
搜索引擎主题模型优化
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心主题模型?本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-18 22:07
网站优化主题模型SEO最新的SEO概念进入了全新的“有质感的内容”算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。下面将结合当今最新的SEO概念来指导你如何优化主题内容。SEO网站的主题模型是什么?关于SEO页面的内容,我们通常可以听到和看到很多旧的方法,这比使用各种H标签来整合关键词 TDK关键词 是否设置为准确匹配但有经验SEO 人员和 网站 大师们很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这是本文的核心。那么什么是主题模型呢?主题模型是页面内容布局的模型,为了让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:1)词系统关联<
他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)。第一步:词关联 无论你用什么方法来优化页面的内容,都必须围绕如何关联词和词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。当我们使用句子和单词时,搜索引擎将根据其他资源中的数据关联您的内容,以生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己的研究关键词的方法,但需要达到以下目标:1)找到同义词和异体词2)找到与内容相关的二类词主题3)找二类词相关的三类词,Thing) 举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据上述目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“
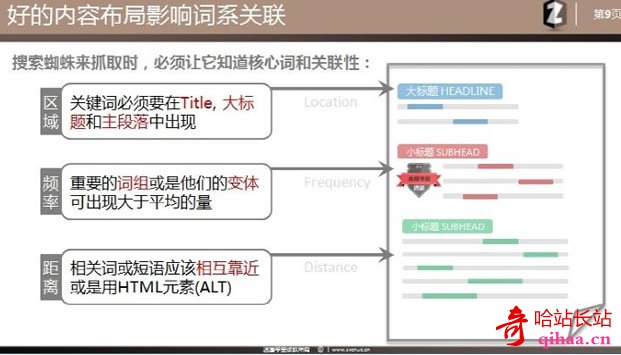
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是关键词的密度!第2步:词系统布局毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要,非常重要。蜘蛛什么时候来到页面发现这么多关键词,他们需要区分哪些是重要的,哪些 关键词 与短语相关。所以词系统布局是要明确核心词和相关性,下面是3个实用的优化方法: 1)Region: 关键词 必须出现在Title、标题和主要段落2) 频率: 重要的短语 or 它是它们的变体可以出现超过平均水平。3) 距离:相关词或词组要尽量靠近或者使用HTML元素(如ALT)的方式(1)是大部分SEO人的必修项目,还是要放核心主题标题和大标题中的词尽量出现在正文的顶部。方法(2)这里不仅仅是关键词的频率(密度),但更复杂的是,第一层的链接频率是核心词的同义词和变体。在同等条件下,不太流行的同义词和变体会得到更好的结果。
现在你要做的就是将那些二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主题(排名词),正如我之前所说的搜索引擎可以使用大数据来识别单词关联。举个简单的例子:主词是【网红】,第一段会重点关注这个词文章。第二段将用几只手完成。文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是一个词系相关内容,通过步骤2来布局词族。第三步:补充内容。或许很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,现在的外链就像一颗不合时宜的炸弹,说不定会被链接炸死。
因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?如果你的网页只是单纯的关键词,缺少文字链接、参考资料和相关资源推荐,那么你的页面就很死板,死路一条,不会给你的页面加分。看右边的页面。网站内有链接(黄色部分),导出链接和内容中的[补充内容]。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是加强页面主题的深化,通过不同网站的内容来强化信息。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。1)在页面底部添加相关资源的链接(推荐站内链接)2)在文中使用引号,如行业内知名人士的话或图标,如文中3) 使用导出链接到网站中的第三方(你不会被K放100。第4步:内容实体这是一个非常难的概念,称为英文实体。强大的搜索引擎会抓取页面 来自动解释内容实体,或者将其理解为内容属性。例如,当内容提到“包老师”时,它的实体是[人]吗?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。
(木木补充说,这涉及到微数据。HTML5 微数据规范是一种标记,用于描述特定类型的信息,例如评论、人物信息或事件。每种类型的信息描述特定类型的项目,例如人物、事件或评论见《结构化微数据丰富网页摘要》)一般搜索引擎都会给站长提供自己的结构化数据(比如“百度新数据标注工具,相当于谷歌数据标注”),什么是结构化数据?就是使用搜索引擎设置的HTML Markup来定义内容,或者统称为使用Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。这个更高级 只是一点点理解。您可以要求您的架构师添加 网站 结构数据。当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。搜索引擎会自动解释内容实体,通过“人、地、物”来寻找关联,所以建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比作“每个实体”。关联。例如,
看看有没有和之前的优化概念不一样。搜索引擎不看页面上是否有这个词以及有多少链接指向它,而是看内容实体是否相关。综上所述,大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技巧整合到你的内容优化中:1)一个高度概括的标题来描述页面的主题2)添加一个开头(简要)来描述页面的内容3)@ > 内容分为几段,每段都有自己的主题。4)尽量扩大主题视角,补充相关答案。5) 查看全部
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心主题模型?本文)
网站优化主题模型SEO最新的SEO概念进入了全新的“有质感的内容”算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。下面将结合当今最新的SEO概念来指导你如何优化主题内容。SEO网站的主题模型是什么?关于SEO页面的内容,我们通常可以听到和看到很多旧的方法,这比使用各种H标签来整合关键词 TDK关键词 是否设置为准确匹配但有经验SEO 人员和 网站 大师们很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这是本文的核心。那么什么是主题模型呢?主题模型是页面内容布局的模型,为了让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:1)词系统关联<
他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)。第一步:词关联 无论你用什么方法来优化页面的内容,都必须围绕如何关联词和词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。当我们使用句子和单词时,搜索引擎将根据其他资源中的数据关联您的内容,以生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己的研究关键词的方法,但需要达到以下目标:1)找到同义词和异体词2)找到与内容相关的二类词主题3)找二类词相关的三类词,Thing) 举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据上述目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是关键词的密度!第2步:词系统布局毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要,非常重要。蜘蛛什么时候来到页面发现这么多关键词,他们需要区分哪些是重要的,哪些 关键词 与短语相关。所以词系统布局是要明确核心词和相关性,下面是3个实用的优化方法: 1)Region: 关键词 必须出现在Title、标题和主要段落2) 频率: 重要的短语 or 它是它们的变体可以出现超过平均水平。3) 距离:相关词或词组要尽量靠近或者使用HTML元素(如ALT)的方式(1)是大部分SEO人的必修项目,还是要放核心主题标题和大标题中的词尽量出现在正文的顶部。方法(2)这里不仅仅是关键词的频率(密度),但更复杂的是,第一层的链接频率是核心词的同义词和变体。在同等条件下,不太流行的同义词和变体会得到更好的结果。
现在你要做的就是将那些二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主题(排名词),正如我之前所说的搜索引擎可以使用大数据来识别单词关联。举个简单的例子:主词是【网红】,第一段会重点关注这个词文章。第二段将用几只手完成。文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是一个词系相关内容,通过步骤2来布局词族。第三步:补充内容。或许很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,现在的外链就像一颗不合时宜的炸弹,说不定会被链接炸死。
因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?如果你的网页只是单纯的关键词,缺少文字链接、参考资料和相关资源推荐,那么你的页面就很死板,死路一条,不会给你的页面加分。看右边的页面。网站内有链接(黄色部分),导出链接和内容中的[补充内容]。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是加强页面主题的深化,通过不同网站的内容来强化信息。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。1)在页面底部添加相关资源的链接(推荐站内链接)2)在文中使用引号,如行业内知名人士的话或图标,如文中3) 使用导出链接到网站中的第三方(你不会被K放100。第4步:内容实体这是一个非常难的概念,称为英文实体。强大的搜索引擎会抓取页面 来自动解释内容实体,或者将其理解为内容属性。例如,当内容提到“包老师”时,它的实体是[人]吗?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。
(木木补充说,这涉及到微数据。HTML5 微数据规范是一种标记,用于描述特定类型的信息,例如评论、人物信息或事件。每种类型的信息描述特定类型的项目,例如人物、事件或评论见《结构化微数据丰富网页摘要》)一般搜索引擎都会给站长提供自己的结构化数据(比如“百度新数据标注工具,相当于谷歌数据标注”),什么是结构化数据?就是使用搜索引擎设置的HTML Markup来定义内容,或者统称为使用Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。这个更高级 只是一点点理解。您可以要求您的架构师添加 网站 结构数据。当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。搜索引擎会自动解释内容实体,通过“人、地、物”来寻找关联,所以建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比作“每个实体”。关联。例如,
看看有没有和之前的优化概念不一样。搜索引擎不看页面上是否有这个词以及有多少链接指向它,而是看内容实体是否相关。综上所述,大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技巧整合到你的内容优化中:1)一个高度概括的标题来描述页面的主题2)添加一个开头(简要)来描述页面的内容3)@ > 内容分为几段,每段都有自己的主题。4)尽量扩大主题视角,补充相关答案。5)
搜索引擎主题模型优化(什么是SEO理念站内网站优化推广主题模型(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-18 03:16
网站优化推广网站站内优化推广最新SEO概念网站优化推广的主题模型SEO进入了“质感内容”的新算法体系,尤其是现在一流的搜索引擎能力更强,从内容的上下文来看,利用内容实体的属性来处理排名,让用户得到更准确的搜索结果。对于网站优化推广者来说,网站站内优化推广不再是简单的内容填充,主题内容网站优化推广需要重新定义。在本文中,川亚传媒科技将结合最新的SEO概念,指导大家如何网站优化和推广主题内容。SEO网站的主题模型是什么?我们通常可以听到和看到很多关于SEO页面内容的旧方法,例如: 使用各种H标签来集成关键词 TDK关键词 是否设置为准确匹配但可以?有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。现在要网站优化和推广好的网站内容,我们必须做的是如何让搜索引擎了解页面的核心主题。这就是我今天文章。核。那么什么是主题模型呢?SEO概念站网站优化推广主题模型网站优化推广网站 优化推广主题模型是一种页面内容布局模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是更多地传达哪个关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。
<p>因此,在主题模型中,我们需要实现全新的网站优化推广方式:1)词系统关联2)词系统布局3)补充内容< @4) 内容属性 对于维基百科等熟悉的网站,亚马逊利用其中的积分获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,不管你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能排名好!(特别是对于谷歌)第 1 步:词法关联不管你现在用什么方法来网站来优化推广页面的内容,但一定要着眼于如何关联词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。SEO 理念 网站 优化网站推广主题模型。当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们的网站优化推广者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方法,但需要达到以下目标:1)查找同义词和异形词< @2)找与主词内容相关的二类词3)找与二类词相关的三类词 查看全部
搜索引擎主题模型优化(什么是SEO理念站内网站优化推广主题模型(组图))
网站优化推广网站站内优化推广最新SEO概念网站优化推广的主题模型SEO进入了“质感内容”的新算法体系,尤其是现在一流的搜索引擎能力更强,从内容的上下文来看,利用内容实体的属性来处理排名,让用户得到更准确的搜索结果。对于网站优化推广者来说,网站站内优化推广不再是简单的内容填充,主题内容网站优化推广需要重新定义。在本文中,川亚传媒科技将结合最新的SEO概念,指导大家如何网站优化和推广主题内容。SEO网站的主题模型是什么?我们通常可以听到和看到很多关于SEO页面内容的旧方法,例如: 使用各种H标签来集成关键词 TDK关键词 是否设置为准确匹配但可以?有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。现在要网站优化和推广好的网站内容,我们必须做的是如何让搜索引擎了解页面的核心主题。这就是我今天文章。核。那么什么是主题模型呢?SEO概念站网站优化推广主题模型网站优化推广网站 优化推广主题模型是一种页面内容布局模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是更多地传达哪个关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。
<p>因此,在主题模型中,我们需要实现全新的网站优化推广方式:1)词系统关联2)词系统布局3)补充内容< @4) 内容属性 对于维基百科等熟悉的网站,亚马逊利用其中的积分获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,不管你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能排名好!(特别是对于谷歌)第 1 步:词法关联不管你现在用什么方法来网站来优化推广页面的内容,但一定要着眼于如何关联词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。SEO 理念 网站 优化网站推广主题模型。当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们的网站优化推广者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方法,但需要达到以下目标:1)查找同义词和异形词< @2)找与主词内容相关的二类词3)找与二类词相关的三类词
搜索引擎主题模型优化(1.什么是SEO站内主题内容优化方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-18 03:14
文章指南
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1. 什么是SEO网站的主题模型
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 查看关键词的密度是否符合标准
· 文章 内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词是否设置为精准匹配
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?
主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
1) 词法关联
2)词系统布局
3)补充内容
4)内容属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
第 1 步:词法关联
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和变体
2)找到与主词内容相关的二类词
3)找到与第二类词相关的三类词
4) 结论是内容属性与主题(人、地、事)有关
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二个-与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到与主词相关的三类词第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4), 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点和事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度!
第二步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。因此,词系统布局是区分核心词及其相关性。以下是3种实用的优化方法:
1)区域:关键词 必须出现在标题、标题和主要段落中
2) 频率:重要短语或其变体的出现频率可能高于平均水平
3) 距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)
方法(1)是大部分SEO人的必修项目,我们还是要把核心主题放在标题,大标题,尽量出现在主条目的顶部。
方法(2)这里不仅仅是关键词的频率(密度),而是一个更复杂层面的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词而且变体词会得到更好的结果。(谷歌有个专利叫TF-IDF,比较难懂)
方法(3)距离产生美在SEO世界里是不适用的。单词、短语或句子应该尽可能靠近放置,或者应该使用HTML元素(例如图像ALT设置)。所以为了提高上下文相关性,应该通过段落、列表、分区等方式让内容更加明显,一看就知道段落在说什么。前后句子之间是否有连通性,不要将内容相似的内容分开意思太远了。因为你不能保证蜘蛛会捕捉到整个文本。
你知道这个方法的原理。现在你要做的就是将二类单词和三类词汇分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会重点介绍这个词文章。第二段用几只手做文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。
因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯粹的关键词,缺少文字链接、参考资料和相关资源推荐,你的页面很死板,这是一个死胡同,但它不会为您的页面添加额外的点。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件。这是给搜索引擎的消息。我有[补充]。想想看,百度百科还是知道为什么要添加相关资源的链接?实际上,就是加强页面主题的深化,通过不同网站的内容强化信息化。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。
1)在页面底部添加相关资源链接(推荐站点链接);
2)在正文中使用引号,如行业内知名人士的话或图标或视频;
3)使用文中的导出链接去第三方网站(你不会被K的100介意)。
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom Teacher”时,是实体[person]吗?提到“咨询道”,是【公司】?因为当你的内容出现在网上的时候,时间还不够久,数量少的时候,搜索引擎可能无法解析内容实体,因为老师可以是姓氏的老师,也可以是可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体。
一般情况下,大部分搜索引擎都会提供站长自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示,世界上只有0.3%网站 使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让您的架构师将 网站 结构化数据纳入其中。
当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的非常笼统的标题
2)添加开场白(简要)描述页面内容
3) 把内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以添加相关答案
5)提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体
----想了解最新SEO概念、网站优化主题模型分享!多关注seo优化教程 查看全部
搜索引擎主题模型优化(1.什么是SEO站内主题内容优化方法)
文章指南
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1. 什么是SEO网站的主题模型
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 查看关键词的密度是否符合标准
· 文章 内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词是否设置为精准匹配
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?

主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
1) 词法关联
2)词系统布局
3)补充内容
4)内容属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
第 1 步:词法关联
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。

当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和变体
2)找到与主词内容相关的二类词
3)找到与第二类词相关的三类词
4) 结论是内容属性与主题(人、地、事)有关
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二个-与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到与主词相关的三类词第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4), 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点和事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度!
第二步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。因此,词系统布局是区分核心词及其相关性。以下是3种实用的优化方法:

1)区域:关键词 必须出现在标题、标题和主要段落中
2) 频率:重要短语或其变体的出现频率可能高于平均水平
3) 距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)
方法(1)是大部分SEO人的必修项目,我们还是要把核心主题放在标题,大标题,尽量出现在主条目的顶部。
方法(2)这里不仅仅是关键词的频率(密度),而是一个更复杂层面的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词而且变体词会得到更好的结果。(谷歌有个专利叫TF-IDF,比较难懂)
方法(3)距离产生美在SEO世界里是不适用的。单词、短语或句子应该尽可能靠近放置,或者应该使用HTML元素(例如图像ALT设置)。所以为了提高上下文相关性,应该通过段落、列表、分区等方式让内容更加明显,一看就知道段落在说什么。前后句子之间是否有连通性,不要将内容相似的内容分开意思太远了。因为你不能保证蜘蛛会捕捉到整个文本。
你知道这个方法的原理。现在你要做的就是将二类单词和三类词汇分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会重点介绍这个词文章。第二段用几只手做文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。

因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯粹的关键词,缺少文字链接、参考资料和相关资源推荐,你的页面很死板,这是一个死胡同,但它不会为您的页面添加额外的点。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件。这是给搜索引擎的消息。我有[补充]。想想看,百度百科还是知道为什么要添加相关资源的链接?实际上,就是加强页面主题的深化,通过不同网站的内容强化信息化。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。
1)在页面底部添加相关资源链接(推荐站点链接);
2)在正文中使用引号,如行业内知名人士的话或图标或视频;
3)使用文中的导出链接去第三方网站(你不会被K的100介意)。
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom Teacher”时,是实体[person]吗?提到“咨询道”,是【公司】?因为当你的内容出现在网上的时候,时间还不够久,数量少的时候,搜索引擎可能无法解析内容实体,因为老师可以是姓氏的老师,也可以是可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体。

一般情况下,大部分搜索引擎都会提供站长自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示,世界上只有0.3%网站 使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让您的架构师将 网站 结构化数据纳入其中。
当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的非常笼统的标题
2)添加开场白(简要)描述页面内容
3) 把内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以添加相关答案
5)提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体
----想了解最新SEO概念、网站优化主题模型分享!多关注seo优化教程
搜索引擎主题模型优化(数据挖掘算法为何物?——基于向量的相似度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-17 20:21
我写这个文章是因为前几天部门成员对部门涉及的一些算法进行了审查和整理。不过比较尴尬的是,既然老板不在,大家讨论讨论就变成吐槽大会了,但有一半时间是吐槽产品和业务部门~~
但这也是一件令人欣慰的事情。这也算是我们的数据部门,已经从轻型挖掘机走向了深挖阶段。
所以,借此机会,把我接触过、了解过、做过的一些勉强能称为算法的事情整理一下。事实上,就我而言,我没有算法背景。在大学里,我更多地了解了互联网,我什至不知道数据挖掘算法是什么。
其实就所谓的算法而言,我个人认为我的一个同事是对的:所谓的算法并不意味着那些复杂的数学模型就是算法。哪怕是你写的简单的计算公式,只要能解决当前存在的业务痛点,并且有自己的模型思路,就是算法,但可能不够通用,只能解决特定的业务需要。
在大规模数据的前提下,其实很多复杂的算法过程都没有这么好的结果。换句话说,我们将找到简化流程的方法。
举个简单的栗子:假设有一个大规模的数据集,以近千万篇博文为例。如果你提供一篇博文,让你查询相似度最高的前N个,我们通常的想法是什么?通常的方法是计算这篇博文与其他博文的相似度。计算相似度的方法有很多。, 最简单的方法是计算矢量角度,并根据矢量角度确定相似度。好吧,就算用最简单的计算过程,计算近千万次需要多长时间?或许,有人说我用hadoop,用分布式算力来完成这个任务,但是如果真的操作起来,你就会发现这是多么的痛苦。
再举一个简单的栗子(好吧,多吃栗子):比如SVM,这是一个很难收敛的算法。在大数据的前提下,有的人想用大数据,但想用更多的数据进行训练。模型毕竟手头的数据太多,很多人还是希望用尽可能多的数据来训练,以达到模型更加精准的目的。但是,随着训练数据量的增加,SVM等难以收敛的算法会消耗大量的计算资源。
(1)贝叶斯
贝叶斯是分类算法中最简单的算法。挖掘机算法初学者肯定会先爱上它。事实上,贝叶斯原理非常简单,基于统计学中的最大概率原理。就是这么简单,但尼玛却是这么好用,多年来一直屹立不倒。
缺乏训练过程。基本上贝叶斯就是这样的。因为是文本,所以用一组过程将词和停用词作为最基本的知识点向量进行分割,然后计算模型概率。但更有趣的是,分类过程是在Storm中完成的,相当于一个实时的分类服务。
(2)分词算法
其实说到分词算法,没什么好说的。现在网上各种开源的分词工具都做得很好,效果也差不了多少。如果要进一步改进,就会窒息。至于深入分词算法,涉及到上下文分析、隐马尔可夫模型等。如果是有兴趣研究的个人,那我无话可说;如果是小公司,会花费人力物力去优化分词效果。只能说闲着就疼;如果是大公司,金朵的任性也是可以理解的。
因此,到目前为止,个人对分词算法的演变、所涉及的内部算法以及几种分词工具的使用的初步理解都受到了限制。
其实在文本挖掘方面,对文本进行分词是不够的,因为我们用分词来切词,往往很多与业务无关,通常的做法是建立相应的业务词典,至于词典的建立当然也需要进行分词,进行进一步的处理,甚至可能会增加一些人工。
(3)实时热点分析
不知道是不是算法 说到实时性,自然和Storm有关系(嗯,我承认我是在做这个之后开始接触数据的)。说到实时热点,大家可能想不通,举个简单的栗子。
玩过 hadoop 的人都知道经典的栗子 WordCount。MapReduce 在 Map to Reduce 的过程中通过类似 hash 的方法自动聚合同一个 Key。因此,需要通过 MR 很容易做到数词。.
Storm 的实时 WordCount 怎么样?嗯,这也是一个可以载入实时技术史册的经典案例(嗯,其实就是一个Storm的HelloWorld)。Storm虽然没有类似MR的自动Hash功能,但也提供了可以达到类似效果的数据包流策略。它不像 MR 那样批处理,它是实时的和流式的。也就是说,可以动态获取当前变化词的词频。
实时热点分析,如果我们把热点映射成文字,能不能实时得到当前Top N的热点?这个方向有很大的研究价值。通过实时掌握用户的热点方向,动态调整业务策略,获取更大的数据价值。
不过总的来说,这个数据模型更多地依赖于实时工具Storm的功能,模型设计的东西比较少。至于是不是算法模型,就像我之前说的,看看我个人的看法,你就说吧~~
(4)很成熟的国产造型--推荐
就目前国内的数据挖掘而言,分类和推荐可能是最常见的两个方向。分类我就不多说了。比如刚才提到的贝叶斯算法,简直就是分类中的鼻祖算法。
说到推荐算法,联想规则、协同过滤、余弦相似度等词可能会立刻浮现在脑海中。这是真的,但我不是在谈论这个。其实我想说的是推荐基于两个方向:基于用户和基于内容。
我们需要注意两点。我们推荐的对象是用户,或者是与用户类似的具有动作行为的实体;而推荐的东西是内容,他没有动作行为,只是属性不同,或者砖块使用较多,业力描述是他必须有知识。
基于用户推荐,我们看重的不是内容的实体,而是用户本身的行为。我们认为用户的行为必然隐含一些信息,比如以人的兴趣为导向,那么既然你有相关的行为,那么我遵循你的行为向你推荐东西总是有意义的。
对于基于内容的推荐,我们关注的是内容,与用户的历史行为无关。我们潜意识地认为,既然你会阅读这个内容,你是否也对与这个内容相关的内容感兴趣?或许这样说有失偏颇,但大方向是正确的。
至于之前提到的关联规则,无论是协同过滤,还是余弦相似度,其实都是通过研究知识点和知识点之间的关系建立的模型。
对于基于内容的推荐,知识点是内容中的各种属性,比如电影推荐。知识点可以是各种评论数据、点播数据,比如数据、电影类型、演员、导演,以及其中的一些情感。分析等;比如博客文章,他们的知识点可能是带权重的词。至于这个词,涉及到词提取。说到字重,可能涉及到TFIDF模型和LDA模型。
对于基于用户的知识,知识点最直接的体现就是用户的行为,也就是用户与内容的关系。但是,再深入下去,你会发现其实和内容的知识点是息息相关的,但可能还不止这些。一个内容实体,而是多个内容实体的集合。
(5)文本词的加权模型
刚才提到了TFIDF和LDA模型,那么顺便说一下与文本词相关的权重模型。
说到文本挖掘,大多数人可能都熟悉 TFIDF 模型。既然涉及到了,我们就简单说一下。我们知道文本的知识点是单个单词。虽然都是词,但总有一些词更重要,哪些词不那么重要。
有些人可能会说更多的话很重要。没错,就是词频。简单地说,这种想法没有错,早期的文本挖掘模型就是这样做的。当然,效果一定是马马虎虎。因为经常出现的词往往是无用的、常用的词,对文章影响不大。
直到TFIDF模型的出现才从根本上解决了文本挖掘知识点建模的问题。如何判断一个词的重要性,或者专业的说,就是判断它对文章的贡献?TFIDF使用词频增加文章中的词权重,然后使用其在文章中的第A个文档频率来降低文章中的权重。说白了,就是降低那些公开言论的权重,把真正贡献很大的言论曝光出来。这基本上就是TFIDF的基本思想。至于如何增加词频权重,如何降低文档频率权重,这涉及到具体的模型公式。可以根据不同的需要进行调整。
文章知识点的主题建模的另一个非常重要的模型是LDA模型。是一个比较通用的文章主题模型。它利用概率原理,说白了就是贝叶斯,建立了知识点(即词)、主题和文章的三层关系结构。词与主题之间存在概率矩阵,主题与文章之间也存在概率矩阵映射关系。
好吧,LDA 不能再谈论它了。因为,我也不是很懂。对于LDA,虽然是部门内部使用的,但我没有做出具体的模型。我刚刚和同事讨论过,或者更准确地说,我问过我的同事关于它的一些原则和一些设计想法。
(6) 相似度计算
相似度计算,如文本相似度计算。这是一个非常基础的建模,用在很多地方,比如我们刚才提到的推荐。当其内部相关时,有时会涉及计算实体之间的相似度。
关于文本相似度,其实有很多方法。通常它涉及到TFIDF模型来获取文本的知识点,即加权词,然后利用这些加权词做一些相似度计算。
比如余弦相似度模型就是计算两个文本的余弦角,它的向量自然是那些带权重的词;比如各种计算距离的方法,最著名的欧式距离,它的向量还是这几个词。最长公共子串、最长公共子序列等模型很多,个人不是很清楚。
总之,方法很多,都不是很复杂,原理也很相似。至于哪个合适,要看具体的业务场景。
(7)文本学科度--信息熵
我和同事尝试过将百万博文的领域划分,将技术博文划分为不同的领域,比如大数据领域、移动互联网领域、安全领域等,其实还是分类。
一开始我们使用贝叶斯分类,效果还可以,但最后我们使用了SVM进行建模。这不是重点,重点是我们要判断技术博客文章归入某个领域的领域级别。
我们想了很多办法,尝试建立数据模型,但效果不是很理想。最后,我们回到了最本质的方法,那就是利用文本的信息熵来尝试描述度。最后的结果还是不错的。这让我又想起同事说的一句话:简单的东西不一定不好!
信息熵描述了一个实体的信息量。通俗地讲,它可以描述一个实体的信息混乱程度。在某个领域,知识点都是相似的,都是带有TFIDF权重的词。因此,是否可以认为文本的信息熵越小,主题越集中、越明显,信息混乱程度越低。另一方面,一些文本主题非常杂乱,可能收录来自多个领域的东西,其领域的程度会降低。
至少从表面上看,这个说法是可行的,实际效果也不错。
(8)用户画像
用户画像方向可能是这两年最火的方向。近年来,各大互联网公司和各大IT公司都自觉地开始从传统推荐向个性化推荐演进。有些可能更深,有些可能很浅。
商业价值的核心是用户,这自然不言而喻。那么如何结合用户进行推荐呢?那就是用户的属性。关键是用户的属性一开始就不存在。我们拥有的只是少数用户的固有属性和用户各种行为的记录。我们甚至不知道用户在做什么,所以让我们推动它!
因此,我们需要了解用户,因此有必要分析用户的用户画像。其实就是给用户打上标签,把用户打上属性标签。通过这种方式,我们知道每个用户是关于什么的。一些商业行为也是有目的的。
至于如何填写每个用户画像的属性,要看具体情况了。简单,用几个简单的模型提取一些信息来填写;复杂,使用复杂的算法,通过一些复杂的转换,标记用户。
(9)文章 热量计算
这里有很多文章,你怎么判断哪个文章更火,哪个文章更漂亮?也就是说,我进入了一个文章列表页面,你能给我提供一个热门文章的排序列表吗?
也许大多数想法都是直截了当的。获取能够反映文章流行度的属性,如点击率、评论情感分析、文章的状态。获取一个简单的加权计算模型,然后单击 Out。
从本质上讲,这是事实。一个简单的模型在实际情况中不一定很难使用。有些属性确实可以体现文章的流行度。加权计算的方法也是正确的。具体重量是要看具体情况。
但如果我这样做了,实际上会发生什么?今天来了,看到了这个热门推荐榜。我明天来了,还是看到了这个名单,后天我来了,还是这个名单。
尼玛,这是什么情况?你要我每天读多少次这个破单?!是的,这就是现实。结果是文章越热越热,越冷文章越冷,永远沉入海底,热的文章永远在前面。
如何解决这个问题呢?让我们添加时间作为参考。我们需要降低旧的文章沉没他人行为的力量,让新的文章有机会领先。也就是说,我们需要在权重上加上创建时间,并随着时间的推移衰减它的热权重,这样就不会出现冷热。至于衰减曲线,要看具体的业务。
这能解决根本问题吗?如果文章本身信息量不够,比如本身大部分都是新的文章,没有点赞,没有评论,甚至连点击都很少曝光。那么以前的模型将不起作用。
没有解决办法吗?有方法。比如我们找到了一个类似的网站,它也提供了类似最流行的文章推荐的功能,效果还不错。那么,我们可以利用它的受欢迎程度吗?我们使用计算文章的相似度的方法重新雕刻一个最热门的列表。如果网站性质相似,用户性质相似,文章的质量是的,相似度计算足够准确,相信这个热榜的效果也会不错(这个方法太琐碎了~~)。
(10)Google 的 PageRank
首先,不要误会我的意思,我从来没有真正写过这个模型,我没有条件写这个模型。
懂它懂懂它来自于和几个老同学合作搞网站(酷网,有兴趣的可以去看看)。既然从事网站,作为IT人,一些基本的SEO技巧还是要懂的。因此,我了解到如果要增加网站的权重,外部链接是必不可少的。
我跟几个老同学说,你去搞外链,抓个网站,让我们网站链接。他们问:网站 放多少链接?尽量多放网站?网站 说什么更好?这不是重点,关键是他们 问:是毛吗?
我问的那个人很无语,所以我一怒之下去研究PageRank。PageRank的具体扣分过程我就不讲了(可能以我三心二意的水平说不清楚)。有几个核心思想:一个网页被引用的次数越多,它的权重就越大;一个网页的权重越大,它所引用的网页的权重就越大;一个网页被引用的次数越多,它所引用的权重就越低。
当我们反复迭代这个过程时,我们会发现某个网页的排名基本是固定的。这就是PageRank的基本思想。当然,还有一个问题需要解决,比如如何给初始网页赋予初始权重,如何简化高计算迭代过程中的计算过程等等。这些问题在谷歌的实际操作中都得到了很好的优化。
(11) 有针对性的从网上抓取数据
其实我猜这跟算法没什么关系,不过既然有数据采集的设计流程,就勉强可以考虑了。
之所以有这个需求,是因为那段时间我在搞网站,为自己成立了一个工作室网站,想为别人打造一个轻量定制的企业,尤其是一些小企业。< @网站(是不是一团糟-_-),确实做了几个案例(我的工作室网站:我有兴趣去看看)。
从那以后,我想,我如何为自己找到客户?工作室的客户应该是那些小企业的老板,目前也一定没有企业门户。作为一个数据程序猿,也是一个挖掘机,虽然他没有中途从蓝翔毕业,没有证书就去上班,但他无论如何也挖了几座山。
现在是互联网泛滥的时代,他们总会在网上留下一些蛛丝马迹,我要抓住!我的目标很明确,我要拿到那些没有企业的企业邮箱网站,然后做自己的EDM营销(邮件营销)。
1) 我先是从智联检索页面,抓取了员工不到40人的公司名称。原来,兆联招聘的页面还是很容易解析的。它们是静态的,格式也很规则,所以很容易分析一组小公司的名称;
2) 公司名我知道了,怎么知道这家公司有独立的公司网站呢?通过分析,我发现在通过搜索引擎搜索公司名称时,如果有公司官网,肯定是在首页。而且它的页面地址也有一定的规律,即:独立官网的开头一般都是www开头,长度一般不会太长,结尾一般是index.html、index.php、index.asp和很快。
通过这些规则,我可以传递拥有官方网站的公司名称。有两个困难。一是搜索引擎的很多页面源代码都是动态加载的,所以我模拟了浏览器访问过程,抓取了页面源代码。这也是爬虫的常见做法;第二个也就是一开始,我尝试通过百度获取。结果,百度似乎有一些措施来发布结果,导致结果不尽人意。于是改变目的,用了360搜索,问题解决了(事实证明百度在搜索引擎方面还是比360强很多),效果也差不多。
3) 排除问题解决了,根本问题就在这里。如何获取公司的企业邮箱?通过对搜索引擎返回结果的分析,我发现很多小企业喜欢使用第三方。网站 提供的一些公司黄页包括公司的联系电子邮件地址;并且一些公司的招聘信息会收录公司的电子邮件地址。
通过数据分析,我终于得到了这部分数据,最后对邮箱是否有效等做了一些基本的分析,最终得到了3000多个企业邮箱,效率达到了80%以上。
问题解决了,但还有一些地方需要优化:首先是效率问题。我跑了将近12个小时才跑完3000多个邮箱。分析的地方太多,模拟浏览器。效率不高;其次,不太好判断邮箱的有效性。有些邮箱只是人为写的;还有一些网站基于图像的邮箱混合处理,类似。验证码是防抢的。我没有分析像图片一样的邮箱数据。其实这个问题是有办法解决的。我们得到了一些样本图片并进行了图片字母识别训练,以便我们可以解析它们。邮箱。
总的来说,体验还是很充实的。毕竟,我在业余时间解决了一些实际的痛点,并且对我学到的一些东西变得精通,或者说我在实施过程中学到了很多东西。
ps:在github上检索webmite就是这个项目。我将代码托管在 github 上或从我的博客输入。
其实,个人的缺点是显而易见的。首先,他没有经过系统的数据挖掘学习(没去过蓝翔,挖掘机自学),就是出身于野鹿子。因此,很多算法的原理还不够清晰。在这种情况下,您可能无法对某些业务场景提出建设性意见。而且,了解很多算法库的使用还是不够的。
二是缺乏数学技能。我们知道一些复杂的算法需要强大的数学基础。算法模型,其本质是数学模型。所以,这方面也是我的不足。
由于个人倾向于通过做大数据来挖掘,因此基于大数据模型的数据挖掘过程可能与传统的数据过程有很大不同。比如数据预处理过程,大数据挖掘的预处理很大程度上依赖于一些比较流行的分布式开源系统,比如实时处理系统Storm、消息队列Kafka、分布式数据采集系统Flume、数据离线批处理处理Hadoop等,可能会依赖Hive和一些Nosql进行数据分析和存储。相反,我对一些传统的挖掘工具比较陌生,比如SAS、SPSS、Excel等工具。但这并不是缺点。侧重点不同。总的来说,大规模数据的挖掘将是一个趋势。 查看全部
搜索引擎主题模型优化(数据挖掘算法为何物?——基于向量的相似度)
我写这个文章是因为前几天部门成员对部门涉及的一些算法进行了审查和整理。不过比较尴尬的是,既然老板不在,大家讨论讨论就变成吐槽大会了,但有一半时间是吐槽产品和业务部门~~
但这也是一件令人欣慰的事情。这也算是我们的数据部门,已经从轻型挖掘机走向了深挖阶段。

所以,借此机会,把我接触过、了解过、做过的一些勉强能称为算法的事情整理一下。事实上,就我而言,我没有算法背景。在大学里,我更多地了解了互联网,我什至不知道数据挖掘算法是什么。
其实就所谓的算法而言,我个人认为我的一个同事是对的:所谓的算法并不意味着那些复杂的数学模型就是算法。哪怕是你写的简单的计算公式,只要能解决当前存在的业务痛点,并且有自己的模型思路,就是算法,但可能不够通用,只能解决特定的业务需要。
在大规模数据的前提下,其实很多复杂的算法过程都没有这么好的结果。换句话说,我们将找到简化流程的方法。
举个简单的栗子:假设有一个大规模的数据集,以近千万篇博文为例。如果你提供一篇博文,让你查询相似度最高的前N个,我们通常的想法是什么?通常的方法是计算这篇博文与其他博文的相似度。计算相似度的方法有很多。, 最简单的方法是计算矢量角度,并根据矢量角度确定相似度。好吧,就算用最简单的计算过程,计算近千万次需要多长时间?或许,有人说我用hadoop,用分布式算力来完成这个任务,但是如果真的操作起来,你就会发现这是多么的痛苦。
再举一个简单的栗子(好吧,多吃栗子):比如SVM,这是一个很难收敛的算法。在大数据的前提下,有的人想用大数据,但想用更多的数据进行训练。模型毕竟手头的数据太多,很多人还是希望用尽可能多的数据来训练,以达到模型更加精准的目的。但是,随着训练数据量的增加,SVM等难以收敛的算法会消耗大量的计算资源。
(1)贝叶斯
贝叶斯是分类算法中最简单的算法。挖掘机算法初学者肯定会先爱上它。事实上,贝叶斯原理非常简单,基于统计学中的最大概率原理。就是这么简单,但尼玛却是这么好用,多年来一直屹立不倒。
缺乏训练过程。基本上贝叶斯就是这样的。因为是文本,所以用一组过程将词和停用词作为最基本的知识点向量进行分割,然后计算模型概率。但更有趣的是,分类过程是在Storm中完成的,相当于一个实时的分类服务。
(2)分词算法
其实说到分词算法,没什么好说的。现在网上各种开源的分词工具都做得很好,效果也差不了多少。如果要进一步改进,就会窒息。至于深入分词算法,涉及到上下文分析、隐马尔可夫模型等。如果是有兴趣研究的个人,那我无话可说;如果是小公司,会花费人力物力去优化分词效果。只能说闲着就疼;如果是大公司,金朵的任性也是可以理解的。
因此,到目前为止,个人对分词算法的演变、所涉及的内部算法以及几种分词工具的使用的初步理解都受到了限制。
其实在文本挖掘方面,对文本进行分词是不够的,因为我们用分词来切词,往往很多与业务无关,通常的做法是建立相应的业务词典,至于词典的建立当然也需要进行分词,进行进一步的处理,甚至可能会增加一些人工。
(3)实时热点分析
不知道是不是算法 说到实时性,自然和Storm有关系(嗯,我承认我是在做这个之后开始接触数据的)。说到实时热点,大家可能想不通,举个简单的栗子。
玩过 hadoop 的人都知道经典的栗子 WordCount。MapReduce 在 Map to Reduce 的过程中通过类似 hash 的方法自动聚合同一个 Key。因此,需要通过 MR 很容易做到数词。.
Storm 的实时 WordCount 怎么样?嗯,这也是一个可以载入实时技术史册的经典案例(嗯,其实就是一个Storm的HelloWorld)。Storm虽然没有类似MR的自动Hash功能,但也提供了可以达到类似效果的数据包流策略。它不像 MR 那样批处理,它是实时的和流式的。也就是说,可以动态获取当前变化词的词频。
实时热点分析,如果我们把热点映射成文字,能不能实时得到当前Top N的热点?这个方向有很大的研究价值。通过实时掌握用户的热点方向,动态调整业务策略,获取更大的数据价值。
不过总的来说,这个数据模型更多地依赖于实时工具Storm的功能,模型设计的东西比较少。至于是不是算法模型,就像我之前说的,看看我个人的看法,你就说吧~~
(4)很成熟的国产造型--推荐
就目前国内的数据挖掘而言,分类和推荐可能是最常见的两个方向。分类我就不多说了。比如刚才提到的贝叶斯算法,简直就是分类中的鼻祖算法。
说到推荐算法,联想规则、协同过滤、余弦相似度等词可能会立刻浮现在脑海中。这是真的,但我不是在谈论这个。其实我想说的是推荐基于两个方向:基于用户和基于内容。
我们需要注意两点。我们推荐的对象是用户,或者是与用户类似的具有动作行为的实体;而推荐的东西是内容,他没有动作行为,只是属性不同,或者砖块使用较多,业力描述是他必须有知识。
基于用户推荐,我们看重的不是内容的实体,而是用户本身的行为。我们认为用户的行为必然隐含一些信息,比如以人的兴趣为导向,那么既然你有相关的行为,那么我遵循你的行为向你推荐东西总是有意义的。
对于基于内容的推荐,我们关注的是内容,与用户的历史行为无关。我们潜意识地认为,既然你会阅读这个内容,你是否也对与这个内容相关的内容感兴趣?或许这样说有失偏颇,但大方向是正确的。
至于之前提到的关联规则,无论是协同过滤,还是余弦相似度,其实都是通过研究知识点和知识点之间的关系建立的模型。
对于基于内容的推荐,知识点是内容中的各种属性,比如电影推荐。知识点可以是各种评论数据、点播数据,比如数据、电影类型、演员、导演,以及其中的一些情感。分析等;比如博客文章,他们的知识点可能是带权重的词。至于这个词,涉及到词提取。说到字重,可能涉及到TFIDF模型和LDA模型。
对于基于用户的知识,知识点最直接的体现就是用户的行为,也就是用户与内容的关系。但是,再深入下去,你会发现其实和内容的知识点是息息相关的,但可能还不止这些。一个内容实体,而是多个内容实体的集合。
(5)文本词的加权模型
刚才提到了TFIDF和LDA模型,那么顺便说一下与文本词相关的权重模型。
说到文本挖掘,大多数人可能都熟悉 TFIDF 模型。既然涉及到了,我们就简单说一下。我们知道文本的知识点是单个单词。虽然都是词,但总有一些词更重要,哪些词不那么重要。
有些人可能会说更多的话很重要。没错,就是词频。简单地说,这种想法没有错,早期的文本挖掘模型就是这样做的。当然,效果一定是马马虎虎。因为经常出现的词往往是无用的、常用的词,对文章影响不大。
直到TFIDF模型的出现才从根本上解决了文本挖掘知识点建模的问题。如何判断一个词的重要性,或者专业的说,就是判断它对文章的贡献?TFIDF使用词频增加文章中的词权重,然后使用其在文章中的第A个文档频率来降低文章中的权重。说白了,就是降低那些公开言论的权重,把真正贡献很大的言论曝光出来。这基本上就是TFIDF的基本思想。至于如何增加词频权重,如何降低文档频率权重,这涉及到具体的模型公式。可以根据不同的需要进行调整。
文章知识点的主题建模的另一个非常重要的模型是LDA模型。是一个比较通用的文章主题模型。它利用概率原理,说白了就是贝叶斯,建立了知识点(即词)、主题和文章的三层关系结构。词与主题之间存在概率矩阵,主题与文章之间也存在概率矩阵映射关系。
好吧,LDA 不能再谈论它了。因为,我也不是很懂。对于LDA,虽然是部门内部使用的,但我没有做出具体的模型。我刚刚和同事讨论过,或者更准确地说,我问过我的同事关于它的一些原则和一些设计想法。
(6) 相似度计算
相似度计算,如文本相似度计算。这是一个非常基础的建模,用在很多地方,比如我们刚才提到的推荐。当其内部相关时,有时会涉及计算实体之间的相似度。
关于文本相似度,其实有很多方法。通常它涉及到TFIDF模型来获取文本的知识点,即加权词,然后利用这些加权词做一些相似度计算。
比如余弦相似度模型就是计算两个文本的余弦角,它的向量自然是那些带权重的词;比如各种计算距离的方法,最著名的欧式距离,它的向量还是这几个词。最长公共子串、最长公共子序列等模型很多,个人不是很清楚。
总之,方法很多,都不是很复杂,原理也很相似。至于哪个合适,要看具体的业务场景。
(7)文本学科度--信息熵
我和同事尝试过将百万博文的领域划分,将技术博文划分为不同的领域,比如大数据领域、移动互联网领域、安全领域等,其实还是分类。
一开始我们使用贝叶斯分类,效果还可以,但最后我们使用了SVM进行建模。这不是重点,重点是我们要判断技术博客文章归入某个领域的领域级别。
我们想了很多办法,尝试建立数据模型,但效果不是很理想。最后,我们回到了最本质的方法,那就是利用文本的信息熵来尝试描述度。最后的结果还是不错的。这让我又想起同事说的一句话:简单的东西不一定不好!
信息熵描述了一个实体的信息量。通俗地讲,它可以描述一个实体的信息混乱程度。在某个领域,知识点都是相似的,都是带有TFIDF权重的词。因此,是否可以认为文本的信息熵越小,主题越集中、越明显,信息混乱程度越低。另一方面,一些文本主题非常杂乱,可能收录来自多个领域的东西,其领域的程度会降低。
至少从表面上看,这个说法是可行的,实际效果也不错。
(8)用户画像
用户画像方向可能是这两年最火的方向。近年来,各大互联网公司和各大IT公司都自觉地开始从传统推荐向个性化推荐演进。有些可能更深,有些可能很浅。
商业价值的核心是用户,这自然不言而喻。那么如何结合用户进行推荐呢?那就是用户的属性。关键是用户的属性一开始就不存在。我们拥有的只是少数用户的固有属性和用户各种行为的记录。我们甚至不知道用户在做什么,所以让我们推动它!
因此,我们需要了解用户,因此有必要分析用户的用户画像。其实就是给用户打上标签,把用户打上属性标签。通过这种方式,我们知道每个用户是关于什么的。一些商业行为也是有目的的。
至于如何填写每个用户画像的属性,要看具体情况了。简单,用几个简单的模型提取一些信息来填写;复杂,使用复杂的算法,通过一些复杂的转换,标记用户。
(9)文章 热量计算
这里有很多文章,你怎么判断哪个文章更火,哪个文章更漂亮?也就是说,我进入了一个文章列表页面,你能给我提供一个热门文章的排序列表吗?
也许大多数想法都是直截了当的。获取能够反映文章流行度的属性,如点击率、评论情感分析、文章的状态。获取一个简单的加权计算模型,然后单击 Out。
从本质上讲,这是事实。一个简单的模型在实际情况中不一定很难使用。有些属性确实可以体现文章的流行度。加权计算的方法也是正确的。具体重量是要看具体情况。
但如果我这样做了,实际上会发生什么?今天来了,看到了这个热门推荐榜。我明天来了,还是看到了这个名单,后天我来了,还是这个名单。
尼玛,这是什么情况?你要我每天读多少次这个破单?!是的,这就是现实。结果是文章越热越热,越冷文章越冷,永远沉入海底,热的文章永远在前面。
如何解决这个问题呢?让我们添加时间作为参考。我们需要降低旧的文章沉没他人行为的力量,让新的文章有机会领先。也就是说,我们需要在权重上加上创建时间,并随着时间的推移衰减它的热权重,这样就不会出现冷热。至于衰减曲线,要看具体的业务。
这能解决根本问题吗?如果文章本身信息量不够,比如本身大部分都是新的文章,没有点赞,没有评论,甚至连点击都很少曝光。那么以前的模型将不起作用。
没有解决办法吗?有方法。比如我们找到了一个类似的网站,它也提供了类似最流行的文章推荐的功能,效果还不错。那么,我们可以利用它的受欢迎程度吗?我们使用计算文章的相似度的方法重新雕刻一个最热门的列表。如果网站性质相似,用户性质相似,文章的质量是的,相似度计算足够准确,相信这个热榜的效果也会不错(这个方法太琐碎了~~)。
(10)Google 的 PageRank
首先,不要误会我的意思,我从来没有真正写过这个模型,我没有条件写这个模型。
懂它懂懂它来自于和几个老同学合作搞网站(酷网,有兴趣的可以去看看)。既然从事网站,作为IT人,一些基本的SEO技巧还是要懂的。因此,我了解到如果要增加网站的权重,外部链接是必不可少的。
我跟几个老同学说,你去搞外链,抓个网站,让我们网站链接。他们问:网站 放多少链接?尽量多放网站?网站 说什么更好?这不是重点,关键是他们 问:是毛吗?
我问的那个人很无语,所以我一怒之下去研究PageRank。PageRank的具体扣分过程我就不讲了(可能以我三心二意的水平说不清楚)。有几个核心思想:一个网页被引用的次数越多,它的权重就越大;一个网页的权重越大,它所引用的网页的权重就越大;一个网页被引用的次数越多,它所引用的权重就越低。
当我们反复迭代这个过程时,我们会发现某个网页的排名基本是固定的。这就是PageRank的基本思想。当然,还有一个问题需要解决,比如如何给初始网页赋予初始权重,如何简化高计算迭代过程中的计算过程等等。这些问题在谷歌的实际操作中都得到了很好的优化。
(11) 有针对性的从网上抓取数据
其实我猜这跟算法没什么关系,不过既然有数据采集的设计流程,就勉强可以考虑了。
之所以有这个需求,是因为那段时间我在搞网站,为自己成立了一个工作室网站,想为别人打造一个轻量定制的企业,尤其是一些小企业。< @网站(是不是一团糟-_-),确实做了几个案例(我的工作室网站:我有兴趣去看看)。
从那以后,我想,我如何为自己找到客户?工作室的客户应该是那些小企业的老板,目前也一定没有企业门户。作为一个数据程序猿,也是一个挖掘机,虽然他没有中途从蓝翔毕业,没有证书就去上班,但他无论如何也挖了几座山。
现在是互联网泛滥的时代,他们总会在网上留下一些蛛丝马迹,我要抓住!我的目标很明确,我要拿到那些没有企业的企业邮箱网站,然后做自己的EDM营销(邮件营销)。
1) 我先是从智联检索页面,抓取了员工不到40人的公司名称。原来,兆联招聘的页面还是很容易解析的。它们是静态的,格式也很规则,所以很容易分析一组小公司的名称;
2) 公司名我知道了,怎么知道这家公司有独立的公司网站呢?通过分析,我发现在通过搜索引擎搜索公司名称时,如果有公司官网,肯定是在首页。而且它的页面地址也有一定的规律,即:独立官网的开头一般都是www开头,长度一般不会太长,结尾一般是index.html、index.php、index.asp和很快。
通过这些规则,我可以传递拥有官方网站的公司名称。有两个困难。一是搜索引擎的很多页面源代码都是动态加载的,所以我模拟了浏览器访问过程,抓取了页面源代码。这也是爬虫的常见做法;第二个也就是一开始,我尝试通过百度获取。结果,百度似乎有一些措施来发布结果,导致结果不尽人意。于是改变目的,用了360搜索,问题解决了(事实证明百度在搜索引擎方面还是比360强很多),效果也差不多。
3) 排除问题解决了,根本问题就在这里。如何获取公司的企业邮箱?通过对搜索引擎返回结果的分析,我发现很多小企业喜欢使用第三方。网站 提供的一些公司黄页包括公司的联系电子邮件地址;并且一些公司的招聘信息会收录公司的电子邮件地址。
通过数据分析,我终于得到了这部分数据,最后对邮箱是否有效等做了一些基本的分析,最终得到了3000多个企业邮箱,效率达到了80%以上。
问题解决了,但还有一些地方需要优化:首先是效率问题。我跑了将近12个小时才跑完3000多个邮箱。分析的地方太多,模拟浏览器。效率不高;其次,不太好判断邮箱的有效性。有些邮箱只是人为写的;还有一些网站基于图像的邮箱混合处理,类似。验证码是防抢的。我没有分析像图片一样的邮箱数据。其实这个问题是有办法解决的。我们得到了一些样本图片并进行了图片字母识别训练,以便我们可以解析它们。邮箱。
总的来说,体验还是很充实的。毕竟,我在业余时间解决了一些实际的痛点,并且对我学到的一些东西变得精通,或者说我在实施过程中学到了很多东西。
ps:在github上检索webmite就是这个项目。我将代码托管在 github 上或从我的博客输入。
其实,个人的缺点是显而易见的。首先,他没有经过系统的数据挖掘学习(没去过蓝翔,挖掘机自学),就是出身于野鹿子。因此,很多算法的原理还不够清晰。在这种情况下,您可能无法对某些业务场景提出建设性意见。而且,了解很多算法库的使用还是不够的。
二是缺乏数学技能。我们知道一些复杂的算法需要强大的数学基础。算法模型,其本质是数学模型。所以,这方面也是我的不足。
由于个人倾向于通过做大数据来挖掘,因此基于大数据模型的数据挖掘过程可能与传统的数据过程有很大不同。比如数据预处理过程,大数据挖掘的预处理很大程度上依赖于一些比较流行的分布式开源系统,比如实时处理系统Storm、消息队列Kafka、分布式数据采集系统Flume、数据离线批处理处理Hadoop等,可能会依赖Hive和一些Nosql进行数据分析和存储。相反,我对一些传统的挖掘工具比较陌生,比如SAS、SPSS、Excel等工具。但这并不是缺点。侧重点不同。总的来说,大规模数据的挖掘将是一个趋势。
搜索引擎主题模型优化(海量文档数据的来源,查找技术又是如何的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-17 16:27
内容:
搜索引擎的使用我们并不陌生。对于正常的搜索过程,比如用户输入查询“搜索引擎技术”,搜索引擎需要将存储在磁盘上的两个词的反向排序索引读入内存,然后进行解压,然后找到打乱根据两个词对应的倒排排序列表的基数,找到所有收录两个词的文档集合,根据排序算法对每个文档的相关度进行打分,根据相关度输入最相关的搜索结果。
但是这一系列步骤中海量文档数据的来源、存储和搜索技术呢?以下是我最近阅读的《这就是搜索引擎:核心技术详解》一书的总结:
一、网络爬虫
首先,搜索引擎的文档数据从何而来?
站长的一个常识是,当他们部署一个网站时,他们会将自己的页面提交给谷歌、百度、必应等搜索引擎提交自己的页面,以方便他们的爬虫。快速抓取提交网站的页面。
什么,你不知道爬虫?不懂科普
爬虫的通用框架
目前的爬虫大多是分布式爬虫,爬取策略包括:
但是,在网站的垂直领域,比如携程的机票数据、京东产品等页面,很难有显示链接指向。您仍然需要输入 关键词 来搜索它。在这种情况下,按照爬虫的规则很难爬到这种页面,所以就出现了暗网爬行。简单来说就是爬虫在搜索页面提交查询,然后在目标网站提交查询后搜索页面的组合,基于暗网爬取,百度提出了“Project Aladdin”,例如Google的Onebox , 例子
但是现在想想,网上最方便的就是抄袭抄袭。统计显示,近似重复页面的数量高达网页总数的29%,而相同的页面约占所有页面的%22。,即相当比例的网页内容相同或大致相似。例如,新闻话题的内容几乎相同,但两个页面的网页布局却大不相同。为了解决这个问题,需要对网页进行去重,尽量不向用户呈现重复的搜索结果,体现原创的本质,提供用户搜索体验。
主要的网页去重算法有:Shingling、I-Match、Simhash、SpotSig等。
二、搜索引擎索引
对于大量的网页文档内容,需要使用索引来快速找到被查询的网页。
为了应对大量的文档和各种查询,搜索引擎经常使用倒排索引作为词到文档的映射。
最简单的倒排索引
倒排索引主要包括单词词典和相应的倒排列表,及其相关的技术选项:
三、搜索模型
拥有大量数据文档并进行相应排序后,如何找到搜索到的相关文档?
判断网页内容是否与用户查询相关,取决于搜索引擎采用的检索模型:
布尔模型:使用简单的“和/或/非”逻辑关系来判断文档是否与查询相关。基于此模型的搜索结果过于粗糙,无法满足用户需求。
向量空间模型:将查询词和文档中的关键词转换为特征向量,然后使用余弦公式
计算文档和查询的相关性并对输出结果进行排序。关于特征向量权重计算,也称为TF*IDF框架。词频TF表示一个词在文档中出现的次数,IDF表示查询词在所有文档中出现的频率的倒数:
特征权重值是他们的产品,具体中文解释是这样描述的:
概率检索模型:对于某个文档D,如果属于相关文档子集的概率大于不属于不相关子集的概率,则该文档与用户的查询相关,即
具体算法是使用MB25模型计算:
这个模型已经是一个非常成功的概率模型方法,然后人们对它还有其他的改进。
四、链接分析算法
搜索引擎的最终搜索结果不仅基于文档相关性,还基于网页的重要性。
搜索引擎在找到能够满足用户请求的网页时,主要考虑两个因素:一方面,用户发送的查询与网页内容的相似度得分;另一方面,通过链接分析方法计算的得分,即网页重要性,搜索引擎两者的融合,联合拟合相似度得分函数,对搜索进行排序。
基本链接分析算法图
搜索引擎经常使用链接分析算法来对网页的重要性进行排名。更基本和众所周知的算法是 PageRank 和 Hits。前者主要通过随机游走模型计算,后者基于子集传播模型。当然,为了弥补其算法的不足,也做了很多类型的改进,比如“话题敏感PageRank”算法来改善原Pagerank的话题偏差,Hilltop结合Hits和pagerank。
但是,在商业利益的驱使下,很多网站站长会分析搜索引擎排名,并采取一些措施提升网站排名,但也存在严重影响搜索引擎用户的恶意优化行为,因此有些算法是还提出了应对各种恶意作弊:TrustRank、BadRank、SpamRank等,并且这些反作弊算法的结果权重占搜索的很大比例。
五:存储与计算
搜索引擎需要存储和计算数以亿计的数据,他们觉得其中一些是非结构化或半结构化数据。如何构建存储平台和计算平台,简化存储和管理成为一个重要的问题。谷歌的一位代表提出了他的三驾马车:/BingTable/MapReduce。谷歌曾就三驾马车相关技术发表详细论文,催生了云计算新宠“Hadoop”。
hadoop和三驾马车的关系
GFS:谷歌分布式文件系统,由大量PC组成,机器故障时正常,支持横向增量扩展,可存储数百亿海量网络信息。(HDFS 被认为是 GFS 的开源实现)
BigTable:是一种基于GFS的海量结构化或半结构化存储的存储模型。它的存储模型介于关系数据和 NoSql 存储系统之间。它特别适用于一次写入和多次读取。减少修改的业务需求。(HBase 被认为是 BigTable 的开源实现)
Map/Reduce:是一种分布式云计算模型,本质上是通过分而治之的思想实现的。它通常是一系列多个 MapRduce 子任务。前面的 Map 阶段经常作为后面的 Reduce 阶段的输入来执行一系列复杂的任务。任务的计算。(使用这个模型最著名的开源代表是Hadoop)
Pregel:基于BSP的同步计算模型,用于解决大规模分布式图计算问题,弥补Map/Reduce在图计算方面的不足。陈伟超步计算一次迭代,系统从一个超到另一个 否,达到算法的终止条件。谷歌早期的PageRank算法主要使用Pregel平台进行计算。(Giraph 被认为是 Pregel 的开源实现。后来卡内基梅隆大学发明了另一个分布式图处理模型:GraphLab)
随着开源Hadoop的出现,驾驭谷歌的三驾马车变得更加容易。目前,Hadoop也已经成功投入业务,得到了Facebook、阿里、腾讯等巨头的支持。
六、搜索引擎缓存机制
现在大家应该都知道,搜索引擎已经成为各大网站的主入口,点击“百度”,往往上面复杂的计算搜索结果会很快的呈现在浏览器上,这么快主要是因为缓存。
搜索引擎的缓存设计主要基于缓存的搜索结果和缓存的搜索词的倒排索引。前者响应速度快,但命中率不高,后者获取缓存后还要重新计算分数。响应速度比较慢,但是命中率比较高。所以现在常用的缓存将两者结合起来,先用结果缓存,再用词表缓存,而且缓存也分为倒排词组合计算得分缓存和独立倒排两级缓存,聚合用户反应速度和命中率是两个优势。
写在后面:
以上总结主要是针对搜索引擎的一般流程。这只是个人阅读本书后的意见。如今,技术的发展比我们阅读的要快得多。所以文中如有不妥之处,请大家指点,共同学习。共同进步。
文章中的插图主要来源于书中。 查看全部
搜索引擎主题模型优化(海量文档数据的来源,查找技术又是如何的呢?)
内容:
搜索引擎的使用我们并不陌生。对于正常的搜索过程,比如用户输入查询“搜索引擎技术”,搜索引擎需要将存储在磁盘上的两个词的反向排序索引读入内存,然后进行解压,然后找到打乱根据两个词对应的倒排排序列表的基数,找到所有收录两个词的文档集合,根据排序算法对每个文档的相关度进行打分,根据相关度输入最相关的搜索结果。
但是这一系列步骤中海量文档数据的来源、存储和搜索技术呢?以下是我最近阅读的《这就是搜索引擎:核心技术详解》一书的总结:
一、网络爬虫
首先,搜索引擎的文档数据从何而来?
站长的一个常识是,当他们部署一个网站时,他们会将自己的页面提交给谷歌、百度、必应等搜索引擎提交自己的页面,以方便他们的爬虫。快速抓取提交网站的页面。
什么,你不知道爬虫?不懂科普
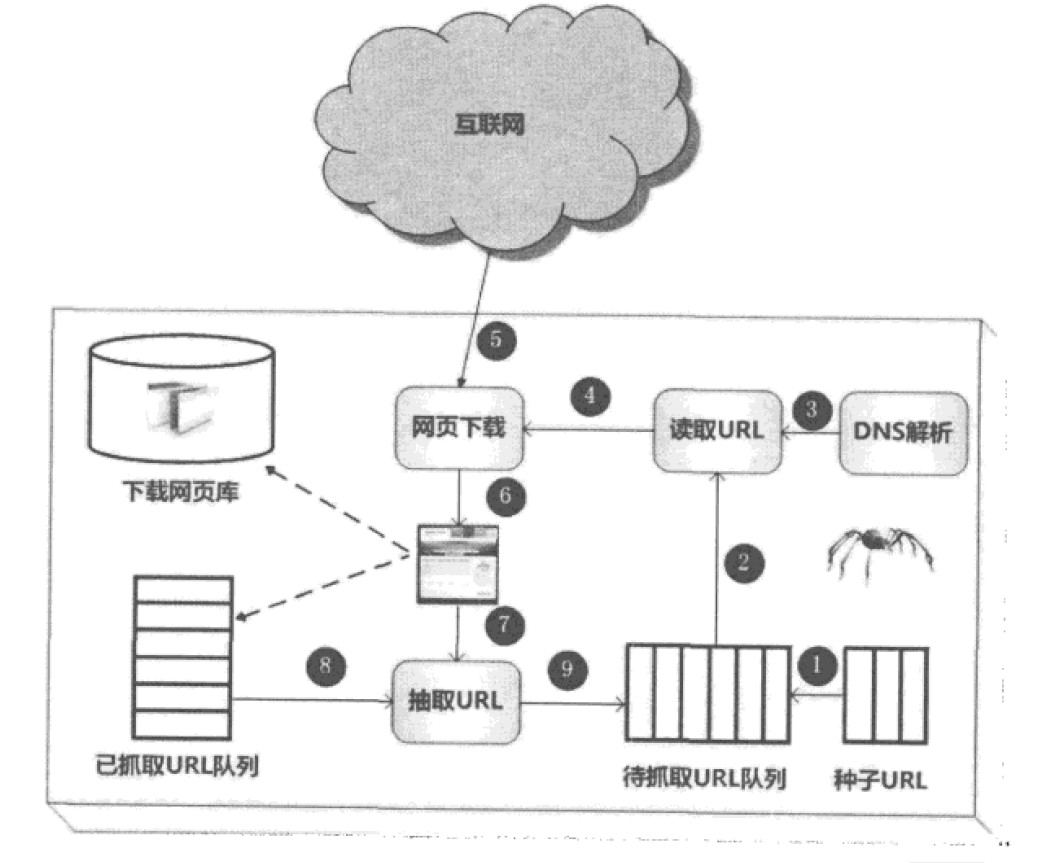
爬虫的通用框架
目前的爬虫大多是分布式爬虫,爬取策略包括:
但是,在网站的垂直领域,比如携程的机票数据、京东产品等页面,很难有显示链接指向。您仍然需要输入 关键词 来搜索它。在这种情况下,按照爬虫的规则很难爬到这种页面,所以就出现了暗网爬行。简单来说就是爬虫在搜索页面提交查询,然后在目标网站提交查询后搜索页面的组合,基于暗网爬取,百度提出了“Project Aladdin”,例如Google的Onebox , 例子
但是现在想想,网上最方便的就是抄袭抄袭。统计显示,近似重复页面的数量高达网页总数的29%,而相同的页面约占所有页面的%22。,即相当比例的网页内容相同或大致相似。例如,新闻话题的内容几乎相同,但两个页面的网页布局却大不相同。为了解决这个问题,需要对网页进行去重,尽量不向用户呈现重复的搜索结果,体现原创的本质,提供用户搜索体验。
主要的网页去重算法有:Shingling、I-Match、Simhash、SpotSig等。
二、搜索引擎索引
对于大量的网页文档内容,需要使用索引来快速找到被查询的网页。
为了应对大量的文档和各种查询,搜索引擎经常使用倒排索引作为词到文档的映射。


