
文章采集调用
文章采集调用(数据具体的采集方案是什么?四种数据采集方法对比 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-02 08:11
)
根据企业在生产经营过程中会产生的数据类型,提供链接标签、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?
四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务端埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击,更好的了解自己产品的特点。
缺点:采集的数据太多,只要是可点击的元素就会是采集,上传数据很多,消耗流量也很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入基于完全嵌入。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:对自定义属性的支持范围有限;重构或页面更改时需要重新配置。
4.服务器埋点
描述:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。
查看全部
文章采集调用(数据具体的采集方案是什么?四种数据采集方法对比
)
根据企业在生产经营过程中会产生的数据类型,提供链接标签、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?

四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务端埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击,更好的了解自己产品的特点。
缺点:采集的数据太多,只要是可点击的元素就会是采集,上传数据很多,消耗流量也很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入基于完全嵌入。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:对自定义属性的支持范围有限;重构或页面更改时需要重新配置。
4.服务器埋点
描述:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。

文章采集调用(利用白帽SEO优化方法快速提升网站权重值的方法有哪些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-01 19:02
文章采集,使得网站有内容,只有有内容才有可能被收录推广,只有收录才能推广能不能提高网站权重。 网站权重是对网站综合价值的总称,包括网站运营能力、用户体验、内容质量、用户热度、SEO指标。综合性能统一名称。
文章采集如何增加网站的权重:日常正规管理和运营网站,使用正规白帽方法来操作网站,比如比如更新内容、检查维护等等,这些都是站长必须要做的事情。挖矿优化精准关键词,根据自己的网站行业,挖矿优化精准网站关键词,必须有流量关键词,如果挖矿关键词@ >与网站的主题定位无关,那么网站的权重就很难增加,甚至网站都会被搜索引擎惩罚。
文章采集改进网站和收录的内容,网站收录索引数据和网站的数量内容更新是成比例的关系,如果你长时间不更新网站,那么你的网站索引数据不仅会增加还会减少。如果你想改进网站网站@收录的内容,那么你需要不断更新网站的优质内容。
同时,站内和站外的SEO也需要做好。除了文章采集还要更新内容,内链优化,网站结构优化,404、网站Sitemap地图和机器人都属于到现场搜索引擎优化的类别。如果你不做好站内优化,你的外链再好也没用,因为你的网站留不住用户,所以站内优化大于站外-网站优化,而外部链接的作用近年来逐渐减弱。如果想通过累计外链数量来增加网站的权重,目前可能很难实现。 .
使用白帽SEO形式优化,为什么一定要使用白帽SEO优化网站?因为有的站长想用黑帽SEO优化方法来快速提升网站的权重值,如果使用这些黑帽SEO,一旦被搜索引擎发现,就等待网站的结果只能被处罚或K站。搜索引擎支持用户使用正式的白帽SEO优化方式,因为这种优化方式可以持续为用户提供有价值的内容。
我们在优化网站的时候,建议不要用黑帽作弊的操作方法优化网站,因为到最后你很可能会花费时间和精力,但是网站 还不是很好的流程。
新站前期以文章采集和挖矿网站长尾关键词为主。长尾关键词不仅竞争程度低,而且排名时间长。短,优化长尾关键词可能只需要几个星期,最长不会超过一个月,新站没有优化基础,搜索引擎对新站信任度不高网站,我们通过优化文章采集和长尾关键词,可以实现更快的收录网站页面,更快的流量获取,然后继续积累,提升网站的流量和权重,最后争夺一些高指数高流量的关键词,新的网站倾向于前期做内容, 文章采集让新站点的内容快写完的时候,我们可以优化站点,交换一些优质的链接。
老站意味着已经有一定的流量基础,但是流量不是特别高。老的网站可以倾向于挖一些有一定索引的关键词,但是不建议选择索引太高的关键词,300到500的索引关键词是比较合适,通过索引关键词来带动全站流量的增加,老的网站权重的增加和高索引流量关键词有一定的关系流量词越多,网站的权重就越高,流量关键词的不断积累,搜索引擎对你网站的信任度会不断增加。老的网站倾向于后期做流量。返回搜狐,查看更多 查看全部
文章采集调用(利用白帽SEO优化方法快速提升网站权重值的方法有哪些)
文章采集,使得网站有内容,只有有内容才有可能被收录推广,只有收录才能推广能不能提高网站权重。 网站权重是对网站综合价值的总称,包括网站运营能力、用户体验、内容质量、用户热度、SEO指标。综合性能统一名称。
文章采集如何增加网站的权重:日常正规管理和运营网站,使用正规白帽方法来操作网站,比如比如更新内容、检查维护等等,这些都是站长必须要做的事情。挖矿优化精准关键词,根据自己的网站行业,挖矿优化精准网站关键词,必须有流量关键词,如果挖矿关键词@ >与网站的主题定位无关,那么网站的权重就很难增加,甚至网站都会被搜索引擎惩罚。
文章采集改进网站和收录的内容,网站收录索引数据和网站的数量内容更新是成比例的关系,如果你长时间不更新网站,那么你的网站索引数据不仅会增加还会减少。如果你想改进网站网站@收录的内容,那么你需要不断更新网站的优质内容。
同时,站内和站外的SEO也需要做好。除了文章采集还要更新内容,内链优化,网站结构优化,404、网站Sitemap地图和机器人都属于到现场搜索引擎优化的类别。如果你不做好站内优化,你的外链再好也没用,因为你的网站留不住用户,所以站内优化大于站外-网站优化,而外部链接的作用近年来逐渐减弱。如果想通过累计外链数量来增加网站的权重,目前可能很难实现。 .
使用白帽SEO形式优化,为什么一定要使用白帽SEO优化网站?因为有的站长想用黑帽SEO优化方法来快速提升网站的权重值,如果使用这些黑帽SEO,一旦被搜索引擎发现,就等待网站的结果只能被处罚或K站。搜索引擎支持用户使用正式的白帽SEO优化方式,因为这种优化方式可以持续为用户提供有价值的内容。
我们在优化网站的时候,建议不要用黑帽作弊的操作方法优化网站,因为到最后你很可能会花费时间和精力,但是网站 还不是很好的流程。
新站前期以文章采集和挖矿网站长尾关键词为主。长尾关键词不仅竞争程度低,而且排名时间长。短,优化长尾关键词可能只需要几个星期,最长不会超过一个月,新站没有优化基础,搜索引擎对新站信任度不高网站,我们通过优化文章采集和长尾关键词,可以实现更快的收录网站页面,更快的流量获取,然后继续积累,提升网站的流量和权重,最后争夺一些高指数高流量的关键词,新的网站倾向于前期做内容, 文章采集让新站点的内容快写完的时候,我们可以优化站点,交换一些优质的链接。

老站意味着已经有一定的流量基础,但是流量不是特别高。老的网站可以倾向于挖一些有一定索引的关键词,但是不建议选择索引太高的关键词,300到500的索引关键词是比较合适,通过索引关键词来带动全站流量的增加,老的网站权重的增加和高索引流量关键词有一定的关系流量词越多,网站的权重就越高,流量关键词的不断积累,搜索引擎对你网站的信任度会不断增加。老的网站倾向于后期做流量。返回搜狐,查看更多
文章采集调用(dedecms如何修改这一上限值)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-22 11:11
dedecmssystem文章调用描述最大字符数为250字节,文章summary(可以通过infolen或description相关标签调用)设置为最大250 个字符。上限的主要目的是减少数据库的冗余,保证网络的良好性能。所以,不给配置文件的内容设置一个上限显然是不合理的,但是如果可以自由控制这个上限,那么就会给网页内容的布局带来积极的影响。NET 源代码在网页设计过程中。dedecms 经常需要在频道列表页面调用文章 的摘要。如果文章的摘要中的字数可以得到有效控制,那么页面布局就可以变得非常灵活。
先说一下如何修改这个上限值,从而体现[field:description function="cn_substr(@me, number of characters)"/]的重要性。
在Dedecms系统中,与抽象文章相关的php文件如下:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面中,有一句:$description = cn_substrR($description, $cfg_auot_description); 这句话实现了[field:description function="cn_substr(@me, number of characters)"/]的功能。由于此声明确实有利于页面布局,因此我们正在尝试不做任何更改。
我在编辑页面,有一句话: $description = cn_substrR($description, 250); ,这句话显示了一个熟悉的字符数 250,也就是 文章 的摘要字符集系统个数的上限,如果是gbk编码,会显示125个字符,如果是utf-8编码,会是81个字符。显然,如果我们要打破抽象字符个数的上限,一定要搞定。是的,你可以在这里把250改成别的值,比如500。这里不建议设置太高。一个是不需要在列表页显示太多的内容(最好直接使用body来显示过多的内容),另一个是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在 article_description_main.php 页面上,找到 if($dsize>250) $dsize = 250; 语句,它限制了后台从摘要中提取的字符数。将此处的 250 更改为 500, 织梦 仿站的意思是和之前修改的字符数不同。(如果你确认你的每一个文章都是手动添加的,如果手动完成就不需要修改这个文件了抽象的采集。按照抽象 次要采集保留给大部分 文章 和 采集。)
最初登录后台,在系统-系统基本参数-其他选项中,后续摘要的长度可以改为500,即可以和之前修改的字符数不同。
完成以上修改后,我们进入频道列表页面,通过标签调用。示例标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[字段:描述函数='cn_substr(@me,500)'/]…
{/dede:列表}
通过以上方法,我们实现了被调用的文章摘要字符为500个字符,完全突破了文章摘要250个字符的系统限制,为网页布局提供了更广阔的空间。
先说一下常用的Dedecms文章或者列表页调用文章summary方法。
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是间接调用文章的抽象。关于被调用字数的问题,在使用[field:info /]时,可以调用{dede:arclist infolen=' ' }{/dede :arclist},设置调用摘要的字符数(最大可以设置为系统设置的250);如果使用[field:description/],则间接使用后台设置的抽象字符上限(后台也有上限250字符)字符)。显然这两种方法是被动的和灵活的。
3、的第四种方法通过function函数实现了对文章摘要中显示字符的灵活调整。当然,当文章的抽象内容中的字符上限没有正常修改的情况下,这四种方式的区别并不大。
============================
1:[字段:信息/]
2:[字段:描述/]
3:[field:info function="cn_substr(@me, 字符数)"/]
4:[field:description function="cn_substr(@me, 字符数)"/]
这四种方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到“if ($dsize>250) $dsize = 250;”语句,将250改为500
2.登录后台,在System-System Basic Parameters-Other Options中,将自动汇总长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar ( 1000 )
调用标签{dede:field.description function='cn_substr(@me,500)'/}.可以显示500个字符 查看全部
文章采集调用(dedecms如何修改这一上限值)
dedecmssystem文章调用描述最大字符数为250字节,文章summary(可以通过infolen或description相关标签调用)设置为最大250 个字符。上限的主要目的是减少数据库的冗余,保证网络的良好性能。所以,不给配置文件的内容设置一个上限显然是不合理的,但是如果可以自由控制这个上限,那么就会给网页内容的布局带来积极的影响。NET 源代码在网页设计过程中。dedecms 经常需要在频道列表页面调用文章 的摘要。如果文章的摘要中的字数可以得到有效控制,那么页面布局就可以变得非常灵活。
先说一下如何修改这个上限值,从而体现[field:description function="cn_substr(@me, number of characters)"/]的重要性。
在Dedecms系统中,与抽象文章相关的php文件如下:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面中,有一句:$description = cn_substrR($description, $cfg_auot_description); 这句话实现了[field:description function="cn_substr(@me, number of characters)"/]的功能。由于此声明确实有利于页面布局,因此我们正在尝试不做任何更改。
我在编辑页面,有一句话: $description = cn_substrR($description, 250); ,这句话显示了一个熟悉的字符数 250,也就是 文章 的摘要字符集系统个数的上限,如果是gbk编码,会显示125个字符,如果是utf-8编码,会是81个字符。显然,如果我们要打破抽象字符个数的上限,一定要搞定。是的,你可以在这里把250改成别的值,比如500。这里不建议设置太高。一个是不需要在列表页显示太多的内容(最好直接使用body来显示过多的内容),另一个是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在 article_description_main.php 页面上,找到 if($dsize>250) $dsize = 250; 语句,它限制了后台从摘要中提取的字符数。将此处的 250 更改为 500, 织梦 仿站的意思是和之前修改的字符数不同。(如果你确认你的每一个文章都是手动添加的,如果手动完成就不需要修改这个文件了抽象的采集。按照抽象 次要采集保留给大部分 文章 和 采集。)
最初登录后台,在系统-系统基本参数-其他选项中,后续摘要的长度可以改为500,即可以和之前修改的字符数不同。
完成以上修改后,我们进入频道列表页面,通过标签调用。示例标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[字段:描述函数='cn_substr(@me,500)'/]…
{/dede:列表}
通过以上方法,我们实现了被调用的文章摘要字符为500个字符,完全突破了文章摘要250个字符的系统限制,为网页布局提供了更广阔的空间。
先说一下常用的Dedecms文章或者列表页调用文章summary方法。
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是间接调用文章的抽象。关于被调用字数的问题,在使用[field:info /]时,可以调用{dede:arclist infolen=' ' }{/dede :arclist},设置调用摘要的字符数(最大可以设置为系统设置的250);如果使用[field:description/],则间接使用后台设置的抽象字符上限(后台也有上限250字符)字符)。显然这两种方法是被动的和灵活的。
3、的第四种方法通过function函数实现了对文章摘要中显示字符的灵活调整。当然,当文章的抽象内容中的字符上限没有正常修改的情况下,这四种方式的区别并不大。
============================
1:[字段:信息/]
2:[字段:描述/]
3:[field:info function="cn_substr(@me, 字符数)"/]
4:[field:description function="cn_substr(@me, 字符数)"/]
这四种方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到“if ($dsize>250) $dsize = 250;”语句,将250改为500
2.登录后台,在System-System Basic Parameters-Other Options中,将自动汇总长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar ( 1000 )
调用标签{dede:field.description function='cn_substr(@me,500)'/}.可以显示500个字符
文章采集调用(用python+selenuim自动框架来爬取京东商品信息(不要))
采集交流 • 优采云 发表了文章 • 0 个评论 • 426 次浏览 • 2022-02-21 23:28
今天我们使用python+ selenium 自动框架爬取京东商品信息(不要再问我为什么是京东了,因为京东不用登录也可以搜索商品),Selenium是用来模仿人类操作的,免费的手,生产力提升,哈哈,这里是对selenuim的一点介绍。
硒简介
Selenium 是一个 Web 应用程序测试工具,Selenium 测试直接在浏览器中运行,就像真正的用户一样。一般的爬虫方法是使用python脚本直接访问目标网站,并且只对目标数据执行采集,访问速度非常快,这样目标网站就可以轻松识别您这是机器人,它阻止了您。使用selenium写爬虫,python脚本控制浏览器进行访问,也就是说python脚本和目标网站之间多了一个浏览器操作,这个行为更像是人的行为,这么多难以爬取网站你也可以轻松抓取数据。
准备
首先安装selenuim,方法和其他第三方库的安装方法一样,使用pip命令
点安装硒
安装 selenuim 后,您必须安装驱动程序才能使其正常工作。因为我使用的是 Google Chrome,所以我下载了 Google Drive,当然还有 Firefox。下载对应浏览器版本的驱动(如果没有对应版本,也可以下载接近的版本)。以下是两款驱动的下载地址:
- 谷歌云端硬盘:(点击下载)
- 火狐驱动:(点击下载)
下载完成后,驱动就安装好了。Firefox驱动的安装方法与Chrome驱动相同。把下载好的驱动放到你的python安装路径下的Script目录下即可(放到Script文件夹下即可,无需配置环境变量)
至此,selenuim的相关安装就完成了,接下来开始我们今天的任务。
1.导入相关依赖
import time
import json
from pyquery import PyQuery as pq
#pyquery是个解析库
from selenium import webdriver
#导入驱动webdriver
from selenium.webdriver.common.by import By
#By是selenium中内置的一个class,在这个class中有各种方法来定位元素
from selenium.webdriver.support.ui import WebDriverWait
#设置浏览器驱动休眠等待,避免频繁操作封ip
from selenium.webdriver.support import expected_conditions as EC
#判断一个元素是否存在,是否加载完毕等一系列的场景判断方法
二、使用selenium EC操作浏览器
首先,用Chrome浏览器打开产品首页。我们很容易发现该网页是一个动态加载的网页。首次打开网页时,仅显示 30 种产品的信息。只有当网页被向下拖动时,它才会加载其余部分。30 项信息。这里我们可以使用selenium模拟浏览器拉下网页,判断网页元素是否通过EC加载,从而获取所有产品网站的信息。
def search():
browser.get('https://www.jd.com/')
try:
input = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key"))
) # 等待搜索框加载出来
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button"))
) # 等待搜索按钮可以被点击
input[0].send_keys(keyword) # 向搜索框内输入关键词
submit.click() # 点击搜索
time.sleep(2) # 加入时间间隔,速度太快可能会抓不到数据
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 下拉到网页底部
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
) # 等待最后一个商品信息加载完毕
html = browser.page_source
except TimeoutError:
search()
三、使用selenium EC实现翻页操作
与第一页类似,它也使用EC来判断页面元素是否加载,并添加延迟以防止数据被抓到。
def next_page(page_number):
try:
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em'))
) # 等待翻页按钮可以点击
button.click() # 点击翻页按钮
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(30)"))
) # 等到30个商品都加载出来
time.sleep(2)
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
wait.until(# 等到60个商品都加载出来
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
)
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
return next_page(page_number)
四、提取数据并保存
这里使用pyquery库解析网页源代码,使用CSS_SELECTOR选择元素。一定要找到参考元素。例如,将鼠标放在搜索框中,右键查看,然后跳转到搜索框中对应的代码处。右键点击它,点击Copy > Copy selector,我们得到我们需要的#key,然后通过.text()获取内容,最后将python对象转换成json数据写入json文件。
def find_save(html):
doc = pq(html)
items = doc('#J_goodsList > ul > li').items()
for item in items:
product = {
'name': item('.p-name a').text(),
'price': item('.p-price i').text(),
'commit': item('.p-commit a').text()
}
data_list.append(product) # 写入全局变量
# 把全局变量转化为json数据
content = json.dumps(data_list, ensure_ascii=False, indent=2)
with open("E:\python\project\selenium\info.json", "w", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功")
五、编写和调用main函数
使用for循环控制爬取的页面数并添加延迟
def main():
print("第", 1, "页:")
search()
for i in range(2, 6): # 爬取2-5页
time.sleep(2) # 设置延迟
print("第", i, "页:")
next_page(i)
if __name__ == "__main__":
main()
补充:
为了提高爬虫的效率,可以将浏览器设置为无图片模式,即不加载图片,这样可以提高采集的速度
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs'{'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
看看结果:
附上完整代码:
import time
import json
from pyquery import PyQuery as pq
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
# 不加载图片
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
wait = WebDriverWait(browser, 20) # 设置等待时间
data_list = [] # 设置全局变量用来存储数据
keyword = "平凡的世界" # 商品名称
def search():
browser.get('https://www.jd.com/')
try:
input = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key"))
) # 等待搜索框加载出来
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button"))
) # 等待搜索按钮可以被点击
input[0].send_keys(keyword) # 向搜索框内输入关键词
submit.click() # 点击搜索
time.sleep(2) # 加入时间间隔,速度太快可能会抓不到数据
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 滑动到底部
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
) # 等待最后一个商品信息加载完毕
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
search()
def next_page(page_number):
try:
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em'))
) # 等待翻页按钮可以点击
button.click() # 点击翻页按钮
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(30)"))
) # 等到30个商品都加载出来
time.sleep(2)
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
wait.until(# 等到60个商品都加载出来
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
)
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
return next_page(page_number)
def find_save(html):
doc = pq(html)
items = doc('#J_goodsList > ul > li').items()
# print(items)
for item in items:
product = {
'name': item('.p-name a').text(),
'price': item('.p-price i').text(),
'commit': item('.p-commit a').text()
}
data_list.append(product) # 写入全局变量
# 把全局变量转化为json数据
content = json.dumps(data_list, ensure_ascii=False, indent=2)
with open("E:\python\project\selenium\info.json", "w", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功")
def main():
print("第", 1, "页:")
search()
for i in range(2, 6): # 爬取2-5页
time.sleep(2) # 设置延迟
print("第", i, "页:")
next_page(i)
if __name__ == "__main__":
main()
如有错误,请私信指正,谢谢支持! 查看全部
文章采集调用(用python+selenuim自动框架来爬取京东商品信息(不要))
今天我们使用python+ selenium 自动框架爬取京东商品信息(不要再问我为什么是京东了,因为京东不用登录也可以搜索商品),Selenium是用来模仿人类操作的,免费的手,生产力提升,哈哈,这里是对selenuim的一点介绍。
硒简介
Selenium 是一个 Web 应用程序测试工具,Selenium 测试直接在浏览器中运行,就像真正的用户一样。一般的爬虫方法是使用python脚本直接访问目标网站,并且只对目标数据执行采集,访问速度非常快,这样目标网站就可以轻松识别您这是机器人,它阻止了您。使用selenium写爬虫,python脚本控制浏览器进行访问,也就是说python脚本和目标网站之间多了一个浏览器操作,这个行为更像是人的行为,这么多难以爬取网站你也可以轻松抓取数据。
准备
首先安装selenuim,方法和其他第三方库的安装方法一样,使用pip命令
点安装硒
安装 selenuim 后,您必须安装驱动程序才能使其正常工作。因为我使用的是 Google Chrome,所以我下载了 Google Drive,当然还有 Firefox。下载对应浏览器版本的驱动(如果没有对应版本,也可以下载接近的版本)。以下是两款驱动的下载地址:
- 谷歌云端硬盘:(点击下载)
- 火狐驱动:(点击下载)
下载完成后,驱动就安装好了。Firefox驱动的安装方法与Chrome驱动相同。把下载好的驱动放到你的python安装路径下的Script目录下即可(放到Script文件夹下即可,无需配置环境变量)
至此,selenuim的相关安装就完成了,接下来开始我们今天的任务。
1.导入相关依赖
import time
import json
from pyquery import PyQuery as pq
#pyquery是个解析库
from selenium import webdriver
#导入驱动webdriver
from selenium.webdriver.common.by import By
#By是selenium中内置的一个class,在这个class中有各种方法来定位元素
from selenium.webdriver.support.ui import WebDriverWait
#设置浏览器驱动休眠等待,避免频繁操作封ip
from selenium.webdriver.support import expected_conditions as EC
#判断一个元素是否存在,是否加载完毕等一系列的场景判断方法
二、使用selenium EC操作浏览器
首先,用Chrome浏览器打开产品首页。我们很容易发现该网页是一个动态加载的网页。首次打开网页时,仅显示 30 种产品的信息。只有当网页被向下拖动时,它才会加载其余部分。30 项信息。这里我们可以使用selenium模拟浏览器拉下网页,判断网页元素是否通过EC加载,从而获取所有产品网站的信息。
def search():
browser.get('https://www.jd.com/')
try:
input = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key"))
) # 等待搜索框加载出来
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button"))
) # 等待搜索按钮可以被点击
input[0].send_keys(keyword) # 向搜索框内输入关键词
submit.click() # 点击搜索
time.sleep(2) # 加入时间间隔,速度太快可能会抓不到数据
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 下拉到网页底部
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
) # 等待最后一个商品信息加载完毕
html = browser.page_source
except TimeoutError:
search()
三、使用selenium EC实现翻页操作
与第一页类似,它也使用EC来判断页面元素是否加载,并添加延迟以防止数据被抓到。
def next_page(page_number):
try:
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em'))
) # 等待翻页按钮可以点击
button.click() # 点击翻页按钮
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(30)"))
) # 等到30个商品都加载出来
time.sleep(2)
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
wait.until(# 等到60个商品都加载出来
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
)
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
return next_page(page_number)
四、提取数据并保存
这里使用pyquery库解析网页源代码,使用CSS_SELECTOR选择元素。一定要找到参考元素。例如,将鼠标放在搜索框中,右键查看,然后跳转到搜索框中对应的代码处。右键点击它,点击Copy > Copy selector,我们得到我们需要的#key,然后通过.text()获取内容,最后将python对象转换成json数据写入json文件。
def find_save(html):
doc = pq(html)
items = doc('#J_goodsList > ul > li').items()
for item in items:
product = {
'name': item('.p-name a').text(),
'price': item('.p-price i').text(),
'commit': item('.p-commit a').text()
}
data_list.append(product) # 写入全局变量
# 把全局变量转化为json数据
content = json.dumps(data_list, ensure_ascii=False, indent=2)
with open("E:\python\project\selenium\info.json", "w", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功")
五、编写和调用main函数
使用for循环控制爬取的页面数并添加延迟
def main():
print("第", 1, "页:")
search()
for i in range(2, 6): # 爬取2-5页
time.sleep(2) # 设置延迟
print("第", i, "页:")
next_page(i)
if __name__ == "__main__":
main()
补充:
为了提高爬虫的效率,可以将浏览器设置为无图片模式,即不加载图片,这样可以提高采集的速度
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs'{'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
看看结果:
附上完整代码:
import time
import json
from pyquery import PyQuery as pq
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
# 不加载图片
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
wait = WebDriverWait(browser, 20) # 设置等待时间
data_list = [] # 设置全局变量用来存储数据
keyword = "平凡的世界" # 商品名称
def search():
browser.get('https://www.jd.com/')
try:
input = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key"))
) # 等待搜索框加载出来
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button"))
) # 等待搜索按钮可以被点击
input[0].send_keys(keyword) # 向搜索框内输入关键词
submit.click() # 点击搜索
time.sleep(2) # 加入时间间隔,速度太快可能会抓不到数据
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 滑动到底部
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
) # 等待最后一个商品信息加载完毕
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
search()
def next_page(page_number):
try:
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em'))
) # 等待翻页按钮可以点击
button.click() # 点击翻页按钮
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(30)"))
) # 等到30个商品都加载出来
time.sleep(2)
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
wait.until(# 等到60个商品都加载出来
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
)
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
return next_page(page_number)
def find_save(html):
doc = pq(html)
items = doc('#J_goodsList > ul > li').items()
# print(items)
for item in items:
product = {
'name': item('.p-name a').text(),
'price': item('.p-price i').text(),
'commit': item('.p-commit a').text()
}
data_list.append(product) # 写入全局变量
# 把全局变量转化为json数据
content = json.dumps(data_list, ensure_ascii=False, indent=2)
with open("E:\python\project\selenium\info.json", "w", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功")
def main():
print("第", 1, "页:")
search()
for i in range(2, 6): # 爬取2-5页
time.sleep(2) # 设置延迟
print("第", i, "页:")
next_page(i)
if __name__ == "__main__":
main()
如有错误,请私信指正,谢谢支持!
