搜索引擎主题模型优化( 中国论文网关键词用户个性化词典二级向量查询扩展个性化服务(组图))
优采云 发布时间: 2021-12-17 09:41搜索引擎主题模型优化(
中国论文网关键词用户个性化词典二级向量查询扩展个性化服务(组图))
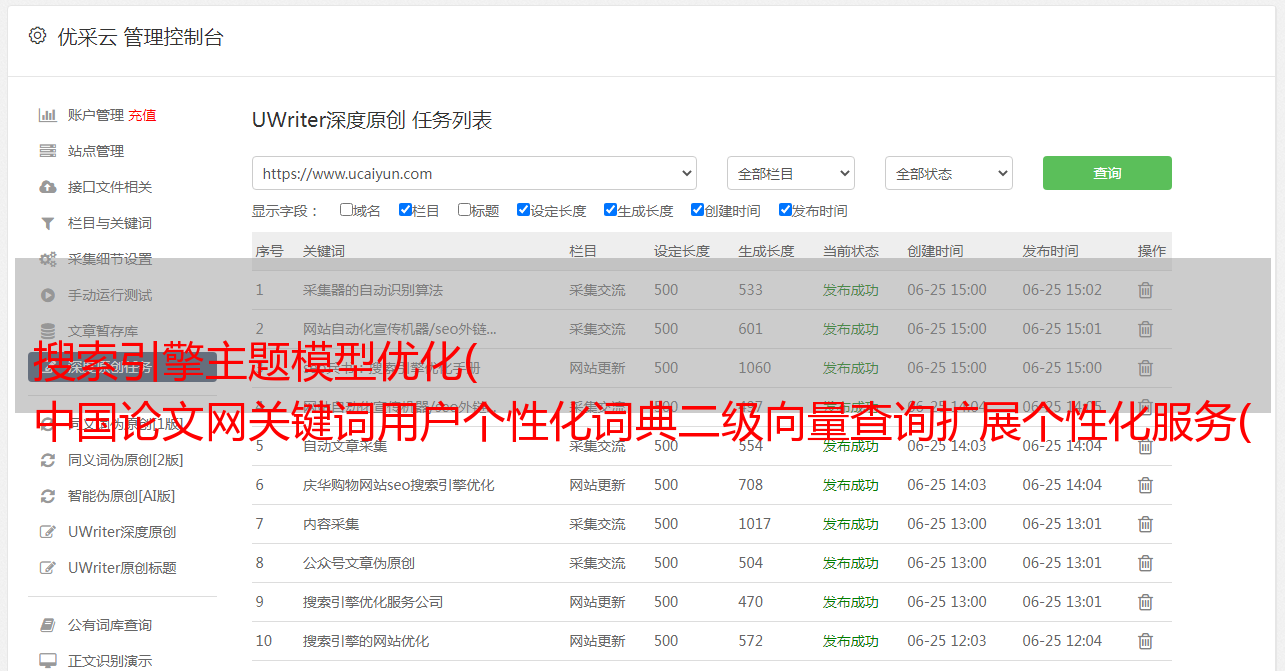
基于个性化词典的搜索引擎查询扩展模型总结 为了给用户提供个性化的网络信息检索服务,本文对*敏*感*词*现值系数表明该模型可以通过搜索引擎提供给用户。有效可行的个性化服务中国论文网关键词用户个性化词典二次向量查询扩展个性化服务搜索引擎中文图书馆分类号TP391文件标识危险废物标识危险废物标识安全警示牌大全危险废物标识牌管道标识色码A 文章 number 128-6764-07 互联网是人们获取知识和传递信息的桥梁。但是,随着近年来互联网的飞速发展,互联网上的信息量也呈指数级增长。在这种背景下,互联网用户往往无法轻松找到自己需要的信息。搜索引擎的出现在一定程度上解决了我们的信息检索需求。当前搜索引擎的概念已经成为互联网信息检索必不可少的工具,但它一方面存在以下几个局限: 1 庞大的搜索结果集,用户花费大量时间和精力去寻找自己真正感兴趣的信息2 不同用户在不同时间使用同一个查询关键词请求得到的搜索结果几乎相同,用户无法提供个性化服务。3 用户在使用搜索引擎进行搜索时有一定的目的,但往往由于用户对相关领域知识的缺乏以及搜索引擎查询界面的限制,导致用户无法清晰表达自己的信息需求[2] 针对传统搜索引擎无法提供给用户的缺陷面向个性化服务,大量专家学者开始研究查询扩展技术并在该领域取得突破。文献 [1] 根据文献分析 提出了局部共现的思想,SEPMBDVDSearchEnginePersonalizationModelBasedonDoubleVectorDescription。其本质也是利用挖掘用户浏览过的历史网页和用户输入产生的用户兴趣模型。通过扩展词添加查询关键词匹配扩展词,使用户在使用搜索引擎检索结果时,可以得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。查询扩展模型依赖于用户兴趣模型。文献[7]使用了一个两级向量模型,通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于用户浏览过的历史网页的全局字典。描述性聚类挖掘后生成的整个模型结构如图1所示。 全局字典太大,因为词汇量太复杂,无法反映用户兴趣等,会对用户兴趣模型的生成产生较大的影响,影响词的扩展。因此,本文使用个性化词典代替全局词典,使用searchVectors和扩展词向量描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后生成的整个模型结构如图1所示,全局字典太大,无法反映词汇量。用户的兴趣等原因会对用户兴趣模型的生成产生较大的影响,从而影响词扩展的效果。因此,本文使用个性化词典代替全局词典,使用searchVectors和扩展词向量描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后生成的整个模型结构如图1所示,全局字典太大,无法反映词汇量。