最简单的倒排索引
倒排索引主要包括单词词典和相应的倒排列表,及其相关的技术选项:
三、搜索模型
拥有大量数据文档并进行相应排序后,如何找到搜索到的相关文档?
判断网页内容是否与用户查询相关,取决于搜索引擎采用的检索模型:
布尔模型:使用简单的“和/或/非”逻辑关系来判断文档是否与查询相关。基于此模型的搜索结果过于粗糙,无法满足用户需求。
向量空间模型:将查询词和文档中的关键词转换为特征向量,然后使用余弦公式
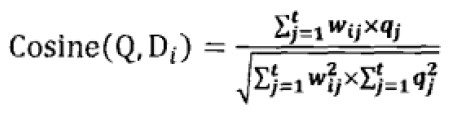
计算文档和查询的相关性并对输出结果进行排序。关于特征向量权重计算,也称为TF*IDF框架。词频TF表示一个词在文档中出现的次数,IDF表示查询词在所有文档中出现的频率的倒数:
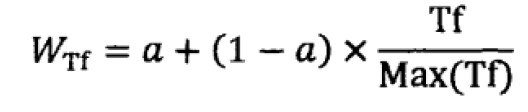
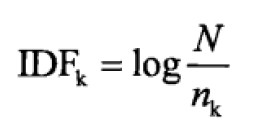
特征权重值是他们的产品,具体中文解释是这样描述的:
概率检索模型:对于某个文档D,如果属于相关文档子集的概率大于不属于不相关子集的概率,则该文档与用户的查询相关,即
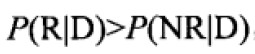
具体算法是使用MB25模型计算:
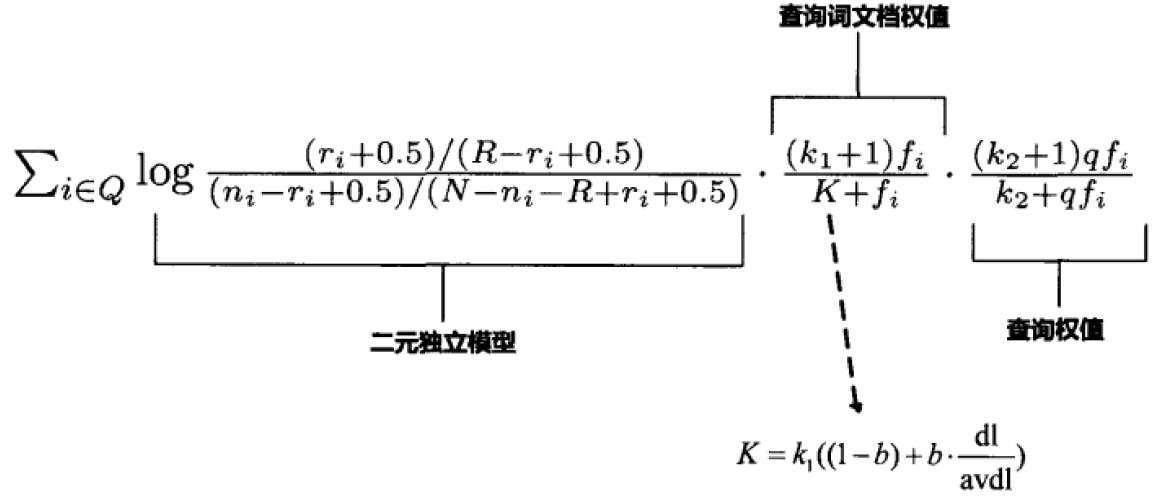
这个模型已经是一个非常成功的概率模型方法,然后人们对它还有其他的改进。
四、链接分析算法
搜索引擎的最终搜索结果不仅基于文档相关性,还基于网页的重要性。
搜索引擎在找到能够满足用户请求的网页时,主要考虑两个因素:一方面,用户发送的查询与网页内容的相似度得分;另一方面,通过链接分析方法计算的得分,即网页重要性,搜索引擎两者的融合,联合拟合相似度得分函数,对搜索进行排序。

基本链接分析算法图
搜索引擎经常使用链接分析算法来对网页的重要性进行排名。更基本和众所周知的算法是 PageRank 和 Hits。前者主要通过随机游走模型计算,后者基于子集传播模型。当然,为了弥补其算法的不足,也做了很多类型的改进,比如“话题敏感PageRank”算法来改善原Pagerank的话题偏差,Hilltop结合Hits和pagerank。
但是,在商业利益的驱使下,很多网站站长会分析搜索引擎排名,并采取一些措施提升网站排名,但也存在严重影响搜索引擎用户的恶意优化行为,因此有些算法是还提出了应对各种恶意作弊:TrustRank、BadRank、SpamRank等,并且这些反作弊算法的结果权重占搜索的很大比例。
五:存储与计算
搜索引擎需要存储和计算数以亿计的数据,他们觉得其中一些是非结构化或半结构化数据。如何构建存储平台和计算平台,简化存储和管理成为一个重要的问题。谷歌的一位代表提出了他的三驾马车:/BingTable/MapReduce。谷歌曾就三驾马车相关技术发表详细论文,催生了云计算新宠“Hadoop”。
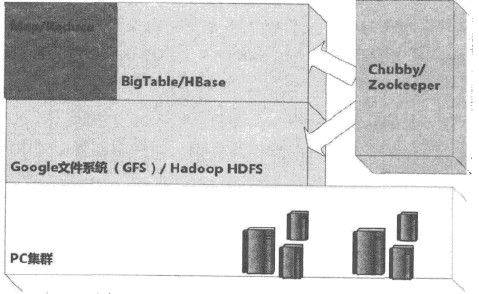
hadoop和三驾马车的关系
GFS:谷歌分布式文件系统,由大量PC组成,机器故障时正常,支持横向增量扩展,可存储数百亿海量网络信息。(HDFS 被认为是 GFS 的开源实现)
BigTable:是一种基于GFS的海量结构化或半结构化存储的存储模型。它的存储模型介于关系数据和 NoSql 存储系统之间。它特别适用于一次写入和多次读取。减少修改的业务需求。(HBase 被认为是 BigTable 的开源实现)
Map/Reduce:是一种分布式云计算模型,本质上是通过分而治之的思想实现的。它通常是一系列多个 MapRduce 子任务。前面的 Map 阶段经常作为后面的 Reduce 阶段的输入来执行一系列复杂的任务。任务的计算。(使用这个模型最著名的开源代表是Hadoop)
Pregel:基于BSP的同步计算模型,用于解决大规模分布式图计算问题,弥补Map/Reduce在图计算方面的不足。陈伟超步计算一次迭代,系统从一个超到另一个 否,达到算法的终止条件。谷歌早期的PageRank算法主要使用Pregel平台进行计算。(Giraph 被认为是 Pregel 的开源实现。后来卡内基梅隆大学发明了另一个分布式图处理模型:GraphLab)
随着开源Hadoop的出现,驾驭谷歌的三驾马车变得更加容易。目前,Hadoop也已经成功投入业务,得到了Facebook、阿里、腾讯等巨头的支持。
六、搜索引擎缓存机制
现在大家应该都知道,搜索引擎已经成为各大网站的主入口,点击“百度”,往往上面复杂的计算搜索结果会很快的呈现在浏览器上,这么快主要是因为缓存。
搜索引擎的缓存设计主要基于缓存的搜索结果和缓存的搜索词的倒排索引。前者响应速度快,但命中率不高,后者获取缓存后还要重新计算分数。响应速度比较慢,但是命中率比较高。所以现在常用的缓存将两者结合起来,先用结果缓存,再用词表缓存,而且缓存也分为倒排词组合计算得分缓存和独立倒排两级缓存,聚合用户反应速度和命中率是两个优势。
写在后面:
以上总结主要是针对搜索引擎的一般流程。这只是个人阅读本书后的意见。如今,技术的发展比我们阅读的要快得多。所以文中如有不妥之处,请大家指点,共同学习。共同进步。
文章中的插图主要来源于书中。
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心主题模型?本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-17 16:25
网站优化主题模型SEO最新的SEO概念进入了全新的“有质感的内容”算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。下面将结合当今最新的SEO概念来指导你如何优化主题内容。SEO网站的主题模型是什么?关于SEO页面的内容,我们通常可以听到和看到很多旧的方法,这比使用各种H标签来整合关键词 TDK关键词 是否设置为准确匹配但有经验SEO 人员和 网站 大师们很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这是本文的核心。那么什么是主题模型呢?主题模型是页面内容布局的模型,为了让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:1)词系统关联<
他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)。第一步:词关联 无论你用什么方法来优化页面的内容,都必须围绕如何关联词和词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。当我们使用句子和单词时,搜索引擎将根据其他资源中的数据关联您的内容,以生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己的研究关键词的方法,但需要达到以下目标:1)找到同义词和异体词2)找到与内容相关的二类词主题3)找二类词相关的三类词,Thing) 举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据上述目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是关键词的密度!第2步:词系统布局毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要,非常重要。蜘蛛什么时候来到页面发现这么多关键词,他们需要区分哪些是重要的,哪些 关键词 与短语相关。所以词系统布局是要明确核心词和相关性,下面是3个实用的优化方法: 1)Region: 关键词 必须出现在Title、标题和主要段落2) 频率: 重要的短语 or 它是它们的变体可以出现超过平均水平。3) 距离:相关词或词组要尽量靠近或者使用HTML元素(如ALT)的方式(1)是大部分SEO人的必修项目,还是要放核心主题标题和大标题中的词尽量出现在正文的顶部。方法(2)这里不仅仅是关键词的频率(密度),但更复杂的是,第一层的链接频率是核心词的同义词和变体。在同等条件下,不太流行的同义词和变体会得到更好的结果。
现在你要做的就是将那些二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主题(排名词),正如我之前所说的搜索引擎可以使用大数据来识别单词关联。举个简单的例子:主词是【网红】,第一段会重点关注这个词文章。第二段将用几只手完成。文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是一个词系相关内容,并通过步骤2来布局词系。第三步:补充内容。或许很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,现在的外链就像一颗不合时宜的炸弹,说不定会被链接炸死。
因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?如果你的网页只是单纯的关键词,缺少文字链接、参考资料和相关资源推荐,那么你的页面就很死板,死路一条,不会给你的页面加分。看右边的页面。网站内有链接(黄色部分),导出链接和内容中的[补充内容]。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是加强页面主题的深化,通过不同网站的内容来强化信息。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。1)在页面底部添加相关资源的链接(推荐站内链接)2)在文中使用引号,如行业内知名人士的话或图标,如文中3) 使用导出链接到网站中的第三方(你不会被K放100。第4步:内容实体这是一个非常难的概念,称为英文实体。强大的搜索引擎会抓取页面 来自动解释内容实体,或者将其理解为内容属性。例如,当内容提到“包老师”时,它的实体是[人]吗?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。
(木木补充说,这涉及到微数据。HTML5 微数据规范是一种标记,用于描述特定类型的信息,例如评论、人物信息或事件。每种类型的信息描述特定类型的项目,例如人物、事件或评论见《结构化微数据丰富网页摘要》)一般搜索引擎都会给站长提供自己的结构化数据(比如“百度新数据标注工具,相当于谷歌数据标注”),什么是结构化数据?就是使用搜索引擎设置的HTML Markup来定义内容,或者统称为使用Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。这个更高级 只是一点点理解。您可以要求您的架构师添加 网站 结构数据。当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。搜索引擎会自动解释内容实体,通过“人、地、物”来寻找关联,所以建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比作“每个实体”。关联。例如,
看看有没有和之前的优化概念不一样。搜索引擎不看页面上是否有这个词以及有多少链接指向它,而是看内容实体是否相关。综上所述,大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技巧整合到你的内容优化中:1)一个高度概括的标题来描述页面的主题2)添加一个开头(简要)来描述页面的内容3)@ > 内容分为几段,每段都有自己的主题。4)尽量扩大主题视角,补充相关答案。5) 查看全部
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心主题模型?本文)
网站优化主题模型SEO最新的SEO概念进入了全新的“有质感的内容”算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。下面将结合当今最新的SEO概念来指导你如何优化主题内容。SEO网站的主题模型是什么?关于SEO页面的内容,我们通常可以听到和看到很多旧的方法,这比使用各种H标签来整合关键词 TDK关键词 是否设置为准确匹配但有经验SEO 人员和 网站 大师们很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这是本文的核心。那么什么是主题模型呢?主题模型是页面内容布局的模型,为了让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:1)词系统关联<
他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)。第一步:词关联 无论你用什么方法来优化页面的内容,都必须围绕如何关联词和词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。当我们使用句子和单词时,搜索引擎将根据其他资源中的数据关联您的内容,以生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己的研究关键词的方法,但需要达到以下目标:1)找到同义词和异体词2)找到与内容相关的二类词主题3)找二类词相关的三类词,Thing) 举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据上述目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是关键词的密度!第2步:词系统布局毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要,非常重要。蜘蛛什么时候来到页面发现这么多关键词,他们需要区分哪些是重要的,哪些 关键词 与短语相关。所以词系统布局是要明确核心词和相关性,下面是3个实用的优化方法: 1)Region: 关键词 必须出现在Title、标题和主要段落2) 频率: 重要的短语 or 它是它们的变体可以出现超过平均水平。3) 距离:相关词或词组要尽量靠近或者使用HTML元素(如ALT)的方式(1)是大部分SEO人的必修项目,还是要放核心主题标题和大标题中的词尽量出现在正文的顶部。方法(2)这里不仅仅是关键词的频率(密度),但更复杂的是,第一层的链接频率是核心词的同义词和变体。在同等条件下,不太流行的同义词和变体会得到更好的结果。
现在你要做的就是将那些二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主题(排名词),正如我之前所说的搜索引擎可以使用大数据来识别单词关联。举个简单的例子:主词是【网红】,第一段会重点关注这个词文章。第二段将用几只手完成。文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是一个词系相关内容,并通过步骤2来布局词系。第三步:补充内容。或许很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,现在的外链就像一颗不合时宜的炸弹,说不定会被链接炸死。
因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?如果你的网页只是单纯的关键词,缺少文字链接、参考资料和相关资源推荐,那么你的页面就很死板,死路一条,不会给你的页面加分。看右边的页面。网站内有链接(黄色部分),导出链接和内容中的[补充内容]。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是加强页面主题的深化,通过不同网站的内容来强化信息。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。1)在页面底部添加相关资源的链接(推荐站内链接)2)在文中使用引号,如行业内知名人士的话或图标,如文中3) 使用导出链接到网站中的第三方(你不会被K放100。第4步:内容实体这是一个非常难的概念,称为英文实体。强大的搜索引擎会抓取页面 来自动解释内容实体,或者将其理解为内容属性。例如,当内容提到“包老师”时,它的实体是[人]吗?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。
(木木补充说,这涉及到微数据。HTML5 微数据规范是一种标记,用于描述特定类型的信息,例如评论、人物信息或事件。每种类型的信息描述特定类型的项目,例如人物、事件或评论见《结构化微数据丰富网页摘要》)一般搜索引擎都会给站长提供自己的结构化数据(比如“百度新数据标注工具,相当于谷歌数据标注”),什么是结构化数据?就是使用搜索引擎设置的HTML Markup来定义内容,或者统称为使用Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。这个更高级 只是一点点理解。您可以要求您的架构师添加 网站 结构数据。当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。搜索引擎会自动解释内容实体,通过“人、地、物”来寻找关联,所以建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比作“每个实体”。关联。例如,
看看有没有和之前的优化概念不一样。搜索引擎不看页面上是否有这个词以及有多少链接指向它,而是看内容实体是否相关。综上所述,大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技巧整合到你的内容优化中:1)一个高度概括的标题来描述页面的主题2)添加一个开头(简要)来描述页面的内容3)@ > 内容分为几段,每段都有自己的主题。4)尽量扩大主题视角,补充相关答案。5)
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心词和关联性页面布局?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-17 16:24
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二-与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到与主词相关的三类词第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
· TDK关键词是否设置为精准匹配
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。因此,词系统布局是区分核心词及其相关性。以下是3种实用的优化方法:
1)区域:关键词 必须出现在标题、标题和主要段落中
· 是否有足够的导入链接(外部链接)?
2)找到与主词内容相关的二类词
第二步:词法系统布局
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
· 文章 内容字数够吗?
2)词系统布局
· 内容够不够原创
1)查找同义词和变体
主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
3)补充内容
· 查看关键词的密度是否符合标准
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
4)内容属性
1. 什么是SEO网站的主题模型
4) 结论是内容属性与主题(人、地、事)有关
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
第 1 步:词法关联
3)找到与第二类词相关的三类词
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 使用各种H标签整合关键词
1) 词法关联
2) 频率:重要短语或其变体的出现频率可能高于平均水平
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度! 查看全部
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心词和关联性页面布局?)
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二-与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到与主词相关的三类词第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
· TDK关键词是否设置为精准匹配
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。因此,词系统布局是区分核心词及其相关性。以下是3种实用的优化方法:
1)区域:关键词 必须出现在标题、标题和主要段落中
· 是否有足够的导入链接(外部链接)?
2)找到与主词内容相关的二类词
第二步:词法系统布局
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
· 文章 内容字数够吗?
2)词系统布局
· 内容够不够原创
1)查找同义词和变体
主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
3)补充内容
· 查看关键词的密度是否符合标准
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
4)内容属性
1. 什么是SEO网站的主题模型
4) 结论是内容属性与主题(人、地、事)有关
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
第 1 步:词法关联
3)找到与第二类词相关的三类词
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 使用各种H标签整合关键词
1) 词法关联
2) 频率:重要短语或其变体的出现频率可能高于平均水平
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度!
搜索引擎主题模型优化(研究以满足用户的效用信息需求为目的构建搜索引擎优化模型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-17 16:20
信息组织 [摘要] 本研究旨在满足用户的需求,提供有效的信息。构建了搜索引擎优化模型,该模型由三个子模型组成,BSga'S行为分析模型、网站知识和信息组织模型和jtsown搜索引擎优化模型。基于三部分关系的分析。作者对搜索引擎优化模型进行了评估,并进一步提出该模型可以有效解决不断增长的信息与用户对有效信息的需求之间的矛盾。【关键词】搜索引擎优化用户网站信息组织简介 目前,搜索引擎研究主要集中在三个方面:搜索引擎。我{{用户行为研究,网站
但往往仅限于搜索引擎技术发展的研究、搜索引擎与用户的信息交互研究、搜索引擎与网站知识信息组织的研究等。引擎用户和网站是隔离的,三者不收录在一个统一的信息系统中。作为搜索引擎,作为信息系统,三者缺一不可。有鉴于此,本文在传统搜索引擎研究的基础上,将搜索引擎的发展、搜索引擎用户和信息组织整合到整体的搜索引擎优化模型中,避免信息孤岛的产生,使信息在搜索引擎之间畅通无阻。三。相互促进,使信息获取的效益最大化。1 搜索引擎优化模型的构成作者在文献1中提出,将用户、知识生产者和知识组织者视为搜索引擎优化的外部环境,三者与搜索引擎共同构成一个信息系统。基于。在进一步的研究中,作者构建了一个搜索引擎优化模型,该模型由用户行为分析模块、网站知识信息组织模块和搜索引擎模块组成。用户行为分析模块和网站知识组织模块构成了搜索引擎优化模型的外部环境,两者都随着搜索引擎自身的发展形成了一条完整的信息链。搜索引擎优化模型的最终目标是满足信息用户对有效信息的需求。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。
例如,用户在使用搜索引擎检索信息时遇到的各种障碍,可以通过数据分析工具传递给搜索引擎。针对用户的困难,搜索引擎可以采用各种技术来提高自身的能力。1.2 网站知识信息组织优化模块网站结构、网站知识信息内容和组织方法、网站功能和网站服务构成整体网站@ >知识信息系统。网站信息组织的优化包括这四个层次的优化策略,分别是网站结构、网站信息及其组织方法、网站函数和网站@ > 服务优化,实现了整个网站信息系统的优化。重点是优化网站知识信息组织。通过优化网站的信息组织,搜索引擎可以更好的检索网站知识信息,从而促进网站与搜索引擎之间的信息交互,让网络用户及时通过搜索引擎学习高质量的信息满足网络用户的公用事业信息需求。1.3 搜索引擎自身发展的优化模型。搜索引擎自身发展的发展包括搜索引擎技术开发、搜索引擎信息内容和搜索引擎服务的优化。搜索引擎技术的发展和搜索引擎内容的发展是搜索引擎优化服务的基础,而搜索引擎技术的发展也是搜索引擎检索更完整、更多网络信息的基础。同时,搜索引擎服务水平和质量的提升,将俘获更多的信息用户,进一步推动搜索引擎技术的发展和完善。2 搜索引擎优化模型的工作机制 搜索引擎优化模型的目的是优化模型中的各个子系统,最大程度满足用户的效用信息需求,同时模型的工作机制起到了改善信息服务的重要作用。
其中,用户信息行为分析系统是基础,网站知识组织系统是保障,搜索引擎本身的优化和发展是根本。三者将统一在搜索引擎优化模型工作机制体系中,相互促进,共同发挥作用。2.1 用户信息行为分析机制 用户信息行为分析机制是搜索引擎优化模型工作机制的基础。网站或搜索引擎使用数据挖掘工具获取私人用户使用网络信息资源的信息,并应用数据处理器对挖掘工具获取的数据信息进行分析,以确定用户的信息行为。同时,将最终得到的数据反馈给网站或搜索引擎,并在此基础上优化网站和搜索引擎。2.2 网站知识组织优化机制网站是网络信息的来源。搜索引擎检索网站 信息资源。索引建立后,会听到用户的检索行为,并输出检索结果,网站信息的终端就是用户,用户的信息需求影响网站@的发展和完善> 在很大程度上。网站知识组织优化机制从网站的结构、内容和组织方式、网站服务等方面进行优化和发展,将构建网站结构合理,丰富的知识,组织科学的、服务充足的信息库。2.3 搜索引擎自身的优化发展机制 搜索引擎直接面向用户,搜索引擎的内容和服务将直接影响用户的进一步使用。搜索引擎自身的开发和优化机制将优化搜索引擎的技术、数据库内容和组织以及搜索引擎服务。
搜索引擎技术的优化是保证搜索引擎进步的关键。数据库的内容和组织是吸引用户的决定性因素。搜索引擎服务是捕获和留住用户的保证。3 搜索引擎优化模型的特点 3.1 独立性 搜索引擎系统即服务主要是为了方便网络信息用户查询所需信息,稳定搜索引擎用户群,增强搜索引擎的实用性和便捷性。搜索引擎优化模型是一个相对独立完整的系统,由用户信息分析优化模块、网站知识组织优化模块、搜索引擎开发优化模块组成。用户信息分析系统首先对采集用户的信息行为数据进行分析,并将用户信息行为数据反馈给网站和搜索引擎。网站根据用户信息分析优化模块返回的数据,采取针对性措施,持续优化网站的结构、架构和服务。同时,搜索引擎还基于用户行为分析模块获取的数据,从技术层面、内容和组织层面、搜索引擎服务三个方面进行优化。3.2 秩序 系统的秩序是指系统的各种要素与要素有机结合而形成的系统结构。搜索引擎优化系统由用户信息分析系统、网站知识组织系统和搜索引擎自身优化系统组成,三者是一个有序的信息系统。在各种内部要素的非线性作用下,系统可以向有序移动并不断增强其有序性。这个顺序是由它的结构支持的。它采用分层的方式进入新的资源空间。
在搜索引擎优化模型中,用户信息行为分析系统将用户信息传输到网站知识组织系统和搜索引擎优化系统。网站知识组织系统基于用户信息数据优化分析知识内容及其组织方式。同时,搜索引擎服务商根据用户信息分析系统返回的数据,对搜索引擎的方方面面进行优化。搜索引擎自身的开发和优化,可以更好地检索和索引网站知识信息,进一步满足信息用户的信息需求。3.3 在服务网络环境中,个体信息使用者的知识结构不同,所以对网络资源的认知也不同,导致网络资源使用上的差异。不同用户对网络资源需求的特点是:最主要的信息需求集中在与工作学习相关的专业和业务信息;信息语言以国语为主,英文信息次之;服务类型以WWW信息搜索为主。此外,用户需求还表现为:信息数据库网络化;可随时获取所需信息;方便和同时回答各种查询;用户最终得到在搜索引擎优化中被识别、选择和处理的有价值的信息在模型中,网站知识组织和服务,搜索引擎服务都是在用户信息行为分析的基础上发展起来的,所以搜索引擎优化服务更具针对性,尤其是个性化、特色化的搜索引擎公司的发展,更能满足信息用户的信息需求。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。
数据挖掘技术和网络信息检索技术有很多相似之处,但也有本质的区别。数据挖掘技术继续利用机器人、全文检索等互联网信息检索的优异成果,同时综合运用人工智能、模式识别、神经网络等领域的各种技术。数据挖掘技术与网络信息检索最重要的区别在于,它可以根据目标特征信息在网络或数据库中进行有目的的信息检索,从而获得用户所需的信息。3.4 时效性 搜索引擎优化模型的时效性体现在三个方面,即用户信息行为分析数据的时效性,网站知识及其组织的时效性,以及搜索引擎自身发展的时效性。用户信息行为的时效性具有牵动全身的影响。网站知识组织和搜索引擎优化基于用户信息行为分析。用户使用搜索引擎的行为分为已经发生的搜索行为、正在发生的搜索行为和潜在的搜索行为。已经发生的搜索行为对于搜索引擎总结经验教训,进一步优化搜索引擎具有建设性意义。行为和停滞搜索行为对搜索引擎的优化起着指导作用。3. 5 封闭传统搜索引擎模式,全面信息搜索。它的优点是有利于积累搜索信息数据和行为数据,有利于满足一般简单的信息需求。本文讨论的搜索引擎优化模型是基于用户信息需求、特定信息用户范围、特定系统的信息服务。内在的深入需求;提供更准确的知识和信息的有利条件。特定范围的信息用户和特定系统。内在的深入需求;提供更准确的知识和信息的有利条件。特定范围的信息用户和特定系统。内在的深入需求;提供更准确的知识和信息的有利条件。
从开放搜索系统到封闭搜索系统的转变,也是从综合搜索到专业垂直搜索的转变,从定量搜索到定性搜索的转变,从搜索引擎服务商到公众参与的单边控制。控制搜索过程的过渡。与传统的搜索引擎模型相比,本文讨论的搜索引擎优化模型并不意味着封闭和保守,而只是从搜索策略、搜索目的和搜索范围等角度的概念上的限制。4 搜索引擎优化模型的评价 4.1 搜索引擎优化模型评价角度的选择 搜索引擎优化模型的评价可以从搜索引擎发展的角度进行,< @网站知识组织与用户信息行为分析。(1) 从搜索引擎发展的角度来看,评价研究更多地考虑了用户和搜索引擎之间的交互过程。用户使用搜索引擎的主要目的是获取相关信息,所以搜索的成功取决于搜索结果的“任务相关性” 4.从搜索引擎开发角度的评价方法保留了以系统为中心的搜索引擎的评价成本低、可比性强等优点,但由于仍然是基于集合的实验,并且不是基于实际的网络检索环境,而是一种非交互式的评价方法,在评价搜索引擎的性能方面还存在很多问题。
然而,基于网站知识组织的搜索引擎优化模型评价仍然是一种非交互式的评价方法。(3)从用户信息行为分析角度评价搜索引擎优化模型。从搜索引擎开发角度评价搜索引擎优化模型时,用户被视为目标信息的被动接受者。信息交互被视为作为简单的输入输出。在从用户信息行为分析的角度进行的搜索引擎优化模型评估中,用户被视为主动利用自己与搜索引擎的信息交互来获取信息。在信息需求的情况下,如何表达信息需要搜索引擎,以及如何使用搜索引擎提供的功能是评价研究的重点。因此,搜索引擎优化模型评价研究的核心是用户信息行为分析。自我发展视角下的评价研究将“相关性”视为系统的一个属性。在从用户信息行为分析的角度评价搜索引擎优化模型时,“相关性”的概念与用户信息认知的过程及其在此过程中的影响有关。知识状态与信息需求的变化密切相关。5.评价主要基于认知科学的思想,研究用户使用搜索引擎进行信息检索的行为,紧密结合用户使用搜索引擎进行信息检索的过程,解决用户信息问题。通过对用户信息需求的影响程度和满足程度来评价搜索引擎的质量。4.2 基于用户信息行为分析的搜索引擎优化模型评价(1)评价指标评价搜索引擎优化模型,首先要确定评价指标体系。
目前基于用户信息行为分析的搜索引擎优化模型评价指标主要分为两大类,即基于用户感知和态度的指标和基于用户感知和态度的指标。一世 {; {用户一一搜索引擎信息交互索引。第一类指标主要包括:效用、意图、影响、满意度、收益和挫折等。第二类指标包括:信息丰富度、系统可用性、易用性、错误率。评价的关键是搜索引擎优化模型能否为用户提供丰富的效用信息6。(2)|}}: l 用户信息行为分析 明确了搜索引擎优化模型的评价指标后,就要对用户信息行为进行分析,目的是通过分析构建用户信息检索过程的认知模型,了解用户如何处理信息,进而改进信息274检索系统的设计。用户信息行为分析在搜索引擎优化模型评价中的目的主要是判断检索过程对改变用户信息状态的帮助。检索效率。信息使用者的需求包括两个基本方面:获取和使用信息的需要和发布和传输信息的需要。基本点是实现对外信息的沟通和交流,并达到一定的社会职业活动和社会生活目标。7、信息用户在进行信息检索以满足这些不同的信息需求时,衡量检索结果质量的标准也不同。例如,当同一主题的文档需要穷尽时,“召回率”就显得更为重要,他们希望获得某个领域的新信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。当同一主题的文档需要穷尽时,“召回率”更重要,他们希望在某个领域获得新的信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。当同一主题的文档需要穷尽时,“召回率”更重要,他们希望在某个领域获得新的信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。
因此,在评价搜索引擎的质量时,需要对用户信息需求进行分类,需要使用不同的指标来评价不同类型需求的检索8。(3)从用户信息行为的角度评价搜索引擎优化模型。传统的搜索引擎系统引入了与网站知识组织和用户信息行为分析的信息交互,因此不能满足信息用户的有效性 信息需求 本文构建的搜索引擎优化模型可以解决快速增长的网络信息资源与信息用户的效用信息需求之间的矛盾。用户最关心的是搜索结果能否满足自己的需求,尤其是在搜索引擎可以获取大量信息资源的时候。由于搜索引擎优化模型是基于对用户信息行为的分析和优化、网站知识组织优化以及搜索引擎本身的优化开发而建立的,可以最大程度地满足信息化的信息需求用户,尤其是信息用户的个性化信息需求。搜索引擎优化模型从用户信息分析、网站知识组织、搜索引擎开发三个方面整合了搜索引擎信息系统。检索、分类、处理、组织、服务等方面的知识信息得到优化。通过优化网站的结构、知识信息及其组织方式,优化搜索引擎自身的技术、内容和组织方式,搜索引擎优化模型能够很好地满足信息用户的信息需求,解决矛盾在不断增加的网络信息资源和用户的公用事业信息需求之间。参考文献 [1] 费伟,黄如华.基于用户行为分析的搜索引擎优化策略。图书情报工作, 2005 (10): 75-77, I10 [2] 李丹. 论网络环境下的书目信息服务策略. 信息工作, 2003 (203740 f3] 王晓华. 基于内容的研究搜索引擎技术与应用硕士' s 学位论文 J. 郑州大学 2005 Reid.ATask-orientedNon-interactiveEvaluation METHODOLOGY forInformation0nformatResource。: L15-129 管理 2000: 533-550 [6] 付鑫.搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993 搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993 搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993 查看全部
搜索引擎主题模型优化(研究以满足用户的效用信息需求为目的构建搜索引擎优化模型)
信息组织 [摘要] 本研究旨在满足用户的需求,提供有效的信息。构建了搜索引擎优化模型,该模型由三个子模型组成,BSga'S行为分析模型、网站知识和信息组织模型和jtsown搜索引擎优化模型。基于三部分关系的分析。作者对搜索引擎优化模型进行了评估,并进一步提出该模型可以有效解决不断增长的信息与用户对有效信息的需求之间的矛盾。【关键词】搜索引擎优化用户网站信息组织简介 目前,搜索引擎研究主要集中在三个方面:搜索引擎。我{{用户行为研究,网站
但往往仅限于搜索引擎技术发展的研究、搜索引擎与用户的信息交互研究、搜索引擎与网站知识信息组织的研究等。引擎用户和网站是隔离的,三者不收录在一个统一的信息系统中。作为搜索引擎,作为信息系统,三者缺一不可。有鉴于此,本文在传统搜索引擎研究的基础上,将搜索引擎的发展、搜索引擎用户和信息组织整合到整体的搜索引擎优化模型中,避免信息孤岛的产生,使信息在搜索引擎之间畅通无阻。三。相互促进,使信息获取的效益最大化。1 搜索引擎优化模型的构成作者在文献1中提出,将用户、知识生产者和知识组织者视为搜索引擎优化的外部环境,三者与搜索引擎共同构成一个信息系统。基于。在进一步的研究中,作者构建了一个搜索引擎优化模型,该模型由用户行为分析模块、网站知识信息组织模块和搜索引擎模块组成。用户行为分析模块和网站知识组织模块构成了搜索引擎优化模型的外部环境,两者都随着搜索引擎自身的发展形成了一条完整的信息链。搜索引擎优化模型的最终目标是满足信息用户对有效信息的需求。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。
例如,用户在使用搜索引擎检索信息时遇到的各种障碍,可以通过数据分析工具传递给搜索引擎。针对用户的困难,搜索引擎可以采用各种技术来提高自身的能力。1.2 网站知识信息组织优化模块网站结构、网站知识信息内容和组织方法、网站功能和网站服务构成整体网站@ >知识信息系统。网站信息组织的优化包括这四个层次的优化策略,分别是网站结构、网站信息及其组织方法、网站函数和网站@ > 服务优化,实现了整个网站信息系统的优化。重点是优化网站知识信息组织。通过优化网站的信息组织,搜索引擎可以更好的检索网站知识信息,从而促进网站与搜索引擎之间的信息交互,让网络用户及时通过搜索引擎学习高质量的信息满足网络用户的公用事业信息需求。1.3 搜索引擎自身发展的优化模型。搜索引擎自身发展的发展包括搜索引擎技术开发、搜索引擎信息内容和搜索引擎服务的优化。搜索引擎技术的发展和搜索引擎内容的发展是搜索引擎优化服务的基础,而搜索引擎技术的发展也是搜索引擎检索更完整、更多网络信息的基础。同时,搜索引擎服务水平和质量的提升,将俘获更多的信息用户,进一步推动搜索引擎技术的发展和完善。2 搜索引擎优化模型的工作机制 搜索引擎优化模型的目的是优化模型中的各个子系统,最大程度满足用户的效用信息需求,同时模型的工作机制起到了改善信息服务的重要作用。
其中,用户信息行为分析系统是基础,网站知识组织系统是保障,搜索引擎本身的优化和发展是根本。三者将统一在搜索引擎优化模型工作机制体系中,相互促进,共同发挥作用。2.1 用户信息行为分析机制 用户信息行为分析机制是搜索引擎优化模型工作机制的基础。网站或搜索引擎使用数据挖掘工具获取私人用户使用网络信息资源的信息,并应用数据处理器对挖掘工具获取的数据信息进行分析,以确定用户的信息行为。同时,将最终得到的数据反馈给网站或搜索引擎,并在此基础上优化网站和搜索引擎。2.2 网站知识组织优化机制网站是网络信息的来源。搜索引擎检索网站 信息资源。索引建立后,会听到用户的检索行为,并输出检索结果,网站信息的终端就是用户,用户的信息需求影响网站@的发展和完善> 在很大程度上。网站知识组织优化机制从网站的结构、内容和组织方式、网站服务等方面进行优化和发展,将构建网站结构合理,丰富的知识,组织科学的、服务充足的信息库。2.3 搜索引擎自身的优化发展机制 搜索引擎直接面向用户,搜索引擎的内容和服务将直接影响用户的进一步使用。搜索引擎自身的开发和优化机制将优化搜索引擎的技术、数据库内容和组织以及搜索引擎服务。
搜索引擎技术的优化是保证搜索引擎进步的关键。数据库的内容和组织是吸引用户的决定性因素。搜索引擎服务是捕获和留住用户的保证。3 搜索引擎优化模型的特点 3.1 独立性 搜索引擎系统即服务主要是为了方便网络信息用户查询所需信息,稳定搜索引擎用户群,增强搜索引擎的实用性和便捷性。搜索引擎优化模型是一个相对独立完整的系统,由用户信息分析优化模块、网站知识组织优化模块、搜索引擎开发优化模块组成。用户信息分析系统首先对采集用户的信息行为数据进行分析,并将用户信息行为数据反馈给网站和搜索引擎。网站根据用户信息分析优化模块返回的数据,采取针对性措施,持续优化网站的结构、架构和服务。同时,搜索引擎还基于用户行为分析模块获取的数据,从技术层面、内容和组织层面、搜索引擎服务三个方面进行优化。3.2 秩序 系统的秩序是指系统的各种要素与要素有机结合而形成的系统结构。搜索引擎优化系统由用户信息分析系统、网站知识组织系统和搜索引擎自身优化系统组成,三者是一个有序的信息系统。在各种内部要素的非线性作用下,系统可以向有序移动并不断增强其有序性。这个顺序是由它的结构支持的。它采用分层的方式进入新的资源空间。
在搜索引擎优化模型中,用户信息行为分析系统将用户信息传输到网站知识组织系统和搜索引擎优化系统。网站知识组织系统基于用户信息数据优化分析知识内容及其组织方式。同时,搜索引擎服务商根据用户信息分析系统返回的数据,对搜索引擎的方方面面进行优化。搜索引擎自身的开发和优化,可以更好地检索和索引网站知识信息,进一步满足信息用户的信息需求。3.3 在服务网络环境中,个体信息使用者的知识结构不同,所以对网络资源的认知也不同,导致网络资源使用上的差异。不同用户对网络资源需求的特点是:最主要的信息需求集中在与工作学习相关的专业和业务信息;信息语言以国语为主,英文信息次之;服务类型以WWW信息搜索为主。此外,用户需求还表现为:信息数据库网络化;可随时获取所需信息;方便和同时回答各种查询;用户最终得到在搜索引擎优化中被识别、选择和处理的有价值的信息在模型中,网站知识组织和服务,搜索引擎服务都是在用户信息行为分析的基础上发展起来的,所以搜索引擎优化服务更具针对性,尤其是个性化、特色化的搜索引擎公司的发展,更能满足信息用户的信息需求。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。
数据挖掘技术和网络信息检索技术有很多相似之处,但也有本质的区别。数据挖掘技术继续利用机器人、全文检索等互联网信息检索的优异成果,同时综合运用人工智能、模式识别、神经网络等领域的各种技术。数据挖掘技术与网络信息检索最重要的区别在于,它可以根据目标特征信息在网络或数据库中进行有目的的信息检索,从而获得用户所需的信息。3.4 时效性 搜索引擎优化模型的时效性体现在三个方面,即用户信息行为分析数据的时效性,网站知识及其组织的时效性,以及搜索引擎自身发展的时效性。用户信息行为的时效性具有牵动全身的影响。网站知识组织和搜索引擎优化基于用户信息行为分析。用户使用搜索引擎的行为分为已经发生的搜索行为、正在发生的搜索行为和潜在的搜索行为。已经发生的搜索行为对于搜索引擎总结经验教训,进一步优化搜索引擎具有建设性意义。行为和停滞搜索行为对搜索引擎的优化起着指导作用。3. 5 封闭传统搜索引擎模式,全面信息搜索。它的优点是有利于积累搜索信息数据和行为数据,有利于满足一般简单的信息需求。本文讨论的搜索引擎优化模型是基于用户信息需求、特定信息用户范围、特定系统的信息服务。内在的深入需求;提供更准确的知识和信息的有利条件。特定范围的信息用户和特定系统。内在的深入需求;提供更准确的知识和信息的有利条件。特定范围的信息用户和特定系统。内在的深入需求;提供更准确的知识和信息的有利条件。
从开放搜索系统到封闭搜索系统的转变,也是从综合搜索到专业垂直搜索的转变,从定量搜索到定性搜索的转变,从搜索引擎服务商到公众参与的单边控制。控制搜索过程的过渡。与传统的搜索引擎模型相比,本文讨论的搜索引擎优化模型并不意味着封闭和保守,而只是从搜索策略、搜索目的和搜索范围等角度的概念上的限制。4 搜索引擎优化模型的评价 4.1 搜索引擎优化模型评价角度的选择 搜索引擎优化模型的评价可以从搜索引擎发展的角度进行,< @网站知识组织与用户信息行为分析。(1) 从搜索引擎发展的角度来看,评价研究更多地考虑了用户和搜索引擎之间的交互过程。用户使用搜索引擎的主要目的是获取相关信息,所以搜索的成功取决于搜索结果的“任务相关性” 4.从搜索引擎开发角度的评价方法保留了以系统为中心的搜索引擎的评价成本低、可比性强等优点,但由于仍然是基于集合的实验,并且不是基于实际的网络检索环境,而是一种非交互式的评价方法,在评价搜索引擎的性能方面还存在很多问题。
然而,基于网站知识组织的搜索引擎优化模型评价仍然是一种非交互式的评价方法。(3)从用户信息行为分析角度评价搜索引擎优化模型。从搜索引擎开发角度评价搜索引擎优化模型时,用户被视为目标信息的被动接受者。信息交互被视为作为简单的输入输出。在从用户信息行为分析的角度进行的搜索引擎优化模型评估中,用户被视为主动利用自己与搜索引擎的信息交互来获取信息。在信息需求的情况下,如何表达信息需要搜索引擎,以及如何使用搜索引擎提供的功能是评价研究的重点。因此,搜索引擎优化模型评价研究的核心是用户信息行为分析。自我发展视角下的评价研究将“相关性”视为系统的一个属性。在从用户信息行为分析的角度评价搜索引擎优化模型时,“相关性”的概念与用户信息认知的过程及其在此过程中的影响有关。知识状态与信息需求的变化密切相关。5.评价主要基于认知科学的思想,研究用户使用搜索引擎进行信息检索的行为,紧密结合用户使用搜索引擎进行信息检索的过程,解决用户信息问题。通过对用户信息需求的影响程度和满足程度来评价搜索引擎的质量。4.2 基于用户信息行为分析的搜索引擎优化模型评价(1)评价指标评价搜索引擎优化模型,首先要确定评价指标体系。
目前基于用户信息行为分析的搜索引擎优化模型评价指标主要分为两大类,即基于用户感知和态度的指标和基于用户感知和态度的指标。一世 {; {用户一一搜索引擎信息交互索引。第一类指标主要包括:效用、意图、影响、满意度、收益和挫折等。第二类指标包括:信息丰富度、系统可用性、易用性、错误率。评价的关键是搜索引擎优化模型能否为用户提供丰富的效用信息6。(2)|}}: l 用户信息行为分析 明确了搜索引擎优化模型的评价指标后,就要对用户信息行为进行分析,目的是通过分析构建用户信息检索过程的认知模型,了解用户如何处理信息,进而改进信息274检索系统的设计。用户信息行为分析在搜索引擎优化模型评价中的目的主要是判断检索过程对改变用户信息状态的帮助。检索效率。信息使用者的需求包括两个基本方面:获取和使用信息的需要和发布和传输信息的需要。基本点是实现对外信息的沟通和交流,并达到一定的社会职业活动和社会生活目标。7、信息用户在进行信息检索以满足这些不同的信息需求时,衡量检索结果质量的标准也不同。例如,当同一主题的文档需要穷尽时,“召回率”就显得更为重要,他们希望获得某个领域的新信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。当同一主题的文档需要穷尽时,“召回率”更重要,他们希望在某个领域获得新的信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。当同一主题的文档需要穷尽时,“召回率”更重要,他们希望在某个领域获得新的信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。
因此,在评价搜索引擎的质量时,需要对用户信息需求进行分类,需要使用不同的指标来评价不同类型需求的检索8。(3)从用户信息行为的角度评价搜索引擎优化模型。传统的搜索引擎系统引入了与网站知识组织和用户信息行为分析的信息交互,因此不能满足信息用户的有效性 信息需求 本文构建的搜索引擎优化模型可以解决快速增长的网络信息资源与信息用户的效用信息需求之间的矛盾。用户最关心的是搜索结果能否满足自己的需求,尤其是在搜索引擎可以获取大量信息资源的时候。由于搜索引擎优化模型是基于对用户信息行为的分析和优化、网站知识组织优化以及搜索引擎本身的优化开发而建立的,可以最大程度地满足信息化的信息需求用户,尤其是信息用户的个性化信息需求。搜索引擎优化模型从用户信息分析、网站知识组织、搜索引擎开发三个方面整合了搜索引擎信息系统。检索、分类、处理、组织、服务等方面的知识信息得到优化。通过优化网站的结构、知识信息及其组织方式,优化搜索引擎自身的技术、内容和组织方式,搜索引擎优化模型能够很好地满足信息用户的信息需求,解决矛盾在不断增加的网络信息资源和用户的公用事业信息需求之间。参考文献 [1] 费伟,黄如华.基于用户行为分析的搜索引擎优化策略。图书情报工作, 2005 (10): 75-77, I10 [2] 李丹. 论网络环境下的书目信息服务策略. 信息工作, 2003 (203740 f3] 王晓华. 基于内容的研究搜索引擎技术与应用硕士' s 学位论文 J. 郑州大学 2005 Reid.ATask-orientedNon-interactiveEvaluation METHODOLOGY forInformation0nformatResource。: L15-129 管理 2000: 533-550 [6] 付鑫.搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993 搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993 搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993
搜索引擎主题模型优化(网页加载速度优化的几种方法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-17 15:21
1、网页加载速度优化
在信息碎片化的时代,没人愿意等你几分钟,所以网站打开加载速度比任何优化点都重要。开通时间越短,用户满意度越高。搜索引擎也是如此。所以首先考虑可以做些什么来加速,比如CDN、删除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
2、用户体验优化
很多用户打开网站都会有印象。网页设计需要用户界面和用户体验的输入,以及品牌自身的声誉来认可,否则用户很难对网站产生信任感和参与感。一个实用的方法是参考业界较好的网站进行模仿,购买付费版的网站模板或让用户参与每一个设计过程。
3、避免过多的弹出窗口
很多弹出窗口、固定窗口和广告位都会让用户体验很差,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更自然的方式嵌入这些元素,或奖励完成过程的用户。同时,避免在使用代码时出现蜘蛛被禁止或难以捕捉的可能性,从而被搜索引擎减少。
网站SEO优化的重点是什么
4、关键词布局
常规的关键词植入也需要继续,比如title、H1、文章中的关键词、外链锚文本、内链锚文本、图片alt、URL、图片命名等,这个是不需要的详细说明。我们都知道。
5、主题模型填充
仅仅5个字是不够的,因为太机械会失去文字的用户体验。所以我们需要做一个主题模型。比如关键词【婚礼搭配】可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚纱市场等相关词汇,形成一个大主题,这样的页面内容会让< @关键词 更全面,帮助更多用户。同时,搜索引擎可以将您要推送的话题内容解读为婚礼相关内容。
6、文本深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、DESC、URL)。这些元素需要在内容上进行优化:标题的创意、描述的红色、URL的规范、文章的日期、结构化数据的使用、在线对话等。 查看全部
搜索引擎主题模型优化(网页加载速度优化的几种方法,你知道吗?)
1、网页加载速度优化
在信息碎片化的时代,没人愿意等你几分钟,所以网站打开加载速度比任何优化点都重要。开通时间越短,用户满意度越高。搜索引擎也是如此。所以首先考虑可以做些什么来加速,比如CDN、删除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
2、用户体验优化
很多用户打开网站都会有印象。网页设计需要用户界面和用户体验的输入,以及品牌自身的声誉来认可,否则用户很难对网站产生信任感和参与感。一个实用的方法是参考业界较好的网站进行模仿,购买付费版的网站模板或让用户参与每一个设计过程。
3、避免过多的弹出窗口
很多弹出窗口、固定窗口和广告位都会让用户体验很差,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更自然的方式嵌入这些元素,或奖励完成过程的用户。同时,避免在使用代码时出现蜘蛛被禁止或难以捕捉的可能性,从而被搜索引擎减少。