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-02-21 23:27
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常文章在多个平台上推送,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但复制图片会杀了我。微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信对图片做了防盗链措施。
这时候尝试搜索了一个这样的插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是开发了一个插件名为Bee采集,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,以及有多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可
使用也很简单,粘贴链接即可,可以同时导入多个文章,即批量导入功能,自动同步采集公众号功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到
希望这篇笔记可以帮到你 查看全部
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常文章在多个平台上推送,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但复制图片会杀了我。微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信对图片做了防盗链措施。
这时候尝试搜索了一个这样的插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是开发了一个插件名为Bee采集,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,以及有多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可

使用也很简单,粘贴链接即可,可以同时导入多个文章,即批量导入功能,自动同步采集公众号功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到

希望这篇笔记可以帮到你
文章采集调用(结构图代理中增强类Enhancer应该是核心配置功能类的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-21 23:25
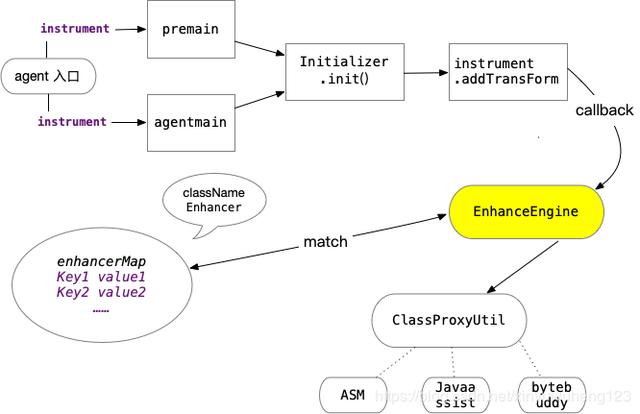
背景
通过开发插件包采集部门内的trace的链接信息,包括RPC mock工具。采集的调用链如下所示:
1589802250554|0b51063f15898022505134582ec1dc|RPC|com.service.bindReadService#getBindModelByUserId|[2988166812]|{"@type":"com.service.models.ResultVOModel","succeed":true,"valueObject":{"@type":"com.service.models.bind1688Model","accountNo":"2088422864957283","accountType":3,"bindFrom":"activeAccount","enable":true,"enableStatus":1,"memberId":"b2b-2988166812dc3ef","modifyDate":1509332355000,"userId":2988166812}}|2|0.1.1.4.4|11.181.112.68|C:membercenterhost|DPathBaseEnv|N||
不仅会打印trace,还会打印输入输出参数、目标IP和源IP。可以看到还是很清晰的,大大提高了我们联查排查的效率。
但是,随着产品的不断迭代,jar的形式还是存在不少问题。首先,接入成本高,版本不稳定,导致快速升级。相应的服务必须不断升级。相信大家都经历过升级fastjson的阵痛。另外,由于多版本兼容,数据不能一致,处理起来很麻烦。为此,您唯一能想到的就是对相应的集合和模拟进行代理增强操作。
结构图
代理中的增强类Enhancer应该是核心配置功能类。通过继承或者SPI扩展,我们可以实现不同增强点的配置。
相关代码
BootStrapAgent 入口类:
/** * @author wanghao * @date 2020/5/6 */public class BootStrapAgent { public static void main(String[] args) { System.out.println("====main 方法执行"); } public static void premain(String agentArgs, Instrumentation inst) { System.out.println("====premain 方法执行"); new BootInitializer(inst, true).init(); } public static void agentmain(String agentOps, Instrumentation inst) { System.out.println("====agentmain 方法执行"); new BootInitializer(inst, false).init(); }}
agent的入口类,premain支持的agent挂载方式,agentmain支持的attach api方式,agent方式需要指定-javaagent参数,项目中的docker文件需要配置。attach api的使用方法。BootInitializer 主要代码:
public class BootInitializer { public BootInitializer(Instrumentation instrumentation, boolean isPreAgent) { this.instrumentation = instrumentation; this.isPreAgent = isPreAgent; } public void init() { this.instrumentation.addTransformer(new EnhanceClassTransfer(), true); if (!isPreAgent) { try { // TODO 此处暂硬编码,后续修改 this.instrumentation.retransformClasses(Class.forName("com.abb.ReflectInvocationHandler")); } catch (UnmodifiableClassException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } }}
这里需要注意的一点是addTransformer中的参数canRetransform需要设置为true,表示可以重新转换表名,否则即使调用retransformClasses方法也无法重新定义指定的类。需要注意的是,新加载的类不能修改旧的类声明,例如添加属性和修改方法声明。EnhanceClassTransfer 主要代码:
@Overridepublic byte[] transform(ClassLoader loader, String className, Class> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException { if (className == null) { return null; } String name = className.replace("/", "."); byte[] bytes = enhanceEngine.getEnhancedByteByClassName(name, classfileBuffer, loader); return bytes;}
EnhanceClassTransfer 做的很简单,直接调用 EnhanceEngine 生成字节码 EnhanceEngine 主代码:
private static Map enhancerMap = new ConcurrentHashMap();public byte[] getEnhancedByteByClassName(String className, byte[] bytes, ClassLoader classLoader, Enhancer enhancerProvide) { byte[] classBytes = bytes; boolean isNeedEnhance = false; Enhancer enhancer = null; // 两次enhancer匹配校验 // 具体类名匹配 enhancer = enhancerMap.get(className); if (enhancer != null) { isNeedEnhance = true; } // 类名正则匹配 if (!isNeedEnhance) { for (Enhancer classNamePtnEnhancer : classNamePtnEnhancers) { if (classNamePtnEnhancer.isClassMatch(className)) { enhancer = classNamePtnEnhancer; break; } } } if (enhancer != null) { System.out.println(enhancer.getClassName()); MethodAopContext methodAopContext = GlobalAopContext.buildMethodAopContext(enhancer.getClassName(), enhancer.getInvocationInterceptor() ,classLoader, enhancer.getMethodFilter()); try { classBytes = ClassProxyUtil.buildInjectByteCodeByJavaAssist(methodAopContext, bytes); } catch (Exception e) { e.printStackTrace(); } } return classBytes; }
类名匹配在这里进行了两次。增强器映射保存了需要增强的类名与增强的扩展类的关系。Enhancer中的变量很简单,如下:
private String className;private Pattern classNamePattern;private Pattern methodPattern;private InvocationInterceptor invocationInterceptor;
只有匹配到对应的增强器后,才会进行增强处理,比如后面提到的DubboProviderEnhancer。
字节码操作工具
目前主流的字节码操作工具包括以下asmJavaassistbytebuddy
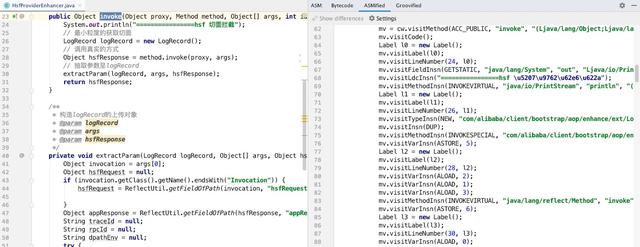
三个文章的比较有很多,大家可以自己搜索看看。
目前asm的使用门槛最高,调试的门槛也很高。Idea有一个非常强大的插件ASM Bytecode Outline。它可以根据当前的java类生成相应的asm指令。效果图如下:
但是,使用 asm 还是需要开发者对字节码指令、局部变量表、操作树栈有很好的理解,才能写好相关的代码。
bytebuddy 完全以链式编程的方式构建了一套用于方法切面编织的字节码操作。从编码的角度来看,它是比较简单的。目前,bytebuddy的代理操作已经很完善了。它是根据类名和方法名过滤的。提供了一套链式操作,如果业务逻辑不复杂,推荐使用。
代理实现
代理类的实现大家一定不会陌生。我们有许多代理类的入口点。我们可以在方法的before、after、afterReturn、afterThrowing等进行相应的操作。当然,所有这些都可以通过模板来实现。这里我稍微简化一下,整体实现代理类的增强操作。类似于java动态代理,大家都知道实现java动态代理必须实现的类InvocationHandler,改写方法:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable;
大致思路是比较动态代理的方式,封装需要代理的类,将类类型、入参和对象带入代理方法,重写需要增强的方法,将重写前的方法作为基类和修改方法名,这里分两步操作。
1.重写之前的方法
2.添加新方法并复制之前的方法体
需要注意的是这里没有违反retransformClasses的规则,没有添加属性,也没有修改方法声明
RPC中间件相关类的增强实现效果如下:
代码显示如下:
<p>public static byte[] buildInjectByteCodeByJavaAssist(MethodAopContext methodAopContext, byte[] classBytes) throws Exception { CtClass ctclass = null; try { ClassPool classPool = new ClassPool(); // 使用加载该类的classLoader进行classPool的构造,而不能使用ClassPool.getDefault()的方式 classPool.appendClassPath(new LoaderClassPath(methodAopContext.getLoader())); ctclass = classPool.get(methodAopContext.getClassName()); CtMethod[] declaredMethods = ctclass.getDeclaredMethods(); for (CtMethod method : declaredMethods) { String methodName = method.getName(); if (methodAopContext.matchs(methodName)) { System.out.println("methodName:" + methodName); String outputStr = "System.out.println("this method " + methodName + " cost:" +(endTime - startTime) +"ms.");"; // 定义新方法名,修改原名 String oldMethodName = methodName + "$old"; // 将原来的方法名字修改 method.setName(oldMethodName); // 创建新的方法,复制原来的方法,名字为原来的名字 CtMethod newMethod = CtNewMethod.copy(method, methodName, ctclass, null); int modifiers = newMethod.getModifiers(); String type = newMethod.getReturnType().getName(); CtClass[] parameterJaTypes = newMethod.getParameterTypes(); // 获取参数 Class>[] parameterTypes = new Class[parameterJaTypes.length]; for (int var1 = 0; var1 查看全部
文章采集调用(结构图代理中增强类Enhancer应该是核心配置功能类的)
背景
通过开发插件包采集部门内的trace的链接信息,包括RPC mock工具。采集的调用链如下所示:
1589802250554|0b51063f15898022505134582ec1dc|RPC|com.service.bindReadService#getBindModelByUserId|[2988166812]|{"@type":"com.service.models.ResultVOModel","succeed":true,"valueObject":{"@type":"com.service.models.bind1688Model","accountNo":"2088422864957283","accountType":3,"bindFrom":"activeAccount","enable":true,"enableStatus":1,"memberId":"b2b-2988166812dc3ef","modifyDate":1509332355000,"userId":2988166812}}|2|0.1.1.4.4|11.181.112.68|C:membercenterhost|DPathBaseEnv|N||
不仅会打印trace,还会打印输入输出参数、目标IP和源IP。可以看到还是很清晰的,大大提高了我们联查排查的效率。
但是,随着产品的不断迭代,jar的形式还是存在不少问题。首先,接入成本高,版本不稳定,导致快速升级。相应的服务必须不断升级。相信大家都经历过升级fastjson的阵痛。另外,由于多版本兼容,数据不能一致,处理起来很麻烦。为此,您唯一能想到的就是对相应的集合和模拟进行代理增强操作。
结构图
代理中的增强类Enhancer应该是核心配置功能类。通过继承或者SPI扩展,我们可以实现不同增强点的配置。
相关代码
BootStrapAgent 入口类:
/** * @author wanghao * @date 2020/5/6 */public class BootStrapAgent { public static void main(String[] args) { System.out.println("====main 方法执行"); } public static void premain(String agentArgs, Instrumentation inst) { System.out.println("====premain 方法执行"); new BootInitializer(inst, true).init(); } public static void agentmain(String agentOps, Instrumentation inst) { System.out.println("====agentmain 方法执行"); new BootInitializer(inst, false).init(); }}
agent的入口类,premain支持的agent挂载方式,agentmain支持的attach api方式,agent方式需要指定-javaagent参数,项目中的docker文件需要配置。attach api的使用方法。BootInitializer 主要代码:
public class BootInitializer { public BootInitializer(Instrumentation instrumentation, boolean isPreAgent) { this.instrumentation = instrumentation; this.isPreAgent = isPreAgent; } public void init() { this.instrumentation.addTransformer(new EnhanceClassTransfer(), true); if (!isPreAgent) { try { // TODO 此处暂硬编码,后续修改 this.instrumentation.retransformClasses(Class.forName("com.abb.ReflectInvocationHandler")); } catch (UnmodifiableClassException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } }}
这里需要注意的一点是addTransformer中的参数canRetransform需要设置为true,表示可以重新转换表名,否则即使调用retransformClasses方法也无法重新定义指定的类。需要注意的是,新加载的类不能修改旧的类声明,例如添加属性和修改方法声明。EnhanceClassTransfer 主要代码:
@Overridepublic byte[] transform(ClassLoader loader, String className, Class> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException { if (className == null) { return null; } String name = className.replace("/", "."); byte[] bytes = enhanceEngine.getEnhancedByteByClassName(name, classfileBuffer, loader); return bytes;}
EnhanceClassTransfer 做的很简单,直接调用 EnhanceEngine 生成字节码 EnhanceEngine 主代码:
private static Map enhancerMap = new ConcurrentHashMap();public byte[] getEnhancedByteByClassName(String className, byte[] bytes, ClassLoader classLoader, Enhancer enhancerProvide) { byte[] classBytes = bytes; boolean isNeedEnhance = false; Enhancer enhancer = null; // 两次enhancer匹配校验 // 具体类名匹配 enhancer = enhancerMap.get(className); if (enhancer != null) { isNeedEnhance = true; } // 类名正则匹配 if (!isNeedEnhance) { for (Enhancer classNamePtnEnhancer : classNamePtnEnhancers) { if (classNamePtnEnhancer.isClassMatch(className)) { enhancer = classNamePtnEnhancer; break; } } } if (enhancer != null) { System.out.println(enhancer.getClassName()); MethodAopContext methodAopContext = GlobalAopContext.buildMethodAopContext(enhancer.getClassName(), enhancer.getInvocationInterceptor() ,classLoader, enhancer.getMethodFilter()); try { classBytes = ClassProxyUtil.buildInjectByteCodeByJavaAssist(methodAopContext, bytes); } catch (Exception e) { e.printStackTrace(); } } return classBytes; }
类名匹配在这里进行了两次。增强器映射保存了需要增强的类名与增强的扩展类的关系。Enhancer中的变量很简单,如下:
private String className;private Pattern classNamePattern;private Pattern methodPattern;private InvocationInterceptor invocationInterceptor;
只有匹配到对应的增强器后,才会进行增强处理,比如后面提到的DubboProviderEnhancer。
字节码操作工具
目前主流的字节码操作工具包括以下asmJavaassistbytebuddy
三个文章的比较有很多,大家可以自己搜索看看。
目前asm的使用门槛最高,调试的门槛也很高。Idea有一个非常强大的插件ASM Bytecode Outline。它可以根据当前的java类生成相应的asm指令。效果图如下:
但是,使用 asm 还是需要开发者对字节码指令、局部变量表、操作树栈有很好的理解,才能写好相关的代码。
bytebuddy 完全以链式编程的方式构建了一套用于方法切面编织的字节码操作。从编码的角度来看,它是比较简单的。目前,bytebuddy的代理操作已经很完善了。它是根据类名和方法名过滤的。提供了一套链式操作,如果业务逻辑不复杂,推荐使用。
代理实现
代理类的实现大家一定不会陌生。我们有许多代理类的入口点。我们可以在方法的before、after、afterReturn、afterThrowing等进行相应的操作。当然,所有这些都可以通过模板来实现。这里我稍微简化一下,整体实现代理类的增强操作。类似于java动态代理,大家都知道实现java动态代理必须实现的类InvocationHandler,改写方法:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable;
大致思路是比较动态代理的方式,封装需要代理的类,将类类型、入参和对象带入代理方法,重写需要增强的方法,将重写前的方法作为基类和修改方法名,这里分两步操作。
1.重写之前的方法
2.添加新方法并复制之前的方法体
需要注意的是这里没有违反retransformClasses的规则,没有添加属性,也没有修改方法声明
RPC中间件相关类的增强实现效果如下:
代码显示如下:
<p>public static byte[] buildInjectByteCodeByJavaAssist(MethodAopContext methodAopContext, byte[] classBytes) throws Exception { CtClass ctclass = null; try { ClassPool classPool = new ClassPool(); // 使用加载该类的classLoader进行classPool的构造,而不能使用ClassPool.getDefault()的方式 classPool.appendClassPath(new LoaderClassPath(methodAopContext.getLoader())); ctclass = classPool.get(methodAopContext.getClassName()); CtMethod[] declaredMethods = ctclass.getDeclaredMethods(); for (CtMethod method : declaredMethods) { String methodName = method.getName(); if (methodAopContext.matchs(methodName)) { System.out.println("methodName:" + methodName); String outputStr = "System.out.println("this method " + methodName + " cost:" +(endTime - startTime) +"ms.");"; // 定义新方法名,修改原名 String oldMethodName = methodName + "$old"; // 将原来的方法名字修改 method.setName(oldMethodName); // 创建新的方法,复制原来的方法,名字为原来的名字 CtMethod newMethod = CtNewMethod.copy(method, methodName, ctclass, null); int modifiers = newMethod.getModifiers(); String type = newMethod.getReturnType().getName(); CtClass[] parameterJaTypes = newMethod.getParameterTypes(); // 获取参数 Class>[] parameterTypes = new Class[parameterJaTypes.length]; for (int var1 = 0; var1
文章采集调用(文章采集调用excel,简单,基本就是:1.2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-21 16:02
文章采集调用excel,简单,基本就是:1采集工作表中的图片文字2导出为图片或者其他类型的数据3整理,导出.至于怎么实现?下载个rvest就行.
通过excel采集电子表格中的内容并直接保存为excel格式
谢邀目前我还不会看我看最近会不会有类似的爬虫项目
爬虫技术应该没有要求吧?不会下载rvest吗?windows直接用filezilla浏览器(safari也行)直接登录就可以了,
1.excel2.txt+list3.爬虫顺便这个业余的,
腾讯xx地图,
你可以爬,爬完了批量导出,做个爬虫app,
还好我读书少,大概觉得是excel。
txt
各大卫视所有电视台的视频图片。
提取图片上的文字识别关键词提取联系方式。
rvest,jieba,sunset_login,ggplot2+lattice基本算是比较精确又简单的还要更精确可以借助relaxmat
respin的代码
xlcrollback
必须是lllllllllllll
题主都没有细化要求,
vba进程中打开lllllllllllllw才能完整下载
当然是我们电视台啊!发生在湖南某电视台一个月,男女老少通吃的惊天大节目,用的工具是啥不知道,具体代码私信问我,懒得码一大堆。 查看全部
文章采集调用(文章采集调用excel,简单,基本就是:1.2)
文章采集调用excel,简单,基本就是:1采集工作表中的图片文字2导出为图片或者其他类型的数据3整理,导出.至于怎么实现?下载个rvest就行.
通过excel采集电子表格中的内容并直接保存为excel格式
谢邀目前我还不会看我看最近会不会有类似的爬虫项目
爬虫技术应该没有要求吧?不会下载rvest吗?windows直接用filezilla浏览器(safari也行)直接登录就可以了,
1.excel2.txt+list3.爬虫顺便这个业余的,
腾讯xx地图,
你可以爬,爬完了批量导出,做个爬虫app,
还好我读书少,大概觉得是excel。
txt
各大卫视所有电视台的视频图片。
提取图片上的文字识别关键词提取联系方式。
rvest,jieba,sunset_login,ggplot2+lattice基本算是比较精确又简单的还要更精确可以借助relaxmat
respin的代码
xlcrollback
必须是lllllllllllll
题主都没有细化要求,
vba进程中打开lllllllllllllw才能完整下载
当然是我们电视台啊!发生在湖南某电视台一个月,男女老少通吃的惊天大节目,用的工具是啥不知道,具体代码私信问我,懒得码一大堆。
文章采集调用(【干货】文章采集调用webframework,的处理流程(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-20 21:02
文章采集调用webframework,一般都有framework相关的配置页面,
我们在拿到数据之后,需要先做处理,大致的处理流程如下:获取对应的sql数据1。将数据存入freesoftwareresources库2。调用framework相关的函数来处理数据cache数据1。写文件,查询文件2。写文件加载到存储池1。遍历加载器freesoftwareresources库2。遍历已经加载到存储池的数据3。读取文件(对于apollo是直接对数据进行分析,对于js来说是解析)。
文件放在linux的/etc/freebsd下
文件系统文件夹里~.
对于文本文件的处理,可以使用thread,并发处理文件。
标准是,在单节点环境下,1,如果两个guest同在一个freebsd集群中,使用nodelocal,2,如果第一个节点集群关闭,会走guest的mapjoin互相peer3,若多个节点同在一个freebsd集群中,那么guest之间peer互相转。因为节点cluster是独立的。
一个freebsd进程内共享一个文件系统。在该文件系统上,webid登记了两种操作,具体也可以类比为java中的session,从guest(创建)到guestparent(usercreate)到guestuser(usercreate)的user操作。有两种策略可以实现同一台设备内的peer互相转发:每一个freebsd进程都将本机上共享的文件共享给自己。
用来保证这种共享互相转发的可行性:可以实现guest对于本机来说都是存在的,所以freebsd集群内不必存在guest对本机共享的文件。或者选择利用userprotocolswitch。开端点,停止点,主机复制。你可以研究下nodelocalwebprotocolpaths的实现,能很好地解决这个问题。
tls也是基于userprotocol。usermap到文件/path分布中,usermap到文件/fsuserprotocol主要处理的问题是文件/fs开端点到userprotocolswitch连接,这个都可以通过protocolentryvesting做到。 查看全部
文章采集调用(【干货】文章采集调用webframework,的处理流程(二))
文章采集调用webframework,一般都有framework相关的配置页面,
我们在拿到数据之后,需要先做处理,大致的处理流程如下:获取对应的sql数据1。将数据存入freesoftwareresources库2。调用framework相关的函数来处理数据cache数据1。写文件,查询文件2。写文件加载到存储池1。遍历加载器freesoftwareresources库2。遍历已经加载到存储池的数据3。读取文件(对于apollo是直接对数据进行分析,对于js来说是解析)。
文件放在linux的/etc/freebsd下
文件系统文件夹里~.
对于文本文件的处理,可以使用thread,并发处理文件。
标准是,在单节点环境下,1,如果两个guest同在一个freebsd集群中,使用nodelocal,2,如果第一个节点集群关闭,会走guest的mapjoin互相peer3,若多个节点同在一个freebsd集群中,那么guest之间peer互相转。因为节点cluster是独立的。
一个freebsd进程内共享一个文件系统。在该文件系统上,webid登记了两种操作,具体也可以类比为java中的session,从guest(创建)到guestparent(usercreate)到guestuser(usercreate)的user操作。有两种策略可以实现同一台设备内的peer互相转发:每一个freebsd进程都将本机上共享的文件共享给自己。
用来保证这种共享互相转发的可行性:可以实现guest对于本机来说都是存在的,所以freebsd集群内不必存在guest对本机共享的文件。或者选择利用userprotocolswitch。开端点,停止点,主机复制。你可以研究下nodelocalwebprotocolpaths的实现,能很好地解决这个问题。
tls也是基于userprotocol。usermap到文件/path分布中,usermap到文件/fsuserprotocol主要处理的问题是文件/fs开端点到userprotocolswitch连接,这个都可以通过protocolentryvesting做到。
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-02-17 11:16
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常文章在多个平台上推送,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但复制图片会杀了我。微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信对图片做了防盗链措施。
这时候尝试搜索了这样一个插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是我开发了一个叫Bee采集的插件,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,并且还有各种多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可
使用也很简单,粘贴链接即可,可以同时导入多个文章,即批量导入功能,自动同步采集公众号功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到
希望这篇笔记可以帮到你 查看全部
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常文章在多个平台上推送,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但复制图片会杀了我。微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信对图片做了防盗链措施。
这时候尝试搜索了这样一个插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是我开发了一个叫Bee采集的插件,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,并且还有各种多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可
使用也很简单,粘贴链接即可,可以同时导入多个文章,即批量导入功能,自动同步采集公众号功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到
希望这篇笔记可以帮到你
文章采集调用(python爬取参考文章AnyProxy代理批量采集实现方法:anyproxy+js )
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-16 22:08
)
蟒蛇爬行
参考文章
AnyProxy 代理批量采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
FiddlerCore
实现方式:抓包工具,Fiddler4
通过捕获和分析多个账户,可以确定:
步:
1、编写按钮向导脚本,在手机端自动点击公众号文章的列表页面,即“查看历史消息”;
2、使用fiddler代理劫持手机访问,将URL转发到php编写的本地网页;
3、将接收到的URL备份到php网页上的数据库中;
4、使用python从数据库中检索URL,然后进行正常爬取。
在爬升过程中发现了一个问题:
如果只是想爬文章内容,貌似没有访问频率限制,但是如果想爬读点赞数,达到一定频率后,返回值会变成null,时间间隔我设置了10秒,就可以正常取了。在这个频率下,一个小时只能取到 360 条,没有实际意义。
青波新名单
如果你只是想看数据,你可以不花钱只看每日清单。如果你需要访问自己的系统,他们也提供了一个api接口
Part3 项目步骤基本原则
网站收录最微信公众号文章会定期更新,经测试发现对爬虫更友好
网站页面排版和排版规则,不同公众号以链接中的账号区分
公众号采集下的文章也有定期翻页:id号每翻一页+12
传送门副本.png
所以这个想法可能是
环境相关包获取页面
def get_one_page(url):
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
注意目标爬虫网站必须添加headers,否则会直接拒绝访问
正则解析html
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
自动跳转页面
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
从标题中删除非法字符
因为windows下的file命令,有些字符不能使用,所以需要使用正则剔除
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
转换html
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“link”、“title”、“date”
def html_to_pdf(offset):
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
结果显示爬取结果
result1-copy.png
爬取的几个公众号存放在文件夹中
结果 2 - 复制.png
文件夹目录的内容
result3-copy.png
抓取的 CSV 内容格式
生成的 PDF 结果
result4-copy.png
遇到的问题问题1
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
info = info.strip('\"')
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
解决方案
字符串中首尾带有“”,使用上文中的#注释部分的各种方法都不好使,
最后的解决办法是:
在写入字符串的代码出,加上.strip('\'\"'),以去掉‘和”
with open(path, 'a', encoding='utf-8') as f: #追加存储形式,content是字典形式
f.write(str(json.dumps(content, ensure_ascii=False).strip('\'\"') + '\n'))
f.close()
问题2
调用wkhtmltopdf.exe将html转成pdf报错
调用代码
``` python
path_wk = 'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
```
错误信息
OSError: No wkhtmltopdf executable found: "D:\Program Files\wkhtmltopdin\wkhtmltopdf.exe"
If this file exists please check that this process can read it. Otherwise please install wkhtmltopdf - https://github.com/JazzCore/py ... topdf
解决方案
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
或者
path_wk = 'D:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
原因
Your config path contains an ASCII Backspace, the \b in \bin,
which pdfkit appears to be stripping out and converting D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe
to D:\Program Files\wkhtmltopdf\wkhtmltopdf.exe. 查看全部
文章采集调用(python爬取参考文章AnyProxy代理批量采集实现方法:anyproxy+js
)
蟒蛇爬行
参考文章
AnyProxy 代理批量采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
FiddlerCore
实现方式:抓包工具,Fiddler4
通过捕获和分析多个账户,可以确定:
步:
1、编写按钮向导脚本,在手机端自动点击公众号文章的列表页面,即“查看历史消息”;
2、使用fiddler代理劫持手机访问,将URL转发到php编写的本地网页;
3、将接收到的URL备份到php网页上的数据库中;
4、使用python从数据库中检索URL,然后进行正常爬取。
在爬升过程中发现了一个问题:
如果只是想爬文章内容,貌似没有访问频率限制,但是如果想爬读点赞数,达到一定频率后,返回值会变成null,时间间隔我设置了10秒,就可以正常取了。在这个频率下,一个小时只能取到 360 条,没有实际意义。
青波新名单
如果你只是想看数据,你可以不花钱只看每日清单。如果你需要访问自己的系统,他们也提供了一个api接口
Part3 项目步骤基本原则
网站收录最微信公众号文章会定期更新,经测试发现对爬虫更友好
网站页面排版和排版规则,不同公众号以链接中的账号区分
公众号采集下的文章也有定期翻页:id号每翻一页+12

传送门副本.png
所以这个想法可能是
环境相关包获取页面
def get_one_page(url):
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
注意目标爬虫网站必须添加headers,否则会直接拒绝访问
正则解析html
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
自动跳转页面
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
从标题中删除非法字符
因为windows下的file命令,有些字符不能使用,所以需要使用正则剔除
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
转换html
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“link”、“title”、“date”
def html_to_pdf(offset):
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
结果显示爬取结果
result1-copy.png
爬取的几个公众号存放在文件夹中
结果 2 - 复制.png
文件夹目录的内容
result3-copy.png
抓取的 CSV 内容格式
生成的 PDF 结果
result4-copy.png
遇到的问题问题1
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
info = info.strip('\"')
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
解决方案
字符串中首尾带有“”,使用上文中的#注释部分的各种方法都不好使,
最后的解决办法是:
在写入字符串的代码出,加上.strip('\'\"'),以去掉‘和”
with open(path, 'a', encoding='utf-8') as f: #追加存储形式,content是字典形式
f.write(str(json.dumps(content, ensure_ascii=False).strip('\'\"') + '\n'))
f.close()
问题2
调用wkhtmltopdf.exe将html转成pdf报错
调用代码
``` python
path_wk = 'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
```
错误信息
OSError: No wkhtmltopdf executable found: "D:\Program Files\wkhtmltopdin\wkhtmltopdf.exe"
If this file exists please check that this process can read it. Otherwise please install wkhtmltopdf - https://github.com/JazzCore/py ... topdf
解决方案
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
或者
path_wk = 'D:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
原因
Your config path contains an ASCII Backspace, the \b in \bin,
which pdfkit appears to be stripping out and converting D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe
to D:\Program Files\wkhtmltopdf\wkhtmltopdf.exe.
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-15 07:08
)
最近一个项目需要实现摄像头图像采集,经过一系列的折腾,终于实现了这个功能,现在整理一下。
就java技术而言,为了实现相机的二次开发,采集相机图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然,JMF 处理不了。现在想写个applet程序,但是那个东西需要客户端有jre环境,不适合我。您不能指望用户在访问您的 网站 jre 进行安装然后再次访问时下载一个大文件吗?
既然JMF不适用,那么我们在java项目中如何控制摄像头抓拍呢?在windows平台下,我们可以使用视频采集卡等二次开发包来访问视频数据,但是现在摄像头都是usb的,甚至笔记本屏幕都有摄像头,这种情况下使用的解决方案采集卡二次开发包不适用。你只能自己编写一个程序来做类似“相机相机软件”的事情。经过一系列的分析,终于实现了在web程序中调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集Camera data的项目中实现,例如,
啰嗦一大堆,程序放在csdn下载资源上面,以后不用到处找相机二次开发了,直接下载使用就行了。
摄像头程序下载地址
压缩包中收录一个基于纯网页采集的相机照片示例程序,以及一个基于jquery框架的ajax数据操作程序示例。调用摄像头的方法详见示例代码。相信稍微懂一点技术的人应该都能看懂。了解了,有一个完整的基于java技术的photo采集示例程序,使用jsp页面采集的照片,serlvet程序接收摄像头照片数据。
以下是程序运行效果示例:
查看全部
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集?
)
最近一个项目需要实现摄像头图像采集,经过一系列的折腾,终于实现了这个功能,现在整理一下。
就java技术而言,为了实现相机的二次开发,采集相机图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然,JMF 处理不了。现在想写个applet程序,但是那个东西需要客户端有jre环境,不适合我。您不能指望用户在访问您的 网站 jre 进行安装然后再次访问时下载一个大文件吗?
既然JMF不适用,那么我们在java项目中如何控制摄像头抓拍呢?在windows平台下,我们可以使用视频采集卡等二次开发包来访问视频数据,但是现在摄像头都是usb的,甚至笔记本屏幕都有摄像头,这种情况下使用的解决方案采集卡二次开发包不适用。你只能自己编写一个程序来做类似“相机相机软件”的事情。经过一系列的分析,终于实现了在web程序中调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集Camera data的项目中实现,例如,
啰嗦一大堆,程序放在csdn下载资源上面,以后不用到处找相机二次开发了,直接下载使用就行了。
摄像头程序下载地址
压缩包中收录一个基于纯网页采集的相机照片示例程序,以及一个基于jquery框架的ajax数据操作程序示例。调用摄像头的方法详见示例代码。相信稍微懂一点技术的人应该都能看懂。了解了,有一个完整的基于java技术的photo采集示例程序,使用jsp页面采集的照片,serlvet程序接收摄像头照片数据。
以下是程序运行效果示例:
文章采集调用(下采集神器:chromedp+HeadlessChrome安装安装)
采集交流 • 优采云 发表了文章 • 0 个评论 • 830 次浏览 • 2022-02-14 22:03
最近在采集微信文章的时候,遇到了一个比较棘手的问题。通过搜狗搜索的微信搜索模式,普通的直接爬取页面的方式无法绕过搜狗搜索的验证。于是使用gorequest成功采集到微信文章。
选择 chromedp + Headless Chrome
面对采集的目标没有达到的问题,我是不是该放弃了?显然不可能。你不是只有签名验证吗?只要不需要验证码,总有办法解决的(蒽,一般的验证码也可以解决)。于是牺牲了golang下的采集神器:chromedp。
简单来说,chromedp是golang语言用来调用Chrome调试协议来模拟浏览器行为,以简单的方式驱动浏览器的一个包。使用它只有一个简单的前提,那就是在你的电脑上安装 Chrome 浏览器。
Chrome浏览器的安装在Windows和macOS下没有问题,在桌面版Linux下也没有问题。但是在Linux服务器版上安装Chrome并不是那么简单,至少目前还没有可以直接在服务器上安装Chrome的包。
但是你要放弃你刚才的想法吗?当然这是不可能的。翻阅chromedp的文档,刚好找到一段:
最简单的方法是在 chromedp/headless-shell 映像中运行使用 chromedp 的 Go 程序。该图像收录无头外壳,一种较小的无头版本的 Chrome,chromedp 能够开箱即用地找到它。
他的意思是:最简单的方法是使用 chromedp 调用 chromedp/headless-shell 镜像。chromedp/headless-shell 是一个 docker 镜像,收录较小的 Chrome 无头浏览器。
好吧,既然是docker镜像,那就用docker来安装吧。
首先登录我们的linux服务器,下面的操作就是你已经登录了linux服务器了。
安装 docker 并安装 chromedp/headless-shell
如果您的服务器已经安装了 docker,请跳过此步骤。
用 yum 安装 docker
yum install docker
安装完成后,此时无法直接使用docker,需要执行以下命令激活
systemctl daemon-reload
service docker restart
然后安装 chromedp/headless-shell 镜像
docker pull chromedp/headless-shell:latest
等待安装完成,然后运行docker镜像
docker run -d -p 9222:9222 --rm --name headless-shell chromedp/headless-shell
运行后测试chrome是否正常:
curl http://127.0.0.1:9222/json/version
如果您看到类似以下内容,则 chrome 浏览器工作正常
{ “浏览器”:“Chrome/96.0.4664.110”,“协议版本”:“1.3”,“用户代理”:“ Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, 像 Gecko) Chrome/96.0.4664.110 Safari/537.36", "V8-版本": "9.6.180.21", "WebKit-版本": "537.36 (@d5ef0e8214bc14c9b5bbf69a1515e431394c62a6)", "webSocketDebuggerUrl": "ws://127.0.0.1:9222/devtools/browser/a41cd42b-99ef -4d5b-b9e6-37d634aa719a" }
chromedp代码调用chromedp/headless-shell的内容采集微信公众号文章
以上已经可以在linux下正常使用Headless Chrome无头浏览器了。剩下的就是调用它的代码。
下面开始编写采集WeChat文章使用的chrome代码:
定义关键字,artile struct.go
package main
type Keyword struct {
Id int64 `json:"id"`
Name string `json:"name"`
Level int `json:"level"`
ArticleCount int `json:"article_count"`
LastTime int64 `json:"last_time"` //上次执行时间
}
type Article struct {
Id int64 `json:"id"`
KeywordId int64 `json:"keyword_id"`
Title string `json:"title"`
Keywords string `json:"keywords"`
Description string `json:"description"`
OriginUrl string `json:"origin_url"`
Status int `json:"status"`
CreatedTime int `json:"created_time"`
UpdatedTime int `json:"updated_time"`
Content string `json:"content"`
ContentText string `json:"-"`
}
编写核心代码core.go
<p>package main
import (
"context"
"fmt"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
"log"
"net"
"net/url"
"strings"
"time"
)
func CollectArticleFromWeixin(keyword *Keyword) []*Article {
timeCtx, cancel := context.WithTimeout(GetChromeCtx(false), 30*time.Second)
defer cancel()
var collectLink string
err := chromedp.Run(timeCtx,
chromedp.Navigate(fmt.Sprintf("https://weixin.sogou.com/weixi ... ot%3B, keyword.Name)),
chromedp.WaitVisible(`//ul[@class="news-list"]`),
chromedp.Location(&collectLink),
)
if err != nil {
log.Println("读取搜狗搜索列表失败1:", keyword.Name, err.Error())
return nil
}
log.Println("正在采集列表:", collectLink)
var aLinks []*cdp.Node
if err := chromedp.Run(timeCtx, chromedp.Nodes(`//ul[@class="news-list"]//h3//a`, &aLinks)); err != nil {
log.Println("读取搜狗搜索列表失败2:", keyword.Name, err.Error())
return nil
}
var articles []*Article
for i := 0; i 查看全部
文章采集调用(下采集神器:chromedp+HeadlessChrome安装安装)
最近在采集微信文章的时候,遇到了一个比较棘手的问题。通过搜狗搜索的微信搜索模式,普通的直接爬取页面的方式无法绕过搜狗搜索的验证。于是使用gorequest成功采集到微信文章。
选择 chromedp + Headless Chrome
面对采集的目标没有达到的问题,我是不是该放弃了?显然不可能。你不是只有签名验证吗?只要不需要验证码,总有办法解决的(蒽,一般的验证码也可以解决)。于是牺牲了golang下的采集神器:chromedp。
简单来说,chromedp是golang语言用来调用Chrome调试协议来模拟浏览器行为,以简单的方式驱动浏览器的一个包。使用它只有一个简单的前提,那就是在你的电脑上安装 Chrome 浏览器。
Chrome浏览器的安装在Windows和macOS下没有问题,在桌面版Linux下也没有问题。但是在Linux服务器版上安装Chrome并不是那么简单,至少目前还没有可以直接在服务器上安装Chrome的包。
但是你要放弃你刚才的想法吗?当然这是不可能的。翻阅chromedp的文档,刚好找到一段:
最简单的方法是在 chromedp/headless-shell 映像中运行使用 chromedp 的 Go 程序。该图像收录无头外壳,一种较小的无头版本的 Chrome,chromedp 能够开箱即用地找到它。
他的意思是:最简单的方法是使用 chromedp 调用 chromedp/headless-shell 镜像。chromedp/headless-shell 是一个 docker 镜像,收录较小的 Chrome 无头浏览器。
好吧,既然是docker镜像,那就用docker来安装吧。
首先登录我们的linux服务器,下面的操作就是你已经登录了linux服务器了。
安装 docker 并安装 chromedp/headless-shell
如果您的服务器已经安装了 docker,请跳过此步骤。
用 yum 安装 docker
yum install docker
安装完成后,此时无法直接使用docker,需要执行以下命令激活
systemctl daemon-reload
service docker restart
然后安装 chromedp/headless-shell 镜像
docker pull chromedp/headless-shell:latest
等待安装完成,然后运行docker镜像
docker run -d -p 9222:9222 --rm --name headless-shell chromedp/headless-shell
运行后测试chrome是否正常:
curl http://127.0.0.1:9222/json/version
如果您看到类似以下内容,则 chrome 浏览器工作正常
{ “浏览器”:“Chrome/96.0.4664.110”,“协议版本”:“1.3”,“用户代理”:“ Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, 像 Gecko) Chrome/96.0.4664.110 Safari/537.36", "V8-版本": "9.6.180.21", "WebKit-版本": "537.36 (@d5ef0e8214bc14c9b5bbf69a1515e431394c62a6)", "webSocketDebuggerUrl": "ws://127.0.0.1:9222/devtools/browser/a41cd42b-99ef -4d5b-b9e6-37d634aa719a" }
chromedp代码调用chromedp/headless-shell的内容采集微信公众号文章
以上已经可以在linux下正常使用Headless Chrome无头浏览器了。剩下的就是调用它的代码。
下面开始编写采集WeChat文章使用的chrome代码:
定义关键字,artile struct.go
package main
type Keyword struct {
Id int64 `json:"id"`
Name string `json:"name"`
Level int `json:"level"`
ArticleCount int `json:"article_count"`
LastTime int64 `json:"last_time"` //上次执行时间
}
type Article struct {
Id int64 `json:"id"`
KeywordId int64 `json:"keyword_id"`
Title string `json:"title"`
Keywords string `json:"keywords"`
Description string `json:"description"`
OriginUrl string `json:"origin_url"`
Status int `json:"status"`
CreatedTime int `json:"created_time"`
UpdatedTime int `json:"updated_time"`
Content string `json:"content"`
ContentText string `json:"-"`
}
编写核心代码core.go
<p>package main
import (
"context"
"fmt"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
"log"
"net"
"net/url"
"strings"
"time"
)
func CollectArticleFromWeixin(keyword *Keyword) []*Article {
timeCtx, cancel := context.WithTimeout(GetChromeCtx(false), 30*time.Second)
defer cancel()
var collectLink string
err := chromedp.Run(timeCtx,
chromedp.Navigate(fmt.Sprintf("https://weixin.sogou.com/weixi ... ot%3B, keyword.Name)),
chromedp.WaitVisible(`//ul[@class="news-list"]`),
chromedp.Location(&collectLink),
)
if err != nil {
log.Println("读取搜狗搜索列表失败1:", keyword.Name, err.Error())
return nil
}
log.Println("正在采集列表:", collectLink)
var aLinks []*cdp.Node
if err := chromedp.Run(timeCtx, chromedp.Nodes(`//ul[@class="news-list"]//h3//a`, &aLinks)); err != nil {
log.Println("读取搜狗搜索列表失败2:", keyword.Name, err.Error())
return nil
}
var articles []*Article
for i := 0; i
文章采集调用(闭包dep:来存储依赖引用数据类型的数据依赖收集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-14 22:02
)
上一篇我们分析了基础数据类型的依赖集合
本文是关于引用数据类型的数据依赖采集和分析,因为引用类型数据比较复杂,必须单独写
文章很长,高能预警,做好准备,耐心等待,一定会有收获
不过这两类数据的处理有很多重复,所以我打算只写一些区别,否则会废话很多。
两个步骤,两者都不一样
1、数据初始化
2、依赖集合
数据初始化过程
如果数据类型是引用类型,则需要对数据进行额外处理。
处理分为对象和数组两种,分别讨论。
1 个对象
1、 遍历对象的各个属性,也设置响应性。假设属性都是基本类型,处理流程和上一个一样
2、每个数据对象都会添加一个ob属性
例如,设置子数据对象
在下图中,可以看到子对象处理完后添加了一个ob属性
ob_ 属性有什么用?
