建一个类似于草稿箱的采集库专栏来存储采集的文章. 在处理完每个采集到的文章之后,计划将其放置在其他官方列下,但是现在的问题是,采集库中未处理的文章也将显示在主页和频道页面上,这不是我想要的. 我以为在创建新列时,我可以选择是否隐藏该列. 我突然打开它,感觉这应该可以解决我的问题,但最终令我失望. 此隐藏列的设置仅在导航菜单中有效. 别无选择,只能硬着头皮学习源代码. 我花了半个多小时才用上了我上学时才知道的一点毛皮,终于解决了这个问题.
实际上非常简单. 只需更改代码,打开/include/taglib/arclist.lib.php文件,然后找到这句话(大约350行):
if($ orwhere!='')$ orwhere =“ WHERE $ orwhere”;
更改为
if($ orwhere!='')$ orwhere =“ WHERE $ orwhere and tp.ishidden!= 1”;
就是这样.
当然,此更改还会带来另一个问题. 如果您在导航菜单中隐藏一列,则该列表下的文章将无法被arclist调用. 我们实际上可能希望它能够使用arclist进行标注.
由于我的网站导航全部用代码硬编码,因此此修改对我基本上没有影响. 如果其他网站管理员与我有相同的需求,他们可以尝试. 查看全部
我从事梦想织造已有近一年了. 我建立的第一个工作站是使用织梦系统. 梦编织本身的功能已经非常强大,并且基本上可以满足我的大多数需求. 在大多数时候,我都在设计界面模板时使用了它,并且我还没有研究过梦编织的背景源代码.
我最近无事可做,并且已经建造了一个新车站. 在设计网站专栏时,我希望构建一个类似于草稿箱的采集库专栏来存储采集的文章. 在处理完每个采集到的文章之后,计划将其放置在其他官方列下,但是现在的问题是,采集库中未处理的文章也将显示在主页和频道页面上,这不是我想要的. 我以为在创建新列时,我可以选择是否隐藏该列. 我突然打开它,感觉这应该可以解决我的问题,但最终令我失望. 此隐藏列的设置仅在导航菜单中有效. 别无选择,只能硬着头皮学习源代码. 我花了半个多小时才用上了我上学时才知道的一点毛皮,终于解决了这个问题.
实际上非常简单. 只需更改代码,打开/include/taglib/arclist.lib.php文件,然后找到这句话(大约350行):
if($ orwhere!='')$ orwhere =“ WHERE $ orwhere”;
更改为
if($ orwhere!='')$ orwhere =“ WHERE $ orwhere and tp.ishidden!= 1”;
就是这样.
当然,此更改还会带来另一个问题. 如果您在导航菜单中隐藏一列,则该列表下的文章将无法被arclist调用. 我们实际上可能希望它能够使用arclist进行标注.
由于我的网站导航全部用代码硬编码,因此此修改对我基本上没有影响. 如果其他网站管理员与我有相同的需求,他们可以尝试.
Python获取网页的指定内容(如何使用BeautifulSoup工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2020-08-07 15:13
1 Pyhton获取网页的内容(即源代码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表URL,内容代表URL对应的源代码,urllib2是需要使用的包,以上三句代码可以获取网页的整个源代码
2在网页中获取所需的内容(首先获取网页的源代码,然后分析网页的源代码,找到相应的标签,然后将其内容提取到标签中)
2.1以豆瓣电影排名为例
URL是,输入URL后将出现以下图片
现在,我需要获取当前页面上所有电影的名称,等级,评论者数量和链接
从上面的图片中,红色圆圈是我想要获取的内容,蓝色水平线是对应的标签,因此分析结束了,现在是编写代码来实现,Python提供了许多获取方法所需的内容,在这里我使用BeautifulSoup来实现,非常简单
#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,您也可以写入文件 查看全部
Python非常适合数据处理. 如果您想成为爬虫,Python是一个不错的选择. 它已经编写了许多软件包. 您只需调用即可完成许多复杂的功能. 本文中的所有功能均基于BeautifulSoup软件包.
1 Pyhton获取网页的内容(即源代码)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表URL,内容代表URL对应的源代码,urllib2是需要使用的包,以上三句代码可以获取网页的整个源代码
2在网页中获取所需的内容(首先获取网页的源代码,然后分析网页的源代码,找到相应的标签,然后将其内容提取到标签中)
2.1以豆瓣电影排名为例
URL是,输入URL后将出现以下图片
现在,我需要获取当前页面上所有电影的名称,等级,评论者数量和链接
从上面的图片中,红色圆圈是我想要获取的内容,蓝色水平线是对应的标签,因此分析结束了,现在是编写代码来实现,Python提供了许多获取方法所需的内容,在这里我使用BeautifulSoup来实现,非常简单
#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,您也可以写入文件
Python爬虫5简介: 获取JS动态内容抓取当今的头条新闻
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-07 15:11
我们之前抓取的网页主要是HTML静态生成的内容. 您可以直接从HTML源代码中找到看到的数据和内容. 但是,并非所有网页都是这样.
某些网站的内容是由前端JS动态生成的. 由于网页上显示的内容是由JS生成的,因此我们可以在浏览器中看到它,但是无法在HTML源代码中找到它. 例如,今天的头条新闻:
浏览器呈现的网页如下:
今天的头条新闻
检查源代码,但是看起来像这样:
HTML源代码
在HTML源代码中找不到该网页的新闻,所有这些都是由JS动态生成和加载的.
在这种情况下,我们应该如何抓取网页?有两种方法:
1. 从网页响应中找到JS脚本返回的JSON数据; 2,使用Selenium模拟对网页的访问
这里仅介绍第一种方法. 有一篇关于硒的使用的特别文章.
1. 从网页响应中找到JS脚本返回的JSON数据
即使Web内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据该接口返回的JSON数据进行加载和呈现.
因此,我们可以找到JS调用的数据接口,并从数据接口中找到网页中显示的最后数据.
以今天的头条新闻为例进行演示:
1. 找到JS请求的数据接口
F12打开Web调试工具
Web调试工具
选择“网络”标签后,我们发现响应很多. 让我们进行过滤,仅查看XHR响应.
(XHR是Ajax中的一个概念,表示XMLHTTPrequest)
然后我们发现缺少很多链接,只需单击一个链接即可查看:
我们选择城市,预览中有一串json数据:
让我们再次单击它:
事实证明,它们都是城市列表,应用于加载区域新闻.
现在您可能了解如何找到JS请求的接口,对吗?但是,现在我们找不到所需的新闻,因此请再次查找:
有一个焦点,让我们单击它以查看: 查看全部
我们之前抓取的网页主要是HTML静态生成的内容. 您可以直接从HTML源代码中找到看到的数据和内容. 但是,并非所有网页都是这样.
