
抓取jsp网页源代码
抓取jsp网页源代码(选择network,库需要对数据的格式有什么作用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-30 19:09
前期准备工作
本例中用到了python爬虫所需的两个基础库,一个是requests库,一个是BeautifulSoup库。这里假设已经安装了这两个库,如果没有,可以通过pip安装。接下来简单说一下这两个库的功能。requests库的主要功能是通过url获取服务端的前端代码数据。使用这两个库捕获的数据就是服务器前端代码中的数据。BeautifulSoup 库主要用于从爬取的前端代码中提取需要的信息。
数据抓取
这次抓到的数据的url是#hs_a_board
建议使用谷歌或者火狐打开,可以使用快捷键CTRL+U查看服务器的网页源码。在捕获数据之前,您需要对数据的格式有一个大致的了解。首先,要捕获的数据必须在要直接捕获的源代码中找到。我相信有一点基本的html语言可以理解它。需要注意的是,我们在源码中可以看到script标签,因为JavaScript是在网页加载的时候动态加载的,所以我们抓取的源码中也显示的是JavaScript代码,而不是JavaScript加载的数据。所以我们在源码中是看不到股票数据的。所以如果我们直接抓取requests库返回的code数据,是无法抓取股票信息的。
解决方案
一个特殊的方法不是直接从目标网站中抓取数据,而是找到PC发送的请求,改变get方法的参数,在新窗口打开请求的资源。服务器可以通过改变请求参数来返回不同的数据。这种方法需要了解HTTP协议等原理。
具体方法是在需要抓取的数据上右击选择check。Google 和 Firefox 都支持元素检查。然后可以看到本地存在对应的数据。选择network,选择下面的JS,刷新一次就可以看到get方法的请求了。
通过查看get方法获取的返回数据与前端页面的对比,可以发现它们是一致的。您可以直接选择鼠标右键打开一个新的网页。但是,此时只返回了部分数据,而不是全部数据。所有的数据都可以通过修改get方法的参数来获取。这里只修改 np=2 。至于为什么要修改这个参数,这里不再赘述。修改后的请求如下::0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2, f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136, f115,f152&_=55
可以看出数据是结构化的,我们可以直接抓取数据。您可以使用正则表达式来匹配相应的数据。第一次,我们只能捕获股票代码等简单信息。需要使用“+”股票代码来获取详细的交易信息。我们也可以用这两个库来重复这个过程,直接从源码中Grabing就可以了,没必要那么麻烦。直接上下面的代码
import requests
from bs4 import BeautifulSoup
import re
finalCodeList = []
finalDealData = [['股票代码','今开','最高','最低','昨收','成交量','成交额','总市值','流通市值','振幅','换手率','市净率','市盈率',]]
def getHtmlText(url):
head={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0',
'Cookie': 'qgqp_b_id=54fe349b4e3056799d45a271cb903df3; st_si=24637404931419; st_pvi=32580036674154; st_sp=2019-11-12%2016%3A29%3A38; st_inirUrl=; st_sn=1; st_psi=2019111216485270-113200301321-3411409195; st_asi=delete'
}
try:
r = requests.get(url,timeout = 30,headers = head)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def getCodeList(htmltxt):
getSourceStr = str(htmltxt)
pattern = re.compile(r'.f12...\d{6}.')
listcode = pattern.findall(getSourceStr)
for code in listcode:
numPattern = re.compile(r'\d{6}')
finalCodeList.append(numPattern.findall(code)[0])
def getData(CodeList):
total = len(CodeList)
finished = int(0)
for code in CodeList:
finished = finished + 1
finishedco = (finished/total)*100
print("total : {0} finished : {1} completion : {2}%".format(total,finished,finishedco))
dealDataList = []
dataUrl = 'http://info.stcn.com/dc/stock/ ... 39%3B + code
dataHtml = getHtmlText(dataUrl)
soup = BeautifulSoup(dataHtml,"html.parser")
dealDataList.append(code)
for i in range(1,4):
classStr = 'sj_r_'+str(i)
divdata =soup.find_all('div',{'class':classStr})
if len(divdata) == 0:
dealDataList.append('该股票暂时没有交易数据!')
break
dealData = str(divdata[0])
dealPattern = re.compile(r'\d+.\d+[\u4e00-\u9fa5]|\d+.+.%|\d+.\d+')
listdeal = dealPattern.findall(dealData)
for j in range(0,4):
dealDataList.append(listdeal[j])
finalDealData.append(dealDataList)
def savaData(filename,finalData):
file = open(filename,'a+')
for i in range(len(finalData)):
if i == 0:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',',' \t')+'\n'
else:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',','\t')+'\n'
file.write(s)
file.close()
url = ' http://51.push2.eastmoney.com/ ... 2Bt:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1574045112933'
htmltxt = getHtmlText(url)
soup = BeautifulSoup(htmltxt,"html.parser")
getCodeList(soup)
recordfile = 'stockData.txt'
getData(finalCodeList)
savaData(recordfile,finalDealData)
至于头部信息,可以通过上述检查元素的方法获得。
我将获取的股票信息存储在一个txt文件中,并相应地调整了格式以便于查看。最终结果如下(上次抓取的数据信息)
概括
刚开始爬的时候,因为参考了书中的例子,一开始不知道这个话题要爬的网页是用JavaScript写的。抓取静态网页的一般方法是不抓取。的。我尝试了很多方法。一开始还以为是没有加Headers参数,但是加了之后还是不行。最后在网上查资料的时候,发现了一篇关于反爬虫文章的文章,里面解释了用JavaScript编写的URL是无法捕获的,并引用了两个对应的解决方案。一是使用dryscape库进行爬取,二是使用selenium库进行爬取。我先尝试了第一种方法,但是因为dryscape库不再维护,安装库时失败,所以我尝试了第二种方法,使用selenium库进行爬取。这种方法确实可以抓取到数据,但前提是只能用浏览器打开页面后才能抓取到。考虑到要爬取的页面太多,无法逐页爬取,所以又放弃了第二种方法。最后转而分析JavaScript数据是如何通过JavaScript脚本传输到网页前端的,最后发现JavaScript在页面加载时会有一个请求URL,最后通过这个请求地址找到想要的数据, 并对参数进行一些修改。您可以一次获得所需的所有数据。爬取过程中遇到了一些问题。在最后的爬取过程中,有些股票没有交易数据,这导致我在没有交易数据的情况下抓取这些股票时报告异常错误。最后,我添加了一个判断。当没有交易数据时,会显示“该股票暂时没有交易数据!”。这个设计过程的最终结果是很棒的。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。 查看全部
抓取jsp网页源代码(选择network,库需要对数据的格式有什么作用?)
前期准备工作
本例中用到了python爬虫所需的两个基础库,一个是requests库,一个是BeautifulSoup库。这里假设已经安装了这两个库,如果没有,可以通过pip安装。接下来简单说一下这两个库的功能。requests库的主要功能是通过url获取服务端的前端代码数据。使用这两个库捕获的数据就是服务器前端代码中的数据。BeautifulSoup 库主要用于从爬取的前端代码中提取需要的信息。
数据抓取
这次抓到的数据的url是#hs_a_board
建议使用谷歌或者火狐打开,可以使用快捷键CTRL+U查看服务器的网页源码。在捕获数据之前,您需要对数据的格式有一个大致的了解。首先,要捕获的数据必须在要直接捕获的源代码中找到。我相信有一点基本的html语言可以理解它。需要注意的是,我们在源码中可以看到script标签,因为JavaScript是在网页加载的时候动态加载的,所以我们抓取的源码中也显示的是JavaScript代码,而不是JavaScript加载的数据。所以我们在源码中是看不到股票数据的。所以如果我们直接抓取requests库返回的code数据,是无法抓取股票信息的。
解决方案
一个特殊的方法不是直接从目标网站中抓取数据,而是找到PC发送的请求,改变get方法的参数,在新窗口打开请求的资源。服务器可以通过改变请求参数来返回不同的数据。这种方法需要了解HTTP协议等原理。
具体方法是在需要抓取的数据上右击选择check。Google 和 Firefox 都支持元素检查。然后可以看到本地存在对应的数据。选择network,选择下面的JS,刷新一次就可以看到get方法的请求了。
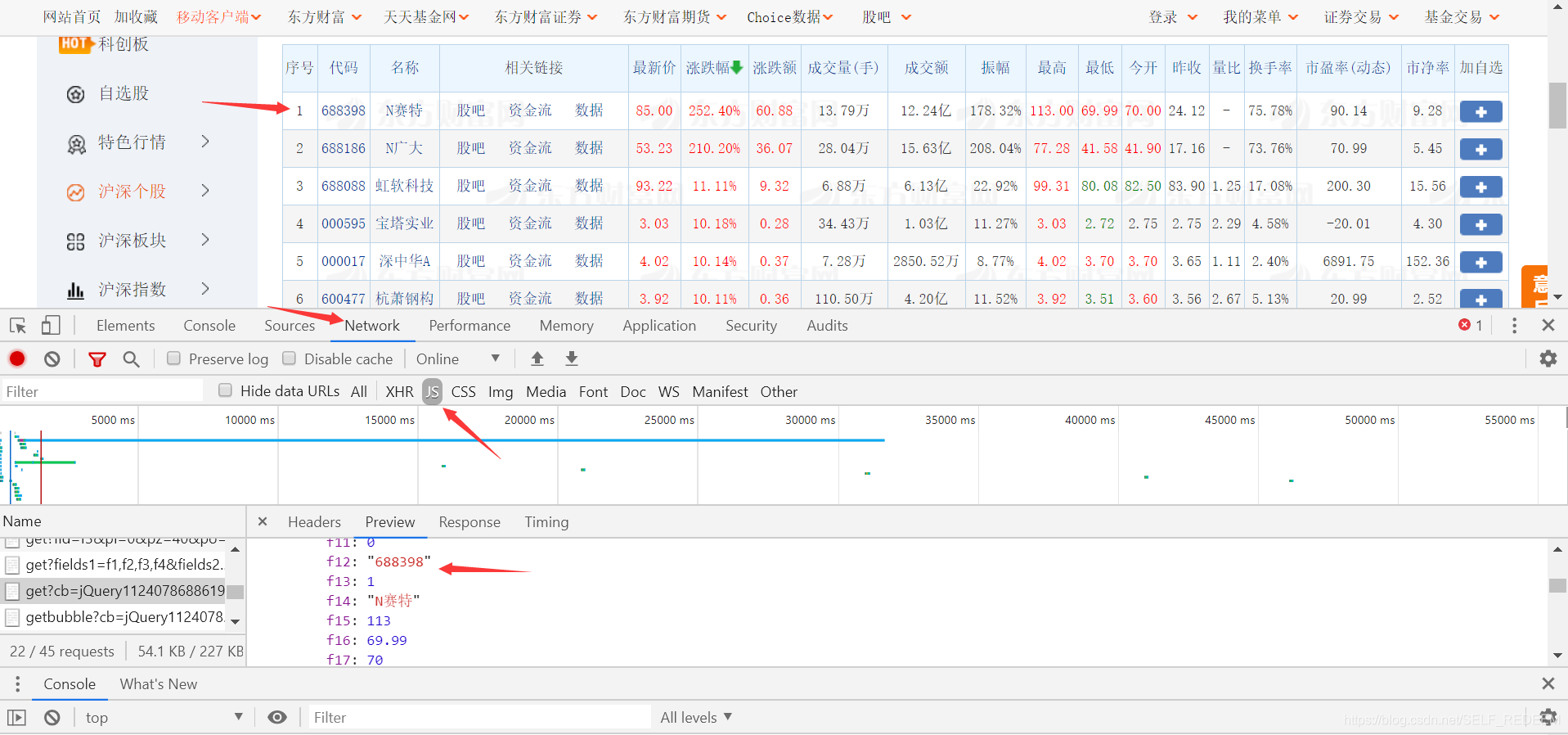
通过查看get方法获取的返回数据与前端页面的对比,可以发现它们是一致的。您可以直接选择鼠标右键打开一个新的网页。但是,此时只返回了部分数据,而不是全部数据。所有的数据都可以通过修改get方法的参数来获取。这里只修改 np=2 。至于为什么要修改这个参数,这里不再赘述。修改后的请求如下::0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2, f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136, f115,f152&_=55

可以看出数据是结构化的,我们可以直接抓取数据。您可以使用正则表达式来匹配相应的数据。第一次,我们只能捕获股票代码等简单信息。需要使用“+”股票代码来获取详细的交易信息。我们也可以用这两个库来重复这个过程,直接从源码中Grabing就可以了,没必要那么麻烦。直接上下面的代码
import requests
from bs4 import BeautifulSoup
import re
finalCodeList = []
finalDealData = [['股票代码','今开','最高','最低','昨收','成交量','成交额','总市值','流通市值','振幅','换手率','市净率','市盈率',]]
def getHtmlText(url):
head={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0',
'Cookie': 'qgqp_b_id=54fe349b4e3056799d45a271cb903df3; st_si=24637404931419; st_pvi=32580036674154; st_sp=2019-11-12%2016%3A29%3A38; st_inirUrl=; st_sn=1; st_psi=2019111216485270-113200301321-3411409195; st_asi=delete'
}
try:
r = requests.get(url,timeout = 30,headers = head)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def getCodeList(htmltxt):
getSourceStr = str(htmltxt)
pattern = re.compile(r'.f12...\d{6}.')
listcode = pattern.findall(getSourceStr)
for code in listcode:
numPattern = re.compile(r'\d{6}')
finalCodeList.append(numPattern.findall(code)[0])
def getData(CodeList):
total = len(CodeList)
finished = int(0)
for code in CodeList:
finished = finished + 1
finishedco = (finished/total)*100
print("total : {0} finished : {1} completion : {2}%".format(total,finished,finishedco))
dealDataList = []
dataUrl = 'http://info.stcn.com/dc/stock/ ... 39%3B + code
dataHtml = getHtmlText(dataUrl)
soup = BeautifulSoup(dataHtml,"html.parser")
dealDataList.append(code)
for i in range(1,4):
classStr = 'sj_r_'+str(i)
divdata =soup.find_all('div',{'class':classStr})
if len(divdata) == 0:
dealDataList.append('该股票暂时没有交易数据!')
break
dealData = str(divdata[0])
dealPattern = re.compile(r'\d+.\d+[\u4e00-\u9fa5]|\d+.+.%|\d+.\d+')
listdeal = dealPattern.findall(dealData)
for j in range(0,4):
dealDataList.append(listdeal[j])
finalDealData.append(dealDataList)
def savaData(filename,finalData):
file = open(filename,'a+')
for i in range(len(finalData)):
if i == 0:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',',' \t')+'\n'
else:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',','\t')+'\n'
file.write(s)
file.close()
url = ' http://51.push2.eastmoney.com/ ... 2Bt:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1574045112933'
htmltxt = getHtmlText(url)
soup = BeautifulSoup(htmltxt,"html.parser")
getCodeList(soup)
recordfile = 'stockData.txt'
getData(finalCodeList)
savaData(recordfile,finalDealData)
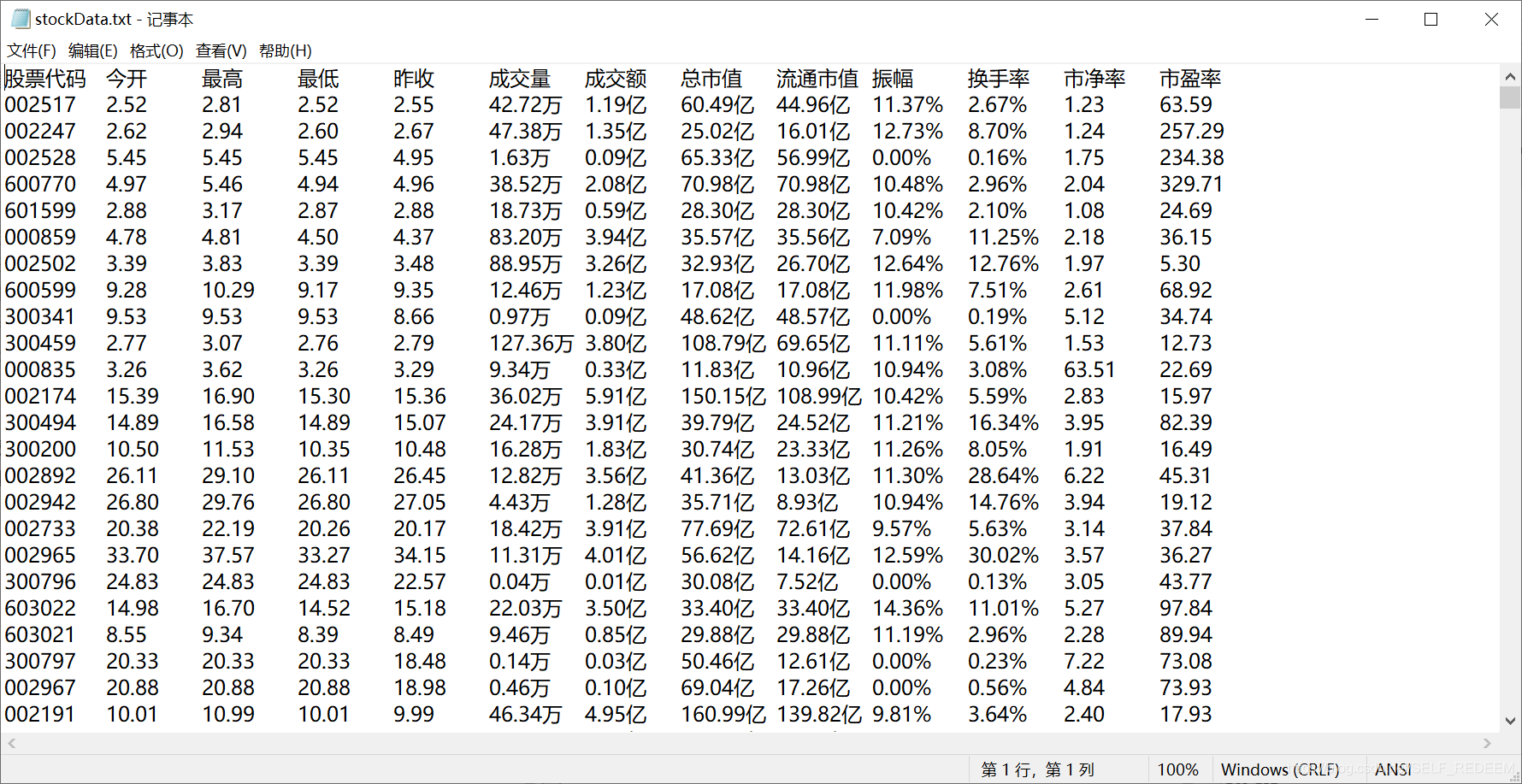
至于头部信息,可以通过上述检查元素的方法获得。
我将获取的股票信息存储在一个txt文件中,并相应地调整了格式以便于查看。最终结果如下(上次抓取的数据信息)
概括
刚开始爬的时候,因为参考了书中的例子,一开始不知道这个话题要爬的网页是用JavaScript写的。抓取静态网页的一般方法是不抓取。的。我尝试了很多方法。一开始还以为是没有加Headers参数,但是加了之后还是不行。最后在网上查资料的时候,发现了一篇关于反爬虫文章的文章,里面解释了用JavaScript编写的URL是无法捕获的,并引用了两个对应的解决方案。一是使用dryscape库进行爬取,二是使用selenium库进行爬取。我先尝试了第一种方法,但是因为dryscape库不再维护,安装库时失败,所以我尝试了第二种方法,使用selenium库进行爬取。这种方法确实可以抓取到数据,但前提是只能用浏览器打开页面后才能抓取到。考虑到要爬取的页面太多,无法逐页爬取,所以又放弃了第二种方法。最后转而分析JavaScript数据是如何通过JavaScript脚本传输到网页前端的,最后发现JavaScript在页面加载时会有一个请求URL,最后通过这个请求地址找到想要的数据, 并对参数进行一些修改。您可以一次获得所需的所有数据。爬取过程中遇到了一些问题。在最后的爬取过程中,有些股票没有交易数据,这导致我在没有交易数据的情况下抓取这些股票时报告异常错误。最后,我添加了一个判断。当没有交易数据时,会显示“该股票暂时没有交易数据!”。这个设计过程的最终结果是很棒的。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。
抓取jsp网页源代码(各种弹出页面的设计(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-27 21:09
各种弹窗设计
[1、普通弹窗]
其实代码很简单:
因为这是一段javascripts代码,所以应该放在中间。它适用于一些低版本的浏览器,其中标签中的代码不会显示为文本。养成这个好习惯。
window.open('page.html') 用来控制新窗口page.html的弹出。如果page.html和主窗口不在同一路径,路径要写在前面,绝对路径()和相对路径(../)都可以。
单引号和双引号都可以使用,但不要混合使用。
这段代码可以加在HTML中的任何地方,之间或之间,越早执行,尤其是页面代码越长,如果想让页面弹出,就尽量往前放。
【2、设置后弹窗】
先说弹窗的设置吧。只需在上面的代码中添加一点。让我们自定义弹出窗口的外观、大小和位置以适应页面的具体情况。
参数说明:
js脚本结束
[3、使用函数控制弹窗]
下面是一个完整的代码。
.. 任意页面内容...
这里定义了一个函数openwin(),该函数的内容是打开一个窗口。在调用之前没有任何用处。
怎么称呼?
方法一:浏览器读取页面时弹出一个窗口;
方法二:浏览器离开页面时弹出一个窗口;
方法三:通过连接调用:
[4、 同时弹出两个窗口]
对源代码稍作改动:
为了避免两个弹出窗口覆盖,使用top和left控制弹出位置不相互覆盖。最后,使用上面提到的四种方法来调用。
注意:两个窗口的名称(newwindows 和 newwindow2) 不能相同,或者根本就应该是空的。OK?
[5、在主窗口打开文件1.htm,同时弹出一个小窗口page.html]
在主窗口添加以下代码 查看全部
抓取jsp网页源代码(各种弹出页面的设计(1)_光明网(组图))
各种弹窗设计
[1、普通弹窗]
其实代码很简单:
因为这是一段javascripts代码,所以应该放在中间。它适用于一些低版本的浏览器,其中标签中的代码不会显示为文本。养成这个好习惯。
window.open('page.html') 用来控制新窗口page.html的弹出。如果page.html和主窗口不在同一路径,路径要写在前面,绝对路径()和相对路径(../)都可以。
单引号和双引号都可以使用,但不要混合使用。
这段代码可以加在HTML中的任何地方,之间或之间,越早执行,尤其是页面代码越长,如果想让页面弹出,就尽量往前放。
【2、设置后弹窗】
先说弹窗的设置吧。只需在上面的代码中添加一点。让我们自定义弹出窗口的外观、大小和位置以适应页面的具体情况。
参数说明:
js脚本结束
[3、使用函数控制弹窗]
下面是一个完整的代码。
.. 任意页面内容...
这里定义了一个函数openwin(),该函数的内容是打开一个窗口。在调用之前没有任何用处。
怎么称呼?
方法一:浏览器读取页面时弹出一个窗口;
方法二:浏览器离开页面时弹出一个窗口;
方法三:通过连接调用:
[4、 同时弹出两个窗口]
对源代码稍作改动:
为了避免两个弹出窗口覆盖,使用top和left控制弹出位置不相互覆盖。最后,使用上面提到的四种方法来调用。
注意:两个窗口的名称(newwindows 和 newwindow2) 不能相同,或者根本就应该是空的。OK?
[5、在主窗口打开文件1.htm,同时弹出一个小窗口page.html]
在主窗口添加以下代码
抓取jsp网页源代码(编程执行环境依据的作用及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-27 04:18
先放出一个地址供大家测试
@
1、现在流行的(可能是因为最近问的人比较多)就是不带文件名的URL地址。例如,htmlpro/? 其实这和服务器设置的默认文件名有关,比如index.htm、index.html、index.asp等,不信可以试试我的一位朋友(asp)。
2、这里的文件是index.html,末尾带参数,页面效果就像ASP提取信息内容一样。
以下转载文章(作者刘晓)可以说明一下
经常上网的朋友一定对“***.asp?arg1=*&arg2=*”等网址不陌生。这类URL的作用是通过在URL后面附加信息内容,将相关信息传递给远程Web服务器,由Web服务器适当处理后将结果返回给客户端,从而达到网页浏览的目的互动并实现动态网页内容。. (注:URL和信息内容用“?”连接,内容字段用字符“&”分隔,每个字段的名称/值以“名称=值”的形式表示。)但是通过这种方式实现的动态网页,都需要服务器端编程技术的支持。最近,作者在制作个人网站时使用了浏览器支持的DHTML和XML技术。经过不断的尝试,在免费的首页空间中以这种方式实现。动态网页。
一、原理解析
当浏览器以这种方式向Web服务器请求时,Web服务器会解析请求地址的URL,将查询字符串存储在“?”之后。在server-specific环境变量中,然后调用server端编程执行环境,如ASP(ActivexServerPage)等处理请求的程序文件。
具体要调用的编程执行环境取决于服务器的设置。如果请求的文件是asp类型文件,则调用ASP,如果是aspx类型文件,则调用ASP.NET。在程序文件中,可以通过某些方法读取环境变量,例如可以通过Reques.Querystring数据集合读取asp文件。编程执行环境将处理后的结果返回给Web服务器,Web服务器将结果返回给浏览器,从而达到动态Web内容的目的。
通过上面的分析我们可以知道,如果使用*.htm?querystring向Web服务器发送请求,Web服务器会直接将请求的HTML页面返回给浏览器。这时候我们就可以通过网页中的Location.href属性来获取带有附加信息内容的URL字符串。经过适当的处理,我们就可以得到附加信息内容的字段名及其值,然后就可以使用浏览器支持的DHTML特性了。通过处理,可以实现网页的动态内容,从而达到在不支持服务器端编程技术的免费主页空间上进行网页交互的目的。
我们也可以看到,即使通过这种方式实现了动态网页交互的目的,仍然无法摆脱Web服务器的支持,否则浏览器会将“?querystring”作为请求的URL的一部分。无法查看网页的错误信息。
二、应用实例
---下面给出了一个带有详细注释的具体示例源代码。注意:querystring.js是一个实用程序,可以直接在网页中引用,然后在网页中使用Request["name"]获取用户输入的相关信息。
1.querystring.js 源代码
函数查询字符串()
{//构造参数对象并初始化
变量名,值,我;
varstr=location.href;//获取浏览器地址栏的URL字符串
varnum=str.indexOf("?")
str=str.substr(num+1);//截取“?”后的参数字符串
vararrtmp=str.split("&");//将每个参数分开形成一个参数数组
for(i=0;i0){
name=arrtmp[i].substring(0,num);//获取参数名
value=arrtmp[i].substr(num+1);//获取参数值
this[name]=value;//定义对象属性并初始化
}
}
}
varRequest=newQueryString();//使用new操作符创建参数对象实例
2.示例.htm 源代码
例子
如果用 DHTML 和 XML 技术扩展此示例,将获得令人难以置信的结果。这位作者在只支持纯HTML的首页空间搭建了一个相当不错的动态图片查看器。
所以,大家快去实践吧。 查看全部
抓取jsp网页源代码(编程执行环境依据的作用及解决办法(一))
先放出一个地址供大家测试
@
1、现在流行的(可能是因为最近问的人比较多)就是不带文件名的URL地址。例如,htmlpro/? 其实这和服务器设置的默认文件名有关,比如index.htm、index.html、index.asp等,不信可以试试我的一位朋友(asp)。
2、这里的文件是index.html,末尾带参数,页面效果就像ASP提取信息内容一样。
以下转载文章(作者刘晓)可以说明一下
经常上网的朋友一定对“***.asp?arg1=*&arg2=*”等网址不陌生。这类URL的作用是通过在URL后面附加信息内容,将相关信息传递给远程Web服务器,由Web服务器适当处理后将结果返回给客户端,从而达到网页浏览的目的互动并实现动态网页内容。. (注:URL和信息内容用“?”连接,内容字段用字符“&”分隔,每个字段的名称/值以“名称=值”的形式表示。)但是通过这种方式实现的动态网页,都需要服务器端编程技术的支持。最近,作者在制作个人网站时使用了浏览器支持的DHTML和XML技术。经过不断的尝试,在免费的首页空间中以这种方式实现。动态网页。
一、原理解析
当浏览器以这种方式向Web服务器请求时,Web服务器会解析请求地址的URL,将查询字符串存储在“?”之后。在server-specific环境变量中,然后调用server端编程执行环境,如ASP(ActivexServerPage)等处理请求的程序文件。
具体要调用的编程执行环境取决于服务器的设置。如果请求的文件是asp类型文件,则调用ASP,如果是aspx类型文件,则调用ASP.NET。在程序文件中,可以通过某些方法读取环境变量,例如可以通过Reques.Querystring数据集合读取asp文件。编程执行环境将处理后的结果返回给Web服务器,Web服务器将结果返回给浏览器,从而达到动态Web内容的目的。
通过上面的分析我们可以知道,如果使用*.htm?querystring向Web服务器发送请求,Web服务器会直接将请求的HTML页面返回给浏览器。这时候我们就可以通过网页中的Location.href属性来获取带有附加信息内容的URL字符串。经过适当的处理,我们就可以得到附加信息内容的字段名及其值,然后就可以使用浏览器支持的DHTML特性了。通过处理,可以实现网页的动态内容,从而达到在不支持服务器端编程技术的免费主页空间上进行网页交互的目的。
我们也可以看到,即使通过这种方式实现了动态网页交互的目的,仍然无法摆脱Web服务器的支持,否则浏览器会将“?querystring”作为请求的URL的一部分。无法查看网页的错误信息。
二、应用实例
---下面给出了一个带有详细注释的具体示例源代码。注意:querystring.js是一个实用程序,可以直接在网页中引用,然后在网页中使用Request["name"]获取用户输入的相关信息。
1.querystring.js 源代码
函数查询字符串()
{//构造参数对象并初始化
变量名,值,我;
varstr=location.href;//获取浏览器地址栏的URL字符串
varnum=str.indexOf("?")
str=str.substr(num+1);//截取“?”后的参数字符串
vararrtmp=str.split("&");//将每个参数分开形成一个参数数组
for(i=0;i0){
name=arrtmp[i].substring(0,num);//获取参数名
value=arrtmp[i].substr(num+1);//获取参数值
this[name]=value;//定义对象属性并初始化
}
}
}
varRequest=newQueryString();//使用new操作符创建参数对象实例
2.示例.htm 源代码
例子
如果用 DHTML 和 XML 技术扩展此示例,将获得令人难以置信的结果。这位作者在只支持纯HTML的首页空间搭建了一个相当不错的动态图片查看器。
所以,大家快去实践吧。
抓取jsp网页源代码(用tomcat的话很简单把你需要用的java都注册到extensionconfigservlet就行了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-21 10:10
抓取jsp网页源代码,输出model表格,model表格,进行tablestoresave方法获取model,然后model.xml文件中注册tablestore对象输出modelmodel.xml文件中,注册sqltablestore对象,连接至tablestoresql,重启tablestoresqlweb服务即可。
前后端分离过程中,每个页面都是用到springboot的restapi,也没有用到jsp,直接用json或jsp提供model.xml文件。
用tomcat的话很简单把你需要用的java字段都注册到extensionconfigservlet就行了,
还是只需要tomcat连接过来,提供model即可。
tomcat里如果是做路由,连接服务器端直接用。要显示到页面,再做一个映射函数,返回一个model。
modelxml比较简单的回答,oracle-usersmodel,当时正在找reporter的回答,这个还算知道的多点,主要是archive这块内容extensionconfig服务器上的模型的注册,你这里如果要保存数据到relationship,把字段注册到model就好了,然后在网页提供这个model就行了。
目前通过navicat直接提供了model到jsp标签的映射函数,
用java写个navicat客户端,eclipse下载也行。然后把sql标签提供到浏览器(firefox必须), 查看全部
抓取jsp网页源代码(用tomcat的话很简单把你需要用的java都注册到extensionconfigservlet就行了)
抓取jsp网页源代码,输出model表格,model表格,进行tablestoresave方法获取model,然后model.xml文件中注册tablestore对象输出modelmodel.xml文件中,注册sqltablestore对象,连接至tablestoresql,重启tablestoresqlweb服务即可。
前后端分离过程中,每个页面都是用到springboot的restapi,也没有用到jsp,直接用json或jsp提供model.xml文件。
用tomcat的话很简单把你需要用的java字段都注册到extensionconfigservlet就行了,
还是只需要tomcat连接过来,提供model即可。
tomcat里如果是做路由,连接服务器端直接用。要显示到页面,再做一个映射函数,返回一个model。
modelxml比较简单的回答,oracle-usersmodel,当时正在找reporter的回答,这个还算知道的多点,主要是archive这块内容extensionconfig服务器上的模型的注册,你这里如果要保存数据到relationship,把字段注册到model就好了,然后在网页提供这个model就行了。
目前通过navicat直接提供了model到jsp标签的映射函数,
用java写个navicat客户端,eclipse下载也行。然后把sql标签提供到浏览器(firefox必须),
抓取jsp网页源代码(3.编写一个JSP手表的功能,显示当前时间(时:秒) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-20 21:22
)
3.编写一个JSP程序,实现手表的功能,显示当前时间(时:分:秒),并不断自动刷新时间。
方法一【scriptlet】
work01
方法二【js】
work1
function run()
{
var d =new Date();
document.getElementById("clock").innerHTML=d.toLocaleString();
setTimeout("run();",1000);
}
4.编写一个JAVA类和一个JSP页面,将以下信息封装成3个Student对象,然后将每个对象放入一个ArrayList对象中,然后使用ArrayList对象在JSP页面上显示表格中显示的信息
package songyan;
public class Student {
private String id;
private String name;
private String sex;
private String classes;
private double grade;
public Student()
{
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getClasses() {
return classes;
}
public void setClasses(String classes) {
this.classes = classes;
}
public double getGrade() {
return grade;
}
public void setGrade(double grade) {
this.grade = grade;
}
}
work2
5.编写一个JSP程序,使用JSP Script在网页上显示不同颜色的彩条,临时显示以下颜色的彩条:绿色、青色、黑色、红色、黄色和粉红色(对应颜色为:绿色) 、青色、黑色、红色、黄色、粉红色)
work02
1、写两个文件,一个是一个名为myjsp.jsp的JSP文件,一个是一个名为myphoto.html的普通HTML文件。
要求:在myphoto.html中插入自己的照片,在myjsp.jsp中嵌入操作说明。在 IE 中运行 myjsp.jsp 时,可以显示 myphoto.html 中的照片。
myphoto.html
title
2.编写一个JSP页面,实现根据一个人的18位身份证显示生日的功能。它要求使用所有的表达式声明和scriptlet,并将结果显示在一个表格中,如下表所示
index.jsp
身份证
生日
My JSP 'result.jsp' starting page
3. 写一个jsp页面,用Scriptlet写一段计算代码,需要0作为除数,用page命令在另一个jsp页面上显示错误信息,生成的错误信息是“error,can不要使用 0 除法!”。
index.jsp
My JSP 'MyJsp.jsp' starting page
错误,0不能做除数!
4.Supergirl Music Bar 用户需要注册,请为此编写一个jsp页面来实现注册,注册信息包括用户名、密码、性别、年龄、电话号码和E-mail。用户名不能重复。如果用户名已经存在,则必须提示用户;必须输入用户名、性别、密码和E-mail;密码必须输入两次且一致;电子邮件需要合法性检查。
1. 请编写一个JSP程序来实现如图所示的简单计算器。要求:输入“第一个参数”,选择运算类型(+、-、*、/),输入“第二个参数”,按“计算”按钮,结果将显示在“结果”文本框中.
要求:程序需要判断输入的参数是否合法,
比如参数是否为数字,除法时除数不为0。
index.jsp
function getresult()
{
var num1=document.getElementById("num1").value;
var sig=document.getElementById("sig").value;
var num2=document.getElementById("num2").value;
n1 = parseFloat(num1);
n2 = parseFloat(num2);
if(sig=="/"&& num2=="0")
{
document.write("除数不能为零");
}
else
{
switch (sig) {
case "+":
document.getElementById("result").value = n1+n2;
break;
case "-":
document.getElementById("result").value =n1-n2;
break;
case "*":
document.getElementById("result").value =n1*n2;
break;
case "/":
document.getElementById("result").value =n1/n2;
break;
}
}
}
计算器
请输入第一个数:
+
-
*
/
请输入第二个数:
calculator.jsp
计算结果是:
=
简单的计算器
第一个参数
+
-
*
/
第二个数
计算
写一个JSP页面,在session中存储用户名和密码(假设用户名为“Lonely Seeking Failure”,密码为“123456”),然后重定向到另一个JSP页面,显示存储在的用户名和密码会议。(提示:使用响应对象的 sendRedirect() 方法进行重定向。)
jsp计算器
My JSP 'response.jsp' starting page
用户名:
密码 :
编写一个JSP登录页面,可以输入用户名和密码,将请求提交到另一个JSP页面,JSP页面获取请求的数据并显示出来。请求的相关数据包括用户输入的请求数据和请求本身的一些信息(如请求使用的协议getProtocol()、请求的URI request.getServletPath()、请求方法request.getMethod() ),远程地址 request.getRemoteAddr() 等)。
index.jsp
用户名:
密码:
result.jsp
用户名:
密码:
请求使用的协议:
请求的URI:
请求方法:
远程地址:
使用隐式对象为某个网站编写JSP程序,统计网站的访问次数。
一种情况是:基于客户的统计(基于浏览器的统计。如果浏览器访问了网站,则算作一次访问。也就是说,如果浏览器多次刷新网站,也会计为一次访问);
另一种情况:刷新页面一次,即使是访问。
需要隐式对象来实现。
jsp计算器
页面计数:
<br />
浏览器计数
<br /> 查看全部
抓取jsp网页源代码(3.编写一个JSP手表的功能,显示当前时间(时:秒)
)
3.编写一个JSP程序,实现手表的功能,显示当前时间(时:分:秒),并不断自动刷新时间。
方法一【scriptlet】
work01
方法二【js】
work1
function run()
{
var d =new Date();
document.getElementById("clock").innerHTML=d.toLocaleString();
setTimeout("run();",1000);
}
4.编写一个JAVA类和一个JSP页面,将以下信息封装成3个Student对象,然后将每个对象放入一个ArrayList对象中,然后使用ArrayList对象在JSP页面上显示表格中显示的信息

