
文章采集调用
文章采集调用( AI技术——指标采集、预测与异常检测的相关内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-04-07 20:23
AI技术——指标采集、预测与异常检测的相关内容)
高斯松鼠俱乐部
学习探索和分享前沿数据库知识和技术,构建数据库技术交流圈
关注之前的图文,我们分享了AI技术的相关内容——智能索引推荐,本文将详细介绍AI技术的相关内容——索引采集,预测和异常检测。8.5指标采集,Prediction and Anomaly Detection 数据库指标监控和异常检测技术,通过监控数据库指标,并基于时序预测和异常检测等算法,发现异常信息,然后进行提醒用户采取措施避免异常情况产生严重后果。8.5.1 使用场景 用户操作数据库的某些行为或某些正在运行的业务的变化可能会导致数据库异常。如果这些异常没有及时发现和处理,导致严重后果。通常,数据库监控指标(指标,如 CPU 使用率、QPS 等)可以反映数据库系统的健康状况。通过监控数据库指标,分析指标数据特征或变化趋势,及时发现数据库异常情况,及时向运维管理人员推送告警信息,避免损失。8.5.2 实现原理 并及时将告警信息推送给运维管理人员,避免损失。8.5.2 实现原理 并及时将告警信息推送给运维管理人员,避免损失。8.5.2 实现原理
图 1 Anomaly-Detection 框架
指标采集,预测和异常检测由同一个系统实现,在openGauss项目中命名为Anomaly-Detection,其结构如图1所示。该工具可分为Agent和Detector两部分. Agent是一个数据库代理模块,负责采集数据库指标数据并将数据推送到Detector;Detector是一个数据库异常检测分析模块,主要有3个功能。(1) 采集并转储 Agent 采集 的数据。(2) 对采集到的数据进行特征分析和异常检测。(3) 将检测到的异常信息推送到1. Agent模块的组成 Agent模块负责采集和指标数据的发送。该模块由三个子模块组成:DBSource、MemoryChannel 和 HttpSink。(1) DBSource作为数据源,负责定时采集数据库指标数据,并将数据发送到数据通道MemoryChannel。(2) MemoryChannel是内存数据通道,本质上是数据的FIFO队列缓存,HttpSink组件消费MemoryChannel Data中的数据,为了防止MemoryChannel中数据过多导致OOM(out of Memory,内存溢出),设置了容量上限,当容量上限为超过,过多的元素将被禁止入队列。(3)HttpSink为数据采集点,该模块周期性的从MemoryChannel获取数据,并以Http(s)的形式转发数据。之后读取数据,它从 MemoryChannel 中清除。2. Detector模块由Detector模块组成,负责数据检测,该模块由Server和Monitor两个子模块组成。(1)Server是一个Web服务,就是Agent采集接收到的数据提供了一个接收接口,将数据存储在本地数据库中。为了防止数据库由于随着数据的增加,我们对数据库中每张表的行数设置了上限。(2) Monitor模块包括时序预测和异常检测等算法。该模块定期从本地数据库,并基于现有算法对数据进行预测和分析。
def forecast(args):
…
# 如果没有指定预测方式,则默认使用’auto_arima’算法
if not args.forecast_method:
forecast_alg = get_instance('auto_arima')
else:
forecast_alg = get_instance(args.forecast_method)
# 指标预测功能函数
def forecast_metric(name, train_ts, save_path=None):
…
forecast_alg.fit(timeseries=train_ts)
dates, values = forecast_alg.forecast(
period=TimeString(args.forecast_periods).standard)
date_range = "{start_date}~{end_date}".format(start_date=dates[0],
end_date=dates[-1])
display_table.add_row(
[name, date_range, min(values), max(values), sum(values) / len(values)]
)
# 校验存储路径
if save_path:
if not os.path.exists(os.path.dirname(save_path)):
os.makedirs(os.path.dirname(save_path))
with open(save_path, mode='w') as f:
for date, value in zip(dates, values):
f.write(date + ',' + str(value) + '\n')
# 从本地sqlite中抽取需要的数据
with sqlite_storage.SQLiteStorage(database_path) as db:
if args.metric_name:
timeseries = db.get_timeseries(table=args.metric_name, period=max_rows)
forecast_metric(args.metric_name, timeseries, args.save_path)
else:
# 获取sqlite中所有的表名
tables = db.get_all_tables()
# 从每个表中抽取训练数据进行预测
for table in tables:
timeseries = db.get_timeseries(table=table, period=max_rows)
forecast_metric(table, timeseries)
# 输出结果
print(display_table.get_string())
# 代码远程部署
def deploy(args):
print('Please input the password of {user}@{host}: '.format(user=args.user, host=args.host))
# 格式化代码远程部署指令
command = 'sh start.sh --deploy {host} {user} {project_path}' \
.format(user=args.user,
host=args.host,
project_path=args.project_path)
# 判断指令执行情况
if subprocess.call(shlex.split(command), cwd=SBIN_PATH) == 0:
print("\nExecute successfully.")
else:
print("\nExecute unsuccessfully.")
…
# 展示当前监控的参数
def show_metrics():
…
# 项目总入口
def main():
…
2. 关键代码段分析(1) 后台线程的实现。前面说过,这个功能可以分为三个角色:Agent、Monitor 和 Detector,这三个不同的角色都是常见的进程驻留在后台执行不同的任务,Daemon类是负责运行不同业务流程的容器类,下面介绍这个类的实现。
class Daemon:
"""
This class implements the function of running a process in the background."""
def __init__(self):
…
def daemon_process(self):
# 注册退出函数
atexit.register(lambda: os.remove(self.pid_file))
signal.signal(signal.SIGTERM, handle_sigterm)
# 启动进程
@staticmethod
def start(self):
try:
self.daemon_process()
except RuntimeError as msg:
abnormal_exit(msg)
self.function(*self.args, **self.kwargs)
# 停止进程
def stop(self):
if not os.path.exists(self.pid_file):
abnormal_exit("Process not running.")
read_pid = read_pid_file(self.pid_file)
if read_pid > 0:
os.kill(read_pid, signal.SIGTERM)
if read_pid_file(self.pid_file) < 0:
os.remove(self.pid_file)
(2)数据库相关指标采集流程。数据库指标采集架构参考了Apache Flume的设计。一个完整的信息采集流程分为三个部分,分别是Source , Channel 和 Sink. 以上三部分被抽象成三个不同的基类, 从中可以派生出不同的采集 数据源, 缓存管道和数据接收者. 前面说过DBSource派生自Source, MemoryChannel派生来源于Channel,HttpSink来源于Sink,下面代码来源于metric_agent.py,负责采集指标,上面的模块是串联的。
def agent_main():
…
# 初始化通道管理器
cm = ChannelManager()
# 初始化数据源
source = DBSource()
http_sink = HttpSink(interval=params['sink_timer_interval'], url=url, context=context)
source.channel_manager = cm
http_sink.channel_manager = cm
# 获取参数文件里面的功能函数
for task_name, task_func in get_funcs(metric_task):
source.add_task(name=task_name,
interval=params['source_timer_interval'],
task=task_func,
maxsize=params['channel_capacity'])
source.start()
http_sink.start()
(3)实现数据存储和监控。Agent将采集收到的指标数据发送到Detector服务器,Detector服务器负责存储。Monitor不断检查存储的数据,以便提前发现异常,这里实现了一个通过SQLite进行本地化存储的方法,代码位于sqlite_storage.py文件中,实现的类为SQLiteStorage,该类实现的主要方法如下:
# 通过时间戳获取最近一段时间的数据
def select_timeseries_by_timestamp(self, table, period):
…
# 通过编号获取最近一段时间的数据
def select_timeseries_by_number(self, table, number):
…
其中,由于不同指标的数据存储在不同的表中,所以上述参数表也代表了不同指标的名称。异常检测目前主要支持基于时间序列预测的方法,包括Prophet算法(Facebook开源的工业级时间序列预测算法工具)和ARIMA算法,封装成类供Forecaster调用。上述时序检测的算法类都继承了AlgModel类,该类的结构如下:
class AlgModel(object):
"""
This is the base class for forecasting algorithms.
If we want to use our own forecast algorithm, we should follow some rules.
"""
def __init__(self):
pass
@abstractmethod
def fit(self, timeseries):
pass
@abstractmethod
def forecast(self, period):
pass
def save(self, model_path):
pass
def load(self, model_path):
pass
在 Forecast 类中,通过调用 fit() 方法,可以根据历史时间序列数据进行训练,通过 forecast() 方法预测未来趋势。获取未来趋势后如何判断是否异常?有很多方法。最简单最基本的方法是通过阈值来判断。在我们的程序中,这个方法也默认用于判断。8.5.4 Anomaly-Detection 工具有五种操作模式:启动、停止、预测、show_metrics 和部署。每种模式的说明如表1所示。 表1 Anomaly-Detection使用模式及说明
模式名称
阐明
开始
启动本地或远程服务
停止
停止本地或远程服务
预报
未来变化的预测器
显示指标
输出当前监控的参数
部署
远程部署代码
Anomaly-Detection 工具的操作模式示例如下所示。① 使用启动方式启动本地采集器服务,代码如下:
python main.py start –role collector
② 使用停止方式停止本地采集器服务,代码如下:
python main.py stop –role collector
③ 使用启动方式启动远程采集器服务,代码如下:
python main.py start --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
④ 使用停止方式停止远程采集器服务,代码如下:
python main.py stop --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
⑤ 显示当前所有监控参数,代码如下:
python main.py show_metrics
⑥ 预测接下来60秒io_read的最大值、最小值和平均值,代码如下:
python main.py forecast –metric-name io_read –forecast-periods 60S –save-path predict_result
⑦ 将代码部署到远程服务器,代码如下:
python main.py deploy –user xxx –host xxx.xxx.xxx.xxx –project-path xxx
8.5.5 进化路线
Anomaly-Detection作为数据库指标监控和异常检测工具,目前具备数据采集、数据存储、异常检测、消息推送等基本功能。但是,存在以下问题。(1)Agent模块采集的数据太简单了,目前Agent只能采集数据库的资源索引数据,包括IO、磁盘、内存、CPU等,< @采集未来需要增强。(2)Monitor内置算法覆盖不够,Monitor目前只支持两种时序预测算法,对于异常检测,只支持基于阈值的简单案例,使用场景有限。(3) Server 仅支持 支持单Agent数据传输。目前Server采用的方案只支持从一个Agent接收数据,不支持多个Agent同时传输。这对于只有一个主节点的openGauss数据库来说暂时够用了,但显然不适合分布式部署。不友好。因此,针对上述三个问题,未来将丰富Agent以采集数据,主要包括安全指标、数据库日志等信息。其次,在算法层面,会写出鲁棒性(即算法的鲁棒性和稳定性)。增强异常检测算法,增加异常监控场景。同时,Server 需要改进以支持多 Agent 模式。最后,
以上内容是对AI技术中的指标采集、预测和异常检测的详细介绍。下一篇将分享“AI查询时间预测”的相关内容,敬请期待!
- 结尾 -
高斯松鼠俱乐部
汇聚数据库从业者和爱好者,互相帮助解决问题,构建数据库技术交流圈 查看全部
文章采集调用(
AI技术——指标采集、预测与异常检测的相关内容)

高斯松鼠俱乐部
学习探索和分享前沿数据库知识和技术,构建数据库技术交流圈
关注之前的图文,我们分享了AI技术的相关内容——智能索引推荐,本文将详细介绍AI技术的相关内容——索引采集,预测和异常检测。8.5指标采集,Prediction and Anomaly Detection 数据库指标监控和异常检测技术,通过监控数据库指标,并基于时序预测和异常检测等算法,发现异常信息,然后进行提醒用户采取措施避免异常情况产生严重后果。8.5.1 使用场景 用户操作数据库的某些行为或某些正在运行的业务的变化可能会导致数据库异常。如果这些异常没有及时发现和处理,导致严重后果。通常,数据库监控指标(指标,如 CPU 使用率、QPS 等)可以反映数据库系统的健康状况。通过监控数据库指标,分析指标数据特征或变化趋势,及时发现数据库异常情况,及时向运维管理人员推送告警信息,避免损失。8.5.2 实现原理 并及时将告警信息推送给运维管理人员,避免损失。8.5.2 实现原理 并及时将告警信息推送给运维管理人员,避免损失。8.5.2 实现原理
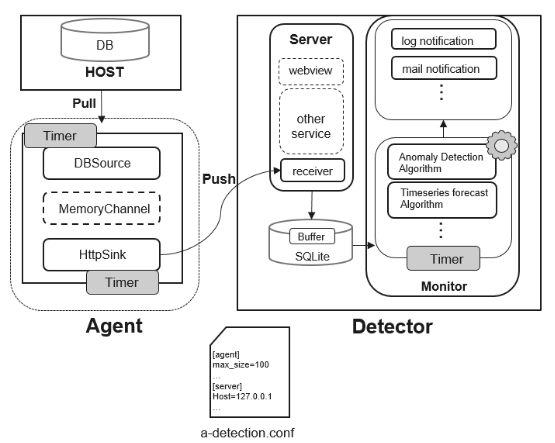
图 1 Anomaly-Detection 框架
指标采集,预测和异常检测由同一个系统实现,在openGauss项目中命名为Anomaly-Detection,其结构如图1所示。该工具可分为Agent和Detector两部分. Agent是一个数据库代理模块,负责采集数据库指标数据并将数据推送到Detector;Detector是一个数据库异常检测分析模块,主要有3个功能。(1) 采集并转储 Agent 采集 的数据。(2) 对采集到的数据进行特征分析和异常检测。(3) 将检测到的异常信息推送到1. Agent模块的组成 Agent模块负责采集和指标数据的发送。该模块由三个子模块组成:DBSource、MemoryChannel 和 HttpSink。(1) DBSource作为数据源,负责定时采集数据库指标数据,并将数据发送到数据通道MemoryChannel。(2) MemoryChannel是内存数据通道,本质上是数据的FIFO队列缓存,HttpSink组件消费MemoryChannel Data中的数据,为了防止MemoryChannel中数据过多导致OOM(out of Memory,内存溢出),设置了容量上限,当容量上限为超过,过多的元素将被禁止入队列。(3)HttpSink为数据采集点,该模块周期性的从MemoryChannel获取数据,并以Http(s)的形式转发数据。之后读取数据,它从 MemoryChannel 中清除。2. Detector模块由Detector模块组成,负责数据检测,该模块由Server和Monitor两个子模块组成。(1)Server是一个Web服务,就是Agent采集接收到的数据提供了一个接收接口,将数据存储在本地数据库中。为了防止数据库由于随着数据的增加,我们对数据库中每张表的行数设置了上限。(2) Monitor模块包括时序预测和异常检测等算法。该模块定期从本地数据库,并基于现有算法对数据进行预测和分析。
def forecast(args):
…
# 如果没有指定预测方式,则默认使用’auto_arima’算法
if not args.forecast_method:
forecast_alg = get_instance('auto_arima')
else:
forecast_alg = get_instance(args.forecast_method)
# 指标预测功能函数
def forecast_metric(name, train_ts, save_path=None):
…
forecast_alg.fit(timeseries=train_ts)
dates, values = forecast_alg.forecast(
period=TimeString(args.forecast_periods).standard)
date_range = "{start_date}~{end_date}".format(start_date=dates[0],
end_date=dates[-1])
display_table.add_row(
[name, date_range, min(values), max(values), sum(values) / len(values)]
)
# 校验存储路径
if save_path:
if not os.path.exists(os.path.dirname(save_path)):
os.makedirs(os.path.dirname(save_path))
with open(save_path, mode='w') as f:
for date, value in zip(dates, values):
f.write(date + ',' + str(value) + '\n')
# 从本地sqlite中抽取需要的数据
with sqlite_storage.SQLiteStorage(database_path) as db:
if args.metric_name:
timeseries = db.get_timeseries(table=args.metric_name, period=max_rows)
forecast_metric(args.metric_name, timeseries, args.save_path)
else:
# 获取sqlite中所有的表名
tables = db.get_all_tables()
# 从每个表中抽取训练数据进行预测
for table in tables:
timeseries = db.get_timeseries(table=table, period=max_rows)
forecast_metric(table, timeseries)
# 输出结果
print(display_table.get_string())
# 代码远程部署
def deploy(args):
print('Please input the password of {user}@{host}: '.format(user=args.user, host=args.host))
# 格式化代码远程部署指令
command = 'sh start.sh --deploy {host} {user} {project_path}' \
.format(user=args.user,
host=args.host,
project_path=args.project_path)
# 判断指令执行情况
if subprocess.call(shlex.split(command), cwd=SBIN_PATH) == 0:
print("\nExecute successfully.")
else:
print("\nExecute unsuccessfully.")
…
# 展示当前监控的参数
def show_metrics():
…
# 项目总入口
def main():
…
2. 关键代码段分析(1) 后台线程的实现。前面说过,这个功能可以分为三个角色:Agent、Monitor 和 Detector,这三个不同的角色都是常见的进程驻留在后台执行不同的任务,Daemon类是负责运行不同业务流程的容器类,下面介绍这个类的实现。
class Daemon:
"""
This class implements the function of running a process in the background."""
def __init__(self):
…
def daemon_process(self):
# 注册退出函数
atexit.register(lambda: os.remove(self.pid_file))
signal.signal(signal.SIGTERM, handle_sigterm)
# 启动进程
@staticmethod
def start(self):
try:
self.daemon_process()
except RuntimeError as msg:
abnormal_exit(msg)
self.function(*self.args, **self.kwargs)
# 停止进程
def stop(self):
if not os.path.exists(self.pid_file):
abnormal_exit("Process not running.")
read_pid = read_pid_file(self.pid_file)
if read_pid > 0:
os.kill(read_pid, signal.SIGTERM)
if read_pid_file(self.pid_file) < 0:
os.remove(self.pid_file)
(2)数据库相关指标采集流程。数据库指标采集架构参考了Apache Flume的设计。一个完整的信息采集流程分为三个部分,分别是Source , Channel 和 Sink. 以上三部分被抽象成三个不同的基类, 从中可以派生出不同的采集 数据源, 缓存管道和数据接收者. 前面说过DBSource派生自Source, MemoryChannel派生来源于Channel,HttpSink来源于Sink,下面代码来源于metric_agent.py,负责采集指标,上面的模块是串联的。
def agent_main():
…
# 初始化通道管理器
cm = ChannelManager()
# 初始化数据源
source = DBSource()
http_sink = HttpSink(interval=params['sink_timer_interval'], url=url, context=context)
source.channel_manager = cm
http_sink.channel_manager = cm
# 获取参数文件里面的功能函数
for task_name, task_func in get_funcs(metric_task):
source.add_task(name=task_name,
interval=params['source_timer_interval'],
task=task_func,
maxsize=params['channel_capacity'])
source.start()
http_sink.start()
(3)实现数据存储和监控。Agent将采集收到的指标数据发送到Detector服务器,Detector服务器负责存储。Monitor不断检查存储的数据,以便提前发现异常,这里实现了一个通过SQLite进行本地化存储的方法,代码位于sqlite_storage.py文件中,实现的类为SQLiteStorage,该类实现的主要方法如下:
# 通过时间戳获取最近一段时间的数据
def select_timeseries_by_timestamp(self, table, period):
…
# 通过编号获取最近一段时间的数据
def select_timeseries_by_number(self, table, number):
…
其中,由于不同指标的数据存储在不同的表中,所以上述参数表也代表了不同指标的名称。异常检测目前主要支持基于时间序列预测的方法,包括Prophet算法(Facebook开源的工业级时间序列预测算法工具)和ARIMA算法,封装成类供Forecaster调用。上述时序检测的算法类都继承了AlgModel类,该类的结构如下:
class AlgModel(object):
"""
This is the base class for forecasting algorithms.
If we want to use our own forecast algorithm, we should follow some rules.
"""
def __init__(self):
pass
@abstractmethod
def fit(self, timeseries):
pass
@abstractmethod
def forecast(self, period):
pass
def save(self, model_path):
pass
def load(self, model_path):
pass
在 Forecast 类中,通过调用 fit() 方法,可以根据历史时间序列数据进行训练,通过 forecast() 方法预测未来趋势。获取未来趋势后如何判断是否异常?有很多方法。最简单最基本的方法是通过阈值来判断。在我们的程序中,这个方法也默认用于判断。8.5.4 Anomaly-Detection 工具有五种操作模式:启动、停止、预测、show_metrics 和部署。每种模式的说明如表1所示。 表1 Anomaly-Detection使用模式及说明
模式名称
阐明
开始
启动本地或远程服务
停止
停止本地或远程服务
预报
未来变化的预测器
显示指标
输出当前监控的参数
部署
远程部署代码
Anomaly-Detection 工具的操作模式示例如下所示。① 使用启动方式启动本地采集器服务,代码如下:
python main.py start –role collector
② 使用停止方式停止本地采集器服务,代码如下:
python main.py stop –role collector
③ 使用启动方式启动远程采集器服务,代码如下:
python main.py start --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
④ 使用停止方式停止远程采集器服务,代码如下:
python main.py stop --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
⑤ 显示当前所有监控参数,代码如下:
python main.py show_metrics
⑥ 预测接下来60秒io_read的最大值、最小值和平均值,代码如下:
python main.py forecast –metric-name io_read –forecast-periods 60S –save-path predict_result
⑦ 将代码部署到远程服务器,代码如下:
python main.py deploy –user xxx –host xxx.xxx.xxx.xxx –project-path xxx
8.5.5 进化路线
Anomaly-Detection作为数据库指标监控和异常检测工具,目前具备数据采集、数据存储、异常检测、消息推送等基本功能。但是,存在以下问题。(1)Agent模块采集的数据太简单了,目前Agent只能采集数据库的资源索引数据,包括IO、磁盘、内存、CPU等,< @采集未来需要增强。(2)Monitor内置算法覆盖不够,Monitor目前只支持两种时序预测算法,对于异常检测,只支持基于阈值的简单案例,使用场景有限。(3) Server 仅支持 支持单Agent数据传输。目前Server采用的方案只支持从一个Agent接收数据,不支持多个Agent同时传输。这对于只有一个主节点的openGauss数据库来说暂时够用了,但显然不适合分布式部署。不友好。因此,针对上述三个问题,未来将丰富Agent以采集数据,主要包括安全指标、数据库日志等信息。其次,在算法层面,会写出鲁棒性(即算法的鲁棒性和稳定性)。增强异常检测算法,增加异常监控场景。同时,Server 需要改进以支持多 Agent 模式。最后,
以上内容是对AI技术中的指标采集、预测和异常检测的详细介绍。下一篇将分享“AI查询时间预测”的相关内容,敬请期待!
- 结尾 -

高斯松鼠俱乐部

汇聚数据库从业者和爱好者,互相帮助解决问题,构建数据库技术交流圈
文章采集调用( 列表页调用的方法有两种是切割副表的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-04-06 11:01
列表页调用的方法有两种是切割副表的)
列表页标签的调用方式有两种,一是切分表的infotags字段,二是从phome_enewstagsdata表中提取。如果 tagid 或 tag 是静态的,建议使用第二种方法,效率更高。如果使用tagname的动态链接方式,可以使用第一种方式。
第一种方法:剪切infotags字段
/* 列表页显示tag 开始*/
$fr=$empire->fetch1("select infotags from {$dbtbpre}ecms_".$class_r[$r['classid']]['tbname']."_data_{$r[stb]} where id='$r[id]'");
$tagstr='';
$infotags_r=explode(',',$fr['infotags']);
$tagscount=count($infotags_r);
for($i=0;$ifetch1("select * from {$dbtbpre}enewstags where tagname='".$tagname."' limit 1");
if(!$tt['tagid']){
continue;
}else{
$tagslink=$public_r['newsurl'].'e/tags/?tagid='.$tagid;;
}
//采用东坡网静态化插件时的tag链接,采用以下6行代码
/* $tt=$empire->fetch1("select * from {$dbtbpre}enewstags where tagname='".$tagname."' limit 1");
if(!$tt['tagid']){
continue;
}else{
$tagslink=user_HtmlTagLink($tt['tagid']);
}*/
//返回单独一个tag的代码
$tagstr.=''.$tagname.'';
}
/*结束*/
$listtemp='其它代码'.$tagstr.'其它代码';
第二种方法:从phome_enewstags数据表中提取
/* 列表页显示tag 开始*/
$tagstr='';
$tsql=$empire->query("select tagid from {$dbtbpre}enewstagsdata where id='$r[id]' and classid='$r[classid]' ");
while($tr=$empire->fetch($tsql)){
$tt=$empire->fetch1("select * from {$dbtbpre}enewstags where tagid=".$tr['tagid']." limit 1");
if(!$tt['tagid']){
continue;
}else{
//tagname的动态 或 伪静态 时的链接,采用以下1行代码
//$tagslink=eReturnRewriteTagsUrl(0,$tt['tagname'],1);
//tagid式的动态链接,采用以下1行代码
$tagslink=$public_r['newsurl'].'e/tags/?tagid='.$tt['tagid'];
//采用东坡网静态化插件时的tag链接,采用以下1行代码
//$tagslink=user_HtmlTagLink($tt['tagid']);
}
$tagstr.=''.$tt['tagname'].'';
}
/*结束*/
$listtemp='其它代码'.$tagstr.'其它代码';
说明:
1、代码中的标签链接有3种方式,可根据实际情况选择。
2、以上代码放入列表内容模板(list.var),应用代码必须开启。
版权说明:本文归东坡网原创所有,版权归东坡网所有。欢迎转载,但请保留东坡网出处。签名转载是对我们最大的支持,谢谢!
下载本文的doc文件/下载本文的PDF文件 查看全部
文章采集调用(
列表页调用的方法有两种是切割副表的)

列表页标签的调用方式有两种,一是切分表的infotags字段,二是从phome_enewstagsdata表中提取。如果 tagid 或 tag 是静态的,建议使用第二种方法,效率更高。如果使用tagname的动态链接方式,可以使用第一种方式。
第一种方法:剪切infotags字段
/* 列表页显示tag 开始*/
$fr=$empire->fetch1("select infotags from {$dbtbpre}ecms_".$class_r[$r['classid']]['tbname']."_data_{$r[stb]} where id='$r[id]'");
$tagstr='';
$infotags_r=explode(',',$fr['infotags']);
$tagscount=count($infotags_r);
for($i=0;$ifetch1("select * from {$dbtbpre}enewstags where tagname='".$tagname."' limit 1");
if(!$tt['tagid']){
continue;
}else{
$tagslink=$public_r['newsurl'].'e/tags/?tagid='.$tagid;;
}
//采用东坡网静态化插件时的tag链接,采用以下6行代码
/* $tt=$empire->fetch1("select * from {$dbtbpre}enewstags where tagname='".$tagname."' limit 1");
if(!$tt['tagid']){
continue;
}else{
$tagslink=user_HtmlTagLink($tt['tagid']);
}*/
//返回单独一个tag的代码
$tagstr.=''.$tagname.'';
}
/*结束*/
$listtemp='其它代码'.$tagstr.'其它代码';
第二种方法:从phome_enewstags数据表中提取
/* 列表页显示tag 开始*/
$tagstr='';
$tsql=$empire->query("select tagid from {$dbtbpre}enewstagsdata where id='$r[id]' and classid='$r[classid]' ");
while($tr=$empire->fetch($tsql)){
$tt=$empire->fetch1("select * from {$dbtbpre}enewstags where tagid=".$tr['tagid']." limit 1");
if(!$tt['tagid']){
continue;
}else{
//tagname的动态 或 伪静态 时的链接,采用以下1行代码
//$tagslink=eReturnRewriteTagsUrl(0,$tt['tagname'],1);
//tagid式的动态链接,采用以下1行代码
$tagslink=$public_r['newsurl'].'e/tags/?tagid='.$tt['tagid'];
//采用东坡网静态化插件时的tag链接,采用以下1行代码
//$tagslink=user_HtmlTagLink($tt['tagid']);
}
$tagstr.=''.$tt['tagname'].'';
}
/*结束*/
$listtemp='其它代码'.$tagstr.'其它代码';
说明:
1、代码中的标签链接有3种方式,可根据实际情况选择。
2、以上代码放入列表内容模板(list.var),应用代码必须开启。
版权说明:本文归东坡网原创所有,版权归东坡网所有。欢迎转载,但请保留东坡网出处。签名转载是对我们最大的支持,谢谢!
下载本文的doc文件/下载本文的PDF文件
文章采集调用(,系统中,文章摘要()字数上限为250字符,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-04-05 15:09
在Dedecms系统中,文章摘要(可以通过infolen或description相关标签调用)设置了250个字符的字符限制。设置上限的主要目的是减少数据库的冗余,保证网站良好的性能,因此,对介绍内容不设置上限显然是不合理的,但如果可以自由控制这个上限,会对网页内容的布局产生积极的影响。列表页调用 文章 的摘要。如果文章的摘要中的字数能够得到有效控制,那么页面布局就可以变得非常灵活。
一、使用infolen来限制称为文章的描述字符个数,如下标签演示所示:
{dede:arclist row=”1″ infolen='170′}
[字段:信息/]…
{/dede:arclist}
上面的infolen='170'表示调用170字节的文章描述
二、使用 [field:description function='cn_substr(@me,250)'/] 代替 [field:info/] 标记,其中 250 是字节限制,您可以将其称为多个字随便改吧,注意这里250是一个字节,一个字等于2个字节,也就是这里调用了125个字
在Dedecms中,列表页调用文章摘要的方法如下:
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是直接调用文章的抽象。在调用字数方面,使用[field:info /]时,可以在{dede:arclist infolen=' ' }{/dede :arclist}中使用,设置调用摘要的字符数(最大值可以设置为系统设置的250);如果使用[field:description/],则直接使用后台设置的摘要字符的上限,显然这两种方法是非常被动,灵活性太差。
3、的第四种方法通过function函数实现了对文章摘要中显示字符的灵活调整。当然,在不修改摘要内容的字符上限的情况下,这四种方法的区别并不大。不过说一下如何修改这个上限值,可以体现[field:description function="cn_substr(@me, number of characters)"/]的重要性。
在Dedecms中,与文章抽象相关的php文件主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$description = cn_substrR($description,$cfg_auot_description);
这句话应验了
[field:description function="cn_substr(@me, 字符数)"/]
这个功能。因为这个语句确实有利于页面布局,所以我们在实验中没有修改它。
在编辑页面,有一句话:
$description = cn_substrR($description,250);
这句话中出现了一个熟悉的字符数“250”,这是系统设置的文章摘要字符的上限。如果是gbk编码,会显示125个字符。如果是utf-8编码,就是81个字。显然,我们将打破 文章summary 字符限制,我们将不得不这样做。是的,您可以在此处将“250”更改为另一个值,例如“500”。这里不建议设置太高。一是不需要在列表页面上显示过多的内容。最好直接使用body来显示过多的内容。一是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面,找到“if($dsize>250) $dsize = 250;”语句,限制后台自动获取的字符数,这里将“250”改为“500”即和之前修改的字符数一样,如果你确认你的每一个文章都是手动添加的,如果你手动完成摘要获取就不需要修改这个文件了。自动抽象获取主要针对很多文章和采集。
最后登录后台,在系统-系统基本参数-其他选项中,自动汇总长度可以改成500,也就是可以和之前修改的字符数一样。
完成以上修改后,我们进入频道列表页面,通过标签调用。示例标签如下:
{dede:list typeid='' row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[字段:描述函数='cn_substr(@me,500)'/]...
{/dede:列表}
通过以上方法,我们实现了调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为网页布局提供了更广阔的空间。 查看全部
文章采集调用(,系统中,文章摘要()字数上限为250字符,)
在Dedecms系统中,文章摘要(可以通过infolen或description相关标签调用)设置了250个字符的字符限制。设置上限的主要目的是减少数据库的冗余,保证网站良好的性能,因此,对介绍内容不设置上限显然是不合理的,但如果可以自由控制这个上限,会对网页内容的布局产生积极的影响。列表页调用 文章 的摘要。如果文章的摘要中的字数能够得到有效控制,那么页面布局就可以变得非常灵活。
一、使用infolen来限制称为文章的描述字符个数,如下标签演示所示:
{dede:arclist row=”1″ infolen='170′}
[字段:信息/]…
{/dede:arclist}
上面的infolen='170'表示调用170字节的文章描述
二、使用 [field:description function='cn_substr(@me,250)'/] 代替 [field:info/] 标记,其中 250 是字节限制,您可以将其称为多个字随便改吧,注意这里250是一个字节,一个字等于2个字节,也就是这里调用了125个字
在Dedecms中,列表页调用文章摘要的方法如下:
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是直接调用文章的抽象。在调用字数方面,使用[field:info /]时,可以在{dede:arclist infolen=' ' }{/dede :arclist}中使用,设置调用摘要的字符数(最大值可以设置为系统设置的250);如果使用[field:description/],则直接使用后台设置的摘要字符的上限,显然这两种方法是非常被动,灵活性太差。
3、的第四种方法通过function函数实现了对文章摘要中显示字符的灵活调整。当然,在不修改摘要内容的字符上限的情况下,这四种方法的区别并不大。不过说一下如何修改这个上限值,可以体现[field:description function="cn_substr(@me, number of characters)"/]的重要性。
在Dedecms中,与文章抽象相关的php文件主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$description = cn_substrR($description,$cfg_auot_description);
这句话应验了
[field:description function="cn_substr(@me, 字符数)"/]
这个功能。因为这个语句确实有利于页面布局,所以我们在实验中没有修改它。
在编辑页面,有一句话:
$description = cn_substrR($description,250);
这句话中出现了一个熟悉的字符数“250”,这是系统设置的文章摘要字符的上限。如果是gbk编码,会显示125个字符。如果是utf-8编码,就是81个字。显然,我们将打破 文章summary 字符限制,我们将不得不这样做。是的,您可以在此处将“250”更改为另一个值,例如“500”。这里不建议设置太高。一是不需要在列表页面上显示过多的内容。最好直接使用body来显示过多的内容。一是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面,找到“if($dsize>250) $dsize = 250;”语句,限制后台自动获取的字符数,这里将“250”改为“500”即和之前修改的字符数一样,如果你确认你的每一个文章都是手动添加的,如果你手动完成摘要获取就不需要修改这个文件了。自动抽象获取主要针对很多文章和采集。
最后登录后台,在系统-系统基本参数-其他选项中,自动汇总长度可以改成500,也就是可以和之前修改的字符数一样。
完成以上修改后,我们进入频道列表页面,通过标签调用。示例标签如下:
{dede:list typeid='' row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[字段:描述函数='cn_substr(@me,500)'/]...
{/dede:列表}
通过以上方法,我们实现了调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为网页布局提供了更广阔的空间。
文章采集调用(微服务中较流行的两款开源分布式tracing系统(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-05 02:18
1.背景说明
由于我们的项目是微服务方向的,中间和后台服务有10多种服务模块,各个服务/模块之间的调用关系比较复杂,一些服务之间还有一些代理服务和服务(许多服务实时部署的实施)。这些现象导致在开发、调试和问题跟踪中逐渐出现问题。因此,前段时间,分别研究了微服务中两个流行的开源分布式追踪系统:Zipkin 和 Jaeger。
在微服务分布式架构的系统中,可能存在复杂而深入的逐层服务调用关系,如下图所示。
微服务架构中各个服务的调用关系是不是和程序中各个函数的调用关系很相似?
上图很容易理解。当用户的浏览器发起请求时,会先到应用程序A;A 将呼叫 B 和 C;B会调用F……这样一层一层的调用到最后一层,最后完成一个客户的请求。处理(可能是读请求或写请求)。
试想一下,在这个过程中会出现哪些可能的问题?
对于第一种情况,如果客户端请求是写请求,调用链中每一步都有写操作,第一步执行成功,第三步失败,那么分布式系统中需要采用分布式事务。回滚前几步的写操作的机制!
对于第二种情况,可能会因为应用F的异常而拖累整个服务环节,甚至出现雪崩现象,严重影响系统的可用性。本文不会讨论如何处理这种场景,而是先提一下,这种问题在分布式系统中使用了熔断机制和降级机制,以确保系统在出现此类异常时具有高可用性!
那么我们来看看1、2、3的场景中可能涉及的问题。在一个复杂的调用链中,假设有一个响应慢或处理异常的调用链。如何定位这个问题?有问题的服务呢?大多数开发者的第一反应可能是查看日志,依次分析调用链路上各个系统的日志文件,然后定位出问题的服务。在海量日志中定位问题真的很痛苦!
2.跟踪链
首先简单解释一下什么是跟踪链。有相关基础的可以跳过,也可以快速通读本段。基本上,任何谈论跟踪链的 文章 都会发布这张图片:
图 1. 一个简单的追踪调用流程
图 1 是来自 Google 的 Dapper 论文的一个示例:图中,五个节点 A~E 代表五个服务。用户向A发起请求RequestX。同时,由于该请求依赖于服务B和C,所以A分别向B和C发送RPC请求,B处理完请求后直接返回给A,但是服务C也依赖于服务 D 和 E。因此,必须分别向 D 和 E 发起两个 RPC 请求。D和E处理完后返回给C,C继续回复A,最后A会回复用户ReplyX。对于这样的请求,分布式跟踪的一个简单实用的实现是为服务器上的每个发送和接收操作采集跟踪标识符和时间戳。
在 Dapper 的论文中,Trace 和 Span 是两个非常重要的术语。我们用Trace来表示一个请求的完整调用链的trace,将上面的服务A和服务B这两个服务的请求/响应过程称为一个Span,通过span来反映trace。一句话概括,我们可以把一条trace看成span的一个有向图,这个有向图的边就是span。为了更好地理解这两个术语,我们可以看一下下面的调用图。
[跨度A] ←←←(根跨度)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C 是 `ChildOf` Span A)
| |
[跨度 D] +---+-----+
| |
[跨度 E] [跨度 F] >>> [跨度 G] >>> [跨度 H]
↑
↑
↑
(Span G`FollowsFrom`Span F) 上图收录8个span信息
图2.一个tracing过程的Spans关系图
––|–––––––|–––––––|–––––––|––––––––––––––|––––––– –|––––––––|–> 时间
[跨度A········································································································································································...
[跨度B················································ ····················································································································································]
[跨度D················································ ········································································································································································································································································································]
[跨度C················································ ]
[跨度 E···] [跨度 F··] [跨度 G··] [跨度 H··]
图3. Spans的时间线图
分布式跟踪系统需要做的是记录每个发送和接收动作的标识符和时间戳,并连接一个请求中涉及的所有服务。只有这样才能理解一个请求的完整调用链。
3. 开放跟踪
在详细介绍Jaeger之前,还有一个关键词需要提一下:OpenTracing。
一句话总结,OpenTracing 是一套标准,通过提供平台无关和厂商无关的 API,开发者可以轻松添加(或替换)跟踪系统的实现(我们在测试中基本上使用两行代码) . 更改为在 Zipkin 和 Jaeger 之间切换)。OpenTracing 为操作支持系统和特定平台提供辅助库。程序库的具体信息请参考详细规范。OpenTracing 已进入 CNCF(Cloud Native Computing Foundation,著名的 Kubernetes、gRPC 和 Prometheus 孵化的地方),正在为全球分布式追踪提供统一的概念和数据标准。
当然,本文前面提到的 Zipkin 和 Jaeger 都支持 OpenTracing 标准。
3.1 引用关系
目前 OpenTracing 标准中定义了两种类型的引用:
3.1.1 ChildOf 参考
一个跨度 A 可以是另一个跨度 B 的 ChildOf。以下所有内容构成了 ChildOf 关系:
[-父跨度---------]
[-孩子跨度----]
[-父跨度-------------]
[-孩子跨度A----]
[-儿童跨度B----]
[-Child Span C----]
[-Child Span D--------------]
[-Child Span E----]
图 4. 的 ChildOf 引用 Span
3.1.2 FollowsFrom 引用
一些父 Span 不以任何方式依赖其子 Span 的结果。在这些情况下,我们只说子跨度是从因果意义上的父跨度派生的。
4. 积家介绍
细心的话,通过上面的CNCF地址,我们可以发现Jaeger现在已经成为CNCF的一个孵化项目。
为了深入了解jaeger的工作原理,首先我们来看一下Jaeger的架构设计图:
图5. Jaeger 架构设计图
上图中,我们看到的是Jaeger系统:黄色部分是我们的应用代码;红色部分代表 Instrument 操作,即加载我们的应用和 jaeger-client ,从而开始应用和 Jaeger 之间的数据交互操作。放大这部分,我们可以参考下图来了解详细的数据交互方式:
图 6. Jaeger 的插桩流程
在图 5 中,我们可以观察到 Jaeger 的完整概览设计。从中我们会发现Jaeger有5个模块元素,如下所列,接下来我们将解释这5个模块的作用:
1.Jaeger 客户端
2.代理
3.采集器
4.数据存储
5.用户界面
Jaeger-client(客户端库)
client就是client lib,方便不同语言的项目介入Jaeger。当我们的应用程序被加载时,客户端将负责采集数据并将其发送给代理。目前 Jaeger SDK 支持如下:
- 官方的
1.去吧
2.Java
3.节点
4.Python
5.C++
- 非官方
1.PHP
3.其他
客户端支持 OpenTracing 标准。如上所述,Zipkin 还支持 OpenTracing 标准,这意味着我们的应用程序可以在嵌入 Jaeger-client 的任何时候替换为 Zipkin,这对业务是完全透明的。
代理(客户端代理)
jaeger 的代理是一个网络守护进程,它在 UDP 端口上侦听接收跨度数据。与大多数分布式系统都有一个 Agent 一样,Jaeger 的 Agent 具有以下特点:
代理采集这些跨度信息并将其汇总到采集器;
代理被设计为基本组件,旨在作为基础架构组件部署到所有主机;
代理将客户端库和采集器解耦,将客户端库与路由和发现采集器的细节屏蔽掉;
采集器(数据采集处理)
采集器,顾名思义,从代理采集跟踪,通过处理管道处理它们,并将它们写入后端。
当前采集器的工作是管理跟踪、构建索引、执行相关转换并最终存储它们。
采样逻辑运行在 Collector 中,它按照我们设置的采样方式对数据进行采集和处理。
数据存储
Jaeger 的数据存储是组件的方式。
目前支持 Cassandra 和 ElasticSearch(当然也支持纯内存模式,但不适合生产环境)。
Query & UI(数据查询和前端界面展示)
查询是一种从存储中检索跟踪并提供显示它们的 UI 的服务。上图是一个trace的数据流,可以在Jaeger UI上展示为一个系统函数的数据传播/执行图。
5. 部署方式
由于解决方案不同,Jaeger 的部署依赖于不同的服务。这些第三方基础服务的部署和安装不再属于本文讨论范围,如docker、Elasticsearch、Cassandra等。
5.1 多合一
为了方便您快速使用,Jaeger 直接提供了一个 All in one docker 镜像。通过 All in one 镜像,我们可以直接启动一个完整的 Jaeger 追踪系统,使用如下命令:
$ 码头工人运行 -d -e \
COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp\
-p 6831:6831/udp\
-p 6832:6832/udp\
-p 5778:5778\
-p 16686:16686 \
-p 14268:14268\
-p 9411:9411\
jaegertracing/all-in-one:最新
启动成功后,可以去:16686看到Jaeger UI如下图。
图 7. Jaeger UI 主页
注意:在 All in one 模式下,Data Store 使用内存,因此如果您重新启动docker 容器,您将无法看到之前的数据。因此,该模式只能用于早期演示或验证,不能部署在生产环境中。
5.2 独立部署
当然,更推荐的方式是独立部署。独立部署也可以分为docker镜像模式和二进制模式。官网对docker镜像模式启动命令有详细的介绍,这里就不贴复制了。
对于二进制部署,请参阅 github 上 Jaeger 的二进制包。该地址提供mac、linux、windows三大操作系统的二进制包。以linux为例,解压后可以找到如下bin包,明显对应我们前面提到的模块:
drwxrwxr-x 3 2000 2000 4.0K 5 月 28 日 23:29 jaeger-ui-build
-rwxrwxr-x 1 2000 2000 27M 5 月 28 日 23:29 jaeger-standalone
-rwxrwxr-x 1 2000 2000 22M 5 月 28 日 23:29 jaeger-query
-rwxrwxr-x 1 2000 2000 25M 5 月 28 日 23:29 jaeger-collector
-rwxrwxr-x 1 2000 2000 16M 5 月 28 日 23:29 jaeger-agent
注意:Jaeger 还为 Kubernetes 和 OpenShift 提供模板。详细介绍请参考github地址
5.3 端口说明
通过上面的 All in one 启动方式,我们直接发现 Jaeger 在启动时占用了大量的端口。当然,并非所有端口都是必需的。以下是这些端口的简要说明:
端口协议所属模块的功能
5775UDPagent通过兼容的Thrift协议接收Zipkin thrift类型的数据
6831UDPagent通过兼容的Thrift协议接收Jaeger thrift类型的数据
6832UDPagent通过二进制Thrift协议接收Jaeger thrift类型数据 查看全部
文章采集调用(微服务中较流行的两款开源分布式tracing系统(图))
1.背景说明
由于我们的项目是微服务方向的,中间和后台服务有10多种服务模块,各个服务/模块之间的调用关系比较复杂,一些服务之间还有一些代理服务和服务(许多服务实时部署的实施)。这些现象导致在开发、调试和问题跟踪中逐渐出现问题。因此,前段时间,分别研究了微服务中两个流行的开源分布式追踪系统:Zipkin 和 Jaeger。
在微服务分布式架构的系统中,可能存在复杂而深入的逐层服务调用关系,如下图所示。
微服务架构中各个服务的调用关系是不是和程序中各个函数的调用关系很相似?
上图很容易理解。当用户的浏览器发起请求时,会先到应用程序A;A 将呼叫 B 和 C;B会调用F……这样一层一层的调用到最后一层,最后完成一个客户的请求。处理(可能是读请求或写请求)。
试想一下,在这个过程中会出现哪些可能的问题?
对于第一种情况,如果客户端请求是写请求,调用链中每一步都有写操作,第一步执行成功,第三步失败,那么分布式系统中需要采用分布式事务。回滚前几步的写操作的机制!
对于第二种情况,可能会因为应用F的异常而拖累整个服务环节,甚至出现雪崩现象,严重影响系统的可用性。本文不会讨论如何处理这种场景,而是先提一下,这种问题在分布式系统中使用了熔断机制和降级机制,以确保系统在出现此类异常时具有高可用性!
那么我们来看看1、2、3的场景中可能涉及的问题。在一个复杂的调用链中,假设有一个响应慢或处理异常的调用链。如何定位这个问题?有问题的服务呢?大多数开发者的第一反应可能是查看日志,依次分析调用链路上各个系统的日志文件,然后定位出问题的服务。在海量日志中定位问题真的很痛苦!
2.跟踪链
首先简单解释一下什么是跟踪链。有相关基础的可以跳过,也可以快速通读本段。基本上,任何谈论跟踪链的 文章 都会发布这张图片:
图 1. 一个简单的追踪调用流程
图 1 是来自 Google 的 Dapper 论文的一个示例:图中,五个节点 A~E 代表五个服务。用户向A发起请求RequestX。同时,由于该请求依赖于服务B和C,所以A分别向B和C发送RPC请求,B处理完请求后直接返回给A,但是服务C也依赖于服务 D 和 E。因此,必须分别向 D 和 E 发起两个 RPC 请求。D和E处理完后返回给C,C继续回复A,最后A会回复用户ReplyX。对于这样的请求,分布式跟踪的一个简单实用的实现是为服务器上的每个发送和接收操作采集跟踪标识符和时间戳。
在 Dapper 的论文中,Trace 和 Span 是两个非常重要的术语。我们用Trace来表示一个请求的完整调用链的trace,将上面的服务A和服务B这两个服务的请求/响应过程称为一个Span,通过span来反映trace。一句话概括,我们可以把一条trace看成span的一个有向图,这个有向图的边就是span。为了更好地理解这两个术语,我们可以看一下下面的调用图。
[跨度A] ←←←(根跨度)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C 是 `ChildOf` Span A)
| |
[跨度 D] +---+-----+
| |
[跨度 E] [跨度 F] >>> [跨度 G] >>> [跨度 H]
↑
↑
↑
(Span G`FollowsFrom`Span F) 上图收录8个span信息
图2.一个tracing过程的Spans关系图
––|–––––––|–––––––|–––––––|––––––––––––––|––––––– –|––––––––|–> 时间
[跨度A········································································································································································...
[跨度B················································ ····················································································································································]
[跨度D················································ ········································································································································································································································································································]
[跨度C················································ ]
[跨度 E···] [跨度 F··] [跨度 G··] [跨度 H··]
图3. Spans的时间线图
分布式跟踪系统需要做的是记录每个发送和接收动作的标识符和时间戳,并连接一个请求中涉及的所有服务。只有这样才能理解一个请求的完整调用链。
3. 开放跟踪
在详细介绍Jaeger之前,还有一个关键词需要提一下:OpenTracing。
一句话总结,OpenTracing 是一套标准,通过提供平台无关和厂商无关的 API,开发者可以轻松添加(或替换)跟踪系统的实现(我们在测试中基本上使用两行代码) . 更改为在 Zipkin 和 Jaeger 之间切换)。OpenTracing 为操作支持系统和特定平台提供辅助库。程序库的具体信息请参考详细规范。OpenTracing 已进入 CNCF(Cloud Native Computing Foundation,著名的 Kubernetes、gRPC 和 Prometheus 孵化的地方),正在为全球分布式追踪提供统一的概念和数据标准。
当然,本文前面提到的 Zipkin 和 Jaeger 都支持 OpenTracing 标准。
3.1 引用关系
目前 OpenTracing 标准中定义了两种类型的引用:
3.1.1 ChildOf 参考
一个跨度 A 可以是另一个跨度 B 的 ChildOf。以下所有内容构成了 ChildOf 关系:
[-父跨度---------]
[-孩子跨度----]
[-父跨度-------------]
[-孩子跨度A----]
[-儿童跨度B----]
[-Child Span C----]
[-Child Span D--------------]
[-Child Span E----]
图 4. 的 ChildOf 引用 Span
3.1.2 FollowsFrom 引用
一些父 Span 不以任何方式依赖其子 Span 的结果。在这些情况下,我们只说子跨度是从因果意义上的父跨度派生的。
4. 积家介绍
细心的话,通过上面的CNCF地址,我们可以发现Jaeger现在已经成为CNCF的一个孵化项目。
为了深入了解jaeger的工作原理,首先我们来看一下Jaeger的架构设计图:
图5. Jaeger 架构设计图
上图中,我们看到的是Jaeger系统:黄色部分是我们的应用代码;红色部分代表 Instrument 操作,即加载我们的应用和 jaeger-client ,从而开始应用和 Jaeger 之间的数据交互操作。放大这部分,我们可以参考下图来了解详细的数据交互方式:
图 6. Jaeger 的插桩流程
在图 5 中,我们可以观察到 Jaeger 的完整概览设计。从中我们会发现Jaeger有5个模块元素,如下所列,接下来我们将解释这5个模块的作用:
1.Jaeger 客户端
2.代理
3.采集器
4.数据存储
5.用户界面
Jaeger-client(客户端库)
client就是client lib,方便不同语言的项目介入Jaeger。当我们的应用程序被加载时,客户端将负责采集数据并将其发送给代理。目前 Jaeger SDK 支持如下:
- 官方的
1.去吧
2.Java
3.节点
4.Python
5.C++
- 非官方
1.PHP
3.其他
客户端支持 OpenTracing 标准。如上所述,Zipkin 还支持 OpenTracing 标准,这意味着我们的应用程序可以在嵌入 Jaeger-client 的任何时候替换为 Zipkin,这对业务是完全透明的。
代理(客户端代理)
jaeger 的代理是一个网络守护进程,它在 UDP 端口上侦听接收跨度数据。与大多数分布式系统都有一个 Agent 一样,Jaeger 的 Agent 具有以下特点:
代理采集这些跨度信息并将其汇总到采集器;
代理被设计为基本组件,旨在作为基础架构组件部署到所有主机;
代理将客户端库和采集器解耦,将客户端库与路由和发现采集器的细节屏蔽掉;
采集器(数据采集处理)
采集器,顾名思义,从代理采集跟踪,通过处理管道处理它们,并将它们写入后端。
当前采集器的工作是管理跟踪、构建索引、执行相关转换并最终存储它们。
采样逻辑运行在 Collector 中,它按照我们设置的采样方式对数据进行采集和处理。
数据存储
Jaeger 的数据存储是组件的方式。
目前支持 Cassandra 和 ElasticSearch(当然也支持纯内存模式,但不适合生产环境)。
Query & UI(数据查询和前端界面展示)
查询是一种从存储中检索跟踪并提供显示它们的 UI 的服务。上图是一个trace的数据流,可以在Jaeger UI上展示为一个系统函数的数据传播/执行图。
5. 部署方式
由于解决方案不同,Jaeger 的部署依赖于不同的服务。这些第三方基础服务的部署和安装不再属于本文讨论范围,如docker、Elasticsearch、Cassandra等。
5.1 多合一
为了方便您快速使用,Jaeger 直接提供了一个 All in one docker 镜像。通过 All in one 镜像,我们可以直接启动一个完整的 Jaeger 追踪系统,使用如下命令:
$ 码头工人运行 -d -e \
COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp\
-p 6831:6831/udp\
-p 6832:6832/udp\
-p 5778:5778\
-p 16686:16686 \
-p 14268:14268\
-p 9411:9411\
jaegertracing/all-in-one:最新
启动成功后,可以去:16686看到Jaeger UI如下图。
图 7. Jaeger UI 主页
注意:在 All in one 模式下,Data Store 使用内存,因此如果您重新启动docker 容器,您将无法看到之前的数据。因此,该模式只能用于早期演示或验证,不能部署在生产环境中。
5.2 独立部署
当然,更推荐的方式是独立部署。独立部署也可以分为docker镜像模式和二进制模式。官网对docker镜像模式启动命令有详细的介绍,这里就不贴复制了。
对于二进制部署,请参阅 github 上 Jaeger 的二进制包。该地址提供mac、linux、windows三大操作系统的二进制包。以linux为例,解压后可以找到如下bin包,明显对应我们前面提到的模块:
drwxrwxr-x 3 2000 2000 4.0K 5 月 28 日 23:29 jaeger-ui-build
-rwxrwxr-x 1 2000 2000 27M 5 月 28 日 23:29 jaeger-standalone
-rwxrwxr-x 1 2000 2000 22M 5 月 28 日 23:29 jaeger-query
-rwxrwxr-x 1 2000 2000 25M 5 月 28 日 23:29 jaeger-collector
-rwxrwxr-x 1 2000 2000 16M 5 月 28 日 23:29 jaeger-agent
注意:Jaeger 还为 Kubernetes 和 OpenShift 提供模板。详细介绍请参考github地址
5.3 端口说明
通过上面的 All in one 启动方式,我们直接发现 Jaeger 在启动时占用了大量的端口。当然,并非所有端口都是必需的。以下是这些端口的简要说明:
端口协议所属模块的功能
5775UDPagent通过兼容的Thrift协议接收Zipkin thrift类型的数据
6831UDPagent通过兼容的Thrift协议接收Jaeger thrift类型的数据
6832UDPagent通过二进制Thrift协议接收Jaeger thrift类型数据
文章采集调用(聚合采集可以自定义采集规则的seo文章采集器采集程序 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-30 17:21
)
Aggregation采集是一种文章聚合全网采集爬虫,而Aggregation采集是一个可以自定义采集的seo文章<规则。@采集器。聚合采集可自定义采集规则,不仅是问答平台,普通站点采集,通过24小时监控采集,实时采集最新文章。聚合采集自动文章过滤(标签、属性、文本),内置全网最新滚动新闻采集。
聚合采集的个性化定制功能,可以对综合页面进行原创标签,让整个网站整合一个统一通用的分类标签体系,不仅内容相关,还原创 内容页面。聚合采集兼容多种静态模式,既有效保证了搜索引擎收录,又增加了网站的持续访问量。聚合采集设置网站的任意顶部导航栏,可以随意添加或删除顶部导航栏,使网站具有高度的自定义性
将采集聚合到任意url连接地址名,不仅使站长的网站独一无二,而且在一定程度上提高了搜索引擎排名。聚合采集支持多个模板集,因为它采用模板编译替换技术,即使只更改一个文件,也可以创建个性化的界面。任意显示数量控制,聚合采集设置专题页各类内容的数量,以及每个列表页的显示数量。
聚合采集内置站长工具,全程记录蜘蛛访问,智能识别99%的搜索引擎蜘蛛访问,全程控制蜘蛛爬取记录。聚合采集自动创建站点地图,自动生成搜索引擎地图,可分类设置,有效提升网站内容收录。一键查看排名和收录,不仅可以查看Alexa排名,还可以准确掌握网站最近收录,还可以添加网站外部链接。聚合采集自动查看网站中的过滤器关键词,自动批量查询网站中是否有过滤的非法内容。
<p>聚合采集的聚合推送,智能系统自动采集网站链接,主动推送到搜索引擎和快速收录界面,大大提升网站@ >收录@ > 率。传统的使用网站js脚本推送的SEO,需要网页有自然流量触发,或者每天导出链接复制到资源平台主动提交,繁琐且效率极低。聚合采集每日自增采集,自动推送,稳步提升索引量,让网站内容爬虫自然增长,从而达到网站全面提升 查看全部
文章采集调用(聚合采集可以自定义采集规则的seo文章采集器采集程序
)
Aggregation采集是一种文章聚合全网采集爬虫,而Aggregation采集是一个可以自定义采集的seo文章<规则。@采集器。聚合采集可自定义采集规则,不仅是问答平台,普通站点采集,通过24小时监控采集,实时采集最新文章。聚合采集自动文章过滤(标签、属性、文本),内置全网最新滚动新闻采集。

