
文章采集调用
文章采集调用(JS方式外部调用WordPress站点文章(图)插件(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-12-16 16:07
人生无止境,折腾也无止境。最近在折腾自己的博客导航,遇到了一个问题。我想在我的博客导航上调用我个人博客上最新的文章。我在网上找了很多方法,很多 两个站点都是调用WordPress程序的教程。折腾了很多方法,终于找到了一个可以用的插件。通过JS对外调用WordPress站点文章,达到了我想要的效果。
Ecall插件介绍
这个Ecall插件(几年前的WordPress插件,WordPress4.9.5个测试可用)可以轻松调用WordPress站点文章,如果其他网站想给你打电话文章,你只需要在你的网站上安装这个插件,然后对方只需要在他的网站网页中插入一段简单的JavaScript代码就可以调用它。该插件具有以下功能:
Ecall插件安装和设置
1、安装:在后台插件>> 搜索安装插件:Ecall,找到后在线安装,或者直接下载插件上传安装(如果不懂安装,请转到“WordPress 插件使用入门教程”),安装后记得启用它。
2、配置:后台设置>> Ecall配置中的简单设置,如下图:
2.1 基本设置
这是设置是否需要隐藏某些类别,默认显示所有类别;缓存时间需要填写缓存时间,如60分钟,如果不填写默认,留空关闭缓存功能。这个基本设置和下面的2.2模板设置共享“更新设置”按钮,所以设置后记得点击2.2模板设置中的“更新设置”按钮。
2.2 模板设置
如下图所示,所有标签都有说明,可以自由展示被调用的文章的样式或内容。比如最简单的就是显示文章标题和文章链接。
2.3 详细设置
这里是要调用的文章的个数和排序方法,都是汉字,直接操作即可。
2.4 说明
这里是站点的授权密钥,对应的密钥必须是可以通过JS调用的。下图调用示例中,默认显示6个文章。
2.5 JS调用代码说明
操作说明:
Ecall插件测试情况
1、插件使用效果
2、根据我自己的测试,我在Ecall配置页面进行了基本设置、模板设置和详细设置并保存后,调用示例中的代码可以正常显示,但是调用数据的数量只能是6。手动修改JS代码。或者直接使用以下代码:
将使用我们设置的调用次数。所以正常的调用代码应该删除 &rows=6。
3、根据测试发现,Ecall插件的授权机制存在防止恶意调用的小漏洞,因为这段JS代码可以看到key。如果我知道有些网站使用JS调用,通过源码可以看到对应的JS代码和key,那么我们就可以用这段代码调用对方调用的文章(PS:这个概率还是存在,如果能绑定对方的域名进行授权调用就完美了)。
站长有话要说
这个文章应该是王尚博客文章的投稿——《从站外调用WordPress网站文章方法》,但是因为提交的内容文章太少了,只有开头部分和下载地址,下面是boke112导航的续篇,所以这个文章算是联合创作,而不是单纯的投稿文章。关于插件相关的投稿文章,建议大家一定要描述一下插件的安装、配置和使用方法,不能只是简单的介绍和下载地址。 查看全部
文章采集调用(JS方式外部调用WordPress站点文章(图)插件(组图))
人生无止境,折腾也无止境。最近在折腾自己的博客导航,遇到了一个问题。我想在我的博客导航上调用我个人博客上最新的文章。我在网上找了很多方法,很多 两个站点都是调用WordPress程序的教程。折腾了很多方法,终于找到了一个可以用的插件。通过JS对外调用WordPress站点文章,达到了我想要的效果。

Ecall插件介绍
这个Ecall插件(几年前的WordPress插件,WordPress4.9.5个测试可用)可以轻松调用WordPress站点文章,如果其他网站想给你打电话文章,你只需要在你的网站上安装这个插件,然后对方只需要在他的网站网页中插入一段简单的JavaScript代码就可以调用它。该插件具有以下功能:
Ecall插件安装和设置
1、安装:在后台插件>> 搜索安装插件:Ecall,找到后在线安装,或者直接下载插件上传安装(如果不懂安装,请转到“WordPress 插件使用入门教程”),安装后记得启用它。
2、配置:后台设置>> Ecall配置中的简单设置,如下图:
2.1 基本设置
这是设置是否需要隐藏某些类别,默认显示所有类别;缓存时间需要填写缓存时间,如60分钟,如果不填写默认,留空关闭缓存功能。这个基本设置和下面的2.2模板设置共享“更新设置”按钮,所以设置后记得点击2.2模板设置中的“更新设置”按钮。

2.2 模板设置
如下图所示,所有标签都有说明,可以自由展示被调用的文章的样式或内容。比如最简单的就是显示文章标题和文章链接。

2.3 详细设置
这里是要调用的文章的个数和排序方法,都是汉字,直接操作即可。

2.4 说明
这里是站点的授权密钥,对应的密钥必须是可以通过JS调用的。下图调用示例中,默认显示6个文章。
2.5 JS调用代码说明
操作说明:
Ecall插件测试情况
1、插件使用效果

2、根据我自己的测试,我在Ecall配置页面进行了基本设置、模板设置和详细设置并保存后,调用示例中的代码可以正常显示,但是调用数据的数量只能是6。手动修改JS代码。或者直接使用以下代码:
将使用我们设置的调用次数。所以正常的调用代码应该删除 &rows=6。
3、根据测试发现,Ecall插件的授权机制存在防止恶意调用的小漏洞,因为这段JS代码可以看到key。如果我知道有些网站使用JS调用,通过源码可以看到对应的JS代码和key,那么我们就可以用这段代码调用对方调用的文章(PS:这个概率还是存在,如果能绑定对方的域名进行授权调用就完美了)。
站长有话要说
这个文章应该是王尚博客文章的投稿——《从站外调用WordPress网站文章方法》,但是因为提交的内容文章太少了,只有开头部分和下载地址,下面是boke112导航的续篇,所以这个文章算是联合创作,而不是单纯的投稿文章。关于插件相关的投稿文章,建议大家一定要描述一下插件的安装、配置和使用方法,不能只是简单的介绍和下载地址。
文章采集调用(非调用wordpress热评热评文章的制作文章 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-16 16:06
)
在制作wordpress博客主题时,经常需要调用wordpress热评论文章
如果你使用插件,它会加载服务器
如果空间配置不高,打开网页的速度也会受到影响。
给大家介绍一下非插件调用wordpress的热评文章
首先在functions.php中添加以下代码:
function most_popular_posts($no_posts = 10, $before = '', $after = '', $show_pass_post = false, $duration='') {
//定制参数,可以自己修改相关参数,以便写样式
global $wpdb;
$request = "SELECT ID, post_title, COUNT($wpdb->comments.comment_post_ID) AS 'comment_count' FROM $wpdb->posts, $wpdb->comments";
//在数据库里选择所需的数据
$request .= " WHERE comment_approved = '1' AND $wpdb->posts.ID=$wpdb->comments.comment_post_ID AND post_status = 'publish'";
//筛选数据,只统计公开的文章
if(!$show_pass_post) $request .= " AND post_password =''";
if($duration !="") { $request .= " AND DATE_SUB(CURDATE(),INTERVAL ".$duration." DAY) < post_date ";
}
$request .= " GROUP BY $wpdb->comments.comment_post_ID ORDER BY comment_count DESC LIMIT $no_posts";
//按评论数排序
$posts = $wpdb->get_results($request);
$output = '';
if ($posts) {
foreach ($posts as $post) {
$post_title = stripslashes($post->post_title);
$comment_count = $post->comment_count;
$permalink = get_permalink($post->ID);
$output .= $before . '' . $post_title . ' (' . $comment_count.')' . $after;
}
//输出文章列表项
} else {
$output .= $before . "None found" . $after;
//没有文章时则输出
}
echo $output;
}
然后在主题文件中要调用热评论文章的位置添加如下调用标签: 查看全部
文章采集调用(非调用wordpress热评热评文章的制作文章
)
在制作wordpress博客主题时,经常需要调用wordpress热评论文章
如果你使用插件,它会加载服务器
如果空间配置不高,打开网页的速度也会受到影响。
给大家介绍一下非插件调用wordpress的热评文章
首先在functions.php中添加以下代码:
function most_popular_posts($no_posts = 10, $before = '', $after = '', $show_pass_post = false, $duration='') {
//定制参数,可以自己修改相关参数,以便写样式
global $wpdb;
$request = "SELECT ID, post_title, COUNT($wpdb->comments.comment_post_ID) AS 'comment_count' FROM $wpdb->posts, $wpdb->comments";
//在数据库里选择所需的数据
$request .= " WHERE comment_approved = '1' AND $wpdb->posts.ID=$wpdb->comments.comment_post_ID AND post_status = 'publish'";
//筛选数据,只统计公开的文章
if(!$show_pass_post) $request .= " AND post_password =''";
if($duration !="") { $request .= " AND DATE_SUB(CURDATE(),INTERVAL ".$duration." DAY) < post_date ";
}
$request .= " GROUP BY $wpdb->comments.comment_post_ID ORDER BY comment_count DESC LIMIT $no_posts";
//按评论数排序
$posts = $wpdb->get_results($request);
$output = '';
if ($posts) {
foreach ($posts as $post) {
$post_title = stripslashes($post->post_title);
$comment_count = $post->comment_count;
$permalink = get_permalink($post->ID);
$output .= $before . '' . $post_title . ' (' . $comment_count.')' . $after;
}
//输出文章列表项
} else {
$output .= $before . "None found" . $after;
//没有文章时则输出
}
echo $output;
}
然后在主题文件中要调用热评论文章的位置添加如下调用标签:
文章采集调用(文章采集调用用到的方法,可以选择优劣都有了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-14 11:06
文章采集调用用到的方法,可以选择方法,优劣都有了。第一种方法,全文检索或者新闻速递。这类方法主要解决的是用户搜索的问题,例如:英文输入“surfacebook2015blackmagicfansforhome”,机器人给你返回了surfacebook2015blackmagicfansforhome网站第二种方法,爬虫方法用户利用搜索自然语言处理模型(nlp)对该文章进行挖掘,例如这个分类问题:“surfacebook2015blackmagicfansforhome”(不考虑年份的数据)机器人会返回:surfacebook2015blackmagicfansforhome(surfacebook2015,黑色)结果是根据用户搜索年份所在位置进行分类。
用户下次再看类别时,只需要在该位置填写数字即可。对外界提供一篇文章的位置,或者百度会返回一条信息的导航路径,让你找到另一篇文章,进而打开百度首页。我们使用surfacefisher&santowaldstock这个公司的公众网站数据,爬取了它的自然语言处理(nlp)模型simnow模型。simnow模型是sandwich的结构化文本数据集合,由270万条训练好的文本子集构成。
其中包含170万条文本集,其中含有描述百度搜索内容的长文本集。1.搜索问题与假设现有的任何nlp技术都能满足用户的搜索需求,对于文本挖掘,搜索问题的定义是:给定一个webservicesscheme(如:tornado)的工作流,用户可以有一个搜索愿望,但是在service中找不到我们想要的所有相关结果。
(如:我想要找到来自互联网一个电影片名的百度结果)问题定义:给定一个webservicesscheme(如:tornado)的工作流,用户可以有一个搜索愿望,但是在service中找不到我们想要的所有相关结果。2.关于搜索算法的比较搜索问题可以是:字符串匹配,如:字符串“,”可以匹配到来自互联网一个电影片名的百度结果。
如果是搜索电影片名相关内容,用中文字符,电影片名中加入yunqi就可以了。文本关键词关键词一般指一个可读,可识别的文本。找与关键词相关的文档(radio)时,文本中的主题词有一个关系:标题中关键词与关键词之间有一个关系,当结果中有多个相关文档,也可以使用list来存储。这样的话,就可以推导出某个词对应的pair中,有多少个关键词被找到了。
3.评估指标优化:优化的意义在于:更好的发现某个关键词在文档中被找到的频率。扩展:后续可以用优化后的结果来分析搜索场景并用于预测。soala算法也是一种关键词匹配算法。方法:soala算法搜索时,按照由关键词开始的顺序依次搜索文档:前一个文档的标题+短文本,顺序搜索第二个文档,第三个文档,用长文本进行深度搜索。这种方法其实可以转化为:无人驾驶中。 查看全部
文章采集调用(文章采集调用用到的方法,可以选择优劣都有了)
文章采集调用用到的方法,可以选择方法,优劣都有了。第一种方法,全文检索或者新闻速递。这类方法主要解决的是用户搜索的问题,例如:英文输入“surfacebook2015blackmagicfansforhome”,机器人给你返回了surfacebook2015blackmagicfansforhome网站第二种方法,爬虫方法用户利用搜索自然语言处理模型(nlp)对该文章进行挖掘,例如这个分类问题:“surfacebook2015blackmagicfansforhome”(不考虑年份的数据)机器人会返回:surfacebook2015blackmagicfansforhome(surfacebook2015,黑色)结果是根据用户搜索年份所在位置进行分类。
用户下次再看类别时,只需要在该位置填写数字即可。对外界提供一篇文章的位置,或者百度会返回一条信息的导航路径,让你找到另一篇文章,进而打开百度首页。我们使用surfacefisher&santowaldstock这个公司的公众网站数据,爬取了它的自然语言处理(nlp)模型simnow模型。simnow模型是sandwich的结构化文本数据集合,由270万条训练好的文本子集构成。
其中包含170万条文本集,其中含有描述百度搜索内容的长文本集。1.搜索问题与假设现有的任何nlp技术都能满足用户的搜索需求,对于文本挖掘,搜索问题的定义是:给定一个webservicesscheme(如:tornado)的工作流,用户可以有一个搜索愿望,但是在service中找不到我们想要的所有相关结果。
(如:我想要找到来自互联网一个电影片名的百度结果)问题定义:给定一个webservicesscheme(如:tornado)的工作流,用户可以有一个搜索愿望,但是在service中找不到我们想要的所有相关结果。2.关于搜索算法的比较搜索问题可以是:字符串匹配,如:字符串“,”可以匹配到来自互联网一个电影片名的百度结果。
如果是搜索电影片名相关内容,用中文字符,电影片名中加入yunqi就可以了。文本关键词关键词一般指一个可读,可识别的文本。找与关键词相关的文档(radio)时,文本中的主题词有一个关系:标题中关键词与关键词之间有一个关系,当结果中有多个相关文档,也可以使用list来存储。这样的话,就可以推导出某个词对应的pair中,有多少个关键词被找到了。
3.评估指标优化:优化的意义在于:更好的发现某个关键词在文档中被找到的频率。扩展:后续可以用优化后的结果来分析搜索场景并用于预测。soala算法也是一种关键词匹配算法。方法:soala算法搜索时,按照由关键词开始的顺序依次搜索文档:前一个文档的标题+短文本,顺序搜索第二个文档,第三个文档,用长文本进行深度搜索。这种方法其实可以转化为:无人驾驶中。
文章采集调用(微信公众号文章发布地址需要重点关注几个地方?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-10 11:07
文章采集调用的是微信公众号发布的相关文章的链接,这里就涉及到文章如何发布,也就是可能会出现没有相关文章的情况。要解决这个问题,需要根据不同文章的不同属性,或者是微信公众号基础内容如何输出等来定。文章发布地址需要重点关注几个地方:1.相关性这个相信大家都能理解,某个公众号的粉丝非常少,所以可能没有太多对文章的关注。
因此,你可以考虑先去获取粉丝,如果粉丝增加得好,那么可以进一步提高相关性。2.去除规则和敏感词去除规则和敏感词是防止你的相关内容被投诉,或者别人恶意投诉导致粉丝降权或者封号。这些都是人工操作,需要一定的经验。3.爬虫爬取可以更加快速的获取更多公众号文章的链接,现在有免费的爬虫可以使用。效果看实际情况,如果数据结构良好,达到你的想法,可以加大推广。
这里为大家总结了几个有用的文章发布方法:1.第三方cms工具,比如勤麦公众号助手,可以满足上面两个方法的需求。2.爬虫,现在是技术瓶颈,主要是各个平台都有了相关的技术人员,通过爬虫,我们可以通过某些东西实现原本我们不能实现的功能。3.人工+爬虫因为每个账号的背景情况,粉丝构成等都不同,所以实现相应的功能也需要用户自己去磨合,这就需要一定的时间,这个时间成本可能就让您放弃相关的计划了。 查看全部
文章采集调用(微信公众号文章发布地址需要重点关注几个地方?)
文章采集调用的是微信公众号发布的相关文章的链接,这里就涉及到文章如何发布,也就是可能会出现没有相关文章的情况。要解决这个问题,需要根据不同文章的不同属性,或者是微信公众号基础内容如何输出等来定。文章发布地址需要重点关注几个地方:1.相关性这个相信大家都能理解,某个公众号的粉丝非常少,所以可能没有太多对文章的关注。
因此,你可以考虑先去获取粉丝,如果粉丝增加得好,那么可以进一步提高相关性。2.去除规则和敏感词去除规则和敏感词是防止你的相关内容被投诉,或者别人恶意投诉导致粉丝降权或者封号。这些都是人工操作,需要一定的经验。3.爬虫爬取可以更加快速的获取更多公众号文章的链接,现在有免费的爬虫可以使用。效果看实际情况,如果数据结构良好,达到你的想法,可以加大推广。
这里为大家总结了几个有用的文章发布方法:1.第三方cms工具,比如勤麦公众号助手,可以满足上面两个方法的需求。2.爬虫,现在是技术瓶颈,主要是各个平台都有了相关的技术人员,通过爬虫,我们可以通过某些东西实现原本我们不能实现的功能。3.人工+爬虫因为每个账号的背景情况,粉丝构成等都不同,所以实现相应的功能也需要用户自己去磨合,这就需要一定的时间,这个时间成本可能就让您放弃相关的计划了。
文章采集调用(解决微信公众号文章文章打印pdf图片无法显示的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-12-09 23:07
python第三方库pdfkit非常好用。基本上,您可以使用它打印出pdf文件。作为干货和灰烬的集合,简直是绝配。这个渣渣还写了很多爬很多干货打印成pdf文章,有微信公众号文章,前段时间继续折腾公众号文章 把pdf打印出来,发现有图我就对比下,别做饭了!
SO,于是就有了这样一篇文章的文章来解决微信公众号文章打印时pdf图片无法显示的问题。不明白的可以直接搜索老大的参考方案,试试百灵!!
让我们回顾一下下面的解决方案!
以这个人渣的公众号文章链接为例:
爬取打印pdf的效果:
关键点
解决pdfkit直接将url转为pdf,无法显示图片的问题。参考博客园xuzifan提供的思路,使用微信中的get_article_content函数提取url中的代码并转换成html字符串,再将html字符串转换为pdf,完美解决。
pip install wechatsogou --upgrade
微信公众号是一个基于搜狗微信搜索的微信公众号爬虫界面。是的,它仍然在调用接口!!
使用Python抓取微信公众号文章并保存为PDF文件(解决不显示图片的问题)
但是这个人渣人渣测试了密码,老是发出验证码,还是不行!
下面是最新的代码参考,大哥的源码:
你可以自己参考!