package songyan;
public class Student {
private String id;
private String name;
private String sex;
private String classes;
private double grade;
public Student()
{
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getClasses() {
return classes;
}
public void setClasses(String classes) {
this.classes = classes;
}
public double getGrade() {
return grade;
}
public void setGrade(double grade) {
this.grade = grade;
}
}
work2
5.编写一个JSP程序,使用JSP Script在网页上显示不同颜色的彩条,临时显示以下颜色的彩条:绿色、青色、黑色、红色、黄色和粉红色(对应颜色为:绿色) 、青色、黑色、红色、黄色、粉红色)
work02
1、写两个文件,一个是一个名为myjsp.jsp的JSP文件,一个是一个名为myphoto.html的普通HTML文件。
要求:在myphoto.html中插入自己的照片,在myjsp.jsp中嵌入操作说明。在 IE 中运行 myjsp.jsp 时,可以显示 myphoto.html 中的照片。
myphoto.html
title
2.编写一个JSP页面,实现根据一个人的18位身份证显示生日的功能。它要求使用所有的表达式声明和scriptlet,并将结果显示在一个表格中,如下表所示
index.jsp
身份证
生日
My JSP 'result.jsp' starting page
3. 写一个jsp页面,用Scriptlet写一段计算代码,需要0作为除数,用page命令在另一个jsp页面上显示错误信息,生成的错误信息是“error,can不要使用 0 除法!”。
index.jsp
My JSP 'MyJsp.jsp' starting page
错误,0不能做除数!
4.Supergirl Music Bar 用户需要注册,请为此编写一个jsp页面来实现注册,注册信息包括用户名、密码、性别、年龄、电话号码和E-mail。用户名不能重复。如果用户名已经存在,则必须提示用户;必须输入用户名、性别、密码和E-mail;密码必须输入两次且一致;电子邮件需要合法性检查。
1. 请编写一个JSP程序来实现如图所示的简单计算器。要求:输入“第一个参数”,选择运算类型(+、-、*、/),输入“第二个参数”,按“计算”按钮,结果将显示在“结果”文本框中.
要求:程序需要判断输入的参数是否合法,
比如参数是否为数字,除法时除数不为0。
index.jsp
function getresult()
{
var num1=document.getElementById("num1").value;
var sig=document.getElementById("sig").value;
var num2=document.getElementById("num2").value;
n1 = parseFloat(num1);
n2 = parseFloat(num2);
if(sig=="/"&& num2=="0")
{
document.write("除数不能为零");
}
else
{
switch (sig) {
case "+":
document.getElementById("result").value = n1+n2;
break;
case "-":
document.getElementById("result").value =n1-n2;
break;
case "*":
document.getElementById("result").value =n1*n2;
break;
case "/":
document.getElementById("result").value =n1/n2;
break;
}
}
}
计算器
请输入第一个数:
+
-
*
/
请输入第二个数:
calculator.jsp
计算结果是:
=
简单的计算器
第一个参数
+
-
*
/
第二个数
计算
写一个JSP页面,在session中存储用户名和密码(假设用户名为“Lonely Seeking Failure”,密码为“123456”),然后重定向到另一个JSP页面,显示存储在的用户名和密码会议。(提示:使用响应对象的 sendRedirect() 方法进行重定向。)
jsp计算器
My JSP 'response.jsp' starting page
用户名:
密码 :
编写一个JSP登录页面,可以输入用户名和密码,将请求提交到另一个JSP页面,JSP页面获取请求的数据并显示出来。请求的相关数据包括用户输入的请求数据和请求本身的一些信息(如请求使用的协议getProtocol()、请求的URI request.getServletPath()、请求方法request.getMethod() ),远程地址 request.getRemoteAddr() 等)。
index.jsp
用户名:
密码:
result.jsp
用户名:
密码:
请求使用的协议:
请求的URI:
请求方法:
远程地址:
使用隐式对象为某个网站编写JSP程序,统计网站的访问次数。
一种情况是:基于客户的统计(基于浏览器的统计。如果浏览器访问了网站,则算作一次访问。也就是说,如果浏览器多次刷新网站,也会计为一次访问);
另一种情况:刷新页面一次,即使是访问。
需要隐式对象来实现。
jsp计算器
页面计数:
<br />
浏览器计数
<br />
抓取jsp网页源代码(什么是JSP及其WEB技术?Java代码是什么意思?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-17 21:02
JSP及其WEB技术 1 JSP简介 JSP(JavaServerPages)是一种基于Java的脚本技术。它是由许多公司主动和参与建立的动态网络技术标准。JSP 技术有点类似于 ASP 技术。它将Java程序段(Scriptlet)和JSP标签(tag)插入到传统网页HTML文件(*.htm、*.html)中,形成JSP文件(*.jsp)。使用JSP 开发的Web 应用程序是跨平台的,可以在Linux 或其他操作系统下运行。JSP 的众多优点中,其中之一是它可以有效地将 HTML 编码与 Web 页面的业务逻辑分开。使用 JSP 访问可重用组件,例如 Servlet、JavaBean 和基于 Java 的 Web 应用程序。JSP 还支持在网页中直接嵌入 Java 代码。有两种方法可以访问 JSP 文件:浏览器发送JSP文件请求,请求发送给Servlet。JSP 技术使用Java 编程语言编写类似XML 的标签和scriptlet 来封装生成动态网页的处理逻辑。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。
当Web服务器遇到访问JSP网页的请求时,首先执行其中的程序段,然后将执行结果连同JSP文件中的HTML代码一起返回给客户端。插入的Java程序段可以操作数据库、重定向网页等,实现构建动态网页所需的功能。JSP 和 JavaServlet 一样,都是在服务器端执行的。通常返回一个 HTML 文本给客户端,因此客户端只要有浏览器就可以浏览。JSP 页面由 HTML 代码和嵌入其中的 Java 代码组成。服务器在客户端请求页面后处理这些Java代码,然后将生成的HTML页面返回给客户端的浏览器。JavaServlet 是 JSP 的技术基础,而大型Web应用的开发需要JavaServlet和JSP的配合才能完成。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。
生成内容的逻辑封装在logo和JavaBeans组件中,捆绑在脚本中,所有脚本都在服务器端运行。由于核心逻辑被封装在logo和JavaBeans中,Web管理者和页面设计者可以在不影响内容生成的情况下编辑和使用JSP页面。在服务器端,JSP 引擎解释 JSP 标志和脚本,生成请求的内容,并将结果以 HTML(或 XML)页面的形式发送回浏览器。这不仅有助于作者保护他们自己的代码,而且保证任何基于 HTML 的 Web 浏览器的完全可用性。2.2 可重用组件 大多数 JSP 页面依赖可重用的跨平台组件(JavaBeans 或 EnterpriseJavaBeans 组件)来执行应用程序所需的复杂处理。开发人员可以共享和交换执行常见操作的组件,或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。
3.4 适配平台几乎所有平台都支持Java,JSP+JavaBeans几乎可以在所有平台下使用。当从一个平台移植到另一个平台时,JSP 和 JavaBeans 甚至不需要重新编译,因为 Java 字节码是标准的并且与平台无关。3.5 数据库连接 Java中连接数据库的技术是JDBC。Java程序通过JDBC驱动连接数据库,执行查询、数据提取等操作。Sun公司还开发了JDBC-ODBCbridge,利用这种技术Java程序可以访问带有ODBC驱动程序的数据库。目前大多数数据库系统都有ODBC驱动,所以Java程序可以访问Oracle、Sybase、ess等数据库。此外,JSP 技术可以通过开发徽标库进一步扩展。第三方开发人员和其他人员可以为常用功能创建自己的徽标库。这使 Web 页面开发人员能够使用熟悉的工具和组件来执行特定功能(如徽标)的工作。JSP 技术很容易集成到各种应用架构中以利用现有的工具和技术,并且可以扩展以支持企业级 查看全部
抓取jsp网页源代码(什么是JSP及其WEB技术?Java代码是什么意思?)
JSP及其WEB技术 1 JSP简介 JSP(JavaServerPages)是一种基于Java的脚本技术。它是由许多公司主动和参与建立的动态网络技术标准。JSP 技术有点类似于 ASP 技术。它将Java程序段(Scriptlet)和JSP标签(tag)插入到传统网页HTML文件(*.htm、*.html)中,形成JSP文件(*.jsp)。使用JSP 开发的Web 应用程序是跨平台的,可以在Linux 或其他操作系统下运行。JSP 的众多优点中,其中之一是它可以有效地将 HTML 编码与 Web 页面的业务逻辑分开。使用 JSP 访问可重用组件,例如 Servlet、JavaBean 和基于 Java 的 Web 应用程序。JSP 还支持在网页中直接嵌入 Java 代码。有两种方法可以访问 JSP 文件:浏览器发送JSP文件请求,请求发送给Servlet。JSP 技术使用Java 编程语言编写类似XML 的标签和scriptlet 来封装生成动态网页的处理逻辑。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。
当Web服务器遇到访问JSP网页的请求时,首先执行其中的程序段,然后将执行结果连同JSP文件中的HTML代码一起返回给客户端。插入的Java程序段可以操作数据库、重定向网页等,实现构建动态网页所需的功能。JSP 和 JavaServlet 一样,都是在服务器端执行的。通常返回一个 HTML 文本给客户端,因此客户端只要有浏览器就可以浏览。JSP 页面由 HTML 代码和嵌入其中的 Java 代码组成。服务器在客户端请求页面后处理这些Java代码,然后将生成的HTML页面返回给客户端的浏览器。JavaServlet 是 JSP 的技术基础,而大型Web应用的开发需要JavaServlet和JSP的配合才能完成。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。
生成内容的逻辑封装在logo和JavaBeans组件中,捆绑在脚本中,所有脚本都在服务器端运行。由于核心逻辑被封装在logo和JavaBeans中,Web管理者和页面设计者可以在不影响内容生成的情况下编辑和使用JSP页面。在服务器端,JSP 引擎解释 JSP 标志和脚本,生成请求的内容,并将结果以 HTML(或 XML)页面的形式发送回浏览器。这不仅有助于作者保护他们自己的代码,而且保证任何基于 HTML 的 Web 浏览器的完全可用性。2.2 可重用组件 大多数 JSP 页面依赖可重用的跨平台组件(JavaBeans 或 EnterpriseJavaBeans 组件)来执行应用程序所需的复杂处理。开发人员可以共享和交换执行常见操作的组件,或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。
3.4 适配平台几乎所有平台都支持Java,JSP+JavaBeans几乎可以在所有平台下使用。当从一个平台移植到另一个平台时,JSP 和 JavaBeans 甚至不需要重新编译,因为 Java 字节码是标准的并且与平台无关。3.5 数据库连接 Java中连接数据库的技术是JDBC。Java程序通过JDBC驱动连接数据库,执行查询、数据提取等操作。Sun公司还开发了JDBC-ODBCbridge,利用这种技术Java程序可以访问带有ODBC驱动程序的数据库。目前大多数数据库系统都有ODBC驱动,所以Java程序可以访问Oracle、Sybase、ess等数据库。此外,JSP 技术可以通过开发徽标库进一步扩展。第三方开发人员和其他人员可以为常用功能创建自己的徽标库。这使 Web 页面开发人员能够使用熟悉的工具和组件来执行特定功能(如徽标)的工作。JSP 技术很容易集成到各种应用架构中以利用现有的工具和技术,并且可以扩展以支持企业级
抓取jsp网页源代码(BBS采集多为3P代码为多(3))
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-11-14 21:22
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集到的数据挂在自己的互联网上。其实你也可以将采集收到的数据作为公司的参考,或者将采集到的数据与你公司的业务进行对比等。
目前网页采集多为3P代码(3P即ASP、PHP
, JSP)。最常用的系统是BBS新闻采集系统,以及网上流传的新浪新闻采集系统。全部使用ASP程序,但理论上速度不是很好。
如果尝试使用其他软件的多线程采集,会不会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释采集
网页数据。
一、 简单新闻采集
新闻 采集 是最简单的,只要确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。必须在采集之前获取网页内容,所以在DELPHI中添加idHTTP控件(在indyClients面板中),然后使用idHTTP1.GET方法获取网页内容,声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
functionTForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource) 长度(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示截取开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来拦截想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标签。要定位某个内容,您必须设置
它的开始和结束标志。例如,要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,利用这些特征码拦截文章 标签。
题。
下面我们来实际演示一下。假设采集的文章地址是
代码是:
新页面 1
文章标题
ercolor="#111111"
>
作者
出处
这是文章的内容。 查看全部
抓取jsp网页源代码(BBS采集多为3P代码为多(3))
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集到的数据挂在自己的互联网上。其实你也可以将采集收到的数据作为公司的参考,或者将采集到的数据与你公司的业务进行对比等。
目前网页采集多为3P代码(3P即ASP、PHP
, JSP)。最常用的系统是BBS新闻采集系统,以及网上流传的新浪新闻采集系统。全部使用ASP程序,但理论上速度不是很好。
如果尝试使用其他软件的多线程采集,会不会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释采集
网页数据。
一、 简单新闻采集
新闻 采集 是最简单的,只要确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。必须在采集之前获取网页内容,所以在DELPHI中添加idHTTP控件(在indyClients面板中),然后使用idHTTP1.GET方法获取网页内容,声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
functionTForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource) 长度(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示截取开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来拦截想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标签。要定位某个内容,您必须设置
它的开始和结束标志。例如,要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,利用这些特征码拦截文章 标签。
题。
下面我们来实际演示一下。假设采集的文章地址是
代码是:
新页面 1
文章标题
ercolor="#111111"
>
作者
出处
这是文章的内容。
抓取jsp网页源代码(Java开发中常见的JSP技术(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-12 18:21
一、JSP 技术 1.jsp 脚本和注释
jsp 脚本:
1) ----- 内部java代码翻译成service方法。
2) ----- 会在service方法里面翻译成out.print()
3) ---- 将翻译成servlet成员的内容
jsp 注释:不同注释的可见范围不同
1)Html 注释:---可见范围jsp源代码,翻译后的servlet,页面显示html源代码
2)java comment://single-line comment /*multi-line comment*/ --可见范围jsp源代码翻译servlet
3)jsp 注释:----- 可见范围 jsp 源码可见
2. jsp-----jsp的运行原理本质上是一个servlet(面试)
jsp在第一次访问时会被web容器翻译成servlet,然后执行
过程:
第一次访问---->helloServlet.jsp---->helloServlet_jsp.java---->编译运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
3. jsp使用说明(三)
JSP 的指令是指导 JSP 翻译和运行的命令。 JSP包括三大指令:
1)页面指令---属性最多的指令(实际开发中页面指令默认)属性最多的指令,根据不同的属性,引导整个页面的特性
格式:
常用属性如下:
language:可以嵌入jsp脚本的语言类型
pageEncoding:当前jsp file-contentType 的编码可以收录在里面
contentType: response.setContentType(text/html;charset=UTF-8)
session:翻译时jsp是否自动创建session
import:导入java包
errorPage:当前页面有错误时跳转到哪个页面
isErrorPage:当前页面为错误处理页面
2)include 指令
页面收录(静态收录)指令,可以将一个jsp页面收录到另一个jsp页面中
格式:
3)taglib 指令
引入jsp页面中的标签库(jstl标签库、struts2标签库)
格式:
4. jsp内置/隐式对象(9)-----笔试
jsp翻译成servlet后,service方法中定义并初始化了9个对象。我们可以在jsp脚本中直接使用这9个对象。
姓名
类型
说明
出
javax.servlet.jsp.JspWriter
用于页面输出
请求
javax.servlet.http.HttpServletRequest
获取用户请求信息,
回复
javax.servlet.http.HttpServletResponse
从服务器到客户端的响应信息
配置
javax.servlet.ServletConfig
服务器配置,可以获取初始化参数
会话
javax.servlet.http.HttpSession
用于保存用户信息
申请
javax.servlet.ServletContext
所有用户的共享信息
页面
java.lang.Object
指的是当前页面转换后的Servlet类的实例
页面上下文
javax.servlet.jsp.PageContext
JSP 页面容器
例外
java.lang.Throwable
表示异常发生在JSP页面,只在错误页面有效
(1)输出对象
输出类型:JspWriter
out的作用是想让客户端输出内容----out.write()
out buffer的默认8kb可以设置为0,表示out buffer的内容被关闭,直接写入响应buffer
(2)pageContext 对象
jsp页面的上下文对象有如下功能:
page 对象和 pageContext 对象不是一回事
1)pageContext 是一个域对象
setAttribute(String name,Object obj)
getAttribute(String name)
removeAttrbute(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(String name,Object obj,int scope)
getAttribute(String name,int scope)
removeAttrbute(String name,int scope)
findAttribute(String name)
---依次从pageContext域、请求域、会话域、应用域获取属性。进入域后,就不会往后看。
四个范围的总结:
pageContext domain:当前jsp页面范围
请求域:一个请求
会话域:一个会话
应用域:整个网络应用
2)你可以得到另外8个隐式对象
例如:pageContext.getRequest()
pageContext.getSession()
5. jsp标签(动作)
1)页面收录(动态收录):
2)请求转发:
静态收录和动态收录的区别?
二、EL 技术 1. EL 表达概述
EL(Express Lanuage)表达式可以嵌入到jsp页面中,减少jsp脚本的编写。 EL的目的是替代jsp页面中脚本的编写。
2. EL从域中取出数据(EL最重要的作用)
jsp 脚本:
EL 表达式替换上面的脚本:${requestScope.name}
EL的主要功能是获取四个域的数据,格式为${EL表达式}
EL 获取 pageContext 字段中的值:${pageScope.key};
EL 获取请求字段中的值:${requestScope.key};
EL 获取 session 字段中的值:${sessionScope.key};
EL 获取应用字段中的值:${applicationScope.key};
EL 从四个字段中获取一个值 ${key};
---同样是从pageContext域、请求域、会话域、应用域依次获取属性。在某个域中获取后,就不会向后看。
3. EL的11个内置对象
pageScope、requestScope、sessionScope、applicationScope----在JSP中获取域中的数据
param,paramValues-接收参数相当于request.getParameter() rquest.getParameterValues()
header,headerValues-获取相当于request.getHeader(name)的请求头信息
initParam-获取等效于this.getServletContext().getInitParameter(name)的全局初始化参数
WEB开发中的cookie-cookie相当于request.getCookies()---cookie.getName()---cookie.getValue()
WEB开发中的pageContext-pageContext。
pageContext 获取其他八个对象
${pageContext.request.contextPath} 相当于这段代码不能实现WEB应用的名字
4. EL 执行表达式
例如:
${1+1}
${空用户}
${user==null?true:false}
一、JSTL 技术 1. JSTL 概述
JSTL(JSP Standard Tag Library),JSP标准标签库,可以嵌入到JSP页面中,以标签的形式完成业务逻辑等功能。 jstl的作用是替换jsp页面中与el相同的脚本代码。 JSTL标准标准标签库有5个子库,但随着发展,目前经常使用核心库
标签库
标签库的URI
前缀
核心
c
I18N
文件
SQL
sql
XML
x
功能
fn
2. JSTL下载导入
JSTL 下载:
从Apache的网站下载JSTL的JAR包。到“”网站下载JSTL安装包。 jakarta-taglibs-standard-1.1.2.zip,然后解压下载的JSTL安装包。这时候可以在lib目录下看到两个JAR文件,分别是jstl.jar和standard.jar。其中,jstl.jar文件收录JSTL规范中定义的接口和相关类,standard.jar文件收录用于实现JSTL的.class文件和JSTL中的5个标签库描述符文件(TLD)
将两个jar包导入到我们项目的lib中
使用jsp的taglib指令导入核心标签库
3. JSTL核心库常用标签
1)标签
其中 test 是返回布尔值的条件
2)标签
有两种用法组合:
四、javaEE 开发模型 1. 什么是模式
模式开发过程中总结的“套路”,总结出一套常规的设计模式
2. javaEE体验模式
model1 模式:
技术构成:jsp+javaBean
model1的缺点:业务复杂,jsp页面比较混乱。
model2 模式
技术构成:jsp+servlet+javaBean
model2的优点:利用各个技术擅长的方面进行开发
Servlet:擅长处理java业务代码
jsp:擅长页面的真实性
MVC:----Web开发的设计模式
M:Model---model javaBean:封装的数据
V: View-----view jsp: 只显示页面
C:Controller----Controller Servelt:获取数据-封装数据-传递数据-分配jsp页面显示
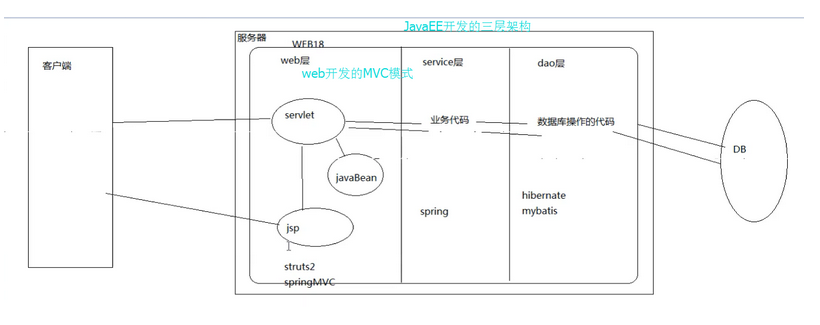
3. JavaEE的三层架构
在服务器开发过程中,分为三层
Web 层:与客户端交互
服务层:复杂的业务处理
dao层:与数据库交互
在开发实践中,三层架构通过包结构体现
MVC 和三层架构是什么关系?
总结:
EL 表达式
从域中检索数据${域中存储的数据的名称}
${pageContext.request.contextPath}
JSTL 标签(核心库)
javaEE 三层架构+MVC
Web层:采集页面数据、封装数据、传输数据、指定响应jsp页面
服务层:编写逻辑业务代码
dao层:数据库访问代码的编译 查看全部
抓取jsp网页源代码(Java开发中常见的JSP技术(一)(组图))
一、JSP 技术 1.jsp 脚本和注释
jsp 脚本:
1) ----- 内部java代码翻译成service方法。
2) ----- 会在service方法里面翻译成out.print()
3) ---- 将翻译成servlet成员的内容
jsp 注释:不同注释的可见范围不同
1)Html 注释:---可见范围jsp源代码,翻译后的servlet,页面显示html源代码
2)java comment://single-line comment /*multi-line comment*/ --可见范围jsp源代码翻译servlet
3)jsp 注释:----- 可见范围 jsp 源码可见
2. jsp-----jsp的运行原理本质上是一个servlet(面试)
jsp在第一次访问时会被web容器翻译成servlet,然后执行
过程:
第一次访问---->helloServlet.jsp---->helloServlet_jsp.java---->编译运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
3. jsp使用说明(三)
JSP 的指令是指导 JSP 翻译和运行的命令。 JSP包括三大指令:
1)页面指令---属性最多的指令(实际开发中页面指令默认)属性最多的指令,根据不同的属性,引导整个页面的特性
格式:
常用属性如下:
language:可以嵌入jsp脚本的语言类型
pageEncoding:当前jsp file-contentType 的编码可以收录在里面
contentType: response.setContentType(text/html;charset=UTF-8)
session:翻译时jsp是否自动创建session
import:导入java包
errorPage:当前页面有错误时跳转到哪个页面
isErrorPage:当前页面为错误处理页面
2)include 指令
页面收录(静态收录)指令,可以将一个jsp页面收录到另一个jsp页面中
格式:
3)taglib 指令
引入jsp页面中的标签库(jstl标签库、struts2标签库)
格式:
4. jsp内置/隐式对象(9)-----笔试
jsp翻译成servlet后,service方法中定义并初始化了9个对象。我们可以在jsp脚本中直接使用这9个对象。
姓名
类型
说明
出
javax.servlet.jsp.JspWriter
用于页面输出
请求
javax.servlet.http.HttpServletRequest
获取用户请求信息,
回复
javax.servlet.http.HttpServletResponse
从服务器到客户端的响应信息
配置
javax.servlet.ServletConfig
服务器配置,可以获取初始化参数
会话
javax.servlet.http.HttpSession
用于保存用户信息
申请
javax.servlet.ServletContext
所有用户的共享信息
页面
java.lang.Object
指的是当前页面转换后的Servlet类的实例
页面上下文
javax.servlet.jsp.PageContext
JSP 页面容器
例外
java.lang.Throwable
表示异常发生在JSP页面,只在错误页面有效
(1)输出对象
输出类型:JspWriter
out的作用是想让客户端输出内容----out.write()
out buffer的默认8kb可以设置为0,表示out buffer的内容被关闭,直接写入响应buffer
(2)pageContext 对象
jsp页面的上下文对象有如下功能:
page 对象和 pageContext 对象不是一回事
1)pageContext 是一个域对象
setAttribute(String name,Object obj)
getAttribute(String name)
removeAttrbute(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(String name,Object obj,int scope)
getAttribute(String name,int scope)
removeAttrbute(String name,int scope)
findAttribute(String name)
---依次从pageContext域、请求域、会话域、应用域获取属性。进入域后,就不会往后看。
四个范围的总结:
pageContext domain:当前jsp页面范围
请求域:一个请求
会话域:一个会话
应用域:整个网络应用
2)你可以得到另外8个隐式对象
例如:pageContext.getRequest()
pageContext.getSession()
5. jsp标签(动作)
1)页面收录(动态收录):
2)请求转发:
静态收录和动态收录的区别?
二、EL 技术 1. EL 表达概述
EL(Express Lanuage)表达式可以嵌入到jsp页面中,减少jsp脚本的编写。 EL的目的是替代jsp页面中脚本的编写。
2. EL从域中取出数据(EL最重要的作用)
jsp 脚本:
EL 表达式替换上面的脚本:${requestScope.name}
EL的主要功能是获取四个域的数据,格式为${EL表达式}
EL 获取 pageContext 字段中的值:${pageScope.key};
EL 获取请求字段中的值:${requestScope.key};
EL 获取 session 字段中的值:${sessionScope.key};
EL 获取应用字段中的值:${applicationScope.key};
EL 从四个字段中获取一个值 ${key};
---同样是从pageContext域、请求域、会话域、应用域依次获取属性。在某个域中获取后,就不会向后看。
3. EL的11个内置对象
pageScope、requestScope、sessionScope、applicationScope----在JSP中获取域中的数据
param,paramValues-接收参数相当于request.getParameter() rquest.getParameterValues()
header,headerValues-获取相当于request.getHeader(name)的请求头信息
initParam-获取等效于this.getServletContext().getInitParameter(name)的全局初始化参数
WEB开发中的cookie-cookie相当于request.getCookies()---cookie.getName()---cookie.getValue()
WEB开发中的pageContext-pageContext。
pageContext 获取其他八个对象
${pageContext.request.contextPath} 相当于这段代码不能实现WEB应用的名字
4. EL 执行表达式
例如:
${1+1}
${空用户}
${user==null?true:false}
一、JSTL 技术 1. JSTL 概述
JSTL(JSP Standard Tag Library),JSP标准标签库,可以嵌入到JSP页面中,以标签的形式完成业务逻辑等功能。 jstl的作用是替换jsp页面中与el相同的脚本代码。 JSTL标准标准标签库有5个子库,但随着发展,目前经常使用核心库
标签库
标签库的URI
前缀
核心
c
I18N
文件
SQL
sql
XML
x
功能
fn
2. JSTL下载导入
JSTL 下载:
从Apache的网站下载JSTL的JAR包。到“”网站下载JSTL安装包。 jakarta-taglibs-standard-1.1.2.zip,然后解压下载的JSTL安装包。这时候可以在lib目录下看到两个JAR文件,分别是jstl.jar和standard.jar。其中,jstl.jar文件收录JSTL规范中定义的接口和相关类,standard.jar文件收录用于实现JSTL的.class文件和JSTL中的5个标签库描述符文件(TLD)

