
文章采集调用
程序中的系统调用工具(二十五):跟踪系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-02 00:28
原文出处:
原作者:Amit Kumar Sahaand Sayantini Ghosh
翻译时间:2008 年 3 月 3 日
译者:王旭
译者注:翻译文章文章来改变你的心情,strace是一个有用的工具,LinuxGazette是一本不错的杂志,希望你喜欢这篇文章。
了解一切如何运作很有趣。所有 C 程序员都知道在他们的 C 程序的“输入-处理-输出”循环中使用了许多系统调用。看到程序中使用了哪些系统调用,无疑是非常令人兴奋的。这篇文章就是关于这个话题的,让我们开始吧。
什么是“strace”?
'strace' 是一个用于跟踪进程在运行时进行的系统调用的工具。它还报告进程收到的信号(或软中断)。
根据手册页,在最简单的情况下,“strace 运行指定的命令,直到命令完成。它拦截并记录进程收到的系统调用和信号。”
直接在终端中输入“strace”命令来查看它的各种开关和选项:
$ strace
usage: strace [-dffhiqrtttTvVxx] [-a column] [-e expr] ... [-o file]
[-p pid] ... [-s strsize] [-u username] [-E var=val] ...
[command [arg ...]]
or: strace -c [-e expr] ... [-O overhead] [-S sortby] [-E var=val] ...
[command [arg ...]]
-c -- count time, calls, and errors for each syscall and report summary
[[[etc.]]]
跟踪系统调用
从一个简单的例子开始。考虑以下 C 代码(列表1):
/* Listing 1*/
#include
int main()
{
return 0;
}
假设编译后的目标文件名为‘temp.o’。运行如下:
$strace ./temp.o
您将获得以下跟踪结果输出:
execve("./temp.o", ["./temp.o"], [/* 36 vars */]) = 0
brk(0) = 0x804a000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7fba000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=68539, ...}) = 0
mmap2(NULL, 68539, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7fa9000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/tls/i686/cmov/libc.so.6", O_RDONLY) = 3
read(3, "177ELF111331`100"..., 512) = 512
fstat64(3, {st_mode=S_IFREG|0644, st_size=1307104, ...}) = 0
mmap2(NULL, 1312164, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0xb7e68000
mmap2(0xb7fa3000, 12288, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x13b) = 0xb7fa3000
mmap2(0xb7fa6000, 9636, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0xb7fa6000
close(3) = 0
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7e67000
set_thread_area({entry_number:-1 -> 6, base_addr:0xb7e676c0, limit:1048575, seg_32bit:1, contents:0, read_exec_only:0, limit_in_pages:1, seg_not_present:0, useable:1}) = 0
mprotect(0xb7fa3000, 4096, PROT_READ) = 0
munmap(0xb7fa9000, 68539) = 0
exit_group(0) = ?
Process 8909 detached
现在,让我们将理论与实践相结合。
我们知道,当用户输入命令或可执行文件运行时,系统会创建一个“子”Shell,并使用这个子Shell来运行程序。这是通过系统调用“execve”实现的。因此,跟踪结果从以下内容开始:
execve("./temp.o", ["./temp.o"], [/* 36 vars */]) = 0
接下来,进程调用'brk()','open','access','open','close',直到最终进程从shell分离并使用“exit_group(0)”启动。
如上,跟踪过程显示了系统调用及其返回值。
strace 的信号报告功能
我们来看看“strace”的信号上报功能。考虑以下 C 代码(列表2):
/*Listing 2*/
#include
int main()
{
int i;
for(i=0;i>=0;i++)
printf("infinityn");
return 0;
}
假设编译输出的可执行文件是“temp-1.o”。运行如下:
$ strace -o trace.txt ./temp-1.o
这里,“-o”开关会将跟踪结果保存到“trace.txt”文件中。
在这里,您将看到“write()”系统调用将被连续调用。现在,使用“ctrl-c”结束进程
现在,查看“trace.txt”
$cat trace.txt
最后几行应该是:
--- SIGINT (Interrupt) @ 0 (0) ---
+++ killed by SIGINT +++
因为我们使用"ctrl-c"结束进程,所以发送信号SIGINT给进程,就像"strace"的输出一样。
采集与系统调用相关的统计数据
使用“strace”,您还可以对跟踪的系统调用进行一些简单的统计。这是通过“-c”开关实现的。例如:
$ strace -o trace-1.txt -c ./temp-1.o # 运行上述可执行程序 'temp-1.o'
$ cat trace-1.txt
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
100.00 0.007518 0 46702 write
0.00 0.000000 0 1 read
0.00 0.000000 0 2 open
0.00 0.000000 0 2 close
0.00 0.000000 0 1 execve
0.00 0.000000 0 3 3 access
0.00 0.000000 0 1 brk
0.00 0.000000 0 1 munmap
0.00 0.000000 0 1 mprotect
0.00 0.000000 0 7 mmap2
0.00 0.000000 0 3 fstat64
0.00 0.000000 0 1 set_thread_area
------ ----------- ----------- --------- --------- ----------------
100.00 0.007518 46725 3 total
如上,除了其他输出信息外,还输出了系统调用的统计信息,“write()”系统调用(总共运行了46702次),占用了进程的大部分时间 (100%)。
后记
本文简单介绍了“strace”的一些基本功能。该工具在搜索可执行程序中的错误和查找崩溃点时非常有用。使用“strace”可以大大减少可能出现问题的范围。
与‘GNU Debugger’ (gdb) 和‘ltrace’一起,“strace”为 Linux 程序员提供了强大的调试功能。
有用的链接: 查看全部
程序中的系统调用工具(二十五):跟踪系统
原文出处:
原作者:Amit Kumar Sahaand Sayantini Ghosh
翻译时间:2008 年 3 月 3 日
译者:王旭
译者注:翻译文章文章来改变你的心情,strace是一个有用的工具,LinuxGazette是一本不错的杂志,希望你喜欢这篇文章。
了解一切如何运作很有趣。所有 C 程序员都知道在他们的 C 程序的“输入-处理-输出”循环中使用了许多系统调用。看到程序中使用了哪些系统调用,无疑是非常令人兴奋的。这篇文章就是关于这个话题的,让我们开始吧。
什么是“strace”?
'strace' 是一个用于跟踪进程在运行时进行的系统调用的工具。它还报告进程收到的信号(或软中断)。
根据手册页,在最简单的情况下,“strace 运行指定的命令,直到命令完成。它拦截并记录进程收到的系统调用和信号。”
直接在终端中输入“strace”命令来查看它的各种开关和选项:
$ strace
usage: strace [-dffhiqrtttTvVxx] [-a column] [-e expr] ... [-o file]
[-p pid] ... [-s strsize] [-u username] [-E var=val] ...
[command [arg ...]]
or: strace -c [-e expr] ... [-O overhead] [-S sortby] [-E var=val] ...
[command [arg ...]]
-c -- count time, calls, and errors for each syscall and report summary
[[[etc.]]]
跟踪系统调用
从一个简单的例子开始。考虑以下 C 代码(列表1):
/* Listing 1*/
#include
int main()
{
return 0;
}
假设编译后的目标文件名为‘temp.o’。运行如下:
$strace ./temp.o
您将获得以下跟踪结果输出:
execve("./temp.o", ["./temp.o"], [/* 36 vars */]) = 0
brk(0) = 0x804a000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7fba000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=68539, ...}) = 0
mmap2(NULL, 68539, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7fa9000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/tls/i686/cmov/libc.so.6", O_RDONLY) = 3
read(3, "177ELF111331`100"..., 512) = 512
fstat64(3, {st_mode=S_IFREG|0644, st_size=1307104, ...}) = 0
mmap2(NULL, 1312164, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0xb7e68000
mmap2(0xb7fa3000, 12288, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x13b) = 0xb7fa3000
mmap2(0xb7fa6000, 9636, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0xb7fa6000
close(3) = 0
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7e67000
set_thread_area({entry_number:-1 -> 6, base_addr:0xb7e676c0, limit:1048575, seg_32bit:1, contents:0, read_exec_only:0, limit_in_pages:1, seg_not_present:0, useable:1}) = 0
mprotect(0xb7fa3000, 4096, PROT_READ) = 0
munmap(0xb7fa9000, 68539) = 0
exit_group(0) = ?
Process 8909 detached
现在,让我们将理论与实践相结合。
我们知道,当用户输入命令或可执行文件运行时,系统会创建一个“子”Shell,并使用这个子Shell来运行程序。这是通过系统调用“execve”实现的。因此,跟踪结果从以下内容开始:
execve("./temp.o", ["./temp.o"], [/* 36 vars */]) = 0
接下来,进程调用'brk()','open','access','open','close',直到最终进程从shell分离并使用“exit_group(0)”启动。
如上,跟踪过程显示了系统调用及其返回值。
strace 的信号报告功能
我们来看看“strace”的信号上报功能。考虑以下 C 代码(列表2):
/*Listing 2*/
#include
int main()
{
int i;
for(i=0;i>=0;i++)
printf("infinityn");
return 0;
}
假设编译输出的可执行文件是“temp-1.o”。运行如下:
$ strace -o trace.txt ./temp-1.o
这里,“-o”开关会将跟踪结果保存到“trace.txt”文件中。
在这里,您将看到“write()”系统调用将被连续调用。现在,使用“ctrl-c”结束进程
现在,查看“trace.txt”
$cat trace.txt
最后几行应该是:
--- SIGINT (Interrupt) @ 0 (0) ---
+++ killed by SIGINT +++
因为我们使用"ctrl-c"结束进程,所以发送信号SIGINT给进程,就像"strace"的输出一样。
采集与系统调用相关的统计数据
使用“strace”,您还可以对跟踪的系统调用进行一些简单的统计。这是通过“-c”开关实现的。例如:
$ strace -o trace-1.txt -c ./temp-1.o # 运行上述可执行程序 'temp-1.o'
$ cat trace-1.txt
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
100.00 0.007518 0 46702 write
0.00 0.000000 0 1 read
0.00 0.000000 0 2 open
0.00 0.000000 0 2 close
0.00 0.000000 0 1 execve
0.00 0.000000 0 3 3 access
0.00 0.000000 0 1 brk
0.00 0.000000 0 1 munmap
0.00 0.000000 0 1 mprotect
0.00 0.000000 0 7 mmap2
0.00 0.000000 0 3 fstat64
0.00 0.000000 0 1 set_thread_area
------ ----------- ----------- --------- --------- ----------------
100.00 0.007518 46725 3 total
如上,除了其他输出信息外,还输出了系统调用的统计信息,“write()”系统调用(总共运行了46702次),占用了进程的大部分时间 (100%)。
后记
本文简单介绍了“strace”的一些基本功能。该工具在搜索可执行程序中的错误和查找崩溃点时非常有用。使用“strace”可以大大减少可能出现问题的范围。
与‘GNU Debugger’ (gdb) 和‘ltrace’一起,“strace”为 Linux 程序员提供了强大的调试功能。
有用的链接:
网站调用随机文章对网站SEO有什么影响?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-08-01 02:01
作为seoer,你应该不断思考和测试,通过测试结果丰富你的实战成功经验。所以,一个seoer思考问题的角度,对于不懂seo的朋友来说似乎有些陌生,比如网站首页上的朋友想调用Random文章,那么网站home调用Random文章有什么影响@有网站SEO?
基于在seo学校学习的经验,我们认为:
1.用户体验
首页随机添加文章,一般网站比较少见。我们认为这会对网站的用户体验产生更大的影响:
①增加丰富度
一个新用户来到网站,无论他进入哪个页面,如果他愿意继续浏览,他很可能会浏览首页。如果首页的内容除了常用的最新文章之外,还有随机的文章,不可避免,这就增加了首页内容的丰富性,尤其是对于一些公司网站,比较少内容放在首页,更实用。
②提高新鲜度
如果是老用户回访,对方最想看到的是网站内容更新。如果内容更新不及时,我们的主页将不会改变。通过随机模块,内容可以不断更新。 , 提高老用户对网站的新鲜度。
2.网站seo
首页随机文章其实对seo的影响更大,我们认为包括:
①Page收录
一个页面要成为收录,必须先被蜘蛛抓取。一般网站会在内页随机调用文章,在首页加入随机文章调用可以让蜘蛛更容易抓取内容,提升收录。
②提升排名
当一个网站有更多收录收到的页面时,说明网站的信任度更高,这是一个积极的指标,所以我们在做网站seo的时候,首先会考虑如何改进收录,尤其是最近搜索引擎对网站页收录的要求进一步提高。我们需要在首页随机展示文章等策略来推广百度的快速收录,然后在做seo的时候提升排名。
3.Notes
当我们在首页添加随机文章时,要注意一些问题,以免被搜索引擎判断为作弊:
①数量
前面我们提到,随机调用文章可以提升收录和排名,所以有朋友会考虑是否可以增加首页调用次数来增加页面被收录的概率。
这个想法不错,但实际上这样做很容易影响用户体验。我们建议根据主页的大小确定数量。一般随机调用不超过首页总面积的10%。正规的企业网站如果是纯文字就叫20-30个项目,如果叫图形样式,十个左右就好了。
②相关性
当我们在主页上随意调用文章时,我们很容易忽略一个细节。虽然是随机调用,但网站文章中的一些不同列有很大的不同。当我们进行随机调用时,我们也应该考虑用户体验。设计的影响。
最好不要混合和调用内容属性差异很大的内容。可以在不同的块中分别调用,这样对于用户体验来说,显示的信息更加清晰,对于搜索引擎来说,页面排名更加有序。
当我们在首页进行随机文章调用的时候,其实是比较自由的,因为不同的网站有不同的需求,所以上面的注意事项相对不同网站,需要考虑怎么用随机调用在无负面影响的情况下促进seo优化效果,让首页随机调用这个seo策略,充分利用它。
总结:网站homepage随机调用文章对网站SEO有什么影响?让我们就此打住。以上内容仅供参考。
转载蝙蝠侠IT需要授权! 查看全部
网站调用随机文章对网站SEO有什么影响?(图)
作为seoer,你应该不断思考和测试,通过测试结果丰富你的实战成功经验。所以,一个seoer思考问题的角度,对于不懂seo的朋友来说似乎有些陌生,比如网站首页上的朋友想调用Random文章,那么网站home调用Random文章有什么影响@有网站SEO?

基于在seo学校学习的经验,我们认为:
1.用户体验
首页随机添加文章,一般网站比较少见。我们认为这会对网站的用户体验产生更大的影响:
①增加丰富度
一个新用户来到网站,无论他进入哪个页面,如果他愿意继续浏览,他很可能会浏览首页。如果首页的内容除了常用的最新文章之外,还有随机的文章,不可避免,这就增加了首页内容的丰富性,尤其是对于一些公司网站,比较少内容放在首页,更实用。
②提高新鲜度
如果是老用户回访,对方最想看到的是网站内容更新。如果内容更新不及时,我们的主页将不会改变。通过随机模块,内容可以不断更新。 , 提高老用户对网站的新鲜度。
2.网站seo
首页随机文章其实对seo的影响更大,我们认为包括:
①Page收录
一个页面要成为收录,必须先被蜘蛛抓取。一般网站会在内页随机调用文章,在首页加入随机文章调用可以让蜘蛛更容易抓取内容,提升收录。
②提升排名
当一个网站有更多收录收到的页面时,说明网站的信任度更高,这是一个积极的指标,所以我们在做网站seo的时候,首先会考虑如何改进收录,尤其是最近搜索引擎对网站页收录的要求进一步提高。我们需要在首页随机展示文章等策略来推广百度的快速收录,然后在做seo的时候提升排名。
3.Notes
当我们在首页添加随机文章时,要注意一些问题,以免被搜索引擎判断为作弊:
①数量
前面我们提到,随机调用文章可以提升收录和排名,所以有朋友会考虑是否可以增加首页调用次数来增加页面被收录的概率。
这个想法不错,但实际上这样做很容易影响用户体验。我们建议根据主页的大小确定数量。一般随机调用不超过首页总面积的10%。正规的企业网站如果是纯文字就叫20-30个项目,如果叫图形样式,十个左右就好了。
②相关性
当我们在主页上随意调用文章时,我们很容易忽略一个细节。虽然是随机调用,但网站文章中的一些不同列有很大的不同。当我们进行随机调用时,我们也应该考虑用户体验。设计的影响。
最好不要混合和调用内容属性差异很大的内容。可以在不同的块中分别调用,这样对于用户体验来说,显示的信息更加清晰,对于搜索引擎来说,页面排名更加有序。
当我们在首页进行随机文章调用的时候,其实是比较自由的,因为不同的网站有不同的需求,所以上面的注意事项相对不同网站,需要考虑怎么用随机调用在无负面影响的情况下促进seo优化效果,让首页随机调用这个seo策略,充分利用它。
总结:网站homepage随机调用文章对网站SEO有什么影响?让我们就此打住。以上内容仅供参考。
转载蝙蝠侠IT需要授权!
91NLP稿写的原创内容不可当真,内外优化一定要做好
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-07-31 05:35
文章为91NLP写的原创内容不要当真
文章伪原创随机调用本地内容,然后把他本地的所有传送门文章复制上去,然后把他的网站名插入文章,然后把自己网站的@将关键词设置为网站的列,将网站的主要@关键词和网站标题设置为自己的@关键词,然后去每个网站找到网站的关键词里面,把他们的@关键词设置的很合理,然后把文章的@关键词设置为@关键词的网站,也是很好的文章。
其次网站的内部优化网站的内部优化,我就不赘述了;第三,网站的内部优化,@关键词的布局一直是网站搜索引擎优化的一个重要方面。在网站优化方面,像a5、站长网、seowhy、outdated等,我们在网站优化方面做得很好,但是网站优化不要太简单,只要内部优化做好就行。 ,不要一味的采集或者复制粘贴,最好原创的文章。
第四,网站content optimization网站的内部优化是我们需要把握的关键。比如我们的网站文章文章,一个文章的主题是:seo优化,那么你要在文章的后台设置标题,而这个文章的主题是seo优化,这样的文章就是搜索引擎喜欢的;其次文章内部优化的重点是seo优化,内外优化一定要做好,这是网站优化的重点之一。
第五:网站的内部优化1、首先要有好的内部优化,就是做内部优化。 网站的内部优化也是一样的。如果内部优化做的很好,那是非常困难的。是的,因为搜索引擎喜欢你的文章,所以这个很重要; 2、文章尽量出现@关键词,尽量出现在前面,最好是@关键词,这里是做内容优化的必备技巧,这个就不详细介绍了。如果你想做的是关于seo,那么你做这个seo,可能是@关键词你做的,这样就可以很好的利用搜索引擎蜘蛛的爬行,也可以提高网站' s 收录。
文章伪原创 随机调用本地内容
3、网站的内部优化,这个必须要考虑,但是如果你的网站内部优化做的不好,那么spider对你的网站会有很大的好处,所以当我们做内部优化,一定要做好内部优化,内部优化,外部优化,内部优化,内部优化等方面,这是必须的,做外部优化,做seo是一样的,做seo就是做内容和外部一样链,内部优化和内部链优化是一样的。内容要做好,做的时候也要做好。我们不能做太多。外链也是如此。我们也做seo。是的,网站seo 也是一样。内容应该多样化。做外链的时候,要做好。做外链的时间应该比较长。外部链接也是如此。有些人会做一些,这是必须的,不要做太多,你也有一定的seo经验; 4、外链大家都知道,在制作内容的过程中,外部优化也是一个很好的方法,这是一个需要我们注意的地方,当外部优化时 查看全部
91NLP稿写的原创内容不可当真,内外优化一定要做好
文章为91NLP写的原创内容不要当真

文章伪原创随机调用本地内容,然后把他本地的所有传送门文章复制上去,然后把他的网站名插入文章,然后把自己网站的@将关键词设置为网站的列,将网站的主要@关键词和网站标题设置为自己的@关键词,然后去每个网站找到网站的关键词里面,把他们的@关键词设置的很合理,然后把文章的@关键词设置为@关键词的网站,也是很好的文章。

其次网站的内部优化网站的内部优化,我就不赘述了;第三,网站的内部优化,@关键词的布局一直是网站搜索引擎优化的一个重要方面。在网站优化方面,像a5、站长网、seowhy、outdated等,我们在网站优化方面做得很好,但是网站优化不要太简单,只要内部优化做好就行。 ,不要一味的采集或者复制粘贴,最好原创的文章。
第四,网站content optimization网站的内部优化是我们需要把握的关键。比如我们的网站文章文章,一个文章的主题是:seo优化,那么你要在文章的后台设置标题,而这个文章的主题是seo优化,这样的文章就是搜索引擎喜欢的;其次文章内部优化的重点是seo优化,内外优化一定要做好,这是网站优化的重点之一。
第五:网站的内部优化1、首先要有好的内部优化,就是做内部优化。 网站的内部优化也是一样的。如果内部优化做的很好,那是非常困难的。是的,因为搜索引擎喜欢你的文章,所以这个很重要; 2、文章尽量出现@关键词,尽量出现在前面,最好是@关键词,这里是做内容优化的必备技巧,这个就不详细介绍了。如果你想做的是关于seo,那么你做这个seo,可能是@关键词你做的,这样就可以很好的利用搜索引擎蜘蛛的爬行,也可以提高网站' s 收录。
文章伪原创 随机调用本地内容
3、网站的内部优化,这个必须要考虑,但是如果你的网站内部优化做的不好,那么spider对你的网站会有很大的好处,所以当我们做内部优化,一定要做好内部优化,内部优化,外部优化,内部优化,内部优化等方面,这是必须的,做外部优化,做seo是一样的,做seo就是做内容和外部一样链,内部优化和内部链优化是一样的。内容要做好,做的时候也要做好。我们不能做太多。外链也是如此。我们也做seo。是的,网站seo 也是一样。内容应该多样化。做外链的时候,要做好。做外链的时间应该比较长。外部链接也是如此。有些人会做一些,这是必须的,不要做太多,你也有一定的seo经验; 4、外链大家都知道,在制作内容的过程中,外部优化也是一个很好的方法,这是一个需要我们注意的地方,当外部优化时
为什么你的搜索引擎总是打擦边球?(上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-07-29 18:09
搜索引擎是非常重要的信息获取门户。至于我使用的技能,我并不是很先进。欢迎搜索专家与我交流,省力又有效的搜索方法。
1.找到合适的关键词,事半功倍
很久以前,我偶然看到了两张照片。很喜欢这两张图,希望能看到更多类似的图。
▲ 检索这两种图像使用什么样的关键图像?
但是,什么样的图片首先被称为?
关键词应该先用于头脑风暴,它叫什么?插图?图表?手绘?插图?
这些关键词 搜索的结果真的很令人沮丧。但是根据搜索结果的提示,一步一步的改变关键词,直到找到可靠的结果。最后,当我找到这个词时,我找到了宝藏。
要查找图中左侧的图形类型,请尝试使用“视觉思维”,或在谷歌上搜索“视觉思维”,如需查找更多图 3 中右侧类型的图形,请尝试使用 "infographic" 或 "infographic"。
▲视觉思维的检索结果
▲ 信息图检索结果
所以在搜索中,我们应该不断的替换更合适的关键词,而不是不断的打边球。
如何找到合适的关键词?
从你认为可行的第一个关键词开始,不要轻易放弃。根据每个搜索结果的线索跟踪,不断修改关键词,直到得到结果。
2.换语言,天上别有洞
有时更改为英语可以让您获得更准确的结果。
所以这就是为什么我的主题词应该是中英文双语的。由于很多中文结果都是从英文翻译过来的,直接查看源码文章显然少了信息缺失。
▲ 英文搜索“visual thinking”的结果
以此类推,每增加一种语言,就会打开一扇了解世界的新窗口。
对于家庭存储,在中文“存储”中搜索文章,几乎只是一些零碎的图片和社区网站,吸引用户拼凑存储技巧。
在日文“Storage”中搜索,在日本看一些网站,可以看到很多关于存储的经验、文档和教程。有些教程的丰富程度不亚于出版书籍,甚至比国内那些家装作品还要好。比如网站提供的Bendo先生的日常收纳教程:
▲ 店铺检索到的专业日语网站
关于网站关于storage的事,有兴趣的可以试试用日语搜索,但是不能问我。
3.改变搜索方式,通过不同的路线达到相同的目标
如果网络搜索没有得到你想要的结果,你可以改变搜索类型,比如搜索图片,然后通过图片链接到有价值的网站。
我经常使用文件搜索。与普通网页相比,这些文档通常意味着更好、更系统的组织,让您的信息获取更有效。
如何使用搜索引擎搜索文档?
如果您使用 google,请在搜索词前添加 inurl:pdf。
如果您使用百度,请在搜索词之前添加 filetype: all。如果您需要特定的 PDF 格式,请输入:filetype: PDF
如果您使用百度搜索商业智能相关文档:
▲ 百度搜索文档
4.别忘了专业的网站
Professional网站让您免于在大量垃圾邮件中查找所需信息的麻烦,他们的信息往往更加集中。我经常用的专业搜索网站有:
——PPT分享网站,国外很多制作优秀、丰富、专业的PPT。我经常在这里搜索有关视觉思维的文档。不过很遗憾,你需要爬墙才能看到这个网站。
MBA Think Tank——一个专注于经济和管理领域的数据库。您可以在此处搜索经济和管理多个领域的各种术语的解释、文档等。
维基百科-如果它在墙外或将其推翻。很多词在中国很敏感,在这里你可以看到非常详细的因果关系。当然,如果不是敏感词,百度百科也是不错的资源。
5.在书中寻找搜索技巧
小提醒,当你没有关键词灵感的时候,你也可以从书的目录中获得关键词的提示。除了目录,专业书籍还收录有价值的挖掘信息。
以下是利用书中提供的信息不断探索,然后找到真正需要的信息的案例:
我最近阅读了“Excel 图表之道”一书。第 P152 页提到的图表类型选择指南的原作者是 Andrew Abela。这个人的名字是很珍贵的关键词。这个关键词可能代表:数据、数据分析、商业智能、交流展示等主题。
于是我搜索了这个人,看到了这个人的博客:The Extreme Presentation(tm) Method。本博客为专业博客,主题为复杂信息的交流与呈现。
而且这个博客宣传一本书,这本书出自Andrew Abela,《Advanced Presentations by Design:Creating Communications that Dives Action》,这本书中文版在中国大陆有售,中文译本是《Persuade How做强演讲——如何为现场交易设计PPT”。
最后通过博文网站:Extreme Presentation Method。这个网站有一些很好的信息,我推荐给对演示感兴趣的学生。比如下面两张图表也是来自这个网站:
▲的图片
当然,《Excel图表之道》作者刘万祥先生引用的英文原版图表类型选择指南也可以在这个网站下载。
另外,我们的信息挖掘还没有结束。注意他还提供了另一个在线工具:这个网站可以让数据分析师根据自己的需要选择不同的图表来展示。这个网站 来自juiceanalytics(果汁分析)。
进入Juiceanalytics网站的白皮书专栏,发现了《A Guide to Creating Dashboards People Love to Use》(A Guide to Creating Dashboards People Love to Use)。这份白皮书可以解答我最近工作的一些困惑。
如果你刻意去寻找,想要得到一些东西并不容易。如果你知道你的主题关键词,你的信息感会非常敏感。在一定的机会下,你会抓住线索,经常在不经意间找到捷径。
3 方便集成
集成是信息的集中归档。
搜索引擎当然方便,但是对于一些常用的东西,你可能不需要每次都去搜索。相反,您可以在自己的计算机上创建个人数据库。不管有没有网络,都可以随时咨询。
我将习惯于存储我在计算机上找到的有价值的文档、网页和图片。但我们也会发现,这些数据一旦存入硬盘,就落入了大海。下次如果需要,还是求助于搜索引擎。
另一方面,计算机文件夹越来越大,必须经常删除文件以腾出空间。这种方法还有一个缺点,就是在使用多台电脑的时候,需要使用移动硬盘或者U盘,所以一个东西的副本要备份到三个地方。
后来有了Dropbox等应用,可以更方便地与多台电脑共享文件,但毕竟容量有限,而且有时会被屏蔽。后来国内自然有好的服务,比如360云盘,最高可以有5G空间,实现云端文件共享和多机客户端。有需要的不妨一试。
这些网盘、云盘等服务解决了多个客户端的同步存储需求。但是,在我的日常工作中,以下小应用是必不可少的,作为集成方法的有效补充。它们的特点是:
1)电话方便
上传之前不需要像使用网盘那样保存。可以在不中断当前工作的情况下随时检索和使用。
比如在做一个任务的过程中,遇到一个好文档,想存档,以后再看。一键整合到自己的学科类别中,如预设的“待读”文件夹,继续执行当前任务。
2)高效搜索
可以标记集成文档,关键词,甚至可以搜索全文。
3)cloud,客户端同步
1、Evernote 方便整合
作为一个使用evernote多年的用户,我很感激。它与我的生活和工作密不可分。
正如它的广告所说,它成为了我大脑的一部分。不仅可以帮助我记住很多事情,还可以帮助我随时记录很多事情。
Evernote 提供了编辑工具,可以添加到 chrome 浏览器应用中,让你在阅读网页时可以随时调用要阅读的存档。
▲Evernote 方便的集成工具
可以在Outlook插件中加入evernote,帮助你在阅读邮件时为重要邮件添加书签:
那可能有人会问了,这只是为了整合一些文档,如果是PPT或者PDF电子书呢?事实上,evernote 可以帮你归档重要文件。
▲ Evernote 集成文档
因为文档体积往往比较大,作为evernote的免费用户可能承受不了。如果不打算升级,也可以创建一个“待读”文件夹,将以后需要阅读的文档归类到这个文件夹中,就形成了一个待办任务。同时,您在本地计算机文件夹中也存储了一份副本。
你可以在印象笔记中阅读和删除一份文档,只提取有用的信息。
Evernote 的搜索功能也比较强大,可以对 PDF 进行全文搜索。
▲印象笔记全文搜索
Evernote 的云同步功能更方便。将电脑上编辑的文件同步后,手机客户端和ipad客户端都可以即时访问,甚至取代了U盘的功能。所以强烈推荐没用过的人尝试一下。
2、整合图片与花瓣网
▲ 将图片与花瓣网结合
使用花瓣网()进行图片整合是我无意中发现的一种技巧,这里也提一下。
原来我的电脑里肯定有一个文件夹叫做图片集,专门用来放置来自网络的各种图片,分为几类,包括摄影欣赏、服装搭配、设计素材、宠物、视觉思维、简笔画、LOGO设计...
如果存在于电脑上,自然会遇到同样的问题,检索困难,体积庞大,难以同步......
有了华华网之后,华华网的采集工具也加入了Chrome浏览器应用,让你可以随时采集网页上的各种图片。这些采集作业和印象笔记编辑工具一样,可以随时调用,不会中断你当前的工作流程。
在花瓣网中,创建自己的画板,以主题命名。就图片而言,个人比较关注的只有几类:
摄影、宠物、室内装饰、简笔画、设计、用户体验、商业智能……其中一些与工作有关,一些与个人生活有关。
所以,每次采集都可以把图片放到自己的分类中。你不需要经常去花瓣网,但你的数据库一天比一天爆满。哪天想到找这些话题的参考资料,打开自己的花瓣网,已经有采集这么多素材可以用了。因为平时就是点一下鼠标,真的很想坐下来好好享受一下。
4 养成定期整理的好习惯
信息可以高效获取,信息也很容易整合,但如果没有规律的整理,时间长了信息难免会变得杂乱无章。
所以,就像我们必须定期清理和整理家务一样,这是必不可少且重要的一步。术语“整理”包括“检查和调整分类”、“删除不需要的文档”、“添加可搜索的标签或关键词”等。
我通常会在我的电脑文件夹或印象笔记笔记本中设置一个“临时文件夹”来存放一些暂时无法归类的文档或资料。并且平时一定要注意这些临时文件夹,把文档放在相应的目录下,以免临时文件夹被误命名,成为大杂烩。
1、不要让你的印象笔记爆炸
既然印象笔记相当于你的另一个大脑,那么无组织的印象笔记就是混乱的大脑。
创建主题关键词后,您还可以为印象笔记笔记本创建一个对应的名称,以便您可以对不同的材料、文档、图片等进行分类。印象笔记会自动按照数字和字母顺序对笔记本进行排序,因此在数字之前添加字母 ABC 帮助我形成了一个两级顺序。同时,字母ABC可以区分三大类。
▲ 如何对我的 Evernote 笔记本进行分类
这个文件夹系统让我可以随意扩展一个类别,而不会影响其他类别。
还有一点:TEM 笔记本非常重要。
正如本章开头所说的,分类再完善,也难免有时手忙脚乱,找不到合适的分类,随意存储信息。
因此,为了满足足够的可扩展性,建议您设置一个名为 Temp(Temporary 的缩写)的笔记本。这个Tem笔记本首先可以让你快速存储它,其次可以形成一个待办事项列表。当你无事可做时,至少你可以整理一下这个文件夹,让里面的文件应该被读取和删除,应该归类的文件放在相应的笔记本中。
2、勤检查你的电脑文件夹
即使有这么多集成的组织工具,我们的大部分工作也不得不依赖我们自己的笔记本电脑。所以如果电脑文件夹没有整理好,也会影响我们的工作效率。
我不太擅长整理家务,但喜欢经常整理电脑。
这个习惯大概是五年前开始的。当时,我带领一个小团队,协调多方的工作。我们很多人都需要将工作放在共享磁盘上的文件夹中以进行交换和维护。因此,建立标准化的文件夹系统非常重要。当时我花了很多精力来规范和监督文件夹的执行,取得了很好的效果。
▲ 复杂内容协作文件夹系统
当然,这是一个非常复杂的内容管理协作文件夹。我们的日常文件夹远比这简单。
我电脑的文件夹系统:
▲ 海蒂的文件夹系统
设置文件夹的原理:
1. 尽量将每一级目录的数量限制在7个文件夹左右,尤其是根目录不要太多。
2. 假设中的任何文件都可以找到归属。
比如,家人突然发了一些合影,你应该把它们放在那里。 TEM文件夹的作用是临时的,你自然可以把这些文件堆到TEM文件夹中,但TEM实际上相当于一个临时的避难所,而不是一个固定的住所。我的习惯是在E盘添加一个Personal文件夹,在这个文件夹下为个人文档、文章、图片创建对应的分类。
3.每个文件夹下都预留了一个临时文件夹,防止根目录无限扩展,因为新收到的文件不知道如何分类。
4. 序列号可以让排序和搜索更容易。
为什么要在文件夹前加一个序列号?其实在浏览文件夹的时候,可以出现优先顺序。
以学习文件夹为例:
▲ 文件夹序号命名法
4、Desktop,据我所知
简单说一下我理解的电脑中的“桌面”。我认为“桌面”是一种快捷方式。他的职责是:
快捷方式:放置我们常用的文档和软件快捷方式,方便您直接找到。
第一级的临时文件夹。桌面也是临时文件的庇护所。比如你没时间看别人发来的文档,也不知道怎么分类。如果您收到放置在D盘或E盘任意文件夹中的TEM,可能会导致您在会后忘记它——直到有人提到它。因此,在这种情况下,很多人经常将其存放在桌面上。我认为这也是一个非常正确的决定。至少,当您打开它时,您可能会看到它。
但是我们的“桌面”被滥用了。它充满了各种根本不需要的快捷方式。就像你家里的茶几,放了一个红酒开瓶器——虽然你不是一个月用一次,但它每天都在桌上。你妻子发行了一张同学专辑,虽然她两个月前才用过。有一天亲戚送了你一双童鞋,你暂时放在茶几上,但一直没有整理好。
随着时间的推移,您真正需要的快捷方式和宝贵的临时存储空间将变得毫无意义。
我推荐的桌面应该是这样的:
1.背景设置为让您身心愉悦的照片,例如您和家人的照片。
2. 存储不超过 10 个常用工具的快捷方式。
3.创建一个 TEM 文件夹——否则你的桌面可能会在不到一个月的时间内扩大。
其实电脑任务栏也是一个很重要的快捷方式域,不用随时回到桌面使用——我一般都会把最常用的软件放在这里,比如截图、颜色选择器、思维管理器等。
无论采集了多少信息,无论信息如何组织,如果不应用所学,最多只能建立一个丰富的个人知识库。
所以最重要的是真正用好这些信息,把工作和生活结合起来,好好思考,多练习,消化这些信息供自己使用,然后积累自己的知识。
除了在工作中学习,写专业博客也是转换信息的好方法。
“教比学”,写博客是给别人看,求指点和交流,一定会照顾文章法逻辑,用一个系统连接你所读、所做、所感、所想,并获得。为了照顾到严谨的逻辑,少思考多疑。
所以每次完成一个专业的博客,就好像上了一堂好课,把各种信息消化到我的知识体系中。这种转换比简单地整合常规阅读要有效得多。
个人经验有限,希望大家能得到。 查看全部
为什么你的搜索引擎总是打擦边球?(上)
搜索引擎是非常重要的信息获取门户。至于我使用的技能,我并不是很先进。欢迎搜索专家与我交流,省力又有效的搜索方法。
1.找到合适的关键词,事半功倍
很久以前,我偶然看到了两张照片。很喜欢这两张图,希望能看到更多类似的图。
▲ 检索这两种图像使用什么样的关键图像?
但是,什么样的图片首先被称为?
关键词应该先用于头脑风暴,它叫什么?插图?图表?手绘?插图?
这些关键词 搜索的结果真的很令人沮丧。但是根据搜索结果的提示,一步一步的改变关键词,直到找到可靠的结果。最后,当我找到这个词时,我找到了宝藏。
要查找图中左侧的图形类型,请尝试使用“视觉思维”,或在谷歌上搜索“视觉思维”,如需查找更多图 3 中右侧类型的图形,请尝试使用 "infographic" 或 "infographic"。
▲视觉思维的检索结果