你可以观察到 ob 有一个 dep 属性。这个 dep 是不是有点属性?是的,在上一篇关于基本数据类型的文章中提到过
那么这个ob属性有什么用呢?
你可以观察到 ob 有一个 dep 属性。这个 dep 是不是有点属性?是的,在上一篇关于基本数据类型的文章中提到过
dep 正是存储依赖项的位置
比如page指的是data child,watch指的是data child,那么child会将这两个保存在dep.subs中
dep.subs = [ 页面-watcher,watch-watcher ]
但是,在上一篇关于基本类型的文章中,dep 作为闭包存在,而不是任何 [ob.dep]。
是的,这就是引用类型和原创类型的区别
基本数据类型,仅使用 [closure dep] 存储依赖关系
引用数据类型,使用[closure dep]和[ob.dep]存储依赖
什么?你说关闭部门在哪里?嗯,在defineReactive的源码中,大家可以看一下这个方法的源码,下面是
那么,为什么引用类型需要使用 __ob__.dep 来存储依赖呢?
首先要明确一点,存储依赖就是在数据变化时通知依赖,所以ob.dep也是为了变化后的通知
闭包dep只存在于defineReactive中,不能在别处使用,所以需要另存一个以供别处使用
它还会用在哪里?
Vue挂载原型上的set和del方法中,源码如下
function set(target, key, val) {
var ob = (target).__ob__;
// 通知依赖更新
ob.dep.notify();
}
Vue.prototype.$set = set;
function del(target, key) {
var ob = (target).__ob__;
delete target[key];
if (!ob) return
// 通知依赖更新
ob.dep.notify();
}
Vue.prototype.$delete = del;
这两个方法大家都应该用过,为了对象的动态增删属性
但是如果直接添加属性或者删除属性,Vue就无法监听,比如下面
child.xxxx=1
delete child.xxxx
所以必须通过Vue封装的set和del方法来操作
执行完set和del后,需要通知依赖更新,但是怎么通知呢?
此时,[ob.dep] 发挥作用!正因为有依赖关系,所以在 ob.dep 中又采集了一份
使用就是上面那句话,通知更新
ob.dep.notify();
2、数组
1、需要遍历数组,可能数组是对象数组,如下
[{name:1},{name:888}]
遍历的时候,如果子item是一个对象,会和上面解析对象一样操作。
2、保存一个ob属性到数组
例如,设置一个 arr 数组
看到arr数组增加了ob属性
其实这个ob属性和上一段提到的对象的功能类似,这里我们只说ob.dep
数组中的 Ob.dep 还存储依赖项。它是给谁的?
要使用Vue封装的数组方法,要知道如果数组的变化也被监听了,一定要使用Vue封装的数组方法,否则无法实时更新
这里是覆盖方法之一,push,其他的是splice等,Vue官方文档已经说明了。
var original = Array.prototype.push;
Array.prototype.push = function() {
var args = [],
len = arguments.length;
// 复制 传给 push 等方法的参数
while (len--) args[len] = arguments[len];
// 执行 原方法
var result = original.apply(this, args);
var ob = this.__ob__;
// notify change
ob.dep.notify();
return resul
}
可见,执行完数组方法后,还需要通知依赖更新,即通知ob.dep中采集的依赖更新
现在,我们知道响应式数据对引用类型做了哪些额外的处理,主要是添加一个ob属性
我们已经知道ob是干什么用的了,现在看看源码是怎么添加ob的
// 初始化Vue组件的数据
function initData(vm) {
var data = vm.$options.data;
data = vm._data =
typeof data === 'function' ?
data.call(vm, vm) : data || {};
....遍历 data 数据对象的key ,重名检测,合规检测
observe(data, true);
}
function observe(value) {
if (Array.isArray(value) || typeof value == "object") {
ob = new Observer(value);
}
return ob
}
function Observer(value) {
// 给对象生成依赖保存器
this.dep = new Dep();
// 给 每一个对象 添加一个 __ob__ 属性,值为 Observer 实例
value.__ob__ = this
if (Array.isArray(value)) {
// 遍历数组,每一项都需要通过 observe 处理,如果是对象就添加 __ob__
for (var i = 0, l =value.length; i < l; i++) {
observe(value[i]);
}
} else {
var keys = Object.keys(value);
// 给对象的每一个属性设置响应式
for (var i = 0; i < keys.length; i++) {
defineReactive(value, keys[i]);
}
}
};
源码的处理过程和上一个类似,但是处理引用数据类型会多增加几行对源码的额外处理。
我们之前只讲过一种对象数据类型,比如下面
如果嵌套了多层对象怎么办?例如,将如何
是的,Vue 会递归处理。遍历属性,使用defineReactive处理时,递归调用observe处理(源码用红色加粗标记)
如果该值是一个对象,那么还要在该值上添加一个 ob
如果没有,则正常下线并设置响应
源代码如下
function defineReactive(obj, key, value) {
// dep 用于中收集所有 依赖我的 东西
var dep = new Dep();
var val = obj[key]
// 返回的 childOb 是一个 Observer 实例
// 如果值是一个对象,需要递归遍历对象
var childOb = observe(val);
Object.defineProperty(obj, key, {
get() {...依赖收集跟初始化无关,下面会讲},
set() { .... }
});
}
绘制流程图仅供参考
哈哈哈,上面的很长,有一点点,但是忍不住了。我想更详细一点。好吧,还有一段,但它有点短。答应我,如果你仔细阅读,请发表评论,让我知道有人仔细阅读过
依赖采集过程
采集过程重点是Object.defineProperty设置的get方法
与基本类型数据相比,引用类型的采集方式只是多了几行处理,区别就在于两行代码
childOb.dep.depend,我将其简化为 childOb.dep.addSub(Dep.target)
依赖数组(值)
可以先看源码,如下
function defineReactive(obj, key, value) {
var dep = new Dep();
var val = obj[key]
var childOb = observe(val);
Object.defineProperty(obj, key, {
get() {
var value = val
if (Dep.target) {
// 收集依赖进 dep.subs
dep.addSub(Dep.target);
// 如果值是一个对象,Observer 实例的 dep 也收集一遍依赖
if (childOb) {
childOb.dep.addSub(Dep.target)
if (Array.isArray(value)) {
dependArray(value);
}
}
}
return value
}
});
}
以上源码混合了对象和数组的处理,我们分开讲
1、对象
在数据初始化的过程中,我们已经知道如果值是一个对象,在ob.dep中会额外存储一份依赖
只有一句话
childOb.dep.depend();
数组有另一种处理方式,即
dependArray(value);
看源码,如下
function dependArray(value) {
for (var i = 0, l = value.length; i < l; i++) {
var e = value[i];
// 只有子项是对象的时候,收集依赖进 dep.subs
e && e.__ob__ && e.__ob__.dep.addSub(Dep.target);
// 如果子项还是 数组,那就继续递归遍历
if (Array.isArray(e)) {
dependArray(e);
}
}
}
显然,为了防止数组中的对象,需要保存数组的子项对象的副本。
你一定要问,为什么子对象还要保存一个依赖?
1、页面依赖数组,数组的子项发生了变化。页面是否也需要更新?但是子项的内部变化是如何通知页面更新的呢?所以你还需要为子对象保存一个依赖项吗?
2、数组子项数组的变化就是对象属性的增删。必须使用 Vue 封装方法 set 和 del。set和del会通知依赖更新,所以子项对象也要保存
看栗子
[外链图片传输失败(img-PuPHYChy-59)()]
页面模板
看数组的数据,有两个ob
总结
至此,引用类型和基本类型的区别就很清楚了。
1、引用类型会添加一个__ob__属性,里面收录dep,用来存放采集到的依赖
2、对象使用ob.dep,作用于Vue的自定义方法set和del
3、数组使用ob.dep,作用于Vue重写的数组方法push等。
终于看完了,真的好长,不过我觉得值得
查看全部
文章采集调用(闭包dep:来存储依赖引用数据类型的数据依赖收集
)
上一篇我们分析了基础数据类型的依赖集合
本文是关于引用数据类型的数据依赖采集和分析,因为引用类型数据比较复杂,必须单独写
文章很长,高能预警,做好准备,耐心等待,一定会有收获
不过这两类数据的处理有很多重复,所以我打算只写一些区别,否则会废话很多。
两个步骤,两者都不一样
1、数据初始化
2、依赖集合
数据初始化过程
如果数据类型是引用类型,则需要对数据进行额外处理。
处理分为对象和数组两种,分别讨论。
1 个对象
1、 遍历对象的各个属性,也设置响应性。假设属性都是基本类型,处理流程和上一个一样
2、每个数据对象都会添加一个ob属性
例如,设置子数据对象
在下图中,可以看到子对象处理完后添加了一个ob属性
ob_ 属性有什么用?
你可以观察到 ob 有一个 dep 属性。这个 dep 是不是有点属性?是的,在上一篇关于基本数据类型的文章中提到过
那么这个ob属性有什么用呢?
你可以观察到 ob 有一个 dep 属性。这个 dep 是不是有点属性?是的,在上一篇关于基本数据类型的文章中提到过
dep 正是存储依赖项的位置
比如page指的是data child,watch指的是data child,那么child会将这两个保存在dep.subs中
dep.subs = [ 页面-watcher,watch-watcher ]
但是,在上一篇关于基本类型的文章中,dep 作为闭包存在,而不是任何 [ob.dep]。
是的,这就是引用类型和原创类型的区别
基本数据类型,仅使用 [closure dep] 存储依赖关系
引用数据类型,使用[closure dep]和[ob.dep]存储依赖
什么?你说关闭部门在哪里?嗯,在defineReactive的源码中,大家可以看一下这个方法的源码,下面是
那么,为什么引用类型需要使用 __ob__.dep 来存储依赖呢?
首先要明确一点,存储依赖就是在数据变化时通知依赖,所以ob.dep也是为了变化后的通知
闭包dep只存在于defineReactive中,不能在别处使用,所以需要另存一个以供别处使用
它还会用在哪里?
Vue挂载原型上的set和del方法中,源码如下
function set(target, key, val) {
var ob = (target).__ob__;
// 通知依赖更新
ob.dep.notify();
}
Vue.prototype.$set = set;
function del(target, key) {
var ob = (target).__ob__;
delete target[key];
if (!ob) return
// 通知依赖更新
ob.dep.notify();
}
Vue.prototype.$delete = del;
这两个方法大家都应该用过,为了对象的动态增删属性
但是如果直接添加属性或者删除属性,Vue就无法监听,比如下面
child.xxxx=1
delete child.xxxx
所以必须通过Vue封装的set和del方法来操作
执行完set和del后,需要通知依赖更新,但是怎么通知呢?
此时,[ob.dep] 发挥作用!正因为有依赖关系,所以在 ob.dep 中又采集了一份
使用就是上面那句话,通知更新
ob.dep.notify();
2、数组
1、需要遍历数组,可能数组是对象数组,如下
[{name:1},{name:888}]
遍历的时候,如果子item是一个对象,会和上面解析对象一样操作。
2、保存一个ob属性到数组
例如,设置一个 arr 数组
看到arr数组增加了ob属性
其实这个ob属性和上一段提到的对象的功能类似,这里我们只说ob.dep
数组中的 Ob.dep 还存储依赖项。它是给谁的?
要使用Vue封装的数组方法,要知道如果数组的变化也被监听了,一定要使用Vue封装的数组方法,否则无法实时更新
这里是覆盖方法之一,push,其他的是splice等,Vue官方文档已经说明了。
var original = Array.prototype.push;
Array.prototype.push = function() {
var args = [],
len = arguments.length;
// 复制 传给 push 等方法的参数
while (len--) args[len] = arguments[len];
// 执行 原方法
var result = original.apply(this, args);
var ob = this.__ob__;
// notify change
ob.dep.notify();
return resul
}
可见,执行完数组方法后,还需要通知依赖更新,即通知ob.dep中采集的依赖更新
现在,我们知道响应式数据对引用类型做了哪些额外的处理,主要是添加一个ob属性
我们已经知道ob是干什么用的了,现在看看源码是怎么添加ob的
// 初始化Vue组件的数据
function initData(vm) {
var data = vm.$options.data;
data = vm._data =
typeof data === 'function' ?
data.call(vm, vm) : data || {};
....遍历 data 数据对象的key ,重名检测,合规检测
observe(data, true);
}
function observe(value) {
if (Array.isArray(value) || typeof value == "object") {
ob = new Observer(value);
}
return ob
}
function Observer(value) {
// 给对象生成依赖保存器
this.dep = new Dep();
// 给 每一个对象 添加一个 __ob__ 属性,值为 Observer 实例
value.__ob__ = this
if (Array.isArray(value)) {
// 遍历数组,每一项都需要通过 observe 处理,如果是对象就添加 __ob__
for (var i = 0, l =value.length; i < l; i++) {
observe(value[i]);
}
} else {
var keys = Object.keys(value);
// 给对象的每一个属性设置响应式
for (var i = 0; i < keys.length; i++) {
defineReactive(value, keys[i]);
}
}
};
源码的处理过程和上一个类似,但是处理引用数据类型会多增加几行对源码的额外处理。
我们之前只讲过一种对象数据类型,比如下面
如果嵌套了多层对象怎么办?例如,将如何
是的,Vue 会递归处理。遍历属性,使用defineReactive处理时,递归调用observe处理(源码用红色加粗标记)
如果该值是一个对象,那么还要在该值上添加一个 ob
如果没有,则正常下线并设置响应
源代码如下
function defineReactive(obj, key, value) {
// dep 用于中收集所有 依赖我的 东西
var dep = new Dep();
var val = obj[key]
// 返回的 childOb 是一个 Observer 实例
// 如果值是一个对象,需要递归遍历对象
var childOb = observe(val);
Object.defineProperty(obj, key, {
get() {...依赖收集跟初始化无关,下面会讲},
set() { .... }
});
}
绘制流程图仅供参考
哈哈哈,上面的很长,有一点点,但是忍不住了。我想更详细一点。好吧,还有一段,但它有点短。答应我,如果你仔细阅读,请发表评论,让我知道有人仔细阅读过
依赖采集过程
采集过程重点是Object.defineProperty设置的get方法
与基本类型数据相比,引用类型的采集方式只是多了几行处理,区别就在于两行代码
childOb.dep.depend,我将其简化为 childOb.dep.addSub(Dep.target)
依赖数组(值)
可以先看源码,如下
function defineReactive(obj, key, value) {
var dep = new Dep();
var val = obj[key]
var childOb = observe(val);
Object.defineProperty(obj, key, {
get() {
var value = val
if (Dep.target) {
// 收集依赖进 dep.subs
dep.addSub(Dep.target);
// 如果值是一个对象,Observer 实例的 dep 也收集一遍依赖
if (childOb) {
childOb.dep.addSub(Dep.target)
if (Array.isArray(value)) {
dependArray(value);
}
}
}
return value
}
});
}
以上源码混合了对象和数组的处理,我们分开讲
1、对象
在数据初始化的过程中,我们已经知道如果值是一个对象,在ob.dep中会额外存储一份依赖
只有一句话
childOb.dep.depend();
数组有另一种处理方式,即
dependArray(value);
看源码,如下
function dependArray(value) {
for (var i = 0, l = value.length; i < l; i++) {
var e = value[i];
// 只有子项是对象的时候,收集依赖进 dep.subs
e && e.__ob__ && e.__ob__.dep.addSub(Dep.target);
// 如果子项还是 数组,那就继续递归遍历
if (Array.isArray(e)) {
dependArray(e);
}
}
}
显然,为了防止数组中的对象,需要保存数组的子项对象的副本。
你一定要问,为什么子对象还要保存一个依赖?
1、页面依赖数组,数组的子项发生了变化。页面是否也需要更新?但是子项的内部变化是如何通知页面更新的呢?所以你还需要为子对象保存一个依赖项吗?
2、数组子项数组的变化就是对象属性的增删。必须使用 Vue 封装方法 set 和 del。set和del会通知依赖更新,所以子项对象也要保存
看栗子
[外链图片传输失败(img-PuPHYChy-59)()]
页面模板
看数组的数据,有两个ob
总结
至此,引用类型和基本类型的区别就很清楚了。
1、引用类型会添加一个__ob__属性,里面收录dep,用来存放采集到的依赖
2、对象使用ob.dep,作用于Vue的自定义方法set和del
3、数组使用ob.dep,作用于Vue重写的数组方法push等。
终于看完了,真的好长,不过我觉得值得
文章采集调用(DS打数机才能自动翻页采集数据(图)案例大全)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-14 04:04
一、操作步骤
采集如果有多个页面列表页,需要设置翻页,以便DS打印机自动翻页采集数据。选择一个以翻页为规则的示例URL,您可以使用该规则批量处理采集相似的URL(适用于一页和多页)。以下是大众点评网的一个例子。
二、案例步骤
先复制上面的例子,来到采集列出数据。本教程在上一篇文章文章中已经提到过,不再重复操作。“GooSeeker Copy Batch 采集 列出带有样本的数据”
三、设置翻页
1.1、新建marker thread:选择“Crawler Route”,点击“New”,选择“Marker Clue”,勾选“Continuous Grab”,“Target Subject Name”会自动填写。这意味着该规则被循环调用。
1.2、一旦设置了标记线索,就做了两个映射,第一个是映射翻页块的范围,第二个是映射翻页标记。
第一次是选择翻页区的页面节点进行映射:点击翻页标志,定位到收录它的翻页区所在的页面节点。这些翻页按钮的翻页区域,然后右键节点选择“Lead Mapping”->“Location”->“Clue*”,爬虫路由中的“Location Number”就会映射节点的编号。
第二次是映射翻页标记值所在的页面节点:双击翻页区域节点逐层展开,找到翻页标记所在的节点,这里指的是翻页按钮的文本节点或属性值节点,右击节点选择“线索映射”->“标记映射”,爬虫路由中的“标记值”和“标记位置编号”会映射值和节点的编号。
1.3、定位选项的默认项是数字id。由于不同页码的翻页区的id值可能会发生变化,所以class值通常保持不变,所以最好改成preference class。
四、保存规则并捕获数据
点击保存规则,爬取数据,在DS计数器中查看翻页是否成功。如果翻页采集成功,会在本地DataScraperWorks文件夹中生成多个XML文件。详见文章如何将采集中的xml文件转换为Excel文件?”。 查看全部
文章采集调用(DS打数机才能自动翻页采集数据(图)案例大全)
一、操作步骤
采集如果有多个页面列表页,需要设置翻页,以便DS打印机自动翻页采集数据。选择一个以翻页为规则的示例URL,您可以使用该规则批量处理采集相似的URL(适用于一页和多页)。以下是大众点评网的一个例子。
二、案例步骤
先复制上面的例子,来到采集列出数据。本教程在上一篇文章文章中已经提到过,不再重复操作。“GooSeeker Copy Batch 采集 列出带有样本的数据”
三、设置翻页
1.1、新建marker thread:选择“Crawler Route”,点击“New”,选择“Marker Clue”,勾选“Continuous Grab”,“Target Subject Name”会自动填写。这意味着该规则被循环调用。
1.2、一旦设置了标记线索,就做了两个映射,第一个是映射翻页块的范围,第二个是映射翻页标记。
第一次是选择翻页区的页面节点进行映射:点击翻页标志,定位到收录它的翻页区所在的页面节点。这些翻页按钮的翻页区域,然后右键节点选择“Lead Mapping”->“Location”->“Clue*”,爬虫路由中的“Location Number”就会映射节点的编号。
第二次是映射翻页标记值所在的页面节点:双击翻页区域节点逐层展开,找到翻页标记所在的节点,这里指的是翻页按钮的文本节点或属性值节点,右击节点选择“线索映射”->“标记映射”,爬虫路由中的“标记值”和“标记位置编号”会映射值和节点的编号。
1.3、定位选项的默认项是数字id。由于不同页码的翻页区的id值可能会发生变化,所以class值通常保持不变,所以最好改成preference class。
四、保存规则并捕获数据
点击保存规则,爬取数据,在DS计数器中查看翻页是否成功。如果翻页采集成功,会在本地DataScraperWorks文件夹中生成多个XML文件。详见文章如何将采集中的xml文件转换为Excel文件?”。
文章采集调用(文章采集调用webhookspider与ss-send等接口采集,提供开源接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-12 22:02
文章采集调用webhookspider与ss-send等接口采集,提供开源接口可以用在线-stats-api,
第一,用golang写爬虫,只要你熟悉golang一个星期学习就会了。这是我用过比较容易上手的一门语言,速度也快。但是,我现在是用ruby开发爬虫。第二,推荐比较有名的gayhub上的一个开源爬虫工具pokes,开源,成熟。我用这个爬虫可以发布在快手、陌陌、探探、趣头条等等。这个应该适合题主,如果有疑问可以到pokesgithub页面上留言。
其实你就是想了解scrapy可以做到什么效果呗,请移步各种flatpages,各种scrapy示例和教程(xwliwubo/scrapy-doc:focusinlightweightscrapydocumentation),里面有很多入门介绍、数据加载和处理等等的算法、规则等等python程序员比较常用的库,前端爬虫基本上也是通过python+beautifulsoup处理图片、正则表达式等等。
根据经验,大部分抓取的数据都可以用现成的库封装好,或者自己封装python程序库,最后通过工具链发送出去。
可以看下我们公司出的这个爬虫系列教程,通俗易懂,分门别类全面的讲解了爬虫基础、高效爬虫、scrapy快速入门及开发等内容, 查看全部
文章采集调用(文章采集调用webhookspider与ss-send等接口采集,提供开源接口)
文章采集调用webhookspider与ss-send等接口采集,提供开源接口可以用在线-stats-api,
第一,用golang写爬虫,只要你熟悉golang一个星期学习就会了。这是我用过比较容易上手的一门语言,速度也快。但是,我现在是用ruby开发爬虫。第二,推荐比较有名的gayhub上的一个开源爬虫工具pokes,开源,成熟。我用这个爬虫可以发布在快手、陌陌、探探、趣头条等等。这个应该适合题主,如果有疑问可以到pokesgithub页面上留言。
其实你就是想了解scrapy可以做到什么效果呗,请移步各种flatpages,各种scrapy示例和教程(xwliwubo/scrapy-doc:focusinlightweightscrapydocumentation),里面有很多入门介绍、数据加载和处理等等的算法、规则等等python程序员比较常用的库,前端爬虫基本上也是通过python+beautifulsoup处理图片、正则表达式等等。
根据经验,大部分抓取的数据都可以用现成的库封装好,或者自己封装python程序库,最后通过工具链发送出去。
可以看下我们公司出的这个爬虫系列教程,通俗易懂,分门别类全面的讲解了爬虫基础、高效爬虫、scrapy快速入门及开发等内容,
文章采集调用(如何直接在nodejs页面中访问splash页面上访问页面)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-11 17:06
文章采集调用splash开发通用githubpage的功能都采用wordpress编写。优点是可扩展性强,通用性高,还可以像zendfish这种hook机制扩展各种参数及解析得到的github页面。缺点是部署维护比较麻烦,且不像freelancer社区推崇的快速制作插件。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中搜索splashpageforwordpress安装扩展。下载地址,查看sfbeta版本,下载之后wordpress插件安装好了,可以通过安装npm包来创建github页面。如何直接在nodejs页面中访问splash页面:wordpress-splash-page文章编辑器使用wordpress开发的编辑器,也就是onepagebutton这种方式。
优点是可以复用原来的vue的页面结构,同时方便维护及更换其他wordpress插件。缺点是nodejs支持度太差,如果你要追求巨大的流量,你就不用想其他插件的安装和运行了。同时你要有一定的开发语言和运行环境基础。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中访问splash页面。安装php开发工具。没有解决nodejs兼容性问题。也就是数据类型显示的各种问题,为了避免这个问题,可以把php安装类型设置为bash及gvim等visualstudio支持的编辑器。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中访问splash页面。引入wordpress开发的url模板文件。对于php的splash页面而言,是用ruby\java\go或wordpress.php等路径来定义的页面。而对于ps/ppt等其他图形语言而言,是用pathname来定义页面,如下图所示:1.在php/extensions/urls.php中添加相应的url资源路径,重定向到对应页面。
最后在浏览器访问/splash/可以访问以上页面。2.在php/extensions/urls.php中添加相应的url资源路径,重定向到对应页面。最后在浏览器访问/splash/可以访问以上页面。3.加入浏览器loading缓存,如果浏览器都是在vscode环境下运行,那么跳转到页面cd,wordpress这种在线visualstudio可运行于浏览器上的编辑器就会重定向在php端。
4.使用spacerebug插件扫描浏览器loading缓存记录如果你的wordpress拥有loading缓存功能,那么可以扫描浏览器的loading缓存记录,这样当访问该链接时,前端代码就不需要后端代码来初始化你的请求,就可以在浏览器端安全地访问你要爬取的页面。githubpie这个插件。 查看全部
文章采集调用(如何直接在nodejs页面中访问splash页面上访问页面)
文章采集调用splash开发通用githubpage的功能都采用wordpress编写。优点是可扩展性强,通用性高,还可以像zendfish这种hook机制扩展各种参数及解析得到的github页面。缺点是部署维护比较麻烦,且不像freelancer社区推崇的快速制作插件。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中搜索splashpageforwordpress安装扩展。下载地址,查看sfbeta版本,下载之后wordpress插件安装好了,可以通过安装npm包来创建github页面。如何直接在nodejs页面中访问splash页面:wordpress-splash-page文章编辑器使用wordpress开发的编辑器,也就是onepagebutton这种方式。
优点是可以复用原来的vue的页面结构,同时方便维护及更换其他wordpress插件。缺点是nodejs支持度太差,如果你要追求巨大的流量,你就不用想其他插件的安装和运行了。同时你要有一定的开发语言和运行环境基础。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中访问splash页面。安装php开发工具。没有解决nodejs兼容性问题。也就是数据类型显示的各种问题,为了避免这个问题,可以把php安装类型设置为bash及gvim等visualstudio支持的编辑器。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中访问splash页面。引入wordpress开发的url模板文件。对于php的splash页面而言,是用ruby\java\go或wordpress.php等路径来定义的页面。而对于ps/ppt等其他图形语言而言,是用pathname来定义页面,如下图所示:1.在php/extensions/urls.php中添加相应的url资源路径,重定向到对应页面。
最后在浏览器访问/splash/可以访问以上页面。2.在php/extensions/urls.php中添加相应的url资源路径,重定向到对应页面。最后在浏览器访问/splash/可以访问以上页面。3.加入浏览器loading缓存,如果浏览器都是在vscode环境下运行,那么跳转到页面cd,wordpress这种在线visualstudio可运行于浏览器上的编辑器就会重定向在php端。
4.使用spacerebug插件扫描浏览器loading缓存记录如果你的wordpress拥有loading缓存功能,那么可以扫描浏览器的loading缓存记录,这样当访问该链接时,前端代码就不需要后端代码来初始化你的请求,就可以在浏览器端安全地访问你要爬取的页面。githubpie这个插件。
文章采集调用(爬虫应该怎么进行测试?的测试方法应该如何进行?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-10 13:18
很多同学不知道应该如何测试爬虫。我也是刚接触一点爬虫测试的新手。通过对爬虫的分析,总结了爬虫的测试方法。其他建议欢迎补充。
一、测试阶段
对于data采集调用第三方平台(比如scorpion)的流程大家可能比较熟悉。在第三方页面授权后,第三方会帮我们完成data采集的任务。我们只需要等待结果被回调。但是如果要自己做爬虫,又是一个什么样的过程呢?
其实爬虫和其他业务一样,也是有流程的。一般是先触发创建任务,爬虫模块对数据采集进行处理,采集完成后,对数据进行解析和存储。对于授权爬虫来说,有SDK页面的也可以直接通过页面进行请求,其他的只能通过请求接口实现。还有一种爬虫,在后台配置好任务后,会定期去网站爬取数据,更新数据库。当然还有很多其他的交互逻辑,每一步都需要分析评估。
因此,我们可以从创建任务的界面入手,连接整个流程,在界面的响应中加入简单的验证。比如创建任务后有任务编号,通过查询接口可以得到任务的结果数据。然后检查数据是否存储,存储是否准确,是否会出现乱码等。从界面入手的好处是我们可以自动化检查爬虫任务,检查数据是否可以创建,是否爬虫能否正常爬取,爬取结果是否入库。解析的逻辑和存储的准确性需要注意。爬虫结果数据的存储与数据分析和应用有关。对于数据分析,如果源数据有误,那么无论分析结果如何,都是没有意义的。.
总结
1.接口测试,调用数据接口采集,测试爬虫进程;接口基础测试和弱网、接口安全、接口性能等。
2.可以通过接口或者SDK测试场景,包括爬取成功的场景和失败的场景,比如无数据和无效数据。
3.完成采集后的分析和存储测试,数据分析和存储逻辑检查。
4.异常测试,主要针对系统间交互的处理逻辑,如失败重试机制、服务间容错机制等。
5.爬虫质量和效率,主要从整体设计和代码实现来分析爬虫的处理方式是否高可用。
二、在线阶段
一旦爬虫上线供其他业务方使用,就需要保证可用性和可靠性。对于爬虫来说,在线监控非常重要!不仅要保证提供的爬虫能够正常运行,还要保证出现异常时,能够在最短的时间内解决。因此,监测应从以下三个方面入手:
1.在线运行接口脚本监控提供的接口可以正常使用,而不是等业务方调整好基础接口,再反馈修复,成本比较大。主动调整界面,判断程序是否正常。您只能验证该接口是否可以运行。如果条件允许,在线运行真实数据并验证结果。
2.监控线上发生的异常情况,如创建任务失败、登录失败、数据采集失败、数据解析失败、回调失败、数据存储失败等。发展应尽快查明原因,尽快找到解决。
3.监控目标网站的状态,可以通过web自动监控目标网站是否可用,是否发生变化等。
对于爬虫来说,稳定性很重要,但是很多不可控的因素会导致爬虫的成功率下降。通过采取良好的监控和预防措施,我们可以将事故发生时的风险降到最低。 查看全部
文章采集调用(爬虫应该怎么进行测试?的测试方法应该如何进行?)