聚合采集的个性化定制功能,可以对综合页面进行原创标签,让整个网站整合一个统一通用的分类标签体系,不仅内容相关,还原创 内容页面。聚合采集兼容多种静态模式,既有效保证了搜索引擎收录,又增加了网站的持续访问量。聚合采集设置网站的任意顶部导航栏,可以随意添加或删除顶部导航栏,使网站具有高度的自定义性

将采集聚合到任意url连接地址名,不仅使站长的网站独一无二,而且在一定程度上提高了搜索引擎排名。聚合采集支持多个模板集,因为它采用模板编译替换技术,即使只更改一个文件,也可以创建个性化的界面。任意显示数量控制,聚合采集设置专题页各类内容的数量,以及每个列表页的显示数量。

聚合采集内置站长工具,全程记录蜘蛛访问,智能识别99%的搜索引擎蜘蛛访问,全程控制蜘蛛爬取记录。聚合采集自动创建站点地图,自动生成搜索引擎地图,可分类设置,有效提升网站内容收录。一键查看排名和收录,不仅可以查看Alexa排名,还可以准确掌握网站最近收录,还可以添加网站外部链接。聚合采集自动查看网站中的过滤器关键词,自动批量查询网站中是否有过滤的非法内容。

<p>聚合采集的聚合推送,智能系统自动采集网站链接,主动推送到搜索引擎和快速收录界面,大大提升网站@ >收录@ > 率。传统的使用网站js脚本推送的SEO,需要网页有自然流量触发,或者每天导出链接复制到资源平台主动提交,繁琐且效率极低。聚合采集每日自增采集,自动推送,稳步提升索引量,让网站内容爬虫自然增长,从而达到网站全面提升
文章采集调用(OBD大数据文章采集器安装使用教程For帝国CMS帝国)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-28 06:12
OBD大数据文章采集器Empire安装使用教程cms
英制cms大数据采集适用于:7.0及以上
首先,安装程序
1、把OBD文件夹和网站主页文件放在同一目录下,
2、初始安装时从地址栏访问install.php文件(访问后删除)
3、接下来,按照教程一步一步来。
安装ONEXIN大数据文章采集器图文教程(修订版)
ONEXIN大数据文章采集器图文教程【最新】
点我看视频教程
然后,将触发代码放入模板末尾的代码中,将oid账号100000替换为自己的。
最后,当你刷新你的网站或者有用户访问权限时,程序会自动更新文章。
如果您在使用中有任何问题,欢迎随时联系我们,ONEXIN新手交流QQ群:189610242
****************常见问题**************
问:安装说明:
A:插件下载:
大数据插件背景:
您的网站地址/obd/
自行申请授权并登录大数据平台:
申请授权的网址是:
你的网站地址/obd/api.php
Q:大数据插件的背景是空白的吗?
A:将大数据采集添加到网站后台,修改AdminMain.php文件:
/e/admin/adminstyle/1/AdminMain.php
/e/admin/adminstyle/2/AdminMain.php
查找:
网站首页
在后面添加:
<p> 查看全部
文章采集调用(OBD大数据文章采集器安装使用教程For帝国CMS帝国)
OBD大数据文章采集器Empire安装使用教程cms
英制cms大数据采集适用于:7.0及以上

首先,安装程序
1、把OBD文件夹和网站主页文件放在同一目录下,
2、初始安装时从地址栏访问install.php文件(访问后删除)
3、接下来,按照教程一步一步来。
安装ONEXIN大数据文章采集器图文教程(修订版)
ONEXIN大数据文章采集器图文教程【最新】

点我看视频教程
然后,将触发代码放入模板末尾的代码中,将oid账号100000替换为自己的。
最后,当你刷新你的网站或者有用户访问权限时,程序会自动更新文章。
如果您在使用中有任何问题,欢迎随时联系我们,ONEXIN新手交流QQ群:189610242
****************常见问题**************
问:安装说明:
A:插件下载:
大数据插件背景:
您的网站地址/obd/
自行申请授权并登录大数据平台:
申请授权的网址是:
你的网站地址/obd/api.php
Q:大数据插件的背景是空白的吗?
A:将大数据采集添加到网站后台,修改AdminMain.php文件:
/e/admin/adminstyle/1/AdminMain.php
/e/admin/adminstyle/2/AdminMain.php
查找:
网站首页
在后面添加:
<p>
文章采集调用(原创错了对吧呃没问题是吧但是我感觉有问题为什么呢)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-03-26 19:02
636 次观看 · 发表于 2021-10-28 20:46 · 原创
使用python采集实现调用金山翻译、加盐加密破解,实现在线翻译翻译
使用python采集实现调用金山翻译、加盐加密破解,实现在线翻译翻译
对不对,呃,没问题,对吧?但我觉得有问题。为什么现在?当我们访问时,我注意到我正在谈论的那首歌。没问题,对吧?他应该翻译吗?中文,那他不会翻译吧?那我看看他翻译不出来的原因,那我应该看看Dibag,看看他返回了什么数据。这样的数据,对吧?所以在这里,我们将使用Dibag,对我对这个错误持乐观态度。身份验证失败。我看没关系。这是一个严重的失败吗?如果严重失败,他会说你不是合法用户。你能明白吗?您是非法用户。你能明白吗?那他为什么会有这个问题?我们是不是说,那个时候地址改了,就得改地址,改内容,改地址,记住?啊,是不是有点?翻译,对吧?现在,我正在从中文翻译成英文,对吧?那是我吗?他也有一个叫自动检测的东西,对吧?我用什么词?我用什么词?我是中国人,对吧?嘿,我是中国人。他翻译了吗?我点这个f 十二看他的问题表格的路径,看看他是谁 不会变吧?好吧,现在不看我们了吗?点击这个表格提交,对吧?提交表格让他翻译,然后他不会接受我们的翻译。等一下我是中国人,等一下那我们看一下我们的内容,点击提交,点击提交英文美文英文哦,上面这个啊所以改回什么英文,用完再重新打开对re -open f 十二 open fTwelve 是打开的,所以我们来看看。现在我' 我要去拜访并提交这个表格,对吧?提交表格,然后我在这里有三个请求,对吧?请求一共有三个,那么我们来看看这个请求,看看这里有没有请求?让我们看看,我们现在改变这个东西之后,你发现这个连接路径和我们原来的连接路径有什么区别吗?来吧,我无法比较和比较它。这是意外的二楼吧?这意外的二楼?来对比一下看看这个ui,有什么区别,ok不要放这里,我放这里ok不要让大家看到this和this有什么区别?前面的部分不一样吗?看见?这就是我们遇到问题的原因。是这个意思吗?你能理解,对吗?你的输入不一样,这意味着当我访问此页面时,当我访问此页面时,它将返回给我这样的内容。错误信息有认证。身份验证失败。被拦截了吗?如果你看到它,它根本不会给你访问权限。他是怎么拦截我们的?你有没有想过?认证失败?到时候,他的关键是制作一串验证码。这个值得穿。验证码能看懂吗?哎,就是说你输入了不同的内容。该值发生变化。你能明白吗?然后你会跌倒。我说什么它如何改变?他应该有规则来改变这个值吗?可以理解吗?那么,那么我们可以看到ah这个词一直在变化,也就是说我的快速推理的直径一直在变化。例如,我是中国人,他' s 单词“比尔”。我再改一次。我很美。我很美。那么,我们来看看他的话。这是一个变化吗?看看这个值。你看着我。我很美。哦这个。这快君是不是叫九八二九八结束?你看见了吗?现在我们必须弄清楚如何加密你这个词以及如何收钱。根据我在表单中提交的数据,提交到服务区后,服务器是否处理这些数据,然后将其变成救护车字符串返回给我?提交下一句的时候可以处理清楚吗?那就是说我先不去获取,根据你的输入内容,按照一定的规则生成我的字符串,你输入的内容是什么?这个字符串可以理解吗?那他这里肯定有算法吧?嘿,如果有算法,他是怎么计算的?我们也是?如果你想研究他的算法,并且你能弄清楚,那我们黑客能黑他吗?你能明白吗?那是关键。我如何找到这个声明?他没有改变的是谁改变了价值。改变地址路径,对吧?这意味着这串生成的内容将替换您的原创路径。你能明白吗?所以我们要看看他是如何生成这个字符串的。让我们看看它是什么样子的。在他面前不是要增加我们的数据吗?所以我点击了数据生产的路径。看看这里有没有明确的?是生产数据吗?正确的?您查看应用程序数据。到时候,他是不是有一串这一段,这一段,这串密码?那他一定要带我走 s用这个支付字符串和他的一些代码生成这种字符串代码,然后按照收费号码的规则拿出我们想要的数据代码。好的,现在我们呢,既然你有这样的生存规则,我不知道我是否应该去找你的语言代码,看看你的规则是什么样的以及它们是如何生成的。首先了解它们是如何生成的。这条规定,对吧?打开就好了,然后我们看看这个规则是怎么生成的,给你安排好了,对吧?我正在寻找要搜索的内容。搜索一下我们是如何生成这个刚刚让他生成的字符串的,对吧?我先去找他,好吧,别看他是怎么生成的,那么总共有多少种方法呢?有多少相同的进步?这是四十三吗?正确的?四十三?这个方法没有 URL 吗?肯定是不对的,那我再看下一个。你只能一一找到。找它,上去,这是?不是吗?没有这样的国王。你看见了吗?没有这个王子,一定是对的吧?咦,这是什么东西,这是什么东西,然后后面和前面发生了意外。二楼后面没有写。嘿,我发现它和我们这里很相似,不是吗?没关系,这很酷。这就是你的算法的意思吗?好吧,我该怎么处理算法?他是怎么做的?好吧,我们看看js有没有实现,对吧?好吧,让我们看看他的实现。嘿,你找到这里定义的方法了吗?然后我用了一个肯定的表达器来获取我的表单提交的内容。看到了,拿到这个内容后,他把所有带空格的空格都去掉了,对吧?你问内容中的空格去掉后是否去掉?如果他去掉这个,就不算给他添加了这串内容。啊,看到了吗?来来来,看看功能,还记得连接功能吗?两个人基本有联系吗?你能听到吗?那就是说他会把这个字符串加到我们输入的字符串中,然后放上去算不算理解?然后说他来了。有一种盐叫盐。不变的东西叫做盐。你能明白吗?嘿,他有一块盐。让我们把这个盐拿出来。这盐出来了吗?他,这个叫做常数圆的东西是加到圆上的吧?圆圆圆的水是什么?这个圈子是我们的深度聚会。是盐加什么是盐加我们的我是你的输入它的内容是你的话对对,你的话对吗?那么,使用数据线法应该用什么方法呢?嘿嘿,他会用兔君的方法,再看一遍,再看看怎么办,怎么办,怎么办,怎么办,杀,杀,杀,君是什么意思?你能看懂十六位数和十六位数吗?好吧,这个函数中还有另一个函数。第二个函数不会自动调用括号中的函数。括号里的函数会不会调用md五加加密?你能理解吗?在这个函数中,他再次调用md五加密,表示我加密他,嗯,md五给他加密后,突然死循环,然后sup,savars,对吧,savars君,去崛起几个,十六在十六前面吧?你能理解吗?前面的十六是零到十六吗?那么,我们了解他的生存和营救规则吗?难道我只是按照他的规则,按照自己的数据说清楚吗?那么让我们看看如何创建这些数据?我们将编写并使用它,对吗?把我们昨天做的复制一份我晚上做的,好吗?那么,在这一个中,我们可以做一些改变,对吧?好吧,首先,让我们先看看它。首先,我们可以得到这个词。那么请求的意外按钮是动态的。我以后要更换它,所以我会删除这块吗?如果我稍后替换它,它不会算作我生成的。我会更换它。你能明白吗?那么他是如何产生的呢?然后我在让我们在这里做一个破解支付钻石是我们的原价。我们追求的内容没有加密。是原价吗?盐和盐就是这块,对吧?拿这个盐然后加水?你想让我得到我输入的单词吗?他会扣除十等,对吧?然后我们将扣除十个等。执行md五加密,对吧?然后在十六位数字之前形成几个十六位数字,对吗?好吧,我怎么起来?md 5如何加密?我打算用md五加密算法吧?Basilibo 然后我们给他加密 mdFive 加密加密 这串内容是谁加密的对不对?那么他对这串内容使用了什么代码呢?我们提交的网页用的是什么代码,那你得看他的代码。代码是做什么用的?点击什么编码是utf干编码,那我是不是要给他做utf干转码,对吧?所以你丢失的东西是最错误的,那我必须转码他,对吧?他进行了一次转码和转码,应该如何转换?单击转码声音按钮。是否可以使用utf bar 8转码?你能听到吗?转码完成后,这个按钮是不是已经在网页上统一了?绳子会出来的,对吧?让他加密统一字符串吧?加密完成后,我们应该使用其中的几个吗?拿16位数的内容就够了吧?那是我们幸存下来的。好的是我们活下来的角色,所以让我们传递下去,角色是什么对?性在哪里?周总,正确的?你创造了这个字符串来吃吗?所以我们把这个字符串给我的加密规则现在和他的加密规则完全一样吗?正确的?然后我会用你的加密规则替换你最初请求的路径。执法部门能理解吗?记住?一直都是这样执法的,对吧?嗯,怎么改?你如何改变它?里面有吗?我会卖的,对吧?我卖给谁?我在卖谁?有没有办法代替季复创?我们这里有吗?谈福利的时候,我们谈过这个张伟夫吗?是不是可以用张伟夫的内容来代替这个张伟夫?你还记得印象吗?这是错的吗?那么,我的程序是简单还是不简单呢?然后让我们做一个弯曲的树循环,让他无限平移。好的,您继续翻译,直到翻译成功并且您不想翻译,那么我接受您的输入。接受输入。拿什么来赢他,对吧?请输入您要翻译的内容,对吗?您要输入内容吗?翻译后,打印出来给你吗?你能清楚地理解它吗?然后这个是他的发音。好吧,我们先来看看这种盐。他在没有我的情况下成功破解了它。四个值先看看他对不对,对不对,是不是我们要的词?来,来看看,现在,我们先跑,跑,跑,然后我'会在里面输入hello,看是不是只是三个a hello,然后搜索,先清除一个,再搜索,然后就可以看到hello这个字符串是不是和我们生产的鞋子一样。从 0020 开始,然后是 3a 是一样的吗?那么,我已经破解了他吗?如果你明白了,你可以破解他,对吧?破解他之后,你可以看到我,我会出去打印信息。请记住,不要打印它。然后我们还有一个,就是他在里面。他也有这个选择。里面有自动检测吗?好吧,让我们来个机动。如果我们有机动,我应该把谁变成机动语言?额头是对的吗?那么,这里是不是很刺激呢?出去?你能明白吗?在提交表达式中是你。您会自动识别我的哪种语言?你能理解吗?好吧,然后我们将开始运行,然后我们将开始翻译。嗯,首先,我是什么,中国人?到了im chinese,对吧?我爱你爱你,翻译成中文,让我们看看他,我爱你,好吗?嗯,你很漂亮,他翻译成英文了吗?喂,你好漂亮,他送你回来了,你看,你好,然后又一个你好,漂亮。太好了,我的制作规则和他的制作规则一样吗?是一样的吗?那说明我已经破解了他。如果我能理解,我会破解他,对吧?等你破解了他,你可以看到我,我就出去把资料放出来。请记住,我不会打印它。那我们还有一个,就是他在里面,他也有这个选项,里面有没有自动检测,那我们来一个机动性好,如果我有机动,我应该把谁变成移动语言?额头对吗?然后,这里也有兴奋吗?出去?兴奋的?你能明白吗?提交表达式。你来自什么语言?你自动给我什么语言?认不认得?好的,然后我们将开始运行,然后我们将开始翻译。好吧,首先,我是什么,中国人?输入并欢迎我是中国人,对吧?什么中国人,快来看他,我爱你,好吗?嘿,那你有一个。你很漂亮,对吧?看看他,对吧?你真美?好吧,你看,你好,然后又是一个你好,然后是美丽的你好,美丽的极好,我的生产规则和他的生产规则是一样的吗?是一样的吗?那说明我已经破解了他。如果我能理解它,我会破解他,正确的?等你破解了他,你可以看到我,我就出去把资料放出来。请记住,我不会打印它。那我们还有另外一个,就是他在里面,他也有这个选项,里面有没有自动检测,那我们来一个 机动性好,如果我有机动性,我应该把谁转成移动语言? 额头对吗?然后,这里也有兴奋吗?出去?兴奋的?你能明白吗?提交表达式。你来自什么语言?你自动给我什么语言?认不认得?好的,然后我们将开始运行,然后我们将开始翻译。好吧,首先,我是什么,中国人?输入并欢迎我是中国人,对吧?什么中国人,快来看他,我爱你,好吗?嘿,那你有一个。你真美,正确的?看看他,对吧?你真美?好吧,你看,你好,然后是另一个你好,然后是美丽的你好,美丽的 查看全部
文章采集调用(原创错了对吧呃没问题是吧但是我感觉有问题为什么呢)
636 次观看 · 发表于 2021-10-28 20:46 · 原创
使用python采集实现调用金山翻译、加盐加密破解,实现在线翻译翻译
使用python采集实现调用金山翻译、加盐加密破解,实现在线翻译翻译
对不对,呃,没问题,对吧?但我觉得有问题。为什么现在?当我们访问时,我注意到我正在谈论的那首歌。没问题,对吧?他应该翻译吗?中文,那他不会翻译吧?那我看看他翻译不出来的原因,那我应该看看Dibag,看看他返回了什么数据。这样的数据,对吧?所以在这里,我们将使用Dibag,对我对这个错误持乐观态度。身份验证失败。我看没关系。这是一个严重的失败吗?如果严重失败,他会说你不是合法用户。你能明白吗?您是非法用户。你能明白吗?那他为什么会有这个问题?我们是不是说,那个时候地址改了,就得改地址,改内容,改地址,记住?啊,是不是有点?翻译,对吧?现在,我正在从中文翻译成英文,对吧?那是我吗?他也有一个叫自动检测的东西,对吧?我用什么词?我用什么词?我是中国人,对吧?嘿,我是中国人。他翻译了吗?我点这个f 十二看他的问题表格的路径,看看他是谁 不会变吧?好吧,现在不看我们了吗?点击这个表格提交,对吧?提交表格让他翻译,然后他不会接受我们的翻译。等一下我是中国人,等一下那我们看一下我们的内容,点击提交,点击提交英文美文英文哦,上面这个啊所以改回什么英文,用完再重新打开对re -open f 十二 open fTwelve 是打开的,所以我们来看看。现在我' 我要去拜访并提交这个表格,对吧?提交表格,然后我在这里有三个请求,对吧?请求一共有三个,那么我们来看看这个请求,看看这里有没有请求?让我们看看,我们现在改变这个东西之后,你发现这个连接路径和我们原来的连接路径有什么区别吗?来吧,我无法比较和比较它。这是意外的二楼吧?这意外的二楼?来对比一下看看这个ui,有什么区别,ok不要放这里,我放这里ok不要让大家看到this和this有什么区别?前面的部分不一样吗?看见?这就是我们遇到问题的原因。是这个意思吗?你能理解,对吗?你的输入不一样,这意味着当我访问此页面时,当我访问此页面时,它将返回给我这样的内容。错误信息有认证。身份验证失败。被拦截了吗?如果你看到它,它根本不会给你访问权限。他是怎么拦截我们的?你有没有想过?认证失败?到时候,他的关键是制作一串验证码。这个值得穿。验证码能看懂吗?哎,就是说你输入了不同的内容。该值发生变化。你能明白吗?然后你会跌倒。我说什么它如何改变?他应该有规则来改变这个值吗?可以理解吗?那么,那么我们可以看到ah这个词一直在变化,也就是说我的快速推理的直径一直在变化。例如,我是中国人,他' s 单词“比尔”。我再改一次。我很美。我很美。那么,我们来看看他的话。这是一个变化吗?看看这个值。你看着我。我很美。哦这个。这快君是不是叫九八二九八结束?你看见了吗?现在我们必须弄清楚如何加密你这个词以及如何收钱。根据我在表单中提交的数据,提交到服务区后,服务器是否处理这些数据,然后将其变成救护车字符串返回给我?提交下一句的时候可以处理清楚吗?那就是说我先不去获取,根据你的输入内容,按照一定的规则生成我的字符串,你输入的内容是什么?这个字符串可以理解吗?那他这里肯定有算法吧?嘿,如果有算法,他是怎么计算的?我们也是?如果你想研究他的算法,并且你能弄清楚,那我们黑客能黑他吗?你能明白吗?那是关键。我如何找到这个声明?他没有改变的是谁改变了价值。改变地址路径,对吧?这意味着这串生成的内容将替换您的原创路径。你能明白吗?所以我们要看看他是如何生成这个字符串的。让我们看看它是什么样子的。在他面前不是要增加我们的数据吗?所以我点击了数据生产的路径。看看这里有没有明确的?是生产数据吗?正确的?您查看应用程序数据。到时候,他是不是有一串这一段,这一段,这串密码?那他一定要带我走 s用这个支付字符串和他的一些代码生成这种字符串代码,然后按照收费号码的规则拿出我们想要的数据代码。好的,现在我们呢,既然你有这样的生存规则,我不知道我是否应该去找你的语言代码,看看你的规则是什么样的以及它们是如何生成的。首先了解它们是如何生成的。这条规定,对吧?打开就好了,然后我们看看这个规则是怎么生成的,给你安排好了,对吧?我正在寻找要搜索的内容。搜索一下我们是如何生成这个刚刚让他生成的字符串的,对吧?我先去找他,好吧,别看他是怎么生成的,那么总共有多少种方法呢?有多少相同的进步?这是四十三吗?正确的?四十三?这个方法没有 URL 吗?肯定是不对的,那我再看下一个。你只能一一找到。找它,上去,这是?不是吗?没有这样的国王。你看见了吗?没有这个王子,一定是对的吧?咦,这是什么东西,这是什么东西,然后后面和前面发生了意外。二楼后面没有写。嘿,我发现它和我们这里很相似,不是吗?没关系,这很酷。这就是你的算法的意思吗?好吧,我该怎么处理算法?他是怎么做的?好吧,我们看看js有没有实现,对吧?好吧,让我们看看他的实现。嘿,你找到这里定义的方法了吗?然后我用了一个肯定的表达器来获取我的表单提交的内容。看到了,拿到这个内容后,他把所有带空格的空格都去掉了,对吧?你问内容中的空格去掉后是否去掉?如果他去掉这个,就不算给他添加了这串内容。啊,看到了吗?来来来,看看功能,还记得连接功能吗?两个人基本有联系吗?你能听到吗?那就是说他会把这个字符串加到我们输入的字符串中,然后放上去算不算理解?然后说他来了。有一种盐叫盐。不变的东西叫做盐。你能明白吗?嘿,他有一块盐。让我们把这个盐拿出来。这盐出来了吗?他,这个叫做常数圆的东西是加到圆上的吧?圆圆圆的水是什么?这个圈子是我们的深度聚会。是盐加什么是盐加我们的我是你的输入它的内容是你的话对对,你的话对吗?那么,使用数据线法应该用什么方法呢?嘿嘿,他会用兔君的方法,再看一遍,再看看怎么办,怎么办,怎么办,怎么办,杀,杀,杀,君是什么意思?你能看懂十六位数和十六位数吗?好吧,这个函数中还有另一个函数。第二个函数不会自动调用括号中的函数。括号里的函数会不会调用md五加加密?你能理解吗?在这个函数中,他再次调用md五加密,表示我加密他,嗯,md五给他加密后,突然死循环,然后sup,savars,对吧,savars君,去崛起几个,十六在十六前面吧?你能理解吗?前面的十六是零到十六吗?那么,我们了解他的生存和营救规则吗?难道我只是按照他的规则,按照自己的数据说清楚吗?那么让我们看看如何创建这些数据?我们将编写并使用它,对吗?把我们昨天做的复制一份我晚上做的,好吗?那么,在这一个中,我们可以做一些改变,对吧?好吧,首先,让我们先看看它。首先,我们可以得到这个词。那么请求的意外按钮是动态的。我以后要更换它,所以我会删除这块吗?如果我稍后替换它,它不会算作我生成的。我会更换它。你能明白吗?那么他是如何产生的呢?然后我在让我们在这里做一个破解支付钻石是我们的原价。我们追求的内容没有加密。是原价吗?盐和盐就是这块,对吧?拿这个盐然后加水?你想让我得到我输入的单词吗?他会扣除十等,对吧?然后我们将扣除十个等。执行md五加密,对吧?然后在十六位数字之前形成几个十六位数字,对吗?好吧,我怎么起来?md 5如何加密?我打算用md五加密算法吧?Basilibo 然后我们给他加密 mdFive 加密加密 这串内容是谁加密的对不对?那么他对这串内容使用了什么代码呢?我们提交的网页用的是什么代码,那你得看他的代码。代码是做什么用的?点击什么编码是utf干编码,那我是不是要给他做utf干转码,对吧?所以你丢失的东西是最错误的,那我必须转码他,对吧?他进行了一次转码和转码,应该如何转换?单击转码声音按钮。是否可以使用utf bar 8转码?你能听到吗?转码完成后,这个按钮是不是已经在网页上统一了?绳子会出来的,对吧?让他加密统一字符串吧?加密完成后,我们应该使用其中的几个吗?拿16位数的内容就够了吧?那是我们幸存下来的。好的是我们活下来的角色,所以让我们传递下去,角色是什么对?性在哪里?周总,正确的?你创造了这个字符串来吃吗?所以我们把这个字符串给我的加密规则现在和他的加密规则完全一样吗?正确的?然后我会用你的加密规则替换你最初请求的路径。执法部门能理解吗?记住?一直都是这样执法的,对吧?嗯,怎么改?你如何改变它?里面有吗?我会卖的,对吧?我卖给谁?我在卖谁?有没有办法代替季复创?我们这里有吗?谈福利的时候,我们谈过这个张伟夫吗?是不是可以用张伟夫的内容来代替这个张伟夫?你还记得印象吗?这是错的吗?那么,我的程序是简单还是不简单呢?然后让我们做一个弯曲的树循环,让他无限平移。好的,您继续翻译,直到翻译成功并且您不想翻译,那么我接受您的输入。接受输入。拿什么来赢他,对吧?请输入您要翻译的内容,对吗?您要输入内容吗?翻译后,打印出来给你吗?你能清楚地理解它吗?然后这个是他的发音。好吧,我们先来看看这种盐。他在没有我的情况下成功破解了它。四个值先看看他对不对,对不对,是不是我们要的词?来,来看看,现在,我们先跑,跑,跑,然后我'会在里面输入hello,看是不是只是三个a hello,然后搜索,先清除一个,再搜索,然后就可以看到hello这个字符串是不是和我们生产的鞋子一样。从 0020 开始,然后是 3a 是一样的吗?那么,我已经破解了他吗?如果你明白了,你可以破解他,对吧?破解他之后,你可以看到我,我会出去打印信息。请记住,不要打印它。然后我们还有一个,就是他在里面。他也有这个选择。里面有自动检测吗?好吧,让我们来个机动。如果我们有机动,我应该把谁变成机动语言?额头是对的吗?那么,这里是不是很刺激呢?出去?你能明白吗?在提交表达式中是你。您会自动识别我的哪种语言?你能理解吗?好吧,然后我们将开始运行,然后我们将开始翻译。嗯,首先,我是什么,中国人?到了im chinese,对吧?我爱你爱你,翻译成中文,让我们看看他,我爱你,好吗?嗯,你很漂亮,他翻译成英文了吗?喂,你好漂亮,他送你回来了,你看,你好,然后又一个你好,漂亮。太好了,我的制作规则和他的制作规则一样吗?是一样的吗?那说明我已经破解了他。如果我能理解,我会破解他,对吧?等你破解了他,你可以看到我,我就出去把资料放出来。请记住,我不会打印它。那我们还有一个,就是他在里面,他也有这个选项,里面有没有自动检测,那我们来一个机动性好,如果我有机动,我应该把谁变成移动语言?额头对吗?然后,这里也有兴奋吗?出去?兴奋的?你能明白吗?提交表达式。你来自什么语言?你自动给我什么语言?认不认得?好的,然后我们将开始运行,然后我们将开始翻译。好吧,首先,我是什么,中国人?输入并欢迎我是中国人,对吧?什么中国人,快来看他,我爱你,好吗?嘿,那你有一个。你很漂亮,对吧?看看他,对吧?你真美?好吧,你看,你好,然后又是一个你好,然后是美丽的你好,美丽的极好,我的生产规则和他的生产规则是一样的吗?是一样的吗?那说明我已经破解了他。如果我能理解它,我会破解他,正确的?等你破解了他,你可以看到我,我就出去把资料放出来。请记住,我不会打印它。那我们还有另外一个,就是他在里面,他也有这个选项,里面有没有自动检测,那我们来一个 机动性好,如果我有机动性,我应该把谁转成移动语言? 额头对吗?然后,这里也有兴奋吗?出去?兴奋的?你能明白吗?提交表达式。你来自什么语言?你自动给我什么语言?认不认得?好的,然后我们将开始运行,然后我们将开始翻译。好吧,首先,我是什么,中国人?输入并欢迎我是中国人,对吧?什么中国人,快来看他,我爱你,好吗?嘿,那你有一个。你真美,正确的?看看他,对吧?你真美?好吧,你看,你好,然后是另一个你好,然后是美丽的你好,美丽的
文章采集调用(追踪调用链路,监控链路性能,排查链路故障(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-03-25 01:11
后台:跟踪调用链路,监控链路性能,排查链路故障
随着微服务架构的普及,一个请求往往需要涉及多个服务,需要一些可以帮助理解系统行为和分析性能问题的工具,以便在发生故障时能够快速定位并解决问题。
在单体架构下,可以使用AOP打印调用具体业务逻辑前后的时间,计算整体调用时间。使用 AOP 捕获异常并知道调用在哪里导致了异常。
基本实现原理
一个完整的请求链路的trace ID(traceid)用来找出这个请求调用的所有服务,每个服务调用的span ID(spanid)用来记录调用顺序
上游服务parenetid用于记录调用的层次关系
调用时间时间戳,记录请求发送、接收、处理的时间,计算业务处理时间和网络时间,然后用可视化的界面展示每个调用环节、性能、故障
还可以记录一些其他的信息,比如调用服务的名字,被调用服务的名字,返回结果,IP,调用服务的名字等等。最后我们把同一个spanid的信息组合成一个大跨度块来完成一个完整的调用链。
SkyWalking的原理和架构设计
定期采样节点数据,采样后定期上报数据,存储在ES、MySQL等持久层中。有了数据,自然要根据数据进行可视化分析。
空中漫步的工作原理
Skywalking的工作机制需要三个配合。工作原理图大致如下:
SkyWalking核心模块介绍:
SkyWalking 采用组件化开发,易于扩展。主要成分如下:
1. Skywalking Agent:链接数据采集tracing(调用链数据)和metric(度量)信息并上报,通过HTTP或gRPC将数据发送到Skywalking Collector。
2. Skywalking Collector :链路数据采集器,对agent发送的tracing和metric数据进行整合分析,通过Analysis Core模块进行处理,落入相关数据存储。同时通过Query Core模块进行二次统计。和监控警报
3. 存储:Skywalking的存储支持ElasticSearch、Mysql、TiDB、H2等主流存储作为数据存储的存储介质。H2 仅用于单机临时演示。
4. SkyWalking UI:用于显示着陆数据的Web可视化平台。目前,RocketBot 被正式采用为 SkyWalking 的主要 UI
如何自动 采集 跨越数据
SkyWalking采用插件+javaagent的形式实现数据自动跨度采集,可以对代码无侵入,插件意味着可插拔,扩展性好
如何跨进程传递上下文
我们知道数据一般分为header和body,就像http有header和body一样,RocketMQ也有MessageHeader、Message Body,body一般都保存业务数据,所以不宜在body中传递context,而是在header中,如图
dubbo中的attachment相当于header,所以我们把context放在attachment里面,解决了context传输的问题。
提示:这里的上下文传递过程由dubbo插件处理,业务不知情
traceId 如何保证全局唯一
为了确保全局唯一性,我们可以使用分布式或本地生成的 ID。如果你使用分布式,你需要有一个发件人。每次发出请求时,都必须先请求发件人。会有网络调用开销,所以 SkyWalking 最终采用了本地生成 ID 的方法,并且采用了著名的雪流算法,具有很高的性能。
但是雪花算法有一个众所周知的问题:时间回溯,会导致产生重复的id。那么 SkyWalking 是如何解决时间回调问题的呢?
每次生成id时,都会记录生成id的时间(lastTimestamp)。如果发现当前时间小于上次生成id的时间(lastTimestamp),则表示发生了时间回调,会生成一个随机数作为traceId。
有这么多请求,所有 采集 都会影响性能吗?
如果每次请求都调用采集,毫无疑问数据量会很大,但是反过来想,真的有必要对每个请求都调用采集吗?实际上,没有必要。我们可以设置采样频率,只对部分数据进行采样。默认情况下,SkyWalking 设置为 3 秒采样 3 次,其余请求不采样,如图
这个采样频率其实已经足够我们分析元器件的性能了。以这种在 3 秒内采样 3 次的频率采样数据有什么问题?理想情况下,每次服务调用都是在同一个时间点进行的(如下图),所以每次都在同一个时间点采样真的没问题。
但是在生产中,每个服务调用基本不可能在同一时间点被调用,因为期间存在网络调用延迟,实际调用情况很可能如下图所示。
在这种情况下,会在服务 A 上采样一些调用,而不会在服务 B 和 C 上采样,因此无法分析调用链的性能,那么 SkyWalking 是如何解决的。
是这样解决的:如果上游携带Context(表示上游已经采样),下游强制采集数据。这确保了链接是完整的。
SkyWalking各模块组件视图介绍
Skywalking 已经支持从 6 个视觉维度分析分布式系统的运行。
1、Dashboard:查看全球服务的基本性能指标
Dashboard主要包括Service Dashboard和Database Dashboard
2、拓扑图:展示分布式服务之间的调用关系:
SkyWalking 可以根据获取的数据自动绘制服务之间的调用关系图,并且可以识别出常用的服务并显示在图标上,比如图上的tomcat、CAS服务
每个连接的颜色反映了服务之间的调用延迟,可以非常直观的看到服务之间的调用状态。点击连接中间的点可以显示两个服务之间的连接的平均值。响应时间、吞吐量和 SLA 等信息
显示服务的性能数据:
选择其中一项服务,查看调用关系及服务基本状态。
拓扑图也有平面显示效果
3、链接跟踪:可以根据需要查看链接调用过程
显示请求响应的内部执行,一个完整的请求经过了哪些服务,执行了哪些代码方法,每个方法的执行时间,执行状态等详细信息,快速定位代码问题。
失败的调用还有一个错误日志:
4、警报:5、Zipkin 原理与指标数据对比
Zipkin 分为两端,Zipkin 服务器和 Zipkin 客户端。客户端是微服务的应用。客户端配置服务器的 URL 地址。一旦服务之间发生调用,就会被微服务中配置的Sleuth监听器监听,并生成相应的Trace和Span信息发送给服务器。发送方式主要有两种,一种是HTTP消息的方式,一种是RabbitMQ等消息总线的方式。
无论哪种方式,我们都需要:一个 Eureka 服务注册中心,首先看一下 Zipkin 运行架构:
左边的应用服务也是Zipkin-clinet和Eureka-client。中间是依赖,包括 Zipkin-server 和 Eureka-server。最右边是WebUI展示和开发界面。
比较计划
Google的Dapper,阿里的鹰眼,大众点评的CAT,Twitter的Zipkin,LINE的pinpoint,国内的skywalking。
市面上的全链路监控理论模型多以Google Dapper论文为基础。本文重点介绍以下三个 APM 组件:
种类
拉链金
空中漫步
基本的 查看全部
文章采集调用(追踪调用链路,监控链路性能,排查链路故障(组图))
后台:跟踪调用链路,监控链路性能,排查链路故障
随着微服务架构的普及,一个请求往往需要涉及多个服务,需要一些可以帮助理解系统行为和分析性能问题的工具,以便在发生故障时能够快速定位并解决问题。
在单体架构下,可以使用AOP打印调用具体业务逻辑前后的时间,计算整体调用时间。使用 AOP 捕获异常并知道调用在哪里导致了异常。
基本实现原理
一个完整的请求链路的trace ID(traceid)用来找出这个请求调用的所有服务,每个服务调用的span ID(spanid)用来记录调用顺序
上游服务parenetid用于记录调用的层次关系
调用时间时间戳,记录请求发送、接收、处理的时间,计算业务处理时间和网络时间,然后用可视化的界面展示每个调用环节、性能、故障
还可以记录一些其他的信息,比如调用服务的名字,被调用服务的名字,返回结果,IP,调用服务的名字等等。最后我们把同一个spanid的信息组合成一个大跨度块来完成一个完整的调用链。
SkyWalking的原理和架构设计
定期采样节点数据,采样后定期上报数据,存储在ES、MySQL等持久层中。有了数据,自然要根据数据进行可视化分析。
空中漫步的工作原理
Skywalking的工作机制需要三个配合。工作原理图大致如下:
SkyWalking核心模块介绍:
SkyWalking 采用组件化开发,易于扩展。主要成分如下:
1. Skywalking Agent:链接数据采集tracing(调用链数据)和metric(度量)信息并上报,通过HTTP或gRPC将数据发送到Skywalking Collector。
2. Skywalking Collector :链路数据采集器,对agent发送的tracing和metric数据进行整合分析,通过Analysis Core模块进行处理,落入相关数据存储。同时通过Query Core模块进行二次统计。和监控警报
3. 存储:Skywalking的存储支持ElasticSearch、Mysql、TiDB、H2等主流存储作为数据存储的存储介质。H2 仅用于单机临时演示。
4. SkyWalking UI:用于显示着陆数据的Web可视化平台。目前,RocketBot 被正式采用为 SkyWalking 的主要 UI
如何自动 采集 跨越数据
SkyWalking采用插件+javaagent的形式实现数据自动跨度采集,可以对代码无侵入,插件意味着可插拔,扩展性好
如何跨进程传递上下文
我们知道数据一般分为header和body,就像http有header和body一样,RocketMQ也有MessageHeader、Message Body,body一般都保存业务数据,所以不宜在body中传递context,而是在header中,如图
dubbo中的attachment相当于header,所以我们把context放在attachment里面,解决了context传输的问题。
提示:这里的上下文传递过程由dubbo插件处理,业务不知情
traceId 如何保证全局唯一
为了确保全局唯一性,我们可以使用分布式或本地生成的 ID。如果你使用分布式,你需要有一个发件人。每次发出请求时,都必须先请求发件人。会有网络调用开销,所以 SkyWalking 最终采用了本地生成 ID 的方法,并且采用了著名的雪流算法,具有很高的性能。
但是雪花算法有一个众所周知的问题:时间回溯,会导致产生重复的id。那么 SkyWalking 是如何解决时间回调问题的呢?
每次生成id时,都会记录生成id的时间(lastTimestamp)。如果发现当前时间小于上次生成id的时间(lastTimestamp),则表示发生了时间回调,会生成一个随机数作为traceId。
有这么多请求,所有 采集 都会影响性能吗?
如果每次请求都调用采集,毫无疑问数据量会很大,但是反过来想,真的有必要对每个请求都调用采集吗?实际上,没有必要。我们可以设置采样频率,只对部分数据进行采样。默认情况下,SkyWalking 设置为 3 秒采样 3 次,其余请求不采样,如图
这个采样频率其实已经足够我们分析元器件的性能了。以这种在 3 秒内采样 3 次的频率采样数据有什么问题?理想情况下,每次服务调用都是在同一个时间点进行的(如下图),所以每次都在同一个时间点采样真的没问题。
但是在生产中,每个服务调用基本不可能在同一时间点被调用,因为期间存在网络调用延迟,实际调用情况很可能如下图所示。
在这种情况下,会在服务 A 上采样一些调用,而不会在服务 B 和 C 上采样,因此无法分析调用链的性能,那么 SkyWalking 是如何解决的。
是这样解决的:如果上游携带Context(表示上游已经采样),下游强制采集数据。这确保了链接是完整的。
SkyWalking各模块组件视图介绍
Skywalking 已经支持从 6 个视觉维度分析分布式系统的运行。
1、Dashboard:查看全球服务的基本性能指标
Dashboard主要包括Service Dashboard和Database Dashboard
2、拓扑图:展示分布式服务之间的调用关系:
SkyWalking 可以根据获取的数据自动绘制服务之间的调用关系图,并且可以识别出常用的服务并显示在图标上,比如图上的tomcat、CAS服务
每个连接的颜色反映了服务之间的调用延迟,可以非常直观的看到服务之间的调用状态。点击连接中间的点可以显示两个服务之间的连接的平均值。响应时间、吞吐量和 SLA 等信息
显示服务的性能数据:
选择其中一项服务,查看调用关系及服务基本状态。
拓扑图也有平面显示效果
3、链接跟踪:可以根据需要查看链接调用过程
显示请求响应的内部执行,一个完整的请求经过了哪些服务,执行了哪些代码方法,每个方法的执行时间,执行状态等详细信息,快速定位代码问题。
失败的调用还有一个错误日志:
4、警报:5、Zipkin 原理与指标数据对比
Zipkin 分为两端,Zipkin 服务器和 Zipkin 客户端。客户端是微服务的应用。客户端配置服务器的 URL 地址。一旦服务之间发生调用,就会被微服务中配置的Sleuth监听器监听,并生成相应的Trace和Span信息发送给服务器。发送方式主要有两种,一种是HTTP消息的方式,一种是RabbitMQ等消息总线的方式。
无论哪种方式,我们都需要:一个 Eureka 服务注册中心,首先看一下 Zipkin 运行架构:
左边的应用服务也是Zipkin-clinet和Eureka-client。中间是依赖,包括 Zipkin-server 和 Eureka-server。最右边是WebUI展示和开发界面。
比较计划
Google的Dapper,阿里的鹰眼,大众点评的CAT,Twitter的Zipkin,LINE的pinpoint,国内的skywalking。
市面上的全链路监控理论模型多以Google Dapper论文为基础。本文重点介绍以下三个 APM 组件:
种类
拉链金
空中漫步
基本的
文章采集调用(云原生及混合云模式下的微服务架构应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-24 11:06
前言
进入云原生时代后,依托容器技术和分布式技术的发展,为适应高并发、高压力、快速迭代的场景,微服务架构成为更多企业的必然选择。微服务架构为互联网时代的软件开发带来了极大的优势,例如增加服务的可扩展性、增强易维护性、减少语言依赖等。
但与此同时,从单体架构到微服务架构的转变在应用监控层面提出了前所未有的挑战。服务的拆分使得应用和服务之间的相互调用关系呈几何级数增长。从用户端发起的请求可能会在微服务和各种中间件之间相互调用,最终形成复杂的调用关系网络。
用户请求发出后,完整的调用链图如下:
此时,基于单机业务的传统监控系统已经无法监控新的关系网络。因此,在微服务架构体系下,迫切需要建立一种新的监控机制,能够及时监控和反馈应用和系统的运行状态,在系统运行异常时辅助开发者定位问题,并提供系统性能调优。 . 充足的数据支持。
1、全链路监控的目标是什么?
微服务架构使得应用程序和中间件之间的调用链更加复杂。同时,云原生和混合云的兴起对全链路监控的实现提出了更高的要求。
为了提高混合云模式下微服务架构应用的健壮性和稳定性,一般来说,我们对全链路监控的三个核心需求如下:
1. 系统间依赖梳理:可完整绘制系统与服务之间的调用关系,帮助开发运维评估上下游依赖关系,判断故障范围;
2.关键性能指标展示:可以展示各个环节对应的关键性能指标,可以给研发人员性能优化的方向,也可以帮助运维人员对系统资源的合理配置提出建议;
3. 端到端问题诊断:当系统出现故障或异常时,可立即发出告警,协助运维人员发现并快速定位并解决问题。
全链路监控就是在解决这些问题的背景下创建的。
全链路监控是一套跨语言、跨应用、跨服务器、跨数据中心的分布式系统服务。通过添加探针等,对应用、系统等性能指标进行采样采集,以调用链为主要方法。分布式监控系统,展示监控数据,帮助开发人员和运维人员分析性能问题,定位异常问题。
一些平台还将全链路监控称为全链路跟踪。可以说,全链路监控是一套覆盖所有关联系统的IT系统。它是一套可以完整记录用户行为、存储日志、显示系统间调用路径和状态的最佳实践解决方案。
在全链路监控系统中,调用链是一个核心概念。就是从请求源,通过微服务调用,到底层中间件之间的所有中间调用环节。
全链路监控的关键价值在于“关联”,即由终端用户、后端微服务应用、云中间件组件构成的编织关系网络。从理论上讲,这个关系网络的覆盖范围越大,采集的关键指标越多,全链路监控的价值就越大。
2、实现全链路监控的难点是什么?
混合云模式下的每个微服务应用可能由不同的研发团队开发,需要部署在多台服务器上实现横向扩展,甚至可能同时部署在云端和自建机房的数据中心. 软件部署和调用方法也有很大不同。
在此背景下,实现全链路监控面临诸多挑战,总结如下:
1. 支持大规模混合云场景:当成千上万的微服务应用部署在公有云和混合云中时,如何快速及时地获得采集应用运行状态信息,同时采集日志到日志中央。如何采集并将第三方中间件集成到监控系统中,是全链路监控研发人员需要面对的最严峻的问题。
2. 降低对业务的影响:如果SDK或探针采集数据进行全链路监控占用过多系统资源或对应用性能影响过大,会降低系统整体阻力。压力,甚至是对业务造成严重后果的不可预测的失败。
3. 丰富完善的监控系统:一般来说,Java编写的应用程序比较容易获取自己的运行状态监控数据,但其他类型的应用程序由于相对不完善,难以从底层架构层面全面支持生态。对于其他语言编写的应用程序,以及多渠道部署的中间件的完整指标采集都是开发者需要考虑的问题。
4. 维护简单可行:除了客户端部署的SDK或探针外,服务器端的一整套全链路监控由接收模块、计算模块、存储模块、显示模块。运维人员需要对每个探头和模块进行维护。因此,全链路监控系统在开发时一定要考虑自身的易维护性,否则,在大型系统中,运维工作将成为一场灾难。
5. 保证自身的高可用:全链路监控系统必须能够保证自身具有一定的高可用。否则,当某个模块或组件出现异常时,可能会失去整个业务系统的正常监控功能。在极端情况下,甚至会造成蝴蝶效应,导致整个系统雪崩。
我们说,全链路监控的价值与其所能覆盖的监控范围成正比,它的挑战也与监控范围成正比。因此,全链路监控开发者在实现功能时必须同时考虑和克服这五个难点。
3、全链路监控的规范是什么?
十多年前,谷歌在著名论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》中详细阐述了如何在大规模系统上构建一个低损耗、应用级透明、可扩展的系统。具有广泛部署属性的分布式系统链接跟踪服务。
在 Dapper 论文中,Google 公开了分布式系统链路跟踪的实现技术细节,包括数据表示、埋点、传输、采集、存储和显示,并提出了跟踪树、Trace、Span 和 Annotation 等重要概念为实现全链路监控提供理论依据。
受 Dapper 的启发,业界开发了许多用于分布式链接跟踪的开源组件。由于需要在链接中记录每个链接的信息,信息不仅限于某个链接,还需要跨不同的应用程序和分布式中间件进行传播。因此,必须制定一套统一的标准规范。整个链接中的所有链接都必须符合本规范和标准,才能实现完整信息的描述、跟踪和传输功能。这组标准称为 OpenTracing。
可以说OpenTracing是一套独立于编程语言和业务逻辑的抽象接口集,可以统一管理链路跟踪领域的各种元素,从而实现完整的全链路监控。
跨度
Span是全链路监控的基本单位。为微服务和中间件之间的每次调用创建一个 Span。此调用可以是 RPC 调用、数据库访问等。跨度由 64 位 ID 标识。UUID更方便,是生成Span ID的首选。Span 记录的信息包括名称、调用时间、键值对形式的标签数据、父调用ID。
值得强调的是,Dapper 通过记录每个 Span 的父 ID 来跟踪完整的链接请求。即Span的每一级只记录调用发起者的ID,一个完整的调用具有相同的trace id。如果 Span 没有父 ID,则称为 Root Span。读取记录时,根据 Trace ID 获取所有 span,根据 parent ID 连接 span,绘制一个请求的完整调用链接。
痕迹
Trace用于标记一个请求的发起,通过各种微服务应用和中间件,直到服务返回并结束。Trace 是一个有向树结构的 Span 集合。
图中,每个颜色标签代表一个Span,访问链路由唯一的Trace ID标识。整个架构用树形结构表示,树中的每个节点都是一个Span。树中节点之间的连线代表了一个 Span 与其父 Span 之间的调用关系。
注解
注释是用来记录事件相关信息的注释,例如发生的时间。一个 Span 可以由多个 Annotation 来描述。
Dapper采集数据处理
如图所示,Dapper daemon采集 业务日志,并将日志信息保存在日志文件中。Dapper Collectors 定期请求提取日志并将它们存储在 Central Bigtable 中。
由于日志量很大,Dapper 在采集logging 时使用了采样率模式。如果采样率设置为 1/1024,则表示每 1024 条日志生成一次采集。 查看全部
文章采集调用(云原生及混合云模式下的微服务架构应用)
前言
进入云原生时代后,依托容器技术和分布式技术的发展,为适应高并发、高压力、快速迭代的场景,微服务架构成为更多企业的必然选择。微服务架构为互联网时代的软件开发带来了极大的优势,例如增加服务的可扩展性、增强易维护性、减少语言依赖等。
但与此同时,从单体架构到微服务架构的转变在应用监控层面提出了前所未有的挑战。服务的拆分使得应用和服务之间的相互调用关系呈几何级数增长。从用户端发起的请求可能会在微服务和各种中间件之间相互调用,最终形成复杂的调用关系网络。
用户请求发出后,完整的调用链图如下:

此时,基于单机业务的传统监控系统已经无法监控新的关系网络。因此,在微服务架构体系下,迫切需要建立一种新的监控机制,能够及时监控和反馈应用和系统的运行状态,在系统运行异常时辅助开发者定位问题,并提供系统性能调优。 . 充足的数据支持。
1、全链路监控的目标是什么?
微服务架构使得应用程序和中间件之间的调用链更加复杂。同时,云原生和混合云的兴起对全链路监控的实现提出了更高的要求。
为了提高混合云模式下微服务架构应用的健壮性和稳定性,一般来说,我们对全链路监控的三个核心需求如下:
1. 系统间依赖梳理:可完整绘制系统与服务之间的调用关系,帮助开发运维评估上下游依赖关系,判断故障范围;
2.关键性能指标展示:可以展示各个环节对应的关键性能指标,可以给研发人员性能优化的方向,也可以帮助运维人员对系统资源的合理配置提出建议;
3. 端到端问题诊断:当系统出现故障或异常时,可立即发出告警,协助运维人员发现并快速定位并解决问题。
全链路监控就是在解决这些问题的背景下创建的。
全链路监控是一套跨语言、跨应用、跨服务器、跨数据中心的分布式系统服务。通过添加探针等,对应用、系统等性能指标进行采样采集,以调用链为主要方法。分布式监控系统,展示监控数据,帮助开发人员和运维人员分析性能问题,定位异常问题。
一些平台还将全链路监控称为全链路跟踪。可以说,全链路监控是一套覆盖所有关联系统的IT系统。它是一套可以完整记录用户行为、存储日志、显示系统间调用路径和状态的最佳实践解决方案。
在全链路监控系统中,调用链是一个核心概念。就是从请求源,通过微服务调用,到底层中间件之间的所有中间调用环节。
全链路监控的关键价值在于“关联”,即由终端用户、后端微服务应用、云中间件组件构成的编织关系网络。从理论上讲,这个关系网络的覆盖范围越大,采集的关键指标越多,全链路监控的价值就越大。
2、实现全链路监控的难点是什么?
混合云模式下的每个微服务应用可能由不同的研发团队开发,需要部署在多台服务器上实现横向扩展,甚至可能同时部署在云端和自建机房的数据中心. 软件部署和调用方法也有很大不同。
在此背景下,实现全链路监控面临诸多挑战,总结如下:
1. 支持大规模混合云场景:当成千上万的微服务应用部署在公有云和混合云中时,如何快速及时地获得采集应用运行状态信息,同时采集日志到日志中央。如何采集并将第三方中间件集成到监控系统中,是全链路监控研发人员需要面对的最严峻的问题。
2. 降低对业务的影响:如果SDK或探针采集数据进行全链路监控占用过多系统资源或对应用性能影响过大,会降低系统整体阻力。压力,甚至是对业务造成严重后果的不可预测的失败。
3. 丰富完善的监控系统:一般来说,Java编写的应用程序比较容易获取自己的运行状态监控数据,但其他类型的应用程序由于相对不完善,难以从底层架构层面全面支持生态。对于其他语言编写的应用程序,以及多渠道部署的中间件的完整指标采集都是开发者需要考虑的问题。
4. 维护简单可行:除了客户端部署的SDK或探针外,服务器端的一整套全链路监控由接收模块、计算模块、存储模块、显示模块。运维人员需要对每个探头和模块进行维护。因此,全链路监控系统在开发时一定要考虑自身的易维护性,否则,在大型系统中,运维工作将成为一场灾难。
5. 保证自身的高可用:全链路监控系统必须能够保证自身具有一定的高可用。否则,当某个模块或组件出现异常时,可能会失去整个业务系统的正常监控功能。在极端情况下,甚至会造成蝴蝶效应,导致整个系统雪崩。
我们说,全链路监控的价值与其所能覆盖的监控范围成正比,它的挑战也与监控范围成正比。因此,全链路监控开发者在实现功能时必须同时考虑和克服这五个难点。
3、全链路监控的规范是什么?
十多年前,谷歌在著名论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》中详细阐述了如何在大规模系统上构建一个低损耗、应用级透明、可扩展的系统。具有广泛部署属性的分布式系统链接跟踪服务。

在 Dapper 论文中,Google 公开了分布式系统链路跟踪的实现技术细节,包括数据表示、埋点、传输、采集、存储和显示,并提出了跟踪树、Trace、Span 和 Annotation 等重要概念为实现全链路监控提供理论依据。

受 Dapper 的启发,业界开发了许多用于分布式链接跟踪的开源组件。由于需要在链接中记录每个链接的信息,信息不仅限于某个链接,还需要跨不同的应用程序和分布式中间件进行传播。因此,必须制定一套统一的标准规范。整个链接中的所有链接都必须符合本规范和标准,才能实现完整信息的描述、跟踪和传输功能。这组标准称为 OpenTracing。
可以说OpenTracing是一套独立于编程语言和业务逻辑的抽象接口集,可以统一管理链路跟踪领域的各种元素,从而实现完整的全链路监控。
跨度
Span是全链路监控的基本单位。为微服务和中间件之间的每次调用创建一个 Span。此调用可以是 RPC 调用、数据库访问等。跨度由 64 位 ID 标识。UUID更方便,是生成Span ID的首选。Span 记录的信息包括名称、调用时间、键值对形式的标签数据、父调用ID。

值得强调的是,Dapper 通过记录每个 Span 的父 ID 来跟踪完整的链接请求。即Span的每一级只记录调用发起者的ID,一个完整的调用具有相同的trace id。如果 Span 没有父 ID,则称为 Root Span。读取记录时,根据 Trace ID 获取所有 span,根据 parent ID 连接 span,绘制一个请求的完整调用链接。
痕迹
Trace用于标记一个请求的发起,通过各种微服务应用和中间件,直到服务返回并结束。Trace 是一个有向树结构的 Span 集合。

图中,每个颜色标签代表一个Span,访问链路由唯一的Trace ID标识。整个架构用树形结构表示,树中的每个节点都是一个Span。树中节点之间的连线代表了一个 Span 与其父 Span 之间的调用关系。
注解
注释是用来记录事件相关信息的注释,例如发生的时间。一个 Span 可以由多个 Annotation 来描述。
Dapper采集数据处理

如图所示,Dapper daemon采集 业务日志,并将日志信息保存在日志文件中。Dapper Collectors 定期请求提取日志并将它们存储在 Central Bigtable 中。
由于日志量很大,Dapper 在采集logging 时使用了采样率模式。如果采样率设置为 1/1024,则表示每 1024 条日志生成一次采集。
文章采集调用( 【魔兽世界】灵棺夜行代码.4更新公告)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-24 11:04
【魔兽世界】灵棺夜行代码.4更新公告)
Python制作爬虫采集新颖
更新时间:2015年10月25日11:08:10 提交人:hebedich
本文将与大家分享使用Python制作爬虫的代码采集小说。它非常简单实用,虽然还是有点瑕疵。一起改变,一起进步
开发工具:python3.4
操作系统:win8
主要功能:指定小说网页爬取小说目录,按章节保存到本地,将爬取的网页保存到本地配置文件。
已爬网网站:
小说名:棺材夜行
代码来源:我自己编码
import urllib.request
import http.cookiejar
import socket
import time
import re
timeout = 20
socket.setdefaulttimeout(timeout)
sleep_download_time = 10
time.sleep(sleep_download_time)
def makeMyOpener(head = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
def saveFile(save_path,txts):
f_obj = open(save_path,'w+')
for item in txts:
f_obj.write(item+'\n')
f_obj.close()
#get_code_list
code_list='http://www.cishuge.com/read/0/771/'
oper = makeMyOpener()
uop = oper.open(code_list,timeout=1000)
data = uop.read().decode('gbk','ignore')
pattern = re.compile('(.*?)',re.S)
items = re.findall(pattern,data)
print ('获取列表完成')
url_path='url_file.txt'
url_r=open(url_path,'r')
url_arr=url_r.readlines(100000)
url_r.close()
print (len(url_arr))
url_file=open(url_path,'a')
print ('获取已下载网址')
for tmp in items:
save_path = tmp[1].replace(' ','')+'.txt'
url = code_list+tmp[0]
if url+'\n' in url_arr:
continue
print('写日志:'+url+'\n')
url_file.write(url+'\n')
opene = makeMyOpener()
op1 = opene.open(url,timeout=1000)
data = op1.read().decode('gbk','ignore')
opene.close()
pattern = re.compile(' (.*?)<br />',re.S)
txts = re.findall(pattern,data)
saveFile(save_path,txts)
url_file.close()
虽然代码还有点瑕疵,但还是分享给大家,一起改进 查看全部
文章采集调用(
【魔兽世界】灵棺夜行代码.4更新公告)
Python制作爬虫采集新颖
更新时间:2015年10月25日11:08:10 提交人:hebedich
本文将与大家分享使用Python制作爬虫的代码采集小说。它非常简单实用,虽然还是有点瑕疵。一起改变,一起进步
开发工具:python3.4
操作系统:win8
主要功能:指定小说网页爬取小说目录,按章节保存到本地,将爬取的网页保存到本地配置文件。
已爬网网站:
小说名:棺材夜行
代码来源:我自己编码
import urllib.request
import http.cookiejar
import socket
import time
import re
timeout = 20
socket.setdefaulttimeout(timeout)
sleep_download_time = 10
time.sleep(sleep_download_time)
def makeMyOpener(head = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
def saveFile(save_path,txts):
f_obj = open(save_path,'w+')
for item in txts:
f_obj.write(item+'\n')
f_obj.close()
#get_code_list
code_list='http://www.cishuge.com/read/0/771/'
oper = makeMyOpener()
uop = oper.open(code_list,timeout=1000)
data = uop.read().decode('gbk','ignore')
pattern = re.compile('(.*?)',re.S)
items = re.findall(pattern,data)
print ('获取列表完成')
url_path='url_file.txt'
url_r=open(url_path,'r')
url_arr=url_r.readlines(100000)
url_r.close()
print (len(url_arr))
url_file=open(url_path,'a')
print ('获取已下载网址')
for tmp in items:
save_path = tmp[1].replace(' ','')+'.txt'
url = code_list+tmp[0]
if url+'\n' in url_arr:
continue
print('写日志:'+url+'\n')
url_file.write(url+'\n')
opene = makeMyOpener()
op1 = opene.open(url,timeout=1000)
data = op1.read().decode('gbk','ignore')
opene.close()
pattern = re.compile(' (.*?)<br />',re.S)
txts = re.findall(pattern,data)
saveFile(save_path,txts)
url_file.close()
虽然代码还有点瑕疵,但还是分享给大家,一起改进
文章采集调用(PageAdminCMS采集是大部分站长做网站的自动更新利器采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-03-21 20:50
PageAdmincms采集,是一款功能强大的网站信息采集工具,现已成为大部分站长必备工具之一。通过下载任意类型文件、多级页面采集、全自动添加采集信息、多页面新闻自动抓取、广告过滤、自动获取各类分类网址等功能实现网站@ > 内容更新。毕竟当前网站中最重要的就是网站的内容了。内容是网站收录、排名和权重的基础。如果基础不牢固,那么一切都会白费。.
PageAdmincms采集可以对收录关键词的网站执行采集,可以实现关键词相关网站的批量采集,只需输入关键词的标题、域名和描述,即可通过搜索引擎获取与采集相关的网站信息。
PageAdmincms采集是大部分站长做网站的自动更新工具,全自动采集发布,运行过程中静默工作,完全无需人工干预。它作为独立软件存在,可以避免网站性能消耗。经反复测试,安全稳定,可连续多年不间断工作。它不仅可以独立运行,还可以在服务器或本地计算机上运行。它不需要打开网站,可以24小时不间断工作。它是网站自动更新网站内容的助手。
<p>PageAdmincms采集是一个功能实用的网络数据采集工具,可以通过搜索引擎搜索结果,获取需要采集的网址,以及 查看全部
文章采集调用(PageAdminCMS采集是大部分站长做网站的自动更新利器采集)
PageAdmincms采集,是一款功能强大的网站信息采集工具,现已成为大部分站长必备工具之一。通过下载任意类型文件、多级页面采集、全自动添加采集信息、多页面新闻自动抓取、广告过滤、自动获取各类分类网址等功能实现网站@ > 内容更新。毕竟当前网站中最重要的就是网站的内容了。内容是网站收录、排名和权重的基础。如果基础不牢固,那么一切都会白费。.

PageAdmincms采集可以对收录关键词的网站执行采集,可以实现关键词相关网站的批量采集,只需输入关键词的标题、域名和描述,即可通过搜索引擎获取与采集相关的网站信息。

PageAdmincms采集是大部分站长做网站的自动更新工具,全自动采集发布,运行过程中静默工作,完全无需人工干预。它作为独立软件存在,可以避免网站性能消耗。经反复测试,安全稳定,可连续多年不间断工作。它不仅可以独立运行,还可以在服务器或本地计算机上运行。它不需要打开网站,可以24小时不间断工作。它是网站自动更新网站内容的助手。

<p>PageAdmincms采集是一个功能实用的网络数据采集工具,可以通过搜索引擎搜索结果,获取需要采集的网址,以及
文章采集调用(采集器郑景承_自己学SEO2022-01-046 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-03-21 15:29
)
采集器郑景成_wordpress采集页面简单改造调用代码和描述增加量收录_自学SEO
2022-01-046
郑景诚:wordpress采集器
采集页面只是简单的转换调用代码和描述,增加收录的数量
郑景诚:wordpress采集页面简单修改为调用代码和描述,增加收录的数量。
昨天抽时间对郑刚的SEO培训网站做了一个简单的页面调整,主要是采集页面。
这个网站是用WP做的,所以如果你也用WP建站或者用它来做采集的内容,你可以采集这个文章,都是有效的代码以及如何操作。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
只需将上面的代码放在你想要的任何页面或位置,就可以直接调用一个随机的TAG标签。接下来的 9 表示调用 9,每个页面都不同。称为随机标签。
原因:这个动作是为了让每个页面调用不同的随机标签来提高标签页的收录概率和入口,因为WP的主要排名多为TAG标签页。
2、采集在内容页插入随机图片**
第一个采集器
步骤修改页面1:functions.php
/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = ;ob_start();ob_end_clean();$output = preg_match_all(//>i, $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = ";zt/".rand(1,3).".png";}return $first_img;}
将上面的代码放在functions.php页面底部,点击保存。记得用你的网址替换中间的网址。
Step 2 修改页面2:single.php
】,郑景承SEO培训提供在线实战SEO最新视频,优化工具,采集器加免费领取SEO教程。 查看全部
文章采集调用(采集器郑景承_自己学SEO2022-01-046
)
采集器郑景成_wordpress采集页面简单改造调用代码和描述增加量收录_自学SEO
2022-01-046
郑景诚:wordpress采集器

采集页面只是简单的转换调用代码和描述,增加收录的数量
郑景诚:wordpress采集页面简单修改为调用代码和描述,增加收录的数量。
昨天抽时间对郑刚的SEO培训网站做了一个简单的页面调整,主要是采集页面。
这个网站是用WP做的,所以如果你也用WP建站或者用它来做采集的内容,你可以采集这个文章,都是有效的代码以及如何操作。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
只需将上面的代码放在你想要的任何页面或位置,就可以直接调用一个随机的TAG标签。接下来的 9 表示调用 9,每个页面都不同。称为随机标签。
原因:这个动作是为了让每个页面调用不同的随机标签来提高标签页的收录概率和入口,因为WP的主要排名多为TAG标签页。
2、采集在内容页插入随机图片**
第一个采集器
步骤修改页面1:functions.php
/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = ;ob_start();ob_end_clean();$output = preg_match_all(//>i, $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = ";zt/".rand(1,3).".png";}return $first_img;}
将上面的代码放在functions.php页面底部,点击保存。记得用你的网址替换中间的网址。
Step 2 修改页面2:single.php
】,郑景承SEO培训提供在线实战SEO最新视频,优化工具,采集器
 加免费领取SEO教程。
加免费领取SEO教程。 文章采集调用(第一章初见网络爬虫1.1网络连接1.2BeautifulSoup简介 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-21 01:06
)
第一章第一个网络爬虫1.1 网络连接
1 本节介绍了浏览器获取信息的主要原理,然后举了个python爬取网页源代码的例子
2
3
1#调用urllib库里的request模块,导入urlopen函数
2from urllib.requrest import urlopen
3#利用调用的urlopen函数打开并读取目标对象,并把结果赋值给html变量
4html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
5#把html中的内容读取并打印出来
6print(html.read())
7
1.2 BeautifulSoup 简介
BeautifulSoup 通过定位 HTML 标签对复杂的网络信息进行格式化和组织,并使用易于使用的 Python 对象为我们展示 XML 结构信息。
1.21 安装 BeautifulSoup
我在win10下使用,所以直接在powershell中输入
1pip install bs4
2
就是这样。
1.21 运行 BeautifulSoup
第一个例子也是用的,不过这次是用bs实现的
1#调用urllib库里的request模块的urlopen函数
2from urllib.request import urlopen
3#调用bs4库里的bs模块(注意大小写)
4from bs4 import BeautifulSoup
5#利用调用的urlopen函数打开并读取目标对象,并把结果赋值给html变量
6html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
7#把html中的内容用bs读取并赋值给bsObj
8bsObj = BeautifulSoup(html.read())
9#打印出bsObj的h1标签
10print(bsObj.h1)
11
主要是想说明,bs可以提取网页信息
1.23 可靠的互联网连接
本节的大意是排除爬虫可能遇到的不可靠因素,防止其发生。
第一
1html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
2
这行代码中可能出现两个主要异常:
该页面在服务器上不存在服务器不存在
当第一个异常发生时,程序返回一个 HTTP 错误。 HTTP 错误可能是“404 Page Not Found”“500 Internal Server Error”异常。我们可以通过以下方式处理:
1#尝试运行这行代码
2try:
3 html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
4#如果抛出HTTPError异常
5except HTTPError as e:
6 #打印出这个异常
7 print(e)
8 #返回空值,因为默认情况为return None,中断程序,或接着执行另一个方案
9#否则
10else:
11 #程序继续。注意:如果已经抛出了上面的错误,这段else语句不会执行。
12
如果服务器不存在,即域名打不开,urlopen会返回一个None对象。我们可以添加判断语句来判断返回的html是否为None:
1if html is None:
2 print('URL is not found')
3else:
4 #程序继续
5
当对象为None时,如果调用None下面的子标签会发生AttributeError。
1try:
2 badContent = bsObj.nonExistingTag.anotherTag
3except AttributeError as e:
4 print('Tag was not found')
5else:
6 if badContent ==None:
7 print('Tag was not found')
8 else:
9 print(badContent)
10
合并上面的代码,方便阅读
1from urllib.request import urlopen
2from urllib.error import HTTPError
3from bs4 import BeautifulSoup
4def getTitle(url):
5 try:
6 html = urlopen(url)
7 except HTTPError as e:
8 return None
9 try:
10 bsObj = BeautifulSoup(html.read())
11 title = bsObj.body.h1
12 except AttributeError as e:
13 return None
14 return title
15title = getTitle('http://www.pythonscraping.com/ ... 23x27;)
16if title == None:
17 print('Title could not be found')
18else:
19 print(title)
20 查看全部
文章采集调用(第一章初见网络爬虫1.1网络连接1.2BeautifulSoup简介
)
第一章第一个网络爬虫1.1 网络连接
1 本节介绍了浏览器获取信息的主要原理,然后举了个python爬取网页源代码的例子
2
3
1#调用urllib库里的request模块,导入urlopen函数
2from urllib.requrest import urlopen
3#利用调用的urlopen函数打开并读取目标对象,并把结果赋值给html变量
4html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
5#把html中的内容读取并打印出来
6print(html.read())
7
1.2 BeautifulSoup 简介
BeautifulSoup 通过定位 HTML 标签对复杂的网络信息进行格式化和组织,并使用易于使用的 Python 对象为我们展示 XML 结构信息。
1.21 安装 BeautifulSoup
我在win10下使用,所以直接在powershell中输入
1pip install bs4
2
就是这样。
1.21 运行 BeautifulSoup
第一个例子也是用的,不过这次是用bs实现的
1#调用urllib库里的request模块的urlopen函数
2from urllib.request import urlopen
3#调用bs4库里的bs模块(注意大小写)
4from bs4 import BeautifulSoup
5#利用调用的urlopen函数打开并读取目标对象,并把结果赋值给html变量
6html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
7#把html中的内容用bs读取并赋值给bsObj
8bsObj = BeautifulSoup(html.read())
9#打印出bsObj的h1标签
10print(bsObj.h1)
11
主要是想说明,bs可以提取网页信息
1.23 可靠的互联网连接
本节的大意是排除爬虫可能遇到的不可靠因素,防止其发生。
第一
1html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
2
这行代码中可能出现两个主要异常:
该页面在服务器上不存在服务器不存在
当第一个异常发生时,程序返回一个 HTTP 错误。 HTTP 错误可能是“404 Page Not Found”“500 Internal Server Error”异常。我们可以通过以下方式处理:
1#尝试运行这行代码
2try:
3 html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
4#如果抛出HTTPError异常
5except HTTPError as e:
6 #打印出这个异常
7 print(e)
8 #返回空值,因为默认情况为return None,中断程序,或接着执行另一个方案
9#否则
10else:
11 #程序继续。注意:如果已经抛出了上面的错误,这段else语句不会执行。
12
如果服务器不存在,即域名打不开,urlopen会返回一个None对象。我们可以添加判断语句来判断返回的html是否为None:
1if html is None:
2 print('URL is not found')
3else:
4 #程序继续
5
当对象为None时,如果调用None下面的子标签会发生AttributeError。
1try:
2 badContent = bsObj.nonExistingTag.anotherTag
3except AttributeError as e:
4 print('Tag was not found')
5else:
6 if badContent ==None:
7 print('Tag was not found')
8 else:
9 print(badContent)
10
合并上面的代码,方便阅读
1from urllib.request import urlopen
2from urllib.error import HTTPError
3from bs4 import BeautifulSoup
4def getTitle(url):
5 try:
6 html = urlopen(url)
7 except HTTPError as e:
8 return None
9 try:
10 bsObj = BeautifulSoup(html.read())
11 title = bsObj.body.h1
12 except AttributeError as e:
13 return None
14 return title
15title = getTitle('http://www.pythonscraping.com/ ... 23x27;)
16if title == None:
17 print('Title could not be found')
18else:
19 print(title)
20
文章采集调用(【语料库】百科调用关键点梳理(二):)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-03-20 21:02
文章采集调用2009-2015年的所有百科全书媒体站点库进行爬取,一共有5542个媒体站点用于记录和收集百科中的数据,分析有利于后期商业报告的数据分析。百科的工作机制:官方指定的流程内是专人负责每日事物,但是依然存在很多纰漏,这里逐条查漏补缺,为后期项目落地提供参考,整理一份我个人的百科调用关键点梳理。
ps:由于百科数据和wiki数据差异巨大,在这里以百科数据作为参考依据,一般官方的工作规范和过程是非常专业,执行过程中也要人性化一些。首先选择了108个国家对应的百科站点,是这十几年排名靠前,无错误记录的站点。因为项目中要爬取的要素太多,而查漏补缺,则很难选择好合适的站点。发现最大的缺点是十几年来知名的百科站点中,基本没有变动的。
因此首先排除掉已经被收录的站点。在已经爬虫过的一些站点中找出数据最为零散的站点,多半出现在公司的分发站,而这些站点的特点就是每天大量更新,看似很多,实际上数据量是十分有限的。这里想到的解决方案是多用些机器爬虫进行处理,把零散的数据处理整合到一起。实际上当时是把百科站点进行分词,然后把查询中的词汇,用自动补全,最后连接到百科语料库中,但是语料库的数据量也是很有限的。
经过处理后,比较耗时间,也容易出错,并且知道在日常爬虫中还是可以避免的。与其从零开始,不如自己先给他们找一找问题,然后在尽量的减少搜索成本,尽量不浪费时间。当年专注在这里,很大原因是因为一些公司过多的收购,对查询结果的重要性选择,导致数据量实在太大,这两年才有了好转。百科相关业务:百科全书工作站(或icrook),定制开发的流程框架整理公司转型和搜索公司的选择搜索公司和爬虫工具的选择企业站类别特点:以(pc)首页和相关页为主,其次是(wap)首页,同时也支持b2c垂直搜索以pc站为主,也支持付费搜索和独立搜索(百度联盟的页面没有站点);首页:无特殊查询或收录量低,正常首页显示,页面相对较大;pc站查询无特殊查询,页面相对较小,甚至找不到;wap站查询无特殊查询,页面相对较小,特别是不存在移动端页面。
实例:主流都有很多其他语言/库存在,不存在特殊查询。但是wap类的很多开发语言正在兴起,其中一些库以及索引库实例语言已经超过10年;pc站是实时查询,几乎没有延迟;wap站几乎没有延迟;实例:pc站超过300家(央企的pc站下部有报告,详细,自己拉外网看);wap站近300家。因此,最佳是选择pc站查询工具和wap站搜索工具组合,最次是使用分发,然后自己根据需求定制独立搜。 查看全部
文章采集调用(【语料库】百科调用关键点梳理(二):)
文章采集调用2009-2015年的所有百科全书媒体站点库进行爬取,一共有5542个媒体站点用于记录和收集百科中的数据,分析有利于后期商业报告的数据分析。百科的工作机制:官方指定的流程内是专人负责每日事物,但是依然存在很多纰漏,这里逐条查漏补缺,为后期项目落地提供参考,整理一份我个人的百科调用关键点梳理。
ps:由于百科数据和wiki数据差异巨大,在这里以百科数据作为参考依据,一般官方的工作规范和过程是非常专业,执行过程中也要人性化一些。首先选择了108个国家对应的百科站点,是这十几年排名靠前,无错误记录的站点。因为项目中要爬取的要素太多,而查漏补缺,则很难选择好合适的站点。发现最大的缺点是十几年来知名的百科站点中,基本没有变动的。
因此首先排除掉已经被收录的站点。在已经爬虫过的一些站点中找出数据最为零散的站点,多半出现在公司的分发站,而这些站点的特点就是每天大量更新,看似很多,实际上数据量是十分有限的。这里想到的解决方案是多用些机器爬虫进行处理,把零散的数据处理整合到一起。实际上当时是把百科站点进行分词,然后把查询中的词汇,用自动补全,最后连接到百科语料库中,但是语料库的数据量也是很有限的。
经过处理后,比较耗时间,也容易出错,并且知道在日常爬虫中还是可以避免的。与其从零开始,不如自己先给他们找一找问题,然后在尽量的减少搜索成本,尽量不浪费时间。当年专注在这里,很大原因是因为一些公司过多的收购,对查询结果的重要性选择,导致数据量实在太大,这两年才有了好转。百科相关业务:百科全书工作站(或icrook),定制开发的流程框架整理公司转型和搜索公司的选择搜索公司和爬虫工具的选择企业站类别特点:以(pc)首页和相关页为主,其次是(wap)首页,同时也支持b2c垂直搜索以pc站为主,也支持付费搜索和独立搜索(百度联盟的页面没有站点);首页:无特殊查询或收录量低,正常首页显示,页面相对较大;pc站查询无特殊查询,页面相对较小,甚至找不到;wap站查询无特殊查询,页面相对较小,特别是不存在移动端页面。
实例:主流都有很多其他语言/库存在,不存在特殊查询。但是wap类的很多开发语言正在兴起,其中一些库以及索引库实例语言已经超过10年;pc站是实时查询,几乎没有延迟;wap站几乎没有延迟;实例:pc站超过300家(央企的pc站下部有报告,详细,自己拉外网看);wap站近300家。因此,最佳是选择pc站查询工具和wap站搜索工具组合,最次是使用分发,然后自己根据需求定制独立搜。
文章采集调用(如何利用织梦采集工具来优化文章内容内容优化?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-03-19 02:20
织梦内容管理系统(Dedecms)是我们站长们非常熟悉的cms建站系统,Dedecms将成为您轻松搭建的强大工具建立一个网站。织梦采集做网站seo优化基本知道写文章很重要。“无处不在”这个词已经使用了很长时间,即使是现在也受到搜索引擎的喜爱!当然,有些新手站长朋友不知道如何优化网站文章。今天给大家讲讲如何使用织梦采集工具优化文章内容??
我们都知道,网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用织梦采集免费工具实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,这个织梦采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需织梦cms采集@ >工具上的简单设置,织梦采集会根据用户设置的关键词准确采集文章,这样织梦 采集 @> 确保与行业 文章 保持一致。采集文章可以选择将修改后的内容保存到本地,
织梦采集自动匹配图片文章如果内容中没有图片,会自动配置相关图片设置并自动下载图片保存到本地或第三方保存内容不再有来自对方的外部链接。百度已经以官方文档的形式直接说明了织梦采集中的文章哪些seo元素是有价值的。织梦采集只需设置任务,自动挂机!
用户搜索到的内容是有价值的,用户搜索到的没有原创的内容在搜索引擎眼中是毫无价值的。织梦采集自动内部链接允许搜索引擎更深入地抓取您的链接。
织梦采集注意关键词的密度,也就是关键词出现的频率,会影响文章相关关键词的当前排名,很多seo从业者都不会忽视这一点。织梦采集网站内容插入或随机作者、随机阅读等称为“高度原创”。织梦采集需要注意的一点是词频不能太高,也就是密度不能太大。很多新手seo用seo来做seo,最后的结果就是极端会逆转。织梦采集无论你有成百上千个不同的cms网站,都可以实现统一管理。我接触的很多人都犯了这个问题,这不是一个孤立的案例,它是一个普遍的问题。
织梦采集关键词密度会影响关键词排名,位置也会影响,而且影响很大。这一点的核心操作点是:把重要的关键词放在文章重要的地方。织梦采集相关性优化文字出现关键词,文字第一段自动插入标题。当描述相关性较低时,当前的采集关键词。织梦采集一个人维护几十万网站文章更新也不是问题。看似简单的操作方法,似乎很少有人能做好。哪些职位最重要?
织梦采集免费工具配备了关键词采集 功能。通常有标题、第一段、每段的开头、摘要调用等。织梦采集在内容或标题之前和之后插入段落或关键词可选的标题和标题插入到相同的 关键词。织梦采集非常好用,输入关键词即可实现采集。这从seo的角度来看也是织梦采集优化文章,从用户的角度来看也是必然的要求。织梦采集排版和排版更多的是关乎网页的质量,而不是内容本身的质量。
织梦采集一个是主体内容应该放在哪里,让用户一目了然。织梦采集网站主动推送可以让搜索引擎更快的发现我们的站点,支持百度、搜狗、神马、360等搜索引擎的主动推送。举个反例,本身并没有太多的内容。假设它也以分页的形式显示。这就是问题。假设在首页,“联系我们”的内容被放在了重要的位置,这也是一个问题。 查看全部
文章采集调用(如何利用织梦采集工具来优化文章内容内容优化?)
织梦内容管理系统(Dedecms)是我们站长们非常熟悉的cms建站系统,Dedecms将成为您轻松搭建的强大工具建立一个网站。织梦采集做网站seo优化基本知道写文章很重要。“无处不在”这个词已经使用了很长时间,即使是现在也受到搜索引擎的喜爱!当然,有些新手站长朋友不知道如何优化网站文章。今天给大家讲讲如何使用织梦采集工具优化文章内容??