网站SEO优化的重点是什么
4、关键词布局
常规的关键词植入也需要继续,比如title、H1、文章中的关键词、外链锚文本、内链锚文本、图片alt、URL、图片命名等,这个是不需要的详细说明。我们都知道。
5、主题模型填充
仅仅5个字是不够的,因为太机械会失去文字的用户体验。所以我们需要做一个主题模型。比如关键词【婚礼搭配】可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚纱市场等相关词汇,形成一个大主题,这样的页面内容会让< @关键词 更全面,帮助更多用户。同时,搜索引擎可以将您要推送的话题内容解读为婚礼相关内容。
6、文本深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、DESC、URL)。这些元素需要在内容上进行优化:标题的创意、描述的红色、URL的规范、文章的日期、结构化数据的使用、在线对话等。
搜索引擎主题模型优化(1.什么是SEO站内主题内容优化方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-17 10:02
文章指南
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1. 什么是SEO网站的主题模型
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 查看关键词的密度是否符合标准
· 文章 内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词是否设置为精准匹配
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?
主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
1) 词法关联
2)词系统布局
3)补充内容
4)内容属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
第 1 步:词法关联
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和变体
2)找到与主词内容相关的二类词
3)找到与第二类词相关的三类词
4) 结论是内容属性与主题(人、地、事)有关
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二- 与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到相关的三类词对于第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度!
第二步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。所以词系统布局就是区分核心词及其相关性。这里有3个实用的优化方法: 1) 区域:关键词 必须出现在标题、标题和主要段落中
2) 频率:重要短语或其变体的出现频率可能高于平均水平
3) 距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)
方法(1)是大多数SEO人的必修项目,我们还是要把核心主题放在标题,大标题,尽量出现在主条目的顶部。
方法(2)这里不仅仅是关键词的频率(密度),而是更复杂的链接频率层面,即核心词的同义词和变体。相同条件下,不太流行的同义词而且变体词会得到更好的结果。(谷歌有一个专利叫TF-IDF,比较难懂)
方法(3)距离产生美在SEO世界里是不适用的。词、词组、句子要尽量靠近,或者使用HTML元素(如图片ALT设置)。所以为了提高上下文相关性,应该通过段落、列表、分区,让内容更加明显,可以一目了然地知道段落在说什么。前后句子之间是否有连通性,不要将内容与类似的意思太远了。因为你不能保证蜘蛛会抓住整个文本。
你知道这个方法的原理。现在你要做的就是将二类单词和三类词汇分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会重点介绍这个词文章。第二段用几只手做文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。
因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么补充内容是什么呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯粹的关键词,缺少文字链接、参考资料和相关资源推荐,你的页面很死板,这是一个死胡同,但它不会为您的页面添加额外的点。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件。这是给搜索引擎的消息。我有[补充]。想想看,百度百科还是知道为什么要添加相关资源的链接?实际上,就是加强页面主题的深化,通过不同网站的内容强化信息化。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。
1)页面底部添加相关资源链接(推荐站点链接)
2)在文本中使用引号,例如业内知名人士的话或图标或视频
3)使用文中的导出链接去第三方网站(你不会被K的100介意)
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom Teacher”时,是实体[person]吗?提到“咨询道”,是【公司】?因为当你的内容出现在互联网上的时候,时间还不够久,在数量少的时候,搜索引擎可能无法解释内容实体,因为老师可以是姓氏的老师,或者它可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体。
一般情况下,大部分搜索引擎都会提供站长自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示,世界上只有0.3%网站 使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让您的架构师将 网站 结构化数据纳入其中。
当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。比如【Boom老师】这个实体可以关联一个叫紫道的公司,一个叫SEO Techniques的热门课件就是一朵云,也可以关联到腾讯课堂上的一个公开课老师。所以,对于搜索引擎来说,可以断定“腾讯课堂的SEO技巧只是浮云”是紫道学院爆款老师分享的内容。不是看页面上有没有这个词,有多少个链接指向它,而是看内容实体是否相关。这样,
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的非常笼统的标题
2)添加开场白(简要)描述页面内容
3) 把内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以添加相关答案
5)提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体 查看全部
搜索引擎主题模型优化(1.什么是SEO站内主题内容优化方法)
文章指南
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1. 什么是SEO网站的主题模型
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 查看关键词的密度是否符合标准
· 文章 内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词是否设置为精准匹配
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?
主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
1) 词法关联
2)词系统布局
3)补充内容
4)内容属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
第 1 步:词法关联
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和变体
2)找到与主词内容相关的二类词
3)找到与第二类词相关的三类词
4) 结论是内容属性与主题(人、地、事)有关
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二- 与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到相关的三类词对于第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度!
第二步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。所以词系统布局就是区分核心词及其相关性。这里有3个实用的优化方法: 1) 区域:关键词 必须出现在标题、标题和主要段落中
2) 频率:重要短语或其变体的出现频率可能高于平均水平
3) 距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)
方法(1)是大多数SEO人的必修项目,我们还是要把核心主题放在标题,大标题,尽量出现在主条目的顶部。
方法(2)这里不仅仅是关键词的频率(密度),而是更复杂的链接频率层面,即核心词的同义词和变体。相同条件下,不太流行的同义词而且变体词会得到更好的结果。(谷歌有一个专利叫TF-IDF,比较难懂)
方法(3)距离产生美在SEO世界里是不适用的。词、词组、句子要尽量靠近,或者使用HTML元素(如图片ALT设置)。所以为了提高上下文相关性,应该通过段落、列表、分区,让内容更加明显,可以一目了然地知道段落在说什么。前后句子之间是否有连通性,不要将内容与类似的意思太远了。因为你不能保证蜘蛛会抓住整个文本。
你知道这个方法的原理。现在你要做的就是将二类单词和三类词汇分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会重点介绍这个词文章。第二段用几只手做文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。
因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么补充内容是什么呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯粹的关键词,缺少文字链接、参考资料和相关资源推荐,你的页面很死板,这是一个死胡同,但它不会为您的页面添加额外的点。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件。这是给搜索引擎的消息。我有[补充]。想想看,百度百科还是知道为什么要添加相关资源的链接?实际上,就是加强页面主题的深化,通过不同网站的内容强化信息化。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。
1)页面底部添加相关资源链接(推荐站点链接)
2)在文本中使用引号,例如业内知名人士的话或图标或视频
3)使用文中的导出链接去第三方网站(你不会被K的100介意)
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom Teacher”时,是实体[person]吗?提到“咨询道”,是【公司】?因为当你的内容出现在互联网上的时候,时间还不够久,在数量少的时候,搜索引擎可能无法解释内容实体,因为老师可以是姓氏的老师,或者它可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体。
一般情况下,大部分搜索引擎都会提供站长自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示,世界上只有0.3%网站 使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让您的架构师将 网站 结构化数据纳入其中。
当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。比如【Boom老师】这个实体可以关联一个叫紫道的公司,一个叫SEO Techniques的热门课件就是一朵云,也可以关联到腾讯课堂上的一个公开课老师。所以,对于搜索引擎来说,可以断定“腾讯课堂的SEO技巧只是浮云”是紫道学院爆款老师分享的内容。不是看页面上有没有这个词,有多少个链接指向它,而是看内容实体是否相关。这样,
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的非常笼统的标题
2)添加开场白(简要)描述页面内容
3) 把内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以添加相关答案
5)提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体
搜索引擎主题模型优化( 中国论文网关键词用户个性化词典二级向量查询扩展个性化服务(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-17 09:41
中国论文网关键词用户个性化词典二级向量查询扩展个性化服务(组图))
基于个性化词典的搜索引擎查询扩展模型总结 为了给用户提供个性化的网络信息检索服务,本文对现有的个性化服务模型进行了改进,引入了一种基于用户个性化词典的搜索引擎查询扩展模型。该模型使用用户个性化字典代替传统的全局字典,并使用查询扩展策略实现个性化服务。用户个性化词典可以优化用户兴趣建模过程,使用户兴趣模型更加准确,优化最终生成的扩展词。搜索引擎可以更轻松地检索到更符合其兴趣的网页。党的积极分子检查清单和毫米对照表的数量。教师职称等级列表。员工考核评分表。普通年金现值系数表明该模型可以通过搜索引擎提供给用户。有效可行的个性化服务中国论文网关键词用户个性化词典二次向量查询扩展个性化服务搜索引擎中文图书馆分类号TP391文件标识危险废物标识危险废物标识安全警示牌大全危险废物标识牌管道标识色码A 文章 number 128-6764-07 互联网是人们获取知识和传递信息的桥梁。但是,随着近年来互联网的飞速发展,互联网上的信息量也呈指数级增长。在这种背景下,互联网用户往往无法轻松找到自己需要的信息。搜索引擎的出现在一定程度上解决了我们的信息检索需求。当前搜索引擎的概念已经成为互联网信息检索必不可少的工具,但它一方面存在以下几个局限: 1 庞大的搜索结果集,用户花费大量时间和精力去寻找自己真正感兴趣的信息2 不同用户在不同时间使用同一个查询关键词请求得到的搜索结果几乎相同,用户无法提供个性化服务。3 用户在使用搜索引擎进行搜索时有一定的目的,但往往由于用户对相关领域知识的缺乏以及搜索引擎查询界面的限制,导致用户无法清晰表达自己的信息需求[2] 针对传统搜索引擎无法提供给用户的缺陷面向个性化服务,大量专家学者开始研究查询扩展技术并在该领域取得突破。文献 [1] 根据文献分析 提出了局部共现的思想,SEPMBDVDSearchEnginePersonalizationModelBasedonDoubleVectorDescription。其本质也是利用挖掘用户浏览过的历史网页和用户输入产生的用户兴趣模型。通过扩展词添加查询关键词匹配扩展词,使用户在使用搜索引擎检索结果时,可以得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。查询扩展模型依赖于用户兴趣模型。文献[7]使用了一个两级向量模型,通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于用户浏览过的历史网页的全局字典。描述性聚类挖掘后生成的整个模型结构如图1所示。 全局字典太大,因为词汇量太复杂,无法反映用户兴趣等,会对用户兴趣模型的生成产生较大的影响,影响词的扩展。因此,本文使用个性化词典代替全局词典,使用searchVectors和扩展词向量描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后生成的整个模型结构如图1所示,全局字典太大,无法反映词汇量。用户的兴趣等原因会对用户兴趣模型的生成产生较大的影响,从而影响词扩展的效果。因此,本文使用个性化词典代替全局词典,使用searchVectors和扩展词向量描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后生成的整个模型结构如图1所示,全局字典太大,无法反映词汇量。用户的兴趣等原因会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。所以,本文使用个性化词典替代全局词典,并使用搜索匹配的扩展词通过扩展词添加,使用户在使用搜索引擎搜索时能够得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。此查询扩展模型取决于用户。兴趣模型文献[7]使用了一个两级向量模型,它通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。经过聚类和挖掘后生成的整个模型结构如图1所示。全局词典过大因为词汇量过大、词汇量太复杂无法体现用户兴趣等,会对用户兴趣模型的生成产生较大影响,进而影响词扩展的效果。因此,本文使用个性替换全局词典,通过扩展词添加匹配的扩展词,使用户在使用搜索引擎搜索时能够得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。此查询扩展模型取决于用户。兴趣模型文献[7]使用了一个两级向量模型,它通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后整个生成的模型结构如图1所示。全局字典太大,因为词汇量太大,词汇量太复杂,无法体现用户兴趣等,会对生成产生较大的影响用户兴趣模型,这会影响词扩展的效果。因此,本文使用个性替换全局字典 会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。因此,本文使用个性替换全局字典 会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。因此,本文使用个性替换全局字典
查询扩展策略,实现个性化服务。设计基于个性化词典 QEMBUPDSEQueryExpansionModelBasedonUserPersonalizationDictionaryforSearchEngine 的搜索引擎查询扩展模型。该模型可以通过个性化词典优化用户兴趣模型,优化查询扩展词,使用户的个性化搜索更快更准确 1 基于个性化词典的搜索引擎查询扩展模型。基于个性化词典的搜索引擎查询扩展模型从用户浏览历史的描述入手。然后数据挖掘方法使用二级向量描述来更直接地生成用户兴趣的二级向量模型。最后根据用户输入关键词进行查询扩展,如图2所示。21 个性化词典定义与实现 [10] 个性化词典UPDUserPersonalizationDictionary 包括两个层次:关键词词典KeyDict和扩展词词典ExDict。二级词典中的词定义为关键词和扩展词。每层词典收录nn个词和词权重组成的二元组,人为设置关键词通常意味着用户浏览兴趣词的权重越大,在用户兴趣中的重要性越大,扩展词用于描述用户的兴趣点为了在查询扩展时提供符合用户偏好的扩展搜索词,特定用户的UPD可以充分表达用户对信息需求的偏好,同时为基于二次向量的用户兴趣模型提供支持,是一种用户兴趣。词典设计中的私人词典主要考虑以下几个主要原则: 1 一个词在网络文档集合中出现的频率越高,对这个词的用户特征的描述就越强 2 收录该词的网页数量越多web文档集合词对越多对用户特征的描述能力越强 3对于网页中一些常用的没有搜索价值的词,我们称之为网页常用词,比如comment copyright文章字典中,应该过滤掉,以免给用户的个人描述带来干扰。公式中身份证号码提取年龄公式电容电压公式电容公式定积分推导公式力学公式1 S是网页集合T是词空间WtS是词t在S中的权重,tftS是词频S中的词t,N为S中收录的网页总数,nt为S中的文档数,分母为归一化因子。在TF-IDF公式中,Nnt001为IDF因子,即逆向文本频率索引在WTUPD中仍沿用此名称。IDF因子越大,词在网页集合中的分布越稀疏,词的重要性越小,权重越小。反之,词的IDF因子越小,说明它在网页集合中越小。分布越密集,单词的重要性越统一,权重就越大。考虑到词在网页集合中的均匀分布不同,本文认为词t在整个网页集合S中的权重与其在网页中的均匀度成正比,因此本文引入了一个因素测量一致性以修改单词 t 的权重。公式1中t这个词的均匀度是通过网页集合中t的标准差来衡量的。集合S中的权重与网页集合中的词频成正比,与其在网页集中分布的稀疏性和均匀性成正比。通过 WTUPD 公式,
超过5个核心兴趣点的用户选择前12个词作为关键词,其余为扩展词,形成关键词词典和扩展词词典。最后,必须清除关键词 字典和扩展时间。字典中的频繁词的特点是它们分布在网页集合中的大多数文档中,并且在单个网页中出现的频率往往低于1-2次。本文使用以下方法过滤这部分词,经过上述公式处理,最终可以构建出满足用户兴趣描述要求的个性化词典 22 基于个性化词典的用户兴趣建模 最终的词扩展依赖于准确的用户兴趣模型,而个性化词典的建立将有助于快速准确地建立用户兴趣模型。因此,本文采用的用户兴趣建模方法如下:首先,利用个性化词典将用户浏览的网页转化为特征向量。由于个性化词典收录二级词典,因此生成的网页特征向量为二级向量,如网页的特征向量。表示为 [单反 005327385 摄影 004826857 像素 003272436 市场 002713352 专业 002639451...] [镜头 001135712 显示 001023895 环 向量,然后是扩展词向量,然后使用网页的特征向量进行聚类分析,得到用户感兴趣的子类别。最后,使用各种类型的网页特征向量将兴趣子类别描述为辅助向量,以生成用户兴趣模型。可以看出,个性化词典使得整个用户兴趣建模过程使用了两个高级向量用户兴趣模型的生成更加直接和流畅,并且因为个性化词典避免了大量的词和频繁出现的词与传统全局词典中用户兴趣无关,网页特征描述更加准确,为后续的聚类分析和兴趣模型生成奠定基础。良好的基础广州货架wwwgzrundacomgzh并通过用户兴趣模型提供符合用户兴趣偏好的扩展词,有利于扩展词的分析比较和23种查询扩展策略的实施。分子是向量ci和Qini各分量的乘积,分母是向量模数。本文产品选择与初始查询相似度最高的兴趣点C作为用户的查询意图,为用户提供尽可能多的查询扩展词。如果在关键词向量中找不到用户的查询词,即Qini和关键词向量的相似度为0,那么扩展词向量将被合并到关键词@ > 参与计算的向量。下一个,为了找到与用户查询最相关的扩展词,需要计算词之间的相关性。本文参考LSI模型[7中的方法]将网页文档集合表示为词文档矩阵TD,如表1所示。提交给搜索引擎的初始查询词是Qini National Team World Cup Australia。是Qini匹配的兴趣类别的扩展词向量中的矩阵单元TDij,扩展词中间的矩阵单元TDij是文档Dj中对应词Ti的权重和频率。变换的结果是因为单词和文档的数量非常多,单个文档中出现的单词非常有限,所以TD一般是一个高阶稀疏矩阵,然后用TD构建词间关系矩阵TT,计算词间关联度构建方法如下: 式6 其中TD为TD转置得到的矩阵TT中各单元TTij的值,反映了特定环境下特定用户特定兴趣类别的词 i 和 j 之间的相似度。我们可以看到,每个词与其自身的相似度为1,并且在兴趣类别的任何文档中都没有相似度。
两个现有词的相似度为0,如表2所示,其中x表示词间关系矩阵TT,与初始查询词Qini相似度最大的候选扩展词对应的相关度x表示其他候选扩展词。与Qini的相关性公式8中的参数[δ]表示x和x之间的相对误差阈值。只要某个候选扩展词与Qini的相关性与x的相对误差小于δ,那么候选扩展词就可以最终推荐给用户。在实际应用中,δ通常取值为10,这样可以更好地保留扩展词,减少计算时间。可以根据情况进行设置,让过滤后的词按照相关性的顺序排序,然后推荐给因为过多的扩展词会减少搜索结果,不利于用户获取足够的信息。通常选择3个扩展词比较合适,所以最后可以从排序好的扩展词队列中选择前3个词进行推荐。当然可以根据用户需要设置推荐的扩展词数。3 实验与分析 31 个人能力评价评价 个人工作评价评价指标 工作条件风险评价方法评价反应指标 SWUI 因为用户个性化词典UPD实际上几乎收录了用户的归属感 兴趣词和词的权重计算公式浏览历史网页也反映了用户对这些词的兴趣。因此,本文采用将查询扩展搜索到的网页集合与用户的个性化词典进行对比的方法进行实验。评估本文提出的个性化服务模型的效果。为了将检索到的网页集合与用户个性化词典进行比较 余弦函数值之间的相似度通过相似度反映网页集合与用户兴趣的相关程度,该相似度称为 SWUISimilaritybetweenWebpagesandUserInterests32 实验数据 本实验为基于三个用户根据自己的兴趣浏览网页,然后自己感兴趣 保存网页,然后对三个用户提供的兴趣网页进行兴趣建模,得到用户兴趣模型。表4限制了每个兴趣类别的长度,只使用了关键词的一部分 表示 33 对比实验 本文在谷歌和百度上进行了以下三组实验,在主流搜索引擎上进行: 1None 实验不使用查询扩展,只使用用户查询关键词检索实验2 标准实验使用文献[7]中提出的SEPMBDVD模型进行查询扩展然后在搜索引擎广州货架wwwgzrundacomgzh上搜索基于3UPD的实验使用本文提出的QEMBUPDSE模型进行查询扩展然后在搜索引擎上进行搜索比较实验由三个实现提供用户兴趣模型的用户。每个用户为他的每个兴趣选择合适的一个。关键词 根据以上三组实验的要求,在谷歌和百度上搜索。每组实验都会使用每一种搜索引擎返回的前100个网页进行保存,然后为每个搜索引擎计算每个搜索引擎搜索引擎集合与UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI 然后为每个搜索引擎计算每个搜索引擎搜索引擎集合和UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI 然后为每个搜索引擎计算每个搜索引擎搜索引擎集合和UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI
最终实验结果如表5所示,以更直观地反映对比效果。本文计算了UPDbased相对于None和Standard的实验结果的百分比增长,如表6所示。从表6可以看出,首先使用QEMBUPDSE模型进行查询扩展后,搜索到的网页显然更相关用户的兴趣比没有查询扩展。其次,与使用SEPMBDVD模型扩展相比,使用QEMBUPDSE模型进行查询扩展后的搜索网页在用户相关性上也有一定的提升。网页更符合用户的兴趣。这主要是因为在用户建模之前使用UPD可以在一定程度上优化整个用户建模过程。最终用户兴趣模型更准确,查询扩展效果更好。4 结论本文基于文献[7]中提出的二次向量对搜索引擎个性化服务模型进行改进,增加用户个性化词典,优化用户兴趣建模过程,提高查询扩展效果。实验表明,个性化词典基于搜索引擎查询扩展模型可以更有效地辅助用户使用搜索引擎搜索他们感兴趣的信息。在接下来的研究中,需要考虑如何更准确地构建个性化词典和用户兴趣模型,提出更好的相似度计算方法。提高整个个性化搜索模型的性能。参考文献 [1] 丁国栋,白硕,王斌,许伟民基于主题的个性化查询扩展模型[J]计算机工程与设计2-4475[7]徐景秋、朱正宇、谭明宏等基于二次向量的搜索引擎个性化服务模型[J]计算机科学2007341189-92[ 8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗应诸正雨研究与实现广州WWW个性化源字典。货架 wwwgzrundacomgzh 谭铭洪和其他搜索引擎的个性化的服务模式基础上的二次载体[J]。计算机科学2007341189-92 [8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗莹朱政宇的研究与实现个性化源广州词典 www. 货架 wwwgzrundacomgzh 谭铭洪和其他搜索引擎的个性化的服务模式基础上的二次载体[J]。计算机科学2007341189-92 [8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗莹朱政宇的研究与实现个性化源广州词典 www. 货架 wwwgzrundacomgzh 查看全部
搜索引擎主题模型优化(
中国论文网关键词用户个性化词典二级向量查询扩展个性化服务(组图))

基于个性化词典的搜索引擎查询扩展模型总结 为了给用户提供个性化的网络信息检索服务,本文对现有的个性化服务模型进行了改进,引入了一种基于用户个性化词典的搜索引擎查询扩展模型。该模型使用用户个性化字典代替传统的全局字典,并使用查询扩展策略实现个性化服务。用户个性化词典可以优化用户兴趣建模过程,使用户兴趣模型更加准确,优化最终生成的扩展词。搜索引擎可以更轻松地检索到更符合其兴趣的网页。党的积极分子检查清单和毫米对照表的数量。教师职称等级列表。员工考核评分表。普通年金现值系数表明该模型可以通过搜索引擎提供给用户。有效可行的个性化服务中国论文网关键词用户个性化词典二次向量查询扩展个性化服务搜索引擎中文图书馆分类号TP391文件标识危险废物标识危险废物标识安全警示牌大全危险废物标识牌管道标识色码A 文章 number 128-6764-07 互联网是人们获取知识和传递信息的桥梁。但是,随着近年来互联网的飞速发展,互联网上的信息量也呈指数级增长。在这种背景下,互联网用户往往无法轻松找到自己需要的信息。搜索引擎的出现在一定程度上解决了我们的信息检索需求。当前搜索引擎的概念已经成为互联网信息检索必不可少的工具,但它一方面存在以下几个局限: 1 庞大的搜索结果集,用户花费大量时间和精力去寻找自己真正感兴趣的信息2 不同用户在不同时间使用同一个查询关键词请求得到的搜索结果几乎相同,用户无法提供个性化服务。3 用户在使用搜索引擎进行搜索时有一定的目的,但往往由于用户对相关领域知识的缺乏以及搜索引擎查询界面的限制,导致用户无法清晰表达自己的信息需求[2] 针对传统搜索引擎无法提供给用户的缺陷面向个性化服务,大量专家学者开始研究查询扩展技术并在该领域取得突破。文献 [1] 根据文献分析 提出了局部共现的思想,SEPMBDVDSearchEnginePersonalizationModelBasedonDoubleVectorDescription。其本质也是利用挖掘用户浏览过的历史网页和用户输入产生的用户兴趣模型。通过扩展词添加查询关键词匹配扩展词,使用户在使用搜索引擎检索结果时,可以得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。查询扩展模型依赖于用户兴趣模型。文献[7]使用了一个两级向量模型,通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于用户浏览过的历史网页的全局字典。描述性聚类挖掘后生成的整个模型结构如图1所示。 全局字典太大,因为词汇量太复杂,无法反映用户兴趣等,会对用户兴趣模型的生成产生较大的影响,影响词的扩展。因此,本文使用个性化词典代替全局词典,使用searchVectors和扩展词向量描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后生成的整个模型结构如图1所示,全局字典太大,无法反映词汇量。用户的兴趣等原因会对用户兴趣模型的生成产生较大的影响,从而影响词扩展的效果。因此,本文使用个性化词典代替全局词典,使用searchVectors和扩展词向量描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后生成的整个模型结构如图1所示,全局字典太大,无法反映词汇量。用户的兴趣等原因会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。所以,本文使用个性化词典替代全局词典,并使用搜索匹配的扩展词通过扩展词添加,使用户在使用搜索引擎搜索时能够得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。此查询扩展模型取决于用户。兴趣模型文献[7]使用了一个两级向量模型,它通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。经过聚类和挖掘后生成的整个模型结构如图1所示。全局词典过大因为词汇量过大、词汇量太复杂无法体现用户兴趣等,会对用户兴趣模型的生成产生较大影响,进而影响词扩展的效果。因此,本文使用个性替换全局词典,通过扩展词添加匹配的扩展词,使用户在使用搜索引擎搜索时能够得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。此查询扩展模型取决于用户。兴趣模型文献[7]使用了一个两级向量模型,它通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后整个生成的模型结构如图1所示。全局字典太大,因为词汇量太大,词汇量太复杂,无法体现用户兴趣等,会对生成产生较大的影响用户兴趣模型,这会影响词扩展的效果。因此,本文使用个性替换全局字典 会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。因此,本文使用个性替换全局字典 会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。因此,本文使用个性替换全局字典

查询扩展策略,实现个性化服务。设计基于个性化词典 QEMBUPDSEQueryExpansionModelBasedonUserPersonalizationDictionaryforSearchEngine 的搜索引擎查询扩展模型。该模型可以通过个性化词典优化用户兴趣模型,优化查询扩展词,使用户的个性化搜索更快更准确 1 基于个性化词典的搜索引擎查询扩展模型。基于个性化词典的搜索引擎查询扩展模型从用户浏览历史的描述入手。然后数据挖掘方法使用二级向量描述来更直接地生成用户兴趣的二级向量模型。最后根据用户输入关键词进行查询扩展,如图2所示。21 个性化词典定义与实现 [10] 个性化词典UPDUserPersonalizationDictionary 包括两个层次:关键词词典KeyDict和扩展词词典ExDict。二级词典中的词定义为关键词和扩展词。每层词典收录nn个词和词权重组成的二元组,人为设置关键词通常意味着用户浏览兴趣词的权重越大,在用户兴趣中的重要性越大,扩展词用于描述用户的兴趣点为了在查询扩展时提供符合用户偏好的扩展搜索词,特定用户的UPD可以充分表达用户对信息需求的偏好,同时为基于二次向量的用户兴趣模型提供支持,是一种用户兴趣。词典设计中的私人词典主要考虑以下几个主要原则: 1 一个词在网络文档集合中出现的频率越高,对这个词的用户特征的描述就越强 2 收录该词的网页数量越多web文档集合词对越多对用户特征的描述能力越强 3对于网页中一些常用的没有搜索价值的词,我们称之为网页常用词,比如comment copyright文章字典中,应该过滤掉,以免给用户的个人描述带来干扰。公式中身份证号码提取年龄公式电容电压公式电容公式定积分推导公式力学公式1 S是网页集合T是词空间WtS是词t在S中的权重,tftS是词频S中的词t,N为S中收录的网页总数,nt为S中的文档数,分母为归一化因子。在TF-IDF公式中,Nnt001为IDF因子,即逆向文本频率索引在WTUPD中仍沿用此名称。IDF因子越大,词在网页集合中的分布越稀疏,词的重要性越小,权重越小。反之,词的IDF因子越小,说明它在网页集合中越小。分布越密集,单词的重要性越统一,权重就越大。考虑到词在网页集合中的均匀分布不同,本文认为词t在整个网页集合S中的权重与其在网页中的均匀度成正比,因此本文引入了一个因素测量一致性以修改单词 t 的权重。公式1中t这个词的均匀度是通过网页集合中t的标准差来衡量的。集合S中的权重与网页集合中的词频成正比,与其在网页集中分布的稀疏性和均匀性成正比。通过 WTUPD 公式,

超过5个核心兴趣点的用户选择前12个词作为关键词,其余为扩展词,形成关键词词典和扩展词词典。最后,必须清除关键词 字典和扩展时间。字典中的频繁词的特点是它们分布在网页集合中的大多数文档中,并且在单个网页中出现的频率往往低于1-2次。本文使用以下方法过滤这部分词,经过上述公式处理,最终可以构建出满足用户兴趣描述要求的个性化词典 22 基于个性化词典的用户兴趣建模 最终的词扩展依赖于准确的用户兴趣模型,而个性化词典的建立将有助于快速准确地建立用户兴趣模型。因此,本文采用的用户兴趣建模方法如下:首先,利用个性化词典将用户浏览的网页转化为特征向量。由于个性化词典收录二级词典,因此生成的网页特征向量为二级向量,如网页的特征向量。表示为 [单反 005327385 摄影 004826857 像素 003272436 市场 002713352 专业 002639451...] [镜头 001135712 显示 001023895 环 向量,然后是扩展词向量,然后使用网页的特征向量进行聚类分析,得到用户感兴趣的子类别。最后,使用各种类型的网页特征向量将兴趣子类别描述为辅助向量,以生成用户兴趣模型。可以看出,个性化词典使得整个用户兴趣建模过程使用了两个高级向量用户兴趣模型的生成更加直接和流畅,并且因为个性化词典避免了大量的词和频繁出现的词与传统全局词典中用户兴趣无关,网页特征描述更加准确,为后续的聚类分析和兴趣模型生成奠定基础。良好的基础广州货架wwwgzrundacomgzh并通过用户兴趣模型提供符合用户兴趣偏好的扩展词,有利于扩展词的分析比较和23种查询扩展策略的实施。分子是向量ci和Qini各分量的乘积,分母是向量模数。本文产品选择与初始查询相似度最高的兴趣点C作为用户的查询意图,为用户提供尽可能多的查询扩展词。如果在关键词向量中找不到用户的查询词,即Qini和关键词向量的相似度为0,那么扩展词向量将被合并到关键词@ > 参与计算的向量。下一个,为了找到与用户查询最相关的扩展词,需要计算词之间的相关性。本文参考LSI模型[7中的方法]将网页文档集合表示为词文档矩阵TD,如表1所示。提交给搜索引擎的初始查询词是Qini National Team World Cup Australia。是Qini匹配的兴趣类别的扩展词向量中的矩阵单元TDij,扩展词中间的矩阵单元TDij是文档Dj中对应词Ti的权重和频率。变换的结果是因为单词和文档的数量非常多,单个文档中出现的单词非常有限,所以TD一般是一个高阶稀疏矩阵,然后用TD构建词间关系矩阵TT,计算词间关联度构建方法如下: 式6 其中TD为TD转置得到的矩阵TT中各单元TTij的值,反映了特定环境下特定用户特定兴趣类别的词 i 和 j 之间的相似度。我们可以看到,每个词与其自身的相似度为1,并且在兴趣类别的任何文档中都没有相似度。

两个现有词的相似度为0,如表2所示,其中x表示词间关系矩阵TT,与初始查询词Qini相似度最大的候选扩展词对应的相关度x表示其他候选扩展词。与Qini的相关性公式8中的参数[δ]表示x和x之间的相对误差阈值。只要某个候选扩展词与Qini的相关性与x的相对误差小于δ,那么候选扩展词就可以最终推荐给用户。在实际应用中,δ通常取值为10,这样可以更好地保留扩展词,减少计算时间。可以根据情况进行设置,让过滤后的词按照相关性的顺序排序,然后推荐给因为过多的扩展词会减少搜索结果,不利于用户获取足够的信息。通常选择3个扩展词比较合适,所以最后可以从排序好的扩展词队列中选择前3个词进行推荐。当然可以根据用户需要设置推荐的扩展词数。3 实验与分析 31 个人能力评价评价 个人工作评价评价指标 工作条件风险评价方法评价反应指标 SWUI 因为用户个性化词典UPD实际上几乎收录了用户的归属感 兴趣词和词的权重计算公式浏览历史网页也反映了用户对这些词的兴趣。因此,本文采用将查询扩展搜索到的网页集合与用户的个性化词典进行对比的方法进行实验。评估本文提出的个性化服务模型的效果。为了将检索到的网页集合与用户个性化词典进行比较 余弦函数值之间的相似度通过相似度反映网页集合与用户兴趣的相关程度,该相似度称为 SWUISimilaritybetweenWebpagesandUserInterests32 实验数据 本实验为基于三个用户根据自己的兴趣浏览网页,然后自己感兴趣 保存网页,然后对三个用户提供的兴趣网页进行兴趣建模,得到用户兴趣模型。表4限制了每个兴趣类别的长度,只使用了关键词的一部分 表示 33 对比实验 本文在谷歌和百度上进行了以下三组实验,在主流搜索引擎上进行: 1None 实验不使用查询扩展,只使用用户查询关键词检索实验2 标准实验使用文献[7]中提出的SEPMBDVD模型进行查询扩展然后在搜索引擎广州货架wwwgzrundacomgzh上搜索基于3UPD的实验使用本文提出的QEMBUPDSE模型进行查询扩展然后在搜索引擎上进行搜索比较实验由三个实现提供用户兴趣模型的用户。每个用户为他的每个兴趣选择合适的一个。关键词 根据以上三组实验的要求,在谷歌和百度上搜索。每组实验都会使用每一种搜索引擎返回的前100个网页进行保存,然后为每个搜索引擎计算每个搜索引擎搜索引擎集合与UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI 然后为每个搜索引擎计算每个搜索引擎搜索引擎集合和UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI 然后为每个搜索引擎计算每个搜索引擎搜索引擎集合和UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI

最终实验结果如表5所示,以更直观地反映对比效果。本文计算了UPDbased相对于None和Standard的实验结果的百分比增长,如表6所示。从表6可以看出,首先使用QEMBUPDSE模型进行查询扩展后,搜索到的网页显然更相关用户的兴趣比没有查询扩展。其次,与使用SEPMBDVD模型扩展相比,使用QEMBUPDSE模型进行查询扩展后的搜索网页在用户相关性上也有一定的提升。网页更符合用户的兴趣。这主要是因为在用户建模之前使用UPD可以在一定程度上优化整个用户建模过程。最终用户兴趣模型更准确,查询扩展效果更好。4 结论本文基于文献[7]中提出的二次向量对搜索引擎个性化服务模型进行改进,增加用户个性化词典,优化用户兴趣建模过程,提高查询扩展效果。实验表明,个性化词典基于搜索引擎查询扩展模型可以更有效地辅助用户使用搜索引擎搜索他们感兴趣的信息。在接下来的研究中,需要考虑如何更准确地构建个性化词典和用户兴趣模型,提出更好的相似度计算方法。提高整个个性化搜索模型的性能。参考文献 [1] 丁国栋,白硕,王斌,许伟民基于主题的个性化查询扩展模型[J]计算机工程与设计2-4475[7]徐景秋、朱正宇、谭明宏等基于二次向量的搜索引擎个性化服务模型[J]计算机科学2007341189-92[ 8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗应诸正雨研究与实现广州WWW个性化源字典。货架 wwwgzrundacomgzh 谭铭洪和其他搜索引擎的个性化的服务模式基础上的二次载体[J]。计算机科学2007341189-92 [8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗莹朱政宇的研究与实现个性化源广州词典 www. 货架 wwwgzrundacomgzh 谭铭洪和其他搜索引擎的个性化的服务模式基础上的二次载体[J]。计算机科学2007341189-92 [8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗莹朱政宇的研究与实现个性化源广州词典 www. 货架 wwwgzrundacomgzh
搜索引擎主题模型优化(哪些方法和技巧可以改善网站特殊页面的速度?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-16 15:10
大家都知道网站的质量好,那么文章的质量应该也好。相应的用户体验会很好,但更新频率很低,所以主题采集速度存在严重滞后。问题。有哪些方法和技巧可以改进网站特殊页面的收录?
首先要区分网站的特殊页面和网站的普通页面。所谓特殊页面就是网站管理员的页面。网站 是为特定活动而设计和制作的。投入了大量的精力(包括艺术、策划、营销、文案的整合)。与普通网页相比,特殊网页更美观。,更抢眼。,更有可能促进交易。然而,华丽并不意味着搜索引擎一定会识别它。毕竟,设计了很多美学的主题页面可能对搜索引擎不友好!
那么面对这种尴尬的情况,我们有什么方法可以提高特色页面的速度呢?
,做好网站基础seo优化
1. 主题页面的基础优化包括图片ALT属性的设置。毕竟漂亮的主题也是美化自己必不可少的网站,所以是让搜索引擎成功读取图片的关键。
2.收录完整的关键字HTML、描述、标题,因为有些主题页面实际上是由整个页面组成的FLASH,无论百度搜索引擎是否能够识别出FLASH文件的内容,我们仍然需要通知大纲百度搜索引擎,主题告诉百度搜索引擎的主题是什么!
4.简化网站代码,删除对搜索引擎不友好的内容(包括关键字堆砌和隐藏关键字的行为)。
不是故意弄网站。可以找一些速度非常快的平台,发几个软链接,引导蜘蛛快速爬行。关键是要了解你的核心。
如果话题页真的很吸引人,相信经过营销后,会引起很多人的点击,必然会引起搜索引擎的关注。当您的主题的一些基本 seo 优化完成后,我相信搜索引擎不会收录它。难的! 查看全部
搜索引擎主题模型优化(哪些方法和技巧可以改善网站特殊页面的速度?(图))
大家都知道网站的质量好,那么文章的质量应该也好。相应的用户体验会很好,但更新频率很低,所以主题采集速度存在严重滞后。问题。有哪些方法和技巧可以改进网站特殊页面的收录?

首先要区分网站的特殊页面和网站的普通页面。所谓特殊页面就是网站管理员的页面。网站 是为特定活动而设计和制作的。投入了大量的精力(包括艺术、策划、营销、文案的整合)。与普通网页相比,特殊网页更美观。,更抢眼。,更有可能促进交易。然而,华丽并不意味着搜索引擎一定会识别它。毕竟,设计了很多美学的主题页面可能对搜索引擎不友好!
那么面对这种尴尬的情况,我们有什么方法可以提高特色页面的速度呢?
,做好网站基础seo优化
1. 主题页面的基础优化包括图片ALT属性的设置。毕竟漂亮的主题也是美化自己必不可少的网站,所以是让搜索引擎成功读取图片的关键。
2.收录完整的关键字HTML、描述、标题,因为有些主题页面实际上是由整个页面组成的FLASH,无论百度搜索引擎是否能够识别出FLASH文件的内容,我们仍然需要通知大纲百度搜索引擎,主题告诉百度搜索引擎的主题是什么!
4.简化网站代码,删除对搜索引擎不友好的内容(包括关键字堆砌和隐藏关键字的行为)。
不是故意弄网站。可以找一些速度非常快的平台,发几个软链接,引导蜘蛛快速爬行。关键是要了解你的核心。
如果话题页真的很吸引人,相信经过营销后,会引起很多人的点击,必然会引起搜索引擎的关注。当您的主题的一些基本 seo 优化完成后,我相信搜索引擎不会收录它。难的!
搜索引擎主题模型优化(网站主页优化有哪些注意事项呢?让我们了解它!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-16 08:35
网站首页的重要性不言而喻。当用户浏览网站时,首先看到的是网站的首页。不仅将网站的有价值的内容和核心传达给用户,更能吸引用户长期留在网站。所以在网站的优化过程中,一定要注意网站首页的优化。网站首页的导航是对网站进行一个整体的分类,让用户可以方便快捷的找到自己需要的信息。那么,网站首页优化有哪些注意事项呢?让我们了解一下
!首先是改进主页的标题。在网站的SEO优化中,一定要精心设计标题,因为标题会影响搜索引擎的抓取,而标题就是对关键词的描述。设计标题时,应收录首页或栏目页的关键词,但必须是完整的句子,不要堆砌关键词。一些网站主要以图片为主。优化这种类型的网站时,必须在图片中添加说明。如果图像处理不好,就很难优化网站。
其次,注意不要在网站的首页添加视频,这样会影响用户体验,增加网站的跳出率。如果网站必须在首页添加视频,那么必须在视频属性中添加文字说明,因为搜索引擎只会抓取文字。如果纯视频不利于搜索引擎抓取,会影响用户打开网站的速度。
最后,我们应该每天检查链接的状态,及时删除问题。在链接的交流上,要和同行业的网站交流,这样才能互补,增加搜索引擎的友好度,增加关键词在首页的密度。
以上就是网站首页优化的注意事项。影响网站首页排名的因素有很多,比如网站的运营、高质量的原创文章等,只有采用正确的优化方法才能使首页的排名靠前。 网站的排名稳步上升。
网站的标题有什么好的优化方法吗?
优化网站标题的关键是关键词的选择,所以第一步是选择关键词。
关键词选择主要根据行业和企业的产品和服务,发散思维总结。
根据用户的搜索关键词,一般有搜索引擎下拉框、相关搜索、搜索工具排名。
使用单词扩展工具扩展大量关键字。
购买关键词数据等
第二步,对所有关键词进行整理汇总,最后制作自己的关键词统计表。
网站 标题优化的原则是尽量多插入关键词,然后把关键词放在前面。
当然网站的整体权重很重要。
主题网站 设计优化时要注意哪些方面?
根据你设计的产品,基本的配色和布局知识就不用说了。要想设计好,就必须考虑用户体验。也了解产品领域的专业知识和用户场景。我认为设计只是一方面。了解业务流程、客户关注点、数据分析等将促进设计优化
优化模型的数学建模有哪些?什么模型可以用于路径优化? 查看全部
搜索引擎主题模型优化(网站主页优化有哪些注意事项呢?让我们了解它!)
网站首页的重要性不言而喻。当用户浏览网站时,首先看到的是网站的首页。不仅将网站的有价值的内容和核心传达给用户,更能吸引用户长期留在网站。所以在网站的优化过程中,一定要注意网站首页的优化。网站首页的导航是对网站进行一个整体的分类,让用户可以方便快捷的找到自己需要的信息。那么,网站首页优化有哪些注意事项呢?让我们了解一下
!首先是改进主页的标题。在网站的SEO优化中,一定要精心设计标题,因为标题会影响搜索引擎的抓取,而标题就是对关键词的描述。设计标题时,应收录首页或栏目页的关键词,但必须是完整的句子,不要堆砌关键词。一些网站主要以图片为主。优化这种类型的网站时,必须在图片中添加说明。如果图像处理不好,就很难优化网站。
其次,注意不要在网站的首页添加视频,这样会影响用户体验,增加网站的跳出率。如果网站必须在首页添加视频,那么必须在视频属性中添加文字说明,因为搜索引擎只会抓取文字。如果纯视频不利于搜索引擎抓取,会影响用户打开网站的速度。
最后,我们应该每天检查链接的状态,及时删除问题。在链接的交流上,要和同行业的网站交流,这样才能互补,增加搜索引擎的友好度,增加关键词在首页的密度。
以上就是网站首页优化的注意事项。影响网站首页排名的因素有很多,比如网站的运营、高质量的原创文章等,只有采用正确的优化方法才能使首页的排名靠前。 网站的排名稳步上升。
网站的标题有什么好的优化方法吗?
优化网站标题的关键是关键词的选择,所以第一步是选择关键词。
关键词选择主要根据行业和企业的产品和服务,发散思维总结。
根据用户的搜索关键词,一般有搜索引擎下拉框、相关搜索、搜索工具排名。
使用单词扩展工具扩展大量关键字。
购买关键词数据等
第二步,对所有关键词进行整理汇总,最后制作自己的关键词统计表。
网站 标题优化的原则是尽量多插入关键词,然后把关键词放在前面。
当然网站的整体权重很重要。
主题网站 设计优化时要注意哪些方面?
根据你设计的产品,基本的配色和布局知识就不用说了。要想设计好,就必须考虑用户体验。也了解产品领域的专业知识和用户场景。我认为设计只是一方面。了解业务流程、客户关注点、数据分析等将促进设计优化
优化模型的数学建模有哪些?什么模型可以用于路径优化?
搜索引擎主题模型优化( 主题聚类一组模子作为最新的搜索引擎优化计策优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-13 23:24
主题聚类一组模子作为最新的搜索引擎优化计策优化)
在风中弹跳
11-10 10:27 阅读 38
注意
主题聚类模型和搜索引擎优化
多年来,SEO 经历了各种变化,从链接方案的消亡到移动优先。然而,业界最大的创新之一是使用主题聚类模型作为最新的搜索引擎优化策略。
主题聚类模型可以将用户过去的搜索与相关的主题和短语联系起来,为用户找到最佳效果。您应该知道,在任何搜索引擎性能页面 (SERP) 上的排名都意味着显示的关键词需要相互关联。
什么是主题集群?
主题组是一组相关的网页,周围环绕着涵盖该主题的构建支柱。特定主题的搜索可见性优于特定关键字的排名。这种策略最终可以帮助您开发影响区域,其中相关长尾关键字的本地搜索总和高于主要关键字的搜索总和。这将帮助您组织 网站 的布局和内容。此外,当集群中的内容排名出色时,整个集群也会排名出色。
主题集群模型收录三个组件:
支柱内容
支柱内容是集群的重点,因为它基于更普遍的主题。它通常有 3000 到 5000 字,涵盖了特定主题的方方面面,但仍有足够的空间来回答不同的帖子。支柱的内容适合那些对某个主题不熟悉但想熟悉所有内容的人。
集群内容
该组件处理与支柱内容直接相关的所有类型的集群内容。与涉及无孔不入主题的支柱内容不同,集群内容侧重于与无孔不入关键字相关的特定关键字,并以更全面和全面的方式组织连接。最后,这些聚集的内容包括一个链接,允许读者返回到支柱内容。
超链接
这是所有三个组件中最重要的,主要是因为超链接是将支柱内容绑定到集群内容的关键。
简而言之,主题聚类模型是特定主题下的一组相关内容,易于被各种搜索引擎识别。它发生的信号旨在证明您在特定主题上的网站权威和专业常识,这将增加网站的知名度,从而带来更多的流量和转换时间。
主题聚类模型的重要性和优势
毫无疑问,关键词一直是并且仍然是内容创作的基础。然而,随着技能的不断创新和转化,用户如何交互或使用一组给定的关键词将逐渐改变他们的行为。
自从 Siri、Alexa 和小爱同学等数字助理出现以来,它们已经成为最常见的满足搜索引擎性能页面 (SERP) 的平台之一,比手动输入查询要快得多。
由于用户行为的变化,百度和其他搜索引擎一直在修改他们的系统以满足基于主题的内容搜索。无法适应行为变化的现有搜索引擎优化策略最终会失效,无法让位于新的更有效的策略,例如主题聚类模型。
虽然关键词还是很重要的,定位整个主题是目前的方法,主要原因如下:
搜索引擎更擅长欣赏相关的想法。
搜索确切的关键词仍然是相关的,但目前搜索算法可以更好地识别同一主题的多个术语。权威可信的功能是百度等搜索引擎希望提供响应用户的功能。
为了向人们和傻瓜式人展示权威,需要针对一个主题一个接一个地构建昂贵而精确的内容,这比针对不相关的关键词构建无组织的内容要好得多。
综上所述
回收新策略确实令人生畏,尤其是当您的 网站 已经有很多内容时。但是,如果你能在完成一个主题的同时规划大量相关的主题,然后将它们拼接在一起,那么你就可以轻松实现这个策略。 查看全部
搜索引擎主题模型优化(
主题聚类一组模子作为最新的搜索引擎优化计策优化)