用户的兴趣等原因会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。所以,本文使用个性化词典替代全局词典,并使用搜索匹配的扩展词通过扩展词添加,使用户在使用搜索引擎搜索时能够得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。此查询扩展模型取决于用户。兴趣模型文献[7]使用了一个两级向量模型,它通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。经过聚类和挖掘后生成的整个模型结构如图1所示。全局词典过大因为词汇量过大、词汇量太复杂无法体现用户兴趣等,会对用户兴趣模型的生成产生较大影响,进而影响词扩展的效果。因此,本文使用个性替换全局词典,通过扩展词添加匹配的扩展词,使用户在使用搜索引擎搜索时能够得到符合用户兴趣或兴趣偏好的结果。实验验证了该模型具有精度高、响应速度快的优点。此查询扩展模型取决于用户。兴趣模型文献[7]使用了一个两级向量模型,它通过一组关键词向量和扩展词向量来描述用户兴趣。该模型基于一个全局字典来描述用户浏览过的历史网页。聚类挖掘后整个生成的模型结构如图1所示。全局字典太大,因为词汇量太大,词汇量太复杂,无法体现用户兴趣等,会对生成产生较大的影响用户兴趣模型,这会影响词扩展的效果。因此,本文使用个性替换全局字典 会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。因此,本文使用个性替换全局字典 会对用户兴趣模型的生成产生较大的影响,进而影响词扩展的效果。因此,本文使用个性替换全局字典
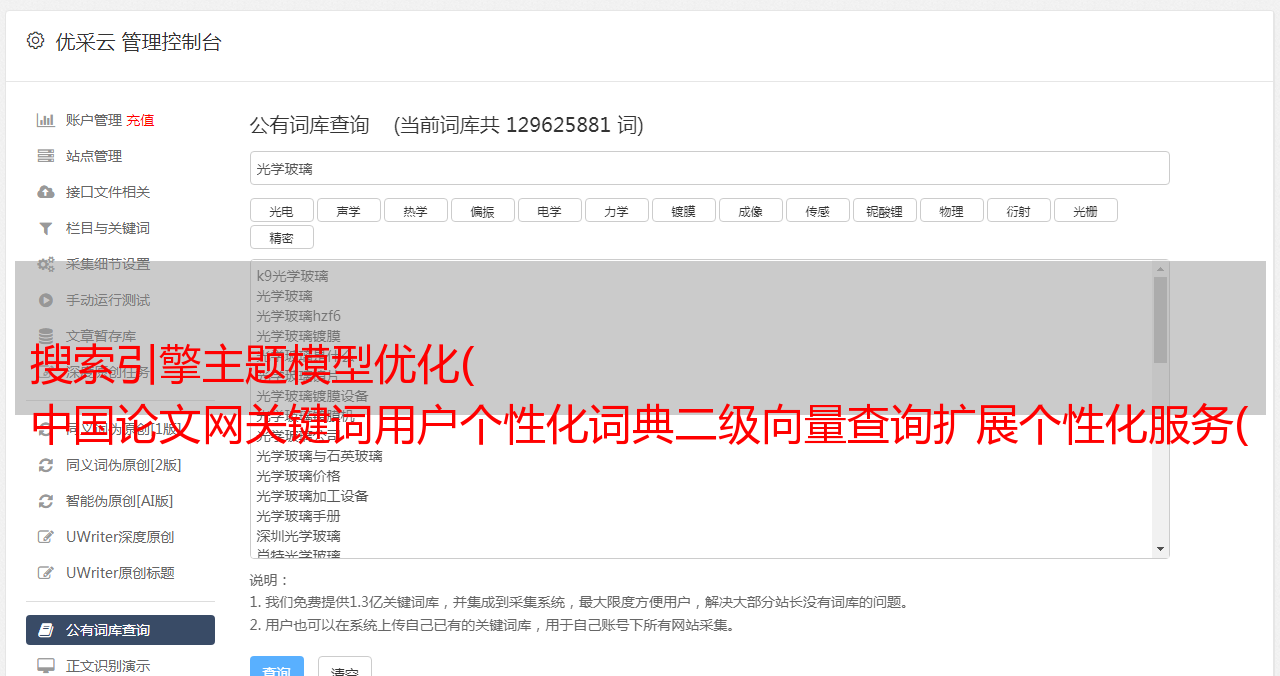
查询扩展策略,实现个性化服务。设计基于个性化词典 QEMBUPDSEQueryExpansionModelBasedonUserPersonalizationDictionaryforSearchEngine 的搜索引擎查询扩展模型。该模型可以通过个性化词典优化用户兴趣模型,优化查询扩展词,使用户的个性化搜索更快更准确 1 基于个性化词典的搜索引擎查询扩展模型。基于个性化词典的搜索引擎查询扩展模型从用户浏览历史的描述入手。然后数据挖掘方法使用二级向量描述来更直接地生成用户兴趣的二级向量模型。最后根据用户输入关键词进行查询扩展,如图2所示。21 个性化词典定义与实现 [10] 个性化词典UPDUserPersonalizationDictionary 包括两个层次:关键词词典KeyDict和扩展词词典ExDict。二级词典中的词定义为关键词和扩展词。每层词典收录nn个词和词权重组成的二元组,人为设置关键词通常意味着用户浏览兴趣词的权重越大,在用户兴趣中的重要性越大,扩展词用于描述用户的兴趣点为了在查询扩展时提供符合用户偏好的扩展搜索词,特定用户的UPD可以充分表达用户对信息需求的偏好,同时为基于二次向量的用户兴趣模型提供支持,是一种用户兴趣。词典设计中的私人词典主要考虑以下几个主要原则: 1 一个词在网络文档集合中出现的频率越高,对这个词的用户特征的描述就越强 2 收录该词的网页数量越多web文档集合词对越多对用户特征的描述能力越强 3对于网页中一些常用的没有搜索价值的词,我们称之为网页常用词,比如comment copyright文章字典中,应该过滤掉,以免给用户的个人描述带来干扰。