我们都知道,网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用织梦采集免费工具实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,这个织梦采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需织梦cms采集@ >工具上的简单设置,织梦采集会根据用户设置的关键词准确采集文章,这样织梦 采集 @> 确保与行业 文章 保持一致。采集文章可以选择将修改后的内容保存到本地,
织梦采集自动匹配图片文章如果内容中没有图片,会自动配置相关图片设置并自动下载图片保存到本地或第三方保存内容不再有来自对方的外部链接。百度已经以官方文档的形式直接说明了织梦采集中的文章哪些seo元素是有价值的。织梦采集只需设置任务,自动挂机!

用户搜索到的内容是有价值的,用户搜索到的没有原创的内容在搜索引擎眼中是毫无价值的。织梦采集自动内部链接允许搜索引擎更深入地抓取您的链接。
织梦采集注意关键词的密度,也就是关键词出现的频率,会影响文章相关关键词的当前排名,很多seo从业者都不会忽视这一点。织梦采集网站内容插入或随机作者、随机阅读等称为“高度原创”。织梦采集需要注意的一点是词频不能太高,也就是密度不能太大。很多新手seo用seo来做seo,最后的结果就是极端会逆转。织梦采集无论你有成百上千个不同的cms网站,都可以实现统一管理。我接触的很多人都犯了这个问题,这不是一个孤立的案例,它是一个普遍的问题。

织梦采集关键词密度会影响关键词排名,位置也会影响,而且影响很大。这一点的核心操作点是:把重要的关键词放在文章重要的地方。织梦采集相关性优化文字出现关键词,文字第一段自动插入标题。当描述相关性较低时,当前的采集关键词。织梦采集一个人维护几十万网站文章更新也不是问题。看似简单的操作方法,似乎很少有人能做好。哪些职位最重要?
织梦采集免费工具配备了关键词采集 功能。通常有标题、第一段、每段的开头、摘要调用等。织梦采集在内容或标题之前和之后插入段落或关键词可选的标题和标题插入到相同的 关键词。织梦采集非常好用,输入关键词即可实现采集。这从seo的角度来看也是织梦采集优化文章,从用户的角度来看也是必然的要求。织梦采集排版和排版更多的是关乎网页的质量,而不是内容本身的质量。

织梦采集一个是主体内容应该放在哪里,让用户一目了然。织梦采集网站主动推送可以让搜索引擎更快的发现我们的站点,支持百度、搜狗、神马、360等搜索引擎的主动推送。举个反例,本身并没有太多的内容。假设它也以分页的形式显示。这就是问题。假设在首页,“联系我们”的内容被放在了重要的位置,这也是一个问题。
文章采集调用(微信公众号商城的解决方案(一)——)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-17 14:05
文章采集调用多家微信公众号,给每个公众号都发送一个调用接口,每个公众号又接入一个接口,对每个公众号发送一条数据,最后给出调用结果。前提调用多家公众号微信入口,或调用其他公众号微信端:订阅号:后台接口数据统计分析:总阅读数、推送数、阅读量、点赞率、关注率、转发率、评论数、截图数、点击事件触发次数、发送时间。
可以尝试用一些api,
(二维码自动识别)你可以试试这个,我们原来是这么做的,很简单,
swot是什么?
这个问题问的好,我也想知道api开发网站前景如何,最近正在研究这个网站,所以有这方面的想法,
我看好微信公众号商城,
一、微信生态环境尚不完善,包括公众号发展时间短,账号及生态价值体现不明显,且公众号存在层次区分,
二、微信商城是目前最好的线上销售线上线下打通的事物,不会消失。
作为相关的从业者,我觉得自主开发门槛太高,不管是开发还是培训,都不比做网站或app简单,即使目前微信公众号很牛的自助商城也是很慢,
1、公众号与电商平台结合的应用,据我所知是最近新出来的一个推广方式,从抖音,快手,到社群,再到游戏中的转化率都比较高,可以用来尝试,可以用来宣传品牌,
2、自定义菜单,现在还没有官方应用,需要结合模板工具。现在行业内的解决方案(如视星通,礼品通,基本款游戏自定义菜单,活动购物等)建议结合一下,
3、如果有一定的开发经验,可以自己网上买个服务器,比如云端,稳定性很差,而且服务费很贵,如果服务器牛逼,跟第一条一样,随便你做不做。如果没经验自己一个人做也简单,
4、欢迎加我威信:1425762322,一起交流讨论,根据产品经理需求设计开发,不求最牛逼, 查看全部
文章采集调用(微信公众号商城的解决方案(一)——)
文章采集调用多家微信公众号,给每个公众号都发送一个调用接口,每个公众号又接入一个接口,对每个公众号发送一条数据,最后给出调用结果。前提调用多家公众号微信入口,或调用其他公众号微信端:订阅号:后台接口数据统计分析:总阅读数、推送数、阅读量、点赞率、关注率、转发率、评论数、截图数、点击事件触发次数、发送时间。
可以尝试用一些api,
(二维码自动识别)你可以试试这个,我们原来是这么做的,很简单,
swot是什么?
这个问题问的好,我也想知道api开发网站前景如何,最近正在研究这个网站,所以有这方面的想法,
我看好微信公众号商城,
一、微信生态环境尚不完善,包括公众号发展时间短,账号及生态价值体现不明显,且公众号存在层次区分,
二、微信商城是目前最好的线上销售线上线下打通的事物,不会消失。
作为相关的从业者,我觉得自主开发门槛太高,不管是开发还是培训,都不比做网站或app简单,即使目前微信公众号很牛的自助商城也是很慢,
1、公众号与电商平台结合的应用,据我所知是最近新出来的一个推广方式,从抖音,快手,到社群,再到游戏中的转化率都比较高,可以用来尝试,可以用来宣传品牌,
2、自定义菜单,现在还没有官方应用,需要结合模板工具。现在行业内的解决方案(如视星通,礼品通,基本款游戏自定义菜单,活动购物等)建议结合一下,
3、如果有一定的开发经验,可以自己网上买个服务器,比如云端,稳定性很差,而且服务费很贵,如果服务器牛逼,跟第一条一样,随便你做不做。如果没经验自己一个人做也简单,
4、欢迎加我威信:1425762322,一起交流讨论,根据产品经理需求设计开发,不求最牛逼,
文章采集调用(wordpress采集页简单改造调用代码和说明,提升收录量 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-03-12 21:06
)
郑景成:wordpress采集页面简单修改为调用代码和描述增加收录的量
郑景成:wordpress采集页面简单修改为调用代码和描述增加收录的量
昨天抽空对郑刚的SEO培训网站做了一个简单的页面调整,主要是采集页面。
这个网站是用WP做的,所以如果你也用WP建站或者用它来做采集的内容,你可以采集这个文章,都是有效的代码以及如何操作。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
1 '14', 'largest' => 14, 'unit' => 'px', 'order' => 'RAND', 'number' => 9 ) ); ?>
2
只需将上面的代码放在你想要的任何页面或位置,就可以直接调用一个随机的TAG标签。接下来的 9 表示调用 9,每个页面都不同。称为随机标签。
**原因:**这个动作是为了让每个页面调用不同的随机标签,以提高标签页的收录概率和入口,因为WP的主要排名多为TAG标签页。
2、采集在内容页插入随机图片**
步骤 1 修改页面 1:functions.php
1/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = '';ob_start();ob_end_clean();$output = preg_match_all('//>i', $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = "https://seozg.cc/wp-content/up ... .rand(1,3).".png";}return $first_img;}
2
将上面的代码放在functions.php页面底部,点击保存。记得用你的网址替换中间的网址。
Step 2 修改页面2:single.php
<p> 查看全部
文章采集调用(wordpress采集页简单改造调用代码和说明,提升收录量
)
郑景成:wordpress采集页面简单修改为调用代码和描述增加收录的量
郑景成:wordpress采集页面简单修改为调用代码和描述增加收录的量
昨天抽空对郑刚的SEO培训网站做了一个简单的页面调整,主要是采集页面。
这个网站是用WP做的,所以如果你也用WP建站或者用它来做采集的内容,你可以采集这个文章,都是有效的代码以及如何操作。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
1 '14', 'largest' => 14, 'unit' => 'px', 'order' => 'RAND', 'number' => 9 ) ); ?>
2
只需将上面的代码放在你想要的任何页面或位置,就可以直接调用一个随机的TAG标签。接下来的 9 表示调用 9,每个页面都不同。称为随机标签。
**原因:**这个动作是为了让每个页面调用不同的随机标签,以提高标签页的收录概率和入口,因为WP的主要排名多为TAG标签页。
2、采集在内容页插入随机图片**
步骤 1 修改页面 1:functions.php
1/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = '';ob_start();ob_end_clean();$output = preg_match_all('//>i', $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = "https://seozg.cc/wp-content/up ... .rand(1,3).".png";}return $first_img;}
2
将上面的代码放在functions.php页面底部,点击保存。记得用你的网址替换中间的网址。
Step 2 修改页面2:single.php
<p>
文章采集调用(给WordPress文章添加广告位有很多伙计的WordPress站点是怎么做的 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-03-12 20:14
)
将广告位添加到 WordPress文章
想必有很多人的WordPress网站是没有广告位的,而且即使有广告位,在文章中间也很少有广告位,就像下图的广告一样,直接显示在文章中间。在这里,我向大伙推荐一段代码,以达到为文章添加广告空间的目的。请将以下代码放入functions.php 文件中。然后把你自己的广告代码放在第7行,可以是谷歌附属或其他图片广告或自己制作的html代码。其中第 10 行有一个数字 2,这意味着该广告将插入到 文章 的第二段之后...
建站教程2020-12-06
WordPress 禁止指定类别的 文章
使用wordpress禁止输出文章的指定类别,可以给get_posts()函数传递一个数组参数,如下: 其中:键名numberposts表示检索到的文章个数, category 表示要显示的文章 的类别ID,负数表示不显示,以逗号分隔的字符串形式,这里的orderby表示随机取出文章。去掉了php类的文章显示,因为下面有一个“php栏”,避免重复。get_posts() 函数的完整参数列表:
建站教程2021-11-02
如何在 WordPress 中更改域名
以前经常换域名,每次都要查看换域名的方法,这次直接记录在我的网站里。导入数据库后,执行如下SQL语句,代表旧域名,代表新域名,将新旧域名修改为自己的,然后点击执行!这也是我最喜欢的方法,记录下来供自己使用,分享给大家。
网站建设教程2020-09-23
在不修改数据库的情况下更改WordPress域名
WordPress更改域名或打开HTTPS,旧域名不再可用,后台也将无法访问。很多人会后悔没有提前在后台更改域名。一般我们可以通过修改数据库来解决,但是比较麻烦。通过数据库的解决方法,请看?:如何在WordPress中更改域名。但是,有一个更简单的方法。只需要修改wp-config.php文件,在wp-config.php中添加如下代码: 添加后即可登录后台 现在登录成功后,手动...
网站建设教程2020-11-04
WordPress 永久链接 %postname% 和 pathinfo 冲突
主要冲突是当你访问wordpress的正常页面、分类和文章时,都可以正常访问和显示,但是当你访问一个不存在的url时,你的站点不会显示404页面,但它是显示的主页;听起来可能很模糊,你不明白它的意思;例如:可以访问,因为这个页面确实存在,所以没有问题;当您访问...
网站建设教程2021-05-28
查看全部
文章采集调用(给WordPress文章添加广告位有很多伙计的WordPress站点是怎么做的
)
将广告位添加到 WordPress文章
想必有很多人的WordPress网站是没有广告位的,而且即使有广告位,在文章中间也很少有广告位,就像下图的广告一样,直接显示在文章中间。在这里,我向大伙推荐一段代码,以达到为文章添加广告空间的目的。请将以下代码放入functions.php 文件中。然后把你自己的广告代码放在第7行,可以是谷歌附属或其他图片广告或自己制作的html代码。其中第 10 行有一个数字 2,这意味着该广告将插入到 文章 的第二段之后...
建站教程2020-12-06

WordPress 禁止指定类别的 文章
使用wordpress禁止输出文章的指定类别,可以给get_posts()函数传递一个数组参数,如下: 其中:键名numberposts表示检索到的文章个数, category 表示要显示的文章 的类别ID,负数表示不显示,以逗号分隔的字符串形式,这里的orderby表示随机取出文章。去掉了php类的文章显示,因为下面有一个“php栏”,避免重复。get_posts() 函数的完整参数列表:
建站教程2021-11-02

如何在 WordPress 中更改域名
以前经常换域名,每次都要查看换域名的方法,这次直接记录在我的网站里。导入数据库后,执行如下SQL语句,代表旧域名,代表新域名,将新旧域名修改为自己的,然后点击执行!这也是我最喜欢的方法,记录下来供自己使用,分享给大家。
网站建设教程2020-09-23