在风中弹跳
11-10 10:27 阅读 38
注意
主题聚类模型和搜索引擎优化
多年来,SEO 经历了各种变化,从链接方案的消亡到移动优先。然而,业界最大的创新之一是使用主题聚类模型作为最新的搜索引擎优化策略。
主题聚类模型可以将用户过去的搜索与相关的主题和短语联系起来,为用户找到最佳效果。您应该知道,在任何搜索引擎性能页面 (SERP) 上的排名都意味着显示的关键词需要相互关联。
什么是主题集群?
主题组是一组相关的网页,周围环绕着涵盖该主题的构建支柱。特定主题的搜索可见性优于特定关键字的排名。这种策略最终可以帮助您开发影响区域,其中相关长尾关键字的本地搜索总和高于主要关键字的搜索总和。这将帮助您组织 网站 的布局和内容。此外,当集群中的内容排名出色时,整个集群也会排名出色。
主题集群模型收录三个组件:
支柱内容
支柱内容是集群的重点,因为它基于更普遍的主题。它通常有 3000 到 5000 字,涵盖了特定主题的方方面面,但仍有足够的空间来回答不同的帖子。支柱的内容适合那些对某个主题不熟悉但想熟悉所有内容的人。
集群内容
该组件处理与支柱内容直接相关的所有类型的集群内容。与涉及无孔不入主题的支柱内容不同,集群内容侧重于与无孔不入关键字相关的特定关键字,并以更全面和全面的方式组织连接。最后,这些聚集的内容包括一个链接,允许读者返回到支柱内容。
超链接
这是所有三个组件中最重要的,主要是因为超链接是将支柱内容绑定到集群内容的关键。
简而言之,主题聚类模型是特定主题下的一组相关内容,易于被各种搜索引擎识别。它发生的信号旨在证明您在特定主题上的网站权威和专业常识,这将增加网站的知名度,从而带来更多的流量和转换时间。
主题聚类模型的重要性和优势
毫无疑问,关键词一直是并且仍然是内容创作的基础。然而,随着技能的不断创新和转化,用户如何交互或使用一组给定的关键词将逐渐改变他们的行为。
自从 Siri、Alexa 和小爱同学等数字助理出现以来,它们已经成为最常见的满足搜索引擎性能页面 (SERP) 的平台之一,比手动输入查询要快得多。
由于用户行为的变化,百度和其他搜索引擎一直在修改他们的系统以满足基于主题的内容搜索。无法适应行为变化的现有搜索引擎优化策略最终会失效,无法让位于新的更有效的策略,例如主题聚类模型。
虽然关键词还是很重要的,定位整个主题是目前的方法,主要原因如下:
搜索引擎更擅长欣赏相关的想法。
搜索确切的关键词仍然是相关的,但目前搜索算法可以更好地识别同一主题的多个术语。权威可信的功能是百度等搜索引擎希望提供响应用户的功能。
为了向人们和傻瓜式人展示权威,需要针对一个主题一个接一个地构建昂贵而精确的内容,这比针对不相关的关键词构建无组织的内容要好得多。
综上所述
回收新策略确实令人生畏,尤其是当您的 网站 已经有很多内容时。但是,如果你能在完成一个主题的同时规划大量相关的主题,然后将它们拼接在一起,那么你就可以轻松实现这个策略。
搜索引擎主题模型优化(搜索引擎主题模型优化以下模型-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-13 09:01
搜索引擎主题模型优化以下模型可对搜索引擎进行主题模型优化:根据搜索引擎的意图、指向和搜索特性,对搜索引擎的结构、形态进行优化,不断提高搜索引擎的特征提取能力、信息智能分发能力和自动排序功能能力,提高用户体验搜索推荐搜索推荐可以基于当前用户习惯的输入来给用户提供该类或者相关的内容。搜索引擎的优化目标搜索引擎优化目标可分为以下五点:。
1、网站排名——上首页,
2、用户体验——改善用户使用网站过程中的体验和意愿,增加用户粘性,
3、用户意图——将网站中符合用户意图的信息提取出来,改善信息查询效率,
4、搜索效率——提高链接质量,
5、价值性——网站结构更合理,提高网站内容生产效率,搜索关键词相关性;优化的方法目前可优化的方法有以下四点:对搜索引擎进行自动诊断;a.内容质量检测——设计好网站链接结构,优化外链;b.页面颜色设计——显示网站链接地址规则;c.可被搜索引擎辨别内容——收录情况分析,存在的问题及优化建议;d.关键词密度分析——主关键词、长尾关键词分析和收录情况分析;e.词汇、短语、句子相似度分析——提高关键词相似度;搜索引擎推荐信息2.1一些常见的搜索引擎排名的搜索推荐方法a.意图搜索推荐——采用用户意图方向,筛选相关的链接;b.行为召回推荐——网站地址结构处理;c.业务聚合推荐——针对某类业务业务专题,推荐相关内容;2.2搜索推荐的工作原理a.基于关键词相似性,即搜索网站不同关键词的情况下,搜索结果同样搜索某一个主题;b.基于网站热度排名,即按照各个用户输入的网站信息,来综合优化不同网站;c.基于常用搜索词,根据用户搜索习惯的排名;d.基于用户输入内容中的关键词,从用户查询语义中寻找最相关的链接。
2.3搜索推荐的模型优化搜索推荐的优化工作方式一般分为三种:倾向型模型优化,多用于分析数据与用户行为的数据方面,数据智能化,多用于资源方面;建模型模型优化,多用于优化数据对外部分析方面;搜索推荐模型优化,多用于垂直行业的优化。1倾向性模型优化倾向性模型优化主要针对于分析数据与用户行为的数据方面,其优化方式多为itemsensemble。
简单的说,就是把一个长尾关键词进行排序后,对于长尾关键词分析存在哪些相似,从而进行聚合操作,从而对长尾词进行分词,得到最终结果。例如:用户输入“北京求职高校”搜索,那么系统就会自动对应匹配“北京”、“求职”等前缀关键词,从。 查看全部
搜索引擎主题模型优化(搜索引擎主题模型优化以下模型-上海怡健医学())
搜索引擎主题模型优化以下模型可对搜索引擎进行主题模型优化:根据搜索引擎的意图、指向和搜索特性,对搜索引擎的结构、形态进行优化,不断提高搜索引擎的特征提取能力、信息智能分发能力和自动排序功能能力,提高用户体验搜索推荐搜索推荐可以基于当前用户习惯的输入来给用户提供该类或者相关的内容。搜索引擎的优化目标搜索引擎优化目标可分为以下五点:。
1、网站排名——上首页,
2、用户体验——改善用户使用网站过程中的体验和意愿,增加用户粘性,
3、用户意图——将网站中符合用户意图的信息提取出来,改善信息查询效率,
4、搜索效率——提高链接质量,
5、价值性——网站结构更合理,提高网站内容生产效率,搜索关键词相关性;优化的方法目前可优化的方法有以下四点:对搜索引擎进行自动诊断;a.内容质量检测——设计好网站链接结构,优化外链;b.页面颜色设计——显示网站链接地址规则;c.可被搜索引擎辨别内容——收录情况分析,存在的问题及优化建议;d.关键词密度分析——主关键词、长尾关键词分析和收录情况分析;e.词汇、短语、句子相似度分析——提高关键词相似度;搜索引擎推荐信息2.1一些常见的搜索引擎排名的搜索推荐方法a.意图搜索推荐——采用用户意图方向,筛选相关的链接;b.行为召回推荐——网站地址结构处理;c.业务聚合推荐——针对某类业务业务专题,推荐相关内容;2.2搜索推荐的工作原理a.基于关键词相似性,即搜索网站不同关键词的情况下,搜索结果同样搜索某一个主题;b.基于网站热度排名,即按照各个用户输入的网站信息,来综合优化不同网站;c.基于常用搜索词,根据用户搜索习惯的排名;d.基于用户输入内容中的关键词,从用户查询语义中寻找最相关的链接。
2.3搜索推荐的模型优化搜索推荐的优化工作方式一般分为三种:倾向型模型优化,多用于分析数据与用户行为的数据方面,数据智能化,多用于资源方面;建模型模型优化,多用于优化数据对外部分析方面;搜索推荐模型优化,多用于垂直行业的优化。1倾向性模型优化倾向性模型优化主要针对于分析数据与用户行为的数据方面,其优化方式多为itemsensemble。
简单的说,就是把一个长尾关键词进行排序后,对于长尾关键词分析存在哪些相似,从而进行聚合操作,从而对长尾词进行分词,得到最终结果。例如:用户输入“北京求职高校”搜索,那么系统就会自动对应匹配“北京”、“求职”等前缀关键词,从。
搜索引擎主题模型优化(关键词:搜索引擎发展方向今天很高兴有机会在这里做)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-11 01:37
关键词:搜索引擎发展方向
今天很高兴有机会在这里做这份题为《搜索引擎研发的难点和发展方向》的报告。几年前,搜狐的地址在建国门附近,是一个商业环境;2003年,公司研发中心在清华同方大厦成立,为公司提供更多的技术支持;2004年,搜狐整体搬迁至清华科技园。基于此,我们看到了一个轨迹:搜狐本身作为一家公司,已经从原来的市场导向转变为现在的技术驱动,并与高校建立了密切的合作关系。
1.搜索和搜索引擎
搜索与搜索引擎的区别在于,搜索引擎是以技术为核心的技术概念和服务;而搜索更加工业化。今天我将重点介绍中文网络搜索遇到的困难和发展方向。
搜狗的成长之路
2003年9月,组建团队;
2004年8月,1.0版本正式发布;
2005年12月,2.5版本正式发布;
预计2006年7月将达到同期行业领先水平。
搜索引擎的研发不同于其他项目。因为它直接依赖于技术,技术和运营密不可分,所以一般来说,搜索引擎应该由商业公司自己开发并投入使用。这里我们需要一个边界来定义哪些任务由研发机构完成,哪些任务由企业完成。只有明确这个界限,才能提高工作效率,才能开发出技术先进、适合市场需求的大型搜索引擎。
2. 搜索引擎面临的挑战
(1)工程
1999年,有人预言搜索引擎的发展是不可能的。由于互联网信息呈指数级增长,检索如此大量的信息是不可能的。但现在,虽然搜索引擎的效果不尽如人意,但至少已经完成了自己的基本功能,在这个领域迈出了一大步。
支持如此复杂的引擎,需要庞大的硬件环境。例如,谷歌在全球拥有超过 140,000 台服务器。如此庞大的系统,在开发、测试、硬件维护等方面都给人们带来了一定的困难甚至挑战。
(2)学术研究
目前,公司已与清华大学建立合作关系,双方优势互补。
在搜索引擎开发过程中,海量数据的处理是一大难题。在研究领域,语言模型可以实现高达97%的识别率;但在实际应用中,面对互联网的海量数据,处理速度受到严重影响,最前沿的技术成果变得无用,导致开发者更倾向于选择效率高、识别率低的技术。
在进行研发工作时,往往需要互联网上的真实数据。采集这些数据在高校很难完成,但在公司很容易获得。同样,很多手工贴标签的工作更适合在公司完成。
工程/运营架构的妥协现在是学术领域和工程领域之间的一个主要问题。例如,研究机构开发的高质量算法在实际应用中不会有很强的可用性,因为算法太复杂,系统太大。
(3)社会方面
首先是垃圾邮件的问题。在互联网上,80%的信息都是垃圾。用户搜索的是准确的信息,公司需要组织团队建立学习系统来处理网络垃圾邮件。
由于搜索引擎难以抓取海量数据,有人考虑在搜索引擎和各种网站之间建立合作关系,由网站自己将数据推送给搜索引擎;或者每个网站都建立了文档来解释他们的有用信息。但这会严重破坏搜索引擎的公平性,大大失去搜索结果的意义,因此没有发展空间。
博客等新事物的出现,也对搜索引擎的发展产生了一定的影响。比如有的Blog的信息比网站的信息更全面,有的则全是垃圾信息,给搜索引擎的检索带来了一定的困难。
三、搜索引擎未来的发展方向
(1) 宽带应用
将互联网上的音视频信息内容组织起来,进行有效的描述,实现高效的存储和传输,是搜索引擎未来的发展方向之一。
(2)互动体验
谷歌改变了用户上网、漫游的浏览习惯,而是将用户需要的信息进行线性排列。未来,导航将成为互联网浏览的主要方式:搜索引擎充分理解用户想要表达的主题,将所需信息按类别排列呈现给用户,增加更多纠错能力,列出错误校正提示。
(3)垂直化和入口占领
未来,搜索引擎将从平行搜索转向垂直搜索,只对某一领域的信息进行精准搜索。这种细化是搜索引擎未来发展的一个方向。所谓入口,是指搜索将成为用户登录互联网的第一道坎,搜索引擎品牌和用户习惯将直接引导市场。
(4)互联网的进步
谷歌不仅在搜索领域处于领先地位,还加入了网站翻译领域并取得了不错的成绩。谷歌之所以能在翻译上取得好成绩,是因为它在其他人无法完成的海量信息方面具有优势。这也是搜索引擎发展的一个趋势。比如在输入法等领域,也可以通过对海量信息的评估,添加传统词典中没有的信息。 查看全部
搜索引擎主题模型优化(关键词:搜索引擎发展方向今天很高兴有机会在这里做)
关键词:搜索引擎发展方向
今天很高兴有机会在这里做这份题为《搜索引擎研发的难点和发展方向》的报告。几年前,搜狐的地址在建国门附近,是一个商业环境;2003年,公司研发中心在清华同方大厦成立,为公司提供更多的技术支持;2004年,搜狐整体搬迁至清华科技园。基于此,我们看到了一个轨迹:搜狐本身作为一家公司,已经从原来的市场导向转变为现在的技术驱动,并与高校建立了密切的合作关系。
1.搜索和搜索引擎
搜索与搜索引擎的区别在于,搜索引擎是以技术为核心的技术概念和服务;而搜索更加工业化。今天我将重点介绍中文网络搜索遇到的困难和发展方向。
搜狗的成长之路
2003年9月,组建团队;
2004年8月,1.0版本正式发布;
2005年12月,2.5版本正式发布;
预计2006年7月将达到同期行业领先水平。
搜索引擎的研发不同于其他项目。因为它直接依赖于技术,技术和运营密不可分,所以一般来说,搜索引擎应该由商业公司自己开发并投入使用。这里我们需要一个边界来定义哪些任务由研发机构完成,哪些任务由企业完成。只有明确这个界限,才能提高工作效率,才能开发出技术先进、适合市场需求的大型搜索引擎。
2. 搜索引擎面临的挑战
(1)工程
1999年,有人预言搜索引擎的发展是不可能的。由于互联网信息呈指数级增长,检索如此大量的信息是不可能的。但现在,虽然搜索引擎的效果不尽如人意,但至少已经完成了自己的基本功能,在这个领域迈出了一大步。
支持如此复杂的引擎,需要庞大的硬件环境。例如,谷歌在全球拥有超过 140,000 台服务器。如此庞大的系统,在开发、测试、硬件维护等方面都给人们带来了一定的困难甚至挑战。
(2)学术研究
目前,公司已与清华大学建立合作关系,双方优势互补。
在搜索引擎开发过程中,海量数据的处理是一大难题。在研究领域,语言模型可以实现高达97%的识别率;但在实际应用中,面对互联网的海量数据,处理速度受到严重影响,最前沿的技术成果变得无用,导致开发者更倾向于选择效率高、识别率低的技术。
在进行研发工作时,往往需要互联网上的真实数据。采集这些数据在高校很难完成,但在公司很容易获得。同样,很多手工贴标签的工作更适合在公司完成。
工程/运营架构的妥协现在是学术领域和工程领域之间的一个主要问题。例如,研究机构开发的高质量算法在实际应用中不会有很强的可用性,因为算法太复杂,系统太大。
(3)社会方面
首先是垃圾邮件的问题。在互联网上,80%的信息都是垃圾。用户搜索的是准确的信息,公司需要组织团队建立学习系统来处理网络垃圾邮件。
由于搜索引擎难以抓取海量数据,有人考虑在搜索引擎和各种网站之间建立合作关系,由网站自己将数据推送给搜索引擎;或者每个网站都建立了文档来解释他们的有用信息。但这会严重破坏搜索引擎的公平性,大大失去搜索结果的意义,因此没有发展空间。
博客等新事物的出现,也对搜索引擎的发展产生了一定的影响。比如有的Blog的信息比网站的信息更全面,有的则全是垃圾信息,给搜索引擎的检索带来了一定的困难。
三、搜索引擎未来的发展方向
(1) 宽带应用
将互联网上的音视频信息内容组织起来,进行有效的描述,实现高效的存储和传输,是搜索引擎未来的发展方向之一。
(2)互动体验
谷歌改变了用户上网、漫游的浏览习惯,而是将用户需要的信息进行线性排列。未来,导航将成为互联网浏览的主要方式:搜索引擎充分理解用户想要表达的主题,将所需信息按类别排列呈现给用户,增加更多纠错能力,列出错误校正提示。
(3)垂直化和入口占领
未来,搜索引擎将从平行搜索转向垂直搜索,只对某一领域的信息进行精准搜索。这种细化是搜索引擎未来发展的一个方向。所谓入口,是指搜索将成为用户登录互联网的第一道坎,搜索引擎品牌和用户习惯将直接引导市场。
(4)互联网的进步
谷歌不仅在搜索领域处于领先地位,还加入了网站翻译领域并取得了不错的成绩。谷歌之所以能在翻译上取得好成绩,是因为它在其他人无法完成的海量信息方面具有优势。这也是搜索引擎发展的一个趋势。比如在输入法等领域,也可以通过对海量信息的评估,添加传统词典中没有的信息。
搜索引擎主题模型优化(如何判断网页和查询的相关性?布尔模型简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-10 22:34
搜索引擎的质量很大程度上取决于搜索结果的网页内容和用户体验。搜索引擎在搜索能够满足用户需求的网页时,主要考虑两个方面:网页与查询的相关性和网页的重要性。网页与查询的相关性是指用户的搜索查询与网页内容之间的内容相似度得分,通常通过链接分析计算方法来评估网页的重要性;这篇文章主要简单描述了搜索引擎如何判断网页和查询的相关性?
判断网页内容是否与用户查询关键词相关,取决于搜索引擎采用的检索模型。几种常用的检索模型:布尔模型、向量空间模型、概率模型、语言模型和机器学习排序算法。
1.布尔模型
简单来说,布尔模型就是用户查询的词是否出现在网页中,对与错,收录在不收录。比如用户搜索关键词是SEO,希望得到与SEO相关的信息,那么当网页内容中出现SEO这个词时,就说明该网页与用户的查询相关。布尔模型也是检索模型中最简单的一种,其优缺点也非常直观。
2.矢量空间模型
向量空间模型将查询词和文档中的关键词转换为特征向量,然后利用余弦公式计算文档与查询的相似度并对输出结果进行排序。其中主要介绍了TF-IDF算法、TF词频和IDF逆文档频率。
TF词频,即一个词在内容中出现的次数。出现次数较多的词往往可以说明内容的主题信息。IDF逆文档频率是衡量单词普遍重要性的指标,突出特征词。如果某个关键词在网页内容中的词频很高,而这个词很少出现在网页搜索结果和其他网页内容中,那么这个关键词的权重就会很高。SEO常用的就是关键词的密度,但是没有统一的衡量标准。不要用2%~8%作为关键词的密度标准。
3.概率模型
最成功的概率模型是 BM25 模型,目前被大多数商业搜索引擎用作相关性排名模型。在TF-IDF算法的基础上,扩展了相关的概率后续词,比如搜索词SEO,大部分可能搜索SEO培训、SEO服务等。从海量大数据中推导出后续需求,多维度满足用户需求。目前百度官方参考的是百度指数的相关需求图。一些后续词是根据他们的,但仅供参考;不限于百度下拉框等后续查询词和相关搜索。
网页是指整体,网页可以分为不同的区域。比如网页标题、描述、网页内容、网页底部的标题等,不同的区域有不同的权重。经常说的网页标题必须具有很高的权重。标题很大程度上收录了相关的关键词。说明网页内容的中心思想。我对搜索引擎判断网页和查询的相关性有一个基本的了解,所以不用去堆砌关键词,琢磨关键词的密度。
(责任编辑:搜索引擎网站优化SEO外包-,原创不容易,转载时必须以链接的形式注明作者、原出处和本声明。) 查看全部
搜索引擎主题模型优化(如何判断网页和查询的相关性?布尔模型简单)
搜索引擎的质量很大程度上取决于搜索结果的网页内容和用户体验。搜索引擎在搜索能够满足用户需求的网页时,主要考虑两个方面:网页与查询的相关性和网页的重要性。网页与查询的相关性是指用户的搜索查询与网页内容之间的内容相似度得分,通常通过链接分析计算方法来评估网页的重要性;这篇文章主要简单描述了搜索引擎如何判断网页和查询的相关性?

判断网页内容是否与用户查询关键词相关,取决于搜索引擎采用的检索模型。几种常用的检索模型:布尔模型、向量空间模型、概率模型、语言模型和机器学习排序算法。
1.布尔模型
简单来说,布尔模型就是用户查询的词是否出现在网页中,对与错,收录在不收录。比如用户搜索关键词是SEO,希望得到与SEO相关的信息,那么当网页内容中出现SEO这个词时,就说明该网页与用户的查询相关。布尔模型也是检索模型中最简单的一种,其优缺点也非常直观。
2.矢量空间模型
向量空间模型将查询词和文档中的关键词转换为特征向量,然后利用余弦公式计算文档与查询的相似度并对输出结果进行排序。其中主要介绍了TF-IDF算法、TF词频和IDF逆文档频率。
TF词频,即一个词在内容中出现的次数。出现次数较多的词往往可以说明内容的主题信息。IDF逆文档频率是衡量单词普遍重要性的指标,突出特征词。如果某个关键词在网页内容中的词频很高,而这个词很少出现在网页搜索结果和其他网页内容中,那么这个关键词的权重就会很高。SEO常用的就是关键词的密度,但是没有统一的衡量标准。不要用2%~8%作为关键词的密度标准。
3.概率模型
最成功的概率模型是 BM25 模型,目前被大多数商业搜索引擎用作相关性排名模型。在TF-IDF算法的基础上,扩展了相关的概率后续词,比如搜索词SEO,大部分可能搜索SEO培训、SEO服务等。从海量大数据中推导出后续需求,多维度满足用户需求。目前百度官方参考的是百度指数的相关需求图。一些后续词是根据他们的,但仅供参考;不限于百度下拉框等后续查询词和相关搜索。
网页是指整体,网页可以分为不同的区域。比如网页标题、描述、网页内容、网页底部的标题等,不同的区域有不同的权重。经常说的网页标题必须具有很高的权重。标题很大程度上收录了相关的关键词。说明网页内容的中心思想。我对搜索引擎判断网页和查询的相关性有一个基本的了解,所以不用去堆砌关键词,琢磨关键词的密度。
(责任编辑:搜索引擎网站优化SEO外包-,原创不容易,转载时必须以链接的形式注明作者、原出处和本声明。)
搜索引擎主题模型优化(2019年10月19日,舟山摄影seo整站优化方案厂家报价)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-10 08:24
2019年10月19日,力果科技宣布!舟山摄影seo优化全站厂家报价,力果科技专注网络营销推广,只做一件事:持续为客户创造价值。基于爱站大数据运营,以各行业亿万站点为媒介,通过爱站内部技术和工具,深入研究、分析、验证搜索引擎算法排名调查机制,形成不同行业的SEO优化模型,避开搜索引擎算法黑洞,快速有效提升网站的排名。通过提供针对性的解决方案,覆盖了行业95%以上的用户需求。增加整个站点的权重等级,提升页面搜索引擎整体得分,带来数万个关键词排名提升。《路亚是怎么抓草鱼和鲤鱼的》、《路亚桥口**假饵》、《路亚钓竿什么牌子的好》等这些内容话题定位可以从流量词“路亚”的分支需求中获取流动。纯原创:适合有专业知识编辑的团队。伪原创:采集互联网域名上最好的内容,加上自己的一些观点和润色,形成了一篇新文章文章。比如这里,我就拆分了“路亚的嘴是什么诱饵?”这个话题的监控。将其监控成三个词:路亚、爱丽丝的嘴、假饵,并设置低俗内容收录这三个词。我们制作了源源不断的内容后,别忘了将内容提交到熊掌后台,让百度最快收录你的文章霸占排行榜,熊掌收录速度比被爬虫被动抓取的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!霸占排行榜,和掌上收录的速度比被爬虫被动爬行的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!霸占排行榜,和掌上收录的速度比被爬虫被动爬行的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!这是新时代。操作方式。网站流量托管,为您提供一站式服务!这是新时代。操作方式。网站流量托管,为您提供一站式服务! 查看全部
搜索引擎主题模型优化(2019年10月19日,舟山摄影seo整站优化方案厂家报价)
2019年10月19日,力果科技宣布!舟山摄影seo优化全站厂家报价,力果科技专注网络营销推广,只做一件事:持续为客户创造价值。基于爱站大数据运营,以各行业亿万站点为媒介,通过爱站内部技术和工具,深入研究、分析、验证搜索引擎算法排名调查机制,形成不同行业的SEO优化模型,避开搜索引擎算法黑洞,快速有效提升网站的排名。通过提供针对性的解决方案,覆盖了行业95%以上的用户需求。增加整个站点的权重等级,提升页面搜索引擎整体得分,带来数万个关键词排名提升。《路亚是怎么抓草鱼和鲤鱼的》、《路亚桥口**假饵》、《路亚钓竿什么牌子的好》等这些内容话题定位可以从流量词“路亚”的分支需求中获取流动。纯原创:适合有专业知识编辑的团队。伪原创:采集互联网域名上最好的内容,加上自己的一些观点和润色,形成了一篇新文章文章。比如这里,我就拆分了“路亚的嘴是什么诱饵?”这个话题的监控。将其监控成三个词:路亚、爱丽丝的嘴、假饵,并设置低俗内容收录这三个词。我们制作了源源不断的内容后,别忘了将内容提交到熊掌后台,让百度最快收录你的文章霸占排行榜,熊掌收录速度比被爬虫被动抓取的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!霸占排行榜,和掌上收录的速度比被爬虫被动爬行的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!霸占排行榜,和掌上收录的速度比被爬虫被动爬行的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!这是新时代。操作方式。网站流量托管,为您提供一站式服务!这是新时代。操作方式。网站流量托管,为您提供一站式服务!
搜索引擎主题模型优化(基于PageRank算法的搜索引擎优化策略(安徽财经大学信息工程学院蚌埠233041))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-10 07:08
基于PageRank算法的搜索引擎优化策略(蚌埠233041),安徽财经大学信息工程学院) 重点:分析Google PageRank(PR值)算法的原理,详细讨论主要方面网站链接的变化:站内链接、入站链接、站内链接的变化对网站PR值的影响,提出通过增加入站链接来优化网站链接,减少外链,避免不必要的内链。为了提高PR和提高网站在搜索引擎中的排名,提出了一种优化策略。关键词:PageRank 网页结构挖掘搜索引擎中文图书馆分类号:TP312 文献识别码:A doi:10.3969 j.issn.1005-8095.201< 本文主要讨论算法PR值的搜索引擎优化策略,其实作为最著名的搜索引擎品牌,谷歌的排名结果是非常权威的。经过针对谷歌优化的网站,通常在百度、雅虎等其他搜索引擎中排名第一。
PR值算法分析2.1 PR值的基本思想PR值是根据“很多优质网页链接的网页一定还是优质网页”的回归关系来确定网页的重要性。PR值利用互联网中巨大的链接关系,以网页之间链接的数量和质量作为网页评价的手段。截至2009年10月末,全球互联网网站网站的数量已经突破了信息量的爆发式增长。在让我们掌握更多信息的同时,也对信息检索提出了严峻的考验。搜索是除电子邮件外最常用的网络行为方式。通过搜索引擎查找信息是互联网用户查找在线信息和资源的主要手段。1998年,谷歌公司提出了著名的PR值算法,该算法可以高效地将用户使用搜索引擎的搜索结果按重要性排序。这种算法让用户得到满意的网络,也让谷歌发展成为搜索引擎行业的代表。对于每一个网站,为了赢得大量相似网站的竞争,提高产品或服务的知名度,必须在大型搜索引擎的搜索排名中排名靠前并提高点击率。这也成为每个网站的重要任务。词-搜索引擎优化。搜索引擎优化由此诞生了一个新名称。
下面的调查报告充分说明了搜索引擎优化的重要性: 链接到另一个网页 b 相当于页面优先。搜索引擎营销公司 iCrossing 投票支持页面的重要性。从链接数来看,一个网页的投票越多,反向链接越多,PR值就越高。从链接质量的角度来看,如果一个网页获得了一个相对高质量的网页的链接,这个网页可以获得更高的PR值。该算法有两个基本假设:(1)一个网页被引用的频率越高,这个页面就越重要;当它被一个非常重要的页面引用时,这个页面就越重要(2)假设用户开始随机访问一个页面,然后点击该页面的链接,调查发现:在线购物以前,搜索引擎是最受欢迎的产品和服务搜索工具,74% 的用户搜索产品,而 54% 的用户搜索 网站。二、中国搜索引擎市场研究年度报告指出,截至2007年底,市场规模已达29.3亿元,同比增长76.5% . 2008年中国搜索引擎市场规模达到51.5元,较2007年同期增长77.1% 谷歌、百度、雅虎市场份额增至96.4%,中国搜索引擎市场集中度进一步提高。正是由于搜索引擎行业的高速发展。稿件日期:2010-05-05 作者简介:黄志东(1983—),男,2008级硕士研究生,研究方向为信息系统;袁巧云(1976—),女,博士,副教授,硕士生导师,研究方向为知识管理、信息系统等。
如何提高网页反向链接的数量和质量是提高页面PR值的关键。基于PR值算法的搜索引擎优化策略是从链接的角度优化搜索引擎。网站链接分为三种类型:入站链接、出站链接和站内链接。3.1 Inbound link pair 从公式可以看出PR值和搜索引擎优化策略的影响(1),Inbound Links的增加会增加vi的数量,PR值( vi)/N(vi)会增加,任何入站连接viB(u)的增加都会直接导致链接网站的PR值增加。另外,如果入站连接的PR值是更大,也就是外部入站页面的质量越高,那么链接的网站 PR 将被接受的值越大。PR(P)=PR(Q1)/2 +PR(Q2) +PR(Q3)/2+PR(T),对于已知的PR(P)变大,对于(P, Q1, Q2, Q3), 整个(P, Q1, Q2, Q3) set)的PR值会通过迭代过程增加。
但所建立的链接不会在今天或明天建立。这样的链接也是徒劳的。(5)提交到大分类目录网站,比如把网页提交到全球最大的分类目录dmoz。
3.2 出站链接对PR值和搜索引擎优化策略的影响。PR值算法基于整个Web的拓扑结构。网站链接会造成网站 PR值的消耗。用一张图来说明出站链PR值的影响。例子中我们假设Q1在任意一个网站上添加一个出站链接,如图,PR值变为PR(P)=PR(Q1) /3+PR(Q< @2) ij,得到移行列列的矩阵(2)为每个网页设置一个初始PR值,一般设置初始PR值作为初始PR(3)进行迭代计算,设置阻尼系数d=0.85,第一次迭代如下: =0.15+0.85m1j PR(n) 0.85m2j PR(n ) = < @0.15+0.85mnj PR(n) =0.15+0.85m1j PR(n) 0.85m2j PR(n) 迭代计算 最后PR (n) 得到每个网页的收敛性。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。@0.85m1j PR(n) 0.85m2j PR(n) 迭代计算最终得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。@0.85m1j PR(n) 0.85m2j PR(n) 迭代计算最终得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的互连。目前常用的搜索引擎优化方法4.@>1 关键词优化 关键词密度是决定网页顺序的一个因素。所谓关键词密度,是指去除了HTML代码的页面中关键词和内容的百分比。流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的互连。目前常用的搜索引擎优化方法4.@>1 关键词优化 关键词密度是决定网页顺序的一个因素。所谓关键词密度,是指去除了HTML代码的页面中关键词和内容的百分比。
每个搜索引擎都有自己的搜索结果排名公式,并严格保密。但基本规律是某个关键词在网页上的密度越高(观察研究表明,大多数搜索引擎的关键词密度在2%到8%是比较合适的范围,有利于网站@ > 在搜索引擎中的排名),则该网页与该关键字的相关度更高,该网页在搜索结果中的排名位置更高。4.@>2 URL Optimized URL是Uniform Resource Locator,是全球www系统服务器资源的标准寻址定位代码,用于确定所需文档在Internet上的位置。URL由三部分组成:网络传输协议、主机号(域名)、主机上文档的路径,以及文件名(子页面名)。因为在URL中收录关键字确实对排名有帮助,所以URL的优化涉及到两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。URL的优化涉及两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。URL的优化涉及两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。
这些标签在不时刷新标签时尤为重要。4.@>4 链接流行度优化网站的链接流行度是指通过网站链接分析得到的权重。对于优化程度相同且内容吸引力相同的两个站点,链接流行度(LP)较高的站点应在搜索引擎排名中占据优势。所谓链接分析,是指对链接的数量和质量进行评价和分析。一段时间以来,一些搜索引擎不再考虑免费站点的外部链接,因此在优化链接流行度时,不仅要考虑到站点的链接数量,还要考虑站点的链接质量。结论 以上我们通过对PR值算法的思想和原理的分析,得到了一些对搜索引擎优化有帮助的搜索引擎优化方法。该方法主要从链接分析的角度进行研究,包括入站链接、出站链接和出站链接。站内链接和站内链接变化对PR值的影响。但是,由于PR值算法本身的不足,如主题漂移、忽略好的Hub页面、对新网页的歧视等,搜索引擎不能单纯依靠PR值算法对网页进行排序。其实谷歌对页面PR值的计算并不是减值。搜索引擎优化有以下两种策略:(1) 不要进行单边前向链接。前向链接会消耗原创网页集合的PR值。为了抵消这种消耗,您需要确保链接是相互的。
相互链接可能会获得或失去 PR 值,因此您在交换链接时需要特别小心。(2)尽量提供一些与网页主题内容相关的行业/专业资源网页的链接,以免泄露主题网页采集的PR值,同时也提高搜索引擎对< @网站 好印象 3.3 网站内链对PR值和搜索引擎优化策略的影响 在网页中循环传播,整个网站的PR值@>等于每个网页的PR值之和。为了说明PR值在网页中的传递,也就是首页,Q1、Q2、Q3是内页。如果页面不是相互排斥的链接和外部链接不被考虑,那么公共 PR(P)=1-d=0.15=PR(Qi)。这时候整个网站的PR值只有0.6 如果加上Q1的连接,那么公式(1)得到PR(Q1)= 0.15+0.85PR(P)=0.2775,整个网站的PR值也从0.6提升到了0.7275. 可以看出在网站的内部页面没有相互链接的情况下添加一个链接可以提高整个网站的PR值当网站的内部链接链接时网站的整个网页,网站的PR值可以最大化。优化网站的时候,我们都希望网站的主页得到更多的关注,参考文章必须保证网站里面的每一个网页
最小化书目记录的功能需求。研究论文的定量分析。肇庆52606,广东肇庆大学图书馆。对时间分布、期刊分布、作者分布、主题分布、关键词频率分布、经费状况进行统计分析,揭示书目记录功能需求的研究特征,分析其未来的研究发展趋势。关键词:书目记录功能需求FRBR研究论文计量分析doi:10.3969 j.issn.1005-8095.2011.01. 012中国图书馆分类号:G254.@>3 文献识别码:研究对象与研究方法 1990年,国际图书馆协会联合会(IFLA)成立了一个专门研究书目记录功能需求的小组,并于1998年发表了最终的新书目模型-FRBR(Functional Requirements BibliographicRecords,书目记录的功能要求),旨在提供一个明确定义结构化框架,使数据记录在与记录用户需求相关的书目记录中,并推荐国家书目机构创建的记录的基本功能级别。本文以FRBR为研究对象,通过“中文期刊全文数据库”进行检索。进入“FRBR”或“标题中的参考书目”已经几年没有引起图书馆和情报界的关注。,
表明人们对FRBR的关注和研究正在逐步深入。2 2 2 2 2 2 年发表论文总数(篇) 1111 12 13 57 百分比(%)1.75 7.028.77 19.@ >30 1 9.30 21.05 22.81 100.00 2.2 期刊分布 FRBR论文在各期刊中的分布。在24种期刊上共发表论文57篇。其中,刊物种类占期刊总数的25%。该期刊共收录32篇论文,占论文总数的56.14%。色散定律。按照布拉德福德的分区法,所有这些期刊都按照文章数量分为三个区域。三个区域的文章比例分别为56.14%、21.05%、22.81%,符合Bradford分散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。21.05%, 22.81%,符合布拉德福德色散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。21.05%, 22.81%,符合布拉德福德色散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究的检索期间为2001年至2009年。检索文件57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究的检索期间为2001年至2009年。检索文件57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。表明图书情报学专业期刊有记录FRBR研究 检索时间为2001-2009年,检索到文献57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。表明图书情报学专业期刊有记录FRBR研究 检索时间为2001-2009年,检索到文献57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。
统计结果与分析 2.1 发表时间及数量分布 对论文发表时间进行统计分析,从时间序列了解研究对象的发展速度和关注度。知道FRBR研究论文是2001年第一次发表,后来往往比较复杂,考虑的变量比较多,比如栏目结构、格式、域名、URL级别、学术价值、页面布局、内容主题相关性、网页标题、网页关键词和摘要标签、网页更新频率、是否存在搜索引擎优化作弊等一系列问题,所以搜索引擎优化的过程中伴随着大量的优化方法和网站结构Web挖掘方法的方法。此外,PR值算法也在不断完善中。国内外一些研究人员提出了一些改进算法,如使用空间向量,考虑网页之间的相关性因素来解决PR值算法中的主题漂移问题;使用分布式PR值算法提高算法性能等。随着算法的改进,搜索引擎优化需要适应这些变化,不断提出新的优化策略和优化方法。参考全球互联网网站数量已超过1亿[EB/OL]。[2010-01-10]。 7077. shtml 网页超链接分析算法研究 HAJIMEBABA.Google secret-PageRank [EB/OL]. [2010-01-03]。/PageRank_cn. htm, 2002 吴涛. 查看全部
搜索引擎主题模型优化(基于PageRank算法的搜索引擎优化策略(安徽财经大学信息工程学院蚌埠233041))
基于PageRank算法的搜索引擎优化策略(蚌埠233041),安徽财经大学信息工程学院) 重点:分析Google PageRank(PR值)算法的原理,详细讨论主要方面网站链接的变化:站内链接、入站链接、站内链接的变化对网站PR值的影响,提出通过增加入站链接来优化网站链接,减少外链,避免不必要的内链。为了提高PR和提高网站在搜索引擎中的排名,提出了一种优化策略。关键词:PageRank 网页结构挖掘搜索引擎中文图书馆分类号:TP312 文献识别码:A doi:10.3969 j.issn.1005-8095.201< 本文主要讨论算法PR值的搜索引擎优化策略,其实作为最著名的搜索引擎品牌,谷歌的排名结果是非常权威的。经过针对谷歌优化的网站,通常在百度、雅虎等其他搜索引擎中排名第一。
PR值算法分析2.1 PR值的基本思想PR值是根据“很多优质网页链接的网页一定还是优质网页”的回归关系来确定网页的重要性。PR值利用互联网中巨大的链接关系,以网页之间链接的数量和质量作为网页评价的手段。截至2009年10月末,全球互联网网站网站的数量已经突破了信息量的爆发式增长。在让我们掌握更多信息的同时,也对信息检索提出了严峻的考验。搜索是除电子邮件外最常用的网络行为方式。通过搜索引擎查找信息是互联网用户查找在线信息和资源的主要手段。1998年,谷歌公司提出了著名的PR值算法,该算法可以高效地将用户使用搜索引擎的搜索结果按重要性排序。这种算法让用户得到满意的网络,也让谷歌发展成为搜索引擎行业的代表。对于每一个网站,为了赢得大量相似网站的竞争,提高产品或服务的知名度,必须在大型搜索引擎的搜索排名中排名靠前并提高点击率。这也成为每个网站的重要任务。词-搜索引擎优化。搜索引擎优化由此诞生了一个新名称。
下面的调查报告充分说明了搜索引擎优化的重要性: 链接到另一个网页 b 相当于页面优先。搜索引擎营销公司 iCrossing 投票支持页面的重要性。从链接数来看,一个网页的投票越多,反向链接越多,PR值就越高。从链接质量的角度来看,如果一个网页获得了一个相对高质量的网页的链接,这个网页可以获得更高的PR值。该算法有两个基本假设:(1)一个网页被引用的频率越高,这个页面就越重要;当它被一个非常重要的页面引用时,这个页面就越重要(2)假设用户开始随机访问一个页面,然后点击该页面的链接,调查发现:在线购物以前,搜索引擎是最受欢迎的产品和服务搜索工具,74% 的用户搜索产品,而 54% 的用户搜索 网站。二、中国搜索引擎市场研究年度报告指出,截至2007年底,市场规模已达29.3亿元,同比增长76.5% . 2008年中国搜索引擎市场规模达到51.5元,较2007年同期增长77.1% 谷歌、百度、雅虎市场份额增至96.4%,中国搜索引擎市场集中度进一步提高。正是由于搜索引擎行业的高速发展。稿件日期:2010-05-05 作者简介:黄志东(1983—),男,2008级硕士研究生,研究方向为信息系统;袁巧云(1976—),女,博士,副教授,硕士生导师,研究方向为知识管理、信息系统等。
如何提高网页反向链接的数量和质量是提高页面PR值的关键。基于PR值算法的搜索引擎优化策略是从链接的角度优化搜索引擎。网站链接分为三种类型:入站链接、出站链接和站内链接。3.1 Inbound link pair 从公式可以看出PR值和搜索引擎优化策略的影响(1),Inbound Links的增加会增加vi的数量,PR值( vi)/N(vi)会增加,任何入站连接viB(u)的增加都会直接导致链接网站的PR值增加。另外,如果入站连接的PR值是更大,也就是外部入站页面的质量越高,那么链接的网站 PR 将被接受的值越大。PR(P)=PR(Q1)/2 +PR(Q2) +PR(Q3)/2+PR(T),对于已知的PR(P)变大,对于(P, Q1, Q2, Q3), 整个(P, Q1, Q2, Q3) set)的PR值会通过迭代过程增加。
但所建立的链接不会在今天或明天建立。这样的链接也是徒劳的。(5)提交到大分类目录网站,比如把网页提交到全球最大的分类目录dmoz。
3.2 出站链接对PR值和搜索引擎优化策略的影响。PR值算法基于整个Web的拓扑结构。网站链接会造成网站 PR值的消耗。用一张图来说明出站链PR值的影响。例子中我们假设Q1在任意一个网站上添加一个出站链接,如图,PR值变为PR(P)=PR(Q1) /3+PR(Q< @2) ij,得到移行列列的矩阵(2)为每个网页设置一个初始PR值,一般设置初始PR值作为初始PR(3)进行迭代计算,设置阻尼系数d=0.85,第一次迭代如下: =0.15+0.85m1j PR(n) 0.85m2j PR(n ) = < @0.15+0.85mnj PR(n) =0.15+0.85m1j PR(n) 0.85m2j PR(n) 迭代计算 最后PR (n) 得到每个网页的收敛性。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。@0.85m1j PR(n) 0.85m2j PR(n) 迭代计算最终得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。@0.85m1j PR(n) 0.85m2j PR(n) 迭代计算最终得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的互连。目前常用的搜索引擎优化方法4.@>1 关键词优化 关键词密度是决定网页顺序的一个因素。所谓关键词密度,是指去除了HTML代码的页面中关键词和内容的百分比。流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的互连。目前常用的搜索引擎优化方法4.@>1 关键词优化 关键词密度是决定网页顺序的一个因素。所谓关键词密度,是指去除了HTML代码的页面中关键词和内容的百分比。
每个搜索引擎都有自己的搜索结果排名公式,并严格保密。但基本规律是某个关键词在网页上的密度越高(观察研究表明,大多数搜索引擎的关键词密度在2%到8%是比较合适的范围,有利于网站@ > 在搜索引擎中的排名),则该网页与该关键字的相关度更高,该网页在搜索结果中的排名位置更高。4.@>2 URL Optimized URL是Uniform Resource Locator,是全球www系统服务器资源的标准寻址定位代码,用于确定所需文档在Internet上的位置。URL由三部分组成:网络传输协议、主机号(域名)、主机上文档的路径,以及文件名(子页面名)。因为在URL中收录关键字确实对排名有帮助,所以URL的优化涉及到两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。URL的优化涉及两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。URL的优化涉及两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。
这些标签在不时刷新标签时尤为重要。4.@>4 链接流行度优化网站的链接流行度是指通过网站链接分析得到的权重。对于优化程度相同且内容吸引力相同的两个站点,链接流行度(LP)较高的站点应在搜索引擎排名中占据优势。所谓链接分析,是指对链接的数量和质量进行评价和分析。一段时间以来,一些搜索引擎不再考虑免费站点的外部链接,因此在优化链接流行度时,不仅要考虑到站点的链接数量,还要考虑站点的链接质量。结论 以上我们通过对PR值算法的思想和原理的分析,得到了一些对搜索引擎优化有帮助的搜索引擎优化方法。该方法主要从链接分析的角度进行研究,包括入站链接、出站链接和出站链接。站内链接和站内链接变化对PR值的影响。但是,由于PR值算法本身的不足,如主题漂移、忽略好的Hub页面、对新网页的歧视等,搜索引擎不能单纯依靠PR值算法对网页进行排序。其实谷歌对页面PR值的计算并不是减值。搜索引擎优化有以下两种策略:(1) 不要进行单边前向链接。前向链接会消耗原创网页集合的PR值。为了抵消这种消耗,您需要确保链接是相互的。
相互链接可能会获得或失去 PR 值,因此您在交换链接时需要特别小心。(2)尽量提供一些与网页主题内容相关的行业/专业资源网页的链接,以免泄露主题网页采集的PR值,同时也提高搜索引擎对< @网站 好印象 3.3 网站内链对PR值和搜索引擎优化策略的影响 在网页中循环传播,整个网站的PR值@>等于每个网页的PR值之和。为了说明PR值在网页中的传递,也就是首页,Q1、Q2、Q3是内页。如果页面不是相互排斥的链接和外部链接不被考虑,那么公共 PR(P)=1-d=0.15=PR(Qi)。这时候整个网站的PR值只有0.6 如果加上Q1的连接,那么公式(1)得到PR(Q1)= 0.15+0.85PR(P)=0.2775,整个网站的PR值也从0.6提升到了0.7275. 可以看出在网站的内部页面没有相互链接的情况下添加一个链接可以提高整个网站的PR值当网站的内部链接链接时网站的整个网页,网站的PR值可以最大化。优化网站的时候,我们都希望网站的主页得到更多的关注,参考文章必须保证网站里面的每一个网页
最小化书目记录的功能需求。研究论文的定量分析。肇庆52606,广东肇庆大学图书馆。对时间分布、期刊分布、作者分布、主题分布、关键词频率分布、经费状况进行统计分析,揭示书目记录功能需求的研究特征,分析其未来的研究发展趋势。关键词:书目记录功能需求FRBR研究论文计量分析doi:10.3969 j.issn.1005-8095.2011.01. 012中国图书馆分类号:G254.@>3 文献识别码:研究对象与研究方法 1990年,国际图书馆协会联合会(IFLA)成立了一个专门研究书目记录功能需求的小组,并于1998年发表了最终的新书目模型-FRBR(Functional Requirements BibliographicRecords,书目记录的功能要求),旨在提供一个明确定义结构化框架,使数据记录在与记录用户需求相关的书目记录中,并推荐国家书目机构创建的记录的基本功能级别。本文以FRBR为研究对象,通过“中文期刊全文数据库”进行检索。进入“FRBR”或“标题中的参考书目”已经几年没有引起图书馆和情报界的关注。,
表明人们对FRBR的关注和研究正在逐步深入。2 2 2 2 2 2 年发表论文总数(篇) 1111 12 13 57 百分比(%)1.75 7.028.77 19.@ >30 1 9.30 21.05 22.81 100.00 2.2 期刊分布 FRBR论文在各期刊中的分布。在24种期刊上共发表论文57篇。其中,刊物种类占期刊总数的25%。该期刊共收录32篇论文,占论文总数的56.14%。色散定律。按照布拉德福德的分区法,所有这些期刊都按照文章数量分为三个区域。三个区域的文章比例分别为56.14%、21.05%、22.81%,符合Bradford分散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。21.05%, 22.81%,符合布拉德福德色散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。21.05%, 22.81%,符合布拉德福德色散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究的检索期间为2001年至2009年。检索文件57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究的检索期间为2001年至2009年。检索文件57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。表明图书情报学专业期刊有记录FRBR研究 检索时间为2001-2009年,检索到文献57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。表明图书情报学专业期刊有记录FRBR研究 检索时间为2001-2009年,检索到文献57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。
统计结果与分析 2.1 发表时间及数量分布 对论文发表时间进行统计分析,从时间序列了解研究对象的发展速度和关注度。知道FRBR研究论文是2001年第一次发表,后来往往比较复杂,考虑的变量比较多,比如栏目结构、格式、域名、URL级别、学术价值、页面布局、内容主题相关性、网页标题、网页关键词和摘要标签、网页更新频率、是否存在搜索引擎优化作弊等一系列问题,所以搜索引擎优化的过程中伴随着大量的优化方法和网站结构Web挖掘方法的方法。此外,PR值算法也在不断完善中。国内外一些研究人员提出了一些改进算法,如使用空间向量,考虑网页之间的相关性因素来解决PR值算法中的主题漂移问题;使用分布式PR值算法提高算法性能等。随着算法的改进,搜索引擎优化需要适应这些变化,不断提出新的优化策略和优化方法。参考全球互联网网站数量已超过1亿[EB/OL]。[2010-01-10]。 7077. shtml 网页超链接分析算法研究 HAJIMEBABA.Google secret-PageRank [EB/OL]. [2010-01-03]。/PageRank_cn. htm, 2002 吴涛.
搜索引擎主题模型优化(近段时间在研究搜索的相关技术涉及到资讯搜索功能的实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-10 04:00
大纲
最近在研究搜索的相关技术,工作主要涉及信息搜索功能的实现。我们采用了elasticsearch搜索引擎,整理了两篇关于elasticsearch的文章:文章:es基础和es进阶 1.由于搜索功能需要迭代,作者继续研究搜索原理和性能深度优化。本文主要研究以下几点:
什么是搜索
搜索引擎的技术建设主要包括三个部分:
(1) 对查询的理解
(2) 对内容(文档)的理解
(3)查询和内容(文档)的匹配排序
图片
搜索通用评价指标基本指标:
召回率(Recall)=检测到的相关文档数/相关文档数,也叫召回率,R∈[0,1]
Precision=检测到的相关文档数/检测到的文档数,也称为准确率,P∈[0,1]
F值:召回率R和正确率P的调和平均值
搜索发展阶段:
什么是意图识别
使用分类方法将我们常说的句子或查询分类成对应的意图类型
属于“理解查询”部分
本质上是一个分类问题
意图识别搜索的一般流程:
S1. 用户的原创查询是“michal jrdan”
S2. Query Correction 模块进行拼写错误纠正的结果是:“Michael Jordan”
S3. Query Suggestion 模块的下拉提示结果为:“Michael Jordan berkley”和“Michael Jordan NBA”,假设用户选择“Michael Jordan berkley”
S4. Query Expansion 模型查询扩展后,结果为:“迈克尔乔丹伯克利”和“迈克尔I.乔丹伯克利”
S5. Query Classification 模块进行查询分类的结果为:academic
S6. 最后,Semantic Tagging模块进行命名实体识别和属性识别的结果是:[Michael Jordan:人名][berkley:location]:academic
意图识别的前提
意图划分问题:技能/领域
用户需求分类:
(1) 导航
(2) 信息
(3) 交易
概念介绍:
用户与搜索引擎之间完整的交互过程称为搜索会话。Session中提供的信息包括:用户查询(Query),用户点击的搜索结果的标题(Title),如果用户在会话期间改变了查询词(例如来自Query1 -->Query2),后续的搜索和点击都会被记录下来,直到用户离开搜索,会话结束。
意图识别方法
1.词汇穷举法/规则分析法
2. 基于查询的点击日志 - 一般搜索日志记录会在结果中收录时间-查询字符串-点击URL记录-位置等信息。
3.机器学习方法(基于规则挖掘,基于Bayes、LR、SVM等传统分类模型)-分类问题
查询分类
eg:识别每个实体词的属性,去索引精确匹配对应的字段,从而提高recall的准确率
4.基于神经网络(深度学习)--FastText
意图识别难点
1、 输入不规范。上一篇说过,不同的用户对同一个请求有不同的表达。
2、多用意,查询词是:“水”,是矿泉水,还是女生用的乳液。
3、数据冷启动。当用户行为数据较少时,很难获得准确的意图。
4、 没有固定的评价标准。pv、ipv、ctr、cvr等量化指标是对搜索系统的整体评价。对于用户意图的预测,目前还没有标准的量化指标。
查询重写
查询重写、类别关联、命名实体识别和
查询重写包括:
查询纠错 - 如果搜索引擎返回空结果/或结果太少,此时应添加拼写错误纠正处理
查询扩展:
例如。“迈克尔·乔丹·伯克利”和“迈克尔·I·乔丹·伯克利”
(1) 同义词扩展表
(2) 使用词向量进行同义词扩展
(3) 如果查询没有相应返回,将根据用户历史数据扩展原查询
查询删除 - 确定要丢弃的单词/单词(实体识别)
参考
搜索意图识别分析
信息检索中的各种评价指标
如何使用桨叶进行意图识别打开
将中文自然语言转化为结构化数据 查看全部
搜索引擎主题模型优化(近段时间在研究搜索的相关技术涉及到资讯搜索功能的实现)
大纲
最近在研究搜索的相关技术,工作主要涉及信息搜索功能的实现。我们采用了elasticsearch搜索引擎,整理了两篇关于elasticsearch的文章:文章:es基础和es进阶 1.由于搜索功能需要迭代,作者继续研究搜索原理和性能深度优化。本文主要研究以下几点:
什么是搜索
搜索引擎的技术建设主要包括三个部分:
(1) 对查询的理解
(2) 对内容(文档)的理解
(3)查询和内容(文档)的匹配排序