附上完整的源代码参考:
#采集微信公众号文章内容转pdf文件
#by 微信:huguo00289
# -*- coding: UTF-8 -*-
import wechatsogou
import pdfkit
#pdfkit本地路径
config = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
# 初始化API
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
def dypdf(h1, data):
# 处理后的html
datas = f'''
{h1}
{h1}
{data}
'''
print("开始打印内容!")
pdfkit.from_string(datas, f'{h1}.pdf', configuration=config)
print("打印保存成功!")
def wx(h1,url):
# 该方法根据文章url对html进行处理,使图片显示
content_info = ws_api.get_article_content(url)
# 得到html代码(代码不完整,需要加入head、body等标签)
html_code = content_info['content_html']
dypdf(h1, html_code)
if __name__=='__main__':
url="https://mp.weixin.qq.com/s%3Fs ... R5cOz*QSjaVDfg38UkPtUqfxL2Lut0jrWNuTAtQMiyWd*tJHqLlPnWH-ewQ46cpjjp-Pyke0ab57WdM&new=1"
h1="【微信采集助手】Python Tkinter 微信公众号文章批量采集工具"
wx(h1,url)
调用接口什么的比较简单,做黄牛还是很厉害的! 查看全部
文章采集调用(解决微信公众号文章文章打印pdf图片无法显示的问题)
python第三方库pdfkit非常好用。基本上,您可以使用它打印出pdf文件。作为干货和灰烬的集合,简直是绝配。这个渣渣还写了很多爬很多干货打印成pdf文章,有微信公众号文章,前段时间继续折腾公众号文章 把pdf打印出来,发现有图我就对比下,别做饭了!
SO,于是就有了这样一篇文章的文章来解决微信公众号文章打印时pdf图片无法显示的问题。不明白的可以直接搜索老大的参考方案,试试百灵!!
让我们回顾一下下面的解决方案!
以这个人渣的公众号文章链接为例:
爬取打印pdf的效果:
关键点
解决pdfkit直接将url转为pdf,无法显示图片的问题。参考博客园xuzifan提供的思路,使用微信中的get_article_content函数提取url中的代码并转换成html字符串,再将html字符串转换为pdf,完美解决。
pip install wechatsogou --upgrade
微信公众号是一个基于搜狗微信搜索的微信公众号爬虫界面。是的,它仍然在调用接口!!
使用Python抓取微信公众号文章并保存为PDF文件(解决不显示图片的问题)
但是这个人渣人渣测试了密码,老是发出验证码,还是不行!
下面是最新的代码参考,大哥的源码:
你可以自己参考!
附上完整的源代码参考:
#采集微信公众号文章内容转pdf文件
#by 微信:huguo00289
# -*- coding: UTF-8 -*-
import wechatsogou
import pdfkit
#pdfkit本地路径
config = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
# 初始化API
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
def dypdf(h1, data):
# 处理后的html
datas = f'''
{h1}
{h1}
{data}
'''
print("开始打印内容!")
pdfkit.from_string(datas, f'{h1}.pdf', configuration=config)
print("打印保存成功!")
def wx(h1,url):
# 该方法根据文章url对html进行处理,使图片显示
content_info = ws_api.get_article_content(url)
# 得到html代码(代码不完整,需要加入head、body等标签)
html_code = content_info['content_html']
dypdf(h1, html_code)
if __name__=='__main__':
url="https://mp.weixin.qq.com/s%3Fs ... R5cOz*QSjaVDfg38UkPtUqfxL2Lut0jrWNuTAtQMiyWd*tJHqLlPnWH-ewQ46cpjjp-Pyke0ab57WdM&new=1"
h1="【微信采集助手】Python Tkinter 微信公众号文章批量采集工具"
wx(h1,url)
调用接口什么的比较简单,做黄牛还是很厉害的!
文章采集调用(微信公众号文章采集调用openinstall是个不错的选择)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-09 15:07
文章采集调用openinstall是个不错的选择,但是该平台属于后付费平台,对于初期在微信公众号文章合作开发者是个福音,但是对于后续的复制内容,打包链接这些就没什么作用了,
我觉得还行,我合作过几次,一般都是我提供调用,平台基本不做要求,不过不要钱总感觉不正规没法。
看看他们有没有代理,
做网上公众号合作现在好多平台都不收费的,只要你的公众号合作商家愿意配合推广,一般都不会收费的。
好久没有玩公众号了。06年有幸跟韩晓光喝酒,曾经有过一段时间经常合作,后来有了飞信。那段时间的飞信有个好处就是用户可以放心的在飞信里推广你的公众号。
你说的好像没有03年那会,但是本人觉得不管做哪个领域不要死盯着花钱收费啊,否则有价无市。现在微信本身也要收费了,微信公众号要开通原创功能,也要收费的。另外,很多公众号做的很大做不起来,是因为没有粘性,不挣钱,没有用户。建议可以找一个靠谱的平台合作,比如大鱼号,0.5%的分成。
谢邀。非常好的合作方式,公众号平台本身要收费。但是如果你推广好,再加上实惠的价格,仍然是公众号平台上最多的合作方式。
别去找微信公众号作者了,去找我这样的,又便宜质量又好。 查看全部
文章采集调用(微信公众号文章采集调用openinstall是个不错的选择)
文章采集调用openinstall是个不错的选择,但是该平台属于后付费平台,对于初期在微信公众号文章合作开发者是个福音,但是对于后续的复制内容,打包链接这些就没什么作用了,
我觉得还行,我合作过几次,一般都是我提供调用,平台基本不做要求,不过不要钱总感觉不正规没法。
看看他们有没有代理,
做网上公众号合作现在好多平台都不收费的,只要你的公众号合作商家愿意配合推广,一般都不会收费的。
好久没有玩公众号了。06年有幸跟韩晓光喝酒,曾经有过一段时间经常合作,后来有了飞信。那段时间的飞信有个好处就是用户可以放心的在飞信里推广你的公众号。
你说的好像没有03年那会,但是本人觉得不管做哪个领域不要死盯着花钱收费啊,否则有价无市。现在微信本身也要收费了,微信公众号要开通原创功能,也要收费的。另外,很多公众号做的很大做不起来,是因为没有粘性,不挣钱,没有用户。建议可以找一个靠谱的平台合作,比如大鱼号,0.5%的分成。
谢邀。非常好的合作方式,公众号平台本身要收费。但是如果你推广好,再加上实惠的价格,仍然是公众号平台上最多的合作方式。
别去找微信公众号作者了,去找我这样的,又便宜质量又好。
文章采集调用(dedecms如何修改这一上限值)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-08 15:08
dedecms系统文章在字符数上最多可调用250个字节,文章摘要(可通过infolen或description相关标签调用)设置为最大250 个字符。上限的次要目的是减少数据库的冗余,保证网络的优良性能。因此,对介绍的内容不设上限显然是不合理的,但如果上限可以自由控制,dedecms仿网站会对网页内容的布局带来积极的影响。在网页设计过程中,NET源代码。dedecms经常需要调用频道列表页面的文章汇总。如果文章摘要中的字数无法有效控制,
我们先说一下如何修改这个上限,然后我们可以展示方法的主要性质[field:description function="cn_substr(@me, number of characters)"/]。
在Dedecms系统中,与文章的摘要相关的php文件有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一句话: $description = cn_substrR($description, $cfg_auot_description); 这句话实现了[field:description function="cn_substr(@me, number of characters)"/]的功能。由于此声明确实对页面布局有利,因此我们尝试不做任何更改。
在编辑页面,有一句:$description = cn_substrR($description, 250);,这句话呈现了熟悉的字符数250,是系统设置的文章汇总字符数字的上限,如果是gbk编码,则显示125个字符,如果是utf-8编码,则是81个字符,显然要突破文章抽象字符的上限,我们一定要搞定了。对,把250改成别的值就好了,比如500。这里不建议设置太高,一是列表页不需要显示太多内容(显示太多内容是不如间接使用body),另一个是避免数据库中的冗余。
完成以上修改是不够的,需要修改article_description_main.php
在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句,该语句限制了后台可以检索到的字符数。把这里的250改为500,织梦仿站只是和之前修改的字符数不同。(如果你确认你的每个文章都是手动添加的,手动完成汇总采集就不需要修改这个文件了.按照总结获取二次元还是为大量文章和采集准备的。)
最初登录后台,在系统-系统基本参数-其他选项中,可以将驱动摘要的长度改为500,与之前修改的字符数不同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象的250个字符系统限制,为网页布局提供了更广阔的空间.
接下来也说一下常规的Dedecms文章或者列表页调用文章汇总方法
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是间接调用文章的summary。在被调用的单词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}{/dede :arclist},设置调用摘要的字符数(最多为250)由系统设置;如果使用[field:description /],会间接使用后台设置的抽象字符上限(后台也有250字符的上限)显然这些两种方法都非常被动和灵活。
第四种方法3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在文章抽象内容的上限不正常修改的情况下,这四种方法区别不大。
==========================
1:[字段:信息/]
2:[字段:描述/]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
这四种方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到这句“if($dsize>250) $dsize = 250;”,将250改为500
2.登录后台,在系统-系统基本参数-其他选项中,将自动汇总的长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar (1000)
调用标签{dede:field.description function='cn_substr(@me,500)'/}。可以显示500个字符)
转载于: 查看全部
文章采集调用(dedecms如何修改这一上限值)
dedecms系统文章在字符数上最多可调用250个字节,文章摘要(可通过infolen或description相关标签调用)设置为最大250 个字符。上限的次要目的是减少数据库的冗余,保证网络的优良性能。因此,对介绍的内容不设上限显然是不合理的,但如果上限可以自由控制,dedecms仿网站会对网页内容的布局带来积极的影响。在网页设计过程中,NET源代码。dedecms经常需要调用频道列表页面的文章汇总。如果文章摘要中的字数无法有效控制,
我们先说一下如何修改这个上限,然后我们可以展示方法的主要性质[field:description function="cn_substr(@me, number of characters)"/]。
在Dedecms系统中,与文章的摘要相关的php文件有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一句话: $description = cn_substrR($description, $cfg_auot_description); 这句话实现了[field:description function="cn_substr(@me, number of characters)"/]的功能。由于此声明确实对页面布局有利,因此我们尝试不做任何更改。
在编辑页面,有一句:$description = cn_substrR($description, 250);,这句话呈现了熟悉的字符数250,是系统设置的文章汇总字符数字的上限,如果是gbk编码,则显示125个字符,如果是utf-8编码,则是81个字符,显然要突破文章抽象字符的上限,我们一定要搞定了。对,把250改成别的值就好了,比如500。这里不建议设置太高,一是列表页不需要显示太多内容(显示太多内容是不如间接使用body),另一个是避免数据库中的冗余。
完成以上修改是不够的,需要修改article_description_main.php
在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句,该语句限制了后台可以检索到的字符数。把这里的250改为500,织梦仿站只是和之前修改的字符数不同。(如果你确认你的每个文章都是手动添加的,手动完成汇总采集就不需要修改这个文件了.按照总结获取二次元还是为大量文章和采集准备的。)
最初登录后台,在系统-系统基本参数-其他选项中,可以将驱动摘要的长度改为500,与之前修改的字符数不同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象的250个字符系统限制,为网页布局提供了更广阔的空间.
接下来也说一下常规的Dedecms文章或者列表页调用文章汇总方法
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是间接调用文章的summary。在被调用的单词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}{/dede :arclist},设置调用摘要的字符数(最多为250)由系统设置;如果使用[field:description /],会间接使用后台设置的抽象字符上限(后台也有250字符的上限)显然这些两种方法都非常被动和灵活。
第四种方法3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在文章抽象内容的上限不正常修改的情况下,这四种方法区别不大。
==========================
1:[字段:信息/]
2:[字段:描述/]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
这四种方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到这句“if($dsize>250) $dsize = 250;”,将250改为500
2.登录后台,在系统-系统基本参数-其他选项中,将自动汇总的长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar (1000)
调用标签{dede:field.description function='cn_substr(@me,500)'/}。可以显示500个字符)
转载于:
文章采集调用(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-07 19:01
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,那没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?
1、 只需输入关键词即可采集:搜狗新闻-搜狗知乎-今日头条-公众号-百度新闻-百度知道-新浪新闻-凤凰新闻(可以同时设置多个采集源采集)
2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布
为什么我不使用 Empire 插件?一是用Empire采集插件来拖延时间,二来要写很多规则,每天管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。
以上是小编采集网站的帝国,只要用心经营网站的帝国,采集的网站的流量也不错!如果你想认识其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!澳门精准四标四码数据, 查看全部
文章采集调用(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,那没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?

1、 只需输入关键词即可采集:搜狗新闻-搜狗知乎-今日头条-公众号-百度新闻-百度知道-新浪新闻-凤凰新闻(可以同时设置多个采集源采集)

2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布

为什么我不使用 Empire 插件?一是用Empire采集插件来拖延时间,二来要写很多规则,每天管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。

以上是小编采集网站的帝国,只要用心经营网站的帝国,采集的网站的流量也不错!如果你想认识其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!澳门精准四标四码数据,
文章采集调用(免费资源网,用调用相关文章的方法在帝国官方论坛上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-12-07 18:20
免费资源网,
使用tag调用相关文章的方法已经在帝国官方论坛发过,但是使用的函数效率太低,无法设置参数,不好用。现在我也在用tag来调用相关的文章,非常好用。
一、自定义函数
自定义函数user_OtherLink,将该函数放入e\class\userfun.php 文件中。
//根据tag获取相关信息
function user_OtherLink($num,$classid=0,$mid=0){
global $dbtbpre,$empire,$navinfor,$class_r;
if(empty($navinfor['infotags'])){
return '暂无相关信息';
}
if($mid&&$classid&&$class_r[$classid]['modid']!=$mid){
return '暂无相关信息';
}
$tr=$empire->fetch1("select otherlinktemp,otherlinktempsub,otherlinktempdate from ".GetTemptb("enewspubtemp")." limit 1");
$temp_r=explode("[!--empirenews.listtemp--]",$tr['otherlinktemp']);
$str='';
$tagsql=$empire->query("select * from {$dbtbpre}enewstagsdata where id='$navinfor[id]' and classid='$navinfor[classid]'");
$i=0;
$isprint=array();
while($tagr=$empire->fetch($tagsql)){
if($i>=$num){
break;
}
$gsql=$empire->query("select * from {$dbtbpre}enewstagsdata where tagid='$tagr[tagid]'");
while($gr=$empire->fetch($gsql)){
$myprint='id'.$gr['id'].'class'.$gr['classid'];
if(array_search($myprint,$isprint)!==false){
continue;
}
$isprint[]=$myprint;
if($classid&&$classid!=$gr['classid']){
continue;
}
if($mid&&$mid!=$gr['mid']){
continue;
}
if($gr['id']==$navinfor['id']&&$gr['classid']==$navinfor['classid']){
continue;
}
$tbname=$class_r[$gr['classid']]['tbname'];
if(!$tbname||InfoIsInTable($tbname)){
continue;
}
$r=$empire->fetch1("select * from {$dbtbpre}ecms_".$tbname." where id='$gr[id]' limit 1");
if(!$r['id']){
continue;
}
$str.=RepOtherTemp($temp_r[1],$r,$tr);
$i+=1;
if($i>=$num){
break;
}
}
}
$keyboardtext=$temp_r[0].$str.$temp_r[2];
if($str){
return $keyboardtext;
}else{
return '暂无相关信息';
}
}
二、使用方法:
功能说明:user_OtherLink(调用次数,指定列id,指定模型id);
相关文章模板使用公共模板中的相关信息模板。
调用示例:
免费资源网,
伟大的
帝国cms
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。 查看全部
文章采集调用(免费资源网,用调用相关文章的方法在帝国官方论坛上)
免费资源网,
使用tag调用相关文章的方法已经在帝国官方论坛发过,但是使用的函数效率太低,无法设置参数,不好用。现在我也在用tag来调用相关的文章,非常好用。
一、自定义函数
自定义函数user_OtherLink,将该函数放入e\class\userfun.php 文件中。
//根据tag获取相关信息
function user_OtherLink($num,$classid=0,$mid=0){
global $dbtbpre,$empire,$navinfor,$class_r;
if(empty($navinfor['infotags'])){
return '暂无相关信息';
}
if($mid&&$classid&&$class_r[$classid]['modid']!=$mid){
return '暂无相关信息';
}
$tr=$empire->fetch1("select otherlinktemp,otherlinktempsub,otherlinktempdate from ".GetTemptb("enewspubtemp")." limit 1");
$temp_r=explode("[!--empirenews.listtemp--]",$tr['otherlinktemp']);
$str='';
$tagsql=$empire->query("select * from {$dbtbpre}enewstagsdata where id='$navinfor[id]' and classid='$navinfor[classid]'");
$i=0;
$isprint=array();
while($tagr=$empire->fetch($tagsql)){
if($i>=$num){
break;
}
$gsql=$empire->query("select * from {$dbtbpre}enewstagsdata where tagid='$tagr[tagid]'");
while($gr=$empire->fetch($gsql)){
$myprint='id'.$gr['id'].'class'.$gr['classid'];
if(array_search($myprint,$isprint)!==false){
continue;
}
$isprint[]=$myprint;
if($classid&&$classid!=$gr['classid']){
continue;
}
if($mid&&$mid!=$gr['mid']){
continue;
}
if($gr['id']==$navinfor['id']&&$gr['classid']==$navinfor['classid']){
continue;
}
$tbname=$class_r[$gr['classid']]['tbname'];
if(!$tbname||InfoIsInTable($tbname)){
continue;
}
$r=$empire->fetch1("select * from {$dbtbpre}ecms_".$tbname." where id='$gr[id]' limit 1");
if(!$r['id']){
continue;
}
$str.=RepOtherTemp($temp_r[1],$r,$tr);
$i+=1;
if($i>=$num){
break;
}
}
}
$keyboardtext=$temp_r[0].$str.$temp_r[2];
if($str){
return $keyboardtext;
}else{
return '暂无相关信息';
}
}
二、使用方法:
功能说明:user_OtherLink(调用次数,指定列id,指定模型id);
相关文章模板使用公共模板中的相关信息模板。
调用示例:
免费资源网,
伟大的
帝国cms
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
文章采集调用(新建js变量就搞定了,你还不知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-06 18:05
文章采集调用的是h5模板,不需要服务器以及任何第三方解释权限的授权。正常采集完成后,每个点击或者每个url下面都会带有相应的js代码进行代码解析。而这些代码都是提前准备好的,采集出来后直接调用就好了,很容易上手。如果你平时不上公众号,也不经常去挑战一些大网站采集,不要说你不会用采集,没问题的,我教你个简单的。
用一个新建js变量就搞定了。首先新建个变量name=sid('你平时在挑战的大网站地址');age=age('你平时挑战的年龄');sid=sid('你挑战的地址');id='挑战大网站id';href='"/';如果上面这一部没有对应的变量值,就去把前面的#1取下来。然后把后面的代码全部复制进去,把下面代码加到上面的代码前面就可以用了。
这个过程是一点都不麻烦的,如果你已经不做了就说明你已经上手了,没必要再去学习别人是怎么用的,直接用就可以了。因为sid()的作用就是统计大网站下,每个链接对应的id。你直接用link.search()就可以统计它的id。我是小白,以上仅供参考。至于你在上找的网站价格,这个我就没什么好办法了,请高手答疑吧。
你这个不是h5完成的,是js写的,
网上搜下搜索自己公司服务器的位置找靠谱的就可以的, 查看全部
文章采集调用(新建js变量就搞定了,你还不知道吗?)