在不修改数据库的情况下更改WordPress域名
WordPress更改域名或打开HTTPS,旧域名不再可用,后台也将无法访问。很多人会后悔没有提前在后台更改域名。一般我们可以通过修改数据库来解决,但是比较麻烦。通过数据库的解决方法,请看?:如何在WordPress中更改域名。但是,有一个更简单的方法。只需要修改wp-config.php文件,在wp-config.php中添加如下代码: 添加后即可登录后台 现在登录成功后,手动...
网站建设教程2020-11-04
WordPress 永久链接 %postname% 和 pathinfo 冲突
主要冲突是当你访问wordpress的正常页面、分类和文章时,都可以正常访问和显示,但是当你访问一个不存在的url时,你的站点不会显示404页面,但它是显示的主页;听起来可能很模糊,你不明白它的意思;例如:可以访问,因为这个页面确实存在,所以没有问题;当您访问...
网站建设教程2021-05-28
文章采集调用(如何加快网站访问速度(1)_e操盘_怎么做)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-03-09 07:21
如何加快网站Access()
很多朋友用虚拟主机做网站,将web文件存放在虚拟空间,但是当页面内容过多时,网站的打开速度显得很慢。如果遇到这种情况,与其寻找更好的空间,不如通过优化网页代码来达到满意的速度。作者总结了一些实用的方法。在制作主页时,以下方法可以大大提高你的网页速度。
一、记得帮页面减肥
我们在浏览网页的时候,其实是把虚拟主机中的网页内容下载到本地硬盘上,然后用浏览器进行解读和查看。网页的下载速度在显示速度中占很大比例,所以网页本身占用的空间越小,浏览速度就会越快。这就要求在制作网页时要遵循一切简洁的原则,例如:不要使用过大的Flash动画、图片等资源。干净、简洁的页面给人一种思路清晰的感觉。
二、如果没有必要,使用静态 HTML 页面
众所周知,ASP、PHP、JSP等程序实现了网页信息的动态交互,运行起来非常方便,因为它们的数据交互性好,并且可以方便地访问和更改数据库的内容,以便网站“移动”,例如:论坛、留言板等。但是,此类程序必须经过服务器处理,生成HTML页面,然后“发送”到客户端进行浏览,这必须消耗一定的服务器资源,如果在虚拟主机上过多使用这类程序,网页的显示速度肯定会变慢,所以尽量不要使用静态HTML页面。
三、不要把整个页面塞进一个表格
这是网页设计的问题。为了追求统一的页面对齐,很多站长把整个页面的内容放到一个Table(表格)中,然后用单元格td来划分各个“块”的布局。网站 的显示速度绝对慢。因为Table要等到里面的所有内容都加载完才会显示出来,所以如果有些内容不能访问,就会耽误整个页面的访问速度。正确的做法是:将内容分成几个格式相同的Table,不要全部塞进一个Table。
四、将ASP、ASPX、PHP等文件的访问权限改为. js参考
这一点在设计ASP、ASPX、PHP等程序时要注意。如果你想在静态 HTML 页面中嵌入动态数据,而这些动态数据是由 ASP、PHP 等程序提供的,你会使用如下语句 Quote: 这样的话,每次有人访问你的网站,服务器会对tongji.asp文件执行一次处理,从数据库中提取相应的数据,然后输出到网页显示。如果有几万人同时访问,就要执行上万次,后果可想而知。建议在这些程序中动态生成数据成一个1.js文件,然后通过首页上<SCRIPT src=""></SCRIPT>的代码引用1.js文件页。这样,
五、使用 iframe 嵌套另一个页面
如果你想在 网站 上插入一些广告代码,但又不想让这些广告 网站 影响速度,那么使用 iframe 是最合适的。方法是:把这些广告代码放在一个单独的页面上,然后用下面的代码把页面嵌入到首页,这样整个首页的显示就不会因为广告页的延迟而被拖拽。代码如下:
< IFRAME marginWidth=0 marginHeight=0 src="***.com" frameBorder=0 width=468 scrolling=no height=60 leftmargin="0" topmargin="0"></IFRAME>
其中 ***.com 是引用文件的路径。
六、注意网站柜台代码放置技巧
在网页中放置计数器可以统计网站的流量,为站长和广告商提供访问依据。但是,无论网站 统计系统多么强大,都会有出错的时候。如果你把统计代码直接放在页面内容前面,或者放在一个Table或者div标签里,那么当计数器无法访问时,你页面上的Table或者div会有几十秒的延迟,导致页面被推迟。很长一段时间访问。因此,为了提高网站的速度,需要注意统计代码的位置。正确的做法是:将统计代码放在页面底部,不要和页面内容放在同一个Table或div标签中。可以直接将统计代码放在页面代码底部,或者在底部制作一个单独的表格或 div 来放置计数器。这样,当计数器无法访问时,您的 网站 速度不会受到丝毫影响。
七、友情链接知识
网站之间的链接可以增加网站的宣传效果,制作LOGO图片链接可以更准确地描述网站的主题和定位,宣传效果会大大增强,但是图片链接做多了,必然会影响网页的显示速度。很多站长喜欢在友情网站上直接引用图片网址,让图片加载后才能显示。每个好友网站的访问速度不一样,整个表格都要等待图片下载完成。可以显示,大大降低了网页的速度。因此,在做附属链接时,您应该尝试:
1. 仅文本链接:文本链接不会减慢页面速度。
2. 将所有链接放到一个单独的页面,然后链接到主页上的页面。
3.如果链接一定要出现在首页,请将链接所在的整个Table放在页面底部,因为页面是从上到下逐行显示的,所以放在底部的页面,而不是其他内容的显示会延迟。
4. 友情链接的LOGO图片先下载,再上传到自己的网站空间。这样,速度由自己的网站空间决定,不受友情网站的影响。
-------------------------------------------------- -------------------------------------------------- --------
本文转载请出自著名来源:Just Do IT ()
一个小的网站,比如个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有页面都存放在一个目录下,比如网站对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过多年的发展,已经细分为非常精细的方面,尤其是对于大型网站来说,使用的技术非常广泛,从硬件到软件,编程语言、数据库、WebServer、防火墙等领域都有很高的要求,不是原来简单的html静态网站可比的。
大型 网站,例如 Portal网站。面对大量用户访问和高并发请求,基本解决方案集中在以下几个环节:使用高性能服务器、高性能数据库、高效编程语言、高性能Web容器。但是除了这些方面,没有办法从根本上解决大网站面临的高负载、高并发问题。
上面提供的几种解决方案在一定程度上也意味着更大的投入,而且这种解决方案存在瓶颈,不具备很好的扩展性。我从低成本、高性能和高扩展性的角度来谈一谈。说说我的一些经历吧。
1、HTML 静态
其实我们都知道纯静态的html页面效率最高,成本也最低,所以我们尽量使用静态页面来实现我们网站上的页面。这种最简单的方法实际上是最有效的。方法。但是对于内容量大、更新频繁的网站,我们无法一一手动实现,于是出现了我们常用的信息发布系统cms,比如各个门户的新闻频道我们经常访问的网站,甚至他们的其他渠道都是通过信息发布系统进行管理和实施的。信息发布系统可以实现最简单的信息录入,自动生成静态页面。还可以具有频道管理、权限管理、自动抓拍等功能。对于大型 网站
除了门户和信息发布类型网站,对于交互性要求高的社区类型网站,尽可能保持静态也是提高性能的必要手段。社区发帖,文章实时静态化,有更新时再静态化也是一种被广泛使用的策略。猫扑的大杂烩使用了这样的策略,网易社区也是如此。
同时,html静态化也是一些缓存策略使用的手段。对于系统中频繁使用数据库查询但内容更新量较小的应用,可以考虑使用html静态化来实现,比如论坛中的论坛公开设置信息。这些信息目前所有主流论坛都可以后台管理,并存储在数据库中。其实很多这些信息都是前台程序调用的,只是更新频率很小。后台更新时可以考虑将这部分内容设为静态,避免大量数据库。访问请求。
2、图像服务器分离
众所周知,对于web服务器来说,无论是Apache、IIS还是其他容器,图片是最耗费资源的,所以需要将图片与页面分离,这基本上是大网站所采用的策略,他们都有独立的图像服务器,甚至很多图像服务器。这样的架构可以减轻提供页面访问请求的服务器系统的压力,并且可以保证系统不会因为图像问题而崩溃。应用服务器和镜像服务器可以进行不同的配置优化。比如apache可以尽量配置ContentType。更少的支持和尽可能少的 LoadModule 确保更高的系统消耗和执行效率。
3、数据库集群和库表哈希
大型网站都有复杂的应用,而这些应用必须用到数据库,所以在面对大量访问时,很快就会出现数据库的瓶颈,一个数据库很快就无法满足应用,所以我们需要使用数据库集群或库表哈希。
在数据库集群方面,很多数据库都有自己的解决方案。Oracle、Sybase 等都有很好的解决方案。MySQL提供的常用的Master/Slave也是类似的解决方案。你用的是什么DB,请参考对应的解决方案。解决方案来实施。
上面提到的数据库集群在架构、成本和可扩展性方面受到所使用的数据库类型的限制。因此,我们需要从应用的角度考虑改进系统架构。库表哈希是最常用和最有效的解决方案。. 我们在应用中安装业务和应用或者功能模块来分离数据库,不同的模块对应不同的数据库或者表,然后按照一定的策略对一个页面或者功能进行较小的数据库hash,比如user table, Hash the根据用户ID创建表,可以低成本提高系统性能,具有良好的可扩展性。搜狐的论坛采用了这样的结构,将论坛的用户、设置、帖子等信息从数据库中分离出来,然后根据section和ID对posts和users的数据库和表进行hash,最后可以在配置文件中简单配置。可以随时将低成本数据库添加到系统中,以补充系统性能。
4、缓存
缓存这个词已经被技术触及,很多地方都用到了缓存。开发中的网站架构和网站缓存也很重要。这是最基本的两种缓存。稍后将描述高级和分布式缓存。
对于架构上的缓存,熟悉Apache的人可以知道,Apache提供了自己的缓存模块,也可以使用额外的Squid模块进行缓存,两者都可以有效提升Apache的访问响应能力。
网站程序开发缓存,Linux上提供的Memory Cache是常用的缓存接口,可以在web开发中使用。比如在Java开发的时候,可以调用MemoryCache来缓存和共享一些数据。大型社区使用这样的架构。另外,在使用web语言开发的时候,各种语言基本都有自己的缓存模块和方法,PHP有Pear的Cache模块,Java有更多,.net不是很熟悉,相信一定有。
5、镜像
镜像是大规模网站常用的提高性能和数据安全性的一种方式。镜像技术可以解决不同网络接入商和地区造成的用户访问速度差异。比如ChinaNet和EduNet的区别,促使很多网站在教育网建立镜像站点,数据定期或者实时更新。关于镜像的详细技术,这里不再赘述。有许多专业的现成解决方案架构和产品可供选择。还有便宜的软件实现思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是 large网站 解决高负载访问和大量并发请求的终极解决方案。
负载均衡技术发展多年,有很多专业的服务商和产品可供选择。我个人遇到过一些解决方案,有两种架构供大家参考。
硬件第 4 层交换
四层交换利用三层和四层报文的报文头信息,根据应用段识别业务流,将整个段的业务流分配给合适的应用服务器进行处理。第四层交换功能就像一个虚拟IP,指向物理服务器。它传输的业务遵循多种协议,包括HTTP、FTP、NFS、Telnet或其他协议。这些服务基于物理服务器,需要复杂的负载平衡算法。在IP世界中,服务类型由终端TCP或UDP端口地址决定,四层交换中的应用范围由源和终端IP地址、TCP和UDP端口决定。
在硬件四层交换产品领域,有一些比较知名的产品可供选择,比如Alteon、F5等,这些产品价格贵但物超所值,可以提供卓越的性能和灵活的管理能力。雅虎中国为其近 2,000 台服务器使用了三四台 Alteon。
软件第 4 层交换
在大家了解了硬件四层交换机的原理之后,基于OSI模型的软件四层交换机应运而生。这种方案的原理是一样的,只是性能稍差一些。但是,仍然很容易满足一定的压力。有人说软件实现方式其实更灵活,处理能力完全取决于你对配置的熟悉程度。
我们可以使用Linux中常用的LVS来解决软件的四层切换。LVS 是 Linux 虚拟服务器。提供基于心跳的实时灾难响应解决方案,提高了系统的健壮性,提供灵活的虚拟VIP。配置和管理功能可以同时满足多个应用的需求,这对于分布式系统来说是必不可少的。
使用负载均衡的一个典型策略是在软件或硬件四层交换的基础上构建一个squid集群。这个想法被用于许多大型网站,包括搜索引擎。这种架构是低成本和高性能的。还有很强的可扩展性,随时可以很容易地在架构中添加或删除节点。我将抽出时间详细梳理一下这样的结构并与您讨论。
对于大规模的网站,可以同时使用上面提到的各个方法。这里我简单介绍一下。具体实现过程中的很多细节需要大家熟悉和体验。有时一个小的 squid 参数或者 apache 参数的设置会对系统性能产生很大的影响。
-------------------------------------------------- -------------------------------------------------- ------
常规方法:
1.使用 ACDSEE 压缩图像
2.分页,把一页变成多页
3.不要把所有的图片、flash等都放在同一个表格中,因为IE下载后会在一个表格中显示所有内容,可以放在多个表格中,下载一个会显示一个。
4.换成更快的服务器空间 查看全部
文章采集调用(如何加快网站访问速度(1)_e操盘_怎么做)
如何加快网站Access()
很多朋友用虚拟主机做网站,将web文件存放在虚拟空间,但是当页面内容过多时,网站的打开速度显得很慢。如果遇到这种情况,与其寻找更好的空间,不如通过优化网页代码来达到满意的速度。作者总结了一些实用的方法。在制作主页时,以下方法可以大大提高你的网页速度。
一、记得帮页面减肥
我们在浏览网页的时候,其实是把虚拟主机中的网页内容下载到本地硬盘上,然后用浏览器进行解读和查看。网页的下载速度在显示速度中占很大比例,所以网页本身占用的空间越小,浏览速度就会越快。这就要求在制作网页时要遵循一切简洁的原则,例如:不要使用过大的Flash动画、图片等资源。干净、简洁的页面给人一种思路清晰的感觉。
二、如果没有必要,使用静态 HTML 页面
众所周知,ASP、PHP、JSP等程序实现了网页信息的动态交互,运行起来非常方便,因为它们的数据交互性好,并且可以方便地访问和更改数据库的内容,以便网站“移动”,例如:论坛、留言板等。但是,此类程序必须经过服务器处理,生成HTML页面,然后“发送”到客户端进行浏览,这必须消耗一定的服务器资源,如果在虚拟主机上过多使用这类程序,网页的显示速度肯定会变慢,所以尽量不要使用静态HTML页面。
三、不要把整个页面塞进一个表格
这是网页设计的问题。为了追求统一的页面对齐,很多站长把整个页面的内容放到一个Table(表格)中,然后用单元格td来划分各个“块”的布局。网站 的显示速度绝对慢。因为Table要等到里面的所有内容都加载完才会显示出来,所以如果有些内容不能访问,就会耽误整个页面的访问速度。正确的做法是:将内容分成几个格式相同的Table,不要全部塞进一个Table。
四、将ASP、ASPX、PHP等文件的访问权限改为. js参考
这一点在设计ASP、ASPX、PHP等程序时要注意。如果你想在静态 HTML 页面中嵌入动态数据,而这些动态数据是由 ASP、PHP 等程序提供的,你会使用如下语句 Quote: 这样的话,每次有人访问你的网站,服务器会对tongji.asp文件执行一次处理,从数据库中提取相应的数据,然后输出到网页显示。如果有几万人同时访问,就要执行上万次,后果可想而知。建议在这些程序中动态生成数据成一个1.js文件,然后通过首页上<SCRIPT src=""></SCRIPT>的代码引用1.js文件页。这样,
五、使用 iframe 嵌套另一个页面
如果你想在 网站 上插入一些广告代码,但又不想让这些广告 网站 影响速度,那么使用 iframe 是最合适的。方法是:把这些广告代码放在一个单独的页面上,然后用下面的代码把页面嵌入到首页,这样整个首页的显示就不会因为广告页的延迟而被拖拽。代码如下:
< IFRAME marginWidth=0 marginHeight=0 src="***.com" frameBorder=0 width=468 scrolling=no height=60 leftmargin="0" topmargin="0"></IFRAME>
其中 ***.com 是引用文件的路径。
六、注意网站柜台代码放置技巧
在网页中放置计数器可以统计网站的流量,为站长和广告商提供访问依据。但是,无论网站 统计系统多么强大,都会有出错的时候。如果你把统计代码直接放在页面内容前面,或者放在一个Table或者div标签里,那么当计数器无法访问时,你页面上的Table或者div会有几十秒的延迟,导致页面被推迟。很长一段时间访问。因此,为了提高网站的速度,需要注意统计代码的位置。正确的做法是:将统计代码放在页面底部,不要和页面内容放在同一个Table或div标签中。可以直接将统计代码放在页面代码底部,或者在底部制作一个单独的表格或 div 来放置计数器。这样,当计数器无法访问时,您的 网站 速度不会受到丝毫影响。
七、友情链接知识
网站之间的链接可以增加网站的宣传效果,制作LOGO图片链接可以更准确地描述网站的主题和定位,宣传效果会大大增强,但是图片链接做多了,必然会影响网页的显示速度。很多站长喜欢在友情网站上直接引用图片网址,让图片加载后才能显示。每个好友网站的访问速度不一样,整个表格都要等待图片下载完成。可以显示,大大降低了网页的速度。因此,在做附属链接时,您应该尝试:
1. 仅文本链接:文本链接不会减慢页面速度。
2. 将所有链接放到一个单独的页面,然后链接到主页上的页面。
3.如果链接一定要出现在首页,请将链接所在的整个Table放在页面底部,因为页面是从上到下逐行显示的,所以放在底部的页面,而不是其他内容的显示会延迟。
4. 友情链接的LOGO图片先下载,再上传到自己的网站空间。这样,速度由自己的网站空间决定,不受友情网站的影响。
-------------------------------------------------- -------------------------------------------------- --------
本文转载请出自著名来源:Just Do IT ()
一个小的网站,比如个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有页面都存放在一个目录下,比如网站对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过多年的发展,已经细分为非常精细的方面,尤其是对于大型网站来说,使用的技术非常广泛,从硬件到软件,编程语言、数据库、WebServer、防火墙等领域都有很高的要求,不是原来简单的html静态网站可比的。
大型 网站,例如 Portal网站。面对大量用户访问和高并发请求,基本解决方案集中在以下几个环节:使用高性能服务器、高性能数据库、高效编程语言、高性能Web容器。但是除了这些方面,没有办法从根本上解决大网站面临的高负载、高并发问题。
上面提供的几种解决方案在一定程度上也意味着更大的投入,而且这种解决方案存在瓶颈,不具备很好的扩展性。我从低成本、高性能和高扩展性的角度来谈一谈。说说我的一些经历吧。
1、HTML 静态
其实我们都知道纯静态的html页面效率最高,成本也最低,所以我们尽量使用静态页面来实现我们网站上的页面。这种最简单的方法实际上是最有效的。方法。但是对于内容量大、更新频繁的网站,我们无法一一手动实现,于是出现了我们常用的信息发布系统cms,比如各个门户的新闻频道我们经常访问的网站,甚至他们的其他渠道都是通过信息发布系统进行管理和实施的。信息发布系统可以实现最简单的信息录入,自动生成静态页面。还可以具有频道管理、权限管理、自动抓拍等功能。对于大型 网站
除了门户和信息发布类型网站,对于交互性要求高的社区类型网站,尽可能保持静态也是提高性能的必要手段。社区发帖,文章实时静态化,有更新时再静态化也是一种被广泛使用的策略。猫扑的大杂烩使用了这样的策略,网易社区也是如此。
同时,html静态化也是一些缓存策略使用的手段。对于系统中频繁使用数据库查询但内容更新量较小的应用,可以考虑使用html静态化来实现,比如论坛中的论坛公开设置信息。这些信息目前所有主流论坛都可以后台管理,并存储在数据库中。其实很多这些信息都是前台程序调用的,只是更新频率很小。后台更新时可以考虑将这部分内容设为静态,避免大量数据库。访问请求。
2、图像服务器分离
众所周知,对于web服务器来说,无论是Apache、IIS还是其他容器,图片是最耗费资源的,所以需要将图片与页面分离,这基本上是大网站所采用的策略,他们都有独立的图像服务器,甚至很多图像服务器。这样的架构可以减轻提供页面访问请求的服务器系统的压力,并且可以保证系统不会因为图像问题而崩溃。应用服务器和镜像服务器可以进行不同的配置优化。比如apache可以尽量配置ContentType。更少的支持和尽可能少的 LoadModule 确保更高的系统消耗和执行效率。
3、数据库集群和库表哈希
大型网站都有复杂的应用,而这些应用必须用到数据库,所以在面对大量访问时,很快就会出现数据库的瓶颈,一个数据库很快就无法满足应用,所以我们需要使用数据库集群或库表哈希。
在数据库集群方面,很多数据库都有自己的解决方案。Oracle、Sybase 等都有很好的解决方案。MySQL提供的常用的Master/Slave也是类似的解决方案。你用的是什么DB,请参考对应的解决方案。解决方案来实施。
上面提到的数据库集群在架构、成本和可扩展性方面受到所使用的数据库类型的限制。因此,我们需要从应用的角度考虑改进系统架构。库表哈希是最常用和最有效的解决方案。. 我们在应用中安装业务和应用或者功能模块来分离数据库,不同的模块对应不同的数据库或者表,然后按照一定的策略对一个页面或者功能进行较小的数据库hash,比如user table, Hash the根据用户ID创建表,可以低成本提高系统性能,具有良好的可扩展性。搜狐的论坛采用了这样的结构,将论坛的用户、设置、帖子等信息从数据库中分离出来,然后根据section和ID对posts和users的数据库和表进行hash,最后可以在配置文件中简单配置。可以随时将低成本数据库添加到系统中,以补充系统性能。
4、缓存
缓存这个词已经被技术触及,很多地方都用到了缓存。开发中的网站架构和网站缓存也很重要。这是最基本的两种缓存。稍后将描述高级和分布式缓存。
对于架构上的缓存,熟悉Apache的人可以知道,Apache提供了自己的缓存模块,也可以使用额外的Squid模块进行缓存,两者都可以有效提升Apache的访问响应能力。
网站程序开发缓存,Linux上提供的Memory Cache是常用的缓存接口,可以在web开发中使用。比如在Java开发的时候,可以调用MemoryCache来缓存和共享一些数据。大型社区使用这样的架构。另外,在使用web语言开发的时候,各种语言基本都有自己的缓存模块和方法,PHP有Pear的Cache模块,Java有更多,.net不是很熟悉,相信一定有。
5、镜像
镜像是大规模网站常用的提高性能和数据安全性的一种方式。镜像技术可以解决不同网络接入商和地区造成的用户访问速度差异。比如ChinaNet和EduNet的区别,促使很多网站在教育网建立镜像站点,数据定期或者实时更新。关于镜像的详细技术,这里不再赘述。有许多专业的现成解决方案架构和产品可供选择。还有便宜的软件实现思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是 large网站 解决高负载访问和大量并发请求的终极解决方案。
负载均衡技术发展多年,有很多专业的服务商和产品可供选择。我个人遇到过一些解决方案,有两种架构供大家参考。
硬件第 4 层交换
四层交换利用三层和四层报文的报文头信息,根据应用段识别业务流,将整个段的业务流分配给合适的应用服务器进行处理。第四层交换功能就像一个虚拟IP,指向物理服务器。它传输的业务遵循多种协议,包括HTTP、FTP、NFS、Telnet或其他协议。这些服务基于物理服务器,需要复杂的负载平衡算法。在IP世界中,服务类型由终端TCP或UDP端口地址决定,四层交换中的应用范围由源和终端IP地址、TCP和UDP端口决定。
在硬件四层交换产品领域,有一些比较知名的产品可供选择,比如Alteon、F5等,这些产品价格贵但物超所值,可以提供卓越的性能和灵活的管理能力。雅虎中国为其近 2,000 台服务器使用了三四台 Alteon。
软件第 4 层交换
在大家了解了硬件四层交换机的原理之后,基于OSI模型的软件四层交换机应运而生。这种方案的原理是一样的,只是性能稍差一些。但是,仍然很容易满足一定的压力。有人说软件实现方式其实更灵活,处理能力完全取决于你对配置的熟悉程度。
我们可以使用Linux中常用的LVS来解决软件的四层切换。LVS 是 Linux 虚拟服务器。提供基于心跳的实时灾难响应解决方案,提高了系统的健壮性,提供灵活的虚拟VIP。配置和管理功能可以同时满足多个应用的需求,这对于分布式系统来说是必不可少的。
使用负载均衡的一个典型策略是在软件或硬件四层交换的基础上构建一个squid集群。这个想法被用于许多大型网站,包括搜索引擎。这种架构是低成本和高性能的。还有很强的可扩展性,随时可以很容易地在架构中添加或删除节点。我将抽出时间详细梳理一下这样的结构并与您讨论。
对于大规模的网站,可以同时使用上面提到的各个方法。这里我简单介绍一下。具体实现过程中的很多细节需要大家熟悉和体验。有时一个小的 squid 参数或者 apache 参数的设置会对系统性能产生很大的影响。
-------------------------------------------------- -------------------------------------------------- ------
常规方法:
1.使用 ACDSEE 压缩图像
2.分页,把一页变成多页
3.不要把所有的图片、flash等都放在同一个表格中,因为IE下载后会在一个表格中显示所有内容,可以放在多个表格中,下载一个会显示一个。
4.换成更快的服务器空间
文章采集调用(function.php中定义功能的实现,做数据库的查询 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-05 16:10
)
其实我是想在博客上实现一个作者专栏页面,但是技术难度有点大,因为typecho的限制就在这里,想了很久才做出来,而且最近的时间确实不如和以前一样丰富,所以这个功能被推回了。现在博客是下一个最好的东西。文章的阅读页面右侧显示作者的基本信息,并调用最近发表的十篇文章文章。我还是简单记录一下体会。原则。
主要是在function.php中定义函数的实现,做数据库查询。
代码显示如下:
/** 输出该作者最近文章列表 */
function authorPosts($authorid){
if($authorid){
$limit = 6;
$db = Typecho_Db::get();
$result = $db->fetchAll($db->select()->from('table.contents')
->where('authorId = ?',$authorid)
->where('status = ?','publish')
->where('type = ?', 'post')
->limit($limit)
->order('cid', Typecho_Db::SORT_DESC)
);
if($result){
foreach($result as $val){
$val = Typecho_Widget::widget('Widget_Abstract_Contents')->push($val);
$post_title = htmlspecialchars($val['title']);
$permalink = $val['permalink'];
echo ''.$post_title.'';
}
}
}else{
echo '请设置要调用的作者ID';
}
}
实现原理是定义一个方法来接收页面上传的作者ID参数,然后通过这个参数查询数据库中的文章表,并将个数限制为6个,然后输出查询到的数组循环到页面,实现整个过程。
模板上的调用代码如下:
其实这个功能还可以进一步开发,比如传入两个参数,作者ID和限制号,这样就可以更方便的控制了。
最终效果可以在博客上看到。
转载并注明出处。
喜欢 0
报酬
千水万山,永远相爱,打赏也无妨。报酬
查看全部
文章采集调用(function.php中定义功能的实现,做数据库的查询
)
其实我是想在博客上实现一个作者专栏页面,但是技术难度有点大,因为typecho的限制就在这里,想了很久才做出来,而且最近的时间确实不如和以前一样丰富,所以这个功能被推回了。现在博客是下一个最好的东西。文章的阅读页面右侧显示作者的基本信息,并调用最近发表的十篇文章文章。我还是简单记录一下体会。原则。
主要是在function.php中定义函数的实现,做数据库查询。
代码显示如下:
/** 输出该作者最近文章列表 */
function authorPosts($authorid){
if($authorid){
$limit = 6;
$db = Typecho_Db::get();
$result = $db->fetchAll($db->select()->from('table.contents')
->where('authorId = ?',$authorid)
->where('status = ?','publish')
->where('type = ?', 'post')
->limit($limit)
->order('cid', Typecho_Db::SORT_DESC)
);
if($result){
foreach($result as $val){
$val = Typecho_Widget::widget('Widget_Abstract_Contents')->push($val);
$post_title = htmlspecialchars($val['title']);
$permalink = $val['permalink'];
echo ''.$post_title.'';
}
}
}else{
echo '请设置要调用的作者ID';
}
}
实现原理是定义一个方法来接收页面上传的作者ID参数,然后通过这个参数查询数据库中的文章表,并将个数限制为6个,然后输出查询到的数组循环到页面,实现整个过程。
模板上的调用代码如下:
其实这个功能还可以进一步开发,比如传入两个参数,作者ID和限制号,这样就可以更方便的控制了。
最终效果可以在博客上看到。
转载并注明出处。
喜欢 0
报酬
千水万山,永远相爱,打赏也无妨。报酬
文章采集调用( AI技术——指标采集、预测与异常检测的相关内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-04-07 20:23
AI技术——指标采集、预测与异常检测的相关内容)
高斯松鼠俱乐部
学习探索和分享前沿数据库知识和技术,构建数据库技术交流圈
关注之前的图文,我们分享了AI技术的相关内容——智能索引推荐,本文将详细介绍AI技术的相关内容——索引采集,预测和异常检测。8.5指标采集,Prediction and Anomaly Detection 数据库指标监控和异常检测技术,通过监控数据库指标,并基于时序预测和异常检测等算法,发现异常信息,然后进行提醒用户采取措施避免异常情况产生严重后果。8.5.1 使用场景 用户操作数据库的某些行为或某些正在运行的业务的变化可能会导致数据库异常。如果这些异常没有及时发现和处理,导致严重后果。通常,数据库监控指标(指标,如 CPU 使用率、QPS 等)可以反映数据库系统的健康状况。通过监控数据库指标,分析指标数据特征或变化趋势,及时发现数据库异常情况,及时向运维管理人员推送告警信息,避免损失。8.5.2 实现原理 并及时将告警信息推送给运维管理人员,避免损失。8.5.2 实现原理 并及时将告警信息推送给运维管理人员,避免损失。8.5.2 实现原理
图 1 Anomaly-Detection 框架
指标采集,预测和异常检测由同一个系统实现,在openGauss项目中命名为Anomaly-Detection,其结构如图1所示。该工具可分为Agent和Detector两部分. Agent是一个数据库代理模块,负责采集数据库指标数据并将数据推送到Detector;Detector是一个数据库异常检测分析模块,主要有3个功能。(1) 采集并转储 Agent 采集 的数据。(2) 对采集到的数据进行特征分析和异常检测。(3) 将检测到的异常信息推送到1. Agent模块的组成 Agent模块负责采集和指标数据的发送。该模块由三个子模块组成:DBSource、MemoryChannel 和 HttpSink。(1) DBSource作为数据源,负责定时采集数据库指标数据,并将数据发送到数据通道MemoryChannel。(2) MemoryChannel是内存数据通道,本质上是数据的FIFO队列缓存,HttpSink组件消费MemoryChannel Data中的数据,为了防止MemoryChannel中数据过多导致OOM(out of Memory,内存溢出),设置了容量上限,当容量上限为超过,过多的元素将被禁止入队列。(3)HttpSink为数据采集点,该模块周期性的从MemoryChannel获取数据,并以Http(s)的形式转发数据。之后读取数据,它从 MemoryChannel 中清除。2. Detector模块由Detector模块组成,负责数据检测,该模块由Server和Monitor两个子模块组成。(1)Server是一个Web服务,就是Agent采集接收到的数据提供了一个接收接口,将数据存储在本地数据库中。为了防止数据库由于随着数据的增加,我们对数据库中每张表的行数设置了上限。(2) Monitor模块包括时序预测和异常检测等算法。该模块定期从本地数据库,并基于现有算法对数据进行预测和分析。
def forecast(args):
…
# 如果没有指定预测方式,则默认使用’auto_arima’算法
if not args.forecast_method:
forecast_alg = get_instance('auto_arima')
else:
forecast_alg = get_instance(args.forecast_method)
# 指标预测功能函数
def forecast_metric(name, train_ts, save_path=None):
…
forecast_alg.fit(timeseries=train_ts)
dates, values = forecast_alg.forecast(
period=TimeString(args.forecast_periods).standard)
date_range = "{start_date}~{end_date}".format(start_date=dates[0],
end_date=dates[-1])
display_table.add_row(
[name, date_range, min(values), max(values), sum(values) / len(values)]
)
# 校验存储路径
if save_path:
if not os.path.exists(os.path.dirname(save_path)):
os.makedirs(os.path.dirname(save_path))
with open(save_path, mode='w') as f:
for date, value in zip(dates, values):
f.write(date + ',' + str(value) + '\n')
# 从本地sqlite中抽取需要的数据
with sqlite_storage.SQLiteStorage(database_path) as db:
if args.metric_name:
timeseries = db.get_timeseries(table=args.metric_name, period=max_rows)
forecast_metric(args.metric_name, timeseries, args.save_path)
else:
# 获取sqlite中所有的表名
tables = db.get_all_tables()
# 从每个表中抽取训练数据进行预测
for table in tables:
timeseries = db.get_timeseries(table=table, period=max_rows)
forecast_metric(table, timeseries)
# 输出结果
print(display_table.get_string())
# 代码远程部署
def deploy(args):
print('Please input the password of {user}@{host}: '.format(user=args.user, host=args.host))
# 格式化代码远程部署指令
command = 'sh start.sh --deploy {host} {user} {project_path}' \
.format(user=args.user,
host=args.host,
project_path=args.project_path)
# 判断指令执行情况
if subprocess.call(shlex.split(command), cwd=SBIN_PATH) == 0:
print("\nExecute successfully.")
else:
print("\nExecute unsuccessfully.")
…
# 展示当前监控的参数
def show_metrics():
…
# 项目总入口
def main():
…
2. 关键代码段分析(1) 后台线程的实现。前面说过,这个功能可以分为三个角色:Agent、Monitor 和 Detector,这三个不同的角色都是常见的进程驻留在后台执行不同的任务,Daemon类是负责运行不同业务流程的容器类,下面介绍这个类的实现。
class Daemon:
"""
This class implements the function of running a process in the background."""
def __init__(self):
…
def daemon_process(self):
# 注册退出函数
atexit.register(lambda: os.remove(self.pid_file))
signal.signal(signal.SIGTERM, handle_sigterm)
# 启动进程
@staticmethod
def start(self):
try:
self.daemon_process()
except RuntimeError as msg:
abnormal_exit(msg)
self.function(*self.args, **self.kwargs)
# 停止进程
def stop(self):
if not os.path.exists(self.pid_file):
abnormal_exit("Process not running.")
read_pid = read_pid_file(self.pid_file)
if read_pid > 0:
os.kill(read_pid, signal.SIGTERM)
if read_pid_file(self.pid_file) < 0:
os.remove(self.pid_file)
(2)数据库相关指标采集流程。数据库指标采集架构参考了Apache Flume的设计。一个完整的信息采集流程分为三个部分,分别是Source , Channel 和 Sink. 以上三部分被抽象成三个不同的基类, 从中可以派生出不同的采集 数据源, 缓存管道和数据接收者. 前面说过DBSource派生自Source, MemoryChannel派生来源于Channel,HttpSink来源于Sink,下面代码来源于metric_agent.py,负责采集指标,上面的模块是串联的。
def agent_main():
…
# 初始化通道管理器
cm = ChannelManager()
# 初始化数据源
source = DBSource()
http_sink = HttpSink(interval=params['sink_timer_interval'], url=url, context=context)
source.channel_manager = cm
http_sink.channel_manager = cm
# 获取参数文件里面的功能函数
for task_name, task_func in get_funcs(metric_task):
source.add_task(name=task_name,
interval=params['source_timer_interval'],
task=task_func,
maxsize=params['channel_capacity'])
source.start()
http_sink.start()
(3)实现数据存储和监控。Agent将采集收到的指标数据发送到Detector服务器,Detector服务器负责存储。Monitor不断检查存储的数据,以便提前发现异常,这里实现了一个通过SQLite进行本地化存储的方法,代码位于sqlite_storage.py文件中,实现的类为SQLiteStorage,该类实现的主要方法如下:
# 通过时间戳获取最近一段时间的数据
def select_timeseries_by_timestamp(self, table, period):
…
# 通过编号获取最近一段时间的数据
def select_timeseries_by_number(self, table, number):
…
其中,由于不同指标的数据存储在不同的表中,所以上述参数表也代表了不同指标的名称。异常检测目前主要支持基于时间序列预测的方法,包括Prophet算法(Facebook开源的工业级时间序列预测算法工具)和ARIMA算法,封装成类供Forecaster调用。上述时序检测的算法类都继承了AlgModel类,该类的结构如下:
class AlgModel(object):
"""
This is the base class for forecasting algorithms.
If we want to use our own forecast algorithm, we should follow some rules.
"""
def __init__(self):
pass
@abstractmethod
def fit(self, timeseries):
pass
@abstractmethod
def forecast(self, period):
pass
def save(self, model_path):
pass
def load(self, model_path):
pass
在 Forecast 类中,通过调用 fit() 方法,可以根据历史时间序列数据进行训练,通过 forecast() 方法预测未来趋势。获取未来趋势后如何判断是否异常?有很多方法。最简单最基本的方法是通过阈值来判断。在我们的程序中,这个方法也默认用于判断。8.5.4 Anomaly-Detection 工具有五种操作模式:启动、停止、预测、show_metrics 和部署。每种模式的说明如表1所示。 表1 Anomaly-Detection使用模式及说明
模式名称
阐明
开始
启动本地或远程服务
停止
停止本地或远程服务
预报
未来变化的预测器
显示指标
输出当前监控的参数
部署
远程部署代码
Anomaly-Detection 工具的操作模式示例如下所示。① 使用启动方式启动本地采集器服务,代码如下:
python main.py start –role collector
② 使用停止方式停止本地采集器服务,代码如下:
python main.py stop –role collector
③ 使用启动方式启动远程采集器服务,代码如下:
python main.py start --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
④ 使用停止方式停止远程采集器服务,代码如下:
python main.py stop --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
⑤ 显示当前所有监控参数,代码如下:
python main.py show_metrics
⑥ 预测接下来60秒io_read的最大值、最小值和平均值,代码如下:
python main.py forecast –metric-name io_read –forecast-periods 60S –save-path predict_result
⑦ 将代码部署到远程服务器,代码如下:
python main.py deploy –user xxx –host xxx.xxx.xxx.xxx –project-path xxx
8.5.5 进化路线
Anomaly-Detection作为数据库指标监控和异常检测工具,目前具备数据采集、数据存储、异常检测、消息推送等基本功能。但是,存在以下问题。(1)Agent模块采集的数据太简单了,目前Agent只能采集数据库的资源索引数据,包括IO、磁盘、内存、CPU等,< @采集未来需要增强。(2)Monitor内置算法覆盖不够,Monitor目前只支持两种时序预测算法,对于异常检测,只支持基于阈值的简单案例,使用场景有限。(3) Server 仅支持 支持单Agent数据传输。目前Server采用的方案只支持从一个Agent接收数据,不支持多个Agent同时传输。这对于只有一个主节点的openGauss数据库来说暂时够用了,但显然不适合分布式部署。不友好。因此,针对上述三个问题,未来将丰富Agent以采集数据,主要包括安全指标、数据库日志等信息。其次,在算法层面,会写出鲁棒性(即算法的鲁棒性和稳定性)。增强异常检测算法,增加异常监控场景。同时,Server 需要改进以支持多 Agent 模式。最后,
以上内容是对AI技术中的指标采集、预测和异常检测的详细介绍。下一篇将分享“AI查询时间预测”的相关内容,敬请期待!
- 结尾 -
高斯松鼠俱乐部
汇聚数据库从业者和爱好者,互相帮助解决问题,构建数据库技术交流圈 查看全部
文章采集调用(
AI技术——指标采集、预测与异常检测的相关内容)
高斯松鼠俱乐部
学习探索和分享前沿数据库知识和技术,构建数据库技术交流圈
关注之前的图文,我们分享了AI技术的相关内容——智能索引推荐,本文将详细介绍AI技术的相关内容——索引采集,预测和异常检测。8.5指标采集,Prediction and Anomaly Detection 数据库指标监控和异常检测技术,通过监控数据库指标,并基于时序预测和异常检测等算法,发现异常信息,然后进行提醒用户采取措施避免异常情况产生严重后果。8.5.1 使用场景 用户操作数据库的某些行为或某些正在运行的业务的变化可能会导致数据库异常。如果这些异常没有及时发现和处理,导致严重后果。通常,数据库监控指标(指标,如 CPU 使用率、QPS 等)可以反映数据库系统的健康状况。通过监控数据库指标,分析指标数据特征或变化趋势,及时发现数据库异常情况,及时向运维管理人员推送告警信息,避免损失。8.5.2 实现原理 并及时将告警信息推送给运维管理人员,避免损失。8.5.2 实现原理 并及时将告警信息推送给运维管理人员,避免损失。8.5.2 实现原理
图 1 Anomaly-Detection 框架
指标采集,预测和异常检测由同一个系统实现,在openGauss项目中命名为Anomaly-Detection,其结构如图1所示。该工具可分为Agent和Detector两部分. Agent是一个数据库代理模块,负责采集数据库指标数据并将数据推送到Detector;Detector是一个数据库异常检测分析模块,主要有3个功能。(1) 采集并转储 Agent 采集 的数据。(2) 对采集到的数据进行特征分析和异常检测。(3) 将检测到的异常信息推送到1. Agent模块的组成 Agent模块负责采集和指标数据的发送。该模块由三个子模块组成:DBSource、MemoryChannel 和 HttpSink。(1) DBSource作为数据源,负责定时采集数据库指标数据,并将数据发送到数据通道MemoryChannel。(2) MemoryChannel是内存数据通道,本质上是数据的FIFO队列缓存,HttpSink组件消费MemoryChannel Data中的数据,为了防止MemoryChannel中数据过多导致OOM(out of Memory,内存溢出),设置了容量上限,当容量上限为超过,过多的元素将被禁止入队列。(3)HttpSink为数据采集点,该模块周期性的从MemoryChannel获取数据,并以Http(s)的形式转发数据。之后读取数据,它从 MemoryChannel 中清除。2. Detector模块由Detector模块组成,负责数据检测,该模块由Server和Monitor两个子模块组成。(1)Server是一个Web服务,就是Agent采集接收到的数据提供了一个接收接口,将数据存储在本地数据库中。为了防止数据库由于随着数据的增加,我们对数据库中每张表的行数设置了上限。(2) Monitor模块包括时序预测和异常检测等算法。该模块定期从本地数据库,并基于现有算法对数据进行预测和分析。
def forecast(args):
…
# 如果没有指定预测方式,则默认使用’auto_arima’算法
if not args.forecast_method:
forecast_alg = get_instance('auto_arima')
else:
forecast_alg = get_instance(args.forecast_method)
# 指标预测功能函数
def forecast_metric(name, train_ts, save_path=None):
…
forecast_alg.fit(timeseries=train_ts)
dates, values = forecast_alg.forecast(
period=TimeString(args.forecast_periods).standard)
date_range = "{start_date}~{end_date}".format(start_date=dates[0],
end_date=dates[-1])
display_table.add_row(
[name, date_range, min(values), max(values), sum(values) / len(values)]
)
# 校验存储路径
if save_path:
if not os.path.exists(os.path.dirname(save_path)):
os.makedirs(os.path.dirname(save_path))
with open(save_path, mode='w') as f:
for date, value in zip(dates, values):
f.write(date + ',' + str(value) + '\n')
# 从本地sqlite中抽取需要的数据
with sqlite_storage.SQLiteStorage(database_path) as db:
if args.metric_name:
timeseries = db.get_timeseries(table=args.metric_name, period=max_rows)
forecast_metric(args.metric_name, timeseries, args.save_path)
else:
# 获取sqlite中所有的表名
tables = db.get_all_tables()
# 从每个表中抽取训练数据进行预测
for table in tables:
timeseries = db.get_timeseries(table=table, period=max_rows)
forecast_metric(table, timeseries)
# 输出结果
print(display_table.get_string())
# 代码远程部署
def deploy(args):
print('Please input the password of {user}@{host}: '.format(user=args.user, host=args.host))
# 格式化代码远程部署指令
command = 'sh start.sh --deploy {host} {user} {project_path}' \
.format(user=args.user,
host=args.host,
project_path=args.project_path)
# 判断指令执行情况
if subprocess.call(shlex.split(command), cwd=SBIN_PATH) == 0:
print("\nExecute successfully.")
else:
print("\nExecute unsuccessfully.")
…
# 展示当前监控的参数
def show_metrics():
…
# 项目总入口
def main():
…
2. 关键代码段分析(1) 后台线程的实现。前面说过,这个功能可以分为三个角色:Agent、Monitor 和 Detector,这三个不同的角色都是常见的进程驻留在后台执行不同的任务,Daemon类是负责运行不同业务流程的容器类,下面介绍这个类的实现。
class Daemon:
"""
This class implements the function of running a process in the background."""
def __init__(self):
…
def daemon_process(self):
# 注册退出函数
atexit.register(lambda: os.remove(self.pid_file))
signal.signal(signal.SIGTERM, handle_sigterm)
# 启动进程
@staticmethod
def start(self):
try:
self.daemon_process()
except RuntimeError as msg:
abnormal_exit(msg)
self.function(*self.args, **self.kwargs)
# 停止进程
def stop(self):
if not os.path.exists(self.pid_file):
abnormal_exit("Process not running.")
read_pid = read_pid_file(self.pid_file)
if read_pid > 0:
os.kill(read_pid, signal.SIGTERM)
if read_pid_file(self.pid_file) < 0:
os.remove(self.pid_file)
(2)数据库相关指标采集流程。数据库指标采集架构参考了Apache Flume的设计。一个完整的信息采集流程分为三个部分,分别是Source , Channel 和 Sink. 以上三部分被抽象成三个不同的基类, 从中可以派生出不同的采集 数据源, 缓存管道和数据接收者. 前面说过DBSource派生自Source, MemoryChannel派生来源于Channel,HttpSink来源于Sink,下面代码来源于metric_agent.py,负责采集指标,上面的模块是串联的。
def agent_main():
…
# 初始化通道管理器
cm = ChannelManager()
# 初始化数据源
source = DBSource()
http_sink = HttpSink(interval=params['sink_timer_interval'], url=url, context=context)
source.channel_manager = cm
http_sink.channel_manager = cm
# 获取参数文件里面的功能函数
for task_name, task_func in get_funcs(metric_task):
source.add_task(name=task_name,
interval=params['source_timer_interval'],
task=task_func,
maxsize=params['channel_capacity'])
source.start()
http_sink.start()
(3)实现数据存储和监控。Agent将采集收到的指标数据发送到Detector服务器,Detector服务器负责存储。Monitor不断检查存储的数据,以便提前发现异常,这里实现了一个通过SQLite进行本地化存储的方法,代码位于sqlite_storage.py文件中,实现的类为SQLiteStorage,该类实现的主要方法如下:
# 通过时间戳获取最近一段时间的数据
def select_timeseries_by_timestamp(self, table, period):
…
# 通过编号获取最近一段时间的数据
def select_timeseries_by_number(self, table, number):
…
其中,由于不同指标的数据存储在不同的表中,所以上述参数表也代表了不同指标的名称。异常检测目前主要支持基于时间序列预测的方法,包括Prophet算法(Facebook开源的工业级时间序列预测算法工具)和ARIMA算法,封装成类供Forecaster调用。上述时序检测的算法类都继承了AlgModel类,该类的结构如下:
class AlgModel(object):
"""
This is the base class for forecasting algorithms.
If we want to use our own forecast algorithm, we should follow some rules.
"""
def __init__(self):
pass
@abstractmethod
def fit(self, timeseries):
pass
@abstractmethod
def forecast(self, period):
pass
def save(self, model_path):
pass
def load(self, model_path):
pass
在 Forecast 类中,通过调用 fit() 方法,可以根据历史时间序列数据进行训练,通过 forecast() 方法预测未来趋势。获取未来趋势后如何判断是否异常?有很多方法。最简单最基本的方法是通过阈值来判断。在我们的程序中,这个方法也默认用于判断。8.5.4 Anomaly-Detection 工具有五种操作模式:启动、停止、预测、show_metrics 和部署。每种模式的说明如表1所示。 表1 Anomaly-Detection使用模式及说明
模式名称
阐明
开始
启动本地或远程服务
停止
停止本地或远程服务
预报
未来变化的预测器
显示指标
输出当前监控的参数
部署
远程部署代码
Anomaly-Detection 工具的操作模式示例如下所示。① 使用启动方式启动本地采集器服务,代码如下:
python main.py start –role collector
