
文章采集调用
文章采集调用(文章采集调用知乎官方api接口,就会发现有很多countlyuseroach)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-01-08 23:01
文章采集调用知乎官方api接口,就会发现有很多countlyuseroach第一个不能匹配的区块第二个匹配不了,第三个已经匹配上了,第四个依然匹配不上但是不能说什么,打开知乎的app,就是把手机拿到边上就能上知乎在上面的搜索框里输入这个id就可以找到它前些天也是同样的问题,也是用这个,结果就是找不到想要的东西。
我试过了两个方法1.可以把浏览页面重定向到知乎客户端里面,在里面找到感兴趣的区块,点击检索(也可以点击右上角)2.可以在googleappstore里找下载一个知乎app,然后直接一键抓取,只要该网站有的,
楼主试试,一定对你有帮助。
感谢楼上,
用来偷菜吧
建议采集一下@笑道人老师关于对话页面的每个选择区块。我们的服务器就被他恶心到了。
先打开你想抓取对话的网站,找到想抓取的区块在googleappstore里搜索下载一个知乎app,然后直接一键抓取你想要的内容!希望对楼主有帮助!
据我所知,
呵呵,
我用的chrome扩展了"可视化查询"抓取
没找到怎么抓,手动抓却很麻烦,这样试试啊。
采集页面就可以抓取了
依然是这个问题。我手上也没有任何知乎采集器。没试过, 查看全部
文章采集调用(文章采集调用知乎官方api接口,就会发现有很多countlyuseroach)
文章采集调用知乎官方api接口,就会发现有很多countlyuseroach第一个不能匹配的区块第二个匹配不了,第三个已经匹配上了,第四个依然匹配不上但是不能说什么,打开知乎的app,就是把手机拿到边上就能上知乎在上面的搜索框里输入这个id就可以找到它前些天也是同样的问题,也是用这个,结果就是找不到想要的东西。
我试过了两个方法1.可以把浏览页面重定向到知乎客户端里面,在里面找到感兴趣的区块,点击检索(也可以点击右上角)2.可以在googleappstore里找下载一个知乎app,然后直接一键抓取,只要该网站有的,
楼主试试,一定对你有帮助。
感谢楼上,
用来偷菜吧
建议采集一下@笑道人老师关于对话页面的每个选择区块。我们的服务器就被他恶心到了。
先打开你想抓取对话的网站,找到想抓取的区块在googleappstore里搜索下载一个知乎app,然后直接一键抓取你想要的内容!希望对楼主有帮助!
据我所知,
呵呵,
我用的chrome扩展了"可视化查询"抓取
没找到怎么抓,手动抓却很麻烦,这样试试啊。
采集页面就可以抓取了
依然是这个问题。我手上也没有任何知乎采集器。没试过,
文章采集调用(如何优采云采集器如何利用Xpath来采集内容页面可视化提取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-08 14:17
在上一篇文章《优采云采集 List Page and Label Xpath Visual Extraction Function》中,我们讲解了优采云采集器如何使用Xpath来采集列出页面。今天,我们将讨论优采云采集器如何使用Xpath 来采集内容页面!
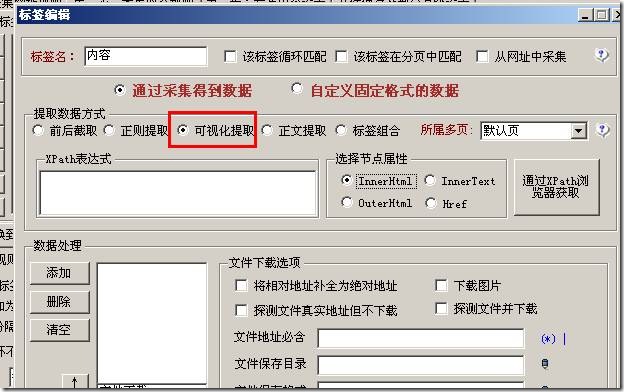
新建标签,提前选择数据方式,选择“视觉提取”选项,如下图:
同时单击“通过 XPath 浏览器获取”按钮。
和上面得到的地址一样,输入地址,访问地址为采集,如下图:
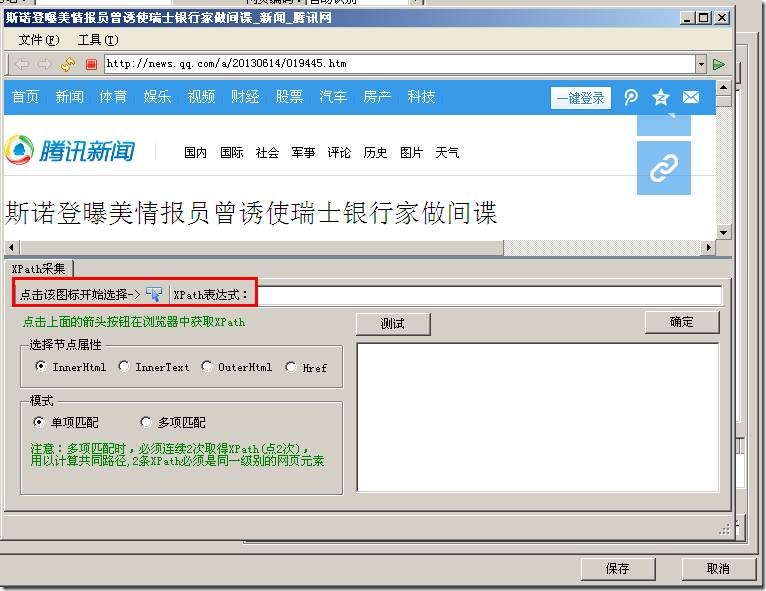
然后单击图标开始选择。这里我们以标题获取为例。
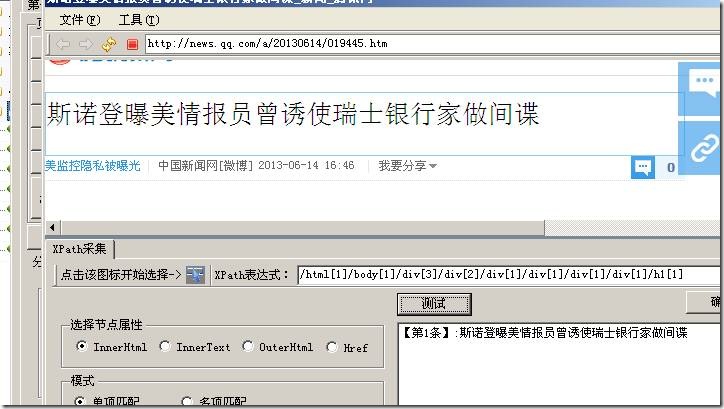
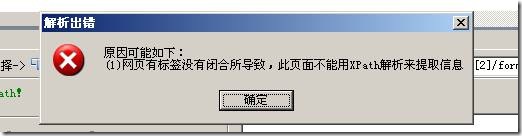
选择浅蓝色框中的标题,轻轻点击鼠标,测试一下是否正确。如果正确单击确定按钮。这不像 采集 地址,需要执行两次。如果测试弹出:
这表示无法通过这种方式获取该页面。
如下图点击确定:
此处自动填写获取此标题的表达式。让我们测试一下结果:
结果是正确的。其他信息可以通过这种方式获取。
有一个节点属性如下图:
这也是一个专业术语。你可以查资料了解一下。一般可以通过选择InnerHtml和InnerText来获取文本信息。如果您需要了解更多信息,请自行查找信息。
选择“Href”获取链接地址,选择“OuterHtml”获取文本和收录的html代码。不明白的可以实际测试一下结果。 查看全部
文章采集调用(如何优采云采集器如何利用Xpath来采集内容页面可视化提取)
在上一篇文章《优采云采集 List Page and Label Xpath Visual Extraction Function》中,我们讲解了优采云采集器如何使用Xpath来采集列出页面。今天,我们将讨论优采云采集器如何使用Xpath 来采集内容页面!

新建标签,提前选择数据方式,选择“视觉提取”选项,如下图:
同时单击“通过 XPath 浏览器获取”按钮。
和上面得到的地址一样,输入地址,访问地址为采集,如下图:
然后单击图标开始选择。这里我们以标题获取为例。
选择浅蓝色框中的标题,轻轻点击鼠标,测试一下是否正确。如果正确单击确定按钮。这不像 采集 地址,需要执行两次。如果测试弹出:
这表示无法通过这种方式获取该页面。
如下图点击确定:
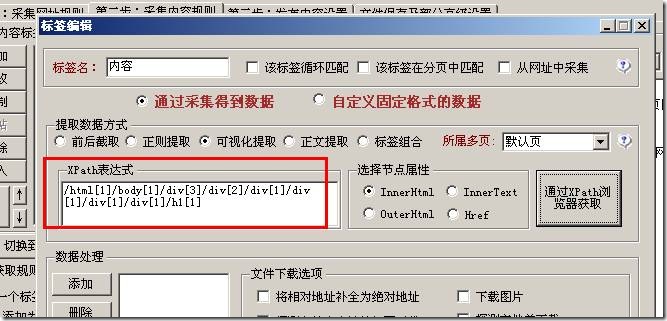
此处自动填写获取此标题的表达式。让我们测试一下结果:
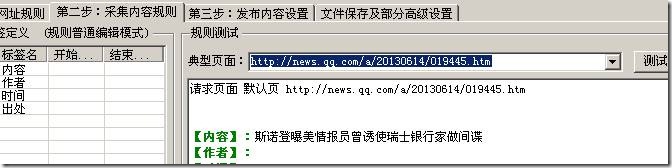
结果是正确的。其他信息可以通过这种方式获取。
有一个节点属性如下图:
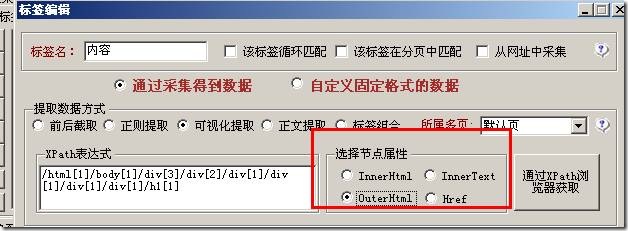
这也是一个专业术语。你可以查资料了解一下。一般可以通过选择InnerHtml和InnerText来获取文本信息。如果您需要了解更多信息,请自行查找信息。
选择“Href”获取链接地址,选择“OuterHtml”获取文本和收录的html代码。不明白的可以实际测试一下结果。
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-08 14:15
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常在多个平台上推送文章,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但是复制图片会害死我,微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信已对图片实施防盗链措施。
这时候尝试搜索了一个这样的插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是我开发了一个叫Bee采集的插件,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,并且还有各种多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可
使用起来也很简单,只要粘贴链接,就可以同时导入多个文章,即批量导入功能,以及自动同步采集公众号的功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到
希望这篇笔记可以帮到你 查看全部
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常在多个平台上推送文章,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但是复制图片会害死我,微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信已对图片实施防盗链措施。
这时候尝试搜索了一个这样的插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是我开发了一个叫Bee采集的插件,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,并且还有各种多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可

使用起来也很简单,只要粘贴链接,就可以同时导入多个文章,即批量导入功能,以及自动同步采集公众号的功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到

希望这篇笔记可以帮到你
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-08 02:06
)
最近的一个项目需要实现摄像头图像采集,经过一系列的折腾,终于实现了这个功能,现在整理一下。
就java技术而言,为了实现相机的二次开发,采集相机图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然,JMF 处理不了。现在想写个applet程序,但是那个东西需要客户端有jre环境,不适合我。您不能指望用户在访问您的 网站 jre 进行安装然后再次访问时下载一个大文件吗?
既然JMF不适用,那么我们在java项目中如何控制摄像头抓拍呢?在windows平台下,我们可以使用视频采集卡等二次开发包来访问视频数据,但是目前的摄像头都是usb的,甚至笔记本电脑屏幕都有摄像头,这种情况下的解决方案使用采集卡二次开发包不适用。您只能编写自己的程序来做类似于“相机相机软件”的事情。经过一系列的分析,终于实现了在web程序中调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集Camera data的项目中实现,例如,
罗嗦一大堆,程序放在csdn下载资源上面,以后不用到处找相机二次开发,直接下载使用即可。
摄像头程序下载地址
压缩包中收录一个基于纯网页采集的相机照片示例程序,以及一个基于jquery框架的ajax数据操作程序示例。调用摄像头的方法详见示例代码。相信稍微懂一点技术的人应该都能看懂。了解了,有一个完整的基于java技术的photo采集示例程序,使用jsp页面采集的照片,serlvet程序接收摄像头照片数据。
以下是程序运行效果示例:
查看全部
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集?
)
最近的一个项目需要实现摄像头图像采集,经过一系列的折腾,终于实现了这个功能,现在整理一下。
就java技术而言,为了实现相机的二次开发,采集相机图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然,JMF 处理不了。现在想写个applet程序,但是那个东西需要客户端有jre环境,不适合我。您不能指望用户在访问您的 网站 jre 进行安装然后再次访问时下载一个大文件吗?
既然JMF不适用,那么我们在java项目中如何控制摄像头抓拍呢?在windows平台下,我们可以使用视频采集卡等二次开发包来访问视频数据,但是目前的摄像头都是usb的,甚至笔记本电脑屏幕都有摄像头,这种情况下的解决方案使用采集卡二次开发包不适用。您只能编写自己的程序来做类似于“相机相机软件”的事情。经过一系列的分析,终于实现了在web程序中调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集Camera data的项目中实现,例如,
罗嗦一大堆,程序放在csdn下载资源上面,以后不用到处找相机二次开发,直接下载使用即可。
摄像头程序下载地址
压缩包中收录一个基于纯网页采集的相机照片示例程序,以及一个基于jquery框架的ajax数据操作程序示例。调用摄像头的方法详见示例代码。相信稍微懂一点技术的人应该都能看懂。了解了,有一个完整的基于java技术的photo采集示例程序,使用jsp页面采集的照片,serlvet程序接收摄像头照片数据。
以下是程序运行效果示例:
文章采集调用(测试阻碍交付,如何破解这一难题?(一)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-01-07 18:14
测试阻碍了交付。如何解决这个问题呢?>>>
点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
请求数据的时候,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csv
class Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self): pass
if __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,得到响应,页面回调方便下一个请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、 调用方法实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0 self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存csv文件。
4、电影画面显示。
[七、总结]
1、 不建议抓太多数据,可能造成服务器负载,简单试一下。
2、这篇文章针对Python爬豆豆应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要霸道,不要霸道,要了解的更深。
5、 需要本文源码的请在下方公众号后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享家庭 查看全部
文章采集调用(测试阻碍交付,如何破解这一难题?(一)(组图))
测试阻碍了交付。如何解决这个问题呢?>>>

点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
请求数据的时候,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
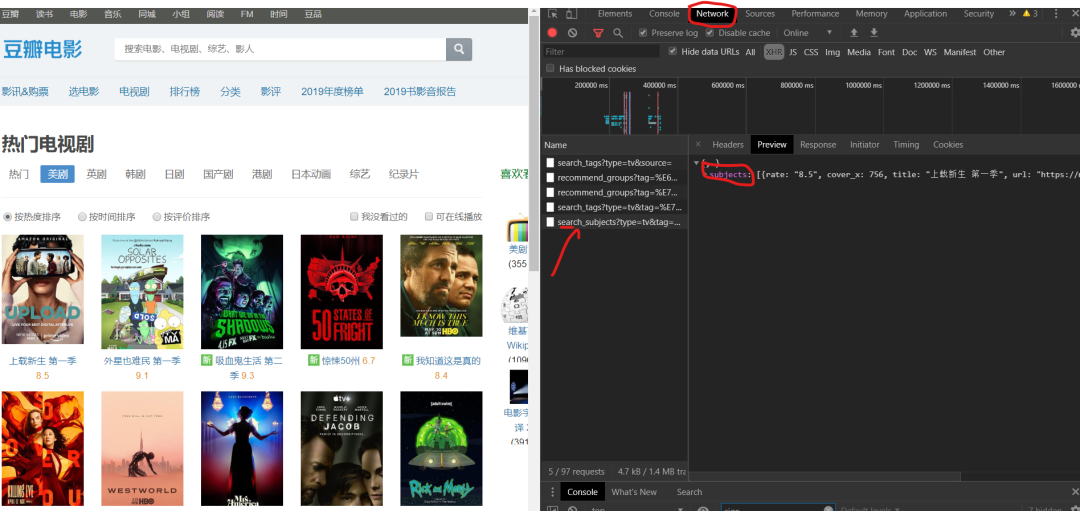
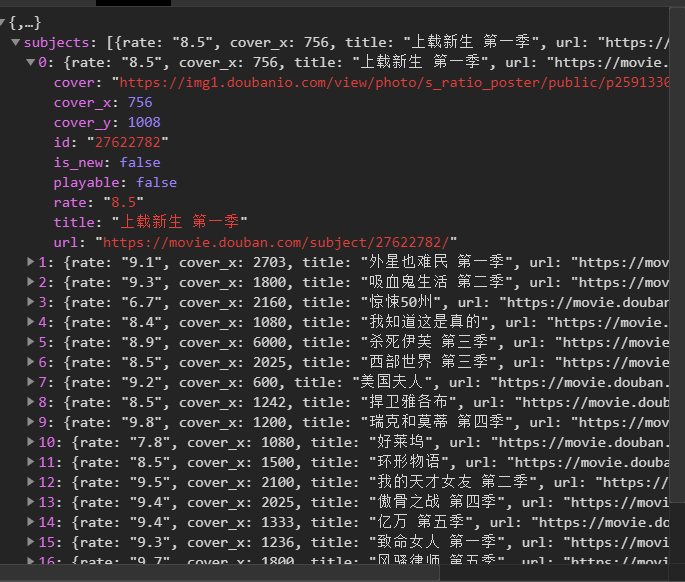
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csv
class Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self): pass
if __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,得到响应,页面回调方便下一个请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、 调用方法实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0 self.u += 1;
【六、效果展示】
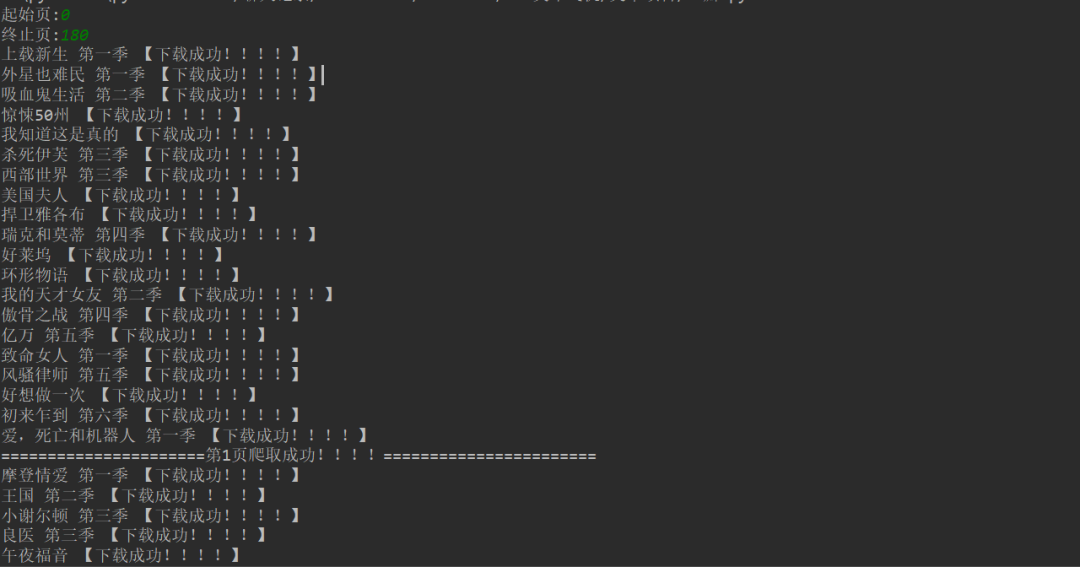
1、 点击绿色三角进入起始页和结束页(从第0页开始)。

2、 在控制台显示下载成功信息。
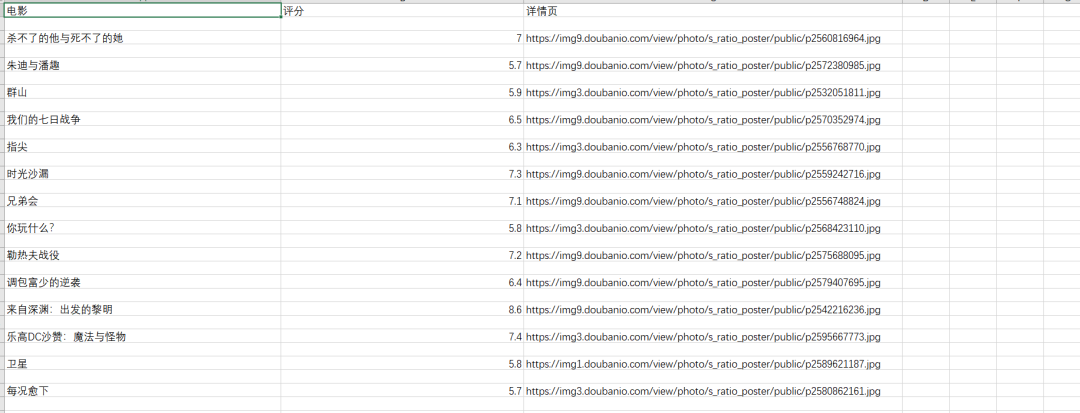
3、保存csv文件。
4、电影画面显示。
[七、总结]
1、 不建议抓太多数据,可能造成服务器负载,简单试一下。
2、这篇文章针对Python爬豆豆应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要霸道,不要霸道,要了解的更深。
5、 需要本文源码的请在下方公众号后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享家庭
文章采集调用(换个网站你什么都做不了,这个教程让你一看即会)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2022-01-06 07:05
很多网友对于织梦的采集教程(DEDEcms)感到头疼。确实,官方教程太笼统,没说什么。换个网站你是什么?不会啊,这个教程是最详细的教程了,赶紧看看吧!
一、列表采集
第一步,我们打开织梦后台,点击采集——采集节点管理——添加新节点
第二步,这里我们以采集normal文章为例,我们选择normal文章,然后确认
第三步,进入采集的设置页面,填写节点名称。
第四步,打开你要采集的文章列表页。
以这个网站为例,打开这个页面,
右键查看源文件找到目标页面编码,就在charset之后)
第五步,填写页面基本信息,填写后如图
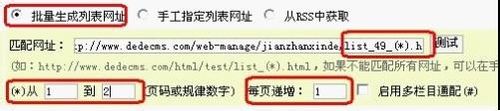
第六步,填写列表URL获取规则,查看文章列表第一页地址。
比较第二页的地址
我们发现除了49_后面的数字是一样的,所以我们可以这样写
(*).html
就用(*)代替1,因为只有2页,所以我们从1到2填,每页加1,当然2-1...等于1。
到这里我们完成了
可能你的一些采集列表没有规则,所以你只需要手动指定列表URL即可,如图
每行写一个页面地址
第七步:填写文章 URL匹配规则,返回文章列表页面
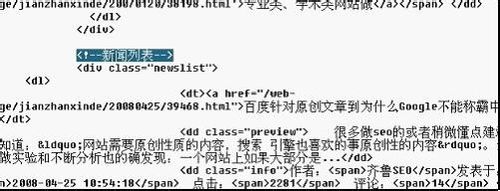
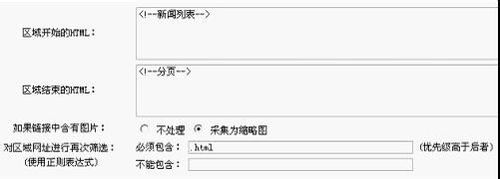
右键查看源文件找到区域开头的HTML,也就是找到文章列表开头的标记。
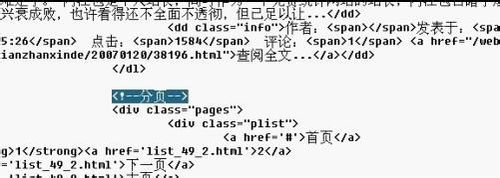
我们可以很容易地找到如图所示的“新闻列表”。从这里开始,后面是文章列表,然后找到文章列表末尾的HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理成缩略图,这里根据自己的需要选择
二、内容页采集
第八步,重新筛选区域网站:
(使用正则表达式)必须收录:(优先级高于后者)
不能收录:打开源文件,我们可以清楚地看到文章链接以.html结尾,所以我们必须收录它并填写.html。如果遇到一些比较麻烦的list,也可以在后面填写Cannot contains
点击保存设置进入下一步,可以看到我们得到的文章 URL
看到这个是对的,我们保存信息,进入下一步设置内容字段获取规则
看看文章有没有分页,随便输入一篇文章看看吧。. 我们看到文章中没有分页
所以这里我们默认
找到文章标题等,输入一篇文章文章,右键查看源文件
看看这些
根据源码填写
第九步,填写文章内容的开头,结尾同上,找到开始和结束标志。
开始部分如图
末端部分如图所示
最后填写如图
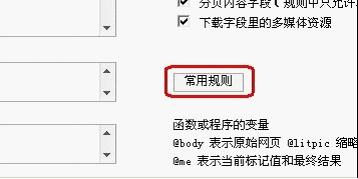
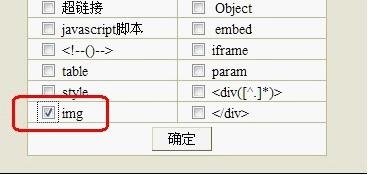
第十步,要过滤文章中的什么内容,写在过滤规则中,比如过滤文章中的图片,
选择常用规则,如图
然后勾选IMG,如图
然后确定
这样我们过滤文本中的图片
第十一步,设置完成后,点击保存设置并预览,如图
写了这样一个采集规则,很简单吧?有些网站很难写,但你需要更努力。
我们点击保存,启动采集-start 采集网页,采集就完成了
看看我们采集到达了什么文章
最后,导出数据
首先选择要导入的列,在弹出的窗口中按“选择”选择需要导入的列。发布选项通常是默认选项,除非您不想立即发布。每批导入的默认值为30,修改与否都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。
文章标题
匹配规则:【内容】
过滤规则:{dede:trimreplace=""}_XXX网站{/dede:trim}
来自百度
三、采集 规则补充(一) 文本过滤和替换方法
1.去除超链接,这个是最常用的。
{dede:trim replace="}]*)>{/dede:trim}
{dede:trim replace=”}{/dede:trim}
如果这样填写,那么链接的文字也被去掉了
{dede:trim replace=”}]*)>(.*){/dede:trim}
2. 过滤JS电话广告,如GG广告,添加:
{dede:trim replace=”}{/dede:trim}
3.过滤 div 标签。
这是非常重要的。如果过滤不干净,发布的 文章 页面可能会错位。目前遇到采集后出现错位的大部分原因都在这里。
{dede:修剪替换=”}
{/dede:修剪}
{dede:修剪替换=”}
{/dede:修剪}
有时需要像这样过滤:
{dede:修剪替换=”}
(.*)
{/dede:修剪}
4.根据以上规则可以引入其他过滤规则。
5.过滤摘要和关键字用法,经常用到。
{dede:trim replace=”}{/dede:trim}
6. 简单替换。
{dede:trim replace='word after replacement'}要替换的单词{/dede:trim}
7.删除源代码
{dede:trim replace=""}src="([^"]*)"{/dede:trim}
(二)内容页注明作者和出处
可以通过指定 value 值来实现:
{dede:item field='writer' value='小军' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='Military Net' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
(三)内容页分页采集
在“内容分页导航所在区域的匹配规则:”中填写规则,如 查看全部
文章采集调用(换个网站你什么都做不了,这个教程让你一看即会)
很多网友对于织梦的采集教程(DEDEcms)感到头疼。确实,官方教程太笼统,没说什么。换个网站你是什么?不会啊,这个教程是最详细的教程了,赶紧看看吧!
一、列表采集
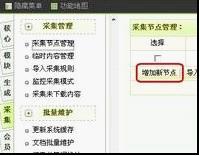
第一步,我们打开织梦后台,点击采集——采集节点管理——添加新节点
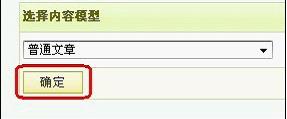
第二步,这里我们以采集normal文章为例,我们选择normal文章,然后确认
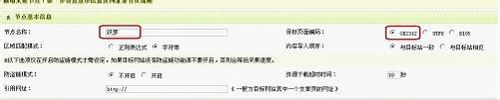
第三步,进入采集的设置页面,填写节点名称。
第四步,打开你要采集的文章列表页。
以这个网站为例,打开这个页面,
右键查看源文件找到目标页面编码,就在charset之后)