图片
搜索通用评价指标基本指标:
召回率(Recall)=检测到的相关文档数/相关文档数,也叫召回率,R∈[0,1]
Precision=检测到的相关文档数/检测到的文档数,也称为准确率,P∈[0,1]
F值:召回率R和正确率P的调和平均值
搜索发展阶段:
什么是意图识别
使用分类方法将我们常说的句子或查询分类成对应的意图类型
属于“理解查询”部分
本质上是一个分类问题
意图识别搜索的一般流程:
S1. 用户的原创查询是“michal jrdan”
S2. Query Correction 模块进行拼写错误纠正的结果是:“Michael Jordan”
S3. Query Suggestion 模块的下拉提示结果为:“Michael Jordan berkley”和“Michael Jordan NBA”,假设用户选择“Michael Jordan berkley”
S4. Query Expansion 模型查询扩展后,结果为:“迈克尔乔丹伯克利”和“迈克尔I.乔丹伯克利”
S5. Query Classification 模块进行查询分类的结果为:academic
S6. 最后,Semantic Tagging模块进行命名实体识别和属性识别的结果是:[Michael Jordan:人名][berkley:location]:academic
意图识别的前提
意图划分问题:技能/领域
用户需求分类:
(1) 导航
(2) 信息
(3) 交易
概念介绍:
用户与搜索引擎之间完整的交互过程称为搜索会话。Session中提供的信息包括:用户查询(Query),用户点击的搜索结果的标题(Title),如果用户在会话期间改变了查询词(例如来自Query1 -->Query2),后续的搜索和点击都会被记录下来,直到用户离开搜索,会话结束。
意图识别方法
1.词汇穷举法/规则分析法
2. 基于查询的点击日志 - 一般搜索日志记录会在结果中收录时间-查询字符串-点击URL记录-位置等信息。
3.机器学习方法(基于规则挖掘,基于Bayes、LR、SVM等传统分类模型)-分类问题
查询分类
eg:识别每个实体词的属性,去索引精确匹配对应的字段,从而提高recall的准确率
4.基于神经网络(深度学习)--FastText
意图识别难点
1、 输入不规范。上一篇说过,不同的用户对同一个请求有不同的表达。
2、多用意,查询词是:“水”,是矿泉水,还是女生用的乳液。
3、数据冷启动。当用户行为数据较少时,很难获得准确的意图。
4、 没有固定的评价标准。pv、ipv、ctr、cvr等量化指标是对搜索系统的整体评价。对于用户意图的预测,目前还没有标准的量化指标。
查询重写
查询重写、类别关联、命名实体识别和
查询重写包括:
查询纠错 - 如果搜索引擎返回空结果/或结果太少,此时应添加拼写错误纠正处理
查询扩展:
例如。“迈克尔·乔丹·伯克利”和“迈克尔·I·乔丹·伯克利”
(1) 同义词扩展表
(2) 使用词向量进行同义词扩展
(3) 如果查询没有相应返回,将根据用户历史数据扩展原查询
查询删除 - 确定要丢弃的单词/单词(实体识别)
参考
搜索意图识别分析
信息检索中的各种评价指标
如何使用桨叶进行意图识别打开
将中文自然语言转化为结构化数据
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心主题模型?本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-18 22:07
网站优化主题模型SEO最新的SEO概念进入了全新的“有质感的内容”算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。下面将结合当今最新的SEO概念来指导你如何优化主题内容。SEO网站的主题模型是什么?关于SEO页面的内容,我们通常可以听到和看到很多旧的方法,这比使用各种H标签来整合关键词 TDK关键词 是否设置为准确匹配但有经验SEO 人员和 网站 大师们很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这是本文的核心。那么什么是主题模型呢?主题模型是页面内容布局的模型,为了让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:1)词系统关联<
他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)。第一步:词关联 无论你用什么方法来优化页面的内容,都必须围绕如何关联词和词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。当我们使用句子和单词时,搜索引擎将根据其他资源中的数据关联您的内容,以生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己的研究关键词的方法,但需要达到以下目标:1)找到同义词和异体词2)找到与内容相关的二类词主题3)找二类词相关的三类词,Thing) 举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据上述目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是关键词的密度!第2步:词系统布局毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要,非常重要。蜘蛛什么时候来到页面发现这么多关键词,他们需要区分哪些是重要的,哪些 关键词 与短语相关。所以词系统布局是要明确核心词和相关性,下面是3个实用的优化方法: 1)Region: 关键词 必须出现在Title、标题和主要段落2) 频率: 重要的短语 or 它是它们的变体可以出现超过平均水平。3) 距离:相关词或词组要尽量靠近或者使用HTML元素(如ALT)的方式(1)是大部分SEO人的必修项目,还是要放核心主题标题和大标题中的词尽量出现在正文的顶部。方法(2)这里不仅仅是关键词的频率(密度),但更复杂的是,第一层的链接频率是核心词的同义词和变体。在同等条件下,不太流行的同义词和变体会得到更好的结果。
现在你要做的就是将那些二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主题(排名词),正如我之前所说的搜索引擎可以使用大数据来识别单词关联。举个简单的例子:主词是【网红】,第一段会重点关注这个词文章。第二段将用几只手完成。文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是一个词系相关内容,通过步骤2来布局词族。第三步:补充内容。或许很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,现在的外链就像一颗不合时宜的炸弹,说不定会被链接炸死。
因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?如果你的网页只是单纯的关键词,缺少文字链接、参考资料和相关资源推荐,那么你的页面就很死板,死路一条,不会给你的页面加分。看右边的页面。网站内有链接(黄色部分),导出链接和内容中的[补充内容]。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是加强页面主题的深化,通过不同网站的内容来强化信息。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。1)在页面底部添加相关资源的链接(推荐站内链接)2)在文中使用引号,如行业内知名人士的话或图标,如文中3) 使用导出链接到网站中的第三方(你不会被K放100。第4步:内容实体这是一个非常难的概念,称为英文实体。强大的搜索引擎会抓取页面 来自动解释内容实体,或者将其理解为内容属性。例如,当内容提到“包老师”时,它的实体是[人]吗?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。
(木木补充说,这涉及到微数据。HTML5 微数据规范是一种标记,用于描述特定类型的信息,例如评论、人物信息或事件。每种类型的信息描述特定类型的项目,例如人物、事件或评论见《结构化微数据丰富网页摘要》)一般搜索引擎都会给站长提供自己的结构化数据(比如“百度新数据标注工具,相当于谷歌数据标注”),什么是结构化数据?就是使用搜索引擎设置的HTML Markup来定义内容,或者统称为使用Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。这个更高级 只是一点点理解。您可以要求您的架构师添加 网站 结构数据。当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。搜索引擎会自动解释内容实体,通过“人、地、物”来寻找关联,所以建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比作“每个实体”。关联。例如,
看看有没有和之前的优化概念不一样。搜索引擎不看页面上是否有这个词以及有多少链接指向它,而是看内容实体是否相关。综上所述,大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技巧整合到你的内容优化中:1)一个高度概括的标题来描述页面的主题2)添加一个开头(简要)来描述页面的内容3)@ > 内容分为几段,每段都有自己的主题。4)尽量扩大主题视角,补充相关答案。5) 查看全部
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心主题模型?本文)
网站优化主题模型SEO最新的SEO概念进入了全新的“有质感的内容”算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。下面将结合当今最新的SEO概念来指导你如何优化主题内容。SEO网站的主题模型是什么?关于SEO页面的内容,我们通常可以听到和看到很多旧的方法,这比使用各种H标签来整合关键词 TDK关键词 是否设置为准确匹配但有经验SEO 人员和 网站 大师们很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这是本文的核心。那么什么是主题模型呢?主题模型是页面内容布局的模型,为了让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:1)词系统关联<
他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)。第一步:词关联 无论你用什么方法来优化页面的内容,都必须围绕如何关联词和词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。当我们使用句子和单词时,搜索引擎将根据其他资源中的数据关联您的内容,以生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己的研究关键词的方法,但需要达到以下目标:1)找到同义词和异体词2)找到与内容相关的二类词主题3)找二类词相关的三类词,Thing) 举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据上述目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是关键词的密度!第2步:词系统布局毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要,非常重要。蜘蛛什么时候来到页面发现这么多关键词,他们需要区分哪些是重要的,哪些 关键词 与短语相关。所以词系统布局是要明确核心词和相关性,下面是3个实用的优化方法: 1)Region: 关键词 必须出现在Title、标题和主要段落2) 频率: 重要的短语 or 它是它们的变体可以出现超过平均水平。3) 距离:相关词或词组要尽量靠近或者使用HTML元素(如ALT)的方式(1)是大部分SEO人的必修项目,还是要放核心主题标题和大标题中的词尽量出现在正文的顶部。方法(2)这里不仅仅是关键词的频率(密度),但更复杂的是,第一层的链接频率是核心词的同义词和变体。在同等条件下,不太流行的同义词和变体会得到更好的结果。
现在你要做的就是将那些二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主题(排名词),正如我之前所说的搜索引擎可以使用大数据来识别单词关联。举个简单的例子:主词是【网红】,第一段会重点关注这个词文章。第二段将用几只手完成。文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是一个词系相关内容,通过步骤2来布局词族。第三步:补充内容。或许很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,现在的外链就像一颗不合时宜的炸弹,说不定会被链接炸死。
因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?如果你的网页只是单纯的关键词,缺少文字链接、参考资料和相关资源推荐,那么你的页面就很死板,死路一条,不会给你的页面加分。看右边的页面。网站内有链接(黄色部分),导出链接和内容中的[补充内容]。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是加强页面主题的深化,通过不同网站的内容来强化信息。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。1)在页面底部添加相关资源的链接(推荐站内链接)2)在文中使用引号,如行业内知名人士的话或图标,如文中3) 使用导出链接到网站中的第三方(你不会被K放100。第4步:内容实体这是一个非常难的概念,称为英文实体。强大的搜索引擎会抓取页面 来自动解释内容实体,或者将其理解为内容属性。例如,当内容提到“包老师”时,它的实体是[人]吗?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。
(木木补充说,这涉及到微数据。HTML5 微数据规范是一种标记,用于描述特定类型的信息,例如评论、人物信息或事件。每种类型的信息描述特定类型的项目,例如人物、事件或评论见《结构化微数据丰富网页摘要》)一般搜索引擎都会给站长提供自己的结构化数据(比如“百度新数据标注工具,相当于谷歌数据标注”),什么是结构化数据?就是使用搜索引擎设置的HTML Markup来定义内容,或者统称为使用Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。这个更高级 只是一点点理解。您可以要求您的架构师添加 网站 结构数据。当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。搜索引擎会自动解释内容实体,通过“人、地、物”来寻找关联,所以建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比作“每个实体”。关联。例如,
看看有没有和之前的优化概念不一样。搜索引擎不看页面上是否有这个词以及有多少链接指向它,而是看内容实体是否相关。综上所述,大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技巧整合到你的内容优化中:1)一个高度概括的标题来描述页面的主题2)添加一个开头(简要)来描述页面的内容3)@ > 内容分为几段,每段都有自己的主题。4)尽量扩大主题视角,补充相关答案。5)
搜索引擎主题模型优化(什么是SEO理念站内网站优化推广主题模型(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-18 03:16
网站优化推广网站站内优化推广最新SEO概念网站优化推广的主题模型SEO进入了“质感内容”的新算法体系,尤其是现在一流的搜索引擎能力更强,从内容的上下文来看,利用内容实体的属性来处理排名,让用户得到更准确的搜索结果。对于网站优化推广者来说,网站站内优化推广不再是简单的内容填充,主题内容网站优化推广需要重新定义。在本文中,川亚传媒科技将结合最新的SEO概念,指导大家如何网站优化和推广主题内容。SEO网站的主题模型是什么?我们通常可以听到和看到很多关于SEO页面内容的旧方法,例如: 使用各种H标签来集成关键词 TDK关键词 是否设置为准确匹配但可以?有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。现在要网站优化和推广好的网站内容,我们必须做的是如何让搜索引擎了解页面的核心主题。这就是我今天文章。核。那么什么是主题模型呢?SEO概念站网站优化推广主题模型网站优化推广网站 优化推广主题模型是一种页面内容布局模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是更多地传达哪个关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。
<p>因此,在主题模型中,我们需要实现全新的网站优化推广方式:1)词系统关联2)词系统布局3)补充内容< @4) 内容属性 对于维基百科等熟悉的网站,亚马逊利用其中的积分获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,不管你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能排名好!(特别是对于谷歌)第 1 步:词法关联不管你现在用什么方法来网站来优化推广页面的内容,但一定要着眼于如何关联词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。SEO 理念 网站 优化网站推广主题模型。当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们的网站优化推广者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方法,但需要达到以下目标:1)查找同义词和异形词< @2)找与主词内容相关的二类词3)找与二类词相关的三类词 查看全部
搜索引擎主题模型优化(什么是SEO理念站内网站优化推广主题模型(组图))
网站优化推广网站站内优化推广最新SEO概念网站优化推广的主题模型SEO进入了“质感内容”的新算法体系,尤其是现在一流的搜索引擎能力更强,从内容的上下文来看,利用内容实体的属性来处理排名,让用户得到更准确的搜索结果。对于网站优化推广者来说,网站站内优化推广不再是简单的内容填充,主题内容网站优化推广需要重新定义。在本文中,川亚传媒科技将结合最新的SEO概念,指导大家如何网站优化和推广主题内容。SEO网站的主题模型是什么?我们通常可以听到和看到很多关于SEO页面内容的旧方法,例如: 使用各种H标签来集成关键词 TDK关键词 是否设置为准确匹配但可以?有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。现在要网站优化和推广好的网站内容,我们必须做的是如何让搜索引擎了解页面的核心主题。这就是我今天文章。核。那么什么是主题模型呢?SEO概念站网站优化推广主题模型网站优化推广网站 优化推广主题模型是一种页面内容布局模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是更多地传达哪个关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。
<p>因此,在主题模型中,我们需要实现全新的网站优化推广方式:1)词系统关联2)词系统布局3)补充内容< @4) 内容属性 对于维基百科等熟悉的网站,亚马逊利用其中的积分获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,不管你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能排名好!(特别是对于谷歌)第 1 步:词法关联不管你现在用什么方法来网站来优化推广页面的内容,但一定要着眼于如何关联词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。SEO 理念 网站 优化网站推广主题模型。当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们的网站优化推广者首先需要通过关键词研究,找出这些句子和单词之间的关系。相信每个人都有自己研究关键词的方法,但需要达到以下目标:1)查找同义词和异形词< @2)找与主词内容相关的二类词3)找与二类词相关的三类词
搜索引擎主题模型优化(1.什么是SEO站内主题内容优化方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-18 03:14
文章指南
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1. 什么是SEO网站的主题模型
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 查看关键词的密度是否符合标准
· 文章 内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词是否设置为精准匹配
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?
主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
1) 词法关联
2)词系统布局
3)补充内容
4)内容属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
第 1 步:词法关联
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和变体
2)找到与主词内容相关的二类词
3)找到与第二类词相关的三类词
4) 结论是内容属性与主题(人、地、事)有关
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二个-与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到与主词相关的三类词第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4), 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点和事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度!
第二步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。因此,词系统布局是区分核心词及其相关性。以下是3种实用的优化方法:
1)区域:关键词 必须出现在标题、标题和主要段落中
2) 频率:重要短语或其变体的出现频率可能高于平均水平
3) 距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)
方法(1)是大部分SEO人的必修项目,我们还是要把核心主题放在标题,大标题,尽量出现在主条目的顶部。
方法(2)这里不仅仅是关键词的频率(密度),而是一个更复杂层面的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词而且变体词会得到更好的结果。(谷歌有个专利叫TF-IDF,比较难懂)
方法(3)距离产生美在SEO世界里是不适用的。单词、短语或句子应该尽可能靠近放置,或者应该使用HTML元素(例如图像ALT设置)。所以为了提高上下文相关性,应该通过段落、列表、分区等方式让内容更加明显,一看就知道段落在说什么。前后句子之间是否有连通性,不要将内容相似的内容分开意思太远了。因为你不能保证蜘蛛会捕捉到整个文本。
你知道这个方法的原理。现在你要做的就是将二类单词和三类词汇分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会重点介绍这个词文章。第二段用几只手做文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。
因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯粹的关键词,缺少文字链接、参考资料和相关资源推荐,你的页面很死板,这是一个死胡同,但它不会为您的页面添加额外的点。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件。这是给搜索引擎的消息。我有[补充]。想想看,百度百科还是知道为什么要添加相关资源的链接?实际上,就是加强页面主题的深化,通过不同网站的内容强化信息化。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。
1)在页面底部添加相关资源链接(推荐站点链接);
2)在正文中使用引号,如行业内知名人士的话或图标或视频;
3)使用文中的导出链接去第三方网站(你不会被K的100介意)。
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom Teacher”时,是实体[person]吗?提到“咨询道”,是【公司】?因为当你的内容出现在网上的时候,时间还不够久,数量少的时候,搜索引擎可能无法解析内容实体,因为老师可以是姓氏的老师,也可以是可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体。
一般情况下,大部分搜索引擎都会提供站长自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示,世界上只有0.3%网站 使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让您的架构师将 网站 结构化数据纳入其中。
当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的非常笼统的标题
2)添加开场白(简要)描述页面内容
3) 把内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以添加相关答案
5)提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体
----想了解最新SEO概念、网站优化主题模型分享!多关注seo优化教程 查看全部
搜索引擎主题模型优化(1.什么是SEO站内主题内容优化方法)
文章指南
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1. 什么是SEO网站的主题模型
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 查看关键词的密度是否符合标准
· 文章 内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词是否设置为精准匹配
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?
主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
1) 词法关联
2)词系统布局
3)补充内容
4)内容属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
第 1 步:词法关联
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和变体
2)找到与主词内容相关的二类词
3)找到与第二类词相关的三类词
4) 结论是内容属性与主题(人、地、事)有关
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二个-与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到与主词相关的三类词第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4), 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点和事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度!
第二步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。因此,词系统布局是区分核心词及其相关性。以下是3种实用的优化方法:
1)区域:关键词 必须出现在标题、标题和主要段落中
2) 频率:重要短语或其变体的出现频率可能高于平均水平
3) 距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)
方法(1)是大部分SEO人的必修项目,我们还是要把核心主题放在标题,大标题,尽量出现在主条目的顶部。
方法(2)这里不仅仅是关键词的频率(密度),而是一个更复杂层面的链接频率,即核心词的同义词和变体。相同条件下,不太流行的同义词而且变体词会得到更好的结果。(谷歌有个专利叫TF-IDF,比较难懂)
方法(3)距离产生美在SEO世界里是不适用的。单词、短语或句子应该尽可能靠近放置,或者应该使用HTML元素(例如图像ALT设置)。所以为了提高上下文相关性,应该通过段落、列表、分区等方式让内容更加明显,一看就知道段落在说什么。前后句子之间是否有连通性,不要将内容相似的内容分开意思太远了。因为你不能保证蜘蛛会捕捉到整个文本。
你知道这个方法的原理。现在你要做的就是将二类单词和三类词汇分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会重点介绍这个词文章。第二段用几只手做文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。
因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯粹的关键词,缺少文字链接、参考资料和相关资源推荐,你的页面很死板,这是一个死胡同,但它不会为您的页面添加额外的点。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件。这是给搜索引擎的消息。我有[补充]。想想看,百度百科还是知道为什么要添加相关资源的链接?实际上,就是加强页面主题的深化,通过不同网站的内容强化信息化。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。
1)在页面底部添加相关资源链接(推荐站点链接);
2)在正文中使用引号,如行业内知名人士的话或图标或视频;
3)使用文中的导出链接去第三方网站(你不会被K的100介意)。
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom Teacher”时,是实体[person]吗?提到“咨询道”,是【公司】?因为当你的内容出现在网上的时候,时间还不够久,数量少的时候,搜索引擎可能无法解析内容实体,因为老师可以是姓氏的老师,也可以是可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体。
一般情况下,大部分搜索引擎都会提供站长自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示,世界上只有0.3%网站 使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让您的架构师将 网站 结构化数据纳入其中。
当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的非常笼统的标题
2)添加开场白(简要)描述页面内容
3) 把内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以添加相关答案
5)提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体
----想了解最新SEO概念、网站优化主题模型分享!多关注seo优化教程
搜索引擎主题模型优化(数据挖掘算法为何物?——基于向量的相似度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-12-17 20:21
我写这个文章是因为前几天部门成员对部门涉及的一些算法进行了审查和整理。不过比较尴尬的是,既然老板不在,大家讨论讨论就变成吐槽大会了,但有一半时间是吐槽产品和业务部门~~
但这也是一件令人欣慰的事情。这也算是我们的数据部门,已经从轻型挖掘机走向了深挖阶段。
所以,借此机会,把我接触过、了解过、做过的一些勉强能称为算法的事情整理一下。事实上,就我而言,我没有算法背景。在大学里,我更多地了解了互联网,我什至不知道数据挖掘算法是什么。
其实就所谓的算法而言,我个人认为我的一个同事是对的:所谓的算法并不意味着那些复杂的数学模型就是算法。哪怕是你写的简单的计算公式,只要能解决当前存在的业务痛点,并且有自己的模型思路,就是算法,但可能不够通用,只能解决特定的业务需要。
在大规模数据的前提下,其实很多复杂的算法过程都没有这么好的结果。换句话说,我们将找到简化流程的方法。
举个简单的栗子:假设有一个大规模的数据集,以近千万篇博文为例。如果你提供一篇博文,让你查询相似度最高的前N个,我们通常的想法是什么?通常的方法是计算这篇博文与其他博文的相似度。计算相似度的方法有很多。, 最简单的方法是计算矢量角度,并根据矢量角度确定相似度。好吧,就算用最简单的计算过程,计算近千万次需要多长时间?或许,有人说我用hadoop,用分布式算力来完成这个任务,但是如果真的操作起来,你就会发现这是多么的痛苦。
再举一个简单的栗子(好吧,多吃栗子):比如SVM,这是一个很难收敛的算法。在大数据的前提下,有的人想用大数据,但想用更多的数据进行训练。模型毕竟手头的数据太多,很多人还是希望用尽可能多的数据来训练,以达到模型更加精准的目的。但是,随着训练数据量的增加,SVM等难以收敛的算法会消耗大量的计算资源。
(1)贝叶斯
贝叶斯是分类算法中最简单的算法。挖掘机算法初学者肯定会先爱上它。事实上,贝叶斯原理非常简单,基于统计学中的最大概率原理。就是这么简单,但尼玛却是这么好用,多年来一直屹立不倒。
缺乏训练过程。基本上贝叶斯就是这样的。因为是文本,所以用一组过程将词和停用词作为最基本的知识点向量进行分割,然后计算模型概率。但更有趣的是,分类过程是在Storm中完成的,相当于一个实时的分类服务。
(2)分词算法
其实说到分词算法,没什么好说的。现在网上各种开源的分词工具都做得很好,效果也差不了多少。如果要进一步改进,就会窒息。至于深入分词算法,涉及到上下文分析、隐马尔可夫模型等。如果是有兴趣研究的个人,那我无话可说;如果是小公司,会花费人力物力去优化分词效果。只能说闲着就疼;如果是大公司,金朵的任性也是可以理解的。
因此,到目前为止,个人对分词算法的演变、所涉及的内部算法以及几种分词工具的使用的初步理解都受到了限制。
其实在文本挖掘方面,对文本进行分词是不够的,因为我们用分词来切词,往往很多与业务无关,通常的做法是建立相应的业务词典,至于词典的建立当然也需要进行分词,进行进一步的处理,甚至可能会增加一些人工。
(3)实时热点分析
不知道是不是算法 说到实时性,自然和Storm有关系(嗯,我承认我是在做这个之后开始接触数据的)。说到实时热点,大家可能想不通,举个简单的栗子。
玩过 hadoop 的人都知道经典的栗子 WordCount。MapReduce 在 Map to Reduce 的过程中通过类似 hash 的方法自动聚合同一个 Key。因此,需要通过 MR 很容易做到数词。.
Storm 的实时 WordCount 怎么样?嗯,这也是一个可以载入实时技术史册的经典案例(嗯,其实就是一个Storm的HelloWorld)。Storm虽然没有类似MR的自动Hash功能,但也提供了可以达到类似效果的数据包流策略。它不像 MR 那样批处理,它是实时的和流式的。也就是说,可以动态获取当前变化词的词频。
实时热点分析,如果我们把热点映射成文字,能不能实时得到当前Top N的热点?这个方向有很大的研究价值。通过实时掌握用户的热点方向,动态调整业务策略,获取更大的数据价值。
不过总的来说,这个数据模型更多地依赖于实时工具Storm的功能,模型设计的东西比较少。至于是不是算法模型,就像我之前说的,看看我个人的看法,你就说吧~~
(4)很成熟的国产造型--推荐
就目前国内的数据挖掘而言,分类和推荐可能是最常见的两个方向。分类我就不多说了。比如刚才提到的贝叶斯算法,简直就是分类中的鼻祖算法。
说到推荐算法,联想规则、协同过滤、余弦相似度等词可能会立刻浮现在脑海中。这是真的,但我不是在谈论这个。其实我想说的是推荐基于两个方向:基于用户和基于内容。
我们需要注意两点。我们推荐的对象是用户,或者是与用户类似的具有动作行为的实体;而推荐的东西是内容,他没有动作行为,只是属性不同,或者砖块使用较多,业力描述是他必须有知识。
基于用户推荐,我们看重的不是内容的实体,而是用户本身的行为。我们认为用户的行为必然隐含一些信息,比如以人的兴趣为导向,那么既然你有相关的行为,那么我遵循你的行为向你推荐东西总是有意义的。
对于基于内容的推荐,我们关注的是内容,与用户的历史行为无关。我们潜意识地认为,既然你会阅读这个内容,你是否也对与这个内容相关的内容感兴趣?或许这样说有失偏颇,但大方向是正确的。
至于之前提到的关联规则,无论是协同过滤,还是余弦相似度,其实都是通过研究知识点和知识点之间的关系建立的模型。
对于基于内容的推荐,知识点是内容中的各种属性,比如电影推荐。知识点可以是各种评论数据、点播数据,比如数据、电影类型、演员、导演,以及其中的一些情感。分析等;比如博客文章,他们的知识点可能是带权重的词。至于这个词,涉及到词提取。说到字重,可能涉及到TFIDF模型和LDA模型。
对于基于用户的知识,知识点最直接的体现就是用户的行为,也就是用户与内容的关系。但是,再深入下去,你会发现其实和内容的知识点是息息相关的,但可能还不止这些。一个内容实体,而是多个内容实体的集合。
(5)文本词的加权模型
刚才提到了TFIDF和LDA模型,那么顺便说一下与文本词相关的权重模型。
说到文本挖掘,大多数人可能都熟悉 TFIDF 模型。既然涉及到了,我们就简单说一下。我们知道文本的知识点是单个单词。虽然都是词,但总有一些词更重要,哪些词不那么重要。
有些人可能会说更多的话很重要。没错,就是词频。简单地说,这种想法没有错,早期的文本挖掘模型就是这样做的。当然,效果一定是马马虎虎。因为经常出现的词往往是无用的、常用的词,对文章影响不大。
直到TFIDF模型的出现才从根本上解决了文本挖掘知识点建模的问题。如何判断一个词的重要性,或者专业的说,就是判断它对文章的贡献?TFIDF使用词频增加文章中的词权重,然后使用其在文章中的第A个文档频率来降低文章中的权重。说白了,就是降低那些公开言论的权重,把真正贡献很大的言论曝光出来。这基本上就是TFIDF的基本思想。至于如何增加词频权重,如何降低文档频率权重,这涉及到具体的模型公式。可以根据不同的需要进行调整。
文章知识点的主题建模的另一个非常重要的模型是LDA模型。是一个比较通用的文章主题模型。它利用概率原理,说白了就是贝叶斯,建立了知识点(即词)、主题和文章的三层关系结构。词与主题之间存在概率矩阵,主题与文章之间也存在概率矩阵映射关系。
好吧,LDA 不能再谈论它了。因为,我也不是很懂。对于LDA,虽然是部门内部使用的,但我没有做出具体的模型。我刚刚和同事讨论过,或者更准确地说,我问过我的同事关于它的一些原则和一些设计想法。
(6) 相似度计算
相似度计算,如文本相似度计算。这是一个非常基础的建模,用在很多地方,比如我们刚才提到的推荐。当其内部相关时,有时会涉及计算实体之间的相似度。
关于文本相似度,其实有很多方法。通常它涉及到TFIDF模型来获取文本的知识点,即加权词,然后利用这些加权词做一些相似度计算。
比如余弦相似度模型就是计算两个文本的余弦角,它的向量自然是那些带权重的词;比如各种计算距离的方法,最著名的欧式距离,它的向量还是这几个词。最长公共子串、最长公共子序列等模型很多,个人不是很清楚。
总之,方法很多,都不是很复杂,原理也很相似。至于哪个合适,要看具体的业务场景。
(7)文本学科度--信息熵
我和同事尝试过将百万博文的领域划分,将技术博文划分为不同的领域,比如大数据领域、移动互联网领域、安全领域等,其实还是分类。
一开始我们使用贝叶斯分类,效果还可以,但最后我们使用了SVM进行建模。这不是重点,重点是我们要判断技术博客文章归入某个领域的领域级别。
我们想了很多办法,尝试建立数据模型,但效果不是很理想。最后,我们回到了最本质的方法,那就是利用文本的信息熵来尝试描述度。最后的结果还是不错的。这让我又想起同事说的一句话:简单的东西不一定不好!
信息熵描述了一个实体的信息量。通俗地讲,它可以描述一个实体的信息混乱程度。在某个领域,知识点都是相似的,都是带有TFIDF权重的词。因此,是否可以认为文本的信息熵越小,主题越集中、越明显,信息混乱程度越低。另一方面,一些文本主题非常杂乱,可能收录来自多个领域的东西,其领域的程度会降低。
至少从表面上看,这个说法是可行的,实际效果也不错。
(8)用户画像
用户画像方向可能是这两年最火的方向。近年来,各大互联网公司和各大IT公司都自觉地开始从传统推荐向个性化推荐演进。有些可能更深,有些可能很浅。
商业价值的核心是用户,这自然不言而喻。那么如何结合用户进行推荐呢?那就是用户的属性。关键是用户的属性一开始就不存在。我们拥有的只是少数用户的固有属性和用户各种行为的记录。我们甚至不知道用户在做什么,所以让我们推动它!
因此,我们需要了解用户,因此有必要分析用户的用户画像。其实就是给用户打上标签,把用户打上属性标签。通过这种方式,我们知道每个用户是关于什么的。一些商业行为也是有目的的。
至于如何填写每个用户画像的属性,要看具体情况了。简单,用几个简单的模型提取一些信息来填写;复杂,使用复杂的算法,通过一些复杂的转换,标记用户。
(9)文章 热量计算
这里有很多文章,你怎么判断哪个文章更火,哪个文章更漂亮?也就是说,我进入了一个文章列表页面,你能给我提供一个热门文章的排序列表吗?
也许大多数想法都是直截了当的。获取能够反映文章流行度的属性,如点击率、评论情感分析、文章的状态。获取一个简单的加权计算模型,然后单击 Out。
从本质上讲,这是事实。一个简单的模型在实际情况中不一定很难使用。有些属性确实可以体现文章的流行度。加权计算的方法也是正确的。具体重量是要看具体情况。
但如果我这样做了,实际上会发生什么?今天来了,看到了这个热门推荐榜。我明天来了,还是看到了这个名单,后天我来了,还是这个名单。
尼玛,这是什么情况?你要我每天读多少次这个破单?!是的,这就是现实。结果是文章越热越热,越冷文章越冷,永远沉入海底,热的文章永远在前面。
如何解决这个问题呢?让我们添加时间作为参考。我们需要降低旧的文章沉没他人行为的力量,让新的文章有机会领先。也就是说,我们需要在权重上加上创建时间,并随着时间的推移衰减它的热权重,这样就不会出现冷热。至于衰减曲线,要看具体的业务。
这能解决根本问题吗?如果文章本身信息量不够,比如本身大部分都是新的文章,没有点赞,没有评论,甚至连点击都很少曝光。那么以前的模型将不起作用。
没有解决办法吗?有方法。比如我们找到了一个类似的网站,它也提供了类似最流行的文章推荐的功能,效果还不错。那么,我们可以利用它的受欢迎程度吗?我们使用计算文章的相似度的方法重新雕刻一个最热门的列表。如果网站性质相似,用户性质相似,文章的质量是的,相似度计算足够准确,相信这个热榜的效果也会不错(这个方法太琐碎了~~)。
(10)Google 的 PageRank
首先,不要误会我的意思,我从来没有真正写过这个模型,我没有条件写这个模型。
懂它懂懂它来自于和几个老同学合作搞网站(酷网,有兴趣的可以去看看)。既然从事网站,作为IT人,一些基本的SEO技巧还是要懂的。因此,我了解到如果要增加网站的权重,外部链接是必不可少的。
我跟几个老同学说,你去搞外链,抓个网站,让我们网站链接。他们问:网站 放多少链接?尽量多放网站?网站 说什么更好?这不是重点,关键是他们 问:是毛吗?
我问的那个人很无语,所以我一怒之下去研究PageRank。PageRank的具体扣分过程我就不讲了(可能以我三心二意的水平说不清楚)。有几个核心思想:一个网页被引用的次数越多,它的权重就越大;一个网页的权重越大,它所引用的网页的权重就越大;一个网页被引用的次数越多,它所引用的权重就越低。
当我们反复迭代这个过程时,我们会发现某个网页的排名基本是固定的。这就是PageRank的基本思想。当然,还有一个问题需要解决,比如如何给初始网页赋予初始权重,如何简化高计算迭代过程中的计算过程等等。这些问题在谷歌的实际操作中都得到了很好的优化。
(11) 有针对性的从网上抓取数据
其实我猜这跟算法没什么关系,不过既然有数据采集的设计流程,就勉强可以考虑了。
之所以有这个需求,是因为那段时间我在搞网站,为自己成立了一个工作室网站,想为别人打造一个轻量定制的企业,尤其是一些小企业。< @网站(是不是一团糟-_-),确实做了几个案例(我的工作室网站:我有兴趣去看看)。
从那以后,我想,我如何为自己找到客户?工作室的客户应该是那些小企业的老板,目前也一定没有企业门户。作为一个数据程序猿,也是一个挖掘机,虽然他没有中途从蓝翔毕业,没有证书就去上班,但他无论如何也挖了几座山。
现在是互联网泛滥的时代,他们总会在网上留下一些蛛丝马迹,我要抓住!我的目标很明确,我要拿到那些没有企业的企业邮箱网站,然后做自己的EDM营销(邮件营销)。
1) 我先是从智联检索页面,抓取了员工不到40人的公司名称。原来,兆联招聘的页面还是很容易解析的。它们是静态的,格式也很规则,所以很容易分析一组小公司的名称;
2) 公司名我知道了,怎么知道这家公司有独立的公司网站呢?通过分析,我发现在通过搜索引擎搜索公司名称时,如果有公司官网,肯定是在首页。而且它的页面地址也有一定的规律,即:独立官网的开头一般都是www开头,长度一般不会太长,结尾一般是index.html、index.php、index.asp和很快。
通过这些规则,我可以传递拥有官方网站的公司名称。有两个困难。一是搜索引擎的很多页面源代码都是动态加载的,所以我模拟了浏览器访问过程,抓取了页面源代码。这也是爬虫的常见做法;第二个也就是一开始,我尝试通过百度获取。结果,百度似乎有一些措施来发布结果,导致结果不尽人意。于是改变目的,用了360搜索,问题解决了(事实证明百度在搜索引擎方面还是比360强很多),效果也差不多。
3) 排除问题解决了,根本问题就在这里。如何获取公司的企业邮箱?通过对搜索引擎返回结果的分析,我发现很多小企业喜欢使用第三方。网站 提供的一些公司黄页包括公司的联系电子邮件地址;并且一些公司的招聘信息会收录公司的电子邮件地址。
通过数据分析,我终于得到了这部分数据,最后对邮箱是否有效等做了一些基本的分析,最终得到了3000多个企业邮箱,效率达到了80%以上。
问题解决了,但还有一些地方需要优化:首先是效率问题。我跑了将近12个小时才跑完3000多个邮箱。分析的地方太多,模拟浏览器。效率不高;其次,不太好判断邮箱的有效性。有些邮箱只是人为写的;还有一些网站基于图像的邮箱混合处理,类似。验证码是防抢的。我没有分析像图片一样的邮箱数据。其实这个问题是有办法解决的。我们得到了一些样本图片并进行了图片字母识别训练,以便我们可以解析它们。邮箱。
总的来说,体验还是很充实的。毕竟,我在业余时间解决了一些实际的痛点,并且对我学到的一些东西变得精通,或者说我在实施过程中学到了很多东西。
ps:在github上检索webmite就是这个项目。我将代码托管在 github 上或从我的博客输入。
其实,个人的缺点是显而易见的。首先,他没有经过系统的数据挖掘学习(没去过蓝翔,挖掘机自学),就是出身于野鹿子。因此,很多算法的原理还不够清晰。在这种情况下,您可能无法对某些业务场景提出建设性意见。而且,了解很多算法库的使用还是不够的。
二是缺乏数学技能。我们知道一些复杂的算法需要强大的数学基础。算法模型,其本质是数学模型。所以,这方面也是我的不足。
由于个人倾向于通过做大数据来挖掘,因此基于大数据模型的数据挖掘过程可能与传统的数据过程有很大不同。比如数据预处理过程,大数据挖掘的预处理很大程度上依赖于一些比较流行的分布式开源系统,比如实时处理系统Storm、消息队列Kafka、分布式数据采集系统Flume、数据离线批处理处理Hadoop等,可能会依赖Hive和一些Nosql进行数据分析和存储。相反,我对一些传统的挖掘工具比较陌生,比如SAS、SPSS、Excel等工具。但这并不是缺点。侧重点不同。总的来说,大规模数据的挖掘将是一个趋势。 查看全部
搜索引擎主题模型优化(数据挖掘算法为何物?——基于向量的相似度)
我写这个文章是因为前几天部门成员对部门涉及的一些算法进行了审查和整理。不过比较尴尬的是,既然老板不在,大家讨论讨论就变成吐槽大会了,但有一半时间是吐槽产品和业务部门~~
但这也是一件令人欣慰的事情。这也算是我们的数据部门,已经从轻型挖掘机走向了深挖阶段。
所以,借此机会,把我接触过、了解过、做过的一些勉强能称为算法的事情整理一下。事实上,就我而言,我没有算法背景。在大学里,我更多地了解了互联网,我什至不知道数据挖掘算法是什么。
其实就所谓的算法而言,我个人认为我的一个同事是对的:所谓的算法并不意味着那些复杂的数学模型就是算法。哪怕是你写的简单的计算公式,只要能解决当前存在的业务痛点,并且有自己的模型思路,就是算法,但可能不够通用,只能解决特定的业务需要。
在大规模数据的前提下,其实很多复杂的算法过程都没有这么好的结果。换句话说,我们将找到简化流程的方法。
举个简单的栗子:假设有一个大规模的数据集,以近千万篇博文为例。如果你提供一篇博文,让你查询相似度最高的前N个,我们通常的想法是什么?通常的方法是计算这篇博文与其他博文的相似度。计算相似度的方法有很多。, 最简单的方法是计算矢量角度,并根据矢量角度确定相似度。好吧,就算用最简单的计算过程,计算近千万次需要多长时间?或许,有人说我用hadoop,用分布式算力来完成这个任务,但是如果真的操作起来,你就会发现这是多么的痛苦。
再举一个简单的栗子(好吧,多吃栗子):比如SVM,这是一个很难收敛的算法。在大数据的前提下,有的人想用大数据,但想用更多的数据进行训练。模型毕竟手头的数据太多,很多人还是希望用尽可能多的数据来训练,以达到模型更加精准的目的。但是,随着训练数据量的增加,SVM等难以收敛的算法会消耗大量的计算资源。
(1)贝叶斯
贝叶斯是分类算法中最简单的算法。挖掘机算法初学者肯定会先爱上它。事实上,贝叶斯原理非常简单,基于统计学中的最大概率原理。就是这么简单,但尼玛却是这么好用,多年来一直屹立不倒。
缺乏训练过程。基本上贝叶斯就是这样的。因为是文本,所以用一组过程将词和停用词作为最基本的知识点向量进行分割,然后计算模型概率。但更有趣的是,分类过程是在Storm中完成的,相当于一个实时的分类服务。
(2)分词算法
其实说到分词算法,没什么好说的。现在网上各种开源的分词工具都做得很好,效果也差不了多少。如果要进一步改进,就会窒息。至于深入分词算法,涉及到上下文分析、隐马尔可夫模型等。如果是有兴趣研究的个人,那我无话可说;如果是小公司,会花费人力物力去优化分词效果。只能说闲着就疼;如果是大公司,金朵的任性也是可以理解的。
因此,到目前为止,个人对分词算法的演变、所涉及的内部算法以及几种分词工具的使用的初步理解都受到了限制。
其实在文本挖掘方面,对文本进行分词是不够的,因为我们用分词来切词,往往很多与业务无关,通常的做法是建立相应的业务词典,至于词典的建立当然也需要进行分词,进行进一步的处理,甚至可能会增加一些人工。
(3)实时热点分析
不知道是不是算法 说到实时性,自然和Storm有关系(嗯,我承认我是在做这个之后开始接触数据的)。说到实时热点,大家可能想不通,举个简单的栗子。
玩过 hadoop 的人都知道经典的栗子 WordCount。MapReduce 在 Map to Reduce 的过程中通过类似 hash 的方法自动聚合同一个 Key。因此,需要通过 MR 很容易做到数词。.
Storm 的实时 WordCount 怎么样?嗯,这也是一个可以载入实时技术史册的经典案例(嗯,其实就是一个Storm的HelloWorld)。Storm虽然没有类似MR的自动Hash功能,但也提供了可以达到类似效果的数据包流策略。它不像 MR 那样批处理,它是实时的和流式的。也就是说,可以动态获取当前变化词的词频。
实时热点分析,如果我们把热点映射成文字,能不能实时得到当前Top N的热点?这个方向有很大的研究价值。通过实时掌握用户的热点方向,动态调整业务策略,获取更大的数据价值。
不过总的来说,这个数据模型更多地依赖于实时工具Storm的功能,模型设计的东西比较少。至于是不是算法模型,就像我之前说的,看看我个人的看法,你就说吧~~
(4)很成熟的国产造型--推荐
就目前国内的数据挖掘而言,分类和推荐可能是最常见的两个方向。分类我就不多说了。比如刚才提到的贝叶斯算法,简直就是分类中的鼻祖算法。
说到推荐算法,联想规则、协同过滤、余弦相似度等词可能会立刻浮现在脑海中。这是真的,但我不是在谈论这个。其实我想说的是推荐基于两个方向:基于用户和基于内容。
我们需要注意两点。我们推荐的对象是用户,或者是与用户类似的具有动作行为的实体;而推荐的东西是内容,他没有动作行为,只是属性不同,或者砖块使用较多,业力描述是他必须有知识。
基于用户推荐,我们看重的不是内容的实体,而是用户本身的行为。我们认为用户的行为必然隐含一些信息,比如以人的兴趣为导向,那么既然你有相关的行为,那么我遵循你的行为向你推荐东西总是有意义的。
对于基于内容的推荐,我们关注的是内容,与用户的历史行为无关。我们潜意识地认为,既然你会阅读这个内容,你是否也对与这个内容相关的内容感兴趣?或许这样说有失偏颇,但大方向是正确的。
至于之前提到的关联规则,无论是协同过滤,还是余弦相似度,其实都是通过研究知识点和知识点之间的关系建立的模型。
对于基于内容的推荐,知识点是内容中的各种属性,比如电影推荐。知识点可以是各种评论数据、点播数据,比如数据、电影类型、演员、导演,以及其中的一些情感。分析等;比如博客文章,他们的知识点可能是带权重的词。至于这个词,涉及到词提取。说到字重,可能涉及到TFIDF模型和LDA模型。
对于基于用户的知识,知识点最直接的体现就是用户的行为,也就是用户与内容的关系。但是,再深入下去,你会发现其实和内容的知识点是息息相关的,但可能还不止这些。一个内容实体,而是多个内容实体的集合。
(5)文本词的加权模型
刚才提到了TFIDF和LDA模型,那么顺便说一下与文本词相关的权重模型。
说到文本挖掘,大多数人可能都熟悉 TFIDF 模型。既然涉及到了,我们就简单说一下。我们知道文本的知识点是单个单词。虽然都是词,但总有一些词更重要,哪些词不那么重要。
有些人可能会说更多的话很重要。没错,就是词频。简单地说,这种想法没有错,早期的文本挖掘模型就是这样做的。当然,效果一定是马马虎虎。因为经常出现的词往往是无用的、常用的词,对文章影响不大。
直到TFIDF模型的出现才从根本上解决了文本挖掘知识点建模的问题。如何判断一个词的重要性,或者专业的说,就是判断它对文章的贡献?TFIDF使用词频增加文章中的词权重,然后使用其在文章中的第A个文档频率来降低文章中的权重。说白了,就是降低那些公开言论的权重,把真正贡献很大的言论曝光出来。这基本上就是TFIDF的基本思想。至于如何增加词频权重,如何降低文档频率权重,这涉及到具体的模型公式。可以根据不同的需要进行调整。
文章知识点的主题建模的另一个非常重要的模型是LDA模型。是一个比较通用的文章主题模型。它利用概率原理,说白了就是贝叶斯,建立了知识点(即词)、主题和文章的三层关系结构。词与主题之间存在概率矩阵,主题与文章之间也存在概率矩阵映射关系。
好吧,LDA 不能再谈论它了。因为,我也不是很懂。对于LDA,虽然是部门内部使用的,但我没有做出具体的模型。我刚刚和同事讨论过,或者更准确地说,我问过我的同事关于它的一些原则和一些设计想法。
(6) 相似度计算
相似度计算,如文本相似度计算。这是一个非常基础的建模,用在很多地方,比如我们刚才提到的推荐。当其内部相关时,有时会涉及计算实体之间的相似度。
关于文本相似度,其实有很多方法。通常它涉及到TFIDF模型来获取文本的知识点,即加权词,然后利用这些加权词做一些相似度计算。
比如余弦相似度模型就是计算两个文本的余弦角,它的向量自然是那些带权重的词;比如各种计算距离的方法,最著名的欧式距离,它的向量还是这几个词。最长公共子串、最长公共子序列等模型很多,个人不是很清楚。
总之,方法很多,都不是很复杂,原理也很相似。至于哪个合适,要看具体的业务场景。
(7)文本学科度--信息熵
我和同事尝试过将百万博文的领域划分,将技术博文划分为不同的领域,比如大数据领域、移动互联网领域、安全领域等,其实还是分类。
一开始我们使用贝叶斯分类,效果还可以,但最后我们使用了SVM进行建模。这不是重点,重点是我们要判断技术博客文章归入某个领域的领域级别。
我们想了很多办法,尝试建立数据模型,但效果不是很理想。最后,我们回到了最本质的方法,那就是利用文本的信息熵来尝试描述度。最后的结果还是不错的。这让我又想起同事说的一句话:简单的东西不一定不好!
信息熵描述了一个实体的信息量。通俗地讲,它可以描述一个实体的信息混乱程度。在某个领域,知识点都是相似的,都是带有TFIDF权重的词。因此,是否可以认为文本的信息熵越小,主题越集中、越明显,信息混乱程度越低。另一方面,一些文本主题非常杂乱,可能收录来自多个领域的东西,其领域的程度会降低。
至少从表面上看,这个说法是可行的,实际效果也不错。
(8)用户画像
用户画像方向可能是这两年最火的方向。近年来,各大互联网公司和各大IT公司都自觉地开始从传统推荐向个性化推荐演进。有些可能更深,有些可能很浅。
商业价值的核心是用户,这自然不言而喻。那么如何结合用户进行推荐呢?那就是用户的属性。关键是用户的属性一开始就不存在。我们拥有的只是少数用户的固有属性和用户各种行为的记录。我们甚至不知道用户在做什么,所以让我们推动它!
因此,我们需要了解用户,因此有必要分析用户的用户画像。其实就是给用户打上标签,把用户打上属性标签。通过这种方式,我们知道每个用户是关于什么的。一些商业行为也是有目的的。
至于如何填写每个用户画像的属性,要看具体情况了。简单,用几个简单的模型提取一些信息来填写;复杂,使用复杂的算法,通过一些复杂的转换,标记用户。
(9)文章 热量计算
这里有很多文章,你怎么判断哪个文章更火,哪个文章更漂亮?也就是说,我进入了一个文章列表页面,你能给我提供一个热门文章的排序列表吗?
也许大多数想法都是直截了当的。获取能够反映文章流行度的属性,如点击率、评论情感分析、文章的状态。获取一个简单的加权计算模型,然后单击 Out。
从本质上讲,这是事实。一个简单的模型在实际情况中不一定很难使用。有些属性确实可以体现文章的流行度。加权计算的方法也是正确的。具体重量是要看具体情况。
但如果我这样做了,实际上会发生什么?今天来了,看到了这个热门推荐榜。我明天来了,还是看到了这个名单,后天我来了,还是这个名单。
尼玛,这是什么情况?你要我每天读多少次这个破单?!是的,这就是现实。结果是文章越热越热,越冷文章越冷,永远沉入海底,热的文章永远在前面。
如何解决这个问题呢?让我们添加时间作为参考。我们需要降低旧的文章沉没他人行为的力量,让新的文章有机会领先。也就是说,我们需要在权重上加上创建时间,并随着时间的推移衰减它的热权重,这样就不会出现冷热。至于衰减曲线,要看具体的业务。
这能解决根本问题吗?如果文章本身信息量不够,比如本身大部分都是新的文章,没有点赞,没有评论,甚至连点击都很少曝光。那么以前的模型将不起作用。
没有解决办法吗?有方法。比如我们找到了一个类似的网站,它也提供了类似最流行的文章推荐的功能,效果还不错。那么,我们可以利用它的受欢迎程度吗?我们使用计算文章的相似度的方法重新雕刻一个最热门的列表。如果网站性质相似,用户性质相似,文章的质量是的,相似度计算足够准确,相信这个热榜的效果也会不错(这个方法太琐碎了~~)。
(10)Google 的 PageRank
首先,不要误会我的意思,我从来没有真正写过这个模型,我没有条件写这个模型。
懂它懂懂它来自于和几个老同学合作搞网站(酷网,有兴趣的可以去看看)。既然从事网站,作为IT人,一些基本的SEO技巧还是要懂的。因此,我了解到如果要增加网站的权重,外部链接是必不可少的。
我跟几个老同学说,你去搞外链,抓个网站,让我们网站链接。他们问:网站 放多少链接?尽量多放网站?网站 说什么更好?这不是重点,关键是他们 问:是毛吗?
我问的那个人很无语,所以我一怒之下去研究PageRank。PageRank的具体扣分过程我就不讲了(可能以我三心二意的水平说不清楚)。有几个核心思想:一个网页被引用的次数越多,它的权重就越大;一个网页的权重越大,它所引用的网页的权重就越大;一个网页被引用的次数越多,它所引用的权重就越低。