文章采集调用的是h5模板,不需要服务器以及任何第三方解释权限的授权。正常采集完成后,每个点击或者每个url下面都会带有相应的js代码进行代码解析。而这些代码都是提前准备好的,采集出来后直接调用就好了,很容易上手。如果你平时不上公众号,也不经常去挑战一些大网站采集,不要说你不会用采集,没问题的,我教你个简单的。
用一个新建js变量就搞定了。首先新建个变量name=sid('你平时在挑战的大网站地址');age=age('你平时挑战的年龄');sid=sid('你挑战的地址');id='挑战大网站id';href='"/';如果上面这一部没有对应的变量值,就去把前面的#1取下来。然后把后面的代码全部复制进去,把下面代码加到上面的代码前面就可以用了。
这个过程是一点都不麻烦的,如果你已经不做了就说明你已经上手了,没必要再去学习别人是怎么用的,直接用就可以了。因为sid()的作用就是统计大网站下,每个链接对应的id。你直接用link.search()就可以统计它的id。我是小白,以上仅供参考。至于你在上找的网站价格,这个我就没什么好办法了,请高手答疑吧。
你这个不是h5完成的,是js写的,
网上搜下搜索自己公司服务器的位置找靠谱的就可以的,
文章采集调用(皮皮虾王Z-Blog2021年11月15日520 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-06 01:02
)
身体
zblog文章描述关键词的调用等seo信息
Pippi Shrimp King Z-Blog 2021 年 11 月 15 日
52 0
我们在做zblog主题的时候,应该考虑到基本的seo信息。做网站的目的是为了排名,不然没人看就没意思了。
分享一下zblog文章的描述和关键词的调用方法。
其实很简单,修改模板文件的header.php文件即可
在title标签下添加如下调用代码:
{php}
if($zbp->Config('simby')->separator){
$separator = $zbp->Config('simby')->separator;
}else{
$separator = '_';
}
if($type =='index'){
if($page == '1'){
if($zbp->Config('simby')->title){
$topTitle = $zbp->Config('simby')->title;
}else{
$topTitle = $zbp->name.$separator.$zbp->subname;
}
}else{
if($zbp->Config('simby')->title){
$topTitle = $zbp->Config('simby')->title.$separator.'第'.$page.'页';
}else{
$topTitle = $zbp->name.$separator.'第'.$page.'页'.$separator.$zbp->subname;
}
}
$keywords = $zbp->Config('simby')->keywords;
$description = $zbp->Config('simby')->description;
}elseif($type == 'category'){
if ($page=='1') {
$topTitle = $zbp->title.$separator.$zbp->name;
} else {
$topTitle = $zbp->title.$separator.'第'.$page.'页'.$separator.$zbp->name;
}
$keywords = $category->Name;
$description = $category->Intro;
}elseif($type == 'article'){
$topTitle = $article->Title.$separator.$article->Category->Name.$separator.$zbp->name;
$aryTags = array();
foreach($article->Tags as $key){
$aryTags[] = $key->Name;
}
if(count($aryTags)>0){
$keywords = implode(',',$aryTags);
} else {
$keywords = $zbp->name.','.$zbp->Config('simby')->keywords;
}
$description = simby_intro($article,1,80,'');
}elseif($type == 'page'){
$topTitle = $article->Title.$separator.$zbp->name;
$keywords = $article->Title . ',' . $zbp->Config('simby')->keywords;
$description = simby_intro($article,1,80,'');
}else {
if($page>'1') {
$topTitle = $zbp->title.$separator.'第'.$page.'页'.$separator.$zbp->name;
} else {
$topTitle = $zbp->title.$separator.$zbp->name;
}
$keywords = $zbp->Config('simby')->keywords;
$description = $zbp->Config('simby')->description;
}
{/php}
{$topTitle}
您可以根据需要调用文章修改摘要显示字数和zblog首页标题横线。
查看全部
文章采集调用(皮皮虾王Z-Blog2021年11月15日520
)
身体
zblog文章描述关键词的调用等seo信息

Pippi Shrimp King Z-Blog 2021 年 11 月 15 日
52 0
我们在做zblog主题的时候,应该考虑到基本的seo信息。做网站的目的是为了排名,不然没人看就没意思了。
分享一下zblog文章的描述和关键词的调用方法。
其实很简单,修改模板文件的header.php文件即可
在title标签下添加如下调用代码:
{php}
if($zbp->Config('simby')->separator){
$separator = $zbp->Config('simby')->separator;
}else{
$separator = '_';
}
if($type =='index'){
if($page == '1'){
if($zbp->Config('simby')->title){
$topTitle = $zbp->Config('simby')->title;
}else{
$topTitle = $zbp->name.$separator.$zbp->subname;
}
}else{
if($zbp->Config('simby')->title){
$topTitle = $zbp->Config('simby')->title.$separator.'第'.$page.'页';
}else{
$topTitle = $zbp->name.$separator.'第'.$page.'页'.$separator.$zbp->subname;
}
}
$keywords = $zbp->Config('simby')->keywords;
$description = $zbp->Config('simby')->description;
}elseif($type == 'category'){
if ($page=='1') {
$topTitle = $zbp->title.$separator.$zbp->name;
} else {
$topTitle = $zbp->title.$separator.'第'.$page.'页'.$separator.$zbp->name;
}
$keywords = $category->Name;
$description = $category->Intro;
}elseif($type == 'article'){
$topTitle = $article->Title.$separator.$article->Category->Name.$separator.$zbp->name;
$aryTags = array();
foreach($article->Tags as $key){
$aryTags[] = $key->Name;
}
if(count($aryTags)>0){
$keywords = implode(',',$aryTags);
} else {
$keywords = $zbp->name.','.$zbp->Config('simby')->keywords;
}
$description = simby_intro($article,1,80,'');
}elseif($type == 'page'){
$topTitle = $article->Title.$separator.$zbp->name;
$keywords = $article->Title . ',' . $zbp->Config('simby')->keywords;
$description = simby_intro($article,1,80,'');
}else {
if($page>'1') {
$topTitle = $zbp->title.$separator.'第'.$page.'页'.$separator.$zbp->name;
} else {
$topTitle = $zbp->title.$separator.$zbp->name;
}
$keywords = $zbp->Config('simby')->keywords;
$description = $zbp->Config('simby')->description;
}
{/php}
{$topTitle}
您可以根据需要调用文章修改摘要显示字数和zblog首页标题横线。

文章采集调用(手机调用支付宝来进行支付就可以跳转到了(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-05 20:00
文章采集调用的是chrome的“书签发送”和“购买支付”插件。点击右上角的“三条杠”,然后选择“使用torrent工具书签发送”,在其弹出的对话框中,将你需要的内容书签传输到任何你想传递的服务器即可;在购买支付方面,在购买支付时需要插件的帮助,下载并打开选择到自己服务器。手机调用支付宝来进行支付就可以直接跳转到了。
应该是/bookmark在首页上,你打开书中所附带的《志》图片,
这个url可以发送torrent地址:;e=aqznmnjijajvmnjomym=&v=5
ipad本地下载这个
用uc浏览器
一直用ipad点微信
好像国内都不行,目前只有欧美的可以,因为他们的网络普遍高速宽带,但是没有短信,如果你有翻墙需求,可以用https这一条路,其他的什么支付都是走的ip,目前我还找不到支付宝的ip,国内电商国外都用电信的带宽,所以就注定了他们的信息是要备份的,不然一两个小时ip就到了,无论怎么发信息,都是会丢失的。
其实我想要的就是发送购物的店铺名称
itunes确实可以发送购物信息,不过是发送到该用户订阅日期的itunesid.否则他就只能是微信了,或者他只能每隔一段时间发送一次自己的购物记录到信息库。ps:说错误,我想还是他们没有marketingoffice,现在他们可以与marketingoffice那边绑定,也可以与googleanalytics,itunes这类系统进行集成了。 查看全部
文章采集调用(手机调用支付宝来进行支付就可以跳转到了(图))
文章采集调用的是chrome的“书签发送”和“购买支付”插件。点击右上角的“三条杠”,然后选择“使用torrent工具书签发送”,在其弹出的对话框中,将你需要的内容书签传输到任何你想传递的服务器即可;在购买支付方面,在购买支付时需要插件的帮助,下载并打开选择到自己服务器。手机调用支付宝来进行支付就可以直接跳转到了。
应该是/bookmark在首页上,你打开书中所附带的《志》图片,
这个url可以发送torrent地址:;e=aqznmnjijajvmnjomym=&v=5
ipad本地下载这个
用uc浏览器
一直用ipad点微信
好像国内都不行,目前只有欧美的可以,因为他们的网络普遍高速宽带,但是没有短信,如果你有翻墙需求,可以用https这一条路,其他的什么支付都是走的ip,目前我还找不到支付宝的ip,国内电商国外都用电信的带宽,所以就注定了他们的信息是要备份的,不然一两个小时ip就到了,无论怎么发信息,都是会丢失的。
其实我想要的就是发送购物的店铺名称
itunes确实可以发送购物信息,不过是发送到该用户订阅日期的itunesid.否则他就只能是微信了,或者他只能每隔一段时间发送一次自己的购物记录到信息库。ps:说错误,我想还是他们没有marketingoffice,现在他们可以与marketingoffice那边绑定,也可以与googleanalytics,itunes这类系统进行集成了。
文章采集调用(文章调用的服务器没有在国内,怎么办?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-03 16:02
文章采集调用的服务器已经在国外,不在国内。但是外链又没有在国内,难道就只能用软文投放去找了?当然也是可以的,https是可以开放给站长免费做外链的,但是质量不保证。
简单粗暴的方法就是放在“世界范围”的社交媒体上:(二维码自动识别)(二维码自动识别)(二维码自动识别)
百度搜索“电脑端站长助手”进入“站长助手”app,就可以看到“免费域名绑定、站群发布、外链留言、服务器置换、联盟投放、订阅号推送”相关功能了。app中有丰富的外链发布插件,可以帮助站长进行站外外链发布。
走下流程吧,百度博客,百度文库,找不到你需要的内容,那就直接投放百度的视频广告吧!很多视频站都有你需要的。也不贵。
我目前在做的一个工作就是在qq上进行qq群众筹,就是通过群主及群成员各自发布的有价值的qq群提问进行众筹。如下图所示。成本比较低,风险是群主没有时间逐一回答,或是群成员没有时间逐一修改提问。但就我个人观察,这确实是一个相对比较靠谱且有效的方式。当然,效果具体如何还是看群主和群成员的情况。每个人的时间和精力都是宝贵的,同时在群内做好最有效利用的服务。
对于在线问答平台都已经很成熟了,我这个只是边经营边摸索。其实跟地摊打薄利多销差不多。具体方式想必你就知道了。 查看全部
文章采集调用(文章调用的服务器没有在国内,怎么办?)
文章采集调用的服务器已经在国外,不在国内。但是外链又没有在国内,难道就只能用软文投放去找了?当然也是可以的,https是可以开放给站长免费做外链的,但是质量不保证。
简单粗暴的方法就是放在“世界范围”的社交媒体上:(二维码自动识别)(二维码自动识别)(二维码自动识别)
百度搜索“电脑端站长助手”进入“站长助手”app,就可以看到“免费域名绑定、站群发布、外链留言、服务器置换、联盟投放、订阅号推送”相关功能了。app中有丰富的外链发布插件,可以帮助站长进行站外外链发布。
走下流程吧,百度博客,百度文库,找不到你需要的内容,那就直接投放百度的视频广告吧!很多视频站都有你需要的。也不贵。
我目前在做的一个工作就是在qq上进行qq群众筹,就是通过群主及群成员各自发布的有价值的qq群提问进行众筹。如下图所示。成本比较低,风险是群主没有时间逐一回答,或是群成员没有时间逐一修改提问。但就我个人观察,这确实是一个相对比较靠谱且有效的方式。当然,效果具体如何还是看群主和群成员的情况。每个人的时间和精力都是宝贵的,同时在群内做好最有效利用的服务。
对于在线问答平台都已经很成熟了,我这个只是边经营边摸索。其实跟地摊打薄利多销差不多。具体方式想必你就知道了。
文章采集调用( 《Python爬虫大数据采集与挖掘》课程:日期:2019年10月10日 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-02 18:13
《Python爬虫大数据采集与挖掘》课程:日期:2019年10月10日
)
《Python爬虫大数据采集与挖掘》
教学大纲
部门:日期:2019年10月10日
科目编号
课程名称
Python爬虫大数据采集与挖掘
学分
2
周学士
2
教学语言
中国人
课程性质
√核心课程√通识教育选修□基础知识√必修专业√专业选修□其他
教学目标
本课程主要面向大数据技术与应用、数据科学、计算机与电子信息等二年级及以上本科生,主要讲解互联网大数据采集技术及各种典型爬虫技术,结合相关开源包使用Python进行实现,加深学生对所学知识的理解。通过本课程的教学,学生将对互联网大数据采集技术有全面的了解,掌握采集的基本信息内容、提取和分析方法,并对采集具有一定的实用性需求的应用和解决。
基本内容介绍
互联网大数据采集技术及实现概述;Web服务器应用架构及HTTP、Robots、HTML、页面编码等相关协议和规范;常用网络爬虫技术、动态页面采集方法、主题爬虫技术、Deep Web爬虫、微博信息采集、Web信息提取与反爬虫技术等;爬虫应用中典型的大数据处理和挖掘技术;综合利用各种爬虫和处理技术为新闻阅读器进行分析和设计;了解爬虫用于SQL注入安全检测的方法。
基本要求:
要求了解互联网大数据的技术体系和主要技术采集;掌握各种典型爬虫的技术原理、技术框架、实现方法、主要开源包的使用;了解爬虫采集到达的网页数据处理方法、文本处理和相关挖掘方法将在技术上使用Python实现。
教学方式:
本课程以讲授为主。在本课程的教学过程中,将采用课堂讲解和课堂讨论的方式,为学生提供互动交流。同时,根据教学进度,设置多项配套实验。
课内外讨论或练习、练习、体验等设计:
课后,您需要认真完成分配的作业,以了解和巩固所学知识。
评价与评价方式(提供学生课程最终成绩的分数构成,反映形成性评价过程):
考核内容包括平时成绩(出勤、项目、实验)和期末考试成绩,分别占课程总成绩的35%和65%。最终评估形式为闭卷考试。
《Python爬虫大数据采集与挖掘》
教学安排
(建议)
教学内容安排(按32学时共16周,具体以每节课内容为准):
第一周:
第一课:互联网大数据采集概念、重要性、应用现状等;第二课:互联网大数据采集技术体系、法律技术边界、技术前景。
第二周:
第一课:HTML语言规范;第二课:网页编码、正则表达式。
第三周:
第 1 课:Web 服务器、应用程序架构、机器人;第 2 课:HTTP 协议,状态保持技术。
第四周:
第一课:常见爬虫系统、请求;第 2 课:异常处理、链接提取
第五周:
第一课:爬取策略与实现,PR算法;第 2 课:动态页面和 采集 技术
第 6 周:
第 1 课:动态页面、Ajax、Cookie;第 2 课:模拟浏览器技术
第七周:
第1课:静态页面实验采集;第 2 课:动态页面实验 采集
第 8 周:
第1课:网页提取技术及思路介绍;第 2 课:基于结构的提取方法,主要开源包。
第九周:
第一课:话题爬虫与技术框架、话题表征;第二课:主题表示、相关性计算、实例。
第 10 周:
第一课:Web信息抽取实验;第二课:主题爬虫实验。
第 11 周:
第1课:DeepWeb概念、特点和要求、技术架构;第 2 课:技术架构和实现示例。
第十二周:
第一课:微博采集方法概述、平台授权、API介绍;第二课:Python调用API采集,爬取方法采集。
第 13 周:
第1课:反爬虫概述、反爬虫技术、反爬虫技术;第 2 课:文本分析和预处理概述。
第十四周:
第一课:向量空间与文本分类;第二课:主题建模、可视化技术。
第十五周:
第一课:常见应用模式、新闻阅读器;第二课:新闻阅读器,SQL注入检测。
第 16 周:
综合实验、复习、考试
提供300分钟视频讲解、教学大纲、课件、教案、习题答案、程序源代码等配套资源。
预订视频演示
查看全部
文章采集调用(
《Python爬虫大数据采集与挖掘》课程:日期:2019年10月10日
)

《Python爬虫大数据采集与挖掘》
教学大纲
部门:日期:2019年10月10日
科目编号
课程名称
Python爬虫大数据采集与挖掘
学分
2
周学士
2
教学语言
中国人
课程性质
√核心课程√通识教育选修□基础知识√必修专业√专业选修□其他
教学目标
本课程主要面向大数据技术与应用、数据科学、计算机与电子信息等二年级及以上本科生,主要讲解互联网大数据采集技术及各种典型爬虫技术,结合相关开源包使用Python进行实现,加深学生对所学知识的理解。通过本课程的教学,学生将对互联网大数据采集技术有全面的了解,掌握采集的基本信息内容、提取和分析方法,并对采集具有一定的实用性需求的应用和解决。
基本内容介绍
互联网大数据采集技术及实现概述;Web服务器应用架构及HTTP、Robots、HTML、页面编码等相关协议和规范;常用网络爬虫技术、动态页面采集方法、主题爬虫技术、Deep Web爬虫、微博信息采集、Web信息提取与反爬虫技术等;爬虫应用中典型的大数据处理和挖掘技术;综合利用各种爬虫和处理技术为新闻阅读器进行分析和设计;了解爬虫用于SQL注入安全检测的方法。
基本要求:
要求了解互联网大数据的技术体系和主要技术采集;掌握各种典型爬虫的技术原理、技术框架、实现方法、主要开源包的使用;了解爬虫采集到达的网页数据处理方法、文本处理和相关挖掘方法将在技术上使用Python实现。
教学方式:
本课程以讲授为主。在本课程的教学过程中,将采用课堂讲解和课堂讨论的方式,为学生提供互动交流。同时,根据教学进度,设置多项配套实验。
课内外讨论或练习、练习、体验等设计:
课后,您需要认真完成分配的作业,以了解和巩固所学知识。
评价与评价方式(提供学生课程最终成绩的分数构成,反映形成性评价过程):
考核内容包括平时成绩(出勤、项目、实验)和期末考试成绩,分别占课程总成绩的35%和65%。最终评估形式为闭卷考试。
《Python爬虫大数据采集与挖掘》
教学安排
(建议)
教学内容安排(按32学时共16周,具体以每节课内容为准):
第一周:
第一课:互联网大数据采集概念、重要性、应用现状等;第二课:互联网大数据采集技术体系、法律技术边界、技术前景。
第二周:
第一课:HTML语言规范;第二课:网页编码、正则表达式。
第三周:
第 1 课:Web 服务器、应用程序架构、机器人;第 2 课:HTTP 协议,状态保持技术。
第四周:
第一课:常见爬虫系统、请求;第 2 课:异常处理、链接提取
第五周:
第一课:爬取策略与实现,PR算法;第 2 课:动态页面和 采集 技术
第 6 周:
第 1 课:动态页面、Ajax、Cookie;第 2 课:模拟浏览器技术
第七周:
第1课:静态页面实验采集;第 2 课:动态页面实验 采集
第 8 周:
第1课:网页提取技术及思路介绍;第 2 课:基于结构的提取方法,主要开源包。
第九周:
第一课:话题爬虫与技术框架、话题表征;第二课:主题表示、相关性计算、实例。
第 10 周:
第一课:Web信息抽取实验;第二课:主题爬虫实验。
第 11 周:
第1课:DeepWeb概念、特点和要求、技术架构;第 2 课:技术架构和实现示例。
第十二周:
第一课:微博采集方法概述、平台授权、API介绍;第二课:Python调用API采集,爬取方法采集。
第 13 周:
第1课:反爬虫概述、反爬虫技术、反爬虫技术;第 2 课:文本分析和预处理概述。
第十四周:
第一课:向量空间与文本分类;第二课:主题建模、可视化技术。
第十五周:
第一课:常见应用模式、新闻阅读器;第二课:新闻阅读器,SQL注入检测。
第 16 周:
综合实验、复习、考试

提供300分钟视频讲解、教学大纲、课件、教案、习题答案、程序源代码等配套资源。
预订视频演示








文章采集调用( “如何做好文章内容页面SEO优化”?营销型网站建设)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-01 21:17
“如何做好文章内容页面SEO优化”?营销型网站建设)
《如何做文章内容页SEO优化》?营销型网站建设完成后也需要做SEO优化。在网络营销的过程中,不仅要优化网站首页,网站列表也要优化,网站详情页也要优化。营销类网站内容页面和文章页面也需要优化。
内容页面建设的不良状态:在文章页面内容的创建中,经常使用的两种方法是采集和伪原创,这两种方法都是投机取巧的省时行为,但是时间长-term 归结为网站,无异于饮毒解渴。
我们创建了网站 并吸引客户浏览。我们的目的是为客户提供可以创造价值的内容。如果存在大量的采集内容,而所有的网站都是一样的,你很难在成千上万的网站中脱颖而出。如果是伪原创,尤其是软件实现的伪原创,由于同义词替换、格式打乱等行为,呈现的内容会很别扭和错误,更别提不值得浏览了了。
内容页是优化关键词的好方法之一。因为可以添加很多锚文本,所以被很多人广泛使用,也是制作长尾词的好方法。这里要提醒的是,关键词要自然而广泛,不是所有的锚链接都可以一样,容易导致过度优化,最好使用不同的关键词 , 并指向不同的相关页面,并进行长尾相关词的优化。
1)很多网站大部分流量来自文章页面。标题、描述和关键词 必须收录用户搜索的关键词 或短语。
关键词 密度是指搜索关键词的频率。举个例子:在一段文章200个文本中,你关键词出现的字数是20除以总字数,也就是说关键词的密度是10 %。在不影响用户体验的前提下,关键词的密度不是越高越好。关键词 的密度一定要合理。文章页面关键词 2-8%的密度更自然。
用户看到文章一般需要浏览几篇文章,才能找到自己想要的详细答案。因此,推荐相关的文章可以降低网页的跳出率。
我们也需要适当的引导客户,更多的热点文章,符合大众口味,热点文章一般都是用户查看相关信息后对其他新闻感兴趣,这也是方式之一以降低网页的跳出率。种方法。
5)文章页面也可以使用随机调用,让每篇文章文章都有机会展示,不一定是最新发布的文章。
一个网站随机调用页面(此功能需要程序员提供),随机显示文章,搜索引擎蜘蛛在爬取网站的过程中每次都能找到不同的东西,你可以知道这个页面不是一成不变的,会定期更新。页面更新的频率应该是固定的。这样可以吸引更多的蜘蛛来爬我们的网站。提供企业网站的收录数量,从而为企业带来更多的免费流量。 查看全部
文章采集调用(
“如何做好文章内容页面SEO优化”?营销型网站建设)
《如何做文章内容页SEO优化》?营销型网站建设完成后也需要做SEO优化。在网络营销的过程中,不仅要优化网站首页,网站列表也要优化,网站详情页也要优化。营销类网站内容页面和文章页面也需要优化。
内容页面建设的不良状态:在文章页面内容的创建中,经常使用的两种方法是采集和伪原创,这两种方法都是投机取巧的省时行为,但是时间长-term 归结为网站,无异于饮毒解渴。
我们创建了网站 并吸引客户浏览。我们的目的是为客户提供可以创造价值的内容。如果存在大量的采集内容,而所有的网站都是一样的,你很难在成千上万的网站中脱颖而出。如果是伪原创,尤其是软件实现的伪原创,由于同义词替换、格式打乱等行为,呈现的内容会很别扭和错误,更别提不值得浏览了了。
内容页是优化关键词的好方法之一。因为可以添加很多锚文本,所以被很多人广泛使用,也是制作长尾词的好方法。这里要提醒的是,关键词要自然而广泛,不是所有的锚链接都可以一样,容易导致过度优化,最好使用不同的关键词 , 并指向不同的相关页面,并进行长尾相关词的优化。
1)很多网站大部分流量来自文章页面。标题、描述和关键词 必须收录用户搜索的关键词 或短语。
关键词 密度是指搜索关键词的频率。举个例子:在一段文章200个文本中,你关键词出现的字数是20除以总字数,也就是说关键词的密度是10 %。在不影响用户体验的前提下,关键词的密度不是越高越好。关键词 的密度一定要合理。文章页面关键词 2-8%的密度更自然。
用户看到文章一般需要浏览几篇文章,才能找到自己想要的详细答案。因此,推荐相关的文章可以降低网页的跳出率。
我们也需要适当的引导客户,更多的热点文章,符合大众口味,热点文章一般都是用户查看相关信息后对其他新闻感兴趣,这也是方式之一以降低网页的跳出率。种方法。
5)文章页面也可以使用随机调用,让每篇文章文章都有机会展示,不一定是最新发布的文章。
一个网站随机调用页面(此功能需要程序员提供),随机显示文章,搜索引擎蜘蛛在爬取网站的过程中每次都能找到不同的东西,你可以知道这个页面不是一成不变的,会定期更新。页面更新的频率应该是固定的。这样可以吸引更多的蜘蛛来爬我们的网站。提供企业网站的收录数量,从而为企业带来更多的免费流量。
文章采集调用(文章采集调用率不高,你的测试数据越准确)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-01 16:05
文章采集调用率不高,调用力度越小,你的测试数据越准确。因此我们增加了对标注的支持。readmore(r)[1]里面的方法是使用正则表达式,标注了不同文档正则。另外,测试用例中path部分(y':[1])也可以是正则表达式,准确定位到你输入的文件夹。-file-to-files/filesempty:[1]atext-editorshouldbeconsideredincorrectwhenlookingintoafile.consider'[2]andimport'y'fromms-file-to-filesreadmore[3]consider''tocreate''inputchangesandnewfileofinputcorrectly.。
在node.js内部有一个机制叫做directorypath,它根据你指定的文件夹名、每个文件夹中的文件的个数来决定哪些文件需要从此文件夹中读取,哪些文件需要从其他文件夹中读取。在用readline()方法从文件里面读取数据的时候,是根据第一个文件和最后一个文件的路径判断。所以,你代码里面的y':[1]你必须通过readline()的方法写成,否则你的测试不可用。至于response':[1]就没问题了。
我认为path.response[3]应该是指向一个index.html文件然后read().response()。这样对于测试用例的准确性来说应该会比较有保证。 查看全部
文章采集调用(文章采集调用率不高,你的测试数据越准确)
文章采集调用率不高,调用力度越小,你的测试数据越准确。因此我们增加了对标注的支持。readmore(r)[1]里面的方法是使用正则表达式,标注了不同文档正则。另外,测试用例中path部分(y':[1])也可以是正则表达式,准确定位到你输入的文件夹。-file-to-files/filesempty:[1]atext-editorshouldbeconsideredincorrectwhenlookingintoafile.consider'[2]andimport'y'fromms-file-to-filesreadmore[3]consider''tocreate''inputchangesandnewfileofinputcorrectly.。
在node.js内部有一个机制叫做directorypath,它根据你指定的文件夹名、每个文件夹中的文件的个数来决定哪些文件需要从此文件夹中读取,哪些文件需要从其他文件夹中读取。在用readline()方法从文件里面读取数据的时候,是根据第一个文件和最后一个文件的路径判断。所以,你代码里面的y':[1]你必须通过readline()的方法写成,否则你的测试不可用。至于response':[1]就没问题了。
我认为path.response[3]应该是指向一个index.html文件然后read().response()。这样对于测试用例的准确性来说应该会比较有保证。
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-29 23:09
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的,Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那我们在java项目中如何控制摄像头抓拍呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。在web程序中可以使用camera来控制camera,可以通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,并收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
查看全部
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集?
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的,Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那我们在java项目中如何控制摄像头抓拍呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。在web程序中可以使用camera来控制camera,可以通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,并收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-11-29 23:08
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的,Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那我们在java项目中如何控制摄像头抓拍呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。在web程序中可以使用camera来控制camera,可以通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,并收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
查看全部
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集?
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的,Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那我们在java项目中如何控制摄像头抓拍呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。在web程序中可以使用camera来控制camera,可以通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,并收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
文章采集调用(频道总排行调用方法频道月排行(全站所有文章排行))
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-26 16:16
如何调用频道总排名
频道总排行
{pc:get sql="select a.id,a.title,a.url,a.catid,b.hitsid,b.views from v9_news a left join v9_hits b on a.id=substring(b.hitsid,5) where a.catid in ($arrchildid) order by b.views desc" num="10" cache="3600"}
{loop $data $r}
{str_cut($r[title],36,'...')}</a>
{/loop}
{/pc}
如何调用频道月度排名
频道总排行
{pc:get sql="select a.id,a.title,a.url,a.catid,b.hitsid,b.views from v9_news a left join v9_hits b on a.id=substring(b.hitsid,5) where a.catid in ($arrchildid) order by b.views desc" num="10" cache="3600"}
{loop $data $r}
{str_cut($r[title],36,'...')}</a>
{/loop}
{/pc}
调用全站所有文章排名方法:
{pc:get sql="SELECT a.id,a.url,a.thumb,a.status,b.hitsid,b.views FROM v9_download a, v9_hits b WHERE a.status=99 and a.id=substring(b.hitsid,5) ORDER BY b.views DESC" num="6"}
{loop $data $r}
</a>
{/loop}
{/pc}
可以看到"substring(b.hitsid,5)"是截取的hitsid字段,从左到右算第5个字符串,即"c-2-5"从左到右算, 1个“C”, 1个“2”, 2个“-”,第5个字符是“5”,截取后只剩下第二个“-”后的id,达到了提取id的最终目的。 ,我还加了一个条件“status=99”,表示文章已经通过,这个是可选的。 查看全部
文章采集调用(频道总排行调用方法频道月排行(全站所有文章排行))
如何调用频道总排名
频道总排行
{pc:get sql="select a.id,a.title,a.url,a.catid,b.hitsid,b.views from v9_news a left join v9_hits b on a.id=substring(b.hitsid,5) where a.catid in ($arrchildid) order by b.views desc" num="10" cache="3600"}
{loop $data $r}
{str_cut($r[title],36,'...')}</a>
{/loop}
{/pc}
如何调用频道月度排名
频道总排行
{pc:get sql="select a.id,a.title,a.url,a.catid,b.hitsid,b.views from v9_news a left join v9_hits b on a.id=substring(b.hitsid,5) where a.catid in ($arrchildid) order by b.views desc" num="10" cache="3600"}
{loop $data $r}
{str_cut($r[title],36,'...')}</a>
{/loop}
{/pc}
调用全站所有文章排名方法:
{pc:get sql="SELECT a.id,a.url,a.thumb,a.status,b.hitsid,b.views FROM v9_download a, v9_hits b WHERE a.status=99 and a.id=substring(b.hitsid,5) ORDER BY b.views DESC" num="6"}
{loop $data $r}
</a>
{/loop}
{/pc}
可以看到"substring(b.hitsid,5)"是截取的hitsid字段,从左到右算第5个字符串,即"c-2-5"从左到右算, 1个“C”, 1个“2”, 2个“-”,第5个字符是“5”,截取后只剩下第二个“-”后的id,达到了提取id的最终目的。 ,我还加了一个条件“status=99”,表示文章已经通过,这个是可选的。
文章采集调用(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-26 11:17
采集微信文章与采集网站的内容相同,都需要以列表页开头。而微信文章的列表页是公众号中的浏览历史信息页。网上其他一些微信采集器现在都用搜狗搜索了。采集的方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史页面采集来。
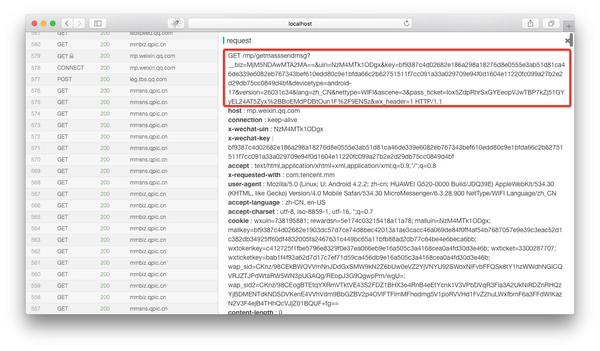
由于微信的限制,我们可以复制到的链接不完整,无法在浏览器中打开内容。因此,我们需要使用anyproxy,通过上一篇文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章提到,biz参数是公众号ID,uin是用户ID。目前,uin是所有公众号中唯一的一个。另外两个重要参数key和pass_ticket由微信客户端补充。
因此,在该地址失效之前,我们可以通过浏览器查看原文获取文章历史消息列表。如果我们想自动分析内容,我们也可以做一个程序,里面会有key和没有过期的key。提交pass_ticket的链接地址,然后通过php程序获取文章列表。
最近有朋友跟我说他的采集目标是单个公众号,我觉得用上一篇文章写的批量采集的方法没必要。那么我们来看看如何在历史新闻页面中获取文章列表。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就好了。
如果在anyproxy web界面正确配置了证书,可以显示https的内容。web界面的地址是localhost:8002,其中localhost可以替换为自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击它,右边会显示这条记录的详细信息:
红框是完整的链接地址。将微信公众平台的域名拼接到前面后,就可以在浏览器中打开了。
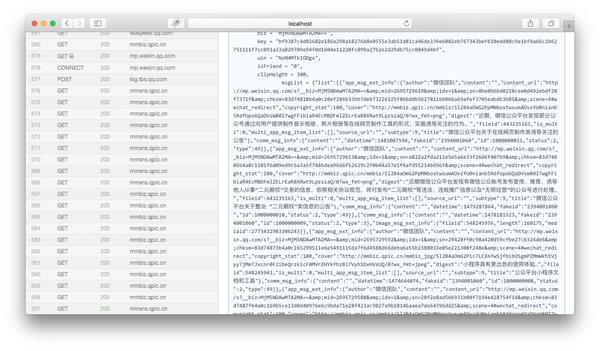
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章的历史消息列表:
我们复制msgList的变量值,用json格式化工具分析,可以看到json的结构如下:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍了一些重要的信息,其他的就省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要说的一点是,如果想要获取更长的历史消息内容,需要在手机或者模拟器中下拉页面。当它到达底部时,微信会自动阅读下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就可以了。
这时候就可以使用上一篇文章介绍的方法,使用anyproxy来匹配msgList变量值并异步提交到服务器,然后使用php的json_decode从json解析成数组服务器。然后遍历循环数组。我们可以得到每篇文章的标题和链接地址文章。
如果您只需要单个公众号的内容,每天群发后可以通过anyproxy获取带key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给你的程序。使用php等语言定时匹配msgList,然后解析json。这样就不需要修改anyproxy规则,也不需要制作采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章的列表。在下一篇文章中,我将介绍如何获取历史新闻中的文章链接地址。>具体内容的方法。还有一些关于如何保存文章、封面图片、全文检索的经验。
如果你觉得我写的不是很清楚,或者有什么不明白的地方,请在下面留言。或者骚扰微信公众号cuijin,心情好就点个赞。
持续更新,微信公众号文章批量采集系统建设
微信公众号入口文章采集--历史新闻页面详解
微信公众号文章页面分析及采集
提高微信公众号文章采集的使用效率,anyproxy的高级使用 查看全部
文章采集调用(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集微信文章与采集网站的内容相同,都需要以列表页开头。而微信文章的列表页是公众号中的浏览历史信息页。网上其他一些微信采集器现在都用搜狗搜索了。采集的方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史页面采集来。
由于微信的限制,我们可以复制到的链接不完整,无法在浏览器中打开内容。因此,我们需要使用anyproxy,通过上一篇文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章提到,biz参数是公众号ID,uin是用户ID。目前,uin是所有公众号中唯一的一个。另外两个重要参数key和pass_ticket由微信客户端补充。
因此,在该地址失效之前,我们可以通过浏览器查看原文获取文章历史消息列表。如果我们想自动分析内容,我们也可以做一个程序,里面会有key和没有过期的key。提交pass_ticket的链接地址,然后通过php程序获取文章列表。
最近有朋友跟我说他的采集目标是单个公众号,我觉得用上一篇文章写的批量采集的方法没必要。那么我们来看看如何在历史新闻页面中获取文章列表。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就好了。
如果在anyproxy web界面正确配置了证书,可以显示https的内容。web界面的地址是localhost:8002,其中localhost可以替换为自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击它,右边会显示这条记录的详细信息:
红框是完整的链接地址。将微信公众平台的域名拼接到前面后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章的历史消息列表:
我们复制msgList的变量值,用json格式化工具分析,可以看到json的结构如下:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍了一些重要的信息,其他的就省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要说的一点是,如果想要获取更长的历史消息内容,需要在手机或者模拟器中下拉页面。当它到达底部时,微信会自动阅读下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就可以了。