▲ 信息图检索结果
所以在搜索中,我们应该不断的替换更合适的关键词,而不是不断的打边球。
如何找到合适的关键词?
从你认为可行的第一个关键词开始,不要轻易放弃。根据每个搜索结果的线索跟踪,不断修改关键词,直到得到结果。
2.换语言,天上别有洞
有时更改为英语可以让您获得更准确的结果。
所以这就是为什么我的主题词应该是中英文双语的。由于很多中文结果都是从英文翻译过来的,直接查看源码文章显然少了信息缺失。

▲ 英文搜索“visual thinking”的结果
以此类推,每增加一种语言,就会打开一扇了解世界的新窗口。
对于家庭存储,在中文“存储”中搜索文章,几乎只是一些零碎的图片和社区网站,吸引用户拼凑存储技巧。
在日文“Storage”中搜索,在日本看一些网站,可以看到很多关于存储的经验、文档和教程。有些教程的丰富程度不亚于出版书籍,甚至比国内那些家装作品还要好。比如网站提供的Bendo先生的日常收纳教程:

▲ 店铺检索到的专业日语网站
关于网站关于storage的事,有兴趣的可以试试用日语搜索,但是不能问我。
3.改变搜索方式,通过不同的路线达到相同的目标
如果网络搜索没有得到你想要的结果,你可以改变搜索类型,比如搜索图片,然后通过图片链接到有价值的网站。
我经常使用文件搜索。与普通网页相比,这些文档通常意味着更好、更系统的组织,让您的信息获取更有效。
如何使用搜索引擎搜索文档?
如果您使用 google,请在搜索词前添加 inurl:pdf。
如果您使用百度,请在搜索词之前添加 filetype: all。如果您需要特定的 PDF 格式,请输入:filetype: PDF
如果您使用百度搜索商业智能相关文档:
▲ 百度搜索文档
4.别忘了专业的网站
Professional网站让您免于在大量垃圾邮件中查找所需信息的麻烦,他们的信息往往更加集中。我经常用的专业搜索网站有:
——PPT分享网站,国外很多制作优秀、丰富、专业的PPT。我经常在这里搜索有关视觉思维的文档。不过很遗憾,你需要爬墙才能看到这个网站。
MBA Think Tank——一个专注于经济和管理领域的数据库。您可以在此处搜索经济和管理多个领域的各种术语的解释、文档等。
维基百科-如果它在墙外或将其推翻。很多词在中国很敏感,在这里你可以看到非常详细的因果关系。当然,如果不是敏感词,百度百科也是不错的资源。

5.在书中寻找搜索技巧
小提醒,当你没有关键词灵感的时候,你也可以从书的目录中获得关键词的提示。除了目录,专业书籍还收录有价值的挖掘信息。
以下是利用书中提供的信息不断探索,然后找到真正需要的信息的案例:
我最近阅读了“Excel 图表之道”一书。第 P152 页提到的图表类型选择指南的原作者是 Andrew Abela。这个人的名字是很珍贵的关键词。这个关键词可能代表:数据、数据分析、商业智能、交流展示等主题。
于是我搜索了这个人,看到了这个人的博客:The Extreme Presentation(tm) Method。本博客为专业博客,主题为复杂信息的交流与呈现。
而且这个博客宣传一本书,这本书出自Andrew Abela,《Advanced Presentations by Design:Creating Communications that Dives Action》,这本书中文版在中国大陆有售,中文译本是《Persuade How做强演讲——如何为现场交易设计PPT”。
最后通过博文网站:Extreme Presentation Method。这个网站有一些很好的信息,我推荐给对演示感兴趣的学生。比如下面两张图表也是来自这个网站:
▲的图片
当然,《Excel图表之道》作者刘万祥先生引用的英文原版图表类型选择指南也可以在这个网站下载。
另外,我们的信息挖掘还没有结束。注意他还提供了另一个在线工具:这个网站可以让数据分析师根据自己的需要选择不同的图表来展示。这个网站 来自juiceanalytics(果汁分析)。
进入Juiceanalytics网站的白皮书专栏,发现了《A Guide to Creating Dashboards People Love to Use》(A Guide to Creating Dashboards People Love to Use)。这份白皮书可以解答我最近工作的一些困惑。
如果你刻意去寻找,想要得到一些东西并不容易。如果你知道你的主题关键词,你的信息感会非常敏感。在一定的机会下,你会抓住线索,经常在不经意间找到捷径。
3 方便集成
集成是信息的集中归档。
搜索引擎当然方便,但是对于一些常用的东西,你可能不需要每次都去搜索。相反,您可以在自己的计算机上创建个人数据库。不管有没有网络,都可以随时咨询。
我将习惯于存储我在计算机上找到的有价值的文档、网页和图片。但我们也会发现,这些数据一旦存入硬盘,就落入了大海。下次如果需要,还是求助于搜索引擎。
另一方面,计算机文件夹越来越大,必须经常删除文件以腾出空间。这种方法还有一个缺点,就是在使用多台电脑的时候,需要使用移动硬盘或者U盘,所以一个东西的副本要备份到三个地方。
后来有了Dropbox等应用,可以更方便地与多台电脑共享文件,但毕竟容量有限,而且有时会被屏蔽。后来国内自然有好的服务,比如360云盘,最高可以有5G空间,实现云端文件共享和多机客户端。有需要的不妨一试。
这些网盘、云盘等服务解决了多个客户端的同步存储需求。但是,在我的日常工作中,以下小应用是必不可少的,作为集成方法的有效补充。它们的特点是:
1)电话方便
上传之前不需要像使用网盘那样保存。可以在不中断当前工作的情况下随时检索和使用。
比如在做一个任务的过程中,遇到一个好文档,想存档,以后再看。一键整合到自己的学科类别中,如预设的“待读”文件夹,继续执行当前任务。
2)高效搜索
可以标记集成文档,关键词,甚至可以搜索全文。
3)cloud,客户端同步
1、Evernote 方便整合
作为一个使用evernote多年的用户,我很感激。它与我的生活和工作密不可分。
正如它的广告所说,它成为了我大脑的一部分。不仅可以帮助我记住很多事情,还可以帮助我随时记录很多事情。
Evernote 提供了编辑工具,可以添加到 chrome 浏览器应用中,让你在阅读网页时可以随时调用要阅读的存档。
▲Evernote 方便的集成工具
可以在Outlook插件中加入evernote,帮助你在阅读邮件时为重要邮件添加书签:

那可能有人会问了,这只是为了整合一些文档,如果是PPT或者PDF电子书呢?事实上,evernote 可以帮你归档重要文件。
▲ Evernote 集成文档
因为文档体积往往比较大,作为evernote的免费用户可能承受不了。如果不打算升级,也可以创建一个“待读”文件夹,将以后需要阅读的文档归类到这个文件夹中,就形成了一个待办任务。同时,您在本地计算机文件夹中也存储了一份副本。
你可以在印象笔记中阅读和删除一份文档,只提取有用的信息。
Evernote 的搜索功能也比较强大,可以对 PDF 进行全文搜索。
▲印象笔记全文搜索
Evernote 的云同步功能更方便。将电脑上编辑的文件同步后,手机客户端和ipad客户端都可以即时访问,甚至取代了U盘的功能。所以强烈推荐没用过的人尝试一下。
2、整合图片与花瓣网
▲ 将图片与花瓣网结合
使用花瓣网()进行图片整合是我无意中发现的一种技巧,这里也提一下。
原来我的电脑里肯定有一个文件夹叫做图片集,专门用来放置来自网络的各种图片,分为几类,包括摄影欣赏、服装搭配、设计素材、宠物、视觉思维、简笔画、LOGO设计...
如果存在于电脑上,自然会遇到同样的问题,检索困难,体积庞大,难以同步......
有了华华网之后,华华网的采集工具也加入了Chrome浏览器应用,让你可以随时采集网页上的各种图片。这些采集作业和印象笔记编辑工具一样,可以随时调用,不会中断你当前的工作流程。
在花瓣网中,创建自己的画板,以主题命名。就图片而言,个人比较关注的只有几类:
摄影、宠物、室内装饰、简笔画、设计、用户体验、商业智能……其中一些与工作有关,一些与个人生活有关。
所以,每次采集都可以把图片放到自己的分类中。你不需要经常去花瓣网,但你的数据库一天比一天爆满。哪天想到找这些话题的参考资料,打开自己的花瓣网,已经有采集这么多素材可以用了。因为平时就是点一下鼠标,真的很想坐下来好好享受一下。
4 养成定期整理的好习惯
信息可以高效获取,信息也很容易整合,但如果没有规律的整理,时间长了信息难免会变得杂乱无章。
所以,就像我们必须定期清理和整理家务一样,这是必不可少且重要的一步。术语“整理”包括“检查和调整分类”、“删除不需要的文档”、“添加可搜索的标签或关键词”等。
我通常会在我的电脑文件夹或印象笔记笔记本中设置一个“临时文件夹”来存放一些暂时无法归类的文档或资料。并且平时一定要注意这些临时文件夹,把文档放在相应的目录下,以免临时文件夹被误命名,成为大杂烩。
1、不要让你的印象笔记爆炸
既然印象笔记相当于你的另一个大脑,那么无组织的印象笔记就是混乱的大脑。
创建主题关键词后,您还可以为印象笔记笔记本创建一个对应的名称,以便您可以对不同的材料、文档、图片等进行分类。印象笔记会自动按照数字和字母顺序对笔记本进行排序,因此在数字之前添加字母 ABC 帮助我形成了一个两级顺序。同时,字母ABC可以区分三大类。
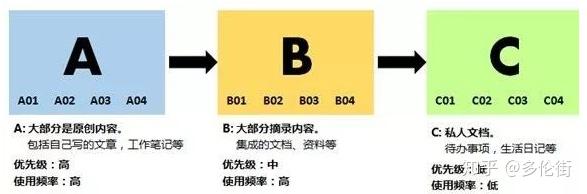
▲ 如何对我的 Evernote 笔记本进行分类
这个文件夹系统让我可以随意扩展一个类别,而不会影响其他类别。
还有一点:TEM 笔记本非常重要。
正如本章开头所说的,分类再完善,也难免有时手忙脚乱,找不到合适的分类,随意存储信息。
因此,为了满足足够的可扩展性,建议您设置一个名为 Temp(Temporary 的缩写)的笔记本。这个Tem笔记本首先可以让你快速存储它,其次可以形成一个待办事项列表。当你无事可做时,至少你可以整理一下这个文件夹,让里面的文件应该被读取和删除,应该归类的文件放在相应的笔记本中。
2、勤检查你的电脑文件夹
即使有这么多集成的组织工具,我们的大部分工作也不得不依赖我们自己的笔记本电脑。所以如果电脑文件夹没有整理好,也会影响我们的工作效率。
我不太擅长整理家务,但喜欢经常整理电脑。
这个习惯大概是五年前开始的。当时,我带领一个小团队,协调多方的工作。我们很多人都需要将工作放在共享磁盘上的文件夹中以进行交换和维护。因此,建立标准化的文件夹系统非常重要。当时我花了很多精力来规范和监督文件夹的执行,取得了很好的效果。

▲ 复杂内容协作文件夹系统
当然,这是一个非常复杂的内容管理协作文件夹。我们的日常文件夹远比这简单。
我电脑的文件夹系统:
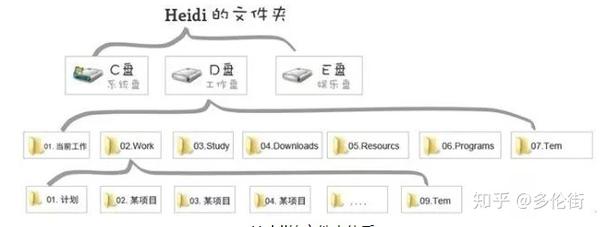
▲ 海蒂的文件夹系统
设置文件夹的原理:
1. 尽量将每一级目录的数量限制在7个文件夹左右,尤其是根目录不要太多。
2. 假设中的任何文件都可以找到归属。
比如,家人突然发了一些合影,你应该把它们放在那里。 TEM文件夹的作用是临时的,你自然可以把这些文件堆到TEM文件夹中,但TEM实际上相当于一个临时的避难所,而不是一个固定的住所。我的习惯是在E盘添加一个Personal文件夹,在这个文件夹下为个人文档、文章、图片创建对应的分类。
3.每个文件夹下都预留了一个临时文件夹,防止根目录无限扩展,因为新收到的文件不知道如何分类。
4. 序列号可以让排序和搜索更容易。
为什么要在文件夹前加一个序列号?其实在浏览文件夹的时候,可以出现优先顺序。
以学习文件夹为例:
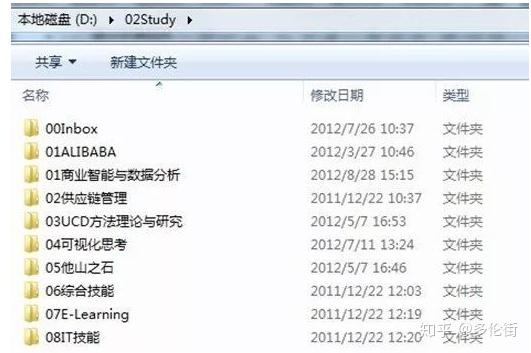
▲ 文件夹序号命名法
4、Desktop,据我所知
简单说一下我理解的电脑中的“桌面”。我认为“桌面”是一种快捷方式。他的职责是:
快捷方式:放置我们常用的文档和软件快捷方式,方便您直接找到。
第一级的临时文件夹。桌面也是临时文件的庇护所。比如你没时间看别人发来的文档,也不知道怎么分类。如果您收到放置在D盘或E盘任意文件夹中的TEM,可能会导致您在会后忘记它——直到有人提到它。因此,在这种情况下,很多人经常将其存放在桌面上。我认为这也是一个非常正确的决定。至少,当您打开它时,您可能会看到它。
但是我们的“桌面”被滥用了。它充满了各种根本不需要的快捷方式。就像你家里的茶几,放了一个红酒开瓶器——虽然你不是一个月用一次,但它每天都在桌上。你妻子发行了一张同学专辑,虽然她两个月前才用过。有一天亲戚送了你一双童鞋,你暂时放在茶几上,但一直没有整理好。
随着时间的推移,您真正需要的快捷方式和宝贵的临时存储空间将变得毫无意义。
我推荐的桌面应该是这样的:
1.背景设置为让您身心愉悦的照片,例如您和家人的照片。
2. 存储不超过 10 个常用工具的快捷方式。
3.创建一个 TEM 文件夹——否则你的桌面可能会在不到一个月的时间内扩大。
其实电脑任务栏也是一个很重要的快捷方式域,不用随时回到桌面使用——我一般都会把最常用的软件放在这里,比如截图、颜色选择器、思维管理器等。

无论采集了多少信息,无论信息如何组织,如果不应用所学,最多只能建立一个丰富的个人知识库。
所以最重要的是真正用好这些信息,把工作和生活结合起来,好好思考,多练习,消化这些信息供自己使用,然后积累自己的知识。
除了在工作中学习,写专业博客也是转换信息的好方法。
“教比学”,写博客是给别人看,求指点和交流,一定会照顾文章法逻辑,用一个系统连接你所读、所做、所感、所想,并获得。为了照顾到严谨的逻辑,少思考多疑。
所以每次完成一个专业的博客,就好像上了一堂好课,把各种信息消化到我的知识体系中。这种转换比简单地整合常规阅读要有效得多。
个人经验有限,希望大家能得到。
织梦的隐藏栏目设置只是在导航菜单中起作用?
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-07-26 21:07
接触织梦近一年,我建的第一个站就是织梦系统。 织梦本身已经很强大了,基本可以满足我的大部分需求。大部分时间我都是用它来设计界面模板,但是没有研究过织梦的后端源码。
最近无事可做,又建了一个新站。在设计网站专栏的时候,希望建立一个类似草稿箱的采集库专栏,专门用来存放采集来的文章。每一个采集文章都是在其他官方栏目下规划之前处理的,但是现在问题来了,采集库中没有处理的文章也会在首页和频道页面显示,这不是我想要的。我以为在创建新列时,我可以选择是否隐藏该列。我突然打开它,觉得这应该可以解决我的问题,但最终让我失望。此隐藏列的设置仅在导航菜单中有效。没有办法,只能硬着头皮研究源代码。用上学时就知道的一点毛皮,用了半个多小时,终于解决了问题。
其实很简单,改一下代码,打开/include/taglib/arclist.lib.php文件,找到这句话(约350行):
if($orwhere!='') $orwhere = "WHERE $orwhere ";
改成
if($orwhere!='') $orwhere ="WHERE $orwhere 和 tp.ishidden != 1 ";
就是这样。
当然,这种变化也会带来另一个问题。如果导航菜单中隐藏了某列,则该列下的文章 将无法用arclist 调用。而我们实际上可能希望它能够使用 arclist 来调用。
因为我的小站点导航在代码中是硬编码的,所以这个修改对我基本没有影响。如果其他站长和我有同样的需求,可以试试。 查看全部
织梦的隐藏栏目设置只是在导航菜单中起作用?
接触织梦近一年,我建的第一个站就是织梦系统。 织梦本身已经很强大了,基本可以满足我的大部分需求。大部分时间我都是用它来设计界面模板,但是没有研究过织梦的后端源码。
最近无事可做,又建了一个新站。在设计网站专栏的时候,希望建立一个类似草稿箱的采集库专栏,专门用来存放采集来的文章。每一个采集文章都是在其他官方栏目下规划之前处理的,但是现在问题来了,采集库中没有处理的文章也会在首页和频道页面显示,这不是我想要的。我以为在创建新列时,我可以选择是否隐藏该列。我突然打开它,觉得这应该可以解决我的问题,但最终让我失望。此隐藏列的设置仅在导航菜单中有效。没有办法,只能硬着头皮研究源代码。用上学时就知道的一点毛皮,用了半个多小时,终于解决了问题。
其实很简单,改一下代码,打开/include/taglib/arclist.lib.php文件,找到这句话(约350行):
if($orwhere!='') $orwhere = "WHERE $orwhere ";
改成
if($orwhere!='') $orwhere ="WHERE $orwhere 和 tp.ishidden != 1 ";
就是这样。
当然,这种变化也会带来另一个问题。如果导航菜单中隐藏了某列,则该列下的文章 将无法用arclist 调用。而我们实际上可能希望它能够使用 arclist 来调用。
因为我的小站点导航在代码中是硬编码的,所以这个修改对我基本没有影响。如果其他站长和我有同样的需求,可以试试。
如何让自定义PostType的内容显示出来?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-24 18:03
之前讲到wordpress添加post_type自定义文章类型,现在讲一下如何调用自定义文章,以product为例,虽然我们自定义了Post Type,但也写了一些内容不显示在主页和列表上。自定义 Post Type 的内容不会自动混入主循环。如何显示自定义 Post Type 的内容?您需要使用 pre_get_posts 操作进行一些处理:
function add_custom_pt( $query ) {
if ( !is_admin() && $query->is_main_query() ) {
$query->set( 'post_type', array( 'post', 'the_custom_pt' ) );
}
}
add_action( 'pre_get_posts', 'add_custom_pt' );
将上述代码添加到主题function.php文件中
第二步,以上操作依赖模板。如果需要高度定制化或者在页面的某个模块中调用列表,则需要使用WP_Query类来调用:
新创建的archive-product.php模板放在theme目录下。这是产品的 post_type 模板。将以上代码添加到archive-product.php中调用文章,刷新缓存即可看到
参考资料: 查看全部
如何让自定义PostType的内容显示出来?-八维教育
之前讲到wordpress添加post_type自定义文章类型,现在讲一下如何调用自定义文章,以product为例,虽然我们自定义了Post Type,但也写了一些内容不显示在主页和列表上。自定义 Post Type 的内容不会自动混入主循环。如何显示自定义 Post Type 的内容?您需要使用 pre_get_posts 操作进行一些处理:
function add_custom_pt( $query ) {
if ( !is_admin() && $query->is_main_query() ) {
$query->set( 'post_type', array( 'post', 'the_custom_pt' ) );
}
}
add_action( 'pre_get_posts', 'add_custom_pt' );
将上述代码添加到主题function.php文件中
第二步,以上操作依赖模板。如果需要高度定制化或者在页面的某个模块中调用列表,则需要使用WP_Query类来调用:
新创建的archive-product.php模板放在theme目录下。这是产品的 post_type 模板。将以上代码添加到archive-product.php中调用文章,刷新缓存即可看到
参考资料:
豆瓣网手游影评:如何获取真正请求的地址和请求?
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-07-23 22:18
[一、项目背景]
豆瓣电影提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。可以录制自己想看的电影电视剧,顺便看,打分,写影评。极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择他们想要的电影。
[二、项目目标]
获取对应的电影名称、评分、详细链接,下载电影图片,保存文件。
[三、相关库和网站]
1、网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、software: PyCharm
[四、项目分析]
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是用javascript动态加载内容来防止采集的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2)点击主题,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页就会增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
[五、项目实施]
1、我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent并构造请求头防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、for 遍历获取对应的电影名称、评分以及下一个详情页的链接。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、picture 地址提出请求。定义图片名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、调用方法实现功能。
9、项目优化:1)设置延时。
time.sleep(1.4)
2)定义了一个变量u,用于遍历,表示爬取的是哪个页面。 (更清晰,更令人印象深刻)。
u = 0
self.u += 1;
[六、效果展示]
1、点击绿色三角运行起始页和结束页(从第0页开始)。
2、 会在控制台显示下载成功的信息。
3、保存 csv 文件。
4、film 图片展示。
[七、Summary]
1、 不建议取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了相关的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。 查看全部
豆瓣网手游影评:如何获取真正请求的地址和请求?
[一、项目背景]
豆瓣电影提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。可以录制自己想看的电影电视剧,顺便看,打分,写影评。极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择他们想要的电影。
[二、项目目标]
获取对应的电影名称、评分、详细链接,下载电影图片,保存文件。
[三、相关库和网站]
1、网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、software: PyCharm
[四、项目分析]
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是用javascript动态加载内容来防止采集的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2)点击主题,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页就会增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
[五、项目实施]
1、我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent并构造请求头防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、for 遍历获取对应的电影名称、评分以及下一个详情页的链接。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、picture 地址提出请求。定义图片名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、调用方法实现功能。
9、项目优化:1)设置延时。
time.sleep(1.4)
2)定义了一个变量u,用于遍历,表示爬取的是哪个页面。 (更清晰,更令人印象深刻)。
u = 0
self.u += 1;
[六、效果展示]
1、点击绿色三角运行起始页和结束页(从第0页开始)。
2、 会在控制台显示下载成功的信息。
3、保存 csv 文件。
4、film 图片展示。
[七、Summary]
1、 不建议取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了相关的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
优化CalledListRequest接口写的不是那么好,循环调用某个接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-07-21 20:43
优化CalledListRequest接口写的不是那么好,循环调用某个接口
AOP 使用示例:log采集function
背景:目的是优化CalledListRequest接口。深入了解后,发现这个接口没有写得那么好,所以循环调用一个接口。导致一些简单的查询被重复执行。从而效率。那么这个接口涉及的业务逻辑太复杂了,不能直接改。相反,编写了一个新接口来替换它。但是为了做更彻底的测试。第一行采集 请求参数。然后测试一下。最后,这是发布和上线的最佳方式。
功能及原理介绍
采集这个在线接口(CalledListRequest)的请求参数。
原理:编写一个方法,将所有传入的参数插入到数据库的日志表中。
但为了减少侵入性(即不改动原接口的实现代码)。我在这里使用了 AOP 切入方法。同时用apollo做了一个switch(控制什么时候开始采集,什么时候关闭采集)
主要技能点之一是AOP的应用。之前实际上没有实际的工作来应用 AOP。这次是机会。
其实很简单,就是直接的核心代码。没有复杂的事情
核心代码
package com.centanet.bizcom.config.log;
import com.alibaba.fastjson.JSON;
import com.centanet.bizcom.config.apollo.ApolloConfig;
import com.centanet.bizcom.config.ddb.MultiTenantChanger;
import com.centanet.bizcom.mapper.BizMapper;
import com.centanet.bizcom.model.entity.LogCollection;
import com.centanet.bizcom.util.CityHelper;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.servlet.http.HttpServletRequest;
import java.util.Date;
/**
* 该类的功能是为了收集日志
* 方便切换接口时使用
* @Author: wbdengtt
* @Date: 2020/10/13 14:58
*/
//声明切面
@Aspect
// 交给Spring管理bean
@Component
public class LogCollectAspect {
// 注入logCollection 这个就是一个简单实体entity。
@Autowired
private LogCollection logCollection;
// 这是将实体存到数据库的mapper
@Autowired
private BizMapper bizMapper;
// 拦截CalledController.calledListRequest方法。通过这个配置。可以拦截更多东西,这个规则相信的可以看下面的参考文章
@Pointcut("execution(* com.centanet.bizcom.controller.CalledController.calledListRequest(..))")
public void myPointCut() {
// 这个其实就是一个切点,不需要方法内容
}
// 这个是具体实现拦截参数,并将参数日志写入到数据库的方法
@Before("myPointCut()")
public void logCollect(JoinPoint joinPoint) {
// 这个是在apoll配置的开关(就是一个String变量)。如果开了才进行下面的拦截。
boolean isLogCollect = "true".equalsIgnoreCase(ApolloConfig.getWebValue(CityHelper.getCityCode(),"isLogCollectionOpen"))
&& ApolloConfig.getWebValue(CityHelper.getCityCode(),"logCollectCity").contains(CityHelper.getCityen());
if (isLogCollect) {
// 设置logCollection的日期字段
logCollection.setRowDate(new Date());
// 获取当前HttpServletRequest 对象 这个是为了拿到各种我需要的信息。关于HttpServletRequest 下面有提供参考链接看相信的介绍
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
//设置logCollection的实体字段,这里是请求类型.城市
logCollection.setMethodName(request.getMethod()+"."+CityHelper.getCityen());
//request.getQueryString() 只能拿到get请求的参数。如果是post请求,得通过joinPoint才能拿到参数(这个不需要手动声明,应该是SpringAOP哪里给自动注入了)
logCollection.setMessage(JSON.toJSONString(joinPoint.getArgs()));
if (logCollection.getMessage() ==null){
logCollection.setMessage("没能拿到参数");
}
// request.getRequestURI()获取方法名
logCollection.setFullName(request.getRequestURI());
// 写入数据库 MultiTenantChanger是因为我有多个数据库,但是这里的操作其实就是讲实体装入数据库
MultiTenantChanger.setDataSourceType(CityHelper.getCityCode()+MultiTenantChanger.CENTA_BIZ);
bizMapper.insertLogCollection(logCollection);
MultiTenantChanger.removeRouteKey();
}
}
}
我在代码中添加了很多注释。应该更容易理解
参考文章:
连接点: 查看全部
优化CalledListRequest接口写的不是那么好,循环调用某个接口
AOP 使用示例:log采集function
背景:目的是优化CalledListRequest接口。深入了解后,发现这个接口没有写得那么好,所以循环调用一个接口。导致一些简单的查询被重复执行。从而效率。那么这个接口涉及的业务逻辑太复杂了,不能直接改。相反,编写了一个新接口来替换它。但是为了做更彻底的测试。第一行采集 请求参数。然后测试一下。最后,这是发布和上线的最佳方式。
功能及原理介绍
采集这个在线接口(CalledListRequest)的请求参数。
原理:编写一个方法,将所有传入的参数插入到数据库的日志表中。
但为了减少侵入性(即不改动原接口的实现代码)。我在这里使用了 AOP 切入方法。同时用apollo做了一个switch(控制什么时候开始采集,什么时候关闭采集)
主要技能点之一是AOP的应用。之前实际上没有实际的工作来应用 AOP。这次是机会。
其实很简单,就是直接的核心代码。没有复杂的事情
核心代码
package com.centanet.bizcom.config.log;
import com.alibaba.fastjson.JSON;
import com.centanet.bizcom.config.apollo.ApolloConfig;
import com.centanet.bizcom.config.ddb.MultiTenantChanger;
import com.centanet.bizcom.mapper.BizMapper;
import com.centanet.bizcom.model.entity.LogCollection;
import com.centanet.bizcom.util.CityHelper;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.servlet.http.HttpServletRequest;
import java.util.Date;
/**
* 该类的功能是为了收集日志
* 方便切换接口时使用
* @Author: wbdengtt
* @Date: 2020/10/13 14:58
*/
//声明切面
@Aspect
// 交给Spring管理bean
@Component
public class LogCollectAspect {
// 注入logCollection 这个就是一个简单实体entity。
@Autowired
private LogCollection logCollection;
// 这是将实体存到数据库的mapper
@Autowired
private BizMapper bizMapper;
// 拦截CalledController.calledListRequest方法。通过这个配置。可以拦截更多东西,这个规则相信的可以看下面的参考文章
@Pointcut("execution(* com.centanet.bizcom.controller.CalledController.calledListRequest(..))")
public void myPointCut() {
// 这个其实就是一个切点,不需要方法内容
}
// 这个是具体实现拦截参数,并将参数日志写入到数据库的方法
@Before("myPointCut()")
public void logCollect(JoinPoint joinPoint) {
// 这个是在apoll配置的开关(就是一个String变量)。如果开了才进行下面的拦截。
boolean isLogCollect = "true".equalsIgnoreCase(ApolloConfig.getWebValue(CityHelper.getCityCode(),"isLogCollectionOpen"))
&& ApolloConfig.getWebValue(CityHelper.getCityCode(),"logCollectCity").contains(CityHelper.getCityen());
if (isLogCollect) {
// 设置logCollection的日期字段
logCollection.setRowDate(new Date());
// 获取当前HttpServletRequest 对象 这个是为了拿到各种我需要的信息。关于HttpServletRequest 下面有提供参考链接看相信的介绍
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
//设置logCollection的实体字段,这里是请求类型.城市
logCollection.setMethodName(request.getMethod()+"."+CityHelper.getCityen());
//request.getQueryString() 只能拿到get请求的参数。如果是post请求,得通过joinPoint才能拿到参数(这个不需要手动声明,应该是SpringAOP哪里给自动注入了)
logCollection.setMessage(JSON.toJSONString(joinPoint.getArgs()));
if (logCollection.getMessage() ==null){
logCollection.setMessage("没能拿到参数");
}
// request.getRequestURI()获取方法名
logCollection.setFullName(request.getRequestURI());
// 写入数据库 MultiTenantChanger是因为我有多个数据库,但是这里的操作其实就是讲实体装入数据库
MultiTenantChanger.setDataSourceType(CityHelper.getCityCode()+MultiTenantChanger.CENTA_BIZ);
bizMapper.insertLogCollection(logCollection);
MultiTenantChanger.removeRouteKey();
}
}
}
我在代码中添加了很多注释。应该更容易理解
参考文章:
连接点:
微信公众号内容采集,比较怪异,其参数,post参数需要话费时间去搞定
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-07-20 07:05
微信公众号采集的内容很奇怪。它的参数和后期参数需要时间来弄清楚。这里采集是topic标签的内容,用pdfkit打印出来的内容。
这里实现了两个版本。第一个是直接网络访问。它的真实地址,post URL,也有更多的参数。我没试过。得到的内容只是部分的,并不理想。第二个版本是使用无头浏览器直接访问,获取网页源代码,分析,获取你想要的内容。
这个人渣现在比较懒,代码都是以前用的,现成的,复制的,修改的,直接用!
版本一:
#微信公众号内容获取打印pdf
#by 微信:huguo00289
#https://mp.weixin.qq.com/mp/ho ... %3D14
# -*- coding: UTF-8 -*-
import requests
from fake_useragent import UserAgent
import os,re
import pdfkit
confg = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
class Du():
def __init__(self,furl):
ua=UserAgent()
self.headers={
"User-Agent": ua.random,
}
self.url=furl
def get_urls(self):
response=requests.get(self.url,headers=self.headers,timeout=8)
html=response.content.decode('utf-8')
req=re.findall(r'var data={(.+?)if',html,re.S)[0]
urls=re.findall(r',"link":"(.+?)",',req,re.S)
urls=set(urls)
print(len(urls))
return urls
def get_content(self,url,category):
response = requests.get(url, headers=self.headers, timeout=8)
print(response.status_code)
html = response.content.decode('utf-8')
req = re.findall(r'(.+?)var first_sceen__time',html,re.S)[0]
#获取标题
h1=re.findall(r'(.+?)',req,re.S)[0]
h1=h1.strip()
pattern = r"[\/\\\:\*\?\"\\|]"
h1 = re.sub(pattern, "_", h1) # 替换为下划线
print(h1)
#获取详情
detail = re.findall(r'(.+?)',req,re.S)[0]
data = f'{h1}\n{detail}'
self.dypdf(h1,data,category)
return data
def dypdf(self,h1,data,category):
datas = f'{data}'
print("开始打印内容!")
pdfkit.from_string(datas, f'{category}/{h1}.pdf', configuration=confg)
print("打印保存成功!")
if __name__=='__main__':
furl="https://mp.weixin.qq.com/mp/ho ... ot%3B
category="潘通色卡(电子版)"
datas = ''
os.makedirs(f'{category}/',exist_ok=True)
spider=Du(furl)
urls=spider.get_urls()
for url in urls:
print(f">> 正在爬取链接:{url} ..")
try:
data=spider.get_content(url,category)
except Exception as e:
print(f"爬取错误,错误代码为:{e}")
datas='%s%s%s'%(datas,'\n',data)
spider.dypdf(category,datas,category)
版本二:
#微信公众号内容获取打印pdf
#by 微信:huguo00289
#https://mp.weixin.qq.com/mp/ho ... %3D14
# -*- coding: UTF-8 -*-
import requests
from selenium import webdriver
import os,re,time
import pdfkit
from bs4 import BeautifulSoup
confg = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
class wx():
def __init__(self,furl):
self.url = furl
self.chrome_driver = r'C:\Users\Administrator\Desktop\chromedriver_win32\chromedriver.exe' # chromedriver的文件位置
self.browser = webdriver.Chrome(executable_path=self.chrome_driver)
def get_urls(self):
urls=[]
self.browser.get(self.url)
hrefs=self.browser.find_elements_by_xpath("//div[@class='article_list']/a[@class='list_item js_post']")
for href in hrefs:
url=href.get_attribute('href')
urls.append(url)
print(len(urls))
return urls
def get_content(self,url,category):
self.browser.get(url)
time.sleep(5)
# 调用driver的page_source属性获取页面源码
pageSource = self.browser.page_source
soup=BeautifulSoup(pageSource,'lxml')
#获取标题
h1=re.findall(r'(.+?)',pageSource,re.S)[0]
h1=h1.strip()
pattern = r"[\/\\\:\*\?\"\\|]"
h1 = re.sub(pattern, "_", h1) # 替换为下划线
print(h1)
#获取详情
detail =soup.find('div',class_="rich_media_content")
detail=str(detail)
del_text="""↑ 点击上方“染整百科”关注我们</strong>"""
detail=detail.replace(del_text,'')
data = f'{h1}\n{detail}'
self.dypdf(h1,data,category)
return data
def dypdf(self,h1,data,category):
datas = f'{data}'
print("开始打印内容!")
pdfkit.from_string(datas, f'{category}/{h1}.pdf', configuration=confg)
print("打印保存成功!")
def quit(self):
self.browser.quit()
if __name__=='__main__':
furl="https://mp.weixin.qq.com/mp/ho ... ot%3B
category="潘通色卡(电子版)"
datas = ''
os.makedirs(f'{category}/',exist_ok=True)
spider=wx(furl)
urls=spider.get_urls()
for url in urls:
print(f">> 正在爬取链接:{url} ..")
try:
data=spider.get_content(url,category)
except Exception as e:
print(f"爬取错误,错误代码为:{e}")
datas='%s%s%s'%(datas,'\n',data)
spider.quit()
spider.dypdf(category,datas,category)
</p>
以上代码仅供参考,如有雷同,必被此人渣抄袭!
查看全部
微信公众号内容采集,比较怪异,其参数,post参数需要话费时间去搞定
微信公众号采集的内容很奇怪。它的参数和后期参数需要时间来弄清楚。这里采集是topic标签的内容,用pdfkit打印出来的内容。

这里实现了两个版本。第一个是直接网络访问。它的真实地址,post URL,也有更多的参数。我没试过。得到的内容只是部分的,并不理想。第二个版本是使用无头浏览器直接访问,获取网页源代码,分析,获取你想要的内容。
这个人渣现在比较懒,代码都是以前用的,现成的,复制的,修改的,直接用!
版本一:
#微信公众号内容获取打印pdf
#by 微信:huguo00289
#https://mp.weixin.qq.com/mp/ho ... %3D14
# -*- coding: UTF-8 -*-
import requests
from fake_useragent import UserAgent
import os,re
import pdfkit
confg = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
class Du():
def __init__(self,furl):
ua=UserAgent()
self.headers={
"User-Agent": ua.random,
}
self.url=furl
def get_urls(self):
response=requests.get(self.url,headers=self.headers,timeout=8)
html=response.content.decode('utf-8')
req=re.findall(r'var data={(.+?)if',html,re.S)[0]
urls=re.findall(r',"link":"(.+?)",',req,re.S)
urls=set(urls)
print(len(urls))
return urls
def get_content(self,url,category):
response = requests.get(url, headers=self.headers, timeout=8)
print(response.status_code)
html = response.content.decode('utf-8')
req = re.findall(r'(.+?)var first_sceen__time',html,re.S)[0]
#获取标题
h1=re.findall(r'(.+?)',req,re.S)[0]
h1=h1.strip()
pattern = r"[\/\\\:\*\?\"\\|]"
h1 = re.sub(pattern, "_", h1) # 替换为下划线
print(h1)
#获取详情
detail = re.findall(r'(.+?)',req,re.S)[0]
data = f'{h1}\n{detail}'
self.dypdf(h1,data,category)
return data
def dypdf(self,h1,data,category):
datas = f'{data}'
print("开始打印内容!")
pdfkit.from_string(datas, f'{category}/{h1}.pdf', configuration=confg)
print("打印保存成功!")
if __name__=='__main__':
furl="https://mp.weixin.qq.com/mp/ho ... ot%3B
category="潘通色卡(电子版)"
datas = ''
os.makedirs(f'{category}/',exist_ok=True)
spider=Du(furl)
urls=spider.get_urls()
for url in urls:
print(f">> 正在爬取链接:{url} ..")
try:
data=spider.get_content(url,category)
except Exception as e:
print(f"爬取错误,错误代码为:{e}")
datas='%s%s%s'%(datas,'\n',data)
spider.dypdf(category,datas,category)
版本二:
#微信公众号内容获取打印pdf
#by 微信:huguo00289
#https://mp.weixin.qq.com/mp/ho ... %3D14
# -*- coding: UTF-8 -*-
import requests
from selenium import webdriver
import os,re,time
import pdfkit
from bs4 import BeautifulSoup
confg = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
class wx():
def __init__(self,furl):
self.url = furl
self.chrome_driver = r'C:\Users\Administrator\Desktop\chromedriver_win32\chromedriver.exe' # chromedriver的文件位置
self.browser = webdriver.Chrome(executable_path=self.chrome_driver)
def get_urls(self):
urls=[]
self.browser.get(self.url)
hrefs=self.browser.find_elements_by_xpath("//div[@class='article_list']/a[@class='list_item js_post']")
for href in hrefs:
url=href.get_attribute('href')
urls.append(url)
print(len(urls))
return urls
def get_content(self,url,category):
self.browser.get(url)
time.sleep(5)
# 调用driver的page_source属性获取页面源码
pageSource = self.browser.page_source
soup=BeautifulSoup(pageSource,'lxml')
#获取标题
h1=re.findall(r'(.+?)',pageSource,re.S)[0]
h1=h1.strip()
pattern = r"[\/\\\:\*\?\"\\|]"
h1 = re.sub(pattern, "_", h1) # 替换为下划线
print(h1)
#获取详情
detail =soup.find('div',class_="rich_media_content")
detail=str(detail)
del_text="""↑ 点击上方“染整百科”关注我们</strong>"""
detail=detail.replace(del_text,'')
data = f'{h1}\n{detail}'
self.dypdf(h1,data,category)
return data
def dypdf(self,h1,data,category):
datas = f'{data}'
print("开始打印内容!")
pdfkit.from_string(datas, f'{category}/{h1}.pdf', configuration=confg)
print("打印保存成功!")
def quit(self):
self.browser.quit()
if __name__=='__main__':
furl="https://mp.weixin.qq.com/mp/ho ... ot%3B
category="潘通色卡(电子版)"
datas = ''
os.makedirs(f'{category}/',exist_ok=True)
spider=wx(furl)
urls=spider.get_urls()
for url in urls:
print(f">> 正在爬取链接:{url} ..")
try:
data=spider.get_content(url,category)
except Exception as e:
print(f"爬取错误,错误代码为:{e}")
datas='%s%s%s'%(datas,'\n',data)
spider.quit()
spider.dypdf(category,datas,category)
</p>
以上代码仅供参考,如有雷同,必被此人渣抄袭!