第五步,填写页面基本信息,填写后如图
第六步,填写列表URL获取规则,查看文章列表第一页地址。
比较第二页的地址
我们发现除了49_后面的数字是一样的,所以我们可以这样写
(*).html
就用(*)代替1,因为只有2页,所以我们从1到2填,每页加1,当然2-1...等于1。
到这里我们完成了
可能你的一些采集列表没有规则,所以你只需要手动指定列表URL即可,如图
每行写一个页面地址

第七步:填写文章 URL匹配规则,返回文章列表页面
右键查看源文件找到区域开头的HTML,也就是找到文章列表开头的标记。
我们可以很容易地找到如图所示的“新闻列表”。从这里开始,后面是文章列表,然后找到文章列表末尾的HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理成缩略图,这里根据自己的需要选择
二、内容页采集
第八步,重新筛选区域网站:
(使用正则表达式)必须收录:(优先级高于后者)
不能收录:打开源文件,我们可以清楚地看到文章链接以.html结尾,所以我们必须收录它并填写.html。如果遇到一些比较麻烦的list,也可以在后面填写Cannot contains
点击保存设置进入下一步,可以看到我们得到的文章 URL
看到这个是对的,我们保存信息,进入下一步设置内容字段获取规则
看看文章有没有分页,随便输入一篇文章看看吧。. 我们看到文章中没有分页
所以这里我们默认
找到文章标题等,输入一篇文章文章,右键查看源文件
看看这些
根据源码填写

第九步,填写文章内容的开头,结尾同上,找到开始和结束标志。
开始部分如图
末端部分如图所示
最后填写如图

第十步,要过滤文章中的什么内容,写在过滤规则中,比如过滤文章中的图片,
选择常用规则,如图
然后勾选IMG,如图
然后确定
这样我们过滤文本中的图片
第十一步,设置完成后,点击保存设置并预览,如图
写了这样一个采集规则,很简单吧?有些网站很难写,但你需要更努力。
我们点击保存,启动采集-start 采集网页,采集就完成了
看看我们采集到达了什么文章


最后,导出数据
首先选择要导入的列,在弹出的窗口中按“选择”选择需要导入的列。发布选项通常是默认选项,除非您不想立即发布。每批导入的默认值为30,修改与否都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。
文章标题
匹配规则:【内容】
过滤规则:{dede:trimreplace=""}_XXX网站{/dede:trim}

来自百度
三、采集 规则补充(一) 文本过滤和替换方法
1.去除超链接,这个是最常用的。
{dede:trim replace="}]*)>{/dede:trim}
{dede:trim replace=”}{/dede:trim}
如果这样填写,那么链接的文字也被去掉了
{dede:trim replace=”}]*)>(.*){/dede:trim}
2. 过滤JS电话广告,如GG广告,添加:
{dede:trim replace=”}{/dede:trim}
3.过滤 div 标签。
这是非常重要的。如果过滤不干净,发布的 文章 页面可能会错位。目前遇到采集后出现错位的大部分原因都在这里。
{dede:修剪替换=”}
{/dede:修剪}
{dede:修剪替换=”}
{/dede:修剪}
有时需要像这样过滤:
{dede:修剪替换=”}
(.*)
{/dede:修剪}
4.根据以上规则可以引入其他过滤规则。
5.过滤摘要和关键字用法,经常用到。
{dede:trim replace=”}{/dede:trim}
6. 简单替换。
{dede:trim replace='word after replacement'}要替换的单词{/dede:trim}
7.删除源代码
{dede:trim replace=""}src="([^"]*)"{/dede:trim}
(二)内容页注明作者和出处
可以通过指定 value 值来实现:
{dede:item field='writer' value='小军' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='Military Net' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
(三)内容页分页采集
在“内容分页导航所在区域的匹配规则:”中填写规则,如
文章采集调用(下采集神器:chromedp+HeadlessChrome安装安装)
采集交流 • 优采云 发表了文章 • 0 个评论 • 456 次浏览 • 2022-01-06 06:06
最近在采集微信文章的时候,遇到了一个比较棘手的问题。通过搜狗搜索的微信搜索模式,正常的直接抓取页面的方式无法绕过搜狗搜索的验证。所以成功使用gorequest采集到微信文章。
选择 chromedp + Headless Chrome
面对采集的目的没有达到的问题,我是不是就此放弃了?显然这是不可能的。不就是签名验证嘛,只要不要求输入验证码,总有办法解决的(蒽,一般的验证码也可以解决)。于是牺牲了golang下的采集神器:chromedp。
简单来说,chromedp是golang语言用来调用Chrome调试协议来模拟浏览器行为的一个包,可以简单的驱动浏览器。使用的前提很简单,就是在电脑上安装Chrome浏览器。
Chrome浏览器的安装在Windows和macOS下没有问题,在桌面版Linux下也没有问题。但是如果要在Linux服务器版本上安装Chrome,就没有那么简单了。至少目前,Chrome 还没有可以直接安装在服务器上的软件包。
但是你必须放弃你刚刚想到的想法吗?当然这是不可能的。翻阅chromedp文档,我刚刚找到了一段:
最简单的方法是在 chromedp/headless-shell 映像中运行使用 chromedp 的 Go 程序。该图像收录 headless-shell,这是一种较小的 Chrome 无头构建,chromedp 可以立即找到它。
他的意思是:最简单的方法就是用chromedp调用chromedp/headless-shell镜像。chromedp/headless-shell 是一个 docker 镜像,收录一个较小的 Chrome 无头浏览器。
好的,既然是docker镜像,我们就用docker安装。
首先登录我们的linux服务器,下面的操作就认为你已经登录到linux服务器了。
安装 docker 并安装 chromedp/headless-shell
如果您的服务器已经安装了 docker,请跳过此步骤。
使用yum安装docker
yum install docker
复制代码
安装完成后,此时无法直接使用docker,需要执行以下命令激活
systemctl daemon-reload
service docker restart
复制代码
然后安装 chromedp/headless-shell 镜像
docker pull chromedp/headless-shell:latest
复制代码
等待安装完成,然后运行docker镜像
docker run -d -p 9222:9222 --rm --name headless-shell chromedp/headless-shell
复制代码
运行后,测试chrome是否正常:
curl http://127.0.0.1:9222/json/version
复制代码
如果看到类似下面的内容,说明chrome浏览器工作正常
{"浏览器": "Chrome/96.0.4664.110","协议版本": "1.3","用户代理":" Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36","V8-Version": "9.6.180.21","WebKit-Version": "537.36 (@d5ef0e8214bc14c9b5bbf69a1515e431394c62a6)","webSocketDebuggerUrl": "ws://127.0.0.1/devers-browse/dev22921 -4d5b-b9e6-37d634aa719a"}
chromedp代码调用chromedp/headless-shell采集微信公众号文章内容
Linux下可以正常使用Headless Chrome无头浏览器。剩下的就是调用它的代码了。
现在我们开始编写采集微信文章使用的chrome代码:
定义关键字,artile struct.go
package main
type Keyword struct {
Id int64 `json:"id"`
Name string `json:"name"`
Level int `json:"level"`
ArticleCount int `json:"article_count"`
LastTime int64 `json:"last_time"` //上次执行时间
}
type Article struct {
Id int64 `json:"id"`
KeywordId int64 `json:"keyword_id"`
Title string `json:"title"`
Keywords string `json:"keywords"`
Description string `json:"description"`
OriginUrl string `json:"origin_url"`
Status int `json:"status"`
CreatedTime int `json:"created_time"`
UpdatedTime int `json:"updated_time"`
Content string `json:"content"`
ContentText string `json:"-"`
}
复制代码
编写核心代码 core.go
package main
import (
"context"
"fmt"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
"log"
"net"
"net/url"
"strings"
"time"
)
func CollectArticleFromWeixin(keyword *Keyword) []*Article {
timeCtx, cancel := context.WithTimeout(GetChromeCtx(false), 30*time.Second)
defer cancel()
var collectLink string
err := chromedp.Run(timeCtx,
chromedp.Navigate(fmt.Sprintf("https://weixin.sogou.com/weixi ... ot%3B, keyword.Name)),
chromedp.WaitVisible(`//ul[@class="news-list"]`),
chromedp.Location(&collectLink),
)
if err != nil {
log.Println("读取搜狗搜索列表失败1:", keyword.Name, err.Error())
return nil
}
log.Println("正在采集列表:", collectLink)
var aLinks []*cdp.Node
if err := chromedp.Run(timeCtx, chromedp.Nodes(`//ul[@class="news-list"]//h3//a`, &aLinks)); err != nil {
log.Println("读取搜狗搜索列表失败2:", keyword.Name, err.Error())
return nil
}
var articles []*Article
for i := 0; i < len(aLinks); i++ {
href := aLinks[i].AttributeValue("href")
href, _ = joinURL("https://weixin.sogou.com/", href)
article := &Article{}
err = chromedp.Run(timeCtx,
chromedp.Navigate(href),
chromedp.WaitVisible(`#js_article`),
chromedp.Location(&article.OriginUrl),
chromedp.Text(`#activity-name`, &article.Title, chromedp.NodeVisible),
chromedp.InnerHTML("#js_content", &article.Content, chromedp.ByID),
chromedp.Text("#js_content", &article.ContentText, chromedp.ByID),
)
if err != nil {
log.Println("读取搜狗搜索列表失败3:", keyword.Name, err.Error())
}
log.Println("采集文章:", article.Title, len(article.Content), article.OriginUrl)
articles = append(articles, article)
}
return articles
}
// 重组url
func joinURL(baseURL, subURL string) (fullURL, fullURLWithoutFrag string) {
baseURL = strings.TrimSpace(baseURL)
subURL = strings.TrimSpace(subURL)
baseURLObj, _ := url.Parse(baseURL)
subURLObj, _ := url.Parse(subURL)
fullURLObj := baseURLObj.ResolveReference(subURLObj)
fullURL = fullURLObj.String()
fullURLObj.Fragment = ""
fullURLWithoutFrag = fullURLObj.String()
return
}
//检查是否有9222端口,来判断是否运行在linux上
func checkChromePort() bool {
addr := net.JoinHostPort("", "9222")
conn, err := net.DialTimeout("tcp", addr, 1*time.Second)
if err != nil {
return false
}
defer conn.Close()
return true
}
// ChromeCtx 使用一个实例
var ChromeCtx context.Context
func GetChromeCtx(focus bool) context.Context {
if ChromeCtx == nil || focus {
allocOpts := chromedp.DefaultExecAllocatorOptions[:]
allocOpts = append(allocOpts,
chromedp.DisableGPU,
chromedp.Flag("blink-settings", "imagesEnabled=false"),
chromedp.UserAgent(`Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36`),
chromedp.Flag("accept-language", `zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6`),
)
if checkChromePort() {
// 不知道为何,不能直接使用 NewExecAllocator ,因此增加 使用 ws://127.0.0.1:9222/ 来调用
c, _ := chromedp.NewRemoteAllocator(context.Background(), "ws://127.0.0.1:9222/")
ChromeCtx, _ = chromedp.NewContext(c)
} else {
c, _ := chromedp.NewExecAllocator(context.Background(), allocOpts...)
ChromeCtx, _ = chromedp.NewContext(c)
}
}
return ChromeCtx
}
复制代码
写入入口文件main.go
package main
import "log"
func main() {
word := Keyword{
Name: "golang",
}
result := CollectArticleFromWeixin(&word)
for i, v := range result {
log.Println(i, v.Title, len(v.Content), v.OriginUrl)
log.Println("纯内容:", v.ContentText)
}
}
复制代码
运行结果测试:
伟大的结果出来了。
如果您对此代码感兴趣,可以从这里获取 /fesiong/gob...。
本采集代码仅供研究学习之用,不得用于非法用途。 查看全部
文章采集调用(下采集神器:chromedp+HeadlessChrome安装安装)
最近在采集微信文章的时候,遇到了一个比较棘手的问题。通过搜狗搜索的微信搜索模式,正常的直接抓取页面的方式无法绕过搜狗搜索的验证。所以成功使用gorequest采集到微信文章。
选择 chromedp + Headless Chrome
面对采集的目的没有达到的问题,我是不是就此放弃了?显然这是不可能的。不就是签名验证嘛,只要不要求输入验证码,总有办法解决的(蒽,一般的验证码也可以解决)。于是牺牲了golang下的采集神器:chromedp。
简单来说,chromedp是golang语言用来调用Chrome调试协议来模拟浏览器行为的一个包,可以简单的驱动浏览器。使用的前提很简单,就是在电脑上安装Chrome浏览器。
Chrome浏览器的安装在Windows和macOS下没有问题,在桌面版Linux下也没有问题。但是如果要在Linux服务器版本上安装Chrome,就没有那么简单了。至少目前,Chrome 还没有可以直接安装在服务器上的软件包。
但是你必须放弃你刚刚想到的想法吗?当然这是不可能的。翻阅chromedp文档,我刚刚找到了一段:
最简单的方法是在 chromedp/headless-shell 映像中运行使用 chromedp 的 Go 程序。该图像收录 headless-shell,这是一种较小的 Chrome 无头构建,chromedp 可以立即找到它。
他的意思是:最简单的方法就是用chromedp调用chromedp/headless-shell镜像。chromedp/headless-shell 是一个 docker 镜像,收录一个较小的 Chrome 无头浏览器。
好的,既然是docker镜像,我们就用docker安装。
首先登录我们的linux服务器,下面的操作就认为你已经登录到linux服务器了。
安装 docker 并安装 chromedp/headless-shell
如果您的服务器已经安装了 docker,请跳过此步骤。
使用yum安装docker
yum install docker
复制代码
安装完成后,此时无法直接使用docker,需要执行以下命令激活
systemctl daemon-reload
service docker restart
复制代码
然后安装 chromedp/headless-shell 镜像
docker pull chromedp/headless-shell:latest
复制代码
等待安装完成,然后运行docker镜像
docker run -d -p 9222:9222 --rm --name headless-shell chromedp/headless-shell
复制代码
运行后,测试chrome是否正常:
curl http://127.0.0.1:9222/json/version
复制代码
如果看到类似下面的内容,说明chrome浏览器工作正常
{"浏览器": "Chrome/96.0.4664.110","协议版本": "1.3","用户代理":" Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36","V8-Version": "9.6.180.21","WebKit-Version": "537.36 (@d5ef0e8214bc14c9b5bbf69a1515e431394c62a6)","webSocketDebuggerUrl": "ws://127.0.0.1/devers-browse/dev22921 -4d5b-b9e6-37d634aa719a"}
chromedp代码调用chromedp/headless-shell采集微信公众号文章内容
Linux下可以正常使用Headless Chrome无头浏览器。剩下的就是调用它的代码了。
现在我们开始编写采集微信文章使用的chrome代码:
定义关键字,artile struct.go
package main
type Keyword struct {
Id int64 `json:"id"`
Name string `json:"name"`
Level int `json:"level"`
ArticleCount int `json:"article_count"`
LastTime int64 `json:"last_time"` //上次执行时间
}
type Article struct {
Id int64 `json:"id"`
KeywordId int64 `json:"keyword_id"`
Title string `json:"title"`
Keywords string `json:"keywords"`
Description string `json:"description"`
OriginUrl string `json:"origin_url"`
Status int `json:"status"`
CreatedTime int `json:"created_time"`
UpdatedTime int `json:"updated_time"`
Content string `json:"content"`
ContentText string `json:"-"`
}
复制代码
编写核心代码 core.go
package main
import (
"context"
"fmt"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
"log"
"net"
"net/url"
"strings"
"time"
)
func CollectArticleFromWeixin(keyword *Keyword) []*Article {
timeCtx, cancel := context.WithTimeout(GetChromeCtx(false), 30*time.Second)
defer cancel()
var collectLink string
err := chromedp.Run(timeCtx,
chromedp.Navigate(fmt.Sprintf("https://weixin.sogou.com/weixi ... ot%3B, keyword.Name)),
chromedp.WaitVisible(`//ul[@class="news-list"]`),
chromedp.Location(&collectLink),
)
if err != nil {
log.Println("读取搜狗搜索列表失败1:", keyword.Name, err.Error())
return nil
}
log.Println("正在采集列表:", collectLink)
var aLinks []*cdp.Node
if err := chromedp.Run(timeCtx, chromedp.Nodes(`//ul[@class="news-list"]//h3//a`, &aLinks)); err != nil {
log.Println("读取搜狗搜索列表失败2:", keyword.Name, err.Error())
return nil
}
var articles []*Article
for i := 0; i < len(aLinks); i++ {
href := aLinks[i].AttributeValue("href")
href, _ = joinURL("https://weixin.sogou.com/", href)
article := &Article{}
err = chromedp.Run(timeCtx,
chromedp.Navigate(href),
chromedp.WaitVisible(`#js_article`),
chromedp.Location(&article.OriginUrl),
chromedp.Text(`#activity-name`, &article.Title, chromedp.NodeVisible),
chromedp.InnerHTML("#js_content", &article.Content, chromedp.ByID),
chromedp.Text("#js_content", &article.ContentText, chromedp.ByID),
)
if err != nil {
log.Println("读取搜狗搜索列表失败3:", keyword.Name, err.Error())
}
log.Println("采集文章:", article.Title, len(article.Content), article.OriginUrl)
articles = append(articles, article)
}
return articles
}
// 重组url
func joinURL(baseURL, subURL string) (fullURL, fullURLWithoutFrag string) {
baseURL = strings.TrimSpace(baseURL)
subURL = strings.TrimSpace(subURL)
baseURLObj, _ := url.Parse(baseURL)
subURLObj, _ := url.Parse(subURL)
fullURLObj := baseURLObj.ResolveReference(subURLObj)
fullURL = fullURLObj.String()
fullURLObj.Fragment = ""
fullURLWithoutFrag = fullURLObj.String()
return
}
//检查是否有9222端口,来判断是否运行在linux上
func checkChromePort() bool {
addr := net.JoinHostPort("", "9222")
conn, err := net.DialTimeout("tcp", addr, 1*time.Second)
if err != nil {
return false
}
defer conn.Close()
return true
}
// ChromeCtx 使用一个实例
var ChromeCtx context.Context
func GetChromeCtx(focus bool) context.Context {
if ChromeCtx == nil || focus {
allocOpts := chromedp.DefaultExecAllocatorOptions[:]
allocOpts = append(allocOpts,
chromedp.DisableGPU,
chromedp.Flag("blink-settings", "imagesEnabled=false"),
chromedp.UserAgent(`Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36`),
chromedp.Flag("accept-language", `zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6`),
)
if checkChromePort() {
// 不知道为何,不能直接使用 NewExecAllocator ,因此增加 使用 ws://127.0.0.1:9222/ 来调用
c, _ := chromedp.NewRemoteAllocator(context.Background(), "ws://127.0.0.1:9222/")
ChromeCtx, _ = chromedp.NewContext(c)
} else {
c, _ := chromedp.NewExecAllocator(context.Background(), allocOpts...)
ChromeCtx, _ = chromedp.NewContext(c)
}
}
return ChromeCtx
}
复制代码
写入入口文件main.go
package main
import "log"
func main() {
word := Keyword{
Name: "golang",
}
result := CollectArticleFromWeixin(&word)
for i, v := range result {
log.Println(i, v.Title, len(v.Content), v.OriginUrl)
log.Println("纯内容:", v.ContentText)
}
}
复制代码
运行结果测试:
伟大的结果出来了。
如果您对此代码感兴趣,可以从这里获取 /fesiong/gob...。
本采集代码仅供研究学习之用,不得用于非法用途。
文章采集调用( 如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-01-04 21:01
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
1、介绍
最近在看Scrapy爬虫框架,尝试用Scrapy框架写一个简单的小程序,可以实现网页信息采集。在尝试的过程中遇到了很多小问题,希望大家给点建议。
本文主要介绍如何使用Scrapy结合PhantomJS采集天猫产品内容。文章中自定义了一个DOWNLOADER_MIDDLEWARES,用于采集需要加载js的动态网页内容。看了很多关于DOWNLOADER_MIDDLEWARES的资料,总结起来,使用简单,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的朋友可以去研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发运行环境需要进行以下步骤:
Python--从官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”。详情请参考《Scrapy的首次运行测试》
selenium--执行“pip install selenium”的命令行界面
PhantomJS --官网下载
以上步骤展示了两种安装方式: 1、安装本地下载的wheel包; 2、使用Python安装管理器进行远程下载安装。注意:包版本需要与python版本匹配
2.2、开发测试流程
首先找到需要采集的网页,这里简单搜索一个天猫产品,网址,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建一个scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建一个middlewares文件夹,然后在该文件夹下创建一个middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,也在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在项目目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在项目目录E:python-3.5.1tmSpidermSpiderspiders下自动生成tmall.py程序文件。该程序中的解析函数处理scrapy下载器返回的网页内容。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider项目目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
提一下,上面的命令一次只能启动一个爬虫。如果你想同时启动多个爬虫怎么办?然后需要自定义一个爬虫启动模块,在spider下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs实现爬虫后,一直在纠结框架阻塞的问题,一直在想解决办法。后面会研究scrapyjs、splash等调用浏览器的方式,看看能不能有效的解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、采集GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-07: V1.0 查看全部
文章采集调用(
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)