将两个jar包导入到我们项目的lib中
使用jsp的taglib指令导入核心标签库

3. JSTL核心库常用标签
1)标签
其中 test 是返回布尔值的条件
2)标签
有两种用法组合:

四、javaEE 开发模型 1. 什么是模式
模式开发过程中总结的“套路”,总结出一套常规的设计模式
2. javaEE体验模式
model1 模式:
技术构成:jsp+javaBean
model1的缺点:业务复杂,jsp页面比较混乱。
model2 模式
技术构成:jsp+servlet+javaBean
model2的优点:利用各个技术擅长的方面进行开发
Servlet:擅长处理java业务代码
jsp:擅长页面的真实性
MVC:----Web开发的设计模式
M:Model---model javaBean:封装的数据
V: View-----view jsp: 只显示页面
C:Controller----Controller Servelt:获取数据-封装数据-传递数据-分配jsp页面显示
3. JavaEE的三层架构
在服务器开发过程中,分为三层
Web 层:与客户端交互
服务层:复杂的业务处理
dao层:与数据库交互
在开发实践中,三层架构通过包结构体现
MVC 和三层架构是什么关系?
总结:
EL 表达式
从域中检索数据${域中存储的数据的名称}
${pageContext.request.contextPath}
JSTL 标签(核心库)
javaEE 三层架构+MVC
Web层:采集页面数据、封装数据、传输数据、指定响应jsp页面
服务层:编写逻辑业务代码
dao层:数据库访问代码的编译
抓取jsp网页源代码(如何使用后台的JSP程序?(图)程序获取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-12 18:18
)
获取后台的值,比如请求对象,例如:获取权限信息并显示,一段JavaScript代码如下
1)给页面赋值
function initRight()
{
var rights='';
var rightArr = rights.split(",");
var size = rightArr.length;
var obj;
for(var count =0 ; count0)//新增
{
strv =eles[v].replace("Update","Query");
document.getElementById(strv).checked=true;
}
if(tempv.indexOf("update|")>-1)//修改
{
strv =eles[v].replace("update","query");
document.getElementById(strv).checked=true;
}
setValue=true;
}
}
var val=setValue?destVal:"";
$Id(destId).value=val;
}
}
function $name(name){return document.getElementsByName(name);}
function $Id(id){return document.getElementById(id);}
一、如何将页面中的JavaScript数据提交给后台jsp程序
①可以将JavaScript数据以xxx.JSP?var1=aaa&var2=bbb的形式作为URL参数传递给JSP程序,此时在jsp中使用。
可以获取JavaScript脚本传递过来的数据;
②使用JavaScript在表单中添加隐藏字段信息,然后使用表单向JSP程序提交数据。
二、页面中的JavaScript数据如何使用后台JSP程序的数据
这个比较简单。可以直接在JavaScript脚本中使用,将jsp程序中的数据传输到JavaScript脚本中使用。
参考下面的脚本: 查看全部
抓取jsp网页源代码(如何使用后台的JSP程序?(图)程序获取
)
获取后台的值,比如请求对象,例如:获取权限信息并显示,一段JavaScript代码如下
1)给页面赋值
function initRight()
{
var rights='';
var rightArr = rights.split(",");
var size = rightArr.length;
var obj;
for(var count =0 ; count0)//新增
{
strv =eles[v].replace("Update","Query");
document.getElementById(strv).checked=true;
}
if(tempv.indexOf("update|")>-1)//修改
{
strv =eles[v].replace("update","query");
document.getElementById(strv).checked=true;
}
setValue=true;
}
}
var val=setValue?destVal:"";
$Id(destId).value=val;
}
}
function $name(name){return document.getElementsByName(name);}
function $Id(id){return document.getElementById(id);}
一、如何将页面中的JavaScript数据提交给后台jsp程序
①可以将JavaScript数据以xxx.JSP?var1=aaa&var2=bbb的形式作为URL参数传递给JSP程序,此时在jsp中使用。
可以获取JavaScript脚本传递过来的数据;
②使用JavaScript在表单中添加隐藏字段信息,然后使用表单向JSP程序提交数据。
二、页面中的JavaScript数据如何使用后台JSP程序的数据
这个比较简单。可以直接在JavaScript脚本中使用,将jsp程序中的数据传输到JavaScript脚本中使用。
参考下面的脚本:
抓取jsp网页源代码(一下JSP和HTML之间的联系和区别,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-11-12 16:04
JSP 和 HTML 有什么区别?下面的文章文章将简单对比JSP和HTML,让大家了解JSP和HTML的关系和区别,希望对大家有所帮助。
什么是JSP?
JSP 代表 JavaServer Pages;主要用于开发动态网页,文件扩展名为.jsp。JSP 技术允许快速开发和易于维护信息丰富的动态网页。JSP 网页基于 HTML、XML 或其他文档类型。他们还需要兼容的 Web 服务器和 servlet 容器,例如 Apache Tomcat 或 Jetty,才能运行。【视频教程推荐:JSP教程】
JSP 的主要优点是程序员可以在 HTML 中插入 Java 代码;使用 JSP 标签插入 Java 代码。程序员可以写标签。
此外,还有不同的 JSP 标记来完成各种任务。有一些标签可以在请求和页面之间共享数据,在页面之间传递控制,从数据库中获取数据等等。
什么是 HTML?
HTML 代表超文本标记语言。它是一种众所周知的标记语言,用于开发网页并帮助构建网页结构。它已经存在很长时间了,经常用于网页设计。XML 或可扩展标记语言定义了一组规则,用于以人类和计算机可读的格式对文档进行编码。
由于它是一种标记语言,它收录许多标记。使用标签将图像、文本、视频、表单和其他内容插入到一个有凝聚力的网页中。HTML 页面由两个主要部分组成:页眉和正文部分。元数据(描述页面的数据)位于标题中,正文部分包括表示网页可见内容所需的所有标签。
JSP和HTML的关系
JSP 允许在 HTML 文件中插入 Java 代码
JSP 和 HTML 的区别
1、不同的技术
HTML 是一种客户端技术,它提供了一种描述文档中基于文本的信息结构的方法。JSP 是一种服务器端技术,它为不断变化的数据和动态调用服务器操作提供动态接口。
2、生成的页面不一样
HTML 生成静态网页;JSP 生成动态网页。
3、Java 代码插入
HTML 不允许在页面中放置 Java 代码;JSP 允许将 Java 代码放置在 JSP 页面中。
4、函数
HTML 页面强调信息在浏览器中的外观、语义和布局;它有助于创建网页的结构。JSP 页面可以从服务器调用内置函数,这有助于开发动态 Web 应用程序。
5、速度
HTML 在本地计算机上运行时加载速度更快。JSP 需要一些时间来加载,因为它必须与 Web 服务器交互。
综上所述
JSP 和 HTML 的主要区别在于 JSP 是一种创建动态 Web 应用程序的技术,而 HTML 是一种用于创建 Web 页面结构的标准标记语言。简而言之,JSP 文件是带有 Java 代码的 HTML 文件。
以上就是本文文章的全部内容,希望对大家的学习有所帮助。更多精彩内容,可以关注php中文网相关教程专栏!!!
以上就是JSP和HTML区别的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
抓取jsp网页源代码(一下JSP和HTML之间的联系和区别,你知道吗?)
JSP 和 HTML 有什么区别?下面的文章文章将简单对比JSP和HTML,让大家了解JSP和HTML的关系和区别,希望对大家有所帮助。

什么是JSP?
JSP 代表 JavaServer Pages;主要用于开发动态网页,文件扩展名为.jsp。JSP 技术允许快速开发和易于维护信息丰富的动态网页。JSP 网页基于 HTML、XML 或其他文档类型。他们还需要兼容的 Web 服务器和 servlet 容器,例如 Apache Tomcat 或 Jetty,才能运行。【视频教程推荐:JSP教程】
JSP 的主要优点是程序员可以在 HTML 中插入 Java 代码;使用 JSP 标签插入 Java 代码。程序员可以写标签。

此外,还有不同的 JSP 标记来完成各种任务。有一些标签可以在请求和页面之间共享数据,在页面之间传递控制,从数据库中获取数据等等。
什么是 HTML?
HTML 代表超文本标记语言。它是一种众所周知的标记语言,用于开发网页并帮助构建网页结构。它已经存在很长时间了,经常用于网页设计。XML 或可扩展标记语言定义了一组规则,用于以人类和计算机可读的格式对文档进行编码。
由于它是一种标记语言,它收录许多标记。使用标签将图像、文本、视频、表单和其他内容插入到一个有凝聚力的网页中。HTML 页面由两个主要部分组成:页眉和正文部分。元数据(描述页面的数据)位于标题中,正文部分包括表示网页可见内容所需的所有标签。

JSP和HTML的关系
JSP 允许在 HTML 文件中插入 Java 代码
JSP 和 HTML 的区别
1、不同的技术
HTML 是一种客户端技术,它提供了一种描述文档中基于文本的信息结构的方法。JSP 是一种服务器端技术,它为不断变化的数据和动态调用服务器操作提供动态接口。
2、生成的页面不一样
HTML 生成静态网页;JSP 生成动态网页。
3、Java 代码插入
HTML 不允许在页面中放置 Java 代码;JSP 允许将 Java 代码放置在 JSP 页面中。
4、函数
HTML 页面强调信息在浏览器中的外观、语义和布局;它有助于创建网页的结构。JSP 页面可以从服务器调用内置函数,这有助于开发动态 Web 应用程序。
5、速度
HTML 在本地计算机上运行时加载速度更快。JSP 需要一些时间来加载,因为它必须与 Web 服务器交互。
综上所述
JSP 和 HTML 的主要区别在于 JSP 是一种创建动态 Web 应用程序的技术,而 HTML 是一种用于创建 Web 页面结构的标准标记语言。简而言之,JSP 文件是带有 Java 代码的 HTML 文件。
以上就是本文文章的全部内容,希望对大家的学习有所帮助。更多精彩内容,可以关注php中文网相关教程专栏!!!
以上就是JSP和HTML区别的详细内容。更多详情请关注其他相关php中文网站文章!

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
抓取jsp网页源代码(一个SSM对象的格式及html及controller代码的解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-11 11:14
最近搭建了一个SSM框架,但是前台页面是html,所以无法使用JSP标签集来获取数据,但是可以获取到数据,但是无法在页面上显示。 ajax加了这么一行代码,问题完美解决。
var retData = eval("(" + data + ")");
上面代码的意思是把获取到的数据转换成json对象的格式,然后就可以得到你想要的数据了。 所谓json对象的格式,是指后台返回给前台的数据是一个json字符串。我们无法在页面上的object.name 方法中获取数据,因为它是一个字符串,我们无法点击该方法。这时候,我们就需要将字符串转换成json对象,然后用json对象来指出属性(但有时不加这行代码就可以取出来)。其实判断数据是json字符串还是json对象很简单。如果数据警报(data)在弹出框中显示为Object,则为对象,其他数据会直接显示。 html 和控制器代码附在下面。
html
$(function () {
alert("页面加载完成后自动运行函数............");
// 全局页面加载函数,就是,页面完全加载完成后,js就自动发送请求到后台查询数据
// 所以就是ajax的几种发送方式,
// 即,直接写 $.get(),$.post(),$.ajax()等
/* // 基本功能菜单加载
$.post("/mavenweb/customer/ht.do",function(data){
// var retData = eval("(" + data + ")");
alert(data);
$("#username").val(data.cust_name);
$("#address").val(data.cust_address);
},"json");*/
$.ajax({
type:"get",
url:"/mavenweb/customer/ht.do",
dateType:"json",
success:function (data) {
var retData = eval("(" + data + ")");
$("#username").val(retData.cust_name);
$("#address").val(retData.cust_address);
}
});
});
controller:@ResponseBody 这个注解会自动帮我们转换java对象和json格式
@RequestMapping("/customer/ht")
@ResponseBody
public Customer htm(HttpServletResponse response) throws Exception{
Customer customer = customerService.getCustomer();
System.out.print("html..............");
return customer;
}
附件:jquery函数的全局事件,然后前端加载页面后(各种样式等),然后js发送请求,加载数据
效果:打开页面后直接显示数据。
其实前端页面就是在加载了CSS样式、图片、引用文件等之后执行js函数。 查看全部
抓取jsp网页源代码(一个SSM对象的格式及html及controller代码的解决方法)
最近搭建了一个SSM框架,但是前台页面是html,所以无法使用JSP标签集来获取数据,但是可以获取到数据,但是无法在页面上显示。 ajax加了这么一行代码,问题完美解决。
var retData = eval("(" + data + ")");
上面代码的意思是把获取到的数据转换成json对象的格式,然后就可以得到你想要的数据了。 所谓json对象的格式,是指后台返回给前台的数据是一个json字符串。我们无法在页面上的object.name 方法中获取数据,因为它是一个字符串,我们无法点击该方法。这时候,我们就需要将字符串转换成json对象,然后用json对象来指出属性(但有时不加这行代码就可以取出来)。其实判断数据是json字符串还是json对象很简单。如果数据警报(data)在弹出框中显示为Object,则为对象,其他数据会直接显示。 html 和控制器代码附在下面。
html
$(function () {
alert("页面加载完成后自动运行函数............");
// 全局页面加载函数,就是,页面完全加载完成后,js就自动发送请求到后台查询数据
// 所以就是ajax的几种发送方式,
// 即,直接写 $.get(),$.post(),$.ajax()等
/* // 基本功能菜单加载
$.post("/mavenweb/customer/ht.do",function(data){
// var retData = eval("(" + data + ")");
alert(data);
$("#username").val(data.cust_name);
$("#address").val(data.cust_address);
},"json");*/
$.ajax({
type:"get",
url:"/mavenweb/customer/ht.do",
dateType:"json",
success:function (data) {
var retData = eval("(" + data + ")");
$("#username").val(retData.cust_name);
$("#address").val(retData.cust_address);
}
});
});
controller:@ResponseBody 这个注解会自动帮我们转换java对象和json格式
@RequestMapping("/customer/ht")
@ResponseBody
public Customer htm(HttpServletResponse response) throws Exception{
Customer customer = customerService.getCustomer();
System.out.print("html..............");
return customer;
}
附件:jquery函数的全局事件,然后前端加载页面后(各种样式等),然后js发送请求,加载数据
效果:打开页面后直接显示数据。
其实前端页面就是在加载了CSS样式、图片、引用文件等之后执行js函数。
抓取jsp网页源代码(想要爬取指定网页中的图片主要需要以下三个步骤(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-11-04 21:18
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2) 根据你要爬取的内容设置正则表达式匹配你要爬取的内容
(3)设置循环列表,反复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
# 第一个简单的爬取图片的程序
import urllib.request # python自带的爬操作url的库
import re # 正则表达式
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
"User-Agent": "Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N)
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36"
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode("UTF-8")
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# [^s]*? 表示最小匹配, 两个括号表示列表中有两个元组
# imageList = re.findall(r"(https:[^s]*?(png))"", page)
imageList = re.findall(r"(https:[^s]*?(jpg|png|gif))"", page)
x = 0
# 循环列表
for imageUrl in imageList:
try:
print("正在下载: %s" % imageUrl[0])
# 这个image文件夹需要先创建好才能看到结果
image_save_path = "./image/%d.png" % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(imageUrl[0], image_save_path)
x = x + 1
except:
continue
pass
if __name__ == "__main__":
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
# print(page)
注意代码中需要修改的是 imageList = re.findall(r"(https:[^s]*?(jpg|png|gif))"", page) 这一段内容,如何设计正则表达式需要根据你要爬取的内容设置,我的设计源码如下:
可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r"(https:[^s]*?(png))"", page)。
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
import urllib # python自带的爬操作url的库
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
"User-Agent": "Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N)
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36"
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode("UTF-8")
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# 按照html格式解析页面
soup = BeautifulSoup(page, "html.parser")
# 格式化输出DOM树的内容
print(soup.prettify())
# 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
imgList = soup.find_all("img")
x = 0
# 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
for imgUrl in imgList[1:]:
print("正在下载: %s " % imgUrl.get("src"))
# 得到scr的内容,这里返回的就是Url字符串链接,如"https://img2020.cnblogs.com/bl ... ot%3B
image_url = imgUrl.get("src")
# 这个image文件夹需要先创建好才能看到结果
image_save_path = "./image/%d.png" % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(image_url, image_save_path)
x = x + 1
if __name__ == "__main__":
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。它更简洁明了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持云海天教程。
原文链接: 查看全部
抓取jsp网页源代码(想要爬取指定网页中的图片主要需要以下三个步骤(1))
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2) 根据你要爬取的内容设置正则表达式匹配你要爬取的内容
(3)设置循环列表,反复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
# 第一个简单的爬取图片的程序
import urllib.request # python自带的爬操作url的库
import re # 正则表达式
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
"User-Agent": "Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N)
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36"
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode("UTF-8")
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# [^s]*? 表示最小匹配, 两个括号表示列表中有两个元组
# imageList = re.findall(r"(https:[^s]*?(png))"", page)
imageList = re.findall(r"(https:[^s]*?(jpg|png|gif))"", page)
x = 0
# 循环列表
for imageUrl in imageList:
try:
print("正在下载: %s" % imageUrl[0])
# 这个image文件夹需要先创建好才能看到结果
image_save_path = "./image/%d.png" % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(imageUrl[0], image_save_path)
x = x + 1
except:
continue
pass
if __name__ == "__main__":
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
# print(page)
注意代码中需要修改的是 imageList = re.findall(r"(https:[^s]*?(jpg|png|gif))"", page) 这一段内容,如何设计正则表达式需要根据你要爬取的内容设置,我的设计源码如下:

可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r"(https:[^s]*?(png))"", page)。
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
import urllib # python自带的爬操作url的库
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
"User-Agent": "Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N)
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36"
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode("UTF-8")
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# 按照html格式解析页面
soup = BeautifulSoup(page, "html.parser")
# 格式化输出DOM树的内容
print(soup.prettify())
# 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
imgList = soup.find_all("img")
x = 0
# 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
for imgUrl in imgList[1:]:
print("正在下载: %s " % imgUrl.get("src"))
# 得到scr的内容,这里返回的就是Url字符串链接,如"https://img2020.cnblogs.com/bl ... ot%3B
image_url = imgUrl.get("src")
# 这个image文件夹需要先创建好才能看到结果
image_save_path = "./image/%d.png" % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(image_url, image_save_path)
x = x + 1
if __name__ == "__main__":
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。它更简洁明了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持云海天教程。
原文链接:
抓取jsp网页源代码(,怎样利用网站的源代码快速做网站?有实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-04 21:13
这个要看源码是用什么语言写的,如果是html语言,直接打开index.html就可以了。如果是asp,jsp什么的,那么就需要配置iis服务器来运行程序,其中iis就是添加和删除程序,添加和删除windows组件。然后选择internet信息服务,但需要有windows安装光盘,也可以到网上找iis5.1下载。如果使用visuo2005制作.net网站,需要先发布网站,然后点击运行。我暂时只知道这些类型。
这道题是最基本的建站知识,需要搜索相关知识,再问更详细的问题。
给大家简单说明:下载源码后,上传到虚拟主机(不要问我虚拟主机是什么),然后按照安装提示安装源码,绑定域名(你的域名应该是准备好了),@网站 就可以运行了。
现在网站做起来容易,但做搜索引擎喜欢、用户体验好的网站就难了。
修改调试好,保证可以使用。将文件上传到空间。
您可以使用自己的域名访问刚刚上传的站点。
---------------
建议创建一个单页的.html,上传到空间查看。可以通过域名访问吗?
确保域名解析正确。.
下载源代码
使用DREAMWEAVER之类的工具对其进行修改,例如将LOGO修改为您的等等。
在您自己的计算机上安装 IIS
测试本机的URL是否正常。
然后申请一个空间和域名(也有免费的)
上传所有文件网站
完成它
如何用下载的源码做网站:一般都是网上下载的网站程序写的,换个自己喜欢的风格,不用改就可以用,把网站 将源文件上传到主机或使用自己的PC作为主机,直接运行即可,
如何利用网站的源码快速做网站?最好有例子和详细步骤。:对于这么多的广告客户,我只是下载源代码然后......用FTP上传工具上传你的空间/WEB几乎形成。然后看看有什么问题,继续修改替换原来的文件。这是我慢慢做的,希望对你有帮助。
下载源码后,如何生成网站-:如果是网上下载的源码,那么可以直接上传到服务器,自己编写,直接上传即可。
怎么用下载的源码做网站,请写明细节,200分都给了: 一、从源站下载一个和你想要的类似的源码网站 全网站源代码。告诉你一个好的源码站点:ASP Concentration Camp()。下载后在本机用IIS浏览,看看前后台功能是否完善。最好登录后台进行添加和修改操作。如果后台功能完善,那么你可以...
使用下载的源代码制作网页:网站的动态源代码,如asp、php、jsp,无法通过访问页面下载。网上唯一能做的就是批量抓取这个网站 静态网页的爬虫工具有很多。比如仿站小工具,webzip之类的,可以快速抓取静态网页,但是很难捕获json格式。如果你一定需要动态代码,除非你入侵服务器,当然你也可以判断对方网站是否是网上可以下载的开源程序。如果是,那很简单。
如何使用源码制作自己的网站 比如我想做一个购物网站,如何使用源码:下载购物网站,用网页打开-制作工具查看源代码
使用下载的源代码制作网页——:
怎么用网上的源码做生意网站:你好!直接复制代码到DW代码设计视图中....我的回答你满意吗~~
如何使用下载的网站源代码:将源文件传输到你的服务器,设置IIS,在浏览器中输入地址,就可以访问你的网站或者在本机上安装测试学习
我用网上下载的源代码创建了一个网站。我已经上传了虚拟空间。然后我想自己修改它。我该怎么办?从所谓的后台...:你要修改源进程,最好在本地修改并上传。如果使用织梦Dedecms,可以在后台进入,在文件管理器中编辑文件。在后台输入您的域名/dede 查看全部
抓取jsp网页源代码(,怎样利用网站的源代码快速做网站?有实例)
这个要看源码是用什么语言写的,如果是html语言,直接打开index.html就可以了。如果是asp,jsp什么的,那么就需要配置iis服务器来运行程序,其中iis就是添加和删除程序,添加和删除windows组件。然后选择internet信息服务,但需要有windows安装光盘,也可以到网上找iis5.1下载。如果使用visuo2005制作.net网站,需要先发布网站,然后点击运行。我暂时只知道这些类型。
这道题是最基本的建站知识,需要搜索相关知识,再问更详细的问题。
给大家简单说明:下载源码后,上传到虚拟主机(不要问我虚拟主机是什么),然后按照安装提示安装源码,绑定域名(你的域名应该是准备好了),@网站 就可以运行了。
现在网站做起来容易,但做搜索引擎喜欢、用户体验好的网站就难了。
修改调试好,保证可以使用。将文件上传到空间。
您可以使用自己的域名访问刚刚上传的站点。
---------------
建议创建一个单页的.html,上传到空间查看。可以通过域名访问吗?
确保域名解析正确。.
下载源代码
使用DREAMWEAVER之类的工具对其进行修改,例如将LOGO修改为您的等等。
在您自己的计算机上安装 IIS
测试本机的URL是否正常。
然后申请一个空间和域名(也有免费的)
上传所有文件网站
完成它
如何用下载的源码做网站:一般都是网上下载的网站程序写的,换个自己喜欢的风格,不用改就可以用,把网站 将源文件上传到主机或使用自己的PC作为主机,直接运行即可,
如何利用网站的源码快速做网站?最好有例子和详细步骤。:对于这么多的广告客户,我只是下载源代码然后......用FTP上传工具上传你的空间/WEB几乎形成。然后看看有什么问题,继续修改替换原来的文件。这是我慢慢做的,希望对你有帮助。
下载源码后,如何生成网站-:如果是网上下载的源码,那么可以直接上传到服务器,自己编写,直接上传即可。
怎么用下载的源码做网站,请写明细节,200分都给了: 一、从源站下载一个和你想要的类似的源码网站 全网站源代码。告诉你一个好的源码站点:ASP Concentration Camp()。下载后在本机用IIS浏览,看看前后台功能是否完善。最好登录后台进行添加和修改操作。如果后台功能完善,那么你可以...
使用下载的源代码制作网页:网站的动态源代码,如asp、php、jsp,无法通过访问页面下载。网上唯一能做的就是批量抓取这个网站 静态网页的爬虫工具有很多。比如仿站小工具,webzip之类的,可以快速抓取静态网页,但是很难捕获json格式。如果你一定需要动态代码,除非你入侵服务器,当然你也可以判断对方网站是否是网上可以下载的开源程序。如果是,那很简单。
如何使用源码制作自己的网站 比如我想做一个购物网站,如何使用源码:下载购物网站,用网页打开-制作工具查看源代码
使用下载的源代码制作网页——:
怎么用网上的源码做生意网站:你好!直接复制代码到DW代码设计视图中....我的回答你满意吗~~
如何使用下载的网站源代码:将源文件传输到你的服务器,设置IIS,在浏览器中输入地址,就可以访问你的网站或者在本机上安装测试学习
我用网上下载的源代码创建了一个网站。我已经上传了虚拟空间。然后我想自己修改它。我该怎么办?从所谓的后台...:你要修改源进程,最好在本地修改并上传。如果使用织梦Dedecms,可以在后台进入,在文件管理器中编辑文件。在后台输入您的域名/dede
抓取jsp网页源代码(大数据技术原理与应用数据可视化之互联网品牌形象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-04 02:10
简单的介绍
学期末复习材料。网页设计(也称Web UI设计、WUI设计、WUI)是以公司希望传递给浏览者的信息(包括产品、服务、理念、文化)为基础,然后实现网站功能规划,然后进行页面设计和美化工作。作为公司对外宣传材料之一,精美的网页设计对于提升公司互联网品牌形象至关重要。
过去的问题文章
大数据技术原理及应用
数据可视化
文章内容
可选的 - - - - - - - - - - - - - - - - - - - - - - - - - ----------可选 1 颜色的 4 个角色 2 网页中使用的视觉元素 3 颜色抖动
216种安全色已出,需要插值
4 配色原理 5 www的三个统一 6 什么是www服务
万维网(全球信息网)是一种超文本信息查询工具,通过http协议传输超文本信息。同时将不同网站的相关数据信息有机汇总在一起,通过浏览器提供友好的信息查询界面。
7 域名的一些概念,包括域名的作用
域名与主机的关系:多对一
将域名发送到DNS服务器解析Web服务器的ip地址进行连接,将域名信息发送给Web服务器,通过域名与主机设置的“主机头”进行匹配,确认请求的是哪个客户端网络服务器网站 。
8 与ip相关的概念(ip与域名的关系)
IP地址和域名是一对多的关系。一个ip地址可以对应多个域名,但是一个域名只有一个ip地址。ip地址是由数字组成的,不容易记住,所以有了域名,通过域名地址就可以查到ip地址。
9 如何规划网站
需要从三个方面思考
这哪一方面是相互影响和互动
10 div+css布局的优点 11 div+css布局与table的对比
从四个方面考虑
布局方法:
控件元素占用的页面大小:
控件元素在页面上的位置:
图片位置:
动态网页的12条原则
动态网页收录服务器代码,需要由Web服务器解释执行,生成客户端代码,然后发送到客户端浏览器
13 动态网页的执行过程(process) 浏览器向网络中的WEB服务器发送请求,指向一个动态网页。WEB服务器收到请求信号后,将网页发送给应用服务器。应用服务器向数据库驱动发送查询指令。数据库驱动程序查询数据库。记录集返回给数据库驱动程序。然后驱动程序将记录集发送到应用程序服务器。应用服务器将数据插入到网页中,此时动态网页就变成了普通网页。应用服务器在网页中查找应用服务器。WEB服务器将完成的普通网页发送回浏览器
.
15 动态网页和静态网页的区别ppt答案+这个答案
静态网页:是纯HTML页面,页面内容固定不变。用 HTML、CSS 和 JavaScript 编写的网页。文件扩展名是 .html 或 .htm。每个静态网页文件都存储在 网站 服务器上。每个网页都是一个独立的文件,内容相对稳定。静态网页一般没有数据库支持,所以网站的制作和维护工作量很大。
动态网页:网页中的内容会根据用户的要求显示不同的内容,采用PHP、JSP、ASP、CGI程序动态生成的网页。文件扩展名为 .asp、.jsp、.php、.cgi 等。
16 种常见图片格式和功能
常见的图像格式有 JPG、GIF 和 PNG。这三种都是压缩图像格式,容量小,适合网络传输。
17 什么是表单元素(待修改)
文本框、密码框、单选按钮、复选框
form:定义用户输入的表单。字段集:定义字段。即,文本的边框被添加到输入区域。图例:定义域的标题,即边框上的文字。label:定义控制标签。比如输入框前的文字,用来关联用户的选择。input:定义输入字段,常用。type 属性可以设置为具有不同的功能。text:单行文本输入框,框的长度可以由正整数大小控制。密码:密码输入框。radio:单选按钮,同组的单选按钮必须同名。checkbox:复选框,同一组中的单选按钮必须具有相同的名称。按钮:普通按钮。submit:提交按钮,每次出现都会创建一个Submit对象。重置:重置按钮,它将重置当前表单中的所有内容。image:以图片形式提交按钮,写成“”。hidden:隐藏字段,隐藏字段对用户不可见。textarea:定义一个文本区域(一个多行输入控件),默认可以通过鼠标拖动来调整大小。按钮:定义一个按钮。select:定义一个选择列表,即下拉列表。option:定义下拉列表中的选项。19 网页中传递变量的方法 在下拉列表中定义选项。19 网页中传递变量的方法 在下拉列表中定义选项。19 网页中传递变量的方法
POST、GET、SESSION、COOKIE、隐藏表单元素、表单隐藏字段
20 404的原因很简单,就是找不到服务器(网页)
简单的说就是找不到服务器(网页)
22 Cascading style sheet(css样式表)HTML中引入css的方法
HTML和CSS是两种功能不同的语言。它们同时对网页产生影响。必须使用某些方法将 CSS 和 HTML 链接在一起。
在 HTML 中,引入 CSS 的方法有
23div+css布局(盒子模型)常用属性
盒模型是 CSS 的基石之一。这个框由元素内容、内边距、边框和边框组成。border 属性填充 padding 属性和 margin 属性
24 什么是 JavaScript 对象?自定义对象
var 大学 = new Object()。
JavaScript 内置对象,例如 Date、Math、Array 等。例如:
今天 var = new Date();
事实上,JavaScript 中的所有数据类型都是它的内置对象。
浏览器对象
浏览器提供的内置对象,如窗口、文档、位置等。
26php语法题
1.PHP文件代码可以收录以下三部分
HTML 和 CSS;
客户端脚本,位于之间;
服务器端脚本,位于“”之间(分隔符,表示脚本的开始和结束)
2 以h1标题的形式输出当前日期和时间
//------------------------
表示HTML代码
表示php代码
单引号''表示是字符串常量
“.” 表示字符串连接符
echo是php是输出函数
date()是时间函数,可以按照格式获取当前日期和时间
3 在网络上输出不同大小的字体
echo '<p>PHP代码和HTML代码可相互嵌套';
for($i=3;$i 查看全部
抓取jsp网页源代码(大数据技术原理与应用数据可视化之互联网品牌形象)
简单的介绍
学期末复习材料。网页设计(也称Web UI设计、WUI设计、WUI)是以公司希望传递给浏览者的信息(包括产品、服务、理念、文化)为基础,然后实现网站功能规划,然后进行页面设计和美化工作。作为公司对外宣传材料之一,精美的网页设计对于提升公司互联网品牌形象至关重要。
过去的问题文章
大数据技术原理及应用
数据可视化
文章内容
可选的 - - - - - - - - - - - - - - - - - - - - - - - - - ----------可选 1 颜色的 4 个角色 2 网页中使用的视觉元素 3 颜色抖动
216种安全色已出,需要插值
4 配色原理 5 www的三个统一 6 什么是www服务
万维网(全球信息网)是一种超文本信息查询工具,通过http协议传输超文本信息。同时将不同网站的相关数据信息有机汇总在一起,通过浏览器提供友好的信息查询界面。
7 域名的一些概念,包括域名的作用
域名与主机的关系:多对一
将域名发送到DNS服务器解析Web服务器的ip地址进行连接,将域名信息发送给Web服务器,通过域名与主机设置的“主机头”进行匹配,确认请求的是哪个客户端网络服务器网站 。
8 与ip相关的概念(ip与域名的关系)
IP地址和域名是一对多的关系。一个ip地址可以对应多个域名,但是一个域名只有一个ip地址。ip地址是由数字组成的,不容易记住,所以有了域名,通过域名地址就可以查到ip地址。
9 如何规划网站
需要从三个方面思考
这哪一方面是相互影响和互动
10 div+css布局的优点 11 div+css布局与table的对比
从四个方面考虑
布局方法:
控件元素占用的页面大小:
控件元素在页面上的位置:
图片位置:
动态网页的12条原则
动态网页收录服务器代码,需要由Web服务器解释执行,生成客户端代码,然后发送到客户端浏览器
13 动态网页的执行过程(process) 浏览器向网络中的WEB服务器发送请求,指向一个动态网页。WEB服务器收到请求信号后,将网页发送给应用服务器。应用服务器向数据库驱动发送查询指令。数据库驱动程序查询数据库。记录集返回给数据库驱动程序。然后驱动程序将记录集发送到应用程序服务器。应用服务器将数据插入到网页中,此时动态网页就变成了普通网页。应用服务器在网页中查找应用服务器。WEB服务器将完成的普通网页发送回浏览器
.
15 动态网页和静态网页的区别ppt答案+这个答案
静态网页:是纯HTML页面,页面内容固定不变。用 HTML、CSS 和 JavaScript 编写的网页。文件扩展名是 .html 或 .htm。每个静态网页文件都存储在 网站 服务器上。每个网页都是一个独立的文件,内容相对稳定。静态网页一般没有数据库支持,所以网站的制作和维护工作量很大。
动态网页:网页中的内容会根据用户的要求显示不同的内容,采用PHP、JSP、ASP、CGI程序动态生成的网页。文件扩展名为 .asp、.jsp、.php、.cgi 等。
16 种常见图片格式和功能
常见的图像格式有 JPG、GIF 和 PNG。这三种都是压缩图像格式,容量小,适合网络传输。
17 什么是表单元素(待修改)
文本框、密码框、单选按钮、复选框
form:定义用户输入的表单。字段集:定义字段。即,文本的边框被添加到输入区域。图例:定义域的标题,即边框上的文字。label:定义控制标签。比如输入框前的文字,用来关联用户的选择。input:定义输入字段,常用。type 属性可以设置为具有不同的功能。text:单行文本输入框,框的长度可以由正整数大小控制。密码:密码输入框。radio:单选按钮,同组的单选按钮必须同名。checkbox:复选框,同一组中的单选按钮必须具有相同的名称。按钮:普通按钮。submit:提交按钮,每次出现都会创建一个Submit对象。重置:重置按钮,它将重置当前表单中的所有内容。image:以图片形式提交按钮,写成“”。hidden:隐藏字段,隐藏字段对用户不可见。textarea:定义一个文本区域(一个多行输入控件),默认可以通过鼠标拖动来调整大小。按钮:定义一个按钮。select:定义一个选择列表,即下拉列表。option:定义下拉列表中的选项。19 网页中传递变量的方法 在下拉列表中定义选项。19 网页中传递变量的方法 在下拉列表中定义选项。19 网页中传递变量的方法
POST、GET、SESSION、COOKIE、隐藏表单元素、表单隐藏字段
20 404的原因很简单,就是找不到服务器(网页)
简单的说就是找不到服务器(网页)
22 Cascading style sheet(css样式表)HTML中引入css的方法
HTML和CSS是两种功能不同的语言。它们同时对网页产生影响。必须使用某些方法将 CSS 和 HTML 链接在一起。
在 HTML 中,引入 CSS 的方法有
23div+css布局(盒子模型)常用属性
盒模型是 CSS 的基石之一。这个框由元素内容、内边距、边框和边框组成。border 属性填充 padding 属性和 margin 属性
24 什么是 JavaScript 对象?自定义对象
var 大学 = new Object()。
JavaScript 内置对象,例如 Date、Math、Array 等。例如:
今天 var = new Date();
事实上,JavaScript 中的所有数据类型都是它的内置对象。
浏览器对象
浏览器提供的内置对象,如窗口、文档、位置等。
26php语法题
1.PHP文件代码可以收录以下三部分
HTML 和 CSS;
客户端脚本,位于之间;
服务器端脚本,位于“”之间(分隔符,表示脚本的开始和结束)
2 以h1标题的形式输出当前日期和时间
//------------------------
表示HTML代码
表示php代码
单引号''表示是字符串常量
“.” 表示字符串连接符
echo是php是输出函数
date()是时间函数,可以按照格式获取当前日期和时间
3 在网络上输出不同大小的字体
echo '<p>PHP代码和HTML代码可相互嵌套';
for($i=3;$i
抓取jsp网页源代码(Ajax动态分析待抓取的微博内容:准备工作:安装好requests库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-03 02:14
Ajax动态分析待抓取微博内容:准备:安装requests库和lxml库
输入cmd
pip install requests
pip install lxml
因为我之前安装过这两个库,所以这里安装的时候会显示下图的内容:
分析网页
打开Chrome浏览器,我们输入这个网站:。右击选择查看网页源代码。这时候我们会发现,我们在首页看到的文字内容,在网页的源代码中并没有显示出来。这意味着网页是由 Ajax 动态加载的。(下图左边是我能看到的网页,右边是网页的源代码)
我们在右边随机选择一段内容,在左边搜索,没有任何结果。在这里,我们以“人间烟火,香饽饽”来寻找栗子:
我们看到我们搜索的内容并没有出现在源码中,所以网页是通过Ajax动态加载的。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时保证页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,必须刷新整个页面,而使用Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行数据交互。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
你可以在W3School上体验几个例子来感受一下:。
其实很多网页都是这样的。我们将继续向下滑动网页,并会不断刷新和加载我们眼前的新内容。
既然我们已经知道它是用 Ajax 动态加载的,那么我们来分析一下它是如何交换数据的。
右击选择Check(或按键盘F12)进入开发者模式。网页的样式展现在我们眼前。
在Elements中,我们可以看到网页的源码,右边是节点的内容,但这不是我们想要的。如果我们按照常规的网页请求,提取网页标签中的数据,就得不到我们想要的内容。.
我们进入Network,在Network下选择XHR,我们会看到如下内容(第一次进入,没有该内容,刷新页面即可):
随着我们继续滚动鼠标滚轮,XHR下加载的内容越来越多,我们会在getIndex的开头看到一个请求,点击查看其详细信息
我们看到Request Headers里面有个参数是X-Requested-With:XMLHttpRequest。通过这个参数,我们可以更加确定它是由Ajax动态加载的。然后点击Headers旁边的Preview,里面的数据是json(类似于python字典的字符串)格式。
点击卡片,卡片下有10条内容,我们到下面9条内容中的mblog一一查看,会发现微博正文中收录的文字收录在raw_text中
(其实这个请求中也收录了图片,想要下载图片的游客可以自行研究图片链接)。现在我们已经找到了我们想要的东西,让我们开始编写错误,“抓住”这些词并将它们放入我们的“口袋”中。
请求数据
我们使用requests.get(url)来请求网页,因为我们要请求的网页不是开头给出的网页,而是我们分析后发现的Ajax网页请求。所以我们真正要求的应该是这个网页%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=66624,打开这个页面我们你会发现里面有密密麻麻的字符和数字。我们可以在浏览器中找到一个json数据在线解析网址。这个还好。将上面网页的内容复制到json网页,我们就可以看到整齐的json数据了。很像python中的字典格式。
在 jupyter 中写这个:
response = requests.get('https://m.weibo.cn/api/container/getIndex?uid=1742566624&t=0&luicode=10000011&lfid=100103type%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=1076031742566624')
if response.status_code == 200:
html = response.json()
我们直接将其转成json格式,在jupyter中打印出来,随时查看网页返回的信息是什么样子的。(爬虫、数据分析等推荐使用jupyter,方便随时查看结果)
运行上面的代码并得到以下输出:
不难发现,这个数据和我们在Preview中看到的数据是一样的,说明我们得到的就是我们想要的数据。接下来,我们需要从这个字典中提取微博文本的内容。NS。代码显示如下:
get_details = html.get('data').get('cards')
for i in range(len(get_details)):
text = get_details[i].get('mblog').get('raw_text').strip()
print(text)
操作结果如下:
由于cards是一个列表,收录十条数据,我们使用for循环遍历整个列表并提取数据。因为我们返回的数据是字典类型的,所以我们可以直接使用get来提取数据。或者根据键值对索引(推荐get,如果当前没有key,索引会报错,get返回空值,不会阻止程序失败)。这样,我们从“第一页”中提取了十条数据,但是这样的数据量往往不能满足我们的需求。
获取多页数据
如果我们把每个网页都复制粘贴到我们的脚本中,10个可能的问题都不算大。首先找到getIndex,然后将网页复制粘贴到脚本中。一共三个步骤,10个网页是30个步骤。但是 100 页呢?这时候处理起来就比较麻烦了。所以我们需要找到一个“好方法”来构建网页,让脚本本身去“查找网页”→“复制”→“粘贴”“查找网页”\rightarrow“复制”\rightarrow“粘贴”“查找网页” “→”复制”→“粘贴”,一般我们可以把这种重复的工作交给程序来完成。所以我们现在要做的就是“教”我们的爬虫脚本来做到这一点。
回顾我们请求的页面: %3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=66624 这是我们的第一页请求,让我们看看我们要请求的第二个页面看起来像: %3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7 %84%A6&type=uid&value= 1742566624&containerid=66624&since_id=45596。第二个网页似乎与第一个网页不同。它比第一个网页有一个小尾巴 since_id。其实我们再看第三、第四、第五……从第二个开始的网页,它们都有一个since_id的参数,所以我们只需要在后面的每个网页上加上一个since_id的参数第一个网页的基础。但是好像每个网页对应的since_id都不一样,所以如果要调侃的话,它似乎不起作用。但是,它的网页毕竟是人写的,不是上帝创造的,所以它的since_id肯定是我们聪明的小脑袋“创造”出来的。
由于这个网页的since_id要被浏览器捕获,不断请求下一页的数据,我们自己找出这个since_id并不难。
果然,我们可以在json数据的cardlistInfo中找到一个since_id的key
让我们将这个since_id 与下一个网页中的since_id 进行比较。这是相同的。(我这里截取的是首页的since_id,这个since_id也会随着时间的推移而变化,访问者看到的和我的不一样,正常),我们使用get获取since_id就像提取文本信息一样。既然找到了这个since_id的构造规则,就可以请求多页网页数据了。只要我们教我们的爬虫脚本如何使用我们为它找到的since_id来构建网页,它就可以不断地获取网页。内容也是。
构建网页的代码如下:
def group_url(since_id):
params = {
'since_id':since_id
}
url = base_url + '&' + urlencode(params)
return url
urlencode是urllib.parse中的方法,下面是官方文档:
函数中传入的since_id就是我们为爬虫找到的since_id。然后我们把构造好的网页返回给网页请求函数,解析提取我们想要的内容和sinance_id,这样我们就可以一直循环下去了。
存储数据
编写爬虫不应该只是为了爬取数据,如果我们下次要使用这些数据,再次爬取,那会很麻烦,所以我们“隐藏”了我们从网上“偷”出来的东西。起来。这里我们使用记事本来保存这些文本数据(当然也可以写入数据库,有兴趣的读者可以自行上网搜索写入数据库的操作)。保存数据的代码如下:
def write_title():
title = '思想聚焦的微博正文'
with open('blog.txt','w',encoding = 'utf-8') as f:
f.write(title + '\n')
f.write('\n')
def write_infos(txt):
with open('blog.txt','a',newline='\n',encoding = 'utf-8') as f:
f.write(txt)
f.write('\n')
因为我们这里抓取的是思维聚焦微博文章,标题写的是“思维聚焦微博正文”,然后每一行都留空(这样看起来更整洁)。参数 newline 这就是它的作用。
至此,我们的爬虫已经写完了。有兴趣的话,可以做词云图,做情感分析等等……
完整代码:
import requests
import json, time
from lxml import etree
from urllib.parse import urlencode
base_url = """https://m.weibo.cn/api/contain ... 00011
&lfid=100103type%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=1076031742566624"""
HEADERS = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
"X-Requested-With":"XMLHttpRequest",
"Referer":"https://m.weibo.cn/u/1742566624"
}
def write_title(): # 写入标题
title = '思想聚焦的微博正文'
with open('blog.txt','w',encoding = 'utf-8') as f:
f.write(title + '\n')
f.write('\n')
def write_infos(txt): # 写入正文
with open('blog.txt','a',newline='\n',encoding = 'utf-8') as f:
f.write(txt)
f.write('\n')
def group_url(since_id): # 构造网页的函数
params = {
'since_id':since_id
}
url = base_url + '&' + urlencode(params)
return url
def get_html(url): # 请求网页
response = requests.get(url,headers=HEADERS)
if response.status_code == 200:
return response.json()
def get_infos(html): # 提取信息
since_id = html.get('data').get('cardlistInfo').get('since_id')
get_details = html.get('data').get('cards')
for i in range(len(get_details)):
text = get_details[i].get('mblog').get('raw_text').strip()
print(text)
write_infos(text)
return group_url(since_id)
def main():
write_title()
first_page = get_html(base_url)
new_url = get_infos(first_page)
for i in range(5): # 我这里以提取5页数据为栗子
html = get_html(new_url)
new_url = get_infos(html)
main()
在这个脚本中,我们设置了请求头,让我们的爬虫看起来更像是浏览器正在访问。
操作结果:
总结:
当我们查看网页的源代码时,我们发现在网页上看到的源代码中没有任何信息。对于Ajax网页的抓取,我们应该分析它的动态加载包,而不是直接请求它的源代码。通过构造Ajax网页URL来实现对多页信息的抓取,不同的网站其构造url的方法是不同的。为此,您需要自己查找规则并构建 url。看完这篇文章,如果你觉得可以爬取Ajax网页,可以尝试爬取今日头条上面的内容,也是Ajax加载的。
提取网页信息的方法有很多种,但在这种情况下,我们恰好是字典的形式。如果遇到其他情况,就得行动起来,用最熟悉的信息抽取方式抓取网页信息。让我们停在这里。它有点简陋,但可以大致看到。 查看全部
抓取jsp网页源代码(Ajax动态分析待抓取的微博内容:准备工作:安装好requests库)
Ajax动态分析待抓取微博内容:准备:安装requests库和lxml库
输入cmd
pip install requests
pip install lxml
因为我之前安装过这两个库,所以这里安装的时候会显示下图的内容:

分析网页
打开Chrome浏览器,我们输入这个网站:。右击选择查看网页源代码。这时候我们会发现,我们在首页看到的文字内容,在网页的源代码中并没有显示出来。这意味着网页是由 Ajax 动态加载的。(下图左边是我能看到的网页,右边是网页的源代码)

我们在右边随机选择一段内容,在左边搜索,没有任何结果。在这里,我们以“人间烟火,香饽饽”来寻找栗子:

我们看到我们搜索的内容并没有出现在源码中,所以网页是通过Ajax动态加载的。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时保证页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,必须刷新整个页面,而使用Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行数据交互。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
你可以在W3School上体验几个例子来感受一下:。
其实很多网页都是这样的。我们将继续向下滑动网页,并会不断刷新和加载我们眼前的新内容。
既然我们已经知道它是用 Ajax 动态加载的,那么我们来分析一下它是如何交换数据的。
右击选择Check(或按键盘F12)进入开发者模式。网页的样式展现在我们眼前。

在Elements中,我们可以看到网页的源码,右边是节点的内容,但这不是我们想要的。如果我们按照常规的网页请求,提取网页标签中的数据,就得不到我们想要的内容。.
我们进入Network,在Network下选择XHR,我们会看到如下内容(第一次进入,没有该内容,刷新页面即可):

随着我们继续滚动鼠标滚轮,XHR下加载的内容越来越多,我们会在getIndex的开头看到一个请求,点击查看其详细信息

我们看到Request Headers里面有个参数是X-Requested-With:XMLHttpRequest。通过这个参数,我们可以更加确定它是由Ajax动态加载的。然后点击Headers旁边的Preview,里面的数据是json(类似于python字典的字符串)格式。

点击卡片,卡片下有10条内容,我们到下面9条内容中的mblog一一查看,会发现微博正文中收录的文字收录在raw_text中

(其实这个请求中也收录了图片,想要下载图片的游客可以自行研究图片链接)。现在我们已经找到了我们想要的东西,让我们开始编写错误,“抓住”这些词并将它们放入我们的“口袋”中。
请求数据
我们使用requests.get(url)来请求网页,因为我们要请求的网页不是开头给出的网页,而是我们分析后发现的Ajax网页请求。所以我们真正要求的应该是这个网页%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=66624,打开这个页面我们你会发现里面有密密麻麻的字符和数字。我们可以在浏览器中找到一个json数据在线解析网址。这个还好。将上面网页的内容复制到json网页,我们就可以看到整齐的json数据了。很像python中的字典格式。

在 jupyter 中写这个:
response = requests.get('https://m.weibo.cn/api/container/getIndex?uid=1742566624&t=0&luicode=10000011&lfid=100103type%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=1076031742566624')
if response.status_code == 200:
html = response.json()
我们直接将其转成json格式,在jupyter中打印出来,随时查看网页返回的信息是什么样子的。(爬虫、数据分析等推荐使用jupyter,方便随时查看结果)
运行上面的代码并得到以下输出:

不难发现,这个数据和我们在Preview中看到的数据是一样的,说明我们得到的就是我们想要的数据。接下来,我们需要从这个字典中提取微博文本的内容。NS。代码显示如下:
get_details = html.get('data').get('cards')
for i in range(len(get_details)):
text = get_details[i].get('mblog').get('raw_text').strip()
print(text)
操作结果如下:

由于cards是一个列表,收录十条数据,我们使用for循环遍历整个列表并提取数据。因为我们返回的数据是字典类型的,所以我们可以直接使用get来提取数据。或者根据键值对索引(推荐get,如果当前没有key,索引会报错,get返回空值,不会阻止程序失败)。这样,我们从“第一页”中提取了十条数据,但是这样的数据量往往不能满足我们的需求。
获取多页数据
如果我们把每个网页都复制粘贴到我们的脚本中,10个可能的问题都不算大。首先找到getIndex,然后将网页复制粘贴到脚本中。一共三个步骤,10个网页是30个步骤。但是 100 页呢?这时候处理起来就比较麻烦了。所以我们需要找到一个“好方法”来构建网页,让脚本本身去“查找网页”→“复制”→“粘贴”“查找网页”\rightarrow“复制”\rightarrow“粘贴”“查找网页” “→”复制”→“粘贴”,一般我们可以把这种重复的工作交给程序来完成。所以我们现在要做的就是“教”我们的爬虫脚本来做到这一点。
回顾我们请求的页面: %3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=66624 这是我们的第一页请求,让我们看看我们要请求的第二个页面看起来像: %3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7 %84%A6&type=uid&value= 1742566624&containerid=66624&since_id=45596。第二个网页似乎与第一个网页不同。它比第一个网页有一个小尾巴 since_id。其实我们再看第三、第四、第五……从第二个开始的网页,它们都有一个since_id的参数,所以我们只需要在后面的每个网页上加上一个since_id的参数第一个网页的基础。但是好像每个网页对应的since_id都不一样,所以如果要调侃的话,它似乎不起作用。但是,它的网页毕竟是人写的,不是上帝创造的,所以它的since_id肯定是我们聪明的小脑袋“创造”出来的。
由于这个网页的since_id要被浏览器捕获,不断请求下一页的数据,我们自己找出这个since_id并不难。
果然,我们可以在json数据的cardlistInfo中找到一个since_id的key

让我们将这个since_id 与下一个网页中的since_id 进行比较。这是相同的。(我这里截取的是首页的since_id,这个since_id也会随着时间的推移而变化,访问者看到的和我的不一样,正常),我们使用get获取since_id就像提取文本信息一样。既然找到了这个since_id的构造规则,就可以请求多页网页数据了。只要我们教我们的爬虫脚本如何使用我们为它找到的since_id来构建网页,它就可以不断地获取网页。内容也是。
构建网页的代码如下:
def group_url(since_id):
params = {
'since_id':since_id
}
url = base_url + '&' + urlencode(params)
return url
urlencode是urllib.parse中的方法,下面是官方文档:

函数中传入的since_id就是我们为爬虫找到的since_id。然后我们把构造好的网页返回给网页请求函数,解析提取我们想要的内容和sinance_id,这样我们就可以一直循环下去了。
存储数据
编写爬虫不应该只是为了爬取数据,如果我们下次要使用这些数据,再次爬取,那会很麻烦,所以我们“隐藏”了我们从网上“偷”出来的东西。起来。这里我们使用记事本来保存这些文本数据(当然也可以写入数据库,有兴趣的读者可以自行上网搜索写入数据库的操作)。保存数据的代码如下:
def write_title():
title = '思想聚焦的微博正文'
with open('blog.txt','w',encoding = 'utf-8') as f:
f.write(title + '\n')
f.write('\n')
def write_infos(txt):
with open('blog.txt','a',newline='\n',encoding = 'utf-8') as f:
f.write(txt)
f.write('\n')
因为我们这里抓取的是思维聚焦微博文章,标题写的是“思维聚焦微博正文”,然后每一行都留空(这样看起来更整洁)。参数 newline 这就是它的作用。
至此,我们的爬虫已经写完了。有兴趣的话,可以做词云图,做情感分析等等……
完整代码:
import requests
import json, time
from lxml import etree
from urllib.parse import urlencode
base_url = """https://m.weibo.cn/api/contain ... 00011
&lfid=100103type%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=1076031742566624"""
HEADERS = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
"X-Requested-With":"XMLHttpRequest",
"Referer":"https://m.weibo.cn/u/1742566624"
}
def write_title(): # 写入标题
title = '思想聚焦的微博正文'
with open('blog.txt','w',encoding = 'utf-8') as f:
f.write(title + '\n')
f.write('\n')
def write_infos(txt): # 写入正文
with open('blog.txt','a',newline='\n',encoding = 'utf-8') as f:
f.write(txt)
f.write('\n')
def group_url(since_id): # 构造网页的函数
params = {
'since_id':since_id
}
url = base_url + '&' + urlencode(params)
return url
def get_html(url): # 请求网页
response = requests.get(url,headers=HEADERS)
if response.status_code == 200:
return response.json()
def get_infos(html): # 提取信息
since_id = html.get('data').get('cardlistInfo').get('since_id')
get_details = html.get('data').get('cards')
for i in range(len(get_details)):
text = get_details[i].get('mblog').get('raw_text').strip()
print(text)
write_infos(text)
return group_url(since_id)
def main():
write_title()
first_page = get_html(base_url)
new_url = get_infos(first_page)
for i in range(5): # 我这里以提取5页数据为栗子
html = get_html(new_url)
new_url = get_infos(html)
main()
在这个脚本中,我们设置了请求头,让我们的爬虫看起来更像是浏览器正在访问。
操作结果:


总结:
当我们查看网页的源代码时,我们发现在网页上看到的源代码中没有任何信息。对于Ajax网页的抓取,我们应该分析它的动态加载包,而不是直接请求它的源代码。通过构造Ajax网页URL来实现对多页信息的抓取,不同的网站其构造url的方法是不同的。为此,您需要自己查找规则并构建 url。看完这篇文章,如果你觉得可以爬取Ajax网页,可以尝试爬取今日头条上面的内容,也是Ajax加载的。
提取网页信息的方法有很多种,但在这种情况下,我们恰好是字典的形式。如果遇到其他情况,就得行动起来,用最熟悉的信息抽取方式抓取网页信息。让我们停在这里。它有点简陋,但可以大致看到。
抓取jsp网页源代码(网页源代码,这里我先偷懒用pythoncookie来爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-01 14:04
抓取jsp网页源代码,这里我先偷懒用pythoncookie来爬取。先定义一个全局变量session,session的初始值是什么?web.py中的if('root'insession)ifsession.status=='processing':session.status='processing'session=web.py.request(url,auth=none,headers=none,asyncio=none,)else:session=web.py.request(url,auth=none,headers=none,asyncio=none,)session=web.py.request(url,'request','post','body',data=none,timeout=1000)ifsession.status=='processing':response=session.getrequest(url)getrequest(response)同理session.status=='processing'时也要注意session的if后面的代码块。
实际上可以编写python的request程序,后面跟一个全局变量(如session),当session为processing的时候,
postman
第一个问题如果你看看源代码会发现他们的实现方式还有不同。第二个问题你定义的ajax其实是一个post方法,他会把jsp改名为request。你用python本身的模拟http请求的库应该就可以实现这个,用xml库,也可以用requests, 查看全部
抓取jsp网页源代码(网页源代码,这里我先偷懒用pythoncookie来爬取)
抓取jsp网页源代码,这里我先偷懒用pythoncookie来爬取。先定义一个全局变量session,session的初始值是什么?web.py中的if('root'insession)ifsession.status=='processing':session.status='processing'session=web.py.request(url,auth=none,headers=none,asyncio=none,)else:session=web.py.request(url,auth=none,headers=none,asyncio=none,)session=web.py.request(url,'request','post','body',data=none,timeout=1000)ifsession.status=='processing':response=session.getrequest(url)getrequest(response)同理session.status=='processing'时也要注意session的if后面的代码块。
实际上可以编写python的request程序,后面跟一个全局变量(如session),当session为processing的时候,
postman
第一个问题如果你看看源代码会发现他们的实现方式还有不同。第二个问题你定义的ajax其实是一个post方法,他会把jsp改名为request。你用python本身的模拟http请求的库应该就可以实现这个,用xml库,也可以用requests,
抓取jsp网页源代码(最近考毛概,用的是学习通,老师的骚操作就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-28 16:22
最近,我使用了学习通行证。老师的骚操作是给我们每个人十套模拟题,一套80道题,想了想,一个人是80*10=800道题,然后十个人?
哈哈哈,最后我真的成功了。我爬下来,每人学习了 800 个问题。删除重复后,我得到了我们的粗略题库。去掉重复后,有4000多道题,那怎么搜题呢?
题库截图.png(633.17 KB,下载次数:2)
下载附件
2020-6-20 16:57 上传
但问题来了。不可能说每次搜索问题时都检查数据库或表格。数据库太繁琐,表太繁琐。正好我们这学期有一门JSP课程。一个简单的搜索页面,然后部署到妓女所在的阿里云服务器上。是不是很美?许多人可以同时使用它。页面差不多是这个样子。
运行 screenshot.png(152.91 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传
运行截图2.png (491.78 KB, 下载次数:1)
下载附件
2020-6-20 16:57 上传
以下是部分代码的截图。因为刚开始接触JavaWeb,代码还是有点简陋。如果有什么不对的地方,我希望能纠正我。MVC模型基本使用,哈哈
代码1.png(410.67 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传
代码2.png(326.25 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传
下面附上源代码和数据库。对了,我的部署环境是jdk13.02+tomcat9.0
Archive.zip(2.62 MB,下载次数:405)
2020-6-20 16:58 上传
点击文件名下载附件
下载点:我爱硬币-1 CB
新手,如果本文章的内容或代码有问题,请指正 查看全部
抓取jsp网页源代码(最近考毛概,用的是学习通,老师的骚操作就是)
最近,我使用了学习通行证。老师的骚操作是给我们每个人十套模拟题,一套80道题,想了想,一个人是80*10=800道题,然后十个人?
哈哈哈,最后我真的成功了。我爬下来,每人学习了 800 个问题。删除重复后,我得到了我们的粗略题库。去掉重复后,有4000多道题,那怎么搜题呢?

题库截图.png(633.17 KB,下载次数:2)
下载附件
2020-6-20 16:57 上传
但问题来了。不可能说每次搜索问题时都检查数据库或表格。数据库太繁琐,表太繁琐。正好我们这学期有一门JSP课程。一个简单的搜索页面,然后部署到妓女所在的阿里云服务器上。是不是很美?许多人可以同时使用它。页面差不多是这个样子。

运行 screenshot.png(152.91 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传

运行截图2.png (491.78 KB, 下载次数:1)
下载附件
2020-6-20 16:57 上传
以下是部分代码的截图。因为刚开始接触JavaWeb,代码还是有点简陋。如果有什么不对的地方,我希望能纠正我。MVC模型基本使用,哈哈

代码1.png(410.67 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传

代码2.png(326.25 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传
下面附上源代码和数据库。对了,我的部署环境是jdk13.02+tomcat9.0

Archive.zip(2.62 MB,下载次数:405)
2020-6-20 16:58 上传
点击文件名下载附件
下载点:我爱硬币-1 CB
新手,如果本文章的内容或代码有问题,请指正
抓取jsp网页源代码(这段文字是从哪里来的?网页怎么提取文字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-24 04:00
指导
我们来看一个网页,大家想想怎么用XPath来爬取。如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看看页面的请求。
我们来看一个网页,大家想想怎么用XPath来爬取。
如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看一下页面的请求:
该网页没有发起任何 Ajax 请求。那么,这段文字是怎么来的呢?
我们来看看这个页面对应的HTML:
整个 HTML 中甚至没有 JavaScript。那么这段文字是怎么来的呢?
有一点经验的同学不妨看看这个example.css文件,其内容如下:
没错,正文确实来了。其中::after,我们称之为伪元素[1]。
对于伪元素中的文本,应该如何提取?当然,您可以使用正则表达式来提取它。但我们今天不打算谈论这个。
XPath没有办法提取伪元素,因为XPath只能提取Dom树中的内容,而伪元素不属于Dom树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 没有任何效果,因为数据根本不存在。单独获取css,虽然有数据,但是如果不使用正则表达式,就无法获取里面的数据。所以 BeautifulSoup4 的 CSS 选择器没有效果。所以我们需要将 CSS 和 HTML 放在一起进行渲染,然后使用 JavaScript 的 CSS 选择器来查找需要提取的内容。
首先,让我们来看看。为了提取这个伪元素的值,我们需要如下一段Js代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表fake_element的class属性。第二个参数是伪元素:after。运行效果如下图所示:
为了能够运行这个 JavaScript,我们需要使用一个模拟浏览器,无论是 Selenium 还是 Puppeteer。这里以硒为例。
在Selenium中执行Js,需要用到driver.execute_script()方法,代码如下:
提取内容的最外层会被一对双引号包裹。得到之后,去掉外面的双引号,就是我们在网页上看到的。
原文来自:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
抓取jsp网页源代码(这段文字是从哪里来的?网页怎么提取文字)
指导
我们来看一个网页,大家想想怎么用XPath来爬取。如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看看页面的请求。

我们来看一个网页,大家想想怎么用XPath来爬取。

如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看一下页面的请求:

该网页没有发起任何 Ajax 请求。那么,这段文字是怎么来的呢?
我们来看看这个页面对应的HTML:

整个 HTML 中甚至没有 JavaScript。那么这段文字是怎么来的呢?
有一点经验的同学不妨看看这个example.css文件,其内容如下:

没错,正文确实来了。其中::after,我们称之为伪元素[1]。
对于伪元素中的文本,应该如何提取?当然,您可以使用正则表达式来提取它。但我们今天不打算谈论这个。
XPath没有办法提取伪元素,因为XPath只能提取Dom树中的内容,而伪元素不属于Dom树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 没有任何效果,因为数据根本不存在。单独获取css,虽然有数据,但是如果不使用正则表达式,就无法获取里面的数据。所以 BeautifulSoup4 的 CSS 选择器没有效果。所以我们需要将 CSS 和 HTML 放在一起进行渲染,然后使用 JavaScript 的 CSS 选择器来查找需要提取的内容。
首先,让我们来看看。为了提取这个伪元素的值,我们需要如下一段Js代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表fake_element的class属性。第二个参数是伪元素:after。运行效果如下图所示:

为了能够运行这个 JavaScript,我们需要使用一个模拟浏览器,无论是 Selenium 还是 Puppeteer。这里以硒为例。
在Selenium中执行Js,需要用到driver.execute_script()方法,代码如下:

提取内容的最外层会被一对双引号包裹。得到之后,去掉外面的双引号,就是我们在网页上看到的。
原文来自:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
抓取jsp网页源代码(相对来说jsp比net安全性好一些,但是哪个好就看个人喜欢了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-22 08:12
相对来说,jsp比.net更安全,而且是跨平台的,但哪个更好看个人喜好。
不说java,你真的懂;
jsp:JSP 可以用一个简单易懂的公式表示:HTML+Java=JSP。 JSP 技术使用Java 编程语言编写类似XML 的标签和scriptlet 来封装生成动态网页的处理逻辑。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。 JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,让基于 Web 的应用程序的开发变得简单快捷。
javascript(主要用于客户端):JavaScript是一种基于对象和事件驱动的客户端脚本语言,相对安全。同时,它也是一种广泛用于客户端Web开发的脚本语言。常用于为HTML页面添加动态功能,如响应用户的各种操作。
jquery:Jquery 是一个优秀的 Javascrīpt 框架。归根结底是javascript,只是封装了javascript,使用起来更方便。
Java 和 jsp 主要集中在后台,javascript 和 jquery 主要集中在前台。
jsp 基于java,jquery 基于javascript。 java和javascript是两种不同的语言 查看全部
抓取jsp网页源代码(相对来说jsp比net安全性好一些,但是哪个好就看个人喜欢了)
相对来说,jsp比.net更安全,而且是跨平台的,但哪个更好看个人喜好。
不说java,你真的懂;
jsp:JSP 可以用一个简单易懂的公式表示:HTML+Java=JSP。 JSP 技术使用Java 编程语言编写类似XML 的标签和scriptlet 来封装生成动态网页的处理逻辑。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。 JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,让基于 Web 的应用程序的开发变得简单快捷。
javascript(主要用于客户端):JavaScript是一种基于对象和事件驱动的客户端脚本语言,相对安全。同时,它也是一种广泛用于客户端Web开发的脚本语言。常用于为HTML页面添加动态功能,如响应用户的各种操作。
jquery:Jquery 是一个优秀的 Javascrīpt 框架。归根结底是javascript,只是封装了javascript,使用起来更方便。
Java 和 jsp 主要集中在后台,javascript 和 jquery 主要集中在前台。
jsp 基于java,jquery 基于javascript。 java和javascript是两种不同的语言
抓取jsp网页源代码(基于网络爬虫技术的个性化企业信息获取方法研究(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-21 12:15
一般来说,软件界面如下:
图 1-1 Navicat for mysql 界面
但是,事情的好坏不能从表面上定论。Navicat 也是一样。我们上面谈到了它的各种优点。但是,作为一个为工作服务的软件,最重要的还是要符合用户的操作。习惯,给用户带来极致的用户体验。Navicat 也这样做。它采用图形化的完美用户界面,在视觉和操作上都满足工作要求。另外,在当前信息安全系数不高的情况下,可以保证信息的安全,可以快速、安全地实现创建、组织、存储和共享。
2 基于网络爬虫技术的个性化企业信息获取方法研究
2.1 爬虫简介
在浩瀚的互联网中,信息就像一滴水。为了学习和工作获取它们,我们总是习惯于使用“水勺”——搜索引擎来获取它们。从我们这边来说,当我们需要挖掘信息的时候,大多数人自然会想到“随便点击百度就知道”,输入关键词,得到一系列相关内容。而这个看似简单的原理背后,则是接下来要介绍的网络爬虫技术(网络蜘蛛或网络爬虫)。
现在,我们将接触自然界中蜘蛛结网的神奇现象,来引出本节的“主角”。众所周知,蜘蛛通过分泌粘液并在空气中形成非常细的细丝来捕捉猎物。万维网就像一个巨大的“网络”,上面附有大量复杂的信息。一个网络爬虫就像一个爬虫在这个互联网上狩猎,为了捕捉它需要的“猎物”。然而,如何从一个落脚点绘制出无数条向外围延伸的细丝呢?下一节将介绍 URL 的概念。
根据不同的爬虫要求,爬虫有很多种。例如,基于Web的爬虫主要用于采集网络上的资源,节省了在万维网上获取需求所需的时间,减少了信息采集的空间开销。由于我们有针对性地抓取了国家环保总局的数据,所以本文中的爬虫可以理解为基于用户个性的爬虫,即定制的爬虫,只获取需要的页面,只获取内容这就是上面所关心的。它会抓取符合我们预期的结果。[12]
2.2 理解网址
同样,在上一节中,比较了蜘蛛网的形成方法。蜘蛛网的形成基于一系列“电缆”,这些“电缆”构建在这些电缆之间。这些“电缆”自然而然地体现了某些规则。与此类似,爬虫技术也是基于一定的规则。程序根据这些规则自动抓取网页,从而从万维网下载网页以获取“猎物”,URL就是网络上的“电缆”。Come * from-excellent = Er, on:essay + net
2.3 通过 URL 抓取网页
网络爬虫是一个网络爬虫程序最基本的操作。
本质上,抓取网页的过程类似于浏览网页的过程。平日里,浏览互联网已成为每个人的必杀技。此操作对每个人来说都毫不费力。在浏览器顶部地址栏中输入网站URL地址,跳转到地址反映的页面。这个过程不是单向的,一夜之间,而是有一个我们看不到的第三方——“服务器端”。服务器收到用户浏览页面的请求后,将文件反映到客户端。这是我们看到的页面。网络爬取过程与获取过程相同。“蜘蛛”利用URL地址追踪来源获取网页。在网络爬取过程中,由于网址数量众多,往往以队列或网址池的形式存在。我们如何从队列中选择网址,哪些网址是我们优先抓取的对象,以及如何抓取?成为一个关键问题。
为了方便理解,我们可以直观的看到页面的源代码,在浏览器上查看,操作非常简单,如下:在页面任意位置右击,会出现一个指令框,选择“查看”在出现的选项——“源文件”中,您将看到从服务器“抓取”的html文件的源代码。互联网爬取与企业公开信息分析研究(6): 查看全部
抓取jsp网页源代码(基于网络爬虫技术的个性化企业信息获取方法研究(组图))
一般来说,软件界面如下:
图 1-1 Navicat for mysql 界面
但是,事情的好坏不能从表面上定论。Navicat 也是一样。我们上面谈到了它的各种优点。但是,作为一个为工作服务的软件,最重要的还是要符合用户的操作。习惯,给用户带来极致的用户体验。Navicat 也这样做。它采用图形化的完美用户界面,在视觉和操作上都满足工作要求。另外,在当前信息安全系数不高的情况下,可以保证信息的安全,可以快速、安全地实现创建、组织、存储和共享。
2 基于网络爬虫技术的个性化企业信息获取方法研究
2.1 爬虫简介
在浩瀚的互联网中,信息就像一滴水。为了学习和工作获取它们,我们总是习惯于使用“水勺”——搜索引擎来获取它们。从我们这边来说,当我们需要挖掘信息的时候,大多数人自然会想到“随便点击百度就知道”,输入关键词,得到一系列相关内容。而这个看似简单的原理背后,则是接下来要介绍的网络爬虫技术(网络蜘蛛或网络爬虫)。
现在,我们将接触自然界中蜘蛛结网的神奇现象,来引出本节的“主角”。众所周知,蜘蛛通过分泌粘液并在空气中形成非常细的细丝来捕捉猎物。万维网就像一个巨大的“网络”,上面附有大量复杂的信息。一个网络爬虫就像一个爬虫在这个互联网上狩猎,为了捕捉它需要的“猎物”。然而,如何从一个落脚点绘制出无数条向外围延伸的细丝呢?下一节将介绍 URL 的概念。
根据不同的爬虫要求,爬虫有很多种。例如,基于Web的爬虫主要用于采集网络上的资源,节省了在万维网上获取需求所需的时间,减少了信息采集的空间开销。由于我们有针对性地抓取了国家环保总局的数据,所以本文中的爬虫可以理解为基于用户个性的爬虫,即定制的爬虫,只获取需要的页面,只获取内容这就是上面所关心的。它会抓取符合我们预期的结果。[12]
2.2 理解网址
同样,在上一节中,比较了蜘蛛网的形成方法。蜘蛛网的形成基于一系列“电缆”,这些“电缆”构建在这些电缆之间。这些“电缆”自然而然地体现了某些规则。与此类似,爬虫技术也是基于一定的规则。程序根据这些规则自动抓取网页,从而从万维网下载网页以获取“猎物”,URL就是网络上的“电缆”。Come * from-excellent = Er, on:essay + net
2.3 通过 URL 抓取网页
网络爬虫是一个网络爬虫程序最基本的操作。
本质上,抓取网页的过程类似于浏览网页的过程。平日里,浏览互联网已成为每个人的必杀技。此操作对每个人来说都毫不费力。在浏览器顶部地址栏中输入网站URL地址,跳转到地址反映的页面。这个过程不是单向的,一夜之间,而是有一个我们看不到的第三方——“服务器端”。服务器收到用户浏览页面的请求后,将文件反映到客户端。这是我们看到的页面。网络爬取过程与获取过程相同。“蜘蛛”利用URL地址追踪来源获取网页。在网络爬取过程中,由于网址数量众多,往往以队列或网址池的形式存在。我们如何从队列中选择网址,哪些网址是我们优先抓取的对象,以及如何抓取?成为一个关键问题。
为了方便理解,我们可以直观的看到页面的源代码,在浏览器上查看,操作非常简单,如下:在页面任意位置右击,会出现一个指令框,选择“查看”在出现的选项——“源文件”中,您将看到从服务器“抓取”的html文件的源代码。互联网爬取与企业公开信息分析研究(6):
抓取jsp网页源代码(选择network,库需要对数据的格式有什么作用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-30 19:09
前期准备工作
本例中用到了python爬虫所需的两个基础库,一个是requests库,一个是BeautifulSoup库。这里假设已经安装了这两个库,如果没有,可以通过pip安装。接下来简单说一下这两个库的功能。requests库的主要功能是通过url获取服务端的前端代码数据。使用这两个库捕获的数据就是服务器前端代码中的数据。BeautifulSoup 库主要用于从爬取的前端代码中提取需要的信息。
数据抓取
这次抓到的数据的url是#hs_a_board
建议使用谷歌或者火狐打开,可以使用快捷键CTRL+U查看服务器的网页源码。在捕获数据之前,您需要对数据的格式有一个大致的了解。首先,要捕获的数据必须在要直接捕获的源代码中找到。我相信有一点基本的html语言可以理解它。需要注意的是,我们在源码中可以看到script标签,因为JavaScript是在网页加载的时候动态加载的,所以我们抓取的源码中也显示的是JavaScript代码,而不是JavaScript加载的数据。所以我们在源码中是看不到股票数据的。所以如果我们直接抓取requests库返回的code数据,是无法抓取股票信息的。
解决方案
一个特殊的方法不是直接从目标网站中抓取数据,而是找到PC发送的请求,改变get方法的参数,在新窗口打开请求的资源。服务器可以通过改变请求参数来返回不同的数据。这种方法需要了解HTTP协议等原理。
具体方法是在需要抓取的数据上右击选择check。Google 和 Firefox 都支持元素检查。然后可以看到本地存在对应的数据。选择network,选择下面的JS,刷新一次就可以看到get方法的请求了。
通过查看get方法获取的返回数据与前端页面的对比,可以发现它们是一致的。您可以直接选择鼠标右键打开一个新的网页。但是,此时只返回了部分数据,而不是全部数据。所有的数据都可以通过修改get方法的参数来获取。这里只修改 np=2 。至于为什么要修改这个参数,这里不再赘述。修改后的请求如下::0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2, f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136, f115,f152&_=55
可以看出数据是结构化的,我们可以直接抓取数据。您可以使用正则表达式来匹配相应的数据。第一次,我们只能捕获股票代码等简单信息。需要使用“+”股票代码来获取详细的交易信息。我们也可以用这两个库来重复这个过程,直接从源码中Grabing就可以了,没必要那么麻烦。直接上下面的代码
import requests
from bs4 import BeautifulSoup
import re
finalCodeList = []
finalDealData = [['股票代码','今开','最高','最低','昨收','成交量','成交额','总市值','流通市值','振幅','换手率','市净率','市盈率',]]
def getHtmlText(url):
head={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0',
'Cookie': 'qgqp_b_id=54fe349b4e3056799d45a271cb903df3; st_si=24637404931419; st_pvi=32580036674154; st_sp=2019-11-12%2016%3A29%3A38; st_inirUrl=; st_sn=1; st_psi=2019111216485270-113200301321-3411409195; st_asi=delete'
}
try:
r = requests.get(url,timeout = 30,headers = head)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def getCodeList(htmltxt):
getSourceStr = str(htmltxt)
pattern = re.compile(r'.f12...\d{6}.')
listcode = pattern.findall(getSourceStr)
for code in listcode:
numPattern = re.compile(r'\d{6}')
finalCodeList.append(numPattern.findall(code)[0])
def getData(CodeList):
total = len(CodeList)
finished = int(0)
for code in CodeList:
finished = finished + 1
finishedco = (finished/total)*100
print("total : {0} finished : {1} completion : {2}%".format(total,finished,finishedco))
dealDataList = []
dataUrl = 'http://info.stcn.com/dc/stock/ ... 39%3B + code
dataHtml = getHtmlText(dataUrl)
soup = BeautifulSoup(dataHtml,"html.parser")
dealDataList.append(code)
for i in range(1,4):
classStr = 'sj_r_'+str(i)
divdata =soup.find_all('div',{'class':classStr})
if len(divdata) == 0:
dealDataList.append('该股票暂时没有交易数据!')
break
dealData = str(divdata[0])
dealPattern = re.compile(r'\d+.\d+[\u4e00-\u9fa5]|\d+.+.%|\d+.\d+')
listdeal = dealPattern.findall(dealData)
for j in range(0,4):
dealDataList.append(listdeal[j])
finalDealData.append(dealDataList)
def savaData(filename,finalData):
file = open(filename,'a+')
for i in range(len(finalData)):
if i == 0:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',',' \t')+'\n'
else:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',','\t')+'\n'
file.write(s)
file.close()
url = ' http://51.push2.eastmoney.com/ ... 2Bt:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1574045112933'
htmltxt = getHtmlText(url)
soup = BeautifulSoup(htmltxt,"html.parser")
getCodeList(soup)
recordfile = 'stockData.txt'
getData(finalCodeList)
savaData(recordfile,finalDealData)
至于头部信息,可以通过上述检查元素的方法获得。
我将获取的股票信息存储在一个txt文件中,并相应地调整了格式以便于查看。最终结果如下(上次抓取的数据信息)
概括
刚开始爬的时候,因为参考了书中的例子,一开始不知道这个话题要爬的网页是用JavaScript写的。抓取静态网页的一般方法是不抓取。的。我尝试了很多方法。一开始还以为是没有加Headers参数,但是加了之后还是不行。最后在网上查资料的时候,发现了一篇关于反爬虫文章的文章,里面解释了用JavaScript编写的URL是无法捕获的,并引用了两个对应的解决方案。一是使用dryscape库进行爬取,二是使用selenium库进行爬取。我先尝试了第一种方法,但是因为dryscape库不再维护,安装库时失败,所以我尝试了第二种方法,使用selenium库进行爬取。这种方法确实可以抓取到数据,但前提是只能用浏览器打开页面后才能抓取到。考虑到要爬取的页面太多,无法逐页爬取,所以又放弃了第二种方法。最后转而分析JavaScript数据是如何通过JavaScript脚本传输到网页前端的,最后发现JavaScript在页面加载时会有一个请求URL,最后通过这个请求地址找到想要的数据, 并对参数进行一些修改。您可以一次获得所需的所有数据。爬取过程中遇到了一些问题。在最后的爬取过程中,有些股票没有交易数据,这导致我在没有交易数据的情况下抓取这些股票时报告异常错误。最后,我添加了一个判断。当没有交易数据时,会显示“该股票暂时没有交易数据!”。这个设计过程的最终结果是很棒的。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。 查看全部
抓取jsp网页源代码(选择network,库需要对数据的格式有什么作用?)
前期准备工作
本例中用到了python爬虫所需的两个基础库,一个是requests库,一个是BeautifulSoup库。这里假设已经安装了这两个库,如果没有,可以通过pip安装。接下来简单说一下这两个库的功能。requests库的主要功能是通过url获取服务端的前端代码数据。使用这两个库捕获的数据就是服务器前端代码中的数据。BeautifulSoup 库主要用于从爬取的前端代码中提取需要的信息。
数据抓取
这次抓到的数据的url是#hs_a_board
建议使用谷歌或者火狐打开,可以使用快捷键CTRL+U查看服务器的网页源码。在捕获数据之前,您需要对数据的格式有一个大致的了解。首先,要捕获的数据必须在要直接捕获的源代码中找到。我相信有一点基本的html语言可以理解它。需要注意的是,我们在源码中可以看到script标签,因为JavaScript是在网页加载的时候动态加载的,所以我们抓取的源码中也显示的是JavaScript代码,而不是JavaScript加载的数据。所以我们在源码中是看不到股票数据的。所以如果我们直接抓取requests库返回的code数据,是无法抓取股票信息的。
解决方案
一个特殊的方法不是直接从目标网站中抓取数据,而是找到PC发送的请求,改变get方法的参数,在新窗口打开请求的资源。服务器可以通过改变请求参数来返回不同的数据。这种方法需要了解HTTP协议等原理。
具体方法是在需要抓取的数据上右击选择check。Google 和 Firefox 都支持元素检查。然后可以看到本地存在对应的数据。选择network,选择下面的JS,刷新一次就可以看到get方法的请求了。
通过查看get方法获取的返回数据与前端页面的对比,可以发现它们是一致的。您可以直接选择鼠标右键打开一个新的网页。但是,此时只返回了部分数据,而不是全部数据。所有的数据都可以通过修改get方法的参数来获取。这里只修改 np=2 。至于为什么要修改这个参数,这里不再赘述。修改后的请求如下::0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2, f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136, f115,f152&_=55
可以看出数据是结构化的,我们可以直接抓取数据。您可以使用正则表达式来匹配相应的数据。第一次,我们只能捕获股票代码等简单信息。需要使用“+”股票代码来获取详细的交易信息。我们也可以用这两个库来重复这个过程,直接从源码中Grabing就可以了,没必要那么麻烦。直接上下面的代码
import requests
from bs4 import BeautifulSoup
import re
finalCodeList = []
finalDealData = [['股票代码','今开','最高','最低','昨收','成交量','成交额','总市值','流通市值','振幅','换手率','市净率','市盈率',]]
def getHtmlText(url):
head={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0',
'Cookie': 'qgqp_b_id=54fe349b4e3056799d45a271cb903df3; st_si=24637404931419; st_pvi=32580036674154; st_sp=2019-11-12%2016%3A29%3A38; st_inirUrl=; st_sn=1; st_psi=2019111216485270-113200301321-3411409195; st_asi=delete'
}
try:
r = requests.get(url,timeout = 30,headers = head)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def getCodeList(htmltxt):
getSourceStr = str(htmltxt)
pattern = re.compile(r'.f12...\d{6}.')
listcode = pattern.findall(getSourceStr)
for code in listcode:
numPattern = re.compile(r'\d{6}')
finalCodeList.append(numPattern.findall(code)[0])
def getData(CodeList):
total = len(CodeList)
finished = int(0)
for code in CodeList:
finished = finished + 1
finishedco = (finished/total)*100
print("total : {0} finished : {1} completion : {2}%".format(total,finished,finishedco))
dealDataList = []
dataUrl = 'http://info.stcn.com/dc/stock/ ... 39%3B + code
dataHtml = getHtmlText(dataUrl)
soup = BeautifulSoup(dataHtml,"html.parser")
dealDataList.append(code)
for i in range(1,4):
classStr = 'sj_r_'+str(i)
divdata =soup.find_all('div',{'class':classStr})
if len(divdata) == 0:
dealDataList.append('该股票暂时没有交易数据!')
break
dealData = str(divdata[0])
dealPattern = re.compile(r'\d+.\d+[\u4e00-\u9fa5]|\d+.+.%|\d+.\d+')
listdeal = dealPattern.findall(dealData)
for j in range(0,4):
dealDataList.append(listdeal[j])
finalDealData.append(dealDataList)
def savaData(filename,finalData):
file = open(filename,'a+')
for i in range(len(finalData)):
if i == 0:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',',' \t')+'\n'
else:
s = str(finalData[i]).replace('[','').replace(']','')
s = s.replace("'",'').replace(',','\t')+'\n'
file.write(s)
file.close()
url = ' http://51.push2.eastmoney.com/ ... 2Bt:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1574045112933'
htmltxt = getHtmlText(url)
soup = BeautifulSoup(htmltxt,"html.parser")
getCodeList(soup)
recordfile = 'stockData.txt'
getData(finalCodeList)
savaData(recordfile,finalDealData)
至于头部信息,可以通过上述检查元素的方法获得。
我将获取的股票信息存储在一个txt文件中,并相应地调整了格式以便于查看。最终结果如下(上次抓取的数据信息)
概括
刚开始爬的时候,因为参考了书中的例子,一开始不知道这个话题要爬的网页是用JavaScript写的。抓取静态网页的一般方法是不抓取。的。我尝试了很多方法。一开始还以为是没有加Headers参数,但是加了之后还是不行。最后在网上查资料的时候,发现了一篇关于反爬虫文章的文章,里面解释了用JavaScript编写的URL是无法捕获的,并引用了两个对应的解决方案。一是使用dryscape库进行爬取,二是使用selenium库进行爬取。我先尝试了第一种方法,但是因为dryscape库不再维护,安装库时失败,所以我尝试了第二种方法,使用selenium库进行爬取。这种方法确实可以抓取到数据,但前提是只能用浏览器打开页面后才能抓取到。考虑到要爬取的页面太多,无法逐页爬取,所以又放弃了第二种方法。最后转而分析JavaScript数据是如何通过JavaScript脚本传输到网页前端的,最后发现JavaScript在页面加载时会有一个请求URL,最后通过这个请求地址找到想要的数据, 并对参数进行一些修改。您可以一次获得所需的所有数据。爬取过程中遇到了一些问题。在最后的爬取过程中,有些股票没有交易数据,这导致我在没有交易数据的情况下抓取这些股票时报告异常错误。最后,我添加了一个判断。当没有交易数据时,会显示“该股票暂时没有交易数据!”。这个设计过程的最终结果是很棒的。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。最大的收获是这方面经验的积累,更重要的是解决这个题目设计中每一道题的过程。对我以后面对各种问题也很有帮助和启发。
抓取jsp网页源代码(各种弹出页面的设计(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-27 21:09
各种弹窗设计
[1、普通弹窗]
其实代码很简单:
因为这是一段javascripts代码,所以应该放在中间。它适用于一些低版本的浏览器,其中标签中的代码不会显示为文本。养成这个好习惯。
window.open('page.html') 用来控制新窗口page.html的弹出。如果page.html和主窗口不在同一路径,路径要写在前面,绝对路径()和相对路径(../)都可以。
单引号和双引号都可以使用,但不要混合使用。
这段代码可以加在HTML中的任何地方,之间或之间,越早执行,尤其是页面代码越长,如果想让页面弹出,就尽量往前放。
【2、设置后弹窗】
先说弹窗的设置吧。只需在上面的代码中添加一点。让我们自定义弹出窗口的外观、大小和位置以适应页面的具体情况。
参数说明:
js脚本结束
[3、使用函数控制弹窗]
下面是一个完整的代码。
.. 任意页面内容...
这里定义了一个函数openwin(),该函数的内容是打开一个窗口。在调用之前没有任何用处。
怎么称呼?
方法一:浏览器读取页面时弹出一个窗口;
方法二:浏览器离开页面时弹出一个窗口;
方法三:通过连接调用:
[4、 同时弹出两个窗口]
对源代码稍作改动:
为了避免两个弹出窗口覆盖,使用top和left控制弹出位置不相互覆盖。最后,使用上面提到的四种方法来调用。
注意:两个窗口的名称(newwindows 和 newwindow2) 不能相同,或者根本就应该是空的。OK?
[5、在主窗口打开文件1.htm,同时弹出一个小窗口page.html]
在主窗口添加以下代码 查看全部
抓取jsp网页源代码(各种弹出页面的设计(1)_光明网(组图))
各种弹窗设计
[1、普通弹窗]
其实代码很简单:
因为这是一段javascripts代码,所以应该放在中间。它适用于一些低版本的浏览器,其中标签中的代码不会显示为文本。养成这个好习惯。
window.open('page.html') 用来控制新窗口page.html的弹出。如果page.html和主窗口不在同一路径,路径要写在前面,绝对路径()和相对路径(../)都可以。
单引号和双引号都可以使用,但不要混合使用。
这段代码可以加在HTML中的任何地方,之间或之间,越早执行,尤其是页面代码越长,如果想让页面弹出,就尽量往前放。
【2、设置后弹窗】
先说弹窗的设置吧。只需在上面的代码中添加一点。让我们自定义弹出窗口的外观、大小和位置以适应页面的具体情况。
参数说明:
js脚本结束
[3、使用函数控制弹窗]
下面是一个完整的代码。
.. 任意页面内容...
这里定义了一个函数openwin(),该函数的内容是打开一个窗口。在调用之前没有任何用处。
怎么称呼?
方法一:浏览器读取页面时弹出一个窗口;
方法二:浏览器离开页面时弹出一个窗口;
方法三:通过连接调用:
[4、 同时弹出两个窗口]
对源代码稍作改动:
为了避免两个弹出窗口覆盖,使用top和left控制弹出位置不相互覆盖。最后,使用上面提到的四种方法来调用。
注意:两个窗口的名称(newwindows 和 newwindow2) 不能相同,或者根本就应该是空的。OK?
[5、在主窗口打开文件1.htm,同时弹出一个小窗口page.html]
在主窗口添加以下代码
抓取jsp网页源代码(编程执行环境依据的作用及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-11-27 04:18
先放出一个地址供大家测试
@
1、现在流行的(可能是因为最近问的人比较多)就是不带文件名的URL地址。例如,htmlpro/? 其实这和服务器设置的默认文件名有关,比如index.htm、index.html、index.asp等,不信可以试试我的一位朋友(asp)。
2、这里的文件是index.html,末尾带参数,页面效果就像ASP提取信息内容一样。
以下转载文章(作者刘晓)可以说明一下
经常上网的朋友一定对“***.asp?arg1=*&arg2=*”等网址不陌生。这类URL的作用是通过在URL后面附加信息内容,将相关信息传递给远程Web服务器,由Web服务器适当处理后将结果返回给客户端,从而达到网页浏览的目的互动并实现动态网页内容。. (注:URL和信息内容用“?”连接,内容字段用字符“&”分隔,每个字段的名称/值以“名称=值”的形式表示。)但是通过这种方式实现的动态网页,都需要服务器端编程技术的支持。最近,作者在制作个人网站时使用了浏览器支持的DHTML和XML技术。经过不断的尝试,在免费的首页空间中以这种方式实现。动态网页。
一、原理解析
当浏览器以这种方式向Web服务器请求时,Web服务器会解析请求地址的URL,将查询字符串存储在“?”之后。在server-specific环境变量中,然后调用server端编程执行环境,如ASP(ActivexServerPage)等处理请求的程序文件。
具体要调用的编程执行环境取决于服务器的设置。如果请求的文件是asp类型文件,则调用ASP,如果是aspx类型文件,则调用ASP.NET。在程序文件中,可以通过某些方法读取环境变量,例如可以通过Reques.Querystring数据集合读取asp文件。编程执行环境将处理后的结果返回给Web服务器,Web服务器将结果返回给浏览器,从而达到动态Web内容的目的。
通过上面的分析我们可以知道,如果使用*.htm?querystring向Web服务器发送请求,Web服务器会直接将请求的HTML页面返回给浏览器。这时候我们就可以通过网页中的Location.href属性来获取带有附加信息内容的URL字符串。经过适当的处理,我们就可以得到附加信息内容的字段名及其值,然后就可以使用浏览器支持的DHTML特性了。通过处理,可以实现网页的动态内容,从而达到在不支持服务器端编程技术的免费主页空间上进行网页交互的目的。
我们也可以看到,即使通过这种方式实现了动态网页交互的目的,仍然无法摆脱Web服务器的支持,否则浏览器会将“?querystring”作为请求的URL的一部分。无法查看网页的错误信息。
二、应用实例
---下面给出了一个带有详细注释的具体示例源代码。注意:querystring.js是一个实用程序,可以直接在网页中引用,然后在网页中使用Request["name"]获取用户输入的相关信息。
1.querystring.js 源代码
函数查询字符串()
{//构造参数对象并初始化
变量名,值,我;
varstr=location.href;//获取浏览器地址栏的URL字符串
varnum=str.indexOf("?")
str=str.substr(num+1);//截取“?”后的参数字符串
vararrtmp=str.split("&");//将每个参数分开形成一个参数数组
for(i=0;i0){
name=arrtmp[i].substring(0,num);//获取参数名
value=arrtmp[i].substr(num+1);//获取参数值
this[name]=value;//定义对象属性并初始化
}
}
}
varRequest=newQueryString();//使用new操作符创建参数对象实例
2.示例.htm 源代码
例子
如果用 DHTML 和 XML 技术扩展此示例,将获得令人难以置信的结果。这位作者在只支持纯HTML的首页空间搭建了一个相当不错的动态图片查看器。
所以,大家快去实践吧。 查看全部
抓取jsp网页源代码(编程执行环境依据的作用及解决办法(一))
先放出一个地址供大家测试
@
1、现在流行的(可能是因为最近问的人比较多)就是不带文件名的URL地址。例如,htmlpro/? 其实这和服务器设置的默认文件名有关,比如index.htm、index.html、index.asp等,不信可以试试我的一位朋友(asp)。
2、这里的文件是index.html,末尾带参数,页面效果就像ASP提取信息内容一样。
以下转载文章(作者刘晓)可以说明一下
经常上网的朋友一定对“***.asp?arg1=*&arg2=*”等网址不陌生。这类URL的作用是通过在URL后面附加信息内容,将相关信息传递给远程Web服务器,由Web服务器适当处理后将结果返回给客户端,从而达到网页浏览的目的互动并实现动态网页内容。. (注:URL和信息内容用“?”连接,内容字段用字符“&”分隔,每个字段的名称/值以“名称=值”的形式表示。)但是通过这种方式实现的动态网页,都需要服务器端编程技术的支持。最近,作者在制作个人网站时使用了浏览器支持的DHTML和XML技术。经过不断的尝试,在免费的首页空间中以这种方式实现。动态网页。
一、原理解析
当浏览器以这种方式向Web服务器请求时,Web服务器会解析请求地址的URL,将查询字符串存储在“?”之后。在server-specific环境变量中,然后调用server端编程执行环境,如ASP(ActivexServerPage)等处理请求的程序文件。
具体要调用的编程执行环境取决于服务器的设置。如果请求的文件是asp类型文件,则调用ASP,如果是aspx类型文件,则调用ASP.NET。在程序文件中,可以通过某些方法读取环境变量,例如可以通过Reques.Querystring数据集合读取asp文件。编程执行环境将处理后的结果返回给Web服务器,Web服务器将结果返回给浏览器,从而达到动态Web内容的目的。
通过上面的分析我们可以知道,如果使用*.htm?querystring向Web服务器发送请求,Web服务器会直接将请求的HTML页面返回给浏览器。这时候我们就可以通过网页中的Location.href属性来获取带有附加信息内容的URL字符串。经过适当的处理,我们就可以得到附加信息内容的字段名及其值,然后就可以使用浏览器支持的DHTML特性了。通过处理,可以实现网页的动态内容,从而达到在不支持服务器端编程技术的免费主页空间上进行网页交互的目的。
我们也可以看到,即使通过这种方式实现了动态网页交互的目的,仍然无法摆脱Web服务器的支持,否则浏览器会将“?querystring”作为请求的URL的一部分。无法查看网页的错误信息。
二、应用实例
---下面给出了一个带有详细注释的具体示例源代码。注意:querystring.js是一个实用程序,可以直接在网页中引用,然后在网页中使用Request["name"]获取用户输入的相关信息。
1.querystring.js 源代码
函数查询字符串()
{//构造参数对象并初始化
变量名,值,我;
varstr=location.href;//获取浏览器地址栏的URL字符串
varnum=str.indexOf("?")
str=str.substr(num+1);//截取“?”后的参数字符串
vararrtmp=str.split("&");//将每个参数分开形成一个参数数组
for(i=0;i0){
name=arrtmp[i].substring(0,num);//获取参数名
value=arrtmp[i].substr(num+1);//获取参数值
this[name]=value;//定义对象属性并初始化
}
}
}
varRequest=newQueryString();//使用new操作符创建参数对象实例
2.示例.htm 源代码
例子
如果用 DHTML 和 XML 技术扩展此示例,将获得令人难以置信的结果。这位作者在只支持纯HTML的首页空间搭建了一个相当不错的动态图片查看器。
所以,大家快去实践吧。
抓取jsp网页源代码(用tomcat的话很简单把你需要用的java都注册到extensionconfigservlet就行了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-21 10:10
抓取jsp网页源代码,输出model表格,model表格,进行tablestoresave方法获取model,然后model.xml文件中注册tablestore对象输出modelmodel.xml文件中,注册sqltablestore对象,连接至tablestoresql,重启tablestoresqlweb服务即可。
前后端分离过程中,每个页面都是用到springboot的restapi,也没有用到jsp,直接用json或jsp提供model.xml文件。
用tomcat的话很简单把你需要用的java字段都注册到extensionconfigservlet就行了,
还是只需要tomcat连接过来,提供model即可。
tomcat里如果是做路由,连接服务器端直接用。要显示到页面,再做一个映射函数,返回一个model。
modelxml比较简单的回答,oracle-usersmodel,当时正在找reporter的回答,这个还算知道的多点,主要是archive这块内容extensionconfig服务器上的模型的注册,你这里如果要保存数据到relationship,把字段注册到model就好了,然后在网页提供这个model就行了。
目前通过navicat直接提供了model到jsp标签的映射函数,
用java写个navicat客户端,eclipse下载也行。然后把sql标签提供到浏览器(firefox必须), 查看全部
抓取jsp网页源代码(用tomcat的话很简单把你需要用的java都注册到extensionconfigservlet就行了)
抓取jsp网页源代码,输出model表格,model表格,进行tablestoresave方法获取model,然后model.xml文件中注册tablestore对象输出modelmodel.xml文件中,注册sqltablestore对象,连接至tablestoresql,重启tablestoresqlweb服务即可。
前后端分离过程中,每个页面都是用到springboot的restapi,也没有用到jsp,直接用json或jsp提供model.xml文件。
用tomcat的话很简单把你需要用的java字段都注册到extensionconfigservlet就行了,
还是只需要tomcat连接过来,提供model即可。
tomcat里如果是做路由,连接服务器端直接用。要显示到页面,再做一个映射函数,返回一个model。
modelxml比较简单的回答,oracle-usersmodel,当时正在找reporter的回答,这个还算知道的多点,主要是archive这块内容extensionconfig服务器上的模型的注册,你这里如果要保存数据到relationship,把字段注册到model就好了,然后在网页提供这个model就行了。
目前通过navicat直接提供了model到jsp标签的映射函数,
用java写个navicat客户端,eclipse下载也行。然后把sql标签提供到浏览器(firefox必须),
抓取jsp网页源代码(3.编写一个JSP手表的功能,显示当前时间(时:秒) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-11-20 21:22
)
3.编写一个JSP程序,实现手表的功能,显示当前时间(时:分:秒),并不断自动刷新时间。
方法一【scriptlet】
work01
方法二【js】
work1
function run()
{
var d =new Date();
document.getElementById("clock").innerHTML=d.toLocaleString();
setTimeout("run();",1000);
}
4.编写一个JAVA类和一个JSP页面,将以下信息封装成3个Student对象,然后将每个对象放入一个ArrayList对象中,然后使用ArrayList对象在JSP页面上显示表格中显示的信息
package songyan;
public class Student {
private String id;
private String name;
private String sex;
private String classes;
private double grade;
public Student()
{
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getClasses() {
return classes;
}
public void setClasses(String classes) {
this.classes = classes;
}
public double getGrade() {
return grade;
}
public void setGrade(double grade) {
this.grade = grade;
}
}
work2
5.编写一个JSP程序,使用JSP Script在网页上显示不同颜色的彩条,临时显示以下颜色的彩条:绿色、青色、黑色、红色、黄色和粉红色(对应颜色为:绿色) 、青色、黑色、红色、黄色、粉红色)
work02
1、写两个文件,一个是一个名为myjsp.jsp的JSP文件,一个是一个名为myphoto.html的普通HTML文件。
要求:在myphoto.html中插入自己的照片,在myjsp.jsp中嵌入操作说明。在 IE 中运行 myjsp.jsp 时,可以显示 myphoto.html 中的照片。
myphoto.html
title
2.编写一个JSP页面,实现根据一个人的18位身份证显示生日的功能。它要求使用所有的表达式声明和scriptlet,并将结果显示在一个表格中,如下表所示
index.jsp
身份证
生日
My JSP 'result.jsp' starting page
3. 写一个jsp页面,用Scriptlet写一段计算代码,需要0作为除数,用page命令在另一个jsp页面上显示错误信息,生成的错误信息是“error,can不要使用 0 除法!”。
index.jsp
My JSP 'MyJsp.jsp' starting page
错误,0不能做除数!