很多同学不知道应该如何测试爬虫。我也是刚接触一点爬虫测试的新手。通过对爬虫的分析,总结了爬虫的测试方法。其他建议欢迎补充。
一、测试阶段
对于data采集调用第三方平台(比如scorpion)的流程大家可能比较熟悉。在第三方页面授权后,第三方会帮我们完成data采集的任务。我们只需要等待结果被回调。但是如果要自己做爬虫,又是一个什么样的过程呢?
其实爬虫和其他业务一样,也是有流程的。一般是先触发创建任务,爬虫模块对数据采集进行处理,采集完成后,对数据进行解析和存储。对于授权爬虫来说,有SDK页面的也可以直接通过页面进行请求,其他的只能通过请求接口实现。还有一种爬虫,在后台配置好任务后,会定期去网站爬取数据,更新数据库。当然还有很多其他的交互逻辑,每一步都需要分析评估。
因此,我们可以从创建任务的界面入手,连接整个流程,在界面的响应中加入简单的验证。比如创建任务后有任务编号,通过查询接口可以得到任务的结果数据。然后检查数据是否存储,存储是否准确,是否会出现乱码等。从界面入手的好处是我们可以自动化检查爬虫任务,检查数据是否可以创建,是否爬虫能否正常爬取,爬取结果是否入库。解析的逻辑和存储的准确性需要注意。爬虫结果数据的存储与数据分析和应用有关。对于数据分析,如果源数据有误,那么无论分析结果如何,都是没有意义的。.
总结
1.接口测试,调用数据接口采集,测试爬虫进程;接口基础测试和弱网、接口安全、接口性能等。
2.可以通过接口或者SDK测试场景,包括爬取成功的场景和失败的场景,比如无数据和无效数据。
3.完成采集后的分析和存储测试,数据分析和存储逻辑检查。
4.异常测试,主要针对系统间交互的处理逻辑,如失败重试机制、服务间容错机制等。
5.爬虫质量和效率,主要从整体设计和代码实现来分析爬虫的处理方式是否高可用。
二、在线阶段
一旦爬虫上线供其他业务方使用,就需要保证可用性和可靠性。对于爬虫来说,在线监控非常重要!不仅要保证提供的爬虫能够正常运行,还要保证出现异常时,能够在最短的时间内解决。因此,监测应从以下三个方面入手:
1.在线运行接口脚本监控提供的接口可以正常使用,而不是等业务方调整好基础接口,再反馈修复,成本比较大。主动调整界面,判断程序是否正常。您只能验证该接口是否可以运行。如果条件允许,在线运行真实数据并验证结果。
2.监控线上发生的异常情况,如创建任务失败、登录失败、数据采集失败、数据解析失败、回调失败、数据存储失败等。发展应尽快查明原因,尽快找到解决。
3.监控目标网站的状态,可以通过web自动监控目标网站是否可用,是否发生变化等。
对于爬虫来说,稳定性很重要,但是很多不可控的因素会导致爬虫的成功率下降。通过采取良好的监控和预防措施,我们可以将事故发生时的风险降到最低。
文章采集调用(文章采集调用的高级设置-extensions-advanced-script查看userprofile以及timeline的计数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-10 05:05
文章采集调用的kpi_based_login接口(感谢@rhomy的指正),请在chrome的设置-高级设置-extensions-advanced-script查看userprofile以及timeline下面的计数。ps:建议读者先看看官方文档:-based-login安装indexjs依赖:这是个很大的坑,我建议直接在文章里面做脚本,webpack-plugin-script-advanced-script-start:先编译vue-markouth.css,发布到indexjs项目:编译的流程如下图所示:编译indexjs的源代码:设置extensions的advancedscript:找到输出中的userprofiles,点击进入login列表:点击view,浏览器会显示账号的状态(安全、非安全)以及一个cookie,用户通过cookie的唯一标识:用户输入账号密码,只要输入一次,账号密码可以推送到服务器,这样就可以实现你需要的效果了。
@吴泽龙回答里已经给出了,我也补充一下他的误区吧1.hookextensions只是为原来的需要抽样的脚本提供了多一次构造时间戳的方法,应该是为了模拟类似cookie/httpsocket这样的事件。2.github的timeline浏览时点击时间是按照kpi-id-login获取的。一次构造一个时间戳,并且每个时间戳不重复3.时间戳的形式不知道是什么形式。
你描述里面显示的列表时间是datetime_index.html,kpi的时间戳是通过useragent获取的时间戳,也是按照kpi-id-login获取的。 查看全部
文章采集调用(文章采集调用的高级设置-extensions-advanced-script查看userprofile以及timeline的计数)
文章采集调用的kpi_based_login接口(感谢@rhomy的指正),请在chrome的设置-高级设置-extensions-advanced-script查看userprofile以及timeline下面的计数。ps:建议读者先看看官方文档:-based-login安装indexjs依赖:这是个很大的坑,我建议直接在文章里面做脚本,webpack-plugin-script-advanced-script-start:先编译vue-markouth.css,发布到indexjs项目:编译的流程如下图所示:编译indexjs的源代码:设置extensions的advancedscript:找到输出中的userprofiles,点击进入login列表:点击view,浏览器会显示账号的状态(安全、非安全)以及一个cookie,用户通过cookie的唯一标识:用户输入账号密码,只要输入一次,账号密码可以推送到服务器,这样就可以实现你需要的效果了。
@吴泽龙回答里已经给出了,我也补充一下他的误区吧1.hookextensions只是为原来的需要抽样的脚本提供了多一次构造时间戳的方法,应该是为了模拟类似cookie/httpsocket这样的事件。2.github的timeline浏览时点击时间是按照kpi-id-login获取的。一次构造一个时间戳,并且每个时间戳不重复3.时间戳的形式不知道是什么形式。
你描述里面显示的列表时间是datetime_index.html,kpi的时间戳是通过useragent获取的时间戳,也是按照kpi-id-login获取的。
文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2022-02-07 06:19
介绍
AnyMetrics - 面向开发人员的、声明性的 Metrics 采集 和监控系统,可以对结构化和非结构化、有界和无界数据执行 采集,通过提取、过滤、逻辑运算等,将结果存储起来在流行的监控系统或存储引擎(如Prometheus、ES)中构建完整的监控系统,用grafana完成数据可视化
数据采集、提取、过滤、存储等都是由配置驱动,无需额外开发。对应AnyMetrics,分别配置数据源、采集规则、采集器。基于这些配置,AnyMetrics 将使用 pipeline 的方式自动完成从 data采集 到数据存储的所有工作
对于有界数据的任务,AnyMetrics 将以固定频率从数据源中提取数据。AnyMetrics 具有内置的 MySQL 数据源。对于具有无限数据的任务,AnyMetrics 会在一个时间窗口内从数据源中拉取数据。批量拉取数据,AnyMetrics 内置 Kafka 类型无界数据源
AnyMetrics的数据源可以是任何系统,例如可以将HTTP请求结果作为数据源,也可以将ES检索结果作为数据源
将非结构化数据转换为结构化数据的目的,可以通过对数据源的原创数据进行提取和过滤来实现。AnyMetrics 中有两个内置的采集规则(Filter),正则表达式和 Spring EL 表达式。完成数据的提取和过滤,使用Spring EL表达式对原创数据和正则表达式提取后的数据完成逻辑运算。过滤器可单独使用或组合使用。FilterChain的方式是顺序执行的
数据提取和过滤后,下一步就是将数据以指定的方式存储在目标系统中。Prometheus 采集器内置于 AnyMetrics 中。通过定义 Metrics,可以将数据推送到 Prometheus 的 PushGateway。
AnyMetrics 的采集器可以将数据推送到任何系统,例如 MySQL、ES 甚至是 WebHook
无论是采集规则配置还是采集器配置,都可以通过可变配置来完成动态配置的替换。变量数据来自正则表达式Filter,通过定义如(.*)可以得到一个名为$1的变量,有Spring EL的地方可以使用#$1来使用变量,其他地方可以使用$1使用变量,以满足从数据提取到数据的重组或者操作操作,什么配置可以支持变量或者Spring EL表达式 根据采集规则和采集器的具体实现,Spring内置的表达式配置AnyMetrics 的 EL 过滤器和 Prometheus 采集器中的值配置支持 Spring EL 表达式和变量(#$1),
AnyMetrics采用插件化设计方式,无论是数据源、采集规则还是采集器都可以扩展。甚至 AnyMetrics 中的内置插件也是以点对点的方式实现的。加载和使用什么插件完全由声明决定。配置
建筑学
技术栈
SpringBoot + Nacos + Vue + ElementUI
安装
启动前需要安装的依赖
安装 nacos(必填)
安装普罗米修斯(可选)
安装推送网关(可选)
启动
启动 AnyMeitris
1 mvn clean package
2 cd boot/target
3 java -Dnacos.address=nacos.ip:8848 -Dnacos.config.dataId=AnyMetricsConfig -Dnacos.config.group=config.app.AnyMetrics -Dauto=true -jar AnyMetrics-boot.jar
启动参数说明
通过 nacos.address 参数指定nacos地址
通过 nacos.config.dataId 参数指定配置在nacos的dataId,默认值为 AnyMetricsConfig
通过 nacos.config.group 参数指定配置在nacos的group,默认值为 DEFAULT
通过 auto 参数控制任务是否自启动,默认值为 false
启动后访问:8080/index.html
如何配置
1、选择任务类型
2.1、有界数据
选择调度间隔,以秒为单位
2.2、选择数据源
选择数据源为mysql(目前只支持mysql),并完善相关配置
3.1、无限数据
输入时间窗口,单位:秒
3.2、选择数据源
选择kafka作为数据源(目前只支持kafka),并完善相关配置
4、采集规则
过滤器支持两种类型,regular 和 el。在正则中使用括号来提取所需的变量。多个变量以 $1、$2 ... $N 的形式命名。在el中,可以使用_#$1 _变量来执行操作
5、采集器
选择prometheus(目前只支持prometheus)并完善metrics相关配置信息,type支持gauge、counter、histogram类型,labels支持$1变量,value支持Spring EL表达式变量操作
运行任务
1、开始任务
点击开始按钮开始任务
2、查看运行日志
点击日志选项卡,查询任务运行日志
3、iframe
点击iframe Tab,将外部系统嵌入到任务中,比如将grafana的dashboard链接嵌入到系统中进行展示
4、停止任务
单击停止按钮以停止任务
例子
示例一:APM 监控 - 采集 所有执行时间超过 3 秒的慢速链接并配置警报策略
1、设置kafka为数据源
从 kafka 读取跟踪日志
{
"groupId":"anymetrics_apm_slow_trace",
"kafkaAddress":"192.168.0.1:9092",
"topic":"p_bigtracer_metric_log",
"type":"kafka"
}
2、设置采集规则
通话记录是结构化数据,例如:
1617953102329,operation-admin-web,10.8.60.41,RESOURCE_MYSQL_LOG,com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList,1,1,0,0,1
因此,第一步是使用正则规则对数据进行提取和过滤,对应的正则规则为:
(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?)
提取的数据为:
{
"$4":"RESOURCE_MYSQL_LOG",
"$5":"com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList",
"$6":"1",
"$7":"1",
"$10":"1",
"$8":"0",
"$9":"0",
"$1":"1617953102329",
"$2":"operation-admin-web",
"$3":"10.8.60.41"
}
我们有 10 个变量,从 1 美元到 10 美元。由于我们监控的是超过3秒的慢速链接,我们只需要采集RT超过3秒的日志数据,所以我们需要定义一个逻辑运算表达式Filter,对应的EL表达式公式为:
(new java.lang.Double(#$10) / #$6) > 3000
其中#$10是链接的总响应时间,#$6是接口的总调用次数,先通过#$10/#$6运算得到平均RT,再通过(#$10/#$过滤掉3 6) > 3000 几秒内的慢速链接数据
根据以上两条采集规则,完整配置为:
{
"timeWindow": 40,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\n",
"type": "regular"
},
{
"expression": "(new java.lang.Double(#$10) / #$6) > 3000",
"type": "el"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_apm_slow_trace",
"labelNames": [
"application",
"type",
"endpoint"
],
"name": "anymetrics_apm_slow_trace",
"type": "gauge",
"value": "new java.lang.Double(#$10) / #$6",
"labels": [
"$2",
"$4",
"$5"
]
}
],
"type": "prometheus",
"job": "anymetrics_apm_slow_trace"
}
promethus的metrics需要定义,名字是anymetrics_apm_slow_trace,类型是gauge,lableNames使用application,type,endpoint,对应变量$2、$4、$5,因为响应时间采集RT,所以值为#$10 / #$6
其中#$10是链接的总响应时间,#$6是接口的总调用次数,通过#$10/#$6的运算得到平均RT
4、配置警报和可视化
4.1 可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_apm_slow_trace{}
关于 PromQL 可以参考
4.2 配置 Grafana 警报
在面板中选择警报选项卡以定义警报规则,例如:
每 1m 评估 1m
条件
NoData 和错误处理
通知
一个比较完整的APM监控组合如下:
通过调用链log采集不同维度的metrics,完成对链路RT、项目错误数、项目平均RT、链路RT分布等的多维度监控。
示例2:可视化注册用户总数
1、设置mysql为数据源
根据sql查询总用户数
{
"password": "root",
"jdbcurl": "jdbc:mysql://192.168.0.1:3306/user",
"type": "mysql",
"sql": "select count(1) from user",
"username": "root"
}
2、设置采集规则
根据sql查询的结果,提取count(1),用正则表达式采集规则:
{
"kind": "schedule",
"interval": 5,
"filters": [
{
"expression": "\\{\\\"count\\(1\\)\\\":(.*)\\}",
"type": "regular"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_member_count",
"name": "anymetrics_member_count",
"type": "gauge",
"value": "#$1"
}
],
"type": "prometheus",
"job": "anymetrics_member_count"
}
promethus的metrics需要定义,名字是anymetrics_member_count,类型是gauge,因为只需要采集用户总数,所以不需要定义labels和labelNames,值为#$1
4、配置可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_member_count{}
示例 3:Nginx 日志监控
Nginx请求延迟监控,Nginx状态码监控
1、设置kafka为数据源
使用 nginx access_log 日志
{
"groupId":"anymetrics_nginx",
"kafkaAddress":"192.168.0.1:9092",
"topic":"nginx_access_log",
"type":"kafka"
}
2、设置采集规则
假设nginx的log_format配置如下:
log_format main '"$http_x_forwarded_for" $remote_addr - $remote_user [$time_local] $http_host "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $upstream_addr $request_method $upstream_status $upstream_response_time';
因此,在第一步中,使用正则Filter对数据进行提取和过滤,对应的正则为:
(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
提取的数据为:
$1:"-"
$2:192.168.198.17
$3: -
$4:13/Apr/2021:10:48:14 +0800
$5:dev.api.com
$6:POST
$7:/yxy-api-gateway/api/json/yuandouActivity/access
$8:HTTP/1.1"
$9:200
$10:87
$11:http://192.168.0.1:8100/yxy-ed ... 3D123
$12:Mozilla/5.0 (iPhone; CPU iPhone OS 13_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko)Mobile/15E148 MicroMessenger/7.0.11(0x17000b21)NetType/WIFI Language/zh_CN
$13:10.8.43.18:8080
$14:POST
$15:200
$16:0.005
一共得到了16个变量,通过对比log_format就可以知道每个变量的含义
完整的采集规则配置为:
{
"timeWindow": 30,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
"type": "regular"
}
]
}
3、设置采集器
采集每个请求的响应时间和请求的状态码,并将数据存储在promethus中
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "nginx_log_host_status",
"labelNames": [
"host",
"status"
],
"name": "nginx_log_host_status",
"type": "gauge",
"value": "1",
"labels": [
"$5",
"$9"
]
},
{
"help": "nginx_log_req_rt (seconds)",
"labelNames": [
"host",
"endpoint"
],
"name": "nginx_log_req_rt",
"type": "gauge",
"value": "new java.lang.Double(#$16)",
"labels": [
"$5",
"$7"
]
}
],
"type": "prometheus",
"job": "anymetrics_nginx_log"
}
4、配置可视化
Nginx状态码监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_host_status{}
Nginx 请求延迟监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_req_rt{}
问答
如何采集 APM 日志?
如果系统中有调用链跟踪系统,可以使用调用链日志,或者通过定义拦截器来记录目标方法。定义好日志格式后,可以直接逐行打印,也可以在内存中聚合后以固定频率打印,日志一般收录RT延迟、错误/成功次数、端点、应用等关键数据。
日志是如何采集到kafka的?
可以使用filebeat采集nginx的access_log和tomcat的应用日志到kafka
目前支持哪些数据源?
有界数据目前支持mysql、http;无界数据目前支持kafka
目前支持哪些采集器?
目前只支持prometheus,使用pushgateway推送数据到prometheus
如果我已经使用了 Skywalking 和 Zipkin 等呼叫链跟踪系统,是否需要使用 AnyMetrics?
两者之间没有冲突。调用链跟踪系统采集链路的调用关系和APM指标数据。AnyMetrics不仅可以将结构化调用链跟踪系统的指标日志作为数据源来监控系统,还可以将结构化日志作为数据源来监控系统运行,比如监控一些Exception事件,还可以可视化或监控数据库表数据。同时,AnyMetrics 支持跨平台系统,任何系统生成的日志都可以作为数据源。监控系统运行
最后附上github项目地址: 查看全部
文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
介绍
AnyMetrics - 面向开发人员的、声明性的 Metrics 采集 和监控系统,可以对结构化和非结构化、有界和无界数据执行 采集,通过提取、过滤、逻辑运算等,将结果存储起来在流行的监控系统或存储引擎(如Prometheus、ES)中构建完整的监控系统,用grafana完成数据可视化
数据采集、提取、过滤、存储等都是由配置驱动,无需额外开发。对应AnyMetrics,分别配置数据源、采集规则、采集器。基于这些配置,AnyMetrics 将使用 pipeline 的方式自动完成从 data采集 到数据存储的所有工作
对于有界数据的任务,AnyMetrics 将以固定频率从数据源中提取数据。AnyMetrics 具有内置的 MySQL 数据源。对于具有无限数据的任务,AnyMetrics 会在一个时间窗口内从数据源中拉取数据。批量拉取数据,AnyMetrics 内置 Kafka 类型无界数据源
AnyMetrics的数据源可以是任何系统,例如可以将HTTP请求结果作为数据源,也可以将ES检索结果作为数据源
将非结构化数据转换为结构化数据的目的,可以通过对数据源的原创数据进行提取和过滤来实现。AnyMetrics 中有两个内置的采集规则(Filter),正则表达式和 Spring EL 表达式。完成数据的提取和过滤,使用Spring EL表达式对原创数据和正则表达式提取后的数据完成逻辑运算。过滤器可单独使用或组合使用。FilterChain的方式是顺序执行的
数据提取和过滤后,下一步就是将数据以指定的方式存储在目标系统中。Prometheus 采集器内置于 AnyMetrics 中。通过定义 Metrics,可以将数据推送到 Prometheus 的 PushGateway。
AnyMetrics 的采集器可以将数据推送到任何系统,例如 MySQL、ES 甚至是 WebHook
无论是采集规则配置还是采集器配置,都可以通过可变配置来完成动态配置的替换。变量数据来自正则表达式Filter,通过定义如(.*)可以得到一个名为$1的变量,有Spring EL的地方可以使用#$1来使用变量,其他地方可以使用$1使用变量,以满足从数据提取到数据的重组或者操作操作,什么配置可以支持变量或者Spring EL表达式 根据采集规则和采集器的具体实现,Spring内置的表达式配置AnyMetrics 的 EL 过滤器和 Prometheus 采集器中的值配置支持 Spring EL 表达式和变量(#$1),
AnyMetrics采用插件化设计方式,无论是数据源、采集规则还是采集器都可以扩展。甚至 AnyMetrics 中的内置插件也是以点对点的方式实现的。加载和使用什么插件完全由声明决定。配置
建筑学
技术栈
SpringBoot + Nacos + Vue + ElementUI
安装
启动前需要安装的依赖
安装 nacos(必填)
安装普罗米修斯(可选)
安装推送网关(可选)
启动
启动 AnyMeitris
1 mvn clean package
2 cd boot/target
3 java -Dnacos.address=nacos.ip:8848 -Dnacos.config.dataId=AnyMetricsConfig -Dnacos.config.group=config.app.AnyMetrics -Dauto=true -jar AnyMetrics-boot.jar
启动参数说明
通过 nacos.address 参数指定nacos地址
通过 nacos.config.dataId 参数指定配置在nacos的dataId,默认值为 AnyMetricsConfig
通过 nacos.config.group 参数指定配置在nacos的group,默认值为 DEFAULT
通过 auto 参数控制任务是否自启动,默认值为 false
启动后访问:8080/index.html
如何配置
1、选择任务类型
2.1、有界数据
选择调度间隔,以秒为单位
2.2、选择数据源
选择数据源为mysql(目前只支持mysql),并完善相关配置
3.1、无限数据
输入时间窗口,单位:秒
3.2、选择数据源
选择kafka作为数据源(目前只支持kafka),并完善相关配置
4、采集规则
过滤器支持两种类型,regular 和 el。在正则中使用括号来提取所需的变量。多个变量以 $1、$2 ... $N 的形式命名。在el中,可以使用_#$1 _变量来执行操作
5、采集器
选择prometheus(目前只支持prometheus)并完善metrics相关配置信息,type支持gauge、counter、histogram类型,labels支持$1变量,value支持Spring EL表达式变量操作
运行任务
1、开始任务
点击开始按钮开始任务
2、查看运行日志
点击日志选项卡,查询任务运行日志
3、iframe
点击iframe Tab,将外部系统嵌入到任务中,比如将grafana的dashboard链接嵌入到系统中进行展示
4、停止任务
单击停止按钮以停止任务
例子
示例一:APM 监控 - 采集 所有执行时间超过 3 秒的慢速链接并配置警报策略
1、设置kafka为数据源
从 kafka 读取跟踪日志
{
"groupId":"anymetrics_apm_slow_trace",
"kafkaAddress":"192.168.0.1:9092",
"topic":"p_bigtracer_metric_log",
"type":"kafka"
}
2、设置采集规则
通话记录是结构化数据,例如:
1617953102329,operation-admin-web,10.8.60.41,RESOURCE_MYSQL_LOG,com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList,1,1,0,0,1
因此,第一步是使用正则规则对数据进行提取和过滤,对应的正则规则为:
(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?)
提取的数据为:
{
"$4":"RESOURCE_MYSQL_LOG",
"$5":"com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList",
"$6":"1",
"$7":"1",
"$10":"1",
"$8":"0",
"$9":"0",
"$1":"1617953102329",
"$2":"operation-admin-web",
"$3":"10.8.60.41"
}
我们有 10 个变量,从 1 美元到 10 美元。由于我们监控的是超过3秒的慢速链接,我们只需要采集RT超过3秒的日志数据,所以我们需要定义一个逻辑运算表达式Filter,对应的EL表达式公式为:
(new java.lang.Double(#$10) / #$6) > 3000
其中#$10是链接的总响应时间,#$6是接口的总调用次数,先通过#$10/#$6运算得到平均RT,再通过(#$10/#$过滤掉3 6) > 3000 几秒内的慢速链接数据
根据以上两条采集规则,完整配置为:
{
"timeWindow": 40,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\n",
"type": "regular"
},
{
"expression": "(new java.lang.Double(#$10) / #$6) > 3000",
"type": "el"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_apm_slow_trace",
"labelNames": [
"application",
"type",
"endpoint"
],
"name": "anymetrics_apm_slow_trace",
"type": "gauge",
"value": "new java.lang.Double(#$10) / #$6",
"labels": [
"$2",
"$4",
"$5"
]
}
],
"type": "prometheus",
"job": "anymetrics_apm_slow_trace"
}
promethus的metrics需要定义,名字是anymetrics_apm_slow_trace,类型是gauge,lableNames使用application,type,endpoint,对应变量$2、$4、$5,因为响应时间采集RT,所以值为#$10 / #$6
其中#$10是链接的总响应时间,#$6是接口的总调用次数,通过#$10/#$6的运算得到平均RT
4、配置警报和可视化
4.1 可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_apm_slow_trace{}
关于 PromQL 可以参考
4.2 配置 Grafana 警报
在面板中选择警报选项卡以定义警报规则,例如:
每 1m 评估 1m
条件
NoData 和错误处理
通知
一个比较完整的APM监控组合如下:
通过调用链log采集不同维度的metrics,完成对链路RT、项目错误数、项目平均RT、链路RT分布等的多维度监控。
示例2:可视化注册用户总数
1、设置mysql为数据源
根据sql查询总用户数
{
"password": "root",
"jdbcurl": "jdbc:mysql://192.168.0.1:3306/user",
"type": "mysql",
"sql": "select count(1) from user",
"username": "root"
}
2、设置采集规则
根据sql查询的结果,提取count(1),用正则表达式采集规则:
{
"kind": "schedule",
"interval": 5,
"filters": [
{
"expression": "\\{\\\"count\\(1\\)\\\":(.*)\\}",
"type": "regular"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_member_count",
"name": "anymetrics_member_count",
"type": "gauge",
"value": "#$1"
}
],
"type": "prometheus",
"job": "anymetrics_member_count"
}
promethus的metrics需要定义,名字是anymetrics_member_count,类型是gauge,因为只需要采集用户总数,所以不需要定义labels和labelNames,值为#$1
4、配置可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_member_count{}
示例 3:Nginx 日志监控
Nginx请求延迟监控,Nginx状态码监控
1、设置kafka为数据源
使用 nginx access_log 日志
{
"groupId":"anymetrics_nginx",
"kafkaAddress":"192.168.0.1:9092",
"topic":"nginx_access_log",
"type":"kafka"
}
2、设置采集规则
假设nginx的log_format配置如下:
log_format main '"$http_x_forwarded_for" $remote_addr - $remote_user [$time_local] $http_host "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $upstream_addr $request_method $upstream_status $upstream_response_time';
因此,在第一步中,使用正则Filter对数据进行提取和过滤,对应的正则为:
(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
提取的数据为:
$1:"-"
$2:192.168.198.17
$3: -
$4:13/Apr/2021:10:48:14 +0800
$5:dev.api.com
$6:POST
$7:/yxy-api-gateway/api/json/yuandouActivity/access
$8:HTTP/1.1"
$9:200
$10:87
$11:http://192.168.0.1:8100/yxy-ed ... 3D123
$12:Mozilla/5.0 (iPhone; CPU iPhone OS 13_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko)Mobile/15E148 MicroMessenger/7.0.11(0x17000b21)NetType/WIFI Language/zh_CN
$13:10.8.43.18:8080
$14:POST
$15:200
$16:0.005
一共得到了16个变量,通过对比log_format就可以知道每个变量的含义
完整的采集规则配置为:
{
"timeWindow": 30,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
"type": "regular"
}
]
}
3、设置采集器
采集每个请求的响应时间和请求的状态码,并将数据存储在promethus中
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "nginx_log_host_status",
"labelNames": [
"host",
"status"
],
"name": "nginx_log_host_status",
"type": "gauge",
"value": "1",
"labels": [
"$5",
"$9"
]
},
{
"help": "nginx_log_req_rt (seconds)",
"labelNames": [
"host",
"endpoint"
],
"name": "nginx_log_req_rt",
"type": "gauge",
"value": "new java.lang.Double(#$16)",
"labels": [
"$5",
"$7"
]
}
],
"type": "prometheus",
"job": "anymetrics_nginx_log"
}
4、配置可视化
Nginx状态码监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_host_status{}
Nginx 请求延迟监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_req_rt{}
问答
如何采集 APM 日志?
如果系统中有调用链跟踪系统,可以使用调用链日志,或者通过定义拦截器来记录目标方法。定义好日志格式后,可以直接逐行打印,也可以在内存中聚合后以固定频率打印,日志一般收录RT延迟、错误/成功次数、端点、应用等关键数据。
日志是如何采集到kafka的?
可以使用filebeat采集nginx的access_log和tomcat的应用日志到kafka
目前支持哪些数据源?
有界数据目前支持mysql、http;无界数据目前支持kafka
目前支持哪些采集器?
目前只支持prometheus,使用pushgateway推送数据到prometheus
如果我已经使用了 Skywalking 和 Zipkin 等呼叫链跟踪系统,是否需要使用 AnyMetrics?
两者之间没有冲突。调用链跟踪系统采集链路的调用关系和APM指标数据。AnyMetrics不仅可以将结构化调用链跟踪系统的指标日志作为数据源来监控系统,还可以将结构化日志作为数据源来监控系统运行,比如监控一些Exception事件,还可以可视化或监控数据库表数据。同时,AnyMetrics 支持跨平台系统,任何系统生成的日志都可以作为数据源。监控系统运行
最后附上github项目地址:
文章采集调用(讲讲如何在首页和列表页实时动态调用文章点击次数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-02-07 04:23
我们都知道,Dedecms中的首页和列表页的文章点击默认不是动态调用的,而是通过一个标签来调用的,只有首页之后才会更新点击并生成列表页面。频率。但是有时候我们的网站更新不是那么频繁,所以我们需要使用点击的动态调用。接下来,织梦技术研究中心将告诉你如何在首页和列表页面实时动态调用文章@。>点击次数,具体方法如下:
首先找到plus/count.php文件,复制并命名为viewclick.php,然后打开文件,在里面找到如下代码:
<a herf="http://www.genban.org" title="织梦源码">
if(!empty($maintable))
{
$dsql->ExecuteNoneQuery(" UPDATE `{$maintable}` SET click=click+1 WHERE {$idtype}='$aid' ");
}
if(!empty($mid))
{
$dsql->ExecuteNoneQuery(" UPDATE `dede_member_tj` SET pagecount=pagecount+1 WHERE mid='$mid' ");
}</a>
删除上面的代码,然后在需要动态调用点击次数的首页和列表页面模板中添加如下代码:
<a herf="http://www.genban.org" title="织梦源码">
</a>
然后重新生成首页和列表页,然后就可以实时动态调用文章的点击次数而不生成。 查看全部
文章采集调用(讲讲如何在首页和列表页实时动态调用文章点击次数)
我们都知道,Dedecms中的首页和列表页的文章点击默认不是动态调用的,而是通过一个标签来调用的,只有首页之后才会更新点击并生成列表页面。频率。但是有时候我们的网站更新不是那么频繁,所以我们需要使用点击的动态调用。接下来,织梦技术研究中心将告诉你如何在首页和列表页面实时动态调用文章@。>点击次数,具体方法如下:
首先找到plus/count.php文件,复制并命名为viewclick.php,然后打开文件,在里面找到如下代码:
<a herf="http://www.genban.org" title="织梦源码">
if(!empty($maintable))
{
$dsql->ExecuteNoneQuery(" UPDATE `{$maintable}` SET click=click+1 WHERE {$idtype}='$aid' ");
}
if(!empty($mid))
{
$dsql->ExecuteNoneQuery(" UPDATE `dede_member_tj` SET pagecount=pagecount+1 WHERE mid='$mid' ");
}</a>
删除上面的代码,然后在需要动态调用点击次数的首页和列表页面模板中添加如下代码:
<a herf="http://www.genban.org" title="织梦源码">
</a>
然后重新生成首页和列表页,然后就可以实时动态调用文章的点击次数而不生成。
文章采集调用(数据具体的采集方案是什么?四种数据采集方法对比 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-02 08:11
)
根据企业在生产经营过程中会产生的数据类型,提供链接标签、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?
四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务端埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击,更好的了解自己产品的特点。
缺点:采集的数据太多,只要是可点击的元素就会是采集,上传数据很多,消耗流量也很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入基于完全嵌入。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:对自定义属性的支持范围有限;重构或页面更改时需要重新配置。
4.服务器埋点
描述:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。
查看全部
文章采集调用(数据具体的采集方案是什么?四种数据采集方法对比
)
根据企业在生产经营过程中会产生的数据类型,提供链接标签、SDK和API三种采集方法,以及基于UTSE数据采集模型对用户的整个生命周期。
那么,数据的具体采集计划是什么?