1、介绍
最近在看Scrapy爬虫框架,尝试用Scrapy框架写一个简单的小程序,可以实现网页信息采集。在尝试的过程中遇到了很多小问题,希望大家给点建议。
本文主要介绍如何使用Scrapy结合PhantomJS采集天猫产品内容。文章中自定义了一个DOWNLOADER_MIDDLEWARES,用于采集需要加载js的动态网页内容。看了很多关于DOWNLOADER_MIDDLEWARES的资料,总结起来,使用简单,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的朋友可以去研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发运行环境需要进行以下步骤:
Python--从官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”。详情请参考《Scrapy的首次运行测试》
selenium--执行“pip install selenium”的命令行界面
PhantomJS --官网下载
以上步骤展示了两种安装方式: 1、安装本地下载的wheel包; 2、使用Python安装管理器进行远程下载安装。注意:包版本需要与python版本匹配
2.2、开发测试流程
首先找到需要采集的网页,这里简单搜索一个天猫产品,网址,页面如下:

然后开始写代码,下面的代码默认在命令行界面执行
1),创建一个scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建一个middlewares文件夹,然后在该文件夹下创建一个middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,也在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在项目目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在项目目录E:python-3.5.1tmSpidermSpiderspiders下自动生成tmall.py程序文件。该程序中的解析函数处理scrapy下载器返回的网页内容。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider项目目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:

提一下,上面的命令一次只能启动一个爬虫。如果你想同时启动多个爬虫怎么办?然后需要自定义一个爬虫启动模块,在spider下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:

3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs实现爬虫后,一直在纠结框架阻塞的问题,一直在想解决办法。后面会研究scrapyjs、splash等调用浏览器的方式,看看能不能有效的解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、采集GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-07: V1.0
文章采集调用(无忧主机php虚拟主机完美支持程序的外部链接,路径知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-01-04 21:00
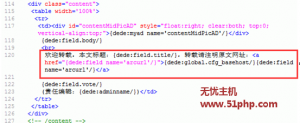
德德cms是一款功能强大的企业建站程序,完美支持无忧主机php虚拟主机。在非常成熟的Dedecms程序面前,总会有一些不完善的地方。文章文章发表后,有可能被其他人转发,或者采集;如果在这个文章的内容中加入当前文档地址和转载说明,则被转载的<@文章将收录当前的文章 URL,一方面,网站@ >内部链接,另一方面,外部链接被转载后无形中形成。像这种一石二鸟的做法,赶紧学起来吧!首先,织梦程序以网站@>的主题为模板,为整个站点生成内容,然后我们直接把需要修改的模板文件下载到本地,文章内容模板文件的名字是:article_article.htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:文章 内容模板文件的名字是:article_article .htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:文章 内容模板文件的名字是:article_article .htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:您可以自己选择主题的名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:您可以自己选择主题的名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:
操作完成后保存上传到网站@>空间,然后在织梦后台更新生成的文档页面。笔记: 查看全部
文章采集调用(无忧主机php虚拟主机完美支持程序的外部链接,路径知道吗?)
德德cms是一款功能强大的企业建站程序,完美支持无忧主机php虚拟主机。在非常成熟的Dedecms程序面前,总会有一些不完善的地方。文章文章发表后,有可能被其他人转发,或者采集;如果在这个文章的内容中加入当前文档地址和转载说明,则被转载的<@文章将收录当前的文章 URL,一方面,网站@ >内部链接,另一方面,外部链接被转载后无形中形成。像这种一石二鸟的做法,赶紧学起来吧!首先,织梦程序以网站@>的主题为模板,为整个站点生成内容,然后我们直接把需要修改的模板文件下载到本地,文章内容模板文件的名字是:article_article.htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:文章 内容模板文件的名字是:article_article .htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:文章 内容模板文件的名字是:article_article .htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:您可以自己选择主题的名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:您可以自己选择主题的名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:
操作完成后保存上传到网站@>空间,然后在织梦后台更新生成的文档页面。笔记:
文章采集调用(pbootcms文章(PbootDemoSkycaiji)插件()(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-04 06:00
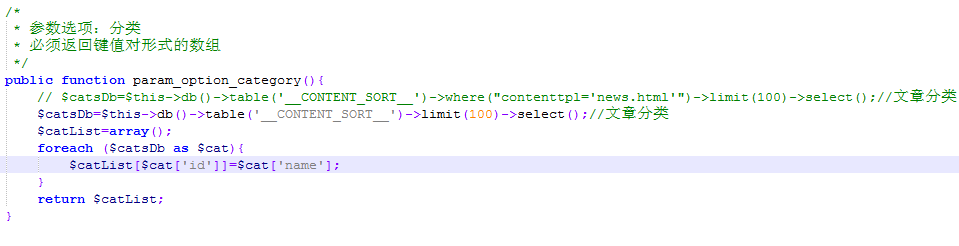
pbootcms文章(PbootDemoSkycaiji)插件直接在优采云采集器云平台下载使用。该插件由无皮小芒果开发。插件默认只能发布新闻栏目,产品案例过滤,需要手动修改。
插件下载后,我们可以在网站根目录优采云采集器安装目录中找到路径:网站根目录采集器安装目录pluginleasecmsPbootDemoSkycaiji.php
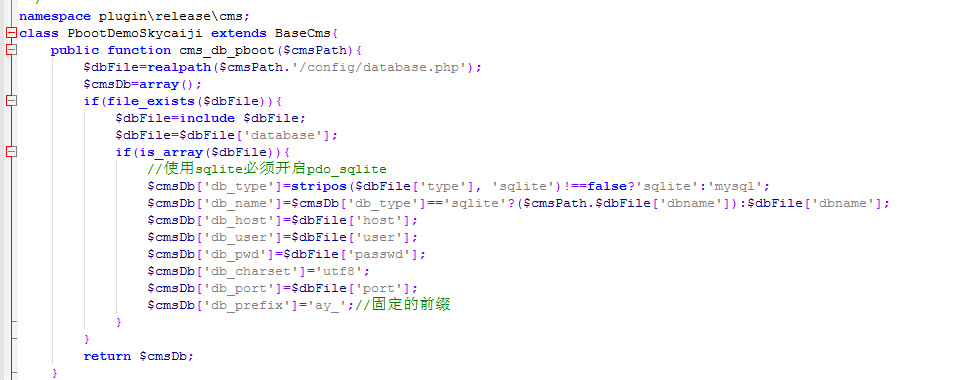
打开这个文件开头的代码就是自动读取我们的数据库信息,不管是mysql还是sqlite数据库都是一样的,自动抓取链接。
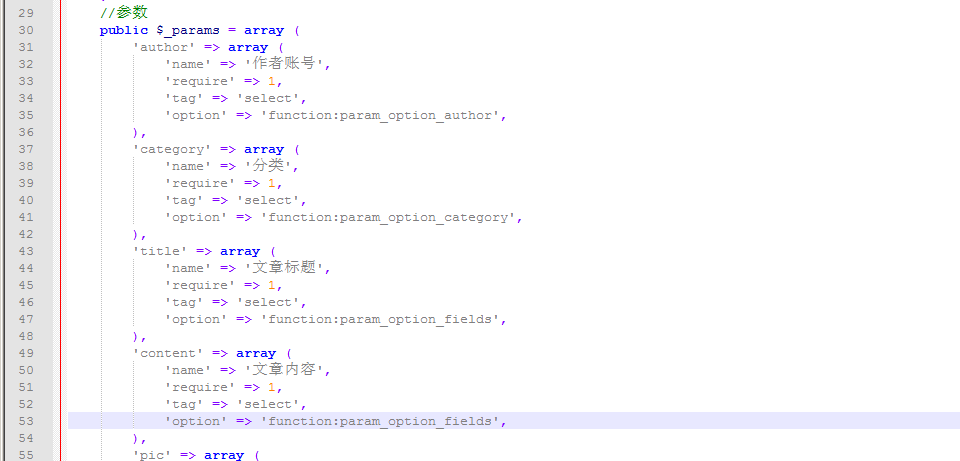
这是我们网站对应的信息,如作者、文章内容、产品分类、缩略图等,这里可以根据我们网站的需要添加更多参数。
此处的信息对应于我们网站 数据库中的字段。如果这里没有字段,可以直接进入数据库添加进去。 有一点需要注意的是,这里的数据库字段必须与前面的参数一一对应。例如,如果我们的参数中添加了缩略图,那么我们必须找到该字段并填写我们在参数中添加的名称。
这里默认过滤其他目录,只取我们数据库中的新闻列表信息。如果我们要发布产品或案例,则无法使用。我们需要做的就是添加
// $catsDb=$this->db()->table('__CONTENT_SORT__')->where("contenttpl='news.html'")->limit(100)->select ();//文章Categories 可以注释或删除。
添加 $catsDb=$this->db()->table('__CONTENT_SORT__')->limit(100)->select();//文章 分类就可以了一个匹配所有网站的目录,上面是pbootcms文章(PbootDemoSkycaiji)插件的详细介绍,上面的描述基本上没有什么问题,怎么能你还可以,如果你明白可以咨询我们。
相关知识点:
本站文章均摘自权威资料、书籍或网络原创文章。如有版权纠纷或侵权,请立即联系我们删除。允许复制和转载!谢谢... 查看全部
文章采集调用(pbootcms文章(PbootDemoSkycaiji)插件()(组图))
pbootcms文章(PbootDemoSkycaiji)插件直接在优采云采集器云平台下载使用。该插件由无皮小芒果开发。插件默认只能发布新闻栏目,产品案例过滤,需要手动修改。
插件下载后,我们可以在网站根目录优采云采集器安装目录中找到路径:网站根目录采集器安装目录pluginleasecmsPbootDemoSkycaiji.php
打开这个文件开头的代码就是自动读取我们的数据库信息,不管是mysql还是sqlite数据库都是一样的,自动抓取链接。
这是我们网站对应的信息,如作者、文章内容、产品分类、缩略图等,这里可以根据我们网站的需要添加更多参数。

此处的信息对应于我们网站 数据库中的字段。如果这里没有字段,可以直接进入数据库添加进去。 有一点需要注意的是,这里的数据库字段必须与前面的参数一一对应。例如,如果我们的参数中添加了缩略图,那么我们必须找到该字段并填写我们在参数中添加的名称。
这里默认过滤其他目录,只取我们数据库中的新闻列表信息。如果我们要发布产品或案例,则无法使用。我们需要做的就是添加
// $catsDb=$this->db()->table('__CONTENT_SORT__')->where("contenttpl='news.html'")->limit(100)->select ();//文章Categories 可以注释或删除。
添加 $catsDb=$this->db()->table('__CONTENT_SORT__')->limit(100)->select();//文章 分类就可以了一个匹配所有网站的目录,上面是pbootcms文章(PbootDemoSkycaiji)插件的详细介绍,上面的描述基本上没有什么问题,怎么能你还可以,如果你明白可以咨询我们。
相关知识点:
本站文章均摘自权威资料、书籍或网络原创文章。如有版权纠纷或侵权,请立即联系我们删除。允许复制和转载!谢谢...
文章采集调用(dedecms如何修改这一上限值)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-03 10:09
dedecmsSystem文章 调用描述最大字符数为250字节,设置文章摘要(可通过infolen或description相关标签调用)最多250个字符,设置上限的次要目的是减少数据库的冗余,保证网络的优良性能。所以,对介绍的内容不设上限显然是不合理的,但如果上限可以自由控制,dedecms仿站会对网页内容的布局带来积极的影响。在网页设计过程中,NET源代码。频道列表页面的文章汇总经常需要调用dedecms。如果文章摘要中的字数可以控制无效,页面布局可以非常灵活。
我们先说一下如何修改这个上限,这样才能显示出方法的要点[field:description function="cn_substr(@me, number of characters)"/]。
获取Dedecms系统中文章抽象相关的php文件。主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面,有一句话: $description = cn_substrR($description, $cfg_auot_description);这句话实现了[field:description function="cn_substr(@me, number of characters)"/] 这个Feature。由于此声明确实对页面布局有益,因此我们尽量不做任何更改。
在编辑页面上,有一句:$description = cn_substrR($description, 250);,这句话出现了熟悉的字符数250,是系统设置文章抽象字符数上限,如果是gbk编码,则显示125个字,如果是utf-8编码,则是81个字,显然我们要突破文章抽象的上限字符,必须取。可以,这里可以把250修改成别的值,比如500。这里不建议设置太高,一是列表页不需要显示太多内容(显示内容太多还不如间接使用body),另一个是避免数据库中的冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句。这个限制了后台可以检索到的字符数,把250改成500。 ,织梦仿站的意思是字符数和之前修改的不一样。(如果你确认你的每个文章都是手动添加的,手动完成就不需要修改这个文件了摘要获取。从摘要中获取minor还是为大量文章和采集准备的。)
首先登录后台,在系统-系统基本参数-其他选项中,可以将驱动摘要的长度改为500,与之前修改的字符数不同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为web提供了更广阔的空间页面布局。
说说德德cms文章或者调用文章列表页上的summary方法
1: [field:info /]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
第二种方法1、是间接调用文章的summary。在被调用的词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}在{/dede:arclist}中,设置摘要中的字符数(最多250)由系统设置;如果使用[field:description /],间接使用后台设置的抽象字符上限(也有后台上限为250个字符)。显然这些两种方法都非常被动和灵活。
方法四3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在文章抽象内容的上限不正常修改的情况下,这四种方法区别不大。
==========================
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me, 字符数)"/]
这四个方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到“if($dsize>250) $dsize = 250;”这句,把250改成500
2.登录后台,在系统-系统基本参数-其他选项中,将自动汇总的长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar(1000)
调用标签{dede:field.description function='cn_substr(@me,500)'/}。可以显示500个字符) 查看全部
文章采集调用(dedecms如何修改这一上限值)
dedecmsSystem文章 调用描述最大字符数为250字节,设置文章摘要(可通过infolen或description相关标签调用)最多250个字符,设置上限的次要目的是减少数据库的冗余,保证网络的优良性能。所以,对介绍的内容不设上限显然是不合理的,但如果上限可以自由控制,dedecms仿站会对网页内容的布局带来积极的影响。在网页设计过程中,NET源代码。频道列表页面的文章汇总经常需要调用dedecms。如果文章摘要中的字数可以控制无效,页面布局可以非常灵活。
我们先说一下如何修改这个上限,这样才能显示出方法的要点[field:description function="cn_substr(@me, number of characters)"/]。
获取Dedecms系统中文章抽象相关的php文件。主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面,有一句话: $description = cn_substrR($description, $cfg_auot_description);这句话实现了[field:description function="cn_substr(@me, number of characters)"/] 这个Feature。由于此声明确实对页面布局有益,因此我们尽量不做任何更改。
在编辑页面上,有一句:$description = cn_substrR($description, 250);,这句话出现了熟悉的字符数250,是系统设置文章抽象字符数上限,如果是gbk编码,则显示125个字,如果是utf-8编码,则是81个字,显然我们要突破文章抽象的上限字符,必须取。可以,这里可以把250修改成别的值,比如500。这里不建议设置太高,一是列表页不需要显示太多内容(显示内容太多还不如间接使用body),另一个是避免数据库中的冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句。这个限制了后台可以检索到的字符数,把250改成500。 ,织梦仿站的意思是字符数和之前修改的不一样。(如果你确认你的每个文章都是手动添加的,手动完成就不需要修改这个文件了摘要获取。从摘要中获取minor还是为大量文章和采集准备的。)
首先登录后台,在系统-系统基本参数-其他选项中,可以将驱动摘要的长度改为500,与之前修改的字符数不同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为web提供了更广阔的空间页面布局。
说说德德cms文章或者调用文章列表页上的summary方法
1: [field:info /]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
第二种方法1、是间接调用文章的summary。在被调用的词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}在{/dede:arclist}中,设置摘要中的字符数(最多250)由系统设置;如果使用[field:description /],间接使用后台设置的抽象字符上限(也有后台上限为250个字符)。显然这些两种方法都非常被动和灵活。
方法四3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在文章抽象内容的上限不正常修改的情况下,这四种方法区别不大。
==========================
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me, 字符数)"/]
这四个方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到“if($dsize>250) $dsize = 250;”这句,把250改成500
2.登录后台,在系统-系统基本参数-其他选项中,将自动汇总的长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar(1000)
调用标签{dede:field.description function='cn_substr(@me,500)'/}。可以显示500个字符)
文章采集调用( 郑刚SEO培训:自动调用随机TAGFTP标签和自定义数量 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-03 00:08
郑刚SEO培训:自动调用随机TAGFTP标签和自定义数量
)
郑景诚:简单改造wordpress采集页面调用代码和指令增加收录
昨天花了一点时间对网站郑刚SEO培训做一个简单的页面调整。主要修改的是采集页面。
这篇网站是用WP做的,所以如果你也用WP建网站或者用采集的内容,可以采集这篇文章文章,这对亲们有效测试代码和操作方法。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
只要把上面的代码放在你想要的任何页面或位置,你就可以直接调用随机的TAG标签,下面的9表示调用9,这是每个页面调用的总和不同。这叫做随机标签。
原因:这个动作是为了让每个页面调用不同的随机标签来提高标签页收录的概率和进入率,因为WP的主要排名多是TAG标签页。
2、采集在内容页插入随机图片**
第一步:修改第1页:functions.php
/* 文章随机插图 */
function catch_that_image() {
global $post, $posts;
$first_img = '';
ob_start();
ob_end_clean();
$output = preg_match_all('/zt/".rand(1,3).".png";
}
return $first_img;
}
将上面的代码放在functions.php页面的底部,点击save。请记住将中间的网址替换为您的网址。
第2步:修改第2页:single.php
<p align="center">】,郑景承SEO培训提供在线实战SEO最新视频,优化工具,加微信611247免费领取SEO教程。 查看全部
文章采集调用(
郑刚SEO培训:自动调用随机TAGFTP标签和自定义数量
)
郑景诚:简单改造wordpress采集页面调用代码和指令增加收录