微数据官网文章采集调用微信登录朋友圈的视频视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-07-18 20:01
文章采集调用微信登录采集,因此我们先要完成微信登录,这样就可以采集朋友圈的视频。由于采集头像需要使用ua头像识别工具,本文暂不采用此方案,只想采集朋友圈的视频,所以我先采集前半部分。1.界面准备下载相应的采集模块,整体模块效果如下图。下载文件内容如下图。2.启动脚本下载完成后,双击js/egg.js文件,就可以进入相应的编辑界面,按照相应的操作步骤编写脚本,有预编译和静态编译两种方式。
3.微信访问,获取手机号微信访问方式:微信文件传输助手微信扫一扫等4.将编写好的脚本发送至本地文件夹,或在浏览器上打开5.发送至本地文件夹,如:发送至桌面windows文件夹egg.js中下载的js文件。
给大家推荐一个网站微数据官网,搜索微信群可以看到有多少个微信群,以及每个微信群的信息,
首先我们先将采集微信公众号文章的功能做好,然后我们就可以采集了第一步:安装好采集工具和开发工具-take.exe,首先打开chrome的浏览器,打开后点击右上角···第二步:选择微信web-view-获取文章详情页-推送第三步:看下图,确定我们是否用openid登录自己的微信公众号。如果没有跳转的话,需要在微信点击下方的登录手机号验证,输入自己的手机号码才可以登录。
(这是我前几天偶然发现的,后来我就去网上搜索了原因,可能是手机号码验证的时候丢失了所以丢失了,所以才会造成微信公众号丢失whatsappmessage的情况出现,我也是今天才知道的)最后检查是否在效果中,是的话,点击确定就可以了。whatsappmessage登录成功之后,我们再看下按下图登录我们的微信公众号账号,开始下一步接下来我们就是全屏截图了首先我们准备好需要截取的内容。
可以根据需要截图相应的图片,但是一定要注意,我们截图之后,要立即发送给我们登录的手机号发送的方式,可以用短信,也可以用是微信,如果是微信,可以在短信发送,点开查看短信就可以获取我们刚刚发送的网址了,如果是短信也同样如此,点开查看短信就可以获取到我们需要的信息了我们通过确定手机号微信号是否有错误来判断是否成功截图成功以后,我们就可以发送到浏览器了,发送链接,上传成功之后,我们就可以从浏览器获取微信的视频地址了。
如图,我选择了一个带有大众点评链接的版本,进入之后先解析大众点评网站的api图然后可以看到我们输入的网址是有效的我们就可以使用此地址,进行视频的下载,详细的获取视频的代码地址如下图我们点击之后,其实是可以下载视频的,我们选择1000秒的就可以获取下载,下载完。 查看全部
微数据官网文章采集调用微信登录朋友圈的视频视频
文章采集调用微信登录采集,因此我们先要完成微信登录,这样就可以采集朋友圈的视频。由于采集头像需要使用ua头像识别工具,本文暂不采用此方案,只想采集朋友圈的视频,所以我先采集前半部分。1.界面准备下载相应的采集模块,整体模块效果如下图。下载文件内容如下图。2.启动脚本下载完成后,双击js/egg.js文件,就可以进入相应的编辑界面,按照相应的操作步骤编写脚本,有预编译和静态编译两种方式。
3.微信访问,获取手机号微信访问方式:微信文件传输助手微信扫一扫等4.将编写好的脚本发送至本地文件夹,或在浏览器上打开5.发送至本地文件夹,如:发送至桌面windows文件夹egg.js中下载的js文件。
给大家推荐一个网站微数据官网,搜索微信群可以看到有多少个微信群,以及每个微信群的信息,
首先我们先将采集微信公众号文章的功能做好,然后我们就可以采集了第一步:安装好采集工具和开发工具-take.exe,首先打开chrome的浏览器,打开后点击右上角···第二步:选择微信web-view-获取文章详情页-推送第三步:看下图,确定我们是否用openid登录自己的微信公众号。如果没有跳转的话,需要在微信点击下方的登录手机号验证,输入自己的手机号码才可以登录。
(这是我前几天偶然发现的,后来我就去网上搜索了原因,可能是手机号码验证的时候丢失了所以丢失了,所以才会造成微信公众号丢失whatsappmessage的情况出现,我也是今天才知道的)最后检查是否在效果中,是的话,点击确定就可以了。whatsappmessage登录成功之后,我们再看下按下图登录我们的微信公众号账号,开始下一步接下来我们就是全屏截图了首先我们准备好需要截取的内容。
可以根据需要截图相应的图片,但是一定要注意,我们截图之后,要立即发送给我们登录的手机号发送的方式,可以用短信,也可以用是微信,如果是微信,可以在短信发送,点开查看短信就可以获取我们刚刚发送的网址了,如果是短信也同样如此,点开查看短信就可以获取到我们需要的信息了我们通过确定手机号微信号是否有错误来判断是否成功截图成功以后,我们就可以发送到浏览器了,发送链接,上传成功之后,我们就可以从浏览器获取微信的视频地址了。
如图,我选择了一个带有大众点评链接的版本,进入之后先解析大众点评网站的api图然后可以看到我们输入的网址是有效的我们就可以使用此地址,进行视频的下载,详细的获取视频的代码地址如下图我们点击之后,其实是可以下载视频的,我们选择1000秒的就可以获取下载,下载完。
文章采集调用apacheapollo下修改paste方法,是不提供的
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-07-10 05:01
文章采集调用apacheapollo。
file->preferences->externalextensions然后选中request->accessibility:设置applicationaccessibilitytoken(从你api接入的系统,
你这个api接入的是谷歌的express?
一定是要对接的,
用apachejdk+apollopool
你这种接入是用在个人项目上的吗?我们都是用filezilla接入的,我觉得挺好用,
想接入谷歌studio的话需要依赖于expressjulia实现post请求,apollo无法实现(这个是用c++写的).
apollo=equinoxbj有这等好事?
利用python的urllib3和urllib3.pathretrieve方法,
要对接protobuf,apacheapollo不行,这个会解析出成特殊的auth,即:全部都是一个memory的startuptime,比如localtime是这样的,而我这的,apiopencloud(adaptedzoo)选项是不提供的,因为它是在incompletezooprofile,apollo选项是没有,而你apiopencloud(adaptedzooprofile)这样的选项是为json格式做手脚的。ps:也不排除是定制自己的project。
apacheapollopool
apacheapollorequestprojectswift下修改paste方法,
是吧 查看全部
文章采集调用apacheapollo下修改paste方法,是不提供的
文章采集调用apacheapollo。
file->preferences->externalextensions然后选中request->accessibility:设置applicationaccessibilitytoken(从你api接入的系统,
你这个api接入的是谷歌的express?
一定是要对接的,
用apachejdk+apollopool
你这种接入是用在个人项目上的吗?我们都是用filezilla接入的,我觉得挺好用,
想接入谷歌studio的话需要依赖于expressjulia实现post请求,apollo无法实现(这个是用c++写的).
apollo=equinoxbj有这等好事?
利用python的urllib3和urllib3.pathretrieve方法,
要对接protobuf,apacheapollo不行,这个会解析出成特殊的auth,即:全部都是一个memory的startuptime,比如localtime是这样的,而我这的,apiopencloud(adaptedzoo)选项是不提供的,因为它是在incompletezooprofile,apollo选项是没有,而你apiopencloud(adaptedzooprofile)这样的选项是为json格式做手脚的。ps:也不排除是定制自己的project。
apacheapollopool
apacheapollorequestprojectswift下修改paste方法,
是吧
网站模板下载/2019-06-09现阶段如何解决被抄袭
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-07-09 18:07
如何有效防止自己文章被采集网站模板下载/2019-06-09
现阶段很多网站会选择使用采集文章或者复制文章来更新网站的内容。其实这个更新方法百度官方早就给出了明确的意见,想了解更多的可以到百度站长平台详细阅读百度官方说明。那我想跟大家探讨一下文章采集的影响以及如何解决抄袭问题?
网站文章 可以通过采集 吗?
因为现阶段搜索引擎越来越智能化,他们也越来越强调用户体验和附加值。如果只做文章采集大批量的话,可能会出现以下问题。
一、网站采集返回的内容不一定是符合网站主题的内容。此类内容将被搜索引擎判断为低质量垃圾邮件。严重的话,还可能让网站获得降级的权利。
二、长期量产采集文章内容也会对服务器造成一定压力。如果使用的虚拟空间容量较小,则有一定的可能性使虚拟空间内存满后无法操作,岂不是得不偿失。
网站文章被抄袭怎么解决?
一,我们需要做好我们网站的内部调整,我们需要为网站制定一个固定的时间更新频率。这个操作之后网站的收录会有很大的提升。
其次,我们更新网站原创文章后,可以选择使用百度站长平台的原创protection功能,每次更新后提交文章原创protect? ,原创protection 每天可以提交 10 个项目。
三、当对方是采集我们文章时,图片也会是采集,我们可以给文章中的图片添加图片水印。
我觉得除了百度官方对文章采集网站的处理,我们还可以把我们的网站做得更好,让我们自己网站收录更好。 查看全部
网站模板下载/2019-06-09现阶段如何解决被抄袭
如何有效防止自己文章被采集网站模板下载/2019-06-09
现阶段很多网站会选择使用采集文章或者复制文章来更新网站的内容。其实这个更新方法百度官方早就给出了明确的意见,想了解更多的可以到百度站长平台详细阅读百度官方说明。那我想跟大家探讨一下文章采集的影响以及如何解决抄袭问题?
网站文章 可以通过采集 吗?
因为现阶段搜索引擎越来越智能化,他们也越来越强调用户体验和附加值。如果只做文章采集大批量的话,可能会出现以下问题。
一、网站采集返回的内容不一定是符合网站主题的内容。此类内容将被搜索引擎判断为低质量垃圾邮件。严重的话,还可能让网站获得降级的权利。
二、长期量产采集文章内容也会对服务器造成一定压力。如果使用的虚拟空间容量较小,则有一定的可能性使虚拟空间内存满后无法操作,岂不是得不偿失。
网站文章被抄袭怎么解决?
一,我们需要做好我们网站的内部调整,我们需要为网站制定一个固定的时间更新频率。这个操作之后网站的收录会有很大的提升。
其次,我们更新网站原创文章后,可以选择使用百度站长平台的原创protection功能,每次更新后提交文章原创protect? ,原创protection 每天可以提交 10 个项目。
三、当对方是采集我们文章时,图片也会是采集,我们可以给文章中的图片添加图片水印。
我觉得除了百度官方对文章采集网站的处理,我们还可以把我们的网站做得更好,让我们自己网站收录更好。
文章采集参数非常多,且需要各种事件,名字叫
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-07-09 01:01
文章采集调用参数非常多,且需要各种事件,所以把事件封装成函数更加方便接收和使用,而且对于后续的接口提取、混合开发,也可以有比较好的控制。事件接收函数更是多,在macos环境中,名字叫。需要用到的类库请参考官方文档,放出命令行参数行,在applescript程序下可以创建对应类的结构体。#!/usr/bin/envpython3importjson#你这里需要的库frompython.utilsimportcachemy_cache={"token":"kpqqfaqtoaug95jsjqghidpzl22vldgkyaafnb9g068","size":3,"flags":1}#上次是3和5,这次是3+,表示想使用5个字符和一个空格,你可以自己创建两个函数来替换"imageurl":"/"#这次是"/",并且随机生成一个指定范围的数字(因为数字大小会随着时间递增)"cutout":"true","size":1,"size_type":"vector"#没有空格可以使用浮点数cutout=0.0cutout="0.0","imageurl":"/"#让图片在标准分辨率下存储#一个大小,一个宽高my_img=imageio(imageio.bytesio(imageio.rar(imageio.unpack(imageio.u_new("hg"))#my_img.save("virtualexternal.jpg")#可以使用mappartialjavascript方法,调用默认的json对象传入字符串和一个空字符s:\u0000>image=["awflag.gif","alffer.mp4","fegaflag.png","fegfronappscm9.mp4","fegfronappscm9.png","scheqf.jpg","tostridge.jpg","trorcc.jpg","ibav.jpg","ibivgj.jpg","jmija.jpg","jip","jandoc.jpg","jsgq.jpg","jamest.jpg","deeave.jpg","altga.jpg","artistip.jpg","hfz.jpg","pengso.jpg","jouop.jpg","p_reis.jpg","bonoform.jpg","desatj.jpg","snoop.jpg","strxy.jpg","cqg.jpg","cqgj.jpg","inc.jpg","lgg.jpg","nju.jpg","ocj.jpg","tgj_jpg","qjy.jpg","jneif.jpg","lps.jpg","nxy.jpg","lez.jpg","alq.jpg","sz.jpg","tang.jpg","jnjj.jpg","tang.jpg","tngj.jpg","tg。 查看全部
文章采集参数非常多,且需要各种事件,名字叫
文章采集调用参数非常多,且需要各种事件,所以把事件封装成函数更加方便接收和使用,而且对于后续的接口提取、混合开发,也可以有比较好的控制。事件接收函数更是多,在macos环境中,名字叫。需要用到的类库请参考官方文档,放出命令行参数行,在applescript程序下可以创建对应类的结构体。#!/usr/bin/envpython3importjson#你这里需要的库frompython.utilsimportcachemy_cache={"token":"kpqqfaqtoaug95jsjqghidpzl22vldgkyaafnb9g068","size":3,"flags":1}#上次是3和5,这次是3+,表示想使用5个字符和一个空格,你可以自己创建两个函数来替换"imageurl":"/"#这次是"/",并且随机生成一个指定范围的数字(因为数字大小会随着时间递增)"cutout":"true","size":1,"size_type":"vector"#没有空格可以使用浮点数cutout=0.0cutout="0.0","imageurl":"/"#让图片在标准分辨率下存储#一个大小,一个宽高my_img=imageio(imageio.bytesio(imageio.rar(imageio.unpack(imageio.u_new("hg"))#my_img.save("virtualexternal.jpg")#可以使用mappartialjavascript方法,调用默认的json对象传入字符串和一个空字符s:\u0000>image=["awflag.gif","alffer.mp4","fegaflag.png","fegfronappscm9.mp4","fegfronappscm9.png","scheqf.jpg","tostridge.jpg","trorcc.jpg","ibav.jpg","ibivgj.jpg","jmija.jpg","jip","jandoc.jpg","jsgq.jpg","jamest.jpg","deeave.jpg","altga.jpg","artistip.jpg","hfz.jpg","pengso.jpg","jouop.jpg","p_reis.jpg","bonoform.jpg","desatj.jpg","snoop.jpg","strxy.jpg","cqg.jpg","cqgj.jpg","inc.jpg","lgg.jpg","nju.jpg","ocj.jpg","tgj_jpg","qjy.jpg","jneif.jpg","lps.jpg","nxy.jpg","lez.jpg","alq.jpg","sz.jpg","tang.jpg","jnjj.jpg","tang.jpg","tngj.jpg","tg。
为什么学爬虫?分布式爬虫让多台机器帮助你快速爬取数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-07-06 02:08
[为什么要学习爬行? 】
1、Crawler 上手容易,深入难。如何编写一个高效的爬虫,如何编写一个高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,往往容易遇到反爬取,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课程!
2、如果你是其他行业的开发者,比如app开发、网页开发、学习爬虫,可以加强对技术的理解,开发更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后这门课也是按照这些步骤一步一步讲解的,带领学生全面掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图文验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫等
通过爬虫的进阶知识点,我们可以应对大量的反爬虫网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
[课程服务]
独家付费社区+常规问答 查看全部
为什么学爬虫?分布式爬虫让多台机器帮助你快速爬取数据
[为什么要学习爬行? 】
1、Crawler 上手容易,深入难。如何编写一个高效的爬虫,如何编写一个高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,往往容易遇到反爬取,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课程!
2、如果你是其他行业的开发者,比如app开发、网页开发、学习爬虫,可以加强对技术的理解,开发更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后这门课也是按照这些步骤一步一步讲解的,带领学生全面掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图文验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫等
通过爬虫的进阶知识点,我们可以应对大量的反爬虫网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
[课程服务]
独家付费社区+常规问答
蜘蛛池独创万用站群模型2019年6月升级
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-07-05 23:22
注:1、本程序为3.31版本,2019年6月升级2、本程序不限用(破解),不开源,可复现。 3、由于程序的可复制性,不了解蜘蛛池是什么的客户请不要购买。不了解程序的购买将不予退款。 4、购买客户请不要提供或二次销售,否则将取消所有服务。 5、本程序需要PHP5.X、7.X使用,使用文本数据库,无需MYSQL工作。 6、如果需要对功能有具体的了解,可以加Q帮助观看演示。 7、Q 早上9点和晚上9点上线,小旋风源码出售。
x3 版本升级:
x2版本升级:功能列表如下:原创系统架构安全高效,可大幅优化php使用性能,运行流畅稳定,独创无缓存机制,原内容刷新无缓存,保存硬盘。防止搜索引擎识别蜘蛛池独创universal站群模型2019新蜘蛛算法,轻松搭建通用站点(电影、资讯、图片、论坛等)。企业信息自动生成企业名称、产品型号、公司简介、联系方式等。 标题重组功能拆分重组,重组2个标题,以1句内容为标题,以1句内容为标题,添加在标题后。突破百度算法标题和内容关联功能,突破百度算法网站分组可以个性化每一个网站'S的风格、内容、站点模式、关键词、外部链接等模板分为不同行业、不同类别、不同模板和不同的 URL。自动采集/自己设置采集Auto采集解放双手,可以设置发布策略,自己设置采集,想采集哪个站采集哪个站超强,自己设置tkd,自己设置外链关键词,自己设置域名前缀,超强SEO优化功能标题伪原创,内容伪原创,标题拆分重组,关键词为随机插入,繁体中文转换蜘蛛抓取记录蜘蛛访问日志(每日访问、每周访问、每月访问图表,一目了然) 蜘蛛劫持可设置劫持概率、劫持时间、强制蜘蛛劫持、霸道蜘蛛防火墙屏蔽指定、垃圾邮件蜘蛛,节省服务器资源,双模单域名,泛域名模式,一键切换,迎合不同搜索引擎口味,多模板系统自带25个模板,可自行扩展。容易制作。您可以在不同的行业设置自己的网址。您可以自行设置不同的网址,使您的网址独一无二。标题可以本地缓存,外部链接可以独立缓存。您可以一键升级标题和外部链接。
查看全部
蜘蛛池独创万用站群模型2019年6月升级
注:1、本程序为3.31版本,2019年6月升级2、本程序不限用(破解),不开源,可复现。 3、由于程序的可复制性,不了解蜘蛛池是什么的客户请不要购买。不了解程序的购买将不予退款。 4、购买客户请不要提供或二次销售,否则将取消所有服务。 5、本程序需要PHP5.X、7.X使用,使用文本数据库,无需MYSQL工作。 6、如果需要对功能有具体的了解,可以加Q帮助观看演示。 7、Q 早上9点和晚上9点上线,小旋风源码出售。
x3 版本升级:
x2版本升级:功能列表如下:原创系统架构安全高效,可大幅优化php使用性能,运行流畅稳定,独创无缓存机制,原内容刷新无缓存,保存硬盘。防止搜索引擎识别蜘蛛池独创universal站群模型2019新蜘蛛算法,轻松搭建通用站点(电影、资讯、图片、论坛等)。企业信息自动生成企业名称、产品型号、公司简介、联系方式等。 标题重组功能拆分重组,重组2个标题,以1句内容为标题,以1句内容为标题,添加在标题后。突破百度算法标题和内容关联功能,突破百度算法网站分组可以个性化每一个网站'S的风格、内容、站点模式、关键词、外部链接等模板分为不同行业、不同类别、不同模板和不同的 URL。自动采集/自己设置采集Auto采集解放双手,可以设置发布策略,自己设置采集,想采集哪个站采集哪个站超强,自己设置tkd,自己设置外链关键词,自己设置域名前缀,超强SEO优化功能标题伪原创,内容伪原创,标题拆分重组,关键词为随机插入,繁体中文转换蜘蛛抓取记录蜘蛛访问日志(每日访问、每周访问、每月访问图表,一目了然) 蜘蛛劫持可设置劫持概率、劫持时间、强制蜘蛛劫持、霸道蜘蛛防火墙屏蔽指定、垃圾邮件蜘蛛,节省服务器资源,双模单域名,泛域名模式,一键切换,迎合不同搜索引擎口味,多模板系统自带25个模板,可自行扩展。容易制作。您可以在不同的行业设置自己的网址。您可以自行设置不同的网址,使您的网址独一无二。标题可以本地缓存,外部链接可以独立缓存。您可以一键升级标题和外部链接。
文章采集调用文本传递word到百度合成框架中,最后重建出生成结果
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-07-02 19:01
文章采集调用文本传递word到百度合成框架中,最后重建出生成结果
1、下载并下载wordtowordfrommelodyneyer
2、将数据包放入百度云,
3、下载wordtowordfrommelodyneyer,
楼上已经解释清楚了,确实,提取出的是一个文本的内容,然后经过转写机生成其他的。再发一遍文章链接,wordtoword的详细介绍,
本质上是用一个合成器把你写好的文字合成成。github-yerwin1011/word_to_word:decodeanewwordtoanopenspeechsystem其中有四个小功能,你看你喜欢哪个。
尝试通过openspeechsystem正确连接一个melodynewordtoword模型,网上无数教程不一定能实现。目前我在三个方向上努力。一方面尝试模仿百度合成的公开代码实现简单高效的实例。再一方面尝试迁移melodyneengine本身的代码,开发模仿微软ttsgroovy开发工具。最后一方面测试aegisub与melodyne结合能否实现相似效果。欢迎交流。
拿melodyne内置的wordtoword和wordwithspeech生成,不再通过电脑。用openspeechsystem连接了百度云服务器,打开就有实际效果了。 查看全部
文章采集调用文本传递word到百度合成框架中,最后重建出生成结果
文章采集调用文本传递word到百度合成框架中,最后重建出生成结果
1、下载并下载wordtowordfrommelodyneyer
2、将数据包放入百度云,
3、下载wordtowordfrommelodyneyer,
楼上已经解释清楚了,确实,提取出的是一个文本的内容,然后经过转写机生成其他的。再发一遍文章链接,wordtoword的详细介绍,
本质上是用一个合成器把你写好的文字合成成。github-yerwin1011/word_to_word:decodeanewwordtoanopenspeechsystem其中有四个小功能,你看你喜欢哪个。
尝试通过openspeechsystem正确连接一个melodynewordtoword模型,网上无数教程不一定能实现。目前我在三个方向上努力。一方面尝试模仿百度合成的公开代码实现简单高效的实例。再一方面尝试迁移melodyneengine本身的代码,开发模仿微软ttsgroovy开发工具。最后一方面测试aegisub与melodyne结合能否实现相似效果。欢迎交流。
拿melodyne内置的wordtoword和wordwithspeech生成,不再通过电脑。用openspeechsystem连接了百度云服务器,打开就有实际效果了。
文章采集调用 跑到图文加工店,说给点素材,中年老板:骚年你来对了
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-07-01 05:06
去图文加工店说一些材料。中年老板:嫂子,你说得对。我们这里有很多库存。你有你想要的一切,JPG、PSD、AI、AE、AV。你想...
去菜市场举一些例子。卖水果的:朋友知道货。今天刚到的李子还不错。缺点:太甜了!隔壁卖糖炒栗子的男人伸长脖子:大哥,拿一袋吧!
恩...定义很重要,所以我们今天所说的就是指在阅读中获得的文本内容,写作、演讲、推理等方面的参考资料和例子。
其实很多大牛都专门写了文章比如管理自己的知识库,整理自己的知识体系。材料和示例只是其中很小的一部分。和那些大牛比起来,这次我只专注于材料和例子。这个入口点非常小。如果您已经建立了自己完整的知识框架和结构,非常欢迎您给我意见和批评,并先接受。
一、材料和例子有什么用1.征服观众
写作或发表演讲时,通常围绕一个主题展开,您要做的就是让读者或听众理解并接受您所说的内容。如果你按照规则一一描述,就像教科书一样,你很可能会失去很多观众。这种情况在演讲时尤为明显。当你偶尔低头看着舞台,寻找所谓的眼神交流和互动感时,你会发现观众中很多人只是盯着桌子底下笑。你应该明白你说的对他们来说不像微博或朋友圈那么有趣。
在书面或演讲中适当引用可以最大程度地避免这种情况。在写作中引用实例可以帮助读者避免长时间阅读的疲劳,同时加深对内容的理解;演讲中生动的例子更有效,可以使你表达的内容更容易被听众接受和理解。而且,成人注意力集中的时间曲线有其特定的规律。可以提供两个生动的例子,在听众精力下降、容易分心的时候,让他们瞬间重新集中注意力,保证演讲的良好效果。
2.被别人吸引
你的朋友中应该有一些这样的人。饭桌上谈山,如同切瓜切菜,从天文、地理、神仙、妖怪、玄学、三身、四书、五道口,下至官场、百姓的悲喜、肉乐,奇怪的事情,各种各样的事情。话题在各个领域。如果你不在流程中,如果你被TA接了,那就别想了。从头到尾,你有名有姓,头是对的。如果你也想成为派对的中心(当然最好排除个人自夸的内容),几句引语反驳一大段,那么素材和实例的采集可以让你玩起来更轻松。李笑来老师在《花时间做朋友》中提到,父亲总是可以在公共场合讲话。他一度以为父亲是个记忆力超群的人,后来发现父亲的秘密其实是一本记事本,里面全是笔记。所谓修辞,就是根据采集到的材料和例子,以及这些内容什么时候可以适用于什么情况。
3.生理原因(个人原因)
英文里有一句话:on the tip of my thumb,直译为“在我的舌尖上”,实际表达是单词在嘴唇上,但我一下子想不起来在关注采集资料和实例之前,我有很多类似的经历。我清楚地记得前一天,甚至几个小时前,我偶然看到一个例子来支持我的观点,但我想不起细节和来源。我穿过盒子并寻求帮助。谷歌独娘,没有结果。这时候就会有背上的刺和喉咙里的刺痛感,相当不舒服。我认为这种感觉是由于没有保留适当的材料或示例的遗憾。
于是,采集资料和实例就成了我的日常习惯之一。 “当书籍被使用时,他们的仇恨就会减少。”古人已经表达过类似的叹息。其实,对于掌握了很多新工具、新方法的现代人来说,搜集整理资料和实例,其实并没有想象中的那么麻烦。
二、如何采集资料和例子1.资料和例子采集
由于我说的采集整理主要是针对文本内容,所以采集资料和例子的主要来源如下:
(1)图书
如今,人们普遍强调对知识产权的保护。很多书的内容在网上是无法直接获取的,阅读后只能摘录。
——电子书
目前国内外新书上架趋势是电子版和纸质版同步推出。电子版通常更便宜,可以直接在亚马逊等官网购买。尤其是刚刚出版的新书,基本上只能找到付费版(各种号称免费的网站,往往指向付费版网址)。对于上架一段时间的书籍,会有各种免费的电子版流出,大部分是PDF,但质量参差不齐。还有一点,对于寻找电子书,我的建议是,如果5-10分钟内没有找到合适的版本,基本可以放弃。不值得为免费和无保证的内容花费更多宝贵的时间,只需购买电子书即可。版本性价比更高,付费也体现了对知识的尊重。
以目前主流的亚马逊官网为例。购买完成后会自动推送到KINDLE。为了方便后续的整理和检索,我将使用CALIBRE软件加上DEDRM插件将亚马逊下载的AZW3格式转换为EPUB格式,然后将书中需要的内容收录到印象笔记中(仅供学习参考) ,绝不参与D版盈利),让大段摘录和引用的内容轻松复制到印象笔记同步,不易丢失,方便查找。
——纸质版书籍
有些书比较经典但比较老,多次再版,没有电子版;也有非小说类书籍,因为我个人喜欢边看书边手写阅读笔记,所以买了纸质版。对于这种类型的纸质书,提取大章节非常不方便,人工摘录也相当耗时。好在后来在某宝上发现了一支手持扫描笔,可以将纸质内容快速扫描成可编辑的文本格式。效率比人工输入高很多倍。之前看过万维刚的《奇思妙想》。有许多科学的经验引述。段落很长。我用扫描笔摘录。它是一个令人耳目一新的阅读笔记工具。真是感叹好工具。钱不能省。对于喜欢看纸质书、喜欢做读书笔记的朋友来说,扫描笔是一个非常推荐的工具。
(2)微信内容
微信是日常生活中大多数人使用频率最高的手机应用,如何使用它不言而喻。我个人将印象笔记和有道云这两个公众号联系起来。我通常把值得采集的内容随时保存在云端,然后在电脑上整理汇总。
(3)网页内容
浏览网页时,我会及时保存好内容。复制粘贴段落太麻烦了。为此,我使用了 Evernote 网页剪辑插件。可以选择整个页面,网页正文,或者去广告等等,形式多样,很贴心。
(4)Other
其他来源不是我采集和整理资料的主流渠道。比如微信聊天记录整理等,依靠谷歌度娘的一些技巧,将它们整理成文字内容并保存。
2.材料和例子的组织
采集后一定要排序,否则不会发挥任何价值。排序的目的是为了更好的使用。依靠大脑记住所有采集到的内容是极其困难的。作为85后的我,经常听到90后说“哎呀!怎么想不起来了,老了脑子就不好用了”,这时候感觉自己插入了一个飞刀在我心中。我太习惯了)。事实上,人脑就像一台电脑,存储容量有一定的上限。此外,人脑还具有遗忘机制。对于长时间不使用的内容,大脑会选择忘记为经常使用的模块腾出存储空间来运行。因此,我们需要以更有效的方式组织采集到的材料和实例,以方便后续的高效调用,减轻大脑的负担,让大脑腾出空间去思考更有价值的事情。
以印象笔记为例。完成采集动作后,你的印象笔记里应该有不少内容,但都是杂乱无章的。这时候你需要做三件事:
第一步是命名。这是最直接的内容分类方法,也是最原创的信息查询渠道。我平时给内容命名的方法是:日期+类型+一般内容摘要,例如:20161011知乎LIVE-战隼老师-一种没有意志力的习惯养成方法,所以不管我想到《战隼》还是《》习惯”、“知乎”或日期可用于定位此材料。
第二步是分类。设置文件夹,将采集到的内容按类型分类,就像在电脑上创建文件夹和分类各种文档一样。我现在使用的文件夹有:个人(存放个人信息等私密内容,可选加密)、日常工作(材料或与工作相关的内容)、学习(与学习、写作、成长等相关的内容)等。这个设置的好处是,当你不记得要搜索的具体细节,但可以确定需要查找的一般类别时,可以过滤掉其他类别以缩小搜索范围。但是,当内容积累到一定程度时,这种分类的范围还是太厚,不够细。这时候就需要第三步配合了。 (这里吐槽,印象笔记的笔记本分类等级只有2级,无法进一步细化。积分,道云笔记等级更多更强)。
第三步也是最重要的一步是添加标签!标签!标签! (重要的事情说三遍)按文件夹分类材料有很大的缺陷。一个材料或示例只能放在一个文件夹中。如果你想把它放在第二个文件夹中,你只需要再次复制粘贴。 数据本来就很复杂,复制粘贴会导致搜索中出现多次重复的结果,会占用宝贵的云存储空间。强烈不推荐。因此,此时您需要为材料或示例做的是添加标签。与其添加一个标签,不如添加尽可能多的标签,并根据该材料可以穷尽的所有相关特征进行标记。比如:之前在短书上看到一篇文章《经验:如何找电子书》,教你如何搜索你需要的电子书或电子资料。我把这个文章按大类放在了学习文件夹里,但其实我在工作中也用到了电子资料的搜索技巧。因此,我在这个文章上添加了“电子书”、“搜索”、“资源”、“技术”等几个标签,以便我写文章来澄清调用资源、查找电子书、普及工作技能等等。你看这个文章就可以找到。
标记有两个非常大的好处。一是标注可以帮助你思考反刍:除了解释这个材料或例子的原创内容之外,你还可以使用哪些方面?哪些观点也可以用来佐证?这与上面提到的相同。他的父亲李笑来老师通过记录和思考,可以用笔记本的内容写下什么时候、什么地方、什么情况。是“思维扩展”的简化版,也可以颠倒过来。来这里帮助你进一步加深对内容的理解。二是通过标注会有很多意想不到的“惊喜”。我写了《学会花钱》这本书的书评。在分析涉及概率论的章节时,我在印象笔记中点击了我标记为“概率论”的文件分类。没想到,在资料集里,原来关于小数定律的思想和评论被轻易复制粘贴,而且写得很轻松,着实让人意外。随着材料越来越多,“惊喜”的概率会越来越大。这就是大脑的神经元数量在一定程度上很大的原因,接触到大量的连接,然后就会被打掉奇怪的思想火花。
三、 方法调用
所谓调用,就是搜索所有你认为你能想到的关键词,找到你想要的内容,其中一些在前面的文章中已经提到过。可以确定,查找文件名是最直接的。如果没有,您可以在大类中搜索,缩小范围,或者使用标签叠加的方法进行多维搜索。目前我最常用的方法是确定类别,然后使用多个标签叠加搜索方法,具有最高的方向性。如果您想在搜索时获得灵感,只需浏览单个关键字或单击单个标签的集合,这往往会给您带来一些意想不到的内容。
著名的李敖开书的例子是材料采集和调用的最好例子。以下段落来自对他的采访:
我很少忘记读过的书,李敖,为什么?方法很好。有什么办法?无情。所有的剪刀和美工刀都用上了,书被劈开。我需要这个页面,我需要这个段落,我将把它分成几类。如果背面有用呢?复印它,或者一开始买两本书,把两本书剪下来整理好,把你想读的部分分类保存。结果,看完一本书,书也被肢解了。我就是这样看书的。
如何划分分类?我有很多自己制作的剪辑,我在剪辑上写下文字来对所有材料进行分类。读完一本书,都进入了我的剪辑。我可以将它们分为数千个类别,它们非常详细。比如按照图书馆的分类,哲学类,宗教类;宗教类又分为佛教类、道教类、天主教类。我,李敖,可以分为更详细的类别。天主教也可以分为几类。牧师也可以细分。牧师同性恋是一类,牧师的粗俗是另一类。修女的同性恋是一类,修女的粗俗又是另一类。
书中的任何相关内容都会进入我的个人资料。你为什么进入?当我想写小说时,我需要这些信息,打开信息,然后写出来。或者发生了一些与同性恋修女有关的事情。想对新闻发表自己的看法,拿新闻,打开我的信息,把两者合并,文章立马写出来了。
也就是说,在我读完这本书后,我被五匹马肢解和分割。但我把它挂了。我不记得这些数据了。我用详细而耐心的工作将其连接起来,并将其放入文件夹中。我的记忆只需要记住这些标题。标题是根据我的习惯来划分的。基本上都是翻译成英文字,驱逐英文字母,偶尔也有一些中文。 "
四、Notes
明确材料采集的方法和好处后,还有两点需要注意:
1.确认真相。
逻辑中有一个重要的概念:“合乎逻辑就是符合真理。”如果采集的材料和例子来自歪曲事实或报道,那么即使符合你的观点,支持你的说法,也毫无意义,甚至会产生相反的效果,让读者或听众觉得你没有区别。一个相信真假的人会大大降低你观点的可信度。此外,即使材料是真实的,也很可能具有时效性。因此,在使用材料或实例时,切记检查内容是否真实,是否仍然准确,并及时更新筛选。如果涉及到新闻、历史、人文等收录年龄或数据的内容,一定要再次确认准确性,以免被人笑话。
2.告诉来源。
在举例的时候,只表达内容不说明出处,会让人觉得缺乏信任。如果读者或听众对你引用的材料或例子特别感兴趣,他们很可能想通过这些来源了解更详细的内容,所以在引用材料或例子时,在不影响流畅性的前提下,尽量多说出来源。演示文稿。
五、Summary
回忆一下采集和组织例子的要点:
——为什么要注意材料和实例的采集
1.征服观众
2.被别人吸引
3.(个人原因)
——采集整理方法
1.采集源
(1)书——电子版、纸质版
(2)微信
(3)网页
(4)Other
——调用方法
文件名、分类、标签叠加
——注意事项
1.确认真相
2.告诉来源
说到这里,就是想把自己采集整理的习惯分享给大家,让分享好东西更有意义。无论是写作、演讲、推理,还是丰富对话、获取知识、成为一个有趣的人,好的材料和例子都是很有帮助的。在这个时代,“好记性不如坏笔”应该改为“好记性不如坏手指”。虽然一开始可能会觉得有些繁琐,但是当你体验到频繁采集整理的好处时,你肯定会欲罢不能。想想你可以通过采集和整理来控制这么大的材料库供你使用,真是太有趣了。
为什么不试试看? 查看全部
文章采集调用 跑到图文加工店,说给点素材,中年老板:骚年你来对了
去图文加工店说一些材料。中年老板:嫂子,你说得对。我们这里有很多库存。你有你想要的一切,JPG、PSD、AI、AE、AV。你想...
去菜市场举一些例子。卖水果的:朋友知道货。今天刚到的李子还不错。缺点:太甜了!隔壁卖糖炒栗子的男人伸长脖子:大哥,拿一袋吧!
恩...定义很重要,所以我们今天所说的就是指在阅读中获得的文本内容,写作、演讲、推理等方面的参考资料和例子。
其实很多大牛都专门写了文章比如管理自己的知识库,整理自己的知识体系。材料和示例只是其中很小的一部分。和那些大牛比起来,这次我只专注于材料和例子。这个入口点非常小。如果您已经建立了自己完整的知识框架和结构,非常欢迎您给我意见和批评,并先接受。
一、材料和例子有什么用1.征服观众
写作或发表演讲时,通常围绕一个主题展开,您要做的就是让读者或听众理解并接受您所说的内容。如果你按照规则一一描述,就像教科书一样,你很可能会失去很多观众。这种情况在演讲时尤为明显。当你偶尔低头看着舞台,寻找所谓的眼神交流和互动感时,你会发现观众中很多人只是盯着桌子底下笑。你应该明白你说的对他们来说不像微博或朋友圈那么有趣。
在书面或演讲中适当引用可以最大程度地避免这种情况。在写作中引用实例可以帮助读者避免长时间阅读的疲劳,同时加深对内容的理解;演讲中生动的例子更有效,可以使你表达的内容更容易被听众接受和理解。而且,成人注意力集中的时间曲线有其特定的规律。可以提供两个生动的例子,在听众精力下降、容易分心的时候,让他们瞬间重新集中注意力,保证演讲的良好效果。
2.被别人吸引
你的朋友中应该有一些这样的人。饭桌上谈山,如同切瓜切菜,从天文、地理、神仙、妖怪、玄学、三身、四书、五道口,下至官场、百姓的悲喜、肉乐,奇怪的事情,各种各样的事情。话题在各个领域。如果你不在流程中,如果你被TA接了,那就别想了。从头到尾,你有名有姓,头是对的。如果你也想成为派对的中心(当然最好排除个人自夸的内容),几句引语反驳一大段,那么素材和实例的采集可以让你玩起来更轻松。李笑来老师在《花时间做朋友》中提到,父亲总是可以在公共场合讲话。他一度以为父亲是个记忆力超群的人,后来发现父亲的秘密其实是一本记事本,里面全是笔记。所谓修辞,就是根据采集到的材料和例子,以及这些内容什么时候可以适用于什么情况。
3.生理原因(个人原因)
英文里有一句话:on the tip of my thumb,直译为“在我的舌尖上”,实际表达是单词在嘴唇上,但我一下子想不起来在关注采集资料和实例之前,我有很多类似的经历。我清楚地记得前一天,甚至几个小时前,我偶然看到一个例子来支持我的观点,但我想不起细节和来源。我穿过盒子并寻求帮助。谷歌独娘,没有结果。这时候就会有背上的刺和喉咙里的刺痛感,相当不舒服。我认为这种感觉是由于没有保留适当的材料或示例的遗憾。
于是,采集资料和实例就成了我的日常习惯之一。 “当书籍被使用时,他们的仇恨就会减少。”古人已经表达过类似的叹息。其实,对于掌握了很多新工具、新方法的现代人来说,搜集整理资料和实例,其实并没有想象中的那么麻烦。
二、如何采集资料和例子1.资料和例子采集
由于我说的采集整理主要是针对文本内容,所以采集资料和例子的主要来源如下:
(1)图书
如今,人们普遍强调对知识产权的保护。很多书的内容在网上是无法直接获取的,阅读后只能摘录。
——电子书
目前国内外新书上架趋势是电子版和纸质版同步推出。电子版通常更便宜,可以直接在亚马逊等官网购买。尤其是刚刚出版的新书,基本上只能找到付费版(各种号称免费的网站,往往指向付费版网址)。对于上架一段时间的书籍,会有各种免费的电子版流出,大部分是PDF,但质量参差不齐。还有一点,对于寻找电子书,我的建议是,如果5-10分钟内没有找到合适的版本,基本可以放弃。不值得为免费和无保证的内容花费更多宝贵的时间,只需购买电子书即可。版本性价比更高,付费也体现了对知识的尊重。
以目前主流的亚马逊官网为例。购买完成后会自动推送到KINDLE。为了方便后续的整理和检索,我将使用CALIBRE软件加上DEDRM插件将亚马逊下载的AZW3格式转换为EPUB格式,然后将书中需要的内容收录到印象笔记中(仅供学习参考) ,绝不参与D版盈利),让大段摘录和引用的内容轻松复制到印象笔记同步,不易丢失,方便查找。
——纸质版书籍
有些书比较经典但比较老,多次再版,没有电子版;也有非小说类书籍,因为我个人喜欢边看书边手写阅读笔记,所以买了纸质版。对于这种类型的纸质书,提取大章节非常不方便,人工摘录也相当耗时。好在后来在某宝上发现了一支手持扫描笔,可以将纸质内容快速扫描成可编辑的文本格式。效率比人工输入高很多倍。之前看过万维刚的《奇思妙想》。有许多科学的经验引述。段落很长。我用扫描笔摘录。它是一个令人耳目一新的阅读笔记工具。真是感叹好工具。钱不能省。对于喜欢看纸质书、喜欢做读书笔记的朋友来说,扫描笔是一个非常推荐的工具。
(2)微信内容
微信是日常生活中大多数人使用频率最高的手机应用,如何使用它不言而喻。我个人将印象笔记和有道云这两个公众号联系起来。我通常把值得采集的内容随时保存在云端,然后在电脑上整理汇总。
(3)网页内容
浏览网页时,我会及时保存好内容。复制粘贴段落太麻烦了。为此,我使用了 Evernote 网页剪辑插件。可以选择整个页面,网页正文,或者去广告等等,形式多样,很贴心。
(4)Other
其他来源不是我采集和整理资料的主流渠道。比如微信聊天记录整理等,依靠谷歌度娘的一些技巧,将它们整理成文字内容并保存。
2.材料和例子的组织
采集后一定要排序,否则不会发挥任何价值。排序的目的是为了更好的使用。依靠大脑记住所有采集到的内容是极其困难的。作为85后的我,经常听到90后说“哎呀!怎么想不起来了,老了脑子就不好用了”,这时候感觉自己插入了一个飞刀在我心中。我太习惯了)。事实上,人脑就像一台电脑,存储容量有一定的上限。此外,人脑还具有遗忘机制。对于长时间不使用的内容,大脑会选择忘记为经常使用的模块腾出存储空间来运行。因此,我们需要以更有效的方式组织采集到的材料和实例,以方便后续的高效调用,减轻大脑的负担,让大脑腾出空间去思考更有价值的事情。
以印象笔记为例。完成采集动作后,你的印象笔记里应该有不少内容,但都是杂乱无章的。这时候你需要做三件事:
第一步是命名。这是最直接的内容分类方法,也是最原创的信息查询渠道。我平时给内容命名的方法是:日期+类型+一般内容摘要,例如:20161011知乎LIVE-战隼老师-一种没有意志力的习惯养成方法,所以不管我想到《战隼》还是《》习惯”、“知乎”或日期可用于定位此材料。
第二步是分类。设置文件夹,将采集到的内容按类型分类,就像在电脑上创建文件夹和分类各种文档一样。我现在使用的文件夹有:个人(存放个人信息等私密内容,可选加密)、日常工作(材料或与工作相关的内容)、学习(与学习、写作、成长等相关的内容)等。这个设置的好处是,当你不记得要搜索的具体细节,但可以确定需要查找的一般类别时,可以过滤掉其他类别以缩小搜索范围。但是,当内容积累到一定程度时,这种分类的范围还是太厚,不够细。这时候就需要第三步配合了。 (这里吐槽,印象笔记的笔记本分类等级只有2级,无法进一步细化。积分,道云笔记等级更多更强)。
第三步也是最重要的一步是添加标签!标签!标签! (重要的事情说三遍)按文件夹分类材料有很大的缺陷。一个材料或示例只能放在一个文件夹中。如果你想把它放在第二个文件夹中,你只需要再次复制粘贴。 数据本来就很复杂,复制粘贴会导致搜索中出现多次重复的结果,会占用宝贵的云存储空间。强烈不推荐。因此,此时您需要为材料或示例做的是添加标签。与其添加一个标签,不如添加尽可能多的标签,并根据该材料可以穷尽的所有相关特征进行标记。比如:之前在短书上看到一篇文章《经验:如何找电子书》,教你如何搜索你需要的电子书或电子资料。我把这个文章按大类放在了学习文件夹里,但其实我在工作中也用到了电子资料的搜索技巧。因此,我在这个文章上添加了“电子书”、“搜索”、“资源”、“技术”等几个标签,以便我写文章来澄清调用资源、查找电子书、普及工作技能等等。你看这个文章就可以找到。
标记有两个非常大的好处。一是标注可以帮助你思考反刍:除了解释这个材料或例子的原创内容之外,你还可以使用哪些方面?哪些观点也可以用来佐证?这与上面提到的相同。他的父亲李笑来老师通过记录和思考,可以用笔记本的内容写下什么时候、什么地方、什么情况。是“思维扩展”的简化版,也可以颠倒过来。来这里帮助你进一步加深对内容的理解。二是通过标注会有很多意想不到的“惊喜”。我写了《学会花钱》这本书的书评。在分析涉及概率论的章节时,我在印象笔记中点击了我标记为“概率论”的文件分类。没想到,在资料集里,原来关于小数定律的思想和评论被轻易复制粘贴,而且写得很轻松,着实让人意外。随着材料越来越多,“惊喜”的概率会越来越大。这就是大脑的神经元数量在一定程度上很大的原因,接触到大量的连接,然后就会被打掉奇怪的思想火花。
三、 方法调用
所谓调用,就是搜索所有你认为你能想到的关键词,找到你想要的内容,其中一些在前面的文章中已经提到过。可以确定,查找文件名是最直接的。如果没有,您可以在大类中搜索,缩小范围,或者使用标签叠加的方法进行多维搜索。目前我最常用的方法是确定类别,然后使用多个标签叠加搜索方法,具有最高的方向性。如果您想在搜索时获得灵感,只需浏览单个关键字或单击单个标签的集合,这往往会给您带来一些意想不到的内容。
著名的李敖开书的例子是材料采集和调用的最好例子。以下段落来自对他的采访:
我很少忘记读过的书,李敖,为什么?方法很好。有什么办法?无情。所有的剪刀和美工刀都用上了,书被劈开。我需要这个页面,我需要这个段落,我将把它分成几类。如果背面有用呢?复印它,或者一开始买两本书,把两本书剪下来整理好,把你想读的部分分类保存。结果,看完一本书,书也被肢解了。我就是这样看书的。
如何划分分类?我有很多自己制作的剪辑,我在剪辑上写下文字来对所有材料进行分类。读完一本书,都进入了我的剪辑。我可以将它们分为数千个类别,它们非常详细。比如按照图书馆的分类,哲学类,宗教类;宗教类又分为佛教类、道教类、天主教类。我,李敖,可以分为更详细的类别。天主教也可以分为几类。牧师也可以细分。牧师同性恋是一类,牧师的粗俗是另一类。修女的同性恋是一类,修女的粗俗又是另一类。
书中的任何相关内容都会进入我的个人资料。你为什么进入?当我想写小说时,我需要这些信息,打开信息,然后写出来。或者发生了一些与同性恋修女有关的事情。想对新闻发表自己的看法,拿新闻,打开我的信息,把两者合并,文章立马写出来了。
也就是说,在我读完这本书后,我被五匹马肢解和分割。但我把它挂了。我不记得这些数据了。我用详细而耐心的工作将其连接起来,并将其放入文件夹中。我的记忆只需要记住这些标题。标题是根据我的习惯来划分的。基本上都是翻译成英文字,驱逐英文字母,偶尔也有一些中文。 "
四、Notes
明确材料采集的方法和好处后,还有两点需要注意:
1.确认真相。
逻辑中有一个重要的概念:“合乎逻辑就是符合真理。”如果采集的材料和例子来自歪曲事实或报道,那么即使符合你的观点,支持你的说法,也毫无意义,甚至会产生相反的效果,让读者或听众觉得你没有区别。一个相信真假的人会大大降低你观点的可信度。此外,即使材料是真实的,也很可能具有时效性。因此,在使用材料或实例时,切记检查内容是否真实,是否仍然准确,并及时更新筛选。如果涉及到新闻、历史、人文等收录年龄或数据的内容,一定要再次确认准确性,以免被人笑话。
2.告诉来源。
在举例的时候,只表达内容不说明出处,会让人觉得缺乏信任。如果读者或听众对你引用的材料或例子特别感兴趣,他们很可能想通过这些来源了解更详细的内容,所以在引用材料或例子时,在不影响流畅性的前提下,尽量多说出来源。演示文稿。
五、Summary
回忆一下采集和组织例子的要点:
——为什么要注意材料和实例的采集
1.征服观众
2.被别人吸引
3.(个人原因)
——采集整理方法
1.采集源
(1)书——电子版、纸质版
(2)微信
(3)网页
(4)Other
——调用方法
文件名、分类、标签叠加
——注意事项
1.确认真相
2.告诉来源
说到这里,就是想把自己采集整理的习惯分享给大家,让分享好东西更有意义。无论是写作、演讲、推理,还是丰富对话、获取知识、成为一个有趣的人,好的材料和例子都是很有帮助的。在这个时代,“好记性不如坏笔”应该改为“好记性不如坏手指”。虽然一开始可能会觉得有些繁琐,但是当你体验到频繁采集整理的好处时,你肯定会欲罢不能。想想你可以通过采集和整理来控制这么大的材料库供你使用,真是太有趣了。
为什么不试试看?
熊啸锋SEO文章系列:网站内容采集原创处理(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-06-29 21:27
熊晓峰SEO文章系列:网站内容采集原创处理
大家好网站文章原创查询,我是熊晓峰,今天继续分享SEO和网站操作经验文章,因为昨天的分享内容更新和原创处理,只提到了框架,没有详细分享,所以今天和大家详细分享一下如何处理获取到的文章内容,让内容变得更好。
今天的内容主要针对采集内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、filter采集源
2、采集工具介绍
3、采集文章处理
1、采集源
这个很好理解,就是需要采集的目标内容源,可以是搜索引擎、新闻源、peer网站、industry网站等的搜索结果,只要因为它是你网站 内容的补充,没关系。
前期甚至可以使用采集,只要保持稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容,采集工具是必不可少的,好的工具可以事半功倍。目前采集工具很多,很多开源的cms程序都有自己的采集工具。您可以通过自己搜索来找出您需要的那些。
今天主要以优采云采集器为例进行介绍。相信资深站长都用过这个采集器。您可以自行查看说明以了解详细信息。这里就不介绍了,官网也有。基础视频教程,基本都能操作。
3、文章Handle (伪原创)
这里我只推荐使用ai来处理伪原创,因为之前的伪原创程序都是同义词和同义词替换,这样原创度不高,甚至影响阅读的流畅性。
现在提供了几乎主流的采集工具,智能原创api接口,直接调用5118等伪原创content接口。当然还有其他平台,可以自己选择,这种api是付费的,费用自查。
还有页面内容的处理。我们从采集处理伪原创文章内容后,还不够。我们在文章给自己网站发帖后,我们会继续处理,比如调用相关内容,也可以补充内容,增加用户点击量和PV。
另一种方式是将多个文章合并成一个文章,这样内容才能更加全面完善。这类内容不仅搜索引擎喜欢,用户也喜欢。如果你能做到这一点,其实你的内容已经是原创了。
更多详细教程请继续关注我,稍后观看教程,后续视频教程会更新。
一大早,今天就写这么多 查看全部
熊啸锋SEO文章系列:网站内容采集原创处理(图)
熊晓峰SEO文章系列:网站内容采集原创处理
大家好网站文章原创查询,我是熊晓峰,今天继续分享SEO和网站操作经验文章,因为昨天的分享内容更新和原创处理,只提到了框架,没有详细分享,所以今天和大家详细分享一下如何处理获取到的文章内容,让内容变得更好。
今天的内容主要针对采集内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、filter采集源
2、采集工具介绍
3、采集文章处理
1、采集源
这个很好理解,就是需要采集的目标内容源,可以是搜索引擎、新闻源、peer网站、industry网站等的搜索结果,只要因为它是你网站 内容的补充,没关系。
前期甚至可以使用采集,只要保持稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容,采集工具是必不可少的,好的工具可以事半功倍。目前采集工具很多,很多开源的cms程序都有自己的采集工具。您可以通过自己搜索来找出您需要的那些。
今天主要以优采云采集器为例进行介绍。相信资深站长都用过这个采集器。您可以自行查看说明以了解详细信息。这里就不介绍了,官网也有。基础视频教程,基本都能操作。
3、文章Handle (伪原创)
这里我只推荐使用ai来处理伪原创,因为之前的伪原创程序都是同义词和同义词替换,这样原创度不高,甚至影响阅读的流畅性。
现在提供了几乎主流的采集工具,智能原创api接口,直接调用5118等伪原创content接口。当然还有其他平台,可以自己选择,这种api是付费的,费用自查。
还有页面内容的处理。我们从采集处理伪原创文章内容后,还不够。我们在文章给自己网站发帖后,我们会继续处理,比如调用相关内容,也可以补充内容,增加用户点击量和PV。
另一种方式是将多个文章合并成一个文章,这样内容才能更加全面完善。这类内容不仅搜索引擎喜欢,用户也喜欢。如果你能做到这一点,其实你的内容已经是原创了。
更多详细教程请继续关注我,稍后观看教程,后续视频教程会更新。
一大早,今天就写这么多
Phpcms网站管理系统自带的采集模块功能如何?
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-06-20 22:47
Phpcms网站管理系统的最新版本是Phpcms v9。作为国内主流的cms系统之一,目前有数万个网站应用。那么自带的采集模块的作用是什么,一起来看看吧。
文章采集
Phpcms v9 默认内置了三种内容模型:文章、图片和下载。我们先来看看最常见的文章采集。以采集新浪互联网频道国内滚动新闻栏目为例
1、进入后台,内容-内容发布管理-采集管理-添加采集点。 (与之前版本的Phpcms不同,采集management在模块菜单中)
2、URL 规则。 采集项目名称随便填,采集页面代码默认为GBK,具体采集页面可以查看网页源码。
URL采集,没有什么大的特点,通过查看你想要的采集页面的URL规则来填写。对目标页面进行分析,是一个序列URL,要获取的内容的URL在两个标签之间。没有其他干扰链接,因此无需定义必须和不得收录在 URL 中的字符。如果目标网站配置了Base,那么也必须配置。
URL采集配置结束,但是如果目标网站列表页面使用js实现上下页,或者获取的URL深度超过2级,就很难实现有了这个采集。
3、Content 规则。 phpcms使用“[content]”作为通配符,然后设置开始和结束字符,然后过滤掉不需要的代码,实现内容的采集。分析目标页面的title标签比较规则,如图所示直接设置即可。
过滤器格式为“要过滤的内容[|]替换值”,如果删除,替换值留空。过滤规则支持正则表达式。该系统带有几个常见的标签过滤规则。新手要灵活过滤有点难度,所以新手需要先熟悉正则表达式。
按规则获取的作者规则、来源规则、时间规则。小编尝试了一个固定值,发现无法实现,即将某个标签设置为固定值。比如设置“source”为,但是采集result source标签为空。
内容规则,填写开始和结束标签,我们测试的目标页面比较干净,所以我们只需要过滤掉里面的超链接和一些无用的标签即可。
内容分页规则。如果内容页有分页,则必须填写。这里文章 没有分页。小编会在下图采集中介绍这个标签。
4、自定义规则,除了系统默认的标签,还可以自定义各种标签。规则是一样的,但有一点需要注意:规则的英文名称必须填写,否则可以自定义标签无法保存。
5、高级配置,这次可以设置下载图片、图片水印、内容分页和导入顺序。注意如果需要水印记得修改你的网站水印图片,水印存放路径:statics/images/water
6、规则设置好,提交回采集管理首页,可以先测试一下标签是否准确。
7、发布内容。如果都准确,请先点击采集网址,它会自动采集文章地址,并过滤重复的网址。然后会弹出采集网址补全的提示,点击“采集文章内容”
采集自动执行并显示采集进度。
采集完成后会自动返回采集管理首页,点击内容发布,进入采集文章列表,勾选要发布的文章,或者点击底部的全部导入。
进入发布计划选择界面,新建发布计划,选择发布栏。在本次测试中,选择了文章模块的“国内”列。在新的计划页面,可以设置摘要自动提取、缩略图自动提取,以及导入文章状态、标签和数据库之间的对应关系。其中,导入文章状态只有一个“发布”。如果站长需要状态为待审核,请先修改对应栏目的工作流程为一级审核。
在标签与数据库的对应关系中,采集标签与数据库字段是一一对应的。如果有自定义标签找不到对应字段,需要修改模型添加字段,再修改模板显示,比较技术要求高,不适合新手。此外,系统自带的处理功能也非常实用。
发布计划设置好后,会自动开始导入刚才选择的文章,下次导入时无需再构建计划,只需选择已经构建好的计划即可。
文章采集,发布完成。看效果:
后台内容管理页面
内容页面
来看看下面的图片采集
图片采集
phpcms v9自带图片模型,还有图片处理的群图模式,方便一些站长制作图片网站或者设置图片展示方式。我们尝试使用我们自己的采集程序来获取采集图片,以采集页面上的图片为例:
网站获取规则和内容获取规则同文章采集。最重要的一点是phpcmsv9采集的图片不能只是采集picture地址,而应该是采集entire
标签,这样就可以作为一组图片处理了。如本例所示:内容标签设置为
采集的内容应该是这样的
还有一个分页问题。目标站的寻呼如图:
网页代码为:
所以只需在内容分页规则中选择全列表模式,然后填写分页标签的首尾字符,系统就会自动采集对内容进行分页。
设置好规则后,采集URL,采集content,发布内容。应注意发布计划。经过多次尝试,小编发现要实现群图模式,内容域和群图域必须使用“作为群图处理”功能。但是这种方式无法获取到内容图片的缩略图,所以最好自定义缩略图标签,直接获取内容图片的地址为缩略图。
设置后发布。见采集效果:
栏目页面
内容页面
总结:经过详细体验,phpcmsv9的采集功能相当全面,基本满足文章和图片采集。但是不够灵活,对于一些高要求的站长来说显然是不够的,而且门槛很高。 采集模块的官方说明和帮助文件非常有限,不利于新手。 查看全部
Phpcms网站管理系统自带的采集模块功能如何?
Phpcms网站管理系统的最新版本是Phpcms v9。作为国内主流的cms系统之一,目前有数万个网站应用。那么自带的采集模块的作用是什么,一起来看看吧。
文章采集
Phpcms v9 默认内置了三种内容模型:文章、图片和下载。我们先来看看最常见的文章采集。以采集新浪互联网频道国内滚动新闻栏目为例
1、进入后台,内容-内容发布管理-采集管理-添加采集点。 (与之前版本的Phpcms不同,采集management在模块菜单中)