② 使用停止方式停止本地采集器服务,代码如下:
python main.py stop –role collector
③ 使用启动方式启动远程采集器服务,代码如下:
python main.py start --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
④ 使用停止方式停止远程采集器服务,代码如下:
python main.py stop --user xxx --host xxx.xxx.xxx.xxx –project-path xxx –role collector
⑤ 显示当前所有监控参数,代码如下:
python main.py show_metrics
⑥ 预测接下来60秒io_read的最大值、最小值和平均值,代码如下:
python main.py forecast –metric-name io_read –forecast-periods 60S –save-path predict_result
⑦ 将代码部署到远程服务器,代码如下:
python main.py deploy –user xxx –host xxx.xxx.xxx.xxx –project-path xxx
8.5.5 进化路线
Anomaly-Detection作为数据库指标监控和异常检测工具,目前具备数据采集、数据存储、异常检测、消息推送等基本功能。但是,存在以下问题。(1)Agent模块采集的数据太简单了,目前Agent只能采集数据库的资源索引数据,包括IO、磁盘、内存、CPU等,< @采集未来需要增强。(2)Monitor内置算法覆盖不够,Monitor目前只支持两种时序预测算法,对于异常检测,只支持基于阈值的简单案例,使用场景有限。(3) Server 仅支持 支持单Agent数据传输。目前Server采用的方案只支持从一个Agent接收数据,不支持多个Agent同时传输。这对于只有一个主节点的openGauss数据库来说暂时够用了,但显然不适合分布式部署。不友好。因此,针对上述三个问题,未来将丰富Agent以采集数据,主要包括安全指标、数据库日志等信息。其次,在算法层面,会写出鲁棒性(即算法的鲁棒性和稳定性)。增强异常检测算法,增加异常监控场景。同时,Server 需要改进以支持多 Agent 模式。最后,
以上内容是对AI技术中的指标采集、预测和异常检测的详细介绍。下一篇将分享“AI查询时间预测”的相关内容,敬请期待!
- 结尾 -
高斯松鼠俱乐部
汇聚数据库从业者和爱好者,互相帮助解决问题,构建数据库技术交流圈
文章采集调用( 列表页调用的方法有两种是切割副表的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-04-06 11:01
列表页调用的方法有两种是切割副表的)
列表页标签的调用方式有两种,一是切分表的infotags字段,二是从phome_enewstagsdata表中提取。如果 tagid 或 tag 是静态的,建议使用第二种方法,效率更高。如果使用tagname的动态链接方式,可以使用第一种方式。
第一种方法:剪切infotags字段
/* 列表页显示tag 开始*/
$fr=$empire->fetch1("select infotags from {$dbtbpre}ecms_".$class_r[$r['classid']]['tbname']."_data_{$r[stb]} where id='$r[id]'");
$tagstr='';
$infotags_r=explode(',',$fr['infotags']);
$tagscount=count($infotags_r);
for($i=0;$ifetch1("select * from {$dbtbpre}enewstags where tagname='".$tagname."' limit 1");
if(!$tt['tagid']){
continue;
}else{
$tagslink=$public_r['newsurl'].'e/tags/?tagid='.$tagid;;
}
//采用东坡网静态化插件时的tag链接,采用以下6行代码
/* $tt=$empire->fetch1("select * from {$dbtbpre}enewstags where tagname='".$tagname."' limit 1");
if(!$tt['tagid']){
continue;
}else{
$tagslink=user_HtmlTagLink($tt['tagid']);
}*/
//返回单独一个tag的代码
$tagstr.=''.$tagname.'';
}
/*结束*/
$listtemp='其它代码'.$tagstr.'其它代码';
第二种方法:从phome_enewstags数据表中提取
/* 列表页显示tag 开始*/
$tagstr='';
$tsql=$empire->query("select tagid from {$dbtbpre}enewstagsdata where id='$r[id]' and classid='$r[classid]' ");
while($tr=$empire->fetch($tsql)){
$tt=$empire->fetch1("select * from {$dbtbpre}enewstags where tagid=".$tr['tagid']." limit 1");
if(!$tt['tagid']){
continue;
}else{
//tagname的动态 或 伪静态 时的链接,采用以下1行代码
//$tagslink=eReturnRewriteTagsUrl(0,$tt['tagname'],1);
//tagid式的动态链接,采用以下1行代码
$tagslink=$public_r['newsurl'].'e/tags/?tagid='.$tt['tagid'];
//采用东坡网静态化插件时的tag链接,采用以下1行代码
//$tagslink=user_HtmlTagLink($tt['tagid']);
}
$tagstr.=''.$tt['tagname'].'';
}
/*结束*/
$listtemp='其它代码'.$tagstr.'其它代码';
说明:
1、代码中的标签链接有3种方式,可根据实际情况选择。
2、以上代码放入列表内容模板(list.var),应用代码必须开启。
版权说明:本文归东坡网原创所有,版权归东坡网所有。欢迎转载,但请保留东坡网出处。签名转载是对我们最大的支持,谢谢!
下载本文的doc文件/下载本文的PDF文件 查看全部
文章采集调用(
列表页调用的方法有两种是切割副表的)
列表页标签的调用方式有两种,一是切分表的infotags字段,二是从phome_enewstagsdata表中提取。如果 tagid 或 tag 是静态的,建议使用第二种方法,效率更高。如果使用tagname的动态链接方式,可以使用第一种方式。
第一种方法:剪切infotags字段
/* 列表页显示tag 开始*/
$fr=$empire->fetch1("select infotags from {$dbtbpre}ecms_".$class_r[$r['classid']]['tbname']."_data_{$r[stb]} where id='$r[id]'");
$tagstr='';
$infotags_r=explode(',',$fr['infotags']);
$tagscount=count($infotags_r);
for($i=0;$ifetch1("select * from {$dbtbpre}enewstags where tagname='".$tagname."' limit 1");
if(!$tt['tagid']){
continue;
}else{
$tagslink=$public_r['newsurl'].'e/tags/?tagid='.$tagid;;
}
//采用东坡网静态化插件时的tag链接,采用以下6行代码
/* $tt=$empire->fetch1("select * from {$dbtbpre}enewstags where tagname='".$tagname."' limit 1");
if(!$tt['tagid']){
continue;
}else{
$tagslink=user_HtmlTagLink($tt['tagid']);
}*/
//返回单独一个tag的代码
$tagstr.=''.$tagname.'';
}
/*结束*/
$listtemp='其它代码'.$tagstr.'其它代码';
第二种方法:从phome_enewstags数据表中提取
/* 列表页显示tag 开始*/
$tagstr='';
$tsql=$empire->query("select tagid from {$dbtbpre}enewstagsdata where id='$r[id]' and classid='$r[classid]' ");
while($tr=$empire->fetch($tsql)){
$tt=$empire->fetch1("select * from {$dbtbpre}enewstags where tagid=".$tr['tagid']." limit 1");
if(!$tt['tagid']){
continue;
}else{
//tagname的动态 或 伪静态 时的链接,采用以下1行代码
//$tagslink=eReturnRewriteTagsUrl(0,$tt['tagname'],1);
//tagid式的动态链接,采用以下1行代码
$tagslink=$public_r['newsurl'].'e/tags/?tagid='.$tt['tagid'];
//采用东坡网静态化插件时的tag链接,采用以下1行代码
//$tagslink=user_HtmlTagLink($tt['tagid']);
}
$tagstr.=''.$tt['tagname'].'';
}
/*结束*/
$listtemp='其它代码'.$tagstr.'其它代码';
说明:
1、代码中的标签链接有3种方式,可根据实际情况选择。
2、以上代码放入列表内容模板(list.var),应用代码必须开启。
版权说明:本文归东坡网原创所有,版权归东坡网所有。欢迎转载,但请保留东坡网出处。签名转载是对我们最大的支持,谢谢!
下载本文的doc文件/下载本文的PDF文件
文章采集调用(,系统中,文章摘要()字数上限为250字符,)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-04-05 15:09
在Dedecms系统中,文章摘要(可以通过infolen或description相关标签调用)设置了250个字符的字符限制。设置上限的主要目的是减少数据库的冗余,保证网站良好的性能,因此,对介绍内容不设置上限显然是不合理的,但如果可以自由控制这个上限,会对网页内容的布局产生积极的影响。列表页调用 文章 的摘要。如果文章的摘要中的字数能够得到有效控制,那么页面布局就可以变得非常灵活。
一、使用infolen来限制称为文章的描述字符个数,如下标签演示所示:
{dede:arclist row=”1″ infolen='170′}
[字段:信息/]…
{/dede:arclist}
上面的infolen='170'表示调用170字节的文章描述
二、使用 [field:description function='cn_substr(@me,250)'/] 代替 [field:info/] 标记,其中 250 是字节限制,您可以将其称为多个字随便改吧,注意这里250是一个字节,一个字等于2个字节,也就是这里调用了125个字
在Dedecms中,列表页调用文章摘要的方法如下:
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是直接调用文章的抽象。在调用字数方面,使用[field:info /]时,可以在{dede:arclist infolen=' ' }{/dede :arclist}中使用,设置调用摘要的字符数(最大值可以设置为系统设置的250);如果使用[field:description/],则直接使用后台设置的摘要字符的上限,显然这两种方法是非常被动,灵活性太差。
3、的第四种方法通过function函数实现了对文章摘要中显示字符的灵活调整。当然,在不修改摘要内容的字符上限的情况下,这四种方法的区别并不大。不过说一下如何修改这个上限值,可以体现[field:description function="cn_substr(@me, number of characters)"/]的重要性。
在Dedecms中,与文章抽象相关的php文件主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$description = cn_substrR($description,$cfg_auot_description);
这句话应验了
[field:description function="cn_substr(@me, 字符数)"/]
这个功能。因为这个语句确实有利于页面布局,所以我们在实验中没有修改它。
在编辑页面,有一句话:
$description = cn_substrR($description,250);
这句话中出现了一个熟悉的字符数“250”,这是系统设置的文章摘要字符的上限。如果是gbk编码,会显示125个字符。如果是utf-8编码,就是81个字。显然,我们将打破 文章summary 字符限制,我们将不得不这样做。是的,您可以在此处将“250”更改为另一个值,例如“500”。这里不建议设置太高。一是不需要在列表页面上显示过多的内容。最好直接使用body来显示过多的内容。一是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面,找到“if($dsize>250) $dsize = 250;”语句,限制后台自动获取的字符数,这里将“250”改为“500”即和之前修改的字符数一样,如果你确认你的每一个文章都是手动添加的,如果你手动完成摘要获取就不需要修改这个文件了。自动抽象获取主要针对很多文章和采集。
最后登录后台,在系统-系统基本参数-其他选项中,自动汇总长度可以改成500,也就是可以和之前修改的字符数一样。
完成以上修改后,我们进入频道列表页面,通过标签调用。示例标签如下:
{dede:list typeid='' row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[字段:描述函数='cn_substr(@me,500)'/]...
{/dede:列表}
通过以上方法,我们实现了调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为网页布局提供了更广阔的空间。 查看全部
文章采集调用(,系统中,文章摘要()字数上限为250字符,)
在Dedecms系统中,文章摘要(可以通过infolen或description相关标签调用)设置了250个字符的字符限制。设置上限的主要目的是减少数据库的冗余,保证网站良好的性能,因此,对介绍内容不设置上限显然是不合理的,但如果可以自由控制这个上限,会对网页内容的布局产生积极的影响。列表页调用 文章 的摘要。如果文章的摘要中的字数能够得到有效控制,那么页面布局就可以变得非常灵活。
一、使用infolen来限制称为文章的描述字符个数,如下标签演示所示:
{dede:arclist row=”1″ infolen='170′}
[字段:信息/]…
{/dede:arclist}
上面的infolen='170'表示调用170字节的文章描述
二、使用 [field:description function='cn_substr(@me,250)'/] 代替 [field:info/] 标记,其中 250 是字节限制,您可以将其称为多个字随便改吧,注意这里250是一个字节,一个字等于2个字节,也就是这里调用了125个字
在Dedecms中,列表页调用文章摘要的方法如下:
1:[字段:信息/]
2:[字段:描述/]
3: [field:info function="cn_substr(@me, 字符数)"/]
4: [field:description function="cn_substr(@me, 字符数)"/]
1、的第二种方法是直接调用文章的抽象。在调用字数方面,使用[field:info /]时,可以在{dede:arclist infolen=' ' }{/dede :arclist}中使用,设置调用摘要的字符数(最大值可以设置为系统设置的250);如果使用[field:description/],则直接使用后台设置的摘要字符的上限,显然这两种方法是非常被动,灵活性太差。
3、的第四种方法通过function函数实现了对文章摘要中显示字符的灵活调整。当然,在不修改摘要内容的字符上限的情况下,这四种方法的区别并不大。不过说一下如何修改这个上限值,可以体现[field:description function="cn_substr(@me, number of characters)"/]的重要性。
在Dedecms中,与文章抽象相关的php文件主要有:
/dede/archives_add.php
/dede/archives_edit.php
/dede/article_add.php
/dede/article_edit.php
/dede/article_description_main.php
//
在添加页面上,有一句话:
$description = cn_substrR($description,$cfg_auot_description);
这句话应验了
[field:description function="cn_substr(@me, 字符数)"/]
这个功能。因为这个语句确实有利于页面布局,所以我们在实验中没有修改它。
在编辑页面,有一句话:
$description = cn_substrR($description,250);
这句话中出现了一个熟悉的字符数“250”,这是系统设置的文章摘要字符的上限。如果是gbk编码,会显示125个字符。如果是utf-8编码,就是81个字。显然,我们将打破 文章summary 字符限制,我们将不得不这样做。是的,您可以在此处将“250”更改为另一个值,例如“500”。这里不建议设置太高。一是不需要在列表页面上显示过多的内容。最好直接使用body来显示过多的内容。一是避免数据库冗余。
完成以上修改还不够,还需要修改article_description_main.php
在article_description_main.php页面,找到“if($dsize>250) $dsize = 250;”语句,限制后台自动获取的字符数,这里将“250”改为“500”即和之前修改的字符数一样,如果你确认你的每一个文章都是手动添加的,如果你手动完成摘要获取就不需要修改这个文件了。自动抽象获取主要针对很多文章和采集。
最后登录后台,在系统-系统基本参数-其他选项中,自动汇总长度可以改成500,也就是可以和之前修改的字符数一样。
完成以上修改后,我们进入频道列表页面,通过标签调用。示例标签如下:
{dede:list typeid='' row='5' titlelen='100' orderby='new' pagesize='5'}
[字段:标题/]
[字段:描述函数='cn_substr(@me,500)'/]...
{/dede:列表}
通过以上方法,我们实现了调用的文章抽象字符为500个字符,彻底突破了文章抽象250个字符的系统限制,为网页布局提供了更广阔的空间。
文章采集调用(微服务中较流行的两款开源分布式tracing系统(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-05 02:18
1.背景说明
由于我们的项目是微服务方向的,中间和后台服务有10多种服务模块,各个服务/模块之间的调用关系比较复杂,一些服务之间还有一些代理服务和服务(许多服务实时部署的实施)。这些现象导致在开发、调试和问题跟踪中逐渐出现问题。因此,前段时间,分别研究了微服务中两个流行的开源分布式追踪系统:Zipkin 和 Jaeger。
在微服务分布式架构的系统中,可能存在复杂而深入的逐层服务调用关系,如下图所示。
微服务架构中各个服务的调用关系是不是和程序中各个函数的调用关系很相似?
上图很容易理解。当用户的浏览器发起请求时,会先到应用程序A;A 将呼叫 B 和 C;B会调用F……这样一层一层的调用到最后一层,最后完成一个客户的请求。处理(可能是读请求或写请求)。
试想一下,在这个过程中会出现哪些可能的问题?
对于第一种情况,如果客户端请求是写请求,调用链中每一步都有写操作,第一步执行成功,第三步失败,那么分布式系统中需要采用分布式事务。回滚前几步的写操作的机制!
对于第二种情况,可能会因为应用F的异常而拖累整个服务环节,甚至出现雪崩现象,严重影响系统的可用性。本文不会讨论如何处理这种场景,而是先提一下,这种问题在分布式系统中使用了熔断机制和降级机制,以确保系统在出现此类异常时具有高可用性!
那么我们来看看1、2、3的场景中可能涉及的问题。在一个复杂的调用链中,假设有一个响应慢或处理异常的调用链。如何定位这个问题?有问题的服务呢?大多数开发者的第一反应可能是查看日志,依次分析调用链路上各个系统的日志文件,然后定位出问题的服务。在海量日志中定位问题真的很痛苦!
2.跟踪链
首先简单解释一下什么是跟踪链。有相关基础的可以跳过,也可以快速通读本段。基本上,任何谈论跟踪链的 文章 都会发布这张图片:
图 1. 一个简单的追踪调用流程
图 1 是来自 Google 的 Dapper 论文的一个示例:图中,五个节点 A~E 代表五个服务。用户向A发起请求RequestX。同时,由于该请求依赖于服务B和C,所以A分别向B和C发送RPC请求,B处理完请求后直接返回给A,但是服务C也依赖于服务 D 和 E。因此,必须分别向 D 和 E 发起两个 RPC 请求。D和E处理完后返回给C,C继续回复A,最后A会回复用户ReplyX。对于这样的请求,分布式跟踪的一个简单实用的实现是为服务器上的每个发送和接收操作采集跟踪标识符和时间戳。
在 Dapper 的论文中,Trace 和 Span 是两个非常重要的术语。我们用Trace来表示一个请求的完整调用链的trace,将上面的服务A和服务B这两个服务的请求/响应过程称为一个Span,通过span来反映trace。一句话概括,我们可以把一条trace看成span的一个有向图,这个有向图的边就是span。为了更好地理解这两个术语,我们可以看一下下面的调用图。
[跨度A] ←←←(根跨度)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C 是 `ChildOf` Span A)
| |
[跨度 D] +---+-----+
| |
[跨度 E] [跨度 F] >>> [跨度 G] >>> [跨度 H]
↑
↑
↑
(Span G`FollowsFrom`Span F) 上图收录8个span信息
图2.一个tracing过程的Spans关系图
––|–––––––|–––––––|–––––––|––––––––––––––|––––––– –|––––––––|–> 时间
[跨度A········································································································································································...
[跨度B················································ ····················································································································································]
[跨度D················································ ········································································································································································································································································································]
[跨度C················································ ]
[跨度 E···] [跨度 F··] [跨度 G··] [跨度 H··]
图3. Spans的时间线图
分布式跟踪系统需要做的是记录每个发送和接收动作的标识符和时间戳,并连接一个请求中涉及的所有服务。只有这样才能理解一个请求的完整调用链。
3. 开放跟踪
在详细介绍Jaeger之前,还有一个关键词需要提一下:OpenTracing。
一句话总结,OpenTracing 是一套标准,通过提供平台无关和厂商无关的 API,开发者可以轻松添加(或替换)跟踪系统的实现(我们在测试中基本上使用两行代码) . 更改为在 Zipkin 和 Jaeger 之间切换)。OpenTracing 为操作支持系统和特定平台提供辅助库。程序库的具体信息请参考详细规范。OpenTracing 已进入 CNCF(Cloud Native Computing Foundation,著名的 Kubernetes、gRPC 和 Prometheus 孵化的地方),正在为全球分布式追踪提供统一的概念和数据标准。
当然,本文前面提到的 Zipkin 和 Jaeger 都支持 OpenTracing 标准。
3.1 引用关系
目前 OpenTracing 标准中定义了两种类型的引用:
3.1.1 ChildOf 参考
一个跨度 A 可以是另一个跨度 B 的 ChildOf。以下所有内容构成了 ChildOf 关系:
[-父跨度---------]
[-孩子跨度----]
[-父跨度-------------]
[-孩子跨度A----]
[-儿童跨度B----]
[-Child Span C----]
[-Child Span D--------------]
[-Child Span E----]
图 4. 的 ChildOf 引用 Span
3.1.2 FollowsFrom 引用
一些父 Span 不以任何方式依赖其子 Span 的结果。在这些情况下,我们只说子跨度是从因果意义上的父跨度派生的。
4. 积家介绍
细心的话,通过上面的CNCF地址,我们可以发现Jaeger现在已经成为CNCF的一个孵化项目。
为了深入了解jaeger的工作原理,首先我们来看一下Jaeger的架构设计图:
图5. Jaeger 架构设计图
上图中,我们看到的是Jaeger系统:黄色部分是我们的应用代码;红色部分代表 Instrument 操作,即加载我们的应用和 jaeger-client ,从而开始应用和 Jaeger 之间的数据交互操作。放大这部分,我们可以参考下图来了解详细的数据交互方式:
图 6. Jaeger 的插桩流程
在图 5 中,我们可以观察到 Jaeger 的完整概览设计。从中我们会发现Jaeger有5个模块元素,如下所列,接下来我们将解释这5个模块的作用:
1.Jaeger 客户端
2.代理
3.采集器
4.数据存储
5.用户界面
Jaeger-client(客户端库)
client就是client lib,方便不同语言的项目介入Jaeger。当我们的应用程序被加载时,客户端将负责采集数据并将其发送给代理。目前 Jaeger SDK 支持如下:
- 官方的
1.去吧
2.Java
3.节点
4.Python
5.C++
- 非官方
1.PHP
3.其他
客户端支持 OpenTracing 标准。如上所述,Zipkin 还支持 OpenTracing 标准,这意味着我们的应用程序可以在嵌入 Jaeger-client 的任何时候替换为 Zipkin,这对业务是完全透明的。
代理(客户端代理)
jaeger 的代理是一个网络守护进程,它在 UDP 端口上侦听接收跨度数据。与大多数分布式系统都有一个 Agent 一样,Jaeger 的 Agent 具有以下特点:
代理采集这些跨度信息并将其汇总到采集器;
代理被设计为基本组件,旨在作为基础架构组件部署到所有主机;
代理将客户端库和采集器解耦,将客户端库与路由和发现采集器的细节屏蔽掉;
采集器(数据采集处理)
采集器,顾名思义,从代理采集跟踪,通过处理管道处理它们,并将它们写入后端。
当前采集器的工作是管理跟踪、构建索引、执行相关转换并最终存储它们。
采样逻辑运行在 Collector 中,它按照我们设置的采样方式对数据进行采集和处理。
数据存储
Jaeger 的数据存储是组件的方式。
目前支持 Cassandra 和 ElasticSearch(当然也支持纯内存模式,但不适合生产环境)。
Query & UI(数据查询和前端界面展示)
查询是一种从存储中检索跟踪并提供显示它们的 UI 的服务。上图是一个trace的数据流,可以在Jaeger UI上展示为一个系统函数的数据传播/执行图。
5. 部署方式
由于解决方案不同,Jaeger 的部署依赖于不同的服务。这些第三方基础服务的部署和安装不再属于本文讨论范围,如docker、Elasticsearch、Cassandra等。
5.1 多合一
为了方便您快速使用,Jaeger 直接提供了一个 All in one docker 镜像。通过 All in one 镜像,我们可以直接启动一个完整的 Jaeger 追踪系统,使用如下命令:
$ 码头工人运行 -d -e \
COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp\
-p 6831:6831/udp\
-p 6832:6832/udp\
-p 5778:5778\
-p 16686:16686 \
-p 14268:14268\
-p 9411:9411\
jaegertracing/all-in-one:最新
启动成功后,可以去:16686看到Jaeger UI如下图。
图 7. Jaeger UI 主页
注意:在 All in one 模式下,Data Store 使用内存,因此如果您重新启动docker 容器,您将无法看到之前的数据。因此,该模式只能用于早期演示或验证,不能部署在生产环境中。
5.2 独立部署
当然,更推荐的方式是独立部署。独立部署也可以分为docker镜像模式和二进制模式。官网对docker镜像模式启动命令有详细的介绍,这里就不贴复制了。
对于二进制部署,请参阅 github 上 Jaeger 的二进制包。该地址提供mac、linux、windows三大操作系统的二进制包。以linux为例,解压后可以找到如下bin包,明显对应我们前面提到的模块:
drwxrwxr-x 3 2000 2000 4.0K 5 月 28 日 23:29 jaeger-ui-build
-rwxrwxr-x 1 2000 2000 27M 5 月 28 日 23:29 jaeger-standalone
-rwxrwxr-x 1 2000 2000 22M 5 月 28 日 23:29 jaeger-query
-rwxrwxr-x 1 2000 2000 25M 5 月 28 日 23:29 jaeger-collector
-rwxrwxr-x 1 2000 2000 16M 5 月 28 日 23:29 jaeger-agent
注意:Jaeger 还为 Kubernetes 和 OpenShift 提供模板。详细介绍请参考github地址
5.3 端口说明
通过上面的 All in one 启动方式,我们直接发现 Jaeger 在启动时占用了大量的端口。当然,并非所有端口都是必需的。以下是这些端口的简要说明:
端口协议所属模块的功能
5775UDPagent通过兼容的Thrift协议接收Zipkin thrift类型的数据
6831UDPagent通过兼容的Thrift协议接收Jaeger thrift类型的数据
6832UDPagent通过二进制Thrift协议接收Jaeger thrift类型数据 查看全部
文章采集调用(微服务中较流行的两款开源分布式tracing系统(图))
1.背景说明
由于我们的项目是微服务方向的,中间和后台服务有10多种服务模块,各个服务/模块之间的调用关系比较复杂,一些服务之间还有一些代理服务和服务(许多服务实时部署的实施)。这些现象导致在开发、调试和问题跟踪中逐渐出现问题。因此,前段时间,分别研究了微服务中两个流行的开源分布式追踪系统:Zipkin 和 Jaeger。
在微服务分布式架构的系统中,可能存在复杂而深入的逐层服务调用关系,如下图所示。
微服务架构中各个服务的调用关系是不是和程序中各个函数的调用关系很相似?
上图很容易理解。当用户的浏览器发起请求时,会先到应用程序A;A 将呼叫 B 和 C;B会调用F……这样一层一层的调用到最后一层,最后完成一个客户的请求。处理(可能是读请求或写请求)。
试想一下,在这个过程中会出现哪些可能的问题?
对于第一种情况,如果客户端请求是写请求,调用链中每一步都有写操作,第一步执行成功,第三步失败,那么分布式系统中需要采用分布式事务。回滚前几步的写操作的机制!
对于第二种情况,可能会因为应用F的异常而拖累整个服务环节,甚至出现雪崩现象,严重影响系统的可用性。本文不会讨论如何处理这种场景,而是先提一下,这种问题在分布式系统中使用了熔断机制和降级机制,以确保系统在出现此类异常时具有高可用性!
那么我们来看看1、2、3的场景中可能涉及的问题。在一个复杂的调用链中,假设有一个响应慢或处理异常的调用链。如何定位这个问题?有问题的服务呢?大多数开发者的第一反应可能是查看日志,依次分析调用链路上各个系统的日志文件,然后定位出问题的服务。在海量日志中定位问题真的很痛苦!
2.跟踪链
首先简单解释一下什么是跟踪链。有相关基础的可以跳过,也可以快速通读本段。基本上,任何谈论跟踪链的 文章 都会发布这张图片:
图 1. 一个简单的追踪调用流程
图 1 是来自 Google 的 Dapper 论文的一个示例:图中,五个节点 A~E 代表五个服务。用户向A发起请求RequestX。同时,由于该请求依赖于服务B和C,所以A分别向B和C发送RPC请求,B处理完请求后直接返回给A,但是服务C也依赖于服务 D 和 E。因此,必须分别向 D 和 E 发起两个 RPC 请求。D和E处理完后返回给C,C继续回复A,最后A会回复用户ReplyX。对于这样的请求,分布式跟踪的一个简单实用的实现是为服务器上的每个发送和接收操作采集跟踪标识符和时间戳。
在 Dapper 的论文中,Trace 和 Span 是两个非常重要的术语。我们用Trace来表示一个请求的完整调用链的trace,将上面的服务A和服务B这两个服务的请求/响应过程称为一个Span,通过span来反映trace。一句话概括,我们可以把一条trace看成span的一个有向图,这个有向图的边就是span。为了更好地理解这两个术语,我们可以看一下下面的调用图。
[跨度A] ←←←(根跨度)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C 是 `ChildOf` Span A)
| |
[跨度 D] +---+-----+
| |
[跨度 E] [跨度 F] >>> [跨度 G] >>> [跨度 H]
↑
↑
↑
(Span G`FollowsFrom`Span F) 上图收录8个span信息
图2.一个tracing过程的Spans关系图
––|–––––––|–––––––|–––––––|––––––––––––––|––––––– –|––––––––|–> 时间
[跨度A········································································································································································...
[跨度B················································ ····················································································································································]
[跨度D················································ ········································································································································································································································································································]
[跨度C················································ ]
[跨度 E···] [跨度 F··] [跨度 G··] [跨度 H··]
图3. Spans的时间线图
分布式跟踪系统需要做的是记录每个发送和接收动作的标识符和时间戳,并连接一个请求中涉及的所有服务。只有这样才能理解一个请求的完整调用链。
3. 开放跟踪
在详细介绍Jaeger之前,还有一个关键词需要提一下:OpenTracing。
一句话总结,OpenTracing 是一套标准,通过提供平台无关和厂商无关的 API,开发者可以轻松添加(或替换)跟踪系统的实现(我们在测试中基本上使用两行代码) . 更改为在 Zipkin 和 Jaeger 之间切换)。OpenTracing 为操作支持系统和特定平台提供辅助库。程序库的具体信息请参考详细规范。OpenTracing 已进入 CNCF(Cloud Native Computing Foundation,著名的 Kubernetes、gRPC 和 Prometheus 孵化的地方),正在为全球分布式追踪提供统一的概念和数据标准。
当然,本文前面提到的 Zipkin 和 Jaeger 都支持 OpenTracing 标准。
3.1 引用关系
目前 OpenTracing 标准中定义了两种类型的引用:
3.1.1 ChildOf 参考
一个跨度 A 可以是另一个跨度 B 的 ChildOf。以下所有内容构成了 ChildOf 关系:
[-父跨度---------]
[-孩子跨度----]
[-父跨度-------------]
[-孩子跨度A----]
[-儿童跨度B----]
[-Child Span C----]
[-Child Span D--------------]
[-Child Span E----]
图 4. 的 ChildOf 引用 Span
3.1.2 FollowsFrom 引用
一些父 Span 不以任何方式依赖其子 Span 的结果。在这些情况下,我们只说子跨度是从因果意义上的父跨度派生的。
4. 积家介绍
细心的话,通过上面的CNCF地址,我们可以发现Jaeger现在已经成为CNCF的一个孵化项目。
为了深入了解jaeger的工作原理,首先我们来看一下Jaeger的架构设计图:
图5. Jaeger 架构设计图
上图中,我们看到的是Jaeger系统:黄色部分是我们的应用代码;红色部分代表 Instrument 操作,即加载我们的应用和 jaeger-client ,从而开始应用和 Jaeger 之间的数据交互操作。放大这部分,我们可以参考下图来了解详细的数据交互方式:
图 6. Jaeger 的插桩流程
在图 5 中,我们可以观察到 Jaeger 的完整概览设计。从中我们会发现Jaeger有5个模块元素,如下所列,接下来我们将解释这5个模块的作用:
1.Jaeger 客户端
2.代理
3.采集器
4.数据存储
5.用户界面
Jaeger-client(客户端库)
client就是client lib,方便不同语言的项目介入Jaeger。当我们的应用程序被加载时,客户端将负责采集数据并将其发送给代理。目前 Jaeger SDK 支持如下:
- 官方的
1.去吧
2.Java
3.节点
4.Python
5.C++
- 非官方
1.PHP
3.其他
客户端支持 OpenTracing 标准。如上所述,Zipkin 还支持 OpenTracing 标准,这意味着我们的应用程序可以在嵌入 Jaeger-client 的任何时候替换为 Zipkin,这对业务是完全透明的。
代理(客户端代理)
jaeger 的代理是一个网络守护进程,它在 UDP 端口上侦听接收跨度数据。与大多数分布式系统都有一个 Agent 一样,Jaeger 的 Agent 具有以下特点:
代理采集这些跨度信息并将其汇总到采集器;
代理被设计为基本组件,旨在作为基础架构组件部署到所有主机;
代理将客户端库和采集器解耦,将客户端库与路由和发现采集器的细节屏蔽掉;
采集器(数据采集处理)
采集器,顾名思义,从代理采集跟踪,通过处理管道处理它们,并将它们写入后端。
当前采集器的工作是管理跟踪、构建索引、执行相关转换并最终存储它们。
采样逻辑运行在 Collector 中,它按照我们设置的采样方式对数据进行采集和处理。
数据存储
Jaeger 的数据存储是组件的方式。
目前支持 Cassandra 和 ElasticSearch(当然也支持纯内存模式,但不适合生产环境)。
Query & UI(数据查询和前端界面展示)
查询是一种从存储中检索跟踪并提供显示它们的 UI 的服务。上图是一个trace的数据流,可以在Jaeger UI上展示为一个系统函数的数据传播/执行图。
5. 部署方式
由于解决方案不同,Jaeger 的部署依赖于不同的服务。这些第三方基础服务的部署和安装不再属于本文讨论范围,如docker、Elasticsearch、Cassandra等。
5.1 多合一
为了方便您快速使用,Jaeger 直接提供了一个 All in one docker 镜像。通过 All in one 镜像,我们可以直接启动一个完整的 Jaeger 追踪系统,使用如下命令:
$ 码头工人运行 -d -e \
COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp\
-p 6831:6831/udp\
-p 6832:6832/udp\
-p 5778:5778\
-p 16686:16686 \
-p 14268:14268\
-p 9411:9411\
jaegertracing/all-in-one:最新
启动成功后,可以去:16686看到Jaeger UI如下图。
图 7. Jaeger UI 主页
注意:在 All in one 模式下,Data Store 使用内存,因此如果您重新启动docker 容器,您将无法看到之前的数据。因此,该模式只能用于早期演示或验证,不能部署在生产环境中。
5.2 独立部署
当然,更推荐的方式是独立部署。独立部署也可以分为docker镜像模式和二进制模式。官网对docker镜像模式启动命令有详细的介绍,这里就不贴复制了。
对于二进制部署,请参阅 github 上 Jaeger 的二进制包。该地址提供mac、linux、windows三大操作系统的二进制包。以linux为例,解压后可以找到如下bin包,明显对应我们前面提到的模块:
drwxrwxr-x 3 2000 2000 4.0K 5 月 28 日 23:29 jaeger-ui-build
-rwxrwxr-x 1 2000 2000 27M 5 月 28 日 23:29 jaeger-standalone
-rwxrwxr-x 1 2000 2000 22M 5 月 28 日 23:29 jaeger-query
-rwxrwxr-x 1 2000 2000 25M 5 月 28 日 23:29 jaeger-collector
-rwxrwxr-x 1 2000 2000 16M 5 月 28 日 23:29 jaeger-agent
注意:Jaeger 还为 Kubernetes 和 OpenShift 提供模板。详细介绍请参考github地址
5.3 端口说明
通过上面的 All in one 启动方式,我们直接发现 Jaeger 在启动时占用了大量的端口。当然,并非所有端口都是必需的。以下是这些端口的简要说明:
端口协议所属模块的功能
5775UDPagent通过兼容的Thrift协议接收Zipkin thrift类型的数据
6831UDPagent通过兼容的Thrift协议接收Jaeger thrift类型的数据
6832UDPagent通过二进制Thrift协议接收Jaeger thrift类型数据
文章采集调用(聚合采集可以自定义采集规则的seo文章采集器采集程序 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-03-30 17:21
)
Aggregation采集是一种文章聚合全网采集爬虫,而Aggregation采集是一个可以自定义采集的seo文章<规则。@采集器。聚合采集可自定义采集规则,不仅是问答平台,普通站点采集,通过24小时监控采集,实时采集最新文章。聚合采集自动文章过滤(标签、属性、文本),内置全网最新滚动新闻采集。
聚合采集的个性化定制功能,可以对综合页面进行原创标签,让整个网站整合一个统一通用的分类标签体系,不仅内容相关,还原创 内容页面。聚合采集兼容多种静态模式,既有效保证了搜索引擎收录,又增加了网站的持续访问量。聚合采集设置网站的任意顶部导航栏,可以随意添加或删除顶部导航栏,使网站具有高度的自定义性
将采集聚合到任意url连接地址名,不仅使站长的网站独一无二,而且在一定程度上提高了搜索引擎排名。聚合采集支持多个模板集,因为它采用模板编译替换技术,即使只更改一个文件,也可以创建个性化的界面。任意显示数量控制,聚合采集设置专题页各类内容的数量,以及每个列表页的显示数量。
聚合采集内置站长工具,全程记录蜘蛛访问,智能识别99%的搜索引擎蜘蛛访问,全程控制蜘蛛爬取记录。聚合采集自动创建站点地图,自动生成搜索引擎地图,可分类设置,有效提升网站内容收录。一键查看排名和收录,不仅可以查看Alexa排名,还可以准确掌握网站最近收录,还可以添加网站外部链接。聚合采集自动查看网站中的过滤器关键词,自动批量查询网站中是否有过滤的非法内容。
<p>聚合采集的聚合推送,智能系统自动采集网站链接,主动推送到搜索引擎和快速收录界面,大大提升网站@ >收录@ > 率。传统的使用网站js脚本推送的SEO,需要网页有自然流量触发,或者每天导出链接复制到资源平台主动提交,繁琐且效率极低。聚合采集每日自增采集,自动推送,稳步提升索引量,让网站内容爬虫自然增长,从而达到网站全面提升 查看全部
文章采集调用(聚合采集可以自定义采集规则的seo文章采集器采集程序
)
Aggregation采集是一种文章聚合全网采集爬虫,而Aggregation采集是一个可以自定义采集的seo文章<规则。@采集器。聚合采集可自定义采集规则,不仅是问答平台,普通站点采集,通过24小时监控采集,实时采集最新文章。聚合采集自动文章过滤(标签、属性、文本),内置全网最新滚动新闻采集。
聚合采集的个性化定制功能,可以对综合页面进行原创标签,让整个网站整合一个统一通用的分类标签体系,不仅内容相关,还原创 内容页面。聚合采集兼容多种静态模式,既有效保证了搜索引擎收录,又增加了网站的持续访问量。聚合采集设置网站的任意顶部导航栏,可以随意添加或删除顶部导航栏,使网站具有高度的自定义性
将采集聚合到任意url连接地址名,不仅使站长的网站独一无二,而且在一定程度上提高了搜索引擎排名。聚合采集支持多个模板集,因为它采用模板编译替换技术,即使只更改一个文件,也可以创建个性化的界面。任意显示数量控制,聚合采集设置专题页各类内容的数量,以及每个列表页的显示数量。
聚合采集内置站长工具,全程记录蜘蛛访问,智能识别99%的搜索引擎蜘蛛访问,全程控制蜘蛛爬取记录。聚合采集自动创建站点地图,自动生成搜索引擎地图,可分类设置,有效提升网站内容收录。一键查看排名和收录,不仅可以查看Alexa排名,还可以准确掌握网站最近收录,还可以添加网站外部链接。聚合采集自动查看网站中的过滤器关键词,自动批量查询网站中是否有过滤的非法内容。
<p>聚合采集的聚合推送,智能系统自动采集网站链接,主动推送到搜索引擎和快速收录界面,大大提升网站@ >收录@ > 率。传统的使用网站js脚本推送的SEO,需要网页有自然流量触发,或者每天导出链接复制到资源平台主动提交,繁琐且效率极低。聚合采集每日自增采集,自动推送,稳步提升索引量,让网站内容爬虫自然增长,从而达到网站全面提升
文章采集调用(OBD大数据文章采集器安装使用教程For帝国CMS帝国)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-28 06:12
OBD大数据文章采集器Empire安装使用教程cms
英制cms大数据采集适用于:7.0及以上
首先,安装程序
1、把OBD文件夹和网站主页文件放在同一目录下,
2、初始安装时从地址栏访问install.php文件(访问后删除)
3、接下来,按照教程一步一步来。
安装ONEXIN大数据文章采集器图文教程(修订版)
ONEXIN大数据文章采集器图文教程【最新】
点我看视频教程
然后,将触发代码放入模板末尾的代码中,将oid账号100000替换为自己的。
最后,当你刷新你的网站或者有用户访问权限时,程序会自动更新文章。
如果您在使用中有任何问题,欢迎随时联系我们,ONEXIN新手交流QQ群:189610242
****************常见问题**************
问:安装说明:
A:插件下载:
大数据插件背景:
您的网站地址/obd/
自行申请授权并登录大数据平台:
申请授权的网址是:
你的网站地址/obd/api.php
Q:大数据插件的背景是空白的吗?
A:将大数据采集添加到网站后台,修改AdminMain.php文件:
/e/admin/adminstyle/1/AdminMain.php
/e/admin/adminstyle/2/AdminMain.php
查找:
网站首页
在后面添加:
<p> 查看全部
文章采集调用(OBD大数据文章采集器安装使用教程For帝国CMS帝国)
OBD大数据文章采集器Empire安装使用教程cms
英制cms大数据采集适用于:7.0及以上
首先,安装程序
1、把OBD文件夹和网站主页文件放在同一目录下,
2、初始安装时从地址栏访问install.php文件(访问后删除)
3、接下来,按照教程一步一步来。
安装ONEXIN大数据文章采集器图文教程(修订版)
ONEXIN大数据文章采集器图文教程【最新】
点我看视频教程
然后,将触发代码放入模板末尾的代码中,将oid账号100000替换为自己的。
最后,当你刷新你的网站或者有用户访问权限时,程序会自动更新文章。
如果您在使用中有任何问题,欢迎随时联系我们,ONEXIN新手交流QQ群:189610242
****************常见问题**************
问:安装说明:
A:插件下载:
大数据插件背景:
您的网站地址/obd/
自行申请授权并登录大数据平台:
申请授权的网址是:
你的网站地址/obd/api.php
Q:大数据插件的背景是空白的吗?
A:将大数据采集添加到网站后台,修改AdminMain.php文件:
/e/admin/adminstyle/1/AdminMain.php
/e/admin/adminstyle/2/AdminMain.php
查找:
网站首页
在后面添加:
<p>
文章采集调用(原创错了对吧呃没问题是吧但是我感觉有问题为什么呢)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-03-26 19:02
636 次观看 · 发表于 2021-10-28 20:46 · 原创
使用python采集实现调用金山翻译、加盐加密破解,实现在线翻译翻译
使用python采集实现调用金山翻译、加盐加密破解,实现在线翻译翻译
对不对,呃,没问题,对吧?但我觉得有问题。为什么现在?当我们访问时,我注意到我正在谈论的那首歌。没问题,对吧?他应该翻译吗?中文,那他不会翻译吧?那我看看他翻译不出来的原因,那我应该看看Dibag,看看他返回了什么数据。这样的数据,对吧?所以在这里,我们将使用Dibag,对我对这个错误持乐观态度。身份验证失败。我看没关系。这是一个严重的失败吗?如果严重失败,他会说你不是合法用户。你能明白吗?您是非法用户。你能明白吗?那他为什么会有这个问题?我们是不是说,那个时候地址改了,就得改地址,改内容,改地址,记住?啊,是不是有点?翻译,对吧?现在,我正在从中文翻译成英文,对吧?那是我吗?他也有一个叫自动检测的东西,对吧?我用什么词?我用什么词?我是中国人,对吧?嘿,我是中国人。他翻译了吗?我点这个f 十二看他的问题表格的路径,看看他是谁 不会变吧?好吧,现在不看我们了吗?点击这个表格提交,对吧?提交表格让他翻译,然后他不会接受我们的翻译。等一下我是中国人,等一下那我们看一下我们的内容,点击提交,点击提交英文美文英文哦,上面这个啊所以改回什么英文,用完再重新打开对re -open f 十二 open fTwelve 是打开的,所以我们来看看。现在我' 我要去拜访并提交这个表格,对吧?提交表格,然后我在这里有三个请求,对吧?请求一共有三个,那么我们来看看这个请求,看看这里有没有请求?让我们看看,我们现在改变这个东西之后,你发现这个连接路径和我们原来的连接路径有什么区别吗?来吧,我无法比较和比较它。这是意外的二楼吧?这意外的二楼?来对比一下看看这个ui,有什么区别,ok不要放这里,我放这里ok不要让大家看到this和this有什么区别?前面的部分不一样吗?看见?这就是我们遇到问题的原因。是这个意思吗?你能理解,对吗?你的输入不一样,这意味着当我访问此页面时,当我访问此页面时,它将返回给我这样的内容。错误信息有认证。身份验证失败。被拦截了吗?如果你看到它,它根本不会给你访问权限。他是怎么拦截我们的?你有没有想过?认证失败?到时候,他的关键是制作一串验证码。这个值得穿。验证码能看懂吗?哎,就是说你输入了不同的内容。该值发生变化。你能明白吗?然后你会跌倒。我说什么它如何改变?他应该有规则来改变这个值吗?可以理解吗?那么,那么我们可以看到ah这个词一直在变化,也就是说我的快速推理的直径一直在变化。例如,我是中国人,他' s 单词“比尔”。我再改一次。我很美。我很美。那么,我们来看看他的话。这是一个变化吗?看看这个值。你看着我。我很美。哦这个。这快君是不是叫九八二九八结束?你看见了吗?现在我们必须弄清楚如何加密你这个词以及如何收钱。根据我在表单中提交的数据,提交到服务区后,服务器是否处理这些数据,然后将其变成救护车字符串返回给我?提交下一句的时候可以处理清楚吗?那就是说我先不去获取,根据你的输入内容,按照一定的规则生成我的字符串,你输入的内容是什么?这个字符串可以理解吗?那他这里肯定有算法吧?嘿,如果有算法,他是怎么计算的?我们也是?如果你想研究他的算法,并且你能弄清楚,那我们黑客能黑他吗?你能明白吗?那是关键。我如何找到这个声明?他没有改变的是谁改变了价值。改变地址路径,对吧?这意味着这串生成的内容将替换您的原创路径。你能明白吗?所以我们要看看他是如何生成这个字符串的。让我们看看它是什么样子的。在他面前不是要增加我们的数据吗?所以我点击了数据生产的路径。看看这里有没有明确的?是生产数据吗?正确的?您查看应用程序数据。到时候,他是不是有一串这一段,这一段,这串密码?那他一定要带我走 s用这个支付字符串和他的一些代码生成这种字符串代码,然后按照收费号码的规则拿出我们想要的数据代码。好的,现在我们呢,既然你有这样的生存规则,我不知道我是否应该去找你的语言代码,看看你的规则是什么样的以及它们是如何生成的。首先了解它们是如何生成的。这条规定,对吧?打开就好了,然后我们看看这个规则是怎么生成的,给你安排好了,对吧?我正在寻找要搜索的内容。搜索一下我们是如何生成这个刚刚让他生成的字符串的,对吧?我先去找他,好吧,别看他是怎么生成的,那么总共有多少种方法呢?有多少相同的进步?这是四十三吗?正确的?四十三?这个方法没有 URL 吗?肯定是不对的,那我再看下一个。你只能一一找到。找它,上去,这是?不是吗?没有这样的国王。你看见了吗?没有这个王子,一定是对的吧?咦,这是什么东西,这是什么东西,然后后面和前面发生了意外。二楼后面没有写。嘿,我发现它和我们这里很相似,不是吗?没关系,这很酷。这就是你的算法的意思吗?好吧,我该怎么处理算法?他是怎么做的?好吧,我们看看js有没有实现,对吧?好吧,让我们看看他的实现。嘿,你找到这里定义的方法了吗?然后我用了一个肯定的表达器来获取我的表单提交的内容。看到了,拿到这个内容后,他把所有带空格的空格都去掉了,对吧?你问内容中的空格去掉后是否去掉?如果他去掉这个,就不算给他添加了这串内容。啊,看到了吗?来来来,看看功能,还记得连接功能吗?两个人基本有联系吗?你能听到吗?那就是说他会把这个字符串加到我们输入的字符串中,然后放上去算不算理解?然后说他来了。有一种盐叫盐。不变的东西叫做盐。你能明白吗?嘿,他有一块盐。让我们把这个盐拿出来。这盐出来了吗?他,这个叫做常数圆的东西是加到圆上的吧?圆圆圆的水是什么?这个圈子是我们的深度聚会。是盐加什么是盐加我们的我是你的输入它的内容是你的话对对,你的话对吗?那么,使用数据线法应该用什么方法呢?嘿嘿,他会用兔君的方法,再看一遍,再看看怎么办,怎么办,怎么办,怎么办,杀,杀,杀,君是什么意思?你能看懂十六位数和十六位数吗?好吧,这个函数中还有另一个函数。第二个函数不会自动调用括号中的函数。括号里的函数会不会调用md五加加密?你能理解吗?在这个函数中,他再次调用md五加密,表示我加密他,嗯,md五给他加密后,突然死循环,然后sup,savars,对吧,savars君,去崛起几个,十六在十六前面吧?你能理解吗?前面的十六是零到十六吗?那么,我们了解他的生存和营救规则吗?难道我只是按照他的规则,按照自己的数据说清楚吗?那么让我们看看如何创建这些数据?我们将编写并使用它,对吗?把我们昨天做的复制一份我晚上做的,好吗?那么,在这一个中,我们可以做一些改变,对吧?好吧,首先,让我们先看看它。首先,我们可以得到这个词。那么请求的意外按钮是动态的。我以后要更换它,所以我会删除这块吗?如果我稍后替换它,它不会算作我生成的。我会更换它。你能明白吗?那么他是如何产生的呢?然后我在让我们在这里做一个破解支付钻石是我们的原价。我们追求的内容没有加密。是原价吗?盐和盐就是这块,对吧?拿这个盐然后加水?你想让我得到我输入的单词吗?他会扣除十等,对吧?然后我们将扣除十个等。执行md五加密,对吧?然后在十六位数字之前形成几个十六位数字,对吗?好吧,我怎么起来?md 5如何加密?我打算用md五加密算法吧?Basilibo 然后我们给他加密 mdFive 加密加密 这串内容是谁加密的对不对?那么他对这串内容使用了什么代码呢?我们提交的网页用的是什么代码,那你得看他的代码。代码是做什么用的?点击什么编码是utf干编码,那我是不是要给他做utf干转码,对吧?所以你丢失的东西是最错误的,那我必须转码他,对吧?他进行了一次转码和转码,应该如何转换?单击转码声音按钮。是否可以使用utf bar 8转码?你能听到吗?转码完成后,这个按钮是不是已经在网页上统一了?绳子会出来的,对吧?让他加密统一字符串吧?加密完成后,我们应该使用其中的几个吗?拿16位数的内容就够了吧?那是我们幸存下来的。好的是我们活下来的角色,所以让我们传递下去,角色是什么对?性在哪里?周总,正确的?你创造了这个字符串来吃吗?所以我们把这个字符串给我的加密规则现在和他的加密规则完全一样吗?正确的?然后我会用你的加密规则替换你最初请求的路径。执法部门能理解吗?记住?一直都是这样执法的,对吧?嗯,怎么改?你如何改变它?里面有吗?我会卖的,对吧?我卖给谁?我在卖谁?有没有办法代替季复创?我们这里有吗?谈福利的时候,我们谈过这个张伟夫吗?是不是可以用张伟夫的内容来代替这个张伟夫?你还记得印象吗?这是错的吗?那么,我的程序是简单还是不简单呢?然后让我们做一个弯曲的树循环,让他无限平移。好的,您继续翻译,直到翻译成功并且您不想翻译,那么我接受您的输入。接受输入。拿什么来赢他,对吧?请输入您要翻译的内容,对吗?您要输入内容吗?翻译后,打印出来给你吗?你能清楚地理解它吗?然后这个是他的发音。好吧,我们先来看看这种盐。他在没有我的情况下成功破解了它。四个值先看看他对不对,对不对,是不是我们要的词?来,来看看,现在,我们先跑,跑,跑,然后我'会在里面输入hello,看是不是只是三个a hello,然后搜索,先清除一个,再搜索,然后就可以看到hello这个字符串是不是和我们生产的鞋子一样。从 0020 开始,然后是 3a 是一样的吗?那么,我已经破解了他吗?如果你明白了,你可以破解他,对吧?破解他之后,你可以看到我,我会出去打印信息。请记住,不要打印它。然后我们还有一个,就是他在里面。他也有这个选择。里面有自动检测吗?好吧,让我们来个机动。如果我们有机动,我应该把谁变成机动语言?额头是对的吗?那么,这里是不是很刺激呢?出去?你能明白吗?在提交表达式中是你。您会自动识别我的哪种语言?你能理解吗?好吧,然后我们将开始运行,然后我们将开始翻译。嗯,首先,我是什么,中国人?到了im chinese,对吧?我爱你爱你,翻译成中文,让我们看看他,我爱你,好吗?嗯,你很漂亮,他翻译成英文了吗?喂,你好漂亮,他送你回来了,你看,你好,然后又一个你好,漂亮。太好了,我的制作规则和他的制作规则一样吗?是一样的吗?那说明我已经破解了他。如果我能理解,我会破解他,对吧?等你破解了他,你可以看到我,我就出去把资料放出来。请记住,我不会打印它。那我们还有一个,就是他在里面,他也有这个选项,里面有没有自动检测,那我们来一个机动性好,如果我有机动,我应该把谁变成移动语言?额头对吗?然后,这里也有兴奋吗?出去?兴奋的?你能明白吗?提交表达式。你来自什么语言?你自动给我什么语言?认不认得?好的,然后我们将开始运行,然后我们将开始翻译。好吧,首先,我是什么,中国人?输入并欢迎我是中国人,对吧?什么中国人,快来看他,我爱你,好吗?嘿,那你有一个。你很漂亮,对吧?看看他,对吧?你真美?好吧,你看,你好,然后又是一个你好,然后是美丽的你好,美丽的极好,我的生产规则和他的生产规则是一样的吗?是一样的吗?那说明我已经破解了他。如果我能理解它,我会破解他,正确的?等你破解了他,你可以看到我,我就出去把资料放出来。请记住,我不会打印它。那我们还有另外一个,就是他在里面,他也有这个选项,里面有没有自动检测,那我们来一个 机动性好,如果我有机动性,我应该把谁转成移动语言? 额头对吗?然后,这里也有兴奋吗?出去?兴奋的?你能明白吗?提交表达式。你来自什么语言?你自动给我什么语言?认不认得?好的,然后我们将开始运行,然后我们将开始翻译。好吧,首先,我是什么,中国人?输入并欢迎我是中国人,对吧?什么中国人,快来看他,我爱你,好吗?嘿,那你有一个。你真美,正确的?看看他,对吧?你真美?好吧,你看,你好,然后是另一个你好,然后是美丽的你好,美丽的 查看全部