公式中*敏*感*词*号码提取年龄公式电容电压公式电容公式定积分推导公式力学公式1 S是网页集合T是词空间WtS是词t在S中的权重,tftS是词频S中的词t,N为S中收录的网页总数,nt为S中的文档数,分母为归一化因子。在TF-IDF公式中,Nnt001为IDF因子,即逆向文本频率索引在WTUPD中仍沿用此名称。IDF因子越大,词在网页集合中的分布越稀疏,词的重要性越小,权重越小。反之,词的IDF因子越小,说明它在网页集合中越小。分布越密集,单词的重要性越统一,权重就越大。考虑到词在网页集合中的均匀分布不同,本文认为词t在整个网页集合S中的权重与其在网页中的均匀度成正比,因此本文引入了一个因素测量一致性以修改单词 t 的权重。公式1中t这个词的均匀度是通过网页集合中t的标准差来衡量的。集合S中的权重与网页集合中的词频成正比,与其在网页集中分布的稀疏性和均匀性成正比。通过 WTUPD 公式,
超过5个核心兴趣点的用户选择前12个词作为关键词,其余为扩展词,形成关键词词典和扩展词词典。最后,必须清除关键词 字典和扩展时间。字典中的频繁词的特点是它们分布在网页集合中的大多数文档中,并且在单个网页中出现的频率往往低于1-2次。本文使用以下方法过滤这部分词,经过上述公式处理,最终可以构建出满足用户兴趣描述要求的个性化词典 22 基于个性化词典的用户兴趣建模 最终的词扩展依赖于准确的用户兴趣模型,而个性化词典的建立将有助于快速准确地建立用户兴趣模型。因此,本文采用的用户兴趣建模方法如下:首先,利用个性化词典将用户浏览的网页转化为特征向量。由于个性化词典收录二级词典,因此生成的网页特征向量为二级向量,如网页的特征向量。表示为 [单反 005327385 摄影 004826857 像素 003272436 市场 002713352 专业 002639451...] [镜头 001135712 显示 001023895 环 向量,然后是扩展词向量,然后使用网页的特征向量进行聚类分析,得到用户感兴趣的子类别。最后,使用各种类型的网页特征向量将兴趣子类别描述为辅助向量,以生成用户兴趣模型。可以看出,个性化词典使得整个用户兴趣建模过程使用了两个高级向量用户兴趣模型的生成更加直接和流畅,并且因为个性化词典避免了大量的词和频繁出现的词与传统全局词典中用户兴趣无关,网页特征描述更加准确,为后续的聚类分析和兴趣模型生成奠定基础。良好的基础广州货架wwwgzrundacomgzh并通过用户兴趣模型提供符合用户兴趣偏好的扩展词,有利于扩展词的分析比较和23种查询扩展策略的实施。分子是向量ci和Qini各分量的乘积,分母是向量模数。本文产品选择与初始查询相似度最高的兴趣点C作为用户的查询意图,为用户提供尽可能多的查询扩展词。如果在关键词向量中找不到用户的查询词,即Qini和关键词向量的相似度为0,那么扩展词向量将被合并到关键词@ > 参与计算的向量。下一个,为了找到与用户查询最相关的扩展词,需要计算词之间的相关性。本文参考LSI模型[7中的方法]将网页文档集合表示为词文档矩阵TD,如表1所示。提交给搜索引擎的初始查询词是Qini National Team World Cup Australia。