当我们反复迭代这个过程时,我们会发现某个网页的排名基本是固定的。这就是PageRank的基本思想。当然,还有一个问题需要解决,比如如何给初始网页赋予初始权重,如何简化高计算迭代过程中的计算过程等等。这些问题在谷歌的实际操作中都得到了很好的优化。
(11) 有针对性的从网上抓取数据
其实我猜这跟算法没什么关系,不过既然有数据采集的设计流程,就勉强可以考虑了。
之所以有这个需求,是因为那段时间我在搞网站,为自己成立了一个工作室网站,想为别人打造一个轻量定制的企业,尤其是一些小企业。< @网站(是不是一团糟-_-),确实做了几个案例(我的工作室网站:我有兴趣去看看)。
从那以后,我想,我如何为自己找到客户?工作室的客户应该是那些小企业的老板,目前也一定没有企业门户。作为一个数据程序猿,也是一个挖掘机,虽然他没有中途从蓝翔毕业,没有证书就去上班,但他无论如何也挖了几座山。
现在是互联网泛滥的时代,他们总会在网上留下一些蛛丝马迹,我要抓住!我的目标很明确,我要拿到那些没有企业的企业邮箱网站,然后做自己的EDM营销(邮件营销)。
1) 我先是从智联检索页面,抓取了员工不到40人的公司名称。原来,兆联招聘的页面还是很容易解析的。它们是静态的,格式也很规则,所以很容易分析一组小公司的名称;
2) 公司名我知道了,怎么知道这家公司有独立的公司网站呢?通过分析,我发现在通过搜索引擎搜索公司名称时,如果有公司官网,肯定是在首页。而且它的页面地址也有一定的规律,即:独立官网的开头一般都是www开头,长度一般不会太长,结尾一般是index.html、index.php、index.asp和很快。
通过这些规则,我可以传递拥有官方网站的公司名称。有两个困难。一是搜索引擎的很多页面源代码都是动态加载的,所以我模拟了浏览器访问过程,抓取了页面源代码。这也是爬虫的常见做法;第二个也就是一开始,我尝试通过百度获取。结果,百度似乎有一些措施来发布结果,导致结果不尽人意。于是改变目的,用了360搜索,问题解决了(事实证明百度在搜索引擎方面还是比360强很多),效果也差不多。
3) 排除问题解决了,根本问题就在这里。如何获取公司的企业邮箱?通过对搜索引擎返回结果的分析,我发现很多小企业喜欢使用第三方。网站 提供的一些公司黄页包括公司的联系电子邮件地址;并且一些公司的招聘信息会收录公司的电子邮件地址。
通过数据分析,我终于得到了这部分数据,最后对邮箱是否有效等做了一些基本的分析,最终得到了3000多个企业邮箱,效率达到了80%以上。
问题解决了,但还有一些地方需要优化:首先是效率问题。我跑了将近12个小时才跑完3000多个邮箱。分析的地方太多,模拟浏览器。效率不高;其次,不太好判断邮箱的有效性。有些邮箱只是人为写的;还有一些网站基于图像的邮箱混合处理,类似。验证码是防抢的。我没有分析像图片一样的邮箱数据。其实这个问题是有办法解决的。我们得到了一些样本图片并进行了图片字母识别训练,以便我们可以解析它们。邮箱。
总的来说,体验还是很充实的。毕竟,我在业余时间解决了一些实际的痛点,并且对我学到的一些东西变得精通,或者说我在实施过程中学到了很多东西。
ps:在github上检索webmite就是这个项目。我将代码托管在 github 上或从我的博客输入。
其实,个人的缺点是显而易见的。首先,他没有经过系统的数据挖掘学习(没去过蓝翔,挖掘机自学),就是出身于野鹿子。因此,很多算法的原理还不够清晰。在这种情况下,您可能无法对某些业务场景提出建设性意见。而且,了解很多算法库的使用还是不够的。
二是缺乏数学技能。我们知道一些复杂的算法需要强大的数学基础。算法模型,其本质是数学模型。所以,这方面也是我的不足。
由于个人倾向于通过做大数据来挖掘,因此基于大数据模型的数据挖掘过程可能与传统的数据过程有很大不同。比如数据预处理过程,大数据挖掘的预处理很大程度上依赖于一些比较流行的分布式开源系统,比如实时处理系统Storm、消息队列Kafka、分布式数据采集系统Flume、数据离线批处理处理Hadoop等,可能会依赖Hive和一些Nosql进行数据分析和存储。相反,我对一些传统的挖掘工具比较陌生,比如SAS、SPSS、Excel等工具。但这并不是缺点。侧重点不同。总的来说,大规模数据的挖掘将是一个趋势。
搜索引擎主题模型优化(海量文档数据的来源,查找技术又是如何的呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-17 16:27
内容:
搜索引擎的使用我们并不陌生。对于正常的搜索过程,比如用户输入查询“搜索引擎技术”,搜索引擎需要将存储在磁盘上的两个词的反向排序索引读入内存,然后进行解压,然后找到打乱根据两个词对应的倒排排序列表的基数,找到所有收录两个词的文档集合,根据排序算法对每个文档的相关度进行打分,根据相关度输入最相关的搜索结果。
但是这一系列步骤中海量文档数据的来源、存储和搜索技术呢?以下是我最近阅读的《这就是搜索引擎:核心技术详解》一书的总结:
一、网络爬虫
首先,搜索引擎的文档数据从何而来?
站长的一个常识是,当他们部署一个网站时,他们会将自己的页面提交给谷歌、百度、必应等搜索引擎提交自己的页面,以方便他们的爬虫。快速抓取提交网站的页面。
什么,你不知道爬虫?不懂科普
爬虫的通用框架
目前的爬虫大多是分布式爬虫,爬取策略包括:
但是,在网站的垂直领域,比如携程的机票数据、京东产品等页面,很难有显示链接指向。您仍然需要输入 关键词 来搜索它。在这种情况下,按照爬虫的规则很难爬到这种页面,所以就出现了暗网爬行。简单来说就是爬虫在搜索页面提交查询,然后在目标网站提交查询后搜索页面的组合,基于暗网爬取,百度提出了“Project Aladdin”,例如Google的Onebox , 例子
但是现在想想,网上最方便的就是抄袭抄袭。统计显示,近似重复页面的数量高达网页总数的29%,而相同的页面约占所有页面的%22。,即相当比例的网页内容相同或大致相似。例如,新闻话题的内容几乎相同,但两个页面的网页布局却大不相同。为了解决这个问题,需要对网页进行去重,尽量不向用户呈现重复的搜索结果,体现原创的本质,提供用户搜索体验。
主要的网页去重算法有:Shingling、I-Match、Simhash、SpotSig等。
二、搜索引擎索引
对于大量的网页文档内容,需要使用索引来快速找到被查询的网页。
为了应对大量的文档和各种查询,搜索引擎经常使用倒排索引作为词到文档的映射。
最简单的倒排索引
倒排索引主要包括单词词典和相应的倒排列表,及其相关的技术选项:
三、搜索模型
拥有大量数据文档并进行相应排序后,如何找到搜索到的相关文档?
判断网页内容是否与用户查询相关,取决于搜索引擎采用的检索模型:
布尔模型:使用简单的“和/或/非”逻辑关系来判断文档是否与查询相关。基于此模型的搜索结果过于粗糙,无法满足用户需求。
向量空间模型:将查询词和文档中的关键词转换为特征向量,然后使用余弦公式
计算文档和查询的相关性并对输出结果进行排序。关于特征向量权重计算,也称为TF*IDF框架。词频TF表示一个词在文档中出现的次数,IDF表示查询词在所有文档中出现的频率的倒数:
特征权重值是他们的产品,具体中文解释是这样描述的:
概率检索模型:对于某个文档D,如果属于相关文档子集的概率大于不属于不相关子集的概率,则该文档与用户的查询相关,即
具体算法是使用MB25模型计算:
这个模型已经是一个非常成功的概率模型方法,然后人们对它还有其他的改进。
四、链接分析算法
搜索引擎的最终搜索结果不仅基于文档相关性,还基于网页的重要性。
搜索引擎在找到能够满足用户请求的网页时,主要考虑两个因素:一方面,用户发送的查询与网页内容的相似度得分;另一方面,通过链接分析方法计算的得分,即网页重要性,搜索引擎两者的融合,联合拟合相似度得分函数,对搜索进行排序。
基本链接分析算法图
搜索引擎经常使用链接分析算法来对网页的重要性进行排名。更基本和众所周知的算法是 PageRank 和 Hits。前者主要通过随机游走模型计算,后者基于子集传播模型。当然,为了弥补其算法的不足,也做了很多类型的改进,比如“话题敏感PageRank”算法来改善原Pagerank的话题偏差,Hilltop结合Hits和pagerank。
但是,在商业利益的驱使下,很多网站站长会分析搜索引擎排名,并采取一些措施提升网站排名,但也存在严重影响搜索引擎用户的恶意优化行为,因此有些算法是还提出了应对各种恶意作弊:TrustRank、BadRank、SpamRank等,并且这些反作弊算法的结果权重占搜索的很大比例。
五:存储与计算
搜索引擎需要存储和计算数以亿计的数据,他们觉得其中一些是非结构化或半结构化数据。如何构建存储平台和计算平台,简化存储和管理成为一个重要的问题。谷歌的一位代表提出了他的三驾马车:/BingTable/MapReduce。谷歌曾就三驾马车相关技术发表详细论文,催生了云计算新宠“Hadoop”。
hadoop和三驾马车的关系
GFS:谷歌分布式文件系统,由大量PC组成,机器故障时正常,支持横向增量扩展,可存储数百亿海量网络信息。(HDFS 被认为是 GFS 的开源实现)
BigTable:是一种基于GFS的海量结构化或半结构化存储的存储模型。它的存储模型介于关系数据和 NoSql 存储系统之间。它特别适用于一次写入和多次读取。减少修改的业务需求。(HBase 被认为是 BigTable 的开源实现)
Map/Reduce:是一种分布式云计算模型,本质上是通过分而治之的思想实现的。它通常是一系列多个 MapRduce 子任务。前面的 Map 阶段经常作为后面的 Reduce 阶段的输入来执行一系列复杂的任务。任务的计算。(使用这个模型最著名的开源代表是Hadoop)
Pregel:基于BSP的同步计算模型,用于解决大规模分布式图计算问题,弥补Map/Reduce在图计算方面的不足。陈伟超步计算一次迭代,系统从一个超到另一个 否,达到算法的终止条件。谷歌早期的PageRank算法主要使用Pregel平台进行计算。(Giraph 被认为是 Pregel 的开源实现。后来卡内基梅隆大学发明了另一个分布式图处理模型:GraphLab)
随着开源Hadoop的出现,驾驭谷歌的三驾马车变得更加容易。目前,Hadoop也已经成功投入业务,得到了Facebook、阿里、腾讯等巨头的支持。
六、搜索引擎缓存机制
现在大家应该都知道,搜索引擎已经成为各大网站的主入口,点击“百度”,往往上面复杂的计算搜索结果会很快的呈现在浏览器上,这么快主要是因为缓存。
搜索引擎的缓存设计主要基于缓存的搜索结果和缓存的搜索词的倒排索引。前者响应速度快,但命中率不高,后者获取缓存后还要重新计算分数。响应速度比较慢,但是命中率比较高。所以现在常用的缓存将两者结合起来,先用结果缓存,再用词表缓存,而且缓存也分为倒排词组合计算得分缓存和独立倒排两级缓存,聚合用户反应速度和命中率是两个优势。
写在后面:
以上总结主要是针对搜索引擎的一般流程。这只是个人阅读本书后的意见。如今,技术的发展比我们阅读的要快得多。所以文中如有不妥之处,请大家指点,共同学习。共同进步。
文章中的插图主要来源于书中。 查看全部
搜索引擎主题模型优化(海量文档数据的来源,查找技术又是如何的呢?)
内容:
搜索引擎的使用我们并不陌生。对于正常的搜索过程,比如用户输入查询“搜索引擎技术”,搜索引擎需要将存储在磁盘上的两个词的反向排序索引读入内存,然后进行解压,然后找到打乱根据两个词对应的倒排排序列表的基数,找到所有收录两个词的文档集合,根据排序算法对每个文档的相关度进行打分,根据相关度输入最相关的搜索结果。
但是这一系列步骤中海量文档数据的来源、存储和搜索技术呢?以下是我最近阅读的《这就是搜索引擎:核心技术详解》一书的总结:
一、网络爬虫
首先,搜索引擎的文档数据从何而来?
站长的一个常识是,当他们部署一个网站时,他们会将自己的页面提交给谷歌、百度、必应等搜索引擎提交自己的页面,以方便他们的爬虫。快速抓取提交网站的页面。
什么,你不知道爬虫?不懂科普
爬虫的通用框架
目前的爬虫大多是分布式爬虫,爬取策略包括:
但是,在网站的垂直领域,比如携程的机票数据、京东产品等页面,很难有显示链接指向。您仍然需要输入 关键词 来搜索它。在这种情况下,按照爬虫的规则很难爬到这种页面,所以就出现了暗网爬行。简单来说就是爬虫在搜索页面提交查询,然后在目标网站提交查询后搜索页面的组合,基于暗网爬取,百度提出了“Project Aladdin”,例如Google的Onebox , 例子
但是现在想想,网上最方便的就是抄袭抄袭。统计显示,近似重复页面的数量高达网页总数的29%,而相同的页面约占所有页面的%22。,即相当比例的网页内容相同或大致相似。例如,新闻话题的内容几乎相同,但两个页面的网页布局却大不相同。为了解决这个问题,需要对网页进行去重,尽量不向用户呈现重复的搜索结果,体现原创的本质,提供用户搜索体验。
主要的网页去重算法有:Shingling、I-Match、Simhash、SpotSig等。
二、搜索引擎索引
对于大量的网页文档内容,需要使用索引来快速找到被查询的网页。
为了应对大量的文档和各种查询,搜索引擎经常使用倒排索引作为词到文档的映射。
最简单的倒排索引
倒排索引主要包括单词词典和相应的倒排列表,及其相关的技术选项:
三、搜索模型
拥有大量数据文档并进行相应排序后,如何找到搜索到的相关文档?
判断网页内容是否与用户查询相关,取决于搜索引擎采用的检索模型:
布尔模型:使用简单的“和/或/非”逻辑关系来判断文档是否与查询相关。基于此模型的搜索结果过于粗糙,无法满足用户需求。
向量空间模型:将查询词和文档中的关键词转换为特征向量,然后使用余弦公式
计算文档和查询的相关性并对输出结果进行排序。关于特征向量权重计算,也称为TF*IDF框架。词频TF表示一个词在文档中出现的次数,IDF表示查询词在所有文档中出现的频率的倒数:
特征权重值是他们的产品,具体中文解释是这样描述的:
概率检索模型:对于某个文档D,如果属于相关文档子集的概率大于不属于不相关子集的概率,则该文档与用户的查询相关,即
具体算法是使用MB25模型计算:
这个模型已经是一个非常成功的概率模型方法,然后人们对它还有其他的改进。
四、链接分析算法
搜索引擎的最终搜索结果不仅基于文档相关性,还基于网页的重要性。
搜索引擎在找到能够满足用户请求的网页时,主要考虑两个因素:一方面,用户发送的查询与网页内容的相似度得分;另一方面,通过链接分析方法计算的得分,即网页重要性,搜索引擎两者的融合,联合拟合相似度得分函数,对搜索进行排序。
基本链接分析算法图
搜索引擎经常使用链接分析算法来对网页的重要性进行排名。更基本和众所周知的算法是 PageRank 和 Hits。前者主要通过随机游走模型计算,后者基于子集传播模型。当然,为了弥补其算法的不足,也做了很多类型的改进,比如“话题敏感PageRank”算法来改善原Pagerank的话题偏差,Hilltop结合Hits和pagerank。
但是,在商业利益的驱使下,很多网站站长会分析搜索引擎排名,并采取一些措施提升网站排名,但也存在严重影响搜索引擎用户的恶意优化行为,因此有些算法是还提出了应对各种恶意作弊:TrustRank、BadRank、SpamRank等,并且这些反作弊算法的结果权重占搜索的很大比例。
五:存储与计算
搜索引擎需要存储和计算数以亿计的数据,他们觉得其中一些是非结构化或半结构化数据。如何构建存储平台和计算平台,简化存储和管理成为一个重要的问题。谷歌的一位代表提出了他的三驾马车:/BingTable/MapReduce。谷歌曾就三驾马车相关技术发表详细论文,催生了云计算新宠“Hadoop”。
hadoop和三驾马车的关系
GFS:谷歌分布式文件系统,由大量PC组成,机器故障时正常,支持横向增量扩展,可存储数百亿海量网络信息。(HDFS 被认为是 GFS 的开源实现)
BigTable:是一种基于GFS的海量结构化或半结构化存储的存储模型。它的存储模型介于关系数据和 NoSql 存储系统之间。它特别适用于一次写入和多次读取。减少修改的业务需求。(HBase 被认为是 BigTable 的开源实现)
Map/Reduce:是一种分布式云计算模型,本质上是通过分而治之的思想实现的。它通常是一系列多个 MapRduce 子任务。前面的 Map 阶段经常作为后面的 Reduce 阶段的输入来执行一系列复杂的任务。任务的计算。(使用这个模型最著名的开源代表是Hadoop)
Pregel:基于BSP的同步计算模型,用于解决大规模分布式图计算问题,弥补Map/Reduce在图计算方面的不足。陈伟超步计算一次迭代,系统从一个超到另一个 否,达到算法的终止条件。谷歌早期的PageRank算法主要使用Pregel平台进行计算。(Giraph 被认为是 Pregel 的开源实现。后来卡内基梅隆大学发明了另一个分布式图处理模型:GraphLab)
随着开源Hadoop的出现,驾驭谷歌的三驾马车变得更加容易。目前,Hadoop也已经成功投入业务,得到了Facebook、阿里、腾讯等巨头的支持。
六、搜索引擎缓存机制
现在大家应该都知道,搜索引擎已经成为各大网站的主入口,点击“百度”,往往上面复杂的计算搜索结果会很快的呈现在浏览器上,这么快主要是因为缓存。
搜索引擎的缓存设计主要基于缓存的搜索结果和缓存的搜索词的倒排索引。前者响应速度快,但命中率不高,后者获取缓存后还要重新计算分数。响应速度比较慢,但是命中率比较高。所以现在常用的缓存将两者结合起来,先用结果缓存,再用词表缓存,而且缓存也分为倒排词组合计算得分缓存和独立倒排两级缓存,聚合用户反应速度和命中率是两个优势。
写在后面:
以上总结主要是针对搜索引擎的一般流程。这只是个人阅读本书后的意见。如今,技术的发展比我们阅读的要快得多。所以文中如有不妥之处,请大家指点,共同学习。共同进步。
文章中的插图主要来源于书中。
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心主题模型?本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-12-17 16:25
网站优化主题模型SEO最新的SEO概念进入了全新的“有质感的内容”算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。下面将结合当今最新的SEO概念来指导你如何优化主题内容。SEO网站的主题模型是什么?关于SEO页面的内容,我们通常可以听到和看到很多旧的方法,这比使用各种H标签来整合关键词 TDK关键词 是否设置为准确匹配但有经验SEO 人员和 网站 大师们很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这是本文的核心。那么什么是主题模型呢?主题模型是页面内容布局的模型,为了让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:1)词系统关联<
他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)。第一步:词关联 无论你用什么方法来优化页面的内容,都必须围绕如何关联词和词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。当我们使用句子和单词时,搜索引擎将根据其他资源中的数据关联您的内容,以生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己的研究关键词的方法,但需要达到以下目标:1)找到同义词和异体词2)找到与内容相关的二类词主题3)找二类词相关的三类词,Thing) 举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据上述目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是关键词的密度!第2步:词系统布局毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要,非常重要。蜘蛛什么时候来到页面发现这么多关键词,他们需要区分哪些是重要的,哪些 关键词 与短语相关。所以词系统布局是要明确核心词和相关性,下面是3个实用的优化方法: 1)Region: 关键词 必须出现在Title、标题和主要段落2) 频率: 重要的短语 or 它是它们的变体可以出现超过平均水平。3) 距离:相关词或词组要尽量靠近或者使用HTML元素(如ALT)的方式(1)是大部分SEO人的必修项目,还是要放核心主题标题和大标题中的词尽量出现在正文的顶部。方法(2)这里不仅仅是关键词的频率(密度),但更复杂的是,第一层的链接频率是核心词的同义词和变体。在同等条件下,不太流行的同义词和变体会得到更好的结果。
现在你要做的就是将那些二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主题(排名词),正如我之前所说的搜索引擎可以使用大数据来识别单词关联。举个简单的例子:主词是【网红】,第一段会重点关注这个词文章。第二段将用几只手完成。文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是一个词系相关内容,并通过步骤2来布局词系。第三步:补充内容。或许很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,现在的外链就像一颗不合时宜的炸弹,说不定会被链接炸死。
因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?如果你的网页只是单纯的关键词,缺少文字链接、参考资料和相关资源推荐,那么你的页面就很死板,死路一条,不会给你的页面加分。看右边的页面。网站内有链接(黄色部分),导出链接和内容中的[补充内容]。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是加强页面主题的深化,通过不同网站的内容来强化信息。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。1)在页面底部添加相关资源的链接(推荐站内链接)2)在文中使用引号,如行业内知名人士的话或图标,如文中3) 使用导出链接到网站中的第三方(你不会被K放100。第4步:内容实体这是一个非常难的概念,称为英文实体。强大的搜索引擎会抓取页面 来自动解释内容实体,或者将其理解为内容属性。例如,当内容提到“包老师”时,它的实体是[人]吗?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。
(木木补充说,这涉及到微数据。HTML5 微数据规范是一种标记,用于描述特定类型的信息,例如评论、人物信息或事件。每种类型的信息描述特定类型的项目,例如人物、事件或评论见《结构化微数据丰富网页摘要》)一般搜索引擎都会给站长提供自己的结构化数据(比如“百度新数据标注工具,相当于谷歌数据标注”),什么是结构化数据?就是使用搜索引擎设置的HTML Markup来定义内容,或者统称为使用Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。这个更高级 只是一点点理解。您可以要求您的架构师添加 网站 结构数据。当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。搜索引擎会自动解释内容实体,通过“人、地、物”来寻找关联,所以建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比作“每个实体”。关联。例如,
看看有没有和之前的优化概念不一样。搜索引擎不看页面上是否有这个词以及有多少链接指向它,而是看内容实体是否相关。综上所述,大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技巧整合到你的内容优化中:1)一个高度概括的标题来描述页面的主题2)添加一个开头(简要)来描述页面的内容3)@ > 内容分为几段,每段都有自己的主题。4)尽量扩大主题视角,补充相关答案。5) 查看全部
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心主题模型?本文)
网站优化主题模型SEO最新的SEO概念进入了全新的“有质感的内容”算法体系,尤其是当今一流的搜索引擎可以从内容场景和内容实体属性进行排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。下面将结合当今最新的SEO概念来指导你如何优化主题内容。SEO网站的主题模型是什么?关于SEO页面的内容,我们通常可以听到和看到很多旧的方法,这比使用各种H标签来整合关键词 TDK关键词 是否设置为准确匹配但有经验SEO 人员和 网站 大师们很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这是本文的核心。那么什么是主题模型呢?主题模型是页面内容布局的模型,为了让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现四步新的优化方法:1)词系统关联<
他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)。第一步:词关联 无论你用什么方法来优化页面的内容,都必须围绕如何关联词和词组。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。当我们使用句子和单词时,搜索引擎将根据其他资源中的数据关联您的内容,以生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己的研究关键词的方法,但需要达到以下目标:1)找到同义词和异体词2)找到与内容相关的二类词主题3)找二类词相关的三类词,Thing) 举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据上述目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是关键词的密度!第2步:词系统布局毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要,非常重要。蜘蛛什么时候来到页面发现这么多关键词,他们需要区分哪些是重要的,哪些 关键词 与短语相关。所以词系统布局是要明确核心词和相关性,下面是3个实用的优化方法: 1)Region: 关键词 必须出现在Title、标题和主要段落2) 频率: 重要的短语 or 它是它们的变体可以出现超过平均水平。3) 距离:相关词或词组要尽量靠近或者使用HTML元素(如ALT)的方式(1)是大部分SEO人的必修项目,还是要放核心主题标题和大标题中的词尽量出现在正文的顶部。方法(2)这里不仅仅是关键词的频率(密度),但更复杂的是,第一层的链接频率是核心词的同义词和变体。在同等条件下,不太流行的同义词和变体会得到更好的结果。
现在你要做的就是将那些二类词和三类词分组到不同的区域或段落或短语中。目的是支持你的主题(排名词),正如我之前所说的搜索引擎可以使用大数据来识别单词关联。举个简单的例子:主词是【网红】,第一段会重点关注这个词文章。第二段将用几只手完成。文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是一个词系相关内容,并通过步骤2来布局词系。第三步:补充内容。或许很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但我们不得不承认,现在的外链就像一颗不合时宜的炸弹,说不定会被链接炸死。
因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么什么是补充内容呢?如果你的网页只是单纯的关键词,缺少文字链接、参考资料和相关资源推荐,那么你的页面就很死板,死路一条,不会给你的页面加分。看右边的页面。网站内有链接(黄色部分),导出链接和内容中的[补充内容]。想想看,百度百科还是知道为什么要添加相关资源的链接?其实就是加强页面主题的深化,通过不同网站的内容来强化信息。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。1)在页面底部添加相关资源的链接(推荐站内链接)2)在文中使用引号,如行业内知名人士的话或图标,如文中3) 使用导出链接到网站中的第三方(你不会被K放100。第4步:内容实体这是一个非常难的概念,称为英文实体。强大的搜索引擎会抓取页面 来自动解释内容实体,或者将其理解为内容属性。例如,当内容提到“包老师”时,它的实体是[人]吗?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。是它的实体[人]?提到“咨询道”时,是【公司】?因为当你的内容在互联网上出现的时间还不够长,而且数量不是很大的时候,搜索引擎可能无法对内容实体进行解读,因为老师可以是姓氏的老师,也可以是老师动词的XX。这时候就需要帮助搜索引擎去。正确解释内容实体。
(木木补充说,这涉及到微数据。HTML5 微数据规范是一种标记,用于描述特定类型的信息,例如评论、人物信息或事件。每种类型的信息描述特定类型的项目,例如人物、事件或评论见《结构化微数据丰富网页摘要》)一般搜索引擎都会给站长提供自己的结构化数据(比如“百度新数据标注工具,相当于谷歌数据标注”),什么是结构化数据?就是使用搜索引擎设置的HTML Markup来定义内容,或者统称为使用Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。这个更高级 只是一点点理解。您可以要求您的架构师添加 网站 结构数据。当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。搜索引擎会自动解释内容实体,通过“人、地、物”来寻找关联,所以建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比作“每个实体”。关联。例如,
看看有没有和之前的优化概念不一样。搜索引擎不看页面上是否有这个词以及有多少链接指向它,而是看内容实体是否相关。综上所述,大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技巧整合到你的内容优化中:1)一个高度概括的标题来描述页面的主题2)添加一个开头(简要)来描述页面的内容3)@ > 内容分为几段,每段都有自己的主题。4)尽量扩大主题视角,补充相关答案。5)
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心词和关联性页面布局?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-17 16:24
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二-与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到与主词相关的三类词第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
· TDK关键词是否设置为精准匹配
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。因此,词系统布局是区分核心词及其相关性。以下是3种实用的优化方法:
1)区域:关键词 必须出现在标题、标题和主要段落中
· 是否有足够的导入链接(外部链接)?
2)找到与主词内容相关的二类词
第二步:词法系统布局
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
· 文章 内容字数够吗?
2)词系统布局
· 内容够不够原创
1)查找同义词和变体
主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
3)补充内容
· 查看关键词的密度是否符合标准
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
4)内容属性
1. 什么是SEO网站的主题模型
4) 结论是内容属性与主题(人、地、事)有关
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
第 1 步:词法关联
3)找到与第二类词相关的三类词
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 使用各种H标签整合关键词
1) 词法关联
2) 频率:重要短语或其变体的出现频率可能高于平均水平
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度! 查看全部
搜索引擎主题模型优化(如何让搜索引擎了解页面的核心词和关联性页面布局?)
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二-与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到与主词相关的三类词第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
· TDK关键词是否设置为精准匹配
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。因此,词系统布局是区分核心词及其相关性。以下是3种实用的优化方法:
1)区域:关键词 必须出现在标题、标题和主要段落中
· 是否有足够的导入链接(外部链接)?
2)找到与主词内容相关的二类词
第二步:词法系统布局
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
· 文章 内容字数够吗?
2)词系统布局
· 内容够不够原创
1)查找同义词和变体
主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
3)补充内容
· 查看关键词的密度是否符合标准
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
4)内容属性
1. 什么是SEO网站的主题模型
4) 结论是内容属性与主题(人、地、事)有关
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
第 1 步:词法关联
3)找到与第二类词相关的三类词
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 使用各种H标签整合关键词
1) 词法关联
2) 频率:重要短语或其变体的出现频率可能高于平均水平
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度!
搜索引擎主题模型优化(研究以满足用户的效用信息需求为目的构建搜索引擎优化模型)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-17 16:20
信息组织 [摘要] 本研究旨在满足用户的需求,提供有效的信息。构建了搜索引擎优化模型,该模型由三个子模型组成,BSga'S行为分析模型、网站知识和信息组织模型和jtsown搜索引擎优化模型。基于三部分关系的分析。作者对搜索引擎优化模型进行了评估,并进一步提出该模型可以有效解决不断增长的信息与用户对有效信息的需求之间的矛盾。【关键词】搜索引擎优化用户网站信息组织简介 目前,搜索引擎研究主要集中在三个方面:搜索引擎。我{{用户行为研究,网站
但往往仅限于搜索引擎技术发展的研究、搜索引擎与用户的信息交互研究、搜索引擎与网站知识信息组织的研究等。引擎用户和网站是隔离的,三者不收录在一个统一的信息系统中。作为搜索引擎,作为信息系统,三者缺一不可。有鉴于此,本文在传统搜索引擎研究的基础上,将搜索引擎的发展、搜索引擎用户和信息组织整合到整体的搜索引擎优化模型中,避免信息孤岛的产生,使信息在搜索引擎之间畅通无阻。三。相互促进,使信息获取的效益最大化。1 搜索引擎优化模型的构成作者在文献1中提出,将用户、知识生产者和知识组织者视为搜索引擎优化的外部环境,三者与搜索引擎共同构成一个信息系统。基于。在进一步的研究中,作者构建了一个搜索引擎优化模型,该模型由用户行为分析模块、网站知识信息组织模块和搜索引擎模块组成。用户行为分析模块和网站知识组织模块构成了搜索引擎优化模型的外部环境,两者都随着搜索引擎自身的发展形成了一条完整的信息链。搜索引擎优化模型的最终目标是满足信息用户对有效信息的需求。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。
例如,用户在使用搜索引擎检索信息时遇到的各种障碍,可以通过数据分析工具传递给搜索引擎。针对用户的困难,搜索引擎可以采用各种技术来提高自身的能力。1.2 网站知识信息组织优化模块网站结构、网站知识信息内容和组织方法、网站功能和网站服务构成整体网站@ >知识信息系统。网站信息组织的优化包括这四个层次的优化策略,分别是网站结构、网站信息及其组织方法、网站函数和网站@ > 服务优化,实现了整个网站信息系统的优化。重点是优化网站知识信息组织。通过优化网站的信息组织,搜索引擎可以更好的检索网站知识信息,从而促进网站与搜索引擎之间的信息交互,让网络用户及时通过搜索引擎学习高质量的信息满足网络用户的公用事业信息需求。1.3 搜索引擎自身发展的优化模型。搜索引擎自身发展的发展包括搜索引擎技术开发、搜索引擎信息内容和搜索引擎服务的优化。搜索引擎技术的发展和搜索引擎内容的发展是搜索引擎优化服务的基础,而搜索引擎技术的发展也是搜索引擎检索更完整、更多网络信息的基础。同时,搜索引擎服务水平和质量的提升,将俘获更多的信息用户,进一步推动搜索引擎技术的发展和完善。2 搜索引擎优化模型的工作机制 搜索引擎优化模型的目的是优化模型中的各个子系统,最大程度满足用户的效用信息需求,同时模型的工作机制起到了改善信息服务的重要作用。
其中,用户信息行为分析系统是基础,网站知识组织系统是保障,搜索引擎本身的优化和发展是根本。三者将统一在搜索引擎优化模型工作机制体系中,相互促进,共同发挥作用。2.1 用户信息行为分析机制 用户信息行为分析机制是搜索引擎优化模型工作机制的基础。网站或搜索引擎使用数据挖掘工具获取私人用户使用网络信息资源的信息,并应用数据处理器对挖掘工具获取的数据信息进行分析,以确定用户的信息行为。同时,将最终得到的数据反馈给网站或搜索引擎,并在此基础上优化网站和搜索引擎。2.2 网站知识组织优化机制网站是网络信息的来源。搜索引擎检索网站 信息资源。索引建立后,会听到用户的检索行为,并输出检索结果,网站信息的终端就是用户,用户的信息需求影响网站@的发展和完善> 在很大程度上。网站知识组织优化机制从网站的结构、内容和组织方式、网站服务等方面进行优化和发展,将构建网站结构合理,丰富的知识,组织科学的、服务充足的信息库。2.3 搜索引擎自身的优化发展机制 搜索引擎直接面向用户,搜索引擎的内容和服务将直接影响用户的进一步使用。搜索引擎自身的开发和优化机制将优化搜索引擎的技术、数据库内容和组织以及搜索引擎服务。
搜索引擎技术的优化是保证搜索引擎进步的关键。数据库的内容和组织是吸引用户的决定性因素。搜索引擎服务是捕获和留住用户的保证。3 搜索引擎优化模型的特点 3.1 独立性 搜索引擎系统即服务主要是为了方便网络信息用户查询所需信息,稳定搜索引擎用户群,增强搜索引擎的实用性和便捷性。搜索引擎优化模型是一个相对独立完整的系统,由用户信息分析优化模块、网站知识组织优化模块、搜索引擎开发优化模块组成。用户信息分析系统首先对采集用户的信息行为数据进行分析,并将用户信息行为数据反馈给网站和搜索引擎。网站根据用户信息分析优化模块返回的数据,采取针对性措施,持续优化网站的结构、架构和服务。同时,搜索引擎还基于用户行为分析模块获取的数据,从技术层面、内容和组织层面、搜索引擎服务三个方面进行优化。3.2 秩序 系统的秩序是指系统的各种要素与要素有机结合而形成的系统结构。搜索引擎优化系统由用户信息分析系统、网站知识组织系统和搜索引擎自身优化系统组成,三者是一个有序的信息系统。在各种内部要素的非线性作用下,系统可以向有序移动并不断增强其有序性。这个顺序是由它的结构支持的。它采用分层的方式进入新的资源空间。
在搜索引擎优化模型中,用户信息行为分析系统将用户信息传输到网站知识组织系统和搜索引擎优化系统。网站知识组织系统基于用户信息数据优化分析知识内容及其组织方式。同时,搜索引擎服务商根据用户信息分析系统返回的数据,对搜索引擎的方方面面进行优化。搜索引擎自身的开发和优化,可以更好地检索和索引网站知识信息,进一步满足信息用户的信息需求。3.3 在服务网络环境中,个体信息使用者的知识结构不同,所以对网络资源的认知也不同,导致网络资源使用上的差异。不同用户对网络资源需求的特点是:最主要的信息需求集中在与工作学习相关的专业和业务信息;信息语言以国语为主,英文信息次之;服务类型以WWW信息搜索为主。此外,用户需求还表现为:信息数据库网络化;可随时获取所需信息;方便和同时回答各种查询;用户最终得到在搜索引擎优化中被识别、选择和处理的有价值的信息在模型中,网站知识组织和服务,搜索引擎服务都是在用户信息行为分析的基础上发展起来的,所以搜索引擎优化服务更具针对性,尤其是个性化、特色化的搜索引擎公司的发展,更能满足信息用户的信息需求。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。
数据挖掘技术和网络信息检索技术有很多相似之处,但也有本质的区别。数据挖掘技术继续利用机器人、全文检索等互联网信息检索的优异成果,同时综合运用人工智能、模式识别、神经网络等领域的各种技术。数据挖掘技术与网络信息检索最重要的区别在于,它可以根据目标特征信息在网络或数据库中进行有目的的信息检索,从而获得用户所需的信息。3.4 时效性 搜索引擎优化模型的时效性体现在三个方面,即用户信息行为分析数据的时效性,网站知识及其组织的时效性,以及搜索引擎自身发展的时效性。用户信息行为的时效性具有牵动全身的影响。网站知识组织和搜索引擎优化基于用户信息行为分析。用户使用搜索引擎的行为分为已经发生的搜索行为、正在发生的搜索行为和潜在的搜索行为。已经发生的搜索行为对于搜索引擎总结经验教训,进一步优化搜索引擎具有建设性意义。行为和停滞搜索行为对搜索引擎的优化起着指导作用。3. 5 封闭传统搜索引擎模式,全面信息搜索。它的优点是有利于积累搜索信息数据和行为数据,有利于满足一般简单的信息需求。本文讨论的搜索引擎优化模型是基于用户信息需求、特定信息用户范围、特定系统的信息服务。内在的深入需求;提供更准确的知识和信息的有利条件。特定范围的信息用户和特定系统。内在的深入需求;提供更准确的知识和信息的有利条件。特定范围的信息用户和特定系统。内在的深入需求;提供更准确的知识和信息的有利条件。
从开放搜索系统到封闭搜索系统的转变,也是从综合搜索到专业垂直搜索的转变,从定量搜索到定性搜索的转变,从搜索引擎服务商到公众参与的单边控制。控制搜索过程的过渡。与传统的搜索引擎模型相比,本文讨论的搜索引擎优化模型并不意味着封闭和保守,而只是从搜索策略、搜索目的和搜索范围等角度的概念上的限制。4 搜索引擎优化模型的评价 4.1 搜索引擎优化模型评价角度的选择 搜索引擎优化模型的评价可以从搜索引擎发展的角度进行,< @网站知识组织与用户信息行为分析。(1) 从搜索引擎发展的角度来看,评价研究更多地考虑了用户和搜索引擎之间的交互过程。用户使用搜索引擎的主要目的是获取相关信息,所以搜索的成功取决于搜索结果的“任务相关性” 4.从搜索引擎开发角度的评价方法保留了以系统为中心的搜索引擎的评价成本低、可比性强等优点,但由于仍然是基于集合的实验,并且不是基于实际的网络检索环境,而是一种非交互式的评价方法,在评价搜索引擎的性能方面还存在很多问题。
然而,基于网站知识组织的搜索引擎优化模型评价仍然是一种非交互式的评价方法。(3)从用户信息行为分析角度评价搜索引擎优化模型。从搜索引擎开发角度评价搜索引擎优化模型时,用户被视为目标信息的被动接受者。信息交互被视为作为简单的输入输出。在从用户信息行为分析的角度进行的搜索引擎优化模型评估中,用户被视为主动利用自己与搜索引擎的信息交互来获取信息。在信息需求的情况下,如何表达信息需要搜索引擎,以及如何使用搜索引擎提供的功能是评价研究的重点。因此,搜索引擎优化模型评价研究的核心是用户信息行为分析。自我发展视角下的评价研究将“相关性”视为系统的一个属性。在从用户信息行为分析的角度评价搜索引擎优化模型时,“相关性”的概念与用户信息认知的过程及其在此过程中的影响有关。知识状态与信息需求的变化密切相关。5.评价主要基于认知科学的思想,研究用户使用搜索引擎进行信息检索的行为,紧密结合用户使用搜索引擎进行信息检索的过程,解决用户信息问题。通过对用户信息需求的影响程度和满足程度来评价搜索引擎的质量。4.2 基于用户信息行为分析的搜索引擎优化模型评价(1)评价指标评价搜索引擎优化模型,首先要确定评价指标体系。
目前基于用户信息行为分析的搜索引擎优化模型评价指标主要分为两大类,即基于用户感知和态度的指标和基于用户感知和态度的指标。一世 {; {用户一一搜索引擎信息交互索引。第一类指标主要包括:效用、意图、影响、满意度、收益和挫折等。第二类指标包括:信息丰富度、系统可用性、易用性、错误率。评价的关键是搜索引擎优化模型能否为用户提供丰富的效用信息6。(2)|}}: l 用户信息行为分析 明确了搜索引擎优化模型的评价指标后,就要对用户信息行为进行分析,目的是通过分析构建用户信息检索过程的认知模型,了解用户如何处理信息,进而改进信息274检索系统的设计。用户信息行为分析在搜索引擎优化模型评价中的目的主要是判断检索过程对改变用户信息状态的帮助。检索效率。信息使用者的需求包括两个基本方面:获取和使用信息的需要和发布和传输信息的需要。基本点是实现对外信息的沟通和交流,并达到一定的社会职业活动和社会生活目标。7、信息用户在进行信息检索以满足这些不同的信息需求时,衡量检索结果质量的标准也不同。例如,当同一主题的文档需要穷尽时,“召回率”就显得更为重要,他们希望获得某个领域的新信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。当同一主题的文档需要穷尽时,“召回率”更重要,他们希望在某个领域获得新的信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。当同一主题的文档需要穷尽时,“召回率”更重要,他们希望在某个领域获得新的信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。
因此,在评价搜索引擎的质量时,需要对用户信息需求进行分类,需要使用不同的指标来评价不同类型需求的检索8。(3)从用户信息行为的角度评价搜索引擎优化模型。传统的搜索引擎系统引入了与网站知识组织和用户信息行为分析的信息交互,因此不能满足信息用户的有效性 信息需求 本文构建的搜索引擎优化模型可以解决快速增长的网络信息资源与信息用户的效用信息需求之间的矛盾。用户最关心的是搜索结果能否满足自己的需求,尤其是在搜索引擎可以获取大量信息资源的时候。由于搜索引擎优化模型是基于对用户信息行为的分析和优化、网站知识组织优化以及搜索引擎本身的优化开发而建立的,可以最大程度地满足信息化的信息需求用户,尤其是信息用户的个性化信息需求。搜索引擎优化模型从用户信息分析、网站知识组织、搜索引擎开发三个方面整合了搜索引擎信息系统。检索、分类、处理、组织、服务等方面的知识信息得到优化。通过优化网站的结构、知识信息及其组织方式,优化搜索引擎自身的技术、内容和组织方式,搜索引擎优化模型能够很好地满足信息用户的信息需求,解决矛盾在不断增加的网络信息资源和用户的公用事业信息需求之间。参考文献 [1] 费伟,黄如华.基于用户行为分析的搜索引擎优化策略。图书情报工作, 2005 (10): 75-77, I10 [2] 李丹. 论网络环境下的书目信息服务策略. 信息工作, 2003 (203740 f3] 王晓华. 基于内容的研究搜索引擎技术与应用硕士' s 学位论文 J. 郑州大学 2005 Reid.ATask-orientedNon-interactiveEvaluation METHODOLOGY forInformation0nformatResource。: L15-129 管理 2000: 533-550 [6] 付鑫.搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993 搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993 搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993 查看全部
搜索引擎主题模型优化(研究以满足用户的效用信息需求为目的构建搜索引擎优化模型)
信息组织 [摘要] 本研究旨在满足用户的需求,提供有效的信息。构建了搜索引擎优化模型,该模型由三个子模型组成,BSga'S行为分析模型、网站知识和信息组织模型和jtsown搜索引擎优化模型。基于三部分关系的分析。作者对搜索引擎优化模型进行了评估,并进一步提出该模型可以有效解决不断增长的信息与用户对有效信息的需求之间的矛盾。【关键词】搜索引擎优化用户网站信息组织简介 目前,搜索引擎研究主要集中在三个方面:搜索引擎。我{{用户行为研究,网站
但往往仅限于搜索引擎技术发展的研究、搜索引擎与用户的信息交互研究、搜索引擎与网站知识信息组织的研究等。引擎用户和网站是隔离的,三者不收录在一个统一的信息系统中。作为搜索引擎,作为信息系统,三者缺一不可。有鉴于此,本文在传统搜索引擎研究的基础上,将搜索引擎的发展、搜索引擎用户和信息组织整合到整体的搜索引擎优化模型中,避免信息孤岛的产生,使信息在搜索引擎之间畅通无阻。三。相互促进,使信息获取的效益最大化。1 搜索引擎优化模型的构成作者在文献1中提出,将用户、知识生产者和知识组织者视为搜索引擎优化的外部环境,三者与搜索引擎共同构成一个信息系统。基于。在进一步的研究中,作者构建了一个搜索引擎优化模型,该模型由用户行为分析模块、网站知识信息组织模块和搜索引擎模块组成。用户行为分析模块和网站知识组织模块构成了搜索引擎优化模型的外部环境,两者都随着搜索引擎自身的发展形成了一条完整的信息链。搜索引擎优化模型的最终目标是满足信息用户对有效信息的需求。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。该模型如下图所示: 网站 搜索引擎 图1 搜索引擎优化模型 1.1 用户行为分析模块 信息用户和搜索引擎是一种互惠互利的关系。在用户行为分析模块中,通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。通过数据分析工具抓取用户信息,对信息进行统计分析,将各种数据及时传送到搜索引擎。搜索引擎接受数据。基于用户信息分析数据,有目的地优化自身的技术、内容和服务。
例如,用户在使用搜索引擎检索信息时遇到的各种障碍,可以通过数据分析工具传递给搜索引擎。针对用户的困难,搜索引擎可以采用各种技术来提高自身的能力。1.2 网站知识信息组织优化模块网站结构、网站知识信息内容和组织方法、网站功能和网站服务构成整体网站@ >知识信息系统。网站信息组织的优化包括这四个层次的优化策略,分别是网站结构、网站信息及其组织方法、网站函数和网站@ > 服务优化,实现了整个网站信息系统的优化。重点是优化网站知识信息组织。通过优化网站的信息组织,搜索引擎可以更好的检索网站知识信息,从而促进网站与搜索引擎之间的信息交互,让网络用户及时通过搜索引擎学习高质量的信息满足网络用户的公用事业信息需求。1.3 搜索引擎自身发展的优化模型。搜索引擎自身发展的发展包括搜索引擎技术开发、搜索引擎信息内容和搜索引擎服务的优化。搜索引擎技术的发展和搜索引擎内容的发展是搜索引擎优化服务的基础,而搜索引擎技术的发展也是搜索引擎检索更完整、更多网络信息的基础。同时,搜索引擎服务水平和质量的提升,将俘获更多的信息用户,进一步推动搜索引擎技术的发展和完善。2 搜索引擎优化模型的工作机制 搜索引擎优化模型的目的是优化模型中的各个子系统,最大程度满足用户的效用信息需求,同时模型的工作机制起到了改善信息服务的重要作用。
其中,用户信息行为分析系统是基础,网站知识组织系统是保障,搜索引擎本身的优化和发展是根本。三者将统一在搜索引擎优化模型工作机制体系中,相互促进,共同发挥作用。2.1 用户信息行为分析机制 用户信息行为分析机制是搜索引擎优化模型工作机制的基础。网站或搜索引擎使用数据挖掘工具获取私人用户使用网络信息资源的信息,并应用数据处理器对挖掘工具获取的数据信息进行分析,以确定用户的信息行为。同时,将最终得到的数据反馈给网站或搜索引擎,并在此基础上优化网站和搜索引擎。2.2 网站知识组织优化机制网站是网络信息的来源。搜索引擎检索网站 信息资源。索引建立后,会听到用户的检索行为,并输出检索结果,网站信息的终端就是用户,用户的信息需求影响网站@的发展和完善> 在很大程度上。网站知识组织优化机制从网站的结构、内容和组织方式、网站服务等方面进行优化和发展,将构建网站结构合理,丰富的知识,组织科学的、服务充足的信息库。2.3 搜索引擎自身的优化发展机制 搜索引擎直接面向用户,搜索引擎的内容和服务将直接影响用户的进一步使用。搜索引擎自身的开发和优化机制将优化搜索引擎的技术、数据库内容和组织以及搜索引擎服务。
搜索引擎技术的优化是保证搜索引擎进步的关键。数据库的内容和组织是吸引用户的决定性因素。搜索引擎服务是捕获和留住用户的保证。3 搜索引擎优化模型的特点 3.1 独立性 搜索引擎系统即服务主要是为了方便网络信息用户查询所需信息,稳定搜索引擎用户群,增强搜索引擎的实用性和便捷性。搜索引擎优化模型是一个相对独立完整的系统,由用户信息分析优化模块、网站知识组织优化模块、搜索引擎开发优化模块组成。用户信息分析系统首先对采集用户的信息行为数据进行分析,并将用户信息行为数据反馈给网站和搜索引擎。网站根据用户信息分析优化模块返回的数据,采取针对性措施,持续优化网站的结构、架构和服务。同时,搜索引擎还基于用户行为分析模块获取的数据,从技术层面、内容和组织层面、搜索引擎服务三个方面进行优化。3.2 秩序 系统的秩序是指系统的各种要素与要素有机结合而形成的系统结构。搜索引擎优化系统由用户信息分析系统、网站知识组织系统和搜索引擎自身优化系统组成,三者是一个有序的信息系统。在各种内部要素的非线性作用下,系统可以向有序移动并不断增强其有序性。这个顺序是由它的结构支持的。它采用分层的方式进入新的资源空间。
在搜索引擎优化模型中,用户信息行为分析系统将用户信息传输到网站知识组织系统和搜索引擎优化系统。网站知识组织系统基于用户信息数据优化分析知识内容及其组织方式。同时,搜索引擎服务商根据用户信息分析系统返回的数据,对搜索引擎的方方面面进行优化。搜索引擎自身的开发和优化,可以更好地检索和索引网站知识信息,进一步满足信息用户的信息需求。3.3 在服务网络环境中,个体信息使用者的知识结构不同,所以对网络资源的认知也不同,导致网络资源使用上的差异。不同用户对网络资源需求的特点是:最主要的信息需求集中在与工作学习相关的专业和业务信息;信息语言以国语为主,英文信息次之;服务类型以WWW信息搜索为主。此外,用户需求还表现为:信息数据库网络化;可随时获取所需信息;方便和同时回答各种查询;用户最终得到在搜索引擎优化中被识别、选择和处理的有价值的信息在模型中,网站知识组织和服务,搜索引擎服务都是在用户信息行为分析的基础上发展起来的,所以搜索引擎优化服务更具针对性,尤其是个性化、特色化的搜索引擎公司的发展,更能满足信息用户的信息需求。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。个性化、特色化的搜索引擎应用数据挖掘和汇总{{技术处理网络信息。网络信息挖掘可以获取信息的内在特征,并以此为基础进行有目的的信息抽取。
数据挖掘技术和网络信息检索技术有很多相似之处,但也有本质的区别。数据挖掘技术继续利用机器人、全文检索等互联网信息检索的优异成果,同时综合运用人工智能、模式识别、神经网络等领域的各种技术。数据挖掘技术与网络信息检索最重要的区别在于,它可以根据目标特征信息在网络或数据库中进行有目的的信息检索,从而获得用户所需的信息。3.4 时效性 搜索引擎优化模型的时效性体现在三个方面,即用户信息行为分析数据的时效性,网站知识及其组织的时效性,以及搜索引擎自身发展的时效性。用户信息行为的时效性具有牵动全身的影响。网站知识组织和搜索引擎优化基于用户信息行为分析。用户使用搜索引擎的行为分为已经发生的搜索行为、正在发生的搜索行为和潜在的搜索行为。已经发生的搜索行为对于搜索引擎总结经验教训,进一步优化搜索引擎具有建设性意义。行为和停滞搜索行为对搜索引擎的优化起着指导作用。3. 5 封闭传统搜索引擎模式,全面信息搜索。它的优点是有利于积累搜索信息数据和行为数据,有利于满足一般简单的信息需求。本文讨论的搜索引擎优化模型是基于用户信息需求、特定信息用户范围、特定系统的信息服务。内在的深入需求;提供更准确的知识和信息的有利条件。特定范围的信息用户和特定系统。内在的深入需求;提供更准确的知识和信息的有利条件。特定范围的信息用户和特定系统。内在的深入需求;提供更准确的知识和信息的有利条件。
从开放搜索系统到封闭搜索系统的转变,也是从综合搜索到专业垂直搜索的转变,从定量搜索到定性搜索的转变,从搜索引擎服务商到公众参与的单边控制。控制搜索过程的过渡。与传统的搜索引擎模型相比,本文讨论的搜索引擎优化模型并不意味着封闭和保守,而只是从搜索策略、搜索目的和搜索范围等角度的概念上的限制。4 搜索引擎优化模型的评价 4.1 搜索引擎优化模型评价角度的选择 搜索引擎优化模型的评价可以从搜索引擎发展的角度进行,< @网站知识组织与用户信息行为分析。(1) 从搜索引擎发展的角度来看,评价研究更多地考虑了用户和搜索引擎之间的交互过程。用户使用搜索引擎的主要目的是获取相关信息,所以搜索的成功取决于搜索结果的“任务相关性” 4.从搜索引擎开发角度的评价方法保留了以系统为中心的搜索引擎的评价成本低、可比性强等优点,但由于仍然是基于集合的实验,并且不是基于实际的网络检索环境,而是一种非交互式的评价方法,在评价搜索引擎的性能方面还存在很多问题。
然而,基于网站知识组织的搜索引擎优化模型评价仍然是一种非交互式的评价方法。(3)从用户信息行为分析角度评价搜索引擎优化模型。从搜索引擎开发角度评价搜索引擎优化模型时,用户被视为目标信息的被动接受者。信息交互被视为作为简单的输入输出。在从用户信息行为分析的角度进行的搜索引擎优化模型评估中,用户被视为主动利用自己与搜索引擎的信息交互来获取信息。在信息需求的情况下,如何表达信息需要搜索引擎,以及如何使用搜索引擎提供的功能是评价研究的重点。因此,搜索引擎优化模型评价研究的核心是用户信息行为分析。自我发展视角下的评价研究将“相关性”视为系统的一个属性。在从用户信息行为分析的角度评价搜索引擎优化模型时,“相关性”的概念与用户信息认知的过程及其在此过程中的影响有关。知识状态与信息需求的变化密切相关。5.评价主要基于认知科学的思想,研究用户使用搜索引擎进行信息检索的行为,紧密结合用户使用搜索引擎进行信息检索的过程,解决用户信息问题。通过对用户信息需求的影响程度和满足程度来评价搜索引擎的质量。4.2 基于用户信息行为分析的搜索引擎优化模型评价(1)评价指标评价搜索引擎优化模型,首先要确定评价指标体系。
目前基于用户信息行为分析的搜索引擎优化模型评价指标主要分为两大类,即基于用户感知和态度的指标和基于用户感知和态度的指标。一世 {; {用户一一搜索引擎信息交互索引。第一类指标主要包括:效用、意图、影响、满意度、收益和挫折等。第二类指标包括:信息丰富度、系统可用性、易用性、错误率。评价的关键是搜索引擎优化模型能否为用户提供丰富的效用信息6。(2)|}}: l 用户信息行为分析 明确了搜索引擎优化模型的评价指标后,就要对用户信息行为进行分析,目的是通过分析构建用户信息检索过程的认知模型,了解用户如何处理信息,进而改进信息274检索系统的设计。用户信息行为分析在搜索引擎优化模型评价中的目的主要是判断检索过程对改变用户信息状态的帮助。检索效率。信息使用者的需求包括两个基本方面:获取和使用信息的需要和发布和传输信息的需要。基本点是实现对外信息的沟通和交流,并达到一定的社会职业活动和社会生活目标。7、信息用户在进行信息检索以满足这些不同的信息需求时,衡量检索结果质量的标准也不同。例如,当同一主题的文档需要穷尽时,“召回率”就显得更为重要,他们希望获得某个领域的新信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。当同一主题的文档需要穷尽时,“召回率”更重要,他们希望在某个领域获得新的信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。当同一主题的文档需要穷尽时,“召回率”更重要,他们希望在某个领域获得新的信息。当涉及到有关进展的信息时,“搜索结果的新颖性”尤其重要。