某些网站的内容是由前端JS动态生成的. 由于网页上显示的内容是由JS生成的,因此我们可以在浏览器中看到它,但是无法在HTML源代码中找到它. 例如,今天的头条新闻:
浏览器呈现的网页如下:
今天的头条新闻
检查源代码,但是看起来像这样:
HTML源代码
在HTML源代码中找不到该网页的新闻,所有这些都是由JS动态生成和加载的.
在这种情况下,我们应该如何抓取网页?有两种方法:
1. 从网页响应中找到JS脚本返回的JSON数据; 2,使用Selenium模拟对网页的访问
这里仅介绍第一种方法. 有一篇关于硒的使用的特别文章.
1. 从网页响应中找到JS脚本返回的JSON数据
即使Web内容是由JS动态生成和加载的,JS也需要调用一个接口,并根据该接口返回的JSON数据进行加载和呈现.
因此,我们可以找到JS调用的数据接口,并从数据接口中找到网页中显示的最后数据.
以今天的头条新闻为例进行演示:
1. 找到JS请求的数据接口
F12打开Web调试工具
Web调试工具
选择“网络”标签后,我们发现响应很多. 让我们进行过滤,仅查看XHR响应.
(XHR是Ajax中的一个概念,表示XMLHTTPrequest)
然后我们发现缺少很多链接,只需单击一个链接即可查看:
我们选择城市,预览中有一串json数据:
让我们再次单击它:
事实证明,它们都是城市列表,应用于加载区域新闻.
现在您可能了解如何找到JS请求的接口,对吗?但是,现在我们找不到所需的新闻,因此请再次查找:
有一个焦点,让我们单击它以查看:
织梦首页/清单页呼叫文章说明字数限制修改方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2020-08-07 11:01
1. 使用infolen可以限制所调用的文章描述中的单词数,例如以下标签演示:
{dede: arclist row =” 1” infolen =’170′}
[field: info /]...
{/ dede: arclist}
上面的infolen ='170'表示调用170字节的文章描述
2. 使用[field: description function ='cn_substr(@ me,250)'/]代替[field: info /]标签,其中250是字节数限制. 根据需要更改此单词数,请注意这里有250个字节,一个单词等于2个字节,即这里有125个单词
在Dedecms中,在列表页面上调用文章摘要的主要方法是:
1: [field: info /]
2: [field: description /]
3: [field: info function =“ cn_substr(@me,字符数)” /]
4: [field: description function =“ cn_substr(@me,字符数)” /]
第一种和第二种方法是直接调用文章摘要. 使用[field: info /]时,可以根据要调用的单词数使用{dede: arclist infolen =''} {/ dede: arclist}. ,设置呼叫摘要中的字符数(系统最多可设置250个字符);如果使用[field: description /],则将直接使用在后台设置的摘要字符的上限. 显然,这两种方法非常被动,灵活性差.
第三和第四种方法通过函数功能实现了文章摘要中显示字符的灵活调整. 当然,当不修改文章摘要内容的上限时,这四种方法之间的差异并不大. 但是,让我们讨论一下如何修改此上限以显示[field: description function =“ cn_substr(@ me,characters of number)” /]的重要性.
在Dedecms中,与文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$ description = cn_substrR($ description,$ cfg_auot_description);
这句话实现了
[field: description function =“ cn_substr(@me,字符数)” /]
此功能. 由于此语句确实有利于页面布局,因此我们在实验中没有对其进行修改.
在编辑页面上,有一句话:
$ description = cn_substrR($ description,250);
此句子中出现了熟悉的字符数“ 250”,这是系统设置的文章摘要中字符数的上限. 如果是gbk编码,则显示125个字符. 如果是utf-8编码,则为81个字符. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,您可以在此处将“ 250”修改为其他值,例如“ 500”. 不建议在这里设置太高. 一种是不需要在列表页面上显示太多内容. 最好直接使用正文显示太多内容. 一种是避免数据库中的冗余.
仅完成上述修改是不够的,还需要修改article_description_main.php
在article_description_main.php页面上,找到“ if($ dsize> 250)$ dsize = 250;”. 语句,它限制了可以在后台自动获取的字符数. 只需将此处的“ 250”更改为“ 500”,即字符数与之前的修改相同. 如果确认手动添加了每篇文章,则如果您手动完成摘要获取,则无需修改此文件. 是的,自动摘要获取主要用于大量文章和馆藏.
最后,登录到后台,然后在系统-系统基本参数-其他选项中,将自动摘要长度更改为500,这与先前修改的字符数相同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 样本标签如下:
{dede: list typeid =''row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}
通过上述方法,我们已经意识到被调用的文章摘要具有500个字符,完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了更广阔的空间. 查看全部
在Dedecms系统中,文章摘要(可以通过infolen或与描述相关的标签调用)设置为最多250个字符. 设置上限的主要目的是减少数据库的冗余并确保网站的良好性能. 因此,如果不为简介内容设置上限显然是不合理的,但是如果可以自由控制该上限,则将对网页内容的布局产生积极的影响. 在网页设计过程中,通常需要在频道列表页面上调用文章摘要,如果可以有效控制文章摘要中的单词数,则可以使页面布局非常灵活.
1. 使用infolen可以限制所调用的文章描述中的单词数,例如以下标签演示:
{dede: arclist row =” 1” infolen =’170′}
[field: info /]...
{/ dede: arclist}
上面的infolen ='170'表示调用170字节的文章描述
2. 使用[field: description function ='cn_substr(@ me,250)'/]代替[field: info /]标签,其中250是字节数限制. 根据需要更改此单词数,请注意这里有250个字节,一个单词等于2个字节,即这里有125个单词
在Dedecms中,在列表页面上调用文章摘要的主要方法是:
1: [field: info /]
2: [field: description /]
3: [field: info function =“ cn_substr(@me,字符数)” /]
4: [field: description function =“ cn_substr(@me,字符数)” /]
第一种和第二种方法是直接调用文章摘要. 使用[field: info /]时,可以根据要调用的单词数使用{dede: arclist infolen =''} {/ dede: arclist}. ,设置呼叫摘要中的字符数(系统最多可设置250个字符);如果使用[field: description /],则将直接使用在后台设置的摘要字符的上限. 显然,这两种方法非常被动,灵活性差.
第三和第四种方法通过函数功能实现了文章摘要中显示字符的灵活调整. 当然,当不修改文章摘要内容的上限时,这四种方法之间的差异并不大. 但是,让我们讨论一下如何修改此上限以显示[field: description function =“ cn_substr(@ me,characters of number)” /]的重要性.
在Dedecms中,与文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$ description = cn_substrR($ description,$ cfg_auot_description);
这句话实现了
[field: description function =“ cn_substr(@me,字符数)” /]
此功能. 由于此语句确实有利于页面布局,因此我们在实验中没有对其进行修改.
在编辑页面上,有一句话:
$ description = cn_substrR($ description,250);
此句子中出现了熟悉的字符数“ 250”,这是系统设置的文章摘要中字符数的上限. 如果是gbk编码,则显示125个字符. 如果是utf-8编码,则为81个字符. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,您可以在此处将“ 250”修改为其他值,例如“ 500”. 不建议在这里设置太高. 一种是不需要在列表页面上显示太多内容. 最好直接使用正文显示太多内容. 一种是避免数据库中的冗余.