是Qini匹配的兴趣类别的扩展词向量中的矩阵单元TDij,扩展词中间的矩阵单元TDij是文档Dj中对应词Ti的权重和频率。变换的结果是因为单词和文档的数量非常多,单个文档中出现的单词非常有限,所以TD一般是一个高阶稀疏矩阵,然后用TD构建词间关系矩阵TT,计算词间关联度构建方法如下: 式6 其中TD为TD转置得到的矩阵TT中各单元TTij的值,反映了特定环境下特定用户特定兴趣类别的词 i 和 j 之间的相似度。我们可以看到,每个词与其自身的相似度为1,并且在兴趣类别的任何文档中都没有相似度。
两个现有词的相似度为0,如表2所示,其中x表示词间关系矩阵TT,与初始查询词Qini相似度最大的候选扩展词对应的相关度x表示其他候选扩展词。与Qini的相关性公式8中的参数[δ]表示x和x之间的相对误差阈值。只要某个候选扩展词与Qini的相关性与x的相对误差小于δ,那么候选扩展词就可以最终推荐给用户。在实际应用中,δ通常取值为10,这样可以更好地保留扩展词,减少计算时间。可以根据情况进行设置,让过滤后的词按照相关性的顺序排序,然后推荐给因为过多的扩展词会减少搜索结果,不利于用户获取足够的信息。通常选择3个扩展词比较合适,所以最后可以从排序好的扩展词队列中选择前3个词进行推荐。当然可以根据用户需要设置推荐的扩展词数。3 实验与分析 31 个人能力评价评价 个人工作评价评价指标 工作条件风险评价方法评价反应指标 SWUI 因为用户个性化词典UPD实际上几乎收录了用户的归属感 兴趣词和词的权重计算公式浏览历史网页也反映了用户对这些词的兴趣。因此,本文采用将查询扩展搜索到的网页集合与用户的个性化词典进行对比的方法进行实验。评估本文提出的个性化服务模型的效果。为了将检索到的网页集合与用户个性化词典进行比较 余弦函数值之间的相似度通过相似度反映网页集合与用户兴趣的相关程度,该相似度称为 SWUISimilaritybetweenWebpagesandUserInterests32 实验数据 本实验为基于三个用户根据自己的兴趣浏览网页,然后自己感兴趣 保存网页,然后对三个用户提供的兴趣网页进行兴趣建模,得到用户兴趣模型。表4限制了每个兴趣类别的长度,只使用了关键词的一部分 表示 33 对比实验 本文在谷歌和百度上进行了以下三组实验,在主流搜索引擎上进行: 1None 实验不使用查询扩展,只使用用户查询关键词检索实验2 标准实验使用文献[7]中提出的SEPMBDVD模型进行查询扩展然后在搜索引擎广州货架wwwgzrundacomgzh上搜索基于3UPD的实验使用本文提出的QEMBUPDSE模型进行查询扩展然后在搜索引擎上进行搜索比较实验由三个实现提供用户兴趣模型的用户。每个用户为他的每个兴趣选择合适的一个。关键词 根据以上三组实验的要求,在谷歌和百度上搜索。每组实验都会使用每一种搜索引擎返回的前100个网页进行保存,然后为每个搜索引擎计算每个搜索引擎搜索引擎集合与UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI 然后为每个搜索引擎计算每个搜索引擎搜索引擎集合和UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI 然后为每个搜索引擎计算每个搜索引擎搜索引擎集合和UPD之间的SWUI。