四种数据采集方法对比
Data采集是通过埋点实现的。诸葛io提供了非常完善的数据访问解决方案,支持代码埋、全埋、可视埋、服务端埋等数据采集方式。
1.代码被埋没
说明:嵌入SDK定义事件和添加事件代码是一种常用的数据采集方法,主要包括网页和h5页面的JS嵌入、移动端的iOS和Android嵌入、微信小程序等。
优点:按需采集,业务信息更全,数据分析更专注,数据采集全面准确,便于后续深入分析。
缺点:需要研发人员配合,有一定的工作量。
2.全葬
说明:通过SDK自动采集页面所有可点击元素的操作数据,无需定义事件,适用于活动页面、登陆页面、关键页面的设计体验测量。
优点:更简单快捷,可以看到页面元素的点击,更好的了解自己产品的特点。
缺点:采集的数据太多,只要是可点击的元素就会是采集,上传数据很多,消耗流量也很大。无法采集到更深层次的维度信息,比如事件的属性、用户的属性等。
3.可视化埋点
注意:视觉嵌入基于完全嵌入。技术同事整合后,业务同事需要圈出页面的元素,选中的元素会是采集。
优点:基于接口配置,无需开发,易于更新,快速生效。
缺点:对自定义属性的支持范围有限;重构或页面更改时需要重新配置。
4.服务器埋点
描述:通过API对存储在服务器上的数据进行结构化处理,通过接口调用其他业务数据采集和集成,比如CRM等用户数据,对数据进行结构化处理,即适合拥有 采集 @采集 能力客户端的用户。
优点:服务端embedding更有针对性,数据更准确,减少编码embedding的发布过程,数据上传更及时。
缺点:用户的一些简单操作,比如点击按钮、切换模块,这些数据不能采集,用户行为不够完整。
总结:以上是诸葛io提供的四种data采集解决方案:code embedding、full embedding、visual embedding、server embedding,data采集目的是为了满足采集详细分析和操作然后执行需求。只有能够达到这个目标,才有可能选择一种或多种采集形式的组合。在企业业务中,选择哪种采集方式要根据企业自身的具体业务需求来决定。
文章采集调用(利用白帽SEO优化方法快速提升网站权重值的方法有哪些)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-03-01 19:02
文章采集,使得网站有内容,只有有内容才有可能被收录推广,只有收录才能推广能不能提高网站权重。 网站权重是对网站综合价值的总称,包括网站运营能力、用户体验、内容质量、用户热度、SEO指标。综合性能统一名称。
文章采集如何增加网站的权重:日常正规管理和运营网站,使用正规白帽方法来操作网站,比如比如更新内容、检查维护等等,这些都是站长必须要做的事情。挖矿优化精准关键词,根据自己的网站行业,挖矿优化精准网站关键词,必须有流量关键词,如果挖矿关键词@ >与网站的主题定位无关,那么网站的权重就很难增加,甚至网站都会被搜索引擎惩罚。
文章采集改进网站和收录的内容,网站收录索引数据和网站的数量内容更新是成比例的关系,如果你长时间不更新网站,那么你的网站索引数据不仅会增加还会减少。如果你想改进网站网站@收录的内容,那么你需要不断更新网站的优质内容。
同时,站内和站外的SEO也需要做好。除了文章采集还要更新内容,内链优化,网站结构优化,404、网站Sitemap地图和机器人都属于到现场搜索引擎优化的类别。如果你不做好站内优化,你的外链再好也没用,因为你的网站留不住用户,所以站内优化大于站外-网站优化,而外部链接的作用近年来逐渐减弱。如果想通过累计外链数量来增加网站的权重,目前可能很难实现。 .
使用白帽SEO形式优化,为什么一定要使用白帽SEO优化网站?因为有的站长想用黑帽SEO优化方法来快速提升网站的权重值,如果使用这些黑帽SEO,一旦被搜索引擎发现,就等待网站的结果只能被处罚或K站。搜索引擎支持用户使用正式的白帽SEO优化方式,因为这种优化方式可以持续为用户提供有价值的内容。
我们在优化网站的时候,建议不要用黑帽作弊的操作方法优化网站,因为到最后你很可能会花费时间和精力,但是网站 还不是很好的流程。
新站前期以文章采集和挖矿网站长尾关键词为主。长尾关键词不仅竞争程度低,而且排名时间长。短,优化长尾关键词可能只需要几个星期,最长不会超过一个月,新站没有优化基础,搜索引擎对新站信任度不高网站,我们通过优化文章采集和长尾关键词,可以实现更快的收录网站页面,更快的流量获取,然后继续积累,提升网站的流量和权重,最后争夺一些高指数高流量的关键词,新的网站倾向于前期做内容, 文章采集让新站点的内容快写完的时候,我们可以优化站点,交换一些优质的链接。
老站意味着已经有一定的流量基础,但是流量不是特别高。老的网站可以倾向于挖一些有一定索引的关键词,但是不建议选择索引太高的关键词,300到500的索引关键词是比较合适,通过索引关键词来带动全站流量的增加,老的网站权重的增加和高索引流量关键词有一定的关系流量词越多,网站的权重就越高,流量关键词的不断积累,搜索引擎对你网站的信任度会不断增加。老的网站倾向于后期做流量。返回搜狐,查看更多 查看全部
文章采集调用(利用白帽SEO优化方法快速提升网站权重值的方法有哪些)
文章采集,使得网站有内容,只有有内容才有可能被收录推广,只有收录才能推广能不能提高网站权重。 网站权重是对网站综合价值的总称,包括网站运营能力、用户体验、内容质量、用户热度、SEO指标。综合性能统一名称。
文章采集如何增加网站的权重:日常正规管理和运营网站,使用正规白帽方法来操作网站,比如比如更新内容、检查维护等等,这些都是站长必须要做的事情。挖矿优化精准关键词,根据自己的网站行业,挖矿优化精准网站关键词,必须有流量关键词,如果挖矿关键词@ >与网站的主题定位无关,那么网站的权重就很难增加,甚至网站都会被搜索引擎惩罚。
文章采集改进网站和收录的内容,网站收录索引数据和网站的数量内容更新是成比例的关系,如果你长时间不更新网站,那么你的网站索引数据不仅会增加还会减少。如果你想改进网站网站@收录的内容,那么你需要不断更新网站的优质内容。
同时,站内和站外的SEO也需要做好。除了文章采集还要更新内容,内链优化,网站结构优化,404、网站Sitemap地图和机器人都属于到现场搜索引擎优化的类别。如果你不做好站内优化,你的外链再好也没用,因为你的网站留不住用户,所以站内优化大于站外-网站优化,而外部链接的作用近年来逐渐减弱。如果想通过累计外链数量来增加网站的权重,目前可能很难实现。 .
使用白帽SEO形式优化,为什么一定要使用白帽SEO优化网站?因为有的站长想用黑帽SEO优化方法来快速提升网站的权重值,如果使用这些黑帽SEO,一旦被搜索引擎发现,就等待网站的结果只能被处罚或K站。搜索引擎支持用户使用正式的白帽SEO优化方式,因为这种优化方式可以持续为用户提供有价值的内容。
我们在优化网站的时候,建议不要用黑帽作弊的操作方法优化网站,因为到最后你很可能会花费时间和精力,但是网站 还不是很好的流程。
新站前期以文章采集和挖矿网站长尾关键词为主。长尾关键词不仅竞争程度低,而且排名时间长。短,优化长尾关键词可能只需要几个星期,最长不会超过一个月,新站没有优化基础,搜索引擎对新站信任度不高网站,我们通过优化文章采集和长尾关键词,可以实现更快的收录网站页面,更快的流量获取,然后继续积累,提升网站的流量和权重,最后争夺一些高指数高流量的关键词,新的网站倾向于前期做内容, 文章采集让新站点的内容快写完的时候,我们可以优化站点,交换一些优质的链接。
老站意味着已经有一定的流量基础,但是流量不是特别高。老的网站可以倾向于挖一些有一定索引的关键词,但是不建议选择索引太高的关键词,300到500的索引关键词是比较合适,通过索引关键词来带动全站流量的增加,老的网站权重的增加和高索引流量关键词有一定的关系流量词越多,网站的权重就越高,流量关键词的不断积累,搜索引擎对你网站的信任度会不断增加。老的网站倾向于后期做流量。返回搜狐,查看更多
文章采集调用(dedecms如何修改这一上限值)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-22 11:11
dedecmssystem文章调用描述最大字符数为250字节,文章summary(可以通过infolen或description相关标签调用)设置为最大250 个字符。上限的主要目的是减少数据库的冗余,保证网络的良好性能。所以,不给配置文件的内容设置一个上限显然是不合理的,但是如果可以自由控制这个上限,那么就会给网页内容的布局带来积极的影响。NET 源代码在网页设计过程中。dedecms 经常需要在频道列表页面调用文章 的摘要。如果文章的摘要中的字数可以得到有效控制,那么页面布局就可以变得非常灵活。
先说一下如何修改这个上限值,从而体现[field:description function="cn_substr(@me, number of characters)"/]的重要性。
在Dedecms系统中,与抽象文章相关的php文件如下:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面中,有一句:$description = cn_substrR($description, $cfg_auot_description); 这句话实现了[field:description function="cn_substr(@me, number of characters)"/]的功能。由于此声明确实有利于页面布局,因此我们正在尝试不做任何更改。
我在编辑页面,有一句话: $description = cn_substrR($description, 250); ,这句话显示了一个熟悉的字符数 250,也就是 文章 的摘要字符集系统个数的上限,如果是gbk编码,会显示125个字符,如果是utf-8编码,会是81个字符。显然,如果我们要打破抽象字符个数的上限,一定要搞定。是的,你可以在这里把250改成别的值,比如500。这里不建议设置太高。一个是不需要在列表页显示太多的内容(最好直接使用body来显示过多的内容),另一个是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在 article_description_main.php 页面上,找到 if($dsize>250) $dsize = 250; 语句,它限制了后台从摘要中提取的字符数。将此处的 250 更改为 500, 织梦 仿站的意思是和之前修改的字符数不同。(如果你确认你的每一个文章都是手动添加的,如果手动完成就不需要修改这个文件了抽象的采集。按照抽象 次要采集保留给大部分 文章 和 采集。)
最初登录后台,在系统-系统基本参数-其他选项中,后续摘要的长度可以改为500,即可以和之前修改的字符数不同。
完成以上修改后,我们进入频道列表页面,通过标签调用。示例标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[字段:描述函数='cn_substr(@me,500)'/]…
{/dede:列表}
通过以上方法,我们实现了被调用的文章摘要字符为500个字符,完全突破了文章摘要250个字符的系统限制,为网页布局提供了更广阔的空间。
先说一下常用的Dedecms文章或者列表页调用文章summary方法。
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是间接调用文章的抽象。关于被调用字数的问题,在使用[field:info /]时,可以调用{dede:arclist infolen=' ' }{/dede :arclist},设置调用摘要的字符数(最大可以设置为系统设置的250);如果使用[field:description/],则间接使用后台设置的抽象字符上限(后台也有上限250字符)字符)。显然这两种方法是被动的和灵活的。
3、的第四种方法通过function函数实现了对文章摘要中显示字符的灵活调整。当然,当文章的抽象内容中的字符上限没有正常修改的情况下,这四种方式的区别并不大。
============================
1:[字段:信息/]
2:[字段:描述/]
3:[field:info function="cn_substr(@me, 字符数)"/]
4:[field:description function="cn_substr(@me, 字符数)"/]
这四种方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到“if ($dsize>250) $dsize = 250;”语句,将250改为500
2.登录后台,在System-System Basic Parameters-Other Options中,将自动汇总长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar ( 1000 )
调用标签{dede:field.description function='cn_substr(@me,500)'/}.可以显示500个字符 查看全部
文章采集调用(dedecms如何修改这一上限值)
dedecmssystem文章调用描述最大字符数为250字节,文章summary(可以通过infolen或description相关标签调用)设置为最大250 个字符。上限的主要目的是减少数据库的冗余,保证网络的良好性能。所以,不给配置文件的内容设置一个上限显然是不合理的,但是如果可以自由控制这个上限,那么就会给网页内容的布局带来积极的影响。NET 源代码在网页设计过程中。dedecms 经常需要在频道列表页面调用文章 的摘要。如果文章的摘要中的字数可以得到有效控制,那么页面布局就可以变得非常灵活。
先说一下如何修改这个上限值,从而体现[field:description function="cn_substr(@me, number of characters)"/]的重要性。
在Dedecms系统中,与抽象文章相关的php文件如下:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面中,有一句:$description = cn_substrR($description, $cfg_auot_description); 这句话实现了[field:description function="cn_substr(@me, number of characters)"/]的功能。由于此声明确实有利于页面布局,因此我们正在尝试不做任何更改。
我在编辑页面,有一句话: $description = cn_substrR($description, 250); ,这句话显示了一个熟悉的字符数 250,也就是 文章 的摘要字符集系统个数的上限,如果是gbk编码,会显示125个字符,如果是utf-8编码,会是81个字符。显然,如果我们要打破抽象字符个数的上限,一定要搞定。是的,你可以在这里把250改成别的值,比如500。这里不建议设置太高。一个是不需要在列表页显示太多的内容(最好直接使用body来显示过多的内容),另一个是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在 article_description_main.php 页面上,找到 if($dsize>250) $dsize = 250; 语句,它限制了后台从摘要中提取的字符数。将此处的 250 更改为 500, 织梦 仿站的意思是和之前修改的字符数不同。(如果你确认你的每一个文章都是手动添加的,如果手动完成就不需要修改这个文件了抽象的采集。按照抽象 次要采集保留给大部分 文章 和 采集。)
最初登录后台,在系统-系统基本参数-其他选项中,后续摘要的长度可以改为500,即可以和之前修改的字符数不同。
完成以上修改后,我们进入频道列表页面,通过标签调用。示例标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[字段:描述函数='cn_substr(@me,500)'/]…
{/dede:列表}
通过以上方法,我们实现了被调用的文章摘要字符为500个字符,完全突破了文章摘要250个字符的系统限制,为网页布局提供了更广阔的空间。
先说一下常用的Dedecms文章或者列表页调用文章summary方法。
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是间接调用文章的抽象。关于被调用字数的问题,在使用[field:info /]时,可以调用{dede:arclist infolen=' ' }{/dede :arclist},设置调用摘要的字符数(最大可以设置为系统设置的250);如果使用[field:description/],则间接使用后台设置的抽象字符上限(后台也有上限250字符)字符)。显然这两种方法是被动的和灵活的。
3、的第四种方法通过function函数实现了对文章摘要中显示字符的灵活调整。当然,当文章的抽象内容中的字符上限没有正常修改的情况下,这四种方式的区别并不大。
============================
1:[字段:信息/]
2:[字段:描述/]
3:[field:info function="cn_substr(@me, 字符数)"/]
4:[field:description function="cn_substr(@me, 字符数)"/]
这四种方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到“if ($dsize>250) $dsize = 250;”语句,将250改为500
2.登录后台,在System-System Basic Parameters-Other Options中,将自动汇总长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar ( 1000 )
调用标签{dede:field.description function='cn_substr(@me,500)'/}.可以显示500个字符
文章采集调用(用python+selenuim自动框架来爬取京东商品信息(不要))
采集交流 • 优采云 发表了文章 • 0 个评论 • 426 次浏览 • 2022-02-21 23:28
今天我们使用python+ selenium 自动框架爬取京东商品信息(不要再问我为什么是京东了,因为京东不用登录也可以搜索商品),Selenium是用来模仿人类操作的,免费的手,生产力提升,哈哈,这里是对selenuim的一点介绍。
硒简介
Selenium 是一个 Web 应用程序测试工具,Selenium 测试直接在浏览器中运行,就像真正的用户一样。一般的爬虫方法是使用python脚本直接访问目标网站,并且只对目标数据执行采集,访问速度非常快,这样目标网站就可以轻松识别您这是机器人,它阻止了您。使用selenium写爬虫,python脚本控制浏览器进行访问,也就是说python脚本和目标网站之间多了一个浏览器操作,这个行为更像是人的行为,这么多难以爬取网站你也可以轻松抓取数据。
准备
首先安装selenuim,方法和其他第三方库的安装方法一样,使用pip命令
点安装硒
安装 selenuim 后,您必须安装驱动程序才能使其正常工作。因为我使用的是 Google Chrome,所以我下载了 Google Drive,当然还有 Firefox。下载对应浏览器版本的驱动(如果没有对应版本,也可以下载接近的版本)。以下是两款驱动的下载地址:
- 谷歌云端硬盘:(点击下载)
- 火狐驱动:(点击下载)
下载完成后,驱动就安装好了。Firefox驱动的安装方法与Chrome驱动相同。把下载好的驱动放到你的python安装路径下的Script目录下即可(放到Script文件夹下即可,无需配置环境变量)
至此,selenuim的相关安装就完成了,接下来开始我们今天的任务。
1.导入相关依赖
import time
import json
from pyquery import PyQuery as pq
#pyquery是个解析库
from selenium import webdriver
#导入驱动webdriver
from selenium.webdriver.common.by import By
#By是selenium中内置的一个class,在这个class中有各种方法来定位元素
from selenium.webdriver.support.ui import WebDriverWait
#设置浏览器驱动休眠等待,避免频繁操作封ip
from selenium.webdriver.support import expected_conditions as EC
#判断一个元素是否存在,是否加载完毕等一系列的场景判断方法
二、使用selenium EC操作浏览器
首先,用Chrome浏览器打开产品首页。我们很容易发现该网页是一个动态加载的网页。首次打开网页时,仅显示 30 种产品的信息。只有当网页被向下拖动时,它才会加载其余部分。30 项信息。这里我们可以使用selenium模拟浏览器拉下网页,判断网页元素是否通过EC加载,从而获取所有产品网站的信息。
def search():
browser.get('https://www.jd.com/')
try:
input = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key"))
) # 等待搜索框加载出来
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button"))
) # 等待搜索按钮可以被点击
input[0].send_keys(keyword) # 向搜索框内输入关键词
submit.click() # 点击搜索
time.sleep(2) # 加入时间间隔,速度太快可能会抓不到数据
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 下拉到网页底部
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
) # 等待最后一个商品信息加载完毕
html = browser.page_source
except TimeoutError:
search()
三、使用selenium EC实现翻页操作
与第一页类似,它也使用EC来判断页面元素是否加载,并添加延迟以防止数据被抓到。
def next_page(page_number):
try:
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em'))
) # 等待翻页按钮可以点击
button.click() # 点击翻页按钮
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(30)"))
) # 等到30个商品都加载出来
time.sleep(2)
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
wait.until(# 等到60个商品都加载出来
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
)
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
return next_page(page_number)
四、提取数据并保存
这里使用pyquery库解析网页源代码,使用CSS_SELECTOR选择元素。一定要找到参考元素。例如,将鼠标放在搜索框中,右键查看,然后跳转到搜索框中对应的代码处。右键点击它,点击Copy > Copy selector,我们得到我们需要的#key,然后通过.text()获取内容,最后将python对象转换成json数据写入json文件。
def find_save(html):
doc = pq(html)
items = doc('#J_goodsList > ul > li').items()
for item in items:
product = {
'name': item('.p-name a').text(),
'price': item('.p-price i').text(),
'commit': item('.p-commit a').text()
}
data_list.append(product) # 写入全局变量
# 把全局变量转化为json数据
content = json.dumps(data_list, ensure_ascii=False, indent=2)
with open("E:\python\project\selenium\info.json", "w", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功")
五、编写和调用main函数
使用for循环控制爬取的页面数并添加延迟
def main():
print("第", 1, "页:")
search()
for i in range(2, 6): # 爬取2-5页
time.sleep(2) # 设置延迟
print("第", i, "页:")
next_page(i)
if __name__ == "__main__":
main()
补充:
为了提高爬虫的效率,可以将浏览器设置为无图片模式,即不加载图片,这样可以提高采集的速度
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs'{'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
看看结果:
附上完整代码:
import time
import json
from pyquery import PyQuery as pq
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
# 不加载图片
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
wait = WebDriverWait(browser, 20) # 设置等待时间
data_list = [] # 设置全局变量用来存储数据
keyword = "平凡的世界" # 商品名称
def search():
browser.get('https://www.jd.com/')
try:
input = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key"))
) # 等待搜索框加载出来
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button"))
) # 等待搜索按钮可以被点击
input[0].send_keys(keyword) # 向搜索框内输入关键词
submit.click() # 点击搜索
time.sleep(2) # 加入时间间隔,速度太快可能会抓不到数据
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 滑动到底部
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
) # 等待最后一个商品信息加载完毕
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
search()
def next_page(page_number):
try:
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em'))
) # 等待翻页按钮可以点击
button.click() # 点击翻页按钮
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(30)"))
) # 等到30个商品都加载出来
time.sleep(2)
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
wait.until(# 等到60个商品都加载出来
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
)
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
return next_page(page_number)
def find_save(html):
doc = pq(html)
items = doc('#J_goodsList > ul > li').items()
# print(items)
for item in items:
product = {
'name': item('.p-name a').text(),
'price': item('.p-price i').text(),
'commit': item('.p-commit a').text()
}
data_list.append(product) # 写入全局变量
# 把全局变量转化为json数据
content = json.dumps(data_list, ensure_ascii=False, indent=2)
with open("E:\python\project\selenium\info.json", "w", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功")
def main():
print("第", 1, "页:")
search()
for i in range(2, 6): # 爬取2-5页
time.sleep(2) # 设置延迟
print("第", i, "页:")
next_page(i)
if __name__ == "__main__":
main()
如有错误,请私信指正,谢谢支持! 查看全部
文章采集调用(用python+selenuim自动框架来爬取京东商品信息(不要))
今天我们使用python+ selenium 自动框架爬取京东商品信息(不要再问我为什么是京东了,因为京东不用登录也可以搜索商品),Selenium是用来模仿人类操作的,免费的手,生产力提升,哈哈,这里是对selenuim的一点介绍。
硒简介
Selenium 是一个 Web 应用程序测试工具,Selenium 测试直接在浏览器中运行,就像真正的用户一样。一般的爬虫方法是使用python脚本直接访问目标网站,并且只对目标数据执行采集,访问速度非常快,这样目标网站就可以轻松识别您这是机器人,它阻止了您。使用selenium写爬虫,python脚本控制浏览器进行访问,也就是说python脚本和目标网站之间多了一个浏览器操作,这个行为更像是人的行为,这么多难以爬取网站你也可以轻松抓取数据。
准备
首先安装selenuim,方法和其他第三方库的安装方法一样,使用pip命令
点安装硒
安装 selenuim 后,您必须安装驱动程序才能使其正常工作。因为我使用的是 Google Chrome,所以我下载了 Google Drive,当然还有 Firefox。下载对应浏览器版本的驱动(如果没有对应版本,也可以下载接近的版本)。以下是两款驱动的下载地址:
- 谷歌云端硬盘:(点击下载)
- 火狐驱动:(点击下载)
下载完成后,驱动就安装好了。Firefox驱动的安装方法与Chrome驱动相同。把下载好的驱动放到你的python安装路径下的Script目录下即可(放到Script文件夹下即可,无需配置环境变量)
至此,selenuim的相关安装就完成了,接下来开始我们今天的任务。
1.导入相关依赖
import time
import json
from pyquery import PyQuery as pq
#pyquery是个解析库
from selenium import webdriver
#导入驱动webdriver
from selenium.webdriver.common.by import By
#By是selenium中内置的一个class,在这个class中有各种方法来定位元素
from selenium.webdriver.support.ui import WebDriverWait
#设置浏览器驱动休眠等待,避免频繁操作封ip
from selenium.webdriver.support import expected_conditions as EC
#判断一个元素是否存在,是否加载完毕等一系列的场景判断方法
二、使用selenium EC操作浏览器
首先,用Chrome浏览器打开产品首页。我们很容易发现该网页是一个动态加载的网页。首次打开网页时,仅显示 30 种产品的信息。只有当网页被向下拖动时,它才会加载其余部分。30 项信息。这里我们可以使用selenium模拟浏览器拉下网页,判断网页元素是否通过EC加载,从而获取所有产品网站的信息。
def search():
browser.get('https://www.jd.com/')
try:
input = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key"))
) # 等待搜索框加载出来
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button"))
) # 等待搜索按钮可以被点击
input[0].send_keys(keyword) # 向搜索框内输入关键词
submit.click() # 点击搜索
time.sleep(2) # 加入时间间隔,速度太快可能会抓不到数据
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 下拉到网页底部
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
) # 等待最后一个商品信息加载完毕
html = browser.page_source
except TimeoutError:
search()
三、使用selenium EC实现翻页操作
与第一页类似,它也使用EC来判断页面元素是否加载,并添加延迟以防止数据被抓到。
def next_page(page_number):
try:
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em'))
) # 等待翻页按钮可以点击
button.click() # 点击翻页按钮
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(30)"))
) # 等到30个商品都加载出来
time.sleep(2)
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
wait.until(# 等到60个商品都加载出来
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
)
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
return next_page(page_number)
四、提取数据并保存
这里使用pyquery库解析网页源代码,使用CSS_SELECTOR选择元素。一定要找到参考元素。例如,将鼠标放在搜索框中,右键查看,然后跳转到搜索框中对应的代码处。右键点击它,点击Copy > Copy selector,我们得到我们需要的#key,然后通过.text()获取内容,最后将python对象转换成json数据写入json文件。
def find_save(html):
doc = pq(html)
items = doc('#J_goodsList > ul > li').items()
for item in items:
product = {
'name': item('.p-name a').text(),
'price': item('.p-price i').text(),
'commit': item('.p-commit a').text()
}
data_list.append(product) # 写入全局变量
# 把全局变量转化为json数据
content = json.dumps(data_list, ensure_ascii=False, indent=2)
with open("E:\python\project\selenium\info.json", "w", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功")
五、编写和调用main函数
使用for循环控制爬取的页面数并添加延迟
def main():
print("第", 1, "页:")
search()
for i in range(2, 6): # 爬取2-5页
time.sleep(2) # 设置延迟
print("第", i, "页:")
next_page(i)
if __name__ == "__main__":
main()
补充:
为了提高爬虫的效率,可以将浏览器设置为无图片模式,即不加载图片,这样可以提高采集的速度
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs'{'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
看看结果:
附上完整代码:
import time
import json
from pyquery import PyQuery as pq
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
# 不加载图片
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {'profile.managed_default_content_settings.images': 2})
browser = webdriver.Chrome(options=options)
wait = WebDriverWait(browser, 20) # 设置等待时间
data_list = [] # 设置全局变量用来存储数据
keyword = "平凡的世界" # 商品名称
def search():
browser.get('https://www.jd.com/')
try:
input = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key"))
) # 等待搜索框加载出来
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button"))
) # 等待搜索按钮可以被点击
input[0].send_keys(keyword) # 向搜索框内输入关键词
submit.click() # 点击搜索
time.sleep(2) # 加入时间间隔,速度太快可能会抓不到数据
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 滑动到底部
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
) # 等待最后一个商品信息加载完毕
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
search()
def next_page(page_number):
try:
button = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em'))
) # 等待翻页按钮可以点击
button.click() # 点击翻页按钮
wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(30)"))
) # 等到30个商品都加载出来
time.sleep(2)
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
wait.until(# 等到60个商品都加载出来
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))
)
html = browser.page_source
find_save(html) # 调用函数筛选数据
except TimeoutError:
return next_page(page_number)
def find_save(html):
doc = pq(html)
items = doc('#J_goodsList > ul > li').items()
# print(items)
for item in items:
product = {
'name': item('.p-name a').text(),
'price': item('.p-price i').text(),
'commit': item('.p-commit a').text()
}
data_list.append(product) # 写入全局变量
# 把全局变量转化为json数据
content = json.dumps(data_list, ensure_ascii=False, indent=2)
with open("E:\python\project\selenium\info.json", "w", encoding="utf-8") as f:
f.write(content)
print("json文件写入成功")
def main():
print("第", 1, "页:")
search()
for i in range(2, 6): # 爬取2-5页
time.sleep(2) # 设置延迟
print("第", i, "页:")
next_page(i)
if __name__ == "__main__":
main()
如有错误,请私信指正,谢谢支持!