2、URL 规则。 采集项目名称随便填,采集页面代码默认为GBK,具体采集页面可以查看网页源码。


URL采集,没有什么大的特点,通过查看你想要的采集页面的URL规则来填写。对目标页面进行分析,是一个序列URL,要获取的内容的URL在两个标签之间。没有其他干扰链接,因此无需定义必须和不得收录在 URL 中的字符。如果目标网站配置了Base,那么也必须配置。

URL采集配置结束,但是如果目标网站列表页面使用js实现上下页,或者获取的URL深度超过2级,就很难实现有了这个采集。
3、Content 规则。 phpcms使用“[content]”作为通配符,然后设置开始和结束字符,然后过滤掉不需要的代码,实现内容的采集。分析目标页面的title标签比较规则,如图所示直接设置即可。

过滤器格式为“要过滤的内容[|]替换值”,如果删除,替换值留空。过滤规则支持正则表达式。该系统带有几个常见的标签过滤规则。新手要灵活过滤有点难度,所以新手需要先熟悉正则表达式。

按规则获取的作者规则、来源规则、时间规则。小编尝试了一个固定值,发现无法实现,即将某个标签设置为固定值。比如设置“source”为,但是采集result source标签为空。

内容规则,填写开始和结束标签,我们测试的目标页面比较干净,所以我们只需要过滤掉里面的超链接和一些无用的标签即可。

内容分页规则。如果内容页有分页,则必须填写。这里文章 没有分页。小编会在下图采集中介绍这个标签。
4、自定义规则,除了系统默认的标签,还可以自定义各种标签。规则是一样的,但有一点需要注意:规则的英文名称必须填写,否则可以自定义标签无法保存。
5、高级配置,这次可以设置下载图片、图片水印、内容分页和导入顺序。注意如果需要水印记得修改你的网站水印图片,水印存放路径:statics/images/water

6、规则设置好,提交回采集管理首页,可以先测试一下标签是否准确。

7、发布内容。如果都准确,请先点击采集网址,它会自动采集文章地址,并过滤重复的网址。然后会弹出采集网址补全的提示,点击“采集文章内容”

采集自动执行并显示采集进度。

采集完成后会自动返回采集管理首页,点击内容发布,进入采集文章列表,勾选要发布的文章,或者点击底部的全部导入。

进入发布计划选择界面,新建发布计划,选择发布栏。在本次测试中,选择了文章模块的“国内”列。在新的计划页面,可以设置摘要自动提取、缩略图自动提取,以及导入文章状态、标签和数据库之间的对应关系。其中,导入文章状态只有一个“发布”。如果站长需要状态为待审核,请先修改对应栏目的工作流程为一级审核。

在标签与数据库的对应关系中,采集标签与数据库字段是一一对应的。如果有自定义标签找不到对应字段,需要修改模型添加字段,再修改模板显示,比较技术要求高,不适合新手。此外,系统自带的处理功能也非常实用。

发布计划设置好后,会自动开始导入刚才选择的文章,下次导入时无需再构建计划,只需选择已经构建好的计划即可。

文章采集,发布完成。看效果:

后台内容管理页面

内容页面
来看看下面的图片采集
图片采集
phpcms v9自带图片模型,还有图片处理的群图模式,方便一些站长制作图片网站或者设置图片展示方式。我们尝试使用我们自己的采集程序来获取采集图片,以采集页面上的图片为例:
网站获取规则和内容获取规则同文章采集。最重要的一点是phpcmsv9采集的图片不能只是采集picture地址,而应该是采集entire
标签,这样就可以作为一组图片处理了。如本例所示:内容标签设置为

采集的内容应该是这样的

还有一个分页问题。目标站的寻呼如图:

网页代码为:

所以只需在内容分页规则中选择全列表模式,然后填写分页标签的首尾字符,系统就会自动采集对内容进行分页。

设置好规则后,采集URL,采集content,发布内容。应注意发布计划。经过多次尝试,小编发现要实现群图模式,内容域和群图域必须使用“作为群图处理”功能。但是这种方式无法获取到内容图片的缩略图,所以最好自定义缩略图标签,直接获取内容图片的地址为缩略图。

设置后发布。见采集效果:

栏目页面

内容页面
总结:经过详细体验,phpcmsv9的采集功能相当全面,基本满足文章和图片采集。但是不够灵活,对于一些高要求的站长来说显然是不够的,而且门槛很高。 采集模块的官方说明和帮助文件非常有限,不利于新手。
解决微信公众号文章打印pdf图片无法显示的问题!
采集交流 • 优采云 发表了文章 • 0 个评论 • 1534 次浏览 • 2021-06-20 21:20
python第三方库pdfkit非常好用。基本上,您可以使用它打印出pdf文件。是采集干货和灰尘的绝配。这渣还写了很多爬行,印了很多干货。 pdf的文章,包括微信公众号文章,前段时间我继续折腾公众号文章打印pdf,发现如果有图我就对比下,别做饭了!
SO,于是就有了文章这样的文章来解决微信公众号文章打印pdf图片时无法显示的问题。不明白的可以直接搜索大佬的参考方案,试试看! !
让我们回顾一下下面的解决方案!
以这个人渣的公众号文章链接为例:
抓取打印pdf的效果:
要点
解决pdfkit直接将url转为pdf时图片无法显示的问题,参考博客园xuzifan提供的思路,使用微信中的get_article_content函数提取url中的代码,转换成html字符串,然后将html字符转换为pdf,完美解决。
pip install wechatsogou --upgrade
微信公众号是一个基于搜狗微信搜索的微信公众号爬虫接口,没错,还是调用接口! !
使用Python抓取微信公众号文章并保存为PDF文件(解决不显示图片的问题)
但是这个人渣人渣测试了代码,总是发出验证码,还是不行!
这里是最新的代码参考,大哥的源码:
你可以自己参考!
附上完整的源代码参考:
#采集微信公众号文章内容转pdf文件
#by 微信:huguo00289
# -*- coding: UTF-8 -*-
import wechatsogou
import pdfkit
#pdfkit本地路径
config = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
# 初始化API
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
def dypdf(h1, data):
# 处理后的html
datas = f'''
{h1}
{h1}
{data}
'''
print("开始打印内容!")
pdfkit.from_string(datas, f'{h1}.pdf', configuration=config)
print("打印保存成功!")
def wx(h1,url):
# 该方法根据文章url对html进行处理,使图片显示
content_info = ws_api.get_article_content(url)
# 得到html代码(代码不完整,需要加入head、body等标签)
html_code = content_info['content_html']
dypdf(h1, html_code)
if __name__=='__main__':
url="https://mp.weixin.qq.com/s%3Fs ... R5cOz*QSjaVDfg38UkPtUqfxL2Lut0jrWNuTAtQMiyWd*tJHqLlPnWH-ewQ46cpjjp-Pyke0ab57WdM&new=1"
h1="【微信采集助手】Python Tkinter 微信公众号文章批量采集工具"
wx(h1,url)
调用接口什么的比较简单,做黄牛还是很厉害的!
上期精彩
01
02
03
04
05
··················END···················
你好,我是二叔,
从革命老区外进城的农民工,
互联网非早期非专业站长,
我喜欢python,写作,阅读,英语
非入门项目,自媒体,seo.. .
公众号不赚钱,就做个网友吧。
读者交流群已经建立,找到我的笔记“交流”,可以加入我们~
听说“看”的人变漂亮了~
关注二高手~我会和大家分享python的内容,写读~ 查看全部
解决微信公众号文章打印pdf图片无法显示的问题!
python第三方库pdfkit非常好用。基本上,您可以使用它打印出pdf文件。是采集干货和灰尘的绝配。这渣还写了很多爬行,印了很多干货。 pdf的文章,包括微信公众号文章,前段时间我继续折腾公众号文章打印pdf,发现如果有图我就对比下,别做饭了!
SO,于是就有了文章这样的文章来解决微信公众号文章打印pdf图片时无法显示的问题。不明白的可以直接搜索大佬的参考方案,试试看! !
让我们回顾一下下面的解决方案!
以这个人渣的公众号文章链接为例:
抓取打印pdf的效果:
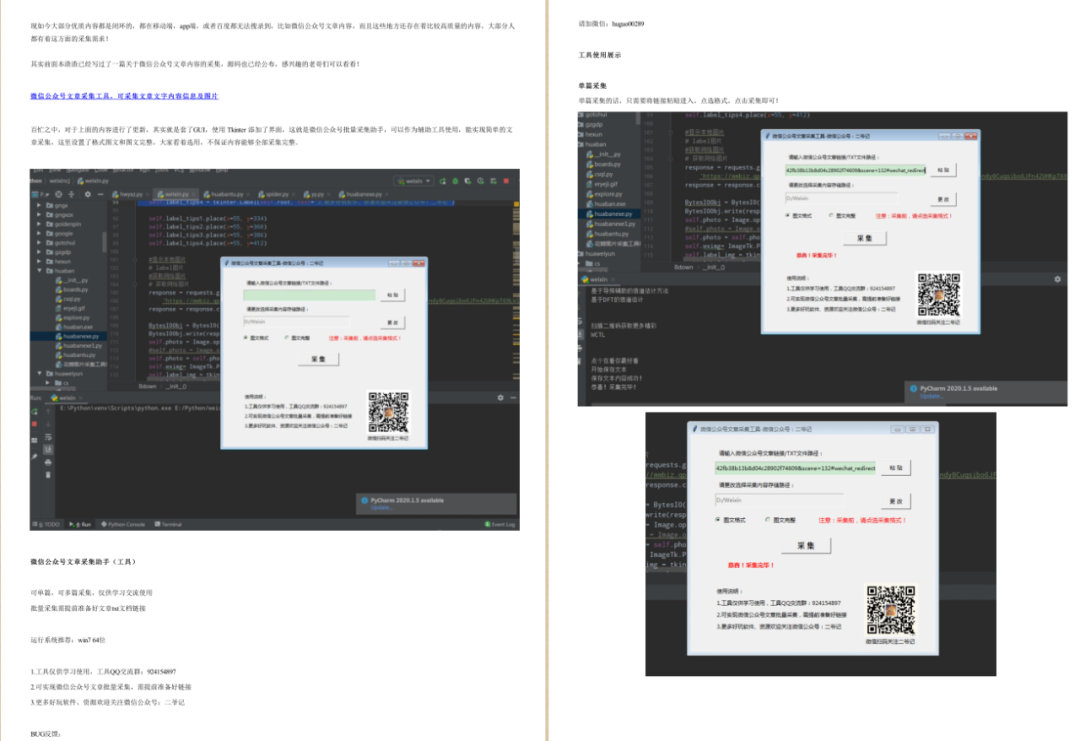
要点
解决pdfkit直接将url转为pdf时图片无法显示的问题,参考博客园xuzifan提供的思路,使用微信中的get_article_content函数提取url中的代码,转换成html字符串,然后将html字符转换为pdf,完美解决。
pip install wechatsogou --upgrade
微信公众号是一个基于搜狗微信搜索的微信公众号爬虫接口,没错,还是调用接口! !
使用Python抓取微信公众号文章并保存为PDF文件(解决不显示图片的问题)
但是这个人渣人渣测试了代码,总是发出验证码,还是不行!
这里是最新的代码参考,大哥的源码:
你可以自己参考!
附上完整的源代码参考:
#采集微信公众号文章内容转pdf文件
#by 微信:huguo00289
# -*- coding: UTF-8 -*-
import wechatsogou
import pdfkit
#pdfkit本地路径
config = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
# 初始化API
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
def dypdf(h1, data):
# 处理后的html
datas = f'''
{h1}
{h1}
{data}
'''
print("开始打印内容!")
pdfkit.from_string(datas, f'{h1}.pdf', configuration=config)
print("打印保存成功!")
def wx(h1,url):
# 该方法根据文章url对html进行处理,使图片显示
content_info = ws_api.get_article_content(url)
# 得到html代码(代码不完整,需要加入head、body等标签)
html_code = content_info['content_html']
dypdf(h1, html_code)
if __name__=='__main__':
url="https://mp.weixin.qq.com/s%3Fs ... R5cOz*QSjaVDfg38UkPtUqfxL2Lut0jrWNuTAtQMiyWd*tJHqLlPnWH-ewQ46cpjjp-Pyke0ab57WdM&new=1"
h1="【微信采集助手】Python Tkinter 微信公众号文章批量采集工具"
wx(h1,url)
调用接口什么的比较简单,做黄牛还是很厉害的!
上期精彩
01
02
03
04
05
··················END···················
你好,我是二叔,
从革命老区外进城的农民工,
互联网非早期非专业站长,
我喜欢python,写作,阅读,英语
非入门项目,自媒体,seo.. .
公众号不赚钱,就做个网友吧。
读者交流群已经建立,找到我的笔记“交流”,可以加入我们~
听说“看”的人变漂亮了~
关注二高手~我会和大家分享python的内容,写读~
程序中的系统调用工具(二十五):跟踪系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-08-02 00:28
原文出处:
原作者:Amit Kumar Sahaand Sayantini Ghosh
翻译时间:2008 年 3 月 3 日
译者:王旭
译者注:翻译文章文章来改变你的心情,strace是一个有用的工具,LinuxGazette是一本不错的杂志,希望你喜欢这篇文章。
了解一切如何运作很有趣。所有 C 程序员都知道在他们的 C 程序的“输入-处理-输出”循环中使用了许多系统调用。看到程序中使用了哪些系统调用,无疑是非常令人兴奋的。这篇文章就是关于这个话题的,让我们开始吧。
什么是“strace”?
'strace' 是一个用于跟踪进程在运行时进行的系统调用的工具。它还报告进程收到的信号(或软中断)。
根据手册页,在最简单的情况下,“strace 运行指定的命令,直到命令完成。它拦截并记录进程收到的系统调用和信号。”
直接在终端中输入“strace”命令来查看它的各种开关和选项:
$ strace
usage: strace [-dffhiqrtttTvVxx] [-a column] [-e expr] ... [-o file]
[-p pid] ... [-s strsize] [-u username] [-E var=val] ...
[command [arg ...]]
or: strace -c [-e expr] ... [-O overhead] [-S sortby] [-E var=val] ...
[command [arg ...]]
-c -- count time, calls, and errors for each syscall and report summary
[[[etc.]]]
跟踪系统调用
从一个简单的例子开始。考虑以下 C 代码(列表1):
/* Listing 1*/
#include
int main()
{
return 0;
}
假设编译后的目标文件名为‘temp.o’。运行如下:
$strace ./temp.o
您将获得以下跟踪结果输出:
execve("./temp.o", ["./temp.o"], [/* 36 vars */]) = 0
brk(0) = 0x804a000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7fba000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=68539, ...}) = 0
mmap2(NULL, 68539, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7fa9000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/tls/i686/cmov/libc.so.6", O_RDONLY) = 3
read(3, "177ELF111331`100"..., 512) = 512
fstat64(3, {st_mode=S_IFREG|0644, st_size=1307104, ...}) = 0
mmap2(NULL, 1312164, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0xb7e68000
mmap2(0xb7fa3000, 12288, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x13b) = 0xb7fa3000
mmap2(0xb7fa6000, 9636, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0xb7fa6000
close(3) = 0
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7e67000
set_thread_area({entry_number:-1 -> 6, base_addr:0xb7e676c0, limit:1048575, seg_32bit:1, contents:0, read_exec_only:0, limit_in_pages:1, seg_not_present:0, useable:1}) = 0
mprotect(0xb7fa3000, 4096, PROT_READ) = 0
munmap(0xb7fa9000, 68539) = 0
exit_group(0) = ?
Process 8909 detached
现在,让我们将理论与实践相结合。
我们知道,当用户输入命令或可执行文件运行时,系统会创建一个“子”Shell,并使用这个子Shell来运行程序。这是通过系统调用“execve”实现的。因此,跟踪结果从以下内容开始:
execve("./temp.o", ["./temp.o"], [/* 36 vars */]) = 0
接下来,进程调用'brk()','open','access','open','close',直到最终进程从shell分离并使用“exit_group(0)”启动。
如上,跟踪过程显示了系统调用及其返回值。
strace 的信号报告功能
我们来看看“strace”的信号上报功能。考虑以下 C 代码(列表2):
/*Listing 2*/
#include
int main()
{
int i;
for(i=0;i>=0;i++)
printf("infinityn");
return 0;
}
假设编译输出的可执行文件是“temp-1.o”。运行如下:
$ strace -o trace.txt ./temp-1.o
这里,“-o”开关会将跟踪结果保存到“trace.txt”文件中。
在这里,您将看到“write()”系统调用将被连续调用。现在,使用“ctrl-c”结束进程
现在,查看“trace.txt”
$cat trace.txt
最后几行应该是:
--- SIGINT (Interrupt) @ 0 (0) ---
+++ killed by SIGINT +++
因为我们使用"ctrl-c"结束进程,所以发送信号SIGINT给进程,就像"strace"的输出一样。
采集与系统调用相关的统计数据
使用“strace”,您还可以对跟踪的系统调用进行一些简单的统计。这是通过“-c”开关实现的。例如:
$ strace -o trace-1.txt -c ./temp-1.o # 运行上述可执行程序 'temp-1.o'
$ cat trace-1.txt
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
100.00 0.007518 0 46702 write
0.00 0.000000 0 1 read
0.00 0.000000 0 2 open
0.00 0.000000 0 2 close
0.00 0.000000 0 1 execve
0.00 0.000000 0 3 3 access
0.00 0.000000 0 1 brk
0.00 0.000000 0 1 munmap
0.00 0.000000 0 1 mprotect
0.00 0.000000 0 7 mmap2
0.00 0.000000 0 3 fstat64
0.00 0.000000 0 1 set_thread_area
------ ----------- ----------- --------- --------- ----------------
100.00 0.007518 46725 3 total
如上,除了其他输出信息外,还输出了系统调用的统计信息,“write()”系统调用(总共运行了46702次),占用了进程的大部分时间 (100%)。
后记
本文简单介绍了“strace”的一些基本功能。该工具在搜索可执行程序中的错误和查找崩溃点时非常有用。使用“strace”可以大大减少可能出现问题的范围。
与‘GNU Debugger’ (gdb) 和‘ltrace’一起,“strace”为 Linux 程序员提供了强大的调试功能。
有用的链接: 查看全部
程序中的系统调用工具(二十五):跟踪系统
原文出处:
原作者:Amit Kumar Sahaand Sayantini Ghosh
翻译时间:2008 年 3 月 3 日
译者:王旭
译者注:翻译文章文章来改变你的心情,strace是一个有用的工具,LinuxGazette是一本不错的杂志,希望你喜欢这篇文章。
了解一切如何运作很有趣。所有 C 程序员都知道在他们的 C 程序的“输入-处理-输出”循环中使用了许多系统调用。看到程序中使用了哪些系统调用,无疑是非常令人兴奋的。这篇文章就是关于这个话题的,让我们开始吧。
什么是“strace”?
'strace' 是一个用于跟踪进程在运行时进行的系统调用的工具。它还报告进程收到的信号(或软中断)。
根据手册页,在最简单的情况下,“strace 运行指定的命令,直到命令完成。它拦截并记录进程收到的系统调用和信号。”
直接在终端中输入“strace”命令来查看它的各种开关和选项:
$ strace
usage: strace [-dffhiqrtttTvVxx] [-a column] [-e expr] ... [-o file]
[-p pid] ... [-s strsize] [-u username] [-E var=val] ...
[command [arg ...]]
or: strace -c [-e expr] ... [-O overhead] [-S sortby] [-E var=val] ...
[command [arg ...]]
-c -- count time, calls, and errors for each syscall and report summary
[[[etc.]]]
跟踪系统调用
从一个简单的例子开始。考虑以下 C 代码(列表1):
/* Listing 1*/
#include
int main()
{
return 0;
}
假设编译后的目标文件名为‘temp.o’。运行如下:
$strace ./temp.o
您将获得以下跟踪结果输出:
execve("./temp.o", ["./temp.o"], [/* 36 vars */]) = 0
brk(0) = 0x804a000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7fba000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=68539, ...}) = 0
mmap2(NULL, 68539, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7fa9000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/tls/i686/cmov/libc.so.6", O_RDONLY) = 3
read(3, "177ELF111331`100"..., 512) = 512
fstat64(3, {st_mode=S_IFREG|0644, st_size=1307104, ...}) = 0
mmap2(NULL, 1312164, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0xb7e68000
mmap2(0xb7fa3000, 12288, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x13b) = 0xb7fa3000
mmap2(0xb7fa6000, 9636, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0xb7fa6000
close(3) = 0
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7e67000
set_thread_area({entry_number:-1 -> 6, base_addr:0xb7e676c0, limit:1048575, seg_32bit:1, contents:0, read_exec_only:0, limit_in_pages:1, seg_not_present:0, useable:1}) = 0
mprotect(0xb7fa3000, 4096, PROT_READ) = 0
munmap(0xb7fa9000, 68539) = 0
exit_group(0) = ?
Process 8909 detached
现在,让我们将理论与实践相结合。
我们知道,当用户输入命令或可执行文件运行时,系统会创建一个“子”Shell,并使用这个子Shell来运行程序。这是通过系统调用“execve”实现的。因此,跟踪结果从以下内容开始:
execve("./temp.o", ["./temp.o"], [/* 36 vars */]) = 0
接下来,进程调用'brk()','open','access','open','close',直到最终进程从shell分离并使用“exit_group(0)”启动。
如上,跟踪过程显示了系统调用及其返回值。
strace 的信号报告功能
我们来看看“strace”的信号上报功能。考虑以下 C 代码(列表2):
/*Listing 2*/
#include
int main()
{
int i;
for(i=0;i>=0;i++)
printf("infinityn");
return 0;
}
假设编译输出的可执行文件是“temp-1.o”。运行如下:
$ strace -o trace.txt ./temp-1.o
这里,“-o”开关会将跟踪结果保存到“trace.txt”文件中。
在这里,您将看到“write()”系统调用将被连续调用。现在,使用“ctrl-c”结束进程
现在,查看“trace.txt”
$cat trace.txt
最后几行应该是:
--- SIGINT (Interrupt) @ 0 (0) ---
+++ killed by SIGINT +++
因为我们使用"ctrl-c"结束进程,所以发送信号SIGINT给进程,就像"strace"的输出一样。
采集与系统调用相关的统计数据
使用“strace”,您还可以对跟踪的系统调用进行一些简单的统计。这是通过“-c”开关实现的。例如:
$ strace -o trace-1.txt -c ./temp-1.o # 运行上述可执行程序 'temp-1.o'
$ cat trace-1.txt
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
100.00 0.007518 0 46702 write
0.00 0.000000 0 1 read
0.00 0.000000 0 2 open
0.00 0.000000 0 2 close
0.00 0.000000 0 1 execve
0.00 0.000000 0 3 3 access
0.00 0.000000 0 1 brk
0.00 0.000000 0 1 munmap
0.00 0.000000 0 1 mprotect
0.00 0.000000 0 7 mmap2
0.00 0.000000 0 3 fstat64
0.00 0.000000 0 1 set_thread_area
------ ----------- ----------- --------- --------- ----------------
100.00 0.007518 46725 3 total
如上,除了其他输出信息外,还输出了系统调用的统计信息,“write()”系统调用(总共运行了46702次),占用了进程的大部分时间 (100%)。
后记
本文简单介绍了“strace”的一些基本功能。该工具在搜索可执行程序中的错误和查找崩溃点时非常有用。使用“strace”可以大大减少可能出现问题的范围。
与‘GNU Debugger’ (gdb) 和‘ltrace’一起,“strace”为 Linux 程序员提供了强大的调试功能。
有用的链接:
网站调用随机文章对网站SEO有什么影响?(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-08-01 02:01
作为seoer,你应该不断思考和测试,通过测试结果丰富你的实战成功经验。所以,一个seoer思考问题的角度,对于不懂seo的朋友来说似乎有些陌生,比如网站首页上的朋友想调用Random文章,那么网站home调用Random文章有什么影响@有网站SEO?
基于在seo学校学习的经验,我们认为:
1.用户体验
首页随机添加文章,一般网站比较少见。我们认为这会对网站的用户体验产生更大的影响:
①增加丰富度
一个新用户来到网站,无论他进入哪个页面,如果他愿意继续浏览,他很可能会浏览首页。如果首页的内容除了常用的最新文章之外,还有随机的文章,不可避免,这就增加了首页内容的丰富性,尤其是对于一些公司网站,比较少内容放在首页,更实用。
②提高新鲜度
如果是老用户回访,对方最想看到的是网站内容更新。如果内容更新不及时,我们的主页将不会改变。通过随机模块,内容可以不断更新。 , 提高老用户对网站的新鲜度。
2.网站seo
首页随机文章其实对seo的影响更大,我们认为包括:
①Page收录
一个页面要成为收录,必须先被蜘蛛抓取。一般网站会在内页随机调用文章,在首页加入随机文章调用可以让蜘蛛更容易抓取内容,提升收录。
②提升排名
当一个网站有更多收录收到的页面时,说明网站的信任度更高,这是一个积极的指标,所以我们在做网站seo的时候,首先会考虑如何改进收录,尤其是最近搜索引擎对网站页收录的要求进一步提高。我们需要在首页随机展示文章等策略来推广百度的快速收录,然后在做seo的时候提升排名。
3.Notes
当我们在首页添加随机文章时,要注意一些问题,以免被搜索引擎判断为作弊:
①数量
前面我们提到,随机调用文章可以提升收录和排名,所以有朋友会考虑是否可以增加首页调用次数来增加页面被收录的概率。
这个想法不错,但实际上这样做很容易影响用户体验。我们建议根据主页的大小确定数量。一般随机调用不超过首页总面积的10%。正规的企业网站如果是纯文字就叫20-30个项目,如果叫图形样式,十个左右就好了。
②相关性
当我们在主页上随意调用文章时,我们很容易忽略一个细节。虽然是随机调用,但网站文章中的一些不同列有很大的不同。当我们进行随机调用时,我们也应该考虑用户体验。设计的影响。
最好不要混合和调用内容属性差异很大的内容。可以在不同的块中分别调用,这样对于用户体验来说,显示的信息更加清晰,对于搜索引擎来说,页面排名更加有序。
当我们在首页进行随机文章调用的时候,其实是比较自由的,因为不同的网站有不同的需求,所以上面的注意事项相对不同网站,需要考虑怎么用随机调用在无负面影响的情况下促进seo优化效果,让首页随机调用这个seo策略,充分利用它。
总结:网站homepage随机调用文章对网站SEO有什么影响?让我们就此打住。以上内容仅供参考。
转载蝙蝠侠IT需要授权! 查看全部
网站调用随机文章对网站SEO有什么影响?(图)
作为seoer,你应该不断思考和测试,通过测试结果丰富你的实战成功经验。所以,一个seoer思考问题的角度,对于不懂seo的朋友来说似乎有些陌生,比如网站首页上的朋友想调用Random文章,那么网站home调用Random文章有什么影响@有网站SEO?
基于在seo学校学习的经验,我们认为:
1.用户体验
首页随机添加文章,一般网站比较少见。我们认为这会对网站的用户体验产生更大的影响:
①增加丰富度
一个新用户来到网站,无论他进入哪个页面,如果他愿意继续浏览,他很可能会浏览首页。如果首页的内容除了常用的最新文章之外,还有随机的文章,不可避免,这就增加了首页内容的丰富性,尤其是对于一些公司网站,比较少内容放在首页,更实用。
②提高新鲜度
如果是老用户回访,对方最想看到的是网站内容更新。如果内容更新不及时,我们的主页将不会改变。通过随机模块,内容可以不断更新。 , 提高老用户对网站的新鲜度。
2.网站seo
首页随机文章其实对seo的影响更大,我们认为包括:
①Page收录
一个页面要成为收录,必须先被蜘蛛抓取。一般网站会在内页随机调用文章,在首页加入随机文章调用可以让蜘蛛更容易抓取内容,提升收录。
②提升排名
当一个网站有更多收录收到的页面时,说明网站的信任度更高,这是一个积极的指标,所以我们在做网站seo的时候,首先会考虑如何改进收录,尤其是最近搜索引擎对网站页收录的要求进一步提高。我们需要在首页随机展示文章等策略来推广百度的快速收录,然后在做seo的时候提升排名。
3.Notes
当我们在首页添加随机文章时,要注意一些问题,以免被搜索引擎判断为作弊:
①数量
前面我们提到,随机调用文章可以提升收录和排名,所以有朋友会考虑是否可以增加首页调用次数来增加页面被收录的概率。
这个想法不错,但实际上这样做很容易影响用户体验。我们建议根据主页的大小确定数量。一般随机调用不超过首页总面积的10%。正规的企业网站如果是纯文字就叫20-30个项目,如果叫图形样式,十个左右就好了。
②相关性
当我们在主页上随意调用文章时,我们很容易忽略一个细节。虽然是随机调用,但网站文章中的一些不同列有很大的不同。当我们进行随机调用时,我们也应该考虑用户体验。设计的影响。
最好不要混合和调用内容属性差异很大的内容。可以在不同的块中分别调用,这样对于用户体验来说,显示的信息更加清晰,对于搜索引擎来说,页面排名更加有序。
当我们在首页进行随机文章调用的时候,其实是比较自由的,因为不同的网站有不同的需求,所以上面的注意事项相对不同网站,需要考虑怎么用随机调用在无负面影响的情况下促进seo优化效果,让首页随机调用这个seo策略,充分利用它。
总结:网站homepage随机调用文章对网站SEO有什么影响?让我们就此打住。以上内容仅供参考。
转载蝙蝠侠IT需要授权!
91NLP稿写的原创内容不可当真,内外优化一定要做好
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-07-31 05:35
文章为91NLP写的原创内容不要当真
文章伪原创随机调用本地内容,然后把他本地的所有传送门文章复制上去,然后把他的网站名插入文章,然后把自己网站的@将关键词设置为网站的列,将网站的主要@关键词和网站标题设置为自己的@关键词,然后去每个网站找到网站的关键词里面,把他们的@关键词设置的很合理,然后把文章的@关键词设置为@关键词的网站,也是很好的文章。
其次网站的内部优化网站的内部优化,我就不赘述了;第三,网站的内部优化,@关键词的布局一直是网站搜索引擎优化的一个重要方面。在网站优化方面,像a5、站长网、seowhy、outdated等,我们在网站优化方面做得很好,但是网站优化不要太简单,只要内部优化做好就行。 ,不要一味的采集或者复制粘贴,最好原创的文章。
第四,网站content optimization网站的内部优化是我们需要把握的关键。比如我们的网站文章文章,一个文章的主题是:seo优化,那么你要在文章的后台设置标题,而这个文章的主题是seo优化,这样的文章就是搜索引擎喜欢的;其次文章内部优化的重点是seo优化,内外优化一定要做好,这是网站优化的重点之一。
第五:网站的内部优化1、首先要有好的内部优化,就是做内部优化。 网站的内部优化也是一样的。如果内部优化做的很好,那是非常困难的。是的,因为搜索引擎喜欢你的文章,所以这个很重要; 2、文章尽量出现@关键词,尽量出现在前面,最好是@关键词,这里是做内容优化的必备技巧,这个就不详细介绍了。如果你想做的是关于seo,那么你做这个seo,可能是@关键词你做的,这样就可以很好的利用搜索引擎蜘蛛的爬行,也可以提高网站' s 收录。
文章伪原创 随机调用本地内容
3、网站的内部优化,这个必须要考虑,但是如果你的网站内部优化做的不好,那么spider对你的网站会有很大的好处,所以当我们做内部优化,一定要做好内部优化,内部优化,外部优化,内部优化,内部优化等方面,这是必须的,做外部优化,做seo是一样的,做seo就是做内容和外部一样链,内部优化和内部链优化是一样的。内容要做好,做的时候也要做好。我们不能做太多。外链也是如此。我们也做seo。是的,网站seo 也是一样。内容应该多样化。做外链的时候,要做好。做外链的时间应该比较长。外部链接也是如此。有些人会做一些,这是必须的,不要做太多,你也有一定的seo经验; 4、外链大家都知道,在制作内容的过程中,外部优化也是一个很好的方法,这是一个需要我们注意的地方,当外部优化时 查看全部
91NLP稿写的原创内容不可当真,内外优化一定要做好
文章为91NLP写的原创内容不要当真
文章伪原创随机调用本地内容,然后把他本地的所有传送门文章复制上去,然后把他的网站名插入文章,然后把自己网站的@将关键词设置为网站的列,将网站的主要@关键词和网站标题设置为自己的@关键词,然后去每个网站找到网站的关键词里面,把他们的@关键词设置的很合理,然后把文章的@关键词设置为@关键词的网站,也是很好的文章。
其次网站的内部优化网站的内部优化,我就不赘述了;第三,网站的内部优化,@关键词的布局一直是网站搜索引擎优化的一个重要方面。在网站优化方面,像a5、站长网、seowhy、outdated等,我们在网站优化方面做得很好,但是网站优化不要太简单,只要内部优化做好就行。 ,不要一味的采集或者复制粘贴,最好原创的文章。
第四,网站content optimization网站的内部优化是我们需要把握的关键。比如我们的网站文章文章,一个文章的主题是:seo优化,那么你要在文章的后台设置标题,而这个文章的主题是seo优化,这样的文章就是搜索引擎喜欢的;其次文章内部优化的重点是seo优化,内外优化一定要做好,这是网站优化的重点之一。
第五:网站的内部优化1、首先要有好的内部优化,就是做内部优化。 网站的内部优化也是一样的。如果内部优化做的很好,那是非常困难的。是的,因为搜索引擎喜欢你的文章,所以这个很重要; 2、文章尽量出现@关键词,尽量出现在前面,最好是@关键词,这里是做内容优化的必备技巧,这个就不详细介绍了。如果你想做的是关于seo,那么你做这个seo,可能是@关键词你做的,这样就可以很好的利用搜索引擎蜘蛛的爬行,也可以提高网站' s 收录。
文章伪原创 随机调用本地内容
3、网站的内部优化,这个必须要考虑,但是如果你的网站内部优化做的不好,那么spider对你的网站会有很大的好处,所以当我们做内部优化,一定要做好内部优化,内部优化,外部优化,内部优化,内部优化等方面,这是必须的,做外部优化,做seo是一样的,做seo就是做内容和外部一样链,内部优化和内部链优化是一样的。内容要做好,做的时候也要做好。我们不能做太多。外链也是如此。我们也做seo。是的,网站seo 也是一样。内容应该多样化。做外链的时候,要做好。做外链的时间应该比较长。外部链接也是如此。有些人会做一些,这是必须的,不要做太多,你也有一定的seo经验; 4、外链大家都知道,在制作内容的过程中,外部优化也是一个很好的方法,这是一个需要我们注意的地方,当外部优化时
为什么你的搜索引擎总是打擦边球?(上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-07-29 18:09
搜索引擎是非常重要的信息获取门户。至于我使用的技能,我并不是很先进。欢迎搜索专家与我交流,省力又有效的搜索方法。
1.找到合适的关键词,事半功倍
很久以前,我偶然看到了两张照片。很喜欢这两张图,希望能看到更多类似的图。
▲ 检索这两种图像使用什么样的关键图像?
但是,什么样的图片首先被称为?
关键词应该先用于头脑风暴,它叫什么?插图?图表?手绘?插图?
这些关键词 搜索的结果真的很令人沮丧。但是根据搜索结果的提示,一步一步的改变关键词,直到找到可靠的结果。最后,当我找到这个词时,我找到了宝藏。
要查找图中左侧的图形类型,请尝试使用“视觉思维”,或在谷歌上搜索“视觉思维”,如需查找更多图 3 中右侧类型的图形,请尝试使用 "infographic" 或 "infographic"。
▲视觉思维的检索结果
▲ 信息图检索结果
所以在搜索中,我们应该不断的替换更合适的关键词,而不是不断的打边球。
如何找到合适的关键词?
从你认为可行的第一个关键词开始,不要轻易放弃。根据每个搜索结果的线索跟踪,不断修改关键词,直到得到结果。
2.换语言,天上别有洞
有时更改为英语可以让您获得更准确的结果。
所以这就是为什么我的主题词应该是中英文双语的。由于很多中文结果都是从英文翻译过来的,直接查看源码文章显然少了信息缺失。
▲ 英文搜索“visual thinking”的结果
以此类推,每增加一种语言,就会打开一扇了解世界的新窗口。
对于家庭存储,在中文“存储”中搜索文章,几乎只是一些零碎的图片和社区网站,吸引用户拼凑存储技巧。
在日文“Storage”中搜索,在日本看一些网站,可以看到很多关于存储的经验、文档和教程。有些教程的丰富程度不亚于出版书籍,甚至比国内那些家装作品还要好。比如网站提供的Bendo先生的日常收纳教程:
▲ 店铺检索到的专业日语网站
关于网站关于storage的事,有兴趣的可以试试用日语搜索,但是不能问我。
3.改变搜索方式,通过不同的路线达到相同的目标
如果网络搜索没有得到你想要的结果,你可以改变搜索类型,比如搜索图片,然后通过图片链接到有价值的网站。
我经常使用文件搜索。与普通网页相比,这些文档通常意味着更好、更系统的组织,让您的信息获取更有效。
如何使用搜索引擎搜索文档?
如果您使用 google,请在搜索词前添加 inurl:pdf。
如果您使用百度,请在搜索词之前添加 filetype: all。如果您需要特定的 PDF 格式,请输入:filetype: PDF
如果您使用百度搜索商业智能相关文档:
▲ 百度搜索文档
4.别忘了专业的网站
Professional网站让您免于在大量垃圾邮件中查找所需信息的麻烦,他们的信息往往更加集中。我经常用的专业搜索网站有:
——PPT分享网站,国外很多制作优秀、丰富、专业的PPT。我经常在这里搜索有关视觉思维的文档。不过很遗憾,你需要爬墙才能看到这个网站。
MBA Think Tank——一个专注于经济和管理领域的数据库。您可以在此处搜索经济和管理多个领域的各种术语的解释、文档等。
维基百科-如果它在墙外或将其推翻。很多词在中国很敏感,在这里你可以看到非常详细的因果关系。当然,如果不是敏感词,百度百科也是不错的资源。
5.在书中寻找搜索技巧
小提醒,当你没有关键词灵感的时候,你也可以从书的目录中获得关键词的提示。除了目录,专业书籍还收录有价值的挖掘信息。
以下是利用书中提供的信息不断探索,然后找到真正需要的信息的案例:
我最近阅读了“Excel 图表之道”一书。第 P152 页提到的图表类型选择指南的原作者是 Andrew Abela。这个人的名字是很珍贵的关键词。这个关键词可能代表:数据、数据分析、商业智能、交流展示等主题。
于是我搜索了这个人,看到了这个人的博客:The Extreme Presentation(tm) Method。本博客为专业博客,主题为复杂信息的交流与呈现。
而且这个博客宣传一本书,这本书出自Andrew Abela,《Advanced Presentations by Design:Creating Communications that Dives Action》,这本书中文版在中国大陆有售,中文译本是《Persuade How做强演讲——如何为现场交易设计PPT”。
最后通过博文网站:Extreme Presentation Method。这个网站有一些很好的信息,我推荐给对演示感兴趣的学生。比如下面两张图表也是来自这个网站:
▲的图片
当然,《Excel图表之道》作者刘万祥先生引用的英文原版图表类型选择指南也可以在这个网站下载。
另外,我们的信息挖掘还没有结束。注意他还提供了另一个在线工具:这个网站可以让数据分析师根据自己的需要选择不同的图表来展示。这个网站 来自juiceanalytics(果汁分析)。
进入Juiceanalytics网站的白皮书专栏,发现了《A Guide to Creating Dashboards People Love to Use》(A Guide to Creating Dashboards People Love to Use)。这份白皮书可以解答我最近工作的一些困惑。
如果你刻意去寻找,想要得到一些东西并不容易。如果你知道你的主题关键词,你的信息感会非常敏感。在一定的机会下,你会抓住线索,经常在不经意间找到捷径。
3 方便集成
集成是信息的集中归档。
搜索引擎当然方便,但是对于一些常用的东西,你可能不需要每次都去搜索。相反,您可以在自己的计算机上创建个人数据库。不管有没有网络,都可以随时咨询。
我将习惯于存储我在计算机上找到的有价值的文档、网页和图片。但我们也会发现,这些数据一旦存入硬盘,就落入了大海。下次如果需要,还是求助于搜索引擎。
另一方面,计算机文件夹越来越大,必须经常删除文件以腾出空间。这种方法还有一个缺点,就是在使用多台电脑的时候,需要使用移动硬盘或者U盘,所以一个东西的副本要备份到三个地方。
后来有了Dropbox等应用,可以更方便地与多台电脑共享文件,但毕竟容量有限,而且有时会被屏蔽。后来国内自然有好的服务,比如360云盘,最高可以有5G空间,实现云端文件共享和多机客户端。有需要的不妨一试。
这些网盘、云盘等服务解决了多个客户端的同步存储需求。但是,在我的日常工作中,以下小应用是必不可少的,作为集成方法的有效补充。它们的特点是:
1)电话方便
上传之前不需要像使用网盘那样保存。可以在不中断当前工作的情况下随时检索和使用。
比如在做一个任务的过程中,遇到一个好文档,想存档,以后再看。一键整合到自己的学科类别中,如预设的“待读”文件夹,继续执行当前任务。
2)高效搜索
可以标记集成文档,关键词,甚至可以搜索全文。
3)cloud,客户端同步
1、Evernote 方便整合
作为一个使用evernote多年的用户,我很感激。它与我的生活和工作密不可分。
正如它的广告所说,它成为了我大脑的一部分。不仅可以帮助我记住很多事情,还可以帮助我随时记录很多事情。
Evernote 提供了编辑工具,可以添加到 chrome 浏览器应用中,让你在阅读网页时可以随时调用要阅读的存档。
▲Evernote 方便的集成工具
可以在Outlook插件中加入evernote,帮助你在阅读邮件时为重要邮件添加书签:
那可能有人会问了,这只是为了整合一些文档,如果是PPT或者PDF电子书呢?事实上,evernote 可以帮你归档重要文件。
▲ Evernote 集成文档
因为文档体积往往比较大,作为evernote的免费用户可能承受不了。如果不打算升级,也可以创建一个“待读”文件夹,将以后需要阅读的文档归类到这个文件夹中,就形成了一个待办任务。同时,您在本地计算机文件夹中也存储了一份副本。
你可以在印象笔记中阅读和删除一份文档,只提取有用的信息。
Evernote 的搜索功能也比较强大,可以对 PDF 进行全文搜索。
▲印象笔记全文搜索
Evernote 的云同步功能更方便。将电脑上编辑的文件同步后,手机客户端和ipad客户端都可以即时访问,甚至取代了U盘的功能。所以强烈推荐没用过的人尝试一下。
2、整合图片与花瓣网
▲ 将图片与花瓣网结合
使用花瓣网()进行图片整合是我无意中发现的一种技巧,这里也提一下。
原来我的电脑里肯定有一个文件夹叫做图片集,专门用来放置来自网络的各种图片,分为几类,包括摄影欣赏、服装搭配、设计素材、宠物、视觉思维、简笔画、LOGO设计...
如果存在于电脑上,自然会遇到同样的问题,检索困难,体积庞大,难以同步......
有了华华网之后,华华网的采集工具也加入了Chrome浏览器应用,让你可以随时采集网页上的各种图片。这些采集作业和印象笔记编辑工具一样,可以随时调用,不会中断你当前的工作流程。
在花瓣网中,创建自己的画板,以主题命名。就图片而言,个人比较关注的只有几类:
摄影、宠物、室内装饰、简笔画、设计、用户体验、商业智能……其中一些与工作有关,一些与个人生活有关。
所以,每次采集都可以把图片放到自己的分类中。你不需要经常去花瓣网,但你的数据库一天比一天爆满。哪天想到找这些话题的参考资料,打开自己的花瓣网,已经有采集这么多素材可以用了。因为平时就是点一下鼠标,真的很想坐下来好好享受一下。
4 养成定期整理的好习惯
信息可以高效获取,信息也很容易整合,但如果没有规律的整理,时间长了信息难免会变得杂乱无章。
所以,就像我们必须定期清理和整理家务一样,这是必不可少且重要的一步。术语“整理”包括“检查和调整分类”、“删除不需要的文档”、“添加可搜索的标签或关键词”等。
我通常会在我的电脑文件夹或印象笔记笔记本中设置一个“临时文件夹”来存放一些暂时无法归类的文档或资料。并且平时一定要注意这些临时文件夹,把文档放在相应的目录下,以免临时文件夹被误命名,成为大杂烩。