最后,根据每个SWUI计算ASWUIICAverageSimilaritybetweenWebpagesandUserInterestineachInterestClass。计算公式如公式9所示。 公式9中,n为某个兴趣类别的测试关键词的次数,所以ASWUIIC表示所有关键词搜索网页的集合之间的SWUI搜索网页集合之间的某个兴趣类别和 UPDSWUI 搜索网页集合和 UPD 之间的 UPDSWUI
最终实验结果如表5所示,以更直观地反映对比效果。本文计算了UPDbased相对于None和Standard的实验结果的百分比增长,如表6所示。从表6可以看出,首先使用QEMBUPDSE模型进行查询扩展后,搜索到的网页显然更相关用户的兴趣比没有查询扩展。其次,与使用SEPMBDVD模型扩展相比,使用QEMBUPDSE模型进行查询扩展后的搜索网页在用户相关性上也有一定的提升。网页更符合用户的兴趣。这主要是因为在用户建模之前使用UPD可以在一定程度上优化整个用户建模过程。最终用户兴趣模型更准确,查询扩展效果更好。4 结论本文基于文献[7]中提出的二次向量对搜索引擎个性化服务模型进行改进,增加用户个性化词典,优化用户兴趣建模过程,提高查询扩展效果。实验表明,个性化词典基于搜索引擎查询扩展模型可以更有效地辅助用户使用搜索引擎搜索他们感兴趣的信息。在接下来的研究中,需要考虑如何更准确地构建个性化词典和用户兴趣模型,提出更好的相似度计算方法。提高整个个性化搜索模型的性能。参考文献 [1] 丁国栋,白硕,王斌,许伟民基于主题的个性化查询扩展模型[J]计算机工程与设计2-4475[7]徐景秋、朱正宇、谭明宏等基于二次向量的搜索引擎个性化服务模型[J]计算机科学2007341189-92[ 8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗应诸正雨研究与实现广州WWW个性化源字典。货架 wwwgzrundacomgzh 谭铭洪和其他搜索引擎的个性化的服务模式基础上的二次载体[J]。计算机科学2007341189-92 [8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗莹朱政宇的研究与实现个性化源广州词典 www. 货架 wwwgzrundacomgzh 谭铭洪和其他搜索引擎的个性化的服务模式基础上的二次载体[J]。计算机科学2007341189-92 [8] ZhengyuZHUYunyanTIANKunfengYUANYongYANGAnImprovedWebDocumentClusteringMethodJournalofComputationalInformationSystems2007331087-1094 [9] KhanMSKhorSEnhancedwebdocumentretrievalusingautomaticqueryexpansion [J] JournaloftheAmericanSocietyforInformationScienceandTechnology200455129-40 [10]罗莹朱政宇的研究与实现个性化源广州词典 www. 货架 wwwgzrundacomgzh