仅完成上述修改是不够的,还需要修改article_description_main.php
在article_description_main.php页面上,找到“ if($ dsize> 250)$ dsize = 250;”. 语句,它限制了可以在后台自动获取的字符数. 只需将此处的“ 250”更改为“ 500”,即字符数与之前的修改相同. 如果确认手动添加了每篇文章,则如果您手动完成摘要获取,则无需修改此文件. 是的,自动摘要获取主要用于大量文章和馆藏.
最后,登录到后台,然后在系统-系统基本参数-其他选项中,将自动摘要长度更改为500,这与先前修改的字符数相同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 样本标签如下:
{dede: list typeid =''row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}
通过上述方法,我们已经意识到被调用的文章摘要具有500个字符,完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了更广阔的空间.
YGBOOK Novel System 6.14商业版常见问题摘要
采集交流 • 优采云 发表了文章 • 0 个评论 • 217 次浏览 • 2020-08-07 08:18
1. YGBOOK新系统伪静态Nginx服务器伪静态规则
location / {if(!-e $ request_filename){rewrite ^(. *)$ / index.php?s = $ 1last; break;}}
Apache服务器伪静态规则
Options + FollowSymlinksRewriteEngineOnRewriteCond%{REQUEST_FILENAME}!-dRewriteCond%{REQUEST_FILENAME}!-fRewriteRule ^(. *)$ index.php?/ $ 1 [QSA,PT,L]
以上是该系统的伪静态数据,您可以使用它. 4-22注意: 一些朋友说apache的伪静态是不正确的. 毕竟,在使用它时要小心,我使用的是NGINX,并且未测试此Apache.
2,YGBOOK新颖系统的采集规则新颖系统附带一个采集规则,这里有一些其他采集规则. 如下.
23us采集规则提取密码: byrg
69shu采集规则提取密码: ti1h
Biqugetw采集规则提取密码: y8mj
pbtxt采集规则提取密码: jket
3. 如何导入采集规则并打开采集规则文件,如下所示
在后台采集位置,点击导入
填写规则信息
最后,提交并保存. 按照相同的步骤,可以导入其他几个规则. 导入23us采集规则时请注意. 导入后需要单击“编辑”,然后在其中填写URL替换规则.
4. 如何批量采集新小说在“采集设置”页面上,单击“采集新书”. 默认值为10,最大限制为100.
最大破解限制: 将上述链接中的更改为您自己的链接,之后的数字由您决定. 您可以突破限制.
5. 如何更新小说. 在采集设置页面上,单击商品信息的批处理. 将提示此操作非常耗时,并占用服务器内存. 建议在人少的情况下使用. 然后输入起始商品ID,或将其保留. 如下.
有关小说的最新信息将被更新.
6. 修改徽标图像F12以找到徽标图像的位置. 修改图片. 默认模板徽标图像位置Public / biquge / images / all.gif
7. 修改公告的两个位置和右侧方框的内容为JS,需要修改模板中的JS文件信息. 找到模板JS并进行更改. 默认模板地址为Public / biquge / js. 在JS文件夹中找到header.js,然后找到要修改的地方. 同样,模板页脚位置信息的更改也在此处进行了修改.
8. 如何更新页面数据采集小说后,发现网站页面未正确填充. 此时,有必要更新下一页数据. 需要更新两个区域,块数据和缓存管理. 单击“更多功能”->“数据块”,然后单击“更新块数据”. 注意: 右上角有默认网站和默认移动网站选择. 您需要更新PC端以选择默认站点,并且需要更新移动端以选择默认移动站点. 单击“缓存管理”以更新系统缓存,主页缓存和列表页面缓存.
9. 该建议未显示在网站首页的左侧. 当我第一次开始使用它时,我发现了这个问题. 如果开始时没有太多采集,则内容不会显示在该位置. 当采集到大约20,000件时,只展示了一部小说. 折腾之后,我发现此位置的块数据设置存在问题. 在数据块中,在默认站点中找到数据块pc_index_fengtui,然后单击“编辑”. 默认情况下,此块由指定的商品ID集调用. 我们可以删除它,以便调用整个网站范围的列,或设置指定的文章ID. 这个职位需要调用6部小说. 在下面的通话次数中填写6. 默认设置是仅在此处填写一个商品ID,我们可以将其更改为6个ID,以逗号分隔. 在(Application \ Home \ View)下修改了一些模板.
10. 如何更改网站模板YGBOOK6.14商业版本,其中收录5个PC模板和2个手机模板. 在“公用”文件夹中,找到几个模板. PC终端: biquge,bluebiquge,默认,singlebiquge,singlenovel移动终端: wap,wapbiquge在后台基本设置中更改PC站和移动站的主题. 只需更改主题文件夹的名称即可.
11. 如何将小说批量推向百度?检查上面的第5点. 文章信息的批处理将触发推送. 每次更新文章时,文章都会自动推送到百度. 但是,首先必须激活百度. 推送API已完全填写. 如果您不更新文章信息,则只要有用户在浏览该小说,小说信息就会自动更新,并且还会触发推送.
12. 如何添加一个友谊链接我已经使用YGBOOK一段时间了,并且我没有使用这个友谊链接的功能. 一些朋友使用它,发现他们无法使用它,所以我不得不折腾它. 实际上,添加朋友链仍然很简单,只需如下所示添加它即可.
填写前面的朋友链接的名称,用|分隔,然后填写后面的链接,就足够了,每行一个链接.
13. 打开ygbook小说分类,小说分类被卡住. 当我第一次使用它时,它也出现了. 单击采集后,即正在采集规则,并且正在采集幻想小说. 它会被卡住. 采集其他类别时也是如此. 以后,不再为每个采集规则单击采集,只需直接单击批采集即可避免这种卡住现象. 如果您的小伙伴遇到相同的问题,则可以直接单击批处理集合,这样集合将更快. 如何分批收取?您可以检查第四点.
14. 前台不会显示或更新小说. 它已被共享很久了,并且有很多使用它的朋友,因此经常有朋友问为什么不显示或不更新上面两个红色圆圈中的小说. 其实有两点. 其一是采集的小说太少,因此无法展示. 另一种是未设置背景,然后在块数据中设置. 左边的框的设置已经在第9点提到. 右边的框是pc_index_jingdian. 默认值为13,但我们可以在此处将其更改为14. 然后注意更新块数据. 设置中有更新频率. 这是当我们不更新块数据时,它将每隔几个小时自动更新一次. 这个时间可以自己设定. 没有显示也没有更新,只有几个问题. 实际上,当您采集大量数据时,可以更新下一个块数据.
15
最后,附加一个演示站: 品文时代与太空小说网 查看全部
这些天如何使用此系统. 到目前为止,这里还遇到了一些问题. 提醒使用它的朋友,以免再次折腾.