因此,在评价搜索引擎的质量时,需要对用户信息需求进行分类,需要使用不同的指标来评价不同类型需求的检索8。(3)从用户信息行为的角度评价搜索引擎优化模型。传统的搜索引擎系统引入了与网站知识组织和用户信息行为分析的信息交互,因此不能满足信息用户的有效性 信息需求 本文构建的搜索引擎优化模型可以解决快速增长的网络信息资源与信息用户的效用信息需求之间的矛盾。用户最关心的是搜索结果能否满足自己的需求,尤其是在搜索引擎可以获取大量信息资源的时候。由于搜索引擎优化模型是基于对用户信息行为的分析和优化、网站知识组织优化以及搜索引擎本身的优化开发而建立的,可以最大程度地满足信息化的信息需求用户,尤其是信息用户的个性化信息需求。搜索引擎优化模型从用户信息分析、网站知识组织、搜索引擎开发三个方面整合了搜索引擎信息系统。检索、分类、处理、组织、服务等方面的知识信息得到优化。通过优化网站的结构、知识信息及其组织方式,优化搜索引擎自身的技术、内容和组织方式,搜索引擎优化模型能够很好地满足信息用户的信息需求,解决矛盾在不断增加的网络信息资源和用户的公用事业信息需求之间。参考文献 [1] 费伟,黄如华.基于用户行为分析的搜索引擎优化策略。图书情报工作, 2005 (10): 75-77, I10 [2] 李丹. 论网络环境下的书目信息服务策略. 信息工作, 2003 (203740 f3] 王晓华. 基于内容的研究搜索引擎技术与应用硕士' s 学位论文 J. 郑州大学 2005 Reid.ATask-orientedNon-interactiveEvaluation METHODOLOGY forInformation0nformatResource。: L15-129 管理 2000: 533-550 [6] 付鑫.搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993 搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993 搜索引擎质量评价研究——基于用户的搜索引擎质量评价体系的建立及中英文搜索引擎的比较研究[硕士论文]. 北京大学,2003 【大胡昌平,黄晓梅,贾俊志.信息服务管理。北京:科学出版社,2003:135 [8] F. Will 题为 Lancasto',Amy J. Warner。今日信息检索。弗吉尼亚:信息资源出版社,1993
搜索引擎主题模型优化(网页加载速度优化的几种方法,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-17 15:21
1、网页加载速度优化
在信息碎片化的时代,没人愿意等你几分钟,所以网站打开加载速度比任何优化点都重要。开通时间越短,用户满意度越高。搜索引擎也是如此。所以首先考虑可以做些什么来加速,比如CDN、删除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
2、用户体验优化
很多用户打开网站都会有印象。网页设计需要用户界面和用户体验的输入,以及品牌自身的声誉来认可,否则用户很难对网站产生信任感和参与感。一个实用的方法是参考业界较好的网站进行模仿,购买付费版的网站模板或让用户参与每一个设计过程。
3、避免过多的弹出窗口
很多弹出窗口、固定窗口和广告位都会让用户体验很差,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更自然的方式嵌入这些元素,或奖励完成过程的用户。同时,避免在使用代码时出现蜘蛛被禁止或难以捕捉的可能性,从而被搜索引擎减少。
网站SEO优化的重点是什么
4、关键词布局
常规的关键词植入也需要继续,比如title、H1、文章中的关键词、外链锚文本、内链锚文本、图片alt、URL、图片命名等,这个是不需要的详细说明。我们都知道。
5、主题模型填充
仅仅5个字是不够的,因为太机械会失去文字的用户体验。所以我们需要做一个主题模型。比如关键词【婚礼搭配】可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚纱市场等相关词汇,形成一个大主题,这样的页面内容会让< @关键词 更全面,帮助更多用户。同时,搜索引擎可以将您要推送的话题内容解读为婚礼相关内容。
6、文本深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、DESC、URL)。这些元素需要在内容上进行优化:标题的创意、描述的红色、URL的规范、文章的日期、结构化数据的使用、在线对话等。 查看全部
搜索引擎主题模型优化(网页加载速度优化的几种方法,你知道吗?)
1、网页加载速度优化
在信息碎片化的时代,没人愿意等你几分钟,所以网站打开加载速度比任何优化点都重要。开通时间越短,用户满意度越高。搜索引擎也是如此。所以首先考虑可以做些什么来加速,比如CDN、删除无用代码、服务器宽带升级、缓存、页面瘦身、纯静态页面等优化动作。
2、用户体验优化
很多用户打开网站都会有印象。网页设计需要用户界面和用户体验的输入,以及品牌自身的声誉来认可,否则用户很难对网站产生信任感和参与感。一个实用的方法是参考业界较好的网站进行模仿,购买付费版的网站模板或让用户参与每一个设计过程。
3、避免过多的弹出窗口
很多弹出窗口、固定窗口和广告位都会让用户体验很差,放弃整个浏览过程。这是优化过程中要避免和去除的部分。考虑以更自然的方式嵌入这些元素,或奖励完成过程的用户。同时,避免在使用代码时出现蜘蛛被禁止或难以捕捉的可能性,从而被搜索引擎减少。
网站SEO优化的重点是什么
4、关键词布局
常规的关键词植入也需要继续,比如title、H1、文章中的关键词、外链锚文本、内链锚文本、图片alt、URL、图片命名等,这个是不需要的详细说明。我们都知道。
5、主题模型填充
仅仅5个字是不够的,因为太机械会失去文字的用户体验。所以我们需要做一个主题模型。比如关键词【婚礼搭配】可以扩展到燕尾服、婚纱、婚纱背心、婚纱、婚纱市场等相关词汇,形成一个大主题,这样的页面内容会让< @关键词 更全面,帮助更多用户。同时,搜索引擎可以将您要推送的话题内容解读为婚礼相关内容。
6、文本深度优化
排名显示的信息对点击率非常重要,所以我们可能要影响显示的信息(主要是title、DESC、URL)。这些元素需要在内容上进行优化:标题的创意、描述的红色、URL的规范、文章的日期、结构化数据的使用、在线对话等。
搜索引擎主题模型优化(1.什么是SEO站内主题内容优化方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-17 10:02
文章指南
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1. 什么是SEO网站的主题模型
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 查看关键词的密度是否符合标准
· 文章 内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词是否设置为精准匹配
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?
主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
1) 词法关联
2)词系统布局
3)补充内容
4)内容属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
第 1 步:词法关联
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和变体
2)找到与主词内容相关的二类词
3)找到与第二类词相关的三类词
4) 结论是内容属性与主题(人、地、事)有关
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二- 与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到相关的三类词对于第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度!
第二步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。所以词系统布局就是区分核心词及其相关性。这里有3个实用的优化方法: 1) 区域:关键词 必须出现在标题、标题和主要段落中
2) 频率:重要短语或其变体的出现频率可能高于平均水平
3) 距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)
方法(1)是大多数SEO人的必修项目,我们还是要把核心主题放在标题,大标题,尽量出现在主条目的顶部。
方法(2)这里不仅仅是关键词的频率(密度),而是更复杂的链接频率层面,即核心词的同义词和变体。相同条件下,不太流行的同义词而且变体词会得到更好的结果。(谷歌有一个专利叫TF-IDF,比较难懂)
方法(3)距离产生美在SEO世界里是不适用的。词、词组、句子要尽量靠近,或者使用HTML元素(如图片ALT设置)。所以为了提高上下文相关性,应该通过段落、列表、分区,让内容更加明显,可以一目了然地知道段落在说什么。前后句子之间是否有连通性,不要将内容与类似的意思太远了。因为你不能保证蜘蛛会抓住整个文本。
你知道这个方法的原理。现在你要做的就是将二类单词和三类词汇分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会重点介绍这个词文章。第二段用几只手做文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。
因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么补充内容是什么呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯粹的关键词,缺少文字链接、参考资料和相关资源推荐,你的页面很死板,这是一个死胡同,但它不会为您的页面添加额外的点。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件。这是给搜索引擎的消息。我有[补充]。想想看,百度百科还是知道为什么要添加相关资源的链接?实际上,就是加强页面主题的深化,通过不同网站的内容强化信息化。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。
1)页面底部添加相关资源链接(推荐站点链接)
2)在文本中使用引号,例如业内知名人士的话或图标或视频
3)使用文中的导出链接去第三方网站(你不会被K的100介意)
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom Teacher”时,是实体[person]吗?提到“咨询道”,是【公司】?因为当你的内容出现在互联网上的时候,时间还不够久,在数量少的时候,搜索引擎可能无法解释内容实体,因为老师可以是姓氏的老师,或者它可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体。
一般情况下,大部分搜索引擎都会提供站长自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示,世界上只有0.3%网站 使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让您的架构师将 网站 结构化数据纳入其中。
当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。比如【Boom老师】这个实体可以关联一个叫紫道的公司,一个叫SEO Techniques的热门课件就是一朵云,也可以关联到腾讯课堂上的一个公开课老师。所以,对于搜索引擎来说,可以断定“腾讯课堂的SEO技巧只是浮云”是紫道学院爆款老师分享的内容。不是看页面上有没有这个词,有多少个链接指向它,而是看内容实体是否相关。这样,
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的非常笼统的标题
2)添加开场白(简要)描述页面内容
3) 把内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以添加相关答案
5)提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体 查看全部
搜索引擎主题模型优化(1.什么是SEO站内主题内容优化方法)
文章指南
SEO进入了“有质感的内容”的新算法体系,尤其是当今一流的搜索引擎,可以从内容场景和内容实体属性来处理排名,让用户得到更精准的搜索结果。对于优化者来说,网站优化不再是简单的内容填充,需要重新定义主题内容优化。本文将结合最新的SEO概念来指导大家如何优化主题内容。
1. 什么是SEO网站的主题模型
通常我们可以听到和看到很多关于SEO页面内容的旧方法,例如:
· 查看关键词的密度是否符合标准
· 文章 内容字数够吗?
· 内容够不够原创
· 是否有足够的导入链接(外部链接)?
· 使用各种H标签整合关键词
· TDK关键词是否设置为精准匹配
但是,有经验的SEO人士和网站高手很快就会发现,这些技巧似乎无法打动搜索引擎的心。没错,这些都是8-9年前的技术。要优化网站的内容,就必须如何让搜索引擎了解页面的核心主题。这就是我今天文章的核心。那么什么是主题模型呢?
主题模型是页面内容布局的模型,目的是让搜索引擎正确理解整个页面的核心主题是什么,而不是传达哪些关键词。因为一个页面可以收录很多信息,有的有用,有的被占用,你只有将真实的核心信息传递给搜索引擎才能获得相应的排名。因此,在主题模型中,我们需要实现全新的四步优化方法:
1) 词法关联
2)词系统布局
3)补充内容
4)内容属性
对于维基百科等熟悉的网站,亚马逊利用其中的积分来获得海量的关键词排名。他们部署在页面布局上是因为他们的“框架”足够强大,可以向搜索引擎大量有效地展示核心内容主题。因此,在内容植入后,可以创建大量的最新页面。所以,无论你是小白还是老手,即使你不懂搜索引擎算法,只要使用主题模型,也能获得不错的排名!(特别是对于谷歌)
第 1 步:词法关联
无论您使用什么方法来优化页面内容,您都必须关注如何关联单词和短语。作为内容编辑者,您编写的内容最直接影响搜索引擎对页面主题的理解。
当我们使用句子和单词时,搜索引擎会根据其他资源中的数据将您的内容关联起来,生成所谓的内容实体。我们优化者首先需要通过关键词研究,找出这些句子和词之间的关系是什么。相信每个人都有自己研究关键词的方式,但你需要达到以下目标:
1)查找同义词和变体
2)找到与主词内容相关的二类词
3)找到与第二类词相关的三类词
4) 结论是内容属性与主题(人、地、事)有关
让我举个例子。比如你要优化一个叫【网红】的关键词,这个词就成为你的主词。根据目的(1)它的同义词和变体词可能是“自媒体”、“意见领袖”、“网络推广”等;根据目的(2)第二- 与主词内容相关的类词 可以是“留几手”、“微博”、“生词”;然后根据目的(3)找到相关的三类词对于第二种词,可以是“留几手”=粗暴,负分,“微博”=粉丝,转发,“新词”=土豪,问题又来了等等。
您可以清楚地看到每层单词和短语之间的一些联系。根据 (4) 我们尝试在这些内容和内容中的主词之间建立联系,特别是如果有人、地点、事物,那么它可以帮助搜索引擎建立这样的内容实体,因为有其他网站上也会有这样的联想(比如首哥会提到他的微博,他的新评论,他的属性等等),那么搜索引擎就会正确理解你的页面主题。记住你想要的传递主题,而不是 关键词 密度!
第二步:词法系统布局
毫无疑问,页面的布局对于搜索引擎理解内容主题也很重要。蜘蛛来到页面后,发现了这么多关键词,就要分清哪些是重要的,哪些是关键词和词组相关的。所以词系统布局就是区分核心词及其相关性。这里有3个实用的优化方法: 1) 区域:关键词 必须出现在标题、标题和主要段落中
2) 频率:重要短语或其变体的出现频率可能高于平均水平
3) 距离:相关词或短语应彼此靠近或使用 HTML 元素(如 ALT)
方法(1)是大多数SEO人的必修项目,我们还是要把核心主题放在标题,大标题,尽量出现在主条目的顶部。
方法(2)这里不仅仅是关键词的频率(密度),而是更复杂的链接频率层面,即核心词的同义词和变体。相同条件下,不太流行的同义词而且变体词会得到更好的结果。(谷歌有一个专利叫TF-IDF,比较难懂)
方法(3)距离产生美在SEO世界里是不适用的。词、词组、句子要尽量靠近,或者使用HTML元素(如图片ALT设置)。所以为了提高上下文相关性,应该通过段落、列表、分区,让内容更加明显,可以一目了然地知道段落在说什么。前后句子之间是否有连通性,不要将内容与类似的意思太远了。因为你不能保证蜘蛛会抓住整个文本。
你知道这个方法的原理。现在你要做的就是将二类单词和三类词汇分组到不同的区域或段落或短语中。目的是支持你的主词(排名词)。前面提到的搜索引擎可以使用大数据来区分单词关联。举个简单的例子:
主词是【网红】,第一段会重点介绍这个词文章。第二段用几只手做文章,第三段用微博中继效果做文章,第四段用新网名做文章。等等。你形成的网页内容是与词族相关的内容,词族是通过步骤2布局的。
第 3 步:补充内容
或许还有很多人认为外链是最有力的信号提醒,告诉搜索引擎这个页面的主题是什么。但是我们不得不承认,今天的外链就像一颗不合时宜的炸弹,很可能会被链接炸死。因此,搜索引擎希望大家可以同时使用内链和外链,积极向好三方网站进行推荐,引导相关网站内容。健康的网站应该进出,让用户得到更多更好的信息,你的网站才有意义。
因此,外部链接并不是决定内容主题的唯一因素,而是平衡导入链接和附加补充内容。那么补充内容是什么呢?从图表中可以看出,如果你的网页和左边一样,说明这种类型的页面只是纯粹的关键词,缺少文字链接、参考资料和相关资源推荐,你的页面很死板,这是一个死胡同,但它不会为您的页面添加额外的点。看看右边的例子。该页面的内容中既有站内链接(黄色部分),也有导出链接。比如SEO技巧是富云的课件,是老师的课件。这是给搜索引擎的消息。我有[补充]。想想看,百度百科还是知道为什么要添加相关资源的链接?实际上,就是加强页面主题的深化,通过不同网站的内容强化信息化。这是可以为用户提供更好信息的补充内容,当然你的页面也会得到搜索引擎的奖励。
1)页面底部添加相关资源链接(推荐站点链接)
2)在文本中使用引号,例如业内知名人士的话或图标或视频
3)使用文中的导出链接去第三方网站(你不会被K的100介意)
第 4 步:内容实体
这是一个非常难的概念,英文叫做Entity。强大的搜索引擎会在抓取页面时自动解释内容实体,或者将它们理解为内容属性。比如图片中的页面,当内容提到“Boom Teacher”时,是实体[person]吗?提到“咨询道”,是【公司】?因为当你的内容出现在互联网上的时候,时间还不够久,在数量少的时候,搜索引擎可能无法解释内容实体,因为老师可以是姓氏的老师,或者它可以是老师的XX。这时候就需要帮助搜索引擎正确解读内容实体。
一般情况下,大部分搜索引擎都会提供站长自己的结构化数据(百度也有)。什么是结构化数据?搜索引擎设置的 HTML Markup 用于定义内容,或统称为 Schema。这样,当内容涉及公司时可以使用结构化数据,而在涉及评分时可以使用另一种结构化数据。统计显示,世界上只有0.3%网站 使用Schema,所以你知道,这太高级了,我们只需要稍微了解一下。有机会让您的架构师将 网站 结构化数据纳入其中。
当然,提到的实体仍然是近年来发展起来的概念。以前大家都用词来定义SEO,现在更多的是针对实体。由于词排名过多使用了以外链为主的链式方式,结果排名总是让用户不满意,尤其是使用百度的人觉得搜索准确率比谷歌差好几条路。
建立内容实体可以解决这个问题,因为搜索引擎存储的大量页面数据可以比较“每个实体”之间的相关性。比如【Boom老师】这个实体可以关联一个叫紫道的公司,一个叫SEO Techniques的热门课件就是一朵云,也可以关联到腾讯课堂上的一个公开课老师。所以,对于搜索引擎来说,可以断定“腾讯课堂的SEO技巧只是浮云”是紫道学院爆款老师分享的内容。不是看页面上有没有这个词,有多少个链接指向它,而是看内容实体是否相关。这样,
总结
大家可以操作这个“主题优化”的方法。一个高质量的页面就像一个高级的大学证书,它记录了你的实体和相关性。最后,将以下优化技术集成到您的内容优化中:
1) 描述页面主题的非常笼统的标题
2)添加开场白(简要)描述页面内容
3) 把内容分成几段,每段都有自己的主题
4)尽量扩大话题角度,可以添加相关答案
5)提供额外的现场或场外辅助资源
6)不在乎一个词的权重,而是构建内容实体
搜索引擎主题模型优化( 中国论文网关键词用户个性化词典二级向量查询扩展个性化服务(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-17 09:41
中国论文网关键词用户个性化词典二级向量查询扩展个性化服务(组图))
基于个性化词典的搜索引擎查询扩展模型总结 为了给用户提供个性化的网络信息检索服务,本文对现有的个性化服务模型进行了改进,引入了一种基于用户个性化词典的搜索引擎查询扩展模型。该模型使用用户个性化字典代替传统的全局字典,并使用查询扩展策略实现个性化服务。用户个性化词典可以优化用户兴趣建模过程,使用户兴趣模型更加准确,优化最终生成的扩展词。搜索引擎可以更轻松地检索到更符合其兴趣的网页。党的积极分子检查清单和毫米对照表的数量。教师职称等级列表。员工考核评分表。普通年金现值系数表明该模型可以通过搜索引擎提供给用户。有效可行的个性化服务中国论文网关键词用户个性化词典二次向量查询扩展个性化服务搜索引擎中文图书馆分类号TP391文件标识危险废物标识危险废物标识安全警示牌大全危险废物标识牌管道标识色码A 文章 number 128-6764-07 互联网是人们获取知识和传递信息的桥梁。但是,随着近年来互联网的飞速发展,互联网上的信息量也呈指数级增长。在这种背景下,互联网用户往往无法轻松找到自己需要的信息。搜索引擎的出现在一定程度上解决了我们的信息检索需求。当前搜索引擎的概念已经成为互联网信息检索必不可少的工具,但它一方面存在以下几个局限: 1 庞大的搜索结果集,用户花费大量时间和精力去寻找自己真正感兴趣的信息2 不同用户在不同时间使用同一个查询关键词请求得到的搜索结果几乎相同,用户无法提供个性化服务。3 用户在使用搜索引擎进行搜索时有一定的目的,但往往由于用户对相关领域知识的缺乏以及搜索引擎查询界面的限制,导致用户无法清晰表达自己的信息需求[2] 针对传统搜索引擎无法提供给用户的缺陷面向个性化服务,大量专家学者开始研究查询扩展技术并在该领域取得突破。文献 [1] 根据文献分析 提出了局部共现的思想,SEPMBDVDSearchEnginePersonalizationModelBasedonDoubleVectorDescription。其本质也是利用挖掘用户浏览过的历史网页和用户输入产生的用户兴趣模型。通过扩展词添加查询关键词匹配扩展词,使用户在使用搜索引擎检索结果时,可以得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。查询扩展模型依赖于用户兴趣模型。文献[7]使用了一个两级向量模型,通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于用户浏览过的历史网页的全局字典。描述性聚类挖掘后生成的整个模型结构如图1所示。 全局字典太大,因为词汇量太复杂,无法反映用户兴趣等,会对用户兴趣模型的生成产生较大的影响,影响词的扩展。因此,本文使用个性化词典代替全局词典,使用searchVectors和扩展词向量描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后生成的整个模型结构如图1所示,全局字典太大,无法反映词汇量。用户的兴趣等原因会对用户兴趣模型的生成产生较大的影响,从而影响词扩展的效果。因此,本文使用个性化词典代替全局词典,使用searchVectors和扩展词向量描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后生成的整个模型结构如图1所示,全局字典太大,无法反映词汇量。用户的兴趣等原因会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。所以,本文使用个性化词典替代全局词典,并使用搜索匹配的扩展词通过扩展词添加,使用户在使用搜索引擎搜索时能够得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。此查询扩展模型取决于用户。兴趣模型文献[7]使用了一个两级向量模型,它通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。经过聚类和挖掘后生成的整个模型结构如图1所示。全局词典过大因为词汇量过大、词汇量太复杂无法体现用户兴趣等,会对用户兴趣模型的生成产生较大影响,进而影响词扩展的效果。因此,本文使用个性替换全局词典,通过扩展词添加匹配的扩展词,使用户在使用搜索引擎搜索时能够得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。此查询扩展模型取决于用户。兴趣模型文献[7]使用了一个两级向量模型,它通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后整个生成的模型结构如图1所示。全局字典太大,因为词汇量太大,词汇量太复杂,无法体现用户兴趣等,会对生成产生较大的影响用户兴趣模型,这会影响词扩展的效果。因此,本文使用个性替换全局字典 会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。因此,本文使用个性替换全局字典 会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。因此,本文使用个性替换全局字典
查询扩展策略,实现个性化服务。设计基于个性化词典 QEMBUPDSEQueryExpansionModelBasedonUserPersonalizationDictionaryforSearchEngine 的搜索引擎查询扩展模型。该模型可以通过个性化词典优化用户兴趣模型,优化查询扩展词,使用户的个性化搜索更快更准确 1 基于个性化词典的搜索引擎查询扩展模型。基于个性化词典的搜索引擎查询扩展模型从用户浏览历史的描述入手。然后数据挖掘方法使用二级向量描述来更直接地生成用户兴趣的二级向量模型。最后根据用户输入关键词进行查询扩展,如图2所示。21 个性化词典定义与实现 [10] 个性化词典UPDUserPersonalizationDictionary 包括两个层次:关键词词典KeyDict和扩展词词典ExDict。二级词典中的词定义为关键词和扩展词。每层词典收录nn个词和词权重组成的二元组,人为设置关键词通常意味着用户浏览兴趣词的权重越大,在用户兴趣中的重要性越大,扩展词用于描述用户的兴趣点为了在查询扩展时提供符合用户偏好的扩展搜索词,特定用户的UPD可以充分表达用户对信息需求的偏好,同时为基于二次向量的用户兴趣模型提供支持,是一种用户兴趣。词典设计中的私人词典主要考虑以下几个主要原则: 1 一个词在网络文档集合中出现的频率越高,对这个词的用户特征的描述就越强 2 收录该词的网页数量越多web文档集合词对越多对用户特征的描述能力越强 3对于网页中一些常用的没有搜索价值的词,我们称之为网页常用词,比如comment copyright文章字典中,应该过滤掉,以免给用户的个人描述带来干扰。公式中身份证号码提取年龄公式电容电压公式电容公式定积分推导公式力学公式1 S是网页集合T是词空间WtS是词t在S中的权重,tftS是词频S中的词t,N为S中收录的网页总数,nt为S中的文档数,分母为归一化因子。在TF-IDF公式中,Nnt001为IDF因子,即逆向文本频率索引在WTUPD中仍沿用此名称。IDF因子越大,词在网页集合中的分布越稀疏,词的重要性越小,权重越小。反之,词的IDF因子越小,说明它在网页集合中越小。分布越密集,单词的重要性越统一,权重就越大。考虑到词在网页集合中的均匀分布不同,本文认为词t在整个网页集合S中的权重与其在网页中的均匀度成正比,因此本文引入了一个因素测量一致性以修改单词 t 的权重。公式1中t这个词的均匀度是通过网页集合中t的标准差来衡量的。集合S中的权重与网页集合中的词频成正比,与其在网页集中分布的稀疏性和均匀性成正比。通过 WTUPD 公式,
超过5个核心兴趣点的用户选择前12个词作为关键词,其余为扩展词,形成关键词词典和扩展词词典。最后,必须清除关键词 字典和扩展时间。字典中的频繁词的特点是它们分布在网页集合中的大多数文档中,并且在单个网页中出现的频率往往低于1-2次。本文使用以下方法过滤这部分词,经过上述公式处理,最终可以构建出满足用户兴趣描述要求的个性化词典 22 基于个性化词典的用户兴趣建模 最终的词扩展依赖于准确的用户兴趣模型,而个性化词典的建立将有助于快速准确地建立用户兴趣模型。因此,本文采用的用户兴趣建模方法如下:首先,利用个性化词典将用户浏览的网页转化为特征向量。由于个性化词典收录二级词典,因此生成的网页特征向量为二级向量,如网页的特征向量。表示为 [单反 005327385 摄影 004826857 像素 003272436 市场 002713352 专业 002639451...] [镜头 001135712 显示 001023895 环 向量,然后是扩展词向量,然后使用网页的特征向量进行聚类分析,得到用户感兴趣的子类别。最后,使用各种类型的网页特征向量将兴趣子类别描述为辅助向量,以生成用户兴趣模型。可以看出,个性化词典使得整个用户兴趣建模过程使用了两个高级向量用户兴趣模型的生成更加直接和流畅,并且因为个性化词典避免了大量的词和频繁出现的词与传统全局词典中用户兴趣无关,网页特征描述更加准确,为后续的聚类分析和兴趣模型生成奠定基础。良好的基础广州货架wwwgzrundacomgzh并通过用户兴趣模型提供符合用户兴趣偏好的扩展词,有利于扩展词的分析比较和23种查询扩展策略的实施。分子是向量ci和Qini各分量的乘积,分母是向量模数。本文产品选择与初始查询相似度最高的兴趣点C作为用户的查询意图,为用户提供尽可能多的查询扩展词。如果在关键词向量中找不到用户的查询词,即Qini和关键词向量的相似度为0,那么扩展词向量将被合并到关键词@ > 参与计算的向量。下一个,为了找到与用户查询最相关的扩展词,需要计算词之间的相关性。本文参考LSI模型[7中的方法]将网页文档集合表示为词文档矩阵TD,如表1所示。提交给搜索引擎的初始查询词是Qini National Team World Cup Australia。是Qini匹配的兴趣类别的扩展词向量中的矩阵单元TDij,扩展词中间的矩阵单元TDij是文档Dj中对应词Ti的权重和频率。变换的结果是因为单词和文档的数量非常多,单个文档中出现的单词非常有限,所以TD一般是一个高阶稀疏矩阵,然后用TD构建词间关系矩阵TT,计算词间关联度构建方法如下: 式6 其中TD为TD转置得到的矩阵TT中各单元TTij的值,反映了特定环境下特定用户特定兴趣类别的词 i 和 j 之间的相似度。我们可以看到,每个词与其自身的相似度为1,并且在兴趣类别的任何文档中都没有相似度。
两个现有词的相似度为0,如表2所示,其中x表示词间关系矩阵TT,与初始查询词Qini相似度最大的候选扩展词对应的相关度x表示其他候选扩展词。与Qini的相关性公式8中的参数[δ]表示x和x之间的相对误差阈值。只要某个候选扩展词与Qini的相关性与x的相对误差小于δ,那么候选扩展词就可以最终推荐给用户。在实际应用中,δ通常取值为10,这样可以更好地保留扩展词,减少计算时间。可以根据情况进行设置,让过滤后的词按照相关性的顺序排序,然后推荐给因为过多的扩展词会减少搜索结果,不利于用户获取足够的信息。通常选择3个扩展词比较合适,所以最后可以从排序好的扩展词队列中选择前3个词进行推荐。当然可以根据用户需要设置推荐的扩展词数。3 实验与分析 31 个人能力评价评价 个人工作评价评价指标 工作条件风险评价方法评价反应指标 SWUI 因为用户个性化词典UPD实际上几乎收录了用户的归属感 兴趣词和词的权重计算公式浏览历史网页也反映了用户对这些词的兴趣。因此,本文采用将查询扩展搜索到的网页集合与用户的个性化词典进行对比的方法进行实验。评估本文提出的个性化服务模型的效果。为了将检索到的网页集合与用户个性化词典进行比较 余弦函数值之间的相似度通过相似度反映网页集合与用户兴趣的相关程度,该相似度称为 SWUISimilaritybetweenWebpagesandUserInterests32 实验数据 本实验为基于三个用户根据自己的兴趣浏览网页,然后自己感兴趣 保存网页,然后对三个用户提供的兴趣网页进行兴趣建模,得到用户兴趣模型。表4限制了每个兴趣类别的长度,只使用了关键词的一部分 表示 33 对比实验 本文在谷歌和百度上进行了以下三组实验,在主流搜索引擎上进行: 1None 实验不使用查询扩展,只使用用户查询关键词检索实验2 标准实验使用文献[7]中提出的SEPMBDVD模型进行查询扩展然后在搜索引擎广州货架wwwgzrundacomgzh上搜索基于3UPD的实验使用本文提出的QEMBUPDSE模型进行查询扩展然后在搜索引擎上进行搜索比较实验由三个实现提供用户兴趣模型的用户。每个用户为他的每个兴趣选择合适的一个。关键词 根据以上三组实验的要求,在谷歌和百度上搜索。每组实验都会使用每一种搜索引擎返回的前100个网页进行保存,然后为每个搜索引擎计算每个搜索引擎搜索引擎集合与UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI 然后为每个搜索引擎计算每个搜索引擎搜索引擎集合和UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI 然后为每个搜索引擎计算每个搜索引擎搜索引擎集合和UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI
最终实验结果如表5所示,以更直观地反映对比效果。本文计算了UPDbased相对于None和Standard的实验结果的百分比增长,如表6所示。从表6可以看出,首先使用QEMBUPDSE模型进行查询扩展后,搜索到的网页显然更相关用户的兴趣比没有查询扩展。其次,与使用SEPMBDVD模型扩展相比,使用QEMBUPDSE模型进行查询扩展后的搜索网页在用户相关性上也有一定的提升。网页更符合用户的兴趣。这主要是因为在用户建模之前使用UPD可以在一定程度上优化整个用户建模过程。最终用户兴趣模型更准确,查询扩展效果更好。4 结论本文基于文献[7]中提出的二次向量对搜索引擎个性化服务模型进行改进,增加用户个性化词典,优化用户兴趣建模过程,提高查询扩展效果。实验表明,个性化词典基于搜索引擎查询扩展模型可以更有效地辅助用户使用搜索引擎搜索他们感兴趣的信息。在接下来的研究中,需要考虑如何更准确地构建个性化词典和用户兴趣模型,提出更好的相似度计算方法。提高整个个性化搜索模型的性能。参考文献 [1] 丁国栋,白硕,王斌,许伟民基于主题的个性化查询扩展模型[J]计算机工程与设计2-4475[7]徐景秋、朱正宇、谭明宏等基于二次向量的搜索引擎个性化服务模型[J]计算机科学2007341189-92[ 8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗应诸正雨研究与实现广州WWW个性化源字典。货架 wwwgzrundacomgzh 谭铭洪和其他搜索引擎的个性化的服务模式基础上的二次载体[J]。计算机科学2007341189-92 [8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗莹朱政宇的研究与实现个性化源广州词典 www. 货架 wwwgzrundacomgzh 谭铭洪和其他搜索引擎的个性化的服务模式基础上的二次载体[J]。计算机科学2007341189-92 [8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗莹朱政宇的研究与实现个性化源广州词典 www. 货架 wwwgzrundacomgzh 查看全部
搜索引擎主题模型优化(
中国论文网关键词用户个性化词典二级向量查询扩展个性化服务(组图))
基于个性化词典的搜索引擎查询扩展模型总结 为了给用户提供个性化的网络信息检索服务,本文对现有的个性化服务模型进行了改进,引入了一种基于用户个性化词典的搜索引擎查询扩展模型。该模型使用用户个性化字典代替传统的全局字典,并使用查询扩展策略实现个性化服务。用户个性化词典可以优化用户兴趣建模过程,使用户兴趣模型更加准确,优化最终生成的扩展词。搜索引擎可以更轻松地检索到更符合其兴趣的网页。党的积极分子检查清单和毫米对照表的数量。教师职称等级列表。员工考核评分表。普通年金现值系数表明该模型可以通过搜索引擎提供给用户。有效可行的个性化服务中国论文网关键词用户个性化词典二次向量查询扩展个性化服务搜索引擎中文图书馆分类号TP391文件标识危险废物标识危险废物标识安全警示牌大全危险废物标识牌管道标识色码A 文章 number 128-6764-07 互联网是人们获取知识和传递信息的桥梁。但是,随着近年来互联网的飞速发展,互联网上的信息量也呈指数级增长。在这种背景下,互联网用户往往无法轻松找到自己需要的信息。搜索引擎的出现在一定程度上解决了我们的信息检索需求。当前搜索引擎的概念已经成为互联网信息检索必不可少的工具,但它一方面存在以下几个局限: 1 庞大的搜索结果集,用户花费大量时间和精力去寻找自己真正感兴趣的信息2 不同用户在不同时间使用同一个查询关键词请求得到的搜索结果几乎相同,用户无法提供个性化服务。3 用户在使用搜索引擎进行搜索时有一定的目的,但往往由于用户对相关领域知识的缺乏以及搜索引擎查询界面的限制,导致用户无法清晰表达自己的信息需求[2] 针对传统搜索引擎无法提供给用户的缺陷面向个性化服务,大量专家学者开始研究查询扩展技术并在该领域取得突破。文献 [1] 根据文献分析 提出了局部共现的思想,SEPMBDVDSearchEnginePersonalizationModelBasedonDoubleVectorDescription。其本质也是利用挖掘用户浏览过的历史网页和用户输入产生的用户兴趣模型。通过扩展词添加查询关键词匹配扩展词,使用户在使用搜索引擎检索结果时,可以得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。查询扩展模型依赖于用户兴趣模型。文献[7]使用了一个两级向量模型,通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于用户浏览过的历史网页的全局字典。描述性聚类挖掘后生成的整个模型结构如图1所示。 全局字典太大,因为词汇量太复杂,无法反映用户兴趣等,会对用户兴趣模型的生成产生较大的影响,影响词的扩展。因此,本文使用个性化词典代替全局词典,使用searchVectors和扩展词向量描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后生成的整个模型结构如图1所示,全局字典太大,无法反映词汇量。用户的兴趣等原因会对用户兴趣模型的生成产生较大的影响,从而影响词扩展的效果。因此,本文使用个性化词典代替全局词典,使用searchVectors和扩展词向量描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后生成的整个模型结构如图1所示,全局字典太大,无法反映词汇量。用户的兴趣等原因会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。所以,本文使用个性化词典替代全局词典,并使用搜索匹配的扩展词通过扩展词添加,使用户在使用搜索引擎搜索时能够得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。此查询扩展模型取决于用户。兴趣模型文献[7]使用了一个两级向量模型,它通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。经过聚类和挖掘后生成的整个模型结构如图1所示。全局词典过大因为词汇量过大、词汇量太复杂无法体现用户兴趣等,会对用户兴趣模型的生成产生较大影响,进而影响词扩展的效果。因此,本文使用个性替换全局词典,通过扩展词添加匹配的扩展词,使用户在使用搜索引擎搜索时能够得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。此查询扩展模型取决于用户。兴趣模型文献[7]使用了一个两级向量模型,它通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后整个生成的模型结构如图1所示。全局字典太大,因为词汇量太大,词汇量太复杂,无法体现用户兴趣等,会对生成产生较大的影响用户兴趣模型,这会影响词扩展的效果。因此,本文使用个性替换全局字典 会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。因此,本文使用个性替换全局字典 会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。因此,本文使用个性替换全局字典
查询扩展策略,实现个性化服务。设计基于个性化词典 QEMBUPDSEQueryExpansionModelBasedonUserPersonalizationDictionaryforSearchEngine 的搜索引擎查询扩展模型。该模型可以通过个性化词典优化用户兴趣模型,优化查询扩展词,使用户的个性化搜索更快更准确 1 基于个性化词典的搜索引擎查询扩展模型。基于个性化词典的搜索引擎查询扩展模型从用户浏览历史的描述入手。然后数据挖掘方法使用二级向量描述来更直接地生成用户兴趣的二级向量模型。最后根据用户输入关键词进行查询扩展,如图2所示。21 个性化词典定义与实现 [10] 个性化词典UPDUserPersonalizationDictionary 包括两个层次:关键词词典KeyDict和扩展词词典ExDict。二级词典中的词定义为关键词和扩展词。每层词典收录nn个词和词权重组成的二元组,人为设置关键词通常意味着用户浏览兴趣词的权重越大,在用户兴趣中的重要性越大,扩展词用于描述用户的兴趣点为了在查询扩展时提供符合用户偏好的扩展搜索词,特定用户的UPD可以充分表达用户对信息需求的偏好,同时为基于二次向量的用户兴趣模型提供支持,是一种用户兴趣。词典设计中的私人词典主要考虑以下几个主要原则: 1 一个词在网络文档集合中出现的频率越高,对这个词的用户特征的描述就越强 2 收录该词的网页数量越多web文档集合词对越多对用户特征的描述能力越强 3对于网页中一些常用的没有搜索价值的词,我们称之为网页常用词,比如comment copyright文章字典中,应该过滤掉,以免给用户的个人描述带来干扰。公式中身份证号码提取年龄公式电容电压公式电容公式定积分推导公式力学公式1 S是网页集合T是词空间WtS是词t在S中的权重,tftS是词频S中的词t,N为S中收录的网页总数,nt为S中的文档数,分母为归一化因子。在TF-IDF公式中,Nnt001为IDF因子,即逆向文本频率索引在WTUPD中仍沿用此名称。IDF因子越大,词在网页集合中的分布越稀疏,词的重要性越小,权重越小。反之,词的IDF因子越小,说明它在网页集合中越小。分布越密集,单词的重要性越统一,权重就越大。考虑到词在网页集合中的均匀分布不同,本文认为词t在整个网页集合S中的权重与其在网页中的均匀度成正比,因此本文引入了一个因素测量一致性以修改单词 t 的权重。公式1中t这个词的均匀度是通过网页集合中t的标准差来衡量的。集合S中的权重与网页集合中的词频成正比,与其在网页集中分布的稀疏性和均匀性成正比。通过 WTUPD 公式,
超过5个核心兴趣点的用户选择前12个词作为关键词,其余为扩展词,形成关键词词典和扩展词词典。最后,必须清除关键词 字典和扩展时间。字典中的频繁词的特点是它们分布在网页集合中的大多数文档中,并且在单个网页中出现的频率往往低于1-2次。本文使用以下方法过滤这部分词,经过上述公式处理,最终可以构建出满足用户兴趣描述要求的个性化词典 22 基于个性化词典的用户兴趣建模 最终的词扩展依赖于准确的用户兴趣模型,而个性化词典的建立将有助于快速准确地建立用户兴趣模型。因此,本文采用的用户兴趣建模方法如下:首先,利用个性化词典将用户浏览的网页转化为特征向量。由于个性化词典收录二级词典,因此生成的网页特征向量为二级向量,如网页的特征向量。表示为 [单反 005327385 摄影 004826857 像素 003272436 市场 002713352 专业 002639451...] [镜头 001135712 显示 001023895 环 向量,然后是扩展词向量,然后使用网页的特征向量进行聚类分析,得到用户感兴趣的子类别。最后,使用各种类型的网页特征向量将兴趣子类别描述为辅助向量,以生成用户兴趣模型。可以看出,个性化词典使得整个用户兴趣建模过程使用了两个高级向量用户兴趣模型的生成更加直接和流畅,并且因为个性化词典避免了大量的词和频繁出现的词与传统全局词典中用户兴趣无关,网页特征描述更加准确,为后续的聚类分析和兴趣模型生成奠定基础。良好的基础广州货架wwwgzrundacomgzh并通过用户兴趣模型提供符合用户兴趣偏好的扩展词,有利于扩展词的分析比较和23种查询扩展策略的实施。分子是向量ci和Qini各分量的乘积,分母是向量模数。本文产品选择与初始查询相似度最高的兴趣点C作为用户的查询意图,为用户提供尽可能多的查询扩展词。如果在关键词向量中找不到用户的查询词,即Qini和关键词向量的相似度为0,那么扩展词向量将被合并到关键词@ > 参与计算的向量。下一个,为了找到与用户查询最相关的扩展词,需要计算词之间的相关性。本文参考LSI模型[7中的方法]将网页文档集合表示为词文档矩阵TD,如表1所示。提交给搜索引擎的初始查询词是Qini National Team World Cup Australia。是Qini匹配的兴趣类别的扩展词向量中的矩阵单元TDij,扩展词中间的矩阵单元TDij是文档Dj中对应词Ti的权重和频率。变换的结果是因为单词和文档的数量非常多,单个文档中出现的单词非常有限,所以TD一般是一个高阶稀疏矩阵,然后用TD构建词间关系矩阵TT,计算词间关联度构建方法如下: 式6 其中TD为TD转置得到的矩阵TT中各单元TTij的值,反映了特定环境下特定用户特定兴趣类别的词 i 和 j 之间的相似度。我们可以看到,每个词与其自身的相似度为1,并且在兴趣类别的任何文档中都没有相似度。
两个现有词的相似度为0,如表2所示,其中x表示词间关系矩阵TT,与初始查询词Qini相似度最大的候选扩展词对应的相关度x表示其他候选扩展词。与Qini的相关性公式8中的参数[δ]表示x和x之间的相对误差阈值。只要某个候选扩展词与Qini的相关性与x的相对误差小于δ,那么候选扩展词就可以最终推荐给用户。在实际应用中,δ通常取值为10,这样可以更好地保留扩展词,减少计算时间。可以根据情况进行设置,让过滤后的词按照相关性的顺序排序,然后推荐给因为过多的扩展词会减少搜索结果,不利于用户获取足够的信息。通常选择3个扩展词比较合适,所以最后可以从排序好的扩展词队列中选择前3个词进行推荐。当然可以根据用户需要设置推荐的扩展词数。3 实验与分析 31 个人能力评价评价 个人工作评价评价指标 工作条件风险评价方法评价反应指标 SWUI 因为用户个性化词典UPD实际上几乎收录了用户的归属感 兴趣词和词的权重计算公式浏览历史网页也反映了用户对这些词的兴趣。因此,本文采用将查询扩展搜索到的网页集合与用户的个性化词典进行对比的方法进行实验。评估本文提出的个性化服务模型的效果。为了将检索到的网页集合与用户个性化词典进行比较 余弦函数值之间的相似度通过相似度反映网页集合与用户兴趣的相关程度,该相似度称为 SWUISimilaritybetweenWebpagesandUserInterests32 实验数据 本实验为基于三个用户根据自己的兴趣浏览网页,然后自己感兴趣 保存网页,然后对三个用户提供的兴趣网页进行兴趣建模,得到用户兴趣模型。表4限制了每个兴趣类别的长度,只使用了关键词的一部分 表示 33 对比实验 本文在谷歌和百度上进行了以下三组实验,在主流搜索引擎上进行: 1None 实验不使用查询扩展,只使用用户查询关键词检索实验2 标准实验使用文献[7]中提出的SEPMBDVD模型进行查询扩展然后在搜索引擎广州货架wwwgzrundacomgzh上搜索基于3UPD的实验使用本文提出的QEMBUPDSE模型进行查询扩展然后在搜索引擎上进行搜索比较实验由三个实现提供用户兴趣模型的用户。每个用户为他的每个兴趣选择合适的一个。关键词 根据以上三组实验的要求,在谷歌和百度上搜索。每组实验都会使用每一种搜索引擎返回的前100个网页进行保存,然后为每个搜索引擎计算每个搜索引擎搜索引擎集合与UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI 然后为每个搜索引擎计算每个搜索引擎搜索引擎集合和UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI 然后为每个搜索引擎计算每个搜索引擎搜索引擎集合和UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI
最终实验结果如表5所示,以更直观地反映对比效果。本文计算了UPDbased相对于None和Standard的实验结果的百分比增长,如表6所示。从表6可以看出,首先使用QEMBUPDSE模型进行查询扩展后,搜索到的网页显然更相关用户的兴趣比没有查询扩展。其次,与使用SEPMBDVD模型扩展相比,使用QEMBUPDSE模型进行查询扩展后的搜索网页在用户相关性上也有一定的提升。网页更符合用户的兴趣。这主要是因为在用户建模之前使用UPD可以在一定程度上优化整个用户建模过程。最终用户兴趣模型更准确,查询扩展效果更好。4 结论本文基于文献[7]中提出的二次向量对搜索引擎个性化服务模型进行改进,增加用户个性化词典,优化用户兴趣建模过程,提高查询扩展效果。实验表明,个性化词典基于搜索引擎查询扩展模型可以更有效地辅助用户使用搜索引擎搜索他们感兴趣的信息。在接下来的研究中,需要考虑如何更准确地构建个性化词典和用户兴趣模型,提出更好的相似度计算方法。提高整个个性化搜索模型的性能。参考文献 [1] 丁国栋,白硕,王斌,许伟民基于主题的个性化查询扩展模型[J]计算机工程与设计2-4475[7]徐景秋、朱正宇、谭明宏等基于二次向量的搜索引擎个性化服务模型[J]计算机科学2007341189-92[ 8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗应诸正雨研究与实现广州WWW个性化源字典。货架 wwwgzrundacomgzh 谭铭洪和其他搜索引擎的个性化的服务模式基础上的二次载体[J]。计算机科学2007341189-92 [8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗莹朱政宇的研究与实现个性化源广州词典 www. 货架 wwwgzrundacomgzh 谭铭洪和其他搜索引擎的个性化的服务模式基础上的二次载体[J]。计算机科学2007341189-92 [8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗莹朱政宇的研究与实现个性化源广州词典 www. 货架 wwwgzrundacomgzh
搜索引擎主题模型优化(哪些方法和技巧可以改善网站特殊页面的速度?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-16 15:10
大家都知道网站的质量好,那么文章的质量应该也好。相应的用户体验会很好,但更新频率很低,所以主题采集速度存在严重滞后。问题。有哪些方法和技巧可以改进网站特殊页面的收录?
首先要区分网站的特殊页面和网站的普通页面。所谓特殊页面就是网站管理员的页面。网站 是为特定活动而设计和制作的。投入了大量的精力(包括艺术、策划、营销、文案的整合)。与普通网页相比,特殊网页更美观。,更抢眼。,更有可能促进交易。然而,华丽并不意味着搜索引擎一定会识别它。毕竟,设计了很多美学的主题页面可能对搜索引擎不友好!
那么面对这种尴尬的情况,我们有什么方法可以提高特色页面的速度呢?
,做好网站基础seo优化
1. 主题页面的基础优化包括图片ALT属性的设置。毕竟漂亮的主题也是美化自己必不可少的网站,所以是让搜索引擎成功读取图片的关键。
2.收录完整的关键字HTML、描述、标题,因为有些主题页面实际上是由整个页面组成的FLASH,无论百度搜索引擎是否能够识别出FLASH文件的内容,我们仍然需要通知大纲百度搜索引擎,主题告诉百度搜索引擎的主题是什么!
4.简化网站代码,删除对搜索引擎不友好的内容(包括关键字堆砌和隐藏关键字的行为)。
不是故意弄网站。可以找一些速度非常快的平台,发几个软链接,引导蜘蛛快速爬行。关键是要了解你的核心。
如果话题页真的很吸引人,相信经过营销后,会引起很多人的点击,必然会引起搜索引擎的关注。当您的主题的一些基本 seo 优化完成后,我相信搜索引擎不会收录它。难的! 查看全部
搜索引擎主题模型优化(哪些方法和技巧可以改善网站特殊页面的速度?(图))
大家都知道网站的质量好,那么文章的质量应该也好。相应的用户体验会很好,但更新频率很低,所以主题采集速度存在严重滞后。问题。有哪些方法和技巧可以改进网站特殊页面的收录?
首先要区分网站的特殊页面和网站的普通页面。所谓特殊页面就是网站管理员的页面。网站 是为特定活动而设计和制作的。投入了大量的精力(包括艺术、策划、营销、文案的整合)。与普通网页相比,特殊网页更美观。,更抢眼。,更有可能促进交易。然而,华丽并不意味着搜索引擎一定会识别它。毕竟,设计了很多美学的主题页面可能对搜索引擎不友好!
那么面对这种尴尬的情况,我们有什么方法可以提高特色页面的速度呢?
,做好网站基础seo优化
1. 主题页面的基础优化包括图片ALT属性的设置。毕竟漂亮的主题也是美化自己必不可少的网站,所以是让搜索引擎成功读取图片的关键。
2.收录完整的关键字HTML、描述、标题,因为有些主题页面实际上是由整个页面组成的FLASH,无论百度搜索引擎是否能够识别出FLASH文件的内容,我们仍然需要通知大纲百度搜索引擎,主题告诉百度搜索引擎的主题是什么!
4.简化网站代码,删除对搜索引擎不友好的内容(包括关键字堆砌和隐藏关键字的行为)。
不是故意弄网站。可以找一些速度非常快的平台,发几个软链接,引导蜘蛛快速爬行。关键是要了解你的核心。
如果话题页真的很吸引人,相信经过营销后,会引起很多人的点击,必然会引起搜索引擎的关注。当您的主题的一些基本 seo 优化完成后,我相信搜索引擎不会收录它。难的!
搜索引擎主题模型优化(网站主页优化有哪些注意事项呢?让我们了解它!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-16 08:35
网站首页的重要性不言而喻。当用户浏览网站时,首先看到的是网站的首页。不仅将网站的有价值的内容和核心传达给用户,更能吸引用户长期留在网站。所以在网站的优化过程中,一定要注意网站首页的优化。网站首页的导航是对网站进行一个整体的分类,让用户可以方便快捷的找到自己需要的信息。那么,网站首页优化有哪些注意事项呢?让我们了解一下
!首先是改进主页的标题。在网站的SEO优化中,一定要精心设计标题,因为标题会影响搜索引擎的抓取,而标题就是对关键词的描述。设计标题时,应收录首页或栏目页的关键词,但必须是完整的句子,不要堆砌关键词。一些网站主要以图片为主。优化这种类型的网站时,必须在图片中添加说明。如果图像处理不好,就很难优化网站。
其次,注意不要在网站的首页添加视频,这样会影响用户体验,增加网站的跳出率。如果网站必须在首页添加视频,那么必须在视频属性中添加文字说明,因为搜索引擎只会抓取文字。如果纯视频不利于搜索引擎抓取,会影响用户打开网站的速度。
最后,我们应该每天检查链接的状态,及时删除问题。在链接的交流上,要和同行业的网站交流,这样才能互补,增加搜索引擎的友好度,增加关键词在首页的密度。
以上就是网站首页优化的注意事项。影响网站首页排名的因素有很多,比如网站的运营、高质量的原创文章等,只有采用正确的优化方法才能使首页的排名靠前。 网站的排名稳步上升。
网站的标题有什么好的优化方法吗?
优化网站标题的关键是关键词的选择,所以第一步是选择关键词。
关键词选择主要根据行业和企业的产品和服务,发散思维总结。
根据用户的搜索关键词,一般有搜索引擎下拉框、相关搜索、搜索工具排名。
使用单词扩展工具扩展大量关键字。
购买关键词数据等
第二步,对所有关键词进行整理汇总,最后制作自己的关键词统计表。
网站 标题优化的原则是尽量多插入关键词,然后把关键词放在前面。
当然网站的整体权重很重要。
主题网站 设计优化时要注意哪些方面?
根据你设计的产品,基本的配色和布局知识就不用说了。要想设计好,就必须考虑用户体验。也了解产品领域的专业知识和用户场景。我认为设计只是一方面。了解业务流程、客户关注点、数据分析等将促进设计优化
优化模型的数学建模有哪些?什么模型可以用于路径优化? 查看全部
搜索引擎主题模型优化(网站主页优化有哪些注意事项呢?让我们了解它!)
网站首页的重要性不言而喻。当用户浏览网站时,首先看到的是网站的首页。不仅将网站的有价值的内容和核心传达给用户,更能吸引用户长期留在网站。所以在网站的优化过程中,一定要注意网站首页的优化。网站首页的导航是对网站进行一个整体的分类,让用户可以方便快捷的找到自己需要的信息。那么,网站首页优化有哪些注意事项呢?让我们了解一下
!首先是改进主页的标题。在网站的SEO优化中,一定要精心设计标题,因为标题会影响搜索引擎的抓取,而标题就是对关键词的描述。设计标题时,应收录首页或栏目页的关键词,但必须是完整的句子,不要堆砌关键词。一些网站主要以图片为主。优化这种类型的网站时,必须在图片中添加说明。如果图像处理不好,就很难优化网站。
其次,注意不要在网站的首页添加视频,这样会影响用户体验,增加网站的跳出率。如果网站必须在首页添加视频,那么必须在视频属性中添加文字说明,因为搜索引擎只会抓取文字。如果纯视频不利于搜索引擎抓取,会影响用户打开网站的速度。
最后,我们应该每天检查链接的状态,及时删除问题。在链接的交流上,要和同行业的网站交流,这样才能互补,增加搜索引擎的友好度,增加关键词在首页的密度。
以上就是网站首页优化的注意事项。影响网站首页排名的因素有很多,比如网站的运营、高质量的原创文章等,只有采用正确的优化方法才能使首页的排名靠前。 网站的排名稳步上升。
网站的标题有什么好的优化方法吗?
优化网站标题的关键是关键词的选择,所以第一步是选择关键词。
关键词选择主要根据行业和企业的产品和服务,发散思维总结。
根据用户的搜索关键词,一般有搜索引擎下拉框、相关搜索、搜索工具排名。
使用单词扩展工具扩展大量关键字。
购买关键词数据等
第二步,对所有关键词进行整理汇总,最后制作自己的关键词统计表。
网站 标题优化的原则是尽量多插入关键词,然后把关键词放在前面。
当然网站的整体权重很重要。
主题网站 设计优化时要注意哪些方面?
根据你设计的产品,基本的配色和布局知识就不用说了。要想设计好,就必须考虑用户体验。也了解产品领域的专业知识和用户场景。我认为设计只是一方面。了解业务流程、客户关注点、数据分析等将促进设计优化
优化模型的数学建模有哪些?什么模型可以用于路径优化?
搜索引擎主题模型优化( 主题聚类一组模子作为最新的搜索引擎优化计策优化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-13 23:24
主题聚类一组模子作为最新的搜索引擎优化计策优化)
在风中弹跳
11-10 10:27 阅读 38
注意
主题聚类模型和搜索引擎优化
多年来,SEO 经历了各种变化,从链接方案的消亡到移动优先。然而,业界最大的创新之一是使用主题聚类模型作为最新的搜索引擎优化策略。
主题聚类模型可以将用户过去的搜索与相关的主题和短语联系起来,为用户找到最佳效果。您应该知道,在任何搜索引擎性能页面 (SERP) 上的排名都意味着显示的关键词需要相互关联。
什么是主题集群?
主题组是一组相关的网页,周围环绕着涵盖该主题的构建支柱。特定主题的搜索可见性优于特定关键字的排名。这种策略最终可以帮助您开发影响区域,其中相关长尾关键字的本地搜索总和高于主要关键字的搜索总和。这将帮助您组织 网站 的布局和内容。此外,当集群中的内容排名出色时,整个集群也会排名出色。
主题集群模型收录三个组件:
支柱内容
支柱内容是集群的重点,因为它基于更普遍的主题。它通常有 3000 到 5000 字,涵盖了特定主题的方方面面,但仍有足够的空间来回答不同的帖子。支柱的内容适合那些对某个主题不熟悉但想熟悉所有内容的人。
集群内容
该组件处理与支柱内容直接相关的所有类型的集群内容。与涉及无孔不入主题的支柱内容不同,集群内容侧重于与无孔不入关键字相关的特定关键字,并以更全面和全面的方式组织连接。最后,这些聚集的内容包括一个链接,允许读者返回到支柱内容。
超链接
这是所有三个组件中最重要的,主要是因为超链接是将支柱内容绑定到集群内容的关键。
简而言之,主题聚类模型是特定主题下的一组相关内容,易于被各种搜索引擎识别。它发生的信号旨在证明您在特定主题上的网站权威和专业常识,这将增加网站的知名度,从而带来更多的流量和转换时间。
主题聚类模型的重要性和优势
毫无疑问,关键词一直是并且仍然是内容创作的基础。然而,随着技能的不断创新和转化,用户如何交互或使用一组给定的关键词将逐渐改变他们的行为。
自从 Siri、Alexa 和小爱同学等数字助理出现以来,它们已经成为最常见的满足搜索引擎性能页面 (SERP) 的平台之一,比手动输入查询要快得多。
由于用户行为的变化,百度和其他搜索引擎一直在修改他们的系统以满足基于主题的内容搜索。无法适应行为变化的现有搜索引擎优化策略最终会失效,无法让位于新的更有效的策略,例如主题聚类模型。