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-02-21 23:27
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常文章在多个平台上推送,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但复制图片会杀了我。微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信对图片做了防盗链措施。
这时候尝试搜索了一个这样的插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是开发了一个插件名为Bee采集,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,以及有多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可
使用也很简单,粘贴链接即可,可以同时导入多个文章,即批量导入功能,自动同步采集公众号功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到
希望这篇笔记可以帮到你 查看全部
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常文章在多个平台上推送,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但复制图片会杀了我。微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信对图片做了防盗链措施。
这时候尝试搜索了一个这样的插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是开发了一个插件名为Bee采集,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,以及有多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可
使用也很简单,粘贴链接即可,可以同时导入多个文章,即批量导入功能,自动同步采集公众号功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到
希望这篇笔记可以帮到你
文章采集调用(结构图代理中增强类Enhancer应该是核心配置功能类的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-02-21 23:25
背景
通过开发插件包采集部门内的trace的链接信息,包括RPC mock工具。采集的调用链如下所示:
1589802250554|0b51063f15898022505134582ec1dc|RPC|com.service.bindReadService#getBindModelByUserId|[2988166812]|{"@type":"com.service.models.ResultVOModel","succeed":true,"valueObject":{"@type":"com.service.models.bind1688Model","accountNo":"2088422864957283","accountType":3,"bindFrom":"activeAccount","enable":true,"enableStatus":1,"memberId":"b2b-2988166812dc3ef","modifyDate":1509332355000,"userId":2988166812}}|2|0.1.1.4.4|11.181.112.68|C:membercenterhost|DPathBaseEnv|N||
不仅会打印trace,还会打印输入输出参数、目标IP和源IP。可以看到还是很清晰的,大大提高了我们联查排查的效率。
但是,随着产品的不断迭代,jar的形式还是存在不少问题。首先,接入成本高,版本不稳定,导致快速升级。相应的服务必须不断升级。相信大家都经历过升级fastjson的阵痛。另外,由于多版本兼容,数据不能一致,处理起来很麻烦。为此,您唯一能想到的就是对相应的集合和模拟进行代理增强操作。
结构图
代理中的增强类Enhancer应该是核心配置功能类。通过继承或者SPI扩展,我们可以实现不同增强点的配置。
相关代码
BootStrapAgent 入口类:
/** * @author wanghao * @date 2020/5/6 */public class BootStrapAgent { public static void main(String[] args) { System.out.println("====main 方法执行"); } public static void premain(String agentArgs, Instrumentation inst) { System.out.println("====premain 方法执行"); new BootInitializer(inst, true).init(); } public static void agentmain(String agentOps, Instrumentation inst) { System.out.println("====agentmain 方法执行"); new BootInitializer(inst, false).init(); }}
agent的入口类,premain支持的agent挂载方式,agentmain支持的attach api方式,agent方式需要指定-javaagent参数,项目中的docker文件需要配置。attach api的使用方法。BootInitializer 主要代码:
public class BootInitializer { public BootInitializer(Instrumentation instrumentation, boolean isPreAgent) { this.instrumentation = instrumentation; this.isPreAgent = isPreAgent; } public void init() { this.instrumentation.addTransformer(new EnhanceClassTransfer(), true); if (!isPreAgent) { try { // TODO 此处暂硬编码,后续修改 this.instrumentation.retransformClasses(Class.forName("com.abb.ReflectInvocationHandler")); } catch (UnmodifiableClassException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } }}
这里需要注意的一点是addTransformer中的参数canRetransform需要设置为true,表示可以重新转换表名,否则即使调用retransformClasses方法也无法重新定义指定的类。需要注意的是,新加载的类不能修改旧的类声明,例如添加属性和修改方法声明。EnhanceClassTransfer 主要代码:
@Overridepublic byte[] transform(ClassLoader loader, String className, Class> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException { if (className == null) { return null; } String name = className.replace("/", "."); byte[] bytes = enhanceEngine.getEnhancedByteByClassName(name, classfileBuffer, loader); return bytes;}
EnhanceClassTransfer 做的很简单,直接调用 EnhanceEngine 生成字节码 EnhanceEngine 主代码:
private static Map enhancerMap = new ConcurrentHashMap();public byte[] getEnhancedByteByClassName(String className, byte[] bytes, ClassLoader classLoader, Enhancer enhancerProvide) { byte[] classBytes = bytes; boolean isNeedEnhance = false; Enhancer enhancer = null; // 两次enhancer匹配校验 // 具体类名匹配 enhancer = enhancerMap.get(className); if (enhancer != null) { isNeedEnhance = true; } // 类名正则匹配 if (!isNeedEnhance) { for (Enhancer classNamePtnEnhancer : classNamePtnEnhancers) { if (classNamePtnEnhancer.isClassMatch(className)) { enhancer = classNamePtnEnhancer; break; } } } if (enhancer != null) { System.out.println(enhancer.getClassName()); MethodAopContext methodAopContext = GlobalAopContext.buildMethodAopContext(enhancer.getClassName(), enhancer.getInvocationInterceptor() ,classLoader, enhancer.getMethodFilter()); try { classBytes = ClassProxyUtil.buildInjectByteCodeByJavaAssist(methodAopContext, bytes); } catch (Exception e) { e.printStackTrace(); } } return classBytes; }
类名匹配在这里进行了两次。增强器映射保存了需要增强的类名与增强的扩展类的关系。Enhancer中的变量很简单,如下:
private String className;private Pattern classNamePattern;private Pattern methodPattern;private InvocationInterceptor invocationInterceptor;
只有匹配到对应的增强器后,才会进行增强处理,比如后面提到的DubboProviderEnhancer。
字节码操作工具
目前主流的字节码操作工具包括以下asmJavaassistbytebuddy
三个文章的比较有很多,大家可以自己搜索看看。
目前asm的使用门槛最高,调试的门槛也很高。Idea有一个非常强大的插件ASM Bytecode Outline。它可以根据当前的java类生成相应的asm指令。效果图如下:
但是,使用 asm 还是需要开发者对字节码指令、局部变量表、操作树栈有很好的理解,才能写好相关的代码。
bytebuddy 完全以链式编程的方式构建了一套用于方法切面编织的字节码操作。从编码的角度来看,它是比较简单的。目前,bytebuddy的代理操作已经很完善了。它是根据类名和方法名过滤的。提供了一套链式操作,如果业务逻辑不复杂,推荐使用。
代理实现
代理类的实现大家一定不会陌生。我们有许多代理类的入口点。我们可以在方法的before、after、afterReturn、afterThrowing等进行相应的操作。当然,所有这些都可以通过模板来实现。这里我稍微简化一下,整体实现代理类的增强操作。类似于java动态代理,大家都知道实现java动态代理必须实现的类InvocationHandler,改写方法:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable;
大致思路是比较动态代理的方式,封装需要代理的类,将类类型、入参和对象带入代理方法,重写需要增强的方法,将重写前的方法作为基类和修改方法名,这里分两步操作。
1.重写之前的方法
2.添加新方法并复制之前的方法体
需要注意的是这里没有违反retransformClasses的规则,没有添加属性,也没有修改方法声明
RPC中间件相关类的增强实现效果如下:
代码显示如下:
<p>public static byte[] buildInjectByteCodeByJavaAssist(MethodAopContext methodAopContext, byte[] classBytes) throws Exception { CtClass ctclass = null; try { ClassPool classPool = new ClassPool(); // 使用加载该类的classLoader进行classPool的构造,而不能使用ClassPool.getDefault()的方式 classPool.appendClassPath(new LoaderClassPath(methodAopContext.getLoader())); ctclass = classPool.get(methodAopContext.getClassName()); CtMethod[] declaredMethods = ctclass.getDeclaredMethods(); for (CtMethod method : declaredMethods) { String methodName = method.getName(); if (methodAopContext.matchs(methodName)) { System.out.println("methodName:" + methodName); String outputStr = "System.out.println("this method " + methodName + " cost:" +(endTime - startTime) +"ms.");"; // 定义新方法名,修改原名 String oldMethodName = methodName + "$old"; // 将原来的方法名字修改 method.setName(oldMethodName); // 创建新的方法,复制原来的方法,名字为原来的名字 CtMethod newMethod = CtNewMethod.copy(method, methodName, ctclass, null); int modifiers = newMethod.getModifiers(); String type = newMethod.getReturnType().getName(); CtClass[] parameterJaTypes = newMethod.getParameterTypes(); // 获取参数 Class>[] parameterTypes = new Class[parameterJaTypes.length]; for (int var1 = 0; var1 查看全部
文章采集调用(结构图代理中增强类Enhancer应该是核心配置功能类的)
背景
通过开发插件包采集部门内的trace的链接信息,包括RPC mock工具。采集的调用链如下所示:
1589802250554|0b51063f15898022505134582ec1dc|RPC|com.service.bindReadService#getBindModelByUserId|[2988166812]|{"@type":"com.service.models.ResultVOModel","succeed":true,"valueObject":{"@type":"com.service.models.bind1688Model","accountNo":"2088422864957283","accountType":3,"bindFrom":"activeAccount","enable":true,"enableStatus":1,"memberId":"b2b-2988166812dc3ef","modifyDate":1509332355000,"userId":2988166812}}|2|0.1.1.4.4|11.181.112.68|C:membercenterhost|DPathBaseEnv|N||
不仅会打印trace,还会打印输入输出参数、目标IP和源IP。可以看到还是很清晰的,大大提高了我们联查排查的效率。
但是,随着产品的不断迭代,jar的形式还是存在不少问题。首先,接入成本高,版本不稳定,导致快速升级。相应的服务必须不断升级。相信大家都经历过升级fastjson的阵痛。另外,由于多版本兼容,数据不能一致,处理起来很麻烦。为此,您唯一能想到的就是对相应的集合和模拟进行代理增强操作。
结构图
代理中的增强类Enhancer应该是核心配置功能类。通过继承或者SPI扩展,我们可以实现不同增强点的配置。
相关代码
BootStrapAgent 入口类:
/** * @author wanghao * @date 2020/5/6 */public class BootStrapAgent { public static void main(String[] args) { System.out.println("====main 方法执行"); } public static void premain(String agentArgs, Instrumentation inst) { System.out.println("====premain 方法执行"); new BootInitializer(inst, true).init(); } public static void agentmain(String agentOps, Instrumentation inst) { System.out.println("====agentmain 方法执行"); new BootInitializer(inst, false).init(); }}
agent的入口类,premain支持的agent挂载方式,agentmain支持的attach api方式,agent方式需要指定-javaagent参数,项目中的docker文件需要配置。attach api的使用方法。BootInitializer 主要代码:
public class BootInitializer { public BootInitializer(Instrumentation instrumentation, boolean isPreAgent) { this.instrumentation = instrumentation; this.isPreAgent = isPreAgent; } public void init() { this.instrumentation.addTransformer(new EnhanceClassTransfer(), true); if (!isPreAgent) { try { // TODO 此处暂硬编码,后续修改 this.instrumentation.retransformClasses(Class.forName("com.abb.ReflectInvocationHandler")); } catch (UnmodifiableClassException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } }}
这里需要注意的一点是addTransformer中的参数canRetransform需要设置为true,表示可以重新转换表名,否则即使调用retransformClasses方法也无法重新定义指定的类。需要注意的是,新加载的类不能修改旧的类声明,例如添加属性和修改方法声明。EnhanceClassTransfer 主要代码:
@Overridepublic byte[] transform(ClassLoader loader, String className, Class> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException { if (className == null) { return null; } String name = className.replace("/", "."); byte[] bytes = enhanceEngine.getEnhancedByteByClassName(name, classfileBuffer, loader); return bytes;}
EnhanceClassTransfer 做的很简单,直接调用 EnhanceEngine 生成字节码 EnhanceEngine 主代码:
private static Map enhancerMap = new ConcurrentHashMap();public byte[] getEnhancedByteByClassName(String className, byte[] bytes, ClassLoader classLoader, Enhancer enhancerProvide) { byte[] classBytes = bytes; boolean isNeedEnhance = false; Enhancer enhancer = null; // 两次enhancer匹配校验 // 具体类名匹配 enhancer = enhancerMap.get(className); if (enhancer != null) { isNeedEnhance = true; } // 类名正则匹配 if (!isNeedEnhance) { for (Enhancer classNamePtnEnhancer : classNamePtnEnhancers) { if (classNamePtnEnhancer.isClassMatch(className)) { enhancer = classNamePtnEnhancer; break; } } } if (enhancer != null) { System.out.println(enhancer.getClassName()); MethodAopContext methodAopContext = GlobalAopContext.buildMethodAopContext(enhancer.getClassName(), enhancer.getInvocationInterceptor() ,classLoader, enhancer.getMethodFilter()); try { classBytes = ClassProxyUtil.buildInjectByteCodeByJavaAssist(methodAopContext, bytes); } catch (Exception e) { e.printStackTrace(); } } return classBytes; }
类名匹配在这里进行了两次。增强器映射保存了需要增强的类名与增强的扩展类的关系。Enhancer中的变量很简单,如下:
private String className;private Pattern classNamePattern;private Pattern methodPattern;private InvocationInterceptor invocationInterceptor;
只有匹配到对应的增强器后,才会进行增强处理,比如后面提到的DubboProviderEnhancer。
字节码操作工具
目前主流的字节码操作工具包括以下asmJavaassistbytebuddy
三个文章的比较有很多,大家可以自己搜索看看。
目前asm的使用门槛最高,调试的门槛也很高。Idea有一个非常强大的插件ASM Bytecode Outline。它可以根据当前的java类生成相应的asm指令。效果图如下:
但是,使用 asm 还是需要开发者对字节码指令、局部变量表、操作树栈有很好的理解,才能写好相关的代码。
bytebuddy 完全以链式编程的方式构建了一套用于方法切面编织的字节码操作。从编码的角度来看,它是比较简单的。目前,bytebuddy的代理操作已经很完善了。它是根据类名和方法名过滤的。提供了一套链式操作,如果业务逻辑不复杂,推荐使用。
代理实现
代理类的实现大家一定不会陌生。我们有许多代理类的入口点。我们可以在方法的before、after、afterReturn、afterThrowing等进行相应的操作。当然,所有这些都可以通过模板来实现。这里我稍微简化一下,整体实现代理类的增强操作。类似于java动态代理,大家都知道实现java动态代理必须实现的类InvocationHandler,改写方法:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable;
大致思路是比较动态代理的方式,封装需要代理的类,将类类型、入参和对象带入代理方法,重写需要增强的方法,将重写前的方法作为基类和修改方法名,这里分两步操作。
1.重写之前的方法
2.添加新方法并复制之前的方法体
需要注意的是这里没有违反retransformClasses的规则,没有添加属性,也没有修改方法声明
RPC中间件相关类的增强实现效果如下:
代码显示如下:
<p>public static byte[] buildInjectByteCodeByJavaAssist(MethodAopContext methodAopContext, byte[] classBytes) throws Exception { CtClass ctclass = null; try { ClassPool classPool = new ClassPool(); // 使用加载该类的classLoader进行classPool的构造,而不能使用ClassPool.getDefault()的方式 classPool.appendClassPath(new LoaderClassPath(methodAopContext.getLoader())); ctclass = classPool.get(methodAopContext.getClassName()); CtMethod[] declaredMethods = ctclass.getDeclaredMethods(); for (CtMethod method : declaredMethods) { String methodName = method.getName(); if (methodAopContext.matchs(methodName)) { System.out.println("methodName:" + methodName); String outputStr = "System.out.println("this method " + methodName + " cost:" +(endTime - startTime) +"ms.");"; // 定义新方法名,修改原名 String oldMethodName = methodName + "$old"; // 将原来的方法名字修改 method.setName(oldMethodName); // 创建新的方法,复制原来的方法,名字为原来的名字 CtMethod newMethod = CtNewMethod.copy(method, methodName, ctclass, null); int modifiers = newMethod.getModifiers(); String type = newMethod.getReturnType().getName(); CtClass[] parameterJaTypes = newMethod.getParameterTypes(); // 获取参数 Class>[] parameterTypes = new Class[parameterJaTypes.length]; for (int var1 = 0; var1
文章采集调用(文章采集调用excel,简单,基本就是:1.2)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-21 16:02
文章采集调用excel,简单,基本就是:1采集工作表中的图片文字2导出为图片或者其他类型的数据3整理,导出.至于怎么实现?下载个rvest就行.
通过excel采集电子表格中的内容并直接保存为excel格式
谢邀目前我还不会看我看最近会不会有类似的爬虫项目
爬虫技术应该没有要求吧?不会下载rvest吗?windows直接用filezilla浏览器(safari也行)直接登录就可以了,
1.excel2.txt+list3.爬虫顺便这个业余的,
腾讯xx地图,
你可以爬,爬完了批量导出,做个爬虫app,
还好我读书少,大概觉得是excel。
txt
各大卫视所有电视台的视频图片。
提取图片上的文字识别关键词提取联系方式。
rvest,jieba,sunset_login,ggplot2+lattice基本算是比较精确又简单的还要更精确可以借助relaxmat
respin的代码
xlcrollback
必须是lllllllllllll
题主都没有细化要求,
vba进程中打开lllllllllllllw才能完整下载
当然是我们电视台啊!发生在湖南某电视台一个月,男女老少通吃的惊天大节目,用的工具是啥不知道,具体代码私信问我,懒得码一大堆。 查看全部
文章采集调用(文章采集调用excel,简单,基本就是:1.2)
文章采集调用excel,简单,基本就是:1采集工作表中的图片文字2导出为图片或者其他类型的数据3整理,导出.至于怎么实现?下载个rvest就行.
通过excel采集电子表格中的内容并直接保存为excel格式
谢邀目前我还不会看我看最近会不会有类似的爬虫项目
爬虫技术应该没有要求吧?不会下载rvest吗?windows直接用filezilla浏览器(safari也行)直接登录就可以了,
1.excel2.txt+list3.爬虫顺便这个业余的,
腾讯xx地图,
你可以爬,爬完了批量导出,做个爬虫app,
还好我读书少,大概觉得是excel。
txt
各大卫视所有电视台的视频图片。
提取图片上的文字识别关键词提取联系方式。
rvest,jieba,sunset_login,ggplot2+lattice基本算是比较精确又简单的还要更精确可以借助relaxmat
respin的代码
xlcrollback
必须是lllllllllllll
题主都没有细化要求,
vba进程中打开lllllllllllllw才能完整下载
当然是我们电视台啊!发生在湖南某电视台一个月,男女老少通吃的惊天大节目,用的工具是啥不知道,具体代码私信问我,懒得码一大堆。
文章采集调用(【干货】文章采集调用webframework,的处理流程(二))
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-20 21:02
文章采集调用webframework,一般都有framework相关的配置页面,
我们在拿到数据之后,需要先做处理,大致的处理流程如下:获取对应的sql数据1。将数据存入freesoftwareresources库2。调用framework相关的函数来处理数据cache数据1。写文件,查询文件2。写文件加载到存储池1。遍历加载器freesoftwareresources库2。遍历已经加载到存储池的数据3。读取文件(对于apollo是直接对数据进行分析,对于js来说是解析)。
文件放在linux的/etc/freebsd下
文件系统文件夹里~.
对于文本文件的处理,可以使用thread,并发处理文件。
标准是,在单节点环境下,1,如果两个guest同在一个freebsd集群中,使用nodelocal,2,如果第一个节点集群关闭,会走guest的mapjoin互相peer3,若多个节点同在一个freebsd集群中,那么guest之间peer互相转。因为节点cluster是独立的。
一个freebsd进程内共享一个文件系统。在该文件系统上,webid登记了两种操作,具体也可以类比为java中的session,从guest(创建)到guestparent(usercreate)到guestuser(usercreate)的user操作。有两种策略可以实现同一台设备内的peer互相转发:每一个freebsd进程都将本机上共享的文件共享给自己。
用来保证这种共享互相转发的可行性:可以实现guest对于本机来说都是存在的,所以freebsd集群内不必存在guest对本机共享的文件。或者选择利用userprotocolswitch。开端点,停止点,主机复制。你可以研究下nodelocalwebprotocolpaths的实现,能很好地解决这个问题。
tls也是基于userprotocol。usermap到文件/path分布中,usermap到文件/fsuserprotocol主要处理的问题是文件/fs开端点到userprotocolswitch连接,这个都可以通过protocolentryvesting做到。 查看全部
文章采集调用(【干货】文章采集调用webframework,的处理流程(二))
文章采集调用webframework,一般都有framework相关的配置页面,
我们在拿到数据之后,需要先做处理,大致的处理流程如下:获取对应的sql数据1。将数据存入freesoftwareresources库2。调用framework相关的函数来处理数据cache数据1。写文件,查询文件2。写文件加载到存储池1。遍历加载器freesoftwareresources库2。遍历已经加载到存储池的数据3。读取文件(对于apollo是直接对数据进行分析,对于js来说是解析)。
文件放在linux的/etc/freebsd下
文件系统文件夹里~.
对于文本文件的处理,可以使用thread,并发处理文件。
标准是,在单节点环境下,1,如果两个guest同在一个freebsd集群中,使用nodelocal,2,如果第一个节点集群关闭,会走guest的mapjoin互相peer3,若多个节点同在一个freebsd集群中,那么guest之间peer互相转。因为节点cluster是独立的。
一个freebsd进程内共享一个文件系统。在该文件系统上,webid登记了两种操作,具体也可以类比为java中的session,从guest(创建)到guestparent(usercreate)到guestuser(usercreate)的user操作。有两种策略可以实现同一台设备内的peer互相转发:每一个freebsd进程都将本机上共享的文件共享给自己。
用来保证这种共享互相转发的可行性:可以实现guest对于本机来说都是存在的,所以freebsd集群内不必存在guest对本机共享的文件。或者选择利用userprotocolswitch。开端点,停止点,主机复制。你可以研究下nodelocalwebprotocolpaths的实现,能很好地解决这个问题。
tls也是基于userprotocol。usermap到文件/path分布中,usermap到文件/fsuserprotocol主要处理的问题是文件/fs开端点到userprotocolswitch连接,这个都可以通过protocolentryvesting做到。
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-02-17 11:16
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常文章在多个平台上推送,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但复制图片会杀了我。微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信对图片做了防盗链措施。
这时候尝试搜索了这样一个插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是我开发了一个叫Bee采集的插件,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,并且还有各种多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可
使用也很简单,粘贴链接即可,可以同时导入多个文章,即批量导入功能,自动同步采集公众号功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到
希望这篇笔记可以帮到你 查看全部
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常文章在多个平台上推送,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但复制图片会杀了我。微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信对图片做了防盗链措施。
这时候尝试搜索了这样一个插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是我开发了一个叫Bee采集的插件,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,并且还有各种多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可
使用也很简单,粘贴链接即可,可以同时导入多个文章,即批量导入功能,自动同步采集公众号功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到
希望这篇笔记可以帮到你
文章采集调用(python爬取参考文章AnyProxy代理批量采集实现方法:anyproxy+js )
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-02-16 22:08
)
蟒蛇爬行
参考文章
AnyProxy 代理批量采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
FiddlerCore
实现方式:抓包工具,Fiddler4
通过捕获和分析多个账户,可以确定:
步:
1、编写按钮向导脚本,在手机端自动点击公众号文章的列表页面,即“查看历史消息”;
2、使用fiddler代理劫持手机访问,将URL转发到php编写的本地网页;
3、将接收到的URL备份到php网页上的数据库中;
4、使用python从数据库中检索URL,然后进行正常爬取。
在爬升过程中发现了一个问题:
如果只是想爬文章内容,貌似没有访问频率限制,但是如果想爬读点赞数,达到一定频率后,返回值会变成null,时间间隔我设置了10秒,就可以正常取了。在这个频率下,一个小时只能取到 360 条,没有实际意义。
青波新名单
如果你只是想看数据,你可以不花钱只看每日清单。如果你需要访问自己的系统,他们也提供了一个api接口
Part3 项目步骤基本原则
网站收录最微信公众号文章会定期更新,经测试发现对爬虫更友好
网站页面排版和排版规则,不同公众号以链接中的账号区分
公众号采集下的文章也有定期翻页:id号每翻一页+12
传送门副本.png
所以这个想法可能是
环境相关包获取页面
def get_one_page(url):
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
注意目标爬虫网站必须添加headers,否则会直接拒绝访问
正则解析html
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
自动跳转页面
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
从标题中删除非法字符
因为windows下的file命令,有些字符不能使用,所以需要使用正则剔除
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
转换html
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“link”、“title”、“date”
def html_to_pdf(offset):
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
结果显示爬取结果
result1-copy.png
爬取的几个公众号存放在文件夹中
结果 2 - 复制.png
文件夹目录的内容
result3-copy.png
抓取的 CSV 内容格式
生成的 PDF 结果
result4-copy.png
遇到的问题问题1
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
info = info.strip('\"')
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
解决方案
字符串中首尾带有“”,使用上文中的#注释部分的各种方法都不好使,
最后的解决办法是:
在写入字符串的代码出,加上.strip('\'\"'),以去掉‘和”
with open(path, 'a', encoding='utf-8') as f: #追加存储形式,content是字典形式
f.write(str(json.dumps(content, ensure_ascii=False).strip('\'\"') + '\n'))
f.close()
问题2
调用wkhtmltopdf.exe将html转成pdf报错
调用代码
``` python
path_wk = 'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
```
错误信息
OSError: No wkhtmltopdf executable found: "D:\Program Files\wkhtmltopdin\wkhtmltopdf.exe"
If this file exists please check that this process can read it. Otherwise please install wkhtmltopdf - https://github.com/JazzCore/py ... topdf
解决方案
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
或者
path_wk = 'D:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
原因
Your config path contains an ASCII Backspace, the \b in \bin,
which pdfkit appears to be stripping out and converting D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe
to D:\Program Files\wkhtmltopdf\wkhtmltopdf.exe. 查看全部
文章采集调用(python爬取参考文章AnyProxy代理批量采集实现方法:anyproxy+js
)
蟒蛇爬行
参考文章
AnyProxy 代理批量采集
实现方式:anyproxy+js
实现方式:anyproxy+java+webmagic
FiddlerCore
实现方式:抓包工具,Fiddler4
通过捕获和分析多个账户,可以确定:
步:
1、编写按钮向导脚本,在手机端自动点击公众号文章的列表页面,即“查看历史消息”;
2、使用fiddler代理劫持手机访问,将URL转发到php编写的本地网页;
3、将接收到的URL备份到php网页上的数据库中;
4、使用python从数据库中检索URL,然后进行正常爬取。
在爬升过程中发现了一个问题:
如果只是想爬文章内容,貌似没有访问频率限制,但是如果想爬读点赞数,达到一定频率后,返回值会变成null,时间间隔我设置了10秒,就可以正常取了。在这个频率下,一个小时只能取到 360 条,没有实际意义。
青波新名单
如果你只是想看数据,你可以不花钱只看每日清单。如果你需要访问自己的系统,他们也提供了一个api接口
Part3 项目步骤基本原则
网站收录最微信公众号文章会定期更新,经测试发现对爬虫更友好
网站页面排版和排版规则,不同公众号以链接中的账号区分
公众号采集下的文章也有定期翻页:id号每翻一页+12
传送门副本.png
所以这个想法可能是
环境相关包获取页面
def get_one_page(url):
#需要加一个请求头部,不然会被网站封禁
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status #若不为200,则引发HTTPError错误
response.encoding = response.apparent_encoding
return response.text
except:
return "产生异常"
注意目标爬虫网站必须添加headers,否则会直接拒绝访问
正则解析html
def parse_one_page(html):
pattern = re.compile('.*?.*?<a class="question_link" href="(.*?)".*?_blank"(.*?)/a.*?"timestamp".*?">(.*?)', re.S)
items = re.findall(pattern, html)
return items
自动跳转页面
def main(offset, i):
url = 'http://chuansong.me/account/' + str(offset) + '?start=' + str(12*i)
print(url)
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
html = get_one_page(url)
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
从标题中删除非法字符
因为windows下的file命令,有些字符不能使用,所以需要使用正则剔除
itle = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
转换html
使用pandas的read_csv函数读取爬取的csv文件,循环遍历“link”、“title”、“date”
def html_to_pdf(offset):
wait = round(random.uniform(1,2),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
path = get_path(offset)
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe' #安装wkhtmltopdf的位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
if path == "" :
print("尚未抓取该公众号")
else:
info = get_url_info(offset)
for indexs in info.index:
url = info.loc[indexs]['链接']
title = re.sub('[\\\\/:*?\"|]', '', info.loc[indexs]['标题'])
date = info.loc[indexs]['日期']
wait = round(random.uniform(4,5),2) # 设置随机爬虫间隔,避免被封
time.sleep(wait)
print(url)
with eventlet.Timeout(4,False):
pdfkit.from_url(url, get_path(offset)+'\\'+ date+'_'+title+'.pdf', configuration=config)
print('转换成功!')
结果显示爬取结果
result1-copy.png
爬取的几个公众号存放在文件夹中
结果 2 - 复制.png
文件夹目录的内容
result3-copy.png
抓取的 CSV 内容格式
生成的 PDF 结果
result4-copy.png
遇到的问题问题1
for item in parse_one_page(html):
info = 'http://chuansong.me'+item[0]+','+ item[1]+','+item[2]+'\n'
info = repr(info.replace('\n', ''))
info = info.strip('\"')
print(info)
#info.strip('\"') #这种去不掉首尾的“
#info = info[1:-1] #这种去不掉首尾的“
#info.Trim("".ToCharArray())
#info.TrimStart('\"').TrimEnd('\"')
write_to_file(info, offset)
解决方案
字符串中首尾带有“”,使用上文中的#注释部分的各种方法都不好使,
最后的解决办法是:
在写入字符串的代码出,加上.strip('\'\"'),以去掉‘和”
with open(path, 'a', encoding='utf-8') as f: #追加存储形式,content是字典形式
f.write(str(json.dumps(content, ensure_ascii=False).strip('\'\"') + '\n'))
f.close()
问题2
调用wkhtmltopdf.exe将html转成pdf报错
调用代码
``` python
path_wk = 'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
```
错误信息
OSError: No wkhtmltopdf executable found: "D:\Program Files\wkhtmltopdin\wkhtmltopdf.exe"
If this file exists please check that this process can read it. Otherwise please install wkhtmltopdf - https://github.com/JazzCore/py ... topdf
解决方案
path_wk = r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
或者
path_wk = 'D:\\Program Files\\wkhtmltopdf\\bin\\wkhtmltopdf.exe'
config = pdfkit.configuration(wkhtmltopdf = path_wk)
pdfkit.from_url(url, get_path(offset)+'\\taobao.pdf', configuration=config)
原因
Your config path contains an ASCII Backspace, the \b in \bin,
which pdfkit appears to be stripping out and converting D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe
to D:\Program Files\wkhtmltopdf\wkhtmltopdf.exe.
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-15 07:08
)
最近一个项目需要实现摄像头图像采集,经过一系列的折腾,终于实现了这个功能,现在整理一下。
就java技术而言,为了实现相机的二次开发,采集相机图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然,JMF 处理不了。现在想写个applet程序,但是那个东西需要客户端有jre环境,不适合我。您不能指望用户在访问您的 网站 jre 进行安装然后再次访问时下载一个大文件吗?
既然JMF不适用,那么我们在java项目中如何控制摄像头抓拍呢?在windows平台下,我们可以使用视频采集卡等二次开发包来访问视频数据,但是现在摄像头都是usb的,甚至笔记本屏幕都有摄像头,这种情况下使用的解决方案采集卡二次开发包不适用。你只能自己编写一个程序来做类似“相机相机软件”的事情。经过一系列的分析,终于实现了在web程序中调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集Camera data的项目中实现,例如,
啰嗦一大堆,程序放在csdn下载资源上面,以后不用到处找相机二次开发了,直接下载使用就行了。
摄像头程序下载地址
压缩包中收录一个基于纯网页采集的相机照片示例程序,以及一个基于jquery框架的ajax数据操作程序示例。调用摄像头的方法详见示例代码。相信稍微懂一点技术的人应该都能看懂。了解了,有一个完整的基于java技术的photo采集示例程序,使用jsp页面采集的照片,serlvet程序接收摄像头照片数据。
以下是程序运行效果示例:
查看全部
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集?
)
最近一个项目需要实现摄像头图像采集,经过一系列的折腾,终于实现了这个功能,现在整理一下。
就java技术而言,为了实现相机的二次开发,采集相机图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然,JMF 处理不了。现在想写个applet程序,但是那个东西需要客户端有jre环境,不适合我。您不能指望用户在访问您的 网站 jre 进行安装然后再次访问时下载一个大文件吗?
既然JMF不适用,那么我们在java项目中如何控制摄像头抓拍呢?在windows平台下,我们可以使用视频采集卡等二次开发包来访问视频数据,但是现在摄像头都是usb的,甚至笔记本屏幕都有摄像头,这种情况下使用的解决方案采集卡二次开发包不适用。你只能自己编写一个程序来做类似“相机相机软件”的事情。经过一系列的分析,终于实现了在web程序中调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集Camera data的项目中实现,例如,
啰嗦一大堆,程序放在csdn下载资源上面,以后不用到处找相机二次开发了,直接下载使用就行了。
摄像头程序下载地址
压缩包中收录一个基于纯网页采集的相机照片示例程序,以及一个基于jquery框架的ajax数据操作程序示例。调用摄像头的方法详见示例代码。相信稍微懂一点技术的人应该都能看懂。了解了,有一个完整的基于java技术的photo采集示例程序,使用jsp页面采集的照片,serlvet程序接收摄像头照片数据。
以下是程序运行效果示例:
文章采集调用(下采集神器:chromedp+HeadlessChrome安装安装)
采集交流 • 优采云 发表了文章 • 0 个评论 • 830 次浏览 • 2022-02-14 22:03
最近在采集微信文章的时候,遇到了一个比较棘手的问题。通过搜狗搜索的微信搜索模式,普通的直接爬取页面的方式无法绕过搜狗搜索的验证。于是使用gorequest成功采集到微信文章。
选择 chromedp + Headless Chrome
面对采集的目标没有达到的问题,我是不是该放弃了?显然不可能。你不是只有签名验证吗?只要不需要验证码,总有办法解决的(蒽,一般的验证码也可以解决)。于是牺牲了golang下的采集神器:chromedp。
简单来说,chromedp是golang语言用来调用Chrome调试协议来模拟浏览器行为,以简单的方式驱动浏览器的一个包。使用它只有一个简单的前提,那就是在你的电脑上安装 Chrome 浏览器。
Chrome浏览器的安装在Windows和macOS下没有问题,在桌面版Linux下也没有问题。但是在Linux服务器版上安装Chrome并不是那么简单,至少目前还没有可以直接在服务器上安装Chrome的包。
但是你要放弃你刚才的想法吗?当然这是不可能的。翻阅chromedp的文档,刚好找到一段:
最简单的方法是在 chromedp/headless-shell 映像中运行使用 chromedp 的 Go 程序。该图像收录无头外壳,一种较小的无头版本的 Chrome,chromedp 能够开箱即用地找到它。
他的意思是:最简单的方法是使用 chromedp 调用 chromedp/headless-shell 镜像。chromedp/headless-shell 是一个 docker 镜像,收录较小的 Chrome 无头浏览器。
好吧,既然是docker镜像,那就用docker来安装吧。
首先登录我们的linux服务器,下面的操作就是你已经登录了linux服务器了。
安装 docker 并安装 chromedp/headless-shell
如果您的服务器已经安装了 docker,请跳过此步骤。
用 yum 安装 docker
yum install docker
安装完成后,此时无法直接使用docker,需要执行以下命令激活
systemctl daemon-reload
service docker restart
然后安装 chromedp/headless-shell 镜像
docker pull chromedp/headless-shell:latest
等待安装完成,然后运行docker镜像
docker run -d -p 9222:9222 --rm --name headless-shell chromedp/headless-shell
运行后测试chrome是否正常:
curl http://127.0.0.1:9222/json/version
如果您看到类似以下内容,则 chrome 浏览器工作正常
{ “浏览器”:“Chrome/96.0.4664.110”,“协议版本”:“1.3”,“用户代理”:“ Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, 像 Gecko) Chrome/96.0.4664.110 Safari/537.36", "V8-版本": "9.6.180.21", "WebKit-版本": "537.36 (@d5ef0e8214bc14c9b5bbf69a1515e431394c62a6)", "webSocketDebuggerUrl": "ws://127.0.0.1:9222/devtools/browser/a41cd42b-99ef -4d5b-b9e6-37d634aa719a" }
chromedp代码调用chromedp/headless-shell的内容采集微信公众号文章
以上已经可以在linux下正常使用Headless Chrome无头浏览器了。剩下的就是调用它的代码。
下面开始编写采集WeChat文章使用的chrome代码:
定义关键字,artile struct.go
package main
type Keyword struct {
Id int64 `json:"id"`
Name string `json:"name"`
Level int `json:"level"`
ArticleCount int `json:"article_count"`
LastTime int64 `json:"last_time"` //上次执行时间
}
type Article struct {
Id int64 `json:"id"`
KeywordId int64 `json:"keyword_id"`
Title string `json:"title"`
Keywords string `json:"keywords"`
Description string `json:"description"`
OriginUrl string `json:"origin_url"`
Status int `json:"status"`
CreatedTime int `json:"created_time"`
UpdatedTime int `json:"updated_time"`
Content string `json:"content"`
ContentText string `json:"-"`
}
编写核心代码core.go
<p>package main
import (
"context"
"fmt"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
"log"
"net"
"net/url"
"strings"
"time"
)
func CollectArticleFromWeixin(keyword *Keyword) []*Article {
timeCtx, cancel := context.WithTimeout(GetChromeCtx(false), 30*time.Second)
defer cancel()
var collectLink string
err := chromedp.Run(timeCtx,
chromedp.Navigate(fmt.Sprintf("https://weixin.sogou.com/weixi ... ot%3B, keyword.Name)),
chromedp.WaitVisible(`//ul[@class="news-list"]`),
chromedp.Location(&collectLink),
)
if err != nil {
log.Println("读取搜狗搜索列表失败1:", keyword.Name, err.Error())
return nil
}
log.Println("正在采集列表:", collectLink)
var aLinks []*cdp.Node
if err := chromedp.Run(timeCtx, chromedp.Nodes(`//ul[@class="news-list"]//h3//a`, &aLinks)); err != nil {
log.Println("读取搜狗搜索列表失败2:", keyword.Name, err.Error())
return nil
}
var articles []*Article
for i := 0; i 查看全部
文章采集调用(下采集神器:chromedp+HeadlessChrome安装安装)
最近在采集微信文章的时候,遇到了一个比较棘手的问题。通过搜狗搜索的微信搜索模式,普通的直接爬取页面的方式无法绕过搜狗搜索的验证。于是使用gorequest成功采集到微信文章。
选择 chromedp + Headless Chrome
面对采集的目标没有达到的问题,我是不是该放弃了?显然不可能。你不是只有签名验证吗?只要不需要验证码,总有办法解决的(蒽,一般的验证码也可以解决)。于是牺牲了golang下的采集神器:chromedp。
简单来说,chromedp是golang语言用来调用Chrome调试协议来模拟浏览器行为,以简单的方式驱动浏览器的一个包。使用它只有一个简单的前提,那就是在你的电脑上安装 Chrome 浏览器。
Chrome浏览器的安装在Windows和macOS下没有问题,在桌面版Linux下也没有问题。但是在Linux服务器版上安装Chrome并不是那么简单,至少目前还没有可以直接在服务器上安装Chrome的包。
但是你要放弃你刚才的想法吗?当然这是不可能的。翻阅chromedp的文档,刚好找到一段:
最简单的方法是在 chromedp/headless-shell 映像中运行使用 chromedp 的 Go 程序。该图像收录无头外壳,一种较小的无头版本的 Chrome,chromedp 能够开箱即用地找到它。
他的意思是:最简单的方法是使用 chromedp 调用 chromedp/headless-shell 镜像。chromedp/headless-shell 是一个 docker 镜像,收录较小的 Chrome 无头浏览器。
好吧,既然是docker镜像,那就用docker来安装吧。
首先登录我们的linux服务器,下面的操作就是你已经登录了linux服务器了。
安装 docker 并安装 chromedp/headless-shell
如果您的服务器已经安装了 docker,请跳过此步骤。
用 yum 安装 docker
yum install docker
安装完成后,此时无法直接使用docker,需要执行以下命令激活
systemctl daemon-reload
service docker restart
然后安装 chromedp/headless-shell 镜像
docker pull chromedp/headless-shell:latest
等待安装完成,然后运行docker镜像
docker run -d -p 9222:9222 --rm --name headless-shell chromedp/headless-shell
运行后测试chrome是否正常:
curl http://127.0.0.1:9222/json/version
如果您看到类似以下内容,则 chrome 浏览器工作正常
{ “浏览器”:“Chrome/96.0.4664.110”,“协议版本”:“1.3”,“用户代理”:“ Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, 像 Gecko) Chrome/96.0.4664.110 Safari/537.36", "V8-版本": "9.6.180.21", "WebKit-版本": "537.36 (@d5ef0e8214bc14c9b5bbf69a1515e431394c62a6)", "webSocketDebuggerUrl": "ws://127.0.0.1:9222/devtools/browser/a41cd42b-99ef -4d5b-b9e6-37d634aa719a" }
chromedp代码调用chromedp/headless-shell的内容采集微信公众号文章
以上已经可以在linux下正常使用Headless Chrome无头浏览器了。剩下的就是调用它的代码。
下面开始编写采集WeChat文章使用的chrome代码:
定义关键字,artile struct.go
package main
type Keyword struct {
Id int64 `json:"id"`
Name string `json:"name"`
Level int `json:"level"`
ArticleCount int `json:"article_count"`
LastTime int64 `json:"last_time"` //上次执行时间
}
type Article struct {
Id int64 `json:"id"`
KeywordId int64 `json:"keyword_id"`
Title string `json:"title"`
Keywords string `json:"keywords"`
Description string `json:"description"`
OriginUrl string `json:"origin_url"`
Status int `json:"status"`
CreatedTime int `json:"created_time"`
UpdatedTime int `json:"updated_time"`
Content string `json:"content"`
ContentText string `json:"-"`
}
编写核心代码core.go
<p>package main
import (
"context"
"fmt"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
"log"
"net"
"net/url"
"strings"
"time"
)
func CollectArticleFromWeixin(keyword *Keyword) []*Article {
timeCtx, cancel := context.WithTimeout(GetChromeCtx(false), 30*time.Second)
defer cancel()
var collectLink string
err := chromedp.Run(timeCtx,
chromedp.Navigate(fmt.Sprintf("https://weixin.sogou.com/weixi ... ot%3B, keyword.Name)),
chromedp.WaitVisible(`//ul[@class="news-list"]`),
chromedp.Location(&collectLink),
)
if err != nil {
log.Println("读取搜狗搜索列表失败1:", keyword.Name, err.Error())
return nil
}
log.Println("正在采集列表:", collectLink)
var aLinks []*cdp.Node
if err := chromedp.Run(timeCtx, chromedp.Nodes(`//ul[@class="news-list"]//h3//a`, &aLinks)); err != nil {
log.Println("读取搜狗搜索列表失败2:", keyword.Name, err.Error())
return nil
}
var articles []*Article
for i := 0; i
文章采集调用(闭包dep:来存储依赖引用数据类型的数据依赖收集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-02-14 22:02
)
上一篇我们分析了基础数据类型的依赖集合
本文是关于引用数据类型的数据依赖采集和分析,因为引用类型数据比较复杂,必须单独写
文章很长,高能预警,做好准备,耐心等待,一定会有收获
不过这两类数据的处理有很多重复,所以我打算只写一些区别,否则会废话很多。
两个步骤,两者都不一样
1、数据初始化
2、依赖集合
数据初始化过程
如果数据类型是引用类型,则需要对数据进行额外处理。
处理分为对象和数组两种,分别讨论。
1 个对象
1、 遍历对象的各个属性,也设置响应性。假设属性都是基本类型,处理流程和上一个一样
2、每个数据对象都会添加一个ob属性
例如,设置子数据对象
在下图中,可以看到子对象处理完后添加了一个ob属性
ob_ 属性有什么用?