1. YGBOOK新系统伪静态Nginx服务器伪静态规则
location / {if(!-e $ request_filename){rewrite ^(. *)$ / index.php?s = $ 1last; break;}}
Apache服务器伪静态规则
Options + FollowSymlinksRewriteEngineOnRewriteCond%{REQUEST_FILENAME}!-dRewriteCond%{REQUEST_FILENAME}!-fRewriteRule ^(. *)$ index.php?/ $ 1 [QSA,PT,L]
以上是该系统的伪静态数据,您可以使用它. 4-22注意: 一些朋友说apache的伪静态是不正确的. 毕竟,在使用它时要小心,我使用的是NGINX,并且未测试此Apache.
2,YGBOOK新颖系统的采集规则新颖系统附带一个采集规则,这里有一些其他采集规则. 如下.
23us采集规则提取密码: byrg
69shu采集规则提取密码: ti1h
Biqugetw采集规则提取密码: y8mj
pbtxt采集规则提取密码: jket
3. 如何导入采集规则并打开采集规则文件,如下所示
在后台采集位置,点击导入
填写规则信息
最后,提交并保存. 按照相同的步骤,可以导入其他几个规则. 导入23us采集规则时请注意. 导入后需要单击“编辑”,然后在其中填写URL替换规则.
4. 如何批量采集新小说在“采集设置”页面上,单击“采集新书”. 默认值为10,最大限制为100.
最大破解限制: 将上述链接中的更改为您自己的链接,之后的数字由您决定. 您可以突破限制.
5. 如何更新小说. 在采集设置页面上,单击商品信息的批处理. 将提示此操作非常耗时,并占用服务器内存. 建议在人少的情况下使用. 然后输入起始商品ID,或将其保留. 如下.
有关小说的最新信息将被更新.
6. 修改徽标图像F12以找到徽标图像的位置. 修改图片. 默认模板徽标图像位置Public / biquge / images / all.gif
7. 修改公告的两个位置和右侧方框的内容为JS,需要修改模板中的JS文件信息. 找到模板JS并进行更改. 默认模板地址为Public / biquge / js. 在JS文件夹中找到header.js,然后找到要修改的地方. 同样,模板页脚位置信息的更改也在此处进行了修改.
8. 如何更新页面数据采集小说后,发现网站页面未正确填充. 此时,有必要更新下一页数据. 需要更新两个区域,块数据和缓存管理. 单击“更多功能”->“数据块”,然后单击“更新块数据”. 注意: 右上角有默认网站和默认移动网站选择. 您需要更新PC端以选择默认站点,并且需要更新移动端以选择默认移动站点. 单击“缓存管理”以更新系统缓存,主页缓存和列表页面缓存.
9. 该建议未显示在网站首页的左侧. 当我第一次开始使用它时,我发现了这个问题. 如果开始时没有太多采集,则内容不会显示在该位置. 当采集到大约20,000件时,只展示了一部小说. 折腾之后,我发现此位置的块数据设置存在问题. 在数据块中,在默认站点中找到数据块pc_index_fengtui,然后单击“编辑”. 默认情况下,此块由指定的商品ID集调用. 我们可以删除它,以便调用整个网站范围的列,或设置指定的文章ID. 这个职位需要调用6部小说. 在下面的通话次数中填写6. 默认设置是仅在此处填写一个商品ID,我们可以将其更改为6个ID,以逗号分隔. 在(Application \ Home \ View)下修改了一些模板.
10. 如何更改网站模板YGBOOK6.14商业版本,其中收录5个PC模板和2个手机模板. 在“公用”文件夹中,找到几个模板. PC终端: biquge,bluebiquge,默认,singlebiquge,singlenovel移动终端: wap,wapbiquge在后台基本设置中更改PC站和移动站的主题. 只需更改主题文件夹的名称即可.
11. 如何将小说批量推向百度?检查上面的第5点. 文章信息的批处理将触发推送. 每次更新文章时,文章都会自动推送到百度. 但是,首先必须激活百度. 推送API已完全填写. 如果您不更新文章信息,则只要有用户在浏览该小说,小说信息就会自动更新,并且还会触发推送.
12. 如何添加一个友谊链接我已经使用YGBOOK一段时间了,并且我没有使用这个友谊链接的功能. 一些朋友使用它,发现他们无法使用它,所以我不得不折腾它. 实际上,添加朋友链仍然很简单,只需如下所示添加它即可.
填写前面的朋友链接的名称,用|分隔,然后填写后面的链接,就足够了,每行一个链接.
13. 打开ygbook小说分类,小说分类被卡住. 当我第一次使用它时,它也出现了. 单击采集后,即正在采集规则,并且正在采集幻想小说. 它会被卡住. 采集其他类别时也是如此. 以后,不再为每个采集规则单击采集,只需直接单击批采集即可避免这种卡住现象. 如果您的小伙伴遇到相同的问题,则可以直接单击批处理集合,这样集合将更快. 如何分批收取?您可以检查第四点.
14. 前台不会显示或更新小说. 它已被共享很久了,并且有很多使用它的朋友,因此经常有朋友问为什么不显示或不更新上面两个红色圆圈中的小说. 其实有两点. 其一是采集的小说太少,因此无法展示. 另一种是未设置背景,然后在块数据中设置. 左边的框的设置已经在第9点提到. 右边的框是pc_index_jingdian. 默认值为13,但我们可以在此处将其更改为14. 然后注意更新块数据. 设置中有更新频率. 这是当我们不更新块数据时,它将每隔几个小时自动更新一次. 这个时间可以自己设定. 没有显示也没有更新,只有几个问题. 实际上,当您采集大量数据时,可以更新下一个块数据.
15
最后,附加一个演示站: 品文时代与太空小说网
Dream weaving dedecms系统修改了文章描述中调用字数的方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2020-08-07 06:21
让我们首先讨论如何修改此上限,以便我们可以显示方法的要点[field: description function =“ cn_substr(@me,character number)”/].
与Dedecms系统中的文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一个句子: $ description = cn_substrR($ description,$ cfg_auot_description);这句话实现了[field: description function =“ cn_substr(@me,字符数)” /]此功能. 由于此语句对页面布局确实有利,因此我们尝试不做任何更改.
在编辑页面上,有一个句子: $ description = cn_substrR($ description,250);该句子的字符数为250,这是系统设置的文章摘要字符数的上限. 如果是gbk编码,则显示125个字符. 如果是utf-8编码,则为81个字符. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,只需将250更改为另一个值,例如500. 建议不要在此处设置太高. 一种是不需要在列表页面上显示太多的内容(显示太多的内容不如间接使用主体好),另一种是避免数据库中的冗余.