虽然关键词还是很重要的,定位整个主题是目前的方法,主要原因如下:
搜索引擎更擅长欣赏相关的想法。
搜索确切的关键词仍然是相关的,但目前搜索算法可以更好地识别同一主题的多个术语。权威可信的功能是百度等搜索引擎希望提供响应用户的功能。
为了向人们和傻瓜式人展示权威,需要针对一个主题一个接一个地构建昂贵而精确的内容,这比针对不相关的关键词构建无组织的内容要好得多。
综上所述
回收新策略确实令人生畏,尤其是当您的 网站 已经有很多内容时。但是,如果你能在完成一个主题的同时规划大量相关的主题,然后将它们拼接在一起,那么你就可以轻松实现这个策略。 查看全部
搜索引擎主题模型优化(
主题聚类一组模子作为最新的搜索引擎优化计策优化)
在风中弹跳
11-10 10:27 阅读 38
注意
主题聚类模型和搜索引擎优化
多年来,SEO 经历了各种变化,从链接方案的消亡到移动优先。然而,业界最大的创新之一是使用主题聚类模型作为最新的搜索引擎优化策略。
主题聚类模型可以将用户过去的搜索与相关的主题和短语联系起来,为用户找到最佳效果。您应该知道,在任何搜索引擎性能页面 (SERP) 上的排名都意味着显示的关键词需要相互关联。
什么是主题集群?
主题组是一组相关的网页,周围环绕着涵盖该主题的构建支柱。特定主题的搜索可见性优于特定关键字的排名。这种策略最终可以帮助您开发影响区域,其中相关长尾关键字的本地搜索总和高于主要关键字的搜索总和。这将帮助您组织 网站 的布局和内容。此外,当集群中的内容排名出色时,整个集群也会排名出色。
主题集群模型收录三个组件:
支柱内容
支柱内容是集群的重点,因为它基于更普遍的主题。它通常有 3000 到 5000 字,涵盖了特定主题的方方面面,但仍有足够的空间来回答不同的帖子。支柱的内容适合那些对某个主题不熟悉但想熟悉所有内容的人。
集群内容
该组件处理与支柱内容直接相关的所有类型的集群内容。与涉及无孔不入主题的支柱内容不同,集群内容侧重于与无孔不入关键字相关的特定关键字,并以更全面和全面的方式组织连接。最后,这些聚集的内容包括一个链接,允许读者返回到支柱内容。
超链接
这是所有三个组件中最重要的,主要是因为超链接是将支柱内容绑定到集群内容的关键。
简而言之,主题聚类模型是特定主题下的一组相关内容,易于被各种搜索引擎识别。它发生的信号旨在证明您在特定主题上的网站权威和专业常识,这将增加网站的知名度,从而带来更多的流量和转换时间。
主题聚类模型的重要性和优势
毫无疑问,关键词一直是并且仍然是内容创作的基础。然而,随着技能的不断创新和转化,用户如何交互或使用一组给定的关键词将逐渐改变他们的行为。
自从 Siri、Alexa 和小爱同学等数字助理出现以来,它们已经成为最常见的满足搜索引擎性能页面 (SERP) 的平台之一,比手动输入查询要快得多。
由于用户行为的变化,百度和其他搜索引擎一直在修改他们的系统以满足基于主题的内容搜索。无法适应行为变化的现有搜索引擎优化策略最终会失效,无法让位于新的更有效的策略,例如主题聚类模型。
虽然关键词还是很重要的,定位整个主题是目前的方法,主要原因如下:
搜索引擎更擅长欣赏相关的想法。
搜索确切的关键词仍然是相关的,但目前搜索算法可以更好地识别同一主题的多个术语。权威可信的功能是百度等搜索引擎希望提供响应用户的功能。
为了向人们和傻瓜式人展示权威,需要针对一个主题一个接一个地构建昂贵而精确的内容,这比针对不相关的关键词构建无组织的内容要好得多。
综上所述
回收新策略确实令人生畏,尤其是当您的 网站 已经有很多内容时。但是,如果你能在完成一个主题的同时规划大量相关的主题,然后将它们拼接在一起,那么你就可以轻松实现这个策略。
搜索引擎主题模型优化(搜索引擎主题模型优化以下模型-上海怡健医学())
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-12-13 09:01
搜索引擎主题模型优化以下模型可对搜索引擎进行主题模型优化:根据搜索引擎的意图、指向和搜索特性,对搜索引擎的结构、形态进行优化,不断提高搜索引擎的特征提取能力、信息智能分发能力和自动排序功能能力,提高用户体验搜索推荐搜索推荐可以基于当前用户习惯的输入来给用户提供该类或者相关的内容。搜索引擎的优化目标搜索引擎优化目标可分为以下五点:。
1、网站排名——上首页,
2、用户体验——改善用户使用网站过程中的体验和意愿,增加用户粘性,
3、用户意图——将网站中符合用户意图的信息提取出来,改善信息查询效率,
4、搜索效率——提高链接质量,
5、价值性——网站结构更合理,提高网站内容生产效率,搜索关键词相关性;优化的方法目前可优化的方法有以下四点:对搜索引擎进行自动诊断;a.内容质量检测——设计好网站链接结构,优化外链;b.页面颜色设计——显示网站链接地址规则;c.可被搜索引擎辨别内容——收录情况分析,存在的问题及优化建议;d.关键词密度分析——主关键词、长尾关键词分析和收录情况分析;e.词汇、短语、句子相似度分析——提高关键词相似度;搜索引擎推荐信息2.1一些常见的搜索引擎排名的搜索推荐方法a.意图搜索推荐——采用用户意图方向,筛选相关的链接;b.行为召回推荐——网站地址结构处理;c.业务聚合推荐——针对某类业务业务专题,推荐相关内容;2.2搜索推荐的工作原理a.基于关键词相似性,即搜索网站不同关键词的情况下,搜索结果同样搜索某一个主题;b.基于网站热度排名,即按照各个用户输入的网站信息,来综合优化不同网站;c.基于常用搜索词,根据用户搜索习惯的排名;d.基于用户输入内容中的关键词,从用户查询语义中寻找最相关的链接。
2.3搜索推荐的模型优化搜索推荐的优化工作方式一般分为三种:倾向型模型优化,多用于分析数据与用户行为的数据方面,数据智能化,多用于资源方面;建模型模型优化,多用于优化数据对外部分析方面;搜索推荐模型优化,多用于垂直行业的优化。1倾向性模型优化倾向性模型优化主要针对于分析数据与用户行为的数据方面,其优化方式多为itemsensemble。
简单的说,就是把一个长尾关键词进行排序后,对于长尾关键词分析存在哪些相似,从而进行聚合操作,从而对长尾词进行分词,得到最终结果。例如:用户输入“北京求职高校”搜索,那么系统就会自动对应匹配“北京”、“求职”等前缀关键词,从。 查看全部
搜索引擎主题模型优化(搜索引擎主题模型优化以下模型-上海怡健医学())
搜索引擎主题模型优化以下模型可对搜索引擎进行主题模型优化:根据搜索引擎的意图、指向和搜索特性,对搜索引擎的结构、形态进行优化,不断提高搜索引擎的特征提取能力、信息智能分发能力和自动排序功能能力,提高用户体验搜索推荐搜索推荐可以基于当前用户习惯的输入来给用户提供该类或者相关的内容。搜索引擎的优化目标搜索引擎优化目标可分为以下五点:。
1、网站排名——上首页,
2、用户体验——改善用户使用网站过程中的体验和意愿,增加用户粘性,
3、用户意图——将网站中符合用户意图的信息提取出来,改善信息查询效率,
4、搜索效率——提高链接质量,
5、价值性——网站结构更合理,提高网站内容生产效率,搜索关键词相关性;优化的方法目前可优化的方法有以下四点:对搜索引擎进行自动诊断;a.内容质量检测——设计好网站链接结构,优化外链;b.页面颜色设计——显示网站链接地址规则;c.可被搜索引擎辨别内容——收录情况分析,存在的问题及优化建议;d.关键词密度分析——主关键词、长尾关键词分析和收录情况分析;e.词汇、短语、句子相似度分析——提高关键词相似度;搜索引擎推荐信息2.1一些常见的搜索引擎排名的搜索推荐方法a.意图搜索推荐——采用用户意图方向,筛选相关的链接;b.行为召回推荐——网站地址结构处理;c.业务聚合推荐——针对某类业务业务专题,推荐相关内容;2.2搜索推荐的工作原理a.基于关键词相似性,即搜索网站不同关键词的情况下,搜索结果同样搜索某一个主题;b.基于网站热度排名,即按照各个用户输入的网站信息,来综合优化不同网站;c.基于常用搜索词,根据用户搜索习惯的排名;d.基于用户输入内容中的关键词,从用户查询语义中寻找最相关的链接。
2.3搜索推荐的模型优化搜索推荐的优化工作方式一般分为三种:倾向型模型优化,多用于分析数据与用户行为的数据方面,数据智能化,多用于资源方面;建模型模型优化,多用于优化数据对外部分析方面;搜索推荐模型优化,多用于垂直行业的优化。1倾向性模型优化倾向性模型优化主要针对于分析数据与用户行为的数据方面,其优化方式多为itemsensemble。
简单的说,就是把一个长尾关键词进行排序后,对于长尾关键词分析存在哪些相似,从而进行聚合操作,从而对长尾词进行分词,得到最终结果。例如:用户输入“北京求职高校”搜索,那么系统就会自动对应匹配“北京”、“求职”等前缀关键词,从。
搜索引擎主题模型优化(关键词:搜索引擎发展方向今天很高兴有机会在这里做)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-11 01:37
关键词:搜索引擎发展方向
今天很高兴有机会在这里做这份题为《搜索引擎研发的难点和发展方向》的报告。几年前,搜狐的地址在建国门附近,是一个商业环境;2003年,公司研发中心在清华同方大厦成立,为公司提供更多的技术支持;2004年,搜狐整体搬迁至清华科技园。基于此,我们看到了一个轨迹:搜狐本身作为一家公司,已经从原来的市场导向转变为现在的技术驱动,并与高校建立了密切的合作关系。
1.搜索和搜索引擎
搜索与搜索引擎的区别在于,搜索引擎是以技术为核心的技术概念和服务;而搜索更加工业化。今天我将重点介绍中文网络搜索遇到的困难和发展方向。
搜狗的成长之路
2003年9月,组建团队;
2004年8月,1.0版本正式发布;
2005年12月,2.5版本正式发布;
预计2006年7月将达到同期行业领先水平。
搜索引擎的研发不同于其他项目。因为它直接依赖于技术,技术和运营密不可分,所以一般来说,搜索引擎应该由商业公司自己开发并投入使用。这里我们需要一个边界来定义哪些任务由研发机构完成,哪些任务由企业完成。只有明确这个界限,才能提高工作效率,才能开发出技术先进、适合市场需求的大型搜索引擎。
2. 搜索引擎面临的挑战
(1)工程
1999年,有人预言搜索引擎的发展是不可能的。由于互联网信息呈指数级增长,检索如此大量的信息是不可能的。但现在,虽然搜索引擎的效果不尽如人意,但至少已经完成了自己的基本功能,在这个领域迈出了一大步。
支持如此复杂的引擎,需要庞大的硬件环境。例如,谷歌在全球拥有超过 140,000 台服务器。如此庞大的系统,在开发、测试、硬件维护等方面都给人们带来了一定的困难甚至挑战。
(2)学术研究
目前,公司已与清华大学建立合作关系,双方优势互补。
在搜索引擎开发过程中,海量数据的处理是一大难题。在研究领域,语言模型可以实现高达97%的识别率;但在实际应用中,面对互联网的海量数据,处理速度受到严重影响,最前沿的技术成果变得无用,导致开发者更倾向于选择效率高、识别率低的技术。
在进行研发工作时,往往需要互联网上的真实数据。采集这些数据在高校很难完成,但在公司很容易获得。同样,很多手工贴标签的工作更适合在公司完成。
工程/运营架构的妥协现在是学术领域和工程领域之间的一个主要问题。例如,研究机构开发的高质量算法在实际应用中不会有很强的可用性,因为算法太复杂,系统太大。
(3)社会方面
首先是垃圾邮件的问题。在互联网上,80%的信息都是垃圾。用户搜索的是准确的信息,公司需要组织团队建立学习系统来处理网络垃圾邮件。
由于搜索引擎难以抓取海量数据,有人考虑在搜索引擎和各种网站之间建立合作关系,由网站自己将数据推送给搜索引擎;或者每个网站都建立了文档来解释他们的有用信息。但这会严重破坏搜索引擎的公平性,大大失去搜索结果的意义,因此没有发展空间。
博客等新事物的出现,也对搜索引擎的发展产生了一定的影响。比如有的Blog的信息比网站的信息更全面,有的则全是垃圾信息,给搜索引擎的检索带来了一定的困难。
三、搜索引擎未来的发展方向
(1) 宽带应用
将互联网上的音视频信息内容组织起来,进行有效的描述,实现高效的存储和传输,是搜索引擎未来的发展方向之一。
(2)互动体验
谷歌改变了用户上网、漫游的浏览习惯,而是将用户需要的信息进行线性排列。未来,导航将成为互联网浏览的主要方式:搜索引擎充分理解用户想要表达的主题,将所需信息按类别排列呈现给用户,增加更多纠错能力,列出错误校正提示。
(3)垂直化和入口占领
未来,搜索引擎将从平行搜索转向垂直搜索,只对某一领域的信息进行精准搜索。这种细化是搜索引擎未来发展的一个方向。所谓入口,是指搜索将成为用户登录互联网的第一道坎,搜索引擎品牌和用户习惯将直接引导市场。
(4)互联网的进步
谷歌不仅在搜索领域处于领先地位,还加入了网站翻译领域并取得了不错的成绩。谷歌之所以能在翻译上取得好成绩,是因为它在其他人无法完成的海量信息方面具有优势。这也是搜索引擎发展的一个趋势。比如在输入法等领域,也可以通过对海量信息的评估,添加传统词典中没有的信息。 查看全部
搜索引擎主题模型优化(关键词:搜索引擎发展方向今天很高兴有机会在这里做)
关键词:搜索引擎发展方向
今天很高兴有机会在这里做这份题为《搜索引擎研发的难点和发展方向》的报告。几年前,搜狐的地址在建国门附近,是一个商业环境;2003年,公司研发中心在清华同方大厦成立,为公司提供更多的技术支持;2004年,搜狐整体搬迁至清华科技园。基于此,我们看到了一个轨迹:搜狐本身作为一家公司,已经从原来的市场导向转变为现在的技术驱动,并与高校建立了密切的合作关系。
1.搜索和搜索引擎
搜索与搜索引擎的区别在于,搜索引擎是以技术为核心的技术概念和服务;而搜索更加工业化。今天我将重点介绍中文网络搜索遇到的困难和发展方向。
搜狗的成长之路
2003年9月,组建团队;
2004年8月,1.0版本正式发布;
2005年12月,2.5版本正式发布;
预计2006年7月将达到同期行业领先水平。
搜索引擎的研发不同于其他项目。因为它直接依赖于技术,技术和运营密不可分,所以一般来说,搜索引擎应该由商业公司自己开发并投入使用。这里我们需要一个边界来定义哪些任务由研发机构完成,哪些任务由企业完成。只有明确这个界限,才能提高工作效率,才能开发出技术先进、适合市场需求的大型搜索引擎。
2. 搜索引擎面临的挑战
(1)工程
1999年,有人预言搜索引擎的发展是不可能的。由于互联网信息呈指数级增长,检索如此大量的信息是不可能的。但现在,虽然搜索引擎的效果不尽如人意,但至少已经完成了自己的基本功能,在这个领域迈出了一大步。
支持如此复杂的引擎,需要庞大的硬件环境。例如,谷歌在全球拥有超过 140,000 台服务器。如此庞大的系统,在开发、测试、硬件维护等方面都给人们带来了一定的困难甚至挑战。
(2)学术研究
目前,公司已与清华大学建立合作关系,双方优势互补。
在搜索引擎开发过程中,海量数据的处理是一大难题。在研究领域,语言模型可以实现高达97%的识别率;但在实际应用中,面对互联网的海量数据,处理速度受到严重影响,最前沿的技术成果变得无用,导致开发者更倾向于选择效率高、识别率低的技术。
在进行研发工作时,往往需要互联网上的真实数据。采集这些数据在高校很难完成,但在公司很容易获得。同样,很多手工贴标签的工作更适合在公司完成。
工程/运营架构的妥协现在是学术领域和工程领域之间的一个主要问题。例如,研究机构开发的高质量算法在实际应用中不会有很强的可用性,因为算法太复杂,系统太大。
(3)社会方面
首先是垃圾邮件的问题。在互联网上,80%的信息都是垃圾。用户搜索的是准确的信息,公司需要组织团队建立学习系统来处理网络垃圾邮件。
由于搜索引擎难以抓取海量数据,有人考虑在搜索引擎和各种网站之间建立合作关系,由网站自己将数据推送给搜索引擎;或者每个网站都建立了文档来解释他们的有用信息。但这会严重破坏搜索引擎的公平性,大大失去搜索结果的意义,因此没有发展空间。
博客等新事物的出现,也对搜索引擎的发展产生了一定的影响。比如有的Blog的信息比网站的信息更全面,有的则全是垃圾信息,给搜索引擎的检索带来了一定的困难。
三、搜索引擎未来的发展方向
(1) 宽带应用
将互联网上的音视频信息内容组织起来,进行有效的描述,实现高效的存储和传输,是搜索引擎未来的发展方向之一。
(2)互动体验
谷歌改变了用户上网、漫游的浏览习惯,而是将用户需要的信息进行线性排列。未来,导航将成为互联网浏览的主要方式:搜索引擎充分理解用户想要表达的主题,将所需信息按类别排列呈现给用户,增加更多纠错能力,列出错误校正提示。
(3)垂直化和入口占领
未来,搜索引擎将从平行搜索转向垂直搜索,只对某一领域的信息进行精准搜索。这种细化是搜索引擎未来发展的一个方向。所谓入口,是指搜索将成为用户登录互联网的第一道坎,搜索引擎品牌和用户习惯将直接引导市场。
(4)互联网的进步
谷歌不仅在搜索领域处于领先地位,还加入了网站翻译领域并取得了不错的成绩。谷歌之所以能在翻译上取得好成绩,是因为它在其他人无法完成的海量信息方面具有优势。这也是搜索引擎发展的一个趋势。比如在输入法等领域,也可以通过对海量信息的评估,添加传统词典中没有的信息。
搜索引擎主题模型优化(如何判断网页和查询的相关性?布尔模型简单)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-10 22:34
搜索引擎的质量很大程度上取决于搜索结果的网页内容和用户体验。搜索引擎在搜索能够满足用户需求的网页时,主要考虑两个方面:网页与查询的相关性和网页的重要性。网页与查询的相关性是指用户的搜索查询与网页内容之间的内容相似度得分,通常通过链接分析计算方法来评估网页的重要性;这篇文章主要简单描述了搜索引擎如何判断网页和查询的相关性?
判断网页内容是否与用户查询关键词相关,取决于搜索引擎采用的检索模型。几种常用的检索模型:布尔模型、向量空间模型、概率模型、语言模型和机器学习排序算法。
1.布尔模型
简单来说,布尔模型就是用户查询的词是否出现在网页中,对与错,收录在不收录。比如用户搜索关键词是SEO,希望得到与SEO相关的信息,那么当网页内容中出现SEO这个词时,就说明该网页与用户的查询相关。布尔模型也是检索模型中最简单的一种,其优缺点也非常直观。
2.矢量空间模型
向量空间模型将查询词和文档中的关键词转换为特征向量,然后利用余弦公式计算文档与查询的相似度并对输出结果进行排序。其中主要介绍了TF-IDF算法、TF词频和IDF逆文档频率。
TF词频,即一个词在内容中出现的次数。出现次数较多的词往往可以说明内容的主题信息。IDF逆文档频率是衡量单词普遍重要性的指标,突出特征词。如果某个关键词在网页内容中的词频很高,而这个词很少出现在网页搜索结果和其他网页内容中,那么这个关键词的权重就会很高。SEO常用的就是关键词的密度,但是没有统一的衡量标准。不要用2%~8%作为关键词的密度标准。
3.概率模型
最成功的概率模型是 BM25 模型,目前被大多数商业搜索引擎用作相关性排名模型。在TF-IDF算法的基础上,扩展了相关的概率后续词,比如搜索词SEO,大部分可能搜索SEO培训、SEO服务等。从海量大数据中推导出后续需求,多维度满足用户需求。目前百度官方参考的是百度指数的相关需求图。一些后续词是根据他们的,但仅供参考;不限于百度下拉框等后续查询词和相关搜索。
网页是指整体,网页可以分为不同的区域。比如网页标题、描述、网页内容、网页底部的标题等,不同的区域有不同的权重。经常说的网页标题必须具有很高的权重。标题很大程度上收录了相关的关键词。说明网页内容的中心思想。我对搜索引擎判断网页和查询的相关性有一个基本的了解,所以不用去堆砌关键词,琢磨关键词的密度。
(责任编辑:搜索引擎网站优化SEO外包-,原创不容易,转载时必须以链接的形式注明作者、原出处和本声明。) 查看全部
搜索引擎主题模型优化(如何判断网页和查询的相关性?布尔模型简单)
搜索引擎的质量很大程度上取决于搜索结果的网页内容和用户体验。搜索引擎在搜索能够满足用户需求的网页时,主要考虑两个方面:网页与查询的相关性和网页的重要性。网页与查询的相关性是指用户的搜索查询与网页内容之间的内容相似度得分,通常通过链接分析计算方法来评估网页的重要性;这篇文章主要简单描述了搜索引擎如何判断网页和查询的相关性?
判断网页内容是否与用户查询关键词相关,取决于搜索引擎采用的检索模型。几种常用的检索模型:布尔模型、向量空间模型、概率模型、语言模型和机器学习排序算法。
1.布尔模型
简单来说,布尔模型就是用户查询的词是否出现在网页中,对与错,收录在不收录。比如用户搜索关键词是SEO,希望得到与SEO相关的信息,那么当网页内容中出现SEO这个词时,就说明该网页与用户的查询相关。布尔模型也是检索模型中最简单的一种,其优缺点也非常直观。
2.矢量空间模型
向量空间模型将查询词和文档中的关键词转换为特征向量,然后利用余弦公式计算文档与查询的相似度并对输出结果进行排序。其中主要介绍了TF-IDF算法、TF词频和IDF逆文档频率。
TF词频,即一个词在内容中出现的次数。出现次数较多的词往往可以说明内容的主题信息。IDF逆文档频率是衡量单词普遍重要性的指标,突出特征词。如果某个关键词在网页内容中的词频很高,而这个词很少出现在网页搜索结果和其他网页内容中,那么这个关键词的权重就会很高。SEO常用的就是关键词的密度,但是没有统一的衡量标准。不要用2%~8%作为关键词的密度标准。
3.概率模型
最成功的概率模型是 BM25 模型,目前被大多数商业搜索引擎用作相关性排名模型。在TF-IDF算法的基础上,扩展了相关的概率后续词,比如搜索词SEO,大部分可能搜索SEO培训、SEO服务等。从海量大数据中推导出后续需求,多维度满足用户需求。目前百度官方参考的是百度指数的相关需求图。一些后续词是根据他们的,但仅供参考;不限于百度下拉框等后续查询词和相关搜索。
网页是指整体,网页可以分为不同的区域。比如网页标题、描述、网页内容、网页底部的标题等,不同的区域有不同的权重。经常说的网页标题必须具有很高的权重。标题很大程度上收录了相关的关键词。说明网页内容的中心思想。我对搜索引擎判断网页和查询的相关性有一个基本的了解,所以不用去堆砌关键词,琢磨关键词的密度。
(责任编辑:搜索引擎网站优化SEO外包-,原创不容易,转载时必须以链接的形式注明作者、原出处和本声明。)
搜索引擎主题模型优化(2019年10月19日,舟山摄影seo整站优化方案厂家报价)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-10 08:24
2019年10月19日,力果科技宣布!舟山摄影seo优化全站厂家报价,力果科技专注网络营销推广,只做一件事:持续为客户创造价值。基于爱站大数据运营,以各行业亿万站点为媒介,通过爱站内部技术和工具,深入研究、分析、验证搜索引擎算法排名调查机制,形成不同行业的SEO优化模型,避开搜索引擎算法黑洞,快速有效提升网站的排名。通过提供针对性的解决方案,覆盖了行业95%以上的用户需求。增加整个站点的权重等级,提升页面搜索引擎整体得分,带来数万个关键词排名提升。《路亚是怎么抓草鱼和鲤鱼的》、《路亚桥口**假饵》、《路亚钓竿什么牌子的好》等这些内容话题定位可以从流量词“路亚”的分支需求中获取流动。纯原创:适合有专业知识编辑的团队。伪原创:采集互联网域名上最好的内容,加上自己的一些观点和润色,形成了一篇新文章文章。比如这里,我就拆分了“路亚的嘴是什么诱饵?”这个话题的监控。将其监控成三个词:路亚、爱丽丝的嘴、假饵,并设置低俗内容收录这三个词。我们制作了源源不断的内容后,别忘了将内容提交到熊掌后台,让百度最快收录你的文章霸占排行榜,熊掌收录速度比被爬虫被动抓取的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!霸占排行榜,和掌上收录的速度比被爬虫被动爬行的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!霸占排行榜,和掌上收录的速度比被爬虫被动爬行的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!这是新时代。操作方式。网站流量托管,为您提供一站式服务!这是新时代。操作方式。网站流量托管,为您提供一站式服务! 查看全部
搜索引擎主题模型优化(2019年10月19日,舟山摄影seo整站优化方案厂家报价)
2019年10月19日,力果科技宣布!舟山摄影seo优化全站厂家报价,力果科技专注网络营销推广,只做一件事:持续为客户创造价值。基于爱站大数据运营,以各行业亿万站点为媒介,通过爱站内部技术和工具,深入研究、分析、验证搜索引擎算法排名调查机制,形成不同行业的SEO优化模型,避开搜索引擎算法黑洞,快速有效提升网站的排名。通过提供针对性的解决方案,覆盖了行业95%以上的用户需求。增加整个站点的权重等级,提升页面搜索引擎整体得分,带来数万个关键词排名提升。《路亚是怎么抓草鱼和鲤鱼的》、《路亚桥口**假饵》、《路亚钓竿什么牌子的好》等这些内容话题定位可以从流量词“路亚”的分支需求中获取流动。纯原创:适合有专业知识编辑的团队。伪原创:采集互联网域名上最好的内容,加上自己的一些观点和润色,形成了一篇新文章文章。比如这里,我就拆分了“路亚的嘴是什么诱饵?”这个话题的监控。将其监控成三个词:路亚、爱丽丝的嘴、假饵,并设置低俗内容收录这三个词。我们制作了源源不断的内容后,别忘了将内容提交到熊掌后台,让百度最快收录你的文章霸占排行榜,熊掌收录速度比被爬虫被动抓取的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!霸占排行榜,和掌上收录的速度比被爬虫被动爬行的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!霸占排行榜,和掌上收录的速度比被爬虫被动爬行的速度要快很多。今天我们重温利用大数据进行交通运营的方法。其实大数据解决的问题是让你准确找到操作的方向,而不是靠直觉。使用准确的数字来指导您的工作。这是新时代。操作方式。网站流量托管,为您提供一站式服务!这是新时代。操作方式。网站流量托管,为您提供一站式服务!这是新时代。操作方式。网站流量托管,为您提供一站式服务!
搜索引擎主题模型优化(基于PageRank算法的搜索引擎优化策略(安徽财经大学信息工程学院蚌埠233041))
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-10 07:08
基于PageRank算法的搜索引擎优化策略(蚌埠233041),安徽财经大学信息工程学院) 重点:分析Google PageRank(PR值)算法的原理,详细讨论主要方面网站链接的变化:站内链接、入站链接、站内链接的变化对网站PR值的影响,提出通过增加入站链接来优化网站链接,减少外链,避免不必要的内链。为了提高PR和提高网站在搜索引擎中的排名,提出了一种优化策略。关键词:PageRank 网页结构挖掘搜索引擎中文图书馆分类号:TP312 文献识别码:A doi:10.3969 j.issn.1005-8095.201< 本文主要讨论算法PR值的搜索引擎优化策略,其实作为最著名的搜索引擎品牌,谷歌的排名结果是非常权威的。经过针对谷歌优化的网站,通常在百度、雅虎等其他搜索引擎中排名第一。
PR值算法分析2.1 PR值的基本思想PR值是根据“很多优质网页链接的网页一定还是优质网页”的回归关系来确定网页的重要性。PR值利用互联网中巨大的链接关系,以网页之间链接的数量和质量作为网页评价的手段。截至2009年10月末,全球互联网网站网站的数量已经突破了信息量的爆发式增长。在让我们掌握更多信息的同时,也对信息检索提出了严峻的考验。搜索是除电子邮件外最常用的网络行为方式。通过搜索引擎查找信息是互联网用户查找在线信息和资源的主要手段。1998年,谷歌公司提出了著名的PR值算法,该算法可以高效地将用户使用搜索引擎的搜索结果按重要性排序。这种算法让用户得到满意的网络,也让谷歌发展成为搜索引擎行业的代表。对于每一个网站,为了赢得大量相似网站的竞争,提高产品或服务的知名度,必须在大型搜索引擎的搜索排名中排名靠前并提高点击率。这也成为每个网站的重要任务。词-搜索引擎优化。搜索引擎优化由此诞生了一个新名称。
下面的调查报告充分说明了搜索引擎优化的重要性: 链接到另一个网页 b 相当于页面优先。搜索引擎营销公司 iCrossing 投票支持页面的重要性。从链接数来看,一个网页的投票越多,反向链接越多,PR值就越高。从链接质量的角度来看,如果一个网页获得了一个相对高质量的网页的链接,这个网页可以获得更高的PR值。该算法有两个基本假设:(1)一个网页被引用的频率越高,这个页面就越重要;当它被一个非常重要的页面引用时,这个页面就越重要(2)假设用户开始随机访问一个页面,然后点击该页面的链接,调查发现:在线购物以前,搜索引擎是最受欢迎的产品和服务搜索工具,74% 的用户搜索产品,而 54% 的用户搜索 网站。二、中国搜索引擎市场研究年度报告指出,截至2007年底,市场规模已达29.3亿元,同比增长76.5% . 2008年中国搜索引擎市场规模达到51.5元,较2007年同期增长77.1% 谷歌、百度、雅虎市场份额增至96.4%,中国搜索引擎市场集中度进一步提高。正是由于搜索引擎行业的高速发展。稿件日期:2010-05-05 作者简介:黄志东(1983—),男,2008级硕士研究生,研究方向为信息系统;袁巧云(1976—),女,博士,副教授,硕士生导师,研究方向为知识管理、信息系统等。
如何提高网页反向链接的数量和质量是提高页面PR值的关键。基于PR值算法的搜索引擎优化策略是从链接的角度优化搜索引擎。网站链接分为三种类型:入站链接、出站链接和站内链接。3.1 Inbound link pair 从公式可以看出PR值和搜索引擎优化策略的影响(1),Inbound Links的增加会增加vi的数量,PR值( vi)/N(vi)会增加,任何入站连接viB(u)的增加都会直接导致链接网站的PR值增加。另外,如果入站连接的PR值是更大,也就是外部入站页面的质量越高,那么链接的网站 PR 将被接受的值越大。PR(P)=PR(Q1)/2 +PR(Q2) +PR(Q3)/2+PR(T),对于已知的PR(P)变大,对于(P, Q1, Q2, Q3), 整个(P, Q1, Q2, Q3) set)的PR值会通过迭代过程增加。
但所建立的链接不会在今天或明天建立。这样的链接也是徒劳的。(5)提交到大分类目录网站,比如把网页提交到全球最大的分类目录dmoz。
3.2 出站链接对PR值和搜索引擎优化策略的影响。PR值算法基于整个Web的拓扑结构。网站链接会造成网站 PR值的消耗。用一张图来说明出站链PR值的影响。例子中我们假设Q1在任意一个网站上添加一个出站链接,如图,PR值变为PR(P)=PR(Q1) /3+PR(Q< @2) ij,得到移行列列的矩阵(2)为每个网页设置一个初始PR值,一般设置初始PR值作为初始PR(3)进行迭代计算,设置阻尼系数d=0.85,第一次迭代如下: =0.15+0.85m1j PR(n) 0.85m2j PR(n ) = < @0.15+0.85mnj PR(n) =0.15+0.85m1j PR(n) 0.85m2j PR(n) 迭代计算 最后PR (n) 得到每个网页的收敛性。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。@0.85m1j PR(n) 0.85m2j PR(n) 迭代计算最终得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。@0.85m1j PR(n) 0.85m2j PR(n) 迭代计算最终得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的互连。目前常用的搜索引擎优化方法4.@>1 关键词优化 关键词密度是决定网页顺序的一个因素。所谓关键词密度,是指去除了HTML代码的页面中关键词和内容的百分比。流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的互连。目前常用的搜索引擎优化方法4.@>1 关键词优化 关键词密度是决定网页顺序的一个因素。所谓关键词密度,是指去除了HTML代码的页面中关键词和内容的百分比。
每个搜索引擎都有自己的搜索结果排名公式,并严格保密。但基本规律是某个关键词在网页上的密度越高(观察研究表明,大多数搜索引擎的关键词密度在2%到8%是比较合适的范围,有利于网站@ > 在搜索引擎中的排名),则该网页与该关键字的相关度更高,该网页在搜索结果中的排名位置更高。4.@>2 URL Optimized URL是Uniform Resource Locator,是全球www系统服务器资源的标准寻址定位代码,用于确定所需文档在Internet上的位置。URL由三部分组成:网络传输协议、主机号(域名)、主机上文档的路径,以及文件名(子页面名)。因为在URL中收录关键字确实对排名有帮助,所以URL的优化涉及到两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。URL的优化涉及两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。URL的优化涉及两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。
这些标签在不时刷新标签时尤为重要。4.@>4 链接流行度优化网站的链接流行度是指通过网站链接分析得到的权重。对于优化程度相同且内容吸引力相同的两个站点,链接流行度(LP)较高的站点应在搜索引擎排名中占据优势。所谓链接分析,是指对链接的数量和质量进行评价和分析。一段时间以来,一些搜索引擎不再考虑免费站点的外部链接,因此在优化链接流行度时,不仅要考虑到站点的链接数量,还要考虑站点的链接质量。结论 以上我们通过对PR值算法的思想和原理的分析,得到了一些对搜索引擎优化有帮助的搜索引擎优化方法。该方法主要从链接分析的角度进行研究,包括入站链接、出站链接和出站链接。站内链接和站内链接变化对PR值的影响。但是,由于PR值算法本身的不足,如主题漂移、忽略好的Hub页面、对新网页的歧视等,搜索引擎不能单纯依靠PR值算法对网页进行排序。其实谷歌对页面PR值的计算并不是减值。搜索引擎优化有以下两种策略:(1) 不要进行单边前向链接。前向链接会消耗原创网页集合的PR值。为了抵消这种消耗,您需要确保链接是相互的。
相互链接可能会获得或失去 PR 值,因此您在交换链接时需要特别小心。(2)尽量提供一些与网页主题内容相关的行业/专业资源网页的链接,以免泄露主题网页采集的PR值,同时也提高搜索引擎对< @网站 好印象 3.3 网站内链对PR值和搜索引擎优化策略的影响 在网页中循环传播,整个网站的PR值@>等于每个网页的PR值之和。为了说明PR值在网页中的传递,也就是首页,Q1、Q2、Q3是内页。如果页面不是相互排斥的链接和外部链接不被考虑,那么公共 PR(P)=1-d=0.15=PR(Qi)。这时候整个网站的PR值只有0.6 如果加上Q1的连接,那么公式(1)得到PR(Q1)= 0.15+0.85PR(P)=0.2775,整个网站的PR值也从0.6提升到了0.7275. 可以看出在网站的内部页面没有相互链接的情况下添加一个链接可以提高整个网站的PR值当网站的内部链接链接时网站的整个网页,网站的PR值可以最大化。优化网站的时候,我们都希望网站的主页得到更多的关注,参考文章必须保证网站里面的每一个网页
最小化书目记录的功能需求。研究论文的定量分析。肇庆52606,广东肇庆大学图书馆。对时间分布、期刊分布、作者分布、主题分布、关键词频率分布、经费状况进行统计分析,揭示书目记录功能需求的研究特征,分析其未来的研究发展趋势。关键词:书目记录功能需求FRBR研究论文计量分析doi:10.3969 j.issn.1005-8095.2011.01. 012中国图书馆分类号:G254.@>3 文献识别码:研究对象与研究方法 1990年,国际图书馆协会联合会(IFLA)成立了一个专门研究书目记录功能需求的小组,并于1998年发表了最终的新书目模型-FRBR(Functional Requirements BibliographicRecords,书目记录的功能要求),旨在提供一个明确定义结构化框架,使数据记录在与记录用户需求相关的书目记录中,并推荐国家书目机构创建的记录的基本功能级别。本文以FRBR为研究对象,通过“中文期刊全文数据库”进行检索。进入“FRBR”或“标题中的参考书目”已经几年没有引起图书馆和情报界的关注。,
表明人们对FRBR的关注和研究正在逐步深入。2 2 2 2 2 2 年发表论文总数(篇) 1111 12 13 57 百分比(%)1.75 7.028.77 19.@ >30 1 9.30 21.05 22.81 100.00 2.2 期刊分布 FRBR论文在各期刊中的分布。在24种期刊上共发表论文57篇。其中,刊物种类占期刊总数的25%。该期刊共收录32篇论文,占论文总数的56.14%。色散定律。按照布拉德福德的分区法,所有这些期刊都按照文章数量分为三个区域。三个区域的文章比例分别为56.14%、21.05%、22.81%,符合Bradford分散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。21.05%, 22.81%,符合布拉德福德色散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。21.05%, 22.81%,符合布拉德福德色散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究的检索期间为2001年至2009年。检索文件57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究的检索期间为2001年至2009年。检索文件57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。表明图书情报学专业期刊有记录FRBR研究 检索时间为2001-2009年,检索到文献57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。表明图书情报学专业期刊有记录FRBR研究 检索时间为2001-2009年,检索到文献57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。
统计结果与分析 2.1 发表时间及数量分布 对论文发表时间进行统计分析,从时间序列了解研究对象的发展速度和关注度。知道FRBR研究论文是2001年第一次发表,后来往往比较复杂,考虑的变量比较多,比如栏目结构、格式、域名、URL级别、学术价值、页面布局、内容主题相关性、网页标题、网页关键词和摘要标签、网页更新频率、是否存在搜索引擎优化作弊等一系列问题,所以搜索引擎优化的过程中伴随着大量的优化方法和网站结构Web挖掘方法的方法。此外,PR值算法也在不断完善中。国内外一些研究人员提出了一些改进算法,如使用空间向量,考虑网页之间的相关性因素来解决PR值算法中的主题漂移问题;使用分布式PR值算法提高算法性能等。随着算法的改进,搜索引擎优化需要适应这些变化,不断提出新的优化策略和优化方法。参考全球互联网网站数量已超过1亿[EB/OL]。[2010-01-10]。 7077. shtml 网页超链接分析算法研究 HAJIMEBABA.Google secret-PageRank [EB/OL]. [2010-01-03]。/PageRank_cn. htm, 2002 吴涛. 查看全部
搜索引擎主题模型优化(基于PageRank算法的搜索引擎优化策略(安徽财经大学信息工程学院蚌埠233041))
基于PageRank算法的搜索引擎优化策略(蚌埠233041),安徽财经大学信息工程学院) 重点:分析Google PageRank(PR值)算法的原理,详细讨论主要方面网站链接的变化:站内链接、入站链接、站内链接的变化对网站PR值的影响,提出通过增加入站链接来优化网站链接,减少外链,避免不必要的内链。为了提高PR和提高网站在搜索引擎中的排名,提出了一种优化策略。关键词:PageRank 网页结构挖掘搜索引擎中文图书馆分类号:TP312 文献识别码:A doi:10.3969 j.issn.1005-8095.201< 本文主要讨论算法PR值的搜索引擎优化策略,其实作为最著名的搜索引擎品牌,谷歌的排名结果是非常权威的。经过针对谷歌优化的网站,通常在百度、雅虎等其他搜索引擎中排名第一。
PR值算法分析2.1 PR值的基本思想PR值是根据“很多优质网页链接的网页一定还是优质网页”的回归关系来确定网页的重要性。PR值利用互联网中巨大的链接关系,以网页之间链接的数量和质量作为网页评价的手段。截至2009年10月末,全球互联网网站网站的数量已经突破了信息量的爆发式增长。在让我们掌握更多信息的同时,也对信息检索提出了严峻的考验。搜索是除电子邮件外最常用的网络行为方式。通过搜索引擎查找信息是互联网用户查找在线信息和资源的主要手段。1998年,谷歌公司提出了著名的PR值算法,该算法可以高效地将用户使用搜索引擎的搜索结果按重要性排序。这种算法让用户得到满意的网络,也让谷歌发展成为搜索引擎行业的代表。对于每一个网站,为了赢得大量相似网站的竞争,提高产品或服务的知名度,必须在大型搜索引擎的搜索排名中排名靠前并提高点击率。这也成为每个网站的重要任务。词-搜索引擎优化。搜索引擎优化由此诞生了一个新名称。
下面的调查报告充分说明了搜索引擎优化的重要性: 链接到另一个网页 b 相当于页面优先。搜索引擎营销公司 iCrossing 投票支持页面的重要性。从链接数来看,一个网页的投票越多,反向链接越多,PR值就越高。从链接质量的角度来看,如果一个网页获得了一个相对高质量的网页的链接,这个网页可以获得更高的PR值。该算法有两个基本假设:(1)一个网页被引用的频率越高,这个页面就越重要;当它被一个非常重要的页面引用时,这个页面就越重要(2)假设用户开始随机访问一个页面,然后点击该页面的链接,调查发现:在线购物以前,搜索引擎是最受欢迎的产品和服务搜索工具,74% 的用户搜索产品,而 54% 的用户搜索 网站。二、中国搜索引擎市场研究年度报告指出,截至2007年底,市场规模已达29.3亿元,同比增长76.5% . 2008年中国搜索引擎市场规模达到51.5元,较2007年同期增长77.1% 谷歌、百度、雅虎市场份额增至96.4%,中国搜索引擎市场集中度进一步提高。正是由于搜索引擎行业的高速发展。稿件日期:2010-05-05 作者简介:黄志东(1983—),男,2008级硕士研究生,研究方向为信息系统;袁巧云(1976—),女,博士,副教授,硕士生导师,研究方向为知识管理、信息系统等。
如何提高网页反向链接的数量和质量是提高页面PR值的关键。基于PR值算法的搜索引擎优化策略是从链接的角度优化搜索引擎。网站链接分为三种类型:入站链接、出站链接和站内链接。3.1 Inbound link pair 从公式可以看出PR值和搜索引擎优化策略的影响(1),Inbound Links的增加会增加vi的数量,PR值( vi)/N(vi)会增加,任何入站连接viB(u)的增加都会直接导致链接网站的PR值增加。另外,如果入站连接的PR值是更大,也就是外部入站页面的质量越高,那么链接的网站 PR 将被接受的值越大。PR(P)=PR(Q1)/2 +PR(Q2) +PR(Q3)/2+PR(T),对于已知的PR(P)变大,对于(P, Q1, Q2, Q3), 整个(P, Q1, Q2, Q3) set)的PR值会通过迭代过程增加。
但所建立的链接不会在今天或明天建立。这样的链接也是徒劳的。(5)提交到大分类目录网站,比如把网页提交到全球最大的分类目录dmoz。
3.2 出站链接对PR值和搜索引擎优化策略的影响。PR值算法基于整个Web的拓扑结构。网站链接会造成网站 PR值的消耗。用一张图来说明出站链PR值的影响。例子中我们假设Q1在任意一个网站上添加一个出站链接,如图,PR值变为PR(P)=PR(Q1) /3+PR(Q< @2) ij,得到移行列列的矩阵(2)为每个网页设置一个初始PR值,一般设置初始PR值作为初始PR(3)进行迭代计算,设置阻尼系数d=0.85,第一次迭代如下: =0.15+0.85m1j PR(n) 0.85m2j PR(n ) = < @0.15+0.85mnj PR(n) =0.15+0.85m1j PR(n) 0.85m2j PR(n) 迭代计算 最后PR (n) 得到每个网页的收敛性。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。@0.85m1j PR(n) 0.85m2j PR(n) 迭代计算最终得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。@0.85m1j PR(n) 0.85m2j PR(n) 迭代计算最终得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。得到每个网页收敛的PR(n)。(4)比较每个网页的PR值,PR值越大+PR(Q3)/2,PR值越小,这样的后果就是导致(P,Q1,Q2, Q3)流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的相互关联。目前常用的搜索引擎优化方法4.@ >1 关键字优化Keyword密度是决定网页顺序的一个因素,所谓关键字密度是指去掉HTML代码的页面中关键字和内容的百分比。流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的互连。目前常用的搜索引擎优化方法4.@>1 关键词优化 关键词密度是决定网页顺序的一个因素。所谓关键词密度,是指去除了HTML代码的页面中关键词和内容的百分比。流出,最后通过遍历网页集合的每一个PR来减少网页中其他页面的互连。目前常用的搜索引擎优化方法4.@>1 关键词优化 关键词密度是决定网页顺序的一个因素。所谓关键词密度,是指去除了HTML代码的页面中关键词和内容的百分比。
每个搜索引擎都有自己的搜索结果排名公式,并严格保密。但基本规律是某个关键词在网页上的密度越高(观察研究表明,大多数搜索引擎的关键词密度在2%到8%是比较合适的范围,有利于网站@ > 在搜索引擎中的排名),则该网页与该关键字的相关度更高,该网页在搜索结果中的排名位置更高。4.@>2 URL Optimized URL是Uniform Resource Locator,是全球www系统服务器资源的标准寻址定位代码,用于确定所需文档在Internet上的位置。URL由三部分组成:网络传输协议、主机号(域名)、主机上文档的路径,以及文件名(子页面名)。因为在URL中收录关键字确实对排名有帮助,所以URL的优化涉及到两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。URL的优化涉及两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。URL的优化涉及两个方面:域名中关键字的使用和子页面名称中关键字的使用。4.@>3 META标签优化 META是嵌入在网页中的一种特殊的HTML标签,其中收录了一些关于网页的隐藏信息。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。META标签的作用是向搜索引擎解释网页是关于什么信息的。META标签有多种,但重要的是:Title标签(严格来说,Title不是标签)、Description标签、Key-words标签。
这些标签在不时刷新标签时尤为重要。4.@>4 链接流行度优化网站的链接流行度是指通过网站链接分析得到的权重。对于优化程度相同且内容吸引力相同的两个站点,链接流行度(LP)较高的站点应在搜索引擎排名中占据优势。所谓链接分析,是指对链接的数量和质量进行评价和分析。一段时间以来,一些搜索引擎不再考虑免费站点的外部链接,因此在优化链接流行度时,不仅要考虑到站点的链接数量,还要考虑站点的链接质量。结论 以上我们通过对PR值算法的思想和原理的分析,得到了一些对搜索引擎优化有帮助的搜索引擎优化方法。该方法主要从链接分析的角度进行研究,包括入站链接、出站链接和出站链接。站内链接和站内链接变化对PR值的影响。但是,由于PR值算法本身的不足,如主题漂移、忽略好的Hub页面、对新网页的歧视等,搜索引擎不能单纯依靠PR值算法对网页进行排序。其实谷歌对页面PR值的计算并不是减值。搜索引擎优化有以下两种策略:(1) 不要进行单边前向链接。前向链接会消耗原创网页集合的PR值。为了抵消这种消耗,您需要确保链接是相互的。
相互链接可能会获得或失去 PR 值,因此您在交换链接时需要特别小心。(2)尽量提供一些与网页主题内容相关的行业/专业资源网页的链接,以免泄露主题网页采集的PR值,同时也提高搜索引擎对< @网站 好印象 3.3 网站内链对PR值和搜索引擎优化策略的影响 在网页中循环传播,整个网站的PR值@>等于每个网页的PR值之和。为了说明PR值在网页中的传递,也就是首页,Q1、Q2、Q3是内页。如果页面不是相互排斥的链接和外部链接不被考虑,那么公共 PR(P)=1-d=0.15=PR(Qi)。这时候整个网站的PR值只有0.6 如果加上Q1的连接,那么公式(1)得到PR(Q1)= 0.15+0.85PR(P)=0.2775,整个网站的PR值也从0.6提升到了0.7275. 可以看出在网站的内部页面没有相互链接的情况下添加一个链接可以提高整个网站的PR值当网站的内部链接链接时网站的整个网页,网站的PR值可以最大化。优化网站的时候,我们都希望网站的主页得到更多的关注,参考文章必须保证网站里面的每一个网页
最小化书目记录的功能需求。研究论文的定量分析。肇庆52606,广东肇庆大学图书馆。对时间分布、期刊分布、作者分布、主题分布、关键词频率分布、经费状况进行统计分析,揭示书目记录功能需求的研究特征,分析其未来的研究发展趋势。关键词:书目记录功能需求FRBR研究论文计量分析doi:10.3969 j.issn.1005-8095.2011.01. 012中国图书馆分类号:G254.@>3 文献识别码:研究对象与研究方法 1990年,国际图书馆协会联合会(IFLA)成立了一个专门研究书目记录功能需求的小组,并于1998年发表了最终的新书目模型-FRBR(Functional Requirements BibliographicRecords,书目记录的功能要求),旨在提供一个明确定义结构化框架,使数据记录在与记录用户需求相关的书目记录中,并推荐国家书目机构创建的记录的基本功能级别。本文以FRBR为研究对象,通过“中文期刊全文数据库”进行检索。进入“FRBR”或“标题中的参考书目”已经几年没有引起图书馆和情报界的关注。,
表明人们对FRBR的关注和研究正在逐步深入。2 2 2 2 2 2 年发表论文总数(篇) 1111 12 13 57 百分比(%)1.75 7.028.77 19.@ >30 1 9.30 21.05 22.81 100.00 2.2 期刊分布 FRBR论文在各期刊中的分布。在24种期刊上共发表论文57篇。其中,刊物种类占期刊总数的25%。该期刊共收录32篇论文,占论文总数的56.14%。色散定律。按照布拉德福德的分区法,所有这些期刊都按照文章数量分为三个区域。三个区域的文章比例分别为56.14%、21.05%、22.81%,符合Bradford分散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。21.05%, 22.81%,符合布拉德福德色散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。21.05%, 22.81%,符合布拉德福德色散定律。其中,图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究 检索时间为2001年至2009年,检索57号文件。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究的检索期间为2001年至2009年。检索文件57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。图书情报核心期刊和一般图书情报期刊,这两类期刊占发表文章总数的92.98%,说明图书情报学专业期刊有记录FRBR研究的检索期间为2001年至2009年。检索文件57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。表明图书情报学专业期刊有记录FRBR研究 检索时间为2001-2009年,检索到文献57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。表明图书情报学专业期刊有记录FRBR研究 检索时间为2001-2009年,检索到文献57。从科学量化的角度对这些文献的发表时间、期刊、作者、主题、关键词频次和资助状况进行分析分析。研究FRBR文献信息的规律,探索FRBR研究的发展趋势。
统计结果与分析 2.1 发表时间及数量分布 对论文发表时间进行统计分析,从时间序列了解研究对象的发展速度和关注度。知道FRBR研究论文是2001年第一次发表,后来往往比较复杂,考虑的变量比较多,比如栏目结构、格式、域名、URL级别、学术价值、页面布局、内容主题相关性、网页标题、网页关键词和摘要标签、网页更新频率、是否存在搜索引擎优化作弊等一系列问题,所以搜索引擎优化的过程中伴随着大量的优化方法和网站结构Web挖掘方法的方法。此外,PR值算法也在不断完善中。国内外一些研究人员提出了一些改进算法,如使用空间向量,考虑网页之间的相关性因素来解决PR值算法中的主题漂移问题;使用分布式PR值算法提高算法性能等。随着算法的改进,搜索引擎优化需要适应这些变化,不断提出新的优化策略和优化方法。参考全球互联网网站数量已超过1亿[EB/OL]。[2010-01-10]。 7077. shtml 网页超链接分析算法研究 HAJIMEBABA.Google secret-PageRank [EB/OL]. [2010-01-03]。/PageRank_cn. htm, 2002 吴涛.
搜索引擎主题模型优化(近段时间在研究搜索的相关技术涉及到资讯搜索功能的实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-12-10 04:00
大纲
最近在研究搜索的相关技术,工作主要涉及信息搜索功能的实现。我们采用了elasticsearch搜索引擎,整理了两篇关于elasticsearch的文章:文章:es基础和es进阶 1.由于搜索功能需要迭代,作者继续研究搜索原理和性能深度优化。本文主要研究以下几点:
什么是搜索
搜索引擎的技术建设主要包括三个部分:
(1) 对查询的理解
(2) 对内容(文档)的理解
(3)查询和内容(文档)的匹配排序
图片
搜索通用评价指标基本指标:
召回率(Recall)=检测到的相关文档数/相关文档数,也叫召回率,R∈[0,1]
Precision=检测到的相关文档数/检测到的文档数,也称为准确率,P∈[0,1]
F值:召回率R和正确率P的调和平均值
搜索发展阶段:
什么是意图识别
使用分类方法将我们常说的句子或查询分类成对应的意图类型
属于“理解查询”部分
本质上是一个分类问题
意图识别搜索的一般流程:
S1. 用户的原创查询是“michal jrdan”
S2. Query Correction 模块进行拼写错误纠正的结果是:“Michael Jordan”
S3. Query Suggestion 模块的下拉提示结果为:“Michael Jordan berkley”和“Michael Jordan NBA”,假设用户选择“Michael Jordan berkley”
S4. Query Expansion 模型查询扩展后,结果为:“迈克尔乔丹伯克利”和“迈克尔I.乔丹伯克利”
S5. Query Classification 模块进行查询分类的结果为:academic
S6. 最后,Semantic Tagging模块进行命名实体识别和属性识别的结果是:[Michael Jordan:人名][berkley:location]:academic
意图识别的前提
意图划分问题:技能/领域
用户需求分类:
(1) 导航
(2) 信息
(3) 交易
概念介绍:
用户与搜索引擎之间完整的交互过程称为搜索会话。Session中提供的信息包括:用户查询(Query),用户点击的搜索结果的标题(Title),如果用户在会话期间改变了查询词(例如来自Query1 -->Query2),后续的搜索和点击都会被记录下来,直到用户离开搜索,会话结束。
意图识别方法
1.词汇穷举法/规则分析法
2. 基于查询的点击日志 - 一般搜索日志记录会在结果中收录时间-查询字符串-点击URL记录-位置等信息。
3.机器学习方法(基于规则挖掘,基于Bayes、LR、SVM等传统分类模型)-分类问题
查询分类
eg:识别每个实体词的属性,去索引精确匹配对应的字段,从而提高recall的准确率
4.基于神经网络(深度学习)--FastText
意图识别难点
1、 输入不规范。上一篇说过,不同的用户对同一个请求有不同的表达。
2、多用意,查询词是:“水”,是矿泉水,还是女生用的乳液。
3、数据冷启动。当用户行为数据较少时,很难获得准确的意图。
4、 没有固定的评价标准。pv、ipv、ctr、cvr等量化指标是对搜索系统的整体评价。对于用户意图的预测,目前还没有标准的量化指标。
查询重写
查询重写、类别关联、命名实体识别和
查询重写包括:
查询纠错 - 如果搜索引擎返回空结果/或结果太少,此时应添加拼写错误纠正处理
查询扩展:
例如。“迈克尔·乔丹·伯克利”和“迈克尔·I·乔丹·伯克利”
(1) 同义词扩展表
(2) 使用词向量进行同义词扩展
(3) 如果查询没有相应返回,将根据用户历史数据扩展原查询
查询删除 - 确定要丢弃的单词/单词(实体识别)
参考
搜索意图识别分析
信息检索中的各种评价指标
如何使用桨叶进行意图识别打开
将中文自然语言转化为结构化数据 查看全部
搜索引擎主题模型优化(近段时间在研究搜索的相关技术涉及到资讯搜索功能的实现)
大纲
最近在研究搜索的相关技术,工作主要涉及信息搜索功能的实现。我们采用了elasticsearch搜索引擎,整理了两篇关于elasticsearch的文章:文章:es基础和es进阶 1.由于搜索功能需要迭代,作者继续研究搜索原理和性能深度优化。本文主要研究以下几点:
什么是搜索
搜索引擎的技术建设主要包括三个部分:
(1) 对查询的理解
(2) 对内容(文档)的理解
(3)查询和内容(文档)的匹配排序
图片
搜索通用评价指标基本指标:
召回率(Recall)=检测到的相关文档数/相关文档数,也叫召回率,R∈[0,1]
Precision=检测到的相关文档数/检测到的文档数,也称为准确率,P∈[0,1]
F值:召回率R和正确率P的调和平均值
搜索发展阶段:
什么是意图识别
使用分类方法将我们常说的句子或查询分类成对应的意图类型
属于“理解查询”部分
本质上是一个分类问题
意图识别搜索的一般流程:
S1. 用户的原创查询是“michal jrdan”
S2. Query Correction 模块进行拼写错误纠正的结果是:“Michael Jordan”
S3. Query Suggestion 模块的下拉提示结果为:“Michael Jordan berkley”和“Michael Jordan NBA”,假设用户选择“Michael Jordan berkley”
S4. Query Expansion 模型查询扩展后,结果为:“迈克尔乔丹伯克利”和“迈克尔I.乔丹伯克利”
S5. Query Classification 模块进行查询分类的结果为:academic
S6. 最后,Semantic Tagging模块进行命名实体识别和属性识别的结果是:[Michael Jordan:人名][berkley:location]:academic
意图识别的前提
意图划分问题:技能/领域
用户需求分类:
(1) 导航
(2) 信息
(3) 交易
概念介绍:
用户与搜索引擎之间完整的交互过程称为搜索会话。Session中提供的信息包括:用户查询(Query),用户点击的搜索结果的标题(Title),如果用户在会话期间改变了查询词(例如来自Query1 -->Query2),后续的搜索和点击都会被记录下来,直到用户离开搜索,会话结束。
意图识别方法
1.词汇穷举法/规则分析法
2. 基于查询的点击日志 - 一般搜索日志记录会在结果中收录时间-查询字符串-点击URL记录-位置等信息。
3.机器学习方法(基于规则挖掘,基于Bayes、LR、SVM等传统分类模型)-分类问题
查询分类
eg:识别每个实体词的属性,去索引精确匹配对应的字段,从而提高recall的准确率
4.基于神经网络(深度学习)--FastText
意图识别难点
1、 输入不规范。上一篇说过,不同的用户对同一个请求有不同的表达。
2、多用意,查询词是:“水”,是矿泉水,还是女生用的乳液。
3、数据冷启动。当用户行为数据较少时,很难获得准确的意图。
4、 没有固定的评价标准。pv、ipv、ctr、cvr等量化指标是对搜索系统的整体评价。对于用户意图的预测,目前还没有标准的量化指标。
查询重写
查询重写、类别关联、命名实体识别和
查询重写包括:
查询纠错 - 如果搜索引擎返回空结果/或结果太少,此时应添加拼写错误纠正处理
查询扩展:
例如。“迈克尔·乔丹·伯克利”和“迈克尔·I·乔丹·伯克利”
(1) 同义词扩展表
(2) 使用词向量进行同义词扩展
(3) 如果查询没有相应返回,将根据用户历史数据扩展原查询
查询删除 - 确定要丢弃的单词/单词(实体识别)
参考
搜索意图识别分析
信息检索中的各种评价指标
如何使用桨叶进行意图识别打开
将中文自然语言转化为结构化数据