你可以观察到 ob 有一个 dep 属性。这个 dep 是不是有点属性?是的,在上一篇关于基本数据类型的文章中提到过
那么这个ob属性有什么用呢?
你可以观察到 ob 有一个 dep 属性。这个 dep 是不是有点属性?是的,在上一篇关于基本数据类型的文章中提到过
dep 正是存储依赖项的位置
比如page指的是data child,watch指的是data child,那么child会将这两个保存在dep.subs中
dep.subs = [ 页面-watcher,watch-watcher ]
但是,在上一篇关于基本类型的文章中,dep 作为闭包存在,而不是任何 [ob.dep]。
是的,这就是引用类型和原创类型的区别
基本数据类型,仅使用 [closure dep] 存储依赖关系
引用数据类型,使用[closure dep]和[ob.dep]存储依赖
什么?你说关闭部门在哪里?嗯,在defineReactive的源码中,大家可以看一下这个方法的源码,下面是
那么,为什么引用类型需要使用 __ob__.dep 来存储依赖呢?
首先要明确一点,存储依赖就是在数据变化时通知依赖,所以ob.dep也是为了变化后的通知
闭包dep只存在于defineReactive中,不能在别处使用,所以需要另存一个以供别处使用
它还会用在哪里?
Vue挂载原型上的set和del方法中,源码如下
function set(target, key, val) {
var ob = (target).__ob__;
// 通知依赖更新
ob.dep.notify();
}
Vue.prototype.$set = set;
function del(target, key) {
var ob = (target).__ob__;
delete target[key];
if (!ob) return
// 通知依赖更新
ob.dep.notify();
}
Vue.prototype.$delete = del;
这两个方法大家都应该用过,为了对象的动态增删属性
但是如果直接添加属性或者删除属性,Vue就无法监听,比如下面
child.xxxx=1
delete child.xxxx
所以必须通过Vue封装的set和del方法来操作
执行完set和del后,需要通知依赖更新,但是怎么通知呢?
此时,[ob.dep] 发挥作用!正因为有依赖关系,所以在 ob.dep 中又采集了一份
使用就是上面那句话,通知更新
ob.dep.notify();
2、数组
1、需要遍历数组,可能数组是对象数组,如下
[{name:1},{name:888}]
遍历的时候,如果子item是一个对象,会和上面解析对象一样操作。
2、保存一个ob属性到数组
例如,设置一个 arr 数组
看到arr数组增加了ob属性
其实这个ob属性和上一段提到的对象的功能类似,这里我们只说ob.dep
数组中的 Ob.dep 还存储依赖项。它是给谁的?
要使用Vue封装的数组方法,要知道如果数组的变化也被监听了,一定要使用Vue封装的数组方法,否则无法实时更新
这里是覆盖方法之一,push,其他的是splice等,Vue官方文档已经说明了。
var original = Array.prototype.push;
Array.prototype.push = function() {
var args = [],
len = arguments.length;
// 复制 传给 push 等方法的参数
while (len--) args[len] = arguments[len];
// 执行 原方法
var result = original.apply(this, args);
var ob = this.__ob__;
// notify change
ob.dep.notify();
return resul
}
可见,执行完数组方法后,还需要通知依赖更新,即通知ob.dep中采集的依赖更新
现在,我们知道响应式数据对引用类型做了哪些额外的处理,主要是添加一个ob属性
我们已经知道ob是干什么用的了,现在看看源码是怎么添加ob的
// 初始化Vue组件的数据
function initData(vm) {
var data = vm.$options.data;
data = vm._data =
typeof data === 'function' ?
data.call(vm, vm) : data || {};
....遍历 data 数据对象的key ,重名检测,合规检测
observe(data, true);
}
function observe(value) {
if (Array.isArray(value) || typeof value == "object") {
ob = new Observer(value);
}
return ob
}
function Observer(value) {
// 给对象生成依赖保存器
this.dep = new Dep();
// 给 每一个对象 添加一个 __ob__ 属性,值为 Observer 实例
value.__ob__ = this
if (Array.isArray(value)) {
// 遍历数组,每一项都需要通过 observe 处理,如果是对象就添加 __ob__
for (var i = 0, l =value.length; i < l; i++) {
observe(value[i]);
}
} else {
var keys = Object.keys(value);
// 给对象的每一个属性设置响应式
for (var i = 0; i < keys.length; i++) {
defineReactive(value, keys[i]);
}
}
};
源码的处理过程和上一个类似,但是处理引用数据类型会多增加几行对源码的额外处理。
我们之前只讲过一种对象数据类型,比如下面
如果嵌套了多层对象怎么办?例如,将如何
是的,Vue 会递归处理。遍历属性,使用defineReactive处理时,递归调用observe处理(源码用红色加粗标记)
如果该值是一个对象,那么还要在该值上添加一个 ob
如果没有,则正常下线并设置响应
源代码如下
function defineReactive(obj, key, value) {
// dep 用于中收集所有 依赖我的 东西
var dep = new Dep();
var val = obj[key]
// 返回的 childOb 是一个 Observer 实例
// 如果值是一个对象,需要递归遍历对象
var childOb = observe(val);
Object.defineProperty(obj, key, {
get() {...依赖收集跟初始化无关,下面会讲},
set() { .... }
});
}
绘制流程图仅供参考
哈哈哈,上面的很长,有一点点,但是忍不住了。我想更详细一点。好吧,还有一段,但它有点短。答应我,如果你仔细阅读,请发表评论,让我知道有人仔细阅读过
依赖采集过程
采集过程重点是Object.defineProperty设置的get方法
与基本类型数据相比,引用类型的采集方式只是多了几行处理,区别就在于两行代码
childOb.dep.depend,我将其简化为 childOb.dep.addSub(Dep.target)
依赖数组(值)
可以先看源码,如下
function defineReactive(obj, key, value) {
var dep = new Dep();
var val = obj[key]
var childOb = observe(val);
Object.defineProperty(obj, key, {
get() {
var value = val
if (Dep.target) {
// 收集依赖进 dep.subs
dep.addSub(Dep.target);
// 如果值是一个对象,Observer 实例的 dep 也收集一遍依赖
if (childOb) {
childOb.dep.addSub(Dep.target)
if (Array.isArray(value)) {
dependArray(value);
}
}
}
return value
}
});
}
以上源码混合了对象和数组的处理,我们分开讲
1、对象
在数据初始化的过程中,我们已经知道如果值是一个对象,在ob.dep中会额外存储一份依赖
只有一句话
childOb.dep.depend();
数组有另一种处理方式,即
dependArray(value);
看源码,如下
function dependArray(value) {
for (var i = 0, l = value.length; i < l; i++) {
var e = value[i];
// 只有子项是对象的时候,收集依赖进 dep.subs
e && e.__ob__ && e.__ob__.dep.addSub(Dep.target);
// 如果子项还是 数组,那就继续递归遍历
if (Array.isArray(e)) {
dependArray(e);
}
}
}
显然,为了防止数组中的对象,需要保存数组的子项对象的副本。
你一定要问,为什么子对象还要保存一个依赖?
1、页面依赖数组,数组的子项发生了变化。页面是否也需要更新?但是子项的内部变化是如何通知页面更新的呢?所以你还需要为子对象保存一个依赖项吗?
2、数组子项数组的变化就是对象属性的增删。必须使用 Vue 封装方法 set 和 del。set和del会通知依赖更新,所以子项对象也要保存
看栗子
[外链图片传输失败(img-PuPHYChy-59)()]
页面模板
看数组的数据,有两个ob
总结
至此,引用类型和基本类型的区别就很清楚了。
1、引用类型会添加一个__ob__属性,里面收录dep,用来存放采集到的依赖
2、对象使用ob.dep,作用于Vue的自定义方法set和del
3、数组使用ob.dep,作用于Vue重写的数组方法push等。
终于看完了,真的好长,不过我觉得值得
查看全部
文章采集调用(闭包dep:来存储依赖引用数据类型的数据依赖收集
)
上一篇我们分析了基础数据类型的依赖集合
本文是关于引用数据类型的数据依赖采集和分析,因为引用类型数据比较复杂,必须单独写
文章很长,高能预警,做好准备,耐心等待,一定会有收获
不过这两类数据的处理有很多重复,所以我打算只写一些区别,否则会废话很多。
两个步骤,两者都不一样
1、数据初始化
2、依赖集合
数据初始化过程
如果数据类型是引用类型,则需要对数据进行额外处理。
处理分为对象和数组两种,分别讨论。
1 个对象
1、 遍历对象的各个属性,也设置响应性。假设属性都是基本类型,处理流程和上一个一样
2、每个数据对象都会添加一个ob属性
例如,设置子数据对象
在下图中,可以看到子对象处理完后添加了一个ob属性
ob_ 属性有什么用?
你可以观察到 ob 有一个 dep 属性。这个 dep 是不是有点属性?是的,在上一篇关于基本数据类型的文章中提到过
那么这个ob属性有什么用呢?
你可以观察到 ob 有一个 dep 属性。这个 dep 是不是有点属性?是的,在上一篇关于基本数据类型的文章中提到过
dep 正是存储依赖项的位置
比如page指的是data child,watch指的是data child,那么child会将这两个保存在dep.subs中
dep.subs = [ 页面-watcher,watch-watcher ]
但是,在上一篇关于基本类型的文章中,dep 作为闭包存在,而不是任何 [ob.dep]。
是的,这就是引用类型和原创类型的区别
基本数据类型,仅使用 [closure dep] 存储依赖关系
引用数据类型,使用[closure dep]和[ob.dep]存储依赖
什么?你说关闭部门在哪里?嗯,在defineReactive的源码中,大家可以看一下这个方法的源码,下面是
那么,为什么引用类型需要使用 __ob__.dep 来存储依赖呢?
首先要明确一点,存储依赖就是在数据变化时通知依赖,所以ob.dep也是为了变化后的通知
闭包dep只存在于defineReactive中,不能在别处使用,所以需要另存一个以供别处使用
它还会用在哪里?
Vue挂载原型上的set和del方法中,源码如下
function set(target, key, val) {
var ob = (target).__ob__;
// 通知依赖更新
ob.dep.notify();
}
Vue.prototype.$set = set;
function del(target, key) {
var ob = (target).__ob__;
delete target[key];
if (!ob) return
// 通知依赖更新
ob.dep.notify();
}
Vue.prototype.$delete = del;
这两个方法大家都应该用过,为了对象的动态增删属性
但是如果直接添加属性或者删除属性,Vue就无法监听,比如下面
child.xxxx=1
delete child.xxxx
所以必须通过Vue封装的set和del方法来操作
执行完set和del后,需要通知依赖更新,但是怎么通知呢?
此时,[ob.dep] 发挥作用!正因为有依赖关系,所以在 ob.dep 中又采集了一份
使用就是上面那句话,通知更新
ob.dep.notify();
2、数组
1、需要遍历数组,可能数组是对象数组,如下
[{name:1},{name:888}]
遍历的时候,如果子item是一个对象,会和上面解析对象一样操作。
2、保存一个ob属性到数组
例如,设置一个 arr 数组
看到arr数组增加了ob属性
其实这个ob属性和上一段提到的对象的功能类似,这里我们只说ob.dep
数组中的 Ob.dep 还存储依赖项。它是给谁的?
要使用Vue封装的数组方法,要知道如果数组的变化也被监听了,一定要使用Vue封装的数组方法,否则无法实时更新
这里是覆盖方法之一,push,其他的是splice等,Vue官方文档已经说明了。
var original = Array.prototype.push;
Array.prototype.push = function() {
var args = [],
len = arguments.length;
// 复制 传给 push 等方法的参数
while (len--) args[len] = arguments[len];
// 执行 原方法
var result = original.apply(this, args);
var ob = this.__ob__;
// notify change
ob.dep.notify();
return resul
}
可见,执行完数组方法后,还需要通知依赖更新,即通知ob.dep中采集的依赖更新
现在,我们知道响应式数据对引用类型做了哪些额外的处理,主要是添加一个ob属性
我们已经知道ob是干什么用的了,现在看看源码是怎么添加ob的
// 初始化Vue组件的数据
function initData(vm) {
var data = vm.$options.data;
data = vm._data =
typeof data === 'function' ?
data.call(vm, vm) : data || {};
....遍历 data 数据对象的key ,重名检测,合规检测
observe(data, true);
}
function observe(value) {
if (Array.isArray(value) || typeof value == "object") {
ob = new Observer(value);
}
return ob
}
function Observer(value) {
// 给对象生成依赖保存器
this.dep = new Dep();
// 给 每一个对象 添加一个 __ob__ 属性,值为 Observer 实例
value.__ob__ = this
if (Array.isArray(value)) {
// 遍历数组,每一项都需要通过 observe 处理,如果是对象就添加 __ob__
for (var i = 0, l =value.length; i < l; i++) {
observe(value[i]);
}
} else {
var keys = Object.keys(value);
// 给对象的每一个属性设置响应式
for (var i = 0; i < keys.length; i++) {
defineReactive(value, keys[i]);
}
}
};
源码的处理过程和上一个类似,但是处理引用数据类型会多增加几行对源码的额外处理。
我们之前只讲过一种对象数据类型,比如下面
如果嵌套了多层对象怎么办?例如,将如何
是的,Vue 会递归处理。遍历属性,使用defineReactive处理时,递归调用observe处理(源码用红色加粗标记)
如果该值是一个对象,那么还要在该值上添加一个 ob
如果没有,则正常下线并设置响应
源代码如下
function defineReactive(obj, key, value) {
// dep 用于中收集所有 依赖我的 东西
var dep = new Dep();
var val = obj[key]
// 返回的 childOb 是一个 Observer 实例
// 如果值是一个对象,需要递归遍历对象
var childOb = observe(val);
Object.defineProperty(obj, key, {
get() {...依赖收集跟初始化无关,下面会讲},
set() { .... }
});
}
绘制流程图仅供参考
哈哈哈,上面的很长,有一点点,但是忍不住了。我想更详细一点。好吧,还有一段,但它有点短。答应我,如果你仔细阅读,请发表评论,让我知道有人仔细阅读过
依赖采集过程
采集过程重点是Object.defineProperty设置的get方法
与基本类型数据相比,引用类型的采集方式只是多了几行处理,区别就在于两行代码
childOb.dep.depend,我将其简化为 childOb.dep.addSub(Dep.target)
依赖数组(值)
可以先看源码,如下
function defineReactive(obj, key, value) {
var dep = new Dep();
var val = obj[key]
var childOb = observe(val);
Object.defineProperty(obj, key, {
get() {
var value = val
if (Dep.target) {
// 收集依赖进 dep.subs
dep.addSub(Dep.target);
// 如果值是一个对象,Observer 实例的 dep 也收集一遍依赖
if (childOb) {
childOb.dep.addSub(Dep.target)
if (Array.isArray(value)) {
dependArray(value);
}
}
}
return value
}
});
}
以上源码混合了对象和数组的处理,我们分开讲
1、对象
在数据初始化的过程中,我们已经知道如果值是一个对象,在ob.dep中会额外存储一份依赖
只有一句话
childOb.dep.depend();
数组有另一种处理方式,即
dependArray(value);
看源码,如下
function dependArray(value) {
for (var i = 0, l = value.length; i < l; i++) {
var e = value[i];
// 只有子项是对象的时候,收集依赖进 dep.subs
e && e.__ob__ && e.__ob__.dep.addSub(Dep.target);
// 如果子项还是 数组,那就继续递归遍历
if (Array.isArray(e)) {
dependArray(e);
}
}
}
显然,为了防止数组中的对象,需要保存数组的子项对象的副本。
你一定要问,为什么子对象还要保存一个依赖?
1、页面依赖数组,数组的子项发生了变化。页面是否也需要更新?但是子项的内部变化是如何通知页面更新的呢?所以你还需要为子对象保存一个依赖项吗?
2、数组子项数组的变化就是对象属性的增删。必须使用 Vue 封装方法 set 和 del。set和del会通知依赖更新,所以子项对象也要保存
看栗子
[外链图片传输失败(img-PuPHYChy-59)()]
页面模板
看数组的数据,有两个ob
总结
至此,引用类型和基本类型的区别就很清楚了。
1、引用类型会添加一个__ob__属性,里面收录dep,用来存放采集到的依赖
2、对象使用ob.dep,作用于Vue的自定义方法set和del
3、数组使用ob.dep,作用于Vue重写的数组方法push等。
终于看完了,真的好长,不过我觉得值得
文章采集调用(DS打数机才能自动翻页采集数据(图)案例大全)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-14 04:04
一、操作步骤
采集如果有多个页面列表页,需要设置翻页,以便DS打印机自动翻页采集数据。选择一个以翻页为规则的示例URL,您可以使用该规则批量处理采集相似的URL(适用于一页和多页)。以下是大众点评网的一个例子。
二、案例步骤
先复制上面的例子,来到采集列出数据。本教程在上一篇文章文章中已经提到过,不再重复操作。“GooSeeker Copy Batch 采集 列出带有样本的数据”
三、设置翻页
1.1、新建marker thread:选择“Crawler Route”,点击“New”,选择“Marker Clue”,勾选“Continuous Grab”,“Target Subject Name”会自动填写。这意味着该规则被循环调用。
1.2、一旦设置了标记线索,就做了两个映射,第一个是映射翻页块的范围,第二个是映射翻页标记。
第一次是选择翻页区的页面节点进行映射:点击翻页标志,定位到收录它的翻页区所在的页面节点。这些翻页按钮的翻页区域,然后右键节点选择“Lead Mapping”->“Location”->“Clue*”,爬虫路由中的“Location Number”就会映射节点的编号。
第二次是映射翻页标记值所在的页面节点:双击翻页区域节点逐层展开,找到翻页标记所在的节点,这里指的是翻页按钮的文本节点或属性值节点,右击节点选择“线索映射”->“标记映射”,爬虫路由中的“标记值”和“标记位置编号”会映射值和节点的编号。
1.3、定位选项的默认项是数字id。由于不同页码的翻页区的id值可能会发生变化,所以class值通常保持不变,所以最好改成preference class。
四、保存规则并捕获数据
点击保存规则,爬取数据,在DS计数器中查看翻页是否成功。如果翻页采集成功,会在本地DataScraperWorks文件夹中生成多个XML文件。详见文章如何将采集中的xml文件转换为Excel文件?”。 查看全部
文章采集调用(DS打数机才能自动翻页采集数据(图)案例大全)
一、操作步骤
采集如果有多个页面列表页,需要设置翻页,以便DS打印机自动翻页采集数据。选择一个以翻页为规则的示例URL,您可以使用该规则批量处理采集相似的URL(适用于一页和多页)。以下是大众点评网的一个例子。
二、案例步骤
先复制上面的例子,来到采集列出数据。本教程在上一篇文章文章中已经提到过,不再重复操作。“GooSeeker Copy Batch 采集 列出带有样本的数据”
三、设置翻页
1.1、新建marker thread:选择“Crawler Route”,点击“New”,选择“Marker Clue”,勾选“Continuous Grab”,“Target Subject Name”会自动填写。这意味着该规则被循环调用。
1.2、一旦设置了标记线索,就做了两个映射,第一个是映射翻页块的范围,第二个是映射翻页标记。
第一次是选择翻页区的页面节点进行映射:点击翻页标志,定位到收录它的翻页区所在的页面节点。这些翻页按钮的翻页区域,然后右键节点选择“Lead Mapping”->“Location”->“Clue*”,爬虫路由中的“Location Number”就会映射节点的编号。
第二次是映射翻页标记值所在的页面节点:双击翻页区域节点逐层展开,找到翻页标记所在的节点,这里指的是翻页按钮的文本节点或属性值节点,右击节点选择“线索映射”->“标记映射”,爬虫路由中的“标记值”和“标记位置编号”会映射值和节点的编号。
1.3、定位选项的默认项是数字id。由于不同页码的翻页区的id值可能会发生变化,所以class值通常保持不变,所以最好改成preference class。
四、保存规则并捕获数据
点击保存规则,爬取数据,在DS计数器中查看翻页是否成功。如果翻页采集成功,会在本地DataScraperWorks文件夹中生成多个XML文件。详见文章如何将采集中的xml文件转换为Excel文件?”。
文章采集调用(文章采集调用webhookspider与ss-send等接口采集,提供开源接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-12 22:02
文章采集调用webhookspider与ss-send等接口采集,提供开源接口可以用在线-stats-api,
第一,用golang写爬虫,只要你熟悉golang一个星期学习就会了。这是我用过比较容易上手的一门语言,速度也快。但是,我现在是用ruby开发爬虫。第二,推荐比较有名的gayhub上的一个开源爬虫工具pokes,开源,成熟。我用这个爬虫可以发布在快手、陌陌、探探、趣头条等等。这个应该适合题主,如果有疑问可以到pokesgithub页面上留言。
其实你就是想了解scrapy可以做到什么效果呗,请移步各种flatpages,各种scrapy示例和教程(xwliwubo/scrapy-doc:focusinlightweightscrapydocumentation),里面有很多入门介绍、数据加载和处理等等的算法、规则等等python程序员比较常用的库,前端爬虫基本上也是通过python+beautifulsoup处理图片、正则表达式等等。
根据经验,大部分抓取的数据都可以用现成的库封装好,或者自己封装python程序库,最后通过工具链发送出去。
可以看下我们公司出的这个爬虫系列教程,通俗易懂,分门别类全面的讲解了爬虫基础、高效爬虫、scrapy快速入门及开发等内容, 查看全部
文章采集调用(文章采集调用webhookspider与ss-send等接口采集,提供开源接口)
文章采集调用webhookspider与ss-send等接口采集,提供开源接口可以用在线-stats-api,
第一,用golang写爬虫,只要你熟悉golang一个星期学习就会了。这是我用过比较容易上手的一门语言,速度也快。但是,我现在是用ruby开发爬虫。第二,推荐比较有名的gayhub上的一个开源爬虫工具pokes,开源,成熟。我用这个爬虫可以发布在快手、陌陌、探探、趣头条等等。这个应该适合题主,如果有疑问可以到pokesgithub页面上留言。
其实你就是想了解scrapy可以做到什么效果呗,请移步各种flatpages,各种scrapy示例和教程(xwliwubo/scrapy-doc:focusinlightweightscrapydocumentation),里面有很多入门介绍、数据加载和处理等等的算法、规则等等python程序员比较常用的库,前端爬虫基本上也是通过python+beautifulsoup处理图片、正则表达式等等。
根据经验,大部分抓取的数据都可以用现成的库封装好,或者自己封装python程序库,最后通过工具链发送出去。
可以看下我们公司出的这个爬虫系列教程,通俗易懂,分门别类全面的讲解了爬虫基础、高效爬虫、scrapy快速入门及开发等内容,
文章采集调用(如何直接在nodejs页面中访问splash页面上访问页面)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-11 17:06
文章采集调用splash开发通用githubpage的功能都采用wordpress编写。优点是可扩展性强,通用性高,还可以像zendfish这种hook机制扩展各种参数及解析得到的github页面。缺点是部署维护比较麻烦,且不像freelancer社区推崇的快速制作插件。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中搜索splashpageforwordpress安装扩展。下载地址,查看sfbeta版本,下载之后wordpress插件安装好了,可以通过安装npm包来创建github页面。如何直接在nodejs页面中访问splash页面:wordpress-splash-page文章编辑器使用wordpress开发的编辑器,也就是onepagebutton这种方式。
优点是可以复用原来的vue的页面结构,同时方便维护及更换其他wordpress插件。缺点是nodejs支持度太差,如果你要追求巨大的流量,你就不用想其他插件的安装和运行了。同时你要有一定的开发语言和运行环境基础。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中访问splash页面。安装php开发工具。没有解决nodejs兼容性问题。也就是数据类型显示的各种问题,为了避免这个问题,可以把php安装类型设置为bash及gvim等visualstudio支持的编辑器。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中访问splash页面。引入wordpress开发的url模板文件。对于php的splash页面而言,是用ruby\java\go或wordpress.php等路径来定义的页面。而对于ps/ppt等其他图形语言而言,是用pathname来定义页面,如下图所示:1.在php/extensions/urls.php中添加相应的url资源路径,重定向到对应页面。
最后在浏览器访问/splash/可以访问以上页面。2.在php/extensions/urls.php中添加相应的url资源路径,重定向到对应页面。最后在浏览器访问/splash/可以访问以上页面。3.加入浏览器loading缓存,如果浏览器都是在vscode环境下运行,那么跳转到页面cd,wordpress这种在线visualstudio可运行于浏览器上的编辑器就会重定向在php端。
4.使用spacerebug插件扫描浏览器loading缓存记录如果你的wordpress拥有loading缓存功能,那么可以扫描浏览器的loading缓存记录,这样当访问该链接时,前端代码就不需要后端代码来初始化你的请求,就可以在浏览器端安全地访问你要爬取的页面。githubpie这个插件。 查看全部
文章采集调用(如何直接在nodejs页面中访问splash页面上访问页面)
文章采集调用splash开发通用githubpage的功能都采用wordpress编写。优点是可扩展性强,通用性高,还可以像zendfish这种hook机制扩展各种参数及解析得到的github页面。缺点是部署维护比较麻烦,且不像freelancer社区推崇的快速制作插件。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中搜索splashpageforwordpress安装扩展。下载地址,查看sfbeta版本,下载之后wordpress插件安装好了,可以通过安装npm包来创建github页面。如何直接在nodejs页面中访问splash页面:wordpress-splash-page文章编辑器使用wordpress开发的编辑器,也就是onepagebutton这种方式。
优点是可以复用原来的vue的页面结构,同时方便维护及更换其他wordpress插件。缺点是nodejs支持度太差,如果你要追求巨大的流量,你就不用想其他插件的安装和运行了。同时你要有一定的开发语言和运行环境基础。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中访问splash页面。安装php开发工具。没有解决nodejs兼容性问题。也就是数据类型显示的各种问题,为了避免这个问题,可以把php安装类型设置为bash及gvim等visualstudio支持的编辑器。对于vscode这种在线visualstudio可运行于浏览器上的编辑器支持一般,且ppt几乎就是在nodejs上做的。
访问官网可以直接在nodejs页面中访问splash页面。引入wordpress开发的url模板文件。对于php的splash页面而言,是用ruby\java\go或wordpress.php等路径来定义的页面。而对于ps/ppt等其他图形语言而言,是用pathname来定义页面,如下图所示:1.在php/extensions/urls.php中添加相应的url资源路径,重定向到对应页面。
最后在浏览器访问/splash/可以访问以上页面。2.在php/extensions/urls.php中添加相应的url资源路径,重定向到对应页面。最后在浏览器访问/splash/可以访问以上页面。3.加入浏览器loading缓存,如果浏览器都是在vscode环境下运行,那么跳转到页面cd,wordpress这种在线visualstudio可运行于浏览器上的编辑器就会重定向在php端。
4.使用spacerebug插件扫描浏览器loading缓存记录如果你的wordpress拥有loading缓存功能,那么可以扫描浏览器的loading缓存记录,这样当访问该链接时,前端代码就不需要后端代码来初始化你的请求,就可以在浏览器端安全地访问你要爬取的页面。githubpie这个插件。
文章采集调用(爬虫应该怎么进行测试?的测试方法应该如何进行?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-10 13:18
很多同学不知道应该如何测试爬虫。我也是刚接触一点爬虫测试的新手。通过对爬虫的分析,总结了爬虫的测试方法。其他建议欢迎补充。
一、测试阶段
对于data采集调用第三方平台(比如scorpion)的流程大家可能比较熟悉。在第三方页面授权后,第三方会帮我们完成data采集的任务。我们只需要等待结果被回调。但是如果要自己做爬虫,又是一个什么样的过程呢?
其实爬虫和其他业务一样,也是有流程的。一般是先触发创建任务,爬虫模块对数据采集进行处理,采集完成后,对数据进行解析和存储。对于授权爬虫来说,有SDK页面的也可以直接通过页面进行请求,其他的只能通过请求接口实现。还有一种爬虫,在后台配置好任务后,会定期去网站爬取数据,更新数据库。当然还有很多其他的交互逻辑,每一步都需要分析评估。
因此,我们可以从创建任务的界面入手,连接整个流程,在界面的响应中加入简单的验证。比如创建任务后有任务编号,通过查询接口可以得到任务的结果数据。然后检查数据是否存储,存储是否准确,是否会出现乱码等。从界面入手的好处是我们可以自动化检查爬虫任务,检查数据是否可以创建,是否爬虫能否正常爬取,爬取结果是否入库。解析的逻辑和存储的准确性需要注意。爬虫结果数据的存储与数据分析和应用有关。对于数据分析,如果源数据有误,那么无论分析结果如何,都是没有意义的。.