仅完成上述修改是不够的,您需要修改article_description_main.php
在article_description_main.php页面上,我发现if($ dsize> 250)$ dsize = 250;语句,它限制了可以从后台检索的字符数. 只需将此处的250更改为500,织梦台就与之前修改的字符数有所不同. (如果确认已手动添加每篇文章,则无需修改此文件即可手动完成摘要获取. 次要摘要获取仍适用于大量文章和馆藏准备. )
首先,登录到后台,然后在系统-系统基本参数-其他选项中,将驱动摘要的长度更改为500,这意味着它与先前修改的字符数不同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 标签示例如下:
{dede: list typeid =” row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}
通过上述方法,我们已经意识到被调用的文本摘要为500个字符,这完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了更多空间.
让我们谈谈如何在常规的Dedecms文章或列表页面上调用文章摘要方法.
1: [field: info /]
2: [field: description /]
3: [field: info function =“ cn_substr(@me,字符数)” /]
4: [field: description function =“ cn_substr(@me,字符数)” /]
第一种和第二种方法是间接调用文章摘要. 就被调用的单词数而言,使用[field: info /]时,可以在{dede: arclist infolen =''} {/ dede: arclist}中,在通话摘要中设置字符数(向上系统设置的250个字符);如果使用[field: description /],则间接使用在后台设置的摘要字符的上限(背景也有上限250个字符). 显然,这两种方法都是非常被动和灵活的.
第三和第四种方法通过函数功能实现了文章摘要中显示字符的灵活调整. 当然,如果没有正确修改文章摘要的上限,则这四种方法之间的差异并不大. 查看全部
dedecms系统文章调用描述的字符数和数字最多为250个字节,并且文章摘要(可通过infolen或与描述相关的标签调用)的字符数限制为250个字符. 设置上限的第二个目的是减少数据库的冗余. 我保证网络的出色性能. 因此,不对引言的内容设置上限显然是不合理的,但是如果可以自由控制该上限,则仿冒网站的仿冒网站将对Web内容的布局产生积极影响. 在网页设计过程中,.NET源代码. 通常需要从渠道列表页面到文章摘要调用dedecms. 如果不能有效地控制文章摘要中的单词数,则页面布局可以非常灵活.
让我们首先讨论如何修改此上限,以便我们可以显示方法的要点[field: description function =“ cn_substr(@me,character number)”/].
与Dedecms系统中的文章摘要相关的主要php文件为:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一个句子: $ description = cn_substrR($ description,$ cfg_auot_description);这句话实现了[field: description function =“ cn_substr(@me,字符数)” /]此功能. 由于此语句对页面布局确实有利,因此我们尝试不做任何更改.
在编辑页面上,有一个句子: $ description = cn_substrR($ description,250);该句子的字符数为250,这是系统设置的文章摘要字符数的上限. 如果是gbk编码,则显示125个字符. 如果是utf-8编码,则为81个字符. 显然,如果要打破文章摘要中字符数的上限,则必须采用. 是的,只需将250更改为另一个值,例如500. 建议不要在此处设置太高. 一种是不需要在列表页面上显示太多的内容(显示太多的内容不如间接使用主体好),另一种是避免数据库中的冗余.
仅完成上述修改是不够的,您需要修改article_description_main.php
在article_description_main.php页面上,我发现if($ dsize> 250)$ dsize = 250;语句,它限制了可以从后台检索的字符数. 只需将此处的250更改为500,织梦台就与之前修改的字符数有所不同. (如果确认已手动添加每篇文章,则无需修改此文件即可手动完成摘要获取. 次要摘要获取仍适用于大量文章和馆藏准备. )
首先,登录到后台,然后在系统-系统基本参数-其他选项中,将驱动摘要的长度更改为500,这意味着它与先前修改的字符数不同.
完成上述修改后,我们可以转到频道列表页面并通过标签进行调用. 标签示例如下:
{dede: list typeid =” row ='5'titlelen ='100'orderby ='new'pagesize ='5'}
[field: title /]
[field: description function ='cn_substr(@ me,500)'/] ...
{/ dede: list}
通过上述方法,我们已经意识到被调用的文本摘要为500个字符,这完全突破了文章摘要的250个字符的系统限制,并为网页布局提供了更多空间.
让我们谈谈如何在常规的Dedecms文章或列表页面上调用文章摘要方法.
1: [field: info /]
2: [field: description /]
3: [field: info function =“ cn_substr(@me,字符数)” /]
4: [field: description function =“ cn_substr(@me,字符数)” /]
第一种和第二种方法是间接调用文章摘要. 就被调用的单词数而言,使用[field: info /]时,可以在{dede: arclist infolen =''} {/ dede: arclist}中,在通话摘要中设置字符数(向上系统设置的250个字符);如果使用[field: description /],则间接使用在后台设置的摘要字符的上限(背景也有上限250个字符). 显然,这两种方法都是非常被动和灵活的.
第三和第四种方法通过函数功能实现了文章摘要中显示字符的灵活调整. 当然,如果没有正确修改文章摘要的上限,则这四种方法之间的差异并不大.
杨浩原创文章生成器
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-07 05:05
工作原理:
构建文章[template],然后在[template]中引用[element].
可以自由创建无限个[Elements],每个[element]可以放置任何内容,然后设置元素内容的分隔符. 随机调用时,元素的内容由分隔符分开,例如分隔符是换行符. 调用[Element]时,它是一行一行的随机
The
分隔符是其他字符的组合,因此您可以随机调用一个段落,一个段落甚至整个文章!调用整个文章时,您无需将文章的内容放在[Element]中,您可以直接放置文件路径,并且在调用时文章的内容将自动被调用! !
调用数千篇文章时,此功能非常有效!
支持非重复随机呼叫: 例如,5个号码1-5,5个呼叫,这5个号码必须出现一次,但是出现的顺序是随机的. 那么6-10个呼叫是新的非重复随机呼叫,11-15个呼叫是相同的,依此类推.
简单地说: 元素负责随机调用的数据,然后在模板中引用该元素,自由匹配,以便可以生成文章! !
从模板的内容中提取生成时的文件名. 它会逐行解释,直到合法文件名(即可以保存的文件名)为止. 当整个文章被解释并且没有合适的文件名时,文件名就会重复. 这时,如果设置了“当文件名重复时不生成”,则生成将被忽略,否则文件名会自动按数字前进,并且将保存文章,直到不再重复文件名!因此,建议将标题元素放在模板的第一行和第二行中. 建议将元素的分隔符设置为换行符,即逐行随机调用,而文章正文可以自由设置并插入元素调用中
Yang Hao原创文章生成器v9.4更新:
修改: “分隔符”已更改为“分隔符”,以使其更易于理解. 换行符是一种将元素内容分成多个块的符号.
新功能: 元素块的多个引号,并支持设置随机时间
新功能: 自然随机调用方法,即允许自然重复调用
新功能: 文章标题的数量随机
解决了百度标题采集器和百度描述采集器无法处理数据的问题.
