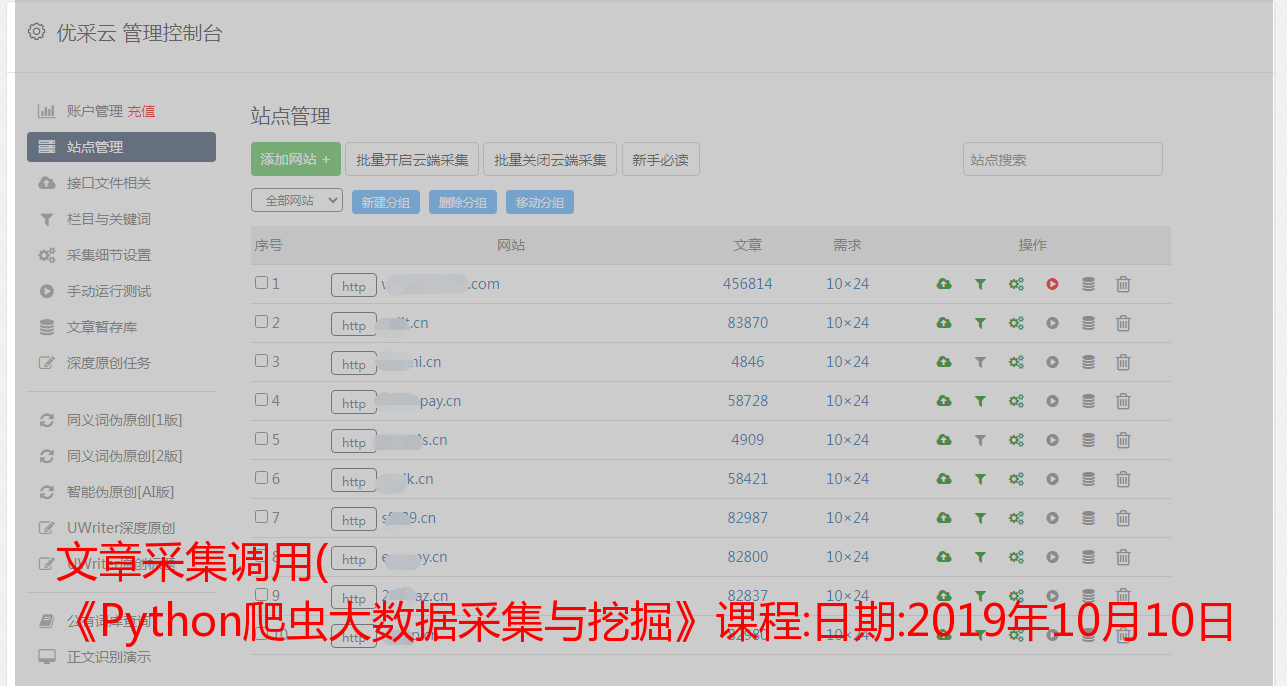
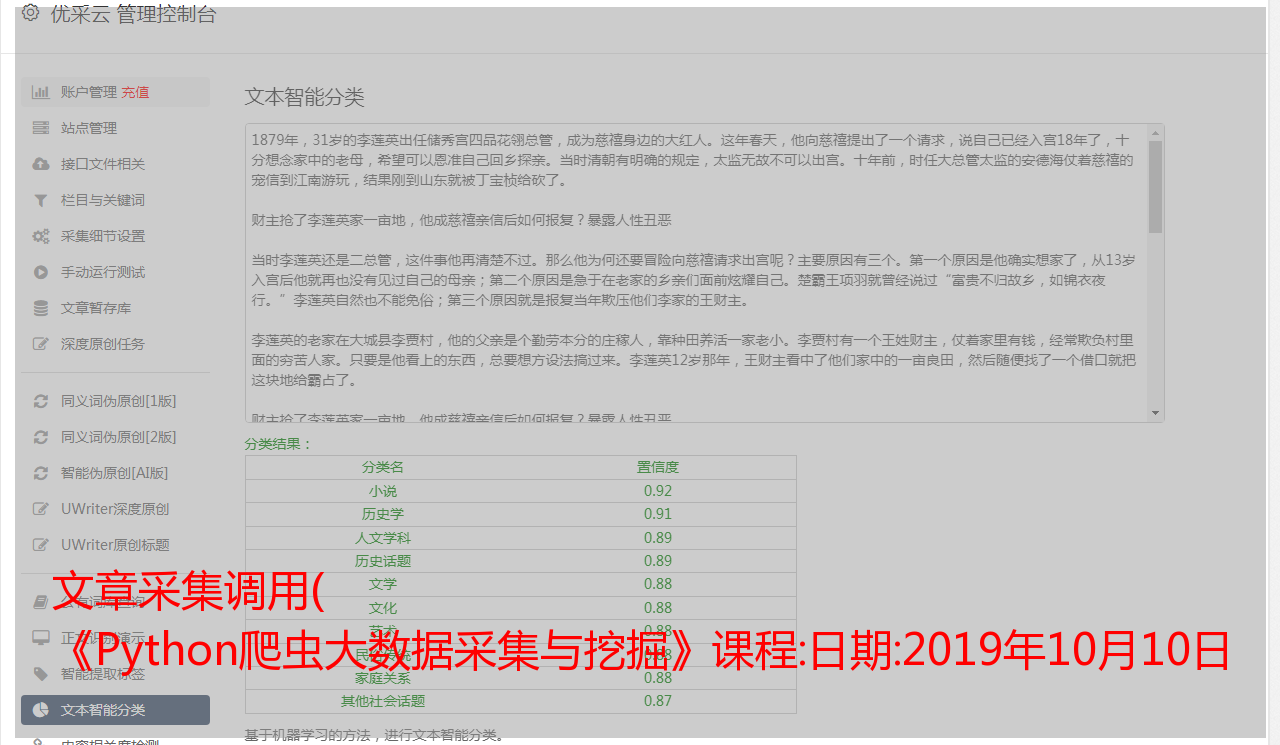
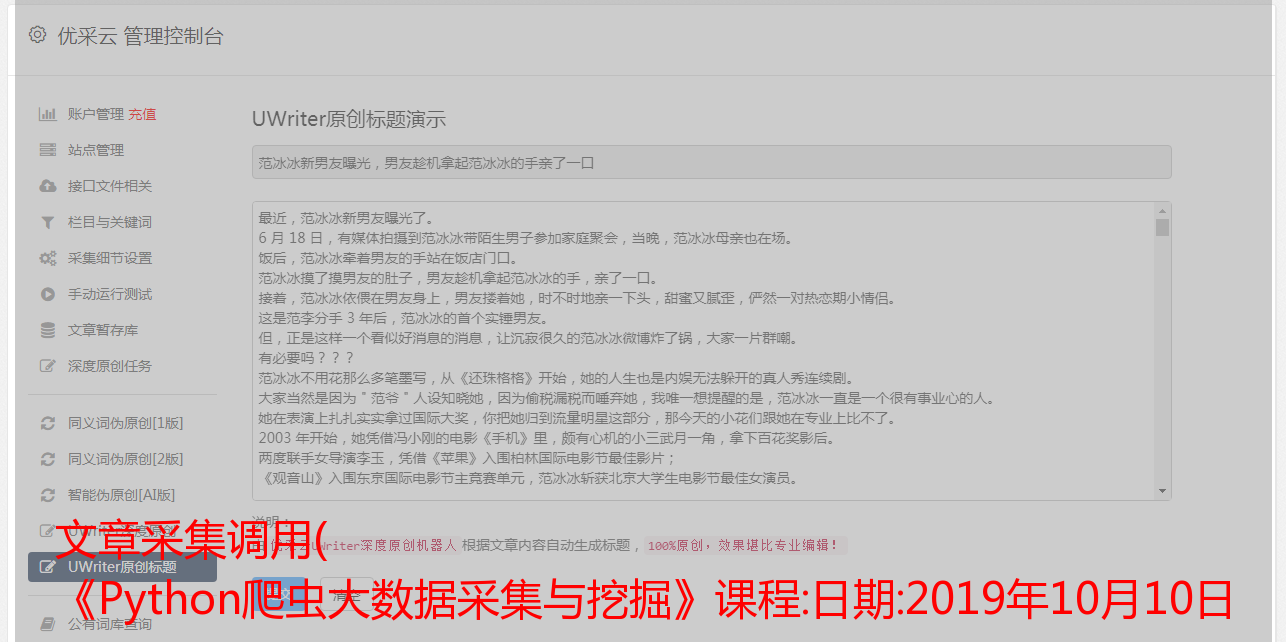
文章采集调用( 《Python爬虫大数据采集与挖掘》课程:日期:2019年10月10日 )
优采云 发布时间: 2021-12-02 18:13文章采集调用(
《Python爬虫大数据采集与挖掘》课程:日期:2019年10月10日
)
《Python爬虫大数据采集与挖掘》
教学大纲
部门:日期:2019年10月10日
科目编号
课程名称
Python爬虫大数据采集与挖掘
学分
2
周学士
2
教学语言
中国人
课程性质
√核心课程√通识教育选修□基础知识√必修专业√专业选修□其他
教学目标
本课程主要面向大数据技术与应用、数据科学、计算机与电子信息等二年级及以上本科生,主要讲解互联网大数据采集技术及各种典型爬虫技术,结合相关开源包使用Python进行实现,加深学生对所学知识的理解。通过本课程的教学,学生将对互联网大数据采集技术有全面的了解,掌握采集的基本信息内容、提取和分析方法,并对采集具有一定的实用性需求的应用和解决。
基本内容介绍