4.Supergirl Music Bar 用户需要注册,请为此编写一个jsp页面来实现注册,注册信息包括用户名、密码、性别、年龄、电话号码和E-mail。用户名不能重复。如果用户名已经存在,则必须提示用户;必须输入用户名、性别、密码和E-mail;密码必须输入两次且一致;电子邮件需要合法性检查。
1. 请编写一个JSP程序来实现如图所示的简单计算器。要求:输入“第一个参数”,选择运算类型(+、-、*、/),输入“第二个参数”,按“计算”按钮,结果将显示在“结果”文本框中.
要求:程序需要判断输入的参数是否合法,
比如参数是否为数字,除法时除数不为0。
index.jsp
function getresult()
{
var num1=document.getElementById("num1").value;
var sig=document.getElementById("sig").value;
var num2=document.getElementById("num2").value;
n1 = parseFloat(num1);
n2 = parseFloat(num2);
if(sig=="/"&& num2=="0")
{
document.write("除数不能为零");
}
else
{
switch (sig) {
case "+":
document.getElementById("result").value = n1+n2;
break;
case "-":
document.getElementById("result").value =n1-n2;
break;
case "*":
document.getElementById("result").value =n1*n2;
break;
case "/":
document.getElementById("result").value =n1/n2;
break;
}
}
}
计算器
请输入第一个数:
+
-
*
/
请输入第二个数:
calculator.jsp
计算结果是:
=
简单的计算器
第一个参数
+
-
*
/
第二个数
计算
写一个JSP页面,在session中存储用户名和密码(假设用户名为“Lonely Seeking Failure”,密码为“123456”),然后重定向到另一个JSP页面,显示存储在的用户名和密码会议。(提示:使用响应对象的 sendRedirect() 方法进行重定向。)
jsp计算器
My JSP 'response.jsp' starting page
用户名:
密码 :
编写一个JSP登录页面,可以输入用户名和密码,将请求提交到另一个JSP页面,JSP页面获取请求的数据并显示出来。请求的相关数据包括用户输入的请求数据和请求本身的一些信息(如请求使用的协议getProtocol()、请求的URI request.getServletPath()、请求方法request.getMethod() ),远程地址 request.getRemoteAddr() 等)。
index.jsp
用户名:
密码:
result.jsp
用户名:
密码:
请求使用的协议:
请求的URI:
请求方法:
远程地址:
使用隐式对象为某个网站编写JSP程序,统计网站的访问次数。
一种情况是:基于客户的统计(基于浏览器的统计。如果浏览器访问了网站,则算作一次访问。也就是说,如果浏览器多次刷新网站,也会计为一次访问);
另一种情况:刷新页面一次,即使是访问。
需要隐式对象来实现。
jsp计算器
页面计数:
<br />
浏览器计数
<br /> 查看全部
抓取jsp网页源代码(3.编写一个JSP手表的功能,显示当前时间(时:秒)
)
3.编写一个JSP程序,实现手表的功能,显示当前时间(时:分:秒),并不断自动刷新时间。
方法一【scriptlet】
work01
方法二【js】
work1
function run()
{
var d =new Date();
document.getElementById("clock").innerHTML=d.toLocaleString();
setTimeout("run();",1000);
}
4.编写一个JAVA类和一个JSP页面,将以下信息封装成3个Student对象,然后将每个对象放入一个ArrayList对象中,然后使用ArrayList对象在JSP页面上显示表格中显示的信息
package songyan;
public class Student {
private String id;
private String name;
private String sex;
private String classes;
private double grade;
public Student()
{
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getClasses() {
return classes;
}
public void setClasses(String classes) {
this.classes = classes;
}
public double getGrade() {
return grade;
}
public void setGrade(double grade) {
this.grade = grade;
}
}
work2
5.编写一个JSP程序,使用JSP Script在网页上显示不同颜色的彩条,临时显示以下颜色的彩条:绿色、青色、黑色、红色、黄色和粉红色(对应颜色为:绿色) 、青色、黑色、红色、黄色、粉红色)
work02
1、写两个文件,一个是一个名为myjsp.jsp的JSP文件,一个是一个名为myphoto.html的普通HTML文件。
要求:在myphoto.html中插入自己的照片,在myjsp.jsp中嵌入操作说明。在 IE 中运行 myjsp.jsp 时,可以显示 myphoto.html 中的照片。
myphoto.html
title
2.编写一个JSP页面,实现根据一个人的18位身份证显示生日的功能。它要求使用所有的表达式声明和scriptlet,并将结果显示在一个表格中,如下表所示
index.jsp
身份证
生日
My JSP 'result.jsp' starting page
3. 写一个jsp页面,用Scriptlet写一段计算代码,需要0作为除数,用page命令在另一个jsp页面上显示错误信息,生成的错误信息是“error,can不要使用 0 除法!”。
index.jsp
My JSP 'MyJsp.jsp' starting page
错误,0不能做除数!
4.Supergirl Music Bar 用户需要注册,请为此编写一个jsp页面来实现注册,注册信息包括用户名、密码、性别、年龄、电话号码和E-mail。用户名不能重复。如果用户名已经存在,则必须提示用户;必须输入用户名、性别、密码和E-mail;密码必须输入两次且一致;电子邮件需要合法性检查。
1. 请编写一个JSP程序来实现如图所示的简单计算器。要求:输入“第一个参数”,选择运算类型(+、-、*、/),输入“第二个参数”,按“计算”按钮,结果将显示在“结果”文本框中.
要求:程序需要判断输入的参数是否合法,
比如参数是否为数字,除法时除数不为0。
index.jsp
function getresult()
{
var num1=document.getElementById("num1").value;
var sig=document.getElementById("sig").value;
var num2=document.getElementById("num2").value;
n1 = parseFloat(num1);
n2 = parseFloat(num2);
if(sig=="/"&& num2=="0")
{
document.write("除数不能为零");
}
else
{
switch (sig) {
case "+":
document.getElementById("result").value = n1+n2;
break;
case "-":
document.getElementById("result").value =n1-n2;
break;
case "*":
document.getElementById("result").value =n1*n2;
break;
case "/":
document.getElementById("result").value =n1/n2;
break;
}
}
}
计算器
请输入第一个数:
+
-
*
/
请输入第二个数:
calculator.jsp
计算结果是:
=
简单的计算器
第一个参数
+
-
*
/
第二个数
计算
写一个JSP页面,在session中存储用户名和密码(假设用户名为“Lonely Seeking Failure”,密码为“123456”),然后重定向到另一个JSP页面,显示存储在的用户名和密码会议。(提示:使用响应对象的 sendRedirect() 方法进行重定向。)
jsp计算器
My JSP 'response.jsp' starting page
用户名:
密码 :
编写一个JSP登录页面,可以输入用户名和密码,将请求提交到另一个JSP页面,JSP页面获取请求的数据并显示出来。请求的相关数据包括用户输入的请求数据和请求本身的一些信息(如请求使用的协议getProtocol()、请求的URI request.getServletPath()、请求方法request.getMethod() ),远程地址 request.getRemoteAddr() 等)。
index.jsp
用户名:
密码:
result.jsp
用户名:
密码:
请求使用的协议:
请求的URI:
请求方法:
远程地址:
使用隐式对象为某个网站编写JSP程序,统计网站的访问次数。
一种情况是:基于客户的统计(基于浏览器的统计。如果浏览器访问了网站,则算作一次访问。也就是说,如果浏览器多次刷新网站,也会计为一次访问);
另一种情况:刷新页面一次,即使是访问。
需要隐式对象来实现。
jsp计算器
页面计数:
<br />
浏览器计数
<br />
抓取jsp网页源代码(什么是JSP及其WEB技术?Java代码是什么意思?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-17 21:02
JSP及其WEB技术 1 JSP简介 JSP(JavaServerPages)是一种基于Java的脚本技术。它是由许多公司主动和参与建立的动态网络技术标准。JSP 技术有点类似于 ASP 技术。它将Java程序段(Scriptlet)和JSP标签(tag)插入到传统网页HTML文件(*.htm、*.html)中,形成JSP文件(*.jsp)。使用JSP 开发的Web 应用程序是跨平台的,可以在Linux 或其他操作系统下运行。JSP 的众多优点中,其中之一是它可以有效地将 HTML 编码与 Web 页面的业务逻辑分开。使用 JSP 访问可重用组件,例如 Servlet、JavaBean 和基于 Java 的 Web 应用程序。JSP 还支持在网页中直接嵌入 Java 代码。有两种方法可以访问 JSP 文件:浏览器发送JSP文件请求,请求发送给Servlet。JSP 技术使用Java 编程语言编写类似XML 的标签和scriptlet 来封装生成动态网页的处理逻辑。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。
当Web服务器遇到访问JSP网页的请求时,首先执行其中的程序段,然后将执行结果连同JSP文件中的HTML代码一起返回给客户端。插入的Java程序段可以操作数据库、重定向网页等,实现构建动态网页所需的功能。JSP 和 JavaServlet 一样,都是在服务器端执行的。通常返回一个 HTML 文本给客户端,因此客户端只要有浏览器就可以浏览。JSP 页面由 HTML 代码和嵌入其中的 Java 代码组成。服务器在客户端请求页面后处理这些Java代码,然后将生成的HTML页面返回给客户端的浏览器。JavaServlet 是 JSP 的技术基础,而大型Web应用的开发需要JavaServlet和JSP的配合才能完成。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。
生成内容的逻辑封装在logo和JavaBeans组件中,捆绑在脚本中,所有脚本都在服务器端运行。由于核心逻辑被封装在logo和JavaBeans中,Web管理者和页面设计者可以在不影响内容生成的情况下编辑和使用JSP页面。在服务器端,JSP 引擎解释 JSP 标志和脚本,生成请求的内容,并将结果以 HTML(或 XML)页面的形式发送回浏览器。这不仅有助于作者保护他们自己的代码,而且保证任何基于 HTML 的 Web 浏览器的完全可用性。2.2 可重用组件 大多数 JSP 页面依赖可重用的跨平台组件(JavaBeans 或 EnterpriseJavaBeans 组件)来执行应用程序所需的复杂处理。开发人员可以共享和交换执行常见操作的组件,或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。
3.4 适配平台几乎所有平台都支持Java,JSP+JavaBeans几乎可以在所有平台下使用。当从一个平台移植到另一个平台时,JSP 和 JavaBeans 甚至不需要重新编译,因为 Java 字节码是标准的并且与平台无关。3.5 数据库连接 Java中连接数据库的技术是JDBC。Java程序通过JDBC驱动连接数据库,执行查询、数据提取等操作。Sun公司还开发了JDBC-ODBCbridge,利用这种技术Java程序可以访问带有ODBC驱动程序的数据库。目前大多数数据库系统都有ODBC驱动,所以Java程序可以访问Oracle、Sybase、ess等数据库。此外,JSP 技术可以通过开发徽标库进一步扩展。第三方开发人员和其他人员可以为常用功能创建自己的徽标库。这使 Web 页面开发人员能够使用熟悉的工具和组件来执行特定功能(如徽标)的工作。JSP 技术很容易集成到各种应用架构中以利用现有的工具和技术,并且可以扩展以支持企业级 查看全部
抓取jsp网页源代码(什么是JSP及其WEB技术?Java代码是什么意思?)
JSP及其WEB技术 1 JSP简介 JSP(JavaServerPages)是一种基于Java的脚本技术。它是由许多公司主动和参与建立的动态网络技术标准。JSP 技术有点类似于 ASP 技术。它将Java程序段(Scriptlet)和JSP标签(tag)插入到传统网页HTML文件(*.htm、*.html)中,形成JSP文件(*.jsp)。使用JSP 开发的Web 应用程序是跨平台的,可以在Linux 或其他操作系统下运行。JSP 的众多优点中,其中之一是它可以有效地将 HTML 编码与 Web 页面的业务逻辑分开。使用 JSP 访问可重用组件,例如 Servlet、JavaBean 和基于 Java 的 Web 应用程序。JSP 还支持在网页中直接嵌入 Java 代码。有两种方法可以访问 JSP 文件:浏览器发送JSP文件请求,请求发送给Servlet。JSP 技术使用Java 编程语言编写类似XML 的标签和scriptlet 来封装生成动态网页的处理逻辑。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web 的应用程序的开发变得快速而简单。
当Web服务器遇到访问JSP网页的请求时,首先执行其中的程序段,然后将执行结果连同JSP文件中的HTML代码一起返回给客户端。插入的Java程序段可以操作数据库、重定向网页等,实现构建动态网页所需的功能。JSP 和 JavaServlet 一样,都是在服务器端执行的。通常返回一个 HTML 文本给客户端,因此客户端只要有浏览器就可以浏览。JSP 页面由 HTML 代码和嵌入其中的 Java 代码组成。服务器在客户端请求页面后处理这些Java代码,然后将生成的HTML页面返回给客户端的浏览器。JavaServlet 是 JSP 的技术基础,而大型Web应用的开发需要JavaServlet和JSP的配合才能完成。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。JSP具有Java技术的所有特点,简单易用,完全面向对象,独立于平台,安全可靠,主要面向Internet。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。2JSP技术方法为了快速方便地开发动态网站,JSP在以下几个方面做了改进,使其成为快速建立跨平台动态网站的首选。2.1 将内容的生成和显示分开。使用JSP 技术,Web 页面开发人员可以使用HTML 或XML 标签来设计和格式化最终页面,并使用JSP 标签或小脚本在页面上生成动态内容。
生成内容的逻辑封装在logo和JavaBeans组件中,捆绑在脚本中,所有脚本都在服务器端运行。由于核心逻辑被封装在logo和JavaBeans中,Web管理者和页面设计者可以在不影响内容生成的情况下编辑和使用JSP页面。在服务器端,JSP 引擎解释 JSP 标志和脚本,生成请求的内容,并将结果以 HTML(或 XML)页面的形式发送回浏览器。这不仅有助于作者保护他们自己的代码,而且保证任何基于 HTML 的 Web 浏览器的完全可用性。2.2 可重用组件 大多数 JSP 页面依赖可重用的跨平台组件(JavaBeans 或 EnterpriseJavaBeans 组件)来执行应用程序所需的复杂处理。开发人员可以共享和交换执行常见操作的组件,或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。或将这些组件提供给更多用户和客户群。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。基于组件的方法加速了整体开发过程,并允许各种组织平衡其现有技能和开发工作以优化结果。2.3 使用徽标的网页开发人员并非都是熟悉脚本语言的程序员。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。JSP 技术将动态内容生成所需的许多功能封装在易于使用的、与 JSP 相关的 XML 标签中。标准的 JSP 标志可以访问和实例化 JavaBeans 组件,设置或检索组件属性,下载小程序,以及执行其他更难编码和耗时功能的方法。
3.4 适配平台几乎所有平台都支持Java,JSP+JavaBeans几乎可以在所有平台下使用。当从一个平台移植到另一个平台时,JSP 和 JavaBeans 甚至不需要重新编译,因为 Java 字节码是标准的并且与平台无关。3.5 数据库连接 Java中连接数据库的技术是JDBC。Java程序通过JDBC驱动连接数据库,执行查询、数据提取等操作。Sun公司还开发了JDBC-ODBCbridge,利用这种技术Java程序可以访问带有ODBC驱动程序的数据库。目前大多数数据库系统都有ODBC驱动,所以Java程序可以访问Oracle、Sybase、ess等数据库。此外,JSP 技术可以通过开发徽标库进一步扩展。第三方开发人员和其他人员可以为常用功能创建自己的徽标库。这使 Web 页面开发人员能够使用熟悉的工具和组件来执行特定功能(如徽标)的工作。JSP 技术很容易集成到各种应用架构中以利用现有的工具和技术,并且可以扩展以支持企业级
抓取jsp网页源代码(BBS采集多为3P代码为多(3))
网站优化 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-11-14 21:22
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集到的数据挂在自己的互联网上。其实你也可以将采集收到的数据作为公司的参考,或者将采集到的数据与你公司的业务进行对比等。
目前网页采集多为3P代码(3P即ASP、PHP
, JSP)。最常用的系统是BBS新闻采集系统,以及网上流传的新浪新闻采集系统。全部使用ASP程序,但理论上速度不是很好。
如果尝试使用其他软件的多线程采集,会不会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释采集
网页数据。
一、 简单新闻采集
新闻 采集 是最简单的,只要确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。必须在采集之前获取网页内容,所以在DELPHI中添加idHTTP控件(在indyClients面板中),然后使用idHTTP1.GET方法获取网页内容,声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
functionTForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource) 长度(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示截取开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来拦截想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标签。要定位某个内容,您必须设置
它的开始和结束标志。例如,要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,利用这些特征码拦截文章 标签。
题。
下面我们来实际演示一下。假设采集的文章地址是
代码是:
新页面 1
文章标题
ercolor="#111111"
>
作者
出处
这是文章的内容。 查看全部
抓取jsp网页源代码(BBS采集多为3P代码为多(3))
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集到的数据挂在自己的互联网上。其实你也可以将采集收到的数据作为公司的参考,或者将采集到的数据与你公司的业务进行对比等。
目前网页采集多为3P代码(3P即ASP、PHP
, JSP)。最常用的系统是BBS新闻采集系统,以及网上流传的新浪新闻采集系统。全部使用ASP程序,但理论上速度不是很好。
如果尝试使用其他软件的多线程采集,会不会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释采集
网页数据。
一、 简单新闻采集
新闻 采集 是最简单的,只要确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。必须在采集之前获取网页内容,所以在DELPHI中添加idHTTP控件(在indyClients面板中),然后使用idHTTP1.GET方法获取网页内容,声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
functionTForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource) 长度(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示截取开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来拦截想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标签。要定位某个内容,您必须设置
它的开始和结束标志。例如,要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,利用这些特征码拦截文章 标签。
题。
下面我们来实际演示一下。假设采集的文章地址是
代码是:
新页面 1
文章标题
ercolor="#111111"
>
作者
出处
这是文章的内容。
抓取jsp网页源代码(Java开发中常见的JSP技术(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-12 18:21
一、JSP 技术 1.jsp 脚本和注释
jsp 脚本:
1) ----- 内部java代码翻译成service方法。
2) ----- 会在service方法里面翻译成out.print()
3) ---- 将翻译成servlet成员的内容
jsp 注释:不同注释的可见范围不同
1)Html 注释:---可见范围jsp源代码,翻译后的servlet,页面显示html源代码
2)java comment://single-line comment /*multi-line comment*/ --可见范围jsp源代码翻译servlet
3)jsp 注释:----- 可见范围 jsp 源码可见
2. jsp-----jsp的运行原理本质上是一个servlet(面试)
jsp在第一次访问时会被web容器翻译成servlet,然后执行
过程:
第一次访问---->helloServlet.jsp---->helloServlet_jsp.java---->编译运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
3. jsp使用说明(三)
JSP 的指令是指导 JSP 翻译和运行的命令。 JSP包括三大指令:
1)页面指令---属性最多的指令(实际开发中页面指令默认)属性最多的指令,根据不同的属性,引导整个页面的特性
格式:
常用属性如下:
language:可以嵌入jsp脚本的语言类型
pageEncoding:当前jsp file-contentType 的编码可以收录在里面
contentType: response.setContentType(text/html;charset=UTF-8)
session:翻译时jsp是否自动创建session
import:导入java包
errorPage:当前页面有错误时跳转到哪个页面
isErrorPage:当前页面为错误处理页面
2)include 指令
页面收录(静态收录)指令,可以将一个jsp页面收录到另一个jsp页面中
格式:
3)taglib 指令
引入jsp页面中的标签库(jstl标签库、struts2标签库)
格式:
4. jsp内置/隐式对象(9)-----笔试
jsp翻译成servlet后,service方法中定义并初始化了9个对象。我们可以在jsp脚本中直接使用这9个对象。
姓名
类型
说明
出
javax.servlet.jsp.JspWriter
用于页面输出
请求
javax.servlet.http.HttpServletRequest
获取用户请求信息,
回复
javax.servlet.http.HttpServletResponse
从服务器到客户端的响应信息
配置
javax.servlet.ServletConfig
服务器配置,可以获取初始化参数
会话
javax.servlet.http.HttpSession
用于保存用户信息
申请
javax.servlet.ServletContext
所有用户的共享信息
页面
java.lang.Object
指的是当前页面转换后的Servlet类的实例
页面上下文
javax.servlet.jsp.PageContext
JSP 页面容器
例外
java.lang.Throwable
表示异常发生在JSP页面,只在错误页面有效
(1)输出对象
输出类型:JspWriter
out的作用是想让客户端输出内容----out.write()
out buffer的默认8kb可以设置为0,表示out buffer的内容被关闭,直接写入响应buffer
(2)pageContext 对象
jsp页面的上下文对象有如下功能:
page 对象和 pageContext 对象不是一回事
1)pageContext 是一个域对象
setAttribute(String name,Object obj)
getAttribute(String name)
removeAttrbute(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(String name,Object obj,int scope)
getAttribute(String name,int scope)
removeAttrbute(String name,int scope)
findAttribute(String name)
---依次从pageContext域、请求域、会话域、应用域获取属性。进入域后,就不会往后看。
四个范围的总结:
pageContext domain:当前jsp页面范围
请求域:一个请求
会话域:一个会话
应用域:整个网络应用
2)你可以得到另外8个隐式对象
例如:pageContext.getRequest()
pageContext.getSession()
5. jsp标签(动作)
1)页面收录(动态收录):
2)请求转发:
静态收录和动态收录的区别?
二、EL 技术 1. EL 表达概述
EL(Express Lanuage)表达式可以嵌入到jsp页面中,减少jsp脚本的编写。 EL的目的是替代jsp页面中脚本的编写。
2. EL从域中取出数据(EL最重要的作用)
jsp 脚本:
EL 表达式替换上面的脚本:${requestScope.name}
EL的主要功能是获取四个域的数据,格式为${EL表达式}
EL 获取 pageContext 字段中的值:${pageScope.key};
EL 获取请求字段中的值:${requestScope.key};
EL 获取 session 字段中的值:${sessionScope.key};
EL 获取应用字段中的值:${applicationScope.key};
EL 从四个字段中获取一个值 ${key};
---同样是从pageContext域、请求域、会话域、应用域依次获取属性。在某个域中获取后,就不会向后看。
3. EL的11个内置对象
pageScope、requestScope、sessionScope、applicationScope----在JSP中获取域中的数据
param,paramValues-接收参数相当于request.getParameter() rquest.getParameterValues()
header,headerValues-获取相当于request.getHeader(name)的请求头信息
initParam-获取等效于this.getServletContext().getInitParameter(name)的全局初始化参数
WEB开发中的cookie-cookie相当于request.getCookies()---cookie.getName()---cookie.getValue()
WEB开发中的pageContext-pageContext。
pageContext 获取其他八个对象
${pageContext.request.contextPath} 相当于这段代码不能实现WEB应用的名字
4. EL 执行表达式
例如:
${1+1}
${空用户}
${user==null?true:false}
一、JSTL 技术 1. JSTL 概述
JSTL(JSP Standard Tag Library),JSP标准标签库,可以嵌入到JSP页面中,以标签的形式完成业务逻辑等功能。 jstl的作用是替换jsp页面中与el相同的脚本代码。 JSTL标准标准标签库有5个子库,但随着发展,目前经常使用核心库
标签库
标签库的URI
前缀
核心
c
I18N
文件
SQL
sql
XML
x
功能
fn
2. JSTL下载导入
JSTL 下载:
从Apache的网站下载JSTL的JAR包。到“”网站下载JSTL安装包。 jakarta-taglibs-standard-1.1.2.zip,然后解压下载的JSTL安装包。这时候可以在lib目录下看到两个JAR文件,分别是jstl.jar和standard.jar。其中,jstl.jar文件收录JSTL规范中定义的接口和相关类,standard.jar文件收录用于实现JSTL的.class文件和JSTL中的5个标签库描述符文件(TLD)
将两个jar包导入到我们项目的lib中
使用jsp的taglib指令导入核心标签库
3. JSTL核心库常用标签
1)标签
其中 test 是返回布尔值的条件
2)标签
有两种用法组合:
四、javaEE 开发模型 1. 什么是模式
模式开发过程中总结的“套路”,总结出一套常规的设计模式
2. javaEE体验模式
model1 模式:
技术构成:jsp+javaBean
model1的缺点:业务复杂,jsp页面比较混乱。
model2 模式
技术构成:jsp+servlet+javaBean
model2的优点:利用各个技术擅长的方面进行开发
Servlet:擅长处理java业务代码
jsp:擅长页面的真实性
MVC:----Web开发的设计模式
M:Model---model javaBean:封装的数据
V: View-----view jsp: 只显示页面
C:Controller----Controller Servelt:获取数据-封装数据-传递数据-分配jsp页面显示
3. JavaEE的三层架构
在服务器开发过程中,分为三层
Web 层:与客户端交互
服务层:复杂的业务处理
dao层:与数据库交互
在开发实践中,三层架构通过包结构体现
MVC 和三层架构是什么关系?
总结:
EL 表达式
从域中检索数据${域中存储的数据的名称}
${pageContext.request.contextPath}
JSTL 标签(核心库)
javaEE 三层架构+MVC
Web层:采集页面数据、封装数据、传输数据、指定响应jsp页面
服务层:编写逻辑业务代码
dao层:数据库访问代码的编译 查看全部
抓取jsp网页源代码(Java开发中常见的JSP技术(一)(组图))
一、JSP 技术 1.jsp 脚本和注释
jsp 脚本:
1) ----- 内部java代码翻译成service方法。
2) ----- 会在service方法里面翻译成out.print()
3) ---- 将翻译成servlet成员的内容
jsp 注释:不同注释的可见范围不同
1)Html 注释:---可见范围jsp源代码,翻译后的servlet,页面显示html源代码
2)java comment://single-line comment /*multi-line comment*/ --可见范围jsp源代码翻译servlet
3)jsp 注释:----- 可见范围 jsp 源码可见
2. jsp-----jsp的运行原理本质上是一个servlet(面试)
jsp在第一次访问时会被web容器翻译成servlet,然后执行
过程:
第一次访问---->helloServlet.jsp---->helloServlet_jsp.java---->编译运行
PS:翻译后的servlet可以在Tomcat的工作目录中找到
3. jsp使用说明(三)
JSP 的指令是指导 JSP 翻译和运行的命令。 JSP包括三大指令:
1)页面指令---属性最多的指令(实际开发中页面指令默认)属性最多的指令,根据不同的属性,引导整个页面的特性
格式:
常用属性如下:
language:可以嵌入jsp脚本的语言类型
pageEncoding:当前jsp file-contentType 的编码可以收录在里面
contentType: response.setContentType(text/html;charset=UTF-8)
session:翻译时jsp是否自动创建session
import:导入java包
errorPage:当前页面有错误时跳转到哪个页面
isErrorPage:当前页面为错误处理页面
2)include 指令
页面收录(静态收录)指令,可以将一个jsp页面收录到另一个jsp页面中
格式:
3)taglib 指令
引入jsp页面中的标签库(jstl标签库、struts2标签库)
格式:
4. jsp内置/隐式对象(9)-----笔试
jsp翻译成servlet后,service方法中定义并初始化了9个对象。我们可以在jsp脚本中直接使用这9个对象。
姓名
类型
说明
出
javax.servlet.jsp.JspWriter
用于页面输出
请求
javax.servlet.http.HttpServletRequest
获取用户请求信息,
回复
javax.servlet.http.HttpServletResponse
从服务器到客户端的响应信息
配置
javax.servlet.ServletConfig
服务器配置,可以获取初始化参数
会话
javax.servlet.http.HttpSession
用于保存用户信息
申请
javax.servlet.ServletContext
所有用户的共享信息
页面
java.lang.Object
指的是当前页面转换后的Servlet类的实例
页面上下文
javax.servlet.jsp.PageContext
JSP 页面容器
例外
java.lang.Throwable
表示异常发生在JSP页面,只在错误页面有效
(1)输出对象
输出类型:JspWriter
out的作用是想让客户端输出内容----out.write()
out buffer的默认8kb可以设置为0,表示out buffer的内容被关闭,直接写入响应buffer
(2)pageContext 对象
jsp页面的上下文对象有如下功能:
page 对象和 pageContext 对象不是一回事
1)pageContext 是一个域对象
setAttribute(String name,Object obj)
getAttribute(String name)
removeAttrbute(字符串名称)
pageContext 可以访问其他指定域的数据
setAttribute(String name,Object obj,int scope)
getAttribute(String name,int scope)
removeAttrbute(String name,int scope)
findAttribute(String name)
---依次从pageContext域、请求域、会话域、应用域获取属性。进入域后,就不会往后看。
四个范围的总结:
pageContext domain:当前jsp页面范围
请求域:一个请求
会话域:一个会话
应用域:整个网络应用
2)你可以得到另外8个隐式对象
例如:pageContext.getRequest()
pageContext.getSession()
5. jsp标签(动作)
1)页面收录(动态收录):
2)请求转发:
静态收录和动态收录的区别?
二、EL 技术 1. EL 表达概述
EL(Express Lanuage)表达式可以嵌入到jsp页面中,减少jsp脚本的编写。 EL的目的是替代jsp页面中脚本的编写。
2. EL从域中取出数据(EL最重要的作用)
jsp 脚本:
EL 表达式替换上面的脚本:${requestScope.name}
EL的主要功能是获取四个域的数据,格式为${EL表达式}
EL 获取 pageContext 字段中的值:${pageScope.key};
EL 获取请求字段中的值:${requestScope.key};
EL 获取 session 字段中的值:${sessionScope.key};
EL 获取应用字段中的值:${applicationScope.key};
EL 从四个字段中获取一个值 ${key};
---同样是从pageContext域、请求域、会话域、应用域依次获取属性。在某个域中获取后,就不会向后看。
3. EL的11个内置对象
pageScope、requestScope、sessionScope、applicationScope----在JSP中获取域中的数据
param,paramValues-接收参数相当于request.getParameter() rquest.getParameterValues()
header,headerValues-获取相当于request.getHeader(name)的请求头信息
initParam-获取等效于this.getServletContext().getInitParameter(name)的全局初始化参数
WEB开发中的cookie-cookie相当于request.getCookies()---cookie.getName()---cookie.getValue()
WEB开发中的pageContext-pageContext。
pageContext 获取其他八个对象
${pageContext.request.contextPath} 相当于这段代码不能实现WEB应用的名字
4. EL 执行表达式
例如:
${1+1}
${空用户}
${user==null?true:false}
一、JSTL 技术 1. JSTL 概述
JSTL(JSP Standard Tag Library),JSP标准标签库,可以嵌入到JSP页面中,以标签的形式完成业务逻辑等功能。 jstl的作用是替换jsp页面中与el相同的脚本代码。 JSTL标准标准标签库有5个子库,但随着发展,目前经常使用核心库
标签库
标签库的URI
前缀
核心
c
I18N
文件
SQL
sql
XML
x
功能
fn
2. JSTL下载导入
JSTL 下载:
从Apache的网站下载JSTL的JAR包。到“”网站下载JSTL安装包。 jakarta-taglibs-standard-1.1.2.zip,然后解压下载的JSTL安装包。这时候可以在lib目录下看到两个JAR文件,分别是jstl.jar和standard.jar。其中,jstl.jar文件收录JSTL规范中定义的接口和相关类,standard.jar文件收录用于实现JSTL的.class文件和JSTL中的5个标签库描述符文件(TLD)
将两个jar包导入到我们项目的lib中
使用jsp的taglib指令导入核心标签库
3. JSTL核心库常用标签
1)标签
其中 test 是返回布尔值的条件
2)标签
有两种用法组合:
四、javaEE 开发模型 1. 什么是模式
模式开发过程中总结的“套路”,总结出一套常规的设计模式
2. javaEE体验模式
model1 模式:
技术构成:jsp+javaBean
model1的缺点:业务复杂,jsp页面比较混乱。
model2 模式
技术构成:jsp+servlet+javaBean
model2的优点:利用各个技术擅长的方面进行开发
Servlet:擅长处理java业务代码
jsp:擅长页面的真实性
MVC:----Web开发的设计模式
M:Model---model javaBean:封装的数据
V: View-----view jsp: 只显示页面
C:Controller----Controller Servelt:获取数据-封装数据-传递数据-分配jsp页面显示
3. JavaEE的三层架构
在服务器开发过程中,分为三层
Web 层:与客户端交互
服务层:复杂的业务处理
dao层:与数据库交互
在开发实践中,三层架构通过包结构体现
MVC 和三层架构是什么关系?
总结:
EL 表达式
从域中检索数据${域中存储的数据的名称}
${pageContext.request.contextPath}
JSTL 标签(核心库)
javaEE 三层架构+MVC
Web层:采集页面数据、封装数据、传输数据、指定响应jsp页面
服务层:编写逻辑业务代码
dao层:数据库访问代码的编译
抓取jsp网页源代码(如何使用后台的JSP程序?(图)程序获取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-11-12 18:18
)
获取后台的值,比如请求对象,例如:获取权限信息并显示,一段JavaScript代码如下
1)给页面赋值
function initRight()
{
var rights='';
var rightArr = rights.split(",");
var size = rightArr.length;
var obj;
for(var count =0 ; count0)//新增
{
strv =eles[v].replace("Update","Query");
document.getElementById(strv).checked=true;
}
if(tempv.indexOf("update|")>-1)//修改
{
strv =eles[v].replace("update","query");
document.getElementById(strv).checked=true;
}
setValue=true;
}
}
var val=setValue?destVal:"";
$Id(destId).value=val;
}
}
function $name(name){return document.getElementsByName(name);}
function $Id(id){return document.getElementById(id);}
一、如何将页面中的JavaScript数据提交给后台jsp程序
①可以将JavaScript数据以xxx.JSP?var1=aaa&var2=bbb的形式作为URL参数传递给JSP程序,此时在jsp中使用。
可以获取JavaScript脚本传递过来的数据;
②使用JavaScript在表单中添加隐藏字段信息,然后使用表单向JSP程序提交数据。
二、页面中的JavaScript数据如何使用后台JSP程序的数据
这个比较简单。可以直接在JavaScript脚本中使用,将jsp程序中的数据传输到JavaScript脚本中使用。
参考下面的脚本: 查看全部
抓取jsp网页源代码(如何使用后台的JSP程序?(图)程序获取
)
获取后台的值,比如请求对象,例如:获取权限信息并显示,一段JavaScript代码如下
1)给页面赋值
function initRight()
{
var rights='';
var rightArr = rights.split(",");
var size = rightArr.length;
var obj;
for(var count =0 ; count0)//新增
{
strv =eles[v].replace("Update","Query");
document.getElementById(strv).checked=true;
}
if(tempv.indexOf("update|")>-1)//修改
{
strv =eles[v].replace("update","query");