1、不要让你的印象笔记爆炸
既然印象笔记相当于你的另一个大脑,那么无组织的印象笔记就是混乱的大脑。
创建主题关键词后,您还可以为印象笔记笔记本创建一个对应的名称,以便您可以对不同的材料、文档、图片等进行分类。印象笔记会自动按照数字和字母顺序对笔记本进行排序,因此在数字之前添加字母 ABC 帮助我形成了一个两级顺序。同时,字母ABC可以区分三大类。
▲ 如何对我的 Evernote 笔记本进行分类
这个文件夹系统让我可以随意扩展一个类别,而不会影响其他类别。
还有一点:TEM 笔记本非常重要。
正如本章开头所说的,分类再完善,也难免有时手忙脚乱,找不到合适的分类,随意存储信息。
因此,为了满足足够的可扩展性,建议您设置一个名为 Temp(Temporary 的缩写)的笔记本。这个Tem笔记本首先可以让你快速存储它,其次可以形成一个待办事项列表。当你无事可做时,至少你可以整理一下这个文件夹,让里面的文件应该被读取和删除,应该归类的文件放在相应的笔记本中。
2、勤检查你的电脑文件夹
即使有这么多集成的组织工具,我们的大部分工作也不得不依赖我们自己的笔记本电脑。所以如果电脑文件夹没有整理好,也会影响我们的工作效率。
我不太擅长整理家务,但喜欢经常整理电脑。
这个习惯大概是五年前开始的。当时,我带领一个小团队,协调多方的工作。我们很多人都需要将工作放在共享磁盘上的文件夹中以进行交换和维护。因此,建立标准化的文件夹系统非常重要。当时我花了很多精力来规范和监督文件夹的执行,取得了很好的效果。
▲ 复杂内容协作文件夹系统
当然,这是一个非常复杂的内容管理协作文件夹。我们的日常文件夹远比这简单。
我电脑的文件夹系统:
▲ 海蒂的文件夹系统
设置文件夹的原理:
1. 尽量将每一级目录的数量限制在7个文件夹左右,尤其是根目录不要太多。
2. 假设中的任何文件都可以找到归属。
比如,家人突然发了一些合影,你应该把它们放在那里。 TEM文件夹的作用是临时的,你自然可以把这些文件堆到TEM文件夹中,但TEM实际上相当于一个临时的避难所,而不是一个固定的住所。我的习惯是在E盘添加一个Personal文件夹,在这个文件夹下为个人文档、文章、图片创建对应的分类。
3.每个文件夹下都预留了一个临时文件夹,防止根目录无限扩展,因为新收到的文件不知道如何分类。
4. 序列号可以让排序和搜索更容易。
为什么要在文件夹前加一个序列号?其实在浏览文件夹的时候,可以出现优先顺序。
以学习文件夹为例:
▲ 文件夹序号命名法
4、Desktop,据我所知
简单说一下我理解的电脑中的“桌面”。我认为“桌面”是一种快捷方式。他的职责是:
快捷方式:放置我们常用的文档和软件快捷方式,方便您直接找到。
第一级的临时文件夹。桌面也是临时文件的庇护所。比如你没时间看别人发来的文档,也不知道怎么分类。如果您收到放置在D盘或E盘任意文件夹中的TEM,可能会导致您在会后忘记它——直到有人提到它。因此,在这种情况下,很多人经常将其存放在桌面上。我认为这也是一个非常正确的决定。至少,当您打开它时,您可能会看到它。
但是我们的“桌面”被滥用了。它充满了各种根本不需要的快捷方式。就像你家里的茶几,放了一个红酒开瓶器——虽然你不是一个月用一次,但它每天都在桌上。你妻子发行了一张同学专辑,虽然她两个月前才用过。有一天亲戚送了你一双童鞋,你暂时放在茶几上,但一直没有整理好。
随着时间的推移,您真正需要的快捷方式和宝贵的临时存储空间将变得毫无意义。
我推荐的桌面应该是这样的:
1.背景设置为让您身心愉悦的照片,例如您和家人的照片。
2. 存储不超过 10 个常用工具的快捷方式。
3.创建一个 TEM 文件夹——否则你的桌面可能会在不到一个月的时间内扩大。
其实电脑任务栏也是一个很重要的快捷方式域,不用随时回到桌面使用——我一般都会把最常用的软件放在这里,比如截图、颜色选择器、思维管理器等。
无论采集了多少信息,无论信息如何组织,如果不应用所学,最多只能建立一个丰富的个人知识库。
所以最重要的是真正用好这些信息,把工作和生活结合起来,好好思考,多练习,消化这些信息供自己使用,然后积累自己的知识。
除了在工作中学习,写专业博客也是转换信息的好方法。
“教比学”,写博客是给别人看,求指点和交流,一定会照顾文章法逻辑,用一个系统连接你所读、所做、所感、所想,并获得。为了照顾到严谨的逻辑,少思考多疑。
所以每次完成一个专业的博客,就好像上了一堂好课,把各种信息消化到我的知识体系中。这种转换比简单地整合常规阅读要有效得多。
个人经验有限,希望大家能得到。 查看全部
为什么你的搜索引擎总是打擦边球?(上)
搜索引擎是非常重要的信息获取门户。至于我使用的技能,我并不是很先进。欢迎搜索专家与我交流,省力又有效的搜索方法。
1.找到合适的关键词,事半功倍
很久以前,我偶然看到了两张照片。很喜欢这两张图,希望能看到更多类似的图。
▲ 检索这两种图像使用什么样的关键图像?
但是,什么样的图片首先被称为?
关键词应该先用于头脑风暴,它叫什么?插图?图表?手绘?插图?
这些关键词 搜索的结果真的很令人沮丧。但是根据搜索结果的提示,一步一步的改变关键词,直到找到可靠的结果。最后,当我找到这个词时,我找到了宝藏。
要查找图中左侧的图形类型,请尝试使用“视觉思维”,或在谷歌上搜索“视觉思维”,如需查找更多图 3 中右侧类型的图形,请尝试使用 "infographic" 或 "infographic"。
▲视觉思维的检索结果
▲ 信息图检索结果
所以在搜索中,我们应该不断的替换更合适的关键词,而不是不断的打边球。
如何找到合适的关键词?
从你认为可行的第一个关键词开始,不要轻易放弃。根据每个搜索结果的线索跟踪,不断修改关键词,直到得到结果。
2.换语言,天上别有洞
有时更改为英语可以让您获得更准确的结果。
所以这就是为什么我的主题词应该是中英文双语的。由于很多中文结果都是从英文翻译过来的,直接查看源码文章显然少了信息缺失。
▲ 英文搜索“visual thinking”的结果
以此类推,每增加一种语言,就会打开一扇了解世界的新窗口。
对于家庭存储,在中文“存储”中搜索文章,几乎只是一些零碎的图片和社区网站,吸引用户拼凑存储技巧。
在日文“Storage”中搜索,在日本看一些网站,可以看到很多关于存储的经验、文档和教程。有些教程的丰富程度不亚于出版书籍,甚至比国内那些家装作品还要好。比如网站提供的Bendo先生的日常收纳教程:
▲ 店铺检索到的专业日语网站
关于网站关于storage的事,有兴趣的可以试试用日语搜索,但是不能问我。
3.改变搜索方式,通过不同的路线达到相同的目标
如果网络搜索没有得到你想要的结果,你可以改变搜索类型,比如搜索图片,然后通过图片链接到有价值的网站。
我经常使用文件搜索。与普通网页相比,这些文档通常意味着更好、更系统的组织,让您的信息获取更有效。
如何使用搜索引擎搜索文档?
如果您使用 google,请在搜索词前添加 inurl:pdf。
如果您使用百度,请在搜索词之前添加 filetype: all。如果您需要特定的 PDF 格式,请输入:filetype: PDF
如果您使用百度搜索商业智能相关文档:
▲ 百度搜索文档
4.别忘了专业的网站
Professional网站让您免于在大量垃圾邮件中查找所需信息的麻烦,他们的信息往往更加集中。我经常用的专业搜索网站有:
——PPT分享网站,国外很多制作优秀、丰富、专业的PPT。我经常在这里搜索有关视觉思维的文档。不过很遗憾,你需要爬墙才能看到这个网站。
MBA Think Tank——一个专注于经济和管理领域的数据库。您可以在此处搜索经济和管理多个领域的各种术语的解释、文档等。
维基百科-如果它在墙外或将其推翻。很多词在中国很敏感,在这里你可以看到非常详细的因果关系。当然,如果不是敏感词,百度百科也是不错的资源。
5.在书中寻找搜索技巧
小提醒,当你没有关键词灵感的时候,你也可以从书的目录中获得关键词的提示。除了目录,专业书籍还收录有价值的挖掘信息。
以下是利用书中提供的信息不断探索,然后找到真正需要的信息的案例:
我最近阅读了“Excel 图表之道”一书。第 P152 页提到的图表类型选择指南的原作者是 Andrew Abela。这个人的名字是很珍贵的关键词。这个关键词可能代表:数据、数据分析、商业智能、交流展示等主题。
于是我搜索了这个人,看到了这个人的博客:The Extreme Presentation(tm) Method。本博客为专业博客,主题为复杂信息的交流与呈现。
而且这个博客宣传一本书,这本书出自Andrew Abela,《Advanced Presentations by Design:Creating Communications that Dives Action》,这本书中文版在中国大陆有售,中文译本是《Persuade How做强演讲——如何为现场交易设计PPT”。
最后通过博文网站:Extreme Presentation Method。这个网站有一些很好的信息,我推荐给对演示感兴趣的学生。比如下面两张图表也是来自这个网站:
▲的图片
当然,《Excel图表之道》作者刘万祥先生引用的英文原版图表类型选择指南也可以在这个网站下载。
另外,我们的信息挖掘还没有结束。注意他还提供了另一个在线工具:这个网站可以让数据分析师根据自己的需要选择不同的图表来展示。这个网站 来自juiceanalytics(果汁分析)。
进入Juiceanalytics网站的白皮书专栏,发现了《A Guide to Creating Dashboards People Love to Use》(A Guide to Creating Dashboards People Love to Use)。这份白皮书可以解答我最近工作的一些困惑。
如果你刻意去寻找,想要得到一些东西并不容易。如果你知道你的主题关键词,你的信息感会非常敏感。在一定的机会下,你会抓住线索,经常在不经意间找到捷径。
3 方便集成
集成是信息的集中归档。
搜索引擎当然方便,但是对于一些常用的东西,你可能不需要每次都去搜索。相反,您可以在自己的计算机上创建个人数据库。不管有没有网络,都可以随时咨询。
我将习惯于存储我在计算机上找到的有价值的文档、网页和图片。但我们也会发现,这些数据一旦存入硬盘,就落入了大海。下次如果需要,还是求助于搜索引擎。
另一方面,计算机文件夹越来越大,必须经常删除文件以腾出空间。这种方法还有一个缺点,就是在使用多台电脑的时候,需要使用移动硬盘或者U盘,所以一个东西的副本要备份到三个地方。
后来有了Dropbox等应用,可以更方便地与多台电脑共享文件,但毕竟容量有限,而且有时会被屏蔽。后来国内自然有好的服务,比如360云盘,最高可以有5G空间,实现云端文件共享和多机客户端。有需要的不妨一试。
这些网盘、云盘等服务解决了多个客户端的同步存储需求。但是,在我的日常工作中,以下小应用是必不可少的,作为集成方法的有效补充。它们的特点是:
1)电话方便
上传之前不需要像使用网盘那样保存。可以在不中断当前工作的情况下随时检索和使用。
比如在做一个任务的过程中,遇到一个好文档,想存档,以后再看。一键整合到自己的学科类别中,如预设的“待读”文件夹,继续执行当前任务。
2)高效搜索
可以标记集成文档,关键词,甚至可以搜索全文。
3)cloud,客户端同步
1、Evernote 方便整合
作为一个使用evernote多年的用户,我很感激。它与我的生活和工作密不可分。
正如它的广告所说,它成为了我大脑的一部分。不仅可以帮助我记住很多事情,还可以帮助我随时记录很多事情。
Evernote 提供了编辑工具,可以添加到 chrome 浏览器应用中,让你在阅读网页时可以随时调用要阅读的存档。
▲Evernote 方便的集成工具
可以在Outlook插件中加入evernote,帮助你在阅读邮件时为重要邮件添加书签:
那可能有人会问了,这只是为了整合一些文档,如果是PPT或者PDF电子书呢?事实上,evernote 可以帮你归档重要文件。
▲ Evernote 集成文档
因为文档体积往往比较大,作为evernote的免费用户可能承受不了。如果不打算升级,也可以创建一个“待读”文件夹,将以后需要阅读的文档归类到这个文件夹中,就形成了一个待办任务。同时,您在本地计算机文件夹中也存储了一份副本。
你可以在印象笔记中阅读和删除一份文档,只提取有用的信息。
Evernote 的搜索功能也比较强大,可以对 PDF 进行全文搜索。
▲印象笔记全文搜索
Evernote 的云同步功能更方便。将电脑上编辑的文件同步后,手机客户端和ipad客户端都可以即时访问,甚至取代了U盘的功能。所以强烈推荐没用过的人尝试一下。
2、整合图片与花瓣网
▲ 将图片与花瓣网结合
使用花瓣网()进行图片整合是我无意中发现的一种技巧,这里也提一下。
原来我的电脑里肯定有一个文件夹叫做图片集,专门用来放置来自网络的各种图片,分为几类,包括摄影欣赏、服装搭配、设计素材、宠物、视觉思维、简笔画、LOGO设计...
如果存在于电脑上,自然会遇到同样的问题,检索困难,体积庞大,难以同步......
有了华华网之后,华华网的采集工具也加入了Chrome浏览器应用,让你可以随时采集网页上的各种图片。这些采集作业和印象笔记编辑工具一样,可以随时调用,不会中断你当前的工作流程。
在花瓣网中,创建自己的画板,以主题命名。就图片而言,个人比较关注的只有几类:
摄影、宠物、室内装饰、简笔画、设计、用户体验、商业智能……其中一些与工作有关,一些与个人生活有关。
所以,每次采集都可以把图片放到自己的分类中。你不需要经常去花瓣网,但你的数据库一天比一天爆满。哪天想到找这些话题的参考资料,打开自己的花瓣网,已经有采集这么多素材可以用了。因为平时就是点一下鼠标,真的很想坐下来好好享受一下。
4 养成定期整理的好习惯
信息可以高效获取,信息也很容易整合,但如果没有规律的整理,时间长了信息难免会变得杂乱无章。
所以,就像我们必须定期清理和整理家务一样,这是必不可少且重要的一步。术语“整理”包括“检查和调整分类”、“删除不需要的文档”、“添加可搜索的标签或关键词”等。
我通常会在我的电脑文件夹或印象笔记笔记本中设置一个“临时文件夹”来存放一些暂时无法归类的文档或资料。并且平时一定要注意这些临时文件夹,把文档放在相应的目录下,以免临时文件夹被误命名,成为大杂烩。
1、不要让你的印象笔记爆炸
既然印象笔记相当于你的另一个大脑,那么无组织的印象笔记就是混乱的大脑。
创建主题关键词后,您还可以为印象笔记笔记本创建一个对应的名称,以便您可以对不同的材料、文档、图片等进行分类。印象笔记会自动按照数字和字母顺序对笔记本进行排序,因此在数字之前添加字母 ABC 帮助我形成了一个两级顺序。同时,字母ABC可以区分三大类。
▲ 如何对我的 Evernote 笔记本进行分类
这个文件夹系统让我可以随意扩展一个类别,而不会影响其他类别。
还有一点:TEM 笔记本非常重要。
正如本章开头所说的,分类再完善,也难免有时手忙脚乱,找不到合适的分类,随意存储信息。
因此,为了满足足够的可扩展性,建议您设置一个名为 Temp(Temporary 的缩写)的笔记本。这个Tem笔记本首先可以让你快速存储它,其次可以形成一个待办事项列表。当你无事可做时,至少你可以整理一下这个文件夹,让里面的文件应该被读取和删除,应该归类的文件放在相应的笔记本中。
2、勤检查你的电脑文件夹
即使有这么多集成的组织工具,我们的大部分工作也不得不依赖我们自己的笔记本电脑。所以如果电脑文件夹没有整理好,也会影响我们的工作效率。
我不太擅长整理家务,但喜欢经常整理电脑。
这个习惯大概是五年前开始的。当时,我带领一个小团队,协调多方的工作。我们很多人都需要将工作放在共享磁盘上的文件夹中以进行交换和维护。因此,建立标准化的文件夹系统非常重要。当时我花了很多精力来规范和监督文件夹的执行,取得了很好的效果。
▲ 复杂内容协作文件夹系统
当然,这是一个非常复杂的内容管理协作文件夹。我们的日常文件夹远比这简单。
我电脑的文件夹系统:
▲ 海蒂的文件夹系统
设置文件夹的原理:
1. 尽量将每一级目录的数量限制在7个文件夹左右,尤其是根目录不要太多。
2. 假设中的任何文件都可以找到归属。
比如,家人突然发了一些合影,你应该把它们放在那里。 TEM文件夹的作用是临时的,你自然可以把这些文件堆到TEM文件夹中,但TEM实际上相当于一个临时的避难所,而不是一个固定的住所。我的习惯是在E盘添加一个Personal文件夹,在这个文件夹下为个人文档、文章、图片创建对应的分类。
3.每个文件夹下都预留了一个临时文件夹,防止根目录无限扩展,因为新收到的文件不知道如何分类。
4. 序列号可以让排序和搜索更容易。
为什么要在文件夹前加一个序列号?其实在浏览文件夹的时候,可以出现优先顺序。
以学习文件夹为例:
▲ 文件夹序号命名法
4、Desktop,据我所知
简单说一下我理解的电脑中的“桌面”。我认为“桌面”是一种快捷方式。他的职责是:
快捷方式:放置我们常用的文档和软件快捷方式,方便您直接找到。
第一级的临时文件夹。桌面也是临时文件的庇护所。比如你没时间看别人发来的文档,也不知道怎么分类。如果您收到放置在D盘或E盘任意文件夹中的TEM,可能会导致您在会后忘记它——直到有人提到它。因此,在这种情况下,很多人经常将其存放在桌面上。我认为这也是一个非常正确的决定。至少,当您打开它时,您可能会看到它。
但是我们的“桌面”被滥用了。它充满了各种根本不需要的快捷方式。就像你家里的茶几,放了一个红酒开瓶器——虽然你不是一个月用一次,但它每天都在桌上。你妻子发行了一张同学专辑,虽然她两个月前才用过。有一天亲戚送了你一双童鞋,你暂时放在茶几上,但一直没有整理好。
随着时间的推移,您真正需要的快捷方式和宝贵的临时存储空间将变得毫无意义。
我推荐的桌面应该是这样的:
1.背景设置为让您身心愉悦的照片,例如您和家人的照片。
2. 存储不超过 10 个常用工具的快捷方式。
3.创建一个 TEM 文件夹——否则你的桌面可能会在不到一个月的时间内扩大。
其实电脑任务栏也是一个很重要的快捷方式域,不用随时回到桌面使用——我一般都会把最常用的软件放在这里,比如截图、颜色选择器、思维管理器等。
无论采集了多少信息,无论信息如何组织,如果不应用所学,最多只能建立一个丰富的个人知识库。
所以最重要的是真正用好这些信息,把工作和生活结合起来,好好思考,多练习,消化这些信息供自己使用,然后积累自己的知识。
除了在工作中学习,写专业博客也是转换信息的好方法。
“教比学”,写博客是给别人看,求指点和交流,一定会照顾文章法逻辑,用一个系统连接你所读、所做、所感、所想,并获得。为了照顾到严谨的逻辑,少思考多疑。
所以每次完成一个专业的博客,就好像上了一堂好课,把各种信息消化到我的知识体系中。这种转换比简单地整合常规阅读要有效得多。
个人经验有限,希望大家能得到。
织梦的隐藏栏目设置只是在导航菜单中起作用?
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-07-26 21:07
接触织梦近一年,我建的第一个站就是织梦系统。 织梦本身已经很强大了,基本可以满足我的大部分需求。大部分时间我都是用它来设计界面模板,但是没有研究过织梦的后端源码。
最近无事可做,又建了一个新站。在设计网站专栏的时候,希望建立一个类似草稿箱的采集库专栏,专门用来存放采集来的文章。每一个采集文章都是在其他官方栏目下规划之前处理的,但是现在问题来了,采集库中没有处理的文章也会在首页和频道页面显示,这不是我想要的。我以为在创建新列时,我可以选择是否隐藏该列。我突然打开它,觉得这应该可以解决我的问题,但最终让我失望。此隐藏列的设置仅在导航菜单中有效。没有办法,只能硬着头皮研究源代码。用上学时就知道的一点毛皮,用了半个多小时,终于解决了问题。
其实很简单,改一下代码,打开/include/taglib/arclist.lib.php文件,找到这句话(约350行):
if($orwhere!='') $orwhere = "WHERE $orwhere ";
改成
if($orwhere!='') $orwhere ="WHERE $orwhere 和 tp.ishidden != 1 ";
就是这样。
当然,这种变化也会带来另一个问题。如果导航菜单中隐藏了某列,则该列下的文章 将无法用arclist 调用。而我们实际上可能希望它能够使用 arclist 来调用。
因为我的小站点导航在代码中是硬编码的,所以这个修改对我基本没有影响。如果其他站长和我有同样的需求,可以试试。 查看全部
织梦的隐藏栏目设置只是在导航菜单中起作用?
接触织梦近一年,我建的第一个站就是织梦系统。 织梦本身已经很强大了,基本可以满足我的大部分需求。大部分时间我都是用它来设计界面模板,但是没有研究过织梦的后端源码。
最近无事可做,又建了一个新站。在设计网站专栏的时候,希望建立一个类似草稿箱的采集库专栏,专门用来存放采集来的文章。每一个采集文章都是在其他官方栏目下规划之前处理的,但是现在问题来了,采集库中没有处理的文章也会在首页和频道页面显示,这不是我想要的。我以为在创建新列时,我可以选择是否隐藏该列。我突然打开它,觉得这应该可以解决我的问题,但最终让我失望。此隐藏列的设置仅在导航菜单中有效。没有办法,只能硬着头皮研究源代码。用上学时就知道的一点毛皮,用了半个多小时,终于解决了问题。
其实很简单,改一下代码,打开/include/taglib/arclist.lib.php文件,找到这句话(约350行):
if($orwhere!='') $orwhere = "WHERE $orwhere ";
改成
if($orwhere!='') $orwhere ="WHERE $orwhere 和 tp.ishidden != 1 ";
就是这样。
当然,这种变化也会带来另一个问题。如果导航菜单中隐藏了某列,则该列下的文章 将无法用arclist 调用。而我们实际上可能希望它能够使用 arclist 来调用。
因为我的小站点导航在代码中是硬编码的,所以这个修改对我基本没有影响。如果其他站长和我有同样的需求,可以试试。
如何让自定义PostType的内容显示出来?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-24 18:03
之前讲到wordpress添加post_type自定义文章类型,现在讲一下如何调用自定义文章,以product为例,虽然我们自定义了Post Type,但也写了一些内容不显示在主页和列表上。自定义 Post Type 的内容不会自动混入主循环。如何显示自定义 Post Type 的内容?您需要使用 pre_get_posts 操作进行一些处理:
function add_custom_pt( $query ) {
if ( !is_admin() && $query->is_main_query() ) {
$query->set( 'post_type', array( 'post', 'the_custom_pt' ) );
}
}
add_action( 'pre_get_posts', 'add_custom_pt' );
将上述代码添加到主题function.php文件中
第二步,以上操作依赖模板。如果需要高度定制化或者在页面的某个模块中调用列表,则需要使用WP_Query类来调用:
新创建的archive-product.php模板放在theme目录下。这是产品的 post_type 模板。将以上代码添加到archive-product.php中调用文章,刷新缓存即可看到
参考资料: 查看全部
如何让自定义PostType的内容显示出来?-八维教育
之前讲到wordpress添加post_type自定义文章类型,现在讲一下如何调用自定义文章,以product为例,虽然我们自定义了Post Type,但也写了一些内容不显示在主页和列表上。自定义 Post Type 的内容不会自动混入主循环。如何显示自定义 Post Type 的内容?您需要使用 pre_get_posts 操作进行一些处理:
function add_custom_pt( $query ) {
if ( !is_admin() && $query->is_main_query() ) {
$query->set( 'post_type', array( 'post', 'the_custom_pt' ) );
}
}
add_action( 'pre_get_posts', 'add_custom_pt' );
将上述代码添加到主题function.php文件中
第二步,以上操作依赖模板。如果需要高度定制化或者在页面的某个模块中调用列表,则需要使用WP_Query类来调用:
新创建的archive-product.php模板放在theme目录下。这是产品的 post_type 模板。将以上代码添加到archive-product.php中调用文章,刷新缓存即可看到
参考资料:
豆瓣网手游影评:如何获取真正请求的地址和请求?
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-07-23 22:18
[一、项目背景]
豆瓣电影提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。可以录制自己想看的电影电视剧,顺便看,打分,写影评。极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择他们想要的电影。
[二、项目目标]
获取对应的电影名称、评分、详细链接,下载电影图片,保存文件。
[三、相关库和网站]
1、网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、software: PyCharm
[四、项目分析]
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是用javascript动态加载内容来防止采集的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2)点击主题,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页就会增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
[五、项目实施]
1、我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent并构造请求头防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、for 遍历获取对应的电影名称、评分以及下一个详情页的链接。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、picture 地址提出请求。定义图片名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、调用方法实现功能。
9、项目优化:1)设置延时。
time.sleep(1.4)
2)定义了一个变量u,用于遍历,表示爬取的是哪个页面。 (更清晰,更令人印象深刻)。
u = 0
self.u += 1;
[六、效果展示]
1、点击绿色三角运行起始页和结束页(从第0页开始)。
2、 会在控制台显示下载成功的信息。
3、保存 csv 文件。
4、film 图片展示。
[七、Summary]
1、 不建议取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了相关的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。 查看全部
豆瓣网手游影评:如何获取真正请求的地址和请求?
[一、项目背景]
豆瓣电影提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。可以录制自己想看的电影电视剧,顺便看,打分,写影评。极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择他们想要的电影。
[二、项目目标]
获取对应的电影名称、评分、详细链接,下载电影图片,保存文件。
[三、相关库和网站]
1、网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、software: PyCharm
[四、项目分析]
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
在请求数据时,发现页面上没有对应的数据。其实豆瓣是用javascript动态加载内容来防止采集的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2)点击主题,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页就会增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
[五、项目实施]
1、我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent并构造请求头防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、for 遍历获取对应的电影名称、评分以及下一个详情页的链接。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义对应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、picture 地址提出请求。定义图片名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、调用方法实现功能。
9、项目优化:1)设置延时。
time.sleep(1.4)
2)定义了一个变量u,用于遍历,表示爬取的是哪个页面。 (更清晰,更令人印象深刻)。
u = 0
self.u += 1;
[六、效果展示]
1、点击绿色三角运行起始页和结束页(从第0页开始)。
2、 会在控制台显示下载成功的信息。
3、保存 csv 文件。
4、film 图片展示。
[七、Summary]
1、 不建议取太多数据,可能造成服务器负载,简单试一下。
2、本文章针对Python爬取豆瓣应用中的难点和关键点,以及如何防止反爬,做了相关的解决方案。
3、希望通过这个项目,可以帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要看最好的,努力去更深入地理解。
优化CalledListRequest接口写的不是那么好,循环调用某个接口
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-07-21 20:43
优化CalledListRequest接口写的不是那么好,循环调用某个接口
AOP 使用示例:log采集function
背景:目的是优化CalledListRequest接口。深入了解后,发现这个接口没有写得那么好,所以循环调用一个接口。导致一些简单的查询被重复执行。从而效率。那么这个接口涉及的业务逻辑太复杂了,不能直接改。相反,编写了一个新接口来替换它。但是为了做更彻底的测试。第一行采集 请求参数。然后测试一下。最后,这是发布和上线的最佳方式。
功能及原理介绍
采集这个在线接口(CalledListRequest)的请求参数。
原理:编写一个方法,将所有传入的参数插入到数据库的日志表中。
但为了减少侵入性(即不改动原接口的实现代码)。我在这里使用了 AOP 切入方法。同时用apollo做了一个switch(控制什么时候开始采集,什么时候关闭采集)
主要技能点之一是AOP的应用。之前实际上没有实际的工作来应用 AOP。这次是机会。
其实很简单,就是直接的核心代码。没有复杂的事情
核心代码
package com.centanet.bizcom.config.log;
import com.alibaba.fastjson.JSON;
import com.centanet.bizcom.config.apollo.ApolloConfig;
import com.centanet.bizcom.config.ddb.MultiTenantChanger;
import com.centanet.bizcom.mapper.BizMapper;
import com.centanet.bizcom.model.entity.LogCollection;
import com.centanet.bizcom.util.CityHelper;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.servlet.http.HttpServletRequest;
import java.util.Date;
/**
* 该类的功能是为了收集日志
* 方便切换接口时使用
* @Author: wbdengtt
* @Date: 2020/10/13 14:58
*/
//声明切面
@Aspect
// 交给Spring管理bean
@Component
public class LogCollectAspect {
// 注入logCollection 这个就是一个简单实体entity。
@Autowired
private LogCollection logCollection;
// 这是将实体存到数据库的mapper
@Autowired
private BizMapper bizMapper;
// 拦截CalledController.calledListRequest方法。通过这个配置。可以拦截更多东西,这个规则相信的可以看下面的参考文章
@Pointcut("execution(* com.centanet.bizcom.controller.CalledController.calledListRequest(..))")
public void myPointCut() {
// 这个其实就是一个切点,不需要方法内容
}
// 这个是具体实现拦截参数,并将参数日志写入到数据库的方法
@Before("myPointCut()")
public void logCollect(JoinPoint joinPoint) {
// 这个是在apoll配置的开关(就是一个String变量)。如果开了才进行下面的拦截。
boolean isLogCollect = "true".equalsIgnoreCase(ApolloConfig.getWebValue(CityHelper.getCityCode(),"isLogCollectionOpen"))
&& ApolloConfig.getWebValue(CityHelper.getCityCode(),"logCollectCity").contains(CityHelper.getCityen());
if (isLogCollect) {
// 设置logCollection的日期字段
logCollection.setRowDate(new Date());
// 获取当前HttpServletRequest 对象 这个是为了拿到各种我需要的信息。关于HttpServletRequest 下面有提供参考链接看相信的介绍
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
//设置logCollection的实体字段,这里是请求类型.城市
logCollection.setMethodName(request.getMethod()+"."+CityHelper.getCityen());
//request.getQueryString() 只能拿到get请求的参数。如果是post请求,得通过joinPoint才能拿到参数(这个不需要手动声明,应该是SpringAOP哪里给自动注入了)
logCollection.setMessage(JSON.toJSONString(joinPoint.getArgs()));
if (logCollection.getMessage() ==null){
logCollection.setMessage("没能拿到参数");
}
// request.getRequestURI()获取方法名
logCollection.setFullName(request.getRequestURI());
// 写入数据库 MultiTenantChanger是因为我有多个数据库,但是这里的操作其实就是讲实体装入数据库
MultiTenantChanger.setDataSourceType(CityHelper.getCityCode()+MultiTenantChanger.CENTA_BIZ);
bizMapper.insertLogCollection(logCollection);
MultiTenantChanger.removeRouteKey();
}
}
}
我在代码中添加了很多注释。应该更容易理解
参考文章:
连接点: 查看全部
优化CalledListRequest接口写的不是那么好,循环调用某个接口
AOP 使用示例:log采集function
背景:目的是优化CalledListRequest接口。深入了解后,发现这个接口没有写得那么好,所以循环调用一个接口。导致一些简单的查询被重复执行。从而效率。那么这个接口涉及的业务逻辑太复杂了,不能直接改。相反,编写了一个新接口来替换它。但是为了做更彻底的测试。第一行采集 请求参数。然后测试一下。最后,这是发布和上线的最佳方式。
功能及原理介绍
采集这个在线接口(CalledListRequest)的请求参数。
原理:编写一个方法,将所有传入的参数插入到数据库的日志表中。
但为了减少侵入性(即不改动原接口的实现代码)。我在这里使用了 AOP 切入方法。同时用apollo做了一个switch(控制什么时候开始采集,什么时候关闭采集)
主要技能点之一是AOP的应用。之前实际上没有实际的工作来应用 AOP。这次是机会。
其实很简单,就是直接的核心代码。没有复杂的事情
核心代码
package com.centanet.bizcom.config.log;
import com.alibaba.fastjson.JSON;
import com.centanet.bizcom.config.apollo.ApolloConfig;
import com.centanet.bizcom.config.ddb.MultiTenantChanger;
import com.centanet.bizcom.mapper.BizMapper;
import com.centanet.bizcom.model.entity.LogCollection;
import com.centanet.bizcom.util.CityHelper;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.servlet.http.HttpServletRequest;
import java.util.Date;
/**
* 该类的功能是为了收集日志
* 方便切换接口时使用
* @Author: wbdengtt
* @Date: 2020/10/13 14:58
*/
//声明切面
@Aspect
// 交给Spring管理bean
@Component
public class LogCollectAspect {
// 注入logCollection 这个就是一个简单实体entity。
@Autowired
private LogCollection logCollection;
// 这是将实体存到数据库的mapper
@Autowired
private BizMapper bizMapper;
// 拦截CalledController.calledListRequest方法。通过这个配置。可以拦截更多东西,这个规则相信的可以看下面的参考文章
@Pointcut("execution(* com.centanet.bizcom.controller.CalledController.calledListRequest(..))")
public void myPointCut() {
// 这个其实就是一个切点,不需要方法内容
}
// 这个是具体实现拦截参数,并将参数日志写入到数据库的方法
@Before("myPointCut()")
public void logCollect(JoinPoint joinPoint) {
// 这个是在apoll配置的开关(就是一个String变量)。如果开了才进行下面的拦截。
boolean isLogCollect = "true".equalsIgnoreCase(ApolloConfig.getWebValue(CityHelper.getCityCode(),"isLogCollectionOpen"))
&& ApolloConfig.getWebValue(CityHelper.getCityCode(),"logCollectCity").contains(CityHelper.getCityen());
if (isLogCollect) {
// 设置logCollection的日期字段
logCollection.setRowDate(new Date());
// 获取当前HttpServletRequest 对象 这个是为了拿到各种我需要的信息。关于HttpServletRequest 下面有提供参考链接看相信的介绍
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
//设置logCollection的实体字段,这里是请求类型.城市
logCollection.setMethodName(request.getMethod()+"."+CityHelper.getCityen());
//request.getQueryString() 只能拿到get请求的参数。如果是post请求,得通过joinPoint才能拿到参数(这个不需要手动声明,应该是SpringAOP哪里给自动注入了)
logCollection.setMessage(JSON.toJSONString(joinPoint.getArgs()));
if (logCollection.getMessage() ==null){
logCollection.setMessage("没能拿到参数");
}
// request.getRequestURI()获取方法名
logCollection.setFullName(request.getRequestURI());
// 写入数据库 MultiTenantChanger是因为我有多个数据库,但是这里的操作其实就是讲实体装入数据库
MultiTenantChanger.setDataSourceType(CityHelper.getCityCode()+MultiTenantChanger.CENTA_BIZ);
bizMapper.insertLogCollection(logCollection);
MultiTenantChanger.removeRouteKey();
}
}
}
我在代码中添加了很多注释。应该更容易理解
参考文章:
连接点:
微信公众号内容采集,比较怪异,其参数,post参数需要话费时间去搞定
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-07-20 07:05
微信公众号采集的内容很奇怪。它的参数和后期参数需要时间来弄清楚。这里采集是topic标签的内容,用pdfkit打印出来的内容。
这里实现了两个版本。第一个是直接网络访问。它的真实地址,post URL,也有更多的参数。我没试过。得到的内容只是部分的,并不理想。第二个版本是使用无头浏览器直接访问,获取网页源代码,分析,获取你想要的内容。
这个人渣现在比较懒,代码都是以前用的,现成的,复制的,修改的,直接用!
版本一:
#微信公众号内容获取打印pdf
#by 微信:huguo00289
#https://mp.weixin.qq.com/mp/ho ... %3D14
# -*- coding: UTF-8 -*-
import requests
from fake_useragent import UserAgent
import os,re
import pdfkit
confg = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
class Du():
def __init__(self,furl):
ua=UserAgent()
self.headers={
"User-Agent": ua.random,
}
self.url=furl
def get_urls(self):
response=requests.get(self.url,headers=self.headers,timeout=8)