修复了在智能第一针之间切换时的一些详细问题. 查看全部
Yang Hao原创文章生成器是一个真正强大的原创文章生成器!只要构建模板并组织元素,就可以生成任何所需的文章!尤其是网站管理员,需要花费一些时间来获取数据,并且一旦生成就可以一劳永逸. 将来将不会缺少文章! ! !它能做什么?它可以转换成千上万的文章,句子或短语,并将其转换为完全原创的文章! !
工作原理:
构建文章[template],然后在[template]中引用[element].
可以自由创建无限个[Elements],每个[element]可以放置任何内容,然后设置元素内容的分隔符. 随机调用时,元素的内容由分隔符分开,例如分隔符是换行符. 调用[Element]时,它是一行一行的随机
The
分隔符是其他字符的组合,因此您可以随机调用一个段落,一个段落甚至整个文章!调用整个文章时,您无需将文章的内容放在[Element]中,您可以直接放置文件路径,并且在调用时文章的内容将自动被调用! !
调用数千篇文章时,此功能非常有效!
支持非重复随机呼叫: 例如,5个号码1-5,5个呼叫,这5个号码必须出现一次,但是出现的顺序是随机的. 那么6-10个呼叫是新的非重复随机呼叫,11-15个呼叫是相同的,依此类推.
简单地说: 元素负责随机调用的数据,然后在模板中引用该元素,自由匹配,以便可以生成文章! !
从模板的内容中提取生成时的文件名. 它会逐行解释,直到合法文件名(即可以保存的文件名)为止. 当整个文章被解释并且没有合适的文件名时,文件名就会重复. 这时,如果设置了“当文件名重复时不生成”,则生成将被忽略,否则文件名会自动按数字前进,并且将保存文章,直到不再重复文件名!因此,建议将标题元素放在模板的第一行和第二行中. 建议将元素的分隔符设置为换行符,即逐行随机调用,而文章正文可以自由设置并插入元素调用中
Yang Hao原创文章生成器v9.4更新:
修改: “分隔符”已更改为“分隔符”,以使其更易于理解. 换行符是一种将元素内容分成多个块的符号.
新功能: 元素块的多个引号,并支持设置随机时间
新功能: 自然随机调用方法,即允许自然重复调用
新功能: 文章标题的数量随机
解决了百度标题采集器和百度描述采集器无法处理数据的问题.
修复了在智能第一针之间切换时的一些详细问题.
呼叫链系列之一,Zipkin体系结构介绍,Springboot集合(springmvc
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2020-08-07 03:19
Zipkin分布式跟踪系统;它可以帮助采集时间数据并解决微服务架构下的延迟问题;它管理这些数据的采集和搜索; Zipkin的设计基于Google的Google Dapper论文.
每个应用程序向Zipkin报告计时数据,Zipkin UI呈现一个依赖关系图以显示通过每个应用程序传递了多少跟踪请求. 如果您想解决延迟问题,则可以对所有跟踪请求进行过滤或排序,并查看每个跟踪请求占总跟踪时间的百分比.
2. 为什么要使用Zipkin
随着业务变得越来越复杂,系统也经历了各种分裂,特别是随着微服务架构和容器技术的兴起,一个看似简单的应用程序可能在后台支持数十甚至数百个服务. 前端请求可能需要多个服务调用才能在最后完成;当请求变慢或不可用时,我们不知道是由哪个后端服务引起的,因此我们需要解决如何快速定位服务失败点的问题,Zipkin分布式跟踪系统可以解决此类问题.
3,Zipkin下载并启动
官员提供了三种启动方式,这是第二种启动方式;
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
访问localhost: 9411
详细参考:
第二个Zipkin架构
跟踪器(Tracer)位于您的应用程序中,它记录发生的操作的时间和元数据,并提供相应的类库,该类库对用户的使用是透明的. 采集的跟踪数据称为Span;
已检测应用程序中将数据发送到Zipkin的组件称为Reporter. 记者通过几种传输方式之一将跟踪数据发送到Zipkin采集器,
然后存储(存储)跟踪数据,并通过API查询存储以向UI提供数据.
体系结构图如下:
1,跟踪
Zipkin使用跟踪结构来跟踪请求. 一个请求可能在后台由几个服务处理. 每个服务的处理都是一个跨度,并且跨度之间存在依赖性. 跟踪是树形结构中的一组Span;
2,跨度
<p>每个服务的处理和跟踪都是一个Span,可以将其理解为基本工作单元,包括一些描述性信息: id,parentId,名称,时间戳,持续时间,注释等,例如: 查看全部
1. 什么是Zipkin
Zipkin分布式跟踪系统;它可以帮助采集时间数据并解决微服务架构下的延迟问题;它管理这些数据的采集和搜索; Zipkin的设计基于Google的Google Dapper论文.
每个应用程序向Zipkin报告计时数据,Zipkin UI呈现一个依赖关系图以显示通过每个应用程序传递了多少跟踪请求. 如果您想解决延迟问题,则可以对所有跟踪请求进行过滤或排序,并查看每个跟踪请求占总跟踪时间的百分比.
2. 为什么要使用Zipkin
随着业务变得越来越复杂,系统也经历了各种分裂,特别是随着微服务架构和容器技术的兴起,一个看似简单的应用程序可能在后台支持数十甚至数百个服务. 前端请求可能需要多个服务调用才能在最后完成;当请求变慢或不可用时,我们不知道是由哪个后端服务引起的,因此我们需要解决如何快速定位服务失败点的问题,Zipkin分布式跟踪系统可以解决此类问题.
3,Zipkin下载并启动
官员提供了三种启动方式,这是第二种启动方式;
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
访问localhost: 9411
详细参考:
第二个Zipkin架构
跟踪器(Tracer)位于您的应用程序中,它记录发生的操作的时间和元数据,并提供相应的类库,该类库对用户的使用是透明的. 采集的跟踪数据称为Span;
已检测应用程序中将数据发送到Zipkin的组件称为Reporter. 记者通过几种传输方式之一将跟踪数据发送到Zipkin采集器,
然后存储(存储)跟踪数据,并通过API查询存储以向UI提供数据.