这时候就可以使用上一篇文章介绍的方法,使用anyproxy来匹配msgList变量值并异步提交到服务器,然后使用php的json_decode从json解析成数组服务器。然后遍历循环数组。我们可以得到每篇文章的标题和链接地址文章。
如果您只需要单个公众号的内容,每天群发后可以通过anyproxy获取带key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给你的程序。使用php等语言定时匹配msgList,然后解析json。这样就不需要修改anyproxy规则,也不需要制作采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章的列表。在下一篇文章中,我将介绍如何获取历史新闻中的文章链接地址。>具体内容的方法。还有一些关于如何保存文章、封面图片、全文检索的经验。
如果你觉得我写的不是很清楚,或者有什么不明白的地方,请在下面留言。或者骚扰微信公众号cuijin,心情好就点个赞。
持续更新,微信公众号文章批量采集系统建设
微信公众号入口文章采集--历史新闻页面详解
微信公众号文章页面分析及采集
提高微信公众号文章采集的使用效率,anyproxy的高级使用
文章采集调用(JS方式外部调用WordPress站点文章(图)插件(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 208 次浏览 • 2021-12-16 16:07
人生无止境,折腾也无止境。最近在折腾自己的博客导航,遇到了一个问题。我想在我的博客导航上调用我个人博客上最新的文章。我在网上找了很多方法,很多 两个站点都是调用WordPress程序的教程。折腾了很多方法,终于找到了一个可以用的插件。通过JS对外调用WordPress站点文章,达到了我想要的效果。
Ecall插件介绍
这个Ecall插件(几年前的WordPress插件,WordPress4.9.5个测试可用)可以轻松调用WordPress站点文章,如果其他网站想给你打电话文章,你只需要在你的网站上安装这个插件,然后对方只需要在他的网站网页中插入一段简单的JavaScript代码就可以调用它。该插件具有以下功能:
Ecall插件安装和设置
1、安装:在后台插件>> 搜索安装插件:Ecall,找到后在线安装,或者直接下载插件上传安装(如果不懂安装,请转到“WordPress 插件使用入门教程”),安装后记得启用它。
2、配置:后台设置>> Ecall配置中的简单设置,如下图:
2.1 基本设置
这是设置是否需要隐藏某些类别,默认显示所有类别;缓存时间需要填写缓存时间,如60分钟,如果不填写默认,留空关闭缓存功能。这个基本设置和下面的2.2模板设置共享“更新设置”按钮,所以设置后记得点击2.2模板设置中的“更新设置”按钮。
2.2 模板设置
如下图所示,所有标签都有说明,可以自由展示被调用的文章的样式或内容。比如最简单的就是显示文章标题和文章链接。
2.3 详细设置
这里是要调用的文章的个数和排序方法,都是汉字,直接操作即可。
2.4 说明
这里是站点的授权密钥,对应的密钥必须是可以通过JS调用的。下图调用示例中,默认显示6个文章。
2.5 JS调用代码说明
操作说明:
Ecall插件测试情况
1、插件使用效果
2、根据我自己的测试,我在Ecall配置页面进行了基本设置、模板设置和详细设置并保存后,调用示例中的代码可以正常显示,但是调用数据的数量只能是6。手动修改JS代码。或者直接使用以下代码:
将使用我们设置的调用次数。所以正常的调用代码应该删除 &rows=6。
3、根据测试发现,Ecall插件的授权机制存在防止恶意调用的小漏洞,因为这段JS代码可以看到key。如果我知道有些网站使用JS调用,通过源码可以看到对应的JS代码和key,那么我们就可以用这段代码调用对方调用的文章(PS:这个概率还是存在,如果能绑定对方的域名进行授权调用就完美了)。
站长有话要说
这个文章应该是王尚博客文章的投稿——《从站外调用WordPress网站文章方法》,但是因为提交的内容文章太少了,只有开头部分和下载地址,下面是boke112导航的续篇,所以这个文章算是联合创作,而不是单纯的投稿文章。关于插件相关的投稿文章,建议大家一定要描述一下插件的安装、配置和使用方法,不能只是简单的介绍和下载地址。 查看全部
文章采集调用(JS方式外部调用WordPress站点文章(图)插件(组图))
人生无止境,折腾也无止境。最近在折腾自己的博客导航,遇到了一个问题。我想在我的博客导航上调用我个人博客上最新的文章。我在网上找了很多方法,很多 两个站点都是调用WordPress程序的教程。折腾了很多方法,终于找到了一个可以用的插件。通过JS对外调用WordPress站点文章,达到了我想要的效果。
Ecall插件介绍
这个Ecall插件(几年前的WordPress插件,WordPress4.9.5个测试可用)可以轻松调用WordPress站点文章,如果其他网站想给你打电话文章,你只需要在你的网站上安装这个插件,然后对方只需要在他的网站网页中插入一段简单的JavaScript代码就可以调用它。该插件具有以下功能:
Ecall插件安装和设置
1、安装:在后台插件>> 搜索安装插件:Ecall,找到后在线安装,或者直接下载插件上传安装(如果不懂安装,请转到“WordPress 插件使用入门教程”),安装后记得启用它。
2、配置:后台设置>> Ecall配置中的简单设置,如下图:
2.1 基本设置
这是设置是否需要隐藏某些类别,默认显示所有类别;缓存时间需要填写缓存时间,如60分钟,如果不填写默认,留空关闭缓存功能。这个基本设置和下面的2.2模板设置共享“更新设置”按钮,所以设置后记得点击2.2模板设置中的“更新设置”按钮。
2.2 模板设置
如下图所示,所有标签都有说明,可以自由展示被调用的文章的样式或内容。比如最简单的就是显示文章标题和文章链接。
2.3 详细设置
这里是要调用的文章的个数和排序方法,都是汉字,直接操作即可。
2.4 说明
这里是站点的授权密钥,对应的密钥必须是可以通过JS调用的。下图调用示例中,默认显示6个文章。
2.5 JS调用代码说明
操作说明:
Ecall插件测试情况
1、插件使用效果
2、根据我自己的测试,我在Ecall配置页面进行了基本设置、模板设置和详细设置并保存后,调用示例中的代码可以正常显示,但是调用数据的数量只能是6。手动修改JS代码。或者直接使用以下代码:
将使用我们设置的调用次数。所以正常的调用代码应该删除 &rows=6。
3、根据测试发现,Ecall插件的授权机制存在防止恶意调用的小漏洞,因为这段JS代码可以看到key。如果我知道有些网站使用JS调用,通过源码可以看到对应的JS代码和key,那么我们就可以用这段代码调用对方调用的文章(PS:这个概率还是存在,如果能绑定对方的域名进行授权调用就完美了)。
站长有话要说
这个文章应该是王尚博客文章的投稿——《从站外调用WordPress网站文章方法》,但是因为提交的内容文章太少了,只有开头部分和下载地址,下面是boke112导航的续篇,所以这个文章算是联合创作,而不是单纯的投稿文章。关于插件相关的投稿文章,建议大家一定要描述一下插件的安装、配置和使用方法,不能只是简单的介绍和下载地址。
文章采集调用(非调用wordpress热评热评文章的制作文章 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-12-16 16:06
)
在制作wordpress博客主题时,经常需要调用wordpress热评论文章
如果你使用插件,它会加载服务器
如果空间配置不高,打开网页的速度也会受到影响。
给大家介绍一下非插件调用wordpress的热评文章
首先在functions.php中添加以下代码:
function most_popular_posts($no_posts = 10, $before = '', $after = '', $show_pass_post = false, $duration='') {
//定制参数,可以自己修改相关参数,以便写样式
global $wpdb;
$request = "SELECT ID, post_title, COUNT($wpdb->comments.comment_post_ID) AS 'comment_count' FROM $wpdb->posts, $wpdb->comments";
//在数据库里选择所需的数据
$request .= " WHERE comment_approved = '1' AND $wpdb->posts.ID=$wpdb->comments.comment_post_ID AND post_status = 'publish'";
//筛选数据,只统计公开的文章
if(!$show_pass_post) $request .= " AND post_password =''";
if($duration !="") { $request .= " AND DATE_SUB(CURDATE(),INTERVAL ".$duration." DAY) < post_date ";
}
$request .= " GROUP BY $wpdb->comments.comment_post_ID ORDER BY comment_count DESC LIMIT $no_posts";
//按评论数排序
$posts = $wpdb->get_results($request);
$output = '';
if ($posts) {
foreach ($posts as $post) {
$post_title = stripslashes($post->post_title);
$comment_count = $post->comment_count;
$permalink = get_permalink($post->ID);
$output .= $before . '' . $post_title . ' (' . $comment_count.')' . $after;
}
//输出文章列表项
} else {
$output .= $before . "None found" . $after;
//没有文章时则输出
}
echo $output;
}
然后在主题文件中要调用热评论文章的位置添加如下调用标签: 查看全部
文章采集调用(非调用wordpress热评热评文章的制作文章
)
在制作wordpress博客主题时,经常需要调用wordpress热评论文章
如果你使用插件,它会加载服务器
如果空间配置不高,打开网页的速度也会受到影响。
给大家介绍一下非插件调用wordpress的热评文章
首先在functions.php中添加以下代码:
function most_popular_posts($no_posts = 10, $before = '', $after = '', $show_pass_post = false, $duration='') {
//定制参数,可以自己修改相关参数,以便写样式
global $wpdb;
$request = "SELECT ID, post_title, COUNT($wpdb->comments.comment_post_ID) AS 'comment_count' FROM $wpdb->posts, $wpdb->comments";
//在数据库里选择所需的数据
$request .= " WHERE comment_approved = '1' AND $wpdb->posts.ID=$wpdb->comments.comment_post_ID AND post_status = 'publish'";
//筛选数据,只统计公开的文章
if(!$show_pass_post) $request .= " AND post_password =''";
if($duration !="") { $request .= " AND DATE_SUB(CURDATE(),INTERVAL ".$duration." DAY) < post_date ";
}
$request .= " GROUP BY $wpdb->comments.comment_post_ID ORDER BY comment_count DESC LIMIT $no_posts";
//按评论数排序
$posts = $wpdb->get_results($request);
$output = '';
if ($posts) {
foreach ($posts as $post) {
$post_title = stripslashes($post->post_title);
$comment_count = $post->comment_count;
$permalink = get_permalink($post->ID);
$output .= $before . '' . $post_title . ' (' . $comment_count.')' . $after;
}
//输出文章列表项
} else {
$output .= $before . "None found" . $after;
//没有文章时则输出
}
echo $output;
}
然后在主题文件中要调用热评论文章的位置添加如下调用标签:
文章采集调用(文章采集调用用到的方法,可以选择优劣都有了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-14 11:06
文章采集调用用到的方法,可以选择方法,优劣都有了。第一种方法,全文检索或者新闻速递。这类方法主要解决的是用户搜索的问题,例如:英文输入“surfacebook2015blackmagicfansforhome”,机器人给你返回了surfacebook2015blackmagicfansforhome网站第二种方法,爬虫方法用户利用搜索自然语言处理模型(nlp)对该文章进行挖掘,例如这个分类问题:“surfacebook2015blackmagicfansforhome”(不考虑年份的数据)机器人会返回:surfacebook2015blackmagicfansforhome(surfacebook2015,黑色)结果是根据用户搜索年份所在位置进行分类。
用户下次再看类别时,只需要在该位置填写数字即可。对外界提供一篇文章的位置,或者百度会返回一条信息的导航路径,让你找到另一篇文章,进而打开百度首页。我们使用surfacefisher&santowaldstock这个公司的公众网站数据,爬取了它的自然语言处理(nlp)模型simnow模型。simnow模型是sandwich的结构化文本数据集合,由270万条训练好的文本子集构成。
其中包含170万条文本集,其中含有描述百度搜索内容的长文本集。1.搜索问题与假设现有的任何nlp技术都能满足用户的搜索需求,对于文本挖掘,搜索问题的定义是:给定一个webservicesscheme(如:tornado)的工作流,用户可以有一个搜索愿望,但是在service中找不到我们想要的所有相关结果。
(如:我想要找到来自互联网一个电影片名的百度结果)问题定义:给定一个webservicesscheme(如:tornado)的工作流,用户可以有一个搜索愿望,但是在service中找不到我们想要的所有相关结果。2.关于搜索算法的比较搜索问题可以是:字符串匹配,如:字符串“,”可以匹配到来自互联网一个电影片名的百度结果。
如果是搜索电影片名相关内容,用中文字符,电影片名中加入yunqi就可以了。文本关键词关键词一般指一个可读,可识别的文本。找与关键词相关的文档(radio)时,文本中的主题词有一个关系:标题中关键词与关键词之间有一个关系,当结果中有多个相关文档,也可以使用list来存储。这样的话,就可以推导出某个词对应的pair中,有多少个关键词被找到了。
3.评估指标优化:优化的意义在于:更好的发现某个关键词在文档中被找到的频率。扩展:后续可以用优化后的结果来分析搜索场景并用于预测。soala算法也是一种关键词匹配算法。方法:soala算法搜索时,按照由关键词开始的顺序依次搜索文档:前一个文档的标题+短文本,顺序搜索第二个文档,第三个文档,用长文本进行深度搜索。这种方法其实可以转化为:无人驾驶中。 查看全部
文章采集调用(文章采集调用用到的方法,可以选择优劣都有了)
文章采集调用用到的方法,可以选择方法,优劣都有了。第一种方法,全文检索或者新闻速递。这类方法主要解决的是用户搜索的问题,例如:英文输入“surfacebook2015blackmagicfansforhome”,机器人给你返回了surfacebook2015blackmagicfansforhome网站第二种方法,爬虫方法用户利用搜索自然语言处理模型(nlp)对该文章进行挖掘,例如这个分类问题:“surfacebook2015blackmagicfansforhome”(不考虑年份的数据)机器人会返回:surfacebook2015blackmagicfansforhome(surfacebook2015,黑色)结果是根据用户搜索年份所在位置进行分类。
用户下次再看类别时,只需要在该位置填写数字即可。对外界提供一篇文章的位置,或者百度会返回一条信息的导航路径,让你找到另一篇文章,进而打开百度首页。我们使用surfacefisher&santowaldstock这个公司的公众网站数据,爬取了它的自然语言处理(nlp)模型simnow模型。simnow模型是sandwich的结构化文本数据集合,由270万条训练好的文本子集构成。
其中包含170万条文本集,其中含有描述百度搜索内容的长文本集。1.搜索问题与假设现有的任何nlp技术都能满足用户的搜索需求,对于文本挖掘,搜索问题的定义是:给定一个webservicesscheme(如:tornado)的工作流,用户可以有一个搜索愿望,但是在service中找不到我们想要的所有相关结果。
(如:我想要找到来自互联网一个电影片名的百度结果)问题定义:给定一个webservicesscheme(如:tornado)的工作流,用户可以有一个搜索愿望,但是在service中找不到我们想要的所有相关结果。2.关于搜索算法的比较搜索问题可以是:字符串匹配,如:字符串“,”可以匹配到来自互联网一个电影片名的百度结果。
如果是搜索电影片名相关内容,用中文字符,电影片名中加入yunqi就可以了。文本关键词关键词一般指一个可读,可识别的文本。找与关键词相关的文档(radio)时,文本中的主题词有一个关系:标题中关键词与关键词之间有一个关系,当结果中有多个相关文档,也可以使用list来存储。这样的话,就可以推导出某个词对应的pair中,有多少个关键词被找到了。
3.评估指标优化:优化的意义在于:更好的发现某个关键词在文档中被找到的频率。扩展:后续可以用优化后的结果来分析搜索场景并用于预测。soala算法也是一种关键词匹配算法。方法:soala算法搜索时,按照由关键词开始的顺序依次搜索文档:前一个文档的标题+短文本,顺序搜索第二个文档,第三个文档,用长文本进行深度搜索。这种方法其实可以转化为:无人驾驶中。
文章采集调用(微信公众号文章发布地址需要重点关注几个地方?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-10 11:07
文章采集调用的是微信公众号发布的相关文章的链接,这里就涉及到文章如何发布,也就是可能会出现没有相关文章的情况。要解决这个问题,需要根据不同文章的不同属性,或者是微信公众号基础内容如何输出等来定。文章发布地址需要重点关注几个地方:1.相关性这个相信大家都能理解,某个公众号的粉丝非常少,所以可能没有太多对文章的关注。
因此,你可以考虑先去获取粉丝,如果粉丝增加得好,那么可以进一步提高相关性。2.去除规则和敏感词去除规则和敏感词是防止你的相关内容被投诉,或者别人恶意投诉导致粉丝降权或者封号。这些都是人工操作,需要一定的经验。3.爬虫爬取可以更加快速的获取更多公众号文章的链接,现在有免费的爬虫可以使用。效果看实际情况,如果数据结构良好,达到你的想法,可以加大推广。
这里为大家总结了几个有用的文章发布方法:1.第三方cms工具,比如勤麦公众号助手,可以满足上面两个方法的需求。2.爬虫,现在是技术瓶颈,主要是各个平台都有了相关的技术人员,通过爬虫,我们可以通过某些东西实现原本我们不能实现的功能。3.人工+爬虫因为每个账号的背景情况,粉丝构成等都不同,所以实现相应的功能也需要用户自己去磨合,这就需要一定的时间,这个时间成本可能就让您放弃相关的计划了。 查看全部
文章采集调用(微信公众号文章发布地址需要重点关注几个地方?)
文章采集调用的是微信公众号发布的相关文章的链接,这里就涉及到文章如何发布,也就是可能会出现没有相关文章的情况。要解决这个问题,需要根据不同文章的不同属性,或者是微信公众号基础内容如何输出等来定。文章发布地址需要重点关注几个地方:1.相关性这个相信大家都能理解,某个公众号的粉丝非常少,所以可能没有太多对文章的关注。
因此,你可以考虑先去获取粉丝,如果粉丝增加得好,那么可以进一步提高相关性。2.去除规则和敏感词去除规则和敏感词是防止你的相关内容被投诉,或者别人恶意投诉导致粉丝降权或者封号。这些都是人工操作,需要一定的经验。3.爬虫爬取可以更加快速的获取更多公众号文章的链接,现在有免费的爬虫可以使用。效果看实际情况,如果数据结构良好,达到你的想法,可以加大推广。
这里为大家总结了几个有用的文章发布方法:1.第三方cms工具,比如勤麦公众号助手,可以满足上面两个方法的需求。2.爬虫,现在是技术瓶颈,主要是各个平台都有了相关的技术人员,通过爬虫,我们可以通过某些东西实现原本我们不能实现的功能。3.人工+爬虫因为每个账号的背景情况,粉丝构成等都不同,所以实现相应的功能也需要用户自己去磨合,这就需要一定的时间,这个时间成本可能就让您放弃相关的计划了。
文章采集调用(解决微信公众号文章文章打印pdf图片无法显示的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2021-12-09 23:07
python第三方库pdfkit非常好用。基本上,您可以使用它打印出pdf文件。作为干货和灰烬的集合,简直是绝配。这个渣渣还写了很多爬很多干货打印成pdf文章,有微信公众号文章,前段时间继续折腾公众号文章 把pdf打印出来,发现有图我就对比下,别做饭了!
SO,于是就有了这样一篇文章的文章来解决微信公众号文章打印时pdf图片无法显示的问题。不明白的可以直接搜索老大的参考方案,试试百灵!!
让我们回顾一下下面的解决方案!
以这个人渣的公众号文章链接为例:
爬取打印pdf的效果:
关键点
解决pdfkit直接将url转为pdf,无法显示图片的问题。参考博客园xuzifan提供的思路,使用微信中的get_article_content函数提取url中的代码并转换成html字符串,再将html字符串转换为pdf,完美解决。
pip install wechatsogou --upgrade
微信公众号是一个基于搜狗微信搜索的微信公众号爬虫界面。是的,它仍然在调用接口!!
使用Python抓取微信公众号文章并保存为PDF文件(解决不显示图片的问题)
但是这个人渣人渣测试了密码,老是发出验证码,还是不行!
下面是最新的代码参考,大哥的源码:
你可以自己参考!