document.getElementById(strv).checked=true;
}
setValue=true;
}
}
var val=setValue?destVal:"";
$Id(destId).value=val;
}
}
function $name(name){return document.getElementsByName(name);}
function $Id(id){return document.getElementById(id);}
一、如何将页面中的JavaScript数据提交给后台jsp程序
①可以将JavaScript数据以xxx.JSP?var1=aaa&var2=bbb的形式作为URL参数传递给JSP程序,此时在jsp中使用。
可以获取JavaScript脚本传递过来的数据;
②使用JavaScript在表单中添加隐藏字段信息,然后使用表单向JSP程序提交数据。
二、页面中的JavaScript数据如何使用后台JSP程序的数据
这个比较简单。可以直接在JavaScript脚本中使用,将jsp程序中的数据传输到JavaScript脚本中使用。
参考下面的脚本:
抓取jsp网页源代码(一下JSP和HTML之间的联系和区别,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-11-12 16:04
JSP 和 HTML 有什么区别?下面的文章文章将简单对比JSP和HTML,让大家了解JSP和HTML的关系和区别,希望对大家有所帮助。
什么是JSP?
JSP 代表 JavaServer Pages;主要用于开发动态网页,文件扩展名为.jsp。JSP 技术允许快速开发和易于维护信息丰富的动态网页。JSP 网页基于 HTML、XML 或其他文档类型。他们还需要兼容的 Web 服务器和 servlet 容器,例如 Apache Tomcat 或 Jetty,才能运行。【视频教程推荐:JSP教程】
JSP 的主要优点是程序员可以在 HTML 中插入 Java 代码;使用 JSP 标签插入 Java 代码。程序员可以写标签。
此外,还有不同的 JSP 标记来完成各种任务。有一些标签可以在请求和页面之间共享数据,在页面之间传递控制,从数据库中获取数据等等。
什么是 HTML?
HTML 代表超文本标记语言。它是一种众所周知的标记语言,用于开发网页并帮助构建网页结构。它已经存在很长时间了,经常用于网页设计。XML 或可扩展标记语言定义了一组规则,用于以人类和计算机可读的格式对文档进行编码。
由于它是一种标记语言,它收录许多标记。使用标签将图像、文本、视频、表单和其他内容插入到一个有凝聚力的网页中。HTML 页面由两个主要部分组成:页眉和正文部分。元数据(描述页面的数据)位于标题中,正文部分包括表示网页可见内容所需的所有标签。
JSP和HTML的关系
JSP 允许在 HTML 文件中插入 Java 代码
JSP 和 HTML 的区别
1、不同的技术
HTML 是一种客户端技术,它提供了一种描述文档中基于文本的信息结构的方法。JSP 是一种服务器端技术,它为不断变化的数据和动态调用服务器操作提供动态接口。
2、生成的页面不一样
HTML 生成静态网页;JSP 生成动态网页。
3、Java 代码插入
HTML 不允许在页面中放置 Java 代码;JSP 允许将 Java 代码放置在 JSP 页面中。
4、函数
HTML 页面强调信息在浏览器中的外观、语义和布局;它有助于创建网页的结构。JSP 页面可以从服务器调用内置函数,这有助于开发动态 Web 应用程序。
5、速度
HTML 在本地计算机上运行时加载速度更快。JSP 需要一些时间来加载,因为它必须与 Web 服务器交互。
综上所述
JSP 和 HTML 的主要区别在于 JSP 是一种创建动态 Web 应用程序的技术,而 HTML 是一种用于创建 Web 页面结构的标准标记语言。简而言之,JSP 文件是带有 Java 代码的 HTML 文件。
以上就是本文文章的全部内容,希望对大家的学习有所帮助。更多精彩内容,可以关注php中文网相关教程专栏!!!
以上就是JSP和HTML区别的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
抓取jsp网页源代码(一下JSP和HTML之间的联系和区别,你知道吗?)
JSP 和 HTML 有什么区别?下面的文章文章将简单对比JSP和HTML,让大家了解JSP和HTML的关系和区别,希望对大家有所帮助。
什么是JSP?
JSP 代表 JavaServer Pages;主要用于开发动态网页,文件扩展名为.jsp。JSP 技术允许快速开发和易于维护信息丰富的动态网页。JSP 网页基于 HTML、XML 或其他文档类型。他们还需要兼容的 Web 服务器和 servlet 容器,例如 Apache Tomcat 或 Jetty,才能运行。【视频教程推荐:JSP教程】
JSP 的主要优点是程序员可以在 HTML 中插入 Java 代码;使用 JSP 标签插入 Java 代码。程序员可以写标签。
此外,还有不同的 JSP 标记来完成各种任务。有一些标签可以在请求和页面之间共享数据,在页面之间传递控制,从数据库中获取数据等等。
什么是 HTML?
HTML 代表超文本标记语言。它是一种众所周知的标记语言,用于开发网页并帮助构建网页结构。它已经存在很长时间了,经常用于网页设计。XML 或可扩展标记语言定义了一组规则,用于以人类和计算机可读的格式对文档进行编码。
由于它是一种标记语言,它收录许多标记。使用标签将图像、文本、视频、表单和其他内容插入到一个有凝聚力的网页中。HTML 页面由两个主要部分组成:页眉和正文部分。元数据(描述页面的数据)位于标题中,正文部分包括表示网页可见内容所需的所有标签。
JSP和HTML的关系
JSP 允许在 HTML 文件中插入 Java 代码
JSP 和 HTML 的区别
1、不同的技术
HTML 是一种客户端技术,它提供了一种描述文档中基于文本的信息结构的方法。JSP 是一种服务器端技术,它为不断变化的数据和动态调用服务器操作提供动态接口。
2、生成的页面不一样
HTML 生成静态网页;JSP 生成动态网页。
3、Java 代码插入
HTML 不允许在页面中放置 Java 代码;JSP 允许将 Java 代码放置在 JSP 页面中。
4、函数
HTML 页面强调信息在浏览器中的外观、语义和布局;它有助于创建网页的结构。JSP 页面可以从服务器调用内置函数,这有助于开发动态 Web 应用程序。
5、速度
HTML 在本地计算机上运行时加载速度更快。JSP 需要一些时间来加载,因为它必须与 Web 服务器交互。
综上所述
JSP 和 HTML 的主要区别在于 JSP 是一种创建动态 Web 应用程序的技术,而 HTML 是一种用于创建 Web 页面结构的标准标记语言。简而言之,JSP 文件是带有 Java 代码的 HTML 文件。
以上就是本文文章的全部内容,希望对大家的学习有所帮助。更多精彩内容,可以关注php中文网相关教程专栏!!!
以上就是JSP和HTML区别的详细内容。更多详情请关注其他相关php中文网站文章!
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
抓取jsp网页源代码(一个SSM对象的格式及html及controller代码的解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-11 11:14
最近搭建了一个SSM框架,但是前台页面是html,所以无法使用JSP标签集来获取数据,但是可以获取到数据,但是无法在页面上显示。 ajax加了这么一行代码,问题完美解决。
var retData = eval("(" + data + ")");
上面代码的意思是把获取到的数据转换成json对象的格式,然后就可以得到你想要的数据了。 所谓json对象的格式,是指后台返回给前台的数据是一个json字符串。我们无法在页面上的object.name 方法中获取数据,因为它是一个字符串,我们无法点击该方法。这时候,我们就需要将字符串转换成json对象,然后用json对象来指出属性(但有时不加这行代码就可以取出来)。其实判断数据是json字符串还是json对象很简单。如果数据警报(data)在弹出框中显示为Object,则为对象,其他数据会直接显示。 html 和控制器代码附在下面。
html
$(function () {
alert("页面加载完成后自动运行函数............");
// 全局页面加载函数,就是,页面完全加载完成后,js就自动发送请求到后台查询数据
// 所以就是ajax的几种发送方式,
// 即,直接写 $.get(),$.post(),$.ajax()等
/* // 基本功能菜单加载
$.post("/mavenweb/customer/ht.do",function(data){
// var retData = eval("(" + data + ")");
alert(data);
$("#username").val(data.cust_name);
$("#address").val(data.cust_address);
},"json");*/
$.ajax({
type:"get",
url:"/mavenweb/customer/ht.do",
dateType:"json",
success:function (data) {
var retData = eval("(" + data + ")");
$("#username").val(retData.cust_name);
$("#address").val(retData.cust_address);
}
});
});
controller:@ResponseBody 这个注解会自动帮我们转换java对象和json格式
@RequestMapping("/customer/ht")
@ResponseBody
public Customer htm(HttpServletResponse response) throws Exception{
Customer customer = customerService.getCustomer();
System.out.print("html..............");
return customer;
}
附件:jquery函数的全局事件,然后前端加载页面后(各种样式等),然后js发送请求,加载数据
效果:打开页面后直接显示数据。
其实前端页面就是在加载了CSS样式、图片、引用文件等之后执行js函数。 查看全部
抓取jsp网页源代码(一个SSM对象的格式及html及controller代码的解决方法)
最近搭建了一个SSM框架,但是前台页面是html,所以无法使用JSP标签集来获取数据,但是可以获取到数据,但是无法在页面上显示。 ajax加了这么一行代码,问题完美解决。
var retData = eval("(" + data + ")");
上面代码的意思是把获取到的数据转换成json对象的格式,然后就可以得到你想要的数据了。 所谓json对象的格式,是指后台返回给前台的数据是一个json字符串。我们无法在页面上的object.name 方法中获取数据,因为它是一个字符串,我们无法点击该方法。这时候,我们就需要将字符串转换成json对象,然后用json对象来指出属性(但有时不加这行代码就可以取出来)。其实判断数据是json字符串还是json对象很简单。如果数据警报(data)在弹出框中显示为Object,则为对象,其他数据会直接显示。 html 和控制器代码附在下面。
html
$(function () {
alert("页面加载完成后自动运行函数............");
// 全局页面加载函数,就是,页面完全加载完成后,js就自动发送请求到后台查询数据
// 所以就是ajax的几种发送方式,
// 即,直接写 $.get(),$.post(),$.ajax()等
/* // 基本功能菜单加载
$.post("/mavenweb/customer/ht.do",function(data){
// var retData = eval("(" + data + ")");
alert(data);
$("#username").val(data.cust_name);
$("#address").val(data.cust_address);
},"json");*/
$.ajax({
type:"get",
url:"/mavenweb/customer/ht.do",
dateType:"json",
success:function (data) {
var retData = eval("(" + data + ")");
$("#username").val(retData.cust_name);
$("#address").val(retData.cust_address);
}
});
});
controller:@ResponseBody 这个注解会自动帮我们转换java对象和json格式
@RequestMapping("/customer/ht")
@ResponseBody
public Customer htm(HttpServletResponse response) throws Exception{
Customer customer = customerService.getCustomer();
System.out.print("html..............");
return customer;
}
附件:jquery函数的全局事件,然后前端加载页面后(各种样式等),然后js发送请求,加载数据
效果:打开页面后直接显示数据。
其实前端页面就是在加载了CSS样式、图片、引用文件等之后执行js函数。
抓取jsp网页源代码(想要爬取指定网页中的图片主要需要以下三个步骤(1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-11-04 21:18
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2) 根据你要爬取的内容设置正则表达式匹配你要爬取的内容
(3)设置循环列表,反复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
# 第一个简单的爬取图片的程序
import urllib.request # python自带的爬操作url的库
import re # 正则表达式
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
"User-Agent": "Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N)
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36"
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode("UTF-8")
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# [^s]*? 表示最小匹配, 两个括号表示列表中有两个元组
# imageList = re.findall(r"(https:[^s]*?(png))"", page)
imageList = re.findall(r"(https:[^s]*?(jpg|png|gif))"", page)
x = 0
# 循环列表
for imageUrl in imageList:
try:
print("正在下载: %s" % imageUrl[0])
# 这个image文件夹需要先创建好才能看到结果
image_save_path = "./image/%d.png" % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(imageUrl[0], image_save_path)
x = x + 1
except:
continue
pass
if __name__ == "__main__":
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
# print(page)
注意代码中需要修改的是 imageList = re.findall(r"(https:[^s]*?(jpg|png|gif))"", page) 这一段内容,如何设计正则表达式需要根据你要爬取的内容设置,我的设计源码如下:
可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r"(https:[^s]*?(png))"", page)。
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
import urllib # python自带的爬操作url的库
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
"User-Agent": "Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N)
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36"
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode("UTF-8")
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# 按照html格式解析页面
soup = BeautifulSoup(page, "html.parser")
# 格式化输出DOM树的内容
print(soup.prettify())
# 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
imgList = soup.find_all("img")
x = 0
# 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
for imgUrl in imgList[1:]:
print("正在下载: %s " % imgUrl.get("src"))
# 得到scr的内容,这里返回的就是Url字符串链接,如"https://img2020.cnblogs.com/bl ... ot%3B
image_url = imgUrl.get("src")
# 这个image文件夹需要先创建好才能看到结果
image_save_path = "./image/%d.png" % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(image_url, image_save_path)
x = x + 1
if __name__ == "__main__":
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。它更简洁明了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持云海天教程。
原文链接: 查看全部
抓取jsp网页源代码(想要爬取指定网页中的图片主要需要以下三个步骤(1))
抓取指定网页中的图片主要需要以下三个步骤:
(1)指定网站链接,获取网站的源码(如果使用google浏览器,鼠标右键->Inspect->Elements中的html内容)
(2) 根据你要爬取的内容设置正则表达式匹配你要爬取的内容
(3)设置循环列表,反复抓取保存内容
下面介绍两种抓取指定网页图片的方法
(1)方法一:使用正则表达式过滤捕获的html内容字符串
# 第一个简单的爬取图片的程序
import urllib.request # python自带的爬操作url的库
import re # 正则表达式
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
"User-Agent": "Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N)
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36"
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode("UTF-8")
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# [^s]*? 表示最小匹配, 两个括号表示列表中有两个元组
# imageList = re.findall(r"(https:[^s]*?(png))"", page)
imageList = re.findall(r"(https:[^s]*?(jpg|png|gif))"", page)
x = 0
# 循环列表
for imageUrl in imageList:
try:
print("正在下载: %s" % imageUrl[0])
# 这个image文件夹需要先创建好才能看到结果
image_save_path = "./image/%d.png" % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(imageUrl[0], image_save_path)
x = x + 1
except:
continue
pass
if __name__ == "__main__":
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
# print(page)
注意代码中需要修改的是 imageList = re.findall(r"(https:[^s]*?(jpg|png|gif))"", page) 这一段内容,如何设计正则表达式需要根据你要爬取的内容设置,我的设计源码如下:
可以看到,因为这个页面的图片都是png格式,所以也可以写成imageList = re.findall(r"(https:[^s]*?(png))"", page)。
(2)方法二:使用BeautifulSoup库解析html网页
from bs4 import BeautifulSoup # BeautifulSoup是python处理HTML/XML的函数库,是Python内置的网页分析工具
import urllib # python自带的爬操作url的库
# 该方法传入url,返回url的html的源代码
def getHtmlCode(url):
# 以下几行注释的代码在本程序中有加没加效果一样,但是为了隐藏自己避免被反爬虫可以假如这个伪装的头部请求
headers = {
"User-Agent": "Mozilla/5.0(Linux; Android 6.0; Nexus 5 Build/MRA58N)
AppleWebKit/537.36(KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36"
}
# 将headers头部添加到url,模拟浏览器访问
url = urllib.request.Request(url, headers=headers)
# 将url页面的源代码保存成字符串
page = urllib.request.urlopen(url).read()
# 字符串转码
page = page.decode("UTF-8")
return page
# 该方法传入html的源代码,通过截取其中的img标签,将图片保存到本机
def getImage(page):
# 按照html格式解析页面
soup = BeautifulSoup(page, "html.parser")
# 格式化输出DOM树的内容
print(soup.prettify())
# 返回所有包含img标签的列表,因为在Html文件中图片的插入呈现形式是...
imgList = soup.find_all("img")
x = 0
# 循环找到的图片列表,注意,这里手动设置从第2张图片开始,是因为我debug看到了第一张图片不是我想要的图片
for imgUrl in imgList[1:]:
print("正在下载: %s " % imgUrl.get("src"))
# 得到scr的内容,这里返回的就是Url字符串链接,如"https://img2020.cnblogs.com/bl ... ot%3B
image_url = imgUrl.get("src")
# 这个image文件夹需要先创建好才能看到结果
image_save_path = "./image/%d.png" % x
# 下载图片并且保存到指定文件夹中
urllib.request.urlretrieve(image_url, image_save_path)
x = x + 1
if __name__ == "__main__":
# 指定要爬取的网站
url = "https://www.cnblogs.com/ttweix ... ot%3B
# 得到该网站的源代码
page = getHtmlCode(url)
# 爬取该网站的图片并且保存
getImage(page)
这两种方法各有优缺点。我认为它们可以灵活组合。比如先用方法二中的指定标签的方法缩小你要查找的内容范围,然后再用正则表达式匹配到需要的内容。它更简洁明了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持云海天教程。
原文链接:
抓取jsp网页源代码(,怎样利用网站的源代码快速做网站?有实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-04 21:13
这个要看源码是用什么语言写的,如果是html语言,直接打开index.html就可以了。如果是asp,jsp什么的,那么就需要配置iis服务器来运行程序,其中iis就是添加和删除程序,添加和删除windows组件。然后选择internet信息服务,但需要有windows安装光盘,也可以到网上找iis5.1下载。如果使用visuo2005制作.net网站,需要先发布网站,然后点击运行。我暂时只知道这些类型。
这道题是最基本的建站知识,需要搜索相关知识,再问更详细的问题。
给大家简单说明:下载源码后,上传到虚拟主机(不要问我虚拟主机是什么),然后按照安装提示安装源码,绑定域名(你的域名应该是准备好了),@网站 就可以运行了。
现在网站做起来容易,但做搜索引擎喜欢、用户体验好的网站就难了。
修改调试好,保证可以使用。将文件上传到空间。
您可以使用自己的域名访问刚刚上传的站点。
---------------
建议创建一个单页的.html,上传到空间查看。可以通过域名访问吗?
确保域名解析正确。.
下载源代码
使用DREAMWEAVER之类的工具对其进行修改,例如将LOGO修改为您的等等。
在您自己的计算机上安装 IIS
测试本机的URL是否正常。
然后申请一个空间和域名(也有免费的)
上传所有文件网站
完成它
如何用下载的源码做网站:一般都是网上下载的网站程序写的,换个自己喜欢的风格,不用改就可以用,把网站 将源文件上传到主机或使用自己的PC作为主机,直接运行即可,
如何利用网站的源码快速做网站?最好有例子和详细步骤。:对于这么多的广告客户,我只是下载源代码然后......用FTP上传工具上传你的空间/WEB几乎形成。然后看看有什么问题,继续修改替换原来的文件。这是我慢慢做的,希望对你有帮助。
下载源码后,如何生成网站-:如果是网上下载的源码,那么可以直接上传到服务器,自己编写,直接上传即可。
怎么用下载的源码做网站,请写明细节,200分都给了: 一、从源站下载一个和你想要的类似的源码网站 全网站源代码。告诉你一个好的源码站点:ASP Concentration Camp()。下载后在本机用IIS浏览,看看前后台功能是否完善。最好登录后台进行添加和修改操作。如果后台功能完善,那么你可以...
使用下载的源代码制作网页:网站的动态源代码,如asp、php、jsp,无法通过访问页面下载。网上唯一能做的就是批量抓取这个网站 静态网页的爬虫工具有很多。比如仿站小工具,webzip之类的,可以快速抓取静态网页,但是很难捕获json格式。如果你一定需要动态代码,除非你入侵服务器,当然你也可以判断对方网站是否是网上可以下载的开源程序。如果是,那很简单。
如何使用源码制作自己的网站 比如我想做一个购物网站,如何使用源码:下载购物网站,用网页打开-制作工具查看源代码
使用下载的源代码制作网页——:
怎么用网上的源码做生意网站:你好!直接复制代码到DW代码设计视图中....我的回答你满意吗~~
如何使用下载的网站源代码:将源文件传输到你的服务器,设置IIS,在浏览器中输入地址,就可以访问你的网站或者在本机上安装测试学习
我用网上下载的源代码创建了一个网站。我已经上传了虚拟空间。然后我想自己修改它。我该怎么办?从所谓的后台...:你要修改源进程,最好在本地修改并上传。如果使用织梦Dedecms,可以在后台进入,在文件管理器中编辑文件。在后台输入您的域名/dede 查看全部
抓取jsp网页源代码(,怎样利用网站的源代码快速做网站?有实例)
这个要看源码是用什么语言写的,如果是html语言,直接打开index.html就可以了。如果是asp,jsp什么的,那么就需要配置iis服务器来运行程序,其中iis就是添加和删除程序,添加和删除windows组件。然后选择internet信息服务,但需要有windows安装光盘,也可以到网上找iis5.1下载。如果使用visuo2005制作.net网站,需要先发布网站,然后点击运行。我暂时只知道这些类型。
这道题是最基本的建站知识,需要搜索相关知识,再问更详细的问题。
给大家简单说明:下载源码后,上传到虚拟主机(不要问我虚拟主机是什么),然后按照安装提示安装源码,绑定域名(你的域名应该是准备好了),@网站 就可以运行了。
现在网站做起来容易,但做搜索引擎喜欢、用户体验好的网站就难了。
修改调试好,保证可以使用。将文件上传到空间。
您可以使用自己的域名访问刚刚上传的站点。
---------------
建议创建一个单页的.html,上传到空间查看。可以通过域名访问吗?
确保域名解析正确。.
下载源代码
使用DREAMWEAVER之类的工具对其进行修改,例如将LOGO修改为您的等等。
在您自己的计算机上安装 IIS
测试本机的URL是否正常。
然后申请一个空间和域名(也有免费的)
上传所有文件网站
完成它
如何用下载的源码做网站:一般都是网上下载的网站程序写的,换个自己喜欢的风格,不用改就可以用,把网站 将源文件上传到主机或使用自己的PC作为主机,直接运行即可,
如何利用网站的源码快速做网站?最好有例子和详细步骤。:对于这么多的广告客户,我只是下载源代码然后......用FTP上传工具上传你的空间/WEB几乎形成。然后看看有什么问题,继续修改替换原来的文件。这是我慢慢做的,希望对你有帮助。
下载源码后,如何生成网站-:如果是网上下载的源码,那么可以直接上传到服务器,自己编写,直接上传即可。
怎么用下载的源码做网站,请写明细节,200分都给了: 一、从源站下载一个和你想要的类似的源码网站 全网站源代码。告诉你一个好的源码站点:ASP Concentration Camp()。下载后在本机用IIS浏览,看看前后台功能是否完善。最好登录后台进行添加和修改操作。如果后台功能完善,那么你可以...
使用下载的源代码制作网页:网站的动态源代码,如asp、php、jsp,无法通过访问页面下载。网上唯一能做的就是批量抓取这个网站 静态网页的爬虫工具有很多。比如仿站小工具,webzip之类的,可以快速抓取静态网页,但是很难捕获json格式。如果你一定需要动态代码,除非你入侵服务器,当然你也可以判断对方网站是否是网上可以下载的开源程序。如果是,那很简单。
如何使用源码制作自己的网站 比如我想做一个购物网站,如何使用源码:下载购物网站,用网页打开-制作工具查看源代码
使用下载的源代码制作网页——:
怎么用网上的源码做生意网站:你好!直接复制代码到DW代码设计视图中....我的回答你满意吗~~
如何使用下载的网站源代码:将源文件传输到你的服务器,设置IIS,在浏览器中输入地址,就可以访问你的网站或者在本机上安装测试学习
我用网上下载的源代码创建了一个网站。我已经上传了虚拟空间。然后我想自己修改它。我该怎么办?从所谓的后台...:你要修改源进程,最好在本地修改并上传。如果使用织梦Dedecms,可以在后台进入,在文件管理器中编辑文件。在后台输入您的域名/dede
抓取jsp网页源代码(大数据技术原理与应用数据可视化之互联网品牌形象)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-04 02:10
简单的介绍
学期末复习材料。网页设计(也称Web UI设计、WUI设计、WUI)是以公司希望传递给浏览者的信息(包括产品、服务、理念、文化)为基础,然后实现网站功能规划,然后进行页面设计和美化工作。作为公司对外宣传材料之一,精美的网页设计对于提升公司互联网品牌形象至关重要。
过去的问题文章
大数据技术原理及应用
数据可视化
文章内容
可选的 - - - - - - - - - - - - - - - - - - - - - - - - - ----------可选 1 颜色的 4 个角色 2 网页中使用的视觉元素 3 颜色抖动
216种安全色已出,需要插值
4 配色原理 5 www的三个统一 6 什么是www服务
万维网(全球信息网)是一种超文本信息查询工具,通过http协议传输超文本信息。同时将不同网站的相关数据信息有机汇总在一起,通过浏览器提供友好的信息查询界面。
7 域名的一些概念,包括域名的作用
域名与主机的关系:多对一
将域名发送到DNS服务器解析Web服务器的ip地址进行连接,将域名信息发送给Web服务器,通过域名与主机设置的“主机头”进行匹配,确认请求的是哪个客户端网络服务器网站 。
8 与ip相关的概念(ip与域名的关系)
IP地址和域名是一对多的关系。一个ip地址可以对应多个域名,但是一个域名只有一个ip地址。ip地址是由数字组成的,不容易记住,所以有了域名,通过域名地址就可以查到ip地址。
9 如何规划网站
需要从三个方面思考
这哪一方面是相互影响和互动
10 div+css布局的优点 11 div+css布局与table的对比
从四个方面考虑
布局方法:
控件元素占用的页面大小:
控件元素在页面上的位置:
图片位置:
动态网页的12条原则
动态网页收录服务器代码,需要由Web服务器解释执行,生成客户端代码,然后发送到客户端浏览器
13 动态网页的执行过程(process) 浏览器向网络中的WEB服务器发送请求,指向一个动态网页。WEB服务器收到请求信号后,将网页发送给应用服务器。应用服务器向数据库驱动发送查询指令。数据库驱动程序查询数据库。记录集返回给数据库驱动程序。然后驱动程序将记录集发送到应用程序服务器。应用服务器将数据插入到网页中,此时动态网页就变成了普通网页。应用服务器在网页中查找应用服务器。WEB服务器将完成的普通网页发送回浏览器
.
15 动态网页和静态网页的区别ppt答案+这个答案
静态网页:是纯HTML页面,页面内容固定不变。用 HTML、CSS 和 JavaScript 编写的网页。文件扩展名是 .html 或 .htm。每个静态网页文件都存储在 网站 服务器上。每个网页都是一个独立的文件,内容相对稳定。静态网页一般没有数据库支持,所以网站的制作和维护工作量很大。
动态网页:网页中的内容会根据用户的要求显示不同的内容,采用PHP、JSP、ASP、CGI程序动态生成的网页。文件扩展名为 .asp、.jsp、.php、.cgi 等。
16 种常见图片格式和功能
常见的图像格式有 JPG、GIF 和 PNG。这三种都是压缩图像格式,容量小,适合网络传输。
17 什么是表单元素(待修改)
文本框、密码框、单选按钮、复选框
form:定义用户输入的表单。字段集:定义字段。即,文本的边框被添加到输入区域。图例:定义域的标题,即边框上的文字。label:定义控制标签。比如输入框前的文字,用来关联用户的选择。input:定义输入字段,常用。type 属性可以设置为具有不同的功能。text:单行文本输入框,框的长度可以由正整数大小控制。密码:密码输入框。radio:单选按钮,同组的单选按钮必须同名。checkbox:复选框,同一组中的单选按钮必须具有相同的名称。按钮:普通按钮。submit:提交按钮,每次出现都会创建一个Submit对象。重置:重置按钮,它将重置当前表单中的所有内容。image:以图片形式提交按钮,写成“”。hidden:隐藏字段,隐藏字段对用户不可见。textarea:定义一个文本区域(一个多行输入控件),默认可以通过鼠标拖动来调整大小。按钮:定义一个按钮。select:定义一个选择列表,即下拉列表。option:定义下拉列表中的选项。19 网页中传递变量的方法 在下拉列表中定义选项。19 网页中传递变量的方法 在下拉列表中定义选项。19 网页中传递变量的方法
POST、GET、SESSION、COOKIE、隐藏表单元素、表单隐藏字段
20 404的原因很简单,就是找不到服务器(网页)
简单的说就是找不到服务器(网页)
22 Cascading style sheet(css样式表)HTML中引入css的方法
HTML和CSS是两种功能不同的语言。它们同时对网页产生影响。必须使用某些方法将 CSS 和 HTML 链接在一起。
在 HTML 中,引入 CSS 的方法有
23div+css布局(盒子模型)常用属性
盒模型是 CSS 的基石之一。这个框由元素内容、内边距、边框和边框组成。border 属性填充 padding 属性和 margin 属性
24 什么是 JavaScript 对象?自定义对象
var 大学 = new Object()。
JavaScript 内置对象,例如 Date、Math、Array 等。例如:
今天 var = new Date();
事实上,JavaScript 中的所有数据类型都是它的内置对象。
浏览器对象
浏览器提供的内置对象,如窗口、文档、位置等。
26php语法题
1.PHP文件代码可以收录以下三部分
HTML 和 CSS;
客户端脚本,位于之间;
服务器端脚本,位于“”之间(分隔符,表示脚本的开始和结束)
2 以h1标题的形式输出当前日期和时间
//------------------------
表示HTML代码
表示php代码
单引号''表示是字符串常量
“.” 表示字符串连接符
echo是php是输出函数
date()是时间函数,可以按照格式获取当前日期和时间
3 在网络上输出不同大小的字体
echo '<p>PHP代码和HTML代码可相互嵌套';
for($i=3;$i 查看全部
抓取jsp网页源代码(大数据技术原理与应用数据可视化之互联网品牌形象)
简单的介绍
学期末复习材料。网页设计(也称Web UI设计、WUI设计、WUI)是以公司希望传递给浏览者的信息(包括产品、服务、理念、文化)为基础,然后实现网站功能规划,然后进行页面设计和美化工作。作为公司对外宣传材料之一,精美的网页设计对于提升公司互联网品牌形象至关重要。
过去的问题文章
大数据技术原理及应用
数据可视化
文章内容
可选的 - - - - - - - - - - - - - - - - - - - - - - - - - ----------可选 1 颜色的 4 个角色 2 网页中使用的视觉元素 3 颜色抖动
216种安全色已出,需要插值
4 配色原理 5 www的三个统一 6 什么是www服务
万维网(全球信息网)是一种超文本信息查询工具,通过http协议传输超文本信息。同时将不同网站的相关数据信息有机汇总在一起,通过浏览器提供友好的信息查询界面。
7 域名的一些概念,包括域名的作用
域名与主机的关系:多对一
将域名发送到DNS服务器解析Web服务器的ip地址进行连接,将域名信息发送给Web服务器,通过域名与主机设置的“主机头”进行匹配,确认请求的是哪个客户端网络服务器网站 。
8 与ip相关的概念(ip与域名的关系)
IP地址和域名是一对多的关系。一个ip地址可以对应多个域名,但是一个域名只有一个ip地址。ip地址是由数字组成的,不容易记住,所以有了域名,通过域名地址就可以查到ip地址。
9 如何规划网站
需要从三个方面思考
这哪一方面是相互影响和互动
10 div+css布局的优点 11 div+css布局与table的对比
从四个方面考虑
布局方法:
控件元素占用的页面大小:
控件元素在页面上的位置:
图片位置:
动态网页的12条原则
动态网页收录服务器代码,需要由Web服务器解释执行,生成客户端代码,然后发送到客户端浏览器
13 动态网页的执行过程(process) 浏览器向网络中的WEB服务器发送请求,指向一个动态网页。WEB服务器收到请求信号后,将网页发送给应用服务器。应用服务器向数据库驱动发送查询指令。数据库驱动程序查询数据库。记录集返回给数据库驱动程序。然后驱动程序将记录集发送到应用程序服务器。应用服务器将数据插入到网页中,此时动态网页就变成了普通网页。应用服务器在网页中查找应用服务器。WEB服务器将完成的普通网页发送回浏览器
.
15 动态网页和静态网页的区别ppt答案+这个答案
静态网页:是纯HTML页面,页面内容固定不变。用 HTML、CSS 和 JavaScript 编写的网页。文件扩展名是 .html 或 .htm。每个静态网页文件都存储在 网站 服务器上。每个网页都是一个独立的文件,内容相对稳定。静态网页一般没有数据库支持,所以网站的制作和维护工作量很大。
动态网页:网页中的内容会根据用户的要求显示不同的内容,采用PHP、JSP、ASP、CGI程序动态生成的网页。文件扩展名为 .asp、.jsp、.php、.cgi 等。
16 种常见图片格式和功能
常见的图像格式有 JPG、GIF 和 PNG。这三种都是压缩图像格式,容量小,适合网络传输。
17 什么是表单元素(待修改)
文本框、密码框、单选按钮、复选框
form:定义用户输入的表单。字段集:定义字段。即,文本的边框被添加到输入区域。图例:定义域的标题,即边框上的文字。label:定义控制标签。比如输入框前的文字,用来关联用户的选择。input:定义输入字段,常用。type 属性可以设置为具有不同的功能。text:单行文本输入框,框的长度可以由正整数大小控制。密码:密码输入框。radio:单选按钮,同组的单选按钮必须同名。checkbox:复选框,同一组中的单选按钮必须具有相同的名称。按钮:普通按钮。submit:提交按钮,每次出现都会创建一个Submit对象。重置:重置按钮,它将重置当前表单中的所有内容。image:以图片形式提交按钮,写成“”。hidden:隐藏字段,隐藏字段对用户不可见。textarea:定义一个文本区域(一个多行输入控件),默认可以通过鼠标拖动来调整大小。按钮:定义一个按钮。select:定义一个选择列表,即下拉列表。option:定义下拉列表中的选项。19 网页中传递变量的方法 在下拉列表中定义选项。19 网页中传递变量的方法 在下拉列表中定义选项。19 网页中传递变量的方法
POST、GET、SESSION、COOKIE、隐藏表单元素、表单隐藏字段
20 404的原因很简单,就是找不到服务器(网页)
简单的说就是找不到服务器(网页)
22 Cascading style sheet(css样式表)HTML中引入css的方法
HTML和CSS是两种功能不同的语言。它们同时对网页产生影响。必须使用某些方法将 CSS 和 HTML 链接在一起。
在 HTML 中,引入 CSS 的方法有
23div+css布局(盒子模型)常用属性
盒模型是 CSS 的基石之一。这个框由元素内容、内边距、边框和边框组成。border 属性填充 padding 属性和 margin 属性
24 什么是 JavaScript 对象?自定义对象
var 大学 = new Object()。
JavaScript 内置对象,例如 Date、Math、Array 等。例如:
今天 var = new Date();
事实上,JavaScript 中的所有数据类型都是它的内置对象。
浏览器对象
浏览器提供的内置对象,如窗口、文档、位置等。
26php语法题
1.PHP文件代码可以收录以下三部分
HTML 和 CSS;
客户端脚本,位于之间;
服务器端脚本,位于“”之间(分隔符,表示脚本的开始和结束)
2 以h1标题的形式输出当前日期和时间
//------------------------
表示HTML代码
表示php代码
单引号''表示是字符串常量
“.” 表示字符串连接符
echo是php是输出函数
date()是时间函数,可以按照格式获取当前日期和时间
3 在网络上输出不同大小的字体
echo '<p>PHP代码和HTML代码可相互嵌套';
for($i=3;$i
抓取jsp网页源代码(Ajax动态分析待抓取的微博内容:准备工作:安装好requests库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-11-03 02:14
Ajax动态分析待抓取微博内容:准备:安装requests库和lxml库
输入cmd
pip install requests
pip install lxml
因为我之前安装过这两个库,所以这里安装的时候会显示下图的内容:
分析网页
打开Chrome浏览器,我们输入这个网站:。右击选择查看网页源代码。这时候我们会发现,我们在首页看到的文字内容,在网页的源代码中并没有显示出来。这意味着网页是由 Ajax 动态加载的。(下图左边是我能看到的网页,右边是网页的源代码)
我们在右边随机选择一段内容,在左边搜索,没有任何结果。在这里,我们以“人间烟火,香饽饽”来寻找栗子:
我们看到我们搜索的内容并没有出现在源码中,所以网页是通过Ajax动态加载的。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时保证页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,必须刷新整个页面,而使用Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行数据交互。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
你可以在W3School上体验几个例子来感受一下:。
其实很多网页都是这样的。我们将继续向下滑动网页,并会不断刷新和加载我们眼前的新内容。
既然我们已经知道它是用 Ajax 动态加载的,那么我们来分析一下它是如何交换数据的。