总结
1.接口测试,调用数据接口采集,测试爬虫进程;接口基础测试和弱网、接口安全、接口性能等。
2.可以通过接口或者SDK测试场景,包括爬取成功的场景和失败的场景,比如无数据和无效数据。
3.完成采集后的分析和存储测试,数据分析和存储逻辑检查。
4.异常测试,主要针对系统间交互的处理逻辑,如失败重试机制、服务间容错机制等。
5.爬虫质量和效率,主要从整体设计和代码实现来分析爬虫的处理方式是否高可用。
二、在线阶段
一旦爬虫上线供其他业务方使用,就需要保证可用性和可靠性。对于爬虫来说,在线监控非常重要!不仅要保证提供的爬虫能够正常运行,还要保证出现异常时,能够在最短的时间内解决。因此,监测应从以下三个方面入手:
1.在线运行接口脚本监控提供的接口可以正常使用,而不是等业务方调整好基础接口,再反馈修复,成本比较大。主动调整界面,判断程序是否正常。您只能验证该接口是否可以运行。如果条件允许,在线运行真实数据并验证结果。
2.监控线上发生的异常情况,如创建任务失败、登录失败、数据采集失败、数据解析失败、回调失败、数据存储失败等。发展应尽快查明原因,尽快找到解决。
3.监控目标网站的状态,可以通过web自动监控目标网站是否可用,是否发生变化等。
对于爬虫来说,稳定性很重要,但是很多不可控的因素会导致爬虫的成功率下降。通过采取良好的监控和预防措施,我们可以将事故发生时的风险降到最低。 查看全部
文章采集调用(爬虫应该怎么进行测试?的测试方法应该如何进行?)
很多同学不知道应该如何测试爬虫。我也是刚接触一点爬虫测试的新手。通过对爬虫的分析,总结了爬虫的测试方法。其他建议欢迎补充。
一、测试阶段
对于data采集调用第三方平台(比如scorpion)的流程大家可能比较熟悉。在第三方页面授权后,第三方会帮我们完成data采集的任务。我们只需要等待结果被回调。但是如果要自己做爬虫,又是一个什么样的过程呢?
其实爬虫和其他业务一样,也是有流程的。一般是先触发创建任务,爬虫模块对数据采集进行处理,采集完成后,对数据进行解析和存储。对于授权爬虫来说,有SDK页面的也可以直接通过页面进行请求,其他的只能通过请求接口实现。还有一种爬虫,在后台配置好任务后,会定期去网站爬取数据,更新数据库。当然还有很多其他的交互逻辑,每一步都需要分析评估。
因此,我们可以从创建任务的界面入手,连接整个流程,在界面的响应中加入简单的验证。比如创建任务后有任务编号,通过查询接口可以得到任务的结果数据。然后检查数据是否存储,存储是否准确,是否会出现乱码等。从界面入手的好处是我们可以自动化检查爬虫任务,检查数据是否可以创建,是否爬虫能否正常爬取,爬取结果是否入库。解析的逻辑和存储的准确性需要注意。爬虫结果数据的存储与数据分析和应用有关。对于数据分析,如果源数据有误,那么无论分析结果如何,都是没有意义的。.
总结
1.接口测试,调用数据接口采集,测试爬虫进程;接口基础测试和弱网、接口安全、接口性能等。
2.可以通过接口或者SDK测试场景,包括爬取成功的场景和失败的场景,比如无数据和无效数据。
3.完成采集后的分析和存储测试,数据分析和存储逻辑检查。
4.异常测试,主要针对系统间交互的处理逻辑,如失败重试机制、服务间容错机制等。
5.爬虫质量和效率,主要从整体设计和代码实现来分析爬虫的处理方式是否高可用。
二、在线阶段
一旦爬虫上线供其他业务方使用,就需要保证可用性和可靠性。对于爬虫来说,在线监控非常重要!不仅要保证提供的爬虫能够正常运行,还要保证出现异常时,能够在最短的时间内解决。因此,监测应从以下三个方面入手:
1.在线运行接口脚本监控提供的接口可以正常使用,而不是等业务方调整好基础接口,再反馈修复,成本比较大。主动调整界面,判断程序是否正常。您只能验证该接口是否可以运行。如果条件允许,在线运行真实数据并验证结果。
2.监控线上发生的异常情况,如创建任务失败、登录失败、数据采集失败、数据解析失败、回调失败、数据存储失败等。发展应尽快查明原因,尽快找到解决。
3.监控目标网站的状态,可以通过web自动监控目标网站是否可用,是否发生变化等。
对于爬虫来说,稳定性很重要,但是很多不可控的因素会导致爬虫的成功率下降。通过采取良好的监控和预防措施,我们可以将事故发生时的风险降到最低。
文章采集调用(文章采集调用的高级设置-extensions-advanced-script查看userprofile以及timeline的计数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-10 05:05
文章采集调用的kpi_based_login接口(感谢@rhomy的指正),请在chrome的设置-高级设置-extensions-advanced-script查看userprofile以及timeline下面的计数。ps:建议读者先看看官方文档:-based-login安装indexjs依赖:这是个很大的坑,我建议直接在文章里面做脚本,webpack-plugin-script-advanced-script-start:先编译vue-markouth.css,发布到indexjs项目:编译的流程如下图所示:编译indexjs的源代码:设置extensions的advancedscript:找到输出中的userprofiles,点击进入login列表:点击view,浏览器会显示账号的状态(安全、非安全)以及一个cookie,用户通过cookie的唯一标识:用户输入账号密码,只要输入一次,账号密码可以推送到服务器,这样就可以实现你需要的效果了。
@吴泽龙回答里已经给出了,我也补充一下他的误区吧1.hookextensions只是为原来的需要抽样的脚本提供了多一次构造时间戳的方法,应该是为了模拟类似cookie/httpsocket这样的事件。2.github的timeline浏览时点击时间是按照kpi-id-login获取的。一次构造一个时间戳,并且每个时间戳不重复3.时间戳的形式不知道是什么形式。
你描述里面显示的列表时间是datetime_index.html,kpi的时间戳是通过useragent获取的时间戳,也是按照kpi-id-login获取的。 查看全部
文章采集调用(文章采集调用的高级设置-extensions-advanced-script查看userprofile以及timeline的计数)
文章采集调用的kpi_based_login接口(感谢@rhomy的指正),请在chrome的设置-高级设置-extensions-advanced-script查看userprofile以及timeline下面的计数。ps:建议读者先看看官方文档:-based-login安装indexjs依赖:这是个很大的坑,我建议直接在文章里面做脚本,webpack-plugin-script-advanced-script-start:先编译vue-markouth.css,发布到indexjs项目:编译的流程如下图所示:编译indexjs的源代码:设置extensions的advancedscript:找到输出中的userprofiles,点击进入login列表:点击view,浏览器会显示账号的状态(安全、非安全)以及一个cookie,用户通过cookie的唯一标识:用户输入账号密码,只要输入一次,账号密码可以推送到服务器,这样就可以实现你需要的效果了。
@吴泽龙回答里已经给出了,我也补充一下他的误区吧1.hookextensions只是为原来的需要抽样的脚本提供了多一次构造时间戳的方法,应该是为了模拟类似cookie/httpsocket这样的事件。2.github的timeline浏览时点击时间是按照kpi-id-login获取的。一次构造一个时间戳,并且每个时间戳不重复3.时间戳的形式不知道是什么形式。
你描述里面显示的列表时间是datetime_index.html,kpi的时间戳是通过useragent获取的时间戳,也是按照kpi-id-login获取的。
文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2022-02-07 06:19
介绍
AnyMetrics - 面向开发人员的、声明性的 Metrics 采集 和监控系统,可以对结构化和非结构化、有界和无界数据执行 采集,通过提取、过滤、逻辑运算等,将结果存储起来在流行的监控系统或存储引擎(如Prometheus、ES)中构建完整的监控系统,用grafana完成数据可视化
数据采集、提取、过滤、存储等都是由配置驱动,无需额外开发。对应AnyMetrics,分别配置数据源、采集规则、采集器。基于这些配置,AnyMetrics 将使用 pipeline 的方式自动完成从 data采集 到数据存储的所有工作
对于有界数据的任务,AnyMetrics 将以固定频率从数据源中提取数据。AnyMetrics 具有内置的 MySQL 数据源。对于具有无限数据的任务,AnyMetrics 会在一个时间窗口内从数据源中拉取数据。批量拉取数据,AnyMetrics 内置 Kafka 类型无界数据源
AnyMetrics的数据源可以是任何系统,例如可以将HTTP请求结果作为数据源,也可以将ES检索结果作为数据源
将非结构化数据转换为结构化数据的目的,可以通过对数据源的原创数据进行提取和过滤来实现。AnyMetrics 中有两个内置的采集规则(Filter),正则表达式和 Spring EL 表达式。完成数据的提取和过滤,使用Spring EL表达式对原创数据和正则表达式提取后的数据完成逻辑运算。过滤器可单独使用或组合使用。FilterChain的方式是顺序执行的
数据提取和过滤后,下一步就是将数据以指定的方式存储在目标系统中。Prometheus 采集器内置于 AnyMetrics 中。通过定义 Metrics,可以将数据推送到 Prometheus 的 PushGateway。
AnyMetrics 的采集器可以将数据推送到任何系统,例如 MySQL、ES 甚至是 WebHook
无论是采集规则配置还是采集器配置,都可以通过可变配置来完成动态配置的替换。变量数据来自正则表达式Filter,通过定义如(.*)可以得到一个名为$1的变量,有Spring EL的地方可以使用#$1来使用变量,其他地方可以使用$1使用变量,以满足从数据提取到数据的重组或者操作操作,什么配置可以支持变量或者Spring EL表达式 根据采集规则和采集器的具体实现,Spring内置的表达式配置AnyMetrics 的 EL 过滤器和 Prometheus 采集器中的值配置支持 Spring EL 表达式和变量(#$1),
AnyMetrics采用插件化设计方式,无论是数据源、采集规则还是采集器都可以扩展。甚至 AnyMetrics 中的内置插件也是以点对点的方式实现的。加载和使用什么插件完全由声明决定。配置
建筑学
技术栈
SpringBoot + Nacos + Vue + ElementUI
安装
启动前需要安装的依赖
安装 nacos(必填)
安装普罗米修斯(可选)
安装推送网关(可选)
启动
启动 AnyMeitris
1 mvn clean package
2 cd boot/target
3 java -Dnacos.address=nacos.ip:8848 -Dnacos.config.dataId=AnyMetricsConfig -Dnacos.config.group=config.app.AnyMetrics -Dauto=true -jar AnyMetrics-boot.jar
启动参数说明
通过 nacos.address 参数指定nacos地址
通过 nacos.config.dataId 参数指定配置在nacos的dataId,默认值为 AnyMetricsConfig
通过 nacos.config.group 参数指定配置在nacos的group,默认值为 DEFAULT
通过 auto 参数控制任务是否自启动,默认值为 false
启动后访问:8080/index.html
如何配置
1、选择任务类型
2.1、有界数据
选择调度间隔,以秒为单位
2.2、选择数据源
选择数据源为mysql(目前只支持mysql),并完善相关配置
3.1、无限数据
输入时间窗口,单位:秒
3.2、选择数据源
选择kafka作为数据源(目前只支持kafka),并完善相关配置
4、采集规则
过滤器支持两种类型,regular 和 el。在正则中使用括号来提取所需的变量。多个变量以 $1、$2 ... $N 的形式命名。在el中,可以使用_#$1 _变量来执行操作
5、采集器
选择prometheus(目前只支持prometheus)并完善metrics相关配置信息,type支持gauge、counter、histogram类型,labels支持$1变量,value支持Spring EL表达式变量操作
运行任务
1、开始任务
点击开始按钮开始任务
2、查看运行日志
点击日志选项卡,查询任务运行日志
3、iframe
点击iframe Tab,将外部系统嵌入到任务中,比如将grafana的dashboard链接嵌入到系统中进行展示
4、停止任务
单击停止按钮以停止任务
例子
示例一:APM 监控 - 采集 所有执行时间超过 3 秒的慢速链接并配置警报策略
1、设置kafka为数据源
从 kafka 读取跟踪日志
{
"groupId":"anymetrics_apm_slow_trace",
"kafkaAddress":"192.168.0.1:9092",
"topic":"p_bigtracer_metric_log",
"type":"kafka"
}
2、设置采集规则
通话记录是结构化数据,例如:
1617953102329,operation-admin-web,10.8.60.41,RESOURCE_MYSQL_LOG,com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList,1,1,0,0,1
因此,第一步是使用正则规则对数据进行提取和过滤,对应的正则规则为:
(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?)
提取的数据为:
{
"$4":"RESOURCE_MYSQL_LOG",
"$5":"com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList",
"$6":"1",
"$7":"1",
"$10":"1",
"$8":"0",
"$9":"0",
"$1":"1617953102329",
"$2":"operation-admin-web",
"$3":"10.8.60.41"
}
我们有 10 个变量,从 1 美元到 10 美元。由于我们监控的是超过3秒的慢速链接,我们只需要采集RT超过3秒的日志数据,所以我们需要定义一个逻辑运算表达式Filter,对应的EL表达式公式为:
(new java.lang.Double(#$10) / #$6) > 3000
其中#$10是链接的总响应时间,#$6是接口的总调用次数,先通过#$10/#$6运算得到平均RT,再通过(#$10/#$过滤掉3 6) > 3000 几秒内的慢速链接数据
根据以上两条采集规则,完整配置为:
{
"timeWindow": 40,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\n",
"type": "regular"
},
{
"expression": "(new java.lang.Double(#$10) / #$6) > 3000",
"type": "el"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_apm_slow_trace",
"labelNames": [
"application",
"type",
"endpoint"
],
"name": "anymetrics_apm_slow_trace",
"type": "gauge",
"value": "new java.lang.Double(#$10) / #$6",
"labels": [
"$2",
"$4",
"$5"
]
}
],
"type": "prometheus",
"job": "anymetrics_apm_slow_trace"
}
promethus的metrics需要定义,名字是anymetrics_apm_slow_trace,类型是gauge,lableNames使用application,type,endpoint,对应变量$2、$4、$5,因为响应时间采集RT,所以值为#$10 / #$6
其中#$10是链接的总响应时间,#$6是接口的总调用次数,通过#$10/#$6的运算得到平均RT
4、配置警报和可视化
4.1 可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_apm_slow_trace{}
关于 PromQL 可以参考
4.2 配置 Grafana 警报
在面板中选择警报选项卡以定义警报规则,例如:
每 1m 评估 1m
条件
NoData 和错误处理
通知
一个比较完整的APM监控组合如下:
通过调用链log采集不同维度的metrics,完成对链路RT、项目错误数、项目平均RT、链路RT分布等的多维度监控。
示例2:可视化注册用户总数
1、设置mysql为数据源
根据sql查询总用户数
{
"password": "root",
"jdbcurl": "jdbc:mysql://192.168.0.1:3306/user",
"type": "mysql",
"sql": "select count(1) from user",
"username": "root"
}
2、设置采集规则
根据sql查询的结果,提取count(1),用正则表达式采集规则:
{
"kind": "schedule",
"interval": 5,
"filters": [
{
"expression": "\\{\\\"count\\(1\\)\\\":(.*)\\}",
"type": "regular"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_member_count",
"name": "anymetrics_member_count",
"type": "gauge",
"value": "#$1"
}
],
"type": "prometheus",
"job": "anymetrics_member_count"
}
promethus的metrics需要定义,名字是anymetrics_member_count,类型是gauge,因为只需要采集用户总数,所以不需要定义labels和labelNames,值为#$1
4、配置可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_member_count{}
示例 3:Nginx 日志监控
Nginx请求延迟监控,Nginx状态码监控
1、设置kafka为数据源
使用 nginx access_log 日志
{
"groupId":"anymetrics_nginx",
"kafkaAddress":"192.168.0.1:9092",
"topic":"nginx_access_log",
"type":"kafka"
}
2、设置采集规则
假设nginx的log_format配置如下:
log_format main '"$http_x_forwarded_for" $remote_addr - $remote_user [$time_local] $http_host "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $upstream_addr $request_method $upstream_status $upstream_response_time';
因此,在第一步中,使用正则Filter对数据进行提取和过滤,对应的正则为:
(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
提取的数据为:
$1:"-"
$2:192.168.198.17
$3: -
$4:13/Apr/2021:10:48:14 +0800
$5:dev.api.com
$6:POST
$7:/yxy-api-gateway/api/json/yuandouActivity/access
$8:HTTP/1.1"
$9:200
$10:87
$11:http://192.168.0.1:8100/yxy-ed ... 3D123
$12:Mozilla/5.0 (iPhone; CPU iPhone OS 13_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko)Mobile/15E148 MicroMessenger/7.0.11(0x17000b21)NetType/WIFI Language/zh_CN
$13:10.8.43.18:8080
$14:POST
$15:200
$16:0.005
一共得到了16个变量,通过对比log_format就可以知道每个变量的含义
完整的采集规则配置为:
{
"timeWindow": 30,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
"type": "regular"
}
]
}
3、设置采集器
采集每个请求的响应时间和请求的状态码,并将数据存储在promethus中
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "nginx_log_host_status",
"labelNames": [
"host",
"status"
],
"name": "nginx_log_host_status",
"type": "gauge",
"value": "1",
"labels": [
"$5",
"$9"
]
},
{
"help": "nginx_log_req_rt (seconds)",
"labelNames": [
"host",
"endpoint"
],
"name": "nginx_log_req_rt",
"type": "gauge",
"value": "new java.lang.Double(#$16)",
"labels": [
"$5",
"$7"
]
}
],
"type": "prometheus",
"job": "anymetrics_nginx_log"
}
4、配置可视化
Nginx状态码监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_host_status{}
Nginx 请求延迟监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_req_rt{}
问答
如何采集 APM 日志?
如果系统中有调用链跟踪系统,可以使用调用链日志,或者通过定义拦截器来记录目标方法。定义好日志格式后,可以直接逐行打印,也可以在内存中聚合后以固定频率打印,日志一般收录RT延迟、错误/成功次数、端点、应用等关键数据。
日志是如何采集到kafka的?
可以使用filebeat采集nginx的access_log和tomcat的应用日志到kafka
目前支持哪些数据源?
有界数据目前支持mysql、http;无界数据目前支持kafka
目前支持哪些采集器?
目前只支持prometheus,使用pushgateway推送数据到prometheus
如果我已经使用了 Skywalking 和 Zipkin 等呼叫链跟踪系统,是否需要使用 AnyMetrics?
两者之间没有冲突。调用链跟踪系统采集链路的调用关系和APM指标数据。AnyMetrics不仅可以将结构化调用链跟踪系统的指标日志作为数据源来监控系统,还可以将结构化日志作为数据源来监控系统运行,比如监控一些Exception事件,还可以可视化或监控数据库表数据。同时,AnyMetrics 支持跨平台系统,任何系统生成的日志都可以作为数据源。监控系统运行
最后附上github项目地址: 查看全部
文章采集调用(无界数据来源于正则表达式Filter帮您解决数据的问题!)
介绍
AnyMetrics - 面向开发人员的、声明性的 Metrics 采集 和监控系统,可以对结构化和非结构化、有界和无界数据执行 采集,通过提取、过滤、逻辑运算等,将结果存储起来在流行的监控系统或存储引擎(如Prometheus、ES)中构建完整的监控系统,用grafana完成数据可视化
数据采集、提取、过滤、存储等都是由配置驱动,无需额外开发。对应AnyMetrics,分别配置数据源、采集规则、采集器。基于这些配置,AnyMetrics 将使用 pipeline 的方式自动完成从 data采集 到数据存储的所有工作
对于有界数据的任务,AnyMetrics 将以固定频率从数据源中提取数据。AnyMetrics 具有内置的 MySQL 数据源。对于具有无限数据的任务,AnyMetrics 会在一个时间窗口内从数据源中拉取数据。批量拉取数据,AnyMetrics 内置 Kafka 类型无界数据源
AnyMetrics的数据源可以是任何系统,例如可以将HTTP请求结果作为数据源,也可以将ES检索结果作为数据源
将非结构化数据转换为结构化数据的目的,可以通过对数据源的原创数据进行提取和过滤来实现。AnyMetrics 中有两个内置的采集规则(Filter),正则表达式和 Spring EL 表达式。完成数据的提取和过滤,使用Spring EL表达式对原创数据和正则表达式提取后的数据完成逻辑运算。过滤器可单独使用或组合使用。FilterChain的方式是顺序执行的
数据提取和过滤后,下一步就是将数据以指定的方式存储在目标系统中。Prometheus 采集器内置于 AnyMetrics 中。通过定义 Metrics,可以将数据推送到 Prometheus 的 PushGateway。
AnyMetrics 的采集器可以将数据推送到任何系统,例如 MySQL、ES 甚至是 WebHook
无论是采集规则配置还是采集器配置,都可以通过可变配置来完成动态配置的替换。变量数据来自正则表达式Filter,通过定义如(.*)可以得到一个名为$1的变量,有Spring EL的地方可以使用#$1来使用变量,其他地方可以使用$1使用变量,以满足从数据提取到数据的重组或者操作操作,什么配置可以支持变量或者Spring EL表达式 根据采集规则和采集器的具体实现,Spring内置的表达式配置AnyMetrics 的 EL 过滤器和 Prometheus 采集器中的值配置支持 Spring EL 表达式和变量(#$1),
AnyMetrics采用插件化设计方式,无论是数据源、采集规则还是采集器都可以扩展。甚至 AnyMetrics 中的内置插件也是以点对点的方式实现的。加载和使用什么插件完全由声明决定。配置
建筑学
技术栈
SpringBoot + Nacos + Vue + ElementUI
安装
启动前需要安装的依赖
安装 nacos(必填)
安装普罗米修斯(可选)
安装推送网关(可选)
启动
启动 AnyMeitris
1 mvn clean package
2 cd boot/target
3 java -Dnacos.address=nacos.ip:8848 -Dnacos.config.dataId=AnyMetricsConfig -Dnacos.config.group=config.app.AnyMetrics -Dauto=true -jar AnyMetrics-boot.jar
启动参数说明
通过 nacos.address 参数指定nacos地址
通过 nacos.config.dataId 参数指定配置在nacos的dataId,默认值为 AnyMetricsConfig
通过 nacos.config.group 参数指定配置在nacos的group,默认值为 DEFAULT
通过 auto 参数控制任务是否自启动,默认值为 false
启动后访问:8080/index.html
如何配置
1、选择任务类型
2.1、有界数据
选择调度间隔,以秒为单位
2.2、选择数据源
选择数据源为mysql(目前只支持mysql),并完善相关配置
3.1、无限数据
输入时间窗口,单位:秒
3.2、选择数据源
选择kafka作为数据源(目前只支持kafka),并完善相关配置
4、采集规则
过滤器支持两种类型,regular 和 el。在正则中使用括号来提取所需的变量。多个变量以 $1、$2 ... $N 的形式命名。在el中,可以使用_#$1 _变量来执行操作
5、采集器
选择prometheus(目前只支持prometheus)并完善metrics相关配置信息,type支持gauge、counter、histogram类型,labels支持$1变量,value支持Spring EL表达式变量操作
运行任务
1、开始任务
点击开始按钮开始任务
2、查看运行日志
点击日志选项卡,查询任务运行日志
3、iframe
点击iframe Tab,将外部系统嵌入到任务中,比如将grafana的dashboard链接嵌入到系统中进行展示
4、停止任务
单击停止按钮以停止任务
例子
示例一:APM 监控 - 采集 所有执行时间超过 3 秒的慢速链接并配置警报策略
1、设置kafka为数据源
从 kafka 读取跟踪日志
{
"groupId":"anymetrics_apm_slow_trace",
"kafkaAddress":"192.168.0.1:9092",
"topic":"p_bigtracer_metric_log",
"type":"kafka"
}
2、设置采集规则
通话记录是结构化数据,例如:
1617953102329,operation-admin-web,10.8.60.41,RESOURCE_MYSQL_LOG,com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList,1,1,0,0,1
因此,第一步是使用正则规则对数据进行提取和过滤,对应的正则规则为:
(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?),(.*?)
提取的数据为:
{
"$4":"RESOURCE_MYSQL_LOG",
"$5":"com.yxy.operation.dao.IHotBroadcastEpisodesDao.getNeedOnlineList",
"$6":"1",
"$7":"1",
"$10":"1",
"$8":"0",
"$9":"0",
"$1":"1617953102329",
"$2":"operation-admin-web",
"$3":"10.8.60.41"
}
我们有 10 个变量,从 1 美元到 10 美元。由于我们监控的是超过3秒的慢速链接,我们只需要采集RT超过3秒的日志数据,所以我们需要定义一个逻辑运算表达式Filter,对应的EL表达式公式为:
(new java.lang.Double(#$10) / #$6) > 3000
其中#$10是链接的总响应时间,#$6是接口的总调用次数,先通过#$10/#$6运算得到平均RT,再通过(#$10/#$过滤掉3 6) > 3000 几秒内的慢速链接数据
根据以上两条采集规则,完整配置为:
{
"timeWindow": 40,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\u0001,(.*?)\n",
"type": "regular"
},
{
"expression": "(new java.lang.Double(#$10) / #$6) > 3000",
"type": "el"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_apm_slow_trace",
"labelNames": [
"application",
"type",
"endpoint"
],
"name": "anymetrics_apm_slow_trace",
"type": "gauge",
"value": "new java.lang.Double(#$10) / #$6",
"labels": [
"$2",
"$4",
"$5"
]
}
],
"type": "prometheus",
"job": "anymetrics_apm_slow_trace"
}
promethus的metrics需要定义,名字是anymetrics_apm_slow_trace,类型是gauge,lableNames使用application,type,endpoint,对应变量$2、$4、$5,因为响应时间采集RT,所以值为#$10 / #$6
其中#$10是链接的总响应时间,#$6是接口的总调用次数,通过#$10/#$6的运算得到平均RT
4、配置警报和可视化
4.1 可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_apm_slow_trace{}
关于 PromQL 可以参考
4.2 配置 Grafana 警报
在面板中选择警报选项卡以定义警报规则,例如:
每 1m 评估 1m
条件
NoData 和错误处理
通知
一个比较完整的APM监控组合如下:
通过调用链log采集不同维度的metrics,完成对链路RT、项目错误数、项目平均RT、链路RT分布等的多维度监控。
示例2:可视化注册用户总数
1、设置mysql为数据源
根据sql查询总用户数
{
"password": "root",
"jdbcurl": "jdbc:mysql://192.168.0.1:3306/user",
"type": "mysql",
"sql": "select count(1) from user",
"username": "root"
}
2、设置采集规则
根据sql查询的结果,提取count(1),用正则表达式采集规则:
{
"kind": "schedule",
"interval": 5,
"filters": [
{
"expression": "\\{\\\"count\\(1\\)\\\":(.*)\\}",
"type": "regular"
}
]
}
3、设置采集器
将数据采集到普罗米修斯
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "anymetrics_member_count",
"name": "anymetrics_member_count",
"type": "gauge",
"value": "#$1"
}
],
"type": "prometheus",
"job": "anymetrics_member_count"
}
promethus的metrics需要定义,名字是anymetrics_member_count,类型是gauge,因为只需要采集用户总数,所以不需要定义labels和labelNames,值为#$1
4、配置可视化
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法anymetrics_member_count{}
示例 3:Nginx 日志监控
Nginx请求延迟监控,Nginx状态码监控
1、设置kafka为数据源
使用 nginx access_log 日志
{
"groupId":"anymetrics_nginx",
"kafkaAddress":"192.168.0.1:9092",
"topic":"nginx_access_log",
"type":"kafka"
}
2、设置采集规则
假设nginx的log_format配置如下:
log_format main '"$http_x_forwarded_for" $remote_addr - $remote_user [$time_local] $http_host "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" $upstream_addr $request_method $upstream_status $upstream_response_time';
因此,在第一步中,使用正则Filter对数据进行提取和过滤,对应的正则为:
(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
提取的数据为:
$1:"-"
$2:192.168.198.17
$3: -
$4:13/Apr/2021:10:48:14 +0800
$5:dev.api.com
$6:POST
$7:/yxy-api-gateway/api/json/yuandouActivity/access
$8:HTTP/1.1"
$9:200
$10:87
$11:http://192.168.0.1:8100/yxy-ed ... 3D123
$12:Mozilla/5.0 (iPhone; CPU iPhone OS 13_4_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko)Mobile/15E148 MicroMessenger/7.0.11(0x17000b21)NetType/WIFI Language/zh_CN
$13:10.8.43.18:8080
$14:POST
$15:200
$16:0.005
一共得到了16个变量,通过对比log_format就可以知道每个变量的含义
完整的采集规则配置为:
{
"timeWindow": 30,
"kind": "stream",
"filters": [
{
"expression": "(.*?)\\s+(.*?)\\s+-(.*?)\\s+\\[(.*?)\\]\\s+(.*?)\\s+\\\"(.*?)\\s+(.*?)\\s+(.*?)\\s+\\\"?(\\d+)\\s+(\\d+)\\s\\\"(.*?)\\\"\\s+\\\"(.*?)\\\"\\s+(.*?)\\s+(.*?)\\s+(\\d+)\\s+(.*)",
"type": "regular"
}
]
}
3、设置采集器
采集每个请求的响应时间和请求的状态码,并将数据存储在promethus中
{
"pushGateway": "192.168.0.1:9091",
"metrics": [
{
"help": "nginx_log_host_status",
"labelNames": [
"host",
"status"
],
"name": "nginx_log_host_status",
"type": "gauge",
"value": "1",
"labels": [
"$5",
"$9"
]
},
{
"help": "nginx_log_req_rt (seconds)",
"labelNames": [
"host",
"endpoint"
],
"name": "nginx_log_req_rt",
"type": "gauge",
"value": "new java.lang.Double(#$16)",
"labels": [
"$5",
"$7"
]
}
],
"type": "prometheus",
"job": "anymetrics_nginx_log"
}
4、配置可视化
Nginx状态码监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_host_status{}
Nginx 请求延迟监控
打开Grafana,创建一个Panel,选择数据源为promethus,图标类型为Graph,在Metrics中输入PromQL语法nginx_log_req_rt{}
问答
如何采集 APM 日志?
如果系统中有调用链跟踪系统,可以使用调用链日志,或者通过定义拦截器来记录目标方法。定义好日志格式后,可以直接逐行打印,也可以在内存中聚合后以固定频率打印,日志一般收录RT延迟、错误/成功次数、端点、应用等关键数据。
日志是如何采集到kafka的?
可以使用filebeat采集nginx的access_log和tomcat的应用日志到kafka
目前支持哪些数据源?
有界数据目前支持mysql、http;无界数据目前支持kafka
目前支持哪些采集器?
目前只支持prometheus,使用pushgateway推送数据到prometheus
如果我已经使用了 Skywalking 和 Zipkin 等呼叫链跟踪系统,是否需要使用 AnyMetrics?
两者之间没有冲突。调用链跟踪系统采集链路的调用关系和APM指标数据。AnyMetrics不仅可以将结构化调用链跟踪系统的指标日志作为数据源来监控系统,还可以将结构化日志作为数据源来监控系统运行,比如监控一些Exception事件,还可以可视化或监控数据库表数据。同时,AnyMetrics 支持跨平台系统,任何系统生成的日志都可以作为数据源。监控系统运行
最后附上github项目地址:
文章采集调用(讲讲如何在首页和列表页实时动态调用文章点击次数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-02-07 04:23
我们都知道,Dedecms中的首页和列表页的文章点击默认不是动态调用的,而是通过一个标签来调用的,只有首页之后才会更新点击并生成列表页面。频率。但是有时候我们的网站更新不是那么频繁,所以我们需要使用点击的动态调用。接下来,织梦技术研究中心将告诉你如何在首页和列表页面实时动态调用文章@。>点击次数,具体方法如下:
首先找到plus/count.php文件,复制并命名为viewclick.php,然后打开文件,在里面找到如下代码:
<a herf="http://www.genban.org" title="织梦源码">
if(!empty($maintable))
{
$dsql->ExecuteNoneQuery(" UPDATE `{$maintable}` SET click=click+1 WHERE {$idtype}='$aid' ");
}
if(!empty($mid))
{
$dsql->ExecuteNoneQuery(" UPDATE `dede_member_tj` SET pagecount=pagecount+1 WHERE mid='$mid' ");
}</a>
删除上面的代码,然后在需要动态调用点击次数的首页和列表页面模板中添加如下代码:
<a herf="http://www.genban.org" title="织梦源码">
</a>
然后重新生成首页和列表页,然后就可以实时动态调用文章的点击次数而不生成。 查看全部
文章采集调用(讲讲如何在首页和列表页实时动态调用文章点击次数)
我们都知道,Dedecms中的首页和列表页的文章点击默认不是动态调用的,而是通过一个标签来调用的,只有首页之后才会更新点击并生成列表页面。频率。但是有时候我们的网站更新不是那么频繁,所以我们需要使用点击的动态调用。接下来,织梦技术研究中心将告诉你如何在首页和列表页面实时动态调用文章@。>点击次数,具体方法如下:
首先找到plus/count.php文件,复制并命名为viewclick.php,然后打开文件,在里面找到如下代码:
<a herf="http://www.genban.org" title="织梦源码">
if(!empty($maintable))
{
$dsql->ExecuteNoneQuery(" UPDATE `{$maintable}` SET click=click+1 WHERE {$idtype}='$aid' ");
}
if(!empty($mid))
{
$dsql->ExecuteNoneQuery(" UPDATE `dede_member_tj` SET pagecount=pagecount+1 WHERE mid='$mid' ");
}</a>
删除上面的代码,然后在需要动态调用点击次数的首页和列表页面模板中添加如下代码:
<a herf="http://www.genban.org" title="织梦源码">
</a>
然后重新生成首页和列表页,然后就可以实时动态调用文章的点击次数而不生成。