体系结构图如下:
1,跟踪
Zipkin使用跟踪结构来跟踪请求. 一个请求可能在后台由几个服务处理. 每个服务的处理都是一个跨度,并且跨度之间存在依赖性. 跟踪是树形结构中的一组Span;
2,跨度
<p>每个服务的处理和跟踪都是一个Span,可以将其理解为基本工作单元,包括一些描述性信息: id,parentId,名称,时间戳,持续时间,注释等,例如:
织梦DEDECMS文章页面呼叫文章浏览时间优化了呼叫代码标签
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2020-08-07 03:18
在使用Dream Weaving建立网站时,在文章页面的信息页面上,调用文章查看次数的正式标签为: {dede: field.click/}该标签调用静态观看次数,也就是说,我们生成文章当时随机生成的视图数量,无论文章页面如何刷新,都不会增加视图数量,并且用户体验非常差. Internet上存在一种解决方案,即将呼叫标签更改为: 这样,可以动态调用,刷新和增加文章视图的数量,但在使用后发现了问题. 每次将页面加载到此位置时,它都会冻结,因为这是一个js调用,每次对服务器发出请求时,此处的标签都会被及时加载,并且肯定会卡在这里. 经过研究,给出了最佳解决方案. 具体想法是: 我们可以首先自定义一个数字(可以定义为0). 第一次加载网页时,它会加载我们预先确定的数字,然后通过最后加载的网页JS调用实际的点击次数. 具体步骤是: 1.使用span标签在点击计数的位置定义0次点击计数. 2.修改Dede核心功能,然后在plus / count.php中找到echo“ document.write('”. $ row ['click'] ..“'); rn”;. 关于第25行,将其替换为echo'document.getElementById(“ countnum”). innerHTML ='. $ row ['click']; 3.在页面底部添加js代码,在页面底部添加js,可以完美解决加载视图数时卡住的问题. 用户体验非常好. 到目前为止,文章页面会动态调用文章浏览量.
WordPress将最新文章称为五种方法,包括排除粘性文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-06 20:22
在不使用插件的情况下调用最新文章是我们在进行wordpress转换和开发时经常遇到的功能. 我们已经在Internet上采集了几种常用方法. 当页面同时收录最新文章和热门文章时,我们应考虑将最新文章排除在列表之外.
一种,最简单的方法wp_get_archvies
可以使用非常简单的单行模板标签wp_get_archvies来实现对最新WordPress文章的调用
(显示10条最新更新的文章)
或
type = postbypost: 按最新帖子排序
限制: 将文章数限制为最新的20条
format = custom: 用于自定义此文章列表的显示样式(也可以省略fromat = custom,文章标题默认显示在UL列表中. )
二,query_posts()函数
最新的帖子列表也可以通过WP的query_posts()函数调用. 尽管代码会更多,但是您可以更好地控制Loop的显示. 例如,您可以设置是否显示摘要. 您也可以查看官方说明以了解具体用法.
调用最新文章: (只需将以下代码直接放在您要显示的位置即可)
最新文章
阅读6篇文章,并排除类别ID为111的文章
三,推荐WP_Query函数
四个. 推荐get_results()函数
5. 从最新文章中排除热门文章
最新文章
六. 摘要
1,使用get_results()函数最快
2. 建议使用WP_Query()函数,该函数非常灵活且控制良好. 这也是官方网站推荐的功能
摘要
以上是WordPress调用Script House为您采集的最新文章. 五种方法包括排除顶部文章的所有内容. 希望本文可以帮助您解决WordPress调用最新文章的问题. 五个方法包括排除上一篇文章遇到的程序开发. 问题.
如果您认为Scripthome网站的内容还不错,欢迎向程序员朋友推荐Scripthome网站. 查看全部
本文由Script House采集并组织,主要介绍了WordPress调用最新文章的五种方法,包括排除热门文章. Script House的编辑认为这是相当不错的. 现在,我将与您分享并提供参考.
在不使用插件的情况下调用最新文章是我们在进行wordpress转换和开发时经常遇到的功能. 我们已经在Internet上采集了几种常用方法. 当页面同时收录最新文章和热门文章时,我们应考虑将最新文章排除在列表之外.
一种,最简单的方法wp_get_archvies
可以使用非常简单的单行模板标签wp_get_archvies来实现对最新WordPress文章的调用
(显示10条最新更新的文章)
或
type = postbypost: 按最新帖子排序
限制: 将文章数限制为最新的20条
format = custom: 用于自定义此文章列表的显示样式(也可以省略fromat = custom,文章标题默认显示在UL列表中. )
二,query_posts()函数
最新的帖子列表也可以通过WP的query_posts()函数调用. 尽管代码会更多,但是您可以更好地控制Loop的显示. 例如,您可以设置是否显示摘要. 您也可以查看官方说明以了解具体用法.
调用最新文章: (只需将以下代码直接放在您要显示的位置即可)
最新文章
阅读6篇文章,并排除类别ID为111的文章
三,推荐WP_Query函数
四个. 推荐get_results()函数
5. 从最新文章中排除热门文章
最新文章
六. 摘要
1,使用get_results()函数最快
2. 建议使用WP_Query()函数,该函数非常灵活且控制良好. 这也是官方网站推荐的功能
摘要
以上是WordPress调用Script House为您采集的最新文章. 五种方法包括排除顶部文章的所有内容. 希望本文可以帮助您解决WordPress调用最新文章的问题. 五个方法包括排除上一篇文章遇到的程序开发. 问题.
如果您认为Scripthome网站的内容还不错,欢迎向程序员朋友推荐Scripthome网站.
Empire CMS内容页面调用当前文章的作者信息,并调用除当前文章以外的成员相关文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2020-08-06 18:15
1. 通话会员信息:
将以下代码添加到内容页面模板中.
$ userr = sys_ShowMemberInfo(0,'');
会员头像:
成员:
会员ID:
注册时间:
会员积分: 积分
发布新闻: 文章
成员组:
作者文章列表: e / space / list.php?userid =&mid = 1“>文章列表
第二,调用用户发布的其他文章的信息(成员投稿的文章):
1,php调用
调用当前成员提交的文章(5篇文章):
---------------------
$ sql = $ empire-> query(“从{$ dbtbpre} ecms_news中选择*,其中userid ='$ navinfor [userid]'和classid ='$ navinfor [classid]'和id $ navinfor [id]和ismember = 1按新闻时间升序限制5“)排序;
while($ r = $ empire-> fetch($ sql))
if($ navinfor [ismember] == 1)
{
$ titleurl = sys_ReturnBqTitleLink($ r); //链接
“ target =” _ blank“ title =”“>
}
其他
{
暂时没有其他文章
}
2,智能标记调用
----------------------
[e: loop = {“从[!db.pre!] ecms_news中选择*,其中userid ='$ navinfor [userid]'和classid ='$ navinfor [classid]'和id $ navinfor [id]和ismember = 1按新闻时间降序限制10“,0,24,0}]
if($ navinfor [ismember] == 1)
{
“ title =”“>
}
其他
{
暂时没有其他文章
}
[/ e: loop]
或
[e: loop = {'selfinfo',10,0,0,“ userid ='$ navinfor [userid]'and classid ='$ navinfor [classid]'and id $ navinfor [id] and ismember = 1 “}]
if($ navinfor [ismember] == 1)
{
“ title =”“>
}
其他
{
暂时没有其他文章
}
[/ e: loop]
=============================================通话用户对其他文章发表的评论============================================ ==========
注意: id $ navinfor [id]或and id!= $ navinfor [id]表示: 不等于当前文章ID
①,classid ='$ navinfor [classid]'的意思是: 仅调用当前列中的文章(如果删除该列,则将调用整个模型中其他列中成员发布的文章)
②,classid也可以指定显示列的id格式,例如: classid = 34或(2,3)中的classid)
③,classid也可以排除当前列. 格式如下: classid $ navinfor [classid]即: 在其他列中调用当前发布者发布的信息
“目前没有其他文章”可以删除
注意: 以上内容(调用用户发布的其他文章信息)可以调用“成员”和“访客”的文章,但背景“网站管理员”发布的文章除外. 查看全部
内容页面调用当前文章的作者信息,并调用当前文章以外的成员相关文章
1. 通话会员信息:
将以下代码添加到内容页面模板中.