昨天花了一点时间对网站郑刚SEO培训做一个简单的页面调整。主要修改的是采集页面。
这篇网站是用WP做的,所以如果你也用WP建网站或者用采集的内容,可以采集这篇文章文章,这对亲们有效测试代码和操作方法。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
只要把上面的代码放在你想要的任何页面或位置,你就可以直接调用随机的TAG标签,下面的9表示调用9,这是每个页面调用的总和不同。这叫做随机标签。
原因:这个动作是为了让每个页面调用不同的随机标签来提高标签页收录的概率和进入率,因为WP的主要排名多是TAG标签页。
2、采集在内容页插入随机图片**
第一步:修改第1页:functions.php
/* 文章随机插图 */
function catch_that_image() {
global $post, $posts;
$first_img = '';
ob_start();
ob_end_clean();
$output = preg_match_all('/zt/".rand(1,3).".png";
}
return $first_img;
}
将上面的代码放在functions.php页面的底部,点击save。请记住将中间的网址替换为您的网址。
第2步:修改第2页:single.php
<p align="center">】,郑景承SEO培训提供在线实战SEO最新视频,优化工具,加微信611247免费领取SEO教程。
文章采集调用(是因为使用分布式追踪系统监控服务(1)_社会万象_光明网(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-12-28 20:07
上周的工作是开发一个运维需求——一个连接到公有云的分布式跟踪系统。在服务上线商业化之前,运维能力需要满足商业化需求,而在商业化运维需求中,使用分布式跟踪系统来监控服务是必须的,所以就有了这个需求。一个星期后,代码已经开发的差不多了,还缺少验证和上线工作。在此之前,我会先回顾一下。
之所以连接分布式跟踪系统如此重要,是因为使用分布式跟踪系统监控服务有以下好处
我们的服务主要使用Python和Go语言开发,您可以分别获取相应的SDK进行开发。整个开发对接流程大致如下:
联系接口人沟通嵌入解决方案,使用统一的SDK进行嵌入代码开发测试,整理服务——微服务——节点——日志路径信息,服务——微服务——业务——URL信息。公司分布式跟踪系统的日志采集借用了现有日志服务的能力。日志服务收到调用链日志后,会直接转发到分布式跟踪系统,因此需要将信息分别反馈给日志采集系统和分布式跟踪系统在服务节点上安装日志采集代理升级微服务,打开开关打印调用链日志(开始打印调用链日志,同时,节点上的日志采集代理将采集到的调用链日志信息上报给日志系统)生产环境验证连接效果:本地打印调用链日志正常,日志采集代理正常上报调用链日志;分布式跟踪系统可以检索到服务的跟踪信息,可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?并且可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?并且可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?
与性能调优类似,管理可以包括:HTTP请求服务/客户端、RPC请求服务/客户端、数据库访问、中间件调用和本地方法调用。
默认情况下应该跟踪哪些点?
我认为对于所有项目,我们应该默认收录
5 种点:
埋点法
听说Go还有办法直接替换Go-SDK来完成嵌入式函数注入...
两个重要的纸张标准
由 Uber 发起的 OpenTracing 现已成为云原生计算基金会的成员项目。OpenTracing 语义规范定义了数据模型和一些用于数据采集
的接口。它应该被视为分布式跟踪系统的接口标准。著名的 Jaeger 和 Zipkin 都实现了 OpenTracing API。
行业实践参考链接 查看全部
文章采集调用(是因为使用分布式追踪系统监控服务(1)_社会万象_光明网(组图))
上周的工作是开发一个运维需求——一个连接到公有云的分布式跟踪系统。在服务上线商业化之前,运维能力需要满足商业化需求,而在商业化运维需求中,使用分布式跟踪系统来监控服务是必须的,所以就有了这个需求。一个星期后,代码已经开发的差不多了,还缺少验证和上线工作。在此之前,我会先回顾一下。
之所以连接分布式跟踪系统如此重要,是因为使用分布式跟踪系统监控服务有以下好处
我们的服务主要使用Python和Go语言开发,您可以分别获取相应的SDK进行开发。整个开发对接流程大致如下:
联系接口人沟通嵌入解决方案,使用统一的SDK进行嵌入代码开发测试,整理服务——微服务——节点——日志路径信息,服务——微服务——业务——URL信息。公司分布式跟踪系统的日志采集借用了现有日志服务的能力。日志服务收到调用链日志后,会直接转发到分布式跟踪系统,因此需要将信息分别反馈给日志采集系统和分布式跟踪系统在服务节点上安装日志采集代理升级微服务,打开开关打印调用链日志(开始打印调用链日志,同时,节点上的日志采集代理将采集到的调用链日志信息上报给日志系统)生产环境验证连接效果:本地打印调用链日志正常,日志采集代理正常上报调用链日志;分布式跟踪系统可以检索到服务的跟踪信息,可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?并且可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?并且可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?
与性能调优类似,管理可以包括:HTTP请求服务/客户端、RPC请求服务/客户端、数据库访问、中间件调用和本地方法调用。
默认情况下应该跟踪哪些点?
我认为对于所有项目,我们应该默认收录
5 种点:
埋点法
听说Go还有办法直接替换Go-SDK来完成嵌入式函数注入...
两个重要的纸张标准
由 Uber 发起的 OpenTracing 现已成为云原生计算基金会的成员项目。OpenTracing 语义规范定义了数据模型和一些用于数据采集
的接口。它应该被视为分布式跟踪系统的接口标准。著名的 Jaeger 和 Zipkin 都实现了 OpenTracing API。
行业实践参考链接
文章采集调用(豆瓣网影评:电影中如何获取真正请求的地址?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 483 次浏览 • 2021-12-27 16:17
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
请求数据的时候,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集
的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
如何上网?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,得到响应,页面回调方便下一个请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、求图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:
1) 设置时间延迟。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 控制台会显示下载成功信息。
3、保存 csv 文件。
4、电影图片显示。
[七、总结]
1、 不建议抓太多数据,可能会造成服务器负载,简单试一下。
2、 这篇文章就Python爬豆瓣的难点和关键点,以及如何防止回爬做了相对的解决。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要霸道,不要霸道,要了解的更深。
5、需要本文源码的可以在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发并分享给更多人****
IT共享家庭 查看全部
文章采集调用(豆瓣网影评:电影中如何获取真正请求的地址?)
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
请求数据的时候,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集
的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
如何上网?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,得到响应,页面回调方便下一个请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、求图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:
1) 设置时间延迟。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 控制台会显示下载成功信息。
3、保存 csv 文件。
4、电影图片显示。
[七、总结]
1、 不建议抓太多数据,可能会造成服务器负载,简单试一下。
2、 这篇文章就Python爬豆瓣的难点和关键点,以及如何防止回爬做了相对的解决。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要霸道,不要霸道,要了解的更深。
5、需要本文源码的可以在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发并分享给更多人****
IT共享家庭
文章采集调用(前台会员中心调用显示wordpress会员投搞发表的文章数量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-26 06:15
想打电话给前台的会员中心,显示WordPress会员发表的文章数,习惯性的搜索谷歌看看有没有相关的教程功能代码。如果没有功能代码,就找插件。如果没有插件,那就自己考虑代码调用。, 有幸找到zwwooooo发布的WordPress:获取某作者文章数的教程,刚好满足需要,无需自己找插件或研究,谢谢作者!
操作方法:通过WP_Query()函数实现,循环获取数量。
在当前主题的functions.php文件中添加如下函数代码:
1
2
3
4
5
6
7
8
9
10
/* number of author's posts by zwwooooo */
function num_of_author_posts($authorID=''){ //根据作者ID获取该作者的文章数量
if ($authorID) {
$author_query = new WP_Query( 'posts_per_page=-1&author='.$authorID );
$i=0;
while ($author_query->have_posts()) : $author_query->the_post(); ++$i; endwhile; wp_reset_postdata();
return $i;
}
return false;
}
在要显示作者文章数量的地方添加调用代码:
1
注意:$authorID的获取方式有很多种,每个页面的获取方式都不一样。自行研究。一般这些函数是get_the_author_meta(), get_userdata()... 去WordPress官方查一下(直接谷歌搜索函数名即可)
相关功能代码来自zwwooooo博客
除特别注明外,文章均由博客网整理发布,欢迎转载。 查看全部
文章采集调用(前台会员中心调用显示wordpress会员投搞发表的文章数量)
想打电话给前台的会员中心,显示WordPress会员发表的文章数,习惯性的搜索谷歌看看有没有相关的教程功能代码。如果没有功能代码,就找插件。如果没有插件,那就自己考虑代码调用。, 有幸找到zwwooooo发布的WordPress:获取某作者文章数的教程,刚好满足需要,无需自己找插件或研究,谢谢作者!
操作方法:通过WP_Query()函数实现,循环获取数量。
在当前主题的functions.php文件中添加如下函数代码:
1
2
3
4
5
6
7
8
9
10
/* number of author's posts by zwwooooo */
function num_of_author_posts($authorID=''){ //根据作者ID获取该作者的文章数量
if ($authorID) {
$author_query = new WP_Query( 'posts_per_page=-1&author='.$authorID );
$i=0;
while ($author_query->have_posts()) : $author_query->the_post(); ++$i; endwhile; wp_reset_postdata();
return $i;
}
return false;
}
在要显示作者文章数量的地方添加调用代码:
1
注意:$authorID的获取方式有很多种,每个页面的获取方式都不一样。自行研究。一般这些函数是get_the_author_meta(), get_userdata()... 去WordPress官方查一下(直接谷歌搜索函数名即可)
相关功能代码来自zwwooooo博客
除特别注明外,文章均由博客网整理发布,欢迎转载。
文章采集调用(微服务下的几个监控维度(下)化服务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-12-26 06:01
前言
微服务是一种架构风格。一个大型复杂的软件应用程序通常由多个微服务组成。系统中的每一个微服务都可以独立部署,每一个微服务都是松耦合的。每个微服务只专注于完成一项任务,并且很好地完成该任务。
微服务之前的很多单体应用,监控复杂度相对较低,场景单一。在微服务下,因为业务逻辑分散在很多流程中(很多大的业务,一个业务流程涉及几十个服务),一旦一个业务出现问题,追根溯源就像大海捞针。这时候就需要一个完整的监控系统。
一个完整的监控系统建设周期长,随着业务场景的变化,也需要迭代优化。本文仅从几个监控维度和雾化场景谈如何建立统一的监控数据采集和展示系统,希望能启发大家继续思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的改变。我们已将监控从机器角度转变为以服务为中心的角度。从微服务的角度,可以从数据和资源两个维度来查看监控。用代码维度分层,如下图:
数据维度
目前的WEB服务是主流。每个WEB服务都有一个入口,无论是APP还是WEB页面,入口负责与用户进行交互,并将用户的信息发送到后端。后端一般可以访问LB或者Gateway,负责负载。将数据平衡转发给特定的应用程序进行处理,最后由应用程序处理后写入数据库。
资源维度
现在很多服务都部署在云中,涉及到虚拟化技术。虚拟主机运行在物理服务器上,虚拟主机通过虚拟网络相互连接。资源层面的监控是必不可少的环节。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器上的CPU、内存、磁盘IO等数据,以及虚拟主机之间的连接情况。虚拟网络的带宽负载等。
代码维度
APM,即代码端的应用性能分析、监控和采集
,随着微服务的兴起而出现。微服务场景下,一个业务流程跨越几十个服务场景,只有传统的监控数据,很难定位问题的根源。
我们可以为代码的技术栈开发一个特定的集合框架。在可接受的性能损失范围内,我们可以采集
函数之间的调用关系,服务之间的调用拓扑,并测量函数或服务的响应时间。有针对性地优化性能或提前预测故障。
关键监测指标情景描述
微服务监控最大的特点可以用一句话概括:服务这么多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关且错综复杂的服务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了每个维度下各个级别可能产生的告警,总结了URL监控、主机监控、产品监控8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以使用 MOCK 调用 API 获取响应时间、响应状态码等指标来展示监控业务的整体健康状况。
主机监控:通过安装代理,采集
主机的基本监控信息,如CPU、内存、IO等。同时,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据采集开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载相应组件的监控采集程序。
自定义监控:服务实例采集
业务相关数据,定期调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户根据资源上报自定义数据。每个资源具有相同的监控项,每个资源的监控项相互独立。
APM:根据各个语言栈的不同,实现服务间函数调用关系和调用拓扑的展示。根据每种语言的不同,有的需要侵入代码,以SDK嵌入的形式采集数据,有的与代码解耦,通过元编程重新加载一些方法来实现数据采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘Reset事件等,提供统一的存储、分析和展示。
通过以上原子场景的数据采集,我们可以通过UI统一展示监控数据,并基于上述三个维度设计图形化页面,以用户体验为核心。图形化一般以时间序列为横轴,显示随时间变化的指标。对于一些统计指标,分析比较结果也可以通过饼图、直方图等方式展示。
本文主要介绍监控系统中数据的采集和展示。至于数据存储和报警过程,感兴趣的同学可以继续关注后续监控相关文章。
关于作者
董磊:UCloud技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。 查看全部
文章采集调用(微服务下的几个监控维度(下)化服务)
前言
微服务是一种架构风格。一个大型复杂的软件应用程序通常由多个微服务组成。系统中的每一个微服务都可以独立部署,每一个微服务都是松耦合的。每个微服务只专注于完成一项任务,并且很好地完成该任务。
微服务之前的很多单体应用,监控复杂度相对较低,场景单一。在微服务下,因为业务逻辑分散在很多流程中(很多大的业务,一个业务流程涉及几十个服务),一旦一个业务出现问题,追根溯源就像大海捞针。这时候就需要一个完整的监控系统。
一个完整的监控系统建设周期长,随着业务场景的变化,也需要迭代优化。本文仅从几个监控维度和雾化场景谈如何建立统一的监控数据采集和展示系统,希望能启发大家继续思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的改变。我们已将监控从机器角度转变为以服务为中心的角度。从微服务的角度,可以从数据和资源两个维度来查看监控。用代码维度分层,如下图:
数据维度
目前的WEB服务是主流。每个WEB服务都有一个入口,无论是APP还是WEB页面,入口负责与用户进行交互,并将用户的信息发送到后端。后端一般可以访问LB或者Gateway,负责负载。将数据平衡转发给特定的应用程序进行处理,最后由应用程序处理后写入数据库。
资源维度
现在很多服务都部署在云中,涉及到虚拟化技术。虚拟主机运行在物理服务器上,虚拟主机通过虚拟网络相互连接。资源层面的监控是必不可少的环节。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器上的CPU、内存、磁盘IO等数据,以及虚拟主机之间的连接情况。虚拟网络的带宽负载等。
代码维度
APM,即代码端的应用性能分析、监控和采集
,随着微服务的兴起而出现。微服务场景下,一个业务流程跨越几十个服务场景,只有传统的监控数据,很难定位问题的根源。
我们可以为代码的技术栈开发一个特定的集合框架。在可接受的性能损失范围内,我们可以采集
函数之间的调用关系,服务之间的调用拓扑,并测量函数或服务的响应时间。有针对性地优化性能或提前预测故障。
关键监测指标情景描述
微服务监控最大的特点可以用一句话概括:服务这么多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关且错综复杂的服务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了每个维度下各个级别可能产生的告警,总结了URL监控、主机监控、产品监控8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以使用 MOCK 调用 API 获取响应时间、响应状态码等指标来展示监控业务的整体健康状况。
主机监控:通过安装代理,采集
主机的基本监控信息,如CPU、内存、IO等。同时,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据采集开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载相应组件的监控采集程序。
自定义监控:服务实例采集
业务相关数据,定期调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户根据资源上报自定义数据。每个资源具有相同的监控项,每个资源的监控项相互独立。
APM:根据各个语言栈的不同,实现服务间函数调用关系和调用拓扑的展示。根据每种语言的不同,有的需要侵入代码,以SDK嵌入的形式采集数据,有的与代码解耦,通过元编程重新加载一些方法来实现数据采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘Reset事件等,提供统一的存储、分析和展示。
通过以上原子场景的数据采集,我们可以通过UI统一展示监控数据,并基于上述三个维度设计图形化页面,以用户体验为核心。图形化一般以时间序列为横轴,显示随时间变化的指标。对于一些统计指标,分析比较结果也可以通过饼图、直方图等方式展示。
本文主要介绍监控系统中数据的采集和展示。至于数据存储和报警过程,感兴趣的同学可以继续关注后续监控相关文章。
关于作者
董磊:UCloud技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
文章采集调用(给你八分钟搞定dedeCMS(织梦内容管理系统)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-23 02:13
给你八分钟搞定dedecms(织梦内容管理系统)
,并且在易用性方面,有了长足的发展。德德cms免费版的主要目标用户锁定在个人站长,功能更侧重于个人网站或中小型门户网站的建设。当然,也有企业用户和学校使用这个系统。当我第一次看到这个界面时,我很陌生。只知道界面有很多功能,但不知道具体是做什么的……我用dedecms做官网,所以没用很多功能。. 第4分钟_这里的核心主要是生成网站的导航,可以在导航中添加文章(这里特别强调,原因是喜欢这里的想法…… 把它放在导航里所有的内容都可以用文章的形式表达)这是工作的第一步,至少我是这么认为的..第5分钟_系统在系统栏,什么我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 至少我是这么认为的.. 第5分钟_系统在系统栏,我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在系统中灵活调用这些变量后续的开发过程。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 至少我是这么认为的.. 第5分钟_系统在系统栏,我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在系统中灵活调用这些变量后续的开发过程。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面
1.3K 查看全部
文章采集调用(给你八分钟搞定dedeCMS(织梦内容管理系统)(图))
给你八分钟搞定dedecms(织梦内容管理系统)
,并且在易用性方面,有了长足的发展。德德cms免费版的主要目标用户锁定在个人站长,功能更侧重于个人网站或中小型门户网站的建设。当然,也有企业用户和学校使用这个系统。当我第一次看到这个界面时,我很陌生。只知道界面有很多功能,但不知道具体是做什么的……我用dedecms做官网,所以没用很多功能。. 第4分钟_这里的核心主要是生成网站的导航,可以在导航中添加文章(这里特别强调,原因是喜欢这里的想法…… 把它放在导航里所有的内容都可以用文章的形式表达)这是工作的第一步,至少我是这么认为的..第5分钟_系统在系统栏,什么我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 至少我是这么认为的.. 第5分钟_系统在系统栏,我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在系统中灵活调用这些变量后续的开发过程。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 至少我是这么认为的.. 第5分钟_系统在系统栏,我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在系统中灵活调用这些变量后续的开发过程。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面
1.3K
文章采集调用(免费开源可商用的PHP万能建站程序-DiYunCMS(帝云CMS))
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-12-20 15:03
免费、开源、可商用的PHP通用建站程序-帝云cms(帝云cms)
对于个性化的需求,需要在首页或者其他模板页面的指定分类下调用文章,那么我们就可以实现:
网上很容易找到这个教程,但是有个问题。调用的文章没有按最新排序,或者发布时间越早排在前面,肯定是不合理的。已修复一流的资源网络。这个问题。
1、首先打开index.php文件,找到如下代码:
$smarty->assign('new_articles', index_get_new_articles()); // 最新文章
在此行下方添加以下代码:
$smarty->assign('class_articles_4', index_get_class_articles(4,6)); // 分类调用文章
4 是 文章 类别 ID,6 是显示的项目数。
如果调用的category很多,只需要复制粘贴上一行即可,但是文章category id和调用次数要根据自己的需要修改。
打开ecshop根目录下的includes/init.php文件,在最下方添加如下代码,并添加到?>。
2、还在这个文件中吗?> 在这之前添加以下函数:
/**
* 获得指定栏目最新的文章列表。
*
* @access private
* @return array
*/
function index_get_class_articles($cat_aid, $cat_num)
{
$sql = "SELECT article_id, title,open_type,cat_id,file_url,description FROM " .$GLOBALS['ecs']->table('article'). " WHERE cat_id = ".$cat_aid." and is_open = 1 ORDER BY add_time DESC LIMIT " . $cat_num;
$res = $GLOBALS['db']->getAll($sql);
$arr = array();
foreach ($res AS $idx => $row)
{
$arr[$idx]['id'] = $row['article_id'];
$arr[$idx]['title'] = $row['title'];
$arr[$idx]['file_url'] = $row['file_url'];
$arr[$idx]['description'] = $row['description'];
$arr[$idx]['short_title'] = $GLOBALS['_CFG']['article_title_length'] > 0 ?
sub_str($row['title'], $GLOBALS['_CFG']['article_title_length']) : $row['title'];
$arr[$idx]['cat_name'] = $row['cat_name'];
$arr[$idx]['add_time'] = local_date($GLOBALS['_CFG']['date_format'], $row['add_time']);
$arr[$idx]['url'] = $row['open_type'] != 1 ?
build_uri('article', array('aid' => $row['article_id']), $row['title']) : trim($row['file_url']);
$arr[$idx]['cat_url'] = build_uri('article_cat', array('acid' => $row['cat_id']));
}
return $arr;
}
<p>3、在要调用index.dwt模板的地方添加如下代码(注意:调整上面设置中的文章列表,类别ID为4): 查看全部
文章采集调用(免费开源可商用的PHP万能建站程序-DiYunCMS(帝云CMS))
免费、开源、可商用的PHP通用建站程序-帝云cms(帝云cms)
对于个性化的需求,需要在首页或者其他模板页面的指定分类下调用文章,那么我们就可以实现:
网上很容易找到这个教程,但是有个问题。调用的文章没有按最新排序,或者发布时间越早排在前面,肯定是不合理的。已修复一流的资源网络。这个问题。
1、首先打开index.php文件,找到如下代码:
$smarty->assign('new_articles', index_get_new_articles()); // 最新文章
在此行下方添加以下代码:
$smarty->assign('class_articles_4', index_get_class_articles(4,6)); // 分类调用文章
4 是 文章 类别 ID,6 是显示的项目数。
如果调用的category很多,只需要复制粘贴上一行即可,但是文章category id和调用次数要根据自己的需要修改。
打开ecshop根目录下的includes/init.php文件,在最下方添加如下代码,并添加到?>。
2、还在这个文件中吗?> 在这之前添加以下函数:
/**
* 获得指定栏目最新的文章列表。
*
* @access private
* @return array
*/
function index_get_class_articles($cat_aid, $cat_num)
{
$sql = "SELECT article_id, title,open_type,cat_id,file_url,description FROM " .$GLOBALS['ecs']->table('article'). " WHERE cat_id = ".$cat_aid." and is_open = 1 ORDER BY add_time DESC LIMIT " . $cat_num;
$res = $GLOBALS['db']->getAll($sql);
$arr = array();
foreach ($res AS $idx => $row)
{
$arr[$idx]['id'] = $row['article_id'];
$arr[$idx]['title'] = $row['title'];
$arr[$idx]['file_url'] = $row['file_url'];
$arr[$idx]['description'] = $row['description'];
$arr[$idx]['short_title'] = $GLOBALS['_CFG']['article_title_length'] > 0 ?
sub_str($row['title'], $GLOBALS['_CFG']['article_title_length']) : $row['title'];
$arr[$idx]['cat_name'] = $row['cat_name'];
$arr[$idx]['add_time'] = local_date($GLOBALS['_CFG']['date_format'], $row['add_time']);
$arr[$idx]['url'] = $row['open_type'] != 1 ?
build_uri('article', array('aid' => $row['article_id']), $row['title']) : trim($row['file_url']);
$arr[$idx]['cat_url'] = build_uri('article_cat', array('acid' => $row['cat_id']));
}
return $arr;
}
<p>3、在要调用index.dwt模板的地方添加如下代码(注意:调整上面设置中的文章列表,类别ID为4):
文章采集调用()
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-12-19 11:12
在Dedecms系统中,文章摘要(可以通过infolen或description相关标签调用)设置为最多250个字符。设置上限的主要目的是减少数据库的冗余,保证网站良好的性能。所以,如果不给profile的内容设置上限,显然是不合理的。但是,如果您可以自由控制此上限,则会对网页内容的布局产生积极的影响。在网页设计过程中,经常需要对文章摘要进行列表页面调用。如果文章摘要中的字数能够得到有效控制,那么页面布局就可以变得非常灵活。
一、使用infolen限制调用文章描述词的数量,如下标签所示:
{dede:arclist row="1" infolen='170'}
[字段:信息/]...
{/dede:arclist}
上面的infolen='170'表示调用170字节的文章描述
二、使用 [field:description function='cn_substr(@me,250)'/] 代替 [field:info/] 标签,其中 250 是字节限制,您可以将其用作多字随你改,注意这里的250是一个字节,一个字等于2个字节,也就是这里调用了125个字。
在Dedecms中,调用列表页文章汇总的主要方法有:
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me,字符数)"/]
1、的第二种方法是直接调用文章的summary。在调用的单词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}{/dede :arclist},设置调用摘要中的字符数(向上到系统设置的250));如果使用[field:description /],则直接使用后台设置的摘要字符上限。很明显,这两种方法都非常被动,灵活性太差。
第四种方法3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在不修改文章抽象内容字符上限的情况下,这四种方法区别不大。不过下面我们来说说如何修改这个上限来体现方法的重要性[field:description function="cn_substr(@me,number of characters)"/]。
在dedecms中,与文章的摘要相关的php文件主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$description = cn_substrR($description,$cfg_autot_description);
这句话实现了
[field:description function="cn_substr(@me,字符数)"/]
此功能。因为这个语句确实有利于页面布局,所以我们在实验中没有修改。
在编辑页面上,有一句话:
$description = cn_substrR($description,250);