右击选择Check(或按键盘F12)进入开发者模式。网页的样式展现在我们眼前。
在Elements中,我们可以看到网页的源码,右边是节点的内容,但这不是我们想要的。如果我们按照常规的网页请求,提取网页标签中的数据,就得不到我们想要的内容。.
我们进入Network,在Network下选择XHR,我们会看到如下内容(第一次进入,没有该内容,刷新页面即可):
随着我们继续滚动鼠标滚轮,XHR下加载的内容越来越多,我们会在getIndex的开头看到一个请求,点击查看其详细信息
我们看到Request Headers里面有个参数是X-Requested-With:XMLHttpRequest。通过这个参数,我们可以更加确定它是由Ajax动态加载的。然后点击Headers旁边的Preview,里面的数据是json(类似于python字典的字符串)格式。
点击卡片,卡片下有10条内容,我们到下面9条内容中的mblog一一查看,会发现微博正文中收录的文字收录在raw_text中
(其实这个请求中也收录了图片,想要下载图片的游客可以自行研究图片链接)。现在我们已经找到了我们想要的东西,让我们开始编写错误,“抓住”这些词并将它们放入我们的“口袋”中。
请求数据
我们使用requests.get(url)来请求网页,因为我们要请求的网页不是开头给出的网页,而是我们分析后发现的Ajax网页请求。所以我们真正要求的应该是这个网页%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=66624,打开这个页面我们你会发现里面有密密麻麻的字符和数字。我们可以在浏览器中找到一个json数据在线解析网址。这个还好。将上面网页的内容复制到json网页,我们就可以看到整齐的json数据了。很像python中的字典格式。
在 jupyter 中写这个:
response = requests.get('https://m.weibo.cn/api/container/getIndex?uid=1742566624&t=0&luicode=10000011&lfid=100103type%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=1076031742566624')
if response.status_code == 200:
html = response.json()
我们直接将其转成json格式,在jupyter中打印出来,随时查看网页返回的信息是什么样子的。(爬虫、数据分析等推荐使用jupyter,方便随时查看结果)
运行上面的代码并得到以下输出:
不难发现,这个数据和我们在Preview中看到的数据是一样的,说明我们得到的就是我们想要的数据。接下来,我们需要从这个字典中提取微博文本的内容。NS。代码显示如下:
get_details = html.get('data').get('cards')
for i in range(len(get_details)):
text = get_details[i].get('mblog').get('raw_text').strip()
print(text)
操作结果如下:
由于cards是一个列表,收录十条数据,我们使用for循环遍历整个列表并提取数据。因为我们返回的数据是字典类型的,所以我们可以直接使用get来提取数据。或者根据键值对索引(推荐get,如果当前没有key,索引会报错,get返回空值,不会阻止程序失败)。这样,我们从“第一页”中提取了十条数据,但是这样的数据量往往不能满足我们的需求。
获取多页数据
如果我们把每个网页都复制粘贴到我们的脚本中,10个可能的问题都不算大。首先找到getIndex,然后将网页复制粘贴到脚本中。一共三个步骤,10个网页是30个步骤。但是 100 页呢?这时候处理起来就比较麻烦了。所以我们需要找到一个“好方法”来构建网页,让脚本本身去“查找网页”→“复制”→“粘贴”“查找网页”\rightarrow“复制”\rightarrow“粘贴”“查找网页” “→”复制”→“粘贴”,一般我们可以把这种重复的工作交给程序来完成。所以我们现在要做的就是“教”我们的爬虫脚本来做到这一点。
回顾我们请求的页面: %3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=66624 这是我们的第一页请求,让我们看看我们要请求的第二个页面看起来像: %3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7 %84%A6&type=uid&value= 1742566624&containerid=66624&since_id=45596。第二个网页似乎与第一个网页不同。它比第一个网页有一个小尾巴 since_id。其实我们再看第三、第四、第五……从第二个开始的网页,它们都有一个since_id的参数,所以我们只需要在后面的每个网页上加上一个since_id的参数第一个网页的基础。但是好像每个网页对应的since_id都不一样,所以如果要调侃的话,它似乎不起作用。但是,它的网页毕竟是人写的,不是上帝创造的,所以它的since_id肯定是我们聪明的小脑袋“创造”出来的。
由于这个网页的since_id要被浏览器捕获,不断请求下一页的数据,我们自己找出这个since_id并不难。
果然,我们可以在json数据的cardlistInfo中找到一个since_id的key
让我们将这个since_id 与下一个网页中的since_id 进行比较。这是相同的。(我这里截取的是首页的since_id,这个since_id也会随着时间的推移而变化,访问者看到的和我的不一样,正常),我们使用get获取since_id就像提取文本信息一样。既然找到了这个since_id的构造规则,就可以请求多页网页数据了。只要我们教我们的爬虫脚本如何使用我们为它找到的since_id来构建网页,它就可以不断地获取网页。内容也是。
构建网页的代码如下:
def group_url(since_id):
params = {
'since_id':since_id
}
url = base_url + '&' + urlencode(params)
return url
urlencode是urllib.parse中的方法,下面是官方文档:
函数中传入的since_id就是我们为爬虫找到的since_id。然后我们把构造好的网页返回给网页请求函数,解析提取我们想要的内容和sinance_id,这样我们就可以一直循环下去了。
存储数据
编写爬虫不应该只是为了爬取数据,如果我们下次要使用这些数据,再次爬取,那会很麻烦,所以我们“隐藏”了我们从网上“偷”出来的东西。起来。这里我们使用记事本来保存这些文本数据(当然也可以写入数据库,有兴趣的读者可以自行上网搜索写入数据库的操作)。保存数据的代码如下:
def write_title():
title = '思想聚焦的微博正文'
with open('blog.txt','w',encoding = 'utf-8') as f:
f.write(title + '\n')
f.write('\n')
def write_infos(txt):
with open('blog.txt','a',newline='\n',encoding = 'utf-8') as f:
f.write(txt)
f.write('\n')
因为我们这里抓取的是思维聚焦微博文章,标题写的是“思维聚焦微博正文”,然后每一行都留空(这样看起来更整洁)。参数 newline 这就是它的作用。
至此,我们的爬虫已经写完了。有兴趣的话,可以做词云图,做情感分析等等……
完整代码:
import requests
import json, time
from lxml import etree
from urllib.parse import urlencode
base_url = """https://m.weibo.cn/api/contain ... 00011
&lfid=100103type%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=1076031742566624"""
HEADERS = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
"X-Requested-With":"XMLHttpRequest",
"Referer":"https://m.weibo.cn/u/1742566624"
}
def write_title(): # 写入标题
title = '思想聚焦的微博正文'
with open('blog.txt','w',encoding = 'utf-8') as f:
f.write(title + '\n')
f.write('\n')
def write_infos(txt): # 写入正文
with open('blog.txt','a',newline='\n',encoding = 'utf-8') as f:
f.write(txt)
f.write('\n')
def group_url(since_id): # 构造网页的函数
params = {
'since_id':since_id
}
url = base_url + '&' + urlencode(params)
return url
def get_html(url): # 请求网页
response = requests.get(url,headers=HEADERS)
if response.status_code == 200:
return response.json()
def get_infos(html): # 提取信息
since_id = html.get('data').get('cardlistInfo').get('since_id')
get_details = html.get('data').get('cards')
for i in range(len(get_details)):
text = get_details[i].get('mblog').get('raw_text').strip()
print(text)
write_infos(text)
return group_url(since_id)
def main():
write_title()
first_page = get_html(base_url)
new_url = get_infos(first_page)
for i in range(5): # 我这里以提取5页数据为栗子
html = get_html(new_url)
new_url = get_infos(html)
main()
在这个脚本中,我们设置了请求头,让我们的爬虫看起来更像是浏览器正在访问。
操作结果:
总结:
当我们查看网页的源代码时,我们发现在网页上看到的源代码中没有任何信息。对于Ajax网页的抓取,我们应该分析它的动态加载包,而不是直接请求它的源代码。通过构造Ajax网页URL来实现对多页信息的抓取,不同的网站其构造url的方法是不同的。为此,您需要自己查找规则并构建 url。看完这篇文章,如果你觉得可以爬取Ajax网页,可以尝试爬取今日头条上面的内容,也是Ajax加载的。
提取网页信息的方法有很多种,但在这种情况下,我们恰好是字典的形式。如果遇到其他情况,就得行动起来,用最熟悉的信息抽取方式抓取网页信息。让我们停在这里。它有点简陋,但可以大致看到。 查看全部
抓取jsp网页源代码(Ajax动态分析待抓取的微博内容:准备工作:安装好requests库)
Ajax动态分析待抓取微博内容:准备:安装requests库和lxml库
输入cmd
pip install requests
pip install lxml
因为我之前安装过这两个库,所以这里安装的时候会显示下图的内容:
分析网页
打开Chrome浏览器,我们输入这个网站:。右击选择查看网页源代码。这时候我们会发现,我们在首页看到的文字内容,在网页的源代码中并没有显示出来。这意味着网页是由 Ajax 动态加载的。(下图左边是我能看到的网页,右边是网页的源代码)
我们在右边随机选择一段内容,在左边搜索,没有任何结果。在这里,我们以“人间烟火,香饽饽”来寻找栗子:
我们看到我们搜索的内容并没有出现在源码中,所以网页是通过Ajax动态加载的。
Ajax,全称是Asynchronous JavaScript and XML,即异步JavaScript和XML。它不是一种编程语言,而是一种使用 JavaScript 与服务器交换数据并更新部分网页的技术,同时保证页面不会被刷新,页面链接不会发生变化。
对于传统的网页,如果要更新其内容,必须刷新整个页面,而使用Ajax,您可以在不完全刷新页面的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行数据交互。获取到数据后,通过JavaScript来改变网页,从而更新网页的内容。
你可以在W3School上体验几个例子来感受一下:。
其实很多网页都是这样的。我们将继续向下滑动网页,并会不断刷新和加载我们眼前的新内容。
既然我们已经知道它是用 Ajax 动态加载的,那么我们来分析一下它是如何交换数据的。
右击选择Check(或按键盘F12)进入开发者模式。网页的样式展现在我们眼前。
在Elements中,我们可以看到网页的源码,右边是节点的内容,但这不是我们想要的。如果我们按照常规的网页请求,提取网页标签中的数据,就得不到我们想要的内容。.
我们进入Network,在Network下选择XHR,我们会看到如下内容(第一次进入,没有该内容,刷新页面即可):
随着我们继续滚动鼠标滚轮,XHR下加载的内容越来越多,我们会在getIndex的开头看到一个请求,点击查看其详细信息
我们看到Request Headers里面有个参数是X-Requested-With:XMLHttpRequest。通过这个参数,我们可以更加确定它是由Ajax动态加载的。然后点击Headers旁边的Preview,里面的数据是json(类似于python字典的字符串)格式。
点击卡片,卡片下有10条内容,我们到下面9条内容中的mblog一一查看,会发现微博正文中收录的文字收录在raw_text中
(其实这个请求中也收录了图片,想要下载图片的游客可以自行研究图片链接)。现在我们已经找到了我们想要的东西,让我们开始编写错误,“抓住”这些词并将它们放入我们的“口袋”中。
请求数据
我们使用requests.get(url)来请求网页,因为我们要请求的网页不是开头给出的网页,而是我们分析后发现的Ajax网页请求。所以我们真正要求的应该是这个网页%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=66624,打开这个页面我们你会发现里面有密密麻麻的字符和数字。我们可以在浏览器中找到一个json数据在线解析网址。这个还好。将上面网页的内容复制到json网页,我们就可以看到整齐的json数据了。很像python中的字典格式。
在 jupyter 中写这个:
response = requests.get('https://m.weibo.cn/api/container/getIndex?uid=1742566624&t=0&luicode=10000011&lfid=100103type%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=1076031742566624')
if response.status_code == 200:
html = response.json()
我们直接将其转成json格式,在jupyter中打印出来,随时查看网页返回的信息是什么样子的。(爬虫、数据分析等推荐使用jupyter,方便随时查看结果)
运行上面的代码并得到以下输出:
不难发现,这个数据和我们在Preview中看到的数据是一样的,说明我们得到的就是我们想要的数据。接下来,我们需要从这个字典中提取微博文本的内容。NS。代码显示如下:
get_details = html.get('data').get('cards')
for i in range(len(get_details)):
text = get_details[i].get('mblog').get('raw_text').strip()
print(text)
操作结果如下:
由于cards是一个列表,收录十条数据,我们使用for循环遍历整个列表并提取数据。因为我们返回的数据是字典类型的,所以我们可以直接使用get来提取数据。或者根据键值对索引(推荐get,如果当前没有key,索引会报错,get返回空值,不会阻止程序失败)。这样,我们从“第一页”中提取了十条数据,但是这样的数据量往往不能满足我们的需求。
获取多页数据
如果我们把每个网页都复制粘贴到我们的脚本中,10个可能的问题都不算大。首先找到getIndex,然后将网页复制粘贴到脚本中。一共三个步骤,10个网页是30个步骤。但是 100 页呢?这时候处理起来就比较麻烦了。所以我们需要找到一个“好方法”来构建网页,让脚本本身去“查找网页”→“复制”→“粘贴”“查找网页”\rightarrow“复制”\rightarrow“粘贴”“查找网页” “→”复制”→“粘贴”,一般我们可以把这种重复的工作交给程序来完成。所以我们现在要做的就是“教”我们的爬虫脚本来做到这一点。
回顾我们请求的页面: %3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=66624 这是我们的第一页请求,让我们看看我们要请求的第二个页面看起来像: %3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7 %84%A6&type=uid&value= 1742566624&containerid=66624&since_id=45596。第二个网页似乎与第一个网页不同。它比第一个网页有一个小尾巴 since_id。其实我们再看第三、第四、第五……从第二个开始的网页,它们都有一个since_id的参数,所以我们只需要在后面的每个网页上加上一个since_id的参数第一个网页的基础。但是好像每个网页对应的since_id都不一样,所以如果要调侃的话,它似乎不起作用。但是,它的网页毕竟是人写的,不是上帝创造的,所以它的since_id肯定是我们聪明的小脑袋“创造”出来的。
由于这个网页的since_id要被浏览器捕获,不断请求下一页的数据,我们自己找出这个since_id并不难。
果然,我们可以在json数据的cardlistInfo中找到一个since_id的key
让我们将这个since_id 与下一个网页中的since_id 进行比较。这是相同的。(我这里截取的是首页的since_id,这个since_id也会随着时间的推移而变化,访问者看到的和我的不一样,正常),我们使用get获取since_id就像提取文本信息一样。既然找到了这个since_id的构造规则,就可以请求多页网页数据了。只要我们教我们的爬虫脚本如何使用我们为它找到的since_id来构建网页,它就可以不断地获取网页。内容也是。
构建网页的代码如下:
def group_url(since_id):
params = {
'since_id':since_id
}
url = base_url + '&' + urlencode(params)
return url
urlencode是urllib.parse中的方法,下面是官方文档:
函数中传入的since_id就是我们为爬虫找到的since_id。然后我们把构造好的网页返回给网页请求函数,解析提取我们想要的内容和sinance_id,这样我们就可以一直循环下去了。
存储数据
编写爬虫不应该只是为了爬取数据,如果我们下次要使用这些数据,再次爬取,那会很麻烦,所以我们“隐藏”了我们从网上“偷”出来的东西。起来。这里我们使用记事本来保存这些文本数据(当然也可以写入数据库,有兴趣的读者可以自行上网搜索写入数据库的操作)。保存数据的代码如下:
def write_title():
title = '思想聚焦的微博正文'
with open('blog.txt','w',encoding = 'utf-8') as f:
f.write(title + '\n')
f.write('\n')
def write_infos(txt):
with open('blog.txt','a',newline='\n',encoding = 'utf-8') as f:
f.write(txt)
f.write('\n')
因为我们这里抓取的是思维聚焦微博文章,标题写的是“思维聚焦微博正文”,然后每一行都留空(这样看起来更整洁)。参数 newline 这就是它的作用。
至此,我们的爬虫已经写完了。有兴趣的话,可以做词云图,做情感分析等等……
完整代码:
import requests
import json, time
from lxml import etree
from urllib.parse import urlencode
base_url = """https://m.weibo.cn/api/contain ... 00011
&lfid=100103type%3D1%26q%3D%E6%80%9D%E6%83%B3%E8%81%9A%E7%84%A6&type=uid&value=1742566624&containerid=1076031742566624"""
HEADERS = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36",
"X-Requested-With":"XMLHttpRequest",
"Referer":"https://m.weibo.cn/u/1742566624"
}
def write_title(): # 写入标题
title = '思想聚焦的微博正文'
with open('blog.txt','w',encoding = 'utf-8') as f:
f.write(title + '\n')
f.write('\n')
def write_infos(txt): # 写入正文
with open('blog.txt','a',newline='\n',encoding = 'utf-8') as f:
f.write(txt)
f.write('\n')
def group_url(since_id): # 构造网页的函数
params = {
'since_id':since_id
}
url = base_url + '&' + urlencode(params)
return url
def get_html(url): # 请求网页
response = requests.get(url,headers=HEADERS)
if response.status_code == 200:
return response.json()
def get_infos(html): # 提取信息
since_id = html.get('data').get('cardlistInfo').get('since_id')
get_details = html.get('data').get('cards')
for i in range(len(get_details)):
text = get_details[i].get('mblog').get('raw_text').strip()
print(text)
write_infos(text)
return group_url(since_id)
def main():
write_title()
first_page = get_html(base_url)
new_url = get_infos(first_page)
for i in range(5): # 我这里以提取5页数据为栗子
html = get_html(new_url)
new_url = get_infos(html)
main()
在这个脚本中,我们设置了请求头,让我们的爬虫看起来更像是浏览器正在访问。
操作结果:
总结:
当我们查看网页的源代码时,我们发现在网页上看到的源代码中没有任何信息。对于Ajax网页的抓取,我们应该分析它的动态加载包,而不是直接请求它的源代码。通过构造Ajax网页URL来实现对多页信息的抓取,不同的网站其构造url的方法是不同的。为此,您需要自己查找规则并构建 url。看完这篇文章,如果你觉得可以爬取Ajax网页,可以尝试爬取今日头条上面的内容,也是Ajax加载的。
提取网页信息的方法有很多种,但在这种情况下,我们恰好是字典的形式。如果遇到其他情况,就得行动起来,用最熟悉的信息抽取方式抓取网页信息。让我们停在这里。它有点简陋,但可以大致看到。
抓取jsp网页源代码(网页源代码,这里我先偷懒用pythoncookie来爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-01 14:04
抓取jsp网页源代码,这里我先偷懒用pythoncookie来爬取。先定义一个全局变量session,session的初始值是什么?web.py中的if('root'insession)ifsession.status=='processing':session.status='processing'session=web.py.request(url,auth=none,headers=none,asyncio=none,)else:session=web.py.request(url,auth=none,headers=none,asyncio=none,)session=web.py.request(url,'request','post','body',data=none,timeout=1000)ifsession.status=='processing':response=session.getrequest(url)getrequest(response)同理session.status=='processing'时也要注意session的if后面的代码块。
实际上可以编写python的request程序,后面跟一个全局变量(如session),当session为processing的时候,
postman
第一个问题如果你看看源代码会发现他们的实现方式还有不同。第二个问题你定义的ajax其实是一个post方法,他会把jsp改名为request。你用python本身的模拟http请求的库应该就可以实现这个,用xml库,也可以用requests, 查看全部
抓取jsp网页源代码(网页源代码,这里我先偷懒用pythoncookie来爬取)
抓取jsp网页源代码,这里我先偷懒用pythoncookie来爬取。先定义一个全局变量session,session的初始值是什么?web.py中的if('root'insession)ifsession.status=='processing':session.status='processing'session=web.py.request(url,auth=none,headers=none,asyncio=none,)else:session=web.py.request(url,auth=none,headers=none,asyncio=none,)session=web.py.request(url,'request','post','body',data=none,timeout=1000)ifsession.status=='processing':response=session.getrequest(url)getrequest(response)同理session.status=='processing'时也要注意session的if后面的代码块。
实际上可以编写python的request程序,后面跟一个全局变量(如session),当session为processing的时候,
postman
第一个问题如果你看看源代码会发现他们的实现方式还有不同。第二个问题你定义的ajax其实是一个post方法,他会把jsp改名为request。你用python本身的模拟http请求的库应该就可以实现这个,用xml库,也可以用requests,
抓取jsp网页源代码(最近考毛概,用的是学习通,老师的骚操作就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-28 16:22
最近,我使用了学习通行证。老师的骚操作是给我们每个人十套模拟题,一套80道题,想了想,一个人是80*10=800道题,然后十个人?
哈哈哈,最后我真的成功了。我爬下来,每人学习了 800 个问题。删除重复后,我得到了我们的粗略题库。去掉重复后,有4000多道题,那怎么搜题呢?
题库截图.png(633.17 KB,下载次数:2)
下载附件
2020-6-20 16:57 上传
但问题来了。不可能说每次搜索问题时都检查数据库或表格。数据库太繁琐,表太繁琐。正好我们这学期有一门JSP课程。一个简单的搜索页面,然后部署到妓女所在的阿里云服务器上。是不是很美?许多人可以同时使用它。页面差不多是这个样子。
运行 screenshot.png(152.91 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传
运行截图2.png (491.78 KB, 下载次数:1)
下载附件
2020-6-20 16:57 上传
以下是部分代码的截图。因为刚开始接触JavaWeb,代码还是有点简陋。如果有什么不对的地方,我希望能纠正我。MVC模型基本使用,哈哈
代码1.png(410.67 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传
代码2.png(326.25 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传
下面附上源代码和数据库。对了,我的部署环境是jdk13.02+tomcat9.0
Archive.zip(2.62 MB,下载次数:405)
2020-6-20 16:58 上传
点击文件名下载附件
下载点:我爱硬币-1 CB
新手,如果本文章的内容或代码有问题,请指正 查看全部
抓取jsp网页源代码(最近考毛概,用的是学习通,老师的骚操作就是)
最近,我使用了学习通行证。老师的骚操作是给我们每个人十套模拟题,一套80道题,想了想,一个人是80*10=800道题,然后十个人?
哈哈哈,最后我真的成功了。我爬下来,每人学习了 800 个问题。删除重复后,我得到了我们的粗略题库。去掉重复后,有4000多道题,那怎么搜题呢?
题库截图.png(633.17 KB,下载次数:2)
下载附件
2020-6-20 16:57 上传
但问题来了。不可能说每次搜索问题时都检查数据库或表格。数据库太繁琐,表太繁琐。正好我们这学期有一门JSP课程。一个简单的搜索页面,然后部署到妓女所在的阿里云服务器上。是不是很美?许多人可以同时使用它。页面差不多是这个样子。
运行 screenshot.png(152.91 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传
运行截图2.png (491.78 KB, 下载次数:1)
下载附件
2020-6-20 16:57 上传
以下是部分代码的截图。因为刚开始接触JavaWeb,代码还是有点简陋。如果有什么不对的地方,我希望能纠正我。MVC模型基本使用,哈哈
代码1.png(410.67 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传
代码2.png(326.25 KB,下载次数:1)
下载附件
2020-6-20 16:57 上传
下面附上源代码和数据库。对了,我的部署环境是jdk13.02+tomcat9.0
Archive.zip(2.62 MB,下载次数:405)
2020-6-20 16:58 上传
点击文件名下载附件
下载点:我爱硬币-1 CB
新手,如果本文章的内容或代码有问题,请指正
抓取jsp网页源代码(这段文字是从哪里来的?网页怎么提取文字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-10-24 04:00
指导
我们来看一个网页,大家想想怎么用XPath来爬取。如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看看页面的请求。
我们来看一个网页,大家想想怎么用XPath来爬取。
如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看一下页面的请求:
该网页没有发起任何 Ajax 请求。那么,这段文字是怎么来的呢?
我们来看看这个页面对应的HTML:
整个 HTML 中甚至没有 JavaScript。那么这段文字是怎么来的呢?
有一点经验的同学不妨看看这个example.css文件,其内容如下:
没错,正文确实来了。其中::after,我们称之为伪元素[1]。
对于伪元素中的文本,应该如何提取?当然,您可以使用正则表达式来提取它。但我们今天不打算谈论这个。
XPath没有办法提取伪元素,因为XPath只能提取Dom树中的内容,而伪元素不属于Dom树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 没有任何效果,因为数据根本不存在。单独获取css,虽然有数据,但是如果不使用正则表达式,就无法获取里面的数据。所以 BeautifulSoup4 的 CSS 选择器没有效果。所以我们需要将 CSS 和 HTML 放在一起进行渲染,然后使用 JavaScript 的 CSS 选择器来查找需要提取的内容。
首先,让我们来看看。为了提取这个伪元素的值,我们需要如下一段Js代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表fake_element的class属性。第二个参数是伪元素:after。运行效果如下图所示:
为了能够运行这个 JavaScript,我们需要使用一个模拟浏览器,无论是 Selenium 还是 Puppeteer。这里以硒为例。
在Selenium中执行Js,需要用到driver.execute_script()方法,代码如下:
提取内容的最外层会被一对双引号包裹。得到之后,去掉外面的双引号,就是我们在网页上看到的。
原文来自:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
抓取jsp网页源代码(这段文字是从哪里来的?网页怎么提取文字)
指导
我们来看一个网页,大家想想怎么用XPath来爬取。如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看看页面的请求。
我们来看一个网页,大家想想怎么用XPath来爬取。
如你所见,没有源代码,请抓紧我!本文。这个页面是异步加载的吗?现在让我们看一下页面的请求:
该网页没有发起任何 Ajax 请求。那么,这段文字是怎么来的呢?
我们来看看这个页面对应的HTML:
整个 HTML 中甚至没有 JavaScript。那么这段文字是怎么来的呢?
有一点经验的同学不妨看看这个example.css文件,其内容如下:
没错,正文确实来了。其中::after,我们称之为伪元素[1]。
对于伪元素中的文本,应该如何提取?当然,您可以使用正则表达式来提取它。但我们今天不打算谈论这个。
XPath没有办法提取伪元素,因为XPath只能提取Dom树中的内容,而伪元素不属于Dom树,所以无法提取。要提取伪元素,您需要使用 CSS 选择器。
因为网页的 HTML 和 CSS 是分开的。如果我们使用requests或者Scrapy,我们只能分别获取HTML和CSS。单独获取 HTML 没有任何效果,因为数据根本不存在。单独获取css,虽然有数据,但是如果不使用正则表达式,就无法获取里面的数据。所以 BeautifulSoup4 的 CSS 选择器没有效果。所以我们需要将 CSS 和 HTML 放在一起进行渲染,然后使用 JavaScript 的 CSS 选择器来查找需要提取的内容。
首先,让我们来看看。为了提取这个伪元素的值,我们需要如下一段Js代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element代表fake_element的class属性。第二个参数是伪元素:after。运行效果如下图所示:
为了能够运行这个 JavaScript,我们需要使用一个模拟浏览器,无论是 Selenium 还是 Puppeteer。这里以硒为例。
在Selenium中执行Js,需要用到driver.execute_script()方法,代码如下:
提取内容的最外层会被一对双引号包裹。得到之后,去掉外面的双引号,就是我们在网页上看到的。
原文来自:
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
抓取jsp网页源代码(相对来说jsp比net安全性好一些,但是哪个好就看个人喜欢了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-22 08:12
相对来说,jsp比.net更安全,而且是跨平台的,但哪个更好看个人喜好。
不说java,你真的懂;
jsp:JSP 可以用一个简单易懂的公式表示:HTML+Java=JSP。 JSP 技术使用Java 编程语言编写类似XML 的标签和scriptlet 来封装生成动态网页的处理逻辑。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。 JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,让基于 Web 的应用程序的开发变得简单快捷。
javascript(主要用于客户端):JavaScript是一种基于对象和事件驱动的客户端脚本语言,相对安全。同时,它也是一种广泛用于客户端Web开发的脚本语言。常用于为HTML页面添加动态功能,如响应用户的各种操作。
jquery:Jquery 是一个优秀的 Javascrīpt 框架。归根结底是javascript,只是封装了javascript,使用起来更方便。
Java 和 jsp 主要集中在后台,javascript 和 jquery 主要集中在前台。
jsp 基于java,jquery 基于javascript。 java和javascript是两种不同的语言 查看全部
抓取jsp网页源代码(相对来说jsp比net安全性好一些,但是哪个好就看个人喜欢了)
相对来说,jsp比.net更安全,而且是跨平台的,但哪个更好看个人喜好。
不说java,你真的懂;
jsp:JSP 可以用一个简单易懂的公式表示:HTML+Java=JSP。 JSP 技术使用Java 编程语言编写类似XML 的标签和scriptlet 来封装生成动态网页的处理逻辑。网页还可以通过标记和脚本小程序访问服务器上存在的资源的应用程序逻辑。 JSP 将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,让基于 Web 的应用程序的开发变得简单快捷。
javascript(主要用于客户端):JavaScript是一种基于对象和事件驱动的客户端脚本语言,相对安全。同时,它也是一种广泛用于客户端Web开发的脚本语言。常用于为HTML页面添加动态功能,如响应用户的各种操作。
jquery:Jquery 是一个优秀的 Javascrīpt 框架。归根结底是javascript,只是封装了javascript,使用起来更方便。
Java 和 jsp 主要集中在后台,javascript 和 jquery 主要集中在前台。
jsp 基于java,jquery 基于javascript。 java和javascript是两种不同的语言
抓取jsp网页源代码(基于网络爬虫技术的个性化企业信息获取方法研究(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-10-21 12:15
一般来说,软件界面如下:
图 1-1 Navicat for mysql 界面
但是,事情的好坏不能从表面上定论。Navicat 也是一样。我们上面谈到了它的各种优点。但是,作为一个为工作服务的软件,最重要的还是要符合用户的操作。习惯,给用户带来极致的用户体验。Navicat 也这样做。它采用图形化的完美用户界面,在视觉和操作上都满足工作要求。另外,在当前信息安全系数不高的情况下,可以保证信息的安全,可以快速、安全地实现创建、组织、存储和共享。
2 基于网络爬虫技术的个性化企业信息获取方法研究
2.1 爬虫简介
在浩瀚的互联网中,信息就像一滴水。为了学习和工作获取它们,我们总是习惯于使用“水勺”——搜索引擎来获取它们。从我们这边来说,当我们需要挖掘信息的时候,大多数人自然会想到“随便点击百度就知道”,输入关键词,得到一系列相关内容。而这个看似简单的原理背后,则是接下来要介绍的网络爬虫技术(网络蜘蛛或网络爬虫)。
现在,我们将接触自然界中蜘蛛结网的神奇现象,来引出本节的“主角”。众所周知,蜘蛛通过分泌粘液并在空气中形成非常细的细丝来捕捉猎物。万维网就像一个巨大的“网络”,上面附有大量复杂的信息。一个网络爬虫就像一个爬虫在这个互联网上狩猎,为了捕捉它需要的“猎物”。然而,如何从一个落脚点绘制出无数条向外围延伸的细丝呢?下一节将介绍 URL 的概念。
根据不同的爬虫要求,爬虫有很多种。例如,基于Web的爬虫主要用于采集网络上的资源,节省了在万维网上获取需求所需的时间,减少了信息采集的空间开销。由于我们有针对性地抓取了国家环保总局的数据,所以本文中的爬虫可以理解为基于用户个性的爬虫,即定制的爬虫,只获取需要的页面,只获取内容这就是上面所关心的。它会抓取符合我们预期的结果。[12]
2.2 理解网址
同样,在上一节中,比较了蜘蛛网的形成方法。蜘蛛网的形成基于一系列“电缆”,这些“电缆”构建在这些电缆之间。这些“电缆”自然而然地体现了某些规则。与此类似,爬虫技术也是基于一定的规则。程序根据这些规则自动抓取网页,从而从万维网下载网页以获取“猎物”,URL就是网络上的“电缆”。Come * from-excellent = Er, on:essay + net
2.3 通过 URL 抓取网页
网络爬虫是一个网络爬虫程序最基本的操作。
本质上,抓取网页的过程类似于浏览网页的过程。平日里,浏览互联网已成为每个人的必杀技。此操作对每个人来说都毫不费力。在浏览器顶部地址栏中输入网站URL地址,跳转到地址反映的页面。这个过程不是单向的,一夜之间,而是有一个我们看不到的第三方——“服务器端”。服务器收到用户浏览页面的请求后,将文件反映到客户端。这是我们看到的页面。网络爬取过程与获取过程相同。“蜘蛛”利用URL地址追踪来源获取网页。在网络爬取过程中,由于网址数量众多,往往以队列或网址池的形式存在。我们如何从队列中选择网址,哪些网址是我们优先抓取的对象,以及如何抓取?成为一个关键问题。
为了方便理解,我们可以直观的看到页面的源代码,在浏览器上查看,操作非常简单,如下:在页面任意位置右击,会出现一个指令框,选择“查看”在出现的选项——“源文件”中,您将看到从服务器“抓取”的html文件的源代码。互联网爬取与企业公开信息分析研究(6): 查看全部
抓取jsp网页源代码(基于网络爬虫技术的个性化企业信息获取方法研究(组图))
一般来说,软件界面如下:
图 1-1 Navicat for mysql 界面
但是,事情的好坏不能从表面上定论。Navicat 也是一样。我们上面谈到了它的各种优点。但是,作为一个为工作服务的软件,最重要的还是要符合用户的操作。习惯,给用户带来极致的用户体验。Navicat 也这样做。它采用图形化的完美用户界面,在视觉和操作上都满足工作要求。另外,在当前信息安全系数不高的情况下,可以保证信息的安全,可以快速、安全地实现创建、组织、存储和共享。
2 基于网络爬虫技术的个性化企业信息获取方法研究
2.1 爬虫简介
在浩瀚的互联网中,信息就像一滴水。为了学习和工作获取它们,我们总是习惯于使用“水勺”——搜索引擎来获取它们。从我们这边来说,当我们需要挖掘信息的时候,大多数人自然会想到“随便点击百度就知道”,输入关键词,得到一系列相关内容。而这个看似简单的原理背后,则是接下来要介绍的网络爬虫技术(网络蜘蛛或网络爬虫)。
现在,我们将接触自然界中蜘蛛结网的神奇现象,来引出本节的“主角”。众所周知,蜘蛛通过分泌粘液并在空气中形成非常细的细丝来捕捉猎物。万维网就像一个巨大的“网络”,上面附有大量复杂的信息。一个网络爬虫就像一个爬虫在这个互联网上狩猎,为了捕捉它需要的“猎物”。然而,如何从一个落脚点绘制出无数条向外围延伸的细丝呢?下一节将介绍 URL 的概念。
根据不同的爬虫要求,爬虫有很多种。例如,基于Web的爬虫主要用于采集网络上的资源,节省了在万维网上获取需求所需的时间,减少了信息采集的空间开销。由于我们有针对性地抓取了国家环保总局的数据,所以本文中的爬虫可以理解为基于用户个性的爬虫,即定制的爬虫,只获取需要的页面,只获取内容这就是上面所关心的。它会抓取符合我们预期的结果。[12]
2.2 理解网址
同样,在上一节中,比较了蜘蛛网的形成方法。蜘蛛网的形成基于一系列“电缆”,这些“电缆”构建在这些电缆之间。这些“电缆”自然而然地体现了某些规则。与此类似,爬虫技术也是基于一定的规则。程序根据这些规则自动抓取网页,从而从万维网下载网页以获取“猎物”,URL就是网络上的“电缆”。Come * from-excellent = Er, on:essay + net
2.3 通过 URL 抓取网页
网络爬虫是一个网络爬虫程序最基本的操作。
本质上,抓取网页的过程类似于浏览网页的过程。平日里,浏览互联网已成为每个人的必杀技。此操作对每个人来说都毫不费力。在浏览器顶部地址栏中输入网站URL地址,跳转到地址反映的页面。这个过程不是单向的,一夜之间,而是有一个我们看不到的第三方——“服务器端”。服务器收到用户浏览页面的请求后,将文件反映到客户端。这是我们看到的页面。网络爬取过程与获取过程相同。“蜘蛛”利用URL地址追踪来源获取网页。在网络爬取过程中,由于网址数量众多,往往以队列或网址池的形式存在。我们如何从队列中选择网址,哪些网址是我们优先抓取的对象,以及如何抓取?成为一个关键问题。
为了方便理解,我们可以直观的看到页面的源代码,在浏览器上查看,操作非常简单,如下:在页面任意位置右击,会出现一个指令框,选择“查看”在出现的选项——“源文件”中,您将看到从服务器“抓取”的html文件的源代码。互联网爬取与企业公开信息分析研究(6):