html=response.content.decode('utf-8')
req=re.findall(r'var data={(.+?)if',html,re.S)[0]
urls=re.findall(r',"link":"(.+?)",',req,re.S)
urls=set(urls)
print(len(urls))
return urls
def get_content(self,url,category):
response = requests.get(url, headers=self.headers, timeout=8)
print(response.status_code)
html = response.content.decode('utf-8')
req = re.findall(r'(.+?)var first_sceen__time',html,re.S)[0]
#获取标题
h1=re.findall(r'(.+?)',req,re.S)[0]
h1=h1.strip()
pattern = r"[\/\\\:\*\?\"\\|]"
h1 = re.sub(pattern, "_", h1) # 替换为下划线
print(h1)
#获取详情
detail = re.findall(r'(.+?)',req,re.S)[0]
data = f'{h1}\n{detail}'
self.dypdf(h1,data,category)
return data
def dypdf(self,h1,data,category):
datas = f'{data}'
print("开始打印内容!")
pdfkit.from_string(datas, f'{category}/{h1}.pdf', configuration=confg)
print("打印保存成功!")
if __name__=='__main__':
furl="https://mp.weixin.qq.com/mp/ho ... ot%3B
category="潘通色卡(电子版)"
datas = ''
os.makedirs(f'{category}/',exist_ok=True)
spider=Du(furl)
urls=spider.get_urls()
for url in urls:
print(f">> 正在爬取链接:{url} ..")
try:
data=spider.get_content(url,category)
except Exception as e:
print(f"爬取错误,错误代码为:{e}")
datas='%s%s%s'%(datas,'\n',data)
spider.dypdf(category,datas,category)
版本二:
#微信公众号内容获取打印pdf
#by 微信:huguo00289
#https://mp.weixin.qq.com/mp/ho ... %3D14
# -*- coding: UTF-8 -*-
import requests
from selenium import webdriver
import os,re,time
import pdfkit
from bs4 import BeautifulSoup
confg = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
class wx():
def __init__(self,furl):
self.url = furl
self.chrome_driver = r'C:\Users\Administrator\Desktop\chromedriver_win32\chromedriver.exe' # chromedriver的文件位置
self.browser = webdriver.Chrome(executable_path=self.chrome_driver)
def get_urls(self):
urls=[]
self.browser.get(self.url)
hrefs=self.browser.find_elements_by_xpath("//div[@class='article_list']/a[@class='list_item js_post']")
for href in hrefs:
url=href.get_attribute('href')
urls.append(url)
print(len(urls))
return urls
def get_content(self,url,category):
self.browser.get(url)
time.sleep(5)
# 调用driver的page_source属性获取页面源码
pageSource = self.browser.page_source
soup=BeautifulSoup(pageSource,'lxml')
#获取标题
h1=re.findall(r'(.+?)',pageSource,re.S)[0]
h1=h1.strip()
pattern = r"[\/\\\:\*\?\"\\|]"
h1 = re.sub(pattern, "_", h1) # 替换为下划线
print(h1)
#获取详情
detail =soup.find('div',class_="rich_media_content")
detail=str(detail)
del_text="""↑ 点击上方“染整百科”关注我们</strong>"""
detail=detail.replace(del_text,'')
data = f'{h1}\n{detail}'
self.dypdf(h1,data,category)
return data
def dypdf(self,h1,data,category):
datas = f'{data}'
print("开始打印内容!")
pdfkit.from_string(datas, f'{category}/{h1}.pdf', configuration=confg)
print("打印保存成功!")
def quit(self):
self.browser.quit()
if __name__=='__main__':
furl="https://mp.weixin.qq.com/mp/ho ... ot%3B
category="潘通色卡(电子版)"
datas = ''
os.makedirs(f'{category}/',exist_ok=True)
spider=wx(furl)
urls=spider.get_urls()
for url in urls:
print(f">> 正在爬取链接:{url} ..")
try:
data=spider.get_content(url,category)
except Exception as e:
print(f"爬取错误,错误代码为:{e}")
datas='%s%s%s'%(datas,'\n',data)
spider.quit()
spider.dypdf(category,datas,category)
</p>
以上代码仅供参考,如有雷同,必被此人渣抄袭!
查看全部
微信公众号内容采集,比较怪异,其参数,post参数需要话费时间去搞定
微信公众号采集的内容很奇怪。它的参数和后期参数需要时间来弄清楚。这里采集是topic标签的内容,用pdfkit打印出来的内容。
这里实现了两个版本。第一个是直接网络访问。它的真实地址,post URL,也有更多的参数。我没试过。得到的内容只是部分的,并不理想。第二个版本是使用无头浏览器直接访问,获取网页源代码,分析,获取你想要的内容。
这个人渣现在比较懒,代码都是以前用的,现成的,复制的,修改的,直接用!
版本一:
#微信公众号内容获取打印pdf
#by 微信:huguo00289
#https://mp.weixin.qq.com/mp/ho ... %3D14
# -*- coding: UTF-8 -*-
import requests
from fake_useragent import UserAgent
import os,re
import pdfkit
confg = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
class Du():
def __init__(self,furl):
ua=UserAgent()
self.headers={
"User-Agent": ua.random,
}
self.url=furl
def get_urls(self):
response=requests.get(self.url,headers=self.headers,timeout=8)
html=response.content.decode('utf-8')
req=re.findall(r'var data={(.+?)if',html,re.S)[0]
urls=re.findall(r',"link":"(.+?)",',req,re.S)
urls=set(urls)
print(len(urls))
return urls
def get_content(self,url,category):
response = requests.get(url, headers=self.headers, timeout=8)
print(response.status_code)
html = response.content.decode('utf-8')
req = re.findall(r'(.+?)var first_sceen__time',html,re.S)[0]
#获取标题
h1=re.findall(r'(.+?)',req,re.S)[0]
h1=h1.strip()
pattern = r"[\/\\\:\*\?\"\\|]"
h1 = re.sub(pattern, "_", h1) # 替换为下划线
print(h1)
#获取详情
detail = re.findall(r'(.+?)',req,re.S)[0]
data = f'{h1}\n{detail}'
self.dypdf(h1,data,category)
return data
def dypdf(self,h1,data,category):
datas = f'{data}'
print("开始打印内容!")
pdfkit.from_string(datas, f'{category}/{h1}.pdf', configuration=confg)
print("打印保存成功!")
if __name__=='__main__':
furl="https://mp.weixin.qq.com/mp/ho ... ot%3B
category="潘通色卡(电子版)"
datas = ''
os.makedirs(f'{category}/',exist_ok=True)
spider=Du(furl)
urls=spider.get_urls()
for url in urls:
print(f">> 正在爬取链接:{url} ..")
try:
data=spider.get_content(url,category)
except Exception as e:
print(f"爬取错误,错误代码为:{e}")
datas='%s%s%s'%(datas,'\n',data)
spider.dypdf(category,datas,category)
版本二:
#微信公众号内容获取打印pdf
#by 微信:huguo00289
#https://mp.weixin.qq.com/mp/ho ... %3D14
# -*- coding: UTF-8 -*-
import requests
from selenium import webdriver
import os,re,time
import pdfkit
from bs4 import BeautifulSoup
confg = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
class wx():
def __init__(self,furl):
self.url = furl
self.chrome_driver = r'C:\Users\Administrator\Desktop\chromedriver_win32\chromedriver.exe' # chromedriver的文件位置
self.browser = webdriver.Chrome(executable_path=self.chrome_driver)
def get_urls(self):
urls=[]
self.browser.get(self.url)
hrefs=self.browser.find_elements_by_xpath("//div[@class='article_list']/a[@class='list_item js_post']")
for href in hrefs:
url=href.get_attribute('href')
urls.append(url)
print(len(urls))
return urls
def get_content(self,url,category):
self.browser.get(url)
time.sleep(5)
# 调用driver的page_source属性获取页面源码
pageSource = self.browser.page_source
soup=BeautifulSoup(pageSource,'lxml')
#获取标题
h1=re.findall(r'(.+?)',pageSource,re.S)[0]
h1=h1.strip()
pattern = r"[\/\\\:\*\?\"\\|]"
h1 = re.sub(pattern, "_", h1) # 替换为下划线
print(h1)
#获取详情
detail =soup.find('div',class_="rich_media_content")
detail=str(detail)
del_text="""↑ 点击上方“染整百科”关注我们</strong>"""
detail=detail.replace(del_text,'')
data = f'{h1}\n{detail}'
self.dypdf(h1,data,category)
return data
def dypdf(self,h1,data,category):
datas = f'{data}'
print("开始打印内容!")
pdfkit.from_string(datas, f'{category}/{h1}.pdf', configuration=confg)
print("打印保存成功!")
def quit(self):
self.browser.quit()
if __name__=='__main__':
furl="https://mp.weixin.qq.com/mp/ho ... ot%3B
category="潘通色卡(电子版)"
datas = ''
os.makedirs(f'{category}/',exist_ok=True)
spider=wx(furl)
urls=spider.get_urls()
for url in urls:
print(f">> 正在爬取链接:{url} ..")
try:
data=spider.get_content(url,category)
except Exception as e:
print(f"爬取错误,错误代码为:{e}")
datas='%s%s%s'%(datas,'\n',data)
spider.quit()
spider.dypdf(category,datas,category)
</p>
以上代码仅供参考,如有雷同,必被此人渣抄袭!
微数据官网文章采集调用微信登录朋友圈的视频视频
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-07-18 20:01
文章采集调用微信登录采集,因此我们先要完成微信登录,这样就可以采集朋友圈的视频。由于采集头像需要使用ua头像识别工具,本文暂不采用此方案,只想采集朋友圈的视频,所以我先采集前半部分。1.界面准备下载相应的采集模块,整体模块效果如下图。下载文件内容如下图。2.启动脚本下载完成后,双击js/egg.js文件,就可以进入相应的编辑界面,按照相应的操作步骤编写脚本,有预编译和静态编译两种方式。
3.微信访问,获取手机号微信访问方式:微信文件传输助手微信扫一扫等4.将编写好的脚本发送至本地文件夹,或在浏览器上打开5.发送至本地文件夹,如:发送至桌面windows文件夹egg.js中下载的js文件。
给大家推荐一个网站微数据官网,搜索微信群可以看到有多少个微信群,以及每个微信群的信息,
首先我们先将采集微信公众号文章的功能做好,然后我们就可以采集了第一步:安装好采集工具和开发工具-take.exe,首先打开chrome的浏览器,打开后点击右上角···第二步:选择微信web-view-获取文章详情页-推送第三步:看下图,确定我们是否用openid登录自己的微信公众号。如果没有跳转的话,需要在微信点击下方的登录手机号验证,输入自己的手机号码才可以登录。
(这是我前几天偶然发现的,后来我就去网上搜索了原因,可能是手机号码验证的时候丢失了所以丢失了,所以才会造成微信公众号丢失whatsappmessage的情况出现,我也是今天才知道的)最后检查是否在效果中,是的话,点击确定就可以了。whatsappmessage登录成功之后,我们再看下按下图登录我们的微信公众号账号,开始下一步接下来我们就是全屏截图了首先我们准备好需要截取的内容。
可以根据需要截图相应的图片,但是一定要注意,我们截图之后,要立即发送给我们登录的手机号发送的方式,可以用短信,也可以用是微信,如果是微信,可以在短信发送,点开查看短信就可以获取我们刚刚发送的网址了,如果是短信也同样如此,点开查看短信就可以获取到我们需要的信息了我们通过确定手机号微信号是否有错误来判断是否成功截图成功以后,我们就可以发送到浏览器了,发送链接,上传成功之后,我们就可以从浏览器获取微信的视频地址了。
如图,我选择了一个带有大众点评链接的版本,进入之后先解析大众点评网站的api图然后可以看到我们输入的网址是有效的我们就可以使用此地址,进行视频的下载,详细的获取视频的代码地址如下图我们点击之后,其实是可以下载视频的,我们选择1000秒的就可以获取下载,下载完。 查看全部
微数据官网文章采集调用微信登录朋友圈的视频视频
文章采集调用微信登录采集,因此我们先要完成微信登录,这样就可以采集朋友圈的视频。由于采集头像需要使用ua头像识别工具,本文暂不采用此方案,只想采集朋友圈的视频,所以我先采集前半部分。1.界面准备下载相应的采集模块,整体模块效果如下图。下载文件内容如下图。2.启动脚本下载完成后,双击js/egg.js文件,就可以进入相应的编辑界面,按照相应的操作步骤编写脚本,有预编译和静态编译两种方式。
3.微信访问,获取手机号微信访问方式:微信文件传输助手微信扫一扫等4.将编写好的脚本发送至本地文件夹,或在浏览器上打开5.发送至本地文件夹,如:发送至桌面windows文件夹egg.js中下载的js文件。
给大家推荐一个网站微数据官网,搜索微信群可以看到有多少个微信群,以及每个微信群的信息,
首先我们先将采集微信公众号文章的功能做好,然后我们就可以采集了第一步:安装好采集工具和开发工具-take.exe,首先打开chrome的浏览器,打开后点击右上角···第二步:选择微信web-view-获取文章详情页-推送第三步:看下图,确定我们是否用openid登录自己的微信公众号。如果没有跳转的话,需要在微信点击下方的登录手机号验证,输入自己的手机号码才可以登录。
(这是我前几天偶然发现的,后来我就去网上搜索了原因,可能是手机号码验证的时候丢失了所以丢失了,所以才会造成微信公众号丢失whatsappmessage的情况出现,我也是今天才知道的)最后检查是否在效果中,是的话,点击确定就可以了。whatsappmessage登录成功之后,我们再看下按下图登录我们的微信公众号账号,开始下一步接下来我们就是全屏截图了首先我们准备好需要截取的内容。
可以根据需要截图相应的图片,但是一定要注意,我们截图之后,要立即发送给我们登录的手机号发送的方式,可以用短信,也可以用是微信,如果是微信,可以在短信发送,点开查看短信就可以获取我们刚刚发送的网址了,如果是短信也同样如此,点开查看短信就可以获取到我们需要的信息了我们通过确定手机号微信号是否有错误来判断是否成功截图成功以后,我们就可以发送到浏览器了,发送链接,上传成功之后,我们就可以从浏览器获取微信的视频地址了。
如图,我选择了一个带有大众点评链接的版本,进入之后先解析大众点评网站的api图然后可以看到我们输入的网址是有效的我们就可以使用此地址,进行视频的下载,详细的获取视频的代码地址如下图我们点击之后,其实是可以下载视频的,我们选择1000秒的就可以获取下载,下载完。
文章采集调用apacheapollo下修改paste方法,是不提供的
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-07-10 05:01
文章采集调用apacheapollo。
file->preferences->externalextensions然后选中request->accessibility:设置applicationaccessibilitytoken(从你api接入的系统,
你这个api接入的是谷歌的express?
一定是要对接的,
用apachejdk+apollopool
你这种接入是用在个人项目上的吗?我们都是用filezilla接入的,我觉得挺好用,
想接入谷歌studio的话需要依赖于expressjulia实现post请求,apollo无法实现(这个是用c++写的).
apollo=equinoxbj有这等好事?
利用python的urllib3和urllib3.pathretrieve方法,
要对接protobuf,apacheapollo不行,这个会解析出成特殊的auth,即:全部都是一个memory的startuptime,比如localtime是这样的,而我这的,apiopencloud(adaptedzoo)选项是不提供的,因为它是在incompletezooprofile,apollo选项是没有,而你apiopencloud(adaptedzooprofile)这样的选项是为json格式做手脚的。ps:也不排除是定制自己的project。
apacheapollopool
apacheapollorequestprojectswift下修改paste方法,
是吧 查看全部
文章采集调用apacheapollo下修改paste方法,是不提供的
文章采集调用apacheapollo。
file->preferences->externalextensions然后选中request->accessibility:设置applicationaccessibilitytoken(从你api接入的系统,
你这个api接入的是谷歌的express?
一定是要对接的,
用apachejdk+apollopool
你这种接入是用在个人项目上的吗?我们都是用filezilla接入的,我觉得挺好用,
想接入谷歌studio的话需要依赖于expressjulia实现post请求,apollo无法实现(这个是用c++写的).
apollo=equinoxbj有这等好事?
利用python的urllib3和urllib3.pathretrieve方法,
要对接protobuf,apacheapollo不行,这个会解析出成特殊的auth,即:全部都是一个memory的startuptime,比如localtime是这样的,而我这的,apiopencloud(adaptedzoo)选项是不提供的,因为它是在incompletezooprofile,apollo选项是没有,而你apiopencloud(adaptedzooprofile)这样的选项是为json格式做手脚的。ps:也不排除是定制自己的project。
apacheapollopool
apacheapollorequestprojectswift下修改paste方法,
是吧
网站模板下载/2019-06-09现阶段如何解决被抄袭
采集交流 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-07-09 18:07
如何有效防止自己文章被采集网站模板下载/2019-06-09
现阶段很多网站会选择使用采集文章或者复制文章来更新网站的内容。其实这个更新方法百度官方早就给出了明确的意见,想了解更多的可以到百度站长平台详细阅读百度官方说明。那我想跟大家探讨一下文章采集的影响以及如何解决抄袭问题?
网站文章 可以通过采集 吗?
因为现阶段搜索引擎越来越智能化,他们也越来越强调用户体验和附加值。如果只做文章采集大批量的话,可能会出现以下问题。
一、网站采集返回的内容不一定是符合网站主题的内容。此类内容将被搜索引擎判断为低质量垃圾邮件。严重的话,还可能让网站获得降级的权利。
二、长期量产采集文章内容也会对服务器造成一定压力。如果使用的虚拟空间容量较小,则有一定的可能性使虚拟空间内存满后无法操作,岂不是得不偿失。
网站文章被抄袭怎么解决?
一,我们需要做好我们网站的内部调整,我们需要为网站制定一个固定的时间更新频率。这个操作之后网站的收录会有很大的提升。
其次,我们更新网站原创文章后,可以选择使用百度站长平台的原创protection功能,每次更新后提交文章原创protect? ,原创protection 每天可以提交 10 个项目。
三、当对方是采集我们文章时,图片也会是采集,我们可以给文章中的图片添加图片水印。
我觉得除了百度官方对文章采集网站的处理,我们还可以把我们的网站做得更好,让我们自己网站收录更好。 查看全部
网站模板下载/2019-06-09现阶段如何解决被抄袭
如何有效防止自己文章被采集网站模板下载/2019-06-09
现阶段很多网站会选择使用采集文章或者复制文章来更新网站的内容。其实这个更新方法百度官方早就给出了明确的意见,想了解更多的可以到百度站长平台详细阅读百度官方说明。那我想跟大家探讨一下文章采集的影响以及如何解决抄袭问题?
网站文章 可以通过采集 吗?
因为现阶段搜索引擎越来越智能化,他们也越来越强调用户体验和附加值。如果只做文章采集大批量的话,可能会出现以下问题。
一、网站采集返回的内容不一定是符合网站主题的内容。此类内容将被搜索引擎判断为低质量垃圾邮件。严重的话,还可能让网站获得降级的权利。
二、长期量产采集文章内容也会对服务器造成一定压力。如果使用的虚拟空间容量较小,则有一定的可能性使虚拟空间内存满后无法操作,岂不是得不偿失。
网站文章被抄袭怎么解决?
一,我们需要做好我们网站的内部调整,我们需要为网站制定一个固定的时间更新频率。这个操作之后网站的收录会有很大的提升。
其次,我们更新网站原创文章后,可以选择使用百度站长平台的原创protection功能,每次更新后提交文章原创protect? ,原创protection 每天可以提交 10 个项目。
三、当对方是采集我们文章时,图片也会是采集,我们可以给文章中的图片添加图片水印。
我觉得除了百度官方对文章采集网站的处理,我们还可以把我们的网站做得更好,让我们自己网站收录更好。
文章采集参数非常多,且需要各种事件,名字叫
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-07-09 01:01
文章采集调用参数非常多,且需要各种事件,所以把事件封装成函数更加方便接收和使用,而且对于后续的接口提取、混合开发,也可以有比较好的控制。事件接收函数更是多,在macos环境中,名字叫。需要用到的类库请参考官方文档,放出命令行参数行,在applescript程序下可以创建对应类的结构体。#!/usr/bin/envpython3importjson#你这里需要的库frompython.utilsimportcachemy_cache={"token":"kpqqfaqtoaug95jsjqghidpzl22vldgkyaafnb9g068","size":3,"flags":1}#上次是3和5,这次是3+,表示想使用5个字符和一个空格,你可以自己创建两个函数来替换"imageurl":"/"#这次是"/",并且随机生成一个指定范围的数字(因为数字大小会随着时间递增)"cutout":"true","size":1,"size_type":"vector"#没有空格可以使用浮点数cutout=0.0cutout="0.0","imageurl":"/"#让图片在标准分辨率下存储#一个大小,一个宽高my_img=imageio(imageio.bytesio(imageio.rar(imageio.unpack(imageio.u_new("hg"))#my_img.save("virtualexternal.jpg")#可以使用mappartialjavascript方法,调用默认的json对象传入字符串和一个空字符s:\u0000>image=["awflag.gif","alffer.mp4","fegaflag.png","fegfronappscm9.mp4","fegfronappscm9.png","scheqf.jpg","tostridge.jpg","trorcc.jpg","ibav.jpg","ibivgj.jpg","jmija.jpg","jip","jandoc.jpg","jsgq.jpg","jamest.jpg","deeave.jpg","altga.jpg","artistip.jpg","hfz.jpg","pengso.jpg","jouop.jpg","p_reis.jpg","bonoform.jpg","desatj.jpg","snoop.jpg","strxy.jpg","cqg.jpg","cqgj.jpg","inc.jpg","lgg.jpg","nju.jpg","ocj.jpg","tgj_jpg","qjy.jpg","jneif.jpg","lps.jpg","nxy.jpg","lez.jpg","alq.jpg","sz.jpg","tang.jpg","jnjj.jpg","tang.jpg","tngj.jpg","tg。 查看全部
文章采集参数非常多,且需要各种事件,名字叫
文章采集调用参数非常多,且需要各种事件,所以把事件封装成函数更加方便接收和使用,而且对于后续的接口提取、混合开发,也可以有比较好的控制。事件接收函数更是多,在macos环境中,名字叫。需要用到的类库请参考官方文档,放出命令行参数行,在applescript程序下可以创建对应类的结构体。#!/usr/bin/envpython3importjson#你这里需要的库frompython.utilsimportcachemy_cache={"token":"kpqqfaqtoaug95jsjqghidpzl22vldgkyaafnb9g068","size":3,"flags":1}#上次是3和5,这次是3+,表示想使用5个字符和一个空格,你可以自己创建两个函数来替换"imageurl":"/"#这次是"/",并且随机生成一个指定范围的数字(因为数字大小会随着时间递增)"cutout":"true","size":1,"size_type":"vector"#没有空格可以使用浮点数cutout=0.0cutout="0.0","imageurl":"/"#让图片在标准分辨率下存储#一个大小,一个宽高my_img=imageio(imageio.bytesio(imageio.rar(imageio.unpack(imageio.u_new("hg"))#my_img.save("virtualexternal.jpg")#可以使用mappartialjavascript方法,调用默认的json对象传入字符串和一个空字符s:\u0000>image=["awflag.gif","alffer.mp4","fegaflag.png","fegfronappscm9.mp4","fegfronappscm9.png","scheqf.jpg","tostridge.jpg","trorcc.jpg","ibav.jpg","ibivgj.jpg","jmija.jpg","jip","jandoc.jpg","jsgq.jpg","jamest.jpg","deeave.jpg","altga.jpg","artistip.jpg","hfz.jpg","pengso.jpg","jouop.jpg","p_reis.jpg","bonoform.jpg","desatj.jpg","snoop.jpg","strxy.jpg","cqg.jpg","cqgj.jpg","inc.jpg","lgg.jpg","nju.jpg","ocj.jpg","tgj_jpg","qjy.jpg","jneif.jpg","lps.jpg","nxy.jpg","lez.jpg","alq.jpg","sz.jpg","tang.jpg","jnjj.jpg","tang.jpg","tngj.jpg","tg。
为什么学爬虫?分布式爬虫让多台机器帮助你快速爬取数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-07-06 02:08
[为什么要学习爬行? 】
1、Crawler 上手容易,深入难。如何编写一个高效的爬虫,如何编写一个高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,往往容易遇到反爬取,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课程!
2、如果你是其他行业的开发者,比如app开发、网页开发、学习爬虫,可以加强对技术的理解,开发更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后这门课也是按照这些步骤一步一步讲解的,带领学生全面掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图文验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫等
通过爬虫的进阶知识点,我们可以应对大量的反爬虫网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
[课程服务]
独家付费社区+常规问答 查看全部
为什么学爬虫?分布式爬虫让多台机器帮助你快速爬取数据
[为什么要学习爬行? 】
1、Crawler 上手容易,深入难。如何编写一个高效的爬虫,如何编写一个高度灵活和可扩展的爬虫是一项技术任务。另外,在爬取过程中,往往容易遇到反爬取,比如字体反爬、IP识别、验证码等,如何克服困难,得到想要的数据,可以学习这门课程!
2、如果你是其他行业的开发者,比如app开发、网页开发、学习爬虫,可以加强对技术的理解,开发更安全的软件和网站
【课程设计】
一个完整的爬虫程序,无论大小,大体上可以分为三个步骤,即:
网络请求:模拟浏览器从互联网获取数据的行为。数据分析:过滤请求的数据,提取我们想要的数据。数据存储:将提取的数据存储到硬盘或内存中。比如使用mysql数据库或者redis。
然后这门课也是按照这些步骤一步一步讲解的,带领学生全面掌握每一步的技术。另外,由于爬虫的多样性,在爬取过程中可能会出现反爬和效率低下的情况。因此,我们又增加了两章来提高爬虫程序的灵活性,即:
爬虫进阶:包括IP代理、多线程爬虫、图文验证码识别、JS加解密、动态网页爬虫、字体反爬识别等。Scrapy及分布式爬虫:Scrapy框架、Scrapy-redis组件、分布式爬虫等
通过爬虫的进阶知识点,我们可以应对大量的反爬虫网站,而Scrapy框架是一个专业的爬虫框架,使用它可以快速提高我们爬虫程序的效率和速度。另外,如果一台机器不能满足你的需求,我们可以使用分布式爬虫,让多台机器帮你快速抓取数据。
从基础爬虫到商业应用爬虫,这套课程满足你的所有需求!
[课程服务]
独家付费社区+常规问答
蜘蛛池独创万用站群模型2019年6月升级
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-07-05 23:22
注:1、本程序为3.31版本,2019年6月升级2、本程序不限用(破解),不开源,可复现。 3、由于程序的可复制性,不了解蜘蛛池是什么的客户请不要购买。不了解程序的购买将不予退款。 4、购买客户请不要提供或二次销售,否则将取消所有服务。 5、本程序需要PHP5.X、7.X使用,使用文本数据库,无需MYSQL工作。 6、如果需要对功能有具体的了解,可以加Q帮助观看演示。 7、Q 早上9点和晚上9点上线,小旋风源码出售。
x3 版本升级:
x2版本升级:功能列表如下:原创系统架构安全高效,可大幅优化php使用性能,运行流畅稳定,独创无缓存机制,原内容刷新无缓存,保存硬盘。防止搜索引擎识别蜘蛛池独创universal站群模型2019新蜘蛛算法,轻松搭建通用站点(电影、资讯、图片、论坛等)。企业信息自动生成企业名称、产品型号、公司简介、联系方式等。 标题重组功能拆分重组,重组2个标题,以1句内容为标题,以1句内容为标题,添加在标题后。突破百度算法标题和内容关联功能,突破百度算法网站分组可以个性化每一个网站'S的风格、内容、站点模式、关键词、外部链接等模板分为不同行业、不同类别、不同模板和不同的 URL。自动采集/自己设置采集Auto采集解放双手,可以设置发布策略,自己设置采集,想采集哪个站采集哪个站超强,自己设置tkd,自己设置外链关键词,自己设置域名前缀,超强SEO优化功能标题伪原创,内容伪原创,标题拆分重组,关键词为随机插入,繁体中文转换蜘蛛抓取记录蜘蛛访问日志(每日访问、每周访问、每月访问图表,一目了然) 蜘蛛劫持可设置劫持概率、劫持时间、强制蜘蛛劫持、霸道蜘蛛防火墙屏蔽指定、垃圾邮件蜘蛛,节省服务器资源,双模单域名,泛域名模式,一键切换,迎合不同搜索引擎口味,多模板系统自带25个模板,可自行扩展。容易制作。您可以在不同的行业设置自己的网址。您可以自行设置不同的网址,使您的网址独一无二。标题可以本地缓存,外部链接可以独立缓存。您可以一键升级标题和外部链接。
查看全部
蜘蛛池独创万用站群模型2019年6月升级
注:1、本程序为3.31版本,2019年6月升级2、本程序不限用(破解),不开源,可复现。 3、由于程序的可复制性,不了解蜘蛛池是什么的客户请不要购买。不了解程序的购买将不予退款。 4、购买客户请不要提供或二次销售,否则将取消所有服务。 5、本程序需要PHP5.X、7.X使用,使用文本数据库,无需MYSQL工作。 6、如果需要对功能有具体的了解,可以加Q帮助观看演示。 7、Q 早上9点和晚上9点上线,小旋风源码出售。
x3 版本升级:
x2版本升级:功能列表如下:原创系统架构安全高效,可大幅优化php使用性能,运行流畅稳定,独创无缓存机制,原内容刷新无缓存,保存硬盘。防止搜索引擎识别蜘蛛池独创universal站群模型2019新蜘蛛算法,轻松搭建通用站点(电影、资讯、图片、论坛等)。企业信息自动生成企业名称、产品型号、公司简介、联系方式等。 标题重组功能拆分重组,重组2个标题,以1句内容为标题,以1句内容为标题,添加在标题后。突破百度算法标题和内容关联功能,突破百度算法网站分组可以个性化每一个网站'S的风格、内容、站点模式、关键词、外部链接等模板分为不同行业、不同类别、不同模板和不同的 URL。自动采集/自己设置采集Auto采集解放双手,可以设置发布策略,自己设置采集,想采集哪个站采集哪个站超强,自己设置tkd,自己设置外链关键词,自己设置域名前缀,超强SEO优化功能标题伪原创,内容伪原创,标题拆分重组,关键词为随机插入,繁体中文转换蜘蛛抓取记录蜘蛛访问日志(每日访问、每周访问、每月访问图表,一目了然) 蜘蛛劫持可设置劫持概率、劫持时间、强制蜘蛛劫持、霸道蜘蛛防火墙屏蔽指定、垃圾邮件蜘蛛,节省服务器资源,双模单域名,泛域名模式,一键切换,迎合不同搜索引擎口味,多模板系统自带25个模板,可自行扩展。容易制作。您可以在不同的行业设置自己的网址。您可以自行设置不同的网址,使您的网址独一无二。标题可以本地缓存,外部链接可以独立缓存。您可以一键升级标题和外部链接。
文章采集调用文本传递word到百度合成框架中,最后重建出生成结果
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-07-02 19:01
文章采集调用文本传递word到百度合成框架中,最后重建出生成结果
1、下载并下载wordtowordfrommelodyneyer
2、将数据包放入百度云,
3、下载wordtowordfrommelodyneyer,
楼上已经解释清楚了,确实,提取出的是一个文本的内容,然后经过转写机生成其他的。再发一遍文章链接,wordtoword的详细介绍,
本质上是用一个合成器把你写好的文字合成成。github-yerwin1011/word_to_word:decodeanewwordtoanopenspeechsystem其中有四个小功能,你看你喜欢哪个。
尝试通过openspeechsystem正确连接一个melodynewordtoword模型,网上无数教程不一定能实现。目前我在三个方向上努力。一方面尝试模仿百度合成的公开代码实现简单高效的实例。再一方面尝试迁移melodyneengine本身的代码,开发模仿微软ttsgroovy开发工具。最后一方面测试aegisub与melodyne结合能否实现相似效果。欢迎交流。
拿melodyne内置的wordtoword和wordwithspeech生成,不再通过电脑。用openspeechsystem连接了百度云服务器,打开就有实际效果了。 查看全部
文章采集调用文本传递word到百度合成框架中,最后重建出生成结果
文章采集调用文本传递word到百度合成框架中,最后重建出生成结果
1、下载并下载wordtowordfrommelodyneyer
2、将数据包放入百度云,
3、下载wordtowordfrommelodyneyer,
楼上已经解释清楚了,确实,提取出的是一个文本的内容,然后经过转写机生成其他的。再发一遍文章链接,wordtoword的详细介绍,
本质上是用一个合成器把你写好的文字合成成。github-yerwin1011/word_to_word:decodeanewwordtoanopenspeechsystem其中有四个小功能,你看你喜欢哪个。
尝试通过openspeechsystem正确连接一个melodynewordtoword模型,网上无数教程不一定能实现。目前我在三个方向上努力。一方面尝试模仿百度合成的公开代码实现简单高效的实例。再一方面尝试迁移melodyneengine本身的代码,开发模仿微软ttsgroovy开发工具。最后一方面测试aegisub与melodyne结合能否实现相似效果。欢迎交流。
拿melodyne内置的wordtoword和wordwithspeech生成,不再通过电脑。用openspeechsystem连接了百度云服务器,打开就有实际效果了。
文章采集调用 跑到图文加工店,说给点素材,中年老板:骚年你来对了
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-07-01 05:06
去图文加工店说一些材料。中年老板:嫂子,你说得对。我们这里有很多库存。你有你想要的一切,JPG、PSD、AI、AE、AV。你想...
去菜市场举一些例子。卖水果的:朋友知道货。今天刚到的李子还不错。缺点:太甜了!隔壁卖糖炒栗子的男人伸长脖子:大哥,拿一袋吧!
恩...定义很重要,所以我们今天所说的就是指在阅读中获得的文本内容,写作、演讲、推理等方面的参考资料和例子。
其实很多大牛都专门写了文章比如管理自己的知识库,整理自己的知识体系。材料和示例只是其中很小的一部分。和那些大牛比起来,这次我只专注于材料和例子。这个入口点非常小。如果您已经建立了自己完整的知识框架和结构,非常欢迎您给我意见和批评,并先接受。
一、材料和例子有什么用1.征服观众
写作或发表演讲时,通常围绕一个主题展开,您要做的就是让读者或听众理解并接受您所说的内容。如果你按照规则一一描述,就像教科书一样,你很可能会失去很多观众。这种情况在演讲时尤为明显。当你偶尔低头看着舞台,寻找所谓的眼神交流和互动感时,你会发现观众中很多人只是盯着桌子底下笑。你应该明白你说的对他们来说不像微博或朋友圈那么有趣。