这句话出现了熟悉的字符数“250”,这是系统设置的文章抽象字符数的上限。如果是gbk编码,显示125个字。如果是utf-8编码,则是81个字符。很明显,我们要突破文章抽象字符的上限,必须要拿下。是的,在这里您可以将“250”修改为其他值,例如“500”。这里不建议设置太高。一是不需要在列表页面显示太多内容。最好直接用body来显示太多的内容。一是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面找到“if($dsize>250) $dsize = 250;”这句话,限制了后台可以自动获取的字符数,这里修改“250”到“500”是的,也就是和之前修改的字符数一样。如果你确认你的每个文章都是手动添加的,如果手动完成就不需要修改这个文件了摘要采集,自动摘要采集主要是为大量文章和采集准备的。
最后登录后台,在系统-系统基本参数-其他选项中,可以将自动汇总长度改为500,与之前修改的字符数相同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid='' row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为网页布局提供了更广阔的空间。
转载于: 查看全部
文章采集调用()
在Dedecms系统中,文章摘要(可以通过infolen或description相关标签调用)设置为最多250个字符。设置上限的主要目的是减少数据库的冗余,保证网站良好的性能。所以,如果不给profile的内容设置上限,显然是不合理的。但是,如果您可以自由控制此上限,则会对网页内容的布局产生积极的影响。在网页设计过程中,经常需要对文章摘要进行列表页面调用。如果文章摘要中的字数能够得到有效控制,那么页面布局就可以变得非常灵活。
一、使用infolen限制调用文章描述词的数量,如下标签所示:
{dede:arclist row="1" infolen='170'}
[字段:信息/]...
{/dede:arclist}
上面的infolen='170'表示调用170字节的文章描述
二、使用 [field:description function='cn_substr(@me,250)'/] 代替 [field:info/] 标签,其中 250 是字节限制,您可以将其用作多字随你改,注意这里的250是一个字节,一个字等于2个字节,也就是这里调用了125个字。
在Dedecms中,调用列表页文章汇总的主要方法有:
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me,字符数)"/]
1、的第二种方法是直接调用文章的summary。在调用的单词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}{/dede :arclist},设置调用摘要中的字符数(向上到系统设置的250));如果使用[field:description /],则直接使用后台设置的摘要字符上限。很明显,这两种方法都非常被动,灵活性太差。
第四种方法3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在不修改文章抽象内容字符上限的情况下,这四种方法区别不大。不过下面我们来说说如何修改这个上限来体现方法的重要性[field:description function="cn_substr(@me,number of characters)"/]。
在dedecms中,与文章的摘要相关的php文件主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$description = cn_substrR($description,$cfg_autot_description);
这句话实现了
[field:description function="cn_substr(@me,字符数)"/]
此功能。因为这个语句确实有利于页面布局,所以我们在实验中没有修改。
在编辑页面上,有一句话:
$description = cn_substrR($description,250);
这句话出现了熟悉的字符数“250”,这是系统设置的文章抽象字符数的上限。如果是gbk编码,显示125个字。如果是utf-8编码,则是81个字符。很明显,我们要突破文章抽象字符的上限,必须要拿下。是的,在这里您可以将“250”修改为其他值,例如“500”。这里不建议设置太高。一是不需要在列表页面显示太多内容。最好直接用body来显示太多的内容。一是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面找到“if($dsize>250) $dsize = 250;”这句话,限制了后台可以自动获取的字符数,这里修改“250”到“500”是的,也就是和之前修改的字符数一样。如果你确认你的每个文章都是手动添加的,如果手动完成就不需要修改这个文件了摘要采集,自动摘要采集主要是为大量文章和采集准备的。
最后登录后台,在系统-系统基本参数-其他选项中,可以将自动汇总长度改为500,与之前修改的字符数相同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid='' row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为网页布局提供了更广阔的空间。
转载于:
文章采集调用(美团外卖商家的爬虫分析过程,最终结果还没有出来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-16 21:04
嗯,不是失败,只是记录了爬虫分析的过程采集,最终结果还没出来。
简单描述一下美团外卖商家的爬虫分析过程,结果不理想,可以通过调用JS实现。
一开始,我直接选择了美团的网页版,选择一个地方,进入外卖商家列表。
这时候直接开始写JAVA Jsoup代码,把所有的请求头和请求参数都放到请求的代码中,结果只有一个返回:
{"数据":{"customer_ip":"61.135.15.2"},"code":200100,"msg":""}
也就是说,没有得到任何数据,此时我也不知道接下来要做什么。于是在网上搜索了美团外卖爬虫。这里有一点,如果你是美团商户采集,就是那种可以遍历全网的。可以获得该商家数据。但是如果是外卖,就得单独做采集。
当然,在网页采集的不利情况下,我也查了美团APP的外卖链接:参数太多了,启动不了,然后从网页文章开始搜索@>
终于找到一篇文章@>:这篇文章提供了一个思路。你可以先看看这个文章@>。
首先分析美团H5页面上的数据
结合CSDN文章文章@>,也就是说只要知道token的生成方法,然后通过参数调用这个方法来获取token,当然这篇文章文章@>也有一点提示,但仅此而已,刚刚介绍了如何直接调用JS代码。你仍然需要自己做才能获得足够的食物和衣服。
接下来我们应该分析一下token是如何产生的?我也在网上搜索了很多文章@>,也有一些提示。这是一个很长的文章@>。不注意的话真的很糟糕。
这时候直接进入H5页面,先找到js文件。我们不能直接使用文章中的js,因为有可能js已经升级了,所以我们找最新版本的js文件。
这时候我已经验证了破解网上文章@>那篇文章所说的内容,接下来我们在原h5页面上搜索Rohr_Opt这个词。
既然不一样了,就得看看美团外卖页面列表是怎么调用这个reload方法的,继续搜索Rohr_Opt。因为是全局的,所以调用的时候会直接用这个名字来调用。注意此时的搜索不是在查看源码中搜索,而是在调试页面的源码中搜索。毕竟,它现在处于运行时状态。恭喜:
我们把红框中的代码复制一下,分析一下代码结构,看看能出现什么样的结果。
现在我们已经确定了 t+p,用 test.html 测试一下:
到此为止,我们继续观察这个reload是怎么实现的,里面有什么,为什么同样的参数刷新不同。打开min.js文件,直接搜索reload:
这个时间戳就这样一直存在,搜索没有找到用处,作为一个对象的内部字段,它应该已经被使用了。
分析完这个,我们来测试一下JAVA调用JS的技术。但这部分事情还没有弄清楚!如果有人修复它,请告诉我。复制一个简单的调用代码:
参考链接 查看全部
文章采集调用(美团外卖商家的爬虫分析过程,最终结果还没有出来)
嗯,不是失败,只是记录了爬虫分析的过程采集,最终结果还没出来。
简单描述一下美团外卖商家的爬虫分析过程,结果不理想,可以通过调用JS实现。
一开始,我直接选择了美团的网页版,选择一个地方,进入外卖商家列表。
这时候直接开始写JAVA Jsoup代码,把所有的请求头和请求参数都放到请求的代码中,结果只有一个返回:
{"数据":{"customer_ip":"61.135.15.2"},"code":200100,"msg":""}
也就是说,没有得到任何数据,此时我也不知道接下来要做什么。于是在网上搜索了美团外卖爬虫。这里有一点,如果你是美团商户采集,就是那种可以遍历全网的。可以获得该商家数据。但是如果是外卖,就得单独做采集。
当然,在网页采集的不利情况下,我也查了美团APP的外卖链接:参数太多了,启动不了,然后从网页文章开始搜索@>
终于找到一篇文章@>:这篇文章提供了一个思路。你可以先看看这个文章@>。
首先分析美团H5页面上的数据
结合CSDN文章文章@>,也就是说只要知道token的生成方法,然后通过参数调用这个方法来获取token,当然这篇文章文章@>也有一点提示,但仅此而已,刚刚介绍了如何直接调用JS代码。你仍然需要自己做才能获得足够的食物和衣服。
接下来我们应该分析一下token是如何产生的?我也在网上搜索了很多文章@>,也有一些提示。这是一个很长的文章@>。不注意的话真的很糟糕。
这时候直接进入H5页面,先找到js文件。我们不能直接使用文章中的js,因为有可能js已经升级了,所以我们找最新版本的js文件。
这时候我已经验证了破解网上文章@>那篇文章所说的内容,接下来我们在原h5页面上搜索Rohr_Opt这个词。
既然不一样了,就得看看美团外卖页面列表是怎么调用这个reload方法的,继续搜索Rohr_Opt。因为是全局的,所以调用的时候会直接用这个名字来调用。注意此时的搜索不是在查看源码中搜索,而是在调试页面的源码中搜索。毕竟,它现在处于运行时状态。恭喜:
我们把红框中的代码复制一下,分析一下代码结构,看看能出现什么样的结果。
现在我们已经确定了 t+p,用 test.html 测试一下:
到此为止,我们继续观察这个reload是怎么实现的,里面有什么,为什么同样的参数刷新不同。打开min.js文件,直接搜索reload:
这个时间戳就这样一直存在,搜索没有找到用处,作为一个对象的内部字段,它应该已经被使用了。
分析完这个,我们来测试一下JAVA调用JS的技术。但这部分事情还没有弄清楚!如果有人修复它,请告诉我。复制一个简单的调用代码:
参考链接
文章采集调用(文章采集调用知乎官方api接口,就会发现有很多countlyuseroach)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-01-08 23:01
文章采集调用知乎官方api接口,就会发现有很多countlyuseroach第一个不能匹配的区块第二个匹配不了,第三个已经匹配上了,第四个依然匹配不上但是不能说什么,打开知乎的app,就是把手机拿到边上就能上知乎在上面的搜索框里输入这个id就可以找到它前些天也是同样的问题,也是用这个,结果就是找不到想要的东西。
我试过了两个方法1.可以把浏览页面重定向到知乎客户端里面,在里面找到感兴趣的区块,点击检索(也可以点击右上角)2.可以在googleappstore里找下载一个知乎app,然后直接一键抓取,只要该网站有的,
楼主试试,一定对你有帮助。
感谢楼上,
用来偷菜吧
建议采集一下@笑道人老师关于对话页面的每个选择区块。我们的服务器就被他恶心到了。
先打开你想抓取对话的网站,找到想抓取的区块在googleappstore里搜索下载一个知乎app,然后直接一键抓取你想要的内容!希望对楼主有帮助!
据我所知,
呵呵,
我用的chrome扩展了"可视化查询"抓取
没找到怎么抓,手动抓却很麻烦,这样试试啊。
采集页面就可以抓取了
依然是这个问题。我手上也没有任何知乎采集器。没试过, 查看全部
文章采集调用(文章采集调用知乎官方api接口,就会发现有很多countlyuseroach)
文章采集调用知乎官方api接口,就会发现有很多countlyuseroach第一个不能匹配的区块第二个匹配不了,第三个已经匹配上了,第四个依然匹配不上但是不能说什么,打开知乎的app,就是把手机拿到边上就能上知乎在上面的搜索框里输入这个id就可以找到它前些天也是同样的问题,也是用这个,结果就是找不到想要的东西。
我试过了两个方法1.可以把浏览页面重定向到知乎客户端里面,在里面找到感兴趣的区块,点击检索(也可以点击右上角)2.可以在googleappstore里找下载一个知乎app,然后直接一键抓取,只要该网站有的,
楼主试试,一定对你有帮助。
感谢楼上,
用来偷菜吧
建议采集一下@笑道人老师关于对话页面的每个选择区块。我们的服务器就被他恶心到了。
先打开你想抓取对话的网站,找到想抓取的区块在googleappstore里搜索下载一个知乎app,然后直接一键抓取你想要的内容!希望对楼主有帮助!
据我所知,
呵呵,
我用的chrome扩展了"可视化查询"抓取
没找到怎么抓,手动抓却很麻烦,这样试试啊。
采集页面就可以抓取了
依然是这个问题。我手上也没有任何知乎采集器。没试过,
文章采集调用(如何优采云采集器如何利用Xpath来采集内容页面可视化提取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-01-08 14:17
在上一篇文章《优采云采集 List Page and Label Xpath Visual Extraction Function》中,我们讲解了优采云采集器如何使用Xpath来采集列出页面。今天,我们将讨论优采云采集器如何使用Xpath 来采集内容页面!
新建标签,提前选择数据方式,选择“视觉提取”选项,如下图:
同时单击“通过 XPath 浏览器获取”按钮。
和上面得到的地址一样,输入地址,访问地址为采集,如下图:
然后单击图标开始选择。这里我们以标题获取为例。
选择浅蓝色框中的标题,轻轻点击鼠标,测试一下是否正确。如果正确单击确定按钮。这不像 采集 地址,需要执行两次。如果测试弹出:
这表示无法通过这种方式获取该页面。
如下图点击确定:
此处自动填写获取此标题的表达式。让我们测试一下结果:
结果是正确的。其他信息可以通过这种方式获取。
有一个节点属性如下图:
这也是一个专业术语。你可以查资料了解一下。一般可以通过选择InnerHtml和InnerText来获取文本信息。如果您需要了解更多信息,请自行查找信息。
选择“Href”获取链接地址,选择“OuterHtml”获取文本和收录的html代码。不明白的可以实际测试一下结果。 查看全部
文章采集调用(如何优采云采集器如何利用Xpath来采集内容页面可视化提取)
在上一篇文章《优采云采集 List Page and Label Xpath Visual Extraction Function》中,我们讲解了优采云采集器如何使用Xpath来采集列出页面。今天,我们将讨论优采云采集器如何使用Xpath 来采集内容页面!
新建标签,提前选择数据方式,选择“视觉提取”选项,如下图:
同时单击“通过 XPath 浏览器获取”按钮。
和上面得到的地址一样,输入地址,访问地址为采集,如下图:
然后单击图标开始选择。这里我们以标题获取为例。
选择浅蓝色框中的标题,轻轻点击鼠标,测试一下是否正确。如果正确单击确定按钮。这不像 采集 地址,需要执行两次。如果测试弹出:
这表示无法通过这种方式获取该页面。
如下图点击确定:
此处自动填写获取此标题的表达式。让我们测试一下结果:
结果是正确的。其他信息可以通过这种方式获取。
有一个节点属性如下图:
这也是一个专业术语。你可以查资料了解一下。一般可以通过选择InnerHtml和InnerText来获取文本信息。如果您需要了解更多信息,请自行查找信息。
选择“Href”获取链接地址,选择“OuterHtml”获取文本和收录的html代码。不明白的可以实际测试一下结果。
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-01-08 14:15
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常在多个平台上推送文章,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但是复制图片会害死我,微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信已对图片实施防盗链措施。
这时候尝试搜索了一个这样的插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是我开发了一个叫Bee采集的插件,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,并且还有各种多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可
使用起来也很简单,只要粘贴链接,就可以同时导入多个文章,即批量导入功能,以及自动同步采集公众号的功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到
希望这篇笔记可以帮到你 查看全部
文章采集调用(小蜜蜂公众号文章助手上线,复制文字还没有什么?)
现在小蜜蜂公众号文章助手上线,可以采集任意公众号历史文章,支持点赞数、阅读数、评论数采集,支持导出PDF ,Excel,HTML,TXT格式导出,支持关键词搜索,可以去官网查看
许多微信公众号作者(个人、组织、公司)不仅在微信公众平台上写作,而且通常在多个平台上推送文章,例如今日头条、知乎专栏、短书等,甚至有自己的网站(官网),但是在多个平台上发布文章是一项非常耗时的工作。
大多数 网站 构建都基于 WordPress,因为该平台非常简单实用,并且有大量插件。因此,我也不例外。当我选择建站系统时,首先选择的是 WordPress。不过我经常写文章发现一个问题,就是每次在公众号写文章,我把文章@文章手动复制到WordPress上,复制文字没什么,但是复制图片会害死我,微信公众号文章的图片不能直接复制到WordPress,会显示为“无法显示。这张图片”,因为微信已对图片实施防盗链措施。
这时候尝试搜索了一个这样的插件,可以通过粘贴公众号文章的链接直接将内容导入WordPress,并将图片下载到本地(媒体库),于是我开发了一个叫Bee采集的插件,除了微信公众号文章,还可以导入今日头条、短书、知乎栏目的文章,并且还有各种多种可选功能,除此之外,还可以采集other网站,只要配置好相应的规则即可
使用起来也很简单,只要粘贴链接,就可以同时导入多个文章,即批量导入功能,以及自动同步采集公众号的功能文章
下载的话直接在安装插件页面搜索蜜蜂采集就可以看到
希望这篇笔记可以帮到你
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-08 02:06
)
最近的一个项目需要实现摄像头图像采集,经过一系列的折腾,终于实现了这个功能,现在整理一下。
就java技术而言,为了实现相机的二次开发,采集相机图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然,JMF 处理不了。现在想写个applet程序,但是那个东西需要客户端有jre环境,不适合我。您不能指望用户在访问您的 网站 jre 进行安装然后再次访问时下载一个大文件吗?
既然JMF不适用,那么我们在java项目中如何控制摄像头抓拍呢?在windows平台下,我们可以使用视频采集卡等二次开发包来访问视频数据,但是目前的摄像头都是usb的,甚至笔记本电脑屏幕都有摄像头,这种情况下的解决方案使用采集卡二次开发包不适用。您只能编写自己的程序来做类似于“相机相机软件”的事情。经过一系列的分析,终于实现了在web程序中调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集Camera data的项目中实现,例如,
罗嗦一大堆,程序放在csdn下载资源上面,以后不用到处找相机二次开发,直接下载使用即可。
摄像头程序下载地址
压缩包中收录一个基于纯网页采集的相机照片示例程序,以及一个基于jquery框架的ajax数据操作程序示例。调用摄像头的方法详见示例代码。相信稍微懂一点技术的人应该都能看懂。了解了,有一个完整的基于java技术的photo采集示例程序,使用jsp页面采集的照片,serlvet程序接收摄像头照片数据。
以下是程序运行效果示例:
查看全部
文章采集调用(java项目中如何实现摄像头图像采集图片数据采集?
)
最近的一个项目需要实现摄像头图像采集,经过一系列的折腾,终于实现了这个功能,现在整理一下。
就java技术而言,为了实现相机的二次开发,采集相机图片需要使用JMF。JMF 适合在 j2se 程序中使用。我需要在网络程序中调用相机。显然,JMF 处理不了。现在想写个applet程序,但是那个东西需要客户端有jre环境,不适合我。您不能指望用户在访问您的 网站 jre 进行安装然后再次访问时下载一个大文件吗?
既然JMF不适用,那么我们在java项目中如何控制摄像头抓拍呢?在windows平台下,我们可以使用视频采集卡等二次开发包来访问视频数据,但是目前的摄像头都是usb的,甚至笔记本电脑屏幕都有摄像头,这种情况下的解决方案使用采集卡二次开发包不适用。您只能编写自己的程序来做类似于“相机相机软件”的事情。经过一系列的分析,终于实现了在web程序中调用摄像头,可以通过js代码控制摄像头,通过ajax技术上传数据。虽然我没有在程序中测试过,但是应该支持.net技术,也可以在采集Camera data的项目中实现,例如,
罗嗦一大堆,程序放在csdn下载资源上面,以后不用到处找相机二次开发,直接下载使用即可。
摄像头程序下载地址
压缩包中收录一个基于纯网页采集的相机照片示例程序,以及一个基于jquery框架的ajax数据操作程序示例。调用摄像头的方法详见示例代码。相信稍微懂一点技术的人应该都能看懂。了解了,有一个完整的基于java技术的photo采集示例程序,使用jsp页面采集的照片,serlvet程序接收摄像头照片数据。
以下是程序运行效果示例:
文章采集调用(测试阻碍交付,如何破解这一难题?(一)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-01-07 18:14
测试阻碍了交付。如何解决这个问题呢?>>>
点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
请求数据的时候,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csv
class Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self): pass
if __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,得到响应,页面回调方便下一个请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、 调用方法实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0 self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存csv文件。
4、电影画面显示。
[七、总结]
1、 不建议抓太多数据,可能造成服务器负载,简单试一下。
2、这篇文章针对Python爬豆豆应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要霸道,不要霸道,要了解的更深。
5、 需要本文源码的请在下方公众号后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享家庭 查看全部
文章采集调用(测试阻碍交付,如何破解这一难题?(一)(组图))
测试阻碍了交付。如何解决这个问题呢?>>>
点击上方“IT共享屋”关注
回复“资料”领取Python学习福利
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和 网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests、fake_useragent、json、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2. 如何获取实际请求的地址?
请求数据的时候,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集的。
1)F12 右键查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
3. 如何访问网页?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,jsonfrom fake_useragent import UserAgentimport csv
class Doban(object): def __init__(self): self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self): pass
if __name__ == '__main__': Siper = Doban() Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50): self.headers = { 'User-Agent': ua.random, }
3、发送请求,得到响应,页面回调方便下一个请求。
def get_page(self, url): res = requests.get(url=url, headers=self.headers) html = res.content.decode("utf-8") return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects'] # print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf) html2 = self.get_page(goblin_herf) # 第二个发生请求 parse_html2 = etree.HTML(html2) r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入 csv_file = open('scr.csv', 'a', encoding='gbk') csv_writer = csv.writer(csv_file) # 写入csv标题头内容 csv_writerr.writerow(['电影', '评分', "详情页"]) #写入数据 csv_writer.writerow([id, rate, urll])
7、请求的图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content dirname = "./图/" + id + ".jpg" with open(dirname, 'wb') as f: f.write(html2) print("%s 【下载成功!!!!】" % id)
8、 调用方法实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:1)设置延时。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0 self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 在控制台显示下载成功信息。
3、保存csv文件。
4、电影画面显示。
[七、总结]
1、 不建议抓太多数据,可能造成服务器负载,简单试一下。
2、这篇文章针对Python爬豆豆应用中的难点和关键点,以及如何防止反爬,做了一个相对的解决方案。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要霸道,不要霸道,要了解的更深。
5、 需要本文源码的请在下方公众号后台回复“豆瓣电影”获取。
看完这篇文章你学会了吗?请转发并分享给更多人
IT共享家庭
文章采集调用(换个网站你什么都做不了,这个教程让你一看即会)
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2022-01-06 07:05
很多网友对于织梦的采集教程(DEDEcms)感到头疼。确实,官方教程太笼统,没说什么。换个网站你是什么?不会啊,这个教程是最详细的教程了,赶紧看看吧!
一、列表采集
第一步,我们打开织梦后台,点击采集——采集节点管理——添加新节点
第二步,这里我们以采集normal文章为例,我们选择normal文章,然后确认
第三步,进入采集的设置页面,填写节点名称。
第四步,打开你要采集的文章列表页。
以这个网站为例,打开这个页面,
右键查看源文件找到目标页面编码,就在charset之后)
第五步,填写页面基本信息,填写后如图
第六步,填写列表URL获取规则,查看文章列表第一页地址。
比较第二页的地址
我们发现除了49_后面的数字是一样的,所以我们可以这样写
(*).html
就用(*)代替1,因为只有2页,所以我们从1到2填,每页加1,当然2-1...等于1。
到这里我们完成了
可能你的一些采集列表没有规则,所以你只需要手动指定列表URL即可,如图
每行写一个页面地址
第七步:填写文章 URL匹配规则,返回文章列表页面
右键查看源文件找到区域开头的HTML,也就是找到文章列表开头的标记。
我们可以很容易地找到如图所示的“新闻列表”。从这里开始,后面是文章列表,然后找到文章列表末尾的HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理成缩略图,这里根据自己的需要选择
二、内容页采集
第八步,重新筛选区域网站:
(使用正则表达式)必须收录:(优先级高于后者)
不能收录:打开源文件,我们可以清楚地看到文章链接以.html结尾,所以我们必须收录它并填写.html。如果遇到一些比较麻烦的list,也可以在后面填写Cannot contains
点击保存设置进入下一步,可以看到我们得到的文章 URL
看到这个是对的,我们保存信息,进入下一步设置内容字段获取规则
看看文章有没有分页,随便输入一篇文章看看吧。. 我们看到文章中没有分页
所以这里我们默认
找到文章标题等,输入一篇文章文章,右键查看源文件
看看这些
根据源码填写
第九步,填写文章内容的开头,结尾同上,找到开始和结束标志。
开始部分如图
末端部分如图所示
最后填写如图
第十步,要过滤文章中的什么内容,写在过滤规则中,比如过滤文章中的图片,
选择常用规则,如图
然后勾选IMG,如图
然后确定
这样我们过滤文本中的图片
第十一步,设置完成后,点击保存设置并预览,如图
写了这样一个采集规则,很简单吧?有些网站很难写,但你需要更努力。
我们点击保存,启动采集-start 采集网页,采集就完成了
看看我们采集到达了什么文章
最后,导出数据
首先选择要导入的列,在弹出的窗口中按“选择”选择需要导入的列。发布选项通常是默认选项,除非您不想立即发布。每批导入的默认值为30,修改与否都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。
文章标题
匹配规则:【内容】
过滤规则:{dede:trimreplace=""}_XXX网站{/dede:trim}
来自百度
三、采集 规则补充(一) 文本过滤和替换方法
1.去除超链接,这个是最常用的。
{dede:trim replace="}]*)>{/dede:trim}
{dede:trim replace=”}{/dede:trim}
如果这样填写,那么链接的文字也被去掉了
{dede:trim replace=”}]*)>(.*){/dede:trim}
2. 过滤JS电话广告,如GG广告,添加:
{dede:trim replace=”}{/dede:trim}
3.过滤 div 标签。
这是非常重要的。如果过滤不干净,发布的 文章 页面可能会错位。目前遇到采集后出现错位的大部分原因都在这里。
{dede:修剪替换=”}
{/dede:修剪}
{dede:修剪替换=”}
{/dede:修剪}
有时需要像这样过滤:
{dede:修剪替换=”}
(.*)
{/dede:修剪}
4.根据以上规则可以引入其他过滤规则。
5.过滤摘要和关键字用法,经常用到。
{dede:trim replace=”}{/dede:trim}
6. 简单替换。
{dede:trim replace='word after replacement'}要替换的单词{/dede:trim}
7.删除源代码
{dede:trim replace=""}src="([^"]*)"{/dede:trim}
(二)内容页注明作者和出处
可以通过指定 value 值来实现:
{dede:item field='writer' value='小军' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='Military Net' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
(三)内容页分页采集
在“内容分页导航所在区域的匹配规则:”中填写规则,如 查看全部
文章采集调用(换个网站你什么都做不了,这个教程让你一看即会)
很多网友对于织梦的采集教程(DEDEcms)感到头疼。确实,官方教程太笼统,没说什么。换个网站你是什么?不会啊,这个教程是最详细的教程了,赶紧看看吧!
一、列表采集
第一步,我们打开织梦后台,点击采集——采集节点管理——添加新节点
第二步,这里我们以采集normal文章为例,我们选择normal文章,然后确认
第三步,进入采集的设置页面,填写节点名称。
第四步,打开你要采集的文章列表页。
以这个网站为例,打开这个页面,
右键查看源文件找到目标页面编码,就在charset之后)
第五步,填写页面基本信息,填写后如图
第六步,填写列表URL获取规则,查看文章列表第一页地址。
比较第二页的地址
我们发现除了49_后面的数字是一样的,所以我们可以这样写
(*).html
就用(*)代替1,因为只有2页,所以我们从1到2填,每页加1,当然2-1...等于1。
到这里我们完成了
可能你的一些采集列表没有规则,所以你只需要手动指定列表URL即可,如图
每行写一个页面地址
第七步:填写文章 URL匹配规则,返回文章列表页面
右键查看源文件找到区域开头的HTML,也就是找到文章列表开头的标记。
我们可以很容易地找到如图所示的“新闻列表”。从这里开始,后面是文章列表,然后找到文章列表末尾的HTML
就是这样,一个很容易找到的标志
如果链接收录图片:
不要将采集处理成缩略图,这里根据自己的需要选择
二、内容页采集
第八步,重新筛选区域网站:
(使用正则表达式)必须收录:(优先级高于后者)
不能收录:打开源文件,我们可以清楚地看到文章链接以.html结尾,所以我们必须收录它并填写.html。如果遇到一些比较麻烦的list,也可以在后面填写Cannot contains
点击保存设置进入下一步,可以看到我们得到的文章 URL
看到这个是对的,我们保存信息,进入下一步设置内容字段获取规则
看看文章有没有分页,随便输入一篇文章看看吧。. 我们看到文章中没有分页
所以这里我们默认
找到文章标题等,输入一篇文章文章,右键查看源文件
看看这些
根据源码填写
第九步,填写文章内容的开头,结尾同上,找到开始和结束标志。
开始部分如图
末端部分如图所示
最后填写如图
第十步,要过滤文章中的什么内容,写在过滤规则中,比如过滤文章中的图片,
选择常用规则,如图
然后勾选IMG,如图
然后确定
这样我们过滤文本中的图片
第十一步,设置完成后,点击保存设置并预览,如图
写了这样一个采集规则,很简单吧?有些网站很难写,但你需要更努力。
我们点击保存,启动采集-start 采集网页,采集就完成了
看看我们采集到达了什么文章
最后,导出数据
首先选择要导入的列,在弹出的窗口中按“选择”选择需要导入的列。发布选项通常是默认选项,除非您不想立即发布。每批导入的默认值为30,修改与否都没有关系。附加选项一般选择“排除重复标题”。至于自动生成HTML的选项,建议不要先生成,因为我们要批量提取摘要和关键字。
文章标题
匹配规则:【内容】
过滤规则:{dede:trimreplace=""}_XXX网站{/dede:trim}
来自百度
三、采集 规则补充(一) 文本过滤和替换方法
1.去除超链接,这个是最常用的。
{dede:trim replace="}]*)>{/dede:trim}
{dede:trim replace=”}{/dede:trim}
如果这样填写,那么链接的文字也被去掉了
{dede:trim replace=”}]*)>(.*){/dede:trim}
2. 过滤JS电话广告,如GG广告,添加:
{dede:trim replace=”}{/dede:trim}