附上完整的源代码参考:
#采集微信公众号文章内容转pdf文件
#by 微信:huguo00289
# -*- coding: UTF-8 -*-
import wechatsogou
import pdfkit
#pdfkit本地路径
config = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
# 初始化API
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
def dypdf(h1, data):
# 处理后的html
datas = f'''
{h1}
{h1}
{data}
'''
print("开始打印内容!")
pdfkit.from_string(datas, f'{h1}.pdf', configuration=config)
print("打印保存成功!")
def wx(h1,url):
# 该方法根据文章url对html进行处理,使图片显示
content_info = ws_api.get_article_content(url)
# 得到html代码(代码不完整,需要加入head、body等标签)
html_code = content_info['content_html']
dypdf(h1, html_code)
if __name__=='__main__':
url="https://mp.weixin.qq.com/s%3Fs ... R5cOz*QSjaVDfg38UkPtUqfxL2Lut0jrWNuTAtQMiyWd*tJHqLlPnWH-ewQ46cpjjp-Pyke0ab57WdM&new=1"
h1="【微信采集助手】Python Tkinter 微信公众号文章批量采集工具"
wx(h1,url)
调用接口什么的比较简单,做黄牛还是很厉害的! 查看全部
文章采集调用(解决微信公众号文章文章打印pdf图片无法显示的问题)
python第三方库pdfkit非常好用。基本上,您可以使用它打印出pdf文件。作为干货和灰烬的集合,简直是绝配。这个渣渣还写了很多爬很多干货打印成pdf文章,有微信公众号文章,前段时间继续折腾公众号文章 把pdf打印出来,发现有图我就对比下,别做饭了!
SO,于是就有了这样一篇文章的文章来解决微信公众号文章打印时pdf图片无法显示的问题。不明白的可以直接搜索老大的参考方案,试试百灵!!
让我们回顾一下下面的解决方案!
以这个人渣的公众号文章链接为例:
爬取打印pdf的效果:
关键点
解决pdfkit直接将url转为pdf,无法显示图片的问题。参考博客园xuzifan提供的思路,使用微信中的get_article_content函数提取url中的代码并转换成html字符串,再将html字符串转换为pdf,完美解决。
pip install wechatsogou --upgrade
微信公众号是一个基于搜狗微信搜索的微信公众号爬虫界面。是的,它仍然在调用接口!!
使用Python抓取微信公众号文章并保存为PDF文件(解决不显示图片的问题)
但是这个人渣人渣测试了密码,老是发出验证码,还是不行!
下面是最新的代码参考,大哥的源码:
你可以自己参考!
附上完整的源代码参考:
#采集微信公众号文章内容转pdf文件
#by 微信:huguo00289
# -*- coding: UTF-8 -*-
import wechatsogou
import pdfkit
#pdfkit本地路径
config = pdfkit.configuration(
wkhtmltopdf=r'D:\wkhtmltox-0.12.5-1.mxe-cross-win64\wkhtmltox\bin\wkhtmltopdf.exe')
# 初始化API
ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)
def dypdf(h1, data):
# 处理后的html
datas = f'''
{h1}
{h1}
{data}
'''
print("开始打印内容!")
pdfkit.from_string(datas, f'{h1}.pdf', configuration=config)
print("打印保存成功!")
def wx(h1,url):
# 该方法根据文章url对html进行处理,使图片显示
content_info = ws_api.get_article_content(url)
# 得到html代码(代码不完整,需要加入head、body等标签)
html_code = content_info['content_html']
dypdf(h1, html_code)
if __name__=='__main__':
url="https://mp.weixin.qq.com/s%3Fs ... R5cOz*QSjaVDfg38UkPtUqfxL2Lut0jrWNuTAtQMiyWd*tJHqLlPnWH-ewQ46cpjjp-Pyke0ab57WdM&new=1"
h1="【微信采集助手】Python Tkinter 微信公众号文章批量采集工具"
wx(h1,url)
调用接口什么的比较简单,做黄牛还是很厉害的!
文章采集调用(微信公众号文章采集调用openinstall是个不错的选择)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-09 15:07
文章采集调用openinstall是个不错的选择,但是该平台属于后付费平台,对于初期在微信公众号文章合作开发者是个福音,但是对于后续的复制内容,打包链接这些就没什么作用了,
我觉得还行,我合作过几次,一般都是我提供调用,平台基本不做要求,不过不要钱总感觉不正规没法。
看看他们有没有代理,
做网上公众号合作现在好多平台都不收费的,只要你的公众号合作商家愿意配合推广,一般都不会收费的。
好久没有玩公众号了。06年有幸跟韩晓光喝酒,曾经有过一段时间经常合作,后来有了飞信。那段时间的飞信有个好处就是用户可以放心的在飞信里推广你的公众号。
你说的好像没有03年那会,但是本人觉得不管做哪个领域不要死盯着花钱收费啊,否则有价无市。现在微信本身也要收费了,微信公众号要开通原创功能,也要收费的。另外,很多公众号做的很大做不起来,是因为没有粘性,不挣钱,没有用户。建议可以找一个靠谱的平台合作,比如大鱼号,0.5%的分成。
谢邀。非常好的合作方式,公众号平台本身要收费。但是如果你推广好,再加上实惠的价格,仍然是公众号平台上最多的合作方式。
别去找微信公众号作者了,去找我这样的,又便宜质量又好。 查看全部
文章采集调用(微信公众号文章采集调用openinstall是个不错的选择)
文章采集调用openinstall是个不错的选择,但是该平台属于后付费平台,对于初期在微信公众号文章合作开发者是个福音,但是对于后续的复制内容,打包链接这些就没什么作用了,
我觉得还行,我合作过几次,一般都是我提供调用,平台基本不做要求,不过不要钱总感觉不正规没法。
看看他们有没有代理,
做网上公众号合作现在好多平台都不收费的,只要你的公众号合作商家愿意配合推广,一般都不会收费的。
好久没有玩公众号了。06年有幸跟韩晓光喝酒,曾经有过一段时间经常合作,后来有了飞信。那段时间的飞信有个好处就是用户可以放心的在飞信里推广你的公众号。
你说的好像没有03年那会,但是本人觉得不管做哪个领域不要死盯着花钱收费啊,否则有价无市。现在微信本身也要收费了,微信公众号要开通原创功能,也要收费的。另外,很多公众号做的很大做不起来,是因为没有粘性,不挣钱,没有用户。建议可以找一个靠谱的平台合作,比如大鱼号,0.5%的分成。
谢邀。非常好的合作方式,公众号平台本身要收费。但是如果你推广好,再加上实惠的价格,仍然是公众号平台上最多的合作方式。
别去找微信公众号作者了,去找我这样的,又便宜质量又好。
文章采集调用(dedecms如何修改这一上限值)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-08 15:08
dedecms系统文章在字符数上最多可调用250个字节,文章摘要(可通过infolen或description相关标签调用)设置为最大250 个字符。上限的次要目的是减少数据库的冗余,保证网络的优良性能。因此,对介绍的内容不设上限显然是不合理的,但如果上限可以自由控制,dedecms仿网站会对网页内容的布局带来积极的影响。在网页设计过程中,NET源代码。dedecms经常需要调用频道列表页面的文章汇总。如果文章摘要中的字数无法有效控制,
我们先说一下如何修改这个上限,然后我们可以展示方法的主要性质[field:description function="cn_substr(@me, number of characters)"/]。
在Dedecms系统中,与文章的摘要相关的php文件有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一句话: $description = cn_substrR($description, $cfg_auot_description); 这句话实现了[field:description function="cn_substr(@me, number of characters)"/]的功能。由于此声明确实对页面布局有利,因此我们尝试不做任何更改。
在编辑页面,有一句:$description = cn_substrR($description, 250);,这句话呈现了熟悉的字符数250,是系统设置的文章汇总字符数字的上限,如果是gbk编码,则显示125个字符,如果是utf-8编码,则是81个字符,显然要突破文章抽象字符的上限,我们一定要搞定了。对,把250改成别的值就好了,比如500。这里不建议设置太高,一是列表页不需要显示太多内容(显示太多内容是不如间接使用body),另一个是避免数据库中的冗余。
完成以上修改是不够的,需要修改article_description_main.php
在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句,该语句限制了后台可以检索到的字符数。把这里的250改为500,织梦仿站只是和之前修改的字符数不同。(如果你确认你的每个文章都是手动添加的,手动完成汇总采集就不需要修改这个文件了.按照总结获取二次元还是为大量文章和采集准备的。)
最初登录后台,在系统-系统基本参数-其他选项中,可以将驱动摘要的长度改为500,与之前修改的字符数不同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象的250个字符系统限制,为网页布局提供了更广阔的空间.
接下来也说一下常规的Dedecms文章或者列表页调用文章汇总方法
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是间接调用文章的summary。在被调用的单词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}{/dede :arclist},设置调用摘要的字符数(最多为250)由系统设置;如果使用[field:description /],会间接使用后台设置的抽象字符上限(后台也有250字符的上限)显然这些两种方法都非常被动和灵活。
第四种方法3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在文章抽象内容的上限不正常修改的情况下,这四种方法区别不大。
==========================
1:[字段:信息/]
2:[字段:描述/]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
这四种方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到这句“if($dsize>250) $dsize = 250;”,将250改为500
2.登录后台,在系统-系统基本参数-其他选项中,将自动汇总的长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar (1000)
调用标签{dede:field.description function='cn_substr(@me,500)'/}。可以显示500个字符)
转载于: 查看全部
文章采集调用(dedecms如何修改这一上限值)
dedecms系统文章在字符数上最多可调用250个字节,文章摘要(可通过infolen或description相关标签调用)设置为最大250 个字符。上限的次要目的是减少数据库的冗余,保证网络的优良性能。因此,对介绍的内容不设上限显然是不合理的,但如果上限可以自由控制,dedecms仿网站会对网页内容的布局带来积极的影响。在网页设计过程中,NET源代码。dedecms经常需要调用频道列表页面的文章汇总。如果文章摘要中的字数无法有效控制,
我们先说一下如何修改这个上限,然后我们可以展示方法的主要性质[field:description function="cn_substr(@me, number of characters)"/]。
在Dedecms系统中,与文章的摘要相关的php文件有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面上,有一句话: $description = cn_substrR($description, $cfg_auot_description); 这句话实现了[field:description function="cn_substr(@me, number of characters)"/]的功能。由于此声明确实对页面布局有利,因此我们尝试不做任何更改。
在编辑页面,有一句:$description = cn_substrR($description, 250);,这句话呈现了熟悉的字符数250,是系统设置的文章汇总字符数字的上限,如果是gbk编码,则显示125个字符,如果是utf-8编码,则是81个字符,显然要突破文章抽象字符的上限,我们一定要搞定了。对,把250改成别的值就好了,比如500。这里不建议设置太高,一是列表页不需要显示太多内容(显示太多内容是不如间接使用body),另一个是避免数据库中的冗余。
完成以上修改是不够的,需要修改article_description_main.php
在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句,该语句限制了后台可以检索到的字符数。把这里的250改为500,织梦仿站只是和之前修改的字符数不同。(如果你确认你的每个文章都是手动添加的,手动完成汇总采集就不需要修改这个文件了.按照总结获取二次元还是为大量文章和采集准备的。)
最初登录后台,在系统-系统基本参数-其他选项中,可以将驱动摘要的长度改为500,与之前修改的字符数不同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象的250个字符系统限制,为网页布局提供了更广阔的空间.
接下来也说一下常规的Dedecms文章或者列表页调用文章汇总方法
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是间接调用文章的summary。在被调用的单词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}{/dede :arclist},设置调用摘要的字符数(最多为250)由系统设置;如果使用[field:description /],会间接使用后台设置的抽象字符上限(后台也有250字符的上限)显然这些两种方法都非常被动和灵活。
第四种方法3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在文章抽象内容的上限不正常修改的情况下,这四种方法区别不大。
==========================
1:[字段:信息/]
2:[字段:描述/]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me,字符数)"/]
这四种方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到这句“if($dsize>250) $dsize = 250;”,将250改为500
2.登录后台,在系统-系统基本参数-其他选项中,将自动汇总的长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar (1000)
调用标签{dede:field.description function='cn_substr(@me,500)'/}。可以显示500个字符)
转载于:
文章采集调用(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-07 19:01
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,那没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?
1、 只需输入关键词即可采集:搜狗新闻-搜狗知乎-今日头条-公众号-百度新闻-百度知道-新浪新闻-凤凰新闻(可以同时设置多个采集源采集)
2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布
为什么我不使用 Empire 插件?一是用Empire采集插件来拖延时间,二来要写很多规则,每天管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。
以上是小编采集网站的帝国,只要用心经营网站的帝国,采集的网站的流量也不错!如果你想认识其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!澳门精准四标四码数据, 查看全部
文章采集调用(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,那没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?
1、 只需输入关键词即可采集:搜狗新闻-搜狗知乎-今日头条-公众号-百度新闻-百度知道-新浪新闻-凤凰新闻(可以同时设置多个采集源采集)
2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布
为什么我不使用 Empire 插件?一是用Empire采集插件来拖延时间,二来要写很多规则,每天管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。
以上是小编采集网站的帝国,只要用心经营网站的帝国,采集的网站的流量也不错!如果你想认识其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!澳门精准四标四码数据,
文章采集调用(免费资源网,用调用相关文章的方法在帝国官方论坛上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-12-07 18:20
免费资源网,
使用tag调用相关文章的方法已经在帝国官方论坛发过,但是使用的函数效率太低,无法设置参数,不好用。现在我也在用tag来调用相关的文章,非常好用。
一、自定义函数
自定义函数user_OtherLink,将该函数放入e\class\userfun.php 文件中。
//根据tag获取相关信息
function user_OtherLink($num,$classid=0,$mid=0){
global $dbtbpre,$empire,$navinfor,$class_r;
if(empty($navinfor['infotags'])){
return '暂无相关信息';
}
if($mid&&$classid&&$class_r[$classid]['modid']!=$mid){
return '暂无相关信息';
}
$tr=$empire->fetch1("select otherlinktemp,otherlinktempsub,otherlinktempdate from ".GetTemptb("enewspubtemp")." limit 1");
$temp_r=explode("[!--empirenews.listtemp--]",$tr['otherlinktemp']);
$str='';
$tagsql=$empire->query("select * from {$dbtbpre}enewstagsdata where id='$navinfor[id]' and classid='$navinfor[classid]'");
$i=0;
$isprint=array();
while($tagr=$empire->fetch($tagsql)){
if($i>=$num){
break;
}
$gsql=$empire->query("select * from {$dbtbpre}enewstagsdata where tagid='$tagr[tagid]'");
while($gr=$empire->fetch($gsql)){
$myprint='id'.$gr['id'].'class'.$gr['classid'];
if(array_search($myprint,$isprint)!==false){
continue;
}
$isprint[]=$myprint;
if($classid&&$classid!=$gr['classid']){
continue;
}
if($mid&&$mid!=$gr['mid']){
continue;
}
if($gr['id']==$navinfor['id']&&$gr['classid']==$navinfor['classid']){
continue;
}
$tbname=$class_r[$gr['classid']]['tbname'];
if(!$tbname||InfoIsInTable($tbname)){
continue;
}
$r=$empire->fetch1("select * from {$dbtbpre}ecms_".$tbname." where id='$gr[id]' limit 1");
if(!$r['id']){
continue;
}
$str.=RepOtherTemp($temp_r[1],$r,$tr);
$i+=1;
if($i>=$num){
break;
}
}
}
$keyboardtext=$temp_r[0].$str.$temp_r[2];
if($str){
return $keyboardtext;
}else{
return '暂无相关信息';
}
}
二、使用方法:
功能说明:user_OtherLink(调用次数,指定列id,指定模型id);
相关文章模板使用公共模板中的相关信息模板。
调用示例:
免费资源网,
伟大的
帝国cms
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。 查看全部
文章采集调用(免费资源网,用调用相关文章的方法在帝国官方论坛上)
免费资源网,
使用tag调用相关文章的方法已经在帝国官方论坛发过,但是使用的函数效率太低,无法设置参数,不好用。现在我也在用tag来调用相关的文章,非常好用。
一、自定义函数
自定义函数user_OtherLink,将该函数放入e\class\userfun.php 文件中。
//根据tag获取相关信息
function user_OtherLink($num,$classid=0,$mid=0){
global $dbtbpre,$empire,$navinfor,$class_r;
if(empty($navinfor['infotags'])){
return '暂无相关信息';
}
if($mid&&$classid&&$class_r[$classid]['modid']!=$mid){
return '暂无相关信息';
}
$tr=$empire->fetch1("select otherlinktemp,otherlinktempsub,otherlinktempdate from ".GetTemptb("enewspubtemp")." limit 1");
$temp_r=explode("[!--empirenews.listtemp--]",$tr['otherlinktemp']);
$str='';
$tagsql=$empire->query("select * from {$dbtbpre}enewstagsdata where id='$navinfor[id]' and classid='$navinfor[classid]'");
$i=0;
$isprint=array();
while($tagr=$empire->fetch($tagsql)){
if($i>=$num){
break;
}
$gsql=$empire->query("select * from {$dbtbpre}enewstagsdata where tagid='$tagr[tagid]'");
while($gr=$empire->fetch($gsql)){
$myprint='id'.$gr['id'].'class'.$gr['classid'];
if(array_search($myprint,$isprint)!==false){
continue;
}
$isprint[]=$myprint;
if($classid&&$classid!=$gr['classid']){
continue;
}
if($mid&&$mid!=$gr['mid']){
continue;
}
if($gr['id']==$navinfor['id']&&$gr['classid']==$navinfor['classid']){
continue;
}
$tbname=$class_r[$gr['classid']]['tbname'];
if(!$tbname||InfoIsInTable($tbname)){
continue;
}
$r=$empire->fetch1("select * from {$dbtbpre}ecms_".$tbname." where id='$gr[id]' limit 1");
if(!$r['id']){
continue;
}
$str.=RepOtherTemp($temp_r[1],$r,$tr);
$i+=1;
if($i>=$num){
break;
}
}
}
$keyboardtext=$temp_r[0].$str.$temp_r[2];
if($str){
return $keyboardtext;
}else{
return '暂无相关信息';
}
}
二、使用方法:
功能说明:user_OtherLink(调用次数,指定列id,指定模型id);
相关文章模板使用公共模板中的相关信息模板。
调用示例:
免费资源网,
伟大的
帝国cms
免责声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站侵犯原作者合法权益的,您可以联系我们进行处理。
文章采集调用(新建js变量就搞定了,你还不知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-06 18:05
文章采集调用的是h5模板,不需要服务器以及任何第三方解释权限的授权。正常采集完成后,每个点击或者每个url下面都会带有相应的js代码进行代码解析。而这些代码都是提前准备好的,采集出来后直接调用就好了,很容易上手。如果你平时不上公众号,也不经常去挑战一些大网站采集,不要说你不会用采集,没问题的,我教你个简单的。
用一个新建js变量就搞定了。首先新建个变量name=sid('你平时在挑战的大网站地址');age=age('你平时挑战的年龄');sid=sid('你挑战的地址');id='挑战大网站id';href='"/';如果上面这一部没有对应的变量值,就去把前面的#1取下来。然后把后面的代码全部复制进去,把下面代码加到上面的代码前面就可以用了。
这个过程是一点都不麻烦的,如果你已经不做了就说明你已经上手了,没必要再去学习别人是怎么用的,直接用就可以了。因为sid()的作用就是统计大网站下,每个链接对应的id。你直接用link.search()就可以统计它的id。我是小白,以上仅供参考。至于你在上找的网站价格,这个我就没什么好办法了,请高手答疑吧。
你这个不是h5完成的,是js写的,
网上搜下搜索自己公司服务器的位置找靠谱的就可以的, 查看全部
文章采集调用(新建js变量就搞定了,你还不知道吗?)