在书面或演讲中适当引用可以最大程度地避免这种情况。在写作中引用实例可以帮助读者避免长时间阅读的疲劳,同时加深对内容的理解;演讲中生动的例子更有效,可以使你表达的内容更容易被听众接受和理解。而且,成人注意力集中的时间曲线有其特定的规律。可以提供两个生动的例子,在听众精力下降、容易分心的时候,让他们瞬间重新集中注意力,保证演讲的良好效果。
2.被别人吸引
你的朋友中应该有一些这样的人。饭桌上谈山,如同切瓜切菜,从天文、地理、神仙、妖怪、玄学、三身、四书、五道口,下至官场、百姓的悲喜、肉乐,奇怪的事情,各种各样的事情。话题在各个领域。如果你不在流程中,如果你被TA接了,那就别想了。从头到尾,你有名有姓,头是对的。如果你也想成为派对的中心(当然最好排除个人自夸的内容),几句引语反驳一大段,那么素材和实例的采集可以让你玩起来更轻松。李笑来老师在《花时间做朋友》中提到,父亲总是可以在公共场合讲话。他一度以为父亲是个记忆力超群的人,后来发现父亲的秘密其实是一本记事本,里面全是笔记。所谓修辞,就是根据采集到的材料和例子,以及这些内容什么时候可以适用于什么情况。
3.生理原因(个人原因)
英文里有一句话:on the tip of my thumb,直译为“在我的舌尖上”,实际表达是单词在嘴唇上,但我一下子想不起来在关注采集资料和实例之前,我有很多类似的经历。我清楚地记得前一天,甚至几个小时前,我偶然看到一个例子来支持我的观点,但我想不起细节和来源。我穿过盒子并寻求帮助。谷歌独娘,没有结果。这时候就会有背上的刺和喉咙里的刺痛感,相当不舒服。我认为这种感觉是由于没有保留适当的材料或示例的遗憾。
于是,采集资料和实例就成了我的日常习惯之一。 “当书籍被使用时,他们的仇恨就会减少。”古人已经表达过类似的叹息。其实,对于掌握了很多新工具、新方法的现代人来说,搜集整理资料和实例,其实并没有想象中的那么麻烦。
二、如何采集资料和例子1.资料和例子采集
由于我说的采集整理主要是针对文本内容,所以采集资料和例子的主要来源如下:
(1)图书
如今,人们普遍强调对知识产权的保护。很多书的内容在网上是无法直接获取的,阅读后只能摘录。
——电子书
目前国内外新书上架趋势是电子版和纸质版同步推出。电子版通常更便宜,可以直接在亚马逊等官网购买。尤其是刚刚出版的新书,基本上只能找到付费版(各种号称免费的网站,往往指向付费版网址)。对于上架一段时间的书籍,会有各种免费的电子版流出,大部分是PDF,但质量参差不齐。还有一点,对于寻找电子书,我的建议是,如果5-10分钟内没有找到合适的版本,基本可以放弃。不值得为免费和无保证的内容花费更多宝贵的时间,只需购买电子书即可。版本性价比更高,付费也体现了对知识的尊重。
以目前主流的亚马逊官网为例。购买完成后会自动推送到KINDLE。为了方便后续的整理和检索,我将使用CALIBRE软件加上DEDRM插件将亚马逊下载的AZW3格式转换为EPUB格式,然后将书中需要的内容收录到印象笔记中(仅供学习参考) ,绝不参与D版盈利),让大段摘录和引用的内容轻松复制到印象笔记同步,不易丢失,方便查找。
——纸质版书籍
有些书比较经典但比较老,多次再版,没有电子版;也有非小说类书籍,因为我个人喜欢边看书边手写阅读笔记,所以买了纸质版。对于这种类型的纸质书,提取大章节非常不方便,人工摘录也相当耗时。好在后来在某宝上发现了一支手持扫描笔,可以将纸质内容快速扫描成可编辑的文本格式。效率比人工输入高很多倍。之前看过万维刚的《奇思妙想》。有许多科学的经验引述。段落很长。我用扫描笔摘录。它是一个令人耳目一新的阅读笔记工具。真是感叹好工具。钱不能省。对于喜欢看纸质书、喜欢做读书笔记的朋友来说,扫描笔是一个非常推荐的工具。
(2)微信内容
微信是日常生活中大多数人使用频率最高的手机应用,如何使用它不言而喻。我个人将印象笔记和有道云这两个公众号联系起来。我通常把值得采集的内容随时保存在云端,然后在电脑上整理汇总。
(3)网页内容
浏览网页时,我会及时保存好内容。复制粘贴段落太麻烦了。为此,我使用了 Evernote 网页剪辑插件。可以选择整个页面,网页正文,或者去广告等等,形式多样,很贴心。
(4)Other
其他来源不是我采集和整理资料的主流渠道。比如微信聊天记录整理等,依靠谷歌度娘的一些技巧,将它们整理成文字内容并保存。
2.材料和例子的组织
采集后一定要排序,否则不会发挥任何价值。排序的目的是为了更好的使用。依靠大脑记住所有采集到的内容是极其困难的。作为85后的我,经常听到90后说“哎呀!怎么想不起来了,老了脑子就不好用了”,这时候感觉自己插入了一个飞刀在我心中。我太习惯了)。事实上,人脑就像一台电脑,存储容量有一定的上限。此外,人脑还具有遗忘机制。对于长时间不使用的内容,大脑会选择忘记为经常使用的模块腾出存储空间来运行。因此,我们需要以更有效的方式组织采集到的材料和实例,以方便后续的高效调用,减轻大脑的负担,让大脑腾出空间去思考更有价值的事情。
以印象笔记为例。完成采集动作后,你的印象笔记里应该有不少内容,但都是杂乱无章的。这时候你需要做三件事:
第一步是命名。这是最直接的内容分类方法,也是最原创的信息查询渠道。我平时给内容命名的方法是:日期+类型+一般内容摘要,例如:20161011知乎LIVE-战隼老师-一种没有意志力的习惯养成方法,所以不管我想到《战隼》还是《》习惯”、“知乎”或日期可用于定位此材料。
第二步是分类。设置文件夹,将采集到的内容按类型分类,就像在电脑上创建文件夹和分类各种文档一样。我现在使用的文件夹有:个人(存放个人信息等私密内容,可选加密)、日常工作(材料或与工作相关的内容)、学习(与学习、写作、成长等相关的内容)等。这个设置的好处是,当你不记得要搜索的具体细节,但可以确定需要查找的一般类别时,可以过滤掉其他类别以缩小搜索范围。但是,当内容积累到一定程度时,这种分类的范围还是太厚,不够细。这时候就需要第三步配合了。 (这里吐槽,印象笔记的笔记本分类等级只有2级,无法进一步细化。积分,道云笔记等级更多更强)。
第三步也是最重要的一步是添加标签!标签!标签! (重要的事情说三遍)按文件夹分类材料有很大的缺陷。一个材料或示例只能放在一个文件夹中。如果你想把它放在第二个文件夹中,你只需要再次复制粘贴。 数据本来就很复杂,复制粘贴会导致搜索中出现多次重复的结果,会占用宝贵的云存储空间。强烈不推荐。因此,此时您需要为材料或示例做的是添加标签。与其添加一个标签,不如添加尽可能多的标签,并根据该材料可以穷尽的所有相关特征进行标记。比如:之前在短书上看到一篇文章《经验:如何找电子书》,教你如何搜索你需要的电子书或电子资料。我把这个文章按大类放在了学习文件夹里,但其实我在工作中也用到了电子资料的搜索技巧。因此,我在这个文章上添加了“电子书”、“搜索”、“资源”、“技术”等几个标签,以便我写文章来澄清调用资源、查找电子书、普及工作技能等等。你看这个文章就可以找到。
标记有两个非常大的好处。一是标注可以帮助你思考反刍:除了解释这个材料或例子的原创内容之外,你还可以使用哪些方面?哪些观点也可以用来佐证?这与上面提到的相同。他的父亲李笑来老师通过记录和思考,可以用笔记本的内容写下什么时候、什么地方、什么情况。是“思维扩展”的简化版,也可以颠倒过来。来这里帮助你进一步加深对内容的理解。二是通过标注会有很多意想不到的“惊喜”。我写了《学会花钱》这本书的书评。在分析涉及概率论的章节时,我在印象笔记中点击了我标记为“概率论”的文件分类。没想到,在资料集里,原来关于小数定律的思想和评论被轻易复制粘贴,而且写得很轻松,着实让人意外。随着材料越来越多,“惊喜”的概率会越来越大。这就是大脑的神经元数量在一定程度上很大的原因,接触到大量的连接,然后就会被打掉奇怪的思想火花。
三、 方法调用
所谓调用,就是搜索所有你认为你能想到的关键词,找到你想要的内容,其中一些在前面的文章中已经提到过。可以确定,查找文件名是最直接的。如果没有,您可以在大类中搜索,缩小范围,或者使用标签叠加的方法进行多维搜索。目前我最常用的方法是确定类别,然后使用多个标签叠加搜索方法,具有最高的方向性。如果您想在搜索时获得灵感,只需浏览单个关键字或单击单个标签的集合,这往往会给您带来一些意想不到的内容。
著名的李敖开书的例子是材料采集和调用的最好例子。以下段落来自对他的采访:
我很少忘记读过的书,李敖,为什么?方法很好。有什么办法?无情。所有的剪刀和美工刀都用上了,书被劈开。我需要这个页面,我需要这个段落,我将把它分成几类。如果背面有用呢?复印它,或者一开始买两本书,把两本书剪下来整理好,把你想读的部分分类保存。结果,看完一本书,书也被肢解了。我就是这样看书的。
如何划分分类?我有很多自己制作的剪辑,我在剪辑上写下文字来对所有材料进行分类。读完一本书,都进入了我的剪辑。我可以将它们分为数千个类别,它们非常详细。比如按照图书馆的分类,哲学类,宗教类;宗教类又分为佛教类、道教类、天主教类。我,李敖,可以分为更详细的类别。天主教也可以分为几类。牧师也可以细分。牧师同性恋是一类,牧师的粗俗是另一类。修女的同性恋是一类,修女的粗俗又是另一类。
书中的任何相关内容都会进入我的个人资料。你为什么进入?当我想写小说时,我需要这些信息,打开信息,然后写出来。或者发生了一些与同性恋修女有关的事情。想对新闻发表自己的看法,拿新闻,打开我的信息,把两者合并,文章立马写出来了。
也就是说,在我读完这本书后,我被五匹马肢解和分割。但我把它挂了。我不记得这些数据了。我用详细而耐心的工作将其连接起来,并将其放入文件夹中。我的记忆只需要记住这些标题。标题是根据我的习惯来划分的。基本上都是翻译成英文字,驱逐英文字母,偶尔也有一些中文。 "
四、Notes
明确材料采集的方法和好处后,还有两点需要注意:
1.确认真相。
逻辑中有一个重要的概念:“合乎逻辑就是符合真理。”如果采集的材料和例子来自歪曲事实或报道,那么即使符合你的观点,支持你的说法,也毫无意义,甚至会产生相反的效果,让读者或听众觉得你没有区别。一个相信真假的人会大大降低你观点的可信度。此外,即使材料是真实的,也很可能具有时效性。因此,在使用材料或实例时,切记检查内容是否真实,是否仍然准确,并及时更新筛选。如果涉及到新闻、历史、人文等收录年龄或数据的内容,一定要再次确认准确性,以免被人笑话。
2.告诉来源。
在举例的时候,只表达内容不说明出处,会让人觉得缺乏信任。如果读者或听众对你引用的材料或例子特别感兴趣,他们很可能想通过这些来源了解更详细的内容,所以在引用材料或例子时,在不影响流畅性的前提下,尽量多说出来源。演示文稿。
五、Summary
回忆一下采集和组织例子的要点:
——为什么要注意材料和实例的采集
1.征服观众
2.被别人吸引
3.(个人原因)
——采集整理方法
1.采集源
(1)书——电子版、纸质版
(2)微信
(3)网页
(4)Other
——调用方法
文件名、分类、标签叠加
——注意事项
1.确认真相
2.告诉来源
说到这里,就是想把自己采集整理的习惯分享给大家,让分享好东西更有意义。无论是写作、演讲、推理,还是丰富对话、获取知识、成为一个有趣的人,好的材料和例子都是很有帮助的。在这个时代,“好记性不如坏笔”应该改为“好记性不如坏手指”。虽然一开始可能会觉得有些繁琐,但是当你体验到频繁采集整理的好处时,你肯定会欲罢不能。想想你可以通过采集和整理来控制这么大的材料库供你使用,真是太有趣了。
为什么不试试看? 查看全部
文章采集调用 跑到图文加工店,说给点素材,中年老板:骚年你来对了
去图文加工店说一些材料。中年老板:嫂子,你说得对。我们这里有很多库存。你有你想要的一切,JPG、PSD、AI、AE、AV。你想...
去菜市场举一些例子。卖水果的:朋友知道货。今天刚到的李子还不错。缺点:太甜了!隔壁卖糖炒栗子的男人伸长脖子:大哥,拿一袋吧!
恩...定义很重要,所以我们今天所说的就是指在阅读中获得的文本内容,写作、演讲、推理等方面的参考资料和例子。
其实很多大牛都专门写了文章比如管理自己的知识库,整理自己的知识体系。材料和示例只是其中很小的一部分。和那些大牛比起来,这次我只专注于材料和例子。这个入口点非常小。如果您已经建立了自己完整的知识框架和结构,非常欢迎您给我意见和批评,并先接受。
一、材料和例子有什么用1.征服观众
写作或发表演讲时,通常围绕一个主题展开,您要做的就是让读者或听众理解并接受您所说的内容。如果你按照规则一一描述,就像教科书一样,你很可能会失去很多观众。这种情况在演讲时尤为明显。当你偶尔低头看着舞台,寻找所谓的眼神交流和互动感时,你会发现观众中很多人只是盯着桌子底下笑。你应该明白你说的对他们来说不像微博或朋友圈那么有趣。
在书面或演讲中适当引用可以最大程度地避免这种情况。在写作中引用实例可以帮助读者避免长时间阅读的疲劳,同时加深对内容的理解;演讲中生动的例子更有效,可以使你表达的内容更容易被听众接受和理解。而且,成人注意力集中的时间曲线有其特定的规律。可以提供两个生动的例子,在听众精力下降、容易分心的时候,让他们瞬间重新集中注意力,保证演讲的良好效果。
2.被别人吸引
你的朋友中应该有一些这样的人。饭桌上谈山,如同切瓜切菜,从天文、地理、神仙、妖怪、玄学、三身、四书、五道口,下至官场、百姓的悲喜、肉乐,奇怪的事情,各种各样的事情。话题在各个领域。如果你不在流程中,如果你被TA接了,那就别想了。从头到尾,你有名有姓,头是对的。如果你也想成为派对的中心(当然最好排除个人自夸的内容),几句引语反驳一大段,那么素材和实例的采集可以让你玩起来更轻松。李笑来老师在《花时间做朋友》中提到,父亲总是可以在公共场合讲话。他一度以为父亲是个记忆力超群的人,后来发现父亲的秘密其实是一本记事本,里面全是笔记。所谓修辞,就是根据采集到的材料和例子,以及这些内容什么时候可以适用于什么情况。
3.生理原因(个人原因)
英文里有一句话:on the tip of my thumb,直译为“在我的舌尖上”,实际表达是单词在嘴唇上,但我一下子想不起来在关注采集资料和实例之前,我有很多类似的经历。我清楚地记得前一天,甚至几个小时前,我偶然看到一个例子来支持我的观点,但我想不起细节和来源。我穿过盒子并寻求帮助。谷歌独娘,没有结果。这时候就会有背上的刺和喉咙里的刺痛感,相当不舒服。我认为这种感觉是由于没有保留适当的材料或示例的遗憾。
于是,采集资料和实例就成了我的日常习惯之一。 “当书籍被使用时,他们的仇恨就会减少。”古人已经表达过类似的叹息。其实,对于掌握了很多新工具、新方法的现代人来说,搜集整理资料和实例,其实并没有想象中的那么麻烦。
二、如何采集资料和例子1.资料和例子采集
由于我说的采集整理主要是针对文本内容,所以采集资料和例子的主要来源如下:
(1)图书
如今,人们普遍强调对知识产权的保护。很多书的内容在网上是无法直接获取的,阅读后只能摘录。
——电子书
目前国内外新书上架趋势是电子版和纸质版同步推出。电子版通常更便宜,可以直接在亚马逊等官网购买。尤其是刚刚出版的新书,基本上只能找到付费版(各种号称免费的网站,往往指向付费版网址)。对于上架一段时间的书籍,会有各种免费的电子版流出,大部分是PDF,但质量参差不齐。还有一点,对于寻找电子书,我的建议是,如果5-10分钟内没有找到合适的版本,基本可以放弃。不值得为免费和无保证的内容花费更多宝贵的时间,只需购买电子书即可。版本性价比更高,付费也体现了对知识的尊重。
以目前主流的亚马逊官网为例。购买完成后会自动推送到KINDLE。为了方便后续的整理和检索,我将使用CALIBRE软件加上DEDRM插件将亚马逊下载的AZW3格式转换为EPUB格式,然后将书中需要的内容收录到印象笔记中(仅供学习参考) ,绝不参与D版盈利),让大段摘录和引用的内容轻松复制到印象笔记同步,不易丢失,方便查找。
——纸质版书籍
有些书比较经典但比较老,多次再版,没有电子版;也有非小说类书籍,因为我个人喜欢边看书边手写阅读笔记,所以买了纸质版。对于这种类型的纸质书,提取大章节非常不方便,人工摘录也相当耗时。好在后来在某宝上发现了一支手持扫描笔,可以将纸质内容快速扫描成可编辑的文本格式。效率比人工输入高很多倍。之前看过万维刚的《奇思妙想》。有许多科学的经验引述。段落很长。我用扫描笔摘录。它是一个令人耳目一新的阅读笔记工具。真是感叹好工具。钱不能省。对于喜欢看纸质书、喜欢做读书笔记的朋友来说,扫描笔是一个非常推荐的工具。
(2)微信内容
微信是日常生活中大多数人使用频率最高的手机应用,如何使用它不言而喻。我个人将印象笔记和有道云这两个公众号联系起来。我通常把值得采集的内容随时保存在云端,然后在电脑上整理汇总。
(3)网页内容
浏览网页时,我会及时保存好内容。复制粘贴段落太麻烦了。为此,我使用了 Evernote 网页剪辑插件。可以选择整个页面,网页正文,或者去广告等等,形式多样,很贴心。
(4)Other
其他来源不是我采集和整理资料的主流渠道。比如微信聊天记录整理等,依靠谷歌度娘的一些技巧,将它们整理成文字内容并保存。
2.材料和例子的组织
采集后一定要排序,否则不会发挥任何价值。排序的目的是为了更好的使用。依靠大脑记住所有采集到的内容是极其困难的。作为85后的我,经常听到90后说“哎呀!怎么想不起来了,老了脑子就不好用了”,这时候感觉自己插入了一个飞刀在我心中。我太习惯了)。事实上,人脑就像一台电脑,存储容量有一定的上限。此外,人脑还具有遗忘机制。对于长时间不使用的内容,大脑会选择忘记为经常使用的模块腾出存储空间来运行。因此,我们需要以更有效的方式组织采集到的材料和实例,以方便后续的高效调用,减轻大脑的负担,让大脑腾出空间去思考更有价值的事情。
以印象笔记为例。完成采集动作后,你的印象笔记里应该有不少内容,但都是杂乱无章的。这时候你需要做三件事:
第一步是命名。这是最直接的内容分类方法,也是最原创的信息查询渠道。我平时给内容命名的方法是:日期+类型+一般内容摘要,例如:20161011知乎LIVE-战隼老师-一种没有意志力的习惯养成方法,所以不管我想到《战隼》还是《》习惯”、“知乎”或日期可用于定位此材料。
第二步是分类。设置文件夹,将采集到的内容按类型分类,就像在电脑上创建文件夹和分类各种文档一样。我现在使用的文件夹有:个人(存放个人信息等私密内容,可选加密)、日常工作(材料或与工作相关的内容)、学习(与学习、写作、成长等相关的内容)等。这个设置的好处是,当你不记得要搜索的具体细节,但可以确定需要查找的一般类别时,可以过滤掉其他类别以缩小搜索范围。但是,当内容积累到一定程度时,这种分类的范围还是太厚,不够细。这时候就需要第三步配合了。 (这里吐槽,印象笔记的笔记本分类等级只有2级,无法进一步细化。积分,道云笔记等级更多更强)。
第三步也是最重要的一步是添加标签!标签!标签! (重要的事情说三遍)按文件夹分类材料有很大的缺陷。一个材料或示例只能放在一个文件夹中。如果你想把它放在第二个文件夹中,你只需要再次复制粘贴。 数据本来就很复杂,复制粘贴会导致搜索中出现多次重复的结果,会占用宝贵的云存储空间。强烈不推荐。因此,此时您需要为材料或示例做的是添加标签。与其添加一个标签,不如添加尽可能多的标签,并根据该材料可以穷尽的所有相关特征进行标记。比如:之前在短书上看到一篇文章《经验:如何找电子书》,教你如何搜索你需要的电子书或电子资料。我把这个文章按大类放在了学习文件夹里,但其实我在工作中也用到了电子资料的搜索技巧。因此,我在这个文章上添加了“电子书”、“搜索”、“资源”、“技术”等几个标签,以便我写文章来澄清调用资源、查找电子书、普及工作技能等等。你看这个文章就可以找到。
标记有两个非常大的好处。一是标注可以帮助你思考反刍:除了解释这个材料或例子的原创内容之外,你还可以使用哪些方面?哪些观点也可以用来佐证?这与上面提到的相同。他的父亲李笑来老师通过记录和思考,可以用笔记本的内容写下什么时候、什么地方、什么情况。是“思维扩展”的简化版,也可以颠倒过来。来这里帮助你进一步加深对内容的理解。二是通过标注会有很多意想不到的“惊喜”。我写了《学会花钱》这本书的书评。在分析涉及概率论的章节时,我在印象笔记中点击了我标记为“概率论”的文件分类。没想到,在资料集里,原来关于小数定律的思想和评论被轻易复制粘贴,而且写得很轻松,着实让人意外。随着材料越来越多,“惊喜”的概率会越来越大。这就是大脑的神经元数量在一定程度上很大的原因,接触到大量的连接,然后就会被打掉奇怪的思想火花。
三、 方法调用
所谓调用,就是搜索所有你认为你能想到的关键词,找到你想要的内容,其中一些在前面的文章中已经提到过。可以确定,查找文件名是最直接的。如果没有,您可以在大类中搜索,缩小范围,或者使用标签叠加的方法进行多维搜索。目前我最常用的方法是确定类别,然后使用多个标签叠加搜索方法,具有最高的方向性。如果您想在搜索时获得灵感,只需浏览单个关键字或单击单个标签的集合,这往往会给您带来一些意想不到的内容。
著名的李敖开书的例子是材料采集和调用的最好例子。以下段落来自对他的采访:
我很少忘记读过的书,李敖,为什么?方法很好。有什么办法?无情。所有的剪刀和美工刀都用上了,书被劈开。我需要这个页面,我需要这个段落,我将把它分成几类。如果背面有用呢?复印它,或者一开始买两本书,把两本书剪下来整理好,把你想读的部分分类保存。结果,看完一本书,书也被肢解了。我就是这样看书的。
如何划分分类?我有很多自己制作的剪辑,我在剪辑上写下文字来对所有材料进行分类。读完一本书,都进入了我的剪辑。我可以将它们分为数千个类别,它们非常详细。比如按照图书馆的分类,哲学类,宗教类;宗教类又分为佛教类、道教类、天主教类。我,李敖,可以分为更详细的类别。天主教也可以分为几类。牧师也可以细分。牧师同性恋是一类,牧师的粗俗是另一类。修女的同性恋是一类,修女的粗俗又是另一类。
书中的任何相关内容都会进入我的个人资料。你为什么进入?当我想写小说时,我需要这些信息,打开信息,然后写出来。或者发生了一些与同性恋修女有关的事情。想对新闻发表自己的看法,拿新闻,打开我的信息,把两者合并,文章立马写出来了。
也就是说,在我读完这本书后,我被五匹马肢解和分割。但我把它挂了。我不记得这些数据了。我用详细而耐心的工作将其连接起来,并将其放入文件夹中。我的记忆只需要记住这些标题。标题是根据我的习惯来划分的。基本上都是翻译成英文字,驱逐英文字母,偶尔也有一些中文。 "
四、Notes
明确材料采集的方法和好处后,还有两点需要注意:
1.确认真相。
逻辑中有一个重要的概念:“合乎逻辑就是符合真理。”如果采集的材料和例子来自歪曲事实或报道,那么即使符合你的观点,支持你的说法,也毫无意义,甚至会产生相反的效果,让读者或听众觉得你没有区别。一个相信真假的人会大大降低你观点的可信度。此外,即使材料是真实的,也很可能具有时效性。因此,在使用材料或实例时,切记检查内容是否真实,是否仍然准确,并及时更新筛选。如果涉及到新闻、历史、人文等收录年龄或数据的内容,一定要再次确认准确性,以免被人笑话。
2.告诉来源。
在举例的时候,只表达内容不说明出处,会让人觉得缺乏信任。如果读者或听众对你引用的材料或例子特别感兴趣,他们很可能想通过这些来源了解更详细的内容,所以在引用材料或例子时,在不影响流畅性的前提下,尽量多说出来源。演示文稿。
五、Summary
回忆一下采集和组织例子的要点:
——为什么要注意材料和实例的采集
1.征服观众
2.被别人吸引
3.(个人原因)
——采集整理方法
1.采集源
(1)书——电子版、纸质版
(2)微信
(3)网页
(4)Other
——调用方法
文件名、分类、标签叠加
——注意事项
1.确认真相
2.告诉来源
说到这里,就是想把自己采集整理的习惯分享给大家,让分享好东西更有意义。无论是写作、演讲、推理,还是丰富对话、获取知识、成为一个有趣的人,好的材料和例子都是很有帮助的。在这个时代,“好记性不如坏笔”应该改为“好记性不如坏手指”。虽然一开始可能会觉得有些繁琐,但是当你体验到频繁采集整理的好处时,你肯定会欲罢不能。想想你可以通过采集和整理来控制这么大的材料库供你使用,真是太有趣了。
为什么不试试看?
熊啸锋SEO文章系列:网站内容采集原创处理(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-06-29 21:27
熊晓峰SEO文章系列:网站内容采集原创处理
大家好网站文章原创查询,我是熊晓峰,今天继续分享SEO和网站操作经验文章,因为昨天的分享内容更新和原创处理,只提到了框架,没有详细分享,所以今天和大家详细分享一下如何处理获取到的文章内容,让内容变得更好。
今天的内容主要针对采集内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、filter采集源
2、采集工具介绍
3、采集文章处理
1、采集源
这个很好理解,就是需要采集的目标内容源,可以是搜索引擎、新闻源、peer网站、industry网站等的搜索结果,只要因为它是你网站 内容的补充,没关系。
前期甚至可以使用采集,只要保持稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容,采集工具是必不可少的,好的工具可以事半功倍。目前采集工具很多,很多开源的cms程序都有自己的采集工具。您可以通过自己搜索来找出您需要的那些。
今天主要以优采云采集器为例进行介绍。相信资深站长都用过这个采集器。您可以自行查看说明以了解详细信息。这里就不介绍了,官网也有。基础视频教程,基本都能操作。
3、文章Handle (伪原创)
这里我只推荐使用ai来处理伪原创,因为之前的伪原创程序都是同义词和同义词替换,这样原创度不高,甚至影响阅读的流畅性。
现在提供了几乎主流的采集工具,智能原创api接口,直接调用5118等伪原创content接口。当然还有其他平台,可以自己选择,这种api是付费的,费用自查。
还有页面内容的处理。我们从采集处理伪原创文章内容后,还不够。我们在文章给自己网站发帖后,我们会继续处理,比如调用相关内容,也可以补充内容,增加用户点击量和PV。
另一种方式是将多个文章合并成一个文章,这样内容才能更加全面完善。这类内容不仅搜索引擎喜欢,用户也喜欢。如果你能做到这一点,其实你的内容已经是原创了。
更多详细教程请继续关注我,稍后观看教程,后续视频教程会更新。
一大早,今天就写这么多 查看全部
熊啸锋SEO文章系列:网站内容采集原创处理(图)
熊晓峰SEO文章系列:网站内容采集原创处理
大家好网站文章原创查询,我是熊晓峰,今天继续分享SEO和网站操作经验文章,因为昨天的分享内容更新和原创处理,只提到了框架,没有详细分享,所以今天和大家详细分享一下如何处理获取到的文章内容,让内容变得更好。
今天的内容主要针对采集内容,手写原创的内容可以直接忽略。
主要分为以下几个部分
1、filter采集源
2、采集工具介绍
3、采集文章处理
1、采集源
这个很好理解,就是需要采集的目标内容源,可以是搜索引擎、新闻源、peer网站、industry网站等的搜索结果,只要因为它是你网站 内容的补充,没关系。
前期甚至可以使用采集,只要保持稳定更新,只要内容不涉及灰黑产品即可。
2、采集工具
对于采集内容,采集工具是必不可少的,好的工具可以事半功倍。目前采集工具很多,很多开源的cms程序都有自己的采集工具。您可以通过自己搜索来找出您需要的那些。
今天主要以优采云采集器为例进行介绍。相信资深站长都用过这个采集器。您可以自行查看说明以了解详细信息。这里就不介绍了,官网也有。基础视频教程,基本都能操作。
3、文章Handle (伪原创)
这里我只推荐使用ai来处理伪原创,因为之前的伪原创程序都是同义词和同义词替换,这样原创度不高,甚至影响阅读的流畅性。
现在提供了几乎主流的采集工具,智能原创api接口,直接调用5118等伪原创content接口。当然还有其他平台,可以自己选择,这种api是付费的,费用自查。
还有页面内容的处理。我们从采集处理伪原创文章内容后,还不够。我们在文章给自己网站发帖后,我们会继续处理,比如调用相关内容,也可以补充内容,增加用户点击量和PV。
另一种方式是将多个文章合并成一个文章,这样内容才能更加全面完善。这类内容不仅搜索引擎喜欢,用户也喜欢。如果你能做到这一点,其实你的内容已经是原创了。
更多详细教程请继续关注我,稍后观看教程,后续视频教程会更新。
一大早,今天就写这么多
Phpcms网站管理系统自带的采集模块功能如何?
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2021-06-20 22:47
Phpcms网站管理系统的最新版本是Phpcms v9。作为国内主流的cms系统之一,目前有数万个网站应用。那么自带的采集模块的作用是什么,一起来看看吧。
文章采集
Phpcms v9 默认内置了三种内容模型:文章、图片和下载。我们先来看看最常见的文章采集。以采集新浪互联网频道国内滚动新闻栏目为例
1、进入后台,内容-内容发布管理-采集管理-添加采集点。 (与之前版本的Phpcms不同,采集management在模块菜单中)
2、URL 规则。 采集项目名称随便填,采集页面代码默认为GBK,具体采集页面可以查看网页源码。
URL采集,没有什么大的特点,通过查看你想要的采集页面的URL规则来填写。对目标页面进行分析,是一个序列URL,要获取的内容的URL在两个标签之间。没有其他干扰链接,因此无需定义必须和不得收录在 URL 中的字符。如果目标网站配置了Base,那么也必须配置。
URL采集配置结束,但是如果目标网站列表页面使用js实现上下页,或者获取的URL深度超过2级,就很难实现有了这个采集。
3、Content 规则。 phpcms使用“[content]”作为通配符,然后设置开始和结束字符,然后过滤掉不需要的代码,实现内容的采集。分析目标页面的title标签比较规则,如图所示直接设置即可。
过滤器格式为“要过滤的内容[|]替换值”,如果删除,替换值留空。过滤规则支持正则表达式。该系统带有几个常见的标签过滤规则。新手要灵活过滤有点难度,所以新手需要先熟悉正则表达式。
按规则获取的作者规则、来源规则、时间规则。小编尝试了一个固定值,发现无法实现,即将某个标签设置为固定值。比如设置“source”为,但是采集result source标签为空。
内容规则,填写开始和结束标签,我们测试的目标页面比较干净,所以我们只需要过滤掉里面的超链接和一些无用的标签即可。
内容分页规则。如果内容页有分页,则必须填写。这里文章 没有分页。小编会在下图采集中介绍这个标签。
4、自定义规则,除了系统默认的标签,还可以自定义各种标签。规则是一样的,但有一点需要注意:规则的英文名称必须填写,否则可以自定义标签无法保存。
5、高级配置,这次可以设置下载图片、图片水印、内容分页和导入顺序。注意如果需要水印记得修改你的网站水印图片,水印存放路径:statics/images/water
6、规则设置好,提交回采集管理首页,可以先测试一下标签是否准确。
7、发布内容。如果都准确,请先点击采集网址,它会自动采集文章地址,并过滤重复的网址。然后会弹出采集网址补全的提示,点击“采集文章内容”
采集自动执行并显示采集进度。
采集完成后会自动返回采集管理首页,点击内容发布,进入采集文章列表,勾选要发布的文章,或者点击底部的全部导入。
进入发布计划选择界面,新建发布计划,选择发布栏。在本次测试中,选择了文章模块的“国内”列。在新的计划页面,可以设置摘要自动提取、缩略图自动提取,以及导入文章状态、标签和数据库之间的对应关系。其中,导入文章状态只有一个“发布”。如果站长需要状态为待审核,请先修改对应栏目的工作流程为一级审核。
在标签与数据库的对应关系中,采集标签与数据库字段是一一对应的。如果有自定义标签找不到对应字段,需要修改模型添加字段,再修改模板显示,比较技术要求高,不适合新手。此外,系统自带的处理功能也非常实用。
发布计划设置好后,会自动开始导入刚才选择的文章,下次导入时无需再构建计划,只需选择已经构建好的计划即可。
文章采集,发布完成。看效果:
后台内容管理页面
内容页面
来看看下面的图片采集
图片采集
phpcms v9自带图片模型,还有图片处理的群图模式,方便一些站长制作图片网站或者设置图片展示方式。我们尝试使用我们自己的采集程序来获取采集图片,以采集页面上的图片为例:
网站获取规则和内容获取规则同文章采集。最重要的一点是phpcmsv9采集的图片不能只是采集picture地址,而应该是采集entire
标签,这样就可以作为一组图片处理了。如本例所示:内容标签设置为
采集的内容应该是这样的
还有一个分页问题。目标站的寻呼如图:
网页代码为:
所以只需在内容分页规则中选择全列表模式,然后填写分页标签的首尾字符,系统就会自动采集对内容进行分页。
设置好规则后,采集URL,采集content,发布内容。应注意发布计划。经过多次尝试,小编发现要实现群图模式,内容域和群图域必须使用“作为群图处理”功能。但是这种方式无法获取到内容图片的缩略图,所以最好自定义缩略图标签,直接获取内容图片的地址为缩略图。
设置后发布。见采集效果:
栏目页面
内容页面
总结:经过详细体验,phpcmsv9的采集功能相当全面,基本满足文章和图片采集。但是不够灵活,对于一些高要求的站长来说显然是不够的,而且门槛很高。 采集模块的官方说明和帮助文件非常有限,不利于新手。 查看全部
Phpcms网站管理系统自带的采集模块功能如何?
Phpcms网站管理系统的最新版本是Phpcms v9。作为国内主流的cms系统之一,目前有数万个网站应用。那么自带的采集模块的作用是什么,一起来看看吧。
文章采集
Phpcms v9 默认内置了三种内容模型:文章、图片和下载。我们先来看看最常见的文章采集。以采集新浪互联网频道国内滚动新闻栏目为例
1、进入后台,内容-内容发布管理-采集管理-添加采集点。 (与之前版本的Phpcms不同,采集management在模块菜单中)
2、URL 规则。 采集项目名称随便填,采集页面代码默认为GBK,具体采集页面可以查看网页源码。
URL采集,没有什么大的特点,通过查看你想要的采集页面的URL规则来填写。对目标页面进行分析,是一个序列URL,要获取的内容的URL在两个标签之间。没有其他干扰链接,因此无需定义必须和不得收录在 URL 中的字符。如果目标网站配置了Base,那么也必须配置。
URL采集配置结束,但是如果目标网站列表页面使用js实现上下页,或者获取的URL深度超过2级,就很难实现有了这个采集。
3、Content 规则。 phpcms使用“[content]”作为通配符,然后设置开始和结束字符,然后过滤掉不需要的代码,实现内容的采集。分析目标页面的title标签比较规则,如图所示直接设置即可。
过滤器格式为“要过滤的内容[|]替换值”,如果删除,替换值留空。过滤规则支持正则表达式。该系统带有几个常见的标签过滤规则。新手要灵活过滤有点难度,所以新手需要先熟悉正则表达式。
按规则获取的作者规则、来源规则、时间规则。小编尝试了一个固定值,发现无法实现,即将某个标签设置为固定值。比如设置“source”为,但是采集result source标签为空。
内容规则,填写开始和结束标签,我们测试的目标页面比较干净,所以我们只需要过滤掉里面的超链接和一些无用的标签即可。
内容分页规则。如果内容页有分页,则必须填写。这里文章 没有分页。小编会在下图采集中介绍这个标签。
4、自定义规则,除了系统默认的标签,还可以自定义各种标签。规则是一样的,但有一点需要注意:规则的英文名称必须填写,否则可以自定义标签无法保存。
5、高级配置,这次可以设置下载图片、图片水印、内容分页和导入顺序。注意如果需要水印记得修改你的网站水印图片,水印存放路径:statics/images/water
6、规则设置好,提交回采集管理首页,可以先测试一下标签是否准确。
7、发布内容。如果都准确,请先点击采集网址,它会自动采集文章地址,并过滤重复的网址。然后会弹出采集网址补全的提示,点击“采集文章内容”
采集自动执行并显示采集进度。
采集完成后会自动返回采集管理首页,点击内容发布,进入采集文章列表,勾选要发布的文章,或者点击底部的全部导入。
进入发布计划选择界面,新建发布计划,选择发布栏。在本次测试中,选择了文章模块的“国内”列。在新的计划页面,可以设置摘要自动提取、缩略图自动提取,以及导入文章状态、标签和数据库之间的对应关系。其中,导入文章状态只有一个“发布”。如果站长需要状态为待审核,请先修改对应栏目的工作流程为一级审核。
在标签与数据库的对应关系中,采集标签与数据库字段是一一对应的。如果有自定义标签找不到对应字段,需要修改模型添加字段,再修改模板显示,比较技术要求高,不适合新手。此外,系统自带的处理功能也非常实用。
发布计划设置好后,会自动开始导入刚才选择的文章,下次导入时无需再构建计划,只需选择已经构建好的计划即可。
文章采集,发布完成。看效果:
后台内容管理页面
内容页面
来看看下面的图片采集
图片采集
phpcms v9自带图片模型,还有图片处理的群图模式,方便一些站长制作图片网站或者设置图片展示方式。我们尝试使用我们自己的采集程序来获取采集图片,以采集页面上的图片为例:
网站获取规则和内容获取规则同文章采集。最重要的一点是phpcmsv9采集的图片不能只是采集picture地址,而应该是采集entire
标签,这样就可以作为一组图片处理了。如本例所示:内容标签设置为
采集的内容应该是这样的
还有一个分页问题。目标站的寻呼如图:
网页代码为:
所以只需在内容分页规则中选择全列表模式,然后填写分页标签的首尾字符,系统就会自动采集对内容进行分页。
设置好规则后,采集URL,采集content,发布内容。应注意发布计划。经过多次尝试,小编发现要实现群图模式,内容域和群图域必须使用“作为群图处理”功能。但是这种方式无法获取到内容图片的缩略图,所以最好自定义缩略图标签,直接获取内容图片的地址为缩略图。
设置后发布。见采集效果:
栏目页面
内容页面
总结:经过详细体验,phpcmsv9的采集功能相当全面,基本满足文章和图片采集。但是不够灵活,对于一些高要求的站长来说显然是不够的,而且门槛很高。 采集模块的官方说明和帮助文件非常有限,不利于新手。
解决微信公众号文章打印pdf图片无法显示的问题!
采集交流 • 优采云 发表了文章 • 0 个评论 • 1534 次浏览 • 2021-06-20 21:20
python第三方库pdfkit非常好用。基本上,您可以使用它打印出pdf文件。是采集干货和灰尘的绝配。这渣还写了很多爬行,印了很多干货。 pdf的文章,包括微信公众号文章,前段时间我继续折腾公众号文章打印pdf,发现如果有图我就对比下,别做饭了!
SO,于是就有了文章这样的文章来解决微信公众号文章打印pdf图片时无法显示的问题。不明白的可以直接搜索大佬的参考方案,试试看! !
让我们回顾一下下面的解决方案!
以这个人渣的公众号文章链接为例:
抓取打印pdf的效果:
要点
解决pdfkit直接将url转为pdf时图片无法显示的问题,参考博客园xuzifan提供的思路,使用微信中的get_article_content函数提取url中的代码,转换成html字符串,然后将html字符转换为pdf,完美解决。
pip install wechatsogou --upgrade
微信公众号是一个基于搜狗微信搜索的微信公众号爬虫接口,没错,还是调用接口! !
使用Python抓取微信公众号文章并保存为PDF文件(解决不显示图片的问题)
但是这个人渣人渣测试了代码,总是发出验证码,还是不行!
这里是最新的代码参考,大哥的源码:
你可以自己参考!
附上完整的源代码参考:
#采集微信公众号文章内容转pdf文件
#by 微信:huguo00289
# -*- coding: UTF-8 -*-
import wechatsogou
import pdfkit
#pdfkit本地路径
config = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
# 初始化API
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
def dypdf(h1, data):
# 处理后的html
datas = f'''
{h1}
{h1}
{data}
'''
print("开始打印内容!")
pdfkit.from_string(datas, f'{h1}.pdf', configuration=config)
print("打印保存成功!")
def wx(h1,url):
# 该方法根据文章url对html进行处理,使图片显示
content_info = ws_api.get_article_content(url)
# 得到html代码(代码不完整,需要加入head、body等标签)
html_code = content_info['content_html']
dypdf(h1, html_code)
if __name__=='__main__':
url="https://mp.weixin.qq.com/s%3Fs ... R5cOz*QSjaVDfg38UkPtUqfxL2Lut0jrWNuTAtQMiyWd*tJHqLlPnWH-ewQ46cpjjp-Pyke0ab57WdM&new=1"
h1="【微信采集助手】Python Tkinter 微信公众号文章批量采集工具"
wx(h1,url)
调用接口什么的比较简单,做黄牛还是很厉害的!
上期精彩
01
02
03
04
05
··················END···················
你好,我是二叔,
从革命老区外进城的农民工,
互联网非早期非专业站长,
我喜欢python,写作,阅读,英语
非入门项目,自媒体,seo.. .
公众号不赚钱,就做个网友吧。
读者交流群已经建立,找到我的笔记“交流”,可以加入我们~
听说“看”的人变漂亮了~
关注二高手~我会和大家分享python的内容,写读~ 查看全部
解决微信公众号文章打印pdf图片无法显示的问题!
python第三方库pdfkit非常好用。基本上,您可以使用它打印出pdf文件。是采集干货和灰尘的绝配。这渣还写了很多爬行,印了很多干货。 pdf的文章,包括微信公众号文章,前段时间我继续折腾公众号文章打印pdf,发现如果有图我就对比下,别做饭了!
SO,于是就有了文章这样的文章来解决微信公众号文章打印pdf图片时无法显示的问题。不明白的可以直接搜索大佬的参考方案,试试看! !
让我们回顾一下下面的解决方案!
以这个人渣的公众号文章链接为例:
抓取打印pdf的效果:
要点
解决pdfkit直接将url转为pdf时图片无法显示的问题,参考博客园xuzifan提供的思路,使用微信中的get_article_content函数提取url中的代码,转换成html字符串,然后将html字符转换为pdf,完美解决。
pip install wechatsogou --upgrade
微信公众号是一个基于搜狗微信搜索的微信公众号爬虫接口,没错,还是调用接口! !
使用Python抓取微信公众号文章并保存为PDF文件(解决不显示图片的问题)
但是这个人渣人渣测试了代码,总是发出验证码,还是不行!
这里是最新的代码参考,大哥的源码:
你可以自己参考!
附上完整的源代码参考:
#采集微信公众号文章内容转pdf文件
#by 微信:huguo00289
# -*- coding: UTF-8 -*-
import wechatsogou
import pdfkit
#pdfkit本地路径
config = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
# 初始化API
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
def dypdf(h1, data):
# 处理后的html
datas = f'''
{h1}
{h1}
{data}
'''
print("开始打印内容!")
pdfkit.from_string(datas, f'{h1}.pdf', configuration=config)
print("打印保存成功!")
def wx(h1,url):
# 该方法根据文章url对html进行处理,使图片显示
content_info = ws_api.get_article_content(url)
# 得到html代码(代码不完整,需要加入head、body等标签)
html_code = content_info['content_html']
dypdf(h1, html_code)
if __name__=='__main__':
url="https://mp.weixin.qq.com/s%3Fs ... R5cOz*QSjaVDfg38UkPtUqfxL2Lut0jrWNuTAtQMiyWd*tJHqLlPnWH-ewQ46cpjjp-Pyke0ab57WdM&new=1"
h1="【微信采集助手】Python Tkinter 微信公众号文章批量采集工具"
wx(h1,url)
调用接口什么的比较简单,做黄牛还是很厉害的!
上期精彩
01
02
03
04
05
··················END···················
你好,我是二叔,
从革命老区外进城的农民工,
互联网非早期非专业站长,
我喜欢python,写作,阅读,英语
非入门项目,自媒体,seo.. .
公众号不赚钱,就做个网友吧。
读者交流群已经建立,找到我的笔记“交流”,可以加入我们~
听说“看”的人变漂亮了~
关注二高手~我会和大家分享python的内容,写读~