$ userr = sys_ShowMemberInfo(0,'');
会员头像:
成员:
会员ID:
注册时间:
会员积分: 积分
发布新闻: 文章
成员组:
作者文章列表: e / space / list.php?userid =&mid = 1“>文章列表
第二,调用用户发布的其他文章的信息(成员投稿的文章):
1,php调用
调用当前成员提交的文章(5篇文章):
---------------------
$ sql = $ empire-> query(“从{$ dbtbpre} ecms_news中选择*,其中userid ='$ navinfor [userid]'和classid ='$ navinfor [classid]'和id $ navinfor [id]和ismember = 1按新闻时间升序限制5“)排序;
while($ r = $ empire-> fetch($ sql))
if($ navinfor [ismember] == 1)
{
$ titleurl = sys_ReturnBqTitleLink($ r); //链接
“ target =” _ blank“ title =”“>
}
其他
{
暂时没有其他文章
}
2,智能标记调用
----------------------
[e: loop = {“从[!db.pre!] ecms_news中选择*,其中userid ='$ navinfor [userid]'和classid ='$ navinfor [classid]'和id $ navinfor [id]和ismember = 1按新闻时间降序限制10“,0,24,0}]
if($ navinfor [ismember] == 1)
{
“ title =”“>
}
其他
{
暂时没有其他文章
}
[/ e: loop]
或
[e: loop = {'selfinfo',10,0,0,“ userid ='$ navinfor [userid]'and classid ='$ navinfor [classid]'and id $ navinfor [id] and ismember = 1 “}]
if($ navinfor [ismember] == 1)
{
“ title =”“>
}
其他
{
暂时没有其他文章
}
[/ e: loop]
=============================================通话用户对其他文章发表的评论============================================ ==========
注意: id $ navinfor [id]或and id!= $ navinfor [id]表示: 不等于当前文章ID
①,classid ='$ navinfor [classid]'的意思是: 仅调用当前列中的文章(如果删除该列,则将调用整个模型中其他列中成员发布的文章)
②,classid也可以指定显示列的id格式,例如: classid = 34或(2,3)中的classid)
③,classid也可以排除当前列. 格式如下: classid $ navinfor [classid]即: 在其他列中调用当前发布者发布的信息
“目前没有其他文章”可以删除
注意: 以上内容(调用用户发布的其他文章信息)可以调用“成员”和“访客”的文章,但背景“网站管理员”发布的文章除外.
织梦调用相关文章时,likearticle不能排除当前文章的解决方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2020-08-06 18:14
/ ************************************************** ****************************************************** **** /
if($ keyword!='')
{
if(!empty($ typeid)){
$ typeid =“ AND arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
其中arc.arcrank> -1AND($ keyword)$ typeid $ orderquery limit 0,$ row“;
}
其他
{
if(!empty($ typeid)){
$ typeid =“ arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
WHERE arc.arcrank> -1AND $ typeid $ orderquery limit 0,$ row“;
}
/ ************************************************** *************************************************** / <//p
p从上面的代码中,我们可以看到dedecms试图在程序开始时对文章进行过滤以排除该文章(AND arc.id'$ aid'“),但失败了. 如何成功排除这很简单. 我们可以在此代码中再次将其排除: AND($ keyword)$ typeid. 必须添加这两个代码. 修改完成后,以下是以下内容(请注意区别)之间的绿色粗体代码):/p
p/ ************************************************** ****************************************************** **** //p
pif($ keyword!='')/p
p{/p
pif(!empty($ typeid)){/p
p$ typeid =“ AND arc.typeid IN($ typeid)AND arc.id'$ aid'”;/p
p}/p
p$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,/p
ptp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath/p
pFROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id/p
p其中arc.arcrank> -1AND($ keyword)$ typeidAND arc.id'$ aid'$ orderquery limit 0,$ row“;
}
其他
{
if(!empty($ typeid)){
$ typeid =“ arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
WHERE arc.arcrank> -1AND $ typeidAND arc.id'$ aid'$ orderquery limit 0,$ row“;
}
<p>/ ************************************************** *************************************************** / 查看全部
通常,当我们发布文章时,为了增加用户的停留时间,我们将在文章末尾或适当位置调用与该文章相关的文章,以再次赢得用户的点击. 在dedecms(V5版本.7)中,在调用类似文章时,实际的调用代码为{dede: likearticle}. 该代码的原理是通过识别文章的标题,类别,关键字等来提出建议,以判断相似性. 后台调用代码如下/include/taglib/likearticle.lib.php,打开文件并找到以下代码:
/ ************************************************** ****************************************************** **** /
if($ keyword!='')
{
if(!empty($ typeid)){
$ typeid =“ AND arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
其中arc.arcrank> -1AND($ keyword)$ typeid $ orderquery limit 0,$ row“;
}
其他
{
if(!empty($ typeid)){
$ typeid =“ arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
WHERE arc.arcrank> -1AND $ typeid $ orderquery limit 0,$ row“;
}
/ ************************************************** *************************************************** / <//p
p从上面的代码中,我们可以看到dedecms试图在程序开始时对文章进行过滤以排除该文章(AND arc.id'$ aid'“),但失败了. 如何成功排除这很简单. 我们可以在此代码中再次将其排除: AND($ keyword)$ typeid. 必须添加这两个代码. 修改完成后,以下是以下内容(请注意区别)之间的绿色粗体代码):/p
p/ ************************************************** ****************************************************** **** //p
pif($ keyword!='')/p
p{/p
pif(!empty($ typeid)){/p
p$ typeid =“ AND arc.typeid IN($ typeid)AND arc.id'$ aid'”;/p
p}/p
p$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,/p
ptp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath/p
pFROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id/p
p其中arc.arcrank> -1AND($ keyword)$ typeidAND arc.id'$ aid'$ orderquery limit 0,$ row“;
}
其他
{
if(!empty($ typeid)){
$ typeid =“ arc.typeid IN($ typeid)AND arc.id'$ aid'”;
}
$ query =“ SELECT arc. *,tp.typedir,tp.typename,tp.corank,tp.isdefault,tp.defaultname,tp.namerule,
tp.namerule2,tp.ispart,tp.moresite,tp.siteurl,tp.sitepath
FROM`dede_archives`弧LEFT JOIN`dede_arctype` tp ON arc.typeid = tp.id
WHERE arc.arcrank> -1AND $ typeidAND arc.id'$ aid'$ orderquery limit 0,$ row“;
}
<p>/ ************************************************** *************************************************** /