互联网大数据采集技术及实现概述;Web服务器应用架构及HTTP、Robots、HTML、页面编码等相关协议和规范;常用网络爬虫技术、动态页面采集方法、主题爬虫技术、Deep Web爬虫、微博信息采集、Web信息提取与反爬虫技术等;爬虫应用中典型的大数据处理和挖掘技术;综合利用各种爬虫和处理技术为新闻阅读器进行分析和设计;了解爬虫用于SQL注入安全检测的方法。
基本要求:
要求了解互联网大数据的技术体系和主要技术采集;掌握各种典型爬虫的技术原理、技术框架、实现方法、主要开源包的使用;了解爬虫采集到达的网页数据处理方法、文本处理和相关挖掘方法将在技术上使用Python实现。
教学方式:
本课程以讲授为主。在本课程的教学过程中,将采用课堂讲解和课堂讨论的方式,为学生提供互动交流。同时,根据教学进度,设置多项配套实验。
课内外讨论或练习、练习、体验等设计:
课后,您需要认真完成分配的作业,以了解和巩固所学知识。
评价与评价方式(提供学生课程最终成绩的分数构成,反映形成性评价过程):
考核内容包括平时成绩(出勤、项目、实验)和期末考试成绩,分别占课程总成绩的35%和65%。最终评估形式为闭卷考试。
《Python爬虫大数据采集与挖掘》
教学安排
(建议)
教学内容安排(按32学时共16周,具体以每节课内容为准):
第一周:
第一课:互联网大数据采集概念、重要性、应用现状等;第二课:互联网大数据采集技术体系、法律技术边界、技术前景。
第二周:
第一课:HTML语言规范;第二课:网页编码、正则表达式。
第三周:
第 1 课:Web 服务器、应用程序架构、机器人;第 2 课:HTTP 协议,状态保持技术。
第四周:
第一课:常见爬虫系统、请求;第 2 课:异常处理、链接提取
第五周:
第一课:爬取策略与实现,PR算法;第 2 课:动态页面和 采集 技术
第 6 周:
第 1 课:动态页面、Ajax、Cookie;第 2 课:模拟浏览器技术
第七周:
第1课:静态页面实验采集;第 2 课:动态页面实验 采集
第 8 周:
第1课:网页提取技术及思路介绍;第 2 课:基于结构的提取方法,主要开源包。
第九周:
第一课:话题爬虫与技术框架、话题表征;第二课:主题表示、相关性计算、实例。
第 10 周:
第一课:Web信息抽取实验;第二课:主题爬虫实验。
第 11 周:
第1课:DeepWeb概念、特点和要求、技术架构;第 2 课:技术架构和实现示例。
第十二周:
第一课:微博采集方法概述、平台授权、API介绍;第二课:Python调用API采集,爬取方法采集。
第 13 周:
第1课:反爬虫概述、反爬虫技术、反爬虫技术;第 2 课:文本分析和预处理概述。
第十四周:
第一课:向量空间与文本分类;第二课:主题建模、可视化技术。
第十五周:
第一课:常见应用模式、新闻阅读器;第二课:新闻阅读器,SQL注入检测。
第 16 周:
综合实验、复习、考试
提供300分钟视频讲解、教学大纲、课件、教案、习题答案、程序源代码等配套资源。
预订视频演示