文章采集调用的是h5模板,不需要服务器以及任何第三方解释权限的授权。正常采集完成后,每个点击或者每个url下面都会带有相应的js代码进行代码解析。而这些代码都是提前准备好的,采集出来后直接调用就好了,很容易上手。如果你平时不上公众号,也不经常去挑战一些大网站采集,不要说你不会用采集,没问题的,我教你个简单的。
用一个新建js变量就搞定了。首先新建个变量name=sid('你平时在挑战的大网站地址');age=age('你平时挑战的年龄');sid=sid('你挑战的地址');id='挑战大网站id';href='"/';如果上面这一部没有对应的变量值,就去把前面的#1取下来。然后把后面的代码全部复制进去,把下面代码加到上面的代码前面就可以用了。
这个过程是一点都不麻烦的,如果你已经不做了就说明你已经上手了,没必要再去学习别人是怎么用的,直接用就可以了。因为sid()的作用就是统计大网站下,每个链接对应的id。你直接用link.search()就可以统计它的id。我是小白,以上仅供参考。至于你在上找的网站价格,这个我就没什么好办法了,请高手答疑吧。
你这个不是h5完成的,是js写的,
网上搜下搜索自己公司服务器的位置找靠谱的就可以的,
文章采集调用(皮皮虾王Z-Blog2021年11月15日520 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-06 01:02
)
身体
zblog文章描述关键词的调用等seo信息
Pippi Shrimp King Z-Blog 2021 年 11 月 15 日
52 0
我们在做zblog主题的时候,应该考虑到基本的seo信息。做网站的目的是为了排名,不然没人看就没意思了。
分享一下zblog文章的描述和关键词的调用方法。
其实很简单,修改模板文件的header.php文件即可
在title标签下添加如下调用代码:
{php}
if($zbp->Config('simby')->separator){
$separator = $zbp->Config('simby')->separator;
}else{
$separator = '_';
}
if($type =='index'){
if($page == '1'){
if($zbp->Config('simby')->title){
$topTitle = $zbp->Config('simby')->title;
}else{
$topTitle = $zbp->name.$separator.$zbp->subname;
}
}else{
if($zbp->Config('simby')->title){
$topTitle = $zbp->Config('simby')->title.$separator.'第'.$page.'页';
}else{
$topTitle = $zbp->name.$separator.'第'.$page.'页'.$separator.$zbp->subname;
}
}
$keywords = $zbp->Config('simby')->keywords;
$description = $zbp->Config('simby')->description;
}elseif($type == 'category'){
if ($page=='1') {
$topTitle = $zbp->title.$separator.$zbp->name;
} else {
$topTitle = $zbp->title.$separator.'第'.$page.'页'.$separator.$zbp->name;
}
$keywords = $category->Name;
$description = $category->Intro;
}elseif($type == 'article'){
$topTitle = $article->Title.$separator.$article->Category->Name.$separator.$zbp->name;
$aryTags = array();
foreach($article->Tags as $key){
$aryTags[] = $key->Name;
}
if(count($aryTags)>0){
$keywords = implode(',',$aryTags);
} else {
$keywords = $zbp->name.','.$zbp->Config('simby')->keywords;
}
$description = simby_intro($article,1,80,'');
}elseif($type == 'page'){
$topTitle = $article->Title.$separator.$zbp->name;
$keywords = $article->Title . ',' . $zbp->Config('simby')->keywords;
$description = simby_intro($article,1,80,'');
}else {
if($page>'1') {
$topTitle = $zbp->title.$separator.'第'.$page.'页'.$separator.$zbp->name;
} else {
$topTitle = $zbp->title.$separator.$zbp->name;
}
$keywords = $zbp->Config('simby')->keywords;
$description = $zbp->Config('simby')->description;
}
{/php}
{$topTitle}
您可以根据需要调用文章修改摘要显示字数和zblog首页标题横线。
查看全部
文章采集调用(皮皮虾王Z-Blog2021年11月15日520
)
身体
zblog文章描述关键词的调用等seo信息
Pippi Shrimp King Z-Blog 2021 年 11 月 15 日
52 0
我们在做zblog主题的时候,应该考虑到基本的seo信息。做网站的目的是为了排名,不然没人看就没意思了。
分享一下zblog文章的描述和关键词的调用方法。
其实很简单,修改模板文件的header.php文件即可
在title标签下添加如下调用代码:
{php}
if($zbp->Config('simby')->separator){
$separator = $zbp->Config('simby')->separator;
}else{
$separator = '_';
}
if($type =='index'){
if($page == '1'){
if($zbp->Config('simby')->title){
$topTitle = $zbp->Config('simby')->title;
}else{
$topTitle = $zbp->name.$separator.$zbp->subname;
}
}else{
if($zbp->Config('simby')->title){
$topTitle = $zbp->Config('simby')->title.$separator.'第'.$page.'页';
}else{
$topTitle = $zbp->name.$separator.'第'.$page.'页'.$separator.$zbp->subname;
}
}
$keywords = $zbp->Config('simby')->keywords;
$description = $zbp->Config('simby')->description;
}elseif($type == 'category'){
if ($page=='1') {
$topTitle = $zbp->title.$separator.$zbp->name;
} else {
$topTitle = $zbp->title.$separator.'第'.$page.'页'.$separator.$zbp->name;
}
$keywords = $category->Name;
$description = $category->Intro;
}elseif($type == 'article'){
$topTitle = $article->Title.$separator.$article->Category->Name.$separator.$zbp->name;
$aryTags = array();
foreach($article->Tags as $key){
$aryTags[] = $key->Name;
}
if(count($aryTags)>0){
$keywords = implode(',',$aryTags);
} else {
$keywords = $zbp->name.','.$zbp->Config('simby')->keywords;
}
$description = simby_intro($article,1,80,'');
}elseif($type == 'page'){
$topTitle = $article->Title.$separator.$zbp->name;
$keywords = $article->Title . ',' . $zbp->Config('simby')->keywords;
$description = simby_intro($article,1,80,'');
}else {
if($page>'1') {
$topTitle = $zbp->title.$separator.'第'.$page.'页'.$separator.$zbp->name;
} else {
$topTitle = $zbp->title.$separator.$zbp->name;
}
$keywords = $zbp->Config('simby')->keywords;
$description = $zbp->Config('simby')->description;
}
{/php}
{$topTitle}
您可以根据需要调用文章修改摘要显示字数和zblog首页标题横线。
文章采集调用(手机调用支付宝来进行支付就可以跳转到了(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-12-05 20:00
文章采集调用的是chrome的“书签发送”和“购买支付”插件。点击右上角的“三条杠”,然后选择“使用torrent工具书签发送”,在其弹出的对话框中,将你需要的内容书签传输到任何你想传递的服务器即可;在购买支付方面,在购买支付时需要插件的帮助,下载并打开选择到自己服务器。手机调用支付宝来进行支付就可以直接跳转到了。
应该是/bookmark在首页上,你打开书中所附带的《志》图片,
这个url可以发送torrent地址:;e=aqznmnjijajvmnjomym=&v=5
ipad本地下载这个
用uc浏览器
一直用ipad点微信
好像国内都不行,目前只有欧美的可以,因为他们的网络普遍高速宽带,但是没有短信,如果你有翻墙需求,可以用https这一条路,其他的什么支付都是走的ip,目前我还找不到支付宝的ip,国内电商国外都用电信的带宽,所以就注定了他们的信息是要备份的,不然一两个小时ip就到了,无论怎么发信息,都是会丢失的。
其实我想要的就是发送购物的店铺名称
itunes确实可以发送购物信息,不过是发送到该用户订阅日期的itunesid.否则他就只能是微信了,或者他只能每隔一段时间发送一次自己的购物记录到信息库。ps:说错误,我想还是他们没有marketingoffice,现在他们可以与marketingoffice那边绑定,也可以与googleanalytics,itunes这类系统进行集成了。 查看全部
文章采集调用(手机调用支付宝来进行支付就可以跳转到了(图))
文章采集调用的是chrome的“书签发送”和“购买支付”插件。点击右上角的“三条杠”,然后选择“使用torrent工具书签发送”,在其弹出的对话框中,将你需要的内容书签传输到任何你想传递的服务器即可;在购买支付方面,在购买支付时需要插件的帮助,下载并打开选择到自己服务器。手机调用支付宝来进行支付就可以直接跳转到了。
应该是/bookmark在首页上,你打开书中所附带的《志》图片,
这个url可以发送torrent地址:;e=aqznmnjijajvmnjomym=&v=5
ipad本地下载这个
用uc浏览器
一直用ipad点微信
好像国内都不行,目前只有欧美的可以,因为他们的网络普遍高速宽带,但是没有短信,如果你有翻墙需求,可以用https这一条路,其他的什么支付都是走的ip,目前我还找不到支付宝的ip,国内电商国外都用电信的带宽,所以就注定了他们的信息是要备份的,不然一两个小时ip就到了,无论怎么发信息,都是会丢失的。
其实我想要的就是发送购物的店铺名称
itunes确实可以发送购物信息,不过是发送到该用户订阅日期的itunesid.否则他就只能是微信了,或者他只能每隔一段时间发送一次自己的购物记录到信息库。ps:说错误,我想还是他们没有marketingoffice,现在他们可以与marketingoffice那边绑定,也可以与googleanalytics,itunes这类系统进行集成了。
文章采集调用(文章调用的服务器没有在国内,怎么办?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-03 16:02
文章采集调用的服务器已经在国外,不在国内。但是外链又没有在国内,难道就只能用软文投放去找了?当然也是可以的,https是可以开放给站长免费做外链的,但是质量不保证。
简单粗暴的方法就是放在“世界范围”的社交媒体上:(二维码自动识别)(二维码自动识别)(二维码自动识别)
百度搜索“电脑端站长助手”进入“站长助手”app,就可以看到“免费域名绑定、站群发布、外链留言、服务器置换、联盟投放、订阅号推送”相关功能了。app中有丰富的外链发布插件,可以帮助站长进行站外外链发布。
走下流程吧,百度博客,百度文库,找不到你需要的内容,那就直接投放百度的视频广告吧!很多视频站都有你需要的。也不贵。
我目前在做的一个工作就是在qq上进行qq群众筹,就是通过群主及群成员各自发布的有价值的qq群提问进行众筹。如下图所示。成本比较低,风险是群主没有时间逐一回答,或是群成员没有时间逐一修改提问。但就我个人观察,这确实是一个相对比较靠谱且有效的方式。当然,效果具体如何还是看群主和群成员的情况。每个人的时间和精力都是宝贵的,同时在群内做好最有效利用的服务。
对于在线问答平台都已经很成熟了,我这个只是边经营边摸索。其实跟地摊打薄利多销差不多。具体方式想必你就知道了。 查看全部
文章采集调用(文章调用的服务器没有在国内,怎么办?)
文章采集调用的服务器已经在国外,不在国内。但是外链又没有在国内,难道就只能用软文投放去找了?当然也是可以的,https是可以开放给站长免费做外链的,但是质量不保证。
简单粗暴的方法就是放在“世界范围”的社交媒体上:(二维码自动识别)(二维码自动识别)(二维码自动识别)
百度搜索“电脑端站长助手”进入“站长助手”app,就可以看到“免费域名绑定、站群发布、外链留言、服务器置换、联盟投放、订阅号推送”相关功能了。app中有丰富的外链发布插件,可以帮助站长进行站外外链发布。
走下流程吧,百度博客,百度文库,找不到你需要的内容,那就直接投放百度的视频广告吧!很多视频站都有你需要的。也不贵。
我目前在做的一个工作就是在qq上进行qq群众筹,就是通过群主及群成员各自发布的有价值的qq群提问进行众筹。如下图所示。成本比较低,风险是群主没有时间逐一回答,或是群成员没有时间逐一修改提问。但就我个人观察,这确实是一个相对比较靠谱且有效的方式。当然,效果具体如何还是看群主和群成员的情况。每个人的时间和精力都是宝贵的,同时在群内做好最有效利用的服务。
对于在线问答平台都已经很成熟了,我这个只是边经营边摸索。其实跟地摊打薄利多销差不多。具体方式想必你就知道了。
文章采集调用( 《Python爬虫大数据采集与挖掘》课程:日期:2019年10月10日 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-02 18:13
《Python爬虫大数据采集与挖掘》课程:日期:2019年10月10日
)
《Python爬虫大数据采集与挖掘》
教学大纲
部门:日期:2019年10月10日
科目编号
课程名称
Python爬虫大数据采集与挖掘
学分
2
周学士
2
教学语言
中国人
课程性质
√核心课程√通识教育选修□基础知识√必修专业√专业选修□其他
教学目标
本课程主要面向大数据技术与应用、数据科学、计算机与电子信息等二年级及以上本科生,主要讲解互联网大数据采集技术及各种典型爬虫技术,结合相关开源包使用Python进行实现,加深学生对所学知识的理解。通过本课程的教学,学生将对互联网大数据采集技术有全面的了解,掌握采集的基本信息内容、提取和分析方法,并对采集具有一定的实用性需求的应用和解决。
基本内容介绍
互联网大数据采集技术及实现概述;Web服务器应用架构及HTTP、Robots、HTML、页面编码等相关协议和规范;常用网络爬虫技术、动态页面采集方法、主题爬虫技术、Deep Web爬虫、微博信息采集、Web信息提取与反爬虫技术等;爬虫应用中典型的大数据处理和挖掘技术;综合利用各种爬虫和处理技术为新闻阅读器进行分析和设计;了解爬虫用于SQL注入安全检测的方法。
基本要求:
要求了解互联网大数据的技术体系和主要技术采集;掌握各种典型爬虫的技术原理、技术框架、实现方法、主要开源包的使用;了解爬虫采集到达的网页数据处理方法、文本处理和相关挖掘方法将在技术上使用Python实现。
教学方式:
本课程以讲授为主。在本课程的教学过程中,将采用课堂讲解和课堂讨论的方式,为学生提供互动交流。同时,根据教学进度,设置多项配套实验。
课内外讨论或练习、练习、体验等设计:
课后,您需要认真完成分配的作业,以了解和巩固所学知识。
评价与评价方式(提供学生课程最终成绩的分数构成,反映形成性评价过程):
考核内容包括平时成绩(出勤、项目、实验)和期末考试成绩,分别占课程总成绩的35%和65%。最终评估形式为闭卷考试。
《Python爬虫大数据采集与挖掘》
教学安排
(建议)
教学内容安排(按32学时共16周,具体以每节课内容为准):
第一周:
第一课:互联网大数据采集概念、重要性、应用现状等;第二课:互联网大数据采集技术体系、法律技术边界、技术前景。
第二周:
第一课:HTML语言规范;第二课:网页编码、正则表达式。
第三周:
第 1 课:Web 服务器、应用程序架构、机器人;第 2 课:HTTP 协议,状态保持技术。
第四周:
第一课:常见爬虫系统、请求;第 2 课:异常处理、链接提取
第五周:
第一课:爬取策略与实现,PR算法;第 2 课:动态页面和 采集 技术
第 6 周:
第 1 课:动态页面、Ajax、Cookie;第 2 课:模拟浏览器技术
第七周:
第1课:静态页面实验采集;第 2 课:动态页面实验 采集
第 8 周:
第1课:网页提取技术及思路介绍;第 2 课:基于结构的提取方法,主要开源包。
第九周:
第一课:话题爬虫与技术框架、话题表征;第二课:主题表示、相关性计算、实例。
第 10 周:
第一课:Web信息抽取实验;第二课:主题爬虫实验。
第 11 周:
第1课:DeepWeb概念、特点和要求、技术架构;第 2 课:技术架构和实现示例。
第十二周:
第一课:微博采集方法概述、平台授权、API介绍;第二课:Python调用API采集,爬取方法采集。
第 13 周:
第1课:反爬虫概述、反爬虫技术、反爬虫技术;第 2 课:文本分析和预处理概述。
第十四周:
第一课:向量空间与文本分类;第二课:主题建模、可视化技术。
第十五周:
第一课:常见应用模式、新闻阅读器;第二课:新闻阅读器,SQL注入检测。
第 16 周:
综合实验、复习、考试
提供300分钟视频讲解、教学大纲、课件、教案、习题答案、程序源代码等配套资源。
预订视频演示
查看全部
文章采集调用(
《Python爬虫大数据采集与挖掘》课程:日期:2019年10月10日
)
《Python爬虫大数据采集与挖掘》
教学大纲
部门:日期:2019年10月10日
科目编号
课程名称
Python爬虫大数据采集与挖掘
学分
2
周学士
2
教学语言
中国人
课程性质
√核心课程√通识教育选修□基础知识√必修专业√专业选修□其他
教学目标
本课程主要面向大数据技术与应用、数据科学、计算机与电子信息等二年级及以上本科生,主要讲解互联网大数据采集技术及各种典型爬虫技术,结合相关开源包使用Python进行实现,加深学生对所学知识的理解。通过本课程的教学,学生将对互联网大数据采集技术有全面的了解,掌握采集的基本信息内容、提取和分析方法,并对采集具有一定的实用性需求的应用和解决。
基本内容介绍
互联网大数据采集技术及实现概述;Web服务器应用架构及HTTP、Robots、HTML、页面编码等相关协议和规范;常用网络爬虫技术、动态页面采集方法、主题爬虫技术、Deep Web爬虫、微博信息采集、Web信息提取与反爬虫技术等;爬虫应用中典型的大数据处理和挖掘技术;综合利用各种爬虫和处理技术为新闻阅读器进行分析和设计;了解爬虫用于SQL注入安全检测的方法。
基本要求:
要求了解互联网大数据的技术体系和主要技术采集;掌握各种典型爬虫的技术原理、技术框架、实现方法、主要开源包的使用;了解爬虫采集到达的网页数据处理方法、文本处理和相关挖掘方法将在技术上使用Python实现。
教学方式:
本课程以讲授为主。在本课程的教学过程中,将采用课堂讲解和课堂讨论的方式,为学生提供互动交流。同时,根据教学进度,设置多项配套实验。
课内外讨论或练习、练习、体验等设计:
课后,您需要认真完成分配的作业,以了解和巩固所学知识。
评价与评价方式(提供学生课程最终成绩的分数构成,反映形成性评价过程):
考核内容包括平时成绩(出勤、项目、实验)和期末考试成绩,分别占课程总成绩的35%和65%。最终评估形式为闭卷考试。
《Python爬虫大数据采集与挖掘》
教学安排
(建议)
教学内容安排(按32学时共16周,具体以每节课内容为准):
第一周:
第一课:互联网大数据采集概念、重要性、应用现状等;第二课:互联网大数据采集技术体系、法律技术边界、技术前景。
第二周:
第一课:HTML语言规范;第二课:网页编码、正则表达式。
第三周:
第 1 课:Web 服务器、应用程序架构、机器人;第 2 课:HTTP 协议,状态保持技术。
第四周:
第一课:常见爬虫系统、请求;第 2 课:异常处理、链接提取
第五周:
第一课:爬取策略与实现,PR算法;第 2 课:动态页面和 采集 技术
第 6 周:
第 1 课:动态页面、Ajax、Cookie;第 2 课:模拟浏览器技术
第七周:
第1课:静态页面实验采集;第 2 课:动态页面实验 采集
第 8 周:
第1课:网页提取技术及思路介绍;第 2 课:基于结构的提取方法,主要开源包。
第九周:
第一课:话题爬虫与技术框架、话题表征;第二课:主题表示、相关性计算、实例。
第 10 周:
第一课:Web信息抽取实验;第二课:主题爬虫实验。
第 11 周:
第1课:DeepWeb概念、特点和要求、技术架构;第 2 课:技术架构和实现示例。
第十二周:
第一课:微博采集方法概述、平台授权、API介绍;第二课:Python调用API采集,爬取方法采集。
第 13 周:
第1课:反爬虫概述、反爬虫技术、反爬虫技术;第 2 课:文本分析和预处理概述。
第十四周:
第一课:向量空间与文本分类;第二课:主题建模、可视化技术。
第十五周:
第一课:常见应用模式、新闻阅读器;第二课:新闻阅读器,SQL注入检测。
第 16 周:
综合实验、复习、考试
提供300分钟视频讲解、教学大纲、课件、教案、习题答案、程序源代码等配套资源。
预订视频演示
文章采集调用( “如何做好文章内容页面SEO优化”?营销型网站建设)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-01 21:17
“如何做好文章内容页面SEO优化”?营销型网站建设)
《如何做文章内容页SEO优化》?营销型网站建设完成后也需要做SEO优化。在网络营销的过程中,不仅要优化网站首页,网站列表也要优化,网站详情页也要优化。营销类网站内容页面和文章页面也需要优化。