3.过滤 div 标签。
这是非常重要的。如果过滤不干净,发布的 文章 页面可能会错位。目前遇到采集后出现错位的大部分原因都在这里。
{dede:修剪替换=”}
{/dede:修剪}
{dede:修剪替换=”}
{/dede:修剪}
有时需要像这样过滤:
{dede:修剪替换=”}
(.*)
{/dede:修剪}
4.根据以上规则可以引入其他过滤规则。
5.过滤摘要和关键字用法,经常用到。
{dede:trim replace=”}{/dede:trim}
6. 简单替换。
{dede:trim replace='word after replacement'}要替换的单词{/dede:trim}
7.删除源代码
{dede:trim replace=""}src="([^"]*)"{/dede:trim}
(二)内容页注明作者和出处
可以通过指定 value 值来实现:
{dede:item field='writer' value='小军' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
{dede:item field='source' value='Military Net' isunit='' isdown=''}
{dede:match}{/dede:match}
{dede:function}{/dede:function}
{/dede:item}
(三)内容页分页采集
在“内容分页导航所在区域的匹配规则:”中填写规则,如
文章采集调用(下采集神器:chromedp+HeadlessChrome安装安装)
采集交流 • 优采云 发表了文章 • 0 个评论 • 456 次浏览 • 2022-01-06 06:06
最近在采集微信文章的时候,遇到了一个比较棘手的问题。通过搜狗搜索的微信搜索模式,正常的直接抓取页面的方式无法绕过搜狗搜索的验证。所以成功使用gorequest采集到微信文章。
选择 chromedp + Headless Chrome
面对采集的目的没有达到的问题,我是不是就此放弃了?显然这是不可能的。不就是签名验证嘛,只要不要求输入验证码,总有办法解决的(蒽,一般的验证码也可以解决)。于是牺牲了golang下的采集神器:chromedp。
简单来说,chromedp是golang语言用来调用Chrome调试协议来模拟浏览器行为的一个包,可以简单的驱动浏览器。使用的前提很简单,就是在电脑上安装Chrome浏览器。
Chrome浏览器的安装在Windows和macOS下没有问题,在桌面版Linux下也没有问题。但是如果要在Linux服务器版本上安装Chrome,就没有那么简单了。至少目前,Chrome 还没有可以直接安装在服务器上的软件包。
但是你必须放弃你刚刚想到的想法吗?当然这是不可能的。翻阅chromedp文档,我刚刚找到了一段:
最简单的方法是在 chromedp/headless-shell 映像中运行使用 chromedp 的 Go 程序。该图像收录 headless-shell,这是一种较小的 Chrome 无头构建,chromedp 可以立即找到它。
他的意思是:最简单的方法就是用chromedp调用chromedp/headless-shell镜像。chromedp/headless-shell 是一个 docker 镜像,收录一个较小的 Chrome 无头浏览器。
好的,既然是docker镜像,我们就用docker安装。
首先登录我们的linux服务器,下面的操作就认为你已经登录到linux服务器了。
安装 docker 并安装 chromedp/headless-shell
如果您的服务器已经安装了 docker,请跳过此步骤。
使用yum安装docker
yum install docker
复制代码
安装完成后,此时无法直接使用docker,需要执行以下命令激活
systemctl daemon-reload
service docker restart
复制代码
然后安装 chromedp/headless-shell 镜像
docker pull chromedp/headless-shell:latest
复制代码
等待安装完成,然后运行docker镜像
docker run -d -p 9222:9222 --rm --name headless-shell chromedp/headless-shell
复制代码
运行后,测试chrome是否正常:
curl http://127.0.0.1:9222/json/version
复制代码
如果看到类似下面的内容,说明chrome浏览器工作正常
{"浏览器": "Chrome/96.0.4664.110","协议版本": "1.3","用户代理":" Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36","V8-Version": "9.6.180.21","WebKit-Version": "537.36 (@d5ef0e8214bc14c9b5bbf69a1515e431394c62a6)","webSocketDebuggerUrl": "ws://127.0.0.1/devers-browse/dev22921 -4d5b-b9e6-37d634aa719a"}
chromedp代码调用chromedp/headless-shell采集微信公众号文章内容
Linux下可以正常使用Headless Chrome无头浏览器。剩下的就是调用它的代码了。
现在我们开始编写采集微信文章使用的chrome代码:
定义关键字,artile struct.go
package main
type Keyword struct {
Id int64 `json:"id"`
Name string `json:"name"`
Level int `json:"level"`
ArticleCount int `json:"article_count"`
LastTime int64 `json:"last_time"` //上次执行时间
}
type Article struct {
Id int64 `json:"id"`
KeywordId int64 `json:"keyword_id"`
Title string `json:"title"`
Keywords string `json:"keywords"`
Description string `json:"description"`
OriginUrl string `json:"origin_url"`
Status int `json:"status"`
CreatedTime int `json:"created_time"`
UpdatedTime int `json:"updated_time"`
Content string `json:"content"`
ContentText string `json:"-"`
}
复制代码
编写核心代码 core.go
package main
import (
"context"
"fmt"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
"log"
"net"
"net/url"
"strings"
"time"
)
func CollectArticleFromWeixin(keyword *Keyword) []*Article {
timeCtx, cancel := context.WithTimeout(GetChromeCtx(false), 30*time.Second)
defer cancel()
var collectLink string
err := chromedp.Run(timeCtx,
chromedp.Navigate(fmt.Sprintf("https://weixin.sogou.com/weixi ... ot%3B, keyword.Name)),
chromedp.WaitVisible(`//ul[@class="news-list"]`),
chromedp.Location(&collectLink),
)
if err != nil {
log.Println("读取搜狗搜索列表失败1:", keyword.Name, err.Error())
return nil
}
log.Println("正在采集列表:", collectLink)
var aLinks []*cdp.Node
if err := chromedp.Run(timeCtx, chromedp.Nodes(`//ul[@class="news-list"]//h3//a`, &aLinks)); err != nil {
log.Println("读取搜狗搜索列表失败2:", keyword.Name, err.Error())
return nil
}
var articles []*Article
for i := 0; i < len(aLinks); i++ {
href := aLinks[i].AttributeValue("href")
href, _ = joinURL("https://weixin.sogou.com/", href)
article := &Article{}
err = chromedp.Run(timeCtx,
chromedp.Navigate(href),
chromedp.WaitVisible(`#js_article`),
chromedp.Location(&article.OriginUrl),
chromedp.Text(`#activity-name`, &article.Title, chromedp.NodeVisible),
chromedp.InnerHTML("#js_content", &article.Content, chromedp.ByID),
chromedp.Text("#js_content", &article.ContentText, chromedp.ByID),
)
if err != nil {
log.Println("读取搜狗搜索列表失败3:", keyword.Name, err.Error())
}
log.Println("采集文章:", article.Title, len(article.Content), article.OriginUrl)
articles = append(articles, article)
}
return articles
}
// 重组url
func joinURL(baseURL, subURL string) (fullURL, fullURLWithoutFrag string) {
baseURL = strings.TrimSpace(baseURL)
subURL = strings.TrimSpace(subURL)
baseURLObj, _ := url.Parse(baseURL)
subURLObj, _ := url.Parse(subURL)
fullURLObj := baseURLObj.ResolveReference(subURLObj)
fullURL = fullURLObj.String()
fullURLObj.Fragment = ""
fullURLWithoutFrag = fullURLObj.String()
return
}
//检查是否有9222端口,来判断是否运行在linux上
func checkChromePort() bool {
addr := net.JoinHostPort("", "9222")
conn, err := net.DialTimeout("tcp", addr, 1*time.Second)
if err != nil {
return false
}
defer conn.Close()
return true
}
// ChromeCtx 使用一个实例
var ChromeCtx context.Context
func GetChromeCtx(focus bool) context.Context {
if ChromeCtx == nil || focus {
allocOpts := chromedp.DefaultExecAllocatorOptions[:]
allocOpts = append(allocOpts,
chromedp.DisableGPU,
chromedp.Flag("blink-settings", "imagesEnabled=false"),
chromedp.UserAgent(`Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36`),
chromedp.Flag("accept-language", `zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6`),
)
if checkChromePort() {
// 不知道为何,不能直接使用 NewExecAllocator ,因此增加 使用 ws://127.0.0.1:9222/ 来调用
c, _ := chromedp.NewRemoteAllocator(context.Background(), "ws://127.0.0.1:9222/")
ChromeCtx, _ = chromedp.NewContext(c)
} else {
c, _ := chromedp.NewExecAllocator(context.Background(), allocOpts...)
ChromeCtx, _ = chromedp.NewContext(c)
}
}
return ChromeCtx
}
复制代码
写入入口文件main.go
package main
import "log"
func main() {
word := Keyword{
Name: "golang",
}
result := CollectArticleFromWeixin(&word)
for i, v := range result {
log.Println(i, v.Title, len(v.Content), v.OriginUrl)
log.Println("纯内容:", v.ContentText)
}
}
复制代码
运行结果测试:
伟大的结果出来了。
如果您对此代码感兴趣,可以从这里获取 /fesiong/gob...。
本采集代码仅供研究学习之用,不得用于非法用途。 查看全部
文章采集调用(下采集神器:chromedp+HeadlessChrome安装安装)
最近在采集微信文章的时候,遇到了一个比较棘手的问题。通过搜狗搜索的微信搜索模式,正常的直接抓取页面的方式无法绕过搜狗搜索的验证。所以成功使用gorequest采集到微信文章。
选择 chromedp + Headless Chrome
面对采集的目的没有达到的问题,我是不是就此放弃了?显然这是不可能的。不就是签名验证嘛,只要不要求输入验证码,总有办法解决的(蒽,一般的验证码也可以解决)。于是牺牲了golang下的采集神器:chromedp。
简单来说,chromedp是golang语言用来调用Chrome调试协议来模拟浏览器行为的一个包,可以简单的驱动浏览器。使用的前提很简单,就是在电脑上安装Chrome浏览器。
Chrome浏览器的安装在Windows和macOS下没有问题,在桌面版Linux下也没有问题。但是如果要在Linux服务器版本上安装Chrome,就没有那么简单了。至少目前,Chrome 还没有可以直接安装在服务器上的软件包。
但是你必须放弃你刚刚想到的想法吗?当然这是不可能的。翻阅chromedp文档,我刚刚找到了一段:
最简单的方法是在 chromedp/headless-shell 映像中运行使用 chromedp 的 Go 程序。该图像收录 headless-shell,这是一种较小的 Chrome 无头构建,chromedp 可以立即找到它。
他的意思是:最简单的方法就是用chromedp调用chromedp/headless-shell镜像。chromedp/headless-shell 是一个 docker 镜像,收录一个较小的 Chrome 无头浏览器。
好的,既然是docker镜像,我们就用docker安装。
首先登录我们的linux服务器,下面的操作就认为你已经登录到linux服务器了。
安装 docker 并安装 chromedp/headless-shell
如果您的服务器已经安装了 docker,请跳过此步骤。
使用yum安装docker
yum install docker
复制代码
安装完成后,此时无法直接使用docker,需要执行以下命令激活
systemctl daemon-reload
service docker restart
复制代码
然后安装 chromedp/headless-shell 镜像
docker pull chromedp/headless-shell:latest
复制代码
等待安装完成,然后运行docker镜像
docker run -d -p 9222:9222 --rm --name headless-shell chromedp/headless-shell
复制代码
运行后,测试chrome是否正常:
curl http://127.0.0.1:9222/json/version
复制代码
如果看到类似下面的内容,说明chrome浏览器工作正常
{"浏览器": "Chrome/96.0.4664.110","协议版本": "1.3","用户代理":" Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36","V8-Version": "9.6.180.21","WebKit-Version": "537.36 (@d5ef0e8214bc14c9b5bbf69a1515e431394c62a6)","webSocketDebuggerUrl": "ws://127.0.0.1/devers-browse/dev22921 -4d5b-b9e6-37d634aa719a"}
chromedp代码调用chromedp/headless-shell采集微信公众号文章内容
Linux下可以正常使用Headless Chrome无头浏览器。剩下的就是调用它的代码了。
现在我们开始编写采集微信文章使用的chrome代码:
定义关键字,artile struct.go
package main
type Keyword struct {
Id int64 `json:"id"`
Name string `json:"name"`
Level int `json:"level"`
ArticleCount int `json:"article_count"`
LastTime int64 `json:"last_time"` //上次执行时间
}
type Article struct {
Id int64 `json:"id"`
KeywordId int64 `json:"keyword_id"`
Title string `json:"title"`
Keywords string `json:"keywords"`
Description string `json:"description"`
OriginUrl string `json:"origin_url"`
Status int `json:"status"`
CreatedTime int `json:"created_time"`
UpdatedTime int `json:"updated_time"`
Content string `json:"content"`
ContentText string `json:"-"`
}
复制代码
编写核心代码 core.go
package main
import (
"context"
"fmt"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
"log"
"net"
"net/url"
"strings"
"time"
)
func CollectArticleFromWeixin(keyword *Keyword) []*Article {
timeCtx, cancel := context.WithTimeout(GetChromeCtx(false), 30*time.Second)
defer cancel()
var collectLink string
err := chromedp.Run(timeCtx,
chromedp.Navigate(fmt.Sprintf("https://weixin.sogou.com/weixi ... ot%3B, keyword.Name)),
chromedp.WaitVisible(`//ul[@class="news-list"]`),
chromedp.Location(&collectLink),
)
if err != nil {
log.Println("读取搜狗搜索列表失败1:", keyword.Name, err.Error())
return nil
}
log.Println("正在采集列表:", collectLink)
var aLinks []*cdp.Node
if err := chromedp.Run(timeCtx, chromedp.Nodes(`//ul[@class="news-list"]//h3//a`, &aLinks)); err != nil {
log.Println("读取搜狗搜索列表失败2:", keyword.Name, err.Error())
return nil
}
var articles []*Article
for i := 0; i < len(aLinks); i++ {
href := aLinks[i].AttributeValue("href")
href, _ = joinURL("https://weixin.sogou.com/", href)
article := &Article{}
err = chromedp.Run(timeCtx,
chromedp.Navigate(href),
chromedp.WaitVisible(`#js_article`),
chromedp.Location(&article.OriginUrl),
chromedp.Text(`#activity-name`, &article.Title, chromedp.NodeVisible),
chromedp.InnerHTML("#js_content", &article.Content, chromedp.ByID),
chromedp.Text("#js_content", &article.ContentText, chromedp.ByID),
)
if err != nil {
log.Println("读取搜狗搜索列表失败3:", keyword.Name, err.Error())
}
log.Println("采集文章:", article.Title, len(article.Content), article.OriginUrl)
articles = append(articles, article)
}
return articles
}
// 重组url
func joinURL(baseURL, subURL string) (fullURL, fullURLWithoutFrag string) {
baseURL = strings.TrimSpace(baseURL)
subURL = strings.TrimSpace(subURL)
baseURLObj, _ := url.Parse(baseURL)
subURLObj, _ := url.Parse(subURL)
fullURLObj := baseURLObj.ResolveReference(subURLObj)
fullURL = fullURLObj.String()
fullURLObj.Fragment = ""
fullURLWithoutFrag = fullURLObj.String()
return
}
//检查是否有9222端口,来判断是否运行在linux上
func checkChromePort() bool {
addr := net.JoinHostPort("", "9222")
conn, err := net.DialTimeout("tcp", addr, 1*time.Second)
if err != nil {
return false
}
defer conn.Close()
return true
}
// ChromeCtx 使用一个实例
var ChromeCtx context.Context
func GetChromeCtx(focus bool) context.Context {
if ChromeCtx == nil || focus {
allocOpts := chromedp.DefaultExecAllocatorOptions[:]
allocOpts = append(allocOpts,
chromedp.DisableGPU,
chromedp.Flag("blink-settings", "imagesEnabled=false"),
chromedp.UserAgent(`Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36`),
chromedp.Flag("accept-language", `zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6`),
)
if checkChromePort() {
// 不知道为何,不能直接使用 NewExecAllocator ,因此增加 使用 ws://127.0.0.1:9222/ 来调用
c, _ := chromedp.NewRemoteAllocator(context.Background(), "ws://127.0.0.1:9222/")
ChromeCtx, _ = chromedp.NewContext(c)
} else {
c, _ := chromedp.NewExecAllocator(context.Background(), allocOpts...)
ChromeCtx, _ = chromedp.NewContext(c)
}
}
return ChromeCtx
}
复制代码
写入入口文件main.go
package main
import "log"
func main() {
word := Keyword{
Name: "golang",
}
result := CollectArticleFromWeixin(&word)
for i, v := range result {
log.Println(i, v.Title, len(v.Content), v.OriginUrl)
log.Println("纯内容:", v.ContentText)
}
}
复制代码
运行结果测试:
伟大的结果出来了。
如果您对此代码感兴趣,可以从这里获取 /fesiong/gob...。
本采集代码仅供研究学习之用,不得用于非法用途。
文章采集调用( 如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-01-04 21:01
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
1、介绍
最近在看Scrapy爬虫框架,尝试用Scrapy框架写一个简单的小程序,可以实现网页信息采集。在尝试的过程中遇到了很多小问题,希望大家给点建议。
本文主要介绍如何使用Scrapy结合PhantomJS采集天猫产品内容。文章中自定义了一个DOWNLOADER_MIDDLEWARES,用于采集需要加载js的动态网页内容。看了很多关于DOWNLOADER_MIDDLEWARES的资料,总结起来,使用简单,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的朋友可以去研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发运行环境需要进行以下步骤:
Python--从官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”。详情请参考《Scrapy的首次运行测试》
selenium--执行“pip install selenium”的命令行界面
PhantomJS --官网下载
以上步骤展示了两种安装方式: 1、安装本地下载的wheel包; 2、使用Python安装管理器进行远程下载安装。注意:包版本需要与python版本匹配
2.2、开发测试流程
首先找到需要采集的网页,这里简单搜索一个天猫产品,网址,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建一个scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建一个middlewares文件夹,然后在该文件夹下创建一个middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,也在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在项目目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在项目目录E:python-3.5.1tmSpidermSpiderspiders下自动生成tmall.py程序文件。该程序中的解析函数处理scrapy下载器返回的网页内容。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider项目目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
提一下,上面的命令一次只能启动一个爬虫。如果你想同时启动多个爬虫怎么办?然后需要自定义一个爬虫启动模块,在spider下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs实现爬虫后,一直在纠结框架阻塞的问题,一直在想解决办法。后面会研究scrapyjs、splash等调用浏览器的方式,看看能不能有效的解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、采集GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-07: V1.0 查看全部
文章采集调用(
如何使用Scrapy结合PhantomJS采集天猫商品内容的小程序?)
1、介绍
最近在看Scrapy爬虫框架,尝试用Scrapy框架写一个简单的小程序,可以实现网页信息采集。在尝试的过程中遇到了很多小问题,希望大家给点建议。
本文主要介绍如何使用Scrapy结合PhantomJS采集天猫产品内容。文章中自定义了一个DOWNLOADER_MIDDLEWARES,用于采集需要加载js的动态网页内容。看了很多关于DOWNLOADER_MIDDLEWARES的资料,总结起来,使用简单,但是会阻塞框架,所以性能不好。有资料提到自定义DOWNLOADER_HANDLER或者使用scrapyjs可以解决框架阻塞的问题。有兴趣的朋友可以去研究一下,这里就不多说了。
2、具体实现2.1、环境要求
准备Python开发运行环境需要进行以下步骤:
Python--从官网下载安装部署环境变量(本文使用的Python版本为3.5.1)
lxml--从官网库下载对应版本的.whl文件,然后在命令行界面执行“pip install .whl文件路径”
Scrapy--在命令行界面执行“pip install Scrapy”。详情请参考《Scrapy的首次运行测试》
selenium--执行“pip install selenium”的命令行界面
PhantomJS --官网下载
以上步骤展示了两种安装方式: 1、安装本地下载的wheel包; 2、使用Python安装管理器进行远程下载安装。注意:包版本需要与python版本匹配
2.2、开发测试流程
首先找到需要采集的网页,这里简单搜索一个天猫产品,网址,页面如下:
然后开始写代码,下面的代码默认在命令行界面执行
1),创建一个scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider
2),修改settings.py配置
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': None
}
3),在项目目录下创建一个middlewares文件夹,然后在该文件夹下创建一个middleware.py文件,代码如下:
# -*- coding: utf-8 -*-
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
import tmSpider.middlewares.downloader as downloader
class CustomMiddlewares(object):
def process_request(self, request, spider):
url = str(request.url)
dl = downloader.CustomDownloader()
content = dl.VisitPersonPage(url)
return HtmlResponse(url, status = 200, body = content)
def process_response(self, request, response, spider):
if len(response.body) == 100:
return IgnoreRequest("body length == 100")
else:
return response
4),使用selenium和PhantomJS编写一个网页内容下载器,也在上一步创建的middlewares文件夹中创建一个downloader.py文件,代码如下:
# -*- coding: utf-8 -*-
import time
from scrapy.exceptions import IgnoreRequest
from scrapy.http import HtmlResponse, Response
from selenium import webdriver
import selenium.webdriver.support.ui as ui
class CustomDownloader(object):
def __init__(self):
# use any browser you wish
cap = webdriver.DesiredCapabilities.PHANTOMJS
cap["phantomjs.page.settings.resourceTimeout"] = 1000
cap["phantomjs.page.settings.loadImages"] = True
cap["phantomjs.page.settings.disk-cache"] = True
cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=3955422793326.2764.1451802953297; '
self.driver = webdriver.PhantomJS(executable_path='F:/phantomjs/bin/phantomjs.exe', desired_capabilities=cap)
wait = ui.WebDriverWait(self.driver,10)
def VisitPersonPage(self, url):
print('正在加载网站.....')
self.driver.get(url)
time.sleep(1)
# 翻到底,详情加载
js="var q=document.documentElement.scrollTop=10000"
self.driver.execute_script(js)
time.sleep(5)
content = self.driver.page_source.encode('gbk', 'ignore')
print('网页加载完毕.....')
return content
def __del__(self):
self.driver.quit()
5) 创建爬虫模块
在项目目录E:python-3.5.1tmSpider,执行如下代码:
E:\python-3.5.1\tmSpider>scrapy genspider tmall 'tmall.com'