文章采集调用(原创错了对吧呃没问题是吧但是我感觉有问题为什么呢)
636 次观看 · 发表于 2021-10-28 20:46 · 原创
使用python采集实现调用金山翻译、加盐加密破解,实现在线翻译翻译
使用python采集实现调用金山翻译、加盐加密破解,实现在线翻译翻译
对不对,呃,没问题,对吧?但我觉得有问题。为什么现在?当我们访问时,我注意到我正在谈论的那首歌。没问题,对吧?他应该翻译吗?中文,那他不会翻译吧?那我看看他翻译不出来的原因,那我应该看看Dibag,看看他返回了什么数据。这样的数据,对吧?所以在这里,我们将使用Dibag,对我对这个错误持乐观态度。身份验证失败。我看没关系。这是一个严重的失败吗?如果严重失败,他会说你不是合法用户。你能明白吗?您是非法用户。你能明白吗?那他为什么会有这个问题?我们是不是说,那个时候地址改了,就得改地址,改内容,改地址,记住?啊,是不是有点?翻译,对吧?现在,我正在从中文翻译成英文,对吧?那是我吗?他也有一个叫自动检测的东西,对吧?我用什么词?我用什么词?我是中国人,对吧?嘿,我是中国人。他翻译了吗?我点这个f 十二看他的问题表格的路径,看看他是谁 不会变吧?好吧,现在不看我们了吗?点击这个表格提交,对吧?提交表格让他翻译,然后他不会接受我们的翻译。等一下我是中国人,等一下那我们看一下我们的内容,点击提交,点击提交英文美文英文哦,上面这个啊所以改回什么英文,用完再重新打开对re -open f 十二 open fTwelve 是打开的,所以我们来看看。现在我' 我要去拜访并提交这个表格,对吧?提交表格,然后我在这里有三个请求,对吧?请求一共有三个,那么我们来看看这个请求,看看这里有没有请求?让我们看看,我们现在改变这个东西之后,你发现这个连接路径和我们原来的连接路径有什么区别吗?来吧,我无法比较和比较它。这是意外的二楼吧?这意外的二楼?来对比一下看看这个ui,有什么区别,ok不要放这里,我放这里ok不要让大家看到this和this有什么区别?前面的部分不一样吗?看见?这就是我们遇到问题的原因。是这个意思吗?你能理解,对吗?你的输入不一样,这意味着当我访问此页面时,当我访问此页面时,它将返回给我这样的内容。错误信息有认证。身份验证失败。被拦截了吗?如果你看到它,它根本不会给你访问权限。他是怎么拦截我们的?你有没有想过?认证失败?到时候,他的关键是制作一串验证码。这个值得穿。验证码能看懂吗?哎,就是说你输入了不同的内容。该值发生变化。你能明白吗?然后你会跌倒。我说什么它如何改变?他应该有规则来改变这个值吗?可以理解吗?那么,那么我们可以看到ah这个词一直在变化,也就是说我的快速推理的直径一直在变化。例如,我是中国人,他' s 单词“比尔”。我再改一次。我很美。我很美。那么,我们来看看他的话。这是一个变化吗?看看这个值。你看着我。我很美。哦这个。这快君是不是叫九八二九八结束?你看见了吗?现在我们必须弄清楚如何加密你这个词以及如何收钱。根据我在表单中提交的数据,提交到服务区后,服务器是否处理这些数据,然后将其变成救护车字符串返回给我?提交下一句的时候可以处理清楚吗?那就是说我先不去获取,根据你的输入内容,按照一定的规则生成我的字符串,你输入的内容是什么?这个字符串可以理解吗?那他这里肯定有算法吧?嘿,如果有算法,他是怎么计算的?我们也是?如果你想研究他的算法,并且你能弄清楚,那我们黑客能黑他吗?你能明白吗?那是关键。我如何找到这个声明?他没有改变的是谁改变了价值。改变地址路径,对吧?这意味着这串生成的内容将替换您的原创路径。你能明白吗?所以我们要看看他是如何生成这个字符串的。让我们看看它是什么样子的。在他面前不是要增加我们的数据吗?所以我点击了数据生产的路径。看看这里有没有明确的?是生产数据吗?正确的?您查看应用程序数据。到时候,他是不是有一串这一段,这一段,这串密码?那他一定要带我走 s用这个支付字符串和他的一些代码生成这种字符串代码,然后按照收费号码的规则拿出我们想要的数据代码。好的,现在我们呢,既然你有这样的生存规则,我不知道我是否应该去找你的语言代码,看看你的规则是什么样的以及它们是如何生成的。首先了解它们是如何生成的。这条规定,对吧?打开就好了,然后我们看看这个规则是怎么生成的,给你安排好了,对吧?我正在寻找要搜索的内容。搜索一下我们是如何生成这个刚刚让他生成的字符串的,对吧?我先去找他,好吧,别看他是怎么生成的,那么总共有多少种方法呢?有多少相同的进步?这是四十三吗?正确的?四十三?这个方法没有 URL 吗?肯定是不对的,那我再看下一个。你只能一一找到。找它,上去,这是?不是吗?没有这样的国王。你看见了吗?没有这个王子,一定是对的吧?咦,这是什么东西,这是什么东西,然后后面和前面发生了意外。二楼后面没有写。嘿,我发现它和我们这里很相似,不是吗?没关系,这很酷。这就是你的算法的意思吗?好吧,我该怎么处理算法?他是怎么做的?好吧,我们看看js有没有实现,对吧?好吧,让我们看看他的实现。嘿,你找到这里定义的方法了吗?然后我用了一个肯定的表达器来获取我的表单提交的内容。看到了,拿到这个内容后,他把所有带空格的空格都去掉了,对吧?你问内容中的空格去掉后是否去掉?如果他去掉这个,就不算给他添加了这串内容。啊,看到了吗?来来来,看看功能,还记得连接功能吗?两个人基本有联系吗?你能听到吗?那就是说他会把这个字符串加到我们输入的字符串中,然后放上去算不算理解?然后说他来了。有一种盐叫盐。不变的东西叫做盐。你能明白吗?嘿,他有一块盐。让我们把这个盐拿出来。这盐出来了吗?他,这个叫做常数圆的东西是加到圆上的吧?圆圆圆的水是什么?这个圈子是我们的深度聚会。是盐加什么是盐加我们的我是你的输入它的内容是你的话对对,你的话对吗?那么,使用数据线法应该用什么方法呢?嘿嘿,他会用兔君的方法,再看一遍,再看看怎么办,怎么办,怎么办,怎么办,杀,杀,杀,君是什么意思?你能看懂十六位数和十六位数吗?好吧,这个函数中还有另一个函数。第二个函数不会自动调用括号中的函数。括号里的函数会不会调用md五加加密?你能理解吗?在这个函数中,他再次调用md五加密,表示我加密他,嗯,md五给他加密后,突然死循环,然后sup,savars,对吧,savars君,去崛起几个,十六在十六前面吧?你能理解吗?前面的十六是零到十六吗?那么,我们了解他的生存和营救规则吗?难道我只是按照他的规则,按照自己的数据说清楚吗?那么让我们看看如何创建这些数据?我们将编写并使用它,对吗?把我们昨天做的复制一份我晚上做的,好吗?那么,在这一个中,我们可以做一些改变,对吧?好吧,首先,让我们先看看它。首先,我们可以得到这个词。那么请求的意外按钮是动态的。我以后要更换它,所以我会删除这块吗?如果我稍后替换它,它不会算作我生成的。我会更换它。你能明白吗?那么他是如何产生的呢?然后我在让我们在这里做一个破解支付钻石是我们的原价。我们追求的内容没有加密。是原价吗?盐和盐就是这块,对吧?拿这个盐然后加水?你想让我得到我输入的单词吗?他会扣除十等,对吧?然后我们将扣除十个等。执行md五加密,对吧?然后在十六位数字之前形成几个十六位数字,对吗?好吧,我怎么起来?md 5如何加密?我打算用md五加密算法吧?Basilibo 然后我们给他加密 mdFive 加密加密 这串内容是谁加密的对不对?那么他对这串内容使用了什么代码呢?我们提交的网页用的是什么代码,那你得看他的代码。代码是做什么用的?点击什么编码是utf干编码,那我是不是要给他做utf干转码,对吧?所以你丢失的东西是最错误的,那我必须转码他,对吧?他进行了一次转码和转码,应该如何转换?单击转码声音按钮。是否可以使用utf bar 8转码?你能听到吗?转码完成后,这个按钮是不是已经在网页上统一了?绳子会出来的,对吧?让他加密统一字符串吧?加密完成后,我们应该使用其中的几个吗?拿16位数的内容就够了吧?那是我们幸存下来的。好的是我们活下来的角色,所以让我们传递下去,角色是什么对?性在哪里?周总,正确的?你创造了这个字符串来吃吗?所以我们把这个字符串给我的加密规则现在和他的加密规则完全一样吗?正确的?然后我会用你的加密规则替换你最初请求的路径。执法部门能理解吗?记住?一直都是这样执法的,对吧?嗯,怎么改?你如何改变它?里面有吗?我会卖的,对吧?我卖给谁?我在卖谁?有没有办法代替季复创?我们这里有吗?谈福利的时候,我们谈过这个张伟夫吗?是不是可以用张伟夫的内容来代替这个张伟夫?你还记得印象吗?这是错的吗?那么,我的程序是简单还是不简单呢?然后让我们做一个弯曲的树循环,让他无限平移。好的,您继续翻译,直到翻译成功并且您不想翻译,那么我接受您的输入。接受输入。拿什么来赢他,对吧?请输入您要翻译的内容,对吗?您要输入内容吗?翻译后,打印出来给你吗?你能清楚地理解它吗?然后这个是他的发音。好吧,我们先来看看这种盐。他在没有我的情况下成功破解了它。四个值先看看他对不对,对不对,是不是我们要的词?来,来看看,现在,我们先跑,跑,跑,然后我'会在里面输入hello,看是不是只是三个a hello,然后搜索,先清除一个,再搜索,然后就可以看到hello这个字符串是不是和我们生产的鞋子一样。从 0020 开始,然后是 3a 是一样的吗?那么,我已经破解了他吗?如果你明白了,你可以破解他,对吧?破解他之后,你可以看到我,我会出去打印信息。请记住,不要打印它。然后我们还有一个,就是他在里面。他也有这个选择。里面有自动检测吗?好吧,让我们来个机动。如果我们有机动,我应该把谁变成机动语言?额头是对的吗?那么,这里是不是很刺激呢?出去?你能明白吗?在提交表达式中是你。您会自动识别我的哪种语言?你能理解吗?好吧,然后我们将开始运行,然后我们将开始翻译。嗯,首先,我是什么,中国人?到了im chinese,对吧?我爱你爱你,翻译成中文,让我们看看他,我爱你,好吗?嗯,你很漂亮,他翻译成英文了吗?喂,你好漂亮,他送你回来了,你看,你好,然后又一个你好,漂亮。太好了,我的制作规则和他的制作规则一样吗?是一样的吗?那说明我已经破解了他。如果我能理解,我会破解他,对吧?等你破解了他,你可以看到我,我就出去把资料放出来。请记住,我不会打印它。那我们还有一个,就是他在里面,他也有这个选项,里面有没有自动检测,那我们来一个机动性好,如果我有机动,我应该把谁变成移动语言?额头对吗?然后,这里也有兴奋吗?出去?兴奋的?你能明白吗?提交表达式。你来自什么语言?你自动给我什么语言?认不认得?好的,然后我们将开始运行,然后我们将开始翻译。好吧,首先,我是什么,中国人?输入并欢迎我是中国人,对吧?什么中国人,快来看他,我爱你,好吗?嘿,那你有一个。你很漂亮,对吧?看看他,对吧?你真美?好吧,你看,你好,然后又是一个你好,然后是美丽的你好,美丽的极好,我的生产规则和他的生产规则是一样的吗?是一样的吗?那说明我已经破解了他。如果我能理解它,我会破解他,正确的?等你破解了他,你可以看到我,我就出去把资料放出来。请记住,我不会打印它。那我们还有另外一个,就是他在里面,他也有这个选项,里面有没有自动检测,那我们来一个 机动性好,如果我有机动性,我应该把谁转成移动语言? 额头对吗?然后,这里也有兴奋吗?出去?兴奋的?你能明白吗?提交表达式。你来自什么语言?你自动给我什么语言?认不认得?好的,然后我们将开始运行,然后我们将开始翻译。好吧,首先,我是什么,中国人?输入并欢迎我是中国人,对吧?什么中国人,快来看他,我爱你,好吗?嘿,那你有一个。你真美,正确的?看看他,对吧?你真美?好吧,你看,你好,然后是另一个你好,然后是美丽的你好,美丽的
文章采集调用(追踪调用链路,监控链路性能,排查链路故障(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-03-25 01:11
后台:跟踪调用链路,监控链路性能,排查链路故障
随着微服务架构的普及,一个请求往往需要涉及多个服务,需要一些可以帮助理解系统行为和分析性能问题的工具,以便在发生故障时能够快速定位并解决问题。
在单体架构下,可以使用AOP打印调用具体业务逻辑前后的时间,计算整体调用时间。使用 AOP 捕获异常并知道调用在哪里导致了异常。
基本实现原理
一个完整的请求链路的trace ID(traceid)用来找出这个请求调用的所有服务,每个服务调用的span ID(spanid)用来记录调用顺序
上游服务parenetid用于记录调用的层次关系
调用时间时间戳,记录请求发送、接收、处理的时间,计算业务处理时间和网络时间,然后用可视化的界面展示每个调用环节、性能、故障
还可以记录一些其他的信息,比如调用服务的名字,被调用服务的名字,返回结果,IP,调用服务的名字等等。最后我们把同一个spanid的信息组合成一个大跨度块来完成一个完整的调用链。
SkyWalking的原理和架构设计
定期采样节点数据,采样后定期上报数据,存储在ES、MySQL等持久层中。有了数据,自然要根据数据进行可视化分析。
空中漫步的工作原理
Skywalking的工作机制需要三个配合。工作原理图大致如下:
SkyWalking核心模块介绍:
SkyWalking 采用组件化开发,易于扩展。主要成分如下:
1. Skywalking Agent:链接数据采集tracing(调用链数据)和metric(度量)信息并上报,通过HTTP或gRPC将数据发送到Skywalking Collector。
2. Skywalking Collector :链路数据采集器,对agent发送的tracing和metric数据进行整合分析,通过Analysis Core模块进行处理,落入相关数据存储。同时通过Query Core模块进行二次统计。和监控警报
3. 存储:Skywalking的存储支持ElasticSearch、Mysql、TiDB、H2等主流存储作为数据存储的存储介质。H2 仅用于单机临时演示。
4. SkyWalking UI:用于显示着陆数据的Web可视化平台。目前,RocketBot 被正式采用为 SkyWalking 的主要 UI
如何自动 采集 跨越数据
SkyWalking采用插件+javaagent的形式实现数据自动跨度采集,可以对代码无侵入,插件意味着可插拔,扩展性好
如何跨进程传递上下文
我们知道数据一般分为header和body,就像http有header和body一样,RocketMQ也有MessageHeader、Message Body,body一般都保存业务数据,所以不宜在body中传递context,而是在header中,如图
dubbo中的attachment相当于header,所以我们把context放在attachment里面,解决了context传输的问题。
提示:这里的上下文传递过程由dubbo插件处理,业务不知情
traceId 如何保证全局唯一
为了确保全局唯一性,我们可以使用分布式或本地生成的 ID。如果你使用分布式,你需要有一个发件人。每次发出请求时,都必须先请求发件人。会有网络调用开销,所以 SkyWalking 最终采用了本地生成 ID 的方法,并且采用了著名的雪流算法,具有很高的性能。
但是雪花算法有一个众所周知的问题:时间回溯,会导致产生重复的id。那么 SkyWalking 是如何解决时间回调问题的呢?
每次生成id时,都会记录生成id的时间(lastTimestamp)。如果发现当前时间小于上次生成id的时间(lastTimestamp),则表示发生了时间回调,会生成一个随机数作为traceId。
有这么多请求,所有 采集 都会影响性能吗?
如果每次请求都调用采集,毫无疑问数据量会很大,但是反过来想,真的有必要对每个请求都调用采集吗?实际上,没有必要。我们可以设置采样频率,只对部分数据进行采样。默认情况下,SkyWalking 设置为 3 秒采样 3 次,其余请求不采样,如图
这个采样频率其实已经足够我们分析元器件的性能了。以这种在 3 秒内采样 3 次的频率采样数据有什么问题?理想情况下,每次服务调用都是在同一个时间点进行的(如下图),所以每次都在同一个时间点采样真的没问题。
但是在生产中,每个服务调用基本不可能在同一时间点被调用,因为期间存在网络调用延迟,实际调用情况很可能如下图所示。
在这种情况下,会在服务 A 上采样一些调用,而不会在服务 B 和 C 上采样,因此无法分析调用链的性能,那么 SkyWalking 是如何解决的。
是这样解决的:如果上游携带Context(表示上游已经采样),下游强制采集数据。这确保了链接是完整的。
SkyWalking各模块组件视图介绍
Skywalking 已经支持从 6 个视觉维度分析分布式系统的运行。
1、Dashboard:查看全球服务的基本性能指标
Dashboard主要包括Service Dashboard和Database Dashboard
2、拓扑图:展示分布式服务之间的调用关系:
SkyWalking 可以根据获取的数据自动绘制服务之间的调用关系图,并且可以识别出常用的服务并显示在图标上,比如图上的tomcat、CAS服务
每个连接的颜色反映了服务之间的调用延迟,可以非常直观的看到服务之间的调用状态。点击连接中间的点可以显示两个服务之间的连接的平均值。响应时间、吞吐量和 SLA 等信息
显示服务的性能数据:
选择其中一项服务,查看调用关系及服务基本状态。
拓扑图也有平面显示效果
3、链接跟踪:可以根据需要查看链接调用过程
显示请求响应的内部执行,一个完整的请求经过了哪些服务,执行了哪些代码方法,每个方法的执行时间,执行状态等详细信息,快速定位代码问题。
失败的调用还有一个错误日志:
4、警报:5、Zipkin 原理与指标数据对比
Zipkin 分为两端,Zipkin 服务器和 Zipkin 客户端。客户端是微服务的应用。客户端配置服务器的 URL 地址。一旦服务之间发生调用,就会被微服务中配置的Sleuth监听器监听,并生成相应的Trace和Span信息发送给服务器。发送方式主要有两种,一种是HTTP消息的方式,一种是RabbitMQ等消息总线的方式。
无论哪种方式,我们都需要:一个 Eureka 服务注册中心,首先看一下 Zipkin 运行架构:
左边的应用服务也是Zipkin-clinet和Eureka-client。中间是依赖,包括 Zipkin-server 和 Eureka-server。最右边是WebUI展示和开发界面。
比较计划
Google的Dapper,阿里的鹰眼,大众点评的CAT,Twitter的Zipkin,LINE的pinpoint,国内的skywalking。
市面上的全链路监控理论模型多以Google Dapper论文为基础。本文重点介绍以下三个 APM 组件:
种类
拉链金
空中漫步
基本的 查看全部
文章采集调用(追踪调用链路,监控链路性能,排查链路故障(组图))
后台:跟踪调用链路,监控链路性能,排查链路故障
随着微服务架构的普及,一个请求往往需要涉及多个服务,需要一些可以帮助理解系统行为和分析性能问题的工具,以便在发生故障时能够快速定位并解决问题。
在单体架构下,可以使用AOP打印调用具体业务逻辑前后的时间,计算整体调用时间。使用 AOP 捕获异常并知道调用在哪里导致了异常。
基本实现原理
一个完整的请求链路的trace ID(traceid)用来找出这个请求调用的所有服务,每个服务调用的span ID(spanid)用来记录调用顺序
上游服务parenetid用于记录调用的层次关系
调用时间时间戳,记录请求发送、接收、处理的时间,计算业务处理时间和网络时间,然后用可视化的界面展示每个调用环节、性能、故障
还可以记录一些其他的信息,比如调用服务的名字,被调用服务的名字,返回结果,IP,调用服务的名字等等。最后我们把同一个spanid的信息组合成一个大跨度块来完成一个完整的调用链。
SkyWalking的原理和架构设计
定期采样节点数据,采样后定期上报数据,存储在ES、MySQL等持久层中。有了数据,自然要根据数据进行可视化分析。
空中漫步的工作原理
Skywalking的工作机制需要三个配合。工作原理图大致如下:
SkyWalking核心模块介绍:
SkyWalking 采用组件化开发,易于扩展。主要成分如下:
1. Skywalking Agent:链接数据采集tracing(调用链数据)和metric(度量)信息并上报,通过HTTP或gRPC将数据发送到Skywalking Collector。
2. Skywalking Collector :链路数据采集器,对agent发送的tracing和metric数据进行整合分析,通过Analysis Core模块进行处理,落入相关数据存储。同时通过Query Core模块进行二次统计。和监控警报
3. 存储:Skywalking的存储支持ElasticSearch、Mysql、TiDB、H2等主流存储作为数据存储的存储介质。H2 仅用于单机临时演示。
4. SkyWalking UI:用于显示着陆数据的Web可视化平台。目前,RocketBot 被正式采用为 SkyWalking 的主要 UI
如何自动 采集 跨越数据
SkyWalking采用插件+javaagent的形式实现数据自动跨度采集,可以对代码无侵入,插件意味着可插拔,扩展性好
如何跨进程传递上下文
我们知道数据一般分为header和body,就像http有header和body一样,RocketMQ也有MessageHeader、Message Body,body一般都保存业务数据,所以不宜在body中传递context,而是在header中,如图
dubbo中的attachment相当于header,所以我们把context放在attachment里面,解决了context传输的问题。
提示:这里的上下文传递过程由dubbo插件处理,业务不知情
traceId 如何保证全局唯一
为了确保全局唯一性,我们可以使用分布式或本地生成的 ID。如果你使用分布式,你需要有一个发件人。每次发出请求时,都必须先请求发件人。会有网络调用开销,所以 SkyWalking 最终采用了本地生成 ID 的方法,并且采用了著名的雪流算法,具有很高的性能。
但是雪花算法有一个众所周知的问题:时间回溯,会导致产生重复的id。那么 SkyWalking 是如何解决时间回调问题的呢?
每次生成id时,都会记录生成id的时间(lastTimestamp)。如果发现当前时间小于上次生成id的时间(lastTimestamp),则表示发生了时间回调,会生成一个随机数作为traceId。
有这么多请求,所有 采集 都会影响性能吗?
如果每次请求都调用采集,毫无疑问数据量会很大,但是反过来想,真的有必要对每个请求都调用采集吗?实际上,没有必要。我们可以设置采样频率,只对部分数据进行采样。默认情况下,SkyWalking 设置为 3 秒采样 3 次,其余请求不采样,如图
这个采样频率其实已经足够我们分析元器件的性能了。以这种在 3 秒内采样 3 次的频率采样数据有什么问题?理想情况下,每次服务调用都是在同一个时间点进行的(如下图),所以每次都在同一个时间点采样真的没问题。
但是在生产中,每个服务调用基本不可能在同一时间点被调用,因为期间存在网络调用延迟,实际调用情况很可能如下图所示。
在这种情况下,会在服务 A 上采样一些调用,而不会在服务 B 和 C 上采样,因此无法分析调用链的性能,那么 SkyWalking 是如何解决的。
是这样解决的:如果上游携带Context(表示上游已经采样),下游强制采集数据。这确保了链接是完整的。
SkyWalking各模块组件视图介绍
Skywalking 已经支持从 6 个视觉维度分析分布式系统的运行。
1、Dashboard:查看全球服务的基本性能指标
Dashboard主要包括Service Dashboard和Database Dashboard
2、拓扑图:展示分布式服务之间的调用关系:
SkyWalking 可以根据获取的数据自动绘制服务之间的调用关系图,并且可以识别出常用的服务并显示在图标上,比如图上的tomcat、CAS服务
每个连接的颜色反映了服务之间的调用延迟,可以非常直观的看到服务之间的调用状态。点击连接中间的点可以显示两个服务之间的连接的平均值。响应时间、吞吐量和 SLA 等信息
显示服务的性能数据:
选择其中一项服务,查看调用关系及服务基本状态。
拓扑图也有平面显示效果
3、链接跟踪:可以根据需要查看链接调用过程
显示请求响应的内部执行,一个完整的请求经过了哪些服务,执行了哪些代码方法,每个方法的执行时间,执行状态等详细信息,快速定位代码问题。
失败的调用还有一个错误日志:
4、警报:5、Zipkin 原理与指标数据对比
Zipkin 分为两端,Zipkin 服务器和 Zipkin 客户端。客户端是微服务的应用。客户端配置服务器的 URL 地址。一旦服务之间发生调用,就会被微服务中配置的Sleuth监听器监听,并生成相应的Trace和Span信息发送给服务器。发送方式主要有两种,一种是HTTP消息的方式,一种是RabbitMQ等消息总线的方式。
无论哪种方式,我们都需要:一个 Eureka 服务注册中心,首先看一下 Zipkin 运行架构:
左边的应用服务也是Zipkin-clinet和Eureka-client。中间是依赖,包括 Zipkin-server 和 Eureka-server。最右边是WebUI展示和开发界面。
比较计划
Google的Dapper,阿里的鹰眼,大众点评的CAT,Twitter的Zipkin,LINE的pinpoint,国内的skywalking。
市面上的全链路监控理论模型多以Google Dapper论文为基础。本文重点介绍以下三个 APM 组件:
种类
拉链金
空中漫步
基本的
文章采集调用(云原生及混合云模式下的微服务架构应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-24 11:06
前言
进入云原生时代后,依托容器技术和分布式技术的发展,为适应高并发、高压力、快速迭代的场景,微服务架构成为更多企业的必然选择。微服务架构为互联网时代的软件开发带来了极大的优势,例如增加服务的可扩展性、增强易维护性、减少语言依赖等。
但与此同时,从单体架构到微服务架构的转变在应用监控层面提出了前所未有的挑战。服务的拆分使得应用和服务之间的相互调用关系呈几何级数增长。从用户端发起的请求可能会在微服务和各种中间件之间相互调用,最终形成复杂的调用关系网络。
用户请求发出后,完整的调用链图如下:
此时,基于单机业务的传统监控系统已经无法监控新的关系网络。因此,在微服务架构体系下,迫切需要建立一种新的监控机制,能够及时监控和反馈应用和系统的运行状态,在系统运行异常时辅助开发者定位问题,并提供系统性能调优。 . 充足的数据支持。
1、全链路监控的目标是什么?
微服务架构使得应用程序和中间件之间的调用链更加复杂。同时,云原生和混合云的兴起对全链路监控的实现提出了更高的要求。
为了提高混合云模式下微服务架构应用的健壮性和稳定性,一般来说,我们对全链路监控的三个核心需求如下:
1. 系统间依赖梳理:可完整绘制系统与服务之间的调用关系,帮助开发运维评估上下游依赖关系,判断故障范围;
2.关键性能指标展示:可以展示各个环节对应的关键性能指标,可以给研发人员性能优化的方向,也可以帮助运维人员对系统资源的合理配置提出建议;
3. 端到端问题诊断:当系统出现故障或异常时,可立即发出告警,协助运维人员发现并快速定位并解决问题。
全链路监控就是在解决这些问题的背景下创建的。
全链路监控是一套跨语言、跨应用、跨服务器、跨数据中心的分布式系统服务。通过添加探针等,对应用、系统等性能指标进行采样采集,以调用链为主要方法。分布式监控系统,展示监控数据,帮助开发人员和运维人员分析性能问题,定位异常问题。
一些平台还将全链路监控称为全链路跟踪。可以说,全链路监控是一套覆盖所有关联系统的IT系统。它是一套可以完整记录用户行为、存储日志、显示系统间调用路径和状态的最佳实践解决方案。
在全链路监控系统中,调用链是一个核心概念。就是从请求源,通过微服务调用,到底层中间件之间的所有中间调用环节。
全链路监控的关键价值在于“关联”,即由终端用户、后端微服务应用、云中间件组件构成的编织关系网络。从理论上讲,这个关系网络的覆盖范围越大,采集的关键指标越多,全链路监控的价值就越大。
2、实现全链路监控的难点是什么?
混合云模式下的每个微服务应用可能由不同的研发团队开发,需要部署在多台服务器上实现横向扩展,甚至可能同时部署在云端和自建机房的数据中心. 软件部署和调用方法也有很大不同。
在此背景下,实现全链路监控面临诸多挑战,总结如下:
1. 支持大规模混合云场景:当成千上万的微服务应用部署在公有云和混合云中时,如何快速及时地获得采集应用运行状态信息,同时采集日志到日志中央。如何采集并将第三方中间件集成到监控系统中,是全链路监控研发人员需要面对的最严峻的问题。
2. 降低对业务的影响:如果SDK或探针采集数据进行全链路监控占用过多系统资源或对应用性能影响过大,会降低系统整体阻力。压力,甚至是对业务造成严重后果的不可预测的失败。
3. 丰富完善的监控系统:一般来说,Java编写的应用程序比较容易获取自己的运行状态监控数据,但其他类型的应用程序由于相对不完善,难以从底层架构层面全面支持生态。对于其他语言编写的应用程序,以及多渠道部署的中间件的完整指标采集都是开发者需要考虑的问题。
4. 维护简单可行:除了客户端部署的SDK或探针外,服务器端的一整套全链路监控由接收模块、计算模块、存储模块、显示模块。运维人员需要对每个探头和模块进行维护。因此,全链路监控系统在开发时一定要考虑自身的易维护性,否则,在大型系统中,运维工作将成为一场灾难。
5. 保证自身的高可用:全链路监控系统必须能够保证自身具有一定的高可用。否则,当某个模块或组件出现异常时,可能会失去整个业务系统的正常监控功能。在极端情况下,甚至会造成蝴蝶效应,导致整个系统雪崩。
我们说,全链路监控的价值与其所能覆盖的监控范围成正比,它的挑战也与监控范围成正比。因此,全链路监控开发者在实现功能时必须同时考虑和克服这五个难点。
3、全链路监控的规范是什么?
十多年前,谷歌在著名论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》中详细阐述了如何在大规模系统上构建一个低损耗、应用级透明、可扩展的系统。具有广泛部署属性的分布式系统链接跟踪服务。
在 Dapper 论文中,Google 公开了分布式系统链路跟踪的实现技术细节,包括数据表示、埋点、传输、采集、存储和显示,并提出了跟踪树、Trace、Span 和 Annotation 等重要概念为实现全链路监控提供理论依据。
受 Dapper 的启发,业界开发了许多用于分布式链接跟踪的开源组件。由于需要在链接中记录每个链接的信息,信息不仅限于某个链接,还需要跨不同的应用程序和分布式中间件进行传播。因此,必须制定一套统一的标准规范。整个链接中的所有链接都必须符合本规范和标准,才能实现完整信息的描述、跟踪和传输功能。这组标准称为 OpenTracing。
可以说OpenTracing是一套独立于编程语言和业务逻辑的抽象接口集,可以统一管理链路跟踪领域的各种元素,从而实现完整的全链路监控。
跨度
Span是全链路监控的基本单位。为微服务和中间件之间的每次调用创建一个 Span。此调用可以是 RPC 调用、数据库访问等。跨度由 64 位 ID 标识。UUID更方便,是生成Span ID的首选。Span 记录的信息包括名称、调用时间、键值对形式的标签数据、父调用ID。
值得强调的是,Dapper 通过记录每个 Span 的父 ID 来跟踪完整的链接请求。即Span的每一级只记录调用发起者的ID,一个完整的调用具有相同的trace id。如果 Span 没有父 ID,则称为 Root Span。读取记录时,根据 Trace ID 获取所有 span,根据 parent ID 连接 span,绘制一个请求的完整调用链接。
痕迹
Trace用于标记一个请求的发起,通过各种微服务应用和中间件,直到服务返回并结束。Trace 是一个有向树结构的 Span 集合。
图中,每个颜色标签代表一个Span,访问链路由唯一的Trace ID标识。整个架构用树形结构表示,树中的每个节点都是一个Span。树中节点之间的连线代表了一个 Span 与其父 Span 之间的调用关系。
注解
注释是用来记录事件相关信息的注释,例如发生的时间。一个 Span 可以由多个 Annotation 来描述。
Dapper采集数据处理
如图所示,Dapper daemon采集 业务日志,并将日志信息保存在日志文件中。Dapper Collectors 定期请求提取日志并将它们存储在 Central Bigtable 中。
由于日志量很大,Dapper 在采集logging 时使用了采样率模式。如果采样率设置为 1/1024,则表示每 1024 条日志生成一次采集。 查看全部
文章采集调用(云原生及混合云模式下的微服务架构应用)
前言
进入云原生时代后,依托容器技术和分布式技术的发展,为适应高并发、高压力、快速迭代的场景,微服务架构成为更多企业的必然选择。微服务架构为互联网时代的软件开发带来了极大的优势,例如增加服务的可扩展性、增强易维护性、减少语言依赖等。
但与此同时,从单体架构到微服务架构的转变在应用监控层面提出了前所未有的挑战。服务的拆分使得应用和服务之间的相互调用关系呈几何级数增长。从用户端发起的请求可能会在微服务和各种中间件之间相互调用,最终形成复杂的调用关系网络。
用户请求发出后,完整的调用链图如下:
此时,基于单机业务的传统监控系统已经无法监控新的关系网络。因此,在微服务架构体系下,迫切需要建立一种新的监控机制,能够及时监控和反馈应用和系统的运行状态,在系统运行异常时辅助开发者定位问题,并提供系统性能调优。 . 充足的数据支持。
1、全链路监控的目标是什么?
微服务架构使得应用程序和中间件之间的调用链更加复杂。同时,云原生和混合云的兴起对全链路监控的实现提出了更高的要求。
为了提高混合云模式下微服务架构应用的健壮性和稳定性,一般来说,我们对全链路监控的三个核心需求如下:
1. 系统间依赖梳理:可完整绘制系统与服务之间的调用关系,帮助开发运维评估上下游依赖关系,判断故障范围;
2.关键性能指标展示:可以展示各个环节对应的关键性能指标,可以给研发人员性能优化的方向,也可以帮助运维人员对系统资源的合理配置提出建议;
3. 端到端问题诊断:当系统出现故障或异常时,可立即发出告警,协助运维人员发现并快速定位并解决问题。
全链路监控就是在解决这些问题的背景下创建的。
全链路监控是一套跨语言、跨应用、跨服务器、跨数据中心的分布式系统服务。通过添加探针等,对应用、系统等性能指标进行采样采集,以调用链为主要方法。分布式监控系统,展示监控数据,帮助开发人员和运维人员分析性能问题,定位异常问题。
一些平台还将全链路监控称为全链路跟踪。可以说,全链路监控是一套覆盖所有关联系统的IT系统。它是一套可以完整记录用户行为、存储日志、显示系统间调用路径和状态的最佳实践解决方案。
在全链路监控系统中,调用链是一个核心概念。就是从请求源,通过微服务调用,到底层中间件之间的所有中间调用环节。
全链路监控的关键价值在于“关联”,即由终端用户、后端微服务应用、云中间件组件构成的编织关系网络。从理论上讲,这个关系网络的覆盖范围越大,采集的关键指标越多,全链路监控的价值就越大。
2、实现全链路监控的难点是什么?
混合云模式下的每个微服务应用可能由不同的研发团队开发,需要部署在多台服务器上实现横向扩展,甚至可能同时部署在云端和自建机房的数据中心. 软件部署和调用方法也有很大不同。
在此背景下,实现全链路监控面临诸多挑战,总结如下:
1. 支持大规模混合云场景:当成千上万的微服务应用部署在公有云和混合云中时,如何快速及时地获得采集应用运行状态信息,同时采集日志到日志中央。如何采集并将第三方中间件集成到监控系统中,是全链路监控研发人员需要面对的最严峻的问题。
2. 降低对业务的影响:如果SDK或探针采集数据进行全链路监控占用过多系统资源或对应用性能影响过大,会降低系统整体阻力。压力,甚至是对业务造成严重后果的不可预测的失败。
3. 丰富完善的监控系统:一般来说,Java编写的应用程序比较容易获取自己的运行状态监控数据,但其他类型的应用程序由于相对不完善,难以从底层架构层面全面支持生态。对于其他语言编写的应用程序,以及多渠道部署的中间件的完整指标采集都是开发者需要考虑的问题。
4. 维护简单可行:除了客户端部署的SDK或探针外,服务器端的一整套全链路监控由接收模块、计算模块、存储模块、显示模块。运维人员需要对每个探头和模块进行维护。因此,全链路监控系统在开发时一定要考虑自身的易维护性,否则,在大型系统中,运维工作将成为一场灾难。
5. 保证自身的高可用:全链路监控系统必须能够保证自身具有一定的高可用。否则,当某个模块或组件出现异常时,可能会失去整个业务系统的正常监控功能。在极端情况下,甚至会造成蝴蝶效应,导致整个系统雪崩。
我们说,全链路监控的价值与其所能覆盖的监控范围成正比,它的挑战也与监控范围成正比。因此,全链路监控开发者在实现功能时必须同时考虑和克服这五个难点。
3、全链路监控的规范是什么?
十多年前,谷歌在著名论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》中详细阐述了如何在大规模系统上构建一个低损耗、应用级透明、可扩展的系统。具有广泛部署属性的分布式系统链接跟踪服务。
在 Dapper 论文中,Google 公开了分布式系统链路跟踪的实现技术细节,包括数据表示、埋点、传输、采集、存储和显示,并提出了跟踪树、Trace、Span 和 Annotation 等重要概念为实现全链路监控提供理论依据。
受 Dapper 的启发,业界开发了许多用于分布式链接跟踪的开源组件。由于需要在链接中记录每个链接的信息,信息不仅限于某个链接,还需要跨不同的应用程序和分布式中间件进行传播。因此,必须制定一套统一的标准规范。整个链接中的所有链接都必须符合本规范和标准,才能实现完整信息的描述、跟踪和传输功能。这组标准称为 OpenTracing。
可以说OpenTracing是一套独立于编程语言和业务逻辑的抽象接口集,可以统一管理链路跟踪领域的各种元素,从而实现完整的全链路监控。
跨度
Span是全链路监控的基本单位。为微服务和中间件之间的每次调用创建一个 Span。此调用可以是 RPC 调用、数据库访问等。跨度由 64 位 ID 标识。UUID更方便,是生成Span ID的首选。Span 记录的信息包括名称、调用时间、键值对形式的标签数据、父调用ID。
值得强调的是,Dapper 通过记录每个 Span 的父 ID 来跟踪完整的链接请求。即Span的每一级只记录调用发起者的ID,一个完整的调用具有相同的trace id。如果 Span 没有父 ID,则称为 Root Span。读取记录时,根据 Trace ID 获取所有 span,根据 parent ID 连接 span,绘制一个请求的完整调用链接。
痕迹
Trace用于标记一个请求的发起,通过各种微服务应用和中间件,直到服务返回并结束。Trace 是一个有向树结构的 Span 集合。
图中,每个颜色标签代表一个Span,访问链路由唯一的Trace ID标识。整个架构用树形结构表示,树中的每个节点都是一个Span。树中节点之间的连线代表了一个 Span 与其父 Span 之间的调用关系。
注解
注释是用来记录事件相关信息的注释,例如发生的时间。一个 Span 可以由多个 Annotation 来描述。
Dapper采集数据处理
如图所示,Dapper daemon采集 业务日志,并将日志信息保存在日志文件中。Dapper Collectors 定期请求提取日志并将它们存储在 Central Bigtable 中。
由于日志量很大,Dapper 在采集logging 时使用了采样率模式。如果采样率设置为 1/1024,则表示每 1024 条日志生成一次采集。
文章采集调用( 【魔兽世界】灵棺夜行代码.4更新公告)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-03-24 11:04
【魔兽世界】灵棺夜行代码.4更新公告)
Python制作爬虫采集新颖
更新时间:2015年10月25日11:08:10 提交人:hebedich
本文将与大家分享使用Python制作爬虫的代码采集小说。它非常简单实用,虽然还是有点瑕疵。一起改变,一起进步
开发工具:python3.4
操作系统:win8
主要功能:指定小说网页爬取小说目录,按章节保存到本地,将爬取的网页保存到本地配置文件。
已爬网网站:
小说名:棺材夜行
代码来源:我自己编码
import urllib.request
import http.cookiejar
import socket
import time
import re
timeout = 20
socket.setdefaulttimeout(timeout)
sleep_download_time = 10
time.sleep(sleep_download_time)
def makeMyOpener(head = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
def saveFile(save_path,txts):
f_obj = open(save_path,'w+')
for item in txts:
f_obj.write(item+'\n')
f_obj.close()
#get_code_list
code_list='http://www.cishuge.com/read/0/771/'
oper = makeMyOpener()
uop = oper.open(code_list,timeout=1000)
data = uop.read().decode('gbk','ignore')
pattern = re.compile('(.*?)',re.S)
items = re.findall(pattern,data)
print ('获取列表完成')
url_path='url_file.txt'
url_r=open(url_path,'r')
url_arr=url_r.readlines(100000)
url_r.close()
print (len(url_arr))
url_file=open(url_path,'a')
print ('获取已下载网址')
for tmp in items:
save_path = tmp[1].replace(' ','')+'.txt'
url = code_list+tmp[0]
if url+'\n' in url_arr:
continue
print('写日志:'+url+'\n')
url_file.write(url+'\n')
opene = makeMyOpener()
op1 = opene.open(url,timeout=1000)
data = op1.read().decode('gbk','ignore')
opene.close()
pattern = re.compile(' (.*?)<br />',re.S)
txts = re.findall(pattern,data)
saveFile(save_path,txts)
url_file.close()
虽然代码还有点瑕疵,但还是分享给大家,一起改进 查看全部
文章采集调用(
【魔兽世界】灵棺夜行代码.4更新公告)
Python制作爬虫采集新颖
更新时间:2015年10月25日11:08:10 提交人:hebedich
本文将与大家分享使用Python制作爬虫的代码采集小说。它非常简单实用,虽然还是有点瑕疵。一起改变,一起进步
开发工具:python3.4
操作系统:win8
主要功能:指定小说网页爬取小说目录,按章节保存到本地,将爬取的网页保存到本地配置文件。
已爬网网站:
小说名:棺材夜行
代码来源:我自己编码
import urllib.request
import http.cookiejar
import socket
import time
import re
timeout = 20
socket.setdefaulttimeout(timeout)
sleep_download_time = 10
time.sleep(sleep_download_time)
def makeMyOpener(head = {
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}):
cj = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
def saveFile(save_path,txts):
f_obj = open(save_path,'w+')
for item in txts:
f_obj.write(item+'\n')
f_obj.close()
#get_code_list
code_list='http://www.cishuge.com/read/0/771/'
oper = makeMyOpener()
uop = oper.open(code_list,timeout=1000)
data = uop.read().decode('gbk','ignore')
pattern = re.compile('(.*?)',re.S)
items = re.findall(pattern,data)
print ('获取列表完成')
url_path='url_file.txt'
url_r=open(url_path,'r')
url_arr=url_r.readlines(100000)
url_r.close()
print (len(url_arr))
url_file=open(url_path,'a')
print ('获取已下载网址')
for tmp in items:
save_path = tmp[1].replace(' ','')+'.txt'
url = code_list+tmp[0]
if url+'\n' in url_arr:
continue
print('写日志:'+url+'\n')
url_file.write(url+'\n')
opene = makeMyOpener()
op1 = opene.open(url,timeout=1000)
data = op1.read().decode('gbk','ignore')
opene.close()
pattern = re.compile(' (.*?)<br />',re.S)
txts = re.findall(pattern,data)
saveFile(save_path,txts)
url_file.close()
虽然代码还有点瑕疵,但还是分享给大家,一起改进
文章采集调用(PageAdminCMS采集是大部分站长做网站的自动更新利器采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-03-21 20:50
PageAdmincms采集,是一款功能强大的网站信息采集工具,现已成为大部分站长必备工具之一。通过下载任意类型文件、多级页面采集、全自动添加采集信息、多页面新闻自动抓取、广告过滤、自动获取各类分类网址等功能实现网站@ > 内容更新。毕竟当前网站中最重要的就是网站的内容了。内容是网站收录、排名和权重的基础。如果基础不牢固,那么一切都会白费。.
PageAdmincms采集可以对收录关键词的网站执行采集,可以实现关键词相关网站的批量采集,只需输入关键词的标题、域名和描述,即可通过搜索引擎获取与采集相关的网站信息。
PageAdmincms采集是大部分站长做网站的自动更新工具,全自动采集发布,运行过程中静默工作,完全无需人工干预。它作为独立软件存在,可以避免网站性能消耗。经反复测试,安全稳定,可连续多年不间断工作。它不仅可以独立运行,还可以在服务器或本地计算机上运行。它不需要打开网站,可以24小时不间断工作。它是网站自动更新网站内容的助手。
<p>PageAdmincms采集是一个功能实用的网络数据采集工具,可以通过搜索引擎搜索结果,获取需要采集的网址,以及 查看全部
文章采集调用(PageAdminCMS采集是大部分站长做网站的自动更新利器采集)
PageAdmincms采集,是一款功能强大的网站信息采集工具,现已成为大部分站长必备工具之一。通过下载任意类型文件、多级页面采集、全自动添加采集信息、多页面新闻自动抓取、广告过滤、自动获取各类分类网址等功能实现网站@ > 内容更新。毕竟当前网站中最重要的就是网站的内容了。内容是网站收录、排名和权重的基础。如果基础不牢固,那么一切都会白费。.
PageAdmincms采集可以对收录关键词的网站执行采集,可以实现关键词相关网站的批量采集,只需输入关键词的标题、域名和描述,即可通过搜索引擎获取与采集相关的网站信息。
PageAdmincms采集是大部分站长做网站的自动更新工具,全自动采集发布,运行过程中静默工作,完全无需人工干预。它作为独立软件存在,可以避免网站性能消耗。经反复测试,安全稳定,可连续多年不间断工作。它不仅可以独立运行,还可以在服务器或本地计算机上运行。它不需要打开网站,可以24小时不间断工作。它是网站自动更新网站内容的助手。
<p>PageAdmincms采集是一个功能实用的网络数据采集工具,可以通过搜索引擎搜索结果,获取需要采集的网址,以及
文章采集调用(采集器郑景承_自己学SEO2022-01-046 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-03-21 15:29
)
采集器郑景成_wordpress采集页面简单改造调用代码和描述增加量收录_自学SEO
2022-01-046
郑景诚:wordpress采集器
采集页面只是简单的转换调用代码和描述,增加收录的数量
郑景诚:wordpress采集页面简单修改为调用代码和描述,增加收录的数量。
昨天抽时间对郑刚的SEO培训网站做了一个简单的页面调整,主要是采集页面。
这个网站是用WP做的,所以如果你也用WP建站或者用它来做采集的内容,你可以采集这个文章,都是有效的代码以及如何操作。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
只需将上面的代码放在你想要的任何页面或位置,就可以直接调用一个随机的TAG标签。接下来的 9 表示调用 9,每个页面都不同。称为随机标签。
原因:这个动作是为了让每个页面调用不同的随机标签来提高标签页的收录概率和入口,因为WP的主要排名多为TAG标签页。
2、采集在内容页插入随机图片**
第一个采集器
步骤修改页面1:functions.php
/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = ;ob_start();ob_end_clean();$output = preg_match_all(//>i, $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = ";zt/".rand(1,3).".png";}return $first_img;}
将上面的代码放在functions.php页面底部,点击保存。记得用你的网址替换中间的网址。
Step 2 修改页面2:single.php
】,郑景承SEO培训提供在线实战SEO最新视频,优化工具,采集器加免费领取SEO教程。 查看全部
文章采集调用(采集器郑景承_自己学SEO2022-01-046
)
采集器郑景成_wordpress采集页面简单改造调用代码和描述增加量收录_自学SEO
2022-01-046
郑景诚:wordpress采集器
采集页面只是简单的转换调用代码和描述,增加收录的数量
郑景诚:wordpress采集页面简单修改为调用代码和描述,增加收录的数量。
昨天抽时间对郑刚的SEO培训网站做了一个简单的页面调整,主要是采集页面。
这个网站是用WP做的,所以如果你也用WP建站或者用它来做采集的内容,你可以采集这个文章,都是有效的代码以及如何操作。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
只需将上面的代码放在你想要的任何页面或位置,就可以直接调用一个随机的TAG标签。接下来的 9 表示调用 9,每个页面都不同。称为随机标签。
原因:这个动作是为了让每个页面调用不同的随机标签来提高标签页的收录概率和入口,因为WP的主要排名多为TAG标签页。
2、采集在内容页插入随机图片**
第一个采集器
步骤修改页面1:functions.php
/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = ;ob_start();ob_end_clean();$output = preg_match_all(//>i, $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = ";zt/".rand(1,3).".png";}return $first_img;}
将上面的代码放在functions.php页面底部,点击保存。记得用你的网址替换中间的网址。
Step 2 修改页面2:single.php
】,郑景承SEO培训提供在线实战SEO最新视频,优化工具,采集器
加免费领取SEO教程。 文章采集调用(第一章初见网络爬虫1.1网络连接1.2BeautifulSoup简介 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-21 01:06
)
第一章第一个网络爬虫1.1 网络连接
1 本节介绍了浏览器获取信息的主要原理,然后举了个python爬取网页源代码的例子
2
3
1#调用urllib库里的request模块,导入urlopen函数
2from urllib.requrest import urlopen
3#利用调用的urlopen函数打开并读取目标对象,并把结果赋值给html变量
4html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
5#把html中的内容读取并打印出来
6print(html.read())
7
1.2 BeautifulSoup 简介
BeautifulSoup 通过定位 HTML 标签对复杂的网络信息进行格式化和组织,并使用易于使用的 Python 对象为我们展示 XML 结构信息。
1.21 安装 BeautifulSoup
我在win10下使用,所以直接在powershell中输入
1pip install bs4
2
就是这样。
1.21 运行 BeautifulSoup
第一个例子也是用的,不过这次是用bs实现的
1#调用urllib库里的request模块的urlopen函数
2from urllib.request import urlopen
3#调用bs4库里的bs模块(注意大小写)
4from bs4 import BeautifulSoup
5#利用调用的urlopen函数打开并读取目标对象,并把结果赋值给html变量
6html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
7#把html中的内容用bs读取并赋值给bsObj
8bsObj = BeautifulSoup(html.read())
9#打印出bsObj的h1标签
10print(bsObj.h1)
11
主要是想说明,bs可以提取网页信息
1.23 可靠的互联网连接
本节的大意是排除爬虫可能遇到的不可靠因素,防止其发生。
第一
1html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
2
这行代码中可能出现两个主要异常:
该页面在服务器上不存在服务器不存在
当第一个异常发生时,程序返回一个 HTTP 错误。 HTTP 错误可能是“404 Page Not Found”“500 Internal Server Error”异常。我们可以通过以下方式处理:
1#尝试运行这行代码
2try:
3 html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
4#如果抛出HTTPError异常
5except HTTPError as e:
6 #打印出这个异常
7 print(e)
8 #返回空值,因为默认情况为return None,中断程序,或接着执行另一个方案
9#否则
10else:
11 #程序继续。注意:如果已经抛出了上面的错误,这段else语句不会执行。
12
如果服务器不存在,即域名打不开,urlopen会返回一个None对象。我们可以添加判断语句来判断返回的html是否为None:
1if html is None:
2 print('URL is not found')
3else:
4 #程序继续
5
当对象为None时,如果调用None下面的子标签会发生AttributeError。
1try:
2 badContent = bsObj.nonExistingTag.anotherTag
3except AttributeError as e:
4 print('Tag was not found')
5else:
6 if badContent ==None:
7 print('Tag was not found')
8 else:
9 print(badContent)
10
合并上面的代码,方便阅读
1from urllib.request import urlopen
2from urllib.error import HTTPError
3from bs4 import BeautifulSoup
4def getTitle(url):
5 try:
6 html = urlopen(url)