内容页面建设的不良状态:在文章页面内容的创建中,经常使用的两种方法是采集和伪原创,这两种方法都是投机取巧的省时行为,但是时间长-term 归结为网站,无异于饮毒解渴。
我们创建了网站 并吸引客户浏览。我们的目的是为客户提供可以创造价值的内容。如果存在大量的采集内容,而所有的网站都是一样的,你很难在成千上万的网站中脱颖而出。如果是伪原创,尤其是软件实现的伪原创,由于同义词替换、格式打乱等行为,呈现的内容会很别扭和错误,更别提不值得浏览了了。
内容页是优化关键词的好方法之一。因为可以添加很多锚文本,所以被很多人广泛使用,也是制作长尾词的好方法。这里要提醒的是,关键词要自然而广泛,不是所有的锚链接都可以一样,容易导致过度优化,最好使用不同的关键词 , 并指向不同的相关页面,并进行长尾相关词的优化。
1)很多网站大部分流量来自文章页面。标题、描述和关键词 必须收录用户搜索的关键词 或短语。
关键词 密度是指搜索关键词的频率。举个例子:在一段文章200个文本中,你关键词出现的字数是20除以总字数,也就是说关键词的密度是10 %。在不影响用户体验的前提下,关键词的密度不是越高越好。关键词 的密度一定要合理。文章页面关键词 2-8%的密度更自然。
用户看到文章一般需要浏览几篇文章,才能找到自己想要的详细答案。因此,推荐相关的文章可以降低网页的跳出率。
我们也需要适当的引导客户,更多的热点文章,符合大众口味,热点文章一般都是用户查看相关信息后对其他新闻感兴趣,这也是方式之一以降低网页的跳出率。种方法。
5)文章页面也可以使用随机调用,让每篇文章文章都有机会展示,不一定是最新发布的文章。
一个网站随机调用页面(此功能需要程序员提供),随机显示文章,搜索引擎蜘蛛在爬取网站的过程中每次都能找到不同的东西,你可以知道这个页面不是一成不变的,会定期更新。页面更新的频率应该是固定的。这样可以吸引更多的蜘蛛来爬我们的网站。提供企业网站的收录数量,从而为企业带来更多的免费流量。 查看全部
文章采集调用(
“如何做好文章内容页面SEO优化”?营销型网站建设)
《如何做文章内容页SEO优化》?营销型网站建设完成后也需要做SEO优化。在网络营销的过程中,不仅要优化网站首页,网站列表也要优化,网站详情页也要优化。营销类网站内容页面和文章页面也需要优化。
内容页面建设的不良状态:在文章页面内容的创建中,经常使用的两种方法是采集和伪原创,这两种方法都是投机取巧的省时行为,但是时间长-term 归结为网站,无异于饮毒解渴。
我们创建了网站 并吸引客户浏览。我们的目的是为客户提供可以创造价值的内容。如果存在大量的采集内容,而所有的网站都是一样的,你很难在成千上万的网站中脱颖而出。如果是伪原创,尤其是软件实现的伪原创,由于同义词替换、格式打乱等行为,呈现的内容会很别扭和错误,更别提不值得浏览了了。
内容页是优化关键词的好方法之一。因为可以添加很多锚文本,所以被很多人广泛使用,也是制作长尾词的好方法。这里要提醒的是,关键词要自然而广泛,不是所有的锚链接都可以一样,容易导致过度优化,最好使用不同的关键词 , 并指向不同的相关页面,并进行长尾相关词的优化。
1)很多网站大部分流量来自文章页面。标题、描述和关键词 必须收录用户搜索的关键词 或短语。
关键词 密度是指搜索关键词的频率。举个例子:在一段文章200个文本中,你关键词出现的字数是20除以总字数,也就是说关键词的密度是10 %。在不影响用户体验的前提下,关键词的密度不是越高越好。关键词 的密度一定要合理。文章页面关键词 2-8%的密度更自然。
用户看到文章一般需要浏览几篇文章,才能找到自己想要的详细答案。因此,推荐相关的文章可以降低网页的跳出率。
我们也需要适当的引导客户,更多的热点文章,符合大众口味,热点文章一般都是用户查看相关信息后对其他新闻感兴趣,这也是方式之一以降低网页的跳出率。种方法。
5)文章页面也可以使用随机调用,让每篇文章文章都有机会展示,不一定是最新发布的文章。
一个网站随机调用页面(此功能需要程序员提供),随机显示文章,搜索引擎蜘蛛在爬取网站的过程中每次都能找到不同的东西,你可以知道这个页面不是一成不变的,会定期更新。页面更新的频率应该是固定的。这样可以吸引更多的蜘蛛来爬我们的网站。提供企业网站的收录数量,从而为企业带来更多的免费流量。
文章采集调用(文章采集调用率不高,你的测试数据越准确)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-01 16:05
文章采集调用率不高,调用力度越小,你的测试数据越准确。因此我们增加了对标注的支持。readmore(r)[1]里面的方法是使用正则表达式,标注了不同文档正则。另外,测试用例中path部分(y':[1])也可以是正则表达式,准确定位到你输入的文件夹。-file-to-files/filesempty:[1]atext-editorshouldbeconsideredincorrectwhenlookingintoafile.consider'[2]andimport'y'fromms-file-to-filesreadmore[3]consider''tocreate''inputchangesandnewfileofinputcorrectly.。
在node.js内部有一个机制叫做directorypath,它根据你指定的文件夹名、每个文件夹中的文件的个数来决定哪些文件需要从此文件夹中读取,哪些文件需要从其他文件夹中读取。在用readline()方法从文件里面读取数据的时候,是根据第一个文件和最后一个文件的路径判断。所以,你代码里面的y':[1]你必须通过readline()的方法写成,否则你的测试不可用。至于response':[1]就没问题了。
我认为path.response[3]应该是指向一个index.html文件然后read().response()。这样对于测试用例的准确性来说应该会比较有保证。 查看全部
文章采集调用(文章采集调用率不高,你的测试数据越准确)
文章采集调用率不高,调用力度越小,你的测试数据越准确。因此我们增加了对标注的支持。readmore(r)[1]里面的方法是使用正则表达式,标注了不同文档正则。另外,测试用例中path部分(y':[1])也可以是正则表达式,准确定位到你输入的文件夹。-file-to-files/filesempty:[1]atext-editorshouldbeconsideredincorrectwhenlookingintoafile.consider'[2]andimport'y'fromms-file-to-filesreadmore[3]consider''tocreate''inputchangesandnewfileofinputcorrectly.。
在node.js内部有一个机制叫做directorypath,它根据你指定的文件夹名、每个文件夹中的文件的个数来决定哪些文件需要从此文件夹中读取,哪些文件需要从其他文件夹中读取。在用readline()方法从文件里面读取数据的时候,是根据第一个文件和最后一个文件的路径判断。所以,你代码里面的y':[1]你必须通过readline()的方法写成,否则你的测试不可用。至于response':[1]就没问题了。
我认为path.response[3]应该是指向一个index.html文件然后read().response()。这样对于测试用例的准确性来说应该会比较有保证。
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-11-29 23:09
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的,Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那我们在java项目中如何控制摄像头抓拍呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。在web程序中可以使用camera来控制camera,可以通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,并收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
查看全部
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集?
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的,Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那我们在java项目中如何控制摄像头抓拍呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。在web程序中可以使用camera来控制camera,可以通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,并收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-11-29 23:08
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的,Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那我们在java项目中如何控制摄像头抓拍呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。在web程序中可以使用camera来控制camera,可以通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,并收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
查看全部
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集?
)
最近的一个项目需要实现摄像头图像采集。经过一系列的折腾,终于实现了这个功能。现在我来整理一下。
就java技术而言,实现摄像头二次开发,采集摄像头图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然JMF是做不到的。现在,我想写一个小程序程序,但是那件事需要客户端有一个jre环境。这不适合我。你不能指望用户在访问你的 网站 时下载一个大的,Jre 会安装并稍后再次访问,对吧?
既然JMF不适用,那我们在java项目中如何控制摄像头抓拍呢?在windows平台本身,我们可以使用显卡等二次开发包来实现视频数据的访问,但是现在摄像头都是usb,连笔记本屏幕都有摄像头了。在这种情况下,使用采集卡的二次开发包的方案是不适用的。您只能编写自己的程序来制作类似于“相机相机软件”的东西。经过一系列的分析,终于实现了。在web程序中可以使用camera来控制camera,可以通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集camera data项目中实现,例如,
罗嗦了很多,程序放在csdn的下载资源上面,以后想做摄像头二次开发的时候不用四处看看,直接下载使用就可以了.
摄像头程序下载地址
压缩包中收录一个基于web的相机拍照采集示例程序,并收录一个基于jquery框架的ajax数据操作程序示例。摄像头的调用方法详见示例代码。我相信任何对技术稍有了解的人都应该能够阅读它。明白了,有一个完整的基于java的photo 采集示例程序,使用jsp页面采集 photo,serlvet程序接收相机照片数据。
以下是程序运行效果示例:
文章采集调用(频道总排行调用方法频道月排行(全站所有文章排行))
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-26 16:16
如何调用频道总排名
频道总排行
{pc:get sql="select a.id,a.title,a.url,a.catid,b.hitsid,b.views from v9_news a left join v9_hits b on a.id=substring(b.hitsid,5) where a.catid in ($arrchildid) order by b.views desc" num="10" cache="3600"}
{loop $data $r}
{str_cut($r[title],36,'...')}</a>
{/loop}
{/pc}
如何调用频道月度排名
频道总排行
{pc:get sql="select a.id,a.title,a.url,a.catid,b.hitsid,b.views from v9_news a left join v9_hits b on a.id=substring(b.hitsid,5) where a.catid in ($arrchildid) order by b.views desc" num="10" cache="3600"}
{loop $data $r}
{str_cut($r[title],36,'...')}</a>
{/loop}
{/pc}
调用全站所有文章排名方法:
{pc:get sql="SELECT a.id,a.url,a.thumb,a.status,b.hitsid,b.views FROM v9_download a, v9_hits b WHERE a.status=99 and a.id=substring(b.hitsid,5) ORDER BY b.views DESC" num="6"}
{loop $data $r}
</a>
{/loop}
{/pc}
可以看到"substring(b.hitsid,5)"是截取的hitsid字段,从左到右算第5个字符串,即"c-2-5"从左到右算, 1个“C”, 1个“2”, 2个“-”,第5个字符是“5”,截取后只剩下第二个“-”后的id,达到了提取id的最终目的。 ,我还加了一个条件“status=99”,表示文章已经通过,这个是可选的。 查看全部
文章采集调用(频道总排行调用方法频道月排行(全站所有文章排行))
如何调用频道总排名
频道总排行
{pc:get sql="select a.id,a.title,a.url,a.catid,b.hitsid,b.views from v9_news a left join v9_hits b on a.id=substring(b.hitsid,5) where a.catid in ($arrchildid) order by b.views desc" num="10" cache="3600"}
{loop $data $r}
{str_cut($r[title],36,'...')}</a>
{/loop}
{/pc}
如何调用频道月度排名
频道总排行
{pc:get sql="select a.id,a.title,a.url,a.catid,b.hitsid,b.views from v9_news a left join v9_hits b on a.id=substring(b.hitsid,5) where a.catid in ($arrchildid) order by b.views desc" num="10" cache="3600"}
{loop $data $r}
{str_cut($r[title],36,'...')}</a>
{/loop}
{/pc}
调用全站所有文章排名方法:
{pc:get sql="SELECT a.id,a.url,a.thumb,a.status,b.hitsid,b.views FROM v9_download a, v9_hits b WHERE a.status=99 and a.id=substring(b.hitsid,5) ORDER BY b.views DESC" num="6"}
{loop $data $r}
</a>
{/loop}
{/pc}
可以看到"substring(b.hitsid,5)"是截取的hitsid字段,从左到右算第5个字符串,即"c-2-5"从左到右算, 1个“C”, 1个“2”, 2个“-”,第5个字符是“5”,截取后只剩下第二个“-”后的id,达到了提取id的最终目的。 ,我还加了一个条件“status=99”,表示文章已经通过,这个是可选的。
文章采集调用(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-26 11:17
采集微信文章与采集网站的内容相同,都需要以列表页开头。而微信文章的列表页是公众号中的浏览历史信息页。网上其他一些微信采集器现在都用搜狗搜索了。采集的方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史页面采集来。
由于微信的限制,我们可以复制到的链接不完整,无法在浏览器中打开内容。因此,我们需要使用anyproxy,通过上一篇文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章提到,biz参数是公众号ID,uin是用户ID。目前,uin是所有公众号中唯一的一个。另外两个重要参数key和pass_ticket由微信客户端补充。
因此,在该地址失效之前,我们可以通过浏览器查看原文获取文章历史消息列表。如果我们想自动分析内容,我们也可以做一个程序,里面会有key和没有过期的key。提交pass_ticket的链接地址,然后通过php程序获取文章列表。
最近有朋友跟我说他的采集目标是单个公众号,我觉得用上一篇文章写的批量采集的方法没必要。那么我们来看看如何在历史新闻页面中获取文章列表。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就好了。
如果在anyproxy web界面正确配置了证书,可以显示https的内容。web界面的地址是localhost:8002,其中localhost可以替换为自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击它,右边会显示这条记录的详细信息:
红框是完整的链接地址。将微信公众平台的域名拼接到前面后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章的历史消息列表:
我们复制msgList的变量值,用json格式化工具分析,可以看到json的结构如下:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍了一些重要的信息,其他的就省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要说的一点是,如果想要获取更长的历史消息内容,需要在手机或者模拟器中下拉页面。当它到达底部时,微信会自动阅读下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就可以了。
这时候就可以使用上一篇文章介绍的方法,使用anyproxy来匹配msgList变量值并异步提交到服务器,然后使用php的json_decode从json解析成数组服务器。然后遍历循环数组。我们可以得到每篇文章的标题和链接地址文章。
如果您只需要单个公众号的内容,每天群发后可以通过anyproxy获取带key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给你的程序。使用php等语言定时匹配msgList,然后解析json。这样就不需要修改anyproxy规则,也不需要制作采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章的列表。在下一篇文章中,我将介绍如何获取历史新闻中的文章链接地址。>具体内容的方法。还有一些关于如何保存文章、封面图片、全文检索的经验。
如果你觉得我写的不是很清楚,或者有什么不明白的地方,请在下面留言。或者骚扰微信公众号cuijin,心情好就点个赞。
持续更新,微信公众号文章批量采集系统建设
微信公众号入口文章采集--历史新闻页面详解
微信公众号文章页面分析及采集
提高微信公众号文章采集的使用效率,anyproxy的高级使用 查看全部
文章采集调用(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集微信文章与采集网站的内容相同,都需要以列表页开头。而微信文章的列表页是公众号中的浏览历史信息页。网上其他一些微信采集器现在都用搜狗搜索了。采集的方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史页面采集来。
由于微信的限制,我们可以复制到的链接不完整,无法在浏览器中打开内容。因此,我们需要使用anyproxy,通过上一篇文章介绍的方法,获取一个完整的微信公众号历史消息页面的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章提到,biz参数是公众号ID,uin是用户ID。目前,uin是所有公众号中唯一的一个。另外两个重要参数key和pass_ticket由微信客户端补充。
因此,在该地址失效之前,我们可以通过浏览器查看原文获取文章历史消息列表。如果我们想自动分析内容,我们也可以做一个程序,里面会有key和没有过期的key。提交pass_ticket的链接地址,然后通过php程序获取文章列表。
最近有朋友跟我说他的采集目标是单个公众号,我觉得用上一篇文章写的批量采集的方法没必要。那么我们来看看如何在历史新闻页面中获取文章列表。通过分析文章列表,我们可以得到这个公众号的所有内容链接地址,然后采集内容就好了。
如果在anyproxy web界面正确配置了证书,可以显示https的内容。web界面的地址是localhost:8002,其中localhost可以替换为自己的IP地址或域名。从列表中找到getmasssendmsg开头的记录,点击它,右边会显示这条记录的详细信息:
红框是完整的链接地址。将微信公众平台的域名拼接到前面后,就可以在浏览器中打开了。
然后将页面下拉到html内容的最后,我们可以看到一个json变量就是文章的历史消息列表:
我们复制msgList的变量值,用json格式化工具分析,可以看到json的结构如下:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
简单分析一下这个json(这里只介绍了一些重要的信息,其他的就省略了):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要说的一点是,如果想要获取更长的历史消息内容,需要在手机或者模拟器中下拉页面。当它到达底部时,微信会自动阅读下一页。内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就可以了。
这时候就可以使用上一篇文章介绍的方法,使用anyproxy来匹配msgList变量值并异步提交到服务器,然后使用php的json_decode从json解析成数组服务器。然后遍历循环数组。我们可以得到每篇文章的标题和链接地址文章。
如果您只需要单个公众号的内容,每天群发后可以通过anyproxy获取带key和pass_ticket的完整链接地址。然后自己做一个程序,手动提交地址给你的程序。使用php等语言定时匹配msgList,然后解析json。这样就不需要修改anyproxy规则,也不需要制作采集队列和跳转页面。
现在我们可以通过公众号的历史消息获取文章的列表。在下一篇文章中,我将介绍如何获取历史新闻中的文章链接地址。>具体内容的方法。还有一些关于如何保存文章、封面图片、全文检索的经验。
如果你觉得我写的不是很清楚,或者有什么不明白的地方,请在下面留言。或者骚扰微信公众号cuijin,心情好就点个赞。
持续更新,微信公众号文章批量采集系统建设
微信公众号入口文章采集--历史新闻页面详解
微信公众号文章页面分析及采集
提高微信公众号文章采集的使用效率,anyproxy的高级使用