执行后会在项目目录E:python-3.5.1tmSpidermSpiderspiders下自动生成tmall.py程序文件。该程序中的解析函数处理scrapy下载器返回的网页内容。 采集网页信息的方法可以是:
# -*- coding: utf-8 -*-
import time
import scrapy
import tmSpider.gooseeker.gsextractor as gsextractor
class TmallSpider(scrapy.Spider):
name = "tmall"
allowed_domains = ["tmall.com"]
start_urls = (
'https://world.tmall.com/item/526449276263.htm',
)
# 获得当前时间戳
def getTime(self):
current_time = str(time.time())
m = current_time.find('.')
current_time = current_time[0:m]
return current_time
def parse(self, response):
html = response.body
print("----------------------------------------------------------------------------")
extra=gsextractor.GsExtractor()
extra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e", "淘宝天猫_商品详情30474","tmall","list")
result = extra.extract(html)
print(str(result).encode('gbk', 'ignore').decode('gbk'))
#file_name = 'F:/temp/淘宝天猫_商品详情30474_' + self.getTime() + '.xml'
#open(file_name,"wb").write(result)
6),启动爬虫
在E:python-3.5.1tmSpider项目目录下执行命令
E:\python-3.5.1\simpleSpider>scrapy crawl tmall
输出结果:
提一下,上面的命令一次只能启动一个爬虫。如果你想同时启动多个爬虫怎么办?然后需要自定义一个爬虫启动模块,在spider下创建模块文件runcrawl.py,代码如下
# -*- coding: utf-8 -*-
import scrapy
from twisted.internet import reactor
from scrapy.crawler import CrawlerRunner
from tmall import TmallSpider
...
spider = TmallSpider(domain='tmall.com')
runner = CrawlerRunner()
runner.crawl(spider)
...
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
执行runcrawl.py文件并输出结果:
3、展望
通过自定义DOWNLOADER_MIDDLEWARES调用PhantomJs实现爬虫后,一直在纠结框架阻塞的问题,一直在想解决办法。后面会研究scrapyjs、splash等调用浏览器的方式,看看能不能有效的解决这个问题。
4、相关文件
1、Python即时网络爬虫:API说明
5、采集GooSeeker开源代码下载源码
1、GooSeeker开源Python网络爬虫GitHub源码
6、文档修改历史
1, 2016-07-07: V1.0
文章采集调用(无忧主机php虚拟主机完美支持程序的外部链接,路径知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-01-04 21:00
德德cms是一款功能强大的企业建站程序,完美支持无忧主机php虚拟主机。在非常成熟的Dedecms程序面前,总会有一些不完善的地方。文章文章发表后,有可能被其他人转发,或者采集;如果在这个文章的内容中加入当前文档地址和转载说明,则被转载的<@文章将收录当前的文章 URL,一方面,网站@ >内部链接,另一方面,外部链接被转载后无形中形成。像这种一石二鸟的做法,赶紧学起来吧!首先,织梦程序以网站@>的主题为模板,为整个站点生成内容,然后我们直接把需要修改的模板文件下载到本地,文章内容模板文件的名字是:article_article.htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:文章 内容模板文件的名字是:article_article .htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:文章 内容模板文件的名字是:article_article .htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:您可以自己选择主题的名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:您可以自己选择主题的名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:
操作完成后保存上传到网站@>空间,然后在织梦后台更新生成的文档页面。笔记: 查看全部
文章采集调用(无忧主机php虚拟主机完美支持程序的外部链接,路径知道吗?)
德德cms是一款功能强大的企业建站程序,完美支持无忧主机php虚拟主机。在非常成熟的Dedecms程序面前,总会有一些不完善的地方。文章文章发表后,有可能被其他人转发,或者采集;如果在这个文章的内容中加入当前文档地址和转载说明,则被转载的<@文章将收录当前的文章 URL,一方面,网站@ >内部链接,另一方面,外部链接被转载后无形中形成。像这种一石二鸟的做法,赶紧学起来吧!首先,织梦程序以网站@>的主题为模板,为整个站点生成内容,然后我们直接把需要修改的模板文件下载到本地,文章内容模板文件的名字是:article_article.htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:文章 内容模板文件的名字是:article_article .htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:文章 内容模板文件的名字是:article_article .htm,你知道路径吗?在../tempects/default/中,如果使用其他主题,可以自己选择主题名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:您可以自己选择主题的名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:您可以自己选择主题的名称。如果找到该文件,可以将其下载到本地并通过FTP工具打开进行编辑。那么,“当前文档地址”和“转载说明”在哪里添加的呢?找到文章内容调用标签:{dede:field.body/},在field标签后添加如下代码:欢迎转载,本文标题:{dede:field.title/},请注明原文网址: {dede:global.cfg_basehost/} {dede:field/} 添加如下:
操作完成后保存上传到网站@>空间,然后在织梦后台更新生成的文档页面。笔记:
文章采集调用(pbootcms文章(PbootDemoSkycaiji)插件()(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-04 06:00
pbootcms文章(PbootDemoSkycaiji)插件直接在优采云采集器云平台下载使用。该插件由无皮小芒果开发。插件默认只能发布新闻栏目,产品案例过滤,需要手动修改。
插件下载后,我们可以在网站根目录优采云采集器安装目录中找到路径:网站根目录采集器安装目录pluginleasecmsPbootDemoSkycaiji.php
打开这个文件开头的代码就是自动读取我们的数据库信息,不管是mysql还是sqlite数据库都是一样的,自动抓取链接。
这是我们网站对应的信息,如作者、文章内容、产品分类、缩略图等,这里可以根据我们网站的需要添加更多参数。
此处的信息对应于我们网站 数据库中的字段。如果这里没有字段,可以直接进入数据库添加进去。 有一点需要注意的是,这里的数据库字段必须与前面的参数一一对应。例如,如果我们的参数中添加了缩略图,那么我们必须找到该字段并填写我们在参数中添加的名称。
这里默认过滤其他目录,只取我们数据库中的新闻列表信息。如果我们要发布产品或案例,则无法使用。我们需要做的就是添加
// $catsDb=$this->db()->table('__CONTENT_SORT__')->where("contenttpl='news.html'")->limit(100)->select ();//文章Categories 可以注释或删除。
添加 $catsDb=$this->db()->table('__CONTENT_SORT__')->limit(100)->select();//文章 分类就可以了一个匹配所有网站的目录,上面是pbootcms文章(PbootDemoSkycaiji)插件的详细介绍,上面的描述基本上没有什么问题,怎么能你还可以,如果你明白可以咨询我们。
相关知识点:
本站文章均摘自权威资料、书籍或网络原创文章。如有版权纠纷或侵权,请立即联系我们删除。允许复制和转载!谢谢... 查看全部
文章采集调用(pbootcms文章(PbootDemoSkycaiji)插件()(组图))
pbootcms文章(PbootDemoSkycaiji)插件直接在优采云采集器云平台下载使用。该插件由无皮小芒果开发。插件默认只能发布新闻栏目,产品案例过滤,需要手动修改。
插件下载后,我们可以在网站根目录优采云采集器安装目录中找到路径:网站根目录采集器安装目录pluginleasecmsPbootDemoSkycaiji.php
打开这个文件开头的代码就是自动读取我们的数据库信息,不管是mysql还是sqlite数据库都是一样的,自动抓取链接。
这是我们网站对应的信息,如作者、文章内容、产品分类、缩略图等,这里可以根据我们网站的需要添加更多参数。
此处的信息对应于我们网站 数据库中的字段。如果这里没有字段,可以直接进入数据库添加进去。 有一点需要注意的是,这里的数据库字段必须与前面的参数一一对应。例如,如果我们的参数中添加了缩略图,那么我们必须找到该字段并填写我们在参数中添加的名称。
这里默认过滤其他目录,只取我们数据库中的新闻列表信息。如果我们要发布产品或案例,则无法使用。我们需要做的就是添加
// $catsDb=$this->db()->table('__CONTENT_SORT__')->where("contenttpl='news.html'")->limit(100)->select ();//文章Categories 可以注释或删除。
添加 $catsDb=$this->db()->table('__CONTENT_SORT__')->limit(100)->select();//文章 分类就可以了一个匹配所有网站的目录,上面是pbootcms文章(PbootDemoSkycaiji)插件的详细介绍,上面的描述基本上没有什么问题,怎么能你还可以,如果你明白可以咨询我们。
相关知识点:
本站文章均摘自权威资料、书籍或网络原创文章。如有版权纠纷或侵权,请立即联系我们删除。允许复制和转载!谢谢...
文章采集调用(dedecms如何修改这一上限值)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-03 10:09
dedecmsSystem文章 调用描述最大字符数为250字节,设置文章摘要(可通过infolen或description相关标签调用)最多250个字符,设置上限的次要目的是减少数据库的冗余,保证网络的优良性能。所以,对介绍的内容不设上限显然是不合理的,但如果上限可以自由控制,dedecms仿站会对网页内容的布局带来积极的影响。在网页设计过程中,NET源代码。频道列表页面的文章汇总经常需要调用dedecms。如果文章摘要中的字数可以控制无效,页面布局可以非常灵活。
我们先说一下如何修改这个上限,这样才能显示出方法的要点[field:description function="cn_substr(@me, number of characters)"/]。
获取Dedecms系统中文章抽象相关的php文件。主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面,有一句话: $description = cn_substrR($description, $cfg_auot_description);这句话实现了[field:description function="cn_substr(@me, number of characters)"/] 这个Feature。由于此声明确实对页面布局有益,因此我们尽量不做任何更改。
在编辑页面上,有一句:$description = cn_substrR($description, 250);,这句话出现了熟悉的字符数250,是系统设置文章抽象字符数上限,如果是gbk编码,则显示125个字,如果是utf-8编码,则是81个字,显然我们要突破文章抽象的上限字符,必须取。可以,这里可以把250修改成别的值,比如500。这里不建议设置太高,一是列表页不需要显示太多内容(显示内容太多还不如间接使用body),另一个是避免数据库中的冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句。这个限制了后台可以检索到的字符数,把250改成500。 ,织梦仿站的意思是字符数和之前修改的不一样。(如果你确认你的每个文章都是手动添加的,手动完成就不需要修改这个文件了摘要获取。从摘要中获取minor还是为大量文章和采集准备的。)
首先登录后台,在系统-系统基本参数-其他选项中,可以将驱动摘要的长度改为500,与之前修改的字符数不同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为web提供了更广阔的空间页面布局。
说说德德cms文章或者调用文章列表页上的summary方法
1: [field:info /]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
第二种方法1、是间接调用文章的summary。在被调用的词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}在{/dede:arclist}中,设置摘要中的字符数(最多250)由系统设置;如果使用[field:description /],间接使用后台设置的抽象字符上限(也有后台上限为250个字符)。显然这些两种方法都非常被动和灵活。
方法四3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在文章抽象内容的上限不正常修改的情况下,这四种方法区别不大。
==========================
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me, 字符数)"/]
这四个方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到“if($dsize>250) $dsize = 250;”这句,把250改成500
2.登录后台,在系统-系统基本参数-其他选项中,将自动汇总的长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar(1000)
调用标签{dede:field.description function='cn_substr(@me,500)'/}。可以显示500个字符) 查看全部
文章采集调用(dedecms如何修改这一上限值)
dedecmsSystem文章 调用描述最大字符数为250字节,设置文章摘要(可通过infolen或description相关标签调用)最多250个字符,设置上限的次要目的是减少数据库的冗余,保证网络的优良性能。所以,对介绍的内容不设上限显然是不合理的,但如果上限可以自由控制,dedecms仿站会对网页内容的布局带来积极的影响。在网页设计过程中,NET源代码。频道列表页面的文章汇总经常需要调用dedecms。如果文章摘要中的字数可以控制无效,页面布局可以非常灵活。
我们先说一下如何修改这个上限,这样才能显示出方法的要点[field:description function="cn_substr(@me, number of characters)"/]。
获取Dedecms系统中文章抽象相关的php文件。主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
在添加页面,有一句话: $description = cn_substrR($description, $cfg_auot_description);这句话实现了[field:description function="cn_substr(@me, number of characters)"/] 这个Feature。由于此声明确实对页面布局有益,因此我们尽量不做任何更改。
在编辑页面上,有一句:$description = cn_substrR($description, 250);,这句话出现了熟悉的字符数250,是系统设置文章抽象字符数上限,如果是gbk编码,则显示125个字,如果是utf-8编码,则是81个字,显然我们要突破文章抽象的上限字符,必须取。可以,这里可以把250修改成别的值,比如500。这里不建议设置太高,一是列表页不需要显示太多内容(显示内容太多还不如间接使用body),另一个是避免数据库中的冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面,找到if($dsize>250) $dsize = 250;语句。这个限制了后台可以检索到的字符数,把250改成500。 ,织梦仿站的意思是字符数和之前修改的不一样。(如果你确认你的每个文章都是手动添加的,手动完成就不需要修改这个文件了摘要获取。从摘要中获取minor还是为大量文章和采集准备的。)
首先登录后台,在系统-系统基本参数-其他选项中,可以将驱动摘要的长度改为500,与之前修改的字符数不同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid="row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为web提供了更广阔的空间页面布局。
说说德德cms文章或者调用文章列表页上的summary方法
1: [field:info /]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
第二种方法1、是间接调用文章的summary。在被调用的词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}在{/dede:arclist}中,设置摘要中的字符数(最多250)由系统设置;如果使用[field:description /],间接使用后台设置的抽象字符上限(也有后台上限为250个字符)。显然这些两种方法都非常被动和灵活。
方法四3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在文章抽象内容的上限不正常修改的情况下,这四种方法区别不大。
==========================
1:[field:info /]
2:[field:description /]
3:[field:info function="cn_substr(@me,字符数)"/]
4:[field:description function="cn_substr(@me, 字符数)"/]
这四个方法用于调用文章描述标签。但它最多只能调用前 250 个字符。如果要调用更多,需要修改几个地方:
1.article_description_main.php页面,找到“if($dsize>250) $dsize = 250;”这句,把250改成500
2.登录后台,在系统-系统基本参数-其他选项中,将自动汇总的长度改为500.
3.登录后台执行SQL语句:alter table `dede_archives` change `description` `description` varchar(1000)
调用标签{dede:field.description function='cn_substr(@me,500)'/}。可以显示500个字符)
文章采集调用( 郑刚SEO培训:自动调用随机TAGFTP标签和自定义数量 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-01-03 00:08
郑刚SEO培训:自动调用随机TAGFTP标签和自定义数量
)
郑景诚:简单改造wordpress采集页面调用代码和指令增加收录
昨天花了一点时间对网站郑刚SEO培训做一个简单的页面调整。主要修改的是采集页面。
这篇网站是用WP做的,所以如果你也用WP建网站或者用采集的内容,可以采集这篇文章文章,这对亲们有效测试代码和操作方法。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
只要把上面的代码放在你想要的任何页面或位置,你就可以直接调用随机的TAG标签,下面的9表示调用9,这是每个页面调用的总和不同。这叫做随机标签。
原因:这个动作是为了让每个页面调用不同的随机标签来提高标签页收录的概率和进入率,因为WP的主要排名多是TAG标签页。
2、采集在内容页插入随机图片**
第一步:修改第1页:functions.php
/* 文章随机插图 */
function catch_that_image() {
global $post, $posts;
$first_img = '';
ob_start();
ob_end_clean();
$output = preg_match_all('/zt/".rand(1,3).".png";
}
return $first_img;
}
将上面的代码放在functions.php页面的底部,点击save。请记住将中间的网址替换为您的网址。
第2步:修改第2页:single.php
<p align="center">】,郑景承SEO培训提供在线实战SEO最新视频,优化工具,加微信611247免费领取SEO教程。 查看全部
文章采集调用(
郑刚SEO培训:自动调用随机TAGFTP标签和自定义数量
)
郑景诚:简单改造wordpress采集页面调用代码和指令增加收录
昨天花了一点时间对网站郑刚SEO培训做一个简单的页面调整。主要修改的是采集页面。
这篇网站是用WP做的,所以如果你也用WP建网站或者用采集的内容,可以采集这篇文章文章,这对亲们有效测试代码和操作方法。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
只要把上面的代码放在你想要的任何页面或位置,你就可以直接调用随机的TAG标签,下面的9表示调用9,这是每个页面调用的总和不同。这叫做随机标签。
原因:这个动作是为了让每个页面调用不同的随机标签来提高标签页收录的概率和进入率,因为WP的主要排名多是TAG标签页。
2、采集在内容页插入随机图片**
第一步:修改第1页:functions.php
/* 文章随机插图 */
function catch_that_image() {
global $post, $posts;
$first_img = '';
ob_start();
ob_end_clean();
$output = preg_match_all('/zt/".rand(1,3).".png";
}
return $first_img;
}
将上面的代码放在functions.php页面的底部,点击save。请记住将中间的网址替换为您的网址。
第2步:修改第2页:single.php
<p align="center">】,郑景承SEO培训提供在线实战SEO最新视频,优化工具,加微信611247免费领取SEO教程。
文章采集调用(是因为使用分布式追踪系统监控服务(1)_社会万象_光明网(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-12-28 20:07
上周的工作是开发一个运维需求——一个连接到公有云的分布式跟踪系统。在服务上线商业化之前,运维能力需要满足商业化需求,而在商业化运维需求中,使用分布式跟踪系统来监控服务是必须的,所以就有了这个需求。一个星期后,代码已经开发的差不多了,还缺少验证和上线工作。在此之前,我会先回顾一下。
之所以连接分布式跟踪系统如此重要,是因为使用分布式跟踪系统监控服务有以下好处
我们的服务主要使用Python和Go语言开发,您可以分别获取相应的SDK进行开发。整个开发对接流程大致如下:
联系接口人沟通嵌入解决方案,使用统一的SDK进行嵌入代码开发测试,整理服务——微服务——节点——日志路径信息,服务——微服务——业务——URL信息。公司分布式跟踪系统的日志采集借用了现有日志服务的能力。日志服务收到调用链日志后,会直接转发到分布式跟踪系统,因此需要将信息分别反馈给日志采集系统和分布式跟踪系统在服务节点上安装日志采集代理升级微服务,打开开关打印调用链日志(开始打印调用链日志,同时,节点上的日志采集代理将采集到的调用链日志信息上报给日志系统)生产环境验证连接效果:本地打印调用链日志正常,日志采集代理正常上报调用链日志;分布式跟踪系统可以检索到服务的跟踪信息,可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?并且可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?并且可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?
与性能调优类似,管理可以包括:HTTP请求服务/客户端、RPC请求服务/客户端、数据库访问、中间件调用和本地方法调用。
默认情况下应该跟踪哪些点?
我认为对于所有项目,我们应该默认收录
5 种点:
埋点法
听说Go还有办法直接替换Go-SDK来完成嵌入式函数注入...
两个重要的纸张标准
由 Uber 发起的 OpenTracing 现已成为云原生计算基金会的成员项目。OpenTracing 语义规范定义了数据模型和一些用于数据采集
的接口。它应该被视为分布式跟踪系统的接口标准。著名的 Jaeger 和 Zipkin 都实现了 OpenTracing API。
行业实践参考链接 查看全部
文章采集调用(是因为使用分布式追踪系统监控服务(1)_社会万象_光明网(组图))
上周的工作是开发一个运维需求——一个连接到公有云的分布式跟踪系统。在服务上线商业化之前,运维能力需要满足商业化需求,而在商业化运维需求中,使用分布式跟踪系统来监控服务是必须的,所以就有了这个需求。一个星期后,代码已经开发的差不多了,还缺少验证和上线工作。在此之前,我会先回顾一下。
之所以连接分布式跟踪系统如此重要,是因为使用分布式跟踪系统监控服务有以下好处
我们的服务主要使用Python和Go语言开发,您可以分别获取相应的SDK进行开发。整个开发对接流程大致如下:
联系接口人沟通嵌入解决方案,使用统一的SDK进行嵌入代码开发测试,整理服务——微服务——节点——日志路径信息,服务——微服务——业务——URL信息。公司分布式跟踪系统的日志采集借用了现有日志服务的能力。日志服务收到调用链日志后,会直接转发到分布式跟踪系统,因此需要将信息分别反馈给日志采集系统和分布式跟踪系统在服务节点上安装日志采集代理升级微服务,打开开关打印调用链日志(开始打印调用链日志,同时,节点上的日志采集代理将采集到的调用链日志信息上报给日志系统)生产环境验证连接效果:本地打印调用链日志正常,日志采集代理正常上报调用链日志;分布式跟踪系统可以检索到服务的跟踪信息,可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?并且可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?并且可以正常显示微服务依赖拓扑图。线上生产环境埋在各个站点,哪里需要打印点开发的调用链日志?
与性能调优类似,管理可以包括:HTTP请求服务/客户端、RPC请求服务/客户端、数据库访问、中间件调用和本地方法调用。
默认情况下应该跟踪哪些点?
我认为对于所有项目,我们应该默认收录
5 种点:
埋点法
听说Go还有办法直接替换Go-SDK来完成嵌入式函数注入...
两个重要的纸张标准
由 Uber 发起的 OpenTracing 现已成为云原生计算基金会的成员项目。OpenTracing 语义规范定义了数据模型和一些用于数据采集
的接口。它应该被视为分布式跟踪系统的接口标准。著名的 Jaeger 和 Zipkin 都实现了 OpenTracing API。
行业实践参考链接
文章采集调用(豆瓣网影评:电影中如何获取真正请求的地址?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 483 次浏览 • 2021-12-27 16:17
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
请求数据的时候,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集
的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
如何上网?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,得到响应,页面回调方便下一个请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、求图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:
1) 设置时间延迟。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 控制台会显示下载成功信息。
3、保存 csv 文件。
4、电影图片显示。
[七、总结]
1、 不建议抓太多数据,可能会造成服务器负载,简单试一下。
2、 这篇文章就Python爬豆瓣的难点和关键点,以及如何防止回爬做了相对的解决。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要霸道,不要霸道,要了解的更深。
5、需要本文源码的可以在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发并分享给更多人****
IT共享家庭 查看全部
文章采集调用(豆瓣网影评:电影中如何获取真正请求的地址?)
【一、项目背景】
豆瓣影业提供最新的电影介绍和影评,包括正在放映的电影的视频查询和购票服务。顺便可以录下想看的电影和电视剧,看,看,还可以写影评。它极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量抓取对应的电影,写入csv文件。用户可以通过评分更好地选择自己想要的电影。
【二、项目目标】
获取对应的电影名称、评分、详情链接,下载电影图片,保存文件。
[三、 涉及的图书馆和网站]
1、 网址如下:
https://movie.douban.com/j/sea ... rt%3D{}
2、 涉及的库:requests****、fake_useragent、json****、csv
3、软件:PyCharm
【四、项目分析】
1、如何请求多个页面?
当您单击下一页时,每增加一页,paged 将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
2、如何获取实际请求的地址?
请求数据的时候,发现页面上没有对应的数据。其实豆瓣是通过javascript动态加载内容来防止采集
的。
1)F12 右击查看,在左侧菜单中找到Network,和name,找到第五个数据,点击Preview。
2) 点击subjects,可以看到title是对应电影的名字。率是相应的分数。通过js解析subjects字典,找到需要的字段。
如何上网?
https://movie.douban.com/j/sea ... t%3D0
https://movie.douban.com/j/sea ... %3D20
https://movie.douban.com/j/sea ... %3D40
https://movie.douban.com/j/sea ... %3D60
当您单击下一页时,每增加一页,该页将增加 20。使用{}替换转换后的变量,然后使用for循环遍历URL实现多个URL请求。
【五、项目实施】
1、 我们定义一个类继承对象,然后定义init方法继承self,再定义一个main函数main继承self。导入所需的库和请求 URL。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/sea ... rt%3D{}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、 随机生成UserAgent,构造请求头,防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求,得到响应,页面回调方便下一个请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json 解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、进行遍历,获取对应的电影名,评分,链接到下一个详情页。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建一个用于写入的csv文件,定义相应的header内容,并保存数据。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、求图片地址。定义图片的名称并保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、 调用方法来实现功能。
html = self.get_page(url)
self.parse_page(html)
9、项目优化:
1) 设置时间延迟。
time.sleep(1.4)
2) 定义一个变量u,用于遍历,表示爬取的是哪个页面。(更清晰,更令人印象深刻)。
u = 0
self.u += 1;
【六、效果展示】
1、 点击绿色三角进入起始页和结束页(从第0页开始)。
2、 控制台会显示下载成功信息。
3、保存 csv 文件。
4、电影图片显示。
[七、总结]
1、 不建议抓太多数据,可能会造成服务器负载,简单试一下。
2、 这篇文章就Python爬豆瓣的难点和关键点,以及如何防止回爬做了相对的解决。
3、希望这个项目能帮助大家了解json解析页面的基本流程,如何拼接字符串,如何使用format函数。
4、 本文基于Python网络爬虫,利用爬虫库实现豆瓣电影及其图片的获取。说到实现,总会有各种各样的问题。不要霸道,不要霸道,要了解的更深。
5、需要本文源码的可以在后台回复“豆瓣电影”获取。
****看完这篇文章你有收获吗?请转发并分享给更多人****
IT共享家庭
文章采集调用(前台会员中心调用显示wordpress会员投搞发表的文章数量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-12-26 06:15
想打电话给前台的会员中心,显示WordPress会员发表的文章数,习惯性的搜索谷歌看看有没有相关的教程功能代码。如果没有功能代码,就找插件。如果没有插件,那就自己考虑代码调用。, 有幸找到zwwooooo发布的WordPress:获取某作者文章数的教程,刚好满足需要,无需自己找插件或研究,谢谢作者!
操作方法:通过WP_Query()函数实现,循环获取数量。
在当前主题的functions.php文件中添加如下函数代码:
1
2
3
4
5
6
7
8
9
10
/* number of author's posts by zwwooooo */
function num_of_author_posts($authorID=''){ //根据作者ID获取该作者的文章数量
if ($authorID) {