7 except HTTPError as e:
8 return None
9 try:
10 bsObj = BeautifulSoup(html.read())
11 title = bsObj.body.h1
12 except AttributeError as e:
13 return None
14 return title
15title = getTitle('http://www.pythonscraping.com/ ... 23x27;)
16if title == None:
17 print('Title could not be found')
18else:
19 print(title)
20 查看全部
文章采集调用(第一章初见网络爬虫1.1网络连接1.2BeautifulSoup简介
)
第一章第一个网络爬虫1.1 网络连接
1 本节介绍了浏览器获取信息的主要原理,然后举了个python爬取网页源代码的例子
2
3
1#调用urllib库里的request模块,导入urlopen函数
2from urllib.requrest import urlopen
3#利用调用的urlopen函数打开并读取目标对象,并把结果赋值给html变量
4html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
5#把html中的内容读取并打印出来
6print(html.read())
7
1.2 BeautifulSoup 简介
BeautifulSoup 通过定位 HTML 标签对复杂的网络信息进行格式化和组织,并使用易于使用的 Python 对象为我们展示 XML 结构信息。
1.21 安装 BeautifulSoup
我在win10下使用,所以直接在powershell中输入
1pip install bs4
2
就是这样。
1.21 运行 BeautifulSoup
第一个例子也是用的,不过这次是用bs实现的
1#调用urllib库里的request模块的urlopen函数
2from urllib.request import urlopen
3#调用bs4库里的bs模块(注意大小写)
4from bs4 import BeautifulSoup
5#利用调用的urlopen函数打开并读取目标对象,并把结果赋值给html变量
6html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
7#把html中的内容用bs读取并赋值给bsObj
8bsObj = BeautifulSoup(html.read())
9#打印出bsObj的h1标签
10print(bsObj.h1)
11
主要是想说明,bs可以提取网页信息
1.23 可靠的互联网连接
本节的大意是排除爬虫可能遇到的不可靠因素,防止其发生。
第一
1html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
2
这行代码中可能出现两个主要异常:
该页面在服务器上不存在服务器不存在
当第一个异常发生时,程序返回一个 HTTP 错误。 HTTP 错误可能是“404 Page Not Found”“500 Internal Server Error”异常。我们可以通过以下方式处理:
1#尝试运行这行代码
2try:
3 html = urlopen('http://pythonscrapying.com/pag ... 23x27;)
4#如果抛出HTTPError异常
5except HTTPError as e:
6 #打印出这个异常
7 print(e)
8 #返回空值,因为默认情况为return None,中断程序,或接着执行另一个方案
9#否则
10else:
11 #程序继续。注意:如果已经抛出了上面的错误,这段else语句不会执行。
12
如果服务器不存在,即域名打不开,urlopen会返回一个None对象。我们可以添加判断语句来判断返回的html是否为None:
1if html is None:
2 print('URL is not found')
3else:
4 #程序继续
5
当对象为None时,如果调用None下面的子标签会发生AttributeError。
1try:
2 badContent = bsObj.nonExistingTag.anotherTag
3except AttributeError as e:
4 print('Tag was not found')
5else:
6 if badContent ==None:
7 print('Tag was not found')
8 else:
9 print(badContent)
10
合并上面的代码,方便阅读
1from urllib.request import urlopen
2from urllib.error import HTTPError
3from bs4 import BeautifulSoup
4def getTitle(url):
5 try:
6 html = urlopen(url)
7 except HTTPError as e:
8 return None
9 try:
10 bsObj = BeautifulSoup(html.read())
11 title = bsObj.body.h1
12 except AttributeError as e:
13 return None
14 return title
15title = getTitle('http://www.pythonscraping.com/ ... 23x27;)
16if title == None:
17 print('Title could not be found')
18else:
19 print(title)
20
文章采集调用(【语料库】百科调用关键点梳理(二):)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-03-20 21:02
文章采集调用2009-2015年的所有百科全书媒体站点库进行爬取,一共有5542个媒体站点用于记录和收集百科中的数据,分析有利于后期商业报告的数据分析。百科的工作机制:官方指定的流程内是专人负责每日事物,但是依然存在很多纰漏,这里逐条查漏补缺,为后期项目落地提供参考,整理一份我个人的百科调用关键点梳理。
ps:由于百科数据和wiki数据差异巨大,在这里以百科数据作为参考依据,一般官方的工作规范和过程是非常专业,执行过程中也要人性化一些。首先选择了108个国家对应的百科站点,是这十几年排名靠前,无错误记录的站点。因为项目中要爬取的要素太多,而查漏补缺,则很难选择好合适的站点。发现最大的缺点是十几年来知名的百科站点中,基本没有变动的。
因此首先排除掉已经被收录的站点。在已经爬虫过的一些站点中找出数据最为零散的站点,多半出现在公司的分发站,而这些站点的特点就是每天大量更新,看似很多,实际上数据量是十分有限的。这里想到的解决方案是多用些机器爬虫进行处理,把零散的数据处理整合到一起。实际上当时是把百科站点进行分词,然后把查询中的词汇,用自动补全,最后连接到百科语料库中,但是语料库的数据量也是很有限的。
经过处理后,比较耗时间,也容易出错,并且知道在日常爬虫中还是可以避免的。与其从零开始,不如自己先给他们找一找问题,然后在尽量的减少搜索成本,尽量不浪费时间。当年专注在这里,很大原因是因为一些公司过多的收购,对查询结果的重要性选择,导致数据量实在太大,这两年才有了好转。百科相关业务:百科全书工作站(或icrook),定制开发的流程框架整理公司转型和搜索公司的选择搜索公司和爬虫工具的选择企业站类别特点:以(pc)首页和相关页为主,其次是(wap)首页,同时也支持b2c垂直搜索以pc站为主,也支持付费搜索和独立搜索(百度联盟的页面没有站点);首页:无特殊查询或收录量低,正常首页显示,页面相对较大;pc站查询无特殊查询,页面相对较小,甚至找不到;wap站查询无特殊查询,页面相对较小,特别是不存在移动端页面。
实例:主流都有很多其他语言/库存在,不存在特殊查询。但是wap类的很多开发语言正在兴起,其中一些库以及索引库实例语言已经超过10年;pc站是实时查询,几乎没有延迟;wap站几乎没有延迟;实例:pc站超过300家(央企的pc站下部有报告,详细,自己拉外网看);wap站近300家。因此,最佳是选择pc站查询工具和wap站搜索工具组合,最次是使用分发,然后自己根据需求定制独立搜。 查看全部
文章采集调用(【语料库】百科调用关键点梳理(二):)
文章采集调用2009-2015年的所有百科全书媒体站点库进行爬取,一共有5542个媒体站点用于记录和收集百科中的数据,分析有利于后期商业报告的数据分析。百科的工作机制:官方指定的流程内是专人负责每日事物,但是依然存在很多纰漏,这里逐条查漏补缺,为后期项目落地提供参考,整理一份我个人的百科调用关键点梳理。
ps:由于百科数据和wiki数据差异巨大,在这里以百科数据作为参考依据,一般官方的工作规范和过程是非常专业,执行过程中也要人性化一些。首先选择了108个国家对应的百科站点,是这十几年排名靠前,无错误记录的站点。因为项目中要爬取的要素太多,而查漏补缺,则很难选择好合适的站点。发现最大的缺点是十几年来知名的百科站点中,基本没有变动的。
因此首先排除掉已经被收录的站点。在已经爬虫过的一些站点中找出数据最为零散的站点,多半出现在公司的分发站,而这些站点的特点就是每天大量更新,看似很多,实际上数据量是十分有限的。这里想到的解决方案是多用些机器爬虫进行处理,把零散的数据处理整合到一起。实际上当时是把百科站点进行分词,然后把查询中的词汇,用自动补全,最后连接到百科语料库中,但是语料库的数据量也是很有限的。
经过处理后,比较耗时间,也容易出错,并且知道在日常爬虫中还是可以避免的。与其从零开始,不如自己先给他们找一找问题,然后在尽量的减少搜索成本,尽量不浪费时间。当年专注在这里,很大原因是因为一些公司过多的收购,对查询结果的重要性选择,导致数据量实在太大,这两年才有了好转。百科相关业务:百科全书工作站(或icrook),定制开发的流程框架整理公司转型和搜索公司的选择搜索公司和爬虫工具的选择企业站类别特点:以(pc)首页和相关页为主,其次是(wap)首页,同时也支持b2c垂直搜索以pc站为主,也支持付费搜索和独立搜索(百度联盟的页面没有站点);首页:无特殊查询或收录量低,正常首页显示,页面相对较大;pc站查询无特殊查询,页面相对较小,甚至找不到;wap站查询无特殊查询,页面相对较小,特别是不存在移动端页面。
实例:主流都有很多其他语言/库存在,不存在特殊查询。但是wap类的很多开发语言正在兴起,其中一些库以及索引库实例语言已经超过10年;pc站是实时查询,几乎没有延迟;wap站几乎没有延迟;实例:pc站超过300家(央企的pc站下部有报告,详细,自己拉外网看);wap站近300家。因此,最佳是选择pc站查询工具和wap站搜索工具组合,最次是使用分发,然后自己根据需求定制独立搜。
文章采集调用(如何利用织梦采集工具来优化文章内容内容优化?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-03-19 02:20
织梦内容管理系统(Dedecms)是我们站长们非常熟悉的cms建站系统,Dedecms将成为您轻松搭建的强大工具建立一个网站。织梦采集做网站seo优化基本知道写文章很重要。“无处不在”这个词已经使用了很长时间,即使是现在也受到搜索引擎的喜爱!当然,有些新手站长朋友不知道如何优化网站文章。今天给大家讲讲如何使用织梦采集工具优化文章内容??
我们都知道,网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用织梦采集免费工具实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,这个织梦采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需织梦cms采集@ >工具上的简单设置,织梦采集会根据用户设置的关键词准确采集文章,这样织梦 采集 @> 确保与行业 文章 保持一致。采集文章可以选择将修改后的内容保存到本地,
织梦采集自动匹配图片文章如果内容中没有图片,会自动配置相关图片设置并自动下载图片保存到本地或第三方保存内容不再有来自对方的外部链接。百度已经以官方文档的形式直接说明了织梦采集中的文章哪些seo元素是有价值的。织梦采集只需设置任务,自动挂机!
用户搜索到的内容是有价值的,用户搜索到的没有原创的内容在搜索引擎眼中是毫无价值的。织梦采集自动内部链接允许搜索引擎更深入地抓取您的链接。
织梦采集注意关键词的密度,也就是关键词出现的频率,会影响文章相关关键词的当前排名,很多seo从业者都不会忽视这一点。织梦采集网站内容插入或随机作者、随机阅读等称为“高度原创”。织梦采集需要注意的一点是词频不能太高,也就是密度不能太大。很多新手seo用seo来做seo,最后的结果就是极端会逆转。织梦采集无论你有成百上千个不同的cms网站,都可以实现统一管理。我接触的很多人都犯了这个问题,这不是一个孤立的案例,它是一个普遍的问题。
织梦采集关键词密度会影响关键词排名,位置也会影响,而且影响很大。这一点的核心操作点是:把重要的关键词放在文章重要的地方。织梦采集相关性优化文字出现关键词,文字第一段自动插入标题。当描述相关性较低时,当前的采集关键词。织梦采集一个人维护几十万网站文章更新也不是问题。看似简单的操作方法,似乎很少有人能做好。哪些职位最重要?
织梦采集免费工具配备了关键词采集 功能。通常有标题、第一段、每段的开头、摘要调用等。织梦采集在内容或标题之前和之后插入段落或关键词可选的标题和标题插入到相同的 关键词。织梦采集非常好用,输入关键词即可实现采集。这从seo的角度来看也是织梦采集优化文章,从用户的角度来看也是必然的要求。织梦采集排版和排版更多的是关乎网页的质量,而不是内容本身的质量。
织梦采集一个是主体内容应该放在哪里,让用户一目了然。织梦采集网站主动推送可以让搜索引擎更快的发现我们的站点,支持百度、搜狗、神马、360等搜索引擎的主动推送。举个反例,本身并没有太多的内容。假设它也以分页的形式显示。这就是问题。假设在首页,“联系我们”的内容被放在了重要的位置,这也是一个问题。 查看全部
文章采集调用(如何利用织梦采集工具来优化文章内容内容优化?)
织梦内容管理系统(Dedecms)是我们站长们非常熟悉的cms建站系统,Dedecms将成为您轻松搭建的强大工具建立一个网站。织梦采集做网站seo优化基本知道写文章很重要。“无处不在”这个词已经使用了很长时间,即使是现在也受到搜索引擎的喜爱!当然,有些新手站长朋友不知道如何优化网站文章。今天给大家讲讲如何使用织梦采集工具优化文章内容??
我们都知道,网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用织梦采集免费工具实现采集伪原创自动发布,主动推送给搜索引擎,增加搜索引擎的抓取频率,这个织梦采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需织梦cms采集@ >工具上的简单设置,织梦采集会根据用户设置的关键词准确采集文章,这样织梦 采集 @> 确保与行业 文章 保持一致。采集文章可以选择将修改后的内容保存到本地,
织梦采集自动匹配图片文章如果内容中没有图片,会自动配置相关图片设置并自动下载图片保存到本地或第三方保存内容不再有来自对方的外部链接。百度已经以官方文档的形式直接说明了织梦采集中的文章哪些seo元素是有价值的。织梦采集只需设置任务,自动挂机!
用户搜索到的内容是有价值的,用户搜索到的没有原创的内容在搜索引擎眼中是毫无价值的。织梦采集自动内部链接允许搜索引擎更深入地抓取您的链接。
织梦采集注意关键词的密度,也就是关键词出现的频率,会影响文章相关关键词的当前排名,很多seo从业者都不会忽视这一点。织梦采集网站内容插入或随机作者、随机阅读等称为“高度原创”。织梦采集需要注意的一点是词频不能太高,也就是密度不能太大。很多新手seo用seo来做seo,最后的结果就是极端会逆转。织梦采集无论你有成百上千个不同的cms网站,都可以实现统一管理。我接触的很多人都犯了这个问题,这不是一个孤立的案例,它是一个普遍的问题。
织梦采集关键词密度会影响关键词排名,位置也会影响,而且影响很大。这一点的核心操作点是:把重要的关键词放在文章重要的地方。织梦采集相关性优化文字出现关键词,文字第一段自动插入标题。当描述相关性较低时,当前的采集关键词。织梦采集一个人维护几十万网站文章更新也不是问题。看似简单的操作方法,似乎很少有人能做好。哪些职位最重要?
织梦采集免费工具配备了关键词采集 功能。通常有标题、第一段、每段的开头、摘要调用等。织梦采集在内容或标题之前和之后插入段落或关键词可选的标题和标题插入到相同的 关键词。织梦采集非常好用,输入关键词即可实现采集。这从seo的角度来看也是织梦采集优化文章,从用户的角度来看也是必然的要求。织梦采集排版和排版更多的是关乎网页的质量,而不是内容本身的质量。
织梦采集一个是主体内容应该放在哪里,让用户一目了然。织梦采集网站主动推送可以让搜索引擎更快的发现我们的站点,支持百度、搜狗、神马、360等搜索引擎的主动推送。举个反例,本身并没有太多的内容。假设它也以分页的形式显示。这就是问题。假设在首页,“联系我们”的内容被放在了重要的位置,这也是一个问题。
文章采集调用(微信公众号商城的解决方案(一)——)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-17 14:05
文章采集调用多家微信公众号,给每个公众号都发送一个调用接口,每个公众号又接入一个接口,对每个公众号发送一条数据,最后给出调用结果。前提调用多家公众号微信入口,或调用其他公众号微信端:订阅号:后台接口数据统计分析:总阅读数、推送数、阅读量、点赞率、关注率、转发率、评论数、截图数、点击事件触发次数、发送时间。
可以尝试用一些api,
(二维码自动识别)你可以试试这个,我们原来是这么做的,很简单,
swot是什么?
这个问题问的好,我也想知道api开发网站前景如何,最近正在研究这个网站,所以有这方面的想法,
我看好微信公众号商城,
一、微信生态环境尚不完善,包括公众号发展时间短,账号及生态价值体现不明显,且公众号存在层次区分,
二、微信商城是目前最好的线上销售线上线下打通的事物,不会消失。
作为相关的从业者,我觉得自主开发门槛太高,不管是开发还是培训,都不比做网站或app简单,即使目前微信公众号很牛的自助商城也是很慢,
1、公众号与电商平台结合的应用,据我所知是最近新出来的一个推广方式,从抖音,快手,到社群,再到游戏中的转化率都比较高,可以用来尝试,可以用来宣传品牌,
2、自定义菜单,现在还没有官方应用,需要结合模板工具。现在行业内的解决方案(如视星通,礼品通,基本款游戏自定义菜单,活动购物等)建议结合一下,
3、如果有一定的开发经验,可以自己网上买个服务器,比如云端,稳定性很差,而且服务费很贵,如果服务器牛逼,跟第一条一样,随便你做不做。如果没经验自己一个人做也简单,
4、欢迎加我威信:1425762322,一起交流讨论,根据产品经理需求设计开发,不求最牛逼, 查看全部
文章采集调用(微信公众号商城的解决方案(一)——)
文章采集调用多家微信公众号,给每个公众号都发送一个调用接口,每个公众号又接入一个接口,对每个公众号发送一条数据,最后给出调用结果。前提调用多家公众号微信入口,或调用其他公众号微信端:订阅号:后台接口数据统计分析:总阅读数、推送数、阅读量、点赞率、关注率、转发率、评论数、截图数、点击事件触发次数、发送时间。
可以尝试用一些api,
(二维码自动识别)你可以试试这个,我们原来是这么做的,很简单,
swot是什么?
这个问题问的好,我也想知道api开发网站前景如何,最近正在研究这个网站,所以有这方面的想法,
我看好微信公众号商城,
一、微信生态环境尚不完善,包括公众号发展时间短,账号及生态价值体现不明显,且公众号存在层次区分,
二、微信商城是目前最好的线上销售线上线下打通的事物,不会消失。
作为相关的从业者,我觉得自主开发门槛太高,不管是开发还是培训,都不比做网站或app简单,即使目前微信公众号很牛的自助商城也是很慢,
1、公众号与电商平台结合的应用,据我所知是最近新出来的一个推广方式,从抖音,快手,到社群,再到游戏中的转化率都比较高,可以用来尝试,可以用来宣传品牌,
2、自定义菜单,现在还没有官方应用,需要结合模板工具。现在行业内的解决方案(如视星通,礼品通,基本款游戏自定义菜单,活动购物等)建议结合一下,
3、如果有一定的开发经验,可以自己网上买个服务器,比如云端,稳定性很差,而且服务费很贵,如果服务器牛逼,跟第一条一样,随便你做不做。如果没经验自己一个人做也简单,
4、欢迎加我威信:1425762322,一起交流讨论,根据产品经理需求设计开发,不求最牛逼,
文章采集调用(wordpress采集页简单改造调用代码和说明,提升收录量 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-03-12 21:06
)
郑景成:wordpress采集页面简单修改为调用代码和描述增加收录的量
郑景成:wordpress采集页面简单修改为调用代码和描述增加收录的量
昨天抽空对郑刚的SEO培训网站做了一个简单的页面调整,主要是采集页面。
这个网站是用WP做的,所以如果你也用WP建站或者用它来做采集的内容,你可以采集这个文章,都是有效的代码以及如何操作。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
1 '14', 'largest' => 14, 'unit' => 'px', 'order' => 'RAND', 'number' => 9 ) ); ?>
2
只需将上面的代码放在你想要的任何页面或位置,就可以直接调用一个随机的TAG标签。接下来的 9 表示调用 9,每个页面都不同。称为随机标签。
**原因:**这个动作是为了让每个页面调用不同的随机标签,以提高标签页的收录概率和入口,因为WP的主要排名多为TAG标签页。
2、采集在内容页插入随机图片**
步骤 1 修改页面 1:functions.php
1/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = '';ob_start();ob_end_clean();$output = preg_match_all('//>i', $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = "https://seozg.cc/wp-content/up ... .rand(1,3).".png";}return $first_img;}
2
将上面的代码放在functions.php页面底部,点击保存。记得用你的网址替换中间的网址。
Step 2 修改页面2:single.php
<p> 查看全部
文章采集调用(wordpress采集页简单改造调用代码和说明,提升收录量
)
郑景成:wordpress采集页面简单修改为调用代码和描述增加收录的量
郑景成:wordpress采集页面简单修改为调用代码和描述增加收录的量
昨天抽空对郑刚的SEO培训网站做了一个简单的页面调整,主要是采集页面。
这个网站是用WP做的,所以如果你也用WP建站或者用它来做采集的内容,你可以采集这个文章,都是有效的代码以及如何操作。
主要目的是让采集的页面变化与原来的内容不同,至少有收获,进一步提高页面收录的概率。
1、自动调用随机TAG标签和自定义数量
1、[修改页面:single.php]
1 '14', 'largest' => 14, 'unit' => 'px', 'order' => 'RAND', 'number' => 9 ) ); ?>
2
只需将上面的代码放在你想要的任何页面或位置,就可以直接调用一个随机的TAG标签。接下来的 9 表示调用 9,每个页面都不同。称为随机标签。
**原因:**这个动作是为了让每个页面调用不同的随机标签,以提高标签页的收录概率和入口,因为WP的主要排名多为TAG标签页。
2、采集在内容页插入随机图片**
步骤 1 修改页面 1:functions.php
1/* 文章随机插图 */function catch_that_image() {global $post, $posts;$first_img = '';ob_start();ob_end_clean();$output = preg_match_all('//>i', $post->post_content, $matches);$first_img = $matches [1] [0];if(empty($first_img)){ //Defines a default image$first_img = "https://seozg.cc/wp-content/up ... .rand(1,3).".png";}return $first_img;}
2
将上面的代码放在functions.php页面底部,点击保存。记得用你的网址替换中间的网址。
Step 2 修改页面2:single.php
<p>
文章采集调用(给WordPress文章添加广告位有很多伙计的WordPress站点是怎么做的 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-03-12 20:14
)
将广告位添加到 WordPress文章
想必有很多人的WordPress网站是没有广告位的,而且即使有广告位,在文章中间也很少有广告位,就像下图的广告一样,直接显示在文章中间。在这里,我向大伙推荐一段代码,以达到为文章添加广告空间的目的。请将以下代码放入functions.php 文件中。然后把你自己的广告代码放在第7行,可以是谷歌附属或其他图片广告或自己制作的html代码。其中第 10 行有一个数字 2,这意味着该广告将插入到 文章 的第二段之后...
建站教程2020-12-06
WordPress 禁止指定类别的 文章
使用wordpress禁止输出文章的指定类别,可以给get_posts()函数传递一个数组参数,如下: 其中:键名numberposts表示检索到的文章个数, category 表示要显示的文章 的类别ID,负数表示不显示,以逗号分隔的字符串形式,这里的orderby表示随机取出文章。去掉了php类的文章显示,因为下面有一个“php栏”,避免重复。get_posts() 函数的完整参数列表:
建站教程2021-11-02
如何在 WordPress 中更改域名
以前经常换域名,每次都要查看换域名的方法,这次直接记录在我的网站里。导入数据库后,执行如下SQL语句,代表旧域名,代表新域名,将新旧域名修改为自己的,然后点击执行!这也是我最喜欢的方法,记录下来供自己使用,分享给大家。
网站建设教程2020-09-23
在不修改数据库的情况下更改WordPress域名
WordPress更改域名或打开HTTPS,旧域名不再可用,后台也将无法访问。很多人会后悔没有提前在后台更改域名。一般我们可以通过修改数据库来解决,但是比较麻烦。通过数据库的解决方法,请看?:如何在WordPress中更改域名。但是,有一个更简单的方法。只需要修改wp-config.php文件,在wp-config.php中添加如下代码: 添加后即可登录后台 现在登录成功后,手动...
网站建设教程2020-11-04
WordPress 永久链接 %postname% 和 pathinfo 冲突
主要冲突是当你访问wordpress的正常页面、分类和文章时,都可以正常访问和显示,但是当你访问一个不存在的url时,你的站点不会显示404页面,但它是显示的主页;听起来可能很模糊,你不明白它的意思;例如:可以访问,因为这个页面确实存在,所以没有问题;当您访问...
网站建设教程2021-05-28
查看全部
文章采集调用(给WordPress文章添加广告位有很多伙计的WordPress站点是怎么做的
)
将广告位添加到 WordPress文章
想必有很多人的WordPress网站是没有广告位的,而且即使有广告位,在文章中间也很少有广告位,就像下图的广告一样,直接显示在文章中间。在这里,我向大伙推荐一段代码,以达到为文章添加广告空间的目的。请将以下代码放入functions.php 文件中。然后把你自己的广告代码放在第7行,可以是谷歌附属或其他图片广告或自己制作的html代码。其中第 10 行有一个数字 2,这意味着该广告将插入到 文章 的第二段之后...
建站教程2020-12-06
WordPress 禁止指定类别的 文章
使用wordpress禁止输出文章的指定类别,可以给get_posts()函数传递一个数组参数,如下: 其中:键名numberposts表示检索到的文章个数, category 表示要显示的文章 的类别ID,负数表示不显示,以逗号分隔的字符串形式,这里的orderby表示随机取出文章。去掉了php类的文章显示,因为下面有一个“php栏”,避免重复。get_posts() 函数的完整参数列表:
建站教程2021-11-02
如何在 WordPress 中更改域名
以前经常换域名,每次都要查看换域名的方法,这次直接记录在我的网站里。导入数据库后,执行如下SQL语句,代表旧域名,代表新域名,将新旧域名修改为自己的,然后点击执行!这也是我最喜欢的方法,记录下来供自己使用,分享给大家。
网站建设教程2020-09-23
在不修改数据库的情况下更改WordPress域名
WordPress更改域名或打开HTTPS,旧域名不再可用,后台也将无法访问。很多人会后悔没有提前在后台更改域名。一般我们可以通过修改数据库来解决,但是比较麻烦。通过数据库的解决方法,请看?:如何在WordPress中更改域名。但是,有一个更简单的方法。只需要修改wp-config.php文件,在wp-config.php中添加如下代码: 添加后即可登录后台 现在登录成功后,手动...
网站建设教程2020-11-04
WordPress 永久链接 %postname% 和 pathinfo 冲突
主要冲突是当你访问wordpress的正常页面、分类和文章时,都可以正常访问和显示,但是当你访问一个不存在的url时,你的站点不会显示404页面,但它是显示的主页;听起来可能很模糊,你不明白它的意思;例如:可以访问,因为这个页面确实存在,所以没有问题;当您访问...
网站建设教程2021-05-28
文章采集调用(如何加快网站访问速度(1)_e操盘_怎么做)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-03-09 07:21
如何加快网站Access()
很多朋友用虚拟主机做网站,将web文件存放在虚拟空间,但是当页面内容过多时,网站的打开速度显得很慢。如果遇到这种情况,与其寻找更好的空间,不如通过优化网页代码来达到满意的速度。作者总结了一些实用的方法。在制作主页时,以下方法可以大大提高你的网页速度。
一、记得帮页面减肥
我们在浏览网页的时候,其实是把虚拟主机中的网页内容下载到本地硬盘上,然后用浏览器进行解读和查看。网页的下载速度在显示速度中占很大比例,所以网页本身占用的空间越小,浏览速度就会越快。这就要求在制作网页时要遵循一切简洁的原则,例如:不要使用过大的Flash动画、图片等资源。干净、简洁的页面给人一种思路清晰的感觉。
二、如果没有必要,使用静态 HTML 页面
众所周知,ASP、PHP、JSP等程序实现了网页信息的动态交互,运行起来非常方便,因为它们的数据交互性好,并且可以方便地访问和更改数据库的内容,以便网站“移动”,例如:论坛、留言板等。但是,此类程序必须经过服务器处理,生成HTML页面,然后“发送”到客户端进行浏览,这必须消耗一定的服务器资源,如果在虚拟主机上过多使用这类程序,网页的显示速度肯定会变慢,所以尽量不要使用静态HTML页面。
三、不要把整个页面塞进一个表格
这是网页设计的问题。为了追求统一的页面对齐,很多站长把整个页面的内容放到一个Table(表格)中,然后用单元格td来划分各个“块”的布局。网站 的显示速度绝对慢。因为Table要等到里面的所有内容都加载完才会显示出来,所以如果有些内容不能访问,就会耽误整个页面的访问速度。正确的做法是:将内容分成几个格式相同的Table,不要全部塞进一个Table。
四、将ASP、ASPX、PHP等文件的访问权限改为. js参考
这一点在设计ASP、ASPX、PHP等程序时要注意。如果你想在静态 HTML 页面中嵌入动态数据,而这些动态数据是由 ASP、PHP 等程序提供的,你会使用如下语句 Quote: 这样的话,每次有人访问你的网站,服务器会对tongji.asp文件执行一次处理,从数据库中提取相应的数据,然后输出到网页显示。如果有几万人同时访问,就要执行上万次,后果可想而知。建议在这些程序中动态生成数据成一个1.js文件,然后通过首页上<SCRIPT src=""></SCRIPT>的代码引用1.js文件页。这样,
五、使用 iframe 嵌套另一个页面
如果你想在 网站 上插入一些广告代码,但又不想让这些广告 网站 影响速度,那么使用 iframe 是最合适的。方法是:把这些广告代码放在一个单独的页面上,然后用下面的代码把页面嵌入到首页,这样整个首页的显示就不会因为广告页的延迟而被拖拽。代码如下:
< IFRAME marginWidth=0 marginHeight=0 src="***.com" frameBorder=0 width=468 scrolling=no height=60 leftmargin="0" topmargin="0"></IFRAME>
其中 ***.com 是引用文件的路径。
六、注意网站柜台代码放置技巧
在网页中放置计数器可以统计网站的流量,为站长和广告商提供访问依据。但是,无论网站 统计系统多么强大,都会有出错的时候。如果你把统计代码直接放在页面内容前面,或者放在一个Table或者div标签里,那么当计数器无法访问时,你页面上的Table或者div会有几十秒的延迟,导致页面被推迟。很长一段时间访问。因此,为了提高网站的速度,需要注意统计代码的位置。正确的做法是:将统计代码放在页面底部,不要和页面内容放在同一个Table或div标签中。可以直接将统计代码放在页面代码底部,或者在底部制作一个单独的表格或 div 来放置计数器。这样,当计数器无法访问时,您的 网站 速度不会受到丝毫影响。
七、友情链接知识
网站之间的链接可以增加网站的宣传效果,制作LOGO图片链接可以更准确地描述网站的主题和定位,宣传效果会大大增强,但是图片链接做多了,必然会影响网页的显示速度。很多站长喜欢在友情网站上直接引用图片网址,让图片加载后才能显示。每个好友网站的访问速度不一样,整个表格都要等待图片下载完成。可以显示,大大降低了网页的速度。因此,在做附属链接时,您应该尝试:
1. 仅文本链接:文本链接不会减慢页面速度。
2. 将所有链接放到一个单独的页面,然后链接到主页上的页面。
3.如果链接一定要出现在首页,请将链接所在的整个Table放在页面底部,因为页面是从上到下逐行显示的,所以放在底部的页面,而不是其他内容的显示会延迟。
4. 友情链接的LOGO图片先下载,再上传到自己的网站空间。这样,速度由自己的网站空间决定,不受友情网站的影响。
-------------------------------------------------- -------------------------------------------------- --------
本文转载请出自著名来源:Just Do IT ()
一个小的网站,比如个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有页面都存放在一个目录下,比如网站对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过多年的发展,已经细分为非常精细的方面,尤其是对于大型网站来说,使用的技术非常广泛,从硬件到软件,编程语言、数据库、WebServer、防火墙等领域都有很高的要求,不是原来简单的html静态网站可比的。
大型 网站,例如 Portal网站。面对大量用户访问和高并发请求,基本解决方案集中在以下几个环节:使用高性能服务器、高性能数据库、高效编程语言、高性能Web容器。但是除了这些方面,没有办法从根本上解决大网站面临的高负载、高并发问题。
上面提供的几种解决方案在一定程度上也意味着更大的投入,而且这种解决方案存在瓶颈,不具备很好的扩展性。我从低成本、高性能和高扩展性的角度来谈一谈。说说我的一些经历吧。
1、HTML 静态
其实我们都知道纯静态的html页面效率最高,成本也最低,所以我们尽量使用静态页面来实现我们网站上的页面。这种最简单的方法实际上是最有效的。方法。但是对于内容量大、更新频繁的网站,我们无法一一手动实现,于是出现了我们常用的信息发布系统cms,比如各个门户的新闻频道我们经常访问的网站,甚至他们的其他渠道都是通过信息发布系统进行管理和实施的。信息发布系统可以实现最简单的信息录入,自动生成静态页面。还可以具有频道管理、权限管理、自动抓拍等功能。对于大型 网站
除了门户和信息发布类型网站,对于交互性要求高的社区类型网站,尽可能保持静态也是提高性能的必要手段。社区发帖,文章实时静态化,有更新时再静态化也是一种被广泛使用的策略。猫扑的大杂烩使用了这样的策略,网易社区也是如此。
同时,html静态化也是一些缓存策略使用的手段。对于系统中频繁使用数据库查询但内容更新量较小的应用,可以考虑使用html静态化来实现,比如论坛中的论坛公开设置信息。这些信息目前所有主流论坛都可以后台管理,并存储在数据库中。其实很多这些信息都是前台程序调用的,只是更新频率很小。后台更新时可以考虑将这部分内容设为静态,避免大量数据库。访问请求。
2、图像服务器分离
众所周知,对于web服务器来说,无论是Apache、IIS还是其他容器,图片是最耗费资源的,所以需要将图片与页面分离,这基本上是大网站所采用的策略,他们都有独立的图像服务器,甚至很多图像服务器。这样的架构可以减轻提供页面访问请求的服务器系统的压力,并且可以保证系统不会因为图像问题而崩溃。应用服务器和镜像服务器可以进行不同的配置优化。比如apache可以尽量配置ContentType。更少的支持和尽可能少的 LoadModule 确保更高的系统消耗和执行效率。
3、数据库集群和库表哈希
大型网站都有复杂的应用,而这些应用必须用到数据库,所以在面对大量访问时,很快就会出现数据库的瓶颈,一个数据库很快就无法满足应用,所以我们需要使用数据库集群或库表哈希。
在数据库集群方面,很多数据库都有自己的解决方案。Oracle、Sybase 等都有很好的解决方案。MySQL提供的常用的Master/Slave也是类似的解决方案。你用的是什么DB,请参考对应的解决方案。解决方案来实施。
上面提到的数据库集群在架构、成本和可扩展性方面受到所使用的数据库类型的限制。因此,我们需要从应用的角度考虑改进系统架构。库表哈希是最常用和最有效的解决方案。. 我们在应用中安装业务和应用或者功能模块来分离数据库,不同的模块对应不同的数据库或者表,然后按照一定的策略对一个页面或者功能进行较小的数据库hash,比如user table, Hash the根据用户ID创建表,可以低成本提高系统性能,具有良好的可扩展性。搜狐的论坛采用了这样的结构,将论坛的用户、设置、帖子等信息从数据库中分离出来,然后根据section和ID对posts和users的数据库和表进行hash,最后可以在配置文件中简单配置。可以随时将低成本数据库添加到系统中,以补充系统性能。
4、缓存
缓存这个词已经被技术触及,很多地方都用到了缓存。开发中的网站架构和网站缓存也很重要。这是最基本的两种缓存。稍后将描述高级和分布式缓存。
对于架构上的缓存,熟悉Apache的人可以知道,Apache提供了自己的缓存模块,也可以使用额外的Squid模块进行缓存,两者都可以有效提升Apache的访问响应能力。
网站程序开发缓存,Linux上提供的Memory Cache是常用的缓存接口,可以在web开发中使用。比如在Java开发的时候,可以调用MemoryCache来缓存和共享一些数据。大型社区使用这样的架构。另外,在使用web语言开发的时候,各种语言基本都有自己的缓存模块和方法,PHP有Pear的Cache模块,Java有更多,.net不是很熟悉,相信一定有。
5、镜像
镜像是大规模网站常用的提高性能和数据安全性的一种方式。镜像技术可以解决不同网络接入商和地区造成的用户访问速度差异。比如ChinaNet和EduNet的区别,促使很多网站在教育网建立镜像站点,数据定期或者实时更新。关于镜像的详细技术,这里不再赘述。有许多专业的现成解决方案架构和产品可供选择。还有便宜的软件实现思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是 large网站 解决高负载访问和大量并发请求的终极解决方案。
负载均衡技术发展多年,有很多专业的服务商和产品可供选择。我个人遇到过一些解决方案,有两种架构供大家参考。
硬件第 4 层交换
四层交换利用三层和四层报文的报文头信息,根据应用段识别业务流,将整个段的业务流分配给合适的应用服务器进行处理。第四层交换功能就像一个虚拟IP,指向物理服务器。它传输的业务遵循多种协议,包括HTTP、FTP、NFS、Telnet或其他协议。这些服务基于物理服务器,需要复杂的负载平衡算法。在IP世界中,服务类型由终端TCP或UDP端口地址决定,四层交换中的应用范围由源和终端IP地址、TCP和UDP端口决定。
在硬件四层交换产品领域,有一些比较知名的产品可供选择,比如Alteon、F5等,这些产品价格贵但物超所值,可以提供卓越的性能和灵活的管理能力。雅虎中国为其近 2,000 台服务器使用了三四台 Alteon。
软件第 4 层交换
在大家了解了硬件四层交换机的原理之后,基于OSI模型的软件四层交换机应运而生。这种方案的原理是一样的,只是性能稍差一些。但是,仍然很容易满足一定的压力。有人说软件实现方式其实更灵活,处理能力完全取决于你对配置的熟悉程度。
我们可以使用Linux中常用的LVS来解决软件的四层切换。LVS 是 Linux 虚拟服务器。提供基于心跳的实时灾难响应解决方案,提高了系统的健壮性,提供灵活的虚拟VIP。配置和管理功能可以同时满足多个应用的需求,这对于分布式系统来说是必不可少的。
使用负载均衡的一个典型策略是在软件或硬件四层交换的基础上构建一个squid集群。这个想法被用于许多大型网站,包括搜索引擎。这种架构是低成本和高性能的。还有很强的可扩展性,随时可以很容易地在架构中添加或删除节点。我将抽出时间详细梳理一下这样的结构并与您讨论。
对于大规模的网站,可以同时使用上面提到的各个方法。这里我简单介绍一下。具体实现过程中的很多细节需要大家熟悉和体验。有时一个小的 squid 参数或者 apache 参数的设置会对系统性能产生很大的影响。
-------------------------------------------------- -------------------------------------------------- ------
常规方法:
1.使用 ACDSEE 压缩图像
2.分页,把一页变成多页
3.不要把所有的图片、flash等都放在同一个表格中,因为IE下载后会在一个表格中显示所有内容,可以放在多个表格中,下载一个会显示一个。
4.换成更快的服务器空间 查看全部
文章采集调用(如何加快网站访问速度(1)_e操盘_怎么做)
如何加快网站Access()
很多朋友用虚拟主机做网站,将web文件存放在虚拟空间,但是当页面内容过多时,网站的打开速度显得很慢。如果遇到这种情况,与其寻找更好的空间,不如通过优化网页代码来达到满意的速度。作者总结了一些实用的方法。在制作主页时,以下方法可以大大提高你的网页速度。
一、记得帮页面减肥
我们在浏览网页的时候,其实是把虚拟主机中的网页内容下载到本地硬盘上,然后用浏览器进行解读和查看。网页的下载速度在显示速度中占很大比例,所以网页本身占用的空间越小,浏览速度就会越快。这就要求在制作网页时要遵循一切简洁的原则,例如:不要使用过大的Flash动画、图片等资源。干净、简洁的页面给人一种思路清晰的感觉。
二、如果没有必要,使用静态 HTML 页面
众所周知,ASP、PHP、JSP等程序实现了网页信息的动态交互,运行起来非常方便,因为它们的数据交互性好,并且可以方便地访问和更改数据库的内容,以便网站“移动”,例如:论坛、留言板等。但是,此类程序必须经过服务器处理,生成HTML页面,然后“发送”到客户端进行浏览,这必须消耗一定的服务器资源,如果在虚拟主机上过多使用这类程序,网页的显示速度肯定会变慢,所以尽量不要使用静态HTML页面。
三、不要把整个页面塞进一个表格
这是网页设计的问题。为了追求统一的页面对齐,很多站长把整个页面的内容放到一个Table(表格)中,然后用单元格td来划分各个“块”的布局。网站 的显示速度绝对慢。因为Table要等到里面的所有内容都加载完才会显示出来,所以如果有些内容不能访问,就会耽误整个页面的访问速度。正确的做法是:将内容分成几个格式相同的Table,不要全部塞进一个Table。
四、将ASP、ASPX、PHP等文件的访问权限改为. js参考
这一点在设计ASP、ASPX、PHP等程序时要注意。如果你想在静态 HTML 页面中嵌入动态数据,而这些动态数据是由 ASP、PHP 等程序提供的,你会使用如下语句 Quote: 这样的话,每次有人访问你的网站,服务器会对tongji.asp文件执行一次处理,从数据库中提取相应的数据,然后输出到网页显示。如果有几万人同时访问,就要执行上万次,后果可想而知。建议在这些程序中动态生成数据成一个1.js文件,然后通过首页上<SCRIPT src=""></SCRIPT>的代码引用1.js文件页。这样,
五、使用 iframe 嵌套另一个页面
如果你想在 网站 上插入一些广告代码,但又不想让这些广告 网站 影响速度,那么使用 iframe 是最合适的。方法是:把这些广告代码放在一个单独的页面上,然后用下面的代码把页面嵌入到首页,这样整个首页的显示就不会因为广告页的延迟而被拖拽。代码如下:
< IFRAME marginWidth=0 marginHeight=0 src="***.com" frameBorder=0 width=468 scrolling=no height=60 leftmargin="0" topmargin="0"></IFRAME>
其中 ***.com 是引用文件的路径。
六、注意网站柜台代码放置技巧
在网页中放置计数器可以统计网站的流量,为站长和广告商提供访问依据。但是,无论网站 统计系统多么强大,都会有出错的时候。如果你把统计代码直接放在页面内容前面,或者放在一个Table或者div标签里,那么当计数器无法访问时,你页面上的Table或者div会有几十秒的延迟,导致页面被推迟。很长一段时间访问。因此,为了提高网站的速度,需要注意统计代码的位置。正确的做法是:将统计代码放在页面底部,不要和页面内容放在同一个Table或div标签中。可以直接将统计代码放在页面代码底部,或者在底部制作一个单独的表格或 div 来放置计数器。这样,当计数器无法访问时,您的 网站 速度不会受到丝毫影响。
七、友情链接知识
网站之间的链接可以增加网站的宣传效果,制作LOGO图片链接可以更准确地描述网站的主题和定位,宣传效果会大大增强,但是图片链接做多了,必然会影响网页的显示速度。很多站长喜欢在友情网站上直接引用图片网址,让图片加载后才能显示。每个好友网站的访问速度不一样,整个表格都要等待图片下载完成。可以显示,大大降低了网页的速度。因此,在做附属链接时,您应该尝试:
1. 仅文本链接:文本链接不会减慢页面速度。
2. 将所有链接放到一个单独的页面,然后链接到主页上的页面。
3.如果链接一定要出现在首页,请将链接所在的整个Table放在页面底部,因为页面是从上到下逐行显示的,所以放在底部的页面,而不是其他内容的显示会延迟。
4. 友情链接的LOGO图片先下载,再上传到自己的网站空间。这样,速度由自己的网站空间决定,不受友情网站的影响。
-------------------------------------------------- -------------------------------------------------- --------
本文转载请出自著名来源:Just Do IT ()
一个小的网站,比如个人的网站,可以用最简单的html静态页面来实现,配上一些图片来达到美化效果,所有页面都存放在一个目录下,比如网站对系统架构和性能的要求非常简单。随着互联网服务的不断丰富,网站相关技术经过多年的发展,已经细分为非常精细的方面,尤其是对于大型网站来说,使用的技术非常广泛,从硬件到软件,编程语言、数据库、WebServer、防火墙等领域都有很高的要求,不是原来简单的html静态网站可比的。
大型 网站,例如 Portal网站。面对大量用户访问和高并发请求,基本解决方案集中在以下几个环节:使用高性能服务器、高性能数据库、高效编程语言、高性能Web容器。但是除了这些方面,没有办法从根本上解决大网站面临的高负载、高并发问题。
上面提供的几种解决方案在一定程度上也意味着更大的投入,而且这种解决方案存在瓶颈,不具备很好的扩展性。我从低成本、高性能和高扩展性的角度来谈一谈。说说我的一些经历吧。
1、HTML 静态
其实我们都知道纯静态的html页面效率最高,成本也最低,所以我们尽量使用静态页面来实现我们网站上的页面。这种最简单的方法实际上是最有效的。方法。但是对于内容量大、更新频繁的网站,我们无法一一手动实现,于是出现了我们常用的信息发布系统cms,比如各个门户的新闻频道我们经常访问的网站,甚至他们的其他渠道都是通过信息发布系统进行管理和实施的。信息发布系统可以实现最简单的信息录入,自动生成静态页面。还可以具有频道管理、权限管理、自动抓拍等功能。对于大型 网站
除了门户和信息发布类型网站,对于交互性要求高的社区类型网站,尽可能保持静态也是提高性能的必要手段。社区发帖,文章实时静态化,有更新时再静态化也是一种被广泛使用的策略。猫扑的大杂烩使用了这样的策略,网易社区也是如此。
同时,html静态化也是一些缓存策略使用的手段。对于系统中频繁使用数据库查询但内容更新量较小的应用,可以考虑使用html静态化来实现,比如论坛中的论坛公开设置信息。这些信息目前所有主流论坛都可以后台管理,并存储在数据库中。其实很多这些信息都是前台程序调用的,只是更新频率很小。后台更新时可以考虑将这部分内容设为静态,避免大量数据库。访问请求。
2、图像服务器分离
众所周知,对于web服务器来说,无论是Apache、IIS还是其他容器,图片是最耗费资源的,所以需要将图片与页面分离,这基本上是大网站所采用的策略,他们都有独立的图像服务器,甚至很多图像服务器。这样的架构可以减轻提供页面访问请求的服务器系统的压力,并且可以保证系统不会因为图像问题而崩溃。应用服务器和镜像服务器可以进行不同的配置优化。比如apache可以尽量配置ContentType。更少的支持和尽可能少的 LoadModule 确保更高的系统消耗和执行效率。
3、数据库集群和库表哈希
大型网站都有复杂的应用,而这些应用必须用到数据库,所以在面对大量访问时,很快就会出现数据库的瓶颈,一个数据库很快就无法满足应用,所以我们需要使用数据库集群或库表哈希。
在数据库集群方面,很多数据库都有自己的解决方案。Oracle、Sybase 等都有很好的解决方案。MySQL提供的常用的Master/Slave也是类似的解决方案。你用的是什么DB,请参考对应的解决方案。解决方案来实施。
上面提到的数据库集群在架构、成本和可扩展性方面受到所使用的数据库类型的限制。因此,我们需要从应用的角度考虑改进系统架构。库表哈希是最常用和最有效的解决方案。. 我们在应用中安装业务和应用或者功能模块来分离数据库,不同的模块对应不同的数据库或者表,然后按照一定的策略对一个页面或者功能进行较小的数据库hash,比如user table, Hash the根据用户ID创建表,可以低成本提高系统性能,具有良好的可扩展性。搜狐的论坛采用了这样的结构,将论坛的用户、设置、帖子等信息从数据库中分离出来,然后根据section和ID对posts和users的数据库和表进行hash,最后可以在配置文件中简单配置。可以随时将低成本数据库添加到系统中,以补充系统性能。
4、缓存
缓存这个词已经被技术触及,很多地方都用到了缓存。开发中的网站架构和网站缓存也很重要。这是最基本的两种缓存。稍后将描述高级和分布式缓存。
对于架构上的缓存,熟悉Apache的人可以知道,Apache提供了自己的缓存模块,也可以使用额外的Squid模块进行缓存,两者都可以有效提升Apache的访问响应能力。
网站程序开发缓存,Linux上提供的Memory Cache是常用的缓存接口,可以在web开发中使用。比如在Java开发的时候,可以调用MemoryCache来缓存和共享一些数据。大型社区使用这样的架构。另外,在使用web语言开发的时候,各种语言基本都有自己的缓存模块和方法,PHP有Pear的Cache模块,Java有更多,.net不是很熟悉,相信一定有。
5、镜像
镜像是大规模网站常用的提高性能和数据安全性的一种方式。镜像技术可以解决不同网络接入商和地区造成的用户访问速度差异。比如ChinaNet和EduNet的区别,促使很多网站在教育网建立镜像站点,数据定期或者实时更新。关于镜像的详细技术,这里不再赘述。有许多专业的现成解决方案架构和产品可供选择。还有便宜的软件实现思路,比如Linux上的rsync等工具。
6、负载均衡
负载均衡将是 large网站 解决高负载访问和大量并发请求的终极解决方案。
负载均衡技术发展多年,有很多专业的服务商和产品可供选择。我个人遇到过一些解决方案,有两种架构供大家参考。
硬件第 4 层交换
四层交换利用三层和四层报文的报文头信息,根据应用段识别业务流,将整个段的业务流分配给合适的应用服务器进行处理。第四层交换功能就像一个虚拟IP,指向物理服务器。它传输的业务遵循多种协议,包括HTTP、FTP、NFS、Telnet或其他协议。这些服务基于物理服务器,需要复杂的负载平衡算法。在IP世界中,服务类型由终端TCP或UDP端口地址决定,四层交换中的应用范围由源和终端IP地址、TCP和UDP端口决定。
在硬件四层交换产品领域,有一些比较知名的产品可供选择,比如Alteon、F5等,这些产品价格贵但物超所值,可以提供卓越的性能和灵活的管理能力。雅虎中国为其近 2,000 台服务器使用了三四台 Alteon。
软件第 4 层交换
在大家了解了硬件四层交换机的原理之后,基于OSI模型的软件四层交换机应运而生。这种方案的原理是一样的,只是性能稍差一些。但是,仍然很容易满足一定的压力。有人说软件实现方式其实更灵活,处理能力完全取决于你对配置的熟悉程度。
我们可以使用Linux中常用的LVS来解决软件的四层切换。LVS 是 Linux 虚拟服务器。提供基于心跳的实时灾难响应解决方案,提高了系统的健壮性,提供灵活的虚拟VIP。配置和管理功能可以同时满足多个应用的需求,这对于分布式系统来说是必不可少的。
使用负载均衡的一个典型策略是在软件或硬件四层交换的基础上构建一个squid集群。这个想法被用于许多大型网站,包括搜索引擎。这种架构是低成本和高性能的。还有很强的可扩展性,随时可以很容易地在架构中添加或删除节点。我将抽出时间详细梳理一下这样的结构并与您讨论。
对于大规模的网站,可以同时使用上面提到的各个方法。这里我简单介绍一下。具体实现过程中的很多细节需要大家熟悉和体验。有时一个小的 squid 参数或者 apache 参数的设置会对系统性能产生很大的影响。
-------------------------------------------------- -------------------------------------------------- ------
常规方法:
1.使用 ACDSEE 压缩图像
2.分页,把一页变成多页
3.不要把所有的图片、flash等都放在同一个表格中,因为IE下载后会在一个表格中显示所有内容,可以放在多个表格中,下载一个会显示一个。
4.换成更快的服务器空间
文章采集调用(function.php中定义功能的实现,做数据库的查询 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-03-05 16:10
)
其实我是想在博客上实现一个作者专栏页面,但是技术难度有点大,因为typecho的限制就在这里,想了很久才做出来,而且最近的时间确实不如和以前一样丰富,所以这个功能被推回了。现在博客是下一个最好的东西。文章的阅读页面右侧显示作者的基本信息,并调用最近发表的十篇文章文章。我还是简单记录一下体会。原则。
主要是在function.php中定义函数的实现,做数据库查询。
代码显示如下:
/** 输出该作者最近文章列表 */
function authorPosts($authorid){
if($authorid){
$limit = 6;
$db = Typecho_Db::get();
$result = $db->fetchAll($db->select()->from('table.contents')
->where('authorId = ?',$authorid)
->where('status = ?','publish')
->where('type = ?', 'post')
->limit($limit)
->order('cid', Typecho_Db::SORT_DESC)
);
if($result){
foreach($result as $val){
$val = Typecho_Widget::widget('Widget_Abstract_Contents')->push($val);
$post_title = htmlspecialchars($val['title']);
$permalink = $val['permalink'];
echo ''.$post_title.'';
}
}
}else{
echo '请设置要调用的作者ID';
}
}
实现原理是定义一个方法来接收页面上传的作者ID参数,然后通过这个参数查询数据库中的文章表,并将个数限制为6个,然后输出查询到的数组循环到页面,实现整个过程。
模板上的调用代码如下:
其实这个功能还可以进一步开发,比如传入两个参数,作者ID和限制号,这样就可以更方便的控制了。
最终效果可以在博客上看到。
转载并注明出处。
喜欢 0
报酬
千水万山,永远相爱,打赏也无妨。报酬
查看全部
文章采集调用(function.php中定义功能的实现,做数据库的查询
)
其实我是想在博客上实现一个作者专栏页面,但是技术难度有点大,因为typecho的限制就在这里,想了很久才做出来,而且最近的时间确实不如和以前一样丰富,所以这个功能被推回了。现在博客是下一个最好的东西。文章的阅读页面右侧显示作者的基本信息,并调用最近发表的十篇文章文章。我还是简单记录一下体会。原则。
主要是在function.php中定义函数的实现,做数据库查询。
代码显示如下:
/** 输出该作者最近文章列表 */
function authorPosts($authorid){
if($authorid){
$limit = 6;
$db = Typecho_Db::get();
$result = $db->fetchAll($db->select()->from('table.contents')
->where('authorId = ?',$authorid)
->where('status = ?','publish')
->where('type = ?', 'post')
->limit($limit)
->order('cid', Typecho_Db::SORT_DESC)
);
if($result){
foreach($result as $val){
$val = Typecho_Widget::widget('Widget_Abstract_Contents')->push($val);
$post_title = htmlspecialchars($val['title']);
$permalink = $val['permalink'];
echo ''.$post_title.'';
}
}
}else{
echo '请设置要调用的作者ID';
}
}
实现原理是定义一个方法来接收页面上传的作者ID参数,然后通过这个参数查询数据库中的文章表,并将个数限制为6个,然后输出查询到的数组循环到页面,实现整个过程。
模板上的调用代码如下:
其实这个功能还可以进一步开发,比如传入两个参数,作者ID和限制号,这样就可以更方便的控制了。
最终效果可以在博客上看到。
转载并注明出处。
喜欢 0
报酬
千水万山,永远相爱,打赏也无妨。报酬