$author_query = new WP_Query( 'posts_per_page=-1&author='.$authorID );
$i=0;
while ($author_query->have_posts()) : $author_query->the_post(); ++$i; endwhile; wp_reset_postdata();
return $i;
}
return false;
}
在要显示作者文章数量的地方添加调用代码:
1
注意:$authorID的获取方式有很多种,每个页面的获取方式都不一样。自行研究。一般这些函数是get_the_author_meta(), get_userdata()... 去WordPress官方查一下(直接谷歌搜索函数名即可)
相关功能代码来自zwwooooo博客
除特别注明外,文章均由博客网整理发布,欢迎转载。 查看全部
文章采集调用(前台会员中心调用显示wordpress会员投搞发表的文章数量)
想打电话给前台的会员中心,显示WordPress会员发表的文章数,习惯性的搜索谷歌看看有没有相关的教程功能代码。如果没有功能代码,就找插件。如果没有插件,那就自己考虑代码调用。, 有幸找到zwwooooo发布的WordPress:获取某作者文章数的教程,刚好满足需要,无需自己找插件或研究,谢谢作者!
操作方法:通过WP_Query()函数实现,循环获取数量。
在当前主题的functions.php文件中添加如下函数代码:
1
2
3
4
5
6
7
8
9
10
/* number of author's posts by zwwooooo */
function num_of_author_posts($authorID=''){ //根据作者ID获取该作者的文章数量
if ($authorID) {
$author_query = new WP_Query( 'posts_per_page=-1&author='.$authorID );
$i=0;
while ($author_query->have_posts()) : $author_query->the_post(); ++$i; endwhile; wp_reset_postdata();
return $i;
}
return false;
}
在要显示作者文章数量的地方添加调用代码:
1
注意:$authorID的获取方式有很多种,每个页面的获取方式都不一样。自行研究。一般这些函数是get_the_author_meta(), get_userdata()... 去WordPress官方查一下(直接谷歌搜索函数名即可)
相关功能代码来自zwwooooo博客
除特别注明外,文章均由博客网整理发布,欢迎转载。
文章采集调用(微服务下的几个监控维度(下)化服务)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-12-26 06:01
前言
微服务是一种架构风格。一个大型复杂的软件应用程序通常由多个微服务组成。系统中的每一个微服务都可以独立部署,每一个微服务都是松耦合的。每个微服务只专注于完成一项任务,并且很好地完成该任务。
微服务之前的很多单体应用,监控复杂度相对较低,场景单一。在微服务下,因为业务逻辑分散在很多流程中(很多大的业务,一个业务流程涉及几十个服务),一旦一个业务出现问题,追根溯源就像大海捞针。这时候就需要一个完整的监控系统。
一个完整的监控系统建设周期长,随着业务场景的变化,也需要迭代优化。本文仅从几个监控维度和雾化场景谈如何建立统一的监控数据采集和展示系统,希望能启发大家继续思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的改变。我们已将监控从机器角度转变为以服务为中心的角度。从微服务的角度,可以从数据和资源两个维度来查看监控。用代码维度分层,如下图:
数据维度
目前的WEB服务是主流。每个WEB服务都有一个入口,无论是APP还是WEB页面,入口负责与用户进行交互,并将用户的信息发送到后端。后端一般可以访问LB或者Gateway,负责负载。将数据平衡转发给特定的应用程序进行处理,最后由应用程序处理后写入数据库。
资源维度
现在很多服务都部署在云中,涉及到虚拟化技术。虚拟主机运行在物理服务器上,虚拟主机通过虚拟网络相互连接。资源层面的监控是必不可少的环节。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器上的CPU、内存、磁盘IO等数据,以及虚拟主机之间的连接情况。虚拟网络的带宽负载等。
代码维度
APM,即代码端的应用性能分析、监控和采集
,随着微服务的兴起而出现。微服务场景下,一个业务流程跨越几十个服务场景,只有传统的监控数据,很难定位问题的根源。
我们可以为代码的技术栈开发一个特定的集合框架。在可接受的性能损失范围内,我们可以采集
函数之间的调用关系,服务之间的调用拓扑,并测量函数或服务的响应时间。有针对性地优化性能或提前预测故障。
关键监测指标情景描述
微服务监控最大的特点可以用一句话概括:服务这么多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关且错综复杂的服务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了每个维度下各个级别可能产生的告警,总结了URL监控、主机监控、产品监控8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以使用 MOCK 调用 API 获取响应时间、响应状态码等指标来展示监控业务的整体健康状况。
主机监控:通过安装代理,采集
主机的基本监控信息,如CPU、内存、IO等。同时,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据采集开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载相应组件的监控采集程序。
自定义监控:服务实例采集
业务相关数据,定期调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户根据资源上报自定义数据。每个资源具有相同的监控项,每个资源的监控项相互独立。
APM:根据各个语言栈的不同,实现服务间函数调用关系和调用拓扑的展示。根据每种语言的不同,有的需要侵入代码,以SDK嵌入的形式采集数据,有的与代码解耦,通过元编程重新加载一些方法来实现数据采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘Reset事件等,提供统一的存储、分析和展示。
通过以上原子场景的数据采集,我们可以通过UI统一展示监控数据,并基于上述三个维度设计图形化页面,以用户体验为核心。图形化一般以时间序列为横轴,显示随时间变化的指标。对于一些统计指标,分析比较结果也可以通过饼图、直方图等方式展示。
本文主要介绍监控系统中数据的采集和展示。至于数据存储和报警过程,感兴趣的同学可以继续关注后续监控相关文章。
关于作者
董磊:UCloud技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。 查看全部
文章采集调用(微服务下的几个监控维度(下)化服务)
前言
微服务是一种架构风格。一个大型复杂的软件应用程序通常由多个微服务组成。系统中的每一个微服务都可以独立部署,每一个微服务都是松耦合的。每个微服务只专注于完成一项任务,并且很好地完成该任务。
微服务之前的很多单体应用,监控复杂度相对较低,场景单一。在微服务下,因为业务逻辑分散在很多流程中(很多大的业务,一个业务流程涉及几十个服务),一旦一个业务出现问题,追根溯源就像大海捞针。这时候就需要一个完整的监控系统。
一个完整的监控系统建设周期长,随着业务场景的变化,也需要迭代优化。本文仅从几个监控维度和雾化场景谈如何建立统一的监控数据采集和展示系统,希望能启发大家继续思考监控系统的建设。
微服务下的几个监控维度
与传统应用的监控相比,微服务监控最明显的变化就是视角的改变。我们已将监控从机器角度转变为以服务为中心的角度。从微服务的角度,可以从数据和资源两个维度来查看监控。用代码维度分层,如下图:
数据维度
目前的WEB服务是主流。每个WEB服务都有一个入口,无论是APP还是WEB页面,入口负责与用户进行交互,并将用户的信息发送到后端。后端一般可以访问LB或者Gateway,负责负载。将数据平衡转发给特定的应用程序进行处理,最后由应用程序处理后写入数据库。
资源维度
现在很多服务都部署在云中,涉及到虚拟化技术。虚拟主机运行在物理服务器上,虚拟主机通过虚拟网络相互连接。资源层面的监控是必不可少的环节。我们不仅需要采集虚拟主机的性能指标,还需要知道运行虚拟主机的服务器上的CPU、内存、磁盘IO等数据,以及虚拟主机之间的连接情况。虚拟网络的带宽负载等。
代码维度
APM,即代码端的应用性能分析、监控和采集
,随着微服务的兴起而出现。微服务场景下,一个业务流程跨越几十个服务场景,只有传统的监控数据,很难定位问题的根源。
我们可以为代码的技术栈开发一个特定的集合框架。在可接受的性能损失范围内,我们可以采集
函数之间的调用关系,服务之间的调用拓扑,并测量函数或服务的响应时间。有针对性地优化性能或提前预测故障。
关键监测指标情景描述
微服务监控最大的特点可以用一句话概括:服务这么多,服务之间的调用也很复杂。当系统出现问题时,要想在数百个相关且错综复杂的服务系统中快速定位故障系统,就需要依靠关键的监控指标。基于以上三个维度,我们分析了每个维度下各个级别可能产生的告警,总结了URL监控、主机监控、产品监控8个原子监控场景。
URL监控:无论是APP还是WEB,本质上都是通过URL发起后台调用。您可以使用 MOCK 调用 API 获取响应时间、响应状态码等指标来展示监控业务的整体健康状况。
主机监控:通过安装代理,采集
主机的基本监控信息,如CPU、内存、IO等。同时,用户可以通过配置文件打开其他开源应用如Tomcat、Nginx等数据采集开关。
产品监控:公有云以产品的形式向用户提供主机、网络、存储和一些中间件。产品服务后台上报各个产品的相关指标数据,监控各个产品资源的健康状况。
组件监控:一些开源组件,如Tomcat、Nginx、Netty等监控数据采集,可以通过宿主机上的代理加载相应组件的监控采集程序。
自定义监控:服务实例采集
业务相关数据,定期调用API接口上报数据,支持多个服务实例同时上报一个监控项,支持多维度查询告警。
资源监控:用户根据资源上报自定义数据。每个资源具有相同的监控项,每个资源的监控项相互独立。
APM:根据各个语言栈的不同,实现服务间函数调用关系和调用拓扑的展示。根据每种语言的不同,有的需要侵入代码,以SDK嵌入的形式采集数据,有的与代码解耦,通过元编程重新加载一些方法来实现数据采集。
事件监控:对公有云产品和业务逻辑中的不连续事件,如云盘不可用事件、SSD硬盘Reset事件等,提供统一的存储、分析和展示。
通过以上原子场景的数据采集,我们可以通过UI统一展示监控数据,并基于上述三个维度设计图形化页面,以用户体验为核心。图形化一般以时间序列为横轴,显示随时间变化的指标。对于一些统计指标,分析比较结果也可以通过饼图、直方图等方式展示。
本文主要介绍监控系统中数据的采集和展示。至于数据存储和报警过程,感兴趣的同学可以继续关注后续监控相关文章。
关于作者
董磊:UCloud技术专家。十年IT行业开发经验,目前负责UCloud混合云及监控产品的设计开发,持续专注于微服务架构、监控、DevOps等领域。
文章采集调用(给你八分钟搞定dedeCMS(织梦内容管理系统)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-12-23 02:13
给你八分钟搞定dedecms(织梦内容管理系统)
,并且在易用性方面,有了长足的发展。德德cms免费版的主要目标用户锁定在个人站长,功能更侧重于个人网站或中小型门户网站的建设。当然,也有企业用户和学校使用这个系统。当我第一次看到这个界面时,我很陌生。只知道界面有很多功能,但不知道具体是做什么的……我用dedecms做官网,所以没用很多功能。. 第4分钟_这里的核心主要是生成网站的导航,可以在导航中添加文章(这里特别强调,原因是喜欢这里的想法…… 把它放在导航里所有的内容都可以用文章的形式表达)这是工作的第一步,至少我是这么认为的..第5分钟_系统在系统栏,什么我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 至少我是这么认为的.. 第5分钟_系统在系统栏,我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在系统中灵活调用这些变量后续的开发过程。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 至少我是这么认为的.. 第5分钟_系统在系统栏,我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在系统中灵活调用这些变量后续的开发过程。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面
1.3K 查看全部
文章采集调用(给你八分钟搞定dedeCMS(织梦内容管理系统)(图))
给你八分钟搞定dedecms(织梦内容管理系统)
,并且在易用性方面,有了长足的发展。德德cms免费版的主要目标用户锁定在个人站长,功能更侧重于个人网站或中小型门户网站的建设。当然,也有企业用户和学校使用这个系统。当我第一次看到这个界面时,我很陌生。只知道界面有很多功能,但不知道具体是做什么的……我用dedecms做官网,所以没用很多功能。. 第4分钟_这里的核心主要是生成网站的导航,可以在导航中添加文章(这里特别强调,原因是喜欢这里的想法…… 把它放在导航里所有的内容都可以用文章的形式表达)这是工作的第一步,至少我是这么认为的..第5分钟_系统在系统栏,什么我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 至少我是这么认为的.. 第5分钟_系统在系统栏,我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在系统中灵活调用这些变量后续的开发过程。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 至少我是这么认为的.. 第5分钟_系统在系统栏,我们需要的是设置我们的一些系统变量,这里设置系统变量后,方便我们在系统中灵活调用这些变量后续的开发过程。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面 方便我们在后续开发过程中灵活调用这些变量。dedecms中的第六分钟_模板,最灵活的应该是系统提供的在这里,我们可以将我们的页面编辑成模板,然后调用....更多模板标签:http:v53archivestag 7th minute_生成最后一分钟,我们已经写好了自己的模板,后面需要用到这些模板,我们可以在导航栏中调用这些模板,最后生成我们的页面
1.3K
文章采集调用(免费开源可商用的PHP万能建站程序-DiYunCMS(帝云CMS))
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-12-20 15:03
免费、开源、可商用的PHP通用建站程序-帝云cms(帝云cms)
对于个性化的需求,需要在首页或者其他模板页面的指定分类下调用文章,那么我们就可以实现:
网上很容易找到这个教程,但是有个问题。调用的文章没有按最新排序,或者发布时间越早排在前面,肯定是不合理的。已修复一流的资源网络。这个问题。
1、首先打开index.php文件,找到如下代码:
$smarty->assign('new_articles', index_get_new_articles()); // 最新文章
在此行下方添加以下代码:
$smarty->assign('class_articles_4', index_get_class_articles(4,6)); // 分类调用文章
4 是 文章 类别 ID,6 是显示的项目数。
如果调用的category很多,只需要复制粘贴上一行即可,但是文章category id和调用次数要根据自己的需要修改。
打开ecshop根目录下的includes/init.php文件,在最下方添加如下代码,并添加到?>。
2、还在这个文件中吗?> 在这之前添加以下函数:
/**
* 获得指定栏目最新的文章列表。
*
* @access private
* @return array
*/
function index_get_class_articles($cat_aid, $cat_num)
{
$sql = "SELECT article_id, title,open_type,cat_id,file_url,description FROM " .$GLOBALS['ecs']->table('article'). " WHERE cat_id = ".$cat_aid." and is_open = 1 ORDER BY add_time DESC LIMIT " . $cat_num;
$res = $GLOBALS['db']->getAll($sql);
$arr = array();
foreach ($res AS $idx => $row)
{
$arr[$idx]['id'] = $row['article_id'];
$arr[$idx]['title'] = $row['title'];
$arr[$idx]['file_url'] = $row['file_url'];
$arr[$idx]['description'] = $row['description'];
$arr[$idx]['short_title'] = $GLOBALS['_CFG']['article_title_length'] > 0 ?
sub_str($row['title'], $GLOBALS['_CFG']['article_title_length']) : $row['title'];
$arr[$idx]['cat_name'] = $row['cat_name'];
$arr[$idx]['add_time'] = local_date($GLOBALS['_CFG']['date_format'], $row['add_time']);
$arr[$idx]['url'] = $row['open_type'] != 1 ?
build_uri('article', array('aid' => $row['article_id']), $row['title']) : trim($row['file_url']);
$arr[$idx]['cat_url'] = build_uri('article_cat', array('acid' => $row['cat_id']));
}
return $arr;
}
<p>3、在要调用index.dwt模板的地方添加如下代码(注意:调整上面设置中的文章列表,类别ID为4): 查看全部
文章采集调用(免费开源可商用的PHP万能建站程序-DiYunCMS(帝云CMS))
免费、开源、可商用的PHP通用建站程序-帝云cms(帝云cms)
对于个性化的需求,需要在首页或者其他模板页面的指定分类下调用文章,那么我们就可以实现:
网上很容易找到这个教程,但是有个问题。调用的文章没有按最新排序,或者发布时间越早排在前面,肯定是不合理的。已修复一流的资源网络。这个问题。
1、首先打开index.php文件,找到如下代码:
$smarty->assign('new_articles', index_get_new_articles()); // 最新文章
在此行下方添加以下代码:
$smarty->assign('class_articles_4', index_get_class_articles(4,6)); // 分类调用文章
4 是 文章 类别 ID,6 是显示的项目数。
如果调用的category很多,只需要复制粘贴上一行即可,但是文章category id和调用次数要根据自己的需要修改。
打开ecshop根目录下的includes/init.php文件,在最下方添加如下代码,并添加到?>。
2、还在这个文件中吗?> 在这之前添加以下函数:
/**
* 获得指定栏目最新的文章列表。
*
* @access private
* @return array
*/
function index_get_class_articles($cat_aid, $cat_num)
{
$sql = "SELECT article_id, title,open_type,cat_id,file_url,description FROM " .$GLOBALS['ecs']->table('article'). " WHERE cat_id = ".$cat_aid." and is_open = 1 ORDER BY add_time DESC LIMIT " . $cat_num;
$res = $GLOBALS['db']->getAll($sql);
$arr = array();
foreach ($res AS $idx => $row)
{
$arr[$idx]['id'] = $row['article_id'];
$arr[$idx]['title'] = $row['title'];
$arr[$idx]['file_url'] = $row['file_url'];
$arr[$idx]['description'] = $row['description'];
$arr[$idx]['short_title'] = $GLOBALS['_CFG']['article_title_length'] > 0 ?
sub_str($row['title'], $GLOBALS['_CFG']['article_title_length']) : $row['title'];
$arr[$idx]['cat_name'] = $row['cat_name'];
$arr[$idx]['add_time'] = local_date($GLOBALS['_CFG']['date_format'], $row['add_time']);
$arr[$idx]['url'] = $row['open_type'] != 1 ?
build_uri('article', array('aid' => $row['article_id']), $row['title']) : trim($row['file_url']);
$arr[$idx]['cat_url'] = build_uri('article_cat', array('acid' => $row['cat_id']));
}
return $arr;
}
<p>3、在要调用index.dwt模板的地方添加如下代码(注意:调整上面设置中的文章列表,类别ID为4):
文章采集调用()
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-12-19 11:12
在Dedecms系统中,文章摘要(可以通过infolen或description相关标签调用)设置为最多250个字符。设置上限的主要目的是减少数据库的冗余,保证网站良好的性能。所以,如果不给profile的内容设置上限,显然是不合理的。但是,如果您可以自由控制此上限,则会对网页内容的布局产生积极的影响。在网页设计过程中,经常需要对文章摘要进行列表页面调用。如果文章摘要中的字数能够得到有效控制,那么页面布局就可以变得非常灵活。
一、使用infolen限制调用文章描述词的数量,如下标签所示:
{dede:arclist row="1" infolen='170'}
[字段:信息/]...
{/dede:arclist}
上面的infolen='170'表示调用170字节的文章描述
二、使用 [field:description function='cn_substr(@me,250)'/] 代替 [field:info/] 标签,其中 250 是字节限制,您可以将其用作多字随你改,注意这里的250是一个字节,一个字等于2个字节,也就是这里调用了125个字。
在Dedecms中,调用列表页文章汇总的主要方法有:
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me,字符数)"/]
1、的第二种方法是直接调用文章的summary。在调用的单词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}{/dede :arclist},设置调用摘要中的字符数(向上到系统设置的250));如果使用[field:description /],则直接使用后台设置的摘要字符上限。很明显,这两种方法都非常被动,灵活性太差。
第四种方法3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在不修改文章抽象内容字符上限的情况下,这四种方法区别不大。不过下面我们来说说如何修改这个上限来体现方法的重要性[field:description function="cn_substr(@me,number of characters)"/]。
在dedecms中,与文章的摘要相关的php文件主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$description = cn_substrR($description,$cfg_autot_description);
这句话实现了
[field:description function="cn_substr(@me,字符数)"/]
此功能。因为这个语句确实有利于页面布局,所以我们在实验中没有修改。
在编辑页面上,有一句话:
$description = cn_substrR($description,250);
这句话出现了熟悉的字符数“250”,这是系统设置的文章抽象字符数的上限。如果是gbk编码,显示125个字。如果是utf-8编码,则是81个字符。很明显,我们要突破文章抽象字符的上限,必须要拿下。是的,在这里您可以将“250”修改为其他值,例如“500”。这里不建议设置太高。一是不需要在列表页面显示太多内容。最好直接用body来显示太多的内容。一是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面找到“if($dsize>250) $dsize = 250;”这句话,限制了后台可以自动获取的字符数,这里修改“250”到“500”是的,也就是和之前修改的字符数一样。如果你确认你的每个文章都是手动添加的,如果手动完成就不需要修改这个文件了摘要采集,自动摘要采集主要是为大量文章和采集准备的。
最后登录后台,在系统-系统基本参数-其他选项中,可以将自动汇总长度改为500,与之前修改的字符数相同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid='' row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为网页布局提供了更广阔的空间。
转载于: 查看全部
文章采集调用()
在Dedecms系统中,文章摘要(可以通过infolen或description相关标签调用)设置为最多250个字符。设置上限的主要目的是减少数据库的冗余,保证网站良好的性能。所以,如果不给profile的内容设置上限,显然是不合理的。但是,如果您可以自由控制此上限,则会对网页内容的布局产生积极的影响。在网页设计过程中,经常需要对文章摘要进行列表页面调用。如果文章摘要中的字数能够得到有效控制,那么页面布局就可以变得非常灵活。
一、使用infolen限制调用文章描述词的数量,如下标签所示:
{dede:arclist row="1" infolen='170'}
[字段:信息/]...
{/dede:arclist}
上面的infolen='170'表示调用170字节的文章描述
二、使用 [field:description function='cn_substr(@me,250)'/] 代替 [field:info/] 标签,其中 250 是字节限制,您可以将其用作多字随你改,注意这里的250是一个字节,一个字等于2个字节,也就是这里调用了125个字。
在Dedecms中,调用列表页文章汇总的主要方法有:
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me,字符数)"/]
1、的第二种方法是直接调用文章的summary。在调用的单词数方面,使用[field:info /]时,可以使用{dede:arclist infolen=''}{/dede :arclist},设置调用摘要中的字符数(向上到系统设置的250));如果使用[field:description /],则直接使用后台设置的摘要字符上限。很明显,这两种方法都非常被动,灵活性太差。
第四种方法3、通过函数函数实现对文章摘要显示字符的灵活调整。当然,在不修改文章抽象内容字符上限的情况下,这四种方法区别不大。不过下面我们来说说如何修改这个上限来体现方法的重要性[field:description function="cn_substr(@me,number of characters)"/]。
在dedecms中,与文章的摘要相关的php文件主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$description = cn_substrR($description,$cfg_autot_description);
这句话实现了
[field:description function="cn_substr(@me,字符数)"/]
此功能。因为这个语句确实有利于页面布局,所以我们在实验中没有修改。
在编辑页面上,有一句话:
$description = cn_substrR($description,250);
这句话出现了熟悉的字符数“250”,这是系统设置的文章抽象字符数的上限。如果是gbk编码,显示125个字。如果是utf-8编码,则是81个字符。很明显,我们要突破文章抽象字符的上限,必须要拿下。是的,在这里您可以将“250”修改为其他值,例如“500”。这里不建议设置太高。一是不需要在列表页面显示太多内容。最好直接用body来显示太多的内容。一是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面找到“if($dsize>250) $dsize = 250;”这句话,限制了后台可以自动获取的字符数,这里修改“250”到“500”是的,也就是和之前修改的字符数一样。如果你确认你的每个文章都是手动添加的,如果手动完成就不需要修改这个文件了摘要采集,自动摘要采集主要是为大量文章和采集准备的。
最后登录后台,在系统-系统基本参数-其他选项中,可以将自动汇总长度改为500,与之前修改的字符数相同。
完成以上修改后,我们就可以进入频道列表页面,通过标签调用。样本标签如下:
{dede:list typeid='' row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[field:description function='cn_substr(@me,500)'/]...
{/dede:list}
通过上述方法,我们实现了被调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为网页布局提供了更广阔的空间。
转载于:
文章采集调用(美团外卖商家的爬虫分析过程,最终结果还没有出来)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-12-16 21:04
嗯,不是失败,只是记录了爬虫分析的过程采集,最终结果还没出来。
简单描述一下美团外卖商家的爬虫分析过程,结果不理想,可以通过调用JS实现。
一开始,我直接选择了美团的网页版,选择一个地方,进入外卖商家列表。
这时候直接开始写JAVA Jsoup代码,把所有的请求头和请求参数都放到请求的代码中,结果只有一个返回:
{"数据":{"customer_ip":"61.135.15.2"},"code":200100,"msg":""}
也就是说,没有得到任何数据,此时我也不知道接下来要做什么。于是在网上搜索了美团外卖爬虫。这里有一点,如果你是美团商户采集,就是那种可以遍历全网的。可以获得该商家数据。但是如果是外卖,就得单独做采集。
当然,在网页采集的不利情况下,我也查了美团APP的外卖链接:参数太多了,启动不了,然后从网页文章开始搜索@>
终于找到一篇文章@>:这篇文章提供了一个思路。你可以先看看这个文章@>。
首先分析美团H5页面上的数据
结合CSDN文章文章@>,也就是说只要知道token的生成方法,然后通过参数调用这个方法来获取token,当然这篇文章文章@>也有一点提示,但仅此而已,刚刚介绍了如何直接调用JS代码。你仍然需要自己做才能获得足够的食物和衣服。
接下来我们应该分析一下token是如何产生的?我也在网上搜索了很多文章@>,也有一些提示。这是一个很长的文章@>。不注意的话真的很糟糕。
这时候直接进入H5页面,先找到js文件。我们不能直接使用文章中的js,因为有可能js已经升级了,所以我们找最新版本的js文件。
这时候我已经验证了破解网上文章@>那篇文章所说的内容,接下来我们在原h5页面上搜索Rohr_Opt这个词。
既然不一样了,就得看看美团外卖页面列表是怎么调用这个reload方法的,继续搜索Rohr_Opt。因为是全局的,所以调用的时候会直接用这个名字来调用。注意此时的搜索不是在查看源码中搜索,而是在调试页面的源码中搜索。毕竟,它现在处于运行时状态。恭喜:
我们把红框中的代码复制一下,分析一下代码结构,看看能出现什么样的结果。
现在我们已经确定了 t+p,用 test.html 测试一下:
到此为止,我们继续观察这个reload是怎么实现的,里面有什么,为什么同样的参数刷新不同。打开min.js文件,直接搜索reload:
这个时间戳就这样一直存在,搜索没有找到用处,作为一个对象的内部字段,它应该已经被使用了。
分析完这个,我们来测试一下JAVA调用JS的技术。但这部分事情还没有弄清楚!如果有人修复它,请告诉我。复制一个简单的调用代码:
参考链接 查看全部
文章采集调用(美团外卖商家的爬虫分析过程,最终结果还没有出来)
嗯,不是失败,只是记录了爬虫分析的过程采集,最终结果还没出来。
简单描述一下美团外卖商家的爬虫分析过程,结果不理想,可以通过调用JS实现。
一开始,我直接选择了美团的网页版,选择一个地方,进入外卖商家列表。
这时候直接开始写JAVA Jsoup代码,把所有的请求头和请求参数都放到请求的代码中,结果只有一个返回:
{"数据":{"customer_ip":"61.135.15.2"},"code":200100,"msg":""}
也就是说,没有得到任何数据,此时我也不知道接下来要做什么。于是在网上搜索了美团外卖爬虫。这里有一点,如果你是美团商户采集,就是那种可以遍历全网的。可以获得该商家数据。但是如果是外卖,就得单独做采集。
当然,在网页采集的不利情况下,我也查了美团APP的外卖链接:参数太多了,启动不了,然后从网页文章开始搜索@>
终于找到一篇文章@>:这篇文章提供了一个思路。你可以先看看这个文章@>。
首先分析美团H5页面上的数据
结合CSDN文章文章@>,也就是说只要知道token的生成方法,然后通过参数调用这个方法来获取token,当然这篇文章文章@>也有一点提示,但仅此而已,刚刚介绍了如何直接调用JS代码。你仍然需要自己做才能获得足够的食物和衣服。
接下来我们应该分析一下token是如何产生的?我也在网上搜索了很多文章@>,也有一些提示。这是一个很长的文章@>。不注意的话真的很糟糕。
这时候直接进入H5页面,先找到js文件。我们不能直接使用文章中的js,因为有可能js已经升级了,所以我们找最新版本的js文件。
这时候我已经验证了破解网上文章@>那篇文章所说的内容,接下来我们在原h5页面上搜索Rohr_Opt这个词。
既然不一样了,就得看看美团外卖页面列表是怎么调用这个reload方法的,继续搜索Rohr_Opt。因为是全局的,所以调用的时候会直接用这个名字来调用。注意此时的搜索不是在查看源码中搜索,而是在调试页面的源码中搜索。毕竟,它现在处于运行时状态。恭喜:
我们把红框中的代码复制一下,分析一下代码结构,看看能出现什么样的结果。
现在我们已经确定了 t+p,用 test.html 测试一下:
到此为止,我们继续观察这个reload是怎么实现的,里面有什么,为什么同样的参数刷新不同。打开min.js文件,直接搜索reload:
这个时间戳就这样一直存在,搜索没有找到用处,作为一个对象的内部字段,它应该已经被使用了。
分析完这个,我们来测试一下JAVA调用JS的技术。但这部分事情还没有弄清楚!如果有人修复它,请告诉我。复制一个简单的调用代码:
参考链接

